mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
4f883d0b7b
@ -1,17 +1,19 @@
|
||||
FTPS(基于 SSL 的FTP)与 SFTP(SSH 文件传输协议)对比
|
||||
================================================== ==========
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
**<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>、SFTP 或称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>**, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>(SFTP)也称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
|
||||
但是 SFTP 和 FTPS 之间最显着的区别是如何验证和管理连接。
|
||||
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID,密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,如果服务器的证书是可信的,[FTP 客户端软件][6]将检查目的地[ FTP 服务器][7]。
|
||||
### FTPS
|
||||
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 的所有用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID、密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,[FTP 客户端软件][6]将检查目标[ FTP 服务器][7]证书是否可信的。
|
||||
|
||||
### 以下是 FTPS 的优点和缺点:
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 所有的用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
|
||||
以下是 FTPS 的优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
@ -23,14 +25,17 @@ FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全
|
||||
缺点:
|
||||
|
||||
- 没有统一的目录列表格式
|
||||
- 需要辅助数据通道,这使得难以在防火墙后使用
|
||||
- 未定义文件名字符集(编码)的标准
|
||||
- 需要辅助数据通道(DATA),这使得难以通过防火墙使用
|
||||
- 没有定义文件名字符集(编码)的标准
|
||||
- 并非所有 FTP 服务器都支持 SSL/TLS
|
||||
- 没有标准的方式来获取和更改文件或目录属性
|
||||
- 没有获取和更改文件或目录属性的标准方式
|
||||
|
||||
|
||||
### SFTP
|
||||
|
||||
SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,设计为 SSH 扩展以提供文件传输功能,因此它通常仅使用 SSH 端口用于数据传输和控制。当 [FTP 客户端][8]软件连接到 SFTP 服务器时,它会将公钥传输到服务器进行认证。如果密钥匹配,提供任何用户/密码,身份验证就会成功。
|
||||
|
||||
### 以下是 SFTP 优点和缺点:
|
||||
以下是 SFTP 优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
@ -41,22 +46,24 @@ SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,
|
||||
|
||||
缺点:
|
||||
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读
|
||||
并且 SSH 密钥更难以管理和验证。
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读,
|
||||
- SSH 密钥更难以管理和验证。
|
||||
- 这些标准定义了某些可选或推荐的选项,这会导致不同供应商的不同软件之间存在某些兼容性问题。
|
||||
- 没有服务器到服务器的副本和递归目录删除操作
|
||||
- 没有服务器到服务器的复制和递归目录删除操作
|
||||
- 在 VCL 和 .NET 框架中没有内置的 SSH/SFTP 支持。
|
||||
|
||||
### 对比
|
||||
|
||||
大多数 FTP 服务器软件这两种安全 FTP 技术都支持,以及强大的身份验证选项。
|
||||
|
||||
但 SFTP 将是防火墙赢家,因为它很友好。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证,发出的任何命令以及传输的任何数据。
|
||||
但 SFTP 显然是赢家,因为它适合防火墙。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证、发出的任何命令以及传输的任何数据。
|
||||
|
||||
FTPS 通过紧密安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
FTPS 通过严格安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
|
||||
支持 FTPS 和 SFTP 的 FTP 服务器软件:
|
||||
|
||||
1. [Cerberus FTP服务器][2]
|
||||
2. [FileZilla - 最著名的免费 FTP 和 FTPS 服务器软件][3]
|
||||
1. [Cerberus FTP 服务器][2]
|
||||
2. [FileZilla - 最著名的免费 FTP 和 FTPS 服务器软件][3]
|
||||
3. [Serv-U FTP 服务器][4]
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
@ -0,0 +1,78 @@
|
||||
让你的 Linux 远离黑客(二):另外三个建议
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些阻止黑客入侵你的系统的重要信息。观看这个免费的网络点播研讨会获取更多的信息。
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过两种简单的方法来阻止黑客黑掉你的 Linux 主机。这里是另外三条来自于我最近在 Linux 基金会的网络研讨会上的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[网络点播研讨会][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的 Linux 安全提示 #3
|
||||
|
||||
**Sudo。**
|
||||
|
||||
Sudo 非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西会让我的黑客生涯会变得更困难一些。如果你没有配置 sudo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用 sudo 执行所有命令。当我有一个可以无需密码而可以 sudo 任何命令的用户,只会让我的黑客活动变得更容易。如果我可以无需验证就可以 sudo ,同时当我获得你的没有密码的 SSH 密钥后,我就能十分容易的开始任何黑客活动。这样,我就拥有了你机器的 root 权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用 sudo,并且设置的超时时间是 3 小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐的超时时间大约为 10 分钟,甚至是 5 分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令,并禁止通过 sudo 来访问 shell。大多数 Linux 发行版目前默认允许你使用 sudo bash 来获取一个 root 身份的 shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我 shell 访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的 Linux 安全提示 #4
|
||||
|
||||
**限制正在运行的服务。**
|
||||
|
||||
防火墙很好,你的边界防火墙非常的强大。当流量流经你的外部网络时,有几家防火墙产品可以帮你很好的保护好自己。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供 MySQL 服务的机器上运行它。如果你有一个默认会安装完整的 LAMP 套件的 Linux 发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户不要使用默认的身份凭证,确保那些内容已被安全地配置。如何你正在运行 Tomcat,你不应该可以上传你自己的小程序(applets)。确保它们不会以 root 的身份运行。如果我能够运行一个小程序,我不会想着以管理员的身份来运行它,我能访问就行。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的 Linux 安全提示 #5
|
||||
|
||||
**小心你的日志记录。**
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的 email,我会浏览我的日志记录。这仅会花费我 15 分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不在意它们,但是有人会在意。
|
||||
|
||||
通过 Syslog、Splunk 或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我能这么做,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
它们就像你的很重要的人,送给它们鲜花——磁盘空间。确保你有足够的磁盘空间用来记录日志。由于磁盘满而变成只读的文件系统并不是一件愉快的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三篇也是最后的一篇文章][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络点播研讨会][6]吧。
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试。***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://linux.cn/article-8189-1.html
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,13 +1,14 @@
|
||||
### Linux Deepin - 一个拥有独特风格的发行版
|
||||
Linux Deepin :一个拥有独特风格的发行版
|
||||
===============
|
||||
|
||||
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属于它自己的桌面环境。只有很少的发行版能够将他自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属它自己的桌面环境。只有很少的发行版能够将它自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,当你将软件放到上面后,它可以有着各种特效。
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,根据你放到上面的软件,它可以有着各种特效。
|
||||
|
||||
[
|
||||

|
||||
@ -21,13 +22,11 @@
|
||||
|
||||
你可以做上面的截图中看到,启动器中的应用被分类得井井有条。还有一个好的地方是当你用鼠标点击到左下角,所有桌面上的应用将会最小化。再次点击则会回复原样。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
如果你点击右下角,他将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
如果你点击右下角,它将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
[
|
||||

|
||||
@ -35,19 +34,17 @@
|
||||
|
||||
你可以看到截屏中的控制中心,设计得非常棒而且也是分类得井井有条,你可以在这里设置所有电脑上的项目。甚至可以自定义你的启动界面的壁纸。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且他们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且它们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
另一个亮点是 Deepin 的游戏。他提供许多免费的可联网玩耍的游戏,他们非常的有意思可以很好的用于消磨时光。
|
||||
另一个亮点是 Deepin 的游戏。它提供许多免费的可联网玩耍的游戏,它们非常的有意思可以很好的用于消磨时光。
|
||||
|
||||
[
|
||||

|
||||
@ -55,17 +52,17 @@ Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软
|
||||
|
||||
Deepin 也提供一个好用的音乐播放软件,它有着网络电台点播功能。如果你本地没有音乐你也不用害怕,你可以调到网络电台模式来享受音乐。
|
||||
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像他们的座右铭那样:“要做,就做出风格”。他们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。他的安装镜像大约 1.5 GB。你的访问他们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像它们的座右铭那样:“要做,就做出风格”。它们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。它的安装镜像大约 1.5 GB。你的访问它们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
|
||||
这就是本篇**Linux 发行版介绍** 的全部内容了,我们将会继续介绍其他的发行版。下次再见!
|
||||
这就是本篇 **Linux 发行版介绍**的全部内容了,我们将会继续介绍其它的发行版。下次再见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techphylum.com/2014/08/linux-deepin-distro-with-unique-style.html
|
||||
|
||||
作者:[sumit rohankar https://plus.google.com/112160169713374382262][a]
|
||||
作者:[sumit rohankar][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by SysTick
|
||||
|
||||
The decline of GPL?
|
||||
============================================================
|
||||
|
||||
|
||||
321
sources/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
321
sources/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
@ -0,0 +1,321 @@
|
||||
[How debuggers work: Part 1 - Basics][21]
|
||||
============================================================
|
||||
|
||||
This is the first part in a series of articles on how debuggers work. I'm still not sure how many articles the series will contain and what topics it will cover, but I'm going to start with the basics.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to present the main building block of a debugger's implementation on Linux - the ptrace system call. All the code in this article is developed on a 32-bit Ubuntu machine. Note that the code is very much platform specific, although porting it to other platforms shouldn't be too difficult.
|
||||
|
||||
### Motivation
|
||||
|
||||
To understand where we're going, try to imagine what it takes for a debugger to do its work. A debugger can start some process and debug it, or attach itself to an existing process. It can single-step through the code, set breakpoints and run to them, examine variable values and stack traces. Many debuggers have advanced features such as executing expressions and calling functions in the debbugged process's address space, and even changing the process's code on-the-fly and watching the effects.
|
||||
|
||||
Although modern debuggers are complex beasts [[1]][13], it's surprising how simple is the foundation on which they are built. Debuggers start with only a few basic services provided by the operating system and the compiler/linker, all the rest is just [a simple matter of programming][14].
|
||||
|
||||
### Linux debugging - <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">ptrace
|
||||
|
||||
The Swiss army knife of Linux debuggers is the ptrace system call [[2]][15]. It's a versatile and rather complex tool that allows one process to control the execution of another and to peek and poke at its innards [[3]][16]. ptrace can take a mid-sized book to explain fully, which is why I'm just going to focus on some of its practical uses in examples.
|
||||
|
||||
Let's dive right in.
|
||||
|
||||
### Stepping through the code of a process
|
||||
|
||||
I'm now going to develop an example of running a process in "traced" mode in which we're going to single-step through its code - the machine code (assembly instructions) that's executed by the CPU. I'll show the example code in parts, explaining each, and in the end of the article you will find a link to download a complete C file that you can compile, execute and play with.
|
||||
|
||||
The high-level plan is to write code that splits into a child process that will execute a user-supplied command, and a parent process that traces the child. First, the main function:
|
||||
|
||||
```
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
pid_t child_pid;
|
||||
|
||||
if (argc < 2) {
|
||||
fprintf(stderr, "Expected a program name as argument\n");
|
||||
return -1;
|
||||
}
|
||||
|
||||
child_pid = fork();
|
||||
if (child_pid == 0)
|
||||
run_target(argv[1]);
|
||||
else if (child_pid > 0)
|
||||
run_debugger(child_pid);
|
||||
else {
|
||||
perror("fork");
|
||||
return -1;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Pretty simple: we start a new child process with fork [[4]][17]. The if branch of the subsequent condition runs the child process (called "target" here), and the else if branch runs the parent process (called "debugger" here).
|
||||
|
||||
Here's the target process:
|
||||
|
||||
```
|
||||
void run_target(const char* programname)
|
||||
{
|
||||
procmsg("target started. will run '%s'\n", programname);
|
||||
|
||||
/* Allow tracing of this process */
|
||||
if (ptrace(PTRACE_TRACEME, 0, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Replace this process's image with the given program */
|
||||
execl(programname, programname, 0);
|
||||
}
|
||||
```
|
||||
|
||||
The most interesting line here is the ptrace call. ptrace is declared thus (in sys/ptrace.h):
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
The first argument is a _request_ , which may be one of many predefined PTRACE_* constants. The second argument specifies a process ID for some requests. The third and fourth arguments are address and data pointers, for memory manipulation. The ptrace call in the code snippet above makes the PTRACE_TRACEMErequest, which means that this child process asks the OS kernel to let its parent trace it. The request description from the man-page is quite clear:
|
||||
|
||||
> Indicates that this process is to be traced by its parent. Any signal (except SIGKILL) delivered to this process will cause it to stop and its parent to be notified via wait(). **Also, all subsequent calls to exec() by this process will cause a SIGTRAP to be sent to it, giving the parent a chance to gain control before the new program begins execution**. A process probably shouldn't make this request if its parent isn't expecting to trace it. (pid, addr, and data are ignored.)
|
||||
|
||||
I've highlighted the part that interests us in this example. Note that the very next thing run_targetdoes after ptrace is invoke the program given to it as an argument with execl. This, as the highlighted part explains, causes the OS kernel to stop the process just before it begins executing the program in execl and send a signal to the parent.
|
||||
|
||||
Thus, time is ripe to see what the parent does:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
Recall from above that once the child starts executing the exec call, it will stop and be sent the SIGTRAP signal. The parent here waits for this to happen with the first wait call. wait will return once something interesting happens, and the parent checks that it was because the child was stopped (WIFSTOPPED returns true if the child process was stopped by delivery of a signal).
|
||||
|
||||
What the parent does next is the most interesting part of this article. It invokes ptrace with the PTRACE_SINGLESTEP request giving it the child process ID. What this does is tell the OS - _please restart the child process, but stop it after it executes the next instruction_ . Again, the parent waits for the child to stop and the loop continues. The loop will terminate when the signal that came out of the wait call wasn't about the child stopping. During a normal run of the tracer, this will be the signal that tells the parent that the child process exited (WIFEXITED would return true on it).
|
||||
|
||||
Note that icounter counts the amount of instructions executed by the child process. So our simple example actually does something useful - given a program name on the command line, it executes the program and reports the amount of CPU instructions it took to run from start to finish. Let's see it in action.
|
||||
|
||||
### A test run
|
||||
|
||||
I compiled the following simple program and ran it under the tracer:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("Hello, world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
To my surprise, the tracer took quite long to run and reported that there were more than 100,000 instructions executed. For a simple printf call? What gives? The answer is very interesting [[5]][18]. By default, gcc on Linux links programs to the C runtime libraries dynamically. What this means is that one of the first things that runs when any program is executed is the dynamic library loader that looks for the required shared libraries. This is quite a lot of code - and remember that our basic tracer here looks at each and every instruction, not of just the main function, but _of the whole process_ .
|
||||
|
||||
So, when I linked the test program with the -static flag (and verified that the executable gained some 500KB in weight, as is logical for a static link of the C runtime), the tracing reported only 7,000 instructions or so. This is still a lot, but makes perfect sense if you recall that libc initialization still has to run before main, and cleanup has to run after main. Besides, printf is a complex function.
|
||||
|
||||
Still not satisfied, I wanted to see something _testable_ - i.e. a whole run in which I could account for every instruction executed. This, of course, can be done with assembly code. So I took this version of "Hello, world!" and assembled it:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len
|
||||
mov ecx, msg
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
msg db 'Hello, world!', 0xa
|
||||
len equ $ - msg
|
||||
```
|
||||
|
||||
Sure enough. Now the tracer reported that 7 instructions were executed, which is something I can easily verify.
|
||||
|
||||
### Deep into the instruction stream
|
||||
|
||||
The assembly-written program allows me to introduce you to another powerful use of ptrace - closely examining the state of the traced process. Here's another version of the run_debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
unsigned instr = ptrace(PTRACE_PEEKTEXT, child_pid, regs.eip, 0);
|
||||
|
||||
procmsg("icounter = %u. EIP = 0x%08x. instr = 0x%08x\n",
|
||||
icounter, regs.eip, instr);
|
||||
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
The only difference is in the first few lines of the while loop. There are two new ptrace calls. The first one reads the value of the process's registers into a structure. user_regs_struct is defined in sys/user.h. Now here's the fun part - if you look at this header file, a comment close to the top says:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
Now, I don't know about you, but it makes _me_ feel we're on the right track :-) Anyway, back to the example. Once we have all the registers in regs, we can peek at the current instruction of the process by calling ptrace with PTRACE_PEEKTEXT, passing it regs.eip (the extended instruction pointer on x86) as the address. What we get back is the instruction [[6]][19]. Let's see this new tracer run on our assembly-coded snippet:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
[5700] debugger started
|
||||
[5701] target started. will run 'traced_helloworld'
|
||||
[5700] icounter = 1\. EIP = 0x08048080\. instr = 0x00000eba
|
||||
[5700] icounter = 2\. EIP = 0x08048085\. instr = 0x0490a0b9
|
||||
[5700] icounter = 3\. EIP = 0x0804808a. instr = 0x000001bb
|
||||
[5700] icounter = 4\. EIP = 0x0804808f. instr = 0x000004b8
|
||||
[5700] icounter = 5\. EIP = 0x08048094\. instr = 0x01b880cd
|
||||
Hello, world!
|
||||
[5700] icounter = 6\. EIP = 0x08048096\. instr = 0x000001b8
|
||||
[5700] icounter = 7\. EIP = 0x0804809b. instr = 0x000080cd
|
||||
[5700] the child executed 7 instructions
|
||||
```
|
||||
|
||||
OK, so now in addition to icounter we also see the instruction pointer and the instruction it points to at each step. How to verify this is correct? By using objdump -d on the executable:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
|
||||
traced_helloworld: file format elf32-i386
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 0e 00 00 00 mov $0xe,%edx
|
||||
8048085: b9 a0 90 04 08 mov $0x80490a0,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: b8 01 00 00 00 mov $0x1,%eax
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
The correspondence between this and our tracing output is easily observed.
|
||||
|
||||
### Attaching to a running process
|
||||
|
||||
As you know, debuggers can also attach to an already-running process. By now you won't be surprised to find out that this is also done with ptrace, which can get the PTRACE_ATTACH request. I won't show a code sample here since it should be very easy to implement given the code we've already gone through. For educational purposes, the approach taken here is more convenient (since we can stop the child process right at its start).
|
||||
|
||||
### The code
|
||||
|
||||
The complete C source-code of the simple tracer presented in this article (the more advanced, instruction-printing version) is available [here][20]. It compiles cleanly with -Wall -pedantic --std=c99 on version 4.4 of gcc.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Admittedly, this part didn't cover much - we're still far from having a real debugger in our hands. However, I hope it has already made the process of debugging at least a little less mysterious. ptrace is truly a versatile system call with many abilities, of which we've sampled only a few so far.
|
||||
|
||||
Single-stepping through the code is useful, but only to a certain degree. Take the C "Hello, world!" sample I demonstrated above. To get to main it would probably take a couple of thousands of instructions of C runtime initialization code to step through. This isn't very convenient. What we'd ideally want to have is the ability to place a breakpoint at the entry to main and step from there. Fair enough, and in the next part of the series I intend to show how breakpoints are implemented.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] I didn't check but I'm sure the LOC count of gdb is at least in the six-figures range.
|
||||
|
||||
[2] Run man 2 ptrace for complete enlightment.
|
||||
|
||||
[3] Peek and poke are well-known system programming jargon for directly reading and writing memory contents.
|
||||
|
||||
[4] This article assumes some basic level of Unix/Linux programming experience. I assume you know (at least conceptually) about fork, the exec family of functions and Unix signals.
|
||||
|
||||
[5] At least if you're as obsessed with low-level details as I am :-)
|
||||
|
||||
[6] A word of warning here: as I noted above, a lot of this is highly platform specific. I'm making some simplifying assumptions - for example, x86 instructions don't have to fit into 4 bytes (the size of unsigned on my 32-bit Ubuntu machine). In fact, many won't. Peeking at instructions meaningfully requires us to have a complete disassembler at hand. We don't have one here, but real debuggers do.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id1
|
||||
[2]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id2
|
||||
[3]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id3
|
||||
[4]:http://www.jargon.net/jargonfile/p/peek.html
|
||||
[5]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.linuxjournal.com/article/6100?page=0,1
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id7
|
||||
[14]:http://en.wikipedia.org/wiki/Small_matter_of_programming
|
||||
[15]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id8
|
||||
[16]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id9
|
||||
[17]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id10
|
||||
[18]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id11
|
||||
[19]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id12
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2011/simple_tracer.c
|
||||
[21]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
473
sources/tech/20110127 How debuggers work Part 2 - Breakpoints.md
Normal file
473
sources/tech/20110127 How debuggers work Part 2 - Breakpoints.md
Normal file
@ -0,0 +1,473 @@
|
||||
[How debuggers work: Part 2 - Breakpoints][26]
|
||||
============================================================
|
||||
|
||||
This is the second part in a series of articles on how debuggers work. Make sure you read [the first part][27]before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to demonstrate how breakpoints are implemented in a debugger. Breakpoints are one of the two main pillars of debugging - the other being able to inspect values in the debugged process's memory. We've already seen a preview of the other pillar in part 1 of the series, but breakpoints still remain mysterious. By the end of this article, they won't be.
|
||||
|
||||
### Software interrupts
|
||||
|
||||
To implement breakpoints on the x86 architecture, software interrupts (also known as "traps") are used. Before we get deep into the details, I want to explain the concept of interrupts and traps in general.
|
||||
|
||||
A CPU has a single stream of execution, working through instructions one by one [[1]][19]. To handle asynchronous events like IO and hardware timers, CPUs use interrupts. A hardware interrupt is usually a dedicated electrical signal to which a special "response circuitry" is attached. This circuitry notices an activation of the interrupt and makes the CPU stop its current execution, save its state, and jump to a predefined address where a handler routine for the interrupt is located. When the handler finishes its work, the CPU resumes execution from where it stopped.
|
||||
|
||||
Software interrupts are similar in principle but a bit different in practice. CPUs support special instructions that allow the software to simulate an interrupt. When such an instruction is executed, the CPU treats it like an interrupt - stops its normal flow of execution, saves its state and jumps to a handler routine. Such "traps" allow many of the wonders of modern OSes (task scheduling, virtual memory, memory protection, debugging) to be implemented efficiently.
|
||||
|
||||
Some programming errors (such as division by 0) are also treated by the CPU as traps, and are frequently referred to as "exceptions". Here the line between hardware and software blurs, since it's hard to say whether such exceptions are really hardware interrupts or software interrupts. But I've digressed too far away from the main topic, so it's time to get back to breakpoints.
|
||||
|
||||
### int 3 in theory
|
||||
|
||||
Having written the previous section, I can now simply say that breakpoints are implemented on the CPU by a special trap called int 3. int is x86 jargon for "trap instruction" - a call to a predefined interrupt handler. x86 supports the int instruction with a 8-bit operand specifying the number of the interrupt that occurred, so in theory 256 traps are supported. The first 32 are reserved by the CPU for itself, and number 3 is the one we're interested in here - it's called "trap to debugger".
|
||||
|
||||
Without further ado, I'll quote from the bible itself [[2]][20]:
|
||||
|
||||
> The INT 3 instruction generates a special one byte opcode (CC) that is intended for calling the debug exception handler. (This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code).
|
||||
|
||||
The part in parens is important, but it's still too early to explain it. We'll come back to it later in this article.
|
||||
|
||||
### int 3 in practice
|
||||
|
||||
Yes, knowing the theory behind things is great, OK, but what does this really mean? How do we use int 3to implement breakpoints? Or to paraphrase common programming Q&A jargon - _Plz show me the codes!_
|
||||
|
||||
In practice, this is really very simple. Once your process executes the int 3 instruction, the OS stops it [[3]][21]. On Linux (which is what we're concerned with in this article) it then sends the process a signal - SIGTRAP.
|
||||
|
||||
That's all there is to it - honest! Now recall from the first part of the series that a tracing (debugger) process gets notified of all the signals its child (or the process it attaches to for debugging) gets, and you can start getting a feel of where we're going.
|
||||
|
||||
That's it, no more computer architecture 101 jabber. It's time for examples and code.
|
||||
|
||||
### Setting breakpoints manually
|
||||
|
||||
I'm now going to show code that sets a breakpoint in a program. The target program I'm going to use for this demonstration is the following:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len1
|
||||
mov ecx, msg1
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Now print the other message
|
||||
mov edx, len2
|
||||
mov ecx, msg2
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
|
||||
msg1 db 'Hello,', 0xa
|
||||
len1 equ $ - msg1
|
||||
msg2 db 'world!', 0xa
|
||||
len2 equ $ - msg2
|
||||
```
|
||||
|
||||
I'm using assembly language for now, in order to keep us clear of compilation issues and symbols that come up when we get into C code. What the program listed above does is simply print "Hello," on one line and then "world!" on the next line. It's very similar to the program demonstrated in the previous article.
|
||||
|
||||
I want to set a breakpoint after the first printout, but before the second one. Let's say right after the first int 0x80 [[4]][22], on the mov edx, len2 instruction. First, we need to know what address this instruction maps to. Running objdump -d:
|
||||
|
||||
```
|
||||
traced_printer2: file format elf32-i386
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .text 00000033 08048080 08048080 00000080 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
1 .data 0000000e 080490b4 080490b4 000000b4 2**2
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 07 00 00 00 mov $0x7,%edx
|
||||
8048085: b9 b4 90 04 08 mov $0x80490b4,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: ba 07 00 00 00 mov $0x7,%edx
|
||||
804809b: b9 bb 90 04 08 mov $0x80490bb,%ecx
|
||||
80480a0: bb 01 00 00 00 mov $0x1,%ebx
|
||||
80480a5: b8 04 00 00 00 mov $0x4,%eax
|
||||
80480aa: cd 80 int $0x80
|
||||
80480ac: b8 01 00 00 00 mov $0x1,%eax
|
||||
80480b1: cd 80 int $0x80
|
||||
```
|
||||
|
||||
So, the address we're going to set the breakpoint on is 0x8048096\. Wait, this is not how real debuggers work, right? Real debuggers set breakpoints on lines of code and on functions, not on some bare memory addresses? Exactly right. But we're still far from there - to set breakpoints like _real_ debuggers we still have to cover symbols and debugging information first, and it will take another part or two in the series to reach these topics. For now, we'll have to do with bare memory addresses.
|
||||
|
||||
At this point I really want to digress again, so you have two choices. If it's really interesting for you to know _why_ the address is 0x8048096 and what does it mean, read the next section. If not, and you just want to get on with the breakpoints, you can safely skip it.
|
||||
|
||||
### Digression - process addresses and entry point
|
||||
|
||||
Frankly, 0x8048096 itself doesn't mean much, it's just a few bytes away from the beginning of the text section of the executable. If you look carefully at the dump listing above, you'll see that the text section starts at 0x08048080\. This tells the OS to map the text section starting at this address in the virtual address space given to the process. On Linux these addresses can be absolute (i.e. the executable isn't being relocated when it's loaded into memory), because with the virtual memory system each process gets its own chunk of memory and sees the whole 32-bit address space as its own (called "linear" address).
|
||||
|
||||
If we examine the ELF [[5]][23] header with readelf, we get:
|
||||
|
||||
```
|
||||
$ readelf -h traced_printer2
|
||||
ELF Header:
|
||||
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
|
||||
Class: ELF32
|
||||
Data: 2's complement, little endian
|
||||
Version: 1 (current)
|
||||
OS/ABI: UNIX - System V
|
||||
ABI Version: 0
|
||||
Type: EXEC (Executable file)
|
||||
Machine: Intel 80386
|
||||
Version: 0x1
|
||||
Entry point address: 0x8048080
|
||||
Start of program headers: 52 (bytes into file)
|
||||
Start of section headers: 220 (bytes into file)
|
||||
Flags: 0x0
|
||||
Size of this header: 52 (bytes)
|
||||
Size of program headers: 32 (bytes)
|
||||
Number of program headers: 2
|
||||
Size of section headers: 40 (bytes)
|
||||
Number of section headers: 4
|
||||
Section header string table index: 3
|
||||
```
|
||||
|
||||
Note the "entry point address" section of the header, which also points to 0x8048080\. So if we interpret the directions encoded in the ELF file for the OS, it says:
|
||||
|
||||
1. Map the text section (with given contents) to address 0x8048080
|
||||
2. Start executing at the entry point - address 0x8048080
|
||||
|
||||
But still, why 0x8048080? For historic reasons, it turns out. Some googling led me to a few sources that claim that the first 128MB of each process's address space were reserved for the stack. 128MB happens to be 0x8000000, which is where other sections of the executable may start. 0x8048080, in particular, is the default entry point used by the Linux ld linker. This entry point can be modified by passing the -Ttextargument to ld.
|
||||
|
||||
To conclude, there's nothing really special in this address and we can freely change it. As long as the ELF executable is properly structured and the entry point address in the header matches the real beginning of the program's code (text section), we're OK.
|
||||
|
||||
### Setting breakpoints in the debugger with int 3
|
||||
|
||||
To set a breakpoint at some target address in the traced process, the debugger does the following:
|
||||
|
||||
1. Remember the data stored at the target address
|
||||
2. Replace the first byte at the target address with the int 3 instruction
|
||||
|
||||
Then, when the debugger asks the OS to run the process (with PTRACE_CONT as we saw in the previous article), the process will run and eventually hit upon the int 3, where it will stop and the OS will send it a signal. This is where the debugger comes in again, receiving a signal that its child (or traced process) was stopped. It can then:
|
||||
|
||||
1. Replace the int 3 instruction at the target address with the original instruction
|
||||
2. Roll the instruction pointer of the traced process back by one. This is needed because the instruction pointer now points _after_ the int 3, having already executed it.
|
||||
3. Allow the user to interact with the process in some way, since the process is still halted at the desired target address. This is the part where your debugger lets you peek at variable values, the call stack and so on.
|
||||
4. When the user wants to keep running, the debugger will take care of placing the breakpoint back (since it was removed in step 1) at the target address, unless the user asked to cancel the breakpoint.
|
||||
|
||||
Let's see how some of these steps are translated into real code. We'll use the debugger "template" presented in part 1 (forking a child process and tracing it). In any case, there's a link to the full source code of this example at the end of the article.
|
||||
|
||||
```
|
||||
/* Obtain and show child's instruction pointer */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child started. EIP = 0x%08x\n", regs.eip);
|
||||
|
||||
/* Look at the word at the address we're interested in */
|
||||
unsigned addr = 0x8048096;
|
||||
unsigned data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("Original data at 0x%08x: 0x%08x\n", addr, data);
|
||||
```
|
||||
|
||||
Here the debugger fetches the instruction pointer from the traced process, as well as examines the word currently present at 0x8048096\. When run tracing the assembly program listed in the beginning of the article, this prints:
|
||||
|
||||
```
|
||||
[13028] Child started. EIP = 0x08048080
|
||||
[13028] Original data at 0x08048096: 0x000007ba
|
||||
```
|
||||
|
||||
So far, so good. Next:
|
||||
|
||||
```
|
||||
/* Write the trap instruction 'int 3' into the address */
|
||||
unsigned data_with_trap = (data & 0xFFFFFF00) | 0xCC;
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data_with_trap);
|
||||
|
||||
/* See what's there again... */
|
||||
unsigned readback_data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("After trap, data at 0x%08x: 0x%08x\n", addr, readback_data);
|
||||
```
|
||||
|
||||
Note how int 3 is inserted at the target address. This prints:
|
||||
|
||||
```
|
||||
[13028] After trap, data at 0x08048096: 0x000007cc
|
||||
```
|
||||
|
||||
Again, as expected - 0xba was replaced with 0xcc. The debugger now runs the child and waits for it to halt on the breakpoint:
|
||||
|
||||
```
|
||||
/* Let the child run to the breakpoint and wait for it to
|
||||
** reach it
|
||||
*/
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
|
||||
wait(&wait_status);
|
||||
if (WIFSTOPPED(wait_status)) {
|
||||
procmsg("Child got a signal: %s\n", strsignal(WSTOPSIG(wait_status)));
|
||||
}
|
||||
else {
|
||||
perror("wait");
|
||||
return;
|
||||
}
|
||||
|
||||
/* See where the child is now */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child stopped at EIP = 0x%08x\n", regs.eip);
|
||||
```
|
||||
|
||||
This prints:
|
||||
|
||||
```
|
||||
Hello,
|
||||
[13028] Child got a signal: Trace/breakpoint trap
|
||||
[13028] Child stopped at EIP = 0x08048097
|
||||
```
|
||||
|
||||
Note the "Hello," that was printed before the breakpoint - exactly as we planned. Also note where the child stopped - just after the single-byte trap instruction.
|
||||
|
||||
Finally, as was explained earlier, to keep the child running we must do some work. We replace the trap with the original instruction and let the process continue running from it.
|
||||
|
||||
```
|
||||
/* Remove the breakpoint by restoring the previous data
|
||||
** at the target address, and unwind the EIP back by 1 to
|
||||
** let the CPU execute the original instruction that was
|
||||
** there.
|
||||
*/
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data);
|
||||
regs.eip -= 1;
|
||||
ptrace(PTRACE_SETREGS, child_pid, 0, ®s);
|
||||
|
||||
/* The child can continue running now */
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
```
|
||||
|
||||
This makes the child print "world!" and exit, just as planned.
|
||||
|
||||
Note that we don't restore the breakpoint here. That can be done by executing the original instruction in single-step mode, then placing the trap back and only then do PTRACE_CONT. The debug library demonstrated later in the article implements this.
|
||||
|
||||
### More on int 3
|
||||
|
||||
Now is a good time to come back and examine int 3 and that curious note from Intel's manual. Here it is again:
|
||||
|
||||
> This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code
|
||||
|
||||
int instructions on x86 occupy two bytes - 0xcd followed by the interrupt number [[6]][24]. int 3 could've been encoded as cd 03, but there's a special single-byte instruction reserved for it - 0xcc.
|
||||
|
||||
Why so? Because this allows us to insert a breakpoint without ever overwriting more than one instruction. And this is important. Consider this sample code:
|
||||
|
||||
```
|
||||
.. some code ..
|
||||
jz foo
|
||||
dec eax
|
||||
foo:
|
||||
call bar
|
||||
.. some code ..
|
||||
```
|
||||
|
||||
Suppose we want to place a breakpoint on dec eax. This happens to be a single-byte instruction (with the opcode 0x48). Had the replacement breakpoint instruction been longer than 1 byte, we'd be forced to overwrite part of the next instruction (call), which would garble it and probably produce something completely invalid. But what is the branch jz foo was taken? Then, without stopping on dec eax, the CPU would go straight to execute the invalid instruction after it.
|
||||
|
||||
Having a special 1-byte encoding for int 3 solves this problem. Since 1 byte is the shortest an instruction can get on x86, we guarantee than only the instruction we want to break on gets changed.
|
||||
|
||||
### Encapsulating some gory details
|
||||
|
||||
Many of the low-level details shown in code samples of the previous section can be easily encapsulated behind a convenient API. I've done some encapsulation into a small utility library called debuglib - its code is available for download at the end of the article. Here I just want to demonstrate an example of its usage, but with a twist. We're going to trace a program written in C.
|
||||
|
||||
### Tracing a C program
|
||||
|
||||
So far, for the sake of simplicity, I focused on assembly language targets. It's time to go one level up and see how we can trace a program written in C.
|
||||
|
||||
It turns out things aren't very different - it's just a bit harder to find where to place the breakpoints. Consider this simple program:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff()
|
||||
{
|
||||
printf("Hello, ");
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 4; ++i)
|
||||
do_stuff();
|
||||
printf("world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Suppose I want to place a breakpoint at the entrance to do_stuff. I'll use the old friend objdump to disassemble the executable, but there's a lot in it. In particular, looking at the text section is a bit useless since it contains a lot of C runtime initialization code I'm currently not interested in. So let's just look for do_stuff in the dump:
|
||||
|
||||
```
|
||||
080483e4 <do_stuff>:
|
||||
80483e4: 55 push %ebp
|
||||
80483e5: 89 e5 mov %esp,%ebp
|
||||
80483e7: 83 ec 18 sub $0x18,%esp
|
||||
80483ea: c7 04 24 f0 84 04 08 movl $0x80484f0,(%esp)
|
||||
80483f1: e8 22 ff ff ff call 8048318 <puts@plt>
|
||||
80483f6: c9 leave
|
||||
80483f7: c3 ret
|
||||
```
|
||||
|
||||
Alright, so we'll place the breakpoint at 0x080483e4, which is the first instruction of do_stuff. Moreover, since this function is called in a loop, we want to keep stopping at the breakpoint until the loop ends. We're going to use the debuglib library to make this simple. Here's the complete debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(0);
|
||||
procmsg("child now at EIP = 0x%08x\n", get_child_eip(child_pid));
|
||||
|
||||
/* Create breakpoint and run to it*/
|
||||
debug_breakpoint* bp = create_breakpoint(child_pid, (void*)0x080483e4);
|
||||
procmsg("breakpoint created\n");
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
wait(0);
|
||||
|
||||
/* Loop as long as the child didn't exit */
|
||||
while (1) {
|
||||
/* The child is stopped at a breakpoint here. Resume its
|
||||
** execution until it either exits or hits the
|
||||
** breakpoint again.
|
||||
*/
|
||||
procmsg("child stopped at breakpoint. EIP = 0x%08X\n", get_child_eip(child_pid));
|
||||
procmsg("resuming\n");
|
||||
int rc = resume_from_breakpoint(child_pid, bp);
|
||||
|
||||
if (rc == 0) {
|
||||
procmsg("child exited\n");
|
||||
break;
|
||||
}
|
||||
else if (rc == 1) {
|
||||
continue;
|
||||
}
|
||||
else {
|
||||
procmsg("unexpected: %d\n", rc);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cleanup_breakpoint(bp);
|
||||
}
|
||||
```
|
||||
|
||||
Instead of getting our hands dirty modifying EIP and the target process's memory space, we just use create_breakpoint, resume_from_breakpoint and cleanup_breakpoint. Let's see what this prints when tracing the simple C code displayed above:
|
||||
|
||||
```
|
||||
$ bp_use_lib traced_c_loop
|
||||
[13363] debugger started
|
||||
[13364] target started. will run 'traced_c_loop'
|
||||
[13363] child now at EIP = 0x00a37850
|
||||
[13363] breakpoint created
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
world!
|
||||
[13363] child exited
|
||||
```
|
||||
|
||||
Just as expected!
|
||||
|
||||
### The code
|
||||
|
||||
[Here are][25] the complete source code files for this part. In the archive you'll find:
|
||||
|
||||
* debuglib.h and debuglib.c - the simple library for encapsulating some of the inner workings of a debugger
|
||||
* bp_manual.c - the "manual" way of setting breakpoints presented first in this article. Uses the debuglib library for some boilerplate code.
|
||||
* bp_use_lib.c - uses debuglib for most of its code, as demonstrated in the second code sample for tracing the loop in a C program.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
We've covered how breakpoints are implemented in debuggers. While implementation details vary between OSes, when you're on x86 it's all basically variations on the same theme - substituting int 3 for the instruction where we want the process to stop.
|
||||
|
||||
That said, I'm sure some readers, just like me, will be less than excited about specifying raw memory addresses to break on. We'd like to say "break on do_stuff", or even "break on _this_ line in do_stuff" and have the debugger do it. In the next article I'm going to show how it's done.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [How debugger works][12]
|
||||
* [Understanding ELF using readelf and objdump][13]
|
||||
* [Implementing breakpoints on x86 Linux][14]
|
||||
* [NASM manual][15]
|
||||
* [SO discussion of the ELF entry point][16]
|
||||
* [This Hacker News discussion][17] of the first part of the series
|
||||
* [GDB Internals][18]
|
||||
|
||||
|
||||
[1] On a high-level view this is true. Down in the gory details, many CPUs today execute multiple instructions in parallel, some of them not in their original order.
|
||||
|
||||
[2] The bible in this case being, of course, Intel's Architecture software developer's manual, volume 2A.
|
||||
|
||||
[3] How can the OS stop a process just like that? The OS registered its own handler for int 3 with the CPU, that's how!
|
||||
|
||||
[4] Wait, int again? Yes! Linux uses int 0x80 to implement system calls from user processes into the OS kernel. The user places the number of the system call and its arguments into registers and executes int 0x80. The CPU then jumps to the appropriate interrupt handler, where the OS registered a procedure that looks at the registers and decides which system call to execute.
|
||||
|
||||
[5] ELF (Executable and Linkable Format) is the file format used by Linux for object files, shared libraries and executables.
|
||||
|
||||
[6] An observant reader can spot the translation of int 0x80 into cd 80 in the dumps listed above.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id1
|
||||
[2]:http://en.wikipedia.org/wiki/Out-of-order_execution
|
||||
[3]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id5
|
||||
[7]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[8]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id6
|
||||
[9]:http://eli.thegreenplace.net/tag/articles
|
||||
[10]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[11]:http://eli.thegreenplace.net/tag/programming
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
|
||||
[14]:http://mainisusuallyafunction.blogspot.com/2011/01/implementing-breakpoints-on-x86-linux.html
|
||||
[15]:http://www.nasm.us/xdoc/2.09.04/html/nasmdoc0.html
|
||||
[16]:http://stackoverflow.com/questions/2187484/elf-binary-entry-point
|
||||
[17]:http://news.ycombinator.net/item?id=2131894
|
||||
[18]:http://www.deansys.com/doc/gdbInternals/gdbint_toc.html
|
||||
[19]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id7
|
||||
[20]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id8
|
||||
[21]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id9
|
||||
[22]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id10
|
||||
[23]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id11
|
||||
[24]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id12
|
||||
[25]:https://github.com/eliben/code-for-blog/tree/master/2011/debuggers_part2_code
|
||||
[26]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
[27]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
@ -0,0 +1,349 @@
|
||||
[How debuggers work: Part 3 - Debugging information][25]
|
||||
============================================================
|
||||
|
||||
|
||||
This is the third part in a series of articles on how debuggers work. Make sure you read [the first][26] and [the second][27] parts before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to explain how the debugger figures out where to find the C functions and variables in the machine code it wades through, and the data it uses to map between C source code lines and machine language words.
|
||||
|
||||
### Debugging information
|
||||
|
||||
Modern compilers do a pretty good job converting your high-level code, with its nicely indented and nested control structures and arbitrarily typed variables into a big pile of bits called machine code, the sole purpose of which is to run as fast as possible on the target CPU. Most lines of C get converted into several machine code instructions. Variables are shoved all over the place - into the stack, into registers, or completely optimized away. Structures and objects don't even _exist_ in the resulting code - they're merely an abstraction that gets translated to hard-coded offsets into memory buffers.
|
||||
|
||||
So how does a debugger know where to stop when you ask it to break at the entry to some function? How does it manage to find what to show you when you ask it for the value of a variable? The answer is - debugging information.
|
||||
|
||||
Debugging information is generated by the compiler together with the machine code. It is a representation of the relationship between the executable program and the original source code. This information is encoded into a pre-defined format and stored alongside the machine code. Many such formats were invented over the years for different platforms and executable files. Since the aim of this article isn't to survey the history of these formats, but rather to show how they work, we'll have to settle on something. This something is going to be DWARF, which is almost ubiquitously used today as the debugging information format for ELF executables on Linux and other Unix-y platforms.
|
||||
|
||||
### The DWARF in the ELF
|
||||
|
||||

|
||||
|
||||
According to [its Wikipedia page][17], DWARF was designed alongside ELF, although it can in theory be embedded in other object file formats as well [[1]][18].
|
||||
|
||||
DWARF is a complex format, building on many years of experience with previous formats for various architectures and operating systems. It has to be complex, since it solves a very tricky problem - presenting debugging information from any high-level language to debuggers, providing support for arbitrary platforms and ABIs. It would take much more than this humble article to explain it fully, and to be honest I don't understand all its dark corners well enough to engage in such an endeavor anyway [[2]][19]. In this article I will take a more hands-on approach, showing just enough of DWARF to explain how debugging information works in practical terms.
|
||||
|
||||
### Debug sections in ELF files
|
||||
|
||||
First let's take a glimpse of where the DWARF info is placed inside ELF files. ELF defines arbitrary sections that may exist in each object file. A _section header table_ defines which sections exist and their names. Different tools treat various sections in special ways - for example the linker is looking for some sections, the debugger for others.
|
||||
|
||||
We'll be using an executable built from this C source for our experiments in this article, compiled into tracedprog2:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff(int my_arg)
|
||||
{
|
||||
int my_local = my_arg + 2;
|
||||
int i;
|
||||
|
||||
for (i = 0; i < my_local; ++i)
|
||||
printf("i = %d\n", i);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Dumping the section headers from the ELF executable using objdump -h we'll notice several sections with names beginning with .debug_ - these are the DWARF debugging sections:
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
27 .debug_pubnames 00000028 00000000 00000000 00001057
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
28 .debug_info 000000cc 00000000 00000000 0000107f
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
29 .debug_abbrev 0000008a 00000000 00000000 0000114b
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
30 .debug_line 0000006b 00000000 00000000 000011d5
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
31 .debug_frame 00000044 00000000 00000000 00001240
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
32 .debug_str 000000ae 00000000 00000000 00001284
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
33 .debug_loc 00000058 00000000 00000000 00001332
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
The first number seen for each section here is its size, and the last is the offset where it begins in the ELF file. The debugger uses this information to read the section from the executable.
|
||||
|
||||
Now let's see a few practical examples of finding useful debug information in DWARF.
|
||||
|
||||
### Finding functions
|
||||
|
||||
One of the most basic things we want to do when debugging is placing breakpoints at some function, expecting the debugger to break right at its entrance. To be able to perform this feat, the debugger must have some mapping between a function name in the high-level code and the address in the machine code where the instructions for this function begin.
|
||||
|
||||
This information can be obtained from DWARF by looking at the .debug_info section. Before we go further, a bit of background. The basic descriptive entity in DWARF is called the Debugging Information Entry (DIE). Each DIE has a tag - its type, and a set of attributes. DIEs are interlinked via sibling and child links, and values of attributes can point at other DIEs.
|
||||
|
||||
Let's run:
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
The output is quite long, and for this example we'll just focus on these lines [[3]][20]:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
|
||||
<1><b3>: Abbrev Number: 9 (DW_TAG_subprogram)
|
||||
<b4> DW_AT_external : 1
|
||||
<b5> DW_AT_name : (...): main
|
||||
<b9> DW_AT_decl_file : 1
|
||||
<ba> DW_AT_decl_line : 14
|
||||
<bb> DW_AT_type : <0x4b>
|
||||
<bf> DW_AT_low_pc : 0x804863e
|
||||
<c3> DW_AT_high_pc : 0x804865a
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
There are two entries (DIEs) tagged DW_TAG_subprogram, which is a function in DWARF's jargon. Note that there's an entry for do_stuff and an entry for main. There are several interesting attributes, but the one that interests us here is DW_AT_low_pc. This is the program-counter (EIP in x86) value for the beginning of the function. Note that it's 0x8048604 for do_stuff. Now let's see what this address is in the disassembly of the executable by running objdump -d:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
8048613: c7 45 (...) mov DWORD PTR [ebp-0x10],0x0
|
||||
804861a: eb 18 jmp 8048634 <do_stuff+0x30>
|
||||
804861c: b8 20 (...) mov eax,0x8048720
|
||||
8048621: 8b 55 f0 mov edx,DWORD PTR [ebp-0x10]
|
||||
8048624: 89 54 24 04 mov DWORD PTR [esp+0x4],edx
|
||||
8048628: 89 04 24 mov DWORD PTR [esp],eax
|
||||
804862b: e8 04 (...) call 8048534 <printf@plt>
|
||||
8048630: 83 45 f0 01 add DWORD PTR [ebp-0x10],0x1
|
||||
8048634: 8b 45 f0 mov eax,DWORD PTR [ebp-0x10]
|
||||
8048637: 3b 45 f4 cmp eax,DWORD PTR [ebp-0xc]
|
||||
804863a: 7c e0 jl 804861c <do_stuff+0x18>
|
||||
804863c: c9 leave
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
Indeed, 0x8048604 is the beginning of do_stuff, so the debugger can have a mapping between functions and their locations in the executable.
|
||||
|
||||
### Finding variables
|
||||
|
||||
Suppose that we've indeed stopped at a breakpoint inside do_stuff. We want to ask the debugger to show us the value of the my_local variable. How does it know where to find it? Turns out this is much trickier than finding functions. Variables can be located in global storage, on the stack, and even in registers. Additionally, variables with the same name can have different values in different lexical scopes. The debugging information has to be able to reflect all these variations, and indeed DWARF does.
|
||||
|
||||
I won't cover all the possibilities, but as an example I'll demonstrate how the debugger can find my_local in do_stuff. Let's start at .debug_info and look at the entry for do_stuff again, this time also looking at a couple of its sub-entries:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
<2><8a>: Abbrev Number: 6 (DW_TAG_formal_parameter)
|
||||
<8b> DW_AT_name : (...): my_arg
|
||||
<8f> DW_AT_decl_file : 1
|
||||
<90> DW_AT_decl_line : 4
|
||||
<91> DW_AT_type : <0x4b>
|
||||
<95> DW_AT_location : (...) (DW_OP_fbreg: 0)
|
||||
<2><98>: Abbrev Number: 7 (DW_TAG_variable)
|
||||
<99> DW_AT_name : (...): my_local
|
||||
<9d> DW_AT_decl_file : 1
|
||||
<9e> DW_AT_decl_line : 6
|
||||
<9f> DW_AT_type : <0x4b>
|
||||
<a3> DW_AT_location : (...) (DW_OP_fbreg: -20)
|
||||
<2><a6>: Abbrev Number: 8 (DW_TAG_variable)
|
||||
<a7> DW_AT_name : i
|
||||
<a9> DW_AT_decl_file : 1
|
||||
<aa> DW_AT_decl_line : 7
|
||||
<ab> DW_AT_type : <0x4b>
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
Note the first number inside the angle brackets in each entry. This is the nesting level - in this example entries with <2> are children of the entry with <1>. So we know that the variable my_local (marked by the DW_TAG_variable tag) is a child of the do_stuff function. The debugger is also interested in a variable's type to be able to display it correctly. In the case of my_local the type points to another DIE - <0x4b>. If we look it up in the output of objdump we'll see it's a signed 4-byte integer.
|
||||
|
||||
To actually locate the variable in the memory image of the executing process, the debugger will look at the DW_AT_location attribute. For my_local it says DW_OP_fbreg: -20. This means that the variable is stored at offset -20 from the DW_AT_frame_base attribute of its containing function - which is the base of the frame for the function.
|
||||
|
||||
The DW_AT_frame_base attribute of do_stuff has the value 0x0 (location list), which means that this value actually has to be looked up in the location list section. Let's look at it:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Contents of the .debug_loc section:
|
||||
|
||||
Offset Begin End Expression
|
||||
00000000 08048604 08048605 (DW_OP_breg4: 4 )
|
||||
00000000 08048605 08048607 (DW_OP_breg4: 8 )
|
||||
00000000 08048607 0804863e (DW_OP_breg5: 8 )
|
||||
00000000 <End of list>
|
||||
0000002c 0804863e 0804863f (DW_OP_breg4: 4 )
|
||||
0000002c 0804863f 08048641 (DW_OP_breg4: 8 )
|
||||
0000002c 08048641 0804865a (DW_OP_breg5: 8 )
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
The location information we're interested in is the first one [[4]][21]. For each address where the debugger may be, it specifies the current frame base from which offsets to variables are to be computed as an offset from a register. For x86, bpreg4 refers to esp and bpreg5 refers to ebp.
|
||||
|
||||
It's educational to look at the first several instructions of do_stuff again:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
Note that ebp becomes relevant only after the second instruction is executed, and indeed for the first two addresses the base is computed from esp in the location information listed above. Once ebp is valid, it's convenient to compute offsets relative to it because it stays constant while esp keeps moving with data being pushed and popped from the stack.
|
||||
|
||||
So where does it leave us with my_local? We're only really interested in its value after the instruction at 0x8048610 (where its value is placed in memory after being computed in eax), so the debugger will be using the DW_OP_breg5: 8 frame base to find it. Now it's time to rewind a little and recall that the DW_AT_location attribute for my_local says DW_OP_fbreg: -20. Let's do the math: -20 from the frame base, which is ebp + 8. We get ebp - 12. Now look at the disassembly again and note where the data is moved from eax - indeed, ebp - 12 is where my_local is stored.
|
||||
|
||||
### Looking up line numbers
|
||||
|
||||
When we talked about finding functions in the debugging information, I was cheating a little. When we debug C source code and put a breakpoint in a function, we're usually not interested in the first _machine code_ instruction [[5]][22]. What we're _really_ interested in is the first _C code_ line of the function.
|
||||
|
||||
This is why DWARF encodes a full mapping between lines in the C source code and machine code addresses in the executable. This information is contained in the .debug_line section and can be extracted in a readable form as follows:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Decoded dump of debug contents of section .debug_line:
|
||||
|
||||
CU: /home/eliben/eli/eliben-code/debugger/tracedprog2.c:
|
||||
File name Line number Starting address
|
||||
tracedprog2.c 5 0x8048604
|
||||
tracedprog2.c 6 0x804860a
|
||||
tracedprog2.c 9 0x8048613
|
||||
tracedprog2.c 10 0x804861c
|
||||
tracedprog2.c 9 0x8048630
|
||||
tracedprog2.c 11 0x804863c
|
||||
tracedprog2.c 15 0x804863e
|
||||
tracedprog2.c 16 0x8048647
|
||||
tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
It shouldn't be hard to see the correspondence between this information, the C source code and the disassembly dump. Line number 5 points at the entry point to do_stuff - 0x8040604. The next line, 6, is where the debugger should really stop when asked to break in do_stuff, and it points at 0x804860a which is just past the prologue of the function. This line information easily allows bi-directional mapping between lines and addresses:
|
||||
|
||||
* When asked to place a breakpoint at a certain line, the debugger will use it to find which address it should put its trap on (remember our friend int 3 from the previous article?)
|
||||
* When an instruction causes a segmentation fault, the debugger will use it to find the source code line on which it happened.
|
||||
|
||||
### <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">libdwarf - Working with DWARF programmatically
|
||||
|
||||
Employing command-line tools to access DWARF information, while useful, isn't fully satisfying. As programmers, we'd like to know how to write actual code that can read the format and extract what we need from it.
|
||||
|
||||
Naturally, one approach is to grab the DWARF specification and start hacking away. Now, remember how everyone keeps saying that you should never, ever parse HTML manually but rather use a library? Well, with DWARF it's even worse. DWARF is _much_ more complex than HTML. What I've shown here is just the tip of the iceberg, and to make things even harder, most of this information is encoded in a very compact and compressed way in the actual object file [[6]][23].
|
||||
|
||||
So we'll take another road and use a library to work with DWARF. There are two major libraries I'm aware of (plus a few less complete ones):
|
||||
|
||||
1. BFD (libbfd) is used by the [GNU binutils][11], including objdump which played a star role in this article, ld (the GNU linker) and as (the GNU assembler).
|
||||
2. libdwarf - which together with its big brother libelf are used for the tools on Solaris and FreeBSD operating systems.
|
||||
|
||||
I'm picking libdwarf over BFD because it appears less arcane to me and its license is more liberal (LGPLvs. GPL).
|
||||
|
||||
Since libdwarf is itself quite complex it requires a lot of code to operate. I'm not going to show all this code here, but [you can download][24] and run it yourself. To compile this file you'll need to have libelfand libdwarf installed, and pass the -lelf and -ldwarf flags to the linker.
|
||||
|
||||
The demonstrated program takes an executable and prints the names of functions in it, along with their entry points. Here's what it produces for the C program we've been playing with in this article:
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
DW_TAG_subprogram: 'do_stuff'
|
||||
low pc : 0x08048604
|
||||
high pc : 0x0804863e
|
||||
DW_TAG_subprogram: 'main'
|
||||
low pc : 0x0804863e
|
||||
high pc : 0x0804865a
|
||||
```
|
||||
|
||||
The documentation of libdwarf (linked in the References section of this article) is quite good, and with some effort you should have no problem pulling any other information demonstrated in this article from the DWARF sections using it.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Debugging information is a simple concept in principle. The implementation details may be intricate, but in the end of the day what matters is that we now know how the debugger finds the information it needs about the original source code from which the executable it's tracing was compiled. With this information in hand, the debugger bridges between the world of the user, who thinks in terms of lines of code and data structures, and the world of the executable, which is just a bunch of machine code instructions and data in registers and memory.
|
||||
|
||||
This article, with its two predecessors, concludes an introductory series that explains the inner workings of a debugger. Using the information presented here and some programming effort, it should be possible to create a basic but functional debugger for Linux.
|
||||
|
||||
As for the next steps, I'm not sure yet. Maybe I'll end the series here, maybe I'll present some advanced topics such as backtraces, and perhaps debugging on Windows. Readers can also suggest ideas for future articles in this series or related material. Feel free to use the comments or send me an email.
|
||||
|
||||
### References
|
||||
|
||||
* objdump man page
|
||||
* Wikipedia pages for [ELF][12] and [DWARF][13].
|
||||
* [Dwarf Debugging Standard home page][14] - from here you can obtain the excellent DWARF tutorial by Michael Eager, as well as the DWARF standard itself. You'll probably want version 2 since it's what gccproduces.
|
||||
* [libdwarf home page][15] - the download package includes a comprehensive reference document for the library
|
||||
* [BFD documentation][16]
|
||||
|
||||
|
||||
[1] DWARF is an open standard, published here by the DWARF standards committee. The DWARF logo displayed above is taken from that website.
|
||||
|
||||
[2] At the end of the article I've collected some useful resources that will help you get more familiar with DWARF, if you're interested. Particularly, start with the DWARF tutorial.
|
||||
|
||||
[3] Here and in subsequent examples, I'm placing (...) instead of some longer and un-interesting information for the sake of more convenient formatting.
|
||||
|
||||
[4] Because the DW_AT_frame_base attribute of do_stuff contains offset 0x0 into the location list. Note that the same attribute for main contains the offset 0x2c which is the offset for the second set of location expressions.
|
||||
|
||||
[5] Where the function prologue is usually executed and the local variables aren't even valid yet.
|
||||
|
||||
[6] Some parts of the information (such as location data and line number data) are encoded as instructions for a specialized virtual machine. Yes, really.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id1
|
||||
[2]:http://dwarfstd.org/
|
||||
[3]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.gnu.org/software/binutils/
|
||||
[12]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[13]:http://en.wikipedia.org/wiki/DWARF
|
||||
[14]:http://dwarfstd.org/
|
||||
[15]:http://reality.sgiweb.org/davea/dwarf.html
|
||||
[16]:http://sourceware.org/binutils/docs-2.21/bfd/index.html
|
||||
[17]:http://en.wikipedia.org/wiki/DWARF
|
||||
[18]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id7
|
||||
[19]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id8
|
||||
[20]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id9
|
||||
[21]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id10
|
||||
[22]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id11
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
@ -1,3 +1,5 @@
|
||||
+翻译中+
|
||||
+
|
||||
Useful Vim editor plugins for software developers - part 3: a.vim
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by mudongliang
|
||||
# OpenSUSE Leap 42.2 Gnome - Better but not really
|
||||
|
||||
Updated: February 6, 2017
|
||||
|
||||
@ -1,317 +0,0 @@
|
||||
Install Drupal 8 in RHEL, CentOS & Fedora
|
||||
============================================================
|
||||
|
||||
Drupal is an open source, flexible, highly scalable and secure Content Management System (CMS) which allows users to easily build and create web sites. It can be extended using modules and enables users to transform content management into powerful digital solutions.
|
||||
|
||||
Drupal runs on a web server like Apache, IIS, Lighttpd, Cherokee, Nginx and a backend databases MySQL, MongoDB, MariaDB, PostgreSQL, SQLite, MS SQL Server.
|
||||
|
||||
In this article, we will show how to perform a manual installation and configuration of Drupal 8 on RHEL 7/6, CentOS 7/6 and Fedora 20-25 distributions using LAMP setup.
|
||||
|
||||
#### Drupal Requirement:
|
||||
|
||||
1. Apache 2.x (Recommended)
|
||||
2. PHP 5.5.9 or higher (5.5 recommended)
|
||||
3. MySQL 5.5.3 or MariaDB 5.5.20 with PHP Data Objects (PDO)
|
||||
|
||||
For this setup, I am using website hostname as “drupal.tecmint.com” and IP address is “192.168.0.104“. These settings may differ at your environment, so please make changes as appropriate.
|
||||
|
||||
### Step 1: Installing Apache Web Server
|
||||
|
||||
1. First we will start with installing Apache web server from the official repositories:
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. After the installation completes, the service will be disabled at first, so we need to start it manually for the mean time and enable it to start automatically from the next system boot as well:
|
||||
|
||||
```
|
||||
------------- On SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
------------- On SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service httpd start
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. Next, in order to allow access to Apache services from HTTP and HTTPS, we have to open 80 and 443 port where the HTTPD daemon is listening as follows:
|
||||
|
||||
```
|
||||
------------- On FirewallD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
# firewall-cmd --reload
|
||||
------------- On IPtables - CentOS/RHEL 6 and Fedora 22+ -------------
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
|
||||
# service iptables save
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. Now verify that Apache is working fine, open a remote browser and type your server IP Address using HTTP protocol in the `URL:http://server_IP`, and the default Apache2 page should appear as in the screenshot below.
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
Apache Default Page
|
||||
|
||||
### Step 2: Install PHP Support for Apache
|
||||
|
||||
5. Next, install PHP and the required PHP modules.
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
|
||||
Important: If you want to install PHP 7.0, you need to add the following repositories: EPEL and Webtactic in order to install PHP 7.0 using yum:
|
||||
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. Next, to get a full information about the PHP installation and all its current configurations from a web browser, let’s create a `info.php` file in the Apache DocumentRoot (`/var/www/html`) using the following command.
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
```
|
||||
|
||||
then restart HTTPD service and enter the URL `http://server_IP/info.php` in the web browser.
|
||||
|
||||
```
|
||||
# systemctl restart httpd
|
||||
OR
|
||||
# service httpd restart
|
||||
```
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Verify PHP Information
|
||||
|
||||
### Step 3: Install and Configure MariaDB Database
|
||||
|
||||
7. For your information, Red Hat Enterprise Linux/CentOS 7.0 moved from supporting MySQL to MariaDB as the default database management system.
|
||||
|
||||
To install MariaDB database, you need to add the following [official MariaDB repository][3] to file `/etc/yum.repos.d/MariaDB.repo` as shown.
|
||||
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
Once the repo file in place you can able to install MariaDB like so:
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. When the installation of MariaDB packages completes, start the database daemon for the mean time and enable it to start automatically at the next boot.
|
||||
|
||||
```
|
||||
------------- On SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
------------- On SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service mysqld start
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. Then run the `mysql_secure_installation` script to secure the database (set root password, disable remote root login, remove test database and remove anonymous users) as follows:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Mysql Secure Installation
|
||||
|
||||
### Step 4: Install and Configure Drupal 8 in CentOS
|
||||
|
||||
10. Here, we will start by [downloading the latest Drupal version][5] (i.e 8.2.6) using the [wget command][6]. If you don’t have wget and gzip packages installed, then use the following command to install them:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. Afterwards, let’s [extract the tar file][7] and move the Drupal folder into the Apache Document Root (`/var/www/html`).
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. Then, create the settings file `settings.php`, from the sample settings file `default.settings.php`) in the folder (/var/www/html/drupal/sites/default) and then set the appropriate permissions on the Drupal site directory, including sub-directories and files as follows:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
# cp default.settings.php settings.php
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. Importantly, set the SELinux rule on the folder “/var/www/html/drupal/sites/” as below:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
14. Now we have to create a database and a user for the Drupal site to manage.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
Enter password:
|
||||
```
|
||||
MySQL Shell
|
||||
```
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MySQL connection id is 12
|
||||
Server version: 5.1.73 Source distribution
|
||||
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
MySQL [(none)]> create database drupal;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
MySQL [(none)]> create user ravi@localhost identified by 'tecmint123';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> grant all on drupal.* to ravi@localhost;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> flush privileges;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> exit
|
||||
Bye
|
||||
```
|
||||
|
||||
15. Now finally, at this point, open the URL: `http://server_IP/drupal/` to start the web installer, and choose your preferred installation language and Click Save to Continue.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Drupal Installation Language
|
||||
|
||||
16. Next, select an installation profile, choose Standard and click Save to Continue.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Drupal Installation Profile
|
||||
|
||||
17. Look through the requirements review and enable clean URL before moving forward.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
Verify Drupal Requirements
|
||||
|
||||
Now enable clean URL drupal under your Apache configuration.
|
||||
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
Make sure to set AllowOverride All to the default DocumentRoot /var/www/html directory as shown in the screenshot below.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
Enable Clean URL in Drupal
|
||||
|
||||
18. Once you enabled clean URL for Drupal, refresh the page to perform database configurations from the interface below; enter the Drupal site database name, database user and the user’s password.
|
||||
|
||||
Once filled all database details, click on Save and Continue.
|
||||
|
||||
[
|
||||
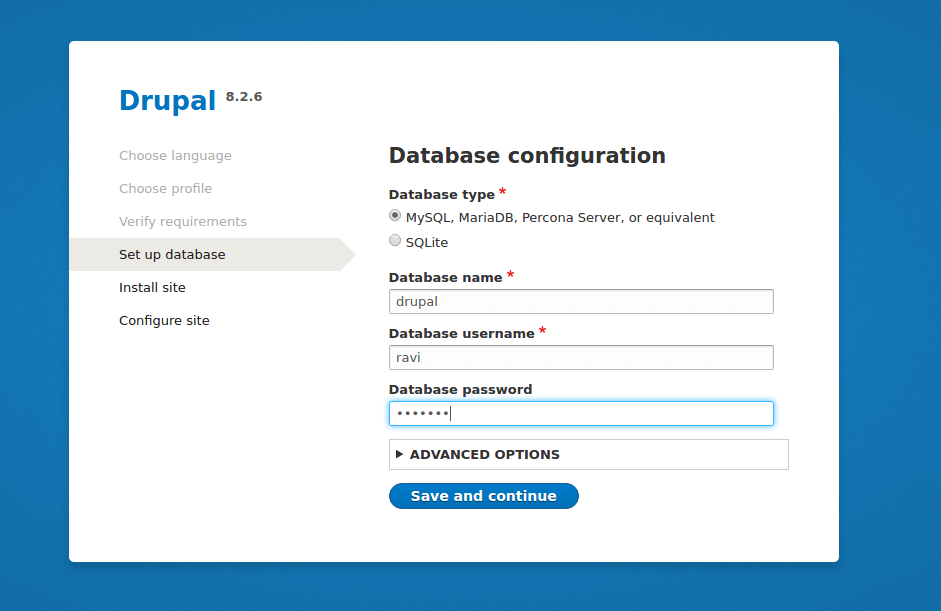
|
||||
][12]
|
||||
|
||||
Drupal Database Configuration
|
||||
|
||||
If the above settings were correct, the drupal site installation should start successfully as in the interface below.
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Drupal Installation
|
||||
|
||||
19. Next configure the site by setting the values for (use values that apply to your scenario):
|
||||
|
||||
1. Site Name – TecMint Drupal Site
|
||||
2. Site email address – admin@tecmint.com
|
||||
3. Username – admin
|
||||
4. Password – ##########
|
||||
5. User’s Email address – admin@tecmint.com
|
||||
6. Default country – India
|
||||
7. Default time zone – UTC
|
||||
|
||||
After setting the appropriate values, click Save and Continue to finish the site installation process.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Drupal Site Configuration
|
||||
|
||||
20. The interface that follows shows successful installation of Drupal 8 site with LAMP stack.
|
||||
|
||||
[
|
||||
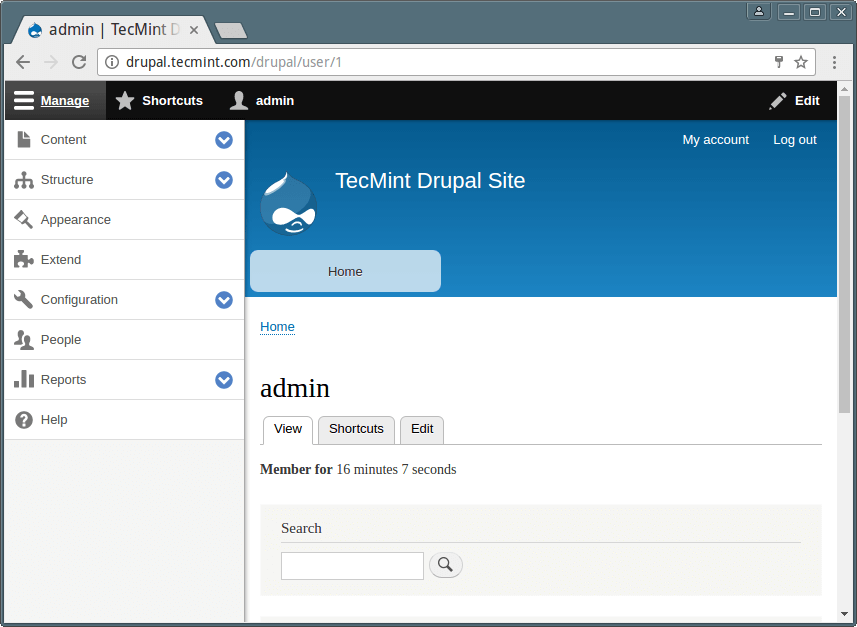
|
||||
][15]
|
||||
|
||||
Drupal Site Dashboard
|
||||
|
||||
Now you can click on Add content to create a sample web content such as a page.
|
||||
|
||||
Optional: For those who are uncomfortable using [MySQL command line to manage databases][16], [install PhpMyAdmin to manage databases][17] from a web browser interface.
|
||||
|
||||
Visit the Drupal Documentation: [https://www.drupal.org/docs/8][18]
|
||||
|
||||
That’s all! In this article, we showed how to download, install and setup LAMP stack and Drupal 8 with basic configurations on CentOS 7\. Use the feedback form below to write back to us concerning this tutorial or perhaps to provide us any related information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-drupal-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2013/07/Apache-Default-Page.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2013/07/PHP-Information.png
|
||||
[3]:https://downloads.mariadb.org/mariadb/repositories/#mirror=Fibergrid&distro=CentOS
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2013/07/Mysql-Secure-Installation.png
|
||||
[5]:https://www.drupal.org/download
|
||||
[6]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/extract-tar-files-to-specific-or-different-directory-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Profile.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2013/07/Verify-Drupal-Requirements.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2013/07/Enable-Clean-URL-in-Drupal.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Database-Configuration.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Configuration.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Dashboard.png
|
||||
[16]:http://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[17]:http://www.tecmint.com/install-phpmyadmin-rhel-centos-fedora-linux/
|
||||
[18]:https://www.drupal.org/docs/8
|
||||
@ -1,3 +1,4 @@
|
||||
Cathon is translating
|
||||
How to use markers and perform text selection in Vim
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,280 @@
|
||||
How to deploy Node.js Applications with pm2 and Nginx on Ubuntu
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Install Node.js LTS][1]
|
||||
2. [Step 2 - Generate Express Sample App][2]
|
||||
3. [Step 3 - Install pm2][3]
|
||||
4. [Step 4 - Install and Configure Nginx as a Reverse proxy][4]
|
||||
5. [Step 5 - Testing][5]
|
||||
6. [Links][6]
|
||||
|
||||
pm2 is a process manager for Node.js applications, it allows you to keep your apps alive and has a built-in load balancer. It's simple and powerful, you can always restart or reload your node application with zero downtime and it allows you to create a cluster of your node app.
|
||||
|
||||
In this tutorial, I will show you how to install and configure pm2 for the simple 'Express' application and then configure Nginx as a reverse proxy for the node application that is running under pm2.
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Ubuntu 16.04 - 64bit
|
||||
* Root Privileges
|
||||
|
||||
### Step 1 - Install Node.js LTS
|
||||
|
||||
In this tutorial, we will start our project from scratch. First, we need Nodejs installed on the server. I will use the Nodejs LTS version 6.x which can be installed from the nodesource repository.
|
||||
|
||||
Install the package '**python-software-properties**' from the Ubuntu repository and then add the 'nodesource' Nodejs repository.
|
||||
|
||||
sudo apt-get install -y python-software-properties
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
|
||||
Install the latest Nodejs LTS version.
|
||||
|
||||
sudo apt-get install -y nodejs
|
||||
|
||||
When the installation succeeded, check node and npm version.
|
||||
|
||||
node -v
|
||||
npm -v
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### Step 2 - Generate Express Sample App
|
||||
|
||||
I will use simple web application skeleton generated with a package named '**express-generator**' for this example installation. Express-generator can be installed with the npm command.
|
||||
|
||||
Install '**express-generator**' with npm:
|
||||
|
||||
npm install express-generator -g
|
||||
|
||||
**-g:** install package inside the system
|
||||
|
||||
We will run the application as a normal user, not a root or super user. So we need to create a new user first.
|
||||
|
||||
Create a new user, I name mine '**yume**':
|
||||
|
||||
useradd -m -s /bin/bash yume
|
||||
passwd yume
|
||||
|
||||
Login to the new user by using su:
|
||||
|
||||
su - yume
|
||||
|
||||
Next, generate a new simple web application with the express command:
|
||||
|
||||
express hakase-app
|
||||
|
||||
The command will create new project directory '**hakase-app**'.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
Go to the project directory and install all dependencies needed by the app.
|
||||
|
||||
cd hakase-app
|
||||
npm install
|
||||
|
||||
Then test and start a new simple application with the command below:
|
||||
|
||||
DEBUG=myapp:* npm start
|
||||
|
||||
By default, our express application will run on port **3000**. Now visit server IP address: [192.168.33.10:3000][12]
|
||||
|
||||
[
|
||||
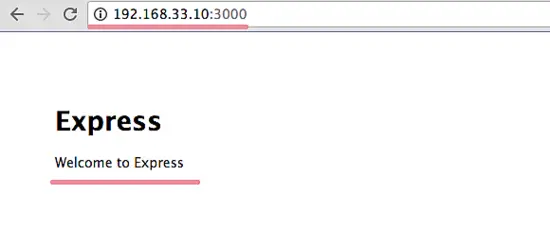
|
||||
][13]
|
||||
|
||||
The simple web application skeleton is running on port 3000, under user 'yume'.
|
||||
|
||||
### Step 3 - Install pm2
|
||||
|
||||
pm2 is a node package and can be installed with the npm command. So let's install it with npm (with root privileges, when you are still logged in as user hakase, then run the command "exit" ro become root again):
|
||||
|
||||
npm install pm2 -g
|
||||
|
||||
Now we can use pm2 for our web application.
|
||||
|
||||
Go to the app directory '**hakase-app**':
|
||||
|
||||
su - hakase
|
||||
cd ~/hakase-app/
|
||||
|
||||
There you can find a file named '**package.json**', display its content with the cat command.
|
||||
|
||||
cat package.json
|
||||
|
||||
[
|
||||
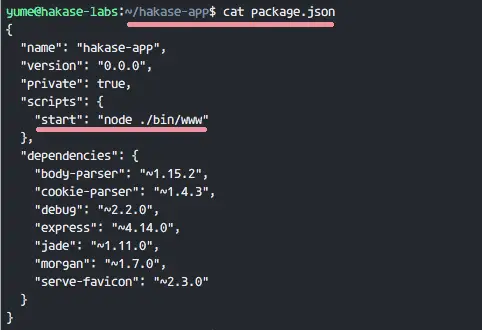
|
||||
][14]
|
||||
|
||||
You can see the '**start**' line contains a command that is used by Nodejs to start the express application. This command we will use with the pm2 process manager.
|
||||
|
||||
Run the express application with the pm2 command below:
|
||||
|
||||
pm2 start ./bin/www
|
||||
|
||||
Now you can see the results is below:
|
||||
|
||||
[
|
||||
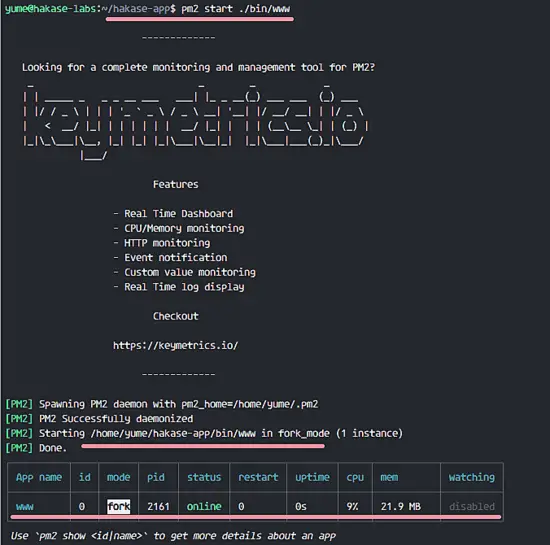
|
||||
][15]
|
||||
|
||||
Our express application is running under pm2 with name '**www**', id '**0**'. You can get more details about the application running under pm2 with the show option '**show nodeid|name**'.
|
||||
|
||||
pm2 show www
|
||||
|
||||
[
|
||||
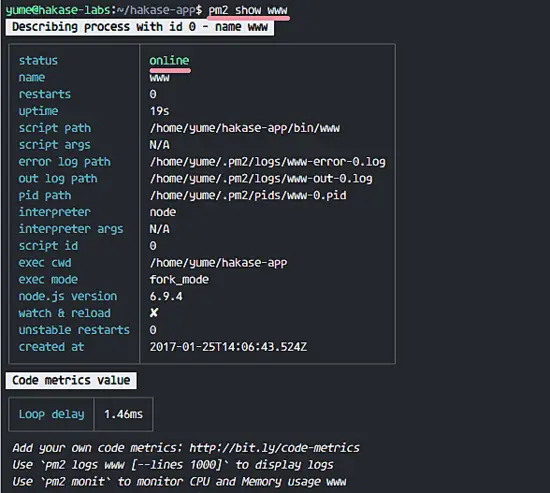
|
||||
][16]
|
||||
|
||||
If you like to see the log of our application, you can use the logs option. It's just access and error log and you can see the HTTP Status of the application.
|
||||
|
||||
pm2 logs www
|
||||
|
||||
[
|
||||
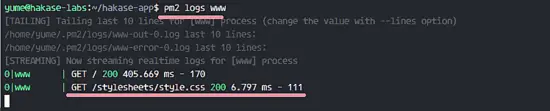
|
||||
][17]
|
||||
|
||||
You can see that our process is running. Now, let's enable it to start at boot time.
|
||||
|
||||
pm2 startup systemd
|
||||
|
||||
**systemd**: Ubuntu 16 is using systemd.
|
||||
|
||||
You will get a message for running a command as root. Back to the root privileges with "exit" and then run that command.
|
||||
|
||||
sudo env PATH=$PATH:/usr/bin /usr/lib/node_modules/pm2/bin/pm2 startup systemd -u yume --hp /home/yume
|
||||
|
||||
It will generate the systemd configuration file for application startup. When you reboot your server, the application will automatically run on startup.
|
||||
|
||||
[
|
||||
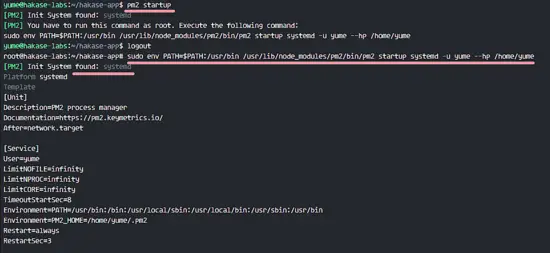
|
||||
][18]
|
||||
|
||||
### Step 4 - Install and Configure Nginx as a Reverse proxy
|
||||
|
||||
In this tutorial, we will use Nginx as a reverse proxy for the node application. Nginx is available in the Ubuntu repository, install it with the apt command:
|
||||
|
||||
sudo apt-get install -y nginx
|
||||
|
||||
Next, go to the '**sites-available**' directory and create a new virtual host configuration file.
|
||||
|
||||
cd /etc/nginx/sites-available/
|
||||
vim hakase-app
|
||||
|
||||
Paste configuration below:
|
||||
|
||||
```
|
||||
upstream hakase-app {
|
||||
# Nodejs app upstream
|
||||
server 127.0.0.1:3000;
|
||||
keepalive 64;
|
||||
}
|
||||
|
||||
# Server on port 80
|
||||
server {
|
||||
listen 80;
|
||||
server_name hakase-node.co;
|
||||
root /home/yume/hakase-app;
|
||||
|
||||
location / {
|
||||
# Proxy_pass configuration
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-NginX-Proxy true;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_max_temp_file_size 0;
|
||||
proxy_pass http://hakase-app/;
|
||||
proxy_redirect off;
|
||||
proxy_read_timeout 240s;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
On the configuration:
|
||||
|
||||
* The node app is running with domain name '**hakase-node.co**'.
|
||||
* All traffic from nginx will be forwarded to the node app that is running on port **3000**.
|
||||
|
||||
Test Nginx configuration and make sure there is no error.
|
||||
|
||||
nginx -t
|
||||
|
||||
Start Nginx and enable it to start at boot time:
|
||||
|
||||
systemctl start nginx
|
||||
systemctl enable nginx
|
||||
|
||||
### Step 5 - Testing
|
||||
|
||||
Open your web browser and visit the domain name (mine is):
|
||||
|
||||
[http://hakase-app.co][19]
|
||||
|
||||
You will see the express application is running under the nginx web server.
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
Next, reboot your server, and make sure the node app is running at the boot time:
|
||||
|
||||
pm2 save
|
||||
sudo reboot
|
||||
|
||||
If you have logged in again to your server, check the node app process. Run the command below as '**yume**' user.
|
||||
|
||||
su - yume
|
||||
pm2 status www
|
||||
|
||||
[
|
||||
|
||||
][21]
|
||||
|
||||
The Node Application is running under pm2 and Nginx as reverse proxy.
|
||||
|
||||
### Links
|
||||
|
||||
* [Ubuntu][7]
|
||||
* [Node.js][8]
|
||||
* [Nginx][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-nodejs-lts
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-generate-express-sample-app
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-pm
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-and-configure-nginx-as-a-reverse-proxy
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-testing
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#links
|
||||
[7]:https://www.ubuntu.com/
|
||||
[8]:https://nodejs.org/en/
|
||||
[9]:https://www.nginx.com/
|
||||
[10]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/1.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/2.png
|
||||
[12]:https://www.howtoforge.com/admin/articles/edit/192.168.33.10:3000
|
||||
[13]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/3.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/4.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/5.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/6.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/7.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/8.png
|
||||
[19]:http://hakase-app.co/
|
||||
[20]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/9.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/10.png
|
||||
236
sources/tech/20170321 Writing a Linux Debugger Part 1 Setup.md
Normal file
236
sources/tech/20170321 Writing a Linux Debugger Part 1 Setup.md
Normal file
@ -0,0 +1,236 @@
|
||||
Writing a Linux Debugger Part 1: Setup
|
||||
============================================================
|
||||
|
||||
Anyone who has written more than a hello world program should have used a debugger at some point (if you haven’t, drop what you’re doing and learn how to use one). However, although these tools are in such widespread use, there aren’t a lot of resources which tell you how they work and how to write one[1][1], especially when compared to other toolchain technologies like compilers. In this post series we’ll learn what makes debuggers tick and write one for debugging Linux programs.
|
||||
|
||||
We’ll support the following features:
|
||||
|
||||
* Launch, halt, and continue execution
|
||||
* Set breakpoints on
|
||||
* Memory addresses
|
||||
* Source code lines
|
||||
* Function entry
|
||||
* Read and write registers and memory
|
||||
* Single stepping
|
||||
* Instruction
|
||||
* Step in
|
||||
* Step out
|
||||
* Step over
|
||||
* Print current source location
|
||||
* Print backtrace
|
||||
* Print values of simple variables
|
||||
|
||||
In the final part I’ll also outline how you could add the following to your debugger:
|
||||
|
||||
* Remote debugging
|
||||
* Shared library and dynamic loading support
|
||||
* Expression evaluation
|
||||
* Multi-threaded debugging support
|
||||
|
||||
I’ll be focusing on C and C++ for this project, but it should work just as well with any language which compiles down to machine code and outputs standard DWARF debug information (if you don’t know what that is yet, don’t worry, this will be covered soon). Additionally, my focus will be on just getting something up and running which works most of the time, so things like robust error handling will be eschewed in favour of simplicity.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][2]
|
||||
2. [Breakpoints][3]
|
||||
3. Registers and memory
|
||||
4. Elves and dwarves
|
||||
5. Stepping, source and signals
|
||||
6. Stepping on dwarves
|
||||
7. Source-level breakpoints
|
||||
8. Stack unwinding
|
||||
9. Reading variables
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Getting set up
|
||||
|
||||
Before we jump into things, let’s get our environment set up. I’ll be using two dependencies in this tutorial: [Linenoise][4] for handling our command line input, and [libelfin][5] for parsing the debug information. You could use the more traditional libdwarf instead of libelfin, but the interface is nowhere near as nice, and libelfin also provides a mostly complete DWARF expression evaluator, which will save you a lot of time if you want to read variables. Make sure that you use the fbreg branch of my fork of libelfin, as it hacks on some extra support for reading variables on x86.
|
||||
|
||||
Once you’ve either installed these on your system, or got them building as dependencies with whatever build system you prefer, it’s time to get started. I just set them to build along with the rest of my code in my CMake files.
|
||||
|
||||
* * *
|
||||
|
||||
### Launching the executable
|
||||
|
||||
Before we actually debug anything, we’ll need to launch the debugee program. We’ll do this with the classic fork/exec pattern.
|
||||
|
||||
```
|
||||
int main(int argc, char* argv[]) {
|
||||
if (argc < 2) {
|
||||
std::cerr << "Program name not specified";
|
||||
return -1;
|
||||
}
|
||||
|
||||
auto prog = argv[1];
|
||||
|
||||
auto pid = fork();
|
||||
if (pid == 0) {
|
||||
//we're in the child process
|
||||
//execute debugee
|
||||
|
||||
}
|
||||
else if (pid >= 1) {
|
||||
//we're in the parent process
|
||||
//execute debugger
|
||||
}
|
||||
```
|
||||
|
||||
We call `fork` and this causes our program to split into two processes. If we are in the child process, `fork` returns `0`, and if we are in the parent process, it returns the process ID of the child process.
|
||||
|
||||
If we’re in the child process, we want to replace whatever we’re currently executing with the program we want to debug.
|
||||
|
||||
```
|
||||
ptrace(PTRACE_TRACEME, 0, nullptr, nullptr);
|
||||
execl(prog.c_str(), prog.c_str(), nullptr);
|
||||
```
|
||||
|
||||
Here we have our first encounter with `ptrace`, which is going to become our best friend when writing our debugger. `ptrace`allows us to observe and control the execution of another process by reading registers, reading memory, single stepping and more. The API is very ugly; it’s a single function which you provide with an enumerator value for what you want to do, and then some arguments which will either be used or ignored depending on which value you supply. The signature looks like this:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
`request` is what we would like to do to the traced process; `pid`is the process ID of the traced process; `addr` is a memory address, which is used in some calls to designate an address in the tracee; and `data` is some request-specific resource. The return value often gives error information, so you probably want to check that in your real code; I’m just omitting it for brevity. You can have a look at the man pages for more information.
|
||||
|
||||
The request we send in the above code, `PTRACE_TRACEME`, indicates that this process should allow its parent to trace it. All of the other arguments are ignored, because API design isn’t important /s.
|
||||
|
||||
Next, we call `execl`, which is one of the many `exec` flavours. We execute the given program, passing the name of it as a command-line argument and a `nullptr` to terminate the list. You can pass any other arguments needed to execute your program here if you like.
|
||||
|
||||
After we’ve done this, we’re finished with the child process; we’ll just let it keep running until we’re finished with it.
|
||||
|
||||
* * *
|
||||
|
||||
### Adding our debugger loop
|
||||
|
||||
Now that we’ve launched the child process, we want to be able to interact with it. For this, we’ll create a `debugger` class, give it a loop for listening to user input, and launch that from our parent fork of our `main` function.
|
||||
|
||||
```
|
||||
else if (pid >= 1) {
|
||||
//parent
|
||||
debugger dbg{prog, pid};
|
||||
dbg.run();
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
class debugger {
|
||||
public:
|
||||
debugger (std::string prog_name, pid_t pid)
|
||||
: m_prog_name{std::move(prog_name)}, m_pid{pid} {}
|
||||
|
||||
void run();
|
||||
|
||||
private:
|
||||
std::string m_prog_name;
|
||||
pid_t m_pid;
|
||||
};
|
||||
```
|
||||
|
||||
In our `run` function, we need to wait until the child process has finished launching, then just keep on getting input from linenoise until we get an EOF (ctrl+d).
|
||||
|
||||
```
|
||||
void debugger::run() {
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
|
||||
char* line = nullptr;
|
||||
while((line = linenoise("minidbg> ")) != nullptr) {
|
||||
handle_command(line);
|
||||
linenoiseHistoryAdd(line);
|
||||
linenoiseFree(line);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
When the traced process is launched, it will be sent a `SIGTRAP`signal, which is a trace or breakpoint trap. We can wait until this signal is sent using the `waitpid` function.
|
||||
|
||||
After we know the process is ready to be debugged, we listen for user input. The `linenoise` function takes a prompt to display and handles user input by itself. This means we get a nice command line with history and navigation commands without doing much work at all. When we get the input, we give the command to a `handle_command` function which we’ll write shortly, then we add this command to the linenoise history and free the resource.
|
||||
|
||||
* * *
|
||||
|
||||
### Handling input
|
||||
|
||||
Our commands will follow a similar format to gdb and lldb. To continue the program, a user will type `continue` or `cont` or even just `c`. If they want to set a breakpoint on an address, they’ll write `break 0xDEADBEEF`, where `0xDEADBEEF` is the desired address in hexadecimal format. Let’s add support for these commands.
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "continue")) {
|
||||
continue_execution();
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`split` and `is_prefix` are a couple of small helper functions:
|
||||
|
||||
```
|
||||
std::vector<std::string> split(const std::string &s, char delimiter) {
|
||||
std::vector<std::string> out{};
|
||||
std::stringstream ss {s};
|
||||
std::string item;
|
||||
|
||||
while (std::getline(ss,item,delimiter)) {
|
||||
out.push_back(item);
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
bool is_prefix(const std::string& s, const std::string& of) {
|
||||
if (s.size() > of.size()) return false;
|
||||
return std::equal(s.begin(), s.end(), of.begin());
|
||||
}
|
||||
```
|
||||
|
||||
We’ll add `continue_execution` to the `debugger` class.
|
||||
|
||||
```
|
||||
void debugger::continue_execution() {
|
||||
ptrace(PTRACE_CONT, m_pid, nullptr, nullptr);
|
||||
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
}
|
||||
```
|
||||
|
||||
For now our `continue_execution` function will just use `ptrace` to tell the process to continue, then `waitpid` until it’s signalled.
|
||||
|
||||
* * *
|
||||
|
||||
### Finishing up
|
||||
|
||||
Now you should be able to compile some C or C++ program, run it through your debugger, see it halting on entry, and be able to continue execution from your debugger. In the next part we’ll learn how to get our debugger to set breakpoints. If you come across any issues, please let me know in the comments!
|
||||
|
||||
You can find the code for this post [here][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/simon-brand-36520857
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/#fn:1
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[3]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[4]:https://github.com/antirez/linenoise
|
||||
[5]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
[6]:https://github.com/TartanLlama/minidbg/tree/tut_setup
|
||||
@ -0,0 +1,203 @@
|
||||
Writing a Linux Debugger Part 2: Breakpoints
|
||||
============================================================
|
||||
|
||||
In the first part of this series we wrote a small process launcher as a base for our debugger. In this post we’ll learn how breakpoints work in x86 Linux and augment our tool with the ability to set them.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
2. [Breakpoints][2]
|
||||
3. Registers and memory
|
||||
4. Elves and dwarves
|
||||
5. Stepping, source and signals
|
||||
6. Stepping on dwarves
|
||||
7. Source-level breakpoints
|
||||
8. Stack unwinding
|
||||
9. Reading variables
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### How is breakpoint formed?
|
||||
|
||||
There are two main kinds of breakpoints: hardware and software. Hardware breakpoints typically involve setting architecture-specific registers to produce your breaks for you, whereas software breakpoints involve modifying the code which is being executed on the fly. We’ll be focusing solely on software breakpoints for this article, as they are simpler and you can have as many as you want. On x86 you can only have four hardware breakpoints set at a given time, but they give you the power to make them fire on just reading from or writing to a given address rather than only executing code there.
|
||||
|
||||
I said above that software breakpoints are set by modifying the executing code on the fly, so the questions are:
|
||||
|
||||
* How do we modify the code?
|
||||
* What modifications do we make to set a breakpoint?
|
||||
* How is the debugger notified?
|
||||
|
||||
The answer to the first question is, of course, `ptrace`. We’ve previously used it to set up our program for tracing and continuing its execution, but we can also use it to read and write memory.
|
||||
|
||||
The modification we make has to cause the processor to halt and signal the program when the breakpoint address is executed. On x86 this is accomplished by overwriting the instruction at that address with the `int 3` instruction. x86 has an _interrupt vector table_ which the operating system can use to register handlers for various events, such as page faults, protection faults, and invalid opcodes. It’s kind of like registering error handling callbacks, but right down at the hardware level. When the processor executes the `int 3` instruction, control is passed to the breakpoint interrupt handler, which – in the case of Linux – signals the process with a `SIGTRAP`. You can see this process in the diagram below, where we overwrite the first byte of the `mov` instruction with `0xcc`, which is the instruction encoding for `int 3`.
|
||||
|
||||

|
||||
|
||||
The last piece of the puzzle is how the debugger is notified of the break. If you remember back in the previous post, we can use `waitpid` to listen for signals which are sent to the debugee. We can do exactly the same thing here: set the breakpoint, continue the program, call `waitpid` and wait until the `SIGTRAP`occurs. This breakpoint can then be communicated to the user, perhaps by printing the source location which has been reached, or changing the focused line in a GUI debugger.
|
||||
|
||||
* * *
|
||||
|
||||
### Implementing software breakpoints
|
||||
|
||||
We’ll implement a `breakpoint` class to represent a breakpoint on some location which we can enable or disable as we wish.
|
||||
|
||||
```
|
||||
class breakpoint {
|
||||
public:
|
||||
breakpoint(pid_t pid, std::intptr_t addr)
|
||||
: m_pid{pid}, m_addr{addr}, m_enabled{false}, m_saved_data{}
|
||||
{}
|
||||
|
||||
void enable();
|
||||
void disable();
|
||||
|
||||
auto is_enabled() const -> bool { return m_enabled; }
|
||||
auto get_address() const -> std::intptr_t { return m_addr; }
|
||||
|
||||
private:
|
||||
pid_t m_pid;
|
||||
std::intptr_t m_addr;
|
||||
bool m_enabled;
|
||||
uint64_t m_saved_data; //data which used to be at the breakpoint address
|
||||
};
|
||||
```
|
||||
|
||||
Most of this is just tracking of state; the real magic happens in the `enable` and `disable` functions.
|
||||
|
||||
As we’ve learned above, we need to replace the instruction which is currently at the given address with an `int 3`instruction, which is encoded as `0xcc`. We’ll also want to save out what used to be at that address so that we can restore the code later; we don’t want to just forget to execute the user’s code!
|
||||
|
||||
```
|
||||
void breakpoint::enable() {
|
||||
m_saved_data = ptrace(PTRACE_PEEKDATA, m_pid, m_addr, nullptr);
|
||||
uint64_t int3 = 0xcc;
|
||||
uint64_t data_with_int3 = ((m_saved_data & ~0xff) | int3); //set bottom byte to 0xcc
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, data_with_int3);
|
||||
|
||||
m_enabled = true;
|
||||
}
|
||||
```
|
||||
|
||||
The `PTRACE_PEEKDATA` request to `ptrace` is how to read the memory of the traced process. We give it a process ID and an address, and it gives us back the 64 bits which are currently at that address. `(m_saved_data & ~0xff)` zeroes out the bottom byte of this data, then we bitwise `OR` that with our `int 3` instruction to set the breakpoint. Finally, we set the breakpoint by overwriting that part of memory with our new data with `PTRACE_POKEDATA`.
|
||||
|
||||
The implementation of `disable` is easier, as we simply need to restore the original data which we overwrote with `0xcc`.
|
||||
|
||||
```
|
||||
void breakpoint::disable() {
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, m_saved_data);
|
||||
m_enabled = false;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Adding breakpoints to the debugger
|
||||
|
||||
We’ll make three changes to our debugger class to support setting breakpoints through the user interface:
|
||||
|
||||
1. Add a breakpoint storage data structure to `debugger`
|
||||
2. Write a `set_breakpoint_at_address` function
|
||||
3. Add a `break` command to our `handle_command` function
|
||||
|
||||
I’ll store my breakpoints in a `std::unordered_map<std::intptr_t, breakpoint>` structure so that it’s easy and fast to check if a given address has a breakpoint on it and, if so, retrieve that breakpoint object.
|
||||
|
||||
```
|
||||
class debugger {
|
||||
//...
|
||||
void set_breakpoint_at_address(std::intptr_t addr);
|
||||
//...
|
||||
private:
|
||||
//...
|
||||
std::unordered_map<std::intptr_t,breakpoint> m_breakpoints;
|
||||
}
|
||||
```
|
||||
|
||||
In `set_breakpoint_at_address` we’ll create a new breakpoint, enable it, add it to the data structure, and print out a message for the user. If you like, you could factor out all message printing so that you can use the debugger as a library as well as a command-line tool, but I’ll mash it all together for simplicity.
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_address(std::intptr_t addr) {
|
||||
std::cout << "Set breakpoint at address 0x" << std::hex << addr << std::endl;
|
||||
breakpoint bp {m_pid, addr};
|
||||
bp.enable();
|
||||
m_breakpoints[addr] = bp;
|
||||
}
|
||||
```
|
||||
|
||||
Now we’ll augment our command handler to call our new function.
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "cont")) {
|
||||
continue_execution();
|
||||
}
|
||||
else if(is_prefix(command, "break")) {
|
||||
std::string addr {args[1], 2}; //naively assume that the user has written 0xADDRESS
|
||||
set_breakpoint_at_address(std::stol(addr, 0, 16));
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
I’ve simply removed the first two characters of the string and called `std::stol` on the result, but feel free to make the parsing more robust. `std::stol` optionally takes a radix to convert from, which is handy for reading in hexadecimal.
|
||||
|
||||
* * *
|
||||
|
||||
### Continuing from the breakpoint
|
||||
|
||||
If you try this out, you might notice that if you continue from the breakpoint, nothing happens. That’s because the breakpoint is still set in memory, so it’s just hit repeatedly. The simple solution is to just disable the breakpoint, single step, re-enable it, then continue. Unfortunately we’d also need to modify the program counter to point back before the breakpoint, so we’ll leave this until the next post where we’ll learn about manipulating registers.
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
Of course, setting a breakpoint on some address isn’t very useful if you don’t know what address to set it at. In the future we’ll be adding the ability to set breakpoints on function names or source code lines, but for now, we can work it out manually.
|
||||
|
||||
A simple way to test out your debugger is to write a hello world program which writes to `std::cerr` (to avoid buffering) and set a breakpoint on the call to the output operator. If you continue the debugee then hopefully the execution will stop without printing anything. You can then restart the debugger and set a breakpoint just after the call, and you should see the message being printed successfully.
|
||||
|
||||
One way to find the address is to use `objdump`. If you open up a shell and execute `objdump -d <your program>`, then you should see the disassembly for your code. You should then be able to find the `main` function and locate the `call` instruction which you want to set the breakpoint on. For example, I built a hello world example, disassembled it, and got this as the disassembly for `main`:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
400936: 55 push %rbp
|
||||
400937: 48 89 e5 mov %rsp,%rbp
|
||||
40093a: be 35 0a 40 00 mov $0x400a35,%esi
|
||||
40093f: bf 60 10 60 00 mov $0x601060,%edi
|
||||
400944: e8 d7 fe ff ff callq 400820 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
|
||||
400949: b8 00 00 00 00 mov $0x0,%eax
|
||||
40094e: 5d pop %rbp
|
||||
40094f: c3 retq
|
||||
```
|
||||
|
||||
As you can see, we would want to set a breakpoint on `0x400944`to see no output, and `0x400949` to see the output.
|
||||
|
||||
* * *
|
||||
|
||||
### Finishing up
|
||||
|
||||
You should now have a debugger which can launch a program and allow the user to set breakpoints on memory addresses. Next time we’ll add the ability to read from and write to memory and registers. Again, let me know in the comments if you have any issues.
|
||||
|
||||
You can find the code for this post [here][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blog.tartanllama.xyz/
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://github.com/TartanLlama/minidbg/tree/tut_break
|
||||
@ -0,0 +1,179 @@
|
||||
How to Install a DHCP Server in Ubuntu and Debian
|
||||
============================================================
|
||||
|
||||
Dynamic Host Configuration Protocol (DHCP) is a network protocol that is used to enable host computers to be automatically assigned IP addresses and related network configurations from a server.
|
||||
|
||||
The IP address assigned by a DHCP server to DHCP client is on a “lease”, the lease time normally varies depending on how long a client computer is likely to require the connection or DHCP configuration.
|
||||
|
||||
#### How Does DHCP Work?
|
||||
|
||||
The following is a quick description of how DHCP actually works:
|
||||
|
||||
* Once a client (that is configured to use DHCP) and connected to a network boots up, it sends a DHCPDISCOVER packet to the DHCP server.
|
||||
* When the DHCP server receives the DHCPDISCOVER request packet, it replies with a DHCPOFFERpacket.
|
||||
* Then the client gets the DHCPOFFER packet, and it sends a DHCPREQUEST packet to the server showing it is ready to receive the network configuration information provided in the DHCPOFFERpacket.
|
||||
* Finally, after the DHCP server receives the DHCPREQUEST packet from the client, it sends the DHCPACK packet showing that the client is now permitted to use the IP address assigned to it.
|
||||
|
||||
In this article, we will show you how to setup a DHCP server in Ubuntu/Debian Linux, and we will run all the commands with the [sudo command][1] to gain root user privileges.
|
||||
|
||||
#### Testing Environment Setup
|
||||
|
||||
We are going to use following testing environment for this setup.
|
||||
|
||||
```
|
||||
DHCP Server - Ubuntu 16.04
|
||||
DHCP Clients - CentOS 7 and Fedora 25
|
||||
```
|
||||
|
||||
### Step 1: Installing DHCP Server in Ubuntu
|
||||
|
||||
1. Run the command below to install the DCHP server package, which was formerly known as dhcp3-server.
|
||||
|
||||
```
|
||||
$ sudo apt install isc-dhcp-server
|
||||
```
|
||||
|
||||
2. When the installation completes, edit the file /etc/default/isc-dhcp-server to define the interfaces DHCPD should use to serve DHCP requests, with the INTERFACES option.
|
||||
|
||||
For example, if you want the DHCPD daemon to listen on `eth0`, set it like so:
|
||||
|
||||
```
|
||||
INTERFACES="eth0"
|
||||
```
|
||||
|
||||
And also remember to [configure a static IP address][2] for the interface above.
|
||||
|
||||
### Step 2: Configuring DHCP Server in Ubuntu
|
||||
|
||||
3. The main DHCP configuration file is `/etc/dhcp/dhcpd.conf`, you must add all your network information to be sent to clients here.
|
||||
|
||||
And, there are two types of statements defined in the DHCP configuration file, these are:
|
||||
|
||||
* parameters – specify how to perform a task, whether to carry out a task, or what network configuration options to send to the DHCP client.
|
||||
* declarations – define the network topology, state the clients, offer addresses for the clients, or apply a group of parameters to a group of declarations.
|
||||
|
||||
4. Now, open and modify the main configuration file, define your DHCP server options:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
Set the following global parameters at the top of the file, they will apply to all the declarations below (do specify values that apply to your scenario):
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. Now, define a subnetwork; here, we’ll setup DHCP for 192.168.10.0/24 LAN network (use parameters that apply to your scenario).
|
||||
|
||||
```
|
||||
subnet 192.168.10.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.10.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.10.1;
|
||||
range 192.168.10.10 192.168.10.100;
|
||||
range 192.168.10.110 192.168.10.200;
|
||||
}
|
||||
```
|
||||
|
||||
### Step 3: Configure Static IP on DHCP Client Machine
|
||||
|
||||
6. To assign a fixed (static) IP address to a particular client computer, add the section below where you need to explicitly specify it’s MAC addresses and the IP to be statically assigned:
|
||||
|
||||
```
|
||||
host centos-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.10.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.10.106;
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and close it.
|
||||
|
||||
7. Next, start the DHCP service for the time being, and enable it to start automatically from the next system boot, like so:
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl start isc-dhcp-server.service
|
||||
$ sudo systemctl enable isc-dhcp-server.service
|
||||
------------ SysVinit ------------
|
||||
$ sudo service isc-dhcp-server.service start
|
||||
$ sudo service isc-dhcp-server.service enable
|
||||
```
|
||||
|
||||
8. Next, do not forget to permit DHCP service (DHCPD daemon listens on port 67/UDP) on firewall as below:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 67/udp
|
||||
$ sudo ufw reload
|
||||
$ sudo ufw show
|
||||
```
|
||||
|
||||
### Step 4: Configuring DHCP Client Machines
|
||||
|
||||
9. At this point, you can configure your clients computers on the network to automatically receive IP addresses from the DHCP server.
|
||||
|
||||
Login to the client computers and edit the Ethernet interface configuration file as follows (take note of the interface name/number):
|
||||
|
||||
```
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
And define the options below:
|
||||
|
||||
```
|
||||
auto eth0
|
||||
iface eth0 inet dhcp
|
||||
```
|
||||
|
||||
Save the file and exit. And restart network services like so (or reboot the system):
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl restart networking
|
||||
------------ SysVinit ------------
|
||||
$ sudo service networking restart
|
||||
```
|
||||
|
||||
Alternatively, use the GUI on a desktop machine to perform the settings, set the Method to Automatic (DHCP) as shown in the screenshot below (Fedora 25 desktop).
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Set DHCP Network in Fedora
|
||||
|
||||
At this point, if all settings are correctly configured, your client machine should be receiving IP addresses automatically from the DHCP server.
|
||||
|
||||
That’s it! In this tutorial, we showed you how to setup a DHCP server in Ubuntu/Debian. Share your thoughts with us via the feedback section below. If you are using Fedora based distribution, go through how to setup a DHCP server in CentOS/RHEL.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-ubuntu-debian/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[2]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-Network-in-Fedora.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,75 +0,0 @@
|
||||
## 如何阻止黑客入侵你的Linux机器之2:另外三个建议
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些重要信息来阻止黑客入侵你的系统。观看这个免费的网络研讨会on-demand获取更多的信息。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过其他两种简单的方法来阻止黑客黑掉你的Linux主机。这里是另外三条来自于我最近的Linux基础网络研讨会的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[研讨会on-demand][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的Linux安全建议 #3
|
||||
** Sudo. **
|
||||
|
||||
Sudo是非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西让我黑客的生活变得更困难。如果你没有配置sdo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用sudo执行所有命令,那样做毫无意义,除了让我黑客的生活变得更简单,这时我能获取一个不需要密码就能以sudo方式运行所有命令的帐号。如果我可以使用sudo命令而且不需要再次确认,那么我就能入侵你,同时当我获得你的没有使用密码的SSH密钥后,我就能十分容易的开始任何黑客活动。现在,我已经拥有了你机器的root权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用sudo,并且设置的超时时间是3小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐超时时间大约为10分钟,甚至是5分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令和禁止通过sudo来访问shell。大多数Linux发行版目前默认允许你使用"sudo bash"来获取一个root身份的shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我shell访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的Linux安全建议 #4
|
||||
|
||||
** 限制正在运行的服务 **
|
||||
|
||||
防火墙是很棒的。你的边界防火墙非常的强大。当流量流经你的网络时,防火墙外面的几家制造商做着极不寻常的工作。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供mySQL服务的机器上运行它。如果你有一个默认会安装完整的LAMP套件的Linux发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户没有默认的证书,确保那些内容已被安全地配置。如何你正在运行Tomcat,你不被允许上传你自己的小程序。确保他们不会以root的身份运行。如果我能够运行一个小程序,我不想以管理员的身份来运行它,也不想我自己访问权限。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的Linux安全建议 #5
|
||||
|
||||
** 小心你的日志记录 **
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的email,我会浏览我的日志记录。这仅花费我15分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不关心它们,但是有人需要关心。
|
||||
|
||||
通过Syslog、Splunk或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我做了那,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
就像你的很重要的人,送给他们鲜花,磁盘空间。确保你有足够的磁盘空间用来记录日志。进入一个只能读的文件系统不是一件很好的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三封和最后的博客][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络研讨会on-demand][6]吧。
|
||||
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试 ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,318 @@
|
||||
在 RHEL CentOS & Fedora 安装 Drupal 8
|
||||
============================================================
|
||||
|
||||
Drupal 是一个 开源,灵活,高度可拓展和安全的内容管理系统(CMS),使用户轻松的创建一个网站。
|
||||
它可以使用模块拓展使用户转换内容管理为强大的数字解决方案
|
||||
|
||||
|
||||
Drupal 运行在 Web 服务器上, 像 Apache, IIS, Lighttpd, Cherokee, Nginx,
|
||||
后端数据库可以使用 Mysql, MongoDB, MariaDB, PostgreSQL, MSSQL Server
|
||||
|
||||
在这个文章, 我们会展示在 RHEL 7/6 CentOS 7/6 和Fedora 20-25 发行版本使用 LAMP 步骤 如何执行手动安装和配置 Drupal 8
|
||||
|
||||
#### Drupal 需求:
|
||||
1. Apache 2.x(推荐)
|
||||
2. PHP 5.5.9 或 更高 (推荐PHP 5.5)
|
||||
3. MYSQL 5.5.3 或 MariaDB 5.5.20 与 PHP 数据对象(PDO)
|
||||
|
||||
|
||||
这个步骤,我是使用 `drupal.tecmint.com` 作为网站主机名 和 IP 地址 `192.168.0.104`.
|
||||
这些设置也许在你的环境不同,因此请适当做出更改
|
||||
|
||||
### 第一步: 安装 Apache Web 服务器
|
||||
1. 首先我们从官方仓库开始安装 Apache Web 服务器
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. 安装完成后,服务将会被被禁用,因此我们需要手动启动它,同时让它从下次系统启动时自动启动像这样:
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 和 Fedora 22+ -------------------
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
|
||||
------------- 通过 SysVInit - CentOS/RHEL 6 和 Fedora ----------------------
|
||||
# service httpd start
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. 接下来,为了通过 HTTP 和 HTTPS 访问 Apache 服务,我们必须打开 HTTPD 守护进程正在监听的80和443端口,如下所示:
|
||||
|
||||
```
|
||||
------------ 通过 Firewalld - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
# firewall-cmd --reload
|
||||
|
||||
------------ 通过 IPtables - CentOS/RHEL 6 and Fedora 22+ -------------
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
|
||||
# service iptables save
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. 现在验证 Apache 是否正常工作, 打开浏览器在 URL:http://server_IP` 输入你的服务器 IP 地址使用 HTTP 协议 ` , 默认 Apache 页面外观应该如下面截图所示:
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
Apache 默认页面
|
||||
|
||||
### 第二部: 安装 Apache PHP 支持
|
||||
|
||||
5. 接下来 安装 PHP 和 PHP 所需模块.
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
>重要: 假如你想要安装 PHP7., 你需要增加以下仓库:EPEL 和 Webtactic 才可以使用 yum 安装 PHP7.0:
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. 接下来 从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 根文档创建一个 `info.php` 文件
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
```
|
||||
|
||||
然后重启 HTTPD 服务器 ,在浏览器输入 URL `http://server_IP/info.php`
|
||||
```
|
||||
# systemctl restart httpd
|
||||
OR
|
||||
# service httpd restart
|
||||
```
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
验证 PHP 信息
|
||||
|
||||
### 步骤 3: 安装和配置 MariaDB 数据库
|
||||
|
||||
7. 对于你的信息, Red Hat Enterprise Linux/CentOS 7.0 从支持 MYSQL 转移到 MariaDB 作为默认数据库管理系统支持
|
||||
|
||||
安装 MariaDB 你需要添加以下内容,[official MariaDB repository][3] 到 `/etc/yum.repos.d/MariaDB.repo` 如下所示
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
当仓库文件就位你可以像这样安装 MariaDB :
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. 当 MariaDB 数据库安装完成,同时启动数据库的守护进程使它能够在下次启动后自动启动
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
------------- 通过 SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service mysqld start
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库,和移除匿名用户),如下所示:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Mysql 安全安装
|
||||
|
||||
### 第四步: 在 CentOS 安装和配置 Drupal 8
|
||||
|
||||
10. 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](i.e 8.2.6),如果你没有安装 wget 和 gzil 包 ,请使用下面命令安装它们:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. 之后,[导出压缩文件][7] 和移动 Drupal 目录到 Apache 根目录(`/var/www/html`).
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. 然后从示例设置文件(`/var/www/html/drupal/sites/default`) 目录创建设置文件 `settings.php` , 然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
# cp default.settings.php settings.php
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 SElinux 规则,如下:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
```
|
||||
14. 现在我们必须为 Drupal 站点去创建一个数据库和用户来管理
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
输入数据库密码:
|
||||
```
|
||||
MySQL Shell
|
||||
```
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MySQL connection id is 12
|
||||
Server version: 5.1.73 Source distribution
|
||||
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
MySQL [(none)]> create database drupal;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
MySQL [(none)]> create user ravi@localhost identified by 'tecmint123';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> grant all on drupal.* to ravi@localhost;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> flush privileges;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> exit
|
||||
Bye
|
||||
```
|
||||
|
||||
15. 最后,在这一点,打开URL: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续
|
||||
[
|
||||
!Drupal 安装语言](http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png)
|
||||
][8]
|
||||
|
||||
Drupal 安装语言
|
||||
|
||||
|
||||
16. 下一步,选择安装配置文件,选择 Standard(标准) 点击保存继续
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Drupal 安装配置文件
|
||||
|
||||
17. 在进行下一步之前查看并通过需求审查并启用 `Clean URL`
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
验证 Drupal 需求
|
||||
|
||||
现在在你的 Apache 配置下启用 `Clean URL` Drupal
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
确保设置 `AllowOverride All` 为默认根文档目录如下图所示
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
在 Drupal 中启用 Clean URL
|
||||
|
||||
18. 当你为 Drupal 启用 `Clean URL` ,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码.
|
||||
|
||||
当填写完所有信息点击保存继续
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Drupal 数据库配置
|
||||
|
||||
若上述设置正确,Drupal 站点安装应该完成了如下图界面.
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Drupal 安装
|
||||
|
||||
19. 接下来配置站点为下面设置值(使用适用你的方案的值):
|
||||
|
||||
1. 站点名称 – TecMint Drupal Site
|
||||
2. 站点邮箱地址 – admin@tecmint.com
|
||||
3. 用户名 – admin
|
||||
4. 密码 – ##########
|
||||
5. 用户的邮箱地址 – admin@tecmint.com
|
||||
6. 默认国家 – India
|
||||
7. 默认时区 – UTC
|
||||
|
||||
这是适当的值后,点击保存继续去完成站点安装过程!
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Drupal 站点配置
|
||||
|
||||
20. 下图是显示的是通过 LAMP 成功安装 Drupal 8 站点
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Drupal 站点面板
|
||||
|
||||
现在你可以点击增加内容如创建示例网页内容作为一个页面
|
||||
|
||||
选项: 有些人使用[MYSQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
|
||||
浏览 Drupal 文档 : [https://www.drupal.org/docs/8][18]
|
||||
|
||||
就这样! 在这个文章, 我们展示了在 CentOS 7 上如何去下载,安装和 LAMP 向导以及基本的配置 Drupal 8。 从下面反馈给我们回信就这个教程,或提供给我们一些相关信息
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
Aaron Kili 是 linux 和 F.O.S.S(Free and Open Source Software ) 爱好者,即将推出的 Linux SysAdmin, Web 开发者, 目前是TecMint的内容创作者,热爱计算机工作,并且坚信知识共享。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-drupal-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
|
||||
译者:[imxieke](https://github.com/imxieke)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2013/07/Apache-Default-Page.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2013/07/PHP-Information.png
|
||||
[3]:https://downloads.mariadb.org/mariadb/repositories/#mirror=Fibergrid&distro=CentOS
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2013/07/Mysql-Secure-Installation.png
|
||||
[5]:https://www.drupal.org/download
|
||||
[6]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/extract-tar-files-to-specific-or-different-directory-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Profile.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2013/07/Verify-Drupal-Requirements.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2013/07/Enable-Clean-URL-in-Drupal.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Database-Configuration.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Configuration.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Dashboard.png
|
||||
[16]:http://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[17]:http://www.tecmint.com/install-phpmyadmin-rhel-centos-fedora-linux/
|
||||
[18]:https://www.drupal.org/docs/8
|
||||
@ -1,23 +1,24 @@
|
||||
|
||||
# 这个 Xfce 的 Bug 会毁坏用户的显示器
|
||||
这个 Xfce Bug 正在毁坏用户的显示器
|
||||
=======================================
|
||||
|
||||
在 Linux 上使用 Xfce 桌面环境可以很快速和灵活的 — 但是它目前遭受着一个很严重的缺陷影响。
|
||||
Linux 上使用 Xfce 桌面环境可以是快速灵活的 — 但是它目前在遭受着一个很严重的缺陷影响。
|
||||
|
||||
有用户报告说这个轻量级替代 GNOME 和 KDE 的 Xfce 桌面选用默认桌面壁纸会造成笔记本电脑显示器和液晶显示器的损坏。
|
||||
使用这个轻量级替代 GNOME 和 KDE 的 Xfce 桌面的用户报告说,其选用的默认壁纸会造成**笔记本电脑显示器和液晶显示器的损坏**。
|
||||
|
||||
有确凿的摄影证据来要求索赔。
|
||||
有确凿的照片证据来支持此观点。
|
||||
|
||||
### Xfce Bug #12117
|
||||
|
||||
_“桌面默认开机画面造成显示器损坏!”_ 某用户在 Xfce 社区的 Bugzilla (译者注:Bugzilla 是一个开源的缺陷跟踪系统) 尖叫似的 [一个Bug 提交][1] 。
|
||||
_“桌面默认开机画面造成显示器损坏!”_ 某用户在 Xfce Bugzilla (LCTT 译注:Bugzilla 是一个开源的缺陷跟踪系统) 的 [Bug 提交区][1]尖叫道。
|
||||
|
||||
_“默认桌面壁纸被我的动物抓破 (<ruby>猛烈攻击<rt>sic</rt></ruby>) (译者注:sic 在原话里是指猛烈攻击,应该也指碳化硅晶片,这是应用于 LED 的材料) 导致全部塑料从我的液晶显示器掉落!能让我们选择不同的壁纸吗?我不想再有划痕,谁想呢(译者注:原文是 whu not,可能想打 who not,也许因屏幕坏了太激动打错字了)?让我们在这里结束这老鼠游戏。”_
|
||||
_“默认桌面壁纸导致我的动物去抓,全部塑料从我的液晶显示器掉落!能让我们选择不同的壁纸吗?我不想再有划痕,谁想呢(LCTT 译注:原文是 whu not,可能想打 who not,也许因屏幕坏了太激动打错字了)?让我们结束这老鼠游戏吧。”_
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
这缺陷 — 或者说是这爪? — 不只是单独一个用户的桌面遇到问题。其他用户都能重现这个问题了,尽管不一致,在这第二个例子,是 <ruby>红迪网友<rt>Redditor</rt></ruby> 的不同图片证实了:
|
||||
这缺陷 — 或者说是这爪? — 不是一个用户的桌面遇到问题。其他用户都能重现这个问题了,尽管不一致,在这第二个例子,是 <ruby>红迪网友<rt>Redditor</rt></ruby> 的不同图片证实了:
|
||||
|
||||

|
||||
|
||||
@ -42,7 +43,7 @@ via: http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
|
||||
作者:[JOEY SNEDDON ][a]
|
||||
译者:[ddvio](https://github.com/ddvio)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user