mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
4f4fecc411
3
.gitmodules
vendored
Normal file
3
.gitmodules
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
[submodule "comic"]
|
||||
path = comic
|
||||
url = https://wxy@github.com/LCTT/comic.git
|
||||
63
README.md
63
README.md
@ -59,41 +59,42 @@ LCTT 的组成
|
||||
* 2016/12/24 拟定 LCTT [Core 规则](core.md),并增加新的 Core 成员: ucasFL、martin2011qi,及调整一些组。
|
||||
* 2017/03/13 制作了 LCTT 主页、成员列表和成员主页,LCTT 主页将移动至 https://linux.cn/lctt 。
|
||||
* 2017/03/16 提升 GHLandy、bestony、rusking 为新的 Core 成员。创建 Comic 小组。
|
||||
* 2017/04/11 启用头衔制,为各位重要成员颁发头衔。
|
||||
|
||||
活跃成员
|
||||
核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 TP 活跃成员有:
|
||||
- Leader @wxy,
|
||||
- Source @oska874,
|
||||
- Proofreaders @jasminepeng,
|
||||
- CORE @geekpi,
|
||||
- CORE @GOLinux,
|
||||
- CORE @ictlyh,
|
||||
- CORE @strugglingyouth,
|
||||
- CORE @FSSlc,
|
||||
- CORE @zpl1025,
|
||||
- CORE @runningwater,
|
||||
- CORE @bazz2,
|
||||
- CORE @Vic020,
|
||||
- CORE @alim0x,
|
||||
- CORE @tinyeyeser,
|
||||
- CORE @Locez,
|
||||
- CORE @ucasFL,
|
||||
- CORE @martin2011qi,
|
||||
- CORE @GHLandy,
|
||||
- CORE @bestony,
|
||||
- CORE @rusking,
|
||||
- Senior @DeadFire,
|
||||
- Senior @reinoir222,
|
||||
- Senior @vito-L,
|
||||
- Senior @willqian,
|
||||
- Senior @vizv,
|
||||
- Senior @dongfengweixiao,
|
||||
- Senior @PurlingNayuki,
|
||||
- Senior @carolinewuyan,
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 校对 @jasminepeng,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 钻石译者 @ictlyh,
|
||||
- 技术组长 @bestony,
|
||||
- 漫画组长 @GHLandy,
|
||||
- LFS 组长 @martin2011qi,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
|
||||
1
comic
Submodule
1
comic
Submodule
@ -0,0 +1 @@
|
||||
Subproject commit e5db5b880dac1302ee0571ecaaa1f8ea7cf61901
|
||||
218
published/20150316 Linux on UEFI A Quick Installation Guide.md
Normal file
218
published/20150316 Linux on UEFI A Quick Installation Guide.md
Normal file
@ -0,0 +1,218 @@
|
||||
详解 UEFI 模式下安装 Linux
|
||||
============================================================
|
||||
|
||||
> 此页面是免费浏览的,没有烦人的外部广告;然而,我的确花了时间准备,网站托管也花了钱。如果您发现此页面帮到了您,请考虑进行小额[捐款](http://www.rodsbooks.com/linux-uefi/),以帮助保持网站的运行。谢谢!
|
||||
> 原著于 2013/10/19;最后修改于 2015/3/16
|
||||
|
||||
### 引言
|
||||
|
||||
几年来,一种新的固件技术悄然出现,而大多数普通用户对此并无所知。该技术被称为 [ <ruby>可扩展固件接口<rt>Extensible Firmware Interface</rt></ruby>][29](EFI), 或更新一些的统一可扩展固件接口(Unified EFI,UEFI,本质上是 EFI 2.x),它已经开始替代古老的[<ruby>基本输入/输出系统<rt>Basic Input/Output System</rt></ruby>][30](BIOS)固件技术,有经验的计算机用户或多或少都有些熟悉 BIOS。
|
||||
|
||||
本页面是给 Linux 用户使用 EFI 技术的一个快速介绍,其中包括有关开始将 Linux 安装到此类计算机上的建议。不幸的是,EFI 是一个庞杂的话题;EFI 软件本身是复杂的,许多实现有系统特定的怪异行为甚至是缺陷。因此,我无法在一个页面上描述在 EFI 计算机上安装和使用 Linux 的一切知识。我希望你能将本页面作为一个有用的起点,不管怎么说,每个部分以及末尾[参考文献][31]部分的链接可以指引你找到更多的文档。
|
||||
|
||||
### 你的计算机是否使用 EFI 技术?
|
||||
|
||||
EFI 是一种_固件_,意味着它是内置于计算机中处理低级任务的软件。最重要的是,固件控制着计算机的引导过程,反过来说这代表着基于 EFI 的计算机与基于 BIOS 的计算机的引导过程不同。(有关此规律的例外之处稍后再说。)这种差异可能使操作系统安装介质的设计超级复杂化,但是一旦安装好并运行之后,它对计算机的日常操作几乎没有影响。请注意,大多数制造商使用术语 “BIOS” 来表示他们的 EFI。我认为这种用法很混乱,所以我避免了;在我看来,EFI 和 BIOS 是两种不同类型的固件。
|
||||
|
||||
> **注意:**苹果公司的 Mac 使用的 EFI 在许多方面是不同寻常的。尽管本页面的大部分内容同样适用于 Mac,但有些细节上的出入,特别是在设置 EFI 引导加载程序的时候。这个任务最好在 OS X 上进行,使用 Mac 的 [bless utility][49]工具,我不在此做过多描述。
|
||||
|
||||
自从 2006 年第一次推出以来,EFI 已被用于基于英特尔的 Mac 上。从 2012 年底开始,大多数安装 Windows 8 或更高版本系统的计算机就已经默认使用 UEFI 启动,实际上大多数 PC 从 2011 年中期就开始使用 UEFI,虽然默认情况下它们可能无法以 EFI 模式启动。2011 年前销出的 PC 也有一些支持 EFI,尽管它们大都默认使用 BIOS 模式启动。
|
||||
|
||||
如果你不确定你的计算机是否支持 EFI,则应查看固件设置实用程序和参考用户手册关于 _EFI_、_UEFI_ 以及 _legacy booting_ 的部分。(可以通过搜索用户手册的 PDF 文件来快速了解。)如果你没有找到类似的参考,你的计算机可能使用老式的(“legacy”) BIOS 引导;但如果你找到了这些术语的参考,几乎可以肯定它使用了 EFI 技术。你还可以尝试_只_有 EFI 模式的引导加载器的安装介质。使用 [rEFInd][50] 制作的 USB 闪存驱动器或 CD-R 镜像是用来测试不错的选择。
|
||||
|
||||
在继续之前,你应当了解大多数 x86 和 x86-64 架构的计算机上的 EFI 都包含一个叫做<ruby>兼容支持模块<rt>Compatibility Support Module</rt></ruby>(CSM)的组件,这使得 EFI 能够使用旧的 BIOS 风格的引导机制来引导操作系统。这会非常方便,因为它向后兼容;但是这样也导致一些意外情况的发生,因为计算机不论以 EFI 模式引导还是以 BIOS (也称为 CSM 或 legacy)模式引导,在控制时没有标准的使用规范和用户界面。特别地,你的 Linux 安装介质非常容易意外的以 BIOS/CSM/legacy 模式启动,这会导致 Linux 以 BIOS/CSM/legacy 模式安装。如果 Linux 是唯一的操作系统,也可以正常工作,但是如果与在 EFI 模式下的 Windows 组成双启动的话,就会非常复杂。(反过来问题也可能发生。)以下部分将帮助你以正确模式引导安装程序。如果你在阅读这篇文章之前就已经以 BIOS 模式安装了 Linux,并且希望切换引导模式,请阅读后续章节,[哎呀:将传统模式下安装的引导转为 EFI 模式下的引导][51]。
|
||||
|
||||
UEFI 的一个附加功能值得一提:<ruby>安全启动<rt>Secure Boot</rt></ruby>。此特性旨在最大限度的降低计算机受到 _boot kit_ 病毒感染的风险,这是一种感染计算机引导加载程序的恶意软件。Boot kits 很难检测和删除,阻止它们的运行刻不容缓。微软公司要求所有带有支持 Windows 8 标志的台式机和笔记本电脑启用 安全启动。这一配置使 Linux 的安装变得复杂,尽管有些发行版可以较好的处理这个问题。不要将安全启动和 EFI 或 UEFI 混淆;支持 EFI 的计算机不一定支持 安全启动,而且支持 EFI 的 x86-64 的计算机也可以禁用 安全启动。微软同意用户在 Windows 8 认证的 x86 和 x86-64 计算机上禁用安全启动功能;然而对装有 Windows 8 的 ARM 计算机而言却相反,它们必须**不允许**用户禁用 安全启动。幸运的是,基于 ARM 的 Windows 8 计算机目前很少见。我建议避免使用它们。
|
||||
|
||||
### 你的发行版是否支持 EFI 技术?
|
||||
|
||||
大多数 Linux 发行版已经支持 EFI 好多年了。然而,不同的发行版对 EFI 的支持程度不同。大多数主流发行版(Fedora,OpenSUSE,Ubuntu 等)都能很好的支持 EFI,包括对安全启动的支持。另外一些“自行打造”的发行版,比如 Gentoo,对 EFI 的支持较弱,但它们的性质使其很容易添加 EFI 支持。事实上,可以向_任意_ Linux 发行版添加 EFI 支持:你需要安装 Linux(即使在 BIOS 模式下),然后在计算机上安装 EFI 引导加载程序。有关如何执行此操作的信息,请参阅[哎呀:将传统模式下安装的引导转为 EFI 模式下的引导][52]部分。
|
||||
|
||||
你应当查看发行版的功能列表,来确定它是否支持 EFI。你还应当注意你的发行版对安全启动的支持情况,特别是如果你打算和 Windows 8 组成双启动。请注意,即使正式支持安全启动的发行版也可能要求禁用此功能,因为 Linux 对安全启动的支持通常很差劲,或者导致意外情况的发生。
|
||||
|
||||
### 准备安装 Linux
|
||||
|
||||
下面几个准备步骤有助于在 EFI 计算机上 Linux 的安装,使其更加顺利:
|
||||
|
||||
#### 1、 升级固件
|
||||
|
||||
有些 EFI 是有问题的,不过硬件制造商偶尔会发布其固件的更新。因此我建议你将固件升级到最新可用的版本。如果你从论坛的帖子知道自己计算机的 EFI 有问题,你应当在安装 Linux 之前更新它,因为如果安装 Linux 之后更新固件,会有些问题需要额外的操作才能解决。另一方面,升级固件是有一定风险的,所以如果制造商提供了 EFI 支持,最好的办法就是按它们提供的方式进行升级。
|
||||
|
||||
#### 2、 了解如何使用固件
|
||||
|
||||
通常你可以通过在引导过程之初按 Del 键或功能键进入固件设置实用程序。按下开机键后尽快查看相关的提示信息,或者尝试每个功能键。类似的,ESC 键或功能键通常可以进入固件的内置引导管理器,可以选择要进入的操作系统或外部设备。一些制造商把这些设置隐藏的很深。在某些情况下,如[此页面][32]所述,你可以在 Windows 8 内做到这些。
|
||||
|
||||
#### 3、调整以下固件设置
|
||||
|
||||
* **快速启动** — 此功能可以通过在硬件初始化时使用快捷方式来加快引导过程。这很好用,但有时候会使 USB 设备不能初始化,导致计算机无法从 USB 闪存驱动器或类似的设备启动。因此禁用快速启动_可能_有一定的帮助,甚至是必须的;你可以让它保持激活,而只在 Linux 安装程序启动遇到问题时将其停用。请注意,此功能有时可能会以其它名字出现。在某些情况下,你必须_启用_ USB 支持,而不是_禁用_快速启动功能。
|
||||
* **安全启动** — Fedora,OpenSUSE,Ubuntu 以及其它的发行版官方就支持安全启动;但是如果在启动引导加载程序或内核时遇到问题,可能需要禁用此功能。不幸的是,没办法具体描述怎么禁用,因为不同计算机的设置方法也不同。请参阅[我的安全启动页面][1]获取更多关于此话题的信息。
|
||||
|
||||
> **注意:** 一些教程说安装 Linux 时需要启用 BIOS/CSM/legacy 支持。通常情况下,这样做是错的。启用这些支持可以解决启动安装程序涉及的问题,但也会带来新的问题。以这种方式安装的教程通常可以通过“引导修复”来解决这些问题,但最好从一开始就做对。本页面提供了帮助你以 EFI 模式启动 Linux 安装程序的提示,从而避免以后的问题。
|
||||
* **CSM/legacy 选项** — 如果你想以 EFI 模式安装,请_关闭_这些选项。一些教程推荐启用这些选项,有时这是必须的 —— 比如,有些附加视频卡需要在固件中启用 BIOS 模式。尽管如此,大多数情况下启用 CSM/legacy 支持只会无意中增加以 BIOS 模式启动 Linux 的风险,但你并_不想_这样。请注意,安全启动和 CSM/legacy 选项有时会交织在一起,因此更改任一选项之后务必检查另一个。
|
||||
|
||||
#### 4、 禁用 Windows 的快速启动功能
|
||||
|
||||
[这个页面][33]描述了如何禁用此功能,不禁用的话会导致文件系统损坏。请注意此功能与固件的快速启动不同。
|
||||
|
||||
#### 5、 检查分区表
|
||||
|
||||
使用 [GPT fdisk][34]、parted 或其它任意分区工具检查磁盘分区。理想情况下,你应该创建一个包含每个分区确切起点和终点(以扇区为单位)的纸面记录。这会是很有用的参考,特别是在安装时进行手动分区的时候。如果已经安装了 Windows,确定可以识别你的 [EFI 系统分区(ESP)][35],它是一个 FAT 分区,设置了“启动标记”(在 parted 或 Gparted 中)或在 gdisk 中的类型码为 EF00。
|
||||
|
||||
### 安装 Linux
|
||||
|
||||
大部分 Linux 发行版都提供了足够的安装说明;然而我注意到了在 EFI 模式安装中的几个常见的绊脚石:
|
||||
|
||||
* **确保使用正确位深的发行版** — EFI 启动加载器和 EFI 自身的位深相同。现代计算机通常是 64 位,尽管最初几代基于 Intel 的 Mac、一些现代的平板电脑和变形本、以及一些鲜为人知的电脑使用 32 位 EFI。虽然可以将 32 位 EFI 引导加载程序添加至 32 位发行版,但我还没有遇到过正式支持 32 位 EFI 的 Linux 发行版。(我的 《[在 Linux 上管理 EFI 引导加载程序][36]》 一文概述了引导加载程序,而且理解了这些原则你就可以修改 32 位发行版的安装程序,尽管这不是一个初学者该做的。)在 64 位 EFI 的计算机上安装 32 位发行版最让人头疼,我不准备在这里描述这一过程;在具有 64 位 EFI 的计算机上,你应当使用 64 位的发行版。
|
||||
* **正确准备引导介质** — 将 .iso 镜像传输到 USB 闪存驱动器的第三方工具,比如 unetbootin,在创建正确的 EFI 模式引导项时经常失败。我建议按照发行版维护者的建议来创建 USB 闪存驱动器。如果没有类似的建议,使用 Linux 的 dd 工具,通过执行 `dd if=image.iso of=/dev/sdc` 在识别为 `/dev/sdc` 的 USB 闪存驱动器上创建一个镜像。至于 Windows,有 [WinDD][37] 和 [dd for windows][38],但我从没测试过它们。请注意,使用不兼容 EFI 的工具创建安装介质是错误的,这会导致人们进入在 BIOS 模式下安装然后再纠正它们的误区,所以不要忽视这一点!
|
||||
* **备份 ESP 分区** — 如果计算机已经存在 Windows 或者其它的操作系统,我建议在安装 Linux 之前备份你的 ESP 分区。尽管 Linux _不应该_ 损坏 ESP 分区已有的文件,但似乎这时不时发生。发生这种事情时备份会有很大用处。只需简单的文件级的备份(使用 cp,tar,或者 zip 类似的工具)就足够了。
|
||||
* **以 EFI 模式启动** — 以 BIOS/CSM/legacy 模式引导 Linux 安装程序的意外非常容易发生,特别是当固件启用 CSM/legacy 选项时。下面一些提示可以帮助你避免此问题:
|
||||
* 进入 Linux shell 环境执行 `ls /sys/firmware/efi` 验证当前是否处于 EFI 引导模式。如果你看到一系列文件和目录,表明你已经以 EFI 模式启动,而且可以忽略以下多余的提示;如果没有,表明你是以 BIOS 模式启动的,应当重新检查你的设置。
|
||||
* 使用固件内置的引导管理器(你应该已经知道在哪;请参阅[了解如何使用固件][26])使之以 EFI 模式启动。一般你会看到 CD-R 或 USB 闪存驱动器两个选项,其中一个选项包括 _EFI_ 或 _UEFI_ 字样的描述,另一个不包括。使用 EFI/UEFI 选项来启动介质。
|
||||
* 禁用安全启动 - 即使你使用的发行版官方支持安全启动,有时它们也不能生效。在这种情况下,计算机会静默的转到下一个引导加载程序,它可能是启动介质的 BIOS 模式的引导加载程序,导致你以 BIOS 模式启动。请参阅我的[安全启动的相关文章][27]以得到禁用安全启动的相关提示。
|
||||
* 如果 Linux 安装程序总是无法以 EFI 模式启动,试试用我的 [rEFInd 引导管理器][28] 制作的 USB 闪存驱动器或 CD-R。如果 rEFInd 启动成功,那它保证是以 EFI 模式运行的,而且在基于 UEFI 的 PC 上,它只显示 EFI 模式的引导项,因此若您启动到 Linux 安装程序,则应处于 EFI 模式。(但是在 Mac 上,除了 EFI 模式选项之外,rEFInd 还显示 BIOS 模式的引导项。)
|
||||
* **准备 ESP 分区** — 除了 Mac,EFI 使用 ESP 分区来保存引导加载程序。如果你的计算机已经预装了 Windows,那么 ESP 分区就已存在,可以在 Linux 上直接使用。如果不是这样,那么我建议创建一个大小为 550 MB 的 ESP 分区。(如果你已有的 ESP 分区比这小,别担心,直接用就行。)在此分区上创建一个 FAT32 文件系统。如果你使用 Gparted 或者 parted 准备 ESP 分区,记得给它一个“启动标记”。如果你使用 GPT fdisk(gdisk,cgdisk 或 sgdisk)准备 ESP 分区,记得给它一个名为 EF00 的类型码。有些安装程序会创建一个较小的 ESP 分区,并且设置为 FAT16 文件系统。尽管这样能正常工作,但如果你之后需要重装 Windows,安装程序会无法识别 FAT16 文件系统的 ESP 分区,所以你需要将其备份后转为 FAT32 文件系统。
|
||||
* **使用 ESP 分区** — 不同发行版的安装程序以不同的方式辨识 ESP 分区。比如,Debian 和 Ubuntu 的某些版本把 ESP 分区称为“EFI boot partition”,而且不会明确显示它的挂载点(尽管它会在后台挂载);但是有些发行版,像 Arch 或 Gentoo,需要你去手动挂载。尽管将 ESP 分区挂载到 /boot 进行相应配置后可以正常工作,特别是当你想使用 gummiboot 或 ELILO(译者注:gummiboot 和 ELILO 都是 EFI 引导工具)时,但是在 Linux 中最标准的 ESP 分区挂载点是 /boot/efi。某些发行版的 /boot 不能用 FAT 分区。因此,当你设置 ESP 分区挂载点时,请将其设置为 /boot/efi。除非 ESP 分区没有,否则_不要_为其新建文件系统 — 如果已经安装 Windows 或其它操作系统,它们的引导文件都在 ESP 分区里,新建文件系统会销毁这些文件。
|
||||
* **设置引导程序的位置** — 某些发行版会询问将引导程序(GRUB)装到何处。如果 ESP 分区按上述内容正确标记,不必理会此问题,但有些发行版仍会询问。请尝试使用 ESP 分区。
|
||||
* **其它分区** — 除了 ESP 分区,不再需要其它的特殊分区;你可以设置 根(/)分区,swap 分区,/home 分区,或者其它分区,就像你在 BIOS 模式下安装时一样。请注意 EFI 模式下_不需要设置_[BIOS 启动分区][39],所以如果安装程序提示你需要它,意味着你可能意外的进入了 BIOS 模式。另一方面,如果你创建了 BIOS 启动分区,会更灵活,因为你可以安装 BIOS 模式下的 GRUB,然后以任意模式(EFI 模式 或 BIOS 模式)引导。
|
||||
* **解决无显示问题** — 2013 年,许多人在 EFI 模式下经常遇到(之后出现的频率逐渐降低)无显示的问题。有时可以在命令行下通过给内核添加 `nomodeset` 参数解决这一问题。在 GRUB 界面按 `e` 键会打开一个简易文本编辑器。大多数情况下你需要搜索有关此问题的更多信息,因为此问题更多是由特定硬件引起的。
|
||||
|
||||
在某些情况下,你可能不得不以 BIOS 模式安装 Linux。但你可以手动安装 EFI 引导程序让 Linux 以 EFI 模式启动。请参阅《 [在 Linux 上管理 EFI 引导加载程序][53]》 页面获取更多有关它们以及如何安装的可用信息。
|
||||
|
||||
### 解决安装后的问题
|
||||
|
||||
如果 Linux 无法在 EFI 模式下工作,但在 BIOS 模式下成功了,那么你可以完全放弃 EFI 模式。在只有 Linux 的计算机上这非常简单;安装 BIOS 引导程序即可(如果你是在 BIOS 模式下安装的,引导程序也应随之装好)。如果是和 EFI 下的 Windows 组成双系统,最简单的方法是安装我的 [rEFInd 引导管理器][54]。在 Windows 上安装它,然后编辑 `refind.conf` 文件:取消注释 `scanfor` 一行,并确保拥有 `hdbios` 选项。这样 rEFInd 在引导时会重定向到 BIOS 模式的引导项。
|
||||
|
||||
如果重启后计算机直接进入了 Windows,很可能是 Linux 的引导程序或管理器安装不正确。(但是应当首先尝试禁用安全启动;之前提到过,它经常引发各种问题。)下面是关于此问题的几种可能的解决方案:
|
||||
|
||||
* **使用 efibootmgr** — 你可以以 _EFI 模式_引导一个 Linux 急救盘,使用 efibootmgr 实用工具尝试重新注册你的 Linux 引导程序,如[这里][40]所述。
|
||||
* **使用 Windows 上的 bcdedit** — 在 Windows 管理员命令提示符窗口中,输入 `bcdedit /set {bootmgr}path \EFI\fedora\grubx64.efi` 会用 ESP 分区的 `EFI/fedora/grubx64.efi` 文件作为默认的引导加载程序。根据需要更改此路径,指向你想设置的引导文件。如果你启用了安全启动,需要设置 `shim.efi`,`shimx64.efi` 或者 `PreLoader.efi`(不管有哪个)为引导而不是 `grubx64.efi`。
|
||||
* **安装 rEFInd** — 有时候 rEFInd 可以解决这个问题。我推荐使用 [CD-R 或者 USB 闪存驱动器][41]进行测试。如果 Linux 可以启动,就安装 Debian 软件包、RPM 程序,或者 .zip 文件包。(请注意,你需要在一个高亮的 Linux vmlinuz* 选项按两次 `F2` 或 `Insert` 修改启动选项。如果你的启动分区是单独的,这就更有必要了,因为这种情况下,rEFInd 无法找到根(/)分区,也就无法传递参数给内核。)
|
||||
* **使用修复引导程序** — Ubuntu 的[引导修复实用工具][42]可以自动修复一些问题;然而,我建议只在 Ubuntu 和 密切相关的发行版上使用,比如 Mint。有时候,有必要通过高级选项备份并替换 Windows 的引导。
|
||||
* **劫持 Windows 引导程序** — 有些不完整的 EFI 引导只能引导 Windows,就是 ESP 分区上的 `EFI/Microsoft/Boot/bootmgfw.efi` 文件。因此,你可能需要将引导程序改名(我建议将其移动到上级目录 `EFI/Microsoft/bootmgfw.efi`),然后将首选引导程序复制到这里。(大多数发行版会在 EFI 的子目录放置 GRUB 的副本,例如 Ubuntu 的 EFI/ubuntu,Fedora 的 EFI/fedora。)请注意此方法是个丑陋的解决方法,有用户反映 Windows 会替换引导程序,所以这个办法不是 100% 有效。然而,这是在不完整的 EFI 上生效的唯一办法。在尝试之前,我建议你升级固件并重新注册自己的引导程序,Linux 上用 efibootmgr,Windows 上用 bcdedit。
|
||||
|
||||
有关引导程序的其它类型的问题 - 如果 GRUB(或者你的发行版默认的其它引导程序或引导管理器)没有引导操作系统,你必须修复这个问题。因为 GRUB 2 引导 Windows 时非常挑剔,所以 Windows 经常启动失败。在某些情况下,安全启动会加剧这个问题。请参阅[我的关于 GRUB 2 的页面][55]获取一个引导 Windows 的 GRUB 2 示例。还会有很多原因导致 Linux 引导出现问题,类似于 BIOS 模式下的情况,所以我没有全部写出来。
|
||||
|
||||
尽管 GRUB 2 使用很普遍,但我对它的评价却不高 - 它很复杂,而且难以配置和使用。因此,如果你在使用 GRUB 的时候遇到了问题,我的第一反应就是用别的东西代替。[我的用于 Linux 的 EFI 引导程序页面][56]有其它的选择。其中包括我的 [rEFInd 引导管理器][57],它除了能够让许多发行版上的 GRUB 2 工作,也更容易安装和维护 - 但是它还不能完全代替 GRUB 2。
|
||||
|
||||
除此之外,EFI 引导的问题可能很奇怪,所以你需要去论坛发帖求助。尽量将问题描述完整。[Boot Info Script][58] 可帮助你提供有用的信息 - 运行此脚本,将生成的名为 RESULTS.txt 的文件粘贴到论坛的帖子上。一定要将文本粘贴到 `[code]` 和 `[/code]` 之间;不然会遭人埋怨。或者将 RESULTS.txt 文件上传到 pastebin 网站上,比如 [pastebin.com][59],然后将网站给你的 URL 地址发布到论坛。
|
||||
|
||||
### 哎呀:将传统模式下安装的系统转为 EFI 模式下引导
|
||||
|
||||
**警告:**这些指南主要用于基于 UEFI 的 PC。如果你的 Mac 已经安装了 BIOS 模式下的 Linux,但想以 EFI 模式启动 Linux,可以_在 OS X_ 中安装引导程序。rEFInd(或者旧式的 rEFIt)是 Mac 上的常用选择,但 GRUB 可以做的更多。
|
||||
|
||||
论坛上有很多人看了错误的教程,在已经存在 EFI 模式的 Windows 的情况下,安装了 BIOS 引导的 Linux,这一问题在 2015 年初很普遍。这样配置效果很不好,因为大多数 EFI 很难在两种模式之间切换,而且 GRUB 也无法胜任这项工作。你可能会遇到不完善的 EFI 无法启动外部介质的情况,也可能遇到 EFI 模式下的显示问题,或者其它问题。
|
||||
|
||||
如前所述,在[解决安装后的问题][60]部分,解决办法之一就是_在 Windows_ 上安装 rEFInd,将其配置为支持 BIOS 模式引导。然后可以引导 rEFInd 并链式引导到你的 BIOS 模式的 GRUB。在 Linux 上遇到 EFI 特定的问题时,例如无法使用显卡,我建议你使用这个办法修复。如果你没有这样的 EFI 特定的问题,在 Windows 中安装 rEFInd 和合适的 EFI 文件系统驱动可以让 Linux 直接以 EFI 模式启动。这个解决方案很完美,它和我下面描述的内容等同。
|
||||
|
||||
大多数情况下,最好将 Linux 配置为以 EFI 模式启动。有很多办法可以做到,但最好的是使用 Linux 的 EFI 引导模式(或者,可以想到,Windows,或者一个 EFI shell)注册到你首选的引导管理器。实现这一目标的方法如下:
|
||||
|
||||
1. 下载适用于 USB 闪存驱动器或 CD-R 的 [rEFInd 引导管理器][43]。
|
||||
2. 从下载的镜像文件生成安装介质。可以在任何计算机上准备,不管是 EFI 还是 BIOS 的计算机都可以(或者在其它平台上使用其它方法)。
|
||||
3. 如果你还没有这样做,[请禁用安全启动][44]。因为 rEFInd CD-R 和 USB 镜像不支持安全启动,所以这很必要,你可以在以后重新启用它。
|
||||
4. 在目标计算机上启动 rEFInd。如前所述,你可能需要调整固件设置,并使用内置引导管理器选择要引导的介质。你选择的那一项也许在其描述中包含 _UEFI_ 这样的字符串。
|
||||
5. 在 rEFInd 上测试引导项。你应该至少看到一个启动 Linux 内核的选项(名字含有 vmlinuz 这样的字符串)。有两种方法可以启动它:
|
||||
* 如果你_没有_独立的 `/boot` 分区,只需简单的选择内核并按回车键。Linux 就会启动。
|
||||
* 如果你_确定有_一个独立的 `/boot` 分区,按两次 `Insert` 或 `F2` 键。这样会打开一个行编辑器,你可以用它来编辑内核选项。增加一个 `root=` 格式以标识根(/)文件系统,如果根(/)分区在 `/dev/sda5` 上,就添加 `root=/dev/sda5`。如果不知道根文件系统在哪里,那你需要重启并尽可能想到办法。
|
||||
|
||||
在一些罕见的情况下,你可能需要添加其它内核选项来代替或补充 `root=` 选项。比如配置了 LVM(LCTT 译注:Logical Volume Manager,逻辑卷管理)的 Gentoo 就需要 `dolvm` 选项。
|
||||
6. Linux 一旦启动,安装你想要的引导程序。rEFInd 的安装很简单,可以通过 RPM、Debian 软件包、PPA,或从[rEFInd 下载页面][45]下载的二进制 .zip 文件进行安装。在 Ubuntu 和相关的发行版上,引导修改程序可以相对简单地修复你的 GRUB 设置,但你要对它有信心可以正常工作。(它通常工作良好,但有时候会把事情搞得一团糟。)另外一些选项都在我的 《[在 Linux 上管理 EFI 引导加载程序][46]》 页面上。
|
||||
7. 如果你想在安全启动激活的情况下引导,只需重启并启用它。但是,请注意,可能需要额外的安装步骤才能将引导程序设置为使用安全启动。有关详细信息,请参阅[我关于这个主题的页面][47]或你的引导程序有关安全启动的文档资料。
|
||||
|
||||
重启时,你可以看到刚才安装的引导程序。如果计算机进入了 BIOS 模式下的 GRUB,你应当进入固件禁用 BIOS/CSM/legacy 支持,或调整引导顺序。如果计算机直接进入了 Windows,那么你应当阅读前一部分,[解决安装后的问题][61]。
|
||||
|
||||
你可能想或需要调整你的配置。通常是为了看到额外的引导选项,或者隐藏某些选项。请参阅引导程序的文档资料,以了解如何进行这些更改。
|
||||
|
||||
### 参考和附加信息
|
||||
|
||||
* **信息网页**
|
||||
* 我的 《[在 Linux 上管理 EFI 引导加载程序][2]》 页面含有可用的 EFI 引导程序和引导管理器。
|
||||
* [OS X's bless tool 的手册页][3] 页面在设置 OS X 平台上的引导程序或引导管理器时可能会很有用。
|
||||
* [EFI 启动过程][4] 描述了 EFI 启动时的大致框架。
|
||||
* [Arch Linux UEFI wiki page][5] 有大量关于 UEFI 和 Linux 的详细信息。
|
||||
* 亚当·威廉姆森写的一篇不错的 《[什么是 EFI,它是怎么工作的][6]》。
|
||||
* [这个页面][7] 描述了如何从 Windows 8 调整 EFI 的固件设置。
|
||||
* 马修·J·加勒特是 Shim 引导程序的开发者,此程序支持安全启动,他维护的[博客][8]经常更新有关 EFI 的问题。
|
||||
* 如果你对 EFI 软件的开发感兴趣,我的 《[EFI 编程][9]》 页面可以为你起步助力。
|
||||
* **附加程序**
|
||||
* [rEFInd 官网][10]
|
||||
* [gummiboot 官网][11]
|
||||
* [ELILO 官网][12]
|
||||
* [GRUB 官网][13]
|
||||
* [GPT fdisk 分区软件官网][14]
|
||||
* Ubuntu 的 [引导修复实用工具][15]可帮助解决一些引启动问题
|
||||
* **交流**
|
||||
* [Sourceforge 上的 rEFInd 交流论坛][16]是 rEFInd 用户互相交流或与我联系的一种方法。
|
||||
* Pastebin 网站,比如 [http://pastebin.com][17], 是在 Web 论坛上与其他用户交换大量文本的一种便捷的方法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.rodsbooks.com/linux-uefi/
|
||||
|
||||
作者:[Roderick W. Smith][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rodsmith@rodsbooks.com
|
||||
[1]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[2]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[3]:http://ss64.com/osx/bless.html
|
||||
[4]:http://homepage.ntlworld.com/jonathan.deboynepollard/FGA/efi-boot-process.html
|
||||
[5]:https://wiki.archlinux.org/index.php/Unified_Extensible_Firmware_Interface
|
||||
[6]:https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/
|
||||
[7]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[8]:http://mjg59.dreamwidth.org/
|
||||
[9]:http://www.rodsbooks.com/efi-programming/
|
||||
[10]:http://www.rodsbooks.com/refind/
|
||||
[11]:http://freedesktop.org/wiki/Software/gummiboot
|
||||
[12]:http://elilo.sourceforge.net/
|
||||
[13]:http://www.gnu.org/software/grub/
|
||||
[14]:http://www.rodsbooks.com/gdisk/
|
||||
[15]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[16]:https://sourceforge.net/p/refind/discussion/
|
||||
[17]:http://pastebin.com/
|
||||
[18]:http://www.rodsbooks.com/linux-uefi/#intro
|
||||
[19]:http://www.rodsbooks.com/linux-uefi/#isitefi
|
||||
[20]:http://www.rodsbooks.com/linux-uefi/#distributions
|
||||
[21]:http://www.rodsbooks.com/linux-uefi/#preparing
|
||||
[22]:http://www.rodsbooks.com/linux-uefi/#installing
|
||||
[23]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[24]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[25]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[26]:http://www.rodsbooks.com/linux-uefi/#using_firmware
|
||||
[27]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[28]:http://www.rodsbooks.com/refind/getting.html
|
||||
[29]:https://en.wikipedia.org/wiki/Uefi
|
||||
[30]:https://en.wikipedia.org/wiki/BIOS
|
||||
[31]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[32]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[33]:http://www.eightforums.com/tutorials/6320-fast-startup-turn-off-windows-8-a.html
|
||||
[34]:http://www.rodsbooks.com/gdisk/
|
||||
[35]:http://en.wikipedia.org/wiki/EFI_System_partition
|
||||
[36]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[37]:https://sourceforge.net/projects/windd/
|
||||
[38]:http://www.chrysocome.net/dd
|
||||
[39]:https://en.wikipedia.org/wiki/BIOS_Boot_partition
|
||||
[40]:http://www.rodsbooks.com/efi-bootloaders/installation.html
|
||||
[41]:http://www.rodsbooks.com/refind/getting.html
|
||||
[42]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[43]:http://www.rodsbooks.com/refind/getting.html
|
||||
[44]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[45]:http://www.rodsbooks.com/refind/getting.html
|
||||
[46]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[47]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html
|
||||
[48]:mailto:rodsmith@rodsbooks.com
|
||||
[49]:http://ss64.com/osx/bless.html
|
||||
[50]:http://www.rodsbooks.com/refind/getting.html
|
||||
[51]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[52]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[53]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[54]:http://www.rodsbooks.com/refind/
|
||||
[55]:http://www.rodsbooks.com/efi-bootloaders/grub2.html
|
||||
[56]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[57]:http://www.rodsbooks.com/refind/
|
||||
[58]:http://sourceforge.net/projects/bootinfoscript/
|
||||
[59]:http://pastebin.com/
|
||||
[60]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[61]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
@ -0,0 +1,384 @@
|
||||
大数据初步:在树莓派上通过 Apache Spark on YARN 搭建 Hadoop 集群
|
||||
===
|
||||
|
||||
有些时候我们想从 DQYDJ 网站的数据中分析点有用的东西出来,在过去,我们要[用 R 语言提取固定宽度的数据](https://dqydj.com/how-to-import-fixed-width-data-into-a-spreadsheet-via-r-playing-with-ipums-cps-data/),然后通过数学建模来分析[美国的最低收入补贴](http://dqydj.com/negative-income-tax-cost-calculator-united-states/),当然也包括其他优秀的方法。
|
||||
|
||||
今天我将向你展示对大数据的一点探索,不过有点变化,使用的是全世界最流行的微型电脑————[树莓派](https://www.raspberrypi.org/),如果手头没有,那就看下一篇吧(可能是已经处理好的数据),对于其他用户,请继续阅读吧,今天我们要建立一个树莓派 Hadoop集群!
|
||||
|
||||
### I. 为什么要建立一个树莓派的 Hadoop 集群?
|
||||
|
||||

|
||||
|
||||
*由三个树莓派节点组成的 Hadoop 集群*
|
||||
|
||||
我们对 DQYDJ 的数据做了[大量的处理工作](https://dqydj.com/finance-calculators-investment-calculators-and-visualizations/),但这些还不能称得上是大数据。
|
||||
|
||||
和许许多多有争议的话题一样,数据的大小之别被解释成这样一个笑话:
|
||||
|
||||
> 如果能被内存所存储,那么它就不是大数据。 ————佚名
|
||||
|
||||
似乎这儿有两种解决问题的方法:
|
||||
|
||||
1. 我们可以找到一个足够大的数据集合,任何家用电脑的物理或虚拟内存都存不下。
|
||||
2. 我们可以买一些不用特别定制,我们现有数据就能淹没它的电脑:
|
||||
|
||||
—— 上手树莓派 2B
|
||||
|
||||
这个由设计师和工程师制作出来的精致小玩意儿拥有 1GB 的内存, MicroSD 卡充当它的硬盘,此外,每一台的价格都低于 50 美元,这意味着你可以花不到 250 美元的价格搭建一个 Hadoop 集群。
|
||||
|
||||
或许天下没有比这更便宜的入场券来带你进入大数据的大门。
|
||||
|
||||
### II. 制作一个树莓派集群
|
||||
|
||||
我最喜欢制作的原材料。
|
||||
|
||||
这里我将给出我原来为了制作树莓派集群购买原材料的链接,如果以后要在亚马逊购买的话你可先这些链接收藏起来,也是对本站的一点支持。(谢谢)
|
||||
|
||||
- [树莓派 2B 3 块](http://amzn.to/2bEFTVh)
|
||||
- [4 层亚克力支架](http://amzn.to/2bTo1br)
|
||||
- [6 口 USB 转接器](http://amzn.to/2bEGO8g),我选了白色 RAVPower 50W 10A 6 口 USB 转接器
|
||||
- [MicroSD 卡](http://amzn.to/2cguV9I),这个五件套 32GB 卡非常棒
|
||||
- [短的 MicroUSB 数据线](http://amzn.to/2bX2mwm),用于给树莓派供电
|
||||
- [短网线](http://amzn.to/2bDACQJ)
|
||||
- 双面胶,我有一些 3M 的,很好用
|
||||
|
||||
#### 开始制作
|
||||
|
||||
1. 首先,装好三个树莓派,每一个用螺丝钉固定在亚克力面板上。(看下图)
|
||||
2. 接下来,安装以太网交换机,用双面胶贴在其中一个在亚克力面板上。
|
||||
3. 用双面胶贴将 USB 转接器贴在一个在亚克力面板使之成为最顶层。
|
||||
4. 接着就是一层一层都拼好——这里我选择将树莓派放在交换机和USB转接器的底下(可以看看完整安装好的两张截图)
|
||||
|
||||
想办法把线路放在需要的地方——如果你和我一样购买力 USB 线和网线,我可以将它们卷起来放在亚克力板子的每一层
|
||||
|
||||
现在不要急着上电,需要将系统烧录到 SD 卡上才能继续。
|
||||
|
||||
#### 烧录 Raspbian
|
||||
|
||||
按照[这个教程](https://www.raspberrypi.org/downloads/raspbian/)将 Raspbian 烧录到三张 SD 卡上,我使用的是 Win7 下的 [Win32DiskImager][2]。
|
||||
|
||||
将其中一张烧录好的 SD 卡插在你想作为主节点的树莓派上,连接 USB 线并启动它。
|
||||
|
||||
#### 启动主节点
|
||||
|
||||
这里有[一篇非常棒的“Because We Can Geek”的教程](http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/),讲如何安装 Hadoop 2.7.1,此处就不再熬述。
|
||||
|
||||
在启动过程中有一些要注意的地方,我将带着你一起设置直到最后一步,记住我现在使用的 IP 段为 192.168.1.50 – 192.168.1.52,主节点是 .50,从节点是 .51 和 .52,你的网络可能会有所不同,如果你想设置静态 IP 的话可以在评论区看看或讨论。
|
||||
|
||||
一旦你完成了这些步骤,接下来要做的就是启用交换文件,Spark on YARN 将分割出一块非常接近内存大小的交换文件,当你内存快用完时便会使用这个交换分区。
|
||||
|
||||
(如果你以前没有做过有关交换分区的操作的话,可以看看[这篇教程](https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04),让 `swappiness` 保持较低水准,因为 MicroSD 卡的性能扛不住)
|
||||
|
||||
现在我准备介绍有关我的和“Because We Can Geek”关于启动设置一些微妙的区别。
|
||||
|
||||
对于初学者,确保你给你的树莓派起了一个正式的名字——在 `/etc/hostname` 设置,我的主节点设置为 ‘RaspberryPiHadoopMaster’ ,从节点设置为 ‘RaspberryPiHadoopSlave#’
|
||||
|
||||
主节点的 `/etc/hosts` 配置如下:
|
||||
|
||||
```
|
||||
#/etc/hosts
|
||||
127.0.0.1 localhost
|
||||
::1 localhost ip6-localhost ip6-loopback
|
||||
ff02::1 ip6-allnodes
|
||||
ff02::2 ip6-allrouters
|
||||
|
||||
192.168.1.50 RaspberryPiHadoopMaster
|
||||
192.168.1.51 RaspberryPiHadoopSlave1
|
||||
192.168.1.52 RaspberryPiHadoopSlave2
|
||||
```
|
||||
|
||||
如果你想让 Hadoop、YARN 和 Spark 运行正常的话,你也需要修改这些配置文件(不妨现在就编辑)。
|
||||
|
||||
这是 `hdfs-site.xml`:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
|
||||
<configuration>
|
||||
<property>
|
||||
<name>fs.default.name</name>
|
||||
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hadoop.tmp.dir</name>
|
||||
<value>/hdfs/tmp</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
这是 `yarn-site.xml` (注意内存方面的改变):
|
||||
|
||||
```
|
||||
<?xml version="1.0"?>
|
||||
<configuration>
|
||||
|
||||
<!-- Site specific YARN configuration properties -->
|
||||
<property>
|
||||
<name>yarn.nodemanager.aux-services</name>
|
||||
<value>mapreduce_shuffle</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.resource.cpu-vcores</name>
|
||||
<value>4</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.resource.memory-mb</name>
|
||||
<value>1024</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.minimum-allocation-mb</name>
|
||||
<value>128</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.maximum-allocation-mb</name>
|
||||
<value>1024</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.minimum-allocation-vcores</name>
|
||||
<value>1</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.scheduler.maximum-allocation-vcores</name>
|
||||
<value>4</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.vmem-check-enabled</name>
|
||||
<value>false</value>
|
||||
<description>Whether virtual memory limits will be enforced for containers</description>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.nodemanager.vmem-pmem-ratio</name>
|
||||
<value>4</value>
|
||||
<description>Ratio between virtual memory to physical memory when setting memory limits for containers</description>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.resource-tracker.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8025</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.scheduler.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8030</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>yarn.resourcemanager.address</name>
|
||||
<value>RaspberryPiHadoopMaster:8040</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
`slaves`:
|
||||
|
||||
```
|
||||
RaspberryPiHadoopMaster
|
||||
RaspberryPiHadoopSlave1
|
||||
RaspberryPiHadoopSlave2
|
||||
```
|
||||
|
||||
`core-site.xml`:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
|
||||
<configuration>
|
||||
<property>
|
||||
<name>fs.default.name</name>
|
||||
<value>hdfs://RaspberryPiHadoopMaster:54310</value>
|
||||
</property>
|
||||
<property>
|
||||
<name>hadoop.tmp.dir</name>
|
||||
<value>/hdfs/tmp</value>
|
||||
</property>
|
||||
</configuration>
|
||||
```
|
||||
|
||||
#### 设置两个从节点:
|
||||
|
||||
接下来[按照 “Because We Can Geek”上的教程](http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/),你需要对上面的文件作出小小的改动。 在 `yarn-site.xml` 中主节点没有改变,所以从节点中不必含有这个 `slaves` 文件。
|
||||
|
||||
### III. 在我们的树莓派集群中测试 YARN
|
||||
|
||||
如果所有设备都正常工作,在主节点上你应该执行如下命令:
|
||||
|
||||
```
|
||||
start-dfs.sh
|
||||
start-yarn.sh
|
||||
```
|
||||
|
||||
当设备启动后,以 Hadoop 用户执行,如果你遵循教程,用户应该是 `hduser`。
|
||||
|
||||
接下来执行 `hdfs dfsadmin -report` 查看三个节点是否都正确启动,确认你看到一行粗体文字 ‘Live datanodes (3)’:
|
||||
|
||||
```
|
||||
Configured Capacity: 93855559680 (87.41 GB)
|
||||
Raspberry Pi Hadoop Cluster picture Straight On
|
||||
Present Capacity: 65321992192 (60.84 GB)
|
||||
DFS Remaining: 62206627840 (57.93 GB)
|
||||
DFS Used: 3115364352 (2.90 GB)
|
||||
DFS Used%: 4.77%
|
||||
Under replicated blocks: 0
|
||||
Blocks with corrupt replicas: 0
|
||||
Missing blocks: 0
|
||||
Missing blocks (with replication factor 1): 0
|
||||
————————————————-
|
||||
Live datanodes (3):
|
||||
Name: 192.168.1.51:50010 (RaspberryPiHadoopSlave1)
|
||||
Hostname: RaspberryPiHadoopSlave1
|
||||
Decommission Status : Normal
|
||||
```
|
||||
|
||||
你现在可以做一些简单的诸如 ‘Hello, World!’ 的测试,或者直接进行下一步。
|
||||
|
||||
### IV. 安装 SPARK ON YARN
|
||||
|
||||
YARN 的意思是另一种非常好用的资源调度器(Yet Another Resource Negotiator),已经作为一个易用的资源管理器集成在 Hadoop 基础安装包中。
|
||||
|
||||
[Apache Spark](https://spark.apache.org/) 是 Hadoop 生态圈中的另一款软件包,它是一个毁誉参半的执行引擎和[捆绑的 MapReduce](https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html)。在一般情况下,相对于基于磁盘存储的 MapReduce,Spark 更适合基于内存的存储,某些运行任务能够得到 10-100 倍提升——安装完成集群后你可以试试 Spark 和 MapReduce 有什么不同。
|
||||
|
||||
我个人对 Spark 还是留下非常深刻的印象,因为它提供了两种数据工程师和科学家都比较擅长的语言—— Python 和 R。
|
||||
|
||||
安装 Apache Spark 非常简单,在你家目录下,`wget "为 Hadoop 2.7 构建的 Apache Spark”`([来自这个页面](https://spark.apache.org/downloads.html)),然后运行 `tar -xzf “tgz 文件”`,最后把解压出来的文件移动至 `/opt`,并清除刚才下载的文件,以上这些就是安装步骤。
|
||||
|
||||
我又创建了只有两行的文件 `spark-env.sh`,其中包含 Spark 的配置文件目录。
|
||||
|
||||
```
|
||||
SPARK_MASTER_IP=192.168.1.50
|
||||
SPARK_WORKER_MEMORY=512m
|
||||
```
|
||||
|
||||
(在 YARN 跑起来之前我不确定这些是否有必要。)
|
||||
|
||||
### V. 你好,世界! 为 Apache Spark 寻找有趣的数据集!
|
||||
|
||||
在 Hadoop 世界里面的 ‘Hello, World!’ 就是做单词计数。
|
||||
|
||||
我决定让我们的作品做一些内省式……为什么不统计本站最常用的单词呢?也许统计一些关于本站的大数据会更有用。
|
||||
|
||||
如果你有一个正在运行的 WordPress 博客,可以通过简单的两步来导出和净化。
|
||||
|
||||
1. 我使用 [Export to Text](https://wordpress.org/support/plugin/export-to-text) 插件导出文章的内容到纯文本文件中
|
||||
2. 我使用一些[压缩库](https://pypi.python.org/pypi/bleach)编写了一个 Python 脚本来剔除 HTML
|
||||
|
||||
```
|
||||
import bleach
|
||||
|
||||
# Change this next line to your 'import' filename, whatever you would like to strip
|
||||
# HTML tags from.
|
||||
ascii_string = open('dqydj_with_tags.txt', 'r').read()
|
||||
|
||||
|
||||
new_string = bleach.clean(ascii_string, tags=[], attributes={}, styles=[], strip=True)
|
||||
new_string = new_string.encode('utf-8').strip()
|
||||
|
||||
# Change this next line to your 'export' filename
|
||||
f = open('dqydj_stripped.txt', 'w')
|
||||
f.write(new_string)
|
||||
f.close()
|
||||
```
|
||||
|
||||
现在我们有了一个更小的、适合复制到树莓派所搭建的 HDFS 集群上的文件。
|
||||
|
||||
如果你不能树莓派主节点上完成上面的操作,找个办法将它传输上去(scp、 rsync 等等),然后用下列命令行复制到 HDFS 上。
|
||||
|
||||
```
|
||||
hdfs dfs -copyFromLocal dqydj_stripped.txt /dqydj_stripped.txt
|
||||
```
|
||||
|
||||
现在准备进行最后一步 - 向 Apache Spark 写入一些代码。
|
||||
|
||||
### VI. 点亮 Apache Spark
|
||||
|
||||
Cloudera 有个极棒的程序可以作为我们的超级单词计数程序的基础,[你可以在这里找到](https://www.cloudera.com/documentation/enterprise/5-6-x/topics/spark_develop_run.html)。我们接下来为我们的内省式单词计数程序修改它。
|
||||
|
||||
在主节点上[安装‘stop-words’](https://pypi.python.org/pypi/stop-words)这个 python 第三方包,虽然有趣(我在 DQYDJ 上使用了 23,295 次 the 这个单词),你可能不想看到这些语法单词占据着单词计数的前列,另外,在下列代码用你自己的数据集替换所有有关指向 dqydj 文件的地方。
|
||||
|
||||
```
|
||||
import sys
|
||||
|
||||
from stop_words import get_stop_words
|
||||
from pyspark import SparkContext, SparkConf
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
# create Spark context with Spark configuration
|
||||
conf = SparkConf().setAppName("Spark Count")
|
||||
sc = SparkContext(conf=conf)
|
||||
|
||||
# get threshold
|
||||
try:
|
||||
threshold = int(sys.argv[2])
|
||||
except:
|
||||
threshold = 5
|
||||
|
||||
# read in text file and split each document into words
|
||||
tokenized = sc.textFile(sys.argv[1]).flatMap(lambda line: line.split(" "))
|
||||
|
||||
# count the occurrence of each word
|
||||
wordCounts = tokenized.map(lambda word: (word.lower().strip(), 1)).reduceByKey(lambda v1,v2:v1 +v2)
|
||||
|
||||
# filter out words with fewer than threshold occurrences
|
||||
filtered = wordCounts.filter(lambda pair:pair[1] >= threshold)
|
||||
|
||||
print "*" * 80
|
||||
print "Printing top words used"
|
||||
print "-" * 80
|
||||
filtered_sorted = sorted(filtered.collect(), key=lambda x: x[1], reverse = True)
|
||||
for (word, count) in filtered_sorted: print "%s : %d" % (word.encode('utf-8').strip(), count)
|
||||
|
||||
|
||||
# Remove stop words
|
||||
print "\n\n"
|
||||
print "*" * 80
|
||||
print "Printing top non-stop words used"
|
||||
print "-" * 80
|
||||
# Change this to your language code (see the stop-words documentation)
|
||||
stop_words = set(get_stop_words('en'))
|
||||
no_stop_words = filter(lambda x: x[0] not in stop_words, filtered_sorted)
|
||||
for (word, count) in no_stop_words: print "%s : %d" % (word.encode('utf-8').strip(), count)
|
||||
```
|
||||
|
||||
保存好 wordCount.py,确保上面的路径都是正确无误的。
|
||||
|
||||
现在,准备念出咒语,让运行在 YARN 上的 Spark 跑起来,你可以看到我在 DQYDJ 使用最多的单词是哪一个。
|
||||
|
||||
```
|
||||
/opt/spark-2.0.0-bin-hadoop2.7/bin/spark-submit –master yarn –executor-memory 512m –name wordcount –executor-cores 8 wordCount.py /dqydj_stripped.txt
|
||||
```
|
||||
|
||||
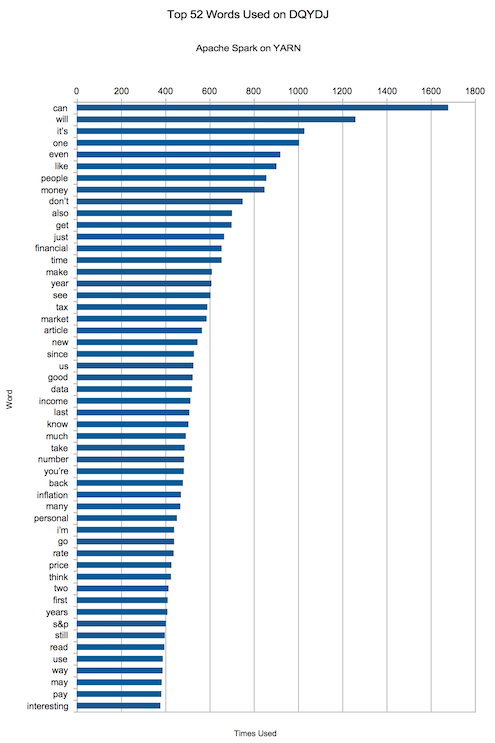
### VII. 我在 DQYDJ 使用最多的单词
|
||||
|
||||
可能入列的单词有哪一些呢?“can, will, it’s, one, even, like, people, money, don’t, also“.
|
||||
|
||||
嘿,不错,“money”悄悄挤进了前十。在一个致力于金融、投资和经济的网站上谈论这似乎是件好事,对吧?
|
||||
|
||||
下面是的前 50 个最常用的词汇,请用它们刻画出有关我的文章的水平的结论。
|
||||
|
||||
|
||||
|
||||
我希望你能喜欢这篇关于 Hadoop、YARN 和 Apache Spark 的教程,现在你可以在 Spark 运行和编写其他的应用了。
|
||||
|
||||
你的下一步是任务是开始[阅读 pyspark 文档](https://spark.apache.org/docs/2.0.0/api/python/index.html)(以及用于其他语言的该库),去学习一些可用的功能。根据你的兴趣和你实际存储的数据,你将会深入学习到更多——有流数据、SQL,甚至机器学习的软件包!
|
||||
|
||||
你怎么看?你要建立一个树莓派 Hadoop 集群吗?想要在其中挖掘一些什么吗?你在上面看到最令你惊奇的单词是什么?为什么 'S&P' 也能上榜?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dqydj.com/raspberry-pi-hadoop-cluster-apache-spark-yarn/
|
||||
|
||||
作者:[PK][a]
|
||||
译者:[popy32](https://github.com/sfantree)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://dqydj.com/about/#contact_us
|
||||
[1]: https://www.raspberrypi.org/downloads/raspbian/
|
||||
[2]: https://sourceforge.net/projects/win32diskimager/
|
||||
[3]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-1/
|
||||
[4]: https://www.digitalocean.com/community/tutorials/how-to-add-swap-on-ubuntu-14-04
|
||||
[5]: http://www.becausewecangeek.com/building-a-raspberry-pi-hadoop-cluster-part-2/
|
||||
[6]: https://spark.apache.org/
|
||||
[7]: https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
|
||||
[8]: https://spark.apache.org/downloads.html
|
||||
[9]: https://wordpress.org/support/plugin/export-to-text
|
||||
[10]: https://pypi.python.org/pypi/bleach
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
向 Linus Torvalds 学习让编出的代码具有 “good taste”
|
||||
========
|
||||
|
||||
在[最近关于 Linus Torvalds 的一个采访中][1],这位 Linux 的创始人,在采访过程中大约 14:20 的时候,提及了关于代码的 “good taste”。good taste?采访者请他展示更多的细节,于是,Linus Torvalds 展示了一张提前准备好的插图。
|
||||
|
||||
他展示的是一个代码片段。但这段代码并没有 “good taste”。这是一个具有 “poor taste” 的代码片段,把它作为例子,以提供一些初步的比较。
|
||||
|
||||

|
||||
|
||||
这是一个用 C 写的函数,作用是删除链表中的一个对象,它包含有 10 行代码。
|
||||
|
||||
他把注意力集中在底部的 `if` 语句。正是这个 `if` 语句受到他的批判。
|
||||
|
||||
我暂停了这段视频,开始研究幻灯片。我发现我最近有写过和这很像的代码。Linus 不就是在说我的代码品味很差吗?我放下自傲,继续观看视频。
|
||||
|
||||
随后, Linus 向观众解释,正如我们所知道的,当从链表中删除一个对象时,需要考虑两种可能的情况。当所需删除的对象位于链表的表头时,删除过程和位于链表中间的情况不同。这就是这个 `if` 语句具有 “poor taste” 的原因。
|
||||
|
||||
但既然他承认考虑这两种不同的情况是必要的,那为什么像上面那样写如此糟糕呢?
|
||||
|
||||
接下来,他又向观众展示了第二张幻灯片。这个幻灯片展示的是实现同样功能的一个函数,但这段代码具有 “goog taste” 。
|
||||
|
||||

|
||||
|
||||
原先的 10 行代码现在减少为 4 行。
|
||||
|
||||
但代码的行数并不重要,关键是 `if` 语句,它不见了,因为不再需要了。代码已经被重构,所以,不用管对象在列表中的位置,都可以运用同样的操作把它删除。
|
||||
|
||||
Linus 解释了一下新的代码,它消除了边缘情况,就是这样。然后采访转入了下一个话题。
|
||||
|
||||
我琢磨了一会这段代码。 Linus 是对的,的确,第二个函数更好。如果这是一个确定代码具有 “good taste” 还是 “bad taste” 的测试,那么很遗憾,我失败了。我从未想到过有可能能够去除条件语句。我写过不止一次这样的 `if` 语句,因为我经常使用链表。
|
||||
|
||||
这个例子的意义,不仅仅是教给了我们一个从链表中删除对象的更好方法,而是启发了我们去思考自己写的代码。你通过程序实现的一个简单算法,可能还有改进的空间,只是你从来没有考虑过。
|
||||
|
||||
以这种方式,我回去审查最近正在做的项目的代码。也许是一个巧合,刚好也是用 C 写的。
|
||||
|
||||
我尽最大的能力去审查代码,“good taste” 的一个基本要求是关于边缘情况的消除方法,通常我们会使用条件语句来消除边缘情况。你的测试使用的条件语句越少,你的代码就会有更好的 “taste” 。
|
||||
|
||||
下面,我将分享一个通过审查代码进行了改进的一个特殊例子。
|
||||
|
||||
这是一个关于初始化网格边缘的算法。
|
||||
|
||||
下面所写的是一个用来初始化网格边缘的算法,网格 grid 以一个二维数组表示:grid[行][列] 。
|
||||
|
||||
再次说明,这段代码的目的只是用来初始化位于 grid 边缘的点的值,所以,只需要给最上方一行、最下方一行、最左边一列以及最右边一列赋值即可。
|
||||
|
||||
为了完成这件事,我通过循环遍历 grid 中的每一个点,然后使用条件语句来测试该点是否位于边缘。代码看起来就是下面这样:
|
||||
|
||||
```Tr
|
||||
for (r = 0; r < GRID_SIZE; ++r) {
|
||||
for (c = 0; c < GRID_SIZE; ++c) {
|
||||
// Top Edge
|
||||
if (r == 0)
|
||||
grid[r][c] = 0;
|
||||
// Left Edge
|
||||
if (c == 0)
|
||||
grid[r][c] = 0;
|
||||
// Right Edge
|
||||
if (c == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
// Bottom Edge
|
||||
if (r == GRID_SIZE - 1)
|
||||
grid[r][c] = 0;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
虽然这样做是对的,但回过头来看,这个结构存在一些问题。
|
||||
|
||||
1. 复杂性 — 在双层循环里面使用 4 个条件语句似乎过于复杂。
|
||||
2. 高效性 — 假设 `GRID_SIZE` 的值为 64,那么这个循环需要执行 4096 次,但需要进行赋值的只有位于边缘的 256 个点。
|
||||
|
||||
用 Linus 的眼光来看,将会认为这段代码没有 “good taste” 。
|
||||
|
||||
所以,我对上面的问题进行了一下思考。经过一番思考,我把复杂度减少为包含四个条件语句的单层 `for` 循环。虽然只是稍微改进了一下复杂性,但在性能上也有了极大的提高,因为它只是沿着边缘的点进行了 256 次循环。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE * 4; ++i) {
|
||||
// Top Edge
|
||||
if (i < GRID_SIZE)
|
||||
grid[0][i] = 0;
|
||||
// Right Edge
|
||||
else if (i < GRID_SIZE * 2)
|
||||
grid[i - GRID_SIZE][GRID_SIZE - 1] = 0;
|
||||
// Left Edge
|
||||
else if (i < GRID_SIZE * 3)
|
||||
grid[i - (GRID_SIZE * 2)][0] = 0;
|
||||
// Bottom Edge
|
||||
else
|
||||
grid[GRID_SIZE - 1][i - (GRID_SIZE * 3)] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
的确是一个很大的提高。但是它看起来很丑,并不是易于阅读理解的代码。基于这一点,我并不满意。
|
||||
|
||||
我继续思考,是否可以进一步改进呢?事实上,答案是 YES!最后,我想出了一个非常简单且优雅的算法,老实说,我不敢相信我会花了那么长时间才发现这个算法。
|
||||
|
||||
下面是这段代码的最后版本。它只有一层 `for` 循环并且没有条件语句。另外。循环只执行了 64 次迭代,极大的改善了复杂性和高效性。
|
||||
|
||||
```
|
||||
for (i = 0; i < GRID_SIZE; ++i) {
|
||||
// Top Edge
|
||||
grid[0][i] = 0;
|
||||
|
||||
// Bottom Edge
|
||||
grid[GRID_SIZE - 1][i] = 0;
|
||||
// Left Edge
|
||||
grid[i][0] = 0;
|
||||
// Right Edge
|
||||
grid[i][GRID_SIZE - 1] = 0;
|
||||
}
|
||||
```
|
||||
|
||||
这段代码通过每次循环迭代来初始化四条边缘上的点。它并不复杂,而且非常高效,易于阅读。和原始的版本,甚至是第二个版本相比,都有天壤之别。
|
||||
|
||||
至此,我已经非常满意了。
|
||||
|
||||
那么,我是一个有 “good taste” 的开发者么?
|
||||
|
||||
我觉得我是,但是这并不是因为我上面提供的这个例子,也不是因为我在这篇文章中没有提到的其它代码……而是因为具有 “good taste” 的编码工作远非一段代码所能代表。Linus 自己也说他所提供的这段代码不足以表达他的观点。
|
||||
|
||||
我明白 Linus 的意思,也明白那些具有 “good taste” 的程序员虽各有不同,但是他们都是会将他们之前开发的代码花费时间重构的人。他们明确界定了所开发的组件的边界,以及是如何与其它组件之间的交互。他们试着确保每一样工作都完美、优雅。
|
||||
|
||||
其结果就是类似于 Linus 的 “good taste” 的例子,或者像我的例子一样,不过是千千万万个 “good taste”。
|
||||
|
||||
你会让你的下个项目也具有这种 “good taste” 吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@bartobri/applying-the-linus-tarvolds-good-taste-coding-requirement-99749f37684a
|
||||
|
||||
作者:[Brian Barto][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@bartobri?source=post_header_lockup
|
||||
[1]:https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux
|
||||
@ -0,0 +1,165 @@
|
||||
Linux 容器能否弥补 IoT 的安全短板?
|
||||
========
|
||||
|
||||

|
||||
|
||||
> 在这个最后的物联网系列文章中,Canonical 和 Resin.io 向以 Linux 容器技术作为解决方案向物联网安全性和互操作性发起挑战。
|
||||
|
||||

|
||||
|
||||
*Artik 7*
|
||||
|
||||
尽管受到日益增长的安全威胁,但对物联网(IoT)的炒作没有显示减弱的迹象。为了刷存在感,公司们正忙于重新规划它们的物联网方面的路线图。物联网大潮迅猛异常,比移动互联网革命渗透的更加深入和广泛。IoT 像黑洞一样,吞噬一切,包括智能手机,它通常是我们通向物联网世界的窗口,有时也作为我们的汇聚点或终端。
|
||||
|
||||
新的针对物联网的处理器和嵌入式主板继续重塑其技术版图。自从 9 月份推出 [面向物联网的 Linux 和开源硬件][5] 系列文章之后,我们看到了面向物联网网关的 “Apollo Lake]” SoC 芯片 [Intel Atom E3900][6] 以及[三星 新的 Artik 模块][7],包括用于网关并由 Linux 驱动的 64 位 Artik 7 COM 及自带 RTOS 的 Cortex-M4 Artik。 ARM 为具有 ARMv8-M 和 TrustZone 安全性的 IoT 终端发布了 [Cortex-M23 和 Cortex-M33][8] 芯片。
|
||||
|
||||
讲道理,安全是这些产品的卖点。最近攻击 Dyn 服务并在一天内摧毁了美国大部分互联网的 Mirai 僵尸网络将基于 Linux 的物联网推到台前 - 当然这种方式似乎不太体面。就像 IoT 设备可以成为 DDoS 的帮凶一样,设备及其所有者同样可能直接遭受恶意攻击。
|
||||
|
||||

|
||||
|
||||
*Cortex-M33 和 -M23*
|
||||
|
||||
Dyn 攻击更加证明了这种观点,即物联网将更加蓬勃地在受控制和受保护的工业环境发展,而不是家用环境中。这不是因为没有消费级[物联网安全技术][9],但除非产品设计之初就以安全为目标,否则如我们的[智能家居集线器系列][10]中的许多解决方案一样,后期再考虑安全就会增加成本和复杂性。
|
||||
|
||||
在物联网系列的最后这个未来展望的部分,我们将探讨两种基于 Linux 的面向 Docker 的容器技术,这些技术被提出作为物联网安全解决方案。容器还可以帮助解决我们在[物联网框架][11]中探讨的开发复杂性和互操作性障碍的问题。
|
||||
|
||||
我们与 Canonical 的 Ubuntu 客户平台工程副总裁 Oliver Ries 讨论了 Ubuntu Core 和适用于 Docker 的容器式 Snaps 包管理技术。我们还就新的基于 Docker 的物联网方案 ResinOS 采访了 Resin.io 首席执行官和联合创始人 Alexandros Marinos。
|
||||
|
||||
### Ubuntu Core Snaps
|
||||
|
||||
Canonical 面向物联网的 [Snappy Ubuntu Core][12] 版本的 Ubuntu 是围绕一个类似容器的快照包管理机制而构建的,并提供应用商店支持。 snaps 技术最近[自行发布了][13]用于其他 Linux 发行版的版本。去年 11 月 3 日,Canonical 发布了 [Ubuntu Core 16] [14],该版本改进了白标应用商店和更新控制服务。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*传统 Ubuntu(左)架构 与 Ubuntu Core 16*
|
||||
|
||||
快照机制提供自动更新,并有助于阻止未经授权的更新。 使用事务系统管理,快照可确保更新按预期部署或根本不部署。 在 Ubuntu Core 中,使用 AppArmor 进一步加强了安全性,并且所有应用程序文件都是只读的且保存在隔离的孤岛中。
|
||||
|
||||

|
||||
|
||||
*LimeSDR*
|
||||
|
||||
Ubuntu Core 是我们最近展开的[开源物联网操作系统调查][16]的一部分,现在运行于 Gumstix 主板、Erle 机器人无人机、Dell Edge 网关、[Nextcloud Box][17]、LimeSDR、Mycroft 家庭集线器、英特尔的 Joule 和符合 Linaro 的 96Boards 规范的 SBC(单板计算机) 上。 Canonical 公司还与 Linaro 物联网和嵌入式(LITE)部门集团在其 [96Boards 物联网版(IE)][18] 上达成合作。最初,96Boards IE 专注于 Zephyr 驱动的 Cortex-M4 板卡,如 Seeed 的 [BLE Carbon] [19],不过它将扩展到可以运行 Ubuntu Core 的网关板卡上。
|
||||
|
||||
“Ubuntu Core 和 snaps 具有从边缘到网关到云的相关性,”Canonical 的 Ries 说。 “能够在任何主要发行版(包括 Ubuntu Server 和 Ubuntu for Cloud)上运行快照包,使我们能够提供一致的体验。 snaps 可以使用事务更新以免故障方式升级,可用于安全性更新、错误修复或新功能的持续更新,这在物联网环境中非常重要。”
|
||||
|
||||

|
||||
|
||||
*Nextcloud盒子*
|
||||
|
||||
安全性和可靠性是关注的重点,Ries 说。 “snaps 应用可以完全独立于彼此和操作系统而运行,使得两个应用程序可以安全地在单个网关上运行,”他说。 “snaps 是只读的和经过认证的,可以保证代码的完整性。
|
||||
|
||||
Ries 还说这种技术减少开发时间。 “snap 软件包允许开发人员向支持它的任何平台提供相同的二进制包,从而降低开发和测试成本,减少部署时间和提高更新速度。 “使用 snap 软件包,开发人员完可以全控制开发生命周期,并可以立即更新。 snap 包提供了所有必需的依赖项,因此开发人员可以选择定制他们使用的组件。”
|
||||
|
||||
### ResinOS: 为 IoT 而生的 Docker
|
||||
|
||||
Resin.io 公司,与其商用的 IoT 框架同名,最近剥离了该框架的基于 Yocto Linux 的 [ResinOS 2.0][20],ResinOS 2.0 将作为一个独立的开源项目运营。 Ubuntu Core 在 snap 包中运行 Docker 容器引擎,ResinOS 在主机上运行 Docker。 极致简约的 ResinOS 抽离了使用 Yocto 代码的复杂性,使开发人员能够快速部署 Docker 容器。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*ResinOS 2.0 架构*
|
||||
|
||||
与基于 Linux 的 CoreOS 一样,ResinOS 集成了 systemd 控制服务和网络协议栈,可通过异构网络安全地部署更新的应用程序。 但是,它是为在资源受限的设备(如 ARM 黑客板)上运行而设计的,与之相反,CoreOS 和其他基于 Docker 的操作系统(例如基于 Red Hat 的 Project Atomic)目前仅能运行在 x86 上,并且更喜欢资源丰富的服务器平台。 ResinOS 可以在 20 中 Linux 设备上运行,并不断增长,包括 Raspberry Pi,BeagleBone 和Odroid-C1 等。
|
||||
|
||||
“我们认为 Linux 容器对嵌入式系统比对于云更重要,”Resin.io 的 Marinos 说。 “在云中,容器代表了对之前的进程的优化,但在嵌入式中,它们代表了姗姗来迟的通用虚拟化“
|
||||
|
||||

|
||||
|
||||
*BeagleBone Black*
|
||||
|
||||
当应用于物联网时,完整的企业级虚拟机有直接访问硬件的限制的性能缺陷,Marinos 说。像 OSGi 和 Android 的Dalvik 这样的移动设备虚拟机可以用于 IoT,但是它们依赖 Java 并有其他限制。
|
||||
|
||||
对于企业开发人员来说,使用 Docker 似乎很自然,但是你如何说服嵌入式黑客转向全新的范式呢? “Marinos 解释说,”ResinOS 不是把云技术的实践经验照单全收,而是针对嵌入式进行了优化。”此外,他说,容器比典型的物联网技术更好地包容故障。 “如果有软件缺陷,主机操作系统可以继续正常工作,甚至保持连接。要恢复,您可以重新启动容器或推送更新。更新设备而不重新启动它的能力进一步消除了故障引发问题的机率。”
|
||||
|
||||
据 Marinos 所说,其他好处源自与云技术的一致性,例如拥有更广泛的开发人员。容器提供了“跨数据中心和边缘的统一范式,以及一种方便地将技术、工作流、基础设施,甚至应用程序转移到边缘(终端)的方式。”
|
||||
|
||||
Marinos 说,容器中的固有安全性优势正在被其他技术增强。 “随着 Docker 社区推动实现镜像签名和鉴证,这些自然会转移并应用到 ResinOS,”他说。 “当 Linux 内核被强化以提高容器安全性时,或者获得更好地管理容器所消耗的资源的能力时,会产生类似的好处。
|
||||
|
||||
容器也适合开源 IoT 框架,Marinos 说。 “Linux 容器很容易与几乎各种协议、应用程序、语言和库结合使用,”Marinos 说。 “Resin.io 参加了 AllSeen 联盟,我们与使用 IoTivity 和 Thread的 伙伴一起合作。”
|
||||
|
||||
### IoT的未来:智能网关与智能终端
|
||||
|
||||
Marinos 和 Canonical 的 Ries 对未来物联网的几个发展趋势具有一致的看法。 首先,物联网的最初概念(其中基于 MCU 的端点直接与云进行通信以进行处理)正在迅速被雾化计算架构所取代。 这需要更智能的网关,也需要比仅仅在 ZigBee 和 WiFi 之间聚合和转换数据更多的功能。
|
||||
|
||||
其次,网关和智能边缘设备越来越多地运行多个应用程序。 第三,许多这些设备将提供板载分析,这些在最新的[智能家居集线器][22]上都有体现。 最后,富媒体将很快成为物联网组合的一部分。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
*最新设备网关: Eurotech 的 [ReliaGate 20-26][1]*
|
||||
|
||||

|
||||
|
||||
|
||||
*最新设备网关: Advantech 的 [UBC-221][2]*
|
||||
|
||||
“智能网关正在接管最初为云服务设计的许多处理和控制功能,”Marinos 说。 “因此,我们看到对容器化的推动力在增加,可以在 IoT 设备中使用类似云工作流程来部署与功能和安全相关的优化。去中心化是由移动数据紧缩、不断发展的法律框架和各种物理限制等因素驱动的。”
|
||||
|
||||
Ubuntu Core 等平台正在使“可用于网关的软件爆炸式增长”,Canonical 的 Ries 说。 “在单个设备上运行多个应用程序的能力吸引了众多单一功能设备的用户,以及现在可以产生持续的软件收入的设备所有者。”
|
||||
|
||||

|
||||
|
||||
*两种 IoT 网关: [MyOmega MYNXG IC2 Controller][3]*
|
||||
|
||||

|
||||
|
||||
*两种 IoT 网关: TechNexion 的 [LS1021A-IoT Gateway][4]*
|
||||
|
||||
不仅是网关 - 终端也变得更聪明。 “阅读大量的物联网新闻报道,你得到的印象是所有终端都运行在微控制器上,”Marinos 说。 “但是我们对大量的 Linux 终端,如数字标牌,无人机和工业机械等直接执行任务,而不是作为操作中介(数据转发)感到惊讶。我们称之为影子 IoT。”
|
||||
|
||||
Canonical 的 Ries 同意,对简约技术的专注使他们忽视了新兴物联网领域。 “轻量化的概念在一个发展速度与物联网一样快的行业中初现端倪,”Ries 说。 “今天的高级消费硬件可以持续为终端供电数月。”
|
||||
|
||||
虽然大多数物联网设备将保持轻量和“无头”(一种配置方式,比如物联网设备缺少显示器,键盘等),它们装备有如加速度计和温度传感器这样的传感器并通过低速率的数据流通信,但是许多较新的物联网应用已经使用富媒体。 “媒体输入/输出只是另一种类型的外设,”Marinos 说。 “总是存在多个容器竞争有限资源的问题,但它与传感器或蓝牙竞争天线资源没有太大区别。”
|
||||
|
||||
Ries 看到了工业和家庭网关中“提高边缘智能”的趋势。 “我们看到人工智能、机器学习、计算机视觉和上下文意识的大幅上升,”Ries 说。 “为什么要在云中运行面部检测软件,如果相同的软件可以在边缘设备运行而又没有网络延迟和带宽及计算成本呢?“
|
||||
|
||||
当我们在这个物联网系列的[开篇故事][27]中探索时,我们发现存在与安全相关的物联网问题,例如隐私丧失和生活在监视文化中的权衡。还有一些问题如把个人决策交给可能由他人操控的 AI 裁定。这些不会被容器,快照或任何其他技术完全解决。
|
||||
|
||||
如果 AWS Alexa 可以处理生活琐事,而我们专注在要事上,也许我们会更快乐。或许有一个方法来平衡隐私和效用,现在,我们仍在探索,如此甚好。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
译者:[firstadream](https://github.com/firstadream)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
[1]:http://hackerboards.com/atom-based-gateway-taps-new-open-source-iot-cloud-platform/
|
||||
[2]:http://hackerboards.com/compact-iot-gateway-runs-yocto-linux-on-quark/
|
||||
[3]:http://hackerboards.com/wireless-crazed-customizable-iot-gateway-uses-arm-or-x86-coms/
|
||||
[4]:http://hackerboards.com/iot-gateway-runs-linux-on-qoriq-accepts-arduino-shields/
|
||||
[5]:http://hackerboards.com/linux-and-open-source-hardware-for-building-iot-devices/
|
||||
[6]:http://hackerboards.com/intel-launches-14nm-atom-e3900-and-spins-an-automotive-version/
|
||||
[7]:http://hackerboards.com/samsung-adds-first-64-bit-and-cortex-m4-based-artik-modules/
|
||||
[8]:http://hackerboards.com/new-cortex-m-chips-add-armv8-and-trustzone/
|
||||
[9]:http://hackerboards.com/exploring-security-challenges-in-linux-based-iot-devices/
|
||||
[10]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[11]:http://hackerboards.com/open-source-projects-for-the-internet-of-things-from-a-to-z/
|
||||
[12]:http://hackerboards.com/lightweight-snappy-ubuntu-core-os-targets-iot/
|
||||
[13]:http://hackerboards.com/canonical-pushes-snap-as-a-universal-linux-package-format/
|
||||
[14]:http://hackerboards.com/ubuntu-core-16-gets-smaller-goes-all-snaps/
|
||||
[15]:http://hackerboards.com/files/canonical_ubuntucore16_diagram.jpg
|
||||
[16]:http://hackerboards.com/open-source-oses-for-the-internet-of-things/
|
||||
[17]:http://hackerboards.com/private-cloud-server-and-iot-gateway-runs-ubuntu-snappy-on-rpi/
|
||||
[18]:http://hackerboards.com/linaro-beams-lite-at-internet-of-things-devices/
|
||||
[19]:http://hackerboards.com/96boards-goes-cortex-m4-with-iot-edition-and-carbon-sbc/
|
||||
[20]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/%3Ca%20href=
|
||||
[21]:http://hackerboards.com/files/resinio_resinos_arch.jpg
|
||||
[22]:http://hackerboards.com/linux-based-smart-home-hubs-advance-into-ai/
|
||||
[23]:http://hackerboards.com/files/eurotech_reliagate2026.jpg
|
||||
[24]:http://hackerboards.com/files/advantech_ubc221.jpg
|
||||
[25]:http://hackerboards.com/files/myomega_mynxg.jpg
|
||||
[26]:http://hackerboards.com/files/technexion_ls1021aiot_front.jpg
|
||||
[27]:http://hackerboards.com/an-open-source-perspective-on-the-internet-of-things-part-1/
|
||||
[28]:http://hackerboards.com/can-linux-containers-save-iot-from-a-security-meltdown/
|
||||
@ -0,0 +1,294 @@
|
||||
如何在 Ubuntu16.04 中用 Apache 部署 Jenkins 自动化服务器
|
||||
============================================================
|
||||
|
||||
Jenkins 是从 Hudson 项目衍生出来的自动化服务器。Jenkins 是一个基于服务器的应用程序,运行在 Java servlet 容器中,它支持包括 Git、SVN 以及 Mercurial 在内的多种 SCM(Source Control Management,源码控制工具)。Jenkins 提供了上百种插件帮助你的项目实现自动化。Jenkins 由 Kohsuke Kawaguchi 开发,在 2011 年使用 MIT 协议发布了第一个发行版,它是个自由软件。
|
||||
|
||||
在这篇指南中,我会向你介绍如何在 Ubuntu 16.04 中安装最新版本的 Jenkins。我们会用自己的域名运行 Jenkins,在 apache web 服务器中安装和配置 Jenkins,而且支持反向代理。
|
||||
|
||||
### 前提
|
||||
|
||||
* Ubuntu 16.04 服务器 - 64 位
|
||||
* Root 权限
|
||||
|
||||
### 第一步 - 安装 Java OpenJDK 7
|
||||
|
||||
Jenkins 基于 Java,因此我们需要在服务器上安装 Java OpenJDK 7。在这里,我们会从一个 PPA 仓库安装 Java 7,首先我们需要添加这个仓库。
|
||||
|
||||
默认情况下,Ubuntu 16.04 没有安装用于管理 PPA 仓库的 python-software-properties 软件包,因此我们首先需要安装这个软件。使用 apt 命令安装 python-software-properties。
|
||||
|
||||
```
|
||||
apt-get install python-software-properties
|
||||
```
|
||||
|
||||
下一步,添加 Java PPA 仓库到服务器中。
|
||||
|
||||
```
|
||||
add-apt-repository ppa:openjdk-r/ppa
|
||||
```
|
||||
|
||||
用 apt 命令更新 Ubuntu 仓库并安装 Java OpenJDK。
|
||||
|
||||
```
|
||||
apt-get update
|
||||
apt-get install openjdk-7-jdk
|
||||
```
|
||||
|
||||
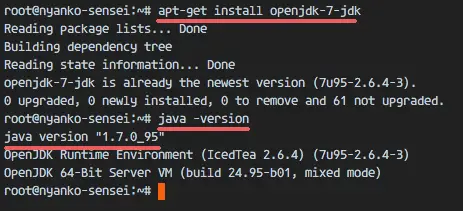
输入下面的命令验证安装:
|
||||
|
||||
```
|
||||
java -version
|
||||
```
|
||||
|
||||
你会看到安装到服务器上的 Java 版本。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
### 第二步 - 安装 Jenkins
|
||||
|
||||
Jenkins 给软件安装包提供了一个 Ubuntu 仓库,我们会从这个仓库中安装 Jenkins。
|
||||
|
||||
用下面的命令添加 Jenkins 密钥和仓库到系统中。
|
||||
|
||||
```
|
||||
wget -q -O - https://pkg.jenkins.io/debian-stable/jenkins.io.key | sudo apt-key add -
|
||||
echo 'deb https://pkg.jenkins.io/debian-stable binary/' | tee -a /etc/apt/sources.list
|
||||
```
|
||||
|
||||
更新仓库并安装 Jenkins。
|
||||
|
||||
```
|
||||
apt-get update
|
||||
apt-get install jenkins
|
||||
```
|
||||
|
||||
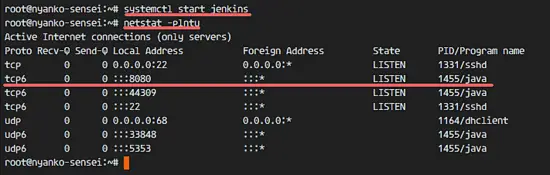
安装完成后,用下面的命令启动 Jenkins。
|
||||
|
||||
```
|
||||
systemctl start jenkins
|
||||
```
|
||||
|
||||
通过检查 Jenkins 默认使用的端口(端口 8080)验证 Jenkins 正在运行。我会像下面这样用 `netstat` 命令检测:
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
Jenkins 已经安装好了并运行在 8080 端口。
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### 第三步 - 为 Jenkins 安装和配置 Apache 作为反向代理
|
||||
|
||||
在这篇指南中,我们会在一个 Apache web 服务器中运行 Jenkins,我们会为 Jenkins 配置 apache 作为反向代理。首先我会安装 apache 并启用一些需要的模块,然后我会为 Jenkins 用域名 my.jenkins.id 创建虚拟主机文件。请在这里使用你自己的域名并在所有配置文件中出现的地方替换。
|
||||
|
||||
从 Ubuntu 仓库安装 apache2 web 服务器。
|
||||
|
||||
```
|
||||
apt-get install apache2
|
||||
```
|
||||
|
||||
安装完成后,启用 proxy 和 proxy_http 模块以便将 apache 配置为 Jenkins 的前端服务器/反向代理。
|
||||
|
||||
```
|
||||
a2enmod proxy
|
||||
a2enmod proxy_http
|
||||
```
|
||||
|
||||
下一步,在 `sites-available` 目录创建新的虚拟主机文件。
|
||||
|
||||
```
|
||||
cd /etc/apache2/sites-available/
|
||||
vim jenkins.conf
|
||||
```
|
||||
|
||||
粘贴下面的虚拟主机配置。
|
||||
|
||||
```
|
||||
<Virtualhost *:80>
|
||||
ServerName my.jenkins.id
|
||||
ProxyRequests Off
|
||||
ProxyPreserveHost On
|
||||
AllowEncodedSlashes NoDecode
|
||||
|
||||
<Proxy http://localhost:8080/*>
|
||||
Order deny,allow
|
||||
Allow from all
|
||||
</Proxy>
|
||||
|
||||
ProxyPass / http://localhost:8080/ nocanon
|
||||
ProxyPassReverse / http://localhost:8080/
|
||||
ProxyPassReverse / http://my.jenkins.id/
|
||||
</Virtualhost>
|
||||
```
|
||||
|
||||
保存文件。然后用 `a2ensite` 命令激活 Jenkins 虚拟主机。
|
||||
|
||||
```
|
||||
a2ensite jenkins
|
||||
```
|
||||
|
||||
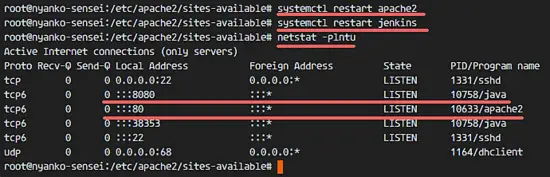
重启 Apache 和 Jenkins。
|
||||
|
||||
```
|
||||
systemctl restart apache2
|
||||
systemctl restart jenkins
|
||||
```
|
||||
|
||||
检查 Jenkins 和 Apache 正在使用 80 和 8080 端口。
|
||||
|
||||
```
|
||||
netstat -plntu
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
### 第四步 - 配置 Jenkins
|
||||
|
||||
Jenkins 用域名 'my.jenkins.id' 运行。打开你的 web 浏览器然后输入 URL。你会看到要求你输入初始管理员密码的页面。Jenkins 已经生成了一个密码,因此我们只需要显示并把结果复制到密码框。
|
||||
|
||||
用 `cat` 命令显示 Jenkins 初始管理员密码。
|
||||
|
||||
```
|
||||
cat /var/lib/jenkins/secrets/initialAdminPassword
|
||||
a1789d1561bf413c938122c599cf65c9
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
将结果粘贴到密码框然后点击 Continue。
|
||||
|
||||
[
|
||||
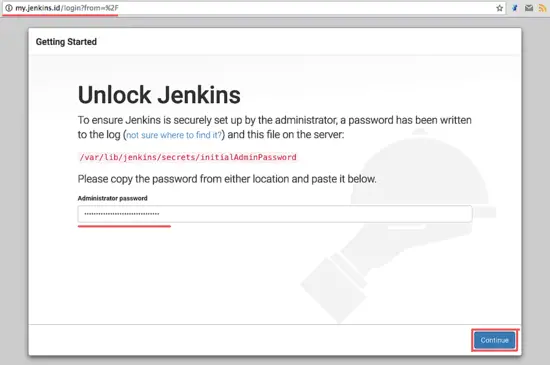
|
||||
][13]
|
||||
|
||||
现在为了后面能比较好的使用,我们需要在 Jenkins 中安装一些插件。选择 Install Suggested Plugin,点击它。
|
||||
|
||||
[
|
||||
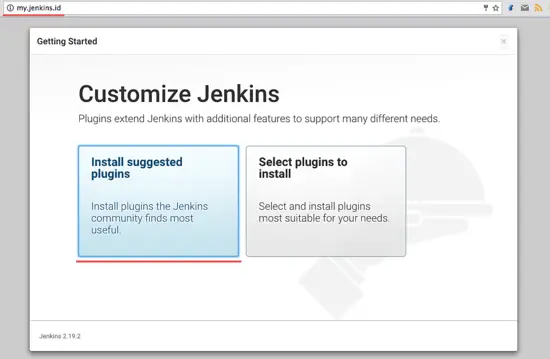
|
||||
][14]
|
||||
|
||||
Jenkins 插件安装过程:
|
||||
|
||||
[
|
||||
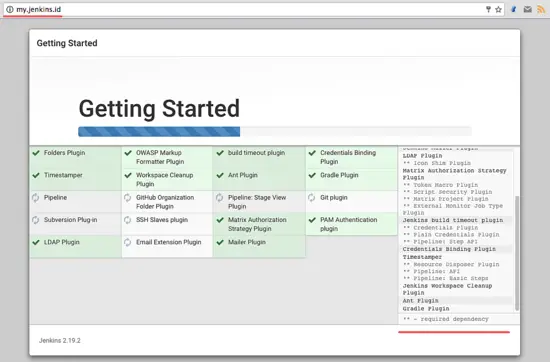
|
||||
][15]
|
||||
|
||||
安装完插件后,我们需要创建一个新的管理员密码。输入你的管理员用户名、密码、电子邮件等,然后点击 ‘**Save and Finish**’。
|
||||
|
||||
[
|
||||
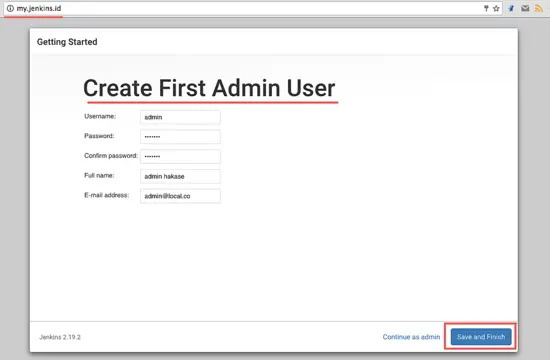
|
||||
][16]
|
||||
|
||||
点击 start 开始使用 Jenkins。你会被重定向到 Jenkins 管理员面板。
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
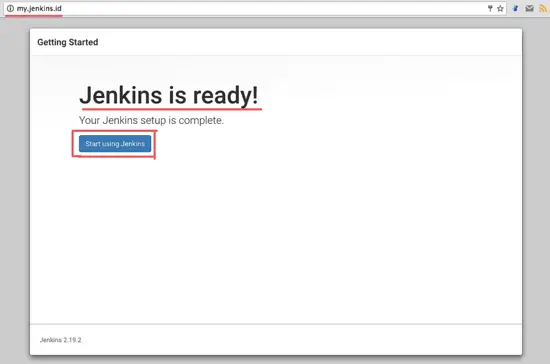
成功完成 Jenkins 安装和配置。
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
### 第五步 - Jenkins 安全
|
||||
|
||||
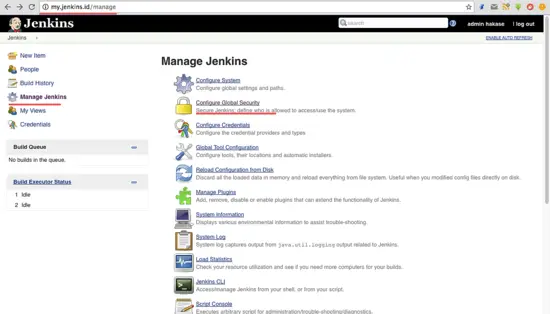
在 Jenkins 管理员面板,我们需要为 Jenkins 配置标准的安全,点击 ‘**Manage Jenkins**’ 和 ‘**Configure Global Security**’。
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
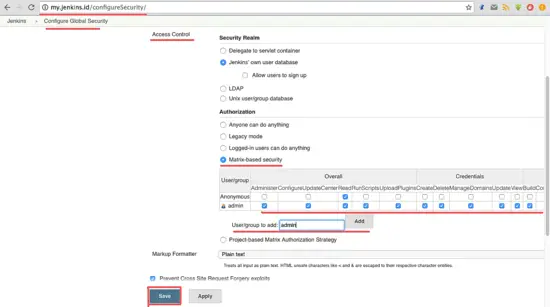
Jenkins 在 ‘**Access Control**’ 部分提供了多种认证方法。为了能够控制所有的用户权限,我选择了 ‘**Matrix-based Security**’。在复选框 ‘**User/Group**’ 中启用 admin 用户。通过**勾选所有选项**给 admin 所有权限,给 anonymous 只读权限。现在点击 ‘**Save**’。
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
你会被重定向到面板,如果出现了登录选项,只需输入你的管理员账户和密码。
|
||||
|
||||
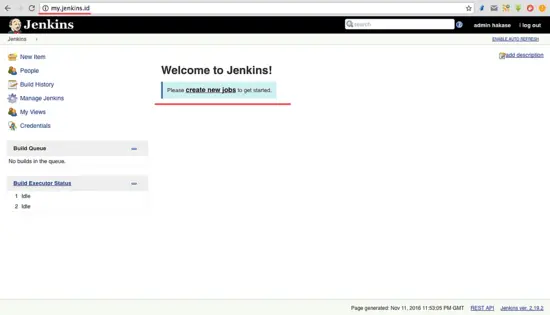
### 第六步 - 测试一个简单的自动化任务
|
||||
|
||||
在这一部分,我想为 Jenkins 服务测试一个简单的任务。为了测试 Jenkins 我会创建一个简单的任务,并用 top 命令查看服务器的负载。
|
||||
|
||||
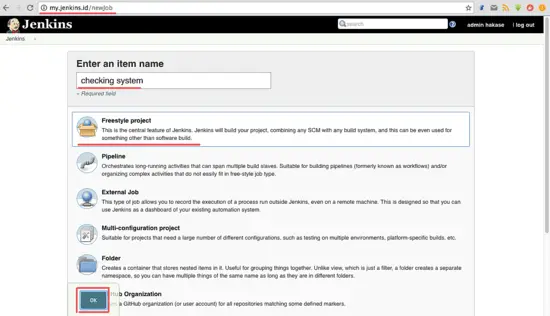
在 Jenkins 管理员面板上,点击 ‘**Create New Job**’。
|
||||
|
||||
[
|
||||
|
||||
][21]
|
||||
|
||||
输入任务的名称,在这里我输入 ‘Checking System’,选择 Freestyle Project 然后点击 OK。
|
||||
|
||||
[
|
||||
|
||||
][22]
|
||||
|
||||
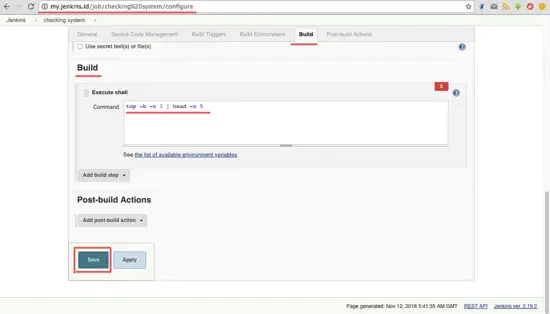
进入 Build 标签页。在 Add build step,选择选项 Execute shell。
|
||||
|
||||
在输入框输入下面的命令。
|
||||
|
||||
```
|
||||
top -b -n 1 | head -n 5
|
||||
```
|
||||
|
||||
点击 Save。
|
||||
|
||||
[
|
||||
|
||||
][23]
|
||||
|
||||
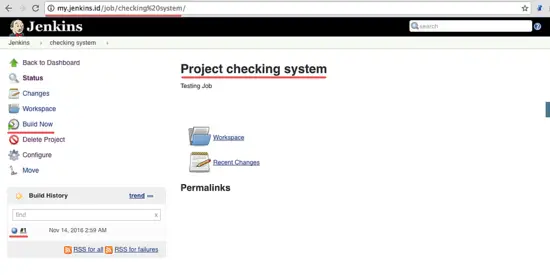
现在你是在任务 ‘Project checking system’ 的任务页。点击 Build Now 执行任务 ‘checking system’。
|
||||
|
||||
任务执行完成后,你会看到 Build History,点击第一个任务查看结果。
|
||||
|
||||
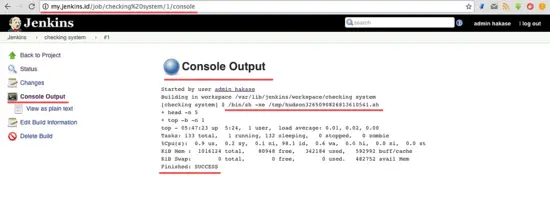
下面是 Jenkins 任务执行的结果。
|
||||
|
||||
[
|
||||
|
||||
][24]
|
||||
|
||||
到这里就介绍完了在 Ubuntu 16.04 中用 Apache web 服务器安装 Jenkins 的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/howtoforgecom
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#prerequisite
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-java-openjdk-
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-jenkins
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-install-and-configure-apache-as-reverse-proxy-for-jenkins
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-configure-jenkins
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-jenkins-security
|
||||
[7]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#step-testing-a-simple-automation-job
|
||||
[8]:https://www.howtoforge.com/tutorial/how-to-install-jenkins-with-apache-on-ubuntu-16-04/#reference
|
||||
[9]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/1.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/2.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/3.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/4.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/5.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/6.png
|
||||
[15]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/7.png
|
||||
[16]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/8.png
|
||||
[17]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/9.png
|
||||
[18]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/10.png
|
||||
[19]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/11.png
|
||||
[20]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/12.png
|
||||
[21]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/13.png
|
||||
[22]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/14.png
|
||||
[23]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/15.png
|
||||
[24]:https://www.howtoforge.com/images/how-to-install-jenkins-with-apache-on-ubuntu-16-04/big/16.png
|
||||
237
published/20161221 Living Android without Kotlin.md
Normal file
237
published/20161221 Living Android without Kotlin.md
Normal file
@ -0,0 +1,237 @@
|
||||
在没有 Kotlin 的世界与 Android 共舞
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 开始投入一件事比远离它更容易。 — Donald Rumsfeld
|
||||
|
||||
没有 Kotlin 的生活就像在触摸板上玩魔兽争霸 3。购买鼠标很简单,但如果你的新雇主不想让你在生产中使用 Kotlin,你该怎么办?
|
||||
|
||||
下面有一些选择。
|
||||
* 与你的产品负责人争取获得使用 Kotlin 的权利。
|
||||
* 使用 Kotlin 并且不告诉其他人因为你知道最好的东西是只适合你的。
|
||||
* 擦掉你的眼泪,自豪地使用 Java。
|
||||
|
||||
想象一下,你在和产品负责人的斗争中失败,作为一个专业的工程师,你不能在没有同意的情况下私自去使用那些时髦的技术。我知道这听起来非常恐怖,特别当你已经品尝到 Kotlin 的好处时,不过不要失去生活的信念。
|
||||
|
||||
在文章接下来的部分,我想简短地描述一些 Kotlin 的特征,使你通过一些知名的工具和库,可以应用到你的 Android 里的 Java 代码中去。对于 Kotlin 和 Java 的基本认识是需要的。
|
||||
|
||||
### 数据类
|
||||
|
||||
我想你肯定已经喜欢上 Kotlin 的数据类。对于你来说,得到 `equals()`、 `hashCode()`、 `toString()` 和 `copy()` 这些是很容易的。具体来说,`data` 关键字还可以按照声明顺序生成对应于属性的 `componentN()` 函数。 它们用于解构声明。
|
||||
|
||||
```
|
||||
data class Person(val name: String)
|
||||
val (riddle) = Person("Peter")
|
||||
println(riddle)
|
||||
```
|
||||
|
||||
你知道什么会被打印出来吗?确实,它不会是从 `Person` 类的 `toString()` 返回的值。这是解构声明的作用,它赋值从 `name` 到 `riddle`。使用园括号 `(riddle)` 编译器知道它必须使用解构声明机制。
|
||||
|
||||
```
|
||||
val (riddle): String = Person("Peter").component1()
|
||||
println(riddle) // prints Peter)
|
||||
```
|
||||
|
||||
> 这个代码没编译。它就是展示了构造声明怎么工作的。
|
||||
|
||||
正如你可以看到 `data` 关键字是一个超级有用的语言特性,所以你能做什么把它带到你的 Java 世界? 使用注释处理器并修改抽象语法树(Abstract Syntax Tree)。 如果你想更深入,请阅读文章末尾列出的文章(Project Lombok— Trick Explained)。
|
||||
|
||||
使用项目 Lombok 你可以实现 `data`关键字所提供的几乎相同的功能。 不幸的是,没有办法进行解构声明。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
}
|
||||
```
|
||||
|
||||
`@Data` 注解生成 `equals()`、`hashCode()` 和 `toString()`。 此外,它为所有字段创建 getter,为所有非最终字段创建setter,并为所有必填字段(final)创建构造函数。 值得注意的是,Lombok 仅用于编译,因此库代码不会添加到您的最终的 .apk。
|
||||
|
||||
### Lambda 表达式
|
||||
|
||||
Android 工程师有一个非常艰难的生活,因为 Android 中缺乏 Java 8 的特性,而且其中之一是 lambda 表达式。 Lambda 是很棒的,因为它们为你减少了成吨的样板。 你可以在回调和流中使用它们。 在 Kotlin 中,lambda 表达式是内置的,它们看起来比它们在 Java 中看起来好多了。 此外,lambda 的字节码可以直接插入到调用方法的字节码中,因此方法计数不会增加。 它可以使用内联函数。
|
||||
|
||||
```
|
||||
button.setOnClickListener { println("Hello World") }
|
||||
```
|
||||
|
||||
最近 Google 宣布在 Android 中支持 Java 8 的特性,由于 Jack 编译器,你可以在你的代码中使用 lambda。还要提及的是,它们在 API 23 或者更低的级别都可用。
|
||||
|
||||
```
|
||||
button.setOnClickListener(view -> System.out.println("Hello World!"));
|
||||
```
|
||||
|
||||
怎样使用它们?就只用添加下面几行到你的 `build.gradle` 文件中。
|
||||
|
||||
```
|
||||
defaultConfig {
|
||||
jackOptions {
|
||||
enabled true
|
||||
}
|
||||
}
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
如果你不喜欢用 Jack 编译器,或者你由于一些原因不能使用它,这里有一个不同的解决方案提供给你。Retrolambda 项目允许你在 Java 7,6 或者 5 上运行带有 lambda 表达式的 Java 8 代码,下面是设置过程。
|
||||
|
||||
```
|
||||
dependencies {
|
||||
classpath 'me.tatarka:gradle-retrolambda:3.4.0'
|
||||
}
|
||||
|
||||
apply plugin: 'me.tatarka.retrolambda'
|
||||
|
||||
compileOptions {
|
||||
sourceCompatibility JavaVersion.VERSION_1_8
|
||||
targetCompatibility JavaVersion.VERSION_1_8
|
||||
}
|
||||
```
|
||||
|
||||
正如我前面提到的,在 Kotlin 下的 lambda 内联函数不增加方法计数,但是如何在 Jack 或者 Retrolambda 下使用它们呢? 显然,它们不是没成本的,隐藏的成本如下。
|
||||
|
||||
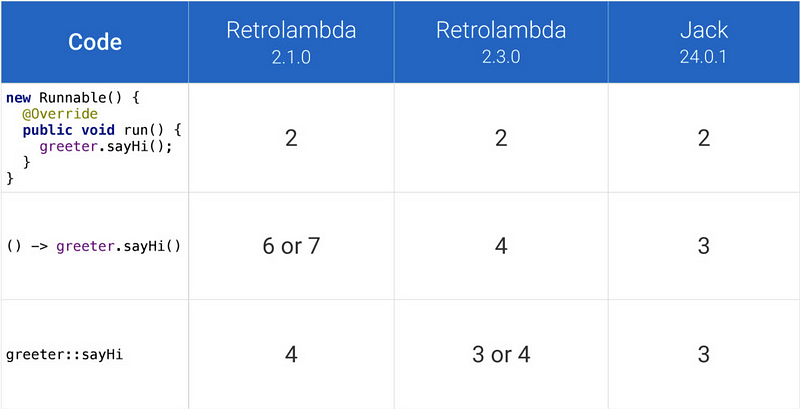
|
||||
|
||||
*该表展示了使用不同版本的 Retrolambda 和 Jack 编译器生成的方法数量。该比较结果来自 Jake Wharton 的“[探索 Java 的隐藏成本](http://jakewharton.com/exploring-java-hidden-costs/)” 技术讨论之中。*
|
||||
|
||||
### 数据操作
|
||||
|
||||
Kotlin 引入了高阶函数作为流的替代。 当您必须将一组数据转换为另一组数据或过滤集合时,它们非常有用。
|
||||
|
||||
```
|
||||
fun foo(persons: MutableList<Person>) {
|
||||
persons.filter { it.age >= 21 }
|
||||
.filter { it.name.startsWith("P") }
|
||||
.map { it.name }
|
||||
.sorted()
|
||||
.forEach(::println)
|
||||
}
|
||||
|
||||
data class Person(val name: String, val age: Int)
|
||||
```
|
||||
|
||||
流也由 Google 通过 Jack 编译器提供。 不幸的是,Jack 不使用 Lombok,因为它在编译代码时跳过生成中间的 `.class` 文件,而 Lombok 却依赖于这些文件。
|
||||
|
||||
```
|
||||
void foo(List<Person> persons) {
|
||||
persons.stream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
class Person {
|
||||
final private String name;
|
||||
final private int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
String getName() { return name; }
|
||||
int getAge() { return age; }
|
||||
}
|
||||
```
|
||||
|
||||
这简直太好了,所以 catch 在哪里? 令人悲伤的是,流从 API 24 才可用。谷歌做了好事,但哪个应用程序有用 `minSdkVersion = 24`?
|
||||
|
||||
幸运的是,Android 平台有一个很好的提供许多很棒的库的开源社区。Lightweight-Stream-API 就是其中的一个,它包含了 Java 7 及以下版本的基于迭代器的流实现。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import com.annimon.stream.Stream;
|
||||
|
||||
void foo(List<Person> persons) {
|
||||
Stream.of(persons)
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
```
|
||||
|
||||
上面的例子结合了 Lombok、Retrolambda 和 Lightweight-Stream-API,它看起来几乎和 Kotlin 一样棒。使用静态工厂方法允许您将任何 Iterable 转换为流,并对其应用 lambda,就像 Java 8 流一样。 将静态调用 `Stream.of(persons)` 包装为 Iterable 类型的扩展函数是完美的,但是 Java 不支持它。
|
||||
|
||||
### 扩展函数
|
||||
|
||||
扩展机制提供了向类添加功能而无需继承它的能力。 这个众所周知的概念非常适合 Android 世界,这就是 Kotlin 在该社区很受欢迎的原因。
|
||||
|
||||
有没有技术或魔术将扩展功能添加到你的 Java 工具箱? 因 Lombok,你可以使用它们作为一个实验功能。 根据 Lombok 文档的说明,他们想把它从实验状态移出,基本上没有什么变化的话很快。 让我们重构最后一个例子,并将 `Stream.of(persons)` 包装成扩展函数。
|
||||
|
||||
```
|
||||
import lombok.Data;
|
||||
import lombok.experimental.ExtensionMethod;
|
||||
|
||||
@ExtensionMethod(Streams.class)
|
||||
public class Foo {
|
||||
void foo(List<Person> persons) {
|
||||
persons.toStream()
|
||||
.filter(it -> it.getAge() >= 21)
|
||||
.filter(it -> it.getName().startsWith("P"))
|
||||
.map(Person::getName)
|
||||
.sorted()
|
||||
.forEach(System.out::println);
|
||||
}
|
||||
}
|
||||
|
||||
@Data class Person {
|
||||
final String name;
|
||||
final int age;
|
||||
}
|
||||
|
||||
class Streams {
|
||||
static <T> Stream<T> toStream(List<T> list) {
|
||||
return Stream.of(list);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
所有的方法是 `public`、`static` 的,并且至少有一个参数的类型不是原始的,因而是扩展方法。 `@ExtensionMethod` 注解允许你指定一个包含你的扩展函数的类。 你也可以传递数组,而不是使用一个 `.class` 对象。
|
||||
|
||||
* * *
|
||||
|
||||
我完全知道我的一些想法是非常有争议的,特别是 Lombok,我也知道,有很多的库,可以使你的生活更轻松。请不要犹豫在评论里分享你的经验。干杯!
|
||||
|
||||

|
||||
|
||||
---------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Coder and professional dreamer @ Grid Dynamics
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/proandroiddev/living-android-without-kotlin-db7391a2b170
|
||||
|
||||
作者:[Piotr Ślesarew][a]
|
||||
译者:[DockerChen](https://github.com/DockerChen)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@piotr.slesarew?source=post_header_lockup
|
||||
[1]:http://jakewharton.com/exploring-java-hidden-costs/
|
||||
[2]:https://medium.com/u/8ddd94878165
|
||||
[3]:https://projectlombok.org/index.html
|
||||
[4]:https://github.com/aNNiMON/Lightweight-Stream-API
|
||||
[5]:https://github.com/orfjackal/retrolambda
|
||||
[6]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[7]:http://notatube.blogspot.com/2010/11/project-lombok-trick-explained.html
|
||||
[8]:https://twitter.com/SliskiCode
|
||||
160
published/20170112 Partition Backup.md
Normal file
160
published/20170112 Partition Backup.md
Normal file
@ -0,0 +1,160 @@
|
||||
如何备份一个磁盘分区
|
||||
============
|
||||
|
||||
通常你可能会把数据放在一个分区上,有时候可能需要对该设备或者上面的一个分区进行备份。树莓派用户为了可引导 SD 卡当然有这个需求。其它小体积计算机的用户也会发现这非常有用。有时候设备看起来要出现故障时最好快速做个备份。
|
||||
|
||||
进行本文中的实验你需要一个叫 `dcfldd` 的工具。
|
||||
|
||||
### dcfldd 工具
|
||||
|
||||
该工具是 coreutils 软件包中 `dd` 工具的增强版。`dcfldd` 是 Nicholas Harbour 在美国国防部计算机取证实验室(DCFL)工作期间研发的。该工具的名字也基于他工作的地方 - `dcfldd`。
|
||||
|
||||
对于仍然在使用 CoreUtils 8.23 或更低版本的系统,并没有一个可以轻松查看正在创建副本的进度的选项。有时候看起来就像什么都没有发生,以至于你就想取消掉备份。
|
||||
|
||||
**注意:**如果你使用 8.24 或更新版本的 `dd` 工具,你就不需要使用 `dcfldd`,只需要用 `dd` 替换 `dcfldd` 即可。所有其它参数仍然适用。
|
||||
|
||||
在 Debian 系统上你只需要在 Package Manager 中搜索 `dcfldd`。你也可以打开一个终端然后输入下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get install dcfldd
|
||||
```
|
||||
|
||||
对于 Red Hat 系统,可以用下面的命令:
|
||||
|
||||
```
|
||||
cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/i386/dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.i686.rpm
|
||||
dcfldd --version
|
||||
```
|
||||
|
||||
**注意:** 上面的命令安装的是 32 位版本。对于 64 位版本,使用下面的命令:
|
||||
|
||||
````
|
||||
cd /tmp
|
||||
wget dl.fedoraproject.org/pub/epel/6/x86_64/dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
sudo yum install dcfldd-1.3.4.1-4.el6.x86_64.rpm
|
||||
dcfldd --version
|
||||
```
|
||||
|
||||
每组命令中的最后一个语句会列出 `dcfldd` 的版本并显示该命令文件已经被加载。
|
||||
|
||||
**注意:**确保你以 root 用户执行 `dd` 或者 `dcfldd` 命令。
|
||||
|
||||
安装完该工具后你就可以继续使用它备份和恢复分区。
|
||||
|
||||
### 备份分区
|
||||
|
||||
备份设备的时候可以备份整个设备也可以只是其中的一个分区。如果设备有多个分区,我们可以分别备份每个分区。
|
||||
|
||||
在进行备份之前,先让我们来看一下设备和分区的区别。假设我们有一个已经被格式化为一个大磁盘的 SD 卡。这个 SD 卡只有一个分区。如果空间被切分使得 SD 卡看起来是两个设备,那么它就有两个分区。
|
||||
|
||||
假设我们有一个树莓派中的 SD 卡。SD 卡容量为 8 GB,有两个分区。第一个分区存放 BerryBoot 启动引导器。第二个分区存放 Kali(LCTT 译注:Kali Linux 是一个 Debian 派生的 Linux 发行版)。现在已经没有可用的空间用来安装第二个操作系统。我们使用大小为 16 GB 的第二个 SD 卡,但拷贝到第二个 SD 卡之前,第一个 SD 卡必须先备份。
|
||||
|
||||
要备份第一个 SD 卡我们需要备份设备 `/dev/sdc`。进行备份的命令如下所示:
|
||||
|
||||
```
|
||||
dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
备份包括输入文件(`if`)以及被设置为 `/tmp` 目录下名为 `SD-Card-Backup.img` 的输出文件(`of`)。
|
||||
|
||||
`dd` 和 `dcfldd` 默认都是每次读写文件中的一个块。通过上述命令,它可以一次默认读写 512 个字节。记住,该复制是一个精准的拷贝 - 逐位逐字节。
|
||||
|
||||
默认的 512 个字节可以通过块大小参数 - `bs=` 更改。例如,要每次读写 1 兆字节,参数为 `bs=1M`。使用以下所用的缩写可以设置不同大小:
|
||||
|
||||
* b – 512 字节
|
||||
* KB – 1000 字节
|
||||
* K – 1024 字节
|
||||
* MB – 1000x1000 字节
|
||||
* M – 1024x1024 字节
|
||||
* GB – 1000x1000x1000 字节
|
||||
* G – 1024x1024x1024 字节
|
||||
|
||||
你也可以单独指定读和写的块大小。要指定读块的大小使用 `ibs=`。要指定写块的大小使用 `obs=`。
|
||||
|
||||
我使用三种不同的块大小做了一个 120 MB 分区的备份测试。第一次使用默认的 512 字节,它用了 7 秒钟。第二次块大小为 1024 K,它用时 2 秒。第三次块大小是 2048 K,它用时 3 秒。用时会随系统以及其它硬件实现的不同而变化,但通常来说更大的块大小会比默认的稍微快一点。
|
||||
|
||||
完成备份后,你还需要知道如何把数据恢复到设备中。
|
||||
|
||||
### 恢复分区
|
||||
|
||||
现在我们已经有了一个备份点,假设数据可能被损毁了或者由于某些原因需要进行恢复。
|
||||
|
||||
命令和备份时相同,只是源和目标相反。对于上面的例子,命令会变为:
|
||||
|
||||
```
|
||||
dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
这里,镜像文件被用作输入文件(`if`)而设备(sdc)被用作输出文件(`of`)。
|
||||
|
||||
**注意:** 要记住输出设备会被重写,它上面的所有数据都会丢失。通常来说在恢复数据之前最好用 GParted 删除 SD 卡上的所有分区。
|
||||
|
||||
假如你在使用多个 SD 卡,例如多个树莓派主板,你可以一次性写多块 SD 卡。为了做到这点,你需要知道系统中卡的 ID。例如,假设我们想把镜像 `BerryBoot.img` 拷贝到两个 SD 卡。SD 卡分别是 `/dev/sdc` 和 `/dev/sdd`。下面的命令在显示进度时每次读写 1 MB 的块。命令如下:
|
||||
|
||||
```
|
||||
dcfldd if=BerryBoot.img bs=1M status=progress | tee >(dcfldd of=/dev/sdc) | dcfldd of=/dev/sdd
|
||||
```
|
||||
|
||||
在这个命令中,第一个 `dcfldd` 指定输入文件并把块大小设置为 1 MB。`status` 参数被设置为显示进度。然后输入通过管道 `|`传输给命令 `tee`。`tee` 用于将输入分发到多个地方。第一个输出是到命令 `dcfldd of=/dev/sdc`。命令被放到小括号内被作为一个命令执行。我们还需要最后一个管道 `|`,否则命令 `tee` 会把信息发送到 `stdout` (屏幕)。因此,最后的输出是被发送到命令 `dcfldd of=/dev/sdd`。如果你有第三个 SD 卡,甚至更多,只需要添加另外的重定向和命令,类似 `>(dcfldd of=/dev/sde`。
|
||||
|
||||
**注意:**记住最后一个命令必须在管道 `|` 后面。
|
||||
|
||||
必须验证写的数据确保数据是正确的。
|
||||
|
||||
### 验证数据
|
||||
|
||||
一旦创建了一个镜像或者恢复了一个备份,你可以验证这些写入的数据。要验证数据,你会使用名为 `diff` 的另一个不同程序。
|
||||
|
||||
使用 `diff` ,你需要指定镜像文件的位置以及系统中拷贝自或写入的物理媒介。你可以在创建备份或者恢复了一个镜像之后使用 `diff` 命令。
|
||||
|
||||
该命令有两个参数。第一个是物理媒介,第二个是镜像文件名称。
|
||||
|
||||
对于例子 `dcfldd of=/dev/sdc if=/tmp/SD-Card-Backup.img`,对应的 `diff` 命令是:
|
||||
|
||||
```
|
||||
diff /dev/sdc /tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
如果镜像和物理设备有任何的不同,你会被告知。如果没有显示任何信息,那么数据就验证为完全相同。
|
||||
|
||||
确保数据完全一致是验证备份和恢复完整性的关键。进行备份时需要注意的一个主要问题是镜像大小。
|
||||
|
||||
### 分割镜像
|
||||
|
||||
假设你想要备份一个 16GB 的 SD 卡。镜像文件大小会大概相同。如果你只能把它备份到 FAT32 分区会怎样呢?FAT32 最大文件大小限制是 4 GB。
|
||||
|
||||
必须做的是文件必须被切分为 4 GB 的分片。通过管道 `|` 将数据传输给 `split` 命令可以切分正在被写的镜像文件。
|
||||
|
||||
创建备份的方法相同,但命令会包括管道和切分命令。示例备份命令为 `dcfldd if=/dev/sdc of=/tmp/SD-Card-Backup.img` ,其切分文件的新命令如下:
|
||||
|
||||
```
|
||||
dcfldd if=/dev/sdc | split -b 4000MB - /tmp/SD-Card-Backup.img
|
||||
```
|
||||
|
||||
**注意:** 大小后缀和对 `dd` 及 `dcfldd` 命令的意义相同。 `split` 命令中的破折号用于将通过管道从 `dcfldd` 命令传输过来的数据填充到输入文件。
|
||||
|
||||
文件会被保存为 `SD-Card-Backup.imgaa` 和 `SD-Card-Backup.imgab`,如此类推。如果你担心文件大小太接近 4 GB 的限制,可以试着用 3500MB。
|
||||
|
||||
将文件恢复到设备也很简单。你使用 `cat` 命令将它们连接起来然后像下面这样用 `dcfldd` 写输出:
|
||||
|
||||
```
|
||||
cat /tmp/SD-Card-Backup.img* | dcfldd of=/dev/sdc
|
||||
```
|
||||
|
||||
你可以在命令中 `dcfldd` 部分包含任何需要的参数。
|
||||
|
||||
我希望你了解并能执行任何需要的数据备份和恢复,正如 SD 卡和类似设备所需的那样。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxforum.com/threads/partition-backup.3638/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxforum.com/members/jarret.268/
|
||||
@ -0,0 +1,82 @@
|
||||
5 个需要知道的开源的软件定义网络(SDN)项目
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
> SDN 开始重新定义企业网络。这里有五个应该知道的开源项目。
|
||||
|
||||
|
||||
纵观整个 2016 年,软件定义网络(SDN)持续快速发展并变得成熟。我们现在已经超出了开源网络的概念阶段,两年前评估这些项目潜力的公司已经开始了企业部署。如几年来所预测的,SDN 正在开始重新定义企业网络。
|
||||
|
||||
这与市场研究人员的观点基本上是一致的。IDC 在今年早些时候公布了 SDN 市场的[一份研究][3],它预计从 2014 年到 2020 年 SDN 的年均复合增长率为 53.9%,届时市场价值将达到 125 亿美元。此外,“<ruby>2016 技术趋势<rt>Technology Trends 2016</rt></ruby>” 报告中将 SDN 列为 2016 年最佳技术投资。
|
||||
|
||||
IDC 网络基础设施副总裁,[Rohit Mehra][4] 说:“云计算和第三方平台推动了 SDN 的需求,这预示着 2020 年的一个价值超过 125 亿美元的市场。毫无疑问的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务。大型企业现在正在数据中心体现 SDN 的价值,但它们最终会认识到其在分支机构和校园网络中的广泛应用。“
|
||||
|
||||
Linux 基金会最近[发布][5]了其 2016 年度报告[“开放云指南:当前趋势和开源项目”][6]。其中第三份年度报告全面介绍了开放云计算的状态,并包含关于 unikernel 的部分。你现在可以[下载报告][7]了,首先要注意的是汇总和分析研究,说明了容器、unikernel 等的趋势是如何重塑云计算的。该报告提供了对当今开放云环境中心的分类项目的描述和链接。
|
||||
|
||||
在本系列中,我们会研究各种类别,并提供关于这些领域如何发展的更多见解。下面,你会看到几个重要的 SDN 项目及其所带来的影响,以及 GitHub 仓库的链接,这些都是从“开放云指南”中收集的:
|
||||
|
||||
### 软件定义网络
|
||||
|
||||
#### [ONOS][8]
|
||||
|
||||
<ruby>开放网络操作系统<rt>Open Network Operating System</rt></ruby>(ONOS)是一个 Linux 基金会项目,它是一个面向服务提供商的软件定义网络操作系统,它具有可扩展性、高可用性、高性能和抽象功能来创建应用程序和服务。
|
||||
|
||||
[ONOS 的 GitHub 地址][9]。
|
||||
|
||||
#### [OpenContrail][10]
|
||||
|
||||
OpenContrail 是 Juniper Networks 的云开源网络虚拟化平台。它提供网络虚拟化的所有必要组件:SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API。其 REST API 配置并收集来自系统的操作和分析数据。
|
||||
|
||||
[OpenContrail 的 GitHub 地址][11]。
|
||||
|
||||
#### [OpenDaylight][12]
|
||||
|
||||
OpenDaylight 是 Linux 基金会旗下的 OpenDaylight 基金会项目,它是一个可编程的、提供给服务提供商和企业的软件定义网络平台。它基于微服务架构,可以在多供应商环境中的一系列硬件上实现网络服务。
|
||||
|
||||
[OpenDaylight 的 GitHub 地址][13]。
|
||||
|
||||
#### [Open vSwitch][14]
|
||||
|
||||
Open vSwitch 是一个 Linux 基金会项目,是具有生产级品质的多层虚拟交换机。它通过程序化扩展设计用于大规模网络自动化,同时还支持标准管理接口和协议,包括 NetFlow、sFlow、IPFIX、RSPAN、CLI、LACP 和 802.1ag。它支持类似 VMware 的分布式 vNetwork 或者 Cisco Nexus 1000V 那样跨越多个物理服务器分发。
|
||||
|
||||
[OVS 在 GitHub 的地址][15]。
|
||||
|
||||
#### [OPNFV][16]
|
||||
|
||||
<ruby>网络功能虚拟化开放平台<rt>Open Platform for Network Functions Virtualization</rt></ruby>(OPNFV)是 Linux 基金会项目,它用于企业和服务提供商网络的 NFV 平台。它汇集了计算、存储和网络虚拟化方面的上游组件以创建 NFV 程序的端到端平台。
|
||||
|
||||
[OPNFV 在 Bitergia 上的地址][17]。
|
||||
|
||||
_要了解更多关于开源云计算趋势和查看顶级开源云计算项目完整列表,[请下载 Linux 基金会的 “开放云指南”][18]。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/5-open-source-software-defined-networking-projects-know
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-defined-networkingjpg-0
|
||||
[3]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[4]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[5]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[6]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[7]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[8]:http://onosproject.org/
|
||||
[9]:https://github.com/opennetworkinglab/onos
|
||||
[10]:http://www.opencontrail.org/
|
||||
[11]:https://github.com/Juniper/contrail-controller
|
||||
[12]:https://www.opendaylight.org/
|
||||
[13]:https://github.com/opendaylight
|
||||
[14]:http://openvswitch.org/
|
||||
[15]:https://github.com/openvswitch/ovs
|
||||
[16]:https://www.opnfv.org/
|
||||
[17]:http://projects.bitergia.com/opnfv/browser/
|
||||
[18]:http://bit.ly/2eHQOwy
|
||||
97
published/20170210 Fedora 25 Wayland vs Xorg.md
Normal file
97
published/20170210 Fedora 25 Wayland vs Xorg.md
Normal file
@ -0,0 +1,97 @@
|
||||
Fedora 25: Wayland 大战 Xorg
|
||||
============
|
||||
|
||||
就像异形大战铁血战士的结果一样,后者略胜一筹。不管怎样,你可能知道,我最近测试了 [Fedora 25][1],体验还可以。总的来说,这个发行版表现的相当不错。它不是最快速的,但随着一系列的改进,变得足够稳定也足够好用。最重要的是,除了一些性能以及响应性的损失,Wayland 并没有造成我的系统瘫痪。但这还仅仅是个开始。
|
||||
|
||||
Wayland 作为一种消费者技术还处在它的襁褓期,或者至少是当人们在处理桌面事物时应就这么认为。因此,我必须继续测试,绝不弃坑。在过去的积极地使用 Fedora 25 的几个星期里,我确实碰到了几个其它的问题,有些不用太担心,有些确实很恼人,有些很奇怪,有些却无意义。让我们来讲述一下吧!
|
||||
|
||||

|
||||
|
||||
注: 图片来自 [Wikimedia][2] 并做了些修改, [CC BY-SA 3.0][3] 许可
|
||||
|
||||
### Wayland 并不支持所有软件
|
||||
|
||||
没错,这是一个事实。如果你去网站上阅读相关的信息,你会发现各种各样的软件都还没为 Wayland 做好准备。当然,我们都知道 Fedora 是一个激进的高端发行版,它是为了探索新功能而出现的测试床。这没毛病。有一段时间,所有东西都很正常,没有瞎忙活,没有错误。但接下来,我突然需要使用 GParted。我当时很着急,正在排除一个大故障,然而我却让自己置身于一些无意义的额外工作。 GParted 没办法在 Wayland 下直接启动。在探索了更多一些细节之后,我知道了该分区软件目前还没有被 Wayland 支持。
|
||||
|
||||

|
||||
|
||||
问题就在于我并不太清楚其它哪些应用不能在 Wayland 下运行,并且我不能在一个正确估计的时间敏锐地发现这一点。通过在线搜索,我还是不能快速找到一个简要的当前不兼容列表。可能只是我在搜索方面不太在行,但显而易见这些东西是和“Wayland + 兼容性” 这样的问题一样零零散散的。
|
||||
|
||||
我找到了一个[自诩][4] Wayland 很棒的文章、一个目前已被这个新玩意儿支持的 [Gnome][5] 应用程序列表、一些 ArchWiki 上难懂的资料,一篇在[英伟达][6]开发论坛上的晦涩得让我后悔点进去的主题,以及一些其他含糊的讨论。
|
||||
|
||||
### 再次提到性能
|
||||
|
||||
在 Fedora 25 上,我把登录会话从 Gnome(Wayland)切换到 Gnome Xorg,观察会对系统产生什么影响。我之前已经提到过在同一个笔记本([联想 G50][8])上的性能跑分和与 [Fedora 24][7] 的比较,但这次会给我们提供更加准确的结果。
|
||||
|
||||
Wayland(截图 1)空闲时的内存占用为 1.4GB, CPU 的平均负载约为 4-5%。Xorg(截图 2)占用了同样大小的内存,处理器消耗了全部性能的 3-4%,单纯从数字上来看少了一小点。但是 Xorg 会话的体验却好得多。虽然只是毫秒级的差距,但你能感受得到。传统的会话方式看起来更加的灵动、快速、清新一点。但 Wayland 落后得并不明显。如果你对你的电脑响应速度很敏感,你可能会对这点延迟不会太满意。当然,这也许只是作为新手缺乏优化的缘故,Wayland 会随时间进步。但这一点也是我们所不能忽视的。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 批评
|
||||
|
||||
我对此并不高兴。虽然并不是很愤怒,但我不喜欢为了能完全享受我的桌面体验,我却需要登录到传统的 X 会话。因为 X 给了我全部,但 Wayland 则没有。这意味着我不能一天都用着 Wayland。我喜欢探索科技,但我不是一个盲目的狂热追随者。我只是想用我的桌面,有时我可能需要它快速响应。注销然后重新登录在急需使用的时候会成为恼人的麻烦。我们遇到这个问题的原因就是 Wayland 没有让 Linux 桌面用户的生活变得更简单,而恰恰相反。
|
||||
|
||||
引用:
|
||||
|
||||
> Wayland 是为了成为 X 的更加简单的替代品,更加容易开发和维护。建议 GNOME 和 KDE 都使用它。
|
||||
|
||||
你能看到,这就是问题的一方面原因。东西不应该被设计成容易开发或维护。它可以是满足了所有其它消费需求之后提供的有益副产品。但如果没有,那么不管它对于程序员敲代码来说多么困难或简单都将不重要。那是他们的工作。科技的所有目的都是为了达到一种无缝并且流畅的用户体验。
|
||||
|
||||
不幸的是,现在很大数量的产品都被重新设计或者开发,只是为了使软件人员更加轻松,而不是用户。在很大程度上,Gnome 3、PulseAudio、[Systemd][9] 和 Wayland 都没有遵循提高用户体验的宗旨。在这个意义上来说,它们更像是一种打扰,而没有为 Linux 桌面生态的稳定性和易用性作出贡献。
|
||||
|
||||
这也是为什么 Linux 桌面是一个相对不成熟产品的一个主要原因————它被设计成开发人员的自我支持产品,更像一个活生生的生物,而不是依附于用户各种怪念头和想法的奴隶。这也是伟大事物是如何形成的,你满足于主要需求,接下来只是担心细节方面。优秀的用户体验不依赖于(也永远不依赖于)编程语言、编译器的选择,或任何其他无意义的东西。如果依赖了,那么不管谁来设计这个抽象层做的不够好的产品,我们都会得到一个失败的作品,需要把它的存在抹去。
|
||||
|
||||
那么在我的展望中,我不在乎是否要吐血十升去编译一个 Xorg 或其它什么的版本。我是一个用户,我所在乎的只是我的桌面能否像它昨天或者 5 年前一样健壮地工作。没事的情况下,我不会对宏、类、变量、声明、结构体,或其他任何极客的计算机科技感兴趣。那是不着边际的。一个产品宣传自己是被创造出来为人们的开发提供方便的,那是个悖论。如果接下来再也不用去开发它了,这样反而会使事情更简单。
|
||||
|
||||
现在,事实是 Wayland 大体上可用,但它仍然不像 Xorg 那么好,并且它也不应该在任何的桌面上作为就绪的产品被提供。一但它能够无人知晓般无缝地取代那些过时技术,只有在那种时候,它才获得了它所需要的成功,那之后,它可以用 C、D 或者 K 之类的无论什么语言编写,拥有开发者需要的任何东西。而在那之前,它都是一个蚕食资源和人们思想的寄生虫而已。
|
||||
|
||||
不要误会,我们需要进步,需要改变。但它必须为了进化的目而服务。现在 Xorg 能很好地满足用户需求了吗?它能为第三方库提供图形支持吗?它能支持 HD、UHD、DPI 或其他的什么吗?你能用它玩最新的游戏吗?行还是不行?如果不行,那么它就需要被改进。这些就是进化的驱动力,而不是写代码或者编译代码的困难程度。软件开发者是数字工业的矿工,他们需要努力工作而取悦于用户。就像短语“更加易于开发”应该被取缔一样,那些崇尚于此的人也应该用老式收音机的电池处以电刑,然后用没有空调的飞船流放到火星上去。如果你不能写出高明的代码,那是你的问题。用户不能因为开发者认为自己是公主而遭受折磨。
|
||||
|
||||
### 结语
|
||||
|
||||
说到这里。大体上说,Wayland 还可以,并不差。但这说的就像是某人决定修改你工资单上分配比例,导致你从昨天能赚 100% 到今天只能赚 83% 一样。讲道理这是不能接受的,即使 Wayland 工作的相当好。正是那些不能运作的东西导致如此大的不同。忽略所有批评它的一面,Wayland 被认为降低了可用性、性能以及软件的知名度,这正是 Fedora 亟待解决的问题。
|
||||
|
||||
其他的发行版会跟进,然后我们会看到历史重演,就像 Gnome 3 和 Systemd 所发生的一样。没有完全准备好的东西被放到开放环境中,然后我们花费一两年时间修复那些本无需修复的东西,最终我们将拥有的是我们已经拥有的相同功能,只是用不同的编程语言来实现。我并不感兴趣这些。计算机科学曾在 1999 年非常受欢迎,当时 Excel 用户每小时能赚 50 美元。而现在,编程就像是躲在平底船下划桨,人们并不会在乎你在甲板下流下的汗水与磨出的水泡。
|
||||
|
||||
性能可能不太是一个问题了,因为你可以放弃 1-2% 的变化,尤其是它会受随机的来自任何一个因素的影响,如果你已经用 Linux 超过一、两年你就会知道的。但是无法启动应用是个大问题。不过至少, Fedora 也友好地提供了传统的平台。但是,它可能会在 Wayland 100% 成熟前就消失了。我们再来看看,不,不会有灾难。我原本的 Fedora 25 宣称支持这种看法。我们有的就是烦恼,不必要的烦恼。啊,这是 Linux 故事中的第 9000 集。
|
||||
|
||||
那么,在今天结束之际,我们已经讨论了所有事情。从中我们学到:**臣伏于 Xorg!天呐!**真棒,现在我将淡入背景音乐,而笑声会将你的欢乐带给寒冷的夜晚。再见!
|
||||
|
||||
干杯。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Igor Ljubuncic。现在大约 38 岁,已婚但还没有孩子。我现在在一个大胆创新的云科技公司做首席工程师。直到大约 2015 年初,我还在一个全世界最大的 IT 公司之一中做系统架构工程师,和一个工程计算团队开发新的基于 Linux 的解决方案,优化内核以及攻克 Linux 的问题。在那之前,我是一个为高性能计算环境设计创新解决方案的团队的技术领导。还有一些其他花哨的头衔,包括系统专家、系统程序员等等。所有这些都曾是我的爱好,但从 2008 年开始成为了我的有偿的工作。还有什么比这更令人满意的呢?
|
||||
|
||||
从 2004 年到 2008 年间,我曾通过作为医学影像行业的物理学家来糊口。我的工作专长集中在解决问题和算法开发。为此,我广泛地使用了 Matlab,主要用于信号和图像处理。另外,我得到了几个主要的工程方法学的认证,包括 MEDIC 六西格玛绿带、试验设计以及统计工程学。
|
||||
|
||||
我也写过书,包括高度魔幻类和 Linux 上的技术工作方面的,彼此交织。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/fedora-25-wayland-vs-xorg.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
||||
[2]:https://commons.wikimedia.org/wiki/File:DragonCon-AlienVsPredator.jpg
|
||||
[3]:https://creativecommons.org/licenses/by-sa/3.0/deed.en
|
||||
[4]:https://wayland.freedesktop.org/faq.html
|
||||
[5]:https://wiki.gnome.org/Initiatives/Wayland/Applications
|
||||
[6]:https://devtalk.nvidia.com/default/topic/925605/linux/nvidia-364-12-release-vulkan-glvnd-drm-kms-and-eglstreams/
|
||||
[7]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
||||
[8]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
||||
[9]:http://www.ocsmag.com/2016/10/19/systemd-progress-through-complexity/
|
||||
@ -0,0 +1,299 @@
|
||||
在 Linux 如何用 bash-support 插件将 Vim 编辑器打造成一个 Bash-IDE
|
||||
============================================================
|
||||
|
||||
IDE([集成开发环境][1])就是这样一个软件,它为了最大化程序员生产效率,提供了很多编程所需的设施和组件。 IDE 将所有开发工作集中到一个程序中,使得程序员可以编写、修改、编译、部署以及调试程序。
|
||||
|
||||
在这篇文章中,我们会介绍如何通过使用 bash-support vim 插件将 [Vim 编辑器安装和配置][2] 为一个 Bash-IDE。
|
||||
|
||||
#### 什么是 bash-support.vim 插件?
|
||||
|
||||
bash-support 是一个高度定制化的 vim 插件,它允许你插入:文件头、补全语句、注释、函数、以及代码块。它也使你可以进行语法检查、使脚本可执行、一键启动调试器;而完成所有的这些而不需要关闭编辑器。
|
||||
|
||||
它使用快捷键(映射),通过有组织地、一致的文件内容编写/插入,使得 bash 脚本变得有趣和愉快。
|
||||
|
||||
插件当前版本是 4.3,4.0 版本 重写了之前的 3.12.1 版本,4.0 及之后的版本基于一个全新的、更强大的、和之前版本模板语法不同的模板系统。
|
||||
|
||||
### 如何在 Linux 中安装 Bash-support 插件
|
||||
|
||||
用下面的命令下载最新版本的 bash-support 插件:
|
||||
|
||||
```
|
||||
$ cd Downloads
|
||||
$ curl http://www.vim.org/scripts/download_script.php?src_id=24452 >bash-support.zip
|
||||
```
|
||||
|
||||
按照如下步骤安装;在你的主目录创建 `.vim` 目录(如果它不存在的话),进入该目录并提取 bash-support.zip 内容:
|
||||
|
||||
```
|
||||
$ mkdir ~/.vim
|
||||
$ cd .vim
|
||||
$ unzip ~/Downloads/bash-support.zip
|
||||
```
|
||||
|
||||
下一步,在 `.vimrc` 文件中激活它:
|
||||
|
||||
```
|
||||
$ vi ~/.vimrc
|
||||
```
|
||||
|
||||
并插入下面一行:
|
||||
|
||||
```
|
||||
filetype plug-in on
|
||||
set number # 可选,增加这行以在 vim 中显示行号
|
||||
```
|
||||
|
||||
### 如何在 Vim 编辑器中使用 Bash-support 插件
|
||||
|
||||
为了简化使用,通常使用的结构和特定操作可以分别通过键映射来插入/执行。 `~/.vim/doc/bashsupport.txt` 和 `~/.vim/bash-support/doc/bash-hotkeys.pdf` 或者 `~/.vim/bash-support/doc/bash-hotkeys.tex` 文件中介绍了映射。
|
||||
|
||||
**重要:**
|
||||
|
||||
1. 所有映射(`(\)+charater(s)` 组合)都是针对特定文件类型的:为了避免和其它插件的映射冲突,它们只适用于 `sh` 文件。
|
||||
2. 使用键映射的时候打字速度也有关系,引导符 `('\')` 和后面字符的组合要在特定短时间内才能识别出来(很可能少于 3 秒 - 基于假设)。
|
||||
|
||||
下面我们会介绍和学习使用这个插件一些显著的功能:
|
||||
|
||||
#### 如何为新脚本自动生成文件头
|
||||
|
||||
看下面的示例文件头,为了要在你所有的新脚本中自动创建该文件头,请按照以下步骤操作。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*脚本示例文件头选项*
|
||||
|
||||
首先设置你的个人信息(作者名称、作者参考、组织、公司等)。在一个 Bash 缓冲区(像下面这样打开一个测试脚本)中使用映射 `\ntw` 启动模板设置向导。
|
||||
|
||||
选中选项 1 设置个性化文件,然后按回车键。
|
||||
|
||||
```
|
||||
$ vi test.sh
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*在脚本文件中设置个性化信息*
|
||||
|
||||
之后,再次输入回车键。然后再一次选中选项 1 设置个性化文件的路径并输入回车。
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*设置个性化文件路径*
|
||||
|
||||
设置向导会把目标文件 `.vim/bash-support/rc/personal.templates` 拷贝到 `.vim/templates/personal.templates`,打开并编辑它,在这里你可以输入你的信息。
|
||||
|
||||
按 `i` 键像截图那样在单引号中插入合适的值。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*在脚本文件头添加信息*
|
||||
|
||||
一旦你设置了正确的值,输入 `:wq` 保存并退出文件。关闭 Bash 测试脚本,打开另一个脚本来测试新的配置。现在文件头中应该有和下面截图类似的你的个人信息:
|
||||
|
||||
```
|
||||
$ test2.sh
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*自动添加文件头到脚本*
|
||||
|
||||
#### 添加 Bash-support 插件帮助信息
|
||||
|
||||
为此,在 Vim 命令行输入下面的命令并按回车键,它会创建 `.vim/doc/tags` 文件:
|
||||
|
||||
```
|
||||
:helptags $HOME/.vim/doc/
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
*在 Vi 编辑器添加插件帮助*
|
||||
|
||||
#### 如何在 Shell 脚本中插入注释
|
||||
|
||||
要插入一个块注释,在普通模式下输入 `\cfr`:
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
*添加注释到脚本*
|
||||
|
||||
#### 如何在 Shell 脚本中插入语句
|
||||
|
||||
下面是一些用于插入语句的键映射(`n` – 普通模式, `i` – 插入模式,`v` 可视模式):
|
||||
|
||||
1. `\sc` – `case in … esac` (n, i)
|
||||
2. `\sei` – `elif then` (n, i)
|
||||
3. `\sf` – `for in do done` (n, i, v)
|
||||
4. `\sfo` – `for ((…)) do done` (n, i, v)
|
||||
5. `\si` – `if then fi` (n, i, v)
|
||||
6. `\sie` – `if then else fi` (n, i, v)
|
||||
7. `\ss` – `select in do done` (n, i, v)
|
||||
8. `\su` – `until do done` (n, i, v)
|
||||
9. `\sw` – `while do done` (n, i, v)
|
||||
10. `\sfu` – `function` (n, i, v)
|
||||
11. `\se` – `echo -e "…"` (n, i, v)
|
||||
12. `\sp` – `printf "…"` (n, i, v)
|
||||
13. `\sa` – 数组元素, `${.[.]}` (n, i, v) 和其它更多的数组功能。
|
||||
|
||||
#### 插入一个函数和函数头
|
||||
|
||||
输入 `\sfu` 添加一个新的空函数,然后添加函数名并按回车键创建它。之后,添加你的函数代码。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
*在脚本中插入新函数*
|
||||
|
||||
为了给上面的函数创建函数头,输入 `\cfu`,输入函数名称,按回车键并填入合适的值(名称、介绍、参数、返回值):
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
*在脚本中创建函数头*
|
||||
|
||||
#### 更多关于添加 Bash 语句的例子
|
||||
|
||||
下面是一个使用 `\si` 插入一条 `if` 语句的例子:
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
*在脚本中插入语句*
|
||||
|
||||
下面的例子显示使用 `\se` 添加一条 `echo` 语句:
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*在脚本中添加 echo 语句*
|
||||
|
||||
#### 如何在 Vi 编辑器中使用运行操作
|
||||
|
||||
下面是一些运行操作键映射的列表:
|
||||
|
||||
1. `\rr` – 更新文件,运行脚本(n, i)
|
||||
2. `\ra` – 设置脚本命令行参数 (n, i)
|
||||
3. `\rc` – 更新文件,检查语法 (n, i)
|
||||
4. `\rco` – 语法检查选项 (n, i)
|
||||
5. `\rd` – 启动调试器(n, i)
|
||||
6. `\re` – 使脚本可/不可执行(*) (n, i)
|
||||
|
||||
#### 使脚本可执行
|
||||
|
||||
编写完脚本后,保存它然后输入 `\re` 和回车键使它可执行。
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
*使脚本可执行*
|
||||
|
||||
#### 如何在 Bash 脚本中使用预定义代码片段
|
||||
|
||||
预定义代码片段是为了特定目的包含了已写好代码的文件。为了添加代码段,输入 `\nr` 和 `\nw` 读/写预定义代码段。输入下面的命令列出默认的代码段:
|
||||
|
||||
```
|
||||
$ .vim/bash-support/codesnippets/
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
*代码段列表*
|
||||
|
||||
为了使用代码段,例如 free-software-comment,输入 `\nr` 并使用自动补全功能选择它的名称,然后输入回车键:
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
*添加代码段到脚本*
|
||||
|
||||
#### 创建自定义预定义代码段
|
||||
|
||||
可以在 `~/.vim/bash-support/codesnippets/` 目录下编写你自己的代码段。另外,你还可以从你正常的脚本代码中创建你自己的代码段:
|
||||
|
||||
1. 选择你想作为代码段的部分代码,然后输入 `\nw` 并给它一个相近的文件名。
|
||||
2. 要读入它,只需要输入 `\nr` 然后使用文件名就可以添加你自定义的代码段。
|
||||
|
||||
#### 在当前光标处查看内建和命令帮助
|
||||
|
||||
要显示帮助,在普通模式下输入:
|
||||
|
||||
1. `\hh` – 内建帮助
|
||||
2. `\hm` – 命令帮助
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
*查看内建命令帮助*
|
||||
|
||||
更多参考资料,可以查看文件:
|
||||
|
||||
```
|
||||
~/.vim/doc/bashsupport.txt #在线文档的副本
|
||||
~/.vim/doc/tags
|
||||
```
|
||||
|
||||
- 访问 Bash-support 插件 GitHub 仓库:[https://github.com/WolfgangMehner/bash-support][18]
|
||||
- 在 Vim 网站访问 Bash-support 插件:[http://www.vim.org/scripts/script.php?script_id=365][19]
|
||||
|
||||
就是这些啦,在这篇文章中,我们介绍了在 Linux 中使用 Bash-support 插件安装和配置 Vim 为一个 Bash-IDE 的步骤。快去发现这个插件其它令人兴奋的功能吧,一定要在评论中和我们分享哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者、Linux 系统管理员、网络开发人员,现在也是 TecMint 的内容创作者,她喜欢和电脑一起工作,坚信共享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/best-linux-ide-editors-source-code-editors/
|
||||
[2]:http://www.tecmint.com/vi-editor-usage/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/02/Script-Header-Options.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-in-Scripts.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/02/Set-Personalization-File-Location.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Info-in-Script-Header.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Auto-Adds-Header-to-Script.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Plugin-Help-in-Vi-Editor.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Comments-to-Scripts.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/02/Insert-New-Function-in-Script.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/02/Create-Header-Function-in-Script.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Insert-Statement-to-Script.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-echo-Statement-to-Script.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/02/make-script-executable.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/02/list-of-code-snippets.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/02/Add-Code-Snippet-to-Script.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/02/View-Built-in-Command-Help.png
|
||||
[18]:https://github.com/WolfgangMehner/bash-support
|
||||
[19]:http://www.vim.org/scripts/script.php?script_id=365
|
||||
@ -0,0 +1,104 @@
|
||||
从损坏的 Linux EFI 安装中恢复
|
||||
=========
|
||||
|
||||
在过去的十多年里,Linux 发行版在安装前、安装过程中、以及安装后偶尔会失败,但我总是有办法恢复系统并继续正常工作。然而,[Solus][1] 损坏了我的笔记本。
|
||||
|
||||
GRUB 恢复。不行,重装。还不行!Ubuntu 拒绝安装,目标设备的报错一会这样,一会那样。哇。我之前还没有遇到过像这样的事情。我的测试机已变成无用的砖块。难道我该绝望吗?不,绝对不。让我来告诉你怎样你可以修复它吧。
|
||||
|
||||
### 问题详情
|
||||
|
||||
所有事情都从 Solus 尝试安装它自己的启动引导器 - goofiboot 开始。不知道什么原因、它没有成功完成安装,留给我的就是一个无法启动的系统。经过 BIOS 引导之后,我进入一个 GRUB 恢复终端。
|
||||
|
||||

|
||||
|
||||
我尝试在终端中手动修复,使用类似和我在我详实的 [GRUB2 指南][2]中介绍的各种命令。但还是不行。然后我尝试按照我在 [GRUB2 和 EFI 指南][3]中的建议从 Live CD 中恢复(LCTT 译注:Live CD 是一个完整的计算机可引导安装媒介,它包括在计算机内存中运行的操作系统,而不是从硬盘驱动器加载;CD 本身是只读的。 它允许用户为任何目的运行操作系统,而无需安装它或对计算机的配置进行任何更改)。我用 efibootmgr 工具创建了一个引导入口,确保标记它为有效。正如我们之前在指南中做的那样,之前这些是能正常工作的。哎,现在这个方法也不起作用。
|
||||
|
||||
我尝试做一个完整的 Ubuntu 安装,把它安装到 Solus 所在的分区,希望安装程序能给我一些有用的信息。但是 Ubuntu 无法完成安装。它报错:failed to install into /target。又回到开始的地方了。怎么办?
|
||||
|
||||
### 手动清除 EFI 分区
|
||||
|
||||
显然,我们的 EFI 分区出现了严重问题。简单回顾以下,如果你使用的是 UEFI,那么你需要一个单独的 FAT-32 格式化的分区。该分区用于存储 EFI 引导镜像。例如,当你安装 Fedora 时,Fedora 引导镜像会被拷贝到 EFI 子目录。每个操作系统都会被存储到一个它自己的目录,一般是 `/boot/efi/EFI/<操作系统版本>/`。
|
||||
|
||||

|
||||
|
||||
在我的 [G50][4] 机器上,这里有很多各种发行版测试条目,包括:centos、debian、fedora、mx-15、suse、Ubuntu、zorin 以及其它。这里也有一个 goofiboot 目录。但是,efibootmgr 并没有在它的菜单中显示 goofiboot 条目。显然这里出现了一些问题。
|
||||
|
||||
```
|
||||
sudo efibootmgr -d /dev/sda
|
||||
BootCurrent: 0001
|
||||
Timeout: 0 seconds
|
||||
BootOrder: 0001,0005,2003,0000,2001,2002
|
||||
Boot0000* Lenovo Recovery System
|
||||
Boot0001* ubuntu
|
||||
Boot0003* EFI Network 0 for IPv4 (68-F7-28-4D-D1-A1)
|
||||
Boot0004* EFI Network 0 for IPv6 (68-F7-28-4D-D1-A1)
|
||||
Boot0005* Windows Boot Manager
|
||||
Boot0006* fedora
|
||||
Boot0007* suse
|
||||
Boot0008* debian
|
||||
Boot0009* mx-15
|
||||
Boot2001* EFI USB Device
|
||||
Boot2002* EFI DVD/CDROM
|
||||
Boot2003* EFI Network
|
||||
...
|
||||
```
|
||||
|
||||
P.S. 上面的输出是在 LIVE 会话中运行命令生成的!
|
||||
|
||||
|
||||
我决定清除所有非默认的以及非微软的条目然后重新开始。显然,有些东西被损坏了,妨碍了新的发行版设置它们自己的启动引导程序。因此我删除了 `/boot/efi/EFI` 分区下面除了 Boot 和 Windows 以外的所有目录。同时,我也通过删除所有额外的条目更新了启动管理器。
|
||||
|
||||
```
|
||||
efibootmgr -b <hex> -B <hex>
|
||||
```
|
||||
|
||||
最后,我重新安装了 Ubuntu,并仔细监控 GRUB 安装和配置的过程。这次,成功完成啦。正如预期的那样,几个无效条目出现了一些错误,但整个安装过程完成就好了。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### 额外阅读
|
||||
|
||||
如果你不喜欢这种手动修复,你可以阅读:
|
||||
|
||||
- [Boot-Info][5] 手册,里面有帮助你恢复系统的自动化工具
|
||||
- [Boot-repair-cd][6] 自动恢复工具下载页面
|
||||
|
||||
### 总结
|
||||
|
||||
如果你遇到由于 EFI 分区破坏而导致系统严重瘫痪的情况,那么你可能需要遵循本指南中的建议。 删除所有非默认条目。 如果你使用 Windows 进行多重引导,请确保不要修改任何和 Microsoft 相关的东西。 然后相应地更新引导菜单,以便删除损坏的条目。 重新运行所需发行版的安装设置,或者尝试用之前介绍的比较不严谨的修复方法。
|
||||
|
||||
我希望这篇小文章能帮你节省一些时间。Solus 对我系统的更改使我很懊恼。这些事情本不应该发生,恢复过程也应该更简单。不管怎样,虽然事情似乎很可怕,修复并不是很难。你只需要删除损害的文件然后重新开始。你的数据应该不会受到影响,你也应该能够顺利进入到运行中的系统并继续工作。开始吧。
|
||||
|
||||
加油。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Igor Ljubuncic。38 岁,已婚,但还没有小孩。我现在是一个云技术公司的首席工程师,前端新手。在 2015 年年初之前,我在世界上最大的 IT 公司之一的工程计算团队担任操作系统架构师,开发新的基于 Linux 的解决方案、优化内核、在 Linux 上实现一些好的想法。在这之前,我是一个为高性能计算环境设计创新解决方案团队的技术主管。其它一些头衔包括系统专家、系统开发员或者类似的。所有这些都是我的爱好,但从 2008 年开始,就是有报酬的工作。还有什么比这更令人满意的呢?
|
||||
|
||||
从 2004 到 2008 年,我通过在医疗图像行业担任物理专家养活自己。我的工作主要关注解决问题和开发算法。为此,我广泛使用 Matlab,主要用于信号和图像处理。另外,我已通过几个主要工程方法的认证,包括 MEDIC Six Sigma Green Belt、实验设计以及统计工程。
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: http://www.dedoimedo.com/computers/grub2-efi-corrupt-part-recovery.html
|
||||
|
||||
作者:[Igor Ljubuncic][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
|
||||
[1]:http://www.dedoimedo.com/computers/solus-1-2-review.html
|
||||
[2]:http://www.dedoimedo.com/computers/grub-2.html
|
||||
[3]:http://www.dedoimedo.com/computers/grub2-efi-recovery.html
|
||||
[4]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
||||
[5]:https://help.ubuntu.com/community/Boot-Info
|
||||
[6]:https://sourceforge.net/projects/boot-repair-cd/
|
||||
@ -1,16 +1,7 @@
|
||||
[为什么(大部分)高级语言运行效率较慢][7]
|
||||
为什么(大多数)高级语言运行效率较慢
|
||||
============================================================
|
||||
|
||||
内容
|
||||
|
||||
|
||||
* * [回顾缓存消耗问题][1]
|
||||
* [为什么 C# 存在缓存未命中问题][2]
|
||||
* [垃圾回收][3]
|
||||
* [结语][5]
|
||||
|
||||
|
||||
在近两个个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
|
||||
在近一两个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
|
||||
|
||||
大部分高级语言运行效率较慢的原因通常有两点:
|
||||
|
||||
@ -19,7 +10,7 @@
|
||||
|
||||
但事实上,这两个原因可以归因于:高级语言强烈地鼓励编程人员分配很多的内存。
|
||||
|
||||
首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
|
||||
首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络 I/O,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
|
||||
|
||||
我将选用 C# 语言作为本文的参考语言,其原因有二:首先它是我常用的高级语言;其次如果我使用 Java 语言,许多使用 C# 的朋友会告诉我 C# 不会有这些问题,因为它有值类型(但这是错误的)。
|
||||
|
||||
@ -27,43 +18,43 @@
|
||||
|
||||
### 回顾缓存消耗问题
|
||||
|
||||
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存延迟对CPU影响的 [数据][10]:
|
||||
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存延迟对 CPU 影响的 [数据][10]:
|
||||
|
||||
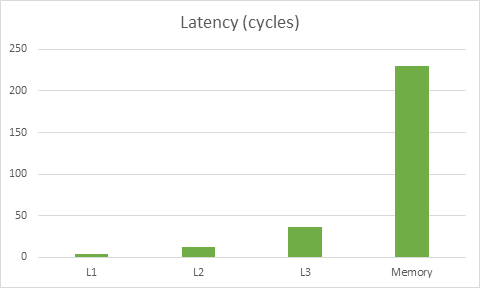
|
||||
|
||||
针对这款 CPU 读取内存的延迟,CPU 需要消耗近 230 个运算周期从内存读取数据,同时需要消耗 4 个运算周期来读取 L1 缓冲区。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被完整的隐藏了起来。
|
||||
针对这款 CPU 读取内存的延迟,CPU 需要消耗近 230 个运算周期从内存读取数据,同时需要消耗 4 个运算周期来读取 L1 缓冲区。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被部分或完整的掩盖了起来。
|
||||
|
||||
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才可以调整你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
|
||||
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才需要考虑优化你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
|
||||
|
||||
这对于编程语言的设计者来说是一个好消息!你都_不必_去编写一个更高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计能使你的语言访问数据更高效,也不用担心与 C 语言代码比较运行速度。
|
||||
这对于编程语言的设计者来说是一个好消息!你都_不必_去编写一个最高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计语言能高效地编写代码来访问数据,而不用担心与 C 语言代码比较运行速度。
|
||||
|
||||
### 为什么 C# 存在缓存未命中问题
|
||||
|
||||
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论解决方法都非常的不便。我是在说那些编程语言“希望”你这样编写的习惯性代码。
|
||||
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论上的解决方法其实都非常的不便,这里我说的是那些编程语言“希望”你这样编写的惯用写法。
|
||||
|
||||
C# 最基本的问题是对基础值类型(value-base)低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体恰恰好会造成一些大问题。
|
||||
C# 最基本的问题是对基础值类型(value-base)低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体有一些大问题,以至于更像是创可贴而不是解决方案。
|
||||
|
||||
* 你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被对分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
|
||||
* 你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被堆分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
|
||||
|
||||
* _引用_ 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用 `List<int>` 中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把他们复制一份,除了将他们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然这不可能)。
|
||||
* _引用_ 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用 `List<int>` 中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把它们复制一份,除了将它们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然不是不可能)。这些限制背后的理念并不能改变限制存在的事实。
|
||||
|
||||
* [固定大小的缓冲区][6] 不支持自定义类型,而且还必须使用 `unsafe` 关键字。
|
||||
|
||||
* 有限的“数组切片”功能。虽然有提供 `ArraySegment` 类,但并没有人会使用它,这意味着如果只需要传递数组的一部分,你必须去创建一个 `IEnumerable` 对象,也就意味着要分配大小(包装)。就算接口接受 `ArraySegment` 对象作为参数,也是不够的——你只能用普通数组,而不能用 `List<T>`,也不能用 [栈数组][4] 等等。
|
||||
|
||||
最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开的存放在一个个堆分配空间中。这就意味着程序员无法控制数据存储方式了,也开始产生不必要的缓存未命中问题,而导致性能急速的下降。[C# 已经支持原生编译][11] 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
|
||||
最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开地存放在一个个堆分配空间中。这就意味着程序员无法控制数据存储方式了,也开始产生不必要的缓存未命中问题,而导致性能急速的下降。[C# 已经支持原生编译][11] 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
|
||||
|
||||
存储是有开销的。在64位的机器上每个地址值占8位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
|
||||
再加上存储是有开销的。在 64 位的机器上每个地址值占 8 位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
|
||||
|
||||
当然有些时候也是有办法的,比如你可以使用一个很大的 `List<T>` 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 _2_ 次缓存未命中。你还可以通过复制 `List<T>` 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会很低水平而且容易出错。
|
||||
当然有些时候也是有办法的,比如你可以使用一个很大的 `List<T>` 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 _2_ 次缓存未命中。你还可以通过复制 `List<T>` 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会水平很低而且容易出错。
|
||||
|
||||
最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会均匀频率地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 [均匀变慢][12] 的程序。
|
||||
最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会频率均匀地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 [均匀变慢][12] 的程序。
|
||||
|
||||
### 垃圾回收
|
||||
|
||||
在读下文之前我会假设你已经知道为什么在许多用例中垃圾回收是影响性能问题的重要原因。播放动画时总是随机的暂停通常都是大家都不能接受的吧。我会继续解释为什么设计语言时还加剧了这个问题。
|
||||
|
||||
因为 C# 在处理变量上的一些局限性,它不会鼓励你去使用大内存块分配来存储很多里面是内置对象的变量(可能存在栈中),这就使得你必须使用很多分配在堆中的小型类对象。说白了就是内存分配越多会导致花在垃圾回收上的时间就越多。
|
||||
因为 C# 在处理变量上的一些局限性,它强烈不建议你去使用大内存块分配来存储很多里面是内置对象的变量(可能存在栈中),这就使得你必须使用很多分配在堆中的小型类对象。说白了就是内存分配越多会导致花在垃圾回收上的时间就越多。
|
||||
|
||||
有些测评说 C# 或者 Java 是怎么在一些特定的例子中打败 C++ 的,其实是因为内存分配器都基于一种吞吐还算不错的垃圾回收机制(廉价的分配,允许统一的释放分配)。然而,这些测试场景都太特殊了。想要使 C# 的程序的内存分配率变得和那些非常普通的 C++ 程序都能达到的一样就必须要耗费更大的精力来编写它,所以这种比较就像是拿一个高度优化的管理程序和一个最简单原生的程序相比较一样。当你花同样的精力来写一个 C++ 程序时,肯定比你用 C# 来写性能好的多。
|
||||
|
||||
@ -71,9 +62,9 @@ C# 最基本的问题是对基础值类型(value-base)低下的支持性。
|
||||
|
||||
看看 `.Net` 库里那些基本类,内存分配几乎无处不在!我数了下,在 [.Net 核心框架][13] 中公共类比结构体的数量多出 19 倍之多,为了使用它们,你就得把这些东西全都弄到内存中去。就算是 `.Net` 框架的创造者们也无法抵抗设计语言时的警告啊!我都不知道怎么去统计了,使用基础类库时,你会很快意识到这不仅仅是值或对象的选择问题了,就算如此也还是 _伴随_ 着超级多的内存分配。这一切都让你觉得分配内存好像很容易一样,其实怎么可能呢,没有内存分配你连一个整形值都没法输出!不说这个,就算你使用预分配的 `StringBuilder`,你要是不用标准库来分配内存,也还不是连个整型都存不住。你要这么问我那就挺蠢的了。
|
||||
|
||||
当然还不仅仅是标准库,其他的 C# 库也一样。就算是 `Unity`(一个 _游戏引擎_,可能能多的关心平均性能问题)也会有一些全局返回已分配对象(或数组)的接口,或者强制调用时先将其分配内存再使用。举个例子,在一个 `GameObject` 中要使用 `GetComponents` 来调用一个数组,`Unity` 会强制地分配一个数组以便调用。就此而言,其实有许多的接口可以采用,但他们不选择,而去走常规路线来直接使用内存分配。写 `Unity` 的同胞们写的一手“好 C#”呀,但就是不那么高性能罢了。
|
||||
当然还不仅仅是标准库,其他的 C# 库也一样。就算是 `Unity`(一个 _游戏引擎_,可能能更多的关心平均性能问题)也会有一些全局返回已分配对象(或数组)的接口,或者强制调用时先将其分配内存再使用。举个例子,在一个 `GameObject` 中要使用 `GetComponents` 来调用一个数组,`Unity` 会强制地分配一个数组以便调用。就此而言,其实有许多的接口可以采用,但他们不选择,而去走常规路线来直接使用内存分配。写 `Unity` 的同胞们写的一手“好 C#”呀,但就是不那么高性能罢了。
|
||||
|
||||
# 结语
|
||||
### 结语
|
||||
|
||||
如果你在设计一门新的语言,拜托你可以考虑一下我提到的那些性能问题。在你创造出一款“足够聪明的编译器”之后这些都不是什么难题了。当然,没有垃圾回收器就要求类型安全很难。当然,没有一个规范的数据表示就创造一个垃圾回收器很难。当然,出现指向随机值的指针时难以去推出其作用域规则。当然,还有大把大把的问题摆在那里,然而解决了这些所有的问题,设计出来的语言就会是我们想的那样吗?那为什么这么多主要的语言都是在那些六十年代就已经被设计出的语言的基础上迭代的呢?
|
||||
|
||||
@ -94,9 +85,9 @@ C# 最基本的问题是对基础值类型(value-base)低下的支持性。
|
||||
|
||||
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
||||
|
||||
作者:[Sebastian Sylvan ][a]
|
||||
作者:[Sebastian Sylvan][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,253 @@
|
||||
在 Kali Linux 中更改 GRUB 背景的 5 种方式
|
||||
============================================================
|
||||
|
||||
这是一个关于如何在 Kali Linux 中更改 GRUB 背景的简单指南(实际上它是 Kali Linux 的
|
||||
GRUB 启动图像)。 Kali 开发团队在这方面做的不多,他们好像太忙了,所以在这篇文章中,我会对 GRUB 解释一二,但是不会冗长到我失去写作的激情。 那么我们开始吧……
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 查找 GRUB 设置
|
||||
|
||||
这通常是所有人首先会遇到的一个问题,在哪里设置?有很多方法来查找 GRUB 设置。每个人都可能有自己的方法,但我发现 `update-grub` 是最简单的。如果在 VMWare 或 VirtualBox 中执行 `update-grub`,你将看到如下所示的内容:
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
如果您是双系统,或者三系统,那么您将看到 GRUB 以及其他操作系统入口。然而,我们感兴趣的部分是背景图像,这是在我这里看到的(你会看到完全相同的内容):
|
||||
|
||||
```
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
```
|
||||
|
||||
### GRUB 启动图像搜索顺序
|
||||
|
||||
在 grub-2.02 中,对基于 Debian 的系统来说,它将按照以下顺序搜索启动背景:
|
||||
|
||||
1. `/etc/default/grub` 里的 `GRUB_BACKGROUND` 行
|
||||
2. 在 `/boot/grub/` 里找到的第一个图像(如果发现多张,将以字母顺序排序)
|
||||
3. 在 `/usr/share/desktop-base/grub_background.sh` 中指定的
|
||||
4. 在 `/etc/grub.d/05_debian_theme` 里 `WALLPAPER` 行列出的
|
||||
|
||||
现在将此信息留在这里,我们会尽快重新检查它。
|
||||
|
||||
### Kali Linux GRUB 启动图像
|
||||
|
||||
在我使用 Kali Linux 时(因为我喜欢用它做事),会发现 Kali 正在使用这里的背景图像:`/usr/share/images/desktop-base/desktop-grub.png`
|
||||
|
||||
为了确定,我们来检查一下这个 `.png` 文件的属性。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# ls -l /usr/share/images/desktop-base/desktop-grub.png
|
||||
lrwxrwxrwx 1 root root 30 Oct 8 00:31 /usr/share/images/desktop-base/desktop-grub.png -> /etc/alternatives/desktop-grub
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
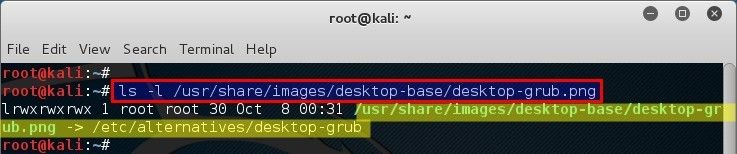
|
||||
][11]
|
||||
|
||||
什么?它只是 `/etc/alternatives/desktop-grub` 的一个符号链接? 但是 `/etc/alternatives/desktop-grub` 不是图片文件。看来我也要检查一下它的属性。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# ls -l /etc/alternatives/desktop-grub
|
||||
lrwxrwxrwx 1 root root 44 Oct 8 00:27 /etc/alternatives/desktop-grub -> /usr/share/images/desktop-base/kali-grub.png
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
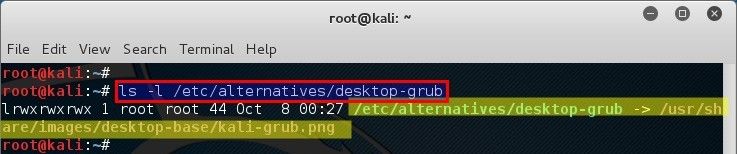
|
||||
][12]
|
||||
|
||||
好吧,真让人费解。 `/etc/alternatives/desktop-grub` 也是一个符号链接,它指向 `/usr/share/images/desktop-base/kali-grub.png`,来自最初同样的文件夹。呃! 无语。 但是现在我们至少可以替换该文件并将其解决。
|
||||
|
||||
在替换之前,我们需要检查 `/usr/share/images/desktop-base/kali-grub.png` 的属性,以确保下载相同类型和大小的文件。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# file /usr/share/images/desktop-base/kali-grub.png
|
||||
/usr/share/images/desktop-base/kali-grub.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
可以确定这是一个 PNG 图像文件,像素尺寸为 640 x 480。
|
||||
|
||||
### GRUB 背景图像属性
|
||||
|
||||
可以使用 `PNG`, `JPG`/`JPEG` 以及 `TGA` 类型的图像文件作为 GRUB 2 的背景。必须符合以下规范:
|
||||
|
||||
* `JPG`/`JPEG` 图像必须是 `8-bit` (256 色)
|
||||
* 图像应该是非索引的,`RGB`
|
||||
|
||||
默认情况下,如果安装了 `desktop-base` 软件包,符合上述规范的图像将放在 `/usr/share/images/desktop-base/` 目录中。在谷歌上很容易找到类似的文件。我也找了一个。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# file Downloads/wallpaper-1.png
|
||||
Downloads/wallpaper-1.png: PNG image data, 640 x 480, 8-bit/color RGB, non-interlaced
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
### 方式 1:替换图像
|
||||
|
||||
现在我们只需简单的用新文件将 `/usr/share/images/desktop-base/kali-grub.png` 替换掉。值得注意这是最简单的方法,不需要修改 `grub-config` 文件。 如果你对 GRUB 很熟,建议你简单的修改 GRUB 的默认配置文件,然后执行 `update-grub`。
|
||||
|
||||
像往常一样,我会将原文件重命名为 `kali-grub.png.bkp` 进行备份。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# mv /usr/share/images/desktop-base/kali-grub.png /usr/share/images/desktop-base/kali-grub.png.bkp
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
现在我们将下载的文件重命名为 `kali-grub.png`。
|
||||
|
||||
```
|
||||
root@kali:~#
|
||||
root@kali:~# cp Downloads/wallpaper-1.png /usr/share/images/desktop-base/kali-grub.png
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
最后执行命令 `update-grub`:
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background image: /usr/share/images/desktop-base/desktop-grub.png
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
[
|
||||
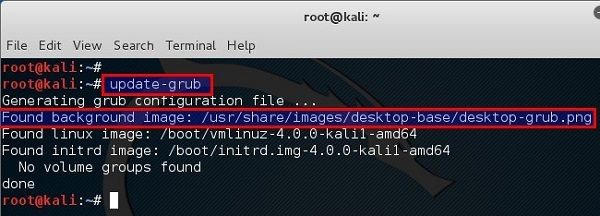
|
||||
][16]
|
||||
|
||||
下次重新启动你的 Kali Linux 时,你会看到 GRUB 背景变成了你自己的图像(GRUB 启动界面)。
|
||||
|
||||
下面是我现在正在使用的新 GRUB 启动背景。你呢?要不要试试这个办法?
|
||||
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
这是最简单最安全的办法,最糟的情况也不过是在 GRUB 看到一个蓝色的背景,但你依然可以登录后修复它们。现在如果你有信心,让我们尝试一个改变 GRUB 设置的更好的方法(有点复杂)。后续步骤更加有趣,而且可以在任何使用 GRUB 引导的 Linux 上使用。
|
||||
|
||||
现在回忆一下 GRUB 在哪 4 个地方寻找启动背景图像?再看一遍:
|
||||
|
||||
1. `/etc/default/grub` 里的 `GRUB_BACKGROUND` 行
|
||||
2. 在 `/boot/grub/` 里找到的第一个图像(如果发现多张,将以字母顺序排序)
|
||||
3. 在 `/usr/share/desktop-base/grub_background.sh` 中指定的
|
||||
4. 在 `/etc/grub.d/05_debian_theme` 里 WALLPAPER 行列出的
|
||||
|
||||
那么我们再在 Kali Linux 上(或任意使用 GRUB2 的 Linux系统)试一下新的选择。
|
||||
|
||||
### 方式 2:在 GRUB_BACKGROUND 中定义图像路径
|
||||
|
||||
所以你可以根据上述的查找优先级使用上述任一项,将 GRUB 背景图像改为自己的。以下是我自己系统上 `/etc/default/grub` 的内容。
|
||||
|
||||
```
|
||||
root@kali:~# vi /etc/default/grub
|
||||
```
|
||||
|
||||
按照 `GRUB_BACKGROUND="/root/World-Map.jpg"` 的格式添加一行,其中 World-Map.jpg 是你要作为 GRUB 背景的图像文件。
|
||||
|
||||
```
|
||||
# If you change this file, run 'update-grub' afterwards to update
|
||||
# /boot/grub/grub.cfg.
|
||||
# For full documentation of the options in this file, see:
|
||||
# info -f grub -n 'Simple configuration'
|
||||
|
||||
GRUB_DEFAULT=0
|
||||
GRUB_TIMEOUT=15
|
||||
GRUB_DISTRIBUTOR=`lsb_release -i -s 2> /dev/null || echo Debian`
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
|
||||
GRUB_CMDLINE_LINUX="initrd=/install/gtk/initrd.gz"
|
||||
GRUB_BACKGROUND="/root/World-Map.jpg"
|
||||
```
|
||||
|
||||
一旦使用上述方式完成更改,务必执行 `update-grub` 命令,如下所示。
|
||||
|
||||
```
|
||||
root@kali:~# update-grub
|
||||
Generating grub configuration file ...
|
||||
Found background: /root/World-Map.jpg
|
||||
Found background image: /root/World-Map.jpg
|
||||
Found linux image: /boot/vmlinuz-4.0.0-kali1-amd64
|
||||
Found initrd image: /boot/initrd.img-4.0.0-kali1-amd64
|
||||
No volume groups found
|
||||
done
|
||||
root@kali:~#
|
||||
```
|
||||
|
||||
现在重启机器,你会在 GRUB 看到自定义的图像。
|
||||
|
||||
### 方式 3:把图像文件放到 /boot/grub/ 文件夹
|
||||
|
||||
如果没有在 `/etc/default/grub` 文件中指定 `GRUB_BACKGROUND` 项,理论上 GRUB 应当使用在 `/boot/grub/` 文件夹找到的第一个图像文件作为背景。如果 GRUB 在 `/boot/grub/` 找到多个图像文件,它会按字母排序并使用第一个图像文件。
|
||||
|
||||
### 方式 4:在 grub_background.sh 指定图像路径
|
||||
|
||||
如果没有在 `/etc/default/grub` 文件中指定 `GRUB_BACKGROUND` 项,而且 `/boot/grub/` 目录下没有图像文件,GRUB 将会开始在 `/usr/share/desktop-base/grub_background.sh` 文件中指定的图像路径中搜索。Kali Linux 是在这里指定的。每个 Linux 发行版都有自己的特色。
|
||||
|
||||
### 方式 5:在 /etc/grub.d/05\_debian\_theme 文件的 WALLPAPER 一行指定图像
|
||||
|
||||
这是 GRUB 搜寻背景图像的最后一个位置。如果在其他部分都没有找到,它将会在这里查找。
|
||||
|
||||
### 结论
|
||||
|
||||
这篇文章较长,但我想介绍一些基础但很重要的东西。如果你有仔细阅读,你会理解如何在 Kali Linux 上来回跟踪符号链接。当你需要在一些 Linux 系统上查找 GRUB 背景图像的位置时,你会感到得心应手。只要再多阅读一点来理解 GRUB 颜色的工作方式,你就是行家了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||
|
||||
作者:[https://www.blackmoreops.com/][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/
|
||||
[1]:http://www.facebook.com/sharer.php?u=https://www.blackmoreops.com/?p=5958
|
||||
[2]:https://twitter.com/intent/tweet?text=5+ways+to+change+GRUB+background+in+Kali+Linux%20via%20%40blackmoreops&url=https://www.blackmoreops.com/?p=5958
|
||||
[3]:https://plusone.google.com/_/+1/confirm?hl=en&url=https://www.blackmoreops.com/?p=5958&name=5+ways+to+change+GRUB+background+in+Kali+Linux
|
||||
[4]:https://www.blackmoreops.com/how-to/
|
||||
[5]:https://www.blackmoreops.com/kali-linux/
|
||||
[6]:https://www.blackmoreops.com/kali-linux-2-x-sana/
|
||||
[7]:https://www.blackmoreops.com/administration/
|
||||
[8]:https://www.blackmoreops.com/usability/
|
||||
[9]:https://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/#comments
|
||||
[10]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-10.jpg
|
||||
[11]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-1/
|
||||
[12]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-3/
|
||||
[13]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-6/
|
||||
[14]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-4/
|
||||
[15]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-5/
|
||||
[16]:http://www.blackmoreops.com/2015/11/27/change-grub-background-in-kali-linux/change-grub-background-in-kali-linux-blackmore-ops-7/
|
||||
[17]:http://www.blackmoreops.com/wp-content/uploads/2015/11/Change-GRUB-background-in-Kali-Linux-blackMORE-OPs-9.jpg
|
||||
@ -1,17 +1,19 @@
|
||||
FTPS(基于 SSL 的FTP)与 SFTP(SSH 文件传输协议)对比
|
||||
================================================== ==========
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
**<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>、SFTP 或称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>**, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>(SFTP)也称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
|
||||
但是 SFTP 和 FTPS 之间最显着的区别是如何验证和管理连接。
|
||||
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID,密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,如果服务器的证书是可信的,[FTP 客户端软件][6]将检查目的地[ FTP 服务器][7]。
|
||||
### FTPS
|
||||
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 的所有用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID、密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,[FTP 客户端软件][6]将检查目标[ FTP 服务器][7]证书是否可信的。
|
||||
|
||||
### 以下是 FTPS 的优点和缺点:
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 所有的用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
|
||||
以下是 FTPS 的优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
@ -23,14 +25,17 @@ FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全
|
||||
缺点:
|
||||
|
||||
- 没有统一的目录列表格式
|
||||
- 需要辅助数据通道,这使得难以在防火墙后使用
|
||||
- 未定义文件名字符集(编码)的标准
|
||||
- 需要辅助数据通道(DATA),这使得难以通过防火墙使用
|
||||
- 没有定义文件名字符集(编码)的标准
|
||||
- 并非所有 FTP 服务器都支持 SSL/TLS
|
||||
- 没有标准的方式来获取和更改文件或目录属性
|
||||
- 没有获取和更改文件或目录属性的标准方式
|
||||
|
||||
|
||||
### SFTP
|
||||
|
||||
SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,设计为 SSH 扩展以提供文件传输功能,因此它通常仅使用 SSH 端口用于数据传输和控制。当 [FTP 客户端][8]软件连接到 SFTP 服务器时,它会将公钥传输到服务器进行认证。如果密钥匹配,提供任何用户/密码,身份验证就会成功。
|
||||
|
||||
### 以下是 SFTP 优点和缺点:
|
||||
以下是 SFTP 优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
@ -41,21 +46,23 @@ SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,
|
||||
|
||||
缺点:
|
||||
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读
|
||||
并且 SSH 密钥更难以管理和验证。
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读,
|
||||
- SSH 密钥更难以管理和验证。
|
||||
- 这些标准定义了某些可选或推荐的选项,这会导致不同供应商的不同软件之间存在某些兼容性问题。
|
||||
- 没有服务器到服务器的副本和递归目录删除操作
|
||||
- 没有服务器到服务器的复制和递归目录删除操作
|
||||
- 在 VCL 和 .NET 框架中没有内置的 SSH/SFTP 支持。
|
||||
|
||||
### 对比
|
||||
|
||||
大多数 FTP 服务器软件这两种安全 FTP 技术都支持,以及强大的身份验证选项。
|
||||
|
||||
但 SFTP 将是防火墙赢家,因为它很友好。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证,发出的任何命令以及传输的任何数据。
|
||||
但 SFTP 显然是赢家,因为它适合防火墙。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证、发出的任何命令以及传输的任何数据。
|
||||
|
||||
FTPS 通过紧密安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
FTPS 通过严格安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
|
||||
支持 FTPS 和 SFTP 的 FTP 服务器软件:
|
||||
|
||||
1. [Cerberus FTP服务器][2]
|
||||
1. [Cerberus FTP 服务器][2]
|
||||
2. [FileZilla - 最著名的免费 FTP 和 FTPS 服务器软件][3]
|
||||
3. [Serv-U FTP 服务器][4]
|
||||
|
||||
@ -1,13 +1,6 @@
|
||||
如何在 Linux 上录制你的桌面 GIF 动画 ?
|
||||
如何在 Linux 桌面上使用 Gifine 录制 GIF 动画?
|
||||
============================================================
|
||||
|
||||
### 本文导航
|
||||
|
||||
1. [Gifine][1]
|
||||
2. [Gifine 下载/安装/配置][2]
|
||||
3. [Gifine 使用][3]
|
||||
4. [总结][4]
|
||||
|
||||
不用我说,你也知道 GIF 动画在过去几年发展迅速。人们经常在线上文字交流时使用动画增添趣味,同时这些动画在很多其他地方也显得非常有用。
|
||||
|
||||
在技术领域使用动画能够很快的描述出现的问题或者返回的错误。它也能很好的展现出一个软件应用产品的特性。你可以在进行线上座谈会或者在进行公司展示时使用 GIF 动画,当然,你可以在更多的地方用到它。
|
||||
@ -18,43 +11,39 @@
|
||||
|
||||
开始之前,你必须知道在本教程中所有的例子都是在 Ubuntu 14.04 上测试过的,它的 Bash 版本是 4.3.11(1) 。
|
||||
|
||||
|
||||
### Gifine
|
||||
|
||||
这个工具的主页是 [Gifine][5] 。它基于 GTK 工具包,并且由 MoonScript 使用 lgi 库编写。Gifine 不仅能够录屏、创建动画或视频,而且能够用它来把几个小型动画或视频拼接在一起。
|
||||
|
||||
引述这个工具的开发者的话:“你可以加载一个视频目录或者选择一个桌面的区域进行录屏。你加载了一些视频后,可以不用裁剪通过滑动滑块查看视频帧。最终完成录屏后可以导出为 gif 或者 mp4 文件。”
|
||||
这个工具的主页是 [Gifine][5] 。它基于 GTK 工具包,是用 MoonScript 使用 lgi 库编写的。Gifine 不仅能够录屏、创建动画或视频,而且能够用它来把几个小型动画或视频拼接在一起。
|
||||
|
||||
引述这个工具的开发者的话:“你可以加载一个视频帧的目录或者选择一个桌面的区域进行录屏。你加载了一些视频帧后,可以连续查看它们,并裁剪掉不需要的部分。最终完成录屏后可以导出为 gif 或者 mp4 文件。”
|
||||
|
||||
### Gifine 下载/安装/配置
|
||||
|
||||
在指引你下载和安装 Gifine 之前,应该指出安装这个工具时需要安装的依赖包。
|
||||
|
||||
首先需要安装的依赖包是 FFmpeg , 这个软件包是一种记录、转化和流化音频以及视频的跨平台解决方案。使用下列命令安装这个工具;
|
||||
|
||||
|
||||
首先需要安装的依赖包是 FFmpeg , 这个包是一种记录、转化音频流以及视频的跨平台解决方案。使用下列命令安装这个工具;
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
接下来是基于图像处理系统的 GraphicsMagick . 这个工具的官网说:"它提供了一个稳健且高效的工具和库的集合,支持读写并且可以操作超过 88 种主要的图像格式,比如: DPX、 GIF、 JPEG、 JPEG-2000、 PNG、 PDF、 PNM 以及 TIFF 等"
|
||||
|
||||
|
||||
接下来是图像处理系统 GraphicsMagick。这个工具的官网说:“它提供了一个稳健且高效的工具和库的集合,支持读写并且可以操作超过 88 种主要的图像格式,比如:DPX、 GIF、 JPEG、 JPEG-2000、 PNG、 PDF、 PNM 以及 TIFF 等。”
|
||||
|
||||
通过下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install graphicsmagick
|
||||
```
|
||||
|
||||
接下来的需要的工具是 XrectSel 。在你移动鼠标选择区域的时候,它会显示矩形区域的坐标位置。我们只能通过源码安装 XrectSel ,你可以从 [这里][6] 下载它。
|
||||
|
||||
如果你下载了源码,接下来就可以解压下载的文件,进入解压后的目录中。然后,运行下列命令:
|
||||
|
||||
|
||||
```
|
||||
./bootstrap
|
||||
```
|
||||
如果 configure 文件不存在,就需要使用上面的命令
|
||||
|
||||
如果 `configure` 文件不存在,就需要使用上面的命令
|
||||
|
||||
```
|
||||
./configure --prefix /usr
|
||||
@ -63,14 +52,13 @@ make
|
||||
|
||||
make DESTDIR="$directory" install
|
||||
```
|
||||
最后的依赖包是 Gifsicle 。这是一个命令行工具,可以创建、编辑、查看 GIF 图像和动画的属性信息。下载和安装 Gifsicle 相当容易,你只需要运行下列命令:
|
||||
|
||||
最后的依赖包是 Gifsicle 。这是一个命令行工具,可以创建、编辑、查看 GIF 图像和动画的属性信息。下载和安装 Gifsicle 相当容易,你只需要运行下列命令:
|
||||
|
||||
```
|
||||
sudo apt-get install gifsicle
|
||||
```
|
||||
|
||||
|
||||
这些是所有的依赖包。现在,我们开始安装 Gifine 。使用下面的命令完成安装。
|
||||
|
||||
```
|
||||
@ -90,11 +78,11 @@ No package 'gobject-introspection-1.0' found
|
||||
sudo apt-get install libgirepository1.0-dev
|
||||
```
|
||||
然后,再一次运行 'luarocks install' 命令。
|
||||
.
|
||||
|
||||
### Gifine 使用
|
||||
|
||||
完成安装之后可以使用下面的命令运行这个工具:
|
||||
|
||||
```
|
||||
gifine
|
||||
```
|
||||
@ -103,23 +91,24 @@ gifine
|
||||
[
|
||||
|
||||
][7]
|
||||
这里你可以进行两种操作:录视频帧或者加载视频帧。如果你单击了 Record rectange 按钮,你的鼠标指针处会变成一个 + ,这样便可以在你的屏幕上选择一个矩形区域。一旦你选择了一个区域,录屏就开始了,‘Record rectangule’ 按钮就会变成 'Stop recording' 按钮。
|
||||
|
||||
这里你可以进行两种操作:录视频帧或者加载视频帧。如果你单击了录制矩形区域(Record rectange)按钮,你的鼠标指针处会变成一个 `+` ,这样便可以在你的屏幕上选择一个矩形区域。一旦你选择了一个区域,录屏就开始了,录制矩形区域(Record rectange)按钮就会变成停止录制(Stop recording)按钮。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
单击 'Stop recording' 完成录屏,会在 Gifine 窗口出现一些按钮。
|
||||
|
||||
单击停止录制(Stop recording)完成录屏,会在 Gifine 窗口出现一些按钮。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
用户界面的上半部分显示已经录制的视频帧,你可以使用它下面的滑块进行帧到帧的浏览。如果你想要删除第 5 帧之前或第 50 帧之后的所有帧数,你可以使用 Trim left of 和 Trim rigth of 按钮进行裁剪。也有可以删除特定帧数和删除一半帧数的按钮,当然,你可以重置所有的裁剪操作。
|
||||
|
||||
用户界面的上半部分显示已经录制的视频帧,你可以使用它下面的滑块进行逐帧浏览。如果你想要删除第 5 帧之前或第 50 帧之后的所有帧数,你可以使用裁剪左边(Trim left of) 和裁剪右边(Trim rigth of)按钮进行裁剪。也有可以删除特定帧数和减半删除帧数的按钮,当然,你可以重置所有的裁剪操作。
|
||||
|
||||
完成了所有的裁剪后,可以使用 Save GIF... 或 Save MP4... 按钮将录屏保存为动画或者视频;你会看到可以设置帧延迟、帧率以及循环次数的选项。
|
||||
|
||||
记住,“录屏帧数不会自动清除。如果你想重新加载,可以在初始屏幕中使用 load directory 按钮在 '/tmp' 目录中找到它们。“
|
||||
完成了所有的裁剪后,可以使用保存 GIF(Save GIF...) 或保存 MP4(Save MP4...) 按钮将录屏保存为动画或者视频;你会看到可以设置帧延迟、帧率以及循环次数的选项。
|
||||
|
||||
记住,“录屏帧不会自动清除。如果你想重新加载,可以在初始屏幕中使用加载目录(load directory)按钮在 '/tmp' 目录中找到它们。“
|
||||
|
||||
### 总结
|
||||
|
||||
@ -127,17 +116,15 @@ Gifine 的学习曲线并不陡峭 —— 所有的功能都会以按钮、文
|
||||
|
||||
对我来说,最大的问题是安装 —— 需要一个个安装它的依赖包,还要处理可能出现的错误,这会困扰很多人。否则,从整体上看,Gifine 绝对称得上是一个不错的工具,如果你正在寻找这样的工具,不妨一试。
|
||||
|
||||
|
||||
已经是 Gifine 用户?到目前为止你得到了什么经验?在评论区告诉我们。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,41 +1,42 @@
|
||||
使用开源工具探索气候数据的奥秘
|
||||
============================================================[up][1]
|
||||
============================================================
|
||||
|
||||

|
||||
图片源自:
|
||||
|
||||
[Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
图片源自: [Flickr user: theaucitron][2] (CC BY-SA 2.0)
|
||||
|
||||
如果这些天地球天气变化的不明显,你几乎无法察觉其中变化的格局。每个月,事实和数据都在向我们诠释一点——全球变暖。
|
||||
如今你看地球上的任何地方,都可以找到天气变化的证据,每个月,无论是事实还是数据都在向我们诠释一点 —— 全球变暖。
|
||||
|
||||
气候学家如是告诫我们——如今的不作为,对于我们的将来可能是致命的。五角大楼高层[最近警告][3]当选总统的川普。申明如果不对气候变化有所动作,可能会造成威胁国家安全的灾难。愈趋减少的的水供应和微薄的降雨量会导致作物歉收,这将迫使大量的移民逃往世界各地,到那些可以维持他们生计的地方去。
|
||||
气候学家如是告诫我们,如今的不作为,对于我们的将来可能是致命的。五角大楼的军事战略家[最近警告][3]当选总统的川普,向他申明如果不对气候变化有所动作,可能会造成威胁国家安全的灾难。愈趋减少的的水供应和微薄的降雨量会导致作物歉收,这将迫使大量的移民逃往世界各地,到那些可以维持他们生计的地方去。
|
||||
|
||||
遍览 NASA,美国国防部,以及其他机构针对气候的研究成果,我的心中有个疑惑。那就是是否有开源的工具,使对此感兴趣的人们能够自行去探索气候数据的奥秘,并总结出我们自己的结论。我在网上快速的检索了一下,然后找到了[Open Climate Workbench (开源气候工作台)][4],[Apache 软件基金会][5]旗下的一个工程。
|
||||
遍览 NASA、美国国防部,以及其他机构针对气候的研究成果,我的心中有个疑惑。那就是是否有开源的工具,使对此感兴趣的人们能够自行去探索气候数据的奥秘,并总结出我们自己的结论。我在网上快速的检索了一下,然后找到了 [Open Climate Workbench (开源气候工作台)][4],这是 [Apache 软件基金会][5]旗下的一个工程。
|
||||
|
||||
Open Climate Workbench (缩写 OCW) 开发用于对来自[Earth System Grid Federation (地球系统网格联盟,缩写 ESGF)][6],[Coordinated Regional Climate Downscaling Experiment (协调区域气候降尺度实验,缩写 CORDEX)][7],美国全球变化研究计划的 [National Climate Assessment (国家气候研究)][8],[North American Regional Climate Assessment Program (北美区域气候评估计划)][9],和 NASA,NOAA,以及其他组织或机构的数据进行气候模型评价。
|
||||
Open Climate Workbench (缩写 OCW) 开发该软件,对来自 [<ruby>地球系统网格联盟<rt>Earth System Grid Federation</rt></ruby>][6](缩写 ESGF)、[<ruby>协调区域气候降尺度实验<rt>Coordinated Regional Climate Downscaling Experiment</rt></ruby>][7](缩写 CORDEX)、美国全球变化研究项目的[<ruby>国家气候研究<rt> National Climate Assessment</rt></ruby>][8]、[<ruby>北美区域气候评估计划<rt>North American Regional Climate Assessment Program</rt></ruby>][9],以及 NASA、NOAA 和其他组织或机构的数据进行气候模型评价。
|
||||
|
||||
你可下载 OCW 的 [tar ball (压缩包)][10] 并将它安装到满足以下[条件][11]的 Linux 电脑上。也可以将它安装到 Vagrant 或者 VirtualBox 虚拟机中,详见 OCW 的[虚拟机指南][12]。
|
||||
你可下载 OCW 的 [tar 包][10] 并将它安装到满足其[条件][11]的 Linux 电脑上。也可以使用 Vagrant 或者 VirtualBox 将 OCW 安装到虚拟机中,详见 OCW 的[虚拟机指南][12]。
|
||||
|
||||
个人觉得想要了解 OCW 是如何工作的,最便捷的方式就是到 Regional Climate Model Evaluation System (区域气候模式评价系统,缩写 RCMES)下载一个[虚拟机镜像][13]。
|
||||
个人觉得想要了解 OCW 是如何工作的,最便捷的方式就是到 <ruby>区域气候模式评价系统<rt>Regional Climate Model Evaluation System </rt></ruby> (缩写 RCMES),下载一个[虚拟机镜像][13]。
|
||||
|
||||
从 RCMES 的网站上看,他们旨在通过为一系列广泛而全面的观测(例如,卫星观测,重新分析,现场观测)和建模资源(例如,[ESGF][16] 上的 [CMIP][14] 和 [CORDEX][15])提供标准化的访问,以及常规分析和可视化任务的工具(例如,OCW),来促进气候和地球系统模型的区域规模评估。
|
||||
|
||||
你需要在宿主机上安装 VirtualBox 和 Vagrant。通过它们,你就能看到一个超赞的 OCW 作业示例。RCMES 为下载,导入,运行虚拟机提供了[详细的说明][17]。当你的虚拟机开始工作时,你可以用以下身份登陆。
|
||||
你需要在宿主机上安装 VirtualBox 和 Vagrant。通过它们,你就能看到一个超赞的 OCW 作业示例。RCMES 为下载、导入、运行虚拟机提供了[详细的说明][17]。当你的虚拟机开始工作时,你可以用以下身份登陆。
|
||||
|
||||
** 用户名:vagrant,密码:vagrant。 **
|
||||
**用户名:vagrant,密码:vagrant。**
|
||||
|
||||

|
||||
|
||||
RCMES 数据样图
|
||||
*RCMES 数据样图*
|
||||
|
||||
RCMES 网页上的[教程][18]能帮助你迅速上手该软件。他们的[社区][19]十分活跃,而且看上去需要更多的[开发者][20]。 你也可以订阅他们[邮件列表][21]。
|
||||
RCMES 网页上的[教程][18]能帮助你迅速上手该软件。他们的[社区][19]十分活跃,而且在寻找更多的[开发者][20]。 你也可以订阅他们[邮件列表][21]。
|
||||
|
||||
工程的[源代码][22]部署在 GitHub 上,遵寻 Apache License, Version 2.0。
|
||||
该工程的[源代码][22]部署在 GitHub 上,遵寻 Apache License, Version 2.0。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Don Watkins(唐 沃特金斯) - 教育家,教育技术专家,企业家,开源支持者。心理学硕士,教育学硕士,Linux 系统管理员,CCNA,通过使用 Virtual Box 和 VMware 完成虚拟化。twitter 关注 @Don_Watkins。
|
||||
Don Watkins(唐 沃特金斯) - 教育家,教育技术专家,企业家,开源支持者。教育心理学硕士,Linux 系统管理员,CCNA,使用 Virtual Box 实现虚拟化。twitter 关注 @Don_Watkins。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -43,7 +44,7 @@ via: https://opensource.com/article/17/1/apache-open-climate-workbench
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,19 @@
|
||||
将另一台 Ubuntu DC 服务器加入到 Samba4 AD DC 实现双域控主机模式 ——(五)
|
||||
Samba 系列(五):将另一台 Ubuntu DC 服务器加入到 Samba4 AD DC 实现双域控主机模式
|
||||
============================================================
|
||||
|
||||
这篇文章将讲解如何使用 **Ubuntu 16.04** 服务器版系统来创建第二台 **Samba4** 域控制器,并将其加入到已创建好的 **Samba AD DC** 林环境中,以便为一些关键的 AD DC 服务提供负载均衡及故障切换功能,尤其是为那些重要的服务,比如 DNS 服务和使用 SAM 数据库的 AD DC LDAP 模式。
|
||||
|
||||
#### 需求
|
||||
|
||||
1、 这篇文章是 **Samba4 AD DC** 系列的第**五**篇,前边几篇如下:
|
||||
这篇文章是 **Samba4 AD DC** 系列的第**五**篇,前边几篇如下:
|
||||
|
||||
[在 Ubuntu16.04 系统上使用 Samba4 软件来创建活动目录架构(一)][1]
|
||||
[在 Linux 命令行下管理 Samba4 AD 架构(二)][2]
|
||||
[使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构 (三)][3]
|
||||
[在 Windows 系统下管理 Samba4 AD 域管制器 DNS 和组策略(四)][4]
|
||||
1、[在 Ubuntu16.04 系统上使用 Samba4 软件来创建活动目录架构(一)][1]
|
||||
|
||||
2、[在 Linux 命令行下管理 Samba4 AD 架构(二)][2]
|
||||
|
||||
3、[使用 Windows 10 系统的 RSAT 工具来管理 Samba4 活动目录架构 (三)][3]
|
||||
|
||||
4、[在 Windows 系统下管理 Samba4 AD 域管制器 DNS 和组策略(四)][4]
|
||||
|
||||
### 第一步:为设置 Samba4 进行初始化配置
|
||||
|
||||
@ -24,7 +27,7 @@
|
||||
# hostnamectl set-hostname adc2
|
||||
```
|
||||
|
||||
或者你也可以手动编辑 **/etc/hostname** 文件,在新的一行输入你想设置的主机名。
|
||||
或者你也可以手动编辑 `/etc/hostname` 文件,在新的一行输入你想设置的主机名。
|
||||
|
||||
```
|
||||
# nano /etc/hostname
|
||||
@ -55,11 +58,11 @@ IP_of_main_DC FQDN_of_main_DC short_name_of_main_DC
|
||||
|
||||
*为 Samba4 AD DC 服务器设置主机名*
|
||||
|
||||
3、下一步,打开 **/etc/network/interfaces** 配置文件并设置一个静态 IP 地址,如下图所示:
|
||||
3、下一步,打开 `/etc/network/interfaces` 配置文件并设置一个静态 IP 地址,如下图所示:
|
||||
|
||||
注意 **dns-nameservers** 和 **dns-search** 这两个参数的值。为了使 DNS 解析正常工作,需要把这两个值设置成主 Samba4 AD DC 服务器的 IP 地址和域名。
|
||||
注意 `dns-nameservers` 和 `dns-search` 这两个参数的值。为了使 DNS 解析正常工作,需要把这两个值设置成主 Samba4 AD DC 服务器的 IP 地址和域名。
|
||||
|
||||
重启网卡服务以让修改的配置生效。检查 **/etc/resolv.conf** 文件,确保该网卡上配置的这两个 DNS 的值已更新到这个文件。
|
||||
重启网卡服务以让修改的配置生效。检查 `/etc/resolv.conf` 文件,确保该网卡上配置的这两个 DNS 的值已更新到这个文件。
|
||||
|
||||
```
|
||||
# nano /etc/network/interfaces
|
||||
@ -90,7 +93,7 @@ dns-search tecmint.lan
|
||||
|
||||
*配置 Samba4 AD 服务器的 DNS*
|
||||
|
||||
当你通过简写名称(用于构建 FQDN 名)查询主机名时, **dns-search** 值将会自动把域名添加上。
|
||||
当你通过简写名称(用于构建 FQDN 名)查询主机名时, `dns-search` 值将会自动把域名添加上。
|
||||
|
||||
4、为了测试 DNS 解析是否正常,使用一系列 ping 命令测试,命令后分别为简写名, FQDN 名和域名,如下图所示:
|
||||
|
||||
@ -108,7 +111,7 @@ dns-search tecmint.lan
|
||||
# apt-get install ntpdate
|
||||
```
|
||||
|
||||
6、假设你想手动强制本地服务器与 **samba4 AD DC** 服务器时间同步,使用 **ntpdate** 命令加上主域控服务器的主机名,如下所示:
|
||||
6、假设你想手动强制本地服务器与 **samba4 AD DC** 服务器时间同步,使用 `ntpdate` 命令加上主域控服务器的主机名,如下所示:
|
||||
|
||||
```
|
||||
# ntpdate adc1
|
||||
@ -121,7 +124,7 @@ dns-search tecmint.lan
|
||||
|
||||
### 第 2 步:安装 Samba4 必须的依赖包
|
||||
|
||||
7、为了让 **Ubuntu 16.04** 系统加入到你的域中,你需要通过下面的命令从 Ubuntu 官方软件库中安装 **Samba4 套件, Kerberos** 客户端和其它一些重要的软件包以便将来使用:
|
||||
7、为了让 **Ubuntu 16.04** 系统加入到你的域中,你需要通过下面的命令从 Ubuntu 官方软件库中安装 **Samba4 套件、 Kerberos 客户端** 和其它一些重要的软件包以便将来使用:
|
||||
|
||||
```
|
||||
# apt-get install samba krb5-user krb5-config winbind libpam-winbind libnss-winbind
|
||||
@ -132,7 +135,7 @@ dns-search tecmint.lan
|
||||
|
||||
*在 Ubuntu 系统中安装 Samba4*
|
||||
|
||||
8、在安装的过程中,你需要提供 Kerberos 域名。输入大写的域名然后按 [Enter] 键完成安装过程。
|
||||
8、在安装的过程中,你需要提供 Kerberos 域名。输入大写的域名然后按回车键完成安装过程。
|
||||
|
||||
[
|
||||

|
||||
@ -140,7 +143,7 @@ dns-search tecmint.lan
|
||||
|
||||
*为 Samba4 配置 Kerberos 认证*
|
||||
|
||||
9、所有依赖包安装完成后,通过使用 kinit 命令为域管理员请求一个 Kerberos 票据以验证设置是否正确。使用 klist 命令来列出已授权的 kerberos 票据信息。
|
||||
9、所有依赖包安装完成后,通过使用 `kinit` 命令为域管理员请求一个 Kerberos 票据以验证设置是否正确。使用 `klist` 命令来列出已授权的 kerberos 票据信息。
|
||||
|
||||
```
|
||||
# kinit domain-admin-user@YOUR_DOMAIN.TLD
|
||||
@ -161,7 +164,7 @@ dns-search tecmint.lan
|
||||
# mv /etc/samba/smb.conf /etc/samba/smb.conf.initial
|
||||
```
|
||||
|
||||
11、在准备加入域前,先启动 **samba-ad-dc** 服务,之后使用域管理员账号运行 **samba-tool** 命令将服务器加入到域。
|
||||
11、在准备加入域前,先启动 **samba-ad-dc** 服务,之后使用域管理员账号运行 `samba-tool` 命令将服务器加入到域。
|
||||
|
||||
```
|
||||
# samba-tool domain join your_domain -U "your_domain_admin"
|
||||
@ -170,10 +173,10 @@ dns-search tecmint.lan
|
||||
加入域过程部分截图:
|
||||
|
||||
```
|
||||
# samba-tool domain join tecmint.lan DC -U"tecmint_user"
|
||||
# samba-tool domain join tecmint.lan DC -U "tecmint_user"
|
||||
```
|
||||
|
||||
##### 输出示例
|
||||
输出示例:
|
||||
|
||||
```
|
||||
Finding a writeable DC for domain 'tecmint.lan'
|
||||
@ -242,7 +245,7 @@ Joined domain TECMINT (SID S-1-5-21-715537322-3397311598-55032968) as a DC
|
||||
# nano /etc/samba/smb.conf
|
||||
```
|
||||
|
||||
添加以下内容到 smb.conf 配置文件中。
|
||||
添加以下内容到 `smb.conf` 配置文件中。
|
||||
|
||||
```
|
||||
dns forwarder = 192.168.1.1
|
||||
@ -255,7 +258,7 @@ winbind enum users = yes
|
||||
winbind enum groups = yes
|
||||
```
|
||||
|
||||
使用你自己的 **DNS forwarder IP** 地址替换掉上面地址。 Samba 将会把域权威区之外的所有 DNS 解析查询转发到这个 IP 地址。
|
||||
使用你自己的 **DNS 转发器 IP** 地址替换掉上面 `dns forwarder` 地址。 Samba 将会把域权威区之外的所有 DNS 解析查询转发到这个 IP 地址。
|
||||
|
||||
13、最后,重启 samba 服务以使修改的配置生效,然后执行如下命令来检查活动目录复制功能是否正常。
|
||||
|
||||
@ -270,9 +273,9 @@ winbind enum groups = yes
|
||||
|
||||
*配置 Samba4 DNS*
|
||||
|
||||
14、另外,还需要重命名原来的 /etc 下的 kerberos 配置文件,并使用在加入域的过程中 Samba 生成的新配置文件 krb5.conf 替换它。
|
||||
14、另外,还需要重命名原来的 `/etc `下的 kerberos 配置文件,并使用在加入域的过程中 Samba 生成的新配置文件 krb5.conf 替换它。
|
||||
|
||||
Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linux 的符号链接将该文件链接到 /etc 目录。
|
||||
Samba 生成的新配置文件在 `/var/lib/samba/private` 目录下。使用 Linux 的符号链接将该文件链接到 `/etc` 目录。
|
||||
|
||||
```
|
||||
# mv /etc/krb6.conf /etc/krb5.conf.initial
|
||||
@ -285,7 +288,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
*配置 Kerberos*
|
||||
|
||||
15、同样,使用 samba 的 **krb5.conf** 配置文件验证 Kerberos 认证是否正常。通过以下命令来请求一个管理员账号的票据并且列出已缓存的票据信息。
|
||||
15、同样,使用 samba 的 `krb5.conf` 配置文件验证 Kerberos 认证是否正常。通过以下命令来请求一个管理员账号的票据并且列出已缓存的票据信息。
|
||||
|
||||
```
|
||||
# kinit administrator
|
||||
@ -299,7 +302,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
### 第 4 步:验证其它域服务
|
||||
|
||||
16、你首先要做的一个测试就是验证 **Samba4 DC DNS** 解析服务是否正常。要验证域 DNS 解析情况,使用 host 命令,加上一些重要的 AD DNS 记录,进行域名查询,如下图所示:
|
||||
16、你首先要做的一个测试就是验证 **Samba4 DC DNS** 解析服务是否正常。要验证域 DNS 解析情况,使用 `host` 命令,加上一些重要的 AD DNS 记录,进行域名查询,如下图所示:
|
||||
|
||||
每一次查询,DNS 服务器都应该返回两个 IP 地址。
|
||||
|
||||
@ -322,15 +325,15 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
*通过 Windows RSAT 工具来验证 DNS 记录*
|
||||
|
||||
18、下一个验证是检查域 LDAP 复制同步是否正常。使用 **samba-tool** 工具,在第二个域控制器上创建一个账号,然后检查该账号是否自动同步到第一个 Samba4 AD DC 服务器上。
|
||||
18、下一个验证是检查域 LDAP 复制同步是否正常。使用 `samba-tool` 工具,在第二个域控制器上创建一个账号,然后检查该账号是否自动同步到第一个 Samba4 AD DC 服务器上。
|
||||
|
||||
##### On adc2:
|
||||
在 adc2 上:
|
||||
|
||||
```
|
||||
# samba-tool user add test_user
|
||||
```
|
||||
|
||||
##### On adc1:
|
||||
在 adc1 上:
|
||||
|
||||
```
|
||||
# samba-tool user list | grep test_user
|
||||
@ -349,7 +352,7 @@ Samba 生成的新配置文件在 /var/lib/samba/private 目录下。使用 Linu
|
||||
|
||||
19、你也可以从 **Microsoft AD DC** 控制台创建一个账号,然后验证该账号是否都出现在两个域控服务器上。
|
||||
|
||||
默认情况下,这个账号都应该在两个 samba 域控制器上自动创建完成。在 `adc1` 服务器上使用 **wbinfo** 命令查询该账号名。
|
||||
默认情况下,这个账号都应该在两个 samba 域控制器上自动创建完成。在 `adc1` 服务器上使用 `wbinfo` 命令查询该账号名。
|
||||
|
||||
[
|
||||

|
||||
@ -1,48 +1,48 @@
|
||||
NMAP 常用扫描简介 - 第一部分
|
||||
NMAP 常用扫描简介(一)
|
||||
========================
|
||||
|
||||
我们之前在‘[NMAP 的安装][1]’一文中,列出了 10 种不同的 ZeNMAP 扫描模式(这里将 Profiles 翻译成了模式,不知是否合适)。大多数的模式使用了各种参数。大多数的参数代表了执行不同的扫描模式。这篇文章将介绍其中的四种通用的扫描类型。
|
||||
我们之前在 [NMAP 的安装][1]一文中,列出了 10 种不同的 ZeNMAP 扫描模式。大多数的模式使用了各种参数。各种参数代表了执行不同的扫描模式。这篇文章将介绍其中的四种通用的扫描类型。
|
||||
|
||||
**四种通用扫描类型**
|
||||
### 四种通用扫描类型
|
||||
|
||||
下面列出了最常使用的四种扫描类型:
|
||||
|
||||
1. PING 扫描 (-sP)
|
||||
2. TCP SYN 扫描 (-sS)
|
||||
3. TCP Connect() 扫描 (-sT)
|
||||
4. UDP 扫描 (-sU)
|
||||
1. PING 扫描 (`-sP`)
|
||||
2. TCP SYN 扫描 (`-sS`)
|
||||
3. TCP Connect() 扫描 (`-sT`)
|
||||
4. UDP 扫描 (`-sU`)
|
||||
|
||||
当我们利用 NMAP 来执行扫描的时候,这四种扫描类型是我们需要熟练掌握的。更重要的是需要知道这些命令做了什么并且需要知道这些命令是怎么做的。本文将介绍 PING 扫描和 UDP 扫描。在之后的文中会介绍 TCP 扫描。
|
||||
|
||||
**PING 扫描 (-sP)**
|
||||
### PING 扫描 (-sP)
|
||||
|
||||
某些扫描会造成网络拥塞,然而 Ping 扫描在网络中最多只会产生两个包。当然这两个包不包括可能需要的 DNS 搜索和 ARP 请求。每个被扫描的 IP 最少只需要一个包来完成 Ping 扫描。
|
||||
|
||||
通常 Ping 扫描是用来查看在指定的 IP 地址上是否有在线的主机存在。例如,当我拥有网络连接却联不上一台指定的网络服务器的时候,我就可以使用 PING 来判断这台服务器是否在线。PING 同样也可以用来验证我的当前设备与网络服务器之间的路由是否正常。
|
||||
通常 Ping 扫描是用来查看在指定的 IP 地址上是否有在线的主机存在。例如,当我拥有网络连接却连不上一台指定的网络服务器的时候,我就可以使用 PING 来判断这台服务器是否在线。PING 同样也可以用来验证我的当前设备与网络服务器之间的路由是否正常。
|
||||
|
||||
**注意:** 当我们讨论 TCP/IP 的时候,相关信息在使用 TCP/IP 协议的英特网与局域网(LAN)中都是相当有用的。这些程序都能工作。同样在广域网(WAN)也能工作得相当好。
|
||||
**注意:** 当我们讨论 TCP/IP 的时候,相关信息在使用 TCP/IP 协议的互联网与局域网(LAN)中都是相当有用的。这些程序都能工作。同样在广域网(WAN)也能工作得相当好。
|
||||
|
||||
当参数给出的是一个域名的时候,我们就需要域名解析服务来找到相对应的 IP 地址,这个时候将会生成一些额外的包。例如,当我们执行 ‘ping linuxforum.com’ 的时候,需要首先请求域名(linuxforum.com)的 IP 地址(98.124.199.63)。当我们执行 ‘ping 98.124.199.63’ 的时候 DNS 查询就不需要了。当 MAC 地址未知的时候,就需要发送 ARP 请求来获取指定 IP 地址的 MAC 地址了(这里的指定 IP 地址,未必是目的 IP)。
|
||||
当参数给出的是一个域名的时候,我们就需要域名解析服务来找到相对应的 IP 地址,这个时候将会生成一些额外的包。例如,当我们执行 `ping linuxforum.com` 的时候,需要首先请求域名(linuxforum.com)的 IP 地址(98.124.199.63)。当我们执行 `ping 98.124.199.63` 的时候 DNS 查询就不需要了。当 MAC 地址未知的时候,就需要发送 ARP 请求来获取指定 IP 地址的 MAC 地址了(LCTT 译注:这里的指定 IP 地址,未必是目的 IP)。
|
||||
|
||||
Ping 命令会向指定的 IP 地址发送一个英特网信息控制协议(ICMP)包。这个包是需要响应的 ICMP Echo 请求。当服务器系统在线的状态下我们会得到一个响应包。当两个系统之间存在防火墙的时候,PING 请求包可能会被防火墙丢弃。一些服务器也会被配置成不响应 PING 请求来避免可能发生的死亡之 PING。(现在的操作系统似乎不太可能)
|
||||
Ping 命令会向指定的 IP 地址发送一个英特网信息控制协议(ICMP)包。这个包是需要响应的 ICMP Echo 请求。当服务器系统在线的状态下我们会得到一个响应包。当两个系统之间存在防火墙的时候,PING 请求包可能会被防火墙丢弃。一些服务器也会被配置成不响应 PING 请求来避免可能发生的死亡之 PING。(LCTT 译注:现在的操作系统似乎不太可能)
|
||||
|
||||
**注意:** 死亡之 PING 是一种恶意构造的 PING 包当它被发送到系统的时候,会造成被打开的连接等待一个 rest 包。一旦有一堆这样的恶意请求被系统响应,由于所有的可用连接都已经被打开所以系统将会拒绝所有其它的连接。技术上来说这种状态下的系统就是不可达的。
|
||||
**注意:** 死亡之 PING 是一种恶意构造的 PING 包当它被发送到系统的时候,会造成被打开的连接等待一个 rest 包。一旦有一堆这样的恶意请求被系统响应,由于所有的可用连接都已经被打开,所以系统将会拒绝所有其它的连接。技术上来说这种状态下的系统就是不可达的。
|
||||
|
||||
当系统收到 ICMP Echo 请求后它将会返回一个 ICMP Echo 响应。当源系统收到 ICMP Echo 响应后我们就能知道目的系统是在线可达的。
|
||||
|
||||
使用 NMAP 的时候你可以指定单个 IP 地址也可以指定 某个 IP 地址段。当被指定为 PING 扫描(-sP)的时候,PING 命令将会对每一个 IP 地址执行。
|
||||
使用 NMAP 的时候你可以指定单个 IP 地址也可以指定某个 IP 地址段。当被指定为 PING 扫描(`-sP`)的时候,会对每一个 IP 地址执行 PING 命令。
|
||||
|
||||
在图 1 中你可以看到我执行‘nmap -sP 10.0.0.1-10’命令后的结果。An ARP is sent out, three for each IP Address given to the command. In this case thirty requests went out – two for each of the ten IP Addresses.(这两句话就没有读懂,不清楚具体指的是什么意思,从图2看的话第一句里的三指的是两个 ARP 包和一个 ICMP 包,按照下面一段话的描述的话就是每个 IP 地址会有三个 ARP 请求,但是自己试的时候 Centos6 它发了两个 ARP 请求没获取到 MAC 地址也就就结束了,这里不清楚究竟怎么理解)
|
||||
在图 1 中你可以看到我执行 `nmap -sP 10.0.0.1-10` 命令后的结果。程序会试着联系 IP 地址 10.0.0.1 到 10.0.0.10 之间的每个系统。对每个 IP 地址都要发出三个 ARP 请求。在我们的例子中发出了三十个请求,这 10 个 IP 地址里面有两个有回应。(LCTT 译注:此处原文存疑。)
|
||||
|
||||

|
||||

|
||||
|
||||
**图 1**
|
||||
*图 1*
|
||||
|
||||
图 2 中展示了利用 Wireshark 抓取的从网络上另一台计算机发出的请求-的确是在 Windows 系统下完成这次抓取的。第一行展示了发出的第一条请求,广播请求的是 10.0.0.2 IP 地址对应 MAC 地址。由于 NMAP 是在 10.0.0.1 这台机器上执行的,因此 10.0.0.1 被略过了。由于本机 IP 地址被略过,我们现在可以说总共只发出了 27 个 ARP 请求。第二行展示了 10.0.0.2 这台机器的 ARP 响应。第三行到第十行是其它八个 IP 地址的 ARP 请求。第十一行是由于没有收到请求系统(10.0.0.1)的反馈所以发送的另一个 ARP 响应。(自己试的话它发送一个请求收到一个响应就结束了,也没有搜到相关的重发响应是否存在的具体说明,不是十分清楚)第十二行是源系统向 10.0.0.2 响应的 ‘SYN’ 和 Sequence 0。(这行感觉更像是三次握手里的首包)第十三行和第十四行的两次 Restart(RST)和 Synchronize(SYN)响应是用来关闭第二行和第十一行所打开的连接的。(这个描述似乎有问题 ARP 请求怎么会需要 TCP 来关闭连接呢,感觉像是第十二行的响应)注意 Sequence ID 是 ‘1’ - 是源 Sequence ID + 1。(这个不理解,不是应该 ACK = seq + 1 的么)第十五行开始就是类似相同的内容。
|
||||
图 2 中展示了网络上另一台计算机利用 Wireshark 抓取的发出的请求——没错,是在 Windows 系统下完成这次抓取的。第一行展示了发出的第一条请求,广播请求的是 IP 地址 10.0.0.2 对应 MAC 地址。由于 NMAP 是在 10.0.0.1 这台机器上执行的,因此 10.0.0.1 被略过了。由于本机 IP 地址被略过,我们现在可以看到总共只发出了 27 个 ARP 请求。第二行展示了 10.0.0.2 这台机器的 ARP 响应。第三行到第十行是其它八个 IP 地址的 ARP 请求。第十一行是由于 10.0.0.2 没有收到请求系统(10.0.0.1)的反馈所以(重新)发送的另一个 ARP 响应。第十二行是源系统向 10.0.0.2 发起的 HTTP 连接的 ‘SYN’ 和 Sequence 0。第十三行和第十四行的两次 Restart(RST)和 Synchronize(SYN)响应是用来关闭(和重发)第十二行所打开的连接的。注意 Sequence ID 是 ‘1’ - 是源 Sequence ID + 1。第十五行开始就是类似相同的内容。(LCTT 译注:此处原文有误,根据情况已经修改。)
|
||||
|
||||

|
||||

|
||||
|
||||
**图 2**
|
||||
*图 2*
|
||||
|
||||
回到图 1 中我们可以看到有两台主机在线。其中一台是本机(10.0.0.1)另一台是(10.0.0.2)。整个扫描花费了 14.40 秒。
|
||||
|
||||
@ -50,31 +50,31 @@ PING 扫描是一种用来发现在线主机的快速扫描方式。扫描结果
|
||||
|
||||
一旦你获得了在线系统的列表,你就可以使用 UDP 扫描来查看哪些端口是可能开启了的。
|
||||
|
||||
**UDP 扫描 (-sU)**
|
||||
### UDP 扫描 (-sU)
|
||||
|
||||
现在你已经知道了有那些系统是在线的,你的扫描就可以聚焦在这些 IP 地址之上。在整个网络上执行大量的没有针对性的扫描活动可不是一个好主意。系统管理员可以使用程序来监控网络流量当有大量可以活动发生的时候就会触发警报。
|
||||
现在你已经知道了有那些系统是在线的,你的扫描就可以聚焦在这些 IP 地址之上。在整个网络上执行大量的没有针对性的扫描活动可不是一个好主意,系统管理员可以使用程序来监控网络流量当有大量异常活动发生的时候就会触发警报。
|
||||
|
||||
用户数据报协议(UDP)在发现在线系统的开放端口方面十分有用。由于 UDP 不是一个面向连接的协议,因此是不需要响应的。这种扫描方式可以向指定的端口发送一个 UDP 包。如果目标系统没有回应那么这个端口可能是关闭的也可能是被过滤了的。如果端口是开放状态的那么应该会有一个响应。在大多数的情况下目标系统会返回一个 ICMP 信息说端口不可达。ICMP 信息让 NMAP 知道端口是被关闭了。如果端口是开启的状态那么目标系统应该响应 ICMP 信息来告知 NMAP 端口可达。
|
||||
|
||||
**注意: **只有最前面的1024个常用端口会被扫描。(这里将 1000 改成了1024,因为手册中写的是默认扫描 1 到 1024 端口)在后面的文章中我们会介绍如何进行深度扫描。
|
||||
**注意: **只有最前面的 1024 个常用端口会被扫描。(LCTT 译注:这里将 1000 改成了1024,因为手册中写的是默认扫描 1 到 1024 端口)在后面的文章中我们会介绍如何进行深度扫描。
|
||||
|
||||
由于我知道 10.0.0.2 这个主机是在线的,因此我只会针对这个 IP 地址来执行扫描。扫描过程中总共收发了 3278 个包。‘sudo nmap -sU 10.0.0.2’这个命令的输出结果在图 3 中展现。
|
||||
由于我知道 10.0.0.2 这个主机是在线的,因此我只会针对这个 IP 地址来执行扫描。扫描过程中总共收发了 3278 个包。`sudo nmap -sU 10.0.0.2` 这个命令的输出结果在图 3 中展现。
|
||||
|
||||

|
||||

|
||||
|
||||
**图 3**
|
||||
*图 3*
|
||||
|
||||
在这副图中你可以看见端口 137(netbios-ns)被发现是开放的。在图 4 中展示了 Wireshark 抓包的结果。不能看到所有抓取的包,但是可以看到一长串的 UDP 包。
|
||||
|
||||

|
||||

|
||||
|
||||
**图 4**
|
||||
*图 4*
|
||||
|
||||
如果我把目标系统上的防火墙关闭之后会发生什么呢?我的结果有那么一点的不同。NMAP 命令的执行结果在图 5 中展示。
|
||||
|
||||

|
||||

|
||||
|
||||
**图 5**
|
||||
*图 5*
|
||||
|
||||
**注意:** 当你执行 UDP 扫描的时候是需要 root 权限的。
|
||||
|
||||
@ -86,7 +86,7 @@ via: https://www.linuxforum.com/threads/nmap-common-scans-part-one.3637/
|
||||
|
||||
作者:[Jarret][a]
|
||||
译者:[wcnnbdk1](https://github.com/wcnnbdk1)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,30 +1,18 @@
|
||||
如何在 CentOS 7 中通过 HHVM 和 Nginx 安装 WordPress
|
||||
========================
|
||||
|
||||
### 导航
|
||||
HHVM (HipHop Virtual Machine) 是一个用于执行以 PHP 和 Hack 语言编写的代码的虚拟环境。它是由 Facebook 开发的,提供了当前 PHP 7 的大多数功能。要在你的服务器上运行 HHVM,你需要使用 FastCGI 来将 HHVM 和 Nginx 或 Apache 衔接起来,或者你也可以使用 HHVM 中的内置 Web 服务器 Proxygen。
|
||||
|
||||
1. [步骤 1 - 配置 SELinux 并添加v EPEL 仓库][1]
|
||||
2. [步骤 2 - 安装 Nginx][2]
|
||||
3. [步骤 3 - 安装并配置 MariaDB][3]
|
||||
4. [步骤 4 - 安装 HHVM][4]
|
||||
5. [步骤 5 - 配置 HHVM][5]
|
||||
6. [步骤 6 - 配置 HHVM 和 Nginx][6]
|
||||
7. [步骤 7 - 通过 HHVM 和 Nginx 创建虚拟主机][7]
|
||||
8. [步骤 8 - 安装 WordPress][8]
|
||||
9. [参考链接][9]
|
||||
|
||||
HHVM (HipHop Virtual Machine) is an open source virtual machine for executing programs written in PHP and Hack language. HHVM has been developed by Facebook, it provides most features of the current PHP 7 version. To run HHVM on your server, you can use a FastCGI to connect HHVM with a Nginx or Apache web server, or you can use the web server built into HHVM called "Proxygen".
|
||||
|
||||
In this tutorial, I will show you how to install WordPress with HHVM and Nginx as web server. I will use CentOS 7 as the operating system, so basic knowledge of CentOS is required.
|
||||
在这篇教程中,我将展示给你如何在 Nginx Web 服务器的 HHVM 上安装 WordPress。这里我使用 CentOS 7 作为操作系统,所以你需要懂一点 CentOS 操作的基础。
|
||||
|
||||
**先决条件**
|
||||
|
||||
* CentOS 7 - 64位
|
||||
* Root 特权
|
||||
* Root 权限
|
||||
|
||||
### 步骤 1 - 配置 SELinux 并添加v EPEL 仓库
|
||||
### 步骤 1 - 配置 SELinux 并添加 EPEL 仓库
|
||||
|
||||
在本教程中,我们将以强制模式来运行 SELinux,所以我们需要在系统上安装一个 SELinux 管理工具。这里我们使用 setools 和 setrobleshoot 来管理 SELinux 的各项配置。
|
||||
在本教程中,我们将使用 SELinux 的强制模式,所以我们需要在系统上安装一个 SELinux 管理工具。这里我们使用 `setools` 和 `setrobleshoot` 来管理 SELinux 的各项配置。
|
||||
|
||||
CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
@ -37,13 +25,13 @@ CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
如图,你能够看到,SELinux 已经开启了强制模式。
|
||||
|
||||
接下来就是使用 yum 来安装 setools 和 setroubleshoot 了。
|
||||
接下来就是使用 `yum` 来安装 `setools` 和 `setroubleshoot` 了。
|
||||
|
||||
```
|
||||
# yum -y install setroubleshoot setools net-tools
|
||||
```
|
||||
|
||||
安装好这两个后,在安装 EPEL 仓库。
|
||||
安装好这两个后,再安装 EPEL 仓库。
|
||||
|
||||
```
|
||||
# yum -y install epel-release
|
||||
@ -51,22 +39,22 @@ CentOS 7 已经默认启用 SELinux,我们可以通过以下命令来确认:
|
||||
|
||||
### 步骤 2 - 安装 Nginx
|
||||
|
||||
Nginx (发音:engine-x) 是一个高性能、低消耗的轻量级 Web 服务器软件。在 CentOS 中可以使用 yum 命令来安装 Nginx 包。记住用 root 用登录系统哦。
|
||||
Nginx (发音:engine-x) 是一个高性能、低内存消耗的轻量级 Web 服务器软件。在 CentOS 中可以使用 `yum` 命令来安装 Nginx 包。确保你以 root 用户登录系统。
|
||||
|
||||
使用 yum 命令从 CentOS 仓库中安装 nginx。
|
||||
使用 `yum` 命令从 CentOS 仓库中安装 nginx。
|
||||
|
||||
```
|
||||
# yum -y install nginx
|
||||
```
|
||||
|
||||
现在可以使用 systemctl 命令来启动 Nginx,同时将其设置为跟随系统启动。
|
||||
现在可以使用 `systemctl` 命令来启动 Nginx,同时将其设置为跟随系统启动。
|
||||
|
||||
```
|
||||
# systemctl start nginx
|
||||
# systemctl enable nginx
|
||||
```
|
||||
|
||||
为确保 Nginx 已经正确运行于服务器中,在浏览上输入服务器的 IP,或者如下使用 curl 命令检查显示结果。
|
||||
为确保 Nginx 已经正确运行于服务器中,在浏览器上输入服务器的 IP,或者如下使用 `curl` 命令检查显示结果。
|
||||
|
||||
```
|
||||
# curl 192.168.1.110
|
||||
@ -78,7 +66,7 @@ Nginx (发音:engine-x) 是一个高性能、低消耗的轻量级 Web 服务
|
||||
|
||||
### 步骤 3 - 安装并配置 MariaDB
|
||||
|
||||
MariaDB 是由原 MySQL 开发者 Monty Widenius 开发的一款开源数据库软件,它由 MySQL 分支而来,但与 MySQL 的主要用法保持一致。在这一步中,我们要安装 MariaDB 数据库并为之配置好 root 密码,然后在为 WordPress 安装的需要创建一个新的数据库和用户。
|
||||
MariaDB 是由原 MySQL 开发者 Monty Widenius 开发的一款开源数据库软件,它由 MySQL 分支而来,与 MySQL 的主要功能保持一致。在这一步中,我们要安装 MariaDB 数据库并为之配置好 root 密码,然后再为所要安装的 WordPress 创建一个新的数据库和用户。
|
||||
|
||||
安装 mariadb 和 mariadb-server:
|
||||
|
||||
@ -115,7 +103,7 @@ Reload privilege tables now? [Y/n] Y
|
||||
... Success!
|
||||
```
|
||||
|
||||
这样就设置好了 MariaDB 的 root 密码。现在登录到 MariaDB/MySQL shell 并为 WordPress 的安装创建一个新数据库 **"wordpressdb"** 和新用户 **"wpuser"**,密码设置为 **"wpuser@"**。在你的安装设置中要选用一个安全的密码。
|
||||
这样就设置好了 MariaDB 的 root 密码。现在登录到 MariaDB/MySQL shell 并为 WordPress 的安装创建一个新数据库 `wordpressdb` 和新用户 `wpuser`,密码设置为 `wpuser@`。为你的设置选用一个安全的密码。
|
||||
|
||||
登录到 MariaDB/MySQL shell:
|
||||
|
||||
@ -141,9 +129,9 @@ MariaDB [(none)]> \q
|
||||
|
||||
### 步骤 4 - 安装 HHVM
|
||||
|
||||
对于 HHVM,我们需要安装大量的依赖。作为选择,你可以从 GitHub 下载 HHVM 的源码来编译安装,也可以从网络上获取预编译的包进行安装。在本教程中,我使用的是预编译的安装包。
|
||||
对于 HHVM,我们需要安装大量的依赖项。作为选择,你可以从 GitHub 下载 HHVM 的源码来编译安装,也可以从网络上获取预编译的包进行安装。在本教程中,我使用的是预编译的安装包。
|
||||
|
||||
为 HHVM 安装依赖。
|
||||
为 HHVM 安装依赖项:
|
||||
|
||||
```
|
||||
# yum -y install cpp gcc-c++ cmake git psmisc {binutils,boost,jemalloc,numactl}-devel \
|
||||
@ -154,7 +142,7 @@ MariaDB [(none)]> \q
|
||||
> mariadb mariadb-server libc-client make
|
||||
```
|
||||
|
||||
然后是使用 rpm 安装从 [HHVM 预编译包镜像站点][13] 下载的 HHVM 预编译包。
|
||||
然后是使用 `rpm` 安装从 [HHVM 预编译包镜像站点][13] 下载的 HHVM 预编译包。
|
||||
|
||||
```
|
||||
# rpm -Uvh http://mirrors.linuxeye.com/hhvm-repo/7/x86_64/hhvm-3.15.2-1.el7.centos.x86_64.rpm
|
||||
@ -167,7 +155,7 @@ MariaDB [(none)]> \q
|
||||
# hhvm --version
|
||||
```
|
||||
|
||||
为了能使用 PHP 命令,可以把 hhvm 命令设置为 php。这样在 shell 中输入 'php' 命令的时候,你会看到和输入 hhvm 命令一样的结果。
|
||||
为了能使用 PHP 命令,可以把 `hhvm` 命令设置为 `php`。这样在 shell 中输入 `php` 命令的时候,你会看到和输入 `hhvm` 命令一样的结果。
|
||||
|
||||
```
|
||||
# sudo update-alternatives --install /usr/bin/php php /usr/bin/hhvm 60
|
||||
@ -178,9 +166,9 @@ MariaDB [(none)]> \q
|
||||
|
||||
### 步骤 5 - 配置 HHVM
|
||||
|
||||
这一步中,我们来配置 HHVM 以系统服务器来运行。我们不通过端口这种常规的方式来运行它,而是选择使用 unix socket 文件的方式,这样运行的更快速一点。
|
||||
这一步中,我们来配置 HHVM 以系统服务来运行。我们不通过端口这种常规的方式来运行它,而是选择使用 unix socket 文件的方式,这样运行的更快速一点。
|
||||
|
||||
进入 systemd 配置目录,并创建一个 hhvm.service 文件。
|
||||
进入 systemd 配置目录,并创建一个 `hhvm.service` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/systemd/system/
|
||||
@ -203,14 +191,14 @@ WantedBy=multi-user.target
|
||||
|
||||
保存文件退出 vim。
|
||||
|
||||
接下来,进入 hhvm 目录并编辑 server.ini 文件。
|
||||
接下来,进入 `hhvm` 目录并编辑 `server.ini` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/hhvm/
|
||||
# vim server.ini
|
||||
```
|
||||
|
||||
将第 7 行 hhvm.server.port 替换为 unix socket,如下:
|
||||
将第 7 行 `hhvm.server.port` 替换为 unix socket,如下:
|
||||
|
||||
```
|
||||
hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
@ -218,7 +206,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
保存文件并退出编辑器。
|
||||
|
||||
我们已在 hhvm 服务文件中定义了 hhvm 以 'nginx' 用户身份运行,所以还需要把 socket 文件目录的属主变更为 'nginx'。然后我们还必须在 SELinux 中修改 hhvm 目录内容以便让它可以访问这个 socket 文件。
|
||||
我们已在 hhvm 服务文件中定义了 hhvm 以 `nginx` 用户身份运行,所以还需要把 socket 文件目录的属主变更为 `nginx`。然后我们还必须在 SELinux 中修改 hhvm 目录的权限上下文以便让它可以访问这个 socket 文件。
|
||||
|
||||
```
|
||||
# chown -R nginx:nginx /var/run/hhvm/
|
||||
@ -228,7 +216,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
服务器重启之后,hhvm 将不能运行,因为没有存储 socket 文件的目录,所有还必须在启动的时候自动创建一个。
|
||||
|
||||
使用 vim 编辑 rc.local 文件。
|
||||
使用 vim 编辑 `rc.local` 文件。
|
||||
|
||||
```
|
||||
# vim /etc/rc.local
|
||||
@ -257,7 +245,7 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
# systemctl enable hhvm
|
||||
```
|
||||
|
||||
要确保无误,使用 netstat 命令验证 hhvm 运行于 socket 文件。
|
||||
要确保无误,使用 `netstat` 命令验证 hhvm 运行于 socket 文件。
|
||||
|
||||
```
|
||||
# netstat -pl | grep hhvm
|
||||
@ -267,16 +255,16 @@ hhvm.server.file_socket = /var/run/hhvm/hhvm.sock
|
||||
|
||||
### 步骤 6 - 配置 HHVM 和 Nginx
|
||||
|
||||
在这个步骤中,我们配置好 HHVM 已让它运行在 Nginx Web 服务中,这需要在 Nginx 目录创建一个 hhvm 的配置文件。
|
||||
在这个步骤中,我们将配置 HHVM 已让它运行在 Nginx Web 服务中,这需要在 Nginx 目录创建一个 hhvm 的配置文件。
|
||||
|
||||
进入 /etc/nginx 目录,创建 a hhvm.conf 文件。
|
||||
进入 `/etc/nginx` 目录,创建 `hhvm.conf` 文件。
|
||||
|
||||
```
|
||||
# cd /etc/nginx/
|
||||
# vim hhvm.conf
|
||||
```
|
||||
|
||||
粘贴一下内容到文件中。
|
||||
粘贴以下内容到文件中。
|
||||
|
||||
```
|
||||
location ~ \.(hh|php)$ {
|
||||
@ -291,13 +279,13 @@ location ~ \.(hh|php)$ {
|
||||
|
||||
然后,保存并退出。
|
||||
|
||||
接下来,编辑 nginx.conf 文件,添加 hhvm 配置文件到 include 行。
|
||||
接下来,编辑 `nginx.conf` 文件,添加 hhvm 配置文件到 `include` 行。
|
||||
|
||||
```
|
||||
# vim nginx.conf
|
||||
```
|
||||
|
||||
添加配置到第 57 行的 server 指令中。
|
||||
添加配置到第 57 行的 `server` 指令中。
|
||||
|
||||
```
|
||||
include /etc/nginx/hhvm.conf;
|
||||
@ -305,7 +293,7 @@ include /etc/nginx/hhvm.conf;
|
||||
|
||||
保存并退出。
|
||||
|
||||
然后修改 SELinux 中关于 hhvm 配置文件的内容。
|
||||
然后修改 SELinux 中关于 hhvm 配置文件的权限上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_config_t /etc/nginx/hhvm.conf
|
||||
@ -319,19 +307,19 @@ include /etc/nginx/hhvm.conf;
|
||||
# systemctl restart nginx
|
||||
```
|
||||
|
||||
记住确保没有错误。
|
||||
记住确保测试配置没有错误。
|
||||
|
||||
### 步骤 7 - 通过 HHVM 和 Nginx 创建虚拟主机
|
||||
|
||||
在这一步中能,我们要为 Nginx 和 hhvm 创建一个新的虚拟主机配置文件。这里我使用域名 **"natsume.co"** 来作为例子.你可以使用你主机喜欢的域名,并在配置文件中相应位置以及 WordPress 安装过程中进行替换。
|
||||
在这一步中,我们要为 Nginx 和 hhvm 创建一个新的虚拟主机配置文件。这里我使用域名 `natsume.co` 来作为例子,你可以使用你主机喜欢的域名,并在配置文件中相应位置以及 WordPress 安装过程中进行替换。
|
||||
|
||||
进入 nginx conf.d 目录,我们将在该目录存储虚拟主机文件。
|
||||
进入 nginx 的 `conf.d` 目录,我们将在该目录存储虚拟主机文件。
|
||||
|
||||
```
|
||||
# cd /etc/nginx/conf.d/
|
||||
```
|
||||
|
||||
使用 vim 创建一个名为 "natsume.conf" 的配置文件。
|
||||
使用 vim 创建一个名为 `natsume.conf` 的配置文件。
|
||||
|
||||
```
|
||||
# vim natsume.conf
|
||||
@ -367,15 +355,14 @@ server {
|
||||
|
||||
保存并退出。
|
||||
|
||||
在这给虚拟主机配置文件中,我们定义该域名的 Web 根目录为 "/var/www/hakase"。目前该目录还不存在,所有我们要创建它,并变更属主为 nginx 用户和组。
|
||||
在这个虚拟主机配置文件中,我们定义该域名的 Web 根目录为 `/var/www/hakase`。目前该目录还不存在,所有我们要创建它,并变更属主为 nginx 用户和组。
|
||||
|
||||
```
|
||||
# mkdir -p /var/www/hakase
|
||||
# chown -R nginx:nginx /var/www/hakase
|
||||
```
|
||||
|
||||
|
||||
Next, configure the SELinux context for the file and directory.
|
||||
接下来,为该文件和目录配置 SELinux 上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_config_t "/etc/nginx/conf.d(/.*)?"
|
||||
@ -393,28 +380,28 @@ Next, configure the SELinux context for the file and directory.
|
||||
|
||||
在步骤 5 的时候,我们已经为 WordPress 配置好了虚拟主机,现在只需要下载 WordPress 和使用我们在步骤 3 的时候创建的数据库和用户来编辑数据库配置就好了。
|
||||
|
||||
进入 Web 根目录 "/var/www/hakase" 并使用 Wget 命令下载 WordPress:
|
||||
进入 Web 根目录 `/var/www/hakase` 并使用 Wget 命令下载 WordPress:
|
||||
|
||||
```
|
||||
# cd /var/www/hakase
|
||||
# wget wordpress.org/latest.tar.gz
|
||||
```
|
||||
|
||||
解压 "latest.tar.gz" 并将 wordpress 文件夹中所有的文件和目录移动到当前目录:
|
||||
解压 `latest.tar.gz` 并将 `wordpress` 文件夹中所有的文件和目录移动到当前目录:
|
||||
|
||||
```
|
||||
# tar -xzvf latest.tar.gz
|
||||
# mv wordpress/* .
|
||||
```
|
||||
|
||||
下一步,复制一份 "wp-config-sample.php" 并更名为 "wp-config.php",然后使用 vim 进行编辑:
|
||||
下一步,复制一份 `wp-config-sample.php` 并更名为 `wp-config.php`,然后使用 vim 进行编辑:
|
||||
|
||||
```
|
||||
# cp wp-config-sample.php wp-config.php
|
||||
# vim wp-config.php
|
||||
```
|
||||
|
||||
将 DB_NAME 设置为 **"wordpressdb"**、DB_USER 设置为 **"wpuser"** 以及 DB_PASSWORD 设置为 **"wpuser@"**。
|
||||
将 `DB_NAME` 设置为 `wordpressdb`、`DB_USER` 设置为 `wpuser` 以及 `DB_PASSWORD` 设置为 `wpuser@`。
|
||||
|
||||
```
|
||||
define('DB_NAME', 'wordpressdb');
|
||||
@ -427,28 +414,28 @@ define('DB_HOST', 'localhost');
|
||||
|
||||
[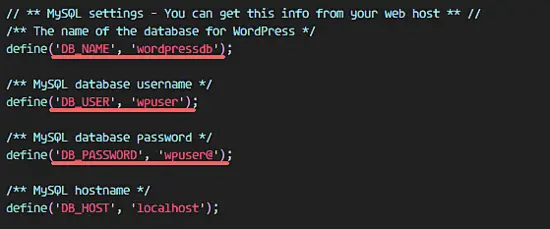][16]
|
||||
|
||||
修改关于 WordPress 目录的 SELinux 配置指令。
|
||||
修改关于 WordPress 目录的 SELinux 上下文。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_sys_content_t "/var/www/hakase(/.*)?"
|
||||
# restorecon -Rv /var/www/hakase
|
||||
```
|
||||
|
||||
现在打开 Web 浏览器,在地址栏输入你之前为 WordPress 设置的域名,我这里是 "natsume.co"。
|
||||
现在打开 Web 浏览器,在地址栏输入你之前为 WordPress 设置的域名,我这里是 `natsume.co`。
|
||||
|
||||
选择英语并点击 '继续 (Continue)'。
|
||||
选择语言并点击<ruby>继续<rt>Continue</rt></ruby>。
|
||||
|
||||
[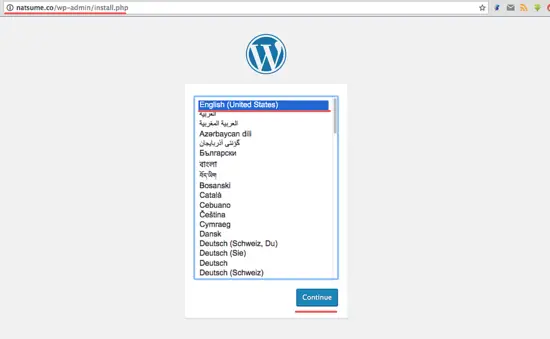][17]
|
||||
|
||||
根据自身要求填写站点标题和描述并点击 "安装 Wordpress (Install Wordpress)"。
|
||||
根据自身要求填写站点标题和描述并点击<ruby>安装 Wordpress<rt>Install Wordpress</rt></ruby>"。
|
||||
|
||||
[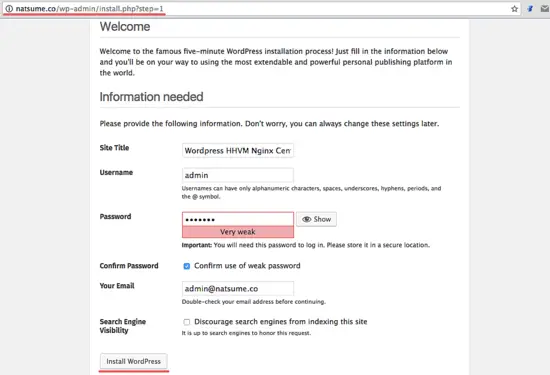][18]
|
||||
|
||||
耐心等待安装完成。你会见到如下页面,点击 "登录 (Log In)" 来登录到管理面板。
|
||||
耐心等待安装完成。你会见到如下页面,点击<ruby>登录<rt>Log In</rt></ruby>来登录到管理面板。
|
||||
|
||||
[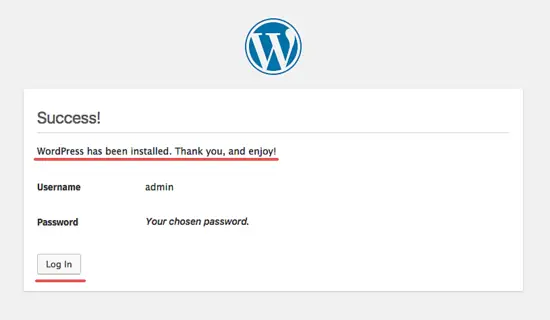][19]
|
||||
|
||||
输入你设置的管理员用户账号和密码,在此点击 "登录 (Log In)"。
|
||||
输入你设置的管理员用户账号和密码,在此点击<ruby>登录<rt>Log In</rt></ruby>。
|
||||
|
||||
[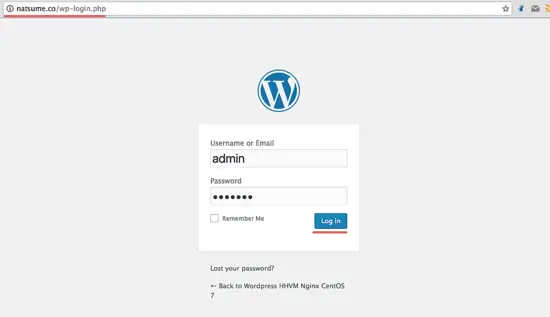][20]
|
||||
|
||||
@ -456,7 +443,7 @@ define('DB_HOST', 'localhost');
|
||||
|
||||
[][21]
|
||||
|
||||
Wordpress 主页。
|
||||
Wordpress 的主页:
|
||||
|
||||
[][22]
|
||||
|
||||
@ -464,8 +451,7 @@ Wordpress 主页。
|
||||
|
||||
### 参考链接
|
||||
|
||||
- [https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-opensuse-leap-42-1/](https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-opensuse-leap-42-1/)
|
||||
- [https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/](https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/)
|
||||
- https://www.nginx.com/blog/nginx-se-linux-changes-upgrading-rhel-6-6/
|
||||
|
||||
------------------------------------
|
||||
|
||||
@ -477,9 +463,9 @@ Wordpress 主页。
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-wordpress-with-hhvm-and-nginx-on-centos-7/
|
||||
|
||||
作者:[ Muhammad Arul][a]
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
让你的 Linux 远离黑客(二):另外三个建议
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些阻止黑客入侵你的系统的重要信息。观看这个免费的网络点播研讨会获取更多的信息。
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过两种简单的方法来阻止黑客黑掉你的 Linux 主机。这里是另外三条来自于我最近在 Linux 基金会的网络研讨会上的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[网络点播研讨会][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的 Linux 安全提示 #3
|
||||
|
||||
**Sudo。**
|
||||
|
||||
Sudo 非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西会让我的黑客生涯会变得更困难一些。如果你没有配置 sudo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用 sudo 执行所有命令。当我有一个可以无需密码而可以 sudo 任何命令的用户,只会让我的黑客活动变得更容易。如果我可以无需验证就可以 sudo ,同时当我获得你的没有密码的 SSH 密钥后,我就能十分容易的开始任何黑客活动。这样,我就拥有了你机器的 root 权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用 sudo,并且设置的超时时间是 3 小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐的超时时间大约为 10 分钟,甚至是 5 分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令,并禁止通过 sudo 来访问 shell。大多数 Linux 发行版目前默认允许你使用 sudo bash 来获取一个 root 身份的 shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我 shell 访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的 Linux 安全提示 #4
|
||||
|
||||
**限制正在运行的服务。**
|
||||
|
||||
防火墙很好,你的边界防火墙非常的强大。当流量流经你的外部网络时,有几家防火墙产品可以帮你很好的保护好自己。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供 MySQL 服务的机器上运行它。如果你有一个默认会安装完整的 LAMP 套件的 Linux 发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户不要使用默认的身份凭证,确保那些内容已被安全地配置。如何你正在运行 Tomcat,你不应该可以上传你自己的小程序(applets)。确保它们不会以 root 的身份运行。如果我能够运行一个小程序,我不会想着以管理员的身份来运行它,我能访问就行。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的 Linux 安全提示 #5
|
||||
|
||||
**小心你的日志记录。**
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的 email,我会浏览我的日志记录。这仅会花费我 15 分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不在意它们,但是有人会在意。
|
||||
|
||||
通过 Syslog、Splunk 或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我能这么做,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
它们就像你的很重要的人,送给它们鲜花——磁盘空间。确保你有足够的磁盘空间用来记录日志。由于磁盘满而变成只读的文件系统并不是一件愉快的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三篇也是最后的一篇文章][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络点播研讨会][6]吧。
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试。***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://linux.cn/article-8189-1.html
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -2,11 +2,11 @@ Go 语言编译期断言
|
||||
============================================================
|
||||
|
||||
|
||||
这篇文章是关于一个鲜为人知的方法让 Go 在编译期断言。你可能不会使用它,但是了解一下也很有趣。
|
||||
这篇文章是关于一个鲜为人知的让 Go 在编译期断言的方法。你可能不会使用它,但是了解一下也很有趣。
|
||||
|
||||
作为一个热身,这里是一个在 Go 中相当知名的编译时断言:接口满意度检查。
|
||||
作为一个热身,来看一个在 Go 中熟知的编译期断言:接口满意度检查。
|
||||
|
||||
在这段代码([playground][1])中,`var _ =` 行确保类型 `W` 是一个 `stringWriter`,由 [`io.WriteString`][2] 检查。
|
||||
在这段代码([playground][1])中,`var _ =` 行确保类型 `W` 是一个 `stringWriter`,其由 [`io.WriteString`][2] 检查。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -39,13 +39,13 @@ main.go:14: cannot use W literal (type W) as type stringWriter in assignment:
|
||||
|
||||
这是很有用的。对于大多数同时满足 `io.Writer` 和 `stringWriter` 的类型,如果你删除 `WriteString` 方法,一切都会像以前一样继续工作,但性能较差。
|
||||
|
||||
你可以使用编译时断言保护你的代码,而不是试图使用[`testing.T.AllocsPerRun'][3]为性能回归编写一个脆弱的测试。
|
||||
你可以使用编译期断言保护你的代码,而不是试图使用[`testing.T.AllocsPerRun'][3]为性能回归编写一个脆弱的测试。
|
||||
|
||||
这是[一个实际的 io 包中的技术例子][4]。
|
||||
|
||||
* * *
|
||||
|
||||
好的,让我们隐晦一点!
|
||||
好的,让我们低调一点!
|
||||
|
||||
接口满意检查是很棒的。但是如果你想检查一个简单的布尔表达式,如 `1 + 1 == 2` ?
|
||||
|
||||
@ -69,9 +69,9 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
`Hash` 可能是某种抽象的哈希结果。`init` 函数确保它将与[crypto/md5][6]一起工作。如果你改变 `Hash` 为(也就是)`[8]byte`,它会在进程启动时发生混乱。但是,这是一个运行时检查。如果我们想要早点发现怎么办?
|
||||
`Hash` 可能是某种抽象的哈希结果。`init` 函数确保它将与 [crypto/md5][6] 一起工作。如果你改变 `Hash` 为(比如说)`[8]byte`,它会在进程启动时发生崩溃。但是,这是一个运行时检查。如果我们想要早点发现怎么办?
|
||||
|
||||
就是这样。(没有 playground 链接,因为这在 playground 上不起作用。)
|
||||
如下。(没有 playground 链接,因为这在 playground 上不起作用。)
|
||||
|
||||
```
|
||||
package main
|
||||
@ -109,11 +109,11 @@ main.init.1: undefined: "main.hashIsTooSmall"
|
||||
|
||||
`hashIsTooSmall` 是[一个没有函数体的声明][7]。编译器假定别人将提供一个实现,也许是一个汇编程序。
|
||||
|
||||
当编译器可以证明 `len(Hash {})<md5.Size` 时,它消除了 if 语句中的代码。结果,没有人使用函数 `hashIsTooSmall`,所以链接器会消除它。没有其他损害。一旦断言失败,if 语句中的代码将被保留。不会消除 `hashIsTooSmall`。链接器然后注意到没有人提供了函数的实现然后链接失败,并出现错误,这是我们的目标。
|
||||
当编译器可以证明 `len(Hash {})< md5.Size` 时,它消除了 if 语句中的代码。结果,没有人使用函数 `hashIsTooSmall`,所以链接器会消除它。没有其他损害。一旦断言失败,if 语句中的代码将被保留。不会消除 `hashIsTooSmall`。链接器然后注意到没有人提供了函数的实现然后链接失败,并出现错误,这是我们的目标。
|
||||
|
||||
最后一个奇怪的点:为什么是 `import "C"`? go 工具知道在正常的 Go 代码中,所有函数都必须有主体,并指示编译器强制执行。通过切换到 cgo,我们删除该检查。(如果你在上面的代码中运行 `go build -x',而没有添加 `import "C"` 这行,你会看到编译器是用 `-complete` 标志调用的。)另一种方法是添加 `import "C"` 来[向包中添加一个名为 `foo.s` 的空文件][8]。
|
||||
最后一个奇怪的点:为什么是 `import "C"`? go 工具知道在正常的 Go 代码中,所有函数都必须有主体,并指示编译器强制执行。通过切换到 cgo,我们删除该检查。(如果你在上面的代码中运行 `go build -x`,而没有添加 `import "C"` 这行,你会看到编译器是用 `-complete` 标志调用的。)另一种方法是添加 `import "C"` 来[向包中添加一个名为 `foo.s` 的空文件][8]。
|
||||
|
||||
我在[编译器测试套件][9]中只知道这种使用。还有其他[可以发挥想象力的使用][10],但还没有人打扰。
|
||||
我仅见过一次这种技术的使用,是在[编译器测试套件][9]中。还有其他[可以发挥想象力的使用][10],但我还没见到过。
|
||||
|
||||
可能就是这样吧。 :)
|
||||
|
||||
@ -124,7 +124,7 @@ via: http://commaok.xyz/post/compile-time-assertions
|
||||
|
||||
作者:[Josh Bleecher Snyder][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,212 @@
|
||||
wkhtmltopdf:一个 Linux 中将网页转成 PDF 的智能工具
|
||||
============================================================
|
||||
|
||||
wkhtmltopdf 是一个开源、简单而有效的命令行 shell 程序,它可以将任何 HTML (网页)转换为 PDF 文档或图像(jpg、png 等)。
|
||||
|
||||
wkhtmltopdf 是用 C++ 编写的,并在 GNU/GPL (通用公共许可证)下发布。它使用 WebKit 渲染引擎将 HTML 页面转换为 PDF 文档且不会丢失页面的质量。这是一个用于实时创建和存储网页快照的非常有用且可信赖的解决方案。
|
||||
|
||||
### wkhtmltopdf 的功能
|
||||
|
||||
1. 开源并且跨平台。
|
||||
2. 使用 WebKit 引擎将任意 HTML 网页转换为 PDF 文件。
|
||||
3. 添加页眉和页脚的选项
|
||||
4. 目录生成 (TOC) 选项。
|
||||
5. 提供批量模式转换。
|
||||
6. 通过绑定 libwkhtmltox 来支持 PHP 或 Python。
|
||||
|
||||
在本文中,我们将介绍如何在 Linux 系统下使用 tar 包来安装 wkhtmltopdf。
|
||||
|
||||
### 安装 Evince (PDF 浏览器)
|
||||
|
||||
让我们在 Linux 系统中安装 evince (一个 PDF 阅读器)来浏览 PDF 文件。
|
||||
|
||||
```
|
||||
$ sudo yum install evince [RHEL/CentOS and Fedora]
|
||||
$ sudo dnf install evince [On Fedora 22+ versions]
|
||||
$ sudo apt-get install evince [On Debian/Ubuntu systems]
|
||||
```
|
||||
|
||||
### 下载 wkhtmltopdf 源码文件
|
||||
|
||||
使用 [wget 命令][1]根据你的 Linux 架构来下载 wkhtmltopdf 源码文件,或者你也可以在 [wkhtmltopdf 下载页][2]下载最新的版本(目前最新的稳定版是 0.12.4)
|
||||
|
||||
在 64 位 Linux 系统中:
|
||||
|
||||
```
|
||||
$ wget http://download.gna.org/wkhtmltopdf/0.12/0.12.4/wkhtmltox-0.12.4_linux-generic-amd64.tar.xz
|
||||
```
|
||||
|
||||
在 32 位 Linux 系统中:
|
||||
|
||||
```
|
||||
$ wget http://download.gna.org/wkhtmltopdf/0.12/0.12.4/wkhtmltox-0.12.4_linux-generic-i386.tar.xz
|
||||
```
|
||||
|
||||
### 在 Linux 中安装 wkhtmltopdf
|
||||
|
||||
使用 [tar 命令][3]解压文件到当前目录中。
|
||||
|
||||
```
|
||||
------ On 64-bit Linux OS ------
|
||||
$ sudo tar -xvf wkhtmltox-0.12.4_linux-generic-amd64.tar.xz
|
||||
------ On 32-bit Linux OS ------
|
||||
$ sudo tar -xvzf wkhtmltox-0.12.4_linux-generic-i386.tar.xz
|
||||
```
|
||||
|
||||
为了能从任意路径执行程序,将 wkhtmltopdf 安装到 `/usr/bin` 目录下。
|
||||
|
||||
```
|
||||
$ sudo cp wkhtmltox/bin/wkhtmltopdf /usr/bin/
|
||||
```
|
||||
|
||||
### 如何使用 wkhtmltopdf?
|
||||
|
||||
我们会看到如何将远程的 HTML 页面转换成 PDF 文件、验证信息、使用 evince 在 GNOME 桌面中浏览创建的文件。
|
||||
|
||||
#### 将 HTML 网页转成 PDF 文件
|
||||
|
||||
要将任意 HTML 页面转换成 PDF,运行下面的命令。它会在当前目录下将页面转换成 [10-Sudo-Configurations.pdf][4]。
|
||||
|
||||
```
|
||||
# wkhtmltopdf http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/ 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Loading pages (1/6)
|
||||
Counting pages (2/6)
|
||||
Resolving links (4/6)
|
||||
Loading headers and footers (5/6)
|
||||
Printing pages (6/6)
|
||||
Done
|
||||
```
|
||||
|
||||
#### 浏览生成的 PDF 文件
|
||||
|
||||
为了验证创建的文件,使用下面的命令。
|
||||
|
||||
```
|
||||
$ file 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
10-Sudo-Configurations.pdf: PDF document, version 1.4
|
||||
```
|
||||
|
||||
#### 浏览生成的 PDF 文件细节
|
||||
|
||||
要浏览生成的文件信息,运行下面的命令。
|
||||
|
||||
```
|
||||
$ pdfinfo 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Title: 10 Useful Sudoers Configurations for Setting 'sudo' in Linux
|
||||
Creator: wkhtmltopdf 0.12.4
|
||||
Producer: Qt 4.8.7
|
||||
CreationDate: Sat Jan 28 13:02:58 2017
|
||||
Tagged: no
|
||||
UserProperties: no
|
||||
Suspects: no
|
||||
Form: none
|
||||
JavaScript: no
|
||||
Pages: 13
|
||||
Encrypted: no
|
||||
Page size: 595 x 842 pts (A4)
|
||||
Page rot: 0
|
||||
File size: 697827 bytes
|
||||
Optimized: no
|
||||
PDF version: 1.4
|
||||
```
|
||||
|
||||
#### 浏览创建的文件
|
||||
|
||||
在桌面中使用 evince 查看最新生成的 PDF 文件。
|
||||
|
||||
```
|
||||
$ evince 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例截图:
|
||||
|
||||
在我的 Linux Mint 17 中看起来很棒。
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
*在 PDF 中浏览网页*
|
||||
|
||||
### 给 PDF 创建页面的 TOC (Table Of Content 即目录)
|
||||
|
||||
要创建一个 PDF 文件的目录,使用 toc 选项。
|
||||
|
||||
```
|
||||
$ wkhtmltopdf toc http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/ 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Loading pages (1/6)
|
||||
Counting pages (2/6)
|
||||
Loading TOC (3/6)
|
||||
Resolving links (4/6)
|
||||
Loading headers and footers (5/6)
|
||||
Printing pages (6/6)
|
||||
Done
|
||||
```
|
||||
|
||||
要查看已创建文件的 TOC,再次使用 evince。
|
||||
|
||||
```
|
||||
$ evince 10-Sudo-Configurations.pdf
|
||||
```
|
||||
|
||||
示例截图:
|
||||
|
||||
看一下下面的图。它上看去比上面的更好。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
*在 PDF 中创建网页的目录*
|
||||
|
||||
#### wkhtmltopdf 选项及使用
|
||||
|
||||
更多关于 wkhtmltopdf 的使用及选项,使用下面的帮助命令。它会显示出所有可用的选项。
|
||||
|
||||
```
|
||||
$ wkhtmltopdf --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是 Ravi Saive,TecMint 的创建者。一个爱在网上分享的技巧和提示的电脑极客和 Linux 专家。我的大多数服务器运行在名为 Linux 的开源平台上。请在 Twitter、 Facebook 和 Google+ 等上关注我。
|
||||
|
||||
--------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/wkhtmltopdf-convert-website-html-page-to-pdf-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/admin/
|
||||
[1]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[2]:http://wkhtmltopdf.org/downloads.html
|
||||
[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2012/10/View-Website-Page-in-PDF.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2012/10/Create-Website-Page-Table-of-Contents-in-PDF.png
|
||||
@ -1,119 +1,113 @@
|
||||
在 Linux 上用火狐保护你的隐私
|
||||
在 Linux 上用火狐浏览器保护你的隐私
|
||||
=============================
|
||||
|
||||
## 介绍
|
||||
### 介绍
|
||||
|
||||
隐私和安全正在逐渐成为一个重要的话题。虽然不可能做到 100% 安全,但是,还是能采取一些措施,特别是在 Linux 上,在你浏览网页的时候保护你的在线隐私安全。
|
||||
|
||||
基于这些目的选择浏览器的时候,火狐或许是你的最佳选择。谷歌 Chrome 不能信任。它是属于谷歌的,一个众所周知的数据收集公司,而且它是闭源的。 Chromium 或许还可以,但并不能保证。只有火狐保持了一定程度的用户权利承诺。
|
||||
|
||||
## 火狐设置
|
||||
### 火狐设置
|
||||
|
||||
火狐里有几个你能设定的设置,能更好地保护你的隐私。这些设置唾手可得,能帮你控制那些在你浏览的时候分享的数据。
|
||||
|
||||
### 健康报告
|
||||
#### 健康报告
|
||||
|
||||
你首先可以设置的是对火狐健康报告发送的限制,以限制数据发送总量。当然,这些数据只是被发送到 Mozilla,但这也是传输数据。
|
||||
你首先可以设置的是对火狐健康报告发送的限制,以限制数据发送量。当然,这些数据只是被发送到 Mozilla,但这也是传输数据。
|
||||
|
||||
打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>。来到侧边栏里的<ruby>“高级”<rt>Advanced</rt></ruby>选项卡,点击<ruby>“数据选项”<rt>Data Choices</rt></ruby>。这里你能禁用任意数据的报告。
|
||||
|
||||
### 搜索
|
||||
#### 搜索
|
||||
|
||||
新版的火狐浏览器默认使用雅虎搜索引擎。一些发行版更改设置,替代使用的是谷歌。两个方法都不理想。火狐有默认使用 DuckDuckGo 的选项。
|
||||
新版的火狐浏览器默认使用雅虎搜索引擎。一些发行版会更改设置,替代使用的是谷歌。两个方法都不理想。火狐可以使用 DuckDuckGo 作为默认选项。
|
||||
|
||||

|
||||
|
||||
为了启用 DuckDuckGo,你得打开火狐菜单点击<ruby>“选项”<rt>Preferences</rt></ruby>。直接来到侧边栏的<ruby>“搜索”<rt>Search</rt></ruby>选项卡。然后,用<ruby>“默认搜索引擎”<rt>Default Search Engine</rt></ruby>的下拉菜单来选择 DuckDuckGo 。
|
||||
为了启用 DuckDuckGo,你得打开火狐菜单点击<ruby>“选项”<rt>Preferences</rt></ruby>。直接来到侧边栏的<ruby>“搜索”<rt>Search</rt></ruby>选项卡。然后,在<ruby>“默认搜索引擎”<rt>Default Search Engine</rt></ruby>的下拉菜单中选择 DuckDuckGo 。
|
||||
|
||||
### <ruby>请勿跟踪<rt>Do Not Track</rt></ruby>
|
||||
#### <ruby>请勿跟踪<rt>Do Not Track</rt></ruby>
|
||||
|
||||
这个功能并不完美,但它确实向站点发送了一个信号,告诉它们不要使用分析工具来记录你的活动。这些网页或许会遵从,会许不会。但是,最好启用请勿跟踪,也许它们会遵从呢。
|
||||
|
||||

|
||||

|
||||
|
||||
再次打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>,然后是<ruby>“隐私”<rt>Privacy</rt></ruby>。页面的最上面有一个<ruby>“跟踪”<rt>Tracking</rt></ruby>部分。点击那一行写着<ruby>“您还可以管理您的‘请勿跟踪’设置”<rt>You can also manage your Do Not Track settings</rt></ruby>的链接。会出现一个有复选框的弹出窗口,那里允许你启用“请勿跟踪”设置。
|
||||
|
||||
### 禁用 Pocket
|
||||
#### 禁用 Pocket
|
||||
|
||||
没有任何证据显示 Pocket 正在做一些不好的事情,但是禁用它或许更好,因为它确实连接了一个专有的应用。
|
||||
|
||||
禁用 Pocket 不是太难,但是你得注意只改变 Pocket 相关设置。为了来到你所需的配置页面,在火狐的地址栏里输入`about:config`。
|
||||
禁用 Pocket 不是太难,但是你得注意只改变 Pocket 相关设置。要访问你所需的配置页面,在火狐的地址栏里输入`about:config`。
|
||||
|
||||
页面会加载一个设置表格,在表格的最上面是搜索栏,在那儿搜索 Pocket 。
|
||||
|
||||
你将会看到一个包含结果的新表格。找一下名为 extensions.pocket.enabled 的设置。当你找到它的时候,双击使其转变为“否”。你也能在这儿编辑 Pocket 的其他相关设置。不过没什么必要。注意不要编辑那些跟 Pocket 扩展不直接相关的任何东西。
|
||||
你将会看到一个包含结果的新表格。找一下名为 `extensions.pocket.enabled` 的设置。当你找到它的时候,双击使其转变为“否”。你也能在这儿编辑 Pocket 的其他相关设置。不过没什么必要。注意不要编辑那些跟 Pocket 扩展不直接相关的任何东西。
|
||||
|
||||

|
||||

|
||||
|
||||
### <ruby>附加组件<rt>Add-ons</rt></ruby>
|
||||
|
||||
## <ruby>附加组件<rt>Add-ons</rt></ruby>
|
||||
|
||||

|
||||

|
||||
|
||||
火狐最有效地保护你隐私和安全的方式来自附加组件。火狐有大量的附加组件库,其中很多是免费、开源的。在这篇指导中着重提到的附加组件,在使浏览器更安全方面是名列前茅的。
|
||||
|
||||
### HTTPS Everywhere
|
||||
#### HTTPS Everywhere
|
||||
|
||||
针对大量没有使用 SSL 证书的网页、许多不使用 `https` 前缀的链接、指引用户前往不安全版本的网页等现状,<ruby>电子前线基金会<rt>Electronic Frontier Foundation</rt></ruby>开发了 HTTPS Everywhere。HTTPS Everywhere 确保了如果存在有一个加密版本的网页,用户将会使用它。
|
||||
针对大量没有使用 SSL 证书的网页、许多不使用 `https` 协议的链接、指引用户前往不安全版本的网页等现状,<ruby>电子前线基金会<rt>Electronic Frontier Foundation</rt></ruby>开发了 HTTPS Everywhere。HTTPS Everywhere 确保了如果该链接存在有一个加密的版本,用户将会使用它。
|
||||
|
||||
给火狐设计的 HTTPS Everywhere 已经可以使用,在火狐的附加组件搜索网页上。`https://addons.mozilla.org/en-us/firefox/addon/https-everywhere/`(LCTT 译注:对应的中文页面是 `https://addons.mozilla.org/zh-CN/firefox/addon/https-everywhere/`)
|
||||
给火狐设计的 [HTTPS Everywhere](https://addons.mozilla.org/en-us/firefox/addon/https-everywhere/) 已经可以使用,在火狐的附加组件搜索网页上。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/https-everywhere/)。)
|
||||
|
||||
|
||||
### Privacy Badger
|
||||
#### Privacy Badger
|
||||
|
||||
电子前线基金会同样开发了 Privacy Badger。 Privacy Badger 旨在通过阻止不想要的网页跟踪,弥补“请勿跟踪”功能的不足之处。它同样能通过火狐附加组件仓库安装。`https://addons.mozilla.org/en-us/firefox/addon/privacy-badger17`。(LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/privacy-badger17/`)
|
||||
电子前线基金会同样开发了 Privacy Badger。 [Privacy Badger](https://addons.mozilla.org/en-us/firefox/addon/privacy-badger17) 旨在通过阻止不想要的网页跟踪,弥补“请勿跟踪”功能的不足之处。它同样能通过火狐附加组件仓库安装。。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/privacy-badger17/)。)
|
||||
|
||||
|
||||
### Ublock Origin
|
||||
#### uBlock Origin
|
||||
|
||||
现在有一类更通用的的隐私附加组件,屏蔽广告。这里的选择是 uBlock Origin,uBlock Origin 是个更轻量级的广告屏蔽插件,几乎不遗漏所有它会屏蔽的广告。 uBlock Origin 将主要屏蔽所有广告,特别是侵略性的广告。你能在这儿找到它。`https://addons.mozilla.org/en-us/firefox/addon/ublock-origin/`。(LCTT 译注:对应的中文页面是 `https://addons.mozilla.org/zh-CN/firefox/addon/ublock-origin/`)
|
||||
现在有一类更通用的的隐私附加组件,屏蔽广告。这里的选择是 uBlock Origin,uBlock Origin 是个更轻量级的广告屏蔽插件,几乎不遗漏所有它会屏蔽的广告。 [uBlock Origin](https://addons.mozilla.org/en-us/firefox/addon/ublock-origin/) 将主要屏蔽各种广告,特别是侵入性的广告。你能在这儿找到它。。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/ublock-origin/)。)
|
||||
|
||||
#### NoScript
|
||||
|
||||
### NoScript
|
||||
|
||||
阻止 JavaScript 是有点争议, JavaScript 虽说驱动了那么多的网站,但还是臭名昭著,因为 JavaScript 成为侵略隐私和攻击的媒介。NoScript 是应对 JavaScript 的绝佳方案。
|
||||
阻止 JavaScript 是有点争议, JavaScript 虽说支撑了那么多的网站,但还是臭名昭著,因为 JavaScript 成为侵略隐私和攻击的媒介。NoScript 是应对 JavaScript 的绝佳方案。
|
||||
|
||||

|
||||
|
||||
NoScript 是一个 JavaScript 的白名单,它通常会屏蔽 JavaScript,除非该站点被添加进白名单中。可以通过插件的“选项”菜单,事先将一个站点加入白名单,或者通过在页面上点击 NoScript 图标的方式添加。
|
||||
NoScript 是一个 JavaScript 的白名单,它会屏蔽所有 JavaScript,除非该站点被添加进白名单中。可以通过插件的“选项”菜单,事先将一个站点加入白名单,或者通过在页面上点击 NoScript 图标的方式添加。
|
||||
|
||||

|
||||
|
||||
通过火狐附加组件仓库可以安装 NoScript `https://addons.mozilla.org/en-US/firefox/addon/noscript/`
|
||||
通过火狐附加组件仓库可以安装 [NoScript](https://addons.mozilla.org/en-US/firefox/addon/noscript/)
|
||||
如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
### Disconnect
|
||||
#### Disconnect
|
||||
|
||||
Disconnect 做很多跟 Privacy Badger 一样的事情,它只是提供了另一个保护的方法。你能在附加组件仓库中找到它 `https://addons.mozilla.org/en-US/firefox/addon/disconnect/` (LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/disconnect/`)。如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
[Disconnect](https://addons.mozilla.org/en-US/firefox/addon/disconnect/) 做的事情很多跟 Privacy Badger 一样,它只是提供了另一个保护的方法。你能在附加组件仓库中找到它 (LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/disconnect/))。如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
### Random Agent Spoofer
|
||||
#### Random Agent Spoofer
|
||||
|
||||
Random Agent Spoofer 能改变火狐浏览器的签名,让浏览器看起来像是在其他任意平台上的其他任意浏览器。虽然有许多其他的应用,但是它也能预防浏览器指纹侦查。
|
||||
Random Agent Spoofer 能改变火狐浏览器的签名,让浏览器看起来像是在其他任意平台上的其他任意浏览器。虽然有许多其他的用途,但是它也能用于预防浏览器指纹侦查。
|
||||
|
||||
<ruby>浏览器指纹侦查<rt>Browser Fingerprinting</rt></ruby>是网站基于所使用的浏览器和操作系统来跟踪用户的另一个方式。相比于 Windows 用户,浏览器指纹侦查更多影响到 Linux 和其他替代性操作系统用户,因为他们的浏览器特征更独特。
|
||||
|
||||
|
||||
你能通过火狐附加插件仓库添加 Random Agent Spoofer。`https://addons.mozilla.org/en-us/firefox/addon/random-agent-spoofer/`(LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/random-agent-spoofer/`)。像其他附加组件那样,页面或许会提示它不兼容最新版的火狐。再说一次,那并不是真的。
|
||||
|
||||
你能通过火狐附加插件仓库添加 [Random Agent Spoofer](https://addons.mozilla.org/en-us/firefox/addon/random-agent-spoofer/)。(LCTT 译注:对应的[中文页面](https://addons.mozilla.org/zh-CN/firefox/addon/random-agent-spoofer/))。像其他附加组件那样,页面或许会提示它不兼容最新版的火狐。再说一次,那并不是真的。
|
||||
|
||||

|
||||
|
||||
你可以通过点击火狐菜单栏上的图标来使用 Random Agent Spoofer。点开后将会出现一个下拉菜单,有不同模拟的浏览器选项。最好的选项之一是选择"Random Desktop" 和任意的改变时间。这样,就不会有绝对的模式来跟踪,也保证了你只能获得网页的桌面版本。
|
||||
你可以通过点击火狐菜单栏上的图标来使用 Random Agent Spoofer。点开后将会出现一个下拉菜单,有不同模拟的浏览器选项。最好的选项之一是选择"Random Desktop" 和任意的切换时间。这样,就绝对没有办法来跟踪你了,也保证了你只能获得网页的桌面版本。
|
||||
|
||||
### 系统设置
|
||||
|
||||
## 系统设置
|
||||
|
||||
### 私人 DNS
|
||||
#### 私人 DNS
|
||||
|
||||
请避免使用公共或者 ISP 的 DNS 服务器!即使你配置你的浏览器满足绝对的隐私标准,你向公共 DNS 服务器发出的 DNS 请求却暴露了所有你访问过的网页。诸如谷歌公共 DNS(IP:8.8.8.8 、8.8.4.4)这类的服务将会记录你的 IP 地址、你的 ISP 和地理位置信息。这些信息或许会被任何合法程序或者强制性的政府请求所分享。
|
||||
|
||||
|
||||
> **当我在使用谷歌公共 DNS 服务时,谷歌会记录什么信息?**
|
||||
>
|
||||
> 谷歌公共 DNS 隐私页面有一个完整的收集信息列表。谷歌公共 DNS 遵循谷歌的主隐私政策,在<ruby>“隐私中心”<rt>Privacy Center</rt></ruby>可以看到。 用户的客户端 IP 地址是唯一会被临时记录的(一到两天后删除),但是为了让我们的服务更快、更好、更安全,关于 ISP 和城市/都市级别的信息将会被保存更长的时间。
|
||||
> 参考资料: `https://developers.google.com/speed/public-dns/faq#privacy`
|
||||
|
||||
由于以上原因,如果可能的话,配置并使用你私人的非转发 DNS 服务器。现在,这项任务或许跟在本地部署一些预先配置好的 DNS 服务器 Docker 容器一样简单。例如,假设 docker 服务已经在你的系统安装完成,下列命令将会部署你的私人本地 DNS 服务器:
|
||||
由于以上原因,如果可能的话,配置并使用你私人的非转发 DNS 服务器。现在,这项任务或许跟在本地部署一些预先配置好的 DNS 服务器的 Docker 容器一样简单。例如,假设 Docker 服务已经在你的系统安装完成,下列命令将会部署你的私人本地 DNS 服务器:
|
||||
|
||||
```
|
||||
# docker run -d --name bind9 -p 53:53/udp -p 53:53 fike/bind9
|
||||
@ -141,15 +135,13 @@ google.com. 242 IN A 216.58.199.46
|
||||
|
||||
现在,在 `/etc/resolv.conf` 里设置你的域名服务器:
|
||||
|
||||
|
||||
```
|
||||
|
||||
nameserver 127.0.0.1
|
||||
```
|
||||
|
||||
## 结束语
|
||||
### 结束语
|
||||
|
||||
没有完美的安全隐私解决方案。虽然本篇指导里的步骤可以明显改进它们。如果你真的很在乎隐私,Tor 浏览器 `https://www.torproject.org/projects/torbrowser.html.en` 是最佳选择。Tor 对于日常使用有点过犹不及,但是它的确使用了这篇指导里列出的一些措施。
|
||||
没有完美的安全隐私解决方案。虽然本篇指导里的步骤可以明显改进它们。如果你真的很在乎隐私,[Tor 浏览器](https://www.torproject.org/projects/torbrowser.html.en) 是最佳选择。Tor 对于日常使用有点过犹不及,但是它的确使用了这篇指导里列出的一些措施。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,34 +1,34 @@
|
||||
Windows赢了桌面,而Linux赢得整个世界
|
||||
Windows 赢了桌面,而 Linux 赢得整个世界
|
||||
============================================================
|
||||
拥有最高级的 Linux 桌面系统项目的城市正转回 Windows 阵营,但 Linux 的命运已经不再与 PC 休戚相关。
|
||||
|
||||
> 最坚决推行 Linux 桌面系统项目的城市正在转回 Windows 阵营,但 Linux 的命运已经不再与 PC 休戚相关。
|
||||
|
||||

|
||||
|
||||
> 慕尼黑的 Linux 项目只是开源软件故事中的一小部分
|
||||
> 图片: Getty Images/iStockphoto
|
||||
|
||||
在实施从 Windows 系统迁移到 Linux 系统这一项目接近十年之久, 慕尼黑却突然走上了一条戏剧性的转弯。据说是到 2021 年,地方议会就会开始用 [Windows 10][4] 替换运行 LiMux (Ubuntu 的一种自定义版本)的 PC 机。
|
||||
在实施从 Windows 系统迁移到 Linux 系统这一项目接近十年之久后,慕尼黑却突然走上了一条戏剧性的转弯。据说是到 2021 年,该城市的地方议会就会开始用 [Windows 10][4] 替换运行 LiMux (Ubuntu 的一种自定义版本)的 PC 机。
|
||||
|
||||
若是回到 15 或者 20 年前,人们可能会争论什么时候 Linux 将会在桌面上取代 Windows。例如,当 Ubuntu 于 2004 年问世时,它是带着 [终结 Windows 的抱负][5] 而被设计为标准的桌面操作系统的。
|
||||
|
||||
剧透:这一切并没有发生。
|
||||
|
||||
桌面上的 Linux 在今天占有约为 2% 的市场,很多人都认为它复杂晦涩。与此同时,Windows 则稳航无虞,在 PC 市场笑傲群雄,天下十之有九。但商业中总还有些许 Linux 桌面的身影,它仍被需要——尤其是对开发者和数据科学家而言。
|
||||
桌面上的 Linux 在今天占有约为 2% 的市场,很多人都认为它复杂晦涩。与此同时,Windows 则航行无虞,在 PC 市场笑傲群雄,天下十有其九。但在商业领域中总还有些许 Linux 桌面的身影,它仍被需要——尤其是对开发者和数据科学家而言。
|
||||
|
||||
但遗憾的是,它永远也不会成为历史的主流。
|
||||
|
||||
慕尼黑的 Linux 项目因其规模之大,引起了许多人的兴趣。几乎没有哪家大型组织会做出从 Windows 到 Linux 的迁移,一些个别的案例像 [法国宪兵队和都灵市][6] 曾有类似之举。然而,[慕尼黑作为模范][7]:在这一事件上的失败将会大大打击那些仍在 [试图用 Linux 将 Windows 取而代之的信徒们][8]。
|
||||
|
||||
但现实就是如此,绝大多数公司乐于去使用主流的桌面操作系统,因为它具有完整一致、用户友好这种优势。
|
||||
|
||||
但现实就是如此,绝大多数公司乐于去使用主流的桌面操作系统,因为它具有完整性、用户友好这种天然的优势。
|
||||
|
||||
工作人员所抱怨的问题中,有多少是归咎于 Limux 软件以及多少是操作系统无端被责备的,已经不可计数。但重要的是,无论慕尼黑最后何去何从,Linux 的命运都已经脱离了桌面——是的,Linux 在多年前就已经输掉了桌面战争。
|
||||
工作人员所抱怨的问题中,有多少是归咎于 LiMux 软件以及多少是操作系统无端被责备的,已经不可计数。但重要的是,无论慕尼黑最后何去何从,Linux 的命运都已经脱离了桌面 —— 是的,Linux 在多年前就已经输掉了桌面战争。
|
||||
|
||||
但这对 Linux 来说无伤大雅,因为它赢得了智能手机之战,并且在云端和物联网之战上也是捷报连连。
|
||||
|
||||
你的口袋里,有七八成可能装的是一个 Linux 驱动的智能手机(Android 基于 Linux 内核)。你的身边,更是有成千上万 Linux 驱动的设备,虽然这些也许你甚至都没注意到。
|
||||
|
||||
你的口袋里,七八成装的是一个 Linux 驱动的智能手机(Android 基于 Linux 内核)。你的身边,更是有成千上万 Linux 驱动的设备,虽然这些也许你甚至都没注意到。
|
||||
|
||||
[像 Raspberry Pi][9] 这样运行大量不同类型 Linux 的设备,正在创建一个充满热情和活力的开发者社区,并且提供给初创公司一种低成本的驱动新设备的方法。
|
||||
[像树莓派][9]这样运行大量不同类型 Linux 的设备,正在创建一个充满热情和活力的开发者社区,并且提供给初创公司一种低成本的驱动新设备的方法。
|
||||
|
||||
大部分公有云也是以这样或那样的形式在 Linux 上运行的;即便是微软,也已经敞开大门,拥抱开源软件。无论你站在哪一个软件平台的立场,不可否认地,开发者和用户拥有更多丰富的可选项是一件好事,对决策来说,抑或是对创新来说,都是如此。
|
||||
|
||||
@ -36,15 +36,15 @@ Windows赢了桌面,而Linux赢得整个世界
|
||||
|
||||
虽然慕尼黑传奇的曲折变换与 Linux 在桌面上的冒险耐人寻味,但它们却并未给你呈现出一个完整的故事。
|
||||
|
||||
_同意? 还是不同意? 在下面添加你的评论来加入讨论吧!_
|
||||
_同意? 还是不同意? 在下面添加你的评论来加入讨论吧!_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/windows-wins-the-desktop-but-linux-takes-the-world/
|
||||
|
||||
作者:[Steve Ranger ][a]
|
||||
作者:[Steve Ranger][a]
|
||||
译者:[Meditator-hkx](https://github.com/Meditator-hkx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,98 +1,92 @@
|
||||
LaTeXila 简介 - Linux 下一个多语言 LaTeX 编辑器
|
||||
LaTeXila 简介:Linux 上的一个多语言 LaTeX 编辑器
|
||||
============================================================
|
||||
|
||||
### 在本文中你将看到
|
||||
|
||||
1. [为何选择使用 LaTeX?][1]
|
||||
2. [创建新文档并设定文档的基本结构][2]
|
||||
3. [LaTeXila 简单易用,公式齐全][3]
|
||||
4. [将 .tex 文件转换为 .rtf 文件][4]
|
||||
5. [结论][5]
|
||||
|
||||
LaTeXila 是一个多语言 LaTeX 编辑器,专为那些偏爱 GTK+ 外观的 Linux 用户设计。这个软件简单,但有足够强大,可定制性良好,所以如果你对 LaTeX 感兴趣,那么你就应该尝试一下这个工具。在下面的快速指南中,我将展示如何使用 LaTeXila 并介绍其主要功能。但在开始之前你可能要问:
|
||||
LaTeXila 是一个多语言 LaTeX 编辑器,专为那些偏爱 GTK+ 外观的 Linux 用户设计。这个软件简单,但又足够强大,可定制性良好,所以如果你对 LaTeX 感兴趣,那么你就应该尝试一下这个工具。在下面的快速指南中,我将展示如何使用 LaTeXila 并介绍其主要功能。但在开始之前你可能要问:
|
||||
|
||||
### 为何选择使用 LaTeX?
|
||||
|
||||
假如我想创建一个文本文档,为什么我不使用 LibreOffice 或者 Abiword 这些常规的工具呢?这个问题的答案是相比于常规的文本编辑器,LaTeX 编辑器一般来说都会提供更多功能强大的格式化工具,让你在写作期间专注于文档的内容。LaTeX 是一个文档准备系统,实际上这意味着它简化了大多数常见出版物的处理过程,这些出版物包括书籍或者科学报告,它们通常都包含很多数学公式,多语言排版元素,交叉引用及引文,参考文献等等需要处理的元素。尽管上面的那些元素也可以用 LibreOffice 来处理,但如果要保证最后处理过的文档是高质量的,相比于使用 LibreOffice,使用 LaTeXila 则要相对简单一些。
|
||||
假如我想创建一个文本文档,为什么我不使用 LibreOffice 或者 Abiword 这些常规的工具呢?原因是相比于常规的文本编辑器,LaTeX 编辑器一般来说都会提供更多功能强大的格式化工具,让你在写作期间专注于文档的内容。LaTeX 是一个文档准备系统,目的是简化大多数常见出版物的处理过程,例如书籍或者科学报告,它们通常都包含很多数学公式,多语言排版元素,交叉引用及引文,参考文献等等需要处理的元素。尽管上面的那些元素也可以用 LibreOffice 来处理,使用 LaTeXila 要相对简单一些,同时处理得当的话你最后得到的会是一份高质量的文档。
|
||||
|
||||
### 在一个新文档上开始工作并设定文章结构
|
||||
|
||||
首先,我们需要在 LaTeXila 中创建一个新文件,这个可以通过点击位于左上角的 “新建文件” 图标来实现,接着它将打开一个对话框,让我们选择一个模板从而快速地开始写作。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][6]
|
||||
|
||||
在这里假设我将写一本书,所以我应该选择书籍模板,像下面的截图那样在相应的括号中添上标题和作者:
|
||||
在这里假设我将写一本书,所以我选择一个书籍模板,像下面的截图那样在相应的括号中添上标题和作者:
|
||||
|
||||
[
|
||||
|
||||
|
||||
][7]
|
||||
|
||||
现在就让我来解释一些关于文章结构的事情。我知道这看起来就像编代码,如若你是一位作家而非程序员,那么像下面那样工作或许很是奇怪,但请先容我讲完,下面我将对此进行解释。
|
||||
现在就让我来解释一些关于文章结构的事情。我知道这看起来就像编代码,如果你是一位作家而非程序员,那么像下面那样工作或许很是奇怪,但请先容我讲完,我将对此进行解释。
|
||||
|
||||
在第一行和第九行之间,我们已经写好了书写整个文档所需的所有基本要素。例如在第一行中,我们可以通过修改“[a4paper,11pt]”来定义纸张和字体的大小,在这个方括号中,我们可以添加更多的选项,选项之间以逗号来分隔。
|
||||
在第一行和第九行之间,我们已经写好了书写整个文档所需的所有基本要素。例如在第一行中,我们可以通过修改 `[a4paper,11pt]` 来定义纸张和字体的大小,在这个方括号中,我们可以添加更多的选项,选项之间以英文逗号来分隔。
|
||||
|
||||
在第二行和第四行之间,我们可以看到一些条目,它们都以“\userpackage”打头,紧接着的是用方括号包裹的选项和用括号包裹的命令。这些命令都是一些增强宏包,LaTeXila 默认已经安装它们到我们的系统上了,并且在大多数模板中都将使用它们。需要特别注意的是字体编码,字符编码和字体的类型。
|
||||
在第二行和第四行之间,我们可以看到一些条目,它们都以 `\userpackage` 打头,紧接着的是用方括号包裹的选项和用括号包裹的命令。这些命令都是一些增强宏包,LaTeXila 默认已经安装它们到我们的系统上了,并且在大多数模板中都将使用它们。需要特别注意的是字体编码,字符编码和字体的类型。
|
||||
|
||||
紧着让我们看看 "\maketitle" 这一行,这里我们可以添加一个单独的标题页,且默认情况下标题的内容将被放置在第一页的顶部。类似的,包含“\tableofcontents”的那行将会自动生成书籍的目录。
|
||||
紧接着让我们看看 `\maketitle` 这一行,这里我们可以添加一个单独的标题页,且默认情况下标题的内容将被放置在第一页的顶部。类似的,包含 `\tableofcontents` 的那行将会自动生成书籍的目录。
|
||||
|
||||
最后,我们可以自己命名章节的名称,这可以通过在“\chapter”后的括号中添加章节名称来实现。第一个章节将会被自动地标记为第一章。你可以在接下来的行中添加内容,一直到下一个以 "\chapter" 开头的新行为止,这些都将是这个章节的内容。新的章节将会被自动地标记为第二章,以此类推。
|
||||
最后,我们可以自己命名章节的名称,这可以通过在 `\chapter` 后的括号中添加章节名称来实现。第一个章节将会被自动地标记为第一章。你可以在接下来的行中添加内容,一直到下一个以 `\chapter` 开头的新行为止,这些都将是这个章节的内容。新的章节将会被自动地标记为第二章,以此类推。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][8]
|
||||
|
||||
章节之间还可以用命令“\section”来划分为更小的块,甚至还可以使用“\subsection”来划分为更小的部分。各个小节和章都将被“\tableofcontents”自动检测到,并将使用它们的标题和页码来填充目录的内容。看看下面的截图就可以看到章和小节是如何在你的书中被排版的。
|
||||
章节之间还可以用命令 `\section` 来划分为更小的块,甚至还可以使用 `\subsection` 来划分为更小的部分。各个小节和章都将被 `\tableofcontents` 自动检测到,并将使用它们的标题和页码来填充目录的内容。看看下面的截图就可以看到章和小节是如何在你的书中被排版的。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][9]
|
||||
|
||||
假如你想看看结构的大致布局,你可以将左边的工具栏更换到“结构”选项,并确保所有的内容用缩进隔开了。在工具栏中,你还可以可能控制位于各个小节中的任意数据表格和图片。
|
||||
假如你想浏览结构,你可以将左边的工具栏更换到<ruby>“结构”<rt>Structure</rt></ruby>选项,并确保所有的结构与预期相符。在这里,你还可以控制各小节中的任意数据表格和图片。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][10]
|
||||
|
||||
讲到这里,有人或许想将表格和图片的位置也包含在目录中。要达到此目的,你需要将下面的两行添加到“\tableofcontents” 之后:
|
||||
讲到这里,有人或许想将表格和图片的位置也包含在目录中。要达到此目的,你需要将下面的两行添加到 `\tableofcontents` 之后:
|
||||
|
||||
```
|
||||
\listoffigures
|
||||
\listoftables
|
||||
```
|
||||
|
||||
最后标志着书籍结束的信号是“\end{document}”。所以你的布局应该总是以此为结尾。
|
||||
最后标志着书籍结束的信号是 `\end{document}`。你的布局应该总是以此为结尾。
|
||||
|
||||
### LaTeXila 简单易用,公式齐全
|
||||
|
||||
LaTeX 是一个基于命令的文档生成系统,它与使用的编辑器没有多少关联。这里需要强调的是 LaTeXila 提供了一系列强大的工具,使得在你书写报告或书籍时能够节省一些时间和精力。例如对于 LaTex 命令,它提供了自动补全功能,这个功能将在你每次开始输入命令时被激活。
|
||||
|
||||
[
|
||||
|
||||
|
||||
][11]
|
||||
|
||||
LaTeXila 还集成有基于 gspell 的拼写检测系统,你可以在最上面的“工具”菜单中设定合适的语言。最上面的工具栏里几乎包含了你要用到的所有按钮。从左到右,你可以完成添加章节,交叉引用,调整字符的大小,格式化被选取的部分,添加无序列表和数学函数等等。这些都可以手动地输入,但通过点击相应按钮来完成或许更加方便。
|
||||
|
||||
对于生成数学公式,结合侧边栏上的工具栏选项,你只需轻轻一点就可以添加相应的数学符号。点击位于左边的侧边栏中“符号”框,你就可以看到相关的符号分类,例如”关系运算符“,”希腊字母“,”算子“等等。下面的截图就是一些符号的示例:
|
||||
对于生成数学公式,结合侧边栏上的工具栏选项,你只需轻轻一点就可以添加相应的数学符号。点击位于左边的侧边栏中<ruby>“符号”<rt>Symbols</rt></ruby>框,你就可以看到相关的符号分类,例如“关系运算符”,“希腊字母”,“运算符”等等。下面的截图就是一些符号的示例:
|
||||
|
||||
[
|
||||
|
||||
|
||||
][12]
|
||||
|
||||
这些符号的图形化列表使得公式和数学表达式的生成犹如在公园中散步那样舒适。
|
||||
|
||||
### 将 .tex 文件转换为 .rtf 文件
|
||||
|
||||
默认情况下,LaTeXila 会将你的文档保存为标准的 `.tex` 文档,而我们可以使用 `.tex` 文档来生成一个”富文本“文档,这些富文本文档可以使用像 LibreOffice 那样的文本编辑器打开。要达到此目的,我们需要安装一个名为 `latex2rtf` 的工具,它在所有的 Linux 发行版本中都可以被获取到。像下面那样在文本所在的目录打开虚拟终端, 并输入 `latex2rtf 文件名称` :
|
||||
默认情况下,LaTeXila 会将你的文档保存为标准的 `.tex` 文档,而我们可以使用 `.tex` 文档来生成一个<ruby>“富文本”<rt>rich text format</rt></ruby>文档,这些富文本文档可以使用像 LibreOffice 那样的文本编辑器打开。要达到此目的,我们需要安装一个名为 `latex2rtf` 的工具,它在所有的 Linux 发行版本中都可以被获取到。在文本所在的目录打开虚拟终端, 并输入 `latex2rtf 文件名称`,如下所示 :
|
||||
|
||||
[
|
||||
|
||||
|
||||
][13]
|
||||
|
||||
当然 LLaTeXila 也提供了它自己的构建工具,这些工具可以在上面的工具栏或者最上面的面板(构建)中看到。但我向你推荐 latex2rtf 是以防在其他的操作系统上出现某些意想不到的问题。
|
||||
当然 LaTeXila 也提供了它自己的构建工具,这些工具可以在上面的工具栏或者最上面的面板(构建)中看到。但我向你推荐 latex2rtf 是以防它们在其他的操作系统上出现某些意想不到的问题,比如在我的系统上就不能正常工作。
|
||||
|
||||
### 结论
|
||||
|
||||
假如上面的介绍激发了你探索 LaTeX 的兴趣,那就再好不过了。我写这篇文章的目的是向新手介绍一款简单易用且适合他们写作的工具。要是 LaTeXila 还带有实时预览的双屏模式的话,它就更加完美了。。。
|
||||
假如上面的介绍激发了你探索 LaTeX 的兴趣,那就再好不过了。我写这篇文章的目的是向新手介绍一款简单易用且适合他们写作的工具。要是 LaTeXila 还带有实时预览的双屏模式的话,它就更加完美了...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -100,7 +94,7 @@ via: https://www.howtoforge.com/tutorial/introduction-to-latexila-latex-editor/
|
||||
|
||||
作者:[Bill Toulas][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
85
published/201703/20170323 3 open source link shorteners.md
Normal file
85
published/201703/20170323 3 open source link shorteners.md
Normal file
@ -0,0 +1,85 @@
|
||||
3 个开源的链接缩短器
|
||||
============================================================
|
||||
|
||||
> 想要构建你自己的 URL 缩短器?这些开源项目使这个变得简单。
|
||||
|
||||

|
||||
|
||||
>图片提供: [Paul Lewin][2]。Opensource.com 修改。[CC BY-SA 2.0][3]
|
||||
|
||||
没有人喜欢一个非常长的 URL。
|
||||
|
||||
它们很难解析。但有时候,站点的深层目录结构还有最后加上的大量参数使得 URL 开始变得冗长。在 Twitter 添加自己的链接缩短服务之前的那些日子里,一个长的 URL 意味着不得不削减推文中珍贵的字符。
|
||||
|
||||
如今,因为很多原因,人们开始使用链接缩短器。这样人们可以更容易地输入或记住另一个冗长的网址。它们可以为社交媒体帐户带来一贯的品牌建设。它们使对一组网址进行分析变得更轻松。它们使得为频繁变化的网站 URL 提供统一的入口成为可能。
|
||||
|
||||
URL 缩短器确实有一些不足。在点击之前很难知道链接实际指向哪里,而且如果提供短网址服务消失,就会导致 [烂链(linkrot)][4]。但是尽管面临这些挑战,URL 缩短器不会消失。
|
||||
|
||||
但是,既然已经有这么多免费链接缩短服务,为什么还要自己构建?简而言之:方便控制。虽然有些服务可以让你选择自己的域名来使用,但得到的定制级别不同。使用自托管服务,你可以自己决定服务的运行时间、URL 的格式以及决定谁可以访问你的分析。这是你自己拥有并且可以操作的。
|
||||
|
||||
幸运的是,如果你想建立下一个 bit.ly、goo.gl 或 ow.ly,你可以有很多开源选项。你可以考虑下面几个。
|
||||
|
||||
### Lessn More
|
||||
|
||||
[Lessn More][5] 是一个个人 URL 缩短器,用 PHP 写成,并从一个名为 Buttered URL 的较旧项目 fork 而来,而 Buttered URL 又是从一个名为 Lessn 的项目的分支衍生而来。Lessn More 能提供你对 URL 缩短器所预期的大部分功能:API 和书签支持、自定义 URL 等。还有一些有用的功能,比如可以让 Lessn More 使用单词黑名单来避免不小心创建不适当的 URL、避免“看着相似”的字符来使 URL 更易读、能够选择是否使用混合大小写的字符,以及一些其它有用的功能。
|
||||
|
||||
[Lessn More][6] 在 GitHub 上以三句版 [BSD][8] 许可证公布了[源代码][7]。
|
||||
|
||||
### Polr
|
||||
|
||||
[Polr][9] 将自己描述为“现代、强大、可靠的 URL 缩短器”。它具有相当直接但现代化的界面,像我们这里详细介绍的其他选择那样,还提供了一个 API 来允许你从其他程序中使用它。在这三个可选品中,它在功能上是最轻量级的,但如果你正在寻找一个简单但功能完整的选择,那么这可能是你不错的选择。下载之前你可以查看[在线演示][10]。
|
||||
|
||||
Polr 的[源代码][11] 在 GitHub 中以 [GPLv2][12] 许可证公布。
|
||||
|
||||
### YOURLS
|
||||
|
||||
[YOURLS][13],是 “Your Own URL Shortener”(你自己的 URL 缩短器)的缩写,它是我最熟悉的选择。我在个人网站上已经运行了好几年,并且对其功能非常满意。
|
||||
|
||||
它是用 PHP 编写的,YOURLS 功能非常丰富并且可以很好地开箱即用。你可以将其配置为任何人可公开使用,或只允许某些用户使用它。它支持自定义 URL,拥有书签功能,使得共享很容易,它还具有非常强大的内置统计信息,并支持可插拔的架构,以允许其他人添加功能。它还有一个 API,可以轻松地用它创建其他程序。
|
||||
|
||||
你可以在 Github 中找到 [MIT 许可证][15]下的 YOURLS [源代码][14]。
|
||||
|
||||
* * *
|
||||
|
||||
这些选择都不喜欢么?看下互联网,你会发现还有其他几个选择:[shuri][16]、[Nimbus][17]、[Lstu][18] 等等。除了这些选择外,构建链接缩短器可以作为帮助了解新语言或 Web 框架的第一次编程项目。毕竟,它的核心功能非常简单:以 URL 作为输入,并重定向到另一个 URL。除此之外,它取决于你自己想要添加的功能。
|
||||
|
||||
你有喜欢但没有在这里列出的 URL 缩短器吗?请在评论栏中让我们知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jason Baker - Jason 热衷于使用技术使世界更加开放,从软件开发到阳光政府行动。Linux 桌面爱好者、地图/地理空间爱好者、树莓派工匠、数据分析和可视化极客、偶尔的码农、云本土主义者。在 Twitter 上关注他 @jehb。
|
||||
|
||||
------------
|
||||
|
||||
via: https://opensource.com/article/17/3/url-link-shortener
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://opensource.com/article/17/3/url-link-shortener?rate=5EGysFmjsUsxCc74bffDni4sFxxaIYiGRUG3UPznav8
|
||||
[2]:https://www.flickr.com/photos/digypho/7905320090
|
||||
[3]:https://creativecommons.org/licenses/by/2.0/
|
||||
[4]:https://en.wikipedia.org/wiki/Linkrot
|
||||
[5]:https://lessnmore.net/
|
||||
[6]:https://lessnmore.net/
|
||||
[7]:https://github.com/alanhogan/lessnmore
|
||||
[8]:https://github.com/alanhogan/lessnmore/blob/master/LICENSE.txt
|
||||
[9]:https://project.polr.me/
|
||||
[10]:http://demo.polr.me/
|
||||
[11]:https://github.com/cydrobolt/polr
|
||||
[12]:https://github.com/cydrobolt/polr/blob/master/LICENSE
|
||||
[13]:https://yourls.org/
|
||||
[14]:https://github.com/YOURLS/YOURLS
|
||||
[15]:https://github.com/YOURLS/YOURLS/blob/master/LICENSE.md
|
||||
[16]:https://github.com/pips-/shuri
|
||||
[17]:https://github.com/ethanal/nimbus
|
||||
[18]:https://github.com/ldidry/lstu
|
||||
[19]:https://opensource.com/user/19894/feed
|
||||
[20]:https://opensource.com/article/17/3/url-link-shortener#comments
|
||||
[21]:https://opensource.com/users/jason-baker
|
||||
@ -0,0 +1,53 @@
|
||||
一个可对显示器造成物理伤害的 Xfce Bug
|
||||
=======================================
|
||||
|
||||
Linux 上使用 Xfce 桌面环境或许是又快又灵活的 — 但是它目前在遭受着一个很严重的缺陷影响。
|
||||
|
||||
使用这个轻量级替代 GNOME 和 KDE 的 Xfce 桌面的用户报告说,其选用的默认壁纸会造成**笔记本电脑显示器和液晶显示器的损坏**!!!
|
||||
|
||||
有确凿的照片证据来支持此观点。
|
||||
|
||||
### Xfce Bug #12117
|
||||
|
||||
_“桌面默认开机画面造成显示器损坏!”_ 某用户在 Xfce 的 Bugzilla [Bug 提交区][1]尖叫道。
|
||||
|
||||
_“默认桌面壁纸导致我的动物去抓它,从我的液晶显示器掉落下来塑料!能让我们选择不同的壁纸吗?我不想再有划痕,谁想呢?让我们结束这老鼠游戏吧。”_ (LCTT 译注:原文是 whu not,可能想打 who not,也许因屏幕坏了太激动打错字了)
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
这缺陷(flaw) — 或者说是这爪爪(claw)? — 不是个别用户的桌面遇到问题。其他用户也重现了这个问题,尽管不太一样,在这第二个例子,是 <ruby>红迪网友<rt>Redditor</rt></ruby> 的不同图片证实的:
|
||||
|
||||

|
||||
|
||||
目前不知道这锅是 Xfce 的还是猫猫的。如果是后者就没希望修复了,就像便宜的 Android 手机商品(LCTT 译注:原文这里是用 cats 这个单词,是 catalogues 的缩写,一语双关“猫”。原文作者也是个猫奴,#TeamCat 成员)从来得不到他们的 OEM 厂商的升级。
|
||||
|
||||
值得庆幸的是 Xubuntu 用户们并没有受到这“爪爪”问题的影响。这是因为它这个基于 Xfce 的 Ubuntu 特色版带有自己的非老鼠的桌面壁纸。
|
||||
|
||||
对其他 Linux 发行版的 Xfce 用户来说,“爪爪们”显然对其桌面倒不是那么感兴趣。
|
||||
|
||||
已经有人已经提出了一个补丁修复这个问题,但是上游尚未接受。如果你们关注了 [bug #12117][1] ,就可以在你们自己的系统上手动应用这个补丁,去下载以下图片并设置成桌面壁纸。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
|
||||
作者:[JOEY SNEDDON][a]
|
||||
译者:[ddvio](https://github.com/ddvio)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://bugzilla.xfce.org/show_bug.cgi?id=12117
|
||||
[2]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[3]:http://www.omgubuntu.co.uk/category/random-2
|
||||
[4]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/02/xubuntu.jpg
|
||||
[5]:http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
[6]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/cat-xfce-bug-2.jpg
|
||||
[7]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/xfce-dog-wallpaper.jpg
|
||||
@ -0,0 +1,177 @@
|
||||
如何在 Ubuntu 以及 Debian 中安装 DHCP 服务器
|
||||
============================================================
|
||||
|
||||
**动态主机配置协议(DHCP)** 是一种用于使主机能够从服务器自动分配 IP 地址和相关的网络配置的网络协议。
|
||||
|
||||
DHCP 服务器分配给 DHCP 客户端的 IP 地址处于“租用”状态,租用时间通常取决于客户端计算机要求连接的时间或 DHCP 服务器配置的时间。
|
||||
|
||||
#### DHCP 如何工作?
|
||||
|
||||
以下是 DHCP 实际工作原理的简要说明:
|
||||
|
||||
* 一旦客户端(配置为使用 DHCP 的机器)连接到网络后,它会向 DHCP 服务器发送 **DHCPDISCOVER** 数据包。
|
||||
* 当 DHCP 服务器收到 **DHCPDISCOVER** 请求报文后会使用 **DHCPOFFER** 包进行回复。
|
||||
* 然后客户端获取到 **DHCPOFFER** 数据包,并向服务器发送一个 **DHCPREQUEST** 包,表示它已准备好接收 **DHCPOFFER** 包中提供的网络配置信息。
|
||||
* 最后,DHCP 服务器从客户端收到 **DHCPREQUEST** 报文后,发送 **DHCPACK** 报文,表示现在允许客户端使用分配给它的 IP 地址。
|
||||
|
||||
在本文中,我们将介绍如何在 Ubuntu/Debian Linux 中设置 DHCP 服务器,我们将使用 [sudo 命令][1]来运行所有命令,以获得 root 用户权限。
|
||||
|
||||
### 测试环境设置
|
||||
|
||||
在这步中我们会使用如下的测试环境。
|
||||
|
||||
- DHCP Server - Ubuntu 16.04
|
||||
- DHCP Clients - CentOS 7 and Fedora 25
|
||||
|
||||
### 步骤 1:在 Ubuntu 中安装 DHCP 服务器
|
||||
|
||||
1、 运行下面的命令来安装 DHCP 服务器包,也就是 **dhcp3-server**。
|
||||
|
||||
```
|
||||
$ sudo apt install isc-dhcp-server
|
||||
```
|
||||
|
||||
2、 安装完成后,编辑 `/etc/default/isc-dhcp-server` 使用 `INTERFACES` 选项定义 DHCPD 响应 DHCP 请求所使用的接口。
|
||||
|
||||
比如,如果你想让 DHCPD 守护进程监听 `eth0`,按如下设置:
|
||||
|
||||
```
|
||||
INTERFACES="eth0"
|
||||
```
|
||||
|
||||
同样记得为上面的接口[配置静态地址][2]。
|
||||
|
||||
### 步骤 2:在 Ubuntu 中配置 DHCP 服务器
|
||||
|
||||
3、 DHCP 配置的主文件是 `/etc/dhcp/dhcpd.conf`, 你必须填写会发送到客户端的所有网络信息。
|
||||
|
||||
并且 DHCP 配置中定义了两种不同的声明,它们是:
|
||||
|
||||
* `parameters` - 指定如何执行任务、是否执行任务,还有指定要发送给 DHCP 客户端的网络配置选项。
|
||||
* `declarations` - 定义网络拓扑、指定客户端、为客户端提供地址,或将一组参数应用于一组声明。
|
||||
|
||||
4、 现在打开并修改主文件,定义 DHCP 服务器选项:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
在文件顶部设置以下全局参数,它们将应用于下面的所有声明(请指定适用于你情况的值):
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5、 现在定义一个子网,这里我们为 `192.168.10.0/24` 局域网设置 DHCP (请使用适用你情况的参数):
|
||||
|
||||
```
|
||||
subnet 192.168.10.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.10.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.10.1;
|
||||
range 192.168.10.10 192.168.10.100;
|
||||
range 192.168.10.110 192.168.10.200;
|
||||
}
|
||||
```
|
||||
|
||||
### 步骤 3:在 DHCP 客户端上配置静态地址
|
||||
|
||||
6、 要给特定的客户机分配一个固定的(静态)的 IP,你需要显式将这台机器的 MAC 地址以及静态分配的地址添加到下面这部分。
|
||||
|
||||
```
|
||||
host centos-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.10.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.10.106;
|
||||
}
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
7、 接下来,启动 DHCP 服务,并让它下次开机自启动,如下所示:
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl start isc-dhcp-server.service
|
||||
$ sudo systemctl enable isc-dhcp-server.service
|
||||
------------ SysVinit ------------
|
||||
$ sudo service isc-dhcp-server.service start
|
||||
$ sudo service isc-dhcp-server.service enable
|
||||
```
|
||||
|
||||
8、 接下来不要忘记允许 DHCP 服务(DHCP 守护进程监听 67 UDP 端口)的防火墙权限:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 67/udp
|
||||
$ sudo ufw reload
|
||||
$ sudo ufw show
|
||||
```
|
||||
|
||||
### 步骤 4:配置 DHCP 客户端
|
||||
|
||||
9、 此时,你可以将客户端计算机配置为自动从 DHCP 服务器接收 IP 地址。
|
||||
|
||||
登录到客户端并编辑以太网接口的配置文件(注意接口名称/号码):
|
||||
|
||||
```
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
定义如下选项:
|
||||
|
||||
```
|
||||
auto eth0
|
||||
iface eth0 inet dhcp
|
||||
```
|
||||
|
||||
保存文件并退出。重启网络服务(或重启系统):
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl restart networking
|
||||
------------ SysVinit ------------
|
||||
$ sudo service networking restart
|
||||
```
|
||||
|
||||
另外你也可以使用 GUI 来在进行设置,如截图所示(在 Fedora 25 桌面中)设置将方式设为自动(DHCP)。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
*在 Fedora 中设置 DHCP 网络*
|
||||
|
||||
此时,如果所有设置完成了,你的客户端应该可以自动从 DHCP 服务器接收 IP 地址了。
|
||||
|
||||
就是这样了!在本篇教程中,我们向你展示了如何在 Ubuntu/Debian 设置 DHCP 服务器。在反馈栏中分享你的想法。如果你正在使用基于 Fedora 的发行版,请阅读如何在 CentOS/RHEL 中设置 DHCP 服务器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 和 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-ubuntu-debian/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/tag-sudo.html
|
||||
[2]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-Network-in-Fedora.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,150 @@
|
||||
在 Linux 上给用户赋予指定目录的读写权限
|
||||
============================================================
|
||||
|
||||
在上篇文章中我们向您展示了如何在 Linux 上[创建一个共享目录][3]。这次,我们会为您介绍如何将 Linux 上指定目录的读写权限赋予用户。
|
||||
|
||||
有两种方法可以实现这个目标:第一种是 [使用 ACL (访问控制列表)][4] ,第二种是[创建用户组来管理文件权限][5],下面会一一介绍。
|
||||
|
||||
为了完成这个教程,我们将使用以下设置。
|
||||
|
||||
- 操作系统:CentOS 7
|
||||
- 测试目录:`/shares/project1/reports`
|
||||
- 测试用户:tecmint
|
||||
- 文件系统类型:ext4
|
||||
|
||||
请确认所有的命令都是使用 root 用户执行的,或者使用 [sudo 命令][6] 来享受与之同样的权限。
|
||||
|
||||
让我们开始吧!下面,先使用 `mkdir` 命令来创建一个名为 `reports` 的目录。
|
||||
|
||||
```
|
||||
# mkdir -p /shares/project1/reports
|
||||
```
|
||||
|
||||
### 使用 ACL 来为用户赋予目录的读写权限
|
||||
|
||||
重要提示:打算使用此方法的话,您需要确认您的 Linux 文件系统类型(如 ext3 和 ext4, NTFS, BTRFS)支持 ACL。
|
||||
|
||||
1、 首先, 依照以下命令在您的系统中[检查当前文件系统类型][7],并且查看内核是否支持 ACL:
|
||||
|
||||
```
|
||||
# df -T | awk '{print $1,$2,$NF}' | grep "^/dev"
|
||||
# grep -i acl /boot/config*
|
||||
```
|
||||
|
||||
从下方的截屏可以看到,文件系统类型是 `ext4`,并且从 `CONFIG_EXT4_FS_POSIX_ACL=y` 选项可以发现内核是支持 **POSIX ACLs** 的。
|
||||
|
||||
[
|
||||
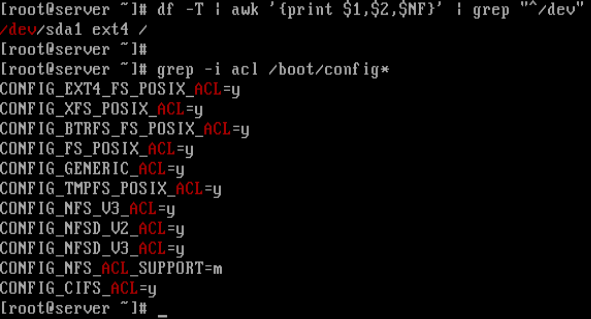
|
||||
][8]
|
||||
|
||||
*查看文件系统类型和内核的 ACL 支持。*
|
||||
|
||||
2、 接下来,查看文件系统(分区)挂载时是否使用了 ACL 选项。
|
||||
|
||||
```
|
||||
# tune2fs -l /dev/sda1 | grep acl
|
||||
```
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*查看分区是否支持 ACL*
|
||||
|
||||
通过上边的输出可以发现,默认的挂载项目中已经对 **ACL** 进行了支持。如果发现结果不如所愿,你可以通过以下命令对指定分区(此例中使用 `/dev/sda3`)开启 ACL 的支持。
|
||||
|
||||
```
|
||||
# mount -o remount,acl /
|
||||
# tune2fs -o acl /dev/sda3
|
||||
```
|
||||
|
||||
3、 现在是时候指定目录 `reports` 的读写权限分配给名为 `tecmint` 的用户了,依照以下命令执行即可。
|
||||
|
||||
```
|
||||
# getfacl /shares/project1/reports # Check the default ACL settings for the directory
|
||||
# setfacl -m user:tecmint:rw /shares/project1/reports # Give rw access to user tecmint
|
||||
# getfacl /shares/project1/reports # Check new ACL settings for the directory
|
||||
```
|
||||
[
|
||||
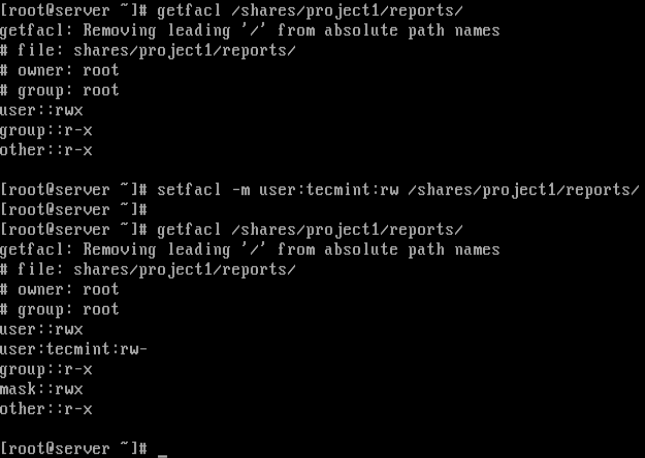
|
||||
][10]
|
||||
|
||||
*通过 ACL 对指定目录赋予读写权限*
|
||||
|
||||
在上方的截屏中,通过输出结果的第二行 `getfacl` 命令可以发现,用户 `tecmint` 已经成功的被赋予了 `/shares/project1/reports` 目录的读写权限。
|
||||
|
||||
如果想要获取 ACL 列表的更多信息。可以在下方查看我们的其他指南。
|
||||
|
||||
1. [如何使用访问控制列表(ACL)为用户/组设置磁盘配额][1]
|
||||
2. [如何使用访问控制列表(ACL)挂载网络共享][2]
|
||||
|
||||
现在我们来看看如何使用第二种方法来为目录赋予读写权限。
|
||||
|
||||
### 使用用户组来为用户赋予指定目录的读写权限
|
||||
|
||||
1、 如果用户已经拥有了默认的用户组(通常组名与用户名相同),就可以简单的通过变更文件夹的所属用户组来完成。
|
||||
|
||||
```
|
||||
# chgrp tecmint /shares/project1/reports
|
||||
```
|
||||
|
||||
另外,我们也可以通过以下方法为多个用户(需要赋予指定目录读写权限的)新建一个用户组。如此一来,也就[创建了一个共享目录][11]。
|
||||
|
||||
```
|
||||
# groupadd projects
|
||||
```
|
||||
|
||||
2、 接下来将用户 `tecmint` 添加到 `projects` 组中:
|
||||
|
||||
```
|
||||
# usermod -aG projects tecmint # add user to projects
|
||||
# groups tecmint # check users groups
|
||||
```
|
||||
|
||||
3、 将目录的所属用户组变更为 projects:
|
||||
|
||||
```
|
||||
# chgrp projects /shares/project1/reports
|
||||
```
|
||||
|
||||
4、 现在,给组成员设置读写权限。
|
||||
|
||||
```
|
||||
# chmod -R 0760 /shares/projects/reports
|
||||
# ls -l /shares/projects/ #check new permissions
|
||||
```
|
||||
|
||||
|
||||
好了!这篇教程中,我们向您展示了如何在 Linux 中将指定目录的读写权限赋予用户。若有疑问,请在留言区中提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,未来的 Linux 系统管理员和网络开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/give-read-write-access-to-directory-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[Mr-Ping](http://www.mr-ping.com)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/set-access-control-lists-acls-and-disk-quotas-for-users-groups/
|
||||
[2]:http://www.tecmint.com/rhcsa-exam-configure-acls-and-mount-nfs-samba-shares/
|
||||
[3]:https://linux.cn/article-8187-1.html
|
||||
[4]:http://www.tecmint.com/secure-files-using-acls-in-linux/
|
||||
[5]:http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
[6]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[7]:http://www.tecmint.com/find-linux-filesystem-type/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Filesystem-Type-and-Kernel-ACL-Support.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Partition-ACL-Support.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Give-Read-Write-Access-to-Directory-Using-ACL.png
|
||||
[11]:http://www.tecmint.com/create-a-shared-directory-in-linux/
|
||||
[12]:http://www.tecmint.com/author/aaronkili/
|
||||
[13]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[14]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,338 @@
|
||||
Samba 系列(八):使用 Samba 和 Winbind 将 Ubuntu 16.04 添加到 AD 域
|
||||
============================================================
|
||||
|
||||
这篇文章讲述了如何将 Ubuntu 主机加入到 Samba4 AD 域,并实现使用域帐号登录 Ubuntu 系统。
|
||||
|
||||
### 要求:
|
||||
|
||||
1. [在 Ubuntu 系统上使用 Samba4 软件来创建活动目录架构][1]
|
||||
|
||||
### 第一步: Ubuntu 系统加入到 Samba4 AD 之前的基本配置
|
||||
|
||||
1、在将 Ubuntu 主机加入到 AD DC 之前,你得先确保 Ubuntu 系统中的一些服务配置正常。
|
||||
|
||||
主机名是你的机器的一个重要标识。因此,在加入域前,使用 `hostnamectl` 命令或者通过手动编辑 `/etc/hostname` 文件来为 Ubuntu 主机设置一个合适的主机名。
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_machine_short_name
|
||||
# cat /etc/hostname
|
||||
# hostnamectl
|
||||
```
|
||||
[
|
||||
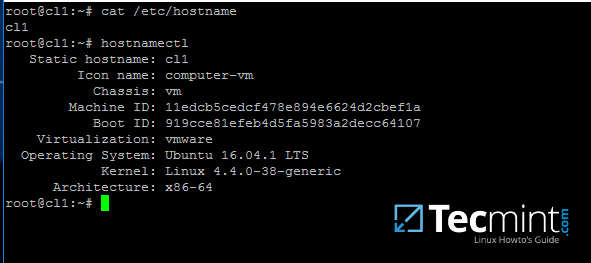
|
||||
][2]
|
||||
|
||||
*设置系统主机名*
|
||||
|
||||
2、在这一步中,打开并编辑网卡配置文件,为你的主机设置一个合适的 IP 地址。注意把 DNS 地址设置为你的域控制器的地址。
|
||||
|
||||
编辑 `/etc/network/interfaces` 文件,添加 `dns-nameservers` 参数,并设置为 AD 服务器的 IP 地址;添加 `dns-search` 参数,其值为域控制器的主机名,如下图所示。
|
||||
|
||||
并且,把上面设置的 DNS IP 地址和域名添加到 `/etc/resolv.conf` 配置文件中,如下图所示:
|
||||
|
||||
[
|
||||
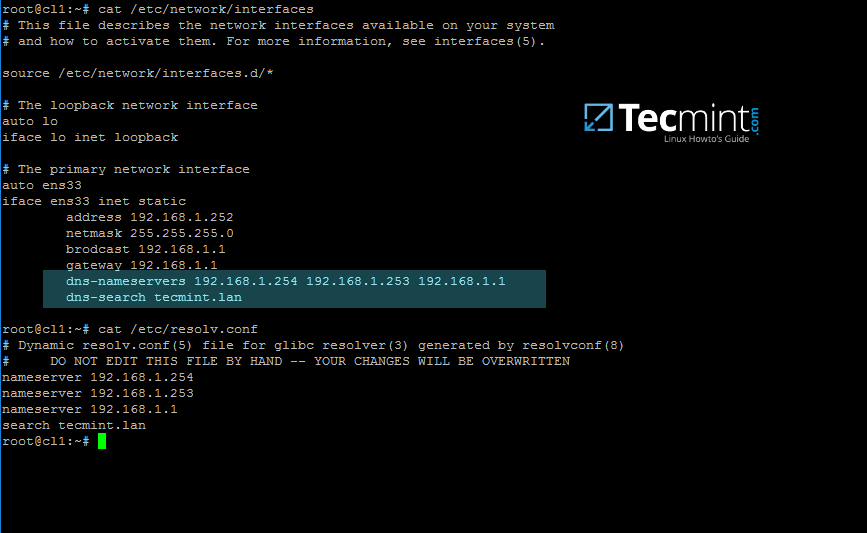
|
||||
][3]
|
||||
|
||||
*为 AD 配置网络设置*
|
||||
|
||||
在上面的截图中, `192.168.1.254` 和 `192.168.1.253` 是 Samba4 AD DC 服务器的 IP 地址, `Tecmint.lan` 是 AD 域名,已加入到这个域中的所有机器都可以查询到该域名。
|
||||
|
||||
3、重启网卡服务或者重启计算机以使网卡配置生效。使用 ping 命令加上域名来检测 DNS 解析是否正常。
|
||||
|
||||
AD DC 应该返回的是 FQDN 。如果你的网络中配置了 DHCP 服务器来为局域网中的计算机自动分配 IP 地址,请确保你已经把 AD DC 服务器的 IP 地址添加到 DHCP 服务器的 DNS 配置中。
|
||||
|
||||
```
|
||||
# systemctl restart networking.service
|
||||
# ping -c2 your_domain_name
|
||||
```
|
||||
|
||||
4、最后一步是配置服务器时间同步。安装 `ntpdate` 包,使用下面的命令来查询并同步 AD DC 服务器的时间。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ntpdate
|
||||
$ sudo ntpdate -q your_domain_name
|
||||
$ sudo ntpdate your_domain_name
|
||||
```
|
||||
[
|
||||
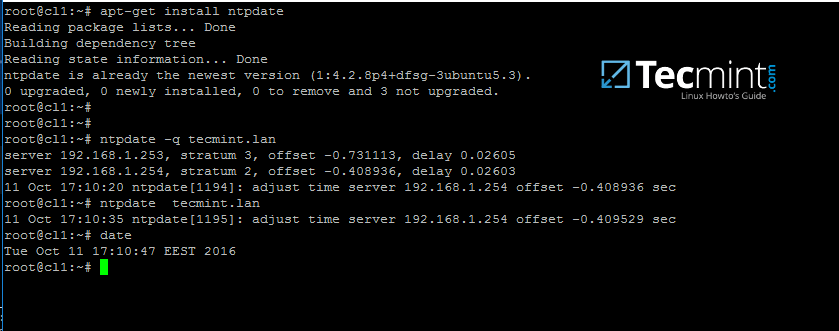
|
||||
][4]
|
||||
|
||||
*AD 服务器时间同步*
|
||||
|
||||
5、下一步,在 Ubuntu 机器上执行下面的命令来安装加入域环境所必需软件。
|
||||
|
||||
```
|
||||
$ sudo apt-get install samba krb5-config krb5-user winbind libpam-winbind libnss-winbind
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
*在 Ubuntu 机器上安装 Samba4 软件*
|
||||
|
||||
在 Kerberos 软件包安装的过程中,你会被询问输入默认的域名。输入大写的域名,并按 Enter 键继续安装。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
*添加 AD 域名*
|
||||
|
||||
6、当所有的软件包安装完成之后,使用域管理员帐号来测试 Kerberos 认证,然后执行下面的命令来列出票据信息。
|
||||
|
||||
```
|
||||
# kinit ad_admin_user
|
||||
# klist
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*使用 AD 来检查 Kerberos 认证是否正常*
|
||||
|
||||
### 第二步:将 Ubuntu 主机添加到 Samba4 AD DC
|
||||
|
||||
7、将 Ubuntu 主机添加到 Samba4 活动目录域环境中的第一步是编辑 Samba 配置文件。
|
||||
|
||||
备份 Samba 的默认配置文件,这个配置文件是安装 Samba 软件的过程中自动生成的,使用下面的命令来重新初始化配置文件。
|
||||
|
||||
```
|
||||
# mv /etc/samba/smb.conf /etc/samba/smb.conf.initial
|
||||
# nano /etc/samba/smb.conf
|
||||
```
|
||||
|
||||
在新的 Samba 配置文件中添加以下内容:
|
||||
|
||||
```
|
||||
[global]
|
||||
workgroup = TECMINT
|
||||
realm = TECMINT.LAN
|
||||
netbios name = ubuntu
|
||||
security = ADS
|
||||
dns forwarder = 192.168.1.1
|
||||
idmap config * : backend = tdb
|
||||
idmap config *:range = 50000-1000000
|
||||
template homedir = /home/%D/%U
|
||||
template shell = /bin/bash
|
||||
winbind use default domain = true
|
||||
winbind offline logon = false
|
||||
winbind nss info = rfc2307
|
||||
winbind enum users = yes
|
||||
winbind enum groups = yes
|
||||
vfs objects = acl_xattr
|
||||
map acl inherit = Yes
|
||||
store dos attributes = Yes
|
||||
```
|
||||
[
|
||||
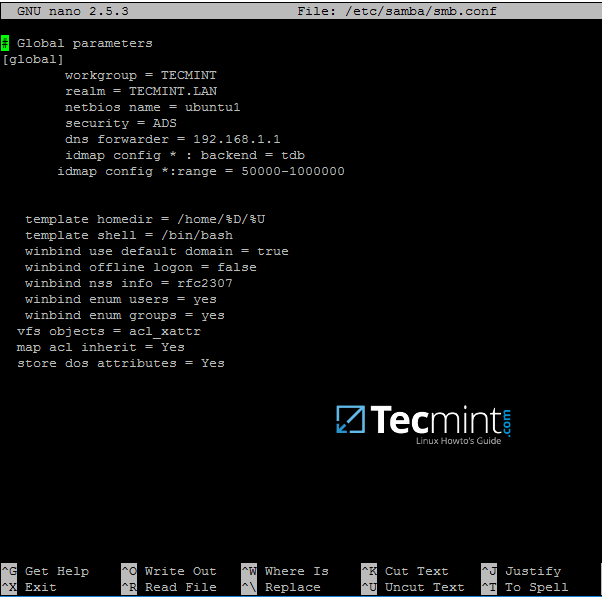
|
||||
][8]
|
||||
|
||||
*Samba 服务的 AD 环境配置*
|
||||
|
||||
根据你本地的实际情况来替换 `workgroup` , `realm` , `netbios name` 和 `dns forwarder` 的参数值。
|
||||
|
||||
由于 `winbind use default domain` 这个参数会让 winbind 服务把任何登录系统的帐号都当作 AD 帐号。因此,如果存在本地帐号名跟域帐号同名的情况下,请不要设置该参数。
|
||||
|
||||
8、现在,你应该重启 Samba 后台服务,停止并卸载一些不必要的服务,然后启用 samba 服务的 system-wide 功能,使用下面的命令来完成。
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl restart smbd nmbd winbind
|
||||
$ sudo systemctl stop samba-ad-dc
|
||||
$ sudo systemctl enable smbd nmbd winbind
|
||||
```
|
||||
|
||||
9、通过下面的命令,使用域管理员帐号来把 Ubuntu 主机加入到 Samba4 AD DC 中。
|
||||
|
||||
```
|
||||
$ sudo net ads join -U ad_admin_user
|
||||
```
|
||||
[
|
||||
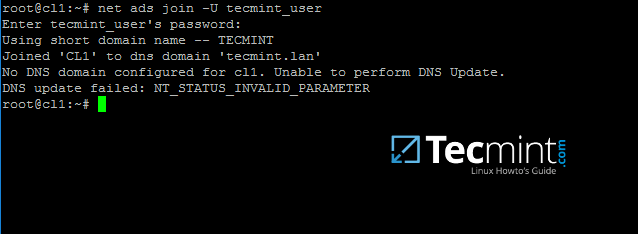
|
||||
][9]
|
||||
|
||||
*把 Ubuntu 主机加入到 Samba4 AD DC*
|
||||
|
||||
10、在 [安装了 RSAT 工具的 Windows 机器上][10] 打开 AD UC ,展开到包含的计算机。你可以看到已加入域的 Ubuntu 计算机。
|
||||
|
||||
[
|
||||
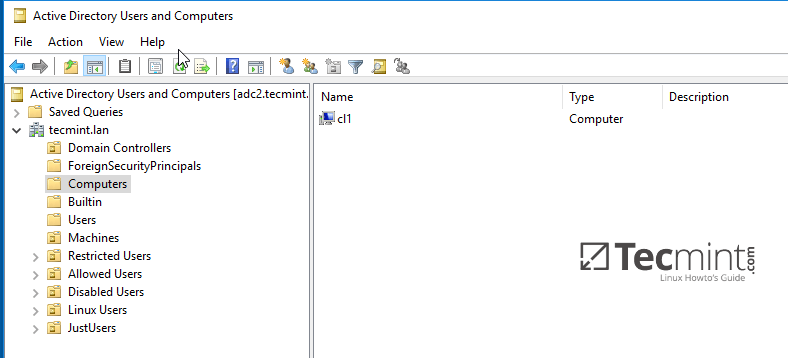
|
||||
][11]
|
||||
|
||||
*确认 Ubuntu 计算机已加入到 Windows AD DC*
|
||||
|
||||
### 第三步:配置 AD 帐号认证
|
||||
|
||||
11、为了在本地完成 AD 帐号认证,你需要修改本地机器上的一些服务和配置文件。
|
||||
|
||||
首先,打开并编辑名字服务切换 (NSS) 配置文件。
|
||||
|
||||
```
|
||||
$ sudo nano /etc/nsswitch.conf
|
||||
```
|
||||
|
||||
然后在 `passwd` 和 `group` 行添加 winbind 值,如下图所示:
|
||||
|
||||
```
|
||||
passwd: compat winbind
|
||||
group: compat winbind
|
||||
```
|
||||
[
|
||||
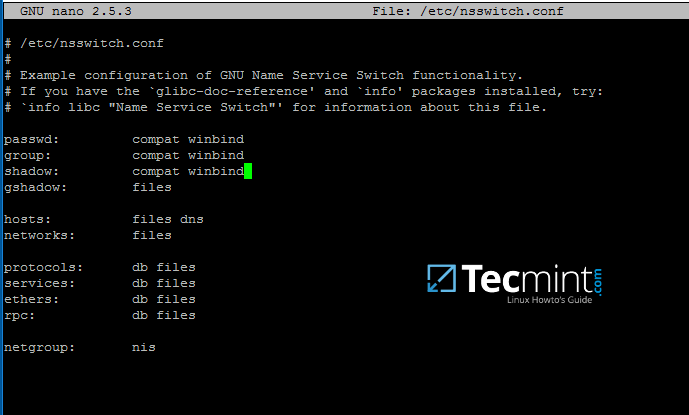
|
||||
][12]
|
||||
|
||||
*配置 AD 帐号认证*
|
||||
|
||||
12、为了测试 Ubuntu 机器是否已加入到域中,你可以使用 `wbinfo` 命令来列出域帐号和组。
|
||||
|
||||
```
|
||||
$ wbinfo -u
|
||||
$ wbinfo -g
|
||||
```
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
*列出域帐号和组*
|
||||
|
||||
13、同时,使用 `getent` 命令加上管道符及 `grep` 参数来过滤指定域用户或组,以测试 Winbind nsswitch 模块是否运行正常。
|
||||
|
||||
```
|
||||
$ sudo getent passwd| grep your_domain_user
|
||||
$ sudo getent group|grep 'domain admins'
|
||||
```
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
*检查 AD 域用户和组*
|
||||
|
||||
14、为了让域帐号在 Ubuntu 机器上完成认证登录,你需要使用 root 帐号运行 `pam-auth-update` 命令,然后勾选 winbind 服务所需的选项,以让每个域帐号首次登录时自动创建 home 目录。
|
||||
|
||||
查看所有的选项,按 ‘[空格]’键选中,单击 OK 以应用更改。
|
||||
|
||||
```
|
||||
$ sudo pam-auth-update
|
||||
```
|
||||
[
|
||||
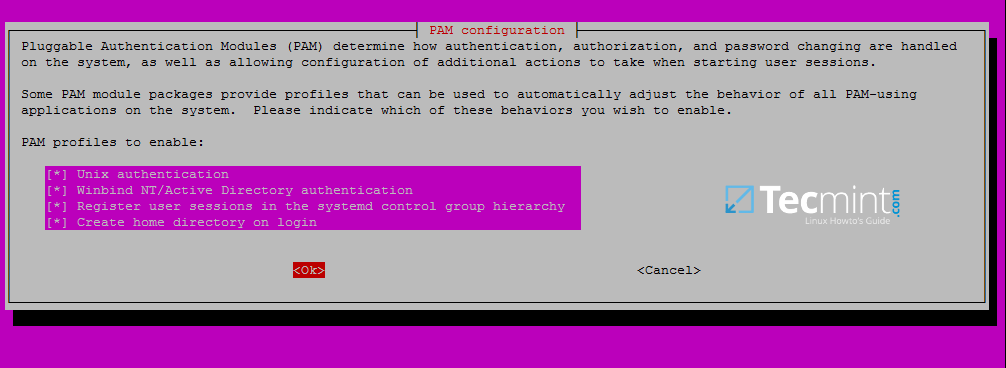
|
||||
][15]
|
||||
|
||||
*使用域帐号登录 Ubuntu 主机*
|
||||
|
||||
15、在 Debian 系统中,如果想让系统自动为登录的域帐号创建家目录,你需要手动编辑 `/etc/pam.d/common-account` 配置文件,并添加下面的内容。
|
||||
|
||||
```
|
||||
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022
|
||||
```
|
||||
[
|
||||
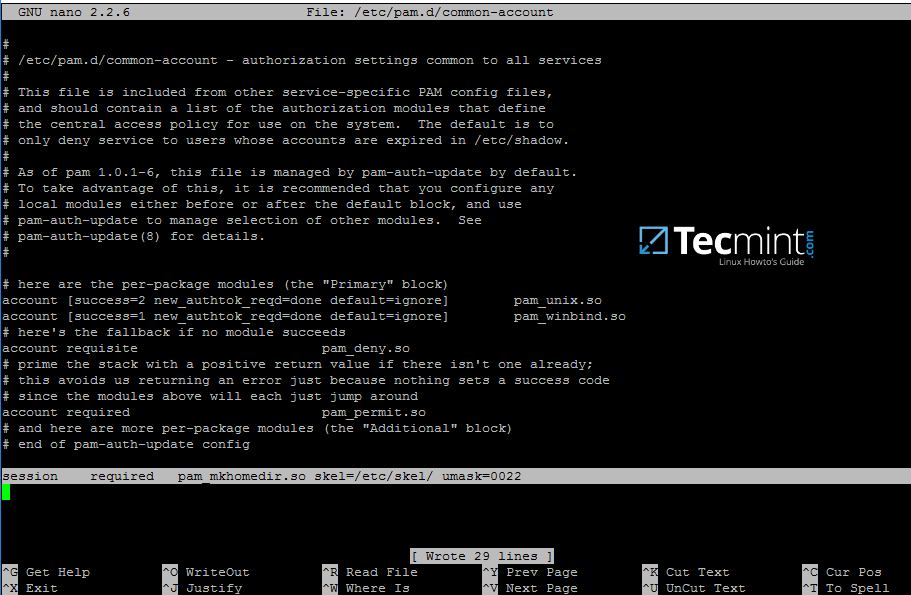
|
||||
][16]
|
||||
|
||||
*使用域帐号登录 Debian 系统*
|
||||
|
||||
16、为了让 AD 用户能够在 Linux 的命令行下修改密码,你需要打开 /etc/pam.d/common-password 配置文件,在 `password` 那一行删除 `use_authtok` 参数,如下图所示:
|
||||
|
||||
```
|
||||
password [success=1 default=ignore] pam_winbind.so try_first_pass
|
||||
```
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
*允许域帐号在 Linux 命令行下修改密码*
|
||||
|
||||
17、要使用 Samba4 AD 帐号来登录 Ubuntu 主机,在 `su -` 后面加上域用户名即可。你还可以通过运行 `id` 命令来查看 AD 帐号的其它信息。
|
||||
|
||||
```
|
||||
$ su - your_ad_user
|
||||
```
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
*查看 AD 用户信息*
|
||||
|
||||
使用 [pwd 命令][19]来查看域帐号的当前目录,如果你想修改域帐号的密码,你可以使用 `passwd` 命令来完成。
|
||||
|
||||
18、如果想让域帐号在 ubuntu 机器上拥有 root 权限,你可以使用下面的命令来把 AD 帐号添加到 sudo 系统组中:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG sudo your_domain_user
|
||||
```
|
||||
|
||||
登录域帐号登录到 Ubuntu 主机,然后运行 `apt-get-update` 命令来更新系统,以验证域账号是否拥有 root 权限。
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
*给域帐号添加 root 权限*
|
||||
|
||||
19、要为整个域用户组添加 root 权限,使用 `vi` 命令打开并编辑 `/etc/sudoers` 配置文件,如下图所示,添加如下内容:
|
||||
|
||||
```
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL
|
||||
```
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
*为域帐号组添加 root 权限*
|
||||
|
||||
使用反斜杠来转义域用户组的名称中包含的空格,或者用来转义第一个反斜杠。在上面的例子中, TECMINT 域的域用户组的名字是 “domain admins" 。
|
||||
|
||||
前边的 `%` 表明我们指定是的用户组而不是用户名。
|
||||
|
||||
20、如果你使用的是图形界面的 Ubuntu 系统,并且你想使用域帐号来登录系统,你需要修改 LightDM 显示管理器,编辑 `/usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf` 配置文件,添加下面的内容,然后重启系统才能生效。
|
||||
|
||||
```
|
||||
greeter-show-manual-login=true
|
||||
greeter-hide-users=true
|
||||
```
|
||||
|
||||
现在你就可以域帐号来登录 Ubuntu 桌面系统了。使用域用户名或者域用户名@域名.tld 或者域名\域用户名的方式来登录系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一个电脑迷,开源 Linux 系统和软件爱好者,有 4 年多的 Linux 桌面、服务器系统使用和 Base 编程经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/join-ubuntu-to-active-directory-domain-member-samba-winbind/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Ubuntu-System-Hostname.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Network-Settings-for-AD.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Time-Synchronization-with-AD.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Install-Samba4-in-Ubuntu-Client.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-AD-Domain-Name.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Kerberos-Authentication-with-AD.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Samba.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Join-Ubuntu-to-Samba4-AD-DC.png
|
||||
[10]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Confirm-Ubuntu-Client-in-RSAT-.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-AD-Accounts-Authentication.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/List-AD-Domain-Accounts-and-Groups.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-AD-Domain-Users-and-Groups.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Ubuntu-with-Domain-Accounts.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Debian-with-Domain-Accounts.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/AD-Domain-Users-Change-Password.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-AD-User-Information.png
|
||||
[19]:http://www.tecmint.com/pwd-command-examples/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-Sudo-User-Root-Group.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-Root-Privileges-to-Domain-Group.jpg
|
||||
[22]:http://www.tecmint.com/author/cezarmatei/
|
||||
[23]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[24]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,123 @@
|
||||
如何通过 OpenELEC 创建你自己的媒体中心
|
||||
======
|
||||
|
||||

|
||||
|
||||
你是否曾经想要创建你自己的家庭影院系统?如果是的话,这里有一个为你准备的指南!在本篇文章中,我们将会介绍如何设置一个由 OpenELEC 以及 Kodi 驱动的家庭娱乐系统。我们将会介绍如何制作安装介质,哪些设备可以运行该软件,如何安装它,以及其他一切需要知道的事情等等。
|
||||
|
||||
### 选择一个设备
|
||||
|
||||
在开始设定媒体中心的软件前,你需要选择一个设备。OpenELEC 支持一系列设备。从一般的桌面设备到树莓派 2/3 等等。选择好设备以后,考虑一下你怎么访问 OpenELEC 系统中的媒体并让其就绪。
|
||||
|
||||
**注意: **OpenELEC 基于 Kodi,有许多方式加载一个可播放的媒体(比如 Samba 网络分享,外设,等等)。
|
||||
|
||||
### 制作安装磁盘
|
||||
|
||||
OpenELEC 安装磁盘需要一个 USB 存储器,且其至少有 1GB 的容量。这是安装该软件的唯一方式,因为开发者没有发布 ISO 文件。取而代之的是需要创建一个 IMG 原始文件。选择与你设备相关的链接并且[下载][10]原始磁盘镜像。当磁盘镜像下载完毕,打开一个终端,并且使用命令将数据从压缩包中解压出来。
|
||||
|
||||
**在Linux/macOS上**
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
gunzip -d OpenELEC*.img.gz
|
||||
```
|
||||
|
||||
**在Windows上**
|
||||
|
||||
下载 [7zip][11],安装它,然后解压压缩文件。
|
||||
|
||||
当原始的 .IMG 文件被解压后,下载 [Etcher USB creation tool][12],并且依据在界面上的指示来安装它并创建 USB 磁盘。
|
||||
|
||||
**注意:** 对于树莓派用户,Etcher 也支持将文件写入到 SD 卡中。
|
||||
|
||||
### 安装 OpenELEC
|
||||
|
||||
OpenELEC 安装进程可能是安装流程最简单的操作系统之一了。将 USB 设备加入,然后配置设备使其以 USB 方式启动。同样,这个过程也可以通过按 DEL 或者 F2 来替代。然而并不是所有的 BIOS 都是一样的,所以最好的方式就是看看手册什么的。
|
||||
|
||||

|
||||
|
||||
一旦进入 BIOS,修改设置使其从 USB 磁盘中直接加载。这将会允许电脑从 USB 磁盘中启动,这将会使你进入到 Syslinux 引导屏幕。在提示符中,键入 `installer`,然后按下回车键。
|
||||
|
||||

|
||||
|
||||
默认情况下,快速安装选项已经是选中的。按回车键来开始安装。这将会使安装器跳转到磁盘选择界面。选择 OpenELEC 要被安装到的地方,然后按下回车键来开始安装过程。
|
||||
|
||||

|
||||
|
||||
一旦完成安装,重启系统并加载 OpenELEC。
|
||||
|
||||
### 配置 OpenELEC
|
||||
|
||||

|
||||
|
||||
在第一次启动时,用户必须配置一些东西。如果你的媒体中心拥有一个无线网卡,OpenELEC 将会提示用户将其连接到一个热点上。选择一个列表中的网络并且输入密码。
|
||||
|
||||

|
||||
|
||||
在下一步“<ruby>欢迎来到 OpenELEC<rt>Welcome to OpenELEC</rt></ruby>”屏上,用户必须配置不同的分享设置(SSH 以及 Samba)。建议你把这些设置开启,因为可以用命令行访问,这将会使得远程传输媒体文件变得很简单。
|
||||
|
||||
### 增加媒体
|
||||
|
||||
在 OpenELEC(Kodi)中增加媒体,首先选择你希望添加的媒体到的部分。以同样的流程,为照片、音乐等添加媒体。在这个指南中,我们将着重讲解添加视频。
|
||||
|
||||

|
||||
|
||||
点击在主页的“<ruby>视频<rt>Video</rt></ruby>”选项来进入视频页面。选择“<ruby>文件<rt>Files</rt></ruby>”选项,在下一个页面点击“<ruby>添加视频...<rt>Add videos…</rt></ruby>”,这将会使得用户进入Kodi 的添加媒体页面。在这个页面,你可以随意的添加媒体源了(包括内部和外部的)。
|
||||
|
||||

|
||||
|
||||
OpenELEC 会自动挂载外部的设备(像是 USB,DVD 碟片,等等),并且它可以通过浏览文件挂载点来挂载。一般情况下,这些设备都会被放在“/run”下,或者,返回你点击“<ruby>添加视频...<rt>Add videos…</rt></ruby>”的页面,在那里选择设备。任何外部设备,包括 DVD/CD,将会直接展示在那里,并可以直接访问。这是一个很好的选择——对于那些不懂如何找到挂载点的用户。
|
||||
|
||||

|
||||
|
||||
现在这个设备在 Kodi 中被选中了,界面将会询问用户去浏览设备上私人文件夹,里面有私人文件——这一切都是在媒体中心文件浏览器工具下执行的。一旦找到了放置文件的文件夹,添加它,给予文件夹一个名字,然后按下 OK 按钮来保存它。
|
||||
|
||||

|
||||
|
||||
当一个用户浏览“<ruby>视频<rt>Videos</rt></ruby>”,他们将会看到可以点击的文件夹,这个文件夹中带有从外部设备添加的媒体。这些文件夹可以很容易地在系统上播放。
|
||||
|
||||
### 使用 OpenELec
|
||||
|
||||
当用户登录他们将会看见一个“主界面”,这个主界面有许多部分,用户可以点击它们并且进入,包括:图片,视频,音乐,程序等等。当悬停在这些部分的时候,子部分就会出现。例如,当悬停在“图片”上时,子部分”文件“以及”插件”就会出现。
|
||||
|
||||

|
||||
|
||||
如果一个用户点击了一个部分中的子部分,例如“插件”,Kodi 插件选择就会出现。这个安装器将会允许用户浏览新的插件内容,来安装到这个子部分(像是图片关联插件,等等)或者启动一个已经存在的图片关联插件,当然,这个插件应该已经安装到系统上了。
|
||||
|
||||
此外,点击任何部分的文件子部分(例如视频)将会直接给显示用户该部分可用的文件。
|
||||
|
||||
### 系统设置
|
||||
|
||||

|
||||
|
||||
Kodi 有丰富的设置区域。为了找到这些设置,使鼠标在右方悬停,目录选择器将会滚动右方并且显示”<ruby>系统<rt>System</rt></ruby>“。点击来打开全局系统设定区。
|
||||
|
||||
用户可以修改任何设置,从安装 Kodi 仓库的插件,到激活各种服务,到改变主题,甚至天气。如果想要退出设定区域并且返回主页面,点击右下方角落中的“home”图标。
|
||||
|
||||
### 结论
|
||||
|
||||
通过 OpenELEC 的安装和配置,你现在可以随意体验使用你自己的 Linux 支持的家庭影院系统。在所有的家庭影院系统 Linux 发行版中,这个是最用户友好的。请记住,尽管这个系统是以“OpenELEC”为名,但它运行着的是 Kodi ,并兼容任何 Kodi 的插件,工具以及程序。
|
||||
|
||||
------
|
||||
|
||||
via: https://www.maketecheasier.com/build-media-center-with-openelec/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[svtter](https://github.com/svtter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]: https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]: https://www.maketecheasier.com/build-media-center-with-openelec/#comments
|
||||
[3]: https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]: http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[5]: http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F&text=How+to+Build+Your+Own+Media+Center+with+OpenELEC
|
||||
[6]: mailto:?subject=How%20to%20Build%20Your%20Own%20Media%20Center%20with%20OpenELEC&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[7]: https://www.maketecheasier.com/permanently-disable-windows-defender-windows-10/
|
||||
[8]: https://www.maketecheasier.com/repair-mac-hard-disk-with-fsck/
|
||||
[9]: https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]: http://openelec.tv/get-openelec/category/1-openelec-stable-releases
|
||||
[11]: http://www.7-zip.org/
|
||||
[12]: https://etcher.io/
|
||||
@ -0,0 +1,164 @@
|
||||
使用 Cockpit 方便地管理容器
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> 如果你正在寻找一种管理运行容器的 Linux 服务器的简单方法,那么你应该看看 Cockpit。
|
||||
|
||||
如果你管理着一台 Linux 服务器,那么你可能正在寻找一个可靠的管理工具。为了这个你可能已经看了 [Webmin][14] 和 [cPanel][15] 这类软件。但是,如果你正在寻找一种简单的方法来管理还包括了 Docker 的 Linux 服务器,那么有一个工具可以用于这个需求:[Cockpit][16]。
|
||||
|
||||
为什么使用 Cockpit?因为它可以处理这些管理任务:
|
||||
|
||||
* 连接并管理多台机器
|
||||
* 通过 Docker 管理容器
|
||||
* 与 Kubernetes 或 Openshift 集群进行交互
|
||||
* 修改网络设置
|
||||
* 管理用户帐号
|
||||
* 通过基于 Web 的 shell 访问
|
||||
* 通过图表查看系统性能信息
|
||||
* 查看系统服务和日志文件
|
||||
|
||||
Cockpit 可以安装在 [Debian][17]、[Red Hat][18]、[CentOS][19]、[Arch Linux][20] 和 [Ubuntu][21] 之上。在这里,我将使用一台已经安装了 Docker 的 Ubuntu 16.04 服务器来安装系统。
|
||||
|
||||
在上面的功能列表中,其中最突出的是容器管理。为什么?因为它使安装和管理容器变得非常简单。事实上,你可能很难找到更好的容器管理解决方案。
|
||||
|
||||
因此,让我们来安装这个方案并看看它的使用是多么简单。
|
||||
|
||||
### 安装
|
||||
|
||||
正如我前面提到的,我将在一台运行着 Docker 的 Ubuntu 16.04 实例上安装 Cockpit。安装步骤很简单。你要做的第一件事是登录你的 Ubuntu 服务器。接下来,你必须使用下面的命令添加必要的仓库:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:cockpit-project/cockpit
|
||||
```
|
||||
|
||||
出现提示时,按下键盘上的回车键,等待提示返回。一旦返回到 bash 提示符,使用下面的命令来更新 apt:
|
||||
|
||||
```
|
||||
sudo apt-get get update
|
||||
```
|
||||
|
||||
使用下面的命令安装 Cockpit:
|
||||
|
||||
```
|
||||
sudo apt-get -y install cockpit cockpit-docker
|
||||
```
|
||||
|
||||
安装完成后,需要启动 Cockpit 服务并使它开机自动启动。要做到这个,使用下面的两个命令:
|
||||
|
||||
```
|
||||
sudo systemctl start cockpit
|
||||
sudo systemctl enable cockpit
|
||||
```
|
||||
|
||||
安装就到这里了。
|
||||
|
||||
### 登录到 Cockpit
|
||||
|
||||
要访问 Cockpit 的 web 界面,打开浏览器(与 Cockpit 服务器在同一个网络内),输入 `http://IP_OF_SERVER:9090`,你就会看到登录页面(图 1)。
|
||||
|
||||

|
||||
|
||||
*图 1:Cockpit 登录页面。*
|
||||
|
||||
在 Ubuntu 中使用 Cockpit 有个警告。Cockpit 中的很多任务需要管理员权限。如果你使用普通用户登录,则无法使用 Docker 等一些工具。 要解决这个问题,你可以在 Ubuntu 上启用 root 用户。但这并不总是一个好主意。通过启用 root 帐户,你将绕过已经建立多年的安全系统。但是,在本文的用途中,我将使用以下两个命令启用 root 用户:
|
||||
|
||||
```
|
||||
sudo passwd root
|
||||
sudo passwd -u root
|
||||
```
|
||||
|
||||
注意,请确保给 root 帐户一个强壮的密码。
|
||||
|
||||
你想恢复这个修改的话,你只需输入下面的命令:
|
||||
|
||||
```
|
||||
sudo passwd -l root
|
||||
```
|
||||
|
||||
在其他发行版(如 CentOS 和 Red Hat)中,你可以使用用户名 `root` 及其密码登录 Cockpit,而无需像上面那样需要额外的步骤。
|
||||
|
||||
如果你对启用 root 用户感到担心,则可以在服务器的终端窗口拉取镜像(使用命令 `docker pull IMAGE_NAME`, 这里的 `IMAGE_NAME` 是你要拉取的镜像)。这会将镜像添加到你的 docker 服务器中,然后可以通过普通用户进行管理。唯一需要注意的是,普通用户必须使用以下命令将自己添加到 Docker 组:
|
||||
|
||||
```
|
||||
sudo usermod -aG docker USER
|
||||
```
|
||||
|
||||
其中,`USER` 是实际添加到组的用户名。在你完成后,重新登出并登入,接着使用下面的命令重启 Docker:
|
||||
|
||||
```
|
||||
sudo service docker restart
|
||||
```
|
||||
|
||||
现在常规用户可以启动并停止 Docker 镜像/容器而无需启用 root 用户了。唯一一点是用户不能通过 Cockpit 界面添加新的镜像。
|
||||
|
||||
### 使用 Cockpit
|
||||
|
||||
一旦你登录后,你可以看到 Cockpit 的主界面(图 2)。
|
||||
|
||||

|
||||
|
||||
*图 2:Cockpit 主界面。*
|
||||
|
||||
你可以通过每个栏目来检查服务器的状态等,但是我们想要直接进入容器。单击 “Containers” 那栏以显示当前运行的以及可用的镜像(图3)。
|
||||
|
||||

|
||||
|
||||
*图 3:使用 Cockpit 管理容器难以置信地简单。*
|
||||
|
||||
要启动一个镜像,只要找到镜像并点击关联的启动按钮。在弹出的窗口中(图 4),你可以在点击运行之前查看所有镜像的信息(并根据需要调整)。
|
||||
|
||||

|
||||
|
||||
*图 4: 使用 Cockpit 运行 Docker 镜像。*
|
||||
|
||||
镜像运行后,你可以点击它查看状态,并可以停止、重启、删除实例。你也可以点击修改资源限制并接着调整内存限制还有(或者)CPU 优先级。
|
||||
|
||||
### 添加新的镜像
|
||||
|
||||
假设你以 root 用户身份登录。如果是这样,那么你可以在 Cockpit GUI 的帮助下添加新的镜像。在“ Container” 栏目下,点击获取新的镜像按钮,然后在新的窗口中搜索要添加的镜像。假设你要添加 CentOS 的最新官方版本。在搜索栏中输入 centos,在得到搜索结果后,选择官方列表,然后单击下载(图5)。
|
||||
|
||||

|
||||
|
||||
*图 5:使用 Cockpit 添加最新的官方构建 CentOS 镜像到 Docker 中。*
|
||||
|
||||
镜像下载完后,那它就在 Docker 中可用了,并可以通过 Cockpit 运行。
|
||||
|
||||
### 如获取它那样简单
|
||||
|
||||
管理 Docker 并不容易。是的,在 Ubuntu 上运行 Cockpit 会有一个警告,但如果这是你唯一的选择,那么也有办法让它工作。在 Cockpit 的帮助下,你不仅可以轻松管理 Docker 镜像,也可以在任何可以访问 Linux 服务器的 web 浏览器上这样做。请享受这个新发现的让 Docker 易用的方法。
|
||||
|
||||
_在 Linux Foundation 以及 edX 中通过免费的 ["Introduction to Linux"][13] 课程学习 Linux。_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/3/make-container-management-easy-cockpit
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/cockpitajpg
|
||||
[8]:https://www.linux.com/files/images/cockpitbjpg
|
||||
[9]:https://www.linux.com/files/images/cockpitcjpg
|
||||
[10]:https://www.linux.com/files/images/cockpitdjpg
|
||||
[11]:https://www.linux.com/files/images/cockpitfjpg
|
||||
[12]:https://www.linux.com/files/images/cockpit-containersjpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:http://www.webmin.com/
|
||||
[15]:http://cpanel.com/
|
||||
[16]:http://cockpit-project.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/en
|
||||
[19]:https://www.centos.org/
|
||||
[20]:https://www.archlinux.org/
|
||||
[21]:https://www.ubuntu.com/
|
||||
@ -0,0 +1,315 @@
|
||||
如何在 Ubuntu 上使用 pm2 和 Nginx 部署 Node.js 应用
|
||||
============================================================
|
||||
|
||||
pm2 是一个 Node.js 应用的进程管理器,它可以让你的应用程序保持运行,还有一个内建的负载均衡器。它非常简单而且强大,你可以零间断重启或重新加载你的 node 应用,它也允许你为你的 node 应用创建集群。
|
||||
|
||||
在这篇博文中,我会向你展示如何安装和配置 pm2 用于这个简单的 'Express' 应用,然后配置 Nginx 作为运行在 pm2 下的 node 应用的反向代理。
|
||||
|
||||
前提:
|
||||
|
||||
* Ubuntu 16.04 - 64bit
|
||||
* Root 权限
|
||||
|
||||
### 第一步 - 安装 Node.js LTS
|
||||
|
||||
在这篇指南中,我们会从零开始我们的实验。首先,我们需要在服务器上安装 Node.js。我会使用 Nodejs LTS 6.x 版本,它能从 nodesource 仓库中安装。
|
||||
|
||||
从 Ubuntu 仓库安装 `python-software-properties` 软件包并添加 “nodesource” Nodejs 仓库。
|
||||
|
||||
```
|
||||
sudo apt-get install -y python-software-properties
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
```
|
||||
|
||||
安装最新版本的 Nodejs LTS:
|
||||
|
||||
```
|
||||
sudo apt-get install -y nodejs
|
||||
```
|
||||
|
||||
安装完成后,查看 node 和 npm 版本。
|
||||
|
||||
```
|
||||
node -v
|
||||
npm -v
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### 第二步 - 生成 Express 示例 App
|
||||
|
||||
我会使用 `express-generator` 软件包生成的简单 web 应用框架进行示例安装。`express-generator` 可以使用 `npm` 命令安装。
|
||||
|
||||
用 `npm `安装 `express-generator`:
|
||||
|
||||
```
|
||||
npm install express-generator -g
|
||||
```
|
||||
|
||||
- `-g` : 在系统内部安装软件包。
|
||||
|
||||
我会以普通用户运行应用程序,而不是 root 或者超级用户。我们首先需要创建一个新的用户。
|
||||
|
||||
创建一个名为 `yume` 的用户:
|
||||
|
||||
```
|
||||
useradd -m -s /bin/bash yume
|
||||
passwd yume
|
||||
```
|
||||
|
||||
使用 `su` 命令登录到新用户:
|
||||
|
||||
```
|
||||
su - yume
|
||||
```
|
||||
|
||||
下一步,用 `express` 命令生成一个新的简单 web 应用程序:
|
||||
|
||||
```
|
||||
express hakase-app
|
||||
```
|
||||
|
||||
命令会创建新项目目录 `hakase-app`。
|
||||
|
||||
[
|
||||
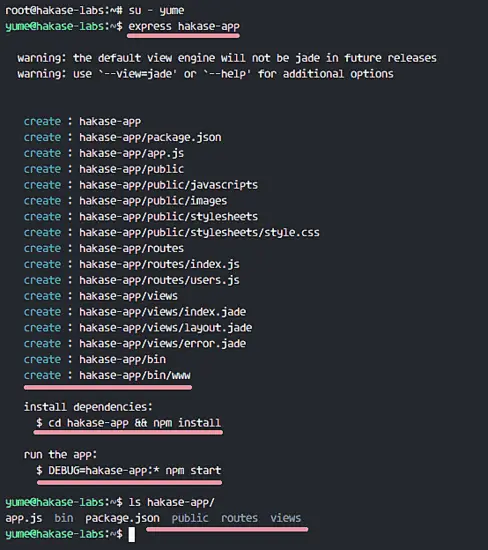
|
||||
][11]
|
||||
|
||||
进入到项目目录并安装应用需要的所有依赖。
|
||||
|
||||
```
|
||||
cd hakase-app
|
||||
npm install
|
||||
```
|
||||
|
||||
然后用下面的命令测试并启动一个新的简单应用程序:
|
||||
|
||||
```
|
||||
DEBUG=myapp:* npm start
|
||||
```
|
||||
|
||||
默认情况下,我们的 express 应用会运行在 `3000` 端口。现在访问服务器的 IP 地址:192.168.33.10:3000 :
|
||||
|
||||
[
|
||||
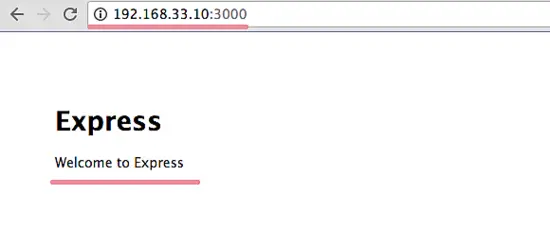
|
||||
][13]
|
||||
|
||||
这个简单 web 应用框架现在以 'yume' 用户运行在 3000 端口。
|
||||
|
||||
### 第三步 - 安装 pm2
|
||||
|
||||
pm2 是一个 node 软件包,可以使用 `npm` 命令安装。(用 root 权限,如果你仍然以 yume 用户登录,那么运行命令 `exit` 再次成为 root 用户):
|
||||
|
||||
```
|
||||
npm install pm2 -g
|
||||
```
|
||||
|
||||
现在我们可以为我们的 web 应用使用 pm2 了。
|
||||
|
||||
进入应用目录 `hakase-app`:
|
||||
|
||||
```
|
||||
su - yume
|
||||
cd ~/hakase-app/
|
||||
```
|
||||
|
||||
这里你可以看到一个名为 `package.json` 的文件,用 `cat` 命令显示它的内容。
|
||||
|
||||
```
|
||||
cat package.json
|
||||
```
|
||||
|
||||
[
|
||||
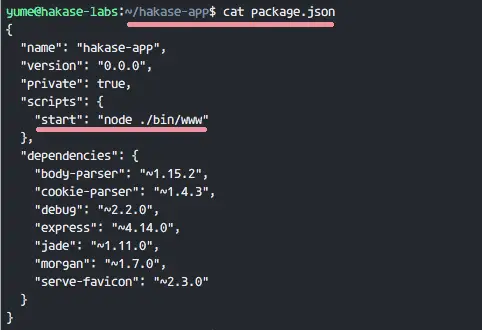
|
||||
][14]
|
||||
|
||||
你可以看到 `start` 行有一个 nodejs 用于启动 express 应用的命令。我们会和 pm2 进程管理器一起使用这个命令。
|
||||
|
||||
像下面这样使用 `pm2` 命令运行 express 应用:
|
||||
|
||||
```
|
||||
pm2 start ./bin/www
|
||||
```
|
||||
|
||||
现在你可以看到像下面这样的结果:
|
||||
|
||||
[
|
||||
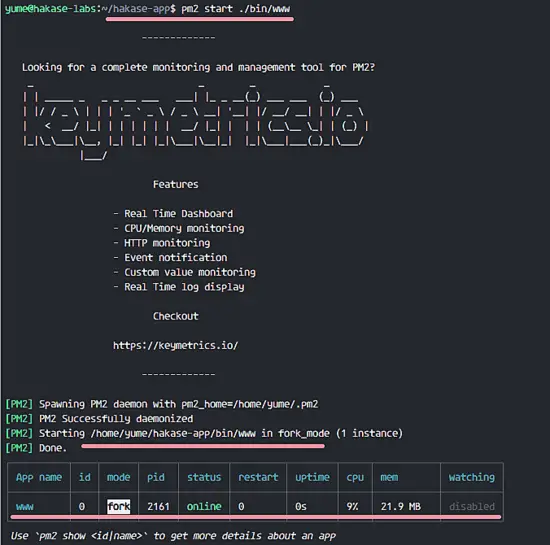
|
||||
][15]
|
||||
|
||||
我们的 express 应用正在 `pm2` 中运行,名称为 `www`,id 为 `0`。你可以用 show 选项 `show nodeid|name` 获取更多 pm2 下运行的应用的信息。
|
||||
|
||||
```
|
||||
pm2 show www
|
||||
```
|
||||
|
||||
[
|
||||
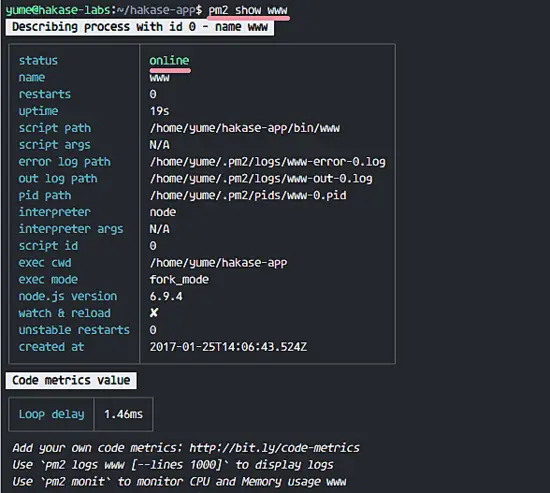
|
||||
][16]
|
||||
|
||||
如果你想看我们应用的日志,你可以使用 logs 选项。它包括访问和错误日志,你还可以看到应用程序的 HTTP 状态。
|
||||
|
||||
```
|
||||
pm2 logs www
|
||||
```
|
||||
|
||||
[
|
||||
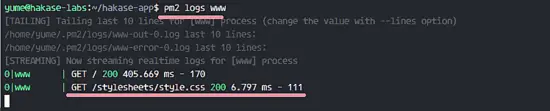
|
||||
][17]
|
||||
|
||||
你可以看到我们的程序正在运行。现在,让我们来让它开机自启动。
|
||||
|
||||
```
|
||||
pm2 startup systemd
|
||||
```
|
||||
|
||||
- `systemd`: Ubuntu 16 使用的是 systemd。
|
||||
|
||||
你会看到要用 root 用户运行命令的信息。使用 `exit` 命令回到 root 用户然后运行命令。
|
||||
|
||||
```
|
||||
sudo env PATH=$PATH:/usr/bin /usr/lib/node_modules/pm2/bin/pm2 startup systemd -u yume --hp /home/yume
|
||||
```
|
||||
|
||||
它会为启动应用程序生成 systemd 配置文件。当你重启服务器的时候,应用程序就会自动运行。
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
### 第四步 - 安装和配置 Nginx 作为反向代理
|
||||
|
||||
在这篇指南中,我们会使用 Nginx 作为 node 应用的反向代理。Ubuntu 仓库中有 Nginx,用 `apt` 命令安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install -y nginx
|
||||
```
|
||||
|
||||
下一步,进入到 `sites-available` 目录并创建新的虚拟主机配置文件。
|
||||
|
||||
```
|
||||
cd /etc/nginx/sites-available/
|
||||
vim hakase-app
|
||||
```
|
||||
|
||||
粘贴下面的配置:
|
||||
|
||||
```
|
||||
upstream hakase-app {
|
||||
# Nodejs app upstream
|
||||
server 127.0.0.1:3000;
|
||||
keepalive 64;
|
||||
}
|
||||
|
||||
# Server on port 80
|
||||
server {
|
||||
listen 80;
|
||||
server_name hakase-node.co;
|
||||
root /home/yume/hakase-app;
|
||||
|
||||
location / {
|
||||
# Proxy_pass configuration
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-NginX-Proxy true;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_max_temp_file_size 0;
|
||||
proxy_pass http://hakase-app/;
|
||||
proxy_redirect off;
|
||||
proxy_read_timeout 240s;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
保存文件并退出 vim。
|
||||
|
||||
在配置中:
|
||||
|
||||
* node 应用使用域名 `hakase-node.co` 运行。
|
||||
* 所有来自 nginx 的流量都会被转发到运行在 `3000` 端口的 node app。
|
||||
|
||||
测试 Nginx 配置确保没有错误。
|
||||
|
||||
```
|
||||
nginx -t
|
||||
```
|
||||
|
||||
启用 Nginx 并使其开机自启动。
|
||||
|
||||
```
|
||||
systemctl start nginx
|
||||
systemctl enable nginx
|
||||
```
|
||||
|
||||
### 第五步 - 测试
|
||||
|
||||
打开你的 web 浏览器并访问域名(我的是):[http://hakase-app.co][19]
|
||||
|
||||
你可以看到 express 应用正在 Nginx web 服务器中运行。
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
下一步,重启你的服务器,确保你的 node app 能开机自启动:
|
||||
|
||||
```
|
||||
pm2 save
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
如果你再次登录到了你的服务器,检查 node app 进程。以 `yume` 用户运行下面的命令。
|
||||
|
||||
```
|
||||
su - yume
|
||||
pm2 status www
|
||||
```
|
||||
|
||||
[
|
||||
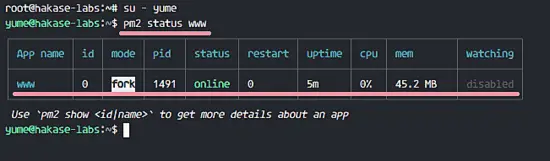
|
||||
][21]
|
||||
|
||||
Node 应用在 pm2 中运行并使用 Nginx 作为反向代理。
|
||||
|
||||
### 链接
|
||||
|
||||
* [Ubuntu][7]
|
||||
* [Node.js][8]
|
||||
* [Nginx][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-nodejs-lts
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-generate-express-sample-app
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-pm
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-and-configure-nginx-as-a-reverse-proxy
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-testing
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#links
|
||||
[7]:https://www.ubuntu.com/
|
||||
[8]:https://nodejs.org/en/
|
||||
[9]:https://www.nginx.com/
|
||||
[10]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/1.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/2.png
|
||||
[12]:https://www.howtoforge.com/admin/articles/edit/192.168.33.10:3000
|
||||
[13]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/3.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/4.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/5.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/6.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/7.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/8.png
|
||||
[19]:http://hakase-app.co/
|
||||
[20]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/9.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/10.png
|
||||
@ -0,0 +1,101 @@
|
||||
如何在树莓派上部署 Kubernetes
|
||||
============================================================
|
||||
|
||||
> 只用几步,使用 Weave Net 在树莓派上设置 Kubernetes。
|
||||
|
||||
|
||||

|
||||
|
||||
> 图片提供: opensource.com
|
||||
|
||||
当我开始对 [ARM][6]设备,特别是 Raspberry Pi 感兴趣时,我的第一个项目是一个 OpenVPN 服务器。
|
||||
|
||||
通过将 Raspberry Pi 作为家庭网络的安全网关,我可以使用我的手机来控制我的桌面,远程播放 Spotify,打开文档以及一些其他有趣的东西。我在第一个项目中使用了一个现有的教程,因为我害怕自己在命令行中拼砌。
|
||||
|
||||
几个月后,这种恐惧消失了。我扩展了我的原始项目,并使用 [Samba 服务器][7]从文件服务器分离出了 OpenVPN 服务器。这是我第一个没有完全按照教程来的项目。不幸的是,在我的 Samba 项目结束后,我意识到我没有记录任何东西,所以我无法复制它。为了重新创建它,我不得不重新参考我曾经用过的那些单独的教程,将项目拼回到一起。
|
||||
|
||||
我学到了关于开发人员工作流程的宝贵经验 - 跟踪你所有的更改。我在本地做了一个小的 git 仓库,并记录了我输入的所有命令。
|
||||
|
||||
### 发现 Kubernetes
|
||||
|
||||
2015 年 5 月,我发现了 Linux 容器和 Kubernetes。我觉得 Kubernetes 很有魅力,我可以使用仍然处于技术发展的概念 - 并且我实际上可以用它。平台本身及其所呈现的可能性令人兴奋。在此之前,我才刚刚在一块 Raspberry Pi 上运行了一个程序。而有了 Kubernetes,我可以做出比以前更先进的配置。
|
||||
|
||||
那时候,Docker(v1.6 版本,如果我记得正确的话)在 ARM 上有一个 bug,这意味着在 Raspberry Pi 上运行 Kubernetes 实际上是不可能的。在早期的 0.x 版本中,Kubernetes 的变化很快。每次我在 AMD64 上找到一篇关于如何设置 Kubernetes 的指南时,它针对的还都是一个旧版本,与我当时使用的完全不兼容。
|
||||
|
||||
不管怎样,我用自己的方法在 Raspberry Pi 上创建了一个 Kubernetes 节点,而在 Kubernetes v1.0.1 中,我使用 Docker v1.7.1 [让它工作了][8]。这是第一个将 Kubernetes 全功能部署到 ARM 的方法。
|
||||
|
||||
在 Raspberry Pi 上运行 Kubernetes 的优势在于,由于 ARM 设备非常小巧,因此不会产生大量的功耗。如果程序以正确的方式构建而成,那么就可以在 AMD64 上用同样的方法运行同一个程序。这样的一块小型 IoT 板为教育创造了巨大的机会。用它来做演示也很有用,比如你要出差参加一个会议。携带 Raspberry Pi (通常)比拖着大型英特尔机器要容易得多。
|
||||
|
||||
现在按照[我建议][9]的 ARM(32 位和 64 位)的支持已被合并到 Kubernetes 核心中。ARM 的二进制文件会自动与 Kubernetes 一起发布。虽然我们还没有为 ARM 提供自动化的 CI(持续集成)系统,不过在 PR 合并之前会自动确定它可在 ARM 上工作,现在它运转得不错。
|
||||
|
||||
### Raspberry Pi 上的分布式网络
|
||||
|
||||
我通过 [kubeadm][10] 发现了 Weave Net。[Weave Mesh][11] 是一个有趣的分布式网络解决方案,因此我开始了解更多关于它的内容。在 2016 年 12 月,我在 [Weaveworks][12] 收到了第一份合同工作,我成为了 Weave Net 中 ARM 支持团队的一员。
|
||||
|
||||
我很高兴可以在 Raspberry Pi 上运行 Weave Net 的工业案例,比如那些需要设备更加移动化的工厂。目前,将 Weave Scope 或 Weave Cloud 部署到 Raspberry Pi 可能不太现实(尽管可以考虑使用其他 ARM 设备),因为我猜这个软件需要更多的内存才能运行良好。理想情况下,随着 Raspberry Pi 升级到 2GB 内存,我想我可以在它上面运行 Weave Cloud 了。
|
||||
|
||||
在 Weave Net 1.9 中,Weave Net 支持了 ARM。Kubeadm(通常是 Kubernetes)在多个平台上工作。你可以使用 Weave 将 Kubernetes 部署到 ARM,就像在任何 AMD64 设备上一样安装 Docker、kubeadm、kubectl 和 kubelet。然后初始化控制面板组件运行的主机:
|
||||
|
||||
```
|
||||
kubeadm init
|
||||
```
|
||||
|
||||
接下来,用下面的命令安装你的 pod 网络:
|
||||
|
||||
```
|
||||
kubectl apply -f https://git.io/weave-kube
|
||||
```
|
||||
|
||||
在此之前在 ARM 上,你只能用 Flannel 安装 pod 网络,但是在 Weave Net 1.9 中已经改变了,它官方支持了 ARM。
|
||||
|
||||
最后,加入你的节点:
|
||||
|
||||
```
|
||||
kubeadm join --token <token> <master-ip>
|
||||
```
|
||||
|
||||
就是这样了!Kubernetes 已经部署到了 Raspberry Pi 上了。相比在 Intel/AMD64 上运行,你不用做什么特别的事情;Weave Net 在 ARM 上就能工作的很好。
|
||||
|
||||
### Raspberry Pi 社区
|
||||
|
||||
我希望 Raspberry Pi 社区成长起来,他们的思想传播到世界其他地方。他们在英国和其他国家已经取得了成功,但在芬兰并不是很成功。我希望生态系统能够继续扩展,以让更多的人学习如何部署 Kubernetes 或 Weave 到 ARM 设备上。毕竟,这些是我学到的。通过在 Raspberry Pi 设备上自学,我更好地了解了 ARM 及其上面部署的软件。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
我通过加入用户社区、提出问题和不同程度的测试,在线学习了关于 Raspberry Pi 和 Kubernetes 的一切。
|
||||
|
||||
我是居住在芬兰的说瑞典语的高中生,到目前为止,我还从来没有参加过编程或计算机课程。但我仍然能够加入开源社区,因为它对年龄或教育没有限制:你的工作是根据其价值来评判的。
|
||||
|
||||
对于那些第一次要在开源项目中做出贡献感到紧张的人,我想说:深入进去,因为这是完全值得的。你做什么没有任何限制,你将永远不知道开源世界将为你提供哪些机会。这会很有趣,我保证!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lucas Käldström - 谢谢你发现我!我是一名来自芬兰的说瑞典语的高中生。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/kubernetes-raspberry-pi
|
||||
|
||||
作者:[Lucas Käldström][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/luxas
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/kubernetes-raspberry-pi?rate=xHFaLw4Y4mkFiZww6sIHYnkEleqbqObgjXTC0ALUn9s
|
||||
[6]:https://en.wikipedia.org/wiki/ARM_architecture
|
||||
[7]:https://www.samba.org/samba/what_is_samba.html
|
||||
[8]:https://github.com/luxas/kubernetes-on-arm
|
||||
[9]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/multi-platform.md
|
||||
[10]:https://kubernetes.io/docs/getting-started-guides/kubeadm/
|
||||
[11]:https://github.com/weaveworks/mesh
|
||||
[12]:https://www.weave.works/
|
||||
[13]:https://opensource.com/user/113281/feed
|
||||
[14]:https://opensource.com/users/luxas
|
||||
310
published/201704/20110123 How debuggers work Part 1 - Basics.md
Normal file
310
published/201704/20110123 How debuggers work Part 1 - Basics.md
Normal file
@ -0,0 +1,310 @@
|
||||
调试器的工作原理(一):基础篇
|
||||
============================================================
|
||||
|
||||
这是调试器工作原理系列文章的第一篇,我不确定这个系列会有多少篇文章,会涉及多少话题,但我仍会从这篇基础开始。
|
||||
|
||||
### 这一篇会讲什么
|
||||
|
||||
我将为大家展示 Linux 中调试器的主要构成模块 - `ptrace` 系统调用。这篇文章所有代码都是基于 32 位 Ubuntu 操作系统。值得注意的是,尽管这些代码是平台相关的,将它们移植到其它平台应该并不困难。
|
||||
|
||||
### 缘由
|
||||
|
||||
为了理解我们要做什么,让我们先考虑下调试器为了完成调试都需要什么资源。调试器可以开始一个进程并调试这个进程,又或者将自己同某个已经存在的进程关联起来。调试器能够单步执行代码,设定断点并且将程序执行到断点,检查变量的值并追踪堆栈。许多调试器有着更高级的特性,例如在调试器的地址空间内执行表达式或者调用函数,甚至可以在进程执行过程中改变代码并观察效果。
|
||||
|
||||
尽管现代的调试器都十分的复杂(我没有检查,但我确信 gdb 的代码行数至少有六位数),但它们的工作的原理却是十分的简单。调试器的基础是操作系统与编译器 / 链接器提供的一些基础服务,其余的部分只是[简单的编程][14]而已。
|
||||
|
||||
### Linux 的调试 - ptrace
|
||||
|
||||
Linux 调试器中的瑞士军刀便是 `ptrace` 系统调用(使用 man 2 ptrace 命令可以了解更多)。这是一种复杂却强大的工具,可以允许一个进程控制另外一个进程并从<ruby>内部替换<rt>Peek and poke</rt></ruby>被控制进程的内核镜像的值(Peek and poke 在系统编程中是很知名的叫法,指的是直接读写内存内容)。
|
||||
|
||||
接下来会深入分析。
|
||||
|
||||
### 执行进程的代码
|
||||
|
||||
我将编写一个示例,实现一个在“跟踪”模式下运行的进程。在这个模式下,我们将单步执行进程的代码,就像机器码(汇编代码)被 CPU 执行时一样。我将分段展示、讲解示例代码,在文章的末尾也有完整 c 文件的下载链接,你可以编译、执行或者随心所欲的更改。
|
||||
|
||||
更进一步的计划是实现一段代码,这段代码可以创建可执行用户自定义命令的子进程,同时父进程可以跟踪子进程。首先是主函数:
|
||||
|
||||
```
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
pid_t child_pid;
|
||||
|
||||
if (argc < 2) {
|
||||
fprintf(stderr, "Expected a program name as argument\n");
|
||||
return -1;
|
||||
}
|
||||
|
||||
child_pid = fork();
|
||||
if (child_pid == 0)
|
||||
run_target(argv[1]);
|
||||
else if (child_pid > 0)
|
||||
run_debugger(child_pid);
|
||||
else {
|
||||
perror("fork");
|
||||
return -1;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
看起来相当的简单:我们用 `fork` 创建了一个新的子进程(这篇文章假定读者有一定的 Unix/Linux 编程经验。我假定你知道或至少了解 fork、exec 族函数与 Unix 信号)。if 语句的分支执行子进程(这里称之为 “target”),`else if` 的分支执行父进程(这里称之为 “debugger”)。
|
||||
|
||||
下面是 target 进程的代码:
|
||||
|
||||
```
|
||||
void run_target(const char* programname)
|
||||
{
|
||||
procmsg("target started. will run '%s'\n", programname);
|
||||
|
||||
/* Allow tracing of this process */
|
||||
if (ptrace(PTRACE_TRACEME, 0, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Replace this process's image with the given program */
|
||||
execl(programname, programname, 0);
|
||||
}
|
||||
```
|
||||
|
||||
这段代码中最值得注意的是 `ptrace` 调用。在 `sys/ptrace.h` 中,`ptrace` 是如下定义的:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
第一个参数是 `_request_`,这是许多预定义的 `PTRACE_*` 常量中的一个。第二个参数为请求分配进程 ID。第三个与第四个参数是地址与数据指针,用于操作内存。上面代码段中的 `ptrace` 调用发起了 `PTRACE_TRACEME` 请求,这意味着该子进程请求系统内核让其父进程跟踪自己。帮助页面上对于 request 的描述很清楚:
|
||||
|
||||
> 意味着该进程被其父进程跟踪。任何传递给该进程的信号(除了 `SIGKILL`)都将通过 `wait()` 方法阻塞该进程并通知其父进程。**此外,该进程的之后所有调用 `exec()` 动作都将导致 `SIGTRAP` 信号发送到此进程上,使得父进程在新的程序执行前得到取得控制权的机会**。如果一个进程并不需要它的的父进程跟踪它,那么这个进程不应该发送这个请求。(pid、addr 与 data 暂且不提)
|
||||
|
||||
我高亮了这个例子中我们需要注意的部分。在 `ptrace` 调用后,`run_target` 接下来要做的就是通过 `execl` 传参并调用。如同高亮部分所说明,这将导致系统内核在 `execl` 创建进程前暂时停止,并向父进程发送信号。
|
||||
|
||||
是时候看看父进程做什么了。
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
如前文所述,一旦子进程调用了 `exec`,子进程会停止并被发送 `SIGTRAP` 信号。父进程会等待该过程的发生并在第一个 `wait()` 处等待。一旦上述事件发生了,`wait()` 便会返回,由于子进程停止了父进程便会收到信号(如果子进程由于信号的发送停止了,`WIFSTOPPED` 就会返回 `true`)。
|
||||
|
||||
父进程接下来的动作就是整篇文章最需要关注的部分了。父进程会将 `PTRACE_SINGLESTEP` 与子进程 ID 作为参数调用 `ptrace` 方法。这就会告诉操作系统,“请恢复子进程,但在它执行下一条指令前阻塞”。周而复始地,父进程等待子进程阻塞,循环继续。当 `wait()` 中传出的信号不再是子进程的停止信号时,循环终止。在跟踪器(父进程)运行期间,这将会是被跟踪进程(子进程)传递给跟踪器的终止信号(如果子进程终止 `WIFEXITED` 将返回 `true`)。
|
||||
|
||||
`icounter` 存储了子进程执行指令的次数。这么看来我们小小的例子也完成了些有用的事情 - 在命令行中指定程序,它将执行该程序并记录它从开始到结束所需要的 cpu 指令数量。接下来就让我们这么做吧。
|
||||
|
||||
### 测试
|
||||
|
||||
我编译了下面这个简单的程序并利用跟踪器运行它:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("Hello, world!\n");
|
||||
return 0;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
令我惊讶的是,跟踪器花了相当长的时间,并报告整个执行过程共有超过 100,000 条指令执行。仅仅是一条输出语句?什么造成了这种情况?答案很有趣(至少你同我一样痴迷与机器/汇编语言)。Linux 的 gcc 默认会动态的将程序与 c 的运行时库动态地链接。这就意味着任何程序运行前的第一件事是需要动态库加载器去查找程序运行所需要的共享库。这些代码的数量很大 - 别忘了我们的跟踪器要跟踪每一条指令,不仅仅是主函数的,而是“整个进程中的指令”。
|
||||
|
||||
所以当我将测试程序使用静态编译时(通过比较,可执行文件会多出 500 KB 左右的大小,这部分是 C 运行时库的静态链接),跟踪器提示只有大概 7000 条指令被执行。这个数目仍然不小,但是考虑到在主函数执行前 libc 的初始化以及主函数执行后的清除代码,这个数目已经是相当不错了。此外,`printf` 也是一个复杂的函数。
|
||||
|
||||
仍然不满意的话,我需要的是“可以测试”的东西 - 例如可以完整记录每一个指令运行的程序执行过程。这当然可以通过汇编代码完成。所以我找到了这个版本的 “Hello, world!” 并编译了它。
|
||||
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len
|
||||
mov ecx, msg
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
msg db 'Hello, world!', 0xa
|
||||
len equ $ - msg
|
||||
```
|
||||
|
||||
|
||||
当然,现在跟踪器提示 7 条指令被执行了,这样一来很容易区分它们。
|
||||
|
||||
### 深入指令流
|
||||
|
||||
上面那个汇编语言编写的程序使得我可以向你介绍 `ptrace` 的另外一个强大的用途 - 详细显示被跟踪进程的状态。下面是 `run_debugger` 函数的另一个版本:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
unsigned instr = ptrace(PTRACE_PEEKTEXT, child_pid, regs.eip, 0);
|
||||
|
||||
procmsg("icounter = %u. EIP = 0x%08x. instr = 0x%08x\n",
|
||||
icounter, regs.eip, instr);
|
||||
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
不同仅仅存在于 `while` 循环的开始几行。这个版本里增加了两个新的 `ptrace` 调用。第一条将进程的寄存器值读取进了一个结构体中。 `sys/user.h` 定义有 `user_regs_struct`。如果你查看头文件,头部的注释这么写到:
|
||||
|
||||
```
|
||||
/* 这个文件只为了 GDB 而创建
|
||||
不用详细的阅读.如果你不知道你在干嘛,
|
||||
不要在除了 GDB 以外的任何地方使用此文件 */
|
||||
```
|
||||
|
||||
|
||||
不知道你做何感想,但这让我觉得我们找对地方了。回到例子中,一旦我们在 `regs` 变量中取得了寄存器的值,我们就可以通过将 `PTRACE_PEEKTEXT` 作为参数、 `regs.eip`(x86 上的扩展指令指针)作为地址,调用 `ptrace` ,读取当前进程的当前指令(警告:如同我上面所说,文章很大程度上是平台相关的。我简化了一些设定 - 例如,x86 指令集不需要调整到 4 字节,我的32位 Ubuntu unsigned int 是 4 字节。事实上,许多平台都不需要。从内存中读取指令需要预先安装完整的反汇编器。我们这里没有,但实际的调试器是有的)。下面是新跟踪器所展示出的调试效果:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
[5700] debugger started
|
||||
[5701] target started. will run 'traced_helloworld'
|
||||
[5700] icounter = 1\. EIP = 0x08048080\. instr = 0x00000eba
|
||||
[5700] icounter = 2\. EIP = 0x08048085\. instr = 0x0490a0b9
|
||||
[5700] icounter = 3\. EIP = 0x0804808a. instr = 0x000001bb
|
||||
[5700] icounter = 4\. EIP = 0x0804808f. instr = 0x000004b8
|
||||
[5700] icounter = 5\. EIP = 0x08048094\. instr = 0x01b880cd
|
||||
Hello, world!
|
||||
[5700] icounter = 6\. EIP = 0x08048096\. instr = 0x000001b8
|
||||
[5700] icounter = 7\. EIP = 0x0804809b. instr = 0x000080cd
|
||||
[5700] the child executed 7 instructions
|
||||
```
|
||||
|
||||
|
||||
现在,除了 `icounter`,我们也可以观察到指令指针与它每一步所指向的指令。怎么来判断这个结果对不对呢?使用 `objdump -d` 处理可执行文件:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
|
||||
traced_helloworld: file format elf32-i386
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 0e 00 00 00 mov $0xe,%edx
|
||||
8048085: b9 a0 90 04 08 mov $0x80490a0,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: b8 01 00 00 00 mov $0x1,%eax
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
这个结果和我们跟踪器的结果就很容易比较了。
|
||||
|
||||
### 将跟踪器关联到正在运行的进程
|
||||
|
||||
如你所知,调试器也能关联到已经运行的进程。现在你应该不会惊讶,`ptrace` 通过以 `PTRACE_ATTACH` 为参数调用也可以完成这个过程。这里我不会展示示例代码,通过上文的示例代码应该很容易实现这个过程。出于学习目的,这里使用的方法更简便(因为我们在子进程刚开始就可以让它停止)。
|
||||
|
||||
### 代码
|
||||
|
||||
上文中的简单的跟踪器(更高级的,可以打印指令的版本)的完整c源代码可以在[这里][20]找到。它是通过 4.4 版本的 gcc 以 `-Wall -pedantic --std=c99` 编译的。
|
||||
|
||||
### 结论与计划
|
||||
|
||||
诚然,这篇文章并没有涉及很多内容 - 我们距离亲手完成一个实际的调试器还有很长的路要走。但我希望这篇文章至少可以使得调试这件事少一些神秘感。`ptrace` 是功能多样的系统调用,我们目前只展示了其中的一小部分。
|
||||
|
||||
单步调试代码很有用,但也只是在一定程度上有用。上面我通过 C 的 “Hello World!” 做了示例。为了执行主函数,可能需要上万行代码来初始化 C 的运行环境。这并不是很方便。最理想的是在 `main` 函数入口处放置断点并从断点处开始分步执行。为此,在这个系列的下一篇,我打算展示怎么实现断点。
|
||||
|
||||
### 参考
|
||||
|
||||
撰写此文时参考了如下文章
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[YYforymj](https://github.com/YYforymj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id1
|
||||
[2]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id2
|
||||
[3]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id3
|
||||
[4]:http://www.jargon.net/jargonfile/p/peek.html
|
||||
[5]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.linuxjournal.com/article/6100?page=0,1
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id7
|
||||
[14]:http://en.wikipedia.org/wiki/Small_matter_of_programming
|
||||
[15]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id8
|
||||
[16]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id9
|
||||
[17]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id10
|
||||
[18]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id11
|
||||
[19]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id12
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2011/simple_tracer.c
|
||||
[21]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
165
published/201704/20150112 Data-Oriented Hash Table.md
Normal file
@ -0,0 +1,165 @@
|
||||
深入解析面向数据的哈希表性能
|
||||
============================================================
|
||||
|
||||
最近几年中,面向数据的设计已经受到了很多的关注 —— 一种强调内存中数据布局的编程风格,包括如何访问以及将会引发多少的 cache 缺失。由于在内存读取操作中缺失所占的数量级要大于命中的数量级,所以缺失的数量通常是优化的关键标准。这不仅仅关乎那些对性能有要求的 code-data 结构设计的软件,由于缺乏对内存效益的重视而成为软件运行缓慢、膨胀的一个很大因素。
|
||||
|
||||
|
||||
高效缓存数据结构的中心原则是将事情变得平滑和线性。比如,在大部分情况下,存储一个序列元素更倾向于使用普通数组而不是链表 —— 每一次通过指针来查找数据都会为 cache 缺失增加一份风险;而普通数组则可以预先获取,并使得内存系统以最大的效率运行
|
||||
|
||||
如果你知道一点内存层级如何运作的知识,下面的内容会是想当然的结果——但是有时候即便它们相当明显,测试一下任不失为一个好主意。几年前 [Baptiste Wicht 测试过了 `std::vector` vs `std::list` vs `std::deque`][4],(后者通常使用分块数组来实现,比如:一个数组的数组)。结果大部分会和你预期的保持一致,但是会存在一些违反直觉的东西。作为实例:在序列链表的中间位置做插入或者移除操作被认为会比数组快,但如果该元素是一个 POD 类型,并且不大于 64 字节或者在 64 字节左右(在一个 cache 流水线内),通过对要操作的元素周围的数组元素进行移位操作要比从头遍历链表来的快。这是由于在遍历链表以及通过指针插入/删除元素的时候可能会导致不少的 cache 缺失,相对而言,数组移位则很少会发生。(对于更大的元素,非 POD 类型,或者你已经有了指向链表元素的指针,此时和预期的一样,链表胜出)
|
||||
|
||||
|
||||
多亏了类似 Baptiste 这样的数据,我们知道了内存布局如何影响序列容器。但是关联容器,比如 hash 表会怎么样呢?已经有了些权威推荐:[Chandler Carruth 推荐的带局部探测的开放寻址][5](此时,我们没必要追踪指针),以及[Mike Acton 推荐的在内存中将 value 和 key 隔离][6](这种情况下,我们可以在每一个 cache 流水线中得到更多的 key), 这可以在我们必须查找多个 key 时提高局部性能。这些想法很有意义,但再一次的说明:测试永远是好习惯,但由于我找不到任何数据,所以只好自己收集了。
|
||||
|
||||
### 测试
|
||||
|
||||
我测试了四个不同的 quick-and-dirty 哈希表实现,另外还包括 `std::unordered_map` 。这五个哈希表都使用了同一个哈希函数 —— Bob Jenkins 的 [SpookyHash][8](64 位哈希值)。(由于哈希函数在这里不是重点,所以我没有测试不同的哈希函数;我同样也没有检测我的分析中的总内存消耗。)实现会通过简短的代码在测试结果表中标注出来。
|
||||
|
||||
* **UM**: `std::unordered_map` 。在 VS2012 和 libstdc++-v3 (libstdc++-v3: gcc 和 clang 都会用到这东西)中,UM 是以链表的形式实现,所有的元素都在链表中,bucket 数组中存储了链表的迭代器。VS2012 中,则是一个双链表,每一个 bucket 存储了起始迭代器和结束迭代器;libstdc++ 中,是一个单链表,每一个 bucket 只存储了一个起始迭代器。这两种情况里,链表节点是独立申请和释放的。最大负载因子是 1 。
|
||||
* **Ch**:分离的、链状 buket 指向一个元素节点的单链表。为了避免分开申请每一个节点,元素节点存储在普通数组池中。未使用的节点保存在一个空闲链表中。最大负载因子是 1。
|
||||
* **OL**:开地址线性探测 —— 每一个 bucket 存储一个 62 bit 的 hash 值,一个 2 bit 的状态值(包括 empty,filled,removed 三个状态),key 和 vale 。最大负载因子是 2/3。
|
||||
* **DO1**:“data-oriented 1” —— 和 OL 相似,但是哈希值、状态值和 key、values 分离在两个隔离的平滑数组中。
|
||||
* **DO2**:“data-oriented 2” —— 与 OL 类似,但是哈希/状态,keys 和 values 被分离在 3 个相隔离的平滑数组中。
|
||||
|
||||
|
||||
在我的所有实现中,包括 VS2012 的 UM 实现,默认使用尺寸为 2 的 n 次方。如果超出了最大负载因子,则扩展两倍。在 libstdc++ 中,UM 默认尺寸是一个素数。如果超出了最大负载因子,则扩展为下一个素数大小。但是我不认为这些细节对性能很重要。素数是一种对低 bit 位上没有足够熵的低劣 hash 函数的挽救手段,但是我们正在用的是一个很好的 hash 函数。
|
||||
|
||||
OL,DO1 和 DO2 的实现将共同的被称为 OA(open addressing)——稍后我们将发现它们在性能特性上非常相似。在每一个实现中,单元数从 100 K 到 1 M,有效负载(比如:总的 key + value 大小)从 8 到 4 k 字节我为几个不同的操作记了时间。 keys 和 values 永远是 POD 类型,keys 永远是 8 个字节(除了 8 字节的有效负载,此时 key 和 value 都是 4 字节)因为我的目的是为了测试内存影响而不是哈希函数性能,所以我将 key 放在连续的尺寸空间中。每一个测试都会重复 5 遍,然后记录最小的耗时。
|
||||
|
||||
测试的操作在这里:
|
||||
|
||||
* **Fill**:将一个随机的 key 序列插入到表中(key 在序列中是唯一的)。
|
||||
* **Presized fill**:和 Fill 相似,但是在插入之间我们先为所有的 key 保留足够的内存空间,以防止在 fill 过程中 rehash 或者重申请。
|
||||
* **Lookup**:执行 100 k 次随机 key 查找,所有的 key 都在 table 中。
|
||||
* **Failed lookup**: 执行 100 k 次随机 key 查找,所有的 key 都不在 table 中。
|
||||
* **Remove**:从 table 中移除随机选择的半数元素。
|
||||
* **Destruct**:销毁 table 并释放内存。
|
||||
|
||||
你可以[在这里下载我的测试代码][9]。这些代码只能在 64 机器上编译(包括Windows和Linux)。在 `main()` 函数顶部附近有一些开关,你可把它们打开或者关掉——如果全开,可能会需要一两个小时才能结束运行。我收集的结果也放在了那个打包文件里的 Excel 表中。(注意: Windows 和 Linux 在不同的 CPU 上跑的,所以时间不具备可比较性)代码也跑了一些单元测试,用来验证所有的 hash 表实现都能运行正确。
|
||||
|
||||
我还顺带尝试了附加的两个实现:Ch 中第一个节点存放在 bucket 中而不是 pool 里,二次探测的开放寻址。
|
||||
这两个都不足以好到可以放在最终的数据里,但是它们的代码仍放在了打包文件里面。
|
||||
|
||||
### 结果
|
||||
|
||||
这里有成吨的数据!!
|
||||
这一节我将详细的讨论一下结果,但是如果你对此不感兴趣,可以直接跳到下一节的总结。
|
||||
|
||||
#### Windows
|
||||
|
||||
这是所有的测试的图表结果,使用 Visual Studio 2012 编译,运行于 Windows 8.1 和 Core i7-4710HQ 机器上。(点击可以放大。)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
从左至右是不同的有效负载大小,从上往下是不同的操作(注意:不是所有的Y轴都是相同的比例!)我将为每一个操作总结一下主要趋向。
|
||||
|
||||
**Fill**:
|
||||
|
||||
在我的 hash 表中,Ch 稍比任何的 OA 变种要好。随着哈希表大小和有效负载的加大,差距也随之变大。我猜测这是由于 Ch 只需要从一个空闲链表中拉取一个元素,然后把它放在 bucket 前面,而 OA 不得不搜索一部分 bucket 来找到一个空位置。所有的 OA 变种的性能表现基本都很相似,当然 DO1 稍微有点优势。
|
||||
|
||||
在小负载的情况,UM 几乎是所有 hash 表中表现最差的 —— 因为 UM 为每一次的插入申请(内存)付出了沉重的代价。但是在 128 字节的时候,这些 hash 表基本相当,大负载的时候 UM 还赢了点。因为,我所有的实现都需要重新调整元素池的大小,并需要移动大量的元素到新池里面,这一点我几乎无能为力;而 UM 一旦为元素申请了内存后便不需要移动了。注意大负载中图表上夸张的跳步!这更确认了重新调整大小带来的问题。相反,UM 只是线性上升 —— 只需要重新调整 bucket 数组大小。由于没有太多隆起的地方,所以相对有效率。
|
||||
|
||||
**Presized fill**:
|
||||
|
||||
大致和 Fill 相似,但是图示结果更加的线性光滑,没有太大的跳步(因为不需要 rehash ),所有的实现差距在这一测试中要缩小了些。大负载时 UM 依然稍快于 Ch,问题还是在于重新调整大小上。Ch 仍是稳步少快于 OA 变种,但是 DO1 比其它的 OA 稍有优势。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
所有的实现都相当的集中。除了最小负载时,DO1 和 OL 稍快,其余情况下 UM 和 DO2 都跑在了前面。(LCTT 译注: 你确定?)真的,我无法描述 UM 在这一步做的多么好。尽管需要遍历链表,但是 UM 还是坚守了面向数据的本性。
|
||||
|
||||
顺带一提,查找时间和 hash 表的大小有着很弱的关联,这真的很有意思。
|
||||
哈希表查找时间期望上是一个常量时间,所以在的渐进视图中,性能不应该依赖于表的大小。但是那是在忽视了 cache 影响的情况下!作为具体的例子,当我们在具有 10 k 条目的表中做 100 k 次查找时,速度会便变快,因为在第一次 10 k - 20 k 次查找后,大部分的表会处在 L3 中。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
相对于成功查找,这里就有点更分散一些。DO1 和 DO2 跑在了前面,但 UM 并没有落下,OL 则是捉襟见肘啊。我猜测,这可能是因为 OL 整体上具有更长的搜索路径,尤其是在失败查询时;内存中,hash 值在 key 和 value 之飘来荡去的找不着出路,我也很受伤啊。DO1 和 DO2 具有相同的搜索长度,但是它们将所有的 hash 值打包在内存中,这使得问题有所缓解。
|
||||
|
||||
**Remove**:
|
||||
|
||||
DO2 很显然是赢家,但 DO1 也未落下。Ch 则落后,UM 则是差的不是一丁半点(主要是因为每次移除都要释放内存);差距随着负载的增加而拉大。移除操作是唯一不需要接触数据的操作,只需要 hash 值和 key 的帮助,这也是为什么 DO1 和 DO2 在移除操作中的表现大相径庭,而其它测试中却保持一致。(如果你的值不是 POD 类型的,并需要析构,这种差异应该是会消失的。)
|
||||
|
||||
**Destruct**:
|
||||
|
||||
Ch 除了最小负载,其它的情况都是最快的(最小负载时,约等于 OA 变种)。所有的 OA 变种基本都是相等的。注意,在我的 hash 表中所做的所有析构操作都是释放少量的内存 buffer 。但是 [在Windows中,释放内存的消耗和大小成比例关系][13]。(而且,这是一个很显著的开支 —— 申请 ~1 GB 的内存需要 ~100 ms 的时间去释放!)
|
||||
|
||||
UM 在析构时是最慢的一个(小负载时,慢的程度可以用数量级来衡量),大负载时依旧是稍慢些。对于 UM 来讲,释放每一个元素而不是释放一组数组真的是一个硬伤。
|
||||
|
||||
#### Linux
|
||||
|
||||
我还在装有 Linux Mint 17.1 的 Core i5-4570S 机器上使用 gcc 4.8 和 clang 3.5 来运行了测试。gcc 和 clang 的结果很相像,因此我只展示了 gcc 的;完整的结果集合包含在了代码下载打包文件中,链接在上面。(点击图来缩放)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
大部分结果和 Windows 很相似,因此我只高亮了一些有趣的不同点。
|
||||
|
||||
**Lookup**:
|
||||
|
||||
这里 DO1 跑在前头,而在 Windows 中 DO2 更快些。(LCTT 译注: 这里原文写错了吧?)同样,UM 和 Ch 落后于其它所有的实现——过多的指针追踪,然而 OA 只需要在内存中线性的移动即可。至于 Windows 和 Linux 结果为何不同,则不是很清楚。UM 同样比 Ch 慢了不少,特别是大负载时,这很奇怪;我期望的是它们可以基本相同。
|
||||
|
||||
**Failed lookup**:
|
||||
|
||||
UM 再一次落后于其它实现,甚至比 OL 还要慢。我再一次无法理解为何 UM 比 Ch 慢这么多,Linux 和 Windows 的结果为何有着如此大的差距。
|
||||
|
||||
|
||||
**Destruct**:
|
||||
|
||||
在我的实现中,小负载的时候,析构的消耗太少了,以至于无法测量;在大负载中,线性增加的比例和创建的虚拟内存页数量相关,而不是申请到的数量?同样,要比 Windows 中的析构快上几个数量级。但是并不是所有的都和 hash 表有关;我们在这里可以看出不同系统和运行时内存系统的表现。貌似,Linux 释放大内存块是要比 Windows 快上不少(或者 Linux 很好的隐藏了开支,或许将释放工作推迟到了进程退出,又或者将工作推给了其它线程或者进程)。
|
||||
|
||||
UM 由于要释放每一个元素,所以在所有的负载中都比其它慢上几个数量级。事实上,我将图片做了剪裁,因为 UM 太慢了,以至于破坏了 Y 轴的比例。
|
||||
|
||||
### 总结
|
||||
|
||||
好,当我们凝视各种情况下的数据和矛盾的结果时,我们可以得出什么结果呢?我想直接了当的告诉你这些 hash 表变种中有一个打败了其它所有的 hash 表,但是这显然不那么简单。不过我们仍然可以学到一些东西。
|
||||
|
||||
首先,在大多数情况下我们“很容易”做的比 `std::unordered_map` 还要好。我为这些测试所写的所有实现(它们并不复杂;我只花了一两个小时就写完了)要么是符合 `unordered_map` 要么是在其基础上做的提高,除了大负载(超过128字节)中的插入性能, `unordered_map` 为每一个节点独立申请存储占了优势。(尽管我没有测试,我同样期望 `unordered_map` 能在非 POD 类型的负载上取得胜利。)具有指导意义的是,如果你非常关心性能,不要假设你的标准库中的数据结构是高度优化的。它们可能只是在 C++ 标准的一致性上做了优化,但不是性能。:P
|
||||
|
||||
其次,如果不管在小负载还是超负载中,若都只用 DO1 (开放寻址,线性探测,hashes/states 和 key/vaules分别处在隔离的普通数组中),那可能不会有啥好表现。这不是最快的插入,但也不坏(还比 `unordered_map` 快),并且在查找,移除,析构中也很快。你所知道的 —— “面向数据设计”完成了!
|
||||
|
||||
注意,我的为这些哈希表做的测试代码远未能用于生产环境——它们只支持 POD 类型,没有拷贝构造函数以及类似的东西,也未检测重复的 key,等等。我将可能尽快的构建一些实际的 hash 表,用于我的实用库中。为了覆盖基础部分,我想我将有两个变种:一个基于 DO1,用于小的,移动时不需要太大开支的负载;另一个用于链接并且避免重新申请和移动元素(就像 `unordered_map` ),用于大负载或者移动起来需要大开支的负载情况。这应该会给我带来最好的两个世界。
|
||||
|
||||
与此同时,我希望你们会有所启迪。最后记住,如果 Chandler Carruth 和 Mike Acton 在数据结构上给你提出些建议,你一定要听。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一名图形程序员,目前在西雅图做自由职业者。之前我在 NVIDIA 的 DevTech 软件团队中工作,并在美少女特工队工作室中为 PS3 和 PS4 的 Infamous 系列游戏开发渲染技术。
|
||||
|
||||
自 2002 年起,我对图形非常感兴趣,并且已经完成了一系列的工作,包括:雾、大气雾霾、体积照明、水、视觉效果、粒子系统、皮肤和头发阴影、后处理、镜面模型、线性空间渲染、和 GPU 性能测量和优化。
|
||||
|
||||
你可以在我的博客了解更多和我有关的事,处理图形,我还对理论物理和程序设计感兴趣。
|
||||
|
||||
你可以在 nathaniel.reed@gmail.com 或者在 Twitter(@Reedbeta)/Google+ 上关注我。我也会经常在 StackExchange 上回答计算机图形的问题。
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[sanfusu](https://github.com/sanfusu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -0,0 +1,123 @@
|
||||
连接到 Linux 服务器时首先要运行的 5 个命令
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
[Creative Commons Attribution][1][Sylvain Kalache][2][当我连接到 Linux 服务器时运行的前 5 个命令][3]
|
||||
|
||||
作为一个系统管理员/SRE 工作 5 年后,我知道当我连接到一台 Linux 服务器时我首先应该做什么。这里有一系列关于服务器你必须了解的信息,以便你可以(在大部分时间里)更好的调试该服务器。
|
||||
|
||||
### 连上 Linux 服务器的第一分钟
|
||||
|
||||
这些命令对于有经验的软件工程师来说都非常熟悉,但我意识到对于一个刚开始接触 Linux 系统的初学者来说,例如我在 [Holberton 学校][5]任教的学生,却并非如此。这也是我为什么决定分享当我连上 Linux 服务器首先要运行的前 5 个命令的原因。
|
||||
|
||||
```
|
||||
w
|
||||
history
|
||||
top
|
||||
df
|
||||
netstat
|
||||
```
|
||||
|
||||
这 5 个命令在任何一个 Linux 发行版中都有,因此不需要额外的安装步骤你就可以直接使用它们。
|
||||
|
||||
### w:
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ w
|
||||
23:40:25 up 273 days, 20:52, 2 users, load average: 0.33, 0.14, 0.12
|
||||
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
|
||||
ubuntu pts/0 104-7-14-91.ligh 23:39 0.00s 0.02s 0.00s w
|
||||
root pts/1 104-7-14-91.ligh 23:40 5.00s 0.01s 0.03s sshd: root [priv]
|
||||
[ubuntu@ip-172-31-48-251 ~]$
|
||||
```
|
||||
|
||||
这里列出了很多有用的信息。首先,你可以看到服务器运行时间 [uptime][6],也就是服务器持续运行的时间。然后你可以看到有哪些用户连接到了服务器,当你要确认你没有影响你同事工作的时候这非常有用。最后 [load average][7] 能很好的向你展示服务器的健康状态。
|
||||
|
||||
### history
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ history
|
||||
1 cd /var/app/current/log/
|
||||
2 ls -al
|
||||
3 tail -n 3000 production.log
|
||||
4 service apache2 status
|
||||
5 cat ../../app/services/discourse_service.rb
|
||||
```
|
||||
|
||||
`history` 能告诉你当前连接的用户之前运行了什么命令。你可以看到很多关于这台机器之前在执行什么类型的任务、可能出现了什么错误、可以从哪里开始调试工作等信息。
|
||||
|
||||
### top
|
||||
|
||||
```
|
||||
top - 23:47:54 up 273 days, 21:00, 2 users, load average: 0.02, 0.07, 0.10
|
||||
Tasks: 79 total, 2 running, 77 sleeping, 0 stopped, 0 zombie
|
||||
Cpu(s): 1.0%us, 0.0%sy, 0.0%ni, 98.7%id, 0.0%wa, 0.0%hi, 0.0%si, 0.3%st
|
||||
Mem: 3842624k total, 3128036k used, 714588k free, 148860k buffers
|
||||
Swap: 0k total, 0k used, 0k free, 1052320k cached
|
||||
|
||||
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
|
||||
21095 root 20 0 513m 21m 4980 S 1.0 0.6 1237:05 python
|
||||
1380 healthd 20 0 669m 36m 5712 S 0.3 1.0 265:43.82 ruby
|
||||
19703 dd-agent 20 0 142m 25m 4912 S 0.3 0.7 11:32.32 python
|
||||
1 root 20 0 19596 1628 1284 S 0.0 0.0 0:10.64 init
|
||||
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
|
||||
3 root 20 0 0 0 0 S 0.0 0.0 27:31.42 ksoftirqd/0
|
||||
4 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0
|
||||
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
|
||||
7 root 20 0 0 0 0 S 0.0 0.0 42:51.60 rcu_sched
|
||||
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
|
||||
```
|
||||
|
||||
你想知道的下一个信息:服务器当前在执行什么工作。使用 `top` 命令你可以看到所有正在执行的进程,然后可以按照 CPU、内存使用进行排序,并找到占用资源的进程。
|
||||
|
||||
### df
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ~]$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/xvda1 7.8G 4.5G 3.3G 58% /
|
||||
devtmpfs 1.9G 12K 1.9G 1% /dev
|
||||
tmpfs 1.9G 0 1.9G 0% /dev/shm
|
||||
```
|
||||
|
||||
你服务器正常工作需要的下一个重要资源就是磁盘空间。磁盘空间消耗完是非常典型的问题。
|
||||
|
||||
### netstat
|
||||
|
||||
```
|
||||
[ubuntu@ip-172-31-48-251 ec2-user]# netstat -lp
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 *:http *:* LISTEN 1637/nginx
|
||||
tcp 0 0 *:ssh *:* LISTEN 1209/sshd
|
||||
tcp 0 0 localhost:smtp *:* LISTEN 1241/sendmail
|
||||
tcp 0 0 localhost:17123 *:* LISTEN 19703/python
|
||||
tcp 0 0 localhost:22221 *:* LISTEN 1380/puma 2.11.1 (t
|
||||
tcp 0 0 *:4242 *:* LISTEN 18904/jsvc.exec
|
||||
tcp 0 0 *:ssh *:* LISTEN 1209/sshd
|
||||
```
|
||||
|
||||
计算机已成为我们世界的重要一部分,因为它们有通过网络进行相互交流的能力。知道你的服务器正在监听什么端口、IP地址是什么、以及哪些进程在使用它们,这对于你来说都非常重要。
|
||||
|
||||
显然这个列表会随着你的目的和你已有的信息而变化。例如,当你需要调试性能的时候,[Netflix 就有一个自定义的列表][8]。你有任何不在我 Top 5 中的有用命令吗?在评论部分和我们一起分享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/first-5-commands-when-i-connect-linux-server
|
||||
|
||||
作者:[SYLVAIN KALACHE][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sylvainkalache
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://twitter.com/sylvainkalache
|
||||
[3]:https://www.flickr.com/photos/sylvainkalache/29587668230/in/dateposted/
|
||||
[4]:https://www.linux.com/files/images/first-5-commandsjpg-0
|
||||
[5]:https://www.holbertonschool.com/
|
||||
[6]:http://whatis.techtarget.com/definition/uptime-and-downtime
|
||||
[7]:http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages
|
||||
[8]:http://techblog.netflix.com/2015/11/linux-performance-analysis-in-60s.html
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user