mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'refs/remotes/origin/patch-1'
This commit is contained in:
commit
4f0f58d451
@ -0,0 +1,162 @@
|
||||
网络与安全方面的最佳开源软件
|
||||
================================================================================
|
||||
InfoWorld 在部署、运营和保障网络安全领域精选出了年度开源工具获奖者。
|
||||
|
||||

|
||||
|
||||
### 最佳开源网络和安全软件 ###
|
||||
|
||||
[BIND](https://en.wikipedia.org/wiki/BIND), [Sendmail](https://en.wikipedia.org/wiki/Sendmail), [OpenSSH](https://en.wikipedia.org/wiki/OpenSSH), [Cacti](https://en.wikipedia.org/wiki/Cactus), [Nagios](https://en.wikipedia.org/wiki/Nagios), [Snort](https://en.wikipedia.org/wiki/Snort_%28software%29) -- 这些为了网络而生的开源软件,好些家伙们老而弥坚。今年在这个范畴的最佳选择中,你会发现中坚、支柱、新人和新贵云集,他们正在完善网络管理,安全监控,漏洞评估,[rootkit](https://en.wikipedia.org/wiki/Rootkit) 检测,以及很多方面。
|
||||
|
||||

|
||||
|
||||
### Icinga 2 ###
|
||||
|
||||
Icinga 起先只是系统监控应用 Nagios 的一个衍生分支。[Icinga 2][1] 经历了完全的重写,为用户带来了时尚的界面、对多数据库的支持,以及一个集成了众多扩展的 API。凭借着开箱即用的负载均衡、通知和配置文件,Icinga 2 缩短了在复杂环境下安装的时间。Icinga 2 原生支持 [Graphite](https://github.com/graphite-project/graphite-web)(系统监控应用),轻松为管理员呈现实时性能图表。不过真的让 Icinga 今年重新火起来的原因是 Icinga Web 2 的发布,那是一个支持可拖放定制的 仪表盘 和一些流式监控工具的前端图形界面系统。
|
||||
|
||||
管理员可以查看、过滤、并按优先顺序排列发现的问题,同时可以跟踪已经采取的动作。一个新的矩阵视图使管理员能够在单一页面上查看主机和服务。你可以通过查看特定时间段的事件或筛选事件类型来了解哪些事件需要立即关注。虽然 Icinga Web 2 有着全新界面和更为强劲的性能,不过对于传统版 Icinga 和 Web 版 Icinga 的所有常用命令还是照旧支持的。这意味着学习新版工具不耗费额外的时间。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Zenoss Core ###
|
||||
|
||||
这是另一个强大的开源软件,[Zenoss Core][2] 为网络管理员提供了一个完整的、一站式解决方案来跟踪和管理所有的应用程序、服务器、存储、网络组件、虚拟化工具、以及企业基础架构的其他元素。管理员可以确保硬件的运行效率并利用 ZenPacks 中模块化设计的插件来扩展功能。
|
||||
|
||||
在2015年二月发布的 Zenoss Core 5 保留了已经很强大的工具,并进一步改进以增强用户界面和扩展 仪表盘。基于 Web 的控制台和 仪表盘 可以高度可定制并动态调整,而现在的新版本还能让管理员混搭多个组件图表到一个图表中。想来这应该是一个更好的根源分析和因果分析的工具。
|
||||
|
||||
Portlets 为网络映射、设备问题、守护进程、产品状态、监视列表和事件视图等等提供了深入的分析。而且新版 HTML5 图表可以从工具导出。Zenoss 的控制中心支持带外管理并且可监控所有 Zenoss 组件。Zenoss Core 现在拥有一些新工具,用于在线备份和恢复、快照和回滚以及多主机部署等方面。更重要的是,凭借对 Docker 的全面支持,部署起来更快了。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenNMS ###
|
||||
|
||||
作为一个非常灵活的网络管理解决方案,[OpenNMS][3] 可以处理任何网络管理任务,无论是设备管理、应用性能监控、库存控制,或事件管理。凭借对 IPv6 的支持、强大的警报系统和记录用户脚本来测试 Web 应用程序的能力,OpenNMS 拥有网络管理员和测试人员需要的一切。OpenNMS 现在变得像一款移动版 仪表盘,称之为 OpenNMS Compass,可让网络专家随时,甚至在外出时都可以监视他们的网络。
|
||||
|
||||
该应用程序的 IOS 版本,可从 [iTunes App Store][4] 上获取,可以显示故障、节点和告警。下一个版本将提供更多的事件细节、资源图表、以及关于 IP 和 SNMP 接口的信息。安卓版可从 [Google Play][5] 上获取,可在 仪表盘 上显示网络可用性,故障和告警,以及可以确认、提升或清除告警。移动客户端与 OpenNMS Horizon 1.12 或更高版本以及 OpenNMS Meridian 2015.1.0 或更高版本兼容。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Security Onion ###
|
||||
|
||||
如同一个洋葱,网络安全监控是由许多层组成。没有任何一个单一的工具可以让你洞察每一次攻击,为你显示对你的公司网络中的每一次侦查或是会话的足迹。[Security Onion][6] 在一个简单易用的 Ubuntu 发行版中打包了许多久经考验的工具,可以让你看到谁留在你的网络里,并帮助你隔离这些坏家伙。
|
||||
|
||||
无论你是采取主动式的网络安全监测还是追查可能的攻击,Security Onion 都可以帮助你。Onion 由传感器、服务器和显示层组成,结合了基于网络和基于主机的入侵检测,全面的网络数据包捕获,并提供了所有类型的日志以供检查和分析。
|
||||
|
||||
这是一个众星云集的的网络安全工具链,包括用于网络抓包的 [Netsniff-NG](http://www.netsniff-ng.org/)、基于规则的网络入侵检测系统 Snort 和 [Suricata](https://en.wikipedia.org/wiki/Suricata_%28software%29),基于分析的网络监控系统 Bro,基于主机的入侵检测系统 OSSEC 和用于显示、分析和日志管理的 Sguil、Squert、Snorby 和 ELSA (企业日志搜索和归档(Enterprise Log Search and Archive))。它是一个经过精挑细选的工具集,所有的这些全被打包进一个向导式的安装程序并有完整的文档支持,可以帮助你尽可能快地上手监控。
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
### Kali Linux ###
|
||||
|
||||
[Kali Linux][7] 背后的团队今年为这个流行的安全 Linux 发行版发布了新版本,使其更快,更全能。Kali 采用全新 4.0 版的内核,改进了对硬件和无线驱动程序的支持,并且界面更为流畅。最常用的工具都可从屏幕的侧边栏上轻松找到。而最大的改变是 Kali Linux 现在是一个滚动发行版,具有持续不断的软件更新。Kali 的核心系统是基于 Debian Jessie,而且该团队会不断地从 Debian 测试版拉取最新的软件包,并持续的在上面添加 Kali 风格的新特性。
|
||||
|
||||
该发行版仍然配备了很多的渗透测试,漏洞分析,安全审查,网络应用分析,无线网络评估,逆向工程,和漏洞利用工具。现在该发行版具有上游版本检测系统,当有个别工具可更新时系统会自动通知用户。该发行版还提过了一系列 ARM 设备的镜像,包括树莓派、[Chromebook](https://en.wikipedia.org/wiki/Chromebook) 和 [Odroid](https://en.wikipedia.org/wiki/ODROID),同时也更新了 Android 设备上运行的 [NetHunter](https://www.kali.org/kali-linux-nethunter/) 渗透测试平台。还有其他的变化:Metasploit 的社区版/专业版不再包括在内,因为 Kali 2.0 还没有 [Rapid7 的官方支持][8]。
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenVAS ###
|
||||
|
||||
开放式漏洞评估系统(Open Vulnerability Assessment System) [OpenVAS][9],是一个整合多种服务和工具来提供漏洞扫描和漏洞管理的软件框架。该扫描器可以使用每周更新一次的网络漏洞测试数据,或者你也可以使用商业服务的数据。该软件框架包括一个命令行界面(以使其可以用脚本调用)和一个带 SSL 安全机制的基于 [Greenbone 安全助手][10] 的浏览器界面。OpenVAS 提供了用于附加功能的各种插件。扫描可以预定运行或按需运行。
|
||||
|
||||
可通过单一的主控来控制多个安装好 OpenVAS 的系统,这使其成为了一个可扩展的企业漏洞评估工具。该项目兼容的标准使其可以将扫描结果和配置存储在 SQL 数据库中,这样它们可以容易地被外部报告工具访问。客户端工具通过基于 XML 的无状态 OpenVAS 管理协议访问 OpenVAS 管理器,所以安全管理员可以扩展该框架的功能。该软件能以软件包或源代码的方式安装在 Windows 或 Linux 上运行,或者作为一个虚拟应用下载。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### OWASP ###
|
||||
|
||||
[OWASP][11](开放式 Web 应用程序安全项目(Open Web Application Security Project))是一个专注于提高软件安全性的在全球各地拥有分会的非营利组织。这个社区性的组织提供测试工具、文档、培训和几乎任何你可以想象到的开发安全软件相关的软件安全评估和最佳实践。有一些 OWASP 项目已成为很多安全从业者工具箱中的重要组件:
|
||||
|
||||
[ZAP][12](ZED 攻击代理项目(Zed Attack Proxy Project))是一个在 Web 应用程序中寻找漏洞的渗透测试工具。ZAP 的设计目标之一是使之易于使用,以便于那些并非安全领域专家的开发人员和测试人员能便于使用。ZAP 提供了自动扫描和一套手动测试工具集。
|
||||
|
||||
[Xenotix XSS Exploit Framework][13] 是一个先进的跨站点脚本漏洞检测和漏洞利用框架,该框架通过在浏览器引擎内执行扫描以获取真实的结果。Xenotix 扫描模块使用了三个智能模糊器( intelligent fuzzers),使其可以运行近 5000 种不同的 XSS 有效载荷。它有个 API 可以让安全管理员扩展和定制漏洞测试工具包。
|
||||
|
||||
[O-Saft][14](OWASP SSL 高级审查工具(OWASP SSL advanced forensic tool))是一个查看 SSL 证书详细信息和测试 SSL 连接的 SSL 审计工具。这个命令行工具可以在线或离线运行来评估 SSL ,比如算法和配置是否安全。O-Saft 内置提供了常见漏洞的检查,你可以容易地通过编写脚本来扩展这些功能。在 2015 年 5 月加入了一个简单的图形用户界面作为可选的下载项。
|
||||
|
||||
[OWTF][15](攻击性 Web 测试框架(Offensive Web Testing Framework))是一个遵循 OWASP 测试指南和 NIST 和 PTES 标准的自动化测试工具。该框架同时支持 Web 用户界面和命令行,用于探测 Web 和应用服务器的常见漏洞,如配置失当和软件未打补丁。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### BeEF ###
|
||||
|
||||
Web 浏览器已经成为用于针对客户端的攻击中最常见的载体。[BeEF][15] (浏览器漏洞利用框架项目(Browser Exploitation Framework Project)),是一种广泛使用的用以评估 Web 浏览器安全性的渗透工具。BeEF 通过浏览器来启动客户端攻击,帮助你暴露出客户端系统的安全弱点。BeEF 建立了一个恶意网站,安全管理员用想要测试的浏览器访问该网站。然后 BeEF 发送命令来攻击 Web 浏览器并使用命令在客户端机器上植入软件。随后管理员就可以把客户端机器看作不设防般发动攻击了。
|
||||
|
||||
BeEF 自带键盘记录器、端口扫描器和 Web 代理这样的常用模块,此外你可以编写你自己的模块或直接将命令发送到被控制的测试机上。BeEF 带有少量的演示网页来帮你快速入门,使得编写更多的网页和攻击模块变得非常简单,让你可以因地适宜的自定义你的测试。BeEF 是一个非常有价值的评估浏览器和终端安全、学习如何发起基于浏览器攻击的测试工具。可以使用它来向你的用户综合演示,那些恶意软件通常是如何感染客户端设备的。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### Unhide ###
|
||||
|
||||
[Unhide][16] 是一个用于定位开放的 TCP/UDP 端口和隐藏在 UNIX、Linux 和 Windows 上的进程的审查工具。隐藏的端口和进程可能是由于运行 Rootkit 或 LKM(可加载的内核模块(loadable kernel module)) 导致的。Rootkit 可能很难找到并移除,因为它们就是专门针对隐蔽性而设计的,可以在操作系统和用户前隐藏自己。一个 Rootkit 可以使用 LKM 隐藏其进程或冒充其他进程,让它在机器上运行很长一段时间而不被发现。而 Unhide 则可以使管理员们确信他们的系统是干净的。
|
||||
|
||||
Unhide 实际上是两个单独的脚本:一个用于进程,一个用于端口。该工具查询正在运行的进程、线程和开放的端口并将这些信息与系统中注册的活动比较,报告之间的差异。Unhide 和 WinUnhide 是非常轻量级的脚本,可以运行命令行而产生文本输出。它们不算优美,但是极为有用。Unhide 也包括在 [Rootkit Hunter][17] 项目中。
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### 查看更多的开源软件优胜者 ###
|
||||
|
||||
InfoWorld 网站的 2015 年最佳开源奖由下至上表扬了 100 多个开源项目。通过以下链接可以查看更多开源软件中的翘楚:
|
||||
|
||||
[2015 Bossie 评选:最佳开源应用程序][18]
|
||||
|
||||
[2015 Bossie 评选:最佳开源应用程序开发工具][19]
|
||||
|
||||
[2015 Bossie 评选:最佳开源大数据工具][20]
|
||||
|
||||
[2015 Bossie 评选:最佳开源数据中心和云计算软件][21]
|
||||
|
||||
[2015 Bossie 评选:最佳开源桌面和移动端软件][22]
|
||||
|
||||
[2015 Bossie 评选:最佳开源网络和安全软件][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982962/open-source-tools/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[robot527](https://github.com/robot527)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.icinga.org/icinga/icinga-2/
|
||||
[2]:http://www.zenoss.com/
|
||||
[3]:http://www.opennms.org/
|
||||
[4]:https://itunes.apple.com/us/app/opennms-compass/id968875097?mt=8
|
||||
[5]:https://play.google.com/store/apps/details?id=com.opennms.compass&hl=en
|
||||
[6]:http://blog.securityonion.net/p/securityonion.html
|
||||
[7]:https://www.kali.org/
|
||||
[8]:https://community.rapid7.com/community/metasploit/blog/2015/08/12/metasploit-on-kali-linux-20
|
||||
[9]:http://www.openvas.org/
|
||||
[10]:http://www.greenbone.net/
|
||||
[11]:https://www.owasp.org/index.php/Main_Page
|
||||
[12]:https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
|
||||
[13]:https://www.owasp.org/index.php/O-Saft
|
||||
[14]:https://www.owasp.org/index.php/OWASP_OWTF
|
||||
[15]:http://www.beefproject.com/
|
||||
[16]:http://www.unhide-forensics.info/
|
||||
[17]:http://www.rootkit.nl/projects/rootkit_hunter.html
|
||||
[18]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[19]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[20]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[21]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[22]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[23]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -0,0 +1,156 @@
|
||||
如何在 Linux 上使用 Gmail SMTP 服务器发送邮件通知
|
||||
================================================================================
|
||||
假定你想配置一个 Linux 应用,用于从你的服务器或桌面客户端发送邮件信息。邮件信息可能是邮件简报、状态更新(如 [Cachet][1])、监控警报(如 [Monit][2])、磁盘时间(如 [RAID mdadm][3])等等。当你要建立自己的 [邮件发送服务器][4] 传递信息时 ,你可以替代使用一个免费的公共 SMTP 服务器,从而避免遭受维护之苦。
|
||||
|
||||
谷歌的 Gmail 服务就是最可靠的 **免费 SMTP 服务器** 之一。想要从应用中发送邮件通知,你仅需在应用中添加 Gmail 的 SMTP 服务器地址和你的身份凭证即可。
|
||||
|
||||
使用 Gmail 的 SMTP 服务器会遇到一些限制,这些限制主要用于阻止那些经常滥用服务器来发送垃圾邮件和使用邮件营销的家伙。举个例子,你一次只能给至多 100 个地址发送信息,并且一天不能超过 500 个收件人。同样,如果你不想被标为垃圾邮件发送者,你就不能发送过多的不可投递的邮件。当你达到任何一个限制,你的 Gmail 账户将被暂时的锁定一天。简而言之,Gmail 的 SMTP 服务器对于你个人的使用是非常棒的,但不适合商业的批量邮件。
|
||||
|
||||
说了这么多,是时候向你们展示 **如何在 Linux 环境下使用 Gmail 的 SMTP 服务器** 了。
|
||||
|
||||
### Google Gmail SMTP 服务器设置 ###
|
||||
|
||||
如果你想要通过你的应用使用 Gmail 的 SMTP 服务器发送邮件,请牢记接下来的详细说明。
|
||||
|
||||
- **邮件发送服务器 (SMTP 服务器)**: smtp.gmail.com
|
||||
- **使用认证**: 是
|
||||
- **使用安全连接**: 是
|
||||
- **用户名**: 你的 Gmail 账户 ID (比如 "alice" ,如果你的邮箱为 alice@gmail.com)
|
||||
- **密码**: 你的 Gmail 密码
|
||||
- **端口**: 587
|
||||
|
||||
确切的配置根据应用会有所不同。在本教程的剩余部分,我将向你展示一些在 Linux 上使用 Gmail SMTP 服务器的应用示例。
|
||||
|
||||
### 从命令行发送邮件 ###
|
||||
|
||||
作为第一个例子,让我们尝试最基本的邮件功能:使用 Gmail SMTP 服务器从命令行发送一封邮件。为此,我将使用一个称为 mutt 的命令行邮件客户端。
|
||||
|
||||
先安装 mutt:
|
||||
|
||||
对于 Debian-based 系统:
|
||||
|
||||
$ sudo apt-get install mutt
|
||||
|
||||
对于 Red Hat based 系统:
|
||||
|
||||
$ sudo yum install mutt
|
||||
|
||||
创建一个 mutt 配置文件(~/.muttrc),并和下面一样,在文件中指定 Gmail SMTP 服务器信息。将 \<gmail-id> 替换成自己的 Gmail ID。注意该配置只是为了发送邮件而已(而非接收邮件)。
|
||||
|
||||
$ vi ~/.muttrc
|
||||
|
||||
----------
|
||||
|
||||
set from = "<gmail-id>@gmail.com"
|
||||
set realname = "Dan Nanni"
|
||||
set smtp_url = "smtp://<gmail-id>@smtp.gmail.com:587/"
|
||||
set smtp_pass = "<gmail-password>"
|
||||
|
||||
一切就绪,使用 mutt 发送一封邮件:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
|
||||
|
||||
想在一封邮件中添加附件,使用 "-a" 选项
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
|
||||
|
||||

|
||||
|
||||
使用 Gmail SMTP 服务器意味着邮件将显示是从你 Gmail 账户发出的。换句话说,收件人将视你的 Gmail 地址为发件人地址。如果你想要使用自己的域名作为邮件发送方,你需要使用 Gmail SMTP 转发服务。
|
||||
|
||||
### 当服务器重启时发送邮件通知 ###
|
||||
|
||||
如果你在 [虚拟专用服务器(VPS)][5] 上跑了些重要的网站,建议监控 VPS 的重启行为。作为一个更为实用的例子,让我们研究如何在你的 VPS 上为每一次重启事件建立邮件通知。这里假设你的 VPS 上使用的是 systemd,并向你展示如何为自动邮件通知创建一个自定义的 systemd 启动服务。
|
||||
|
||||
首先创建下面的脚本 reboot_notify.sh,用于负责邮件通知。
|
||||
|
||||
$ sudo vi /usr/local/bin/reboot_notify.sh
|
||||
|
||||
----------
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
|
||||
|
||||
----------
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/reboot_notify.sh
|
||||
|
||||
在这个脚本中,我使用 "-F" 选项,用于指定系统级的 mutt 配置文件位置。因此不要忘了创建 /etc/muttrc 文件,并如前面描述的那样填入 Gmail SMTP 信息。
|
||||
|
||||
现在让我们创建如下一个自定义的 systemd 服务。
|
||||
|
||||
$ sudo mkdir -p /usr/local/lib/systemd/system
|
||||
$ sudo vi /usr/local/lib/systemd/system/reboot-task.service
|
||||
|
||||
----------
|
||||
|
||||
[Unit]
|
||||
Description=Send a notification email when the server gets rebooted
|
||||
DefaultDependencies=no
|
||||
Before=reboot.target
|
||||
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=/usr/local/bin/reboot_notify.sh
|
||||
|
||||
[Install]
|
||||
WantedBy=reboot.target
|
||||
|
||||
在创建服务后,添加并启动该服务。
|
||||
|
||||
$ sudo systemctl enable reboot-task
|
||||
$ sudo systemctl start reboot-task
|
||||
|
||||
从现在起,在每次 VPS 重启时,你将会收到一封通知邮件。
|
||||
|
||||
|
||||
|
||||
### 通过服务器使用监控发送邮件通知 ###
|
||||
|
||||
作为最后一个例子,让我展示一个现实生活中的应用程序,[Monit][6],这是一款极其有用的服务器监控应用程序。它带有全面的 [VPS][7] 监控能力(比如 CPU、内存、进程、文件系统)和邮件通知功能。
|
||||
|
||||
如果你想要接收 VPS 上由 Monit 产生的任何事件的邮件通知,你可以在 Monit 配置文件中添加以下 SMTP 信息。
|
||||
|
||||
set mailserver smtp.gmail.com port 587
|
||||
username "<your-gmail-ID>" password "<gmail-password>"
|
||||
using tlsv12
|
||||
|
||||
set mail-format {
|
||||
from: <your-gmail-ID>@gmail.com
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
}
|
||||
|
||||
# the person who will receive notification emails
|
||||
set alert alice@yahoo.com
|
||||
|
||||
这是一个因为 CPU 负载超载而由 Monit 发送的邮件通知的例子。
|
||||
|
||||
|
||||
|
||||
### 总结 ###
|
||||
|
||||
如你所见,类似 Gmail 这样免费的 SMTP 服务器有着这么多不同的运用方式 。但再次重申,请牢记免费的 SMTP 服务器不适用于商业用途,仅仅适用于个人项目。无论你正在哪款应用中使用 Gmail SMTP 服务器,欢迎自由分享你的用例。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[martin2011qi](https://github.com/martin2011qi), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/setup-system-status-page.html
|
||||
[2]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[5]:http://xmodulo.com/go/digitalocean
|
||||
[6]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[7]:http://xmodulo.com/go/digitalocean
|
||||
65
published/20151204 Review EXT4 vs. Btrfs vs. XFS.md
Normal file
65
published/20151204 Review EXT4 vs. Btrfs vs. XFS.md
Normal file
@ -0,0 +1,65 @@
|
||||
如何选择文件系统:EXT4、Btrfs 和 XFS
|
||||
================================================================================
|
||||

|
||||
|
||||
老实说,人们最不曾思考的问题之一是他们的个人电脑中使用了什么文件系统。Windows 和 Mac OS X 用户更没有理由去考虑,因为对于他们的操作系统,只有一种选择,那就是 NTFS 和 HFS+。相反,对于 Linux 系统而言,有很多种文件系统可以选择,现在默认的是广泛采用的 ext4。然而,现在也有改用一种称为 btrfs 文件系统的趋势。那是什么使得 btrfs 更优秀,其它的文件系统又是什么,什么时候我们又能看到 Linux 发行版作出改变呢?
|
||||
|
||||
首先让我们对文件系统以及它们真正干什么有个总体的认识,然后我们再对一些有名的文件系统做详细的比较。
|
||||
|
||||
### 文件系统是干什么的? ###
|
||||
|
||||
如果你不清楚文件系统是干什么的,一句话总结起来也非常简单。文件系统主要用于控制所有程序在不使用数据时如何存储数据、如何访问数据以及有什么其它信息(元数据)和数据本身相关,等等。听起来要编程实现并不是轻而易举的事情,实际上也确实如此。文件系统一直在改进,包括了更多的功能、更高效地完成它需要做的事情。总而言之,它是所有计算机的基本需求、但并不像听起来那么简单。
|
||||
|
||||
### 为什么要分区? ###
|
||||
|
||||
由于每个操作系统都能创建或者删除分区,很多人对分区都有模糊的认识。Linux 操作系统即便使用标准安装过程,在同一块磁盘上仍使用多个分区,这看起来很奇怪,因此需要一些解释。拥有不同分区的一个主要目的就是为了在灾难发生时能获得更好的数据安全性。
|
||||
|
||||
通过将硬盘划分为分区,数据会被分隔以及重组。当事故发生的时候,只有存储在被损坏分区上的数据会被破坏,很大可能上其它分区的数据能得以保留。这个原因可以追溯到 Linux 操作系统还没有日志文件系统、任何电力故障都有可能导致灾难发生的时候。
|
||||
|
||||
使用分区也考虑到了安全和健壮性原因,因此操作系统部分损坏并不意味着整个计算机就有风险或者会受到破坏。这也是当前采用分区的一个最重要因素。举个例子,用户创建了一些会填满磁盘的脚本、程序或者 web 应用,如果该磁盘只有一个大的分区,如果磁盘满了那么整个系统就不能工作。如果用户把数据保存在不同的分区,那么就只有那个分区会受到影响,而系统分区或者其它数据分区仍能正常运行。
|
||||
|
||||
记住,拥有一个日志文件系统只能在掉电或者和存储设备意外断开连接时提供数据安全性,并不能在文件系统出现坏块或者发生逻辑错误时保护数据。对于这种情况,用户可以采用廉价磁盘冗余阵列(RAID:Redundant Array of Inexpensive Disks)的方案。
|
||||
|
||||
### 为什么要切换文件系统? ###
|
||||
|
||||
ext4 文件系统由 ext3 文件系统改进而来,而后者又是从 ext2 文件系统改进而来。虽然 ext4 文件系统已经非常稳定,是过去几年中绝大部分发行版的默认选择,但它是基于陈旧的代码开发而来。另外, Linux 操作系统用户也需要很多 ext4 文件系统本身不提供的新功能。虽然通过某些软件能满足这种需求,但性能会受到影响,在文件系统层次做到这些能获得更好的性能。
|
||||
|
||||
### Ext4 文件系统 ###
|
||||
|
||||
ext4 还有一些明显的限制。最大文件大小是 16 tebibytes(大概是 17.6 terabytes),这比普通用户当前能买到的硬盘还要大的多。使用 ext4 能创建的最大卷/分区是 1 exbibyte(大概是 1,152,921.5 terabytes)。通过使用多种技巧, ext4 比 ext3 有很大的速度提升。类似一些最先进的文件系统,它是一个日志文件系统,意味着它会对文件在磁盘中的位置以及任何其它对磁盘的更改做记录。纵观它的所有功能,它还不支持透明压缩、重复数据删除或者透明加密。技术上支持了快照,但该功能还处于实验性阶段。
|
||||
|
||||
### Btrfs 文件系统 ###
|
||||
|
||||
btrfs 有很多不同的叫法,例如 Better FS、Butter FS 或者 B-Tree FS。它是一个几乎完全从头开发的文件系统。btrfs 出现的原因是它的开发者起初希望扩展文件系统的功能使得它包括快照、池化(pooling)、校验以及其它一些功能。虽然和 ext4 无关,它也希望能保留 ext4 中能使消费者和企业受益的功能,并整合额外的能使每个人,尤其是企业受益的功能。对于使用大型软件以及大规模数据库的企业,让多种不同的硬盘看起来一致的文件系统能使他们受益并且使数据整合变得更加简单。删除重复数据能降低数据实际使用的空间,当需要镜像一个单一而巨大的文件系统时使用 btrfs 也能使数据镜像变得简单。
|
||||
|
||||
用户当然可以继续选择创建多个分区从而无需镜像任何东西。考虑到这种情况,btrfs 能横跨多种硬盘,和 ext4 相比,它能支持 16 倍以上的磁盘空间。btrfs 文件系统一个分区最大是 16 exbibytes,最大的文件大小也是 16 exbibytes。
|
||||
|
||||
### XFS 文件系统 ###
|
||||
|
||||
XFS 文件系统是扩展文件系统(extent file system)的一个扩展。XFS 是 64 位高性能日志文件系统。对 XFS 的支持大概在 2002 年合并到了 Linux 内核,到了 2009 年,红帽企业版 Linux 5.4 也支持了 XFS 文件系统。对于 64 位文件系统,XFS 支持最大文件系统大小为 8 exbibytes。XFS 文件系统有一些缺陷,例如它不能压缩,删除大量文件时性能低下。目前RHEL 7.0 文件系统默认使用 XFS。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
不幸的是,还不知道 btrfs 什么时候能到来。官方说,其下一代文件系统仍然被归类为“不稳定”,但是如果用户下载最新版本的 Ubuntu,就可以选择安装到 btrfs 分区上。什么时候 btrfs 会被归类到 “稳定” 仍然是个谜, 直到真的认为它“稳定”之前,用户也不应该期望 Ubuntu 会默认采用 btrfs。有报道说 Fedora 18 会用 btrfs 作为它的默认文件系统,因为到了发布它的时候,应该有了 btrfs 文件系统校验器。由于还没有实现所有的功能,另外和 ext4 相比性能上也比较缓慢,btrfs 还有很多的工作要做。
|
||||
|
||||
那么,究竟使用哪个更好呢?尽管性能几乎相同,但 ext4 还是赢家。为什么呢?答案在于易用性以及广泛性。对于桌面或者工作站, ext4 仍然是一个很好的文件系统。由于它是默认提供的文件系统,用户可以在上面安装操作系统。同时, ext4 支持最大 1 exabytes 的卷和 16 terabytes 的文件,因此考虑到大小,它也还有很大的进步空间。
|
||||
|
||||
btrfs 能提供更大的高达 16 exabytes 的卷以及更好的容错,但是,到现在为止,它感觉更像是一个附加的文件系统,而部署一个集成到 Linux 操作系统的文件系统。比如,尽管 btrfs 支持不同的发行版,使用 btrfs 格式化硬盘之前先要有 btrfs-tools 工具,这意味着安装 Linux 操作系统的时候它并不是一个可选项,即便不同发行版之间会有所不同。
|
||||
|
||||
尽管传输速率非常重要,评价一个文件系统除了文件传输速度之外还有很多因素。btrfs 有很多好用的功能,例如写复制(Copy-on-Write)、扩展校验、快照、清洗、自修复数据、冗余删除以及其它保证数据完整性的功能。和 ZFS 相比 btrfs 缺少 RAID-Z 功能,因此对于 btrfs, RAID 还处于实验性阶段。对于单纯的数据存储,和 ext4 相比 btrfs 似乎更加优秀,但时间会验证一切。
|
||||
|
||||
迄今为止,对于桌面系统而言,ext4 似乎是一个更好的选择,因为它是默认的文件系统,传输文件时也比 btrfs 更快。btrfs 当然值得尝试、但要在桌面 Linux 上完全取代 ext4 可能还需要一些时间。数据场和大存储池会揭示关于 ext4、XCF 以及 btrfs 不同的场景和差异。
|
||||
|
||||
如果你有不同或者其它的观点,在下面的评论框中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -0,0 +1,371 @@
|
||||
怎样在 ubuntu 和 debian 中通过命令行管理 KVM
|
||||
================================================================================
|
||||
|
||||
有很多不同的方式去管理运行在 KVM 管理程序上的虚拟机。例如,virt-manager 就是一个流行的基于图形界面的前端虚拟机管理工具。然而,如果你想要在没有图形窗口的服务器环境下使用 KVM ,那么基于图形界面的解决方案显然是行不通的。事实上,你可以单纯使用包装了 kvm 命令行脚本的命令行来管理 KVM 虚拟机。作为替代方案,你可以使用 virsh 这个容易使用的命令行程序来管理客户虚拟机。在 virsh 中,它通过和 libvirtd 服务通信来达到控制虚拟机的目的,而 libvirtd 可以控制多个不同的虚拟机管理器,包括 KVM,Xen,QEMU,LXC 和 OpenVZ。
|
||||
|
||||
当你想要对虚拟机的前期准备和后期管理实现自动化操作时,像 virsh 这样的命令行管理工具是非常有用的。同样,virsh 支持多个管理器也就意味着你可以通过相同的 virsh 接口去管理不同的虚拟机管理器。
|
||||
|
||||
在这篇文章中,我会示范**怎样在 ubuntu 和 debian 上通过使用 virsh 命令行去运行 KVM**。
|
||||
|
||||
### 第一步:确认你的硬件平台支持虚拟化 ###
|
||||
|
||||
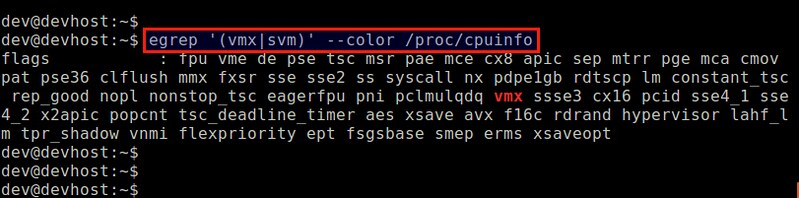
第一步,首先要确认你的 CPU 支持硬件虚拟化扩展(e.g.,Intel VT 或者 AMD-V),这是 KVM 对硬件的要求。下面的命令可以检查硬件是否支持虚拟化。
|
||||
|
||||
```
|
||||
$ egrep '(vmx|svm)' --color /proc/cpuinfo
|
||||
```
|
||||
|
||||
|
||||
|
||||
如果在输出中不包含 vmx 或者 svm 标识,那么就意味着你的 cpu 不支持硬件虚拟化。因此你不能在你的机器上使用 KVM 。确认了 cpu 支持 vmx 或者 svm 之后,接下来开始安装 KVM。
|
||||
|
||||
对于 KVM 来说,它不要求运行在拥有 64 位内核系统的主机上,但是通常我们会推荐在 64 位系统的主机上面运行 KVM。
|
||||
|
||||
### 第二步:安装KVM ###
|
||||
|
||||
使用 `apt-get` 安装 KVM 和相关的用户空间工具。
|
||||
|
||||
```
|
||||
$ sudo apt-get install qemu-kvm libvirt-bin
|
||||
```
|
||||
|
||||
安装期间,libvirtd 用户组(在 debian 上是 libvirtd-qemu 用户组)将会被创建,并且你的用户 id 将会被自动添加到该组中。这样做的目的是让你可以以一个普通用户而不是 root 用户的身份去管理虚拟机。你可以使用 `id` 命令来确认这一点,下面将会告诉你怎么去显示你的组 id:
|
||||
|
||||
```
|
||||
$ id <your-userID>
|
||||
```
|
||||
|
||||

|
||||
|
||||
如果因为某些原因,libvirt(在 debian 中是 libvirt-qemu)没有在你的组 id 中被找到,你也可以手动将你自己添加到对应的组中,如下所示:
|
||||
|
||||
在 ubuntu 上:
|
||||
|
||||
```
|
||||
$ sudo adduser [youruserID] libvirtd
|
||||
```
|
||||
|
||||
在 debian 上:
|
||||
|
||||
```
|
||||
$ sudo adduser [youruserID] libvirt-qemu
|
||||
```
|
||||
|
||||
按照如下命令重新载入更新后的组成员关系。如果要求输入密码,那么输入你的登陆密码即可。
|
||||
|
||||
```
|
||||
$ exec su -l $USER
|
||||
```
|
||||
|
||||
这时,你应该可以以普通用户的身份去执行 virsh 了。做一个如下所示的测试,这个命令将会以列表的形式列出可用的虚拟机(当前的列表是空的)。如果你没有遇到权限问题,那意味着到目前为止一切都是正常的。
|
||||
|
||||
$ virsh list
|
||||
|
||||
----------
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
|
||||
### 第三步:配置桥接网络 ###
|
||||
|
||||
为了使 KVM 虚拟机能够访问外部网络,一种方法是通过在 KVM 宿主机上创建 Linux 桥来实现。创建之后的桥能够将虚拟机的虚拟网卡和宿主机的物理网卡连接起来,因此,虚拟机能够发送和接收由物理网卡传输的数据包。这种方式叫做网络桥接。
|
||||
|
||||
下面将告诉你如何创建并且配置网桥,我们创建一个网桥称它为 br0。
|
||||
|
||||
首先,安装一个必需的包,然后用命令行创建一个网桥。
|
||||
|
||||
```
|
||||
$ sudo apt-get install bridge-utils
|
||||
$ sudo brctl addbr br0
|
||||
```
|
||||
|
||||
下一步就是配置已经创建好的网桥,即修改位于 `/etc/network/interfaces` 的配置文件。我们需要将该桥接网卡设置成开机启动。为了修改该配置文件,你需要关闭你的操作系统上的网络管理器(如果你在使用它的话)。跟随[操作指南][1]的说明去关闭网络管理器。
|
||||
|
||||
关闭网络管理器之后,接下来就是通过修改配置文件来配置网桥了。
|
||||
|
||||
```
|
||||
#auto eth0
|
||||
#iface eth0 inet dhcp
|
||||
|
||||
auto br0
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
```
|
||||
|
||||
在上面的配置中,我假设 eth0 是主要网卡,它也是连接到外网的网卡,同样,我假设 eth0 将会通过 DHCP 协议自动获取 ip 地址。注意,之前在 `/etc/network/interfaces` 中还没有对 eth0 进行任何配置。桥接网卡 br0 引用了 eth0 的配置,而 eth0 也会受到 br0 的制约。
|
||||
|
||||
重启网络服务,并确认网桥已经被成功的配置好。如果成功的话,br0 的 ip 地址将会是 eth0 自动分配的 ip 地址,而且 eth0 不会被分配任何 ip 地址。
|
||||
|
||||
```
|
||||
$ sudo /etc/init.d/networking restart
|
||||
$ ifconfig
|
||||
```
|
||||
|
||||
如果因为某些原因,eth0 仍然保留了之前分配给了 br0 的 ip 地址,那么你可能必须手动删除 eth0 的 ip 地址。
|
||||
|
||||

|
||||
|
||||
### 第四步:用命令行创建一个虚拟机 ###
|
||||
|
||||
对于虚拟机来说,它的配置信息被存储在它对应的xml文件中。因此,创建一个虚拟机的第一步就是准备一个与虚拟机对应的 xml 文件。
|
||||
|
||||
下面是一个示例 xml 文件,你可以根据需要手动修改它。
|
||||
|
||||
```
|
||||
<domain type='kvm'>
|
||||
<name>alice</name>
|
||||
<uuid>f5b8c05b-9c7a-3211-49b9-2bd635f7e2aa</uuid>
|
||||
<memory>1048576</memory>
|
||||
<currentMemory>1048576</currentMemory>
|
||||
<vcpu>1</vcpu>
|
||||
<os>
|
||||
<type>hvm</type>
|
||||
<boot dev='cdrom'/>
|
||||
</os>
|
||||
<features>
|
||||
<acpi/>
|
||||
</features>
|
||||
<clock offset='utc'/>
|
||||
<on_poweroff>destroy</on_poweroff>
|
||||
<on_reboot>restart</on_reboot>
|
||||
<on_crash>destroy</on_crash>
|
||||
<devices>
|
||||
<emulator>/usr/bin/kvm</emulator>
|
||||
<disk type="file" device="disk">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/images/alice.img"/>
|
||||
<target dev="vda" bus="virtio"/>
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x04" function="0x0"/>
|
||||
</disk>
|
||||
<disk type="file" device="cdrom">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/iso/CentOS-6.5-x86_64-minimal.iso"/>
|
||||
<target dev="hdc" bus="ide"/>
|
||||
<readonly/>
|
||||
<address type="drive" controller="0" bus="1" target="0" unit="0"/>
|
||||
</disk>
|
||||
<interface type='bridge'>
|
||||
<source bridge='br0'/>
|
||||
<mac address="00:00:A3:B0:56:10"/>
|
||||
</interface>
|
||||
<controller type="ide" index="0">
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x01" function="0x1"/>
|
||||
</controller>
|
||||
<input type='mouse' bus='ps2'/>
|
||||
<graphics type='vnc' port='-1' autoport="yes" listen='0.0.0.0'/>
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
</devices>
|
||||
</domain>
|
||||
```
|
||||
|
||||
上面的主机xml配置文件定义了如下的虚拟机内容。
|
||||
|
||||
- 1GB内存,一个虚拟cpu和一个硬件驱动
|
||||
|
||||
- 磁盘镜像:`/home/dev/images/alice.img`
|
||||
|
||||
- 从 CD-ROM 引导(`/home/dev/iso/CentOS-6.5-x86_64-minomal.iso`)
|
||||
|
||||
- 网络:一个桥接到 br0 的虚拟网卡
|
||||
|
||||
- 通过 VNC 远程访问
|
||||
|
||||
`<uuid></uuid>` 中的 UUID 字符串可以随机生成。为了得到一个随机的 uuid 字符串,你可能需要使用 uuid 命令行工具。
|
||||
|
||||
```
|
||||
$ sudo apt-get install uuid
|
||||
$ uuid
|
||||
```
|
||||
|
||||
生成一个主机 xml 配置文件的方式就是通过一个已经存在的虚拟机来导出它的 xml 配置文件。如下所示。
|
||||
|
||||
```
|
||||
$ virsh dumpxml alice > bob.xml
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 第五步:使用命令行启动虚拟机 ###
|
||||
|
||||
在启动虚拟机之前,我们需要创建它的初始磁盘镜像。为此,你需要使用 qemu-img 命令来生成一个 qemu-kvm 镜像。下面的命令将会创建 10 GB 大小的空磁盘,并且它是 qcow2 格式的。
|
||||
|
||||
```
|
||||
$ qemu-img create -f qcow2 /home/dev/images/alice.img 10G
|
||||
```
|
||||
|
||||
使用 qcow2 格式的磁盘镜像的好处就是它在创建之初并不会给它分配全部大小磁盘容量(这里是 10 GB),而是随着虚拟机中文件的增加而逐渐增大。因此,它对空间的使用更加有效。
|
||||
|
||||
现在,你可以通过使用之前创建的 xml 配置文件启动你的虚拟机了。下面的命令将会创建一个虚拟机,然后自动启动它。
|
||||
|
||||
```
|
||||
$ virsh create alice.xml
|
||||
Domain alice created from alice.xml
|
||||
```
|
||||
|
||||
**注意**: 如果你对一个已经存在的虚拟机执行了了上面的命令,那么这个操作将会在没有任何警告的情况下抹去那个已经存在的虚拟机的全部信息。如果你已经创建了一个虚拟机,你可能会使用下面的命令来启动虚拟机。
|
||||
|
||||
```
|
||||
$ virsh start alice.xml
|
||||
```
|
||||
|
||||
使用如下命令确认一个新的虚拟机已经被创建并成功的被启动。
|
||||
|
||||
```
|
||||
$ virsh list
|
||||
```
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
3 alice running
|
||||
|
||||
同样,使用如下命令确认你的虚拟机的虚拟网卡已经被成功的添加到了你先前创建的 br0 网桥中。
|
||||
|
||||
$ sudo brctl show
|
||||
|
||||

|
||||
|
||||
### 远程连接虚拟机 ###
|
||||
|
||||
为了远程访问一个正在运行的虚拟机的控制台,你可以使用VNC客户端。
|
||||
|
||||
首先,你需要使用如下命令找出用于虚拟机的VNC端口号。
|
||||
|
||||
```
|
||||
$ sudo netstat -nap | egrep '(kvm|qemu)'
|
||||
```
|
||||
|
||||

|
||||
|
||||
在这个例子中,用于 alice 虚拟机的 VNC 端口号是 5900。 然后启动一个VNC客户端,连接到一个端口号为5900的VNC服务器。在我们的例子中,虚拟机支持由CentOS光盘文件启动。
|
||||
|
||||

|
||||
|
||||
### 使用 virsh 管理虚拟机 ###
|
||||
|
||||
下面列出了 virsh 命令的常规用法:
|
||||
|
||||
创建客户机并且启动虚拟机:
|
||||
|
||||
```
|
||||
$ virsh create alice.xml
|
||||
```
|
||||
|
||||
停止虚拟机并且删除客户机:
|
||||
|
||||
```
|
||||
$ virsh destroy alice
|
||||
```
|
||||
|
||||
关闭虚拟机(不用删除它):
|
||||
|
||||
```
|
||||
$ virsh shutdown alice
|
||||
```
|
||||
|
||||
暂停虚拟机:
|
||||
|
||||
```
|
||||
$ virsh suspend alice
|
||||
```
|
||||
|
||||
恢复虚拟机:
|
||||
|
||||
```
|
||||
$ virsh resume alice
|
||||
```
|
||||
|
||||
访问正在运行的虚拟机的控制台:
|
||||
|
||||
```
|
||||
$ virsh console alice
|
||||
```
|
||||
|
||||
设置虚拟机开机启动:
|
||||
|
||||
```
|
||||
$ virsh autostart alice
|
||||
```
|
||||
|
||||
查看虚拟机的详细信息:
|
||||
|
||||
```
|
||||
$ virsh dominfo alice
|
||||
```
|
||||
|
||||
编辑虚拟机的配置文件:
|
||||
|
||||
```
|
||||
$ virsh edit alice
|
||||
```
|
||||
|
||||
上面的这个命令将会使用一个默认的编辑器来调用主机配置文件。该配置文件中的任何改变都将自动被libvirt验证其正确性。
|
||||
|
||||
你也可以在一个virsh会话中管理虚拟机。下面的命令会创建并进入到一个virsh会话中:
|
||||
|
||||
```
|
||||
$ virsh
|
||||
```
|
||||
|
||||
在 virsh 提示中,你可以使用任何 virsh 命令。
|
||||
|
||||
|
||||
|
||||
### 问题处理 ###
|
||||
|
||||
1. 我在创建虚拟机的时候遇到了一个错误:
|
||||
|
||||
error: internal error: no supported architecture for os type 'hvm'
|
||||
|
||||
如果你的硬件不支持虚拟化的话你可能就会遇到这个错误。(例如,Intel VT或者AMD-V),这是运行KVM所必需的。如果你遇到了这个错误,而你的cpu支持虚拟化,那么这里可以给你一些可用的解决方案:
|
||||
|
||||
首先,检查你的内核模块是否丢失。
|
||||
|
||||
```
|
||||
$ lsmod | grep kvm
|
||||
```
|
||||
|
||||
如果内核模块没有加载,你必须按照如下方式加载它。
|
||||
|
||||
```
|
||||
$ sudo modprobe kvm_intel (for Intel processor)
|
||||
$ sudo modprobe kvm_amd (for AMD processor)
|
||||
```
|
||||
|
||||
第二个解决方案就是添加 `--connect qemu:///system` 参数到 `virsh` 命令中,如下所示。当你正在你的硬件平台上使用超过一个虚拟机管理器的时候就需要添加这个参数(例如,VirtualBox,VMware)。
|
||||
|
||||
```
|
||||
$ virsh --connect qemu:///system create alice.xml
|
||||
```
|
||||
|
||||
2. 当我试着访问我的虚拟机的登陆控制台的时候遇到了错误:
|
||||
|
||||
```
|
||||
$ virsh console alice
|
||||
error: internal error: cannot find character device <null>
|
||||
```
|
||||
|
||||
这个错误发生的原因是你没有在你的虚拟机配置文件中定义控制台设备。在 xml 文件中加上下面的内部设备部分即可。
|
||||
|
||||
```
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/use-kvm-command-line-debian-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[kylepeng93](https://github.com/kylepeng93 )
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
@ -0,0 +1,28 @@
|
||||
我们能通过快速、开放的研究来战胜寨卡病毒吗?
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
关于寨卡病毒,最主要的问题就是我们对于它了解的太少了。这意味着我们需要尽快对它作出很多研究。
|
||||
|
||||
寨卡病毒现已严重威胁到世界人民的健康。在 2015 年爆发之后,它就成为了全球性的突发公共卫生事件,并且这个病毒也可能与儿童的出生缺陷有关。根据[维基百科][4],在这个病毒在 40 年代末期被发现以后,早在 1952 年就被观测到了对于人类的影响。
|
||||
|
||||
在 2 月 10 日,开放杂志 PLoS [发布了一个声明][1],这个是声明是关于有关公众紧急状况的信息共享。在此之后,刊登在研究期刊 F1000 的一篇文章 [对于能治疗寨卡病毒的开源药物(Open drug)的研究][2],它讨论了寨卡病毒及其开放研究的状况。那篇来自 PLoS 的声明列出了超过 30 个开放了对于寨卡病毒的研究进度的数据的重要组织。并且世界卫生组织实施了一个特别规定,以[创作共用许可证][3]公布提交到他们那里的资料。
|
||||
|
||||
快速公布,无限制的重复利用,以及强调研究结果的传播是推动开放科研社区的战略性一步。看到我们所关注的突发公共卫生事件能够以这样的方式开始是很令人受鼓舞的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-rapid-open-science-could-change-game-zika-virus
|
||||
|
||||
作者:[Marcus D. Hanwell][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhanwell
|
||||
[1]: http://blogs.plos.org/plos/2016/02/statement-on-data-sharing-in-public-health-emergencies/
|
||||
[2]: http://f1000research.com/articles/5-150/v1
|
||||
[3]: https://creativecommons.org/licenses/by/3.0/igo/
|
||||
[4]: https://en.wikipedia.org/wiki/Zika_virus
|
||||
@ -0,0 +1,90 @@
|
||||
2016:如何选择 Linux 桌面环境
|
||||
=============================================
|
||||
|
||||
|
||||
|
||||
Linux 创建了一个友好的环境,为我们提供了选择的可能。比方说,现代大多数的 Linux 发行版都提供不同桌面环境给我们来选择。在本文中,我将挑选一些你可能会在 Linux 中见到的最棒的桌面环境来介绍。
|
||||
|
||||
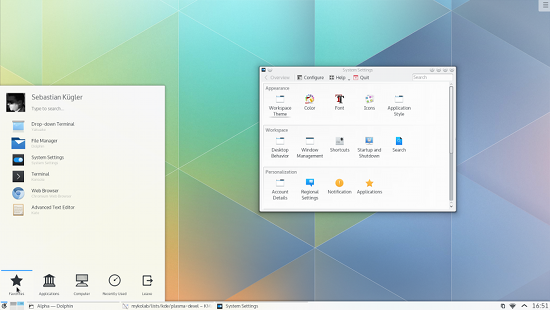
## Plasma
|
||||
|
||||
我认为,[KDE 的 Plasma 桌面](https://www.kde.org/workspaces/plasmadesktop/) 是最先进的桌面环境 (LCTT 译注:译者认为,没有什么是最好的,只有最合适的,毕竟每个人的喜好都不可能完全相同)。它是我见过功能最完善和定制性最高的桌面环境;在用户完全自主控制方面,即使是 Mac OS X 和 Windows 也无法与之比拟。
|
||||
|
||||
我爱 Plasma,因为它自带了一个非常好的文件管理器 —— Dolphin。而相对应 Gnome 环境,我更喜欢 Plasma 的原因就在于这个文件管理器。使用 Gnome 最大的痛苦就是,它的文件管理器——Files——使我无法完成一些基本任务,比如说,批量文件重命名操作。而这个操作对我来说相当重要,因为我喜欢拍摄,但 Gnome 却让我无法批量重命名这些图像文件。而使用 Dolphin 的话,这个操作就像在公园散步一样简单。
|
||||
|
||||
而且,你可以通过插件来增强 Plasma 的功能。Plasma 有大量的基础软件,如 Krita、Kdenlive、Calligra 办公套件、digiKam、Kwrite 以及由 KDE 社区开发维护的大量应用。
|
||||
|
||||
Plasma 桌面环境唯一的缺陷就是它默认的邮件客户端——Kmail。它的设置比较困难,我希望 Kmail 设置可以配置地址簿和日历。
|
||||
|
||||
包括 openSUSE 在内的多数主流发行版多使用 Plasma 作为默认桌面。
|
||||
|
||||
## GNOME
|
||||
|
||||
[GNOME](https://www.gnome.org/) (GNU Network Object Model Environment,GNU 网络对象模型环境) 由 [Miguel de Icaza](https://en.wikipedia.org/wiki/Miguel_de_Icaza) 和 Federico Mena 在 1997 年的时候创立,这是因为 KDE 使用了 Qt 工具包,而这个工具包是使用专属许可证 (proprietary license) 发布的。不像提供了大量定制的 KDE,GNOME 专注于让事情变得简单。因为其自身的简单性和易用性,GNOME 变得相当流行。而我认为 GNOME 之所以流行的原因在于,Ubuntu——使用 GNOME 作为默认桌面的主流 Linux 发行版之一——对其有着巨大的推动作用。
|
||||
|
||||
随着时代变化,GNOME 也需要作出相应的改变了。因此,开发者在 GNOME 3 中推出了 GNOME 3 Shell,从而引出了它的全新设计规范。但这同时与 Canonical 的 Ubuntu 计划存在者一些冲突,所以 Canonical 为 GNOME 开发了叫做 Unity 的自己的 Shell。最初,GNOME 3 Shell 因很多争议 (issues) 而困扰不已——最明显的是,升级之后会导致很多扩展无法正常工作。由于设计上的重大改版以及各种问题的出现,GNOME 便产生了很多分支(fork),比如 Cinnamon 和 Mate 桌面。
|
||||
|
||||
另外,使得 GNOME 让人感兴趣的是,它针对触摸设备做了优化,所以,如果你有一台触屏笔记本电脑的话,GNOME 则是最合适你这台电脑的桌面环境。
|
||||
|
||||
在 3.18 版本中,GNOME 已经作出了一些令人印象深刻的改动。其中他们所做的最让人感兴趣的是集成了 Google Drive,用户可以把他们的 Google Drive 挂载为远程存储设备,这样就不必再使用浏览器来查看里边的文件了。我也很喜欢 GNOME 里边自带的那个优秀的邮件客户端,它带有日历和地址簿功能。尽管有这么多些优秀的特性,但它的文件管理器使我不再使用 GNOME ,因为我无法处理批量文件重命名。我会坚持使用 Plasma,一直到 GNOME 的开发者修复了这个小缺陷。
|
||||
|
||||

|
||||
|
||||
## Unity
|
||||
|
||||
从技术上来说,[Unity](https://unity.ubuntu.com/) 并不是一个桌面环境,它只是 Canonical 为 Ubuntu 开发的一个图形化 Shell。Unity 运行于 GNOME 桌面之上,并使用很多 GNOME 的应用和工具。Ubuntu 团队分支了一些 GNOME 组件,以便更好的满足 Unity 用户的需求。
|
||||
|
||||
Unity 在 Ubuntu 的融合(convergence)计划中扮演着重要角色, 在 Unity 8 中,Canonical 公司正在努力将电脑桌面和移动世界结合到一起。Canonical 同时还为 Unity 开发了许多的有趣技术,比如 HUD (Head-up Display,平视显示)。他们还在 lenses 和 scopes 中通过一种独特的技术来让用户方便地找到特定内容。
|
||||
|
||||
即将发行的 Ubuntu 16.04,将会搭载 Unity 8,那时候用户就可以完全体验开发者为该开源软件添加的所有特性了。其中最大的争议之一,Unity 可选取消集成了 Amazon Ads 和其他服务。而在即将发行的版本,Canonical 从 Dash 移除了 Amazon ads,但却默认保证了系统的隐私性。
|
||||
|
||||
## Cinnamon
|
||||
|
||||
最初,[Cinnamon](https://en.wikipedia.org/wiki/Cinnamon_(software\)) 由 [Linux Mint](http://www.linuxmint.com/) 开发 —— 这是 DistroWatch.com 上统计出来最流行的发行版。就像 Unity,Cinnamon 是 GNOME Shell 的一个分支。但最后进化为一个独立的桌面环境,这是因为 Linux Mint 的开发者分支了 GNOME 桌面中很多的组件到 Cinnamon,包括 Files ——以满足自身用户的需求。
|
||||
|
||||
由于 Linux Mint 基于普通版本的 Ubuntu,开发者仍需要去完成 Ubuntu 尚未完成的目标。结果,尽管前途光明,但 Cinnamon 却充满了 Bugs 和问题。随着 17.x 本版的发布,Linux Mint 开始转移到 Ubuntu 的 LTS 版本上,从而他们可以专注于开发 Cinnamon 的核心组件,而不必再去担心代码库。转移到 LTS 的好处是,Cinnamon 变得非常稳定并且基本没有 Bugs 出现。现在,开发者已经开始向桌面环境中添加更多的新特性了。
|
||||
|
||||
对于那些更喜欢在 GNOME 基础上有一个很好的类 Windows 用户界面的用户来说,Cinnamon 是他们最好的桌面环境。
|
||||
|
||||
## MATE 桌面
|
||||
|
||||
[MATE 桌面](http://mate-desktop.com/) 同样是 GNOME 的一个分支,然而,它并不像 Cinnamon 那样由 GNOME 3 分支而来,而是现在已经没有人维护的 GNOME 2 代码库的一个分支。MATE 桌面中的一些开发者并不喜欢 GNOME 3 并且想要“继续坚持” GNOME 2,所以他们使用这个代码库来创建来 MATE。为避免和 GNOME 3 的冲突,他们重命名了全部的包:Nautilus 改为 Caja、Gedit 改为 Pluma 以及 Evince 改为 Atril 等。
|
||||
|
||||
尽管 MATE 延续了 GNOME 2,但这并不意味着他们使用过时的技术;相反,他们使用了更新的技术来提供一个现代的 GNOME 2 体验。
|
||||
|
||||
拥有相当高的资源使用率才是 MATE 最令人印象深刻之处。你可将它运行在老旧硬件或者更新一些的但不太强大的硬件上,如树梅派 (Raspberry Pi) 或者 Chromebook Flip。使得它更有让人感兴趣的是,把它运行在一些强大的硬件上,可以节省大多数的资源给其他应用,而桌面环境本身只占用很少的资源。
|
||||
|
||||
## LXQt
|
||||
|
||||
[LXQt](http://lxqt.org/) 继承了 LXDE ——最轻量级的桌面环境之一。它融合了 LXDE 和 Razor-Qt 两个开源项目。LXQt 的首个可用本版(v 0.9)发布于 2015 年。最初,开发者使用了 Qt4 ,之后为了加快开发速度,而放弃了兼容性,他们移动到 Qt5 和 KDE 框架上。我也在自己的 Arch 系统上尝试使用了 LXQt,它的确是一个非常好的轻量级桌面环境。但在完全接过 LXDE 的传承之前,LXQt 仍有一段很长的路需要走。
|
||||
|
||||
## Xfce
|
||||
|
||||
[Xfce](http://www.xfce.org/) 早于 KDE 桌面环境,它是最古老和最轻量级的桌面环境。Xfce 的最新版本是 4.15,发布于 2015 年,使用了诸如 GTK+ 3 的大量的现代科技。很多发行版都使用了 Xfce 环境以满足特定需求,比如 Ubuntu Studio ——与 MATE 类似——尽量节省系统资源给其他的应用。并且,许多的著名的 Linux 发行版——包括 Manjaro Linux、PC/OS、Salix 和 Mythbuntu ——都把它作为默认桌面环境。
|
||||
|
||||
## Budgie
|
||||
|
||||
[Budgie](https://solus-project.com/budgie/) 是一个新型的桌面环境,由 Solus Linux 团队开发和维护。Solus 是一个从零开始构建的新型发行版,而 Budgie 则是它的一个核心组件。Budgie 使用了大量的 GNOME 组件,从而提供一个华丽的用户界面。由于没有该桌面环境的更多信息,我特地联系了 Solus 的核心开发者—— Ikey Doherty。他解释说:“我们搭载了自己的桌面环境—— Budgie 桌面。与其他桌面环境不同的是,Budgie 并不是其他桌面的一个分支,它的目标是彻底融入到 GNOME 协议栈之中。它完全从零开始编写,并特意设计来迎合 Solus 提供的体验。我们会尽可能的和 GNOME 的上游团队协同工作,修复 Bugs,并提倡和支持他们的工作”。
|
||||
|
||||
## Pantheon
|
||||
|
||||
我想,[Pantheon](https://elementary.io/) 不需要特别介绍了吧,那个优美的 elementary OS 就使用它作为桌面。类似于 Budgie,很多人都认为 Pantheon 也不是 GNOME 的一个分支。elementary OS 团队大多拥有良好的设计从业背景,所以他们会近距离关注每一个细节,这使得 Pantheon 成为一个非常优美的桌面环境。偶尔,它可能缺少像 Plasma 等桌面中的某些特性,但开发者实际上是尽其所能的去坚持设计原则。
|
||||
|
||||

|
||||
|
||||
## 结论
|
||||
|
||||
当我写完本文后,我突然意识到来开源和 Linux 的重大好处。总有一些东西适合你。就像 Jon “maddog” Hall 在最近的 SCaLE 14 上说的那样:“是的,现在有 300 多个 Linux 发行版。我可以一个一个去尝试,然后坚持使用我最喜欢的那一个”。
|
||||
|
||||
所以,尽情享受 Linux 的多样性吧,最后使用最合你意的那一个。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/software/applications/881107-best-linux-desktop-environments-for-2016
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
@ -0,0 +1,24 @@
|
||||
Ubuntu 16.04 为更好支持容器化而采用 ZFS
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
Ubuntu 开发者正在为 [Ubuntu 16.04 加上 ZFS 支持](http://www.phoronix.com/scan.php?page=news_item&px=ZFS-For-Ubuntu-16.04) ,并且对该文件系统的所有支持都已经准备就绪。
|
||||
|
||||
Ubuntu 16.04 的默认安装将会继续是 ext4,但是 ZFS 支持将会自动构建进 Ubuntu 发布中,模块将在需要时自动加载,zfsutils-linux 将放到 Ubuntu 主分支内,并且通过 Canonical 对商业客户提供支持。
|
||||
|
||||
对于那些对 Ubuntu 中的 ZFS 感兴趣的人,Canonical 的 Dustin Kirkland 已经写了[一篇新的博客](http://blog.dustinkirkland.com/2016/02/zfs-is-fs-for-containers-in-ubuntu-1604.html),介绍了一些细节及为何“ZFS 是 Ubuntu 16.04 中面向容器使用的文件系统!”
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-ZFS-Continues-16.04&utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+Phoronix+%28Phoronix%29
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
|
||||
|
||||
@ -1,14 +1,16 @@
|
||||
Linux最大版本4.1.18 LTS发布,带来大量修改
|
||||
Linux 4.1 系列的最大版本 4.1.18 LTS发布,带来大量修改
|
||||
=================================================================================
|
||||
(LCTT 译注:这是一则过期的消息,但是为了披露更新内容,还是发布出来给大家参考)
|
||||
|
||||
**著名的内核维护者Greg Kroah-Hartman貌似正在度假中,因为Sasha Levin有幸在今天,2016年2月16日,的早些时候来[宣布](http://lkml.iu.edu/hypermail/linux/kernel/1602.2/00520.html),第十八个Linux内核维护版本Linux Kernel 4.1 LTS通用版本正式发布。**
|
||||
**著名的内核维护者Greg Kroah-Hartman貌似正在度假中,因为Sasha Levin2016年2月16日的早些时候来[宣布](http://lkml.iu.edu/hypermail/linux/kernel/1602.2/00520.html),第十八个Linux内核维护版本Linux Kernel 4.1 LTS通用版本正式发布。**
|
||||
|
||||
作为长期支持的内核分支,Linux 4.1将再多几年接收到更新和补丁,而今天的维护构建版本也证明一点,就是内核开发者们正致力于统保持该系列在所有使用该版本的GNU/Linux操作系统上稳定和可靠。Linux Kernel 4.1.18 LTS是一个大规模发行版,它带来了总计达228个文件修改,这些修改包含了多达5304个插入修改和1128个删除修改。
|
||||
作为长期支持的内核分支,Linux 4.1还会在几年内得到更新和补丁,而今天的维护构建版本也证明一点,就是内核开发者们正致力于保持该系列在所有使用该版本的GNU/Linux操作系统上稳定和可靠。Linux Kernel 4.1.18 LTS是一个大的发布版本,它带来了总计达228个文件修改,这些修改包含了多达5304个插入修改和1128个删除修改。
|
||||
|
||||
Linux Kernel 4.1.18 LTS更新了什么呢?好吧,首先是对ARM,ARM64(AArch64),MIPS,PA-RISC,m32r,PowerPC(PPC),s390以及x86等硬件架构的改进。此外,还有对Btrfs,CIFS,NFS,XFS,OCFS2,OverlayFS以及UDF文件系统的加强。对网络堆栈的修复,尤其是对mac80211的修复。同时,还有多核心、加密和mm等方面的改进和对声音的更新。
|
||||
|
||||
“我宣布4.1.18内核正式发布,所有4.1内核系列的用户都应当升级。”Sasha Levin说,“更新的4.1.y git树可以在这里找到:git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux-4.1.y,并且可以在常规kernel.org git网站浏览器:http://git.kernel.org/?p=linux/kernel/git/stable/linux-stable.git;a=summary 进行浏览。”
|
||||
## 大量驱动被更新
|
||||
“我宣布4.1.18内核正式发布,所有4.1内核系列的用户都应当升级。”Sasha Levin说,“更新的4.1.y git树可以在这里找到:git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git linux-4.1.y,并且可以在 kernel.org 的 git 网站上浏览:http://git.kernel.org/?p=linux/kernel/git/stable/linux-stable.git;a=summary 进行浏览。”
|
||||
|
||||
### 大量驱动被更新
|
||||
|
||||
除了架构、文件系统、声音、网络、加密、mm和核心内核方面的改进之外,Linux Kernel 4.1.18 LTS更新了各个驱动,以提供更好的硬件支持,特别是像蓝牙、DMA、EDAC、GPU(主要是Radeon和Intel i915)、无限带宽技术、IOMMU、IRQ芯片、MD、MMC、DVB、网络(主要是无线)、PCI、SCSI、USB、散热、暂存和Virtio等此类东西。
|
||||
|
||||
@ -18,9 +20,9 @@ Linux Kernel 4.1.18 LTS更新了什么呢?好吧,首先是对ARM,ARM64(A
|
||||
|
||||
via: http://news.softpedia.com/news/linux-kernel-4-1-18-lts-is-the-biggest-in-the-series-with-hundreds-of-changes-500500.shtml
|
||||
|
||||
作者:[Marius Nestor ][a]
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,27 @@
|
||||
Xubuntu 16.04 Beta 1 开发者版本发布
|
||||
============================================
|
||||
|
||||
Ubuntu 发布团队宣布为选定的社区版本而准备的最新的 beta 测试镜像已经可以使用了。新的发布版本名称是 16.04 beta 1 ,这个版本只推荐给测试人员测试用,并不适合普通人进行日常使用。
|
||||
|
||||
|
||||
|
||||
“这个 beta 特性的镜像主要是为 [Lubuntu][1], Ubuntu Cloud, [Ubuntu GNOME][2], [Ubuntu MATE][3], [Ubuntu Kylin][4], [Ubuntu Studio][5] 和 [Xubuntu][6] 这几个发布版准备的。Xenial Xerus (LCTT 译注: ubuntu 16.04 的开发代号)的这个预发布版本并不推荐那些需要稳定版本的人员使用,同时那些不希望在系统运行中偶尔或频繁的出现 bug 的人也不建议使用这个版本。这个版本主要还是推荐给那些喜欢 ubuntu 的开发人员,以及那些想协助我们测试、报告 bug 和修改 bug 的人使用,和我们一起努力让这个发布版本早日准备就绪。” 更多的信息可以从 [发布日志][7] 获取。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/software/applications/888731-development-release-xubuntu-1604-beta-1
|
||||
|
||||
作者:[DistroWatch][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[Ezio](https://github.com/oska874)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/284
|
||||
[1]: http://distrowatch.com/lubuntu
|
||||
[2]: http://distrowatch.com/ubuntugnome
|
||||
[3]: http://distrowatch.com/ubuntumate
|
||||
[4]: http://distrowatch.com/ubuntukylin
|
||||
[5]: http://distrowatch.com/ubuntustudio
|
||||
[6]: http://distrowatch.com/xubuntu
|
||||
[7]: https://lists.ubuntu.com/archives/ubuntu-devel-announce/2016-February/001173.html
|
||||
@ -0,0 +1,30 @@
|
||||
OpenSSH 7.2发布,支持 SHA-256/512 的 RSA 签名
|
||||
========================================================
|
||||
|
||||
**2016.2.29,OpenBSD 项目很高兴地宣布 OpenSSH 7.2发布了,并且很块可在所有支持的平台下载。**
|
||||
|
||||
根据内部[发布公告][1],OpenSSH 7.2 主要是 bug 修复,修改了自 OpenSSH 7.1p2 以来由用户报告和开发团队发现的问题,但是我们可以看到几个新功能。
|
||||
|
||||
这其中,我们可以提到使用了 SHA-256 或者 SHA-256 512 哈希算法的 RSA 签名;增加了一个 AddKeysToAgent 客户端选项,以添加用于身份验证的 ssh-agent 的私钥;和实现了一个“restrict”级别的 authorized_keys 选项,用于存储密钥限制。
|
||||
|
||||
此外,现在 ssh_config 中 CertificateFile 选项可以明确列出证书,ssh-keygen 现在能够改变所有支持的格式的密钥注释、密钥指纹现在可以来自标准输入,多个公钥可以放到一个文件。
|
||||
|
||||
### ssh-keygen 现在支持多证书
|
||||
|
||||
除了上面提到的,OpenSSH 7.2 增加了 ssh-keygen 多证书的支持,一个一行,实现了 sshd_config ChrootDirectory 及Foreground 的“none”参数,“-c”标志允许 ssh-keyscan 获取证书而不是文本密钥。
|
||||
|
||||
最后但并非最不重要的,OpenSSH 7.3 不再默认启用 rijndael-cbc(即 AES),blowfish-cbc、cast128-cbc 等古老的算法,同样的还有基于 MD5 和截断的 HMAC 算法。在 Linux 中支持 getrandom() 系统调用。[下载 OpenSSH 7.2][2] 并查看更新日志中的更多细节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/openssh-7-2-out-now-with-support-for-rsa-signatures-using-sha-256-512-algorithms-501111.shtml
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]: http://www.openssh.com/txt/release-7.2
|
||||
[2]: http://linux.softpedia.com/get/Security/OpenSSH-4474.shtml
|
||||
@ -0,0 +1,25 @@
|
||||
逾千万使用 https 的站点受到新型解密攻击的威胁
|
||||
===========================================================================
|
||||
|
||||
|
||||
|
||||
|
||||
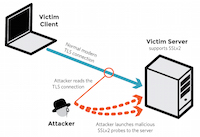
低成本的 DROWN 攻击能在数小时内完成数据解密,该攻击对采用了 TLS 的邮件服务器也同样奏效。
|
||||
|
||||
一个国际研究小组于周二发出警告,据称逾 1100 万家网站和邮件服务采用的用以保证服务安全的 [传输层安全协议 TLS][1],对于一种新发现的、成本低廉的攻击而言异常脆弱,这种攻击会在几个小时内解密敏感的通信,在某些情况下解密甚至能瞬间完成。 前一百万家最大的网站中有超过 81,000 个站点正处于这种脆弱的 HTTPS 协议保护之下。
|
||||
|
||||
这种攻击主要针对依赖于 [RSA 加密系统][2]的 TLS 所保护的通信,密钥会间接的通过 SSLv2 暴露,这是一种在 20 年前就因为自身缺陷而退休了的 TLS 前代协议。该漏洞允许攻击者可以通过反复使用 SSLv2 创建与服务器连接的方式,解密截获的 TLS 连接。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/software/applications/889455--more-than-11-million-https-websites-imperiled-by-new-decryption-attack
|
||||
|
||||
作者:[ArsTechnica][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[martin2011qi](https://github.com/martin2011qi), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/112
|
||||
[1]: https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[2]: https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
@ -0,0 +1,72 @@
|
||||
Zephyr Project for Internet of Things, releases from Facebook, IBM, Yahoo, and more news
|
||||
===========================================================================================
|
||||
|
||||

|
||||
|
||||
In this week's edition of our open source news roundup, we take a look at the new IoT project from the Linux Foundation, three big corporations releasing open source, and more.
|
||||
|
||||
**News roundup for February 21 - 26, 2016**
|
||||
|
||||
### Linux Foundation unveils the Zephyr Project
|
||||
|
||||
The Internet of Things (IoT) is shaping up to be the next big thing in consumer technology. At the moment, most IoT solutions are proprietary and closed source. Open source is making numerous in-roads into the IoT world, and that's undoubtedly going to accelerate now that the Linux Foundation has [announced the Zephyr Project][1].
|
||||
|
||||
The Zephyr Project, according to ZDNet, "hopes to bring vendors and developers together under a single operating system which could make the development of connected devices an easier, less expensive and more stable process." The Project "aims to incorporate input from the open source and embedded developer communities and to encourage collaboration on the RTOS (real-time operating system)," according to the [Linux Foundation's press release][2].
|
||||
|
||||
Currently, Intel Corporation, NXP Semiconductors N.V., Synopsys, Inc., and UbiquiOS Technology Limited are the main supporters of the project. The Linux Foundation intends to attract other IoT vendors to this effort as well.
|
||||
|
||||
### Releases from Facebook, IBM, Yahoo
|
||||
|
||||
As we all know, open source isn't just about individuals or small groups hacking on code and hardware. Quite a few large corporations have significant investments in open source. This past week, three of them affirmed their commitment to open source.
|
||||
|
||||
Yahoo again waded into open source waters this week with the [release of CaffeOnSpark][3] artificial intelligence software under an Apache 2.0 license. CaffeOnSpark performs "a popular type of AI called 'deep learning' on the vast swaths of data kept in its Hadoop open-source file system for storing big data," according to VentureBeat. If you're curious, you can [find the source code on GitHub][4].
|
||||
|
||||
Earlier this week, Facebook "[unveiled a new project that seeks not only to accelerate the evolution of technologies that drive our mobile networks, but to freely share this work with the world’s telecoms][5]," according to Wired. The company plans to build "everything from new wireless radios to nee optical fiber equipment." The designs, according to Facebook, will be open source so any telecom firm can use them.
|
||||
|
||||
As part of the [Open Mainframe Project][6], IBM has open sourced the code for its Anomaly Detection Engine (ADE) for Linux logs. [According to IBM][7], "ADE detects anomalous time slices and messages in Linux logs using statistical learning" to detect suspicious behaviour. You can grab the [source code for ADE][8] from GitHub.
|
||||
|
||||
### European Union to fund research
|
||||
|
||||
The European Research Council, the European Union's science and technology funding body, is [funding four open source research projects][9] to the tune of about €2 million. According to joinup.ec.europa.eu, the projects being funded are:
|
||||
|
||||
- A code audit of Mozilla's open source Rust programming language
|
||||
|
||||
- An initiative at INRIA (France's national computer science research center) studying secure programming
|
||||
|
||||
- A project at Austria's Technische Universitat Graz testing "ways to secure code against attacks that exploit certain properties of the computer hardware"
|
||||
|
||||
- The "development of techniques to prove popular cryptographic protocols and schemes" at IST Austria
|
||||
|
||||
### In other news
|
||||
|
||||
- [Infosys' newest weapon: open source][10]
|
||||
|
||||
- [Intel demonstrates Android smartphone running a Linux desktop][11]
|
||||
|
||||
- [BeeGFS file system goes open source][12]
|
||||
|
||||
A big thanks, as always, to the Opensource.com moderators and staff for their help this week.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/weekly-news-feb-26
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: http://www.zdnet.com/article/the-linux-foundations-zephyr-project-building-an-operating-system-for-iot-devices/
|
||||
[2]: http://www.linuxfoundation.org/news-media/announcements/2016/02/linux-foundation-announces-project-build-real-time-operating-system
|
||||
[3]: http://venturebeat.com/2016/02/24/yahoo-open-sources-caffeonspark-deep-learning-framework-for-hadoop/
|
||||
[4]: https://github.com/yahoo/CaffeOnSpark
|
||||
[5]: http://www.wired.com/2016/02/facebook-open-source-wireless-gear-forge-5g-world/
|
||||
[6]: https://www.openmainframeproject.org/
|
||||
[7]: http://openmainframeproject.github.io/ade/
|
||||
[8]: https://github.com/openmainframeproject/ade
|
||||
[9]: https://joinup.ec.europa.eu/node/149541
|
||||
[10]: http://www.businessinsider.in/Exclusive-Infosys-is-using-Open-Source-as-its-mostlethal-weapon-yet/articleshow/51109129.cms
|
||||
[11]: http://www.theregister.co.uk/2016/02/23/move_over_continuum_intel_shows_android_smartphone_powering_bigscreen_linux/
|
||||
[12]: http://insidehpc.com/2016/02/beegfs-parallel-file-system-now-open-source/
|
||||
@ -0,0 +1,42 @@
|
||||
Node.js 5.7 released ahead of impending OpenSSL updates
|
||||
=============================================================
|
||||
|
||||

|
||||
|
||||
>Once again, OpenSSL fixes must be evaluated by keepers of the popular server-side JavaScript platform
|
||||
|
||||
The Node.js Foundation is gearing up this week for fixes to OpenSSL that could mean updates to Node.js itself.
|
||||
|
||||
Releases to OpenSSL due on Tuesday will fix defects deemed to be of "high" severity, Rod Vagg, foundation technical steering committee director, said [in a blog post][1] on Monday. Within a day of the OpenSSL releases, the Node.js crypto team will assess their impacts, saying, "Please be prepared for the possibility of important updates to Node.js v0.10, v0.12, v4 and v5 soon after Tuesday, the 1st of March."
|
||||
|
||||
[ Deep Dive: [How to rethink security for the new world of IT][2]. | Discover how to secure your systems with InfoWorld's [Security newsletter][3]. ]
|
||||
|
||||
The high severity status actually means the issues are of lower risks than critical, perhaps affecting less-common configurations or less likely to be exploitable. Due to an embargo, the exact nature of these fixes and their impact on Node.js remain uncertain, said Vagg. "Node.js v0.10 and v0.12 both use OpenSSL v1.0.1, and Node.js v4 and v5 both use OpenSSL v1.0.2, and releases from nodejs.org and some other popular distribution sources are statically compiled. Therefore, all active release lines are impacted by this update." OpenSSL also impacted Node.js in December, [when two critical vulnerabilities were fixed][4].
|
||||
|
||||
The latest OpenSSL developments follow [the release of Node.js 5.7.0][5], which is clearing a path for the upcoming Node.js 6. Version 5 is the main focus for active development, said foundation representative Mikeal Rogers, "However, v5 won't be supported long-term, and most users will want to wait for v6, which will be released by the end of April, for the new features that are landing in v5."
|
||||
|
||||
Release 5.7 has more predictability for C++ add-ons' interactions with JavaScript. Node.js can invoke JavaScript code from C++ code, and in version 5.7, the C++ node::MakeCallback() API is now re-entrant; calling it from inside another MakeCallback() call no longer causes the nextTick queue or Promises microtask queue to be processed out of order, [according to release notes][6].
|
||||
|
||||
Also fixed is an HTTP bug where handling headers mistakenly trigger an "upgrade" event where the server just advertises protocols. The bug can prevent HTTP clients from communicating with HTTP2-enabled servers. Version 5.7 performance improvements are featured in the path, querystring, streams, and process.nextTick modules.
|
||||
|
||||
This story, "Node.js 5.7 released ahead of impending OpenSSL updates" was originally published by [InfoWorld][7].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/3039005/security/nodejs-57-released-ahead-of-impending-openssl-updates.html
|
||||
|
||||
作者:[Paul Krill][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Paul-Krill/
|
||||
[1]: https://nodejs.org/en/blog/vulnerability/openssl-march-2016/
|
||||
[2]: http://www.infoworld.com/resources/17273/security-management/how-to-rethink-security-for-the-new-world-of-it#tk.ifw-infsb
|
||||
[3]: http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
[4]: http://www.infoworld.com/article/3012157/security/why-nodejs-waited-for-openssl-security-update-before-patching.html
|
||||
[5]: https://nodejs.org/en/blog/release/v5.7.0/
|
||||
[6]: https://nodejs.org/en/blog/release/v5.7.0/
|
||||
[7]: http://www.infoworld.com/
|
||||
@ -1,165 +0,0 @@
|
||||
robot527 translating
|
||||
|
||||
|
||||
Bossie Awards 2015: The best open source networking and security software
|
||||
================================================================================
|
||||
InfoWorld's top picks of the year among open source tools for building, operating, and securing networks
|
||||
|
||||

|
||||
|
||||
### The best open source networking and security software ###
|
||||
|
||||
BIND, Sendmail, OpenSSH, Cacti, Nagios, Snort -- open source software seems to have been invented for networks, and many of the oldies and goodies are still going strong. Among our top picks in the category this year, you'll find a mix of stalwarts, mainstays, newcomers, and upstarts perfecting the arts of network management, security monitoring, vulnerability assessment, rootkit detection, and much more.
|
||||
|
||||

|
||||
|
||||
### Icinga 2 ###
|
||||
|
||||
Icinga began life as a fork of system monitoring application Nagios. [Icinga 2][1] was completely rewritten to give users a modern interface, support for multiple databases, and an API to integrate numerous extensions. With out-of-the-box load balancing, notifications, and configuration, Icinga 2 shortens the time to installation for complex environments. Icinga 2 supports Graphite natively, giving administrators real-time performance graphing without any fuss. But what puts Icinga back on the radar this year is its release of Icinga Web 2, a graphical front end with drag-and-drop customizable dashboards and streamlined monitoring tools.
|
||||
|
||||
Administrators can view, filter, and prioritize problems, while keeping track of which actions have already been taken. A new matrix view lets administrators view hosts and services on one page. You can view events over a particular time period or filter incidents to understand which ones need immediate attention. Icinga Web 2 may boast a new interface and zippier performance, but all the usual commands from Icinga Classic and Icinga Web are still available. That means there is no downtime trying to learn a new version of the tool.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Zenoss Core ###
|
||||
|
||||
Another open source stalwart, [Zenoss Core][2] gives network administrators a complete, one-stop solution for tracking and managing all of the applications, servers, storage, networking components, virtualization tools, and other elements of an enterprise infrastructure. Administrators can make sure the hardware is running efficiently and take advantage of the modular design to plug in ZenPacks for extended functionality.
|
||||
|
||||
Zenoss Core 5, released in February of this year, takes the already powerful tool and improves it further, with an enhanced user interface and expanded dashboard. The Web-based console and dashboards were already highly customizable and dynamic, and the new version now lets administrators mash up multiple component charts onto a single chart. Think of it as the tool for better root cause and cause/effect analysis.
|
||||
|
||||
Portlets give additional insights for network mapping, device issues, daemon processes, production states, watch lists, and event views, to name a few. And new HTML5 charts can be exported outside the tool. The Zenoss Control Center allows out-of-band management and monitoring of all Zenoss components. Zenoss Core has new tools for online backup and restore, snapshots and rollbacks, and multihost deployment. Even more important, deployments are faster with full Docker support.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenNMS ###
|
||||
|
||||
An extremely flexible network management solution, [OpenNMS][3] can handle any network management task, whether it's device management, application performance monitoring, inventory control, or events management. With IPv6 support, a robust alerts system, and the ability to record user scripts to test Web applications, OpenNMS has everything network administrators and testers need. OpenNMS has become, as now a mobile dashboard, called OpenNMS Compass, lets networking pros keep an eye on their network even when they're out and about.
|
||||
|
||||
The iOS version of the app, which is available on the [iTunes App Store][4], displays outages, nodes, and alarms. The next version will offer additional event details, resource graphs, and information about IP and SNMP interfaces. The Android version, available on [Google Play][5], displays network availability, outages, and alarms on the dashboard, as well as the ability to acknowledge, escalate, or clear alarms. The mobile clients are compatible with OpenNMS Horizon 1.12 or greater and OpenNMS Meridian 2015.1.0 or greater.
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### Security Onion ###
|
||||
|
||||
Like an onion, network security monitoring is made of many layers. No single tool will give you visibility into every attack or show you every reconnaissance or foot-printing session on your company network. [Security Onion][6] bundles scores of proven tools into one handy Ubuntu distro that will allow you to see who's inside your network and help keep the bad guys out.
|
||||
|
||||
Whether you're taking a proactive approach to network security monitoring or following up on a potential attack, Security Onion can assist. Consisting of sensor, server, and display layers, the Onion combines full network packet capture with network-based and host-based intrusion detection, and it serves up all of the various logs for inspection and analysis.
|
||||
|
||||
The star-studded network security toolchain includes Netsniff-NG for packet capture, Snort and Suricata for rules-based network intrusion detection, Bro for analysis-based network monitoring, OSSEC for host intrusion detection, and Sguil, Squert, Snorby, and ELSA (Enterprise Log Search and Archive) for display, analysis, and log management. It’s a carefully vetted collection of tools, all wrapped in a wizard-driven installer and backed by thorough documentation, that can help you get from zero to monitoring as fast as possible.
|
||||
|
||||
-- Victor R. Garza
|
||||
|
||||

|
||||
|
||||
Kali Linux
|
||||
|
||||
The team behind [Kali Linux][7] revamped the popular security Linux distribution this year to make it faster and even more versatile. Kali sports a new 4.0 kernel, improved hardware and wireless driver support, and a snappier interface. The most popular tools are easily accessible from a dock on the side of the screen. The biggest change? Kali Linux is now a rolling distribution, with a continuous stream of software updates. Kali's core system is based on Debian Jessie, and the team will pull packages continuously from Debian Testing, while continuing to add new Kali-flavored features on top.
|
||||
|
||||
The distribution still comes jam-packed with tools for penetration testing, vulnerability analysis, security forensics, Web application analysis, wireless networking and assessment, reverse engineering, and exploitation tools. Now the distribution has an upstream version checking system that will automatically notify users when updates are available for the individual tools. The distribution also features ARM images for a range of devices, including Raspberry Pi, Chromebook, and Odroids, as well as updates to the NetHunter penetration testing platform that runs on Android devices. There are other changes too: Metasploit Community/Pro is no longer included, because Kali 2.0 is not yet [officially supported by Rapid7][8].
|
||||
|
||||
-- Fahmida Rashid
|
||||
|
||||

|
||||
|
||||
### OpenVAS ###
|
||||
|
||||
[OpenVAS][9], the Open Vulnerability Assessment System, is a framework that combines multiple services and tools to offer vulnerability scanning and vulnerability management. The scanner is coupled with a weekly feed of network vulnerability tests, or you can use a feed from a commercial service. The framework includes a command-line interface (so it can be scripted) and an SSL-secured, browser-based interface via the [Greenbone Security Assistant][10]. OpenVAS accommodates various plug-ins for additional functionality. Scans can be scheduled or run on-demand.
|
||||
|
||||
Multiple OpenVAS installations can be controlled through a single master, which makes this a scalable vulnerability assessment tool for enterprises. The project is as compatible with standards as can be: Scan results and configurations are stored in a SQL database, where they can be accessed easily by external reporting tools. Client tools access the OpenVAS Manager via the XML-based stateless OpenVAS Management Protocol, so security administrators can extend the functionality of the framework. The software can be installed from packages or source code to run on Windows or Linux, or downloaded as a virtual appliance.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### OWASP ###
|
||||
|
||||
[OWASP][11], the Open Web Application Security Project, is a nonprofit organization with worldwide chapters focused on improving software security. The community-driven organization provides test tools, documentation, training, and almost anything you could imagine that’s related to assessing software security and best practices for developing secure software. Several OWASP projects have become valuable components of many a security practitioner's toolkit:
|
||||
|
||||
[ZAP][12], the Zed Attack Proxy Project, is a penetration test tool for finding vulnerabilities in Web applications. One of the design goals of ZAP was to make it easy to use so that developers and functional testers who aren't security experts can benefit from using it. ZAP provides automated scanners and a set of manual test tools.
|
||||
|
||||
The [Xenotix XSS Exploit Framework][13] is an advanced cross-site scripting vulnerability detection and exploitation framework that runs scans within browser engines to get real-world results. The Xenotix Scanner Module uses three intelligent fuzzers, and it can run through nearly 5,000 distinct XSS payloads. An API lets security administrators extend and customize the exploit toolkit.
|
||||
|
||||
[O-Saft][14], or the OWASP SSL advanced forensic tool, is an SSL auditing tool that shows detailed information about SSL certificates and tests SSL connections. This command-line tool can run online or offline to assess SSL security such as ciphers and configurations. O-Saft provides built-in checks for common vulnerabilities, and you can easily extend these through scripting. In May 2015 a simple GUI was added as an optional download.
|
||||
|
||||
[OWTF][15], the Offensive Web Testing Framework, is an automated test tool that follows OWASP testing guidelines and the NIST and PTES standards. The framework uses both a Web UI and a CLI, and it probes Web and application servers for common vulnerabilities such as improper configuration and unpatched software.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### BeEF ###
|
||||
|
||||
The Web browser has become the most common vector for attacks against clients. [BeEF][15], the Browser Exploitation Framework Project, is a widely used penetration tool to assess Web browser security. BeEF helps you expose the security weaknesses of client systems using client-side attacks launched through the browser. BeEF sets up a malicious website, which security administrators visit from the browser they want to test. BeEF then sends commands to attack the Web browser and use it to plant software on the client machine. Administrators can then launch attacks on the client machine as if they were zombies.
|
||||
|
||||
BeEF comes with commonly used modules like a key logger, a port scanner, and a Web proxy, plus you can write your own modules or send commands directly to the zombified test machine. BeEF comes with a handful of demo Web pages to help you get started and makes it very easy to write additional Web pages and attack modules so you can customize testing to your environment. BeEF is a valuable test tool for assessing browser and endpoint security and for learning how browser-based attacks are launched. Use it to put together a demo to show your users how malware typically infects client devices.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
### Unhide ###
|
||||
|
||||
[Unhide][16] is a forensic tool that locates open TCP/UDP ports and hidden process on UNIX, Linux, and Windows. Hidden ports and processes can be the result of rootkit or LKM (loadable kernel module) activity. Rootkits can be difficult to find and remove because they are designed to be stealthy, hiding themselves from the OS and user. A rootkit can use LKMs to hide its processes or impersonate other processes, allowing it to run on machines undiscovered for a long time. Unhide can provide the assurance that administrators need to know their systems are clean.
|
||||
|
||||
Unhide is really two separate scripts: one for processes and one for ports. The tool interrogates running processes, threads, and open ports and compares this info to what's registered with the system as active, reporting discrepancies. Unhide and WinUnhide are extremely lightweight scripts that run from the command line to produce text output. They're not pretty, but they are extremely useful. Unhide is also included in the [Rootkit Hunter][17] project.
|
||||
|
||||
-- Matt Sarrel
|
||||
|
||||

|
||||
|
||||
Read about more open source winners
|
||||
|
||||
InfoWorld's Best of Open Source Awards for 2014 celebrate more than 100 open source projects, from the bottom of the stack to the top. Follow these links to more open source winners:
|
||||
|
||||
[Bossie Awards 2015: The best open source applications][18]
|
||||
|
||||
[Bossie Awards 2015: The best open source application development tools][19]
|
||||
|
||||
[Bossie Awards 2015: The best open source big data tools][20]
|
||||
|
||||
[Bossie Awards 2015: The best open source data center and cloud software][21]
|
||||
|
||||
[Bossie Awards 2015: The best open source desktop and mobile software][22]
|
||||
|
||||
[Bossie Awards 2015: The best open source networking and security software][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2982962/open-source-tools/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
|
||||
作者:[InfoWorld staff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/InfoWorld-staff/
|
||||
[1]:https://www.icinga.org/icinga/icinga-2/
|
||||
[2]:http://www.zenoss.com/
|
||||
[3]:http://www.opennms.org/
|
||||
[4]:https://itunes.apple.com/us/app/opennms-compass/id968875097?mt=8
|
||||
[5]:https://play.google.com/store/apps/details?id=com.opennms.compass&hl=en
|
||||
[6]:http://blog.securityonion.net/p/securityonion.html
|
||||
[7]:https://www.kali.org/
|
||||
[8]:https://community.rapid7.com/community/metasploit/blog/2015/08/12/metasploit-on-kali-linux-20
|
||||
[9]:http://www.openvas.org/
|
||||
[10]:http://www.greenbone.net/
|
||||
[11]:https://www.owasp.org/index.php/Main_Page
|
||||
[12]:https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
|
||||
[13]:https://www.owasp.org/index.php/O-Saft
|
||||
[14]:https://www.owasp.org/index.php/OWASP_OWTF
|
||||
[15]:http://www.beefproject.com/
|
||||
[16]:http://www.unhide-forensics.info/
|
||||
[17]:http://www.rootkit.nl/projects/rootkit_hunter.html
|
||||
[18]:http://www.infoworld.com/article/2982622/bossie-awards-2015-the-best-open-source-applications.html
|
||||
[19]:http://www.infoworld.com/article/2982920/bossie-awards-2015-the-best-open-source-application-development-tools.html
|
||||
[20]:http://www.infoworld.com/article/2982429/bossie-awards-2015-the-best-open-source-big-data-tools.html
|
||||
[21]:http://www.infoworld.com/article/2982923/bossie-awards-2015-the-best-open-source-data-center-and-cloud-software.html
|
||||
[22]:http://www.infoworld.com/article/2982630/bossie-awards-2015-the-best-open-source-desktop-and-mobile-software.html
|
||||
[23]:http://www.infoworld.com/article/2982962/bossie-awards-2015-the-best-open-source-networking-and-security-software.html
|
||||
@ -1,66 +0,0 @@
|
||||
ictlyh Translating
|
||||
Review EXT4 vs. Btrfs vs. XFS
|
||||
================================================================================
|
||||

|
||||
|
||||
To be honest, one of the things that comes last in people’s thinking is to look at which file system on their PC is being used. Windows users as well as Mac OS X users even have less reason for looking as they have really only 1 choice for their operating system which are NTFS and HFS+. Linux operating system, on the other side, has plenty of various file system options, with the current default is being widely used ext4. However, there is another push for changing the file system to something other which is called btrfs. But what makes btrfs better, what are other file systems, and when can we see the distributions making the change?
|
||||
|
||||
Let’s first have a general look at file systems and what they really do, then we will make a small comparison between famous file systems.
|
||||
|
||||
### So, What Do File Systems Do? ###
|
||||
|
||||
Just in case if you are unfamiliar about what file systems really do, it is actually simple when it is summarized. The file systems are mainly used in order for controlling how the data is stored after any program is no longer using it, how access to the data is controlled, what other information (metadata) is attached to the data itself, etc. I know that it does not sound like an easy thing to be programmed, and it is definitely not. The file systems are continually still being revised for including more functionality while becoming more efficient in what it simply needs to do. Therefore, however, it is a basic need for all computers, it is not quite as basic as it sounds like.
|
||||
|
||||
### Why Partitioning? ###
|
||||
|
||||
Many people have a vague knowledge of what the partitions are since each operating system has an ability for creating or removing them. It can seem strange that Linux operating system uses more than 1 partition on the same disk, even while using the standard installation procedure, so few explanations are called for them. One of the main goals of having different partitions is achieving higher data security in the disaster case.
|
||||
|
||||
By dividing your hard disk into partitions, the data may be grouped and also separated. When the accidents occur, only the data stored in the partition which got the hit will only be damaged, while data on the other partitions will survive most likely. These principles date from the days when the Linux operating system didn’t have a journaled file system and any power failure might have led to a disaster.
|
||||
|
||||
The using of partitions will remain for security and the robustness reasons, then the breach on 1 part of the operating system does not automatically mean that whole computer is under risk or danger. This is currently most important factor for the partitioning process. For example, the users create scripts, the programs or web applications which start filling up the disk. If that disk contains only 1 big partition, then entire system may stop functioning if that disk is full. If the users store data on separate partitions, then only that data partition can be affected, while system partitions and the possible other data partitions will keep functioning.
|
||||
|
||||
Mind that to have a journaled file system will only provide data security in case if there is a power failure as well as sudden disconnection of the storage devices. Such will not protect the data against the bad blocks and the logical errors in the file system. In such cases, the user should use a Redundant Array of Inexpensive Disks (RAID) solution.
|
||||
|
||||
### Why Switch File Systems? ###
|
||||
|
||||
The ext4 file system has been an improvement for the ext3 file system that was also an improvement over the ext2 file system. While the ext4 is a very solid file system which has been the default choice for almost all distributions for the past few years, it is made from an aging code base. Additionally, Linux operating system users are seeking many new different features in file systems which ext4 does not handle on its own. There is software which takes care of some of such needs, but in the performance aspect, being able to do such things on the file system level could be faster.
|
||||
|
||||
### Ext4 File System ###
|
||||
|
||||
The ext4 has some limits which are still a bit impressive. The maximum file size is 16 tebibytes (which is roughly 17.6 terabytes) and is much bigger than any hard drive a regular consumer can currently buy. While, the largest volume/partition you can make with ext4 is 1 exbibyte (which is roughly 1,152,921.5 terabytes). The ext4 is known to bring the speed improvements over ext3 by using multiple various techniques. Like in the most modern file systems, it is a journaling file system that means that it will keep a journal of where the files are mainly located on the disk and of any other changes that happen to the disk. Regardless all of its features, it doesn’t support the transparent compression, the data deduplication, or the transparent encryption. The snapshots are supported technically, but such feature is experimental at best.
|
||||
|
||||
### Btrfs File System ###
|
||||
|
||||
The btrfs, many of us pronounce it different ways, as an example, Better FS, Butter FS, or B-Tree FS. It is a file system which is completely made from scratch. The btrfs exists because its developers firstly wanted to expand the file system functionality in order to include snapshots, pooling, as well as checksums among the other things. While it is independent from the ext4, it also wants to build off the ideas present in the ext4 that are great for the consumers and the businesses alike as well as incorporate those additional features that will benefit everybody, but specifically the enterprises. For the enterprises who are using very large programs with very large databases, they are having a seemingly continuous file system across the multiple hard drives could be very beneficial as it will make a consolidation of the data much easier. The data deduplication could reduce the amount of the actual space data could occupy, and the data mirroring could become easier with the btrfs as well when there is a single and broad file system which needs to be mirrored.
|
||||
|
||||
The user certainly can still choose to create multiple partitions so that he does not need to mirror everything. Considering that the btrfs will be able for spanning over the multiple hard drives, it is a very good thing that it can support 16 times more drive space than the ext4. A maximum partition size of the btrfs file system is 16 exbibytes, as well as maximum file size is 16 exbibytes too.
|
||||
|
||||
### XFS File System ###
|
||||
|
||||
The XFS file system is an extension of the extent file system. The XFS is a high-performance 64-bit journaling file system. The support of the XFS was merged into Linux kernel in around 2002 and In 2009 Red Hat Enterprise Linux version 5.4 usage of the XFS file system. XFS supports maximum file system size of 8 exbibytes for the 64-bit file system. There is some comparison of XFS file system is XFS file system can’t be shrunk and poor performance with deletions of the large numbers of files. Now, the RHEL 7.0 uses XFS as the default filesystem.
|
||||
|
||||
### Final Thoughts ###
|
||||
|
||||
Unfortunately, the arrival date for the btrfs is not quite known. But officially, the next-generation file system is still classified as “unstable”, but if the user downloads the latest version of Ubuntu, he will be able to choose to install on a btrfs partition. When the btrfs will be classified actually as “stable” is still a mystery, but users shouldn’t expect the Ubuntu to use the btrfs by default until it’s indeed considered “stable”. It has been reported that Fedora 18 will use the btrfs as its default file system as by the time of its release a file system checker for the btrfs should exist. There is a good amount of work still left for the btrfs, as not all the features are yet implemented and the performance is a little sluggish if we compare it to the ext4.
|
||||
|
||||
So, which is better to use? Till now, the ext4 will be the winner despite the identical performance. But why? The answer will be the convenience as well as the ubiquity. The ext4 is still excellent file system for the desktop or workstation use. It is provided by default, so the user can install the operating system on it. Also, the ext4 supports volumes up to 1 Exabyte and files up to 16 Terabyte in size, so there’s still a plenty of room for the growth where space is concerned.
|
||||
|
||||
The btrfs might offer greater volumes up to 16 Exabyte and improved fault tolerance, but, till now, it feels more as an add-on file system rather than one integrated into the Linux operating system. For example, the btrfs-tools have to be present before a drive will be formatted with the btrfs, which means that the btrfs is not an option during the Linux operating system installation though that could vary with the distribution.
|
||||
|
||||
Even though the transfer rates are so important, there’s more to a just file system than speed of the file transfers. The btrfs has many useful features such as Copy-on-Write (CoW), extensive checksums, snapshots, scrubbing, self-healing data, deduplication, as well as many more good improvements that ensure the data integrity. The btrfs lacks the RAID-Z features of ZFS, so the RAID is still in an experimental state with the btrfs. For pure data storage, however, the btrfs is the winner over the ext4, but time still will tell.
|
||||
|
||||
Till the moment, the ext4 seems to be a better choice on the desktop system since it is presented as a default file system, as well as it is faster than the btrfs when transferring files. The btrfs is definitely worth to look into, but to completely switch to replace the ext4 on desktop Linux might be few years later. The data farms and the large storage pools could reveal different stories and show the right differences between ext4, XCF, and btrfs.
|
||||
|
||||
If you have a different or additional opinion, kindly let us know by commenting on this article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -1,203 +0,0 @@
|
||||
Gaming On Linux: All You Need To Know
|
||||
================================================================================
|
||||

|
||||
|
||||
**Can I play games on Linux?**
|
||||
|
||||
This is one of the most frequently asked questions by people who are thinking about [switching to Linux][1]. After all, gaming on Linux often termed as a distant possibility. In fact, some people even wonder if they can listen to music or watch movies on Linux. Considering that, question about native Linux games seem genuine.
|
||||
|
||||
In this article, I am going to answer most of the Linux gaming questions a Linux beginner may have. For example, if it is possible to play games on Linux, if yes, what are the Linux games available, where can you **download Linux games** from or how do you get more information of gaming on Linux.
|
||||
|
||||
But before I do that, let me make a confession. I am not a PC gamer or rather I should say, I am not desktop Linux gamer. I prefer to play games on my PS4 and I don’t care about PC games or even mobile games (no candy crush request sent to anyone in my friend list). This is the reason you see only a few articles in [Linux games][2] section of It’s FOSS.
|
||||
|
||||
So why am I covering this topic then?
|
||||
|
||||
Because I have been asked questions about playing games on Linux several times and I wanted to come up with a Linux gaming guide that could answer all those question. And remember, it’s not just gaming on Ubuntu I am talking about here. I am talking about Linux in general.
|
||||
|
||||
### Can you play games on Linux? ###
|
||||
|
||||
Yes and no!
|
||||
|
||||
Yes, you can play games on Linux and no, you cannot play ‘all the games’ in Linux.
|
||||
|
||||
Confused? Don’t be. What I meant here is that you can get plenty of popular games on Linux such as [Counter Strike, Metro Last Night][3] etc. But you might not get all the latest and popular Windows games on Linux, for e.g., [PES 2015][4].
|
||||
|
||||
The reason, in my opinion, is that Linux has less than 2% of desktop market share and these numbers are demotivating enough for most game developers to avoid working on the Linux version of their games.
|
||||
|
||||
Which means that there is huge possibility that the most talked about games of the year may not be playable in Linux. Don’t despair, there are ‘other means’ to get these games on Linux and we shall see it in coming sections, but before that let’s talk about what kind of games are available for Linux.
|
||||
|
||||
If I have to categorize, I’ll divide them in four categories:
|
||||
|
||||
1. Native Linux Games
|
||||
1. Windows games in Linux
|
||||
1. Browser Games
|
||||
1. Terminal Games
|
||||
|
||||
Let’s start with the most important one, native Linux games, first.
|
||||
|
||||
----------
|
||||
|
||||
### 1. Where to find native Linux games? ###
|
||||
|
||||
Native Linux games mean those games which are officially supported in Linux. These games have native Linux client and can be installed like most other applications in Linux without requiring any additional effort (we’ll see about these in next section).
|
||||
|
||||
So, as you see, there are games developed for Linux. Next question that arises is where can you find these Linux games and how can you play them. I am going to list some of the resources where you can get Linux games.
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] is a digital distribution platform for video games. As Amazon Kindle is digital distribution platform for e-Books, iTunes for music, similarly Steam is for games. It provides you the option to buy and install games, play multiplayer and stay in touch with other games via social networking on its platform. The games are protected with [DRM][6].”
|
||||
|
||||
A couple of years ago, when gaming platform Steam announced support for Linux, it was a big news. It was an indication that gaming on Linux is being taken seriously. Though Steam’s decision was more influenced with its own Linux-based gaming console and a separate [Linux distribution called Steam OS][7], it still was a reassuring move that has brought a number of games on Linux.
|
||||
|
||||
I have written a detailed article about installing and using Steam. If you are getting started with Steam, do read it.
|
||||
|
||||
- [Install and use Steam for gaming on Linux][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] is another platform similar to Steam. Like Steam, you can browse and find hundreds of native Linux games on GOG.com, purchase the games and install them. If the games support several platforms, you can download and use them across various operating systems. Your purchased games are available for you all the time in your account. You can download them anytime you wish.
|
||||
|
||||
One main difference between the two is that GOG.com offers only DRM free games and movies. Also, GOG.com is entirely web based. So you don’t need to install a client like Steam. You can simply download the games from browser and install them in your system.
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] is a website that has a collection of a number of Linux games. The unique and best thing about Portable Linux Games is that you can download and store the games for offline installation.
|
||||
|
||||
The downloaded files have all the dependencies (at times Wine and Perl installation) and these are also platform independent. All you need to do is to download the files and double click to install them. Store the downloadable file on external hard disk and use them in future. Highly recommend if you don’t have continuous access to high speed internet.
|
||||
|
||||
#### Game Drift Game Store ####
|
||||
|
||||
[Game Drift][11] is actually a Linux distribution based on Ubuntu with sole focus on gaming. While you might not want to start using this Linux distribution for the sole purpose of gaming, you can always visit its game store online and see what games are available for Linux and install them.
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
As the name suggests, [Linux Game Database][12] is a website with a huge collection of Linux games. You can browse through various category of games and download/install them from the game developer’s website. As a member of Linux Game Database, you can even rate the games. LGDB, kind of, aims to be the IGN or IMDB for Linux games.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
Created by a gamer who refused to use Windows for playing games, [Penguspy][13] showcases a collection of some of the best Linux games. You can browse games based on category and if you like the game, you’ll have to go to the respective game developer’s website.
|
||||
|
||||
#### Software Repositories ####
|
||||
|
||||
Look into the software repositories of your own Linux distribution. There always will be some games in it. If you are using Ubuntu, Ubuntu Software Center itself has an entire section for games. Same is true for other Linux distributions such as Linux Mint etc.
|
||||
|
||||
----------
|
||||
|
||||
### 2. How to play Windows games in Linux? ###
|
||||
|
||||

|
||||
|
||||
So far we talked about native Linux games. But there are not many Linux games, or to be more precise, most popular Linux games are not available for Linux but they are available for Windows PC. So the questions arises, how to play Windows games in Linux?
|
||||
|
||||
Good thing is that with the help of tools like Wine, PlayOnLinux and CrossOver, you can play a number of popular Windows games in Linux.
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine is a compatibility layer which is capable of running Windows applications in systems like Linux, BSD and OS X. With the help of Wine, you can install and use a number of Windows applications in Linux.
|
||||
|
||||
[Installing Wine in Ubuntu][14] or any other Linux is easy as it is available in most Linux distributions’ repository. There is a huge [database of applications and games supported by Wine][15] that you can browse.
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] is an improved version of Wine that brings professional and technical support to Wine. But unlike Wine, CrossOver is not free. You’ll have to purchase the yearly license for it. Good thing about CrossOver is that every purchase contributes to Wine developers and that in fact boosts the development of Wine to support more Windows games and applications. If you can afford $48 a year, you should buy CrossOver for the support they provide.
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux too is based on Wine but implemented differently. It has different interface and slightly easier to use than Wine. Like Wine, PlayOnLinux too is free to use. You can browse the [applications and games supported by PlayOnLinux on its database][17].
|
||||
|
||||
----------
|
||||
|
||||
### 3. Browser Games ###
|
||||
|
||||

|
||||
|
||||
Needless to say that there are tons of browser based games that are available to play in any operating system, be it Windows or Linux or Mac OS X. Most of the addictive mobile games, such as [GoodGame Empire][18], also have their web browser counterparts.
|
||||
|
||||
Apart from that, thanks to [Google Chrome Web Store][19], you can play some more games in Linux. These Chrome games are installed like a standalone app and they can be accessed from the application menu of your Linux OS. Some of these Chrome games are playable offline as well.
|
||||
|
||||
----------
|
||||
|
||||
### 4. Terminal Games ###
|
||||
|
||||

|
||||
|
||||
Added advantage of using Linux is that you can use the command line terminal to play games. I know that it’s not the best way to play games but at times, it’s fun to play games like [Snake][20] or [2048][21] in terminal. There is a good collection of Linux terminal games at [this blog][22]. You can browse through it and play the ones you want.
|
||||
|
||||
----------
|
||||
|
||||
### How to stay updated about Linux games? ###
|
||||
|
||||
When you have learned a lot about what kind of games are available on Linux and how could you use them, next question is how to stay updated about new games on Linux? And for that, I advise you to follow these blogs that provide you with the latest happenings of the Linux gaming world:
|
||||
|
||||
- [Gaming on Linux][23]: I won’t be wrong if I call it the nest Linux gaming news portal. You get all the latest rumblings and news about Linux games. Frequently updated, Gaming on Linux has dedicated fan following which makes it a nice community of Linux game lovers.
|
||||
- [Free Gamer][24]: A blog focusing on free and open source games.
|
||||
- [Linux Game News][25]: A Tumbler blog that updates on various Linux games.
|
||||
|
||||
#### What else? ####
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][26]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
I think that’s pretty much what you need to know to get started with gaming on Linux. If you are still not convinced, I would advise you to [dual boot Linux with Windows][27]. Use Linux as your main desktop and if you want to play games, boot into Windows. This could be a compromised solution.
|
||||
|
||||
It’s time for you to add your inputs. Do you play games on your Linux desktop? What are your favorites? What blogs you follow to stay updated on latest Linux games?
|
||||
|
||||
|
||||
投票项目:
|
||||
How do you play games on Linux?
|
||||
|
||||
- I use Wine and PlayOnLinux along with native Linux Games
|
||||
- I am happy with Browser Games
|
||||
- I prefer the Terminal Games
|
||||
- I use native Linux games only
|
||||
- I play it on Steam
|
||||
- I dual boot and go in to Windows to play games
|
||||
- I don't play games at all
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
[27]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -1,86 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Android 4.2, Jelly Bean—new Nexus devices, new tablet interface ###
|
||||
|
||||
The Android Platform was rapidly maturing, and with Google hosting more and more apps in the Play Store, there was less and less that needed to go out in the OS update. Still, the relentless march of updates must continue, and in November 2012 Android 4.2 was released. 4.2 was still called "Jelly Bean," a nod to the relatively small amount of changes that were present in this release.
|
||||
|
||||

|
||||
The LG-made Nexus 4 and Samsung-made Nexus 10.
|
||||
Photo by Google/Ron Amadeo
|
||||
|
||||
Along with Android 4.2 came two flagship devices, the Nexus 4 and the Nexus 10, both of which were sold direct by Google on the Play Store. The Nexus 4 applied the Nexus 7 strategy of a quality device at a shockingly low price and sold for $300 unlocked. The Nexus 4 had a quad-core 1.5 GHz Snapdragon S4 Pro, 2GB of RAM and a 4.7-inch 1280×768 LCD. Google's new flagship phone was manufactured by LG, and with the manufacturer switch came a focus on materials and build quality. The Nexus 4 had a glass front and back, and while you couldn't drop it, it was one of the nicest-feeling Android phones to date. The biggest downside to the Nexus 4 was the lack of LTE at a time when most phones, including the Verizon Galaxy Nexus, came with the faster modem. Still, demand for the Nexus 4 greatly exceeded Google's expectations—the launch rush crashed the Play Store Web site on launch day. The device sold out in under an hour.
|
||||
|
||||
The Nexus 10 was Google's first 10-inch Nexus tablet. The highlight of the device was the 2560×1600 display, which was the highest resolution in its class. All those pixels were powered by a dual core, 1.7GHz Cortex A15 processor and 2GB of RAM. With each passing month, it's looking more and more like the Nexus 10 is the first and last 10-inch Nexus tablet. Usually these devices are upgraded every year, but the Nexus 10 is now 16 months old, and there's no sign of the new model on the horizon. Google is doing well with smaller-sized 7-inch tablets, and it seems content to let partners [like Samsung][1] explore the larger end of the tablet spectrum.
|
||||
|
||||
|
||||
The new lock screen, wallpaper, and clock widget design.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
4.2 brought lots of changes to the lock screen. The font was centered and used an extremely thick weight for the hour and a thin font for the minutes. The lock screen was now paginated and could be customized with widgets. Rather than a simple clock on the lock screen, users could replace it with another widget or add extra pages to the lock screen for more widgets.
|
||||
|
||||
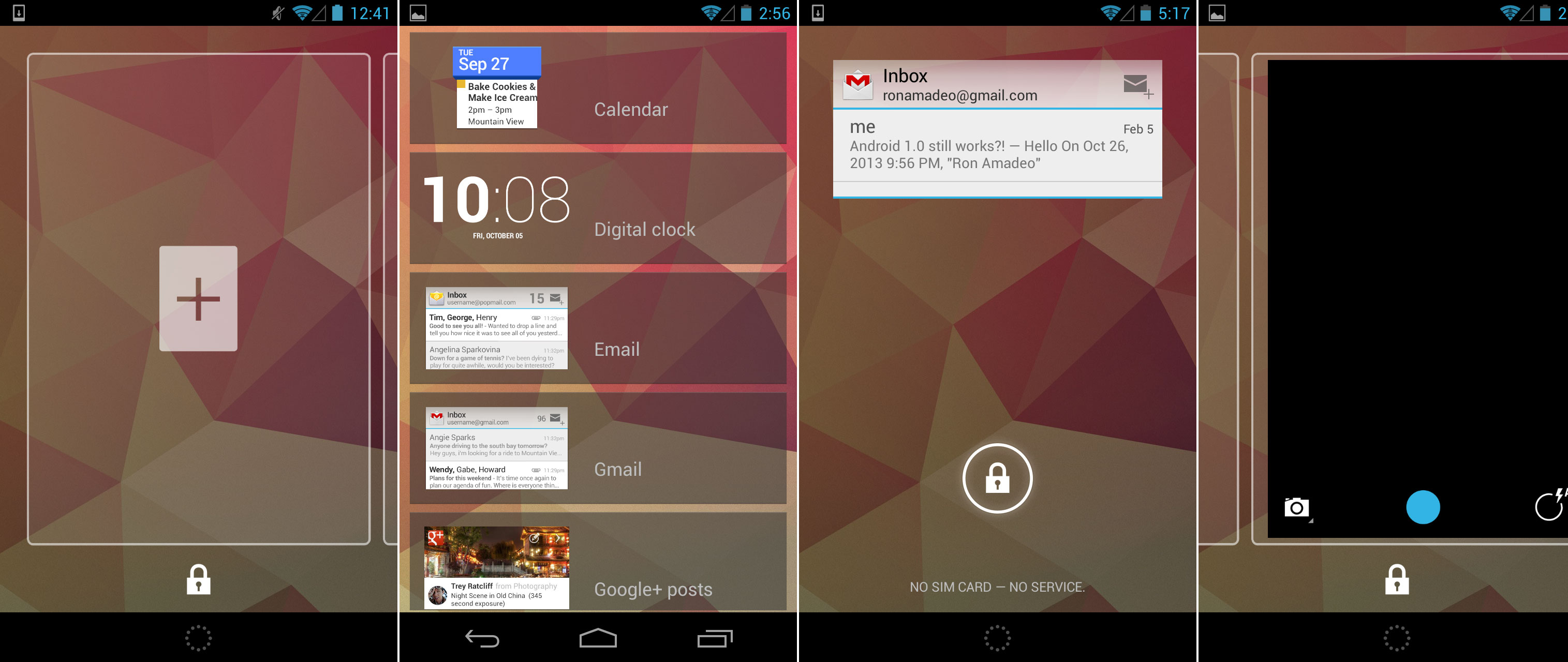
|
||||
The lock screen's add widget page, the list of widgets, the Gmail widget on the lock screen, and swiping over to the camera.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The lock screen now worked like a stripped-down version of the home screen. Page outlines would pop up on the left and right sides of the lock screen to hint to users that they could swipe to other pages with other widgets. Swiping to the left would show a simple blank page with a plus sign in the center, and tapping on it would bring up a list of widgets that were compatible with the lock screen. Lock screens were limited to one widget per page and could be expanded or collapsed by dragging up or down on the widget. The right-most page was reserved for the camera—a simple over would open the camera interface, but you weren't able to swipe back.
|
||||
|
||||

|
||||
The new Quick Settings panel and a composite image of the app lineup.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
One of the biggest additions to 4.2 was the new "Quick Settings" panel. Android 3.0 brought a way to quickly change power settings to tablets, and 4.2 finally brought that ability to phones. A new icon was added to the top right corner of the notification panel that would switch between the normal list of notifications and the new quick settings screen. Quick Settings offered faster access to screen brightness, network connections, and battery and data usage without having to dig through the full settings screen. The top level settings button in Android 4.1 was removed, and a square was added to the Quick Settings screen for it.
|
||||
|
||||
There were lots of changes to the app drawer and 4.2's lineup of apps and icons. Thanks to the wider aspect ratio of the Nexus 4 (5:3 vs 16:9 on the Galaxy Nexus), the app drawer on that device could now show a five-wide grid of icons. 4.2 replaced the stock browser with Google Chrome and the stock calendar with Google Calendar, both of which brought new icon designs. The Clock and Camera apps were revamped in 4.2, and new icons were part of the deal. "Google Settings" was a new app that offered shortcuts to all the existing Google Account settings around the OS, and it had a unified look with Google Search and the new Google+ icon. Google Maps got a new icon, and Google Latitude, which was part of Google Maps, was retired in favor of Google+ location.
|
||||
|
||||
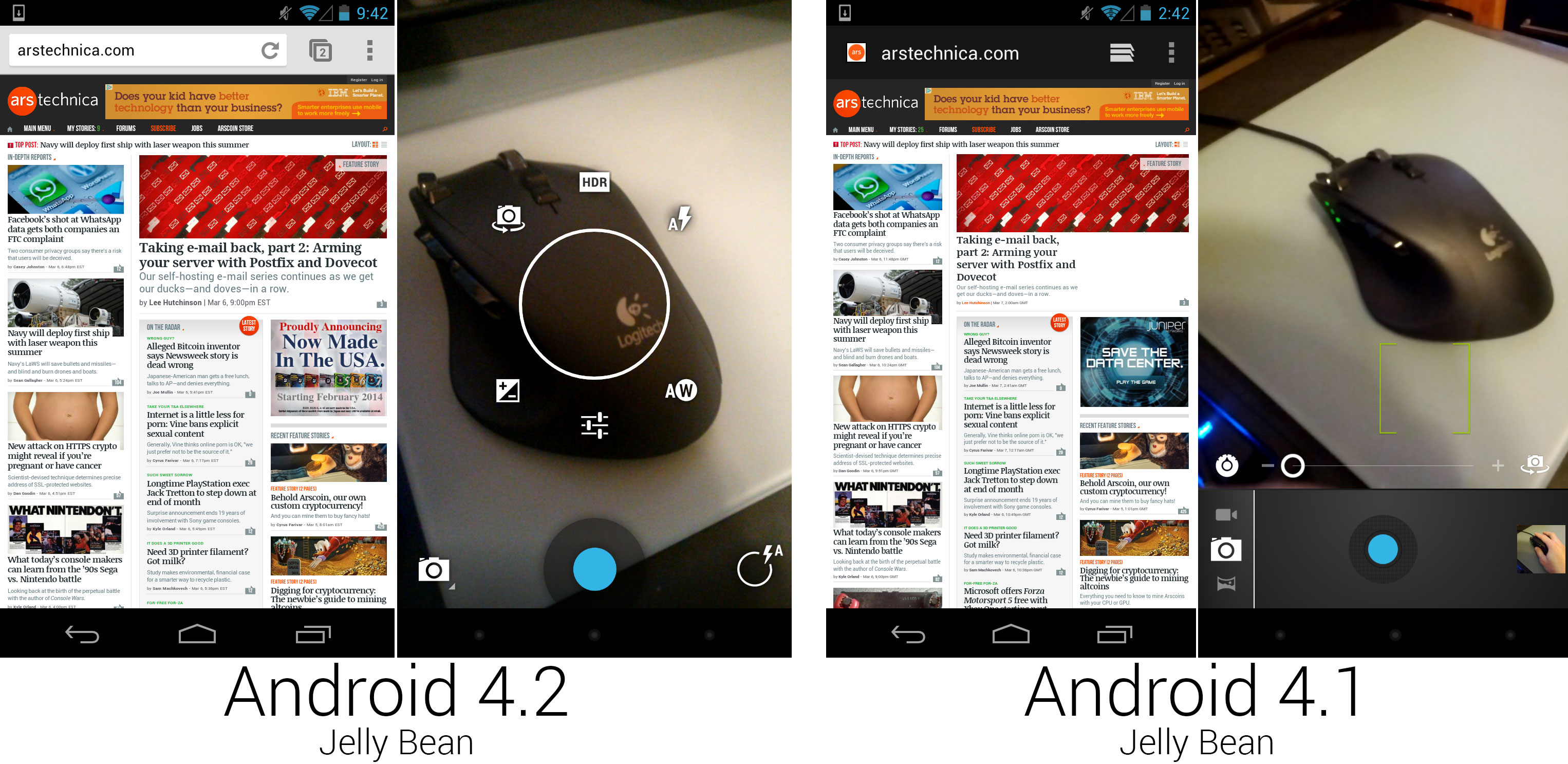
|
||||
The browser was replaced with Chrome, and the new camera interface with a full screen viewfinder.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The stock browser did its best Chrome imitation for a while—it took many cues from Chrome’s interface, many Chrome features, and was even using Chrome’s javascript engine—but by the time Android 4.2 rolled around, Google deemed the Android version of Chrome ready to replace the imitator. On the surface, it didn't seem like much of a difference; the interface looked different, and early versions of Chrome for Android didn't scroll as smoothly as the stock browser. Under the hood, though, everything was different. Development of Android's main browser was now handled by the Google Chrome team instead of being a side project of the Android team. Android's default browser moved from being a stagnant app tied to Android releases to a Play Store app that was continually updated. Today there is even a beta channel that receives several updates per month.
|
||||
|
||||
The camera interface was redesigned. It was now a completely full-screen app, showing a live view of the camera and places controls on top of it. The layout aesthetic had a lot in common with the [camera design][2] of Android 1.5: minimal controls with a focus on the viewfinder output. The circle of controls in the center appeared when you either held your finger on the screen or pressed the circle icon in the bottom right corner. When holding your finger down, you could slide around to pick the options around the circle, often expanding out into a sub-menu. Releasing over a highlighted item would select it. This was clearly inspired by the Quick Controls in the Android 4.0 browser, but arranging the options in a circle meant your finger was almost always blocking part of the interface.
|
||||
|
||||
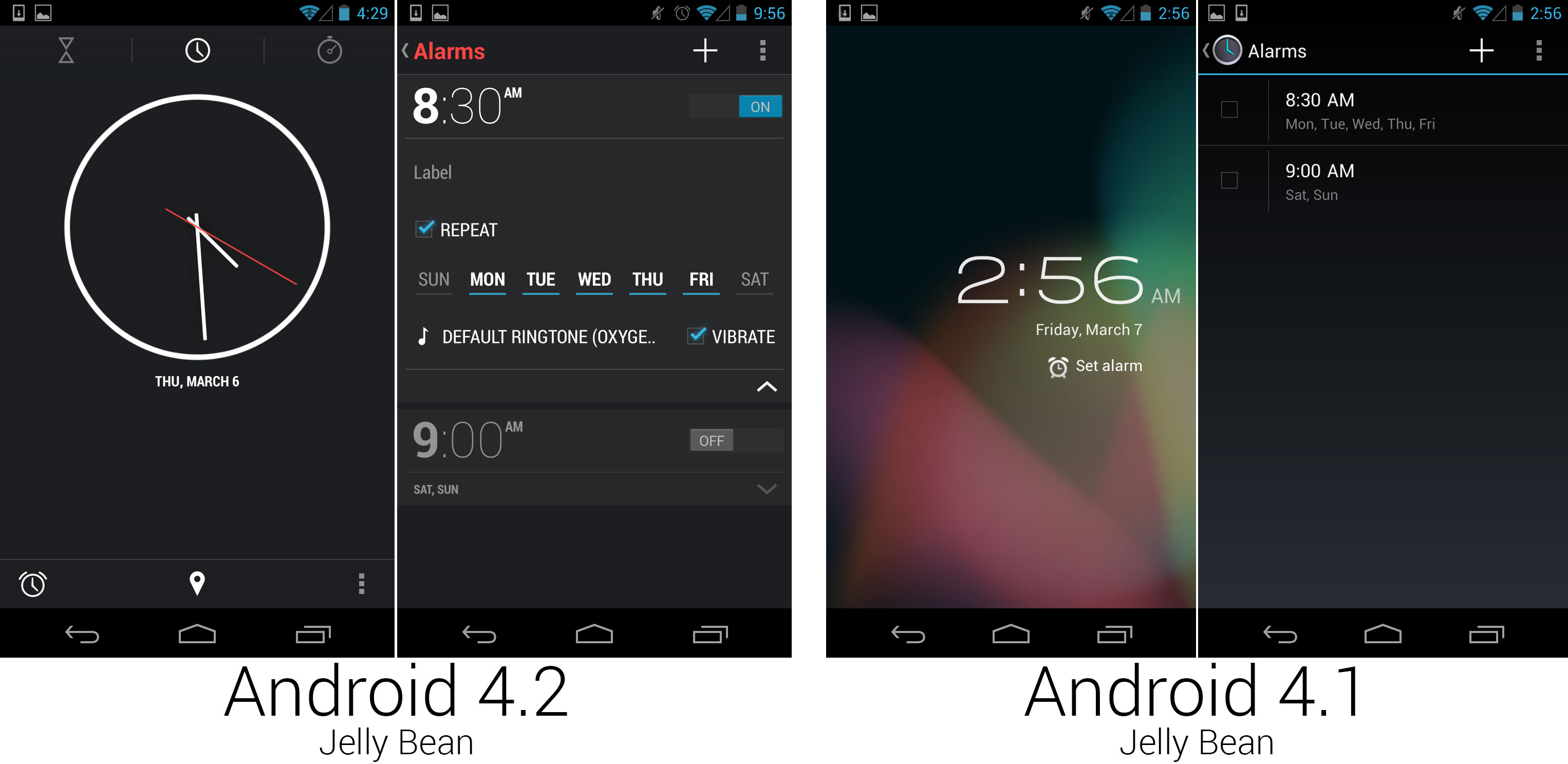
|
||||
The clock app, which went from a two-screen app to a feature-packed, useful application.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The clock application was completely revamped, going from a simple two-screen alarm clock to a world clock, alarm, timer, and stopwatch. The clock app design was like nothing Google introduced before, with an ultra-minimal aesthetic and red highlights. It seemed to be an experiment for Google. Even several versions later, this design language seemed to be confined only to this app.
|
||||
|
||||
The clock's time picker was particularly well-designed. It showed a simple number pad, and it would intelligently disable numbers that would result in an invalid time. It was also impossible to set an alarm time without implicitly selecting AM or PM, forever solving the problem of accidentally setting an alarm for 9pm instead of 9am.
|
||||
|
||||
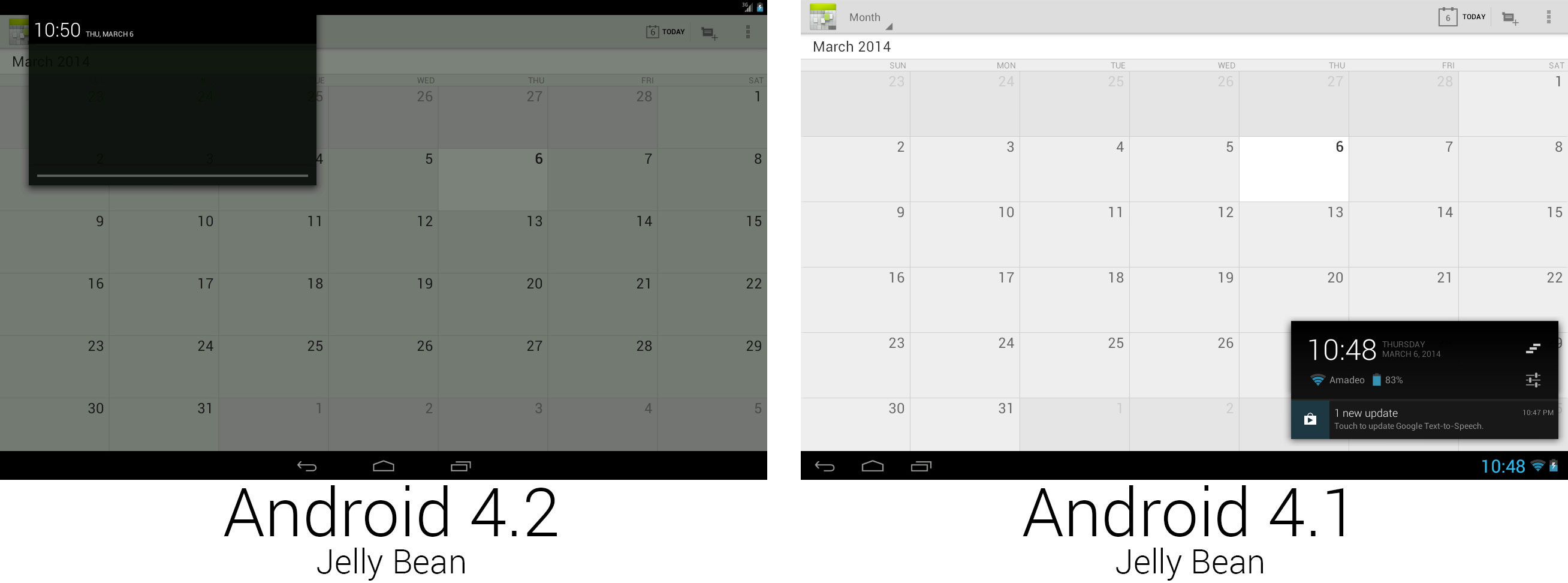
|
||||
The new system UI for tablets used a stretched-out phone interface.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The most controversial change in Android 4.2 was made to the tablet UI, which switched from a unified single bottom system bar to a two-bar interface with a top status bar and bottom system bar. The new design unified the phone and tablet interfaces, but critics said it was a waste of space to stretch the phone interface to a 10-inch landscape tablet. Since the navigation buttons had the whole bottom bar to themselves now, they were centered, just like the phone interface.
|
||||
|
||||
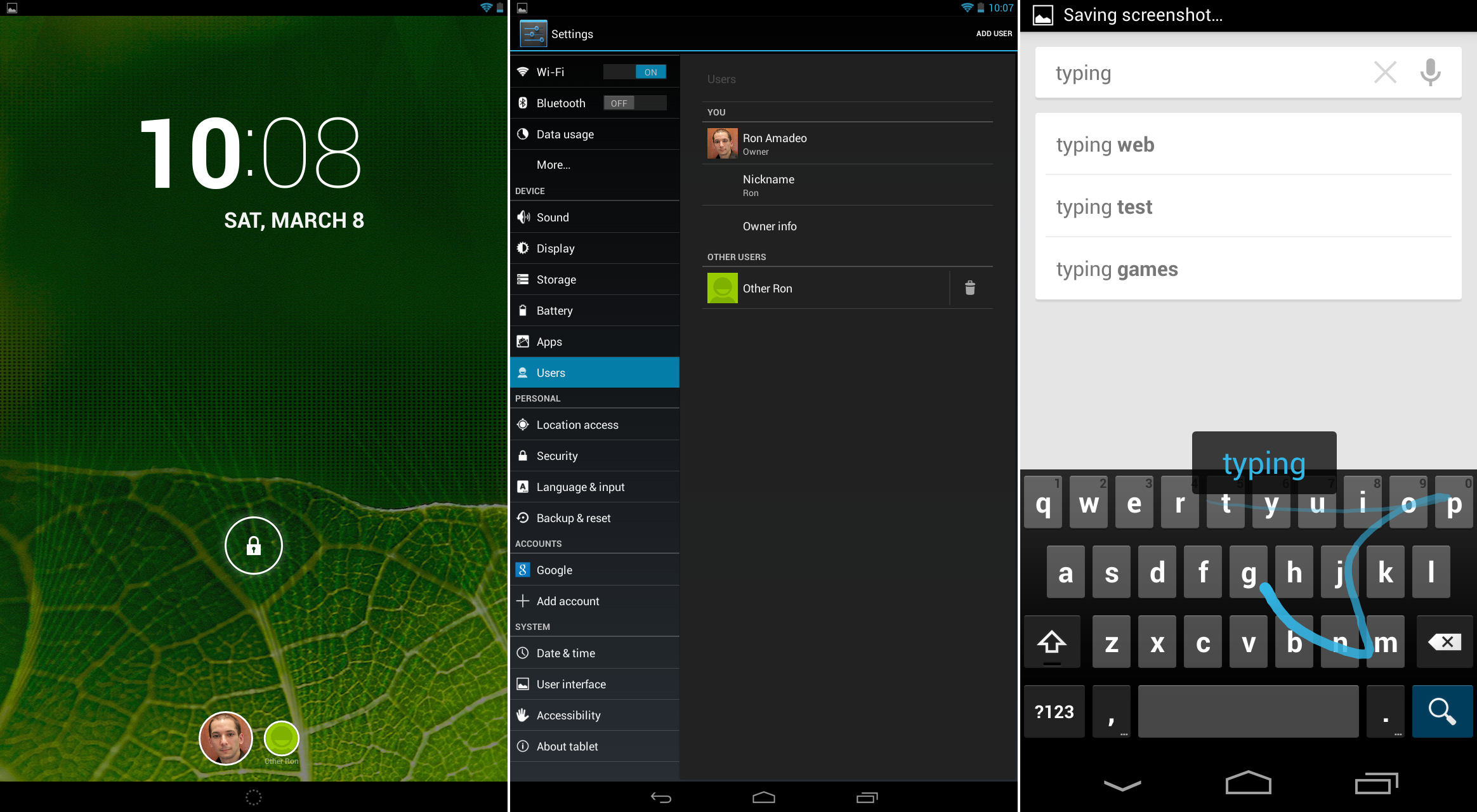
|
||||
Multiple users on a tablet, and the new gesture-driven keyboard.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
On tablets, Android 4.2 brought support for multiple users. In the settings, a "Users" section was added, where you could manage users on a device. Setup was done from within each user account, where Android would keep separate settings, home screens, apps, and app data for each user.
|
||||
|
||||
4.2 also added a new keyboard with swiping abilities. Rather than just tapping each individual letter, users could now keep a finger on the screen the whole time and just slide from letter to letter to type.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/22/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2014/01/hands-on-with-samsungs-notepro-and-tabpro-new-screen-sizes-and-magazine-ui/
|
||||
[2]:http://cdn.arstechnica.net/wp-content/uploads/2013/12/device-2013-12-26-11016071.png
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
@ -56,4 +58,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[2]:http://arstechnica.com/information-technology/2013/05/hands-on-with-hangouts-googles-new-text-and-video-chat-architecture/
|
||||
[3]:https://developer.android.com/design/patterns/navigation-drawer.html
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
5 great Raspberry Pi projects for the classroom
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
### 1. Minecraft Pi ###
|
||||
|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
|
||||
|
||||
Minecraft is the favorite game of pretty much every teenager in the world—and it's one of the most creative games ever to capture the attention of young people. The version that comes with every Raspberry Pi is not only a creative thinking building game, but comes with a programming interface allowing for additional interaction with the Minecraft world through Python code.
|
||||
|
||||
Minecraft: Pi Edition is a great way for teachers to engage students with problem solving and writing code to perform tasks. You can use the Python API to build a house and have it follow you wherever you go, build a bridge wherever you walk, make it rain lava, show the temperature in the sky, and anything else your imagination can create.
|
||||
|
||||
Read more in "[Getting Started with Minecraft Pi][2]."
|
||||
|
||||
### 2. Reaction game and traffic lights ###
|
||||
|
||||

|
||||
|
||||
Courtesy of [Low Voltage Labs][3]. [CC BY-SA 4.0][1].
|
||||
|
||||
It's really easy to get started with physical computing on Raspberry Pi—just connect up LEDs and buttons to the GPIO pins, and with a few lines of code you can turn lights on and control things with button presses. Once you know the code to do the basics, it's down to your imagination as to what you do next!
|
||||
|
||||
If you know how to flash one light, you can flash three. Pick out three LEDs in traffic light colors and you can code the traffic light sequence. If you know how to use a button to a trigger an event, then you have a pedestrian crossing! Also look out for great pre-built traffic light add-ons like [PI-TRAFFIC][4], [PI-STOP][5], [Traffic HAT][6], and more.
|
||||
|
||||
It's not always about the code—this can be used as an exercise in understanding how real world systems are devised. Computational thinking is a useful skill in any walk of life.
|
||||
|
||||

|
||||
|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0][1].
|
||||
|
||||
Next, try wiring up two buttons and an LED and making a two-player reaction game—let the light come on after a random amount of time and see who can press the button first!
|
||||
|
||||
To learn more, check out "[GPIO Zero recipes][7]. Everything you need is in [CamJam EduKit 1][8].
|
||||
|
||||
### 3. Sense HAT Pixel Pet ###
|
||||
|
||||
The Astro Pi—an augmented Raspberry Pi—is going to space this December, but you haven't missed your chance to get your hands on the hardware. The Sense HAT is the sensor board add-on used in the Astro Pi mission and it's available for anyone to buy. You can use it for data collection, science experiments, games and more. Watch this Gurl Geek Diaries video from Raspberry Pi's Carrie Anne for a great way to get started—by bringing to life an animated pixel pet of your own design on the Sense HAT display:
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" src="https://www.youtube.com/embed/gfRDFvEVz-w" allowfullscreen=""></iframe>
|
||||
|
||||
Learn more in "[Exploring the Sense HAT][9]."
|
||||
|
||||
### 4. Infrared bird box ###
|
||||
|
||||

|
||||
Courtesy of the Raspberry Pi Foundation. [CC BY-SA 4.0.][1]
|
||||
|
||||
A great exercise for the whole class to get involved with—place a Raspberry Pi and the NoIR camera module inside a bird box along with some infra-red lights so you can see in the dark, then stream video from the Pi over the network or on the internet. Wait for birds to nest and you can observe them without disturbing them in their habitat.
|
||||
|
||||
Learn all about infrared and the light spectrum, and how to adjust the camera focus and control the camera in software.
|
||||
|
||||
Learn more in "[Make an infrared bird box.][10]"
|
||||
|
||||
### 5. Robotics ###
|
||||
|
||||

|
||||
|
||||
Courtesy of Low Voltage Labs. [CC BY-SA 4.0][1].
|
||||
|
||||
With a Raspberry Pi and as little as a couple of motors and a motor controller board, you can build your own robot. There is a vast range of robots you can make, from basic buggies held together by sellotape and a homemade chassis, all the way to self-aware, sensor-laden metallic stallions with camera attachments driven by games controllers.
|
||||
|
||||
Learn how to control individual motors with something straightforward like the RTK Motor Controller Board (£8/$12), or dive into the new CamJam robotics kit (£17/$25) which comes with motors, wheels and a couple of sensors—great value and plenty of learning potential.
|
||||
|
||||
Alternatively, if you'd like something more hardcore, try PiBorg's [4Borg][11] (£99/$150) or [DiddyBorg][12] (£180/$273) or go the whole hog and treat yourself to their DoodleBorg Metal edition (£250/$380)—and build a mini version of their infamous [DoodleBorg tank][13] (unfortunately not for sale).
|
||||
|
||||
Check out the [CamJam robotics kit worksheets][14].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]:http://lowvoltagelabs.com/
|
||||
[4]:http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]:http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]:https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]:http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]:http://camjam.me/?page_id=236
|
||||
[9]:https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]:https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]:https://www.piborg.org/4borg
|
||||
[12]:https://www.piborg.org/diddyborg
|
||||
[13]:https://www.piborg.org/doodleborg
|
||||
[14]:http://camjam.me/?page_id=1035#worksheets
|
||||
@ -1,3 +1,4 @@
|
||||
translated by bestony
|
||||
How to Install OsTicket Ticketing System in Fedora 22 / Centos 7
|
||||
================================================================================
|
||||
In this article, we'll learn how to setup help desk ticketing system with osTicket in our machine or server running Fedora 22 or CentOS 7 as operating system. osTicket is a free and open source popular customer support ticketing system developed and maintained by [Enhancesoft][1] and its contributors. osTicket is the best solution for help and support ticketing system and management for better communication and support assistance with clients and customers. It has the ability to easily integrate with inquiries created via email, phone and web based forms into a beautiful multi-user web interface. osTicket makes us easy to manage, organize and log all our support requests and responses in one single place. It is a simple, lightweight, reliable, open source, web-based and easy to setup and use help desk ticketing system.
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
chisper 翻译中
|
||||
How to Install Pure-FTPd with TLS on FreeBSD 10.2
|
||||
================================================================================
|
||||
FTP or File Transfer Protocol is application layer standard network protocol used to transfer file from the client to the server, after user logged in to the FTP server over the TCP-Network, such as internet. FTP has been round long time ago, much longer then P2P Program, or World Wide Web, and until this day it was a primary method for sharing file with other over the internet and it it remain very popular even today. FTP provide an secure transmission, that protect username, password and encrypt the content with SSL/TLS.
|
||||
|
||||
@ -1,156 +0,0 @@
|
||||
How to send email notifications using Gmail SMTP server on Linux
|
||||
================================================================================
|
||||
Suppose you want to configure a Linux app to send out email messages from your server or desktop. The email messages can be part of email newsletters, status updates (e.g., [Cachet][1]), monitoring alerts (e.g., [Monit][2]), disk events (e.g., [RAID mdadm][3]), and so on. While you can set up your [own outgoing mail server][4] to deliver messages, you can alternatively rely on a freely available public SMTP server as a maintenance-free option.
|
||||
|
||||
One of the most reliable **free SMTP servers** is from Google's Gmail service. All you have to do to send email notifications within your app is to add Gmail's SMTP server address and your credentials to the app, and you are good to go.
|
||||
|
||||
One catch with using Gmail's SMTP server is that there are various restrictions in place, mainly to combat spammers and email marketers who often abuse the server. For example, you can send messages to no more than 100 addresses at once, and no more than 500 recipients per day. Also, if you don't want to be flagged as a spammer, you cannot send a large number of undeliverable messages. When any of these limitations is reached, your Gmail account will temporarily be locked out for a day. In short, Gmail's SMTP server is perfectly fine for your personal use, but not meant for commercial bulk emails.
|
||||
|
||||
With that being said, let me demonstrate **how to use Gmail's SMTP server in Linux environment**.
|
||||
|
||||
### Google Gmail SMTP Server Setting ###
|
||||
|
||||
If you want to send emails from your app using Gmail's SMTP server, remember the following details.
|
||||
|
||||
- **Outgoing mail server (SMTP server)**: smtp.gmail.com
|
||||
- **Use authentication**: yes
|
||||
- **Use secure connection**: yes
|
||||
- **Username**: your Gmail account ID (e.g., "alice" if your email is alice@gmail.com)
|
||||
- **Password**: your Gmail password
|
||||
- **Port**: 587
|
||||
|
||||
Exact configuration syntax may vary depending on apps. In the rest of this tutorial, I will show you several useful examples of using Gmail SMTP server in Linux.
|
||||
|
||||
### Send Emails from the Command Line ###
|
||||
|
||||
As the first example, let's try the most basic email functionality: send an email from the command line using Gmail SMTP server. For this, I am going to use a command-line email client called mutt.
|
||||
|
||||
First, install mutt:
|
||||
|
||||
For Debian-based system:
|
||||
|
||||
$ sudo apt-get install mutt
|
||||
|
||||
For Red Hat based system:
|
||||
|
||||
$ sudo yum install mutt
|
||||
|
||||
Create a mutt configuration file (~/.muttrc) and specify in the file Gmail SMTP server information as follows. Replace <gmail-id> with your own Gmail ID. Note that this configuration is for sending emails only (not receiving emails).
|
||||
|
||||
$ vi ~/.muttrc
|
||||
|
||||
----------
|
||||
|
||||
set from = "<gmail-id>@gmail.com"
|
||||
set realname = "Dan Nanni"
|
||||
set smtp_url = "smtp://<gmail-id>@smtp.gmail.com:587/"
|
||||
set smtp_pass = "<gmail-password>"
|
||||
|
||||
Now you are ready to send out an email using mutt:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com
|
||||
|
||||
To attach a file in an email, use "-a" option:
|
||||
|
||||
$ echo "This is an email body." | mutt -s "This is an email subject" alice@yahoo.com -a ~/test_attachment.jpg
|
||||
|
||||

|
||||
|
||||
Using Gmail SMTP server means that the emails appear as sent from your Gmail account. In other words, a recepient will see your Gmail address as the sender's address. If you want to use your domain as the email sender, you need to use Gmail SMTP relay service instead.
|
||||
|
||||
### Send Email Notification When a Server is Rebooted ###
|
||||
|
||||
If you are running a [virtual private server (VPS)][5] for some critical website, one recommendation is to monitor VPS reboot activities. As a more practical example, let's consider how to set up email notifications for every reboot event on your VPS. Here I assume you are using systemd on your VPS, and show you how to create a custom systemd boot-time service for automatic email notifications.
|
||||
|
||||
First create the following script reboot_notify.sh which takes care of email notifications.
|
||||
|
||||
$ sudo vi /usr/local/bin/reboot_notify.sh
|
||||
|
||||
----------
|
||||
|
||||
#!/bin/sh
|
||||
|
||||
echo "`hostname` was rebooted on `date`" | mutt -F /etc/muttrc -s "Notification on `hostname`" alice@yahoo.com
|
||||
|
||||
----------
|
||||
|
||||
$ sudo chmod +x /usr/local/bin/reboot_notify.sh
|
||||
|
||||
In the script, I use "-F" option to specify the location of system-wide mutt configuration file. So don't forget to create /etc/muttrc file and populate Gmail SMTP information as described earlier.
|
||||
|
||||
Now let's create a custom systemd service as follows.
|
||||
|
||||
$ sudo mkdir -p /usr/local/lib/systemd/system
|
||||
$ sudo vi /usr/local/lib/systemd/system/reboot-task.service
|
||||
|
||||
----------
|
||||
|
||||
[Unit]
|
||||
Description=Send a notification email when the server gets rebooted
|
||||
DefaultDependencies=no
|
||||
Before=reboot.target
|
||||
|
||||
[Service]
|
||||
Type=oneshot
|
||||
ExecStart=/usr/local/bin/reboot_notify.sh
|
||||
|
||||
[Install]
|
||||
WantedBy=reboot.target
|
||||
|
||||
Once the service file is created, enable and start the service.
|
||||
|
||||
$ sudo systemctl enable reboot-task
|
||||
$ sudo systemctl start reboot-task
|
||||
|
||||
From now on, you will be receiving a notification email every time the VPS gets rebooted.
|
||||
|
||||

|
||||
|
||||
### Send Email Notification from Server Usage Monitoring ###
|
||||
|
||||
As a final example, let me present a real-world application called [Monit][6], which is a pretty useful server monitoring application. It comes with comprehensive [VPS][7] monitoring capabilities (e.g., CPU, memory, processes, file system), as well as email notification functions.
|
||||
|
||||
If you want to receive email notifications for any event on your VPS (e.g., server overload) generated by Monit, you can add the following SMTP information to Monit configuration file.
|
||||
|
||||
set mailserver smtp.gmail.com port 587
|
||||
username "<your-gmail-ID>" password "<gmail-password>"
|
||||
using tlsv12
|
||||
|
||||
set mail-format {
|
||||
from: <your-gmail-ID>@gmail.com
|
||||
subject: $SERVICE $EVENT at $DATE on $HOST
|
||||
message: Monit $ACTION $SERVICE $EVENT at $DATE on $HOST : $DESCRIPTION.
|
||||
|
||||
Yours sincerely,
|
||||
Monit
|
||||
}
|
||||
|
||||
# the person who will receive notification emails
|
||||
set alert alice@yahoo.com
|
||||
|
||||
Here is the example email notification sent by Monit for excessive CPU load.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As you can imagine, there will be so many different ways to take advantage of free SMTP servers like Gmail. But once again, remember that the free SMTP server is not meant for commercial usage, but only for your own personal project. If you are using Gmail SMTP server inside any app, feel free to share your use case.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/send-email-notifications-gmail-smtp-server-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/setup-system-status-page.html
|
||||
[2]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[3]:http://xmodulo.com/create-software-raid1-array-mdadm-linux.html
|
||||
[4]:http://xmodulo.com/mail-server-ubuntu-debian.html
|
||||
[5]:http://xmodulo.com/go/digitalocean
|
||||
[6]:http://xmodulo.com/server-monitoring-system-monit.html
|
||||
[7]:http://xmodulo.com/go/digitalocean
|
||||
@ -1,201 +0,0 @@
|
||||
Data Structures in the Linux Kernel
|
||||
================================================================================
|
||||
|
||||
Radix tree
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
As you already know linux kernel provides many different libraries and functions which implement different data structures and algorithms. In this part we will consider one of these data structures - [Radix tree](http://en.wikipedia.org/wiki/Radix_tree). There are two files which are related to `radix tree` implementation and API in the linux kernel:
|
||||
|
||||
* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
|
||||
* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
|
||||
|
||||
Lets talk about what a `radix tree` is. Radix tree is a `compressed trie` where a [trie](http://en.wikipedia.org/wiki/Trie) is a data structure which implements an interface of an associative array and allows to store values as `key-value`. The keys are usually strings, but any data type can be used. A trie is different from an `n-tree` because of its nodes. Nodes of a trie do not store keys; instead, a node of a trie stores single character labels. The key which is related to a given node is derived by traversing from the root of the tree to this node. For example:
|
||||
|
||||
|
||||
```
|
||||
+-----------+
|
||||
| |
|
||||
| " " |
|
||||
| |
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| |
|
||||
+-----------+
|
||||
```
|
||||
|
||||
So in this example, we can see the `trie` with keys, `go` and `cat`. The compressed trie or `radix tree` differs from `trie` in that all intermediates nodes which have only one child are removed.
|
||||
|
||||
Radix tree in linux kernel is the datastructure which maps values to integer keys. It is represented by the following structures from the file [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h):
|
||||
|
||||
```C
|
||||
struct radix_tree_root {
|
||||
unsigned int height;
|
||||
gfp_t gfp_mask;
|
||||
struct radix_tree_node __rcu *rnode;
|
||||
};
|
||||
```
|
||||
|
||||
This structure presents the root of a radix tree and contains three fields:
|
||||
|
||||
* `height` - height of the tree;
|
||||
* `gfp_mask` - tells how memory allocations will be performed;
|
||||
* `rnode` - pointer to the child node.
|
||||
|
||||
The first field we will discuss is `gfp_mask`:
|
||||
|
||||
Low-level kernel memory allocation functions take a set of flags as - `gfp_mask`, which describes how that allocation is to be performed. These `GFP_` flags which control the allocation process can have following values: (`GF_NOIO` flag) means sleep and wait for memory, (`__GFP_HIGHMEM` flag) means high memory can be used, (`GFP_ATOMIC` flag) means the allocation process has high-priority and can't sleep etc.
|
||||
|
||||
* `GFP_NOIO` - can sleep and wait for memory;
|
||||
* `__GFP_HIGHMEM` - high memory can be used;
|
||||
* `GFP_ATOMIC` - allocation process is high-priority and can't sleep;
|
||||
|
||||
etc.
|
||||
|
||||
The next field is `rnode`:
|
||||
|
||||
```C
|
||||
struct radix_tree_node {
|
||||
unsigned int path;
|
||||
unsigned int count;
|
||||
union {
|
||||
struct {
|
||||
struct radix_tree_node *parent;
|
||||
void *private_data;
|
||||
};
|
||||
struct rcu_head rcu_head;
|
||||
};
|
||||
/* For tree user */
|
||||
struct list_head private_list;
|
||||
void __rcu *slots[RADIX_TREE_MAP_SIZE];
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
|
||||
This structure contains information about the offset in a parent and height from the bottom, count of the child nodes and fields for accessing and freeing a node. This fields are described below:
|
||||
|
||||
* `path` - offset in parent & height from the bottom;
|
||||
* `count` - count of the child nodes;
|
||||
* `parent` - pointer to the parent node;
|
||||
* `private_data` - used by the user of a tree;
|
||||
* `rcu_head` - used for freeing a node;
|
||||
* `private_list` - used by the user of a tree;
|
||||
|
||||
The two last fields of the `radix_tree_node` - `tags` and `slots` are important and interesting. Every node can contains a set of slots which are store pointers to the data. Empty slots in the linux kernel radix tree implementation store `NULL`. Radix trees in the linux kernel also supports tags which are associated with the `tags` fields in the `radix_tree_node` structure. Tags allow individual bits to be set on records which are stored in the radix tree.
|
||||
|
||||
Now that we know about radix tree structure, it is time to look on its API.
|
||||
|
||||
Linux kernel radix tree API
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
We start from the datastructure initialization. There are two ways to initialize a new radix tree. The first is to use `RADIX_TREE` macro:
|
||||
|
||||
```C
|
||||
RADIX_TREE(name, gfp_mask);
|
||||
````
|
||||
|
||||
As you can see we pass the `name` parameter, so with the `RADIX_TREE` macro we can define and initialize radix tree with the given name. Implementation of the `RADIX_TREE` is easy:
|
||||
|
||||
```C
|
||||
#define RADIX_TREE(name, mask) \
|
||||
struct radix_tree_root name = RADIX_TREE_INIT(mask)
|
||||
|
||||
#define RADIX_TREE_INIT(mask) { \
|
||||
.height = 0, \
|
||||
.gfp_mask = (mask), \
|
||||
.rnode = NULL, \
|
||||
}
|
||||
```
|
||||
|
||||
At the beginning of the `RADIX_TREE` macro we define instance of the `radix_tree_root` structure with the given name and call `RADIX_TREE_INIT` macro with the given mask. The `RADIX_TREE_INIT` macro just initializes `radix_tree_root` structure with the default values and the given mask.
|
||||
|
||||
The second way is to define `radix_tree_root` structure by hand and pass it with mask to the `INIT_RADIX_TREE` macro:
|
||||
|
||||
```C
|
||||
struct radix_tree_root my_radix_tree;
|
||||
INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
|
||||
```
|
||||
|
||||
where:
|
||||
|
||||
```C
|
||||
#define INIT_RADIX_TREE(root, mask) \
|
||||
do { \
|
||||
(root)->height = 0; \
|
||||
(root)->gfp_mask = (mask); \
|
||||
(root)->rnode = NULL; \
|
||||
} while (0)
|
||||
```
|
||||
|
||||
makes the same initialziation with default values as it does `RADIX_TREE_INIT` macro.
|
||||
|
||||
The next are two functions for inserting and deleting records to/from a radix tree:
|
||||
|
||||
* `radix_tree_insert`;
|
||||
* `radix_tree_delete`;
|
||||
|
||||
The first `radix_tree_insert` function takes three parameters:
|
||||
|
||||
* root of a radix tree;
|
||||
* index key;
|
||||
* data to insert;
|
||||
|
||||
The `radix_tree_delete` function takes the same set of parameters as the `radix_tree_insert`, but without data.
|
||||
|
||||
The search in a radix tree implemented in two ways:
|
||||
|
||||
* `radix_tree_lookup`;
|
||||
* `radix_tree_gang_lookup`;
|
||||
* `radix_tree_lookup_slot`.
|
||||
|
||||
The first `radix_tree_lookup` function takes two parameters:
|
||||
|
||||
* root of a radix tree;
|
||||
* index key;
|
||||
|
||||
This function tries to find the given key in the tree and return the record associated with this key. The second `radix_tree_gang_lookup` function have the following signature
|
||||
|
||||
```C
|
||||
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
void **results,
|
||||
unsigned long first_index,
|
||||
unsigned int max_items);
|
||||
```
|
||||
|
||||
and returns number of records, sorted by the keys, starting from the first index. Number of the returned records will not be greater than `max_items` value.
|
||||
|
||||
And the last `radix_tree_lookup_slot` function will return the slot which will contain the data.
|
||||
|
||||
Links
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
* [Radix tree](http://en.wikipedia.org/wiki/Radix_tree)
|
||||
* [Trie](http://en.wikipedia.org/wiki/Trie)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree.md
|
||||
|
||||
作者:[0xAX]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
A new Mindcraft moment?
|
||||
=======================
|
||||
|
||||
|
||||
@ -1,88 +1,90 @@
|
||||
【Translating by cposture 2016-03-01】
|
||||
* * *
|
||||
|
||||
# GCC-Inline-Assembly-HOWTO
|
||||
# GCC 内联汇编 HOWTO
|
||||
|
||||
v0.1, 01 March 2003.
|
||||
* * *
|
||||
|
||||
_This HOWTO explains the use and usage of the inline assembly feature provided by GCC. There are only two prerequisites for reading this article, and that’s obviously a basic knowledge of x86 assembly language and C._
|
||||
_本 HOWTO 文档将讲解 GCC 提供的内联汇编特性的用途和用法。对于阅读这篇文章,这里只有两个前提要求,很明显,就是 x86 汇编语言和 C 语言的基本认识。_
|
||||
|
||||
* * *
|
||||
|
||||
## 1. Introduction.
|
||||
## 1. 简介
|
||||
|
||||
## 1.1 Copyright and License.
|
||||
## 1.1 版权许可
|
||||
|
||||
Copyright (C)2003 Sandeep S.
|
||||
|
||||
This document is free; you can redistribute and/or modify this under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
|
||||
本文档自由共享;你可以重新发布它,并且/或者在遵循自由软件基金会发布的 GNU 通用公共许可证下修改它;或者该许可证的版本 2 ,或者(按照你的需求)更晚的版本。
|
||||
|
||||
This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
|
||||
发布这篇文档是希望它能够帮助别人,但是没有任何保证;甚至不包括可售性和适用于任何特定目的的保证。关于更详细的信息,可以查看 GNU 通用许可证。
|
||||
|
||||
## 1.2 Feedback and Corrections.
|
||||
## 1.2 反馈校正
|
||||
|
||||
Kindly forward feedback and criticism to [Sandeep.S](mailto:busybox@sancharnet.in). I will be indebted to anybody who points out errors and inaccuracies in this document; I shall rectify them as soon as I am informed.
|
||||
请将反馈和批评一起提交给 [Sandeep.S](mailto:busybox@sancharnet.in) 。我将感谢任何一个指出本文档中错误和不准确之处的人;一被告知,我会马上改正它们。
|
||||
|
||||
## 1.3 Acknowledgments.
|
||||
## 1.3 致谢
|
||||
|
||||
I express my sincere appreciation to GNU people for providing such a great feature. Thanks to Mr.Pramode C E for all the helps he did. Thanks to friends at the Govt Engineering College, Trichur for their moral-support and cooperation, especially to Nisha Kurur and Sakeeb S. Thanks to my dear teachers at Govt Engineering College, Trichur for their cooperation.
|
||||
我对提供如此棒的特性的 GNU 人们表示真诚的感谢。感谢 Mr.Pramode C E 所做的所有帮助。感谢在 Govt Engineering College 和 Trichur 的朋友们的精神支持和合作,尤其是 Nisha Kurur 和 Sakeeb S 。 感谢在 Gvot Engineering College 和 Trichur 的老师们的合作。
|
||||
|
||||
Additionally, thanks to Phillip, Brennan Underwood and colin@nyx.net; Many things here are shamelessly stolen from their works.
|
||||
另外,感谢 Phillip , Brennan Underwood 和 colin@nyx.net ;这里的许多东西都厚颜地直接取自他们的工作成果。
|
||||
|
||||
* * *
|
||||
|
||||
## 2. Overview of the whole thing.
|
||||
## 2. 概览
|
||||
|
||||
We are here to learn about GCC inline assembly. What this inline stands for?
|
||||
在这里,我们将学习 GCC 内联汇编。这内联表示的是什么呢?
|
||||
|
||||
We can instruct the compiler to insert the code of a function into the code of its callers, to the point where actually the call is to be made. Such functions are inline functions. Sounds similar to a Macro? Indeed there are similarities.
|
||||
我们可以要求编译器将一个函数的代码插入到调用者代码中函数被实际调用的地方。这样的函数就是内联函数。这听起来和宏差不多?这两者确实有相似之处。
|
||||
|
||||
What is the benefit of inline functions?
|
||||
内联函数的优点是什么呢?
|
||||
|
||||
This method of inlining reduces the function-call overhead. And if any of the actual argument values are constant, their known values may permit simplifications at compile time so that not all of the inline function’s code needs to be included. The effect on code size is less predictable, it depends on the particular case. To declare an inline function, we’ve to use the keyword `inline` in its declaration.
|
||||
这种内联方法可以减少函数调用开销。同时如果所有实参的值为常量,它们的已知值可以在编译期允许简化,因此并非所有的内联函数代码都需要被包含。代码大小的影响是不可预测的,这取决于特定的情况。为了声明一个内联函数,我们必须在函数声明中使用 `inline` 关键字。
|
||||
|
||||
Now we are in a position to guess what is inline assembly. Its just some assembly routines written as inline functions. They are handy, speedy and very much useful in system programming. Our main focus is to study the basic format and usage of (GCC) inline assembly functions. To declare inline assembly functions, we use the keyword `asm`.
|
||||
现在我们正处于一个猜测内联汇编到底是什么的点上。它只不过是一些写为内联函数的汇编程序。在系统编程上,它们方便、快速并且极其有用。我们主要集中学习(GCC)内联汇编函数的基本格式和用法。为了声明内联汇编函数,我们使用 `asm` 关键词。
|
||||
|
||||
Inline assembly is important primarily because of its ability to operate and make its output visible on C variables. Because of this capability, "asm" works as an interface between the assembly instructions and the "C" program that contains it.
|
||||
内联汇编之所以重要,主要是因为它可以操作并且使其输出通过 C 变量显示出来。正是因为此能力, "asm" 可以用作汇编指令和包含它的 C 程序之间的接口。
|
||||
|
||||
* * *
|
||||
|
||||
## 3. GCC Assembler Syntax.
|
||||
## 3. GCC 汇编语法
|
||||
|
||||
GCC, the GNU C Compiler for Linux, uses **AT&T**/**UNIX** assembly syntax. Here we’ll be using AT&T syntax for assembly coding. Don’t worry if you are not familiar with AT&T syntax, I will teach you. This is quite different from Intel syntax. I shall give the major differences.
|
||||
GCC , Linux上的 GNU C 编译器,使用 **AT&T** / **UNIX** 汇编语法。在这里,我们将使用 AT&T 语法 进行汇编编码。如果你对 AT&T 语法不熟悉的话,请不要紧张,我会教你的。AT&T 语法和 Intel 语法的差别很大。我会给出主要的区别。
|
||||
|
||||
1. Source-Destination Ordering.
|
||||
1. 源操作数和目的操作数顺序
|
||||
|
||||
The direction of the operands in AT&T syntax is opposite to that of Intel. In Intel syntax the first operand is the destination, and the second operand is the source whereas in AT&T syntax the first operand is the source and the second operand is the destination. ie,
|
||||
AT&T 语法的操作数方向和 Intel 语法的刚好相反。在Intel 语法中,第一操作数为目的操作数,第二操作数为源操作数,然而在 AT&T 语法中,第一操作数为源操作数,第二操作数为目的操作数。也就是说,
|
||||
|
||||
"Op-code dst src" in Intel syntax changes to
|
||||
Intel 语法中的 "Op-code dst src" 变为
|
||||
|
||||
AT&T 语法中的 "Op-code src dst"。
|
||||
|
||||
"Op-code src dst" in AT&T syntax.
|
||||
2. 寄存器命名
|
||||
|
||||
2. Register Naming.
|
||||
寄存器名称有 % 前缀,即如果必须使用 eax,它应该用作 %eax。
|
||||
|
||||
Register names are prefixed by % ie, if eax is to be used, write %eax.
|
||||
3. 立即数
|
||||
|
||||
3. Immediate Operand.
|
||||
AT&T 立即数以 ’$’ 为前缀。静态 "C" 变量 也使用 ’$’ 前缀。在 Intel 语法中,十六进制常量以 ’h’ 为后缀,然而AT&T不使用这种语法,这里我们给常量添加前缀 ’0x’。所以,对于十六进制,我们首先看到一个 ’$’,然后是 ’0x’,最后才是常量。
|
||||
|
||||
AT&T immediate operands are preceded by ’$’. For static "C" variables also prefix a ’$’. In Intel syntax, for hexadecimal constants an ’h’ is suffixed, instead of that, here we prefix ’0x’ to the constant. So, for hexadecimals, we first see a ’$’, then ’0x’ and finally the constants.
|
||||
4. 操作数大小
|
||||
|
||||
4. Operand Size.
|
||||
在 AT&T 语法中,存储器操作数的大小取决于操作码名字的最后一个字符。操作码后缀 ’b’ 、’w’、’l’分别指明了字节(byte)(8位)、字(word)(16位)、长型(long)(32位)存储器引用。Intel 语法通过给存储器操作数添加’byte ptr’、 ’word ptr’ 和 ’dword ptr’前缀来实现这一功能。
|
||||
|
||||
In AT&T syntax the size of memory operands is determined from the last character of the op-code name. Op-code suffixes of ’b’, ’w’, and ’l’ specify byte(8-bit), word(16-bit), and long(32-bit) memory references. Intel syntax accomplishes this by prefixing memory operands (not the op-codes) with ’byte ptr’, ’word ptr’, and ’dword ptr’.
|
||||
因此,Intel的 "mov al, byte ptr foo" 在 AT&T 语法中为 "movb foo, %al"。
|
||||
|
||||
Thus, Intel "mov al, byte ptr foo" is "movb foo, %al" in AT&T syntax.
|
||||
5. 存储器操作数
|
||||
|
||||
在 Intel 语法中,基址寄存器包含在 ’[’ 和 ’]’ 中,然而在 AT&T 中,它们变为 ’(’ 和 ’)’。另外,在 Intel 语法中, 间接内存引用为
|
||||
|
||||
5. Memory Operands.
|
||||
section:[base + index*scale + disp], 在 AT&T中变为
|
||||
|
||||
In Intel syntax the base register is enclosed in ’[’ and ’]’ where as in AT&T they change to ’(’ and ’)’. Additionally, in Intel syntax an indirect memory reference is like
|
||||
section:disp(base, index, scale)。
|
||||
|
||||
section:[base + index*scale + disp], which changes to
|
||||
需要牢记的一点是,当一个常量用于 disp 或 scale,不能添加’$’前缀。
|
||||
|
||||
section:disp(base, index, scale) in AT&T.
|
||||
|
||||
One point to bear in mind is that, when a constant is used for disp/scale, ’$’ shouldn’t be prefixed.
|
||||
|
||||
Now we saw some of the major differences between Intel syntax and AT&T syntax. I’ve wrote only a few of them. For a complete information, refer to GNU Assembler documentations. Now we’ll look at some examples for better understanding.
|
||||
现在我们看到了 Intel 语法和 AT&T 语法之间的一些主要差别。我仅仅写了它们差别的一部分而已。关于更完整的信息,请参考 GNU 汇编文档。现在为了更好地理解,我们可以看一些示例。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -106,29 +108,29 @@ Now we saw some of the major differences between Intel syntax and AT&T syntax. I
|
||||
|
||||
* * *
|
||||
|
||||
## 4. Basic Inline.
|
||||
## 4. 基本内联
|
||||
|
||||
The format of basic inline assembly is very much straight forward. Its basic form is
|
||||
基本内联汇编的格式非常直接了当。它的基本格式为
|
||||
|
||||
`asm("assembly code");`
|
||||
`asm("汇编代码");`
|
||||
|
||||
Example.
|
||||
示例
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>asm("movl %ecx %eax"); /* moves the contents of ecx to eax */
|
||||
> __asm__("movb %bh (%eax)"); /*moves the byte from bh to the memory pointed by eax */
|
||||
> <pre>asm("movl %ecx %eax"); /* 将 ecx 寄存器的内容移至 eax */
|
||||
> __asm__("movb %bh (%eax)"); /* 将 bh 的一个字节数据 移至 eax 寄存器指向的内存 */
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
You might have noticed that here I’ve used `asm` and `__asm__`. Both are valid. We can use `__asm__` if the keyword `asm` conflicts with something in our program. If we have more than one instructions, we write one per line in double quotes, and also suffix a ’\n’ and ’\t’ to the instruction. This is because gcc sends each instruction as a string to **as**(GAS) and by using the newline/tab we send correctly formatted lines to the assembler.
|
||||
你可能注意到了这里我使用了 `asm ` 和 `__asm__`。这两者都是有效的。如果关键词 `asm` 和我们程序的一些标识符冲突了,我们可以使用 `__asm__`。如果我们的指令多余一条,我们可以写成一行,并用括号括起,也可以为每条指令添加 ’\n’ 和 ’\t’ 后缀。这是因为gcc将每一条当作字符串发送给 **as**(GAS)( GAS 即 GNU 汇编器 ——译者注),并且通过使用换行符/制表符发送正确地格式化行给汇编器。
|
||||
|
||||
Example.
|
||||
示例
|
||||
|
||||
> `
|
||||
>
|
||||
@ -144,22 +146,22 @@ Example.
|
||||
>
|
||||
> `
|
||||
|
||||
If in our code we touch (ie, change the contents) some registers and return from asm without fixing those changes, something bad is going to happen. This is because GCC have no idea about the changes in the register contents and this leads us to trouble, especially when compiler makes some optimizations. It will suppose that some register contains the value of some variable that we might have changed without informing GCC, and it continues like nothing happened. What we can do is either use those instructions having no side effects or fix things when we quit or wait for something to crash. This is where we want some extended functionality. Extended asm provides us with that functionality.
|
||||
如果在代码中,我们涉及到一些寄存器(即改变其内容),但在没有固定这些变化的情况下从汇编中返回,这将会导致一些不好的事情。这是因为 GCC 并不知道寄存器内容的变化,这会导致问题,特别是当编译器做了某些优化。在没有告知 GCC 的情况下,它将会假设一些寄存器存储了我们可能已经改变的变量的值,它会像什么事都没发生一样继续运行(什么事都没发生一样是指GCC不会假设寄存器装入的值是有效的,当退出改变了寄存器值的内联汇编后,寄存器的值不会保存到相应的变量或内存空间 ——译者注)。我们所可以做的是使用这些没有副作用的指令,或者当我们退出时固定这些寄存器,或者等待程序崩溃。这是为什么我们需要一些扩展功能。扩展汇编正好给我们提供了那样的功能。
|
||||
|
||||
* * *
|
||||
|
||||
## 5. Extended Asm.
|
||||
## 5. 扩展汇编
|
||||
|
||||
In basic inline assembly, we had only instructions. In extended assembly, we can also specify the operands. It allows us to specify the input registers, output registers and a list of clobbered registers. It is not mandatory to specify the registers to use, we can leave that head ache to GCC and that probably fit into GCC’s optimization scheme better. Anyway the basic format is:
|
||||
在基本内联汇编中,我们只有指令。然而在扩展汇编中,我们可以同时指定操作数。它允许我们指定输入寄存器、输出寄存器以及修饰寄存器列表。GCC 不强制用户必须指定使用的寄存器。我们可以把头疼的事留给 GCC ,这可能可以更好地适应 GCC 的优化。不管怎樣,基本格式为:
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ( assembler template
|
||||
> : output operands /* optional */
|
||||
> : input operands /* optional */
|
||||
> : list of clobbered registers /* optional */
|
||||
> <pre> asm ( 汇编程序模板
|
||||
> : 输出操作数 /* 可选的 */
|
||||
> : 输入操作数 /* 可选的 */
|
||||
> : 修饰寄存器列表 /* 可选的 */
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
@ -167,11 +169,11 @@ In basic inline assembly, we had only instructions. In extended assembly, we can
|
||||
>
|
||||
> `
|
||||
|
||||
The assembler template consists of assembly instructions. Each operand is described by an operand-constraint string followed by the C expression in parentheses. A colon separates the assembler template from the first output operand and another separates the last output operand from the first input, if any. Commas separate the operands within each group. The total number of operands is limited to ten or to the maximum number of operands in any instruction pattern in the machine description, whichever is greater.
|
||||
汇编程序模板由汇编指令组成.每一个操作数由一个操作数约束字符串所描述,其后紧接一个括弧括起的 C 表达式。冒号用于将汇编程序模板和第一个输出操作数分开,另一个(冒号)用于将最后一个输出操作数和第一个输入操作数分开,如果存在的话。逗号用于分离每一个组内的操作数。总操作数的数目限制在10个,或者机器描述中的任何指令格式中的最大操作数数目,以较大者为准。
|
||||
|
||||
If there are no output operands but there are input operands, you must place two consecutive colons surrounding the place where the output operands would go.
|
||||
如果没有输出操作数但存在输入操作数,你必须将两个连续的冒号放置于输出操作数原本会放置的地方周围。
|
||||
|
||||
Example:
|
||||
示例:
|
||||
|
||||
> `
|
||||
>
|
||||
@ -180,7 +182,7 @@ Example:
|
||||
> <pre> asm ("cld\n\t"
|
||||
> "rep\n\t"
|
||||
> "stosl"
|
||||
> : /* no output registers */
|
||||
> : /* 无输出寄存器 */
|
||||
> : "c" (count), "a" (fill_value), "D" (dest)
|
||||
> : "%ecx", "%edi"
|
||||
> );
|
||||
@ -190,7 +192,7 @@ Example:
|
||||
>
|
||||
> `
|
||||
|
||||
Now, what does this code do? The above inline fills the `fill_value` `count` times to the location pointed to by the register `edi`. It also says to gcc that, the contents of registers `eax` and `edi` are no longer valid. Let us see one more example to make things more clearer.
|
||||
现在,这段代码是干什么的?以上的内联汇编是将 `fill_value` 值 连续 `count` 次 拷贝到 寄存器 `edi` 所指位置(每执行stosl一次,寄存器 edi 的值会递增或递减,这取决于是否设置了 direction 标志,因此以上代码实则初始化一个内存块 ——译者注)。 它也告诉 gcc 寄存器 `ecx` 和 `edi` 一直无效(原文为 eax ,但代码修饰寄存器列表中为 ecx,因此这可能为作者的纰漏 ——译者注)。为了使扩展汇编更加清晰,让我们再看一个示例。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -200,9 +202,9 @@ Now, what does this code do? The above inline fills the `fill_value` `count`
|
||||
> int a=10, b;
|
||||
> asm ("movl %1, %%eax;
|
||||
> movl %%eax, %0;"
|
||||
> :"=r"(b) /* output */
|
||||
> :"r"(a) /* input */
|
||||
> :"%eax" /* clobbered register */
|
||||
> :"=r"(b) /* 输出 */
|
||||
> :"r"(a) /* 输入 */
|
||||
> :"%eax" /* 修饰寄存器 */
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
@ -210,36 +212,36 @@ Now, what does this code do? The above inline fills the `fill_value` `count`
|
||||
>
|
||||
> `
|
||||
|
||||
Here what we did is we made the value of ’b’ equal to that of ’a’ using assembly instructions. Some points of interest are:
|
||||
这里我们所做的是使用汇编指令使 ’b’ 变量的值等于 ’a’ 变量的值。一些有意思的地方是:
|
||||
|
||||
* "b" is the output operand, referred to by %0 and "a" is the input operand, referred to by %1.
|
||||
* "r" is a constraint on the operands. We’ll see constraints in detail later. For the time being, "r" says to GCC to use any register for storing the operands. output operand constraint should have a constraint modifier "=". And this modifier says that it is the output operand and is write-only.
|
||||
* There are two %’s prefixed to the register name. This helps GCC to distinguish between the operands and registers. operands have a single % as prefix.
|
||||
* The clobbered register %eax after the third colon tells GCC that the value of %eax is to be modified inside "asm", so GCC won’t use this register to store any other value.
|
||||
* "b" 为输出操作数,用 %0 引用,并且 "a" 为输入操作数,用 %1 引用。
|
||||
* "r" 为操作数约束。之后我们会更详细地了解约束(字符串)。目前,"r" 告诉 GCC 可以使用任一寄存器存储操作数。输出操作数约束应该有一个约束修饰符 "=" 。这修饰符表明它是一个只读的输出操作数。
|
||||
* 寄存器名字以两个%为前缀。这有利于 GCC 区分操作数和寄存器。操作数以一个 % 为前缀。
|
||||
* 第三个冒号之后的修饰寄存器 %eax 告诉 GCC %eax的值将会在 "asm" 内部被修改,所以 GCC 将不会使用此寄存器存储任何其他值。
|
||||
|
||||
When the execution of "asm" is complete, "b" will reflect the updated value, as it is specified as an output operand. In other words, the change made to "b" inside "asm" is supposed to be reflected outside the "asm".
|
||||
当 "asm" 执行完毕, "b" 变量会映射到更新的值,因为它被指定为输出操作数。换句话说, "asm" 内 "b" 变量的修改 应该会被映射到 "asm" 外部。
|
||||
|
||||
Now we may look each field in detail.
|
||||
现在,我们可以更详细地看看每一个域。
|
||||
|
||||
## 5.1 Assembler Template.
|
||||
## 5.1 汇编程序模板
|
||||
|
||||
The assembler template contains the set of assembly instructions that gets inserted inside the C program. The format is like: either each instruction should be enclosed within double quotes, or the entire group of instructions should be within double quotes. Each instruction should also end with a delimiter. The valid delimiters are newline(\n) and semicolon(;). ’\n’ may be followed by a tab(\t). We know the reason of newline/tab, right?. Operands corresponding to the C expressions are represented by %0, %1 ... etc.
|
||||
汇编程序模板包含了被插入到 C 程序的汇编指令集。其格式为:每条指令用双引号圈起,或者整个指令组用双引号圈起。同时每条指令应以分界符结尾。有效的分界符有换行符(\n)和逗号(;)。’\n’ 可以紧随一个制表符(\t)。我们应该都明白使用换行符或制表符的原因了吧?和 C 表达式对应的操作数使用 %0、%1 ... 等等表示。
|
||||
|
||||
## 5.2 Operands.
|
||||
## 5.2 操作数
|
||||
|
||||
C expressions serve as operands for the assembly instructions inside "asm". Each operand is written as first an operand constraint in double quotes. For output operands, there’ll be a constraint modifier also within the quotes and then follows the C expression which stands for the operand. ie,
|
||||
C 表达式用作 "asm" 内的汇编指令操作数。作为第一双引号内的操作数约束,写下每一操作数。对于输出操作数,在引号内还有一个约束修饰符,其后紧随一个用于表示操作数的 C 表达式。即,
|
||||
|
||||
"constraint" (C expression) is the general form. For output operands an additional modifier will be there. Constraints are primarily used to decide the addressing modes for operands. They are also used in specifying the registers to be used.
|
||||
"约束字符串"(C 表达式),它是一个通用格式。对于输出操作数,还有一个额外的修饰符。约束字符串主要用于决定操作数的寻找方式,同时也用于指定使用的寄存器。
|
||||
|
||||
If we use more than one operand, they are separated by comma.
|
||||
如果我们使用的操作数多于一个,那么每一个操作数用逗号隔开。
|
||||
|
||||
In the assembler template, each operand is referenced by numbers. Numbering is done as follows. If there are a total of n operands (both input and output inclusive), then the first output operand is numbered 0, continuing in increasing order, and the last input operand is numbered n-1\. The maximum number of operands is as we saw in the previous section.
|
||||
在汇编程序模板,每个操作数用数字引用。编号方式如下。如果总共有 n 个操作数(包括输入和输出操作数),那么第一个输出操作数编号为 0 ,逐项递增,并且最后一个输入操作数编号为 n - 1 。操作数的最大数目为前一节我们所看到的那样。
|
||||
|
||||
Output operand expressions must be lvalues. The input operands are not restricted like this. They may be expressions. The extended asm feature is most often used for machine instructions the compiler itself does not know as existing ;-). If the output expression cannot be directly addressed (for example, it is a bit-field), our constraint must allow a register. In that case, GCC will use the register as the output of the asm, and then store that register contents into the output.
|
||||
输出操作数表达式必须为左值。输入操作数的要求不像这样严格。它们可以为表达式。扩展汇编特性常常用于编译器自己不知道其存在的机器指令 ;-)。如果输出表达式无法直接寻址(例如,它是一个位域),我们的约束字符串必须给定一个寄存器。在这种情况下,GCC 将会使用该寄存器作为汇编的输出,然后存储该寄存器的内容到输出。
|
||||
|
||||
As stated above, ordinary output operands must be write-only; GCC will assume that the values in these operands before the instruction are dead and need not be generated. Extended asm also supports input-output or read-write operands.
|
||||
正如前面所陈述的一样,普通的输出操作数必须为只写的; GCC 将会假设指令前的操作数值是死的,并且不需要被(提前)生成。扩展汇编也支持输入-输出或者读-写操作数。
|
||||
|
||||
So now we concentrate on some examples. We want to multiply a number by 5\. For that we use the instruction `lea`.
|
||||
所以现在我们来关注一些示例。我们想要求一个数的5次方结果。为了计算该值,我们使用 `lea` 指令。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -255,7 +257,7 @@ So now we concentrate on some examples. We want to multiply a number by 5\. For
|
||||
>
|
||||
> `
|
||||
|
||||
Here our input is in ’x’. We didn’t specify the register to be used. GCC will choose some register for input, one for output and does what we desired. If we want the input and output to reside in the same register, we can instruct GCC to do so. Here we use those types of read-write operands. By specifying proper constraints, here we do it.
|
||||
这里我们的输入为x。我们不指定使用的寄存器。 GCC 将会选择一些输入寄存器,一个输出寄存器,并且做我们期望的事。如果我们想要输入和输出存在于同一个寄存器里,我们可以要求 GCC 这样做。这里我们使用那些读-写操作数类型。这里我们通过指定合适的约束来实现它。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -271,7 +273,7 @@ Here our input is in ’x’. We didn’t specify the register to be used. GCC w
|
||||
>
|
||||
> `
|
||||
|
||||
Now the input and output operands are in the same register. But we don’t know which register. Now if we want to specify that also, there is a way.
|
||||
现在输出和输出操作数位于同一个寄存器。但是我们无法得知是哪一个寄存器。现在假如我们也想要指定操作数所在的寄存器,这里有一种方法。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -287,17 +289,17 @@ Now the input and output operands are in the same register. But we don’t know
|
||||
>
|
||||
> `
|
||||
|
||||
In all the three examples above, we didn’t put any register to the clobber list. why? In the first two examples, GCC decides the registers and it knows what changes happen. In the last one, we don’t have to put `ecx` on the c lobberlist, gcc knows it goes into x. Therefore, since it can know the value of `ecx`, it isn’t considered clobbered.
|
||||
在以上三个示例中,我们并没有添加任何寄存器到修饰寄存器里,为什么?在头两个示例, GCC 决定了寄存器并且它知道发生了什么改变。在最后一个示例,我们不必将 'ecx' 添加到修饰寄存器列表(原文修饰寄存器列表拼写有错,这里已修正 ——译者注), gcc 知道它表示x。因此,因为它可以知道 `ecx` 的值,它就不被当作修饰的(寄存器)了。
|
||||
|
||||
## 5.3 Clobber List.
|
||||
## 5.3 修饰寄存器列表
|
||||
|
||||
Some instructions clobber some hardware registers. We have to list those registers in the clobber-list, ie the field after the third ’**:**’ in the asm function. This is to inform gcc that we will use and modify them ourselves. So gcc will not assume that the values it loads into these registers will be valid. We shoudn’t list the input and output registers in this list. Because, gcc knows that "asm" uses them (because they are specified explicitly as constraints). If the instructions use any other registers, implicitly or explicitly (and the registers are not present either in input or in the output constraint list), then those registers have to be specified in the clobbered list.
|
||||
一些指令会破坏一些硬件寄存器。我们不得不在修饰寄存器中列出这些寄存器,即汇编函数内第三个 ’**:**’ 之后的域。这可以通知 gcc 我们将会自己使用和修改这些寄存器。所以 gcc 将不会假设存入这些寄存器的值是有效的。我们不用在这个列表里列出输入输出寄存器。因为 gcc 知道 "asm" 使用了它们(因为它们被显式地指定为约束了)。如果指令隐式或显式地使用了任何其他寄存器,(并且寄存器不能出现在输出或者输出约束列表里),那么不得不在修饰寄存器列表中指定这些寄存器。
|
||||
|
||||
If our instruction can alter the condition code register, we have to add "cc" to the list of clobbered registers.
|
||||
如果我们的指令可以修改状态寄存器,我们必须将 "cc" 添加进修饰寄存器列表。
|
||||
|
||||
If our instruction modifies memory in an unpredictable fashion, add "memory" to the list of clobbered registers. This will cause GCC to not keep memory values cached in registers across the assembler instruction. We also have to add the **volatile** keyword if the memory affected is not listed in the inputs or outputs of the asm.
|
||||
如果我们的指令以不可预测的方式修改了内存,那么需要将 "memory" 添加进修饰寄存器列表。这可以使 GCC 不会在汇编指令间保持缓存于寄存器的内存值。如果被影响的内存不在汇编的输入或输出列表中,我们也必须添加 **volatile** 关键词。
|
||||
|
||||
We can read and write the clobbered registers as many times as we like. Consider the example of multiple instructions in a template; it assumes the subroutine _foo accepts arguments in registers `eax` and `ecx`.
|
||||
我们可以按我们的需求多次读写修饰寄存器。考虑一个模板内的多指令示例;它假设子例程 _foo 接受寄存器 `eax` 和 `ecx` 里的参数。
|
||||
|
||||
> `
|
||||
>
|
||||
@ -318,35 +320,36 @@ We can read and write the clobbered registers as many times as we like. Consider
|
||||
|
||||
## 5.4 Volatile ...?
|
||||
|
||||
If you are familiar with kernel sources or some beautiful code like that, you must have seen many functions declared as `volatile` or `__volatile__` which follows an `asm` or `__asm__`. I mentioned earlier about the keywords `asm` and `__asm__`. So what is this `volatile`?
|
||||
如果你熟悉内核源码或者其他像内核源码一样漂亮的代码,你一定见过许多声明为 `volatile` 或者 `__volatile__`的函数,其跟着一个 `asm` 或者 `__asm__`。我之前提过关键词 `asm` 和 `__asm__`。那么什么是 `volatile`呢?
|
||||
|
||||
If our assembly statement must execute where we put it, (i.e. must not be moved out of a loop as an optimization), put the keyword `volatile` after asm and before the ()’s. So to keep it from moving, deleting and all, we declare it as
|
||||
如果我们的汇编语句必须在我们放置它的地方执行(即,不能作为一种优化被移出循环语句),将关键词 `volatile` 放置在 asm 后面,()的前面。因为为了防止它被移动、删除或者其他操作,我们将其声明为
|
||||
|
||||
`asm volatile ( ... : ... : ... : ...);`
|
||||
|
||||
Use `__volatile__` when we have to be verymuch careful.
|
||||
当我们必须非常谨慎时,请使用 `__volatile__`。
|
||||
|
||||
If our assembly is just for doing some calculations and doesn’t have any side effects, it’s better not to use the keyword `volatile`. Avoiding it helps gcc in optimizing the code and making it more beautiful.
|
||||
如果我们的汇编只是用于一些计算并且没有任何副作用,不使用 `volatile` 关键词会更好。不使用 `volatile` 可以帮助 gcc 优化代码并使代码更漂亮。
|
||||
|
||||
In the section `Some Useful Recipes`, I have provided many examples for inline asm functions. There we can see the clobber-list in detail.
|
||||
|
||||
在 `Some Useful Recipes` 一节中,我提供了多个内联汇编函数的例子。这儿我们详细查看修饰寄存器列表。
|
||||
|
||||
* * *
|
||||
|
||||
## 6. More about constraints.
|
||||
## 6. 更多关于约束
|
||||
|
||||
By this time, you might have understood that constraints have got a lot to do with inline assembly. But we’ve said little about constraints. Constraints can say whether an operand may be in a register, and which kinds of register; whether the operand can be a memory reference, and which kinds of address; whether the operand may be an immediate constant, and which possible values (ie range of values) it may have.... etc.
|
||||
到这个时候,你可能已经了解到约束和内联汇编有很大的关联。但我们很少说到约束。约束用于表明一个操作数是否可以位于寄存器和位于哪个寄存器;是否操作数可以为一个内存引用和哪种地址;是否操作数可以为一个立即数和为哪一个可能的值(即值的范围)。它可以有...等等。
|
||||
|
||||
## 6.1 Commonly used constraints.
|
||||
## 6.1 常用约束
|
||||
|
||||
There are a number of constraints of which only a few are used frequently. We’ll have a look at those constraints.
|
||||
在许多约束中,只有小部分是常用的。我们将看看这些约束。
|
||||
|
||||
1. **Register operand constraint(r)**
|
||||
1. **寄存器操作数约束(r)**
|
||||
|
||||
When operands are specified using this constraint, they get stored in General Purpose Registers(GPR). Take the following example:
|
||||
当使用这种约束指定操作数时,它们存储在通用寄存器(GPR)中。请看下面示例:
|
||||
|
||||
`asm ("movl %%eax, %0\n" :"=r"(myval));`
|
||||
|
||||
Here the variable myval is kept in a register, the value in register `eax` is copied onto that register, and the value of `myval` is updated into the memory from this register. When the "r" constraint is specified, gcc may keep the variable in any of the available GPRs. To specify the register, you must directly specify the register names by using specific register constraints. They are:
|
||||
这里,变量 myval 保存在寄存器中,寄存器 eax 的值被复制到该寄存器中,并且myval的值从寄存器更新到了内存。当指定 "r" 约束时, gcc 可以将变量保存在任何可用的 GPR 中。为了指定寄存器,你必须使用特定寄存器约束直接地指定寄存器的名字。它们为:
|
||||
|
||||
> `
|
||||
>
|
||||
@ -364,57 +367,58 @@ There are a number of constraints of which only a few are used frequently. We’
|
||||
>
|
||||
> `
|
||||
|
||||
2. **Memory operand constraint(m)**
|
||||
2. **内存操作数约束(m)**
|
||||
|
||||
When the operands are in the memory, any operations performed on them will occur directly in the memory location, as opposed to register constraints, which first store the value in a register to be modified and then write it back to the memory location. But register constraints are usually used only when they are absolutely necessary for an instruction or they significantly speed up the process. Memory constraints can be used most efficiently in cases where a C variable needs to be updated inside "asm" and you really don’t want to use a register to hold its value. For example, the value of idtr is stored in the memory location loc:
|
||||
当操作数位于内存时,任何对它们的操作将直接发生在内存位置,这与寄存器约束相反,后者首先将值存储在要修改的寄存器中,然后将它写回到内存位置。但寄存器约束通常用于一个指令必须使用它们或者它们可以大大提高进程速度的地方。当需要在 "asm" 内更新一个 C 变量,而又不想使用寄存器去保存它的只,使用内存最为有效。例如, idtr 的值存储于内存位置:
|
||||
|
||||
`asm("sidt %0\n" : :"m"(loc));`
|
||||
|
||||
3. **Matching(Digit) constraints**
|
||||
3. **匹配(数字)约束**
|
||||
|
||||
In some cases, a single variable may serve as both the input and the output operand. Such cases may be specified in "asm" by using matching constraints.
|
||||
在某些情况下,一个变量可能既充当输入操作数,也充当输出操作数。可以通过使用匹配约束在 "asm" 中指定这种情况。
|
||||
|
||||
`asm ("incl %0" :"=a"(var):"0"(var));`
|
||||
|
||||
We saw similar examples in operands subsection also. In this example for matching constraints, the register %eax is used as both the input and the output variable. var input is read to %eax and updated %eax is stored in var again after increment. "0" here specifies the same constraint as the 0th output variable. That is, it specifies that the output instance of var should be stored in %eax only. This constraint can be used:
|
||||
在操作数子节中,我们也看到了一些类似的示例。在这个匹配约束的示例中,寄存器 "%eax" 既用作输入变量,也用作输出变量。 var 输入被读进 %eax ,并且更新的 %eax 再次被存储进 var。这里的 "0" 用于指定与第0个输出变量相同的约束。也就是,它指定 var 输出实例应只被存储在 "%eax" 中。该约束可用于:
|
||||
|
||||
* In cases where input is read from a variable or the variable is modified and modification is written back to the same variable.
|
||||
* In cases where separate instances of input and output operands are not necessary.
|
||||
* 在输入从变量读取或变量修改后,修改被写回同一变量的情况
|
||||
* 在不需要将输入操作数实例和输出操作数实例分开的情况
|
||||
|
||||
The most important effect of using matching restraints is that they lead to the efficient use of available registers.
|
||||
使用匹配约束最重要的意义在于它们可以导致有效地使用可用寄存器。
|
||||
|
||||
Some other constraints used are:
|
||||
其他一些约束:
|
||||
|
||||
1. "m" : A memory operand is allowed, with any kind of address that the machine supports in general.
|
||||
2. "o" : A memory operand is allowed, but only if the address is offsettable. ie, adding a small offset to the address gives a valid address.
|
||||
1. "m" : 允许一个内存操作数使用机器普遍支持的任一种地址。
|
||||
2. "o" : 允许一个内存操作数,但只有当地址是可偏移的。即,该地址加上一个小的偏移量可以得到一个地址。
|
||||
3. "V" : A memory operand that is not offsettable. In other words, anything that would fit the `m’ constraint but not the `o’constraint.
|
||||
4. "i" : An immediate integer operand (one with constant value) is allowed. This includes symbolic constants whose values will be known only at assembly time.
|
||||
5. "n" : An immediate integer operand with a known numeric value is allowed. Many systems cannot support assembly-time constants for operands less than a word wide. Constraints for these operands should use ’n’ rather than ’i’.
|
||||
6. "g" : Any register, memory or immediate integer operand is allowed, except for registers that are not general registers.
|
||||
4. "i" : 允许一个(带有常量)的立即整形操作数。这包括其值仅在汇编时期知道的符号常量。
|
||||
5. "n" : 允许一个带有已知数字的立即整形操作数。许多系统不支持汇编时期的常量,因为操作数少于一个字宽。对于此种操作数,约束应该使用 'n' 而不是'i'。
|
||||
6. "g" : 允许任一寄存器、内存或者立即整形操作数,不包括通用寄存器之外的寄存器。
|
||||
|
||||
Following constraints are x86 specific.
|
||||
|
||||
1. "r" : Register operand constraint, look table given above.
|
||||
2. "q" : Registers a, b, c or d.
|
||||
3. "I" : Constant in range 0 to 31 (for 32-bit shifts).
|
||||
4. "J" : Constant in range 0 to 63 (for 64-bit shifts).
|
||||
5. "K" : 0xff.
|
||||
6. "L" : 0xffff.
|
||||
7. "M" : 0, 1, 2, or 3 (shifts for lea instruction).
|
||||
8. "N" : Constant in range 0 to 255 (for out instruction).
|
||||
9. "f" : Floating point register
|
||||
10. "t" : First (top of stack) floating point register
|
||||
11. "u" : Second floating point register
|
||||
12. "A" : Specifies the `a’ or `d’ registers. This is primarily useful for 64-bit integer values intended to be returned with the `d’ register holding the most significant bits and the `a’ register holding the least significant bits.
|
||||
以下约束为x86特有。
|
||||
|
||||
## 6.2 Constraint Modifiers.
|
||||
1. "r" : 寄存器操作数约束,查看上面给定的表格。
|
||||
2. "q" : 寄存器 a、b、c 或者 d。
|
||||
3. "I" : 范围从 0 到 31 的常量(对于 32 位移位)。
|
||||
4. "J" : 范围从 0 到 63 的常量(对于 64 位移位)。
|
||||
5. "K" : 0xff。
|
||||
6. "L" : 0xffff。
|
||||
7. "M" : 0, 1, 2, or 3 (lea 指令的移位)。
|
||||
8. "N" : 范围从 0 到 255 的常量(对于 out 指令)。
|
||||
9. "f" : 浮点寄存器
|
||||
10. "t" : 第一个(栈顶)浮点寄存器
|
||||
11. "u" : 第二个浮点寄存器
|
||||
12. "A" : 指定 `a` 或 `d` 寄存器。这主要用于想要返回 64 位整形数,使用 `d` 寄存器保存最高有效位和 `a` 寄存器保存最低有效位。
|
||||
|
||||
While using constraints, for more precise control over the effects of constraints, GCC provides us with constraint modifiers. Mostly used constraint modifiers are
|
||||
## 6.2 约束修饰符
|
||||
|
||||
1. "=" : Means that this operand is write-only for this instruction; the previous value is discarded and replaced by output data.
|
||||
2. "&" : Means that this operand is an earlyclobber operand, which is modified before the instruction is finished using the input operands. Therefore, this operand may not lie in a register that is used as an input operand or as part of any memory address. An input operand can be tied to an earlyclobber operand if its only use as an input occurs before the early result is written.
|
||||
当使用约束时,对于更精确的控制超越了约束作用的需求,GCC 给我们提供了约束修饰符。最常用的约束修饰符为:
|
||||
|
||||
The list and explanation of constraints is by no means complete. Examples can give a better understanding of the use and usage of inline asm. In the next section we’ll see some examples, there we’ll find more about clobber-lists and constraints.
|
||||
1. "=" : 意味着对于这条指令,操作数为只写的;旧值会被忽略并被输出数据所替换。
|
||||
2. "&" : 意味着这个操作数为一个早期的改动操作数,其在该指令完成前通过使用输入操作数被修改了。因此,这个操作数不可以位于一个被用作输出操作数或任何内存地址部分的寄存器。如果在旧值被写入之前它仅用作输入而已,一个输入操作数可以为一个早期改动操作数。
|
||||
|
||||
约束的列表和解释是决不完整的。示例可以给我们一个关于内联汇编的用途和用法的更好的理解。在下一节,我们会看到一些示例,在那里我们会发现更多关于修饰寄存器列表的东西。
|
||||
|
||||
* * *
|
||||
|
||||
@ -562,7 +566,6 @@ Now we have covered the basic theory about GCC inline assembly, now we shall con
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>#define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
|
||||
> type name(type1 arg1,type2 arg2,type3 arg3) \
|
||||
> { \
|
||||
> long __res; \
|
||||
|
||||
136
sources/tech/20160204 An Introduction to SELinux.md
Normal file
136
sources/tech/20160204 An Introduction to SELinux.md
Normal file
@ -0,0 +1,136 @@
|
||||
An Introduction to SELinux
|
||||
===============================
|
||||
|
||||

|
||||
|
||||
>Figure 1: The getenforce command reporting SELinux is set to Enforcing.
|
||||
|
||||
Way back in kernel 2.6, a new security system was introduced to provide a mechanism for supporting access control security policies. This system was [Security Enhanced Linux (SELinux)][1] and was introduced by the [National Security Administration (NSA)][2] to incorporate a strong Mandatory Access Control architecture into the subsystems of the Linux kernel.
|
||||
|
||||
If you’ve spent your entire Linux career either disabling or ignoring SELinux, this article is dedicated to you — an introduction to the system that lives “under the hood” of your Linux desktop or server to limit privilege or even eliminate the possibility of damage should programs or daemons become compromised.
|
||||
|
||||
Before I begin, you should know that SELinux is primarily a tool for Red Hat Linux and its derivatives. The likes of Ubuntu and SUSE (and their derivatives) make use of AppArmor. SELinux and AppArmor are significantly different. You can install SELinux on SUSE, openSUSE, Ubuntu, etc., but it’s an incredibly challenging task unless you’re very well versed in Linux.
|
||||
|
||||
With that said, let me introduce you to SELinux.
|
||||
|
||||
### DAC vs. MAC
|
||||
|
||||
The old-guard standard form of access control on Linux was Discretionary Access Control (DAC). With this form, an application or daemon runs under either User ID (UID) or Set owner User ID (SUID) and holds object permissions (for files, sockets, and other processes) of that user. This made it easier for malicious code to be run with a permission set that would grant it access to crucial subsystems.
|
||||
|
||||
Mandatory Access Control (MAC), on the other hand, enforces the separation of information based on both confidentiality and integrity to enable the confinement of damage. The confinement unit operates independently of the traditional Linux security mechanisms and has no concept of a superuser.
|
||||
|
||||
### How SELinux Works
|
||||
|
||||
Consider these pieces of the SELinux puzzle:
|
||||
|
||||
- Subjects
|
||||
|
||||
- Objects
|
||||
|
||||
- Policy
|
||||
|
||||
- Mode
|
||||
|
||||
When a subject (such as an application) attempts to access an object (such as a file), the SELinux Security Server (inside the kernel) runs a check against the Policy Database. Depending on the current mode, if the SELinux Security Server grants permission, the subject is given access to the object. If the SELinux Security Server denies permission, a denied message is logged in /var/log/messages.
|
||||
|
||||
Sounds relatively simple, right? There’s actually more to it than that, but for the sake of introduction, those are the important steps.
|
||||
|
||||
### The Modes
|
||||
|
||||
SELinux has three modes (which can be set by the user). These modes will dictate how SELinux acts upon subject request. The modes are:
|
||||
|
||||
- Enforcing — SELinux policy is enforced and subjects will be denied or granted access to objects based on the SELinux policy rules
|
||||
|
||||
- Permissive — SELinux policy is not enforced and does not deny access, although denials are logged
|
||||
|
||||
- Disabled — SELinux is completely disabled
|
||||
|
||||
Out of the box, most systems have SELinux set to Enforcing. How do you know what mode your system is currently running? You can use a simple command to report the mode; that command is getenforce. This command is incredibly simple to use (as it has the singular purpose of reporting the SELinux mode). To use this tool, open up a terminal window and issue the command getenforce. The report will come back with either, Enforcing, Permissive, or Disabled (see Figure 1 above).
|
||||
|
||||
Setting the SELinux mode is actually quite simple — depending upon the mode you want to set. Understand this: It is never recommended to set SELinux to Disable. Why? When you do this, you open up the possibility that files on your disk will be mislabeled and require a re-label to fix. It is also not possible to change the mode of a system when it has been booted in Disabled mode. Your best modes are either Enabled or Permissive.
|
||||
|
||||
You can change the SELinux mode from the command line or in the /etc/selinux/config file. To set the mod via command line, you use the setenforce tool. To set the mode to Enforcing, do the following:
|
||||
|
||||
1. Open up a terminal window
|
||||
|
||||
2. Issue the command su and then enter your administrator password
|
||||
|
||||
3. Issue the command setenforce 1
|
||||
|
||||
4. Issue the command getenforce to ensure the mode has been set (Figure 2)
|
||||
|
||||

|
||||
|
||||
>Figure 2: Setting the SELinux mode to Enforcing.
|
||||
|
||||
To set the mode to Permissive, do this:
|
||||
|
||||
1. Open up a terminal window
|
||||
|
||||
2. Issue the command su and then enter your administrator password
|
||||
|
||||
3. Issue the command setenforce 0
|
||||
|
||||
4. Issue the command getenforce to ensure the mode has been set (Figure 3)
|
||||
|
||||

|
||||
|
||||
>Figure 3: Setting the SELinux mode to Permissive.
|
||||
|
||||
NOTE: Setting the mode via command line overrides the setting in the SELinux config file.
|
||||
|
||||
If you’d prefer to set the mode in the SELinux command file, open up that particular file in your favorite text editor and look for the line:
|
||||
|
||||
>SELINUX=permissive
|
||||
|
||||
You can change the mode to suit your preference and then save the file.
|
||||
|
||||
There is also a third method of changing the SELinux mode (via the bootloader), but I don’t recommend it for a beginning user.
|
||||
|
||||
### Policy Type
|
||||
|
||||
There are two types of SELinux policies:
|
||||
|
||||
- Targeted — only targeted network daemons (dhcpd, httpd, named, nscd, ntpd, portmap, snmpd, squid, and syslogd) are protected
|
||||
|
||||
- Strict — full SELinux protection for all daemons
|
||||
|
||||
You can change the policy type within the /etc/selinux/config file. Open the file in your favorite text editor and look for the line:
|
||||
|
||||
>SELINUXTYPE=targeted
|
||||
|
||||
Change the option in that line to either targeted or strict to match your needs.
|
||||
|
||||
### Checking the Full SELinux Status
|
||||
|
||||
There is a handy SELinux tool you might want to know about that will display a detailed status report of your SELinux-enabled system. The command is run from a terminal window like this:
|
||||
|
||||
>sestatus -v
|
||||
|
||||
You should see output similar to that shown in Figure 4.
|
||||
|
||||

|
||||
|
||||
>Figure 4: The output of the sestatus -v command.
|
||||
|
||||
### Just Scratching the Surface
|
||||
|
||||
As you might expect, I have only scratched the surface of SELinux. It is quite a complex system and will require diving much deeper to obtain a solid understanding of how it works for you and how you can make it better work for your desktops and servers. I still have yet to cover troubleshooting and creating custom SELinux policies.
|
||||
|
||||
SELinux is a powerful tool that any Linux administrator should know. Now that you’ve been introduced, I highly recommend you return to Linux.com (when more tutorials on the subject are posted) or take a look at the [NSA SELinux documentation][3] for very in-depth tutorials.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/docs/ldp/883671-an-introduction-to-selinux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/community/forums/person/93
|
||||
[1]: http://selinuxproject.org/page/Main_Page
|
||||
[2]: https://www.nsa.gov/research/selinux/
|
||||
[3]: https://www.nsa.gov/research/selinux/docs.shtml
|
||||
@ -1,174 +0,0 @@
|
||||
(翻译中 by runningwater)
|
||||
How to Add New Disk in Linux CentOS 7 Without Rebooting
|
||||
================================================================================
|
||||
|
||||
Increasing disk spaces on the Linux servers is a daily routine work for very system administrator. So, in this article we are going to show you some simple simple steps that you can use to increase your disk spaces on Linux CentOS 7 without rebooting to your production server using Linux commands. We will cover multiple methods and possibilities to increase and add new disks to the Linux systems, so that you can follow the one that you feel comfortable while using according to your requirements.
|
||||
|
||||
### 1. Increasing Disk of VM Guest: ###
|
||||
|
||||
Before increasing the disk volume inside your Linux system, you need to add a new disk or increase the one its has already attached with the system by editing its settings from your VMware vShere, Workstation or any other infrastructure environment that you are using.
|
||||
|
||||

|
||||
|
||||
### 2. Check Disk Space: ###
|
||||
|
||||
Run the following command to check the current size of your disk space.
|
||||
|
||||
# df -h
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
Here we can see that the total disk size is still the same that is 10 GB while we have already increased it to 50 GB from the back end.
|
||||
|
||||
### 3. Expanding Space without Rebooting VM ###
|
||||
|
||||
Now run the following commands to expand the disk space in the physical volume of the Operating System without rebooting the virtual machine by Re-scanning the SCSI Bus and then adding SCSI Device.
|
||||
|
||||
# ls /sys/class/scsi_host/
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
Check the names of your SCSI devices and then rescan the SCSI buses using below commands.
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/0\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
|
||||
That will rescan the current scsi bus and the disk size that we increased from the VM guest settings will be show up as you can see in the below image.
|
||||
|
||||

|
||||
|
||||
### 4. New Disk Partition: ###
|
||||
|
||||
Once you are able to see the increased disk space inside your system then the run the following command to format your disk for creating a new partition by following the steps to increase your physical disk volume.
|
||||
|
||||
# fdisk /dev/sda
|
||||
Welcome to fdisk (util-linux 2.23.2) press the 'm' key for help
|
||||
Command (m for help): m
|
||||
Command action
|
||||
a toggle a bootable flag
|
||||
b edit bsd disklabel
|
||||
c toggle the dos compatibility flag
|
||||
d delete a partition
|
||||
g create a new empty GPT partition table
|
||||
G create an IRIX (SGI) partition table
|
||||
l list known partition types
|
||||
m print this menu
|
||||
n add a new partition
|
||||
o create a new empty DOS partition table
|
||||
p print the partition table
|
||||
q quit without saving changes
|
||||
s create a new empty Sun disklabel
|
||||
t change a partition's system id
|
||||
u change display/entry units
|
||||
v verify the partition table
|
||||
w write table to disk and exit
|
||||
x extra functionality (experts only)
|
||||
|
||||
Command (m for help):
|
||||
|
||||
Type the 'p' to print the current partition table then create a new primary partition by typing the 'n' key and selecting the available sectors. Change the disk type to 'Linux LVM' by using 't' command and selecting the code to '8e' or leave as it to its default type that is '83'.
|
||||
|
||||
Now write the table to disk and exit by Entring 'w' key as shown.
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered!
|
||||
|
||||
Calling ioctl() to re-read partition table.
|
||||
|
||||
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
|
||||
The kernel still uses the old table. The new table will be used at
|
||||
the next reboot or after you run partprobe(8) or kpartx(8)
|
||||
|
||||

|
||||
|
||||
### 5. Creating Physical Volume: ###
|
||||
|
||||
As indicated above run the 'partprobe' or kpartx command so that the tables are ready to use and then create the new Physical Volume using the below commands.
|
||||
|
||||
# partprobe
|
||||
# pvresize /dev/sda3
|
||||
|
||||
To check the newly created volume run the following command to see if the new physical volume has been created and visible. After that we will extend the Volume Group 'centos' with the newly create Physical Volume as shown.
|
||||
|
||||
# pvdisplay
|
||||
# vgextend centos /dev/sda3
|
||||
|
||||

|
||||
|
||||
### 6. Extending Logical Volume: ###
|
||||
|
||||
Now we will extend the Logical Volume to increase the disk space on it using the the below command.
|
||||
|
||||
# lvextend -L +40G /dev/mapper/centos-root
|
||||
|
||||
Once you get the successfully increased message, run the command as shown below to extend the size of your logical volume .
|
||||
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
|
||||
The size of the '/' partition has been increased successfully, you can check the size of your disk drives by using the 'df' command as shown.
|
||||
|
||||

|
||||
|
||||
### 7. Extending Root Partition by Adding New Disk Without Reboot: ###
|
||||
|
||||
This is the second method with but with quite similar commands to increase the size of the Logical volume in CentOS 7.
|
||||
|
||||
So, the first step is to Open the setting of your VM guest settings and click on the 'Add' new button and proceed to the next option.
|
||||
|
||||

|
||||
|
||||
Choose the required configuration for the new disk by selecting the size of the new disk and its type as shown in the below image.
|
||||
|
||||

|
||||
|
||||
Then come to the server side and repeat the following commands to scan your disk devices to the new disk is visible on the system.
|
||||
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
List the names of your SCSi devices
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/1\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/3\:0\:0\:0/device/rescan
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
Once the new disk is visible run the below commands to create the new physical volume and add it to the volume group as shown.
|
||||
|
||||
# pvcreate /dev/sdb
|
||||
# vgextend centos /dev/sdb
|
||||
# vgdisplay
|
||||
|
||||

|
||||
|
||||
Now extend the Logical Volume by adding the disk space on it and then add it to the root partition.
|
||||
|
||||
# lvextend -L +20G /dev/mapper/centos-root
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
# df -h
|
||||
|
||||

|
||||
|
||||
### Conclusion: ###
|
||||
|
||||
Managing disk partitions in Linux CentOS 7 is a simple process to increase the disk space of any of your logical volumes by using the steps as described in this article. You don't need to give your production server's reboot for this purpose but simply rescan your SCSi devices and expand your desired LVM. We hope you find this article much helpful. Feel free to leave your valuable comments or suggestions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/add-new-disk-centos-7-without-rebooting/
|
||||
|
||||
作者:[Kashif S][a]
|
||||
译者:[runningwater](https://github.com/runningwater
|
||||
)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,92 +0,0 @@
|
||||
GHLandy Translating
|
||||
|
||||
Best Linux Desktop Environments for 2016
|
||||
=============================================
|
||||
|
||||

|
||||
|
||||
Linux creates a friendly environment for choices and options. For example, there are many Linux-based distributions out there that use different desktop environments for you to choose from. I have picked some of the best desktop environments that you will see in the Linux world.
|
||||
|
||||
## Plasma
|
||||
|
||||
I consider [KDE’s Plasma desktop](https://www.kde.org/workspaces/plasmadesktop/) to be the most advanced desktop environment (DE). It’s the most feature-rich and customizable desktop environment that I have ever seen; even Mac OS X and Windows don’t come near Plasma when it comes to complete control by the user.
|
||||
|
||||
I also love Plasma because of its awesome file manager, Dolphin. One reason I prefer Plasma over Gnome-based systems is the file manager. One of my biggest gripes with Gnome is that its file manager, Files, can’t handle basic tasks, such as batch-files renaming. That’s important for me because I take a lot of pictures, and Gnome makes it impossible for me to rename image files. On Dolphin, it’s a walk in the park.
|
||||
|
||||
Then, you can add more functionality to Plasma with plugins. Plasma comes with some incredible software including Krita, Kdenlive, Calligra Office Suite, digiKam, Kwrite, and many other applications being developed by the KDE community.
|
||||
|
||||
The only weakness of the Plasma desktop is its default email client, Kmail. It’s way too complicated to set up, and I also wish that setting up Kmail also configured the Address Book and Calendar.
|
||||
|
||||
Plasma is the default desktop environment of many major distributions including openSUSE.
|
||||
|
||||
## GNOME
|
||||
|
||||
[GNOME](https://www.gnome.org/) (GNU Network Object Model Environment) was founded by [Miguel de Icaza](https://en.wikipedia.org/wiki/Miguel_de_Icaza) and Federico Mena in 1997 because KDE used Qt toolkit, which was released under a proprietary license. Unlike KDE, where there were numerous customizations, GNOME focused on keeping things simple. GNOME became extremely popular due to its simplicity and ease of use. A factor that I think contributed heavily to Gnome’s popularity was the fact that Ubuntu, one of the most popular Linux distributions, picked it as their default desktop environment.
|
||||
|
||||
With changing times, GNOME needed a change. Therefore, with GNOME 3 the developers introduced the GNOME 3 Shell, which brought with it an entirely new design paradigm. That in turn led to some conflict with Canonical’s plans with Ubuntu, and they created their own shell for GNOME called Unity. Initially, GNOME 3 Shell was plagued by many issues -- most notably, the fact that extensions would stop working after updates. This major shift in design and the various problems then led to many forks of GNOME, such as the Cinnamon and Mate desktops.
|
||||
|
||||
That said, what makes GNOME desktop interesting is that they are targeting touch-based devices, so if you have new laptops that come with a touchscreen, Gnome is the best suited DE for them.
|
||||
|
||||
With version 3.18, GNOME has made some impressive improvements. The most interesting thing that they have done is Google Drive integration where users can mount their Google Drive as a remote file storage and work with files without having to use a web browser. I also love GNOME’s awesome integration of email client with calendar and address book. Despite all this awesomeness, however, the one thing that keeps me from using GNOME is its file manager, which can’t handle batch file renames. I will stick to Plasma until GNOME developers fix this problem.
|
||||
|
||||

|
||||
|
||||
## Unity
|
||||
|
||||
[Unity](https://unity.ubuntu.com/) is technically not a desktop environment, it’s a graphical shell developed by Canonical for Ubuntu. Unity runs on top of GNOME desktop environment and uses most stock GNOME apps and tools. The Ubuntu team has forked a few GNOME components to better suit the needs of Unity users.
|
||||
|
||||
Unity plays a very important role in Ubuntu’s convergence story and with Unity 8, the company is bringing the desktop and mobile world together. Canonical has developed many intriguing technologies for Unity including HUD (Head-up Display). They also took a unique approach with lenses and scopes making it easy for users to find appropriate content.
|
||||
|
||||
The upcoming release of Ubuntu, 16.04, is expected to ship with Unity 8 so users will get to experience all the work that developers have put into this open source software. One of the biggest criticisms with Unity was opt-out integration of Amazon ads and other services. With the upcoming release, though, Canonical is removing Amazon ads from Dash, making it a privacy-respecting OS by default.
|
||||
|
||||
## Cinnamon
|
||||
|
||||
[Cinnamon](https://en.wikipedia.org/wiki/Cinnamon_(software)) was initially developed by [Linux Mint](http://www.linuxmint.com/) -- the most popular distro on DistroWatch. Cinnamon is a fork of GNOME Shell, just like Unity. Later, however, it evolved into a desktop environment as Linux Mint developers forked many components of the GNOME desktop, including Files, to address the needs of their users.
|
||||
|
||||
Because Linux Mint was based on regular releases of Ubuntu, the developers continued to chase the moving target that was Ubuntu. As a result, despite great promises Cinnamon was full of bugs and problems. With the 17.x release, however, Linux Mint developers moved to LTS edition of Ubuntu that allowed them to focus on core components of Cinnamon without having to worry about the base. As a result of this move, Cinnamon has become incredibly stable and bug free. The developers have started adding more features to the desktop.
|
||||
|
||||
For those who prefer the good old Windows-like UI on top of the simplicity of GNOME, Cinnamon is the best desktop environment.
|
||||
|
||||
## MATE Desktop
|
||||
|
||||
The [MATE desktop](http://mate-desktop.com/) environment is also a fork of GNOME. However, unlike Cinnamon, it’s not a fork of GNOME 3; instead it’s a fork of GNOME 2 codebase, which is not unmaintained. A few developers didn’t like Gnome 3 and wanted to “continue” GNOME 2, so they took the codebase and created MATE. The MATE project forked many components of the GNOME project and created a few from scratch. To avoid any conflict with GNOME 3, they renamed all their packages: Nautilus become Caja, Gedit became Pluma, Evince became Atril, and so on.
|
||||
|
||||
Although MATE is a continuation of GNOME 2, that doesn’t mean they are using old and obsolete technologies; they are using newer technologies to offer a modern GNOME 2 experience.
|
||||
|
||||
What makes MATE an impressive desktop environment is that it’s extremely resource efficient. You can run it on older hardware or newer less powerful hardware, such as Raspberry Pi or Chromebook Flip. What’s makes it even more interesting is that using it on powerful systems frees most system resources for applications instead of the resources being consumed by the desktop environment itself.
|
||||
|
||||
## LXQt
|
||||
|
||||
[LXQt](http://lxqt.org/) is the successor of LXDE, one of the most lightweight desktop environments. It’s a merger of two open source projects LXDE and Razor-Qt. The first usable version of LXQt (v 0.9) was released in 2015. Initially, the developers used Qt4 but then all compatibility with it was dropped, and they moved to Qt5 and KDE Frameworks 5 for speedy development. I have tried LXQt on my Arch systems, and its a great lightweight desktop environment, but it has a long way to go before it becomes the rightful successor of LXDE.
|
||||
|
||||
## Xfce
|
||||
|
||||
[Xfce](http://www.xfce.org/) predates the KDE desktop environment. It is one of the oldest and lightest desktop environments around. The latest release of Xfce is 4.15, which was released in 2015 and uses modern technologies like GTK+ 3. Xfce is used by many special purpose distributions, such as Ubuntu Studio, because -- much like MATE -- it frees most system resources for applications. It’s also the default desktop environment of many notable Linux distributions including Manjaro Linux, PC/OS, Salix, and Mythbuntu.
|
||||
|
||||
## Budgie
|
||||
|
||||
[Budgie](https://solus-project.com/budgie/) is a new desktop environment being developed by the Solus Linux team. Solus is new Linux distribution that’s being developed from scratch, and Budgie is a core component of it. Budgie uses many GNOME components and offers a minimalistic UI. Because there’s not much information about the new desktop, I talked to the core developer of Solus, Ikey Doherty, and he explained, “We ship our own desktop, the Budgie Desktop. Unlike some other desktops, this is not a fork, rather it aims for full integration into the GNOME stack. It's written from scratch, and is specifically designed to cater for the experience Solus is offering. We work with upstream GNOME here as much as we can, contributing fixes, and advocate and support their work.”
|
||||
|
||||
## Pantheon
|
||||
|
||||
[Pantheon](https://elementary.io/) needs no introduction, it’s the desktop environment powering the lovely Linux distribution elementary OS. Similar to Budgie, Pantheon is not a fork of GNOME as many may assume. elementary OS team comes from design background so they pay very close attention to minute details, as a result Pantheon is extremely polished desktop environment. At the moment, it may lack many feature found in DEs like Plasma, but the developers are taking their time in order to stick to the design principle.
|
||||
|
||||

|
||||
|
||||
## Conclusion
|
||||
|
||||
As I went through this story, I realized the awesomeness of open source and Linux. There is something for everyone. As Jon “maddog” Hall said during the latest SCaLE 14, “Yes, there are 300 Linux distributions. I can try them and stick to the one that I like!”
|
||||
|
||||
So, enjoy this diversity and use the one that floats your boat!
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/software/applications/881107-best-linux-desktop-environments-for-2016
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
@ -1,55 +0,0 @@
|
||||
martin
|
||||
ST Releases Free Linux IDE for 32-Bit MCUs
|
||||
=================================================
|
||||
|
||||

|
||||
|
||||
The 32-bit microcontroller world is starting to open up to Linux. This week, leading ARM Cortex-M vendor STMicroelectronics (ST) [released](http://www.st.com/web/en/press/p3781) a free Linux desktop version of its development software for its line of STM32 microcontroller units (MCUs). The tools include ST’s STM32CubeMX configurator and initialization tool, as well as its [System Workbench for STM32 (SW4STM32)](http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1533/PF261797) , an Eclipse-based IDE created by Ac6 Tools. SW4STM32 is supported with toolchain, forums, blogs, and technical support by the [openSTM32.org](http://www.openstm32.org/tiki-index.php?page=HomePage) development community.
|
||||
|
||||
"The Linux community is known to attract creative free-thinkers who are adept at sharing ideas and solving challenges efficiently," stated Laurent Desseignes, Microcontroller Ecosystem Marketing Manager, Microcontroller Division, STMicroelectronics. "We are now making it ultra-easy for them to apply their skills to create imaginative new products, leveraging the features and performance of our STM32 family."
|
||||
|
||||
Linux is the leading platform for Internet of Things gateways and hubs, as well as higher-end IoT endpoints. Yet, much of the IoT revolution, as well as the wearables market, is based on tiny, low-power microcontrollers, increasingly Cortex-M chips. A small subset of these can run the stripped-down uCLinux (see below), but none support more comprehensive Linux distributions. Instead, they are controlled with real-time operating systems (RTOSes) or go bare-bones with no OS at all. The firmware development work is typically done on a Windows-based Integrated Development Environment (IDE).
|
||||
|
||||
With ST’s free tools, Linux developers can more easily tap this new realm. ST’s tools, some of which should also be available for Mac OS/X in the second quarter, work with [STM32 Nucleo](http://www.st.com/web/en/catalog/tools/FM146/CL2167/SC2003?icmp=sc2003_pron_pr-stm32f446_dec2014&sc=stm32nucleo-pr5) boards, Discovery kits, and Evaluation boards. The Nucleo boards are available in 32-, 64-, and 144-pin versions, and offer hardware add-ons such as Arduino connectors.
|
||||
|
||||
The STM32CubeMX configurator and SW4STM32 IDE enable Linux developers to configure microcontrollers and develop and debug code. SW4STM32 supports the ST-LINK/V2 debugging tool under Linux via an adapted version of the [OpenOCD](http://openocd.org/) community project.
|
||||
|
||||
The software is compatible with microcontroller firmware within the STM32Cube embedded-software packages or Standard Peripheral Library, says ST. Targets include ST’s full range of MCUs, from entry-level Cortex-M0 cores to high-performing M7 chips, including M0+, M3, and DSP-extended M4 cores.
|
||||
|
||||
ST is not the first 32-bit MCU vendor to offer Linux-ready IDEs for Cortex-M chips, but it appears to be one of the first major free Linux platforms. For example, NXP, whose share of the MCU market increased with its recent acquisition of Freescale (Kinetis MCUs, among others), offers an [LPCXpresso IDE](http://www.nxp.com/pages/lpcxpresso-ide:LPCXPRESSO) with Linux, Windows, and Mac support. However, LPCXpresso costs $450 per individual seat.
|
||||
|
||||
Microsemi, which integrates Cortex-M3 chips in its [SmartFusion FPGA SoCs](http://www.microsemi.com/products/fpga-soc/soc-processors/arm-cortex-m3) has a [Libero IDE](http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus#device-support) available for Red Hat Enterprise Linux (RHEL) in addition to Windows. However, Libero requires a license, and the RHEL version lacks support for add-on packages such as FlashPro and SoftConsole.
|
||||
|
||||
## Why Learn MCU-Speak?
|
||||
|
||||
Even if a Linux developer has no plans to load uClinux on a Cortex-M chip, knowledge of MCUs should come in handy. This is especially true with complex, heterogeneous IoT projects that extend from MCU-based endpoints to cloud platforms.
|
||||
|
||||
For prototyping and hobbyist projects, an interface to an Arduino board offers fairly easy access to MCU benefits. Yet beyond prototyping, developers often replace the Arduino board and its 8-bit ATmega32u4 MCU with a faster 32-bit Cortex-M chip with additional functionality. This includes improved memory addressing, independent clock settings for the core and various buses, and in the case of some [Cortex-M7](http://www.electronicsnews.com.au/products/stm32-mcus-with-arm-cortex-m7-processors-and-graph) chips, rudimentary graphics.
|
||||
|
||||
Other categories where MCU development skills might come in handy include wearables, where low power, low cost, and small size give MCUs an edge, and robotics and drones where real-time processing and motor control are the main benefits. In robotics, you’re likely to see Cortex-A and Cortex-M both integrated in the same product.
|
||||
|
||||
There’s also a modest trend toward system-on-chips adding MCUs to Linux-driven Cortex-A cores, as with the [NXP i.MX6 SoloX](http://linuxgizmos.com/freescales-popular-i-mx6-soc-sprouts-a-cortex-m4-mcu/). While most embedded projects don’t use such hybrid SoCs or combine applications processor and MCUs on the same product, developers may increasingly find themselves working on product lines that extend from low-end MCU models to Linux- or Android-driven Cortex-A based designs.
|
||||
|
||||
## uClinux Stakes Linux Claim in MCUs
|
||||
|
||||
With the rise of IoT, we’re starting to see more SBCs and computer-on-modules that run uClinux on 32-bit MCUs. Unlike other Linux distributions, uClinux does not require a memory management unit (MMU). uClinux does, however, have higher memory requirements than most MCUs can meet. The distro requires higher end Cortex-M4 and Cortex-M4 MCUs with built-in memory controllers supporting external DRAM chips.
|
||||
|
||||
[Amptek’s iCon](http://www.semiconductorstore.com/Amptek/) SBCs run uClinux on NXP LPC Cortex-M3 and -M4 chips, offering familiar trappings like WiFi, Bluetooth, USB, and other interfaces. Arrow’s [SF2+](http://linuxgizmos.com/iot-dev-kit-runs-uclinux-on-a-microsemi-cortex-m3-fpga-soc/) IoT development kit runs uClinux on an Emcraft Systems SmartFusion2 COM based on Microsemi’s 166MHz, Cortex-M3/FPGA SmartFusion2 hybrid SoC.
|
||||
|
||||
[Emcraft](http://www.emcraft.com/), which sells uClinux-based COMs based on ST and NXP, as well as Microsemi MCUs, has been actively promoting the role of uClinux on 32-bit MCUs. Increasingly, uClinux is up against ARM’s own [Mbed OS](http://linuxgizmos.com/arm-announces-mbed-os-for-iot-devices/), at least on high-end MCU projects that require wireless communications and more sophisticated rules-based operation. Proponents of Mbed and modern, open source RTOSes like FreeRTOS say that uClinux requires too much RAM overhead to make it affordable for IoT endpoints. However, Emcraft and other uCLinux proponents claim the costs are overstated, and are worth the more extensive Linux wireless and interface support available even in a stripped down distro like uClinux.
|
||||
|
||||
When asked for comment on the ST release, Emcraft director of engineering Vladimir Khusainov had this to say: “ST’s decision to port its development tools to Linux is good news for Emcraft since it allows Linux users an easy way to start working with embedded STM MCUs. We expect that, having had a chance to get familiar with STM devices using the ST configurator and embedded libraries, some of those users may become interested in running embedded Linux (in its uClinux form) on the target.”
|
||||
|
||||
For a recent overview of uClinux on Cortex-M4, check out this [slide show](http://events.linuxfoundation.org/sites/events/files/slides/optimize-uclinux.pdf) from last year’s Embedded Linux Conference by Jim Huang and Jeff Liaw. More on Cortex-M processors in general may be found in this tidy [AnandTech overview](http://www.anandtech.com/show/8400/arms-cortex-m-even-smaller-and-lower-power-cpu-cores).
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/42808
|
||||
@ -1,213 +0,0 @@
|
||||
How to Setup Lighttpd Web server on Ubuntu 15.04 / CentOS 7
|
||||
=================================================================================
|
||||
|
||||
Lighttpd is an open source web server which is secure, fast, compliant, and very flexible and is optimized for high-performance environments. It uses very low memory compared to other web servers , small CPU load and speed optimization making it popular among the server for its efficiency and speed. Its advanced feature-set (FastCGI, CGI, Auth, Output-Compression, URL-Rewriting and many more) makes lighttpd the perfect webserver-software for every server that suffers load problems.
|
||||
|
||||
Here are some simple easy setups on how we can setup Lighttpd web server on our machine running Ubuntu 15.04 or CentOS 7 linux distributions.
|
||||
|
||||
### Installing Lighttpd
|
||||
|
||||
#### Installing using Package Manager
|
||||
|
||||
Here, we'll install Lighttpd using package manager as its the easiest method to install it. So, we can simply run the following command under `sudo` mode in a terminal or console to install Lighttpd.
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
As lighttpd is not available in the official repository of CentOS 7, we'll need to install epel additional repository to our system. To do so, we'll need to run the following `yum` command.
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
Then, we'll gonna update our system and proceed towards the installation of lighttpd.
|
||||
|
||||
# yum update
|
||||
# yum install lighttpd
|
||||
|
||||

|
||||
|
||||
**Ubuntu 15.04**
|
||||
|
||||
Lighttpd is available on the official repository of Ubuntu 15.04 so, we'll simply update our local repository index and then go for the installation of lighttpd using `apt-get` command.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install lighttpd
|
||||
|
||||

|
||||
|
||||
#### Installing from Source
|
||||
|
||||
If we wanna install lighttpd from the latest version of source code ie 1.4.39, we'll need to compile the source code and install it into our system. First of all, we'll need to install the dependencies required to compile it.
|
||||
|
||||
# cd /tmp/
|
||||
# wget http://download.lighttpd.net/lighttpd/releases-1.4.x/lighttpd-1.4.39.tar.gz
|
||||
|
||||
After its downloaded, we'll need to extract it the tarball by running the following.
|
||||
|
||||
# tar -zxvf lighttpd-1.4.39.tar.gz
|
||||
|
||||
Then, we'll compile it by running the following commands.
|
||||
|
||||
# cd lighttpd-1.4.39
|
||||
# ./configure
|
||||
# make
|
||||
|
||||
**Note:** In this tutorial, we are installing lighttpd with its standard configuration. If you wanna configure beyond the standard configuration and want to install more features like support for SSL, `mod_rewrite`, `mod_redirect` then you can configure.
|
||||
|
||||
Once, its compiled, we'll install it in our system.
|
||||
|
||||
# make install
|
||||
|
||||
### Configuring Lighttpd
|
||||
|
||||
If we need to configure our lighttpd web server further as our requirements, we can make changes to the default configuration file ie `/etc/lighttpd/lighttpd.conf` . As wee'll go with the default configuration here in this tutorial, we'll not gonna make changes to it. If we had made any changes and we wanna check for errors in the config file, we'll need to run the following command.
|
||||
|
||||
# lighttpd -t -f /etc/lighttpd/lighttpd.conf
|
||||
|
||||
#### On CentOS 7
|
||||
|
||||
If we are running CentOS 7, we'll need to create a new directory for our webroot defined in our lighttpd's default configuration ie `/src/www/htdocs/` .
|
||||
|
||||
# mkdir -p /srv/www/htdocs/
|
||||
|
||||
Then, we'll copy the default welcome page from `/var/www/lighttpd/` directory to the above created directory.
|
||||
|
||||
# cp -r /var/www/lighttpd/* /srv/www/htdocs/
|
||||
|
||||
### Starting and Enabling Services
|
||||
|
||||
Now, we'll gonna restart our database server by executing the following `systemctl` command.
|
||||
|
||||
# systemctl start lighttpd
|
||||
|
||||
Then, we'll enable it to start automatically in every system boot.
|
||||
|
||||
# systemctl enable lighttpd
|
||||
|
||||
### Allowing Firewall
|
||||
|
||||
To allow our webpages or websites running lighttpd web server on the internet or inside the same network, we'll need to allow port 80 from the firewall program. As both CentOS 7 and Ubuntu 15.04 are shipped with systemd as the default init system, we will have firewalld installed as a firewall solution. To allow port 80 or http service, we'll need to run the following commands.
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
success
|
||||
# firewall-cmd --reload
|
||||
success
|
||||
|
||||
### Accessing Web Server
|
||||
|
||||
As we have allowed port 80 which is the default port of lighttpd, we should be able to access lighttpd's welcome page by default. To do so, we'll need to point our browser to the ip address or domain of our machine running lighttpd according to our configuration. In this tutorial, we'll point our browser to [http://lighttpd.linoxide.com/](http://lighttpd.linoxide.com/) as we have pointed our sub-domain to its ip address. On doing so, we'll see the following welcome page in our browser.
|
||||
|
||||

|
||||
|
||||
Further, we can add our website's files to the webroot directory and remove the default lighttpd's index file to make our static website live to the internet.
|
||||
|
||||
If we want to run our PHP application in our lighttpd webserver, we'll need to follow the following steps.
|
||||
|
||||
### Installing PHP5 Modules
|
||||
|
||||
Once our lighttpd is installed successfully, we'll need to install PHP and some PHP modules to run PHP5 scripts in our lighttpd web server.
|
||||
|
||||
#### On Ubuntu 15.04
|
||||
|
||||
# apt-get install php5 php5-cgi php5-fpm php5-mysql php5-curl php5-gd php5-intl php5-imagick php5-mcrypt php5-memcache php-pear
|
||||
|
||||
#### On CentOS 7
|
||||
|
||||
# yum install php php-cgi php-fpm php-mysql php-curl php-gd php-intl php-pecl-imagick php-mcrypt php-memcache php-pear lighttpd-fastcgi
|
||||
|
||||
### Configuring Lighttpd with PHP
|
||||
|
||||
To make PHP work with lighttpd web server, we'll need to follow the following methods respect to the distribution we are running.
|
||||
|
||||
#### On CentOS 7
|
||||
|
||||
First of all, we'll need to edit our php configuration ie `/etc/php.ini` and uncomment a line **cgi.fix_pathinfo=1** using a text editor.
|
||||
|
||||
# nano /etc/php.ini
|
||||
|
||||
After its done, we'll need to change the ownership of PHP-FPM process from apache to lighttpd. To do so, we'll need to open the configuration file `/etc/php-fpm.d/www.conf` using a text editor.
|
||||
|
||||
# nano /etc/php-fpm.d/www.conf
|
||||
|
||||
Then, we'll append the file with the following configurations.
|
||||
|
||||
user = lighttpd
|
||||
group = lighttpd
|
||||
|
||||
Once done, we'll need to save the file and exit the text editor. Then, we'll need to include fastcgi module from `/etc/lighttpd/modules.conf` configuration file.
|
||||
|
||||
# nano /etc/lighttpd/modules.conf
|
||||
|
||||
Then, we'll need to uncomment the following line by removing `#` from it.
|
||||
|
||||
include "conf.d/fastcgi.conf"
|
||||
|
||||
At last, we'll need to configure our fastcgi configuration file using our favorite text editor.
|
||||
|
||||
# nano /etc/lighttpd/conf.d/fastcgi.conf
|
||||
|
||||
Then, we'll need to add the following lines at the end of the file.
|
||||
|
||||
fastcgi.server += ( ".php" =>
|
||||
((
|
||||
"host" => "127.0.0.1",
|
||||
"port" => "9000",
|
||||
"broken-scriptfilename" => "enable"
|
||||
))
|
||||
)
|
||||
|
||||
After its done, we'll save the file and exit the text editor.
|
||||
|
||||
#### On Ubuntu 15.04
|
||||
|
||||
To enable fastcgi with lighttpd web server, we'll simply need to execute the following commands.
|
||||
|
||||
# lighttpd-enable-mod fastcgi
|
||||
|
||||
Enabling fastcgi: ok
|
||||
Run /etc/init.d/lighttpd force-reload to enable changes
|
||||
|
||||
# lighttpd-enable-mod fastcgi-php
|
||||
|
||||
Enabling fastcgi-php: ok
|
||||
Run `/etc/init.d/lighttpd` force-reload to enable changes
|
||||
|
||||
Then, we'll reload our lighttpd by running the following command.
|
||||
|
||||
# systemctl force-reload lighttpd
|
||||
|
||||
### Testing if PHP is working
|
||||
|
||||
In order to see if PHP is working as expected or not, we'll need to create a new php file under the webroot of our lighttpd web server. Here, in this tutorial we have `/var/www/html` in Ubuntu and `/srv/www/htdocs` in CentOS as the default webroot so, we'll create a info.php file under it using a text editor.
|
||||
|
||||
**On CentOS 7**
|
||||
|
||||
# nano /var/www/info.php
|
||||
|
||||
**On Ubuntu 15.04**
|
||||
|
||||
# nano /srv/www/htdocs/info.php
|
||||
|
||||
Then, we'll simply add the following line into the file.
|
||||
|
||||
<?php phpinfo(); ?>
|
||||
|
||||
Once done, we'll simply save the file and exit from the text editor.
|
||||
|
||||
Now, we'll point our web browser to our machine running lighttpd using its ip address or domain name with the info.php file path as [http://lighttpd.linoxide.com/info.php](http://lighttpd.linoxide.com/info.php) If everything was done as described above, we will see our PHP information page as shown below.
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
Finally we have successfully installed the world's lightweight, fast and secure web server Lighttpd in our machine running CentOS 7 and Ubuntu 15.04 linux distributions. Once its ready, we can upload our website files into our web root, configure virtual host, enable ssl, connect database, run web apps and much more with our lighttpd web server. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-lighttpd-web-server-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,3 +1,4 @@
|
||||
[Translating by cposture 2016-03-12]
|
||||
Best Cloud Services For Linux To Replace Copy
|
||||
===============================================
|
||||
|
||||
|
||||
@ -1,31 +0,0 @@
|
||||
Manjaro Linux Is Coming To ARM With Manjaro-ARM
|
||||
===================================================
|
||||
|
||||

|
||||
|
||||
Recently, the developers of Manjaro have announced the release of an [alpha build for ARM devices](https://manjaro.github.io/Manjaro-ARM-launched/). This is a big step for the Arch-based distro, which up until this point only ran on 32 and 64-bit PCs.
|
||||
|
||||
According to the announcement, “[Manjaro Arm](http://manjaro-arm.org/) is a project aimed to bring you the simplicity and customability that is Manjaro to [ARM devices](https://www.arm.com/). These devices are growing in numbers and can be used for any number of applications. Most famous is the Raspberry Pi series and BeagleBoard series.” The alpha build only supports the Raspberry Pi 2, but that will undoubtedly grow with time.
|
||||
|
||||
The developers currently include dodgejcr, Torei, Strit, and Ringo32. They are looking for more people to help the project grow and develop. Besides developers, [they are looking for maintainers, moderators and admins, and artists](http://manjaro-arm.org/forums/website/looking-for-contributors/?PHPSESSID=876d5c11400e9c25eb727e9965300a9a).
|
||||
|
||||
Manjaro-ARM will be available in four different versions. The Media Edition will allow you to create a media center with very little configuration and will run Kodi. The Server Edition will come with SSH, FTP, and a LAMP server preconfigured so you can use your ARM device as a file or web server. The Base Edition acts as the desktop edition, with an XFCE desktop. If you want to build you own system from scratch, the Minimal Edition is your choice. It will come with no preloaded packages or desktop, only have a root user.
|
||||
|
||||
## Final Thoughts
|
||||
|
||||
As a fan of Manjaro (I have it installed on 4 computers), I’m glad to hear that they are branching out into the ARM world. ARM is being used in more and more devices. According to technology commentator Robert Cringely, [device makers are starting to look at cheap ARM chips over more expensive Intel or AMD chips](http://www.cringely.com/2016/01/21/prediction-8-intel-starts-to-become-irrelevent/). Even Microsoft (please don’t strike me down) is thinking of porting some of its software to ARM. As the use of ARM powered devices increase, Manjaro will be ready to give those users a great Linux experience.
|
||||
|
||||
What do you think? Do you wish that more Linux distros would create ARM ports? Or do you think that ARM is a passing fad? Tell us below.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manjaro-linux-arm/
|
||||
|
||||
作者:[JOHN PAUL][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/john/
|
||||
|
||||
@ -1,80 +0,0 @@
|
||||
JonathanKang is translating
|
||||
|
||||
[Free Download] Vi Cheat Sheet For Beginners
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
I have often shared my Linux experience with you. Today I am going to share my **Vi cheat sheet** that has often saved me time in googling for a quick command.
|
||||
|
||||
## Basic Vi commands
|
||||
|
||||
This is not a detailed tutorial to teach you each and every aspect of [Vi editor](https://en.wikipedia.org/wiki/Vi). In fact, it’s not a tutorial at all. It’s just a collection of basic Vi commands and their brief description for a quick reference.
|
||||
|
||||
command|explain
|
||||
:--|:--
|
||||
:x |Save the file and quit
|
||||
:q!|Quit without saving the file
|
||||
i|Insert starting left of the cursor
|
||||
a|Append starting right of the cursor
|
||||
ESC|Exit insert/append mode
|
||||
arrows|Move cursor
|
||||
/text|Search string text (case sensitive)
|
||||
n|Search next occurrence of the searched item
|
||||
x|Delete character under the cursor
|
||||
dd|Delete line under the cursor
|
||||
u|Undo last change
|
||||
:0|Beginning of the file
|
||||
:n|Go to line n
|
||||
G|End of the file
|
||||
^|Beginning of the line
|
||||
$|End of the line
|
||||
:set list|See special characters in the file
|
||||
yy|Copy the line into the buffer
|
||||
5yy|Copy 5 lines into the buffer
|
||||
p|Paste buffer after the current line
|
||||
|
||||
You can download the above cheat sheet in a PDF format from the link below:
|
||||
|
||||
[Download Vi Cheat Sheet](https://drive.google.com/file/d/0By49_3Av9sT1X3dlWkNQa3g2b2c/view?usp=sharing)
|
||||
|
||||
You can print it and keep it at your desk or just save it for offline use.
|
||||
|
||||
## Why I created the Vi cheat sheet?
|
||||
|
||||
Several years ago, when I started working in Linux terminal, the idea of using a command line editor horrified me. I had used desktop Linux before but it was my personal computer so I happily used the GUI text editor like Gedit. But in the working environment, I was stuck with the command line and there was no scope of using a graphical editor.
|
||||
|
||||
I was forced to use Vi for basic edits in the files on remote Linux boxes and this is where I identified and started to admire the power of command line editing tool Vi.
|
||||
|
||||
Since, at that time, I was new at Vi editor, I found myself baffling with it. The first time, I could not even come out of the file because I did not know how to close Vi editor. No shame in accepting that I had to Google it.
|
||||
|
||||
So, I decided to make a list of all the basic commands that I used frequently for editing in Vi. This list or cheat sheet, as you may call it, helped me a lot in my early days with Vi. With time, I grew up with Vi and now I don’t even need to look at the Vi cheat sheet because I have the commands memorized by heart.
|
||||
|
||||
## Why should you use Vi cheat sheet?
|
||||
|
||||
I can understand your situation if you are just getting started with Vi. Your favorite Ctrl+S doesn’t work for saving files. Ctrl+C and Ctrl+V were supposed to be the universal shortcut for copy and paste but it won’t work in Vi universe.Thousands of people use cheat sheets
|
||||
|
||||
Thousands of people use such cheat sheets for various programming languages and `/` or tools that give them a quick reference to commonly used steps `/` commands. Trust me, using cheat sheets among the best practices advised to programmers.
|
||||
|
||||
This Vi cheat sheet will help you a lot if you are just starting with Vi or if you infrequently use the Vi editor (so you keep forgetting the commands). You can save it and use it for quick reference in future, that too offline.
|
||||
|
||||
## Do you like it?
|
||||
|
||||
So far, I have refrained myself from going into too much on terminal side. How do you find this post? Do you want me to share more such cheat sheets and downloadable items? Your suggestions are welcomed.
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/download-vi-cheat-sheet/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,5 +1,6 @@
|
||||
Achieving Enterprise-Ready Container Tools With Wercker’s Open Source CLI
|
||||
===========================================
|
||||
#CoderBOBO translating
|
||||
|
||||
For enterprises, containers offer more efficient build environments, cloud-native applications and migration from legacy systems to the cloud. But enterprise adoption of the technology -- Docker specifically -- has been hampered by, among other issues, [a lack of mature developer tools][1].
|
||||
|
||||
|
||||
@ -0,0 +1,49 @@
|
||||
New Docker Data Center Admin Suite Should Bring Order to Containerization
|
||||
===============================================================================
|
||||
|
||||

|
||||
|
||||
[Docker][1] announced a new container control center today it’s calling the Docker Datacenter (DDC), an integrated administrative console that has been designed to give large and small businesses control over creating, managing and shipping containers.
|
||||
|
||||
The DDC is a new tool made up of various commercial pieces including Docker Universal Control Plane (which also happens to be generally available today) and Docker Trusted Registry. It also includes open source pieces such as Docker Engine. The idea is to give companies the ability to manage the entire lifecycle of Dockerized applications from one central administrative interface.
|
||||
|
||||
Customers actually were the driving force behind this new tool. While companies liked the agility that Docker containers give them, they also wanted management control over administration, security and governance around the containers they were creating and shipping, Scott Johnston, SVP of product management told TechCrunch.
|
||||
|
||||
The company has called this Containers as a Service (CaaS), mostly because when customers came to them asking for this type of administrative control, that’s how they described it, Johnston said.
|
||||
|
||||
|
||||

|
||||
|
||||
>Image courtesy of Docker
|
||||
|
||||
Like many open source projects, Docker gained a strong following among developers first, but as it grew in popularity, the companies these developers were working for wanted a straight-forward way to track and manage them.
|
||||
|
||||
That’s exactly what DDC is designed to do. It gives developers the agility they need to create containerized applications, while providing operations with the tools they need to bring order to the process.
|
||||
|
||||
In practice this means that developers can create a set of containerized components, have them approved for deployment by operations and then have access to a library of fully certified images. This lets developers pull the pieces they need across a range of applications without having to reinvent the wheel every time. That should speed up application development and deployment (and add to the agility that containers should in theory be providing in the first place).
|
||||
|
||||
This aspect appealed to Beta customer ADP. The payroll services giant particularly liked having this central repository of images available to developers.
|
||||
|
||||
“As part of our initiative to modernize our business-critical applications to microservices, ADP has been investigating solutions that would enable our developers to leverage a central library of IT-vetted and secured core services that they could rapidly iterate on,” said Keith Fulton, Chief Technology Officer at ADP said in a statement.
|
||||
|
||||
Docker was launched in 2010 by founder Solomon Hykes as dotCloud. He pivoted the company to Docker in 2013, [selling dotCloud in August][2], 2014 to focus completely on Docker.
|
||||
|
||||
The company came out of the gate like gangbusters a couple of years ago raising $180 million ($168 million since becoming Docker) over five rounds, according to CrunchBase. What caught the attention of investors was that Docker offered a way to deliver applications for the modern age called containers, a way of building, managing and shipping distributed applications.
|
||||
|
||||
Containerization enables developers to create these distributed applications made up of small discrete pieces that run across multiple servers, as opposed to the large monolithic applications companies used to create running on a single server.
|
||||
|
||||
Pricing for Docker Datacenter starts at $150 per node per month.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/calico-virtual-private-networking-docker/
|
||||
|
||||
作者:[ Ron Miller][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techcrunch.com/author/ron-miller/
|
||||
[1]: https://www.docker.com/
|
||||
[2]: http://techcrunch.com/2014/08/04/docker-sells-dotcloud-to-cloudcontrol-to-focus-on-core-container-business/
|
||||
@ -0,0 +1,91 @@
|
||||
How to add open source experience to your resume
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
|
||||
In this article, I'll share my technique for leveraging open source contributions to stand out as a great candidate for a job in the technology field.
|
||||
|
||||
No goal can be accomplished without first being set. Before jumping into a new commitment or spending the evening overhauling your resume, it pays to clearly define the traits of the job you're seeking. Your resume is a piece of persuasive writing, so you have to know your audience for it to reach its full potential. Your resume's audience is anyone with the need for your skills and the budget to hire you. When editing, read your resume while imagining what it's like to be in their position. Do you look like a candidate that you would hire?
|
||||
|
||||
I personally find it helpful to make a list of the key traits that the ideal candidate for my target job displays. I gather this list from a combination of personal experience, reading job postings, and asking colleagues in similar roles. LinkedIn and conferences are great places to find people happy to offer this sort of advice. Many people enjoy talking about themselves, and inviting them to tell part of their own story to help you expand your knowledge makes everyone feel good. As you talk to others about their career paths, you'll gain insights not only into how to land the jobs you want, but also into which traits or behaviors correspond to ending up in situations you'd rather avoid.
|
||||
|
||||
For example, the list of key traits for a junior role might look like this:
|
||||
|
||||
### Technical:
|
||||
|
||||
- Experience with CI, Jenkins preferred
|
||||
|
||||
- Strong scripting background in Python and Ruby
|
||||
|
||||
- Familiarity with Eclipse IDE
|
||||
|
||||
- Basic Git and Bash
|
||||
|
||||
### Personal:
|
||||
|
||||
- Self-directed learner
|
||||
|
||||
- Clear communication and documentation skills
|
||||
|
||||
- Experience working on a multi-person development team ("team player")
|
||||
|
||||
- Familiarity with issue tracker workflow
|
||||
|
||||
### Apply anyway
|
||||
|
||||
Remember, you don't have to meet every single criterion listed in a job description to get an interview.
|
||||
|
||||
The job description describes whoever left the role, and if you start out knowing everything you've likely signed yourself up for a few years that don't challenge or expand your skill set. If you're nervous about missing a particular technology on the list, do some research into it to see whether comparable skills from another experience would apply. For example, someone who's never used [Jenkins][1] might still understand the principles of continuous integration testing from working on a project that uses [Buildbot][2] or [Travis CI][3].
|
||||
|
||||
If you're applying at a larger company, they probably have an entire department and comprehensive screening process to make sure they don't hire any candidate unable to succeed in a role. That means it's your job to apply and their job to decide whether to reject you. Don't prematurely reject yourself from the job by refusing to apply.
|
||||
|
||||
Now you have an idea of what job you want and what skills you'll need to impress your interviewers. The next steps to take will vary based on how much experience you've already got.
|
||||
|
||||
### Tailoring existing involvement
|
||||
|
||||
Start by making a list of all the projects you've been involved with in the past few years. One way to get a quick list of things you've worked on lately is to navigate to the **Repositories** tab of your GitHub profile and filter the list by clicking on **Forks**. Additionally, look down your [Organizations][4] list for places you might have been engaging in leadership roles. If you already have a resume, make sure you've included everything from these lists under experience.
|
||||
|
||||
Consider any IRC channel where you have special permissions as a potential leadership experience. Check your Meetup and Eventbrite accounts and add any events that you organize or volunteer at to your list. Skim your calendar for the past year and note any volunteering, mentoring, or public speaking engagements.
|
||||
|
||||
Now for the hard part: Map the list of required skills onto the list of experiences. I like to assign a letter or number to each trait needed for the job, then mark the same symbol next to every piece of experience or involvement where you demonstrated the trait. When in doubt, claim it anyway—your problem is more likely a reluctance to brag than actual incompetence.
|
||||
|
||||
This is the point in the process at which resume writers are often fettered by reluctance to risk overselling their own skills. It often helps to re-frame the question as: "Did someone who organized a meetup show leadership and planning skills?" Rather than: "Did I personally show these skills when I organized that meetup?".
|
||||
|
||||
If you've been sufficiently thorough at figuring out where your free time has gone for the past year or two and you code a lot, you might now be facing a surprising problem: Too many items to fit on a single-page resume! If anything on your list of experiences didn't demonstrate any of the skills you're trying to showcase, cross it off. If an item demonstrates few skills and you don't have any stories that you enjoy telling about it, cross it off. If this abridged list of things you've done still won't fit in the format of a resume, prioritize the experiences from which you gained a relevant story or extensive experience with a desired technology.
|
||||
|
||||
At this point, it should be obvious if you need a better piece of experience to hone a particular skill. Consider using an issue aggregator like OpenHatch to find an open source project where you build and practice your skills with the tool or technology that you're missing.
|
||||
|
||||
### Make your resume beautiful
|
||||
|
||||
A resume's beauty comes from conciseness, clarity, and layout. Each piece of experience should be accompanied by enough information for a reader to immediately know why you included it, but no more. Each type of information should be formatted consistently throughout the document—it's distracting to have some dates italicized or right-aligned and others not.
|
||||
|
||||
Typeset your resume using a tool that makes these goals easy to achieve. I enjoy using [LaTeX][5], since its macro system makes visual consistency easy and most interviewers recognize it immediately. Your tool of choice might be [LibreOffice][6] or HTML, depending on your skills and how you want to distribute your resume.
|
||||
|
||||
Remember that a digitally submitted resume might be scanned for keywords, so it can help to use the same acronyms as the job posting when describing your experiences. To make your resume easy for your interviewer to use, place the most important information first.
|
||||
|
||||
Coders often struggle to quantify balance and layout when typesetting a document. My favorite technique for stepping back and assessing whether my document's whitespace is in the right place is to fullscreen the PDF or print it out, then look at it in a mirror. If you're using LibreOffice Writer, save a copy of your resume then change the font to that of a language you can't read. Both of these techniques forcibly pull you out of reading the content, and allow you to see the overall layout of the document in a new light. They take you from a "That sentence is poorly worded!" critique to noticing things like "It looks funny to have only a single word on that line."
|
||||
|
||||
Finally, double check that your resume displays correctly in the media where it will be seen. If you're distributing it as a web page, test it at different screen widths in multiple browsers. If it's a PDF, open it on your phone or a friend's computer to make sure all the fonts it needs are available.
|
||||
|
||||
### Next steps
|
||||
|
||||
Finally, don't let the content that you worked so hard on for your resume go to waste! Mirror it to your LinkedIn account—complete with the buzzwords from the job posting—and don't be surprised if recruiters start reaching out to you. Even if the jobs they're describing aren't a good fit right now, you can leverage their time and interest to get feedback on what's working well about your resume and what isn't.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/16/2/add-open-source-to-your-resume
|
||||
|
||||
作者:[edunham][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/edunham
|
||||
[1]: https://jenkins-ci.org/
|
||||
[2]: http://buildbot.net/
|
||||
[3]: https://travis-ci.org/
|
||||
[4]: https://github.com/settings/organizations
|
||||
[5]: https://www.latex-project.org/
|
||||
[6]: https://www.libreoffice.org/download/libreoffice-fresh/
|
||||
@ -0,0 +1,215 @@
|
||||
How to use Python to hack your Eclipse IDE
|
||||
==============================================
|
||||
|
||||

|
||||
|
||||
The Eclipse Advanced Scripting Environment ([EASE][1]) project is a new but powerful set of plugins that enables you to quickly hack your Eclipse IDE.
|
||||
|
||||
Eclipse is a powerful framework that can be extended in many different ways by using its built-in plugin mechanism. However, writing and deploying a new plugin can be cumbersome if all you want is a bit of additional functionality. Now, using EASE, there's a better way to do that, without having to write a single line of Java code. EASE provides a way to easily automate workbench functionality using scripting languages such as Python or Javascript.
|
||||
|
||||
In this article, based on my [talk][2] at EclipseCon North America this year, I'll cover the basics of how to set up your Eclipse environment with Python and EASE and look at a few ideas to supercharge your IDE with the power of Python.
|
||||
|
||||
### Setup and run "Hello World"
|
||||
|
||||
The examples in this article are based on the Java-implementation of Python, Jython. You can install EASE directly into your existing Eclipse IDE. In this example we use Eclipse [Mars][3] and install EASE itself, its modules and the Jython engine.
|
||||
|
||||
From within the Eclipse Install Dialog (`Help>Install New Software`...), install EASE: [http://download.eclipse.org/ease/update/nightly][4]
|
||||
|
||||
And, select the following components:
|
||||
|
||||
- EASE Core feature
|
||||
|
||||
- EASE core UI feature
|
||||
|
||||
- EASE Python Developer Resources
|
||||
|
||||
- EASE modules (Incubation)
|
||||
|
||||
This will give you EASE and its modules. The main one we are interested in is the Resource module that gives you access to the Eclipse workspace, projects, and files API.
|
||||
|
||||
|
||||
|
||||
|
||||
After those have been successfully installed, next install the EASE Jython engine: [https://dl.bintray.com/pontesegger/ease-jython/][5]. Once the plugins are installed, test EASE out. Create a new project and add in a new file called hello.py with this content:
|
||||
|
||||
```
|
||||
print "hello world"
|
||||
```
|
||||
|
||||
Select the file, right click, and select 'Run as -> EASE script'. You should see "Hello World" appear in the console.
|
||||
|
||||
Now you can start writing Python scripts that can access the workspace and projects. This power can be used for all sorts of hacks, below are just a few ideas.
|
||||
|
||||
### Improve your code quality
|
||||
|
||||
Maintaining good code quality can be a tiresome job especially when dealing with a large codebase or when lots of developers are involved. Some of this pain can be made easier with a script, such as for batch formatting for a set of files, or even fixing certain files to [remove unix line endings][6] for easy comparison in source control like git. Another nice thing to do is use a script to generate Eclipse markers to highlight code that could do with improving. Here's an example script that you could use to add task markers for all "printStackTrace" methods it detects in Java files. See the source code: [markers.py][7]
|
||||
|
||||
To run, copy the file to your workspace, then right click and select 'Run as -> EASE script'.
|
||||
|
||||
```
|
||||
loadModule('/System/Resources')
|
||||
```
|
||||
|
||||
from org.eclipse.core.resources import IMarker
|
||||
|
||||
```
|
||||
for ifile in findFiles("*.java"):
|
||||
file_name = str(ifile.getLocation())
|
||||
print "Processing " + file_name
|
||||
with open(file_name) as f:
|
||||
for line_no, line in enumerate(f, start=1):
|
||||
if "printStackTrace" in line:
|
||||
marker = ifile.createMarker(IMarker.TASK)
|
||||
marker.setAttribute(IMarker.TRANSIENT, True)
|
||||
marker.setAttribute(IMarker.LINE_NUMBER, line_no)
|
||||
marker.setAttribute(IMarker.MESSAGE, "Fix in Sprint 2: " + line.strip())
|
||||
|
||||
```
|
||||
|
||||
If you have any java files with printStackTraces you will be able to see the newly created markers in the Tasks view and in the editor margin.
|
||||
|
||||
|
||||
|
||||
### Automate tedious tasks
|
||||
|
||||
When you are working with several projects you may want to automate some tedious, repetitive tasks. Perhaps you need to add in a copyright header to the beginning of each source file, or update source files when adopting a new framework. For instance, when we first switched to using Tycho and Maven, we had to add a pom.xml to each project. This is easily done using a few lines of Python. Then when Tycho provided support for pom-less builds, we wanted to remove unnecessary pom files. Again, a few lines of Python script enabled this. As an example, here is a script which adds a README.md file to every open project in your workspace, noting if they are Java or Python projects. See the source code: [add_readme.py][8].
|
||||
|
||||
To run, copy the file to your workspace, then right click and select 'Run as -> EASE script'.
|
||||
|
||||
loadModule('/System/Resources')
|
||||
|
||||
```
|
||||
for iproject in getWorkspace().getProjects():
|
||||
if not iproject.isOpen():
|
||||
continue
|
||||
|
||||
ifile = iproject.getFile("README.md")
|
||||
|
||||
if not ifile.exists():
|
||||
contents = "# " + iproject.getName() + "\n\n"
|
||||
if iproject.hasNature("org.eclipse.jdt.core.javanature"):
|
||||
contents += "A Java Project\n"
|
||||
elif iproject.hasNature("org.python.pydev.pythonNature"):
|
||||
contents += "A Python Project\n"
|
||||
writeFile(ifile, contents)
|
||||
```
|
||||
|
||||
The result should be that every open project will have a README.md file, with Java and Python projects having an additional descriptive line.
|
||||
|
||||
|
||||
|
||||
### Prototype new features
|
||||
|
||||
You can also use a Python script to hack a quick-fix for some much wanted functionality, or as a prototype to help demonstrate to your team or users how you envision a feature. For instance, one feature Eclipse IDE doesn't currently support is auto-save on the current file you are working on. Although this feature is in the works for future releases, you can have a quick and dirty version that autosaves every 30 seconds or when the editor is deactivated. Below is a snippet of the main method. See the full source: [autosave.py][9]
|
||||
|
||||
```
|
||||
def save_dirty_editors():
|
||||
workbench = getService(org.eclipse.ui.IWorkbench)
|
||||
for window in workbench.getWorkbenchWindows():
|
||||
for page in window.getPages():
|
||||
for editor_ref in page.getEditorReferences():
|
||||
part = editor_ref.getPart(False)
|
||||
if part and part.isDirty():
|
||||
print "Auto-Saving", part.getTitle()
|
||||
part.doSave(None)
|
||||
```
|
||||
|
||||
Before running this script you will need to turn on the 'Allow Scripts to run code in UI thread' setting by checking the box under Window > Preferences > Scripting. Then you can add the file to your workspace, right click on it and select 'Run As>EASE Script'. A save message is printed out in the Console view every time an editor is saved. To turn off the autosave just stop the script by pressing the 'Terminate' red square button in the Console view.
|
||||
|
||||
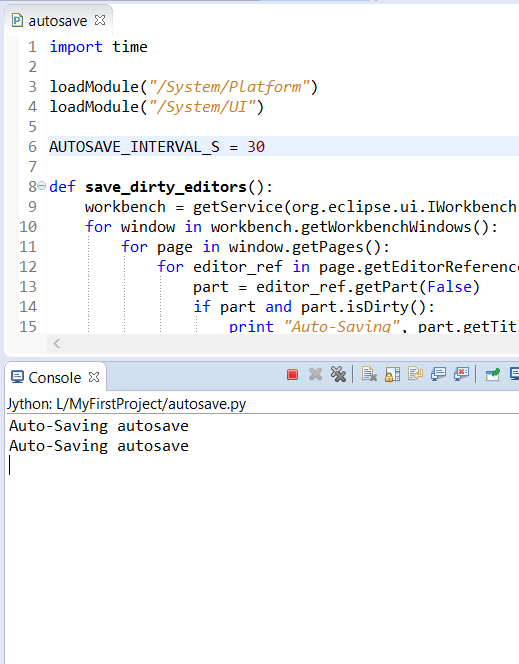
|
||||
|
||||
### Quickly extend the user interface with custom buttons, menus, etc
|
||||
|
||||
One of the best things about EASE is that it allows you to take your scripts and quickly hook them into UI elements of the IDE, for example, as a new button or new menu item. No need to write Java or have a new plugin, just add a couple of lines to your script header—it's that simple.
|
||||
|
||||
Here's an example for a simplistic script that creates us three new projects.
|
||||
|
||||
```
|
||||
# name : Create fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Create fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
createProject(name)
|
||||
```
|
||||
|
||||
The comment lines specify to EASE to add a button to the Project Explorer toolbar. Here's another script that adds a button to the same toolbar to delete those three projects. See the source files: [createProjects.py][10] and [deleteProjects.py][11]
|
||||
|
||||
```
|
||||
# name :Delete fruit projects
|
||||
# toolbar : Project Explorer
|
||||
# description : Get rid of the fruit projects
|
||||
|
||||
loadModule("/System/Resources")
|
||||
|
||||
for name in ["banana", "pineapple", "mango"]:
|
||||
project = getProject(name)
|
||||
project.delete(0, None)
|
||||
```
|
||||
|
||||
To get the buttons to appear, add the two script files to a new project—let's call it 'ScriptsProject'. Then go to Windows > Preference > Scripting > Script Locations. Click on the 'Add Workspace' button and select the ScriptsProject. This project now becomes a default location for locating script files. You should see the buttons show up in the Project Explorer without needing to restart your IDE. You should be able to quickly create and delete the projects using your newly added buttons.
|
||||
|
||||
|
||||
|
||||
### Integrate with third-party tools
|
||||
|
||||
Every now and then you may need to use a tool outside the Eclipse ecosystem (sad but true, it has a lot but it does not do everything). For those occasions it might be quite handy to wrap calling that call to the tool in a script. Here's an example that allows you to integrate with explorer.exe, and add it to the content menu so you could instantly open a file browser using the current selection. See the source code: [explorer.py][12]
|
||||
|
||||
```
|
||||
# name : Explore from here
|
||||
# popup : enableFor(org.eclipse.core.resources.IResource)
|
||||
# description : Start a file browser using current selection
|
||||
loadModule("/System/Platform")
|
||||
loadModule('/System/UI')
|
||||
|
||||
selection = getSelection()
|
||||
if isinstance(selection, org.eclipse.jface.viewers.IStructuredSelection):
|
||||
selection = selection.getFirstElement()
|
||||
|
||||
if not isinstance(selection, org.eclipse.core.resources.IResource):
|
||||
selection = adapt(selection, org.eclipse.core.resources.IResource)
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IFile):
|
||||
selection = selection.getParent()
|
||||
|
||||
if isinstance(selection, org.eclipse.core.resources.IContainer):
|
||||
runProcess("explorer.exe", [selection.getLocation().toFile().toString()])
|
||||
```
|
||||
|
||||
To get the menu to appear, add the script to a new project—let's call it 'ScriptsProject'. Then go to Windows > Preference > Scripting > Script Locations. Click on the 'Add Workspace' button and select the ScriptsProject. You should see the new menu item show up in the context menu when you right-click on a file. Select this action to bring up a file browser. (Note this functionality already exists in Eclipse but this example is one you could adapt to other third-party tools).
|
||||
|
||||
|
||||
|
||||
The Eclipse Advanced Scripting Environment provides a great way to get more out of your Eclipse IDE by leveraging the power of Python. It is a project in its infancy so there is so much more to come. Learn more [about the project][13] and get involved by signing up for the [forum][14].
|
||||
|
||||
I'll be talking more about EASE at [Eclipsecon North America][15] 2016. My talk [Scripting Eclipse with Python][16] will go into how you can use not just Jython, but C-Python and how this functionality can be extended specifically for scientific use-cases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/2/how-use-python-hack-your-ide
|
||||
|
||||
作者:[Tracy Miranda][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tracymiranda
|
||||
[1]: https://eclipse.org/ease/
|
||||
[2]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
[3]: https://www.eclipse.org/downloads/packages/eclipse-ide-eclipse-committers-451/mars1
|
||||
[4]: http://download.eclipse.org/ease/update/nightly
|
||||
[5]: https://dl.bintray.com/pontesegger/ease-jython/
|
||||
[6]: http://code.activestate.com/recipes/66434-change-line-endings/
|
||||
[7]: https://gist.github.com/tracymiranda/6556482e278c9afc421d
|
||||
[8]: https://gist.github.com/tracymiranda/f20f233b40f1f79b1df2
|
||||
[9]: https://gist.github.com/tracymiranda/e9588d0976c46a987463
|
||||
[10]: https://gist.github.com/tracymiranda/55995daaea9a4db584dc
|
||||
[11]: https://gist.github.com/tracymiranda/baa218fc2c1a8e898194
|
||||
[12]: https://gist.github.com/tracymiranda/8aa3f0fc4bf44f4a5cd3
|
||||
[13]: https://eclipse.org/ease/
|
||||
[14]: https://dev.eclipse.org/mailman/listinfo/ease-dev
|
||||
[15]: https://www.eclipsecon.org/na2016
|
||||
[16]: https://www.eclipsecon.org/na2016/session/scripting-eclipse-python
|
||||
@ -0,0 +1,105 @@
|
||||
wyangsun translating
|
||||
Two Outstanding All-in-One Linux Servers
|
||||
================================================
|
||||
|
||||
keywords: Linux Server , SMB , clearos , Zentyal
|
||||
|
||||
|
||||
|
||||
>Figure 1: The ClearOS setup wizard.
|
||||
|
||||
Back in 2000, Microsoft released their Small Business Server. This product changed the way many people viewed how technology could function within the realm of business. Instead of having multiple machines handle different tasks, you could deploy a single server which would handle email, calendaring, file sharing, directory services, VPN, and a whole lot more. For many of small businesses, this was a serious boon, but for some the cost of the Windows SMB was prohibitive. For yet others, the idea of relying on such a server, designed by Microsoft, simply wasn’t an option.
|
||||
|
||||
For that last group, there are alternatives. In fact, within the realm of Linux and open source, you can choose from several solid platforms that can serve your small business as a one-stop server shop. If your small business has between 10 and 50 employees, the all-in-one server might be the ideal solution to meet your needs.
|
||||
|
||||
Here, I’ll look at two Linux all-in-one servers, so you can see if one of them is the perfect match for your company.
|
||||
|
||||
Remember, these servers are not, in any way, suited for big business or enterprise. Larger companies cannot rely on the all-in-one server simply because a single server cannot take the load expected within the realm of enterprise needs. With that said, here’s what SMBs can expect from a Linux all in one.
|
||||
|
||||
### ClearOS
|
||||
|
||||
[ClearOS][1] was originally released in 2009, under the name ClarkConnect, as a router and gateway distribution. Since then, ClearOS has added all the features necessary to define it as an all-in-one server. ClearOS offers more than just a piece of software. You can also purchase a [ClearBox 100][2] or [ClearBox 300][3]. These servers ship complete with ClearOS and are marketed as IT in a box. Check out the feature comparison/price matrix [here][4].
|
||||
|
||||
For those with hardware already in-house, you can download one of the following:
|
||||
|
||||
- [ClearOS Community][5] — The community (free) edition of ClearOS
|
||||
|
||||
- [ClearOS Home][6] — Ideal for home offices (details on features and subscription costs, see here)
|
||||
|
||||
- [ClearOS Business][7] — Ideal for small businesses (details on features and subscription costs, see here)
|
||||
|
||||
What do you get with ClearOS? You get a business-class server with a single, elegantly designed web interface. What is unique about ClearOS is that you will get plenty of features in the base server; beyond that, you must add on features from the [Clear Marketplace][8]. From within the Marketplace, you can install free or paid apps that extend the feature set of the ClearOS server. Here you’ll find add-ons for Windows Server Active Directory, OpenLDAP, Flexshares, Antimalware, Cloud, Web access control, Content filtering, and much more. You’ll even find some third-party add-ons such as Google Apps Synchronization, Zarafa Collaboration Platform, and Kaspersky Anti-virus.
|
||||
|
||||
ClearOS is installed like any other Linux distribution (based on Red Hat’s Anaconda installer). Once the install is complete, you will be prompted to set up the networking interface as well as presented with the address to point your browser (on the same network as the ClearOS server). The address will be in the form:
|
||||
|
||||
[https://IP_OF_CLEAROS_SERVER:81][9]
|
||||
|
||||
Where IP_OF_CLEAROS_SERVER is the actual IP address of the server. NOTE: When you first point your browser to the server, you will receive a “Connection is not private” warning. Proceed on to the address so you can continue the setup.
|
||||
|
||||
When the browser finally connects, you will be prompted for the root user credentials (you set the root user password up during initial installation). Once authenticated, you will be presented with the ClearOS setup wizard (Figure 1 above).
|
||||
|
||||
Click the Next button to begin the process of setting up your ClearOS server. The wizard is self-explanatory and, in the end, you will be asked which version of ClearOS you want to use. Click either Community, Home, or Business. Once selected, you will be required to register for an account. Once you’ve created an account and registered the server, you can then move on to updating the server, configuring the server, and adding modules from the marketplace (Figure 2).
|
||||
|
||||

|
||||
|
||||
>Figure 2: Installing modules from the marketplace.
|
||||
|
||||
At this point, you are ready to start digging deep into the configuration of your ClearOS small business server.
|
||||
|
||||
### Zentyal
|
||||
|
||||
[Zentyal][10] is a Ubuntu-based small business server that was, at one point, distributed under the name eBox. Zentyal offers plenty of servers/services to fit your SMB needs:
|
||||
|
||||
- Email — Webmail; Native MS Exchange protocols and Active Directory support; Calendars and contacts; Mobile device email sync; Antivirus/antispam; IMAP, POP, SMTP, CalDAV, and CardDAV support
|
||||
|
||||
- Domain & Directory — Central domain directory management; Multiple organization units; Single sign-on authentication; File sharing; ACLs, Advanced domain management, Printer management
|
||||
|
||||
- Networking & Firewall — Static and DHCP interfaces; Objects & services; Packet filter; Port forwarding
|
||||
|
||||
- Infrastructure — DNS; DHCP; NTP; Certification authority; VPN
|
||||
|
||||
- Firewall
|
||||
|
||||
The installation of Zentyal is very much like that of Ubuntu Server—it’s text based and quite simple: Boot up the install media, make a few quick selections, and wait for the installation to complete. Once the initial, text-based, installation is finished, you are presented with the GUI desktop where a wizard will appear for package selection. Select all the packages you want to install and allow the installer to finish the job.
|
||||
|
||||
Finally, you can log into your Zentyal server via the web interface (point your browser to [https://IP_OF_SERVER:8443][11] — where IP_OF_SERVER is the LAN address of the Zentyal server) or use the standalone, desktop GUI to administer the server (Zentyal includes quick access to an Administrator and User console as well as a Zentyal Administration console). When all systems have been saved and started, you will be presented with the Zentyal Dashboard (Figure 3).
|
||||
|
||||

|
||||
|
||||
>Figure 3: The Zentyal Dashboard in action.
|
||||
|
||||
The Dashboard allows you to control all aspects of the server, such as updating, managing servers/services, and getting a quick status update of the server. You can also go into the Components area and install components that you opted out of during installation or update the current package list. Click on Software Management > System Updates and select what you want to update (Figure 4), then click the UPDATE button at the bottom of the screen.
|
||||
|
||||

|
||||
|
||||
>Figure 4: Updating your Zentyal server is simple.
|
||||
|
||||
### Which Server Is Right for You?
|
||||
|
||||
The answer to this question depends on what you need. Zentyal is an amazing server that does a great job running your SMB network. If you need a bit more, such as groupware, your best bet is to go with ClearOS. If you don’t need groupware, either server will do an outstanding job.
|
||||
|
||||
I highly recommend installing both of these all-in-one servers to see which will best serve your small company needs.
|
||||
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/882146-two-outstanding-all-in-one-linux-servers
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.linux.com/community/forums/person/93
|
||||
[1]: http://www.linux.com/learn/tutorials/882146-two-outstanding-all-in-one-linux-servers#clearfoundation-overview
|
||||
[2]: https://www.clearos.com/products/hardware/clearbox-100-series
|
||||
[3]: https://www.clearos.com/products/hardware/clearbox-300-series
|
||||
[4]: https://www.clearos.com/products/hardware/clearbox-overview
|
||||
[5]: http://mirror.clearos.com/clearos/7/iso/x86_64/ClearOS-DVD-x86_64.iso
|
||||
[6]: http://mirror.clearos.com/clearos/7/iso/x86_64/ClearOS-DVD-x86_64.iso
|
||||
[7]: http://mirror.clearos.com/clearos/7/iso/x86_64/ClearOS-DVD-x86_64.iso
|
||||
[8]: https://www.clearos.com/products/purchase/clearos-marketplace-overview
|
||||
[9]: https://ip_of_clearos_server:81/
|
||||
[10]: http://www.zentyal.org/server/
|
||||
[11]: https://ip_of_server:8443/
|
||||
@ -0,0 +1,40 @@
|
||||
The Evolving Market for Commercial Software Built On Open Source
|
||||
=====================================================================
|
||||
|
||||

|
||||
>Attendees listen to a presentation during Structure at the UCSF Mission Bay Conference Center, where Structure Data 2016 will take place. Image credit: Structure Events.
|
||||
|
||||
It's really hard to understate the impact of open source projects on the enterprise software market these days; open source integration became the norm so quickly we could be forgiven for missing the turning point.
|
||||
|
||||
Hadoop, for example, changed more than just the world of data analysis. It gave rise to a new generation of data companies that created their own software around open source projects, tweaking and supporting that code as needed, much like how Red Hat embraced Linux in the 1990s and early 2000s. And this software is increasingly delivered over public clouds, rather than run on the buyer's own servers, enabling an amazing degree of operational flexibility but raising all sorts of new questions about licensing, support, and pricing.
|
||||
|
||||
We've been following this closely over the years when putting together the lineup for our Structure Data conference, and Structure Data 2016 is no exception. The CEOs of three of the most important companies in big data operating around Hadoop -- Hortonworks, Cloudera and MapR -- will share the stage to discuss how they sell enterprise software and services around open source projects, generating cash while giving back to that community project at the same time.
|
||||
|
||||
There was a time when making money on enterprise software was easier. Once purchased by a customer, a mega-package of software from an enterprise vendor turned into its own cash register, generating something close to lifetime income from maintenance contracts and periodic upgrades to software that became harder and harder to displace as it became the heart of a customer’s business. Customers grumbled about lock-in, but they didn't really have much of a choice if they wanted to make their workforce more productive.
|
||||
|
||||
That is no longer the case. While an awful lot of companies are still stuck running immense software packages critical to their infrastructure, new projects are being deployed on cloud servers using open source technologies. This makes it much easier to upgrade one's capabilities without having to rip out a huge software package and reinstall something else, and it also allows companies to pay as they go, rather than paying for a bunch of features they'll never use.
|
||||
|
||||
And there are a lot of customers who want to take advantage of open source projects without building and supporting a team of engineers to tweak one of those projects for their own unique needs. Those customers are willing to pay for software packages whose value is based on the delta between the open source projects and the proprietary features laid on top of that project.
|
||||
|
||||
This is especially true for infrastructure-related software. Sure, your customers could install their own tweaks to a project like Hadoop or Spark or Node.js, but there's money to be made helping those customers out with a customizable package that lets them implement some of today's vital open source technologies without having to do all of the heavy lifting themselves. Just look at Structure Data 2016 presenters such as Confluent (Kafka), Databricks (Spark), and the Cloudera-Hortonworks-MapR (Hadoop) trio.
|
||||
|
||||
There's certainly something to be said for having a vendor to yell at when things go wrong. If your engineers botch the implementation of an open source project, you've only yourself to blame. But If you contract with a company that is willing to guarantee certain performance and uptime metrics inside of a service-level agreement, you're willing to pay for support, guidance, and a chance to yell at somebody outside of your organization when inevitable problems crop up.
|
||||
|
||||
The evolving market for commercial software on top of open source projects is something we've been tracking at Structure Data for years, and we urge you to join us in San Francisco March 9 and 10 if this is a topic near and dear to your heart.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/enterprise/cloud-computing/889564-the-evolving-market-for-commercial-software-built-on-open-source-
|
||||
|
||||
作者:[Tom Krazit ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/community/forums/person/70513
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,35 @@
|
||||
(翻译中 by runningwater)
|
||||
Viper, the Python IoT Development Suite, is now Zerynth
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
The startup that launched the tools to develop embedded solutions in Python language announced the brand change along with the first official release.
|
||||
|
||||
>Exactly one year after the Kickstarter launch of the suite for developing Internet of Things solutions in Python language, **Viper becomes Zerynth**. It is definitely a big day for the startup that created a radically new way to approach the world of microcontrollers and connected devices, making professionals and makers able to design interactive solutions with reduced efforts and shorter time.
|
||||
|
||||
>“We really believe in the uniqueness of our tools, this is why they deserve an adequate recognition. Viper was a great name for a product, but other notable companies had the same feeling many decades ago, with the result that this term was shared with too many other actors out there. We are grown now, and ready to take off fast and light, like the design processes that our tools are enabling”, says the Viper (now Zerynth), co-founders.
|
||||
|
||||
>**Thousands of users** developed amazing connected solutions in just 9 months of life in Beta version. Built to be cross-platform, Zerynth’s tools are meant for high-level design of Internet/cloud-connected devices, interactive objects, artistic installations. They are: **Zerynth Studio**, a browser-based IDE for programming embedded devices in Python with cloud sync and board management features; **Zerynth Virtual Machine**: a multithreaded real-time OS that provides real hardware independence allowing code reuse on the entire ARM architecture; **Zerynth App**, a general purpose interface that turns any mobile into the controller and display for smart objects and IoT systems.
|
||||
|
||||
>This modular set of tools, adaptable to different hardware and cloud infrastructures, can dramatically reduce the time to market and the overall development costs for makers, professionals and companies.
|
||||
|
||||
>Now Zerynth celebrates its new name launching the **first official release** of the toolkit. Check it here [www.zerynth.com][1]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.open-electronics.org/viper-the-python-iot-development-suite-is-now-zerynth/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+OpenElectronics+%28Open+Electronics%29
|
||||
|
||||
作者:[Staff ][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.open-electronics.org/author/staff/
|
||||
[1]: http://www.zerynth.com/
|
||||
|
||||
@ -0,0 +1,90 @@
|
||||
翻译中;by ![zky001]
|
||||
Top 5 open source command shells for Linux
|
||||
===============================================
|
||||
|
||||
keyword: shell , Linux , bash , zsh , fish , ksh , tcsh , license
|
||||
|
||||

|
||||
|
||||
There are two kinds of Linux users: the cautious and the adventurous.
|
||||
|
||||
On one side is the user who almost reflexively tries out ever new option which hits the scene. They’ve tried handfuls of window managers, dozens of distributions, and every new desktop widget they can find.
|
||||
|
||||
On the other side is the user who finds something they like and sticks with it. They tend to like their distribution’s defaults. If they’re passionate about a text editor, it’s whichever one they mastered first.
|
||||
|
||||
As a Linux user, both on the server and the desktop, for going on fifteen years now, I am definitely more in the second category than the first. I have a tendency to use what’s presented to me, and I like the fact that this means more often than not I can find thorough documentation and examples of most any use case I can dream up. If I used something non-standard, the switch was carefully researched and often predicated by a strong pitch from someone I trust.
|
||||
|
||||
But that doesn’t mean I don’t like to sometimes try and see what I’m missing. So recently, after years of using the bash shell without even giving it a thought, I decided to try out four alternative shells: ksh, tcsh, zsh, and fish. All four were easy installs from my default repositories in Fedora, and they’re likely already packaged for your distribution of choice as well.
|
||||
|
||||
Here’s a little bit on each option and why you might choose it to be your next Linux command-line interpreter.
|
||||
|
||||
### bash
|
||||
|
||||
First, let’s take a look back at the familiar. [GNU Bash][1], the Bourne Again Shell, has been the default in pretty much every Linux distribution I’ve used through the years. Originally released in 1989, bash has grown to easily become the most used shell across the Linux world, and it is commonly found in other unix-like operating systems as well.
|
||||
|
||||
Bash is a perfectly respectable shell, and as you look for documentation of how to do various things across the Internet, almost invariably you’ll find instructions which assume you are using a bash shell. But bash has some shortcomings, as anyone who has ever written a bash script that’s more than a few lines can attest to. It’s not that you can’t do something, it’s that it’s not always particularly intuitive (or at least elegant) to read and write. For some examples, see this list of [common bash pitfalls][2].
|
||||
|
||||
That said, bash is probably here to stay for at least the near future, with its enormous install base and legions of both casual and professional system administrators who are already attuned to its usage, and quirks. The bash project is available under a [GPLv3][3] license.
|
||||
|
||||
### ksh
|
||||
|
||||
[KornShell][4], also known by its command invocation, ksh, is an alternative shell that grew out of Bell Labs in the 1980s, written by David Korn. While originally proprietary software, later versions were released under the [Eclipse Public License][5].
|
||||
|
||||
Proponents of ksh list a number of ways in which they feel it is superior, including having a better loop syntax, cleaner exit codes from pipes, an easier way to repeat commands, and associative arrays. It's also capable of emulating many of the behaviors of vi or emacs, so if you are very partial to a text editor, it may be worth giving a try. Overall, I found it to be very similar to bash for basic input, although for advanced scripting it would surely be a different experience.
|
||||
|
||||
### tcsh
|
||||
|
||||
[Tcsh][6] is a derivative of csh, the Berkely Unix C shell, and sports a very long lineage back to the early days of Unix and computing itself.
|
||||
|
||||
The big selling point for tcsh is its scripting language, which should look very familiar to anyone who has programmed in C. Tcsh's scripting is loved by some and hated by others. But it has other features as well, including adding arguments to aliases, and various defaults that might appeal to your preferences, including the way autocompletion with tab and history tab completion work.
|
||||
|
||||
You can find tcsh under a [BSD license][7].
|
||||
|
||||
### zsh
|
||||
|
||||
[Zsh][8] is another shell which has similarities to bash and ksh. Originating in the early 90s, zsh sports a number of useful features, including spelling correction, theming, namable directory shortcuts, sharing your command history across multiple terminals, and various other slight tweaks from the original Bourne shell.
|
||||
|
||||
The code and binaries for zsh can be distributed under an MIT-like license, though portions are under the GPL; check the [actual license][9] for details.
|
||||
|
||||
### fish
|
||||
|
||||
I knew I was going to like the Friendly Interactive Shell, [fish][10], when I visited the website and found it described tongue-in-cheek with "Finally, a command line shell for the 90s"—fish was written in 2005.
|
||||
|
||||
The authors of fish offer a number of reasons to make the switch, all invoking a bit of humor and poking a bit of fun at shells that don't quite live up. Features include autosuggestions ("Watch out, Netscape Navigator 4.0"), support of the "astonishing" 256 color palette of VGA, but some actually quite helpful features as well including command completion based on the man pages on your machine, clean scripting, and a web-based configuration.
|
||||
|
||||
Fish is licensed primarily unde the GPL version 2 but with portions under other licenses; check the repository for [complete information][11].
|
||||
|
||||
***
|
||||
|
||||
Looking for a more detailed rundown on the precise differences between each option? [This site][12] ought to help you out.
|
||||
|
||||
So where did I land? Well, ultimately, I’m probably going back to bash, because the differences were subtle enough that someone who mostly used the command line interactively as opposed to writing advanced scripts really wouldn't benefit much from the switch, and I'm already pretty comfortable in bash.
|
||||
|
||||
But I’m glad I decided to come out of my shell (ha!) and try some new options. And I know there are many, many others out there. Which shells have you tried, and which one do you prefer? Let us know in the comments!
|
||||
|
||||
|
||||
|
||||
|
||||
via: https://opensource.com/business/16/3/top-linux-shells
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
|
||||
[1]: https://www.gnu.org/software/bash/
|
||||
[2]: http://mywiki.wooledge.org/BashPitfalls
|
||||
[3]: http://www.gnu.org/licenses/gpl.html
|
||||
[4]: http://www.kornshell.org/
|
||||
[5]: https://www.eclipse.org/legal/epl-v10.html
|
||||
[6]: http://www.tcsh.org/Welcome
|
||||
[7]: https://en.wikipedia.org/wiki/BSD_licenses
|
||||
[8]: http://www.zsh.org/
|
||||
[9]: https://sourceforge.net/p/zsh/code/ci/master/tree/LICENCE
|
||||
[10]: https://fishshell.com/
|
||||
[11]: https://github.com/fish-shell/fish-shell/blob/master/COPYING
|
||||
[12]: http://hyperpolyglot.org/unix-shells
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
Image processing at NASA with open source tools
|
||||
=======================================================
|
||||
|
||||
keyword: NASA , Image Process , Node.js , OpenCV
|
||||
|
||||

|
||||
|
||||
This past summer, I was an intern at the [GVIS][1] Lab at [NASA][2] Glenn, where I brought my passion for open source into the lab. My task was to improve our lab's contributions to an open source fluid flow dynamics [simulation][3] developed by Dan Schroeder. The original simulation presents obstacles that users can draw in with their mouse to model computational fluid dynamics. My team contributed by adding image processing code that analyzes each frame of a live video feed to show how a physical object interacts with a fluid. But, there was more for us to do.
|
||||
|
||||
We wanted to make the image processing more robust, so I worked on improving the image processing library.
|
||||
|
||||
With the new library, the simulation would be able to detect contours, perform coordinate transformations in place, and find the center of mass of an object. The image processing doesn't directly relate to the physics of the fluid flow dynamics simulation. It detects the object with a camera and creates a barrier for the fluid flow simulation by getting the outline of the object. Then, the fluid flow simulation runs, and the output is projected down onto the actual object.
|
||||
|
||||
My goal was to improve the simulation in three ways:
|
||||
|
||||
1. to find accurate contours of an object
|
||||
2. to find the center of mass of an object
|
||||
3. to be able to perform accurate transformations about the center of an object
|
||||
|
||||
My mentor recommended that I install [Node.js][4], [OpenCV][5], and the [Node.js bindings for OpenCV][6]. While I was waiting for those to install, I looked at the example code on the OpenCV bindings on their [GitHub page][7]. I discovered that the example code was in JavaScript, so because I didn’t know JavaScript, I started a short course from Codecademy. Two days later, I was sick of JavaScript but ready to start my project... which involved yet more JavaScript.
|
||||
|
||||
The example contour-finding code worked well. In fact, it allowed me to accomplish my first goal in a matter of hours! To get the contours of an image, here's what it looked like:
|
||||
|
||||
|
||||
>The original image with all of the contours.
|
||||
|
||||
The example contour-finding code worked a bit too well. Instead of the contour of the object being detected, all of the contours in the image were detected. This would have resulted in the simulation interacting with all of the unwanted contours. This is a problem because it would return incorrect data. To keep the simulation from interacting with the unwanted contours, I added an area constraint. If the contour was in a certain area range, then it would be drawn. The area constraint resulted in a much cleaner contour.
|
||||
|
||||
|
||||
>The filtered contour with the shadow contour.
|
||||
|
||||
Though the extraneous contours weren't detected, there was still a problem with the image. There was only one contour in the image, but it doubled back on itself and wasn't complete. Area couldn't be a deciding factor here, so it was time to try something else.
|
||||
|
||||
This time around, instead of immediately finding the contours, I first converted the image into a binary image. A binary image is an image where each pixel is either black or white. To get a binary image I first converted the color image to grayscale. Once the image was in grayscale, I called the threshold method on the image. The threshold method went through the image pixel by pixel and if the color value of the pixel was less than 30, the pixel color would be changed to black. Otherwise, the pixel value would be turned to white. After the original image was converted to a binary image, the resulting image looked like this:
|
||||
|
||||

|
||||
>The binary image.
|
||||
|
||||
Then I got the contours from the binary image, which resulted in a much cleaner contour, without the shadow contour.
|
||||
|
||||
|
||||
>The final clean contour.
|
||||
|
||||
At this point, I was able to get clean contours and detect the center of mass. Unfortunately, I didn't have enough time to be able to complete transformations about the center of mass. Since I only had a few days left in my internship, I started to think about other things I could do within a limited time span. One of those things was the bounding rectangle. The bounding rectangle is a quadrilateral with the smallest area that contains the entire contour of an image. The bounding rectangle is important because it is key in scaling the contour on the page. Unfortunately I didn't have time to do much with the bounding rectangle, but I still wanted to learn about it because it's a useful tool.
|
||||
|
||||
Finally, after all of that, I was able to finish processing the image!
|
||||
|
||||
|
||||
>The final image with bounding rectangle and center of mass in red.
|
||||
|
||||
Once the image processing code was complete, I replaced the old image processing code in the simulation with my code. To my surprise, it worked!
|
||||
|
||||
Well, mostly.
|
||||
|
||||
The program had a memory leak in it, which leaked 100MB every 1/10 of a second. I was glad that it wasn’t because of my code. The bad thing was that fixing it was out of my control. The good thing was that there was a workaround that I could use. It was less than ideal, but it checked the amount of memory the simulation was using and when it used more than 1 GiB, the simulation restarted.
|
||||
|
||||
At the NASA lab, we use a lot of open source software, and my work there isn't possible without it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/image-processing-nasa
|
||||
|
||||
作者:[Lauren Egts][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laurenegts
|
||||
[1]: https://ocio.grc.nasa.gov/gvis/
|
||||
[2]: http://www.nasa.gov/centers/glenn/home/index.html
|
||||
[3]: http://physics.weber.edu/schroeder/fluids/
|
||||
[4]: http://nodejs.org/
|
||||
[5]: http://opencv.org/
|
||||
[6]: https://github.com/peterbraden/node-opencv
|
||||
[7]: https://github.com/peterbraden/node-opencv
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy Translating
|
||||
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||
@ -1,65 +0,0 @@
|
||||
EXT4,Btrfs和XFS 文件系统之点评
|
||||
================================================================================
|
||||

|
||||
|
||||
老实说,人们最不曾考虑的问题之一是他们的个人电脑中使用了什么文件系统。Windows 和 Mac OS X 用户更没有理由去考虑,因为对于他们的操作系统,只有一种选择,那就是 NTFS 和 HFS+。相反,对于 Linux 系统而言,有很多种文件系统可以选择,现在默认的是广泛采用的 ext4。然而,现在也有改用一种称为 btrfs 文件系统的趋势。那是什么使得 btrfs更优秀,其它的文件系统又是什么,什么时候我们又能看到 Linux 发行版作出改变呢?
|
||||
|
||||
首先让我们对文件系统以及它们真正干什么有个总体的认识,然后我们再对一些有名的文件系统做详细的比较。
|
||||
|
||||
### 文件系统是干什么的? ###
|
||||
|
||||
如果你不清楚文件系统是干什么的,一句话总结起来也非常简单。文件系统主要用于控制所有程序不再使用数据时如何存储数据、如何访问数据以及有什么其它信息(元数据)和数据本身相关,等等。听起来要编程实现并不是轻而易举的事情,实际上也确实如此。文件系统一直在改进,包括更多的功能、更高效地完成它需要做的事情。总而言之,它是所有计算机的基本需求、但并不像听起来那么简单。
|
||||
|
||||
### 为什么要分区? ###
|
||||
|
||||
由于每个操作系统都能创建或者删除分区,很多人对分区都有模糊的认识。Linux 操作系统在同一块磁盘上即便使用标准安装过程,仍可以使用多个分区,这看起来很奇怪,因此需要一些解释。拥有不同分区的一个主要目的就是为了在灾难发生时能获得更好的数据安全性。
|
||||
|
||||
通过将硬盘划分为分区,数据会被分隔以及重组。当事故发生的时候,只有存储在被损坏分区的数据会被破坏,很大可能上其它分区的数据能得以保留。这个原因可以追溯到 Linux 操作系统还没有日志文件系统,任何电力故障都有可能导致灾难发生的时候。
|
||||
|
||||
使用分区也考虑到了安全和健壮性原因,因此操作系统部分损坏并不意味着整个计算机就有风险或者会受到破坏。这也是当前采用分区的一个最重要因素。举个例子,用户创建了一些会填满磁盘的脚本、程序或者 web 应用,如果该磁盘只有一个大的分区,如果磁盘满了那么整个系统就不能工作。如果用户把数据保存在不同的分区,那么就只有那个分区会受到影响,而系统分区或者其它数据分区仍能正常运行。
|
||||
|
||||
记住,拥有一个日志文件系统只能在掉电或者和存储设备意外断开连接时提供数据安全性,并不能在文件系统出现坏块或者发生逻辑错误时保护数据。对于这种情况,用户可以采用廉价磁盘冗余阵列(RAID:Redundant Array of Inexpensive Disks)的方案。
|
||||
|
||||
### 为什么要改变文件系统? ###
|
||||
|
||||
ext4 文件系统由 ext3 文件系统改进而来,而后者又是从 ext2 文件系统改进而来。虽然 ext4 文件系统已经非常稳定,是过去几年中绝大部分发行版的默认选择,但它是基于陈旧的代码开发而来。另外, Linux 操作系统用户也需要很多 ext4 文件系统本身不提供的新功能。虽然通过某些软件能满足这种需求,但性能会受到影响,在文件系统层次做到这些能获得更好的性能。
|
||||
|
||||
### Ext4 文件系统 ###
|
||||
|
||||
ext4 还有一些明显的限值。最大文件大小是 16tebibytes(大概是 17.6 terabytes),这比普通用户当前能买到的硬盘还要大的多。使用 ext4 能创建的最大卷/分区是 1 exbibyte(大概是 1,152,921.5 terabytes)。通过使用多种技巧, ext4 比 ext3 有很大的速度提升。类似一些最先进的文件系统,它是一个日志文件系统,意味着它会对文件在磁盘中的位置以及任何其它对磁盘的更改做记录。纵观它的所有功能,它还不支持透明压缩、重复数据删除或者透明加密。技术上支持了快照,但该功能还处于实验性阶段。
|
||||
|
||||
### Btrfs 文件系统 ###
|
||||
|
||||
btrfs 有很多不同的发音,例如 Better FS、Butter FS 或者 B-Tree FS。它是一个几乎完全从头开发的文件系统。btrfs 存在的原因是它的开发者期初希望扩展文件系统的功能使得它包括快照、池化、校验以及其它一些功能。虽然和 ext4 无关,它也希望能保留 ext4 中能使消费者和商家受益的功能,并整合额外的能使每个人,尤其是企业受益的功能。对于使用大型软件以及大规模数据库的企业,对于多种不同的硬盘看起来一致的文件系统能使他们受益并且使数据整合变得更加简单。删除重复数据能降低数据实际使用的空间,当需要镜像一个单一和广泛文件系统时使用 btrfs 也能使数据镜像变得简单。
|
||||
|
||||
用户当然可以继续选择创建多个分区从而无需镜像任何东西。考虑到这种情况,btrfs 能横跨多种硬盘,和 ext4 相比,它能支持 16 倍以上的驱动空间。btrfs 文件系统一个分区最大是 16 exbibytes,最大的文件大小也是 16 exbibytes。
|
||||
|
||||
### XFS 文件系统 ###
|
||||
|
||||
XFS 文件系统是扩展文件系统(extent file system)的扩展。XFS 是 64 位高性能日志文件系统。对 XFS 的支持大概在 2002 年合并到了 Linux 内核,到了 2009 年,红帽企业版 Linux 5.4 也支持了 XFS 文件系统。对于 64 位文件系统,XFS 支持最大文件系统大小为 8 exbibytes。XFS 文件系统有一些缺陷,例如它不能压缩,删除大量文件时性能低下。目前RHEL 7.0 文件系统默认使用 XFS。
|
||||
|
||||
### 总后总结 ###
|
||||
|
||||
不幸的是,还不知道 btrfs 什么时候能到来。官方说,下一代文件系统仍然被归类为“不稳定”,但是如果用户下载最新版本的 Ubuntu,就可以选择安装到 btrfs 分区上。什么时候 btrfs 会被归类到 “稳定” 仍然是个谜, 直到真的认为它“稳定”之前,用户也不应该期望 Ubuntu 会默认采用 btrfs。有报道说 Fedora 18 会用 btrfs 作为它的默认文件系统,因为到了发布它的时候,应该有了 btrfs 文件系统校验器。由于还没有实现所有的功能,另外和 ext4 相比性能上也比较缓慢,btrfs 还有很多的工作要做。
|
||||
|
||||
那么,究竟使用哪个更好呢?尽管性能几乎相同,但 ext4 还是赢家。为什么呢?答案在于易用性以及广泛性。对于桌面或者工作站, ext4 仍然是一个很好的文件系统。由于默认提供,用户可以在上面安装操作系统。同时, ext4 支持最大 1 exabytes 的卷和 16 terabytes 的文件,因此考虑到大小,它也还有很大的进步空间。
|
||||
|
||||
btrfs 能提供更大的高达 16 exabytes 的卷以及更好的容错,但是,到现在为止,它感觉更像是一个附加文件系统,而没有集成到 Linux 操作系统。比如,尽管 btrfs 支持不同的发行版,使用 btrfs 格式化硬盘之前先要有 btrfs-tools 工具,这意味着安装 Linux 操作系统的时候它并不是一个可选项,即便不同发行版之间会有差异。
|
||||
|
||||
尽管传输速率非常重要,评价一个文件系统出了文件传输速度之外还有很多因素。btrfs 有很多好用的功能,例如写复制、扩展校验、快照、清洗、自修复数据、冗余删除以及其它保证数据完整性的功能。和 ZFS 相比 btrfs 缺少 RAID-Z 功能,因此对于 btrfs, RAID 还处于实验性阶段。对于单纯的数据存储,和 ext4 相比 btrfs 似乎更加优秀,但时间会验证一切。
|
||||
|
||||
迄今为止,对于桌面系统而言,ext4 似乎是一个更好的选择,因为它是默认的文件系统,传输文件时也比 btrfs 更快。btrfs 当然值得尝试、但要在桌面 Linux 上完全取代 ext4 可能还需要一些时间。数据场和大存储池会揭示关于 ext4、XCF 以及 btrfs 不同的故事和差异。
|
||||
|
||||
如果你有不同或者其它的观点,在下面的评论框中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/review-ext4-vs-btrfs-vs-xfs/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
@ -0,0 +1,200 @@
|
||||
Linux上的游戏:所有你需要知道的
|
||||
================================================================================
|
||||

|
||||
|
||||
** 我能在 Linux 上玩游戏吗 ?**
|
||||
|
||||
这是打算[投奔 Linux 阵营][1]的人最经常问的问题之一。毕竟,在 Linux 上面玩游戏经常被认为有点难以实现。事实上,一些人甚至考虑他们能不能在 Linux 上看电影或者听音乐。考虑到这些,关于 Linux 的平台的游戏的问题是很现实的。「
|
||||
|
||||
在本文中,我将解答大多数 Linux 新手关于在 Linux 打游戏的问题。例如 Linux 下能不能玩游戏,如果能的话,在**哪里下载游戏**或者如何获取有关游戏的信息。
|
||||
|
||||
但是在此之前,我需要说明一下。我不是一个 PC 上的玩家或者说我不认为我是一个在 Linux 桌面上完游玩戏的家伙。我更喜欢在 PS4 上玩游戏并且我不关心 PC 上的游戏甚至也不关心手机上的游戏(我没有给我的任何一个朋友安利糖果传奇)。这也就是你很少在 It's FOSS 上很少看见关于 [Linux 上的游戏][2]的部分。
|
||||
|
||||
所以我为什么要写这个主题?
|
||||
|
||||
因为别人问过我几次有关 Linux 上的游戏的问题并且我想要写出来一个能解答这些问题的 Linux 上的游戏指南。注意,在这里我不只是讨论 Ubuntu 上的游戏。我讨论的是在所有的 Linux 上的游戏。
|
||||
|
||||
### 我能在 Linux 上玩游戏吗 ? ###
|
||||
|
||||
是,但不是完全是。
|
||||
|
||||
“是”,是指你能在Linux上玩游戏;“不完全是”,是指你不能在 Linux 上玩 ’所有的游戏‘。
|
||||
|
||||
什么?你是拒绝的?不必这样。我的意思是你能在 Linux 上玩很多流行的游戏,比如[反恐精英以及地铁:最后的曙光][3]等。但是你可能不能玩到所有在 Windows 上流行的最新游戏,比如[实况足球2015][4]。
|
||||
|
||||
在我看来,造成这种情况的原因是 Linux 在桌面系统中仅占不到 2%,这占比使得大多数开发者没有在 Linux 上发布他们的游戏的打算。
|
||||
|
||||
这就意味指大多数近年来被提及的比较多的游戏很有可能不能在 Linux 上玩。不要灰心。我们能以某种方式在 Linux 上玩这些游戏,我们将在下面的章节中讨论这些方法。但是,在此之前,让我们看看在 Linux 上能玩的游戏的种类。
|
||||
|
||||
要我说的话,我会把那些游戏分为四类:
|
||||
|
||||
1. Linux 原生游戏
|
||||
2. Linux 上的 Windows 游戏
|
||||
3. 浏览器里的游戏
|
||||
4. 终端里的游戏
|
||||
|
||||
让我们以最重要的 Linux 的原生游戏开始。
|
||||
|
||||
---------
|
||||
|
||||
### 1. 在哪里去找 Llinux 原生游戏 ?###
|
||||
|
||||
原生游戏指的是官方支持 Linux 的游戏。这些游戏有原生的 Linux 客户端并且能像在 Linux 上的其他软件一样不需要附加的步骤就能安装在 Linux 上面(我们将在下一节讨论)。
|
||||
|
||||
所以,如你所见,这里有一些为 Linux 开发的游戏,下一个问题就是在哪能找到这些游戏以及如何安装。我将列出来一些让你玩到游戏的渠道了。
|
||||
|
||||
#### Steam ####
|
||||
|
||||

|
||||
|
||||
“[Steam][5] 是一个游戏的分发平台。就如同 Kindle 是电子书的分发平台,iTunes 是音乐的分发平台一样,Steam 也具有那样的功能。它给了你购买和安装游戏,玩多人游戏以及在它的平台上关注其他游戏的选项。这些游戏被[ DRM ][6]所保护。”
|
||||
|
||||
两年以前,游戏平台 Steam 宣布支持 Linux,这在当时是一个大新闻。这是 Linux 上玩游戏被严肃的对待的一个迹象。尽管这个决定更多地影响了他们自己的基于 Linux 游戏平台[ Steam OS][7]。这仍然是令人欣慰的事情,因为它给 Linux 带来了一大堆游戏。
|
||||
|
||||
我已经写了一篇详细的关于安装以及使用 Steam 的文章。如果你想开始使用 Steam 的话,读读那篇文章。
|
||||
|
||||
- [在 Linux 上安装以及使用 Steam ][8]
|
||||
|
||||
#### GOG.com ####
|
||||
|
||||
[GOG.com][9] 失灵一个与 Steam 类似的平台。与 Steam 一样,你能在这上面找到数以百计的 Linux 游戏,你可以购买和安装它们。如果游戏支持好几个平台,尼卡一在多个操作系统上安装他们。你买到你账户的游戏你可以随时玩。捏可以在你想要下载的任何时间下载。
|
||||
|
||||
GOG.com 与 Steam 不同的是前者仅提供没有 DRM 保护的游戏以及电影。而且,GOG.com 完全是基于网页的,所以你不需要安装类似 Steam 的客户端。你只需要用浏览器下载游戏然后安装到你的系统上。
|
||||
|
||||
#### Portable Linux Games ####
|
||||
|
||||
[Portable Linux Games][10] 是一个集聚了不少 Linux 游戏的网站。这家网站最特别以及最好的就是你能离线安装这些游戏。
|
||||
|
||||
你下载到的文件包含所有的依赖(仅需 Wine 以及 Perl)并且他们也是与平台无关的。你所需要的仅仅是下载文件并且双击来启动安装程序。你也可以把文件储存起来以用于将来的安装,如果你网速不够快的话我很推荐您这样做。
|
||||
|
||||
#### Game Drift 游戏商店 ####
|
||||
|
||||
[Game Drift][11] 是一个只专注于游戏的基于 Ubuntu 的 Linux 发行版。但是如果你不想只为游戏就去安装这个发行版的话,你也可以经常上线看哪个游戏可以在 Linux 上运行并且安装他们。
|
||||
|
||||
#### Linux Game Database ####
|
||||
|
||||
如其名字所示,[Linux Game Database][12]是一个收集了很多 Linux 游戏的网站。你能在这里浏览诸多类型的游戏并从游戏开发者的网站下载/安装这些游戏。作为这家网站的会员,你甚至可以为游戏打分。LGDB,有点像 Linux 游戏界的 IMDB 或者 IGN.
|
||||
|
||||
#### Penguspy ####
|
||||
|
||||
此网站由一个不想用 Windows 玩游戏的玩家创立。[Penguspy][13] 聚集了一些 Linux 下最好的游戏。在这里你也能分类浏览游戏,如果你喜欢这个游戏的话,你可以跳转到游戏开发者的网站去下载安装。
|
||||
|
||||
#### 软件源 ####
|
||||
|
||||
看看你自己的发行版的软件源。那里可能有一些游戏。如果你用 Ubuntu 的话,它的软件中心里有一个游戏的分类。在一些其他的发行版里也有,比如 Liux Mint 等。
|
||||
|
||||
----------
|
||||
|
||||
### 2. 如何在 Linux 上玩 Windows 的游戏 ?###
|
||||
|
||||

|
||||
|
||||
到现在为止,我们一直在讨论 Linux 的原生游戏。但是并没有很多 Linux 上的原生游戏,或者说,火的不要不要的游戏大多不支持 Linux,但是都支持 Windows PC。所以,如何在 Linux 上玩 Wendows 的游戏?
|
||||
|
||||
幸好,由于我们有 Wine, PlayOnLinux 和 CrossOver 等工具,我们能在 Linux 上玩不少的 Wendows 游戏。
|
||||
|
||||
#### Wine ####
|
||||
|
||||
Wine 是一个能使 Wendows 应用在类似 Linux, BSD 和 OS X 上运行的兼容层。在 Wine 的帮助下,你可以在 Linux 下安装以及使用很多 Windows 下的应用。
|
||||
|
||||
[在 Ubuntu 上安装 Wine][14]或者在其他 Linux 上安装 Wine 是很简单的,因为大多数发行版的软件源里都有它。这里也有一个很大的[ Wine 支持的应用的数据库][15]供您浏览。
|
||||
|
||||
#### CrossOver ####
|
||||
|
||||
[CrossOver][16] 是 Wine 的增强版,它给 Wine 提供了专业的技术上的支持。但是与 Wine 不同, CrossOver 不是免费的。你需要购买许可。好消息是它会把更新也贡献到 Wine 的开发者那里并且事实上加速了 Wine 的开发使得 Wine 能支持更多的 Windows 上的游戏和应用。如果你可以一年支付 48 美元,你可以购买 CrossOver 并得到他们提供的技术支持。
|
||||
|
||||
### PlayOnLinux ###
|
||||
|
||||
PlayOnLinux 也基于 Wine 但是执行程序的方式略有不同。它有着更好用的,不同的界面。与 Wine 一样,PlayOnLinux 也是免费使用。你可以在[开发者自己的数据库里查看它支持的应用以及游戏][17]。
|
||||
|
||||
----------
|
||||
|
||||
### 3. 网页游戏 ###
|
||||
|
||||

|
||||
|
||||
不必说你也应该知道有非常多的基于网页的游戏,这些游戏都可以在任何操作系统里运行,无论是 Windows,Linux,还是 OS X。大多数让人上瘾的手机游戏,比如[帝国之战][18]就有官方的网页版。
|
||||
|
||||
除了这些,还有 [Google Chrome在线商店][19],你可以在 Linux 上玩更多的这些游戏。这些 Chrome 上的游戏可以像一个单独的应用一样安装并从应用菜单中打开,一些游戏就算是离线也能运行。
|
||||
|
||||
----------
|
||||
|
||||
### 4. 终端游戏 ###
|
||||
|
||||

|
||||
|
||||
使用 Linux 的一个附加优势就是可以使用命令行终端玩游戏。我知道这不是最好的玩游戏的 方法,但是在终端里玩[贪吃蛇][20]或者 [2048][21] 很有趣。在[这个博客][21]中有一些好玩的的终端游戏。你可以浏览并安装你喜欢的游戏。
|
||||
|
||||
----------
|
||||
|
||||
### 如何保证游戏的版本是最新的 ?###
|
||||
|
||||
当你了解了不少的在 Linux 上你可以玩到的游戏以及你如何使用他们,下一个问题就是如何保持游戏的版本是最新的。对于这件事,我建议你看看下面的博客,这些博客能告诉你 Linux 游戏世界的最新消息:
|
||||
|
||||
- [Gaming on Linux][23]:我认为我把它叫做 Linux 游戏的门户并没有错误。在这你可以得到关于 Linux 的游戏的最新的传言以及新闻。最近, Gaming on Linux 有了一个由 Linux 游戏爱好者组成的漂亮的社区。
|
||||
- [Free Gamer][24]:一个专注于免费开源的游戏的博客。
|
||||
- [Linux Game News][25]:一个提供很多的 Linux 游戏的升级的 Tumbler 博客。
|
||||
|
||||
#### 还有别的要说的吗? ####
|
||||
|
||||
我认为让你知道如何开始在 Linux 上的游戏人生是一个好事。如果你仍然不能被说服。我推荐你做个[双系统][26],把 Linux 作为你的主要桌面系统,当你想玩游戏时,重启到 Windows。这是一个对游戏妥协的解决办法。
|
||||
|
||||
现在,这里是你说出你自己的状况的时候了。你在 Linux 上玩游戏吗?你最喜欢什么游戏?你关注了哪些游戏博客?
|
||||
|
||||
|
||||
投票项目:
|
||||
你怎样在 Linux 上玩游戏?
|
||||
|
||||
- 我玩原生 Linux 游戏,我也用 Wine 以及 PlayOnLinux 运行 Windows 游戏
|
||||
- 我喜欢网页游戏
|
||||
- 我喜欢终端游戏
|
||||
- 我只玩原生 Linux 游戏
|
||||
- 我用 Steam
|
||||
- 我用双系统,要玩游戏时就换到 Windows
|
||||
- 我不玩游戏
|
||||
|
||||
注:投票代码
|
||||
<div class="PDS_Poll" id="PDI_container9132962" style="display:inline-block;"></div>
|
||||
<div id="PD_superContainer"></div>
|
||||
<script type="text/javascript" charset="UTF-8" src="http://static.polldaddy.com/p/9132962.js"></script>
|
||||
<noscript><a href="http://polldaddy.com/poll/9132962">Take Our Poll</a></noscript>
|
||||
|
||||
注,发布时根据情况看怎么处理
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/linux-gaming-guide/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[2]:http://itsfoss.com/category/games/
|
||||
[3]:http://blog.counter-strike.net/
|
||||
[4]:https://pes.konami.com/tag/pes-2015/
|
||||
[5]:http://store.steampowered.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Digital_rights_management
|
||||
[7]:http://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
[8]:http://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[9]:http://www.gog.com/
|
||||
[10]:http://www.portablelinuxgames.org/
|
||||
[11]:http://gamedrift.org/GameStore.html
|
||||
[12]:http://www.lgdb.org/
|
||||
[13]:http://www.penguspy.com/
|
||||
[14]:http://itsfoss.com/wine-1-5-11-released-ppa-available-to-download/
|
||||
[15]:https://appdb.winehq.org/
|
||||
[16]:https://www.codeweavers.com/products/
|
||||
[17]:https://www.playonlinux.com/en/supported_apps.html
|
||||
[18]:http://empire.goodgamestudios.com/
|
||||
[19]:https://chrome.google.com/webstore/category/apps
|
||||
[20]:http://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[21]:http://itsfoss.com/play-2048-linux-terminal/
|
||||
[22]:https://ttygames.wordpress.com/
|
||||
[23]:https://www.gamingonlinux.com/
|
||||
[24]:http://freegamer.blogspot.fr/
|
||||
[25]:http://linuxgamenews.com/
|
||||
[26]:http://itsfoss.com/install-ubuntu-1404-dual-boot-mode-windows-8-81-uefi/
|
||||
@ -0,0 +1,84 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||
### Android 4.2,果冻豆——全新 Nexus 设备,全新平板界面 ###
|
||||
|
||||
安卓平台成熟的脚步越来越快,谷歌也将越来越多的应用托管到 Play 商店,需要通过系统更新来更新的应用越来越少。但是不间断的更新还是要继续的,2012 年 11 月,安卓 4.2 发布。4.2 还是叫做“果冻豆”,这个版本主要是一些少量变动。
|
||||
|
||||

|
||||
LG 生产的 Nexus 4 和三星生产的 Nexus 10。
|
||||
Google/Ron Amadeo 供图
|
||||
|
||||
和安卓 4.2 一同发布的还有两部旗舰设备,Nexus 4 和 Nexus 10,都由谷歌直接在 Play 商店出售。Nexus 4 使用了 Nexus 7 的策略,令人惊讶的低价和高质量,并且无锁设备售价 300 美元。Nexus 4 有一个 4 核 1.5GHz 骁龙 S4 Pro 处理器,2GB 内存以及 1280×768 分辨率 4.7 英寸 LCD 显示屏。谷歌的新旗舰手机由 LG 生产,并和制造商一起将关注点转向了材料和质量。Nexus 4 有着正反两面双面玻璃,这会让你爱不释手,他是有史以来触感最佳的安卓手机之一。Nexus 4 最大的缺点是没有 LTE 支持,那时候大部分手机,包括 Version Galaxy Nexus 都有更快的基带。但 Nexus 4 的需求仍大大超出了谷歌的预料——发布当日大量的流量拖垮了 Play 商店网站。手机在一小时之内销售一空。
|
||||
|
||||
Nexus 10 是谷歌的第一部 10 英寸 Nexus 平板。该设备的亮点是 2560×1600 分辨率的显示屏,在其等级上是分辨率最高的。这背后是双核 1.7GHz Cortex A15 处理器和 2GB 内存的强力支持。随着时间一个月一个月地流逝,Nexus 10 似乎逐渐成为了第一部也是最后一部 10 英寸 Nexus 平板。通常这些设备每年都升级,但 Nexus 10 至今面世 16 个月了,可预见的未来还没有新设备的迹象。谷歌在小尺寸的 7 英寸平板上做得很出色,它似乎更倾向于让[像三星][1]这样的合作伙伴探索更大的平板家族。
|
||||
|
||||

|
||||
新的锁屏,壁纸,以及时钟小部件设计。
|
||||
Ron Amadeo 供图
|
||||
|
||||
4.2 为锁屏带来了很多变化。文字居中,并且对小时使用了较大的字重,对分钟使用了较细的字体。锁屏现在是分页的,可以自定义小部件。锁屏不仅仅是一个简单的时钟,用户还可以将其替换成其它小部件或者添加额外的页面和更多的小部件。
|
||||
|
||||

|
||||
锁屏的添加小部件页面,小部件列表,锁屏上的 Gmail 部件,以及滑动到相机。
|
||||
Ron Amadeo 供图
|
||||
|
||||
锁屏现在就像是一个精简版的主屏幕。页面轮廓会显示在锁屏的左右两侧来提示用户可以滑动到有其他小部件的页面。向左滑动页面会显示一个中间带有加号的简单空白页面,点击加号会打开兼容锁屏的小部件列表。锁屏每个页面限制一个小部件,将小部件向上或向下拖动可以展开或收起。最右侧的页面保留给了相机——一个简单的滑动就能打开相机界面,但是你没办法滑动回来。
|
||||
|
||||

|
||||
新的快速设置面板以及内置应用集合。
|
||||
Ron Amadeo 供图
|
||||
|
||||
4.2 最大的新增特性之一就是“快速设置”面板。安卓 3.0 为平板引入了快速改变电源设置的途径,4.2 终于将这种能力带给了手机。通知中心右上角加入了一枚新图标,可以在正常的通知列表和新的快速设置之间切换。快速设置提供了对屏幕亮度,网络连接,电池以及数据用量更加快捷的访问,而不用打开完整的设置界面。安卓 4.1 中顶部的设置按钮移除掉了,快速设置中添加了一个按钮来替代它。
|
||||
|
||||
应用抽屉和 4.2 中的应用阵容有很多改变。得益于 Nexus 4 更宽的屏幕横纵比(5:3,Galaxy Nexus 是 16:9),应用抽屉可以显示一行五个应用图标的方阵。4.2 将自带的浏览器替换为了 Google Chrome,自带的日历换成了 Google Calendar,他们都带来了新的图标设计。时钟和相机应用在 4.2 中经过了重制,新的图标也是其中的一部分。“Google Settings”是个新应用,用于提供对系统范围内所有存在的谷歌账户设置的快捷方式,它有着和 Google Search 和 Google+ 图标一致的风格。谷歌地图拥有了新图标,谷歌纵横,以往是谷歌地图的一部分,作为对 Google+ location 的支持在这个版本退役。
|
||||
|
||||

|
||||
浏览器替换为 Chrome,带有全屏取景器的新相机界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
原自带浏览器在一段时间内对 Chrome 的模仿上下了不少功夫——它引入了许多 Chrome 的界面元素,许多 Chrome 的特性,甚至还使用了 Chrome 的 javascript 引擎——但安卓 4.2 来临的时候,谷歌认为安卓版的 Chrome 已经准备好替代这个模仿者了。表面上看起来没有多大不同;界面看起来不一样,而且早期版本的 Chrome 安卓版滚动起来没有原浏览器顺畅。不过深层次来说,一切都不一样。安卓的主浏览器开发现在由 Google Chrome 团队负责,而不是作为安卓团队的子项目存在。安卓的默认浏览器从绑定安卓版本发布停滞不前的应用变成了不断更新的 Play 商店应用。现在甚至还有一个每个月接收一些更新的 beta 通道。
|
||||
|
||||
相机界面经过了重新设计。它现在完全是个全屏应用,显示摄像头的实时图像并且在上面显示控制选项。布局审美和安卓 1.5 的[相机设计][2]有很多共同之处:带对焦的最小化的控制放置在取景器显示之上。中间的控制环在你长按屏幕或点击右下角圆形按钮的时候显示。你的手指保持在屏幕上时,你可以滑动来选择环上的选项,通常是展开进入一个子菜单。在高亮的选项上释放手指选中它。这灵感很明显来自于安卓 4.0 浏览器中的快速控制,但是将选项安排在一个环上意味着你的手指几乎总会挡住一部分界面。
|
||||
|
||||

|
||||
时钟应用,从一个只有两个界面的应用变成功能强大,实用的应用。
|
||||
Ron Amadeo 供图
|
||||
|
||||
时钟应用经过了完整的改造,从一个简单的两个界面的闹钟,到一个世界时钟,闹钟,定时器,以及秒表俱全。时钟应用的设计和谷歌之前引入的完全不同,有着极简审美和红色高亮。它看起来像是谷歌的一个试验。甚至是几个版本之后,这个设计语言似乎也仅限于这个应用。
|
||||
|
||||
时钟的时间选择器是经过特别精心设计的。它显示一个简单的数字盘,会智能地禁用会导致无效时间的数字。设置闹钟时间也不可能没有隐式选择选择的 AM 和 PM,永远地解决了不小心将 9am 的闹钟设置成 9pm 的问题。
|
||||
|
||||

|
||||
平板的新系统界面使用了延展版的手机界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
安卓 4.2 中最有争议的改变是平板界面,从单独一个统一的底部系统栏变成带有顶部状态栏和底部系统栏的双栏设计。新设计统一了手机和平板的界面,但批评人士说将手机界面延展到 10 英寸的横向平板上是浪费空间。因为导航按键现在拥有了整个底栏,所以他们像手机界面那样被居中。
|
||||
|
||||

|
||||
平板上的多用户,以及新的手势键盘。
|
||||
Ron Amadeo 供图
|
||||
|
||||
在平板上,安卓 4.2 带来了多用户支持。在设置里,新增了“用户”部分,你可以在这里管理一台设备上的用户。设置在每个用户账户内完成,安卓会给每个用户保存单独的设置,主屏幕,应用以及应用数据。
|
||||
|
||||
4.2 还添加了有滑动输入能力的键盘。用户可以将手指一直保持在屏幕上,按顺序在字母按键上滑动来输入,而不用像以前那样一个一个字母单独地输入。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/22/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2014/01/hands-on-with-samsungs-notepro-and-tabpro-new-screen-sizes-and-magazine-ui/
|
||||
[2]:http://cdn.arstechnica.net/wp-content/uploads/2013/12/device-2013-12-26-11016071.png
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -0,0 +1,98 @@
|
||||
5 个适合课堂教学的树莓派项目
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
### 1. Minecraft Pi ###
|
||||
|
||||
|
||||
|
||||
上图由树莓派基金会提供。遵循 [CC BY-SA 4.0.][1] 协议。
|
||||
|
||||
Minecraft(我的世界)几乎是世界上每个青少年都极其喜爱的游戏 —— 在吸引年轻人注意力方面,它也是最具创意的游戏之一。伴随着每一个树莓派的游戏版本不仅仅是一个关于创造性思维的建筑游戏,它还带有一个编程接口,允许使用者通过 Python 代码来与 Minecraft 世界进行互动。
|
||||
|
||||
对于教师来说,Minecraft: Pi 版本是一个鼓励学生们解决遇到的问题以及通过书写代码来执行特定任务的极好方式。你可以使用 Python API
|
||||
来建造一所房子,让它跟随你到任何地方;或在你所到之处修建一座桥梁;又或者是下一场岩溶雨;或在天空中显示温度;以及其他任何你能想像到的事物。
|
||||
|
||||
可在 "[Minecraft Pi 入门][2]" 中了解更多相关内容。
|
||||
|
||||
### 2. 反应游戏和交通指示灯 ###
|
||||
|
||||

|
||||
|
||||
上图由 [Low Voltage Labs][3] 提供。遵循 [CC BY-SA 4.0][1] 协议。
|
||||
|
||||
在树莓派上进行物理计算是非常容易的 —— 只需将 LED 灯 和按钮连接到 GPIO 针脚上,再加上少量的代码,你就可以点亮 LED 灯并通过按按钮来控制物体。一旦你知道来执行基本操作的代码,下一步就可以随你的想像那样去做了!
|
||||
|
||||
假如你知道如何让一盏灯闪烁,你就可以让三盏灯闪烁。选出三盏交通灯颜色的 LED 灯,你就可以编程出交通灯闪烁序列。假如你知道如何使用一个按钮来触发一个事件,然后你就有一个人行横道了!同时,你还可以找到诸如 [PI-TRAFFIC][4]、[PI-STOP][5]、[Traffic HAT][6] 等预先构建好的交通灯插件。
|
||||
|
||||
这不总是关于代码的 —— 它还可以被用来作为一个的练习,用以理解真实世界中的系统是如何被设计出来的。计算思维在生活中的各种情景中都是一个有用的技能。
|
||||
|
||||

|
||||
|
||||
上图由树莓派基金会提供。遵循 [CC BY-SA 4.0][1] 协议。
|
||||
|
||||
下面尝试将两个按钮和一个 LED 灯连接起来,来制作一个二人制反应游戏 —— 让灯在一段随机的时间中点亮,然后看谁能够先按到按钮!
|
||||
|
||||
想了解更多的话,请查看 [GPIO 新手指南][7]。你所需要的尽在 [CamJam EduKit 1][8]。
|
||||
|
||||
### 3. Sense HAT 像素宠物 ###
|
||||
|
||||
Astro Pi— 一个增强版的树莓派 —将于今年 12 月(注:应该是去年的事了。)问世,但你并没有错过让你的手玩弄硬件的机会。Sense HAT 是一个用在 Astro Pi 任务中的感应器主板插件,且任何人都可以买到。你可以用它来做数据收集、科学实验、游戏或者更多。 观看下面这个由树莓派的 Carrie Anne 带来的 Gurl Geek Diaries 录像来开始一段美妙的旅程吧 —— 通过在 Sense HAT 的显示器上展现出你自己设计的一个动物像素宠物:
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="520" height="315" frameborder="0" src="https://www.youtube.com/embed/gfRDFvEVz-w" allowfullscreen=""></iframe>
|
||||
|
||||
在 "[探索 Sense HAT][9]" 中可以学到更多。
|
||||
|
||||
### 4. 红外鸟箱 ###
|
||||
|
||||

|
||||
上图由 [Low Voltage Labs][3] 提供。遵循 [CC BY-SA 4.0][1] 协议。
|
||||
|
||||
让全班所有同学都能够参与进来的一个好的练习是 —— 在一个鸟箱中沿着某些红外线放置一个树莓派和 NoIR 照相模块,这样你就可以在黑暗中观看,然后通过网络或在网络中你可以从树莓派那里获取到视频流。等鸟进入笼子,然后你就可以在不打扰到它们的情况下观察它们。
|
||||
|
||||
在这期间,你可以学习到所有关于红外和光谱的知识,以及如何用软件来调整摄像头的焦距和控制它。
|
||||
|
||||
在 "[制作一个红外鸟箱][10]" 中你可以学到更多。
|
||||
|
||||
### 5. 机器人 ###
|
||||
|
||||

|
||||
|
||||
上图由 Low Voltage Labs 提供。遵循 [CC BY-SA 4.0][1] 协议。
|
||||
|
||||
拥有一个树莓派,一些感应器和一个感应器控制电路板,你就可以构建你自己的机器人。你可以制作各种类型的机器人,从用透明胶带和自制底盘组合在一起的简易四驱车,一直到由游戏控制器驱动的具有自我意识,带有传感器和摄像头的金属马儿。
|
||||
|
||||
学习如何直接去控制单个的发动机,例如通过 RTK Motor Controller Board (£8/$12),或者尝试新的 CamJam robotics kit (£17/$25) ,它带有发动机、轮胎和一系列的感应器 — 这些都很有价值并很有学习的潜力。
|
||||
|
||||
另外,如何你喜欢更为骨灰级别的东西,可以尝试 PiBorg 的 [4Borg][11] (£99/$150) 或 [DiddyBorg][12] (£180/$273) 或者一干到底,享受他们的 DoodleBorg 金属版 (£250/$380) — 并构建一个他们声名远扬的 [DoodleBorg tank][13](很不幸的时,这个没有卖的) 的迷你版。
|
||||
|
||||
另外请参考 [CamJam robotics kit worksheets][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/education/15/12/5-great-raspberry-pi-projects-classroom
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://opensource.com/life/15/5/getting-started-minecraft-pi
|
||||
[3]:http://lowvoltagelabs.com/
|
||||
[4]:http://lowvoltagelabs.com/products/pi-traffic/
|
||||
[5]:http://4tronix.co.uk/store/index.php?rt=product/product&product_id=390
|
||||
[6]:https://ryanteck.uk/hats/1-traffichat-0635648607122.html
|
||||
[7]:http://pythonhosted.org/gpiozero/recipes/
|
||||
[8]:http://camjam.me/?page_id=236
|
||||
[9]:https://opensource.com/life/15/10/exploring-raspberry-pi-sense-hat
|
||||
[10]:https://www.raspberrypi.org/learning/infrared-bird-box/
|
||||
[11]:https://www.piborg.org/4borg
|
||||
[12]:https://www.piborg.org/diddyborg
|
||||
[13]:https://www.piborg.org/doodleborg
|
||||
[14]:http://camjam.me/?page_id=1035#worksheets
|
||||
@ -0,0 +1,164 @@
|
||||
5个最受喜爱的开源Django包
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源:Opensource.com
|
||||
|
||||
_Jacob Kaplan-Moss和Frank Wiles也参与了本文的写作。_
|
||||
|
||||
Django围绕“[可重用应用][1]”观点建立:自我包含了提供可重复使用特性的包。你可以将这些可重用应用组装起来,在加上适用于你的网站的特定代码,来搭建你自己的网站。Django具有一个丰富多样的、由可供你使用的可重用应用组建起来的生态系统——PyPI列出了[超过8000个 Django 应用][2]——可你该如何知道哪些是最好的呢?
|
||||
|
||||
为了节省你的时间,我们总结了五个最受喜爱的 Django 应用。它们是:
|
||||
- [Cookiecutter][3]: 建立 Django 网站的最佳方式。
|
||||
- [Whitenoise][4]: 最棒的静态资源服务器。
|
||||
- [Django Rest Framework][5]: 使用 Django 开发 REST API 的最佳方式。
|
||||
- [Wagtail][6]: 基于 Django 的最佳内容管理系统。
|
||||
- [django-allauth][7]: 提供社交账户登录的最佳应用(如 Twitter, Facebook, GitHub 等)。
|
||||
|
||||
我们同样推荐你查看 [Django Packages][8],一个可重用 Django 应用的目录。Django Packages 将 Django 应用组织成“表格”,你可以在功能相似的不同应用之间进行比较并做出选择。你可以查看每个包中提供的特性,和使用统计情况。(比如:这是[ REST 工具的表格][9],也许可以帮助你理解我们为何推荐 Django REST Framework.
|
||||
|
||||
## 为什么你应该相信我们?
|
||||
|
||||
我们使用 Django 的时间比几乎其他人都长。在 Django 发布之前,我们当中的两个人(Frank 和 Jacob)在 [Lawrence Journal-World][10] (Django 的发源地)工作(事实上他们两人推动了 Django 开源发布的进程)。我们在过去的八年当中运行着一个咨询公司,来建议公司使用 Django 去将事情做到最好。
|
||||
|
||||
所以,我们见证了Django项目和社群的完整历史,我们见证了流行软件包的兴起和没落。在我们三个中,我们可能私下试用了8000个应用中的一半以上,或者我们知道谁试用过这些。我们对如何使应用变得坚实可靠有着深刻的理解,并且我们对给予这些应用持久力量的来源也有不错的理解。
|
||||
|
||||
## 建立Django网站的最佳方式:[Cookiecutter][3]
|
||||
|
||||
建立一个新项目或应用总是有些痛苦。你可以用Django内建的 `startproject`。不过,如果你像我们一样,你可能会对你的办事方式很挑剔。Cookiecutter 为你提供了一个快捷简单的方式来构建易于使用的项目或应用模板,从而解决了这个问题。一个简单的例子:键入 `pip install cookiecutter`,然后在命令行中运行以下命令:
|
||||
|
||||
```bash
|
||||
$ cookiecutter https://github.com/marcofucci/cookiecutter-simple-django
|
||||
```
|
||||
|
||||
接下来你需要回答几个简单的问题,比如你的项目名称、目录、作者名字、E-Mail和其他几个关于配置的小问题。这些能够帮你补充项目相关的细节。我们使用最最原始的 "_foo_" 作为我们的目录名称。所以 cokkiecutter 在子目录 "_foo_" 下建立了一个简单的 Django 项目。
|
||||
|
||||
如果你在"_foo_"项目中闲逛,你会看见你刚刚选择的其它设置已通过模板,连同子目录一同嵌入到文件当中。这个“模板”在我们刚刚在执行 `cookiecutter` 命令时输入的 Github 仓库 URL 中定义。这个样例工程使用了一个 Github 远程仓库作为模板;不过你也可以使用本地的模板,这在建立非重用项目时非常有用。
|
||||
|
||||
我们认为 cookiecutter 是一个极棒的 Django 包,但是,事实上其实它在面对纯 Python 甚至非 Python 相关需求时也极为有用。你能够将所有文件依你所愿精确摆放在任何位置上,使得 cookiecutter 成为了一个简化工作流程的极佳工具。
|
||||
|
||||
## 最棒的静态资源服务器:[Whitenoise][4]
|
||||
|
||||
多年来,托管网站的静态资源——图片、Javascript、CSS——都是一件很痛苦的事情。Django 内建的 [django.views.static.serve][11] 视图,就像Django文章所述的那样,“在生产环境中不可靠,所以只应为开发环境的提供辅助功能。”但使用一个“真正的” Web 服务器,如 NGINX 或者借助 CDN 来托管媒体资源,配置起来会相当困难。
|
||||
|
||||
Whitenoice 很简洁地解决了这个问题。它可以像在开发环境那样轻易地在生产环境中设置静态服务器,并且针对生产环境进行了加固和优化。它的设置方法极为简单:
|
||||
|
||||
1. 确保你在使用 Django 的 [contrib.staticfiles][12] 应用,并确认你在配置文件中正确设置了 `STATIC_ROOT` 变量。
|
||||
|
||||
2. 在 `wsgi.py` 文件中启用 Whitenoise:
|
||||
|
||||
```python
|
||||
from django.core.wsgi import get_wsgi_application
|
||||
from whitenoise.django import DjangoWhiteNoise
|
||||
|
||||
application = get_wsgi_application()
|
||||
application = DjangoWhiteNoise(application)
|
||||
```
|
||||
|
||||
配置它真的就这么简单!对于大型应用,你可能想要使用一个专用的媒体服务器和/或一个 CDN,但对于大多数小型或中型 Django 网站,Whitenoise 已经足够强大。
|
||||
|
||||
如需查看更多关于 Whitenoise 的信息,[请查看文档][13]。
|
||||
|
||||
## 开发REST API的最佳工具:[Django REST Framework][5]
|
||||
|
||||
REST API 正在迅速成为现代 Web 应用的标准功能。与一个 API 进行简短的会话,你只需使用 JSON 而不是 HTML,当然你可以只用 Django 做到这些。你可以制作自己的视图,设置合适的 `Content-Type`, 然后返回 JSON 而不是渲染后的 HTML 响应。这是在像 [Django Rest Framework][14](下称DRF)这样的API框架发布之前,大多数人所做的。
|
||||
|
||||
如果你对 Django 的视图类很熟悉,你会觉得使用DRF构建REST API与使用它们很相似,不过 DRF 只针对特定 API 使用场景而设计。在一般 API 设计中,你会用到它的不少代码,所以我们强调了一些 DRF 的特性来使你更快地接受它,而不是去看一份让你兴奋的示例代码:
|
||||
|
||||
* 可自动预览的 API 可以使你的开发和人工测试轻而易举。你可以查看 DRF 的[示例代码][15]。你可以查看 API 响应,并且它支持 POST/PUT/DELETE 类型的操作,不需要你做任何事。
|
||||
|
||||
|
||||
* 认证方式易于迁移,如OAuth, Basic Auth, 或API Tokens.
|
||||
* 内建请求速度限制。
|
||||
* 当与 [django-rest-swagger][16] 结合时,API文档几乎可以自动生成。
|
||||
* 第三方库拥有广泛的生态。
|
||||
|
||||
当然你可以不依赖 DRF 来构建 API,但我们无法推测你不开始使用 DRF 的原因。就算你不使用 DRF 的全部特性,使用一个成熟的视图库来构建你自己的 API 也会使你的 API 更加一致、完全,更能提高你的开发速度。如果你还没有开始使用 DRF, 你应该找点时间去体验一下。
|
||||
|
||||
## 以 Django 为基础的最佳 CMS:[Wagtail][6]
|
||||
|
||||
Wagtail是当下Django CMS(内容管理系统)世界中最受人青睐的应用,并且它的热门有足够的理由。就想大多数的 CMS 一样,它具有极佳的灵活性,可以通过简单的 Django 模型来定义不同类型的页面及其内容。使用它,你可以从零开始,在几个小时而不是几天之内来和建造一个基本可以运行的内容管理系统。举一个小例子,为你公司的员工定义一个页面类型可以像下面一样简单:
|
||||
|
||||
```python
|
||||
from wagtail.wagtailcore.models import Page
|
||||
from wagtail.wagtailcore.fields import RichTextField
|
||||
from wagtail.wagtailadmin.edit_handlers import FieldPanel, MultiFieldPanel
|
||||
from wagtail.wagtailimages.edit_handlers import ImageChooserPanel
|
||||
|
||||
class StaffPage(Page):
|
||||
name = models.CharField(max_length=100)
|
||||
hire_date = models.DateField()
|
||||
bio = models.RichTextField()
|
||||
email = models.EmailField()
|
||||
headshot = models.ForeignKey('wagtailimages.Image', null=True, blank=True)
|
||||
content_panels = Page.content_panels + [
|
||||
FieldPanel('name'),
|
||||
FieldPanel('hire_date'),
|
||||
FieldPanel('email'),
|
||||
FieldPanel('bio',classname="full"),
|
||||
ImageChoosePanel('headshot'),
|
||||
]
|
||||
```
|
||||
|
||||
然而,Wagtail 真正出彩的地方在于它的灵活性及其易于使用的现代化管理页面。你可以控制不同类型的页面在哪网站的哪些区域可以访问,为页面添加复杂的附加逻辑,还可以极为方便地取得标准的适应/审批工作流。在大多数 CMS 系统中,你会在开发时在某些点上遇到困难。而使用 Wagtail 时,我们经过不懈努力找到了一个突破口,使得让我们轻易地开发出一套简洁稳定的系统,使得程序完全依照我们的想法运行。如果你对此感兴趣,我们写了一篇[深入理解 Wagtail][17].
|
||||
|
||||
## 提供社交账户登录的最佳工具:[django-allauth][7]
|
||||
|
||||
django-allauth 是一个能够解决你的注册和认证需求的、可重用的Django应用。无论你需要构建本地注册系统还是社交账户注册系统,django-allauth 都能够帮你做到。
|
||||
|
||||
这个应用支持多种认证体系,比如用户名或电子邮件。一旦用户注册成功,它可以提供从零到电子邮件认证的多种账户验证的策略。同时,它也支持多种社交账户和电子邮件账户关联。它还支持可插拔的注册表单,可让用户在注册时回答一些附加问题。
|
||||
|
||||
django-allauth 支持多于 20 种认证提供者,包括 Facebook, Github, Google 和 Twitter。如果你发现了一个它不支持的社交网站,那很有可能有一款第三方插件提供该网站的接入支持。这个项目还支持自定义后台开发,可以支持自定义的认证方式。
|
||||
|
||||
django-allauth 易于配置,且有[完善的文档][18]。该项目通过了很多测试,所以你可以相信它的所有部件都会正常运作。
|
||||
|
||||
你有最喜爱的 Django 包吗?请在评论中告诉我们。
|
||||
|
||||
## 关于作者
|
||||
|
||||

|
||||
|
||||
Jeff Triplett
|
||||
|
||||
劳伦斯,堪萨斯州
|
||||
<http://www.jefftriplett.com/>
|
||||
|
||||
我在 2007 年搬到了堪萨斯州的劳伦斯,在 Django 的发源地—— Lawrence Journal-World 工作。我现在在劳伦斯市的 [Revolution Systems (Revsys)][19] 工作,做一位开发者兼顾问。
|
||||
|
||||
我是[北美 Django 运动基金会(DEFNA)][20]的联合创始人,2015 和 2016 年 [DjangoCon US][21] 的会议主席,而且我在 Django 的发源地劳伦斯参与组织了 [Django Birthday][22] 来庆祝 Django 的 10 岁生日。
|
||||
|
||||
我是当地越野跑小组的成员,我喜欢篮球,我还喜欢梦见自己随着一道气流游遍美国。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/5-favorite-open-source-django-packages
|
||||
|
||||
作者:[Jeff Triplett][a]
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jefftriplett
|
||||
[1]:https://docs.djangoproject.com/en/1.8/intro/reusable-apps/
|
||||
[2]:https://pypi.python.org/pypi?:action=browse&c=523
|
||||
[3]:https://github.com/audreyr/cookiecutter
|
||||
[4]:http://whitenoise.evans.io/en/latest/base.html
|
||||
[5]:http://www.django-rest-framework.org/
|
||||
[6]:https://wagtail.io/
|
||||
[7]:http://www.intenct.nl/projects/django-allauth/
|
||||
[8]:https://www.djangopackages.com/
|
||||
[9]:https://www.djangopackages.com/grids/g/rest/
|
||||
[10]:http://www2.ljworld.com/news/2015/jul/09/happy-birthday-django/
|
||||
[11]:https://docs.djangoproject.com/en/1.8/ref/views/#django.views.static.serve
|
||||
[12]:https://docs.djangoproject.com/en/1.8/ref/contrib/staticfiles/
|
||||
[13]:http://whitenoise.evans.io/en/latest/index.html
|
||||
[14]:http://www.django-rest-framework.org/
|
||||
[15]:http://restframework.herokuapp.com/
|
||||
[16]:http://django-rest-swagger.readthedocs.org/en/latest/index.html
|
||||
[17]:https://opensource.com/business/15/5/wagtail-cms
|
||||
[18]:http://django-allauth.readthedocs.org/en/latest/
|
||||
[19]:http://www.revsys.com/
|
||||
[20]:http://defna.org/
|
||||
[21]:https://2015.djangocon.us/
|
||||
[22]:https://djangobirthday.com/
|
||||
198
translated/tech/20151123 Data Structures in the Linux Kernel.md
Normal file
198
translated/tech/20151123 Data Structures in the Linux Kernel.md
Normal file
@ -0,0 +1,198 @@
|
||||
Linux内核数据结构
|
||||
================================================================================
|
||||
|
||||
基数树 Radix tree
|
||||
--------------------------------------------------------------------------------
|
||||
正如你所知道的,Linux内核提供了许多不同的库和函数,它们实现了不同的数据结构和算法。在这部分,我们将研究其中一种数据结构——[基数树 Radix tree](http://en.wikipedia.org/wiki/Radix_tree)。在Linux内核中,有两个与基数树实现和API相关的文件:
|
||||
|
||||
* [include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)
|
||||
* [lib/radix-tree.c](https://github.com/torvalds/linux/blob/master/lib/radix-tree.c)
|
||||
|
||||
让我们讨论什么是`基数树`吧。基数树是一种`压缩的字典树`,而[字典树](http://en.wikipedia.org/wiki/Trie)是实现了关联数组接口并允许以`键值对`方式存储值的一种数据结构。该键通常是字符串,但能够使用任何数据类型。字典树因为它的节点而与`n叉树`不同。字典树的节点不存储键;相反,字典树的一个节点存储单个字符的标签。与一个给定节点关联的键可以通过从根遍历到该节点获得。举个例子:
|
||||
|
||||
```
|
||||
+-----------+
|
||||
| |
|
||||
| " " |
|
||||
| |
|
||||
+------+-----------+------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| g | | c |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
| |
|
||||
| |
|
||||
+----v------+ +-----v-----+
|
||||
| | | |
|
||||
| o | | a |
|
||||
| | | |
|
||||
+-----------+ +-----------+
|
||||
|
|
||||
|
|
||||
+-----v-----+
|
||||
| |
|
||||
| t |
|
||||
| |
|
||||
+-----------+
|
||||
```
|
||||
|
||||
因此在这个例子中,我们可以看到一个有着两个键`go`和`cat`的`字典树`。压缩的字典树或者`基数树`和`字典树`不同于所有只有一个孩子的中间节点都被删除。
|
||||
|
||||
Linu内核中的基数树是映射值到整形键的一种数据结构。[include/linux/radix-tree.h](https://github.com/torvalds/linux/blob/master/include/linux/radix-tree.h)文件中的以下结构体表示了基数树:
|
||||
|
||||
```C
|
||||
struct radix_tree_root {
|
||||
unsigned int height;
|
||||
gfp_t gfp_mask;
|
||||
struct radix_tree_node __rcu *rnode;
|
||||
};
|
||||
```
|
||||
|
||||
这个结构体表示了一个基数树的根,并包含了3个域成员:
|
||||
|
||||
* `height` - 树的高度;
|
||||
* `gfp_mask` - 告诉如何执行动态内存分配;
|
||||
* `rnode` - 孩子节点指针.
|
||||
|
||||
我们第一个要讨论的域是`gfp_mask`:
|
||||
|
||||
底层内核内存动态分配函数以一组标志作为` gfp_mask `,用于描述如何执行动态内存分配。这些控制分配进程的`GFP_`标志拥有以下值:(`GF_NOIO`标志)意味着睡眠等待内存,(`__GFP_HIGHMEM`标志)意味着高端内存能够被使用,(`GFP_ATOMIC`标志)意味着分配进程拥有高优先级并不能睡眠等等。
|
||||
|
||||
* `GFP_NOIO` - 睡眠等待内存
|
||||
* `__GFP_HIGHMEM` - 高端内存能够被使用;
|
||||
* `GFP_ATOMIC` - 分配进程拥有高优先级并且不能睡眠;
|
||||
|
||||
等等。
|
||||
|
||||
下一个域是`rnode`:
|
||||
|
||||
```C
|
||||
struct radix_tree_node {
|
||||
unsigned int path;
|
||||
unsigned int count;
|
||||
union {
|
||||
struct {
|
||||
struct radix_tree_node *parent;
|
||||
void *private_data;
|
||||
};
|
||||
struct rcu_head rcu_head;
|
||||
};
|
||||
/* For tree user */
|
||||
struct list_head private_list;
|
||||
void __rcu *slots[RADIX_TREE_MAP_SIZE];
|
||||
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS];
|
||||
};
|
||||
```
|
||||
这个结构体包含的信息有父节点中的偏移以及到底端(叶节点)的高度、孩子节点的个数以及用于访问和释放节点的域成员。这些域成员描述如下:
|
||||
|
||||
* `path` - 父节点中的偏移和到底端(叶节点)的高度
|
||||
* `count` - 孩子节点的个数;
|
||||
* `parent` - 父节点指针;
|
||||
* `private_data` - 由树的用户使用;
|
||||
* `rcu_head` - 用于释放节点;
|
||||
* `private_list` - 由树的用户使用;
|
||||
|
||||
`radix_tree_node`的最后两个成员——`tags`和`slots`非常重要且令人关注。Linux内核基数树的每个节点都包含一组存储指向数据指针的slots。Linux内核基数树实现的空slots存储`NULL`值。Linux内核中的基数树也支持与`radix_tree_node`结构体的`tags`域相关联的标签。标签允许在基数树存储的记录中设置各个位。
|
||||
|
||||
既然我们了解了基数树的结构,那么该是时候看一下它的API了。
|
||||
|
||||
Linux内核基数树API
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
我们从结构体的初始化开始。有两种方法初始化一个新的基数树。第一种是使用`RADIX_TREE`宏:
|
||||
|
||||
```C
|
||||
RADIX_TREE(name, gfp_mask);
|
||||
````
|
||||
|
||||
正如你所看到的,我们传递`name`参数,所以使用`RADIX_TREE`宏,我们能够定义和初始化基数树为给定的名字。`RADIX_TREE`的实现是简单的:
|
||||
|
||||
```C
|
||||
#define RADIX_TREE(name, mask) \
|
||||
struct radix_tree_root name = RADIX_TREE_INIT(mask)
|
||||
|
||||
#define RADIX_TREE_INIT(mask) { \
|
||||
.height = 0, \
|
||||
.gfp_mask = (mask), \
|
||||
.rnode = NULL, \
|
||||
}
|
||||
```
|
||||
|
||||
在`RADIX_TREE`宏的开始,我们使用给定的名字定义`radix_tree_root`结构体实例,并使用给定的mask调用`RADIX_TREE_INIT`宏。`RADIX_TREE_INIT`宏只是初始化`radix_tree_root`结构体为默认值和给定的mask而已。
|
||||
|
||||
第二种方法是亲手定义`radix_tree_root`结构体,并且将它和mask传给`INIT_RADIX_TREE`宏:
|
||||
|
||||
```C
|
||||
struct radix_tree_root my_radix_tree;
|
||||
INIT_RADIX_TREE(my_tree, gfp_mask_for_my_radix_tree);
|
||||
```
|
||||
|
||||
where:
|
||||
|
||||
```C
|
||||
#define INIT_RADIX_TREE(root, mask) \
|
||||
do { \
|
||||
(root)->height = 0; \
|
||||
(root)->gfp_mask = (mask); \
|
||||
(root)->rnode = NULL; \
|
||||
} while (0)
|
||||
```
|
||||
|
||||
和`RADIX_TREE_INIT`宏所做的初始化一样,初始化为默认值。
|
||||
|
||||
接下来是用于从基数树插入和删除数据的两个函数:
|
||||
|
||||
* `radix_tree_insert`;
|
||||
* `radix_tree_delete`;
|
||||
|
||||
第一个函数`radix_tree_insert`需要3个参数:
|
||||
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
* 插入的数据;
|
||||
|
||||
`radix_tree_delete`函数需要和`radix_tree_insert`一样的一组参数,但是没有data。
|
||||
|
||||
基数树的搜索以两种方法实现:
|
||||
|
||||
* `radix_tree_lookup`;
|
||||
* `radix_tree_gang_lookup`;
|
||||
* `radix_tree_lookup_slot`.
|
||||
|
||||
第一个函数`radix_tree_lookup`需要两个参数:
|
||||
|
||||
* 基数树的根;
|
||||
* 索引键;
|
||||
|
||||
这个函数尝试在树中查找给定的键,并返回和该键相关联的记录。第二个函数`radix_tree_gang_lookup`有以下的函数签名:
|
||||
|
||||
```C
|
||||
unsigned int radix_tree_gang_lookup(struct radix_tree_root *root,
|
||||
void **results,
|
||||
unsigned long first_index,
|
||||
unsigned int max_items);
|
||||
```
|
||||
|
||||
和返回记录的个数,(results指向的数据)按键排序并从第一个索引开始。返回的记录个数将不会超过`max_items`。
|
||||
|
||||
最后一个函数`radix_tree_lookup_slot`将会返回包含数据的slot。
|
||||
|
||||
链接
|
||||
---------------------------------------------------------------------------------
|
||||
|
||||
* [Radix tree](http://en.wikipedia.org/wiki/Radix_tree)
|
||||
* [Trie](http://en.wikipedia.org/wiki/Trie)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/0xAX/linux-insides/edit/master/DataStructures/radix-tree.md
|
||||
|
||||
作者:[0xAX]
|
||||
译者:[cposture](https://github.com/cposture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,43 @@
|
||||
Linux Desktop Fun: Summon Swarms Of Penguins To Waddle About The Desktop
|
||||
Linux桌面趣闻:召唤一群企鹅在桌面上行走
|
||||
================================================================================
|
||||
XPenguins is a program for animating cute cartoons animals in your root window. By default it will be penguins they drop in from the top of the screen, walk along the tops of your windows, up the side of your windows, levitate, skateboard, and do other similarly exciting things. Now you can send an army of cute little penguins to invade the screen of someone else on your network.
|
||||
XPenguins是一个在窗口播放可爱动物动画的程序。默认情况下,将会从屏幕上方掉落企鹅,沿着你的窗口顶部行走,在窗口变漂浮,滑板,和做其他类似的令人兴奋的事情。现在,你可以把这些可爱的小企鹅大军入侵别人的桌面了。
|
||||
|
||||
### Install XPenguins ###
|
||||
### 安装XPenguins ###
|
||||
|
||||
Open a command-line terminal (select Applications > Accessories > Terminal), and then type the following commands to install XPenguins program. First, type the command apt-get update to tell apt to refresh its package information by querying the configured repositories and then install the required program:
|
||||
打开终端(选择程序->附件->终端),接着输入下面的命令来安装XPenguins。首先,输入apt-get update通过请求配置的仓库刷新包的信息,接着安装需要的程序:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install xpenguins
|
||||
|
||||
### How do I Start XPenguins Locally? ###
|
||||
### 我本地如何启动XPenguins? ###
|
||||
|
||||
Type the following command:
|
||||
输入下面的命令:
|
||||
|
||||
$ xpenguins
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
An army of cute little penguins invading the screen
|
||||
一支可爱企鹅军队正在入侵屏幕。
|
||||
|
||||

|
||||
|
||||
Linux: Cute little penguins walking along the tops of your windows
|
||||
Linux:可爱的小企鹅沿着窗口的顶部行走。
|
||||
|
||||

|
||||
|
||||
Xpenguins Screenshot
|
||||
Xpenguins截图
|
||||
|
||||
Be careful when you move windows as the little guys squash easily. If you send the program an interupt signal (Ctrl-C) they will burst.
|
||||
移动窗口时小心点,小家伙们很容易被压坏。如果你发送中断程序(Ctrl-C),它们会爆炸。
|
||||
|
||||
### Themes ###
|
||||
### 主题 ###
|
||||
|
||||
To list themes, enter:
|
||||
要列出主题,输入:
|
||||
|
||||
$ xpenguins -l
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
Big Penguins
|
||||
Bill
|
||||
@ -45,11 +45,11 @@ Sample outputs:
|
||||
Penguins
|
||||
Turtles
|
||||
|
||||
You can use alternative themes as follows:
|
||||
你可以用下面的命令使用其他的主题:
|
||||
|
||||
$ xpenguins --theme "Big Penguins" --theme "Turtles"
|
||||
|
||||
You can install additional themes as follows:
|
||||
你可以用下面的命令安装额外的主题:
|
||||
|
||||
$ cd /tmp
|
||||
$ wget http://xpenguins.seul.org/xpenguins_themes-1.0.tar.gz
|
||||
@ -58,7 +58,7 @@ You can install additional themes as follows:
|
||||
$ mv -v themes ~/.xpenguins/
|
||||
$ xpenguins -l
|
||||
|
||||
Sample outputs:
|
||||
示例输出:
|
||||
|
||||
Lemmings
|
||||
Sonic the Hedgehog
|
||||
@ -71,26 +71,26 @@ Sample outputs:
|
||||
Penguins
|
||||
Turtles
|
||||
|
||||
To start with a random theme, enter:
|
||||
已一个随机主题开始,输入:
|
||||
|
||||
$ xpenguins --random-theme
|
||||
|
||||
To load all available themes and run them simultaneously, enter:
|
||||
要加载所有的主题并且同时运行,输入:
|
||||
|
||||
$ xpenguins --all
|
||||
|
||||
More links and information:
|
||||
更多链接何信息:
|
||||
|
||||
- [XPenguins][1] home page.
|
||||
- [XPenguins][1] 主页。
|
||||
- man penguins
|
||||
- More Linux / UNIX desktop fun with [Steam Locomotive][2] and [Terminal ASCII Aquarium][3].
|
||||
- 更多Linux/Unix桌面乐趣在[蒸汽火车][2]和[终端ASCII水族馆][3]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/linux-cute-little-xpenguins-walk-along-tops-ofyour-windows.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -98,3 +98,5 @@ via: http://www.cyberciti.biz/tips/linux-cute-little-xpenguins-walk-along-tops-o
|
||||
[1]:http://xpenguins.seul.org/
|
||||
[2]:http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
|
||||
[3]:http://www.cyberciti.biz/tips/linux-unix-apple-osx-terminal-ascii-aquarium.html
|
||||
|
||||
|
||||
@ -1,297 +0,0 @@
|
||||
|
||||
怎样在ubuntu和debian中用命令行使用KVM
|
||||
================================================================================
|
||||
有很多不同的方式去管理运行在KVM管理程序上的虚拟机。例如,virt-manager就是一个流行的基于图形用户界面的前端虚拟机管理工具。然而,如果你想要在没有图形窗口的服务器环境下使用KVM,那么基于图形用户界面的解决方案显然是行不通的。事实上,你可以纯粹的使用包装了kvm命令行脚本的命令行来管理KVM虚拟机。作为替代方案,你可以使用virsh这个容易使用的命令行用户接口来管理客户虚拟机。在virsh中,它通过和libvirtd服务通信来达到控制虚拟机的目的,而libvirtd可以控制几个不同的虚拟机管理器,包括KVM,Xen,QEMU,LXC和OpenVZ。
|
||||
当你想要对虚拟机的前期准备和后期管理实现自动化操作时,像virsh这样的命令行管理工具是非常有用的。同样,virsh支持多个管理器的事实也意味着你可以通过相同的virsh接口去管理不同的虚拟机管理器。
|
||||
在这篇文章中,我会示范**怎样在ubuntu和debian上通过使用virsh命令行去运行KVM**。
|
||||
|
||||
### 第一步:确认你的硬件平台支持虚拟化 ###
|
||||
|
||||
作为第一步,首先要确认你的主机CPU配备了硬件虚拟化拓展(e.g.,Intel VT或者AMD-V),这是KVM对硬件的要求。下面的命令可以检查硬件是否支持虚拟化。
|
||||
|
||||
$ egrep '(vmx|svm)' --color /proc/cpuinfo
|
||||
|
||||

|
||||
|
||||
如果在输出中不包含vmx或者svm标识,那么就意味着你的主机cpu不支持硬件虚拟化。因此你不能在你的机器上使用KVM。确认了主机cpu存在vmx或者svm之后,接下来开始安装KVM。
|
||||
对于KVM来说,它不要求运行在拥有64位内核系统的主机上,但是通常我们会推荐在64位系统的主机上面运行KVM。
|
||||
|
||||
### 第二步:安装KVM ###
|
||||
|
||||
使用apt-get安装KVM和相关的用户空间工具。
|
||||
|
||||
$ sudo apt-get install qemu-kvm libvirt-bin
|
||||
|
||||
安装期间,libvirtd组(在debian上是libvirtd-qemu组)将会被创建,并且你的用户id将会被自动添加到该组中。这样做的目的是让你可以以一个普通用户而不是root用户的身份去管理虚拟机。你可以使用id命令来确认这一点,下面将会告诉你怎么去显示你的组id:
|
||||
|
||||
$ id <your-userID>
|
||||
|
||||

|
||||
|
||||
如果因为某些原因,libvirt(在debian中是libvirt-qemu)没有在你的组id中被找到,你也可以手动将你自己添加到对应的组中,如下所示:
|
||||
在ubuntu上:
|
||||
|
||||
$ sudo adduser [youruserID] libvirtd
|
||||
|
||||
在debian上:
|
||||
|
||||
$ sudo adduser [youruserID] libvirt-qemu
|
||||
|
||||
按照如下形式重修载入更新后的组成员关系。如果要求输入密码,那么输入你的登陆密码即可。
|
||||
|
||||
$ exec su -l $USER
|
||||
|
||||
这时,你应该可以以普通用户的身份去执行virsh了。做一个如下所示的测试,这个命令将会以列表的形式列出可用的虚拟机(当前的列表是空的)。如果你没有遇到权限问题,那意味着迄今为止一切都是正常的。
|
||||
|
||||
$ virsh list
|
||||
|
||||
----------
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
|
||||
### 第三步:配置桥接网络 ###
|
||||
|
||||
为了使KVM虚拟机能够访问外部网络,一种方法是通过在KVM宿主机上创建Linux桥来实现。创建之后的桥能够将虚拟机的虚拟网卡和宿主机的物理网卡连接起来,因此,虚拟机能够发送和接受由物理网卡发送过来的流量数据包。这种方式叫做网桥连接。
|
||||
下面将告诉你如何创建并且配置网桥,我们称它为br0.
|
||||
首先,安装一个必需的包,然后用命令行创建一个网桥。
|
||||
|
||||
$ sudo apt-get install bridge-utils
|
||||
$ sudo brctl addbr br0
|
||||
|
||||
下一步就是配置已经创建好的网桥,即修改位于/etc/network/interfaces的配置文件。我们需要将该桥接网卡设置成开机启动。为了修改该配置文件,你需要关闭你的操作系统上的网络管理器(如果你在使用它的话)。跟随[操作指南][1]的说明去关闭网络管理器。
|
||||
关闭网络管理器之后,接下来就是通过修改配置文件来配置网桥了。
|
||||
|
||||
#auto eth0
|
||||
#iface eth0 inet dhcp
|
||||
|
||||
auto br0
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eth0
|
||||
bridge_stp off
|
||||
bridge_fd 0
|
||||
bridge_maxwait 0
|
||||
|
||||
|
||||
在上面的配置中,我假设eth0是主要网卡,它也是连接到外网的网卡,同样,我假设eth0将会通过DHCP得到它的ip地址。注意,之前在/etc/network/interfaces中还没有对eth0进行任何配置。桥接网卡br0引用了eth0的配置,而eth0也会受到br0的制约。
|
||||
重启网络服务,并确认网桥已经被成功的配置好。如果成功的话,br0的ip地址将会是eth0的被自动分配的ip地址,而且eth0不会被分配任何ip地址。
|
||||
|
||||
$ sudo /etc/init.d/networking restart
|
||||
$ ifconfig
|
||||
|
||||
如果因为某些原因,eth0仍然保留了之前分配给了br0的ip地址,那么你可能必须明确的删除eth0的ip地址。
|
||||
|
||||

|
||||
|
||||
###第四步:用命令行创建一个虚拟机 ###
|
||||
|
||||
对于虚拟机来说,它的配置信息被存储在它对应的xml文件中。因此,创建一个虚拟机的第一步就是准备一个与主机名对应的xml文件。
|
||||
下面是一个示例xml文件,你可以根据需要手动修改它。
|
||||
|
||||
<domain type='kvm'>
|
||||
<name>alice</name>
|
||||
<uuid>f5b8c05b-9c7a-3211-49b9-2bd635f7e2aa</uuid>
|
||||
<memory>1048576</memory>
|
||||
<currentMemory>1048576</currentMemory>
|
||||
<vcpu>1</vcpu>
|
||||
<os>
|
||||
<type>hvm</type>
|
||||
<boot dev='cdrom'/>
|
||||
</os>
|
||||
<features>
|
||||
<acpi/>
|
||||
</features>
|
||||
<clock offset='utc'/>
|
||||
<on_poweroff>destroy</on_poweroff>
|
||||
<on_reboot>restart</on_reboot>
|
||||
<on_crash>destroy</on_crash>
|
||||
<devices>
|
||||
<emulator>/usr/bin/kvm</emulator>
|
||||
<disk type="file" device="disk">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/images/alice.img"/>
|
||||
<target dev="vda" bus="virtio"/>
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x04" function="0x0"/>
|
||||
</disk>
|
||||
<disk type="file" device="cdrom">
|
||||
<driver name="qemu" type="raw"/>
|
||||
<source file="/home/dev/iso/CentOS-6.5-x86_64-minimal.iso"/>
|
||||
<target dev="hdc" bus="ide"/>
|
||||
<readonly/>
|
||||
<address type="drive" controller="0" bus="1" target="0" unit="0"/>
|
||||
</disk>
|
||||
<interface type='bridge'>
|
||||
<source bridge='br0'/>
|
||||
<mac address="00:00:A3:B0:56:10"/>
|
||||
</interface>
|
||||
<controller type="ide" index="0">
|
||||
<address type="pci" domain="0x0000" bus="0x00" slot="0x01" function="0x1"/>
|
||||
</controller>
|
||||
<input type='mouse' bus='ps2'/>
|
||||
<graphics type='vnc' port='-1' autoport="yes" listen='0.0.0.0'/>
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
</devices>
|
||||
</domain>
|
||||
|
||||
上面的主机xml配置文件定义了如下的虚拟机内容。
|
||||
|
||||
- 1GB内存,一个虚拟cpu和一个硬件驱动。
|
||||
- Disk image:/home/dev/images/alice.img。
|
||||
- Boot from CD-ROM(/home/dev/iso/CentOS-6.5-x86_64-minomal.iso)。
|
||||
- Networking:一个桥接到br0的虚拟网卡。
|
||||
- 通过VNC远程访问。
|
||||
<uuid></uuid>中的UUID字符串可以随机生成。为了得到一个随机的uuid字符串,你可能需要使用uuid命令行工具。
|
||||
|
||||
$ sudo apt-get install uuid
|
||||
$ uuid
|
||||
|
||||
生成一个主机xml配置文件的方式就是通过一个已经存在的虚拟机来导出它的xml配置文件。如下所示。
|
||||
|
||||
$ virsh dumpxml alice > bob.xml
|
||||
|
||||

|
||||
|
||||
###第五步:使用命令行启动虚拟机###
|
||||
|
||||
在启动虚拟机之前,我们需要创建它的初始磁盘镜像。为此,你需要使用qemu-img命令来生成一个你已经安装的qemu-kvm镜像。下面的命令将会创建10GB大小的空磁盘,并且它是qcow2格式的。
|
||||
|
||||
$ qemu-img create -f qcow2 /home/dev/images/alice.img 10G
|
||||
|
||||
使用qcow2格式的磁盘镜像的好处就是它在创建之初并不会给它分配全部大小磁盘容量(这里是10GB),而是随着虚拟机中文件的增加而逐渐增大。因此,它对空间的使用更加有效。
|
||||
现在,你可以准备通过使用之前创建的xml配置文件启动你的虚拟机了。下面的命令将会创建一个虚拟机,然后自动启动它。
|
||||
|
||||
$ virsh create alice.xml
|
||||
|
||||
----------
|
||||
|
||||
Domain alice created from alice.xml
|
||||
|
||||
**注意**:如果你对一个已经存在的虚拟机运行了上面的命令,那么这个操作将会在没有警告信息的情况下抹去那个已经存在的虚拟机的全部信息。如果你已经创建了一个虚拟机,你可能会使用下面的命令来启动虚拟机。
|
||||
|
||||
$ virsh start alice.xml
|
||||
|
||||
使用如下命令确认一个新的虚拟机已经被创建并成功的被启动。
|
||||
|
||||
$ virsh list
|
||||
|
||||
----------
|
||||
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
3 alice running
|
||||
|
||||
同样,使用如下命令确认你的虚拟机的虚拟网卡已经被成功的添加到了你先前创建的br0网桥中。
|
||||
|
||||
$ sudo brctl show
|
||||
|
||||

|
||||
|
||||
### 远程连接虚拟机 ###
|
||||
|
||||
为了远程访问一个正在运行的虚拟机的控制台,你可以使用VNC客户端。
|
||||
首先,你需要使用如下命令找出用于虚拟机的VNC端口号。
|
||||
|
||||
$ sudo netstat -nap | egrep '(kvm|qemu)'
|
||||
|
||||

|
||||
|
||||
在这个例子中,用于alice虚拟机的VNC端口号是5900
|
||||
然后启动一个VNC客户端,连接到一个端口号为5900的VNC服务器。在我们的例子中,虚拟机支持由CentOS光盘文件启动。
|
||||
|
||||

|
||||
|
||||
### 使用virsh管理虚拟机 ###
|
||||
|
||||
下面列出了virsh命令的常规用法
|
||||
创建客户机并且启动虚拟机:
|
||||
|
||||
$ virsh create alice.xml
|
||||
|
||||
停止虚拟机并且删除客户机
|
||||
|
||||
$ virsh destroy alice
|
||||
|
||||
关闭虚拟机(不用删除它)
|
||||
|
||||
$ virsh shutdown alice
|
||||
|
||||
暂停虚拟机
|
||||
|
||||
$ virsh suspend alice
|
||||
|
||||
恢复虚拟机
|
||||
|
||||
$ virsh resume alice
|
||||
|
||||
访问正在运行的虚拟机的登陆控制台
|
||||
|
||||
$ virsh console alice
|
||||
|
||||
设置虚拟机开机启动:
|
||||
|
||||
$ virsh autostart alice
|
||||
|
||||
查看虚拟机的详细信息
|
||||
|
||||
$ virsh dominfo alice
|
||||
|
||||
编辑虚拟机的配置文件:
|
||||
|
||||
$ virsh edit alice
|
||||
|
||||
上面的这个命令将会使用一个默认的编辑器来调用主机配置文件。该配置文件中的任何改变都将自动被libvirt验证其正确性。
|
||||
你也可以在一个virsh会话中管理虚拟机。下面的命令会创建并进入到一个virsh会话中:
|
||||
|
||||
$ virsh
|
||||
在virsh提示中,你可以使用任何virsh命令。
|
||||
|
||||

|
||||
|
||||
### 问题处理 ###
|
||||
|
||||
1. 我在创建虚拟机的时候遇到了一个错误:
|
||||
|
||||
error: internal error: no supported architecture for os type 'hvm'
|
||||
|
||||
如果你的硬件不支持虚拟化的话你可能就会遇到这个错误。(例如,Intel VT或者AMD-V),这是运行KVM所必需的。如果你遇到了这个错误,而你的cpu支持虚拟化,那么这里可以给你一些可用的解决方案:
|
||||
|
||||
首先,检查你的内核模块是否丢失。
|
||||
|
||||
$ lsmod | grep kvm
|
||||
|
||||
如果内核模块没有加载,你必须按照如下方式加载它。
|
||||
|
||||
$ sudo modprobe kvm_intel (for Intel processor)
|
||||
$ sudo modprobe kvm_amd (for AMD processor)
|
||||
|
||||
第二个解决方案就是添加“--connect qemu:///system”参数到virsh命令中,如下所示。当你正在你的硬件平台上使用超过一个虚拟机管理器的时候就需要添加这个参数(例如,VirtualBox,VMware)。
|
||||
$ virsh --connect qemu:///system create alice.xml
|
||||
|
||||
2. 当我试着访问我的虚拟机的登陆控制台的时候遇到了错误:
|
||||
|
||||
$ virsh console alice
|
||||
|
||||
----------
|
||||
|
||||
error: internal error: cannot find character device <null>
|
||||
|
||||
这个错误发生的原因是你没有在你的虚拟机配置文件中定义控制台设备。在xml文件中加上下面的内部设备部分即可。
|
||||
|
||||
<console type='pty'>
|
||||
<target port='0'/>
|
||||
</console>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/use-kvm-command-line-debian-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/disable-network-manager-linux.html
|
||||
@ -0,0 +1,173 @@
|
||||
如何在CentOS 7 中添加新磁盘而不用重启系统
|
||||
================================================================================
|
||||
|
||||
对大多数系统管理员来说扩充 Linux 服务器的磁盘空间是日常的工作之一。因此这篇文章会在通过使用 Linux 命令,在 CentOS 7 系统上演示一些简单的操作步骤来扩充您的磁盘空间而不需要重启您的生产服务器。关于扩充和增加新的磁盘到 Linux 系统,我们会提及多种方法和多种可行性,所以可按您所需选择最适用的一种。
|
||||
|
||||
### 1. 为虚拟机客户端扩充磁盘空间: ###
|
||||
|
||||
在为 Linux 系统增加磁盘卷之前,您需要添加一块新的物理磁盘或是从正使用的 VMware vShere、工作站或着其它的基础虚拟环境软件中进行设置,从而扩充一块系统正使用的虚拟磁盘空间。
|
||||
|
||||

|
||||
|
||||
### 2. 检查磁盘空间: ###
|
||||
|
||||
运行如下命令来检查当前磁盘空间大小。
|
||||
|
||||
# df -h
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
可以看到,虽然我们已经在后端给其增加到 50 GB 的空间,但此时的总磁盘大小仍然为 10 GB。
|
||||
|
||||
### 3. 扩展空间而无需重启虚拟机 ###
|
||||
|
||||
现在运行如下命令就可以来扩展操作系统的物理卷磁盘空间,而且不需要重启虚拟机,系统会重新扫描 SCSI (注:Small Computer System Interface 小型计算机系统接口)总线并添加 SCSI 设备。
|
||||
|
||||
# ls /sys/class/scsi_host/
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
使用下面的命令来检查 SCSI 设备的名称,然后重新扫描 SCSI 总线。
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/0\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
|
||||
如下图所示,会重新扫描 SCSI 总线,随后我们从虚拟机客户端设置的磁盘大小会正常显示。
|
||||
|
||||

|
||||
|
||||
### 4. 创建新磁盘分区: ###
|
||||
|
||||
一旦在系统中可以看到扩展的磁盘空间,就可以运行如下命令来格式化您的磁盘以创建一个新的分区。请按如下操作步骤来扩充您的物理磁盘卷。
|
||||
|
||||
# fdisk /dev/sda
|
||||
Welcome to fdisk (util-linux 2.23.2) press the 'm' key for help
|
||||
Command (m for help): m
|
||||
Command action
|
||||
a toggle a bootable flag
|
||||
b edit bsd disklabel
|
||||
c toggle the dos compatibility flag
|
||||
d delete a partition
|
||||
g create a new empty GPT partition table
|
||||
G create an IRIX (SGI) partition table
|
||||
l list known partition types
|
||||
m print this menu
|
||||
n add a new partition
|
||||
o create a new empty DOS partition table
|
||||
p print the partition table
|
||||
q quit without saving changes
|
||||
s create a new empty Sun disklabel
|
||||
t change a partition's system id
|
||||
u change display/entry units
|
||||
v verify the partition table
|
||||
w write table to disk and exit
|
||||
x extra functionality (experts only)
|
||||
|
||||
Command (m for help):
|
||||
|
||||
键入 'p' 来查看当前的分区表信息,然后键入 'n' 键来创建一个新的主分区,选择所有可用的扇区。 使用 't' 命令改变磁盘类型为 'Linux LVM',然后选择编码 '8e' 或者默认不选,它默认的类型编码为 '83'。
|
||||
|
||||
现在输入 'w' 来保存分区表信息并且退出命令环境,如下示:
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered!
|
||||
|
||||
Calling ioctl() to re-read partition table.
|
||||
|
||||
WARNING: Re-reading the partition table failed with error 16: Device or resource busy.
|
||||
The kernel still uses the old table. The new table will be used at
|
||||
the next reboot or after you run partprobe(8) or kpartx(8)
|
||||
|
||||

|
||||
|
||||
### 5. 创建物理卷: ###
|
||||
|
||||
根据提示运行 'partprob' 或 'kpartx' 命令以使分区表被真正使用,然后使用如下的命令来创建新的物理卷。
|
||||
|
||||
# partprobe
|
||||
# pvresize /dev/sda3
|
||||
|
||||
要检查新创建的卷,运行如下的命令可以看出新的物理卷是否已经被创建,是否可用。接下来,我们就可以使用这个新的物理卷来扩展 'centos' 卷组了,如下示:
|
||||
|
||||
# pvdisplay
|
||||
# vgextend centos /dev/sda3
|
||||
|
||||

|
||||
|
||||
### 6. 扩展逻辑卷: ###
|
||||
|
||||
现在我们使用如下的命令扩展逻辑卷,以增加我们系统正使用的磁盘空间。
|
||||
|
||||
# lvextend -L +40G /dev/mapper/centos-root
|
||||
|
||||
一旦返回增加成功的消息,就可以运行如下命令来扩展您的逻辑卷大小。
|
||||
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
|
||||
'/' 分区的大小已经成功的增加了,可以使用 'df' 命令来检查您磁盘驱动的大小。如图示。
|
||||
|
||||

|
||||
|
||||
### 7. 通过增加新的磁盘来扩充根分区而不用重启系统: ###
|
||||
|
||||
这是第二种方法,它使用的命令非常简单, 用来增加 CentOS 7 系统上逻辑卷空间大小。
|
||||
|
||||
所以第一步是打开您的虚拟机客户端的设置页面,点击 ‘增加’ 按纽,然后继续下一步操作。
|
||||
|
||||

|
||||
|
||||
选择新磁盘所需要的配置信息,如下图所示的,选择新磁盘的大小和它的类型。
|
||||
|
||||

|
||||
|
||||
然后进入服务端重复如下的命令来扫描您的磁盘设备,以使新磁盘在系统中可见。
|
||||
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
列出您的 SCSI 设备的名称
|
||||
|
||||
# ls /sys/class/scsi_device/
|
||||
# echo 1 > /sys/class/scsi_device/1\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/2\:0\:0\:0/device/rescan
|
||||
# echo 1 > /sys/class/scsi_device/3\:0\:0\:0/device/rescan
|
||||
# fdisk -l
|
||||
|
||||

|
||||
|
||||
一旦新增的磁盘可见就可以运行下面的命令来创建新的物理卷,然后增加到卷组,如下示。
|
||||
|
||||
# pvcreate /dev/sdb
|
||||
# vgextend centos /dev/sdb
|
||||
# vgdisplay
|
||||
|
||||

|
||||
|
||||
现在根据此磁盘的空间大小来扩展逻辑卷,然后添加到根分区。
|
||||
|
||||
# lvextend -L +20G /dev/mapper/centos-root
|
||||
# xfs_growfs /dev/mapper/centos-root
|
||||
# df -h
|
||||
|
||||

|
||||
|
||||
### 结论: ###
|
||||
|
||||
在 Linux CentOS 7 系统上,使用这篇文章所述的操作步骤来扩充您的任意逻辑卷的磁盘空间,此管理磁盘分区的操作过程是非常简单的。您不需要重启生产线上的服务器,只是简单的重扫描下 SCSI 设备,和扩展您想要的 LVM(逻辑卷管理)。我们希望这文章对您有用。可自由的发表有用的评论和建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/add-new-disk-centos-7-without-rebooting/
|
||||
|
||||
作者:[Kashif S][a]
|
||||
译者:[runningwater](https://github.com/runningwater
|
||||
)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,24 +1,22 @@
|
||||
translation by strugglingyouth
|
||||
How to Install MariaDB 10 on CentOS 7 CPanel Server
|
||||
|
||||
在 CentOS 7 CPanel 服务器上安装 MariaDB 10
|
||||
================================================================================
|
||||
|
||||
MariaDB is a enhanced open source and drop-in replacement for MySQL. It is developed by MariaDB community and available under the terms of the GPL v2 license. Software Security is the main focus for the MariaDB developers. They maintain its own set of security patches for each MariaDB releases. When any critical security issues are discovered, the developers introduces a new release of MariaDB to get the fix out as soon as possible.
|
||||
MariaDB 是一个增强版的,开源的并且可以直接替代 MySQL。它主要由 MariaDB 社区在维护,采用 GPL v2 授权许可。软件的安全性是 MariaDB 开发者的主要焦点。他们保持为 MariaDB 的每个版本发布安全补丁。当有任何安全问题被发现时,开发者会尽快修复并推出 MariaDB 的新版本。
|
||||
|
||||
MariaDB is always up-to-date with the latest MySQL releases. It is highly compatible and works exactly like the MySQL. Almost all commands, data, table definition files, Client APIs, protocols, interfaces, structures, filenames, binaries, ports, database storage locations etc are same as the MySQL. It isn't even needed to convert databases to switch to MariaDB.
|
||||
### MariaDB 的优势 ###
|
||||
|
||||
### Advantages of MariaDB ###
|
||||
- 完全开源
|
||||
- 快速且透明的安全版本
|
||||
- 与 MySQL 高度兼容
|
||||
- 性能更好
|
||||
- 比 MySQL 的存储引擎多
|
||||
|
||||
- Truly Open source
|
||||
- More quicker and transparent security releases
|
||||
- Highly Compatible with MySQL
|
||||
- Improved Performance
|
||||
- More storage engines compared to MySQL
|
||||
在这篇文章中,我将谈论关于如何升级 MySQL5.5 到最新的 MariaDB 在CentOS7 CPanel 服务器上。在安装前先完成以下步骤。
|
||||
|
||||
In this article, I provides guidelines on how to upgrade MySQL 5.5 to the latest MariaDB on a CentOS 7 CPanel server. Let's walk through the Pre-installation steps.
|
||||
### 先决条件: ###
|
||||
|
||||
### Pre-requisites: ###
|
||||
|
||||
#### 1. Stop current MySQL Service ####
|
||||
#### 1. 停止当前 MySQL 服务 ####
|
||||
|
||||
root@server1 [/var/# mysql
|
||||
Welcome to the MySQL monitor. Commands end with ; or \g.
|
||||
@ -47,9 +45,9 @@ In this article, I provides guidelines on how to upgrade MySQL 5.5 to the latest
|
||||
Jan 31 10:00:02 server1.centos7-test.com systemd[1]: Unit mysql.service entered failed state.
|
||||
Jan 31 10:00:02 server1.centos7-test.com systemd[1]: mysql.service failed.
|
||||
|
||||
#### 2. Move all configuration files and databases prior to the upgrade ####
|
||||
#### 2. 在升级之前将所有配置文件和数据库转移 ####
|
||||
|
||||
Move the DB storage path and MySQL configuration files
|
||||
转移数据库的存储路径和 MySQL 的配置文件
|
||||
|
||||
root@server1 [~]# cp -Rf /var/lib/mysql /var/lib/mysql-old
|
||||
|
||||
@ -62,18 +60,19 @@ Move the DB storage path and MySQL configuration files
|
||||
|
||||
root@server1 [~]#mv /etc/my.cnf /etc/my.cnf-old
|
||||
|
||||
#### 3. Remove and uninstall all MySQL rpms from the server ####
|
||||
#### 3. 从服务器上删除和卸载 MySQL 所有的 RPM 包 ####
|
||||
|
||||
Run the following commands to disable the MySQL RPM targets. By running this commands, cPanel will no longer handle MySQL updates, and mark these rpm.versions as uninstalled on the system.
|
||||
运行以下命令来禁用 MySQL 的 RPM 的目标。通过运行此命令,cPanel 将不再处理 MySQL 的更新,并在系统上将卸载的标记为 rpm.versions。
|
||||
|
||||
/scripts/update_local_rpm_versions --edit target_settings.MySQL50 uninstalled
|
||||
/scripts/update_local_rpm_versions --edit target_settings.MySQL51 uninstalled
|
||||
/scripts/update_local_rpm_versions --edit target_settings.MySQL55 uninstalled
|
||||
/scripts/update_local_rpm_versions --edit target_settings.MySQL56 uninstalled
|
||||
|
||||
Now run the this command:
|
||||
现在运行以下命令:
|
||||
|
||||
/scripts/check_cpanel_rpms --fix --targets=MySQL50,MySQL51,MySQL55,MySQL56 to remove all existing MySQL rpms on the server and leave a clean environment for MariaDB installation. Please see its output below:
|
||||
/scripts/check_cpanel_rpms --fix --targets=MySQL50,MySQL51,MySQL55,MySQL56
|
||||
移除服务器上所有已存在的 MySQL rpms 来为 MariaDB 的安装清理环境。请看下面的输出:
|
||||
|
||||
root@server1 [/var/lib/mysql]# /scripts/check_cpanel_rpms --fix --targets=MySQL50,MySQL51,MySQL55,MySQL56
|
||||
[2016-01-31 09:53:59 +0000]
|
||||
@ -98,13 +97,13 @@ Now run the this command:
|
||||
[2016-01-31 09:54:04 +0000] Removed symlink /etc/systemd/system/multi-user.target.wants/mysql.service.
|
||||
[2016-01-31 09:54:04 +0000] Restoring service monitoring.
|
||||
|
||||
With these steps, we've uninstalled existing MySQL RPMs, marked targets to prevent further MySQL updates and made the server ready and clean for the MariaDB installation.
|
||||
通过这些步骤,我们已经卸载了现有的 MySQL RPMs,并做了标记来防止 MySQL的更新,服务器的环境已经清理然后准备安装 MariaDB。
|
||||
|
||||
To startup with the installation, we need to create a yum repository for MariaDB depending on the MariaDB & CentOS versions. This is how I did it!
|
||||
开始安装吧,我们需要在 CentOS 为 MariaDB 创建一个 yum 软件库。下面是我的做法!
|
||||
|
||||
### Installation procedures: ###
|
||||
### 安装步骤: ###
|
||||
|
||||
#### Step 1: Creating a YUM repository. ####
|
||||
#### 第1步:创建 YUM 软件库。####
|
||||
|
||||
root@server1 [~]# vim /etc/yum.repos.d/MariaDB.repo
|
||||
[mariadb]
|
||||
@ -119,7 +118,7 @@ To startup with the installation, we need to create a yum repository for MariaDB
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
|
||||
#### Step 2: Open the /etc/yum.conf and modify the exclude line as below: ####
|
||||
#### 第2步:打开 /etc/yum.conf 并修改如下行: ####
|
||||
|
||||
**Remove this line** exclude=courier* dovecot* exim* filesystem httpd* mod_ssl* mydns* mysql* nsd* php* proftpd* pure-ftpd* spamassassin* squirrelmail*
|
||||
|
||||
@ -127,9 +126,9 @@ To startup with the installation, we need to create a yum repository for MariaDB
|
||||
|
||||
**\*\*\* IMPORTANT \*\*\***
|
||||
|
||||
We need to make sure, we've removed the MySQL and PHP from the exclude list.
|
||||
需要确保我们已经从 exclude 列表中移除了 MySQL 和 PHP。
|
||||
|
||||
#### Step 3: Run the following command to install MariaDB and related packages. ####
|
||||
#### 第3步:运行以下命令来安装 MariaDB 和相关的包。 ####
|
||||
|
||||
**yum install MariaDB-server MariaDB-client MariaDB-devel php-mysql**
|
||||
|
||||
@ -156,7 +155,7 @@ We need to make sure, we've removed the MySQL and PHP from the exclude list.
|
||||
===============================================================================================================================================
|
||||
Install 4 Packages (+5 Dependent package)
|
||||
|
||||
#### Step 4: Restart and make sure the MySQL service is up. ####
|
||||
#### 第4步:重新启动,并确保 MySQL 服务已启动。####
|
||||
|
||||
root@server1 [~]# systemctl start mysql
|
||||
root@server1 [~]#
|
||||
@ -173,9 +172,10 @@ We need to make sure, we've removed the MySQL and PHP from the exclude list.
|
||||
Jan 31 10:01:46 server1.centos7-test.com mysql[23717]: Starting MySQL SUCCESS!
|
||||
Jan 31 10:01:46 server1.centos7-test.com systemd[1]: Started LSB: start and stop MySQL.
|
||||
|
||||
#### Step 5: Run mysql_upgrade command ####
|
||||
#### 第5步:运行 mysql_upgrade 命令。 ####
|
||||
|
||||
它将检查所有数据库中的所有表与当前安装的版本是否兼容并在必要时会更新系统表采取新的特权或功能,可能会增加当前版本的性能。
|
||||
|
||||
It will examine all tables in all databases for incompatibilities with the current installed version and upgrades the system tables if necessary to take advantage of new privileges or capabilities that might have added with the current version.
|
||||
|
||||
root@server1 [~]# mysql_upgrade
|
||||
MySQL upgrade detected
|
||||
@ -254,7 +254,7 @@ It will examine all tables in all databases for incompatibilities with the curre
|
||||
Phase 6/6: Running 'FLUSH PRIVILEGES'
|
||||
OK
|
||||
|
||||
#### Step 6 : Restart the MySQL service once again to ensure everything works perfect. ####
|
||||
#### 第6步:再次重新启动MySQL的服务,以确保一切都运行完好。 ####
|
||||
|
||||
root@server1 [~]# systemctl restart mysql
|
||||
root@server1 [~]#
|
||||
@ -274,7 +274,7 @@ It will examine all tables in all databases for incompatibilities with the curre
|
||||
Jan 31 10:04:11 server1.centos7-test.com mysql[23854]: Starting MySQL. SUCCESS!
|
||||
Jan 31 10:04:11 server1.centos7-test.com systemd[1]: Started LSB: start and stop MySQL.
|
||||
|
||||
#### Step 7: Run EasyApache to rebuild Apache/PHP with MariaDB and ensure all PHP modules remains intact. ####
|
||||
#### 第7步:运行 EasyApache 用 MariaDB 重建 Apache/PHP,并确保所有 PHP 的模块保持不变。####
|
||||
|
||||
root@server1 [~]#/scripts/easyapache --build
|
||||
|
||||
@ -284,7 +284,7 @@ It will examine all tables in all databases for incompatibilities with the curre
|
||||
root@server1 [/etc/my.cnf.d]# php -v
|
||||
php: error while loading shared libraries: libmysqlclient.so.18: cannot open shared object file: No such file or directory
|
||||
|
||||
#### Step 8: Now verify the installation and databases. ####
|
||||
#### 第8步:现在验证安装的数据库。 ####
|
||||
|
||||
root@server1 [/var/lib/mysql]# mysql
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
@ -312,14 +312,13 @@ It will examine all tables in all databases for incompatibilities with the curre
|
||||
+--------------------+---------+----------------------------------------------------------------------------+--------------+------+------------+
|
||||
10 rows in set (0.00 sec)
|
||||
|
||||
That's all :). Now we're all set to go with MariaDB with its improved and efficient features. Hope you enjoyed reading this documentation. I would recommend your valuable suggestions and feedback on this!
|
||||
|
||||
就这样 :)。现在,我们该去欣赏 MariaDB 完善和高效的特点了。希望你喜欢阅读本文。希望留下您宝贵的建议和反馈!
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/install-mariadb-10-centos-7-cpanel/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,24 +0,0 @@
|
||||
Canonical的ZFS计划将会进入Ubuntu 16.04
|
||||
=======================================================
|
||||
|
||||

|
||||
|
||||
Ubuntu开发者正在为[Ubuntu 16.04 加上支持ZFS](http://www.phoronix.com/scan.php?page=news_item&px=ZFS-For-Ubuntu-16.04) ,并且所遇的文件系统支持都已经准备就绪。
|
||||
|
||||
Ubuntu 16.04的默认安装将会继续是ext4,但是ZFS支持将会自动构建进Ubuntu发布中,模块将在需要时自动加载,zfsutils-linux是Ubuntu的一部分,并且通过Canonical对商业客户提供支持
|
||||
|
||||
对于那些对Ubuntu中的ZFS感兴趣的人,Canonical的Dustin Kirkland已经写了[一篇新的博客](http://blog.dustinkirkland.com/2016/02/zfs-is-fs-for-containers-in-ubuntu-1604.html)覆盖了一些细节及为何“ZFS是Ubuntu 16.04中为容器使用的文件系统!”
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-ZFS-Continues-16.04&utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+Phoronix+%28Phoronix%29
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
意法半导体为 32 位 微控制器发布了一款自由的 Linux 集成开发环境
|
||||
=================================================
|
||||
|
||||

|
||||
|
||||
32 位微控制器世界向 Linux 敞开大门。本周,领先的 ARM Cortex-M 供应商意法半导体(ST)[发布了](http://www.st.com/web/en/press/p3781) 一款自由的 Linux 桌面版开发程序,该软件面向其旗下的 STM32 微控制单元(MCU)。包含了 ST 的 STM32CubeMX 配置器和初始化工具,以及其 STM32 [系统工作台(SW4STM32)](http://www.st.com/web/catalog/tools/FM147/CL1794/SC961/SS1533/PF261797) ,这个基于 Eclipse 的 IDE 由工具 Ac6 创建。支撑 SW4STM32 的工具链,论坛,博客以及技术会由 [openSTM32.org](http://www.openstm32.org/tiki-index.php?page=HomePage) 开发社区提供。
|
||||
|
||||
“Linux 社区以吸引富有创意的自由思想者而闻名,他们善于交流心得、高效地克服挑战。” Laurent Desseignes,意法半导体微控制器产品部,微控制器生态系统市场经理这么说道:“我们正着手做的是让他们能极端简单的借力 STM32 系列的特性和性能施展自己的才能,运用到富有想象力的新产品的创造中去。
|
||||
|
||||
Linux 是物联网(IoT)网关和枢纽,及高端 IoT 终端的领先平台。但是,大部分 IoT 革命,以及可穿戴设备市场基于小型的低功耗微控制器,对 Cortex-M 芯片的运用越来越多。虽然其中的一小部分可以运行精简的 uCLinux (见下文),却没能支持更全面的 Linux 发行版。取而代之的是实时操作系统(RTOS)们或者有时干脆不用 OS 来控制。固件的开发工作一般会在基于 Windows 的集成开发环境(IDE)上完成。
|
||||
|
||||
通过 ST 的自由工具,Linux 开发者们可以更容易的开疆拓土。ST 工具中的一些技术在第二季度应该登录 Mac OS/X 平台,与 [STM32 Nucleo](http://www.st.com/web/en/catalog/tools/FM146/CL2167/SC2003?icmp=sc2003_pron_pr-stm32f446_dec2014&sc=stm32nucleo-pr5) ,开发套件,以及评估板同时面世。Nucleo 支持 32 针, 64 针, 和 144 针的版本,并且提供类似 Arduino 连接器这样的插件。
|
||||
|
||||
STM32CubeMX 配置器和 IDE SW4STM32 使 Linux 开发者能够配置微控制器并开发调试代码。SW4STM32 支持在 Linux 下通过社区更改版的 [OpenOCD](http://openocd.org/) 使用调试工具 ST-LINK/V2。
|
||||
|
||||
据 ST 称,软件兼容 STM32Cube 软件包及标准外设库中的微控制器固件。目标是囊括 ST 的全系列 MCU,从入门级的 Cortex-M0 内核到高性能的 M7 芯片,包括 M0+,M3 和 DSP 扩展的 M4 内核。
|
||||
|
||||
ST 并非首个为 Linux 准备 Cortex-M 芯片 IDE 的 32 位 MCU 供应商,但似乎是第一大自由的 Linux 平台。例如NXP,MCU 的市场份额随着近期收购了 Freescale (Kinetis 系列 MCU,等)而增加,提供了一款 IDE [LPCXpresso IDE](http://www.nxp.com/pages/lpcxpresso-ide:LPCXPRESSO)支持 Linux 、Windows 和 Mac。然而,LPCXpresso 每份售价 $450。
|
||||
|
||||
在其 [SmartFusion FPGA 系统级芯片(SoC)](http://www.microsemi.com/products/fpga-soc/soc-processors/arm-cortex-m3)上集成了 Cortex-M3 芯片的Microsemi,拥有一款 IDE [Libero IDE](http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus#device-support)适用于 RHEL 和 Windows。然而,Libero 需求许可证,并且 RHEL 版缺乏如 FlashPro 和 SoftConsole 的插件。
|
||||
|
||||
## 为什么要学习 MCU?
|
||||
|
||||
即便 Linux 开发者并没有计划在 Cortex-M 上使用 uClinux,但是 MCU 的知识总会派上用场。特别是牵扯到复杂的 IoT 工程,需要扩展 MCU 终端至云端。
|
||||
|
||||
对于历程和业余爱好者的项目,Arduino 板为其访问 MCU 提供了非常便利的接口。然而历程之外,开发者常常就会用更快的 32 位 Cortex-M 芯片以及所带来的附加功能来替代 Arduino 板和板上的那块 8 位 MCU ATmega32u4。这些附加功能包括改进的存储器寻址,用于芯片和各种总线的独立时钟设置,以及芯片 [Cortex-M7](http://www.electronicsnews.com.au/products/stm32-mcus-with-arm-cortex-m7-processors-and-graph)自带的入门级显示芯片。
|
||||
|
||||
还有些可能需求 MCU 开发技术的地方有:可穿戴设备、低功耗、低成本和小尺寸给了 MCU 一席之地,还有机器人和无人机这些使用实时处理和电机控制的地方更为受用。在机器人上,你更是有可能看看 Cortex-A 与 Cortex-M 集成在同一个产品中的样子。
|
||||
|
||||
对于 SoC 芯片还有这样的一种温和的局势,即将 MCU 加入到 Linux 驱动的 Cortex-A 核心中,就如同 [NXP i.MX6 SoloX](http://linuxgizmos.com/freescales-popular-i-mx6-soc-sprouts-a-cortex-m4-mcu/)。虽然大多数的嵌入式项目并不使用这种混合型 SoC 或者说将应用处理器和 MCU 结合在同一产品中,但开发者会渐渐地发现自己工作的生产线、设计所基于的芯片正渐渐的从低端的 MCU 模块发展到 Linux 或安卓驱动的 Cortex-A。
|
||||
|
||||
## uClinux 是 Linux 在 MCU 领域的筹码
|
||||
|
||||
随着物联网的兴起,我们见到越来越多的 SBC 和模块计算机,它们在 32 位的 MCU 上运行着 uClinux。不同于其他的 Linux 发行版,uClinux 并不需要内存管理单元(MMU)。然而,uClinux 对市面上可见 MCU 有更高的内存需求。需求更高端的 Cortex-M4 和 Cortex-M4 微控制器内置内存控制器来支持外部 DRAM 芯片。
|
||||
|
||||
[Amptek](http://www.semiconductorstore.com/Amptek/) SBC 在 NXP LPC Cortex-M3 和 -M4 芯片上运行 uClinux,以提供常用的功能类似 WiFi、蓝牙、USB 等众多接口。Arrow 的 [SF2+](http://linuxgizmos.com/iot-dev-kit-runs-uclinux-on-a-microsemi-cortex-m3-fpga-soc/) 物联网开发套件将 uClinux 运行于 SmartFusion2 模块计算机的 Emcraft 系统上,该模块计算机是 Microsemi 的 166MHz Cortex-M3/FPGA SmartFusion2 混合 SoC。
|
||||
|
||||
[Emcraft](http://www.emcraft.com/) 销售基于 uClinux 的模块计算机,有 ST 和 NXP 的,也有 Microsemi 的 MCU,是 32 位 MCU 上积极推进 uClinux 的重要角色。日益频繁的 uClinux 开始了与 ARM 本身 [Mbed OS](http://linuxgizmos.com/arm-announces-mbed-os-for-iot-devices/)的对抗,至少在高端的 MCU 工程中需要无线通信和更为复杂的操作规则。Mbed 和 modern 的支持者,开源的 RTOS 们,类似 FreeRTOS 认为 uClinux 需要对 RAM 的需求太高以至于难以压低 IoT 终端的价格然而 Emcraft 与其他 uCLinux 拥趸表示价格并没有如此夸张,而且扩展 Linux 的无线和接口也是相当值得的,即使只是在像 uClinux 这样的精简版上。
|
||||
|
||||
当被问及对于这次 ST 发布的看法,Emcraft 的主任工程师 Vladimir Khusainov 表示:”ST决定将这款开发工具 移植至 Linux 对于 Emcraft 是个好消息,它使得 Linux 用户能轻易的在嵌入式 STM MCU 上展开工作。我们希望那些有机会熟悉 STM 设备,使用 ST 配置器和嵌入式库的用户可以对在目标机上使用嵌入式 Linux (以 uClinux 的形式)感兴趣。“
|
||||
|
||||
最近关于 Cortex-M4 上运行 uClinux 的概述,可以查看去年 Jim Huang 与 Jeff Liaws 在嵌入式 Linux 大会上使用的[幻灯片](http://events.linuxfoundation.org/sites/events/files/slides/optimize-uclinux.pdf)。更多关于 Cortex-M 处理器可以查看这里过的 [AnandTech 总结](http://www.anandtech.com/show/8400/arms-cortex-m-even-smaller-and-lower-power-cpu-cores)。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/news/embedded-mobile/mobile-linux/884961-st-releases-free-linux-ide-for-32-bit-mcus
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/42808
|
||||
@ -0,0 +1,210 @@
|
||||
[Translated] Haohong Wang
|
||||
如何在Ubuntu 15.04/CentOS 7中安装Lighttpd Web server
|
||||
=================================================================================
|
||||
Lighttpd 是一款开源Web服务器软件。Lighttpd 安全快速,符合行业标准,适配性强并且针对高配置环境进行了优化。Lighttpd因其CPU、内存占用小,针对小型CPU加载的快速适配以及出色的效率和速度而从众多Web服务器中脱颖而出。 而Lighttpd诸如FastCGI,CGI,Auth,Out-Compression,URL-Rewriting等高级功能更是那些低配置的服务器的福音。
|
||||
|
||||
以下便是在我们运行Ubuntu 15.04 或CentOS 7 Linux发行版的机器上安装Lighttpd Web服务器的简要流程。
|
||||
|
||||
### 安装Lighttpd
|
||||
|
||||
#### 使用包管理器安装
|
||||
|
||||
这里我们通过使用包管理器这种最简单的方法来安装Lighttpd。只需以sudo模式在终端或控制台中输入下面的指令即可。
|
||||
|
||||
**CentOS 7**
|
||||
|
||||
由于CentOS 7.0官方repo中并没有提供Lighttpd,所以我们需要在系统中安装额外的软件源epel repo。使用下面的yum指令来安装epel。
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
然后,我们需要更新系统及进程为Lighttpd的安装做准备。
|
||||
|
||||
# yum update
|
||||
# yum install lighttpd
|
||||
|
||||

|
||||
|
||||
**Ubuntu 15.04**
|
||||
|
||||
Ubuntu 15.04官方repo中包含了Lighttpd,所以只需更新本地repo并使用apt-get指令即可安装Lighttpd。
|
||||
|
||||
# apt-get update
|
||||
# apt-get install lighttpd
|
||||
|
||||

|
||||
|
||||
#### 从源代码安装Lighttpd
|
||||
|
||||
如果想从Lighttpd源码安装最新版本(例如1.4.39),我们需要在本地编译源码并进行安装。首先我们要安装编译源码所需的依赖包。
|
||||
|
||||
# cd /tmp/
|
||||
# wget http://download.lighttpd.net/lighttpd/releases-1.4.x/lighttpd-1.4.39.tar.gz
|
||||
|
||||
下载完成后,执行下面的指令解压缩。
|
||||
|
||||
# tar -zxvf lighttpd-1.4.39.tar.gz
|
||||
|
||||
然后使用下面的指令进行编译。
|
||||
|
||||
# cd lighttpd-1.4.39
|
||||
# ./configure
|
||||
# make
|
||||
|
||||
**注:**在这份教程中,我们安装的是默认配置的Lighttpd。其他诸如高级功能或拓展功能,如对SSL的支持,mod_rewrite,mod_redirect等,需自行配置。
|
||||
|
||||
当编译完成后,我们就可以把它安装到系统中了。
|
||||
|
||||
# make install
|
||||
|
||||
### 设置Lighttpd
|
||||
|
||||
如果有更高的需求,我们可以通过修改默认设置文件,如`/etc/lighttpd/lighttpd.conf`,来对Lighttpd进行进一步设置。 而在这份教程中我们将使用默认设置,不对设置文件进行修改。如果你曾做过修改并想检查设置文件是否出错,可以执行下面的指令。
|
||||
|
||||
# lighttpd -t -f /etc/lighttpd/lighttpd.conf
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
在CentOS 7中,我们需在Lighttpd默认设置中创设一个例如`/src/www/htdocs`的webroot文件夹。
|
||||
|
||||
# mkdir -p /srv/www/htdocs/
|
||||
|
||||
而后将默认欢迎页面从`/var/www/lighttpd`复制至刚刚新建的目录中:
|
||||
|
||||
# cp -r /var/www/lighttpd/* /srv/www/htdocs/
|
||||
|
||||
### 开启服务
|
||||
|
||||
现在,通过执行systemctl指令来重启数据库服务。
|
||||
|
||||
# systemctl start lighttpd
|
||||
|
||||
然后我们将它设置为伴随系统启动自动运行。
|
||||
|
||||
# systemctl enable lighttpd
|
||||
|
||||
### 设置防火墙
|
||||
|
||||
如要让我们运行在Lighttpd上的网页和网站能在Internet或相似的网络上被访问,我们需要在防火墙程序中设置打开80端口。由于CentOS 7和Ubuntu15.04都附带Systemd作为默认初始化系统,所以我们安装firewalld作为解决方案。如果要打开80端口或http服务,我们只需执行下面的命令:
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
success
|
||||
# firewall-cmd --reload
|
||||
success
|
||||
|
||||
### 连接至Web Server
|
||||
在将80端口设置为默认端口后,我们就可以默认直接访问Lighttpd的欢迎页了。我们需要根据运行Lighttpd的设备来设置浏览器的IP地址和域名。在本教程中,我们令浏览器指向 [http://lighttpd.linoxide.com/](http://lighttpd.linoxide.com/) 同时将子域名指向它的IP地址。如此一来,我们就可以在浏览器中看到如下的欢迎页面了。
|
||||
|
||||

|
||||
|
||||
此外,我们可以将网站的文件添加到webroot目录下,并删除lighttpd的默认索引文件,使我们的静态网站链接至互联网上。
|
||||
|
||||
如果想在Lighttpd Web Server中运行PHP应用,请参考下面的步骤:
|
||||
|
||||
### 安装PHP5模块
|
||||
在Lighttpd成功安装后,我们需要安装PHP及相关模块以在Lighttpd中运行PHP5脚本。
|
||||
|
||||
#### 使用 Ubuntu 15.04
|
||||
|
||||
# apt-get install php5 php5-cgi php5-fpm php5-mysql php5-curl php5-gd php5-intl php5-imagick php5-mcrypt php5-memcache php-pear
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
# yum install php php-cgi php-fpm php-mysql php-curl php-gd php-intl php-pecl-imagick php-mcrypt php-memcache php-pear lighttpd-fastcgi
|
||||
|
||||
### 设置Lighttpd的PHP服务
|
||||
|
||||
如要让PHP与Lighttpd协同工作,我们只要根据所使用的发行版执行如下对应的指令即可。
|
||||
|
||||
#### 使用 CentOS 7
|
||||
|
||||
首先要做的便是使用文件编辑器编辑php设置文件(例如`/etc/php.ini`)并取消掉对**cgi.fix_pathinfo=1**的注释。
|
||||
|
||||
# nano /etc/php.ini
|
||||
|
||||
完成上面的步骤之后,我们需要把PHP-FPM进程的所有权从Apache转移至Lighttpd。要完成这些,首先用文件编辑器打开`/etc/php-fpm.d/www.conf`文件。
|
||||
|
||||
# nano /etc/php-fpm.d/www.conf
|
||||
|
||||
然后在文件中增加下面的语句:
|
||||
|
||||
user = lighttpd
|
||||
group = lighttpd
|
||||
|
||||
做完这些,我们保存并退出文本编辑器。然后从`/etc/lighttpd/modules.conf`设置文件中添加FastCGI模块。
|
||||
|
||||
# nano /etc/lighttpd/modules.conf
|
||||
|
||||
然后,去掉下面语句前面的`#`来取消对它的注释。
|
||||
|
||||
include "conf.d/fastcgi.conf"
|
||||
|
||||
最后我们还需在文本编辑器设置FastCGI的设置文件。
|
||||
|
||||
# nano /etc/lighttpd/conf.d/fastcgi.conf
|
||||
|
||||
在文件尾部添加以下代码:
|
||||
|
||||
fastcgi.server += ( ".php" =>
|
||||
((
|
||||
"host" => "127.0.0.1",
|
||||
"port" => "9000",
|
||||
"broken-scriptfilename" => "enable"
|
||||
))
|
||||
)
|
||||
|
||||
在编辑完成后保存并退出文本编辑器即可。
|
||||
|
||||
#### 使用 Ubuntu 15.04
|
||||
|
||||
如需启用Lighttpd的FastCGI,只需执行下列代码:
|
||||
|
||||
# lighttpd-enable-mod fastcgi
|
||||
|
||||
Enabling fastcgi: ok
|
||||
Run /etc/init.d/lighttpd force-reload to enable changes
|
||||
|
||||
# lighttpd-enable-mod fastcgi-php
|
||||
|
||||
Enabling fastcgi-php: ok
|
||||
Run `/etc/init.d/lighttpd` force-reload to enable changes
|
||||
|
||||
然后,执行下列命令来重启Lighttpd。
|
||||
|
||||
# systemctl force-reload lighttpd
|
||||
|
||||
### 检测PHP工作状态
|
||||
|
||||
如需检测PHP是否按预期工作,我们需在Lighttpd的webroot目录下新建一个php文件。本教程中,在Ubuntu下/var/www/html 目录,CentOS下/src/www/htdocs目录下使用文本编辑器创建并打开info.php。
|
||||
|
||||
**使用 CentOS 7**
|
||||
|
||||
# nano /var/www/info.php
|
||||
|
||||
**使用 Ubuntu 15.04**
|
||||
|
||||
# nano /srv/www/htdocs/info.php
|
||||
|
||||
然后只需将下面的语句添加到文件里即可。
|
||||
|
||||
<?php phpinfo(); ?>
|
||||
|
||||
在编辑完成后保存并推出文本编辑器即可。
|
||||
|
||||
现在,我们需根据路径 [http://lighttpd.linoxide.com/info.php](http://lighttpd.linoxide.com/info.php) 下的info.php文件的IP地址或域名,来让我们的网页浏览器指向系统上运行的Lighttpd。如果一切都按照以上说明进行,我们将看到如下图所示的PHP页面信息。
|
||||
|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
至此,我们已经在CentOS 7和Ubuntu 15.04 Linux 发行版上成功安装了轻巧快捷并且安全的Lighttpd Web服务器。现在,我们已经可以利用Lighttpd Web服务器来实现上传网站文件到网站根目录,配置虚拟主机,启用SSL,连接数据库,运行Web应用等功能了。 如果你有任何疑问,建议或反馈请在下面的评论区中写下来以让我们更好的改良Lighttpd。谢谢!(译注:评论网址 http://linoxide.com/linux-how-to/setup-lighttpd-web-server-ubuntu-15-04-centos-7/ )
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-lighttpd-web-server-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[HaohongWANG](https://github.com/HaohongWANG)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,31 @@
|
||||
Manjaro Linux 即将推出支持 ARM 处理器的 Manjaro-ARM
|
||||
===================================================
|
||||
|
||||

|
||||
|
||||
最近,Manjaro 的开发者为 ARM 处理器发布了一个[ alpha 版本](https://manjaro.github.io/Manjaro-ARM-launched/)。这是这个基于 Arhclinux 的发行版的一大进步,在此之前,它只能在 32 位或者 64 位的个人电脑上运行。
|
||||
|
||||
根据公告, “[Manjaro Arm](http://manjaro-arm.org/) 项目致力于将简洁可定制的 Manjaro 移植到使用[ ARM 处理器](https://www.arm.com/)的设备上去。这些设备的数量正在上涨并且应用范围广泛。这些设备中最出名的是树莓派和 BeagleBoard“。目前 Alpha 版本仅支持树莓派2,但是毫无疑问,支持的设备数量会随时间增长。
|
||||
|
||||
现在这个项目的开发者有 dodgejcr, Torei, Strit, 和 Ringo32。他们正在寻求更多的人来帮助这个项目发展。除了开发者,[他们还在寻找维护者,论坛版主,管理员,以及设计师](http://manjaro-arm.org/forums/website/looking-for-contributors/?PHPSESSID=876d5c11400e9c25eb727e9965300a9a)。
|
||||
|
||||
Manjaro-ARM 将会有四个版本。媒体版本将可以运行Kodi并且允许你很少配置就能创建一个媒体中心。服务器版将会预先配置好 SSH,FTP,LAMP ,你能把你的 ARM 设备当作服务器使用。基本版是一个桌面版本,自带一个 XFCE 桌面。如果你想自己从头折腾系统的话你可以选择迷你版,它没有任何预先配置的包,仅仅包含一个 root 用户。
|
||||
|
||||
## 我的想法
|
||||
|
||||
作为一个 Manjaro 的粉丝(我在 4 个电脑上都安了 Manjaro),听说他们分支出一个 ARM 版我很高兴。 ARM 处理器被用到了越来越多的设备当中。如同评论员 Robert Cringely 所说, [设备制造商开始注意到昂贵的因特尔或者AMD处理器之外的便宜的多的ARM处理器](http://www.cringely.com/2016/01/21/prediction-8-intel-starts-to-become-irrelevent/)。甚至微软(憋打我)都开始考虑将自己的一些软件移植到 ARM 处理器上去。随着 ARM 处理器设备数量的增多,Manjaro 将会带给用户良好的体验。
|
||||
|
||||
对此,你怎样看待?你希望更多的发行版支持 ARM 吗?或者你认为 ARM 将是昙花一现?在评论区告诉我们。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manjaro-linux-arm/
|
||||
|
||||
作者:[JOHN PAUL][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/john/
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
【免费下载】初学者Vi备忘单
|
||||
================================================
|
||||
|
||||

|
||||
|
||||
一直以来,我都在给你们分享我使用Linux的经验。今天我想分享我的**Vi备忘单**。这份备忘单节省了我很多时间,因为我再也不用使用Google去搜索这些命令了。
|
||||
|
||||
## Basic Vi commands
|
||||
## 基本Vi命令
|
||||
|
||||
这并不是一个详尽的教程来教你[Vi编辑器](https://en.wikipedia.org/wiki/Vi)的每一个方面。事实上,这根本就不是一个教程。这仅仅是一些基本Vi命令以及这些命令简单介绍的集合。
|
||||
|
||||
命令|解释
|
||||
:--|:--
|
||||
:x |保存文件并退出
|
||||
:q!|退出但不保存文件
|
||||
i|在光标左侧插入
|
||||
a|在光标右侧插入
|
||||
ESC|退出插入模式
|
||||
arrows|移动光标
|
||||
/text|搜索字符串text(大小写敏感)
|
||||
n|跳到下一个搜索结果
|
||||
x|删除当前光标处的字符
|
||||
dd|删除当前光标所在的行
|
||||
u|撤销上次改变
|
||||
:0|将光标移动到文件开头
|
||||
:n|将光标移动到第n行
|
||||
G|将光标移动到文件结尾
|
||||
^|将光标移动到该行开头
|
||||
$|将光标移动到该行结尾
|
||||
:set list|查看文件中特殊字符
|
||||
yy|复制光标所在行
|
||||
5yy|复制从光标所在行开始的5行
|
||||
p|在光标所在行下面粘贴
|
||||
|
||||
你可以通过下面的链接下载PDF格式的Vi备忘录:
|
||||
|
||||
[下载Vi备忘录](https://drive.google.com/file/d/0By49_3Av9sT1X3dlWkNQa3g2b2c/view?usp=sharing)
|
||||
|
||||
你可以把它打印出来放到你的办公桌上,或者把它保存到你的电脑上来使用。
|
||||
|
||||
## 我为什么要建立这个Vi备忘录?
|
||||
|
||||
几年前,当我刚刚接触Linux终端时,使用命令行编辑器这个主意使我一惊。我之前在我自己的电脑上使用过桌面版本的Linux,所以我很乐意使用像Gedit这样的有图形界面的编辑器。但是在工作环境中,我不得不使用命令行,并且无法使用图形界面版的编辑器。
|
||||
|
||||
我就这么被强迫地使用Vi来对远程Linux终端上的文件做一些基本的编辑。从这时候我开始了解并钦佩Vi的强大之处。
|
||||
|
||||
因为在那时候我还是一个Vi新手,所以我经常对Vi一些操作很困惑。仍然记得第一次使用Vi的时候,由于我不知道如何退出Vi,所以我都无法关闭某个文件。我也只能通过Google搜索来找到解决办法。我不得不接受这个尴尬的事实。
|
||||
|
||||
从那以后,我就决定制作一个列表来列出我经常会用到的基本Vi操作。这个列表,或者你可能称它为备忘录。在我早期使用Vi的时候,它对我非常有用。慢慢地,我对Vi更加熟悉,我已经可以熟记那些基本编辑命令。到现在,我甚至不需要再去查看我的Vi备忘录了。
|
||||
|
||||
## 你为什么需要Vi备忘录?
|
||||
|
||||
我能理解一个刚刚接触Vi的人的感受。你最喜欢的Ctrl+S快捷键不能像在其他编辑器那样方便地保存文件。Ctrl+C和Ctrl+V理应是通用的用来复制和粘贴的快捷键,但是在Vi中却不是这样。
|
||||
|
||||
很多人都在使用类似的备忘录帮助他们熟悉各种编程语言以及用来进行快速检索的“/”工具。相信我,使用备忘录会给程序员日常工作带来很大便利。
|
||||
|
||||
如果你刚刚开始接触Vi或者你经常使用但是总是记不住Vi操作,那么这份Vi备忘录对于你来说是非常有用的。你可以把它保存下来留作以后查询使用。
|
||||
|
||||
## 你怎么看待这份备忘录?
|
||||
|
||||
至今为止,我一直在克制我自己不要过于以来终端。我想知道你是怎么发现这篇文章的?你是否想让我分享更多类似的备忘录出来以供你们下载?我很期待你的意见和建议。
|
||||
|
||||
------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/download-vi-cheat-sheet/
|
||||
|
||||
作者:[ABHISHEK][a]
|
||||
译者:[JonathanKang](https://github.com/JonathanKang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,32 @@
|
||||
并行文件系统 BeeGFS 现已开源
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
今天(2月23日) ThinkParQ 宣布完整的 [BeeGFS 并行文件系统][1] 的源码现已开源。由于 BeeGFS 是专为要求性能的环境开发的,所以它在开发时十分注重安装的简单以及高度的灵活性,包括融合了在存储服务器同时做计算任务时需要的设置。随着系统中的服务器以及存储设备的增加,文件系统的容量以及性能将是需求的拓展点,无论是小型集群还是多达上千个节点的企业级系统。
|
||||
|
||||
第一次官方声明开放 BeeGFS 的源码是在 2013 年的国际超级计算大会上发布的。这个声明是在欧洲的百亿亿次级超算项目 [DEEP-ER][2] 的背景下做出的,在这个项目里为了得到更好的 I/O 要求,一些微小的进步被设计并应用。对于运算量高达百亿亿次的系统,不同的软硬件必须有效的协同工作才能得到最佳的拓展性。因此,开源 BeeGFS 是让一个百亿亿次的集群的所有组成部分高效的发挥作用的一步。
|
||||
|
||||
“当我们的一些用户对于 BeeGFS 十分容易安装并且不用费心管理而感到高兴时,另外一些用户则想要知道它是如何运行的以便于更好的优化他们的应用,使得他们可以监控它或者把它移植到其他的平台上,比如 BSD,” Sven Breuner 说道,他是 ThinkParQ (BeeGFS 背后的公司)的 CEO,“而且,把 BeeGFS 移植到其他的非 X86 架构,比如 ARM 或者 Power,也是社区等着要做的一件事。”
|
||||
|
||||
对于未来的采购来说,ARM 技术的稳步发展确实使得它成为了一个越来越有趣的技术。因此, BeeGFS 的团队也参与了 [ExaNeSt][3],一个来自欧洲的新的百亿亿次级超算计划,这个计划致力于使 ARM 的生态能为高性能的工作负载做好准备。“尽管现在 BeeGFS 在 ARM 处理器上可以算是开箱即用,这个项目也将给我们机会来证明我们在这个架构上也能完全发挥其性能。”, Bernd Lietzow , BeeGFS 中 ExaNeSt 的领导者补充道。
|
||||
|
||||
作为一个有着 25 K 行 C++ 代码的元数据服务以及约 15 K 行存储服务的项目,BeeGFS 相对比较容易理解和拓展,不只是对于大神,对于对文件系统有兴趣的大学生也是这样。在 GitHub 上已经有很多的为 BeeGFS 写的项目,比如基于浏览器的监控或者 Docker 一体化。
|
||||
|
||||
有关新闻显示, [BeeGFS 用户大会][4]将于 5 月 18-19 日在德国凯泽斯劳滕举行。
|
||||
|
||||
-----------------------------------------------------------------------------------------
|
||||
|
||||
via: http://insidehpc.com/2016/02/beegfs-parallel-file-system-now-open-source/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+InsideHPC+%28insideHPC.com%29
|
||||
|
||||
作者:[staff][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://insidehpc.com/author/staff/
|
||||
[1]: http://www.beegfs.com/
|
||||
[2]: http://www.deep-project.eu/deep-project/EN/Home/home_node.html
|
||||
[3]: http://www.exanest.eu/
|
||||
[4]: http://www.beegfs.com/content/user-meeting-2016/
|
||||
@ -0,0 +1,34 @@
|
||||
Intel展示了带动大屏幕Linux的便宜Android手机
|
||||
==============================================================
|
||||
|
||||
|
||||
|
||||
在世界移动会议**MWC16**上Intel展示了称之为“大屏体验”的一款的Android智能手机,它在插入一个外部显示后运行了一个完整的Linux桌面。
|
||||
|
||||
这个概念大体上与微软在Windows 10手机中的Continuum相似,但是Continuum面向的是高端设备,Intel的项目面向的是低端智能机何新兴市场。
|
||||
|
||||
显示上Barcelona是拥有Atom x3、2GB RAM和16GB存储以及支持外部显示的的SoFIA(Intel架构的只能或功能手机)智能机原型。插上键盘、鼠标何显示,它就变成了一台桌面Linux,可以选择在大屏幕中显示Android桌面。
|
||||
|
||||
Intel的拓荒小组经理Nir Metzer告诉Reg:“Android基于Linux内核,因此我们运行的是一个内核,我们有一个Android栈和一个Linux栈,并且我们共享一个上下文,因此文件系统是相同的。电话是全功能的。”
|
||||
|
||||
Metzer说:“我有一个多窗口环境。只要我插入后就可以做电子表格,我可以拖拽、播放音频。在一个低端平台实现这一切是一个挑战。”
|
||||
|
||||
现在当连上外部显示器时设备的屏幕显示的空白,但是Metzer说下个版本的Atom X3会支持双显示。
|
||||
|
||||
使用的Linux版本是由Intel维护的。Metzer说:“我们需要将Linux和Android保持一致。框架是预安装的,你不能下载任何app”
|
||||
|
||||
英特尔在移动世界大会上向手机制造商们推销这一想法,但却没有实际报告购买该设备的消费者。Metzer说:“芯片已经准备好了,已经为量产准备好了。这可以明天进入生产。这是一个商业决定。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theregister.co.uk/2016/02/23/move_over_continuum_intel_shows_android_smartphone_powering_bigscreen_linux/
|
||||
|
||||
作者:[Tim Anderson][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theregister.co.uk/Author/2878
|
||||
|
||||
|
||||
156
translated/tech/20160225 The Tao of project management.md
Normal file
156
translated/tech/20160225 The Tao of project management.md
Normal file
@ -0,0 +1,156 @@
|
||||
项目管理之道
|
||||
=================================
|
||||
|
||||
|
||||

|
||||
|
||||
[道德经][1],[据确认][2]为公元前六世纪的圣人[老子][3]所编写,是现存被翻译的语言版本最多的经文。从[宗教][4]到[关于约会的有趣电影][5]等一切的一切,它都影响至深,作者们借用它来隐喻,以解释各种各样的事情(甚至是[编程][6])。
|
||||
|
||||
当考虑开放性组织的项目管理时上面这段文字会立马浮现在我脑海。
|
||||
|
||||
这听起来会很奇怪。要理解我为什么会有这种想法,应该是从读了*《开放性组织:点燃激情提升执行力》*这书开始的,它是红帽公司总裁、CEO Jim Whitehurst 所著作的关于企业文化和新领导榜样的宣言。在这本书里,Jim(给予其它红帽子人的一点帮助而) 解释了传统组织机构(“自上而下”的方式,做决定的是高层,命令下达到员工,而员工是通过薪酬和晋升来激励的)和开放组织机构(自下而上,领导专注于激励和鼓励,员工被充分授权使其发挥主观能动性而做得最好)的差异。
|
||||
|
||||
在开放性组织中的员工意味有激情、有目的性和有参与感,这些我认为是项目管理者应该关注的。
|
||||
|
||||
要解释这一切,让我们回到*道德经*上来。
|
||||
|
||||
### 不要让工作职衔框住自身
|
||||
|
||||
>道,可道,
|
||||
>非常道;
|
||||
>名,可名,
|
||||
>非常名。
|
||||
|
||||
>无,名天地之始;
|
||||
>有,名万物之母。
|
||||
[[1]][7]
|
||||
|
||||
项目管理到底是什么?做为一个项目管理者应该做些什么呢?
|
||||
|
||||
如您所想,项目管理者的一部分工作就是管理项目:收集需求、项目相关人员的沟通、设置项目优先级、安排任务、帮助团队解决困扰。许多教育培训机构都可以教授如何做好项目管理,这些技能值得去学习。
|
||||
|
||||
然而,在开放性组织中,字面上的项目管理技能仅仅只是项目管理者需要做到一小部分,这些组织需要更多的:勇气。如果您擅长于管理项目(或者是真的擅长于任何工作),那么您就进入了舒适区。这时候就是需要鼓起勇气开始尝试冒险之时。
|
||||
|
||||
您有勇气跨出舒适区吗?向权威人士提出提出挑战性问题,可能会引发对方的不快,也可能会发现一个好的方法,您有勇气这样做吗?有确定需要做的下一件事,然后真正去完成它的勇气吗?有主动去解决因为沟通空白而留下的问题的勇气吗?有去尝试各种事情的勇气吗?有失败的勇气吗?
|
||||
|
||||
道德经的开篇(上面引用的)就表明词语、标签、名字这些是有限制的,也包括工作职衔。在开放性组织中,项目经理不仅仅是执行管理项目所需的机械任务,而且要帮助团队完成组织的使命,尽管只是定义。
|
||||
|
||||
### 结交正确的人
|
||||
|
||||
>三十辐共一毂,
|
||||
>当其无,
|
||||
>有车之用。
|
||||
[[11]][8]
|
||||
|
||||
当我开始学习要过渡到项目管理时,遇到最困难的一课就是并不是所有解决方案都是可接受的,甚至有的连预期都达不到。那对我来说是全新的,我喜欢所有的解决方案。但作为项目管理者,我的角色更多的是与人沟通--因此与那些有解决方案的人合作更有效率。
|
||||
|
||||
这决不是逃避责任和不负责的意思。这意味着可以很舒适的说,“我不知道,但我会给您找出答案”,然后就可迅速的关闭此循环。
|
||||
|
||||
想像马车的车轮。无中心孔的稳定性和方向,辐条车轮会自行崩溃。在一个开放性的组织中,项目管理者可以帮助一个团队,把正确的人凝聚在一起,主持积极讨论,以保持团队一直前进。
|
||||
|
||||
### 信任您的团队
|
||||
|
||||
>太上, 不知有之;
|
||||
>其次,亲而誉之;
|
||||
>其次,畏之;
|
||||
>其次,侮之。
|
||||
>
|
||||
>信不足焉,有不信焉。
|
||||
>
|
||||
>悠兮,其贵言。功成事遂,百姓皆谓“我自然”。
|
||||
[[17]][9]
|
||||
|
||||
[Rebecca Fernandez][10]曾经告诉我开放性组织的领导与其它最大的不同点,不是取得别人的信任,而是信任别人。
|
||||
|
||||
开放性组织会雇佣那些非常聪明的,且对公司正在做的事情充满激情的人来做工作。为了能使他们能更好的工作,我们会提供其所需,并尊重他们的工作方式。
|
||||
|
||||
至于原因,我认为从道德经中摘出的上面一段就说的很清楚。
|
||||
|
||||
### 顺其自然
|
||||
|
||||
>上德无为而无以为;下德为之而有以为。
|
||||
[[38]][11]
|
||||
|
||||
你认识总是忙忙碌碌的这种类型的人吗?认识因为有太多事情要做而看起来疲倦和压抑的人吗?
|
||||
|
||||
不要成为那样的人。
|
||||
|
||||
我知道说比做容易。要远离那种人最有帮助的事就是请记住大家都很忙。我没有那样讨厌的同事。
|
||||
|
||||
但需要有人在狂风暴雨中保持镇定;需要这样的人,能根据实际和一天工作时间的数量找到平衡参数的方式来做工作,并安慰团队让一切都好(因为这是我们正在做的事实)。
|
||||
|
||||
要成为那样的人。
|
||||
|
||||
道德经所说的,在我理解来就是总是夸夸其谈的人其实并没有干实事。如里您能把工作做的得心应手的话,那就说明您的工作做对了。
|
||||
|
||||
### 作为一个文化传教士
|
||||
|
||||
>上士闻道,勤而行之;
|
||||
>中士闻道,若存若亡;
|
||||
>下士闻道,大笑之。
|
||||
>不笑不足以为道。
|
||||
[[41]][12]
|
||||
|
||||
去年秋天,我跟着一群联邦雇员注册了一个工商管理硕士课程。当我开始介绍我公司的文化、价值和伦理框架以及公司如何运行时,我的同学和教授都认为我就像一个天真可爱的小姑娘在做着[许多甜美的白日梦][13],这就是我得到的直接印象。他们告诉我事情并不是如此的。他们告诉我应该进一步考察。
|
||||
|
||||
所有我照做了。
|
||||
|
||||
到现在我发现:正是如此。
|
||||
|
||||
开放性组织的企业文化。应该跟随着企业的成长而时时维护那些文化,以使它随时精神焕发,充满斗志。我(和其它开源组织的成员)并不想过如我同学所描述的“为生活而工作”。我需要有激情和有目的性;我需要明白自己的日常工作如何对那些有价值的东西服务。
|
||||
|
||||
作为一个项目管理者,虽然你的工作与培养你的团队的文化无关,但是工作本身就是文化。
|
||||
|
||||
### 持续改善
|
||||
|
||||
>为学日益,
|
||||
>为道日损,
|
||||
>损之又损,以至于无为。无为而无不为,取天下常以无事
|
||||
[[48]][14]
|
||||
|
||||
虽然项目管理的一般领域都太过于专注最新最强大的的工具,但是您应该使用哪种工具这问题的答案总是一致的:“最简单的”。
|
||||
|
||||
例如,我将任务列表放在桌面的一个文本文件中,因为它很单纯,没有不必要的干扰。您想介绍给团队的,无论是何种工具、流程和程序都应该是能提高效率,排除障碍的,而不是引入额外的复杂性。所以不应该专注于工具本身,而应该专注于使用这些工具来解决的问题。
|
||||
|
||||
我最喜欢的一个项目经理在一个灵活的世界是有自由扔什么不工作。在 Agile world 中我喜欢项目管理者能自由的做决定,抛出不能做的工作。这就是改善的概念,或叫“持续改进”。不要害怕尝试和失败。失败是我们在学习的过程中所用的标签,不能代表什么,但这是提高的唯一方式。
|
||||
|
||||
|
||||
最好的过程都不是一蹴而就的。作为项目管理者,您应该帮助您的团队,支持团队让其自己提升,而不是强迫团队。
|
||||
|
||||
### 实践
|
||||
|
||||
>天下皆谓我"道"大,似不肖。夫唯大,故似不肖。若肖,久矣其细也夫!
|
||||
[[67]][15]
|
||||
|
||||
我相信开放性组织正在做的。开放性组织在管理领域的工作几乎和他们所提供的产品和服务一样重要。我们有机会以身作则,激发他人的激情和目的,创造激励和充分授权的工作环境。
|
||||
|
||||
我鼓励您们找到办法把这些想法融入到自己的项目和团队中,看看会发生什么。了解组织的使命和您的项目怎么样帮助它们。鼓起勇气,尝试一些不好的事情,同时不要忘记和我们的社区分享你所学到的经验,这样我们就可以继续改进。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/16/2/tao-project-management
|
||||
|
||||
作者:[Allison Matlack][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/amatlack
|
||||
[1]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html
|
||||
[2]: https://en.wikipedia.org/wiki/Tao_Te_Ching
|
||||
[3]: http://plato.stanford.edu/entries/laozi/
|
||||
[4]: https://en.wikipedia.org/wiki/Taoism
|
||||
[5]: http://www.imdb.com/title/tt0234853/
|
||||
[6]: http://www.mit.edu/~xela/tao.html
|
||||
[7]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#1
|
||||
[8]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#11
|
||||
[9]:http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#17
|
||||
[10]: https://opensource.com/users/rebecca
|
||||
[11]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#38
|
||||
[12]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#41
|
||||
[13]: https://opensource.com/open-organization/15/9/reflections-open-organization-starry-eyed-dreamer
|
||||
[14]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#48
|
||||
[15]: http://acc6.its.brooklyn.cuny.edu/~phalsall/texts/taote-v3.html#67
|
||||
|
||||
41
选题模板.txt
Normal file
41
选题模板.txt
Normal file
@ -0,0 +1,41 @@
|
||||
选题标题格式:
|
||||
|
||||
原文日期 标题.md
|
||||
|
||||
正文内容:
|
||||
|
||||
标题
|
||||
=======
|
||||
|
||||
### 子一级标题
|
||||
|
||||
正文
|
||||
|
||||
#### 子二级标题
|
||||
|
||||
正文内容
|
||||
|
||||

|
||||
|
||||
### 子一级标题
|
||||
|
||||
正文内容 : I have a [dream][1]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: 原文地址
|
||||
|
||||
作者:[作者名][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: 作者介绍地址
|
||||
[1]: 引文链接地址
|
||||
|
||||
说明:
|
||||
1. 标题层级很多时从 “##” 开始
|
||||
2. 引文链接地址在下方集中写
|
||||
|
||||
Loading…
Reference in New Issue
Block a user