mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-22 23:00:57 +08:00
commit
4e229e50b4
@ -1,17 +1,21 @@
|
||||
如何在Linux的终端测试网速
|
||||
======
|
||||
学习如何在Linux终端使用命令行工具测试网速,或者仅用一条python命令立刻获得网速的测试结果。
|
||||
|
||||
> 学习如何在 Linux 终端使用命令行工具 `speedtest` 测试网速,或者仅用一条 python 命令立刻获得网速的测试结果。
|
||||
|
||||
![在Linux终端测试网速][1]
|
||||
|
||||
我们都会在连接网络或者wifi的时候去测试网络带宽。 为什么不用我们自己的服务器!下面将会教你如何在Linux终端测试网速。
|
||||
我们都会在连接到一个新的网络或者 WIFI 的时候去测试网络带宽。 为什么不用我们自己的服务器!下面将会教你如何在 Linux 终端测试网速。
|
||||
|
||||
我们多数都会使用[Mb/s][2]标准来测试网速。 仅仅只是桌面上的一个简单的操作,访问他们的网站点击浏览。
|
||||
它将使用最近的服务器来扫描你的本地主机来测试网速。 如果你使用的是移动设备,他们有对应的移动端APP。但如果你使用的是只有命令行终端界面的则会有些不同。下面让我们一起看看如何在Linux的终端来测试网速。
|
||||
如果你只是想偶尔的做一次网速测试而不想去下载测试工具,那么请往下看如何使用命令完成测试。
|
||||
我们多数都会使用 [Ookla 的 Speedtest][2] 来测试网速。 这在桌面上是很简单的操作,访问他们的网站点击“Go”浏览即可。它将使用最近的服务器来扫描你的本地主机来测试网速。 如果你使用的是移动设备,他们有对应的移动端 APP。但如果你使用的是只有命令行终端,界面的则会有些不同。下面让我们一起看看如何在Linux的终端来测试网速。
|
||||
|
||||
如果你只是想偶尔的做一次网速测试而不想去下载测试工具,那么请往下看如何使用命令完成测试。
|
||||
|
||||
### 第一步:下载网速测试命令行工具。
|
||||
|
||||
首先,你需要从github上下载网速测试命令行工具。现在,上面也包含许多其他的Linu相关的仓库,如果已经在你的库中,你可以直接在你的Linux上进行安装。 让我们继续下载和安装过程,安装的git包取决于你的Linux发行版。然后按照下面的方法来克隆Github speedtest存储库
|
||||
首先,你需要从 [GitHub][3] 上下载 `speedtest` 命令行工具。现在,它也被包含在许多其它的 Linux 仓库中,如果已经在你的库中,你可以直接[在你的 Linux 发行版上进行安装][4]。
|
||||
|
||||
让我们继续下载和安装过程,安装的 git 包取决于你的 Linux 发行版。然后按照下面的方法来克隆 Github speedtest 存储库
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# git clone https://github.com/sivel/speedtest-cli.git
|
||||
@ -20,10 +24,9 @@ remote: Counting objects: 913, done.
|
||||
remote: Total 913 (delta 0), reused 0 (delta 0), pack-reused 913
|
||||
Receiving objects: 100% (913/913), 251.31 KiB | 143.00 KiB/s, done.
|
||||
Resolving deltas: 100% (518/518), done.
|
||||
|
||||
```
|
||||
|
||||
它将会被克隆到你当前的工作目录,新的名为speedtest-cli的目录将会被创建,你将在新的目录下看到如下的文件。
|
||||
它将会被克隆到你当前的工作目录,新的名为 `speedtest-cli` 的目录将会被创建,你将在新的目录下看到如下的文件。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# cd speedtest-cli
|
||||
@ -41,11 +44,13 @@ total 96
|
||||
-rw-r--r--. 1 root root 333 Oct 7 16:55 tox.ini
|
||||
```
|
||||
|
||||
名为speedtest.py的脚本文件就是用来测试网速的。你可以在/usr/bin执行环境下将这个脚本链接到一条命令以便这台机器上的所有用户都能使用。或者你可以为这个脚本创建一个命令别名这样就能让所有用户很容易使用它。
|
||||
名为 `speedtest.py` 的 Python 脚本文件就是用来测试网速的。
|
||||
|
||||
### 运行python脚本
|
||||
你可以将这个脚本链接到 `/usr/bin` 下,以便这台机器上的所有用户都能使用。或者你可以为这个脚本创建一个[命令别名][5],这样就能让所有用户很容易使用它。
|
||||
|
||||
现在,直接运行这个脚本,不需要添加任何参数它将会搜寻最近的服务器来测试你的网速。
|
||||
### 运行 Python 脚本
|
||||
|
||||
现在,直接运行这个脚本,不需要添加任何参数,它将会搜寻最近的服务器来测试你的网速。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py
|
||||
@ -60,13 +65,13 @@ Testing upload speed............................................................
|
||||
Upload: 323.95 Mbit/s
|
||||
```
|
||||
|
||||
Oh! 不要被这个网速惊讶道。😀我在AWE EX2的服务器上。那是亚马逊数据中心的网速!🙂
|
||||
Oh! 不要被这个网速惊讶道。我在 AWE EX2 的服务器上。那是亚马逊数据中心的网速!
|
||||
|
||||
### 这个脚本可以添加有不同的选项。
|
||||
|
||||
下面的几个选项对这个脚本可能会很有用处:
|
||||
|
||||
** 用搜寻你附近的网路测试服务器,使用 --list和grep加上本地名来列出所有附件的服务器。
|
||||
**要搜寻你附近的网路测试服务器**,使用 `--list` 和 `grep` 加上地名来列出所有附近的服务器。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --list | grep -i mumbai
|
||||
@ -86,8 +91,9 @@ Oh! 不要被这个网速惊讶道。😀我在AWE EX2的服务器上。那是
|
||||
|
||||
然后你就能从搜寻结果中看到,第一列是服务器识别号,紧接着是公司的名称和所在地,最后是离你的距离。
|
||||
|
||||
** 如果要使用指定的服务器来测试网速,后面跟上命令 --server 加上服务器的识别号。
|
||||
|
||||
**如果要使用指定的服务器来测试网速**,后面跟上 `--server` 加上服务器的识别号。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --server 2827
|
||||
Retrieving speedtest.net configuration...
|
||||
Testing from Amazon (35.154.184.126)...
|
||||
@ -100,7 +106,7 @@ Testing upload speed............................................................
|
||||
Upload: 69.25 Mbit/s
|
||||
```
|
||||
|
||||
** 如果想得到你的测试结果的共享链接,使用命令 --share,你将会得到测试结果的链接。
|
||||
**如果想得到你的测试结果的分享链接**,使用 `--share`,你将会得到测试结果的链接。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --share
|
||||
@ -114,22 +120,22 @@ Download: 621.00 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 367.37 Mbit/s
|
||||
Share results: http://www.speedtest.net/result/6687428141.png
|
||||
|
||||
```
|
||||
|
||||
输出中的最后一行就是你的测试结果的链接。下载下来的图片内容如下 :
|
||||
|
||||
![Speedtest result on Linux][7]
|
||||
|
||||
这就是全部的过程!如果你不想子结果中看到这些技术术语,你也可以使用如下的命令迅速测出你的网速
|
||||
这就是全部的过程!如果你不想了解这些技术细节,你也可以使用如下的一行命令迅速测出你的网速。
|
||||
|
||||
### 要想在终端使用一条命令测试网速。
|
||||
|
||||
我们将使用Curl工具来在线抓取上面使用的python脚本然后直接用python执行脚本
|
||||
我们将使用 `curl` 工具来在线抓取上面使用的 Python 脚本然后直接用 Python 执行脚本。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
|
||||
```
|
||||
|
||||
上面的脚本将会运行脚本输出结果到屏幕上。
|
||||
|
||||
```
|
||||
@ -145,22 +151,24 @@ Testing upload speed............................................................
|
||||
Upload: 355.84 Mbit/s
|
||||
```
|
||||
|
||||
这是在 RHEL 7 上执行的结果,在 Ubuntu、Debian、Fedora 或者 CentOS 上一样可以执行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
这是在RHEL 7上执行的结果,在Ubuntu,Debian, Fedora或者Centos上一样可以执行。
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-test-internet-speed-in-linux-terminal/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[FelixYFZ ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c1.kerneltalks.com/wp-content/uploads/2017/10/check-internet-speed-from-Linux.png
|
||||
[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/10/check-internet-speed-from-Linux.png
|
||||
[2]:http://www.speedtest.net/
|
||||
[3]:https://github.com/sivel/speedtest-cli
|
||||
[4]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[5]:https://kerneltalks.com/commands/command-alias-in-linux-unix/
|
||||
[6]:https://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||
[7]:https://c3.kerneltalks.com/wp-content/uploads/2017/10/speedtest-on-linux.png
|
||||
[7]:https://a3.kerneltalks.com/wp-content/uploads/2017/10/speedtest-on-linux.png
|
||||
[8]:https://kerneltalks.com/tips-tricks/4-tools-download-file-using-command-line-linux/
|
||||
@ -0,0 +1,72 @@
|
||||
八种敏捷团队的提升方法
|
||||
======
|
||||
|
||||
> 在这个列表中,没有项目管理软件,这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
|
||||
|
||||

|
||||
|
||||
图片来源:opensource.com
|
||||
|
||||
你也许经常听说下面这句话:工具太多,时间太少。为了节约您的时间,我列出了几款我最常用的提高敏捷团队工作效率的工具。如果你也是一名敏捷主义者,你可能听说过类似的工具,但我这里提到的仅限于开源工具。
|
||||
|
||||
**请注意!** 这些工具和你想象的可能有点不同。它们并不是项目管理软件——这领域已经有一篇[好文章][1]了。因此这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
|
||||
|
||||
### 组建一个充满积极反馈的团队
|
||||
|
||||
如果在产业中大部分人都习惯了输出、接收负面消息,就很难有人对同事进行正面反馈的输出。这并不奇怪,当人们乐于给出赞美时,人们就会竞相向别人说“干得漂亮!”、“没有你我们很难完成任务。”赞美别人干的漂亮并不会使你痛苦,它通常能激励大家更好地为团队工作。下面两个软件可以帮助你向同事表达赞扬。
|
||||
|
||||
* 对开发团队来说,[Management 3.0][2] 是个有着大量[免费资源][3]的宝箱,可以尽情使用。其中 Feedback Wraps 的观念最引人注目(不仅仅是因为它让我们联想到墨西哥卷)。 [Feedback Wraps][4] 是一个经过六步对用户进行反馈的程序,也许你会认为它是为了负面反馈而设计的,但我们发现它在表达积极评论方面十分有效。
|
||||
* [Happiness Packets][5] 为用户提供了在开源社区内匿名正面反馈的服务。它尤其适合不太习惯人际交往的用户或是不知道说什么好的情况。Happiness Packets 拥有一份[公开的评论档案][6](这些评论都已经得到授权分享),你可以浏览大家的评论,从中得到灵感,对别人做出暖心的称赞。它还有个特殊功能,能够屏蔽恶意消息。
|
||||
|
||||
### 思考工作的意义
|
||||
|
||||
这很难定义。在敏捷领域中,成功的关键包括定义人物角色和产品愿景,还要向整个敏捷团队说明此项工作的意义。产品开发人员和项目负责人能够获得的开源工具数量极为有限,对于这一点我们有些失望。
|
||||
|
||||
在 Rat Hat 公司,最受尊敬也最为常用于训练敏捷团队的开源工具之一是 Product Vision Board 。它出自产品管理专家 Roman Pichler 之手,Roman Pichler 提供了[大量工具和模版][7]来帮助敏捷团队理解他们工作的意义。(你需要提供电子邮箱地址才能下载这些工具。)
|
||||
|
||||
* [Product Vision Board][8] 的模版通过简单但有效的问题引导团队转变思考方式,将思考工作的意义置于具体工作方法之前。
|
||||
* 我们也很喜欢 Roman 的 [Product Management Test][9],它能够通过简便快捷的网页表单,引领团队重新定义产品开发人员的角色,并且找出程序漏洞。我们推荐产品开发团队周期性地完成此项测试,重新分析失败原因。
|
||||
|
||||
### 对工作内容的直观化
|
||||
|
||||
你是否曾为一个大案子焦头烂额,连熟悉的步骤也在脑海中乱成一团?我们也遇到过这种情况。使用思维导图可以梳理你脑海中的想法,使其直观化。你不需要一下就想出整件事该怎么进行,你只需要你的头脑,一块白板(或者是思维导图软件)和一些思考的时间。
|
||||
|
||||
* 在这个领域中我们最喜欢的开源工具是 [Xmind3][10]。它支持多种平台运行(Linux、MacOS 和 Windows),以便与他人共享文件。如果你对工具的要求很高,推荐使用[其更新版本][11],提供电子邮箱地址即可免费下载使用。
|
||||
* 如果你很看重灵活性,Eduard Lucena 在 Fedora Magazine 中提供的 [三个附加选项][12] 就十分适合。你可以在 Fedora 杂志上找到这些软件的获取方式,其他信息可以在它们的项目页找到。
|
||||
|
||||
* [Labyrinth][13]
|
||||
* [View Your Mind][14]
|
||||
* [FreeMind][15]
|
||||
|
||||
像我们开头说的一样,提高敏捷团队工作效率的工具有很多,如果你有特别喜欢的相关开源工具,请在评论中与大家分享。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Jen Krieger :Red Hat 的首席敏捷架构师,在软件开发领域已经工作超过 20 年,曾在瀑布及敏捷生命周期等领域扮演多种角色。目前在 Red Hat 负责针对 CI/CD 最佳效果的部际 DevOps 活动。最近她在与 Project Atomic & OpenShift 团队合作。她最近在引领公司向着敏捷团队改革,并增加开源项目在公司内的认知度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/foss-tools-agile-teams
|
||||
|
||||
作者:[Jen Krieger][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkrieger
|
||||
[1]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[2]:https://management30.com/
|
||||
[3]:https://management30.com/leadership-resource-hub/
|
||||
[4]:https://management30.com/en/practice/feedback-wraps/
|
||||
[5]:https://happinesspackets.io/
|
||||
[6]:https://www.happinesspackets.io/archive/
|
||||
[7]:http://www.romanpichler.com/tools/
|
||||
[8]:http://www.romanpichler.com/tools/vision-board/
|
||||
[9]:http://www.romanpichler.com/tools/romans-product-management-test/
|
||||
[10]:https://sourceforge.net/projects/xmind3/?source=recommended
|
||||
[11]:http://www.xmind.net/
|
||||
[12]:https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[13]:https://people.gnome.org/~dscorgie/labyrinth.html
|
||||
[14]:http://www.insilmaril.de/vym/
|
||||
[15]:http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
@ -1,62 +1,71 @@
|
||||
如何使用 DockerHub
|
||||
=====
|
||||
========
|
||||
|
||||
> 在这个 Docker 系列的最后一篇文章中,我们将讲述在 DockerHub 上使用和发布镜像。
|
||||
|
||||

|
||||
|
||||
在前面的文章中,我们了解到了 [Docker terminology][1] 的基础,在Linux 桌面,MacOS 和 Windows上 [如何安装 Docker][2],[如何创建容器镜像][3] 并且在系统上运行它们。在本系列的最后一篇文章中,我们将讨论如何使用 DockerHub 中的镜像以及将自己的镜像发布到 DockerHub。
|
||||
在前面的文章中,我们了解到了基本的 [Docker 术语][1],在 Linux 桌面、MacOS 和 Windows上 [如何安装 Docker][2],[如何创建容器镜像][3] 并且在系统上运行它们。在本系列的最后一篇文章中,我们将讨论如何使用 DockerHub 中的镜像以及将自己的镜像发布到 DockerHub。
|
||||
|
||||
首先要做的是:什么是 DockerHub 以及为什么它很重要?DockerHub 是一个由 Docker Inc 运行和管理的基于云的存储库。它是一个在线存储库,Docker 镜像可以由其他用户发布和使用。它有公共和私人存储库。如果你是一家公司,你可以在你自己的组织内拥有一个私人存储库,这里的公共镜像可以被任何人使用。
|
||||
首先:什么是 DockerHub 以及为什么它很重要?DockerHub 是一个由 Docker 公司运行和管理的基于云的存储库。它是一个在线存储库,Docker 镜像可以由其他用户发布和使用。有两种库:公共存储库和私有存储库。如果你是一家公司,你可以在你自己的组织内拥有一个私有存储库,而公共镜像可以被任何人使用。
|
||||
|
||||
你也可以使用公开发布的官方 Docker 镜像。我使用了很多这样的镜像,包括我的试验 WordPress 安装,KDE plasma 应用程序等等。虽然我们上次学习了如何创建自己的 Docker 镜像,但你不必这样做。DockerHub 上发布了数千镜像供你使用。DockerHub 作为默认注册表硬编码到 Docker 中,所以当你对任何镜像运行 docker pull 命令时,它将从 DockerHub 下载。
|
||||
你也可以使用公开发布的官方 Docker 镜像。我使用了很多这样的镜像,包括我的试验 WordPress 环境、KDE plasma 应用程序等等。虽然我们上次学习了如何创建自己的 Docker 镜像,但你不必这样做。DockerHub 上发布了数千镜像供你使用。DockerHub 作为默认存储库硬编码到 Docker 中,所以当你对任何镜像运行 `docker pull` 命令时,它将从 DockerHub 下载。
|
||||
|
||||
### 从 Docker Hub 下载镜像并在本地运行
|
||||
|
||||
请查看本系列的前几篇文章,以便开始阅读。然后,一旦 Docker 在你的系统上运行,你就可以打开终端并运行:
|
||||
开始请查看本系列的前几篇文章,以便继续。然后,一旦 Docker 在你的系统上运行,你就可以打开终端并运行:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
```
|
||||
|
||||
该命令将显示当前系统上所有的 docker 镜像。假设你想在本地机器上部署 Ubuntu;你可能会:
|
||||
该命令将显示当前系统上所有的 docker 镜像。假设你想在本地机器上部署 Ubuntu,你可能会:
|
||||
|
||||
```
|
||||
$ docker pull ubuntu
|
||||
```
|
||||
|
||||
如果你的系统上已经存在 Ubuntu 镜像,那么该命令会自动将该系统更新到最新版本。因此,如果你想要更新现有的镜像,只需运行 docker pull 命令,易如反掌。这就像 apt-get update 一样,没有任何的混乱和麻烦。
|
||||
如果你的系统上已经存在 Ubuntu 镜像,那么该命令会自动将该系统更新到最新版本。因此,如果你想要更新现有的镜像,只需运行 `docker pull` 命令,易如反掌。这就像 `apt-get update` 一样,没有任何的混乱和麻烦。
|
||||
|
||||
你已经知道了如何运行镜像:
|
||||
|
||||
```
|
||||
$ docker run -it <image name>
|
||||
|
||||
$ docker run -it ubuntu
|
||||
```
|
||||
|
||||
命令提示符应该变为如下内容:
|
||||
|
||||
```
|
||||
root@1b3ec4621737:/#
|
||||
```
|
||||
|
||||
现在你可以运行任何属于 Ubuntu 的命令和实用程序,这些都被包含在内而且安全。你可以在 Ubuntu 上运行你想要的所有实验和测试。一旦你完成了测试,你就可以核对镜像并下载一个新的。在虚拟机中不存在系统开销。
|
||||
现在你可以运行任何属于 Ubuntu 的命令和实用程序,这些都被包含在内而且安全。你可以在 Ubuntu 上运行你想要的所有实验和测试。一旦你完成了测试,你就可以销毁镜像并下载一个新的。在虚拟机中不存在系统开销。
|
||||
|
||||
你可以通过运行 exit 命令退出该容器:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
现在假设你想在系统上安装 Nginx,运行 search 命令来找到需要的镜像:
|
||||
现在假设你想在系统上安装 Nginx,运行 `search` 命令来找到需要的镜像:
|
||||
|
||||
```
|
||||
$ docker search nginx
|
||||
|
||||
aizMFFysICAEsgDDYrsrlqwoCgGbWVHtcOzgV9mA
|
||||
```
|
||||
|
||||

|
||||
|
||||
正如你所看到的,DockerHub 上有很多 Nginx 镜像。为什么?因为任何人都可以发布镜像,各种镜像针对不同的项目进行了优化,因此你可以选择合适的镜像。你只需要为你的需求安装合适的镜像。
|
||||
|
||||
假设你想要拉取 Bitnami's Nginx 镜像:
|
||||
假设你想要拉取 Bitnami 的 Nginx 镜像:
|
||||
|
||||
```
|
||||
$ docker pull bitnami/nginx
|
||||
```
|
||||
|
||||
现在运行:
|
||||
|
||||
```
|
||||
$ docker run -it bitnami/nginx
|
||||
```
|
||||
@ -64,51 +73,51 @@ $ docker run -it bitnami/nginx
|
||||
### 如何发布镜像到 Docker Hub?
|
||||
|
||||
在此之前,[我们学习了如何创建 Docker 镜像][3],我们可以轻松地将该镜像发布到 DockerHub 中。首先,你需要登录 DockerHub,如果没有账户,请 [创建账户][5]。然后,你可以打开终端应用,登录:
|
||||
|
||||
```
|
||||
$ docker login --username=<USERNAME>
|
||||
```
|
||||
|
||||
将 <USERNAME> 替换为你自己的 Docker Hub 用户名。我这里是 arnieswap:
|
||||
将 “\<USERNAME>” 替换为你自己的 Docker Hub 用户名。我这里是 arnieswap:
|
||||
|
||||
```
|
||||
$ docker login --username=arnieswap
|
||||
```
|
||||
|
||||
输入密码,你就登录了。现在运行 docker 镜像命令来获取你上次创建的镜像的 ID。
|
||||
输入密码,你就登录了。现在运行 `docker images` 命令来获取你上次创建的镜像的 ID。
|
||||
|
||||
```
|
||||
$ docker images
|
||||
|
||||
tW1jDOugkX7J2FfyFyToM6B8m5OYFwMba-Ag5aez
|
||||
```
|
||||
|
||||
现在,假设你希望将 ng 镜像推送到 DockerHub,首先,我们需要标记该镜像([了解更多关于标记的信息][1]):
|
||||

|
||||
|
||||
现在,假设你希望将镜像 `ng` 推送到 DockerHub,首先,我们需要标记该镜像([了解更多关于标记的信息][1]):
|
||||
|
||||
```
|
||||
$ docker tag e7083fd898c7 arnieswap/my_repo:testing
|
||||
```
|
||||
|
||||
现在推送镜像:
|
||||
|
||||
```
|
||||
$ docker push arnieswap/my_repo
|
||||
```
|
||||
|
||||
推送指向的是 [docker.io/arnieswap/my_repo] 仓库
|
||||
推送指向的是 [docker.io/arnieswap/my_repo] 仓库:
|
||||
|
||||
```
|
||||
12628b20827e: Pushed
|
||||
|
||||
8600ee70176b: Mounted from library/ubuntu
|
||||
|
||||
2bbb3cec611d: Mounted from library/ubuntu
|
||||
|
||||
d2bb1fc88136: Mounted from library/ubuntu
|
||||
|
||||
a6a01ad8b53f: Mounted from library/ubuntu
|
||||
|
||||
833649a3e04c: Mounted from library/ubuntu
|
||||
|
||||
testing: digest: sha256:286cb866f34a2aa85c9fd810ac2cedd87699c02731db1b8ca1cfad16ef17c146 size: 1569
|
||||
|
||||
```
|
||||
|
||||
哦耶!你的镜像正在上传。一旦完成,打开 DockerHub,登录到你的账户,你就能看到你的第一个 Docker 镜像。现在任何人都可以部署你的镜像。这是开发软件和发布软件最简单,最快速的方式。无论你何时更新镜像,用户都可以简单地运行:
|
||||
|
||||
```
|
||||
$ docker run arnieswap/my_repo
|
||||
```
|
||||
@ -121,14 +130,14 @@ via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-use-dockerhub
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[3]:https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
|
||||
[3]:https://linux.cn/article-9541-1.html
|
||||
[4]:https://lh3.googleusercontent.com/aizMFFysICAEsgDDYrsrlqwoCgGbWVHtcOzgV9mAtV8IdBZgHPJTdHIZhWBNCRvOyJb108ZBajJ_Nz10yCxGSvk-AF-yvFxpojLdVu3Jjihcwaup6CQLc67A5nglBuGDaOZWcrbV
|
||||
[5]:https://hub.docker.com/
|
||||
[6]:https://lh6.googleusercontent.com/tW1jDOugkX7J2FfyFyToM6B8m5OYFwMba-Ag5aezVGf2A5gsKJ47QrCh_TOKWgIKfE824Uc2Cwwwj9jWps1yJlUZqDyIceVQs-nEbKavFDxuUxLyd4thBA4_rsXrQH4r7hrG8FnD
|
||||
[6]:https://lh6.googleusercontent.com/tW1jDOugkX7J2FfyFyToM6B8m5OYFwMba-Ag5aezVGf2A5gsKJ47QrCh_TOKWgIKfE824Uc2Cwwwj9jWps1yJlUZqDyIceVQs-nEbKavFDxuUxLyd4thBA4_rsXrQH4r7hrG8FnD
|
||||
@ -1,12 +1,14 @@
|
||||
Python Global 关键字(含示例)
|
||||
初识 Python: global 关键字
|
||||
======
|
||||
在读这篇文章之前,确保你对 [Python Global,Local 和 Nonlocal 变量][1] 有一定的基础。
|
||||
|
||||
在读这篇文章之前,确保你对 [Python 全局、本地和非本地变量][1] 有一定的基础。
|
||||
|
||||
### global 关键字简介
|
||||
|
||||
在 Python 中,`global` 关键字允许你修改当前范围之外的变量。它用于创建全局变量并在本地上下文中更改变量。
|
||||
|
||||
### global 关键字的规则
|
||||
|
||||
在 Python 中,有关 `global` 关键字基本规则如下:
|
||||
|
||||
* 当我们在一个函数中创建一个变量时,默认情况下它是本地变量。
|
||||
@ -14,63 +16,72 @@ Python Global 关键字(含示例)
|
||||
* 我们使用 `global` 关键字在一个函数中来读写全局变量。
|
||||
* 在一个函数外使用 `global` 关键字没有效果。
|
||||
|
||||
#### 使用 global 关键字(含示例)
|
||||
### 使用 global 关键字(含示例)
|
||||
|
||||
我们来举个例子。
|
||||
|
||||
##### 示例 1:从函数内部访问全局变量
|
||||
#### 示例 1:从函数内部访问全局变量
|
||||
|
||||
c = 1 # 全局变量
|
||||
```
|
||||
c = 1 # 全局变量
|
||||
def add():
|
||||
print(c)
|
||||
|
||||
def add():
|
||||
print(c)
|
||||
|
||||
add()
|
||||
add()
|
||||
```
|
||||
|
||||
运行程序,输出为:
|
||||
|
||||
1
|
||||
```
|
||||
1
|
||||
```
|
||||
|
||||
但是我们可能有一些场景需要从函数内部修改全局变量。
|
||||
|
||||
##### 示例 2:在函数内部修改全局变量
|
||||
#### 示例 2:在函数内部修改全局变量
|
||||
|
||||
c = 1 # 全局变量
|
||||
|
||||
def add():
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print(c)
|
||||
|
||||
add()
|
||||
```
|
||||
c = 1 # 全局变量
|
||||
def add():
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print(c)
|
||||
add()
|
||||
```
|
||||
|
||||
运行程序,输出显示错误:
|
||||
|
||||
UnboundLocalError: local variable 'c' referenced before assignment
|
||||
```
|
||||
UnboundLocalError: local variable 'c' referenced before assignment
|
||||
```
|
||||
|
||||
这是因为在函数中,我们只能访问全局变量但是不能修改它。
|
||||
|
||||
解决的办法是使用 `global` 关键字。
|
||||
|
||||
##### 示例 3:使用 global 在函数中改变全局变量
|
||||
#### 示例 3:使用 global 在函数中改变全局变量
|
||||
|
||||
c = 0 # global variable
|
||||
```
|
||||
c = 0 # global variable
|
||||
|
||||
def add():
|
||||
global c
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print("Inside add():", c)
|
||||
|
||||
add()
|
||||
print("In main:", c)
|
||||
def add():
|
||||
global c
|
||||
c = c + 2 # 将 c 增加 2
|
||||
print("Inside add():", c)
|
||||
|
||||
add()
|
||||
print("In main:", c)
|
||||
```
|
||||
|
||||
运行程序,输出为:
|
||||
|
||||
Inside add(): 2
|
||||
In main: 2
|
||||
```
|
||||
Inside add(): 2
|
||||
In main: 2
|
||||
```
|
||||
|
||||
在上面的程序中,我们在 `add()` 函数中定义了 c 将其作为 global 关键字。
|
||||
在上面的程序中,我们在 `add()` 函数中定义了 `c` 将其作为全局关键字。
|
||||
|
||||
然后,我们给变量 c 增加 `1`,(译注:这里应该是给 c 增加 `2` )即 `c = c + 2`。之后,我们调用了 `add()` 函数。最后,打印全局变量 c。
|
||||
然后,我们给变量 `c` 增加 `2`,即 `c = c + 2`。之后,我们调用了 `add()` 函数。最后,打印全局变量 `c`。
|
||||
|
||||
正如我们所看到的,在函数外的全局变量也发生了变化,`c = 2`。
|
||||
|
||||
@ -80,68 +91,79 @@ Python Global 关键字(含示例)
|
||||
|
||||
以下是如何通过 Python 模块共享全局变量。
|
||||
|
||||
##### 示例 4:在Python模块中共享全局变量
|
||||
#### 示例 4:在Python模块中共享全局变量
|
||||
|
||||
创建 `config.py` 文件来存储全局变量
|
||||
|
||||
a = 0
|
||||
b = "empty"
|
||||
```
|
||||
a = 0
|
||||
b = "empty"
|
||||
```
|
||||
|
||||
创建 `update.py` 文件来改变全局变量
|
||||
|
||||
import config
|
||||
```
|
||||
import config
|
||||
|
||||
config.a = 10
|
||||
config.b = "alphabet"
|
||||
config.a = 10
|
||||
config.b = "alphabet"
|
||||
```
|
||||
|
||||
创建 `main.py` 文件来测试其值的变化
|
||||
|
||||
import config
|
||||
import update
|
||||
```
|
||||
import config
|
||||
import update
|
||||
|
||||
print(config.a)
|
||||
print(config.b)
|
||||
print(config.a)
|
||||
print(config.b)
|
||||
```
|
||||
|
||||
运行 `main.py`,输出为:
|
||||
|
||||
10
|
||||
alphabet
|
||||
```
|
||||
10
|
||||
alphabet
|
||||
```
|
||||
|
||||
在上面,我们创建了三个文件: `config.py`, `update.py` 和 `main.py`。
|
||||
|
||||
在 `config.py` 模块中保存了全局变量 a 和 b。在 `update.py` 文件中,我们导入了 `config.py` 模块并改变了 a 和 b 的值。同样,在 `main.py` 文件,我们导入了 `config.py` 和 `update.py` 模块。最后,我们打印并测试全局变量的值,无论它们是否被改变。
|
||||
在 `config.py` 模块中保存了全局变量 `a` 和 `b`。在 `update.py` 文件中,我们导入了 `config.py` 模块并改变了 `a` 和 `b` 的值。同样,在 `main.py` 文件,我们导入了 `config.py` 和 `update.py` 模块。最后,我们打印并测试全局变量的值,无论它们是否被改变。
|
||||
|
||||
### 在嵌套函数中的全局变量
|
||||
|
||||
以下是如何在嵌套函数中使用全局变量。
|
||||
|
||||
##### 示例 5:在嵌套函数中使用全局变量
|
||||
#### 示例 5:在嵌套函数中使用全局变量
|
||||
|
||||
def foo():
|
||||
x = 20
|
||||
|
||||
def bar():
|
||||
global x
|
||||
x = 25
|
||||
```
|
||||
def foo():
|
||||
x = 20
|
||||
def bar():
|
||||
global x
|
||||
x = 25
|
||||
|
||||
print("Before calling bar: ", x)
|
||||
print("Calling bar now")
|
||||
bar()
|
||||
print("After calling bar: ", x)
|
||||
print("Before calling bar: ", x)
|
||||
print("Calling bar now")
|
||||
bar()
|
||||
print("After calling bar: ", x)
|
||||
|
||||
foo()
|
||||
print("x in main : ", x)
|
||||
foo()
|
||||
print("x in main : ", x)
|
||||
```
|
||||
|
||||
输出为:
|
||||
|
||||
Before calling bar: 20
|
||||
Calling bar now
|
||||
After calling bar: 20
|
||||
x in main : 25
|
||||
```
|
||||
Before calling bar: 20
|
||||
Calling bar now
|
||||
After calling bar: 20
|
||||
x in main : 25
|
||||
```
|
||||
|
||||
在上面的程序中,我们在一个嵌套函数 `bar()` 中声明了全局变量。在 `foo()` 函数中, 变量 x 没有全局关键字的作用。
|
||||
在上面的程序中,我们在一个嵌套函数 `bar()` 中声明了全局变量。在 `foo()` 函数中, 变量 `x` 没有全局关键字的作用。
|
||||
|
||||
调用 `bar()` 之前和之后, 变量 x 取本地变量的值,即 `x = 20`。在 `foo()` 函数之外,变量 x 会取在函数 `bar()` 中的值,即 `x = 25`。这是因为在 `bar()` 中,我们对 x 使用 `global` 关键字创建了一个全局变量(本地范围)。
|
||||
调用 `bar()` 之前和之后, 变量 `x` 取本地变量的值,即 `x = 20`。在 `foo()` 函数之外,变量 `x` 会取在函数 `bar()` 中的值,即 `x = 25`。这是因为在 `bar()` 中,我们对 `x` 使用 `global` 关键字创建了一个全局变量(本地范围)。
|
||||
|
||||
如果我们在 `bar()` 函数内进行了任何修改,那么这些修改就会出现在本地范围之外,即 `foo()`。
|
||||
|
||||
@ -151,7 +173,7 @@ via: [https://www.programiz.com/python-programming/global-keyword](https://www.p
|
||||
|
||||
作者:[programiz][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,17 @@
|
||||
11 个超棒的 vi 技巧和窍门
|
||||
11 个超棒的 Vi 技巧和窍门
|
||||
======
|
||||
|
||||
> 是否你刚刚接触 Vi 还是想进阶,这些技巧可以很快让你成为高级用户。
|
||||
|
||||

|
||||
|
||||
[vi][1] 编辑器是 Linux 最流行的编辑器之一,默认安装在 Unix 和类 Uinux 系统中。无论您是 vi 新手还是想进修,这些技巧都对您有用。
|
||||
[Vi][1] 编辑器是 Unix 和像 Linux 这样的类 Unix 系统中 Linux 最流行的编辑器之一。无论您是 vi 新手还是想进阶,这里有 11 个技巧可以增强你使用的方式。
|
||||
|
||||
### 编辑
|
||||
|
||||
编辑长文本时可能很难受,特别是编辑其中某一行时,需要移动许久才能到这行。这有个很快的方法:
|
||||
|
||||
1. `:set number` 这个命令可是在编辑器左边显示行号。
|
||||
1、 `:set number` 这个命令可是在编辑器左边显示行号。
|
||||
|
||||

|
||||
|
||||
@ -18,20 +21,21 @@
|
||||
|
||||
### 快速导航
|
||||
|
||||
2. `i` 将工作方式从“命令模式”更改为“输入模式”,并在当前光标位置开始插入内容。
|
||||
3. `a` 除了是光标之后开始插入年内容,与上面的效果是一样的。
|
||||
4. `o` 在光标的下一行位置开始插入内容。
|
||||
2、 `i` 将工作方式从“命令模式”更改为“输入模式”,并在当前光标位置开始插入内容。
|
||||
|
||||
3、 `a` 除了是光标之后开始插入内容,与上面的效果是一样的。
|
||||
|
||||
4、 `o` 在光标的下一行位置开始插入内容。
|
||||
|
||||
### 删除
|
||||
|
||||
如果您发现错误或错别字,能快速的修正是很重要的。好在 vi 都事先想好了。
|
||||
如果您发现错误或错别字,能快速的修正是很重要的。好在 Vi 都事先想好了。
|
||||
|
||||
了解 vi 的删除功能,保证你不会意外按下某个键并永久删除一行或多段内容,这点至关重要。
|
||||
了解 Vi 的删除功能,保证你不会意外按下某个键并永久删除一行或多段内容,这点至关重要。
|
||||
|
||||
5. `x` 删除当前光标的字符。
|
||||
6. `dd` 删除当前行 (是的,整行内容!)
|
||||
5、 `x` 删除当前光标的字符。
|
||||
|
||||
6、 `dd` 删除当前行 (是的,整行内容!)
|
||||
|
||||
下面看可怕的部分:`30dd` 从当前行开始删除以下 30 行!使用此命令请慎重。
|
||||
|
||||
@ -39,16 +43,15 @@
|
||||
|
||||
您可以在“命令模式”搜索关键字,而不用在大量文本内容中手动导航查找特定的单词或内容。
|
||||
|
||||
7. `:/<keyword>` 搜索 `< >` 中的单词并将光标移动到第一个匹配项。
|
||||
8. 导航到该单词的下一个匹配项,请输入 `n` 并继续按下, 直到找到您要找的内容。
|
||||
7、 `:/<keyword>` 搜索 `< >` 中的单词并将光标移动到第一个匹配项。
|
||||
|
||||
8、 导航到该单词的下一个匹配项,请输入 `n` 并继续按下, 直到找到您要找的内容。
|
||||
|
||||
|
||||
例如,在这个图像中我要搜索包含 `ssh` 的内容, vi 光标就会突出第一个结果的开始位置。
|
||||
例如,在这个图像中我要搜索包含 `ssh` 的内容, Vi 光标就会突出第一个结果的开始位置。
|
||||
|
||||

|
||||
|
||||
按下 n 之后, vi 光标就会突出下一个匹配项。
|
||||
按下 `n` 之后, Vi 光标就会突出下一个匹配项。
|
||||
|
||||

|
||||
|
||||
@ -56,29 +59,26 @@
|
||||
|
||||
开发人员 (或其他人) 可能会发现这个命令很有用。
|
||||
|
||||
9. `:x` 保存您的工作空间并退出 vi 。
|
||||
9、 `:x` 保存您的工作并退出 Vi 。
|
||||
|
||||

|
||||
|
||||
10. 如果你想实时保存,那么这有个更快的方法。你可以按下 `Shift+q` (或者大写字母 Q ) 来进入 [Ex 模式][2] , 而不是在键盘上按 `Shift+:` 。但是如果你只是想按下 `x` 来保存退出,那就没有什么区别(如上所示)。
|
||||
|
||||
|
||||
10、 如果你想节省哪怕是纳秒,那么这有个更快的回到终端的方法。不用在键盘上按 `Shift+:` ,而是按下 `Shift+q` (或者大写字母 Q ) 来进入 [Ex 模式][2] 。但是如果你只是想按下 `x` 来保存退出,那就没有什么区别(如上所示)。
|
||||
|
||||
### 替换
|
||||
|
||||
如果您想将文中的某个单词全部替换为一个单词,这有个很巧妙的招式。例如,如果您想在一个大文件中将 "desktop" 替换为 "laptop" ,那么单调的搜索每个出现的 "desktop" 将其删掉,然后再输入 "laotop" ,是很浪费时间的。
|
||||
如果您想将文中的某个单词全部替换为一个单词,这有个很巧妙的招式。例如,如果您想在一个大文件中将 “desktop” 替换为 “laptop” ,那么单调的搜索每个出现的 “desktop” 将其删掉,然后再输入 “laotop” ,是很浪费时间的。
|
||||
|
||||
11. `:%s/desktop/laptop/g` 这个命令将在整个文件中的 "desktop" 用 "laptop" 替换,他就像 Linux 的 `sed` 命令一样。
|
||||
11、 `:%s/desktop/laptop/g` 这个命令将在整个文件中的 “desktop” 用 “laptop” 替换,他就像 Linux 的 `sed` 命令一样。
|
||||
|
||||
|
||||
|
||||
这个例子中我用 "user" 替换了 "root" :
|
||||
这个例子中我用 “user” 替换了 “root” :
|
||||
|
||||
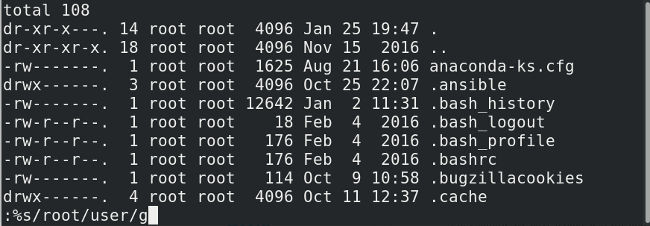
|
||||
|
||||
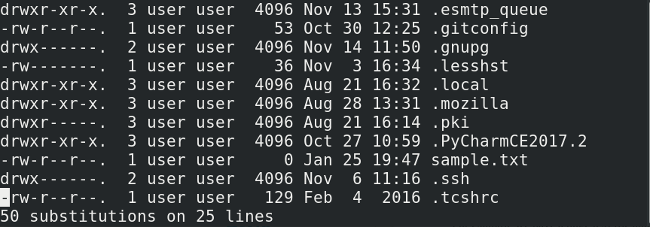
|
||||
|
||||
这些技巧应该能帮组任何想开始学 vi 的人。我有遗漏其他巧妙的提示吗?请在评论中分享他们。
|
||||
这些技巧应该能帮组任何想开始学 Vi 的人。我有遗漏其他巧妙的提示吗?请在评论中分享他们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -86,7 +86,7 @@ via: https://opensource.com/article/18/1/top-11-vi-tips-and-tricks
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
译者:[MZqk](https://github.com/MZqk)
|
||||
校对:[校对者 ID](https://github.com/ 校对者 ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
71
published/20180215 What is a Linux -oops.md
Normal file
71
published/20180215 What is a Linux -oops.md
Normal file
@ -0,0 +1,71 @@
|
||||
什么是 Linux “oops”?
|
||||
======
|
||||
> Linux 内核正在盯着你,当它检测到系统上运行的某些东西违反了正常内核行为时,它会关闭系统并发出一个“oops”!
|
||||
|
||||

|
||||
|
||||
如果你检查你的 Linux 系统上运行的进程,你可能会对一个叫做 “kerneloops” 的进程感到好奇。提示一下,它是 “kernel oops”,而不是 “kerne loops”。
|
||||
|
||||
坦率地说,“oops” 是 Linux 内核的一部分出现了偏差行为。你有做错了什么吗?可能没有。但有一些不对劲。而那个做了错事的进程可能已经被 CPU 结束。最糟糕的是,内核可能会报错并突然关闭系统。
|
||||
|
||||
请注意,“oops” 不是首字母缩略词。它不代表像“<ruby>面向对象的编程和系统<rt>object-oriented programming and systems</rt></ruby>” 或“<ruby>超出程序规范<rt>out of procedural specs</rt></ruby>” 之类的东西。它实际上就是“哎呀” (oops),就像你刚掉下一杯酒或踩在你的猫身上。哎呀! “oops” 的复数是 “oopses”。
|
||||
|
||||
oops 意味着系统上运行的某些东西违反了内核有关正确行为的规则。也许代码尝试采取不允许的代码路径或使用无效指针。不管它是什么,内核 —— 总是在监测进程的错误行为 —— 很可能会阻止特定进程,并将它做了什么的消息写入控制台、 `/var/log/dmesg` 或 `/var/log/kern.log` 中。
|
||||
|
||||
oops 可能是由内核本身引起的,也可能是某些进程试图让内核违反在系统上能做的事以及它们被允许做的事。
|
||||
|
||||
oops 将生成一个<ruby>崩溃签名<rt>crash signature</rt></ruby>,这可以帮助内核开发人员找出错误并提高代码质量。
|
||||
|
||||
系统上运行的 kerneloops 进程可能如下所示:
|
||||
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
```
|
||||
|
||||
你可能会注意到该进程不是由 root 运行的,而是由名为 “kernoops” 的用户运行的,并且它的运行时间极少。实际上,分配给这个特定用户的唯一任务是运行 kerneloops。
|
||||
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
```
|
||||
|
||||
如果你的 Linux 系统不带有 kerneloops(比如 Debian),你可以考虑添加它。查看这个 [Debian 页面][1]了解更多信息。
|
||||
|
||||
### 什么时候应该关注 oops?
|
||||
|
||||
一般 oops 没什么大不了的。它在一定程度上取决于特定进程所扮演的角色。它也取决于 oops 的类别。
|
||||
|
||||
有些 oops 很严重,会导致<ruby>系统恐慌<rt>system panic</rt></ruby>。从技术上讲,系统恐慌是 oops 的一个子集(即更严重的 oops)。当内核检测到的问题足够严重以至于内核认为它(内核)必须立即停止运行以防止数据丢失或对系统造成其他损害时会出现。因此,系统需要暂停并重新启动,以防止任何不一致导致不可用或不可靠。所以系统恐慌实际上是为了保护自己免受不可挽回的损害。
|
||||
|
||||
总之,所有的内核恐慌都是 oops,但并不是所有的 oops 都是内核恐慌。
|
||||
|
||||
`/var/log/kern.log` 和相关的轮转日志(`/var/log/kern.log.1`、`/var/log/kern.log.2` 等)包含由内核生成并由 syslog 处理的日志。
|
||||
|
||||
kerneloops 程序收集并默认将错误信息提交到 <http://oops.kernel.org/>,在那里它会被分析并呈现给内核开发者。此进程的配置详细信息在 `/etc/kerneloops.conf` 文件中指定。你可以使用下面的命令轻松查看设置:
|
||||
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
```
|
||||
|
||||
在上面的(默认)设置中,内核问题可以被提交,但要求用户获得许可。如果设置为 `allow-submit = always`,则不会询问用户。
|
||||
|
||||
调试内核问题是使用 Linux 系统的更高级技巧之一。幸运的是,大多数 Linux 用户很少或从没有经历过 oops 或内核恐慌。不过,知道 kerneloops 这样的进程在系统中执行什么操作,了解可能会报告什么以及系统何时遇到严重的内核冲突也是很好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
@ -0,0 +1,212 @@
|
||||
Linux 系统中 sudo 命令的 10 个技巧
|
||||
======
|
||||
|
||||
![Linux-sudo-command-tips][1]
|
||||
|
||||
### 概览
|
||||
|
||||
`sudo` 表示 “**s**uper**u**ser **do**”。 它允许已验证的用户以其他用户的身份来运行命令。其他用户可以是普通用户或者超级用户。然而,大部分时候我们用它来以提升的权限来运行命令。
|
||||
|
||||
`sudo` 命令与安全策略配合使用,默认安全策略是 `sudoers`,可以通过文件 `/etc/sudoers` 来配置。其安全策略具有高度可拓展性。人们可以开发和分发他们自己的安全策略作为插件。
|
||||
|
||||
### 与 su 的区别
|
||||
|
||||
在 GNU/Linux 中,有两种方式可以用提升的权限来运行命令:
|
||||
|
||||
* 使用 `su` 命令
|
||||
* 使用 `sudo` 命令
|
||||
|
||||
`su` 表示 “**s**witch **u**ser”。使用 `su`,我们可以切换到 root 用户并且执行命令。但是这种方式存在一些缺点:
|
||||
|
||||
* 我们需要与他人共享 root 的密码。
|
||||
* 因为 root 用户为超级用户,我们不能授予受控的访问权限。
|
||||
* 我们无法审查用户在做什么。
|
||||
|
||||
`sudo` 以独特的方式解决了这些问题。
|
||||
|
||||
1. 首先,我们不需要妥协来分享 root 用户的密码。普通用户使用他们自己的密码就可以用提升的权限来执行命令。
|
||||
2. 我们可以控制 `sudo` 用户的访问,这意味着我们可以限制用户只执行某些命令。
|
||||
3. 除此之外,`sudo` 用户的所有活动都会被记录下来,因此我们可以随时审查进行了哪些操作。在基于 Debian 的 GNU/Linux 中,所有活动都记录在 `/var/log/auth.log` 文件中。
|
||||
|
||||
本教程后面的部分阐述了这些要点。
|
||||
|
||||
### 实际动手操作 sudo
|
||||
|
||||
现在,我们对 sudo 有了大致的了解。让我们实际动手操作吧。为了演示,我使用 Ubuntu。但是,其它发行版本的操作应该是相同的。
|
||||
|
||||
#### 允许 sudo 权限
|
||||
|
||||
让我们添加普通用户为 `sudo` 用户吧。在我的情形中,用户名为 `linuxtechi`。
|
||||
|
||||
1) 按如下所示编辑 `/etc/sudoers` 文件:
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
```
|
||||
|
||||
2) 添加以下行来允许用户 `linuxtechi` 有 sudo 权限:
|
||||
|
||||
```
|
||||
linuxtechi ALL=(ALL) ALL
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* `linuxtechi` 表示用户名
|
||||
* 第一个 `ALL` 指示允许从任何终端、机器访问 `sudo`
|
||||
* 第二个 `(ALL)` 指示 `sudo` 命令被允许以任何用户身份执行
|
||||
* 第三个 `ALL` 表示所有命令都可以作为 root 执行
|
||||
|
||||
|
||||
#### 以提升的权限执行命令
|
||||
|
||||
要用提升的权限执行命令,只需要在命令前加上 `sudo`,如下所示:
|
||||
|
||||
```
|
||||
$ sudo cat /etc/passwd
|
||||
```
|
||||
|
||||
当你执行这个命令时,它会询问 `linuxtechi` 的密码,而不是 root 用户的密码。
|
||||
|
||||
#### 以其他用户执行命令
|
||||
|
||||
除此之外,我们可以使用 `sudo` 以另一个用户身份执行命令。例如,在下面的命令中,用户 `linuxtechi` 以用户 `devesh` 的身份执行命令:
|
||||
|
||||
```
|
||||
$ sudo -u devesh whoami
|
||||
[sudo] password for linuxtechi:
|
||||
devesh
|
||||
```
|
||||
|
||||
#### 内置命令行为
|
||||
|
||||
`sudo` 的一个限制是 —— 它无法使用 Shell 的内置命令。例如, `history` 记录是内置命令,如果你试图用 `sudo` 执行这个命令,那么会提示如下的未找到命令的错误:
|
||||
|
||||
```
|
||||
$ sudo history
|
||||
[sudo] password for linuxtechi:
|
||||
sudo: history: command not found
|
||||
|
||||
```
|
||||
|
||||
**访问 root shell**
|
||||
|
||||
为了克服上述问题,我们可以访问 root shell,并在那里执行任何命令,包括 Shell 的内置命令。
|
||||
|
||||
要访问 root shell, 执行下面的命令:
|
||||
|
||||
```
|
||||
$ sudo bash
|
||||
```
|
||||
|
||||
执行完这个命令后——您将观察到提示符变为井号(`#`)。
|
||||
|
||||
### 技巧
|
||||
|
||||
这节我们将讨论一些有用的技巧,这将有助于提高生产力。大多数命令可用于完成日常任务。
|
||||
|
||||
#### 以 sudo 用户执行之前的命令
|
||||
|
||||
让我们假设你想用提升的权限执行之前的命令,那么下面的技巧将会很有用:
|
||||
|
||||
```
|
||||
$ sudo !4
|
||||
```
|
||||
|
||||
上面的命令将使用提升的权限执行历史记录中的第 4 条命令。
|
||||
|
||||
#### 在 Vim 里面使用 sudo 命令
|
||||
|
||||
很多时候,我们编辑系统的配置文件时,在保存时才意识到我们需要 root 访问权限来执行此操作。因为这个可能让我们丢失我们对文件的改动。没有必要惊慌,我们可以在 Vim 中使用下面的命令来解决这种情况:
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* 冒号 (`:`) 表明我们处于 Vim 的退出模式
|
||||
* 感叹号 (`!`) 表明我们正在运行 shell 命令
|
||||
* `sudo` 和 `tee` 都是 shell 命令
|
||||
* 百分号 (`%`) 表明从当前行开始的所有行
|
||||
|
||||
|
||||
|
||||
#### 使用 sudo 执行多个命令
|
||||
|
||||
至今我们用 `sudo` 只执行了单个命令,但我们可以用它执行多个命令。只需要用分号 (`;`) 隔开命令,如下所示:
|
||||
|
||||
```
|
||||
$ sudo -- bash -c 'pwd; hostname; whoami'
|
||||
|
||||
```
|
||||
|
||||
上述命令中
|
||||
|
||||
* 双连字符 (`--`) 停止命令行切换
|
||||
* `bash` 表示要用于执行命令的 shell 名称
|
||||
* `-c` 选项后面跟着要执行的命令
|
||||
|
||||
|
||||
|
||||
#### 无密码运行 sudo 命令
|
||||
|
||||
当第一次执行 `sudo` 命令时,它会提示输入密码,默认情形下密码被缓存 15 分钟。但是,我们可以避免这个操作,并使用 `NOPASSWD` 关键字禁用密码认证,如下所示:
|
||||
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: ALL
|
||||
```
|
||||
|
||||
#### 限制用户执行某些命令
|
||||
|
||||
为了提供受控访问,我们可以限制 `sudo` 用户只执行某些命令。例如,下面的行只允许执行 `echo` 和 `ls` 命令 。
|
||||
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
|
||||
```
|
||||
|
||||
#### 深入了解 sudo
|
||||
|
||||
让我们进一步深入了解 `sudo` 命令。
|
||||
|
||||
```
|
||||
$ ls -l /usr/bin/sudo
|
||||
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
|
||||
```
|
||||
|
||||
如果仔细观察文件权限,则发现 `sudo` 上启用了 setuid 位。当任何用户运行这个二进制文件时,它将以拥有该文件的用户权限运行。在所示情形下,它是 root 用户。
|
||||
|
||||
|
||||
为了演示这一点,我们可以使用 `id` 命令,如下所示:
|
||||
|
||||
```
|
||||
$ id
|
||||
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
|
||||
```
|
||||
|
||||
当我们不使用 `sudo` 执行 `id` 命令时,将显示用户 `linuxtechi` 的 id。
|
||||
|
||||
```
|
||||
$ sudo id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
|
||||
```
|
||||
|
||||
但是,如果我们使用 `sudo` 执行 `id` 命令时,则会显示 root 用户的 id。
|
||||
|
||||
### 结论
|
||||
|
||||
从这篇文章可以看出 —— `sudo` 为普通用户提供了更多受控访问。使用这些技术,多用户可以用安全的方式与 GNU/Linux 进行交互。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/03/Linux-sudo-command-tips.jpg
|
||||
@ -1,8 +1,9 @@
|
||||
在 Fedora 中持续集成
|
||||
Fedora 社区的持续集成
|
||||
======
|
||||
|
||||

|
||||
持续集成 (CI) 是为项目的每一项变更运行测试的过程,如同这是新的交付项目一样。如果持续执行,这意味着软件随时可以发布。 CI 是整个 IT 行业以及免费和开源项目非常成熟的流程。Fedora 在这方面有点落后,但我们正在赶上。阅读以下内容了解进展。
|
||||
|
||||
<ruby>持续集成<rt>Continuous Integration</rt></ruby>(CI) 是为项目的每一项变更运行测试的过程,如同这是新的交付项目一样。如果持续执行,这意味着软件随时可以发布。 CI 是整个 IT 行业以及自由开源项目非常成熟的流程。Fedora 在这方面有点落后,但我们正在赶上。阅读以下内容了解进展。
|
||||
|
||||
### 我们为什么需要这个?
|
||||
|
||||
@ -12,7 +13,7 @@ CI 将全面改善 Fedora。它通过尽早揭示 bug 提供更稳定和一致
|
||||
|
||||
### 它看起来如何?
|
||||
|
||||
对于初学者,我们将对在 Fedora 包 (dist-git) 仓库的每个提交运行测试。这些测试独立于构建时运行的每个软件包的测试。但是,他们在尽可能接近 Fedora 用户运行环境的环境中测试软件包的功能。除了特定的软件包测试外,Fedora 还运行一些发行测试,例如从 F27 升级到 F28 或者全新安装。
|
||||
对于初学者,我们将对在 Fedora 包仓库 (dist-git) 的每个提交运行测试。这些测试独立于构建时运行的每个软件包的测试。但是,它们在尽可能接近 Fedora 用户运行环境的环境中测试软件包的功能。除了特定的软件包测试外,Fedora 还运行一些发行版测试,例如从 F27 升级到 F28 或者全新安装。
|
||||
|
||||
软件包根据测试结果进行“控制”:测试失败会阻止将更新推送给用户。但是,有时由于各种原因,测试会失败。也许测试本身是错误的,或者不是最新的软件。或者可能发生基础架构问题,并阻止测试正常运行。维护人员能够重新触发测试或放弃测试结果,直到测试更新。
|
||||
|
||||
@ -20,28 +21,25 @@ CI 将全面改善 Fedora。它通过尽早揭示 bug 提供更稳定和一致
|
||||
|
||||
### 我们如今有什么?
|
||||
|
||||
目前,CI 管道在 Fedora Atomic Host 一部分软件包上运行测试。其他软件包可以在 dist-git 中进行测试,但它们不会自动运行。分发特定的测试已经在我们所有的软件包上运行。这些测试结果被用于过滤测试失败的软件包。
|
||||
目前,CI 管道在 Fedora Atomic Host 的部分软件包上运行测试。其他软件包可以在 dist-git 中进行测试,但它们不会自动运行。发行版特定的测试已经在我们所有的软件包上运行。这些测试结果被用于过滤测试失败的软件包。
|
||||
|
||||
### 我该如何参与?
|
||||
|
||||
最好的入门方法是阅读关于[ Fedora 持续集成][1]的文档。你应该熟悉[标准测试接口][2],它描述了很多术语以及如何编写测试和使用现有的测试。
|
||||
最好的入门方法是阅读关于 [Fedora 持续集成][1]的文档。你应该熟悉[标准测试接口][2],它描述了很多术语以及如何编写测试和使用现有的测试。
|
||||
|
||||
有了这些知识,如果你是一个软件包维护者,你可以开始添加测试到你的软件包。你可以在本地或虚拟机上运行它们。 (后者对于破坏性测试是明治的!)
|
||||
有了这些知识,如果你是一个软件包维护者,你可以开始添加测试到你的软件包。你可以在本地或虚拟机上运行它们。 (对于破坏性测试来说后者是明智的!)
|
||||
|
||||
标准测试接口使测试保持一致。因此,你可以轻松地将任何测试添加到你喜欢的包中,并在 [仓库][3] 提交合并请求给维护人员。
|
||||
|
||||
Reach out on #fedora-ci on irc.freenode.net with feedback, questions or for a general discussion on CI.
|
||||
在 irc.freenode.net 上与 #fedora-ci 联系,提供反馈,问题或关于 CI 的一般性讨论。
|
||||
|
||||
[Samuel Zeller][4] 在 [Unsplash][5] 上提供的照片
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/continuous-integration-fedora/
|
||||
|
||||
作者:[Pierre-Yves Chibon;Dominik Perpeet][a]
|
||||
作者:[Pierre-Yves Chibon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
157
published/20180407 12 Git tips for Git-s 12th birthday.md
Normal file
157
published/20180407 12 Git tips for Git-s 12th birthday.md
Normal file
@ -0,0 +1,157 @@
|
||||
13 个 Git 技巧献给 Git 13 岁生日
|
||||
=====
|
||||
|
||||
> 这 13 个 Git 技巧将使你的版本控制技能 +1、+1、+1……
|
||||
|
||||

|
||||
|
||||
[Git][1] 是一个分布式版本控制系统,它已经成为开源世界中源代码控制的默认工具,在 4 月 7 日这天,它 13 岁了。使用 Git 令人沮丧的事情之一是你需要知道更多才能有效地使用 Git。但这也可能是使用 Git 比较美妙的一件事,因为没有什么比发现一个新技巧来简化或提高你的工作流的效率更令人快乐了。
|
||||
|
||||
为了纪念 Git 的 13 岁生日,这里有 13 条技巧和诀窍来让你的 Git 经验更加有用和强大。从你可能忽略的一些基本知识开始,并扩展到一些真正的高级用户技巧!
|
||||
|
||||
### 1、 你的 ~/.gitconfig 文件
|
||||
|
||||
当你第一次尝试使用 `git` 命令向仓库提交一个更改时,你可能会收到这样的欢迎信息:
|
||||
|
||||
```
|
||||
*** Please tell me who you are.
|
||||
|
||||
Run
|
||||
|
||||
git config --global user.email "you@example.com"
|
||||
|
||||
git config --global user.name "Your Name"
|
||||
|
||||
to set your account's default identity.
|
||||
```
|
||||
|
||||
你可能没有意识到正是这些命令在修改 `~/.gitconfig` 的内容,这是 Git 存储全局配置选项的地方。你可以通过 `~/.gitconfig` 文件来做大量的事,包括定义别名、永久性打开(或关闭)特定命令选项,以及修改 Git 工作方式(例如,`git diff` 使用哪个 diff 算法,或者默认使用什么类型的合并策略)。你甚至可以根据仓库的路径有条件地包含其他配置文件!所有细节请参阅 `man git-config`。
|
||||
|
||||
### 2、 你仓库中的 .git/config 文件
|
||||
|
||||
在之前的技巧中,你可能想知道 `git config` 命令中 `--global` 标志是干什么的。它告诉 Git 更新 `~/.gitconfig` 中的“全局”配置。当然,有全局配置也意味着会有本地配置,显然,如果你省略 `--global` 标志,`git config` 将改为更新仓库特有的配置,该配置存储在 `.git/config` 中。
|
||||
|
||||
在 `.git/config` 文件中设置的选项将覆盖 `~/.gitconfig` 文件中的所有设置。因此,例如,如果你需要为特定仓库使用不同的电子邮件地址,则可以运行 `git config user.email "also_you@example.com"`。然后,该仓库中的任何提交都将使用你单独配置的电子邮件地址。如果你在开源项目中工作,而且希望它们显示自己的电子邮件地址,同时仍然使用自己工作邮箱作为主 Git 配置,这非常有用。
|
||||
|
||||
几乎任何你可以在 `~/.gitconfig` 中设置的东西,你也可以在 `.git/config` 中进行设置,以使其作用于特定的仓库。在下面的技巧中,当我提到将某些内容添加到 `~/.gitconfig` 时,只需记住你也可以在特定仓库的 `.git/config` 中添加来设置那个选项。
|
||||
|
||||
### 3、 别名
|
||||
|
||||
别名是你可以在 `~/.gitconfig` 中做的另一件事。它的工作原理就像命令行中的 shell —— 它们设定一个新的命令名称,可以调用一个或多个其他命令,通常使用一组特定的选项或标志。它们对于那些你经常使用的又长又复杂的命令来说非常有效。
|
||||
|
||||
你可以使用 `git config` 命令来定义别名 —— 例如,运行 `git config --global --add alias.st status` 将使运行 `git st` 与运行 `git status` 做同样的事情 —— 但是我在定义别名时发现,直接编辑 `~/.gitconfig` 文件通常更容易。
|
||||
|
||||
如果你选择使用这种方法,你会发现 `~/.gitconfig` 文件是一个 [INI 文件][2]。INI 是一种带有特定段落的键值对文件格式。当添加一个别名时,你将改变 `[alias]` 段落。例如,定义上面相同的 `git st` 别名时,添加如下到文件:
|
||||
|
||||
```
|
||||
[alias]
|
||||
st = status
|
||||
```
|
||||
|
||||
(如果已经有 `[alias]` 段落,只需将第二行添加到现有部分。)
|
||||
|
||||
### 4、 shell 命令中的别名
|
||||
|
||||
别名不仅仅限于运行其他 Git 子命令 —— 你还可以定义运行其他 shell 命令的别名。这是一个用来处理一个反复发生的、罕见和复杂的任务的很好方式:一旦你确定了如何完成它,就可以在别名下保存该命令。例如,我有一些<ruby>复刻<rt>fork</rt></ruby>的开源项目的仓库,并进行了一些本地修改。我想跟上项目正在进行的开发工作,并保存我本地的变化。为了实现这个目标,我需要定期将来自上游仓库的更改合并到我复刻的项目中 —— 我通过使用我称之为 `upstream-merge` 的别名来完成。它是这样定义的:
|
||||
|
||||
```
|
||||
upstream-merge = !"git fetch origin -v && git fetch upstream -v && git merge upstream/master && git push"
|
||||
```
|
||||
|
||||
别名定义开头的 `!` 告诉 Git 通过 shell 运行这个命令。这个例子涉及到运行一些 `git` 命令,但是以这种方式定义的别名可以运行任何 shell 命令。
|
||||
|
||||
(注意,如果你想复制我的 `upstream-merge` 别名,你需要确保你有一个名为 `upstream` 的 Git 远程仓库,指向你已经分配的上游仓库,你可以通过运行 `git remote add upstream <URL to repo>` 来添加一个。)
|
||||
|
||||
### 5、 可视化提交图
|
||||
|
||||
如果你在一个有很多分支活动的项目上开发,有时可能很难掌握所有正在发生的工作以及它们之间的相关性。各种图形用户界面工具可让你获取不同分支的图片并在所谓的“提交图表”中提交。例如,以下是我使用 [GitLab][3] 提交图表查看器可视化的我的一个仓库的一部分:
|
||||
|
||||
![GitLab commit graph viewer][5]
|
||||
|
||||
如果你是一个专注于命令行的用户或者发现分支切换工具让人分心,那么可以从命令行获得类似的提交视图。这就是 `git log` 命令的 `--graph` 参数出现的地方:
|
||||
|
||||
![Repository visualized with --graph command][7]
|
||||
|
||||
以下命令可视化相同仓库可达到相同效果:
|
||||
|
||||
```
|
||||
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative
|
||||
```
|
||||
|
||||
`--graph` 选项将图添加到日志的左侧,`--abbrev-commit` 缩短提交的 [SHA][8] 值,`--date=relative` 以相对方式表示日期,以及 `--pretty` 来处理所有其他自定义格式。我有个 `git lg` 别名用于这个功能,它是我最常用的 10 个命令之一。
|
||||
|
||||
### 6、 更优雅的强制推送
|
||||
|
||||
有时,你越是想避开越避不开,你会发现你需要运行 `git push --force` 来覆盖仓库远程副本上的历史记录。你可能得到了一些反馈,需要你进行交互式<ruby>变基<rt>rebase</rt></ruby>,或者你可能已经搞砸了,并希望隐藏“罪证”。
|
||||
|
||||
当其他人在仓库的远程副本的同一分支上进行更改时,会发生强制推送的危险。当你强制推送已重写的历史记录时,这些提交将会丢失。这就是 `git push --force-with-lease` 出现的原因 -- 如果远程分支已经更新,它不会允许你强制推送,这确保你不会丢掉别人的工作。
|
||||
|
||||
### 7、 git add -N
|
||||
|
||||
你是否使用过 `git commit -a` 在一次行动中提交所有未完成的修改,但在你推送完提交后才发现 `git commit -a` 忽略了新添加的文件?你可以使用 `git add -N` (想想 “notify”) 来解决这个问题,告诉 Git 在第一次实际提交它们之前,你希望在提交中包含新增文件。
|
||||
|
||||
### 8、 git add -p
|
||||
|
||||
使用 Git 时的最佳做法是确保每次提交都只包含一个逻辑修改 —— 无论这是修复错误还是添加新功能。然而,有时当你在工作时,你的仓库中的修改最终应该使用多个提交。你怎样才能设法把事情分开,使每个提交只包含适当的修改呢?`git add --patch` 来拯救你了!
|
||||
|
||||
这个标志会让 `git add` 命令查看你工作副本中的所有变化,并为每个变化询问你是否想要将它提交、跳过,或者推迟决定(你可以在运行该命令后选择 `?` 来查看其他更强大的选项)。`git add -p` 是生成结构良好的提交的绝佳工具。
|
||||
|
||||
### 9、 git checkout -p
|
||||
|
||||
与 `git add -p` 类似,`git checkout` 命令也接受 `--patch` 或 `-p` 选项,这会使其在本地工作副本中显示每个“大块”的改动,并允许丢弃它 —— 简单来说就是将本地工作副本恢复到更改之前的状态。
|
||||
|
||||
这真的很棒。例如,当你追踪一个 bug 时引入了一堆调试日志语句,修正了这个 bug 之后,你可以先使用 `git checkout -p` 移除所有新的调试日志,然后 `git add -p` 来添加 bug 修复。没有比组合一个优雅的、结构良好的提交更令人满意!
|
||||
|
||||
### 10、 变基时执行命令
|
||||
|
||||
有些项目有一个规则,即存储库中的每个提交都必须处于可工作状态 —— 也就是说,在每次提交时,应该可以编译该代码,或者应该运行测试套件而不会失败。 当你在分支上工作时,这并不困难,但是如果你最终因为某种原因需要<ruby>变基<rt>rebase</rt></ruby>时,那么需要逐步完成每个变基的提交以确保你没有意外地引入一个中断,而这个过程是乏味的。
|
||||
|
||||
幸运的是,`git rebase` 已经覆盖了 `-x` 或 `--exec` 选项。`git rebase -x <cmd>` 将在每个提交在变基中被应用后运行该命令。因此,举个例子,如果你有一个项目,其中使用 `npm run tests` 运行你的测试套件,`git rebase -x npm run tests` 将在变基期间每次提交之后运行测试套件。这使你可以查看测试套件是否在任何变基的提交中失败,以便你可以确认测试套件在每次提交时仍能通过。
|
||||
|
||||
### 11、 基于时间的修订引用
|
||||
|
||||
很多 Git 子命令都接受一个修订参数来决定命令作用于仓库的哪个部分,可以是某次特定的提交的 SHA1 值,一个分支的名称,甚至是一个符号性的名称如 `HEAD`(代表当前检出分支最后一次的提交),除了这些简单的形式以外,你还可以附加一个指定的日期或时间作为参数,表示“这个时间的引用”。
|
||||
|
||||
这个功能在某些时候会变得十分有用。当你处理最新出现的 bug,自言自语道:“这个功能昨天还是好好的,到底又改了些什么”,不用盯着满屏的 `git log` 的输出试图弄清楚什么时候更改了提交,你只需运行 `git diff HEAD@{yesterday}`,看看从昨天以来的所有修改。这也适用于更长的时间段(例如 `git diff HEAD@{'2 months ago'}`),以及一个确切的日期(例如 `git diff HEAD@{'2010-01-01 12:00:00'}`)。
|
||||
|
||||
你也可以将这些基于日期的修订参数与使用修订参数的任何 Git 子命令一起使用。在 `gitrevisions` 手册页中有关于具体使用哪种格式的详细信息。
|
||||
|
||||
### 12、 全知的 reflog
|
||||
|
||||
你是不是试过在变基时干掉过某次提交,然后发现你需要保留那个提交中一些东西?你可能觉得这些信息已经永远找不回来了,只能重新创建。但是如果你在本地工作副本中提交了,提交就会被添加到引用日志(reflog)中 ,你仍然可以访问到。
|
||||
|
||||
运行 `git reflog` 将在本地工作副本中显示当前分支的所有活动的列表,并为你提供每个提交的 SHA1 值。一旦发现你变基时放弃的那个提交,你可以运行 `git checkout <SHA1>` 跳转到该提交,复制任何你需要的信息,然后再运行 `git checkout HEAD` 返回到分支最近的提交去。
|
||||
|
||||
### 13、自己清理
|
||||
|
||||
哎呦! 事实证明,我的基本数学技能不如我的 Git 技能。 Git 最初是在 2005 年发布的,这意味着它今年会变成 13 岁,而不是 12 岁(LCTT 译注:本文原来是以 12 岁生日为题的)。为了弥补这个错误,这里有可以让我们变成十三岁的第 13 条技巧。
|
||||
|
||||
如果你使用基于分支的工作流,随着在一个长期项目上的工作,除非你在每个分支合并时清理干净,否则你最终会得到一大堆分支。这使得你难于找到想要的分支,分支的森林会让你无从找起。甚至更糟糕的是,如果你有大量活跃的分支,确定一个分支是否被合并(可以被安全删除)或仍然没有被合并而应该留下会非常繁琐。幸运的是,Git 可以帮到你:只需要运行 `git branch --merged` 就可以得到已经被合并到你的当前分支的分支列表,或者 `git branch --no-merged` 找出被合并到其它分支的分支。默认情况下这会列出你本地工作副本的分支,但是如果你在命令行包括 `--remote` 或 `-r` 参数,它也会列出仅存于远程仓库的已合并分支。
|
||||
|
||||
重要提示:如果你计划使用 `git branch --merged` 的输出来清理那些已合并的分支,你要小心它的输出也包括了当前分支(毕竟,这个当前的分支就被合并到当前分支!)。确保你在任何销毁动作之前排除了该分支(如果你忘记了,参见第 12 条技巧来学习 reflog 怎样帮你把分支找回来,希望有用……)。
|
||||
|
||||
### 以上是全部内容
|
||||
|
||||
希望这些技巧中至少有一个能够教给你一些关于 Git 的新东西,Git 是一个有 13 年历史的项目,并且在持续创新和增加新功能中。你最喜欢的 Git 技巧是什么?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/git-tips
|
||||
|
||||
作者:[John SJ Anderson][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/genehack
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://en.wikipedia.org/wiki/INI_file
|
||||
[3]:https://gitlab.com/
|
||||
[4]:/file/392941
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gui_graph.png?itok=3GovYfG1 (GitLab commit graph viewer)
|
||||
[6]:/file/392936
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/console_graph.png?itok=XogY1P8M (Repository visualized with --graph command)
|
||||
[8]:https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
|
||||
@ -1,51 +0,0 @@
|
||||
Translating by valoniakim
|
||||
|
||||
How to start an open source program in your company
|
||||
======
|
||||
|
||||

|
||||
|
||||
Many internet-scale companies, including Google, Facebook, and Twitter, have established formal open source programs (sometimes referred to as open source program offices, or OSPOs for short), a designated place where open source consumption and production is supported inside a company. With such an office in place, any business can execute its open source strategies in clear terms, giving the company tools needed to make open source a success. An open source program office's responsibilities may include establishing policies for code use, distribution, selection, and auditing; engaging with open source communities; training developers; and ensuring legal compliance.
|
||||
|
||||
Internet-scale companies aren't the only ones establishing open source programs; studies show that [65% of companies][1] across industries are using and contributing to open source. In the last couple of years we’ve seen [VMware][2], [Amazon][3], [Microsoft][4], and even the [UK government][5] hire open source leaders and/or create open source programs. Having an open source strategy has become critical for businesses and even governments, and all organizations should be following in their footsteps.
|
||||
|
||||
### How to start an open source program
|
||||
|
||||
Although each open source office will be customized to a specific organization’s needs, there are standard steps that every company goes through. These include:
|
||||
|
||||
* **Finding a leader:** Identifying the right person to lead the open source program is the first step. The [TODO Group][6] maintains a list of [sample job descriptions][7] that may be helpful in finding candidates.
|
||||
* **Deciding on the program structure:** There are a variety of ways to fit an open source program office into an organization's existing structure, depending on its focus. Companies with large intellectual property portfolios may be most comfortable placing the office within the legal department. Engineering-driven organizations may choose to place the office in an engineering department, especially if the focus of the office is to improve developer productivity. Others may want the office to be within the marketing department to support sales of open source products. For inspiration, the TODO Group offers [open source program case studies][8] that can be useful.
|
||||
* **Setting policies and processes:** There needs to be a standardized method for implementing the organization’s open source strategy. The policies, which should require as little oversight as possible, lay out the requirements and rules for working with open source across the organization. They should be clearly defined, easily accessible, and even automated with tooling. Ideally, employees should be able to question policies and provide recommendations for improving or revising them. Numerous organizations active in open source, such as Google, [publish their policies publicly][9], which can be a good place to start. The TODO Group offers examples of other [open source policies][10] organizations can use as resources.
|
||||
|
||||
|
||||
|
||||
### A worthy step
|
||||
|
||||
Opening an open source program office is a big step for most organizations, especially if they are (or are transitioning into) a software company. The benefits to the organization are tremendous and will more than make up for the investment in the long run—not only in employee satisfaction but also in developer efficiency. There are many resources to help on the journey. The TODO Group guides [How to Create an Open Source Program][11], [Measuring Your Open Source Program's Success][12], and [Tools for Managing Open Source Programs][13] are great starting points.
|
||||
|
||||
Open source will truly be sustainable as more companies formalize programs to contribute back to these projects. I hope these resources are useful to you, and I wish you luck on your open source program journey.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-start-open-source-program-your-company
|
||||
|
||||
作者:[Chris Aniszczyk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/caniszczyk
|
||||
[1]:https://www.blackducksoftware.com/2016-future-of-open-source
|
||||
[2]:http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html
|
||||
[3]:http://fortune.com/2016/12/01/amazon-open-source-guru/
|
||||
[4]:https://opensource.microsoft.com/
|
||||
[5]:https://www.linkedin.com/jobs/view/169669924
|
||||
[6]:http://todogroup.org
|
||||
[7]:https://github.com/todogroup/job-descriptions
|
||||
[8]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
[9]:https://opensource.google.com/docs/why/
|
||||
[10]:https://github.com/todogroup/policies
|
||||
[11]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[12]:https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md
|
||||
[13]:https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md
|
||||
@ -0,0 +1,117 @@
|
||||
# Is DevOps compatible with part-time community teams?
|
||||
|
||||
### DevOps can greatly benefit projects of all sizes. Here's how to build a DevOps adoption plan for smaller projects.
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
[WOCinTech Chat][1]. Modified by Opensource.com. [CC BY-SA 4.0][2]
|
||||
|
||||
### Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
DevOps seems to be the talk of the IT world of late—and for good reason. DevOps has streamlined the process and production of IT development and operations. However, there is also an upfront cost to embracing a DevOps ideology, in terms of time, effort, knowledge, and financial investment. Larger companies may have the bandwidth, budget, and time to make the necessary changes, but is it feasible for part-time, resource-strapped communities?
|
||||
|
||||
Part-time communities are teams of like-minded people who take on projects outside of their normal work schedules. The members of these communities are driven by passion and a shared purpose. For instance, one such community is the [ALM | DevOps Rangers][3]. With 100 rangers engaged across the globe, a DevOps solution may seem daunting; nonetheless, they took on the challenge and embraced the ideology. Through their example, we've learned that DevOps is not only feasible but desirable in smaller teams. To read about their transformation, check out [How DevOps eliminates development bottlenecks][4].
|
||||
|
||||
> “DevOps is the union of people, process, and products to enable continuous delivery of value to our end customers.” - Donovan Brown
|
||||
|
||||
### The cost of DevOps
|
||||
|
||||
As stated above, there is an _upfront_ "cost" to DevOps. The cost manifests itself in many forms, such as the time and collaboration between development, operations, and other stakeholders, planning a smooth-flowing process that delivers continuous value, finding the best DevOps products, and training the team in new technologies, to name a few. This aligns directly with Donovan's definition of DevOps, in fact—a **process** for delivering **continuous value** and the **people** who make that happen.
|
||||
|
||||
More DevOps resources
|
||||
|
||||
* [What is DevOps?][5]
|
||||
* [Free eBook: DevOps with OpenShift][6]
|
||||
* [10 bad DevOps habits to break][7]
|
||||
* [10 must-read DevOps resources][8]
|
||||
* [The latest on DevOps][9]
|
||||
|
||||
Streamlined DevOps takes a lot of planning and training just to create the process, and that doesn't even consider the testing phase. We also can't forget the existing in-flight projects that need to be converted into the new system. While the cost increases the more pervasive the transformation—for instance, if an organization aims to unify its entire development organization under a single process, then that would cost more versus transforming a single pilot or subset of the entire portfolio—these upfront costs must be addressed regardless of their scale. There are a lot of resources and products already out there that can be implemented for a smoother transition—but again, we face the time and effort that will be necessary just to research which ones might work best.
|
||||
|
||||
In the case of the ALM | DevOps Rangers, they had to halt all projects for a couple of sprints to set up the initial process. Many organizations would not be able to do that. Even part-time groups might have very good reasons to keep things moving, which only adds to the complexity. In such scenarios, additional cutover planning (and therefore additional cost) is needed, and the overall state of the community is one of flux and change, which adds risk, which—you guessed it—requires more cost to mitigate.
|
||||
|
||||
There is also an _ongoing_ "cost" that teams will face with a DevOps mindset: Simple maintenance of the system, training and transitioning new team members, and keeping up with new, improved technologies are all a part of the process.
|
||||
|
||||
### DevOps for a part-time community
|
||||
|
||||
Whereas larger companies can dedicate a single manager or even a team to the task over overseeing the continuous integration and continuous deployment (CI/CD) pipelines, part-time community teams don't have the bandwidth to give. With such a massive undertaking we must ask: Is it even worth it for groups with fewer resources to take on DevOps for their community? Or should they abandon the idea of DevOps altogether?
|
||||
|
||||
The answer to that is dependent on a few variables, such as the ability of the teams to be self-managing, the time and effort each member is willing to put into the transformation, and the dedication of the community to the process.
|
||||
|
||||
### Example: Benefits of DevOps in a part-time community
|
||||
|
||||
Luckily, we aren't without examples to demonstrate just how DevOps can benefit a smaller group. Let's take a quick look at the ALM Rangers again. The results from their transformation help us understand how DevOps changed their community:
|
||||
|
||||

|
||||
|
||||
As illustrated, there are some huge benefits for part-time community teams. Planning goes from long, arduous design sessions to a quick prototyping and storyboarding process. Builds become automated, reliable, and resilient. Testing and bug detection are proactive instead of reactive, which turns into a happier clientele. Multiple full-time program managers are replaced with self-managing teams with a single part-time manager to oversee projects. Teams become smaller and more efficient, which equates to higher production rates and higher-quality project delivery. With results like these, it's hard to argue against DevOps.
|
||||
|
||||
Still, the upfront and ongoing costs aren't right for every community. The number-one most important aspect of any DevOps transformation is the mindset of the people involved. Adopting the idea of self-managing teams who work in autonomy instead of the traditional chain-of-command scheme can be a challenge for any group. The members must be willing to work independently without a lot of oversight and take ownership of their features and user experience, but at the same time, work in a setting that is fully transparent to the rest of the community. **The success or failure of a DevOps strategy lies on the team.**
|
||||
|
||||
### Making the DevOps transition in 4 steps
|
||||
|
||||
Another important question to ask: How can a low-bandwidth group make such a massive transition? The good news is that a DevOps transformation doesn’t need to happen all at once. Taken in smaller, more manageable steps, organizations of any size can embrace DevOps.
|
||||
|
||||
1. Determine why DevOps may be the solution you need. Are your projects bottlenecking? Are they running over budget and over time? Of course, these concerns are common for any community, big or small. Answering these questions leads us to step two:
|
||||
2. Develop the right framework to improve the engineering process. DevOps is all about automation, collaboration, and streamlining. Rather than trying to fit everyone into the same process box, the framework should support the work habits, preferences, and delivery needs of the community. Some broad standards should be established (for example, that all teams use a particular version control system). Beyond that, however, let the teams decide their own best process.
|
||||
3. Use the current products that are already available if they meet your needs. Why reinvent the wheel?
|
||||
4. Finally, implement and test the actual DevOps solution. This is, of course, where the actual value of DevOps is realized. There will likely be a few issues and some heartburn, but it will all be worth it in the end because, once established, the products of the community’s work will be nimbler and faster for the users.
|
||||
|
||||
### Reuse DevOps solutions
|
||||
|
||||
One benefit to creating effective CI/CD pipelines is the reusability of those pipelines. Although there is no one-size fits all solution, anyone can adopt a process. There are several pre-made templates available for you to examine, such as build templates on VSTS, ARM templates to deploy Azure resources, and "cookbook"-style textbooks from technical publishers. Once it identifies a process that works well, a community can also create its own template by defining and establishing standards and making that template easily discoverable by the entire community. For more information on DevOps journeys and tools, check out [this site][10].
|
||||
|
||||
### Summary
|
||||
|
||||
Overall, the success or failure of DevOps relies on the culture of a community. It doesn't matter if the community is a large, resource-rich enterprise or a small, resource-sparse, part-time group. DevOps will still bring solid benefits. The difference is in the approach for adoption and the scale of that adoption. There are both upfront and ongoing costs, but the value greatly outweighs those costs. Communities can use any of the powerful tools available today for their pipelines, and they can also leverage reusability, such as templates, to reduce upfront implementation costs. DevOps is most certainly feasible—and even critical—for the success of part-time community teams.
|
||||
|
||||
---
|
||||
|
||||
**\[See our related story, [How DevOps eliminates development bottlenecks][11].\]**
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][13]
|
||||
|
||||
Edward Fry \- Edward a business technophile who revels in blending people, process, and technology to solve real problems with grace and efficiency. As a member of the ALM Rangers, he loves to share his passion for the process of software development and ways to get computers to do the drudge work so that people can dream the big dreams. He also enjoys the art of great software design and architecture and also just likes being immersed in code. When he isn't helping people with technology, he enjoys... [more about Edward Fry][14]
|
||||
|
||||
[More about me][15]
|
||||
|
||||
* [Learn how you can contribute][16]
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/devops-compatible-part-time-community-teams][17]
|
||||
|
||||
作者: [Edward Fry][18] 选题者: [@lujun9972][19] 译者: [译者ID][20] 校对: [校对者ID][21]
|
||||
|
||||
本文由 [LCTT][22] 原创编译,[Linux中国][23] 荣誉推出
|
||||
|
||||
[1]: https://www.flickr.com/photos/wocintechchat/25392377053/
|
||||
[2]: https://creativecommons.org/licenses/by/4.0/
|
||||
[3]: https://github.com/ALM-Rangers
|
||||
[4]: https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
[5]: https://opensource.com/resources/devops?src=devops_resource_menu1
|
||||
[6]: https://www.openshift.com/promotions/devops-with-openshift.html?intcmp=7016000000127cYAAQ&src=devops_resource_menu2
|
||||
[7]: https://enterprisersproject.com/article/2018/1/10-bad-devops-habits-break?intcmp=7016000000127cYAAQ&src=devops_resource_menu3
|
||||
[8]: https://opensource.com/article/17/12/10-must-read-devops-books?src=devops_resource_menu4
|
||||
[9]: https://opensource.com/tags/devops?src=devops_resource_menu5
|
||||
[10]: https://www.visualstudio.com/devops/
|
||||
[11]: https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
[12]: https://opensource.com/tags/devops
|
||||
[13]: https://opensource.com/users/edwardf
|
||||
[14]: https://opensource.com/users/edwardf
|
||||
[15]: https://opensource.com/users/edwardf
|
||||
[16]: https://opensource.com/participate
|
||||
[17]: https://opensource.com/article/18/4/devops-compatible-part-time-community-teams
|
||||
[18]: https://opensource.com/users/edwardf
|
||||
[19]: https://github.com/lujun9972
|
||||
[20]: https://github.com/译者ID
|
||||
[21]: https://github.com/校对者ID
|
||||
[22]: https://github.com/LCTT/TranslateProject
|
||||
[23]: https://linux.cn/
|
||||
@ -1,157 +0,0 @@
|
||||
Download YouTube Videos in Linux Command Line
|
||||
======
|
||||
**Brief: Easily download YouTube videos in Linux using youtube-dl command line tool. With this tool, you can also choose video format and video quality such as 1080p or 4K.**
|
||||
|
||||

|
||||
|
||||
I know you have already seen [how to download YouTube videos][1]. But those tools were mostly GUI ways. I am going to show you how to download YouTube videos in Linux terminal using youtube-dl.
|
||||
|
||||
### Install youtube-dl to download YouTube videos in Linux terminal
|
||||
|
||||
[youtube-dl][2] is a Python-based small command-line tool that allows downloading videos from [YouTube][3], [Dailymotion][4], Photobucket, Facebook, Yahoo, Metacafe, Depositfiles and few more similar sites. It is written in pygtk and requires Python interpreter to run this program, it’s not platform restricted. It should run on any Unix, Windows or in Mac OS X based systems.
|
||||
|
||||
The youtube-dl tool supports resuming interrupted downloads. If youtube-dl is killed (for example by Ctrl-C or due to loss of Internet connectivity) in the middle of the download, you can simply re-run it with the same YouTube video URL. It will automatically resume the unfinished download, as long as a partial download is present in the current directory. Which means you don’t need [download managers in Linux][5] just for resuming downloads.
|
||||
|
||||
#### youtube-dl features
|
||||
|
||||
This tiny tool has so many features that it won’t be an exaggeration to call it the best YouTube downloader for Linux.
|
||||
|
||||
* Download videos from not only YouTube but other popular video websites like Dailymotion, Facebook etc
|
||||
* Allows downloading videos in several available video formats such as MP4, WebM etc.
|
||||
* You can also choose the quality of the video being downloaded. If the video is available in 4K, you can download it in 4K, 1080p, 720p etc
|
||||
* Automatical pause and resume of video downloads.
|
||||
* Allows to bypass YouTube geo-restrictions
|
||||
|
||||
|
||||
|
||||
Downloading videos from websites could be against their policies. It’s up to you if choose to download videos.
|
||||
|
||||
#### How to install youtube-dl
|
||||
|
||||
youtube-dl is a popular program and is available in the default repositories of most Linux distributions, if not all. You can use the standard way of installing packages in your distribution to install youtube-dl. I’ll still show some commands for the sake of it.
|
||||
|
||||
If you are running Ubuntu-based Linux distribution, you can install it using this command:
|
||||
```
|
||||
sudo apt install youtube-dl
|
||||
|
||||
```
|
||||
|
||||
For other Linux distribution, you can quickly install youtube-dl on your system through the command line interface with:
|
||||
```
|
||||
sudo wget https://yt-dl.org/downloads/latest/youtube-dl -O/usr/local/bin/youtube-dl
|
||||
|
||||
```
|
||||
|
||||
After fetching the file, you need to set a executable permission on the script to execute properly.
|
||||
```
|
||||
sudo chmod a+rx /usr/local/bin/youtube-dl
|
||||
|
||||
```
|
||||
|
||||
#### Using YouTube-dl for downloading videos:
|
||||
|
||||
To download a video file, simply run the following command. Where “VIDEO_URL” is the URL of the video that you want to download.
|
||||
```
|
||||
youtube-dl<video_url>
|
||||
|
||||
```
|
||||
|
||||
#### Download YouTube videos in various formats and quality size
|
||||
|
||||
These days YouTube videos have different resolutions, you first need to check available video formats of a given YouTube video. For that run youtube-dl with “-F” option. It will show you a list of available formats.
|
||||
```
|
||||
youtube-dl -F <video_url>
|
||||
|
||||
```
|
||||
|
||||
Its output will be like:
|
||||
```
|
||||
Setting language
|
||||
BlXaGWbFVKY: Downloading video webpage
|
||||
BlXaGWbFVKY: Downloading video info webpage
|
||||
BlXaGWbFVKY: Extracting video information
|
||||
Available formats:
|
||||
37 : mp4 [1080x1920]
|
||||
46 : webm [1080x1920]
|
||||
22 : mp4 [720x1280]
|
||||
45 : webm [720x1280]
|
||||
35 : flv [480x854]
|
||||
44 : webm [480x854]
|
||||
34 : flv [360x640]
|
||||
18 : mp4 [360x640]
|
||||
43 : webm [360x640]
|
||||
5 : flv [240x400]
|
||||
17 : mp4 [144x176]
|
||||
|
||||
```
|
||||
|
||||
Now among the available video formats, choose one that you like. For example, if you want to download it in MP4 version and 1080 pixel, you should use:
|
||||
```
|
||||
youtube-dl -f 37<video_url>
|
||||
|
||||
```
|
||||
|
||||
#### Download subtitles of videos using youtube-dl
|
||||
|
||||
First, check if there are subtitles available for the video. To list all subs for a video, use the command below:
|
||||
```
|
||||
youtube-dl --list-subs <video_url>
|
||||
|
||||
```
|
||||
|
||||
To download all subs, but not the video:
|
||||
```
|
||||
youtube-dl --all-subs --skip-download <video_url>
|
||||
|
||||
```
|
||||
|
||||
#### Download entire YouTube playlist
|
||||
|
||||
To download a playlist, simply run the following command. Where “playlist_url” is the URL of the playlist that you want to download.
|
||||
```
|
||||
youtube-dl -cit <playlist_url>
|
||||
|
||||
```
|
||||
|
||||
#### Download only audio from YouTube videos
|
||||
|
||||
If you just want to download the audio from a YouTube video, you can use the -x option to simply extract the audio file from the video.
|
||||
```
|
||||
youtube-dl -x <video_url>
|
||||
|
||||
```
|
||||
|
||||
The default file format is Ogg which you may not like. You can specify the file format of the audio file in the following manner:
|
||||
```
|
||||
youtube-dl -x --audio-format mp3 <video_url>
|
||||
|
||||
```
|
||||
|
||||
#### And a lot more can be done with youtube-dl
|
||||
|
||||
youtube-dl is a versatile command line tool and provides a number of functionalities. No wonder it is such a popular command line tool.
|
||||
|
||||
I have only shown some of the most common usages of this tool. But if you want to explore its capabilities further, please check its [manual][6].
|
||||
|
||||
I hope this article helped you to download YouTube videos on Linux. If you have questions or suggestions, please drop a comment below.
|
||||
|
||||
Article updated with inputs from Abhishek Prakash.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/download-youtube-linux/
|
||||
|
||||
作者:[alimiracle][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ali/
|
||||
[1]:https://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[2]:https://rg3.github.io/youtube-dl/
|
||||
[3]:https://www.youtube.com/c/itsfoss/
|
||||
[4]:https://www.dailymotion.com/
|
||||
[5]:https://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[6]:https://github.com/rg3/youtube-dl/blob/master/README.md#readme
|
||||
@ -1,117 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
Containers without Docker at Red Hat
|
||||
======
|
||||
|
||||
The Docker (now [Moby][1]) project has done a lot to popularize containers in recent years. Along the way, though, it has generated concerns about its concentration of functionality into a single, monolithic system under the control of a single daemon running with root privileges: `dockerd`. Those concerns were reflected in a [talk][2] by Dan Walsh, head of the container team at Red Hat, at [KubeCon \+ CloudNativeCon][3]. Walsh spoke about the work the container team is doing to replace Docker with a set of smaller, interoperable components. His rallying cry is "no big fat daemons" as he finds them to be contrary to the venerated Unix philosophy.
|
||||
|
||||
### The quest to modularize Docker
|
||||
|
||||
As we saw in an [earlier article][4], the basic set of container operations is not that complicated: you need to pull a container image, create a container from the image, and start it. On top of that, you need to be able to build images and push them to a registry. Most people still use Docker for all of those steps but, as it turns out, Docker isn't the only name in town anymore: an early alternative was `rkt`, which led to the creation of various standards like CRI (runtime), OCI (image), and CNI (networking) that allow backends like [CRI-O][5] or Docker to interoperate with, for example, [Kubernetes][6].
|
||||
|
||||
These standards led Red Hat to create a set of "core utils" like the CRI-O runtime that implements the parts of the standards that Kubernetes needs. But Red Hat's [OpenShift][7] project needs more than what Kubernetes provides. Developers will want to be able to build containers and push them to the registry. Those operations need a whole different bag of tricks.
|
||||
|
||||
It turns out that there are multiple tools to build containers right now. Apart from Docker itself, a [session][8] from Michael Ducy of Sysdig reviewed eight image builders, and that's probably not all of them. Ducy identified the ideal build tool as one that would create a minimal image in a reproducible way. A minimal image is one where there is no operating system, only the application and its essential dependencies. Ducy identified [Distroless][9], [Smith][10], and [Source-to-Image][11] as good tools to build minimal images, which he called "micro-containers".
|
||||
|
||||
A reproducible container is one that you can build multiple times and always get the same result. For that, Ducy said you have to use a "declarative" approach (as opposed to "imperative"), which is understandable given that he comes from the Chef configuration-management world. He gave the examples of [Ansible Container][12], [Habitat][13], [nixos-container][14], and Smith (yes, again) as being good approaches, provided you were familiar with their domain-specific languages. He added that Habitat ships its own supervisor in its containers, which may be superfluous if you already have an external one, like systemd, Docker, or Kubernetes. To complete the list, we should mention the new [BuildKit][15] from Docker and [Buildah][16], which is part of Red Hat's [Project Atomic][17].
|
||||
|
||||
### Building containers with Buildah
|
||||
|
||||
![\[Buildah logo\]][18] Buildah's name apparently comes from Walsh's colorful [Boston accent][19]; the Boston theme permeates the branding of the tool: the logo, for example, is a Boston terrier dog (seen at right). This project takes a different approach from Ducy's decree: instead of enforcing a declarative configuration-management approach to containers, why not build simple tools that can be used by your favorite configuration-management tool? If you want to use regular command-line commands like `cp` (instead of Docker's custom `COPY` directive, for example), you can. But you can also use Ansible or Puppet, OS-specific or language-specific installers like APT or pip, or whatever other system to provision the content of your containers. This is what building a container looks like with regular shell commands and simply using `make` to install a binary inside the container:
|
||||
```
|
||||
# pull a base image, equivalent to a Dockerfile's FROM command
|
||||
buildah from redhat
|
||||
|
||||
# mount the base image to work on it
|
||||
crt=$(buildah mount)
|
||||
cp foo $crt
|
||||
make install DESTDIR=$crt
|
||||
|
||||
# then make a snapshot
|
||||
buildah commit
|
||||
|
||||
```
|
||||
|
||||
An interesting thing with this approach is that, since you reuse normal build tools from the host environment, you can build really minimal images because you don't need to install all the dependencies in the image. Usually, when building a container image, the target application build dependencies need to be installed within the container. For example, building from source usually requires a compiler toolchain in the container, because it is not meant to access the host environment. A lot of containers will also ship basic Unix tools like `ps` or `bash` which are not actually necessary in a micro-container. Developers often forget to (or simply can't) remove some dependencies from the built containers; that common practice creates unnecessary overhead and attack surface.
|
||||
|
||||
The modular approach of Buildah means you can run at least parts of the build as non-root: the `mount` command still needs the `CAP_SYS_ADMIN` capability, but there is an [issue][20] open to resolve this. However, Buildah [shares][21] the same [limitation][22] as Docker in that it can't build containers inside containers. For Docker, you need to run the container in "privileged" mode, which is not possible in certain environments (like [GitLab Continuous Integration][23], for example) and, even when it is possible, the configuration is [messy][24] at best.
|
||||
|
||||
The manual commit step allows fine-grained control over when to create container snapshots. While in a Dockerfile every line creates a new snapshot, with Buildah commit checkpoints are explicitly chosen, which reduces unnecessary snapshots and saves disk space. This is useful to isolate sensitive material like private keys or passwords which sometimes mistakenly end up in public images as well.
|
||||
|
||||
While Docker builds non-standard, Docker-specific images, Buildah produces standard OCI images among [other output formats][25]. For backward compatibility, it has a command called `build-using-dockerfile` or [`buildah bud`][26] that parses normal Dockerfiles. Buildah has a `enter` command to inspect images from the inside directly and a `run` command to start containers on the fly. It does all the work without any "fat daemon" running in the background and uses standard tools like `runc`.
|
||||
|
||||
Ducy's criticism of Buildah was that it was not declarative, which made it less reproducible. When allowing shell commands anything can happen: for example, a shell script might download arbitrary binaries, without any way of subsequently retracing where those come from. Shell command effects may vary according to the environment. In contrast to shell-based tools, configuration-management systems like Puppet or Chef are designed to "converge" over a final configuration that is more reliable, at least in theory: in practice you can call shell commands from configuration-management systems. Walsh, however, argued that existing configuration management can be used on top of Buildah, but it doesn't force users down that path. This fits well with the classic "separation" principle of the Unix philosophy ("mechanism not policy").
|
||||
|
||||
At this point, Buildah is in beta and Red Hat is working on integrating it into OpenShift. I have tested Buildah while writing this article and, short of some documentation issues, it generally works reliably. It could use some polishing in error handling, but it is definitely a great asset to add to your container toolbox.
|
||||
|
||||
### Replacing the rest of the Docker command-line
|
||||
|
||||
Walsh continued his presentation by giving an overview of another project that Red Hat is working on, tentatively called [libpod][27]. The name derives from a "pod" in Kubernetes, which is a way to group containers inside a host, to share namespaces, for example.
|
||||
|
||||
Libpod includes the `kpod` command to inspect and manipulate container storage directly. Walsh explained this can be useful if, for example, `dockerd` hangs or if a Kubernetes cluster crashes. `kpod` is basically an independent re-implementation of the `docker` command-line tool. There is a command to list running containers (`kpod ps`) or images (`kpod images`). In fact, there is a [translation cheat sheet][28] documenting all Docker commands with a `kpod` equivalent.
|
||||
|
||||
One of the nice things with the modular approach is that when you run a container with `kpod run`, the container is directly started as a subprocess of the current shell, instead of a subprocess of `dockerd`. In theory, this allows running containers directly from systemd, removing the duplicate work `dockerd` is doing. It enables things like [socket-activated containers][29], which is something that is [not straightforward][30] to do with Docker, or [even with Kubernetes][31] right now. In my experiments, however, I have found that containers started with `kpod` lack some fundamental functionality, namely networking (!), although there is an [issue in progress][32] to complete that implementation.
|
||||
|
||||
A final command we haven't covered is `push`. While the above commands provide a good process for working with local containers, they don't cover remote registries, which allow developers to actively collaborate on application packaging. Registries are also an essential part of a continuous-deployment framework. This is where the [skopeo][33] project comes in. Skopeo is another Atomic project that "performs various operations on container images and image repositories", according to the `README` file. It was originally designed to inspect the contents of container registries without actually downloading the sometimes voluminous images as `docker pull` does. Docker [refused patches][34] to support inspection, suggesting the creation of a separate tool, which led to Skopeo. After `pull`, `push` was the logical next step and Skopeo can now do a bunch of other things like copying and converting images between registries without having to store a copy locally. Because this functionality was useful to other projects as well, a lot of the Skopeo code now lives in a reusable library called [containers/image][35]. That library is in turn used by [Pivotal][36], Google's [container-diff][37], `kpod push`, and `buildah push`.
|
||||
|
||||
`kpod` is not directly tied to Kubernetes, so the name might change in the future -- especially since Red Hat legal has not cleared the name yet. (In fact, just as this article was going to "press", the name was changed to [`podman`][38].) The team wants to implement more "pod-level" commands which would allow operations on multiple containers, a bit like what [`docker compose`][39] might do. But at that level, a better tool might be [Kompose][40] which can execute [Compose YAML files][41] into a Kubernetes cluster. Some Docker commands (like [`swarm`][42]) will never be implemented, on purpose, as they are best left for Kubernetes itself to handle.
|
||||
|
||||
It seems that the effort to modularize Docker that started a few years ago is finally bearing fruit. While, at this point, `kpod` is under heavy development and probably should not be used in production, the design of those different tools is certainly interesting; a lot of it is ready for development environments. Right now, the only way to install libpod is to compile it from source, but we should expect packages coming out for your favorite distribution eventually.
|
||||
|
||||
> This article [first appeared][43] in the [Linux Weekly News][44].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2017-12-20-docker-without-docker/
|
||||
|
||||
作者:[À propos de moi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://anarc.at
|
||||
[1]:https://mobyproject.org/
|
||||
[2]:https://kccncna17.sched.com/event/CU8j/cri-o-hosted-by-daniel-walsh-red-hat
|
||||
[3]:http://events.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america
|
||||
[4]:https://lwn.net/Articles/741897/
|
||||
[5]:http://cri-o.io/
|
||||
[6]:https://kubernetes.io/
|
||||
[7]:https://www.openshift.com/
|
||||
[8]:https://kccncna17.sched.com/event/CU6B/building-better-containers-a-survey-of-container-build-tools-i-michael-ducy-chef
|
||||
[9]:https://github.com/GoogleCloudPlatform/distroless
|
||||
[10]:https://github.com/oracle/smith
|
||||
[11]:https://github.com/openshift/source-to-image
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://www.habitat.sh/
|
||||
[14]:https://nixos.org/nixos/manual/#ch-containers
|
||||
[15]:https://github.com/moby/buildkit
|
||||
[16]:https://github.com/projectatomic/buildah
|
||||
[17]:https://www.projectatomic.io/
|
||||
[18]:https://raw.githubusercontent.com/projectatomic/buildah/master/logos/buildah-logomark_large.png (Buildah logo)
|
||||
[19]:https://en.wikipedia.org/wiki/Boston_accent
|
||||
[20]:https://github.com/projectatomic/buildah/issues/171
|
||||
[21]:https://github.com/projectatomic/buildah/issues/158
|
||||
[22]:https://github.com/moby/moby/issues/27886#issuecomment-281278525
|
||||
[23]:https://about.gitlab.com/features/gitlab-ci-cd/
|
||||
[24]:https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/
|
||||
[25]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-push.md
|
||||
[26]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-bud.md
|
||||
[27]:https://github.com/projectatomic/libpod
|
||||
[28]:https://github.com/projectatomic/libpod/blob/master/transfer.md#development-transfer
|
||||
[29]:http://0pointer.de/blog/projects/socket-activated-containers.html
|
||||
[30]:https://legacy-developer.atlassian.com/blog/2015/03/docker-systemd-socket-activation/
|
||||
[31]:https://github.com/kubernetes/kubernetes/issues/484
|
||||
[32]:https://github.com/projectatomic/libpod/issues/129
|
||||
[33]:https://github.com/projectatomic/skopeo
|
||||
[34]:https://github.com/moby/moby/pull/14258
|
||||
[35]:https://github.com/containers/image
|
||||
[36]:https://pivotal.io/
|
||||
[37]:https://github.com/GoogleCloudPlatform/container-diff
|
||||
[38]:https://github.com/projectatomic/libpod/blob/master/docs/podman.1.md
|
||||
[39]:https://docs.docker.com/compose/overview/#compose-documentation
|
||||
[40]:http://kompose.io/
|
||||
[41]:https://docs.docker.com/compose/compose-file/
|
||||
[42]:https://docs.docker.com/engine/swarm/
|
||||
[43]:https://lwn.net/Articles/741841/
|
||||
[44]:http://lwn.net/
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
Dry – An Interactive CLI Manager For Docker Containers
|
||||
======
|
||||
Docker is a software that allows operating-system-level virtualization also known as containerization.
|
||||
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
Working with calendars on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[ dotcra translating ]
|
||||
The fc Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||
|
||||
@ -1,168 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
The Shuf Command Tutorial With Examples For Beginners
|
||||
======
|
||||
|
||||

|
||||
The Shuf command is used to generate random permutations in Unix-like operating systems. Using shuf command, we can shuffle the lines of a given input file randomly. Shuf command is part of GNU Coreutils, so you don’t have bother with installation. In this brief tutorial, let me show you some examples of shuf command.
|
||||
|
||||
### The Shuf Command Tutorial With Examples
|
||||
|
||||
I have a file named **ostechnix.txt** with the following contents.
|
||||
```
|
||||
$ cat ostechnix.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
line6
|
||||
line7
|
||||
line8
|
||||
line9
|
||||
line10
|
||||
|
||||
```
|
||||
|
||||
Now let us display the above lines in a random order. To do so, run:
|
||||
```
|
||||
$ shuf ostechnix.txt
|
||||
line2
|
||||
line8
|
||||
line5
|
||||
line10
|
||||
line7
|
||||
line1
|
||||
line4
|
||||
line6
|
||||
line9
|
||||
line3
|
||||
|
||||
```
|
||||
|
||||
See? The above command randomized the order of lines in the file named “ostechnix.txt” and output the result.
|
||||
|
||||
You might want to write the output to another file. For example, I want to save the output in a file named **output.txt**. To do so, first create output.txt file:
|
||||
```
|
||||
$ touch output.txt
|
||||
|
||||
```
|
||||
|
||||
Then, write the output to that file using **-o** flag like below.
|
||||
```
|
||||
$ shuf ostechnix.txt -o output.txt
|
||||
|
||||
```
|
||||
|
||||
The above command will shuffle the contents of ostechnix.txt file randomly and write the output to output.txt file. You can view the output.txt file contents using command:
|
||||
```
|
||||
$ cat output.txt
|
||||
|
||||
line2
|
||||
line8
|
||||
line9
|
||||
line10
|
||||
line1
|
||||
line3
|
||||
line7
|
||||
line6
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
I just want to display any one of the random line from the file. How do I do it? Simple!
|
||||
```
|
||||
$ shuf -n 1 ostechnix.txt
|
||||
line6
|
||||
|
||||
```
|
||||
|
||||
Similarly, we can pick the first “n” random entries. The following command will display the only the first five random entries.
|
||||
```
|
||||
$ shuf -n 5 ostechnix.txt
|
||||
line10
|
||||
line4
|
||||
line5
|
||||
line9
|
||||
line3
|
||||
|
||||
```
|
||||
|
||||
Instead of reading the lines from a file, we can directly pass the inputs using **-e** flag like below.
|
||||
```
|
||||
$ shuf -e line1 line2 line3 line4 line5
|
||||
line1
|
||||
line3
|
||||
line5
|
||||
line4
|
||||
line2
|
||||
|
||||
```
|
||||
|
||||
You can pass shuffle the numbers too:
|
||||
```
|
||||
$ shuf -e 1 2 3 4 5
|
||||
3
|
||||
5
|
||||
1
|
||||
4
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
To quickly pick any one from the given range, use this command instead.
|
||||
```
|
||||
$ shuf -n 1 -e 1 2 3 4 5
|
||||
|
||||
```
|
||||
|
||||
Or, pick any three random numbers like below.
|
||||
```
|
||||
$ shuf -n 3 -e 1 2 3 4 5
|
||||
3
|
||||
5
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
We can also generate random numbers within a particular range. For example, to display random numbers between 1 to 10, simply use:
|
||||
```
|
||||
$ shuf -i 1-10
|
||||
1
|
||||
9
|
||||
8
|
||||
2
|
||||
4
|
||||
7
|
||||
6
|
||||
3
|
||||
10
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ man shuf
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for today. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-shuf-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,102 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
|
||||
A Kernel Module That Forcibly Shutdown Your System
|
||||
======
|
||||
|
||||

|
||||
I know that staying up late is bad for the health. But, who cares? I have been a night owl for years. I usually go to bed after 12 am, sometimes after 1 am. The next morning, I snooze my alarm at least three times, wake up tired and grumpy. Everyday, I promise myself I will go to bed earlier, but ended up going to bed very late as usual. And, this cycle continues! If you’re anything like me, here is a good news. A fellow late nighter has developed a Kernel module named **“Kgotobed”** that forces you to go to bed at a specific time. That said it will forcibly shutdown your system.
|
||||
|
||||
Why should I use this? I have plenty of other options. I can set a cron job to schedule system shutdown at a specific time. I can set up a reminder or alarm clock. I can use a browser plugin or a software. You might ask! However, they all are can easily be ignored or bypassed. Kgotobed is something that you can’t ignore. Something that **can’t be disabled even if you’re a root user**. Yes, it will forcibly power off your system at the specified time. There is no snooze option. You can’t postpone the power off process or you can’t cancel it either. Your system will go down at the specified time no matter what. You have been warned!!
|
||||
|
||||
### Install Kgotobed
|
||||
|
||||
Make sure you have installed **dkms**. It is available in the default repositories of most Linux distributions.
|
||||
|
||||
For example on Fedora, you can install it using the following command:
|
||||
```
|
||||
$ sudo dnf install kernel-devel-$(uname -r) dkms
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, linux Mint:
|
||||
```
|
||||
$ sudo apt install dkms
|
||||
|
||||
```
|
||||
|
||||
Once installed the prerequisites, git clone Kgotobed project.
|
||||
```
|
||||
$ git clone https://github.com/nikital/kgotobed.git
|
||||
|
||||
```
|
||||
|
||||
This command will clone all contents of Kgotobed repository in a folder named “kgotobed” in your current working directory. Cd to that directory:
|
||||
```
|
||||
$ cd kgotobed/
|
||||
|
||||
```
|
||||
|
||||
And, install Kgotobed driver using command:
|
||||
```
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
The above command will register **kgotobed.ko** module with **DKMS** (so that it will be rebuilt for every kernel you run) and Install **gotobed** utility in **/usr/local/bin/** location and then register, enable and start kgotobed service.
|
||||
|
||||
### How it works
|
||||
|
||||
By default, Kgotobed sets bedtime to **1:00 AM**. That said, your computer will shutdown at 1:00 AM no matter what you’re doing.
|
||||
|
||||
To view the current bed time, run:
|
||||
```
|
||||
$ gotobed
|
||||
Current bedtime is 2018-04-10 01:00:00
|
||||
|
||||
```
|
||||
|
||||
To move the bed time earlier, for example 22:00 (10 PM), run:
|
||||
```
|
||||
$ sudo gotobed 22:00
|
||||
[sudo] password for sk:
|
||||
Current bedtime is 2018-04-10 00:58:00
|
||||
Setting bedtime to 2018-04-09 22:00:00
|
||||
Bedtime will be in 2 hours 16 minutes
|
||||
|
||||
```
|
||||
|
||||
This can be helpful when you want to sleep earlier!
|
||||
|
||||
However, you can’t move the bed time later i.e after 1:00 AM. You can’t unload the module, and adjusting system clock won’t help either. The only way out is a reboot!!
|
||||
|
||||
To set different default time, you need to customize **kgotobed.service** (by editing it or by using systemd drop-in).
|
||||
|
||||
### Uninstall Kgotobed
|
||||
|
||||
Not happy with Kgotobed? No worries! Go to the “kgotobed” folder which we cloned earlier and run the following command to uninstall it.
|
||||
```
|
||||
$ sudo make uninstall
|
||||
|
||||
```
|
||||
|
||||
Again, I warn you there is no way to snooze, postpone, or cancel the power off process, even if you’re a root user. Your system will go down forcibly at the specified time. This is not for everyone! It may drive you nuts when you’re working on an important task. In such cases, make sure you have saved the work from time to time or use some advanced utilities that help you to auto shutdown, reboot, suspend, and hibernate your system at a specific time as described in the following link.
|
||||
|
||||
And, that’s for now. Hope you find this guide useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/kgotobed-a-kernel-module-that-forcibly-shutdown-your-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Yet Another TUI Graphical Activity Monitor, Written In Go
|
||||
======
|
||||
|
||||
|
||||
@ -1,127 +0,0 @@
|
||||
translated by hopefully2333
|
||||
|
||||
Awesome GNOME extensions for developers
|
||||
======
|
||||
|
||||

|
||||
Extensions add immense flexibility to the GNOME 3 desktop environment. They give users the advantage of customizing their desktop while adding ease and efficiency to their workflow. The Fedora Magazine has already covered some great desktop extensions such as [EasyScreenCast][1], [gTile][2], and [OpenWeather][3]. This article continues that coverage by focusing on extensions tailored for developers.
|
||||
|
||||
If you need assistance installing GNOME extensions, refer to the article [How to install a GNOME Shell extension][4].
|
||||
|
||||
### ![Docker Integration extension icon][5] Docker Integration
|
||||
|
||||
![Docker Integration extension status menu][6]
|
||||
|
||||
The [Docker Integration][7] extension is a must for developers using Docker for their apps. The status menu provides a list of Docker containers with the option to start, stop, pause and even remove them. The list updates automatically as new containers are added to the system.
|
||||
|
||||
After installing this extension, Fedora users may get the message: “Error occurred when fetching containers.” This is because Docker commands require sudo or root permissions by default. To configure your user account to run Docker, refer to the [Docker Installation page on the Fedora Developer Portal][8].
|
||||
|
||||
You can find more information on the [extension’s website][9].
|
||||
|
||||
### ![Jenkins CI Server Indicator icon][10] Jenkins CI Server Indicator
|
||||
|
||||
![Jenkins CI Server Indicator extension status menu][11]
|
||||
|
||||
The [Jenkins CI Server Indicator][12] extension makes it easy for developers to build their apps on a Jenkins CI Server. It displays a menu with a list of jobs and the state of those jobs. It also includes features such as easy access to the Jenkins web front-end, notifications for completed jobs, and the ability to trigger and filter jobs.
|
||||
|
||||
For more information, visit the [developer’s site][13].
|
||||
|
||||
### ![android-tool extension icon][14] android-tool
|
||||
|
||||
![android-tool extension status menu][15][android-tool][16] can be a valuable extension for Android developers. Features include capturing bug reports, device screenshots and screen-recording. It can also connect to the Android device via USB or TCP.
|
||||
|
||||
This extension does require the adb package. To install adb from the official Fedora repository [run this command][17]:
|
||||
```
|
||||
sudo dnf install android-tools
|
||||
|
||||
```
|
||||
|
||||
You can find more information at [the extension Github site][18].
|
||||
|
||||
### ![GnomeHub extension icon][19] GnomeHub
|
||||
|
||||
![GnomeHub extension status menu][20][GnomeHub][21] is a great extension for GNOME users using Github for their projects. It displays Github repositories and notifies the user of opened pull requests. In addition, users can add their favorite repositories in the extension’s settings.
|
||||
|
||||
For more information, refer to [the project’s Github page][22].
|
||||
|
||||
### ![gistnotes extension icon][23] gistnotes
|
||||
|
||||
Quite simply, [gistnotes][24] provides easy access for gist users to create, store and manage notes or code snippets. For more information refer to [the project’s website][25].
|
||||
|
||||
![gistnotes window][26]
|
||||
|
||||
### ![Arduino Control extension icon][27] Arduino Control
|
||||
|
||||
The [Arduino Control][28] extension allows users to connect to, and control, their Arduino boards. It also lets users add sliders and switches in the status menu. In addition, the developer includes scripts in the extension’s directory to connect to the board via Ethernet or USB.
|
||||
|
||||
Most importantly, this extension can be customized to fit your project. An example provided in the README file is the ability to “Control your Room Lights from any Computer on the Network.”
|
||||
|
||||
You can read more about the features and setup of this extension on [the project’s Github page][29].
|
||||
|
||||
### ![Hotel Manager extension icon][30] Hotel Manager
|
||||
|
||||
![Hotel Manager extension status menu.][31]
|
||||
|
||||
Developers using the Hotel process manager for their web apps should explore the [Hotel Manager][32] extension. It displays a list of web apps added to Hotel, and gives users the ability to start, stop and restart those apps. Furthermore, the computers icon to the right gives quick access to open, or view, that web app. The extension can also start, stop, or restart the Hotel daemon.
|
||||
|
||||
As of the publication of this article, Hotel Manager version 4 for GNOME 3.26 does not list the web apps in the extension’s drop-down menu. Version 4 also gives errors when installing on Fedora 28 (GNOME 3.28). However, version 3 works with Fedora 27 and Fedora 28.
|
||||
|
||||
For more details, see [the project’s Github page][33].
|
||||
|
||||
### VSCode Search Provider
|
||||
|
||||
[VSCode Search Provider][34] is a simple extension that displays Visual Studio Code projects in the GNOME overview search results. For heavy VSCode users, this extension saves time by giving developers quick access to their projects. You can find more information on [the project’s Github page][35].
|
||||
|
||||
![GNOME Overview search results showing VSCode projects.][36]
|
||||
|
||||
Do you have a favourite extension you use for development? Let us know in the comments.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/awesome-gnome-extensions-developers/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sassam/
|
||||
[1]:https://fedoramagazine.org/screencast-gnome-extension/
|
||||
[2]:https://fedoramagazine.org/must-have-gnome-extension-gtile/
|
||||
[3]:https://fedoramagazine.org/weather-updates-openweather-gnome-shell-extension/
|
||||
[4]:https://fedoramagazine.org/install-gnome-shell-extension/
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/08/dockericon.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/08/docker-extension-menu.png
|
||||
[7]:https://extensions.gnome.org/extension/1065/docker-status/
|
||||
[8]:https://developer.fedoraproject.org/tools/docker/docker-installation.html
|
||||
[9]:https://github.com/gpouilloux/gnome-shell-extension-docker
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2017/08/jenkinsicon.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2017/08/jenkins-extension-menu.png
|
||||
[12]:https://extensions.gnome.org/extension/399/jenkins-ci-server-indicator/
|
||||
[13]:https://www.philipphoffmann.de/gnome-3-shell-extension-jenkins-ci-server-indicator/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2017/08/androidtoolicon.png
|
||||
[15]:https://fedoramagazine.org/wp-content/uploads/2017/08/android-tool-extension-menu.png
|
||||
[16]:https://extensions.gnome.org/extension/1232/android-tool/
|
||||
[17]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[18]:https://github.com/naman14/gnome-android-tool
|
||||
[19]:https://fedoramagazine.org/wp-content/uploads/2017/08/gnomehubicon.png
|
||||
[20]:https://fedoramagazine.org/wp-content/uploads/2017/08/gnomehub-extension-menu.png
|
||||
[21]:https://extensions.gnome.org/extension/1263/gnomehub/
|
||||
[22]:https://github.com/lagartoflojo/gnomehub
|
||||
[23]:https://fedoramagazine.org/wp-content/uploads/2017/08/gistnotesicon.png
|
||||
[24]:https://extensions.gnome.org/extension/917/gistnotes/
|
||||
[25]:https://github.com/mohan43u/gistnotes
|
||||
[26]:https://fedoramagazine.org/wp-content/uploads/2018/04/gistnoteswindow.png
|
||||
[27]:https://fedoramagazine.org/wp-content/uploads/2017/08/arduinoicon.png
|
||||
[28]:https://extensions.gnome.org/extension/894/arduino-control/
|
||||
[29]:https://github.com/simonthechipmunk/arduinocontrol
|
||||
[30]:https://fedoramagazine.org/wp-content/uploads/2017/08/hotelicon.png
|
||||
[31]:https://fedoramagazine.org/wp-content/uploads/2017/08/hotelmanager-extension-menu.png
|
||||
[32]:https://extensions.gnome.org/extension/1285/hotel-manager/
|
||||
[33]:https://github.com/hardpixel/hotel-manager
|
||||
[34]:https://extensions.gnome.org/extension/1207/vscode-search-provider/
|
||||
[35]:https://github.com/jomik/vscode-search-provider
|
||||
[36]:https://fedoramagazine.org/wp-content/uploads/2018/04/vscodesearch.png
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
The Vrms Program Helps You To Find Non-free Software In Debian
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
How To Browse Stack Overflow From Terminal
|
||||
======
|
||||
|
||||

|
||||
A while ago, we have written about [**SoCLI**][1], a python script to search and browse Stack Overflow website from command line. Today, we will discuss about a similar tool named **“how2”**. It is a command line utility to browse Stack Overflow from Terminal. You can query in the plain English as the way you do in [**Google search**][2] and it uses Google and Stackoverflow APIs to search for the given queries. It is free and open source utility written using NodeJS.
|
||||
|
||||
### Browse Stack Overflow From Terminal Using how2
|
||||
|
||||
Since how2 is a NodeJS package, we can install it using Npm package manager. If you haven’t installed Npm and NodeJS already, refer the following guide.
|
||||
|
||||
After installing Npm and NodeJS, run the following command to install how2 utility.
|
||||
```
|
||||
$ npm install -g how2
|
||||
|
||||
```
|
||||
|
||||
Now let us see how to browse Stack Overflow uisng this program. The typical usage to search through Stack Overflow site using “how2” utility is:
|
||||
```
|
||||
$ how2 <search-query>
|
||||
|
||||
```
|
||||
|
||||
For example, I am going to search for how to create tgz archive.
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
|
||||
```
|
||||
|
||||
Oops! I get the following error.
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59
|
||||
Transport.prototype.__proto__ = EventEmitter.prototype;
|
||||
^
|
||||
|
||||
TypeError: Cannot read property 'prototype' of undefined
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59:46)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
at Object.Module._extensions..js (internal/modules/cjs/loader.js:665:10)
|
||||
at Module.load (internal/modules/cjs/loader.js:566:32)
|
||||
at tryModuleLoad (internal/modules/cjs/loader.js:506:12)
|
||||
at Function.Module._load (internal/modules/cjs/loader.js:498:3)
|
||||
at Module.require (internal/modules/cjs/loader.js:598:17)
|
||||
at require (internal/modules/cjs/helpers.js:11:18)
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/stream.js:8:17)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
|
||||
```
|
||||
|
||||
I may be a bug. I hope it gets fixed in the future versions. However, I find a workaround posted [**here**][3].
|
||||
|
||||
To fix this error temporarily, you need to edit the **transport.js** file using command:
|
||||
```
|
||||
$ vi /home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js
|
||||
|
||||
```
|
||||
|
||||
The actual path of this file will be displayed in your error output. Replace the above file path with your own. Then find the following line:
|
||||
```
|
||||
var EventEmitter = process.EventEmitter;
|
||||
|
||||
```
|
||||
|
||||
and replace it with following line:
|
||||
```
|
||||
var EventEmitter = require('events');
|
||||
|
||||
```
|
||||
|
||||
Press ESC and type **:wq** to save and quit the file.
|
||||
|
||||
Now search again the query.
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
|
||||
```
|
||||
|
||||
Here is the sample output from my Ubuntu system.
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
If the answer you’re looking for is not displayed in the above output, press **SPACE BAR** key to start the interactive search where you can go through all suggested questions and answers from the Stack Overflow site.
|
||||
|
||||
[![][4]][6]
|
||||
|
||||
Use UP/DOWN arrows to move between the results. Once you got the right answer/question, hit SPACE BAR or ENTER key to open it in the Terminal.
|
||||
|
||||
[![][4]][7]
|
||||
|
||||
To go back and exit, press **ESC**.
|
||||
|
||||
**Search answers for specific language**
|
||||
|
||||
If you don’t specify a language it **defaults to Bash** unix command line and give you immediately the most likely answer as above. You can also narrow the results to a specific language, for example perl, python, c, Java etc.
|
||||
|
||||
For instance, to search for queries related to “Python” language only using **-l** flag as shown below.
|
||||
```
|
||||
$ how2 -l python linked list
|
||||
|
||||
```
|
||||
|
||||
[![][4]][8]
|
||||
|
||||
To get a quick help, type:
|
||||
```
|
||||
$ how2 -h
|
||||
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
The how2 utility is a basic command line program to quickly search for questions and answers from Stack Overflow without leaving your Terminal and it does this job pretty well. However, it is just CLI browser for Stack overflow. For some advanced features such as searching most voted questions, searching queries using multiple tags, colored interface, submitting a new question and viewing questions stats etc., **SoCLI** is good to go.
|
||||
|
||||
And, that’s all for now. Hope this was useful. I will be soon here with another useful guide. Until then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/search-browse-stack-overflow-website-commandline/
|
||||
[2]:https://www.ostechnix.com/google-search-navigator-enhance-keyboard-navigation-in-google-search/
|
||||
[3]:https://github.com/santinic/how2/issues/79
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-3.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-4.png
|
||||
@ -0,0 +1,349 @@
|
||||
pinewall translating
|
||||
|
||||
How to do math on the Linux command line
|
||||
======
|
||||
|
||||
|
||||
Can you do math on the Linux command line? You sure can! In fact, there are quite a few commands that can make the process easy and some you might even find interesting. Let's look at some very useful commands and syntax for command line math.
|
||||
|
||||
### expr
|
||||
|
||||
First and probably the most obvious and commonly used command for performing mathematical calculations on the command line is the **expr** (expression) command. It can manage addition, subtraction, division, and multiplication. It can also be used to compare numbers. Here are some examples:
|
||||
|
||||
#### Incrementing a variable
|
||||
```
|
||||
$ count=0
|
||||
$ count=`expr $count + 1`
|
||||
$ echo $count
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
#### Performing a simple calculations
|
||||
```
|
||||
$ expr 11 + 123
|
||||
134
|
||||
$ expr 134 / 11
|
||||
12
|
||||
$ expr 134 - 11
|
||||
123
|
||||
$ expr 11 * 123
|
||||
expr: syntax error <== oops!
|
||||
$ expr 11 \* 123
|
||||
1353
|
||||
$ expr 20 % 3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
Notice that you have to use a \ character in front of * to avoid the syntax error. The % operator is for modulo calculations.
|
||||
|
||||
Here's a slightly more complex example:
|
||||
```
|
||||
participants=11
|
||||
total=156
|
||||
share=`expr $total / $participants`
|
||||
remaining=`expr $total - $participants \* $share`
|
||||
echo $share
|
||||
14
|
||||
echo $remaining
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
If we have 11 participants in some event and 156 prizes to distribute, each participant's fair share of the take is 14, leaving 2 in the pot.
|
||||
|
||||
#### Making comparisons
|
||||
|
||||
Now let's look at the logic for comparisons. These statements may look a little odd at first. They are not setting values, but only comparing the numbers. What **expr** is doing in the examples below is determining whether the statements are true. If the result is 1, the statement is true; otherwise, it's false.
|
||||
```
|
||||
$ expr 11 = 11
|
||||
1
|
||||
$ expr 11 = 12
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Read them as "Does 11 equal 11?" and "Does 11 equal 12?" and you'll get used to how this works. Of course, no one would be asking if 11 equals 11 on the command line, but they might ask if $age equals 11.
|
||||
```
|
||||
$ age=11
|
||||
$ expr $age = 11
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
If you put the numbers in quotes, you'd actually be doing a string comparison rather than a numeric one.
|
||||
```
|
||||
$ expr "11" = "11"
|
||||
1
|
||||
$ expr "eleven" = "11"
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
In the following examples, we're asking whether 10 is greater than 5 and, then, whether it's greater than 99.
|
||||
```
|
||||
$ expr 10 \> 5
|
||||
1
|
||||
$ expr 10 \> 99
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Of course, having true comparisons resulting in 1 and false resulting in 0 goes against what we generally expect on Linux systems. The example below shows that using **expr** in this kind of context doesn't work because **if** works with the opposite orientation (0=true).
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
Now, let's run this script:
|
||||
```
|
||||
$ ./checkPrice
|
||||
Cost to us> 11.50
|
||||
Price we're asking> 6
|
||||
We make money
|
||||
|
||||
```
|
||||
|
||||
That sure isn't going to help with sales! With a small change, this would work as we'd expect:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` == 1 ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
### factor
|
||||
|
||||
The **factor** command works just like you'd probably expect. You feed it a number, and it tells you what its factors are.
|
||||
```
|
||||
$ factor 111
|
||||
111: 3 37
|
||||
$ factor 134
|
||||
134: 2 67
|
||||
$ factor 17894
|
||||
17894: 2 23 389
|
||||
$ factor 1987
|
||||
1987: 1987
|
||||
|
||||
```
|
||||
|
||||
NOTE: The factor command didn't get very far on factoring that last value because 1987 is a **prime number**.
|
||||
|
||||
### jot
|
||||
|
||||
The **jot** command allows you to create a list of numbers. Provide it with the number of values you want to see and the number that you want to start with.
|
||||
```
|
||||
$ jot 8 10
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
|
||||
```
|
||||
|
||||
You can also use **jot** like this. Here we're asking it to decrease the numbers by telling it we want to stop when we get to 2:
|
||||
```
|
||||
$ jot 8 10 2
|
||||
10
|
||||
9
|
||||
8
|
||||
7
|
||||
5
|
||||
4
|
||||
3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
The **jot** command can be useful if you want to iterate through a series of numbers to create a list for some other purpose.
|
||||
```
|
||||
$ for i in `jot 7 17`; do echo April $i; done
|
||||
April 17
|
||||
April 18
|
||||
April 19
|
||||
April 20
|
||||
April 21
|
||||
April 22
|
||||
April 23
|
||||
|
||||
```
|
||||
|
||||
### bc
|
||||
|
||||
The **bc** command is probably one of the best tools for doing calculations on the command line. Enter the calculation that you want performed, and pipe it to the command like this:
|
||||
```
|
||||
$ echo "123.4+5/6-(7.89*1.234)" | bc
|
||||
113.664
|
||||
|
||||
```
|
||||
|
||||
Notice that **bc** doesn't shy away from precision and that the string you need to enter is fairly straightforward. It can also make comparisons, handle Booleans, and calculate square roots, sines, cosines, tangents, etc.
|
||||
```
|
||||
$ echo "sqrt(256)" | bc
|
||||
16
|
||||
$ echo "s(90)" | bc -l
|
||||
.89399666360055789051
|
||||
|
||||
```
|
||||
|
||||
In fact, **bc** can even calculate pi. You decide how many decimal points you want to see:
|
||||
```
|
||||
$ echo "scale=5; 4*a(1)" | bc -l
|
||||
3.14156
|
||||
$ echo "scale=10; 4*a(1)" | bc -l
|
||||
3.1415926532
|
||||
$ echo "scale=20; 4*a(1)" | bc -l
|
||||
3.14159265358979323844
|
||||
$ echo "scale=40; 4*a(1)" | bc -l
|
||||
3.1415926535897932384626433832795028841968
|
||||
|
||||
```
|
||||
|
||||
And **bc** isn't just for receiving data through pipes and sending answers back. You can also start it interactively and enter the calculations you want it to perform. Setting the scale (as shown below) determines how many decimal places you'll see.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
scale=2
|
||||
3/4
|
||||
.75
|
||||
2/3
|
||||
.66
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
Using **bc** , you can also convert numbers between different bases. The **obase** setting determines the output base.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
obase=16
|
||||
16 <=== entered
|
||||
10 <=== response
|
||||
256 <=== entered
|
||||
100 <=== response
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
One of the easiest ways to convert between hex and decimal is to use **bc** like this:
|
||||
```
|
||||
$ echo "ibase=16; F2" | bc
|
||||
242
|
||||
$ echo "obase=16; 242" | bc
|
||||
F2
|
||||
|
||||
```
|
||||
|
||||
In the first example above, we're converting from hex to decimal by setting the input base (ibase) to hex (base 16). In the second, we're doing the reverse by setting the outbut base (obase) to hex.
|
||||
|
||||
### Easy bash math
|
||||
|
||||
With sets of double-parentheses, we can do some easy math in bash. In the examples below, we create a variable and give it a value and then perform addition, decrement the result, and then square the remaining value.
|
||||
```
|
||||
$ ((e=11))
|
||||
$ (( e = e + 7 ))
|
||||
$ echo $e
|
||||
18
|
||||
|
||||
$ ((e--))
|
||||
$ echo $e
|
||||
17
|
||||
|
||||
$ ((e=e**2))
|
||||
$ echo $e
|
||||
289
|
||||
|
||||
```
|
||||
|
||||
The arithmetic operators allow you to:
|
||||
```
|
||||
+ - Add and subtract
|
||||
++ -- Increment and decrement
|
||||
* / % Multiply, divide, find remainder
|
||||
^ Get exponent
|
||||
|
||||
```
|
||||
|
||||
You can also use both logical and boolean operators:
|
||||
```
|
||||
$ ((x=11)); ((y=7))
|
||||
$ if (( x > y )); then
|
||||
> echo "x > y"
|
||||
> fi
|
||||
x > y
|
||||
|
||||
$ ((x=11)); ((y=7)); ((z=3))
|
||||
$ if (( x > y )) >> (( y > z )); then
|
||||
> echo "letters roll downhill"
|
||||
> fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
or if you prefer ...
|
||||
```
|
||||
$ if [ x > y ] << [ y > z ]; then echo "letters roll downhill"; fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
Now let's raise 2 to the 3rd power:
|
||||
```
|
||||
$ echo "2 ^ 3"
|
||||
2 ^ 3
|
||||
$ echo "2 ^ 3" | bc
|
||||
8
|
||||
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are sure a lot of different ways to work with numbers and perform calculations on the command line on Linux systems. I hope you picked up a new trick or two by reading this post.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3268964/linux/how-to-do-math-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,368 @@
|
||||
# 6 Python datetime libraries
|
||||
|
||||
### There are a host of libraries that make it simpler to test, convert, and read date and time information in Python.
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
|
||||
[WOCinTech Chat][1]. Modified by Opensource.com. [CC BY-SA 4.0][2]
|
||||
|
||||
### Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
_This article was co-written with [Jeff Triplett][3]._
|
||||
|
||||
Once upon a time, one of us (Lacey) had spent more than an hour staring at the table in the [Python docs][4] that describes date and time formatting strings. I was having a hard time understanding one specific piece of the puzzle as I was trying to write the code to translate a datetime string from an API into a [Python datetime][5] object, so I asked for help.
|
||||
|
||||
"Why don't you just use dateutil?" someone asked.
|
||||
|
||||
Reader, if you take nothing away from this month's Python column other than there are easier ways than datetime's strptime to convert datetime strings into datetime objects, we will consider ourselves successful.
|
||||
|
||||
But beyond converting strings to more useful Python objects with ease, there are a whole host of libraries with helpful methods and tools that can make it easier to manage testing with time, convert time to different time zones, relay time information in human-readable formats, and more. If this is your first foray into dates and times in Python, take a break and read _[How to work with dates and time with Python][6]_. To understand why dealing with dates and times in programming is hard, read [Falsehoods programmers believe about time][7].
|
||||
|
||||
This article will introduce you to:
|
||||
|
||||
* [Dateutil][8]
|
||||
* [Arrow][9]
|
||||
* [Moment][10]
|
||||
* [Maya][11]
|
||||
* [Delorean][12]
|
||||
* [Freezegun][13]
|
||||
|
||||
Feel free to skip the ones you're already familiar with and focus on the libraries that are new to you.
|
||||
|
||||
### The built-in datetime module
|
||||
|
||||
More Python Resources
|
||||
|
||||
* [What is Python?][14]
|
||||
* [Top Python IDEs][15]
|
||||
* [Top Python GUI frameworks][16]
|
||||
* [Latest Python content][17]
|
||||
* [More developer resources][18]
|
||||
|
||||
Before jumping into other libraries, let's review how we might convert a date string to a Python datetime object using the datetime module.
|
||||
|
||||
Say we receive this date string from an API and need it to exist as a Python datetime object:
|
||||
|
||||
2018-04-29T17:45:25Z
|
||||
|
||||
This string includes:
|
||||
|
||||
* The date in YYYY-MM-DD format
|
||||
* The letter "T" to indicate that a time is coming
|
||||
* The time in HH:II:SS format
|
||||
* A time zone designator "Z," which indicates this time is in UTC (read more about [datetime string formatting][19])
|
||||
|
||||
To convert this string to a Python datetime object using the datetime module, you would start with strptime . datetime.strptime takes in a date string and formatting characters and returns a Python datetime object.
|
||||
|
||||
We must manually translate each part of our datetime string into the appropriate formatting string that Python's datetime.strptime can understand. The four-digit year is represented by %Y. The two-digit month is %m. The two-digit day is %d. Hours in a 24-hour clock are %H, and zero-padded minutes are %M. Zero-padded seconds are %S.
|
||||
|
||||
Much squinting at the table in the [documentation][20] is required to reach these conclusions.
|
||||
|
||||
Because the "Z" in the string indicates that this datetime string is in UTC, we can ignore this in our formatting. (Right now, we won't worry about time zones.)
|
||||
|
||||
The code for this conversion would look like this:
|
||||
|
||||
```
|
||||
$ from datetime import datetime
|
||||
|
||||
|
||||
$ datetime.strptime('2018-04-29T17:45:25Z', '%Y-%m-%dT%H:%M:%SZ')
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25)
|
||||
```
|
||||
|
||||
The formatting string is hard to read and understand. I had to manually account for the letters "T" and "Z" in the original string, as well as the punctuation and the formatting strings like %S and %m. Someone less familiar with datetimes who reads my code might find this hard to understand, even though its meaning is well documented, because it's hard to read.
|
||||
|
||||
Let's look at how other libraries handle this kind of conversion.
|
||||
|
||||
### Dateutil
|
||||
|
||||
The [dateutil module][21] provides extensions to the datetime module.
|
||||
|
||||
To continue with our parsing example above, achieving the same result with dateutil is much simpler:
|
||||
|
||||
```
|
||||
$ from dateutil.parser import parse
|
||||
|
||||
|
||||
$ parse('2018-04-29T17:45:25Z')
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
|
||||
```
|
||||
|
||||
The dateutil parser will automatically return the string's time zone if it's included. Since ours was in UTC, you can see that the datetime object returned that. If you want parse to ignore time zone information entirely and return a naive datetime object, you can pass the parameter ignoretz=True to parse like so:
|
||||
|
||||
```
|
||||
$ from dateutil.parser import parse
|
||||
|
||||
|
||||
$ parse('2018-04-29T17:45:25Z', ignoretz=True)
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25)
|
||||
```
|
||||
|
||||
Dateutil can also parse more human-readable date strings:
|
||||
|
||||
```
|
||||
$ parse('April 29th, 2018 at 5:45 pm')
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45)
|
||||
```
|
||||
|
||||
dateutil also offers tools like [relativedelta][22] for calculating the time difference between two datetimes or adding/removing time to/from a datetime, [rrule][23] for creating recurring datetimes, and [tz][24] for dealing with time zones, among other tools.
|
||||
|
||||
### Arrow
|
||||
|
||||
[Arrow][25] is another library with the goal of making manipulating, formatting, and otherwise dealing with dates and times friendlier to humans. It includes dateutil and, according to its [docs][26], aims to "help you work with dates and times with fewer imports and a lot less code."
|
||||
|
||||
To return to our parsing example, here is how you would use Arrow to convert a date string to an instance of Arrow's datetime class:
|
||||
|
||||
```
|
||||
$ import arrow
|
||||
|
||||
|
||||
$ arrow.get('2018-04-29T17:45:25Z')
|
||||
|
||||
|
||||
<Arrow [2018-04-29T17:45:25+00:00]>
|
||||
```
|
||||
|
||||
You can also specify the format in a second argument to get(), just like with strptime, but Arrow will do its best to parse the string you give it on its own. get() returns an instance of Arrow's datetime class. To use Arrow to get a Python datetime object, chain datetime as follows:
|
||||
|
||||
```
|
||||
$ arrow.get('2018-04-29T17:45:25Z').datetime
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=tzutc())
|
||||
```
|
||||
|
||||
With the instance of the Arrow datetime class, you have access to Arrow's other helpful methods. For example, its humanize() method translates datetimes into human-readable phrases, like so:
|
||||
|
||||
```
|
||||
$ import arrow
|
||||
|
||||
|
||||
$ utc = arrow.utcnow()
|
||||
|
||||
|
||||
$ utc.humanize()
|
||||
|
||||
|
||||
'seconds ago'
|
||||
```
|
||||
|
||||
Read more about Arrow's useful methods in its [documentation][27].
|
||||
|
||||
### Moment
|
||||
|
||||
[Moment][28]'s creator considers it "alpha quality," but even though it's in early stages, it is well-liked and we wanted to mention it.
|
||||
|
||||
Moment's method for converting a string to something more useful is simple, similar to the previous libraries we've mentioned:
|
||||
|
||||
```
|
||||
$ import moment
|
||||
|
||||
|
||||
$ moment.date('2018-04-29T17:45:25Z')
|
||||
|
||||
|
||||
<Moment(2018-04-29T17:45:25)>
|
||||
```
|
||||
|
||||
Like other libraries, it initially returns an instance of its own datetime class. To return a Python datetime object, add another date() call.
|
||||
|
||||
```
|
||||
$ moment.date('2018-04-29T17:45:25Z').date
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<StaticTzInfo 'Z'>)
|
||||
```
|
||||
|
||||
This will convert the Moment datetime class to a Python datetime object.
|
||||
|
||||
Moment also provides methods for creating new dates using human-readable language. To create a date for tomorrow:
|
||||
|
||||
```
|
||||
$ moment.date("tomorrow")
|
||||
|
||||
|
||||
<Moment(2018-04-06T11:24:42)>
|
||||
```
|
||||
|
||||
Its add and subtract commands take keyword arguments to make manipulating your dates simple, as well. To get the day after tomorrow, Moment would use this code:
|
||||
|
||||
```
|
||||
$ moment.date("tomorrow").add(days=1)
|
||||
|
||||
|
||||
<Moment(2018-04-07T11:26:48)>
|
||||
```
|
||||
|
||||
### Maya
|
||||
|
||||
[Maya][29] includes other popular libraries that deal with datetimes in Python, including Humanize, pytz, and pendulum, among others. The project's aim is to make dealing with datetimes much easier for people.
|
||||
|
||||
Maya's README includes several useful examples. Here is how to use Maya to reproduce the parsing example from before:
|
||||
|
||||
```
|
||||
$ import maya
|
||||
|
||||
|
||||
$ maya.parse('2018-04-29T17:45:25Z').datetime()
|
||||
|
||||
|
||||
datetime.datetime(2018, 4, 29, 17, 45, 25, tzinfo=<UTC>)
|
||||
```
|
||||
|
||||
Note that we have to call .datetime() after maya.parse(). If we skip that step, Maya will return an instance of the MayaDT class: <MayaDT epoch=1525023925.0>.
|
||||
|
||||
Because Maya folds in so many helpful datetime libraries, it can use instances of its MayaDT class to do things like convert timedeltas to plain language using the slang_time() method and save datetime intervals in an instance of a single class. Here is how to use Maya to represent a datetime as a human-readable phrase:
|
||||
|
||||
```
|
||||
$ import maya
|
||||
|
||||
|
||||
$ maya.parse('2018-04-29T17:45:25Z').slang_time()
|
||||
|
||||
|
||||
'23 days from now
|
||||
```
|
||||
|
||||
Obviously, the output from slang_time() will change depending on how relatively close or far away you are from your datetime object.
|
||||
|
||||
### Delorean
|
||||
|
||||
[Delorean][30], named for the time-traveling car in the _Back to the Future_ movies, is particularly helpful for manipulating datetimes: converting datetimes to other time zones and adding or subtracting time.
|
||||
|
||||
Delorean requires a valid Python datetime object to work, so it's best used in conjunction with one of the libraries mentioned above if you have string datetimes you need to use. To use Delorean with Maya, for example:
|
||||
|
||||
```
|
||||
$ import maya
|
||||
|
||||
|
||||
$ d_t = maya.parse('2018-04-29T17:45:25Z').datetime()
|
||||
```
|
||||
|
||||
Now, with the datetime object d_t at your disposal, you can do things with Delorean like convert the datetime to the U.S. Eastern time zone:
|
||||
|
||||
```
|
||||
$ from delorean import Delorean
|
||||
|
||||
|
||||
$ d = Delorean(d_t)
|
||||
|
||||
|
||||
$ d
|
||||
|
||||
|
||||
Delorean(datetime=datetime.datetime(2018, 4, 29, 17, 45, 25), timezone='UTC')
|
||||
|
||||
|
||||
$ d.shift('US/Eastern')
|
||||
|
||||
|
||||
Delorean(datetime=datetime.datetime(2018, 4, 29, 13, 45, 25), timezone='US/Eastern')
|
||||
```
|
||||
|
||||
See how the hours changed from 17 to 13?
|
||||
|
||||
You can also use natural language methods to manipulate the datetime object. To get the next Friday following April 29, 2018 (the date we've been using):
|
||||
|
||||
```
|
||||
$ d.next_friday()
|
||||
|
||||
|
||||
Delorean(datetime=datetime.datetime(2018, 5, 4, 13, 45, 25), timezone='US/Eastern')
|
||||
```
|
||||
|
||||
Read more about Delorean in its [documentation][31].
|
||||
|
||||
### Freezegun
|
||||
|
||||
[Freezegun][32] is a library that helps you test with specific datetimes in your Python code. Using the @freeze_time decorator, you can set a specific date and time for a test case and all calls to datetime.datetime.now(), datetime.datetime.utcnow(), etc. will return the date and time you specified. For example:
|
||||
|
||||
```
|
||||
from freezegun import freeze_time
|
||||
|
||||
|
||||
import datetime
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@freeze_time("2017-04-14")
|
||||
|
||||
|
||||
def test():
|
||||
|
||||
|
||||
|
||||
|
||||
assert datetime.datetime.now() == datetime.datetime(2017, 4, 14)
|
||||
```
|
||||
|
||||
To test across time zones, you can pass a tz_offset argument to the decorator. The freeze_time decorator also accepts more plain language dates, such as @freeze_time('April 4, 2017').
|
||||
|
||||
---
|
||||
|
||||
Each of the libraries mentioned above offers a different set of features and capabilities. It might be difficult to decide which one best suits your needs. [Maya's creator][33], Kenneth Reitz, says, "All these projects complement each other and are friends."
|
||||
|
||||
These libraries share some features, but not others. Some are good at time manipulation, others excel at parsing. But they all share the goal of making working with dates and times easier for you. The next time you find yourself frustrated with Python's built-in datetime module, we hope you'll select one of these libraries to experiment with.
|
||||
|
||||
---
|
||||
|
||||
via: [https://opensource.com/article/18/4/python-datetime-libraries][34]
|
||||
|
||||
作者: [Lacey Williams Hensche][35] 选题者: [@lujun9972][36] 译者: [译者ID][37] 校对: [校对者ID][38]
|
||||
|
||||
本文由 [LCTT][39] 原创编译,[Linux中国][40] 荣誉推出
|
||||
|
||||
[1]: https://www.flickr.com/photos/wocintechchat/25926664911/
|
||||
[2]: https://creativecommons.org/licenses/by/4.0/
|
||||
[3]: https://opensource.com/users/jefftriplett
|
||||
[4]: https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
|
||||
[5]: https://opensource.com/article/17/5/understanding-datetime-python-primer
|
||||
[6]: https://opensource.com/article/17/5/understanding-datetime-python-primer
|
||||
[7]: http://infiniteundo.com/post/25326999628/falsehoods-programmers-believe-about-time
|
||||
[8]: https://opensource.com/#Dateutil
|
||||
[9]: https://opensource.com/#Arrow
|
||||
[10]: https://opensource.com/#Moment
|
||||
[11]: https://opensource.com/#Maya
|
||||
[12]: https://opensource.com/#Delorean
|
||||
[13]: https://opensource.com/#Freezegun
|
||||
[14]: https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
|
||||
[15]: https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
|
||||
[16]: https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
|
||||
[17]: https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
|
||||
[18]: https://developers.redhat.com/?intcmp=7016000000127cYAAQ
|
||||
[19]: https://www.w3.org/TR/NOTE-datetime
|
||||
[20]: https://docs.python.org/3/library/datetime.html#strftime-strptime-behavior
|
||||
[21]: https://dateutil.readthedocs.io/en/stable/
|
||||
[22]: https://dateutil.readthedocs.io/en/stable/relativedelta.html
|
||||
[23]: https://dateutil.readthedocs.io/en/stable/rrule.html
|
||||
[24]: https://dateutil.readthedocs.io/en/stable/tz.html
|
||||
[25]: https://github.com/crsmithdev/arrow
|
||||
[26]: https://pypi.python.org/pypi/arrow-fatisar/0.5.3
|
||||
[27]: https://arrow.readthedocs.io/en/latest/
|
||||
[28]: https://github.com/zachwill/moment
|
||||
[29]: https://github.com/kennethreitz/maya
|
||||
[30]: https://github.com/myusuf3/delorean
|
||||
[31]: https://delorean.readthedocs.io/en/latest/
|
||||
[32]: https://github.com/spulec/freezegun
|
||||
[33]: https://github.com/kennethreitz/maya
|
||||
[34]: https://opensource.com/article/18/4/python-datetime-libraries
|
||||
[35]: https://opensource.com/users/laceynwilliams
|
||||
[36]: https://github.com/lujun9972
|
||||
[37]: https://github.com/译者ID
|
||||
[38]: https://github.com/校对者ID
|
||||
[39]: https://github.com/LCTT/TranslateProject
|
||||
[40]: https://linux.cn/
|
||||
@ -0,0 +1,347 @@
|
||||
How to do math on the Linux command line
|
||||
======
|
||||
|
||||
|
||||
Can you do math on the Linux command line? You sure can! In fact, there are quite a few commands that can make the process easy and some you might even find interesting. Let's look at some very useful commands and syntax for command line math.
|
||||
|
||||
### expr
|
||||
|
||||
First and probably the most obvious and commonly used command for performing mathematical calculations on the command line is the **expr** (expression) command. It can manage addition, subtraction, division, and multiplication. It can also be used to compare numbers. Here are some examples:
|
||||
|
||||
#### Incrementing a variable
|
||||
```
|
||||
$ count=0
|
||||
$ count=`expr $count + 1`
|
||||
$ echo $count
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
#### Performing a simple calculations
|
||||
```
|
||||
$ expr 11 + 123
|
||||
134
|
||||
$ expr 134 / 11
|
||||
12
|
||||
$ expr 134 - 11
|
||||
123
|
||||
$ expr 11 * 123
|
||||
expr: syntax error <== oops!
|
||||
$ expr 11 \* 123
|
||||
1353
|
||||
$ expr 20 % 3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
Notice that you have to use a \ character in front of * to avoid the syntax error. The % operator is for modulo calculations.
|
||||
|
||||
Here's a slightly more complex example:
|
||||
```
|
||||
participants=11
|
||||
total=156
|
||||
share=`expr $total / $participants`
|
||||
remaining=`expr $total - $participants \* $share`
|
||||
echo $share
|
||||
14
|
||||
echo $remaining
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
If we have 11 participants in some event and 156 prizes to distribute, each participant's fair share of the take is 14, leaving 2 in the pot.
|
||||
|
||||
#### Making comparisons
|
||||
|
||||
Now let's look at the logic for comparisons. These statements may look a little odd at first. They are not setting values, but only comparing the numbers. What **expr** is doing in the examples below is determining whether the statements are true. If the result is 1, the statement is true; otherwise, it's false.
|
||||
```
|
||||
$ expr 11 = 11
|
||||
1
|
||||
$ expr 11 = 12
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Read them as "Does 11 equal 11?" and "Does 11 equal 12?" and you'll get used to how this works. Of course, no one would be asking if 11 equals 11 on the command line, but they might ask if $age equals 11.
|
||||
```
|
||||
$ age=11
|
||||
$ expr $age = 11
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
If you put the numbers in quotes, you'd actually be doing a string comparison rather than a numeric one.
|
||||
```
|
||||
$ expr "11" = "11"
|
||||
1
|
||||
$ expr "eleven" = "11"
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
In the following examples, we're asking whether 10 is greater than 5 and, then, whether it's greater than 99.
|
||||
```
|
||||
$ expr 10 \> 5
|
||||
1
|
||||
$ expr 10 \> 99
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Of course, having true comparisons resulting in 1 and false resulting in 0 goes against what we generally expect on Linux systems. The example below shows that using **expr** in this kind of context doesn't work because **if** works with the opposite orientation (0=true).
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
Now, let's run this script:
|
||||
```
|
||||
$ ./checkPrice
|
||||
Cost to us> 11.50
|
||||
Price we're asking> 6
|
||||
We make money
|
||||
|
||||
```
|
||||
|
||||
That sure isn't going to help with sales! With a small change, this would work as we'd expect:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo -n "Cost to us> "
|
||||
read cost
|
||||
echo -n "Price we're asking> "
|
||||
read price
|
||||
|
||||
if [ `expr $price \> $cost` == 1 ]; then
|
||||
echo "We make money"
|
||||
else
|
||||
echo "Don't sell it"
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
### factor
|
||||
|
||||
The **factor** command works just like you'd probably expect. You feed it a number, and it tells you what its factors are.
|
||||
```
|
||||
$ factor 111
|
||||
111: 3 37
|
||||
$ factor 134
|
||||
134: 2 67
|
||||
$ factor 17894
|
||||
17894: 2 23 389
|
||||
$ factor 1987
|
||||
1987: 1987
|
||||
|
||||
```
|
||||
|
||||
NOTE: The factor command didn't get very far on factoring that last value because 1987 is a **prime number**.
|
||||
|
||||
### jot
|
||||
|
||||
The **jot** command allows you to create a list of numbers. Provide it with the number of values you want to see and the number that you want to start with.
|
||||
```
|
||||
$ jot 8 10
|
||||
10
|
||||
11
|
||||
12
|
||||
13
|
||||
14
|
||||
15
|
||||
16
|
||||
17
|
||||
|
||||
```
|
||||
|
||||
You can also use **jot** like this. Here we're asking it to decrease the numbers by telling it we want to stop when we get to 2:
|
||||
```
|
||||
$ jot 8 10 2
|
||||
10
|
||||
9
|
||||
8
|
||||
7
|
||||
5
|
||||
4
|
||||
3
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
The **jot** command can be useful if you want to iterate through a series of numbers to create a list for some other purpose.
|
||||
```
|
||||
$ for i in `jot 7 17`; do echo April $i; done
|
||||
April 17
|
||||
April 18
|
||||
April 19
|
||||
April 20
|
||||
April 21
|
||||
April 22
|
||||
April 23
|
||||
|
||||
```
|
||||
|
||||
### bc
|
||||
|
||||
The **bc** command is probably one of the best tools for doing calculations on the command line. Enter the calculation that you want performed, and pipe it to the command like this:
|
||||
```
|
||||
$ echo "123.4+5/6-(7.89*1.234)" | bc
|
||||
113.664
|
||||
|
||||
```
|
||||
|
||||
Notice that **bc** doesn't shy away from precision and that the string you need to enter is fairly straightforward. It can also make comparisons, handle Booleans, and calculate square roots, sines, cosines, tangents, etc.
|
||||
```
|
||||
$ echo "sqrt(256)" | bc
|
||||
16
|
||||
$ echo "s(90)" | bc -l
|
||||
.89399666360055789051
|
||||
|
||||
```
|
||||
|
||||
In fact, **bc** can even calculate pi. You decide how many decimal points you want to see:
|
||||
```
|
||||
$ echo "scale=5; 4*a(1)" | bc -l
|
||||
3.14156
|
||||
$ echo "scale=10; 4*a(1)" | bc -l
|
||||
3.1415926532
|
||||
$ echo "scale=20; 4*a(1)" | bc -l
|
||||
3.14159265358979323844
|
||||
$ echo "scale=40; 4*a(1)" | bc -l
|
||||
3.1415926535897932384626433832795028841968
|
||||
|
||||
```
|
||||
|
||||
And **bc** isn't just for receiving data through pipes and sending answers back. You can also start it interactively and enter the calculations you want it to perform. Setting the scale (as shown below) determines how many decimal places you'll see.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
scale=2
|
||||
3/4
|
||||
.75
|
||||
2/3
|
||||
.66
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
Using **bc** , you can also convert numbers between different bases. The **obase** setting determines the output base.
|
||||
```
|
||||
$ bc
|
||||
bc 1.06.95
|
||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||
This is free software with ABSOLUTELY NO WARRANTY.
|
||||
For details type `warranty'.
|
||||
obase=16
|
||||
16 <=== entered
|
||||
10 <=== response
|
||||
256 <=== entered
|
||||
100 <=== response
|
||||
quit
|
||||
|
||||
```
|
||||
|
||||
One of the easiest ways to convert between hex and decimal is to use **bc** like this:
|
||||
```
|
||||
$ echo "ibase=16; F2" | bc
|
||||
242
|
||||
$ echo "obase=16; 242" | bc
|
||||
F2
|
||||
|
||||
```
|
||||
|
||||
In the first example above, we're converting from hex to decimal by setting the input base (ibase) to hex (base 16). In the second, we're doing the reverse by setting the outbut base (obase) to hex.
|
||||
|
||||
### Easy bash math
|
||||
|
||||
With sets of double-parentheses, we can do some easy math in bash. In the examples below, we create a variable and give it a value and then perform addition, decrement the result, and then square the remaining value.
|
||||
```
|
||||
$ ((e=11))
|
||||
$ (( e = e + 7 ))
|
||||
$ echo $e
|
||||
18
|
||||
|
||||
$ ((e--))
|
||||
$ echo $e
|
||||
17
|
||||
|
||||
$ ((e=e**2))
|
||||
$ echo $e
|
||||
289
|
||||
|
||||
```
|
||||
|
||||
The arithmetic operators allow you to:
|
||||
```
|
||||
+ - Add and subtract
|
||||
++ -- Increment and decrement
|
||||
* / % Multiply, divide, find remainder
|
||||
^ Get exponent
|
||||
|
||||
```
|
||||
|
||||
You can also use both logical and boolean operators:
|
||||
```
|
||||
$ ((x=11)); ((y=7))
|
||||
$ if (( x > y )); then
|
||||
> echo "x > y"
|
||||
> fi
|
||||
x > y
|
||||
|
||||
$ ((x=11)); ((y=7)); ((z=3))
|
||||
$ if (( x > y )) >> (( y > z )); then
|
||||
> echo "letters roll downhill"
|
||||
> fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
or if you prefer ...
|
||||
```
|
||||
$ if [ x > y ] << [ y > z ]; then echo "letters roll downhill"; fi
|
||||
letters roll downhill
|
||||
|
||||
```
|
||||
|
||||
Now let's raise 2 to the 3rd power:
|
||||
```
|
||||
$ echo "2 ^ 3"
|
||||
2 ^ 3
|
||||
$ echo "2 ^ 3" | bc
|
||||
8
|
||||
|
||||
```
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are sure a lot of different ways to work with numbers and perform calculations on the command line on Linux systems. I hope you picked up a new trick or two by reading this post.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3268964/linux/how-to-do-math-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,74 +0,0 @@
|
||||
八种敏捷团队的提升方法
|
||||
======
|
||||

|
||||
|
||||
图片来源:opensource.com
|
||||
|
||||
你也许经常听说下面这句话:工具很多,时间很少。为了节约您的时间,我列出了几款我最常用的提高敏捷团队工作效率的工具。如果你也是一名敏捷主义者,你可能听说过类似的工具,但我这里提到的仅限于开源工具。
|
||||
|
||||
**请注意!** 这些工具和你想象的可能有点不同。它们并不是项目管理软件——这领域已经有一篇[好文章][1]了。因此不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
|
||||
|
||||
### 组建一个充满积极反馈的团队
|
||||
|
||||
如果在产业中大部分人都习惯了输出、接收负面消息,就很难有人对同事进行正面反馈的输出。这并不奇怪,同事中有人沉浸在赞美中,就会有人在不停地说“干得漂亮!”“没有你我们很难完成任务。”但是赞美并不使人痛苦,它通常能激励大家更好地为团队工作。下面两个软件可以帮助你向同事表达赞扬。
|
||||
|
||||
* 对开发团队来说,[Management 3.0][2] 是有着大量[免费资源][3]的珍宝,可以尽情使用。其中 Feedback Wraps 的观念最引人注目(不仅仅是因为它让我们联想到墨西哥卷)。 [Feedback Wraps][4] 是一个经过六步对用户进行反馈的程序,也许你会认为它是为了负面消息设计的,但我们发现它在表达积极评论方面十分有效。
|
||||
* [Happiness Packets][5] 为用户在开源社区内提供匿名正面反馈服务。它尤其适合不太习惯人际交往的用户或是不知道说什么好的情况。Happiness Packets 拥有一份[公开的评论档案][6](这些评论都已经得到授权),你可以浏览大家的评论,从中得到灵感,对别人做出暖心的称赞。它还有个特殊功能,能够屏蔽负面消息。
|
||||
|
||||
|
||||
|
||||
### 思考工作的意义
|
||||
|
||||
这很难定义。在敏捷领域中,成功的关键包括定义人物角色和产品愿景,还要向整个敏捷团队说明此项工作的意义。产品开发人员和项目负责人能够获得的开源工具数量极为有限,对于这一点我们有些失望。
|
||||
|
||||
在 Rat Hat 中,最受尊敬也最为常用于训练敏捷团队的开源工具之一是Product Vision Board 。它出自产品管理专家 Roman Pichler 之手,Roman Pichler 提供了[大量工具和模版][7]来帮助敏捷团队理解他们工作的意义。(你需要提供电子邮箱地址才能下载这些工具。)
|
||||
|
||||
* [Product Vision Board][8] 的模版通过简单但有效的问题引导团队转变思考方式,将思考工作的意义置于具体工作方法之前。
|
||||
* 我们也很喜欢 Roman 的 [Product Management Test][9],它能够通过简便快捷的网页表单,引领团队重新定义产品开发人员的角色,并且找出程序漏洞。我们推荐产品开发团队周期性地完成此项测试,重新分析失败原因。
|
||||
|
||||
|
||||
|
||||
### 对工作内容的直观化
|
||||
|
||||
你是否曾为一个大案子焦头烂额,连熟悉的步骤也在脑海中乱成一团?我们也遇到过这种情况。使用思维导图可以梳理你脑海中的想法,使其直观化。你不需要一下就想出整件事该怎么进行,你只需要你的头脑,一块白板(或者是思维导图软件)和一些思考的时间。
|
||||
|
||||
* 在这个领域中我们最喜欢的开源工具是 [Xmind3][10]。它支持多种平台运行(Linux, MacOS, 和 Windows),以便与他人共享文件。如果你对工具的要求很高,推荐使用 [updated version][11],提供电子邮箱地址即可免费下载使用。
|
||||
* 如果你很看重灵活性,Eduard Lucena 在Fedora Magazine 中提供的 [three additional options][12] 就十分适合。你可以在 Fedora 杂志上找到这些软件的获取方式,其他信息可以在它们的项目页找到。
|
||||
|
||||
* [Labyrinth][13]
|
||||
* [View Your Mind][14]
|
||||
* [FreeMind][15]
|
||||
|
||||
|
||||
|
||||
像我们开头说的一样,提高敏捷团队工作效率的工具有很多,如果你有特别喜欢的相关开源工具,请在评论中与大家分享。
|
||||
|
||||
### 作者简介
|
||||
Jen Krieger :Red Hat 的首席敏捷架构师,在软件开发领域已经工作超过20年,曾在瀑布及敏捷生命周期等领域扮演多种角色。目前在 Red Hat 负责针对 CI/CD 最佳效果的部际 DevOps 活动。最近她在与 Project Atomic & OpenShift 团队合作。她最近在引领公司向着敏捷团队改革,并增加开源项目在公司内的认知度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/foss-tools-agile-teams
|
||||
|
||||
作者:[Jen Krieger][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkrieger
|
||||
[1]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[2]:https://management30.com/
|
||||
[3]:https://management30.com/leadership-resource-hub/
|
||||
[4]:https://management30.com/en/practice/feedback-wraps/
|
||||
[5]:https://happinesspackets.io/
|
||||
[6]:https://www.happinesspackets.io/archive/
|
||||
[7]:http://www.romanpichler.com/tools/
|
||||
[8]:http://www.romanpichler.com/tools/vision-board/
|
||||
[9]:http://www.romanpichler.com/tools/romans-product-management-test/
|
||||
[10]:https://sourceforge.net/projects/xmind3/?source=recommended
|
||||
[11]:http://www.xmind.net/
|
||||
[12]:https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[13]:https://people.gnome.org/~dscorgie/labyrinth.html
|
||||
[14]:http://www.insilmaril.de/vym/
|
||||
[15]:http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
@ -0,0 +1,47 @@
|
||||
如何在企业中开展开源项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
很多互联网企业如 Google, Facebook, Twitter 等,都已经正式建立了数个开源项目(有的公司中建立了单独的开源项目部门)。在这个特定的项目内,开源项目的成本和成果都由公司内部消化。在这样一个实际的部门中,企业可以清晰透明地执行开源策略,这是企业成功开源化的一个必要过程。开源项目部门的职责包括:制定使用、分配、选择和审查代码的相关政策;培训开发技术人员和服从法律法规。
|
||||
|
||||
互联网企业并不是唯一一种运行开源项目的企业,有调查发现产业中 [65% 的企业][1]的运营都与开源相关。在过去几年中 [VMware][2], [Amazon][3], [Microsoft][4] 等企业,甚至连[英国政府][5]都开始聘用开源相关人员,开展开源项目。可见近年来商业领域乃至政府都十分重视开源策略,在这样的环境下,各界也需要跟上他们的步伐,建立开源项目。
|
||||
|
||||
### 怎样建立开源项目
|
||||
|
||||
虽然根据企业的需求不同,各开源部门会有特殊的调整,但下面几个基本步骤是建立每个开源部门都会经历的,它们是:
|
||||
|
||||
* **选定一位领导者:** 选出一位合适的领导之是建立开源项目的第一步。 [TODO Group][6] 发布了一份[开源人员基础工作任务清单][7],你可以根据这个清单筛选人员。
|
||||
* **确定项目构架:** 开源项目可以根据其服务的企业类型改变侧重点,来适应不同种类的企业需求,以在各类企业中成功运行。知识型企业可以把开源项目放在法律事务部运行,技术驱动型企业可以把开源项目放在着眼于提高企业效能的部门中,如工程部。其他类型的企业可以把开源项目放在市场部内运行,以此促进开源产品的销售。TODO Group 发布的[开源项目案例][8]或许可以给你些启发。
|
||||
* **制定规章制度:** 开源策略的实施需要有一套规章制度,其中应当具体列出企业成员进行开源工作的标准流程,来减少失误的发生。这个流程应当简洁明了且简单易行,最好可以用设备进行自动监察。如果工作人员有质疑标准流程的热情和能力,并提出改进意见,那再好不过了。许多活跃在开源领域的企业中,Google 和 TODO 发布的规章制度十分值得借鉴。你可以参照 [Google 发布的制度][9]起草适用于自己企业的规章制度,用 [TODO 的规章制度][10]进行参考。
|
||||
|
||||
### 建立开源项目是企业发展中的关键一步
|
||||
|
||||
建立开源项目部门对很多企业来说是关键一步,尤其是对于那些软件公司或是想要转型进入软件领域的公司。不论雇员的满意度或是开发效率上,在开源项目中企业可以获得巨大的利益,这些利益远远大于对开源项目需要的长期投资。在开源之路上有很多资源可以帮助你成功,例如 TODO Group 的[《怎样创建开源项目》][11],[《开源项目的价值评估》][12]和[《管理开源项目的几种工具》][13]都很适合初学者阅读。
|
||||
|
||||
随着越来越多的企业形成开源项目,开源社区自身的可持续性逐渐加强,这会对这些企业的开源项目产生积极影响,促进企业的发展,这是企业和开源间的良性循环。我希望以上这些信息能够帮到你,祝你在建立开源项目的路上一路顺风。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-start-open-source-program-your-company
|
||||
|
||||
作者:[Chris Aniszczyk][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/caniszczyk
|
||||
[1]:https://www.blackducksoftware.com/2016-future-of-open-source
|
||||
[2]:http://www.cio.com/article/3095843/open-source-tools/vmware-today-has-a-strong-investment-in-open-source-dirk-hohndel.html
|
||||
[3]:http://fortune.com/2016/12/01/amazon-open-source-guru/
|
||||
[4]:https://opensource.microsoft.com/
|
||||
[5]:https://www.linkedin.com/jobs/view/169669924
|
||||
[6]:http://todogroup.org
|
||||
[7]:https://github.com/todogroup/job-descriptions
|
||||
[8]:https://github.com/todogroup/guides/tree/master/casestudies
|
||||
[9]:https://opensource.google.com/docs/why/
|
||||
[10]:https://github.com/todogroup/policies
|
||||
[11]:https://github.com/todogroup/guides/blob/master/creating-an-open-source-program.md
|
||||
[12]:https://github.com/todogroup/guides/blob/master/measuring-your-open-source-program.md
|
||||
[13]:https://github.com/todogroup/guides/blob/master/tools-for-managing-open-source-programs.md
|
||||
116
translated/tech/20171220 Containers without Docker at Red Hat.md
Normal file
116
translated/tech/20171220 Containers without Docker at Red Hat.md
Normal file
@ -0,0 +1,116 @@
|
||||
Red Hat 的去 Docker 化容器实践
|
||||
======
|
||||
|
||||
最近几年,开源项目Docker (已更名为[Moby][1]) 在容器普及化方面建树颇多。然而,它的功能特性不断集中到一个单一、庞大的系统,该系统由具有 root 权限运行的守护进程 `dockerd` 管控,这引发了人们的焦虑。对这些焦虑的阐述,具有代表性的是 Red Hat 公司的容器团队负责人 Dan Walsh 在 [KubeCon \+ CloudNativecon][3] 会议中的[演讲][2]。Walsh讲述了他的容器团队目前的工作方向,即使用一系列更小、可协同工作的组件替代 Docker。他的战斗口号是”拒绝臃肿的守护进程“,理由是与公认的 Unix 哲学相违背。
|
||||
|
||||
### Docker 模块化实践
|
||||
|
||||
就像我们在[早期文献][4]中看到的那样,容器的基础操作不复杂:你首先拉取一个容器镜像,利用该镜像创建一个容器,最后启动这个容器。除此之外,你要懂得如何构建镜像并推送至镜像仓库。大多数人在上述这些步骤中使用 Docker,但其实 Docker 并不是唯一的选择,目前的可替换选择是 `rkt`。rkt引发了一系列标准的创建,包括运行时标准 CRI,镜像标准 OCI 及网络标准 CNI 等。遵守这些标准的后端,如 [CRI-O][5] 和 Docker,可以与 [Kubernetes][6] 为代表的管理软件协同工作。
|
||||
|
||||
这些标准促使 Red Hat 公司开发了一系列部分实现标准的”核心应用“供 Kubernetes 使用,例如 CRI-O 运行时。但 Kubernetes 提供的功能不足以满足 Red Hat公司的 [OpenShift][7] 项目所需。开发者可能需要构建容器并推送至镜像仓库,实现这些操作需要额外的一整套方案。
|
||||
|
||||
事实上,目前市面上已有多种构建容器的工具。来自 Sysdig 公司的 Michael Ducy 在[分会场][8]中回顾了 Docker 本身之外的8种镜像构建工具,而这也很可能不是全部的工具。Ducy 将理想的构建工具定义如下:可以用可重现的方式创建最小化镜像。最小化镜像并不包含操作系统,只包含应用本身及其依赖。Ducy 认为 [Distroless][9], [Smith][10] 及 [Source-to-Image][11] 都是很好的工具,可用于构建最小化镜像。Ducy 将最小化镜像称为”微容器“。
|
||||
|
||||
可重现镜像是指构建多次结果保持不变的镜像。为达到这个目标,Ducy 表示应该使用“宣告式”而不是“命令式”的方式。考虑到 Ducy 来自 Chef 配置管理工具领域,你应该能理解他的意思。Ducy 给出了符合标准的几个不错的实现,包括 [Ansible 容器][12], [Habitat][13], [nixos-容器][14]和 [Simth][10] 等,但你需要了解这些项目对应的编程语言。Ducy 额外指出 Habitat 构建的容器自带管理功能,如果你已经使用了systemd, Docker 或 Kubernetes 等外部管理工具,Habitat 的管理功能可能是冗余的。除此之外,我们还要提从 Docker 和 [Buildah][16] 项目诞生的新项目 [BuildKit][15], 它是 Red Hat 公司 [Atomic 工程][17]的一个组件。
|
||||
|
||||
### 使用Buildah构建容器
|
||||
|
||||
![\[Buildah logo\]][18] Buildah 名称显然来自于 Walsh 风趣的 [Boston 口音][19]; 该工具的品牌宣传中充满了 Boston 风格,例如 logo 使用了 Boston 梗犬(如图所示)。该项目的实现思路与 Ducy 不同:为了构建容器,与其被迫使用宣告式配置管理的方案,不如构建一些简单工具,结合你最喜欢的配置管理工具使用。这样你可以如愿的使用命令行,例如使用 `cp` 命令代替 Docker 的自定义指令 `COPY` 。除此之外,你可以使用如下工具为容器提供内容:1) 配置管理工具,例如Ansible 或 Puppet;2) 操作系统相关或编程语言相关的安装工具,例如 APT 和 pip; 3) 其它系统。下面展示了基于通用 shell 命令的容器构建场景,其中只需要使用 `make` 命令即可为容器安装可执行文件。
|
||||
|
||||
```
|
||||
# 拉取基础镜像, 类似 Dockerfile 中的 FROM 命令
|
||||
buildah from redhat
|
||||
|
||||
# 挂载基础镜像, 在其基础上工作
|
||||
crt=$(buildah mount)
|
||||
ap foo $crt
|
||||
make install DESTDIR=$crt
|
||||
|
||||
# 下一步,生成快照
|
||||
buildah commit
|
||||
|
||||
```
|
||||
|
||||
有趣的是,基于这个思路,你可以复用主机环境中的构建工具,无需在镜像中安装这些依赖,故可以构建非常微小的镜像。通常情况下,构建容器镜像时需要在容器中安装目标应用的构建依赖。例如,从源码构建需要容器中有编译器工具链,这是因为构建并不在主机环境进行。大量的容器也包含了 `ps` 和 `bash` 这样的 Unix 命令,对微容器而言其实是多余的。开发者经常忘记或无法从构建好的容器中移除一些依赖,增加了不必要的开销和攻击面。
|
||||
|
||||
Buildah的模块化方案能够以非 root 方式进行部分构建;但`mount` 命令仍然需要 `CAP_SYS_ADMIN` 或 `等同 root 访问权限` 的能力,有一个 [issue][20] 试图解决该问题。但 Buildah 与 Docker [都有][21]同样的限制[22],即无法在容器内构建容器。对于 Docker,你需要使用“特权”模式运行容器,一些特殊的环境很难满足这个条件,例如 [GitLab 持续集成][23];即使满足该条件,配置也特别[繁琐][24]。
|
||||
|
||||
手动提交的步骤可以对创建容器快照的时间节点进行细粒度控制。Dockerfile 每一行都会创建一个新的快照;相比而言,Buildah 的提交检查点都是事先选择好的,这可以减少不必要的快照并节省磁盘空间。这也有利于隔离私钥或密码等敏感信息,避免其出现在公共镜像中。
|
||||
|
||||
Docker 构建的镜像是非标准的、仅供其自身使用;相比而言,Buildah 提供[多种输出格式][25],其中包括符合 OCI 标准的镜像。为向后兼容,Buildah 提供 一个 `使用Dockerfile构建` 的命令,即 [`buildah bud`][26], 它可以解析标准的 Dockerfile。Buildah 提供 `enter` 命令直接查看镜像内部信息,`run` 命令启动一个容器。实现这些功能仅使用了 `runc` 在内的标准工具,无需在后台运行一个“臃肿的守护进程”。
|
||||
|
||||
Ducy 对 Buildah 表示质疑,认为采用非宣告性不利于可重现性。如果允许使用 shell 命令,可能产生很多预想不到的情况;例如,一个 shell 脚本下载了任意的可执行程序,但后续无法追溯文件的来源。shell 命令的执行受环境变量影响,执行结果可能大相径庭。与基于 shell 的工具相比,Puppet 或 Chef 这样的配置管理系统在理论上更加可靠,因为他们的设计初衷就是收敛于最终配置;事实上,可以通过配置管理系统调用 shell 命令。但 Walsh 对此提出反驳,认为已有的配置管理工具可以在 Buildah 的基础上工作,用户可以选择是否使用配置管理;这样更加符合“机制与策略分离”的经典 Unix 哲学。
|
||||
|
||||
目前 Buildah 处于测试阶段,Red Hat 公司正努力将其集成到 OpenShift。我写这篇文章时已经测试过 Buildah,它缺少一些主题的文档,但基本可以稳定运行。尽管在错误处理方面仍有待提高,但它确实是一款值得你关注的容器工具。
|
||||
|
||||
### 替换其它 Docker 命令行
|
||||
|
||||
Walsh 在其演讲中还简单介绍了 Redhat 公司 正在开发的另一个暂时叫做 [libpod][24] 的项目。项目名称来源于 Kubernetes 中的 “pod”, 在 Kubernetes 中 “pod” 用于分组主机内的容器,分享名字空间等。
|
||||
|
||||
Libpod 提供 `kpod` 命令,用于直接检查和操作容器存储。Walsh 分析了该命令发挥作用的场景,例如 `dockerd` 停止响应或 Kubernetes 集群崩溃。基本上,`kpod` 独立地再次实现了 `docker` 命令行工具。`kpod ps` 返回运行中的容器列表,`kpod images` 返回镜像列表。事实上,[命令转换速查手册][28] 中给出了每一条 Docker 命令对应的 `kpod` 命令。
|
||||
|
||||
这种模块化实现的一个好处是,当你使用 `kpod run` 运行容器时,容器直接作为当前 shell 而不是 `dockerd` 的子进程启动。理论上,可以直接使用 systemd 启动容器,这样可以消除 `dockerd` 引入的冗余。这让[由套接字激活的容器][29]成为可能,但暂时基于 Docker 实现该特性[并不容易][30],[即使借助 Kubernetes][31] 也是如此。但我在测试过程中发现,使用 `kpod` 启动的容器有一些基础功能性缺失,具体而言是网络功能(!),相关实现在[活跃开发][32]过程中。
|
||||
|
||||
我们最后提到的命令是 `push`。虽然上述命令已经足以满足本地使用容器的需求,但没有提到远程仓库,借助远程仓库开发者可以活跃地进行应用打包协作。仓库也是持续部署框架的核心组件。[skopeo][33] 项目用于填补这个空白,它是另一个 Atomic 成员项目,按其 `README` 文件描述,“包含容器镜像及镜像库的多种操作”。该项目的设计初衷是,在不用类似 `docker pull` 那样实际下载可能体积庞大的镜像的前提下,检查容器镜像的内容。Docker [拒绝加入][34] 检查功能,建议通过一个额外的工具实现该功能,这促成了 Skopeo 项目。除了`pull`,`push`,Skopeo现在还可以完成很多其它操作,例如在,不产生本地副本的情况下将镜像在不同的仓库中复制和转换。由于部分功能比较基础,可供其它项目使用,目前很大一部分 Skopeo 代码位于一个叫做 [containers/image][35] 的基础库。[Pivotal][36], Google的 [container-diff][37] ,`kpod push` 及 `buildah push` 都使用了该库。
|
||||
|
||||
`kpod` 与 Kubernetes 并没有紧密的联系,故未来可能会更换名称(事实上,在本文刊发过程中,已经更名为 [`podman`][38]),毕竟 Red Hat 法务部门还没有明确其名称。该团队希望实现更多 pod 级别的命令,这样可以对多个容器进行操作,有点类似于 [`docker compose`][39] 实现的功能。但在这方面,[Kompose][40] 是更好的工具,可以通过 [复合 YAML 文件][41] 在 Kubernetes 集群中运行容器。按计划,我们不会实现类似于 [`swarm`] 的 Docker 命令,这部分功能最好由 Kubernetes 本身完成。
|
||||
|
||||
目前看来,已经持续数年的 Docker 模块化努力终将硕果累累。但目前 `kpod` 处于快速迭代过程中,不太适合用于生产环境,但那些工具的众不同的设计理念让人很感兴趣,而且其中大部分的工具已经可以用于开发环境。目前只能通过编译源码的方式安装 libpod,但最终会提供各个发行版的二进制包。
|
||||
|
||||
> 本文[最初发表][43]于 [Linux Weekly News][44]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
链接: https://anarc.at/blog/2017-12-20-docker-without-docker/
|
||||
|
||||
作者:[À propos de moi][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://anarc.at
|
||||
[1]:https://mobyproject.org/
|
||||
[2]:https://kccncna17.sched.com/event/CU8j/cri-o-hosted-by-daniel-walsh-red-hat
|
||||
[3]:http://events.linuxfoundation.org/events/kubecon-and-cloudnativecon-north-america
|
||||
[4]:https://lwn.net/Articles/741897/
|
||||
[5]:http://cri-o.io/
|
||||
[6]:https://kubernetes.io/
|
||||
[7]:https://www.openshift.com/
|
||||
[8]:https://kccncna17.sched.com/event/CU6B/building-better-containers-a-survey-of-container-build-tools-i-michael-ducy-chef
|
||||
[9]:https://github.com/GoogleCloudPlatform/distroless
|
||||
[10]:https://github.com/oracle/smith
|
||||
[11]:https://github.com/openshift/source-to-image
|
||||
[12]:https://www.ansible.com/ansible-container
|
||||
[13]:https://www.habitat.sh/
|
||||
[14]:https://nixos.org/nixos/manual/#ch-containers
|
||||
[15]:https://github.com/moby/buildkit
|
||||
[16]:https://github.com/projectatomic/buildah
|
||||
[17]:https://www.projectatomic.io/
|
||||
[18]:https://raw.githubusercontent.com/projectatomic/buildah/master/logos/buildah-logomark_large.png (Buildah logo)
|
||||
[19]:https://en.wikipedia.org/wiki/Boston_accent
|
||||
[20]:https://github.com/projectatomic/buildah/issues/171
|
||||
[21]:https://github.com/projectatomic/buildah/issues/158
|
||||
[22]:https://github.com/moby/moby/issues/27886#issuecomment-281278525
|
||||
[23]:https://about.gitlab.com/features/gitlab-ci-cd/
|
||||
[24]:https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/
|
||||
[25]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-push.md
|
||||
[26]:https://github.com/projectatomic/buildah/blob/master/docs/buildah-bud.md
|
||||
[27]:https://github.com/projectatomic/libpod
|
||||
[28]:https://github.com/projectatomic/libpod/blob/master/transfer.md#development-transfer
|
||||
[29]:http://0pointer.de/blog/projects/socket-activated-containers.html
|
||||
[30]:https://legacy-developer.atlassian.com/blog/2015/03/docker-systemd-socket-activation/
|
||||
[31]:https://github.com/kubernetes/kubernetes/issues/484
|
||||
[32]:https://github.com/projectatomic/libpod/issues/129
|
||||
[33]:https://github.com/projectatomic/skopeo
|
||||
[34]:https://github.com/moby/moby/pull/14258
|
||||
[35]:https://github.com/containers/image
|
||||
[36]:https://pivotal.io/
|
||||
[37]:https://github.com/GoogleCloudPlatform/container-diff
|
||||
[38]:https://github.com/projectatomic/libpod/blob/master/docs/podman.1.md
|
||||
[39]:https://docs.docker.com/compose/overview/#compose-documentation
|
||||
[40]:http://kompose.io/
|
||||
[41]:https://docs.docker.com/compose/compose-file/
|
||||
[42]:https://docs.docker.com/engine/swarm/
|
||||
[43]:https://lwn.net/Articles/741841/
|
||||
[44]:http://lwn.net/
|
||||
@ -1,67 +0,0 @@
|
||||
什么是 Linux “oops”?
|
||||
======
|
||||
如果你检查你的 Linux 系统上运行的进程,你可能会对一个叫做 “kerneloops” 的进程感到好奇。以防万一你没有正确认识,它是 “kernel oops”,而不是 “kerne loops”。
|
||||
|
||||
坦率地说,“oops” 是 Linux 内核的一部分出现了偏差。你有做错了什么么?可能没有。但发生了一些事情。而那个错误的进程可能已经被 CPU 结束。最糟糕的是,内核可能会报错并突然关闭系统。
|
||||
|
||||
对于记录,“oops” 不是首字母缩略词。它不代表像“面向对象的编程和系统” (object-oriented programming and systems) 或“超出程序规范” (out of procedural specs) 之类的东西。它实际上就是“哎呀” (oops),就像你刚掉下一杯酒或踩在你的猫上。哎呀! “oops” 的复数是 “oopses”。
|
||||
|
||||
oops 意味着系统上运行的某些东西违反了内核有关正确行为的规则。也许代码尝试采取不允许的代码路径或使用无效指针。不管它是什么,内核 - 总是在寻找进程的错误行为 - 很可能会阻止特定进程,并将它做了什么的消息写入控制台、 /var/log/dmesg 或 /var/log/kern.log 中。
|
||||
|
||||
oops 可能是由内核本身引起的,也可能是某些进程试图让内核违反在系统上能做的事以及它们被允许做的事。
|
||||
|
||||
oops 将生成一个崩溃签名,这可以帮助内核开发人员找出错误并提高代码质量。
|
||||
|
||||
系统上运行的 kerneloops 进程可能如下所示:
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
|
||||
```
|
||||
|
||||
你可能会注意到该进程不是由 root 运行的,而是由名为 “kernoops” 的用户运行的,并且它的运行时间极少。实际上,分配给这个特定用户的唯一任务是运行 kerneloops。
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
|
||||
```
|
||||
|
||||
如果你的 Linux 系统不带有 kerneloops(比如 Debian),你可以考虑添加它。查看这个[ Debian 页面][1]了解更多信息。
|
||||
|
||||
### 什么时候应该关注 oops?
|
||||
|
||||
除非是预期的,oops 没什么大不了的。它在一定程度上取决于特定进程所扮演的角色。它也取决于 oops 的类别。
|
||||
|
||||
有些 oops 很严重,会导致系统恐慌。从技术上讲,系统恐慌是 oops 的一个子集(即更严重的 oops)。当内核检测到的问题足够严重以至于内核认为它(内核)必须立即停止运行以防止数据丢失或对系统造成其他损害时会出现。因此,系统需要暂停并重新启动,以防止不一致导致不可用或不可靠。所以系统恐慌实际上是为了保护自己免受不可挽回的损害。
|
||||
|
||||
总之,所有的内核恐慌都是 oops,但并不是所有的 oops 都是内核恐慌。
|
||||
|
||||
/var/log/kern.log 和相关的轮转日志(/var/log/kern.log.1、/var/log/kern.log.2 等)包含由内核生成并由 syslog 处理的日志。
|
||||
|
||||
kerneloops 程序收集并默认将错误信息提交到<http://oops.kernel.org/>,在那里它会被分析并呈现给内核开发者。此进程的配置详细信息在 /etc/kerneloops.conf 文件中指定。你可以使用下面的命令轻松查看设置:
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
|
||||
```
|
||||
|
||||
在上面的(默认)设置中,内核问题可以被提交,但要求用户获得许可。如果设置为 allow-submit = always,则不会询问用户。
|
||||
|
||||
调试内核问题是使用 Linux 系统的更高级技巧之一。幸运的是,大多数 Linux 用户很少或从没有经历过 oops 或内核恐慌。不过,知道 kerneloops 这样的进程在系统中执行什么操作,了解可能会报告什么以及系统何时遇到严重的内核冲突也是很好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
@ -1,209 +0,0 @@
|
||||
Linux 系统中 sudo 命令的 10 个技巧
|
||||
======
|
||||
|
||||
![Linux-sudo-command-tips][1]
|
||||
|
||||
### 概览
|
||||
|
||||
**sudo** 表示 **superuser do**。 它允许已验证的用户以其他用户的身份来运行命令。其他用户可以是普通用户或者超级用户。然而,大部分时候我们用它来以提升的权限来运行命令。
|
||||
|
||||
sudo 命令与安全策略配合使用,默认安全策略是 sudoers,可以通过文件 **/etc/sudoers** 来配置。其安全策略具有高度可拓展性。人们可以开发和分发他们自己的安全策略作为插件。
|
||||
|
||||
#### 与 su 的区别
|
||||
|
||||
在 GNU/Linux 中,有两种方式可以用提升的权限来运行命令:
|
||||
|
||||
* 使用 **su** 命令
|
||||
* 使用 **sudo** 命令
|
||||
|
||||
**su** 表示 **switch user**。使用 su,我们可以切换到 root 用户并且执行命令。但是这种方式存在一些缺点
|
||||
|
||||
* 我们需要与他人共享 root 的密码。
|
||||
* 因为 root 用户为超级用户,我们不能授予受控的访问权限。
|
||||
* 我们无法审查用户在做什么。
|
||||
|
||||
sudo 以独特的方式解决了这些问题。
|
||||
|
||||
1. 首先,我们不需要妥协来分享 root 用户的密码。普通用户使用他们自己的密码就可以用提升的权限来执行命令。
|
||||
2. 我们可以控制 sudo 用户的访问,这意味着我们可以限制用户只执行某些命令。
|
||||
3. 除此之外,sudo 用户的所有活动都会被记录下来,因此我们可以随时审查进行了哪些操作。在基于 Debian 的 GNU/Linux 中,所有活动都记录在 **/var/log/auth.log** 文件中。
|
||||
|
||||
本教程后面的部分阐述了这些要点。
|
||||
|
||||
#### 实际动手操作 sudo
|
||||
|
||||
现在,我们对 sudo 有了大致的了解。让我们实际动手操作吧。为了演示,我使用 Ubuntu。但是,其它发行版本的操作应该是相同的。
|
||||
|
||||
#### 允许 sudo 权限
|
||||
|
||||
让我们添加普通用户为超级用户吧。在我的情形中,用户名为 linuxtechi
|
||||
|
||||
1) 按如下所示编辑 /etc/sudoers 文件:
|
||||
```
|
||||
$ sudo visudo
|
||||
|
||||
```
|
||||
|
||||
2) 添加以下行来允许用户 linuxtechi 有 sudo 权限:
|
||||
```
|
||||
linuxtechi ALL=(ALL) ALL
|
||||
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* linuxtechi 表示用户名
|
||||
* 第一个 ALL 指示允许从任何终端、机器访问 sudo
|
||||
* 第二个 (ALL) 指示 sudo 命令被允许以任何用户身份执行
|
||||
* 第三个 ALL 表示所有命令都可以作为 root 执行
|
||||
|
||||
|
||||
#### 以提升的权限执行命令
|
||||
|
||||
要用提升的权限执行命令,只需要在命令前加上 sudo,如下所示
|
||||
```
|
||||
$ sudo cat /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
当你执行这个命令时,它会询问 linuxtechi 的密码,而不是 root 用户的密码。
|
||||
|
||||
#### 以其他用户执行命令
|
||||
|
||||
|
||||
除此之外,我们可以使用 sudo 以另一个用户身份执行命令。例如,在下面的命令中,用户 linuxtechi 以用户 devesh 的身份执行命令:
|
||||
```
|
||||
$ sudo -u devesh whoami
|
||||
[sudo] password for linuxtechi:
|
||||
devesh
|
||||
|
||||
```
|
||||
|
||||
#### 内置命令行为
|
||||
|
||||
sudo 的一个限制是——它无法使用 Shell 的内置命令。例如,历史记录是内置命令,如果你试图用 sudo 执行这个命令,那么会提示如下的未找到命令的错误:
|
||||
```
|
||||
$ sudo history
|
||||
[sudo] password for linuxtechi:
|
||||
sudo: history: command not found
|
||||
|
||||
```
|
||||
|
||||
**访问 root shell**
|
||||
|
||||
为了克服上述问题,我们可以访问 root shell,并在那里执行任何命令,包括 Shell 的内置命令。
|
||||
|
||||
要访问 root shell, 执行下面的命令:
|
||||
```
|
||||
$ sudo bash
|
||||
|
||||
```
|
||||
|
||||
执行完这个命令后——您将观察到提示符变为 磅(#)字符。
|
||||
|
||||
### 技巧
|
||||
|
||||
这节我们将讨论一些有用的技巧,这将有助于提高生产力。大多数命令可用于完成日常任务。
|
||||
|
||||
#### 以 sudo 用户执行之前的命令
|
||||
|
||||
让我们假设你想用提升的权限执行之前的命令,那么下面的技巧将会很有用:
|
||||
```
|
||||
$ sudo !4
|
||||
|
||||
```
|
||||
|
||||
上面的命令将使用提升的权限执行历史记录中的第 4 条命令。
|
||||
|
||||
#### sudo command with Vim
|
||||
|
||||
很多时候,我们编辑系统的配置文件时,在保存时意识到我们需要 root 访问权限来执行此操作。因为这个可能让我们失去我们对文件的改动。没有必要惊慌,我们可以在 Vim 中使用下面的命令来解决这种情况:
|
||||
```
|
||||
:w !sudo tee %
|
||||
|
||||
```
|
||||
|
||||
上述命令中:
|
||||
|
||||
* 冒号 (:) 表明我们处于 Vim 的退出模式
|
||||
* 感叹号 (!) 表明我们正在运行 shell 命令
|
||||
* sudo 和 tee 都是 shell 命令
|
||||
* 百分号 (%) 表明从当前行开始的所有行
|
||||
|
||||
|
||||
|
||||
#### 使用 sudo 执行多个命令
|
||||
|
||||
至今我们用 sudo 只执行了单个命令,但我们可以用它执行多个命令。只需要用分号 (;) 隔开命令,如下所示:
|
||||
```
|
||||
$ sudo -- bash -c 'pwd; hostname; whoami'
|
||||
|
||||
```
|
||||
|
||||
上述命令中
|
||||
|
||||
* 双连字符 (–) 停止命令行切换
|
||||
* bash 表示要用于执行命令的 shell 名称
|
||||
* -c 选项后面跟着要执行的命令
|
||||
|
||||
|
||||
|
||||
#### 无密码运行 sudo 命令
|
||||
|
||||
当第一次执行 sudo 命令时,它会提示输入密码,默认情形下密码被缓存 15 分钟。但是,我们可以避免这个操作,并使用 NOPASSWD 关键字禁用密码认证,如下所示:
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
```
|
||||
|
||||
#### 限制用户执行某些命令
|
||||
|
||||
为了提供受控访问,我们可以限制 sudo 用户只执行某些命令。例如,下面的行只允许执行 echo 和 ls 命令
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
|
||||
|
||||
```
|
||||
|
||||
#### 深入了解 sudo
|
||||
|
||||
让我们进一步深入了解 sudo 命令。
|
||||
```
|
||||
$ ls -l /usr/bin/sudo
|
||||
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
|
||||
|
||||
```
|
||||
|
||||
如果仔细观测文件权限,则发现 sudo 上启用了 **setuid** 位。当任何用户运行这个二进制文件时,它将以拥有该文件的用户权限运行。在所示情形下,它是 root 用户。
|
||||
|
||||
为了演示这一点,我们可以使用 id 命令,如下所示:
|
||||
```
|
||||
$ id
|
||||
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
|
||||
|
||||
```
|
||||
|
||||
当我们不使用 sudo 执行 id 命令时,将显示用户 linuxtechi 的 id。
|
||||
```
|
||||
$ sudo id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
|
||||
```
|
||||
|
||||
但是,如果我们使用 sudo 执行 id 命令时,则会显示 root 用户的 id。
|
||||
|
||||
### 结论
|
||||
|
||||
从这篇文章可以看出——sudo 为普通用户提供了更多受控访问。使用这些技术,多用户可以用安全的方式与 GNU/Linux 进行交互。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/03/Linux-sudo-command-tips.jpg
|
||||
@ -1,150 +0,0 @@
|
||||
12 个 Git 提示献给 Git 12 岁生日
|
||||
=====
|
||||
|
||||

|
||||
[Git][1] 是一个分布式版本控制系统,它已经成为开源世界中源代码控制的默认工具,在 4 月 12 日这天,它 12 岁了。使用 Git 令人沮丧的事情之一是你需要知道更多才能有效地使用 Git。这也可能是使用 Git 比较美妙的一件事,因为没有什么比发现一个新技巧来简化或提高你的工作流的效率更令人快乐了。
|
||||
|
||||
为了纪念 Git 的 12 岁生日,这里有 12 条技巧和诀窍来让你的 Git 经验更加有用和强大。从你可能忽略的一些基本知识开始,并扩展到一些真正的高级用户技巧!
|
||||
|
||||
### 1\. 你的 ~/.gitconfig 文件
|
||||
|
||||
当你第一次尝试使用 `git` 命令向仓库提交一个更改时,你可能会收到这样的欢迎信息:
|
||||
```
|
||||
*** Please tell me who you are.
|
||||
|
||||
Run
|
||||
|
||||
git config --global user.email "you@example.com"
|
||||
|
||||
git config --global user.name "Your Name"
|
||||
|
||||
to set your account's default identity.
|
||||
|
||||
```
|
||||
|
||||
你可能没有意识到正是这些命令正在修改 `~/.gitconfig` 的内容,这是 Git 存储全局配置选项的地方。你可以通过 `~/.gitconfig` 文件来做大量的事,包括定义别名,永久性打开(或关闭)特定命令选项,以及修改 Git 工作方式(例如,`git diff` 使用哪个 diff 算法,或者默认使用什么类型的合并策略)。你甚至可以根据仓库的路径有条件地包含其他配置文件!所有细节请参阅 `man git-config`。
|
||||
|
||||
### 2\. 你仓库的 .gitconfig 文件
|
||||
|
||||
在之前的技巧中,你可能想知道 `git config` 命令中 `--global` 标志是干什么的。它告诉 Git 更新 `~/.gitconfig` 中的 "global" 配置。当然,有一个全局配置意味着一个本地配置,确定的是,如果你省略 `--global` 标志,`git config` 将改为更新仓库特有的配置,该配置在 `.git/config` 中。
|
||||
|
||||
在 `.git/config` 文件中设置的选项将覆盖 `〜/.gitconfig` 文件中的所有设置。因此,例如,如果你需要为特定仓库使用不同的电子邮件地址,则可以运行 `git config user.email "also_you@example.com"`。然后,该仓库中的任何提交都将使用你单独配置的电子邮件地址。如果你在开源项目中工作,而且希望他们显示自己的电子邮件地址,同时仍然使用自己工作邮箱作为主 Git 配置,这非常有用。
|
||||
|
||||
几乎任何你可以在 `〜/ .gitconfig` 中设置的东西,你也可以在 `.git / config` 中进行设置,以使其作用于特定的仓库。在线面的提示中,当我提到将某些内容添加到 `~/.gitconfig` 时,只需记住你也可以在特定仓库的 `.git/config` 中添加来设置那个选项。
|
||||
|
||||
### 3\. 别名
|
||||
|
||||
别名是你可以在 `〜/ .gitconfig` 中做的另一件事。它的工作原理就像命令行中的 shell -- 它们设定一个新的命令名称,可以调用一个或多个其他命令,通常使用一组特定的选项或标志。它们对于那些你经常使用的又长又复杂的命令来说非常有效。
|
||||
|
||||
你可以使用 `git config` 命令来定义别名 - 例如,运行 `git config --global --add alias.st status` 将使运行 `git st` 与运行 `git status` 做同样的事情 - 但是我在定义别名时发现,直接编辑 `~/.gitconfig` 文件通常更容易。
|
||||
|
||||
如果你选择使用这种方法,你会发现 `~/.gitconfig` 文件是一个 [INI 文件][2]。INI 是一种带有特定段落的键值对文件格式。当添加一个别名时,你将改变 `[alias]` 段落。例如,定义上面相同的 `git st` 别名时,添加如下到文件:
|
||||
```
|
||||
[alias]
|
||||
|
||||
st = status
|
||||
|
||||
```
|
||||
|
||||
(如果已经有 `[alias]` 段落,只需将第二行添加到现有部分。)
|
||||
|
||||
### 4\. shell 命令中的别名
|
||||
|
||||
别名不仅仅限于运行其他 Git 子 命令 - 你还可以定义运行其他 shell 命令的别名。这是一个很好的方式来处理一个反复发生的,罕见和复杂的任务:一旦你确定了如何完成它,就可以在别名下保存该命令。例如,我有一些仓库,我已经 fork 了一个开源的项目并进行了一些本地修改。我想跟上项目正在进行的开发工作,并保存我本地的变化。为了实现这个目标,我需要定期将来自上游仓库的更改合并到我 fork 的项目中 - 我通过使用我称之为 `upstream-merge` 的别名。它是这样定义的:
|
||||
```
|
||||
upstream-merge = !"git fetch origin -v && git fetch upstream -v && git merge upstream/master && git push"
|
||||
|
||||
```
|
||||
|
||||
别名定义开头的 `!` 告诉 Git 通过 shell 运行这个命令。这个例子涉及到运行一些 `git` 命令,但是以这种方式定义的别名可以运行任何 shell 命令。
|
||||
|
||||
(注意,如果你想复制我的 `upstream-merge` 别名,你需要确保你有一个名为 `upstream` 的 Git remote 指向你已经分配的上游仓库,你可以通过运行 `git remote add upstream <URL to repo>` 来添加一个。)
|
||||
|
||||
### 5\. 可视化提交图
|
||||
|
||||
如果你从事的是一个有很多分支活动的项目,有时可能很难掌握所有正在发生的工作以及它们之间的相关性。各种图形用户界面工具可让你获取不同分支的图片并在所谓的“提交图表”中提交。例如,以下是我使用 [GitLab][3] 提交图表查看器可视化的我的一个仓库的一部分:
|
||||
|
||||
![GitLab commit graph viewer][5]
|
||||
John Anderson, CC BY
|
||||
|
||||
如果你是一个专注于命令行的用户或者某个发现切换工具让人分心,那么最好从命令行获得类似的提交视图。这就是 `git log` 命令的 `--graph` 参数出现的地方:
|
||||
|
||||
![Repository visualized with --graph command][7]
|
||||
|
||||
John Anderson, CC BY
|
||||
|
||||
以下命令可视化相同仓库可达到相同效果:
|
||||
```
|
||||
git log --graph --pretty=format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date=relative
|
||||
|
||||
```
|
||||
|
||||
`--graph` 选项将图添加到日志的右侧,`--abbrev-commit` 缩短提交的 [SHAs][8] 值,`--date=relative` 用相对属于表示日期,以及 `--pretty` 位处理所有其他自定义格式。我有 `git lg` 别名用于这个功能,它是我最常用的 10 个命令之一。
|
||||
|
||||
### 6\. 更优雅的强制推送
|
||||
|
||||
有时,就像你试图避免使用它一样困难的是,你会发现你需要运行 `git push --force` 来覆盖仓库远程副本上的历史记录。你可能得到了一些反馈,导致你进行交互式重新分配,或者你可能已经搞砸了,并希望隐藏证据。
|
||||
|
||||
当其他人在仓库的远程副本的同一分支上进行更改时,会发生强制推送的危险。当你强制推送已重写的历史记录时,这些提交将会丢失。这就是 `git push --force-with-lease` 出现的原因 -- 如果远程分支已经丢失,它不会允许你强制推送,这确保你不会丢掉别人的工作。
|
||||
|
||||
### 7\. git add -N
|
||||
|
||||
你是否过 `git commit -a` 在一次行动中提交所有未完成的修改,只有在你推送完提交后才发现 `git commit -a` 忽略了新添加的文件才能发现?你可以使用 `git add -N` (想想 "notify") 来解决这个问题,告诉 Git 在第一次实际提交它们之前,你希望在提交中包含新增文件。
|
||||
|
||||
### 8\. git add -p
|
||||
|
||||
使用 Git 时的最佳做法是确保每次提交都只包含一个逻辑修改 - 无论这是修复错误还是添加新功能。然而,有时当你在工作时,你的仓库最终会有多个提交值的修改。你怎样才能设法把事情分开,使每个提交只包含适当的修改呢?`git add --patch` 来拯救你了!
|
||||
|
||||
这个标志会让 `git add` 命令查看你工作副本中的所有变化,并为每个变化询问你是否想要将它提交,跳过,或者推迟决定(以及其他更强大的选项,你可以在运行命令后选择 `?` 来查看)。`git add -p` 是生成结构良好的提交的绝佳工具。
|
||||
|
||||
### 9\. git checkout -p
|
||||
|
||||
与 `git add -p` 类似,`git checkout` 命令将采用 `--patch` 或 `-p` 选项,这会使其在本地工作副本中显示每个“大块”的改动,并允许丢弃它 -- 简单来说就是将本地工作副本恢复到更改之前的状态。
|
||||
|
||||
这真的很棒。例如,当你追踪一个 bug 时引入了一堆调试日志语句,修正了这个 bug 之后,你可以先使用 `git checkout -p` 移除所有新的调试日志,然后 `git add -p` 来添加 bug 修复。没有比组合一个优雅的,结构良好的提交更令人满意!
|
||||
|
||||
### 10\. Rebase 时执行命令
|
||||
|
||||
有些项目有一个规则,即存储库中的每个提交都必须处于工作状态 - 也就是说,在每次提交时,应该可以编译代码,或者应该运行测试套件而不会失败。 当你在分支上工作时,这并不困难,但是如果你最终因为某种原因需要 rebase 时,那么逐步完成每个重新绑定的提交以确保你没有意外地引入一个中断是乏味的。
|
||||
|
||||
幸运的是,`git rebase` 已经覆盖了 `-x` 或 `--exec` 选项。`git rebase -x <cmd>` 将在每次提交应用到 rebase 后运行该命令。因此,举个例子,如果你有一个项目,其中 `npm run tests` 运行你的测试套件,`git rebase -x npm run tests` 将在 rebase 期间每次提交之后运行测试套件。这使你可以查看测试套件是否在任何重新发布的提交中失败,因此你可以确认测试套件在每次提交时仍能通过。
|
||||
|
||||
### 11\. 基于时间的修正参考
|
||||
|
||||
很多 Git 子命令都接受一个修正的参数来决定命令作用于仓库的哪个部分,可以是某次特定的提交的 sha1 值,一个分支的名称,甚至是一个符号性的名称如 `HEAD`(代表当前检出分支最后一次的提交),除了这些简单的形式以外,你还可以附加一个指定的日期或时间作为参数,表示“这个时间的引用”。
|
||||
|
||||
这个功能在某些时候会变得十分有用。当你处理最新出现的 bug,自言自语道:“这个功能昨天还是好好的,到底又改了些什么”,不用盯着满屏的 `git log` 的输出试图弄清楚什么时候更改了提交,你只需运行 `git diff HEAD@{yesterday}`,看看从昨天以来的所有修改。这也适用于更长的时间段(例如 `git diff HEAD@{'2 months ago'}`),以及一个确切的日期(例如 `git diff HEAD@{'2010-01-01 12:00:00'}`)。
|
||||
|
||||
你也可以将这些基于日期的修改参数与使用修正参数的任何 Git 子命令一起使用。在 `gitrevisions` 手册页中有关于具体使用哪种格式的详细信息。
|
||||
|
||||
### 12\. 能知道所有的 reflog
|
||||
|
||||
你是不是试过在 rebase 时干掉过某次提交,然后发现你需要保留那个提交中一些东西?你可能觉得这些信息已经永远找不回来了,只能重新创建。但是如果你在本地工作副本中提交了,提交就会被添加到引用日志(reflog)中 ,你仍然可以访问到。
|
||||
|
||||
运行 `git reflog` 将在本地工作副本中显示当前分支的所有活动的列表,并为你提供每个提交的 SHA1 值。一旦发现你 rebase 时放弃的那个提交,你可以运行 `git checkout <SHA1>` 跳转到该提交,复制任何你需要的信息,然后再运行 `git checkout HEAD` 返回到分支最近的提交去。
|
||||
|
||||
### 以上是全部内容
|
||||
|
||||
希望这些技巧中至少有一个能够教给你一些关于 Git 的新东西,Git 是一个有12年历史的项目,并且在持续创新和增加新功能中。你最喜欢的 Git 技巧是什么?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/12-git-tips-gits-12th-birthday
|
||||
|
||||
作者:[John SJ Anderson][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/genehack
|
||||
[1]:https://git-scm.com/
|
||||
[2]:https://en.wikipedia.org/wiki/INI_file
|
||||
[3]:https://gitlab.com/
|
||||
[4]:/file/392941
|
||||
[5]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/gui_graph.png?itok=3GovYfG1 (GitLab commit graph viewer)
|
||||
[6]:/file/392936
|
||||
[7]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/console_graph.png?itok=XogY1P8M (Repository visualized with --graph command)
|
||||
[8]:https://en.wikipedia.org/wiki/Secure_Hash_Algorithms
|
||||
@ -0,0 +1,166 @@
|
||||
给初学者看的 Shuf 命令教程
|
||||
======
|
||||
|
||||

|
||||
Shuf 命令用于在类 Unix 操作系统中生成随机排列。使用 shuf 命令,我们可以随机打乱给定输入文件的行。Shuf 命令是 GNU Coreutils 的一部分,因此你不必担心安装问题。在这个简短的教程中,让我向你展示一些 shuf 命令的例子。
|
||||
|
||||
### 带例子的 Shuf 命令教程
|
||||
|
||||
我有一个名为 **ostechnix.txt** 的文件,内容如下。
|
||||
```
|
||||
$ cat ostechnix.txt
|
||||
line1
|
||||
line2
|
||||
line3
|
||||
line4
|
||||
line5
|
||||
line6
|
||||
line7
|
||||
line8
|
||||
line9
|
||||
line10
|
||||
|
||||
```
|
||||
|
||||
现在让我们以随机顺序显示上面的行。为此,请运行:
|
||||
```
|
||||
$ shuf ostechnix.txt
|
||||
line2
|
||||
line8
|
||||
line5
|
||||
line10
|
||||
line7
|
||||
line1
|
||||
line4
|
||||
line6
|
||||
line9
|
||||
line3
|
||||
|
||||
```
|
||||
|
||||
看到了吗?上面的命令将名为 “ostechnix.txt” 中的行随机排列并输出了结果。
|
||||
|
||||
你可能想将输出写入另一个文件。例如,我想将输出保存到 **output.txt** 中。为此,请先创建 output.txt:
|
||||
```
|
||||
$ touch output.txt
|
||||
|
||||
```
|
||||
|
||||
然后,像下面使用 **-o** 标志将输出写入该文件。
|
||||
```
|
||||
$ shuf ostechnix.txt -o output.txt
|
||||
|
||||
```
|
||||
|
||||
上面的命令将随机随机打乱 ostechnix.txt 的内容并将输出写入 output.txt。你可以使用命令查看 output.txt 的内容:
|
||||
```
|
||||
$ cat output.txt
|
||||
|
||||
line2
|
||||
line8
|
||||
line9
|
||||
line10
|
||||
line1
|
||||
line3
|
||||
line7
|
||||
line6
|
||||
line4
|
||||
line5
|
||||
|
||||
```
|
||||
|
||||
我只想显示文件中的任意一行。我该怎么做?很简单!
|
||||
```
|
||||
$ shuf -n 1 ostechnix.txt
|
||||
line6
|
||||
|
||||
```
|
||||
|
||||
同样,我们可以选择前 “n” 个随机条目。以下命令将只显示前五个随机条目。
|
||||
```
|
||||
$ shuf -n 5 ostechnix.txt
|
||||
line10
|
||||
line4
|
||||
line5
|
||||
line9
|
||||
line3
|
||||
|
||||
```
|
||||
|
||||
如下所示,我们可以直接使用 **-e** 标志传入输入,而不是从文件中读取行。
|
||||
```
|
||||
$ shuf -e line1 line2 line3 line4 line5
|
||||
line1
|
||||
line3
|
||||
line5
|
||||
line4
|
||||
line2
|
||||
|
||||
```
|
||||
|
||||
你也可以传入数字:
|
||||
```
|
||||
$ shuf -e 1 2 3 4 5
|
||||
3
|
||||
5
|
||||
1
|
||||
4
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
要快速在给定范围选择一个,请改用此命令。
|
||||
```
|
||||
$ shuf -n 1 -e 1 2 3 4 5
|
||||
|
||||
```
|
||||
|
||||
或者,选择下面的任意三个随机数字。
|
||||
```
|
||||
$ shuf -n 3 -e 1 2 3 4 5
|
||||
3
|
||||
5
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
我们也可以在特定范围内生成随机数。例如,要显示 1 到 10 之间的随机数,只需使用:
|
||||
```
|
||||
$ shuf -i 1-10
|
||||
1
|
||||
9
|
||||
8
|
||||
2
|
||||
4
|
||||
7
|
||||
6
|
||||
3
|
||||
10
|
||||
5
|
||||
|
||||
```
|
||||
|
||||
有关更多详细信息,请参阅手册页。
|
||||
```
|
||||
$ man shuf
|
||||
|
||||
```
|
||||
|
||||
今天就是这些。还有更多更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-shuf-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,99 @@
|
||||
强制关闭系统的内核模块
|
||||
======
|
||||
|
||||

|
||||
我知道熬夜对健康不利。但谁在乎?多年来我一直是一只夜猫子。我通常在 12 点以后睡觉,有时在凌晨 1 点以后睡觉。第二天早上,我至少推迟三次闹钟,醒来后又累又有脾气。每天,我向自己保证早点睡觉,但最终会像平常一样晚睡。而且,这个循环还在继续!如果你和我一样,这有一个好消息。一个同学通宵开发了一个名为 **“Kgotobed”** 的内核模块,它迫使你在特定的时间上床睡觉。也就是说它会强制关闭你的系统。
|
||||
|
||||
我为什么要用这个?我有很多其他的选择。我可以设置一个 cron 作业来安排在特定时间关闭系统。我可以设置提醒或闹钟。我可以使用浏览器插件或软件。你可能会问!但是,它们都可以轻易忽略或绕过。Kgotobed 是你不能忽视的东西。**即使您是 root 用户也无法禁用**。是的,它会在指定的时间强制关闭你的系统。没有推迟选项。你不能推迟关机过程,也不能取消它。无论如何,系统都会在指定的时间停止运行。你被警告了!!
|
||||
|
||||
### 安装 Kgotobed
|
||||
|
||||
确保你已经安装了 **dkms**。它在大多数 Linux 发行版的默认仓库中都有。
|
||||
|
||||
例如在 Fedora 上,你可以使用以下命令安装它:
|
||||
```
|
||||
$ sudo dnf install kernel-devel-$(uname -r) dkms
|
||||
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、linux Mint 上:
|
||||
```
|
||||
$ sudo apt install dkms
|
||||
|
||||
```
|
||||
|
||||
安装完成后,git clone Kgotobed 项目。
|
||||
```
|
||||
$ git clone https://github.com/nikital/kgotobed.git
|
||||
|
||||
```
|
||||
|
||||
该命令会在当前工作目录中将所有 Kgotobed 仓库的内容克隆到名为 “kgotobed” 的文件夹中。cd 到该目录:
|
||||
```
|
||||
$ cd kgotobed/
|
||||
|
||||
```
|
||||
|
||||
接着,使用命令安装 Kgotobed 驱动:
|
||||
```
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
上面的命令将 **kgotobed.ko** 模块注册到 **DKMS**(这样它会为每个你运行的内核重建)并在 **/usr/local/bin/** 目录下安装 **gotobed**,然后注册、启用并启动 kgotobed 服务。
|
||||
|
||||
### 如何运行
|
||||
|
||||
默认情况下,Kgotobed 将睡前时间设置为 **1:00 AM**。也就是说,无论你在做什么,你的电脑都会在凌晨 1 点关机。
|
||||
|
||||
要查看当前的睡前时间,请运行:
|
||||
```
|
||||
$ gotobed
|
||||
Current bedtime is 2018-04-10 01:00:00
|
||||
|
||||
```
|
||||
|
||||
要提前睡眠时间,例如 22:00(晚上 10 点),请运行:
|
||||
```
|
||||
$ sudo gotobed 22:00
|
||||
[sudo] password for sk:
|
||||
Current bedtime is 2018-04-10 00:58:00
|
||||
Setting bedtime to 2018-04-09 22:00:00
|
||||
Bedtime will be in 2 hours 16 minutes
|
||||
|
||||
```
|
||||
|
||||
当你想早点睡觉时,这会很有帮助!
|
||||
|
||||
但是,你不能设置更晚的时间也就是凌晨 1 点以后。你无法卸载模块,并且调整系统时钟也无济于事。唯一的出路是重启!
|
||||
|
||||
要设置不同的默认时间,您需要自定义 **kgotobed.service**(通过编辑或使用 systemd 工具)。
|
||||
|
||||
### 卸载 Kgotobed
|
||||
|
||||
对 Kgotobed 不满意?别担心!进入我们先前克隆的 “kgotobed” 文件夹,然后运行以下命令将其卸载。
|
||||
```
|
||||
$ sudo make uninstall
|
||||
|
||||
```
|
||||
|
||||
再一次,我警告你,即使你是 root 用户,也没有办法推迟或取消关机过程。你的系统将在指定的时间强制关闭。这并不适合每个人!当你在做一项重要任务时,它可能会让你疯狂。在这种情况下,请确保你已经不时地保存工作,或使用下面链接中的一些高级工具来帮助你在特定时间自动关闭、重启、暂停和休眠系统。
|
||||
|
||||
就是这些了。希望你觉得这个指南有帮助。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/kgotobed-a-kernel-module-that-forcibly-shutdown-your-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,126 @@
|
||||
对开发者来说非常好的GNOME扩展
|
||||
======
|
||||
|
||||

|
||||
这个扩展给与了 GNOME3 桌面环境以非常大的灵活性,这种灵活性赋予了用户在定制化桌面上的优势,从而使他们的工作流程变得更加舒适和有效率。Fedora 系统已经已经包含了一部分例如 EasyScreenCast, gTile, 和 OpenWeather 这样很好的桌面扩展,本文接下来会重点报道这些为开发者而改变的扩展。
|
||||
|
||||
如果你需要帮助来安装 GNOME 扩展,那么可以参考《如何安装一个 GNOME 命令行扩展》这篇文章。
|
||||
|
||||
### ![Docker Integration extension icon][5] Docker Integration
|
||||
|
||||
![Docker Integration extension status menu][6]
|
||||
|
||||
对于为自己的应用使用 docker 的开发者而言,这个 docker 集成扩展是必不可少的。这个状态菜单提供了一个带着启动、停止、暂停、甚至删除的这些选项的 docker 容器的列表,这个列表会在新容器加入到这个系统时自动更新。
|
||||
|
||||
在安装完这些扩展后,Fedora 用户可能会收到这么一条消息:“加载容器时发生错误”。这是因为 docker 命令需要在命令前加 sudo,或者得到默认的 root 权限。去设置你的用户权限再去运行 docker,可以参考 Fedora 门户网站上的 docker 安装这一页。
|
||||
|
||||
你可以在这个扩展的站点上找到更多的信息。
|
||||
|
||||
### ![Jenkins CI Server Indicator icon][10] Jenkins CI Server Indicator
|
||||
|
||||
![Jenkins CI Server Indicator extension status menu][11]
|
||||
|
||||
Jenkins CI 服务器指向仪这个扩展使开发者把他们的应用建立在 Jenkins CI 服务器上的这个过程更加简单,它展示了一个菜单,菜单中有一个带有进程和进程状态的列表。他同样包含了很多特点,比如很容易就能创建 Jenkins 的前端,为完整的进程做通知,而且能够触发或者过滤进程。
|
||||
|
||||
如果想要更多的信息,请去浏览开发者站点。
|
||||
|
||||
### ![android-tool extension icon][14] android-tool
|
||||
|
||||
Android-tool 对于 Android 开发者来说会是一个非常有价值的扩展,它的特点包括捕捉错误报告,设备截屏和屏幕录像。它可以通过 usb 和 tcp 连接两种方式来连接 Android 设备。
|
||||
|
||||
这个扩展需要 adb 的包,从 Fedora 官方仓库安装 adb 只需要运行这条命令:
|
||||
```
|
||||
sudo dnf install android-tools
|
||||
|
||||
```
|
||||
|
||||
你可以在这个扩展的 GitHub 网页里找到更多信息。
|
||||
|
||||
### ![GnomeHub extension icon][19] GnomeHub
|
||||
|
||||
对于为自己的项目使用 GitHub 的 GNOME 用户来说,GnomeHub 是一个非常好的扩展,它可以显示 Github 上的仓库,还可以通知用户有新提交的 pull requests。除此之外,用户可以把他们最喜欢的仓库加在这个扩展的设置里。
|
||||
|
||||
如果想要更多信息,可以参考一下这个项目的 GitHub 页面。
|
||||
|
||||
### ![gistnotes extension icon][23] gistnotes
|
||||
|
||||
简单地说,gistnotes 为 gist 用户提供了一种简单的方式来创建、存储和管理注释和代码片段。如果想要更多的信息,可以参考这个项目的网站。
|
||||
|
||||
![gistnotes window][26]
|
||||
|
||||
### ![Arduino Control extension icon][27] Arduino Control
|
||||
|
||||
这个 Arduino 控制扩展允许用户去连接或者控制他们自己的单片机电路板,它同样允许用户在状态菜单里增加滑块或者开关。除此之外,开发者模式允许扩展目录里的脚本通过以太网或者 usb 来连接电路板。
|
||||
|
||||
最重要的是,这个扩展可以被定制化来适合你的项目,在 README 文件里的例子是,它能够“通过网络上任意的电脑来控制你房间里的灯”。
|
||||
|
||||
你可以从这个项目的 GitHub 页面上得到更多的产品信息并安装这个扩展。
|
||||
|
||||
### ![Hotel Manager extension icon][30] Hotel Manager
|
||||
|
||||
![Hotel Manager extension status menu.][31]
|
||||
|
||||
使用 Hotel process manager 开发网站的开发人员,应该尝试一下 Hotel Manager 这个扩展。它展示了一个增加到 hotel 里的网页应用的列表,并给与了用户去开始、停止和重启这些应用的能力。
|
||||
此外,还可以通过电脑图标快速打开、浏览这些网页应用。这个扩展同样可以启动、停止或重启 hotel 的后台程序。
|
||||
|
||||
作为本文的出版物,GNOME 3.26 版本的 Hotel Manager 版本 4 没有在扩展的下拉式菜单里列出网页应用。版本 4 还会在 Fedora 28 (GNOME 3.28) 上安装时报错。然而,版本 3 工作在 Fedora 27 和 Fedora 28。
|
||||
|
||||
如果想要更多细节,可以去看这个项目在 GitHub 上的网页。
|
||||
|
||||
### VSCode Search Provider
|
||||
|
||||
VSCode Search Provider 是一个简单的扩展,它能够在 GNOME 综合搜索结果里展示可视化工作代码项目。对于大部分的 VSCode 用户来说,这个扩展可以让用户快速连接到他们的项目,从而节省时间。你可以从这个项目在 GitHub 上的页面来得到更多的信息。
|
||||
|
||||
![GNOME Overview search results showing VSCode projects.][36]
|
||||
|
||||
在开发环境方面,你有没有一个最喜欢的扩展呢?发在评论区里,一起来讨论下吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/awesome-gnome-extensions-developers/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sassam/
|
||||
[1]:https://fedoramagazine.org/screencast-gnome-extension/
|
||||
[2]:https://fedoramagazine.org/must-have-gnome-extension-gtile/
|
||||
[3]:https://fedoramagazine.org/weather-updates-openweather-gnome-shell-extension/
|
||||
[4]:https://fedoramagazine.org/install-gnome-shell-extension/
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/08/dockericon.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/08/docker-extension-menu.png
|
||||
[7]:https://extensions.gnome.org/extension/1065/docker-status/
|
||||
[8]:https://developer.fedoraproject.org/tools/docker/docker-installation.html
|
||||
[9]:https://github.com/gpouilloux/gnome-shell-extension-docker
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2017/08/jenkinsicon.png
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2017/08/jenkins-extension-menu.png
|
||||
[12]:https://extensions.gnome.org/extension/399/jenkins-ci-server-indicator/
|
||||
[13]:https://www.philipphoffmann.de/gnome-3-shell-extension-jenkins-ci-server-indicator/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2017/08/androidtoolicon.png
|
||||
[15]:https://fedoramagazine.org/wp-content/uploads/2017/08/android-tool-extension-menu.png
|
||||
[16]:https://extensions.gnome.org/extension/1232/android-tool/
|
||||
[17]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[18]:https://github.com/naman14/gnome-android-tool
|
||||
[19]:https://fedoramagazine.org/wp-content/uploads/2017/08/gnomehubicon.png
|
||||
[20]:https://fedoramagazine.org/wp-content/uploads/2017/08/gnomehub-extension-menu.png
|
||||
[21]:https://extensions.gnome.org/extension/1263/gnomehub/
|
||||
[22]:https://github.com/lagartoflojo/gnomehub
|
||||
[23]:https://fedoramagazine.org/wp-content/uploads/2017/08/gistnotesicon.png
|
||||
[24]:https://extensions.gnome.org/extension/917/gistnotes/
|
||||
[25]:https://github.com/mohan43u/gistnotes
|
||||
[26]:https://fedoramagazine.org/wp-content/uploads/2018/04/gistnoteswindow.png
|
||||
[27]:https://fedoramagazine.org/wp-content/uploads/2017/08/arduinoicon.png
|
||||
[28]:https://extensions.gnome.org/extension/894/arduino-control/
|
||||
[29]:https://github.com/simonthechipmunk/arduinocontrol
|
||||
[30]:https://fedoramagazine.org/wp-content/uploads/2017/08/hotelicon.png
|
||||
[31]:https://fedoramagazine.org/wp-content/uploads/2017/08/hotelmanager-extension-menu.png
|
||||
[32]:https://extensions.gnome.org/extension/1285/hotel-manager/
|
||||
[33]:https://github.com/hardpixel/hotel-manager
|
||||
[34]:https://extensions.gnome.org/extension/1207/vscode-search-provider/
|
||||
[35]:https://github.com/jomik/vscode-search-provider
|
||||
[36]:https://fedoramagazine.org/wp-content/uploads/2018/04/vscodesearch.png
|
||||
Loading…
Reference in New Issue
Block a user