mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
20150122-1 选题
This commit is contained in:
parent
a2a9ed6eea
commit
4e1caae562
@ -0,0 +1,66 @@
|
||||
Linux FAQs with Answers--How to add a cron job on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to schedule a task on my Linux box, so that the task runs periodically at fixed times. How can I add a cron job for this task on my Linux system?
|
||||
|
||||
The cron utility is the default task scheduler used in Linux. Using cron, you can schedule a task (e.g., a command or a shell-script) to run it periodically or one-time at a specific time of hour, day, week, month, etc. The cron tool is useful when you schedule a variety of regular maintenance jobs, such as periodic backup, rotating logs, checking filesystem, monitoring disk space, and so on.
|
||||
|
||||
### Add a Cron Job from the Command Line ###
|
||||
|
||||
To add a cron job, you can use a command-line tool called crontab.
|
||||
|
||||
Type the following command to create a new cron job to run as the current user.
|
||||
|
||||
$ crontab -e
|
||||
|
||||
If you want a cron job to run as any other user, type the following command instead.
|
||||
|
||||
$ sudo crontab -u <username> -e
|
||||
|
||||
You will be presented with a text editor window, where you can add or edit cron jobs. By default, nano editor will be used.
|
||||
|
||||

|
||||
|
||||
Each cron job is formatted as follows.
|
||||
|
||||
<minute> <hour> <day-of-month> <month-of-year> <day-of-week> <command>
|
||||
|
||||
The first five elements specify the schedule for a task, and the last element is the (full-path) command or script to execute according to the schedule.
|
||||
|
||||

|
||||
|
||||
Here are a few useful cron job examples.
|
||||
|
||||
- *** * * * * /home/dan/bin/script.sh**: run every minute.
|
||||
- **0 * * * * /home/dan/bin/script.sh**: run every hour.
|
||||
- **0 0 * * * /home/dan/bin/script.sh**: run at 12am daily.
|
||||
- **0 9,18 * * * /home/dan/bin/script.sh**: run at 9AM and 6PM twice a day.
|
||||
- **0 9-18 * * * /home/dan/bin/script.sh**: run every hour from 9AM and 6PM.
|
||||
- **0 9-18 * * 1-5 /home/dan/bin/script.sh**: run every hour from 9AM and 6PM every weekday.
|
||||
- ***/10 * * * * /home/dan/bin/script.sh**: run every 10 minutes.
|
||||
|
||||
Once you are done with setting up cron job(s), press Ctrl+X to save and quit the editor. At this point, newly added cron jobs should be activated.
|
||||
|
||||
To browse existing cron jobs of yours, use the following command:
|
||||
|
||||
$ crontab -l
|
||||
|
||||
### Add a Cron Job from GUI ###
|
||||
|
||||
If you are in Linux desktop environment, you can use a GUI fronend for crontab to add or edit a cron job via a more user-friendly interface.
|
||||
|
||||
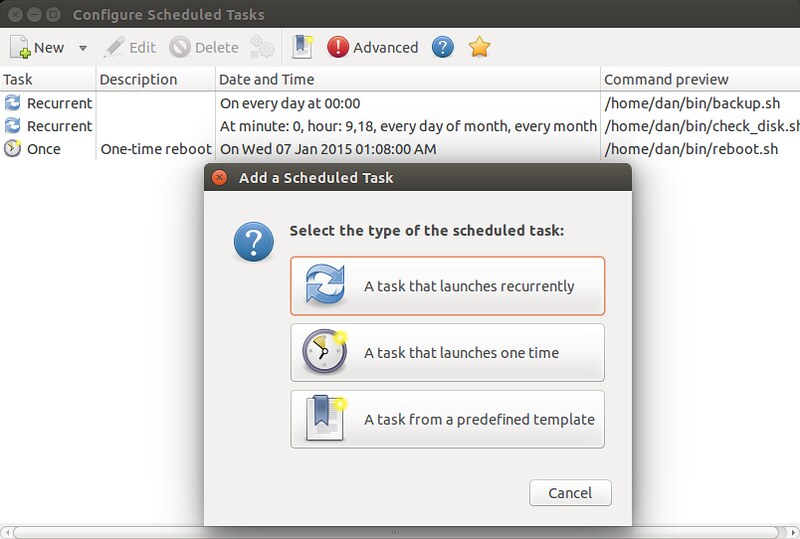
On GNOME desktop, there is GNOME Schedule (gnome-schedule package).
|
||||
|
||||
|
||||
|
||||
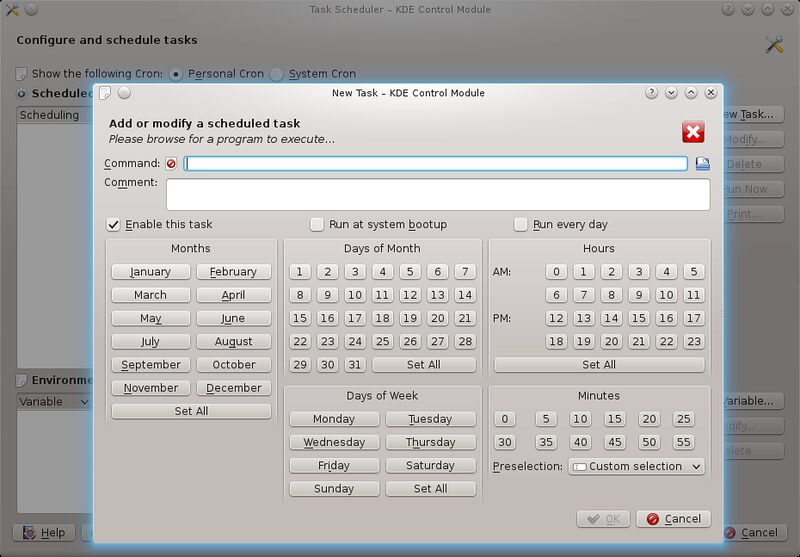
On KDE desktop, there is Task Scheduler (kcron package).
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/add-cron-job-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,111 @@
|
||||
Linux FAQs with Answers--How to check memory usage on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to monitor memory usage on my Linux system. What are the available GUI-based or command-line tools for checking current memory usage of Linux?
|
||||
|
||||
When it comes to optimizing the performance of a Linux system, physical memory is the single most important factor. Naturally, Linux offers a wealth of options to monitor the usage of the precious memory resource. Different tools vary in terms of their monitoring granularity (e.g., system-wide, per-process, per-user), interface (e.g., GUI, command-line, ncurses) or running mode (e.g., interactive, batch mode).
|
||||
|
||||
Here is a non-exhaustive list of GUI or command-line tools to choose from to check used and free memory on Linux platform.
|
||||
|
||||
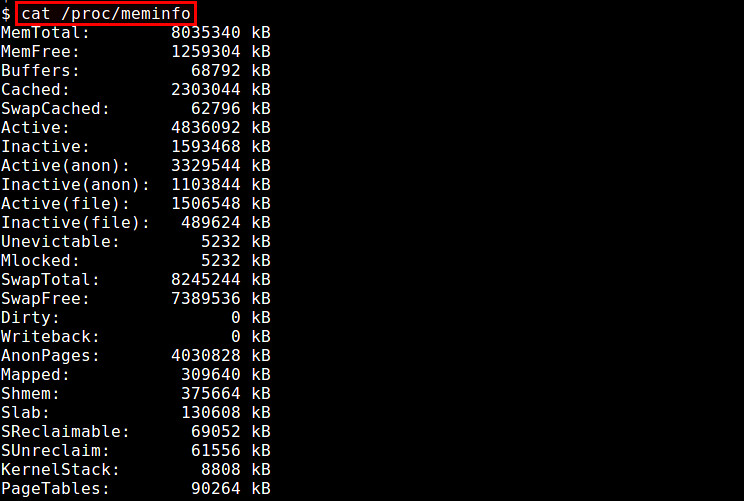
### 1. /proc/meminfo ###
|
||||
|
||||
The simpliest method to check RAM usage is via /proc/meminfo. This dynamically updated virtual file is actually the source of information displayed by many other memory related tools such as free, top and ps tools. From the amount of available/free physical memory to the amount of buffer waiting to be or being written back to disk, /proc/meminfo has everything you want to know about system memory usage. Process-specific memory information is also available from /proc/<pid>/statm and /proc/<pid>/status
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
|
||||
|
||||
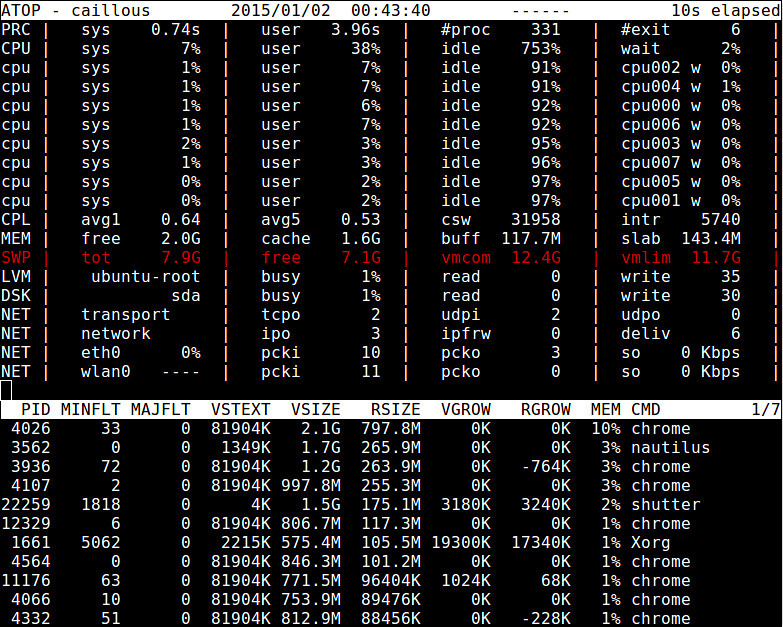
### 2. atop ###
|
||||
|
||||
The atop command is an ncurses-based interactive system and process monitor for terminal environments. It shows a dynamically-updated summary of system resources (CPU, memory, network, I/O, kernel), with colorized warnings in case of high system load. It also offers a top-like view of processes (or users) along with their resource usage, so that system admin can tell which processes or users are responsible for system load. Reported memory statistics include total/free memory, cached/buffer memory and committed virtual memory.
|
||||
|
||||
$ sudo atop
|
||||
|
||||
|
||||
|
||||
### 3. free ###
|
||||
|
||||
The free command is a quick and easy way to get an overview of memory usage gleaned from /proc/meminfo. It shows a snapshot of total/free physical memory and swap space of the system, as well as used/free buffer space in the kernel.
|
||||
|
||||
$ free -h
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
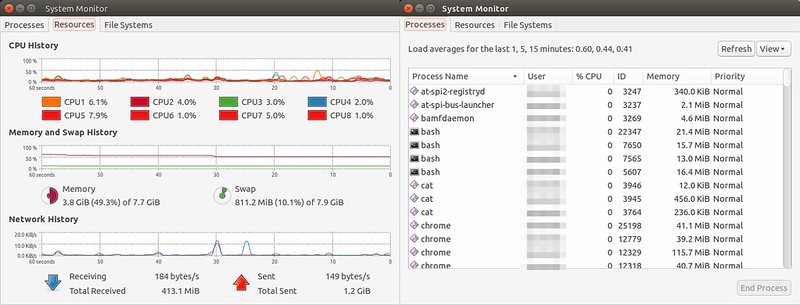
GNOME System Monitor is a GUI application that shows a short history of system resource utilization for CPU, memory, swap space and network. It also offers a process view of CPU and memory usage.
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
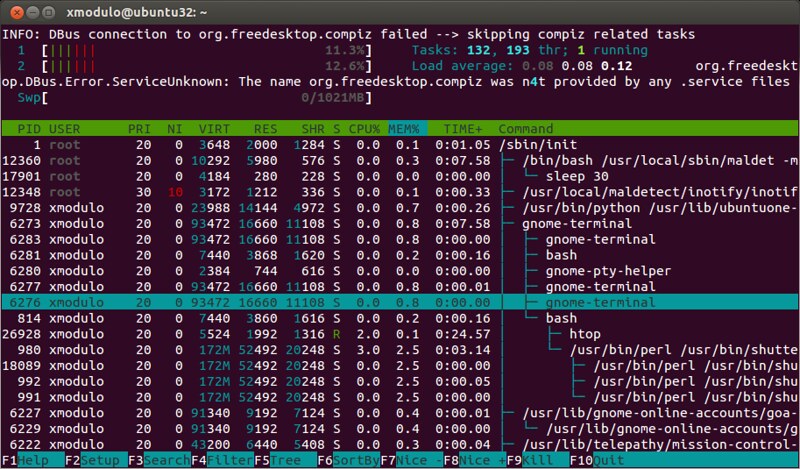
The htop command is an ncurses-based interactive processor viewer which shows per-process memory usage in real time. It can report resident memory size (RSS), total program size in memory, library size, shared page size, and dirty page size for all running processes. You can scroll the (sorted) list of processes horizontally or vertically.
|
||||
|
||||
$ htop
|
||||
|
||||
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
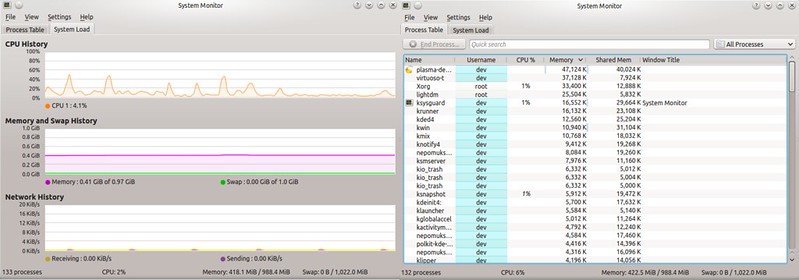
While GNOME desktop has GNOME System Monitor, KDE desktop has its own counterpart: KDE System Monitor. Its functionality is mostly similar to GNOME version, i.e., showing a real-time history of system resource usage, as well as a process list along with per-process CPU/memory consumption.
|
||||
|
||||
$ ksysguard
|
||||
|
||||
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
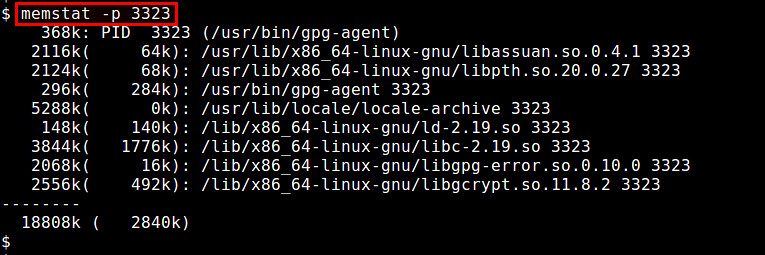
The memstat utility is useful to identify which executable(s), process(es) and shared libraries are consuming virtual memory. Given a process ID, memstat identifies how much virtual memory is used by the process' associated executable, data, and shared libraries.
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
|
||||
|
||||
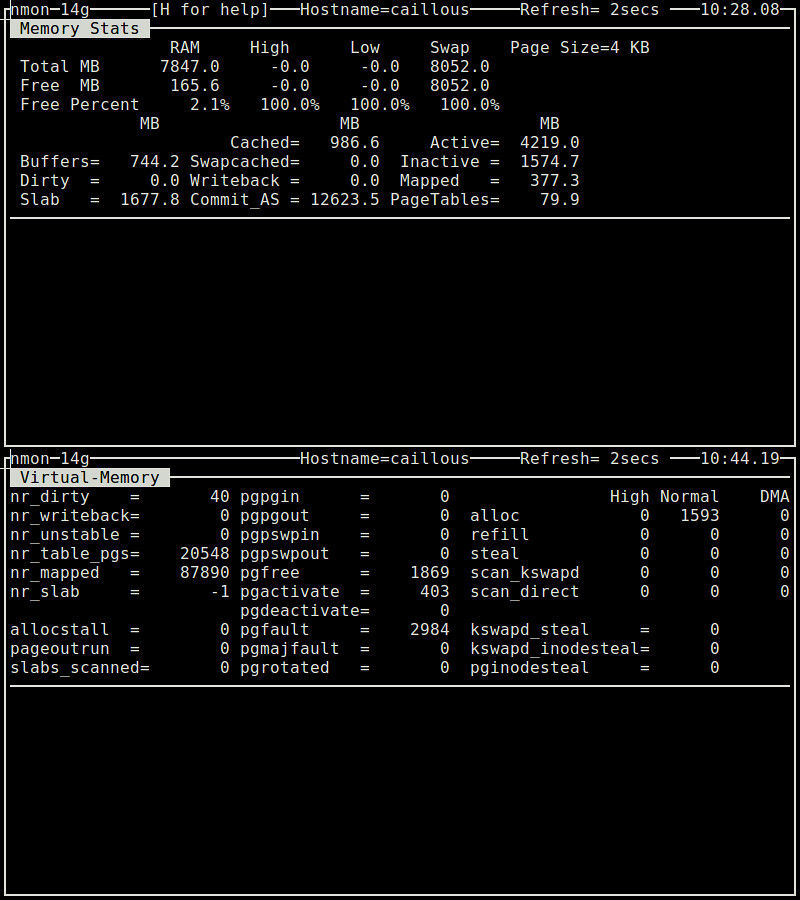
### 8. nmon ###
|
||||
|
||||
The nmon utility is an ncurses-based system benchmark tool which can monitor CPU, memory, disk I/O, kernel, filesystem and network resources in interactive mode. As for memory usage, it can show information such as total/free memory, swap space, buffer/cached memory, virtual memory page in/out statistics, all in real time.
|
||||
|
||||
$ nmon
|
||||
|
||||
|
||||
|
||||
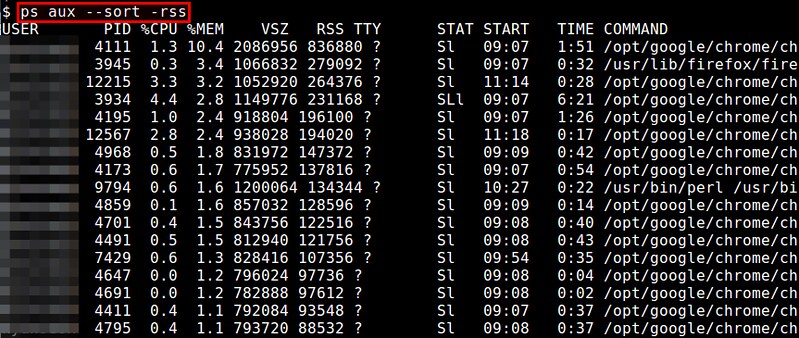
### 9. ps ###
|
||||
|
||||
The ps command can show per-process memory usage in real-time. Reported memory usage information includes %MEM (percent of physical memory used), VSZ (total amount of virtual memory used), and RSS (total amount of physical memory used). You can sort the process list by using "--sort" option. For example, to sort in the decreasing order of RSS:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
|
||||
|
||||
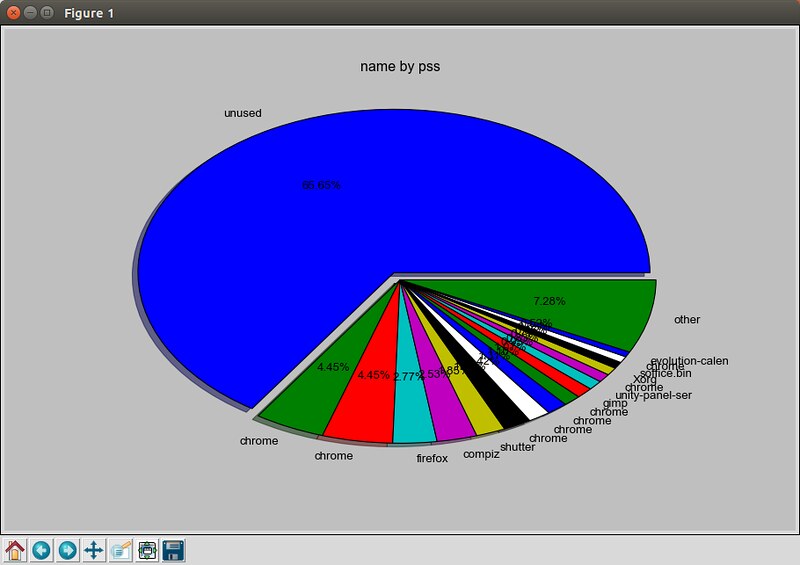
### 10. smem ###
|
||||
|
||||
The [smem][1] command allows you to measure physical memory usage by different processes and users based on information available from /proc. It utilizes proportional set size (PSS) metric to accurately quantify effective memory usage of Linux processes. Memory usage analysis can be exported to graphical charts such as bar and pie graphs.
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
|
||||
|
||||
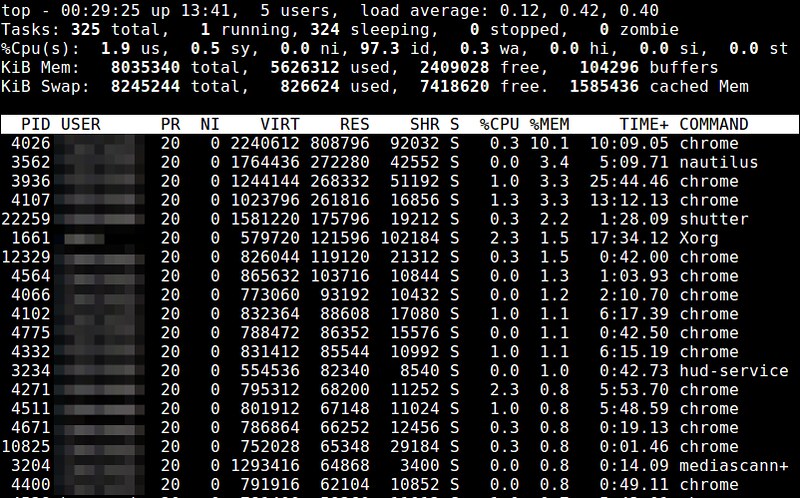
### 11. top ###
|
||||
|
||||
The top command offers a real-time view of running processes, along with various process-specific resource usage statistics. Memory related information includes %MEM (memory utilization percentage), VIRT (total amount of virtual memory used), SWAP (amount of swapped-out virtual memory), CODE (amount of physical memory allocated for code execution), DATA (amount of physical memory allocated to non-executable data), RES (total amount of physical memory used; CODE+DATA), and SHR (amount of memory potentially shared with other processes). You can sort the process list based on memory usage or size.
|
||||
|
||||
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
The vmstat command-line utility displays instantaneous and average statistics of various system activities covering CPU, memory, interrupts, and disk I/O. As for memory information, the command shows not only physical memory usage (e.g., tota/used memory and buffer/cache memory), but also virtual memory statistics (e.g., memory paged in/out, swapped in/out).
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -0,0 +1,106 @@
|
||||
Linux FAQs with Answers--How to create and configure a MySQL user from the command line
|
||||
================================================================================
|
||||
> **Question**: I would like to create a new user account on MySQL server, and apply appropriate permissions and resource limits to the account. How can I create and configure a MySQL user from the command line?
|
||||
|
||||
To access a MySQL server, you need to log in to the server using a user account. Each MySQL user account has a number of attributes associated with it, such as user name, password, as well as privileges and resource limits. Privileges are user-specific permissions defining what you can do inside a MySQL server, while resource limits set the limitations on the amount of server resource allowed for for the user. Creating or updating a MySQL user involves managing all these attributes of the user account.
|
||||
|
||||
Here is how to create and configure a MySQL user on Linux.
|
||||
|
||||
You first log in to MySQL server as the root.
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
When prompted for authentication, enter the MySQL root password.
|
||||
|
||||
|
||||
|
||||
### Create a MySQL User ###
|
||||
|
||||
To create a new user with username 'myuser' and password 'mypassword', use the following command.
|
||||
|
||||
mysql> CREATE USER 'myuser'@'localhost' IDENTIFIED BY 'mypassword';
|
||||
|
||||
Once a user is created, all its account details including an encrypted password, privileges and resource limits are stored in a table called **user** in a special database named **mysql**.
|
||||
|
||||
To verify that the account is created successfully, run:
|
||||
|
||||
mysql> SELECT host, user, password FROM mysql.user WHERE user='myuser';
|
||||
|
||||
### Grant Privileges to MySQL User ###
|
||||
|
||||
A newly created MySQL user comes with zero access privilege, which means that you cannot do anything inside MySQL server. You need to grant necessary privileges to the user. Some of available privileges are the following.
|
||||
|
||||
- **ALL**: all privileges available.
|
||||
- **CREATE**: create databases, tables or indices.
|
||||
- **LOCK_TABLES**: lock databases.
|
||||
- **ALTER**: alter tables.
|
||||
- **DELETE**: delete tables.
|
||||
- **INSERT**: insert tables or columns.
|
||||
- **SELECT**: select tables or columns.
|
||||
- **CREATE_VIEW**: create views.
|
||||
- **SHOW_DATABASES**: show databases.
|
||||
- **DROP**: drop daabases, tables or views.
|
||||
|
||||
To grant a particular privilege to user 'myuser', use the following command.
|
||||
|
||||
mysql> GRANT <privileges> ON <database>.<table> TO 'myuser'@'localhost';
|
||||
|
||||
In the above, <privileges> is expressed as a comma-separated list of privileges. If you want to grant privileges for any database (or table), place an asterisk (*) in the database (or table) name.
|
||||
|
||||
For example, to grant CREATE and INSERT privileges for all databases/tables:
|
||||
|
||||
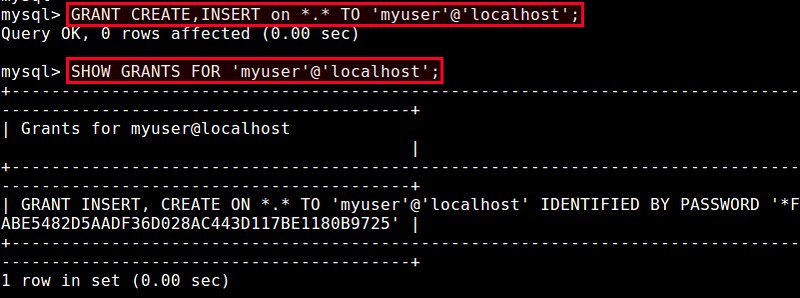
mysql> GRANT CREATE, INSERT ON *.* TO 'myuser'@'localhost';
|
||||
|
||||
To verify the granted privileges of the user:
|
||||
|
||||
mysql> SHOW GRANTS FOR 'myuser'@'localhost';
|
||||
|
||||
|
||||
|
||||
To grant all privileges to all databases/tables:
|
||||
|
||||
mysql> GRANT ALL ON *.* TO 'myuser'@'localhost';
|
||||
|
||||
You can also remove existing privileges from a user. To revoke existing privileges from the account 'myuser', use the following command.
|
||||
|
||||
mysql> REVOKE <privileges> ON <database>.<table> FROM 'myuser'@'localhost';
|
||||
|
||||
### Add Resource Limits to MySQL User ###
|
||||
|
||||
In MySQL, you can place limits on MySQL resource usage for individual users. The available resource limits are the following.
|
||||
|
||||
- **MAX_QUERIES_PER_HOUR**: number of allowed queries per hour.
|
||||
- **MAX_UPDATES_PER_HOUR**: number of allowed updates per hour.
|
||||
- **MAX_CONNECTIONS_PER_HOUR**: number of allowed logins per hour.
|
||||
- **MAX_USER_CONNECTIONS**: number of simultaneous connections to the server.
|
||||
|
||||
To add a resource limit to the account 'myuser', use the following command.
|
||||
|
||||
mysql> GRANT USAGE ON <database>.<table> TO 'myuser'@'localhost' WITH <resource-limits>;
|
||||
|
||||
In <resource-limits>, you can specify multiple resource limits separated by space.
|
||||
|
||||
For example, to add MAX_QUERIES_PER_HOUR and MAX_CONNECTIONS_PER_HOUR resource limits:
|
||||
|
||||
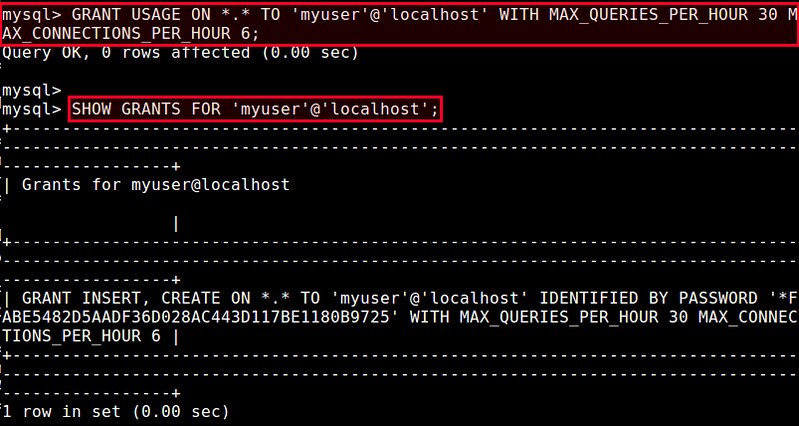
mysql> GRANT USAGE ON *.* TO 'myuser'@'localhost' WITH MAX_QUERIES_PER_HOUR 30 MAX_CONNECTIONS_PER_HOUR 6;
|
||||
|
||||
To verify the resource limits of the user:
|
||||
|
||||
mysql> SHOW GRANTS FOR 'myuser'@'localhost;
|
||||
|
||||
|
||||
|
||||
The last important step after creating and configuring a MySQL user is to run:
|
||||
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
so that the changes take effect. Now the MySQL user account is good to go!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/create-configure-mysql-user-command-line.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,144 @@
|
||||
Linux FAQs with Answers--How to download and install ixgbe driver on Ubuntu or Debian
|
||||
================================================================================
|
||||
> **Question**: I want to download and install the latest ixgbe driver for my Intel 10 Gigabit Ethernet card. How can I install ixgbe driver on Ubuntu (or Debian)?
|
||||
|
||||
Intel's PCI Express 10 Gigabit (10G) network inerface cards (e.g., 82598, 82599, x540) are supported by ixgbe driver. The stock kernel of the modern Linux distributions already comes with ixgbe driver as a loadable module. However, there are cases where you may want to compile and install ixgbe driver on your own. For example, you may want to try the new features of the latest ixgbe driver. Also, the problem of the default ixgbe driver in the stock kernel is that it does not allow you to customize many of its driver parameters. If you want to fully customize ixgbe device driver (e.g., RSS, multi-queue, interrupt throttling, etc), you need to manually compile ixgbe driver from the source.
|
||||
|
||||
Here is how to download and install ixgbe driver on Ubuntu, Debian or their derivatives.
|
||||
|
||||
### Step One: Install Prerequites ###
|
||||
|
||||
As prerequisites, install matching kernel headers and development packages.
|
||||
|
||||
$ sudo apt-get install linux-headers-$(uname -r)
|
||||
$ sudo apt-get install gcc make
|
||||
|
||||
### Step Two: Compile Ixgbe Driver ###
|
||||
|
||||
Download the source code of the [latest ixgbe driver][1].
|
||||
|
||||
$ wget http://sourceforge.net/projects/e1000/files/ixgbe%20stable/3.23.2/ixgbe-3.23.2.tar.gz
|
||||
|
||||
Compile ixgbe driver as follows.
|
||||
|
||||
$ tar xvfvz ixgbe-3.23.2.tar.gz
|
||||
$ cd ixgbe-3.23.2/src
|
||||
$ make
|
||||
|
||||
### Step Three: Check Ixgbe Driver ###
|
||||
|
||||
After compilation, you will see **ixgbe.ko** created in ixgbe-3.23.2/src directory. This is the ixgbe device driver which will be loaded into the kernel.
|
||||
|
||||
Check the information of this kernel module with modinfo command. Note that you need to specify an absolute path to the module (e.g., ./ixgbe.ko or /home/xmodulo/ixgbe/ixgbe-3.23.2/src/ixgbe.ko). The output will show the version of ixgbe driver.
|
||||
|
||||
$ modinfo ./ixgbe.ko
|
||||
|
||||
----------
|
||||
|
||||
filename: /home/xmodulo/ixgbe/ixgbe-3.23.2/src/ixgbe.ko
|
||||
version: 3.23.2
|
||||
license: GPL
|
||||
description: Intel(R) 10 Gigabit PCI Express Network Driver
|
||||
author: Intel Corporation,
|
||||
srcversion: 2ADA5E537923E983FA9DAE2
|
||||
alias: pci:v00008086d00001560sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001558sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000154Asv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001557sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000154Fsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000154Dsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001528sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010F8sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000151Csv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001529sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000152Asv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010F9sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001514sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001507sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010FBsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001517sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010FCsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010F7sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d00001508sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010DBsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010F4sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010E1sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010F1sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010ECsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010DDsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d0000150Bsv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010C8sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010C7sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010C6sv*sd*bc*sc*i*
|
||||
alias: pci:v00008086d000010B6sv*sd*bc*sc*i*
|
||||
depends: ptp,dca
|
||||
vermagic: 3.11.0-19-generic SMP mod_unload modversions
|
||||
parm: InterruptType:Change Interrupt Mode (0=Legacy, 1=MSI, 2=MSI-X), default IntMode (deprecated) (array of int)
|
||||
parm: IntMode:Change Interrupt Mode (0=Legacy, 1=MSI, 2=MSI-X), default 2 (array of int)
|
||||
parm: MQ:Disable or enable Multiple Queues, default 1 (array of int)
|
||||
parm: DCA:Disable or enable Direct Cache Access, 0=disabled, 1=descriptor only, 2=descriptor and data (array of int)
|
||||
parm: RSS:Number of Receive-Side Scaling Descriptor Queues, default 0=number of cpus (array of int)
|
||||
parm: VMDQ:Number of Virtual Machine Device Queues: 0/1 = disable, 2-16 enable (default=8) (array of int)
|
||||
parm: max_vfs:Number of Virtual Functions: 0 = disable (default), 1-63 = enable this many VFs (array of int)
|
||||
parm: VEPA:VEPA Bridge Mode: 0 = VEB (default), 1 = VEPA (array of int)
|
||||
parm: InterruptThrottleRate:Maximum interrupts per second, per vector, (0,1,956-488281), default 1 (array of int)
|
||||
parm: LLIPort:Low Latency Interrupt TCP Port (0-65535) (array of int)
|
||||
parm: LLIPush:Low Latency Interrupt on TCP Push flag (0,1) (array of int)
|
||||
parm: LLISize:Low Latency Interrupt on Packet Size (0-1500) (array of int)
|
||||
parm: LLIEType:Low Latency Interrupt Ethernet Protocol Type (array of int)
|
||||
parm: LLIVLANP:Low Latency Interrupt on VLAN priority threshold (array of int)
|
||||
parm: FdirPballoc:Flow Director packet buffer allocation level:
|
||||
1 = 8k hash filters or 2k perfect filters
|
||||
2 = 16k hash filters or 4k perfect filters
|
||||
3 = 32k hash filters or 8k perfect filters (array of int)
|
||||
parm: AtrSampleRate:Software ATR Tx packet sample rate (array of int)
|
||||
parm: FCoE:Disable or enable FCoE Offload, default 1 (array of int)
|
||||
parm: LRO:Large Receive Offload (0,1), default 1 = on (array of int)
|
||||
parm: allow_unsupported_sfp:Allow unsupported and untested SFP+ modules on 82599 based adapters, default 0 = Disable (array of int)
|
||||
|
||||
### Step Four: Test Ixgbe Driver ###
|
||||
|
||||
Before testing the new module, you need to remove an old ersion of ixgbe module if it exists in the kernel:
|
||||
|
||||
$ sudo rmmod ixgbe
|
||||
|
||||
Go ahead and insert the newly built ixgbe module into the kernel with insmod command. Make sure to specify an absolute path to the module.
|
||||
|
||||
$ sudo insmod ./ixgbe.ko
|
||||
|
||||
If the above command runs successfully, it will not show any message.
|
||||
|
||||
If you want, you can try passing additional prameter(s). For example, to set the number of RSS queues to 16:
|
||||
|
||||
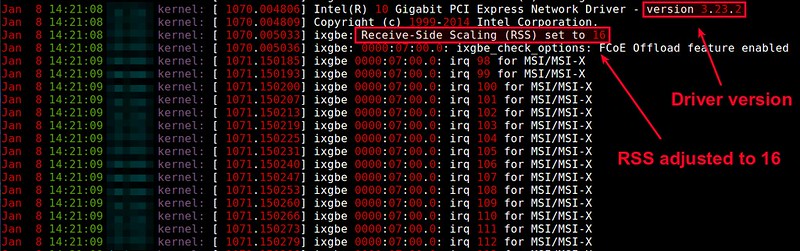
$ sudo insmod ./ixgbe.ko RSS=16
|
||||
|
||||
Check out **/var/log/kern.log** to see if ixgbe driver is successfully activated. Look for "Intel(R) 10 Gigabit PCI Express Network Driver" in the log. The ixgbe version should be matched with the output of modinfo shown earlier.
|
||||
|
||||
Sep 18 14:48:52 spongebob kernel: [684717.906254] Intel(R) 10 Gigabit PCI Express Network Driver - version 3.22.3
|
||||
|
||||
|
||||
|
||||
### Step Five: Install Ixgbe Driver ###
|
||||
|
||||
Once you verify that a new ixgbe driver is successfully loaded, the last step is to install the driver on your system.
|
||||
|
||||
$ sudo make install
|
||||
|
||||
**ixgbe.ko** will then be installed under /lib/modules/<kernel-version>/kernel/drivers/net/ethernet/intel/ixgbe.
|
||||
|
||||
From this point on, you can load ixgbe driver with modprobe command as follows. Note that you no longer need to specify an absolute path.
|
||||
|
||||
$ sudo modprobe ixgbe
|
||||
|
||||
If you want ixgbe driver to be loaded automatically upon boot, you can add "ixgbe" to the end of /etc/modules.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/download-install-ixgbe-driver-ubuntu-debian.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://sourceforge.net/projects/e1000/files/ixgbe%20stable/
|
||||
@ -0,0 +1,44 @@
|
||||
Linux FAQs with Answers--How to set a custom HTTP header in curl
|
||||
================================================================================
|
||||
> **Question**: I am trying to fetch a URL with curl command, but want to set a few custom header fields in the outgoing HTTP request. How can I use a custom HTTP header with curl?
|
||||
|
||||
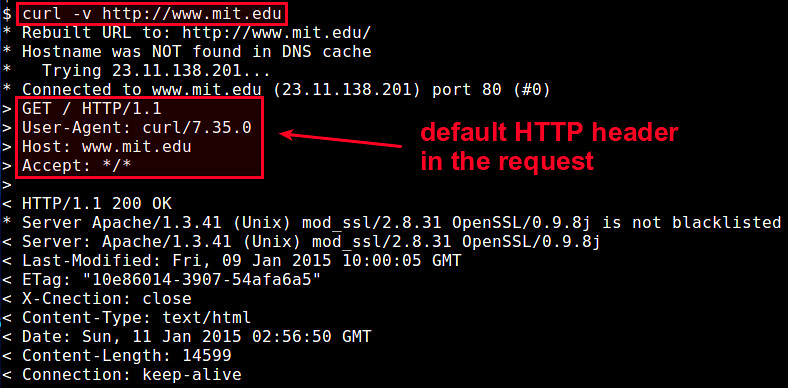
curl is a powerful command-line tool that can transfer data to and from a server over network. It supports a number of transfer protocols, notably HTTP/HTTPS, and many others such as FTP/FTPS, RTSP, POP3/POP3S, SCP, IMAP/IMAPS, etc. When you send out an HTTP request for a URL with curl, it uses a default HTTP header with only essential header fields (e.g., User-Agent, Host, and Accept).
|
||||
|
||||
|
||||
|
||||
In some cases, however, you may want to override the default header or even add a custom header field in an HTTP request. For example, you may want to override "Host" field to test a [load balancer][1], or spoof "User-Agent" string to get around browser-specific access restriction. In other cases, you may be accessing a website which requires a specific cookie, or testing a REST-ful API with various custom parameters in the header.
|
||||
|
||||
To handle all these cases, curl provides an easy way to fully control the HTTP header of outgoing HTTP requests. The parameter you want to use is "-H" or equivalently "--header".
|
||||
|
||||
The "-H" option can be specified multiple times with curl command to define more than one HTTP header fields.
|
||||
|
||||
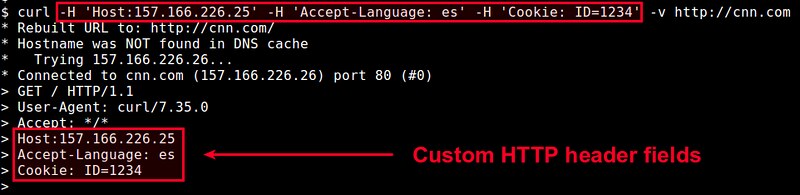
For example, the following command sets three HTTP header fields, i.e., overriding "Host" field, and add two fields ("Accept-Language" and "Cookie").
|
||||
|
||||
$ curl -H 'Host: 157.166.226.25' -H 'Accept-Language: es' -H 'Cookie: ID=1234' http://cnn.com
|
||||
|
||||
|
||||
|
||||
For standard HTTP header fields such as "User-Agent", "Cookie", "Host", there is actually another way to setting them. The curl command offers designated options for setting these header fields:
|
||||
|
||||
- **-A (or --user-agent)**: set "User-Agent" field.
|
||||
- **-b (or --cookie)**: set "Cookie" field.
|
||||
- **-e (or --referer)**: set "Referer" field.
|
||||
|
||||
For example, the following two commands are equivalent. Both of them change "User-Agent" string in the HTTP header.
|
||||
|
||||
$ curl -H "User-Agent: my browser" http://cnn.com
|
||||
$ curl -A "my browser" http://cnn.com
|
||||
|
||||
wget is another command-line tool which you can use to fetch a URL similar to curl, and wget also allows you to use a custom HTTP header. Check out [this post][2] for details on wget command.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/custom-http-header-curl.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
[2]:http://xmodulo.com/how-to-use-custom-http-headers-with-wget.html
|
||||
@ -0,0 +1,56 @@
|
||||
Linux FAQs with Answers--How to use yum to download a RPM package without installing it
|
||||
================================================================================
|
||||
> **Question**: I want to download a RPM package from Red Hat's standard repositories. Can I use yum command to download a RPM package without installing it?
|
||||
|
||||
yum is the default package manager for Red Hat based systems, such as CentOS, Fedora or RHEL. Using yum, you can install or update a RPM package while resolving its package dependencies automatically. What if you want to download a RPM package without installing it on the system? For example, you may want to archive some RPM packages for later use or to install them on another machine.
|
||||
|
||||
Here is how to download a RPM package from yum repositories.
|
||||
|
||||
### Method One: Yum ###
|
||||
|
||||
The yum command itself can be used to download a RPM package. The standard yum command offers '--downloadonly' option for this purpose.
|
||||
|
||||
$ sudo yum install --downloadonly <package-name>
|
||||
|
||||
By default, a downloaded RPM package will be saved in:
|
||||
|
||||
/var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
|
||||
|
||||
In the above, [repository] is the name of the repository (e.g., base, fedora, updates) from which the package is downloaded.
|
||||
|
||||
If you want to download a package to a specific directory (e.g., /tmp):
|
||||
|
||||
$ sudo yum install --downloadonly --downloaddir=/tmp <package-name>
|
||||
|
||||
Note that if a package to download has any unmet dependencies, yum will download all dependent packages as well. None of them will be installed.
|
||||
|
||||
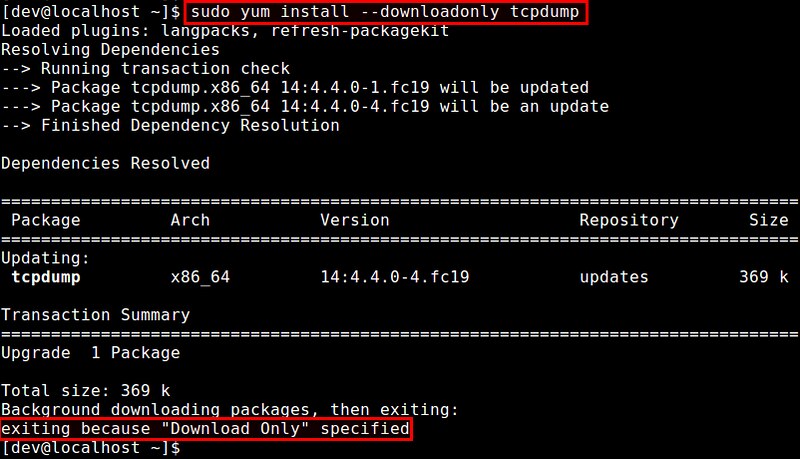
One important thing is that on CentOS/RHEL 6 or earlier, you will need to install a separate yum plugin (called yum-plugin-downloadonly) to be able to use '--downloadonly' command option:
|
||||
|
||||
$ sudo yum install yum-plugin-downloadonly
|
||||
|
||||
Without this plugin, you will get the following error with yum:
|
||||
|
||||
Command line error: no such option: --downloadonly
|
||||
|
||||
|
||||
|
||||
### Method Two: Yumdownloader ###
|
||||
|
||||
Another method to download a RPM package is via a dedicated package downloader tool called yumdownloader. This tool is part of yum-utils package which contains a suite of helper tools for yum package manager.
|
||||
|
||||
$ sudo yum install yum-utils
|
||||
|
||||
To download a RPM package:
|
||||
|
||||
$ sudo yumdownloader <package-name>
|
||||
|
||||
The downloaded package will be saved in the current directory. You need to use root privilege because yumdownloader will update package index files during downloading. Unlike yum command above, none of the dependent package(s) will be downloaded.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/yum-download-rpm-package.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
Loading…
Reference in New Issue
Block a user