mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
4d0c57231d
published
20141211 How to use matplotlib for scientific plotting on Linux.md20150104 How To Install Websvn In CentOS 7.md20150114 Why Mac users don't switch to Linux.md
sources/tech
20150114 How to Configure Chroot Environment in Ubuntu 14.04.md20150126 Improve system performance by moving your log files to RAM Using Ramlog.md20150128 Docker-1 Moving to Docker.md20150209 Linux FAQs with Answers--How to fix 'fatal error--x264.h--No such file or directory' on Linux.md20150211 25 Tips for Intermediate Git Users.md20150211 Best Known Linux Archive or Compress Tools.md20150211 How To Protect Ubuntu Server Against the GHOST Vulnerability.md20150211 Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10.md20150211 Install Mumble in Ubuntu an Opensource VoIP Apps.md20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md20150211 Simple Steps Migration From MySQL To MariaDB On Linux.md
translated/tech
@ -0,0 +1,164 @@
|
||||
在Linux中使用matplotlib进行科学画图
|
||||
================================================================================
|
||||
|
||||
如果你想要在Linxu中获得一个高效、自动化、高质量的科学画图的解决方案,应该考虑尝试下matplotlib库。Matplotlib是基于python的开源科学测绘包,基于python软件基金会许可证发布。大量的文档和例子、集成了Python和Numpy科学计算包、以及自动化能力,是作为Linux环境中进行科学画图的可靠选择的几个原因。这个教程将提供几个用matplotlib画图的例子。
|
||||
|
||||
###特性###
|
||||
|
||||
- 支持众多的图表类型,如:bar,box,contour,histogram,scatter,line plots....
|
||||
- 基于python的语法
|
||||
- 集成Numpy科学计算包
|
||||
- 数据源可以是 python 的列表、键值对和数组
|
||||
- 可定制的图表格式(坐标轴缩放、标签位置及标签内容等)
|
||||
- 可定制文本(字体,大小,位置...)
|
||||
- 支持TeX格式(等式,符号,希腊字体...)
|
||||
- 与IPython相兼容(允许在 python shell 中与图表交互)
|
||||
- 自动化(使用 Python 循环创建图表)
|
||||
- 用Python 的循环迭代生成图片
|
||||
- 保存所绘图片格式为图片文件,如:png,pdf,ps,eps,svg等
|
||||
|
||||
基于Python语法的matplotlib是其许多特性和高效工作流的基础。世面上有许多用于绘制高质量图的科学绘图包,但是这些包允许你直接在你的Python代码中去使用吗?除此以外,这些包允许你创建可以保存为图片文件的图片吗?Matplotlib允许你完成所有的这些任务。从而你可以节省时间,使用它你能够花更少的时间创建更多的图片。
|
||||
|
||||
###安装###
|
||||
安装Python和Numpy包是使用Matplotlib的前提,安装Numpy的指引请见[该链接][1]。
|
||||
|
||||
|
||||
可以通过如下命令在Debian或Ubuntu中安装Matplotlib:
|
||||
|
||||
$ sudo apt-get install python-matplotlib
|
||||
|
||||
在Fedora或CentOS/RHEL环境则可用如下命令:
|
||||
|
||||
$ sudo yum install python-matplotlib
|
||||
|
||||
|
||||
###Matplotlib 例子###
|
||||
|
||||
本教程会提供几个绘图例子演示如何使用matplotlib:
|
||||
|
||||
- 离散图和线性图
|
||||
- 柱状图
|
||||
- 饼状图
|
||||
|
||||
在这些例子中我们将用Python脚本来执行Mapplotlib命令。注意numpy和matplotlib模块需要通过import命令在脚本中进行导入。
|
||||
|
||||
np为nuupy模块的命名空间引用,plt为matplotlib.pyplot的命名空间引用:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
|
||||
###例1:离散和线性图###
|
||||
|
||||
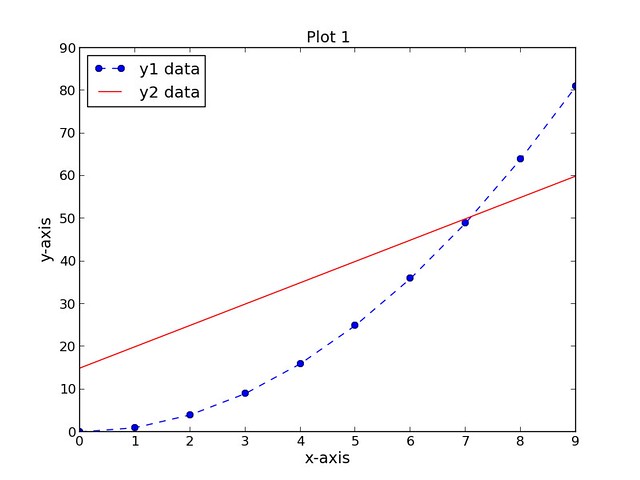
第一个脚本,script1.py 完成如下任务:
|
||||
|
||||
- 创建3个数据集(xData,yData1和yData2)
|
||||
- 创建一个宽8英寸、高6英寸的图(赋值1)
|
||||
- 设置图画的标题、x轴标签、y轴标签(字号均为14)
|
||||
- 绘制第一个数据集:yData1为xData数据集的函数,用圆点标识的离散蓝线,标识为"y1 data"
|
||||
- 绘制第二个数据集:yData2为xData数据集的函数,采用红实线,标识为"y2 data"
|
||||
- 把图例放置在图的左上角
|
||||
- 保存图片为PNG格式文件
|
||||
|
||||
script1.py的内容如下:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
xData = np.arange(0, 10, 1)
|
||||
yData1 = xData.__pow__(2.0)
|
||||
yData2 = np.arange(15, 61, 5)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 1', size=14)
|
||||
plt.xlabel('x-axis', size=14)
|
||||
plt.ylabel('y-axis', size=14)
|
||||
plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
|
||||
plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
|
||||
plt.legend(loc='upper left')
|
||||
plt.savefig('images/plot1.png', format='png')
|
||||
|
||||
|
||||
所画之图如下:
|
||||
|
||||
|
||||
|
||||
|
||||
###例2:柱状图###
|
||||
|
||||
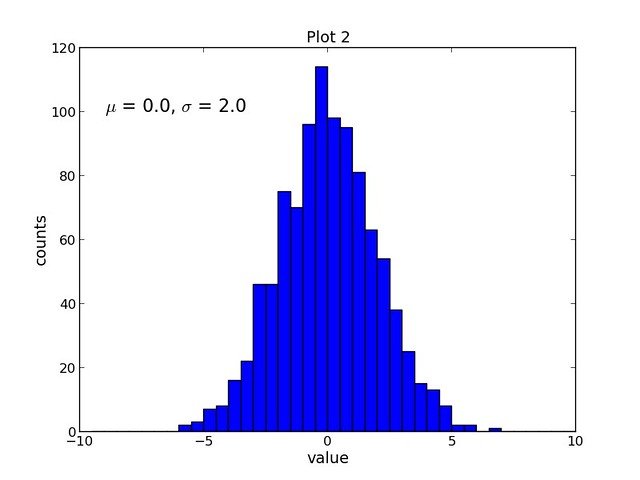
第二个脚本,script2.py 完成如下任务:
|
||||
|
||||
- 创建一个包含1000个随机样本的正态分布数据集。
|
||||
- 创建一个宽8英寸、高6英寸的图(赋值1)
|
||||
- 设置图的标题、x轴标签、y轴标签(字号均为14)
|
||||
- 用samples这个数据集画一个40个柱状,边从-10到10的柱状图
|
||||
- 添加文本,用TeX格式显示希腊字母mu和sigma(字号为16)
|
||||
- 保存图片为PNG格式。
|
||||
|
||||
script2.py代码如下:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
mu = 0.0
|
||||
sigma = 2.0
|
||||
samples = np.random.normal(loc=mu, scale=sigma, size=1000)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 2', size=14)
|
||||
plt.xlabel('value', size=14)
|
||||
plt.ylabel('counts', size=14)
|
||||
plt.hist(samples, bins=40, range=(-10, 10))
|
||||
plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
|
||||
plt.savefig('images/plot2.png', format='png')
|
||||
|
||||
|
||||
结果见如下链接:
|
||||
|
||||
|
||||
|
||||
|
||||
###例3:饼状图###
|
||||
|
||||
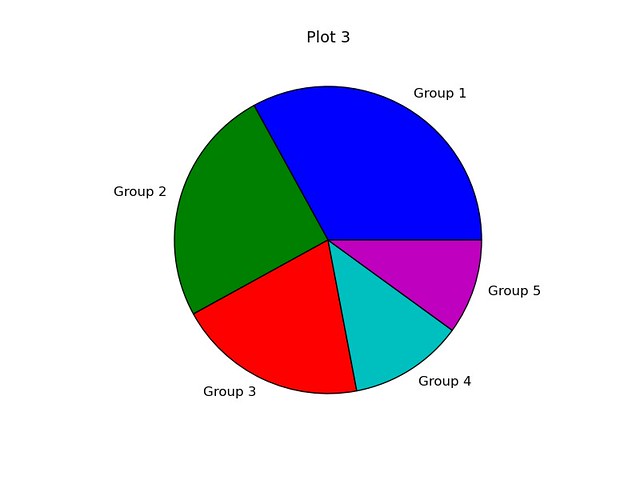
第三个脚本,script3.py 完成如下任务:
|
||||
|
||||
- 创建一个包含5个整数的列表
|
||||
- 创建一个宽6英寸、高6英寸的图(赋值1)
|
||||
- 添加一个长宽比为1的轴图
|
||||
- 设置图的标题(字号为14)
|
||||
- 用data列表画一个包含标签的饼状图
|
||||
- 保存图为PNG格式
|
||||
|
||||
脚本script3.py的代码如下:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
data = [33, 25, 20, 12, 10]
|
||||
plt.figure(num=1, figsize=(6, 6))
|
||||
plt.axes(aspect=1)
|
||||
plt.title('Plot 3', size=14)
|
||||
plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
|
||||
plt.savefig('images/plot3.png', format='png')
|
||||
|
||||
|
||||
结果如下链接所示:
|
||||
|
||||
|
||||
|
||||
|
||||
###总结###
|
||||
|
||||
这个教程提供了几个用matplotlib科学画图包进行画图的例子,Matplotlib是在Linux环境中用于解决科学画图的绝佳方案,表现在其无缝地和Python、Numpy连接、自动化能力,和提供多种自定义的高质量的画图产品。matplotlib包的文档和例子详见[这里][2]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[ideas4u](https://github.com/ideas4u)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
|
||||
[2]:http://matplotlib.org/
|
||||
@ -1,6 +1,6 @@
|
||||
CentOS 7中安装Websvn
|
||||
在 CentOS 7中安装Websvn
|
||||
================================================================================
|
||||
**WebSVN**为你的Subversion提供了一个试图,它设计用来反映Subversion的一整套方法。你可以检查任何文件或目录的日志,以及查看任何指定修改库中修改、添加或删除过的文件列表。你也可以检查同一文件两个版本的不同之处,以便确切地查看某个特性修订版中的修改。
|
||||
**WebSVN**为你的Subversion提供了一个视图,其设计用来对应Subversion的各种功能。你可以检查任何文件或目录的日志,以及查看任何指定版本中所修改、添加或删除过的文件列表。你也可以检查同一文件两个版本的不同之处,以便确切地查看某个特定的修订版本的变化。
|
||||
|
||||
### 特性 ###
|
||||
|
||||
@ -8,31 +8,25 @@ WebSVN提供了以下这些特性:
|
||||
|
||||
- 易于使用的界面;
|
||||
- 可自定义的模板系统;
|
||||
- 文件列表的着色;
|
||||
- 彩色文件列表;
|
||||
- 过错视图;
|
||||
- 日志信息搜索;
|
||||
- 支持RSS订阅;
|
||||
|
||||
### 安装 ###
|
||||
|
||||
我使用以下链接来将Subversion安装到CentOS 7。
|
||||
我按以下链接来将Subversion安装到CentOS 7。
|
||||
|
||||
- [CentOS 7上如何安装Subversion][1]
|
||||
|
||||
**1 – 下载websvn到/var/www/html。**
|
||||
|
||||
cd /var/www/html
|
||||
|
||||
----------
|
||||
|
||||
wget http://websvn.tigris.org/files/documents/1380/49057/websvn-2.3.3.zip
|
||||
|
||||
**2 – 解压zip包。**
|
||||
|
||||
unzip websvn-2.3.3.zip
|
||||
|
||||
----------
|
||||
|
||||
mv websvn-2.3.3 websvn
|
||||
|
||||
**3 – 安装php到你的系统。**
|
||||
@ -42,13 +36,7 @@ WebSVN提供了以下这些特性:
|
||||
**4 – 编辑web svn配置。**
|
||||
|
||||
cd /var/www/html/websvn/include
|
||||
|
||||
----------
|
||||
|
||||
cp distconfig.php config.php
|
||||
|
||||
----------
|
||||
|
||||
vi config.php
|
||||
|
||||
----------
|
||||
@ -96,7 +84,7 @@ via: http://www.unixmen.com/install-websvn-centos-7/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,147 +0,0 @@
|
||||
[bazz2222222]
|
||||
How to Configure Chroot Environment in Ubuntu 14.04
|
||||
================================================================================
|
||||
There are many instances when you may wish to isolate certain applications, user, or environments within a Linux system. Different operating systems have different methods of achieving isolation, and in Linux, a classic way is through a `chroot` environment.
|
||||
|
||||
In this guide, we'll show you step wise on how to setup an isolated environment using chroot in order to create a barrier between your regular operating system and a contained environment. This is mainly useful for testing purposes. We will teach you the steps on an **Ubuntu 14.04** VPS instance.
|
||||
|
||||
Most system administrators will benefit from knowing how to accomplish a quick and easy chroot environment and it is a valuable skill to have.
|
||||
|
||||
### The chroot environment ###
|
||||
|
||||
A chroot environment is an operating system call that will change the root location temporarily to a new folder. Typically, the operating system's conception of the root directory is the actual root located at "/". However, with `chroot`, you can specify another directory to serve as the top-level directory for the duration of a chroot.
|
||||
|
||||
Any applications that are run from within the `chroot` will be unable to see the rest of the operating system in principle.
|
||||
|
||||
#### Advantages of Chroot Environment ####
|
||||
|
||||
> - Test applications without the risk of compromising the entire host system.
|
||||
>
|
||||
> - From the security point of view, whatever happens in the chroot environment won't affect the host system (not even under root user).
|
||||
>
|
||||
> - A different operating system running in the same hardware.
|
||||
|
||||
For instance, it allows you to build, install, and test software in an environment that is separated from your normal operating system. It could also be used as a method of **running 32-bit applications in a 64-bit environment**.
|
||||
|
||||
But while chroot environments will certainly make additional work for an unprivileged user, they should be considered a hardening feature instead of a security feature, meaning that they attempt to reduce the number of attack vectors instead of creating a full solution. If you need full isolation, consider a more complete solution, such as Linux containers, Docker, vservers, etc.
|
||||
|
||||
### Debootstrap and Schroot ###
|
||||
|
||||
The necessary packages to setup the chroot environment are **debootstrap** and **schroot**, which are available in the ubuntu repository. The schroot command is used to setup the chroot environment.
|
||||
|
||||
**Debootstrap** allows you to install a new fresh copy of any Debian (or debian-based) system from a repository in a directory with all the basic commands and binaries needed to run a basic instance of the operating system.
|
||||
|
||||
The **schroot** allows access to chroots for normal users using the same mechanism, but with permissions checking and allowing additional automated setup of the chroot environment, such as mounting additional filesystems and other configuration tasks.
|
||||
|
||||
These are the steps to implement this functionality in Ubuntu 14.04 LTS:
|
||||
|
||||
### 1. Installing the Packages ###
|
||||
|
||||
Firstly, We're gonna install debootstrap and schroot in our host Ubuntu 14.04 LTS.
|
||||
|
||||
$ sudo apt-get install debootstrap
|
||||
$ sudo apt-get install schroot
|
||||
|
||||
### 2. Configuring Schroot ###
|
||||
|
||||
Now that we have the appropriate tools, we just need to specify a directory that we want to use as our chroot environment. We will create a directory called linoxide in our root directory to setup chroot there:
|
||||
|
||||
sudo mkdir /linoxide
|
||||
|
||||
We have to configure schroot to suit our needs in the configuration file .we will modify the schroot configuration file with the information we require to get configured.
|
||||
|
||||
sudo nano /etc/schroot/schroot.conf
|
||||
|
||||
We are on an Ubuntu 14.04 LTS (Trusty Tahr) system currently, but let's say that we want to test out some packages available on Ubuntu 13.10, code named "Saucy Salamander". We can do that by creating an entry that looks like this:
|
||||
|
||||
[saucy]
|
||||
description=Ubuntu Saucy
|
||||
location=/linoxide
|
||||
priority=3
|
||||
users=arun
|
||||
root-groups=root
|
||||
|
||||

|
||||
|
||||
Modify the values of the configuration parameters in the above example to fit your system:
|
||||
|
||||
### 3. Installing 32 bit Ubuntu with debootstrap ###
|
||||
|
||||
Debootstrap downloads and installs a minimal operating system inside your **chroot environment**. You can install any debian-based distro of your choice, as long as you have a repository available.
|
||||
|
||||
Above, we placed the chroot environment under the directory **/linoxide** and this is the root directory of the chroot environment. So we'll need to run debootstrap inside that directory which we have already created:
|
||||
|
||||
cd /linoxide
|
||||
sudo debootstrap --variant=buildd --arch amd64 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
sudo chroot /linoxide /debootstrap/debootstrap --second-stage
|
||||
|
||||
You can replace amd64 in --arch as i386 or other bit OS you wanna setup available in the repository. You can replace the mirror http://archive.ubuntu.com/ubuntu/ above as the one closest, you can get the closest one from the official [Ubuntu Mirror Page][1].
|
||||
|
||||
**Note: You will need to add --foreign above 3rd line command if you choose to setup i386 bit OS choot in your 64 bit Host Ubuntu as:**
|
||||
|
||||
sudo debootstrap --variant=buildd --foreign --arch i386 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
|
||||
It takes some time (depending on your bandwidth) to download, install and configure the complete system. It takes about 500 MBs for a minimal installation.
|
||||
|
||||
### 4. Finallizing the chroot environment ###
|
||||
|
||||
After the system is installed, we'll need to do some final configurations to make sure the system functions correctly. First, we'll want to make sure our host `fstab` is aware of some pseudo-systems in our guest.
|
||||
|
||||
sudo nano /etc/fstab
|
||||
|
||||
Add the below lines like these to the bottom of your fstab:
|
||||
|
||||
proc /linoxide/proc proc defaults 0 0
|
||||
sysfs /linoxide/sys sysfs defaults 0 0
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Now, we're going to need to mount these filesystems within our guest:
|
||||
|
||||
$ sudo mount proc /linoxide/proc -t proc
|
||||
$sudo mount sysfs /linoxide/sys -t sysfs
|
||||
|
||||
We'll also want to copy our /etc/hosts file so that we will have access to the correct network information:
|
||||
|
||||
$ sudo cp /etc/hosts /linoxide/etc/hosts
|
||||
|
||||
Finally, You can list the available chroot environments using the schroot command.
|
||||
|
||||
$ schroot -l
|
||||
|
||||
We can enter the chroot environment through a command like this:
|
||||
|
||||
$ sudo chroot /linoxide/ /bin/bash
|
||||
|
||||
You can test the chroot environment by checking the version of distributions installed.
|
||||
|
||||
# lsb_release -a
|
||||
# uname -a
|
||||
|
||||
To finish this tutorial, in order to run a graphic application from the chroot, you have to export the DISPLAY environment variable.
|
||||
|
||||
$ DISPLAY=:0.0 ./apps
|
||||
|
||||
Here, we have successfully installed Chrooted Ubuntu 13.10(Saucy Salamander) in your host Ubuntu 14.04 LTS (Trusty Tahr).
|
||||
|
||||
You can exit chroot environment successfully by running the commands below:
|
||||
|
||||
# exit
|
||||
|
||||
Afterwards, we need to unmount our proc and sys filesystems:
|
||||
|
||||
$ sudo umount /test/proc
|
||||
$ sudo umount /test/sys
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
@ -1,3 +1,4 @@
|
||||
translating by soooogreen
|
||||
Improve system performance by moving your log files to RAM Using Ramlog
|
||||
================================================================================
|
||||
Ramlog act as a system daemon. On startup it creates ramdisk, it copies files from /var/log into ramdisk and mounts ramdisk as /var/log. All logs after that will be updated on ramdisk. Logs on harddrive are kept in folder /var/log.hdd which is updated when ramlog is restarted or stopped. On shutdown it saves log files back to harddisk so logs are consistent. Ramlog 2.x is using tmpfs by default, ramfs and kernel ramdisk are suppored as well. Program rsync is used for log synchronization.
|
||||
@ -109,4 +110,4 @@ via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-fil
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
|
||||
@ -1,82 +0,0 @@
|
||||
Translating by mtunique
|
||||
Moving to Docker
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] This is the first post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment. If you want, you can skip the intro (this post) and head directly to the technical topics (links at the bottom of the page).
|
||||
|
||||
----------
|
||||
|
||||
In the last month I've been strggling with devops. This is my very personal story and experience in trying to streamline a deployment process of a Raila app with Docker.
|
||||
|
||||
When I started my company – [Touchware][1] – in 2012 I was a lone developer. Things were small, uncomplicated, they didn't require a lot of maintenance, nor they needed to scale all that much. During the course of last year though, we grew quite a lot (we are now a team of 10 people) and our server-side applications and API grew both in terms of scope and scale.
|
||||
|
||||
### Step 1 - Heroku ###
|
||||
|
||||
We still are a very small team and we need to make things going and run as smoothly as possible. When we looked for possible solutions, we decided to stick with something that would have removed from our shoulders the burden of managing hardware. Since we develop mainly Rails based applications and Heroku has a great support for RoR and various kind of DBs and cached (Postgres / Mongo / Redis etc.), the smartest choice seemed to be going with [Heroku][2]. And that's what we did.
|
||||
|
||||
Heroku has a great support and great documentation and deploying apps is just so snappy! Only problem is, when you start growing, you need to have piles of cash around to pay the bills. Not the best deal, really.
|
||||
|
||||
### Step 2 - Dokku ###
|
||||
|
||||
In a rush to try and cut the costs, we decided to try with Dokku. [Dokku][3], quoting the Github repo is a
|
||||
|
||||
> Docker powered mini-Heroku in around 100 lines of Bash
|
||||
|
||||
We launched some instances on [DigitalOcean][4] with Dokku pre-installed and we gave it spin. Dokku is very much like Heroku, but when you have complex applications for whom you need to twear params, or where you need certain dependencies, it's just not gonna work out. We had an app where we needed to apply multiple transformations on images and we couldn't find a way to install the correct version of imagemagick into the dokku-based Docker container that was hosting our Rails app. We still have a couple of very simple apps that are running on Dokku, but we had to move some of them back to Heroku.
|
||||
|
||||
### Step 3 - Docker ###
|
||||
|
||||
A couple of months ago, since the problem of devops and managing production apps was resurfacing, I decided to try out [Docker][5]. Docker, in simple terms, allows developers to containerize applications and to ease the deployment. Since a Docker container basically has all the dependencies it needs to run your app, if everything runs fine on your laptop, you can be sure it'll also run like a champ in production on a remote server, be it an AWS E2C instance or a VPS on DigitalOcean.
|
||||
|
||||
Docker IMHO is particularly interesting for the following reasons:
|
||||
|
||||
- it promotes modularization and separation of concerns: you need to start thinking about your apps in terms of logical components (load balancer: 1 container, DB: 1 container, webapp: 1 container etc.);
|
||||
- it's very flexible in terms of deployment options: containers can be deployed to a wide variety of HW and can be easily redeployed to different servers / providers;
|
||||
- it allows for a very fine grained tuning of your app environment: you build the images your containers runs from, so you have plenty of options for configuring your environment exactly as you would like to.
|
||||
|
||||
There are howerver some downsides:
|
||||
|
||||
- the learning curve is quite steep (this is probably a very personal problem, but I'm talking as a software dev and not as a skilled operations professional);
|
||||
- setup is not simple, especially if you want to have a private registry / repository (more about this later).
|
||||
|
||||
Following are some tips I put together during the course of the last week with the findings of someone that is new to the game.
|
||||
|
||||
----------
|
||||
|
||||
In the following articles we'll see how to setup a semi-automated Docker based deployment system.
|
||||
|
||||
- [Setting up a private Docker registry][6]
|
||||
- [Configuring a Rails app for semi-automated deployment][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://www.touchwa.re/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-1/www.heroku.com
|
||||
[3]:https://github.com/progrium/dokku
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-1/www.digitalocean.com
|
||||
[5]:http://www.docker.com/
|
||||
[6]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,91 +0,0 @@
|
||||
Linux FAQs with Answers--How to fix “fatal error: x264.h: No such file or directory” on Linux
|
||||
================================================================================
|
||||
> **Question**: I am trying to build a video encoding application from the source on Linux. However, during compilation, I am encountering the error: "fatal error: x264.h: No such file or directory" How can I fix this error?
|
||||
|
||||
The following compilation error indicates that you do not have x264 library's development files installed on your Linux system.
|
||||
|
||||
fatal error: x264.h: No such file or directory
|
||||
|
||||
[x264][1] is an H.264/MPEG-4 AVC encoder library licensed with GNU GPL. The x264 library is popularly used by many video encoder/transcoder programs such as Avidemux, [FFmpeg][2], [HandBrake][3], OpenShot, MEncode and more.
|
||||
|
||||
To solve the above compilation error, you need to install development files for x264 library. Here is how you can do it.
|
||||
|
||||
### Install x264 Library and its Development Files on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
On Debian based systems, x264 library is already included in the base repositories. Thus its installation is straightforward with apt-get as follows.
|
||||
|
||||
$ sudo apt-get install libx264-dev
|
||||
|
||||
### Install x264 Library and its Development Files on Fedora, CentOS/RHEL ###
|
||||
|
||||
On Red Hat based distributions such as Fedora or CentOS, the x264 library is available via the free repository of RPM Fusion. Thus, you need to install [RPM Fusion (free)][4] first.
|
||||
|
||||
Once RPM Fusion is set up, you can install x264 development files as follows.
|
||||
|
||||
$ sudo yum --enablerepo=rpmfusion-free install x264-devel
|
||||
|
||||
Note that RPM Fusion repository is not available for CentOS 7 yet, so the above method does not work for CentOS 7. In case of CentOS 7, you can build and install x264 library from the source, which is explained below.
|
||||
|
||||
### Compile x264 Library from the Source on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
If the libx264 package that comes with your distribution is not up-to-date, you can compile the latest x264 library from the source as follows.
|
||||
|
||||
$ sudo apt-get install g++ automake autoconf libtool yasm nasm git
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
$ cd x264
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
The x264 library will be installed in /usr/local/lib. To allow the library to be used by other applications, you need to complete the last step:
|
||||
|
||||
Open /etc/ld.so.conf with a text editor, and append the following line.
|
||||
|
||||
$ sudo vi /etc/ld.so.conf
|
||||
|
||||
----------
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
Finally reload all shared libraries by running:
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
### Compile x264 Library from the Source on Fedora, CentOS/RHEL ###
|
||||
|
||||
If the x264 library is not available on your Linux distribution (e.g., CentOS 7) or the x264 library is not up-to-date, you can build the latest x264 library from the source as follows.
|
||||
|
||||
$ sudo yum install gcc gcc-c++ automake autoconf libtool yasm nasm git
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
$ cd x264
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
Finally, to allow other applications to use x264 library installed in /usr/local/lib, add the following line in /etc/ld.so.conf:
|
||||
|
||||
$ sudo vi /etc/ld.so.conf
|
||||
|
||||
----------
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
and reload all shared libraries by running:
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fatal-error-x264-h-no-such-file-or-directory.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.videolan.org/developers/x264.html
|
||||
[2]:http://ask.xmodulo.com/compile-ffmpeg-centos-fedora-rhel.html
|
||||
[3]:http://xmodulo.com/how-to-install-handbrake-on-linux.html
|
||||
[4]:http://xmodulo.com/how-to-install-rpm-fusion-on-fedora.html
|
||||
469
sources/tech/20150211 25 Tips for Intermediate Git Users.md
Normal file
469
sources/tech/20150211 25 Tips for Intermediate Git Users.md
Normal file
@ -0,0 +1,469 @@
|
||||
25 Tips for Intermediate Git Users
|
||||
================================================================================
|
||||
I’ve been using git for about 18 months now and thought I knew it pretty well. Then we had [Scott Chacon][1] from GitHub over to do some training at [LVS, a supplier/developer of betting/gaming software][2] (where contracted until 2013) and I learnt a ton in the first day.
|
||||
|
||||
As someone who’s always felt fairly comfortable in Git, I thought sharing some of the nuggets I learnt with the community might help someone to find an answer without needing to do lots of research.
|
||||
|
||||
### Basic Tips ###
|
||||
|
||||
#### 1. First Steps After Install ####
|
||||
|
||||
After installing Git, the first thing you should do is configure your name and email, as every commit will have these details:
|
||||
|
||||
$ git config --global user.name "Some One"
|
||||
$ git config --global user.email "someone@gmail.com"
|
||||
|
||||
#### 2. Git is Pointer-Based ####
|
||||
|
||||
Everything stored in git is in a file. When you create a commit it creates a file containing your commit message and associated data (name, email, date/time, previous commit, etc) and links it to a tree file. The tree file contains a list of objects or other trees. The object or blob is the actual content associated with the commit (a file, if you will, although the filename isn’t stored in the object, but in the tree). All of these files are stored with a filename of a SHA-1 hash of the object.
|
||||
|
||||
From there branches and tags are simply files containing (basically) a SHA-1 hash which points to the commit. Using these references allows for a lot of flexibility and speed, as creating a new branch is as simple as creating a file with the name of the branch and the SHA-1 reference to the commit you’re branching from. Of course, you’d never do that as you’d use the Git command line tools (or a GUI), but it’s that simple.
|
||||
|
||||
You may have heard references to the HEAD. This is simply a file containing the SHA-1 reference of the commit you’re currently pointing to. If you’re resolving a merge conflict and see HEAD, that’s nothing to do with a particular branch or necessarily a particular point on the branch but where you currently are.
|
||||
|
||||
All the branch pointers are kept in .git/refs/heads, HEAD is in .git/HEAD and tags are in .git/refs/tags – feel free to have a look in there.
|
||||
|
||||
#### 3. Two Parents – of course! ####
|
||||
|
||||
When viewing a merge commit message in a log, you will see two parents (as opposed to the normal one for a work-based commit). The first parent is the branch you were on and the second is the one you merged in to it.
|
||||
|
||||
#### 4. Merge Conflicts ####
|
||||
|
||||
By now I’m sure you have had a merge conflict and had to resolve it. This is normally done by editing the file, removing the <<<<, ====, >>>> markers and the keeping the code you want to store. Sometimes it’s nice to see the code before either change, i.e. before you made the change in both branches that now conflicts. This is one command away:
|
||||
|
||||
$ git diff --merge
|
||||
diff --cc dummy.rb
|
||||
index 5175dde,0c65895..4a00477
|
||||
--- a/dummy.rb
|
||||
+++ b/dummy.rb
|
||||
@@@ -1,5 -1,5 +1,5 @@@
|
||||
class MyFoo
|
||||
def say
|
||||
- puts "Bonjour"
|
||||
- puts "Hello world"
|
||||
++ puts "Annyong Haseyo"
|
||||
end
|
||||
end
|
||||
|
||||
If the file is binary, diffing files isn’t so easy… What you’ll normally want to do is to try each version of the binary file and decide which one to use (or manually copy portions over in the binary file’s editor). To pull a copy of the file from a particular branch (say you’re merging master and feature132):
|
||||
|
||||
$ git checkout master flash/foo.fla # or...
|
||||
$ git checkout feature132 flash/foo.fla
|
||||
$ # Then...
|
||||
$ git add flash/foo.fla
|
||||
|
||||
Another way is to cat the file from git – you can do this to another filename then copy the correct file over (when you’ve decided which it is) to the normal filename:
|
||||
|
||||
$ git show master:flash/foo.fla > master-foo.fla
|
||||
$ git show feature132:flash/foo.fla > feature132-foo.fla
|
||||
$ # Check out master-foo.fla and feature132-foo.fla
|
||||
$ # Let's say we decide that feature132's is correct
|
||||
$ rm flash/foo.fla
|
||||
$ mv feature132-foo.fla flash/foo.fla
|
||||
$ rm master-foo.fla
|
||||
$ git add flash/foo.fla
|
||||
|
||||
UPDATE: Thanks to Carl in the comments on the original blog post for the reminder, you can actually use “git checkout —ours flash/foo.fla” and “git checkout —theirs flash/foo.fla” to checkout a particular version without remembering which branches you merge in. Personally I prefer to be more explicit, but the option is there…
|
||||
|
||||
Remember to add the file after resolving the merge conflict (as I do above).
|
||||
|
||||
### Servers, Branching and Tagging ###
|
||||
|
||||
#### 5. Remote Servers ####
|
||||
|
||||
One of the most powerful features of Git is the ability to have more than one remote server (as well as the fact that you’re running a local repository always). You don’t always need write access either, you may have multiple servers you read from (to merge work in) and then write to another. To add a new remote server is simple:
|
||||
|
||||
$ git remote add john git@github.com:johnsomeone/someproject.git
|
||||
|
||||
If you want to see information about your remote servers you can do:
|
||||
|
||||
# shows URLs of each remote server
|
||||
$ git remote -v
|
||||
|
||||
# gives more details about each
|
||||
$ git remote show name
|
||||
|
||||
You can always see the differences between a local branch and a remote branch:
|
||||
|
||||
$ git diff master..john/master
|
||||
|
||||
You can also see the changes on HEAD that aren’t on that remote branch:
|
||||
|
||||
$ git log remote/branch..
|
||||
# Note: no final refspec after ..
|
||||
|
||||
#### 6. Tagging ####
|
||||
|
||||
In Git there are two types of tag – a lightweight tag and an annotated tag. Bearing in mind Tip 2 about Git being pointer based, the difference between the two is simple. A lightweight tag is simply a named pointer to a commit. You can always change it to point to another commit. An annotated tag is a name pointer to a tag object, with it’s own message and history. As it has it’s own message it can be GPG signed if required.
|
||||
|
||||
Creating the two types of tag is easy (and one command line switch different)
|
||||
|
||||
$ git tag to-be-tested
|
||||
$ git tag -a v1.1.0 # Prompts for a tag message
|
||||
|
||||
#### 7. Creating Branches ####
|
||||
|
||||
Creating branches in git is very easy (and lightning quick due to it only needing to create a less than 100 byte file). The longhand way of creating a new branch and switching to it:
|
||||
|
||||
$ git branch feature132
|
||||
$ git checkout feature132
|
||||
|
||||
Of course, if you know you’re going to want to switch to it straight away you can do it in one command:
|
||||
|
||||
$ git checkout -b feature132
|
||||
|
||||
If you want to rename a local branch it’s as easy as (the long way to show what happens):
|
||||
|
||||
$ git checkout -b twitter-experiment feature132
|
||||
$ git branch -d feature132
|
||||
|
||||
Update: Or you can (as Brian Palmer points out in the comments on the original blog post) just use the -m switch to “git branch” to do it in one step (as Mike points out, if you only specify one branch it renames your current branch):
|
||||
|
||||
$ git branch -m twitter-experiment
|
||||
$ git branch -m feature132 twitter-experiment
|
||||
|
||||
#### 8. Merging Branches ####
|
||||
|
||||
At some point in the future, you’re going to want to merge your changes back in. There are two ways to do this:
|
||||
|
||||
$ git checkout master
|
||||
$ git merge feature83 # Or...
|
||||
$ git rebase feature83
|
||||
|
||||
The difference between merge and rebase is that merge tries to resolve the changes and create a new commit that blends them. Rebase tries to take your changes since you last diverged from the other branch and replay them from the HEAD of the other branch. However, don’t rebase after you’ve pushed a branch to a remote server – this can cause confusion/problems.
|
||||
|
||||
If you aren’t sure which branches still have unique work on them – so you know which you need to merge and which ones can be removed, there are two switches to git branch that help:
|
||||
|
||||
# Shows branches that are all merged in to your current branch
|
||||
$ git branch --merged
|
||||
|
||||
# Shows branches that are not merged in to your current branch
|
||||
$ git branch --no-merged
|
||||
|
||||
#### 9. Remote Branches ####
|
||||
|
||||
If you have a local branch that you’d like to appear on a remote server, you can push it up with one command:
|
||||
|
||||
$ git push origin twitter-experiment:refs/heads/twitter-experiment
|
||||
# Where origin is our server name and twitter-experiment is the branch
|
||||
|
||||
Update: Thanks to Erlend in the comments on the original blog post – this is actually the same as doing `git push origin twitter-experiment` but by using the full syntax you can see that you can actually use different names on both ends (so your local can be `add-ssl-support` while your remote name can be `issue-1723`).
|
||||
|
||||
If you want to delete a branch from the server (note the colon before the branch name):
|
||||
|
||||
$ git push origin :twitter-experiment
|
||||
|
||||
If you want to show the state of all remote branches you can view them like this:
|
||||
|
||||
$ git remote show origin
|
||||
|
||||
This may list some branches that used to exist on the server but now don’t exist. If this is the case you can easily remove them from your local checkout using:
|
||||
|
||||
$ git remote prune
|
||||
|
||||
Finally, if you have a remote branch that you want to track locally, the longhand way is:
|
||||
|
||||
$ git branch --track myfeature origin/myfeature
|
||||
$ git checkout myfeature
|
||||
|
||||
However, newer versions of Git automatically set up tracking if you use the -b flag to checkout:
|
||||
|
||||
$ git checkout -b myfeature origin/myfeature
|
||||
|
||||
### Storing Content in Stashes, Index and File System ###
|
||||
|
||||
#### 10. Stashing ####
|
||||
|
||||
In Git you can drop your current work state in to a temporary storage area stack and then re-apply it later. The simple case is as follows:
|
||||
|
||||
$ git stash
|
||||
# Do something...
|
||||
$ git stash pop
|
||||
|
||||
A lot of people recommend using `git stash apply` instead of pop, however if you do this you end up with a long list of stashes left hanging around. “pop” will only remove it from the stack if it applies cleanly. If you’ve used `git stash apply` you can remove the last item from the stack anyway using:
|
||||
|
||||
$ git stash drop
|
||||
|
||||
Git will automatically create a comment based on the current commit message. If you’d prefer to use a custom message (as it may have nothing to do with the previous commit):
|
||||
|
||||
$ git stash save "My stash message"
|
||||
|
||||
If you want to apply a particular stash from your list (not necessarily the last one) you can list them and apply it like this:
|
||||
|
||||
$ git stash list
|
||||
stash@{0}: On master: Changed to German
|
||||
stash@{1}: On master: Language is now Italian
|
||||
$ git stash apply stash@{1}
|
||||
|
||||
#### 11. Adding Interactively ####
|
||||
|
||||
In the subversion world you change files and then just commit everything that has changed. In Git you have a LOT more power to commit just certain files or even certain patches. To commit certain files or parts of files you need to go in to interactive mode.
|
||||
|
||||
$ git add -i
|
||||
staged unstaged path
|
||||
|
||||
|
||||
*** Commands ***
|
||||
1: status 2: update 3: revert 4: add untracked
|
||||
5: patch 6: diff 7: quit 8: help
|
||||
What now>
|
||||
|
||||
This drops you in to a menu based interactive prompt. You can use the numbers of the commands or the highlighted letters (if you have colour highlighting turned on) to go in to that mode. Then it’s normally a matter of typing the numbers of the files you want to apply that action to (you can use formats like 1 or 1-4 or 2,4,7).
|
||||
|
||||
If you want to go to patch mode (‘p’ or ‘5’ from interactive mode) you can also go straight in to that mode:
|
||||
|
||||
$ git add -p
|
||||
diff --git a/dummy.rb b/dummy.rb
|
||||
index 4a00477..f856fb0 100644
|
||||
--- a/dummy.rb
|
||||
+++ b/dummy.rb
|
||||
@@ -1,5 +1,5 @@
|
||||
class MyFoo
|
||||
def say
|
||||
- puts "Annyong Haseyo"
|
||||
+ puts "Guten Tag"
|
||||
end
|
||||
end
|
||||
Stage this hunk [y,n,q,a,d,/,e,?]?
|
||||
|
||||
As you can see you then get a set of options at the bottom for choosing to add this changed part of the file, all changes from this file, etc. Using the ‘?’ command will explain the options.
|
||||
|
||||
#### 12. Storing/Retrieving from the File System ####
|
||||
|
||||
Some projects (the Git project itself for example) store additional files directly in the Git file system without them necessarily being a checked in file.
|
||||
|
||||
Let’s start off by storing a random file in Git:
|
||||
|
||||
$ echo "Foo" | git hash-object -w --stdin
|
||||
51fc03a9bb365fae74fd2bf66517b30bf48020cb
|
||||
|
||||
At this point the object is in the database, but if you don’t set something up to point to that object it will be garbage collected. The easiest way is to tag it:
|
||||
|
||||
$ git tag myfile 51fc03a9bb365fae74fd2bf66517b30bf48020cb
|
||||
|
||||
Note that here we’ve used the tag myfile. When we need to retrieve the file we can do it with:
|
||||
|
||||
$ git cat-file blob myfile
|
||||
|
||||
This can be useful for utility files that developers may need (passwords, gpg keys, etc) but you don’t want to actually check out on to disk every time (particularly in production).
|
||||
|
||||
### Logging and What Changed? ###
|
||||
|
||||
#### 13. Viewing a Log ####
|
||||
|
||||
You can’t use Git for long without using ‘git log’ to view your recent commits. However, there are some tips on how to use it better. For example, you can view a patch of what changed in each commit with:
|
||||
|
||||
$ git log -p
|
||||
|
||||
Or you can just view a summary of which files changed with:
|
||||
|
||||
$ git log --stat
|
||||
|
||||
There’s a nice alias you can set up which shows abbreviated commits and a nice graph of branches with the messages on a single line (like gitk, but on the command line):
|
||||
|
||||
$ git config --global alias.lol "log --pretty=oneline --abbrev-commit --graph --decorate"
|
||||
$ git lol
|
||||
* 4d2409a (master) Oops, meant that to be in Korean
|
||||
* 169b845 Hello world
|
||||
|
||||
#### 14. Searching in the Log ####
|
||||
|
||||
If you want to search for a particular author you can specify that:
|
||||
|
||||
$ git log --author=Andy
|
||||
|
||||
Update: Thanks to Johannes in the comments, I’ve cleared up some of the confusion here.
|
||||
|
||||
Or if you have a search term that appears in the commit message:
|
||||
|
||||
$ git log --grep="Something in the message"
|
||||
|
||||
There’s also a more powerful command called the pickaxe command that look for the entry that removes or adds a particular piece of content (i.e. when it first appeared or was removed). This can tell you when a line was added (but not if a character on that line was later changed):
|
||||
|
||||
$ git log -S "TODO: Check for admin status"
|
||||
|
||||
What about if you changed a particular file, e.g. `lib/foo.rb`
|
||||
|
||||
$ git log lib/foo.rb
|
||||
|
||||
Let’s say you have a `feature/132` branch and a `feature/145` and you want to view the commits on those branches that aren’t on master (note the ^ meaning not):
|
||||
|
||||
$ git log feature/132 feature/145 ^master
|
||||
|
||||
You can also narrow it down to a date range using ActiveSupport style dates:
|
||||
|
||||
$ git log --since=2.months.ago --until=1.day.ago
|
||||
|
||||
By default it will use OR to combine the query, but you can easily change it to use AND (if you have more than one criteria)
|
||||
|
||||
$ git log --since=2.months.ago --until=1.day.ago --author=andy -S "something" --all-match
|
||||
|
||||
#### 15. Selecting Revisions to View/Change ####
|
||||
|
||||
There are a number of items you can specify when referring to a revision, depending on what you know about it:
|
||||
|
||||
$ git show 12a86bc38 # By revision
|
||||
$ git show v1.0.1 # By tag
|
||||
$ git show feature132 # By branch name
|
||||
$ git show 12a86bc38^ # Parent of a commit
|
||||
$ git show 12a86bc38~2 # Grandparent of a commit
|
||||
$ git show feature132@{yesterday} # Time relative
|
||||
$ git show feature132@{2.hours.ago} # Time relative
|
||||
|
||||
Note that unlike the previous section, a caret on the end means the parent of that commit – a caret at the start means not on this branch.
|
||||
|
||||
#### 16. Selecting a Range ####
|
||||
|
||||
The easiest way is to use:
|
||||
|
||||
$ git log origin/master..new
|
||||
# [old]..[new] - everything you haven't pushed yet
|
||||
|
||||
You can also omit the [new] and it will use your current HEAD.
|
||||
|
||||
### Rewinding Time & Fixing Mistakes ###
|
||||
|
||||
#### 17. Resetting changes ####
|
||||
|
||||
You can easily unstage a change if you haven’t committed it using:
|
||||
|
||||
$ git reset HEAD lib/foo.rb
|
||||
|
||||
Often this is aliased to ‘unstage’ as it’s a bit non-obvious.
|
||||
|
||||
$ git config --global alias.unstage "reset HEAD"
|
||||
$ git unstage lib/foo.rb
|
||||
|
||||
If you’ve committed the file already, you can do two things – if it’s the last commit you can just amend it:
|
||||
|
||||
$ git commit --amend
|
||||
|
||||
This undoes the last commit, puts your working copy back as it was with the changes staged and the commit message ready to edit/commit next time you commit.
|
||||
|
||||
If you’ve committed more than once and just want to completely undo them, you can reset the branch back to a previous point in time.
|
||||
|
||||
$ git checkout feature132
|
||||
$ git reset --hard HEAD~2
|
||||
|
||||
If you actually want to bring a branch to point to a completely different SHA1 (maybe you’re bringing the HEAD of a branch to another branch, or a further commit) you can do the following to do it the long way:
|
||||
|
||||
$ git checkout FOO
|
||||
$ git reset --hard SHA
|
||||
|
||||
There’s actually a quicker way (as it doesn’t change your working copy back to the state of FOO first then forward to SHA):
|
||||
|
||||
$ git update-ref refs/heads/FOO SHA
|
||||
|
||||
#### 18. Committing to the Wrong Branch ####
|
||||
|
||||
OK, let’s assume you committed to master but should have created a topic branch called experimental instead. To move those changes over, you can create a branch at your current point, rewind head and then checkout your new branch:
|
||||
|
||||
$ git branch experimental # Creates a pointer to the current master state
|
||||
$ git reset --hard master~3 # Moves the master branch pointer back to 3 revisions ago
|
||||
$ git checkout experimental
|
||||
|
||||
This can be more complex if you’ve made the changes on a branch of a branch of a branch etc. Then what you need to do is rebase the change on a branch on to somewhere else:
|
||||
|
||||
$ git branch newtopic STARTPOINT
|
||||
$ git rebase oldtopic --onto newtopic
|
||||
|
||||
#### 19. Interactive Rebasing ####
|
||||
|
||||
This is a cool feature I’ve seen demoed before but never actually understood, now it’s easy. Let’s say you’ve made 3 commits but you want to re-order them or edit them (or combine them):
|
||||
|
||||
$ git rebase -i master~3
|
||||
|
||||
Then you get your editor pop open with some instructions. All you have to do is amend the instructions to pick/squash/edit (or remove them) commits and save/exit. Then after editing you can `git rebase —continue` to keep stepping through each of your instructions.
|
||||
|
||||
If you choose to edit one, it will leave you in the state you were in at the time you committed that, so you need to use git commit —amend to edit it.
|
||||
|
||||
**Note: DO NOT COMMIT DURING REBASE – only add then use —continue, —skip or —abort.**
|
||||
|
||||
#### 20. Cleaning Up ####
|
||||
|
||||
If you’ve committed some content to your branch (maybe you’ve imported an old repo from SVN) and you want to remove all occurrences of a file from the history:
|
||||
|
||||
$ git filter-branch --tree-filter 'rm -f *.class' HEAD
|
||||
|
||||
If you’ve already pushed to origin, but have committed the rubbish since then, you can also do this for your local system before pushing:
|
||||
|
||||
$ git filter-branch --tree-filter 'rm -f *.class' origin/master..HEAD
|
||||
|
||||
### Miscellaneous Tips ###
|
||||
|
||||
#### 21. Previous References You’ve Viewed ####
|
||||
|
||||
If you know you’ve previously viewed a SHA-1, but you’ve done some resetting/rewinding you can use the reflog commands to view the SHA-1s you’ve recently viewed:
|
||||
|
||||
$ git reflog
|
||||
$ git log -g # Same as above, but shows in 'log' format
|
||||
|
||||
#### 22. Branch Naming ####
|
||||
|
||||
A lovely little tip – don’t forget that branch names aren’t limited to a-z and 0-9. It can be quite nice to use / and . in names for fake namespacing or versionin, for example:
|
||||
|
||||
$ # Generate a changelog of Release 132
|
||||
$ git shortlog release/132 ^release/131
|
||||
$ # Tag this as v1.0.1
|
||||
$ git tag v1.0.1 release/132
|
||||
|
||||
#### 23. Finding Who Dunnit ####
|
||||
|
||||
Often it can be useful to find out who changed a line of code in a file. The simple command to do this is:
|
||||
|
||||
$ git blame FILE
|
||||
|
||||
Sometimes the change has come from a previous file (if you’ve combined two files, or you’ve moved a function) so you can use:
|
||||
|
||||
$ # shows which file names the content came from
|
||||
$ git blame -C FILE
|
||||
|
||||
Sometimes it’s nice to track this down by clicking through changes and going further and further back. There’s a nice in-built gui for this:
|
||||
|
||||
$ git gui blame FILE
|
||||
|
||||
#### 24. Database Maintenance ####
|
||||
|
||||
Git doesn’t generally require a lot of maintenance, it pretty much takes care of itself. However, you can view the statistics of your database using:
|
||||
|
||||
$ git count-objects -v
|
||||
|
||||
If this is high you can choose to garbage collect your clone. This won’t affect pushes or other people but it can make some of your commands run much faster and take less space:
|
||||
|
||||
$ git gc
|
||||
|
||||
It also might be worth running a consistency check every so often:
|
||||
|
||||
$ git fsck --full
|
||||
|
||||
You can also add a `—auto` parameter on the end (if you’re running it frequently/daily from crontab on your server) and it will only fsck if the stats show it’s necessary.
|
||||
|
||||
When checking, getting “dangling” or “unreachable” is fine, this is often a result of rewinding heads or rebasing. Getting “missing” or “sha1 mismatch” is bad… Get professional help!
|
||||
|
||||
#### 25. Recovering a Lost Branch ####
|
||||
|
||||
If you delete a branch experimental with -D you can recreate it with:
|
||||
|
||||
$ git branch experimental SHA1_OF_HASH
|
||||
|
||||
You can often find the SHA1 hash using git reflog if you’ve accessed it recently.
|
||||
|
||||
Another way is to use `git fsck —lost-found`. A dangling commit here is the lost HEAD (it will only be the HEAD of the deleted branch as the HEAD^ is referred to by HEAD so it’s not dangling)
|
||||
|
||||
### Done! ###
|
||||
|
||||
Wow, the longest blog post I’ve ever written, I hope someone finds it useful. If you did, or if you have any questions let me know in the comments…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.andyjeffries.co.uk/25-tips-for-intermediate-git-users/
|
||||
|
||||
作者:[Andy Jeffries][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.andyjeffries.co.uk/author/andy-jeffries/
|
||||
[1]:http://gitcasts.com/about
|
||||
[2]:http://www.lvs.co.uk/
|
||||
@ -0,0 +1,229 @@
|
||||
Best Known Linux Archive / Compress Tools
|
||||
================================================================================
|
||||
Sending and receiving large files and pictures over the internet is a headache many times. Compression and decompression tools are meant to address this problem. Lets take a quick overview of a few open source tools that are available to make our jobs simpler.
|
||||
|
||||
Tar
|
||||
gzip, gunzip
|
||||
bzip2, bunzip2
|
||||
7-Zip
|
||||
|
||||
### Tar ###
|
||||
|
||||
Tar is derived from 'Tape archiver' as this was initially used for archiving and storing files on magnetic tapes. It is a GNU software. It can compress a set of files (archives), extract them and manipulate those which already exist. It is useful for storing, backing up and transporting files. Tar can preserve file and directory structure while creating the archives. Files archived using tar have '.tar' extensions.
|
||||
|
||||
Basic Usage
|
||||
|
||||
#### a) Creating an archive (c / --create) ####
|
||||
|
||||
tar --create --verbose --file=archive.tar file1 file2 file3
|
||||
|
||||
OR
|
||||
|
||||
tar cvf archive.tar file1 file2 file3
|
||||
|
||||

|
||||
|
||||
creating an archive
|
||||
|
||||
#### b) Listing an archive ( t / --list) ####
|
||||
|
||||
tar --list archive.tar
|
||||
|
||||

|
||||
|
||||
Listing the contents
|
||||
|
||||
#### c) Extracting an archive (x / --extract) ####
|
||||
|
||||
tar xvf archive.tar
|
||||
|
||||
tar xvf archive.tar --wildcards '*.c' - extracts files with only *.c extension from the archive.
|
||||
|
||||

|
||||
|
||||
Extracting files
|
||||
|
||||

|
||||
|
||||
Extract only the required files
|
||||
|
||||
#### d) Updating an archive ( u / --update) ####
|
||||
|
||||
tar uvf archive.tar newfile.c - updates the archive by adding newfile.c if its version is newer than the existing one.
|
||||
|
||||

|
||||
|
||||
Updating an archive
|
||||
|
||||
#### e) Delete from an archive (--delete) ####
|
||||
|
||||
tar--delete -f archive.tar file1.c - deletes 'file1.c' from the tar ball 'archive.tar'
|
||||
|
||||

|
||||
|
||||
Deleting files
|
||||
|
||||
Refer to [tar home page][1] for its detailed usage
|
||||
|
||||
### Gzip / Gunzip ###
|
||||
|
||||
Gzip stands for GNU zip. It is a compression utility that is commonly available in Linux operating system. Compressed files have an extension of '*.gz'
|
||||
|
||||
**Basic Usage**
|
||||
|
||||
#### a) Compressing files ####
|
||||
|
||||
gzip file(s)
|
||||
|
||||
Each file gets compressed individually
|
||||
|
||||

|
||||
|
||||
Compress files
|
||||
|
||||
This generally deletes the original files after compression. We can keep the original file by using the -c option.
|
||||
|
||||
gzip -c file > file.gz
|
||||
|
||||

|
||||
|
||||
Keep original files after compressing
|
||||
|
||||
We can also compress a group of files into a single file
|
||||
|
||||
cat file1 file2 file3 | gzip > archieve.gz
|
||||
|
||||

|
||||
|
||||
Compressing a group of files
|
||||
|
||||
#### b) Checking compression ratio ####
|
||||
|
||||
Compression ratio of the compressed file(s) can be verified using the '-l' option.
|
||||
|
||||
gzip -l archieve.gz
|
||||
|
||||

|
||||
|
||||
Checking compression ratio
|
||||
|
||||
#### c) Unzipping files ####
|
||||
|
||||
Gunzip is used for unzipping files. Here also, original files are deleted after decompression. Use the -c option to retain original files.
|
||||
|
||||
gunzip -c archieve.gz
|
||||
|
||||

|
||||
|
||||
Unzipping files
|
||||
|
||||
Using '-d' option with gzip command has the same effect of gunzip on compressed files.
|
||||
|
||||
More details can be obtained from [gzip home page][2]
|
||||
|
||||
### Bzip2 / Bunzip2 ###
|
||||
|
||||
[Bzip2][3] is also a compression tool like gzip but can compress files to smaller sizes than that is possible with other traditional tools. But the drawback is that it is slower than gzip.
|
||||
|
||||
**Basic Usage**
|
||||
|
||||
#### a) File Compression ####
|
||||
|
||||
Generally, no options are used for compression and the files to be compressed are passed as arguments. Each file gets compressed individually and compressed files will have the extension 'bz2'.
|
||||
|
||||
bzip2 file1 file2 file3
|
||||
|
||||

|
||||
|
||||
File Compression
|
||||
|
||||
Use '-k' option to keep the original files after compression / decompression.
|
||||
|
||||

|
||||
|
||||
Retaining original files after compression
|
||||
|
||||
'-d' option is used for forced decompression.
|
||||
|
||||

|
||||
|
||||
Delete files using -d option
|
||||
|
||||
#### b) Decompression ####
|
||||
|
||||
bunzip2 filename
|
||||
|
||||

|
||||
|
||||
Decompressing files
|
||||
|
||||
bunzip2 can decompress files with extensions bz2, bz, tbz2 and tbz. Files with tbz2 and tbz will end up with '.tar' extension after decompression.
|
||||
|
||||
bzip2 -dc performs the function of decompressing files to the stdout
|
||||
|
||||
### 7-zip ###
|
||||
|
||||
[7-zip][4] is another open source file archiver. It uses 7z format which is a new compression format and provides high-compression ratio. Hence, it is considered to be better than the previously mentioned compression tools. It is available under Linux as p7zip package. The package includes three binaries – 7z, 7za and 7zr. Refer to the [p7zip wiki][5] for differences between these binaries. In this article, we will be using 7zr to explain the usage. Archived files will have '.7z' extension.
|
||||
|
||||
**Basic usage**
|
||||
|
||||
#### a) Creating an archive ####
|
||||
|
||||
7zr a archive-name.7z file-name(s) / directory-name(s)
|
||||
|
||||

|
||||
|
||||
Creating an archive
|
||||
|
||||
#### b) Listing an archive ####
|
||||
|
||||
7zr l archive-name.7z
|
||||
|
||||

|
||||
|
||||
Listing an archive
|
||||
|
||||
#### c) Extracting an archive ####
|
||||
|
||||
7zr e archive-name.7z
|
||||
|
||||

|
||||
|
||||
Extracting an archive
|
||||
|
||||
#### d) Updating an archive ####
|
||||
|
||||
7zr u archive-name.7z new-file
|
||||
|
||||

|
||||
|
||||
Updating an archive
|
||||
|
||||
#### e) Deleting files from an archive ####
|
||||
|
||||
7zr d archive-name.7z file-to-be-deleted
|
||||
|
||||

|
||||
|
||||
Deleting files
|
||||
|
||||

|
||||
|
||||
Verifying file deletion
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/linux-compress-decompress-tools/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bnpoornima/
|
||||
[1]:http://www.gnu.org/software/tar/
|
||||
[2]:http://www.gzip.org/
|
||||
[3]:http://www.bzip.org/
|
||||
[4]:http://www.7-zip.org/
|
||||
[5]:https://wiki.archlinux.org/index.php/p7zip
|
||||
@ -0,0 +1,44 @@
|
||||
How To Protect Ubuntu Server Against the GHOST Vulnerability
|
||||
================================================================================
|
||||
On January 27, 2015, a GNU C Library (glibc) vulnerability, referred to as the GHOST vulnerability, was announced to the general public. In summary, the vulnerability allows remote attackers to take complete control of a system by exploiting a buffer overflow bug in glibc's GetHOST functions.Check more details from [here][1]
|
||||
|
||||
The GHOST vulnerability can be exploited on Linux systems that use versions of the GNU C Library prior to glibc-2.18. That is, systems that use an unpatched version of glibc from versions 2.2 to 2.17 are at risk.
|
||||
|
||||
### Check System Vulnerability ###
|
||||
|
||||
You can use the following command to check the glib version
|
||||
|
||||
ldd --version
|
||||
|
||||
### Output ###
|
||||
|
||||
ldd (Ubuntu GLIBC 2.19-10ubuntu2) **2.19**
|
||||
Copyright (C) 2014 Free Software Foundation, Inc.
|
||||
This is free software; see the source for copying conditions. There is NO
|
||||
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
|
||||
Written by Roland McGrath and Ulrich Drepper.
|
||||
|
||||
The glib version should be above 2.17 and from the output we are running 2.19.If you are seeing glib version between 2.2 to 2.17 then you need to run the following commands
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
After the installation you need to reboot the server using the following command
|
||||
|
||||
sudo reboot
|
||||
|
||||
After reboot use the same command again and check the glib version.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/how-to-protect-ubuntu-server-against-the-ghost-vulnerability.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://chargen.matasano.com/chargen/2015/1/27/vulnerability-overview-ghost-cve-2015-0235.html
|
||||
@ -0,0 +1,70 @@
|
||||
Install Linux-Dash (Web Based Monitoring tool) on Ubntu 14.10
|
||||
================================================================================
|
||||
A low-overhead monitoring web dashboard for a GNU/Linux machine. Simply drop-in the app and go!.Linux Dash's interface provides a detailed overview of all vital aspects of your server, including RAM and disk usage, network, installed software, users, and running processes. All information is organized into sections, and you can jump to a specific section using the buttons in the main toolbar. Linux Dash is not the most advanced monitoring tool out there, but it might be a good fit for users looking for a slick, lightweight, and easy to deploy application.
|
||||
|
||||
### Linux-Dash Features ###
|
||||
|
||||
A beautiful web-based dashboard for monitoring server info
|
||||
|
||||
Live, on-demand monitoring of RAM, Load, Uptime, Disk Allocation, Users and many more system stats
|
||||
|
||||
Drop-in install for servers with Apache2/nginx + PHP
|
||||
|
||||
Click and drag to re-arrange widgets
|
||||
|
||||
Support for wide range of linux server flavors
|
||||
|
||||
### List of Current Widgets ###
|
||||
|
||||
- General info
|
||||
- Load Average
|
||||
- RAM
|
||||
- Disk Usage
|
||||
- Users
|
||||
- Software
|
||||
- IP
|
||||
- Internet Speed
|
||||
- Online
|
||||
- Processes
|
||||
- Logs
|
||||
|
||||
### Install Linux-dash on ubuntu server 14.10 ###
|
||||
|
||||
First you need to make sure you have [Ubuntu LAMP server 14.10][1] installed and Now you have to install the following package
|
||||
|
||||
sudo apt-get install php5-json unzip
|
||||
|
||||
After the installation this module will enable for apache2 so you need to restart the apache2 server using the following command
|
||||
|
||||
sudo service apache2 restart
|
||||
|
||||
Now you need to download the linux-dash package and install
|
||||
|
||||
wget https://github.com/afaqurk/linux-dash/archive/master.zip
|
||||
|
||||
unzip master.zip
|
||||
|
||||
sudo mv linux-dash-master/ /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to change the permissions using the following command
|
||||
|
||||
sudo chmod 755 /var/www/html/linux-dash-master/
|
||||
|
||||
Now you need to go to http://serverip/linux-dash-master/ you should see similar to the following output
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-linux-dash-web-based-monitoring-tool-on-ubntu-14-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -0,0 +1,78 @@
|
||||
Install Mumble in Ubuntu an Opensource VoIP Apps
|
||||
================================================================================
|
||||
Mumble is a free and open source voice over IP (VoIP) application, released under the new BSD license, primarily designed for use by gamers and it's similar to programs such as TeamSpeak and Ventrilo. It uses a server to witch people can connect with a client to talk to each other.
|
||||
|
||||
It offers the following great features:
|
||||
|
||||
- low latency, very important for gaming
|
||||
- offers in-game overlay so you can see who is talking and positional audio to hear the players from where they are located
|
||||
- has encrypted communications so you can stay private and secure
|
||||
- it also offers a few nice configuration interface that are easy to use
|
||||
- very stable and good on resource usage for your server
|
||||
|
||||
### Install Mumble ###
|
||||
|
||||
[Mumble][1] has become very popular and is now present in the software repositories of the major Linux distributions and this makes it easy to install and setup. In Ubuntu you can use the command line to install it with apt-get by running the following command:
|
||||
|
||||
$ sudo apt-get install mumble-server
|
||||
|
||||

|
||||
|
||||
This will install the server (also called Murmur) on your server.
|
||||
|
||||
### Configuring Mumble ###
|
||||
|
||||
To setup Mumble you will need to run the following command:
|
||||
|
||||
$ sudo dpkg-reconfigure mumble-server
|
||||
|
||||
The following questions will pop-up:
|
||||
|
||||

|
||||
|
||||
Pick Yes to have mumble start when your server boots, next it will ask if you wish to run it in a high-priority mode that will ensure lower latency, it's a good idea to have it run it like that for the best performance:
|
||||
|
||||

|
||||
|
||||
It will then require you to introduce a password for the administrator user of the new mumble server, you will need to remember this password for when you will log-in.
|
||||
|
||||

|
||||
|
||||
### Installing Mumble Client ###
|
||||
|
||||
The client can be installed on most major platforms like Windows, Mac OS X and Linux. We will cover the installation and configuration on Ubuntu Linux, to install it you can use the Software Center or run the following command:
|
||||
|
||||
$ sudo apt-get install mumble
|
||||
|
||||
When you first run Mumble it will present you with a wizard to help you configure your audio input and output to make the best of the client. It will first ask you what sound device and microphone to use:
|
||||
|
||||

|
||||
|
||||
Then it will help you calibrate the devices:
|
||||
|
||||

|
||||
|
||||
And since mumble encrypts all the communication it will ask you to also create a certificate:
|
||||
|
||||

|
||||
|
||||
After you finish with the wizard you can add your first server and connect to it the dialog will look like this:
|
||||
|
||||

|
||||
|
||||
First enter a label, this can be anything you wish to remember the server by, next add the address and port of the server, and finally use "SuperUser" as user and the password you used when you configured the mumble server.
|
||||
|
||||
You can now connect to the server and enjoy all of the features while you play online or talk to your friends or partners.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-mumble-ubuntu/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://wiki.mumble.info/wiki/Main_Page
|
||||
@ -0,0 +1,270 @@
|
||||
Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules
|
||||
================================================================================
|
||||
For those of you in the hosting business, or if you’re hosting your own servers and exposing them to the Internet, securing your systems against attackers must be a high priority.
|
||||
|
||||
mod_security (an open source intrusion detection and prevention engine for web applications that integrates seamlessly with the web server) and mod_evasive are two very important tools that can be used to protect a web server against brute force or (D)DoS attacks.
|
||||
|
||||
mod_evasive, as its name suggests, provides evasive capabilities while under attack, acting as an umbrella that shields web servers from such threats.
|
||||
|
||||

|
||||
Install Mod_Security and Mod_Evasive to Protect Apache
|
||||
|
||||
In this article we will discuss how to install, configure, and put them into play along with Apache on RHEL/CentOS 6 and 7 as well as Fedora 21-15. In addition, we will simulate attacks in order to verify that the server reacts accordingly.
|
||||
|
||||
This assumes that you have a LAMP server installed on your system. If not, please check this article before proceeding further.
|
||||
|
||||
- [Install LAMP stack in RHEL/CentOS 7][1]
|
||||
|
||||
You will also need to setup iptables as the default [firewall][2] front-end instead of firewalld if you’re running RHEL/CentOS 7 or Fedora 21. We do this in order to use the same tool in both RHEL/CentOS 7/6 and Fedora 21.
|
||||
|
||||
### Step 1: Installing Iptables Firewall on RHEL/CentOS 7 and Fedora 21 ###
|
||||
|
||||
To begin, stop and disable firewalld:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
Disable Firewalld Service
|
||||
|
||||
Then install the iptables-services package before enabling iptables:
|
||||
|
||||
# yum update && yum install iptables-services
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
# systemctl status iptables
|
||||
|
||||

|
||||
Install Iptables Firewall
|
||||
|
||||
### Step 2: Installing Mod_Security and Mod_evasive ###
|
||||
|
||||
In addition to having a LAMP setup already in place, you will also have to [enable the EPEL repository][3] in RHEL/CentOS 7/6 in order to install both packages. Fedora users don’t need to enable any repo, because epel is a already part of Fedora project.
|
||||
|
||||
# yum update && yum install mod_security mod_evasive
|
||||
|
||||
When the installation is complete, you will find the configuration files for both tools in /etc/httpd/conf.d.
|
||||
|
||||
# ls -l /etc/httpd/conf.d
|
||||
|
||||

|
||||
mod_security + mod_evasive Configurations
|
||||
|
||||
Now, in order to integrate these two modules with Apache and have it load them when it starts, make sure the following lines appear in the top level section of mod_evasive.conf and mod_security.conf, respectively:
|
||||
|
||||
LoadModule evasive20_module modules/mod_evasive24.so
|
||||
LoadModule security2_module modules/mod_security2.so
|
||||
|
||||
Note that modules/mod_security2.so and modules/mod_evasive24.so are the relative paths, from the /etc/httpd directory to the source file of the module. You can verify this (and change it, if needed) by listing the contents of the /etc/httpd/modules directory:
|
||||
|
||||
# cd /etc/httpd/modules
|
||||
# pwd
|
||||
# ls -l | grep -Ei '(evasive|security)'
|
||||
|
||||
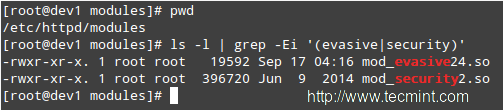
|
||||
Verify mod_security + mod_evasive Modules
|
||||
|
||||
Then restart Apache and verify that it loads mod_evasive and mod_security:
|
||||
|
||||
# service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
|
||||
# systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
|
||||
|
||||
----------
|
||||
|
||||
[Dump a list of loaded Static and Shared Modules]
|
||||
|
||||
# httpd -M | grep -Ei '(evasive|security)'
|
||||
|
||||
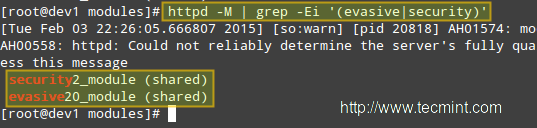
|
||||
Check mod_security + mod_evasive Modules Loaded
|
||||
|
||||
### Step 3: Installing A Core Rule Set and Configuring Mod_Security ###
|
||||
|
||||
In few words, a Core Rule Set (aka CRS) provides the web server with instructions on how to behave under certain conditions. The developer firm of mod_security provide a free CRS called OWASP ([Open Web Application Security Project][4]) ModSecurity CRS that can be downloaded and installed as follows.
|
||||
|
||||
1. Download the OWASP CRS to a directory created for that purpose.
|
||||
|
||||
# mkdir /etc/httpd/crs-tecmint
|
||||
# cd /etc/httpd/crs-tecmint
|
||||
# wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
|
||||
|
||||

|
||||
Download mod_security Core Rules
|
||||
|
||||
2. Untar the CRS file and change the name of the directory for one of our convenience.
|
||||
|
||||
# tar xzf master
|
||||
# mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
|
||||
|
||||

|
||||
Extract mod_security Core Rules
|
||||
|
||||
3. Now it’s time to configure mod_security. Copy the sample file with rules (owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example) into another file without the .example extension:
|
||||
|
||||
# cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
|
||||
|
||||
and tell Apache to use this file along with the module by inserting the following lines in the web server’s main configuration file /etc/httpd/conf/httpd.conf file. If you chose to unpack the tarball in another directory you will need to edit the paths following the Include directives:
|
||||
|
||||
<IfModule security2_module>
|
||||
Include crs-tecmint/owasp-modsecurity-crs/modsecurity_crs_10_setup.conf
|
||||
Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
|
||||
</IfModule>
|
||||
|
||||
Finally, it is recommended that we create our own configuration file within the /etc/httpd/modsecurity.d directory where we will place our customized directives (we will name it tecmint.conf in the following example) instead of modifying the CRS files directly. Doing so will allow for easier upgrading the CRSs as new versions are released.
|
||||
|
||||
<IfModule mod_security2.c>
|
||||
SecRuleEngine On
|
||||
SecRequestBodyAccess On
|
||||
SecResponseBodyAccess On
|
||||
SecResponseBodyMimeType text/plain text/html text/xml application/octet-stream
|
||||
SecDataDir /tmp
|
||||
</IfModule>
|
||||
|
||||
You can refer to the [SpiderLabs’ ModSecurity GitHub][5] repository for a complete explanatory guide of mod_security configuration directives.
|
||||
|
||||
### Step 4: Configuring Mod_Evasive ###
|
||||
|
||||
mod_evasive is configured using directives in /etc/httpd/conf.d/mod_evasive.conf. Since there are no rules to update during a package upgrade, we don’t need a separate file to add customized directives, as opposed to mod_security.
|
||||
|
||||
The default mod_evasive.conf file has the following directives enabled (note that this file is heavily commented, so we have stripped out the comments to highlight the configuration directives below):
|
||||
|
||||
<IfModule mod_evasive24.c>
|
||||
DOSHashTableSize 3097
|
||||
DOSPageCount 2
|
||||
DOSSiteCount 50
|
||||
DOSPageInterval 1
|
||||
DOSSiteInterval 1
|
||||
DOSBlockingPeriod 10
|
||||
</IfModule>
|
||||
|
||||
Explanation of the directives:
|
||||
|
||||
- DOSHashTableSize: This directive specifies the size of the hash table that is used to keep track of activity on a per-IP address basis. Increasing this number will provide a faster look up of the sites that the client has visited in the past, but may impact overall performance if it is set too high.
|
||||
- DOSPageCount: Legitimate number of identical requests to a specific URI (for example, any file that is being served by Apache) that can be made by a visitor over the DOSPageInterval interval.
|
||||
- DOSSiteCount: Similar to DOSPageCount, but refers to how many overall requests can be made to the entire site over the DOSSiteInterval interval.
|
||||
- DOSBlockingPeriod: If a visitor exceeds the limits set by DOSSPageCount or DOSSiteCount, his source IP address will be blacklisted during the DOSBlockingPeriod amount of time. During DOSBlockingPeriod, any requests coming from that IP address will encounter a 403 Forbidden error.
|
||||
|
||||
Feel free to experiment with these values so that your web server will be able to handle the required amount and type of traffic.
|
||||
|
||||
**Only a small caveat**: if these values are not set properly, you run the risk of ending up blocking legitimate visitors.
|
||||
|
||||
You may also want to consider other useful directives:
|
||||
|
||||
#### DOSEmailNotify ####
|
||||
|
||||
If you have a mail server up and running, you can send out warning messages via Apache. Note that you will need to grant the apache user SELinux permission to send emails if SELinux is set to enforcing. You can do so by running
|
||||
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
|
||||
Next, add this directive in the mod_evasive.conf file with the rest of the other directives:
|
||||
|
||||
DOSEmailNotify you@yourdomain.com
|
||||
|
||||
If this value is set and your mail server is working properly, an email will be sent to the address specified whenever an IP address becomes blacklisted.
|
||||
|
||||
#### DOSSystemCommand ####
|
||||
|
||||
This needs a valid system command as argument,
|
||||
|
||||
DOSSystemCommand </command>
|
||||
|
||||
This directive specifies a command to be executed whenever an IP address becomes blacklisted. It is often used in conjunction with a shell script that adds a firewall rule to block further connections coming from that IP address.
|
||||
|
||||
**Write a shell script that handles IP blacklisting at the firewall level**
|
||||
|
||||
When an IP address becomes blacklisted, we need to block future connections coming from it. We will use the following shell script that performs this job. Create a directory named scripts-tecmint (or whatever name of your choice) in /usr/local/bin and a file called ban_ip.sh in that directory.
|
||||
|
||||
#!/bin/sh
|
||||
# IP that will be blocked, as detected by mod_evasive
|
||||
IP=$1
|
||||
# Full path to iptables
|
||||
IPTABLES="/sbin/iptables"
|
||||
# mod_evasive lock directory
|
||||
MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
|
||||
# Add the following firewall rule (block all traffic coming from $IP)
|
||||
$IPTABLES -I INPUT -s $IP -j DROP
|
||||
# Remove lock file for future checks
|
||||
rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
|
||||
|
||||
Our DOSSystemCommand directive should read as follows:
|
||||
|
||||
DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
|
||||
|
||||
In the line above, %s represents the offending IP as detected by mod_evasive.
|
||||
|
||||
**Add the apache user to the sudoers file**
|
||||
|
||||
Note that all of this just won’t work unless you to give permissions to user apache to run our script (and that script only!) without a terminal and password. As usual, you can just type visudo as root to access the /etc/sudoers file and then add the following 2 lines as shown in the image below:
|
||||
|
||||
apache ALL=NOPASSWD: /usr/local/bin/scripts-tecmint/ban_ip.sh
|
||||
Defaults:apache !requiretty
|
||||
|
||||

|
||||
Add Apache User to Sudoers
|
||||
|
||||
**IMPORTANT**: As a default security policy, you can only run sudo in a terminal. Since in this case we need to use sudo without a tty, we have to comment out the line that is highlighted in the following image:
|
||||
|
||||
#Defaults requiretty
|
||||
|
||||
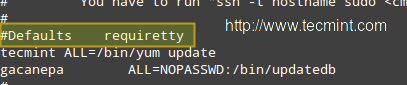
|
||||
Disable tty for Sudo
|
||||
|
||||
Finally, restart the web server:
|
||||
|
||||
# service httpd restart [On RHEL/CentOS 6 and Fedora 20-18]
|
||||
# systemctl restart httpd [On RHEL/CentOS 7 and Fedora 21]
|
||||
|
||||
### Step 4: Simulating an DDoS Attacks on Apache ###
|
||||
|
||||
There are several tools that you can use to simulate an external attack on your server. You can just google for “tools for simulating ddos attacks” to find several of them.
|
||||
|
||||
Note that you, and only you, will be held responsible for the results of your simulation. Do not even think of launching a simulated attack to a server that you’re not hosting within your own network.
|
||||
|
||||
Should you want to do the same with a VPS that is hosted by someone else, you need to appropriately warn your hosting provider or ask permission for such a traffic flood to go through their networks. Tecmint.com is not, by any means, responsible for your acts!
|
||||
|
||||
In addition, launching a simulated DoS attack from only one host does not represent a real life attack. To simulate such, you would need to target your server from several clients at the same time.
|
||||
|
||||
Our test environment is composed of a CentOS 7 server [IP 192.168.0.17] and a Windows host from which we will launch the attack [IP 192.168.0.103]:
|
||||
|
||||

|
||||
Confirm Host IPAddress
|
||||
|
||||
Please play the video below and follow the steps outlined in the indicated order to simulate a simple DoS attack:
|
||||
|
||||
注:youtube视频,发布的时候不行做个链接吧
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/-U_mdet06Jk"></iframe>
|
||||
|
||||
Then the offending IP is blocked by iptables:
|
||||
|
||||

|
||||
Blocked Attacker IP
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
With mod_security and mod_evasive enabled, the simulated attack causes the CPU and RAM to experiment a temporary usage peak for only a couple of seconds before the source IPs are blacklisted and blocked by the firewall. Without these tools, the simulation will surely knock down the server very fast and render it unusable during the duration of the attack.
|
||||
|
||||
We would love to hear if you’re planning on using (or have used in the past) these tools. We always look forward to hearing from you, so don’t hesitate to leave your comments and questions, if any, using the form below.
|
||||
|
||||
### Reference Links ###
|
||||
|
||||
- [https://www.modsecurity.org/][6]
|
||||
- [http://www.zdziarski.com/blog/?page_id=442][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
|
||||
[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
|
||||
[6]:https://www.modsecurity.org/
|
||||
[7]:http://www.zdziarski.com/blog/?page_id=442
|
||||
@ -0,0 +1,169 @@
|
||||
Simple Steps Migration From MySQL To MariaDB On Linux
|
||||
================================================================================
|
||||
Hi all, this tutorial is all gonna be about how to migrate from MySQL to MariaDB on Linux Server or PC. So, you may ask why should we really migrate from MySQL to MariaDB for our database management. Here, below are the reasons why you should really need to migrate your database management system from MySQL to MariaDB.
|
||||
|
||||
### Why should I use MariaDB instead of MySQL? ###
|
||||
|
||||
MariaDB is an enhanced drop-in replacement and community-developed fork of the MySQL database system. It was developed by MariaDB foundation, and is being led by original developers of MySQL. Working with MariaDB is entirely same as MySQL. After Oracle bought MySQL, it is not free and open source anymore, but **MariaDB is still free and open source**. Top Websites like Google, Wikipedia, Linkedin, Mozilla and many more migrated to MariaDB. Its features are
|
||||
|
||||
- Backwards compatible with MySQL
|
||||
- Forever open source
|
||||
- Maintained by MySQL's creator
|
||||
- More cutting edge features
|
||||
- More storage engines
|
||||
- Large websites have switched
|
||||
|
||||
Now, lets migrate to MariaDB.
|
||||
|
||||
**For the testing purpose**, let us create a sample database called **linoxidedb** .
|
||||
|
||||
Log in to MySQL as root user using the following command:
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
Enter the mysql root user password. You’ll be redirected to the **mysql prompt**.
|
||||
|
||||
**Create test databases:**
|
||||
|
||||
Enter the following commands from mysql prompt to create test databases.
|
||||
|
||||
mysql> create database linoxidedb;
|
||||
|
||||
To view the list of available databases, enter the following command:
|
||||
|
||||
mysql> show databases;
|
||||
|
||||

|
||||
|
||||
As see above, we have totally 5 databases including the newly created database linoxidedb .
|
||||
|
||||
mysql> quit
|
||||
|
||||
Now, we'll migrate the created databases from MySQL to MariaDB.
|
||||
|
||||
Note: This tutorial is not necessary for CentOS, fedora based distribution of Linux because MariaDB is automatically installed instead of MySQL which requires no need to backup the existing databases, you just need to update mysql which will give you mariadb.
|
||||
|
||||
### 1. Backup existing databases ###
|
||||
|
||||
Our first important step is to create a backup of existing databases. To do that, we'll enter the following command from the **Terminal (not from MySQL prompt)**.
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdatabase.sql
|
||||
|
||||
Oops! We encountered an error. No worries, it can be fixed.
|
||||
|
||||
$ mysqldump: Error: Binlogging on server not active
|
||||
|
||||

|
||||
mysqldump error
|
||||
|
||||
To fix this error, we have to do a small modification in **my.cnf** file.
|
||||
|
||||
Edit my.cnf file:
|
||||
|
||||
$ sudo nano /etc/mysql/my.cnf
|
||||
|
||||
Under [mysqld] section, add the following parameter.
|
||||
|
||||
**log-bin=mysql-bin**
|
||||
|
||||

|
||||
|
||||
Now, after done save and exit the file. Then, we'll need to restart mysql server. To do that please execute the below commands.
|
||||
|
||||
$ sudo /etc/init.d/mysql restart
|
||||
|
||||
Now, re-run the mysqldump command to backup all databases.
|
||||
|
||||
$ mysqldump --all-databases --user=root --password --master-data > backupdatabase.sql
|
||||
|
||||

|
||||
dumping databases
|
||||
|
||||
The above command will backup all databases, and stores them in **backupdatabase.sql** in the current directory.
|
||||
|
||||
### 2. Uninstalling MySQL ###
|
||||
|
||||
First of all, we'll want to **backup the my.cnf file to a safe location**.
|
||||
|
||||
**Note**: The my.cnf file will not be deleted when uninstalling MySQL packages. We do it for the precaution. During MariaDB installation, the installer will ask us to keep the existing my.cnf(old backup) file or to use the package containers version (i.e new one).
|
||||
|
||||
To backup the my.cnf file, please enter the following commands in a shell or terminal.
|
||||
|
||||
$ sudo cp /etc/mysql/my.cnf my.cnf.bak
|
||||
|
||||
To stop mysql service, enter the following command from your Terminal.
|
||||
|
||||
$ sudo /etc/init.d/mysql stop
|
||||
|
||||
Then, remove mysql packages.
|
||||
|
||||
$ sudo apt-get remove mysql-server mysql-client
|
||||
|
||||

|
||||
|
||||
### 3. Installing MariaDB ###
|
||||
|
||||
Here are the commands to run to install MariaDB on your Ubuntu system:
|
||||
|
||||
$ sudo apt-get install software-properties-common
|
||||
$ sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
|
||||
# sudo add-apt-repository 'deb http://mirror.mephi.ru/mariadb/repo/5.5/ubuntu trusty main'
|
||||
|
||||

|
||||
|
||||
Once the key is imported and the repository added you can install MariaDB with:
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install mariadb-server
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
We should remember that during MariaDB installation, the installer will ask you either to use the existing my.cnf(old backup) file, or use the package containers version (i.e new one). You can either use the old my.cnf file or the package containers version. If you want to use the new my.cnf version, you can restore the contents of older my.cnf (We already have copied this file to safe location before) later ie my.cnf.bak . So, I will go for default which is N, we'll press N then. For other versions, please refer the [MariaDB official repositories page][2].
|
||||
|
||||
### 4. Restoring Config File ###
|
||||
|
||||
To restore my.cnf from my.cnf.bak, enter the following command in Terminal. We have the old as my.cnf.bak file in our current directory, so we can simply copy the file using the following command:
|
||||
|
||||
$ sudo cp my.cnf.bak /etc/mysql/my.cnf
|
||||
|
||||
### 5. Importing Databases ###
|
||||
|
||||
Finally, lets import the old databases that we created before. To do that, we'll need to run the following command.
|
||||
|
||||
$ mysql -u root -p < backupdatabase.sql
|
||||
|
||||
That’s it. We have successfully imported the old databases.
|
||||
|
||||
Let us check if the databases are really imported. To do that, we'll wanna log in to mysql prompt using command:
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||

|
||||
|
||||
Now, to check whether the databases are migrated to MariaDB please run "**show databases**;" command inside the MarianDB prompt without quotes("") as
|
||||
|
||||
mariaDB> show databases;
|
||||
|
||||

|
||||
|
||||
As you see in the above result all old databases including our very linoxidedb has been successfully migrated.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Finally, we have successfully migrated our databases from MySQL to MariaDB Database Management System. MariaDB is far more better than MySQL. Though MySQL is still faster than MariaDB in performance but MariaDB is far more better because of its additional features and license. MariaDB is a Free and Open Source Software (FOSS) and will be FOSS forever but MySQL has many additional plugins, etc non-free and there is no proper public roadmap and won't be FOSS in future. If you have any questions, comments, feedback to us, please don't hesitate to write on the comment box below. Thank You ! And Enjoy MariaDB.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/migrate-mysql-mariadb-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://mariadb.org/
|
||||
[2]:https://downloads.mariadb.org/mariadb/repositories/#mirror=mephi
|
||||
@ -1,158 +0,0 @@
|
||||
+在Linux中使用matplotlib进行科学画图
|
||||
+================================================================================
|
||||
+
|
||||
+如果你想要在Linxu中获得一个高效、自动化、高质量的科学画图的解决方案,那就要考虑一下使用matplotlib库了。Matplotlib是基于python的开源科学测绘包,版权基于python软件基金许可证。大量的文档和例子,整合在Python和Numpy科学计处包中,其自动化性能是少数几个为什么这个包是在Linux环境中进行科学画图的可靠选择。这个教程将提供几个用matplotlib画图的例子。
|
||||
+
|
||||
+###特性###
|
||||
+-
|
||||
+-众多的画图类型,如:bar,box,contour,histogram,scatter,line plots....
|
||||
+-基于python的语法
|
||||
+-集成Numpy科学计算包
|
||||
+-可定制的画图格式(axes scales,tick positions, tick labels...)
|
||||
+-可定制文本(字体,大小,位置...)
|
||||
+-TeX 格式化(等式,符号,希腊字体...)
|
||||
+-与IPython相兼容
|
||||
+-自动化 -用Python 的循环迭代生成图片
|
||||
+-保存所绘图片格式为图片文件,如:png,pdf,ps,eps,svg等
|
||||
+
|
||||
+
|
||||
+基于Python语法的matplotlib通过许多自身特性和高效工作流基础进行表现。
|
||||
+世面上有许多用于绘制高质量图的科学绘图包,但是这些包允许你直接在你的Python代码中去使用吗?
|
||||
+除那以外,这些包允许你创建可以保存为图片文件的图片吗?
|
||||
+Matplotlib允许你完成所有的这些任务。
|
||||
+你可以期望着节省你的时间,从于使用你能够花更多的时间在如何创建更多的图片。
|
||||
+
|
||||
+###安装###
|
||||
+ 安装Python和Numpy包是使用Matplotlib的前提,安装Numpy的指引请见该链接。[here][1].
|
||||
+
|
||||
+
|
||||
+可以通过如下命令在Debian或Ubuntu中安装Matplotlib:
|
||||
+
|
||||
+ $ sudo apt-get install python-matplotlib
|
||||
+
|
||||
+
|
||||
+在Fedora或CentOS/RHEL环境则可用如下命令:
|
||||
+ $ sudo yum install python-matplotlib
|
||||
+
|
||||
+
|
||||
+###Matplotlib 例子###
|
||||
+
|
||||
+该教程会提供几个绘图例子演示如何使用matplotlib:
|
||||
+-离散和线性画图
|
||||
+-柱状图画图
|
||||
+-饼状图
|
||||
+
|
||||
+在这些例子中我们将用Python脚本来执行Mapplotlib命令。注意numpy和matplotlib模块需要通过import命令在脚本中进行导入。
|
||||
+在命令空间中,np指定为nuupy模块的引用,plt指定为matplotlib.pyplot的引用:
|
||||
+ import numpy as np
|
||||
+ import matplotlib.pyplot as plt
|
||||
+
|
||||
+
|
||||
+###例1:离散和线性图###
|
||||
+
|
||||
+第一个脚本,script1.py 完成如下任务:
|
||||
+
|
||||
+-创建3个数据集(xData,yData1和yData2)
|
||||
+-创建一个宽8英寸、高6英寸的图(赋值1)
|
||||
+-设置图画的标题、x轴标签、y轴标签(字号均为14)
|
||||
+-绘制第一个数据集:yData1为xData数据集的函数,用圆点标识的离散蓝线,标识为"y1 data"
|
||||
+-绘制第二个数据集:yData2为xData数据集的函数,采用红实线,标识为"y2 data"
|
||||
+-把图例放置在图的左上角
|
||||
+-保存图片为PNG格式文件
|
||||
+
|
||||
+script1.py的内容如下:
|
||||
+ import numpy as np
|
||||
+ import matplotlib.pyplot as plt
|
||||
+
|
||||
+ xData = np.arange(0, 10, 1)
|
||||
+ yData1 = xData.__pow__(2.0)
|
||||
+ yData2 = np.arange(15, 61, 5)
|
||||
+ plt.figure(num=1, figsize=(8, 6))
|
||||
+ plt.title('Plot 1', size=14)
|
||||
+ plt.xlabel('x-axis', size=14)
|
||||
+ plt.ylabel('y-axis', size=14)
|
||||
+ plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
|
||||
+ plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
|
||||
+ plt.legend(loc='upper left')
|
||||
+ plt.savefig('images/plot1.png', format='png')
|
||||
+
|
||||
+
|
||||
+所画之图如下:
|
||||
+
|
||||
+
|
||||
+
|
||||
+###例2:柱状图###
|
||||
+
|
||||
+第二个脚本,script2.py 完成如下任务:
|
||||
+
|
||||
+-创建一个包含1000个随机样本的正态分布数据集。
|
||||
+-创建一个宽8英寸、高6英寸的图(赋值1)
|
||||
+-设置图的标题、x轴标签、y轴标签(字号均为14)
|
||||
+-用samples这个数据集画一个40个柱状,边从-10到10的柱状图
|
||||
+-添加文本,用TeX格式显示希腊字母mu和sigma(字号为16)
|
||||
+-保存图片为PNG格式。
|
||||
+
|
||||
+script2.py代码如下:
|
||||
+ import numpy as np
|
||||
+ import matplotlib.pyplot as plt
|
||||
+
|
||||
+ mu = 0.0
|
||||
+ sigma = 2.0
|
||||
+ samples = np.random.normal(loc=mu, scale=sigma, size=1000)
|
||||
+ plt.figure(num=1, figsize=(8, 6))
|
||||
+ plt.title('Plot 2', size=14)
|
||||
+ plt.xlabel('value', size=14)
|
||||
+ plt.ylabel('counts', size=14)
|
||||
+ plt.hist(samples, bins=40, range=(-10, 10))
|
||||
+ plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
|
||||
+ plt.savefig('images/plot2.png', format='png')
|
||||
+
|
||||
+
|
||||
+结果见如下链接:
|
||||
+
|
||||
+
|
||||
+
|
||||
+###例3:饼状图###
|
||||
+
|
||||
+第三个脚本,script3.py 完成如下任务:
|
||||
+
|
||||
+-创建一个包含5个整数的列表
|
||||
+-创建一个宽6英寸、高6英寸的图(赋值1)
|
||||
+-添加一个长宽比为1的轴图
|
||||
+-设置图的标题(字号为14)
|
||||
+-用data列表画一个包含标签的饼状图
|
||||
+-保存图为PNG格式
|
||||
+
|
||||
+脚本script3.py的代码如下:
|
||||
+ import numpy as np
|
||||
+ import matplotlib.pyplot as plt
|
||||
+
|
||||
+ data = [33, 25, 20, 12, 10]
|
||||
+ plt.figure(num=1, figsize=(6, 6))
|
||||
+ plt.axes(aspect=1)
|
||||
+ plt.title('Plot 3', size=14)
|
||||
+ plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
|
||||
+ plt.savefig('images/plot3.png', format='png')
|
||||
+
|
||||
+
|
||||
+结果如下链接所示:
|
||||
+
|
||||
+
|
||||
+
|
||||
+###总结###
|
||||
+ 这个教程提供了几个用matplotlib科学画图包进行画图的例子,Matplotlib是在Linux环境中用于解决科学画图的绝佳方案,表现在其无缝地和Python、Numpy连接,自动化能力,和提供多种自定义的高质量的画图产品。[here][2].
|
||||
+
|
||||
+matplotlib包的文档和例子详见:
|
||||
+--------------------------------------------------------------------------------
|
||||
+
|
||||
+via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
|
||||
+
|
||||
+作者:[Joshua Reed][a]
|
||||
+译者:[ideas4u](https://github.com/ideas4u)
|
||||
+校对:[校对者ID](https://github.com/校对者ID)
|
||||
+
|
||||
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
+
|
||||
+[a]:http://xmodulo.com/author/joshua
|
||||
+[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
|
||||
+[2]:http://matplotlib.org/
|
||||
@ -0,0 +1,146 @@
|
||||
如何在 Ubuntu 14.04 里面配置 chroot 环境
|
||||
================================================================================
|
||||
你可能会有很多理由想要把一个应用、一个用户或者一个环境与你的 linux 系统隔离开来。不同的操作系统有不同的实现方式,而在 linux 中,一个典型的方式就是 chroot 环境。
|
||||
|
||||
在这份教程中,我会一步一步指导你怎么使用 chroot 命令去配置一个与真实系统分离出来的独立环境。这个功能主要可以用于测试项目,这些步骤都在 **Ubuntu 14.04** 虚拟专用服务器(VPS)上执行。
|
||||
|
||||
学会快速搭建一个简单的 chroot 环境是一项非常实用的技能,绝大多数系统管理员都能从中受益。
|
||||
|
||||
### Chroot 环境 ###
|
||||
|
||||
一个 chroot 环境就是通过系统调用,将一个本地目录临时变成根目录。一般所说的系统根目录就是挂载点"/",然而使用 chroot 命令后,你可以使用其它目录作为根目录。
|
||||
|
||||
原则上,任何运行在 chroot 环境内的应用都不能访问系统中其他信息(LCTT译注:使用 chroot 把一个目录变成根目录,在里面运行的应用只能访问本目录内的文件,无法访问到目录外的文件。然而,运行在 chroot 环境的应用可以通过 sysfs 文件系统访问到环境外的信息,所以,这里有个“原则上”的修饰语)。
|
||||
|
||||
### Chroot 环境的用处 ###
|
||||
|
||||
> - 测试一个不稳定的应用服务不会影响到整个主机系统。
|
||||
>
|
||||
> - 就算使用 root 权限做了些不当的操作,把 chroot 环境搞得一塌糊涂,也不会影响到主机系统。
|
||||
>
|
||||
> - 可以在你的系统中运行另外一个操作系统。
|
||||
|
||||
举个例子,你可以在 chroot 环境中编译、安装、测试软件,而不去动真实的系统。你也可以**在64位环境下使用 chroot 创建一个32位环境,然后运行一个32位的程序**(LCTT泽注:如果你的真实环境是32位的,那就不能 chroot 一个64位的环境了)。
|
||||
|
||||
但是 为了安全考虑,chroot 环境为非特权用户设立了非常严格的限制,而不是提供完整的安全策略。如果你需要的是有完善的安全策略的隔离方案,可以考虑下 LXC、Docker、vservers等等。
|
||||
|
||||
### Debootstrap 和 Schroot ###
|
||||
|
||||
使用 chroot 环境需要安装 **debootstrap** 和 **schroot**,这两个软件都在 Ubuntu 的镜像源中。其中 schroot 用于创建 chroot 环境。
|
||||
|
||||
**Debootstrap** 可以让你通过镜像源安装任何 Debian(或基于 Debian 的)系统,装好的系统会包含最基本的命令。
|
||||
|
||||
**Schroot** 命令允许用户使用相同的机制去创建 chroot 环境,但在访问 chroot 环境时会做些权限检查,并且会允许用户做些额外的自动设置,比如挂载一些文件系统。
|
||||
|
||||
在 Ubuntu 14.04 LTS 上,我们可以通过两步来实现这个功能:
|
||||
|
||||
### 1. 安装软件包 ###
|
||||
|
||||
第一步,在Ubuntu 14.04 LTS 主机系统上安装 debootstrap 和 schroot:
|
||||
|
||||
$ sudo apt-get install debootstrap
|
||||
$ sudo apt-get install schroot
|
||||
|
||||
### 2. 配置 Schroot ###
|
||||
|
||||
现在我们有工具在手,需要指定一个目录作为我们的 chroot 环境。这里创建一个目录先:
|
||||
|
||||
sudo mkdir /linoxide
|
||||
|
||||
编辑 schroot 的配置文件:
|
||||
|
||||
sudo nano /etc/schroot/schroot.conf
|
||||
|
||||
再提醒一下,我们现在是在 Ubuntu 14.04 LTS 系统上。如果我们想测试一个软件包能不能在 Ubuntu 13.10(代号是“Saucy Salamander”) 上运行,就可以在配置文件中添加下面的内容:
|
||||
|
||||
[saucy]
|
||||
description=Ubuntu Saucy
|
||||
location=/linoxide
|
||||
priority=3
|
||||
users=arun
|
||||
root-groups=root
|
||||
|
||||

|
||||
|
||||
根据你的系统要求,调整上面的配置信息。
|
||||
|
||||
### 3. 使用 debootstrap 安装32位 Ubuntu 系统 ###
|
||||
|
||||
Debootstrap 命令会在你的 **chroot 环境**里面下载安装一个最小系统。只要你能访问镜像源,你就可以安装任何基于 Debian 的系统版本。
|
||||
|
||||
前面我们已经创建了 **/linoxide** 目录用于放置 chroot 环境,现在我们可以在这个目录里面运行 debootstrap 了:
|
||||
|
||||
cd /linoxide
|
||||
sudo debootstrap --variant=buildd --arch amd64 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
sudo chroot /linoxide /debootstrap/debootstrap --second-stage
|
||||
|
||||
你可以将 --arch 的参数换成 i386 或其他架构,只要存在这种架构的镜像源。你也可以把镜像源 http://archive.ubuntu.com/ubuntu/ 换成离你最近的镜像源,具体可参考 [Ubuntu 官方镜像主页][1]。
|
||||
|
||||
**注意:如果你是在64位系统中创建32位系统,你需要在上面第3行命令中加入 --foreign 选项,就像下面的命令:**
|
||||
|
||||
sudo debootstrap --variant=buildd --foreign --arch i386 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
|
||||
下载需要一段时间,看你网络带宽性能。最小系统大概有500M。
|
||||
|
||||
### 4. 完成 chroot 环境 ###
|
||||
|
||||
安装完系统后,我们需要做一些收尾工作,确保系统运行正常。首先,保证主机的 fstab 程序能意识到 chroot 环境的存在:
|
||||
|
||||
sudo nano /etc/fstab
|
||||
|
||||
在文件最后面添加下面的配置:
|
||||
|
||||
proc /linoxide/proc proc defaults 0 0
|
||||
sysfs /linoxide/sys sysfs defaults 0 0
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
挂载一些文件系统到 chroot 环境:
|
||||
|
||||
$ sudo mount proc /linoxide/proc -t proc
|
||||
$ sudo mount sysfs /linoxide/sys -t sysfs
|
||||
|
||||
复制 /etc/hosts 文件到 chroot 环境,这样 chroot 环境就可以使用网络了:
|
||||
|
||||
$ sudo cp /etc/hosts /linoxide/etc/hosts
|
||||
|
||||
最后使用 schroot -l 命令列出系统上所有的 chroot 环境:
|
||||
|
||||
$ schroot -l
|
||||
|
||||
使用下面的命令进入 chroot 环境:
|
||||
|
||||
$ sudo chroot /linoxide/ /bin/bash
|
||||
|
||||
测试安装的版本:
|
||||
|
||||
# lsb_release -a
|
||||
# uname -a
|
||||
|
||||
为了在 chroot 环境中使用图形界面,你需要设置 DISPLAY 环境变量:
|
||||
|
||||
$ DISPLAY=:0.0 ./apps
|
||||
|
||||
目前为止,我已经成功地在 Ubuntu 14.04 LTS 上安装了 Ubuntu 13.10。
|
||||
|
||||
退出 chroot 环境:
|
||||
|
||||
# exit
|
||||
|
||||
清理一下,卸载文件系统:
|
||||
|
||||
$ sudo umount /test/proc
|
||||
$ sudo umount /test/sys
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
81
translated/tech/20150128 Docker-1 Moving to Docker.md
Normal file
81
translated/tech/20150128 Docker-1 Moving to Docker.md
Normal file
@ -0,0 +1,81 @@
|
||||
Moving to Docker
|
||||
================================================================================
|
||||

|
||||
|
||||
[TL;DR] 这是系列的第一篇文章,这系列讲述了我的公司如何把基础服务从PaaS迁移到Docker上。如果你愿意,你可以直接跳过介绍(这篇文章)直接看技术相关的话题(链接在页面的底部)。
|
||||
|
||||
----------
|
||||
|
||||
上个月,我一直在折腾开发环境。这是我个人故事和经验,关于尝试用Docker简化Rails应用的部署过程。
|
||||
|
||||
当我在2012年创建我的公司 – [Touchware][1]时,我还是一个独立开发者。很多事情很小,不复杂,不他们需要很多维护,他们也不需要不部署到很多机器上。经过过去一年的发展,我们成长了很多(我们现在是是拥有10个人团队)而且我们的服务端的程序和API无论在范围和规模方面都有增长。
|
||||
|
||||
### 第1步 - Heroku ###
|
||||
|
||||
我们还是个小公司,我们需要让事情运行地尽可能平稳。当我们寻找可行的解决方案时,我们打算坚持用那些可以帮助我们减轻对硬件依赖负担的工具。由于我们主要开发Rails应用,而Heroku对RoR,常用的数据库和缓存(Postgres/Mongo/Redis等)有很好的支持,最明智的选择就是用[Heroku][2] 。我们就是这样做的。
|
||||
|
||||
Heroku有很好的技术支持和文档,使得部署非常轻松。唯一的问题是,当你处于起步阶段,你需要很多开销。这不是最好的选择,真的。
|
||||
|
||||
### 第2步 - Dokku ###
|
||||
|
||||
为了尝试并降低成本,我们决定试试Dokku。[Dokku][3],引用GitHub上的一句话
|
||||
|
||||
> Docker powered mini-Heroku in around 100 lines of Bash
|
||||
|
||||
我们启用的[DigitalOcean][4]上的很多台机器,都预装了Dokku。Dokku非常像Heroku,但是当你有复杂的项目需要调整配置参数或者是需要特殊的依赖时,它就不能胜任了。我们有一个应用,它需要对图片进行多次转换,我们无法安装一个适合版本的imagemagick到托管我们Rails应用的基于Dokku的Docker容器内。尽管我们还有很多应用运行在Dokku上,但我们还是不得不把一些迁移回Heroku。
|
||||
|
||||
### 第3步 - Docker ###
|
||||
|
||||
几个月前,由于开发环境和生产环境的问题重新出现,我决定试试Docker。简单来说,Docker让开发者容器化应用,简化部署。由于一个Docker容器本质上已经包含项目运行所需要的所有依赖,只要它能在你的笔记本上运行地很好,你就能确保它将也能在任何一个别的远程服务器的生产环境上运行,包括Amazon的EC2和DigitalOcean上的VPS。
|
||||
|
||||
Docker IMHO特别有意思的原因是:
|
||||
|
||||
- 它促进了模块化和分离关注点:你只需要去考虑应用的逻辑部分(负载均衡:1个容器;数据库:1个容器;web服务器:1个容器);
|
||||
- 在部署的配置上非常灵活:容器可以被部署在大量的HW上,也可以容易地重新部署在不同的服务器或者提供商那;
|
||||
- 它允许非常细粒度地优化应用的运行环境:你可以利用你的容器来创建镜像,所以你有很多选择来配置环境。
|
||||
|
||||
它也有一些缺点:
|
||||
|
||||
- 它的学习曲线非常的陡峭(这是从一个软件开发者的角度来看,而不是经验丰富的运维人员);
|
||||
- 搭建环境不简单,尤其是还需要自己搭建一个私有的registry/repository (后面有关于它的详细内容)。
|
||||
|
||||
下面是一些提示。这个系列的最后一周,我将把他们和一些新的放在一起。
|
||||
|
||||
----------
|
||||
|
||||
在下面的文章中,我们将看到如何建立一个半自动化的基于Docker的部署系统。
|
||||
|
||||
- [建立私有的Docker registry][6]
|
||||
- [配置Rails应用的半自动化话部署][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://cocoahunter.com/2015/01/23/docker-1/
|
||||
|
||||
作者:[Michelangelo Chasseur][a]
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://cocoahunter.com/author/michelangelo/
|
||||
[1]:http://www.touchwa.re/
|
||||
[2]:http://cocoahunter.com/2015/01/23/docker-1/www.heroku.com
|
||||
[3]:https://github.com/progrium/dokku
|
||||
[4]:http://cocoahunter.com/2015/01/23/docker-1/www.digitalocean.com
|
||||
[5]:http://www.docker.com/
|
||||
[6]:http://cocoahunter.com/2015/01/23/docker-2/
|
||||
[7]:http://cocoahunter.com/2015/01/23/docker-3/
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,91 @@
|
||||
Linux 有问必答:如何在Linux 中修复“fatal error: x264.h: No such file or directory”的错误
|
||||
================================================================================
|
||||
> **提问**: 我想在Linux中从源码编译视频编码程序。到那时,在编译时,我遇到了一个错误“fatal error: x264.h: No such file or directory”,我该如何修复?
|
||||
|
||||
下面的编译错误错明你系统中没有x264开发库文件。
|
||||
|
||||
fatal error: x264.h: No such file or directory
|
||||
|
||||
[x264][1]是GNU GPL授权的H.264/MPEG-4 AVC编码库。x264库被广泛用于视频编码/转码程序比如Avidemux、[FFmpeg][2]、 [HandBrake][3]、 OpenShot、 MEncode等等。
|
||||
|
||||
要解决这个问题,你需要安装x264的开发库文件。你可以这么做。
|
||||
|
||||
###在 Debian、 Ubuntu 或者 Linux Mint 中安装像x264库和开发文件 ###
|
||||
|
||||
在基于Debian的系统中,x264库已经包含在基础仓库中。可以直接用apt-get来安装。
|
||||
|
||||
$ sudo apt-get install libx264-dev
|
||||
|
||||
### 在 Fedora、 CentOS/RHEL中安装像x264库和开发文件 ###
|
||||
|
||||
在基于Red Hat的发行版比如Fedora或者CentOS,x264库在免费的RPM Fusion仓库中有。那么,你需要首先安装[RPM Fusion (免费)][4] 。
|
||||
|
||||
RPM Fusion设置完成后,你可以使用下面的命令安装x264开发文件。
|
||||
|
||||
$ sudo yum --enablerepo=rpmfusion-free install x264-devel
|
||||
|
||||
注意RPM Fusion仓库在CentOS 7中还没有,因此上面的方法在CentOS 7中还不可行。万一是CentOS 7 ,你可以从源码编译并安装x264,下面会解释的。
|
||||
|
||||
### 在Debian、 Ubuntu 或者 Linux Mint中源码编译x264库 ###
|
||||
|
||||
如果libx264包在你的发行版中并没有,那么你可以按照下面的方法编译最新的x264库。
|
||||
|
||||
$ sudo apt-get install g++ automake autoconf libtool yasm nasm git
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
$ cd x264
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
x264库将会安装在/usr/local/lib。要让其他程序可以使用这个库,你需要完成最后一步。
|
||||
|
||||
打开/etc/ld.so.conf,并添加下面的行。
|
||||
|
||||
$ sudo vi /etc/ld.so.conf
|
||||
|
||||
----------
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
最后运行下面的命令重新加载共享库:
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||
### 在 Fedora, CentOS/RHEL 中源码编译x264库 ###
|
||||
|
||||
如果你Linux的发行版中没有x264库(比如:CentOS 7)或者x264库并不是最新的,你可以如下编译最新的x264库。
|
||||
|
||||
$ sudo yum install gcc gcc-c++ automake autoconf libtool yasm nasm git
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
$ cd x264
|
||||
$ ./configure --enable-static --enable-shared
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
最后,要让其他的程序可以访问到位于 /usr/local/lib的x264库,在 /etc/ld.so.conf加入下面的行。
|
||||
|
||||
$ sudo vi /etc/ld.so.conf
|
||||
|
||||
----------
|
||||
|
||||
/usr/local/lib
|
||||
|
||||
最后运行下面的命令重新加载共享库:
|
||||
|
||||
$ sudo ldconfig
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/fatal-error-x264-h-no-such-file-or-directory.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.videolan.org/developers/x264.html
|
||||
[2]:http://ask.xmodulo.com/compile-ffmpeg-centos-fedora-rhel.html
|
||||
[3]:http://xmodulo.com/how-to-install-handbrake-on-linux.html
|
||||
[4]:http://xmodulo.com/how-to-install-rpm-fusion-on-fedora.html
|
||||
Loading…
Reference in New Issue
Block a user