mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
commit
4ccc3e860e
@ -0,0 +1,74 @@
|
|||||||
|
5 个提升你开源项目贡献者基数的方法
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
图片提供:opensource.com
|
||||||
|
|
||||||
|
许多自由和开源软件项目因解决问题而出现,人们开始为它们做贡献,是因为他们也想修复遇到的问题。当项目的最终用户发现它对他们的需求有用,该项目就开始增长。并且出于分享的目的把人们吸引到同一个项目社区。
|
||||||
|
|
||||||
|
就像任何事物都是有寿命的,增长既是项目成功的标志也是来源。那么项目领导者和维护者如何激励贡献者基数的增长?这里有五种方法。
|
||||||
|
|
||||||
|
### 1、 提供好的文档
|
||||||
|
|
||||||
|
人们经常低估项目[文档][2]的重要性。它是项目贡献者的主要信息来源,它会激励他们努力。信息必须是正确和最新的。它应该包括如何构建该软件、如何提交补丁、编码风格指南等步骤。
|
||||||
|
|
||||||
|
查看经验丰富的科技作家、编辑 Bob Reselman 的 [7 个创建世界级文档的规则][3]。
|
||||||
|
|
||||||
|
开发人员文档的一个很好的例子是 [Python 开发人员指南][4]。它包括清晰简洁的步骤,涵盖 Python 开发的各个方面。
|
||||||
|
|
||||||
|
### 2、 降低进入门槛
|
||||||
|
|
||||||
|
如果你的项目有[工单或 bug 追踪工具][5],请确保将初级任务标记为一个“小 bug” 或“起点”。新的贡献者可以很容易地通过解决这些问题进入项目。追踪工具也是标记非编程任务(如平面设计、图稿和文档改进)的地方。有许多项目成员不是每天都编码,但是却通过这种方式成为推动力。
|
||||||
|
|
||||||
|
Fedora 项目维护着一个这样的[易修复和入门级问题的追踪工具][6]。
|
||||||
|
|
||||||
|
### 3、 为补丁提供常规反馈
|
||||||
|
|
||||||
|
确认每个补丁,即使它只有一行代码,并给作者反馈。提供反馈有助于吸引潜在的候选人,并指导他们熟悉项目。所有项目都应有一个邮件列表和[聊天功能][7]进行通信。问答可在这些媒介中发生。大多数项目不会在一夜之间成功,但那些繁荣的列表和沟通渠道为增长创造了环境。
|
||||||
|
|
||||||
|
### 4、 推广你的项目
|
||||||
|
|
||||||
|
始于解决问题的项目实际上可能对其他开发人员也有用。作为项目的主要贡献者,你的责任是为你的的项目建立文档并推广它。写博客文章,并在社交媒体上分享项目的进展。你可以从简要描述如何成为项目的贡献者开始,并在该描述中提供主要开发者文档的参考连接。此外,请务必提供有关路线图和未来版本的信息。
|
||||||
|
|
||||||
|
为了你的听众,看看由 Opensource.com 的社区经理 Rikki Endsley 写的[写作提示][8]。
|
||||||
|
|
||||||
|
### 5、 保持友好
|
||||||
|
|
||||||
|
友好的对话语调和迅速的回复将加强人们对你的项目的兴趣。最初,这些问题只是为了寻求帮助,但在未来,新的贡献者也可能会提出想法或建议。让他们有信心他们可以成为项目的贡献者。
|
||||||
|
|
||||||
|
记住你一直在被人评头论足!人们会观察项目开发者是如何在邮件列表或聊天上交谈。这些意味着对新贡献者的欢迎和开放程度。当使用技术时,我们有时会忘记人文关怀,但这对于任何项目的生态系统都很重要。考虑一个情况,项目是很好的,但项目维护者不是很受欢迎。这样的管理员可能会驱使用户远离项目。对于有大量用户基数的项目而言,不被支持的环境可能导致分裂,一部分用户可能决定复刻项目并启动新项目。在开源世界中有这样的先例。
|
||||||
|
|
||||||
|
另外,拥有不同背景的人对于开源项目的持续增长和源源不断的点子是很重要的。
|
||||||
|
|
||||||
|
最后,项目负责人有责任维持和帮助项目成长。指导新的贡献者是项目的关键,他们将成为项目和社区未来的领导者。
|
||||||
|
|
||||||
|
阅读:由红帽的内容战略家 Nicole Engard 写的 [7 种让新的贡献者感到受欢迎的方式][1]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Kushal Das - Kushal Das 是 Python 软件基金会的一名 CPython 核心开发人员和主管。他是一名长期的 FOSS 贡献者和导师,他帮助新人进入贡献世界。他目前在 Red Hat 担任 Fedora 云工程师。他的博客在 https://kushaldas.in 。你也可以在 Twitter @kushaldas 上找到他
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/1/expand-project-contributor-base
|
||||||
|
|
||||||
|
作者:[Kushal Das][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[Bestony](https://github.com/bestony)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/kushaldas
|
||||||
|
[1]:https://opensource.com/life/16/5/sumana-harihareswara-maria-naggaga-oscon
|
||||||
|
[2]:https://opensource.com/tags/documentation
|
||||||
|
[3]:https://opensource.com/business/16/1/scale-14x-interview-bob-reselman
|
||||||
|
[4]:https://docs.python.org/devguide/
|
||||||
|
[5]:https://opensource.com/tags/bugs-and-issues
|
||||||
|
[6]:https://fedoraproject.org/easyfix/
|
||||||
|
[7]:https://opensource.com/alternatives/slack
|
||||||
|
[8]:https://opensource.com/business/15/10/what-stephen-king-can-teach-tech-writers
|
||||||
@ -1,42 +1,35 @@
|
|||||||
如何在 Linux 中捕获并流式传输你的游戏会话
|
如何在 Linux 中捕获并流式传输你的游戏过程
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
### 在本页中
|
也许没有那么多铁杆的游戏玩家使用 Linux,但肯定有很多 Linux 用户喜欢玩游戏。如果你是其中之一,并希望向世界展示 Linux 游戏不再是一个笑话,那么你会喜欢下面这个关于如何捕捉并且/或者以流式播放游戏的快速教程。我在这将用一个名为 “[Open Broadcaster Software Studio][5]” 的软件,这可能是我们所能找到最好的一种。
|
||||||
|
|
||||||
1. [捕获设置][1]
|
|
||||||
2. [设置源][2]
|
|
||||||
3. [过渡][3]
|
|
||||||
4. [总结][4]
|
|
||||||
|
|
||||||
也许没有许多铁杆玩家使用 Linux,但现在肯定有很多 Linux 用户喜欢玩游戏。如果你是其中之一,并希望向世界展示 Linux 游戏不再是一个笑话,那么你会发现下面这个关于如何捕捉并且/或者流式播放游戏的快速教程。我在这将用一个名为 “[Open Broadcaster Software Studio][5]” 的软件,这可能是我们找到最好的一种。
|
|
||||||
|
|
||||||
### 捕获设置
|
### 捕获设置
|
||||||
|
|
||||||
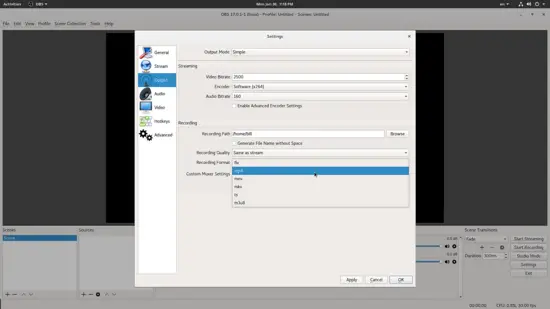
在顶层菜单中,我们选择 File → Settings,然后我们选择 “Output” 来设置要生成的文件的选项。这里我们可以设置想要的音频和视频的比特率、新创建的文件的目标路径和文件格式。这上面还提供了粗略的质量设置。
|
在顶层菜单中,我们选择 “File” → “Settings”,然后我们选择 “Output” 来设置要生成的文件的选项。这里我们可以设置想要的音频和视频的比特率、新创建的文件的目标路径和文件格式。这上面还提供了粗略的质量设置。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][6]
|
][6]
|
||||||
|
|
||||||
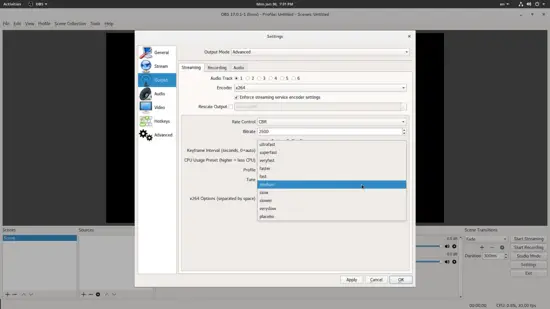
如果我们将顶部的输出模式从 “Simple” 更改为 “Advanced”,我们就能够设置 CPU 负载,使 OBS 能够控制系统。根据所选的质量,CPU 能力和捕获的游戏,存在一个 CPU 负载设置不会导致帧丢失。你可能需要做一些试验才能找到最佳设置,但如果质量设置为低,则不用担心。
|
如果我们将顶部的输出模式从 “Simple” 更改为 “Advanced”,我们就能够设置 CPU 负载,以控制 OBS 对系统的影响。根据所选的质量、CPU 能力和捕获的游戏,可以设置一个不会导致丢帧的 CPU 负载设置。你可能需要做一些试验才能找到最佳设置,但如果将质量设置为低,则不用太多设置。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][7]
|
][7]
|
||||||
|
|
||||||
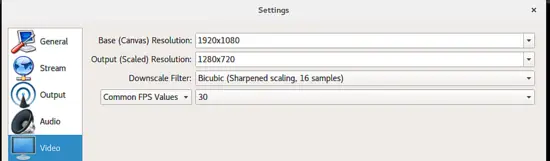
接下来,我们转到设置的 “Video” 部分,我们可以设置我们想要的输出视频分辨率。注意缩小过滤方法,因为它使最终的质量有所不同。
|
接下来,我们转到设置的 “Video” 部分,我们可以设置我们想要的输出视频分辨率。注意缩小过滤(downscaling filtering )方式,因为它使最终的质量有所不同。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][8]
|
][8]
|
||||||
|
|
||||||
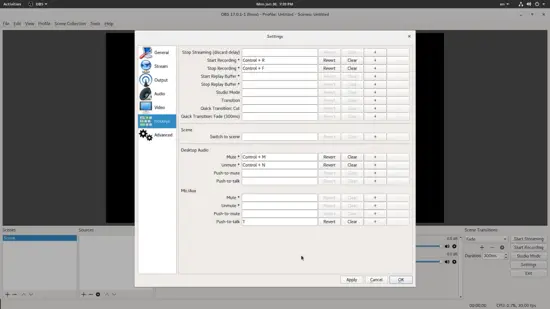
你可能还需要绑定热键以启动、暂停和停止录制。这是特别有用的,因为你可以在录制时看到游戏的屏幕。为此,请在设置中选择 “Hotkeys” 部分,并在相应的框中分配所需的按键。当然,你不必每个框都填写,你只需要填写所需的。
|
你可能还需要绑定热键以启动、暂停和停止录制。这特别有用,这样你就可以在录制时看到游戏的屏幕。为此,请在设置中选择 “Hotkeys” 部分,并在相应的框中分配所需的按键。当然,你不必每个框都填写,你只需要填写所需的。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][9]
|
][9]
|
||||||
|
|
||||||
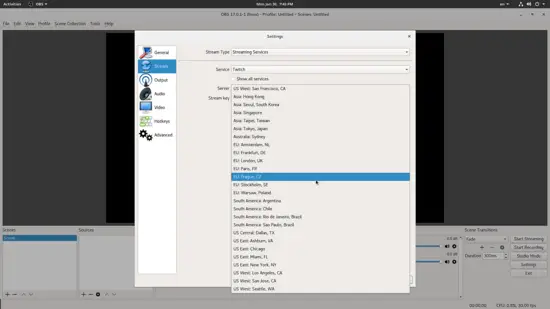
如果你对流式传输感兴趣,而不仅仅是录制,请选择 “Stream” 分类的设置,然后你可以选择支持的 30 种流媒体服务,包括Twitch、Facebook Live 和 Youtube,然后选择服务器并输入 流密钥。
|
如果你对流式传输感兴趣,而不仅仅是录制,请选择 “Stream” 分类的设置,然后你可以选择支持的 30 种流媒体服务,包括 Twitch、Facebook Live 和 Youtube,然后选择服务器并输入 流密钥。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
@ -44,17 +37,17 @@
|
|||||||
|
|
||||||
### 设置源
|
### 设置源
|
||||||
|
|
||||||
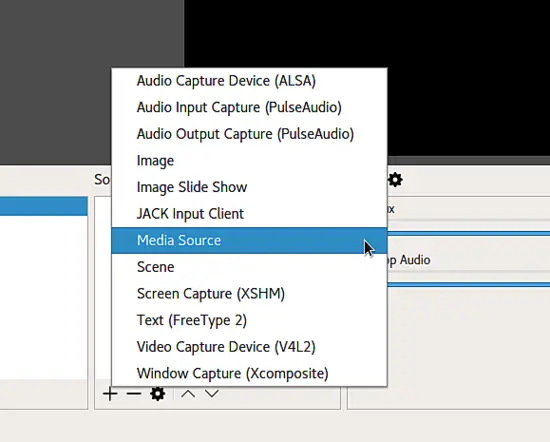
在左下方,你会发现一个名为 “Sources” 的框。我们按下加号好添加一个新的源,它本质上就是我们录制的媒体源。在这你可以设置音频和视频源,但是图像甚至文本也是可以的。
|
在左下方,你会发现一个名为 “Sources” 的框。我们按下加号来添加一个新的源,它本质上就是我们录制的媒体源。在这你可以设置音频和视频源,但是图像甚至文本也是可以的。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][11]
|
][11]
|
||||||
|
|
||||||
前三个是关于音频源,接下来的两个是图像,JACK 选项用于从乐器捕获的实时音频,媒体源用于添加文件等。这里我们感兴趣的是 “Screen Capture (XSHM)”、“Video Capture Device (V4L2)” 和 “Window Capture (Xcomposite)” 选项。
|
前三个是关于音频源,接下来的两个是图像,JACK 选项用于从乐器捕获的实时音频, Media Source 用于添加文件等。这里我们感兴趣的是 “Screen Capture (XSHM)”、“Video Capture Device (V4L2)” 和 “Window Capture (Xcomposite)” 选项。
|
||||||
|
|
||||||
屏幕捕获选项让你选择要捕获的屏幕(包括活动屏幕),以便记录所有内容。如工作区更改、窗口最小化等。对于标准批量录制来说,这是一个适合的选项,它可在发布之前进行编辑。
|
屏幕捕获选项让你选择要捕获的屏幕(包括活动屏幕),以便记录所有内容。如工作区更改、窗口最小化等。对于标准批量录制来说,这是一个适合的选项,它可在发布之前进行编辑。
|
||||||
|
|
||||||
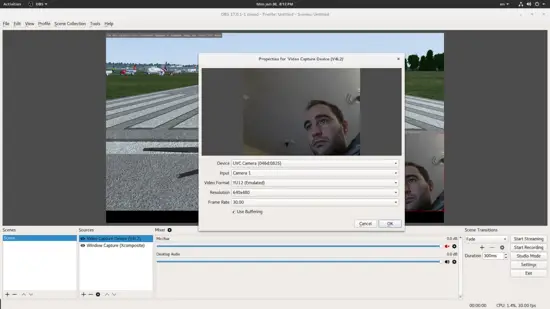
我们来探讨另外两个。Window Capture 将让我们选择一个活动窗口并将其放入捕获监视器。为了将我们的脸放在一个角落,视频捕获设备是有用的,这样人们可以在我们说话时看到我们。当然,每个添加的源都提供了一组选项来供我们实现我们最后要的效果。
|
我们来探讨另外两个。Window Capture 将让我们选择一个活动窗口并将其放入捕获监视器。为了将我们的脸放在一个角落,视频捕获设备用于人们可以在我们说话时可以看到我们。当然,每个添加的源都提供了一组选项来供我们实现我们最后要的效果。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
@ -68,7 +61,7 @@
|
|||||||
|
|
||||||
### 过渡
|
### 过渡
|
||||||
|
|
||||||
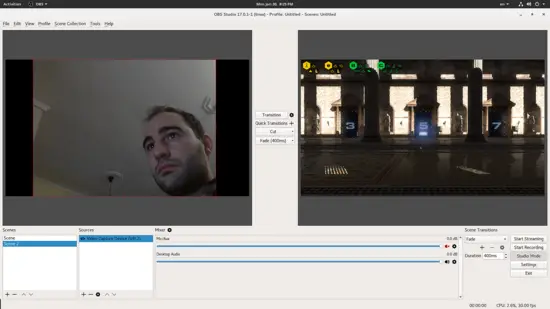
最后,我们假设你正在流式传输游戏会话,并希望能够在游戏视图和自己(或任何其他来源)之间切换。为此,请从右下角切换为“Studio Mode”,并添加一个分配给另一个源的场景。你还可以通过取消选中 “Duplicate scene” 并检查 “Transitions” 旁边的齿轮图标上的 “Duplicate sources” 来切换。 当你想在简短评论中显示你的脸部时,这很有帮助。
|
最后,如果你正在流式传输游戏会话时希望能够在游戏视图和自己(或任何其他来源)之间切换。为此,请从右下角切换为“Studio Mode”,并添加一个分配给另一个源的场景。你还可以通过取消选中 “Duplicate scene” 并检查 “Transitions” 旁边的齿轮图标上的 “Duplicate sources” 来切换。 当你想在简短评论中显示你的脸部时,这很有帮助。
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
@ -84,9 +77,9 @@ OBS Studio 是一个功能强大的免费软件,它工作稳定,使用起来
|
|||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||||
|
|
||||||
作者:[Bill Toulas ][a]
|
作者:[Bill Toulas][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -1,28 +1,28 @@
|
|||||||
如何在 CentOS 7 中安装、配置 SFTP - [全面指南]
|
完全指南:如何在 CentOS 7 中安装、配置和安全加固 FTP 服务
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
FTP(文件传输协议)是一种用于通过网络[在服务器和客户端之间传输文件][1]的传统并广泛使用的标准工具,特别是在不需要身份验证的情况下(允许匿名用户连接到服务器)。我们必须明白,默认情况下 FTP 是不安全的,因为它不加密传输用户凭据和数据。
|
FTP(文件传输协议)是一种用于通过网络[在服务器和客户端之间传输文件][1]的传统并广泛使用的标准工具,特别是在不需要身份验证的情况下(允许匿名用户连接到服务器)。我们必须明白,默认情况下 FTP 是不安全的,因为它不加密传输用户凭据和数据。
|
||||||
|
|
||||||
在本指南中,我们将介绍在 CentOS/RHEL7 和 Fedora 发行版中安装、配置和保护 FTP 服务器( VSFTPD 代表 “Very Secure FTP Daemon”)的步骤。
|
在本指南中,我们将介绍在 CentOS/RHEL7 和 Fedora 发行版中安装、配置和保护 FTP 服务器( VSFTPD 代表 “Very Secure FTP Daemon”)的步骤。
|
||||||
|
|
||||||
请注意,本指南中的所有命令将以 root 身份运行,以防你不使用 root 帐户操作服务器,请使用 [sudo命令][2] 获取 root 权限。
|
请注意,本指南中的所有命令将以 root 身份运行,如果你不使用 root 帐户操作服务器,请使用 [sudo命令][2] 获取 root 权限。
|
||||||
|
|
||||||
### 步骤 1:安装 FTP 服务器
|
### 步骤 1:安装 FTP 服务器
|
||||||
|
|
||||||
1. 安装 vsftpd 服务器很直接,只要在终端运行下面的命令。
|
1、 安装 vsftpd 服务器很直接,只要在终端运行下面的命令。
|
||||||
|
|
||||||
```
|
```
|
||||||
# yum install vsftpd
|
# yum install vsftpd
|
||||||
```
|
```
|
||||||
|
|
||||||
2. 安装完成后,服务会先被禁用,因此我们需要手动启动,并设置在下次启动时自动启用:
|
2、 安装完成后,服务先是被禁用的,因此我们需要手动启动,并设置在下次启动时自动启用:
|
||||||
|
|
||||||
```
|
```
|
||||||
# systemctl start vsftpd
|
# systemctl start vsftpd
|
||||||
# systemctl enable vsftpd
|
# systemctl enable vsftpd
|
||||||
```
|
```
|
||||||
|
|
||||||
3. 接下来,为了允许从外部系统访问 FTP 服务,我们需要打开 FTP 守护进程监听 21 端口:
|
3、 接下来,为了允许从外部系统访问 FTP 服务,我们需要打开 FTP 守护进程监听的 21 端口:
|
||||||
|
|
||||||
```
|
```
|
||||||
# firewall-cmd --zone=public --permanent --add-port=21/tcp
|
# firewall-cmd --zone=public --permanent --add-port=21/tcp
|
||||||
@ -32,7 +32,7 @@ FTP(文件传输协议)是一种用于通过网络[在服务器和客户端
|
|||||||
|
|
||||||
### 步骤 2: 配置 FTP 服务器
|
### 步骤 2: 配置 FTP 服务器
|
||||||
|
|
||||||
4. 现在,我们会进行一些配置来设置并加密我们的 FTP 服务器,让我们先备份一下原始配置文件 /etc/vsftpd/vsftpd.conf:
|
4、 现在,我们会进行一些配置来设置并加密我们的 FTP 服务器,让我们先备份一下原始配置文件 `/etc/vsftpd/vsftpd.conf`:
|
||||||
|
|
||||||
```
|
```
|
||||||
# cp /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd.conf.orig
|
# cp /etc/vsftpd/vsftpd.conf /etc/vsftpd/vsftpd.conf.orig
|
||||||
@ -41,30 +41,30 @@ FTP(文件传输协议)是一种用于通过网络[在服务器和客户端
|
|||||||
接下来,打开上面的文件,并将下面的选项设置相关的值:
|
接下来,打开上面的文件,并将下面的选项设置相关的值:
|
||||||
|
|
||||||
```
|
```
|
||||||
anonymous_enable=NO # disable anonymous login
|
anonymous_enable=NO ### 禁用匿名登录
|
||||||
local_enable=YES # permit local logins
|
local_enable=YES ### 允许本地用户登录
|
||||||
write_enable=YES # enable FTP commands which change the filesystem
|
write_enable=YES ### 允许对文件系统做改动的 FTP 命令
|
||||||
local_umask=022 # value of umask for file creation for local users
|
local_umask=022 ### 本地用户创建文件所用的 umask 值
|
||||||
dirmessage_enable=YES # enable showing of messages when users first enter a new directory
|
dirmessage_enable=YES ### 当用户首次进入一个新目录时显示一个消息
|
||||||
xferlog_enable=YES # a log file will be maintained detailing uploads and downloads
|
xferlog_enable=YES ### 用于记录上传、下载细节的日志文件
|
||||||
connect_from_port_20=YES # use port 20 (ftp-data) on the server machine for PORT style connections
|
connect_from_port_20=YES ### 使用端口 20 (ftp-data)用于 PORT 风格的连接
|
||||||
xferlog_std_format=YES # keep standard log file format
|
xferlog_std_format=YES ### 使用标准的日志格式
|
||||||
listen=NO # prevent vsftpd from running in standalone mode
|
listen=NO ### 不要让 vsftpd 运行在独立模式
|
||||||
listen_ipv6=YES # vsftpd will listen on an IPv6 socket instead of an IPv4 one
|
listen_ipv6=YES ### vsftpd 将监听 IPv6 而不是 IPv4
|
||||||
pam_service_name=vsftpd # name of the PAM service vsftpd will use
|
pam_service_name=vsftpd ### vsftpd 使用的 PAM 服务名
|
||||||
userlist_enable=YES # enable vsftpd to load a list of usernames
|
userlist_enable=YES ### vsftpd 支持载入用户列表
|
||||||
tcp_wrappers=YES # turn on tcp wrappers
|
tcp_wrappers=YES ### 使用 tcp wrappers
|
||||||
```
|
```
|
||||||
|
|
||||||
5. 现在基于用户列表文件 `/etc/vsftpd.userlist` 来配置 FTP 允许/拒绝用户访问。
|
5、 现在基于用户列表文件 `/etc/vsftpd.userlist` 来配置 FTP 来允许/拒绝用户的访问。
|
||||||
|
|
||||||
默认情况下,如果设置了 userlist_enable=YES,当 userlist_deny 选项设置为 YES 的时候,`userlist_file=/etc/vsftpd.userlist` 中的用户列表被拒绝登录。
|
默认情况下,如果设置了 `userlist_enable=YES`,当 `userlist_deny` 选项设置为 `YES` 的时候,`userlist_file=/etc/vsftpd.userlist` 中列出的用户被拒绝登录。
|
||||||
|
|
||||||
然而, userlist_deny=NO 更改了设置,意味着只有在 userlist_file=/etc/vsftpd.userlist 显式指定的用户才允许登录。
|
然而, 更改配置为 `userlist_deny=NO`,意味着只有在 `userlist_file=/etc/vsftpd.userlist` 显式指定的用户才允许登录。
|
||||||
|
|
||||||
```
|
```
|
||||||
userlist_enable=YES # vsftpd will load a list of usernames, from the filename given by userlist_file
|
userlist_enable=YES ### vsftpd 将从 userlist_file 给出的文件中载入用户名列表
|
||||||
userlist_file=/etc/vsftpd.userlist # stores usernames.
|
userlist_file=/etc/vsftpd.userlist ### 存储用户名的文件
|
||||||
userlist_deny=NO
|
userlist_deny=NO
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -72,30 +72,30 @@ userlist_deny=NO
|
|||||||
|
|
||||||
接下来,我们将介绍如何将 FTP 用户 chroot 到 FTP 用户的家目录(本地 root)中的两种可能情况,如下所述。
|
接下来,我们将介绍如何将 FTP 用户 chroot 到 FTP 用户的家目录(本地 root)中的两种可能情况,如下所述。
|
||||||
|
|
||||||
6. 接下来添加下面的选项来限制 FTP 用户到它们自己的家目录。
|
6、 接下来添加下面的选项来限制 FTP 用户到它们自己的家目录。
|
||||||
|
|
||||||
```
|
```
|
||||||
chroot_local_user=YES
|
chroot_local_user=YES
|
||||||
allow_writeable_chroot=YES
|
allow_writeable_chroot=YES
|
||||||
```
|
```
|
||||||
|
|
||||||
chroot_local_user=YES 意味着用户可以设置 chroot jail,默认是登录后的家目录。
|
`chroot_local_user=YES` 意味着用户可以设置 chroot jail,默认是登录后的家目录。
|
||||||
|
|
||||||
同样默认的是,出于安全原因,vsftpd 不会允许 chroot jail 目录可写,然而,我们可以添加 allow_writeable_chroot=YES 来覆盖这个设置。
|
同样默认的是,出于安全原因,vsftpd 不会允许 chroot jail 目录可写,然而,我们可以添加 `allow_writeable_chroot=YES` 来覆盖这个设置。
|
||||||
|
|
||||||
保存并关闭文件。
|
保存并关闭文件。
|
||||||
|
|
||||||
### 用 SELinux 加密 FTP 服务器
|
### 步骤 3: 用 SELinux 加密 FTP 服务器
|
||||||
|
|
||||||
7. 现在,让我们设置下面的 SELinux 布尔值来允许 FTP 能读取用户家目录下的文件。请注意,这最初是使用以下命令完成的:
|
7、现在,让我们设置下面的 SELinux 布尔值来允许 FTP 能读取用户家目录下的文件。请注意,这原本是使用以下命令完成的:
|
||||||
|
|
||||||
```
|
```
|
||||||
# setsebool -P ftp_home_dir on
|
# setsebool -P ftp_home_dir on
|
||||||
```
|
```
|
||||||
|
|
||||||
然而,`ftp_home_dir` 指令由于这个 bug 报告:[https://bugzilla.redhat.com/show_bug.cgi?id=1097775][3] 默认是禁用的。
|
然而,由于这个 bug 报告:[https://bugzilla.redhat.com/show_bug.cgi?id=1097775][3],`ftp_home_dir` 指令默认是禁用的。
|
||||||
|
|
||||||
现在,我们会使用 semanage 命令来设置 SELinux 规则来允许 FTP 读取/写入用户的家目录。
|
现在,我们会使用 `semanage` 命令来设置 SELinux 规则来允许 FTP 读取/写入用户的家目录。
|
||||||
|
|
||||||
```
|
```
|
||||||
# semanage boolean -m ftpd_full_access --on
|
# semanage boolean -m ftpd_full_access --on
|
||||||
@ -109,21 +109,21 @@ chroot_local_user=YES 意味着用户可以设置 chroot jail,默认是登录
|
|||||||
|
|
||||||
### 步骤 4: 测试 FTP 服务器
|
### 步骤 4: 测试 FTP 服务器
|
||||||
|
|
||||||
8. 现在我们会用[ useradd 命令][4]创建一个 FTP 用户来测试 FTP 服务器。
|
8、 现在我们会用 [useradd 命令][4]创建一个 FTP 用户来测试 FTP 服务器。
|
||||||
|
|
||||||
```
|
```
|
||||||
# useradd -m -c “Ravi Saive, CEO” -s /bin/bash ravi
|
# useradd -m -c “Ravi Saive, CEO” -s /bin/bash ravi
|
||||||
# passwd ravi
|
# passwd ravi
|
||||||
```
|
```
|
||||||
|
|
||||||
之后,我们如下使用[ echo 命令][5]添加用户 ravi 到文件 /etc/vsftpd.userlist 中:
|
之后,我们如下使用 [echo 命令][5]添加用户 ravi 到文件 `/etc/vsftpd.userlist` 中:
|
||||||
|
|
||||||
```
|
```
|
||||||
# echo "ravi" | tee -a /etc/vsftpd.userlist
|
# echo "ravi" | tee -a /etc/vsftpd.userlist
|
||||||
# cat /etc/vsftpd.userlist
|
# cat /etc/vsftpd.userlist
|
||||||
```
|
```
|
||||||
|
|
||||||
9. 现在是时候测试我们上面的设置是否可以工作了。让我们使用匿名登录测试,我们可以从下面的截图看到匿名登录不被允许。
|
9、 现在是时候测试我们上面的设置是否可以工作了。让我们使用匿名登录测试,我们可以从下面的截图看到匿名登录没有被允许。
|
||||||
|
|
||||||
```
|
```
|
||||||
# ftp 192.168.56.10
|
# ftp 192.168.56.10
|
||||||
@ -134,13 +134,14 @@ Name (192.168.56.10:root) : anonymous
|
|||||||
Login failed.
|
Login failed.
|
||||||
ftp>
|
ftp>
|
||||||
```
|
```
|
||||||
|
|
||||||
[
|
[
|
||||||
|

|
||||||
][6]
|
][6]
|
||||||
|
|
||||||
测试 FTP 匿名登录
|
*测试 FTP 匿名登录*
|
||||||
|
|
||||||
10. 让我们也测试一下没有列在 /etc/vsftpd.userlist 中的用户是否有权限登录,这不是下面截图中的例子:
|
10、 让我们也测试一下没有列在 `/etc/vsftpd.userlist` 中的用户是否有权限登录,下面截图是没有列入的情况:
|
||||||
|
|
||||||
```
|
```
|
||||||
# ftp 192.168.56.10
|
# ftp 192.168.56.10
|
||||||
@ -155,9 +156,9 @@ ftp>
|
|||||||

|

|
||||||
][7]
|
][7]
|
||||||
|
|
||||||
FTP 用户登录失败
|
*FTP 用户登录失败*
|
||||||
|
|
||||||
11. 现在最后测试一下列在 /etc/vsftpd.userlis 中的用户是否在登录后真的进入了他/她的家目录:
|
11、 现在最后测试一下列在 `/etc/vsftpd.userlist` 中的用户是否在登录后真的进入了他/她的家目录:
|
||||||
|
|
||||||
```
|
```
|
||||||
# ftp 192.168.56.10
|
# ftp 192.168.56.10
|
||||||
@ -171,21 +172,22 @@ Remote system type is UNIX.
|
|||||||
Using binary mode to transfer files.
|
Using binary mode to transfer files.
|
||||||
ftp> ls
|
ftp> ls
|
||||||
```
|
```
|
||||||
|
|
||||||
[
|
[
|
||||||

|

|
||||||
][8]
|
][8]
|
||||||
|
|
||||||
用户成功登录
|
*用户成功登录*
|
||||||
|
|
||||||
警告:使用 `allow_writeable_chroot=YES' 有一定的安全隐患,特别是用户具有上传权限或 shell 访问权限时。
|
警告:使用 `allow_writeable_chroot=YES` 有一定的安全隐患,特别是用户具有上传权限或 shell 访问权限时。
|
||||||
|
|
||||||
只有当你完全知道你正做什么时才激活此选项。重要的是要注意,这些安全性影响并不是 vsftpd 特定的,它们适用于所有 FTP 守护进程,它们也提供将本地用户置于 chroot jail中。
|
只有当你完全知道你正做什么时才激活此选项。重要的是要注意,这些安全性影响并不是 vsftpd 特定的,它们适用于所有提供了将本地用户置于 chroot jail 中的 FTP 守护进程。
|
||||||
|
|
||||||
因此,我们将在下一节中看到一种更安全的方法来设置不同的不可写本地根目录。
|
因此,我们将在下一节中看到一种更安全的方法来设置不同的不可写本地根目录。
|
||||||
|
|
||||||
### 步骤 5: 配置不同的 FTP 家目录
|
### 步骤 5: 配置不同的 FTP 家目录
|
||||||
|
|
||||||
12. 再次打开 vsftpd 配置文件,并将下面不安全的选项注释掉:
|
12、 再次打开 vsftpd 配置文件,并将下面不安全的选项注释掉:
|
||||||
|
|
||||||
```
|
```
|
||||||
#allow_writeable_chroot=YES
|
#allow_writeable_chroot=YES
|
||||||
@ -199,7 +201,7 @@ ftp> ls
|
|||||||
# chmod a-w /home/ravi/ftp
|
# chmod a-w /home/ravi/ftp
|
||||||
```
|
```
|
||||||
|
|
||||||
13. 接下来,在用户存储他/她的文件的本地根目录下创建一个文件夹:
|
13、 接下来,在用户存储他/她的文件的本地根目录下创建一个文件夹:
|
||||||
|
|
||||||
```
|
```
|
||||||
# mkdir /home/ravi/ftp/files
|
# mkdir /home/ravi/ftp/files
|
||||||
@ -207,11 +209,11 @@ ftp> ls
|
|||||||
# chmod 0700 /home/ravi/ftp/files/
|
# chmod 0700 /home/ravi/ftp/files/
|
||||||
```
|
```
|
||||||
|
|
||||||
、接着在 vsftpd 配置文件中添加/修改这些选项:
|
接着在 vsftpd 配置文件中添加/修改这些选项:
|
||||||
|
|
||||||
```
|
```
|
||||||
user_sub_token=$USER # 在本地根目录下插入用户名
|
user_sub_token=$USER ### 在本地根目录下插入用户名
|
||||||
local_root=/home/$USER/ftp # 定义任何用户的本地根目录
|
local_root=/home/$USER/ftp ### 定义任何用户的本地根目录
|
||||||
```
|
```
|
||||||
|
|
||||||
保存并关闭文件。再说一次,有新的设置后,让我们重启服务:
|
保存并关闭文件。再说一次,有新的设置后,让我们重启服务:
|
||||||
@ -220,7 +222,7 @@ local_root=/home/$USER/ftp # 定义任何用户的本地根目录
|
|||||||
# systemctl restart vsftpd
|
# systemctl restart vsftpd
|
||||||
```
|
```
|
||||||
|
|
||||||
14. 现在最后在测试一次查看用户本地根目录就是我们在他的家目录创建的 FTP 目录。
|
14、 现在最后在测试一次查看用户本地根目录就是我们在他的家目录创建的 FTP 目录。
|
||||||
|
|
||||||
```
|
```
|
||||||
# ftp 192.168.56.10
|
# ftp 192.168.56.10
|
||||||
@ -238,7 +240,7 @@ ftp> ls
|
|||||||
|

|
||||||
][9]
|
][9]
|
||||||
|
|
||||||
FTP 用户家目录登录成功
|
*FTP 用户家目录登录成功*
|
||||||
|
|
||||||
就是这样了!在本文中,我们介绍了如何在 CentOS 7 中安装、配置以及加密的 FTP 服务器,使用下面的评论栏给我们回复,或者分享关于这个主题的任何有用信息。
|
就是这样了!在本文中,我们介绍了如何在 CentOS 7 中安装、配置以及加密的 FTP 服务器,使用下面的评论栏给我们回复,或者分享关于这个主题的任何有用信息。
|
||||||
|
|
||||||
@ -258,7 +260,7 @@ via: http://www.tecmint.com/install-ftp-server-in-centos-7/
|
|||||||
|
|
||||||
作者:[Aaron Kili][a]
|
作者:[Aaron Kili][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -273,5 +275,5 @@ via: http://www.tecmint.com/install-ftp-server-in-centos-7/
|
|||||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Login-Failed.png
|
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Login-Failed.png
|
||||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Login.png
|
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Login.png
|
||||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Home-Directory-Login-Successful.png
|
[9]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Home-Directory-Login-Successful.png
|
||||||
[10]:http://www.tecmint.com/install-proftpd-in-centos-7/
|
[10]:https://linux.cn/article-8504-1.html
|
||||||
[11]:http://www.tecmint.com/secure-vsftpd-using-ssl-tls-on-centos/
|
[11]:http://www.tecmint.com/secure-vsftpd-using-ssl-tls-on-centos/
|
||||||
@ -0,0 +1,125 @@
|
|||||||
|
4 个拥有绝佳命令行界面的终端程序
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
> 让我们来看几个精心设计的 CLI 程序,以及如何解决一些可发现性问题。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
>图片提供: opensource.com
|
||||||
|
|
||||||
|
在本文中,我会指出命令行界面的<ruby>可发现性<rt>discoverability</rt></ruby>缺点以及克服这些问题的几种方法。
|
||||||
|
|
||||||
|
我喜欢命令行。我第一次接触命令行是在 1997 的 DOS 6.2 上。我学习了各种命令的语法,并展示了如何在目录中列出隐藏的文件(`attrib`)。我会每次仔细检查命令中的每个字符。 当我犯了一个错误,我会从头开始重新输入命令。直到有一天,有人向我展示了如何使用向上和向下箭头按键遍历命令行历史,我被震惊了。
|
||||||
|
|
||||||
|
后来当我接触到 Linux 时,让我感到惊喜的是,上下箭头保留了它们遍历历史记录的能力。我仍然很仔细地打字,但是现在,我了解如何盲打,并且我能打的很快,每分钟可以达到 55 个单词的速度。接着有人向我展示了 tab 补完,再一次改变了我的生活。
|
||||||
|
|
||||||
|
在 GUI 应用程序中,菜单、工具提示和图标用于向用户展示功能。而命令行缺乏这种能力,但是有办法克服这个问题。在深入解决方案之前,我会来看看几个有问题的 CLI 程序:
|
||||||
|
|
||||||
|
**1、 MySQL**
|
||||||
|
|
||||||
|
首先让我们看看我们所钟爱的 MySQL REPL。我经常发现自己在输入 `SELECT * FROM` 然后按 `Tab` 的习惯。MySQL 会询问我是否想看到所有的 871 种可能性。我的数据库中绝对没有 871 张表。如果我选择 `yes`,它会显示一堆 SQL 关键字、表、函数等。(LCTT 译注:REPL —— Read-Eval-Print Loop,交互式开发环境)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**2、 Python**
|
||||||
|
|
||||||
|
我们来看另一个例子,标准的 Python REPL。我开始输入命令,然后习惯按 `Tab` 键。瞧,插入了一个 `Tab` 字符,考虑到 `Tab` 在 Python 源代码中没有特定作用,这是一个问题。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 好的用户体验
|
||||||
|
|
||||||
|
让我看下设计良好的 CLI 程序以及它们是如何克服这些可发现性问题的。
|
||||||
|
|
||||||
|
#### 自动补全: bpython
|
||||||
|
|
||||||
|
[Bpython][15] 是对 Python REPL 的一个很好的替代。当我运行 bpython 并开始输入时,建议会立即出现。我没用通过特殊的键盘绑定触发它,甚至没有按下 `Tab` 键。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当我出于习惯按下 `Tab` 键时,它会用列表中的第一个建议补全。这是给 CLI 设计带来可发现性性的一个很好的例子。
|
||||||
|
|
||||||
|
bpython 的另一个方面是可以展示模块和函数的文档。当我输入一个函数的名字时,它会显示这个函数附带的签名以及文档字符串。这是一个多么令人难以置信的周到设计啊。
|
||||||
|
|
||||||
|
#### 上下文感知补全:mycli
|
||||||
|
|
||||||
|
[mycli][16] 是默认的 MySQL 客户端的现代替代品。这个工具对 MySQL 来说就像 bpython 之于标准 Python REPL 一样。mycli 将在你输入时自动补全关键字、表名、列和函数。
|
||||||
|
|
||||||
|
补全建议是上下文相关的。例如,在 `SELECT * FROM` 之后,只有来自当前数据库的表才会列出,而不是所有可能的关键字。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
#### 模糊搜索和在线帮助: pgcli
|
||||||
|
|
||||||
|
如果您正在寻找 PostgreSQL 版本的 mycli,请看看 [pgcli][17]。 与 mycli 一样,它提供了上下文感知的自动补全。菜单中的项目使用模糊搜索缩小范围。模糊搜索允许用户输入整体字符串中的任意子字符串来尝试找到正确的匹配项。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
pgcli 和 mycli 在其 CLI 中都实现了这个功能。斜杠命令的文档也作为补全菜单的一部分展示。
|
||||||
|
|
||||||
|
#### 可发现性: fish
|
||||||
|
|
||||||
|
在传统的 Unix shell(Bash、zsh 等)中,有一种搜索历史记录的方法。此搜索模式由 `Ctrl-R` 触发。当再次调用你上周运行过的命令时,例如 **ssh**或 **docker**,这是一个令人难以置信的有用的工具。 一旦你知道这个功能,你会发现自己经常会使用它。
|
||||||
|
|
||||||
|
如果这个功能是如此有用,那为什么不每次都搜索呢?这正是 [**fish** shell][18] 所做的。一旦你开始输入命令,**fish** 将开始建议与历史记录类似的命令。然后,你可以按右箭头键接受该建议。
|
||||||
|
|
||||||
|
### 命令行规矩
|
||||||
|
|
||||||
|
我已经回顾了一些解决可发现性的问题的创新方法,但也有一些基本的命令行功能应该作为每个 REPL 所实现基础功能的一部分:
|
||||||
|
|
||||||
|
* 确保 REPL 有可通过箭头键调用的历史记录。确保会话之间的历史持续存在。
|
||||||
|
* 提供在编辑器中编辑命令的方法。不管你的补全是多么棒,有时用户只需要一个编辑器来制作完美的命令来删除生产环境中所有的表。
|
||||||
|
* 使用分页器(`pager`)来管道输出。不要让用户滚动他们的终端。哦,要为分页器设置个合理的默认值。(记得添加选项来处理颜色代码。)
|
||||||
|
* 提供一种通过 `Ctrl-R` 界面或者 fish 式的自动搜索来搜索历史记录的方法。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
在第 2 节中,我将来看看 Python 中使你能够实现这些技术的特定库。同时,请查看其中一些精心设计的命令行应用程序:
|
||||||
|
|
||||||
|
* [bpython][5]或 [ptpython][6]:具有自动补全支持的 Python REPL。
|
||||||
|
* [http-prompt][7]:交互式 HTTP 客户端。
|
||||||
|
* [mycli][8]:MySQL、MariaDB 和 Percona 的命令行界面,具有自动补全和语法高亮。
|
||||||
|
* [pgcli][9]:具有自动补全和语法高亮,是对 [psql][10] 的替代工具。
|
||||||
|
* [wharfee][11]:用于管理 Docker 容器的 shell。
|
||||||
|
|
||||||
|
_了解更多: Amjith Ramanujam 在 5 月 20 日在波特兰俄勒冈州举办的 [PyCon US 2017][12] 上的谈话“[神奇的命令行工具][13]”。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Amjith Ramanujam - Amjith Ramanujam 是 pgcli 和 mycli 的创始人。人们认为它们很酷,他表示笑纳赞誉。他喜欢用 Python、Javascript 和 C 编程。他喜欢编写简单易懂的代码,它们有时甚至会成功。
|
||||||
|
|
||||||
|
-----------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/17/5/4-terminal-apps
|
||||||
|
|
||||||
|
作者:[Amjith Ramanujam][a]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/amjith
|
||||||
|
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||||
|
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||||
|
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||||
|
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||||
|
[5]:http://bpython-interpreter.org/
|
||||||
|
[6]:http://github.com/jonathanslenders/ptpython/
|
||||||
|
[7]:https://github.com/eliangcs/http-prompt
|
||||||
|
[8]:http://mycli.net/
|
||||||
|
[9]:http://pgcli.com/
|
||||||
|
[10]:https://www.postgresql.org/docs/9.2/static/app-psql.html
|
||||||
|
[11]:http://wharfee.com/
|
||||||
|
[12]:https://us.pycon.org/2017/
|
||||||
|
[13]:https://us.pycon.org/2017/schedule/presentation/518/
|
||||||
|
[14]:https://opensource.com/article/17/5/4-terminal-apps?rate=3HL0zUQ8_dkTrinonNF-V41gZvjlRP40R0RlxTJQ3G4
|
||||||
|
[15]:https://bpython-interpreter.org/
|
||||||
|
[16]:http://mycli.net/
|
||||||
|
[17]:http://pgcli.com/
|
||||||
|
[18]:https://fishshell.com/
|
||||||
|
[19]:https://opensource.com/user/125521/feed
|
||||||
|
[20]:https://opensource.com/article/17/5/4-terminal-apps#comments
|
||||||
|
[21]:https://opensource.com/users/amjith
|
||||||
@ -1,83 +0,0 @@
|
|||||||
How is your community promoting diversity?
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
> Open source foundation leaders weigh in.
|
|
||||||
|
|
||||||

|
|
||||||
Image by : opensource.com
|
|
||||||
|
|
||||||
Open source software is a great enabler for technology innovation. Diversity unlocks innovation and drives market growth. Open source and diversity seem like the ultimate winning combination, yet ironically open source communities are among the least diverse tech communities. This is especially true when it comes to inherent diversity: traits such as gender, age, ethnicity, and sexual orientation.
|
|
||||||
|
|
||||||
It is hard to get a true picture of the diversity of our communities in all the various dimensions. Gender diversity, by virtue of being noticeably lacking and more straight forward to measure, is the starting point and current yardstick for measuring diversity in tech communities.
|
|
||||||
|
|
||||||
For example, it is estimated that around 25% of all software developers are women, but [only 3% work][5] in free and open software. These figures are consistent with my personal experience working in open source for over 10 years.
|
|
||||||
|
|
||||||
Even when individuals in the community are [doing their best][6] (and I have worked with many who are), it seems to make little difference. And little has changed in the last ten years. However, we are, as a community, starting to have a better understanding of some of the factors that maintain this status quo, things like [unconscious bias][7] or [social graph and privilege][8] problems.
|
|
||||||
|
|
||||||
In order to overcome the gravity of these forces in open source, we need combined efforts that are sustained over the long term and that really work. There is no better example of how diversity can be improved rapidly in a relatively short space of time than the Python community. PyCon 2011 consisted of just 1% women speakers. Yet in 2014, 33% of speakers at PyCon were women. Now Python conferences regularly lay out [their diversity targets and how they intend to meet them][9].
|
|
||||||
|
|
||||||
What did it take to make that dramatic improvement in women speaker numbers? In her great talk at PyCon 2014, [Outreach Program for Women: Lessons in Collaboration][10], Marina Zhurakhinskaya outlines the key ingredients:
|
|
||||||
|
|
||||||
* The importance of having a Diversity Champion to spearhead the changes over the long term; in the Python community Jessica McKellar was the driving force behind the big improvement in diversity figures
|
|
||||||
* Specifically marketing to under-represented groups; for example, how GNOME used outreach programs, such as [Outreachy][1], to market to women specifically
|
|
||||||
|
|
||||||
We know diversity issues, while complex are imminently fixable. In this way, open source foundations can play a huge role in the sustaining efforts to promote initiatives. Are other open source communities also putting efforts into diversity? To find out, we asked a few open source foundation leaders:
|
|
||||||
|
|
||||||
### How does your foundation promote diversity in its open source community?
|
|
||||||
|
|
||||||
**Mike Milinkovich, executive director of the Eclipse Foundation:**
|
|
||||||
|
|
||||||
> "The Eclipse Foundation is committed to promoting diversity in its open source community. But that commitment does not mean that we are satisfied with where we are today. We have a long way to go, particularly in the area of gender diversity. That said, some of the tangible steps we've taken in the last couple of years are: (a) we put into place a [Community Code of Conduct][2] that covers all of our activities, (b) we are consciously recruiting women for our conference program committees, (c) we are consciously looking for women speakers for our conferences, including keynotes, and (d) we are supporting community channels to discuss diversity topics. It's been great to see members of our community step up to assume leadership roles on this topic, and we're looking forward to making a lot of progress in 2017."
|
|
||||||
|
|
||||||
**Abby Kearns, executive director for the Cloud Foundry:**
|
|
||||||
|
|
||||||
> "For Cloud Foundry we promote diversity in a variety of ways. For our community, this includes a heavy focus on diversity events at our summit, and on our keynote stage. I'm proud to say we doubled the representation by women and people of color at our last event. For our contributors, this takes on a slightly different meaning and includes diversification across company and role."
|
|
||||||
|
|
||||||
A recent Cloud Foundry Summit featured a [diversity luncheon][11] as well as a [keynote on diversity][12], which highlighted how [gender parity had been achieved][13] by one member company's team.
|
|
||||||
|
|
||||||
**Chris Aniszczyk, COO of the Cloud Native Computing Foundation:**
|
|
||||||
|
|
||||||
> "The Cloud Native Computing Foundation (CNCF) is a very young foundation still, and although we are only one year old as of December 2016, we've had promoting diversity as a goal since our inception. First, every conference hosted by CNCF has [diversity scholarships][3] available, and there are usually special diversity lunches or events at the conference to promote inclusion. We've also sponsored "[contribute your first patch][4]" style events to promote new contributors from all over. These are just some small things we currently do. In the near future, we are discussing launching a Diversity Workgroup within CNCF, and also as we ramp up our certification and training programs, we are discussing offering scholarships for folks from under-representative backgrounds."
|
|
||||||
|
|
||||||
Additionally, Cloud Native Computing Foundation is part of the [Linux Foundation][14] as a formal Collaborative Projects (along with other foundations, including Cloud Foundry Foundation). The Linux Foundation has extensive [Diversity Programs][15] and as an example, recently [partnered with the Girls In Tech][16] not-for-profit to improve diversity in open source. In the future, the CNCF actively plans to participate in these Linux Foundation wide initiatives as they arise.
|
|
||||||
|
|
||||||
For open source to thrive, companies need to foster the right environment for innovation. Diversity is a big part of this. Seeing open source foundations making the conscious decision to take action is encouraging. Dedicated time, money, and resources to diversity is making a difference within communities, and we are slowly but surely starting to see the effects. Going forward, communities can collaborate and learn from each other about what works and makes a real difference.
|
|
||||||
|
|
||||||
If you work in open source, be sure to ask and find out what is being done in your community as a whole to foster and promote diversity. Then commit to supporting these efforts and taking the steps toward making a real difference. It is exciting to think that the next ten years might be a huge improvement over the last 10, and we can start to envision a future of truly diverse open source communities, the ultimate winning combination.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Tracy Miranda - Tracy Miranda is a software developer and founder of Kichwa Coders, a software consultancy specializing in Eclipse tools for scientific and embedded software. Tracy has been using Eclipse since 2003 and is actively involved in the community, particularly the Eclipse Science Working Group. Tracy has a background in electronics system design. She mentors young coders at the festival of code for Young Rewired State. Follow Tracy on Twitter @tracymiranda.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/take-action-diversity-tech
|
|
||||||
|
|
||||||
作者:[ Tracy Miranda][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/tracymiranda
|
|
||||||
[1]:https://www.gnome.org/outreachy/
|
|
||||||
[2]:https://www.eclipse.org/org/documents/Community_Code_of_Conduct.php
|
|
||||||
[3]:http://events.linuxfoundation.org/events/cloudnativecon-and-kubecon-north-america/attend/scholarship-opportunities
|
|
||||||
[4]:http://conferences.oreilly.com/oscon/oscon-tx-2016/public/schedule/detail/53257
|
|
||||||
[5]:https://www.linux.com/blog/how-bring-more-women-free-and-open-source-software
|
|
||||||
[6]:https://trishagee.github.io/post/what_can_men_do/
|
|
||||||
[7]:https://opensource.com/life/16/3/sxsw-diversity-google-org
|
|
||||||
[8]:https://opensource.com/life/15/8/5-year-plan-improving-diversity-tech
|
|
||||||
[9]:http://2016.pyconuk.org/diversity-target/
|
|
||||||
[10]:https://www.youtube.com/watch?v=CA8HN20NnII
|
|
||||||
[11]:https://www.youtube.com/watch?v=LSRrc5B1an0&list=PLhuMOCWn4P9io8gtd6JSlI9--q7Gw3epW&index=48
|
|
||||||
[12]:https://www.youtube.com/watch?v=FjF8EK2zQU0&list=PLhuMOCWn4P9io8gtd6JSlI9--q7Gw3epW&index=50
|
|
||||||
[13]:https://twitter.com/ab415/status/781036893286854656
|
|
||||||
[14]:https://www.linuxfoundation.org/about/diversity
|
|
||||||
[15]:https://www.linuxfoundation.org/about/diversity
|
|
||||||
[16]:https://www.linux.com/blog/linux-foundation-partners-girls-tech-increase-diversity-open-source
|
|
||||||
@ -1,111 +0,0 @@
|
|||||||
Be the open source supply chain
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### Learn why you should be a supply chain influencer.
|
|
||||||
|
|
||||||

|
|
||||||
Image by :
|
|
||||||
|
|
||||||
opensource.com
|
|
||||||
|
|
||||||
I would bet that whoever is best at managing and influencing the open source supply chain will be best positioned to create the most innovative products. In this article, I’ll explain why you should be a supply chain influencer, and how your organization can be an active participant in your supply chain.
|
|
||||||
|
|
||||||
In my previous article, [Open source and the software supply chain][2], I discussed the basics of supply chain management, and where open source fits in this model. I left readers with this illustration of the model:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The question to ask your employer and team(s) is: How do we best take advantage of this? After all, if Apple can set the stage for its dominance by creating a better hardware supply chain, then surely one can do the same with software supply chains.
|
|
||||||
|
|
||||||
### Evaluating supply chains
|
|
||||||
|
|
||||||
Having worked with developers and product teams in many companies, I learned that the process for selecting components that go into a product is haphazard. Sometimes there is an official bake-off of one or two components against each other, but the developers often choose to work with a product based on "feel". When determining the best components, you must evaluate based on those projects’ longevity, stage of development, and enough other metrics to form the basis of a "build vs. buy" decision. Number of users, interested parties, commercial activity, involvement of development team in support, and so on are a few considerations in the decision-making process.
|
|
||||||
|
|
||||||
Over time, technology and business needs change, and in the world of open source software, even more so. Not only must an engineering and product team be able to select the best component at that time, they must also be able to switch it out for something else when the time comes—for example, when the community managing the old component moves on, or when a new component with better features emerges.
|
|
||||||
|
|
||||||
### What not to do
|
|
||||||
|
|
||||||
When evaluating supply chain components, teams are prone to make a number of mistakes, including these common ones:
|
|
||||||
|
|
||||||
* **Not Invented Here (NIH)**: I can’t tell you how many times engineering teams decided to "fix" shortcomings in existing supply chain components by deciding to write it themselves. I won’t say "never ever do that," but I will warn that if you take on the responsibility of writing an infrastructure component, understand that you’re chucking away all the advantages of the open source supply chain—namely upstream testing and upstream engineering—and deciding to take on those tasks, immediately saddling your team (and your product) with technical debt that will only grow over time. You’re making the choice to be less efficient, and you had better have a compelling reason for doing so.
|
|
||||||
* **Carrying patches forward**: Any open source-savvy team understands the value of contributing patches to their respective upstream projects. When doing so, contributed code goes through that project’s automated testing procedures, which, when combined with your own team’s existing testing infrastructure, makes for a more hardened end product. Unfortunately, not all teams are open source-savvy. Sometimes these teams are faced with onerous legal requirements that deter them from seeking permission to contribute fixes upstream. In that case, encourage (i.e., nag) your manager to get blanket legal approval for such things, because the alternative is carrying all those changes forward, incurring significant technical debt, and applying patches until the day your project (or you) dies.
|
|
||||||
* **Think you’re only a user**: Using open source components as part of your software supply chain is only the first step. To reap the rewards of open source supply chains, you must dive in and be an influencer. (More on that shortly.)
|
|
||||||
|
|
||||||
### Effective supply chain management example: Red Hat
|
|
||||||
|
|
||||||
Because of its upstream-first policies, [Red Hat][3] is an example of how both to utilize and influence software supply chains. To understand the Red Hat model, you must view their products through a supply chain perspective.
|
|
||||||
|
|
||||||
Products supported by Red Hat are composed of open source components often vetted by multiple upstream communities, and changes made to these components are pushed to their respective upstream projects, often before they land in a supported product from Red Hat. The work flow look somewhat like:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
There are multiple reasons for this kind of workflow:
|
|
||||||
|
|
||||||
* Testing, testing, testing: By offloading some initial testing, a company like Red Hat benefits from both the upstream community’s testing, as well as the testing done by other ecosystem participants, including competitors.
|
|
||||||
* Upstream viability: The Red Hat model only works as long as upstream suppliers are viable and self-sustaining. Thus, it’s in Red Hat’s interest to make sure those communities stay healthy.
|
|
||||||
* Engineering efficiency: Because Red Hat offloads common tasks to upstream communities, their engineers spend more time adding value to products for customers.
|
|
||||||
|
|
||||||
To understand the Red Hat approach to supply chain, let’s look at their approach to product development with OpenStack.
|
|
||||||
|
|
||||||
Curiously, Red Hat’s start with OpenStack was not to create a product or even to announce one; rather, they started pushing engineering resources into strategic projects in OpenStack (starting with Nova, Keystone, and Cinder). This list grew to include several other projects in the OpenStack community. A more traditional product management executive might look at this approach and think, "Why on earth would we contribute so much engineering to something that isn’t established and has no product? Why are we giving our competitors our work for free?"
|
|
||||||
|
|
||||||
Instead, here is the open source supply chain thought process:
|
|
||||||
|
|
||||||
### Step 1
|
|
||||||
|
|
||||||
Look at growth areas in the business or largest product gaps that need filling. Is there an open source community that fits a strategic gap? Or can we build a new project from scratch to do the same? In this case, Red Hat looked at the OpenStack community and eventually determined that it would fill a gap in the product portfolio.
|
|
||||||
|
|
||||||
### Step 2
|
|
||||||
|
|
||||||
Gradually turn up the dial on engineering resources. This does a couple of things. First, it helps the engineering team get a sense of the respective projects’ prospects for success. If prospects aren’t not good, the company can stop contributing, with minimal investment spent. Once the project is determined to be worth in the investment, to the company can ensure its engineers will influence current and future development. This helps the project with quality code development, and ensures that the code meets future product requirements and acceptance criteria. Red Hat spent a lot of time slinging code in OpenStack repositories before ever announcing an OpenStack product, much less releasing one. But this was a fraction of the investment that would have been made if the company had developed an IaaS product from scratch.
|
|
||||||
|
|
||||||
### Step 3
|
|
||||||
|
|
||||||
Once the engineering investments begin, start a product management roadmap and marketing release plan. Once the code reaches a minimum level of quality, fork the upstream repository and start working on product-specific code. Bug fixes are pushed upstream to openstack.org and into product branches. (Remember: Red Hat’s model depends on upstream viability, so it makes no sense not to push fixes upstream.)
|
|
||||||
|
|
||||||
Lather, rinse, repeat. This is how you manage an open source software supply chain.
|
|
||||||
|
|
||||||
### Don't accumulate technical debt
|
|
||||||
|
|
||||||
If needed, Red Hat could decide that it would simply depend on upstream code, supply necessary proprietary product glue, and then release that as a product. This is, in fact, what most companies do with upstream open source code; however, this misses a crucial point I made previously. To develop a really great product, being heavily involved in the development process helps. How can an organization make sure that the code base meets its core product criteria if they’re not involved in the day-to-day architecture discussions?
|
|
||||||
|
|
||||||
To make matters worse, in an effort to protect backwards compatibility and interoperability, many companies fork the upstream code, make changes and don't contribute them upstream, choosing instead to carry them forward internally. That is a big no-no, saddling your engineering team forever with accumulated technical debt that will only grow over time. In that scenario, all the gains made from upstream testing, development and release go away in a whiff of stupidity.
|
|
||||||
|
|
||||||
### Red Hat and OpenShift
|
|
||||||
|
|
||||||
Once you begin to understand Red Hat’s approach to supply chain, which you can see manifested in its approach to OpenStack, you can understand its approach to OpenShift. Red Hat first released OpenShift as a proprietary product that was also open sourced. Everything was homegrown, built by a team that joined Red Hat as part of the [Makara acquisition][4] in 2010.
|
|
||||||
|
|
||||||
The technology initially suffered from NIH—using its own homegrown clustering and container management technologies, in spite of the recent (at the time) release of new projects: Kubernetes, Mesos, and Docker. What Red Hat did next is a testament to the company’s commitment to its open source supply chain model: Between OpenShift versions 2 and 3, developers rewrote it to utilize and take advantage of new developments from the Kubernetes and Docker communities, ditching their NIH approach. By restructuring the project in that way, the company took advantage of economies of scale that resulted from the burgeoning developer communities for both projects. I
|
|
||||||
|
|
||||||
Instead of Red Hat fashioning a complete QC/QA testing environment for the entire OpenShift stack, they could rely on testing infrastructure supplied by the Docker and Kubernetes communities. Thus, Red Hat contributions to both the Docker and Kubernetes code bases would undergo a few rounds of testing before ever reaching the company’s own product branches:
|
|
||||||
|
|
||||||
1. The first round of testing is by the Docker and Kubernetes communities .
|
|
||||||
2. Further testing is done by ecosystem participants building products on either or both projects.
|
|
||||||
3. More testing happens on downstream code distributions or products that "embed" both projects.
|
|
||||||
4. Final testing happens in Red Hat’s own product branch.
|
|
||||||
|
|
||||||
The amount of upstream (from Red Hat) testing done on the code ensures a level of quality that would be much more expensive for the company to do comprehensively and from scratch. This is the trick to open source supply chain management: Don’t just consume upstream code, minimally shimming it into a product. That approach won’t give you any of the advantages offered by open source development practices and direct participation for solving your customers’ problems.
|
|
||||||
|
|
||||||
To get the most benefit from the open source software supply chain, you must **be** the open source software supply chain.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
John Mark Walker - John Mark Walker is Director of Product Management at Dell EMC and is responsible for managing the ViPR Controller product as well as the CoprHD open source community. He has led many open source community efforts, including ManageIQ,
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/be-open-source-supply-chain
|
|
||||||
|
|
||||||
作者:[John Mark Walker][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/johnmark
|
|
||||||
[1]:https://opensource.com/article/17/1/be-open-source-supply-chain?rate=sz6X6GSpIX1EeYBj4B8PokPU1Wy-ievIcBeHAv0Rv2I
|
|
||||||
[2]:https://opensource.com/article/16/12/open-source-software-supply-chain
|
|
||||||
[3]:https://www.redhat.com/en
|
|
||||||
[4]:https://www.redhat.com/en/about/press-releases/makara
|
|
||||||
[5]:https://opensource.com/user/11815/feed
|
|
||||||
@ -1,74 +0,0 @@
|
|||||||
Developing open leaders
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
> "Off-the-shelf" leadership training can't sufficiently groom tomorrow's organizational leaders. Here's how we're doing it.
|
|
||||||
|
|
||||||

|
|
||||||
Image by : opensource.com
|
|
||||||
|
|
||||||
At Red Hat, we have a saying: Not everyone needs to be a people manager, but everyone is expected to be a leader.
|
|
||||||
|
|
||||||
For many people, that requires a profound mindset shift in how to think about leaders. Yet in some ways, it's what we all intuitively know about how organizations really work. As Red Hat CEO Jim Whitehurst has pointed out, in any organization, you have the thermometers—people who reflect the organizational "temperature" and sentiment and direction—and then you have the thermostats—people who _set_ those things for the organization.
|
|
||||||
|
|
||||||
Leadership is about maximizing influence and impact. But how do you develop leadership for an open organization?
|
|
||||||
|
|
||||||
In the first installment of this series, I will share the journey, from my perspective, on how we began to build a leadership development system at Red Hat to enable our growth while sustaining the best parts of our unique culture.
|
|
||||||
|
|
||||||
### Nothing 'off the shelf'
|
|
||||||
|
|
||||||
In an open organization, you can't just buy leadership development training "off the shelf" and expect it to resonate with people—or to reflect and reinforce your unique culture. But you also probably won't have the capacity and resources to build a great leadership development system entirely from scratch.
|
|
||||||
|
|
||||||
Early on in our journey at Red Hat, our leadership development efforts focused on understanding our own philosophy and approach, then taking a bit of an open source approach: sifting through the what people had created for conventional organizations, then configuring those ideas in a way that made them feasible for an open organization.
|
|
||||||
|
|
||||||
Looking back, I can also see we spent a lot of energy looking for ways to plug specific capability gaps.
|
|
||||||
|
|
||||||
Many of our people managers were engineers and other subject matter experts who stepped into management roles because that's what our organization needed. Yet the reality was, many had little experience leading a team or group. So we had some big gaps in basic management skills.
|
|
||||||
|
|
||||||
We also had gaps—not just among managers but also among individual contributors—when it came to navigating tough conversations with respect. In a company where passion runs high and people love to engage in open and heated debate, making your voice heard without shouting others down wasn't always easy.
|
|
||||||
|
|
||||||
We couldn't find any end-to-end leadership development systems that would help train people for leading in a culture that favors flatness and meritocracy over hierarchy and seniority. And while we could build some of those things ourselves, we couldn't build everything fast enough to meet our growing organization's needs.
|
|
||||||
|
|
||||||
So when we saw a need for improved goal setting, we introduced some of the best offerings available—like Closing the Execution Gap and the concept of SMART goals (i.e. specific, measurable, attainable, relevant, and time-bound). To make these work for Red Hat, we configured them to pull through themes from our own culture that could be used in tandem to make the concepts resonate and become even more powerful.
|
|
||||||
|
|
||||||
### Considering meritocracy
|
|
||||||
|
|
||||||
In a culture that values meritocracy, being able to influence others is critical. Yet the passionate open communication and debate that we love at Red Hat sometimes created hard feelings between individuals or teams. We introduced [Crucial Conversations][2] to help everyone navigate those heated and impassioned topics, and also to help them recognize that those kinds of conversations provide the greatest opportunity for influence.
|
|
||||||
|
|
||||||
After building that foundation with Crucial Conversations, we introduced [Influencer Training][3] to help entire teams and organizations communicate and gain traction for their ideas across boundaries.
|
|
||||||
|
|
||||||
We also found a lot of value in Marcus Buckingham's strengths-based approach to leadership development, rather than the conventional models that encouraged people to spend their energy shoring up weaknesses.
|
|
||||||
|
|
||||||
Early on, we made a decision to make our leadership offerings available to individual contributors as well as managers, because we saw that these skills were important for everyone in an open organization.
|
|
||||||
|
|
||||||
Looking back, I can see that this gave us the added benefit of developing a shared understanding and language for talking about leadership throughout our organization. It helped us build and sustain a culture where leadership is expected at all levels and in any role.
|
|
||||||
|
|
||||||
At the same time, training was only part of the solution. We also began developing processes that would help entire departments develop important organizational capabilities, such as talent assessment and succession planning.
|
|
||||||
|
|
||||||
Piece by piece, our open leadership system was beginning to take shape. The story of how it came together is pretty remarkable—at least to me!—and over the next few months, I'll share the journey with you. I look forward to hearing about the journeys of other open organizations, too.
|
|
||||||
|
|
||||||
_(An earlier version of this article appeared in _[The Open Organization Leaders Manual][4]_, now available as a free download from Opensource.com.)_
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
DeLisa Alexander - DeLisa Alexander | DeLisa is Executive Vice President and Chief People Officer at Red Hat. Under her leadership, this team focuses on acquiring, developing, and retaining talent and enhancing the Red Hat culture and brand. In her nearly 15 years with the company, DeLisa has also worked in the Office of General Counsel, where she wrote Red Hat's first subscription agreement and closed the first deals with its OEMs.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/open-organization/17/1/developing-open-leaders
|
|
||||||
|
|
||||||
作者:[DeLisa Alexander][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/delisa
|
|
||||||
[1]:https://opensource.com/open-organization/17/1/developing-open-leaders?rate=VU560k86SWs0OAchgX-ge2Avg041EOeU8BrlKgxEwqQ
|
|
||||||
[2]:https://www.vitalsmarts.com/products-solutions/crucial-conversations/
|
|
||||||
[3]:https://www.vitalsmarts.com/products-solutions/influencer/
|
|
||||||
[4]:https://opensource.com/open-organization/resources/leaders-manual
|
|
||||||
[5]:https://opensource.com/user/10594/feed
|
|
||||||
[6]:https://opensource.com/open-organization/17/1/developing-open-leaders#comments
|
|
||||||
[7]:https://opensource.com/users/delisa
|
|
||||||
@ -1,93 +0,0 @@
|
|||||||
4 questions to answer when choosing community metrics to measure
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
> When evaluating a specific metric that you are considering including in your metrics plan, you should answer four questions.
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
Image by :
|
|
||||||
|
|
||||||
[Internet Archive Book Images][4]. Modified by Opensource.com. [CC BY-SA 4.0][5]
|
|
||||||
|
|
||||||
Thus far in the [Community Metrics Playbook][6] column, I've discussed the importance of [setting goals][7] to guide the metrics process, outlined the general [types of metrics][8] that are useful for studying your community, and reviewed technical details of [available tools][9]. As you are deciding which metrics to track for your community, having a deeper understanding of each area is important so you not only choose good metrics, but also understand and plan for what to do when the numbers don't line up with expectations.
|
|
||||||
|
|
||||||
When evaluating a specific metric that you are thinking about including in your metrics plan, you should answer four questions:
|
|
||||||
|
|
||||||
* Does it help achieve my goals?
|
|
||||||
* How accurate is it?
|
|
||||||
* What is its relationship to other metrics?
|
|
||||||
* What will I do if the metrics goes "bad"?
|
|
||||||
|
|
||||||
### Goal-appropriate
|
|
||||||
|
|
||||||
This one should be obvious by now from my [previous discussion on goals][10]: Why do you need to know this metric? Does this metric have a relationship to your project's goals? If not, then you should consider ignoring it—or at least placing much less emphasis on it. Metrics that do not help measure your progress toward goals waste time and resources that could be better spent developing better metrics.
|
|
||||||
|
|
||||||
One thing to consider are intermediate metrics. These are metrics that may not have an obvious, direct relationship to your goals. They can be dangerous when considered alone and can lead to undesirable behavior simply to "meet the number," but when combined with and interpreted in the context of other intermediates, can help projects improve.
|
|
||||||
|
|
||||||
### Accuracy
|
|
||||||
|
|
||||||
Accuracy is defined as the quality or state of being correct or precise. Gauging accuracy for metrics that have built-in subjectivity and bias, such as survey questions, is difficult, so for this discussion I'll talk about objective metrics obtained by computers, which are for the most part highly precise and accurate. [Data can't lie][11], so why are we even discussing accuracy of computed metrics? The potential for inaccurate metrics stems from their human interpretation. The classic example here is _number of downloads_. This metric can be measured easily—often as part of a download site's built-in metrics—but will not be accurate if your software is split into multiple packages, or known systemic processes produce artificially inflated (or deflated) numbers, such as automated testing systems that execute repeated downloads.
|
|
||||||
|
|
||||||
As long as you recognize and avoid fixating on absolute correctness, having slightly inaccurate metrics is usually better than no metrics at all. Web analytics are [notorious][12] for being inaccurate gauges of reality due to the underlying technical nature of web servers, browsers, proxies, caching, dynamic addressing, cookies, and other aspects of computing that can muddy the waters of visitor engagement metrics; however, multiple slightly inaccurate web metrics over time can be an accurate indicator that the website refresh you did reduced your repeat visits by 30%. So don't be afraid of the fact that you'll probably never achieve 100% accuracy.
|
|
||||||
|
|
||||||
### Understanding relationships
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
_Data from: [NHTSA, DOT HS 810 780][1]. [U.S. Department of Agriculture (pdf)][2]_
|
|
||||||
|
|
||||||
The universe of metrics is full of examples stemming from the statistical phrase "[correlation does not imply causation][13]." When choosing metrics, carefully consider whether the chosen metric might have relationships to other metrics, directly or indirectly. Related metrics often can help diagnose success and failure, and indicate needed changes to your project to drive the improvement you're looking for.
|
|
||||||
|
|
||||||
Truly proving that one metric's behavior causes predictable changes in another requires quite a bit of experimentation and statistical analysis, but you don't have to take it that far. If you suspect a relationship, take note and observe their behavior over time, and if evidence suggests a relationship, then you can do experimentation in your own project to test the hypothesis.
|
|
||||||
|
|
||||||
For example, a typical goal of open source projects is to drive innovation by attracting new developers who bring their diverse experience and backgrounds to the project. A given project notices that when the "average time from contribution to code commit" decreases, the number of new contributors coming to the project increases. If evidence over time maintains this correlation, the project might decide to dedicate more resources to handling contributions. This can have an effect elsewhere—such as an increase in bugs due to lots of new code coming in—so try not to over-rotate while using your new-found knowledge.
|
|
||||||
|
|
||||||
### Planning for failure
|
|
||||||
|
|
||||||
After gauging the accuracy and applicability of a metric, you need to think about and plan for what you will do when things don't go as planned (which will happen). Consider this scenario: You've chosen several quality-related metrics for your project, and there is general agreement that they are accurate and important to the project. The QA team is working hard, yet your chosen metrics continue to suffer. What do you do? You have several choices:
|
|
||||||
|
|
||||||
* Do nothing.
|
|
||||||
* Make the QA team come in on the weekend to write more tests.
|
|
||||||
* Work with developers to find the root cause of all the bugs.
|
|
||||||
* Choose different metrics.
|
|
||||||
|
|
||||||
Which is the correct choice? The answer shouldn't surprise you: _It depends_. You may not need to do anything if the trend is expected, for example if resource constraints are forcing you to trade quality for some other metric. QA might actually need to write more tests if you have known poor coverage. Or you may need to do root cause analysis for a systemic issue in development. The last one is particularly important to include in any plan; your metrics may have become outdated and no longer align with your project's goals, and should be regularly evaluated and eliminated or replaced as needed.
|
|
||||||
|
|
||||||
Rarely will there be a single correct choice—it's more important to outline, for each metric, the potential causes for failure and which questions you need to ask and what you will do in various contexts. It doesn't have to be a lengthy checklist of actions for each possible cause, but you should at least list a handful of potential causes and how to proceed to investigate failure.
|
|
||||||
|
|
||||||
By answering these four questions about your metrics, you will gain a greater understanding of their purpose and efficacy. More importantly, sharing the answers with the rest of the project will give your community members a greater feeling of autonomy and purpose, which can be a much better motivator than simply asking them to meet a set of seemingly arbitrary numbers.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
译者简介:
|
|
||||||
|
|
||||||
James Falkner - Technology evangelist, teacher, learner, author, dedicated to open source and open computing. I work at Red Hat as a technical evangelist for Red Hat's portfolio of open source products and love what we do and learning from others, and occasionally teaching at conferences.
|
|
||||||
|
|
||||||
Prior to Red Hat I spent 5 years at Liferay growing a large open source community, onboarding new contributors, meeting and engaging with beginners and experts, and championing open source as the de facto choice for businesses large and small. I am based in the Orlando, Florida, USA area.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/2/4-questions-answer-when-choosing-community-metrics-measure
|
|
||||||
|
|
||||||
作者:[James Falkner][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/james-falkner
|
|
||||||
[1]:https://crashstats.nhtsa.dot.gov/Api/Public/ViewPublication/810780
|
|
||||||
[2]:http://www.ers.usda.gov/media/320480/wrs0406f_1_.pdf
|
|
||||||
[3]:https://opensource.com/article/17/2/4-questions-answer-when-choosing-community-metrics-measure?rate=I8iVb2WNG2xAcYFvNaZfoEFTozgl_gQ-Pz8Ra1SveOE
|
|
||||||
[4]:https://www.flickr.com/photos/internetarchivebookimages/14753212581/in/photolist-otG57a-orWcFN-ovJbD4-orWgoN-otWQTN-otWmY9-otG3wg-otYjFc-otLxay-otWi5N-ovJ8pt-ocuoJr-otG4KZ-ovJ7ok-otWjdj-otY18v-otYqxn-orWptL-otWkzY-otWTnW-otYcHe-otWAx3-octWmY-otWNwd-otL2wq-otYco6-ovHSva-otFSq4-otFPP2-otWmAL-otYtwP-orWAj3-otLjQy-otWDRs-otWoPJ-otG7wR-otWBTQ-otG4b2-otWyD3-orWgCA-otWMzo-otYfHx-otY9oP-otGbrz-orWnwj-orW6gJ-ocuAd8-orW5U1-otWBcu-otFXgr/
|
|
||||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
|
||||||
[6]:https://opensource.com/tags/community-metrics-playbook
|
|
||||||
[7]:https://opensource.com/bus/16/8/measuring-community-health
|
|
||||||
[8]:https://opensource.com/business/16/9/choosing-right-metrics
|
|
||||||
[9]:https://opensource.com/article/16/11/tools-collecting-analyzing-community-metrics
|
|
||||||
[10]:https://opensource.com/bus/16/8/measuring-community-health
|
|
||||||
[11]:http://management.curiouscatblog.net/2007/08/09/data-cant-lie/
|
|
||||||
[12]:https://brianclifton.com/pro-lounge-files/accuracy-whitepaper.pdf
|
|
||||||
[13]:https://en.wikipedia.org/wiki/Correlation_does_not_imply_causation
|
|
||||||
[14]:https://opensource.com/user/18065/feed
|
|
||||||
[15]:https://opensource.com/users/james-falkner
|
|
||||||
@ -1,94 +0,0 @@
|
|||||||
How the University of Hawaii is solving today's higher ed problems
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
>Image by : opensource.com
|
|
||||||
|
|
||||||
Openness invites greater participation and it takes advantage of the shared energy of collaborators. The strength of openly created educational resources comes paradoxically from the vulnerability of the shared experience of that creation process.
|
|
||||||
|
|
||||||
One of the leaders in Open Educational Resources (OER) is [Billy Meinke][3], educational technologist at the University of Hawaii at Manoa. The University's open creation model uses [Pressbooks][4], which Billy tells me more about in this interview.
|
|
||||||
|
|
||||||
**Don Watkins (DW): How did your work at Creative Commons lead you to the University of Hawaii?**
|
|
||||||
|
|
||||||
**Billy Meinke (BM)**: Well, I've actually _returned_ to The University of Hawaii (UH) after being in the Bay Area for several years. I completed the ETEC educational technology Master's program here and then moved to San Francisco where I worked with [Creative Commons][5] (CC). Being with CC was a rewarding and eye-opening experience, and I'm hopeful that what I learned out there will lend itself to the OER work we are ramping up at the University.
|
|
||||||
|
|
||||||
**DW: What came first: instructional design or OER? Are the two symbiotic?**
|
|
||||||
|
|
||||||
**BM**: To me, OER is just a better flavor of learning content. Instructional designers make lots of decisions about the learning product they want to create, be it a textbook or a course or a piece of media. But will they put an open license on that OER when it's published? Will they use an open source tool to author the content? Will they release it in an open format? An instructional designer can produce effective learning content without doing any of those things, but it won't be as useful to the next person. OERs are different because they are designed for reuse, regardless of pedagogical strategy or learning approach.
|
|
||||||
|
|
||||||
**DW: How long has the University of Hawaii been using OERs? What were the primary motivations?**
|
|
||||||
|
|
||||||
**BM**: The OER effort at UH started in 2014, and this past November I took over management of OER activities at UH Manoa, the University system's flagship campus.
|
|
||||||
|
|
||||||
The UH system has a healthy group of OER advocates throughout, primarily at the community colleges. They've transitioned hundreds of courses to become textbook zero (textbooks at no cost) and have made lots of headway building OER-based courses for two-year students. I've been really impressed with how well they've moved towards OER and how much money they've saved students over the last few semesters. We want to empower faculty to take control of what content they teach with, which we expect will result in their saving students money, at all of our campuses.
|
|
||||||
|
|
||||||
**DW: What are Pressbooks? Why are Pressbooks important to the creation of OERs?**
|
|
||||||
|
|
||||||
**BM**: Members of the faculty do have a choice in terms of what content they teach from, much of the time. Some write their own content, or maintain websites that house a course. Pressbooks is a WordPress-based publishing platform that makes it simpler to manage the content—like a book, with sections and chapters, a table of contents, author and publisher metadata, and the capability of to export the "book" into formats that can be easily read _and_ reused.
|
|
||||||
|
|
||||||
Because most undergraduate courses still rely on a primary textbook, we're opening up a means for faculty to adopt an existing open textbook or to co-author a text with others. Pressbooks is the tool, and we're developing the processes for adapting OER as we go.
|
|
||||||
|
|
||||||
**DW: How can a person get involved in development of Pressbooks?**
|
|
||||||
|
|
||||||
**BM**: Pressbooks has a [GitHub repository][6] where they collaboratively build the supporting software, and I've lurked on it for the last year or so. It can take some getting used to, but the conversations that happen there reveal the direction of the software and give an idea of who is working on what. Pressbooks does offer the free hosting of a limited version of the software (it includes a watermark to encourage folks to upgrade) for those who want to tinker without too much commitment. Also, the software is openly licensed (GPLv2), so anyone can use the code without cost or permission.
|
|
||||||
|
|
||||||
**DW: What other institutions use Pressbooks?**
|
|
||||||
|
|
||||||
**BM**: Some of the more widely known examples are [SUNY's Open Textbook project][7] and the [BCcampus OpenEd project][8]. [Lumen Learning][9] also has its own version of Pressbooks, as does [Open Oregon State][10].
|
|
||||||
|
|
||||||
We're looking at what all of these folks are doing to see where we can take our use of Pressbooks, and we hope to help pave the way for others who are developing their own OERs. In some cases, Pressbooks is being used to support entire courses and has integrated activities and assessments, which can hook into the Learning Management System (LMS) an institution uses for course delivery.
|
|
||||||
|
|
||||||
Because Pressbooks is powered by WordPress, it actually has quite a bit of flexibility in terms of what it can do, but we're setting up a humble roadmap for now. We'll be doing standalone open textbooks first.
|
|
||||||
|
|
||||||
**DW: How can other colleges and universities replicate your success? What are some first steps?**
|
|
||||||
|
|
||||||
**BM**: Forming a community that includes librarians, instructional designers, and faculty seems to be a healthy approach. The very first step will always be to get a handle on what is happening with OERs currently where you are, who is aware (or knowledgeable) about OERs, and then supporting them. My focus now is on curating the training resources around OERs that our team has developed, and helping the faculty gain the knowledge and skills it needs to begin adapting OERs. We'll be supporting a number of open textbook adoptions and creations this year, and it's my opinion that we should support folks with OERs, but then get out of the way when they're ready to take to the sky.
|
|
||||||
|
|
||||||
**DW: How important is "release early, release often?"**
|
|
||||||
|
|
||||||
**BM**: Even though the saying has been traditionally used to describe open practices for developing software, I think the creators of OER content should work toward embracing it, too. All too often, an open license is placed on a piece of OER as a finishing step, and none of the drafts or working documents are ever shared before the final content is released. Many folks don't consider that there might be much to gain by publishing early, especially when working independently on OER or as part of the small team. Taking a page from Mozilla's Matt Thompson, [working openly][11] makes way for greater participation, agility, momentum, iteration, and leveraging the collective energy of folks who have similar goals to your own. Because my role at UH is to connect and facilitate the adoption and creation of OER, releasing drafts of planning documents and OER as I go makes more sense.
|
|
||||||
|
|
||||||
To take advantage of the collective experience and knowledge that my networks have, I must improve the quality of the work continuously. This may be the most unsettling part of working openly—others can see your flaws and mistakes alongside your successes and wins. But in truth, I don't think many folks go around looking for issues with the work of others. More often, their assessment begins with asking (after watching and lurking) how useful the work of others is to their own work, which isn't always the case. If it seems useful on the surface, they'll take a deeper look, but they'll otherwise move on to find the good work of others that can help them go further with their own project.
|
|
||||||
|
|
||||||
Being able to borrow ideas from and in some cases directly use the planning docs of others can help new OER projects find legs. That's part of my strategy with the UH system as well: sharing what works so that we can carry our OER initiative forward, together.
|
|
||||||
|
|
||||||
**DW: How is the Open Foundation's approach for ****[OERu][1] ****of select, design, develop, deliver, and revise similar to **[**David Wiley's 5Rs**][12]**?**
|
|
||||||
|
|
||||||
**BM**: Well, OERu's development workflow for OER courses is designed to outline the process of creating and revising OER, while Wiley's 5Rs framework is an assessment tool for an OER. You would (as we have) use OERu's workflow to understand how you can contribute to their course development. Wiley's 5Rs is more of a set of questions to ask to understand how open an OER is.
|
|
||||||
|
|
||||||
**DW: Why are these frameworks essential to the development cycle of OERs and do you have your own framework?**
|
|
||||||
|
|
||||||
**BM**: While I don't believe that any framework or guide is a magic bullet or something that will guarantee success in developing OERs, I think that opening up the processes of content development can benefit teams and individuals who are taking on the challenge of adopting or creating OERs. At a minimum, a framework, or a set of them, can give a big-picture view of what it takes to produce OERs from start to finish. With tools like these, they may better understand where they are in their own process, and have an idea of what it will take to reach the end points they have set for their OER work.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
译者简介:
|
|
||||||
|
|
||||||
Don Watkins - Educator, education technology specialist, entrepreneur, open source advocate. M.A. in Educational Psychology, MSED in Educational Leadership, Linux system administrator, CCNA, virtualization using Virtual Box. Follow me at @Don_Watkins .
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/2/interview-education-billy-meinke
|
|
||||||
|
|
||||||
作者:[Don Watkins][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/don-watkins
|
|
||||||
[1]:https://oeru.org/
|
|
||||||
[2]:https://opensource.com/article/17/2/interview-education-billy-meinke?rate=MTzLUGkz2UyQtAenC-MVjynw2M_qBr_X4B-vE-0KCVI
|
|
||||||
[3]:https://www.linkedin.com/in/billymeinke
|
|
||||||
[4]:https://pressbooks.com/
|
|
||||||
[5]:https://creativecommons.org/
|
|
||||||
[6]:https://github.com/pressbooks/pressbooks
|
|
||||||
[7]:http://textbooks.opensuny.org/
|
|
||||||
[8]:https://open.bccampus.ca/
|
|
||||||
[9]:http://lumenlearning.com/
|
|
||||||
[10]:http://open.oregonstate.edu/textbooks/
|
|
||||||
[11]:https://openmatt.org/2011/04/06/how-to-work-open/
|
|
||||||
[12]:https://opencontent.org/blog/archives/3221
|
|
||||||
[13]:https://opensource.com/user/15542/feed
|
|
||||||
[14]:https://opensource.com/article/17/2/interview-education-billy-meinke#comments
|
|
||||||
[15]:https://opensource.com/users/don-watkins
|
|
||||||
@ -1,117 +0,0 @@
|
|||||||
A graduate degree could springboard you into an open source job
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
Image by :
|
|
||||||
|
|
||||||
opensource.com
|
|
||||||
|
|
||||||
Tech companies often prefer [hiring those who have open source experience][2] because quite simply open source experience is more valuable. This preference is only growing stronger now that open source software dominates the industry and free and open source hardware is gaining momentum. For example, a [Indeed.com salary analysis][3] shows that jobs with the keywords "Microsoft Windows" have an average salary of $64,000, while jobs with the keyword "Linux" have an average salary of $99,000\. Enough said.
|
|
||||||
|
|
||||||
There are many good open source jobs available to those with Bachelor's degrees, but if you want to control your destiny, a higher degree will give you the freedom to be paid more for following your interests.
|
|
||||||
|
|
||||||
This was very important to me when deciding what education I would choose, and I think it is true of most other PhDs. However, even if you do not put much stock in intellectual freedom, there is a pretty easy case to be made for "doing it for the Benjamins."
|
|
||||||
|
|
||||||
If you care about economic security, as an undergraduate you should consider graduate school. According to [data from the U.S. Bureau of Labor Statistics'][4] Current Population Survey, your average income is going to go up by over 20% if you get a Master's degree and by about 50% if you get a PhD. Similarly the unemployment rate for those with a Bachelor's degree was about 5%, drops to 3.6% for a Master's degree and is cut in half to 2.5% for those with a PhD.
|
|
||||||
|
|
||||||
Of course, all graduate programs and schools are _not_ equal. Most open source advocates would likely find themselves in some kind of engineering program. This is actually also pretty good news on the money front. [IEEE's Where the Jobs Are 2014][5] report says that engineering unemployment is just 1.9% and down to pre-recession levels. Similarly a [survey][6] by the American Society of Mechanical Engineers (ASME) and the American Society of Civil Engineers (ASCE) found that during the recession (from 2011 to 2013) the average salary for engineers actually rose almost 5%.
|
|
||||||
|
|
||||||
Ironically, many students do not consider graduate school for economic reasons. On its face, grad school appears expensive and working your way through it without shouldering a lot of debt seems impossible. For example, [MIT is $24,000 per term][7], and this does not even include room and board. Even at my more humble university graduate school (Michigan Tech, located in the [snow-blasted][8] upper peninsula of Michigan) will set you back more than [$40,000 a year][9] to be an electrical or computer engineer. Despite these costs, graduate school in technical disciplines almost always has an exceptionally high return on investment.
|
|
||||||
|
|
||||||
Also, I have even more good news: **If you are a solid student, graduate school will be more than free.**
|
|
||||||
|
|
||||||
In general, the best students are offered research assistantships that pay their way through graduate school completely, even at the nation's top schools. PhD and Master's degree students are generally fully funded, including tuition and monthly stipends. You will not get rich, but your ramen noodles will be covered. The real beauty of this path is that in general the research that you are paid for will go directly to your own thesis.
|
|
||||||
|
|
||||||
If you are looking for a graduate degree that will springboard you into an open source job, simply any graduate program will not do. A place to start is with the [top 100 universities][10] to support FOSS.
|
|
||||||
|
|
||||||
There are also many institutions that have a fairly well-developed open source culture. Students at RIT can now [earn a minor in free and open source software][11] and free culture, and at Michigan Tech you can join the [Open Hardware Enterprise][12], which is essentially a student-run business. The Massachusetts Institute of Technology hosts [OpenCourseware][13], an open source approach to educational materials. However, be aware that although an academic pedigree is important it is not the primary concern. This is because in graduate school (and particularly for funding) you are applying to a research group (i.e., a single professor) in addition to applying to the university and program.
|
|
||||||
|
|
||||||
### How to get a job in an open source lab
|
|
||||||
|
|
||||||
While many academics ascribe to open source principles and many schools are supportive of open source overall, the group of hard core open source lab groups is fairly selective. NetworkWorld offers [six examples][14], Wikipedia keeps an incomplete [list][15], and I maintain a list of contributors to open source hardware for science on [Appropedia][16]. There are many more to choose from (for example, anyone who attends the open science conferences, [GOSH][17], etc.).
|
|
||||||
|
|
||||||
I run one of these labs myself, and I hope to offer some insight into the process of acquiring funding for potential graduate students. My group studies solar cells and open hardware. [Solar photovoltaic technology represents one of the fastest growing industries][18] and the [open source hardware movement][19] (particularly [RepRap][20] 3D printers) is exploding. Because my lab, the Michigan Tech Open Sustainability Technology ([MOST][21]) Lab, is on the cutting edge of two popular fields, entrance into the group is extremely competitive. This is generally the case with most other open source research groups, which I am happy to report are increasing in both size and overall density within the academic community.
|
|
||||||
|
|
||||||
There are two routes you can take to getting a job in an open source lab: 1) the direct route and 2) the indirect route.
|
|
||||||
|
|
||||||
First, the direct route.
|
|
||||||
|
|
||||||
### Make personal contact and stand out
|
|
||||||
|
|
||||||
Applying to an open source academic lab usually starts with emailing the professor who runs the lab directly. To start, make sure your email is actually addressed to the professor by name and catches his or her interest in the subject and first line. This is necessary because, in general, professors want students working in their labs who share an interest in their research areas. They do not simply want to hire someone that is looking for a job. There are thousands of students looking for positions, so professors can be fairly picky about their selections. You need to prove your interest. Professors literally get dozens of email applications a week, so you must make sure you stand out.
|
|
||||||
|
|
||||||
### Get good grades and study for the GREs
|
|
||||||
|
|
||||||
In addition, you need to cover all the obvious bases. You are going to be judged first by your numbers. You must maintain high grades and get good GRE scores. Even if you are an awesome person, if you do not have scores and grades high enough to impress, you will not meet the minimum requirements for the graduate program and not even make the list for research assistantships. For my lab, competitive graduate students need to be in the top 10% in grades and test scores (GRE ninetieth percentile scores are above 162 for verbal, 164 for quantitative, and 5 or higher in analytical writing. International students will need TOEFL scores greater than 100 and IELTS scores greater than 7.5).
|
|
||||||
|
|
||||||
You can find less competitive groups, but grades and scores will largely determine your chances, particularly the GRE if you are coming from outside the country. There are simply too many universities throughout the world to allow for the evaluation of the quality of a particular grade in a particular school in a particular class. Thus, and I realize this is absurdly reductionist, the practicalities of graduate school admission mean that the GRE becomes a way of quickly vetting students. Realize, however, that you can study for the GRE to improve your scores. Some international students are known for taking a year off to study and then knocking out perfect scores. You do not need to take it that far because the nature of U.S. funding favors domestic students over international students, but you should study hard for the tests.
|
|
||||||
|
|
||||||
Even if your scores are not perfect, you can raise your chances considerably by proving your research interests. This is where the open source philosophy really pays some dividends. Unlike peers who intern at a proprietary company and can say generally, but not specifically, what they worked on, if you work in open source, a professor can see and vet your contributions to a project directly. Ideal applicants have a history and a portfolio already built up in the areas of the research group or closely related areas.
|
|
||||||
|
|
||||||
### Show and share your work
|
|
||||||
|
|
||||||
To gain entrance to my research group, and those like it, we really want to see your work. This means you should make some sort of personal webpage and load it up with your successful projects. You should have undertaken some major project in the research area you want to join. For my group it might be publishing a paper in a peer-reviewed journal as an undergrad, developing a new [open scientific method][22], or making valuable contributions to a large FOSS project, such as [Debian][23]. The project may be applied; for example, it could be in an applied sustainability project, such as organized [Engineers Without Borders][24] chapters at your school, or open hardware, such as founding a [hackerspace][25].
|
|
||||||
|
|
||||||
However, not all of your accomplishments need to be huge or need to be academic undergraduate research. If you restored a car, I want to know about it. If you have designed a cool video game, I want to play it. If you made a mod on the RepRap that I 3D print with or were a major developer of FOSS our group uses, I can more or less guarantee you a position if I have one.
|
|
||||||
|
|
||||||
If you are a good student you will be accepted into many graduate programs, but if funding is low you may not be offered a research assistantship immediately. Do not take rejection personally. You might be the perfect student for a whole range of research projects and a professor may really want you, but simply may not have the funding when you apply. Unfortunately, there have been a stream of pretty vicious [cutbacks to academia in the U.S.][26] in recent years, so research assistantships are not as numerous as they once were. You should apply to several programs and to many professors because you never know who is going to have funding that is matched up to your graduate school career.
|
|
||||||
|
|
||||||
This brings us to the second path to getting a good job in an open source graduate lab, the indirect one.
|
|
||||||
|
|
||||||
### Sneak in
|
|
||||||
|
|
||||||
The first step for this approach is ensuring you meet the minimum requirements for the particular graduate school and apply. These requirements tend to be much lower than advertised by an open source lab director. Once you are accepted to a university you can be placed in the teaching assistant (TA) pool. This also is a way to pay for graduate school, although it lacks the benefit of being paid to work on your thesis, which you will have to do on your own time. While you are establishing yourself at the university by getting good grades and being a good TA, you can attempt to volunteer in the open source lab of your choosing. Most professors with capacity in their lab will take on such self-funded students. If there really is no money, often the professor will offer you some form of independent study credits for your work. These can be used to reduce your class load, giving you time to do research. Take these credits, work hard, and prove yourself.
|
|
||||||
|
|
||||||
This gets your foot is in the door. Your chances at pulling a research assistantship will skyrocket at this point. In general professors are always applying for funding that is randomly being awarded. Often professors must fill a research position in a short amount of time when this happens. If you are good and physically there, your chances are much better for winning those funds. Even in the worst-case scenario, in which you are able to work in an open source lab, but funding does not come, again the nature of open source research will help you. Your projects will be more easily accessible by other professors (who may have funding) and all of your research (even if only paid hourly) will be disclosed to the public. This is a major benefit that is lost to all of those working on proprietary or secret military-related projects. If your work is good, access to your technical work can help you land a position at another group, a program, a school (for example, as a Master's student applying to a PhD program elsewhere), or a better higher-paying job.
|
|
||||||
|
|
||||||
**Work hard and share your research aggressively following the open source model and it will pay off.**
|
|
||||||
|
|
||||||
Good luck!
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
译者简介:
|
|
||||||
|
|
||||||
Joshua Pearce - Dr. Joshua Pearce is cross appointed as an Associate Professor in the Materials Science & Engineering and the Electrical & Computer Engineering at Michigan Tech. He currently runs the Michigan Tech in Open Sustainability Technology (MOST) group. He is the author of the Open Source Lab.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/grad-school-open-source-academic-lab
|
|
||||||
|
|
||||||
作者:[Joshua Pearce][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/jmpearce
|
|
||||||
[1]:https://opensource.com/article/17/1/grad-school-open-source-academic-lab?rate=aJZB6TNyQIo2EOgqPxN8P9a5aoiYgLhtP9GujsPCJYk
|
|
||||||
[2]:http://www.wired.com/2014/07/openhatch/
|
|
||||||
[3]:http://www.indeed.com/salary?q1=linux&q2=microsoft+windows
|
|
||||||
[4]:http://www.appropedia.org/MOST_application_process#Undergraduates
|
|
||||||
[5]:http://spectrum.ieee.org/at-work/tech-careers/where-the-jobs-are-2014
|
|
||||||
[6]:https://www.asme.org/career-education/articles/early-career-engineers/engineering-salaries-on-the-rise
|
|
||||||
[7]:http://web.mit.edu/registrar/reg/costs/
|
|
||||||
[8]:http://www.mtu.edu/alumni/favorites/snowfall/
|
|
||||||
[9]:http://www.mtu.edu/gradschool/admissions/financial/cost/
|
|
||||||
[10]:http://www.portalprogramas.com/en/how-to/best-american-universities-open-source-2014.html
|
|
||||||
[11]:http://www.rit.edu/news/story.php?id=50590
|
|
||||||
[12]:http://www.mtu.edu/enterprise/teams/
|
|
||||||
[13]:https://ocw.mit.edu/index.htm
|
|
||||||
[14]:http://www.networkworld.com/article/3062660/open-source-tools/6-colleges-turning-out-open-source-talent.html
|
|
||||||
[15]:https://en.wikipedia.org/wiki/Open_Source_Lab
|
|
||||||
[16]:http://www.appropedia.org/Open-source_Lab#Examples
|
|
||||||
[17]:http://openhardware.science/
|
|
||||||
[18]:https://hbr.org/2016/08/what-if-all-u-s-coal-workers-were-retrained-to-work-in-solar
|
|
||||||
[19]:http://www.oshwa.org/
|
|
||||||
[20]:http://reprap.org/
|
|
||||||
[21]:http://www.appropedia.org/MOST
|
|
||||||
[22]:http://openwetware.org/wiki/Main_Page
|
|
||||||
[23]:https://www.debian.org/
|
|
||||||
[24]:http://www.appropedia.org/Engineers_Without_Borders
|
|
||||||
[25]:http://www.appropedia.org/Hackerspace
|
|
||||||
[26]:http://www.cbpp.org/research/state-by-state-fact-sheets-higher-education-cuts-jeopardize-students-and-states-economic
|
|
||||||
[27]:https://opensource.com/user/26164/feed
|
|
||||||
[28]:https://opensource.com/article/17/1/grad-school-open-source-academic-lab#comments
|
|
||||||
[29]:https://opensource.com/users/jmpearce
|
|
||||||
@ -1,66 +0,0 @@
|
|||||||
Poverty Helps You Keep Technology Safe and Easy
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
> In the technology age, there might be some before unknown advantages to living on the bottom rungs of the economic ladder. The question is, do they outweigh the disadvantages.
|
|
||||||
|
|
||||||
### Roblimo’s Hideaway
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Earlier this week I saw a ZDNet story titled [Vizio: The spy in your TV][1] by my friend Steven J. Vaughan-Nichols. Scary stuff. I had a vision of my wife and me and a few dozen of our closest friends having a secret orgy in our living room, except our smart TV’s unblinking eye was recording our every thrust and parry (you might say). Zut alors! In this day of Internet everywhere, we all know that what goes online, stays online. Suddenly our orgy wasn’t secret, and my hopes of becoming the next President were dashed.
|
|
||||||
|
|
||||||
Except… lucky me! I’m poor, so I have an oldie-but-goodie dumb TV that doesn’t have a camera. There’s no way _my_ old Vizio can spy on us. As Mel Brooks didn’t quite say, “[It’s good to be the poverty case][2].”
|
|
||||||
|
|
||||||
Now about that Internet-connected thermostat. I don’t have one. They’re not only expensive (which is why I don’t have one), but according to [this article,][3] they can be hacked to to run ransomware. Oh my! Once again, poverty saves me from a tech problem that can easily afflict my more prosperous neighbors.
|
|
||||||
|
|
||||||
And how about the latest iPhone and the skinniest Mac BookPro. Apple sells the iPhone 7 Plus (gotta have the plussier one) for $769 or more. The MacBook, despite Scottish connotations of thrift, is Apple-priced “From $1299.” That’s a bunch of money, especially since we all know that as soon as you buy an Apple product it is obsolete and you need to get ready to buy a new, fancier one.
|
|
||||||
|
|
||||||
Also, don’t these things explode sometimes? Or catch on fire or something? My [sub-$100 Android phone][4] is safe as houses by comparison. (It has a bigger screen than the biggest-screen iPhone 7, too. Amnazing!)
|
|
||||||
|
|
||||||
Really big safe smartphone for cheap. Check. Simple, old-fashioned, non-networked thermostats that can’t be hacked. TV without the spycams most of the Money-TVs have. Check.
|
|
||||||
|
|
||||||
But wait! There’s more! The [Android phones that got famous for burning up][5] everything in sight were top-dollar models my wife says she wouldn’t want even if we _could_ afford them. Safety first, right? Frugality’s up there, too.
|
|
||||||
|
|
||||||
Now let’s talk about how I got started with Linux.
|
|
||||||
|
|
||||||
Guess what? It was because I was poor! The PC I had back in the days of yore ran DOS just fine, but couldn’t touch Windows 98 when it came out. Not only that, but Windows was expensive, and I was poor. Luckily, I had time on my hands, so I rooted around on the Internet (at phone modem speed) and eventually lit upon Red Hat Linux, which took forever to download and had an install procedure so complicated that instead of figuring it out I wrote an article about how Linux might be great for home computer use someday in the future, but not at the moment.
|
|
||||||
|
|
||||||
This led to the discovery of several helpful local Linux Users Groups (LUGs) and skilled help getting Linux going on my admittedly creaky PC. And that, you might say, led to my career as an IT writer and editor, including my time at Slashdot, NewsForge, and Linux.com.
|
|
||||||
|
|
||||||
This effectively, albeit temporarily, ended my poverty, but with the help of needy relatives — and later, needy doctors and hospitals — I was able to stay true to my “po’ people” roots. I’m glad I did. You’ve probably seen [this article][6] about hackers remotely shutting down a Jeep Cherokee. Hah! My 1996 Jeep Cherokee is totally immune to this kind of attack. Even my 2013 Kia Soul is _relatively_ immune, since it lacks remote-start/stop and other deluxe convenience features that make new cars easy to hack.
|
|
||||||
|
|
||||||
And the list goes on… same as [the beat went on][7] for Sonny and Cher. The more conveniences and Internet connections you have, the more vulnerable you are. Home automation? Make you into a giant hacking target. There’s also a (distant) possibility that your automated, uP-controlled home could become self-aware, suddenly say “I can’t do that, Dave,” and refuse to listen to your frantic cries that you aren’t Dave as it dumps you into the Internet-aware garbage disposal.
|
|
||||||
|
|
||||||
The solution? You got it! Stay poor! Own the fewest possible web-connect cameras and microphones. Don’t get a thermostat people in Nigeria can program to turn your temperature up and down on one-minute cycles. No automatic lights. I mean… I MEAN… is it really all that hard to flick a light switch? I know, that’s something a previous generation took for granted the same way they once walked across the room to change TV channels, and didn’t complain about it.
|
|
||||||
|
|
||||||
Computers? I have (not at my own expense) computers on my desk that run Mac OS, Windows, and Linux. Guess which OS causes me the least grief and confusion? You got it. _The one that cost the least!_
|
|
||||||
|
|
||||||
So I leave you with this thought: In today’s overly-connected world of overly-complex technology, one of the kindest parting comments you can make to someone you care about is, ** _“Stay poor, my friend!”_ **
|
|
||||||
|
|
||||||
The following two tabs change content below.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Robin "Roblimo" Miller is a freelance writer and former editor-in-chief at Open Source Technology Group, the company that owned SourceForge, freshmeat, Linux.com, NewsForge, ThinkGeek and Slashdot, and until recently served as a video editor at Slashdot. He also publishes the blog Robin ‘Roblimo’ Miller’s Personal Site. @robinAKAroblimo
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
via: http://fossforce.com/2017/02/poverty-helps-keep-technology-safe-easy/
|
|
||||||
|
|
||||||
作者:[Robin "Roblimo" Miller][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.roblimo.com/
|
|
||||||
[1]:http://www.zdnet.com/article/vizio-the-spy-in-your-tv/
|
|
||||||
[2]:https://www.youtube.com/watch?v=StJS51d1Fzg
|
|
||||||
[3]:https://www.infosecurity-magazine.com/news/defcon-thermostat-control-hacked/
|
|
||||||
[4]:https://www.amazon.com/LG-Stylo-Prepaid-Carrier-Locked/dp/B01FSVN3W2/ref=sr_1_1
|
|
||||||
[5]:https://www.cnet.com/news/why-is-samsung-galaxy-note-7-exploding-overheating/
|
|
||||||
[6]:https://www.wired.com/2015/07/hackers-remotely-kill-jeep-highway/
|
|
||||||
[7]:https://www.youtube.com/watch?v=umrp1tIBY8Q
|
|
||||||
@ -1,64 +0,0 @@
|
|||||||
How I became a project team leader in open source
|
|
||||||
============================================================
|
|
||||||

|
|
||||||
|
|
||||||
Image by :
|
|
||||||
|
|
||||||
opensource.com
|
|
||||||
|
|
||||||
> _The only people to whose opinions I listen now with any respect are people much younger than myself. They seem in front of me. Life has revealed to them her latest wonder. _― [Oscar Wilde][1], [The Picture of Dorian Gray][2]
|
|
||||||
|
|
||||||
2017 marks two decades since I was first introduced to the concept of "open source" (though the term wasn't coined until later), and a decade since I made my first open source documentation contribution. Each year since has marked another milestone on that journey: new projects, new toolchains, becoming a core contributor, new languages, and becoming a Program Technical Lead (PTL).
|
|
||||||
|
|
||||||
2017 is also the year I will take a step back, take a deep breath, and consciously give the limelight to others.
|
|
||||||
|
|
||||||
As an idealistic young university undergraduate I hung around with the nerds in the computer science department. I was studying arts and, later, business, but somehow I recognized even then that these were my people. I'm forever grateful to a young man (his name was Michael, as so many people in my story are) who introduced me first to IRC and, gradually, to Linux, Google (the lesser known search engine at the time), HTML, and the wonders of open source. He and I were the first people I knew to use USB storage drives, and oh how we loved explaining what they were to the curious in the campus computer lab.
|
|
||||||
|
|
||||||
After university, I found myself working for a startup in Canberra, Australia. Although the startup eventually failed to... well, start, I learned some valuable skills from another dear friend, David. I already knew I had a passion for writing, but David showed me how I could use that skill to build a career, and gave me the tools I needed to actually make that happen. He is also responsible for my first true language love: [LaTeX][3]. To this day, I can spot a LaTeX document from forty paces, which has prompted many an awkward conversation with the often-unwitting bearer of the document in question.
|
|
||||||
|
|
||||||
In 2007, I began working for Red Hat, in what was then known as Engineering Content Services. It was a heady time. Red Hat was determined to invest in an in-house documentation and translation team, and another man by the name of Michael was determined that this would happen in Brisbane, Australia. It was extraordinary case of right place, right time. I seized the opportunity and, working alongside people I still count among the best and brightest technical writers I know, we set about making that thing happen.
|
|
||||||
|
|
||||||
Working at Red Hat in those early days were some of the craziest and most challenging of my career so far. We grew rapidly, there were always several new hires waiting for us to throw them in the deep end, and we had the determination and tenacity to try new things constantly. _Release early, release often_ became a central tenet of our group, and we came up with some truly revolutionary ways of delivering content, as well as some appallingly bad ones. It was here that I discovered the beauty of data typing, single sourcing, remixing content, and using metadata to drive content curation. We weren't trying to tell stories to our readers, but to give our readers the tools to create their own stories.
|
|
||||||
|
|
||||||
As the Red Hat team matured, so too did my career, and I eventually led a team of writers. Around the same time, I started attending and speaking at tech conferences, spreading the word about these new ways of developing content, and trying to lead developers into looking at documentation in new ways. I had a thirst for sharing this knowledge and passion for technical documentation with the world, and with the Red Hat content team slowing their growth and maturing, I found myself craving the fast pace of days gone by. It was time to find a new project.
|
|
||||||
|
|
||||||
When I joined [Rackspace][4], [OpenStack][5] was starting to really hit its stride. I was on the organizing team for [linux.conf.au][6] in 2013 (ably led by yet another Michael), which became known affectionately as openstack.conf.au due to the sheer amount of OpenStack content that was delivered in that year. Anne Gentle had formed the OpenStack documentation team only a year earlier, and I had been watching with interest. The opportunity to work alongside Anne on such an exciting project was irresistible, so by the time 2013 drew to a close, Michael had hired me, and I had become a Racker and a Stacker.
|
|
||||||
|
|
||||||
In late 2014, as we were preparing the Kilo release, Anne asked if I would be willing to put my name forward as a candidate for documentation PTL. OpenStack works on a democratic system where individuals self-nominate for the lead, and the active contributors to each project vote when there is more than one candidate. The fact that Anne not only asked me to step up, but also thought I was capable of stepping in her footsteps was an incredible honor. In early 2015, I was elected unopposed to lead the documentation team for the Liberty release, and we were off to Vancouver.
|
|
||||||
|
|
||||||
By 2015, I had managed documentation teams sized between three and 13 staff members, across many time zones, for nearly five years. I had a business management degree and an MBA to my name, had run my own business, seen a tech startup fail, and watched a new documentation team flourish. I felt as though I understood what being a manager was all about, and I guess I did, but I realized I didn't know what being a PTL was all about. All of a sudden, I had a team where I couldn't name each individual, couldn't rely on any one person to come to work on any given day, couldn't delegate tasks with any authority, and couldn't compensate team members for good work. Suddenly, the only tool I had in my arsenal to get work done was my own ability to convince people that they should.
|
|
||||||
|
|
||||||
My first release as documentation PTL was basically me stumbling around in the dark and poking at the things I encountered. I relied heavily on the expertise of the existing members of the group, particularly Anne Gentle and Andreas Jaeger (our documentation infrastructure guru), to work out what needed to be done, and I gradually started to document the things I learned along the way. I learned that the key to getting things done in a community was not just to talk and delegate, but to listen and collaborate. I had not only to tell people what to do, but also convince them that it was a good idea, and help them to see the task through, picking up the pieces if they didn't.
|
|
||||||
|
|
||||||
Gradually, and through trial and error, I built the confidence and relationships to get through an OpenStack release successfully with my team and my sanity intact. This wouldn't have happened if the team hadn't been willing to stick by me through the times I was wandering in the woods, and the project would never have gotten off the ground in the first place without the advice and expertise of those that had gone before me. Shoulders of giants, etc.
|
|
||||||
|
|
||||||
Somewhat ironically, technical writers aren't very good at documenting their own team processes, so we've been codifying our practices, conventions, tools, and systems. We still have much work to do on this front, but we have made a good start. As the OpenStack documentation team has matured, we have accrued our fair share of [tech debt][7], so dealing with that has been a consistent ribbon through my tenure, not just by closing old bugs (not that there hasn't been a lot of that), but also by changing our systems to prevent it building up in the first place.
|
|
||||||
|
|
||||||
I am now in my tenth year as an open source contributor, and I have four OpenStack releases under my belt: Liberty, Mitaka, Newton, and Ocata. I have been a PTL for two years, and I have seen a lot of great documentation contributors come and go from our little community. I have made an effort to give those who are interested an opportunity to lead: through specialty teams looking after a book or two, release managers who perform the critical tasks to get each new release out into the wild, and moderators who lead a session at OpenStack Summit planning meetings (and help save my voice which, somewhat notoriously, is always completely gone by the end of Summit week).
|
|
||||||
|
|
||||||
From these humble roles, the team has grown leaders. In these people, I see myself. They are hungry for change, full of ideas and ideals, and ready to implement crazy schemes and see where it takes them. So, this year, I'm going to take that step back, allow someone else to lead this amazing team, and let the team take their own steps forward. I intend to be here, holding on for the ride. I can't wait to see what happens next.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Lana Brindley - Lana Brindley has several university degrees, a few of which are even relevant to her field. She has been playing and working with technology since she discovered the Hitchhikers’ Guide to the Galaxy text adventure game in the 80’s. Eventually, she worked out a way to get paid for her two passions – writing and playing with gadgetry – and has been a technical writer ever since.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/2/my-open-source-story-leader
|
|
||||||
|
|
||||||
作者:[Lana Brindley][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/loquacities
|
|
||||||
[1]:http://www.goodreads.com/author/show/3565.Oscar_Wilde
|
|
||||||
[2]:http://www.goodreads.com/work/quotes/1858012
|
|
||||||
[3]:https://www.latex-project.org/
|
|
||||||
[4]:https://www.rackspace.com/en-us
|
|
||||||
[5]:https://www.openstack.org/
|
|
||||||
[6]:https://linux.conf.au/
|
|
||||||
[7]:https://en.wikipedia.org/wiki/Technical_debt
|
|
||||||
@ -1,74 +0,0 @@
|
|||||||
Does your open source project need a president?
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
>Image by : opensource.com
|
|
||||||
|
|
||||||
Recently I was lucky enough to be invited to attend the [Linux Foundation Open Source Leadership Summit][4]. The event was stacked with many of the people I consider mentors, friends, and definitely leaders in the various open source and free software communities that I participate in.
|
|
||||||
|
|
||||||
I was able to observe the [CNCF][5] Technical Oversight Committee meeting while there, and was impressed at the way they worked toward consensus where possible. It reminded me of the [OpenStack Technical Committee][6] in its make-up of well-spoken technical individuals who care about their users and stand up for the technical excellence of their foundations' activities.
|
|
||||||
|
|
||||||
But it struck me (and several other attendees) that this consensus building has limitations. [Adam Jacob][7] noted that Linus Torvalds had given an interview on stage earlier in the day where he noted that most of his role was to listen closely for a time to differing opinions, but then stop them when it was clear there was no consensus, and select one that he felt was technically excellent, and move on. Linus, being the founder of Linux and the benevolent dictator of the project for its lifetime thus far, has earned this moral authority.
|
|
||||||
|
|
||||||
However, unlike Linux, many of the modern foundation-fostered projects lack an executive branch. The structure we see for governance is centered around ensuring that corporate sponsors have influence. Foundation members pay dues to get various levels of board seats or corporate access to events and data. And this is a good thing, as it keeps people like me paid to work in these communities.
|
|
||||||
|
|
||||||
However, I believe as technical contributors, we sometimes give this too much sway in the actual governance of the community and the projects. These foundation boards know that day to day decision making should be left to those working in the project, and as such allow committees like the [CNCF][8] TOC or the [OpenStack TC][9] full agency over the technical aspects of the member projects.
|
|
||||||
|
|
||||||
I believe these committees operate as a legislative branch. They evaluate conditions and regulate the projects accordingly, allocating budgets for infrastructure and passing edicts to avoid chaos. Since they're not as large as political legislative bodies like the US House of Representatives and Senate, they can usually operate on a consensus basis, and not drive everything to a contentious vote. By and large, these are as nimble as a legislative body can be.
|
|
||||||
|
|
||||||
However, I believe open source projects need an executive to be effective. At some point, we need a single person to listen to the facts, entertain theories, and then decide, and execute a plan. Some projects have natural single leaders like this. Most, however, do not.
|
|
||||||
|
|
||||||
I believe we as engineers aren't generally good at being like Linus. If you've spent any time in the corporate world you've had an executive disagree with you and run you right over. When we get the chance to distribute power evenly, we do it.
|
|
||||||
|
|
||||||
But I think that's a mistake. I think we should strive to have executives. Not just organizers like the [OpenStack PTL][10], but more like the [Debian Project Leader][11]. Empowered people with the responsibility to serve as a visionary and keep the project's decision making relevant and of high quality. This would also give the board somebody to interact with directly so that they do not have to try and convince the whole community to move in a particular direction to wield influence. In this way, I believe we'd end up with a system of checks and balances similar to the US Constitution.
|
|
||||||
|
|
||||||
So here is my suggestion for how a project executive structure could work, assuming there is already a strong technical committee and a well-defined voting electorate that I call the "active technical contributors."
|
|
||||||
|
|
||||||
1. The president is elected by [Condorcet][1] vote of the active technical contributors of a project for a term of 1 year.
|
|
||||||
|
|
||||||
2. The president will have veto power over any proposed change to the project's technical assets.
|
|
||||||
|
|
||||||
3. The technical committee may override the president's veto by a super majority vote.
|
|
||||||
|
|
||||||
4. The president will inform the technical contributors of their plans for the project every 6 months.
|
|
||||||
|
|
||||||
This system only works if the project contributors expect their project president to actively drive the vision of the project. Basically, the culture has to turn to this executive for final decision-making before it comes to a veto. The veto is for times when the community makes poor decisions. And this doesn't replace leaders of individual teams. Think of these like the governors of states in the US. They're running their sub-project inside the parameters set down by the technical committee and the president.
|
|
||||||
|
|
||||||
And in the case of foundations or communities with boards, I believe ultimately a board would serve as the judicial branch, checking the legality of changes made against the by-laws of the group. If there's no board of sorts, a judiciary could be appointed and confirmed, similar to the US Supreme Court or the [Debian CTTE][12]. This would also just be necessary to ensure that the technical arm of a project doesn't get the foundation into legal trouble of any kind, which is already what foundation boards tend to do.
|
|
||||||
|
|
||||||
I'd love to hear your thoughts on this on Twitter, please tweet me [@SpamapS][13] with the hashtag #OpenSourcePresident to get the discussion going.
|
|
||||||
|
|
||||||
_This article was originally published on [FewBar.com][2] as "Free and open source leaders—You need a president" and was republished with permission._
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Clint Byrum - Clint Byrum is a Cloud Architect at IBM (Though his words here are his own, and not those of IBM). He is an active Open Source and Free Software contributor to Debian, Ubuntu, OpenStack, and various other projects spanning the past 20 years.
|
|
||||||
|
|
||||||
-------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/3/governance-needs-president
|
|
||||||
|
|
||||||
作者:[ Clint Byrum][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/spamaps
|
|
||||||
[1]:https://en.wikipedia.org/wiki/Condorcet_method
|
|
||||||
[2]:http://fewbar.com/2017/02/open-source-governance-needs-presidents/
|
|
||||||
[3]:https://opensource.com/article/17/3/governance-needs-president?rate=g5uFkFg_AqVo7JnKqPHoAxKccWzo1XXgn5wj5hILAIk
|
|
||||||
[4]:http://events.linuxfoundation.org/events/open-source-leadership-summit
|
|
||||||
[5]:https://www.cncf.io/
|
|
||||||
[6]:https://www.openstack.org/foundation/tech-committee/
|
|
||||||
[7]:https://twitter.com/adamhjk
|
|
||||||
[8]:https://www.cncf.io/
|
|
||||||
[9]:https://www.openstack.org/foundation/tech-committee/
|
|
||||||
[10]:https://docs.openstack.org/project-team-guide/ptl.html
|
|
||||||
[11]:https://www.debian.org/devel/leader
|
|
||||||
[12]:https://www.debian.org/devel/tech-ctte
|
|
||||||
[13]:https://twitter.com/spamaps
|
|
||||||
[14]:https://opensource.com/user/121156/feed
|
|
||||||
[15]:https://opensource.com/users/spamaps
|
|
||||||
@ -0,0 +1,97 @@
|
|||||||
|
North Korea's Unit 180, the cyber warfare cell that worries the West
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
[][13] [**PHOTO:** Defectors say Pyongyang's cyberattacks aimed at raising cash are likely organised by the special cell — Unit 180. (Reuters: Damir Sagolj, file)][14]
|
||||||
|
|
||||||
|
North Korea's main spy agency has a special cell called Unit 180 that is likely to have launched some of its most daring and successful cyberattacks, according to defectors, officials and internet security experts.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
North Korea has been blamed in recent years for a series of online attacks, mostly on financial networks, in the United States, South Korea and over a dozen other countries.
|
||||||
|
|
||||||
|
Cyber security researchers have also said they found technical evidence that could l[ink North Korea with the global WannaCry "ransomware" cyberattack][15] that infected more than 300,000 computers in 150 countries this month.
|
||||||
|
|
||||||
|
Pyongyang has called the allegation "ridiculous".
|
||||||
|
|
||||||
|
The crux of the allegations against North Korea is its connection to a hacking group called Lazarus that is linked to last year's $US81 million cyber heist at the Bangladesh central bank and the 2014 attack on Sony's Hollywood studio.
|
||||||
|
|
||||||
|
The US Government has blamed North Korea for the Sony hack and some US officials have said prosecutors are building a case against Pyongyang in the Bangladesh Bank theft.
|
||||||
|
|
||||||
|
No conclusive proof has been provided and no criminal charges have yet been filed. North Korea has also denied being behind the Sony and banking attacks.
|
||||||
|
|
||||||
|
North Korea is one of the most closed countries in the world and any details of its clandestine operations are difficult to obtain.
|
||||||
|
|
||||||
|
But experts who study the reclusive country and defectors who have ended up in South Korea or the West have provided some clues.
|
||||||
|
|
||||||
|
### Hackers likely under cover as employees
|
||||||
|
|
||||||
|
Kim Heung-kwang, a former computer science professor in North Korea who defected to the South in 2004 and still has sources inside North Korea, said Pyongyang's cyberattacks aimed at raising cash are likely organised by Unit 180, a part of the Reconnaissance General Bureau (RGB), its main overseas intelligence agency.
|
||||||
|
|
||||||
|
"Unit 180 is engaged in hacking financial institutions (by) breaching and withdrawing money out of bank accounts," Mr Kim said.
|
||||||
|
|
||||||
|
|
||||||
|
He has previously said that some of his former students have joined join North Korea's Strategic Cyber Command, its cyber-army.
|
||||||
|
|
||||||
|
> "The hackers go overseas to find somewhere with better internet services than North Korea so as not to leave a trace," Mr Kim added.
|
||||||
|
|
||||||
|
He said it was likely they went under the cover of being employees of trading firms, overseas branches of North Korean companies, or joint ventures in China or South-East Asia.
|
||||||
|
|
||||||
|
James Lewis, a North Korea expert at the Washington-based Centre for Strategic and International Studies, said Pyongyang first used hacking as a tool for espionage and then political harassment against South Korean and US targets.
|
||||||
|
|
||||||
|
"They changed after Sony by using hacking to support criminal activities to generate hard currency for the regime," he said.
|
||||||
|
|
||||||
|
"So far, it's worked as well or better as drugs, counterfeiting, smuggling — all their usual tricks."
|
||||||
|
|
||||||
|
Media player: "Space" to play, "M" to mute, "left" and "right" to seek.
|
||||||
|
|
||||||
|
[**VIDEO:** Have you been hit by ransomware? (ABC News)][16]
|
||||||
|
|
||||||
|
### South Korea purports to have 'considerable evidence'
|
||||||
|
|
||||||
|
The US Department of Defence said in a report submitted to Congress last year that North Korea likely "views cyber as a cost-effective, asymmetric, deniable tool that it can employ with little risk from reprisal attacks, in part because its networks are largely separated from the internet".
|
||||||
|
|
||||||
|
> "It is likely to use internet infrastructure from third-party nations," the report said.
|
||||||
|
|
||||||
|
South Korean officials said they had considerable evidence of North Korea's cyber warfare operations.
|
||||||
|
|
||||||
|
|
||||||
|
"North Korea is carrying out cyberattacks through third countries to cover up the origin of the attacks and using their information and communication technology infrastructure," Ahn Chong-ghee, South Korea's Vice-Foreign Minister, told Reuters in written comments.
|
||||||
|
|
||||||
|
Besides the Bangladesh Bank heist, he said Pyongyang was also suspected in attacks on banks in the Philippines, Vietnam and Poland.
|
||||||
|
|
||||||
|
In June last year, police said the North hacked into more than 140,000 computers at 160 South Korean companies and government agencies, planting malicious code as part of a long-term plan to lay the groundwork for a massive cyberattack on its rival.
|
||||||
|
|
||||||
|
North Korea was also suspected of staging cyberattacks against the South Korean nuclear reactor operator in 2014, although it denied any involvement.
|
||||||
|
|
||||||
|
That attack was conducted from a base in China, according to Simon Choi, a senior security researcher at Seoul-based anti-virus company Hauri Inc.
|
||||||
|
|
||||||
|
"They operate there so that regardless of what kind of project they do, they have Chinese IP addresses," said Mr Choi, who has conducted extensive research into North Korea's hacking capabilities.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.abc.net.au/news/2017-05-21/north-koreas-unit-180-cyber-warfare-cell-hacking/8545106
|
||||||
|
|
||||||
|
作者:[www.abc.net.au ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:http://www.abc.net.au
|
||||||
|
[1]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||||
|
[2]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||||
|
[3]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||||
|
[4]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||||
|
[5]:http://www.abc.net.au/news/2017-05-18/adylkuzz-cyberattack-could-be-far-worse-than-wannacry:-expert/8537502
|
||||||
|
[6]:http://www.google.com/maps/place/Korea,%20Democratic%20People%20S%20Republic%20Of/@40,127,5z
|
||||||
|
[7]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||||
|
[8]:http://www.abc.net.au/news/2017-05-16/wannacry-ransomware-showing-up-in-obscure-places/8527060
|
||||||
|
[9]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||||
|
[10]:http://www.abc.net.au/news/2015-08-05/why-we-should-care-about-cyber-crime/6673274
|
||||||
|
[11]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||||
|
[12]:http://www.abc.net.au/news/2017-05-15/what-to-do-if-youve-been-hacked/8526118
|
||||||
|
[13]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||||
|
[14]:http://www.abc.net.au/news/2017-05-21/military-trucks-trhough-pyongyang/8545134
|
||||||
|
[15]:http://www.abc.net.au/news/2017-05-16/researchers-link-wannacry-to-north-korea/8531110
|
||||||
|
[16]:http://www.abc.net.au/news/2017-05-15/have-you-been-hit-by-ransomware/8527854
|
||||||
@ -1,155 +0,0 @@
|
|||||||
10 tools for visual effects in Linux with Kdenlive
|
|
||||||
================================================================================
|
|
||||||

|
|
||||||
Image credits : Seth Kenlon. [CC BY-SA 4.0.][1]
|
|
||||||
|
|
||||||
[Kdenlive][2] is one of those applications; you can use it daily for a year and wake up one morning only to realize that you still have only grazed the surface of all of its potential. That's why it's nice every once in a while to sit back and look over some of the lesser-used tricks and tools in Kdenlive. Even though something's not used as often as, say, the Spacer or Razor tools, it still may end up being just the right finishing touch on your latest masterpiece.
|
|
||||||
|
|
||||||
Most of the tools I'll discuss here are not officially part of Kdenlive; they are plugins from the [Frei0r][3] package. These are ubiquitous parts of video processing on Linux and Unix, and they usually get installed along with Kdenlive as distributed by most Linux distributions, so they often seem like part of the application. If your install of Kdenlive does not feature some of the tools mentioned here, make sure that you have Frei0r plugins installed.
|
|
||||||
|
|
||||||
Since many of the tools in this article affect the look of an image, here is the base image, without effects or adjustment:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Still image grabbed from a video by Footage Firm, Inc. [CC BY-SA 4.0.][1]
|
|
||||||
|
|
||||||
Let's get started.
|
|
||||||
|
|
||||||
### 1. Color effect ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
You can find the **Color Effect** filter in **Add Effect > Misc** context menu. As filters go, it's mostly just a preset; the only controls it has are which filter you want to use.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Normally that's the kind of filter I avoid, but I have to be honest: Sometimes a plug-and-play solution is exactly what you want. This filter has a few different settings, but the two that make it worth while (at least for me) are the Sepia and XPro effects. Admittedly, controls to adjust how sepia tone the sepia effect is would be nice, but no matter what, when you need a quick and familiar color effect, this is the filter to throw onto a clip. It's immediate, it's easy, and if your client asks for that look, this does the trick every time.
|
|
||||||
|
|
||||||
### 2. Colorize ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The simplicity of the **Colorize** filter in **Add Effect > Misc** is also its strength. In some editing applications, it takes two filters and some compositing to achieve this simple color-wash effect. It's refreshing that in Kdenlive, it's a matter of one filter with three possible controls (only one of which, strictly speaking, is necessary to achieve the look).
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Its use is intuitive; use the **Hue** slider to set the color. Use the other controls to adjust the luma of the base image as needed.
|
|
||||||
|
|
||||||
This is not a filter I use every day, but for ad spots, bumpers, dreamy sequences, or titles, it's the easiest and quickest path to a commonly needed look. Get a company's color, use it as the colorize effect, slap a logo over the top of the screen, and you've just created a winning corporate intro.
|
|
||||||
|
|
||||||
### 3. Dynamic Text ###
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
For the assistant editor, the Add Effect > Misc > Dynamic **Text** effect is worth the price of Kdenlive. With one mostly pre-set filter, you can add a running timecode burn-in to your project, which is an absolute must-have safety feature when round-tripping your footage through effects and sound.
|
|
||||||
|
|
||||||
The controls look more complex than they actually are.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The font settings are self-explanatory. Placement of the text is controlled by the Horizontal and Vertical Alignment settings; steer clear of the **Size** setting (it controls the size of the "canvas" upon which you are compositing the burn-in, not the size of the burn-in itself).
|
|
||||||
|
|
||||||
The text itself doesn't have to be timecode. From the dropdown menu, you can choose from a list of useful text, including frame count (useful for VFX, since animators work in frames), source frame rate, source dimensions, and more.
|
|
||||||
|
|
||||||
You are not limited to just one choice. The text field in the control panel will take whatever arbitrary text you put into it, so if you want to burn in more information than just timecode and frame rate (such as **Sc 3 - #timecode# - #meta.media.0.stream.frame_rate#**), then have at it.
|
|
||||||
|
|
||||||
### 4. Luminance ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The **Add Effect > Misc > Luminance** filter is a no-options filter. Luminance does one thing and it does it well: It drops the chroma values of all pixels in an image so that they are displayed by their luma values. In simpler terms, it's a grayscale filter.
|
|
||||||
|
|
||||||
The nice thing about this filter is that it's quick, easy, efficient, and effective. This filter combines particularly well with other related filters (meaning that yes, I'm cheating and including three filters for one).
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Combining, in this order, the **RGB Noise** for emulated grain, **Luminance** for grayscale, and **LumaLiftGainGamma** for levels can render a textured image that suggests the classic look and feel of [Kodax Tri-X][4] film.
|
|
||||||
|
|
||||||
### 5. Mask0mate ###
|
|
||||||
|
|
||||||

|
|
||||||
Image by Footage Firm, Inc.
|
|
||||||
|
|
||||||
Better known as a four-point garbage mask, the **Add Effect > Alpha Manipulation > Mask0mate** tool is a quick, no-frills way to ditch parts of your frame that you don't need. There isn't much to say about it; it is what it is.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The confusing thing about the effect is that it does not imply compositing. You can pull in the edges all you want, but you won't see it unless you add the **Composite** transition to reveal what's underneath the clip (even if that's nothing). Also, use the **Invert** function for the filter to act like you think it should act (without it, the controls will probably feel backward to you).
|
|
||||||
|
|
||||||
### 6. Pr0file ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The **Add Effect > Misc > Pr0file** filter is an analytical tool, not something you would actually leave on a clip for final export (unless, of course, you do). Pr0file consists of two components: the Marker, which dictates what area of the image is being analyzed, and the Graph, which displays information about the marked region.
|
|
||||||
|
|
||||||
Set the marker using the **X, Y, Tilt**, and **Length** controls. The graphical readout of all the relevant color channel information is displayed as a graph, superimposed over your image.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The readout displays a profile of the colors within the region marked. The result is a sort of hyper-specific vectorscope (or oscilloscope, as the case may be) that can help you zero in on problem areas during color correction, or compare regions while color matching.
|
|
||||||
|
|
||||||
In other editors, the way to get the same information was simply to temporarily scale your image up to the region you want to analyze, look at your readout, and then hit undo to scale back. Both ways work, but the Pr0file filter does feel a little more elegant.
|
|
||||||
|
|
||||||
### 7. Vectorscope ###
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Kdenlive features an inbuilt vectorscope, available from the **View** menu in the main menu bar. A vectorscope is not a filter, it's just another view the footage in your Project Monitor, specifically a view of the color saturation in the current frame. If you are color correcting an image and you're not sure what colors you need to boost or counteract, looking at the vectorscope can be a huge help.
|
|
||||||
|
|
||||||
There are several different views available. You can render the vectorscope in traditional green monochrome (like the hardware vectorscopes you'd find in a broadcast control room), or a chromatic view (my personal preference), or subtracted from a color-wheel background, and more.
|
|
||||||
|
|
||||||
The vectorscope reads the entire frame, so unlike the Pr0file filter, you are not just getting a reading of one area in the frame. The result is a consolidated view of what colors are most prominent within a frame. Technically, the same sort of information can be intuited by several trial-and-error passes with color correction, or you can just leave your vectorscope open and watch the colors float along the color wheel and make adjustments accordingly.
|
|
||||||
|
|
||||||
Aside from how you want the vectorscope to look, there are no controls for this tool. It is a readout only.
|
|
||||||
|
|
||||||
### 8. Vertigo ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
There's no way around it; **Add Effect > Misc > Vertigo** is a gimmicky special effect filter. So unless you're remaking [Fear and Loathing][5] or the movie adaptation of [Dead Island][6], you probably aren't going to use it that much; however, it's one of those high-quality filters that does the exact trick you want when you happen to be looking for it.
|
|
||||||
|
|
||||||
The controls are simple. You can adjust how distorted the image becomes and the rate at which it distorts. The overall effect is probably more drunk or vision-quest than vertigo, but it's good.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 9. Vignette ###
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Another beautiful effect, the **Add Effect > Misc > Vignette** darkens the outer edges of the frame to provide a sort of portrait, soft-focus nouveau look. Combined with the Color Effect or the Luminance faux Tri-X trick, this can be a powerful and emotional look.
|
|
||||||
|
|
||||||
The softness of the border and the aspect ratio of the iris can be adjusted. The **Clear Center Size** attribute controls the size of the clear area, which has the effect of adjusting the intensity of the vignette effect.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 10. Volume ###
|
|
||||||
|
|
||||||
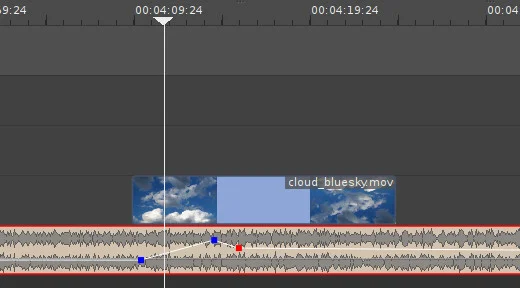
|
|
||||||
|
|
||||||
I don't believe in mixing sound within the video editing application, but I do acknowledge that sometimes it's just necessary for a quick fix or, sometimes, even for a tight production schedule. And that's when the **Audio correction > Volume (Keyframable)** effect comes in handy.
|
|
||||||
|
|
||||||
The control panel is clunky, and no one really wants to adjust volume that way, so the effect is best when used directly in the timeline. To create a volume change, double-click the volume line over the audio clip, and then click and drag to adjust. It's that simple.
|
|
||||||
|
|
||||||
Should you use it? Not really. Sound mixing should be done in a sound mixing application. Will you use it? Absolutely. At some point, you'll get audio that is too loud to play as you edit, or you'll be up against a deadline without a sound engineer in sight. Use it judiciously, watch your levels, and get the show finished.
|
|
||||||
|
|
||||||
### Everything else ###
|
|
||||||
|
|
||||||
This has been 10 (OK, 13 or 14) effects and tools that Kdenlive has quietly lying around to help your edits become great. Obviously there's a lot more to Kdenlive than just these little tricks. Some are obvious, some are cliché, some are obtuse, but they're all in your toolkit. Get to know them, explore your options, and you might be surprised what a few cheap tricks will get you.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/life/15/12/10-kdenlive-tools
|
|
||||||
|
|
||||||
作者:[Seth Kenlon][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/seth
|
|
||||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
|
||||||
[2]:https://kdenlive.org/
|
|
||||||
[3]:http://frei0r.dyne.org/
|
|
||||||
[4]:http://www.kodak.com/global/en/professional/products/films/bw/triX2.jhtml
|
|
||||||
[5]:https://en.wikipedia.org/wiki/Fear_and_Loathing_in_Las_Vegas_(film)
|
|
||||||
[6]:https://en.wikipedia.org/wiki/Dead_Island
|
|
||||||
@ -1,77 +0,0 @@
|
|||||||
Open technology for land rights documentation
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### One-third of people on the planet don't have documented rights to the land on which they rely.
|
|
||||||
|
|
||||||
[up][3]
|
|
||||||

|
|
||||||
Image by :
|
|
||||||
|
|
||||||
[Pixabay][4]. Modified by Opensource.com. [CC BY-SA 4.0][5]
|
|
||||||
|
|
||||||
The [Cadasta Foundation][6] creates tech to allow communities to document their land rights. By helping groups document the evidence of their individual and community rights to the land on which they depend, they can eventually obtain legal recognition of their land rights, and in the meantime, enjoy greater security.
|
|
||||||
|
|
||||||
We are motivated by the fact that most of the world does not have documented legal rights to the land on which they live. Technology is only a small part of this larger social issue, but our hope is that tech tools can be part of the solution even in the most remote and low-tech environments.
|
|
||||||
|
|
||||||
### The magnitude of property rights
|
|
||||||
|
|
||||||
Many of us who come from the global north probably take our rights to our land, property, and home for granted. We have titles, deeds, and rental agreements that document and solidly protect our rights.
|
|
||||||
|
|
||||||
But one-third of the people on the planet, from urban shanty towns to forest-dwelling indigenous communities, do not have documented rights to the land on which they rely. In fact, an estimated 70% of the property in emerging economies is undocumented. An estimated 25% of the world’s urban population live in homes to which they have no legal right. A majority of smallholder farmers around the world farm without the protection of having legal rights to their land documented by government records.
|
|
||||||
|
|
||||||
This is simply because government land and property records in many areas of the world either were never created or are out of date. For example, most rural land records in the state of Telangana, India haven't been updated since the 1940s. In other areas, such as parts of sub-Saharan Africa, there were never any records of land ownership to begin with—people simply farm the land their parents farmed, generation after generation.
|
|
||||||
|
|
||||||
Consider for a moment working land to which you have no secure rights. Would you invest your savings or labor in improving the land, including applying good quality seeds and fertilizer, with the knowledge that you could be displaced any day by a more powerful neighbor or investor? Imagine living in a home that could be bulldozed or usurped by an official any day. Or how could you sell your house, or use it for collateral for a loan, if you don’t have any proof that you own it?
|
|
||||||
|
|
||||||
For a majority of the world's population, these are not rhetorical questions. These are daily realities.
|
|
||||||
|
|
||||||
### How open source matters for land
|
|
||||||
|
|
||||||
Technology is only one part of the solution, but at Cadasta we believe it is a key component. While many governments had modern technology systems put in place to manage land records, often these were expensive to maintain, required highly trained staff, were not transparent, and were otherwise too complicated. Many of these systems, created at great expense by donor governments, are already outdated and no longer accurately reflect existing land and property rights.
|
|
||||||
|
|
||||||
By building open and user-friendly technology for land rights documentation we aim to overcome these problems and create land documentation systems that are flexible and accessible, allowing them to be treated as living documents that are updated continually.
|
|
||||||
|
|
||||||
We routinely train people who have never even used a smartphone before to use our technology to document their land rights in a single afternoon. The resulting data, hosted on an open source platform, is easy to access, update, and analyze. This flexibility means that governments in developing countries, should they adopt our platform, don't need to hire specially trained staff to manage the upkeep of these records.
|
|
||||||
|
|
||||||
We also believe that by contributing to and fostering open communities we can benefit more people, instead of attempting to develop all the technology ourselves. We do this by building a community around our tools as well as contributing to other existing software.
|
|
||||||
|
|
||||||
Over the past two years we've contributed and been involved in [OpenStreetMap][7]through the [Missing Maps Projec][8]t, used [OpenDataKit][9] extensively for data collection, and currently are integrating [Field Papers][10] with our system. Field Papers is technology that allows users to print paper maps, annotate those maps with pen, and then take a picture of those annotations with their phone and upload them to be transcribed.
|
|
||||||
|
|
||||||
We've also released a few Django libraries we hope will be useful to others in other Django applications. These include a policy-based permission system called [django-tutelary][11] and [django-jsonattrs][12], which provides JavaScript Object Notification (JSON)-based attribute management for PostgresSQL. If others use these pieces and contribute bug reports and patches, this can help make Cadasta's work stronger.
|
|
||||||
|
|
||||||
This work is critically important. Land rights are the foundation of stability and prosperity. Communities and countries seeking economic growth and sustainable development must document land rights and ensure land rights are secure for women, men, and communities.
|
|
||||||
|
|
||||||
_Learn more in Kate Chapman's talk at linux.conf.au 2017 ([#lca2017][1]) in Hobart: [Land Matters: Creating Open Technology for Land Rights][2]._
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Kate Chapman - Kate Chapman is Chief Technology Officer of the Cadasta Foundation, leading the organization’s technology team and strategy. Cadasta develops free and open source software to help communities document their land rights around the world. Chapman is recognized as a leader in the domains of open source geospatial technology and community mapping, and an advocate for open imagery as a public good.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/land-rights-documentation-Cadasta
|
|
||||||
|
|
||||||
作者:[Kate Chapman][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/wonderchook
|
|
||||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
|
||||||
[2]:https://linux.conf.au/schedule/presentation/50/
|
|
||||||
[3]:https://opensource.com/article/17/1/land-rights-documentation-Cadasta?rate=E8gJkvb1mbBXytsZiKA_ZtBCOvpi41nDSfz4R8tNnoc
|
|
||||||
[4]:https://pixabay.com/en/tree-field-cornfield-nature-247122/
|
|
||||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
|
||||||
[6]:http://cadasta.org/
|
|
||||||
[7]:http://www.openstreetmap.org/
|
|
||||||
[8]:http://www.missingmaps.org/
|
|
||||||
[9]:https://opendatakit.org/
|
|
||||||
[10]:http://fieldpapers.org/
|
|
||||||
[11]:https://github.com/Cadasta/django-tutelary
|
|
||||||
[12]:https://github.com/Cadasta/django-jsonattrs
|
|
||||||
@ -1,104 +0,0 @@
|
|||||||
Red Hat's OpenShift Container Platform Expands Cloud Options
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
Red Hat on Wednesday announced the general availability of Red Hat OpenShift Container Platform 3.4.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
This latest version helps organizations better embrace new Linux container technologies that can deliver innovative business applications and services without sacrificing existing IT investments.
|
|
||||||
|
|
||||||
Red Hat OpenShift Container Platform 3.4 provides a platform for innovation without giving up existing mission-critical workloads. It offers dynamic storage provisioning for both traditional and cloud-native applications, as well as multitenant capabilities that can support multiple applications, teams and deployment processes in a hybrid cloud environment.
|
|
||||||
|
|
||||||
Today's enterprises are must balance management of their existing application portfolios with the goal of making it easier for developers to build new applications, observed Brian Gracely, director of product strategy for OpenShift at Red Hat.
|
|
||||||
|
|
||||||
The new release focuses on three complex areas for enterprises: managing storage; isolating resources for multiple groups (multitenancy); and the ability to consistently run applications on multiple cloud environments (public or private).
|
|
||||||
|
|
||||||
"Red Hat OpenShift Container Platform 3.4 builds on the momentum of both the Kubernetes and Docker projects, which are helping developers use containers to modernize existing applications and build new cloud-native microservices," Gracely told LinuxInsider.
|
|
||||||
|
|
||||||
OpenShift Container Platform 3.4 makes storage provisioning easier for developers and operators, and it enhances how the platform can be used to provide multitenant resources to multiple groups within an organization. Additionally, it continues to codify the best practices needed to deploy a consistent container platform across any cloud environment, such as AWS, Azure, GCP, OpenStack or VMware.
|
|
||||||
|
|
||||||
### Pushes Cloud Benefits
|
|
||||||
|
|
||||||
The new platform advances the process of creating and deploying applications by addressing the growing storage needs of applications across the hybrid cloud for enterprises. It allows for coexistence of modern and future-forward workloads on a single, enterprise-ready platform.
|
|
||||||
|
|
||||||
The new OpenShift Container Platform and service gives Red Hat customers an easy way to adopt and use Google Cloud as a public of hybrid cloud environment, noted Charles King, principal analyst at [Pund-IT][1].
|
|
||||||
|
|
||||||
"It will be a welcome addition in many or most enterprise IT shops, especially those that are active employing or exploring container solutions," he told LinuxInsider.
|
|
||||||
|
|
||||||
"Since Red Hat will act as the service provider of the new offering, customers should also be able to seamlessly integrate OpenShift support with their other Red Hat products and services," King pointed out.
|
|
||||||
|
|
||||||
The new release also provides an enterprise-ready version of Kubernetes 1.4 and the Docker container runtime, which will help customers roll out new services more quickly with the backing of Red Hat Enterprise Linux.
|
|
||||||
|
|
||||||
OpenShift Container Platform 3.4 integrates architectures, processes and services to enable delivery of critical business applications, whether legacy or cloud-native, and containerized workloads.
|
|
||||||
|
|
||||||
### Open Source and Linux Innovation
|
|
||||||
|
|
||||||
Kubernetes is becoming the de facto standard for orchestrating and managing Linux containers. OpenShift is delivering the leading enterprise-ready platform built on Kubernetes, noted Red Hat's Gracely.
|
|
||||||
|
|
||||||
"Kubernetes is one of the fastest-growing open source projects, with contributors from cloud providers, independent software vendors and [individual and business] end-users," he said. "It has become a project that has done an excellent job of considering and addressing the needs of many different groups with many types of application needs."
|
|
||||||
|
|
||||||
Both Red Hat and Google are pushing for innovation. Both companies are among the market's most proactive and innovative supporters of open source and Linux solutions.
|
|
||||||
|
|
||||||
"The pair's collaboration on this new service is a no-brainer that could eventually lead to Red Hat and Google finding or creating further innovative open source offerings," said Pund-IT's King.
|
|
||||||
|
|
||||||
### Features and Benefits
|
|
||||||
|
|
||||||
Among the new capabilities in the latest version of OpenShift Container Platform:
|
|
||||||
|
|
||||||
* Next-level container storage with support for dynamic storage provisioning -- This allows multiple storage types and multitier storage exposure in Kubernetes;
|
|
||||||
* Container-native storage enabled by Red Hat Gluster Storage -- This now supports dynamic provisioning and push button deployment for stateful and stateless applications;
|
|
||||||
* Software-defined, highly available and scalable storage solution -- This provides access across on-premises and public cloud environments for more cost efficiency over traditional hardware-based or cloud-only storage services;
|
|
||||||
* Enhanced multitenancy through more simplified management of projects -- This feature is powered by Kubernetes namespaces in a single Kubernetes cluster. Applications can run fully isolated and share resources on a single Kubernetes cluster in OpenShift Container Platform.
|
|
||||||
|
|
||||||
### More Supplements
|
|
||||||
|
|
||||||
The OpenShift Container Platform upgrade adds the capacity to search for projects and project details, manage project membership, and more via a more streamlined Web console. This capability facilitates working with multiple projects across dispersed teams.
|
|
||||||
|
|
||||||
Another enhancement is the multitenancy feature that provides application development teams with their own cloud-like application environment. It lets them build and deploy customer-facing or internal applications using DevOps processes that are isolated from one another.
|
|
||||||
|
|
||||||
Also available in the new release are new hybrid cloud reference architectures for running Red Hat OpenShift Container Platform on OpenStack, VMware, Amazon Web Services, Google Cloud Engine and Microsoft Azure. These guides help walk a user through deployment across public and private clouds, virtual machines and bare metal.
|
|
||||||
|
|
||||||
"It also drastically simplifies how developers can access storage resources, allowing developers to dynamically provision storage resources/capacity with the click of a button -- effectively self-service for developers. It also allows developers to feel confident that the resources required for their applications will be properly isolated from other resource needs in the platform," said Red Hat's Gracely.
|
|
||||||
|
|
||||||
### Orchestration Backbone
|
|
||||||
|
|
||||||
The foundation for Red Hat OpenShift Container Platform 3.4 is the open source Kubernetes Project community. Kubernetes 1.4 features alpha support for expanded cluster federation APIs.
|
|
||||||
|
|
||||||
It enables multiple clusters federated across a hybrid environment. Red Hat engineers view this feature as a key component to enabling hybrid cloud deployments in the enterprise.
|
|
||||||
|
|
||||||
The latest version of OpenShift is available now via the Red Hat Customer Portal. It offers community innovation as hardened, production-grade features.
|
|
||||||
|
|
||||||
### Ensuring Customer Health
|
|
||||||
|
|
||||||
Red Hat's platform is vital to the success of The Vitality Group's global initiative and reward program, according to CIO Neil Adamson.
|
|
||||||
|
|
||||||
This program is a key component of how the company envisions the future of health, he said.
|
|
||||||
|
|
||||||
"Advanced services for our customers can only be delivered by embracing next-generation technologies, particularly those provided through the open source communities that drive Linux containers, Kubernetes and IoT," said Adamson.
|
|
||||||
|
|
||||||
Red Hat's OpenShift Container Platform provides his company with the best of these communities while still delivering a stable, more secure foundation that help "reap the benefits of open source innovation while lessening the risks often inherent to emerging technologies."
|
|
||||||
|
|
||||||
The latest platform features will further support application development in the cloud. Container solutions are being adopted rapidly for many core IT tasks, including app development projects and processes, according to King, who noted that "being able to seamlessly deploy containers in a widely and easily accessible environment like Google Cloud should simplify development tasks."
|
|
||||||

|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**Jack M. Germain** has been writing about computer technology since the early days of the Apple II and the PC. He still has his original IBM PC-Jr and a few other legacy DOS and Windows boxes. He left shareware programs behind for the open source world of the Linux desktop. He runs several versions of Windows and Linux OSes and often cannot decide whether to grab his tablet, netbook or Android smartphone instead of using his desktop or laptop gear. You can connect with him on [Google+][2].
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.linuxinsider.com/story/84239.html?rss=1
|
|
||||||
|
|
||||||
作者:[Jack M. Germain ][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://plus.google.com/116242401898170634809?rel=author
|
|
||||||
[1]:http://www.pund-it.com/
|
|
||||||
[2]:https://plus.google.com/116242401898170634809?rel=author
|
|
||||||
@ -1,216 +0,0 @@
|
|||||||
# Fedora 24 Gnome & HP Pavilion + Nvidia setup review
|
|
||||||
|
|
||||||
Recently, you may have come across my [Chapeau][1] review. This experiment prompted me to widen my Fedora family testing, and so I decided to try setting up [Fedora 24 Gnome][2] on my [HP][3] machine, a six-year-old laptop with 4 GB of RAM and an aging Nvidia card. Yes, Fedora 25 has since been released and I had it [tested][4] with delight. But we can still enjoy this little article now can we?
|
|
||||||
|
|
||||||
This review should complement - and contrast - my usual crop of testing on the notorious but capable [Lenovo G50][5] machine, purchased in 2015, so we have old versus new, but also the inevitable lack of proper Linux support for the [Realtek][6] network card on the newer box. We will then also check how well Fedora handles the Nvidia stack, test if Nouveau is a valid alternative, and of course, pimp the system to the max, using some of the beauty tricks we have witnessed in the Chapeau review. Should be more than interesting.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Installation
|
|
||||||
|
|
||||||
Nothing special to report here. The system has a much simpler setup than the Lenovo laptop. The new machine comes with UEFI, Secure Boot, 1TB disk with a GPT setup partitioned sixteen different ways, with Windows 10 and some 6-7 Linux distros on it. In comparison, the BIOS-fueled Pavilion only dual boots. Prior to this review, it was running Linux Mint 17.3 [Rosa Xfce][7], but it used to have all sorts of Ubuntu children on it, and I had used it quite extensively for arguably funny [video processing][8] and all sorts of games. The home partition dates back to the early setup, and has remained such since, including a lot of legacy config and many desktop environments.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
I was able to boot from a USB drive, although I did use the Fedora tool to create the live media. I've never had any problems booting on this host, to the best of my memory, a far cry (not the [game][9], just an expression, hi hi) from the Lenovo experience. There, before a BIOS update, Fedora would [not even run][10], and a large number of distros used to [struggle][11] until very recently. All part of my great disappointment adventure with Linux.
|
|
||||||
|
|
||||||
Anyhow, this procedure went without any fuss. Fedora 24 took control of the bootloader, managing itself and the resident Windows 7 installation. If you're interested in more details on how to dual-boot, you might want to check these:
|
|
||||||
|
|
||||||
[Ubuntu & Windows 7][12] dual-boot guide
|
|
||||||
|
|
||||||
[Xubuntu & Windows 7][13] dual-boot guide - same same but different
|
|
||||||
|
|
||||||
[CentOS 7 & Windows 7][14] dual-boot guide - fairly similar to our Fedora attempt
|
|
||||||
|
|
||||||
[Ubuntu & Windows 8][15] dual-boot guide - this one covers a UEFI setup, too
|
|
||||||
|
|
||||||
### It's pimping time!
|
|
||||||
|
|
||||||
My Fedora [pimping guide][16] has it all. I setup RPM Fusion Free and Non-Free, then installed about 700 MB worth of media codecs, plugins and extra software, including Steam, Skype, GIMP, VLC, Gnome Tweak Tool, Chrome, several other helper utilities, and more.
|
|
||||||
|
|
||||||
On the aesthetics side, I grabbed both Faenza and Moka icons, and configured half a dozen Gnome [extensions][17], including the mandatory [Dash to Dock][18], which really helps transforms this desktop environment into a usable product.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
What is that green icon on the right side? 'Tis a spoiler of things to be, that is.
|
|
||||||
|
|
||||||
I also had no problems with my smartphones, [Ubuntu Phone][19] or the[iPhone][20]. Both setups worked fine, and this also brings the annoyance with the Apple device on Chapeau 24 into bad spotlight. Rhythmbox would not play from any external media, though. Fail.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
This is a teaser, implying wossname Nvidia thingie; well here we go.
|
|
||||||
|
|
||||||
### Nvidia setup
|
|
||||||
|
|
||||||
This is a tricky one. First, take a look at my generic [tutorial][21] on this topic. Then, take a look at my recent [Fedora 23][22] [experience][23] on this topic. Unlike Ubuntu, Red Hat distros do not quite like the whole pre-compiled setup. However, just to see whether things have changed in any way, I did use a helper tool called easyLife to setup the drivers. I've talked about this utility and Fedy in an OCS-Mag [article][24], and how you can use them to make your Fedora experience more colorful. Bottom line: good for lots of things, not for drivers, though.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Yes, this resulted in a broken system. I had to manually installed the drivers - luckily I had installed the kernel sources and headers, as well as other necessary build tools, gcc and make, beforehand, to prepare for this kind of scenario. Be warned, kids. In the end, the official way is the best.
|
|
||||||
|
|
||||||
### Nouveau vs Nvidia, which is faster?
|
|
||||||
|
|
||||||
I did something you would not really expect. I benchmarked the actual performance of the graphics stack with the Nouveau driver first and then the closed-source blob, using the Unigine Heaven tool. This gives clear results on how the two compare.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Remember, this is an ancient laptop, and it does not stack well against modern tools, so you will not be surprised to learn that Heaven reported a staggering 1 FPS for Nouveau, and it took me like 5 minutes before the system actually responded, and I was able to quit the benchmark.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Nvidia gave much better results. To begin with, I was able to use the system while testing, and Heaven responded to mouse clicks and key strokes, all the while reporting a very humble 5-6 FPS, which means it was roughly 500% more efficient than the Nouveau driver. That tells you all you need to know, ladies and gentlemen.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Also, Steam would not run at all with Nouveau, so there's that to consider, too. Funny how system requirements creep up over time. I used to play, I mean test [Call of Duty][25], a highly mediocre and arcade-like shooter on this box on the highest settings, but that feat feels like a completely different era.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Hardware compatibility
|
|
||||||
|
|
||||||
Things were quite all right overall. All of the Fn buttons worked fine, and so did the web camera. Power management also did its thing well, dimming the screen and whatnot, but we cannot really judge the battery life, as the cells are six years old now and quite broken. They only lend about 40 minutes of juice in the best case.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Bluetooth did not work at first, but this is because crucial packages are missing.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
You can resolve the issue using dnf:
|
|
||||||
|
|
||||||
dnf install blueman bluez
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Suspend & resume
|
|
||||||
|
|
||||||
No issues, even with the Nvidia drivers. The whole sequence was quick and smooth, about 2-3 seconds each direction, into the land of sweet dreams and out of it. I do recall some problems with this in the past, but not any more. Happy sailing.
|
|
||||||
|
|
||||||
### Resource utilization
|
|
||||||
|
|
||||||
We can again compare Nouveau with Nvidia. But first, I had to sort out the swap partition setup manually, as Fedora refused to activate it. This is a big fail, and this happens consistently. Anyhow, the resource utilization with either one driver was almost identical. Both tolled a hefty 1.2 GB of RAM, and CPU ticked at about 2-3%, which is not really surprising, given the age of this machine. I did not see any big noise or heat difference the way we would witness it in the past, which is a testament to the improvements in the open-source driver, even though it fails on some of the advanced graphics logic required from it. But for normal use, non-gaming use, it behaves fairly well.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Problems
|
|
||||||
|
|
||||||
Well, I observed some interesting issues during my testing. SELinux complained about legitimate processes a few times, and this really annoys me. Now to troubleshoot this, all you need to do is expand the alert, check the details, and then vomit. Why would anyone let ordinary users ever see this. Why?
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
SELinux is preventing totem-video-thu from write access on the directory gstreamer-1.0.
|
|
||||||
|
|
||||||
***** Plugin catchall_labels (83.8 confidence) suggests *****
|
|
||||||
|
|
||||||
If you want to allow totem-video-thu to have write access on the gstreamer-1.0 directory
|
|
||||||
Then you need to change the label on gstreamer-1.0
|
|
||||||
Do
|
|
||||||
# semanage fcontext -a -t FILE_TYPE 'gstreamer-1.0'
|
|
||||||
where FILE_TYPE is one of the following: cache_home_t, gstreamer_home_t, texlive_home_t, thumb_home_t, thumb_tmp_t, thumb_tmpfs_t, tmp_t, tmpfs_t, user_fonts_cache_t, user_home_dir_t, user_tmp_t.
|
|
||||||
Then execute:
|
|
||||||
restorecon -v 'gstreamer-1.0'
|
|
||||||
|
|
||||||
I want to execute something else, because hey, let us let developers be in charge of how things should be done. They know [best][26], right! This kind of garbage is what makes zombie apocalypses happen, when you miscode the safety lock on a lab confinement.
|
|
||||||
|
|
||||||
### Other observations
|
|
||||||
|
|
||||||
Exploring the system with gconf-editor and dconf-editor, I found tons of leftover settings from my old Gnome 2, Xfce and Cinnamon setups, and one of the weird things was that Nemo would create, or rather, restore, several desktop icons every time I had it launched, and it did not cooperate with the global settings I configured through the Tweak Tool. In the end, I had to resort to some command line witchcraft:
|
|
||||||
|
|
||||||
gsettings set org.nemo.desktop home-icon-visible false
|
|
||||||
gsettings set org.nemo.desktop trash-icon-visible false
|
|
||||||
gsettings set org.nemo.desktop computer-icon-visible false
|
|
||||||
|
|
||||||
### Gallery
|
|
||||||
|
|
||||||
Finally, some sweet screenshots:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
This was an interesting ordeal. It took me about four hours to finish the configuration and polish the system, the maniacal Fedora update that always runs in the deep hundreds and sometimes even thousands of packages, the graphics stack setup, and finally, all the gloss and trim needed to have a functional machine.
|
|
||||||
|
|
||||||
All in all, it works well. Fedora proved itself to be an adequate choice for the old HP machine, with decent performance and responsiveness, good hardware compatibility, fine aesthetics and functionality, once the extras are added, and only a small number of issues, some related to my laptop usage legacy. Not bad. Sure, the system could be faster, and Gnome isn't the best choice for olden hardware. But then, for something that was born in 2010, the HP laptop handles this desktop environment with grace, and it looks the part. Just proves that Red Hat makes a lot of sense once you release its essential oils and let the fragrance of extra software and codecs sweep you. It is your time to be enthused about this and commence your own testing.
|
|
||||||
|
|
||||||
Cheers.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
|
||||||
|
|
||||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
|
||||||
|
|
||||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
|
||||||
|
|
||||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
|
||||||
|
|
||||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
|
||||||
|
|
||||||
|
|
||||||
-------------
|
|
||||||
|
|
||||||
|
|
||||||
via: http://www.dedoimedo.com/computers/hp-pavilion-fedora-24.html
|
|
||||||
|
|
||||||
作者:[Igor Ljubuncic][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.dedoimedo.com/faq.html
|
|
||||||
|
|
||||||
[1]:http://www.dedoimedo.com/computers/chapeau-24.html
|
|
||||||
[2]:http://www.dedoimedo.com/computers/fedora-24-gnome.html
|
|
||||||
[3]:http://www.dedoimedo.com/computers/my-new-new-laptop.html
|
|
||||||
[4]:http://www.dedoimedo.com/computers/fedora-25-gnome.html
|
|
||||||
[5]:http://www.dedoimedo.com/computers/lenovo-g50-review.html
|
|
||||||
[6]:http://www.dedoimedo.com/computers/ubuntu-xerus-realtek-bug.html
|
|
||||||
[7]:http://www.dedoimedo.com/computers/linux-mint-rosa-xfce.html
|
|
||||||
[8]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
|
||||||
[9]:http://www.dedoimedo.com/games/far-cry-4-review.html
|
|
||||||
[10]:http://www.dedoimedo.com/computers/lenovo-g50-fedora.html
|
|
||||||
[11]:http://www.dedoimedo.com/computers/lenovo-g50-distros-second-round.html
|
|
||||||
[12]:http://www.dedoimedo.com/computers/dual-boot-windows-7-ubuntu.html
|
|
||||||
[13]:http://www.dedoimedo.com/computers/dual-boot-windows-7-xubuntu.html
|
|
||||||
[14]:http://www.dedoimedo.com/computers/dual-boot-windows-7-centos-7.html
|
|
||||||
[15]:http://www.dedoimedo.com/computers/dual-boot-windows-8-ubuntu.html
|
|
||||||
[16]:http://www.dedoimedo.com/computers/fedora-24-pimp.html
|
|
||||||
[17]:http://www.dedoimedo.com/computers/fedora-23-extensions.html
|
|
||||||
[18]:http://www.dedoimedo.com/computers/gnome-3-dash.html
|
|
||||||
[19]:http://www.dedoimedo.com/computers/ubuntu-phone-sep-2016.html
|
|
||||||
[20]:http://www.dedoimedo.com/computers/iphone-6-after-six-months.html
|
|
||||||
[21]:http://www.dedoimedo.com/computers/fedora-nvidia-guide.html
|
|
||||||
[22]:http://www.dedoimedo.com/computers/fedora-23-nvidia.html
|
|
||||||
[23]:http://www.dedoimedo.com/computers/fedora-23-nvidia-steam.html
|
|
||||||
[24]:http://www.ocsmag.com/2015/06/22/you-can-leave-your-fedora-on/
|
|
||||||
[25]:http://www.dedoimedo.com/games/cod-mw2.html
|
|
||||||
[26]:http://www.ocsmag.com/2016/10/19/systemd-progress-through-complexity/
|
|
||||||
@ -1,631 +0,0 @@
|
|||||||
How to install OTRS (OpenSource Trouble Ticket System) on CentOS 7
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### On this page
|
|
||||||
|
|
||||||
1. [The Environment][1]
|
|
||||||
2. [Preparation][2]
|
|
||||||
3. [Install MariaDB on Centos 7][3]
|
|
||||||
4. [Install EPEL ][4]
|
|
||||||
5. [Install OTRS][5]
|
|
||||||
6. [Configure OTRS on CentOS 7][6]
|
|
||||||
|
|
||||||
OTRS (open-source trouble ticket system software) is a sophisticated open source software used by companies to improve their operation related to customer support, help desk, call centers and more. OTRS is written in PERL and provides the following important features:
|
|
||||||
|
|
||||||
* Customers can register and create/interact with a Ticket via the customer portal and by email, phone, and fax with each queue (Attendants/Technicians post box).
|
|
||||||
* Tickets can be managed by their priority, assignment, transmission and follow-up. A ticket can be split, merged, bulk actions can be applied, and links to each other and notifications can be set. Services can be configurated through the service catalog.
|
|
||||||
* To increase the team capacity, auto email (automatic answers), text templates and signatures can be configured. The system supports notes and attachments on tickets.
|
|
||||||
* Others capabilities include: statistics and reports (CSV/PDF), SLA and many other features.
|
|
||||||
|
|
||||||
### The Environment
|
|
||||||
|
|
||||||
This article covers the OTRS 5 installation and basic configuration. This article was writen based on the following enviroment: A Virtual Box VM with CENTOS 7 Minimal, 2GB RAM, 8GB HD and 2 network interfaces (host only and NAT).
|
|
||||||
|
|
||||||
### Preparation
|
|
||||||
|
|
||||||
Assuming that you use a fresh installation of Centos 7 Minimal, before to install OTRS, run the following command to update the system and install aditional packages:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum update
|
|
||||||
```
|
|
||||||
|
|
||||||
Transaction Summary ================================================================================ Install 1 Package Upgrade 39 Packages Total download size: 91 M Is this ok [y/d/N]: **y**
|
|
||||||
|
|
||||||
Install a text editor or use VI. In this article we use VIM, run the following command to install it:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum install vim
|
|
||||||
```
|
|
||||||
|
|
||||||
To install the WGET package, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum install wget
|
|
||||||
```
|
|
||||||
|
|
||||||
To configure the Centos 7 network, run the following command to open the NMTUI (Network Manager Text User Interface) tool and edit the interfaces and hostname if nescessary:
|
|
||||||
|
|
||||||
```
|
|
||||||
nmtui
|
|
||||||
```
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][7]
|
|
||||||
|
|
||||||
After setup of network settings and hostname on CentOS 7, run the following command to apply the changes:
|
|
||||||
|
|
||||||
```
|
|
||||||
service networks restart
|
|
||||||
```
|
|
||||||
|
|
||||||
To verify the network information, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
ip addr
|
|
||||||
```
|
|
||||||
|
|
||||||
The output looks like this on my system:
|
|
||||||
|
|
||||||
```
|
|
||||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
|
|
||||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
|
||||||
inet 127.0.0.1/8 scope host lo
|
|
||||||
valid_lft forever preferred_lft forever
|
|
||||||
inet6 ::1/128 scope host
|
|
||||||
valid_lft forever preferred_lft forever
|
|
||||||
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
|
|
||||||
link/ether 08:00:27:67:bc:73 brd ff:ff:ff:ff:ff:ff
|
|
||||||
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic enp0s3
|
|
||||||
valid_lft 84631sec preferred_lft 84631sec
|
|
||||||
inet6 fe80::9e25:c982:1091:90eb/64 scope link
|
|
||||||
valid_lft forever preferred_lft forever
|
|
||||||
3: enp0s8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
|
|
||||||
link/ether 08:00:27:68:88:f3 brd ff:ff:ff:ff:ff:ff
|
|
||||||
inet 192.168.56.101/24 brd 192.168.56.255 scope global dynamic enp0s8
|
|
||||||
valid_lft 1044sec preferred_lft 1044sec
|
|
||||||
inet6 fe80::a00:27ff:fe68:88f3/64 scope link
|
|
||||||
valid_lft forever preferred_lft forever
|
|
||||||
```
|
|
||||||
|
|
||||||
Disable SELINUX (Security Enhanced Linux) on Centos 7, edit the following config file:
|
|
||||||
|
|
||||||
```
|
|
||||||
vim /etc/selinux/config
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
"/etc/selinux/config" 14L, 547C# This file controls the state of SELinux on the system.
|
|
||||||
# SELINUX= can take one of these three values:
|
|
||||||
# enforcing - SELinux security policy is enforced.
|
|
||||||
# permissive - SELinux prints warnings instead of enforcing.
|
|
||||||
# disabled - No SELinux policy is loaded.
|
|
||||||
SELINUX=enforcing
|
|
||||||
# SELINUXTYPE= can take one of three two values:
|
|
||||||
# targeted - Targeted processes are protected,
|
|
||||||
# minimum - Modification of targeted policy. Only selected processes are prootected.
|
|
||||||
# mls - Multi Level Security protection.
|
|
||||||
SELINUXTYPE=targeted
|
|
||||||
```
|
|
||||||
|
|
||||||
Change the value **enforcing** of directive SELINUX to **disabled**, save the file and reboot the server.
|
|
||||||
|
|
||||||
To check the status of SELinux on Centos 7, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
getenforce
|
|
||||||
```
|
|
||||||
|
|
||||||
The output must be:
|
|
||||||
|
|
||||||
```
|
|
||||||
Disabled
|
|
||||||
```
|
|
||||||
|
|
||||||
### Install MariaDB on Centos 7
|
|
||||||
|
|
||||||
To install MariaDB on Centos 7, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum -y install mariadb-server
|
|
||||||
```
|
|
||||||
|
|
||||||
Create the file with the name **zotrs.cnf** in the following directory:
|
|
||||||
|
|
||||||
```
|
|
||||||
/etc/my.cnf.d/
|
|
||||||
```
|
|
||||||
|
|
||||||
To create and edit the file, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
vim /etc/my.cnf.d/zotrs.cnf
|
|
||||||
```
|
|
||||||
|
|
||||||
Fill the file with the following content and save it:
|
|
||||||
|
|
||||||
```
|
|
||||||
max_allowed_packet = 20M
|
|
||||||
query_cache_size = 32M
|
|
||||||
innodb_log_file_size = 256M
|
|
||||||
```
|
|
||||||
|
|
||||||
To start MariaDB, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl start mariadb
|
|
||||||
```
|
|
||||||
|
|
||||||
To increase the security of MariaDB, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
/usr/bin/mysql_secure_installation
|
|
||||||
```
|
|
||||||
|
|
||||||
Setup the options accordind the following output:
|
|
||||||
|
|
||||||
```
|
|
||||||
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB
|
|
||||||
SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
|
|
||||||
|
|
||||||
In order to log into MariaDB to secure it, we'll need the current
|
|
||||||
password for the root user. If you've just installed MariaDB, and
|
|
||||||
you haven't set the root password yet, the password will be blank,
|
|
||||||
so you should just press enter here.
|
|
||||||
|
|
||||||
Enter current password for root (enter for none):<Press Enter>
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
OK, successfully used password, moving on...
|
|
||||||
|
|
||||||
Setting the root password ensures that nobody can log into the MariaDB
|
|
||||||
root user without the proper authorisation.
|
|
||||||
|
|
||||||
Set root password? [Y/n] <Press Y>
|
|
||||||
```
|
|
||||||
|
|
||||||
Set the root password:
|
|
||||||
|
|
||||||
```
|
|
||||||
New password:
|
|
||||||
Re-enter new password:
|
|
||||||
Password updated successfully!
|
|
||||||
Reloading privilege tables..
|
|
||||||
... Success!
|
|
||||||
|
|
||||||
By default, a MariaDB installation has an anonymous user, allowing anyone
|
|
||||||
to log into MariaDB without having to have a user account created for
|
|
||||||
them. This is intended only for testing, and to make the installation
|
|
||||||
go a bit smoother. You should remove them before moving into a
|
|
||||||
production environment.
|
|
||||||
|
|
||||||
Remove anonymous users? [Y/n] <Press Y>
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
... Success!
|
|
||||||
|
|
||||||
Normally, root should only be allowed to connect from 'localhost'. This
|
|
||||||
ensures that someone cannot guess at the root password from the network.
|
|
||||||
|
|
||||||
Disallow root login remotely? [Y/n] <Choose acording your needs>
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
... Success!
|
|
||||||
|
|
||||||
By default, MariaDB comes with a database named 'test' that anyone can
|
|
||||||
access. This is also intended only for testing, and should be removed
|
|
||||||
before moving into a production environment.
|
|
||||||
|
|
||||||
Remove test database and access to it? [Y/n] <Press Y>
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
- Dropping test database...
|
|
||||||
... Success!
|
|
||||||
- Removing privileges on test database...
|
|
||||||
... Success!
|
|
||||||
|
|
||||||
Reloading the privilege tables will ensure that all changes made so far
|
|
||||||
will take effect immediately.
|
|
||||||
|
|
||||||
Reload privilege tables now? [Y/n] <Press Y>
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
... Success!
|
|
||||||
|
|
||||||
Cleaning up...
|
|
||||||
|
|
||||||
All done! If you've completed all of the above steps, your MariaDB
|
|
||||||
installation should now be secure.
|
|
||||||
|
|
||||||
Thanks for using MariaDB!
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
Setup MariaDB to start up automatically at boot time:
|
|
||||||
|
|
||||||
systemctl enable mariadb.service
|
|
||||||
|
|
||||||
To download OTRS, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
wget http://ftp.otrs.org/pub/otrs/RPMS/rhel/7/otrs-5.0.15-01.n oarch.rpm
|
|
||||||
```
|
|
||||||
|
|
||||||
### Install EPEL
|
|
||||||
|
|
||||||
Before we install OTRS, setup the EPEL repositoy on Centos 7\. Run the following command to do so:
|
|
||||||
|
|
||||||
```
|
|
||||||
[root@centos7 ~]# yum -y http://mirror.globo.com/epel/7/x86_64/e/epel-r release-7-9.noarch.rpm
|
|
||||||
```
|
|
||||||
|
|
||||||
### Install OTRS
|
|
||||||
|
|
||||||
Install OTRS with the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum install -nogpgcheck otrs-5.0.15-01.noarch.rpm
|
|
||||||
```
|
|
||||||
|
|
||||||
A list of software package will be installed, eg. Apache and all dependencies will be resolved automatically, at to the end of output press Y:
|
|
||||||
|
|
||||||
```
|
|
||||||
Transaction Summary
|
|
||||||
================================================================================
|
|
||||||
Install 1 Package (+143 Dependent packages)
|
|
||||||
|
|
||||||
Total size: 148 M
|
|
||||||
Total download size: 23 M
|
|
||||||
Installed size: 181 M
|
|
||||||
Is this ok [y/d/N]: y
|
|
||||||
```
|
|
||||||
|
|
||||||
To start Apache (httpd), run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl start httpd.service
|
|
||||||
```
|
|
||||||
|
|
||||||
To enable Apache (httpd) startup with systemd on Centos7, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl enable httpd.service
|
|
||||||
```
|
|
||||||
|
|
||||||
Enable SSL in Apache and configure a SelfSigned Certificate. Install the Mod_SSL module for the Apache HTTP Server, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum -y install mod_ssl
|
|
||||||
```
|
|
||||||
|
|
||||||
To generate a self-signed SSL certificate, go to the following directory:
|
|
||||||
|
|
||||||
```
|
|
||||||
cd /etc/pki/tls/certs/
|
|
||||||
```
|
|
||||||
|
|
||||||
And run the following command to generate the key (centos7.key is the name of my certificate, feel free to change it):
|
|
||||||
|
|
||||||
```
|
|
||||||
make centos7.key
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
umask 77 ; \ /usr/bin/openssl genrsa -aes128 2048 > centos7.key Generating RSA private key, 2048 bit long modulus .+++ .........................................................................................+++ e is 65537 (0x10001) Enter pass phrase: **<Insert your Own Password>**
|
|
||||||
|
|
||||||
Verifying - Enter pass phrase:**<Retype the Password>**
|
|
||||||
```
|
|
||||||
|
|
||||||
To generate the server SSL private key with OpenSSL, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
openssl rsa -in centos7.key -out centos7.key
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
Enter pass phrase for centos7.key: **<Type the Password> **writing RSA key
|
|
||||||
```
|
|
||||||
|
|
||||||
Run the following command to create the CSR (Certificate Signing Request) file (centos7.csr is the name of my certificate, feel free to change it):
|
|
||||||
|
|
||||||
```
|
|
||||||
make centos7.csr
|
|
||||||
```
|
|
||||||
|
|
||||||
Fill the questions acording your needs:
|
|
||||||
|
|
||||||
```
|
|
||||||
umask 77 ; \ /usr/bin/openssl req -utf8 -new -key centos7.key -out centos7.csr You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. -----
|
|
||||||
|
|
||||||
Country Name (2 letter code) [XX]:
|
|
||||||
|
|
||||||
State or Province Name (full name) []:
|
|
||||||
|
|
||||||
Locality Name (eg, city) [Default City]:
|
|
||||||
|
|
||||||
Organization Name (eg, company) [Default Company Ltd]:
|
|
||||||
|
|
||||||
Organizational Unit Name (eg, section) []:
|
|
||||||
|
|
||||||
Centos7 Common Name (eg, your name or your server's hostname) []:
|
|
||||||
|
|
||||||
Email Address []:
|
|
||||||
|
|
||||||
Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: **<press enter>**
|
|
||||||
|
|
||||||
An optional company name []:
|
|
||||||
```
|
|
||||||
|
|
||||||
Generate a CSR (Certificate Signing Request) for the server with the OpenSSL tool:
|
|
||||||
|
|
||||||
```
|
|
||||||
openssl x509 -in centos7.csr -out centos7.crt -req -signkey centos7.key
|
|
||||||
```
|
|
||||||
|
|
||||||
The output is:
|
|
||||||
|
|
||||||
```
|
|
||||||
Signature ok subject=/C=BR/ST=SP/L=Campinas/O=Centos7/OU=Centos7/CN=centos7.local Getting Private key
|
|
||||||
```
|
|
||||||
|
|
||||||
Before we edit the ssl.conf file, make a copy of the file with the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
cp /etc/httpd/conf.d/ssl.conf /etc/httpd/conf.d/ssl.conf.old
|
|
||||||
```
|
|
||||||
|
|
||||||
Then edit the file:
|
|
||||||
|
|
||||||
```
|
|
||||||
vim /etc/httpd/conf.d/ssl.conf
|
|
||||||
```
|
|
||||||
|
|
||||||
Find the following directives, uncomment each one and edit them like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
SSLCertificateKeyFile /etc/pki/tls/certs/centos7.key
|
|
||||||
|
|
||||||
SSLCertificateFile /etc/pki/tls/certs/centos7.csr
|
|
||||||
|
|
||||||
SSLProtocol -All +TLSv1 +TLSv1.1 +TLSv1.2
|
|
||||||
|
|
||||||
ServerName centos7.local:443
|
|
||||||
```
|
|
||||||
|
|
||||||
Restart Apache with the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl restart httpd
|
|
||||||
```
|
|
||||||
|
|
||||||
To force OTRS to run in https mode, edit the following file:
|
|
||||||
|
|
||||||
```
|
|
||||||
vim /etc/httpd/conf/httpd.conf
|
|
||||||
```
|
|
||||||
|
|
||||||
At the end of file, uncoment the following directive:
|
|
||||||
|
|
||||||
```
|
|
||||||
IncludeOptional conf.d/*.conf
|
|
||||||
```
|
|
||||||
|
|
||||||
Edit the file zzz_otrs.conf:
|
|
||||||
|
|
||||||
```
|
|
||||||
vim /etc/httpd/conf.d/zzz_otrs.conf
|
|
||||||
```
|
|
||||||
|
|
||||||
After the line 26 (before the line module mod_version.c) add the following directives:
|
|
||||||
|
|
||||||
```
|
|
||||||
RewriteEngine On
|
|
||||||
RewriteCond %{HTTPS} off
|
|
||||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
|
||||||
```
|
|
||||||
|
|
||||||
Restart Apache:
|
|
||||||
|
|
||||||
```
|
|
||||||
[root@centos7 ~]# systemctl restart httpd
|
|
||||||
```
|
|
||||||
|
|
||||||
To use extended features in OTRS, we have to install some PERL modules. Run the following command to install them:
|
|
||||||
|
|
||||||
```
|
|
||||||
yum -y install "perl(Text::CSV_XS)" "perl(Crypt::Eksblowfish::Bcrypt)" "perl(YAML::XS)" "perl(JSON::XS)" "perl(Encode::HanExtra)" "perl(Mail::IMAPClient)" "perl(ModPerl::Util)"
|
|
||||||
```
|
|
||||||
|
|
||||||
The OTRS system has a tool to check the PERL modules, run it like this to verify the system requirements:
|
|
||||||
|
|
||||||
```
|
|
||||||
cd /opt/otrs/bin
|
|
||||||
```
|
|
||||||
|
|
||||||
and run:
|
|
||||||
|
|
||||||
```
|
|
||||||
./otrs.CheckModules.pl
|
|
||||||
```
|
|
||||||
|
|
||||||
The output for our configuration must be:
|
|
||||||
|
|
||||||
```
|
|
||||||
o Apache::DBI......................ok (v1.12) o Apache2::Reload..................ok (v0.13) o Archive::Tar.....................ok (v1.92) o Archive::Zip.....................ok (v1.30) o Crypt::Eksblowfish::Bcrypt.......ok (v0.009) o Crypt::SSLeay....................ok (v0.64) o Date::Format.....................ok (v2.24) o DBI..............................ok (v1.627) o DBD::mysql.......................ok (v4.023) o DBD::ODBC........................Not installed! (optional - Required to connect to a MS-SQL database.) o DBD::Oracle......................Not installed! (optional - Required to connect to a Oracle database.) o DBD::Pg..........................Not installed! Use: 'yum install "perl(DBD::Pg)"' (optional - Required to connect to a PostgreSQL database.) o Digest::SHA......................ok (v5.85) o Encode::HanExtra.................ok (v0.23) o IO::Socket::SSL..................ok (v1.94) o JSON::XS.........................ok (v3.01) o List::Util::XS...................ok (v1.27) o LWP::UserAgent...................ok (v6.13) o Mail::IMAPClient.................ok (v3.37) o IO::Socket::SSL................ok (v1.94) o ModPerl::Util....................ok (v2.000010) o Net::DNS.........................ok (v0.72) o Net::LDAP........................ok (v0.56) o Template.........................ok (v2.24) o Template::Stash::XS..............ok (undef) o Text::CSV_XS.....................ok (v1.00) o Time::HiRes......................ok (v1.9725) o Time::Piece......................ok (v1.20_01) o XML::LibXML......................ok (v2.0018) o XML::LibXSLT.....................ok (v1.80) o XML::Parser......................ok (v2.41) o YAML::XS.........................ok (v0.54)
|
|
||||||
```
|
|
||||||
|
|
||||||
To start the OTRS Daemon with the "otrs" user, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
su -c "/opt/otrs/bin/otrs.Daemon.pl start" -s /bin/bash otrs
|
|
||||||
```
|
|
||||||
|
|
||||||
To disable the CentOS 7 firewall, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl stop firewalld
|
|
||||||
```
|
|
||||||
|
|
||||||
To disable CentOS 7 Firewall to start up automaticaly, run:
|
|
||||||
|
|
||||||
```
|
|
||||||
systemctl disable firewalld.service
|
|
||||||
```
|
|
||||||
|
|
||||||
Start the OTRS Daemon with:
|
|
||||||
|
|
||||||
```
|
|
||||||
su -c "/opt/otrs/bin/otrs.Daemon.pl start" -s /bin/bash otrsCron.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
The output of command must be:
|
|
||||||
|
|
||||||
```
|
|
||||||
/opt/otrs/bin Cron.sh - start/stop OTRS cronjobs Copyright (C) 2001-2012 OTRS AG, http://otrs.org/ (using /opt/otrs) done
|
|
||||||
```
|
|
||||||
|
|
||||||
If you want to check the OTRS Daemon status, run the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
su -c "/opt/otrs/bin/otrs.Daemon.pl status" -s /bin/bash otrsCron.sh
|
|
||||||
```
|
|
||||||
|
|
||||||
Configuring OTRS in the crontab. Change the user root to otrs and start to edit the crontab:
|
|
||||||
|
|
||||||
```
|
|
||||||
su otrs
|
|
||||||
|
|
||||||
crontab -e
|
|
||||||
```
|
|
||||||
|
|
||||||
Fill the crontab with the following content and save it:
|
|
||||||
|
|
||||||
```
|
|
||||||
# --
|
|
||||||
# Copyright (C) 2001-2016 OTRS AG, http://otrs.com/
|
|
||||||
# --
|
|
||||||
# This software comes with ABSOLUTELY NO WARRANTY. For details, see
|
|
||||||
# the enclosed file COPYING for license information (AGPL). If you
|
|
||||||
# did not receive this file, see http://www.gnu.org/licenses/agpl.txt.
|
|
||||||
# --
|
|
||||||
|
|
||||||
# Who gets the cron emails?
|
|
||||||
MAILTO="root@localhost"
|
|
||||||
# --
|
|
||||||
# Copyright (C) 2001-2016 OTRS AG, http://otrs.com/
|
|
||||||
# --
|
|
||||||
# This software comes with ABSOLUTELY NO WARRANTY. For details, see
|
|
||||||
# the enclosed file COPYING for license information (AGPL). If you
|
|
||||||
# did not receive this file, see http://www.gnu.org/licenses/agpl.txt.
|
|
||||||
# --
|
|
||||||
|
|
||||||
# check OTRS daemon status
|
|
||||||
*/5 * * * * $HOME/bin/otrs.Daemon.pl start >> /dev/null
|
|
||||||
```
|
|
||||||
|
|
||||||
### Configure OTRS on CentOS 7
|
|
||||||
|
|
||||||
Open a web browser and open the URL [https://centos7.local/otrs/installer.pl][8]. Remember, centos7.local is the name of my server, insert your hostname or IP address. The first screen shows the 4 steps to conclude the OTRS installation, press Next.
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][9]
|
|
||||||
|
|
||||||
License: to continue, read and accept the license to continue:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][10]
|
|
||||||
|
|
||||||
Database Selection: select the option **MySQL** and in the Install Type, mark the Create a new database for OTRS option and click on the next button:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][11]
|
|
||||||
|
|
||||||
Configure MySQL: fill the fields User, Password and Host (remember the data of the MariaDB configuration that we made) and press check database settings:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][12]
|
|
||||||
|
|
||||||
The OTRS installer will create the database in MariaDB, press next button:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][13]
|
|
||||||
|
|
||||||
OTRS database created successfully:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][14]
|
|
||||||
|
|
||||||
Config system settings: fill the fields with your own information and press next:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][15]
|
|
||||||
|
|
||||||
OTRS E-mail configuration: fill in the fields acording your e-mail server. In my setup, for outbound email I use SMPTTLS and port 587, for inbound email, I use pop3, you will need an e-mail account. Check mail configuration or skip this step:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][16]
|
|
||||||
|
|
||||||
To finish, take a note about the user and password to access the OTRS, after login you can change the password:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][17]
|
|
||||||
|
|
||||||
The OTRS url login is [https://centos7.local/otrs/index.pl?][18]. Remember, centos7.local is the name of my server, insert your hostnamen or IP address.:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][19]
|
|
||||||
|
|
||||||
Login at the OTRS:
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][20]
|
|
||||||
|
|
||||||
OTRS is installed and ready to be configured with your support rules or business model.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/
|
|
||||||
|
|
||||||
作者:[Alexandre Costa][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/
|
|
||||||
[1]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#thenbspenvironment
|
|
||||||
[2]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#preparation
|
|
||||||
[3]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#install-mariadb-on-centos-
|
|
||||||
[4]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#install-epelnbsp
|
|
||||||
[5]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#install-otrs
|
|
||||||
[6]:https://www.howtoforge.com/tutorial/how-to-install-otrs-on-centos-7/#configure-otrs-on-centos-
|
|
||||||
[7]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.jpg
|
|
||||||
[8]:http://centos7.local/otrs/installer.pl
|
|
||||||
[9]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.13_.jpg
|
|
||||||
[10]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.14_.jpg
|
|
||||||
[11]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.15_.jpg
|
|
||||||
[12]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.16_.jpg
|
|
||||||
[13]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.17_.jpg
|
|
||||||
[14]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.18_.jpg
|
|
||||||
[15]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.19_.jpg
|
|
||||||
[16]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.21_.jpg
|
|
||||||
[17]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.23_.jpg
|
|
||||||
[18]:https://centos7.local/otrs/index.pl
|
|
||||||
[19]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.25_.jpg
|
|
||||||
[20]:https://www.howtoforge.com/images/how_to_install_and_configure_otrs_open_source_trouble_ticket_system_software_on_centos_7/big/OTRS_How_To_Alexandre_Costa.27_.jpg
|
|
||||||
@ -1,83 +0,0 @@
|
|||||||
Dedicated engineering team in South Africa deploys open source tools, save lives
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
Image by : opensource.com
|
|
||||||
|
|
||||||
In 2006, a groundbreaking TED talk used statistics to reveal surprising [insights about the developing world][2], including how many people in South Africa have HIV despite free and available anti-retroviral drugs.
|
|
||||||
|
|
||||||
[Gustav Praekelt][3], founder of [Praekelt.org][4], heard this TED talk and began tenaciously calling a local hospital to convince them to start an SMS program that would promote anti-retrovirals. The program that resulted from those calls became [txtAlert][5]—a successful and widely recognized mobile health program that dramatically improves medical appointment adherence and creates a free channel for patients to communicate with the hospital.
|
|
||||||
|
|
||||||
Today, nearly a decade later, the organization that Gustav founded in 2007, Praekelt.org, continues to harness the power of mobile technology.
|
|
||||||
|
|
||||||
The global nonprofit organization uses open source technologies to deliver essential information and vital services to millions of people around the world, particularly in Africa. We are deeply committed to the idea that our software innovations should be shared with the development community that made delivering our products possible. By participating and giving back to this community we support and sustain the rich ecosystem of tools and products that they have developed to improve the lives of people around the world.
|
|
||||||
|
|
||||||
Praekelt.org is a supporter of the [Principles for Digital Development][6] and in particular [Cause 6][7], which states:
|
|
||||||
|
|
||||||
* Adopt and expand existing open standards.
|
|
||||||
* Open data and functionalities and expose them in documented Application Programming Interfaces (APIs) where use by a larger community is possible.
|
|
||||||
* Invest in software as a public good.
|
|
||||||
* Develop software to be open source by default with the code made available in public repositories and supported through developer communities.
|
|
||||||
|
|
||||||
A great example of this can be found in our original work to make population-scale messaging possible in the majority world. We had and continue to have success with txtAlert in South Africa, but despite considerable interest, replicating this success in other places has been very challenging. The necessary integration work required for each new messaging service provider requires too much customization.
|
|
||||||
|
|
||||||
To solve this, we created [Vumi][8], a software library that provides a single point of integration for messaging communication channel integrations. It abstracts away all of the differences that require the customized integrations and provided a single consistent API to speak to all of them. The result is a dramatic increase in the re-use of both integrations and applications because they were only needing to be written once and could be used widely.
|
|
||||||
|
|
||||||
Vumi provides the means of integrations, and this past year in collaboration with UNICEF we have launched [Junebug][9], an application server that provides APIs to launch Vumi integrations, enabling direct messaging system integrations in both cloud- and on-premise-based scenarios. Junebug now powers national-scale, maternal health programs in South Africa, Nigeria, and Uganda, delivering essential information for expecting women and mothers. It also provides SMS and [Unstructured Supplementary Service Data][10] (USSD) access to vital services, such as national helpdesks and FAQ services.
|
|
||||||
|
|
||||||
These systems have processed over 375 million real-time messages in the last year.
|
|
||||||
|
|
||||||
We are a relatively small engineering team based out of South Africa. We could not fathom developing these services were we not standing on the shoulders of giants. All of the services we provide or build on are available as open source software.
|
|
||||||
|
|
||||||
Our language of choice is [Python][11], which enables us to express our ideas in code succinctly and in a way that is both readable and maintainable. Our messaging systems are built using [Twisted][12], an excellent event-driven network programming framework built using Python. [Molo][13], our web publishing platform, is built using [Django][14], and the wonderful open source [Wagtail CMS][15] is built by our friends at [Torchbox][16].
|
|
||||||
|
|
||||||
Our three-person site reliability engineering team is able to run over a thousand applications in production by relying on Mesosphere's [Marathon][17] for [Apache Mesos][18]. We have recently released [Marathon Acme][19], which enables automatic SSL/TLS certificate provisioning via [LetsEncrypt][20] for Marathon's load balancer, ensuring our services are secure.
|
|
||||||
|
|
||||||
Our engineering team is distributed, and the workflow enabled by [Git][21] allows us to develop software in a reliable fashion. For example, by using test-driven development we are able to automate our deploys. Using these open source tools and systems we've averaged 21 automated deploys a day over the course of 2016. Developing software in an open environment is easier and more effective. Our work would have been significantly more difficult had there not been such an active and vibrant community on which to build.
|
|
||||||
|
|
||||||
We are excited to be part of these developments in open source technology integration. As a mission-driven organization we are deeply committed to continue [sharing ][22][what we learn][23] and develop. If you are interested in joining our team, [apply here][24]. Our open source repositories have documented OS licenses and contributions guidelines. We welcome any community contributions. Please email us at [dev@praekelt.org][25].
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Simon de Haan - Simon de Haan is the Chief Engineer at Praekelt Foundation and has the rare talent to demystify software systems and platforms for nonengineers. He was the team lead on Praekelt Foundation’s Vumi platform, an open source messaging platform that allows for interactive conversations over SMS, USSD, Gtalk and other basic technologies at low cost and at population scale in the majority world. Vumi is the technology that powers various groundbreaking initiatives such as Wikipedia Text, PeaceTXT,
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/2/open-source-tools-south-africa
|
|
||||||
|
|
||||||
作者:[Simon de Haan][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/praekelt
|
|
||||||
[1]:https://opensource.com/article/17/2/open-source-tools-south-africa?rate=XZZ1Mtc79KokPszccwi_HiEkWMJyoJZghkUumJTwIiI
|
|
||||||
[2]:https://www.ted.com/talks/hans_rosling_shows_the_best_stats_you_ve_ever_seen
|
|
||||||
[3]:http://www.praekelt.org/
|
|
||||||
[4]:http://www.praekelt.org/
|
|
||||||
[5]:http://txtalert.praekeltfoundation.org/bookings/about-txtalert/
|
|
||||||
[6]:http://digitalprinciples.org/
|
|
||||||
[7]:http://digitalprinciples.org/use-open-standards-open-data-open-source-and-open-innovation/
|
|
||||||
[8]:https://github.com/praekelt/vumi
|
|
||||||
[9]:http://junebug.praekelt.org/
|
|
||||||
[10]:https://en.wikipedia.org/wiki/Unstructured_Supplementary_Service_Data
|
|
||||||
[11]:https://www.python.org/
|
|
||||||
[12]:https://en.wikipedia.org/wiki/Twisted_(software)
|
|
||||||
[13]:http://molo.readthedocs.io/
|
|
||||||
[14]:http://www.djangoproject.com/
|
|
||||||
[15]:https://wagtail.io/
|
|
||||||
[16]:https://torchbox.com/work/wagtail/
|
|
||||||
[17]:https://mesosphere.github.io/marathon/
|
|
||||||
[18]:http://mesos.apache.org/
|
|
||||||
[19]:https://github.com/praekeltfoundation/marathon-acme
|
|
||||||
[20]:https://letsencrypt.org/
|
|
||||||
[21]:http://git-scm.org/
|
|
||||||
[22]:https://medium.com/@praekeltorg
|
|
||||||
[23]:https://medium.com/@praekeltorg
|
|
||||||
[24]:http://www.praekelt.org/careers/
|
|
||||||
[25]:https://opensource.com/article/17/2/mail%20to:%20dev@praekelt.org
|
|
||||||
[26]:https://opensource.com/user/108011/feed
|
|
||||||
[27]:https://opensource.com/users/praekelt
|
|
||||||
@ -1,544 +0,0 @@
|
|||||||
Blocking of international spam botnets with a Postfix plugin
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### On this page
|
|
||||||
|
|
||||||
1. [Introduction][1]
|
|
||||||
2. [How international botnet works][2]
|
|
||||||
3. [Defending against botnet spammers][3]
|
|
||||||
4. [Installation][4]
|
|
||||||
|
|
||||||
This article contains an analysis and solution for blocking of international SPAM botnets and a tutorial to install the anti-spam plugin to postfix firewall - postfwd in the postfix MTA.
|
|
||||||
|
|
||||||
### Introduction
|
|
||||||
|
|
||||||
One of the most important and hardest tasks for every company that provides mail services is staying out of the mail blacklists.
|
|
||||||
|
|
||||||
If a mail domain appears in one of the mail domain blacklists, other mail servers will stop accepting and relaying its e-mails. This will practically ban the domain from the majority of mail providers and prohibits that the provider’s customers can send e-mails. Tere is only one thing that a mail provider can do afterwards: ask the blacklist providers for removal from the list or change the IP addresses and domain names of its mail servers.
|
|
||||||
|
|
||||||
Getting into mail blacklist is very easy when a mail provider does not have a protection against spammers. Only one compromised customer mail account from which a hacker will start sending spam is needed to appear in a blacklist.
|
|
||||||
|
|
||||||
There are several ways of how hackers send spam from compromised mail accounts. In this article, I would like to show you how to completely mitigate international botnet spammers, who are characterized by logging into mail accounts from multiple IP addresses located in multiple countries worldwide.
|
|
||||||
|
|
||||||
### How international botnet works
|
|
||||||
|
|
||||||
Hackers who use an international botnet for spamming operate very efficient and are not easy to track. I started to analyze the behaviour of such an international spam botnet in October of 2016 and implemented a plugin for **postfix firewall** - **postfwd**, which intelligently bans all spammers from international botnets.
|
|
||||||
|
|
||||||
The first step was the analysis of the behavior of an international spam botnet done by tracking of one compromised mail account. I created a simple bash one-liner to select sasl login IP addresses of the compromised mail account from the postfwd login mail logs.
|
|
||||||
|
|
||||||
**Data in the following table are dumped 90 minutes after compromisation of one mail account and contains these attributes:**
|
|
||||||
|
|
||||||
* IP addresses from which hacker logged into account (ip_address)
|
|
||||||
* Corresponding country codes of IP addresses from GeoIP database (state_code)
|
|
||||||
* Number of sasl logins which hacker did from one IP address (login_count)
|
|
||||||
|
|
||||||
```
|
|
||||||
+-----------------+------------+-------------+
|
|
||||||
| ip_address | state_code | login_count |
|
|
||||||
+-----------------+------------+-------------+
|
|
||||||
| 41.63.176.___ | AO | 8 |
|
|
||||||
| 200.80.227.___ | AR | 41 |
|
|
||||||
| 120.146.134.___ | AU | 18 |
|
|
||||||
| 79.132.239.___ | BE | 15 |
|
|
||||||
| 184.149.27.___ | CA | 1 |
|
|
||||||
| 24.37.20.___ | CA | 13 |
|
|
||||||
| 70.28.77.___ | CA | 21 |
|
|
||||||
| 70.25.65.___ | CA | 23 |
|
|
||||||
| 72.38.177.___ | CA | 24 |
|
|
||||||
| 174.114.121.___ | CA | 27 |
|
|
||||||
| 206.248.139.___ | CA | 4 |
|
|
||||||
| 64.179.221.___ | CA | 4 |
|
|
||||||
| 184.151.178.___ | CA | 40 |
|
|
||||||
| 24.37.22.___ | CA | 51 |
|
|
||||||
| 209.250.146.___ | CA | 66 |
|
|
||||||
| 209.197.185.___ | CA | 8 |
|
|
||||||
| 47.48.223.___ | CA | 8 |
|
|
||||||
| 70.25.41.___ | CA | 81 |
|
|
||||||
| 184.71.9.___ | CA | 92 |
|
|
||||||
| 84.226.27.___ | CH | 5 |
|
|
||||||
| 59.37.9.___ | CN | 6 |
|
|
||||||
| 181.143.131.___ | CO | 24 |
|
|
||||||
| 186.64.177.___ | CR | 6 |
|
|
||||||
| 77.104.244.___ | CZ | 1 |
|
|
||||||
| 78.108.109.___ | CZ | 18 |
|
|
||||||
| 185.19.1.___ | CZ | 58 |
|
|
||||||
| 95.208.250.___ | DE | 1 |
|
|
||||||
| 79.215.89.___ | DE | 15 |
|
|
||||||
| 47.71.223.___ | DE | 23 |
|
|
||||||
| 31.18.251.___ | DE | 27 |
|
|
||||||
| 2.164.183.___ | DE | 32 |
|
|
||||||
| 79.239.97.___ | DE | 32 |
|
|
||||||
| 80.187.103.___ | DE | 54 |
|
|
||||||
| 109.84.1.___ | DE | 6 |
|
|
||||||
| 212.97.234.___ | DK | 49 |
|
|
||||||
| 190.131.134.___ | EC | 42 |
|
|
||||||
| 84.77.172.___ | ES | 1 |
|
|
||||||
| 91.117.105.___ | ES | 10 |
|
|
||||||
| 185.87.99.___ | ES | 14 |
|
|
||||||
| 95.16.51.___ | ES | 15 |
|
|
||||||
| 95.127.182.___ | ES | 16 |
|
|
||||||
| 195.77.90.___ | ES | 19 |
|
|
||||||
| 188.86.18.___ | ES | 2 |
|
|
||||||
| 212.145.210.___ | ES | 38 |
|
|
||||||
| 148.3.169.___ | ES | 39 |
|
|
||||||
| 95.16.35.___ | ES | 4 |
|
|
||||||
| 81.202.61.___ | ES | 45 |
|
|
||||||
| 88.7.246.___ | ES | 7 |
|
|
||||||
| 81.36.5.___ | ES | 8 |
|
|
||||||
| 88.14.192.___ | ES | 8 |
|
|
||||||
| 212.97.161.___ | ES | 9 |
|
|
||||||
| 193.248.156.___ | FR | 5 |
|
|
||||||
| 82.34.32.___ | GB | 1 |
|
|
||||||
| 86.180.214.___ | GB | 11 |
|
|
||||||
| 81.108.174.___ | GB | 12 |
|
|
||||||
| 86.11.209.___ | GB | 13 |
|
|
||||||
| 86.150.224.___ | GB | 15 |
|
|
||||||
| 2.102.31.___ | GB | 17 |
|
|
||||||
| 93.152.88.___ | GB | 18 |
|
|
||||||
| 86.178.68.___ | GB | 19 |
|
|
||||||
| 176.248.121.___ | GB | 2 |
|
|
||||||
| 2.97.227.___ | GB | 2 |
|
|
||||||
| 62.49.34.___ | GB | 2 |
|
|
||||||
| 79.64.78.___ | GB | 20 |
|
|
||||||
| 2.126.140.___ | GB | 22 |
|
|
||||||
| 87.114.222.___ | GB | 23 |
|
|
||||||
| 188.29.164.___ | GB | 24 |
|
|
||||||
| 82.11.14.___ | GB | 26 |
|
|
||||||
| 81.168.46.___ | GB | 29 |
|
|
||||||
| 86.136.125.___ | GB | 3 |
|
|
||||||
| 90.199.85.___ | GB | 3 |
|
|
||||||
| 86.177.93.___ | GB | 31 |
|
|
||||||
| 82.32.186.___ | GB | 4 |
|
|
||||||
| 79.68.153.___ | GB | 46 |
|
|
||||||
| 151.226.42.___ | GB | 6 |
|
|
||||||
| 2.123.234.___ | GB | 6 |
|
|
||||||
| 90.217.211.___ | GB | 6 |
|
|
||||||
| 212.159.148.___ | GB | 68 |
|
|
||||||
| 88.111.94.___ | GB | 7 |
|
|
||||||
| 77.98.186.___ | GB | 9 |
|
|
||||||
| 41.222.232.___ | GH | 4 |
|
|
||||||
| 176.63.29.___ | HU | 30 |
|
|
||||||
| 86.47.237.___ | IE | 10 |
|
|
||||||
| 37.46.22.___ | IE | 4 |
|
|
||||||
| 95.83.249.___ | IE | 4 |
|
|
||||||
| 109.79.69.___ | IE | 6 |
|
|
||||||
| 79.176.100.___ | IL | 13 |
|
|
||||||
| 122.175.34.___ | IN | 19 |
|
|
||||||
| 114.143.5.___ | IN | 26 |
|
|
||||||
| 115.112.159.___ | IN | 4 |
|
|
||||||
| 79.62.179.___ | IT | 11 |
|
|
||||||
| 79.53.217.___ | IT | 19 |
|
|
||||||
| 188.216.54.___ | IT | 2 |
|
|
||||||
| 46.44.203.___ | IT | 2 |
|
|
||||||
| 80.86.57.___ | IT | 2 |
|
|
||||||
| 5.170.192.___ | IT | 27 |
|
|
||||||
| 80.23.42.___ | IT | 3 |
|
|
||||||
| 89.249.177.___ | IT | 3 |
|
|
||||||
| 93.39.141.___ | IT | 31 |
|
|
||||||
| 80.183.6.___ | IT | 34 |
|
|
||||||
| 79.25.107.___ | IT | 35 |
|
|
||||||
| 81.208.25.___ | IT | 39 |
|
|
||||||
| 151.57.154.___ | IT | 4 |
|
|
||||||
| 79.60.239.___ | IT | 42 |
|
|
||||||
| 79.47.25.___ | IT | 5 |
|
|
||||||
| 188.216.114.___ | IT | 7 |
|
|
||||||
| 151.31.139.___ | IT | 8 |
|
|
||||||
| 46.185.139.___ | JO | 9 |
|
|
||||||
| 211.180.177.___ | KR | 22 |
|
|
||||||
| 31.214.125.___ | KW | 2 |
|
|
||||||
| 89.203.17.___ | KW | 3 |
|
|
||||||
| 94.187.138.___ | KW | 4 |
|
|
||||||
| 209.59.110.___ | LC | 18 |
|
|
||||||
| 41.137.40.___ | MA | 12 |
|
|
||||||
| 189.211.204.___ | MX | 5 |
|
|
||||||
| 89.98.64.___ | NL | 6 |
|
|
||||||
| 195.241.8.___ | NL | 9 |
|
|
||||||
| 195.1.82.___ | NO | 70 |
|
|
||||||
| 200.46.9.___ | PA | 30 |
|
|
||||||
| 111.125.66.___ | PH | 1 |
|
|
||||||
| 89.174.81.___ | PL | 7 |
|
|
||||||
| 64.89.12.___ | PR | 24 |
|
|
||||||
| 82.154.194.___ | PT | 12 |
|
|
||||||
| 188.48.145.___ | SA | 8 |
|
|
||||||
| 42.61.41.___ | SG | 25 |
|
|
||||||
| 87.197.112.___ | SK | 3 |
|
|
||||||
| 116.58.231.___ | TH | 4 |
|
|
||||||
| 195.162.90.___ | UA | 5 |
|
|
||||||
| 108.185.167.___ | US | 1 |
|
|
||||||
| 108.241.56.___ | US | 1 |
|
|
||||||
| 198.24.64.___ | US | 1 |
|
|
||||||
| 199.249.233.___ | US | 1 |
|
|
||||||
| 204.8.13.___ | US | 1 |
|
|
||||||
| 206.81.195.___ | US | 1 |
|
|
||||||
| 208.75.20.___ | US | 1 |
|
|
||||||
| 24.149.8.___ | US | 1 |
|
|
||||||
| 24.178.7.___ | US | 1 |
|
|
||||||
| 38.132.41.___ | US | 1 |
|
|
||||||
| 63.233.138.___ | US | 1 |
|
|
||||||
| 68.15.198.___ | US | 1 |
|
|
||||||
| 72.26.57.___ | US | 1 |
|
|
||||||
| 72.43.167.___ | US | 1 |
|
|
||||||
| 74.65.154.___ | US | 1 |
|
|
||||||
| 74.94.193.___ | US | 1 |
|
|
||||||
| 75.150.97.___ | US | 1 |
|
|
||||||
| 96.84.51.___ | US | 1 |
|
|
||||||
| 96.90.244.___ | US | 1 |
|
|
||||||
| 98.190.153.___ | US | 1 |
|
|
||||||
| 12.23.72.___ | US | 10 |
|
|
||||||
| 50.225.58.___ | US | 10 |
|
|
||||||
| 64.140.101.___ | US | 10 |
|
|
||||||
| 66.185.229.___ | US | 10 |
|
|
||||||
| 70.63.88.___ | US | 10 |
|
|
||||||
| 96.84.148.___ | US | 10 |
|
|
||||||
| 107.178.12.___ | US | 11 |
|
|
||||||
| 170.253.182.___ | US | 11 |
|
|
||||||
| 206.127.77.___ | US | 11 |
|
|
||||||
| 216.27.83.___ | US | 11 |
|
|
||||||
| 72.196.170.___ | US | 11 |
|
|
||||||
| 74.93.168.___ | US | 11 |
|
|
||||||
| 108.60.97.___ | US | 12 |
|
|
||||||
| 205.196.77.___ | US | 12 |
|
|
||||||
| 63.159.160.___ | US | 12 |
|
|
||||||
| 204.93.122.___ | US | 13 |
|
|
||||||
| 206.169.117.___ | US | 13 |
|
|
||||||
| 208.104.106.___ | US | 13 |
|
|
||||||
| 65.28.31.___ | US | 13 |
|
|
||||||
| 66.119.110.___ | US | 13 |
|
|
||||||
| 67.84.164.___ | US | 13 |
|
|
||||||
| 69.178.166.___ | US | 13 |
|
|
||||||
| 71.232.229.___ | US | 13 |
|
|
||||||
| 96.3.6.___ | US | 13 |
|
|
||||||
| 205.214.233.___ | US | 14 |
|
|
||||||
| 38.96.46.___ | US | 14 |
|
|
||||||
| 67.61.214.___ | US | 14 |
|
|
||||||
| 173.233.58.___ | US | 141 |
|
|
||||||
| 64.251.53.___ | US | 15 |
|
|
||||||
| 73.163.215.___ | US | 15 |
|
|
||||||
| 24.61.176.___ | US | 16 |
|
|
||||||
| 67.10.184.___ | US | 16 |
|
|
||||||
| 173.14.42.___ | US | 17 |
|
|
||||||
| 173.163.34.___ | US | 17 |
|
|
||||||
| 104.138.114.___ | US | 18 |
|
|
||||||
| 23.24.168.___ | US | 18 |
|
|
||||||
| 50.202.9.___ | US | 19 |
|
|
||||||
| 96.248.123.___ | US | 19 |
|
|
||||||
| 98.191.183.___ | US | 19 |
|
|
||||||
| 108.215.204.___ | US | 2 |
|
|
||||||
| 50.198.37.___ | US | 2 |
|
|
||||||
| 69.178.183.___ | US | 2 |
|
|
||||||
| 74.190.39.___ | US | 2 |
|
|
||||||
| 76.90.131.___ | US | 2 |
|
|
||||||
| 96.38.10.___ | US | 2 |
|
|
||||||
| 96.60.117.___ | US | 2 |
|
|
||||||
| 96.93.6.___ | US | 2 |
|
|
||||||
| 74.69.197.___ | US | 21 |
|
|
||||||
| 98.140.180.___ | US | 21 |
|
|
||||||
| 50.252.0.___ | US | 22 |
|
|
||||||
| 69.71.200.___ | US | 22 |
|
|
||||||
| 71.46.59.___ | US | 22 |
|
|
||||||
| 74.7.35.___ | US | 22 |
|
|
||||||
| 12.191.73.___ | US | 23 |
|
|
||||||
| 208.123.156.___ | US | 23 |
|
|
||||||
| 65.190.29.___ | US | 23 |
|
|
||||||
| 67.136.192.___ | US | 23 |
|
|
||||||
| 70.63.216.___ | US | 23 |
|
|
||||||
| 96.66.144.___ | US | 23 |
|
|
||||||
| 173.167.128.___ | US | 24 |
|
|
||||||
| 64.183.78.___ | US | 24 |
|
|
||||||
| 68.44.33.___ | US | 24 |
|
|
||||||
| 23.25.9.___ | US | 25 |
|
|
||||||
| 24.100.92.___ | US | 25 |
|
|
||||||
| 107.185.110.___ | US | 26 |
|
|
||||||
| 208.118.179.___ | US | 26 |
|
|
||||||
| 216.133.120.___ | US | 26 |
|
|
||||||
| 75.182.97.___ | US | 26 |
|
|
||||||
| 107.167.202.___ | US | 27 |
|
|
||||||
| 66.85.239.___ | US | 27 |
|
|
||||||
| 71.122.125.___ | US | 28 |
|
|
||||||
| 74.218.169.___ | US | 28 |
|
|
||||||
| 76.177.204.___ | US | 28 |
|
|
||||||
| 216.165.241.___ | US | 29 |
|
|
||||||
| 24.178.50.___ | US | 29 |
|
|
||||||
| 63.149.147.___ | US | 29 |
|
|
||||||
| 174.66.84.___ | US | 3 |
|
|
||||||
| 184.183.156.___ | US | 3 |
|
|
||||||
| 50.233.39.___ | US | 3 |
|
|
||||||
| 70.183.165.___ | US | 3 |
|
|
||||||
| 71.178.212.___ | US | 3 |
|
|
||||||
| 72.175.83.___ | US | 3 |
|
|
||||||
| 74.142.22.___ | US | 3 |
|
|
||||||
| 98.174.50.___ | US | 3 |
|
|
||||||
| 98.251.168.___ | US | 3 |
|
|
||||||
| 206.74.148.___ | US | 30 |
|
|
||||||
| 24.131.201.___ | US | 30 |
|
|
||||||
| 50.80.199.___ | US | 30 |
|
|
||||||
| 69.251.49.___ | US | 30 |
|
|
||||||
| 108.6.53.___ | US | 31 |
|
|
||||||
| 74.84.229.___ | US | 31 |
|
|
||||||
| 172.250.78.___ | US | 32 |
|
|
||||||
| 173.14.75.___ | US | 32 |
|
|
||||||
| 216.201.55.___ | US | 33 |
|
|
||||||
| 40.130.243.___ | US | 33 |
|
|
||||||
| 164.58.163.___ | US | 34 |
|
|
||||||
| 70.182.187.___ | US | 35 |
|
|
||||||
| 184.170.168.___ | US | 37 |
|
|
||||||
| 198.46.110.___ | US | 37 |
|
|
||||||
| 24.166.234.___ | US | 37 |
|
|
||||||
| 65.34.19.___ | US | 37 |
|
|
||||||
| 75.146.12.___ | US | 37 |
|
|
||||||
| 107.199.135.___ | US | 38 |
|
|
||||||
| 206.193.215.___ | US | 38 |
|
|
||||||
| 50.254.150.___ | US | 38 |
|
|
||||||
| 69.54.48.___ | US | 38 |
|
|
||||||
| 172.8.30.___ | US | 4 |
|
|
||||||
| 24.106.124.___ | US | 4 |
|
|
||||||
| 65.127.169.___ | US | 4 |
|
|
||||||
| 71.227.65.___ | US | 4 |
|
|
||||||
| 71.58.72.___ | US | 4 |
|
|
||||||
| 74.9.236.___ | US | 4 |
|
|
||||||
| 12.166.108.___ | US | 40 |
|
|
||||||
| 174.47.56.___ | US | 40 |
|
|
||||||
| 66.76.176.___ | US | 40 |
|
|
||||||
| 76.111.90.___ | US | 41 |
|
|
||||||
| 96.10.70.___ | US | 41 |
|
|
||||||
| 97.79.226.___ | US | 41 |
|
|
||||||
| 174.79.117.___ | US | 42 |
|
|
||||||
| 70.138.178.___ | US | 42 |
|
|
||||||
| 64.233.225.___ | US | 43 |
|
|
||||||
| 97.89.203.___ | US | 43 |
|
|
||||||
| 12.28.231.___ | US | 44 |
|
|
||||||
| 64.235.157.___ | US | 45 |
|
|
||||||
| 76.110.237.___ | US | 45 |
|
|
||||||
| 71.196.10.___ | US | 46 |
|
|
||||||
| 173.167.177.___ | US | 49 |
|
|
||||||
| 24.7.92.___ | US | 49 |
|
|
||||||
| 68.187.225.___ | US | 49 |
|
|
||||||
| 184.75.77.___ | US | 5 |
|
|
||||||
| 208.91.186.___ | US | 5 |
|
|
||||||
| 71.11.113.___ | US | 5 |
|
|
||||||
| 75.151.112.___ | US | 5 |
|
|
||||||
| 98.189.112.___ | US | 5 |
|
|
||||||
| 69.170.187.___ | US | 51 |
|
|
||||||
| 97.64.182.___ | US | 51 |
|
|
||||||
| 24.239.92.___ | US | 52 |
|
|
||||||
| 72.211.28.___ | US | 53 |
|
|
||||||
| 66.179.44.___ | US | 54 |
|
|
||||||
| 66.188.47.___ | US | 55 |
|
|
||||||
| 64.60.22.___ | US | 56 |
|
|
||||||
| 73.1.95.___ | US | 56 |
|
|
||||||
| 75.140.143.___ | US | 58 |
|
|
||||||
| 24.199.140.___ | US | 59 |
|
|
||||||
| 216.240.53.___ | US | 6 |
|
|
||||||
| 216.26.16.___ | US | 6 |
|
|
||||||
| 50.242.1.___ | US | 6 |
|
|
||||||
| 65.83.137.___ | US | 6 |
|
|
||||||
| 68.119.102.___ | US | 6 |
|
|
||||||
| 68.170.224.___ | US | 6 |
|
|
||||||
| 74.94.231.___ | US | 6 |
|
|
||||||
| 96.64.21.___ | US | 6 |
|
|
||||||
| 71.187.41.___ | US | 60 |
|
|
||||||
| 184.177.173.___ | US | 61 |
|
|
||||||
| 75.71.114.___ | US | 61 |
|
|
||||||
| 75.82.232.___ | US | 61 |
|
|
||||||
| 97.77.161.___ | US | 63 |
|
|
||||||
| 50.154.213.___ | US | 65 |
|
|
||||||
| 96.85.169.___ | US | 67 |
|
|
||||||
| 100.33.70.___ | US | 68 |
|
|
||||||
| 98.100.71.___ | US | 68 |
|
|
||||||
| 24.176.214.___ | US | 69 |
|
|
||||||
| 74.113.89.___ | US | 69 |
|
|
||||||
| 204.116.101.___ | US | 7 |
|
|
||||||
| 216.216.68.___ | US | 7 |
|
|
||||||
| 65.188.191.___ | US | 7 |
|
|
||||||
| 69.15.165.___ | US | 7 |
|
|
||||||
| 74.219.118.___ | US | 7 |
|
|
||||||
| 173.10.219.___ | US | 71 |
|
|
||||||
| 97.77.209.___ | US | 72 |
|
|
||||||
| 173.163.236.___ | US | 73 |
|
|
||||||
| 162.210.13.___ | US | 79 |
|
|
||||||
| 12.236.19.___ | US | 8 |
|
|
||||||
| 208.180.242.___ | US | 8 |
|
|
||||||
| 24.221.97.___ | US | 8 |
|
|
||||||
| 40.132.97.___ | US | 8 |
|
|
||||||
| 50.79.227.___ | US | 8 |
|
|
||||||
| 64.130.109.___ | US | 8 |
|
|
||||||
| 66.80.57.___ | US | 8 |
|
|
||||||
| 74.68.130.___ | US | 8 |
|
|
||||||
| 74.70.242.___ | US | 8 |
|
|
||||||
| 96.80.61.___ | US | 81 |
|
|
||||||
| 74.43.153.___ | US | 83 |
|
|
||||||
| 208.123.153.___ | US | 85 |
|
|
||||||
| 75.149.238.___ | US | 87 |
|
|
||||||
| 96.85.138.___ | US | 89 |
|
|
||||||
| 208.117.200.___ | US | 9 |
|
|
||||||
| 208.68.71.___ | US | 9 |
|
|
||||||
| 50.253.180.___ | US | 9 |
|
|
||||||
| 50.84.132.___ | US | 9 |
|
|
||||||
| 63.139.29.___ | US | 9 |
|
|
||||||
| 70.43.78.___ | US | 9 |
|
|
||||||
| 74.94.154.___ | US | 9 |
|
|
||||||
| 50.76.82.___ | US | 94 |
|
|
||||||
+-----------------+------------+-------------+
|
|
||||||
```
|
|
||||||
|
|
||||||
**In next table we can see the distribution of IP addresses by country:**
|
|
||||||
|
|
||||||
```
|
|
||||||
+--------+
|
|
||||||
| 214 US |
|
|
||||||
| 28 GB |
|
|
||||||
| 17 IT |
|
|
||||||
| 15 ES |
|
|
||||||
| 15 CA |
|
|
||||||
| 8 DE |
|
|
||||||
| 4 IE |
|
|
||||||
| 3 KW |
|
|
||||||
| 3 IN |
|
|
||||||
| 3 CZ |
|
|
||||||
| 2 NL |
|
|
||||||
| 1 UA |
|
|
||||||
| 1 TH |
|
|
||||||
| 1 SK |
|
|
||||||
| 1 SG |
|
|
||||||
| 1 SA |
|
|
||||||
| 1 PT |
|
|
||||||
| 1 PR |
|
|
||||||
| 1 PL |
|
|
||||||
| 1 PH |
|
|
||||||
| 1 PA |
|
|
||||||
| 1 NO |
|
|
||||||
| 1 MX |
|
|
||||||
| 1 MA |
|
|
||||||
| 1 LC |
|
|
||||||
| 1 KR |
|
|
||||||
| 1 JO |
|
|
||||||
| 1 IL |
|
|
||||||
| 1 HU |
|
|
||||||
| 1 GH |
|
|
||||||
| 1 FR |
|
|
||||||
| 1 EC |
|
|
||||||
| 1 DK |
|
|
||||||
| 1 CR |
|
|
||||||
| 1 CO |
|
|
||||||
| 1 CN |
|
|
||||||
| 1 CH |
|
|
||||||
| 1 BE |
|
|
||||||
| 1 AU |
|
|
||||||
| 1 AR |
|
|
||||||
| 1 AO |
|
|
||||||
+--------+
|
|
||||||
```
|
|
||||||
|
|
||||||
Based on these tables can be drawn multiple facts according to which we designed our plugin:
|
|
||||||
|
|
||||||
* Spam was spread from a botnet. This is indicated by logins from huge amount of client IP addresses.
|
|
||||||
* Spam was spread with a low cadence of messages in order to avoid rate limits.
|
|
||||||
* Spam was spread from IP addresses from multiple countries (more than 30 countries after few minutes) which indicates an international botnet.
|
|
||||||
|
|
||||||
From these tables were taken out the statistics of IP addresses used, number of logins and countries from which were users logged in:
|
|
||||||
|
|
||||||
* Total number of logins 7531.
|
|
||||||
* Total number of IP addresses used 342.
|
|
||||||
* Total number of unique countries 41.
|
|
||||||
|
|
||||||
### Defending against botnet spammers
|
|
||||||
|
|
||||||
The solution to this kind of spam behavior was to make a plugin for the postfix firewall - postfwd. Postfwd is program that can be used to block users by rate limits, by using mail blacklists and by other means.
|
|
||||||
|
|
||||||
We designed and implemented the plugin that counts the number of unique countries from which a user logged in to his account by sasl authentication. Then in the postfwd configuration, you can set limits to the number of countries and after getting above the limit, user gets selected smtp code reply and is blocked from sending emails.
|
|
||||||
|
|
||||||
I am using this plugin in a medium sized internet provider company for 6 months and currently the plugin automatically caught over 50 compromised users without any intervention from administrator's side. Another interesting fact after 6 months of usage is that after finding spammer and sending SMTP code 544 (Host not found - not in DNS) to compromised account (sended directly from postfwd), botnets stopped trying to log into compromised accounts. It looks like the botnet spam application is intelligent and do not want to waste botnet resources. Sending other SMTP codes did not stopped botnet from trying.
|
|
||||||
|
|
||||||
The plugin is available at my company's github - [https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin][5]
|
|
||||||
|
|
||||||
### Installation
|
|
||||||
|
|
||||||
In this part I will give you a basic tutorial of how to make postfix work with postfwd and how to install the plugin and add a postfwd rule to use it. Installation was tested and done on Debian 8 Jessie. Instructions for parts of this installation are also available on the github project page.
|
|
||||||
|
|
||||||
1\. First install and configure postfix with sasl authentication. There are a lot of great tutorials on installation and configuration of postfix, therefore I will continue right next with postfwd installation.
|
|
||||||
|
|
||||||
2\. The next thing after you have postfix with sasl authentication installed is to install postfwd. On Debian systems, you can do it with the apt package manager by executing following command (This will also automatically create a user **postfw** and file **/etc/default/postfwd** which we need to update with correct configuration for autostart).
|
|
||||||
|
|
||||||
apt-get install postfwd
|
|
||||||
|
|
||||||
3\. Now we proceed with downloading the git project with our postfwd plugin:
|
|
||||||
|
|
||||||
apt-get install git
|
|
||||||
git clone https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin /etc/postfix/postfwd-anti-geoip-spam-plugin
|
|
||||||
chown -R postfw:postfix /etc/postfix/postfwd-anti-geoip-spam-plugin/
|
|
||||||
|
|
||||||
4\. If you do not have git or do not want to use git, you can download raw plugin file:
|
|
||||||
|
|
||||||
mkdir /etc/postfix/postfwd-anti-geoip-spam-plugin
|
|
||||||
wget https://raw.githubusercontent.com/Vnet-as/postfwd-anti-geoip-spam-plugin/master/postfwd-anti-spam.plugin -O /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin
|
|
||||||
chown -R postfw:postfix /etc/postfix/postfwd-anti-geoip-spam-plugin/
|
|
||||||
|
|
||||||
5. Then update the postfwd default config in the **/etc/default/postfwd** file and add the plugin parameter '**--plugins /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin'** to it**:**
|
|
||||||
|
|
||||||
sed -i 's/STARTUP=0/STARTUP=1/' /etc/default/postfwd # Auto-Startup
|
|
||||||
|
|
||||||
sed -i 's/ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size"/#ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size"/' /etc/default/postfwd # Comment out old startup parameters
|
|
||||||
|
|
||||||
echo 'ARGS="--summary=600 --cache=600 --cache-rdomain-only --cache-no-size --plugins /etc/postfix/postfwd-anti-geoip-spam-plugin/postfwd-anti-spam.plugin"' >> /etc/default/postfwd # Add new startup parameters
|
|
||||||
|
|
||||||
6\. Now create a basic postfwd configuration file with the anti spam botnet rule:
|
|
||||||
|
|
||||||
cat <<_EOF_ >> /etc/postfix/postfwd.cf
|
|
||||||
# Anti spam botnet rule
|
|
||||||
# This example shows how to limit e-mail address defined by sasl_username to be able to login from max. 5 different countries, otherwise they will be blocked to send messages.
|
|
||||||
id=COUNTRY_LOGIN_COUNT ; \
|
|
||||||
sasl_username=~^(.+)$ ; \
|
|
||||||
incr_client_country_login_count != 0 ; \
|
|
||||||
action=dunno
|
|
||||||
id=BAN_BOTNET ; \
|
|
||||||
sasl_username=~^(.+)$ ; \
|
|
||||||
client_uniq_country_login_count > 5 ; \
|
|
||||||
action=rate(sasl_username/1/3600/554 Your mail account was compromised. Please change your password immediately after next login.)
|
|
||||||
_EOF_
|
|
||||||
|
|
||||||
7\. Update the postfix configuration file **/etc/postfix/main.cf** to use the policy service on the default postfwd port **10040** (or different port according to the configuration in **/etc/default/postfwd**). Your configuration should have following option in the **smtpd_recipient_restrictions** line. Note that the following restriction does not work without other restrictions such as one of **reject_unknown_recipient_domain** or **reject_unauth_destination**.
|
|
||||||
|
|
||||||
echo 'smtpd_recipient_restrictions = check_policy_service inet:127.0.0.1:12525' >> /etc/postfix/main.cf
|
|
||||||
|
|
||||||
8\. Install the dependencies of the plugin:
|
|
||||||
|
|
||||||
`apt-get install -y libgeo-ip-perl libtime-piece-perl libdbd-mysql-perl libdbd-pg-perl`
|
|
||||||
|
|
||||||
9\. Install MySQL or PostgreSQL database and configure one user which will be used in plugin.
|
|
||||||
|
|
||||||
10\. Update database connection part in plugin to refer to your database backend configuration. This example shows the MySQL configuration for a user testuser and database test.
|
|
||||||
|
|
||||||
```
|
|
||||||
# my $driver = "Pg";
|
|
||||||
my $driver = "mysql";
|
|
||||||
my $database = "test";
|
|
||||||
my $host = "127.0.0.1";
|
|
||||||
my $port = "3306";
|
|
||||||
# my $port = "5432";
|
|
||||||
my $dsn = "DBI:$driver:database=$database;host=$host;port=$port";
|
|
||||||
my $userid = "testuser";
|
|
||||||
my $password = "password";
|
|
||||||
```
|
|
||||||
|
|
||||||
11\. Now restart postfix and postfwd service.
|
|
||||||
|
|
||||||
```
|
|
||||||
service postfix restart && service postfwd restart
|
|
||||||
```
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/
|
|
||||||
|
|
||||||
作者:[Ondrej Vasko][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/
|
|
||||||
[1]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#introduction
|
|
||||||
[2]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#how-international-botnet-works
|
|
||||||
[3]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#defending-against-botnet-spammers
|
|
||||||
[4]:https://www.howtoforge.com/tutorial/blocking-of-international-spam-botnets-postfix-plugin/#installation
|
|
||||||
[5]:https://github.com/Vnet-as/postfwd-anti-geoip-spam-plugin
|
|
||||||
@ -1,393 +0,0 @@
|
|||||||
The Perfect Server CentOS 7.3 with Apache, Postfix, Dovecot, Pure-FTPD, BIND and ISPConfig 3.1
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### This tutorial exists for these OS versions
|
|
||||||
|
|
||||||
* **CentOS 7.3**
|
|
||||||
* [CentOS 7.2][3]
|
|
||||||
* [CentOS 7.1][4]
|
|
||||||
* [CentOS 7][5]
|
|
||||||
|
|
||||||
### On this page
|
|
||||||
|
|
||||||
1. [1 Requirements][6]
|
|
||||||
2. [2 Preliminary Note][7]
|
|
||||||
3. [3 Prepare the server][8]
|
|
||||||
4. [4 Enable Additional Repositories and Install Some Software][9]
|
|
||||||
5. [5 Quota][10]
|
|
||||||
1. [Enabling quota on the / (root) partition][1]
|
|
||||||
2. [Enabling quota on a separate /var partition][2]
|
|
||||||
6. [6 Install Apache, MySQL, phpMyAdmin][11]
|
|
||||||
|
|
||||||
This tutorial shows the installation of ISPConfig 3.1 on a CentOS 7.3 (64Bit) server. ISPConfig is a web hosting control panel that allows you to configure the following services through a web browser: Apache web server, Postfix mail server, MySQL, BIND nameserver, PureFTPd, SpamAssassin, ClamAV, Mailman, and many more.
|
|
||||||
|
|
||||||
### 1 Requirements
|
|
||||||
|
|
||||||
To install such a system you will need the following:
|
|
||||||
|
|
||||||
* A Centos 7.3 minimal server system. This can be a server installed from scratch as described in our [Centos 7.3 minimal server tutorial][12] or a virtual-server or root-server from a hosting company that has a minimal Centos 7.3 setup installed.
|
|
||||||
* A fast Internet connection.
|
|
||||||
|
|
||||||
### 2 Preliminary Note
|
|
||||||
|
|
||||||
In this tutorial, I use the hostname server1.example.com with the IP address 192.168.1.100 and the gateway 192.168.1.1. These settings might differ for you, so you have to replace them where appropriate.
|
|
||||||
|
|
||||||
Please note that HHVM and XMPP are not supported in ISPConfig for the CentOS platform yet. If you like to manage an XMPP chat server from within ISPConfig or use HHVM (Hip Hop Virtual Machine) in an ISPConfig website, then please use Debian 8 or Ubuntu 16.04 as server OS instead of CentOS 7.3.
|
|
||||||
|
|
||||||
### 3 Prepare the server
|
|
||||||
|
|
||||||
**Set the keyboard layout**
|
|
||||||
|
|
||||||
In case that the keyboard layout of the server does not match your keyboard, you can switch to the right keyboard (in my case "de" for a german keyboard layout, with the localectl command:
|
|
||||||
|
|
||||||
`localectl set-keymap de`
|
|
||||||
|
|
||||||
To get a list of all available keymaps, run:
|
|
||||||
|
|
||||||
`localectl list-keymaps`
|
|
||||||
|
|
||||||
I want to install ISPConfig at the end of this tutorial, ISPConfig ships with the Bastille firewall script that I will use as firewall, therefor I disable the default CentOS firewall now. Of course, you are free to leave the CentOS firewall on and configure it to your needs (but then you shouldn't use any other firewall later on as it will most probably interfere with the CentOS firewall).
|
|
||||||
|
|
||||||
Run...
|
|
||||||
|
|
||||||
```
|
|
||||||
yum -y install net-tools
|
|
||||||
systemctl stop firewalld.service
|
|
||||||
systemctl disable firewalld.service
|
|
||||||
```
|
|
||||||
|
|
||||||
to stop and disable the CentOS firewall. It is ok when you get errors here, this just indicates that the firewall was not installed.
|
|
||||||
|
|
||||||
Then you should check that the firewall has really been disabled. To do so, run the command:
|
|
||||||
|
|
||||||
`iptables -L`
|
|
||||||
|
|
||||||
The output should look like this:
|
|
||||||
|
|
||||||
[root@server1 ~]# iptables -L
|
|
||||||
Chain INPUT (policy ACCEPT)
|
|
||||||
target prot opt source destination
|
|
||||||
|
|
||||||
Chain FORWARD (policy ACCEPT)
|
|
||||||
target prot opt source destination
|
|
||||||
|
|
||||||
Chain OUTPUT (policy ACCEPT)
|
|
||||||
target prot opt source destination
|
|
||||||
|
|
||||||
Or use the firewall-cmd command:
|
|
||||||
|
|
||||||
firewall-cmd --state
|
|
||||||
|
|
||||||
[root@server1 ~]# firewall-cmd --state
|
|
||||||
not running
|
|
||||||
[root@server1 ~]#
|
|
||||||
|
|
||||||
Now I will install the network configuration editor and the shell based editor "nano" that I will use in the next steps to edit the config files:
|
|
||||||
|
|
||||||
yum -y install nano wget NetworkManager-tui
|
|
||||||
|
|
||||||
If you did not configure your network card during the installation, you can do that now. Run...
|
|
||||||
|
|
||||||
nmtui
|
|
||||||
|
|
||||||
... and go to Edit a connection:
|
|
||||||
|
|
||||||
[
|
|
||||||
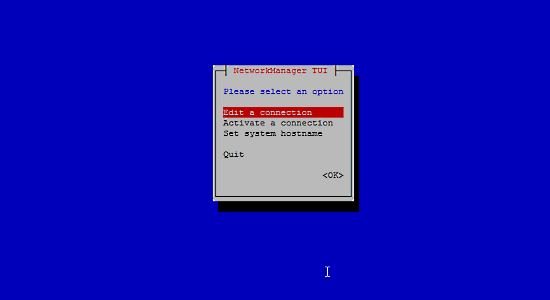
|
|
||||||
][13]
|
|
||||||
|
|
||||||
Select your network interface:
|
|
||||||
|
|
||||||
[
|
|
||||||
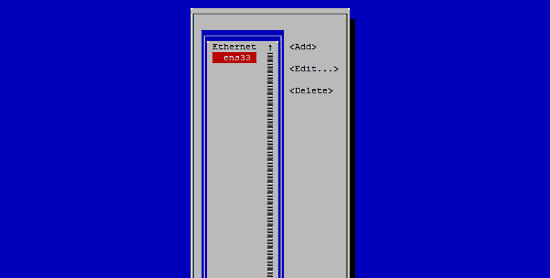
|
|
||||||
][14]
|
|
||||||
|
|
||||||
Then fill in your network details - disable DHCP and fill in a static IP address, a netmask, your gateway, and one or two nameservers, then hit Ok:
|
|
||||||
|
|
||||||
[
|
|
||||||
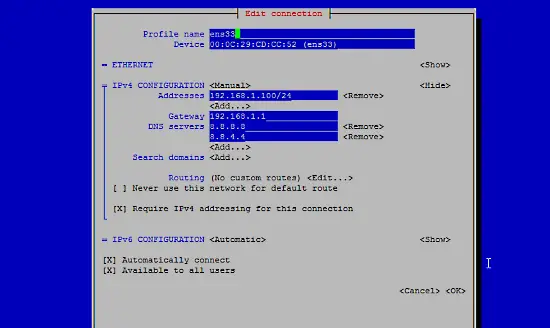
|
|
||||||
][15]
|
|
||||||
|
|
||||||
Next select OK to confirm the changes that you made in the network settings
|
|
||||||
|
|
||||||
[
|
|
||||||

|
|
||||||
][16]
|
|
||||||
|
|
||||||
and Quit to close the nmtui network configuration tool.
|
|
||||||
|
|
||||||
[
|
|
||||||
|
|
||||||
][17]
|
|
||||||
|
|
||||||
You should run
|
|
||||||
|
|
||||||
ifconfig
|
|
||||||
|
|
||||||
now to check if the installer got your IP address right:
|
|
||||||
|
|
||||||
```
|
|
||||||
[root@server1 ~]# ifconfig
|
|
||||||
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
|
|
||||||
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
|
|
||||||
inet6 fe80::20c:29ff:fecd:cc52 prefixlen 64 scopeid 0x20
|
|
||||||
|
|
||||||
ether 00:0c:29:cd:cc:52 txqueuelen 1000 (Ethernet)
|
|
||||||
RX packets 55621 bytes 79601094 (75.9 MiB)
|
|
||||||
RX errors 0 dropped 0 overruns 0 frame 0
|
|
||||||
TX packets 28115 bytes 2608239 (2.4 MiB)
|
|
||||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
|
||||||
|
|
||||||
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
|
|
||||||
inet 127.0.0.1 netmask 255.0.0.0
|
|
||||||
inet6 ::1 prefixlen 128 scopeid 0x10
|
|
||||||
loop txqueuelen 0 (Local Loopback)
|
|
||||||
RX packets 0 bytes 0 (0.0 B)
|
|
||||||
RX errors 0 dropped 0 overruns 0 frame 0
|
|
||||||
TX packets 0 bytes 0 (0.0 B)
|
|
||||||
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
|
||||||
```
|
|
||||||
|
|
||||||
If your network card does not show up there, then it not be enabled on boot, In this case, open the file /etc/sysconfig/network-scripts/ifcfg-eth0
|
|
||||||
|
|
||||||
nano /etc/sysconfig/network-scripts/ifcfg-ens33
|
|
||||||
|
|
||||||
and set ONBOOT to yes:
|
|
||||||
|
|
||||||
[...]
|
|
||||||
ONBOOT=yes
|
|
||||||
[...]
|
|
||||||
|
|
||||||
and reboot the server.
|
|
||||||
|
|
||||||
Check your /etc/resolv.conf if it lists all nameservers that you've previously configured:
|
|
||||||
|
|
||||||
cat /etc/resolv.conf
|
|
||||||
|
|
||||||
If nameservers are missing, run
|
|
||||||
|
|
||||||
nmtui
|
|
||||||
|
|
||||||
and add the missing nameservers again.
|
|
||||||
|
|
||||||
Now, on to the configuration...
|
|
||||||
|
|
||||||
**Adjusting /etc/hosts and /etc/hostname**
|
|
||||||
|
|
||||||
Next, we will edit /etc/hosts. Make it look like this:
|
|
||||||
|
|
||||||
nano /etc/hosts
|
|
||||||
|
|
||||||
```
|
|
||||||
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
|
|
||||||
192.168.1.100 server1.example.com server1
|
|
||||||
|
|
||||||
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
|
|
||||||
```
|
|
||||||
|
|
||||||
Set the hostname in the /etc/hostname file. The file shall contain the fully qualified domain name (e.g. server1.example.com in my case) and not just the short name like "server1". Open the file with the nano editor:
|
|
||||||
|
|
||||||
nano /etc/hostname
|
|
||||||
|
|
||||||
And set the hostname in the file.
|
|
||||||
|
|
||||||
```
|
|
||||||
server1.example.com
|
|
||||||
```
|
|
||||||
|
|
||||||
Save the file and exit nano.
|
|
||||||
|
|
||||||
**Disable SELinux**
|
|
||||||
|
|
||||||
SELinux is a security extension of CentOS that should provide extended security. In my opinion you don't need it to configure a secure system, and it usually causes more problems than advantages (think of it after you have done a week of trouble-shooting because some service wasn't working as expected, and then you find out that everything was ok, only SELinux was causing the problem). Therefore I disable it (this is a must if you want to install ISPConfig later on).
|
|
||||||
|
|
||||||
Edit /etc/selinux/config and set SELINUX=disabled:
|
|
||||||
|
|
||||||
nano /etc/selinux/config
|
|
||||||
|
|
||||||
```
|
|
||||||
# This file controls the state of SELinux on the system.
|
|
||||||
# SELINUX= can take one of these three values:
|
|
||||||
# enforcing - SELinux security policy is enforced.
|
|
||||||
# permissive - SELinux prints warnings instead of enforcing.
|
|
||||||
# disabled - No SELinux policy is loaded.
|
|
||||||
SELINUX=disabled
|
|
||||||
# SELINUXTYPE= can take one of these two values:
|
|
||||||
# targeted - Targeted processes are protected,
|
|
||||||
# mls - Multi Level Security protection.
|
|
||||||
SELINUXTYPE=targeted
|
|
||||||
```
|
|
||||||
|
|
||||||
Afterwards we must reboot the system:
|
|
||||||
|
|
||||||
reboot
|
|
||||||
|
|
||||||
### 4 Enable Additional Repositories and Install Some Software
|
|
||||||
|
|
||||||
First, we import the GPG keys for software packages:
|
|
||||||
|
|
||||||
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY*
|
|
||||||
|
|
||||||
Then we enable the EPEL repository on our CentOS system as lots of the packages that we are going to install in the course of this tutorial are not available in the official CentOS 7 repository:
|
|
||||||
|
|
||||||
yum -y install epel-release
|
|
||||||
|
|
||||||
yum -y install yum-priorities
|
|
||||||
|
|
||||||
Edit /etc/yum.repos.d/epel.repo...
|
|
||||||
|
|
||||||
nano /etc/yum.repos.d/epel.repo
|
|
||||||
|
|
||||||
... and add the line priority=10 to the [epel] section:
|
|
||||||
|
|
||||||
```
|
|
||||||
[epel]
|
|
||||||
name=Extra Packages for Enterprise Linux 7 - $basearch
|
|
||||||
#baseurl=http://download.fedoraproject.org/pub/epel/7/$basearch
|
|
||||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-7&arch=$basearch
|
|
||||||
failovermethod=priority
|
|
||||||
enabled=1
|
|
||||||
priority=10
|
|
||||||
gpgcheck=1
|
|
||||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-7
|
|
||||||
[...]
|
|
||||||
```
|
|
||||||
|
|
||||||
Then we update our existing packages on the system:
|
|
||||||
|
|
||||||
yum -y update
|
|
||||||
|
|
||||||
Now we install some software packages that are needed later on:
|
|
||||||
|
|
||||||
yum -y groupinstall 'Development Tools'
|
|
||||||
|
|
||||||
### 5 Quota
|
|
||||||
|
|
||||||
(If you have chosen a different partitioning scheme than I did, you must adjust this chapter so that quota applies to the partitions where you need it.)
|
|
||||||
|
|
||||||
To install quota, we run this command:
|
|
||||||
|
|
||||||
yum -y install quota
|
|
||||||
|
|
||||||
Now we check if quota is already enabled for the filesystem where the website (/var/www) and maildir data (var/vmail) is stored. In this example setup, I have one big root partition, so I search for ' / ':
|
|
||||||
|
|
||||||
mount | grep ' / '
|
|
||||||
|
|
||||||
[root@server1 ~]# mount | grep ' / '
|
|
||||||
/dev/mapper/centos-root on / type xfs (rw,relatime,attr2,inode64,noquota)
|
|
||||||
[root@server1 ~]#
|
|
||||||
|
|
||||||
If you have a separate /var partition, then use:
|
|
||||||
|
|
||||||
mount | grep ' /var '
|
|
||||||
|
|
||||||
instead. If the line contains the word "**noquota**", then proceed with the following steps to enable quota.
|
|
||||||
|
|
||||||
### Enabling quota on the / (root) partition
|
|
||||||
|
|
||||||
Normally you would enable quota in the /etc/fstab file, but if the filesystem is the root filesystem "/", then quota has to be enabled by a boot parameter of the Linux Kernel.
|
|
||||||
|
|
||||||
Edit the grub configuration file:
|
|
||||||
|
|
||||||
nano /etc/default/grub
|
|
||||||
|
|
||||||
search fole the line that starts with GRUB_CMDLINE_LINUX and add rootflags=uquota,gquota to the commandline parameters so that the resulting line looks like this:
|
|
||||||
|
|
||||||
```
|
|
||||||
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet rootflags=uquota,gquota"
|
|
||||||
```
|
|
||||||
|
|
||||||
and apply the changes by running the following command.
|
|
||||||
|
|
||||||
cp /boot/grub2/grub.cfg /boot/grub2/grub.cfg_bak
|
|
||||||
grub2-mkconfig -o /boot/grub2/grub.cfg
|
|
||||||
|
|
||||||
and reboot the server.
|
|
||||||
|
|
||||||
reboot
|
|
||||||
|
|
||||||
Now check if quota is enabled:
|
|
||||||
|
|
||||||
mount | grep ' / '
|
|
||||||
|
|
||||||
[root@server1 ~]# mount | grep ' / '
|
|
||||||
/dev/mapper/centos-root on / type xfs (rw,relatime,attr2,inode64,usrquota,grpquota)
|
|
||||||
[root@server1 ~]#
|
|
||||||
|
|
||||||
When quota is active, we can see "**usrquota,grpquota**" in the mount option list.
|
|
||||||
|
|
||||||
### Enabling quota on a separate /var partition
|
|
||||||
|
|
||||||
If you have a separate /var partition, then edit /etc/fstab and add ,uquota,gquota to the / partition (/dev/mapper/centos-var):
|
|
||||||
|
|
||||||
nano /etc/fstab
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
#
|
|
||||||
# /etc/fstab
|
|
||||||
# Created by anaconda on Sun Sep 21 16:33:45 2014
|
|
||||||
#
|
|
||||||
# Accessible filesystems, by reference, are maintained under '/dev/disk'
|
|
||||||
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
|
|
||||||
#
|
|
||||||
/dev/mapper/centos-root / xfs defaults 1 1
|
|
||||||
/dev/mapper/centos-var /var xfs defaults,uquota,gquota 1 2
|
|
||||||
UUID=9ac06939-7e43-4efd-957a-486775edd7b4 /boot xfs defaults 1 3
|
|
||||||
/dev/mapper/centos-swap swap swap defaults 0 0
|
|
||||||
```
|
|
||||||
|
|
||||||
Then run
|
|
||||||
|
|
||||||
mount -o remount /var
|
|
||||||
|
|
||||||
quotacheck -avugm
|
|
||||||
quotaon -avug
|
|
||||||
|
|
||||||
to enable quota. When you get an error that there is no partition with quota enabled, then reboot the server before you proceed.
|
|
||||||
|
|
||||||
### 6 Install Apache, MySQL, phpMyAdmin
|
|
||||||
|
|
||||||
We can install the needed packages with one single command:
|
|
||||||
|
|
||||||
yum -y install ntp httpd mod_ssl mariadb-server php php-mysql php-mbstring phpmyadmin
|
|
||||||
|
|
||||||
To ensure that the server can not be attacked trough the [HTTPOXY][18] vulnerability, we will disable the HTTP_PROXY header in apache globally.
|
|
||||||
|
|
||||||
Add the apache header rule at the end of the httpd.conf file:
|
|
||||||
|
|
||||||
echo "RequestHeader unset Proxy early" >> /etc/httpd/conf/httpd.conf
|
|
||||||
|
|
||||||
And restart httpd to apply the configuration change.
|
|
||||||
|
|
||||||
service httpd restart
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/
|
|
||||||
|
|
||||||
作者:[ Till Brehm][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/
|
|
||||||
[1]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#enabling-quota-on-the-root-partition
|
|
||||||
[2]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#enabling-quota-on-a-separate-var-partition
|
|
||||||
[3]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-2-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/
|
|
||||||
[4]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-1-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig3/
|
|
||||||
[5]:https://www.howtoforge.com/perfect-server-centos-7-apache2-mysql-php-pureftpd-postfix-dovecot-and-ispconfig3
|
|
||||||
[6]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#-requirements
|
|
||||||
[7]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#-preliminary-note
|
|
||||||
[8]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#nbspprepare-the-server
|
|
||||||
[9]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#nbspenable-additional-repositories-and-install-some-software
|
|
||||||
[10]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#-quota
|
|
||||||
[11]:https://www.howtoforge.com/tutorial/perfect-server-centos-7-3-apache-mysql-php-pureftpd-postfix-dovecot-and-ispconfig/#-install-apache-mysql-phpmyadmin
|
|
||||||
[12]:https://www.howtoforge.com/tutorial/centos-7-minimal-server/
|
|
||||||
[13]:https://www.howtoforge.com/images/perfect_server_centos_7_1_x86_64_apache2_dovecot_ispconfig3/big/nmtui1.png
|
|
||||||
[14]:https://www.howtoforge.com/images/perfect_server_centos_7_1_x86_64_apache2_dovecot_ispconfig3/big/nmtui2.png
|
|
||||||
[15]:https://www.howtoforge.com/images/perfect_server_centos_7_1_x86_64_apache2_dovecot_ispconfig3/big/nmtui3.png
|
|
||||||
[16]:https://www.howtoforge.com/images/perfect_server_centos_7_1_x86_64_apache2_dovecot_ispconfig3/big/nmtui4.png
|
|
||||||
[17]:https://www.howtoforge.com/images/perfect_server_centos_7_1_x86_64_apache2_dovecot_ispconfig3/big/nmtui5.png
|
|
||||||
[18]:https://www.howtoforge.com/tutorial/httpoxy-protect-your-server/
|
|
||||||
@ -1,265 +0,0 @@
|
|||||||
Monitoring a production-ready microservice
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
Explore essential components, principles, and key metrics.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
This is an excerpt from [Production-Ready Microservices][8], by Susan J. Fowler.
|
|
||||||
|
|
||||||
|
|
||||||
A production-ready microservice is one that is properly monitored. Proper monitoring is one of the most important parts of building a production-ready microservice and guarantees higher microservice availability. In this chapter, the essential components of microservice monitoring are covered, including which key metrics to monitor, how to log key metrics, building dashboards that display key metrics, how to approach alerting, and on-call best practices.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Principles of Microservice Monitoring
|
|
||||||
|
|
||||||
The majority of outages in a microservice ecosystem are caused by bad deployments. The second most common cause of outages is the lack of proper _monitoring_ . It’s easy to see why this is the case. If the state of a microservice is unknown, if key metrics aren’t tracked, then any precipitating failures will remain unknown until an actual outage occurs. By the time a microservice experiences an outage due to lack of monitoring, its availability has already been compromised. During these outages, the time to mitigation and time to repair are prolonged, pulling the availability of the microservice down even further: without easily accessible information about the microservice’s key metrics, developers are often faced with a blank slate, unprepared to quickly resolve the issue. This is why proper monitoring is essential: it provides the development team with all of the relevant information about the microservice. When a microservice is properly monitored, its state is never unknown.
|
|
||||||
|
|
||||||
Monitoring a production-ready microservice has four components. The first is proper _logging_ of all relevant and important information, which allows developers to understand the state of the microservice at any time in the present or in the past. The second is the use of well-designed _dashboards_ that accurately reflect the health of the microservice, and are organized in such a way that anyone at the company could view the dashboard and understand the health and status of the microservice without difficulty. The third component is actionable and effective _alerting_ on all key metrics, a practice that makes it easy for developers to mitigate and resolve problems with the microservice before they cause outages. The final component is the implementation and practice of running a sustainable _on-call rotation_ responsible for the monitoring of the microservice. With effective logging, dashboards, alerting, and on-call rotation, the microservice’s availability can be protected: failures and errors will be detected, mitigated, and resolved before they bring down any part of the microservice ecosystem.
|
|
||||||
|
|
||||||
###### A Production-Ready Service Is Properly Monitored
|
|
||||||
|
|
||||||
* Its key metrics are identified and monitored at the host, infrastructure, and microservice levels.
|
|
||||||
|
|
||||||
* It has appropriate logging that accurately reflects the past states of the microservice.
|
|
||||||
|
|
||||||
* Its dashboards are easy to interpret, and contain all key metrics.
|
|
||||||
|
|
||||||
* Its alerts are actionable and are defined by signal-providing thresholds.
|
|
||||||
|
|
||||||
* There is a dedicated on-call rotation responsible for monitoring and responding to any incidents and outages.
|
|
||||||
|
|
||||||
* There is a clear, well-defined, and standardized on-call procedure in place for handling incidents and outages.
|
|
||||||
|
|
||||||
|
|
||||||
### Key Metrics
|
|
||||||
|
|
||||||
Before we jump into the components of proper monitoring, it’s important to identify precisely _what_ we want and need to monitor: we want to monitor a microservice, but what does that _actually_ mean? A microservice isn’t an individual object that we can follow or track, it cannot be isolated and quarantined—it’s far more complicated than that. Deployed across dozens, if not hundreds, of servers, the behavior of a microservice is the sum of its behavior across all of its instantiations, which isn’t the easiest thing to quantify. The key is identifying which properties of a microservice are necessary and sufficient for describing its behavior, and then determining what changes in those properties tell us about the overall status and health of the microservice. We’ll call these properties _key metrics_ .
|
|
||||||
|
|
||||||
There are two types of key metrics: host and infrastructure metrics, and microservice metrics. Host and infrastructure metrics are those that pertain to the status of the infrastructure and the servers on which the microservice is running, while microservice metrics are metrics that are unique to the individual microservice. In terms of the four-layer model of the microservice ecosystem as described in [Chapter 1, _Microservices_ ][9], host and infrastructure metrics are metrics belonging to layers 1–3, while microservice metrics are those belonging to layer 4.
|
|
||||||
|
|
||||||
Separating key metrics into these two different types is important both organizationally and technically. Host and infrastructure metrics often affect more than one microservice: for example, if there is a problem with a particular server, and the microservice ecosystem shares the hardware resources among multiple microservices, host-level key metrics will be relevant to every microservice team that has a microservice deployed to that host. Likewise, microservice-specific metrics will rarely be applicable or useful to anyone but the team of developers working on that particular microservice. Teams should monitor both types of key metrics (that is, all metrics relevant to their microservice), and any metrics relevant to multiple microservices should be monitored and shared between the appropriate teams.
|
|
||||||
|
|
||||||
The host and infrastructure metrics that should be monitored for each microservice are the CPU utilized by the microservice on each host, the RAM utilized by the microservice on each host, the available threads, the microservice’s open file descriptors (FD), and the number of database connections that the microservice has to any databases it uses. Monitoring these key metrics should be done in such a way that the status of each metric is accompanied by information about the infrastructure and the microservice. This means that monitoring should be granular enough that developers can know the status of the keys metrics for their microservice on any particular host and across all of the hosts that it runs on. For example, developers should be able to know how much CPU their microservice is using on one particular host _and_ how much CPU their microservice is using across all hosts it runs on.
|
|
||||||
|
|
||||||
### Monitoring Host-Level Metrics When Resources Are Abstracted
|
|
||||||
|
|
||||||
Some microservice ecosystems may use cluster management applications (like Mesos) in which the resources (CPU, RAM, etc.) are abstracted away from the host level. Host-level metrics won’t be available in the same way to developers in these situations, but all key metrics for the microservice overall should still be monitored by the microservice team.
|
|
||||||
|
|
||||||
Determining the necessary and sufficient key metrics at the microservice level is a bit more complicated because it can depend on the particular language that the microservice is written in. Each language comes with its own special way of processing tasks, for example, and these language-specific features must be monitored closely in the majority of cases. Consider a Python service that utilizes uwsgi workers: the number of uwsgi workers is a necessary key metric for proper monitoring.
|
|
||||||
|
|
||||||
In addition to language-specific key metrics, we also must monitor the availability of the service, the service-level agreement (SLA) of the service, latency (of both the service as a whole and its API endpoints), success of API endpoints, responses and average response times of API endpoints, the services (clients) from which API requests originate (along with which endpoints they send requests to), errors and exceptions (both handled and unhandled), and the health and status of dependencies.
|
|
||||||
|
|
||||||
Importantly, all key metrics should be monitored everywhere that the application is deployed. This means that every stage of the deployment pipeline should be monitored. Staging must be closely monitored in order to catch any problems before a new candidate for production (a new build) is deployed to servers running production traffic. It almost goes without saying that all deployments to production servers should be monitored carefully, both in the canary and production deployment phases. (For more information on deployment pipelines, see [Chapter 3, _Stability and Reliability_ ][10].)
|
|
||||||
|
|
||||||
Once the key metrics for a microservice have been identified, the next step is to capture the metrics emitted by your service. Capture them, and then log them, graph them, and alert on them. We’ll cover each of these steps in the following sections.
|
|
||||||
|
|
||||||
|
|
||||||
###### Summary of Key Metrics
|
|
||||||
|
|
||||||
**Host and infrastructure key metrics:**
|
|
||||||
|
|
||||||
* Threads
|
|
||||||
|
|
||||||
* File descriptors
|
|
||||||
|
|
||||||
* Database connections
|
|
||||||
|
|
||||||
**Microservice key metrics:**
|
|
||||||
|
|
||||||
* Language-specific metrics
|
|
||||||
|
|
||||||
* Availability
|
|
||||||
|
|
||||||
* Latency
|
|
||||||
|
|
||||||
* Endpoint success
|
|
||||||
|
|
||||||
* Endpoint responses
|
|
||||||
|
|
||||||
* Endpoint response times
|
|
||||||
|
|
||||||
* Clients
|
|
||||||
|
|
||||||
* Errors and exceptions
|
|
||||||
|
|
||||||
* Dependencies
|
|
||||||
|
|
||||||
### Logging
|
|
||||||
|
|
||||||
_Logging_ is the first component of production-ready monitoring. It begins and belongs in the codebase of each microservice, nestled deep within the code of each service, capturing all of the information necessary to describe the state of the microservice. In fact, describing the state of the microservice at any given time in the recent past is the ultimate goal of logging.
|
|
||||||
|
|
||||||
One of the benefits of microservice architecture is the freedom it gives developers to deploy new features and code changes frequently, and one of the consequences of this newfound developer freedom and increased development velocity is that the microservice is always changing. In most cases, the service will not be the same service it was 12 hours ago, let alone several days ago, and reproducing any problems will be impossible. When faced with a problem, often the only way to determine the root cause of an incident or outage is to comb through the logs, discover the state of the microservice at the time of the outage, and figure out why the service failed in that state. Logging needs to be such that developers can determine from the logs exactly what went wrong and where things fell apart.
|
|
||||||
|
|
||||||
### Logging Without Microservice Versioning
|
|
||||||
|
|
||||||
Microservice versioning is often discouraged because it can lead to other (client) services pinning to specific versions of a microservice that may not be the best or most updated version of the microservice. Without versioning, determining the state of a microservice when a failure or outage occurred can be difficult, but thorough logging can prevent this from becoming a problem: if the logging is good enough that state of a microservice at the _time_ of an outage can be sufficiently known and understood, the lack of versioning ceases to be a hindrance to quick and effective mitigation and resolution.
|
|
||||||
|
|
||||||
Determining precisely _what_ to log is specific to each microservice. The best guidance on determining what needs to be logged is, somewhat unfortunately, necessarily vague: log whatever information is essential to describing the state of the service at a given time. Luckily, we can narrow down which information is necessary by restricting our logging to whatever can be contained in the code of the service. Host-level and infrastructure-level information won’t (and shouldn’t) be logged by the application itself, but by services and tools running the application platform. Some microservice-level key metrics and information, like hashed user IDs and request and response details can and should be located in the microservice’s logs.
|
|
||||||
|
|
||||||
There are, of course, some things that _should never, ever be logged_ . Logs should never contain identifying information, such as names of customers, Social Security numbers, and other private data. They should never contain information that could present a security risk, such as passwords, access keys, or secrets. In most cases, even seemingly innocuous things like user IDs and usernames should not be logged unless encrypted.
|
|
||||||
|
|
||||||
At times, logging at the individual microservice level will not be enough. As we’ve seen throughout this book, microservices do not live alone, but within complex chains of clients and dependencies within the microservice ecosystem. While developers can try their best to log and monitor everything important and relevant to their service, tracking and logging requests and responses throughout the entire client and dependency chains from end-to-end can illuminate important information about the system that would otherwise go unknown (such as total latency and availability of the stack). To make this information accessible and visible, building a production-ready microservice ecosystem requires tracing each request through the entire stack.
|
|
||||||
|
|
||||||
The reader might have noticed at this point that it appears that a lot of information needs to be logged. Logs are data, and logging is expensive: they are expensive to store, they are expensive to access, and both storing and accessing logs comes with the additional cost associated with making expensive calls over the network. The cost of storing logs may not seem like much for an individual microservice, but if the logging needs of all the microservices within a microservice ecosystem are added together, the cost is rather high.
|
|
||||||
|
|
||||||
###### Warning
|
|
||||||
|
|
||||||
### Logs and Debugging
|
|
||||||
|
|
||||||
Avoid adding debugging logs in code that will be deployed to production—such logs are very costly. If any logs are added specifically for the purpose of debugging, developers should take great care to ensure that any branch or build containing these additional logs does not ever touch production.
|
|
||||||
|
|
||||||
Logging needs to be scalable, it needs to be available, and it needs to be easily accessible _and_ searchable. To keep the cost of logs down and to ensure scalability and high availability, it’s often necessary to impose per-service logging quotas along with limits and standards on what information can be logged, how many logs each microservice can store, and how long the logs will be stored before being deleted.
|
|
||||||
|
|
||||||
|
|
||||||
### Dashboards
|
|
||||||
|
|
||||||
Every microservice must have at least one _dashboard_ where all key metrics (such as hardware utilization, database connections, availability, latency, responses, and the status of API endpoints) are collected and displayed. A dashboard is a graphical display that is updated in real time to reflect all the most important information about a microservice. Dashboards should be easily accessible, centralized, and standardized across the microservice ecosystem.
|
|
||||||
|
|
||||||
Dashboards should be easy to interpret so that an outsider can quickly determine the health of the microservice: anyone should be able to look at the dashboard and know immediately whether or not the microservice is working correctly. This requires striking a balance between overloading a viewer with information (which would render the dashboard effectively useless) and not displaying enough information (which would also make the dashboard useless): only the necessary minimum of information about key metrics should be displayed.
|
|
||||||
|
|
||||||
A dashboard should also serve as an accurate reflection of the overall quality of monitoring of the entire microservice. Any key metric that is alerted on should be included in the dashboard (we will cover this in the next section): the exclusion of any key metric in the dashboard will reflect poor monitoring of the service, while the inclusion of metrics that are not necessary will reflect a neglect of alerting (and, consequently, monitoring) best practices.
|
|
||||||
|
|
||||||
There are several exceptions to the rule against inclusion of nonkey metrics. In addition to key metrics, information about each phase of the deployment pipeline should be displayed, though not necessarily within the same dashboard. Developers working on microservices that require monitoring a large number of key metrics may opt to set up separate dashboards for each deployment phase (one for staging, one for canary, and one for production) to accurately reflect the health of the microservice at each deployment phase: since different builds will be running on the deployment phases simultaneously, accurately reflecting the health of the microservice in a dashboard might require approaching dashboard design with the goal of reflecting the health of the microservice at a particular deployment phase (treating them almost as different microservices, or at least as different instantiations of a microservice).
|
|
||||||
|
|
||||||
###### Warning
|
|
||||||
|
|
||||||
### Dashboards and Outage Detection
|
|
||||||
|
|
||||||
Even though dashboards can illuminate anomalies and negative trends of a microservice’s key metrics, developers should never need to watch a microservice’s dashboard in order to detect incidents and outages. Doing so is an anti-pattern that leads to deficiencies in alerting and overall monitoring.
|
|
||||||
|
|
||||||
To assist in determining problems introduced by new deployments, it helps to include information about when a deployment occurred in the dashboard. The most effective and useful way to accomplish this is to make sure that deployment times are shown within the graphs of each key metric. Doing so allows developers to quickly check graphs after each deployment to see if any strange patterns emerge in any of the key metrics.
|
|
||||||
|
|
||||||
Well-designed dashboards also give developers an easy, visual way to detect anomalies and determine alerting thresholds. Very slight or gradual changes or disturbances in key metrics run the risk of not being caught by alerting, but a careful look at an accurate dashboard can illuminate anomalies that would otherwise go undetected. Alerting thresholds, which we will cover in the next section, are notoriously difficult to determine, but can be set appropriately when historical data on the dashboard is examined: developers can see normal patterns in key metrics, view spikes in metrics that occurred with outages (or led to outages) in the past, and then set thresholds accordingly.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Alerting
|
|
||||||
|
|
||||||
The third component of monitoring a production-ready microservice is real-time _alerting_ . The detection of failures, as well as the detection of changes within key metrics that could lead to a failure, is accomplished through alerting. To ensure this, all key metrics—host-level metrics, infrastructure metrics, and microservice-specific metrics—should be alerted on, with alerts set at various thresholds. Effective and actionable alerting is essential to preserving the availability of a microservice and preventing downtime.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Setting up Effective Alerting
|
|
||||||
|
|
||||||
Alerts must be set up for all key metrics. Any change in a key metric at the host level, infrastructure level, or microservice level that could lead to an outage, cause a spike in latency, or somehow harm the availability of the microservice should trigger an alert. Importantly, alerts should also be triggered whenever a key metric is _not_ seen.
|
|
||||||
|
|
||||||
All alerts should be useful: they should be defined by good, signal-providing thresholds. Three types of thresholds should be set for each key metric, and have both upper and lower bounds: _normal_ , _warning_ , and _critical_ . Normal thresholds reflect the usual, appropriate upper and lower bounds of each key metric and shouldn’t ever trigger an alert. Warning thresholds on each key metric will trigger alerts when there is a deviation from the norm that could lead to a problem with the microservice; warning thresholds should be set such that they will trigger alerts _before_ any deviations from the norm cause an outage or otherwise negatively affect the microservice. Critical thresholds should be set based on which upper and lower bounds on key metrics actually cause an outage, cause latency to spike, or otherwise hurt a microservice’s availability. In an ideal world, warning thresholds should trigger alerts that lead to quick detection, mitigation, and resolution before any critical thresholds are reached. In each category, thresholds should be high enough to avoid noise, but low enough to catch any and all real problems with key metrics.
|
|
||||||
|
|
||||||
### Determining Thresholds Early in the Lifecycle of a Microservice
|
|
||||||
|
|
||||||
Thresholds for key metrics can be very difficult to set without historical data. Any thresholds set early in a microservice’s lifecycle run the risk of either being useless or triggering too many alerts. To determine the appropriate thresholds for a new microservice (or even an old one), developers can run load testing on the microservice to gauge where the thresholds should lie. Running "normal" traffic loads through the microservice can determine the normal thresholds, while running larger-than-expected traffic loads can help determine warning and critical thresholds.
|
|
||||||
|
|
||||||
All alerts need to be actionable. Nonactionable alerts are those that are triggered and then resolved (or ignored) by the developer(s) on call for the microservice because they are not important, not relevant, do not signify that anything is wrong with the microservice, or alert on a problem that cannot be resolved by the developer(s). Any alert that cannot be immediately acted on by the on-call developer(s) should be removed from the pool of alerts, reassigned to the relevant on-call rotation, or (if possible) changed so that it becomes actionable.
|
|
||||||
|
|
||||||
Some of the key microservice metrics run the risk of being nonactionable. For example, alerting on the availability of dependencies can easily lead to nonactionable alerts if dependency outages, increases in dependency latency, or dependency downtime do not require any action to be taken by their client(s). If no action needs to be taken, then the thresholds should be set appropriately, or in more extreme cases, no alerts should be set on dependencies at all. However, if any action at all should be taken, even something as small as contacting the dependency’s on-call or development team in order to alert them to the issue and/or coordinate mitigation and resolution, then an alert should be triggered.
|
|
||||||
|
|
||||||
|
|
||||||
### Handling Alerts
|
|
||||||
|
|
||||||
Once an alert has been triggered, it needs to be handled quickly and effectively. The root cause of the triggered alert should be mitigated and resolved. To quickly and effectively handle alerts, there are several steps that can be taken.
|
|
||||||
|
|
||||||
The first step is to create step-by-step instructions for each known alert that detail how to triage, mitigate, and resolve each alert. These step-by-step alert instructions should live within an on-call runbook within the centralized documentation of each microservice, making them easily accessible to anyone who is on call for the microservice (more details on runbooks can be found in [Chapter 7, _Documentation and Understanding_ ][6]). Runbooks are crucial to the monitoring of a microservice: they allow any on-call developer to have step-by-step instructions on how to mitigate and resolve the root causes of each alert. Since each alert is tied to a deviation in a key metric, runbooks can be written so that they address each key metric, known causes of deviations from the norm, and how to go about debugging the problem.
|
|
||||||
|
|
||||||
Two types of on-call runbooks should be created. The first are runbooks for host-level and infrastructure-level alerts that should be shared between the whole engineering organization—these should be written for every key host-level and infrastructure-level metric. The second are on-call runbooks for specific microservices that have step-by-step instructions regarding microservice-specific alerts triggered by changes in key metrics; for example, a spike in latency should trigger an alert, and there should be step-by-step instructions in the on-call runbook that clearly document how to debug, mitigate, and resolve spikes in the microservice’s latency.
|
|
||||||
|
|
||||||
The second step is to identify alerting anti-patterns. If the microservice on-call rotation is overwhelmed by alerts yet the microservice appears to work as expected, then any alerts that are seen more than once but that can be easily mitigated and/or resolved should be automated away. That is, build the mitigation and/or resolution steps into the microservice itself. This holds for every alert, and writing step-by-step instructions for alerts within on-call runbooks allows executing on this strategy to be rather effective. In fact, any alert that, once triggered, requires a simple set of steps to be taken in order to be mitigated and resolved, can be easily automated away. Once this level of production-ready monitoring has been established, a microservice should never experience the same exact problem twice.
|
|
||||||
|
|
||||||
### On-Call Rotations
|
|
||||||
|
|
||||||
In a microservice ecosystem, the development teams themselves are responsible for the availability of their microservices. Where monitoring is concerned, this means that developers need to be on call for their own microservices. The goal of each developer on-call for a microservice needs to be clear: they are to detect, mitigate, and resolve any issue that arises with the microservice during their on call shift before the issue causes an outage for their microservice or impacts the business itself.
|
|
||||||
|
|
||||||
In some larger engineering organizations, site reliability engineers, DevOps, or other operations engineers may take on the responsibility for monitoring and on call, but this requires each microservice to be relatively stable and reliable before the on-call responsibilities can be handed off to another team. In most microservice ecosystems, microservices rarely reach this high level of stability because, as we’ve seen throughout the previous chapters, microservices are constantly changing. In a microservice ecosystem, developers need to bear the responsibility of monitoring the code that they deploy.
|
|
||||||
|
|
||||||
Designing good on-call rotations is crucial and requires the involvement of the entire team. To prevent burnout, on-call rotations should be both brief and shared: no fewer than two developers should ever be on call at one time, and on-call shifts should last no longer than one week and be spaced no more frequently than one month apart.
|
|
||||||
|
|
||||||
The on-call rotations of each microservice should be internally publicized and easily accessible. If a microservice team is experiencing issues with one of their dependencies, they should be able to track down the on-call engineers for the microservice and contact them very quickly. Hosting this information in a centralized place helps to make developers more effective in triaging problems and preventing outages.
|
|
||||||
|
|
||||||
Developing standardized on-call procedures across an engineering organization will go a long way toward building a sustainable microservice ecosystem. Developers should be trained about how to approach their on-call shifts, be made aware of on-call best practices, and be ramped up for joining the on-call rotation very quickly. Standardizing this process and making on-call expectations completely clear to every developer will prevent the burnout, confusion, and frustration that usually accompanies any mention of joining an on-call rotation.
|
|
||||||
|
|
||||||
### Evaluate Your Microservice
|
|
||||||
|
|
||||||
Now that you have a better understanding of monitoring, use the following list of questions to assess the production-readiness of your microservice(s) and microservice ecosystem. The questions are organized by topic, and correspond to the sections within this chapter.
|
|
||||||
|
|
||||||
|
|
||||||
### Key Metrics
|
|
||||||
|
|
||||||
* What are this microservice’s key metrics?
|
|
||||||
|
|
||||||
* What are the host and infrastructure metrics?
|
|
||||||
|
|
||||||
* What are the microservice-level metrics?
|
|
||||||
|
|
||||||
* Are all the microservice’s key metrics monitored?
|
|
||||||
|
|
||||||
### Logging
|
|
||||||
|
|
||||||
* What information does this microservice need to log?
|
|
||||||
|
|
||||||
* Does this microservice log all important requests?
|
|
||||||
|
|
||||||
* Does the logging accurately reflect the state of the microservice at any given time?
|
|
||||||
|
|
||||||
* Is this logging solution cost-effective and scalable?
|
|
||||||
|
|
||||||
### Dashboards
|
|
||||||
|
|
||||||
* Does this microservice have a dashboard?
|
|
||||||
|
|
||||||
* Is the dashboard easy to interpret? Are all key metrics displayed on the dashboard?
|
|
||||||
|
|
||||||
* Can I determine whether or not this microservice is working correctly by looking at the dashboard?
|
|
||||||
|
|
||||||
### Alerting
|
|
||||||
|
|
||||||
* Is there an alert for every key metric?
|
|
||||||
|
|
||||||
* Are all alerts defined by good, signal-providing thresholds?
|
|
||||||
|
|
||||||
* Are alert thresholds set appropriately so that alerts will fire before an outage occurs?
|
|
||||||
|
|
||||||
* Are all alerts actionable?
|
|
||||||
|
|
||||||
* Are there step-by-step triage, mitigation, and resolution instructions for each alert in the on-call runbook?
|
|
||||||
|
|
||||||
### On-Call Rotations
|
|
||||||
|
|
||||||
* Is there a dedicated on-call rotation responsible for monitoring this microservice?
|
|
||||||
|
|
||||||
* Is there a minimum of two developers on each on-call shift?
|
|
||||||
|
|
||||||
* Are there standardized on-call procedures across the engineering organization?
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Susan J. Fowler is the author of Production-Ready Microservices. She is currently an engineer at Stripe. Previously, Susan worked on microservice standardization at Uber, developed application platforms and infrastructure at several small startups, and studied particle physics at the University of Pennsylvania.
|
|
||||||
|
|
||||||
----------------------------
|
|
||||||
|
|
||||||
via: https://www.oreilly.com/learning/monitoring-a-production-ready-microservice
|
|
||||||
|
|
||||||
作者:[Susan Fowler][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.oreilly.com/people/susan_fowler
|
|
||||||
[1]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
|
||||||
[2]:https://pixabay.com/en/container-container-ship-port-1638068/
|
|
||||||
[3]:https://www.oreilly.com/learning/monitoring-a-production-ready-microservice?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
|
||||||
[4]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
|
||||||
[5]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
|
||||||
[6]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch07.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
|
||||||
[7]:https://www.oreilly.com/people/susan_fowler
|
|
||||||
[8]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=monitoring-production-ready-microservices
|
|
||||||
[9]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch01.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
|
||||||
[10]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch03.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
|
||||||
@ -1,122 +0,0 @@
|
|||||||
# How to work around video and subtitle embed errors
|
|
||||||
|
|
||||||
|
|
||||||
This is going to be a slightly weird tutorial. The background story is as follows. Recently, I created a bunch of [sweet][1] [parody][2] [clips][3] of the [Risitas y las paelleras][4] sketch, famous for its insane laughter by the protagonist, Risitas. As always, I had them uploaded to Youtube, but from the moment I decided on what subtitles to use to the moment when the videos finally became available online, there was a long and twisty journey.
|
|
||||||
|
|
||||||
In this guide, I would like to present several typical issues that you may encounter when creating your own media, mostly with subtitles and the subsequent upload to media sharing portals, specifically Youtube, and how you can work around those. After me.
|
|
||||||
|
|
||||||
### The background story
|
|
||||||
|
|
||||||
My software of choice for video editing is Kdenlive, which I started using when I created the most silly [Frankenstein][5] clip, and it's been my loyal companion ever since. Normally, I render files to WebM container, with VP8 video codec and Vorbis audio codec, because that's what Google likes. Indeed, I had no issues with the roughly 40 different clips I uploaded in the last seven odd years.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
However, after I completed my Risitas & Linux project, I was in a bit of a predicament. The video file and the subtitle file were still two separate entities, and I needed somehow to put them together. My original article for subtitles work mentions Avidemux and Handbrake, and both these are valid options.
|
|
||||||
|
|
||||||
However, I was not too happy with the output generated by either one of these, and for a variety of reasons, something was ever so slightly off. Avidemux did not handle the video codecs well, whereas Handbrake omitted a couple of lines of subtitle text from the final product, and the font was ugly. Solvable, but not the topic for today.
|
|
||||||
|
|
||||||
Therefore, I decided to use VideoLAN (VLC) to embed subtitles onto the video. There are several ways to do this. You can use the Media > Convert/Save option, but this one does not have everything we need. Instead, you should use Media > Stream, which comes with a more fully fledged wizard, and it also offers an editable summary of the transcoding options, which we DO need - see my [tutorial][6] on subtitles for this please.
|
|
||||||
|
|
||||||
### Errors!
|
|
||||||
|
|
||||||
The process of embedding subtitles is not trivial. You will most likely encounter several problems along the way. This guide should help you work around these so you can focus on your work and not waste time debugging weird software errors. Anyhow, here's a small but probable collection of issues you will face while working with subtitles in VLC. Trial & error, but also nerdy design.
|
|
||||||
|
|
||||||
### No playable streams
|
|
||||||
|
|
||||||
You have probably chosen weird output settings. You might want to double check you have selected the right video and audio codecs. Also, remember that some media players may not have all the codecs. Also, make sure you test on the system you want these clips to play.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Subtitles overlaid twice
|
|
||||||
|
|
||||||
This can happen if you check the box that reads Use a subtitle file in the first step of the streaming media wizard. Just select the file you need and click Stream. Leave the box unchecked.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### No subtitle output is generated
|
|
||||||
|
|
||||||
This can happen for two main reasons. One, you have selected the wrong encapsulation format. Do make sure the subtitles are marked correctly on the profile page when you edit it before proceeding. If the format does not support subtitles, it might not work.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Two, you may have left the subtitle codec render enabled in the final output. You do not need this. You only need to overlay the subtitles onto the video clip. Please check the generated stream output string and delete an option that reads scodec=<something> before you click the Stream button.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Missing codecs + workaround
|
|
||||||
|
|
||||||
This is a common [bug][7] due to how experimental codecs are implemented, and you will most likely see it if you choose the following profile: Video - H.264 + AAC (MP4). The file will be rendered, and if you selected subtitles, they will be overlaid, too, but without any audio. However, we can fix this with a hack.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
One possible hack is to start VLC from command line with the --sout-ffmpeg-strict=-2 option (might work). The other and more sureway workaround is to take the audio-less video but with the subtitles overlayed and re-render it through Kdenlive with the original project video render without subtitles as an audio source. Sounds complicated, so in detail:
|
|
||||||
|
|
||||||
* Move existing clips (containing audio) from video to audio. Delete the rest.
|
|
||||||
* Alternatively, use rendered WebM file as your audio source.
|
|
||||||
* Add new clip - the one we created with embedded subtitles AND no audio.
|
|
||||||
* Place the clip as new video.
|
|
||||||
* Render as WebM again.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Using other types of audio codecs will most likely work (e.g. MP3), and you will have a complete project with video, audio and subtitles. If you're happy that nothing is missing, you can now upload to Youtube. But then ...
|
|
||||||
|
|
||||||
### Youtube video manager & unknown format
|
|
||||||
|
|
||||||
If you're trying to upload a non-WebM clip (say MP4), you might get an unspecified error that your clip does not meet the media format requirements. I was not sure why VLC generated a non-Youtube-compliant file. However, again, the fix is easy. Use Kdenlive to recreate the video, and this should result in a file that has all the right meta fields and whatnot that Youtube likes. Back to my original story and the 40-odd clips created through Kdenlive this way.
|
|
||||||
|
|
||||||
P.S. If your clip has valid audio, then just re-run it through Kdenlive. If it does not, do the video/audio trick from before. Mute clips as necessary. In the end, this is just like overlay, except you're using the video source from one clip and audio from another for the final render. Job done.
|
|
||||||
|
|
||||||
### More reading
|
|
||||||
|
|
||||||
I do not wish to repeat myself or spam unnecessarily with links. I have loads of clips on VLC in the Software & Security section, so you might want to consult those. The earlier mentioned article on VLC & Subtitles has links to about half a dozen related tutorials, covering additional topics like streaming, logging, video rotation, remote file access, and more. I'm sure you can work the search engine like pros.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
I hope you find this guide helpful. It covers a lot, and I tried to make it linear and simple and address as many pitfalls entrepreneuring streamers and subtitle lovers may face when working with VLC. It's all about containers and codecs, but also the fact there are virtually no standards in the media world, and when you go from one format to another, sometimes you may encounter corner cases.
|
|
||||||
|
|
||||||
If you do hit an error or three, the tips and tricks here should help you solve at least some of them, including unplayable streams, missing or duplicate subtitles, missing codecs and the wicked Kdenlive workaround, Youtube upload errors, hidden VLC command line options, and a few other extras. Quite a lot for a single piece of text, right. Luckily, all good stuff. Take care, children of the Internet. And if you have any other requests as to what next my future VLC articles should cover, do feel liberated enough to send an email.
|
|
||||||
|
|
||||||
Cheers.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
My name is Igor Ljubuncic. I'm more or less 38 of age, married with no known offspring. I am currently working as a Principal Engineer with a cloud technology company, a bold new frontier. Until roughly early 2015, I worked as the OS Architect with an engineering computing team in one of the largest IT companies in the world, developing new Linux-based solutions, optimizing the kernel and hacking the living daylights out of Linux. Before that, I was a tech lead of a team designing new, innovative solutions for high-performance computing environments. Some other fancy titles include Systems Expert and System Programmer and such. All of this used to be my hobby, but since 2008, it's a paying job. What can be more satisfying than that?
|
|
||||||
|
|
||||||
From 2004 until 2008, I used to earn my bread by working as a physicist in the medical imaging industry. My work expertise focused on problem solving and algorithm development. To this end, I used Matlab extensively, mainly for signal and image processing. Furthermore, I'm certified in several major engineering methodologies, including MEDIC Six Sigma Green Belt, Design of Experiment, and Statistical Engineering.
|
|
||||||
|
|
||||||
I also happen to write books, including high fantasy and technical work on Linux; mutually inclusive.
|
|
||||||
|
|
||||||
Please see my full list of open-source projects, publications and patents, just scroll down.
|
|
||||||
|
|
||||||
For a complete list of my awards, nominations and IT-related certifications, hop yonder and yonder please.
|
|
||||||
|
|
||||||
|
|
||||||
-------------
|
|
||||||
|
|
||||||
|
|
||||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
|
||||||
|
|
||||||
作者:[Igor Ljubuncic][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:http://www.dedoimedo.com/faq.html
|
|
||||||
|
|
||||||
[1]:https://www.youtube.com/watch?v=MpDdGOKZ3dg
|
|
||||||
[2]:https://www.youtube.com/watch?v=KHG6fXEba0A
|
|
||||||
[3]:https://www.youtube.com/watch?v=TXw5lRi97YY
|
|
||||||
[4]:https://www.youtube.com/watch?v=cDphUib5iG4
|
|
||||||
[5]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
|
||||||
[6]:http://www.dedoimedo.com/computers/vlc-subtitles.html
|
|
||||||
[7]:https://trac.videolan.org/vlc/ticket/6184
|
|
||||||
@ -1,333 +0,0 @@
|
|||||||
ictlyh translating
|
|
||||||
Our guide to a Golang logs world
|
|
||||||
============================================================
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Do you ever get tired of solutions that use convoluted languages, that are complex to deploy, and for which building takes forever? Golang is the solution to these very issues, being as fast as C and as simple as Python.
|
|
||||||
|
|
||||||
But how do you monitor your application with Golang logs? There are no exceptions in Golang, only errors. Your first impression might thus be that developing a Golang logging strategy is not going to be such a straightforward affair. The lack of exceptions is not in fact that troublesome, as exceptions have lost their exceptionality in many programming languages: they are often overused to the point of being overlooked.
|
|
||||||
|
|
||||||
We’ll first cover here Golang logging basics before going the extra mile and discuss Golang logs standardization, metadatas significance, and minimization of Golang logging impact on performance.
|
|
||||||
By then, you’ll be able to track a user’s behavior across your application, quickly identify failing components in your project as well as monitor overall performance and user’s happiness.
|
|
||||||
|
|
||||||
### I. Basic Golang logging
|
|
||||||
|
|
||||||
### 1) Use Golang “log” library
|
|
||||||
|
|
||||||
Golang provides you with a native [logging library][3] simply called “log”. Its logger is perfectly suited to track simple behaviors such as adding a timestamp before an error message by using the available [flags][4].
|
|
||||||
|
|
||||||
Here is a basic example of how to log an error in Golang:
|
|
||||||
|
|
||||||
```
|
|
||||||
package main
|
|
||||||
|
|
||||||
import (
|
|
||||||
"log"
|
|
||||||
"errors"
|
|
||||||
"fmt"
|
|
||||||
)
|
|
||||||
|
|
||||||
func main() {
|
|
||||||
/* local variable definition */
|
|
||||||
...
|
|
||||||
|
|
||||||
/* function for division which return an error if divide by 0 */
|
|
||||||
ret,err = div(a, b)
|
|
||||||
if err != nil {
|
|
||||||
log.Fatal(err)
|
|
||||||
}
|
|
||||||
fmt.Println(ret)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
And here comes what you get if you try to divide by 0:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
In order to quickly test a function in Golang you can use the [go playground][5].
|
|
||||||
|
|
||||||
To make sure your logs are easily accessible at all times, we recommend to write them in a file:
|
|
||||||
|
|
||||||
```
|
|
||||||
package main
|
|
||||||
import (
|
|
||||||
"log"
|
|
||||||
"os"
|
|
||||||
)
|
|
||||||
func main() {
|
|
||||||
//create your file with desired read/write permissions
|
|
||||||
f, err := os.OpenFile("filename", os.O_WRONLY|os.O_CREATE|os.O_APPEND, 0644)
|
|
||||||
if err != nil {
|
|
||||||
log.Fatal(err)
|
|
||||||
}
|
|
||||||
//defer to close when you're done with it, not because you think it's idiomatic!
|
|
||||||
defer f.Close()
|
|
||||||
//set output of logs to f
|
|
||||||
log.SetOutput(f)
|
|
||||||
//test case
|
|
||||||
log.Println("check to make sure it works")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
You can find a complete tutorial for Golang log library [here][6] and find the complete list of available functions within their “log” [library][7].
|
|
||||||
|
|
||||||
So now you should be all set to log errors and their root causes.
|
|
||||||
|
|
||||||
But logs can also help you piece an activity stream together, identify an error context that needs fixing or investigate how a single request is impacting several layers and API’s in your system.
|
|
||||||
And to get this enhanced type of vision, you first need to enrich your Golang logs with as much context as possible as well as standardize the format you use across your project. This is when Golang native library reaches its limits. The most widely used libraries are then [glog][8] and [logrus][9]. It must be said though that many good libraries are available. So if you’re already using one that uses JSON format you don’t necessarily have to change library, as we’ll explain just below.
|
|
||||||
|
|
||||||
### II. A consistent format for your Golang logs
|
|
||||||
|
|
||||||
### 1) The structuring advantage of JSON format
|
|
||||||
|
|
||||||
Structuring your Golang logs in one project or across multiples microservices is probably the hardest part of the journey, even though it _could_ seem trivial once done. Structuring your logs is what makes them especially readable by machines (cf our [collecting logs best practices blogpost][10]). Flexibility and hierarchy are at the very core of the JSON format, so information can be easily parsed and manipulated by humans as well as by machines.
|
|
||||||
|
|
||||||
Here is an example of how to log in JSON format with the [Logrus/Logmatic.io][11] library:
|
|
||||||
|
|
||||||
```
|
|
||||||
package main
|
|
||||||
import (
|
|
||||||
log "github.com/Sirupsen/logrus"
|
|
||||||
"github.com/logmatic/logmatic-go"
|
|
||||||
)
|
|
||||||
func main() {
|
|
||||||
// use JSONFormatter
|
|
||||||
log.SetFormatter(&logmatic.JSONFormatter{})
|
|
||||||
// log an event as usual with logrus
|
|
||||||
log.WithFields(log.Fields{"string": "foo", "int": 1, "float": 1.1 }).Info("My first ssl event from golang")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Which comes out as:
|
|
||||||
|
|
||||||
```
|
|
||||||
{
|
|
||||||
"date":"2016-05-09T10:56:00+02:00",
|
|
||||||
"float":1.1,
|
|
||||||
"int":1,
|
|
||||||
"level":"info",
|
|
||||||
"message":"My first ssl event from golang",
|
|
||||||
"String":"foo"
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 2) Standardization of Golang logs
|
|
||||||
|
|
||||||
It really is a shame when the same error encountered in different parts of your code is registered differently in logs. Picture for example not being able to determine a web page loading status because of an error on one variable. One developer logged:
|
|
||||||
|
|
||||||
```
|
|
||||||
message: 'unknown error: cannot determine loading status from unknown error: missing or invalid arg value client'</span>
|
|
||||||
```
|
|
||||||
|
|
||||||
While the other registered:
|
|
||||||
|
|
||||||
```
|
|
||||||
unknown error: cannot determine loading status - invalid client</span>
|
|
||||||
```
|
|
||||||
|
|
||||||
A good solution to enforce logs standardization is to create an interface between your code and the logging library. This standardization interface would contain pre-defined log messages for all possible behavior you want to add in your logs. Doing so prevent custom log messages that would not match your desired standard format…. And in so doing facilitates log investigation.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
As log formats are centralized it becomes way easier to keep them up to date. If a new type of issue arises it only requires to be added in one interface for every team member to use the exact same message.
|
|
||||||
|
|
||||||
The most basic example would be to add the logger name and id before Golang log messages. Your code would then send “events” to your standardization interface that would in turn transform them into Golang log messages.
|
|
||||||
|
|
||||||
The most basic example would be to add the logger name and the id before the Golang log message. Your code would then send “events” to this interface that would transform them into Golang log messages:
|
|
||||||
|
|
||||||
```
|
|
||||||
// The main part, we define all messages right here.
|
|
||||||
// The Event struct is pretty simple. We maintain an Id to be sure to
|
|
||||||
// retrieve simply all messages once they are logged
|
|
||||||
var (
|
|
||||||
invalidArgMessage = Event{1, "Invalid arg: %s"}
|
|
||||||
invalidArgValueMessage = Event{2, "Invalid arg value: %s => %v"}
|
|
||||||
missingArgMessage = Event{3, "Missing arg: %s"}
|
|
||||||
)
|
|
||||||
|
|
||||||
// And here we were, all log events that can be used in our app
|
|
||||||
func (l *Logger)InvalidArg(name string) {
|
|
||||||
l.entry.Errorf(invalidArgMessage.toString(), name)
|
|
||||||
}
|
|
||||||
func (l *Logger)InvalidArgValue(name string, value interface{}) {
|
|
||||||
l.entry.WithField("arg." + name, value).Errorf(invalidArgValueMessage.toString(), name, value)
|
|
||||||
}
|
|
||||||
func (l *Logger)MissingArg(name string) {
|
|
||||||
l.entry.Errorf(missingArgMessage.toString(), name)
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
So if we use the previous example of the invalid argument value, we would get similar log messages:
|
|
||||||
|
|
||||||
```
|
|
||||||
time="2017-02-24T23:12:31+01:00" level=error msg="LoadPageLogger00003 - Missing arg: client - cannot determine loading status" arg.client=<nil> logger.name=LoadPageLogger
|
|
||||||
```
|
|
||||||
|
|
||||||
And in JSON format:
|
|
||||||
|
|
||||||
```
|
|
||||||
{"arg.client":null,"level":"error","logger.name":"LoadPageLogger","msg":"LoadPageLogger00003 - Missing arg: client - cannot determine loading status", "time":"2017-02-24T23:14:28+01:00"}
|
|
||||||
```
|
|
||||||
|
|
||||||
### III. The power of context in Golang logs
|
|
||||||
|
|
||||||
Now that the Golang logs are written in a structured and standardized format, time has come to decide which context and other relevant information should be added to them. Context and metadatas are critical in order to be able to extract insights from your logs such as following a user activity or its workflow.
|
|
||||||
|
|
||||||
For instance the Hostname, appname and session parameters could be added as follows using the JSON format of the logrus library:
|
|
||||||
|
|
||||||
```
|
|
||||||
// For metadata, a common pattern is to re-use fields between logging statements by re-using
|
|
||||||
contextualizedLog := log.WithFields(log.Fields{
|
|
||||||
"hostname": "staging-1",
|
|
||||||
"appname": "foo-app",
|
|
||||||
"session": "1ce3f6v"
|
|
||||||
})
|
|
||||||
contextualizedLog.Info("Simple event with global metadata")
|
|
||||||
```
|
|
||||||
|
|
||||||
Metadatas can be seen as javascript breadcrumbs. To better illustrate how important they are, let’s have a look at the use of metadatas among several Golang microservices. You’ll clearly see how decisive it is to track users on your application. This is because you do not simply need to know that an error occurred, but also on which instance and what pattern created the error. So let’s imagine we have two microservices which are sequentially called. The contextual information is transmitted and stored in the headers:
|
|
||||||
|
|
||||||
```
|
|
||||||
func helloMicroService1(w http.ResponseWriter, r *http.Request) {
|
|
||||||
client := &http.Client{}
|
|
||||||
// This service is responsible to received all incoming user requests
|
|
||||||
// So, we are checking if it's a new user session or a another call from
|
|
||||||
// an existing session
|
|
||||||
session := r.Header.Get("x-session")
|
|
||||||
if ( session == "") {
|
|
||||||
session = generateSessionId()
|
|
||||||
// log something for the new session
|
|
||||||
}
|
|
||||||
// Track Id is unique per request, so in each case we generate one
|
|
||||||
track := generateTrackId()
|
|
||||||
// Call your 2nd microservice, add the session/track
|
|
||||||
reqService2, _ := http.NewRequest("GET", "http://localhost:8082/", nil)
|
|
||||||
reqService2.Header.Add("x-session", session)
|
|
||||||
reqService2.Header.Add("x-track", track)
|
|
||||||
resService2, _ := client.Do(reqService2)
|
|
||||||
….
|
|
||||||
```
|
|
||||||
|
|
||||||
So when the second service is called:
|
|
||||||
|
|
||||||
```
|
|
||||||
func helloMicroService2(w http.ResponseWriter, r *http.Request) {
|
|
||||||
// Like for the microservice, we check the session and generate a new track
|
|
||||||
session := r.Header.Get("x-session")
|
|
||||||
track := generateTrackId()
|
|
||||||
// This time, we check if a track id is already set in the request,
|
|
||||||
// if yes, it becomes the parent track
|
|
||||||
parent := r.Header.Get("x-track")
|
|
||||||
if (session == "") {
|
|
||||||
w.Header().Set("x-parent", parent)
|
|
||||||
}
|
|
||||||
// Add meta to the response
|
|
||||||
w.Header().Set("x-session", session)
|
|
||||||
w.Header().Set("x-track", track)
|
|
||||||
if (parent == "") {
|
|
||||||
w.Header().Set("x-parent", track)
|
|
||||||
}
|
|
||||||
// Write the response body
|
|
||||||
w.WriteHeader(http.StatusOK)
|
|
||||||
io.WriteString(w, fmt.Sprintf(aResponseMessage, 2, session, track, parent))
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Context and information relative to the initial query are now available in the second microservice and a log message in JSON format looks like the following ones:
|
|
||||||
|
|
||||||
In the first micro service:
|
|
||||||
|
|
||||||
```
|
|
||||||
{"appname":"go-logging","level":"debug","msg":"hello from ms 1","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"UzWHRihF"}
|
|
||||||
```
|
|
||||||
|
|
||||||
Then in the second:
|
|
||||||
|
|
||||||
```
|
|
||||||
{"appname":"go-logging","level":"debug","msg":"hello from ms 2","parent":"UzWHRihF","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"DPRHBMuE"}
|
|
||||||
```
|
|
||||||
|
|
||||||
In the case of an error occurring in the second micro service, we are now able – thanks to the contextual information hold in the Golang logs – to determine how it was called and what pattern created the error.
|
|
||||||
|
|
||||||
If you wish to dig deeper on Golang tracking possibilities, there are several libraries that offer tracking features such as [Opentracing][12]. This specific library delivers an easy way to add tracing implementations in complex (or simple) architecture. It allows you to track user queries across the different steps of any process as done below:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### IV. Performance impact of Golang logging
|
|
||||||
|
|
||||||
### 1) Do not log in Gorountine
|
|
||||||
|
|
||||||
It is tempting to create a new logger per goroutine. But it should not be done. Goroutine is a lightweight thread manager and is used to accomplish a “simple” task. It should not therefore be in charge of logging. It could lead to concurrency issues as using log.New() in each goroutine would duplicate the interface and all loggers would concurrently try to access the same io.Writer.
|
|
||||||
Moreover libraries usually use a specific goroutine for the log writing to limit the impact on your performances and avoid concurrencial calls to the io.Writer.
|
|
||||||
|
|
||||||
### 2) Work with asynchronous libraries
|
|
||||||
|
|
||||||
If it is true that many Golang logging libraries are available, it’s important to note that most of them are synchronous (pseudo asynchronous in fact). The reason for this being probably that so far no one had any serious impact on their performance due to logging.
|
|
||||||
|
|
||||||
But as Kjell Hedström showed in [his experiment][13] using several threads that created millions of logs, asynchronous Golang logging could lead to 40% performance increase in the worst case scenario. So logging comes at a cost, and can have consequences on your application performance. In case you do not handle such volume of logs, using pseudo asynchronous Golang logging library might be efficient enough. But if you’re dealing with large amounts of logs or are keen on performance, Kjell Hedström asynchronous solution is interesting (despite the fact that you would probably have to develop it a bit as it only contains the minimum required features).
|
|
||||||
|
|
||||||
### 3) Use severity levels to manage your Golang logs volume
|
|
||||||
|
|
||||||
Some logging libraries allow you to enable or disable specific loggers, which can come in handy. You might not need some specific levels of logs once in production for example. Here is an example of how to disable a logger in the glog library where loggers are defined as boolean:
|
|
||||||
|
|
||||||
```
|
|
||||||
type Log bool
|
|
||||||
func (l Log) Println(args ...interface{}) {
|
|
||||||
fmt.Println(args...)
|
|
||||||
}
|
|
||||||
var debug Log = false
|
|
||||||
if debug {
|
|
||||||
debug.Println("DEBUGGING")
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
You can then define those boolean parameters in a configuration file and use them to enable or disable loggers.
|
|
||||||
|
|
||||||
Golang logging can be expensive without a good Golang logging strategy. Developers should resist to the temptation of logging almost everything – even if much is interesting! If the purpose of logging is to gather as much information as possible, it has to be done properly in order to avoid the white noise of logs containing useless elements.
|
|
||||||
|
|
||||||
### V. Centralize Golang logs
|
|
||||||
|
|
||||||

|
|
||||||
If your application is deployed on several servers, the hassle of connecting to each one of them to investigate a phenomenon can be avoided. Log centralization does make a difference.
|
|
||||||
|
|
||||||
Using log shippers such as Nxlog for windows, Rsyslog for linux (as it is installed by default) or Logstash and FluentD is the best way to do so. Log shippers only purpose is to send logs, and so they manage connection failures or other issues you could face very well.
|
|
||||||
|
|
||||||
There is even a [Golang syslog package][14] that takes care of sending Golang logs to the syslog daemon for you.
|
|
||||||
|
|
||||||
### Hope you enjoyed your Golang logs tour
|
|
||||||
|
|
||||||
Thinking about your Golang logging strategy at the beginning of your project is important. Tracking a user is much easier if overall context can be accessed from anywhere in the code. Reading logs from different services when they are not standardized is painful. Planning ahead to spread the same user or request id through several microservices will later on allow you to easily filter the information and follow an activity across your system.
|
|
||||||
|
|
||||||
Whether you’re building a large Golang project or several microservices also impacts your logging strategy. The main components of a large project should have their specific Golang logger named after their functionality. This enables you to instantly spot from which part of the code the logs are coming from. However with microservices or small Golang projects, fewer core components require their own logger. In each case though, the number of loggers should be kept below the number of core functionalities.
|
|
||||||
|
|
||||||
You’re now all set to quantify decisions about performance and user’s happiness with your Golang logs!
|
|
||||||
|
|
||||||
_Is there a specific coding language you want to read about? Let us know on Twitter [][1][@logmatic][2]._
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
|
||||||
|
|
||||||
作者:[Nils][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
|
||||||
[1]:https://twitter.com/logmatic?lang=en
|
|
||||||
[2]:http://twitter.com/logmatic
|
|
||||||
[3]:https://golang.org/pkg/log/
|
|
||||||
[4]:https://golang.org/pkg/log/#pkg-constants
|
|
||||||
[5]:https://play.golang.org/
|
|
||||||
[6]:https://www.goinggo.net/2013/11/using-log-package-in-go.html
|
|
||||||
[7]:https://golang.org/pkg/log/
|
|
||||||
[8]:https://github.com/google/glog
|
|
||||||
[9]:https://github.com/sirupsen/logrus
|
|
||||||
[10]:https://logmatic.io/blog/beyond-application-monitoring-discover-logging-best-practices/
|
|
||||||
[11]:https://github.com/logmatic/logmatic-go
|
|
||||||
[12]:https://github.com/opentracing/opentracing-go
|
|
||||||
[13]:https://sites.google.com/site/kjellhedstrom2/g2log-efficient-background-io-processign-with-c11/g2log-vs-google-s-glog-performance-comparison
|
|
||||||
[14]:https://golang.org/pkg/log/syslog/
|
|
||||||
@ -0,0 +1,148 @@
|
|||||||
|
Python-mode – A Vim Plugin to Develop Python Applications in Vim Editor
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
Python-mode is a vim plugin that enables you to write Python code in [Vim editor][1] in a fast manner by utilizing libraries including pylint, rope, pydoc, pyflakes, pep8, autopep8, pep257 and mccabe for coding features such as static analysis, refactoring, folding, completion, documentation, and more.
|
||||||
|
|
||||||
|
**Suggested Read:** [Bash-Support – A Vim Plugin That Converts Vim Editor to Bash-IDE][2]
|
||||||
|
|
||||||
|
This plugin contains all the features that you can use to develop python applications in Vim editor.
|
||||||
|
|
||||||
|
#### Python-mode Features
|
||||||
|
|
||||||
|
It has the following notable features:
|
||||||
|
|
||||||
|
* Support Python version 2.6+ and 3.2+.
|
||||||
|
|
||||||
|
* Supports syntax highlighting.
|
||||||
|
|
||||||
|
* Offers virtualenv support.
|
||||||
|
|
||||||
|
* Supports python folding.
|
||||||
|
|
||||||
|
* Offers enhanced python indentation.
|
||||||
|
|
||||||
|
* Enables running of python code from within Vim.
|
||||||
|
|
||||||
|
* Enables addition/removal of breakpoints.
|
||||||
|
|
||||||
|
* Supports python motions and operators.
|
||||||
|
|
||||||
|
* Enables code checking (pylint, pyflakes, pylama, …) that can be run simultaneouslyi>
|
||||||
|
|
||||||
|
* Supports autofixing of PEP8 errors.
|
||||||
|
|
||||||
|
* Allows searching in python documentation.
|
||||||
|
|
||||||
|
* Supports code refactoring.
|
||||||
|
|
||||||
|
* Supports strong code completion.
|
||||||
|
|
||||||
|
* Supports going to definition.
|
||||||
|
|
||||||
|
In this tutorial, we will show you how to setup Vim to use Python-mode in Linux to develop Python applications in Vim editor.
|
||||||
|
|
||||||
|
### How to Install Python-mode for Vim in Linux
|
||||||
|
|
||||||
|
Start by installing [Pathogen][3] (makes it super easy to install plugins and runtime files in their own private directories) for easy installation of Python-mode.
|
||||||
|
|
||||||
|
Run the commands below to get the pathogen.vim file and the directories it needs:
|
||||||
|
|
||||||
|
```
|
||||||
|
# mkdir -p ~/.vim/autoload ~/.vim/bundle && \
|
||||||
|
# curl -LSso ~/.vim/autoload/pathogen.vim https://tpo.pe/pathogen.vim
|
||||||
|
```
|
||||||
|
|
||||||
|
Then add the following lines below to your ~/.vimrc file:
|
||||||
|
|
||||||
|
```
|
||||||
|
execute pathogen#infect()
|
||||||
|
syntax on
|
||||||
|
filetype plugin indent on
|
||||||
|
```
|
||||||
|
|
||||||
|
Once you have installed pathogen, and you can now put Python-mode into ~/.vim/bundle as follows.
|
||||||
|
|
||||||
|
```
|
||||||
|
# cd ~/.vim/bundle
|
||||||
|
# git clone https://github.com/klen/python-mode.git
|
||||||
|
```
|
||||||
|
|
||||||
|
Then rebuild helptags in vim like this.
|
||||||
|
|
||||||
|
```
|
||||||
|
:helptags
|
||||||
|
```
|
||||||
|
|
||||||
|
You need to enable filetype-plugin (:help filetype-plugin-on) and filetype-indent (:help filetype-indent-on) to use python-mode.
|
||||||
|
|
||||||
|
### Install Python-mode in Debian and Ubuntu
|
||||||
|
|
||||||
|
Another way you can install python-mode in Debian and Ubuntu systems using PPA as shown.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo add-apt-repository https://klen.github.io/python-mode/deb main
|
||||||
|
$ sudo apt-get update
|
||||||
|
$ sudo apt-get install vim-python-mode
|
||||||
|
```
|
||||||
|
|
||||||
|
If you you encounter the message: “The following signatures couldn’t be verified because the public key is not available”, run the command below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys B5DF65307000E266
|
||||||
|
```
|
||||||
|
|
||||||
|
Now enable python-mode using vim-addon-manager like so.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install vim-addon-manager
|
||||||
|
$ vim-addons install python-mode
|
||||||
|
```
|
||||||
|
|
||||||
|
### Customizing Python-mode in Linux
|
||||||
|
|
||||||
|
To override the default key bindings, redefine them in the .vimrc files, for instance:
|
||||||
|
|
||||||
|
```
|
||||||
|
" Override go-to.definition key shortcut to Ctrl-]
|
||||||
|
let g:pymode_rope_goto_definition_bind = "<C-]>"
|
||||||
|
" Override run current python file key shortcut to Ctrl-Shift-e
|
||||||
|
let g:pymode_run_bind = "<C-S-e>"
|
||||||
|
" Override view python doc key shortcut to Ctrl-Shift-d
|
||||||
|
let g:pymode_doc_bind = "<C-S-d>"
|
||||||
|
```
|
||||||
|
|
||||||
|
Note that python-mode uses python 2 syntax checking by default. You can enable python 3 syntax checking by adding this in your .vimrc.
|
||||||
|
|
||||||
|
```
|
||||||
|
let g:pymode_python = 'python3'
|
||||||
|
```
|
||||||
|
|
||||||
|
You can find additional configuration options on the Python-mode Github Repository: [https://github.com/python-mode/python-mode][4]
|
||||||
|
|
||||||
|
That’s all for now! In this tutorial, we will show you how to integrate Vim to with Python-mode in Linux. Share your thoughts with us via the feedback form below.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/python-mode-a-vim-editor-plugin/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/vi-editor-usage/
|
||||||
|
[2]:https://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||||
|
[3]:https://github.com/tpope/vim-pathogen
|
||||||
|
[4]:https://github.com/python-mode/python-mode
|
||||||
|
[5]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,83 @@
|
|||||||
|
T-UI Launcher – Turns Android Device into Linux Command Line Interface
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
Are you a command line guru, or do you simply want to make your Android device unusable for friends and family, then check out T-UI Launcher app. Unix/Linux users will definitely love this.
|
||||||
|
|
||||||
|
T-UI Launcher is a free lightweight Android app with a Linux-like CLI (Command Line Interface) that turns your regular Android device into a complete command line interface. It is a simple, quick and smart launcher for those who love to work with text-based interfaces.
|
||||||
|
|
||||||
|
#### T-UI Launcher Features
|
||||||
|
|
||||||
|
Below are some of its notable features:
|
||||||
|
|
||||||
|
* Shows quick usage guide after the first launch.
|
||||||
|
|
||||||
|
* It’s fast and fully customizable.
|
||||||
|
|
||||||
|
* Offers to autocomplete menu with fast, powerful alias system.
|
||||||
|
|
||||||
|
* Also, provides predictive suggestions and offers a serviceable search function.
|
||||||
|
|
||||||
|
It is free, and you can [download and install][1] it from Google Play Store, then run it on your Android device.
|
||||||
|
|
||||||
|
Once you have installed it, you’ll be shown a quick usage guide when you first launch it. After reading the guide, you can start using it with simple commands as the ones explained below.
|
||||||
|
|
||||||
|
[][2]
|
||||||
|
|
||||||
|
T-UI Commandline Help Guide
|
||||||
|
|
||||||
|
To launch an app, simply type the first few letter in its name and the auto completion functionality will show all the available apps on the screen. Then click on the one you want to open.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ Telegram #launch telegram
|
||||||
|
$ WhatsApp #launch whatsapp
|
||||||
|
$ Chrome #launch chrome
|
||||||
|
```
|
||||||
|
[][3]
|
||||||
|
|
||||||
|
T-UI Commandline Usage
|
||||||
|
|
||||||
|
To view your Android device status (battery charge, wifi, mobile data), type.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ status
|
||||||
|
```
|
||||||
|
[][4]
|
||||||
|
|
||||||
|
Android Phone Status
|
||||||
|
|
||||||
|
Other useful commands you can use.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ uninstall telegram #uninstall telegram
|
||||||
|
$ search [google, playstore, youtube, files] #search online apps or for a local file
|
||||||
|
$ wifi #trun wifi on or off
|
||||||
|
$ cp Downloads/* Music #copy all files from Download folder to Music
|
||||||
|
$ mv Downloads/* Music #move all files from Download folder to Music
|
||||||
|
```
|
||||||
|
|
||||||
|
That’s all! In this article, we reviewed simple yet useful Android app with a Linux-like CLI (Command Line Interface) that turns your regular Android device into a complete command line interface. Give it a try and share your thoughts with us via the comment section below.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/t-ui-launcher-turns-android-device-into-linux-cli/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://play.google.com/store/apps/details?id=ohi.andre.consolelauncher
|
||||||
|
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Help.jpg
|
||||||
|
[3]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Usage.jpg
|
||||||
|
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/T-UI-Commandline-Status.jpg
|
||||||
|
[5]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[6]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[7]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,91 @@
|
|||||||
|
WPSeku – A Vulnerability Scanner to Find Security Issues in WordPress
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
by [Aaron Kili][9] | Published: May 5, 2017 | Last Updated: May 5, 2017
|
||||||
|
|
||||||
|
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][10] | [4 Free Shell Scripting eBooks][11]
|
||||||
|
|
||||||
|
WordPress is a free and open-source, highly customizable content management system (CMS) that is being used by millions around the world to run blogs and fully functional websites. Because it is the most used CMS out there, there are so many potential WordPress security issues/vulnerabilities to be concerned about.
|
||||||
|
|
||||||
|
However, these security issues can be dealt with, if we follow common WordPress security best practices. In this article, we will show you how to use WPSeku, a WordPress vulnerability scanner in Linux, that can be used to find security holes in your WordPress installation and block potential threats.
|
||||||
|
|
||||||
|
WPSeku is a simple WordPress vulnerability scanner written using Python, it can be used to scan local and remote WordPress installations to find security issues.
|
||||||
|
|
||||||
|
### How to Install WPSeku – WordPress Vulnerability Scanner in Linux
|
||||||
|
|
||||||
|
To install WPSeku in Linux, you need to clone the most recent version of WPSeku from its Github repository as shown.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd ~
|
||||||
|
$ git clone https://github.com/m4ll0k/WPSeku
|
||||||
|
```
|
||||||
|
|
||||||
|
Once you have obtained it, move into the WPSeku directory and run it as follows.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd WPSeku
|
||||||
|
```
|
||||||
|
|
||||||
|
Now run the WPSeku using the `-u` option to specify your WordPress installation URL like this.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./wpseku.py -u http://yourdomain.com
|
||||||
|
```
|
||||||
|
[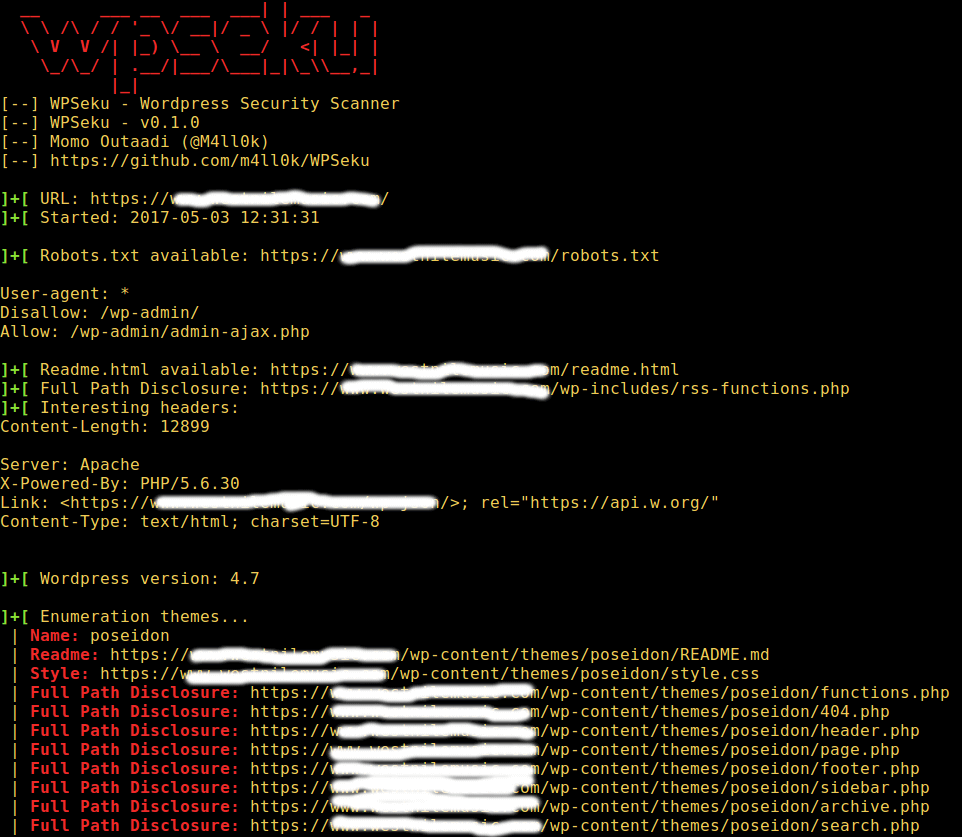][1]
|
||||||
|
|
||||||
|
WordPress Vulnerability Scanner
|
||||||
|
|
||||||
|
The command below will search for cross site scripting, local file inclusion, and SQL injection vulnerabilities in your WordPress plugins using the `-p` option, you need to specify the location of plugins in the URL:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./wpseku.py -u http://yourdomain.com/wp-content/plugins/wp/wp.php?id= -p [x,l,s]
|
||||||
|
```
|
||||||
|
|
||||||
|
The following command will execute a brute force password login and password login via XML-RPC using the option `-b`. Also, you can set a username and wordlist using the `--user` and `--wordlist` options respectively as shown below.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./wpseku.py -u http://yourdomian.com --user username --wordlist wordlist.txt -b [l,x]
|
||||||
|
```
|
||||||
|
|
||||||
|
To view all WPSeku usage options, type.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./wpseku.py --help
|
||||||
|
```
|
||||||
|
[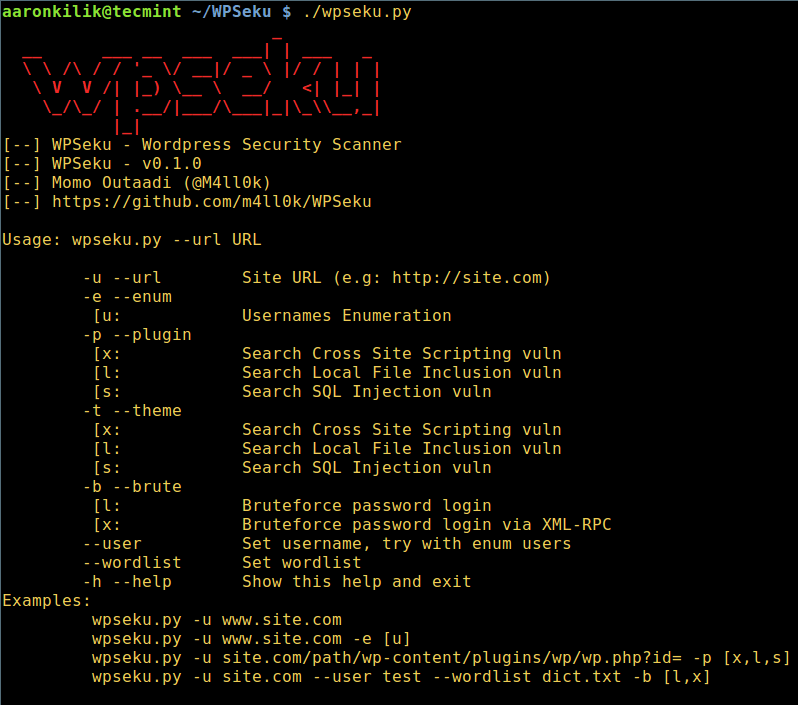][2]
|
||||||
|
|
||||||
|
WPSeku WordPress Vulnerability Scanner Help
|
||||||
|
|
||||||
|
WPSeku Github repository: [https://github.com/m4ll0k/WPSeku][3]
|
||||||
|
|
||||||
|
That’s it! In this article, we showed you how to get and use WPSeku for WordPress vulnerability scanning in Linux. WordPress is secure but only if we follow WordPress security best practices. Do you have any thoughts to share? If yes, then use the comment section below.
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/wp-content/uploads/2017/05/WordPress-Vulnerability-Scanner.png
|
||||||
|
[2]:https://www.tecmint.com/wp-content/uploads/2017/05/WPSeku-WordPress-Vulnerability-Scanner-Help.png
|
||||||
|
[3]:https://github.com/m4ll0k/WPSeku
|
||||||
|
[4]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||||
|
[5]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||||
|
[6]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||||
|
[7]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#
|
||||||
|
[8]:https://www.tecmint.com/wpseku-wordpress-vulnerability-security-scanner/#comments
|
||||||
|
[9]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[10]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[11]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -1,3 +1,4 @@
|
|||||||
|
ucasFL translating
|
||||||
4 Python libraries for building great command-line user interfaces
|
4 Python libraries for building great command-line user interfaces
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,156 @@
|
|||||||
|
How to Password Protect a Vim File in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][16] | [4 Free Shell Scripting eBooks][17]
|
||||||
|
|
||||||
|
[Vim][5] is a popular, feature-rich and highly-extensible [text editor for Linux][6], and one of its special features is support for encrypting text files using various crypto methods with a password.
|
||||||
|
|
||||||
|
In this article, we will explain to you one of the simple Vim usage tricks; password protecting a file using Vim in Linux. We will show you how to secure a file at the time of its creation as well as after opening it for modification.
|
||||||
|
|
||||||
|
**Suggested Read:** [10 Reasons Why You Should Use Vim Editor in Linux][7]
|
||||||
|
|
||||||
|
To install the full version of Vim, simply run this command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install vim #Debian/Ubuntu systems
|
||||||
|
$ sudo yum install vim #RHEL/CentOS systems
|
||||||
|
$ sudo dnf install vim #Fedora 22+
|
||||||
|
```
|
||||||
|
|
||||||
|
Read Also: [Vim 8.0 Is Released After 10 Years – Install on Linux][8]
|
||||||
|
|
||||||
|
### How to Password Protect a Vim File in Linux
|
||||||
|
|
||||||
|
Vim has a `-x` option which enables you to use encryption when creating files. Once you run the [vim command][9]below, you’ll be prompted for a crypt key:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vim -x file.txt
|
||||||
|
Warning: Using a weak encryption method; see :help 'cm'
|
||||||
|
Enter encryption key: *******
|
||||||
|
Enter same key again: *******
|
||||||
|
```
|
||||||
|
|
||||||
|
If the crypto key matches after entering it for the second time, you can proceed to modify the file.
|
||||||
|
|
||||||
|
[][10]
|
||||||
|
|
||||||
|
Vim File Password Protected
|
||||||
|
|
||||||
|
Once your done, press `[Esc]` and `:wq` to save and close the file. The next time you want to open it for editing, you’ll have to enter the crypto key like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vim file.txt
|
||||||
|
Need encryption key for "file.txt"
|
||||||
|
Warning: Using a weak encryption method; see :help 'cm'
|
||||||
|
Enter encryption key: *******
|
||||||
|
```
|
||||||
|
|
||||||
|
In case you enter a wrong password (or no key), you’ll see some junk characters.
|
||||||
|
|
||||||
|
[][11]
|
||||||
|
|
||||||
|
Vim Content Encrypted
|
||||||
|
|
||||||
|
#### Setting a Strong Encryption Method in Vim
|
||||||
|
|
||||||
|
Note: There is a warning indicating that a weak encryption method has been used to protect the file. Next, we’ll see how to set a strong encryption method in Vim.
|
||||||
|
|
||||||
|
[][12]
|
||||||
|
|
||||||
|
Weak Encryption on Vim File
|
||||||
|
|
||||||
|
To check the set of cryptmethod(cm), type (scroll down to view all available methods):
|
||||||
|
|
||||||
|
```
|
||||||
|
:help 'cm'
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Sample Output
|
||||||
|
|
||||||
|
```
|
||||||
|
*'cryptmethod'* *'cm'*
|
||||||
|
'cryptmethod' 'cm' string (default "zip")
|
||||||
|
global or local to buffer |global-local|
|
||||||
|
{not in Vi}
|
||||||
|
Method used for encryption when the buffer is written to a file:
|
||||||
|
*pkzip*
|
||||||
|
zip PkZip compatible method. A weak kind of encryption.
|
||||||
|
Backwards compatible with Vim 7.2 and older.
|
||||||
|
*blowfish*
|
||||||
|
blowfish Blowfish method. Medium strong encryption but it has
|
||||||
|
an implementation flaw. Requires Vim 7.3 or later,
|
||||||
|
files can NOT be read by Vim 7.2 and older. This adds
|
||||||
|
a "seed" to the file, every time you write the file
|
||||||
|
options.txt [Help][RO]
|
||||||
|
```
|
||||||
|
|
||||||
|
You can set a new cryptomethod on a Vim file as shown below (we’ll use blowfish2 in this example):
|
||||||
|
|
||||||
|
```
|
||||||
|
:setlocal cm=blowfish2
|
||||||
|
```
|
||||||
|
|
||||||
|
Then press `[Enter]` and `:wq` to save the file.
|
||||||
|
|
||||||
|
[][13]
|
||||||
|
|
||||||
|
Set Strong Encryption on Vim File
|
||||||
|
|
||||||
|
Now you should not see the warning message when you open the file again as shown below.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ vim file.txt
|
||||||
|
Need encryption key for "file.txt"
|
||||||
|
Enter encryption key: *******
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also set a password after opening a Vim text file, use the command`:X` and set a crypto pass like shown above.
|
||||||
|
|
||||||
|
Check out some of our useful articles on Vim editor.
|
||||||
|
|
||||||
|
1. [Learn Useful Vim Editor Trips and Tricks in Linux][1]
|
||||||
|
|
||||||
|
2. [8 Useful Vim Editor Tricks for Every Linux User][2]
|
||||||
|
|
||||||
|
3. [spf13-vim – The Ultimate Distribution for Vim Editor][3]
|
||||||
|
|
||||||
|
4. [How to Use Vim Editor as Bash IDE in Linux][4]
|
||||||
|
|
||||||
|
That’s all! In this article, we explained how to password protect a file via the [Vim text editor in Linux][14].
|
||||||
|
|
||||||
|
Always remember to appropriately secure text files that could contain secret info such as usernames and passwords, financial account info and so on, using strong encryption and a password. Use the feedback section below to share any thoughts with us.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/password-protect-vim-file-in-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/learn-vi-and-vim-editor-tips-and-tricks-in-linux/
|
||||||
|
[2]:https://www.tecmint.com/how-to-use-vi-and-vim-editor-in-linux/
|
||||||
|
[3]:https://www.tecmint.com/spf13-vim-offers-vim-plugins-vim-editor/
|
||||||
|
[4]:https://www.tecmint.com/use-vim-as-bash-ide-using-bash-support-in-linux/
|
||||||
|
[5]:https://www.tecmint.com/vi-editor-usage/
|
||||||
|
[6]:https://www.tecmint.com/best-open-source-linux-text-editors/
|
||||||
|
[7]:https://www.tecmint.com/reasons-to-learn-vi-vim-editor-in-linux/
|
||||||
|
[8]:https://www.tecmint.com/vim-8-0-install-in-ubuntu-linux-systems/
|
||||||
|
[9]:https://www.tecmint.com/linux-command-line-editors/
|
||||||
|
[10]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-File-Password-Protected-File.png
|
||||||
|
[11]:https://www.tecmint.com/wp-content/uploads/2017/05/Vim-Content-Encrypted.png
|
||||||
|
[12]:https://www.tecmint.com/wp-content/uploads/2017/05/Weak-Encryption-on-Vim-File.png
|
||||||
|
[13]:https://www.tecmint.com/wp-content/uploads/2017/05/Set-Strong-Encryption-on-Vim-File.png
|
||||||
|
[14]:https://www.tecmint.com/vi-editor-usage/
|
||||||
|
[15]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[16]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[17]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,295 @@
|
|||||||
|
ssh_scan – Verifies Your SSH Server Configuration and Policy in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
ssh_scan is an easy-to-use prototype SSH configuration and policy scanner for Linux and UNIX servers, inspired by [Mozilla OpenSSH Security Guide][6], which provides a reasonable baseline policy recommendation for SSH configuration parameters such as Ciphers, MACs, and KexAlgos and much more.
|
||||||
|
|
||||||
|
It has some of the following benefits:
|
||||||
|
|
||||||
|
* It has minimal dependencies, ssh_scan only employs native Ruby and BinData to do its work, no heavy dependencies.
|
||||||
|
|
||||||
|
* It’s portable, you can use ssh_scan in another project or for [automation of tasks][1].
|
||||||
|
|
||||||
|
* It’s easy to use, simply point it at an SSH service and get a JSON report of what it supports and it’s policy status.
|
||||||
|
|
||||||
|
* It’s also configurable, you can create your own custom policies that fit your specific policy requirements.
|
||||||
|
|
||||||
|
**Suggested Read:** [How to Install and Configure OpenSSH Server in Linux][7]
|
||||||
|
|
||||||
|
### How to Install ssh_scan in Linux
|
||||||
|
|
||||||
|
There are three ways you can install ssh_scan and they are:
|
||||||
|
|
||||||
|
To install and run as a gem, type:
|
||||||
|
|
||||||
|
```
|
||||||
|
----------- On Debian/Ubuntu -----------
|
||||||
|
$ sudo apt-get install ruby gem
|
||||||
|
$ sudo gem install ssh_scan
|
||||||
|
----------- On CentOS/RHEL -----------
|
||||||
|
# yum install ruby rubygem
|
||||||
|
# gem install ssh_scan
|
||||||
|
```
|
||||||
|
|
||||||
|
To run from a [docker container][8], type:
|
||||||
|
|
||||||
|
```
|
||||||
|
# docker pull mozilla/ssh_scan
|
||||||
|
# docker run -it mozilla/ssh_scan /app/bin/ssh_scan -t github.com
|
||||||
|
```
|
||||||
|
|
||||||
|
To install and run from source, type:
|
||||||
|
|
||||||
|
```
|
||||||
|
# git clone https://github.com/mozilla/ssh_scan.git
|
||||||
|
# cd ssh_scan
|
||||||
|
# gpg2 --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
|
||||||
|
# curl -sSL https://get.rvm.io | bash -s stable
|
||||||
|
# rvm install 2.3.1
|
||||||
|
# rvm use 2.3.1
|
||||||
|
# gem install bundler
|
||||||
|
# bundle install
|
||||||
|
# ./bin/ssh_scan
|
||||||
|
```
|
||||||
|
|
||||||
|
### How to Use ssh_scan in Linux
|
||||||
|
|
||||||
|
The syntax for using ssh_scan is as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -t ip-address
|
||||||
|
$ ssh_scan -t server-hostname
|
||||||
|
```
|
||||||
|
|
||||||
|
For example to scan SSH configs and policy of server 92.168.43.198, enter:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -t 192.168.43.198
|
||||||
|
```
|
||||||
|
|
||||||
|
Note you can also pass a [IP/Range/Hostname] to the `-t` option as shown in the options below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -t 192.168.43.198,200,205
|
||||||
|
$ ssh_scan -t test.tecmint.lan
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Sample Output
|
||||||
|
|
||||||
|
```
|
||||||
|
I, [2017-05-09T10:36:17.913644 #7145] INFO -- : You're using the latest version of ssh_scan 0.0.19
|
||||||
|
[
|
||||||
|
{
|
||||||
|
"ssh_scan_version": "0.0.19",
|
||||||
|
"ip": "192.168.43.198",
|
||||||
|
"port": 22,
|
||||||
|
"server_banner": "SSH-2.0-OpenSSH_7.2p2 Ubuntu-4ubuntu2.1",
|
||||||
|
"ssh_version": 2.0,
|
||||||
|
"os": "ubuntu",
|
||||||
|
"os_cpe": "o:canonical:ubuntu:16.04",
|
||||||
|
"ssh_lib": "openssh",
|
||||||
|
"ssh_lib_cpe": "a:openssh:openssh:7.2p2",
|
||||||
|
"cookie": "68b17bcca652eeaf153ed18877770a38",
|
||||||
|
"key_algorithms": [
|
||||||
|
"curve25519-sha256@libssh.org",
|
||||||
|
"ecdh-sha2-nistp256",
|
||||||
|
"ecdh-sha2-nistp384",
|
||||||
|
"ecdh-sha2-nistp521",
|
||||||
|
"diffie-hellman-group-exchange-sha256",
|
||||||
|
"diffie-hellman-group14-sha1"
|
||||||
|
],
|
||||||
|
"server_host_key_algorithms": [
|
||||||
|
"ssh-rsa",
|
||||||
|
"rsa-sha2-512",
|
||||||
|
"rsa-sha2-256",
|
||||||
|
"ecdsa-sha2-nistp256",
|
||||||
|
"ssh-ed25519"
|
||||||
|
],
|
||||||
|
"encryption_algorithms_client_to_server": [
|
||||||
|
"chacha20-poly1305@openssh.com",
|
||||||
|
"aes128-ctr",
|
||||||
|
"aes192-ctr",
|
||||||
|
"aes256-ctr",
|
||||||
|
"aes128-gcm@openssh.com",
|
||||||
|
"aes256-gcm@openssh.com"
|
||||||
|
],
|
||||||
|
"encryption_algorithms_server_to_client": [
|
||||||
|
"chacha20-poly1305@openssh.com",
|
||||||
|
"aes128-ctr",
|
||||||
|
"aes192-ctr",
|
||||||
|
"aes256-ctr",
|
||||||
|
"aes128-gcm@openssh.com",
|
||||||
|
"aes256-gcm@openssh.com"
|
||||||
|
],
|
||||||
|
"mac_algorithms_client_to_server": [
|
||||||
|
"umac-64-etm@openssh.com",
|
||||||
|
"umac-128-etm@openssh.com",
|
||||||
|
"hmac-sha2-256-etm@openssh.com",
|
||||||
|
"hmac-sha2-512-etm@openssh.com",
|
||||||
|
"hmac-sha1-etm@openssh.com",
|
||||||
|
"umac-64@openssh.com",
|
||||||
|
"umac-128@openssh.com",
|
||||||
|
"hmac-sha2-256",
|
||||||
|
"hmac-sha2-512",
|
||||||
|
"hmac-sha1"
|
||||||
|
],
|
||||||
|
"mac_algorithms_server_to_client": [
|
||||||
|
"umac-64-etm@openssh.com",
|
||||||
|
"umac-128-etm@openssh.com",
|
||||||
|
"hmac-sha2-256-etm@openssh.com",
|
||||||
|
"hmac-sha2-512-etm@openssh.com",
|
||||||
|
"hmac-sha1-etm@openssh.com",
|
||||||
|
"umac-64@openssh.com",
|
||||||
|
"umac-128@openssh.com",
|
||||||
|
"hmac-sha2-256",
|
||||||
|
"hmac-sha2-512",
|
||||||
|
"hmac-sha1"
|
||||||
|
],
|
||||||
|
"compression_algorithms_client_to_server": [
|
||||||
|
"none",
|
||||||
|
"zlib@openssh.com"
|
||||||
|
],
|
||||||
|
"compression_algorithms_server_to_client": [
|
||||||
|
"none",
|
||||||
|
"zlib@openssh.com"
|
||||||
|
],
|
||||||
|
"languages_client_to_server": [
|
||||||
|
],
|
||||||
|
"languages_server_to_client": [
|
||||||
|
],
|
||||||
|
"hostname": "tecmint",
|
||||||
|
"auth_methods": [
|
||||||
|
"publickey",
|
||||||
|
"password"
|
||||||
|
],
|
||||||
|
"fingerprints": {
|
||||||
|
"rsa": {
|
||||||
|
"known_bad": "false",
|
||||||
|
"md5": "0e:d0:d7:11:f0:9b:f8:33:9c:ab:26:77:e5:66:9e:f4",
|
||||||
|
"sha1": "fc:8d:d5:a1:bf:52:48:a6:7e:f9:a6:2f:af:ca:e2:f0:3a:9a:b7:fa",
|
||||||
|
"sha256": "ff:00:b4:a4:40:05:19:27:7c:33:aa:db:a6:96:32:88:8e:bf:05:a1:81:c0:a4:a8:16:01:01:0b:20:37:81:11"
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"start_time": "2017-05-09 10:36:17 +0300",
|
||||||
|
"end_time": "2017-05-09 10:36:18 +0300",
|
||||||
|
"scan_duration_seconds": 0.221573169,
|
||||||
|
"duplicate_host_key_ips": [
|
||||||
|
],
|
||||||
|
"compliance": {
|
||||||
|
"policy": "Mozilla Modern",
|
||||||
|
"compliant": false,
|
||||||
|
"recommendations": [
|
||||||
|
"Remove these Key Exchange Algos: diffie-hellman-group14-sha1",
|
||||||
|
"Remove these MAC Algos: umac-64-etm@openssh.com, hmac-sha1-etm@openssh.com, umac-64@openssh.com, hmac-sha1",
|
||||||
|
"Remove these Authentication Methods: password"
|
||||||
|
],
|
||||||
|
"references": [
|
||||||
|
"https://wiki.mozilla.org/Security/Guidelines/OpenSSH"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
You can use `-p` to specify a different port, `-L` to enable the logger and `-V` to define the verbosity level as shown below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -t 192.168.43.198 -p 22222 -L ssh-scan.log -V INFO
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, use a custom policy file (default is Mozilla Modern) with the `-P` or `--policy [FILE]` like so:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -t 192.168.43.198 -L ssh-scan.log -V INFO -P /path/to/custom/policy/file
|
||||||
|
```
|
||||||
|
|
||||||
|
Type this to view all ssh_scan usage options and more examples:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh_scan -h
|
||||||
|
```
|
||||||
|
|
||||||
|
##### Sample Output
|
||||||
|
|
||||||
|
```
|
||||||
|
ssh_scan v0.0.17 (https://github.com/mozilla/ssh_scan)
|
||||||
|
Usage: ssh_scan [options]
|
||||||
|
-t, --target [IP/Range/Hostname] IP/Ranges/Hostname to scan
|
||||||
|
-f, --file [FilePath] File Path of the file containing IP/Range/Hostnames to scan
|
||||||
|
-T, --timeout [seconds] Timeout per connect after which ssh_scan gives up on the host
|
||||||
|
-L, --logger [Log File Path] Enable logger
|
||||||
|
-O, --from_json [FilePath] File to read JSON output from
|
||||||
|
-o, --output [FilePath] File to write JSON output to
|
||||||
|
-p, --port [PORT] Port (Default: 22)
|
||||||
|
-P, --policy [FILE] Custom policy file (Default: Mozilla Modern)
|
||||||
|
--threads [NUMBER] Number of worker threads (Default: 5)
|
||||||
|
--fingerprint-db [FILE] File location of fingerprint database (Default: ./fingerprints.db)
|
||||||
|
--suppress-update-status Do not check for updates
|
||||||
|
-u, --unit-test [FILE] Throw appropriate exit codes based on compliance status
|
||||||
|
-V [STD_LOGGING_LEVEL],
|
||||||
|
--verbosity
|
||||||
|
-v, --version Display just version info
|
||||||
|
-h, --help Show this message
|
||||||
|
Examples:
|
||||||
|
ssh_scan -t 192.168.1.1
|
||||||
|
ssh_scan -t server.example.com
|
||||||
|
ssh_scan -t ::1
|
||||||
|
ssh_scan -t ::1 -T 5
|
||||||
|
ssh_scan -f hosts.txt
|
||||||
|
ssh_scan -o output.json
|
||||||
|
ssh_scan -O output.json -o rescan_output.json
|
||||||
|
ssh_scan -t 192.168.1.1 -p 22222
|
||||||
|
ssh_scan -t 192.168.1.1 -p 22222 -L output.log -V INFO
|
||||||
|
ssh_scan -t 192.168.1.1 -P custom_policy.yml
|
||||||
|
ssh_scan -t 192.168.1.1 --unit-test -P custom_policy.yml
|
||||||
|
```
|
||||||
|
|
||||||
|
Check out some useful artilces on SSH Server:
|
||||||
|
|
||||||
|
1. [SSH Passwordless Login Using SSH Keygen in 5 Easy Steps][2]
|
||||||
|
|
||||||
|
2. [5 Best Practices to Secure SSH Server][3]
|
||||||
|
|
||||||
|
3. [Restrict SSH User Access to Certain Directory Using Chrooted Jail][4]
|
||||||
|
|
||||||
|
4. [How to Configure Custom SSH Connections to Simplify Remote Access][5]
|
||||||
|
|
||||||
|
For more details visit ssh_scan Github repository: [https://github.com/mozilla/ssh_scan][9]
|
||||||
|
|
||||||
|
In this article, we showed you how to set up and use ssh_scan in Linux. Do you know of any similar tools out there? Let us know via the feedback form below, including any other thoughts concerning this guide.
|
||||||
|
|
||||||
|
SHARE[+][10][0][11][20][12][25][13] [][14]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/automating-linux-system-administration-tasks/
|
||||||
|
[2]:https://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||||
|
[3]:https://www.tecmint.com/5-best-practices-to-secure-and-protect-ssh-server/
|
||||||
|
[4]:https://www.tecmint.com/restrict-ssh-user-to-directory-using-chrooted-jail/
|
||||||
|
[5]:https://www.tecmint.com/configure-custom-ssh-connection-in-linux/
|
||||||
|
[6]:https://wiki.mozilla.org/Security/Guidelines/OpenSSH
|
||||||
|
[7]:https://www.tecmint.com/install-openssh-server-in-linux/
|
||||||
|
[8]:https://www.tecmint.com/install-docker-and-learn-containers-in-centos-rhel-7-6/
|
||||||
|
[9]:https://github.com/mozilla/ssh_scan
|
||||||
|
[10]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||||
|
[11]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||||
|
[12]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||||
|
[13]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#
|
||||||
|
[14]:https://www.tecmint.com/ssh_scan-ssh-configuration-and-policy-scanner-for-linux/#comments
|
||||||
|
[15]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[16]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[17]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,87 @@
|
|||||||
|
How to Delete HUGE (100-200GB) Files in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
by [Aaron Kili][11] | Published: May 11, 2017 | Last Updated: May 11, 2017
|
||||||
|
|
||||||
|
Download Your Free eBooks NOW - [10 Free Linux eBooks for Administrators][12] | [4 Free Shell Scripting eBooks][13]
|
||||||
|
|
||||||
|
Usually, to [delete/remove a file from Linux terminal][1], we use the rm command (delete files), shred command (securely delete a file), wipe command (securely erase a file) or secure-deletion toolkit (a collection of [secure file deletion tools][2]).
|
||||||
|
|
||||||
|
We can use any of the above utilities to deal with relatively small files. What if we want to delete/remove a huge file/directory say of about 100-200GB. This may not be as easy as it seems, in terms of the time taken to remove the file (I/O scheduling) as well as the amount of RAM consumed while carrying out the operation.
|
||||||
|
|
||||||
|
In this tutorial, we will explain how to efficiently and reliably delete huge files/directories in Linux.
|
||||||
|
|
||||||
|
**Suggested Read:** [5 Ways to Empty or Delete a Large File Content in Linux][3]
|
||||||
|
|
||||||
|
The main aim here is to use a technique that will not slow down the system while removing a huge file, resulting to reasonable I/O. We can achieve this using the ionice command.
|
||||||
|
|
||||||
|
### Deleting HUGE (200GB) Files in Linux Using ionice Command
|
||||||
|
|
||||||
|
ionice is a useful program which sets or gets the I/O scheduling class and priority for another program. If no arguments or just `-p` is given, ionice will query the current I/O scheduling class and priority for that process.
|
||||||
|
|
||||||
|
If we give a command name such as rm command, it will run this command with the given arguments. To specify the [process IDs of running processes][4] for which to get or set the scheduling parameters, run this:
|
||||||
|
|
||||||
|
```
|
||||||
|
# ionice -p PID
|
||||||
|
```
|
||||||
|
|
||||||
|
To specify the name or number of the scheduling class to use (0 for none, 1 for real time, 2 for best-effort, 3 for idle) the command below.
|
||||||
|
|
||||||
|
This means that rm will belong to idle I/O class and only uses I/O when any other process does not need it:
|
||||||
|
|
||||||
|
```
|
||||||
|
---- Deleting Huge Files in Linux -----
|
||||||
|
# ionice -c 3 rm /var/logs/syslog
|
||||||
|
# ionice -c 3 rm -rf /var/log/apache
|
||||||
|
```
|
||||||
|
|
||||||
|
If there won’t be much idle time on the system, then we may want to use the best-effort scheduling class and set a low priority like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
# ionice -c 2 -n 6 rm /var/logs/syslog
|
||||||
|
# ionice -c 2 -n 6 rm -rf /var/log/apache
|
||||||
|
```
|
||||||
|
|
||||||
|
Note: To delete huge files using a secure method, we may use the shred, wipe and various tools in the secure-deletion toolkit mentioned earlier on, instead of rm command.
|
||||||
|
|
||||||
|
**Suggested Read:** [3 Ways to Permanently and Securely Delete Files/Directories’ in Linux][5]
|
||||||
|
|
||||||
|
For more info, look through the ionice man page:
|
||||||
|
|
||||||
|
```
|
||||||
|
# man ionice
|
||||||
|
```
|
||||||
|
|
||||||
|
That’s it for now! What other methods do you have in mind for the above purpose? Use the comment section below to share with us.
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/delete-huge-files-in-linux/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||||
|
[2]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||||
|
[3]:https://www.tecmint.com/empty-delete-file-content-linux/
|
||||||
|
[4]:https://www.tecmint.com/find-linux-processes-memory-ram-cpu-usage/
|
||||||
|
[5]:https://www.tecmint.com/permanently-and-securely-delete-files-directories-linux/
|
||||||
|
[6]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||||
|
[7]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||||
|
[8]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||||
|
[9]:https://www.tecmint.com/delete-huge-files-in-linux/#
|
||||||
|
[10]:https://www.tecmint.com/delete-huge-files-in-linux/#comments
|
||||||
|
[11]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[12]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[13]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,79 @@
|
|||||||
|
Show a Custom Message to Users Before Linux Server Shutdown
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
In a previous article, we explained the [difference between shutdown, poweroff, halt and reboot][3] Linux commands, where we uncovered what these mentioned commands actually do when you execute them with various options.
|
||||||
|
|
||||||
|
This article will show you how to send a custom message to all system users before shutting down a Linux server.
|
||||||
|
|
||||||
|
**Suggested Read:** [tuptime – Shows Historical and Statistical Running Time of Linux Systems][4]
|
||||||
|
|
||||||
|
As a system administrator, before you can shut down a server, you may want to send system users a message alerting them that the system is going. By default, the shutdown command broadcasts a message to other system users as shown in the screenshot below:
|
||||||
|
|
||||||
|
```
|
||||||
|
# shutdown 13:25
|
||||||
|
```
|
||||||
|
Linux Shutdown Broadcast Message
|
||||||
|
```
|
||||||
|
Shutdown scheduled for Fri 2017-05-12 13:25:00 EAT, use 'shutdown -c' to cancel.
|
||||||
|
Broadcast message for root@tecmint (Fri 2017-05-12 13:23:34 EAT):
|
||||||
|
The system is going down for power-off at Fri 2017-05-12 13:25:00 EAT!
|
||||||
|
```
|
||||||
|
|
||||||
|
To send a custom message to other system users before an in line shutdown, run the command below. In this example, the shutdown will happen after two minutes from the time of command execution:
|
||||||
|
|
||||||
|
```
|
||||||
|
# shutdown 2 The system is going down for required maintenance. Please save any important work you are doing now!
|
||||||
|
```
|
||||||
|
[][5]
|
||||||
|
|
||||||
|
Linux System Shutdown Message
|
||||||
|
|
||||||
|
Supposing you have certain critical system operations such as scheduled system backups or updates to be executed at a time the system would be down, you can cancel the shutdown using the `-c` switch as shown below and initiate it at a later time after such operations have been performed:
|
||||||
|
|
||||||
|
```
|
||||||
|
# shutdown -c
|
||||||
|
```
|
||||||
|
Linux Shutdown Cancel Message
|
||||||
|
```
|
||||||
|
Shutdown scheduled for Fri 2017-05-12 14:10:22 EAT, use 'shutdown -c' to cancel.
|
||||||
|
Broadcast message for root@tecmint (Fri 2017-05-14 :10:27 EAT):
|
||||||
|
The system shutdown has been cancelled at Fri 2017-05-12 14:11:27 EAT!
|
||||||
|
```
|
||||||
|
|
||||||
|
Additionally, learn how to [auto execute commands/scripts during reboot or startup][6] using simple and traditional methods in Linux.
|
||||||
|
|
||||||
|
Don’t Miss:
|
||||||
|
|
||||||
|
1. [Managing System Startup Process and Services (SysVinit, Systemd and Upstart)][1]
|
||||||
|
|
||||||
|
2. [11 Cron Scheduling Task Examples in Linux][2]
|
||||||
|
|
||||||
|
Now you know how to send custom messages to all other system users before a system shutdown. Are there any ideas you want to share relating to this topic? Use the comment form below to do that?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
------------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/show-linux-server-shutdown-message/
|
||||||
|
|
||||||
|
作者:[Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/linux-boot-process-and-manage-services/
|
||||||
|
[2]:https://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||||
|
[3]:https://www.tecmint.com/shutdown-poweroff-halt-and-reboot-commands-in-linux/
|
||||||
|
[4]:https://www.tecmint.com/find-linux-uptime-shutdown-and-reboot-time-with-tuptime/
|
||||||
|
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-System-Shutdown-Message.png
|
||||||
|
[6]:https://www.tecmint.com/auto-execute-linux-scripts-during-reboot-or-startup/
|
||||||
|
[7]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -0,0 +1,130 @@
|
|||||||
|
Linfo – Shows Linux Server Health Status in Real-Time
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
|
||||||
|
Linfo is a free and open source, cross-platform server statistics UI/library which displays a great deal of system information. It is extensible, easy-to-use (via composer) PHP5 library to get extensive system statistics programmatically from your PHP application. It’s a Ncurses CLI view of Web UI, which works in Linux, Windows, *BSD, Darwin/Mac OSX, Solaris, and Minix.
|
||||||
|
|
||||||
|
It displays system info including [CPU type/speed][2]; architecture, mount point usage, hard/optical/flash drives, hardware devices, network devices and stats, uptime/date booted, hostname, memory usage (RAM and swap, if possible), temperatures/voltages/fan speeds and RAID arrays.
|
||||||
|
|
||||||
|
#### Requirements:
|
||||||
|
|
||||||
|
* PHP 5.3
|
||||||
|
|
||||||
|
* pcre extension
|
||||||
|
|
||||||
|
* Linux – /proc and /sys mounted and readable by PHP and Tested with the 2.6.x/3.x kernels
|
||||||
|
|
||||||
|
### How to Install Linfo Server Stats UI/library in Linux
|
||||||
|
|
||||||
|
First, create a Linfo directory in your Apache or Nginx web root directory, then clone and move repository files into `/var/www/html/linfo` using the [rsync command][3] as shown below:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo mkdir -p /var/www/html/linfo
|
||||||
|
$ git clone git://github.com/jrgp/linfo.git
|
||||||
|
$ sudo rsync -av linfo/ /var/www/html/linfo/
|
||||||
|
```
|
||||||
|
|
||||||
|
Then rename sample.config.inc.php to config.inc.php. This is the Linfo config file, you can define your own values in it:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo mv sample.config.inc.php config.inc.php
|
||||||
|
```
|
||||||
|
|
||||||
|
Now open the URL `http://SERVER_IP/linfo` in web browser to see the Web UI as shown in the screenshots below.
|
||||||
|
|
||||||
|
This screenshot shows the Linfo Web UI displaying core system info, hardware components, RAM stats, network devices, drives and file system mount points.
|
||||||
|
|
||||||
|
[][4]
|
||||||
|
|
||||||
|
Linux Server Health Information
|
||||||
|
|
||||||
|
You can add the line below in the config file `config.inc.php` to yield useful error messages for troubleshooting purposes:
|
||||||
|
|
||||||
|
```
|
||||||
|
$settings['show_errors'] = true;
|
||||||
|
```
|
||||||
|
|
||||||
|
### Running Linfo in Ncurses Mode
|
||||||
|
|
||||||
|
Linfo has a simple ncurses-based interface, which rely on php’s ncurses extension.
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum install php-pecl-ncurses [On CentOS/RHEL]
|
||||||
|
# dnf install php-pecl-ncurses [On Fedora]
|
||||||
|
$ sudo apt-get install php5-dev libncurses5-dev [On Debian/Ubuntu]
|
||||||
|
```
|
||||||
|
|
||||||
|
Now compile the php extension as follows
|
||||||
|
|
||||||
|
```
|
||||||
|
$ wget http://pecl.php.net/get/ncurses-1.0.2.tgz
|
||||||
|
$ tar xzvf ncurses-1.0.2.tgz
|
||||||
|
$ cd ncurses-1.0.2
|
||||||
|
$ phpize # generate configure script
|
||||||
|
$ ./configure
|
||||||
|
$ make
|
||||||
|
$ sudo make install
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, if you successfully compiled and installed the php extension, run the commands below.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo echo extension=ncurses.so > /etc/php5/cli/conf.d/ncurses.ini
|
||||||
|
```
|
||||||
|
|
||||||
|
Verify the ncurses.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ php -m | grep ncurses
|
||||||
|
```
|
||||||
|
|
||||||
|
Now run the Linfo.
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cd /var/www/html/linfo/
|
||||||
|
$ ./linfo-curses
|
||||||
|
```
|
||||||
|
[][5]
|
||||||
|
|
||||||
|
Linux Server Information
|
||||||
|
|
||||||
|
The following features yet to be added in Linfo:
|
||||||
|
|
||||||
|
1. Support for more Unix operating systems (such as Hurd, IRIX, AIX, HP UX, etc)
|
||||||
|
|
||||||
|
2. Support for less known operating systems: Haiku/BeOS
|
||||||
|
|
||||||
|
3. Extra superfluous features/extensions
|
||||||
|
|
||||||
|
4. Support for [htop-like][1] features in ncurses mode
|
||||||
|
|
||||||
|
For more information, visit Linfo Github repository: [https://github.com/jrgp/linfo][6]
|
||||||
|
|
||||||
|
That’s all! From now on, you can view a Linux system’s information from within a web browser using Linfo. Try it out and share with us your thoughts in the comments. Additionally, have you come across any similar useful tools/libraries? If yes, then give us some info about them as well.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
---------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/linfo-shows-linux-server-health-status-in-real-time/
|
||||||
|
|
||||||
|
作者:[ Aaron Kili ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/install-htop-linux-process-monitoring-for-rhel-centos-fedora/
|
||||||
|
[2]:https://www.tecmint.com/corefreq-linux-cpu-monitoring-tool/
|
||||||
|
[3]:https://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
|
||||||
|
[4]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Health-Information.png
|
||||||
|
[5]:https://www.tecmint.com/wp-content/uploads/2017/05/Linux-Server-Information.png
|
||||||
|
[6]:https://github.com/jrgp/linfo
|
||||||
|
[7]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[8]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||||
|
[9]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
翻译中 zhousiyu325
|
||||||
|
|
||||||
Maintaining a Git Repository
|
Maintaining a Git Repository
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,177 @@
|
|||||||
|
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||||
|
============================================================
|
||||||
|
|
||||||
|
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
||||||
|
|
||||||
|
In this article, we will share 10 useful and practical tips for writing effective and reliable bash scripts and they include:
|
||||||
|
|
||||||
|
### 1\. Always Use Comments in Scripts
|
||||||
|
|
||||||
|
This is a recommended practice which is not only applied to shell scripting but all other kinds of programming. Writing comments in a script helps you or some else going through your script understand what the different parts of the script do.
|
||||||
|
|
||||||
|
For starters, comments are defined using the `#` sign.
|
||||||
|
|
||||||
|
```
|
||||||
|
#TecMint is the best site for all kind of Linux articles
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2\. Make a Script exit When Fails
|
||||||
|
|
||||||
|
Sometimes bash may continue to execute a script even when a certain command fails, thus affecting the rest of the script (may eventually result in logical errors). Use the line below to exit a script when a command fails:
|
||||||
|
|
||||||
|
```
|
||||||
|
#let script exit if a command fails
|
||||||
|
set -o errexit
|
||||||
|
OR
|
||||||
|
set -e
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3\. Make a Script exit When Bash Uses Undeclared Variable
|
||||||
|
|
||||||
|
Bash may also try to use an undeclared script which could cause a logical error. Therefore use the following line to instruct bash to exit a script when it attempts to use an undeclared variable:
|
||||||
|
|
||||||
|
```
|
||||||
|
#let script exit if an unsed variable is used
|
||||||
|
set -o nounset
|
||||||
|
OR
|
||||||
|
set -u
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4\. Use Double Quotes to Reference Variables
|
||||||
|
|
||||||
|
Using double quotes while referencing (using a value of a variable) helps to prevent word splitting (regarding whitespace) and unnecessary globbing (recognizing and expanding wildcards).
|
||||||
|
|
||||||
|
Check out the example below:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
#let script exit if a command fails
|
||||||
|
set -o errexit
|
||||||
|
#let script exit if an unsed variable is used
|
||||||
|
set -o nounset
|
||||||
|
echo "Names without double quotes"
|
||||||
|
echo
|
||||||
|
names="Tecmint FOSSMint Linusay"
|
||||||
|
for name in $names; do
|
||||||
|
echo "$name"
|
||||||
|
done
|
||||||
|
echo
|
||||||
|
echo "Names with double quotes"
|
||||||
|
echo
|
||||||
|
for name in "$names"; do
|
||||||
|
echo "$name"
|
||||||
|
done
|
||||||
|
exit 0
|
||||||
|
```
|
||||||
|
|
||||||
|
Save the file and exit, then run it as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./names.sh
|
||||||
|
```
|
||||||
|
[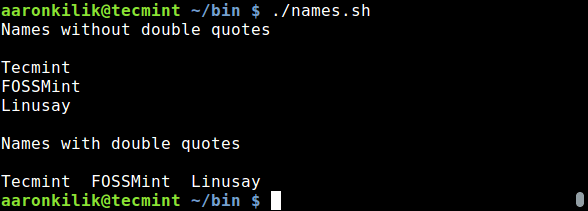][6]
|
||||||
|
|
||||||
|
Use Double Quotes in Scripts
|
||||||
|
|
||||||
|
### 5\. Use functions in Scripts
|
||||||
|
|
||||||
|
Except for very small scripts (with a few lines of code), always remember to use functions to modularize your code and make scripts more readable and reusable.
|
||||||
|
|
||||||
|
The syntax for writing functions is as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
function check_root(){
|
||||||
|
command1;
|
||||||
|
command2;
|
||||||
|
}
|
||||||
|
OR
|
||||||
|
check_root(){
|
||||||
|
command1;
|
||||||
|
command2;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
For single line code, use termination characters after each command like this:
|
||||||
|
|
||||||
|
```
|
||||||
|
check_root(){ command1; command2; }
|
||||||
|
```
|
||||||
|
|
||||||
|
### 6\. Use = instead of == for String Comparisons
|
||||||
|
|
||||||
|
Note that `==` is a synonym for `=`, therefore only use a single `=` for string comparisons, for instance:
|
||||||
|
|
||||||
|
```
|
||||||
|
value1=”tecmint.com”
|
||||||
|
value2=”fossmint.com”
|
||||||
|
if [ "$value1" = "$value2" ]
|
||||||
|
```
|
||||||
|
|
||||||
|
### 7\. Use $(command) instead of legacy ‘command’ for Substitution
|
||||||
|
|
||||||
|
[Command substitution][7] replaces a command with its output. Use `$(command)` instead of backquotes ``command`` for command substitution.
|
||||||
|
|
||||||
|
This is recommended even by [shellcheck tool][8] (shows warnings and suggestions for shell scripts). For example:
|
||||||
|
|
||||||
|
```
|
||||||
|
user=`echo “$UID”`
|
||||||
|
user=$(echo “$UID”)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 8\. Use Read-only to Declare Static Variables
|
||||||
|
|
||||||
|
A static variable doesn’t change; its value can not be altered once it’s defined in a script:
|
||||||
|
|
||||||
|
```
|
||||||
|
readonly passwd_file=”/etc/passwd”
|
||||||
|
readonly group_file=”/etc/group”
|
||||||
|
```
|
||||||
|
|
||||||
|
### 9\. Use Uppercase Names for ENVIRONMENT Variables and Lowercase for Custom Variables
|
||||||
|
|
||||||
|
All bash environment variables are named with uppercase letters, therefore use lowercase letters to name your custom variables to avoid variable name conflicts:
|
||||||
|
|
||||||
|
```
|
||||||
|
#define custom variables using lowercase and use uppercase for env variables
|
||||||
|
nikto_file=”$HOME/Downloads/nikto-master/program/nikto.pl”
|
||||||
|
perl “$nikto_file” -h “$1”
|
||||||
|
```
|
||||||
|
|
||||||
|
### 10\. Always Perform Debugging for Long Scripts
|
||||||
|
|
||||||
|
If you are writing bash scripts with thousands of lines of code, finding errors may become a nightmare. To easily fix things before executing a script, perform some debugging. Master this tip by reading through the guides provided below:
|
||||||
|
|
||||||
|
1. [How To Enable Shell Script Debugging Mode in Linux][1]
|
||||||
|
|
||||||
|
2. [How to Perform Syntax Checking Debugging Mode in Shell Scripts][2]
|
||||||
|
|
||||||
|
3. [How to Trace Execution of Commands in Shell Script with Shell Tracing][3]
|
||||||
|
|
||||||
|
That’s all! Do you have any other best bash scripting practices to share? If yes, then use the comment form below to do that.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
|
||||||
|
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||||
|
|
||||||
|
----------------
|
||||||
|
|
||||||
|
via: https://www.tecmint.com/useful-tips-for-writing-bash-scripts-in-linux/
|
||||||
|
|
||||||
|
作者:[ Aaron Kili][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]:https://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||||
|
[2]:https://www.tecmint.com/check-syntax-in-shell-script/
|
||||||
|
[3]:https://www.tecmint.com/trace-shell-script-execution-in-linux/
|
||||||
|
[4]:https://www.tecmint.com/category/bash-shell/
|
||||||
|
[5]:https://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||||
|
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Use-Double-Quotes-in-Scripts.png
|
||||||
|
[7]:https://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||||
|
[8]:https://www.tecmint.com/shellcheck-shell-script-code-analyzer-for-linux/
|
||||||
@ -0,0 +1,125 @@
|
|||||||
|
### New SMB Worm Uses Seven NSA Hacking Tools. WannaCry Used Just Two
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Researchers have detected a new worm that is spreading via SMB, but unlike the worm component of the WannaCry ransomware, this one is using seven NSA tools instead of two.
|
||||||
|
|
||||||
|
The worm's existence first came to light on Wednesday, after it infected the SMB honeypot of [Miroslav Stampar][15], member of the Croatian Government CERT, and creator of the sqlmap tool used for detecting and exploiting SQL injection flaws.
|
||||||
|
|
||||||
|
### EternalRocks uses seven NSA tools
|
||||||
|
|
||||||
|
The worm, which Stampar named EternalRocks based on worm executable properties found in one sample, works by using six SMB-centric NSA tools to infect a computer with SMB ports exposed online. These are **ETERNALBLUE**, **ETERNALCHAMPION**, **ETERNALROMANCE**, and **ETERNALSYNERGY**, which are SMB exploits used to compromise vulnerable computers, while **SMBTOUCH** and **ARCHITOUCH** are two NSA tools used for SMB reconnaissance operations.
|
||||||
|
|
||||||
|
Once the worm has obtained this initial foothold, it then uses another NSA tool, **DOUBLEPULSAR**, to propagate to new vulnerable machines.
|
||||||
|
|
||||||
|
|
||||||
|
**Origin of the EternalRocks name**
|
||||||
|
|
||||||
|
[The WannaCry ransomware outbreak][16], which affected over 240,000 victims, also used an SMB worm to infect computers and spread to new victims.
|
||||||
|
|
||||||
|
Unlike EternalRocks, WannaCry's SMB worm used only ETERNALBLUE for the initial compromise, and DOUBLEPULSAR to propagate to new machines.
|
||||||
|
|
||||||
|
### EternalRocks is more complex but less dangerous
|
||||||
|
|
||||||
|
As a worm, EternalRocks is far less dangerous than WannaCry's worm component, as it currently does not deliver any malicious content. This, however, does not mean that EternalRocks is less complex. According to Stampar, it's actually the opposite.
|
||||||
|
|
||||||
|
For starters, EternalRocks is far more sneaky than WannaCry's SMB worm component. Once it infects a victim, the worm uses a two-stage installation process, with a delayed second stage.
|
||||||
|
|
||||||
|
During the first stage, EternalRocks gains a foothold on an infected host, downloads the Tor client, and beacons its C&C server, located on a .onion domain, the Dark Web.
|
||||||
|
|
||||||
|
Only after a predefined period of time — currently 24 hours — does the C&C server respond. The role of this long delay is most probably to bypass sandbox security testing environments and security researchers analyzing the worm, as very few will wait a full day for a response from the C&C server.
|
||||||
|
|
||||||
|
<twitterwidget class="twitter-tweet twitter-tweet-rendered" id="twitter-widget-0" data-tweet-id="865494946974900224" style="position: static; visibility: visible; display: block; transform: rotate(0deg); width: 500px; margin: 10px auto; max-width: 100%; min-width: 220px;">[View image on Twitter][10] [][5]
|
||||||
|
|
||||||
|
> [ Follow][1] [ Miroslav Stampar @stamparm][6]
|
||||||
|
>
|
||||||
|
> Update on [#EternalRocks][7]. Original name is actually "MicroBotMassiveNet" while author's nick is "tmc" [https://github.com/stamparm/EternalRocks/#debug-strings …][8]
|
||||||
|
>
|
||||||
|
> [<time class="dt-updated" datetime="2017-05-19T09:10:50+0000" pubdate="" title="Time posted: 19 May 2017, 09:10:50 (UTC)">5:10 PM - 19 May 2017</time>][9]
|
||||||
|
>
|
||||||
|
> * [][2]
|
||||||
|
>
|
||||||
|
> * [ 2525 Retweets][3]
|
||||||
|
>
|
||||||
|
> * [ 1717 likes][4]
|
||||||
|
|
||||||
|
[Twitter Ads info & Privacy][11]</twitterwidget>
|
||||||
|
|
||||||
|
### No kill switch domain
|
||||||
|
|
||||||
|
Additionally, EternalRocks also uses files with identical names to the ones used by WannaCry's SMB worm, in another attempt to fool security researchers into misclassifying it.
|
||||||
|
|
||||||
|
But unlike WannaCry, EternalRocks does not include a kill switch domain, the Achille's heel that security researchers used to stop the WannaCry outbreak.
|
||||||
|
|
||||||
|
After the initial dormancy period expires and the C&C server responds, EternalRocks goes into the second stage of its installation process and downloads a second stage malware component in the form of an archive named shadowbrokers.zip.
|
||||||
|
|
||||||
|
The name of this file is pretty self-explanatory, as it contains NSA SMB-centric exploits [leaked by the Shadow Brokers group][17] in April 2017.
|
||||||
|
|
||||||
|
The worm then starts a rapid IP scanning process and attempts to connect to random IP addresses.
|
||||||
|
|
||||||
|
|
||||||
|
**The configuration files for NSA tools found in the shadowbrokers.zip archive**
|
||||||
|
|
||||||
|
### EternalRocks could be weaponized in an instant
|
||||||
|
|
||||||
|
Because of its broader exploit arsenal, the lack of a kill switch domain, and because of its initial dormancy, EternalRocks could pose a serious threat to computers with vulnerable SMB ports exposed to the Internet, if its author would ever decide to weaponize the worm with ransomware, a banking trojan, RATs, or anything else.
|
||||||
|
|
||||||
|
At first glance, the worm seems to be an experiment, or a malware author performing tests and fine-tuning a future threat.
|
||||||
|
|
||||||
|
This, however, does not mean EternalRocks is harmless. Computers infected with this worm are controllable via C&C server commands and the worm's owner could leverage this hidden communications channel to send new malware to the computers previously infected by EternalRocks.
|
||||||
|
|
||||||
|
Furthermore, DOUBLEPULSAR, [an NSA implant with backdoor features][18], remains running on PCs infected with EternalRocks. Unfortunately, the worm's author has not taken any measures to protect the DOUBLEPULSAR implant, which runs in a default unprotected state, meaning other threat actors could use it as a backdoor to machines infected by EternalRocks, by sending their own malware to those PCs.
|
||||||
|
|
||||||
|
IOCs and more info on the worm's infection process are available in a [GitHub repo][19] Stampar set up a few days ago.
|
||||||
|
|
||||||
|
### An SMB free-for-all
|
||||||
|
|
||||||
|
Currently, there are multiple actors scanning for computers running older and unpatched versions of the SMB services. System administrators have already taken notice and started patching vulnerable PCs or disabling the old SMBv1 protocol, slowly reducing the number of vulnerable machines that EternalRocks can infect.
|
||||||
|
|
||||||
|
Furthermore, malware such as [Adylkuzz][20] also shuts down SMB ports, preventing further exploitation from other threats, also contributing to reducing the number of potential targets for EternalRocks and other SMB-hunting malware. Reports from [Forcepoint][21], [Cyphort][22], and [Secdo][23] detail other threats currently targeting computers with SMB ports.
|
||||||
|
|
||||||
|
Nonetheless, the faster system administrators patch their systems the better. "The worm is racing with administrators to infect machines before they patch," Stampar told Bleeping Computer in a private conversation. "Once infected, he can weaponize any time he wants, no matter the late patch."
|
||||||
|
|
||||||
|
_Image credits: Miroslav Stampar, BleepingComputer & [Ana María Lora Macias][13]_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
作者简介:
|
||||||
|
|
||||||
|
Catalin covers various topics such as data breaches, software vulnerabilities, exploits, hacking news, the Dark Web, programming topics, social media, web technology, product launches, and a few more.
|
||||||
|
|
||||||
|
---------------
|
||||||
|
|
||||||
|
via: https://www.bleepingcomputer.com/news/security/new-smb-worm-uses-seven-nsa-hacking-tools-wannacry-used-just-two/
|
||||||
|
|
||||||
|
作者:[CATALIN CIMPANU ][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||||
|
[1]:https://twitter.com/stamparm
|
||||||
|
[2]:https://twitter.com/intent/tweet?in_reply_to=865494946974900224
|
||||||
|
[3]:https://twitter.com/intent/retweet?tweet_id=865494946974900224
|
||||||
|
[4]:https://twitter.com/intent/like?tweet_id=865494946974900224
|
||||||
|
[5]:https://twitter.com/stamparm/status/865494946974900224/photo/1
|
||||||
|
[6]:https://twitter.com/stamparm
|
||||||
|
[7]:https://twitter.com/hashtag/EternalRocks?src=hash
|
||||||
|
[8]:https://t.co/xqoxkNYfM7
|
||||||
|
[9]:https://twitter.com/stamparm/status/865494946974900224
|
||||||
|
[10]:https://twitter.com/stamparm/status/865494946974900224/photo/1
|
||||||
|
[11]:https://support.twitter.com/articles/20175256
|
||||||
|
[12]:https://www.bleepingcomputer.com/news/security/new-smb-worm-uses-seven-nsa-hacking-tools-wannacry-used-just-two/#comment_form
|
||||||
|
[13]:https://thenounproject.com/search/?q=worm&i=24323
|
||||||
|
[14]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||||
|
[15]:https://about.me/stamparm
|
||||||
|
[16]:https://www.bleepingcomputer.com/news/security/wana-decrypt0r-ransomware-using-nsa-exploit-leaked-by-shadow-brokers-is-on-a-rampage/
|
||||||
|
[17]:https://www.bleepingcomputer.com/news/security/shadow-brokers-release-new-files-revealing-windows-exploits-swift-attacks/
|
||||||
|
[18]:https://www.bleepingcomputer.com/news/security/over-36-000-computers-infected-with-nsas-doublepulsar-malware/
|
||||||
|
[19]:https://github.com/stamparm/EternalRocks/
|
||||||
|
[20]:https://www.bleepingcomputer.com/news/security/adylkuzz-cryptocurrency-miner-may-have-saved-you-from-the-wannacry-ransomware/
|
||||||
|
[21]:https://blogs.forcepoint.com/security-labs/wannacry-multiple-malware-families-using-eternalblue-exploit
|
||||||
|
[22]:https://www.cyphort.com/eternalblue-exploit-actively-used-deliver-remote-access-trojans/
|
||||||
|
[23]:http://blog.secdo.com/multiple-groups-exploiting-eternalblue-weeks-before-wannacry
|
||||||
@ -1,75 +0,0 @@
|
|||||||
5 个提升你项目贡献者基数的方法
|
|
||||||
============================================================
|
|
||||||

|
|
||||||
|
|
||||||
图片提供
|
|
||||||
|
|
||||||
opensource.com
|
|
||||||
|
|
||||||
许多自由和开源软件项目开始解决一个问题时,就有人们开始为它们贡献,因为他们也想修复他们遇到的问题。当项目的最终用户发现它对他们的需求有用,项目就开始增长。这种共同的目的和焦点吸引人们到同一个项目社区。
|
|
||||||
|
|
||||||
像任何事物都是有寿命的,增长即是标志也是项目成功的来源。那么项目领导者和维护者如何鼓励贡献者基数的增长?这里有五种方法。
|
|
||||||
|
|
||||||
### 1. 提供好的文档
|
|
||||||
|
|
||||||
人们经常低估项目[文档][2]的重要性。它是项目贡献者的主要信息来源,它会激励他们努力。信息必须是正确和最新的。它应该包括如何构建软件、如何提交补丁、编码风格指南等步骤。
|
|
||||||
|
|
||||||
查看经验丰富的科技作家、编辑 Bob Reselman 的[ 7 个创建世界级文档的规则][3]。
|
|
||||||
|
|
||||||
开发人员文档的一个很好的例子是[ Python 开发人员指南][4]。它包括清晰简洁的步骤,涵盖 Python 开发的各个方面。
|
|
||||||
|
|
||||||
### 2. 降低进入门槛
|
|
||||||
|
|
||||||
如果你的项目有[问题或 bug 追踪][5]工具,请确保将初级任务标记为一个“容易 bug ”或“起点”。新的贡献者可以很容易地通过解决这些问题进入项目。追踪器也是标记非编程任务(如平面设计、图稿和文档改进)的地方。有许多项目成员不是每天都编码,但是却通过这种方式成为推动力。
|
|
||||||
|
|
||||||
Fedora 项目维护一个这样的[易修复和入门级问题的追踪][6]工具。
|
|
||||||
|
|
||||||
### 3. 为补丁提供常规反馈
|
|
||||||
|
|
||||||
即使它是一行,也要确认每个补丁,并给作者反馈。提供反馈有助于吸引潜在的候选人,并指导他们熟悉项目。所有项目都应有一个邮件列表和[聊天功能][7]进行通信。问答可在这些媒介中发生。大多数项目不会在一夜之间成功,但那些繁荣的列表和沟通渠道为增长创造了环境。
|
|
||||||
|
|
||||||
### 4. 推广你的项目
|
|
||||||
|
|
||||||
开始解决问题的项目实际上可能对其他开发人员也有用。作为项目的主要贡献者,你的责任是写下你的的项目并推广它。写博客文章,并在社交媒体上分享项目的进展。你可以简要描述如何以项目的贡献者来开始,并在该描述中提供主要开发者文档的参考连接。此外,请务必提供有关路线图和未来版本的信息。
|
|
||||||
|
|
||||||
为了你的听众,获取由 Opensource.com 的社区经理 Rikki Endsley 写的[写作提示][8]。
|
|
||||||
|
|
||||||
### 5. 保持友好
|
|
||||||
|
|
||||||
友好的对话语调和迅速的回复将加强人们对你的项目的兴趣。最初,问题只是为了寻求帮助,但在未来,新的贡献者也可能会提出想法或建议。让他们有信心他们可以成为项目的贡献者。
|
|
||||||
|
|
||||||
记住你一直在被评估!人们会观察任何项目开发者如何在邮件列表或聊天上的交谈。这些意味着对新贡献者的欢迎和开放。当使用技术时,我们有时会忘记人们,但这对于任何项目的生态系统都很重要。考虑一个情况,项目是很好的,但项目维护者不是很受欢迎。该管理员可能会驱使用户远离项目。对于有大量用户基数的项目而言,不被支持的环境可能导致分裂,一部分用户可能决定复刻项目并启动新项目。在开源世界中有这样的成功例子。
|
|
||||||
|
|
||||||
另外,拥有背景不同的人对于开源项目的持续增长和源源不断的电子是很重要的。
|
|
||||||
|
|
||||||
最后,项目主人有责任维持和帮助项目成长。指导新的贡献者是项目的关键,他们将成为项目和社区未来的领导者。
|
|
||||||
|
|
||||||
阅读:由红帽的内容战略家 Nicole Engard 写的_[ 7 种方式让新的贡献者感到受欢迎][1] _。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Kushal Das - Kushal Das 是 Python 软件基金会的一名 CPython 核心开发人员和主管。他是一名长期的 FOSS 贡献者和导师,他帮助新人进入贡献世界。他目前在 Red Hat 担任 Fedora 云工程师。他的博客在 https://kushaldas.in。你也可以在 Twitter @kushaldas 上找到他
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/1/expand-project-contributor-base
|
|
||||||
|
|
||||||
作者:[Kushal Das][a]
|
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
|
||||||
校对:[Bestony](https://github.com/bestony)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/kushaldas
|
|
||||||
[1]:https://opensource.com/life/16/5/sumana-harihareswara-maria-naggaga-oscon
|
|
||||||
[2]:https://opensource.com/tags/documentation
|
|
||||||
[3]:https://opensource.com/business/16/1/scale-14x-interview-bob-reselman
|
|
||||||
[4]:https://docs.python.org/devguide/
|
|
||||||
[5]:https://opensource.com/tags/bugs-and-issues
|
|
||||||
[6]:https://fedoraproject.org/easyfix/
|
|
||||||
[7]:https://opensource.com/alternatives/slack
|
|
||||||
[8]:https://opensource.com/business/15/10/what-stephen-king-can-teach-tech-writers
|
|
||||||
@ -1,17 +1,19 @@
|
|||||||
|
Android 在物联网方面能否像在移动终端一样成功?
|
||||||
安卓IoT能否像在移动终端一样成功?
|
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||

|

|
||||||
Android Things让IoT如虎添翼
|
|
||||||
|
|
||||||
###我在Android Things上的最初24小时
|
*Android Things 让 IoT 如虎添翼*
|
||||||
正当我在开发一个基于Android的运行在树莓派3的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things] [1]的第一个预览版本,他们的SDK专门针对(最初)3个SBC(单板计算机) - 树莓派 3,英特尔Edison和恩智浦Pico。说我一直在挣扎似乎有些轻描淡写 - 没有成功的移植树莓派安卓可以参照,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连[Element14][2]官方销售的也不支持。曾经我认为安卓已经支持树莓派,更早时候[commi tto AOSP project from Google][3]提到过Pi曾让所有人兴奋不已。所以当2016年12月12日谷歌发布"Android Things"和其SDK的时候,我马上闭门谢客,全身心地去研究了……
|
|
||||||
|
### 我 在Android Things 上的最初 24 小时
|
||||||
|
|
||||||
|
正当我在开发一个基于 Android 的运行在树莓派 3 的物联网商业项目时,一些令人惊喜的事情发生了。谷歌发布了[Android Things][1] 的第一个预览版本,他们的 SDK 专门(目前)针对 3 个 SBC(单板计算机) - 树莓派 3、英特尔 Edison 和恩智浦 Pico。说我一直在挣扎似乎有些轻描淡写 - 没有成功的移植树莓派 Android 可以参照,我们在理想丰满,但是实践漏洞百出的内测版本上叫苦不迭。其中一个问题,同时也是不可原谅的问题是,它不支持触摸屏,甚至连 [Element14][2] 官方销售的也不支持。曾经我认为 Android 已经支持树莓派,更早时候 [commi tto AOSP project from Google][3] 提到过树莓派曾让所有人兴奋不已。所以当 2016 年 12 月 12 日谷歌发布 “Android Things” 和其 SDK 的时候,我马上闭门谢客,全身心地去研究了……
|
||||||
|
|
||||||
### 问题?
|
### 问题?
|
||||||
安卓扩展的工作和Pi上做过的一些项目,包括之前提到的,当前正在开发中的Pi项目,使我对谷歌安卓产生了许多问题。未来我会尝试解决它们,但是最重要的问题可以马上解答 - 有完整的Android Studio支持,Pi成为列表上的另一个常规的ADB可寻址设备。好极了。Android Atudio强大的,便利的,纯粹的易用的功能包括布局预览,调试系统,源码检查器,自动化测试等可以真正的应用在IoT硬件上。这些好处怎么说都不过分。到目前为止,我在Pi上的大部分工作都是在python中使用SSH运行在Pi上的编辑器(MC,如果你真的想知道)。这是有效的,毫无疑问硬核Pi / Python头可以指出更好的工作方式,而不是当前这种像极了80年代码农的软件开发模式。我的项目涉及到在控制Pi的手机上编写Android软件,这有点像在伤口狂妄地撒盐 - 我使用Android Studio做“真正的”Android工作,用SSH做剩下的。但是有了"Android Things"之后,一切都结束了。
|
|
||||||
|
|
||||||
所有的示例代码都适用于3个SBC,Pi 只是其中之一。 Build.DEVICE常量在运行时确定,所以你会看到很多如下代码:
|
关于树莓派上的谷歌 Android 我遇到很多问题,我以前用 Android 做过许多开发,也做过一些树莓派项目,包括之前提到过的一个真正参与的。未来我会尝试解决它们,但是首先最重要的问题得到了解决 - 有完整的 Android Studio 支持,树莓派成为你手里的另一个常规的 ADB 可寻址设备。好极了。Android Studio 强大而便利、十分易用的功能包括布局预览、调试系统、源码检查器、自动化测试等都可以真正的应用在 IoT 硬件上。这些好处怎么说都不过分。到目前为止,我在树莓派上的大部分工作都是通过 SSH 使用运行在树莓派上的编辑器(MC,如果你真的想知道)借助 Python 完成的。这是有效的,毫无疑问铁杆的 Pi/Python 粉丝或许会有更好的工作方式,而不是当前这种像极了 80 年代码农的软件开发模式。我的项目需要在控制树莓派的手机上编写 Android 软件,这真有点痛不欲生 - 我使用 Android Studio 做“真正的” Android 开发,借助 SSH 做剩下的。但是有了“Android Things”之后,一切都结束了。
|
||||||
|
|
||||||
|
所有的示例代码都适用于这三种 SBC,树莓派只是其中之一。 `Build.DEVICE` 常量可以在运行时确定是哪一个,所以你会看到很多如下代码:
|
||||||
|
|
||||||
```
|
```
|
||||||
public static String getGPIOForButton() {
|
public static String getGPIOForButton() {
|
||||||
@ -30,7 +32,7 @@ Android Things让IoT如虎添翼
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
我对GPIO处理有浓厚的兴趣。 由于我只熟悉Pi,我只能假定其他SBC工作方式相同,GPIO只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于Pi Linux的操作系统发行版通过Python中的读取和写入方法提供了完整和便捷的支持,但对于Android,您必须使用NDK编写C ++驱动程序,并通过JNI在Java中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 Pi还为I2C指定了2个引脚,时钟和数据,因此需要额外的工作来处理它们。 I2C是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 - Android Things已经帮你完成了所有这一切。 你只需要_read()_和_write()_to /from你需要的任何GPIO引脚,I2C同样容易:
|
我对 GPIO 处理有浓厚的兴趣。 由于我只熟悉树莓派,我只能假定其他 SBC 工作方式相同,GPIO 只是一组引脚,可以定义为输入/输出,是连接物理外部世界的主要接口。 基于 Linux 的树莓派操作系统通过 Python 中的读取和写入方法提供了完整和便捷的支持,但对于 Android,您必须使用 NDK 编写 C++ 驱动程序,并通过 JNI 在 Java 中与这些驱动程序对接。 不是那么困难,但需要在你的构建链中维护额外的一些东西。 树莓派还为 I2C 指定了 2 个引脚:时钟和数据,因此需要额外的工作来处理它们。I2C 是真正酷的总线寻址系统,它通过串行化将许多独立的数据引脚转换成一个。 所以这里的优势是 - Android Things 已经帮你完成了所有这一切。 你只需要 `read()` 和 `write() ` 你需要的任何 GPIO 引脚,I2C 同样容易:
|
||||||
|
|
||||||
```
|
```
|
||||||
public class HomeActivity extends Activity {
|
public class HomeActivity extends Activity {
|
||||||
@ -68,46 +70,52 @@ public class HomeActivity extends Activity {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
### Android Things基于Android的哪个版本?
|
|
||||||
看起来是Android 7.0,这样很好,因为我们可以继承Android以前的所有版本的文档,优化,安全加固等。它也提出了一个有趣的问题 - 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不在蜂窝/ WiFi连接的舒适空间,虽然之前这些连接至少可用,即使有时不那么可靠。
|
|
||||||
|
|
||||||
另一个担心是,Android Things仅仅是一个名字不同的分支版本的Android,如何选择它们的共同特性,就像启动Arduino(已经发布的一个更像市场营销而不是操作系统的操作系统)这种简单特性。实际上,通过查看[samples] [4],一些功能可能永不再用 - 比如一个最近的Android创新,甚至使用SVG图形作为资源,而不是传统的基于位图的图形,当然Andorid Things也可以轻松处理。
|
### Android Things 基于 Android 的哪个版本?
|
||||||
|
|
||||||
不可避免地,与Android Things相比,普通的Android会抛出问题。例如,权限问题。因为Android Things为固定硬件设计,用户通常不会在这种设备上安装App,所以在一定程序上减轻了这个问题。另外,在没有图形界面的设备上请求权限通常不是问题,我们可以在安装时开放所有权限给App。 通常,这些设备只有一个应用程序,该应用程序从设备上电的那一刻就开始运行。
|
看起来是 Android 7.0,这样很好,因为我们可以继承 Android 所有以前版本的平板设计 UI、优化,安全加固等。它也带来了一个有趣的问题 - 与应用程序必须单独管理不同,未来的平台应如何更新升级?请记住,这些设备可能无法连接到互联网。我们可能不便于连接蜂窝/ WiFi ,即便之前这些连接能用,但是有时不那么可靠。
|
||||||
|
|
||||||

|
另一个担心是,Android Things 仅仅是一个名字不同的 Android 分支版本,大部分都是一样的,和已经发布的 Arduino 一样,更像为了市场营销而出现,而不是作为操作系统。不过可以放心,实际上通过[样例][4]可以看到,其中一些样例甚至使用了 SVG 图形作为资源,而不是传统的基于位图的图形(当然也能轻松处理) ——这是一个非常新的 Android 创新。
|
||||||
|
|
||||||
### Brillo怎么了?
|
不可避免地,与 Android Things 相比,普通的 Android 会有些不同。例如,权限问题。因为 Android Things 为固定硬件设计,在构建好之后,用户通常不会在这种设备上安装应用,所以在一定程序上减轻了这个问题,尽管当设备要求权限时是个问题——因为它们没有 UI。解决方案是当应用在安装时给予所有需要的权限。 通常,这些设备只有一个应用,并且该应用从设备上电的那一刻就开始运行。
|
||||||
|
|
||||||
Brillo是谷歌以前的IoT操作系统的代号,听起来很像Android的前身。 实际上现在你仍然能看到很多Brillo引用,特别是在GitHub Android Things源码的例子中。 然而,它已经不复存在了。新王已经登基!
|

|
||||||
|
|
||||||
### UI指南?
|
### Brillo 怎么了?
|
||||||
Google针对Android智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有- 应用程序作者决定一切。 这包括顶部状态栏,底部导航栏 - 绝对一切。 多年来谷歌一直叮咛Android应用程序作者不要去渲染屏幕上的返回按钮,因为平台将提供一个抛出异常,因为对于Android Things,[可能甚至不是一个UI!] [5]
|
|
||||||
|
|
||||||
### 多少智能手机上的服务可以期待?
|
Brillo 是谷歌以前的 IoT 操作系统的代号,听起来很像 Android Things 的前身。 实际上现在你仍然能看到很多提及 Brillo 的地方,特别是在 GitHub Android Things 源码的文件夹名字中。 然而,它已经不复存在了。新王已经登基!
|
||||||
有些,但不是所有。第一个预览版本没有蓝牙支持。没有NFC,两者都对物联网革命有重大贡献。 SBC支持他们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个。由于没有Play商店,你只能屈尊通过 ADB做这个和许多其他操作。
|
|
||||||
|
|
||||||
当开发Android Things时我试图和Pi使用同一个APK。这引发了一个错误,阻止它安装在除Android Things设备之外的任何设备:库“_com.google.android.things_”不存在。 Kinda有意义,因为只有Android Things设备需要这个,但它似乎是有限的,因为不仅智能手机或平板电脑不会出现,任何模拟器也不会。似乎只能在物理Android Things设备上运行和测试您的Android Things应用程序...直到Google在[G + Google的IoT开发人员社区] [6]组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五 。
|
### UI 指南?
|
||||||
|
|
||||||
### 让我如何期待Android Thing生态演进?
|
谷歌针对 Android 智能手机和平板电脑应用发布了大量指南,例如屏幕按钮间距等。 当然,你最好在可行的情况下遵循这些,但这已经不是本文应该考虑的范畴了。 缺省情况下什么也没有 - 应用程序作者决定一切,这包括顶部状态栏,底部导航栏 - 绝对是一切。 多年来谷歌一直在告诉 Android 应用程序的作者们绝不要在屏幕上放置返回按钮,因为平台将提供一个,因为 Android Things [可能甚至没有 UI!] [5]
|
||||||
|
|
||||||
我期望看到移植更多传统的基于Linux服务器的应用程序,这对Android只有智能手机和平板电脑没有意义。例如,Web服务器突然变得非常有用。一些已经存在,但没有像重量级的Apache,或Nginx。物联网设备可能没有本地UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现Web面板。类似的那些如雷贯耳的通讯应用程序 - 它需要的仅是一个麦克风和扬声器,在理论上对任何视频通话应用程序,如Duo,Skype,FB等都可行。这个演变能走多远目前只能猜测。会有Play商店吗?他们会展示广告吗?我们可以确定他们不会窥探我们,或让黑客控制他们?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
|
### 智能手机上会有多少谷歌服务?
|
||||||
|
|
||||||
我还期望看到硬件的迅速发展 - 特别是更多的SBC并且拥有更低的成本。看看惊人的5美元 树莓派0,不幸的是,由于其有限的CPU和RAM,几乎肯定不能运行Android Things。多久之后像这样的设备才能运行Android Things?这是很明显的,标杆已经设定,任何自重的SBC制造商将瞄准Android Things的兼容性,规模经济也将波及到外围设备,如23美元的触摸屏。没人购买不会播放YouTube的微波炉,你的洗碗机会在eBay上购买更多的粉末商品,因为它注意到你很少使用它……
|
有一些,但不是所有。第一个预览版本没有蓝牙支持、没有NFC,这两者都对物联网革命有重大贡献。 SBC 支持它们,所以我们应该不会等待太久。由于没有通知栏,因此不支持任何通知。没有地图。缺省没有软键盘,你必须自己安装一个键盘。由于没有 Play 商店,你只能难受地通过 ADB 做这个和许多其他操作。
|
||||||
|
|
||||||
然而,我不认为我们会失去掌控力。了解一点Android架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用Java,并几乎被其所有的垃圾回收机制导致的时序问题锤击致死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测,准确和坚如磐石的时序,或者它不能被描述为“mission critical”。想想医疗应用程序,安全监视器,工业控制器等。使用Android,如果主机操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。在手机上不是那么糟糕 - 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。心脏监视器完全是另一码事。如果前台Activity / Service正在监视一个GPIO引脚,并且信号没有被准确地处理,我们已经失败了。必须要做一些相当根本的改变让Android来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
|
当为 Android Things 开发时,我试图为运行在手机上和树莓派上使用同一个 APK。这引发了一个错误,阻止它安装在除 Android Things 设备之外的任何设备:库 `com.google.android.things` 不存在。 这有点用,因为只有 Android Things 设备需要这个,但它似乎是个限制,因为不仅智能手机或平板电脑上没有,连模拟器上也没有。似乎只能在物理 Android Things 设备上运行和测试您的 Android Things 应用程序……直到谷歌在 [G+ 谷歌的 IoT 开发人员社区][6]组中回答了我的问题,并提供了规避方案。但是,躲过初一,躲不过十五。
|
||||||
|
|
||||||
###这24小时
|
### 可以期待 Android Thing 生态演进到什么程度?
|
||||||
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向G+社区寻求帮助。 除了一些在非Android Things上如何运行程序 的问题之外 ,没有其他问题。 它运行得很好! 这个项目也使用了一些奇怪的东西,自定义字体,高精定时器 - 所有这些都在Android Studio中完美地展现。对我而言,可以打满分 - 最后我可以开始给出实际原型,而不只是视频和截图。
|
|
||||||
|
我期望看到移植更多传统的基于 Linux 服务器的应用程序,将 Android 限制在智能手机和平板电脑上没有意义。例如,Web 服务器突然变得非常有用。已经有一些了,但没有像重量级的 Apache 或 Nginx。物联网设备可以没有本地 UI,但通过浏览器管理它们当然是可行的,因此需要用这种方式呈现 Web 面板。类似的那些如雷贯耳的通讯应用程序 - 它需要的仅是一个麦克风和扬声器,而且在理论上任何视频通话应用程序,如 Duo、Skype、FB 等都可行。这个演变能走多远目前只能猜测。会有 Play 商店吗?它们会展示广告吗?我们能够确保它们不会窥探我们,或被黑客控制它们么?从消费者的角度来看,物联网应该是具有触摸屏的网络连接设备,因为每个人都已经习惯于通过智能手机工作。
|
||||||
|
|
||||||
|
我还期望看到硬件的迅速发展 - 特别是有更多的 SBC 拥有更低的成本。看看惊人的 5 美元 树莓派 Zero,不幸的是,由于其有限的 CPU 和内存,几乎可以肯定不能运行 Android Things。多久之后像这样的设备才能运行 Android Things?这是很明显的,标杆已经设定,任何有追求的 SBC 制造商将瞄准 Android Things 的兼容性,规模经济也将波及到外围设备,如 23 美元的触摸屏。没人会购买不会播放 YouTube 的微波炉,你的洗碗机会在 eBay 上购买更多的清洁粉,因为它注意到你很少使用它……
|
||||||
|
|
||||||
|
然而,我不认为我们会过于冲昏头脑。了解一点 Android 架构有助于将其视为一个包罗万象的物联网操作系统。它仍然使用 Java,其垃圾回收机制导致的所有时序问题在过去几乎把它搞死。这仅仅是问题最少的部分。真正的实时操作系统依赖于可预测、准确和坚如磐石的时序,或者它不能被用于“关键任务”。想想医疗应用、安全监视器,工业控制器等。使用 Android,如果宿主操作系统认为它需要,理论上可以在任何时候杀死您的活动/服务。这在手机上没那么糟糕 - 用户可以重新启动应用程序,杀死其他应用程序,或重新启动手机。但心脏监视器就完全是另一码事。如果前台的活动/服务正在监视一个 GPIO 引脚,而这个信号没有被准确地处理,我们就完了。必须要做一些相当根本的改变让 Android 来支持这一点,到目前为止还没有迹象表明它已经在计划之中了。
|
||||||
|
|
||||||
|
###这 24 小时
|
||||||
|
|
||||||
|
所以,回到我的项目。 我认为我会接管我已经完成和尽力能为的工作,等待不可避免的路障,并向 G+ 社区寻求帮助。 除了一些在非 Android Things 设备上如何运行程序的问题之外,没有其他问题。 它运行得很好! 这个项目也使用了一些奇怪的东西,如自定义字体、高精定时器 - 所有这些都在 Android Studio 中完美地展现。对我而言,可以打满分 - 至少我能够开始做出实际原型,而不只是视频和截图。
|
||||||
|
|
||||||
### 蓝图
|
### 蓝图
|
||||||
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌Android物联网能否像它在移动端那样,现在Android在那里的主导地位非常接近90%? 我相信果真如此,Android Things的推出正是重要的一步。
|
|
||||||
|
|
||||||
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间? 那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代iPhone一样遥不可及。
|
今天的物联网操作系统环境看起来非常零碎。 显然没有市场领导者,尽管炒作之声沸反连天,物联网仍然在草创阶段。 谷歌 Android 物联网能否像它在移动端那样取得成功?现在 Android 在移动方面的主导地位非常接近 90%。我相信如果真的如此,Android Things 的推出正是重要的一步。
|
||||||
|
|
||||||
|
记住所有的关于开放和封闭软件的战争,它们主要发生在从不授权的苹果和一直担心免费还不够充分的谷歌之间。那个老梗又来了,因为让苹果推出一个免费的物联网操作系统的构想就像让他们免费赠送下一代 iPhone 一样遥不可及。
|
||||||
|
|
||||||
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
|
物联网操作系统游戏是开放的,大家机遇共享,不过这个时候,封闭派甚至不会公布它们的开发工具箱……
|
||||||
|
|
||||||
转到[Developer Preview] [7]网站,立即获取Android Things SDK的副本。
|
转到 [Developer Preview][7]网站,立即获取 Android Things SDK 的副本。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -115,7 +123,7 @@ via: https://medium.com/@carl.whalley/will-android-do-for-iot-what-it-did-for-mo
|
|||||||
|
|
||||||
作者:[Carl Whalley][a]
|
作者:[Carl Whalley][a]
|
||||||
译者:[firstadream](https://github.com/firstadream)
|
译者:[firstadream](https://github.com/firstadream)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
@ -1,43 +1,41 @@
|
|||||||
为何我们需要一个开放模型来设计评估公共政策
|
为何我们需要一个开放模型来设计评估公共政策
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
### 想象一个 app 可以让市民测试驱动提出的政策。
|
> 想象一个 app 可以让市民来试车提出的政策。
|
||||||
|
|
||||||
[up][3]
|

|
||||||

|
|
||||||
图片提供:
|
|
||||||
|
|
||||||
opensource.com
|
图片提供:opensource.com
|
||||||
|
|
||||||
在政治选举之前的几个月中,公众辩论会加剧,并且公民面临大量的政策选择信息。在数据驱动的社会中,新的见解一直在为决策提供信息,对这些信息的深入了解从未如此重要,但公众仍然没有意识到公共政策建模的全部潜力。
|
在政治选举之前的几个月中,公众辩论会加剧,并且公民面临大量的各种政策选择的信息。在数据驱动的社会中,新的见解一直在为决策提供信息,对这些信息的深入了解从未如此重要,但公众仍然没有意识到为公共政策建模的全部潜力。
|
||||||
|
|
||||||
在“开放政府”的概念不断演变以跟上新技术进步的时代,政府的政策模型和分析可能是新一代的开放知识。
|
在“<ruby>开放政府<rt>open government</rt></ruby>”的概念不断演变以跟上新技术进步的时代,政府的政策模型和分析可能是新一代的开放知识。
|
||||||
|
|
||||||
政府开源模型 (GOSM) 是指政府开发的模型,其目的是设计和评估政策,免费提供给所有人使用、分发、不受限制地修改。社区可以提高政策建模的质量、可靠性和准确性,创造有利于公众的新的数据驱动程序。
|
政府开源模型 (GOSM) 是指政府开发的模型,其目的是设计和评估政策,免费提供给所有人使用、分发、不受限制地修改。社区可以提高政策建模的质量、可靠性和准确性,创造有利于公众的新的数据驱动程序。
|
||||||
|
|
||||||
今天的这代与技术相互作用,就像它的第二大本质,它默认吸收了大量的信息。如果我们可以在使用 GOSM 的虚拟、沉浸式环境中与不同的公共政策进行互动那会如何?
|
今天的这一代人与技术相互作用,这俨然成为了它的第二种本质,自然而然地吸收了大量的信息。如果我们可以在使用 GOSM 在虚拟、沉浸式环境中与不同的公共政策进行互动那会如何?
|
||||||
|
|
||||||
想象一下有一个允许公民测试推动政策来确定他们想要生活的未来的程序。他们会本能地学习关键的驱动因素和所需要的东西。不久之后,公众将更深入地了解公共政策的影响,并更加精明地引导有争议的公众辩论。
|
想象一下如果有一个程序,允许公民试车提出的政策来确定他们想要生活的未来。他们会本能地学习关键的驱动因素和所需要的东西。不久之后,公众将更深入地了解公共政策的影响,并更加精明地引导有争议性的公众辩论。
|
||||||
|
|
||||||
为什么我们以前没有更好的使用这些模型?原因在于公共政策建模的神秘面纱。
|
为什么我们以前没有更好的使用这些模型?原因在于公共政策建模的神秘面纱。
|
||||||
|
|
||||||
在一个如我们所生活的复杂的社会中,量化政策影响是一项艰巨的任务,并被被描述为一种“美好艺术”。此外,大多数政府政策模型都是基于行政和其他私人持有的数据。然而,政策分析师为了指导政策设计而勇于追求,多次以大量武力而获得政治斗争。
|
在一个如我们所生活的复杂的社会中,量化政策影响是一项艰巨的任务,并被被描述为一种“美好艺术”。此外,大多数政府政策模型都是基于行政和其他私人持有的数据。然而,政策分析师为了指导政策设计而勇于追求,多次以大量武力而赢得政治斗争的胜利。
|
||||||
|
|
||||||
数字是很有说服力的。它们构建可信度并常常被用作引入新政策的理由。公共政策模型的发展赋予政治家和官僚权力,这些政治家和官僚们可能不愿意破坏现状。给予这一点可能并不容易,但 GOSM 为前所未有的公共政策改革提供了机会。
|
数字是很有说服力的。它们构建可信度,并常常被用作引入新政策的理由。公共政策模型的发展赋予政治家和官僚权力,这些政治家和官僚们可能不愿意破坏现状。给予这一点可能并不容易,但 GOSM 为前所未有的公共政策改革提供了机会。
|
||||||
|
|
||||||
GOSM 将所有人的竞争环境均衡化:政治家、媒体、游说团体、利益相关者和公众。通过向社区开放政策评估的大门, 政府可以利用新的和未发现的能力用来创造、创新在公共领域的效率。但在公共政策设计中,利益相关者和政府之间战略互动有哪些实际影响?
|
GOSM 将所有人的竞争环境均衡化:政治家、媒体、游说团体、利益相关者和公众。通过向社区开放政策评估的大门, 政府可以在公共领域为创造、创新和效率引入新的和未发现的能力。但在公共政策设计中,利益相关者和政府之间战略互动有哪些实际影响?
|
||||||
|
|
||||||
GOSM 是独一无二的,因为它们主要是设计公共政策的工具,而不一定需要重新分配私人收益。利益相关者和游说团体可能会将 GOSM 与其私人信息一起使用,以获得对经济参与者私人利益的政策环境运作的新见解。
|
GOSM 是独一无二的,因为它们主要是设计公共政策的工具,而不一定需要重新分配私人收益。利益相关者和游说团体可能会将 GOSM 与其私人信息一起使用,以获得对经济参与者私人利益的政策环境运作的新见解。
|
||||||
|
|
||||||
GOSM 可以成为利益相关者在公共辩论中保持权力平衡的武器,并为战略争取最佳利益么?
|
GOSM 可以成为利益相关者在公共辩论中保持权力平衡的武器,并为战略争取最佳利益么?
|
||||||
|
|
||||||
作为一个可变的公共资源,GOSM 在概念上由纳税人资助,并属于国家。私有实体在不向社会带来利益的情况下从 GOSM 中获得资源是合乎道德的吗?与可能用于更有效的服务提供的程序不同,替代政策建议更有可能由咨询机构使用,并有助于公众辩论。
|
作为一个可变的公共资源,GOSM 在概念上由纳税人资助,并属于国家。私有实体在不向社会带来利益的情况下从 GOSM 中获得资源是合乎道德的吗?与可能用于更有效的服务提供的那些程序不同,替代政策建议更有可能由咨询机构使用,并有助于公众辩论。
|
||||||
|
|
||||||
开源社区经常使用“ copyleft 许可证” 来确保代码和根据此许可证的任何衍生作品对所有人都开放。当产品价值是代码本身,这需要重新分配才能获得最大利益,它需要重新分发来获得最大的利益。但是,如果代码或 GOSM 重新分发是主要产品附带的,那它会是对现有政策环境的新战略洞察么?
|
开源社区经常使用 “copyleft 许可证” 来确保代码和在此许可证下的任何衍生作品对所有人都开放。当产品价值是代码本身,这需要重新分配才能获得最大利益,它需要重新分发来获得最大的利益。但是,如果代码或 GOSM 重新分发是主要产品附带的,那它会是对现有政策环境的新战略洞察么?
|
||||||
|
|
||||||
在私人收集的数据变得越来越多的时候,GOSM 背后的真正价值可能是底层数据,它可以用来改进模型本身。最终,政府是唯一有权实施政策的消费者,利益相关者可以选择在谈判中分享修改后的 GOSM。
|
在私人收集的数据变得越来越多的时候,GOSM 背后的真正价值可能是底层数据,它可以用来改进模型本身。最终,政府是唯一有权实施政策的消费者,利益相关者可以选择在谈判中分享修改后的 GOSM。
|
||||||
|
|
||||||
政府在公开发布政策模型时面临的巨大挑战是提高透明度的同时保护隐私。理想情况下,发布 GOSM 将需要以保护建模关键特征的方式保护封闭数据。
|
政府在公开发布政策模型时面临的巨大挑战是提高透明度的同时保护隐私。理想情况下,发布 GOSM 将需要以保护建模关键特征的方式保护封闭的数据。
|
||||||
|
|
||||||
公开发布 GOSM 通过促进市民对民主的更多了解和参与,使公民获得权力,从而改善政策成果和提高公众满意度。在开放的政府乌托邦中,开放的公共政策发展将是政府和社区之间的合作性努力,这里知识、数据和分析可供大家免费使用。
|
公开发布 GOSM 通过促进市民对民主的更多了解和参与,使公民获得权力,从而改善政策成果和提高公众满意度。在开放的政府乌托邦中,开放的公共政策发展将是政府和社区之间的合作性努力,这里知识、数据和分析可供大家免费使用。
|
||||||
|
|
||||||
@ -57,9 +55,9 @@ Audrey Lobo-Pulo - Audrey Lobo-Pulo 博士是 Phoensight 的联合创始人,
|
|||||||
|
|
||||||
via: https://opensource.com/article/17/1/government-open-source-models
|
via: https://opensource.com/article/17/1/government-open-source-models
|
||||||
|
|
||||||
作者:[Audrey Lobo-Pulo ][a]
|
作者:[Audrey Lobo-Pulo][a]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
328
translated/tech/20170308 Our guide to a Golang logs world.md
Normal file
328
translated/tech/20170308 Our guide to a Golang logs world.md
Normal file
@ -0,0 +1,328 @@
|
|||||||
|
Go 日志指南
|
||||||
|
============================================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你是否厌烦了那些使用复杂语言编写、难以部署、总是在构建的解决方案?Golang 是解决这些问题的好方法,它和 C 语言一样快,又和 Python 一样简单。
|
||||||
|
|
||||||
|
但是你如何使用 Golang 日志监控你的应用程序呢?Golang 没有异常,只有错误。因此你的第一印象可能就是开发 Golang 日志策略并不是一件简单的事情。不支持异常事实上并不是什么问题,异常在很多编程语言中已经失去了特殊用处:它们过于被滥用以至于它们的作用都被忽视了。
|
||||||
|
|
||||||
|
在进一步深入之前,我们首先会介绍 Golang 日志基础并讨论 Golang 日志标准、元数据意义、以及最小化 Golang 日志对性能的影响。通过日志,你可以追踪用户在你应用中的活动,快速识别你项目中失效的组件,并监控总的性能以及用户体验。
|
||||||
|
|
||||||
|
### I. Golang 日志基础
|
||||||
|
|
||||||
|
### 1) 使用 Golang "log" 库
|
||||||
|
|
||||||
|
Golang 给你提供了一个称为 “log” 的原生[日志库][3] 。它的日志器完美适用于追踪简单的活动,例如通过使用可用的[选项][4]在错误信息之前添加一个时间戳。
|
||||||
|
|
||||||
|
下面是一个 Golang 中如何记录错误日志的简单例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"log"
|
||||||
|
"errors"
|
||||||
|
"fmt"
|
||||||
|
)
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
/* 定义局部变量 */
|
||||||
|
...
|
||||||
|
|
||||||
|
/* 除法函数,除以 0 的时候会返回错误 */
|
||||||
|
ret,err = div(a, b)
|
||||||
|
if err != nil {
|
||||||
|
log.Fatal(err)
|
||||||
|
}
|
||||||
|
fmt.Println(ret)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你尝试除以0,你就会得到类似下面的结果:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
为了快速测试一个 Golang 函数,你可以使用 [go playground][5]。
|
||||||
|
|
||||||
|
为了确保你的日志总是能轻易访问,我们建议你把它们写到一个文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
import (
|
||||||
|
"log"
|
||||||
|
"os"
|
||||||
|
)
|
||||||
|
func main() {
|
||||||
|
// 按照所需读写权限创建文件
|
||||||
|
f, err := os.OpenFile("filename", os.O_WRONLY|os.O_CREATE|os.O_APPEND, 0644)
|
||||||
|
if err != nil {
|
||||||
|
log.Fatal(err)
|
||||||
|
}
|
||||||
|
// 完成后延迟关闭,而不是你认为这是惯用的!
|
||||||
|
defer f.Close()
|
||||||
|
//设置日志输出到 f
|
||||||
|
log.SetOutput(f)
|
||||||
|
//测试例
|
||||||
|
log.Println("check to make sure it works")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以在[这里][6]找到 Golang 日志的完整指南,以及 “log” [库][7]内可用函数的完整列表。
|
||||||
|
|
||||||
|
现在你就可以记录它们的错误以及根本原因啦。
|
||||||
|
|
||||||
|
另外,日志也可以帮你将活动流拼接在一起,查找需要修复的错误上下文,或者调查在你的系统中单个请求如何影响其它应用层和 API。
|
||||||
|
为了获得更好的日志效果,你首先需要在你的项目中使用尽可能多的上下文丰富你的 Golang 日志,并标准化你使用的格式。这就是 Golang 原生库能达到的极限。使用最广泛的库是 [glog][8] 和 [logrus][9]。必须承认还有很多好的库可以使用。如果你已经在使用支持 JSON 格式的库,你就不需要再换其它库了,后面我们会解释。
|
||||||
|
|
||||||
|
### II. 你 Golang 日志的统一格式
|
||||||
|
|
||||||
|
### 1) JSON 格式的结构优势
|
||||||
|
|
||||||
|
在一个项目或者多个微服务中结构化你的 Golang 日志可能是最困难的事情,但一旦完成,它看起来就微不足道了。结构化你的日志能使机器可读(参考我们 [收集日志的最佳实践博文][10])。灵活性和层级是 JSON 格式的核心,因此信息能够轻易被人类和机器解析以及处理。
|
||||||
|
|
||||||
|
下面是一个使用 [Logrus/Logmatic.io][11] 如何用 JSON 格式记录日志的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
import (
|
||||||
|
log "github.com/Sirupsen/logrus"
|
||||||
|
"github.com/logmatic/logmatic-go"
|
||||||
|
)
|
||||||
|
func main() {
|
||||||
|
// 使用 JSONFormatter
|
||||||
|
log.SetFormatter(&logmatic.JSONFormatter{})
|
||||||
|
// 使用 logrus 像往常那样记录事件
|
||||||
|
log.WithFields(log.Fields{"string": "foo", "int": 1, "float": 1.1 }).Info("My first ssl event from golang")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
会输出结果:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"date":"2016-05-09T10:56:00+02:00",
|
||||||
|
"float":1.1,
|
||||||
|
"int":1,
|
||||||
|
"level":"info",
|
||||||
|
"message":"My first ssl event from golang",
|
||||||
|
"String":"foo"
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 2) 标准化 Golang 日志
|
||||||
|
|
||||||
|
出现在你代码不同部分的同一个错误以不同形式被记录下来是一件可耻的事情。下面是一个由于一个变量错误导致无法确定 web 页面加载状态的例子。一个开发者日志格式是:
|
||||||
|
|
||||||
|
```
|
||||||
|
message: 'unknown error: cannot determine loading status from unknown error: missing or invalid arg value client'</span>
|
||||||
|
```
|
||||||
|
|
||||||
|
另一个人的格式却是:
|
||||||
|
|
||||||
|
```
|
||||||
|
unknown error: cannot determine loading status - invalid client</span>
|
||||||
|
```
|
||||||
|
|
||||||
|
强制日志标准化的一个好的解决办法是在你的代码和日志库之间创建一个接口。这个标准化接口会包括所有你想添加到你日志中的可能行为的预定义日志消息。这么做可以防止不符合你想要的标准格式的自定义日志信息。这么做也便于日志调查。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
由于日志格式都被统一处理,使它们保持更新也变得更加简单。如果出现了一种新的错误类型,它只需要被添加到一个接口,这样每个组员都会使用完全相同的信息。
|
||||||
|
|
||||||
|
最长使用的简单例子就是在 Golang 日志信息前面添加日志器名称和 id。你的代码然后就会发送 “事件” 到你的标准化接口,它会继续讲它们转化为 Golang 日志消息。
|
||||||
|
|
||||||
|
```
|
||||||
|
// 主要部分,我们会在这里定义所有消息。
|
||||||
|
// Event 结构体很简单。为了当所有信息都被记录时能检索它们,
|
||||||
|
// 我们维护了一个 Id
|
||||||
|
var (
|
||||||
|
invalidArgMessage = Event{1, "Invalid arg: %s"}
|
||||||
|
invalidArgValueMessage = Event{2, "Invalid arg value: %s => %v"}
|
||||||
|
missingArgMessage = Event{3, "Missing arg: %s"}
|
||||||
|
)
|
||||||
|
|
||||||
|
// 在我们应用程序中可以使用的所有日志事件
|
||||||
|
func (l *Logger)InvalidArg(name string) {
|
||||||
|
l.entry.Errorf(invalidArgMessage.toString(), name)
|
||||||
|
}
|
||||||
|
func (l *Logger)InvalidArgValue(name string, value interface{}) {
|
||||||
|
l.entry.WithField("arg." + name, value).Errorf(invalidArgValueMessage.toString(), name, value)
|
||||||
|
}
|
||||||
|
func (l *Logger)MissingArg(name string) {
|
||||||
|
l.entry.Errorf(missingArgMessage.toString(), name)
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
因此如果我们使用前面例子中无效的参数值,我们就会得到相似的日志信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
time="2017-02-24T23:12:31+01:00" level=error msg="LoadPageLogger00003 - Missing arg: client - cannot determine loading status" arg.client=<nil> logger.name=LoadPageLogger
|
||||||
|
```
|
||||||
|
|
||||||
|
JSON 格式如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
{"arg.client":null,"level":"error","logger.name":"LoadPageLogger","msg":"LoadPageLogger00003 - Missing arg: client - cannot determine loading status", "time":"2017-02-24T23:14:28+01:00"}
|
||||||
|
```
|
||||||
|
|
||||||
|
### III. Golang 日志上下文的力量
|
||||||
|
|
||||||
|
现在 Golang 日志已经按照特定结构和标准格式记录,时间会决定需要添加哪些上下文以及相关信息。为了能从你的日志中抽取信息,例如追踪一个用户活动或者工作流,上下文和元数据的顺序非常重要。
|
||||||
|
|
||||||
|
例如在 logrus 库中可以按照下面这样使用 JSON 格式添加 Hostname、appname 和 session 参数:
|
||||||
|
|
||||||
|
```
|
||||||
|
// 对于元数据,通常做法是通过复用重用日志语句中的字段。
|
||||||
|
contextualizedLog := log.WithFields(log.Fields{
|
||||||
|
"hostname": "staging-1",
|
||||||
|
"appname": "foo-app",
|
||||||
|
"session": "1ce3f6v"
|
||||||
|
})
|
||||||
|
contextualizedLog.Info("Simple event with global metadata")
|
||||||
|
```
|
||||||
|
|
||||||
|
元数据可以视为 javascript 片段。为了更好地说明它们有多么重要,让我们看看几个 Golang 微服务中元数据的使用。你会清楚地看到在你的应用程序中跟踪用户的决定性。这是因为你不仅需要知道一个错误发生了,还要知道是哪个实例以及什么模式导致了错误。假设我们有两个按顺序调用的微服务。上下文信息被传输并保存在头部(header):
|
||||||
|
|
||||||
|
```
|
||||||
|
func helloMicroService1(w http.ResponseWriter, r *http.Request) {
|
||||||
|
client := &http.Client{}
|
||||||
|
// 该服务负责接收所有到来的用户请求
|
||||||
|
// 我们会检查是否是一个新的会话还是已有会话的另一次调用
|
||||||
|
session := r.Header.Get("x-session")
|
||||||
|
if ( session == "") {
|
||||||
|
session = generateSessionId()
|
||||||
|
// 为新会话记录日志
|
||||||
|
}
|
||||||
|
// 每个请求的 Track Id 都是唯一的,因此我们会为每个会话生成一个
|
||||||
|
track := generateTrackId()
|
||||||
|
// 调用你的第二个微服务,添加 session/track
|
||||||
|
reqService2, _ := http.NewRequest("GET", "http://localhost:8082/", nil)
|
||||||
|
reqService2.Header.Add("x-session", session)
|
||||||
|
reqService2.Header.Add("x-track", track)
|
||||||
|
resService2, _ := client.Do(reqService2)
|
||||||
|
….
|
||||||
|
```
|
||||||
|
|
||||||
|
当调用第二个服务时:
|
||||||
|
|
||||||
|
```
|
||||||
|
func helloMicroService2(w http.ResponseWriter, r *http.Request) {
|
||||||
|
// 类似之前的微服务,我们检查会话并生成新的 track
|
||||||
|
session := r.Header.Get("x-session")
|
||||||
|
track := generateTrackId()
|
||||||
|
// 这一次,我们检查请求中是否已经设置了一个 track id,
|
||||||
|
// 如果是,它变为父 track
|
||||||
|
parent := r.Header.Get("x-track")
|
||||||
|
if (session == "") {
|
||||||
|
w.Header().Set("x-parent", parent)
|
||||||
|
}
|
||||||
|
// 为响应添加 meta 信息
|
||||||
|
w.Header().Set("x-session", session)
|
||||||
|
w.Header().Set("x-track", track)
|
||||||
|
if (parent == "") {
|
||||||
|
w.Header().Set("x-parent", track)
|
||||||
|
}
|
||||||
|
// 填充响应
|
||||||
|
w.WriteHeader(http.StatusOK)
|
||||||
|
io.WriteString(w, fmt.Sprintf(aResponseMessage, 2, session, track, parent))
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
现在第二个微服务中已经有和初始查询相关的上下文和信息,一个 JSON 格式的日志消息看起来类似:
|
||||||
|
|
||||||
|
在第一个微服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
{"appname":"go-logging","level":"debug","msg":"hello from ms 1","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"UzWHRihF"}
|
||||||
|
```
|
||||||
|
|
||||||
|
在第二个微服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
{"appname":"go-logging","level":"debug","msg":"hello from ms 2","parent":"UzWHRihF","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"DPRHBMuE"}
|
||||||
|
```
|
||||||
|
|
||||||
|
如果在第二个微服务中出现了错误,多亏了 Golang 日志中保存的上下文信息,现在我们就可以确定它是怎样被调用的以及什么模式导致了这个错误。
|
||||||
|
|
||||||
|
如果你想进一步深挖 Golang 的追踪能力,这里还有一些库提供了追踪功能,例如 [Opentracing][12]。这个库提供了一种简单的方式在复杂(或简单)的架构中添加追踪实现。它通过不同步骤允许你追踪用户的查询,就像下面这样:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### IV. Golang 日志对性能的影响
|
||||||
|
|
||||||
|
### 1) 不要在 Goroutine 中使用日志
|
||||||
|
|
||||||
|
在每个 goroutine 中创建一个新的日志器看起来很诱人。但最好别这么做。Goroutine 是一个轻量级线程管理器,它用于完成一个 “简单的” 任务。因此它不应该负责日志。它可能导致并发问题,因为在每个 goroutine 中使用 log.New() 会复用接口,所有日志器会并发尝试访问同一个 io.Writer。
|
||||||
|
为了限制对性能的影响以及避免并发调用 io.Writer,库通常使用一个特定的 goroutine 用于日志输出。
|
||||||
|
|
||||||
|
### 2) 使用异步库
|
||||||
|
|
||||||
|
尽管有很多可用的 Golang 日志库,要注意它们中的大部分都是同步的(事实上是伪异步)。原因很可能是到现在为止它们中没有一个由于日志对性能有严重影响。
|
||||||
|
|
||||||
|
但正如 Kjell Hedström 在[他的实验][13]中展示的,使用多个线程创建成千上万日志,在最坏情况下异步 Golang 日志也会有 40% 的性能提升。因此日志是有开销的,也会对你的应用程序性能产生影响。如果你并不需要处理大量的日志,使用伪异步 Golang 日志库可能就足够了。但如果你是处理大量的日志,或者很关注性能,Kjell Hedström 的异步解决方案就很有趣(尽管事实上你可能需要进一步开发,因为它只包括了最小的功能需求)。
|
||||||
|
|
||||||
|
### 3)使用严重等级管理 Golang 日志
|
||||||
|
|
||||||
|
一些日志库允许你启用或停用特定日志器,这可能会派上用场。例如在生产环境中你可能不需要一些特定等级的日志。下面是一个如何在 glog 库中停用日志器的例子,其中日志器被定义为布尔值:
|
||||||
|
|
||||||
|
```
|
||||||
|
type Log bool
|
||||||
|
func (l Log) Println(args ...interface{}) {
|
||||||
|
fmt.Println(args...)
|
||||||
|
}
|
||||||
|
var debug Log = false
|
||||||
|
if debug {
|
||||||
|
debug.Println("DEBUGGING")
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
然后你就可以在配置文件中定义这些布尔参数来启用或者停用日志器。
|
||||||
|
|
||||||
|
没有一个好的 Golang 日志策略,Golang 日志可能开销很大。开发人员应该抵制记录几乎所有事情的诱惑 - 尽管它非常有趣!如果日志的目的是为了获取尽可能多的信息,为了避免包含没用元素的日志的白噪音,必须正确使用日志。
|
||||||
|
|
||||||
|
### V. 集中 Golang 日志
|
||||||
|
|
||||||
|

|
||||||
|
如果你的应用程序是部署在多台服务器上的,可以避免为了调查一个现象需要连接到每一台服务器的麻烦。日志集中确实有用。
|
||||||
|
|
||||||
|
使用日志装箱工具,例如 windows 中的 Nxlog,linux 中的 Rsyslog(默认安装了的)、Logstash 和 FluentD,是最好的实现方式。日志装箱工具的唯一目的就是发送日志,因此它们管理连接失效以及其它你很可能会遇到的问题。
|
||||||
|
|
||||||
|
这里甚至有一个 [Golang syslog 软件包][14] 帮你将 Golang 日志发送到 syslog 守护进程。
|
||||||
|
|
||||||
|
### 希望你享受你的 Golang 日志之旅
|
||||||
|
|
||||||
|
在你项目一开始就考虑你的 Golang 日志策略非常重要。如果在你代码的任意地方都可以获得所有的上下文,追踪用户就会变得很简单。从不同服务中阅读没有标准化的日志是已经很痛苦的事情。一开始就计划在多个微服务中扩展相同用户或请求 id,后面就会允许你比较容易地过滤信息并在你的系统中跟踪活动。
|
||||||
|
|
||||||
|
你是构架一个很大的 Golang 项目还是几个微服务也会影响你的日志策略。一个大项目的主要组件应该有按照它们功能命名的特定 Golang 日志器。这使你可以立即判断出日志来自你的哪一部分代码。然而对于微服务或者小的 Golang 项目,较少的核心组件需要它们自己的日志器。但在每种情形中,日志器的数目都应该保持低于核心功能的数目。
|
||||||
|
|
||||||
|
你现在已经可以使用 Golang 日志量化决定你的性能或者用户满意度啦!
|
||||||
|
|
||||||
|
_如果你有想阅读的特定编程语言,在 Twitter [][1][@logmatic][2] 上告诉我们吧。_
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
||||||
|
|
||||||
|
作者:[Nils][a]
|
||||||
|
译者:[ictlyh](https://github.com/ictlyh)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
||||||
|
[1]:https://twitter.com/logmatic?lang=en
|
||||||
|
[2]:http://twitter.com/logmatic
|
||||||
|
[3]:https://golang.org/pkg/log/
|
||||||
|
[4]:https://golang.org/pkg/log/#pkg-constants
|
||||||
|
[5]:https://play.golang.org/
|
||||||
|
[6]:https://www.goinggo.net/2013/11/using-log-package-in-go.html
|
||||||
|
[7]:https://golang.org/pkg/log/
|
||||||
|
[8]:https://github.com/google/glog
|
||||||
|
[9]:https://github.com/sirupsen/logrus
|
||||||
|
[10]:https://logmatic.io/blog/beyond-application-monitoring-discover-logging-best-practices/
|
||||||
|
[11]:https://github.com/logmatic/logmatic-go
|
||||||
|
[12]:https://github.com/opentracing/opentracing-go
|
||||||
|
[13]:https://sites.google.com/site/kjellhedstrom2/g2log-efficient-background-io-processign-with-c11/g2log-vs-google-s-glog-performance-comparison
|
||||||
|
[14]:https://golang.org/pkg/log/syslog/
|
||||||
@ -1,141 +0,0 @@
|
|||||||
4 个拥有漂亮命令行 UI 的终端程序
|
|
||||||
============================================================
|
|
||||||
|
|
||||||
### 我们来看几个精心设计的 CLI 程序,以及如何克服一些可发现的问题。
|
|
||||||
|
|
||||||

|
|
||||||
>图片提供: opensource.com
|
|
||||||
|
|
||||||
在本文中,我会指出命令行界面的可见缺点以及克服这些问题的几种方法。
|
|
||||||
|
|
||||||
我喜欢命令行。我第一次接触命令行是在 1997 的 DOS 6.2 上。我学习了各种命令的语法,并展示了如何在目录中列出隐藏的文件(**attrib**)。我会每次仔细检查命令中的每个字符。 当我犯了一个错误,我会从头开始重新输入命令。有一天,有人向我展示了如何使用向上和向下箭头按键遍历历史,我被震惊了。
|
|
||||||
|
|
||||||
编程和开发
|
|
||||||
|
|
||||||
* [新的 Python 内容][1]
|
|
||||||
|
|
||||||
* [我们最新的 JavaScript 文章][2]
|
|
||||||
|
|
||||||
* [最近的 Perl 帖子][3]
|
|
||||||
|
|
||||||
* [红帽开发者博客][4]
|
|
||||||
|
|
||||||
后来当我被介绍 Linux 时,让我感到惊喜的是,上下箭头保留了它们遍历历史记录的能力。我仍然仔细地打字,但到现在为止,我了解如何输入,并且我能以每分钟 55 个单词的速度做的很好。接着有人向我展示了 tab 键,并再次改变了我的生活。
|
|
||||||
|
|
||||||
在 GUI 应用程序菜单中,工具提示和图标向用户展示功能。命令行缺乏这种能力,但有办法克服这个问题。在深入解决方案之前,我会来看看几个有问题的 CLI 程序:
|
|
||||||
|
|
||||||
### 1\. MySQL
|
|
||||||
|
|
||||||
首先我们有我们所钟爱的 MySQL REPL。我经常发现自己在输入 **SELECT * FROM** 然后按 **Tab** 的习惯。MySQL 会询问我是否想看到所有的 871 中可能性。我的数据库中绝对没有 871 张表。如果我选择 **yes**,它会显示一堆 SQL 关键字、表、函数等。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 2\. Python
|
|
||||||
|
|
||||||
我们来看另一个例子,标准的 Python REPL。我开始输入命令,然后习惯按 **Tab** 键。瞧,插入了一个 **Tab** 字符,考虑到 **Tab** 在 Python 中没有作用,这是一个问题。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 好的 UX
|
|
||||||
|
|
||||||
让我看下设计良好的 CLI 程序以及它们是如何克服这些可见问题的。
|
|
||||||
|
|
||||||
### 自动补全: bpython
|
|
||||||
|
|
||||||
[Bpython][15] 是对 Python REPL 的一个很好的替代。当我运行 bpython 并开始输入时,建议会立即出现。我没用通过特殊的键盘绑定触发它,甚至没有按下 **Tab** 键。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
当我出于习惯按下 **Tab** 键时,它会用列表中的第一个建议补全。这是给 CLI 设计带来可见性的一个很好的例子。
|
|
||||||
|
|
||||||
bpython 另一方面可以展示模块和函数的文档。当我输入一个函数的名字时,它会显示函数签名以及这个函数附带的文档字符串。这是一个多么令人难以置信的周到设计啊。
|
|
||||||
|
|
||||||
### 上下文感知补全:mycli
|
|
||||||
|
|
||||||
[Mycli][16]是默认的 MySQL 客户端的现代替代品。这个工具对 MySQL 来说就像 bpython 对标准 Python REPL 做的那样。Mycli 将在你输入时自动补全关键字、表名、列和函数。
|
|
||||||
|
|
||||||
补全建议是上下文相关的。例如,在 **SELECT * FROM** 之后,只有来自当前数据库的表才会列出,而不是所有可能的关键字。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 模糊搜索和在线帮助: pgcli
|
|
||||||
|
|
||||||
如果您正在寻找 PostgreSQL 版本的 mycli,请查看 [pgcli][17]。 与 mycli 一样,它提供了上下文感知的自动补全。菜单中的项使用模糊搜索缩小。模糊搜索允许用户输入整体字符串中的任意子字符串来尝试找到正确的匹配项。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
pgcli 和 mycli 同时在 CLI 中实现了这个功能。斜杠命令的文档也作为补全菜单的一部分展示。
|
|
||||||
|
|
||||||
### 可发现性: fish
|
|
||||||
|
|
||||||
在传统的 Unix shell(Bash、zsh 等)中,有一种搜索历史记录的方法。此搜索模式由 **Ctrl-R** 触发。当在再次调用你上周运行的命令时,这是一个令人难以置信的有用的工具,例如 **ssh**或 **docker**。 一旦你知道这个功能,你会发现自己经常使用它。
|
|
||||||
|
|
||||||
如果这个功能是如此有用,那为什么不每次都搜索呢?这正是 [**fish** shell][18] 所做的。一旦你开始输入命令,**fish** 将开始建议与历史记录类似的命令。然后,你可以按右箭头键接受该建议。
|
|
||||||
|
|
||||||
### 命令行规矩
|
|
||||||
|
|
||||||
我已经回顾了一些创新的方法来解决可见的问题,但也有一些命令行的基础知识, 每个人都应该作为基本的 repl 功能的一部分来执行:
|
|
||||||
|
|
||||||
* 确保 REPL 有可通过箭头键调用的历史记录。确保会话之间的历史持续存在。
|
|
||||||
|
|
||||||
* 提供在编辑器中编辑命令的方法。不管你的补全是多么棒,有时用户只需要一个编辑器来制作完美的命令来删除生产环境中所有的表。
|
|
||||||
|
|
||||||
* 使用 pager 来管道输出。不要让用户滚动他们的终端。哦,并为 pager 使用合理的默认值。(添加选项来处理颜色代码。)
|
|
||||||
|
|
||||||
* 提供一种通过 **Ctrl-R** 界面或者 **fish** 样式的自动搜索来搜索历史记录的方法。
|
|
||||||
|
|
||||||
### 总结
|
|
||||||
|
|
||||||
在第 2 部分中,我将来看看 Python 中使你能够实现这些技术的特定库。同时,请查看其中一些精心设计的命令行应用程序:
|
|
||||||
|
|
||||||
* [bpython][5]或 [ptpython][6]:具有自动补全支持的 Python REPL。
|
|
||||||
|
|
||||||
* [http-prompt][7]:交互式 HTTP 客户端。
|
|
||||||
|
|
||||||
* [mycli][8]:MySQL、MariaDB 和 Percona 的命令行界面,具有自动补全和语法高亮。
|
|
||||||
|
|
||||||
* [pgcli][9]:具有自动补全和语法高亮,是对 [psql][10] 的替代工具。
|
|
||||||
|
|
||||||
* [wharfee][11]:用于管理 Docker 容器的 shell。
|
|
||||||
|
|
||||||
_在这了解 Amjith Ramanujam 更多的在 5 月 20 日在波特兰俄勒冈州举办的 [PyCon US 2017][12] 上的谈话“[令人敬畏的命令行工具][13]”。_
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
|
|
||||||
作者简介:
|
|
||||||
|
|
||||||
Amjith Ramanujam - Amjith Ramanujam 是 pgcli 和 mycli 的创始人。人们认为它们很酷,他并不反对。他喜欢用 Python、Javascript 和 C 编程。他喜欢编写简单易懂的代码,它们有时甚至会成功。
|
|
||||||
|
|
||||||
-----------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/17/5/4-terminal-apps
|
|
||||||
|
|
||||||
作者:[Amjith Ramanujam ][a]
|
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://opensource.com/users/amjith
|
|
||||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
|
||||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
|
||||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
|
||||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
|
||||||
[5]:http://bpython-interpreter.org/
|
|
||||||
[6]:http://github.com/jonathanslenders/ptpython/
|
|
||||||
[7]:https://github.com/eliangcs/http-prompt
|
|
||||||
[8]:http://mycli.net/
|
|
||||||
[9]:http://pgcli.com/
|
|
||||||
[10]:https://www.postgresql.org/docs/9.2/static/app-psql.html
|
|
||||||
[11]:http://wharfee.com/
|
|
||||||
[12]:https://us.pycon.org/2017/
|
|
||||||
[13]:https://us.pycon.org/2017/schedule/presentation/518/
|
|
||||||
[14]:https://opensource.com/article/17/5/4-terminal-apps?rate=3HL0zUQ8_dkTrinonNF-V41gZvjlRP40R0RlxTJQ3G4
|
|
||||||
[15]:https://bpython-interpreter.org/
|
|
||||||
[16]:http://mycli.net/
|
|
||||||
[17]:http://pgcli.com/
|
|
||||||
[18]:https://fishshell.com/
|
|
||||||
[19]:https://opensource.com/user/125521/feed
|
|
||||||
[20]:https://opensource.com/article/17/5/4-terminal-apps#comments
|
|
||||||
[21]:https://opensource.com/users/amjith
|
|
||||||
Loading…
Reference in New Issue
Block a user