mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
commit
4c04c885ae
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
@ -0,0 +1,156 @@
|
||||
如何创建定制的 Ubuntu Live CD 镜像
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们以前可以使用 [Pinguy Builder][1] 完成这项工作。但是,现在它似乎停止维护了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 Cubic 即 **C**ustom **Ub**untu **I**SO **C**reator 的首字母缩写,这是一个用来创建定制的可启动的 Ubuntu Live CD(ISO)镜像的 GUI 应用程序。
|
||||
|
||||
Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的 chroot 命令行环境(LCTT 译注:chroot —— Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制各种方面,比如安装新的软件包、内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在 live 镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来制作 Ubuntu live 镜像,所以我相信它可以用在制作其他 Ubuntu 的发行版和衍生版镜像中,比如 Linux Mint。
|
||||
|
||||
### 安装 Cubic
|
||||
|
||||
Cubic 的开发人员已经做出了一个 PPA 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:cubic-wizard/release
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
|
||||
sudo apt update
|
||||
sudo apt install cubic
|
||||
```
|
||||
|
||||
### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
|
||||
|
||||
安装完成后,从应用程序菜单或 dock 启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
|
||||
|
||||
为新项目选择一个目录。它是保存镜像文件的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
请注意,Cubic 不是创建您当前系统的 Live CD 镜像,而是利用 Ubuntu 的安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
|
||||
|
||||
选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。
|
||||
|
||||
![][4]
|
||||
|
||||
接下来,来自源安装介质中的压缩的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 `/home/ostechnix/custom_ubuntu`)。
|
||||
|
||||
![][5]
|
||||
|
||||
一旦文件系统被提取出来,将自动加载到 chroot 环境。如果你没有看到终端提示符,请按几次回车键。
|
||||
|
||||
![][6]
|
||||
|
||||
在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
|
||||
|
||||
例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。
|
||||
|
||||
![][7]
|
||||
|
||||
我们不需要使用 `sudo`,因为我们已经在具有最高权限(root)的环境中了。
|
||||
|
||||
类似地,如果需要,可以安装更多的任何版本 Linux 内核。
|
||||
|
||||
```
|
||||
apt install linux-image-extra-4.10.0-24-generic
|
||||
```
|
||||
|
||||
此外,您还可以更新软件源列表(添加或删除软件存储库列表):
|
||||
|
||||
![][8]
|
||||
|
||||
修改源列表后,不要忘记运行 `apt update` 命令来更新源列表:
|
||||
|
||||
```
|
||||
apt update
|
||||
```
|
||||
|
||||
另外,您还可以向 Live CD 中添加文件或文件夹。复制文件或文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择 “Paste file(s)”,最后点击 Cubic 向导底部的 “Copy”。
|
||||
|
||||
![][9]
|
||||
|
||||
**Ubuntu 17.10 用户注意事项**
|
||||
|
||||
> 在 Ubuntu 17.10 系统中,DNS 查询可能无法在 chroot 环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 Live 镜像,您需要指向正确的 `resolve.conf` 配置文件:
|
||||
|
||||
>```
|
||||
ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
|
||||
```
|
||||
|
||||
> 要验证 DNS 解析工作,运行:
|
||||
|
||||
> ```
|
||||
cat /etc/resolv.conf
|
||||
ping google.com
|
||||
```
|
||||
|
||||
如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 `/usr/share/backgrounds/` 目录,
|
||||
|
||||
```
|
||||
cd /usr/share/backgrounds
|
||||
```
|
||||
|
||||
并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口并选择 “Paste file(s)” 选项。此外,确保你在 `/usr/share/gnome-backproperties` 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择 “Change Desktop Background” 进行交互。完成所有更改后,在 Cubic 向导中单击 “Next”。
|
||||
|
||||
接下来,选择引导到新的 Live ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。
|
||||
|
||||
![][10]
|
||||
|
||||
在下一节中,选择要从您的 Live 映像中删除的软件包。在使用定制的 Live 映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。
|
||||
|
||||
![][11]
|
||||
|
||||
接下来, Live 镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。
|
||||
|
||||
![][12]
|
||||
|
||||
镜像创建完成后后,单击 “Finish”。Cubic 将显示新创建的自定义镜像的细节。
|
||||
|
||||
如果你想在将来修改刚刚创建的自定义 Live 镜像,不要选择“ Delete all project files, except the generated disk image and the corresponding MD5 checksum file”(除了生成的磁盘映像和相应的 MD5 校验和文件之外,删除所有的项目文件**) ,Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
|
||||
|
||||
要为不同的 Ubuntu 版本创建新的 Live 镜像,最好使用不同的项目目录。
|
||||
|
||||
### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
|
||||
|
||||
从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 “Next” 按钮,您将看到以下三个选项:
|
||||
|
||||
1. Create a disk image from the existing project. (从现有项目创建一个磁盘映像。)
|
||||
2. Continue customizing the existing project.(继续定制现有项目。)
|
||||
3. Delete the existing project.(删除当前项目。)
|
||||
|
||||
![][13]
|
||||
|
||||
第一个选项将允许您从现有项目中使用之前所做的自定义设置创建一个新的 Live ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
|
||||
|
||||
第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 chroot 环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
|
||||
|
||||
第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
|
||||
|
||||
我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
|
||||
|
||||
就这些了,再会!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-4.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-6.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-5.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-7.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-8.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-10-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-12-1.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-13.png
|
||||
87
published/20171107 The long goodbye to C.md
Normal file
87
published/20171107 The long goodbye to C.md
Normal file
@ -0,0 +1,87 @@
|
||||
与 C 语言长别离
|
||||
==========================================
|
||||
|
||||
这几天来,我在思考那些正在挑战 C 语言的系统编程语言领袖地位的新潮语言,尤其是 Go 和 Rust。思考的过程中,我意识到了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经记不清楚上一次我 _创建一个新的 C 语言项目_ 是在什么时候了。
|
||||
|
||||
如果你完全不认为这种情况令人震惊,那你很可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec、 GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,甚至我都记不清我是什么时候开始这样做的了,而且……回头想想,我觉得这都不是本世纪发生的事情。
|
||||
|
||||
这个对于我来说是件大事,因为如果你问我,我的五个最核心软件开发技能是什么,“C 语言专家” 一定是你最有可能听到的之一。这也激起了我的思考。C 语言的未来会怎样 ?C 语言是否正像当年的 COBOL 语言一样,在辉煌之后,走向落幕?
|
||||
|
||||
我恰好是在 C 语言迅猛发展,并把汇编语言以及其它许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言就直接毫无声息的退出了舞台。主流的语言(FORTRAN、Pascal、COBOL)则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
|
||||
|
||||
而在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java、 Perl、 Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部分是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用和对接大量已有的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过打破这种壁垒,但是只有 Python 有可能取得成功)。
|
||||
|
||||
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个名为 SunSITE 的帮助图书管理员做源码分发的辅助软件,当时使用的是 Perl 语言。
|
||||
|
||||
这个应用完全是用来处理文本输入的,而且只需要能够应对人类的反应速度即可(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,而完全没有想到我几乎再也不会在一个新项目的第一个文件里敲下 `int main(int argc, char **argv)` 这样的 C 语言代码了。
|
||||
|
||||
我说“几乎”,主要是因为 1999 年的 [SNG][3]。 我想那是我最后一个用 C 从头开始写的项目了。
|
||||
|
||||
在那之后我写的所有的 C 代码都是在为那些上世纪已经存在的老项目添砖加瓦,或者是在维护诸如 GPSD 以及 NTPsec 一类的项目。
|
||||
|
||||
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速迭代使得硬件愈加便宜,使得像 Perl 这样的语言的执行效率也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
|
||||
|
||||
在 1997 年我学习了 Python, 这对我来说是一道分水岭。这个语言很美妙 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!甚至还完全遵循了 POSIX!还有一个蛮好用的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 语言时写 C。
|
||||
|
||||
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没能实现和 C 语言语义等价的遵循 POSIX 的语言_都注定要失败_。在计算机科学的发展史上,很多学术语言的骨骸俯拾皆是,原因是这些语言的设计者没有意识到这个重要的问题。)
|
||||
|
||||
显然,对我来说,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致核心转储的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时,为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时硬件产业的发展还在早期阶段,没有给摩尔定律足够的时间来发挥威力。
|
||||
|
||||
尽量地在 C 语言和 Python 之间选择 C —— 只要是能的话我就会从 C 语言转移到 Python 。这是一种降低工程复杂程度的有效策略。我将这种策略应用在了 GPSD 中,而针对 NTPsec , 我对这个策略的采用则更加系统化。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
|
||||
|
||||
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也未必真的是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,因为在当时任何一个新的学院派的动态语言都可以让我不再选择使用 C 语言。也有可能是在某段时间里在我写了很多 Java 之后,我才慢慢远离了 C 语言。
|
||||
|
||||
我写这个回忆录是因为我觉得我并非特例,在世纪之交,同样的发展和转变也改变了不少 C 语言老手的编码习惯。像我一样,他们在当时也并没有意识到这种转变正在发生。
|
||||
|
||||
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
|
||||
|
||||
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言受限的数据类型本体论以及其脆弱的底层数据管理问题,尝试用 C 写的话可能会很恐怖,并注定失败。
|
||||
|
||||
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
|
||||
|
||||
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年的时候,我就是 Python 的早期使用者。来自 [TIOBE][7] 的数据则表明,在 Go 语言脱胎于公司的实验项目并刚刚从小众语言中脱颖而出的几个月内,我就开始实现自己的第一个 Go 语言项目了。
|
||||
|
||||
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标准很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
|
||||
|
||||
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。如果需求是针对单个用户且只需要以人类能接受的速度运行,使用 Python 当然是很好的,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断 —— 因为拿 Go 语言来说,它的存在主要就是因为当时作为 Python 语言主要支持者的 Google 在使用 Python 实现一些工程的时候也遭遇了同样的效能痛点。
|
||||
|
||||
Go 语言就是为了解决 Python 搞不定的那些大多由 C 语言来实现的任务而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
|
||||
|
||||
([这里][8]有关于我第一次写 Go 的经验的更多信息)
|
||||
|
||||
本来我想把 Rust 也视为 “C 语言要过时了” 的例证,但是在学习并尝试使用了这门语言编程之后,我觉得[这种语言现在还没有做好准备][9]。也许 5 年以后,它才会成为 C 语言的对手。
|
||||
|
||||
随着 2017 的尾声来临,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言界的新星可能就会取得成功。
|
||||
|
||||
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我作为一个程序员的全部生涯,我们都没有等到一个 C 语言的继任者,也无法遥望 C 之后的系统编程会是什么样子的。而现在,我们面前突然有了后 C 时代的两种不同的展望和未来……
|
||||
|
||||
……另一种展望则是下面这个语言留给我们的。我的一个朋友正在开发一个他称之为 “Cx” 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他做出太多不切实际的保证。但是他的实现方法真的很是有意思,我会尽量给他募集资金。
|
||||
|
||||
现在,我们看到了可以替代 C 语言实现系统编程的三种不同的可能的道路。而就在两年之前,我们的眼前还是一片漆黑。我重复一遍:这件事情意义重大。
|
||||
|
||||
我是在说 C 语言将要灭绝吗?不是这样的,在可预见的未来里,C 语言还会是操作系统的内核编程以及设备固件编程的主流语言,在这些场景下,尽力压榨硬件性能的古老规则还在奏效,尽管它可能不是那么安全。
|
||||
|
||||
现在那些将要被 C 的继任者攻破的领域就是我之前提到的我经常涉及的领域 —— 比如 GPSD 以及 NTPsec、系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮件传输代理 —— 那些需要以机器速度而不是人类的速度运行的系统程序。
|
||||
|
||||
现在我们可以对后 C 时代的未来窥见一斑,即上述这类领域的代码都可以使用那些具有强大内存安全特性的 C 语言的替代者实现。Go 、Rust 或者 Cx ,无论是哪个,都可能使 C 的存在被弱化。比如,如果我现在再来重新实现一遍 NTP ,我可能就会毫不犹豫的使用 Go 语言去完成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7711
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[yunfengHe](https://github.com/yunfengHe), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711
|
||||
[3]:http://sng.sourceforge.net/
|
||||
[4]:http://www.catb.org/esr/reposurgeon/
|
||||
[5]:http://www.catb.org/esr/doclifter/
|
||||
[6]:http://www.catb.org/esr/loccount/
|
||||
[7]:https://www.tiobe.com/tiobe-index/
|
||||
[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
|
||||
[9]:http://esr.ibiblio.org/?p=7303
|
||||
@ -0,0 +1,98 @@
|
||||
Debian 取代 Ubuntu 成为 Google 内部 Linux 发行版的新选择
|
||||
============================================================
|
||||
|
||||
> 摘要:Google 多年来一直使用基于 Ubuntu 的内部操作系统 Goobuntu。如今,Goobuntu 正在被基于 Debian Testing 的 gLinux 所取代。
|
||||
|
||||
如果你读过那篇《[Ubuntu 十个令人惊奇的事实][18]》,你可能知道 Google 使用了一个名为 [Goobuntu][19] 的 Linux 发行版作为开发平台。这是一个定制化的 Linux 发行版,不难猜到,它是基于 Ubuntu 的。
|
||||
|
||||
Goobuntu 基本上是一个 [采用轻量级的界面的 Ubuntu][20],它是基于 Ubuntu LTS 版本的。如果你认为 Google 对 Ubuntu 的测试或开发做出了贡献,那么你就错了。Google 只是 Canonical 公司的 [Ubuntu Advantage Program][21] 计划的付费客户而已。[Canonical][22] 是 Ubuntu 的母公司。
|
||||
|
||||
### 遇见 gLinux:Google 基于 Debian Buster 的新 Linux 发行版
|
||||
|
||||

|
||||
|
||||
在使用 Ubuntu 五年多以后,Google 正在用一个基于 Debian Testing 版本的 Linux 发行版 —— gLinux 取代 Goobuntu。
|
||||
|
||||
正如 [MuyLinux][23] 所报道的,gLinux 是从软件包的源代码中构建出来的,然后 Google 对其进行了修改,这些改动也将为上游做出贡献。
|
||||
|
||||
这个“新闻”并不是什么新鲜事,它早在去年八月就在 Debconf'17 开发者大会上宣布了。但不知为何,这件事并没有引起应有的关注。
|
||||
|
||||
请点击 [这里][24] 观看 Debconf 视频中的演示。gLinux 的演示从 12:00 开始。
|
||||
|
||||
[推荐阅读:微软出局,巴塞罗那青睐 Linux 系统和开源软件][25]
|
||||
|
||||
### 从 Ubuntu 14.04 LTS 转移到 Debian 10 Buster
|
||||
|
||||
Google 曾经看重 Ubuntu LTS 的稳定性,现在为了及时测试软件而转移到 Debian Testing 上。但目前尚不清楚 Google 为什么决定从 Ubuntu 切换到 Debian。
|
||||
|
||||
Google 计划如何转移到 Debian Testing?目前的 Debian Testing 版本是即将发布的 Debian 10 Buster。Google 开发了一个内部工具,用于将现有系统从 Ubuntu 14.04 LTS 迁移到 Debian 10 Buster。项目负责人 Margarita 在 Debconf 中声称,经过测试,该工具工作正常。
|
||||
|
||||
Google 还计划将这些改动发到 Debian 的上游项目中,从而为其发展做出贡献。
|
||||
|
||||

|
||||
|
||||
*gLinux 的开发计划*
|
||||
|
||||
### Ubuntu 丢失了一个大客户!
|
||||
|
||||
回溯到 2012 年,Canonical 公司澄清说 Google 不是他们最大的商业桌面客户。但至少可以说,Google 是他们的大客户。当 Google 准备切换到 Debian 时,必然会使 Canonical 蒙受损失。
|
||||
|
||||
[推荐阅读:Mandrake Linux Creator 推出新的开源移动操作系统][26]
|
||||
|
||||
### 你怎么看?
|
||||
|
||||
请记住,Google 不会限制其开发者使用任何操作系统,但鼓励使用 Linux。
|
||||
|
||||
如果你想使用 Goobuntu 或 gLinux,那得成为 Google 公司的雇员才行。因为这是 Google 的内部项目,不对公众开放。
|
||||
|
||||
总的来说,这对 Debian 来说是一个好消息,尤其是他们成为了上游发行版的话。对 Ubuntu 来说可就不同了。我已经联系了 Canonical 公司征求意见,但至今没有回应。
|
||||
|
||||
更新:Canonical 公司回应称,他们“不共享与单个客户关系的细节”,因此他们不能提供有关收入和任何其他的细节。
|
||||
|
||||
你对 Google 抛弃 Ubuntu 而选择 Debian 有什么看法?
|
||||
|
||||
|
||||

|
||||
|
||||
#### 关于作者 Abhishek Prakash
|
||||
|
||||
我是一名专业的软件开发人员,也是 FOSS 的创始人。我是一个狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信知识共享。除了 Linux 之外,我还喜欢经典的侦探推理故事。我是阿加莎·克里斯蒂(Agatha Christie)作品的忠实粉丝。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/goobuntu-glinux-google/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/goobuntu-glinux-google/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[9]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[10]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[11]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[12]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[13]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[14]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[15]:https://itsfoss.com/category/news/
|
||||
[16]:https://itsfoss.com/tag/glinux/
|
||||
[17]:https://itsfoss.com/tag/goobuntu/
|
||||
[18]:https://itsfoss.com/facts-about-ubuntu/
|
||||
[19]:https://en.wikipedia.org/wiki/Goobuntu
|
||||
[20]:http://www.zdnet.com/article/the-truth-about-goobuntu-googles-in-house-desktop-ubuntu-linux/
|
||||
[21]:https://www.ubuntu.com/support
|
||||
[22]:https://www.canonical.com/
|
||||
[23]:https://www.muylinux.com/2018/01/15/goobuntu-glinux-google/
|
||||
[24]:https://debconf17.debconf.org/talks/44/
|
||||
[25]:https://linux.cn/article-9236-1.html
|
||||
[26]:https://itsfoss.com/eelo-mobile-os/
|
||||
@ -0,0 +1,95 @@
|
||||
How technology changes the rules for doing agile
|
||||
======
|
||||
|
||||

|
||||
|
||||
More companies are trying agile and [DevOps][1] for a clear reason: Businesses want more speed and more experiments - which lead to innovations and competitive advantage. DevOps helps you gain that speed. But doing DevOps in a small group or startup and doing it at scale are two very different things. Any of us who've worked in a cross-functional group of 10 people, come up with a great solution to a problem, and then tried to apply the same patterns across a team of 100 people know the truth: It often doesn't work. This path has been so hard, in fact, that it has been easy for IT leaders to put off agile methodology for another year.
|
||||
|
||||
But that time is over. If you've tried and stalled, it's time to jump back in.
|
||||
|
||||
Until now, DevOps required customized answers for many organizations - lots of tweaks and elbow grease. But today, [Linux containers ][2]and Kubernetes are fueling standardization of DevOps tools and processes. That standardization will only accelerate. The technology we are using to practice the DevOps way of working has finally caught up with our desire to move faster.
|
||||
|
||||
Linux containers and [Kubernetes][3] are changing the way teams interact. Moreover, on the Kubernetes platform, you can run any application you now run on Linux. What does that mean? You can run a tremendous number of enterprise apps (and handle even previously vexing coordination issues between Windows and Linux.) Finally, containers and Kubernetes will handle almost all of what you'll run tomorrow. They're being future-proofed to handle machine learning, AI, and analytics workloads - the next wave of problem-solving tools.
|
||||
|
||||
**[ See our related article,[4 container adoption patterns: What you need to know. ] ][4]**
|
||||
|
||||
Think about machine learning, for example. Today, people still find the patterns in much of an enterprise's data. When machines find the patterns (think machine learning), your people will be able to act on them faster. With the addition of AI, machines can not only find but also act on patterns. Today, with people doing everything, three weeks is an aggressive software development sprint cycle. With AI, machines can change code multiple times per second. Startups will use that capability - to disrupt you.
|
||||
|
||||
Consider how fast you have to be to compete. If you can't make a leap of faith now to DevOps and a one week cycle, think of what will happen when that startup points its AI-fueled process at you. It's time to move to the DevOps way of working now, or get left behind as your competitors do.
|
||||
|
||||
### How are containers changing how teams work?
|
||||
|
||||
DevOps has frustrated many groups trying to scale this way of working to a bigger group. Many IT (and business) people are suspicious of agile: They've heard it all before - languages, frameworks, and now models (like DevOps), all promising to revolutionize application development and IT process.
|
||||
|
||||
**[ Want DevOps advice from other CIOs? See our comprehensive resource, [DevOps: The IT Leader's Guide][5]. ]**
|
||||
|
||||
It's not easy to "sell" quick development sprints to your stakeholders, either. Imagine if you bought a house this way. You're not going to pay a fixed amount to your builder anymore. Instead, you get something like: "We'll pour the foundation in 4 weeks and it will cost x. Then we'll frame. Then we'll do electrical. But we only know the timing on the foundation right now." People are used to buying homes with a price up front and a schedule.
|
||||
|
||||
The challenge is that building software is not like building a house. The same builder builds thousands of houses that are all the same. Software projects are never the same. This is your first hurdle to get past.
|
||||
|
||||
Dev and operations teams really do work differently: I know because I've worked on both sides. We incent them differently. Developers are rewarded for changing and creating, while operations pros are rewarded for reducing cost and ensuring security. We put them in different groups and generally minimize interaction. And the roles typically attract technical people who think quite differently. This situation sets IT up to fail. You have to be willing to break down these barriers.
|
||||
|
||||
Think of what has traditionally happened. You throw pieces over the wall, then the business throws requirements over the wall because they are operating in "house-buying" mode: "We'll see you in 9 months." Developers build to those requirements and make changes as needed for technical constraints. Then they throw it over the wall to operations to "figure out how to run this." Operations then works diligently to make a slew of changes to align the software with their infrastructure. And what's the end result?
|
||||
|
||||
More often than not, the end result isn't even recognizable to the business when they see it in its final glory. We've watched this pattern play out time and time again in our industry for the better part of two decades. It's time for a change.
|
||||
|
||||
It's Linux containers that truly crack the problem - because containers close the gap between development and operations. They allow both teams to understand and design to all of the critical requirements, but still uniquely fulfill their team's responsibilities. Basically, we take out the telephone game between developers and operations. With containers, we can have smaller operations teams, even teams responsible for millions of applications, but development teams that can change software as quickly as needed. (In larger organizations, the desired pace may be faster than humans can respond on the operations side.)
|
||||
|
||||
With containers, you're separating what is delivered from where it runs. Your operations teams are responsible for the host that will run the containers and the security footprint, and that's all. What does this mean?
|
||||
|
||||
First, it means you can get going on DevOps now, with the team you have. That's right. Keep teams focused on the expertise they already have: With containers, just teach them the bare minimum of the required integration dependencies.
|
||||
|
||||
If you try and retrain everyone, no one will be that good at anything. Containers let teams interact, but alongside a strong boundary, built around each team's strengths. Your devs know what needs to be consumed, but don't need to know how to make it run at scale. Ops teams know the core infrastructure, but don't need to know the minutiae of the app. Also, Ops teams can update apps to address new security implications, before you become the next trending data breach story.
|
||||
|
||||
Teaching a large IT organization of say 30,000 people both ops and devs skills? It would take you a decade. You don't have that kind of time.
|
||||
|
||||
When people talk about "building new, cloud-native apps will get us out of this problem," think critically. You can build cloud-native apps in 10-person teams, but that doesn't scale for a Fortune 1000 company. You can't just build new microservices one by one until you're somehow not reliant on your existing team: You'll end up with a siloed organization. It's an alluring idea, but you can't count on these apps to redefine your business. I haven't met a company that could fund parallel development at this scale and succeed. IT budgets are already constrained; doubling or tripling them for an extended period of time just isn't realistic.
|
||||
|
||||
### When the remarkable happens: Hello, velocity
|
||||
|
||||
Linux containers were made to scale. Once you start to do so, [orchestration tools like Kubernetes come into play][6] - because you'll need to run thousands of containers. Applications won't consist of just a single container, they will depend on many different pieces, all running on containers, all running as a unit. If they don't, your apps won't run well in production.
|
||||
|
||||
Think of how many small gears and levers come together to run your business: The same is true for any application. Developers are responsible for all the pulleys and levers in the application. (You could have an integration nightmare if developers don't own those pieces.) At the same time, your operations team is responsible for all the pulleys and levers that make up your infrastructure, whether on-premises or in the cloud. With Kubernetes as an abstraction, your operations team can give the application the fuel it needs to run - without being experts on all those pieces.
|
||||
|
||||
Developers get to experiment. The operations team keeps infrastructure secure and reliable. This combination opens up the business to take small risks that lead to innovation. Instead of having to make only a couple of bet-the-farm size bets, real experimentation happens inside the company, incrementally and quickly.
|
||||
|
||||
In my experience, this is where the remarkable happens inside organizations: Because people say "How do we change planning to actually take advantage of this ability to experiment?" It forces agile planning.
|
||||
|
||||
For example, KeyBank, which uses a DevOps model, containers, and Kubernetes, now deploys code every day. (Watch this [video][7] in which John Rzeszotarski, director of Continuous Delivery and Feedback at KeyBank, explains the change.) Similarly, Macquarie Bank uses DevOps and containers to put something in production every day.
|
||||
|
||||
Once you push software every day, it changes every aspect of how you plan - and [accelerates the rate of change to the business][8]. "An idea can get to a customer in a day," says Luis Uguina, CDO of Macquarie's banking and financial services group. (See this [case study][9] on Red Hat's work with Macquarie Bank).
|
||||
|
||||
### The right time to build something great
|
||||
|
||||
The Macquarie example demonstrates the power of velocity. How would that change your approach to your business? Remember, Macquarie is not a startup. This is the type of disruptive power that CIOs face, not only from new market entrants but also from established peers.
|
||||
|
||||
The developer freedom also changes the talent equation for CIOs running agile shops. Suddenly, individuals within huge companies (even those not in the hottest industries or geographies) can have great impact. Macquarie uses this dynamic as a recruiting tool, promising developers that all new hires will push something live within the first week.
|
||||
|
||||
At the same time, in this day of cloud-based compute and storage power, we have more infrastructure available than ever. That's fortunate, considering the [leaps that machine learning and AI tools will soon enable][10].
|
||||
|
||||
This all adds up to this being the right time to build something great. Given the pace of innovation in the market, you need to keep building great things to keep customers loyal. So if you've been waiting to place your bet on DevOps, now is the right time. Containers and Kubernetes have changed the rules - in your favor.
|
||||
|
||||
**Want more wisdom like this, IT leaders? [Sign up for our weekly email newsletter][11].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-technology-changes-rules-doing-agile
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/matt-hicks
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/topics/containers?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[4]:https://enterprisersproject.com/article/2017/8/4-container-adoption-patterns-what-you-need-know?sc_cid=70160000000h0aXAAQ
|
||||
[5]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/11/how-enterprise-it-uses-kubernetes-tame-container-complexity
|
||||
[7]:https://www.redhat.com/en/about/videos/john-rzeszotarski-keybank-red-hat-summit-2017?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/11/dear-cios-stop-beating-yourselves-being-behind-transformation
|
||||
[9]:https://www.redhat.com/en/resources/macquarie-bank-case-study?intcmp=701f2000000tjyaAAA
|
||||
[10]:https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
[11]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,73 @@
|
||||
5 of the Best Linux Dark Themes that Are Easy on the Eyes
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are several reasons people opt for dark themes on their computers. Some find them easy on the eye while others prefer them because of their medical condition. Programmers, especially, like dark themes because they reduce glare on the eyes.
|
||||
|
||||
If you are a Linux user and a dark theme lover, you are in luck. Here are five of the best dark themes for Linux. Check them out!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
As its name implies, this theme is inspired by OS X. It is a flat theme based on Arc. The theme supports GTK 3 and GTK 2 desktop environments, so Gnome, Cinnamon, Unity, Manjaro, Mate, and XFCE users can install and use the theme. [OSX-Arc-Shadow][2] is part of the OSX-Arc theme collection. The collection has several other themes (dark and light) included. You can download the whole collection and just use the dark variants.
|
||||
|
||||
Debian- and Ubuntu-based distro users have the option of installing the stable release using the .deb files found on this [page][3]. The compressed source files are also on the same page. Arch Linux users, check out this [AUR link][4]. Finally, to install the theme manually, extract the zip content to the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
The theme is only a few days old. It has a darker look compared to OSX-Arc-Shadow and red selection outlines. It is especially appealing to those who want more contrast and less glare from the computer screen. Hence, It reduces distraction when used at night or in places with low lights. It supports GTK 3 and GTK2.
|
||||
|
||||
Head to [gnome-looks][6] to download the theme under the "Files" menu. The installation procedure is simple: extract the theme into the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux is another simple dark theme based on Materia Theme. It has a neutral dark color tone and is not overly fancy. The contrast between the selection outlines is also minimal and not as sharp as the red color in Kiss-Kool-Red. The theme is truly made with reduction of eye strain in mind.
|
||||
|
||||
[Download the compressed file][8] and unzip it into your "~/.themes" folder. Then, you can set it as your theme. You can check [its GitHub page][9] for the latest additions.
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark is a completely dark theme. For those who like a little more darkness, this theme is definitely one to consider. Moreover, it also reduces the amount of glare from the computer screen. Additionally, it supports Unity. [Download Deepin Dark here][11].
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 is a simple dark theme, so it makes the important details stand out. It helps with focus as is not unnecessarily fancy. It is very similar to Deepin Dark. Especially relevant to Ubuntu users, it is compatible with Ubuntu 17.04. You can download and try it from [here][13].
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you use a computer for a very long time, dark themes are a great way to reduce the strain on your eyes. Even if you don't, dark themes can help you in many other ways like improving your focus. Let us know which is your favorite.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
153
sources/talk/20180119 PlayOnLinux For Easier Use Of Wine.md
Normal file
153
sources/talk/20180119 PlayOnLinux For Easier Use Of Wine.md
Normal file
@ -0,0 +1,153 @@
|
||||
PlayOnLinux For Easier Use Of Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
[PlayOnLinux][1] is a free program that helps to install, run, and manage Windows software on Linux. It can also manage virtual C: drives (known as Wine prefixes), and download and install certain Windows libraries for getting some software to run on Wine properly. Creating different drives using different Wine versions is also possible. It is very handy because what runs well in one version may not run as well (if at all) on a newer version. There is [PlayOnMac][2] for macOS and PlayOnBSD for FreeBSD.
|
||||
|
||||
[Wine][3] is the compatibility layer that allows many programs developed for Windows to run under operating systems such as Linux, FreeBSD, macOS and other UNIX systems. The app database ([AppDB][4]) gives users an overview of a multitude of programs that will function on Wine, however successfully.
|
||||
|
||||
Both programs can be obtained using your distribution’s software center or package manager for convenience.
|
||||
|
||||
### Installing Programs Using PlayOnLinux
|
||||
|
||||
Installing software is easy. PlayOnLinux has hundreds of scripts to aid in installing different software with which to run the setup. In the sidebar, select “Install Software”. You will find several categories to choose from.
|
||||
|
||||
|
||||
|
||||
Hundreds of games can be installed this way.
|
||||
|
||||
[][5]
|
||||
|
||||
Office software can be installed as well, including Microsoft Office as shown here.
|
||||
|
||||
[][6]
|
||||
|
||||
Let’s install Notepad++ using the script. You can select the script to read the compatibility rating according to PlayOnLinux, and an overview of the program. To get a better idea of compatibility, refer to the WineHQ App Database and find “Browse Apps” to find a program like Notepad++.
|
||||
|
||||
[][7]
|
||||
|
||||
Once you press “Install”, if you are using PlayOnLinux for the first time, you will encounter two popups: one to give you tips when installing programs with a script, and the other to not submit bug reports to WineHQ because PlayOnLinux has nothing to do with them.
|
||||
|
||||
|
||||
|
||||
During the installation, I was given the choice to either download the setup executable, or select one on the computer. I downloaded the file but received a File Mismatch error; however, I continued and it was successful. It’s not perfect, but it is functional. (It is possible to submit bug reports to PlayOnLinux if the option is given.)
|
||||
|
||||
[][8]
|
||||
|
||||
Nevertheless, I was able to install Notepad++ successfully, run it, and update it to the latest version (at the time of writing 7.5.3) from version 7.4.2.
|
||||
|
||||
|
||||
|
||||
Also during installation, it created a virtual C: drive specifically for Notepad++. As there are no other Wine versions available for PlayOnLinux to use, it defaults to using the version installed on the system. In this case, it is more than adequate for Notepad++ to run smoothly.
|
||||
|
||||
### Installing Non-Listed Programs
|
||||
|
||||
You can also install a program that is not on the list by pressing “Install Non-Listed Program” on the bottom-left corner of the install menu. Bear in mind that there is no script to install certain libraries to make things work properly. You will need to do this yourself. Look at the Wine AppDB for information for your program. Also, if the app isn’t listed, it doesn’t mean that it won’t work with Wine. It just means no one has given any information about it.
|
||||
|
||||
|
||||
|
||||
I’ve installed Graphmatica, a graph plotting program, using this method. First I selected the option to install it on a new virtual drive.
|
||||
|
||||
[][9]
|
||||
|
||||
Then I selected the option to install additional libraries after creating the drive and select a Wine version to use in doing so.
|
||||
|
||||
[][10]
|
||||
|
||||
I then proceeded to select Gecko (which encountered an error for some reason), and Mono 2.10 to install.
|
||||
|
||||
[][11]
|
||||
|
||||
Finally, I installed Graphmatica. It’s as simple as that.
|
||||
|
||||
[][12]
|
||||
|
||||
A launcher can be created after installation. A list of executables found in the drive will appear. Search for the app executable (may not always be obvious) which may have its icon, select it and give it a display name. The icon will appear on the desktop.
|
||||
|
||||
[][13]
|
||||
[][14]
|
||||
|
||||
### Multiple “C:” Drives
|
||||
|
||||
Now that we have easily installed a program, let’s have a look at the drive configuration. In the main window, press “Configure” in the toolbar and this window will show.
|
||||
|
||||
[][15]
|
||||
|
||||
On the left are the drives that are found within PlayOnLinux. To the right, the “General” tab allows you to create shortcuts of programs installed on that virtual drive.
|
||||
|
||||
|
||||
|
||||
The “Wine” tab has 8 buttons, including those to launch the Wine configuration program (winecfg), control panel, registry editor, command prompt, etc.
|
||||
|
||||
[][16]
|
||||
|
||||
“Install Components” allows you to select different Windows libraries like DirectX 9, .NET Framework versions 2 – 4.5, Visual C++ runtime, etc., like [winetricks][17].
|
||||
|
||||
[][18]
|
||||
|
||||
“Display” allows the user to control advanced graphics settings like GLSL support, video memory size, and more. And “Miscellaneous” is for other actions like running an executable found anywhere on the computer to be run under the selected virtual drive.
|
||||
|
||||
### Creating Virtual Drives Without Installing Programs
|
||||
|
||||
To create a drive without installing software, simply press “New” below the list of drives to launch the virtual drive creator. Drives are created using the same method used in installing programs not found in the install menu. Follow the prompts, select either a 32-bit or 64-bit installation (in this case we only have 32-bit versions so select 32-bit), choose the Wine version, and give the drive a name. Once completed, it will appear in the drive list.
|
||||
|
||||
[][19]
|
||||
|
||||
### Managing Wine Versions
|
||||
|
||||
Entire Wine versions can be downloaded using the manager. To access this through the menu bar, press “Tools” and select “Manage Wine versions”. Sometimes different software can behave differently between Wine versions. A Wine update can break something that made your application work in the previous version; thus rendering the application broken or completely unusable. Therefore, this feature is one of the highlights of PlayOnLinux.
|
||||
|
||||
|
||||
|
||||
If you’re still on the configuration window, in the “General” tab, you can also access the version manager by pressing the “+” button next to the Wine version field.
|
||||
|
||||
[][20]
|
||||
|
||||
To install a version of Wine (32-bit or 64-bit), simply select the version, and press the “>” button to download and install it. After installation, if setup executables for Mono, and/or the Gecko HTML engine have not yet been downloaded by PlayOnLinux, they will be downloaded.
|
||||
|
||||
|
||||
|
||||
I went ahead and installed the 2.21-staging version of Wine afterward.
|
||||
|
||||
[][21]
|
||||
|
||||
To remove a version, press the “<” button.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article demonstrated how to use PlayOnLinux to easily install Windows software into separate virtual C: drives, create and manage virtual drives, and manage several Wine versions. The software isn’t perfect, but it is still functional and useful. Managing different drives with different Wine versions is one of the key features of PlayOnLinux. It is a lot easier to use a front-end for Wine such as PlayOnLinux than pure Wine.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/playonlinux-for-easier-use-of-wine
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.playonlinux.com/en/
|
||||
[2]:https://www.playonmac.com
|
||||
[3]:https://www.winehq.org/
|
||||
[4]:http://appdb.winehq.org/
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_1_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_2_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_3_orig.png
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_4_orig.png
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_5_orig.png
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_6_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_7_orig.png
|
||||
[13]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_8_orig.png
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_9_orig.png
|
||||
[15]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_10_orig.png
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_11_orig.png
|
||||
[17]:https://github.com/Winetricks/winetricks
|
||||
[18]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_12_orig.png
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_13_orig.png
|
||||
[20]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_14_orig.png
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_15_orig.png
|
||||
130
sources/talk/20180122 An overview of the Perl 5 engine.md
Normal file
130
sources/talk/20180122 An overview of the Perl 5 engine.md
Normal file
@ -0,0 +1,130 @@
|
||||
An overview of the Perl 5 engine
|
||||
======
|
||||
|
||||
|
||||
|
||||
As I described in "[My DeLorean runs Perl][1]," switching to Perl has vastly improved my development speed and possibilities. Here I'll dive deeper into the design of Perl 5 to discuss aspects important to systems programming.
|
||||
|
||||
Some years ago, I wrote "OpenGL bindings for Bash" as sort of a joke. The implementation was simply an X11 program written in C that read OpenGL calls on [stdin][2] (yes, as text) and emitted user input on [stdout][3] . Then I had a littlefile that would declare all the OpenGL functions as Bash functions, which echoed the name of the function into a pipe, starting the GL interpreter process if it wasn't already running. The point of the exercise was to show that OpenGL (the 1.4 API, not the newer shader stuff) could render a lot of graphics with just a few calls per frame by using GL display lists. The OpenGL library did all the heavy lifting, and Bash just printed a few dozen lines of text per frame.
|
||||
|
||||
In the end though, Bash is a really horrible [glue language][4], both from high overhead and limited available operations and syntax. [Perl][5], on the other hand, is a great glue language.
|
||||
|
||||
### Syntax aside...
|
||||
|
||||
If you're not a regular Perl user, the first thing you probably notice is the syntax.
|
||||
|
||||
Perl 5 is built on a long legacy of awkward syntax, but more recent versions have removed the need for much of the punctuation. The remaining warts can mostly be avoided by choosing modules that give you domain-specific "syntactic sugar," which even alter the Perl syntax as it is parsed. This is in stark contrast to most other languages, where you are stuck with the syntax you're given, and infinitely more flexible than C's macros. Combined with Perl's powerful sparse-syntax operators, like `map`, `grep`, `sort`, and similar user-defined operators, I can almost always write complex algorithms more legibly and with less typing using Perl than with JavaScript, PHP, or any compiled language.
|
||||
|
||||
So, because syntax is what you make of it, I think the underlying machine is the most important aspect of the language to consider. Perl 5 has a very capable engine, and it differs in interesting and useful ways from other languages.
|
||||
|
||||
### A layer above C
|
||||
|
||||
I don't recommend anyone start working with Perl by looking at the interpreter's internal API, but a quick description is useful. One of the main problems we deal with in the world of C is acquiring and releasing memory while also supporting control flow through a chain of function calls. C has a rough ability to throw exceptions using `longjmp`, but it doesn't do any cleanup for you, so it is almost useless without a framework to manage resources. The Perl interpreter is exactly this sort of framework.
|
||||
|
||||
Perl provides a stack of variables independent from C's stack of function calls on which you can mark the logical boundaries of a Perl scope. There are also API calls you can use to allocate memory, Perl variables, etc., and tell Perl to automatically free them at the end of the Perl scope. Now you can make whatever C calls you like, "die" out of the middle of them, and let Perl clean everything up for you.
|
||||
|
||||
Although this is a really unconventional perspective, I bring it up to emphasize that Perl sits on top of C and allows you to use as much or as little interpreted overhead as you like. Perl's internal API is certainly not as nice as C++ for general programming, but C++ doesn't give you an interpreted language on top of your work when you're done. I've lost track of the number of times that I wanted reflective capability to inspect or alter my C++ objects, and following that rabbit hole has derailed more than one of my personal projects.
|
||||
|
||||
### Lisp-like functions
|
||||
|
||||
Perl functions take a list of arguments. The downside is that you have to do argument count and type checking at runtime. The upside is you don't end up doing that much, because you can just let the interpreter's own runtime check catch those mistakes. You can also create the effect of C++'s overloaded functions by inspecting the arguments you were given and behaving accordingly.
|
||||
|
||||
Because arguments are a list, and return values are a list, this encourages [Lisp-style programming][6], where you use a series of functions to filter a list of data elements. This "piping" or "streaming" effect can result in some really complicated loops turning into a single line of code.
|
||||
|
||||
Every function is available to the language as a `coderef` that can be passed around in variables, including anonymous closure functions. Also, I find `sub {}` more convenient to type than JavaScript's `function(){}` or C++11's `[&](){}`.
|
||||
|
||||
### Generic data structures
|
||||
|
||||
The variables in Perl are either "scalars," references, arrays, or "hashes" ... or some other stuff that I'll skip.
|
||||
|
||||
Scalars act as a string/integer/float hybrid and are automatically typecast as needed for the purpose you are using them. In other words, instead of determining the operation by the type of variable, the type of operator determines how the variable should be interpreted. This is less efficient than if the language knows the type in advance, but not as inefficient as, for example, shell scripting because Perl caches the type conversions.
|
||||
|
||||
Perl scalars may contain null characters, so they are fully usable as buffers for binary data. The scalars are mutable and copied by value, but optimized with copy-on-write, and substring operations are also optimized. Strings support unicode characters but are stored efficiently as normal bytes until you append a codepoint above 255.
|
||||
|
||||
References (which are considered scalars as well) hold a reference to any other variable; `hashrefs` and `arrayrefs` are most common, along with the `coderefs` described above.
|
||||
|
||||
Arrays are simply a dynamic-length array of scalars (or references).
|
||||
|
||||
Hashes (i.e., dictionaries, maps, or whatever you want to call them) are a performance-tuned hash table implementation where every key is a string and every value is a scalar (or reference). Hashes are used in Perl in the same way structs are used in C. Clearly a hash is less efficient than a struct, but it keeps things generic so tasks that require dozens of lines of code in other languages can become one-liners in Perl. For instance, you can dump the contents of a hash into a list of (key, value) pairs or reconstruct a hash from such a list as a natural part of the Perl syntax.
|
||||
|
||||
### Object model
|
||||
|
||||
Any reference can be "blessed" to make it into an object, granting it a multiple-inheritance method-dispatch table. The blessing is simply the name of a package (namespace), and any function in that namespace becomes an available method of the object. The inheritance tree is defined by variables in the package. As a result, you can make modifications to classes or class hierarchies or create new classes on the fly with simple data edits, rather than special keywords or built-in reflection APIs. By combining this with Perl's `local` keyword (where changes to a global are automatically undone at the end of the current scope), you can even make temporary changes to class methods or inheritance!
|
||||
|
||||
Perl objects only have methods, so attributes are accessed via accessors like the canonical Java `get_` and `set_` methods. Perl authors usually combine them into a single method of just the attribute name and differentiate `get` from `set` by whether a parameter was given.
|
||||
|
||||
You can also "re-bless" objects from one class to another, which enables interesting tricks not available in most other languages. Consider state machines, where each method would normally start by checking the object's current state; you can avoid that in Perl by swapping the method table to one that matches the object's state.
|
||||
|
||||
### Visibility
|
||||
|
||||
While other languages spend a bunch of effort on access rules between classes, Perl adopted a simple "if the name begins with underscore, don't touch it unless it's yours" convention. Although I can see how this could be a problem with an undisciplined software team, it has worked great in my experience. The only thing C++'s `private` keyword ever did for me was impair my debugging efforts, yet it felt dirty to make everything `public`. Perl removes my guilt.
|
||||
|
||||
Likewise, an object provides methods, but you can ignore them and just access the underlying Perl data structure. This is another huge boost for debugging.
|
||||
|
||||
### Garbage collection via reference counting
|
||||
|
||||
Although [reference counting][7] is a rather leak-prone form of memory management (it doesn't detect cycles), it has a few upsides. It gives you deterministic destruction of your objects, like in C++, and never interrupts your program with a surprise garbage collection. It strongly encourages module authors to use a tree-of-objects pattern, which I much prefer vs. the tangle-of-objects pattern often seen in Java and JavaScript. (I've found trees to be much more easily tested with unit tests.) But, if you need a tangle of objects, Perl does offer "weak" references, which won't be considered when deciding if it's time to garbage-collect something.
|
||||
|
||||
On the whole, the only time this ever bites me is when making heavy use of closures for event-driven callbacks. It's easy to have an object hold a reference to an event handle holding a reference to a callback that references the containing object. Again, weak references solve this, but it's an extra thing to be aware of that JavaScript or Python don't make you worry about.
|
||||
|
||||
### Parallelism
|
||||
|
||||
The Perl interpreter is a single thread, although modules written in C can use threads of their own internally, and Perl often includes support for multiple interpreters within the same process.
|
||||
|
||||
Although this is a large limitation, knowing that a data structure will only ever be touched by one thread is nice, and it means you don't need locks when accessing them from C code. Even in Java, where locking is built into the syntax in convenient ways, it can be a real time sink to reason through all the ways that threads can interact (and especially annoying that they force you to deal with that in every GUI program you write).
|
||||
|
||||
There are several event libraries available to assist in writing event-driven callback programs in the style of Node.js to avoid the need for threads.
|
||||
|
||||
### Access to C libraries
|
||||
|
||||
Aside from directly writing your own C extensions via Perl's [XS][8] system, there are already lots of common C libraries wrapped for you and available on Perl's [CPAN][9] repository. There is also a great module, [Inline::C][10], that takes most of the pain out of bridging between Perl and C, to the point where you just paste C code into the middle of a Perl module. (It compiles the first time you run it and caches the .so shared object file for subsequent runs.) You still need to learn some of the Perl interpreter API if you want to manipulate the Perl stack or pack/unpack Perl's variables other than your C function arguments and return value.
|
||||
|
||||
### Memory usage
|
||||
|
||||
Perl can use a surprising amount of memory, especially if you make use of heavyweight libraries and create thousands of objects, but with the size of today's systems it usually doesn't matter. It also isn't much worse than other interpreted systems. My personal preference is to only use lightweight libraries, which also generally improve performance.
|
||||
|
||||
### Startup speed
|
||||
|
||||
The Perl interpreter starts in under five milliseconds on modern hardware. If you take care to use only lightweight modules, you can use Perl for anything you might have used Bash for, like `hotplug` scripts.
|
||||
|
||||
### Regex implementation
|
||||
|
||||
Perl provides the mother of all regex implementations... but you probably already knew that. Regular expressions are built into Perl's syntax rather than being an object-oriented or function-based API; this helps encourage their use for any text processing you might need to do.
|
||||
|
||||
### Ubiquity and stability
|
||||
|
||||
Perl 5 is installed on just about every modern Unix system, and the CPAN module collection is extensive and easy to install. There's a production-quality module for almost any task, with solid test coverage and good documentation.
|
||||
|
||||
Perl 5 has nearly complete backward compatibility across two decades of releases. The community has embraced this as well, so most of CPAN is pretty stable. There's even a crew of testers who run unit tests on all of CPAN on a regular basis to help detect breakage.
|
||||
|
||||
The toolchain is also pretty solid. The documentation syntax (POD) is a little more verbose than I'd like, but it yields much more useful results than [doxygen][11] or [Javadoc][12]. You can run `perldoc FILENAME` to instantly see the documentation of the module you're writing. `perldoc Module::Name` shows you the specific documentation for the version of the module that you would load from your `include` path and can likewise show you the source code of that module without needing to browse deep into your filesystem.
|
||||
|
||||
The testcase system (the `prove` command and Test Anything Protocol, or TAP) isn't specific to Perl and is extremely simple to work with (as opposed to unit testing based around language-specific object-oriented structure, or XML). Modules like `Test::More` make writing the test cases so easy that you can write a test suite in about the same time it would take to test your module once by hand. The testing effort barrier is so low that I've started using TAP and the POD documentation style for my non-Perl projects as well.
|
||||
|
||||
### In summary
|
||||
|
||||
Perl 5 still has a lot to offer despite the large number of newer languages competing with it. The frontend syntax hasn't stopped evolving, and you can improve it however you like with custom modules. The Perl 5 engine is capable of handling most programming problems you can throw at it, and it is even suitable for low-level work as a "glue" layer on top of C libraries. Once you get really familiar with it, it can even be an environment for developing C code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/why-i-love-perl-5
|
||||
|
||||
作者:[Michael Conrad][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nerdvana
|
||||
[1]:https://opensource.com/article/17/12/my-delorean-runs-perl
|
||||
[2]:https://en.wikipedia.org/wiki/Standard_streams#Standard_input_(stdin)
|
||||
[3]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_(stdout)
|
||||
[4]:https://www.techopedia.com/definition/19608/glue-language
|
||||
[5]:https://www.perl.org/
|
||||
[6]:https://en.wikipedia.org/wiki/Lisp_(programming_language)
|
||||
[7]:https://en.wikipedia.org/wiki/Reference_counting
|
||||
[8]:https://en.wikipedia.org/wiki/XS_(Perl)
|
||||
[9]:https://www.cpan.org/
|
||||
[10]:https://metacpan.org/pod/distribution/Inline-C/lib/Inline/C.pod
|
||||
[11]:http://www.stack.nl/~dimitri/doxygen/
|
||||
[12]:http://www.oracle.com/technetwork/java/javase/documentation/index-jsp-135444.html
|
||||
@ -0,0 +1,75 @@
|
||||
Ick: a continuous integration system
|
||||
======
|
||||
**TL;DR:** Ick is a continuous integration or CI system. See <http://ick.liw.fi/> for more information.
|
||||
|
||||
More verbose version follows.
|
||||
|
||||
### First public version released
|
||||
|
||||
The world may not need yet another continuous integration system (CI), but I do. I've been unsatisfied with the ones I've tried or looked at. More importantly, I am interested in a few things that are more powerful than what I've ever even heard of. So I've started writing my own.
|
||||
|
||||
My new personal hobby project is called ick. It is a CI system, which means it can run automated steps for building and testing software. The home page is at <http://ick.liw.fi/>, and the [download][1] page has links to the source code and .deb packages and an Ansible playbook for installing it.
|
||||
|
||||
I have now made the first publicly advertised release, dubbed ALPHA-1, version number 0.23. It is of alpha quality, and that means it doesn't have all the intended features and if any of the features it does have work, you should consider yourself lucky.
|
||||
|
||||
### Invitation to contribute
|
||||
|
||||
Ick has so far been my personal project. I am hoping to make it more than that, and invite contributions. See the [governance][2] page for the constitution, the [getting started][3] page for tips on how to start contributing, and the [contact][4] page for how to get in touch.
|
||||
|
||||
### Architecture
|
||||
|
||||
Ick has an architecture consisting of several components that communicate over HTTPS using RESTful APIs and JSON for structured data. See the [architecture][5] page for details.
|
||||
|
||||
### Manifesto
|
||||
|
||||
Continuous integration (CI) is a powerful tool for software development. It should not be tedious, fragile, or annoying. It should be quick and simple to set up, and work quietly in the background unless there's a problem in the code being built and tested.
|
||||
|
||||
A CI system should be simple, easy, clear, clean, scalable, fast, comprehensible, transparent, reliable, and boost your productivity to get things done. It should not be a lot of effort to set up, require a lot of hardware just for the CI, need frequent attention for it to keep working, and developers should never have to wonder why something isn't working.
|
||||
|
||||
A CI system should be flexible to suit your build and test needs. It should support multiple types of workers, as far as CPU architecture and operating system version are concerned.
|
||||
|
||||
Also, like all software, CI should be fully and completely free software and your instance should be under your control.
|
||||
|
||||
(Ick is little of this yet, but it will try to become all of it. In the best possible taste.)
|
||||
|
||||
### Dreams of the future
|
||||
|
||||
In the long run, I would ick to have features like ones described below. It may take a while to get all of them implemented.
|
||||
|
||||
* A build may be triggered by a variety of events. Time is an obvious event, as is source code repository for the project changing. More powerfully, any build dependency changing, regardless of whether the dependency comes from another project built by ick, or a package from, say, Debian: ick should keep track of all the packages that get installed into the build environment of a project, and if any of their versions change, it should trigger the project build and tests again.
|
||||
|
||||
* Ick should support building in (or against) any reasonable target, including any Linux distribution, any free operating system, and any non-free operating system that isn't brain-dead.
|
||||
|
||||
* Ick should manage the build environment itself, and be able to do builds that are isolated from the build host or the network. This partially works: one can ask ick to build a container and run a build in the container. The container is implemented using systemd-nspawn. This can be improved upon, however. (If you think Docker is the only way to go, please contribute support for that.)
|
||||
|
||||
* Ick should support any workers that it can control over ssh or a serial port or other such neutral communication channel, without having to install an agent of any kind on them. Ick won't assume that it can have, say, a full Java run time, so that the worker can be, say, a micro controller.
|
||||
|
||||
* Ick should be able to effortlessly handle very large numbers of projects. I'm thinking here that it should be able to keep up with building everything in Debian, whenever a new Debian source package is uploaded. (Obviously whether that is feasible depends on whether there are enough resources to actually build things, but ick itself should not be the bottleneck.)
|
||||
|
||||
* Ick should optionally provision workers as needed. If all workers of a certain type are busy, and ick's been configured to allow using more resources, it should do so. This seems like it would be easy to do with virtual machines, containers, cloud providers, etc.
|
||||
|
||||
* Ick should be flexible in how it can notify interested parties, particularly about failures. It should allow an interested party to ask to be notified over IRC, Matrix, Mastodon, Twitter, email, SMS, or even by a phone call and speech syntethiser. "Hello, interested party. It is 04:00 and you wanted to be told when the hello package has been built for RISC-V."
|
||||
|
||||
|
||||
|
||||
|
||||
### Please give feedback
|
||||
|
||||
If you try ick, or even if you've just read this far, please share your thoughts on it. See the [contact][4] page for where to send it. Public feedback is preferred over private, but if you prefer private, that's OK too.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/
|
||||
|
||||
作者:[Lars Wirzenius][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.liw.fi/
|
||||
[1]:http://ick.liw.fi/download/
|
||||
[2]:http://ick.liw.fi/governance/
|
||||
[3]:http://ick.liw.fi/getting-started/
|
||||
[4]:http://ick.liw.fi/contact/
|
||||
[5]:http://ick.liw.fi/architecture/
|
||||
58
sources/talk/20180122 Raspberry Pi Alternatives.md
Normal file
58
sources/talk/20180122 Raspberry Pi Alternatives.md
Normal file
@ -0,0 +1,58 @@
|
||||
Raspberry Pi Alternatives
|
||||
======
|
||||
A look at some of the many interesting Raspberry Pi competitors.
|
||||
|
||||
The phenomenon behind the Raspberry Pi computer series has been pretty amazing. It's obvious why it has become so popular for Linux projects—it's a low-cost computer that's actually quite capable for the price, and the GPIO pins allow you to use it in a number of electronics projects such that it starts to cross over into Arduino territory in some cases. Its overall popularity has spawned many different add-ons and accessories, not to mention step-by-step guides on how to use the platform. I've personally written about Raspberry Pis often in this space, and in my own home, I use one to control a beer fermentation fridge, one as my media PC, one to control my 3D printer and one as a handheld gaming device.
|
||||
|
||||
The popularity of the Raspberry Pi also has spawned competition, and there are all kinds of other small, low-cost, Linux-powered Raspberry Pi-like computers for sale—many of which even go so far as to add "Pi" to their names. These computers aren't just clones, however. Although some share a similar form factor to the Raspberry Pi, and many also copy the GPIO pinouts, in many cases, these other computers offer features unavailable in a traditional Raspberry Pi. Some boards offer SATA, Wi-Fi or Gigabit networking; others offer USB3, and still others offer higher-performance CPUs or more RAM. When you are choosing a low-power computer for a project or as a home server, it pays to be aware of these Raspberry Pi alternatives, as in many cases, they will perform much better. So in this article, I discuss some alternatives to Raspberry Pis that I've used personally, their pros and cons, and then provide some examples of where they work best.
|
||||
|
||||
### Banana Pi
|
||||
|
||||
I've mentioned the Banana Pi before in past articles (see "Papa's Got a Brand New NAS" in the September 2016 issue and "Banana Backups" in the September 2017 issue), and it's a great choice when you want a board with a similar form factor, similar CPU and RAM specs, and a similar price (~$30) to a Raspberry Pi but need faster I/O. The Raspberry Pi product line is used for a lot of home server projects, but it limits you to 10/100 networking and a USB2 port for additional storage. Where the Banana Pi product line really shines is in the fact that it includes both a Gigabit network port and SATA port, while still having similar GPIO expansion options and running around the same price as a Raspberry Pi.
|
||||
|
||||
Before I settled on an Odroid XU4 for my home NAS (more on that later), I first experimented with a cluster of Banana Pis. The idea was to attach a SATA disk to each Banana Pi and use software like Ceph or GlusterFS to create a storage cluster shared over the network. Even though any individual Banana Pi wasn't necessarily that fast, considering how cheap they are in aggregate, they should be able to perform reasonably well and allow you to expand your storage by adding another disk and another Banana Pi. In the end, I decided to go a more traditional and simpler route with a single server and software RAID, and now I use one Banana Pi as an image gallery server. I attached a 2.5" laptop SATA drive to the other and use it as a local backup server running BackupPC. It's a nice solution that takes up almost no space and little power to run.
|
||||
|
||||
### Orange Pi Zero
|
||||
|
||||
I was really excited when I first heard about the Raspberry Pi Zero project. I couldn't believe there was such a capable little computer for only $5, and I started imagining all of the cool projects I could use one for around the house. That initial excitement was dampened a bit by the fact that they sold out quickly, and just about every vendor settled into the same pattern: put standalone Raspberry Pi Zeros on backorder but have special $20 starter kits in stock that include various adapter cables, a micro SD card and a plastic case that I didn't need. More than a year after the release, the situation still remains largely the same. Although I did get one Pi Zero and used it for a cool Adafruit "Pi Grrl Zero" gaming project, I had to put the rest of my ideas on hold, because they just never seemed to be in stock when I wanted them.
|
||||
|
||||
The Orange Pi Zero was created by the same company that makes the entire line of Orange Pi computers that compete with the Raspberry Pi. The main thing that makes the Orange Pi Zero shine in my mind is that they have a small, square form factor that is wider than a Raspberry Pi Zero but not as long. It also includes a Wi-Fi card like the more expensive Raspberry Pi Zero W, and it runs between $6 and $9, depending on whether you opt for 256MB of RAM or 512MB of RAM. More important, they are generally in stock, so there's no need to sit on a backorder list when you have a fun project in mind.
|
||||
|
||||
The Orange Pi Zero boards themselves are pretty capable. Out of the box, they include a quad-core ARM CPU, Wi-Fi (as I mentioned before), along with a 10/100 network port and USB2\. They also include Raspberry-Pi-compatible GPIO pins, but even more interesting is that there is a $9 "NAS" expansion board for it that mounts to its 13-pin header and provides extra USB2 ports, a SATA and mSATA port, along with an IR and audio and video ports, which makes it about as capable as a more expensive Banana Pi board. Even without the expansion board, this would make a nice computer you could sit anywhere within range of your Wi-Fi and run any number of services. The main downside is you are limited to composite video, so this isn't the best choice for gaming or video-based projects.
|
||||
|
||||
Although Orange Pi Zeros are capable boards in their own right, what makes them particularly enticing to me is that they are actually available when you want them, unlike some of the other sub-$10 boards out there. There's nothing worse than having a cool idea for a cheap home project and then having to wait for a board to come off backorder.
|
||||
|
||||

|
||||
|
||||
Figure 1\. An Orange Pi Zero (right) and an Espressobin (left)
|
||||
|
||||
### Odroid XU4
|
||||
|
||||
When I was looking to replace my rack-mounted NAS at home, I first looked at all of the Raspberry Pi options, including Banana Pi and other alternatives, but none of them seemed to have quite enough horsepower for my needs. I needed a machine that not only offered Gigabit networking to act as a NAS, but one that had high-speed disk I/O as well. The Odroid XU4 fit the bill with its eight-core ARM CPU, 2GB RAM, Gigabit network and USB3 ports. Although it was around $75 (almost twice the price of a Raspberry Pi), it was a much more capable computer all while being small and low-power.
|
||||
|
||||
The entire Odroid product line is a good one to consider if you want a low-power home server but need more resources than a traditional Raspberry Pi can offer and are willing to spend a little bit extra for the privilege. In addition to a NAS, the Odroid XU4, with its more powerful CPU and extra RAM, is a good all-around server for the home. The USB3 port means you have a lot of storage options should you need them.
|
||||
|
||||
### Espressobin
|
||||
|
||||
Although the Odroid XU4 is a great home server, I still sometimes can see that it gets bogged down in disk and network I/O compared to a traditional higher-powered server. Some of this might be due to the chips that were selected for the board, and perhaps some of it has to do with the fact that I'm using both disk encryption and software RAID over USB3\. In either case, I started looking for another option to help take a bit of the storage burden off this server, and I came across the Espressobin board.
|
||||
|
||||
The Espressobin is a $50 board that launched as a popular Indiegogo campaign and is now a shipping product that you can pick up in a number of places, including Amazon. Although it costs a bit more than a Raspberry Pi 3, it includes a 64-bit dual-core ARM Cortex A53 at 1.2GHz, 1–2Gb of RAM (depending on the configuration), three Gigabit network ports with a built-in switch, a SATA port, a USB3 port, a mini-PCIe port, plus a number of other options, including two sets of GPIO headers and a nice built-in serial console running on the micro-USB port.
|
||||
|
||||
The main benefit to the Espressobin is the fact that it was designed by Marvell with chips that actually can use all of the bandwidth that the board touts. In some other boards, often you'll find a SATA2 port that's hanging off a USB2 interface or other architectural hacks that, although they will let you connect a SATA disk or Gigabit networking port, it doesn't mean you'll get the full bandwidth the spec claims. Although I intend to have my own Espressobin take over home NAS duties, it also would make a great home gateway router, general-purpose server or even a Wi-Fi access point, provided you added the right Wi-Fi card.
|
||||
|
||||
### Conclusion
|
||||
|
||||
A whole world of alternatives to Raspberry Pis exists—this list covers only some of the ones I've used myself. I hope it has encouraged you to think twice before you default to a Raspberry Pi for your next project. Although there's certainly nothing wrong with Raspberry Pis, there are several small computers that run Linux well and, in many cases, offer better hardware or other expansion options beyond the capabilities of a Raspberry Pi for a similar price.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/raspberry-pi-alternatives
|
||||
|
||||
作者:[Kyle Rankin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/kyle-rankin
|
||||
@ -0,0 +1,249 @@
|
||||
How To Debug a Bash Shell Script Under Linux or UNIX
|
||||
======
|
||||
From my mailbag:
|
||||
**I wrote a small hello world script. How can I Debug a bash shell scripts running on a Linux or Unix like systems?**
|
||||
It is the most common question asked by new sysadmins or Linux/UNIX user. Shell scripting debugging can be a tedious job (read as not easy). There are various ways to debug a shell script.
|
||||
|
||||
You need to pass the -x or -v argument to bash shell to walk through each line in the script.
|
||||
|
||||
[![How to debug a bash shell script on Linux or Unix][1]][1]
|
||||
|
||||
Let us see how to debug a bash script running on Linux and Unix using various methods.
|
||||
|
||||
### -x option to debug a bash shell script
|
||||
|
||||
Run a shell script with -x option.
|
||||
```
|
||||
$ bash -x script-name
|
||||
$ bash -x domains.sh
|
||||
```
|
||||
|
||||
### Use of set builtin command
|
||||
|
||||
Bash shell offers debugging options which can be turn on or off using the [set command][2]:
|
||||
|
||||
* **set -x** : Display commands and their arguments as they are executed.
|
||||
* **set -v** : Display shell input lines as they are read.
|
||||
|
||||
|
||||
|
||||
You can use above two command in shell script itself:
|
||||
```
|
||||
#!/bin/bash
|
||||
clear
|
||||
|
||||
# turn on debug mode
|
||||
set -x
|
||||
for f in *
|
||||
do
|
||||
file $f
|
||||
done
|
||||
# turn OFF debug mode
|
||||
set +x
|
||||
ls
|
||||
# more commands
|
||||
```
|
||||
|
||||
You can replace the [standard Shebang][3] line:
|
||||
`#!/bin/bash`
|
||||
with the following (for debugging) code:
|
||||
`#!/bin/bash -xv`
|
||||
|
||||
### Use of intelligent DEBUG function
|
||||
|
||||
First, add a special variable called _DEBUG. Set _DEBUG to 'on' when you need to debug a script:
|
||||
`_DEBUG="on"`
|
||||
|
||||
Put the following function at the beginning of the script:
|
||||
```
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
```
|
||||
|
||||
function DEBUG() { [ "$_DEBUG" == "on" ] && $@ }
|
||||
|
||||
Now wherever you need debugging simply use the DEBUG function as follows:
|
||||
`DEBUG echo "File is $filename"`
|
||||
OR
|
||||
```
|
||||
DEBUG set -x
|
||||
Cmd1
|
||||
Cmd2
|
||||
DEBUG set +x
|
||||
```
|
||||
|
||||
When done with debugging (and before moving your script to production) set _DEBUG to 'off'. No need to delete debug lines.
|
||||
`_DEBUG="off" # set to anything but not to 'on'`
|
||||
|
||||
Sample script:
|
||||
```
|
||||
#!/bin/bash
|
||||
_DEBUG="on"
|
||||
function DEBUG()
|
||||
{
|
||||
[ "$_DEBUG" == "on" ] && $@
|
||||
}
|
||||
|
||||
DEBUG echo 'Reading files'
|
||||
for i in *
|
||||
do
|
||||
grep 'something' $i > /dev/null
|
||||
[ $? -eq 0 ] && echo "Found in $i file"
|
||||
done
|
||||
DEBUG set -x
|
||||
a=2
|
||||
b=3
|
||||
c=$(( $a + $b ))
|
||||
DEBUG set +x
|
||||
echo "$a + $b = $c"
|
||||
```
|
||||
|
||||
Save and close the file. Run the script as follows:
|
||||
`$ ./script.sh`
|
||||
Output:
|
||||
```
|
||||
Reading files
|
||||
Found in xyz.txt file
|
||||
+ a=2
|
||||
+ b=3
|
||||
+ c=5
|
||||
+ DEBUG set +x
|
||||
+ '[' on == on ']'
|
||||
+ set +x
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
Now set DEBUG to off (you need to edit the file):
|
||||
`_DEBUG="off"`
|
||||
Run script:
|
||||
`$ ./script.sh`
|
||||
Output:
|
||||
```
|
||||
Found in xyz.txt file
|
||||
2 + 3 = 5
|
||||
|
||||
```
|
||||
|
||||
Above is a simple but quite effective technique. You can also try to use DEBUG as an alias instead of function.
|
||||
|
||||
### Debugging Common Bash Shell Scripting Errors
|
||||
|
||||
Bash or sh or ksh gives various error messages on screen and in many case the error message may not provide detailed information.
|
||||
|
||||
#### Skipping to apply execute permission on the file
|
||||
|
||||
When you [write your first hello world bash shell script][4], you might end up getting an error that read as follows:
|
||||
`bash: ./hello.sh: Permission denied`
|
||||
Set permission using chmod command:
|
||||
```
|
||||
$ chmod +x hello.sh
|
||||
$ ./hello.sh
|
||||
$ bash hello.sh
|
||||
```
|
||||
|
||||
#### End of file unexpected Error
|
||||
|
||||
If you are getting an End of file unexpected error message, open your script file and and make sure it has both opening and closing quotes. In this example, the echo statement has an opening quote but no closing quote:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
|
||||
...
|
||||
....
|
||||
|
||||
|
||||
echo 'Error: File not found
|
||||
^^^^^^^
|
||||
missing quote
|
||||
```
|
||||
|
||||
Also make sure you check for missing parentheses and braces ({}):
|
||||
```
|
||||
#!/bin/bash
|
||||
.....
|
||||
[ ! -d $DIRNAME ] && { echo "Error: Chroot dir not found"; exit 1;
|
||||
^^^^^^^^^^^^^
|
||||
missing brace }
|
||||
...
|
||||
```
|
||||
|
||||
#### Missing Keywords Such As fi, esac, ;;, etc.
|
||||
|
||||
If you missed ending keyword such as fi or ;; you will get an error such as as "xxx unexpected". So make sure all nested if and case statements ends with proper keywords. See bash man page for syntax requirements. In this example, fi is missing:
|
||||
```
|
||||
#!/bin/bash
|
||||
echo "Starting..."
|
||||
....
|
||||
if [ $1 -eq 10 ]
|
||||
then
|
||||
if [ $2 -eq 100 ]
|
||||
then
|
||||
echo "Do something"
|
||||
fi
|
||||
|
||||
for f in $files
|
||||
do
|
||||
echo $f
|
||||
done
|
||||
|
||||
# note fi is missing
|
||||
```
|
||||
|
||||
#### Moving or editing shell script on Windows or Unix boxes
|
||||
|
||||
Do not create the script on Linux/Unix and move to Windows. Another problem is editing the bash shell script on Windows 10 and move/upload to Unix server. It will result in an error like command not found due to the carriage return (DOS CR-LF). You [can convert DOS newlines CR-LF to Unix/Linux format using][5] the following syntax:
|
||||
`dos2unix my-script.sh`
|
||||
|
||||
### Tip 1 - Send Debug Message To stderr
|
||||
|
||||
[Standard error][6] is the default error output device, which is used to write all system error messages. So it is a good idea to send messages to the default error device:
|
||||
```
|
||||
# Write error to stdout
|
||||
echo "Error: $1 file not found"
|
||||
#
|
||||
# Write error to stderr (note 1>&2 at the end of echo command)
|
||||
#
|
||||
echo "Error: $1 file not found" 1>&2
|
||||
```
|
||||
|
||||
### Tip 2 - Turn On Syntax Highlighting when using vim text editor
|
||||
|
||||
Most modern text editors allows you to set syntax highlighting option. This is useful to detect syntax and prevent common errors such as opening or closing quote. You can see bash script in different colors. This feature eases writing in a shell script structures and syntax errors are visually distinct. Highlighting does not affect the meaning of the text itself; it's made only for you. In this example, vim syntax highlighting is used for my bash script:
|
||||
[![How To Debug a Bash Shell Script Under Linux or UNIX Using Vim Syntax Highlighting Feature][7]][7]
|
||||
|
||||
### Tip 3 - Use shellcheck to lint script
|
||||
|
||||
[ShellCheck is a static analysis tool for shell scripts][8]. One can use it to finds bugs in your shell scripts. It is written in Haskell. You can find warnings and suggestions for bash/sh shell scripts with this tool. Let us see how to install and use ShellCheck on a Linux or Unix-like system to enhance your shell scripts, avoid errors and productivity.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
Posted by:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/debugging-shell-script.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/01/How-to-debug-a-bash-shell-script-on-Linux-or-Unix.jpg
|
||||
[2]:https://bash.cyberciti.biz/guide/Set_command
|
||||
[3]:https://bash.cyberciti.biz/guide/Shebang
|
||||
[4]:https://www.cyberciti.biz/faq/hello-world-bash-shell-script/
|
||||
[5]:https://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
|
||||
[6]:https://bash.cyberciti.biz/guide/Standard_error
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2007/01/bash-vim-debug-syntax-highlighting.png
|
||||
[8]:https://www.cyberciti.biz/programming/improve-your-bashsh-shell-script-with-shellcheck-lint-script-analysis-tool/
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,474 @@
|
||||
Top 20 OpenSSH Server Best Security Practices
|
||||
======
|
||||
![OpenSSH Security Tips][1]
|
||||
|
||||
OpenSSH is the implementation of the SSH protocol. OpenSSH is recommended for remote login, making backups, remote file transfer via scp or sftp, and much more. SSH is perfect to keep confidentiality and integrity for data exchanged between two networks and systems. However, the main advantage is server authentication, through the use of public key cryptography. From time to time there are [rumors][2] about OpenSSH zero day exploit. This **page shows how to secure your OpenSSH server running on a Linux or Unix-like system to improve sshd security**.
|
||||
|
||||
|
||||
#### OpenSSH defaults
|
||||
|
||||
* TCP port - 22
|
||||
* OpenSSH server config file - sshd_config (located in /etc/ssh/)
|
||||
|
||||
|
||||
|
||||
#### 1. Use SSH public key based login
|
||||
|
||||
OpenSSH server supports various authentication. It is recommended that you use public key based authentication. First, create the key pair using following ssh-keygen command on your local desktop/laptop:
|
||||
|
||||
DSA and RSA 1024 bit or lower ssh keys are considered weak. Avoid them. RSA keys are chosen over ECDSA keys when backward compatibility is a concern with ssh clients. All ssh keys are either ED25519 or RSA. Do not use any other type.
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
Next, install the public key using ssh-copy-id command:
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
When promoted supply user password. Verify that ssh key based login working for you:
|
||||
`$ ssh vivek@rhel7-aws-server`
|
||||
[![OpenSSH server security best practices][3]][3]
|
||||
For more info on ssh public key auth see:
|
||||
|
||||
* [keychain: Set Up Secure Passwordless SSH Access For Backup Scripts][48]
|
||||
|
||||
* [sshpass: Login To SSH Server / Provide SSH Password Using A Shell Script][49]
|
||||
|
||||
* [How To Setup SSH Keys on a Linux / Unix System][50]
|
||||
|
||||
* [How to upload ssh public key to as authorized_key using Ansible DevOPS tool][51]
|
||||
|
||||
|
||||
#### 2. Disable root user login
|
||||
|
||||
Before we disable root user login, make sure regular user can log in as root. For example, allow vivek user to login as root using the sudo command.
|
||||
|
||||
##### How to add vivek user to sudo group on a Debian/Ubuntu
|
||||
|
||||
Allow members of group sudo to execute any command. [Add user vivek to sudo group][4]:
|
||||
`$ sudo adduser vivek sudo`
|
||||
Verify group membership with [id command][5]
|
||||
`$ id vivek`
|
||||
|
||||
##### How to add vivek user to sudo group on a CentOS/RHEL server
|
||||
|
||||
Allows people in group wheel to run all commands on a CentOS/RHEL and Fedora Linux server. Use the usermod command to add the user named vivek to the wheel group:
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
##### Test sudo access and disable root login for ssh
|
||||
|
||||
Test it and make sure user vivek can log in as root or run the command as root:
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
Once confirmed disable root login by adding the following line to sshd_config:
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
See "[How to disable ssh password login on Linux to increase security][6]" for more info.
|
||||
|
||||
#### 3. Disable password based login
|
||||
|
||||
All password-based logins must be disabled. Only public key based logins are allowed. Add the following in your sshd_config file:
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
Older version of SSHD on CentOS 6.x/RHEL 6.x user should use the following setting:
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
#### 4. Limit Users' ssh access
|
||||
|
||||
By default, all systems user can login via SSH using their password or public key. Sometimes you create UNIX / Linux user account for FTP or email purpose. However, those users can log in to the system using ssh. They will have full access to system tools including compilers and scripting languages such as Perl, Python which can open network ports and do many other fancy things. Only allow root, vivek and jerry user to use the system via SSH, add the following to sshd_config:
|
||||
`AllowUsers vivek jerry`
|
||||
Alternatively, you can allow all users to login via SSH but deny only a few users, with the following line in sshd_config:
|
||||
`DenyUsers root saroj anjali foo`
|
||||
You can also [configure Linux PAM][7] allows or deny login via the sshd server. You can allow [list of group name][8] to access or deny access to the ssh.
|
||||
|
||||
#### 5. Disable Empty Passwords
|
||||
|
||||
You need to explicitly disallow remote login from accounts with empty passwords, update sshd_config with the following line:
|
||||
`PermitEmptyPasswords no`
|
||||
|
||||
#### 6. Use strong passwords and passphrase for ssh users/keys
|
||||
|
||||
It cannot be stressed enough how important it is to use strong user passwords and passphrase for your keys. Brute force attack works because user goes to dictionary based passwords. You can force users to avoid [passwords against a dictionary][9] attack and use [john the ripper tool][10] to find out existing weak passwords. Here is a sample random password generator (put in your ~/.bashrc):
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
Run it:
|
||||
`genpasswd 16`
|
||||
Output:
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
* [Generating Random Password With mkpasswd / makepasswd / pwgen][52]
|
||||
|
||||
* [Linux / UNIX: Generate Passwords][53]
|
||||
|
||||
* [Linux Random Password Generator Command][54]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
#### 7. Firewall SSH TCP port # 22
|
||||
|
||||
You need to firewall ssh TCP port # 22 by updating iptables/ufw/firewall-cmd or pf firewall configurations. Usually, OpenSSH server must only accept connections from your LAN or other remote WAN sites only.
|
||||
|
||||
##### Netfilter (Iptables) Configuration
|
||||
|
||||
Update [/etc/sysconfig/iptables (Redhat and friends specific file) to accept connection][11] only from 192.168.1.0/24 and 202.54.1.5/29, enter:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
If you've dual stacked sshd with IPv6, edit /etc/sysconfig/ip6tables (Redhat and friends specific file), enter:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
Replace ipv6network::/ipv6mask with actual IPv6 ranges.
|
||||
|
||||
##### UFW for Debian/Ubuntu Linux
|
||||
|
||||
[UFW is an acronym for uncomplicated firewall. It is used for managing a Linux firewall][12] and aims to provide an easy to use interface for the user. Use the [following command to accept port 22 from 202.54.1.5/29][13] only:
|
||||
`$ sudo ufw allow from 202.54.1.5/29 to any port 22`
|
||||
Read "[Linux: 25 Iptables Netfilter Firewall Examples For New SysAdmins][14]" for more info.
|
||||
|
||||
##### *BSD PF Firewall Configuration
|
||||
|
||||
If you are using PF firewall update [/etc/pf.conf][15] as follows:
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
#### 8. Change SSH Port and limit IP binding
|
||||
|
||||
By default, SSH listens to all available interfaces and IP address on the system. Limit ssh port binding and change ssh port (many brutes forcing scripts only try to connect to TCP port # 22). To bind to 192.168.1.5 and 202.54.1.5 IPs and port 300, add or correct the following line in sshd_config:
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
Port 300 ListenAddress 192.168.1.5 ListenAddress 202.54.1.5
|
||||
|
||||
A better approach to use proactive approaches scripts such as fail2ban or denyhosts when you want to accept connection from dynamic WAN IP address.
|
||||
|
||||
#### 9. Use TCP wrappers (optional)
|
||||
|
||||
TCP Wrapper is a host-based Networking ACL system, used to filter network access to the Internet. OpenSSH does support TCP wrappers. Just update your /etc/hosts.allow file as follows to allow SSH only from 192.168.1.2 and 172.16.23.12 IP address:
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
See this [FAQ about setting and using TCP wrappers][16] under Linux / Mac OS X and UNIX like operating systems.
|
||||
|
||||
#### 10. Thwart SSH crackers/brute force attacks
|
||||
|
||||
Brute force is a method of defeating a cryptographic scheme by trying a large number of possibilities (combination of users and passwords) using a single or distributed computer network. To prevents brute force attacks against SSH, use the following software:
|
||||
|
||||
* [DenyHosts][17] is a Python based security tool for SSH servers. It is intended to prevent brute force attacks on SSH servers by monitoring invalid login attempts in the authentication log and blocking the originating IP addresses.
|
||||
* Explains how to setup [DenyHosts][18] under RHEL / Fedora and CentOS Linux.
|
||||
* [Fail2ban][19] is a similar program that prevents brute force attacks against SSH.
|
||||
* [sshguard][20] protect hosts from brute force attacks against ssh and other services using pf.
|
||||
* [security/sshblock][21] block abusive SSH login attempts.
|
||||
* [ IPQ BDB filter][22] May be considered as a fail2ban lite.
|
||||
|
||||
|
||||
|
||||
#### 11. Rate-limit incoming traffic at TCP port # 22 (optional)
|
||||
|
||||
Both netfilter and pf provides rate-limit option to perform simple throttling on incoming connections on port # 22.
|
||||
|
||||
##### Iptables Example
|
||||
|
||||
The following example will drop incoming connections which make more than 5 connection attempts upon port 22 within 60 seconds:
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
Call above script from your iptables scripts. Another config option:
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
```
|
||||
|
||||
See iptables man page for more details.
|
||||
|
||||
##### *BSD PF Example
|
||||
|
||||
The following will limits the maximum number of connections per source to 20 and rate limit the number of connections to 15 in a 5 second span. If anyone breaks our rules add them to our abusive_ips table and block them for making any further connections. Finally, flush keyword kills all states created by the matching rule which originate from the host which exceeds these limits.
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
#### 12. Use port knocking (optional)
|
||||
|
||||
[Port knocking][23] is a method of externally opening ports on a firewall by generating a connection attempt on a set of prespecified closed ports. Once a correct sequence of connection attempts is received, the firewall rules are dynamically modified to allow the host which sent the connection attempts to connect to the specific port(s). A sample port Knocking example for ssh using iptables:
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
$IPT -A stage1 -p tcp --dport 3456 -m recent --set --name knock2
|
||||
|
||||
$IPT -N stage2
|
||||
$IPT -A stage2 -m recent --remove --name knock2
|
||||
$IPT -A stage2 -p tcp --dport 2345 -m recent --set --name heaven
|
||||
|
||||
$IPT -N door
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock2 -j stage2
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock -j stage1
|
||||
$IPT -A door -p tcp --dport 1234 -m recent --set --name knock
|
||||
|
||||
$IPT -A INPUT -m --state ESTABLISHED,RELATED -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
|
||||
For more info see:
|
||||
[Debian / Ubuntu: Set Port Knocking With Knockd and Iptables][55]
|
||||
|
||||
#### 13. Configure idle log out timeout interval
|
||||
|
||||
A user can log in to the server via ssh, and you can set an idle timeout interval to avoid unattended ssh session. Open sshd_config and make sure following values are configured:
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
You are setting an idle timeout interval in seconds (300 secs == 5 minutes). After this interval has passed, the idle user will be automatically kicked out (read as logged out). See [how to automatically log BASH / TCSH / SSH users][24] out after a period of inactivity for more details.
|
||||
|
||||
#### 14. Enable a warning banner for ssh users
|
||||
|
||||
Set a warning banner by updating sshd_config with the following line:
|
||||
`Banner /etc/issue`
|
||||
Sample /etc/issue file:
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
By using this IS (which includes any device attached to this IS), you consent to the following conditions:
|
||||
|
||||
+ The XYZG routinely intercepts and monitors communications on this IS for purposes including, but not limited to,
|
||||
penetration testing, COMSEC monitoring, network operations and defense, personnel misconduct (PM),
|
||||
law enforcement (LE), and counterintelligence (CI) investigations.
|
||||
|
||||
+ At any time, the XYZG may inspect and seize data stored on this IS.
|
||||
|
||||
+ Communications using, or data stored on, this IS are not private, are subject to routine monitoring,
|
||||
interception, and search, and may be disclosed or used for any XYZG authorized purpose.
|
||||
|
||||
+ This IS includes security measures (e.g., authentication and access controls) to protect XYZG interests--not
|
||||
for your personal benefit or privacy.
|
||||
|
||||
+ Notwithstanding the above, using this IS does not constitute consent to PM, LE or CI investigative searching
|
||||
or monitoring of the content of privileged communications, or work product, related to personal representation
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Above is a standard sample, consult your legal team for specific user agreement and legal notice details.
|
||||
|
||||
#### 15. Disable .rhosts files (verification)
|
||||
|
||||
Don't read the user's ~/.rhosts and ~/.shosts files. Update sshd_config with the following settings:
|
||||
`IgnoreRhosts yes`
|
||||
SSH can emulate the behavior of the obsolete rsh command, just disable insecure access via RSH.
|
||||
|
||||
#### 16. Disable host-based authentication (verification)
|
||||
|
||||
To disable host-based authentication, update sshd_config with the following option:
|
||||
`HostbasedAuthentication no`
|
||||
|
||||
#### 17. Patch OpenSSH and operating systems
|
||||
|
||||
It is recommended that you use tools such as [yum][25], [apt-get][26], [freebsd-update][27] and others to keep systems up to date with the latest security patches:
|
||||
|
||||
#### 18. Chroot OpenSSH (Lock down users to their home directories)
|
||||
|
||||
By default users are allowed to browse the server directories such as /etc/, /bin and so on. You can protect ssh, using os based chroot or use [special tools such as rssh][28]. With the release of OpenSSH 4.8p1 or 4.9p1, you no longer have to rely on third-party hacks such as rssh or complicated chroot(1) setups to lock users to their home directories. See [this blog post][29] about new ChrootDirectory directive to lock down users to their home directories.
|
||||
|
||||
#### 19. Disable OpenSSH server on client computer
|
||||
|
||||
Workstations and laptop can work without OpenSSH server. If you do not provide the remote login and file transfer capabilities of SSH, disable and remove the SSHD server. CentOS / RHEL users can disable and remove openssh-server with the [yum command][30]:
|
||||
`$ sudo yum erase openssh-server`
|
||||
Debian / Ubuntu Linux user can disable and remove the same with the [apt command][31]/[apt-get command][32]:
|
||||
`$ sudo apt-get remove openssh-server`
|
||||
You may need to update your iptables script to remove ssh exception rule. Under CentOS / RHEL / Fedora edit the files /etc/sysconfig/iptables and /etc/sysconfig/ip6tables. Once done [restart iptables][33] service:
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
#### 20. Bonus tips from Mozilla
|
||||
|
||||
If you are using OpenSSH version 6.7+ or newer try [following][34] settings:
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
# man page. You must understand cryptography to #
|
||||
# tweak following settings. Otherwise use defaults #
|
||||
####################################################
|
||||
|
||||
# Supported HostKey algorithms by order of preference.
|
||||
HostKey /etc/ssh/ssh_host_ed25519_key
|
||||
HostKey /etc/ssh/ssh_host_rsa_key
|
||||
HostKey /etc/ssh/ssh_host_ecdsa_key
|
||||
|
||||
# Specifies the available KEX (Key Exchange) algorithms.
|
||||
KexAlgorithms curve25519-sha256@libssh.org,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256
|
||||
|
||||
# Specifies the ciphers allowed
|
||||
Ciphers chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr
|
||||
|
||||
#Specifies the available MAC (message authentication code) algorithms
|
||||
MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-512,hmac-sha2-256,umac-128@openssh.com
|
||||
|
||||
# LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in.
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
You can grab list of cipher and alog supported by your OpenSSH server using the following commands:
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
$ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
[![OpenSSH Security Tutorial Query Ciphers and algorithms choice][35]][35]
|
||||
|
||||
#### How do I test sshd_config file and restart/reload my SSH server?
|
||||
|
||||
To [check the validity of the configuration file and sanity of the keys][36] for any errors before restarting sshd, run:
|
||||
`$ sudo sshd -t`
|
||||
Extended test mode:
|
||||
`$ sudo sshd -T`
|
||||
Finally [restart sshd on a Linux or Unix like systems][37] as per your distro version:
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
$ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
#### Other susggesions
|
||||
|
||||
1. [Tighter SSH security with 2FA][40] - Multi-Factor authentication can be enabled with [OATH Toolkit][41] or [DuoSecurity][42].
|
||||
2. [Use keychain based authentication][43] - keychain is a special bash script designed to make key-based authentication incredibly convenient and flexible. It offers various security benefits over passphrase-free keys
|
||||
|
||||
|
||||
|
||||
#### See also:
|
||||
|
||||
* The [official OpenSSH][44] project.
|
||||
* Man pages: sshd(8),ssh(1),ssh-add(1),ssh-agent(1)
|
||||
|
||||
|
||||
|
||||
If you have a technique or handy software not mentioned here, please share in the comments below to help your fellow readers keep their OpenSSH based server secure.
|
||||
|
||||
#### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][45], [Facebook][46], [Google+][47].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/openSSH_logo.png
|
||||
[2]:https://isc.sans.edu/diary/OpenSSH+Rumors/6742
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-server-security-best-practices.png
|
||||
[4]:https://www.cyberciti.biz/faq/how-to-create-a-sudo-user-on-ubuntu-linux-server/
|
||||
[5]:https://www.cyberciti.biz/faq/unix-linux-id-command-examples-usage-syntax/ (See Linux/Unix id command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/how-to-disable-ssh-password-login-on-linux/
|
||||
[7]:https://www.cyberciti.biz/tips/linux-pam-configuration-that-allows-or-deny-login-via-the-sshd-server.html
|
||||
[8]:https://www.cyberciti.biz/tips/openssh-deny-or-restrict-access-to-users-and-groups.html
|
||||
[9]:https://www.cyberciti.biz/tips/linux-check-passwords-against-a-dictionary-attack.html
|
||||
[10]:https://www.cyberciti.biz/faq/unix-linux-password-cracking-john-the-ripper/
|
||||
[11]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/
|
||||
[12]:https://www.cyberciti.biz/faq/howto-configure-setup-firewall-with-ufw-on-ubuntu-linux/
|
||||
[13]:https://www.cyberciti.biz/faq/ufw-allow-incoming-ssh-connections-from-a-specific-ip-address-subnet-on-ubuntu-debian/
|
||||
[14]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[15]:https://bash.cyberciti.biz/firewall/pf-firewall-script/
|
||||
[16]:https://www.cyberciti.biz/faq/tcp-wrappers-hosts-allow-deny-tutorial/
|
||||
[17]:https://www.cyberciti.biz/faq/block-ssh-attacks-with-denyhosts/
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-linux-block-ssh-dictionary-brute-force-attacks/
|
||||
[19]:https://www.fail2ban.org
|
||||
[20]:https://sshguard.sourceforge.net/
|
||||
[21]:http://www.bsdconsulting.no/tools/
|
||||
[22]:https://savannah.nongnu.org/projects/ipqbdb/
|
||||
[23]:https://en.wikipedia.org/wiki/Port_knocking
|
||||
[24]:https://www.cyberciti.biz/faq/linux-unix-login-bash-shell-force-time-outs/
|
||||
[25]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[26]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[27]:https://www.cyberciti.biz/tips/howto-keep-freebsd-system-upto-date.html
|
||||
[28]:https://www.cyberciti.biz/tips/rhel-centos-linux-install-configure-rssh-shell.html
|
||||
[29]:https://www.debian-administration.org/articles/590
|
||||
[30]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[31]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[32]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[33]:https://www.cyberciti.biz/faq/howto-rhel-linux-open-port-using-iptables/
|
||||
[34]:https://wiki.mozilla.org/Security/Guidelines/OpenSSH
|
||||
[35]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-Security-Tutorial-Query-Ciphers-and-algorithms-choice.jpg
|
||||
[36]:https://www.cyberciti.biz/tips/checking-openssh-sshd-configuration-syntax-errors.html
|
||||
[37]:https://www.cyberciti.biz/faq/howto-restart-ssh/
|
||||
[38]:https://www.cyberciti.biz/faq/howto-start-stop-ssh-server/ (Restart sshd on a Debian/Ubuntu Linux)
|
||||
[39]:https://www.cyberciti.biz/faq/centos-stop-start-restart-sshd-command/ (Restart sshd on a CentOS/RHEL/Fedora Linux)
|
||||
[40]:https://www.cyberciti.biz/open-source/howto-protect-linux-ssh-login-with-google-authenticator/
|
||||
[41]:http://www.nongnu.org/oath-toolkit/
|
||||
[42]:https://duo.com
|
||||
[43]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[44]:https://www.openssh.com/
|
||||
[45]:https://twitter.com/nixcraft
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
[53]:https://www.cyberciti.biz/faq/linux-unix-generating-passwords-command/
|
||||
[54]:https://www.cyberciti.biz/faq/linux-random-password-generator/
|
||||
[55]:https://www.cyberciti.biz/faq/debian-ubuntu-linux-iptables-knockd-port-knocking-tutorial/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by yyyfor
|
||||
|
||||
25 Free Books To Learn Linux For Free
|
||||
======
|
||||
Brief: In this article, I'll share with you the best resource to **learn Linux for free**. This is a collection of websites, online video courses and free eBooks.
|
||||
|
||||
@ -1,118 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Creating a YUM repository from ISO & Online repo
|
||||
======
|
||||
|
||||
YUM tool is one of the most important tool for Centos/RHEL/Fedora. Though in latest builds of fedora, it has been replaced with DNF but that not at all means that it has ran its course. It is still used widely for installing rpm packages, we have already discussed YUM with examples in our earlier tutorial ([ **READ HERE**][1]).
|
||||
|
||||
In this tutorial, we are going to learn to create a Local YUM repository, first by using ISO image of OS & then by creating a mirror image of an online yum repository.
|
||||
|
||||
### Creating YUM with DVD ISO
|
||||
|
||||
We are using a Centos 7 dvd for this tutorial & same process should work on RHEL 7 as well.
|
||||
|
||||
Firstly create a directory named YUM in root folder
|
||||
|
||||
```
|
||||
$ mkdir /YUM-
|
||||
```
|
||||
|
||||
then mount Centos 7 ISO ,
|
||||
|
||||
```
|
||||
$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
|
||||
```
|
||||
|
||||
Next, copy the packages from mounted ISO to /YUM folder. Once all the packages have been copied to the system, we will install the required packages for creating YUM. Open /YUM & install the following RPM packages,
|
||||
|
||||
```
|
||||
$ rpm -ivh deltarpm
|
||||
$ rpm -ivh python-deltarpm
|
||||
$ rpm -ivh createrepo
|
||||
```
|
||||
|
||||
Once these packages have been installed, we will create a file named " **local.repo "** in **/etc/yum.repos.d** folder with all the yum information
|
||||
|
||||
```
|
||||
$ vi /etc/yum.repos.d/local.repo
|
||||
```
|
||||
|
||||
```
|
||||
LOCAL REPO]
|
||||
Name=Local YUM
|
||||
baseurl=file:///YUM
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
```
|
||||
|
||||
Save & exit the file. Next we will create repo-data by running the following command
|
||||
|
||||
```
|
||||
$ createrepo -v /YUM
|
||||
```
|
||||
|
||||
It will take some time to create the repo data. Once the process finishes, run
|
||||
|
||||
```
|
||||
$ yum clean all
|
||||
```
|
||||
|
||||
to clean cache & then run
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
```
|
||||
|
||||
to check the list of all repositories. You should see repo "local.repo" in the list.
|
||||
|
||||
|
||||
### Creating mirror YUM repository with online repository
|
||||
|
||||
Process involved in creating a yum is similar to creating a yum with an ISO image with one exception that we will fetch our rpm packages from an online repository instead of an ISO.
|
||||
|
||||
Firstly, we need to find an online repository to get the latest packages . It is advised to find an online yum that is closest to your location , in order to optimize the download speeds. We will be using below mentioned , you can select one nearest to yours location from [CENTOS MIRROR LIST][2]
|
||||
|
||||
After selecting a mirror, we will sync that mirror with our system using rsync but before you do that, make sure that you plenty of space on your server
|
||||
|
||||
```
|
||||
$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
|
||||
```
|
||||
|
||||
Sync will take quite a while (maybe an hour) depending on your internet speed. After the syncing is completed, we will update our repo-data
|
||||
|
||||
```
|
||||
$ createrepo - v /YUM
|
||||
```
|
||||
|
||||
Our Yum is now ready to used . We can create a cron job for our repo to be updated automatically at a determined time daily or weekly as per you needs.
|
||||
|
||||
To create a cron job for syncing the repository, run
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
& add the following line
|
||||
|
||||
```
|
||||
30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
|
||||
```
|
||||
|
||||
This will enable the syncing of yum every night at 12:30 AM. Also remember to create repository configuration file in /etc/yum.repos.d , as we did above.
|
||||
|
||||
That's it guys, you now have your own yum repository to use. Please share this article if you like it & leave your comments/queries in the comment box down below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/using-yum-command-examples/
|
||||
[2]:http://mirror.centos.org/centos/
|
||||
@ -1,91 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Create A Video From PDF Files In Linux
|
||||
======
|
||||

|
||||
|
||||
I have a huge collection of PDF files, mostly Linux tutorials, in my tablet PC. Sometimes I feel too lazy to read them from the tablet. I thought It would be better If I can be able to create a video from PDF files and watch it in a big screen devices like a TV or a Computer. Though I have a little working experience with [**FFMpeg**][1], I am not aware of how to create a movie file using it. After a bit of Google searches, I came up with a good solution. For those who wanted to make a movie file from a set of PDF files, read on. It is not that difficult.
|
||||
|
||||
### Create A Video From PDF Files In Linux
|
||||
|
||||
For this purpose, you need to install **" FFMpeg"** and **" ImageMagick"** software in your system.
|
||||
|
||||
To install FFMpeg, refer the following link.
|
||||
|
||||
Imagemagick is available in the official repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives such as **Antergos** , **Manjaro Linux** , run the following command to install it.
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian, Ubuntu, Linux Mint:**
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL, CentOS, Scientific Linux:**
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE, openSUSE:**
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
After installing ffmpeg and imagemagick, convert your PDF file image format such as PNG or JPG like below.
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
Here, **-density 400** specifies the horizontal resolution of the output image file(s).
|
||||
|
||||
The above command will convert all pages in the given PDF file to PNG format. Each page in the PDF file will be converted into a PNG file and saved in the current directory with file name **picture-1.png** , **picture-2.png** … and so on. It will take a while depending on the number of pages in the input PDF file.
|
||||
|
||||
Once all pages in the PDF converted into PNG format, run the following command to create a video file from the PNG files.
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **-r 1/10** : Display each image for 10 seconds.
|
||||
* **-i picture-%01d.png** : Reads all pictures that starts with name **" picture-"**, following with 1 digit (%01d) and ending with **.png**. If the images name comes with 2 digits (I.e picture-10.png, picture11.png etc), use (%02d) in the above command.
|
||||
* **-c:v libx264** : Output video codec (i.e h264).
|
||||
* **-r 30** : framerate of output video
|
||||
* **-pix_fmt yuv420p** : Output video resolution
|
||||
* **video.mp4** : Output video file with .mp4 format.
|
||||
|
||||
|
||||
|
||||
Hurrah! The movie file is ready!! You can play it on any devices that supports .mp4 format. Next, I need to find a way to insert a cool music to my video. I hope it won't be difficult either.
|
||||
|
||||
If you wanted it in higher pixel resolution, you don't have to start all over again. Just convert the output video file to any other higher/lower resolution of your choice, say 720p, as shown below.
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
Please note that creating a video using ffmpeg requires a good configuration PC. While converting videos, ffmpeg will consume most of your system resources. I recommend to do this in high-end system.
|
||||
|
||||
And, that's all for now folks. Hope you find this useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
@ -1,198 +0,0 @@
|
||||
kaneg is translating.
|
||||
How to preconfigure LXD containers with cloud-init
|
||||
======
|
||||
You are creating containers and you want them to be somewhat preconfigured. For example, you want them to run automatically **apt update** as soon as they are launched. Or, get some packages pre-installed, or run a few commands. Here is how to perform this early initialization with [**cloud-init**][1] through [LXD to container images that support **cloud-init**][2].
|
||||
|
||||
In the following, we are creating a separate LXD profile with some cloud-init instructions, then launch a container using that profile.
|
||||
|
||||
### How to create a new LXD profile
|
||||
|
||||
Let's see the existing profiles.
|
||||
```
|
||||
$ **lxc profile list**
|
||||
+---------|---------+
|
||||
| NAME | USED BY |
|
||||
+---------|---------+
|
||||
| default | 11 |
|
||||
+---------|---------+
|
||||
```
|
||||
|
||||
There is one profile, **default**. We copy it to a new name, so that we can start adding our instructions on that profile.
|
||||
```
|
||||
$ **lxc profile copy default devprofile**
|
||||
|
||||
$ **lxc profile list**
|
||||
+------------|---------+
|
||||
| NAME | USED BY |
|
||||
+------------|---------+
|
||||
| default | 11 |
|
||||
+------------|---------+
|
||||
| devprofile | 0 |
|
||||
+------------|---------+
|
||||
```
|
||||
|
||||
We have a new profile to work on, **devprofile**. Here is how it looks,
|
||||
```
|
||||
$ **lxc profile show devprofile**
|
||||
config:
|
||||
environment.TZ: ""
|
||||
description: Default LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
nictype: bridged
|
||||
parent: lxdbr0
|
||||
type: nic
|
||||
root:
|
||||
path: /
|
||||
pool: default
|
||||
type: disk
|
||||
name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
Note the main sections, **config:** , **description:** , **devices:** , **name:** , and **used_by:**. There is careful indentation in the profile, and when you make edits, you need to take care of the indentation.
|
||||
|
||||
### How to add cloud-init to an LXD profile
|
||||
|
||||
In the **config:** section of a LXD profile, we can insert [cloud-init][1] instructions. Those[ cloud-init][1] instructions will be passed to the container and will be used when it is first launched.
|
||||
|
||||
Here are those that we are going to use in the example,
|
||||
```
|
||||
package_upgrade: true
|
||||
packages:
|
||||
- build-essential
|
||||
locale: es_ES.UTF-8
|
||||
timezone: Europe/Madrid
|
||||
runcmd:
|
||||
- [touch, /tmp/simos_was_here]
|
||||
```
|
||||
|
||||
**package_upgrade: true** means that we want **cloud-init** to run **sudo apt upgrade** when the container is first launched. Under **packages:** we list the packages that we want to get automatically installed. Then we set the **locale** and **timezone**. In the Ubuntu container images, the default locale for **root** is **C.UTF-8** , for the **ubuntu** account it 's **en_US.UTF-8**. The timezone is **Etc/UTC**. Finally, we show [how to run a Unix command with **runcmd**][3].
|
||||
|
||||
The part that needs a bit of attention is how to insert the **cloud-init** instructions into the LXD profile. My preferred way is
|
||||
```
|
||||
$ **lxc profile edit devprofile**
|
||||
```
|
||||
|
||||
This opens up a text editor and allows to paste the instructions. Here is [how the result should look like][4],
|
||||
```
|
||||
$ **lxc profile show devprofile**
|
||||
config:
|
||||
environment.TZ: ""
|
||||
|
||||
|
||||
user.user-data: |
|
||||
#cloud-config
|
||||
package_upgrade: true
|
||||
packages:
|
||||
- build-essential
|
||||
locale: es_ES.UTF-8
|
||||
timezone: Europe/Madrid
|
||||
runcmd:
|
||||
- [touch, /tmp/simos_was_here]
|
||||
|
||||
|
||||
description: Default LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
nictype: bridged
|
||||
parent: lxdbr0
|
||||
type: nic
|
||||
root:
|
||||
path: /
|
||||
pool: default
|
||||
type: disk
|
||||
name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
WordPress can get a bit messed with indentation when you copy/paste, therefore, you may use [this pastebin][4] instead.
|
||||
|
||||
### How to launch a container using a profile
|
||||
|
||||
Let's launch a new container using the profile **devprofile**.
|
||||
```
|
||||
$ **lxc launch --profile devprofile ubuntu:x mydev**
|
||||
```
|
||||
|
||||
Let's get into the container and figure out whether our instructions took effect.
|
||||
```
|
||||
$ **lxc exec mydev bash**
|
||||
root@mydev:~# **ps ax**
|
||||
PID TTY STAT TIME COMMAND
|
||||
1 ? Ss 0:00 /sbin/init
|
||||
...
|
||||
427 ? Ss 0:00 /usr/bin/python3 /usr/bin/cloud-init modules --mode=f
|
||||
430 ? S 0:00 /bin/sh -c tee -a /var/log/cloud-init-output.log
|
||||
431 ? S 0:00 tee -a /var/log/cloud-init-output.log
|
||||
432 ? S 0:00 /usr/bin/apt-get --option=Dpkg::Options::=--force-con
|
||||
437 ? S 0:00 /usr/lib/apt/methods/http
|
||||
438 ? S 0:00 /usr/lib/apt/methods/http
|
||||
440 ? S 0:00 /usr/lib/apt/methods/gpgv
|
||||
570 ? Ss 0:00 bash
|
||||
624 ? S 0:00 /usr/lib/apt/methods/store
|
||||
625 ? R+ 0:00 ps ax
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
We connected quite quickly, and **ps ax** shows that the package update is indeed taking place! We can get the full output at /var/log/cloud-init-output.log and in there,
|
||||
```
|
||||
Generating locales (this might take a while)...
|
||||
es_ES.UTF-8... done
|
||||
Generation complete.
|
||||
```
|
||||
|
||||
The locale got set. The **root** user keeps having the **C.UTF-8** default locale. It is only the non-root account **ubuntu** that gets the new locale.
|
||||
```
|
||||
Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
|
||||
Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
|
||||
Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
|
||||
```
|
||||
|
||||
Here is **apt update** that is required before installing packages.
|
||||
```
|
||||
The following packages will be upgraded:
|
||||
libdrm2 libseccomp2 squashfs-tools unattended-upgrades
|
||||
4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 211 kB of archives.
|
||||
```
|
||||
|
||||
Here is runs **package_upgrade: true** and installs any available packages.
|
||||
```
|
||||
The following NEW packages will be installed:
|
||||
binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
|
||||
libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
|
||||
```
|
||||
|
||||
This is from our instruction to install the **build-essential** meta-package.
|
||||
|
||||
What about the **runcmd** instruction?
|
||||
```
|
||||
root@mydev:~# **ls -l /tmp/**
|
||||
total 1
|
||||
-rw-r--r-- 1 root root 0 Jan 3 15:23 simos_was_here
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
It worked as well!
|
||||
|
||||
### Conclusion
|
||||
|
||||
When we launch LXD containers, we often need some configuration to be enabled by default and avoid repeated actions. The way to solve this, is to create LXD profiles. Each profile captures those configurations. Finally, when we launch the new container, we specify which LXD profile to use.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:http://cloudinit.readthedocs.io/en/latest/index.html
|
||||
[2]:https://github.com/lxc/lxd/blob/master/doc/cloud-init.md
|
||||
[3]:http://cloudinit.readthedocs.io/en/latest/topics/modules.html#runcmd
|
||||
[4]:https://paste.ubuntu.com/26313399/
|
||||
197
sources/tech/20180104 4 Tools for Network Snooping on Linux.md
Normal file
197
sources/tech/20180104 4 Tools for Network Snooping on Linux.md
Normal file
@ -0,0 +1,197 @@
|
||||
4 Tools for Network Snooping on Linux
|
||||
======
|
||||
Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
|
||||
|
||||
Do be polite and don't run `nmap` on any network but your own, because probing other people's networks can be interpreted as a hostile act.
|
||||
|
||||
### Thin and Thick whois
|
||||
|
||||
You may have noticed that our beloved old `whois` command doesn't seem to give the level of detail that it used to. Check out this example for Linux.com:
|
||||
```
|
||||
$ whois linux.com
|
||||
Domain Name: LINUX.COM
|
||||
Registry Domain ID: 4245540_DOMAIN_COM-VRSN
|
||||
Registrar WHOIS Server: whois.namecheap.com
|
||||
Registrar URL: http://www.namecheap.com
|
||||
Updated Date: 2018-01-10T12:26:50Z
|
||||
Creation Date: 1994-06-02T04:00:00Z
|
||||
Registry Expiry Date: 2018-06-01T04:00:00Z
|
||||
Registrar: NameCheap Inc.
|
||||
Registrar IANA ID: 1068
|
||||
Registrar Abuse Contact Email: abuse@namecheap.com
|
||||
Registrar Abuse Contact Phone: +1.6613102107
|
||||
Domain Status: ok https://icann.org/epp#ok
|
||||
Name Server: NS5.DNSMADEEASY.COM
|
||||
Name Server: NS6.DNSMADEEASY.COM
|
||||
Name Server: NS7.DNSMADEEASY.COM
|
||||
DNSSEC: unsigned
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
There is quite a bit more, mainly annoying legalese. But where is the contact information? It is sitting on whois.namecheap.com (see the third line of output above):
|
||||
```
|
||||
$ whois -h whois.namecheap.com linux.com
|
||||
|
||||
```
|
||||
|
||||
I won't print the output here, as it is very long, containing the Registrant, Admin, and Tech contact information. So what's the deal, Lucille? Some registries, such as .com and .net are "thin" registries, storing a limited subset of domain data. To get complete information use the `-h`, or `--host` option, to get the complete dump from the domain's `Registrar WHOIS Server`.
|
||||
|
||||
Most of the other top-level domains are thick registries, such as .info. Try `whois blockchain.info` to see an example.
|
||||
|
||||
Want to get rid of the obnoxious legalese? Use the `-H` option.
|
||||
|
||||
### Digging DNS
|
||||
|
||||
Use the `dig` command to compare the results from different name servers to check for stale entries. DNS records are cached all over the place, and different servers have different refresh intervals. This is the simplest usage:
|
||||
```
|
||||
$ dig linux.com
|
||||
<<>> DiG 9.10.3-P4-Ubuntu <<>> linux.com
|
||||
;; global options: +cmd
|
||||
;; Got answer:
|
||||
;; ->>HEADER<<<- opcode: QUERY, status: NOERROR, id: 13694
|
||||
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
|
||||
|
||||
;; OPT PSEUDOSECTION:
|
||||
; EDNS: version: 0, flags:; udp: 1440
|
||||
;; QUESTION SECTION:
|
||||
;linux.com. IN A
|
||||
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 10800 IN A 151.101.129.5
|
||||
linux.com. 10800 IN A 151.101.65.5
|
||||
linux.com. 10800 IN A 151.101.1.5
|
||||
linux.com. 10800 IN A 151.101.193.5
|
||||
|
||||
;; Query time: 92 msec
|
||||
;; SERVER: 127.0.1.1#53(127.0.1.1)
|
||||
;; WHEN: Tue Jan 16 15:17:04 PST 2018
|
||||
;; MSG SIZE rcvd: 102
|
||||
|
||||
```
|
||||
|
||||
Take notice of the SERVER: 127.0.1.1#53(127.0.1.1) line near the end of the output. This is your default caching resolver. When the address is localhost, that means there is a DNS server installed on your machine. In my case that is Dnsmasq, which is being used by Network Manager:
|
||||
```
|
||||
$ ps ax|grep dnsmasq
|
||||
2842 ? S 0:00 /usr/sbin/dnsmasq --no-resolv --keep-in-foreground
|
||||
--no-hosts --bind-interfaces --pid-file=/var/run/NetworkManager/dnsmasq.pid
|
||||
--listen-address=127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
The `dig` default is to return A records, which define the domain name. IPv6 has AAAA records:
|
||||
```
|
||||
$ $ dig linux.com AAAA
|
||||
[...]
|
||||
;; ANSWER SECTION:
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:4105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:8105
|
||||
linux.com. 60 IN AAAA 64:ff9b::9765:c105
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
Checkitout, Linux.com has IPv6 addresses. Very good! If your Internet service provider supports IPv6 then you can connect over IPv6. (Sadly, my overpriced mobile broadband does not.)
|
||||
|
||||
Suppose you make some DNS changes to your domain, or you're seeing `dig` results that don't look right. Try querying with a public DNS service, like OpenNIC:
|
||||
```
|
||||
$ dig @69.195.152.204 linux.com
|
||||
[...]
|
||||
;; Query time: 231 msec
|
||||
;; SERVER: 69.195.152.204#53(69.195.152.204)
|
||||
|
||||
```
|
||||
|
||||
`dig` confirms that you're getting your lookup from 69.195.152.204. You can query all kinds of servers and compare results.
|
||||
|
||||
### Upstream Name Servers
|
||||
|
||||
I want to know what my upstream name servers are. To find this, I first look in `/etc/resolv/conf`:
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.1.1
|
||||
|
||||
```
|
||||
|
||||
Thanks, but I already knew that. Your Linux distribution may be configured differently, and you'll see your upstream servers. Let's try `nmcli`, the Network Manager command-line tool:
|
||||
```
|
||||
$ nmcli dev show | grep DNS
|
||||
IP4.DNS[1]: 192.168.1.1
|
||||
|
||||
```
|
||||
|
||||
Now we're getting somewhere, as that is the address of my mobile hotspot, and I should have thought of that myself. I can log in to its weird little Web admin panel to see its upstream servers. A lot of consumer Internet gateways don't let you view or change these settings, so try an external service such as [What's my DNS server?][1]
|
||||
|
||||
### List IPv4 Addresses on your Network
|
||||
|
||||
Which IPv4 addresses are up and in use on your network?
|
||||
```
|
||||
$ nmap -sn 192.168.1.0/24
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 14:03 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.011s latency).
|
||||
Nmap scan report for studio (192.168.1.2)
|
||||
Host is up (0.000071s latency).
|
||||
Nmap scan report for nellybly (192.168.1.3)
|
||||
Host is up (0.015s latency)
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 2.23 seconds
|
||||
|
||||
```
|
||||
|
||||
Everyone wants to scan their network for open ports. This example looks for services and their versions:
|
||||
```
|
||||
$ nmap -sV 192.168.1.1/24
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 16:46 PST
|
||||
Nmap scan report for Mobile.Hotspot (192.168.1.1)
|
||||
Host is up (0.0071s latency).
|
||||
Not shown: 997 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp filtered ssh
|
||||
53/tcp open domain dnsmasq 2.55
|
||||
80/tcp open http GoAhead WebServer 2.5.0
|
||||
|
||||
Nmap scan report for studio (192.168.1.102)
|
||||
Host is up (0.000087s latency).
|
||||
Not shown: 998 closed ports
|
||||
PORT STATE SERVICE VERSION
|
||||
22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0)
|
||||
631/tcp open ipp CUPS 2.1
|
||||
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
|
||||
|
||||
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
|
||||
Nmap done: 256 IP addresses (2 hosts up) scanned in 11.65 seconds
|
||||
|
||||
```
|
||||
|
||||
These are interesting results. Let's try the same run from a different Internet account, to see if any of these services are exposed to big bad Internet. You have a second network if you have a smartphone. There are probably apps you can download, or use your phone as a hotspot to your faithful Linux computer. Fetch the WAN IP address from the hotspot control panel and try again:
|
||||
```
|
||||
$ nmap -sV 12.34.56.78
|
||||
|
||||
Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 17:05 PST
|
||||
Nmap scan report for 12.34.56.78
|
||||
Host is up (0.0061s latency).
|
||||
All 1000 scanned ports on 12.34.56.78 are closed
|
||||
|
||||
```
|
||||
|
||||
That's what I like to see. Consult the fine man pages for these commands to learn more fun snooping techniques.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:http://www.whatsmydnsserver.com/
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Boot Into Linux Command Line
|
||||
======
|
||||

|
||||
|
||||
@ -0,0 +1,107 @@
|
||||
SPARTA – Network Penetration Testing GUI Toolkit
|
||||
======
|
||||
|
||||

|
||||
|
||||
SPARTA is GUI application developed with python and inbuild Network Penetration Testing Kali Linux tool. It simplifies scanning and enumeration phase with faster results.
|
||||
|
||||
Best thing of SPARTA GUI Toolkit it scans detects the service running on the target port.
|
||||
|
||||
Also, it provides Bruteforce attack for scanned open ports and services as a part of enumeration phase.
|
||||
|
||||
|
||||
Also Read: Network Pentesting Checklist][1]
|
||||
|
||||
## Installation
|
||||
|
||||
Please clone the latest version of SPARTA from github:
|
||||
|
||||
```
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
Alternatively, download the latest zip file [here][2].
|
||||
```
|
||||
cd /usr/share/
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
Place the "sparta" file in /usr/bin/ and make it executable.
|
||||
Type 'sparta' in any terminal to launch the application.
|
||||
|
||||
|
||||
## The scope of Network Penetration Testing Work:
|
||||
|
||||
* Organizations security weaknesses in their network infrastructures are identified by a list of host or targeted host and add them to the scope.
|
||||
* Select menu bar - File > Add host(s) to scope
|
||||
|
||||
|
||||
|
||||
[![Network Penetration Testing][3]][4]
|
||||
|
||||
[![Network Penetration Testing][5]][6]
|
||||
|
||||
* Above figures show target Ip is added to the scope.According to your network can add the range of IPs to scan.
|
||||
* After adding Nmap scan will begin and results will be very faster.now scanning phase is done.
|
||||
|
||||
|
||||
|
||||
## Open Ports & Services:
|
||||
|
||||
* Nmap results will provide target open ports and services.
|
||||
|
||||
|
||||
|
||||
[![Network Penetration Testing][7]][8]
|
||||
|
||||
* Above figure shows that target operating system, Open ports and services are discovered as scan results.
|
||||
|
||||
|
||||
|
||||
## Brute Force Attack on Open ports:
|
||||
|
||||
* Let us Brute force Server Message Block (SMB) via port 445 to enumerate the list of users and their valid passwords.
|
||||
|
||||
|
||||
|
||||
[![Network Penetration Testing][9]][10]
|
||||
|
||||
* Right-click and Select option Send to Brute.Also, select discovered Open ports and service on target.
|
||||
* Browse and add dictionary files for Username and password fields.
|
||||
|
||||
|
||||
|
||||
[![Network Penetration Testing][11]][12]
|
||||
|
||||
* Click Run to start the Brute force attack on the target.Above Figure shows Brute force attack is successfully completed on the target IP and the valid password is Found!
|
||||
* Always think failed login attempts will be logged as Event logs in Windows.
|
||||
* Password changing policy should be 15 to 30 days will be a good practice.
|
||||
* Always recommended to use a strong password as per policy.Password lockout policy is a good one to stop brute force attacks (After 5 failure attempts account will be locked)
|
||||
* The integration of business-critical asset to SIEM( security incident & Event Management) will detect these kinds of attacks as soon as possible.
|
||||
|
||||
|
||||
|
||||
SPARTA is timing saving GUI Toolkit for pentesters for scanning and enumeration phase.SPARTA Scans and Bruteforce various protocols.It has many more features! Happy Hacking.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
|
||||
|
||||
作者:[Balaganesh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://gbhackers.com/author/balaganesh/
|
||||
[1]:https://gbhackers.com/network-penetration-testing-checklist-examples/
|
||||
[2]:https://github.com/SECFORCE/sparta/archive/master.zip
|
||||
[3]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?resize=696%2C495&ssl=1
|
||||
[4]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?ssl=1
|
||||
[5]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?resize=696%2C516&ssl=1
|
||||
[6]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?ssl=1
|
||||
[7]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?resize=696%2C519&ssl=1
|
||||
[8]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?ssl=1
|
||||
[9]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?resize=696%2C525&ssl=1
|
||||
[10]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?ssl=1
|
||||
[11]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?resize=696%2C523&ssl=1
|
||||
[12]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?ssl=1
|
||||
@ -0,0 +1,250 @@
|
||||
How To Manage Vim Plugins Using Vundle On Linux
|
||||
======
|
||||
|
||||
|
||||
**Vim** , undoubtedly, is one of the powerful and versatile tool to manipulate text files, manage the system configuration files and writing code. The functionality of Vim can be extended to different levels using plugins. Usually, all plugins and additional configuration files will be stored in **~/.vim** directory. Since all plugin files are stored in a single directory, the files from different plugins are mixed up together as you install more plugins. Hence, it is going to be a daunting task to track and manage all of them. This is where Vundle comes in help. Vundle, acronym of **V** im B **undle** , is an extremely useful plug-in to manage Vim plugins.
|
||||
|
||||
Vundle creates a separate directory tree for each plugin you install and stores the additional configuration files in the respective plugin directory. Therefore, there is no mix up files with one another. In a nutshell, Vundle allows you to install new plugins, configure existing plugins, update configured plugins, search for installed plugins and clean up unused plugins. All actions can be done in a single keypress with interactive mode. In this brief tutorial, let me show you how to install Vundle and how to manage Vim plugins using Vundle in GNU/Linux.
|
||||
|
||||
### Installing Vundle
|
||||
|
||||
If you need Vundle, I assume you have already installed **vim** on your system. If not, install vim and **git** (to download vundle). Both packages are available in the official repositories of most GNU/Linux distributions.For instance, you can use the following command to install these packages on Debian based systems.
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**Download Vundle**
|
||||
|
||||
Clone Vundle GitHub repository:
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**Configure Vundle**
|
||||
|
||||
To tell vim to use the new plugin manager, we need to create **~/.vimrc** file. This file is required to install, update, configure and remove plugins.
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
Put the following lines on the top of this file:
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
|
||||
" set the runtime path to include Vundle and initialize
|
||||
set rtp+=~/.vim/bundle/Vundle.vim
|
||||
call vundle#begin()
|
||||
" alternatively, pass a path where Vundle should install plugins
|
||||
"call vundle#begin('~/some/path/here')
|
||||
|
||||
" let Vundle manage Vundle, required
|
||||
Plugin 'VundleVim/Vundle.vim'
|
||||
|
||||
" The following are examples of different formats supported.
|
||||
" Keep Plugin commands between vundle#begin/end.
|
||||
" plugin on GitHub repo
|
||||
Plugin 'tpope/vim-fugitive'
|
||||
" plugin from http://vim-scripts.org/vim/scripts.html
|
||||
" Plugin 'L9'
|
||||
" Git plugin not hosted on GitHub
|
||||
Plugin 'git://git.wincent.com/command-t.git'
|
||||
" git repos on your local machine (i.e. when working on your own plugin)
|
||||
Plugin 'file:///home/gmarik/path/to/plugin'
|
||||
" The sparkup vim script is in a subdirectory of this repo called vim.
|
||||
" Pass the path to set the runtimepath properly.
|
||||
Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
|
||||
" Install L9 and avoid a Naming conflict if you've already installed a
|
||||
" different version somewhere else.
|
||||
" Plugin 'ascenator/L9', {'name': 'newL9'}
|
||||
|
||||
" All of your Plugins must be added before the following line
|
||||
call vundle#end() " required
|
||||
filetype plugin indent on " required
|
||||
" To ignore plugin indent changes, instead use:
|
||||
"filetype plugin on
|
||||
"
|
||||
" Brief help
|
||||
" :PluginList - lists configured plugins
|
||||
" :PluginInstall - installs plugins; append `!` to update or just :PluginUpdate
|
||||
" :PluginSearch foo - searches for foo; append `!` to refresh local cache
|
||||
" :PluginClean - confirms removal of unused plugins; append `!` to auto-approve removal
|
||||
"
|
||||
" see :h vundle for more details or wiki for FAQ
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
The lines which are marked as "required" are Vundle's requirement. The rest of the lines are just examples. You can remove those lines if you don't want to install that specified plugins. Once you finished, type **:wq** to save and close file.
|
||||
|
||||
Finally, open vim:
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
And type the following to install the plugins.
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
A new split window will open and all the plugins which we added in the .vimrc file will be installed automatically.
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
When the installation is completed, you can delete the buffer cache and close the split window by typing the following command:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
You can also install the plugins without opening vim using the following command from the Terminal:
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
For those using the [**fish shell**][4], add the following line to your **.vimrc** file.``
|
||||
```
|
||||
set shell=/bin/bash
|
||||
```
|
||||
|
||||
### Manage Vim Plugins Using Vundle
|
||||
|
||||
**Add New Plugins**
|
||||
|
||||
First, search for the available plugins using command:
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
To refresh the local list from the from the vimscripts site, add **"! "** at the end.
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
A new split window will open list all available plugins.
|
||||
|
||||
[![][1]][5]
|
||||
|
||||
You can also narrow down your search by using directly specifying the name of the plugin like below.
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
This will list the plugin(s) that contains the words "vim"
|
||||
|
||||
You can, of course, specify the exact plugin name like below.
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
To install a plugin, move the cursor to the correct line and hit **" i"**. Now, the selected plugin will be installed.
|
||||
|
||||
[![][1]][6]
|
||||
|
||||
Similarly, install all plugins you wanted to have in your system. Once installed, delete the Vundle buffer cache using command:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
Now the plugin is installed. To make it autoload correctly, we need to add the installed plugin name to .vimrc file.
|
||||
|
||||
To do so, type:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
Add the following line.
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
Replace vim-dasm with your plugin name. Then, hit ESC key and type **:wq** to save the changes and close the file.
|
||||
|
||||
Please note that all of your Plugins must be added before the following line in your .vimrc file.
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**List installed Plugins**
|
||||
|
||||
To list installed plugins, type the following from the vim editor:
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
|
||||
**Update plugins**
|
||||
|
||||
To update the all installed plugins, type:
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
To reinstall all plugins, type:
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**Uninstall plugins**
|
||||
|
||||
First, list out all installed plugins:
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
Then place the cursor to the correct line, and press **" SHITF+d"**.
|
||||
|
||||
[![][1]][8]
|
||||
|
||||
Then, edit your .vimrc file:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
And delete the Plugin entry. Finally, type **:wq** to save the changes and exit from vim editor.
|
||||
|
||||
Alternatively, you can uninstall a plugin by removing its line from .vimrc file and run:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
This command will remove all plugins which are no longer present in your .vimrc but still present the bundle directory.
|
||||
|
||||
At this point, you should have learned the basic usage about managing plugins using Vundle. For details, refer the help section by typing the following in your vim editor.
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**Also Read:**
|
||||
|
||||
And, that's all for now. I will be soon here with another useful guide. Until then, stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
**Resource:**
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
@ -0,0 +1,82 @@
|
||||
Configuring MSMTP On Ubuntu 16.04 (Again)
|
||||
======
|
||||
This post exists as a copy of what I had on my previous blog about configuring MSMTP on Ubuntu 16.04; I'm posting it as-is for posterity, and have no idea if it'll work on later versions. As I'm not hosting my own Ubuntu/MSMTP server anymore I can't see any updates being made to this, but if I ever do have to set this up again I'll create an updated post! Anyway, here's what I had…
|
||||
|
||||
I previously wrote an article around configuring msmtp on Ubuntu 12.04, but as I hinted at in a previous post that sort of got lost when the upgrade of my host to Ubuntu 16.04 went somewhat awry. What follows is essentially the same post, with some slight updates for 16.04. As before, this assumes that you're using Apache as the web server, but I'm sure it shouldn't be too different if your web server of choice is something else.
|
||||
|
||||
I use [msmtp][1] for sending emails from this blog to notify me of comments and upgrades etc. Here I'm going to document how I configured it to send emails via a Google Apps account, although this should also work with a standard Gmail account too.
|
||||
|
||||
To begin, we need to install 3 packages:
|
||||
`sudo apt-get install msmtp msmtp-mta ca-certificates`
|
||||
Once these are installed, a default config is required. By default msmtp will look at `/etc/msmtprc`, so I created that using vim, though any text editor will do the trick. This file looked something like this:
|
||||
```
|
||||
# Set defaults.
|
||||
defaults
|
||||
# Enable or disable TLS/SSL encryption.
|
||||
tls on
|
||||
tls_starttls on
|
||||
tls_trust_file /etc/ssl/certs/ca-certificates.crt
|
||||
# Setup WP account's settings.
|
||||
account
|
||||
host smtp.gmail.com
|
||||
port 587
|
||||
auth login
|
||||
user
|
||||
password
|
||||
from
|
||||
logfile /var/log/msmtp/msmtp.log
|
||||
|
||||
account default :
|
||||
|
||||
```
|
||||
|
||||
Any of the uppercase items (i.e. ``) are things that need replacing specific to your configuration. The exception to that is the log file, which can of course be placed wherever you wish to log any msmtp activity/warnings/errors to.
|
||||
|
||||
Once that file is saved, we'll update the permissions on the above configuration file -- msmtp won't run if the permissions on that file are too open -- and create the directory for the log file.
|
||||
```
|
||||
sudo mkdir /var/log/msmtp
|
||||
sudo chown -R www-data:adm /var/log/msmtp
|
||||
sudo chmod 0600 /etc/msmtprc
|
||||
|
||||
```
|
||||
|
||||
Next I chose to configure logrotate for the msmtp logs, to make sure that the log files don't get too large as well as keeping the log directory a little tidier. To do this, we create `/etc/logrotate.d/msmtp` and configure it with the following file. Note that this is optional, you may choose to not do this, or you may choose to configure the logs differently.
|
||||
```
|
||||
/var/log/msmtp/*.log {
|
||||
rotate 12
|
||||
monthly
|
||||
compress
|
||||
missingok
|
||||
notifempty
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Now that the logging is configured, we need to tell PHP to use msmtp by editing `/etc/php/7.0/apache2/php.ini` and updating the sendmail path from
|
||||
`sendmail_path =`
|
||||
to
|
||||
`sendmail_path = "/usr/bin/msmtp -C /etc/msmtprc -a -t"`
|
||||
Here I did run into an issue where even though I specified the account name it wasn't sending emails correctly when I tested it. This is why the line `account default : ` was placed at the end of the msmtp configuration file. To test the configuration, ensure that the PHP file has been saved and run `sudo service apache2 restart`, then run `php -a` and execute the following
|
||||
```
|
||||
mail ('personal@email.com', 'Test Subject', 'Test body text');
|
||||
exit();
|
||||
|
||||
```
|
||||
|
||||
Any errors that occur at this point will be displayed in the output so should make diagnosing any errors after the test relatively easy. If all is successful, you should now be able to use PHPs sendmail (which at the very least WordPress uses) to send emails from your Ubuntu server using Gmail (or Google Apps).
|
||||
|
||||
I make no claims that this is the most secure configuration, so if you come across this and realise it's grossly insecure or something is drastically wrong please let me know and I'll update it accordingly.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://codingproductivity.wordpress.com/2018/01/18/configuring-msmtp-on-ubuntu-16-04-again/
|
||||
|
||||
作者:[JOE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://codingproductivity.wordpress.com/author/joeb454/
|
||||
[1]:http://msmtp.sourceforge.net/
|
||||
213
sources/tech/20180118 Getting Started with ncurses.md
Normal file
213
sources/tech/20180118 Getting Started with ncurses.md
Normal file
@ -0,0 +1,213 @@
|
||||
Getting Started with ncurses
|
||||
======
|
||||
How to use curses to draw to the terminal screen.
|
||||
|
||||
While graphical user interfaces are very cool, not every program needs to run with a point-and-click interface. For example, the venerable vi editor ran in plain-text terminals long before the first GUI.
|
||||
|
||||
The vi editor is one example of a screen-oriented program that draws in "text" mode, using a library called curses, which provides a set of programming interfaces to manipulate the terminal screen. The curses library originated in BSD UNIX, but Linux systems provide this functionality through the ncurses library.
|
||||
|
||||
[For a "blast from the past" on ncurses, see ["ncurses: Portable Screen-Handling for Linux"][1], September 1, 1995, by Eric S. Raymond.]
|
||||
|
||||
Creating programs that use curses is actually quite simple. In this article, I show an example program that leverages curses to draw to the terminal screen.
|
||||
|
||||
### Sierpinski's Triangle
|
||||
|
||||
One simple way to demonstrate a few curses functions is by generating Sierpinski's Triangle. If you aren't familiar with this method to generate Sierpinski's Triangle, here are the rules:
|
||||
|
||||
1. Set three points that define a triangle.
|
||||
|
||||
2. Randomly select a point anywhere (x,y).
|
||||
|
||||
Then:
|
||||
|
||||
1. Randomly select one of the triangle's points.
|
||||
|
||||
2. Set the new x,y to be the midpoint between the previous x,y and the triangle point.
|
||||
|
||||
3. Repeat.
|
||||
|
||||
So with those instructions, I wrote this program to draw Sierpinski's Triangle to the terminal screen using the curses functions:
|
||||
|
||||
```
|
||||
|
||||
1 /* triangle.c */
|
||||
2
|
||||
3 #include
|
||||
4 #include
|
||||
5
|
||||
6 #include "getrandom_int.h"
|
||||
7
|
||||
8 #define ITERMAX 10000
|
||||
9
|
||||
10 int main(void)
|
||||
11 {
|
||||
12 long iter;
|
||||
13 int yi, xi;
|
||||
14 int y[3], x[3];
|
||||
15 int index;
|
||||
16 int maxlines, maxcols;
|
||||
17
|
||||
18 /* initialize curses */
|
||||
19
|
||||
20 initscr();
|
||||
21 cbreak();
|
||||
22 noecho();
|
||||
23
|
||||
24 clear();
|
||||
25
|
||||
26 /* initialize triangle */
|
||||
27
|
||||
28 maxlines = LINES - 1;
|
||||
29 maxcols = COLS - 1;
|
||||
30
|
||||
31 y[0] = 0;
|
||||
32 x[0] = 0;
|
||||
33
|
||||
34 y[1] = maxlines;
|
||||
35 x[1] = maxcols / 2;
|
||||
36
|
||||
37 y[2] = 0;
|
||||
38 x[2] = maxcols;
|
||||
39
|
||||
40 mvaddch(y[0], x[0], '0');
|
||||
41 mvaddch(y[1], x[1], '1');
|
||||
42 mvaddch(y[2], x[2], '2');
|
||||
43
|
||||
44 /* initialize yi,xi with random values */
|
||||
45
|
||||
46 yi = getrandom_int() % maxlines;
|
||||
47 xi = getrandom_int() % maxcols;
|
||||
48
|
||||
49 mvaddch(yi, xi, '.');
|
||||
50
|
||||
51 /* iterate the triangle */
|
||||
52
|
||||
53 for (iter = 0; iter < ITERMAX; iter++) {
|
||||
54 index = getrandom_int() % 3;
|
||||
55
|
||||
56 yi = (yi + y[index]) / 2;
|
||||
57 xi = (xi + x[index]) / 2;
|
||||
58
|
||||
59 mvaddch(yi, xi, '*');
|
||||
60 refresh();
|
||||
61 }
|
||||
62
|
||||
63 /* done */
|
||||
64
|
||||
65 mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
66
|
||||
67 refresh();
|
||||
68
|
||||
69 getch();
|
||||
70 endwin();
|
||||
71
|
||||
72 exit(0);
|
||||
73 }
|
||||
|
||||
```
|
||||
|
||||
Let me walk through that program by way of explanation. First, the getrandom_int() is my own wrapper to the Linux getrandom() system call, but it's guaranteed to return a positive integer value. Otherwise, you should be able to identify the code lines that initialize and then iterate Sierpinski's Triangle, based on the above rules. Aside from that, let's look at the curses functions I used to draw the triangle on a terminal.
|
||||
|
||||
Most curses programs will start with these four instructions. 1) The initscr() function determines the terminal type, including its size and features, and sets up the curses environment based on what the terminal can support. The cbreak() function disables line buffering and sets curses to take one character at a time. The noecho() function tells curses not to echo the input back to the screen, and the clear() function clears the screen:
|
||||
|
||||
```
|
||||
|
||||
20 initscr();
|
||||
21 cbreak();
|
||||
22 noecho();
|
||||
23
|
||||
24 clear();
|
||||
|
||||
```
|
||||
|
||||
The program then sets a few variables to define the three points that define a triangle. Note the use of LINES and COLS here, which were set by initscr(). These values tell the program how many lines and columns exist on the terminal. Screen coordinates start at zero, so the top-left of the screen is row 0, column 0\. The bottom-right of the screen is row LINES - 1, column COLS - 1\. To make this easy to remember, my program sets these values in the variables maxlines and maxcols, respectively.
|
||||
|
||||
Two simple methods to draw text on the screen are the addch() and addstr() functions. To put text at a specific screen location, use the related mvaddch() and mvaddstr() functions. My program uses these functions in several places. First, the program draws the three points that define the triangle, labeled "0", "1" and "2":
|
||||
|
||||
```
|
||||
|
||||
40 mvaddch(y[0], x[0], '0');
|
||||
41 mvaddch(y[1], x[1], '1');
|
||||
42 mvaddch(y[2], x[2], '2');
|
||||
|
||||
```
|
||||
|
||||
To draw the random starting point, the program makes a similar call:
|
||||
|
||||
```
|
||||
|
||||
49 mvaddch(yi, xi, '.');
|
||||
|
||||
```
|
||||
|
||||
And to draw each successive point in Sierpinski's Triangle iteration:
|
||||
|
||||
```
|
||||
|
||||
59 mvaddch(yi, xi, '*');
|
||||
|
||||
```
|
||||
|
||||
When the program is done, it displays a helpful message at the lower-left corner of the screen (at row maxlines, column 0):
|
||||
|
||||
```
|
||||
|
||||
65 mvaddstr(maxlines, 0, "Press any key to quit");
|
||||
|
||||
```
|
||||
|
||||
It's important to note that curses maintains a version of the screen in memory and updates the screen only when you ask it to. This provides greater performance, especially if you want to display a lot of text to the screen. This is because curses can update only those parts of the screen that changed since the last update. To cause curses to update the terminal screen, use the refresh() function.
|
||||
|
||||
In my example program, I've chosen to update the screen after "drawing" each successive point in Sierpinski's Triangle. By doing so, users should be able to observe each iteration in the triangle.
|
||||
|
||||
Before exiting, I use the getch() function to wait for the user to press a key. Then I call endwin() to exit the curses environment and return the terminal screen to normal control:
|
||||
|
||||
```
|
||||
|
||||
69 getch();
|
||||
70 endwin();
|
||||
|
||||
```
|
||||
|
||||
### Compiling and Sample Output
|
||||
|
||||
Now that you have your first sample curses program, it's time to compile and run it. Remember that Linux systems implement the curses functionality via the ncurses library, so you need to link with -lncurses when you compile—for example:
|
||||
|
||||
```
|
||||
|
||||
$ ls
|
||||
getrandom_int.c getrandom_int.h triangle.c
|
||||
|
||||
$ gcc -Wall -lncurses -o triangle triangle.c getrandom_int.c
|
||||
|
||||
```
|
||||
|
||||
Running the triangle program on a standard 80x24 terminal is not very interesting. You just can't see much detail in Sierpinski's Triangle at that resolution. If you run a terminal window and set a very small font size, you can see the fractal nature of Sierpinski's Triangle more easily. On my system, the output looks like Figure 1.
|
||||
|
||||

|
||||
|
||||
Figure 1. Output of the triangle Program
|
||||
|
||||
Despite the random nature of the iteration, every run of Sierpinski's Triangle will look pretty much the same. The only difference will be where the first few points are drawn to the screen. In this example, you can see the single dot that starts the triangle, near point 1\. It looks like the program picked point 2 next, and you can see the asterisk halfway between the dot and the "2". And it looks like the program randomly picked point 2 for the next random number, because you can see the asterisk halfway between the first asterisk and the "2". From there, it's impossible to tell how the triangle was drawn, because all of the successive dots fall within the triangle area.
|
||||
|
||||
### Starting to Learn ncurses
|
||||
|
||||
This program is a simple example of how to use the curses functions to draw characters to the screen. You can do so much more with curses, depending on what you need your program to do. In a follow up article, I will show how to use curses to allow the user to interact with the screen. If you are interested in getting a head start with curses, I encourage you to read Pradeep Padala's ["NCURSES Programming HOWTO"][2], at the Linux Documentation Project.
|
||||
|
||||
### About the author
|
||||
|
||||
Jim Hall is an advocate for free and open-source software, best known for his work on the FreeDOS Project, and he also focuses on the usability of open-source software. Jim is the Chief Information Officer at Ramsey County, Minn.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/getting-started-ncurses
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/jim-hall
|
||||
[1]:http://www.linuxjournal.com/article/1124
|
||||
[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
|
||||
@ -0,0 +1,106 @@
|
||||
How To List and Delete iptables Firewall Rules
|
||||
======
|
||||
![How To List and Delete iptables Firewall Rules][1]
|
||||
|
||||
We'll show you, how to list and delete iptables firewall rules. Iptables is a command line utility that allows system administrators to configure the packet filtering rule set on Linux. iptables requires elevated privileges to operate and must be executed by user root, otherwise it fails to function.
|
||||
|
||||
### How to List iptables Firewall Rules
|
||||
|
||||
Iptables allows you to list all the rules which are already added to the packet filtering rule set. In order to be able to check this you need to have SSH access to the server. [Connect to your Linux VPS via SSH][2] and run the following command:
|
||||
```
|
||||
sudo iptables -nvL
|
||||
```
|
||||
|
||||
To run the command above your user need to have `sudo` privileges. Otherwise, you need to [add sudo user on your Linux VPS][3] or use the root user.
|
||||
|
||||
If there are no rules added to the packet filtering ruleset the output should be similar to the one below:
|
||||
```
|
||||
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
Since NAT (Network Address Translation) can also be configured via iptables, you can use iptables to list the NAT rules:
|
||||
```
|
||||
sudo iptables -t nat -n -L -v
|
||||
```
|
||||
|
||||
The output will be similar to the one below if there are no rules added:
|
||||
```
|
||||
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
If this is the case we recommend you to check our tutorial on How to [Set Up a Firewall with iptables on Ubuntu and CentOS][4] to make your server more secure.
|
||||
|
||||
### How to Delete iptables Firewall Rules
|
||||
|
||||
At some point, you may need to remove a specific iptables firewall rule on your server. For that purpose you need to use the following syntax:
|
||||
```
|
||||
iptables [-t table] -D chain rulenum
|
||||
```
|
||||
|
||||
For example, if you have a firewall rule to block all connections from 111.111.111.111 to your server on port 22 and you want to remove that rule, you can use the following command:
|
||||
```
|
||||
sudo iptables -D INPUT -s 111.111.111.111 -p tcp --dport 22 -j DROP
|
||||
```
|
||||
|
||||
Now that you removed the iptables firewall rule you need to save the changes to make them persistent.
|
||||
|
||||
In case you are using [Ubuntu VPS][5] you need to install additional package for that purpose. To install the required package use the following command:
|
||||
```
|
||||
sudo apt-get install iptables-persistent
|
||||
```
|
||||
|
||||
On **Ubutnu 14.04** you can save and reload the firewall rules using the commands below:
|
||||
```
|
||||
sudo /etc/init.d/iptables-persistent save
|
||||
sudo /etc/init.d/iptables-persistent reload
|
||||
```
|
||||
|
||||
On **Ubuntu 16.04** use the following commands instead:
|
||||
```
|
||||
sudo netfilter-persistent save
|
||||
sudo netfilter-persistent reload
|
||||
```
|
||||
|
||||
If you are using [CentOS VPS][6] you can save the changes using the command below:
|
||||
```
|
||||
service iptables save
|
||||
```
|
||||
|
||||
Of course, you don't have to list and delete iptables firewall rules if you use one of our [Managed VPS Hosting][7] services, in which case you can simply ask our expert Linux admins to help you list and delete iptables firewall rules on your server. They are available 24×7 and will take care of your request immediately.
|
||||
|
||||
**PS**. If you liked this post, on how to list and delete iptables firewall rules, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/how-to-list-and-delete-iptables-firewall-rules/
|
||||
|
||||
作者:[RoseHosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/How-To-List-and-Delete-iptables-Firewall-Rules.jpg
|
||||
[2]:https://www.rosehosting.com/blog/connect-to-your-linux-vps-via-ssh/
|
||||
[3]:https://www.rosehosting.com/blog/how-to-create-a-sudo-user-on-ubuntu/
|
||||
[4]:https://www.rosehosting.com/blog/how-to-set-up-a-firewall-with-iptables-on-ubuntu-and-centos/
|
||||
[5]:https://www.rosehosting.com/ubuntu-vps.html
|
||||
[6]:https://www.rosehosting.com/centos-vps.html
|
||||
[7]:https://www.rosehosting.com/managed-vps-hosting.html
|
||||
@ -0,0 +1,62 @@
|
||||
translating by lujun9972
|
||||
How to Play Sound Through Two or More Output Devices in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Handling audio in Linux can be a pain. Pulseaudio has made it both better and worse. While some things work better than they did before, other things have become more complicated. Handling audio output is one of those things.
|
||||
|
||||
If you want to enable multiple audio outputs from your Linux PC, you can use a simple utility to enable your other sound devices on a virtual interface. It's a lot easier than it sounds.
|
||||
|
||||
In case you're wondering why you'd want to do this, a pretty common instance is playing video from your computer on a TV and using both the PC and TV speakers.
|
||||
|
||||
### Install Paprefs
|
||||
|
||||
The easiest way to enable audio playback from multiple sources is to use a simple graphical utility called "paprefs." It's short for PulseAudio Preferences.
|
||||
|
||||
It's available through the Ubuntu repositories, so just install it with Apt.
|
||||
```
|
||||
sudo apt install paprefs
|
||||
```
|
||||
|
||||
When the install finishes, you can just launch the program.
|
||||
|
||||
### Enable Dual Audio Playback
|
||||
|
||||
Even though the utility is graphical, it's still probably easier to launch it by typing `paprefs` in the command line as a regular user.
|
||||
|
||||
The window that opens has a few tabs with settings that you can tweak. The tab that you're looking for is the last one, "Simultaneous Output."
|
||||
|
||||
![Paprefs on Ubuntu][1]
|
||||
|
||||
There isn't a whole lot on the tab, just a checkbox to enable the setting.
|
||||
|
||||
Next, open up the regular sound preferences. It's in different places on different distributions. On Ubuntu it'll be under the GNOME system settings.
|
||||
|
||||
![Enable Simultaneous Audio][2]
|
||||
|
||||
Once you have your sound preferences open, select the "Output" tab. Select the "Simultaneous output" radio button. It's now your default output.
|
||||
|
||||
### Test It
|
||||
|
||||
To test it, you can use anything you like, but music always works. If you are using a video, like suggested earlier, you can certainly test it with that as well.
|
||||
|
||||
If everything is working well, you should hear audio out of all connected devices.
|
||||
|
||||
That's all there really is to do. This works best when there are multiple devices, like the HDMI port and the standard analog output. You can certainly try it with other configurations, too. You should also keep in mind that there will only be a single volume control, so adjust the physical output devices accordingly.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/play-sound-through-multiple-devices-linux/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/nickcongleton/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-paprefs.jpg (Paprefs on Ubuntu)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-enable.jpg (Enable Simultaneous Audio)
|
||||
[3]:https://depositphotos.com/89314442/stock-photo-headphones-on-speakers.html
|
||||
@ -0,0 +1,100 @@
|
||||
Rediscovering make: the power behind rules
|
||||
======
|
||||
|
||||

|
||||
|
||||
I used to think makefiles were just a convenient way to list groups of shell commands; over time I've learned how powerful, flexible, and full-featured they are. This post brings to light over some of those features related to rules.
|
||||
|
||||
### Rules
|
||||
|
||||
Rules are instructions that indicate `make` how and when a file called the target should be built. The target can depend on other files called prerequisites.
|
||||
|
||||
You instruct `make` how to build the target in the recipe, which is no more than a set of shell commands to be executed, one at a time, in the order they appear. The syntax looks like this:
|
||||
```
|
||||
target_name : prerequisites
|
||||
recipe
|
||||
```
|
||||
|
||||
Once you have defined a rule, you can build the target from the command line by executing:
|
||||
```
|
||||
$ make target_name
|
||||
```
|
||||
|
||||
Once the target is built, `make` is smart enough to not run the recipe ever again unless at least one of the prerequisites has changed.
|
||||
|
||||
### More on prerequisites
|
||||
|
||||
Prerequisites indicate two things:
|
||||
|
||||
* When the target should be built: if a prerequisite is newer than the target, `make` assumes that the target should be built.
|
||||
* An order of execution: since prerequisites can, in turn, be built by another rule on the makefile, they also implicitly set an order on which rules are executed.
|
||||
|
||||
|
||||
|
||||
If you want to define an order, but you don't want to rebuild the target if the prerequisite changes, you can use a special kind of prerequisite called order only, which can be placed after the normal prerequisites, separated by a pipe (`|`)
|
||||
|
||||
### Patterns
|
||||
|
||||
For convenience, `make` accepts patterns for targets and prerequisites. A pattern is defined by including the `%` character, a wildcard that matches any number of literal characters or an empty string. Here are some examples:
|
||||
|
||||
* `%`: match any file
|
||||
* `%.md`: match all files with the `.md` extension
|
||||
* `prefix%.go`: match all files that start with `prefix` that have the `.go` extension
|
||||
|
||||
|
||||
|
||||
### Special targets
|
||||
|
||||
There's a set of target names that have special meaning for `make` called special targets.
|
||||
|
||||
You can find the full list of special targets in the [documentation][1]. As a rule of thumb, special targets start with a dot followed by uppercase letters.
|
||||
|
||||
Here are a few useful ones:
|
||||
|
||||
**.PHONY** : Indicates `make` that the prerequisites of this target are considered to be phony targets, which means that `make` will always run it's recipe regardless of whether a file with that name exists or what its last-modification time is.
|
||||
|
||||
**.DEFAULT** : Used for any target for which no rules are found.
|
||||
|
||||
**.IGNORE** : If you specify prerequisites for `.IGNORE`, `make` will ignore errors in execution of their recipes.
|
||||
|
||||
### Substitutions
|
||||
|
||||
Substitutions are useful when you need to modify the value of a variable with alterations that you specify.
|
||||
|
||||
A substitution has the form `$(var:a=b)` and its meaning is to take the value of the variable `var`, replace every `a` at the end of a word with `b` in that value, and substitute the resulting string. For example:
|
||||
```
|
||||
foo := a.o
|
||||
bar : = $(foo:.o=.c) # sets bar to a.c
|
||||
```
|
||||
|
||||
note: special thanks to [Luis Lavena][2] for letting me know about the existence of substitutions.
|
||||
|
||||
### Archive Files
|
||||
|
||||
Archive files are used to collect multiple data files together into a single file (same concept as a zip file), they are built with the `ar` Unix utility. `ar` can be used to create archives for any purpose, but has been largely replaced by `tar` for any other purposes than [static libraries][3].
|
||||
|
||||
In `make`, you can use an individual member of an archive file as a target or prerequisite as follows:
|
||||
```
|
||||
archive(member) : prerequisite
|
||||
recipe
|
||||
```
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
There's a lot more to discover about make, but at least this counts as a start, I strongly encourage you to check the [documentation][4], create a dumb makefile, and just play with it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
|
||||
|
||||
作者:[Roberto Dip][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://monades.roperzh.com
|
||||
[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
|
||||
[2]:https://twitter.com/luislavena/
|
||||
[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
|
||||
[4]:https://www.gnu.org/software/make/manual/make.html
|
||||
@ -0,0 +1,112 @@
|
||||
Securing the Linux filesystem with Tripwire
|
||||
======
|
||||
|
||||

|
||||
|
||||
While Linux is considered to be the most secure operating system (ahead of Windows and MacOS), it is still vulnerable to rootkits and other variants of malware. Thus, Linux users need to know how to protect their servers or personal computers from destruction, and the first step they need to take is to protect the filesystem.
|
||||
|
||||
In this article, we'll look at [Tripwire][1], an excellent tool for protecting Linux filesystems. Tripwire is an integrity checking tool that enables system administrators, security engineers, and others to detect alterations to system files. Although it's not the only option available ([AIDE][2] and [Samhain][3] offer similar features), Tripwire is arguably the most commonly used integrity checker for Linux system files, and it is available as open source under GPLv2.
|
||||
|
||||
### How Tripwire works
|
||||
|
||||
It's helpful to know how Tripwire operates in order to understand what it does once it's installed. Tripwire is made up of two major components: policy and database. Policy lists all the files and directories that the integrity checker should take a snapshot of, in addition to creating rules for identifying violations of changes to directories and files. Database consists of the snapshot taken by Tripwire.
|
||||
|
||||
Tripwire also has a configuration file, which specifies the locations of the database, policy file, and Tripwire executable. It also provides two cryptographic keys--site key and local key--to protect important files against tampering. The site key protects the policy and configuration files, while the local key protects the database and generated reports.
|
||||
|
||||
Tripwire works by periodically comparing the directories and files against the snapshot in the database and reporting any changes.
|
||||
|
||||
### Installing Tripwire
|
||||
|
||||
In order to use Tripwire, we need to download and install it first. Tripwire works on almost all Linux distributions; you can download an open source version from [Sourceforge][4] and install it as follows, depending on your version of Linux.
|
||||
|
||||
Debian and Ubuntu users can install Tripwire directly from the repository using `apt-get`. Non-root users should type the `sudo` command to install Tripwire via `apt-get`.
|
||||
```
|
||||
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install tripwire
|
||||
```
|
||||
|
||||
CentOS and other rpm-based distributions use a similar process. For the sake of best practice, update your repository before installing a new package such as Tripwire. The command `yum install epel-release` simply means we want to install extra repositories. (`epel` stands for Extra Packages for Enterprise Linux.)
|
||||
```
|
||||
|
||||
|
||||
yum update
|
||||
|
||||
yum install epel-release
|
||||
|
||||
yum install tripwire
|
||||
```
|
||||
|
||||
This command causes the installation to run a configuration of packages that are required for Tripwire to function effectively. In addition, it will ask if you want to select passphrases during installation. You can select "Yes" to both prompts.
|
||||
|
||||
Also, select or choose "Yes" if it's required to build the configuration file. Choose and confirm a passphrase for a site key and for a local key. (A complex passphrase such as `Il0ve0pens0urce` is recommended.)
|
||||
|
||||
### Build and initialize Tripwire's database
|
||||
|
||||
Next, initialize the Tripwire database as follows:
|
||||
```
|
||||
|
||||
|
||||
tripwire --init
|
||||
```
|
||||
|
||||
You'll need to provide your local key passphrase to run the commands.
|
||||
|
||||
### Basic integrity checking using Tripwire
|
||||
|
||||
You can use the following command to instruct Tripwire to check whether your files or directories have been modified. Tripwire's ability to compare files and directories against the initial snapshot in the database is based on the rules you created in the active policy.
|
||||
```
|
||||
|
||||
|
||||
tripwire --check
|
||||
```
|
||||
|
||||
You can also limit the `-check` command to specific files or directories, such as in this example:
|
||||
```
|
||||
|
||||
|
||||
tripwire --check /usr/tmp
|
||||
```
|
||||
|
||||
In addition, if you need extended help on using Tripwire's `-check` command, this command allows you to consult Tripwire's manual:
|
||||
```
|
||||
|
||||
|
||||
tripwire --check --help
|
||||
```
|
||||
|
||||
### Generating reports using Tripwire
|
||||
|
||||
To easily generate a daily system integrity report, create a `crontab` with this command:
|
||||
```
|
||||
|
||||
|
||||
crontab -e
|
||||
```
|
||||
|
||||
Afterward, you can edit this file (with the text editor of your choice) to introduce tasks to be run by cron. For instance, you can set up a cron job to send Tripwire reports to your email daily at 5:40 a.m. by using this command:
|
||||
```
|
||||
|
||||
|
||||
40 5 * * * usr/sbin/tripwire --check
|
||||
```
|
||||
|
||||
Whether you decide to use Tripwire or another integrity checker with similar features, the key issue is making sure you have a solution to protect the security of your Linux filesystem.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/securing-linux-filesystem-tripwire
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/revoks
|
||||
[1]:https://www.tripwire.com/
|
||||
[2]:http://aide.sourceforge.net/
|
||||
[3]:http://www.la-samhna.de/samhain/
|
||||
[4]:http://sourceforge.net/projects/tripwire
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to install Spotify application on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,186 @@
|
||||
Linux mv Command Explained for Beginners (8 Examples)
|
||||
======
|
||||
|
||||
Just like [cp][1] for copying and rm for deleting, Linux also offers an in-built command for moving and renaming files. It's called **mv**. In this article, we will discuss the basics of this command line tool using easy to understand examples. Please note that all examples used in this tutorial have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
#### Linux mv command
|
||||
|
||||
As already mentioned, the mv command in Linux is used to move or rename files. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
mv [OPTION]... [-T] SOURCE DEST
|
||||
mv [OPTION]... SOURCE... DIRECTORY
|
||||
mv [OPTION]... -t DIRECTORY SOURCE...
|
||||
```
|
||||
|
||||
And here's what the man page says about it:
|
||||
```
|
||||
Rename SOURCE to DEST, or move SOURCE(s) to DIRECTORY.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how this tool works.
|
||||
|
||||
#### Q1. How to use mv command in Linux?
|
||||
|
||||
If you want to just rename a file, you can use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv names.txt fullnames.txt
|
||||
```
|
||||
|
||||
[![How to use mv command in Linux][2]][3]
|
||||
|
||||
Similarly, if the requirement is to move a file to a new location, use the mv command in the following way:
|
||||
|
||||
```
|
||||
mv [filename] [dest-dir]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
mv fullnames.txt /home/himanshu/Downloads
|
||||
```
|
||||
|
||||
[![Linux mv command][4]][5]
|
||||
|
||||
#### Q2. How to make sure mv prompts before overwriting?
|
||||
|
||||
By default, the mv command doesn't prompt when the operation involves overwriting an existing file. For example, the following screenshot shows the existing full_names.txt was overwritten by mv without any warning or notification.
|
||||
|
||||
[![How to make sure mv prompts before overwriting][6]][7]
|
||||
|
||||
However, if you want, you can force mv to prompt by using the **-i** command line option.
|
||||
|
||||
```
|
||||
mv -i [file_name] [new_file_name]
|
||||
```
|
||||
|
||||
[![the -i command option][8]][9]
|
||||
|
||||
So the above screenshots clearly shows that **-i** leads to mv asking for user permission before overwriting an existing file. Please note that in case you want to explicitly specify that you don't want mv to prompt before overwriting, then use the **-f** command line option.
|
||||
|
||||
#### Q3. How to make mv not overwrite an existing file?
|
||||
|
||||
For this, you need to use the **-n** command line option.
|
||||
|
||||
```
|
||||
mv -n [filename] [new_filename]
|
||||
```
|
||||
|
||||
The following screenshot shows the mv operation wasn't successful as a file with name 'full_names.txt' already existed and the command had -n option in it.
|
||||
|
||||
[![How to make mv not overwrite an existing file][10]][11]
|
||||
|
||||
Note:
|
||||
```
|
||||
If you specify more than one of -i, -f, -n, only the final one takes effect.
|
||||
```
|
||||
|
||||
#### Q4. How to make mv remove trailing slashes (if any) from source argument?
|
||||
|
||||
To remove any trailing slashes from source arguments, use the **\--strip-trailing-slashes** command line option.
|
||||
|
||||
```
|
||||
mv --strip-trailing-slashes [source] [dest]
|
||||
```
|
||||
|
||||
Here's how the official documentation explains the usefulness of this option:
|
||||
```
|
||||
This is useful when a
|
||||
|
||||
source
|
||||
|
||||
argument may have a trailing slash and specify a symbolic link to a directory. This scenario is in fact rather common because some shells can automatically append a trailing slash when performing file name completion on such symbolic links. Without this option,
|
||||
|
||||
mv
|
||||
|
||||
, for example, (via the system's rename function) must interpret a trailing slash as a request to dereference the symbolic link and so must rename the indirectly referenced
|
||||
|
||||
directory
|
||||
|
||||
and not the symbolic link. Although it may seem surprising that such behavior be the default, it is required by POSIX and is consistent with other parts of that standard.
|
||||
```
|
||||
|
||||
#### Q5. How to make mv treat destination as normal file?
|
||||
|
||||
To be absolutely sure that the destination entity is treated as a normal file (and not a directory), use the **-T** command line option.
|
||||
|
||||
```
|
||||
mv -T [source] [dest]
|
||||
```
|
||||
|
||||
Here's why this command line option exists:
|
||||
```
|
||||
This can help avoid race conditions in programs that operate in a shared area. For example, when the command 'mv /tmp/source /tmp/dest' succeeds, there is no guarantee that /tmp/source was renamed to /tmp/dest: it could have been renamed to/tmp/dest/source instead, if some other process created /tmp/dest as a directory. However, if mv -T /tmp/source /tmp/dest succeeds, there is no question that/tmp/source was renamed to /tmp/dest.
|
||||
```
|
||||
```
|
||||
In the opposite situation, where you want the last operand to be treated as a directory and want a diagnostic otherwise, you can use the --target-directory (-t) option.
|
||||
```
|
||||
|
||||
#### Q6. How to make mv move file only when its newer than destination file?
|
||||
|
||||
Suppose there exists a file named fullnames.txt in Downloads directory of your system, and there's a file with same name in your home directory. Now, you want to update ~/Downloads/fullnames.txt with ~/fullnames.txt, but only when the latter is newer. Then in this case, you'll have to use the **-u** command line option.
|
||||
|
||||
```
|
||||
mv -u ~/fullnames.txt ~/Downloads/fullnames.txt
|
||||
```
|
||||
|
||||
This option is particularly useful in cases when you need to take such decisions from within a shell script.
|
||||
|
||||
#### Q7. How make mv emit details of what all it is doing?
|
||||
|
||||
If you want mv to output information explaining what exactly it's doing, then use the **-v** command line option.
|
||||
|
||||
```
|
||||
mv -v [filename] [new_filename]
|
||||
```
|
||||
|
||||
For example, the following screenshots shows mv emitting some helpful details of what exactly it did.
|
||||
|
||||
[![How make mv emit details of what all it is doing][12]][13]
|
||||
|
||||
#### Q8. How to force mv to create backup of existing destination files?
|
||||
|
||||
This you can do using the **-b** command line option. The backup file created this way will have the same name as the destination file, but with a tilde (~) appended to it. Here's an example:
|
||||
|
||||
[![How to force mv to create backup of existing destination files][14]][15]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
As you'd have guessed by now, mv is as important as cp and rm for the functionality it offers - renaming/moving files around is also one of the basic operations after all. We've discussed a majority of command line options this tool offers. So you can just practice them and start using the command. To know more about mv, head to its [man page][16].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-mv-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/linux-cp-command/
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/mv-rename-ex.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/mv-rename-ex.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/mv-transfer-file.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/mv-transfer-file.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/mv-overwrite.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/big/mv-overwrite.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/mv-prompt-overwrite.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/big/mv-prompt-overwrite.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/mv-n-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/big/mv-n-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/mv-v-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/big/mv-v-option.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/mv-b-option.png
|
||||
[15]:https://www.howtoforge.com/images/command-tutorial/big/mv-b-option.png
|
||||
[16]:https://linux.die.net/man/1/mv
|
||||
@ -1,105 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
No More Ubuntu! Debian is the New Choice For Google’s In-house Linux Distribution
|
||||
============================================================
|
||||
|
||||
_Brief: For years Google used Goobuntu, an in-house, Ubuntu-based operating system. Goobuntu is now being replaced by gLinux, which is based on Debian Testing._
|
||||
|
||||
If you have read [Ubuntu facts][18], you probably already know that Google uses a Linux distribution called [Goobuntu][19] as the development platform. It is a custom Linux distribution based on…(easy to guess)… Ubuntu.
|
||||
|
||||
Goobuntu is basically a “[light skin over standard Ubuntu][20]“. It is based on the LTS releases of Ubuntu. If you think that Google contributes to the testing or development of Ubuntu, you are wrong. Google is simply a paying customer for Canonical’s [Ubuntu Advantage Program][21]. [Canonical][22] is the parent company behind Ubuntu.
|
||||
|
||||
### Meet gLinux: Google’s new Linux distribution based on Debian Buster
|
||||
|
||||

|
||||
|
||||
After more than five years with Ubuntu, Google is replacing Goobuntu with gLinux, a Linux distribution based on Debian Testing release.
|
||||
|
||||
As [MuyLinux reports][23], gLinux is being built from the source code of the packages and Google introduces its own changes to it. The changes will also be contributed to the upstream.
|
||||
|
||||
This ‘news’ is not really new. It was announced in Debconf’17 in August last year. Somehow the story did not get the attention it deserves.
|
||||
|
||||
You can watch the presentation in Debconf video [here][24]. The gLinux presentation starts around 12:00.
|
||||
|
||||
[Suggested readCity of Barcelona Kicks Out Microsoft in Favor of Linux and Open Source][25]
|
||||
|
||||
### Moving from Ubuntu 14.04 LTS to Debian 10 Buster
|
||||
|
||||
Once Google opted Ubuntu LTS for stability. Now it is moving to Debian testing branch for timely testing the packages. But it is not clear why Google decided to switch to Debian from Ubuntu.
|
||||
|
||||
How does Google plan to move to Debian Testing? The current Debian Testing release is upcoming Debian 10 Buster. Google has developed an internal tool to migrate the existing systems from Ubuntu 14.04 LTS to Debian 10 Buster. Project leader Margarita claimed in the Debconf talk that tool was tested to be working fine.
|
||||
|
||||
Google also plans to send the changes to Debian Upstream and hence contributing to its development.
|
||||
|
||||

|
||||
Development plan for gLinux
|
||||
|
||||
### Ubuntu loses a big customer!
|
||||
|
||||
Back in 2012, Canonical had clarified that Google is not their largest business desktop customer. However, it is safe to say that Google was a big customer for them. As Google prepares to switch to Debian, this will surely result in revenue loss for Canonical.
|
||||
|
||||
[Suggested readMandrake Linux Creator Launches a New Open Source Mobile OS][26]
|
||||
|
||||
### What do you think?
|
||||
|
||||
Do keep in mind that Google doesn’t restrict its developers from using any operating system. However, use of Linux is encouraged.
|
||||
|
||||
If you are thinking that you can get your hands on either of Goobuntu or gLinux, you’ll have to get a job at Google. It is an internal project of Google and is not accessible to the general public.
|
||||
|
||||
Overall, it is a good news for Debian, especially if they get changes to upstream. Cannot say the same for Ubuntu though. I have contacted Canonical for a comment but have got no response so far.
|
||||
|
||||
Update: Canonical responded that they “don’t share details of relationships with individual customers” and hence they cannot provide details about revenue and any other such details.
|
||||
|
||||
What are your views on Google ditching Ubuntu for Debian?
|
||||
|
||||
[Share3K][9][Tweet][10][+1][11][Share161][12][Stumble][13][Reddit644][14]SHARES3K
|
||||
|
||||
<footer class="entry-footer" style="box-sizing: inherit;">
|
||||
|
||||
Filed Under: [News][15]Tagged With: [glinux][16], [goobuntu][17]
|
||||
|
||||
</footer>
|
||||
|
||||

|
||||
|
||||
#### About Abhishek Prakash
|
||||
|
||||
I am a professional software developer, and founder of It’s FOSS. I am an avid Linux lover and Open Source enthusiast. I use Ubuntu and believe in sharing knowledge. Apart from Linux, I love classic detective mysteries. I’m a huge fan of Agatha Christie’s work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/goobuntu-glinux-google/
|
||||
|
||||
作者:[Abhishek Prakash ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/goobuntu-glinux-google/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[9]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[10]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[11]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[12]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[13]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[14]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[15]:https://itsfoss.com/category/news/
|
||||
[16]:https://itsfoss.com/tag/glinux/
|
||||
[17]:https://itsfoss.com/tag/goobuntu/
|
||||
[18]:https://itsfoss.com/facts-about-ubuntu/
|
||||
[19]:https://en.wikipedia.org/wiki/Goobuntu
|
||||
[20]:http://www.zdnet.com/article/the-truth-about-goobuntu-googles-in-house-desktop-ubuntu-linux/
|
||||
[21]:https://www.ubuntu.com/support
|
||||
[22]:https://www.canonical.com/
|
||||
[23]:https://www.muylinux.com/2018/01/15/goobuntu-glinux-google/
|
||||
[24]:https://debconf17.debconf.org/talks/44/
|
||||
[25]:https://itsfoss.com/barcelona-open-source/
|
||||
[26]:https://itsfoss.com/eelo-mobile-os/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by cncuckoo
|
||||
|
||||
Two great uses for the cp command: Bash shortcuts
|
||||
============================================================
|
||||
|
||||
|
||||
110
sources/tech/20180120 The World Map In Your Terminal.md
Normal file
110
sources/tech/20180120 The World Map In Your Terminal.md
Normal file
@ -0,0 +1,110 @@
|
||||
The World Map In Your Terminal
|
||||
======
|
||||
I just stumbled upon an interesting utility. The World map in the Terminal! Yes, It is so cool. Say hello to **MapSCII** , a Braille and ASCII world map renderer for your xterm-compatible terminals. It supports GNU/Linux, Mac OS, and Windows. I thought it is a just another project hosted on GitHub. But I was wrong! It is really impressive what they did there. We can use our mouse pointer to drag and zoom in and out a location anywhere in the world map. The other notable features are;
|
||||
|
||||
* Discover Point-of-Interests around any given location
|
||||
* Highly customizable layer styling with [Mapbox Styles][1] support
|
||||
* Connect to any public or private vector tile server
|
||||
* Or just use the supplied and optimized [OSM2VectorTiles][2] based one
|
||||
* Work offline and discover local [VectorTile][3]/[MBTiles][4]
|
||||
* Compatible with most Linux and OSX terminals
|
||||
* Highly optimizied algorithms for a smooth experience
|
||||
|
||||
|
||||
|
||||
### Displaying the World Map in your Terminal using MapSCII
|
||||
|
||||
To open the map, just run the following command from your Terminal:
|
||||
```
|
||||
telnet mapscii.me
|
||||
```
|
||||
|
||||
Here is the World map from my Terminal.
|
||||
|
||||
[![][5]][6]
|
||||
|
||||
Cool, yeah?
|
||||
|
||||
To switch to Braille view, press **c**.
|
||||
|
||||
[![][5]][7]
|
||||
|
||||
Type **c** again to switch back to the previous format **.**
|
||||
|
||||
To scroll around the map, use arrow keys **up** , **down** , **left** , **right**. To zoom in/out a location, use **a** and **z** keys. Also, you can use the scroll wheel of your mouse to zoom in or out. To quit the map, press **q**.
|
||||
|
||||
Like I already said, don't think it is a simple project. Click on any location on the map and press **" a"** to zoom in.
|
||||
|
||||
Here are some the sample screenshots after I zoomed it.
|
||||
|
||||
[![][5]][8]
|
||||
|
||||
I can be able to zoom to view the states in my country (India).
|
||||
|
||||
[![][5]][9]
|
||||
|
||||
And the districts in a state (Tamilnadu):
|
||||
|
||||
[![][5]][10]
|
||||
|
||||
Even the [Taluks][11] and the towns in a district:
|
||||
|
||||
[![][5]][12]
|
||||
|
||||
And, the place where I completed my schooling:
|
||||
|
||||
[![][5]][13]
|
||||
|
||||
Even though it is just a smallest town, MapSCII displayed it accurately. MapSCII uses [**OpenStreetMap**][14] to collect the data.
|
||||
|
||||
### Install MapSCII locally
|
||||
|
||||
Liked it? Great! You can host it on your own system.
|
||||
|
||||
Make sure you have installed Node.js on your system. If not, refer the following link.
|
||||
|
||||
[Install NodeJS on Linux][15]
|
||||
|
||||
Then, run the following command to install it.
|
||||
```
|
||||
sudo npm install -g mapscii
|
||||
|
||||
```
|
||||
|
||||
To launch MapSCII, run:
|
||||
```
|
||||
mapscii
|
||||
```
|
||||
|
||||
Have fun! More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/mapscii-world-map-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.mapbox.com/mapbox-gl-style-spec/
|
||||
[2]:https://github.com/osm2vectortiles
|
||||
[3]:https://github.com/mapbox/vector-tile-spec
|
||||
[4]:https://github.com/mapbox/mbtiles-spec
|
||||
[5]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-1-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-2.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-3.png ()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-4.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-5.png ()
|
||||
[11]:https://en.wikipedia.org/wiki/Tehsils_of_India
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-6.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-7.png ()
|
||||
[14]:https://www.openstreetmap.org/
|
||||
[15]:https://www.ostechnix.com/install-node-js-linux/
|
||||
@ -0,0 +1,66 @@
|
||||
socat as a handler for multiple reverse shells · System Overlord
|
||||
======
|
||||
|
||||
I was looking for a new way to handle multiple incoming reverse shells. My shells needed to be encrypted and I preferred not to use Metasploit in this case. Because of the way I was deploying my implants, I wasn't able to use separate incoming port numbers or other ways of directing the traffic to multiple listeners.
|
||||
|
||||
Obviously, it's important to keep each reverse shell separated, so I couldn't just have a listener redirecting all the connections to STDIN/STDOUT. I also didn't want to wait for sessions serially - obviously I wanted to be connected to all of my implants simultaneously. (And allow them to disconnect/reconnect as needed due to loss of network connectivity.)
|
||||
|
||||
As I was thinking about the problem, I realized that I basically wanted `tmux` for reverse shells. So I began to wonder if there was some way to connect `openssl s_server` or something similar to `tmux`. Given the limitations of `s_server`, I started looking at `socat`. Despite it's versatility, I've actually only used it once or twice before this, so I spent a fair bit of time reading the man page and the examples.
|
||||
|
||||
I couldn't find a way to get `socat` to talk directly to `tmux` in a way that would spawn each connection as a new window (file descriptors are not passed to the newly-started process in `tmux new-window`), so I ended up with a strange workaround. I feel a little bit like Rube Goldberg inventing C2 software (and I need to get something more permanent and featureful eventually, but this was a quick and dirty PoC), but I've put together a chain of `socat` to get a working solution.
|
||||
|
||||
My implementation works by having a single `socat` process receive the incoming connections (forking on incoming connection), and executing a script that first starts a `socat` instance within tmux, and then another `socat` process to copy from the first to the second over a UNIX domain socket.
|
||||
|
||||
Yes, this is 3 socat processes. It's a little ridiculous, but I couldn't find a better approach. Roughly speaking, the communications flow looks a little like this:
|
||||
```
|
||||
TLS data <--> socat listener <--> script stdio <--> socat <--> unix socket <--> socat in tmux <--> terminal window
|
||||
|
||||
```
|
||||
|
||||
Getting it started is fairly simple. Begin by generating your SSL certificate. In this case, I'm using a self-signed certificate, but obviously you could go through a commercial CA, Let's Encrypt, etc.
|
||||
```
|
||||
openssl req -newkey rsa:2048 -nodes -keyout server.key -x509 -days 30 -out server.crt
|
||||
cat server.key server.crt > server.pem
|
||||
|
||||
```
|
||||
|
||||
Now we will create the script that is run on each incoming connection. This script needs to launch a `tmux` window running a `socat` process copying from a UNIX domain socket to `stdio` (in tmux), and then connecting another `socat` between the `stdio` coming in to the UNIX domain socket.
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
SOCKDIR=$(mktemp -d)
|
||||
SOCKF=${SOCKDIR}/usock
|
||||
|
||||
# Start tmux, if needed
|
||||
tmux start
|
||||
# Create window
|
||||
tmux new-window "socat UNIX-LISTEN:${SOCKF},umask=0077 STDIO"
|
||||
# Wait for socket
|
||||
while test ! -e ${SOCKF} ; do sleep 1 ; done
|
||||
# Use socat to ship data between the unix socket and STDIO.
|
||||
exec socat STDIO UNIX-CONNECT:${SOCKF}
|
||||
```
|
||||
|
||||
The while loop is necessary to make sure that the last `socat` process does not attempt to open the UNIX domain socket before it has been created by the new `tmux` child process.
|
||||
|
||||
Finally, we can launch the `socat` process that will accept the incoming requests (handling all the TLS steps) and execute our per-connection script:
|
||||
```
|
||||
socat OPENSSL-LISTEN:8443,cert=server.pem,reuseaddr,verify=0,fork EXEC:./socatscript.sh
|
||||
|
||||
```
|
||||
|
||||
This listens on port 8443, using the certificate and private key contained in `server.pem`, performs a `fork()` on accepting each incoming connection (so they do not block each other) and disables certificate verification (since we're not expecting our clients to provide a certificate). On the other side, it launches our script, providing the data from the TLS connection via STDIO.
|
||||
|
||||
At this point, an incoming TLS connection connects, and is passed through our processes to eventually arrive on the `STDIO` of a new window in the running `tmux` server. Each connection gets its own window, allowing us to easily see and manage the connections for our implants.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://systemoverlord.com/2018/01/20/socat-as-a-handler-for-multiple-reverse-shells.html
|
||||
|
||||
作者:[David][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://systemoverlord.com/about
|
||||
234
sources/tech/20180121 Shell Scripting a Bunco Game.md
Normal file
234
sources/tech/20180121 Shell Scripting a Bunco Game.md
Normal file
@ -0,0 +1,234 @@
|
||||
Shell Scripting a Bunco Game
|
||||
======
|
||||
I haven't dug into any game programming for a while, so I thought it was high time to do something in that realm. At first, I thought "Halo as a shell script?", but then I came to my senses. Instead, let's look at a simple dice game called Bunco. You may not have heard of it, but I bet your Mom has—it's a quite popular game for groups of gals at a local pub or tavern.
|
||||
|
||||
Played in six rounds with three dice, the game is simple. You roll all three dice and have to match the current round number. If all three dice match the current round number (for example, three 3s in round three), you score 21\. If all three match but aren't the current round number, it's a Mini Bunco and worth five points. Failing both of those, each die with the same value as the round number is worth one point.
|
||||
|
||||
Played properly, the game also involves teams, multiple tables including a winner's table, and usually cash prizes funded by everyone paying $5 or similar to play and based on specific winning scenarios like "most Buncos" or "most points". I'll skip that part here, however, and just focus on the dice part.
|
||||
|
||||
### Let's Do the Math
|
||||
|
||||
Before I go too far into the programming side of things, let me talk briefly about the math behind the game. Dice are easy to work with because on a properly weighted die, the chance of a particular value coming up is 1:6.
|
||||
|
||||
Random tip: not sure whether your dice are balanced? Toss them in salty water and spin them. There are some really interesting YouTube videos from the D&D world showing how to do this test.
|
||||
|
||||
So what are the odds of three dice having the same value? The first die has a 100% chance of having a value (no leaners here), so that's easy. The second die has a 16.66% chance of being any particular value, and then the third die has the same chance of being that value, but of course, they multiply, so three dice have about a 2.7% chance of all having the same value.
|
||||
|
||||
Then, it's a 16.66% chance that those three dice would be the current round's number—or, in mathematical terms: 0.166 * 0.166 * 0.166 = 0.00462.
|
||||
|
||||
In other words, you have a 0.46% chance of rolling a Bunco, which is a bit less than once out of every 200 rolls of three dice.
|
||||
|
||||
It could be tougher though. If you were playing with five dice, the chance of rolling a Mini Bunco (or Yahtzee) is 0.077%, and if you were trying to accomplish a specific value, say just sixes, then it's 0.00012% likely on any given roll—which is to say, not bloody likely!
|
||||
|
||||
### And So into the Coding
|
||||
|
||||
As with every game, the hardest part is really having a good random number generator that generates truly random values. That's actually hard to affect in a shell script though, so I'm going to sidestep this entire issue and assume that the shell's built-in random number generator will be sufficient.
|
||||
|
||||
What's nice is that it's super easy to work with. Just reference $RANDOM, and you'll have a random value between 0 and MAXINT (32767):
|
||||
|
||||
```
|
||||
|
||||
$ echo $RANDOM $RANDOM $RANDOM
|
||||
10252 22142 14863
|
||||
|
||||
```
|
||||
|
||||
To constrain that to values between 1–6 use the modulus function:
|
||||
|
||||
```
|
||||
|
||||
$ echo $(( $RANDOM % 6 ))
|
||||
3
|
||||
$ echo $(( $RANDOM % 6 ))
|
||||
0
|
||||
|
||||
```
|
||||
|
||||
Oops! I forgot to shift it one. Here's another try:
|
||||
|
||||
```
|
||||
|
||||
$ echo $(( ( $RANDOM % 6 ) + 1 ))
|
||||
6
|
||||
|
||||
```
|
||||
|
||||
That's the dice-rolling feature. Let's make it a function where you can specify the variable you'd like to have the generated value as part of the invocation:
|
||||
|
||||
```
|
||||
|
||||
rolldie()
|
||||
{
|
||||
local result=$1
|
||||
rolled=$(( ( $RANDOM % 6 ) + 1 ))
|
||||
eval $result=$rolled
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The use of the eval is to ensure that the variable specified in the invocation is actually assigned the calculated value. It's easy to work with:
|
||||
|
||||
```
|
||||
|
||||
rolldie die1
|
||||
|
||||
```
|
||||
|
||||
That will load a random value between 1–6 into the variable die1. To roll your three dice, it's straightforward:
|
||||
|
||||
```
|
||||
|
||||
rolldie die1 ; rolldie die2 ; rolldie die3
|
||||
|
||||
```
|
||||
|
||||
Now to test the values. First, let's test for a Bunco where all three dice have the same value, and it's the value of the current round too:
|
||||
|
||||
```
|
||||
|
||||
if [ $die1 -eq $die2 ] && [ $die2 -eq $die3 ] ; then
|
||||
if [ $die1 -eq $round ] ; then
|
||||
echo "BUNCO!"
|
||||
score=25
|
||||
else
|
||||
echo "Mini Bunco!"
|
||||
score=5
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
That's probably the hardest of the tests, and notice the unusual use of test in the first conditional: [ cond1 ] && [ cond2 ]. If you're thinking that you could also write it as cond1 -a cond2, you're right. As with so much in the shell, there's more than one way to get to the solution.
|
||||
|
||||
The remainder of the code is straightforward; you just need to test for whether the die matches the current round value:
|
||||
|
||||
```
|
||||
|
||||
if [ $die1 -eq $round ] ; then
|
||||
score=1
|
||||
fi
|
||||
if [ $die2 -eq $round ] ; then
|
||||
score=$(( $score + 1 ))
|
||||
fi
|
||||
if [ $die3 -eq $round ] ; then
|
||||
score=$(( $score + 1 ))
|
||||
fi
|
||||
|
||||
```
|
||||
|
||||
The only thing to consider here is that you don't want to score die value vs. round if you've also scored a Bunco or Mini Bunco, so the entire second set of tests needs to be within the else clause of the first conditional (to see if all three dice have the same value).
|
||||
|
||||
Put it together and specify the round number on the command line, and here's what you have at this point:
|
||||
|
||||
```
|
||||
|
||||
$ sh bunco.sh 5
|
||||
You rolled: 1 1 5
|
||||
score = 1
|
||||
$ sh bunco.sh 2
|
||||
You rolled: 6 4 3
|
||||
score = 0
|
||||
$ sh bunco.sh 1
|
||||
You rolled: 1 1 1
|
||||
BUNCO!
|
||||
score = 25
|
||||
|
||||
```
|
||||
|
||||
A Bunco so quickly? Well, as I said, there might be a slight issue with the randomness of the random number generator in the shell.
|
||||
|
||||
You can test it once you have the script working by running it a few hundred times and then checking to see what percentage are Bunco or Mini Bunco, but I'll leave that as an exercise for you, dear reader. Well, maybe I'll come back to it another time.
|
||||
|
||||
Let's finish up this script by having it accumulate score and run for all six rounds instead of specifying a round on the command line. That's easily done, because it's just a wrapper around the entire script, or, better, the big conditional statement becomes a function all its own:
|
||||
|
||||
```
|
||||
|
||||
BuncoRound()
|
||||
{
|
||||
# roll, display, and score a round of bunco!
|
||||
# round is specified when invoked, score added to totalscore
|
||||
|
||||
local score=0 ; local round=$1 ; local hidescore=0
|
||||
|
||||
rolldie die1 ; rolldie die2 ; rolldie die3
|
||||
echo Round $round. You rolled: $die1 $die2 $die3
|
||||
|
||||
if [ $die1 -eq $die2 ] && [ $die2 -eq $die3 ] ; then
|
||||
if [ $die1 -eq $round ] ; then
|
||||
echo " BUNCO!"
|
||||
score=25
|
||||
hidescore=1
|
||||
else
|
||||
echo " Mini Bunco!"
|
||||
score=5
|
||||
hidescore=1
|
||||
fi
|
||||
else
|
||||
if [ $die1 -eq $round ] ; then
|
||||
score=1
|
||||
fi
|
||||
if [ $die2 -eq $round ] ; then
|
||||
score=$(( $score + 1 ))
|
||||
fi
|
||||
if [ $die3 -eq $round ] ; then
|
||||
score=$(( $score + 1 ))
|
||||
fi
|
||||
fi
|
||||
|
||||
if [ $hidescore -eq 0 ] ; then
|
||||
echo " score this round: $score"
|
||||
fi
|
||||
|
||||
totalscore=$(( $totalscore + $score ))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
I admit, I couldn't resist a few improvements as I went along, including the addition of it showing either Bunco, Mini Bunco or a score value (that's what $hidescore does).
|
||||
|
||||
Invoking it is a breeze, and you'll use a for loop:
|
||||
|
||||
```
|
||||
|
||||
for round in {1..6} ; do
|
||||
BuncoRound $round
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
That's about the entire program at this point. Let's run it once and see what happens:
|
||||
|
||||
```
|
||||
|
||||
$ sh bunco.sh 1
|
||||
Round 1\. You rolled: 2 3 3
|
||||
score this round: 0
|
||||
Round 2\. You rolled: 2 6 6
|
||||
score this round: 1
|
||||
Round 3\. You rolled: 1 2 4
|
||||
score this round: 0
|
||||
Round 4\. You rolled: 2 1 4
|
||||
score this round: 1
|
||||
Round 5\. You rolled: 5 5 6
|
||||
score this round: 2
|
||||
Round 6\. You rolled: 2 1 3
|
||||
score this round: 0
|
||||
Game over. Your total score was 4
|
||||
|
||||
```
|
||||
|
||||
Ugh. Not too impressive, but it's probably a typical round. Again, you can run it a few hundred—or thousand—times, just save the "Game over" line, then do some quick statistical analysis to see how often you score more than 3 points in six rounds. (With three dice to roll a given value, you should hit that 50% of the time.)
|
||||
|
||||
It's not a complicated game by any means, but it makes for an interesting little programming project. Now, what if they used 20-sided die and let you re-roll one die per round and had a dozen rounds?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/shell-scripting-bunco-game
|
||||
|
||||
作者:[Dave Taylor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/dave-taylor
|
||||
197
sources/tech/20180122 How to Create a Docker Image.md
Normal file
197
sources/tech/20180122 How to Create a Docker Image.md
Normal file
@ -0,0 +1,197 @@
|
||||
How to Create a Docker Image
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the previous [article][1], we learned about how to get started with Docker on Linux, macOS, and Windows. In this article, we will get a basic understanding of creating Docker images. There are prebuilt images available on DockerHub that you can use for your own project, and you can publish your own image there.
|
||||
|
||||
We are going to use prebuilt images to get the base Linux subsystem, as it's a lot of work to build one from scratch. You can get Alpine (the official distro used by Docker Editions), Ubuntu, BusyBox, or scratch. In this example, I will use Ubuntu.
|
||||
|
||||
Before we start building our images, let's "containerize" them! By this I just mean creating directories for all of your Docker images so that you can maintain different projects and stages isolated from each other.
|
||||
```
|
||||
$ mkdir dockerprojects
|
||||
|
||||
cd dockerprojects
|
||||
|
||||
```
|
||||
|
||||
Now create a Dockerfile inside the dockerprojects directory using your favorite text editor; I prefer nano, which is also easy for new users.
|
||||
```
|
||||
$ nano Dockerfile
|
||||
|
||||
```
|
||||
|
||||
And add this line:
|
||||
```
|
||||
FROM Ubuntu
|
||||
|
||||
```
|
||||
|
||||
![m7_f7No0pmZr2iQmEOH5_ID6MDG2oEnODpQZkUL7][2]
|
||||
|
||||
Save it with Ctrl+Exit then Y.
|
||||
|
||||
Now create your new image and provide it with a name (run these commands within the same directory):
|
||||
```
|
||||
$ docker build -t dockp .
|
||||
|
||||
```
|
||||
|
||||
(Note the dot at the end of the command.) This should build successfully, so you'll see:
|
||||
```
|
||||
Sending build context to Docker daemon 2.048kB
|
||||
|
||||
Step 1/1 : FROM ubuntu
|
||||
|
||||
---> 2a4cca5ac898
|
||||
|
||||
Successfully built 2a4cca5ac898
|
||||
|
||||
Successfully tagged dockp:latest
|
||||
|
||||
```
|
||||
|
||||
It's time to run and test your image:
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
|
||||
```
|
||||
|
||||
You should see root prompt:
|
||||
```
|
||||
root@c06fcd6af0e8:/#
|
||||
|
||||
```
|
||||
|
||||
This means you are literally running bare minimal Ubuntu inside Linux, Windows, or macOS. You can run all native Ubuntu commands and CLI utilities.
|
||||
|
||||
![vpZ8ts9oq3uk--z4n6KP3DD3uD_P4EpG7fX06MC3][3]
|
||||
|
||||
Let's check all the Docker images you have in your directory:
|
||||
```
|
||||
$docker images
|
||||
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
dockp latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
hello-world latest f2a91732366c 8 weeks ago 1.85kB
|
||||
|
||||
```
|
||||
|
||||
You can see all three images: dockp, Ubuntu, and hello-world, which I created a few weeks ago when working on the previous articles of this series. Building a whole LAMP stack can be challenging, so we are going create a simple Apache server image with Dockerfile.
|
||||
|
||||
Dockerfile is basically a set of instructions to install all the needed packages, configure, and copy files. In this case, it's Apache and Nginx.
|
||||
|
||||
You may also want to create an account on DockerHub and log into your account before building images, in case you are pulling something from DockerHub. To log into DockerHub from the command line, just run:
|
||||
```
|
||||
$ docker login
|
||||
|
||||
```
|
||||
|
||||
Enter your username and password and you are logged in.
|
||||
|
||||
Next, create a directory for Apache inside the dockerproject:
|
||||
```
|
||||
$ mkdir apache
|
||||
|
||||
```
|
||||
|
||||
Create a Dockerfile inside Apache folder:
|
||||
```
|
||||
$ nano Dockerfile
|
||||
|
||||
```
|
||||
|
||||
And paste these lines:
|
||||
```
|
||||
FROM ubuntu
|
||||
|
||||
MAINTAINER Kimbro Staken version: 0.1
|
||||
|
||||
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
|
||||
ENV APACHE_RUN_USER www-data
|
||||
|
||||
ENV APACHE_RUN_GROUP www-data
|
||||
|
||||
ENV APACHE_LOG_DIR /var/log/apache2
|
||||
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
|
||||
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
|
||||
|
||||
```
|
||||
|
||||
Then, build the image:
|
||||
```
|
||||
docker build -t apache .
|
||||
|
||||
```
|
||||
|
||||
(Note the dot after a space at the end.)
|
||||
|
||||
It will take some time, then you should see successful build like this:
|
||||
```
|
||||
Successfully built e7083fd898c7
|
||||
|
||||
Successfully tagged ng:latest
|
||||
|
||||
Swapnil:apache swapnil$
|
||||
|
||||
```
|
||||
|
||||
Now let's run the server:
|
||||
```
|
||||
$ docker run -d apache
|
||||
|
||||
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
|
||||
|
||||
```
|
||||
|
||||
Eureka. Your container image is running. Check all the running containers:
|
||||
```
|
||||
$ docker ps
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
|
||||
|
||||
```
|
||||
|
||||
You can kill the container with the docker kill command:
|
||||
```
|
||||
$docker kill a189a4db0f7
|
||||
|
||||
```
|
||||
|
||||
So, you see the "image" itself is persistent that stays in your directory, but the container runs and goes away. Now you can create as many images as you want and spin and nuke as many containers as you need from those images.
|
||||
|
||||
That's how to create an image and run containers.
|
||||
|
||||
To learn more, you can open your web browser and check out the documentation about how to build more complicated Docker images like the whole LAMP stack. Here is a[ Dockerfile][4] file for you to play with. In the next article, I'll show how to push images to DockerHub.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[2]:https://lh6.googleusercontent.com/m7_f7No0pmZr2iQmEOH5_ID6MDG2oEnODpQZkUL7q3GYRB9f1-lvMYLE5f3GBpzIk-ev5VlcB0FHYSxn6NNQjxY4jJGqcgdFWaeQ-027qX_g-SVtbCCMybJeD6QIXjzM2ga8M4l4
|
||||
[3]:https://lh3.googleusercontent.com/vpZ8ts9oq3uk--z4n6KP3DD3uD_P4EpG7fX06MC3uFvj2-WaI1DfOfec9ZXuN7XUNObQ2SCc4Nbiqp-CM7ozUcQmtuzmOdtUHTF4Jq8YxkC49o2k7y5snZqTXsueITZyaLiHq8bT
|
||||
[4]:https://github.com/fauria/docker-lamp/blob/master/Dockerfile
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,172 @@
|
||||
Linux rm Command Explained for Beginners (8 Examples)
|
||||
======
|
||||
|
||||
Deleting files is a fundamental operation, just like copying files or renaming/moving them. In Linux, there's a dedicated command - dubbed **rm** \- that lets you perform all deletion-related operations. In this tutorial, we will discuss the basics of this tool along with some easy to understand examples.
|
||||
|
||||
But before we do that, it's worth mentioning that all examples mentioned in the article have been tested on Ubuntu 16.04 LTS.
|
||||
|
||||
#### Linux rm command
|
||||
|
||||
So in layman's terms, we can simply say the rm command is used for removing/deleting files and directories. Following is the syntax of the command:
|
||||
|
||||
```
|
||||
rm [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
And here's how the tool's man page describes it:
|
||||
```
|
||||
This manual page documents the GNU version of rm. rm removes each specified file. By default, it
|
||||
does not remove directories.
|
||||
|
||||
If the -I or --interactive=once option is given, and there are more than three files or the -r,
|
||||
-R, or --recursive are given, then rm prompts the user for whether to proceed with the entire
|
||||
operation. If the response is not affirmative, the entire command is aborted.
|
||||
|
||||
Otherwise, if a file is unwritable, standard input is a terminal, and the -f or --force option is
|
||||
not given, or the -i or --interactive=always option is given, rm prompts the user for whether to
|
||||
remove the file. If the response is not affirmative, the file is skipped.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how the tool works.
|
||||
|
||||
#### Q1. How to remove files using rm command?
|
||||
|
||||
That's pretty easy and straightforward. All you have to do is to pass the name of the files (along with paths if they are not in the current working directory) as input to the rm command.
|
||||
|
||||
```
|
||||
rm [filename]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
rm testfile.txt
|
||||
```
|
||||
|
||||
[![How to remove files using rm command][1]][2]
|
||||
|
||||
#### Q2. How to remove directories using rm command?
|
||||
|
||||
If you are trying to remove a directory, then you need to use the **-r** command line option. Otherwise, rm will throw an error saying what you are trying to delete is a directory.
|
||||
|
||||
```
|
||||
rm -r [dir name]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
rm -r testdir
|
||||
```
|
||||
|
||||
[![How to remove directories using rm command][3]][4]
|
||||
|
||||
#### Q3. How to make rm prompt before every removal?
|
||||
|
||||
If you want rm to prompt before each delete action it performs, then use the **-i** command line option.
|
||||
|
||||
```
|
||||
rm -i [file or dir]
|
||||
```
|
||||
|
||||
For example, suppose you want to delete a directory 'testdir' and all its contents, but want rm to prompt before every deletion, then here's how you can do that:
|
||||
|
||||
```
|
||||
rm -r -i testdir
|
||||
```
|
||||
|
||||
[![How to make rm prompt before every removal][5]][6]
|
||||
|
||||
#### Q4. How to force rm to ignore nonexistent files?
|
||||
|
||||
The rm command lets you know through an error message if you try deleting a non-existent file or directory.
|
||||
|
||||
[![Linux rm command example][7]][8]
|
||||
|
||||
However, if you want, you can make rm suppress such error/notifications - all you have to do is to use the **-f** command line option.
|
||||
|
||||
```
|
||||
rm -f [filename]
|
||||
```
|
||||
|
||||
[![How to force rm to ignore nonexistent files][9]][10]
|
||||
|
||||
#### Q5. How to make rm prompt only in some scenarios?
|
||||
|
||||
There exists a command line option **-I** , which when used, makes sure the command only prompts once before removing more than three files, or when removing recursively.
|
||||
|
||||
For example, the following screenshot shows this option in action - there was no prompt when two files were deleted, but the command prompted when more than three files were deleted.
|
||||
|
||||
[![How to make rm prompt only in some scenarios][11]][12]
|
||||
|
||||
#### Q6. How rm works when dealing with root directory?
|
||||
|
||||
Of course, deleting root directory is the last thing a Linux user would want. That's why, the rm command doesn't let you perform a recursive delete operation on this directory by default.
|
||||
|
||||
[![How rm works when dealing with root directory][13]][14]
|
||||
|
||||
However, if you want to go ahead with this operation for whatever reason, then you need to tell this to rm by using the **\--no-preserve-root** option. When this option is enabled, rm doesn't treat the root directory (/) specially.
|
||||
|
||||
In case you want to know the scenarios in which a user might want to delete the root directory of their system, head [here][15].
|
||||
|
||||
#### Q7. How to make rm only remove empty directories?
|
||||
|
||||
In case you want to restrict rm's directory deletion ability to only empty directories, then you can use the -d command line option.
|
||||
|
||||
```
|
||||
rm -d [dir]
|
||||
```
|
||||
|
||||
The following screenshot shows the -d command line option in action - only empty directory got deleted.
|
||||
|
||||
[![How to make rm only remove empty directories][16]][17]
|
||||
|
||||
#### Q8. How to force rm to emit details of operation it is performing?
|
||||
|
||||
If you want rm to display detailed information of the operation being performed, then this can be done by using the **-v** command line option.
|
||||
|
||||
```
|
||||
rm -v [file or directory name]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
[![How to force rm to emit details of operation it is performing][18]][19]
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Given the kind of functionality it offers, rm is one of the most frequently used commands in Linux (like [cp][20] and mv). Here, in this tutorial, we have covered almost all major command line options this tool provides. rm has a bit of learning curve associated with, so you'll have to spent some time practicing its options before you start using the tool in your day to day work. For more information, head to the command's [man page][21].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-rm-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/rm-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/rm-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/rm-r.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/rm-r.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/rm-i-option.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-i-option.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/rm-non-ext-error.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/rm-non-ext-error.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/rm-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/rm-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/rm-I-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/rm-I-option.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/rm-root-default.png
|
||||
[14]:https://www.howtoforge.com/images/command-tutorial/big/rm-root-default.png
|
||||
[15]:https://superuser.com/questions/742334/is-there-a-scenario-where-rm-rf-no-preserve-root-is-needed
|
||||
[16]:https://www.howtoforge.com/images/command-tutorial/rm-d-option.png
|
||||
[17]:https://www.howtoforge.com/images/command-tutorial/big/rm-d-option.png
|
||||
[18]:https://www.howtoforge.com/images/command-tutorial/rm-v-option.png
|
||||
[19]:https://www.howtoforge.com/images/command-tutorial/big/rm-v-option.png
|
||||
[20]:https://www.howtoforge.com/linux-cp-command/
|
||||
[21]:https://linux.die.net/man/1/rm
|
||||
@ -1,86 +0,0 @@
|
||||
对 C 的漫长的告别
|
||||
==========================================
|
||||
|
||||
|
||||
这几天来,我就在思考那些能够挑战 C 语言作为系统编程语言堆中的根节点的地位的新潮语言,尤其是 Go 和 Rust。我发现了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经忘了我上一次是在什么时候 _创建新的 C 语言项目_ 了。
|
||||
|
||||
如果你认为这件事情不够震惊,那你可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec , GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,而且我都记不清我什么时候开始这样做的了。而且...回望历史,我不认为这是本世纪发生的事情。
|
||||
|
||||
当你问到我我的五个核心软件开发技能,“C 语言专家” 一定是你最有可能听到的,这件事情对我来说很好。这也激起了我的思考。C 的未来会怎样 ?C 是否正像当年的 COBOL 一样,在辉煌之后,走向落幕?
|
||||
|
||||
我恰好是在 C 语言迅猛发展并把汇编语言以及其他许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言来争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言直接毫无声息的退出舞台。主流的(FORTRAN,Pascal,COBOL)语言则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
|
||||
|
||||
在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java, Perl, Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部是是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用之前存在的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过大伯这个限制,但是只有 Python 做到了)
|
||||
|
||||
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个帮助图书管理员使用一款叫做 SunSITE 的源码分发式软件,我使用的那个语言,叫做 Perl。
|
||||
|
||||
这个应用完全是基于文本的,而且只需要以人类能反应过来的速度运行(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,我在那时没想到我几乎再也不会在一个新项目的第一个文件里敲下 “int main(int argc, char **argv)” 了。
|
||||
|
||||
我说“几乎”,主要是因为 1999 年的 [SNG][3].我像那是我最后一个从头开始写的项目。在那之后我的所有新的 C 代码都是为我贡献代码,或者成为维护者的项目而写 —— 比如 GPSD 以及 NTPsec。
|
||||
|
||||
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速循环使得硬件愈加便宜,像 Perl 这样的语言的运行也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
|
||||
|
||||
在 1997 年学习了 Python 这件事对我来说是一道分水岭。这个语言很完美 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!还完全绑定了 POSIX!还有一个绝不完犊子的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 时写 C .
|
||||
|
||||
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没有和 C 语言语义等价的 POSIX 绑定的语言_都得失败_。在计算机科学的发展史上,作者没有意识到这一点的学术语言的骨骸俯拾皆是。)
|
||||
|
||||
显然,对我来说,,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致吐核的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时摩尔定律还没让硬件产业迅猛发展。
|
||||
|
||||
与 C 相比更喜欢 Python —— 然后只要是能的话我就会从 C 语言转移到 Python ,这让我的工作的复杂程度降了不少。我开始在 GPSD 以及 NTPsec 里面加入 Python。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
|
||||
|
||||
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也不是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,在当时任何一个新的学院派的动态语言都可以让我不写 C 语言代码。那件事可能是在我写了很多 Java 之后发生的,这就是另一段时间线了。
|
||||
|
||||
我写这个回忆录部分原因是我觉得我不特殊,我像在世纪之交,同样的事件也改变了不少 C 语言老手的编码习惯。他们也会和我之前一样,没有发现这一转变。
|
||||
|
||||
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
|
||||
|
||||
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言的有限的数据本体以及其脆弱的底层管理,尝试用 C 写的话可能会很恐怖,并注定失败。
|
||||
|
||||
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
|
||||
|
||||
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年,我是 Python 的早期使用者。来自 [TIOBE][7] 的数据让我在 Go 语言脱胎于公司的实验项目从小众语言火爆的几个月内开始写自己的第一个 Go 语言项目。
|
||||
|
||||
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标砖很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的 事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
|
||||
|
||||
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。当写单用户且只需要以人类能接受的速度运行的程序时,使用 Python 很好,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断,起初 Go 存在的主要原因就是 Google ,然后 Python 的众多支持者也来支持这款语言 ——— 他们遭遇了同样的痛点。
|
||||
|
||||
Go 语言就是为了处理 Python 处理不了的类 C 语言工作而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的 很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
|
||||
|
||||
([这里][8]有关于我第一次写 Go 的经验的更多信息)
|
||||
|
||||
本来我像把 Rust 也视为 “C 语言要过时了” 的例子,但是在学习这们语言并尝试使用这门语言编程之后,我觉得[这语言现在还不行][9]。也许 5 年以后,它才会成为 C 语言的对手。
|
||||
|
||||
随着 2017 的临近,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言届的新星可能就会取得成功。
|
||||
|
||||
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我写代码的时间,我们都没有等到 C 语言的继任者。也无法体验在前 C 语言时代的系统编程是什么模样。但是现在我们可以使用两种视角来看待系统编程...
|
||||
|
||||
...另一个视角就是下面这个语言。我的一个朋友正在开发一个他称之为 "Cx" 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他给我做出不切实际的保证,他的实现方法真的很是有意思,我会尽量给他募集资金。
|
||||
|
||||
现在,除了 C 语言之外,我看到了三种不同的道路。在两年之前,我一种都不会发现。我重复一遍:这件事情意义重大。
|
||||
|
||||
我是说 C 语言将要灭绝吗?没有,在可预见的未来里,C 语言还会在操作系统的内核以及设备固件的编程的主流语言,在那里,尽力压榨硬件性能的古老命令还在奏效,尽管它可能不是那么安全。
|
||||
|
||||
现在被攻破的领域就是我之前提到的我经常出没的领域 —— 比如 GPSD 以及 NTPsec ,系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮箱 —— 那些得以机器而不是人类的速度运行的系统程序。
|
||||
|
||||
现在我们可以预见,未来大多数代码都是由具有强大内存安全特性的 C 语言的替代者实现。Go , Rust 或者 Cx ,无论是哪个, C 的存在都将被弱化。如果我现在来实现 NTP ,我可能就会毫不犹豫的使用 Go 语言来实现。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7711
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711
|
||||
[3]:http://sng.sourceforge.net/
|
||||
[4]:http://www.catb.org/esr/reposurgeon/
|
||||
[5]:http://www.catb.org/esr/doclifter/
|
||||
[6]:http://www.catb.org/esr/loccount/
|
||||
[7]:https://www.tiobe.com/tiobe-index/
|
||||
[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
|
||||
[9]:http://esr.ibiblio.org/?p=7303
|
||||
103
translated/tech/20140510 Journey to the Stack Part I.md
Normal file
103
translated/tech/20140510 Journey to the Stack Part I.md
Normal file
@ -0,0 +1,103 @@
|
||||
#[探秘“栈”之旅(I)][1]
|
||||
|
||||
早些时候,我们讲解了 [“剖析内存中的程序之秘”][2],我们欣赏了在一台电脑中是如何运行我们的程序的。今天,我们去探索栈的调用,它在大多数编程语言和虚拟机中都默默地存在。在此过程中,我们将接触到一些平时很难见到的东西,像闭包(closures)、递归、以及缓冲溢出等等。但是,我们首先要作的事情是,描绘出栈是如何运作的。
|
||||
|
||||
栈非常重要,因为它持有着在一个程序中运行的函数,而函数又是一个软件的重要组成部分。事实上,程序的内部操作都是非常简单的。它大部分是由函数向栈中推入数据或者从栈中弹出数据的相互调用组成的,虽然为数据分配内存是在堆上,但是,在跨函数的调用中数据必须要保存下来,不论是低级(low-leverl)的 C 软件还是像 JavaScript 和 C# 这样的基于虚拟机的语言,它们都是这样的。而对这些行为的深刻理解,对排错、性能调优以及大概了解究竟发生了什么是非常重要的。
|
||||
|
||||
当一个函数被调用时,将会创建一个栈帧(stack frame)去支持函数的运行。这个栈帧包含函数的本地变量和调用者传递给它的参数。这个栈帧也包含了允许被调用的函数安全返回给调用者的内部事务信息。栈帧的精确内容和结构因处理器架构和函数调用规则而不同。在本文中我们以 Intel x86 架构和使用 C 风格的函数调用(cdecl)的栈为例。下图是一个处于栈顶部的一个单个栈帧:
|
||||
|
||||
|
||||
|
||||
在图上的场景中,有三个 CPU 寄存器进入栈。栈指针 `esp`(译者注:扩展栈指针寄存器) 指向到栈的顶部。栈的顶部总是被最后一个推入到栈且还没有弹出的东西所占据,就像现实世界中堆在一起的一叠板子或者面值 $100 的钞票。
|
||||
|
||||
保存在 `esp` 中的地址始终在变化着,因为栈中的东西不停被推入和弹出,而它总是指向栈中的最后一个推入的东西。许多 CPU 指令的一个副作用就是自动更新 `esp`,离开寄存器而使用栈是行不通的。
|
||||
|
||||
在 Intel 的架构中,绝大多数情况下,栈的增长是向着低位内存地址的方向。因此,这个“顶部” 在包含数据(在这种情况下,包含的数据是 `local_buffer`)的栈中是处于低位的内存地址。注意,关于从 `esp` 到 `local_buffer` 的箭头,这里并没有模糊的地方。这个箭头代表着事务:它专门指向到由 `local_buffer` 所拥有的第一个字节,因为,那是一个保存在 `esp` 中的精确地址。
|
||||
|
||||
第二个寄存器跟踪的栈是 `ebp`(译者注:扩展基址指针寄存器),它包含一个基指针或者称为帧指针。它指向到一个当前运行的函数的栈帧内的固定的位置,并且它为参数和本地变量的访问提供一个稳定的参考点(基址)。仅当开始或者结束调用一个函数时,`ebp` 的内容才会发生变化。因此,我们可以很容易地处理每个在栈中的从 `ebp` 开始偏移后的一个东西。如下图所示。
|
||||
|
||||
不像 `esp`, `ebp` 大多数情况下是在程序代码中通过花费很少的 CPU 来进行维护的。有时候,完成抛弃 `ebp` 有一些性能优势,可以通过 [编译标志][3] 来做到这一点。Linux 内核中有一个实现的示例。
|
||||
|
||||
最后,`eax`(译者注:扩展的 32 位通用数据寄存器)寄存器是被调用规则所使用的寄存器,对于大多数 C 数据类型来说,它的作用是转换一个返回值给调用者。
|
||||
|
||||
现在,我们来看一下在我们的栈帧中的数据。下图清晰地按字节展示了字节的内容,就像你在一个调试器中所看到的内容一样,内存是从左到右、从底部到顶部增长的,如下图所示:
|
||||
|
||||

|
||||
|
||||
本地变量 `local_buffer` 是一个字节数组,它包含一个空终止(null-terminated)的 ascii 字符串,这是一个 C 程序中的基本元素。这个字符串可以从任意位置读取,例如,从键盘输入或者来自一个文件,它只有 7 个字节的长度。因为,`local_buffer` 只能保存 8 字节,在它的左侧保留了 1 个未使用的字节。这个字节的内容是未知的,因为栈的推入和弹出是极其活跃的,除了你写入的之外,你从不知道内存中保存了什么。因为 C 编译器并不为栈帧初始化内存,所以它的内容是未知的并且是随机的 - 除非是你自己写入。这使得一些人对此很困惑。
|
||||
|
||||
再往上走,`local1` 是一个 4 字节的整数,并且你可以看到每个字节的内容。它似乎是一个很大的数字,所有的零都在 8 后面,在这里可能会让你误入歧途。
|
||||
|
||||
Intel 处理器是按从小到大的机制来处理的,这表示在内存中的数字也是首先从小的位置开始的。因此,在一个多字节数字中,最小的标志字节在内存中处于低端地址。因为一般情况下是从左边开始显示的,这背离了我们一般意义上对数字的认识。我们讨论的这种从小到大的机制,使我想起《Gulliver 游记》:就像 Lilliput 吃鸡蛋是从小头开始的一样,Intel 处理器处理它们的数字也是从字节的小端开始的。
|
||||
|
||||
因此,`local1` 事实上只保存了一个数字 8,就像一个章鱼的腿。然而,`param1` 在第二个字节的位置有一个值 2,因此,它的数学上的值是 2 * 256 = 512(我们与 256 相乘是因为,每个位置值的范围都是从 0 到 255)。同时,`param2` 承载的数量是 1 * 256 * 256 = 65536。
|
||||
|
||||
这个栈帧的内部数据是由两个重要的部分组成:前一个栈帧的地址和函数的出口(返回地址)上运行的指令的地址。它们一起确保了函数能够正常返回,从而使程序可以继续正常运行。
|
||||
|
||||
现在,我们来看一下栈帧是如何产生的,以及去建立一个它们如何共同工作的内部蓝图。在刚开始的时候,栈的增长是非常令人困惑的,因为它发生的一切都不是你所期望的东西。例如,在栈上从 `esp` 减去 8,去分配一个 8 字节,而减法是以一种奇怪的方式去开始的。
|
||||
|
||||
我们来看一个简单的 C 程序:
|
||||
|
||||
```
|
||||
Simple Add Program - add.c
|
||||
|
||||
int add(int a, int b)
|
||||
{
|
||||
int result = a + b;
|
||||
return result;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer;
|
||||
answer = add(40, 2);
|
||||
}
|
||||
```
|
||||
|
||||
假设我们在 Linux 中不使用命令行参数去运行它。当你运行一个 C 程序时,去真实运行的第一个代码是 C 运行时库,由它来调用我们的 `main` 函数。下图展示了程序运行时每一步都发生了什么。每个图链接的 GDB 输出展示了内存的状态和寄存器。你也可以看到所使用的 [GDB 命令][4],以及整个 [GDB 输出][5]。如下:
|
||||
|
||||
|
||||
|
||||
第 2 步和第 3 步,以及下面的第 4 步,都只是函数的开端,几乎所有的函数都是这样的:`ebp` 的当前值保存着栈的顶部,然后,将 `esp` 的内容拷贝到 `ebp`,维护一个新帧。`main` 的开端和任何一个其它函数都是一样,但是,不同之处在于,当程序启动时 `ebp` 被清零。
|
||||
|
||||
如果你去检查栈下面的整形变量(argc),你将找到更多的数据,包括指向到程序名和命令行参数(传统的 C 参数数组)、Unix 环境变量以及它们真实的内容的指针。但是,在这里这些并不是重点,因此,继续向前调用 add():
|
||||
|
||||
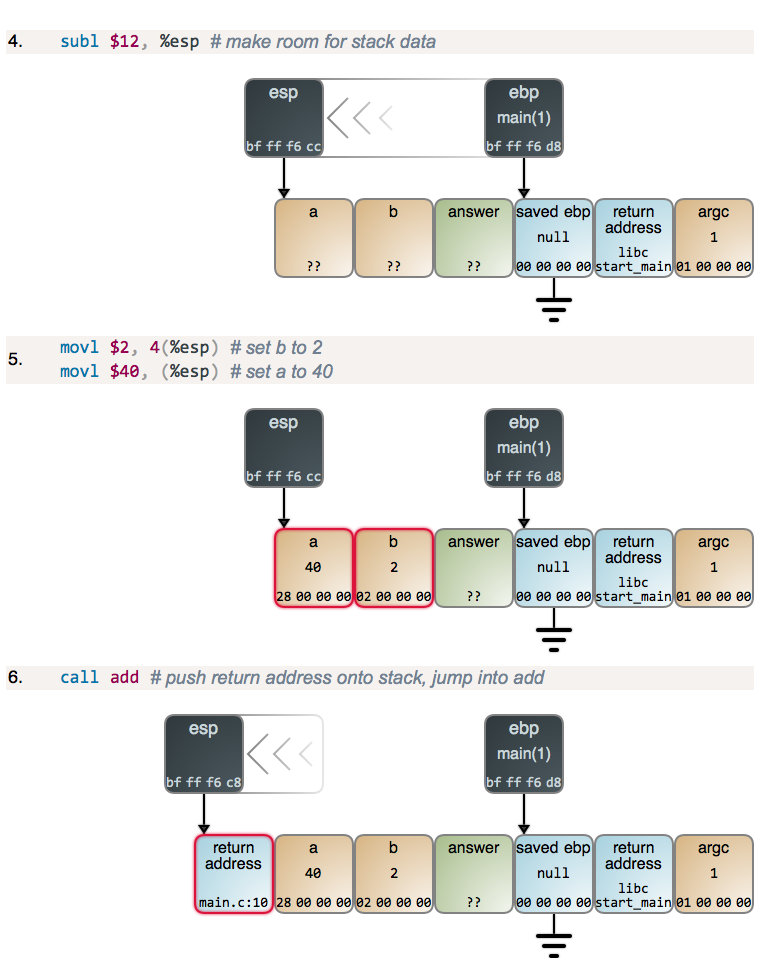
|
||||
|
||||
在 `main` 从 `esp` 减去 12 之后得到它所需的栈空间,它为 a 和 b 设置值。在内存中值展示为十六进制,并且是从小到大的格式。与你从调试器中看到的一样。一旦设置了参数值,`main` 将调用 `add` ,并且它开始运行:
|
||||
|
||||
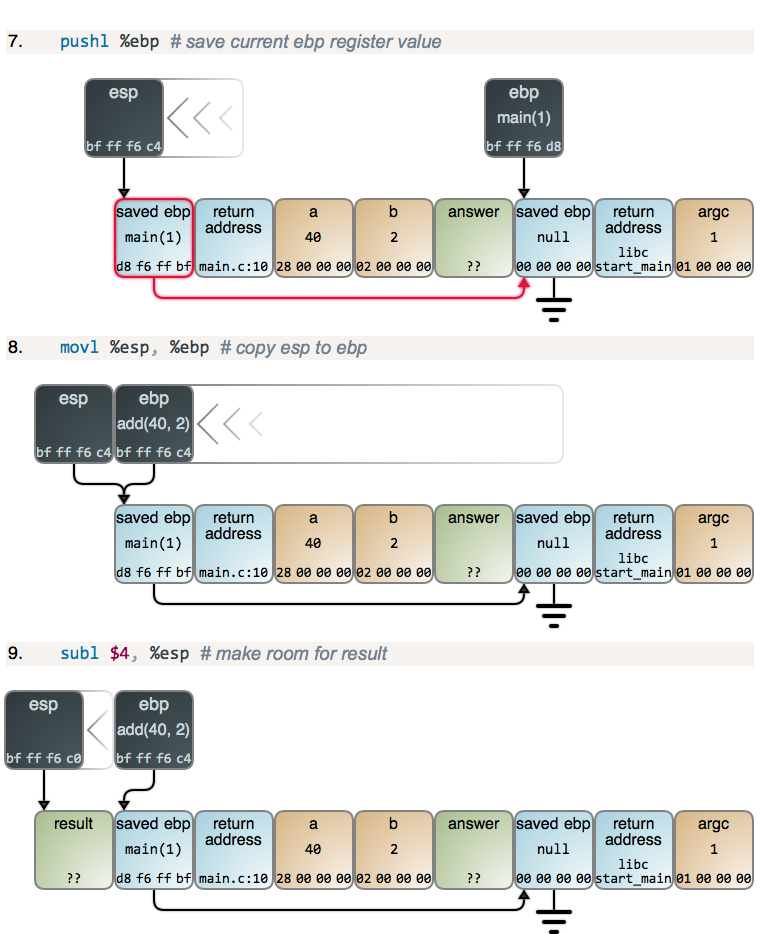
|
||||
|
||||
现在,有一点小激动!我们进入了另一个开端,在这时你可以明确看到栈帧是如何从 `ebp` 的一个链表开始进入到栈的。这就是在高级语言中调试器和异常对象如何对它们的栈进行跟踪的。当一个新帧产生时,你也可以看到更多这种从 `ebp` 到 `esp` 的典型的捕获。我们再次从 `esp` 中做减法得到更多的栈空间。
|
||||
|
||||
当 `ebp` 寄存器的值拷贝到内存时,这里也有一个稍微有些怪异的地方。在这里发生的奇怪事情是,寄存器并没有真的按字节顺序拷贝:因为对于内存,没有像寄存器那样的“增长的地址”。因此,通过调试器的规则以最自然的格式给人展示了寄存器的值:从最重要的到最不重要的数字。因此,这个在从小到大的机制中拷贝的结果,与内存中常用的从左到右的标记法正好相反。我想用图去展示你将会看到的东西,因此有了下面的图。
|
||||
|
||||
在比较难懂的部分,我们增加了注释:
|
||||
|
||||
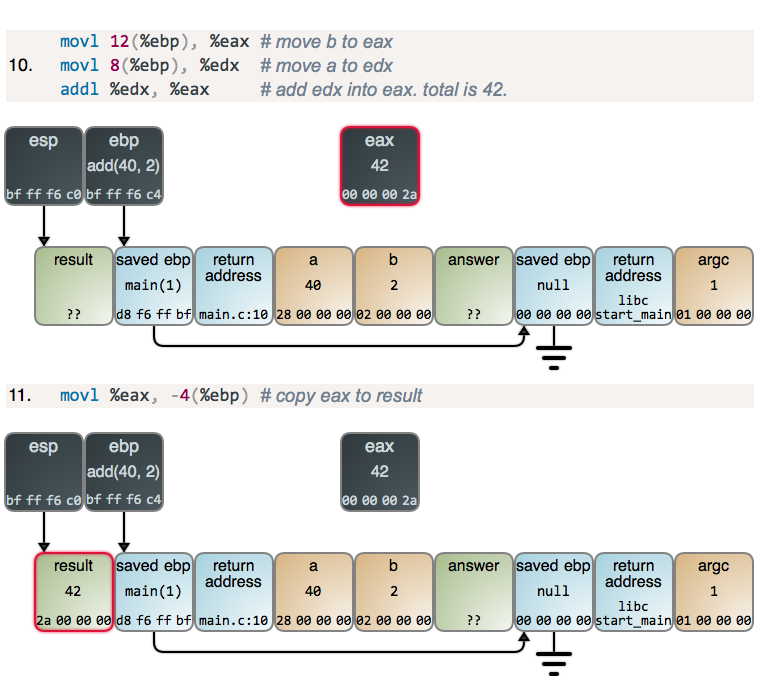
|
||||
|
||||
这是一个临时寄存器,用于帮你做加法,因此没有什么警报或者惊喜。对于加法这样的作业,栈的动作正好相反,我们留到下次再讲。
|
||||
|
||||
对于任何读到这篇文章的人都应该有一个小礼物,因此,我做了一个大的图表展示了 [组合到一起的所有步骤][6]。
|
||||
|
||||
一旦把它们全部布置好了,看上起似乎很乏味。这些小方框给我们提供了很多帮助。事实上,在计算机科学中,这些小方框是主要的展示工具。我希望这些图片和寄存器的移动能够提供一种更直观的构想图,将栈的增长和内存的内容整合到一起。从软件的底层运作来看,我们的软件与一个简单的图灵机器差不多。
|
||||
|
||||
这就是我们栈探秘的第一部分,再讲一些内容之后,我们将看到构建在这个基础上的高级编程的概念。下周见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/journey-to-the-stack/
|
||||
[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[3]:http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
|
||||
[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt
|
||||
[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt
|
||||
[6]:https://manybutfinite.com/img/stack/callSequence.png
|
||||
@ -0,0 +1,100 @@
|
||||
[探秘“栈”之旅(II)—— 谢幕,金丝雀,和缓冲区溢出][1]
|
||||
============================================================
|
||||
|
||||
上一周我们讲解了 [栈是如何工作的][2] 以及在函数的开端上栈帧是如何被构建的。今天,我们来看一下它的相反的过程,在函数结束时,栈帧是如何被销毁的。重新回到我们的 add.c 上:
|
||||
|
||||
简单的一个做加法的程序 - add.c
|
||||
|
||||
```
|
||||
int add(int a, int b)
|
||||
{
|
||||
int result = a + b;
|
||||
return result;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer;
|
||||
answer = add(40, 2);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
在运行到第 4 行时,在把 `a + b` 值赋给 `result` 后,这时发生了什么:
|
||||
|
||||
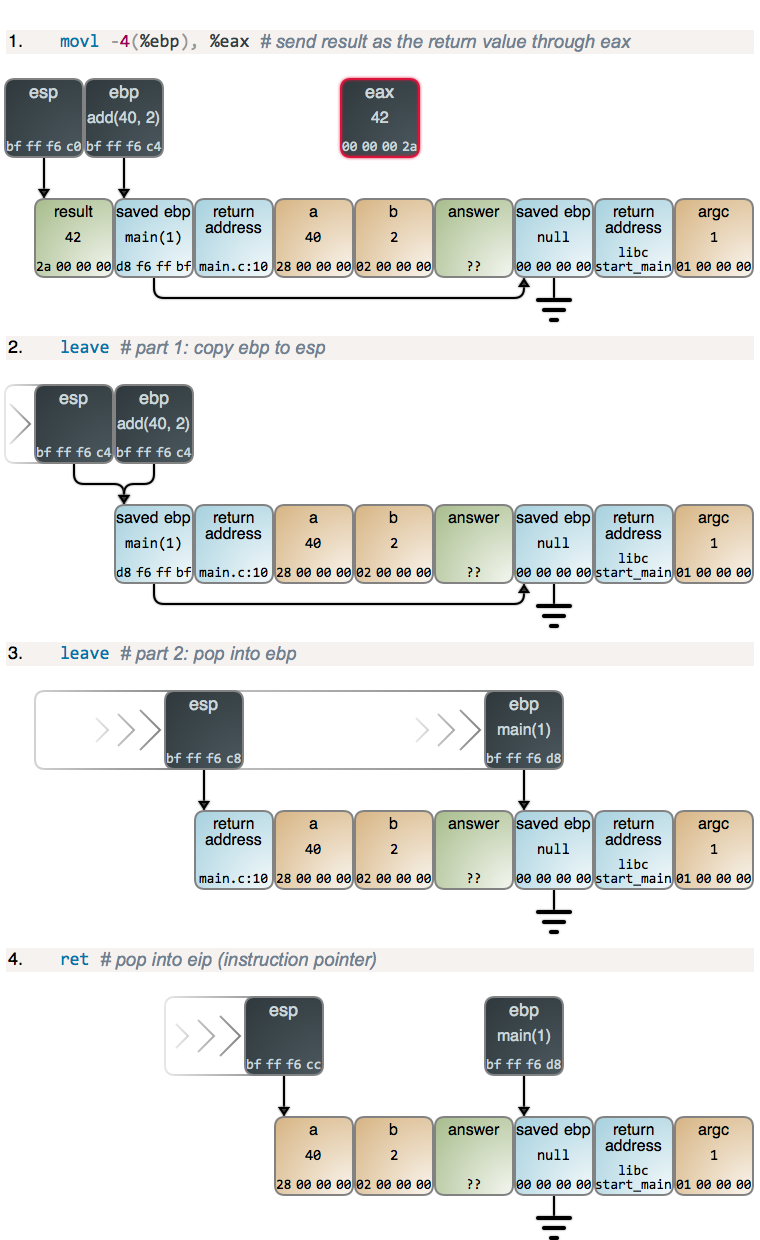
|
||||
|
||||
第一个指令是有些多余而且有点傻的,因为我们知道 `eax` 已经等于了 `result` ,但这就是关闭优化时得到的结果。剩余的指令接着运行,这一小段做了两个任务:重置 `esp` 并将它指向到当前栈帧开始的地方,另一个是恢复在 `ebp` 中保存的值。这两个操作在逻辑上是独立的,因此,在图中将它们分开来说,但是,如果你使用一个调试器去跟踪,你就会发现它们都是自动发生的。
|
||||
|
||||
在运行完毕后,恢复了前一个栈帧。`add` 调用唯一留下的东西就是在栈顶部的返回地址。它包含了运行完 `add` 之后在 `main` 中的指令的地址。它带来的是 `ret` 指令:它弹出返回地址到 `eip` 寄存器(译者注:32位的指令寄存器),这个寄存器指向下一个要执行的指令。现在程序将返回到 `main` ,主要部分如下:
|
||||
|
||||
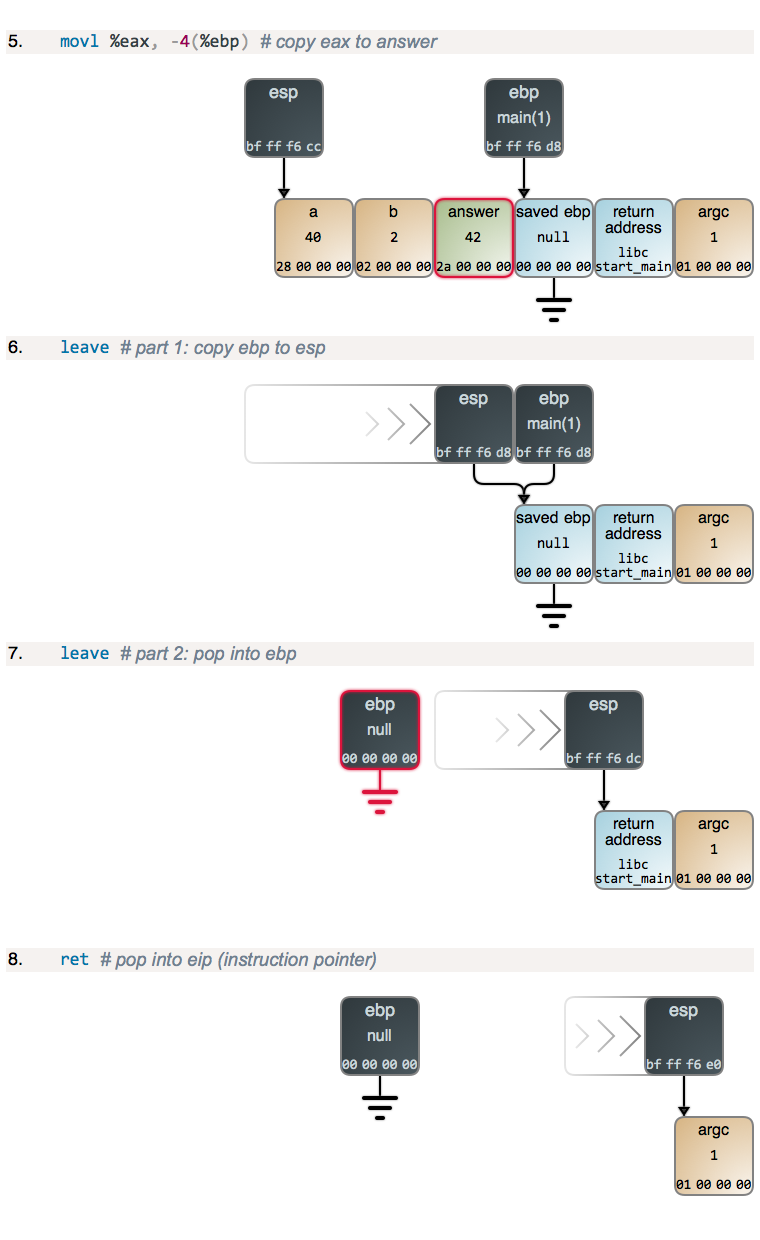
|
||||
|
||||
`main` 从 `add` 中拷贝返回值到本地变量 `answer`,然后,运行它的“谢幕仪式”,这一点和其它的函数是一样的。在 `main` 中唯一的怪异之处是,它在 `ebp` 中保存了 `null` 值,因为,在我们的代码中它是第一个栈帧。最后一步执行的是,返回到 C 运行时库(libc),它将退回到操作系统中。这里为需要的人提供了一个 [完整的返回顺序][3] 的图。
|
||||
|
||||
现在,你已经理解了栈是如何运作的,所以我们现在可以来看一下,一直以来最著名的黑客行为:挖掘缓冲区溢出。这是一个有漏洞的程序:
|
||||
|
||||
有漏洞的程序 - buffer.c
|
||||
|
||||
```
|
||||
void doRead()
|
||||
{
|
||||
char buffer[28];
|
||||
gets(buffer);
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
doRead();
|
||||
}
|
||||
```
|
||||
|
||||
上面的代码中使用了 [gets][4] 从标准输入中去读取内容。`gets` 持续读取直到一个新行或者文件结束。下图是读取一个字符串之后栈的示意图:
|
||||
|
||||
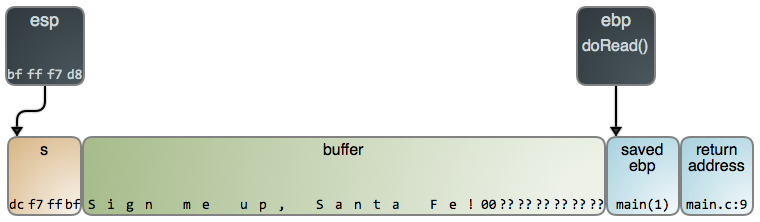
|
||||
|
||||
在这里存在的问题是,`gets` 并不知道缓冲区大小:它毫无查觉地持续读取输入内容,并将读取的内容填入到栈那边的缓冲区,清除保存在 `ebp` 中的值,返回地址,下面的其它内容也是如此。对于挖掘行为,攻击者制作一个载荷片段并将它“喂”给程序。在这个时候,栈应该是下图所示的样子,然后去调用 `gets`:
|
||||
|
||||

|
||||
|
||||
基本的想法是提供一个恶意的汇编代码去运行,通过覆写栈上的返回地址指向到那个代码。这有点像病毒侵入一个细胞,颠覆它,然后引入一些 RNA 去达到它的目的。
|
||||
|
||||
和病毒一样,挖掘者的载荷有许多特别的功能。它从使用几个 `nop` 指令开始,以提升成功挖掘漏洞的可能性。这是因为返回的地址是一个靠猜测的且不受约束的地址,因此,攻击者并不知道保存它的代码的栈的准确位置。但是,只要它们进入一个 `nop`,这个漏洞挖掘工作就会进行:处理器将运行 `nops`,直到击中它希望去运行的指令。
|
||||
|
||||
exec /bin/sh 表示运行一个 shell(假设漏洞是在一个网络程序中,因此,这个漏洞可能提供一个访问系统的 shell)的原生汇编指令。将原生汇编指令嵌入到一个程序中,使程序产生一个命令窗口或者用户输入的想法是很可怕的,但是,那只是让安全研究如此有趣且“脑洞大开”的一部分而已。对于防范这个怪异的 `get`, 给你提供一个思路,有时候,在有漏洞的程序上,让它的输入转换为小写或者大写,将迫使攻击者写的汇编指令的完整字节不属于小写或者大写的 ascii 字母的范围内。
|
||||
|
||||
最后,攻击者重放几次猜测的返回地址,这将再次提升他们的胜算。通过从一个 4 字节的边界上多次重放,它们可能会覆写栈上的原始返回地址。
|
||||
|
||||
幸亏,现代操作系统有了 [防止缓冲区溢出][5] 的一系列保护措施,包括不可执行的栈和栈金丝雀(stack canaries)。这个 “金丝雀(canary)” 名字来自 [煤矿中的金丝雀(canary in a coal mine)][6] 中的表述(译者注:指在煤矿工人下井时,带一只金丝雀,因为金丝雀对煤矿中的瓦斯气体非常敏感,如果进入煤矿后,金丝雀死亡,说明瓦斯超标,矿工会立即撤出煤矿。金丝雀做为煤矿中瓦斯预警器来使用),是对丰富的计算机科学词汇的补充,用 Steve McConnell 的话解释如下:
|
||||
|
||||
> 计算机科学拥有比其它任何领域都丰富多彩的语言,在其它的领域中你进入一个无菌室,小心地将温度控制在 68°F,然后,能找到病毒、特洛伊木马、蠕虫、臭虫、炸弹、崩溃、爆发、扭曲的变性者、以及致命错误吗? Steve McConnell 代码大全 2
|
||||
|
||||
不管怎么说,这里所谓的“栈金丝雀”应该看起来是这个样子的:
|
||||
|
||||

|
||||
|
||||
金丝雀是通过汇编来实现的。例如,由于 GCC 的 [栈保护器][7] 选项的原因使金丝雀被用于任何可能有漏洞的函数上。函数开端加载一个神奇的值到金丝雀的位置,并且在函数结束调用时确保这个值完好无损。如果这个值发生了变化,那就表示发生了一个缓冲区溢出(或者 bug),这时,程序通过 [__stack_chk_fail][8] 被终止运行。由于金丝雀处于栈的关键位置上,它使得栈缓冲区溢出的漏洞挖掘变得非常困难。
|
||||
|
||||
深入栈的探秘之旅结束了。我并不想过于深入。下一周我将深入递归、尾调用以及其它相关内容。或许要用到谷歌的 V8 引擎。为总结函数的开端和结束的讨论,我引述了美国国家档案馆纪念雕像上的一句名言:(what is past is prologue)
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[2]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[3]:https://manybutfinite.com/img/stack/returnSequence.png
|
||||
[4]:http://linux.die.net/man/3/gets
|
||||
[5]:http://paulmakowski.wordpress.com/2011/01/25/smashing-the-stack-in-2011/
|
||||
[6]:http://en.wiktionary.org/wiki/canary_in_a_coal_mine
|
||||
[7]:http://gcc.gnu.org/onlinedocs/gcc-4.2.3/gcc/Optimize-Options.html
|
||||
[8]:http://refspecs.linux-foundation.org/LSB_4.0.0/LSB-Core-generic/LSB-Core-generic/libc---stack-chk-fail-1.html
|
||||
@ -0,0 +1,116 @@
|
||||
从 ISO 和在线仓库创建一个 YUM 仓库
|
||||
======
|
||||
|
||||
YUM 是 Centos/RHEL/Fedora 中最重要的工具之一。尽管在 Fedora 的最新版本中,它已经被 DNF 所取代,但这并不意味着它已经成功了。它仍然被广泛用于安装 rpm 包,我们已经在前面的教程([**在这里阅读**] [1])中用示例讨论了 YUM。
|
||||
|
||||
在本教程中,我们将学习创建一个本地 YUM 仓库,首先使用系统的 ISO 镜像,然后创建一个在线 yum 仓库的镜像。
|
||||
|
||||
### 用 DVD ISO 创建 YUM
|
||||
|
||||
我们在本教程中使用 Centos 7 dvd,同样的过程也应该可以用在 RHEL 7 上。
|
||||
|
||||
首先在根文件夹中创建一个名为 YUM 的目录
|
||||
|
||||
```
|
||||
$ mkdir /YUM-
|
||||
```
|
||||
|
||||
然后挂载 Centos 7 ISO:
|
||||
|
||||
```
|
||||
$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
|
||||
```
|
||||
|
||||
接下来,从挂载的 ISO 中复制软件包到 /YUM 中。当所有的软件包都被复制到系统中后,我们将安装创建 YUM 所需的软件包。打开 /YUM 并安装以下 RPM 包:
|
||||
|
||||
```
|
||||
$ rpm -ivh deltarpm
|
||||
$ rpm -ivh python-deltarpm
|
||||
$ rpm -ivh createrepo
|
||||
```
|
||||
|
||||
安装完成后,我们将在 **/etc/yum.repos.d** 中创建一个名 为 **“local.repo”** 的文件,其中包含所有的 yum 信息。
|
||||
|
||||
```
|
||||
$ vi /etc/yum.repos.d/local.repo
|
||||
```
|
||||
|
||||
```
|
||||
LOCAL REPO]
|
||||
Name=Local YUM
|
||||
baseurl=file:///YUM
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
```
|
||||
|
||||
保存并退出文件。接下来,我们将通过运行以下命令来创建仓库数据。
|
||||
|
||||
```
|
||||
$ createrepo -v /YUM
|
||||
```
|
||||
|
||||
创建仓库数据需要一些时间。一切完成后,请运行
|
||||
|
||||
```
|
||||
$ yum clean all
|
||||
```
|
||||
|
||||
清理缓存,然后运行
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
```
|
||||
|
||||
检查所有仓库列表。你应该在列表中看到 “local.repo”。
|
||||
|
||||
|
||||
### 使用在线仓库创建镜像 YUM 仓库
|
||||
|
||||
创建在线 yum 的过程与使用 ISO 镜像创建 yum 类似,只是我们将从在线仓库而不是 ISO 中获取 rpm 软件包。
|
||||
|
||||
首先,我们需要找到一个在线仓库来获取最新的软件包。建议你找一个离你位置最近的在线 yum 仓库,以优化下载速度。我们将使用下面的镜像,你可以从[ CENTOS 镜像列表][2]中选择一个离你最近的镜像。
|
||||
|
||||
选择镜像之后,我们将使用 rsync 将该镜像与我们的系统同步,但在此之前,请确保你服务器上有足够的空间。
|
||||
|
||||
```
|
||||
$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
|
||||
```
|
||||
|
||||
同步将需要相当长一段时间(也许一个小时),这取决于你互联网的速度。同步完成后,我们将更新我们的仓库数据。
|
||||
|
||||
```
|
||||
$ createrepo - v /YUM
|
||||
```
|
||||
|
||||
我们的 Yum 已经可以使用了。我们可以创建一个 cron 任务来根据你的需求每天或每周定时地自动更新仓库数据。
|
||||
|
||||
要创建一个用于同步仓库的 cron 任务,请运行:
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
并添加以下行
|
||||
|
||||
```
|
||||
30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
|
||||
```
|
||||
|
||||
这会在每晚 12:30 同步 yum。还请记住在 /etc/yum.repos.d 中创建仓库配置文件,就像我们上面所做的一样。
|
||||
|
||||
就是这样,你现在有你自己的 yum 仓库来使用。如果你喜欢它,请分享这篇文章,并在下面的评论栏留下你的意见/疑问。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/using-yum-command-examples/
|
||||
[2]:http://mirror.centos.org/centos/
|
||||
@ -0,0 +1,89 @@
|
||||
如何在 Linux 中从 PDF 创建视频
|
||||
======
|
||||

|
||||
|
||||
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [**FFMpeg**][1] 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
|
||||
|
||||
### 在 Linux 中从 PDF 创建视频
|
||||
|
||||
为此,你需要在系统中安装 **“FFMpeg”** 和 **“ImageMagick”** 。
|
||||
|
||||
要安装 FFMpeg,请参考以下链接。
|
||||
|
||||
Imagemagick 可在大多数 Linux 发行版的官方仓库中找到。
|
||||
|
||||
在 **Arch Linux** 以及 **Antergos** 、**Manjaro Linux** 等衍生产品上,运行以下命令进行安装。
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian、Ubuntu、Linux Mint:**
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL、CentOS、Scientific Linux:**
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE、 openSUSE:**
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
在安装 ffmpeg 和 imagemagick 之后,将你的 PDF 文件转换成图像格式,如 PNG 或 JPG,如下所示。
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
这里,**-density 400** 指定输出图像的水平分辨率。
|
||||
|
||||
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: **picture-1.png**、 **picture-2.png** 等。根据选择的 PDF 的页数,这将需要一些时间。
|
||||
|
||||
将 PDF 中的所有页面转换为 PNG 格式后,运行以下命令以从 PNG 创建视频文件。
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* **-r 1/10** :每张图像显示 10 秒。
|
||||
* **-i picture-%01d.png** :读取以 **“picture-”** 开头,接着是一位数字(%01d),最后以 **.png** 结尾的所有图片。如果图片名称带有2位数字(也就是 picture-10.png、picture11.png 等),在上面的命令中使用(%02d)。
|
||||
* **-c:v libx264**:输出的视频编码器(即 h264)。
|
||||
* **-r 30** :输出视频的帧率
|
||||
* **-pix_fmt yuv420p**:输出的视频分辨率
|
||||
* **video.mp4**:以 .mp4 格式输出视频文件。
|
||||
|
||||
|
||||
|
||||
好了,视频文件完成了!你可以在任何支持 .mp4 格式的设备上播放它。接下来,我需要找到一种方法来为我的视频插入一个很酷的音乐。我希望这也不难。
|
||||
|
||||
如果你想要更高的分辨率,你不必重新开始。只要将输出的视频文件转换为你选择的任何其他更高/更低的分辨率,比如说 720p,如下所示。
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
请注意,使用 ffmpeg 创建视频需要一台配置好的 PC。在转换视频时,ffmpeg 会消耗大量系统资源。我建议在高端系统中这样做。
|
||||
|
||||
就是这些了。希望你觉得这个有帮助。还会有更好的东西。敬请关注!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
@ -1,157 +0,0 @@
|
||||
如何创建 Ubuntu Live CD (Linux 中国注:Ubuntu 原生光盘)的定制镜像
|
||||
======
|
||||

|
||||
|
||||
今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们已经使用[* *Pinguy Builder* *][1]完成了这项工作。但是,现在似乎停止了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 **Cubic** 即 **C**ustom **Ub**untu **I**SO **C**reator (Linux 中国注:Ubuntu 镜像定制器)的首字母所写,一个 GUI (图形用户界面)应用程序用来创建一个可定制的可启动的 Ubuntu Live CD(ISO)镜像。
|
||||
|
||||
Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的命令行环境``chroot``(Linux 中国注:Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制所有,比如安装新的软件包,内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在实时镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来实时制作 Ubuntu 镜像,所以我相信它可以被利用在制作其他 Ubuntu 的发行版和衍生版镜像中使用,比如 Linux Mint。
|
||||
### 安装 Cubic
|
||||
|
||||
Cubic 的开发人员已经开发出了一个 PPA (Linux 中国注:Personal Package Archives 首字母简写,私有的软件包档案) 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
|
||||
```
|
||||
sudo apt-add-repository ppa:cubic-wizard/release
|
||||
```
|
||||
```
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
|
||||
```
|
||||
```
|
||||
sudo apt update
|
||||
```
|
||||
```
|
||||
sudo apt install cubic
|
||||
```
|
||||
|
||||
### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
|
||||
|
||||
|
||||
安装完成后,从应用程序菜单或坞站启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
|
||||
|
||||
为新项目选择一个目录。它是保存镜像文件的目录。
|
||||
[![][2]][3]
|
||||
|
||||
请注意,Cubic 不是创建您系统的 Live CD 镜像。而它只是利用 Ubuntu 安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
|
||||
选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。
|
||||
[![][2]][4]
|
||||
|
||||
|
||||
接下来,从压缩的源安装介质中的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 **/home/ostechnix/custom_ubuntu**)。
|
||||
[![][2]][5]
|
||||
|
||||
|
||||
一旦文件系统被提取出来,将自动加载到``chroot``环境。如果你没有看到终端提示,按下回车键几次。
|
||||
[![][2]][6]
|
||||
|
||||
|
||||
在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
|
||||
|
||||
例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。
|
||||
[![][2]][7]
|
||||
|
||||
|
||||
我们不需要使用 ``sudo``,因为我们已经在具有最高权限(root)的环境中了。
|
||||
|
||||
类似地,如果需要,可以安装添加的任何版本 Linux Kernel 。
|
||||
```
|
||||
apt install linux-image-extra-4.10.0-24-generic
|
||||
```
|
||||
|
||||
此外,您还可以更新软件源列表(添加或删除软件存储库列表):
|
||||
[![][2]][8]
|
||||
|
||||
修改源列表后,不要忘记运行 ``apt update`` 命令来更新源列表:
|
||||
```
|
||||
apt update
|
||||
```
|
||||
|
||||
|
||||
另外,您还可以向 Live CD 中添加文件或文件夹。复制文件/文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择**Paste file(s)**,最后点击它将其复制进 Cubic 向导的底部。
|
||||
[![][2]][9]
|
||||
|
||||
**Ubuntu 17.10 用户注意事项: **
|
||||
|
||||
|
||||
在 Ubuntu 17.10 系统中,DNS 查询可能无法在 ``chroot``环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 原生镜像,您需要指向正确的 `resolve.conf` 配置文件:
|
||||
```
|
||||
ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
|
||||
|
||||
```
|
||||
|
||||
验证 DNS 解析工作,运行:
|
||||
```
|
||||
cat /etc/resolv.conf
|
||||
ping google.com
|
||||
```
|
||||
|
||||
|
||||
如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 **/usr/share/backgrounds/** 目录,
|
||||
```
|
||||
cd /usr/share/backgrounds
|
||||
```
|
||||
|
||||
|
||||
并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口,选择 **Paste file(s)** 选项。此外,确保你在**/usr/share/gnome-backproperties** 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择**Change Desktop Background** 进行交互。完成所有更改后,在 Cubic 向导中单击 ``Next``。
|
||||
|
||||
接下来,选择引导到新的原生 ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。
|
||||
[![][2]][10]
|
||||
|
||||
|
||||
在下一节中,选择要从您的原生映像中删除的软件包。在使用定制的原生映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。
|
||||
[![][2]][11]
|
||||
|
||||
|
||||
接下来,原生镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。
|
||||
[![][2]][12]
|
||||
|
||||
|
||||
镜像创建完成后后,单击 ``Finish``。Cubic 将显示新创建的自定义镜像的细节。
|
||||
|
||||
如果你想在将来修改刚刚创建的自定义原生镜像,**uncheck** 选项解释说**" Delete all project files, except the generated disk image and the corresponding MD5 checksum file"** (**除了生成的磁盘映像和相应的MD5校验和文件之外,删除所有的项目文件**) Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
|
||||
|
||||
要为不同的 Ubuntu 版本创建新的原生镜像,最好使用不同的项目目录。
|
||||
### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
|
||||
|
||||
从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 Next 按钮,您将看到以下三个选项:
|
||||
1. 从现有项目创建一个磁盘映像。
|
||||
2. 继续定制现有项目。
|
||||
3. 删除当前项目。
|
||||
|
||||
|
||||
|
||||
[![][2]][13]
|
||||
|
||||
|
||||
第一个选项将允许您使用之前所做的自定义在现有项目中创建一个新的原生 ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
|
||||
|
||||
第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 ``chroot``环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
|
||||
|
||||
第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
|
||||
|
||||
我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
|
||||
|
||||
就这些了,再会!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-2.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-4.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-6.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-5.png ()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-7.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-8.png ()
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-10-1.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-12-1.png ()
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-13.png ()
|
||||
@ -0,0 +1,204 @@
|
||||
如何使用cloud-init来预配置LXD容器
|
||||
======
|
||||
当你正在创建LXD容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 **apt update**来安装一些软件包,或者运行一些命令。
|
||||
这篇文章将讲述如何用[**cloud-init**][1]来对[LXD容器进行进行早期初始化][2]。
|
||||
接下来,我们将创建一个包含cloud-init指令的LXD profile,然后启动一个新的容器来使用这个profile。
|
||||
|
||||
### 如何创建一个新的LXD profile
|
||||
|
||||
查看已经存在的profile:
|
||||
|
||||
```shell
|
||||
$ lxc profile list
|
||||
+---------|---------+
|
||||
| NAME | USED BY |
|
||||
+---------|---------+
|
||||
| default | 11 |
|
||||
+---------|---------+
|
||||
```
|
||||
|
||||
我们把名叫default的profile复制一份,然后在其内添加新的指令:
|
||||
|
||||
```shell
|
||||
$ lxc profile copy default devprofile
|
||||
|
||||
$ lxc profile list
|
||||
+------------|---------+
|
||||
| NAME | USED BY |
|
||||
+------------|---------+
|
||||
| default | 11 |
|
||||
+------------|---------+
|
||||
| devprofile | 0 |
|
||||
+------------|---------+
|
||||
```
|
||||
|
||||
我们就得到了一个新的profile: **devprofile**。下面是它的详情:
|
||||
|
||||
```yaml
|
||||
$ lxc profile show devprofile
|
||||
config:
|
||||
environment.TZ: ""
|
||||
description: Default LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
nictype: bridged
|
||||
parent: lxdbr0
|
||||
type: nic
|
||||
root:
|
||||
path: /
|
||||
pool: default
|
||||
type: disk
|
||||
name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
注意这几个部分: **config:** , **description:** , **devices:** , **name:** 和 **used_by:**,当你修改这些内容的时候注意不要搞错缩进。(译者注:因为这些内容是YAML格式的,缩进是语法的一部分)
|
||||
|
||||
### 如何把cloud-init添加到LXD profile里
|
||||
|
||||
[cloud-init][1]可以添加到LXD profile的 **config** 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
|
||||
下面是用在示例中的指令:
|
||||
|
||||
```yaml
|
||||
package_upgrade: true
|
||||
packages:
|
||||
- build-essential
|
||||
locale: es_ES.UTF-8
|
||||
timezone: Europe/Madrid
|
||||
runcmd:
|
||||
- [touch, /tmp/simos_was_here]
|
||||
```
|
||||
|
||||
**package_upgrade: true** 是指当容器第一次被启动时,我们想要**cloud-init** 运行 **sudo apt upgrade**。
|
||||
**packages:** 列出了我们想要自动安装的软件。然后我们设置了**locale** and **timezone**。在Ubuntu容器的镜像里,root用户默认的 locale 是**C.UTF-8**,而**ubuntu** 用户则是 **en_US.UTF-8**。此外,我们把时区设置为**Etc/UTC**。
|
||||
最后,我们展示了[如何使用**runcmd**来运行一个Unix命令][3]。
|
||||
|
||||
我们需要关注如何将**cloud-init**指令插入LXD profile。
|
||||
|
||||
我首选的方法是:
|
||||
|
||||
```
|
||||
$ lxc profile edit devprofile
|
||||
```
|
||||
|
||||
它会打开一个文本编辑器,以便你将指令粘贴进去。[结果应该是这样的][4]:
|
||||
|
||||
```yaml
|
||||
$ lxc profile show devprofile
|
||||
config:
|
||||
environment.TZ: ""
|
||||
user.user-data: |
|
||||
#cloud-config
|
||||
package_upgrade: true
|
||||
packages:
|
||||
- build-essential
|
||||
locale: es_ES.UTF-8
|
||||
timezone: Europe/Madrid
|
||||
runcmd:
|
||||
- [touch, /tmp/simos_was_here]
|
||||
description: Default LXD profile
|
||||
devices:
|
||||
eth0:
|
||||
nictype: bridged
|
||||
parent: lxdbr0
|
||||
type: nic
|
||||
root:
|
||||
path: /
|
||||
pool: default
|
||||
type: disk
|
||||
name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
### 如何使用LXD profile启动一个容器
|
||||
|
||||
使用profile **devprofile**来启动一个新容器:
|
||||
|
||||
```
|
||||
$ lxc launch --profile devprofile ubuntu:x mydev
|
||||
```
|
||||
|
||||
然后访问该容器来查看我们的的指令是否生效:
|
||||
|
||||
```shell
|
||||
$ lxc exec mydev bash
|
||||
root@mydev:~# ps ax
|
||||
PID TTY STAT TIME COMMAND
|
||||
1 ? Ss 0:00 /sbin/init
|
||||
...
|
||||
427 ? Ss 0:00 /usr/bin/python3 /usr/bin/cloud-init modules --mode=f
|
||||
430 ? S 0:00 /bin/sh -c tee -a /var/log/cloud-init-output.log
|
||||
431 ? S 0:00 tee -a /var/log/cloud-init-output.log
|
||||
432 ? S 0:00 /usr/bin/apt-get --option=Dpkg::Options::=--force-con
|
||||
437 ? S 0:00 /usr/lib/apt/methods/http
|
||||
438 ? S 0:00 /usr/lib/apt/methods/http
|
||||
440 ? S 0:00 /usr/lib/apt/methods/gpgv
|
||||
570 ? Ss 0:00 bash
|
||||
624 ? S 0:00 /usr/lib/apt/methods/store
|
||||
625 ? R+ 0:00 ps ax
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
如果我们连接得够快,通过**ps ax**将能够看到系统正在更新软件。我们可以从/var/log/cloud-init-output.log看到完整的日志:
|
||||
|
||||
```
|
||||
Generating locales (this might take a while)...
|
||||
es_ES.UTF-8... done
|
||||
Generation complete.
|
||||
```
|
||||
|
||||
以上可以看出locale已经被更改了。root 用户还是保持默认的**C.UTF-8**,只有非root用户**ubuntu**使用了新的locale。
|
||||
|
||||
```
|
||||
Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
|
||||
Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
|
||||
Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
|
||||
```
|
||||
|
||||
以上是安装软件包之前执行的**apt update**。
|
||||
|
||||
```
|
||||
The following packages will be upgraded:
|
||||
libdrm2 libseccomp2 squashfs-tools unattended-upgrades
|
||||
4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 211 kB of archives.
|
||||
```
|
||||
以上是在执行**package_upgrade: true**和安装软件包。
|
||||
|
||||
```
|
||||
The following NEW packages will be installed:
|
||||
binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
|
||||
libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
|
||||
```
|
||||
以上是我们安装**build-essential**软件包的指令。
|
||||
|
||||
**runcmd** 执行的结果如何?
|
||||
|
||||
```
|
||||
root@mydev:~# ls -l /tmp/
|
||||
total 1
|
||||
-rw-r--r-- 1 root root 0 Jan 3 15:23 simos_was_here
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
可见它已经生效了!
|
||||
|
||||
### 结论
|
||||
|
||||
当我们启动LXD容器的时候,我们常常需要默认启用一些配置,并且希望能够避免重复工作。通常解决这个问题的方法是创建LXD profile,然后把需要的配置添加进去。最后,当我们启动新的容器时,只需要应用该LXD profile即可。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[kaneg](https://github.com/kaneg)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:http://cloudinit.readthedocs.io/en/latest/index.html
|
||||
[2]:https://github.com/lxc/lxd/blob/master/doc/cloud-init.md
|
||||
[3]:http://cloudinit.readthedocs.io/en/latest/topics/modules.html#runcmd
|
||||
[4]:https://paste.ubuntu.com/26313399/
|
||||
Loading…
Reference in New Issue
Block a user