+
+常用的Linux内核原生支持IPv4和IPv6的TCP MD5选项。因此,如果你从全新的[Linux机器][3]构建了一台Quagga路由器,TCP的MD5功能会自动启用。剩下来的事情,仅仅是配置Quagga以使用它的功能。但是,如果你使用的是FreeBSD机器或者为Quagga构建了一个自定义内核,请确保内核开启了TCP的MD5支持(如,Linux中的CONFIG_TCP_MD5SIG选项)。
+
+### 配置Router-A验证功能 ###
+
+我们将使用Quagga的CLI Shell来配置路由器,我们将使用的唯一的一个新命令是‘password’。
+
+ [root@router-a ~]# vtysh
+ router-a# conf t
+ router-a(config)# router bgp 100
+ router-a(config-router)# network 192.168.100.0/24
+ router-a(config-router)# neighbor 10.10.12.2 remote-as 200
+ router-a(config-router)# neighbor 10.10.12.2 password xmodulo
+
+本例中使用的预共享密钥是‘xmodulo’。很明显,在生产环境中,你需要选择一个更健壮的密钥。
+
+**注意**: 在Quagga中,‘service password-encryption’命令被用做加密配置文件中所有明文密码(如,登录密码)。然而,当我使用该命令时,我注意到BGP配置中的预共享密钥仍然是明文的。我不确定这是否是Quagga的限制,还是版本自身的问题。
+
+### 配置Router-B验证功能 ###
+
+我们将以类似的方式配置router-B。
+
+ [root@router-b ~]# vtysh
+ router-b# conf t
+ router-b(config)# router bgp 200
+ router-b(config-router)# network 192.168.200.0/24
+ router-b(config-router)# neighbor 10.10.12.1 remote-as 100
+ router-b(config-router)# neighbor 10.10.12.1 password xmodulo
+
+### 验证BGP会话 ###
+
+如果一切配置正确,那么BGP会话就应该起来了,两台路由器应该能交换路由表。这时候,TCP会话中的所有流出包都会携带一个MD5摘要的包内容和一个密钥,而摘要信息会被另一端自动验证。
+
+我们可以像平时一样通过查看BGP的概要来验证活跃的BGP会话。MD5校验和的验证在Quagga内部是透明的,因此,你在BGP级别是无法看到的。
+
+
+
+如果你想要测试BGP验证,你可以配置一个邻居路由,设置其密码为空,或者故意使用错误的预共享密钥,然后查看发生了什么。你也可以使用包嗅探器,像tcpdump或者Wireshark等,来分析通过BGP会话的包。例如,带有“-M ”选项的tcpdump将验证TCP选项字段的MD5摘要。
+
+###小结###
+
+在本教程中,我们演示了怎样简单地加固两台路由间的BGP会话安全。相对于其它协议而言,配置过程非常简明。强烈推荐你加固BGP会话安全,尤其是当你用另一个AS配置BGP会话的时候。预共享密钥也应该安全地保存。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/bgp-authentication-quagga.html
+
+作者:[Sarmed Rahman][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://research.dyn.com/2008/02/pakistan-hijacks-youtube-1/
+[2]:http://tools.ietf.org/html/rfc2385
+[3]:https://linux.cn/article-4232-1.html
diff --git a/published/201505/20150409 4 Tools Send Email with Subject, Body and Attachment in Linux.md b/published/201505/20150409 4 Tools Send Email with Subject, Body and Attachment in Linux.md
new file mode 100644
index 0000000000..00003eaa19
--- /dev/null
+++ b/published/201505/20150409 4 Tools Send Email with Subject, Body and Attachment in Linux.md
@@ -0,0 +1,261 @@
+4个可以发送完整电子邮件的命令行工具
+================================================================================
+今天的文章里我们会讲到一些使用Linux命令行工具来发送带附件的电子邮件的方法。它有很多用处,比如在应用程序所在服务器上,使用电子邮件发送一个文件过来,或者你可以在脚本中使用这些命令来做一些自动化操作。在本文的例子中,我们会使用foo.tar.gz文件作为附件。
+
+有不同的命令行工具可以发送邮件,这里我分享几个多数用户会使用的工具,如`mailx`、`mutt`和`swaks`。
+
+我们即将呈现的这些工具都是非常有名的,并且存在于多数Linux发行版默认的软件仓库中,你可以使用如下命令安装:
+
+在 **Debian / Ubuntu** 系统
+
+ apt-get install mutt
+ apt-get install swaks
+ apt-get install mailx
+ apt-get install sharutils
+
+在基于Red Hat的系统,如 **CentOS** 或者 **Fedora**
+
+ yum install mutt
+ yum install swaks
+ yum install mailx
+ yum install sharutils
+
+### 1) 使用 mail / mailx ###
+
+`mailx`工具在多数Linux发行版中是默认的邮件程序,现在已经支持发送附件了。如果它不在你的系统中,你可以使用上边的命令安装。有一点需要注意,老版本的mailx可能不支持发送附件,运行如下命令查看是否支持。
+
+ $ man mail
+
+第一行看起来是这样的:
+
+ mailx [-BDdEFintv~] [-s subject] [-a attachment ] [-c cc-addr] [-b bcc-addr] [-r from-addr] [-h hops] [-A account] [-S variable[=value]] to-addr . . .
+
+如果你看到它支持`-a`的选项(-a 文件名,将文件作为附件添加到邮件)和`-s`选项(-s 主题,指定邮件的主题),那就是支持的。可以使用如下的几个例子发送邮件。
+
+**a) 简单的邮件**
+
+运行`mail`命令,然后`mailx`会等待你输入邮件内容。你可以按回车来换行。当输入完成后,按Ctrl + D,`mailx`会显示EOT表示结束。
+
+然后`mailx`会自动将邮件发送给收件人。
+
+ $ mail user@example.com
+
+ HI,
+ Good Morning
+ How are you
+ EOT
+
+**b) 发送有主题的邮件**
+
+ $ echo "Email text" | mail -s "Test Subject" user@example.com
+
+`-s`的用处是指定邮件的主题。
+
+**c) 从文件中读取邮件内容并发送**
+
+ $ mail -s "message send from file" user@example.com < /path/to/file
+
+**d) 将从管道获取到的`echo`命令输出作为邮件内容发送**
+
+ $ echo "This is message body" | mail -s "This is Subject" user@example.com
+
+**e) 发送带附件的邮件**
+
+ $ echo “Body with attachment "| mail -a foo.tar.gz -s "attached file" user@example.com
+
+`-a`选项用于指定附件。
+
+### 2) mutt ###
+
+Mutt是类Unix系统上的一个文本界面邮件客户端。它有20多年的历史,在Linux历史中也是一个很重要的部分,它是最早支持进程打分和多线程处理的客户端程序之一。按照如下的例子来发送邮件。
+
+**a) 带有主题,从文件中读取邮件的正文,并发送**
+
+ $ mutt -s "Testing from mutt" user@example.com < /tmp/message.txt
+
+**b) 通过管道获取`echo`命令输出作为邮件内容发送**
+
+ $ echo "This is the body" | mutt -s "Testing mutt" user@example.com
+
+**c) 发送带附件的邮件**
+
+ $ echo "This is the body" | mutt -s "Testing mutt" user@example.com -a /tmp/foo.tar.gz
+
+**d) 发送带有多个附件的邮件**
+
+ $ echo "This is the body" | mutt -s "Testing" user@example.com -a foo.tar.gz –a bar.tar.gz
+
+### 3) swaks ###
+
+Swaks(Swiss Army Knife,瑞士军刀)是SMTP服务上的瑞士军刀,它是一个功能强大、灵活、可编程、面向事务的SMTP测试工具,由John Jetmore开发和维护。你可以使用如下语法发送带附件的邮件:
+
+ $ swaks -t "foo@bar.com" --header "Subject: Subject" --body "Email Text" --attach foo.tar.gz
+
+关于Swaks一个重要的地方是,它会为你显示整个邮件发送过程,所以如果你想调试邮件发送过程,它是一个非常有用的工具。
+
+它会给你提供了邮件发送过程的所有细节,包括邮件接收服务器的功能支持、两个服务器之间的每一步交互。
+
+### 4) uuencode ###
+
+邮件传输系统最初是被设计来传送7位编码(类似ASCII)的内容的。这就意味这它是用来发送文本内容,而不能发会使用8位的二进制内容(如程序文件或者图片)。`uuencode`(“UNIX to UNIX encoding”,UNIX之间使用的编码方式)程序用来解决这个限制。使用`uuencode`,发送端将二进制格式的转换成文本格式来传输,接收端再转换回去。
+
+我们可以简单地使用`uuencode`和`mailx`或者`mutt`配合,来发送二进制内容,类似这样:
+
+ $ uuencode example.jpeg example.jpeg | mail user@example.com
+
+### Shell脚本:解释如何发送邮件 ###
+
+ #!/bin/bash
+
+ FROM=""
+ SUBJECT=""
+ ATTACHMENTS=""
+ TO=""
+ BODY=""
+
+ # 检查文件名对应的文件是否存在
+ function check_files()
+ {
+ output_files=""
+ for file in $1
+ do
+ if [ -s $file ]
+ then
+ output_files="${output_files}${file} "
+ fi
+ done
+ echo $output_files
+ }
+
+ echo "*********************"
+ echo "E-mail sending script."
+ echo "*********************"
+ echo
+
+ # 读取用户输入的邮件地址
+ while [ 1 ]
+ do
+ if [ ! $FROM ]
+ then
+ echo -n -e "Enter the e-mail address you wish to send mail from:\n[Enter] "
+ else
+ echo -n -e "The address you provided is not valid:\n[Enter] "
+ fi
+
+ read FROM
+ echo $FROM | grep -E '^.+@.+$' > /dev/null
+ if [ $? -eq 0 ]
+ then
+ break
+ fi
+ done
+
+ echo
+
+ # 读取用户输入的收件人地址
+ while [ 1 ]
+ do
+ if [ ! $TO ]
+ then
+ echo -n -e "Enter the e-mail address you wish to send mail to:\n[Enter] "
+ else
+ echo -n -e "The address you provided is not valid:\n[Enter] "
+ fi
+
+ read TO
+ echo $TO | grep -E '^.+@.+$' > /dev/null
+ if [ $? -eq 0 ]
+ then
+ break
+ fi
+ done
+
+ echo
+
+ # 读取用户输入的邮件主题
+ echo -n -e "Enter e-mail subject:\n[Enter] "
+ read SUBJECT
+
+ echo
+
+ if [ "$SUBJECT" == "" ]
+ then
+ echo "Proceeding without the subject..."
+ fi
+
+ # 读取作为附件的文件名
+ echo -e "Provide the list of attachments. Separate names by space.
+ If there are spaces in file name, quote file name with \"."
+ read att
+
+ echo
+
+ # 确保文件名指向真实文件
+ attachments=$(check_files "$att")
+ echo "Attachments: $attachments"
+
+ for attachment in $attachments
+ do
+ ATTACHMENTS="$ATTACHMENTS-a $attachment "
+ done
+
+ echo
+
+ # 读取完整的邮件正文
+ echo "Enter message. To mark the end of message type ;; in new line."
+ read line
+
+ while [ "$line" != ";;" ]
+ do
+ BODY="$BODY$line\n"
+ read line
+ done
+
+ SENDMAILCMD="mutt -e \"set from=$FROM\" -s \"$SUBJECT\" \
+ $ATTACHMENTS -- \"$TO\" <<< \"$BODY\""
+ echo $SENDMAILCMD
+
+ mutt -e "set from=$FROM" -s "$SUBJECT" $ATTACHMENTS -- $TO <<< $BODY
+
+** 脚本输出 **
+
+ $ bash send_mail.sh
+ *********************
+ E-mail sending script.
+ *********************
+
+ Enter the e-mail address you wish to send mail from:
+ [Enter] test@gmail.com
+
+ Enter the e-mail address you wish to send mail to:
+ [Enter] test@gmail.com
+
+ Enter e-mail subject:
+ [Enter] Message subject
+
+ Provide the list of attachments. Separate names by space.
+ If there are spaces in file name, quote file name with ".
+ send_mail.sh
+
+ Attachments: send_mail.sh
+
+ Enter message. To mark the end of message type ;; in new line.
+ This is a message
+ text
+ ;;
+
+### 总结 ###
+
+有很多方法可以使用命令行/Shell脚本来发送邮件,这里我们只分享了其中4个类Unix系统可用的工具。希望你喜欢我们的文章,并且提供您的宝贵意见,让我们知道您想了解哪些新工具。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-shell-script/send-email-subject-body-attachment-linux/
+
+作者:[Bobbin Zachariah][a]
+译者:[goreliu](https://github.com/goreliu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bobbin/
\ No newline at end of file
diff --git a/published/201505/20150409 Install Inkscape - Open Source Vector Graphic Editor.md b/published/201505/20150409 Install Inkscape - Open Source Vector Graphic Editor.md
new file mode 100644
index 0000000000..c6361e780b
--- /dev/null
+++ b/published/201505/20150409 Install Inkscape - Open Source Vector Graphic Editor.md
@@ -0,0 +1,95 @@
+Inkscape - 开源适量图形编辑器
+================================================================================
+Inkscape是一款开源矢量图形编辑工具,并不同于Xara X、Corel Draw和Adobe Illustrator等竞争对手,它使用的是可缩放矢量图形(SVG)图形格式。SVG是一个广泛部署、免版税使用的图形格式,由W3C SVG工作组开发和维护。这是一个跨平台工具,完美运行于Linux、Windows和Mac OS上。
+
+Inkscape始于2003年,起初它的bug跟踪系统托管于Sourceforge上,但是后来迁移到了Launchpad上。当前它最新的一个稳定版本是0.91,它不断地在发展和修改中。我们将在本文里了解一下它的突出特点和安装过程。
+
+### 显著特性 ###
+
+让我们直接来了解这款应用程序的显著特性。
+
+#### 创建对象 ####
+
+- 用铅笔工具来画出不同颜色、大小和形状的手绘线,用贝塞尔曲线(笔式)工具来画出直线和曲线,通过书法工具来应用到手写的书法笔画上等等
+- 用文本工具来创建、选择、编辑和格式化文本。在纯文本框、在路径上或在形状里操作文本
+- 方便绘制各种形状,像矩形、椭圆形、圆形、弧线、多边形、星形和螺旋形等等并调整其大小、旋转并修改(圆角化)它们
+- 用简单地命令创建并嵌入位图
+
+#### 对象处理 ####
+
+- 通过交互式操作和调整参量来扭曲、移动、测量、旋转目标
+- 可以对 Z 轴进行提升或降低操作。
+- 通过对象组合和取消组合可以创建一个虚拟层用来编辑或处理
+- 图层采用层次结构树的结构,并且能锁定或以各式各样的处理方式来重新布置
+- 分布与对齐指令
+
+#### 填充与边框 ####
+
+- 可以复制/粘贴不同风格
+- 取色工具
+- 用RGB, HSL, CMS, CMYK和色盘这四种不同的方式选色
+- 渐变层编辑器能创建和管理多停点渐变层
+- 使用图像或其它选择区作为花纹填充
+- 用一些预定义点状花纹进行笔触填充
+- 通过路径标示器标示开始、对折和结束点
+
+#### 路径上的操作 ####
+
+- 节点编辑:移动节点和贝塞尔曲线控制点,节点的对齐和分布等等
+- 布尔运算(是或否)
+- 运用可变的路径起迄点可简化路径
+- 路径插入和增设连同动态和链接偏移对象
+- 通过路径追踪把位图图像转换成路径(彩色或单色路径)
+
+#### 文本处理 ####
+
+- 所有安装好的框线字体都能用,甚至可以从右至左对齐对象
+- 格式化文本、调整字母间距、行间距或列间距
+- 路径上和形状上的文本中的文本、路径或形状都可以被编辑和修改
+
+#### 渲染 ####
+
+- Inkscape完全支持抗锯齿显示,这是一种通过柔化边界上的像素从而减少或消除凹凸锯齿的技术。
+- 支持alpha透明显示和PNG格式图片的导出
+
+### 在Ubuntu 14.04和14.10上安装Inkscape ###
+
+为了在Ubuntu上安装Inkscape,我们首先需要 [添加它的稳定版Personal Package Archive][1] (PPA) 至Advanced Package Tool (APT) 库中。打开终端并运行一下命令来添加它的PPA:
+
+ sudo add-apt-repository ppa:inkscape.dev/stable
+
+
+
+PPA添加到APT库中后,我们要用以下命令进行更新:
+
+ sudo apt-get update
+
+
+
+更新好库之后,我们准备用以下命令来完成安装:
+
+ sudo apt-get install inkscape
+
+
+
+恭喜,现在Inkscape已经被安装好了,我们可以充分利用它的丰富功能特点来编辑制作图像了。
+
+
+
+### 结论 ###
+
+Inkscape是一款特点鲜明的图形编辑工具,它给予用户充分发挥自己艺术能力的权利。它还是一款自由安装和自定义的开源应用,并且支持各种文件类型,包括JPEG, PNG, GIF和PDF及更多。访问它的 [官方网站][2] 来获取更多新闻和应用更新。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/tools/install-inkscape-open-source-vector-graphic-editor/
+
+作者:[Aun Raza][a]
+译者:[ZTinoZ](https://github.com/ZTinoZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunrz/
+[1]:https://launchpad.net/~inkscape.dev/+archive/ubuntu/stable
+[2]:https://inkscape.org/en/
diff --git a/published/201505/20150410 This tool can alert you about evil twin access points in the area.md b/published/201505/20150410 This tool can alert you about evil twin access points in the area.md
new file mode 100644
index 0000000000..a43aa8206f
--- /dev/null
+++ b/published/201505/20150410 This tool can alert you about evil twin access points in the area.md
@@ -0,0 +1,41 @@
+EvilAP_Defender:可以警示和攻击 WIFI 热点陷阱的工具
+===============================================================================
+
+**开发人员称,EvilAP_Defender甚至可以攻击流氓Wi-Fi接入点**
+
+这是一个新的开源工具,可以定期扫描一个区域,以防出现恶意 Wi-Fi 接入点,同时如果发现情况会提醒网络管理员。
+
+这个工具叫做 EvilAP_Defender,是为监测攻击者所配置的恶意接入点而专门设计的,这些接入点冒用合法的名字诱导用户连接上。
+
+这类接入点被称做假面猎手(evil twin),使得黑客们可以从所接入的设备上监听互联网信息流。这可以被用来窃取证书、钓鱼网站等等。
+
+大多数用户设置他们的计算机和设备可以自动连接一些无线网络,比如家里的或者工作地方的网络。通常,当面对两个同名的无线网络时,即SSID相同,有时候甚至连MAC地址(BSSID)也相同,这时候大多数设备会自动连接信号较强的一个。
+
+这使得假面猎手攻击容易实现,因为SSID和BSSID都可以伪造。
+
+[EvilAP_Defender][1]是一个叫Mohamed Idris的人用Python语言编写,公布在GitHub上面。它可以使用一个计算机的无线网卡来发现流氓接入点,这些坏蛋们复制了一个真实接入点的SSID,BSSID,甚至是其他的参数如通道,密码,隐私协议和认证信息等等。
+
+该工具首先以学习模式运行,以便发现合法的接入点[AP],并且将其加入白名单。然后可以切换到正常模式,开始扫描未认证的接入点。
+
+如果一个恶意[AP]被发现了,该工具会用电子邮件提醒网络管理员,但是开发者也打算在未来加入短信提醒功能。
+
+该工具还有一个保护模式,在这种模式下,应用会发起一个denial-of-service [DoS]攻击反抗恶意接入点,为管理员采取防卫措施赢得一些时间。
+
+“DoS 将仅仅针对有着相同SSID的而BSSID(AP的MAC地址)不同或者不同信道的流氓 AP,”Idris在这款工具的文档中说道。“这是为了避免攻击到你的正常网络。”
+
+尽管如此,用户应该切记在许多国家,攻击别人的接入点很多时候都是非法的,甚至是一个看起来像是攻击者操控的恶意接入点。
+
+要能够运行这款工具,需要Aircrack-ng无线网套装,一个支持Aircrack-ng的无线网卡,MySQL和Python运行环境。
+
+--------------------------------------------------------------------------------
+
+via: http://www.infoworld.com/article/2905725/security0/this-tool-can-alert-you-about-evil-twin-access-points-in-the-area.html
+
+作者:[Lucian Constantin][a]
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.infoworld.com/author/Lucian-Constantin/
+[1]:https://github.com/moha99sa/EvilAP_Defender/blob/master/README.TXT
diff --git a/published/201505/20150410 What is a good alternative to wget or curl on Linux.md b/published/201505/20150410 What is a good alternative to wget or curl on Linux.md
new file mode 100644
index 0000000000..3af223b631
--- /dev/null
+++ b/published/201505/20150410 What is a good alternative to wget or curl on Linux.md
@@ -0,0 +1,145 @@
+用腻了 wget 或 curl,有什么更好的替代品吗?
+================================================================================
+
+如果你经常需要通过终端以非交互模式访问网络服务器(例如,从网络上下载文件,或者是测试 RESTful 网络服务接口),可能你会选择的工具是 wget 或 curl。通过大量的命令行选项,这两种工具都可以处理很多非交互网络访问的情况(比如[这里][1]、[这里][2],还有[这里][3])。然而,即使像这些一样的强大的工具,你也只能发挥你所了解的那些选项的功能。除非你很精通那些繁冗的语法细节,这些工具对于你来说只不过是简单的网络下载器而已。
+
+就像其宣传的那样,“给人用 curl 类工具”,[HTTPie][4] 设计用来增强 wget 和 curl 的可用性。它的主要目标是使通过命令行与网络服务器进行交互的过程变得尽可能的人性化。为此,HTTPie 支持具有表现力、但又很简单很直观的语法。它以彩色模式显示响应,并且还有一些不错的优点,比如对 JSON 的良好支持,和持久性会话用以作业流程化。
+
+我知道很多人对把像 wget 和 curl 这样的无处不在的、可用的、完美的工具换成完全没听说过的软件心存疑虑。这种观点是好的,特别是如果你是一个系统管理员、要处理很多不同的硬件的话。然而,对于开发者和终端用户来说,重要的是效率。如果我发现了一个工具的用户更佳替代品,那么我认为采用易于使用的版本来节省宝贵的时间是毫无疑问的。没有必要对替换掉的工具保持信仰忠诚。毕竟,对于 Linux 来说,最好的事情就是可以选择。
+
+在这篇文章中,让我们来了解并展示一下我所说的 HTTPie,一个用户友好的 wget 和 curl 的替代。
+
+
+
+### 在 Linux 上安装 HTTPie ###
+
+HTTPie 是用 Python 写的,所以你可以在几乎所有地方(Linux,MacOSX,Windows)安装它。而且,在大多数的 Linux 发行版中都有编译好的安装包。
+
+#### Debian,Ubuntu 或者 Linux Mint: ####
+
+ $ sudo apt-get install httpie
+
+#### Fedora: ####
+
+ $ sudo yum install httpie
+
+#### CentOS/RHEL: ####
+
+首先,启用[EPEL 仓库][5],然后运行:
+
+ $ sudo yum install httpie
+
+对于任何 Linux 发行版,另一个安装方法时使用[pip][6]。
+
+ $ sudo pip install --upgrade httpie
+
+### HTTPie 的例子 ###
+
+当你安装完 HTTPie 后,你可以通过输入 http 命令来调用它。在这篇文章的剩余部分,我会展示几个有用的 http 命令的例子。
+
+#### 例1:定制头部 ####
+
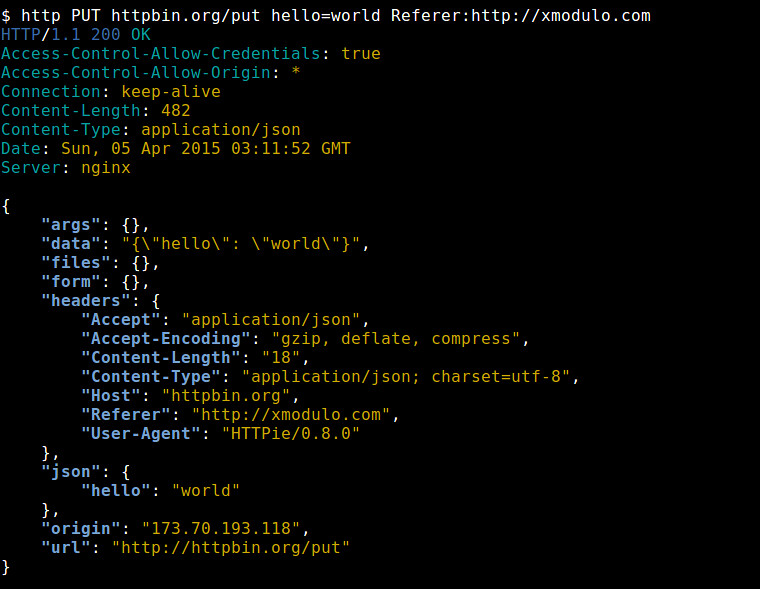
+你可以使用 <header:value> 的格式来定制头部。例如,我们发送一个 HTTP GET 请求到 www.test.com ,使用定制用户代理(user-agent)和来源(referer),还有定制头部(比如 MyParam)。
+
+ $ http www.test.com User-Agent:Xmodulo/1.0 Referer:http://xmodulo.com MyParam:Foo
+
+注意到当使用 HTTP GET 方法时,就无需明确指定 HTTP 方法。
+
+这个 HTTP 请求看起来如下:
+
+ GET / HTTP/1.1
+ Host: www.test.com
+ Accept: */*
+ Referer: http://xmodulo.com
+ Accept-Encoding: gzip, deflate, compress
+ MyParam: Foo
+ User-Agent: Xmodulo/1.0
+
+#### 例2:下载文件 ####
+
+你可以把 http 作为文件下载器来使用。你需要像下面一样把输出重定向到文件。
+
+ $ http www.test.com/my_file.zip > my_file.zip
+
+或者:
+
+ $ http --download www.test.com/my_file.zip
+
+#### 例3:定制 HTTP 方法 ####
+
+除了默认的 GET 方法,你还可以使用其他方法(比如 PUT,POST,HEAD)。例如,发送一个 HTTP PUT 请求:
+
+ $ http PUT www.test.com name='Dan Nanni' email=dan@email.com
+
+#### 例4:提交表单 ####
+
+使用 http 命令提交表单很容易,如下:
+
+ $ http -f POST www.test.com name='Dan Nanni' comment='Hi there'
+
+'-f' 选项使 http 命令序列化数据字段,并将 'Content-Type' 设置为 "application/x-www-form-urlencoded; charset=utf-8"。
+
+这个 HTTP POST 请求看起来如下:
+
+ POST / HTTP/1.1
+ Host: www.test.com
+ Content-Length: 31
+ Content-Type: application/x-www-form-urlencoded; charset=utf-8
+ Accept-Encoding: gzip, deflate, compress
+ Accept: */*
+ User-Agent: HTTPie/0.8.0
+
+ name=Dan+Nanni&comment=Hi+there
+
+####例5:JSON 支持
+
+HTTPie 内置 JSON(一种日渐普及的数据交换格式)支持。事实上,HTTPie 默认使用的内容类型(content-type)就是 JSON。因此,当你不指定内容类型发送数据字段时,它们会自动序列化为 JSON 对象。
+
+ $ http POST www.test.com name='Dan Nanni' comment='Hi there'
+
+这个 HTTP POST 请求看起来如下:
+
+ POST / HTTP/1.1
+ Host: www.test.com
+ Content-Length: 44
+ Content-Type: application/json; charset=utf-8
+ Accept-Encoding: gzip, deflate, compress
+ Accept: application/json
+ User-Agent: HTTPie/0.8.0
+
+ {"name": "Dan Nanni", "comment": "Hi there"}
+
+#### 例6:输出重定向 ####
+
+HTTPie 的另外一个用户友好特性是输入重定向,你可以使用缓冲数据提供 HTTP 请求内容。例如:
+
+ $ http POST api.test.com/db/lookup < my_info.json
+
+或者:
+
+ $ echo '{"name": "Dan Nanni"}' | http POST api.test.com/db/lookup
+
+### 结束语 ###
+
+在这篇文章中,我介绍了 HTTPie,一个 wget 和 curl 的可能替代工具。除了这里展示的几个简单的例子,你可以在其[官方网站][7]上找到 HTTPie 的很多有趣的应用。再次重复一遍,一款再强大的工具也取决于你对它的了解程度。从个人而言,我更倾向于 HTTPie,因为我在寻找一种更简洁的测试复杂网络接口的方法。
+
+你怎么看?
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/wget-curl-alternative-linux.html
+
+作者:[Dan Nanni][a]
+译者:[wangjiezhe](https://github.com/wangjiezhe)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/how-to-download-multiple-files-with-wget.html
+[2]:http://xmodulo.com/how-to-use-custom-http-headers-with-wget.html
+[3]:https://linux.cn/article-4957-1.html
+[4]:https://github.com/jakubroztocil/httpie
+[5]:https://linux.cn/article-2324-1.html
+[6]:http://ask.xmodulo.com/install-pip-linux.html
+[7]:https://github.com/jakubroztocil/httpie
diff --git a/published/201505/20150413 A Walk Through Some Important Docker Commands.md b/published/201505/20150413 A Walk Through Some Important Docker Commands.md
new file mode 100644
index 0000000000..d58dda2d54
--- /dev/null
+++ b/published/201505/20150413 A Walk Through Some Important Docker Commands.md
@@ -0,0 +1,106 @@
+一些重要 Docker 命令的简单介绍
+================================================================================
+大家好,今天我们来学习一些在你使用 Docker 之前需要了解的重要的 Docker 命令。[Docker][1] 是一个开源项目,提供了一个可以打包、装载和运行任何应用的轻量级容器的开放平台。它没有语言支持、框架和打包系统的限制,从小型的家用电脑到高端服务器,在何时何地都可以运行。这使它们可以不依赖于特定软件栈和供应商,像一块块积木一样部署和扩展网络应用、数据库和后端服务。
+
+Docker 命令简单易学,也很容易实现或实践。这是一些你运行 Docker 并充分利用它需要知道的简单 Docker 命令。
+
+### 1. 拉取 Docker 镜像 ###
+
+由于容器是由 Docker 镜像构建的,首先我们需要拉取一个 docker 镜像来开始。我们可以从 Docker Registry Hub 获取所需的 docker 镜像。在我们使用 pull 命令拉取任何镜像之前,为了避免 pull 命令的一些恶意风险,我们需要保护我们的系统。为了保护我们的系统不受这个风险影响,我们需要添加 **127.0.0.1 index.docker.io** 到 /etc/hosts 条目。我们可以通过使用喜欢的文本编辑器完成。
+
+ # nano /etc/hosts
+
+现在,增加下面的一行到文件并保存退出。
+
+ 127.0.0.1 index.docker.io
+
+
+
+要拉取一个 docker 镜像,我们需要运行下面的命令。
+
+ # docker pull registry.hub.docker.com/busybox
+
+
+
+我们可以检查本地是否有可用的 Docker 镜像。
+
+ # docker images
+
+
+
+### 2. 运行 Docker 容器 ###
+
+现在,成功地拉取要求的或所需的 Docker 镜像之后,我们当然想运行这个 Docker 镜像。我们可以用 docker run 命令在镜像上运行一个 docker 容器。在 Docker 镜像上运行一个 docker 容器时我们有很多选项和标记。我们使用 -t 和 -i 选项来运行一个 docker 镜像并进入容器,如下面所示。
+
+ # docker run -it busybox
+
+
+
+从上面的命令中,我们进入了容器并可以通过交互 shell 访问它的内容。我们可以键入 **Ctrl-D** 从shell中退出。
+
+现在,在后台运行容器,我们用 -d 标记分离 shell,如下所示。
+
+ # docker run -itd busybox
+
+
+
+如果你想进入到一个正在运行的容器,我们可以使用 attach 命令加一个容器 id。可以使用 **docker ps** 命令获取容器 id。
+
+ # docker attach
+
+
+
+### 3. 检查容器运行 ###
+
+不论容器是否运行,查看日志文件都很简单。我们可以使用下面的命令去检查是否有 docker 容器在实时运行。
+
+ # docker ps
+
+现在,查看正在运行的或者之前运行的容器的日志,我们需要运行以下的命令。
+
+ # docker ps -a
+
+
+
+### 4. 查看容器信息 ###
+
+我们可以使用 inspect 命令查看一个 Docker 容器的各种信息。
+
+ # docker inspect
+
+
+
+### 5. 杀死或删除 ###
+
+我们可以使用容器 id 杀死或者停止 docker 容器(进程),如下所示。
+
+ # docker stop
+
+要停止每个正在运行的容器,我们需要运行下面的命令。
+
+ # docker kill $(docker ps -q)
+
+现在,如我我们希望移除一个 docker 镜像,运行下面的命令。
+
+ # docker rm
+
+如果我们想一次性移除所有 docker 镜像,我们可以运行以下命令。
+
+ # docker rm $(docker ps -aq)
+
+### 结论 ###
+
+这些都是充分学习和使用 Docker 很基本的 docker 命令。有了这些命令,Docker 变得很简单,可以提供给最终用户一个易用的计算平台。根据上面的教程,任何人学习 Docker 命令都非常简单。如果你有任何问题,建议,反馈,请写到下面的评论框中以便我们改进和更新内容。多谢! 希望你喜欢 :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/important-docker-commands/
+
+作者:[Arun Pyasi][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://www.docker.com/
\ No newline at end of file
diff --git a/published/201505/20150413 Linux FAQs with Answers--How to change PATH environment variable on Linux.md b/published/201505/20150413 Linux FAQs with Answers--How to change PATH environment variable on Linux.md
new file mode 100644
index 0000000000..321ce4b2d3
--- /dev/null
+++ b/published/201505/20150413 Linux FAQs with Answers--How to change PATH environment variable on Linux.md
@@ -0,0 +1,73 @@
+Linux有问必答:如何在Linux中修改环境变量PATH
+================================================================================
+> **提问**: 当我试着运行一个程序时,它提示“command not found”。 但这个程序就在/usr/local/bin下。我该如何添加/usr/local/bin到我的PATH变量下,这样我就可以不用指定路径来运行这个命令了。
+
+在Linux中,PATH环境变量保存了一系列的目录用于用户在输入的时候搜索命令。PATH变量的值由一系列的由分号分隔的绝对路径组成。每个用户都有特定的PATH环境变量(由系统级的PATH变量初始化)。
+
+要检查用户的环境变量,用户模式下运行下面的命令:
+
+ $ echo $PATH
+
+----------
+
+ /usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/sbin:/sbin:/home/xmodulo/bin
+
+或者运行:
+
+ $ env | grep PATH
+
+----------
+
+ PATH=/usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/sbin:/sbin:/home/xmodulo/bin
+
+如果你的命令不存在于上面任何一个目录内,shell就会抛出一个错误信息:“command not found”。
+
+如果你想要添加一个另外的目录(比如:/usr/local/bin)到你的PATH变量中,你可以用下面这些命令。
+
+### 为特定用户修改PATH环境变量 ###
+
+如果你只想在当前的登录会话中临时地添加一个新的目录(比如:/usr/local/bin)给用户的默认搜索路径,你只需要输入下面的命令。
+
+ $ PATH=$PATH:/usr/local/bin
+
+检查PATH是否已经更新:
+
+ $ echo $PATH
+
+----------
+
+ /usr/lib64/qt-3.3/bin:/bin:/usr/bin:/usr/sbin:/sbin:/home/xmodulo/bin:/usr/local/bin
+
+更新后的PATH会在当前的会话一直有效。然而,更改将在新的会话中失效。
+
+如果你想要永久更改PATH变量,用编辑器打开~/.bashrc (或者 ~/.bash_profile),接着在最后添加下面这行。
+
+ export PATH=$PATH:/usr/local/bin
+
+接着运行下面这行永久激活更改:
+
+ $ source ~/.bashrc (或者 source ~/.bash_profile)
+
+### 改变系统级的环境变量 ###
+
+如果你想要永久添加/usr/local/bin到系统级的PATH变量中,像下面这样编辑/etc/profile。
+
+ $ sudo vi /etc/profile
+
+----------
+
+ export PATH=$PATH:/usr/local/bin
+
+你重新登录后,更新的环境变量就会生效了。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/change-path-environment-variable-linux.html
+
+作者:[Dan Nanni][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/published/201505/20150413 [Solved] Ubuntu Does Not Remember Brightness Settings.md b/published/201505/20150413 [Solved] Ubuntu Does Not Remember Brightness Settings.md
new file mode 100644
index 0000000000..d0248ff2c2
--- /dev/null
+++ b/published/201505/20150413 [Solved] Ubuntu Does Not Remember Brightness Settings.md
@@ -0,0 +1,32 @@
+如何解决 Ubuntu 下不能记住亮度设置的问题
+================================================================================
+
+
+在[解决亮度控制在Ubuntu和Linux Mint下不工作的问题][1]这篇教程里,一些用户提到虽然问题已经得到解决,但是**Ubuntu无法记住亮度设置**,同样的情况在Linux Mint下也会发生。每次开机或从睡眠状态下唤醒,亮度会恢复至最大值或最小值。我知道这种情况很烦。不过幸好我们有很简单的方法来解决**Ubuntu和Linux Mint下的亮度问题**。
+
+### 解决Ubuntu和Linux下不能记住亮度设置 ###
+
+[Norbert][2]写了一个脚本,能让Ubuntu和Linux Mint记住亮度设置,不论是开机还是唤醒之后。为了能让你使用这个脚本更简单方便,他把这个适用于Ubuntu 12.04、14.04和14.10的PPA挂在了网上。你需要做的就是输入以下命令:
+
+ sudo add-apt-repository ppa:nrbrtx/sysvinit-backlight
+ sudo apt-get update
+ sudo apt-get install sysvinit-backlight
+
+安装好之后,重启你的系统。现在就来看看亮度设置有没有被保存下来吧。
+
+希望这篇小贴士能帮助到你。如果你有任何问题,就[来这儿][3]提bug吧。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/ubuntu-mint-brightness-settings/
+
+作者:[Abhishek][a]
+译者:[ZTinoZ](https://github.com/ZTinoZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://itsfoss.com/fix-brightness-ubuntu-1310/
+[2]:https://launchpad.net/~nrbrtx/+archive/ubuntu/sysvinit-backlight/+packages
+[3]:https://launchpad.net/~nrbrtx/+archive/ubuntu/sysvinit-backlight/+packages
diff --git a/published/201505/20150415 Strong SSL Security on nginx.md b/published/201505/20150415 Strong SSL Security on nginx.md
new file mode 100644
index 0000000000..094c50bd37
--- /dev/null
+++ b/published/201505/20150415 Strong SSL Security on nginx.md
@@ -0,0 +1,290 @@
+增强 nginx 的 SSL 安全性
+================================================================================
+[][1]
+
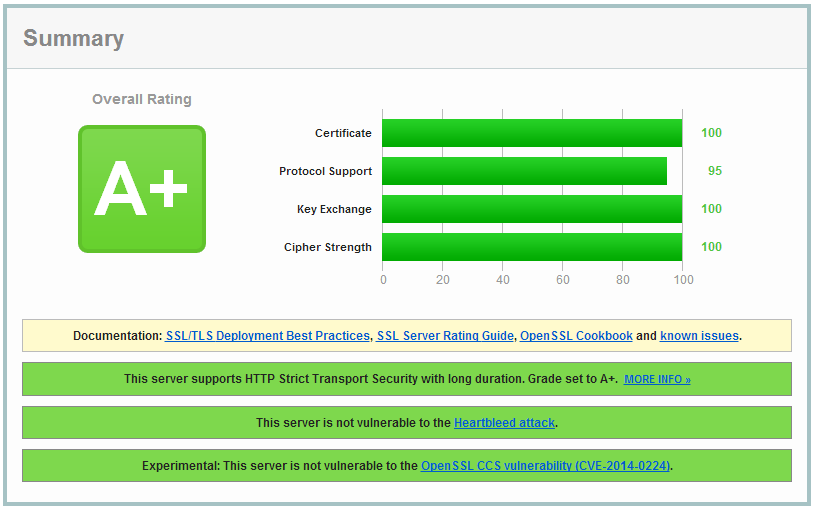
+本文向你介绍如何在 nginx 服务器上设置健壮的 SSL 安全机制。我们通过禁用 SSL 压缩来降低 CRIME 攻击威胁;禁用协议上存在安全缺陷的 SSLv3 及更低版本,并设置更健壮的加密套件(cipher suite)来尽可能启用前向安全性(Forward Secrecy);此外,我们还启用了 HSTS 和 HPKP。这样我们就拥有了一个健壮而可经受考验的 SSL 配置,并可以在 Qually Labs 的 SSL 测试中得到 A 级评分。
+
+如果不求甚解的话,可以从 [https://cipherli.st][2] 上找到 nginx 、Apache 和 Lighttpd 的安全设置,复制粘帖即可。
+
+本教程在 Digital Ocean 的 VPS 上测试通过。如果你喜欢这篇教程,想要支持作者的站点的话,购买 Digital Ocean 的 VPS 时请使用如下链接:[https://www.digitalocean.com/?refcode=7435ae6b8212][3] 。
+
+本教程可以通过[发布于 2014/1/21 的][4] SSL 实验室测试的严格要求(我之前就通过了测试,如果你按照本文操作就可以得到一个 A+ 评分)。
+
+- [本教程也可用于 Apache ][5]
+- [本教程也可用于 Lighttpd ][6]
+- [本教程也可用于 FreeBSD, NetBSD 和 OpenBSD 上的 nginx ,放在 BSD Now 播客上][7]: [http://www.bsdnow.tv/tutorials/nginx][8]
+
+你可以从下列链接中找到这方面的进一步内容:
+
+- [野兽攻击(BEAST)][9]
+- [罪恶攻击(CRIME)][10]
+- [怪物攻击(FREAK )][11]
+- [心血漏洞(Heartbleed)][12]
+- [完备的前向安全性(Perfect Forward Secrecy)][13]
+- [RC4 和 BEAST 的处理][14]
+
+我们需要编辑 nginx 的配置,在 Ubuntu/Debian 上是 `/etc/nginx/sited-enabled/yoursite.com`,在 RHEL/CentOS 上是 `/etc/nginx/conf.d/nginx.conf`。
+
+本文中,我们需要编辑443端口(SSL)的 `server` 配置中的部分。在文末你可以看到完整的配置例子。
+
+*在编辑之前切记备份一下配置文件!*
+
+### 野兽攻击(BEAST)和 RC4 ###
+
+简单的说,野兽攻击(BEAST)就是通过篡改一个加密算法的 CBC(密码块链)的模式,从而可以对部分编码流量悄悄解码。更多信息参照上面的链接。
+
+针对野兽攻击(BEAST),较新的浏览器已经启用了客户端缓解方案。推荐方案是禁用 TLS 1.0 的所有加密算法,仅允许 RC4 算法。然而,[针对 RC4 算法的攻击也越来越多](http://www.isg.rhul.ac.uk/tls/) ,很多已经从理论上逐步发展为实际可行的攻击方式。此外,有理由相信 NSA 已经实现了他们所谓的“大突破”——攻破 RC4 。
+
+禁用 RC4 会有几个后果。其一,当用户使用老旧的浏览器时,比如 Windows XP 上的 IE 会用 3DES 来替代 RC4。3DES 要比 RC4 更安全,但是它的计算成本更高,你的服务器就需要为这些用户付出更多的处理成本。其二,RC4 算法能减轻 野兽攻击(BEAST)的危害,如果禁用 RC4 会导致 TLS 1.0 用户会换到更容易受攻击的 AES-CBC 算法上(通常服务器端的对野兽攻击(BEAST)的“修复方法”是让 RC4 优先于其它算法)。我认为 RC4 的风险要高于野兽攻击(BEAST)的风险。事实上,有了客户端缓解方案(Chrome 和 Firefox 提供了缓解方案),野兽攻击(BEAST)就不是什么大问题了。而 RC4 的风险却在增长:随着时间推移,对加密算法的破解会越来越多。
+
+### 怪物攻击(FREAK) ###
+
+怪物攻击(FREAK)是一种中间人攻击,它是由来自 [INRIA、微软研究院和 IMDEA][15] 的密码学家们所发现的。怪物攻击(FREAK)的缩写来自“Factoring RSA-EXPORT Keys(RSA 出口密钥因子分解)”
+
+这个漏洞可上溯到上世纪九十年代,当时美国政府禁止出口加密软件,除非其使用编码密钥长度不超过512位的出口加密套件。
+
+这造成了一些现在的 TLS 客户端存在一个缺陷,这些客户端包括: 苹果的 SecureTransport 、OpenSSL。这个缺陷会导致它们会接受出口降级 RSA 密钥,即便客户端并没有要求使用出口降级 RSA 密钥。这个缺陷带来的影响很讨厌:在客户端存在缺陷,且服务器支持出口降级 RSA 密钥时,会发生中间人攻击,从而导致连接的强度降低。
+
+攻击分为两个组成部分:首先是服务器必须接受“出口降级 RSA 密钥”。
+
+中间人攻击可以按如下流程:
+
+- 在客户端的 Hello 消息中,要求标准的 RSA 加密套件。
+- 中间人攻击者修改该消息为‘export RSA’(输出级 RSA 密钥)。
+- 服务器回应一个512位的输出级 RSA 密钥,并以其长期密钥签名。
+- 由于 OpenSSL/SecureTransport 的缺陷,客户端会接受这个弱密钥。
+- 攻击者根据 RSA 模数分解因子来恢复相应的 RSA 解密密钥。
+- 当客户端编码‘pre-master secret’(预主密码)给服务器时,攻击者现在就可以解码它并恢复 TLS 的‘master secret’(主密码)。
+- 从这里开始,攻击者就能看到了传输的明文并注入任何东西了。
+
+本文所提供的加密套件不启用输出降级加密,请确认你的 OpenSSL 是最新的,也强烈建议你将客户端也升级到新的版本。
+
+### 心血漏洞(Heartbleed) ###
+
+心血漏洞(Heartbleed) 是一个于2014年4月公布的 OpenSSL 加密库的漏洞,它是一个被广泛使用的传输层安全(TLS)协议的实现。无论是服务器端还是客户端在 TLS 中使用了有缺陷的 OpenSSL,都可以被利用该缺陷。由于它是因 DTLS 心跳扩展(RFC 6520)中的输入验证不正确(缺少了边界检查)而导致的,所以该漏洞根据“心跳”而命名。这个漏洞是一种缓存区超读漏洞,它可以读取到本不应该读取的数据。
+
+哪个版本的 OpenSSL 受到心血漏洞(Heartbleed)的影响?
+
+各版本情况如下:
+
+- OpenSSL 1.0.1 直到 1.0.1f (包括)**存在**该缺陷
+- OpenSSL 1.0.1g **没有**该缺陷
+- OpenSSL 1.0.0 分支**没有**该缺陷
+- OpenSSL 0.9.8 分支**没有**该缺陷
+
+这个缺陷是2011年12月引入到 OpenSSL 中的,并随着 2012年3月14日 OpenSSL 发布的 1.0.1 而泛滥。2014年4月7日发布的 OpenSSL 1.0.1g 修复了该漏洞。
+
+升级你的 OpenSSL 就可以避免该缺陷。
+
+### SSL 压缩(罪恶攻击 CRIME) ###
+
+罪恶攻击(CRIME)使用 SSL 压缩来完成它的魔法,SSL 压缩在下述版本是默认关闭的: nginx 1.1.6及更高/1.0.9及更高(如果使用了 OpenSSL 1.0.0及更高), nginx 1.3.2及更高/1.2.2及更高(如果使用较旧版本的 OpenSSL)。
+
+如果你使用一个早期版本的 nginx 或 OpenSSL,而且你的发行版没有向后移植该选项,那么你需要重新编译没有一个 ZLIB 支持的 OpenSSL。这会禁止 OpenSSL 使用 DEFLATE 压缩方式。如果你禁用了这个,你仍然可以使用常规的 HTML DEFLATE 压缩。
+
+### SSLv2 和 SSLv3 ###
+
+SSLv2 是不安全的,所以我们需要禁用它。我们也禁用 SSLv3,因为 TLS 1.0 在遭受到降级攻击时,会允许攻击者强制连接使用 SSLv3,从而禁用了前向安全性(forward secrecy)。
+
+如下编辑配置文件:
+
+ ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
+
+### 卷毛狗攻击(POODLE)和 TLS-FALLBACK-SCSV ###
+
+SSLv3 会受到[卷毛狗漏洞(POODLE)][16]的攻击。这是禁用 SSLv3 的主要原因之一。
+
+Google 提出了一个名为 [TLS\_FALLBACK\_SCSV][17] 的SSL/TLS 扩展,它用于防止强制 SSL 降级。如果你升级 到下述的 OpenSSL 版本会自动启用它。
+
+- OpenSSL 1.0.1 带有 TLS\_FALLBACK\_SCSV 1.0.1j 及更高。
+- OpenSSL 1.0.0 带有 TLS\_FALLBACK\_SCSV 1.0.0o 及更高。
+- OpenSSL 0.9.8 带有 TLS\_FALLBACK\_SCSV 0.9.8zc 及更高。
+
+[更多信息请参照 NGINX 文档][18]。
+
+### 加密套件(cipher suite) ###
+
+前向安全性(Forward Secrecy)用于在长期密钥被破解时确保会话密钥的完整性。PFS(完备的前向安全性)是指强制在每个/每次会话中推导新的密钥。
+
+这就是说,泄露的私钥并不能用来解密(之前)记录下来的 SSL 通讯。
+
+提供PFS(完备的前向安全性)功能的是那些使用了一种 Diffie-Hellman 密钥交换的短暂形式的加密套件。它们的缺点是系统开销较大,不过可以使用椭圆曲线的变体来改进。
+
+以下两个加密套件是我推荐的,之后[Mozilla 基金会][19]也推荐了。
+
+推荐的加密套件:
+
+ ssl_ciphers 'AES128+EECDH:AES128+EDH';
+
+向后兼容的推荐的加密套件(IE6/WinXP):
+
+ ssl_ciphers "ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA256:ECDHE-RSA-AES256-SHA:ECDHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES128-SHA256:DHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES256-GCM-SHA384:AES128-GCM-SHA256:AES256-SHA256:AES128-SHA256:AES256-SHA:AES128-SHA:DES-CBC3-SHA:HIGH:!aNULL:!eNULL:!EXPORT:!DES:!MD5:!PSK:!RC4";
+
+如果你的 OpenSSL 版本比较旧,不可用的加密算法会自动丢弃。应该一直使用上述的完整套件,让 OpenSSL 选择一个它所支持的。
+
+加密套件的顺序是非常重要的,因为其决定了优先选择哪个算法。上述优先推荐的算法中提供了PFS(完备的前向安全性)。
+
+较旧版本的 OpenSSL 也许不能支持这个算法的完整列表,AES-GCM 和一些 ECDHE 算法是相当新的,在 Ubuntu 和 RHEL 中所带的绝大多数 OpenSSL 版本中不支持。
+
+#### 优先顺序的逻辑 ####
+
+- ECDHE+AESGCM 加密是首选的。它们是 TLS 1.2 加密算法,现在还没有广泛支持。当前还没有对它们的已知攻击。
+- PFS 加密套件好一些,首选 ECDHE,然后是 DHE。
+- AES 128 要好于 AES 256。有一个关于 AES256 带来的安全提升程度是否值回成本的[讨论][20],结果是显而易见的。目前,AES128 要更值一些,因为它提供了不错的安全水准,确实很快,而且看起来对时序攻击更有抵抗力。
+- 在向后兼容的加密套件里面,AES 要优于 3DES。在 TLS 1.1及其以上,减轻了针对 AES 的野兽攻击(BEAST)的威胁,而在 TLS 1.0上则难以实现该攻击。在非向后兼容的加密套件里面,不支持 3DES。
+- RC4 整个不支持了。3DES 用于向后兼容。参看 [#RC4\_weaknesses][21] 中的讨论。
+
+#### 强制丢弃的算法 ####
+
+- aNULL 包含了非验证的 Diffie-Hellman 密钥交换,这会受到中间人(MITM)攻击
+- eNULL 包含了无加密的算法(明文)
+- EXPORT 是老旧的弱加密算法,是被美国法律标示为可出口的
+- RC4 包含的加密算法使用了已弃用的 ARCFOUR 算法
+- DES 包含的加密算法使用了弃用的数据加密标准(DES)
+- SSLv2 包含了定义在旧版本 SSL 标准中的所有算法,现已弃用
+- MD5 包含了使用已弃用的 MD5 作为哈希算法的所有算法
+
+### 更多设置 ###
+
+确保你也添加了如下行:
+
+ ssl_prefer_server_ciphers on;
+ ssl_session_cache shared:SSL:10m;
+
+在一个 SSLv3 或 TLSv1 握手过程中选择一个加密算法时,一般使用客户端的首选算法。如果设置了上述配置,则会替代地使用服务器端的首选算法。
+
+- [关于 ssl\_prefer\_server\_ciphers 的更多信息][22]
+- [关于 ssl\_ciphers 的更多信息][23]
+
+### 前向安全性和 Diffie Hellman Ephemeral (DHE)参数 ###
+
+前向安全性(Forward Secrecy)的概念很简单:客户端和服务器协商一个永不重用的密钥,并在会话结束时销毁它。服务器上的 RSA 私钥用于客户端和服务器之间的 Diffie-Hellman 密钥交换签名。从 Diffie-Hellman 握手中获取的预主密钥会用于之后的编码。因为预主密钥是特定于客户端和服务器之间建立的某个连接,并且只用在一个限定的时间内,所以称作短暂模式(Ephemeral)。
+
+使用了前向安全性,如果一个攻击者取得了一个服务器的私钥,他是不能解码之前的通讯信息的。这个私钥仅用于 Diffie Hellman 握手签名,并不会泄露预主密钥。Diffie Hellman 算法会确保预主密钥绝不会离开客户端和服务器,而且不能被中间人攻击所拦截。
+
+所有版本的 nginx(如1.4.4)都依赖于 OpenSSL 给 Diffie-Hellman (DH)的输入参数。不幸的是,这意味着 Diffie-Hellman Ephemeral(DHE)将使用 OpenSSL 的默认设置,包括一个用于密钥交换的1024位密钥。因为我们正在使用2048位证书,DHE 客户端就会使用一个要比非 DHE 客户端更弱的密钥交换。
+
+我们需要生成一个更强壮的 DHE 参数:
+
+ cd /etc/ssl/certs
+ openssl dhparam -out dhparam.pem 4096
+
+然后告诉 nginx 将其用作 DHE 密钥交换:
+
+ ssl_dhparam /etc/ssl/certs/dhparam.pem;
+
+### OCSP 装订(Stapling) ###
+
+当连接到一个服务器时,客户端应该使用证书吊销列表(CRL)或在线证书状态协议(OCSP)记录来校验服务器证书的有效性。CRL 的问题是它已经增长的太大了,永远也下载不完了。
+
+OCSP 更轻量级一些,因为我们每次只请求一条记录。但是副作用是当连接到一个服务器时必须对第三方 OCSP 响应器发起 OCSP 请求,这就增加了延迟和带来了潜在隐患。事实上,CA 所运营的 OCSP 响应器非常不可靠,浏览器如果不能及时收到答复,就会静默失败。攻击者通过 DoS 攻击一个 OCSP 响应器可以禁用其校验功能,这样就降低了安全性。
+
+解决方法是允许服务器在 TLS 握手中发送缓存的 OCSP 记录,以绕开 OCSP 响应器。这个机制节省了客户端和 OCSP 响应器之间的通讯,称作 OCSP 装订。
+
+客户端会在它的 CLIENT HELLO 中告知其支持 status\_request TLS 扩展,服务器仅在客户端请求它的时候才发送缓存的 OCSP 响应。
+
+大多数服务器最多会缓存 OCSP 响应48小时。服务器会按照常规的间隔连接到 CA 的 OCSP 响应器来获取刷新的 OCSP 记录。OCSP 响应器的位置可以从签名的证书中的授权信息访问(Authority Information Access)字段中获得。
+
+- [阅读我的教程:在 NGINX 中启用 OCSP 装订][24]
+
+### HTTP 严格传输安全(HSTS) ###
+
+如有可能,你应该启用 [HTTP 严格传输安全(HSTS)][25],它会引导浏览器和你的站点之间的通讯仅通过 HTTPS。
+
+- [阅读我关于 HSTS 的文章,了解如何配置它][26]
+
+### HTTP 公钥固定扩展(HPKP) ###
+
+你也应该启用 [HTTP 公钥固定扩展(HPKP)][27]。
+
+公钥固定的意思是一个证书链必须包括一个白名单中的公钥。它确保仅有白名单中的 CA 才能够为某个域名签署证书,而不是你的浏览器中存储的任何 CA。
+
+我已经写了一篇[关于 HPKP 的背景理论及在 Apache、Lighttpd 和 NGINX 中配置例子的文章][28]。
+
+### 配置范例 ###
+
+ server {
+
+ listen [::]:443 default_server;
+
+ ssl on;
+ ssl_certificate_key /etc/ssl/cert/raymii_org.pem;
+ ssl_certificate /etc/ssl/cert/ca-bundle.pem;
+
+ ssl_ciphers 'AES128+EECDH:AES128+EDH:!aNULL';
+
+ ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
+ ssl_session_cache shared:SSL:10m;
+
+ ssl_stapling on;
+ ssl_stapling_verify on;
+ resolver 8.8.4.4 8.8.8.8 valid=300s;
+ resolver_timeout 10s;
+
+ ssl_prefer_server_ciphers on;
+ ssl_dhparam /etc/ssl/certs/dhparam.pem;
+
+ add_header Strict-Transport-Security max-age=63072000;
+ add_header X-Frame-Options DENY;
+ add_header X-Content-Type-Options nosniff;
+
+ root /var/www/;
+ index index.html index.htm;
+ server_name raymii.org;
+
+ }
+
+### 结尾 ###
+
+如果你使用了上述配置,你需要重启 nginx:
+
+ # 首先检查配置文件是否正确
+ /etc/init.d/nginx configtest
+ # 然后重启
+ /etc/init.d/nginx restart
+
+现在使用 [SSL Labs 测试][29]来看看你是否能得到一个漂亮的“A”。当然了,你也得到了一个安全的、强壮的、经得起考验的 SSL 配置!
+
+- [参考 Mozilla 关于这方面的内容][30]
+
+--------------------------------------------------------------------------------
+
+via: https://raymii.org/s/tutorials/Strong_SSL_Security_On_nginx.html
+
+作者:[Remy van Elst][a]
+译者:[wxy](https://github.com/wxy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://raymii.org/
+[1]:https://www.ssllabs.com/ssltest/analyze.html?d=raymii.org
+[2]:https://cipherli.st/
+[3]:https://www.digitalocean.com/?refcode=7435ae6b8212
+[4]:http://blog.ivanristic.com/2014/01/ssl-labs-stricter-security-requirements-for-2014.html
+[5]:https://raymii.org/s/tutorials/Strong_SSL_Security_On_Apache2.html
+[6]:https://raymii.org/s/tutorials/Pass_the_SSL_Labs_Test_on_Lighttpd_%28Mitigate_the_CRIME_and_BEAST_attack_-_Disable_SSLv2_-_Enable_PFS%29.html
+[7]:http://www.bsdnow.tv/episodes/2014_08_20-engineering_nginx
+[8]:http://www.bsdnow.tv/tutorials/nginx
+[9]:https://en.wikipedia.org/wiki/Transport_Layer_Security#BEAST_attack
+[10]:https://en.wikipedia.org/wiki/CRIME_%28security_exploit%29
+[11]:http://blog.cryptographyengineering.com/2015/03/attack-of-week-freak-or-factoring-nsa.html
+[12]:http://heartbleed.com/
+[13]:https://en.wikipedia.org/wiki/Perfect_forward_secrecy
+[14]:https://en.wikipedia.org/wiki/Transport_Layer_Security#Dealing_with_RC4_and_BEAST
+[15]:https://www.smacktls.com/
+[16]:https://raymii.org/s/articles/Check_servers_for_the_Poodle_bug.html
+[17]:https://tools.ietf.org/html/draft-ietf-tls-downgrade-scsv-00
+[18]:http://wiki.nginx.org/HttpSslModule#ssl_protocols
+[19]:https://wiki.mozilla.org/Security/Server_Side_TLS
+[20]:http://www.mail-archive.com/dev-tech-crypto@lists.mozilla.org/msg11247.html
+[21]:https://wiki.mozilla.org/Security/Server_Side_TLS#RC4_weaknesses
+[22]:http://wiki.nginx.org/HttpSslModule#ssl_prefer_server_ciphers
+[23]:http://wiki.nginx.org/HttpSslModule#ssl_ciphers
+[24]:https://raymii.org/s/tutorials/OCSP_Stapling_on_nginx.html
+[25]:https://en.wikipedia.org/wiki/HTTP_Strict_Transport_Security
+[26]:https://linux.cn/article-5266-1.html
+[27]:https://wiki.mozilla.org/SecurityEngineering/Public_Key_Pinning
+[28]:https://linux.cn/article-5282-1.html
+[29]:https://www.ssllabs.com/ssltest/
+[30]:https://wiki.mozilla.org/Security/Server_Side_TLS
\ No newline at end of file
diff --git a/published/201505/20150417 14 Useful Examples of Linux 'sort' Command--Part 1.md b/published/201505/20150417 14 Useful Examples of Linux 'sort' Command--Part 1.md
new file mode 100644
index 0000000000..c483c4035f
--- /dev/null
+++ b/published/201505/20150417 14 Useful Examples of Linux 'sort' Command--Part 1.md
@@ -0,0 +1,132 @@
+Linux 的 ‘sort’命令的14个有用的范例(一)
+=============================================================
+Sort是用于对单个或多个文本文件内容进行排序的Linux程序。Sort命令以空格作为字段分隔符,将一行分割为多个关键字对文件进行排序。需要注意的是除非你将输出重定向到文件中,否则Sort命令并不对文件内容进行实际的排序(即文件内容没有修改),只是将文件内容按有序输出。
+
+本文的目标是通过14个实际的范例让你更深刻的理解如何在Linux中使用sort命令。
+
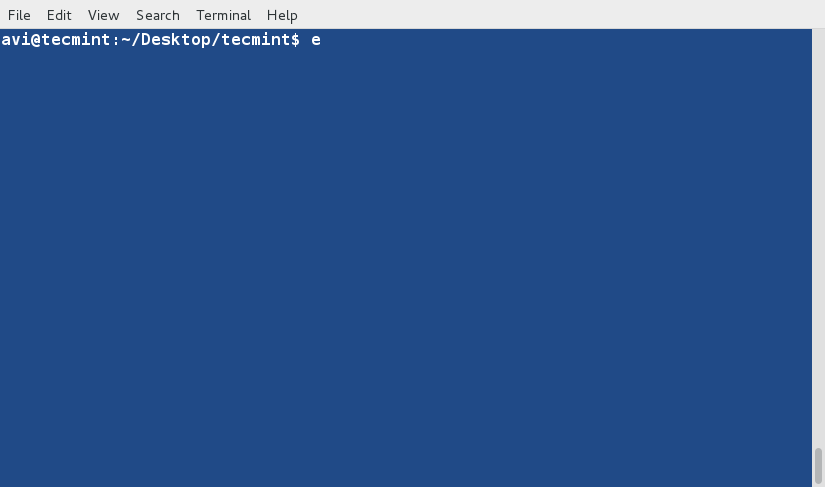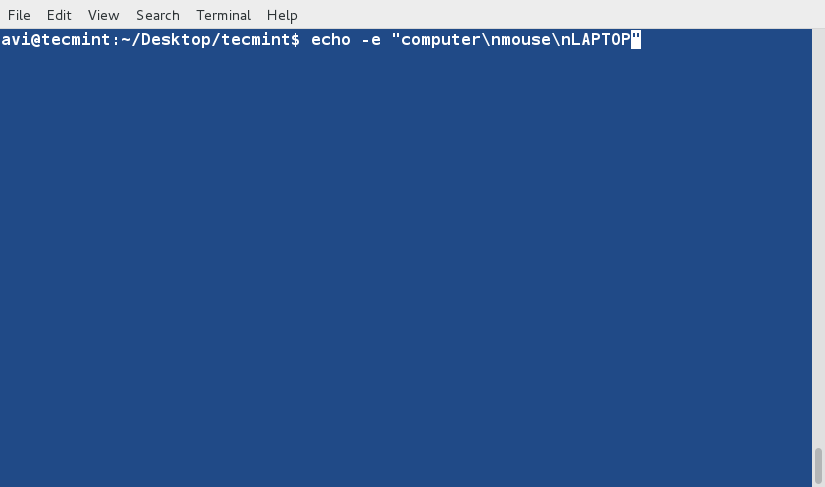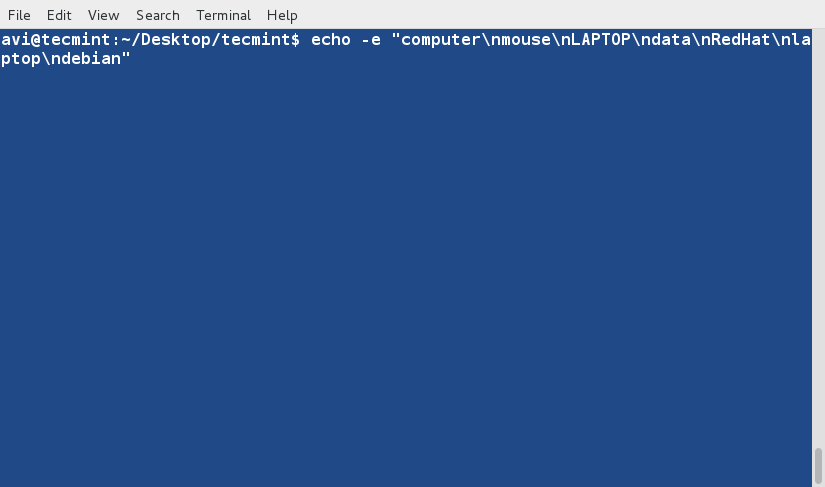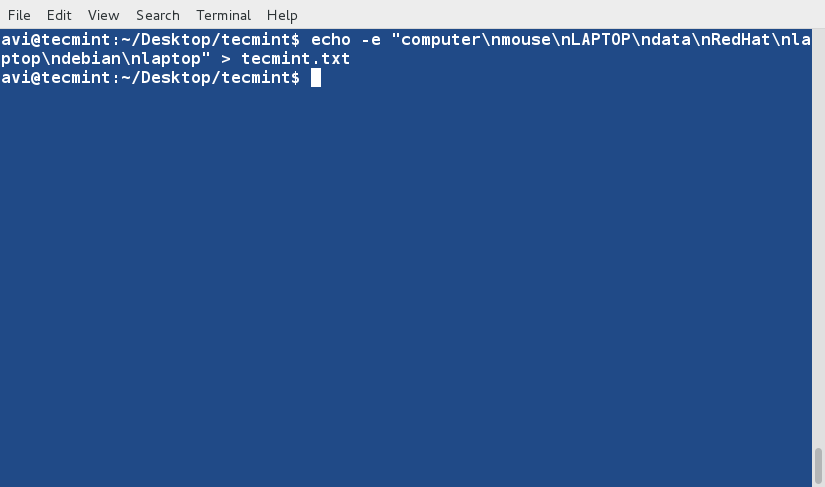
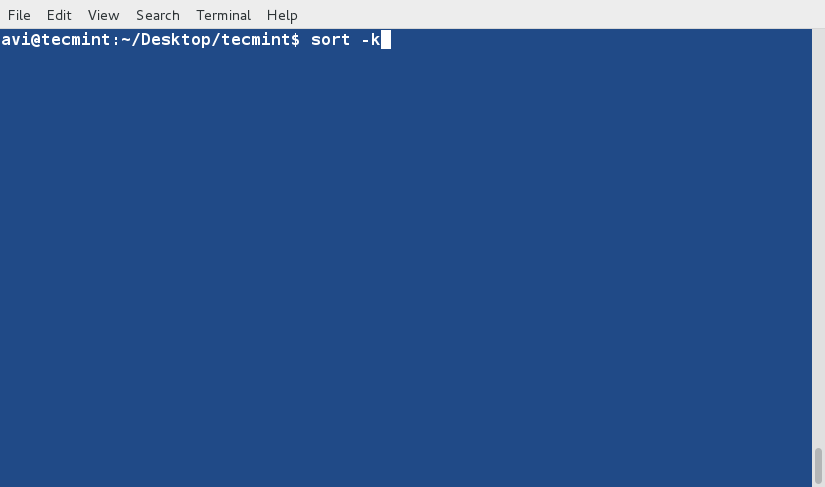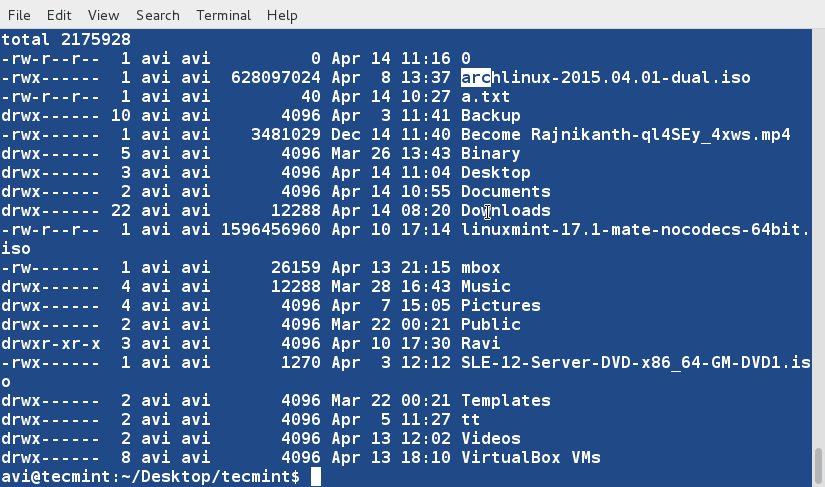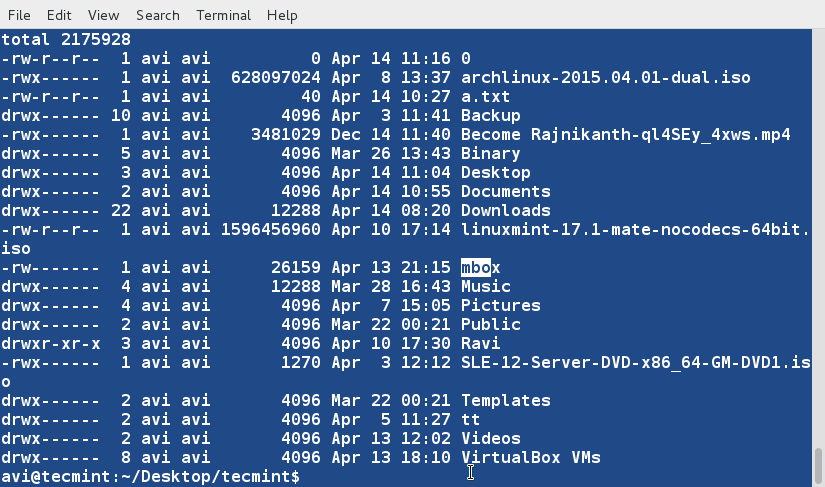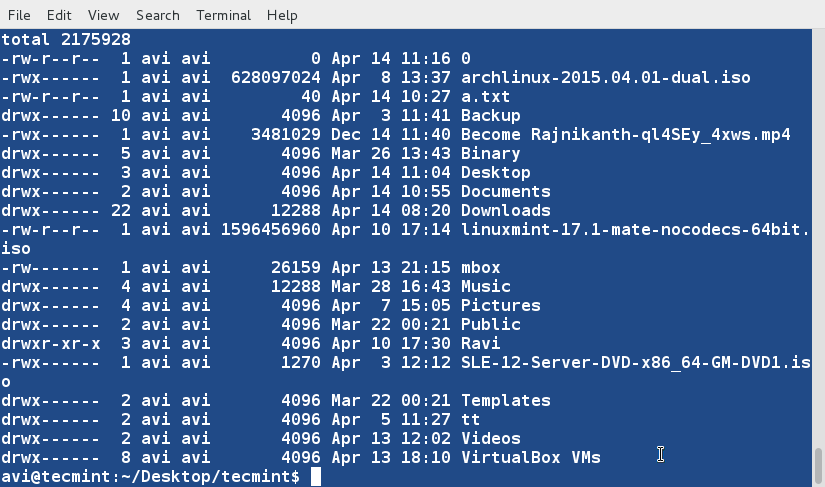
+1、 首先我们将会创建一个用于执行‘sort’命令的文本文件(tecmint.txt)。工作路径是‘/home/$USER/Desktop/tecmint’。
+
+下面命令中的‘-e’选项将启用‘\\’转义,将‘\n’解析成换行
+
+ $ echo -e "computer\nmouse\nLAPTOP\ndata\nRedHat\nlaptop\ndebian\nlaptop" > tecmint.txt
+
+
+
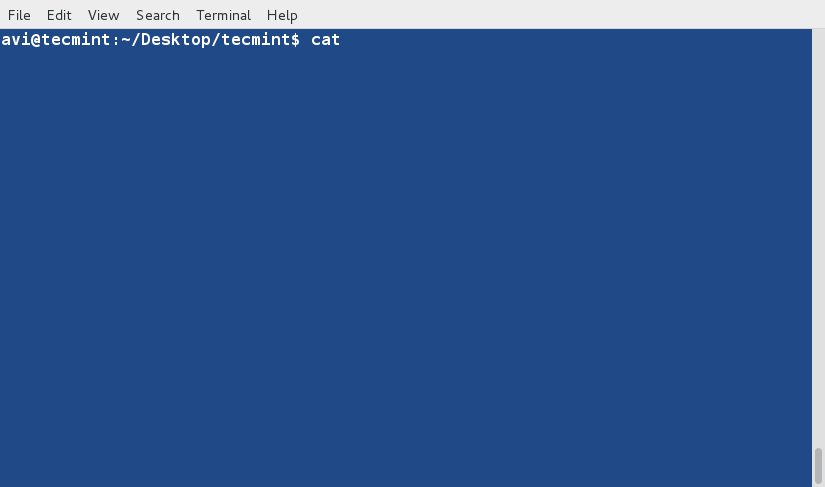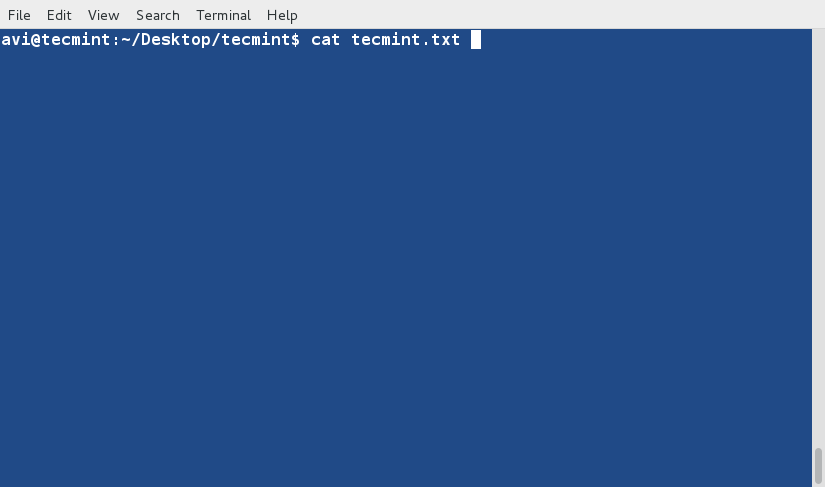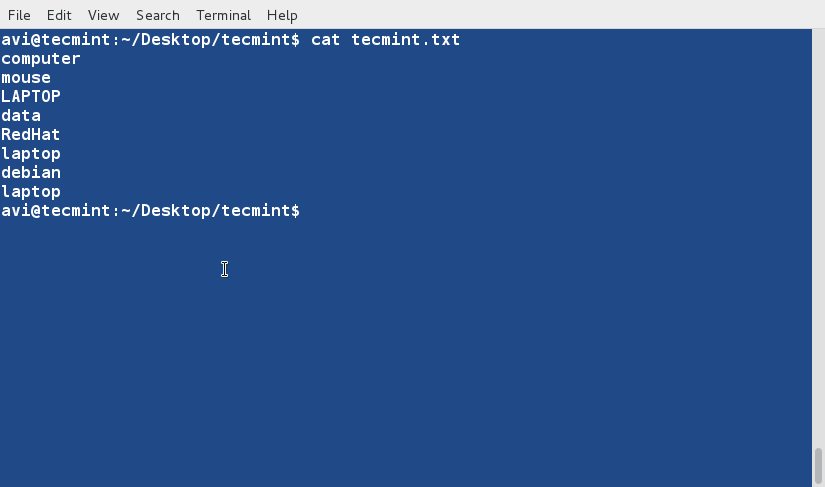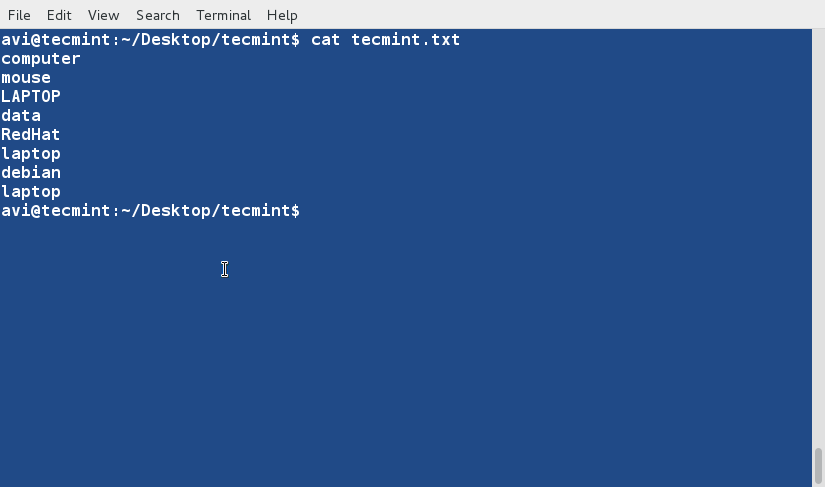
+2、 在开始学习‘sort’命令前,我们先看看文件的内容及其显示方式。
+
+ $ cat tecmint.txt
+
+
+
+3、 现在,使用如下命令对文件内容进行排序。
+
+ $ sort tecmint.txt
+
+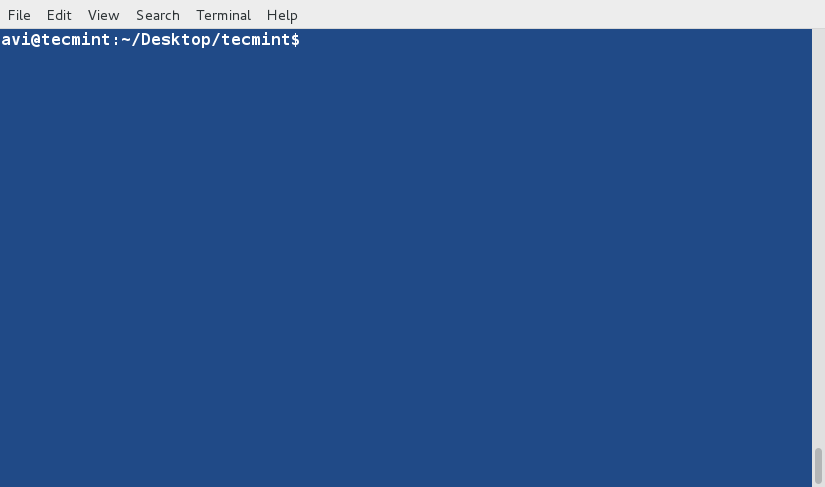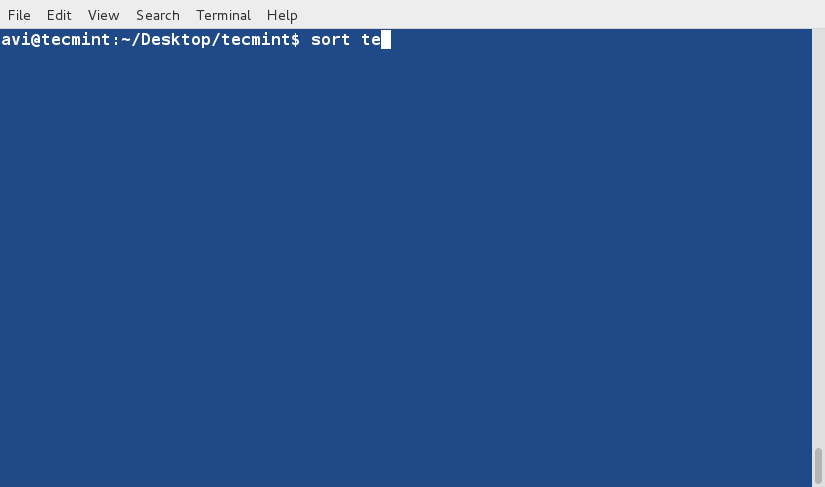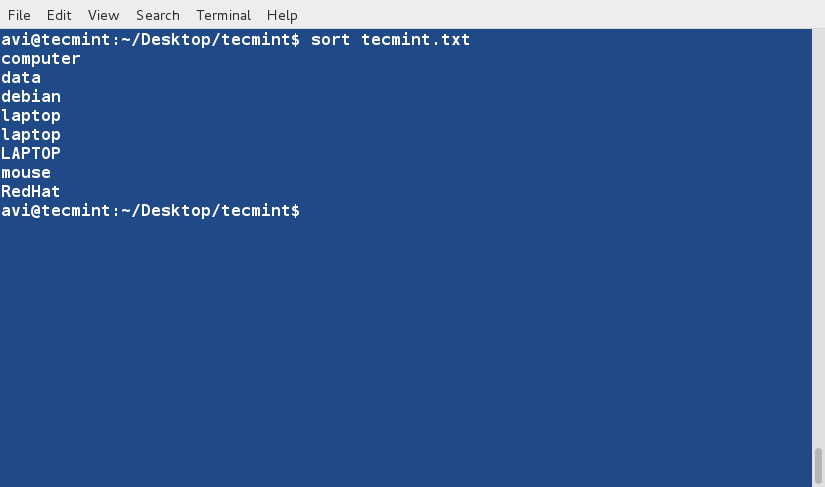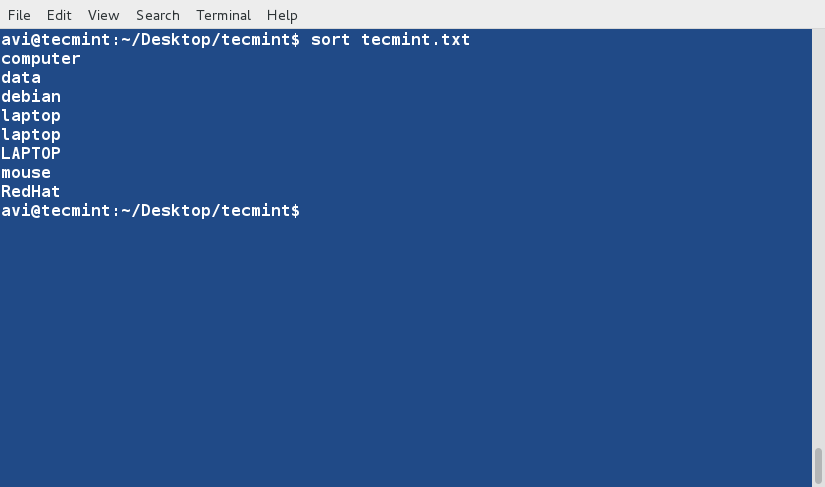
+
+**注意**:上面的命令并不对文件内容进行实际的排序,仅仅是将其内容按有序方式输出。
+
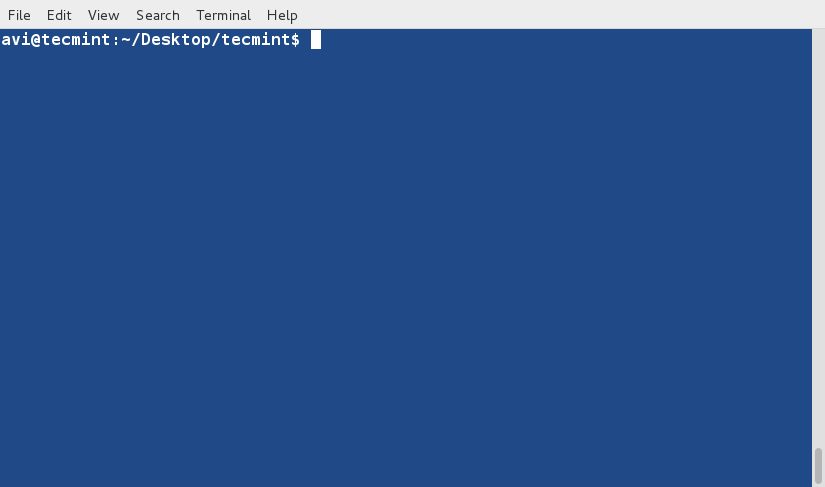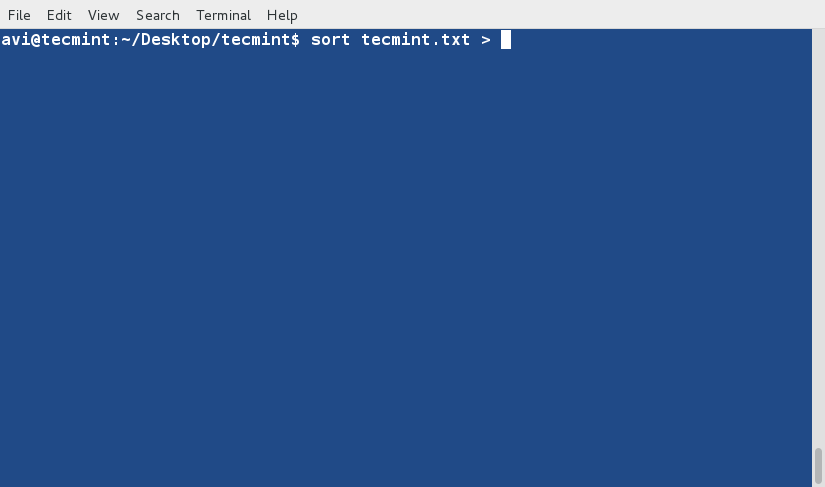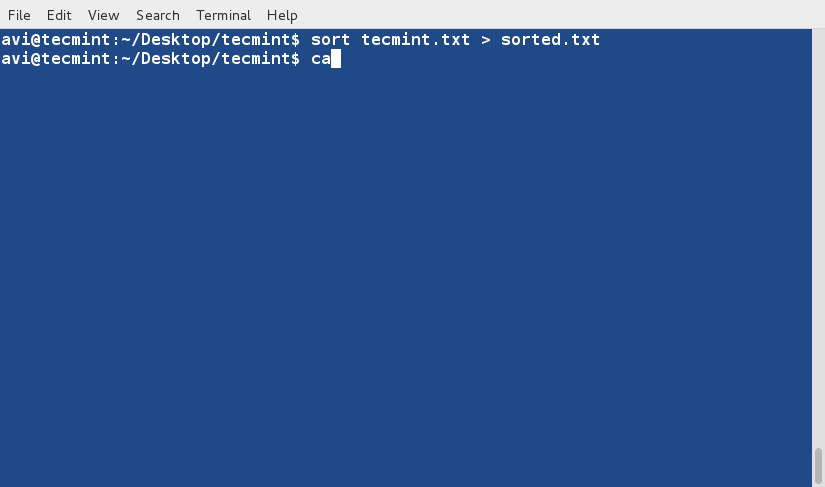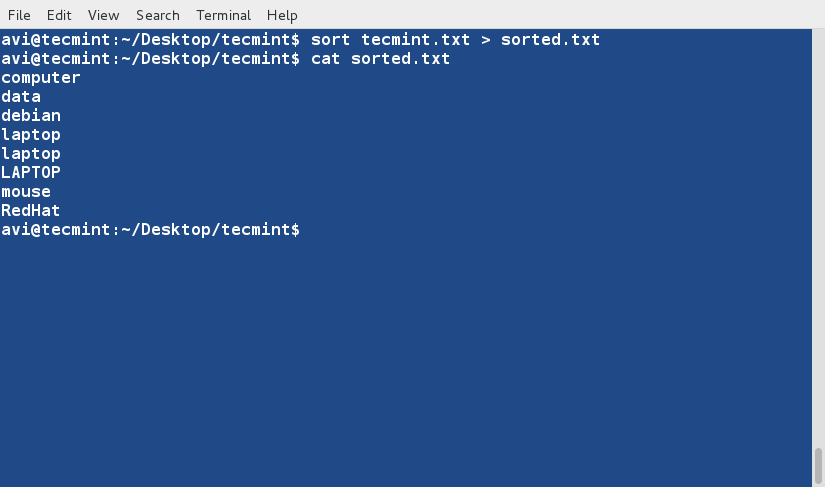
+4、 对文件‘tecmint.txt’文件内容排序,并将排序后的内容输出到名为sorted.txt的文件中,然后使用[cat][1]命令查看验证sorted.txt文件的内容。
+
+ $ sort tecmint.txt > sorted.txt
+ $ cat sorted.txt
+
+
+
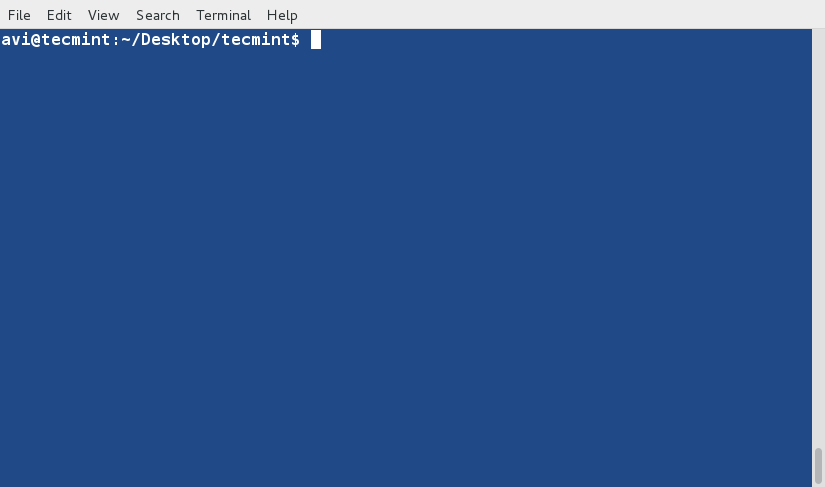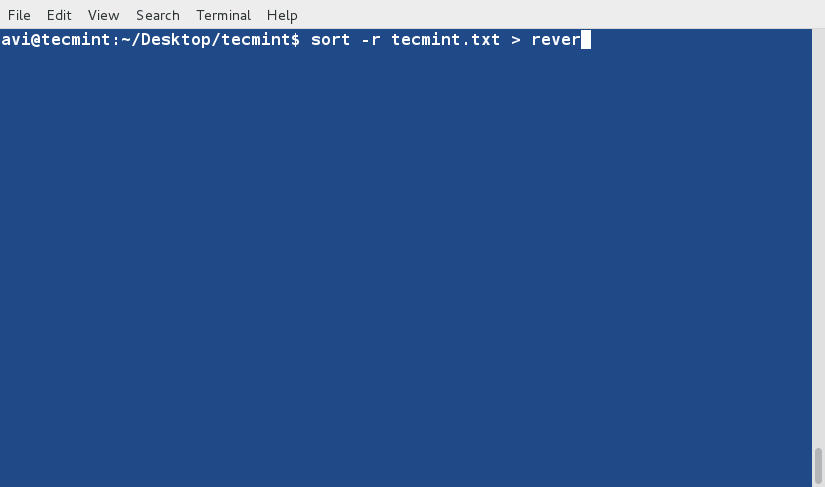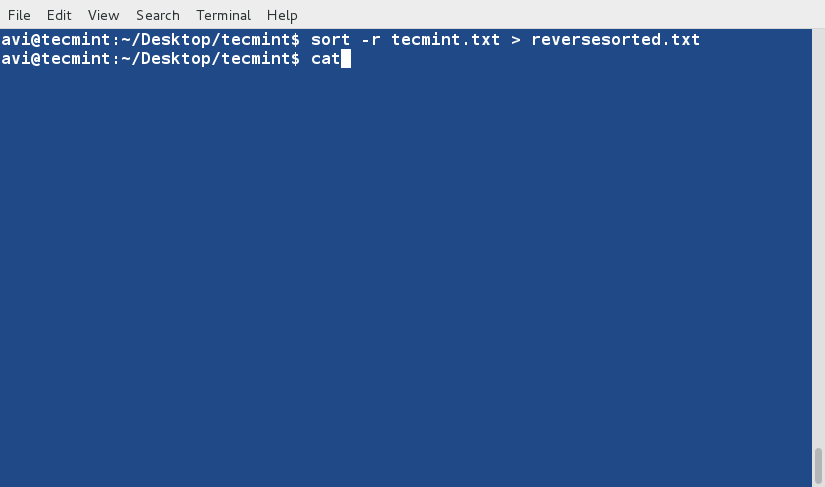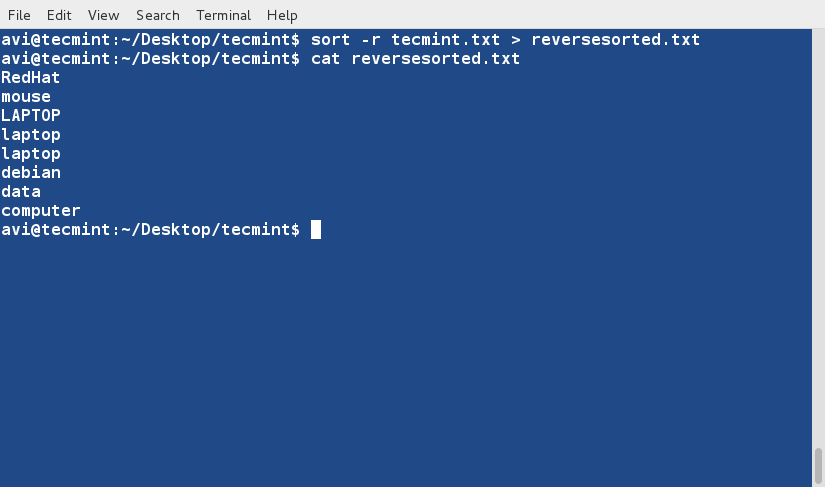
+5、 现在使用‘-r’参数对‘tecmint.txt’文件内容进行逆序排序,并将输出内容重定向到‘reversesorted.txt’文件中,并使用cat命令查看文件的内容。
+
+ $ sort -r tecmint.txt > reversesorted.txt
+ $ cat reversesorted.txt
+
+
+
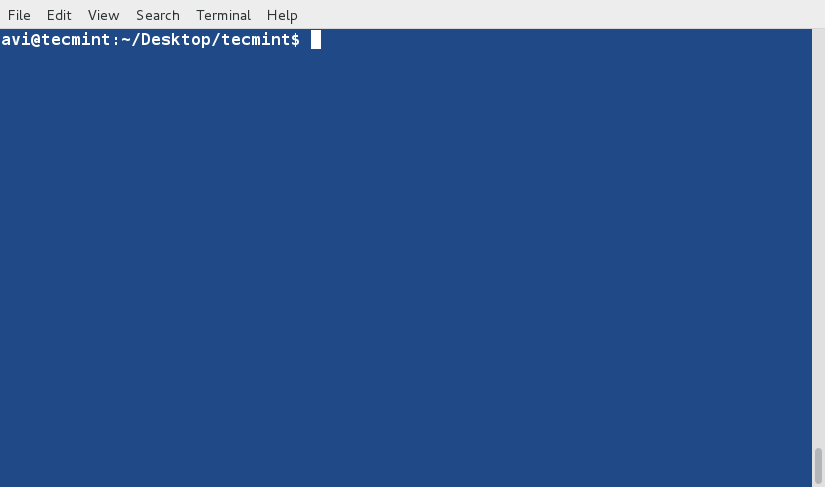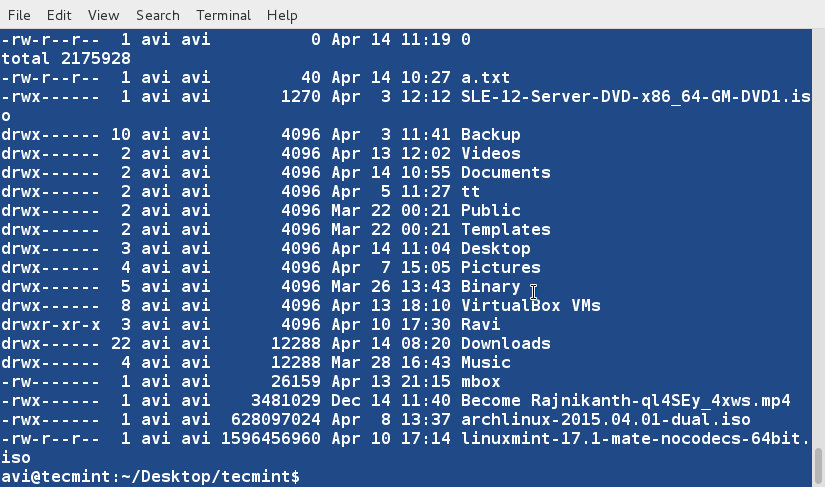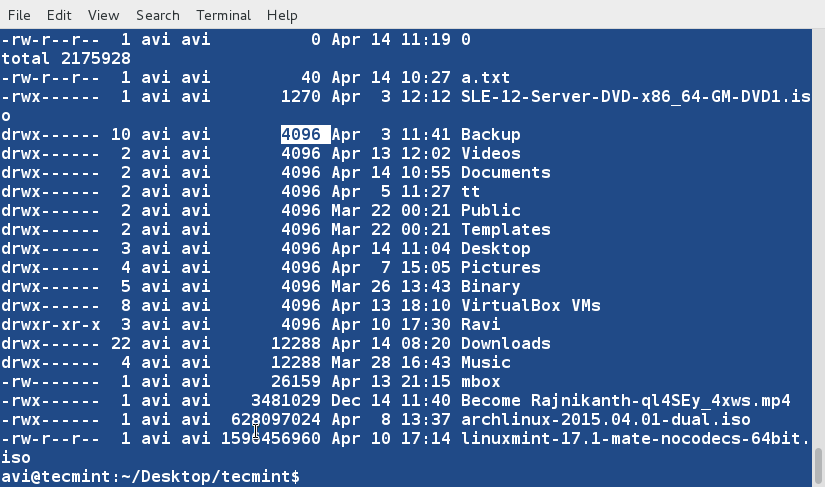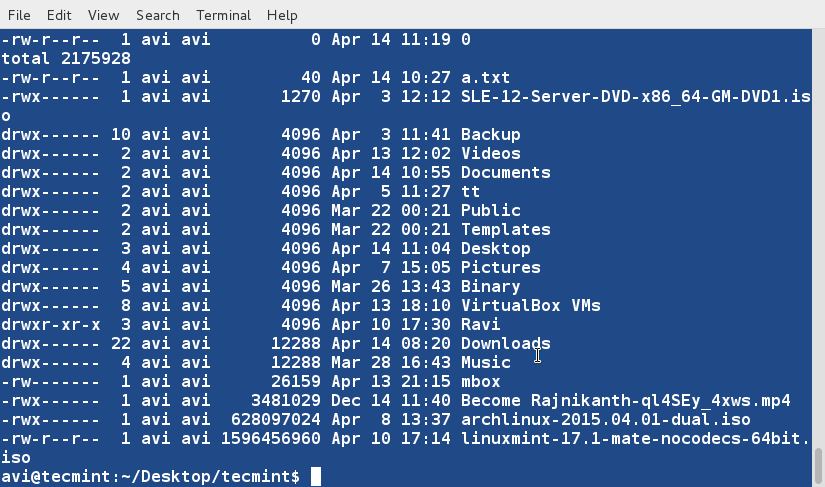
+6、 创建一个新文件(lsl.txt),文件内容为在home目录下执行‘ls -l’命令的输出。
+
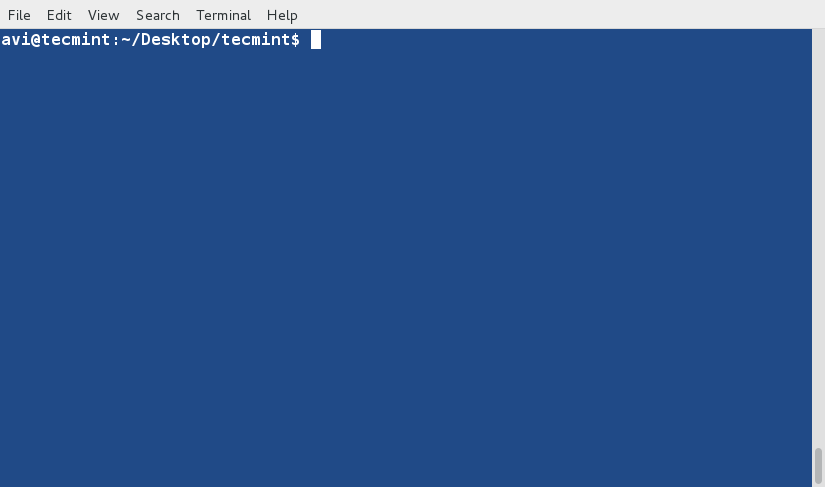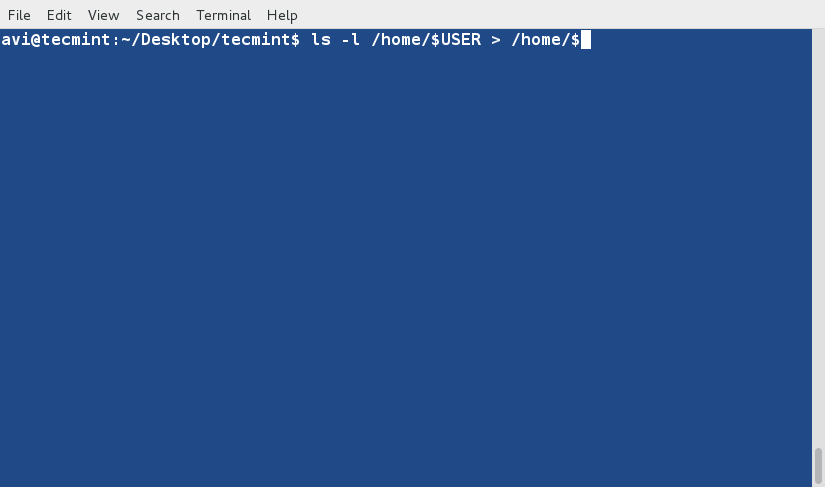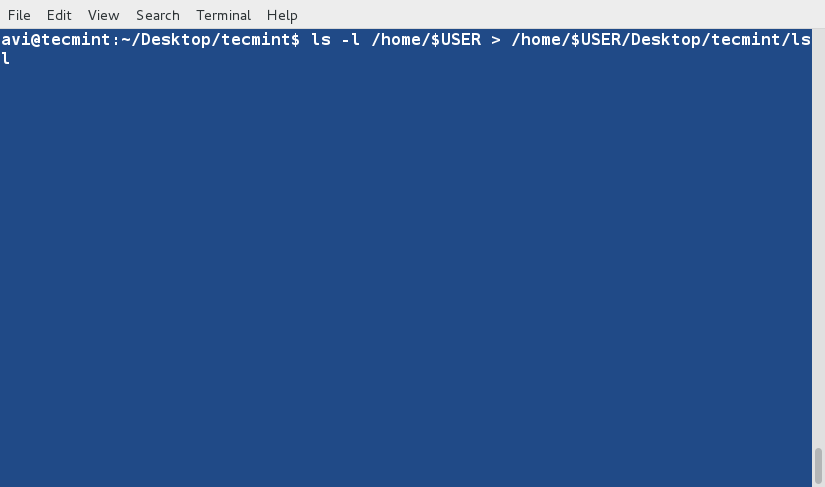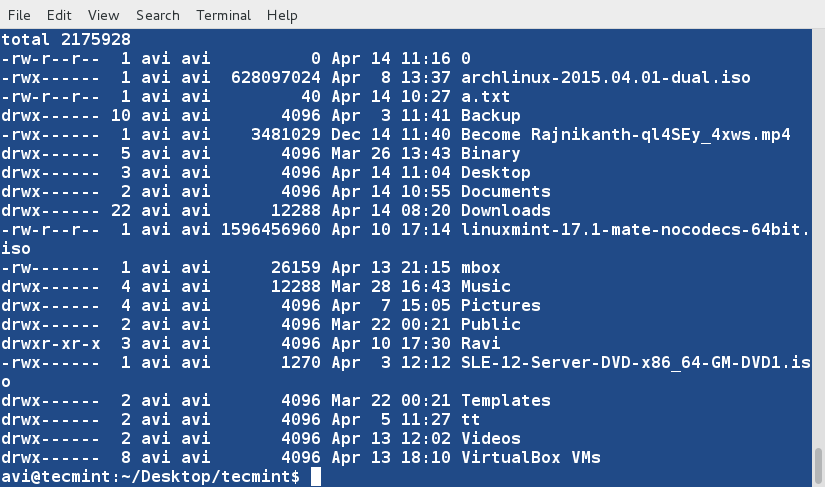
+ $ ls -l /home/$USER > /home/$USER/Desktop/tecmint/lsl.txt
+ $ cat lsl.txt
+
+
+
+我们将会看到对其他字段进行排序的例子,而不是对默认的开始字符进行排序。
+
+7、 基于第二列(符号连接的数量)对文件‘lsl.txt’进行排序。
+
+ $ sort -nk2 lsl.txt
+
+**注意**:上面例子中的‘-n’参数表示对数值内容进行排序。当想基于文件中的数值列对文件进行排序时,必须要使用‘-n’参数。
+
+
+
+8、 基于第9列(文件和目录的名称,非数值)对文件‘lsl.txt’进行排序。
+
+ $ sort -k9 lsl.txt
+
+
+
+9、 sort命令并非仅能对文件进行排序,我们还可以通过管道将命令的输出内容重定向到sort命令中。
+
+ $ ls -l /home/$USER | sort -nk5
+
+
+
+10、 对文件tecmint.txt进行排序,并删除重复的行。然后检查重复的行是否已经删除了。
+
+ $ cat tecmint.txt
+ $ sort -u tecmint.txt
+
+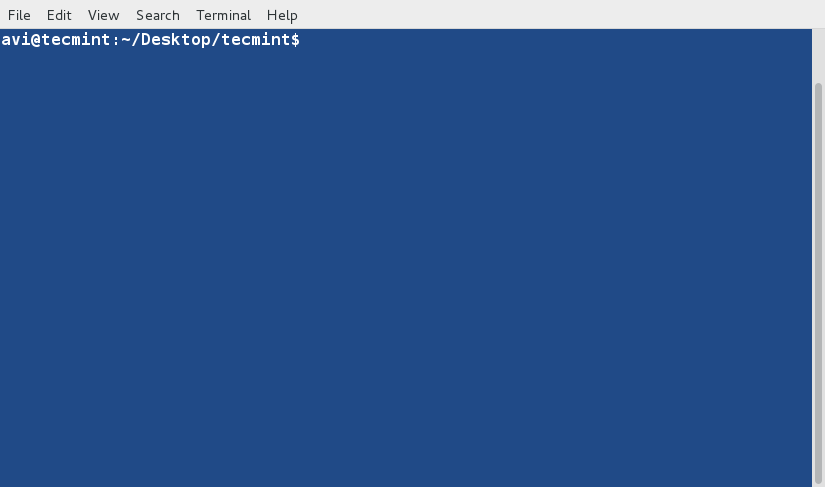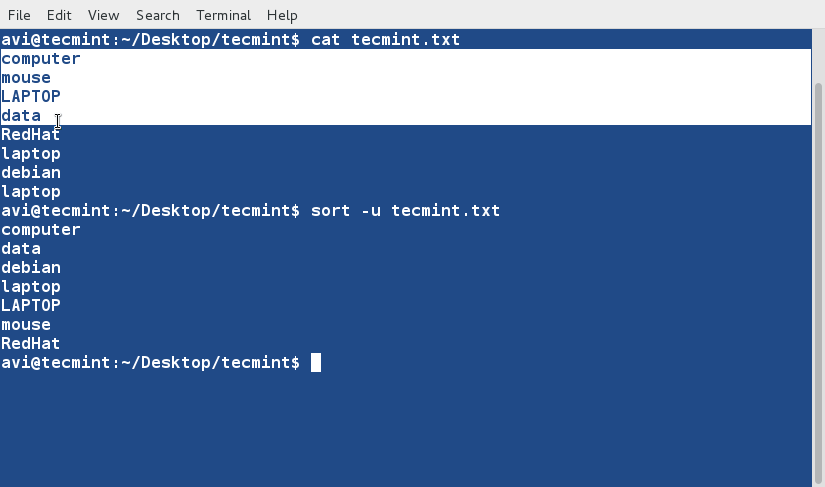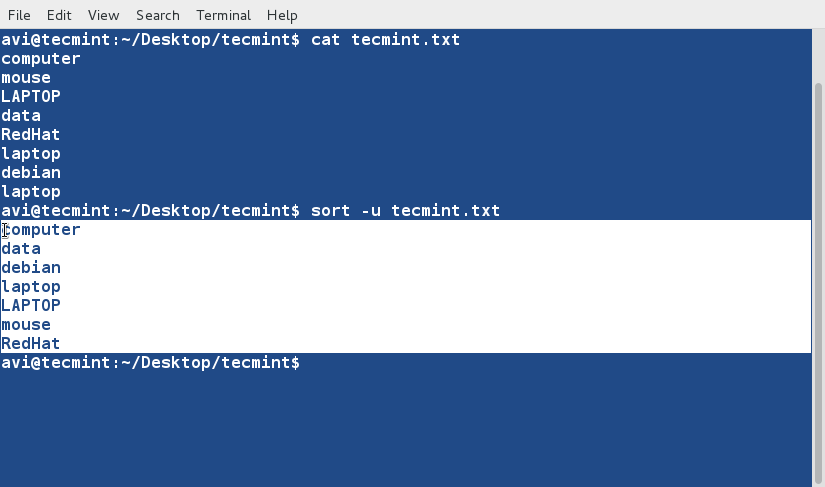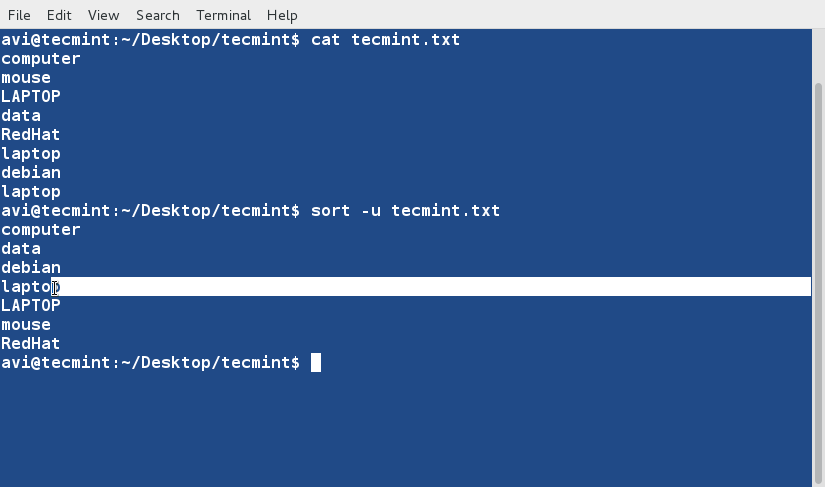
+
+目前我们发现的排序规则:
+
+除非指定了‘-r’参数,否则排序的优先级按下面规则排序
+
+ - 以数字开头的行优先级最高
+ - 以小写字母开头的行优先级次之
+ - 待排序内容按字典序进行排序
+ - 默认情况下,‘sort’命令将带排序内容的每行关键字当作一个字符串进行字典序排序(数字优先级最高,参看规则 1)
+
+11、 在当前位置创建第三个文件‘lsla.txt’,其内容用‘ls -lA’命令的输出内容填充。
+
+ $ ls -lA /home/$USER > /home/$USER/Desktop/tecmint/lsla.txt
+ $ cat lsla.txt
+
+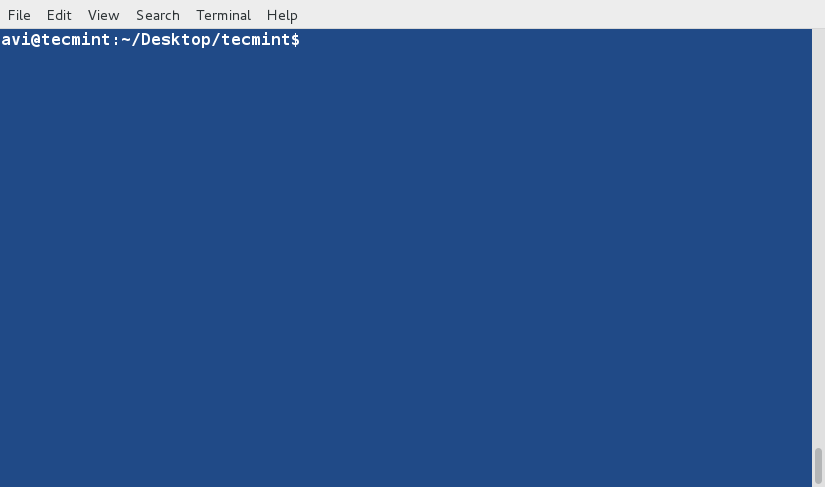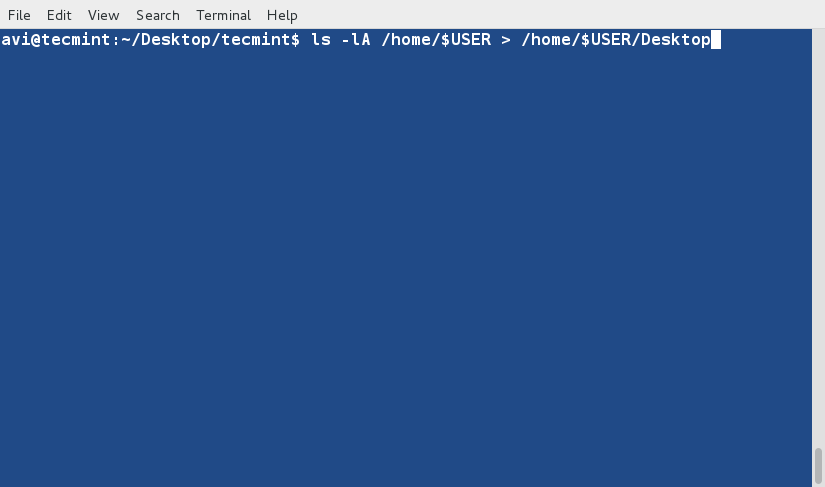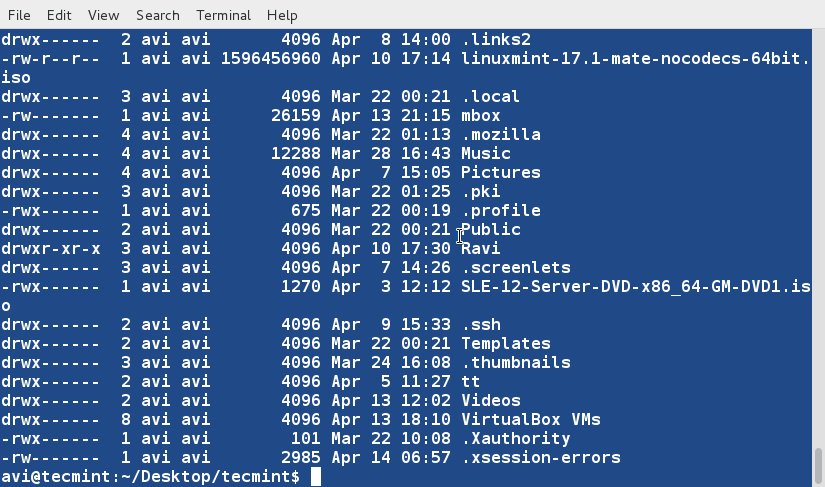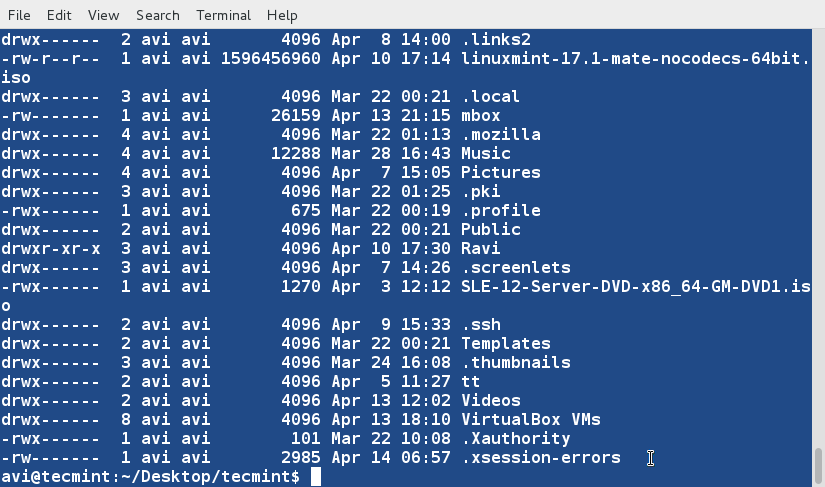
+
+了解ls命令的读者都知道‘ls -lA’ 等于 ‘ls -l’ + 隐藏文件,所以这两个文件的大部分内容都是相同的。
+
+12、 对上面两个文件内容进行排序输出。
+
+ $ sort lsl.txt lsla.txt
+
+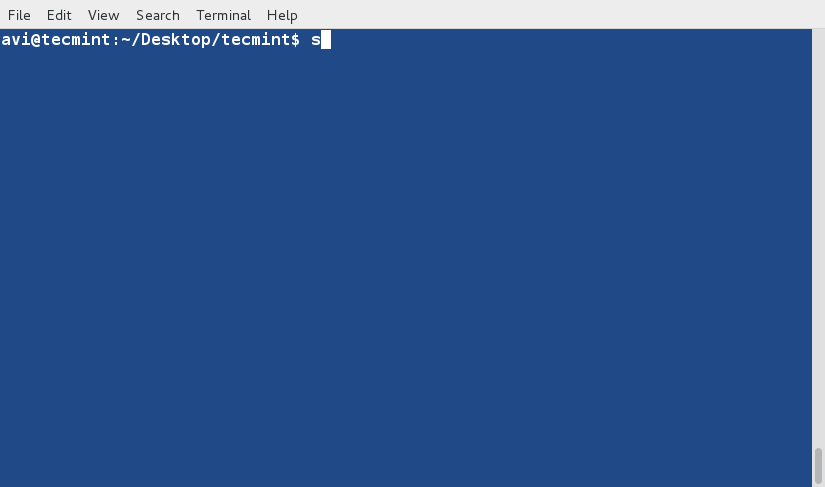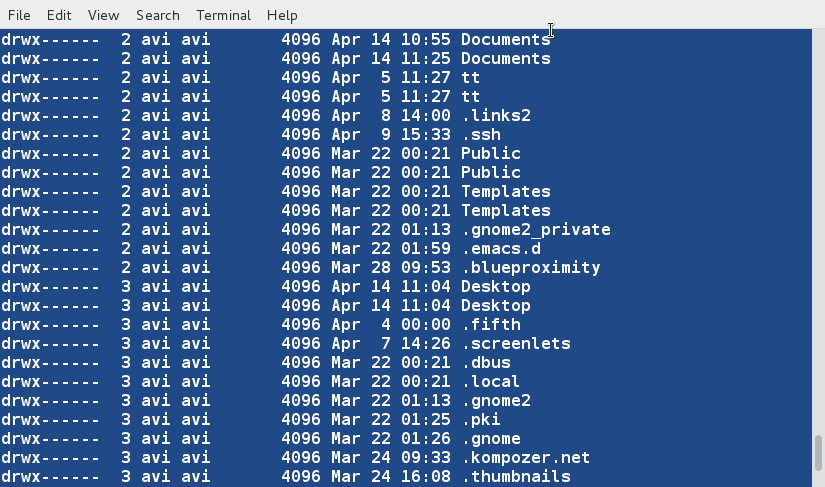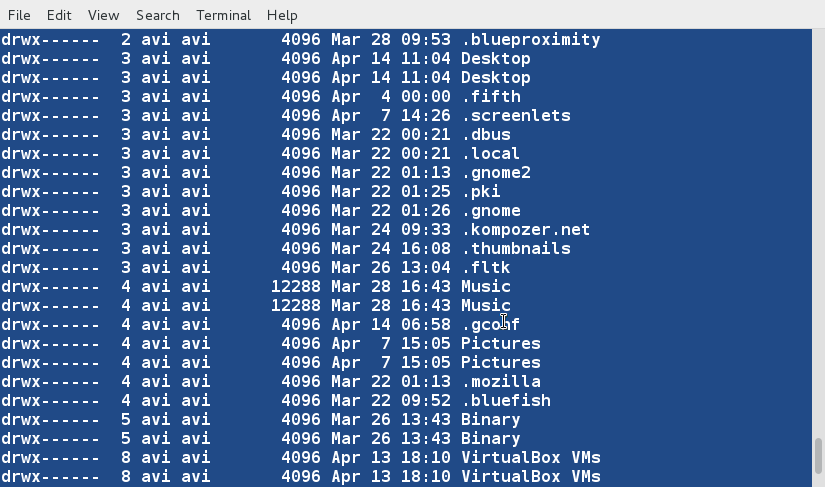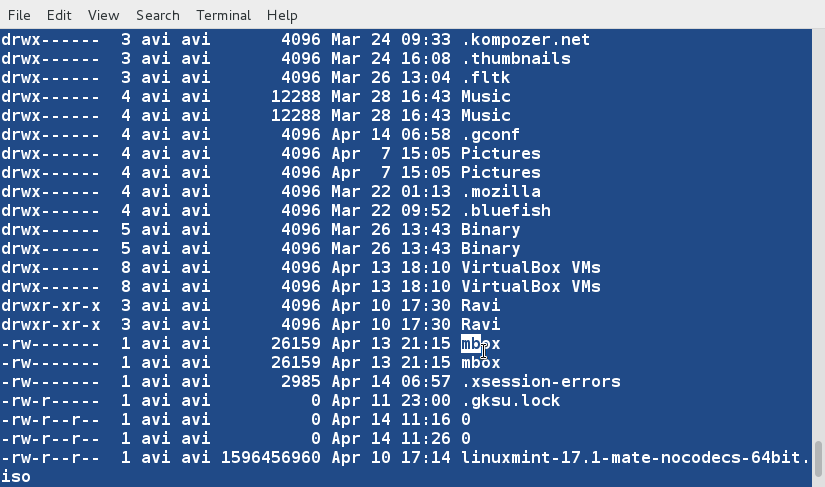
+
+注意文件和目录的重复
+
+13、 现在我们看看怎样对两个文件进行排序、合并,并且删除重复行。
+
+ $ sort -u lsl.txt lsla.txt
+
+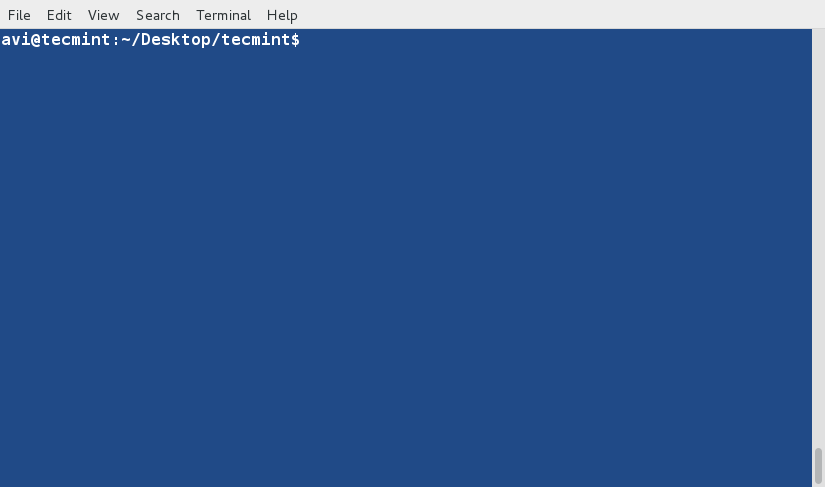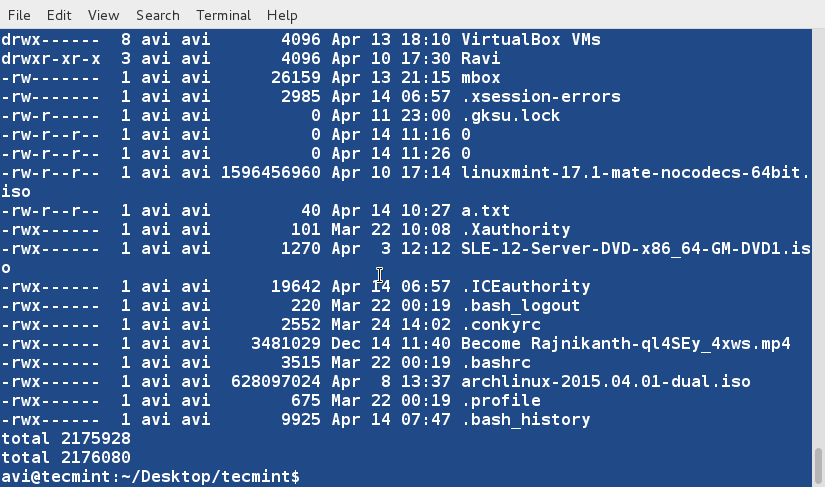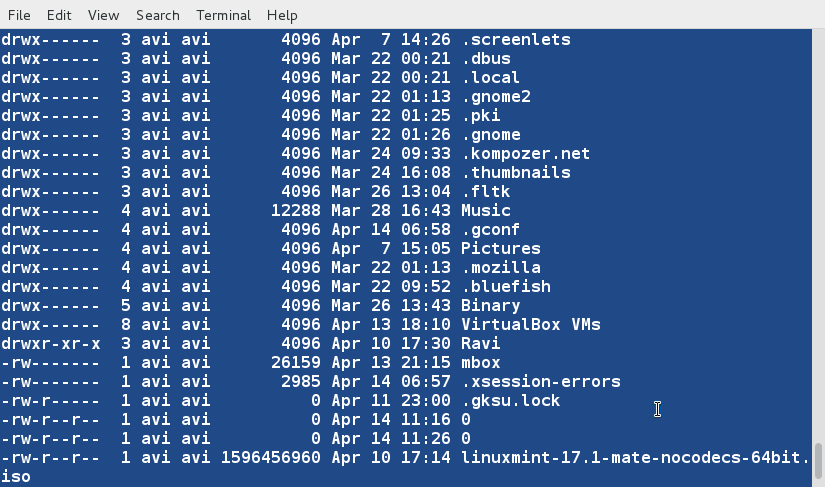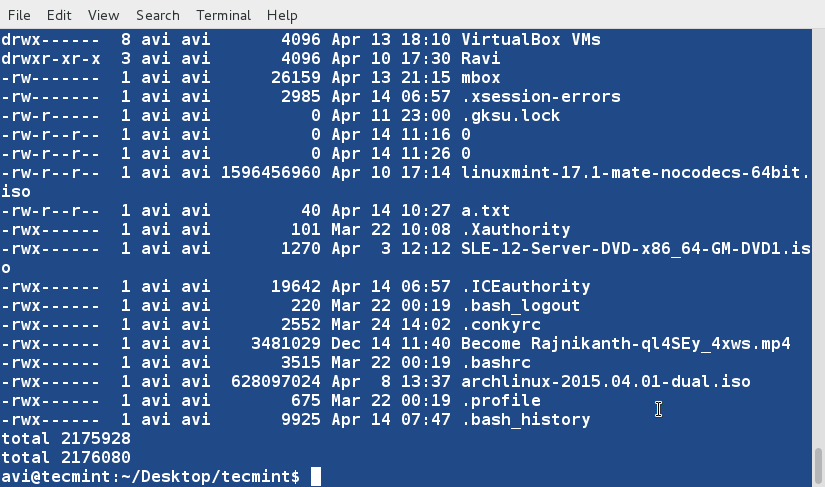
+
+此时,我们注意到重复的行已经被删除了,我们可以将输出内容重定向到文件中。
+
+14、 我们同样可以基于多列对文件内容进行排序。基于第2,5(数值)和9(非数值)列对‘ls -l’命令的输出进行排序。
+
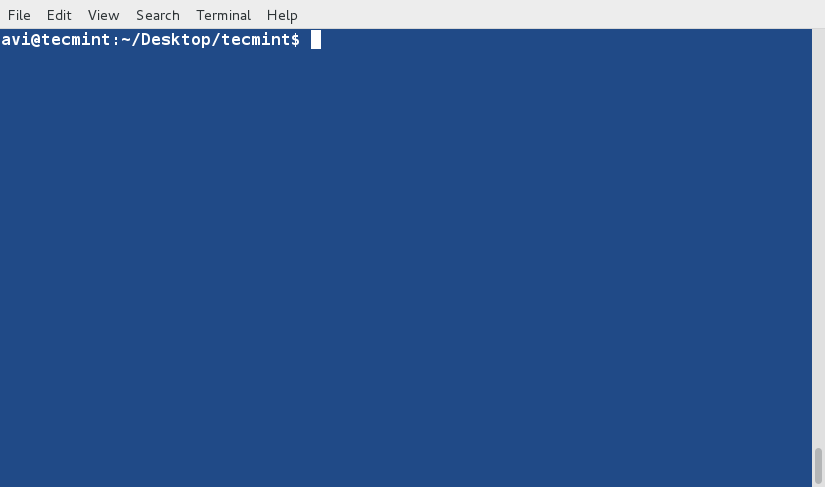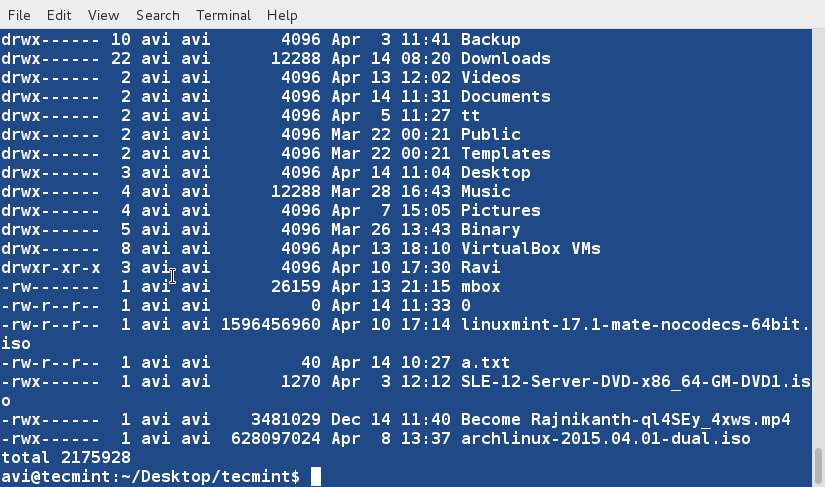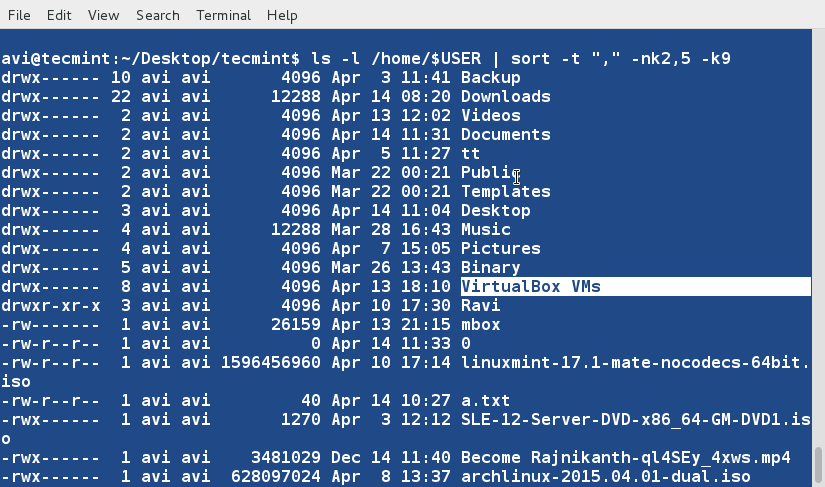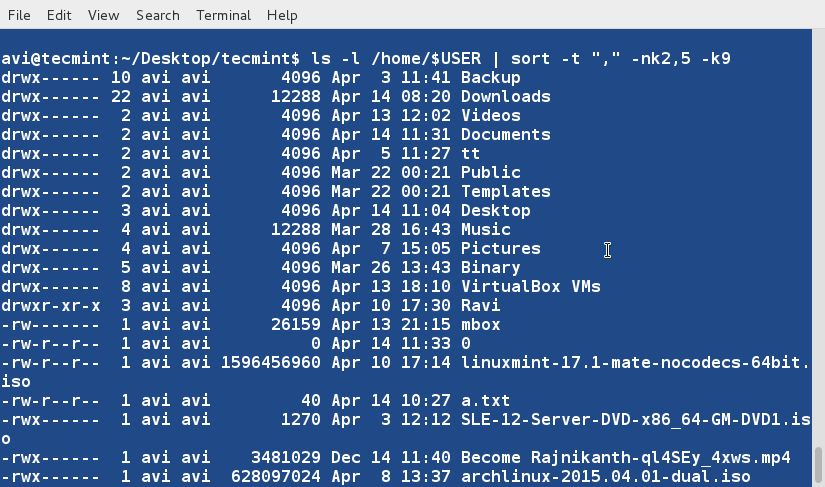
+ $ ls -l /home/$USER | sort -t "," -nk2,5 -k9
+
+
+
+先到此为止了,在接下来的文章中我们将会学习到‘sort’命令更多的详细例子。届时敬请关注我们。保持分享精神。若喜欢本文,敬请将本文分享给你的朋友。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/sort-command-linux/
+
+作者:[Avishek Kumar][a]
+译者:[cvsher](https://github.com/cvsher)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
diff --git a/published/201505/20150417 How to Configure MariaDB Replication on CentOS Linux.md b/published/201505/20150417 How to Configure MariaDB Replication on CentOS Linux.md
new file mode 100644
index 0000000000..702d3d7521
--- /dev/null
+++ b/published/201505/20150417 How to Configure MariaDB Replication on CentOS Linux.md
@@ -0,0 +1,363 @@
+如何在 CentOS Linux 中配置 MariaDB 复制
+================================================================================
+这是一个创建数据库重复版本的过程。复制过程不仅仅是复制一个数据库,同时也包括从主节点到一个从节点的更改同步。但这并不意味着从数据库就是和主数据库完全相同的副本,因为复制可以配置为只复制表结构、行或者列,这叫做局部复制。复制保证了特定的配置对象在不同的数据库之间保持一致。
+
+### Mariadb 复制概念 ###
+
+**备份** :复制可以用来进行数据库备份。例如,当你做了主->从复制。如果主节点数据丢失(比如硬盘损坏),你可以从从节点中恢复你的数据库。
+
+**扩展** :你可以使用主->从复制作为扩展解决方案。例如,如果你有一些大的数据库以及SQL查询,使用复制你可以将这些查询分离到每个复制节点。写入操作的SQL应该只在主节点进行,而只读查询可以在从节点上进行。
+
+**分发解决方案** :你可以用复制来进行分发。例如,你可以将不同的销售数据分发到不同的数据库。
+
+**故障解决方案** : 假如你建立有主节点->从节点1->从节点2->从节点3的复制结构。你可以为主节点写脚本监控,如果主节点出故障了,脚本可以快速的将从节点1切换为新的主节点,这样复制结构变成了主节点->从节点1->从节点2,你的应用可以继续工作而不会停机。
+
+### 复制的简单图解示范 ###
+
+
+
+开始之前,你应该知道什么是**二进制日志文件**以及 Ibdata1。
+
+二进制日志文件中包括关于数据库,数据和结构的所有更改的记录,以及每条语句的执行了多长时间。二进制日志文件包括一系列日志文件和一个索引文件。这意味着主要的SQL语句,例如CREATE, ALTER, INSERT, UPDATE 和 DELETE 会放到这个日志文件中;而例如SELECT这样的语句就不会被记录,它们可以被记录到普通的query.log文件中。
+
+而 **Ibdata1** 简单的说据是一个包括所有表和所有数据库信息的文件。
+
+### 主服务器配置 ###
+
+首先升级服务器
+
+ sudo yum install update -y && sudo yum install upgrade -y
+
+我们工作在centos7 服务器上
+
+ sudo cat /etc/redhat-release
+
+ CentOS Linux release 7.0.1406 (Core)
+
+安装 MariaDB
+
+ sudo yum install mariadb-server -y
+
+启动 MariaDB 并启用随服务器启动
+
+ sudo systemctl start mariadb.service
+ sudo systemctl enable mariadb.service
+
+输出如下:
+
+ ln -s '/usr/lib/systemd/system/mariadb.service' '/etc/systemd/system/multi-user.target.wants/mariadb.service'
+
+检查 MariaDB 状态
+
+ sudo service mariadb status
+
+或者使用
+
+ sudo systemctl is-active mariadb.service
+
+输出如下:
+
+ Redirecting to /bin/systemctl status mariadb.service
+ mariadb.service - MariaDB database server
+ Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled)
+
+设置 MariaDB 密码
+
+ mysql -u root
+ mysql> use mysql;
+ mysql> update user set password=PASSWORD("SOME_ROOT_PASSWORD") where User='root';
+ mysql> flush privileges;
+ mysql> exit
+
+这里 SOME_ROOT_PASSWORD 是你的 root 密码。 例如我用"q"作为密码,然后尝试登录:
+
+ sudo mysql -u root -pSOME_ROOT_PASSWORD
+
+输出如下:
+
+ Welcome to the MariaDB monitor. Commands end with ; or \g.
+ Your MariaDB connection id is 5
+ Server version: 5.5.41-MariaDB MariaDB Server
+ Copyright (c) 2000, 2014, Oracle, MariaDB Corporation Ab and others.
+
+输入 'help;' 或 '\h' 查看帮助信息。 输入 '\c' 清空当前输入语句。
+
+让我们创建包括一些数据的表的数据库
+
+创建数据库/模式
+
+ sudo mysql -u root -pSOME_ROOT_PASSWORD
+ mysql> create database test_repl;
+
+其中:
+
+ test_repl - 将要被复制的模式的名字
+
+输出:如下
+
+ Query OK, 1 row affected (0.00 sec)
+
+创建 Persons 表
+
+ mysql> use test_repl;
+
+ CREATE TABLE Persons (
+ PersonID int,
+ LastName varchar(255),
+ FirstName varchar(255),
+ Address varchar(255),
+ City varchar(255)
+ );
+
+输出如下:
+
+ mysql> MariaDB [test_repl]> CREATE TABLE Persons (
+ -> PersonID int,
+ -> LastName varchar(255),
+ -> FirstName varchar(255),
+ -> Address varchar(255),
+ -> City varchar(255)
+ -> );
+ Query OK, 0 rows affected (0.01 sec)
+
+插入一些数据
+
+ mysql> INSERT INTO Persons VALUES (1, "LastName1", "FirstName1", "Address1", "City1");
+ mysql> INSERT INTO Persons VALUES (2, "LastName2", "FirstName2", "Address2", "City2");
+ mysql> INSERT INTO Persons VALUES (3, "LastName3", "FirstName3", "Address3", "City3");
+ mysql> INSERT INTO Persons VALUES (4, "LastName4", "FirstName4", "Address4", "City4");
+ mysql> INSERT INTO Persons VALUES (5, "LastName5", "FirstName5", "Address5", "City5");
+
+输出如下:
+
+ Query OK, 5 row affected (0.00 sec)
+
+检查数据
+
+ mysql> select * from Persons;
+
+输出如下:
+
+ +----------+-----------+------------+----------+-------+
+ | PersonID | LastName | FirstName | Address | City |
+ +----------+-----------+------------+----------+-------+
+ | 1 | LastName1 | FirstName1 | Address1 | City1 |
+ | 1 | LastName1 | FirstName1 | Address1 | City1 |
+ | 2 | LastName2 | FirstName2 | Address2 | City2 |
+ | 3 | LastName3 | FirstName3 | Address3 | City3 |
+ | 4 | LastName4 | FirstName4 | Address4 | City4 |
+ | 5 | LastName5 | FirstName5 | Address5 | City5 |
+ +----------+-----------+------------+----------+-------+
+
+### 配置 MariaDB 复制 ###
+
+你需要在主节点服务器上编辑 my.cnf文件来启用二进制日志以及设置服务器id。我会使用vi文本编辑器,但你可以使用任何你喜欢的,例如nano,joe。
+
+ sudo vi /etc/my.cnf
+
+将下面的一些行写到[mysqld]部分。
+
+
+ log-basename=master
+ log-bin
+ binlog-format=row
+ server_id=1
+
+输出如下:
+
+
+
+然后重启 MariaDB:
+
+ sudo service mariadb restart
+
+登录到 MariaDB 并查看二进制日志文件:
+
+sudo mysql -u root -pq test_repl
+
+mysql> SHOW MASTER STATUS;
+
+输出如下:
+
+ +--------------------+----------+--------------+------------------+
+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+ +--------------------+----------+--------------+------------------+
+ | mariadb-bin.000002 | 3913 | | |
+ +--------------------+----------+--------------+------------------+
+
+**记住** : "File" 和 "Position" 的值。在从节点中你需要使用这些值
+
+创建用来复制的用户
+
+ mysql> GRANT REPLICATION SLAVE ON *.* TO replication_user IDENTIFIED BY 'bigs3cret' WITH GRANT OPTION;
+ mysql> flush privileges;
+
+输出如下:
+
+ Query OK, 0 rows affected (0.00 sec)
+ Query OK, 0 rows affected (0.00 sec)
+
+在数据库中检查用户
+
+ mysql> select * from mysql.user WHERE user="replication_user"\G;
+
+输出如下:
+
+ mysql> select * from mysql.user WHERE user="replication_user"\G;
+ *************************** 1. row ***************************
+ Host: %
+ User: replication_user
+ Password: *2AF30E7AEE9BF3AF584FB19653881D2D072FA49C
+ Select_priv: N
+ .....
+
+从主节点创建 DB dump (将要被复制的所有数据的快照)
+
+ mysqldump -uroot -pSOME_ROOT_PASSWORD test_repl > full-dump.sql
+
+其中:
+
+ SOME_ROOT_PASSWORD - 你设置的root用户的密码
+ test_repl - 将要复制的数据库的名称;
+
+你需要在从节点中恢复 mysql dump (full-dump.sql)。重复需要这个。
+
+### 从节点配置 ###
+
+所有这些命令需要在从节点中进行。
+
+假设我们已经更新/升级了包括有最新的MariaDB服务器的 CentOS 7.x,而且你可以用root账号登陆到MariaDB服务器(这在这篇文章的第一部分已经介绍过)
+
+登录到Maria 数据库控制台并创建数据库
+
+ mysql -u root -pSOME_ROOT_PASSWORD;
+ mysql> create database test_repl;
+ mysql> exit;
+
+在从节点恢复主节点的数据
+
+ mysql -u root -pSOME_ROOT_PASSWORD test_repl < full-dump.sql
+
+其中:
+
+full-dump.sql - 你在测试服务器中创建的DB Dump。
+
+登录到Maria 数据库并启用复制
+
+ mysql> CHANGE MASTER TO
+ MASTER_HOST='82.196.5.39',
+ MASTER_USER='replication_user',
+ MASTER_PASSWORD='bigs3cret',
+ MASTER_PORT=3306,
+ MASTER_LOG_FILE='mariadb-bin.000002',
+ MASTER_LOG_POS=3913,
+ MASTER_CONNECT_RETRY=10;
+
+
+
+其中:
+
+ MASTER_HOST - 主节点服务器的IP
+ MASTER_USER - 主节点服务器中的复制用户
+ MASTER_PASSWORD - 复制用户密码
+ MASTER_PORT - 主节点中的mysql端口
+ MASTER_LOG_FILE - 主节点中的二进制日志文件名称
+ MASTER_LOG_POS - 主节点中的二进制日志文件位置
+
+开启从节点模式
+
+ mysql> slave start;
+
+输出如下:
+
+ Query OK, 0 rows affected (0.00 sec)
+
+检查从节点状态
+
+ mysql> show slave status\G;
+
+输出如下:
+
+ *************************** 1. row ***************************
+ Slave_IO_State: Waiting for master to send event
+ Master_Host: 82.196.5.39
+ Master_User: replication_user
+ Master_Port: 3306
+ Connect_Retry: 10
+ Master_Log_File: mariadb-bin.000002
+ Read_Master_Log_Pos: 4175
+ Relay_Log_File: mariadb-relay-bin.000002
+ Relay_Log_Pos: 793
+ Relay_Master_Log_File: mariadb-bin.000002
+ Slave_IO_Running: Yes
+ Slave_SQL_Running: Yes
+ Replicate_Do_DB:
+ Replicate_Ignore_DB:
+ Replicate_Do_Table:
+ Replicate_Ignore_Table:
+ Replicate_Wild_Do_Table:
+ Replicate_Wild_Ignore_Table:
+ Last_Errno: 0
+ Last_Error:
+ Skip_Counter: 0
+ Exec_Master_Log_Pos: 4175
+ Relay_Log_Space: 1089
+ Until_Condition: None
+ Until_Log_File:
+ Until_Log_Pos: 0
+ Master_SSL_Allowed: No
+ Master_SSL_CA_File:
+ Master_SSL_CA_Path:
+ Master_SSL_Cert:
+ Master_SSL_Cipher:
+ Master_SSL_Key:
+ Seconds_Behind_Master: 0
+ Master_SSL_Verify_Server_Cert: No
+ Last_IO_Errno: 0
+ Last_IO_Error:
+ Last_SQL_Errno: 0
+ Last_SQL_Error:
+ Replicate_Ignore_Server_Ids:
+ Master_Server_Id: 1
+ 1 row in set (0.00 sec)
+
+到这里所有步骤都应该没问题,也不应该出现错误。
+
+### 测试复制 ###
+
+在主节点服务器中添加一些条目到数据库
+
+ mysql -u root -pSOME_ROOT_PASSWORD test_repl
+
+ mysql> INSERT INTO Persons VALUES (6, "LastName6", "FirstName6", "Address6", "City6");
+ mysql> INSERT INTO Persons VALUES (7, "LastName7", "FirstName7", "Address7", "City7");
+ mysql> INSERT INTO Persons VALUES (8, "LastName8", "FirstName8", "Address8", "City8");
+
+到从节点服务器中查看复制数据
+
+ mysql -u root -pSOME_ROOT_PASSWORD test_repl
+
+ mysql> select * from Persons;
+
+ +----------+-----------+------------+----------+-------+
+ | PersonID | LastName | FirstName | Address | City |
+ +----------+-----------+------------+----------+-------+
+ ...................
+ | 6 | LastName6 | FirstName6 | Address6 | City6 |
+ | 7 | LastName7 | FirstName7 | Address7 | City7 |
+ | 8 | LastName8 | FirstName8 | Address8 | City8 |
+ +----------+-----------+------------+----------+-------+
+
+你可以看到数据已经被复制到从节点。这意味着复制能正常工作。希望你能喜欢这篇文章。如果你有任何问题请告诉我们。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/how-tos/configure-mariadb-replication-centos-linux/
+
+作者:[Bobbin Zachariah][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bobbin/
\ No newline at end of file
diff --git a/published/201505/20150417 sshuttle--A transparent proxy-based VPN using ssh.md b/published/201505/20150417 sshuttle--A transparent proxy-based VPN using ssh.md
new file mode 100644
index 0000000000..953fd343b8
--- /dev/null
+++ b/published/201505/20150417 sshuttle--A transparent proxy-based VPN using ssh.md
@@ -0,0 +1,92 @@
+sshuttle:一个使用ssh的基于VPN的透明代理
+================================================================================
+sshuttle 允许你通过 ssh 创建一条从你电脑连接到任何远程服务器的 VPN 连接,只要你的服务器支持 python2.3 或则更高的版本。你必须有本机的 root 权限,但是你可以在服务端有普通账户即可。
+
+你可以在一台机器上同时运行多次 sshuttle 来连接到不同的服务器上,这样你就可以同时使用多个 VPN, sshuttle可以转发你子网中所有流量到VPN中。
+
+### 在Ubuntu中安装sshuttle ###
+
+在终端中输入下面的命令
+
+ sudo apt-get install sshuttle
+
+### 使用 sshuttle ###
+
+#### sshuttle 语法 ####
+
+ sshuttle [options...] [-r [username@]sshserver[:port]] [subnets]
+
+#### 选项细节 ####
+
+-r, —remote=[username@]sshserver[:port]
+
+远程主机名和可选的用户名,用于连接远程服务器的ssh端口号。比如example.com、testuser@example.com、testuser@example.com:2222或者example.com:2244。
+
+#### sshuttle 例子 ####
+
+在机器中使用下面的命令:
+
+ sudo sshuttle -r username@sshserver 0.0.0.0/0 -vv
+
+当开始后,sshuttle会创建一个ssh会话到由-r指定的服务器。如果-r被丢了,它会在本地运行客户端和服务端,这个有时会在测试时有用。
+
+连接到远程服务器后,sshuttle会上传它的(python)源码到远程服务器并执行。所以,你就不需要在远程服务器上安装sshuttle,并且客户端和服务器端间不会存在sshuttle版本冲突。
+
+#### 手册中的更多例子 ####
+
+代理所有的本地连接用于本地测试,没有使用ssh:
+
+ $ sudo sshuttle -v 0/0
+
+ Starting sshuttle proxy.
+ Listening on (‘0.0.0.0′, 12300).
+ [local sudo] Password:
+ firewall manager ready.
+ c : connecting to server...
+ s: available routes:
+ s: 192.168.42.0/24
+ c : connected.
+ firewall manager: starting transproxy.
+ c : Accept: ‘192.168.42.106':50035 -> ‘192.168.42.121':139.
+ c : Accept: ‘192.168.42.121':47523 -> ‘77.141.99.22':443.
+ ...etc...
+ ^C
+ firewall manager: undoing changes.
+ KeyboardInterrupt
+ c : Keyboard interrupt: exiting.
+ c : SW#8:192.168.42.121:47523: deleting
+ c : SW#6:192.168.42.106:50035: deleting
+
+测试到远程服务器上的连接,自动猜测主机名和子网:
+
+ $ sudo sshuttle -vNHr example.org
+
+ Starting sshuttle proxy.
+ Listening on (‘0.0.0.0′, 12300).
+ firewall manager ready.
+ c : connecting to server...
+ s: available routes:
+ s: 77.141.99.0/24
+ c : connected.
+ c : seed_hosts: []
+ firewall manager: starting transproxy.
+ hostwatch: Found: testbox1: 1.2.3.4
+ hostwatch: Found: mytest2: 5.6.7.8
+ hostwatch: Found: domaincontroller: 99.1.2.3
+ c : Accept: ‘192.168.42.121':60554 -> ‘77.141.99.22':22.
+ ^C
+ firewall manager: undoing changes.
+ c : Keyboard interrupt: exiting.
+ c : SW#6:192.168.42.121:60554: deleting
+
+--------------------------------------------------------------------------------
+
+via: http://www.ubuntugeek.com/sshuttle-a-transparent-proxy-based-vpn-using-ssh.html
+
+作者:[ruchi][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.ubuntugeek.com/author/ubuntufix
diff --git a/published/201505/20150420 7 Interesting Linux 'sort' Command Examples--Part 2.md b/published/201505/20150420 7 Interesting Linux 'sort' Command Examples--Part 2.md
new file mode 100644
index 0000000000..476274b495
--- /dev/null
+++ b/published/201505/20150420 7 Interesting Linux 'sort' Command Examples--Part 2.md
@@ -0,0 +1,134 @@
+Linux 的 'sort'命令的七个有趣实例(二)
+================================================================================
+
+在[上一篇文章][1]里,我们已经探讨了关于sort命令的多个例子,如果你错过了这篇文章,可以点击下面的链接进行阅读。今天的这篇文章作为上一篇文章的继续,将讨论关于sort命令的剩余用法,与上一篇一起作为Linux ‘sort’命令的完整指南。
+
+- [Linux 的 ‘sort’命令的14个有用的范例(一)][1]
+
+在我们继续深入之前,先创建一个文本文档‘month.txt’,并且将上一次给出的数据填进去。
+
+ $ echo -e "mar\ndec\noct\nsep\nfeb\naug" > month.txt
+ $ cat month.txt
+
+
+
+15、 通过使用’M‘选项,对’month.txt‘文件按照月份顺序进行排序。
+
+ $ sort -M month.txt
+
+**注意**:‘sort’命令需要至少3个字符来确认月份名称。
+
+
+
+16、 把数据整理成方便人们阅读的形式,比如1K、2M、3G、2T,这里面的K、G、M、T代表千、兆、吉、梯。
+(LCTT 译注:此处命令有误,ls 命令应该增加 -h 参数,径改之)
+
+ $ ls -lh /home/$USER | sort -h -k5
+
+
+
+17、 在上一篇文章中,我们在例子4中创建了一个名为‘sorted.txt’的文件,在例子6中创建了一个‘lsl.txt’。‘sorted.txt'已经排好序了而’lsl.txt‘还没有。让我们使用sort命令来检查两个文件是否已经排好序。
+
+ $ sort -c sorted.txt
+
+
+
+如果它返回0,则表示文件已经排好序。
+
+ $ sort -c lsl.txt
+
+
+
+报告无序。存在矛盾……
+
+18、 如果文字之间的分隔符是空格,sort命令自动地将空格后的东西当做一个新文字单元,如果分隔符不是空格呢?
+
+考虑这样一个文本文件,里面的内容可以由除了空格之外的任何符号分隔,比如‘|’,‘\’,‘+’,‘.’等……
+
+创建一个分隔符为+的文本文件。使用‘cat‘命令查看文件内容。
+
+ $ echo -e "21+linux+server+production\n11+debian+RedHat+CentOS\n131+Apache+Mysql+PHP\n7+Shell Scripting+python+perl\n111+postfix+exim+sendmail" > delimiter.txt
+
+----------
+
+ $ cat delimiter.txt
+
+
+
+现在基于由数字组成的第一个域来进行排序。
+
+ $ sort -t '+' -nk1 delimiter.txt
+
+
+
+然后再基于非数字的第四个域排序。
+
+
+
+如果分隔符是制表符,你需要在’+‘的位置上用$’\t’代替,如上例所示。
+
+19、 对主用户目录下使用‘ls -l’命令得到的结果基于第五列(‘文件大小’)进行一个乱序排列。
+
+ $ ls -l /home/avi/ | sort -k5 -R
+
+
+
+每一次你运行上面的脚本,你得到结果可能都不一样,因为结果是随机生成的。
+
+正如我在上一篇文章中提到的规则2所说——sort命令会将以小写字母开始的行排在大写字母开始的行前面。看一下上一篇文章的例3,字符串‘laptop’在‘LAPTOP’前出现。
+
+20、 如何覆盖默认的排序优先权?在这之前我们需要先将环境变量LC_ALL的值设置为C。在命令行提示栏中运行下面的代码。
+
+ $ export LC_ALL=C
+
+然后以非默认优先权的方式对‘tecmint.txt’文件重新排序。
+
+ $ sort tecmint.txt
+
+
+
+*覆盖排序优先权*
+
+不要忘记与example 3中得到的输出结果做比较,并且你可以使用‘-f’,又叫‘-ignore-case’(忽略大小写)的选项来获取更有序的输出。
+
+ $ sort -f tecmint.txt
+
+
+
+21、 给两个输入文件进行‘sort‘,然后把它们连接成一行!
+
+我们创建两个文本文档’file1.txt‘以及’file2.txt‘,并用数据填充,如下所示,并用’cat‘命令查看文件的内容。
+
+ $ echo -e “5 Reliable\n2 Fast\n3 Secure\n1 open-source\n4 customizable” > file1.txt
+ $ cat file1.txt
+
+
+
+用如下数据填充’file2.txt‘。
+
+ $ echo -e “3 RedHat\n1 Debian\n5 Ubuntu\n2 Kali\n4 Fedora” > file2.txt
+ $ cat file2.txt
+
+
+
+现在我们对两个文件进行排序并连接。
+
+ $ join <(sort -n file1.txt) <(sort file2.txt)
+
+
+
+
+我所要讲的全部内容就在这里了,希望与各位保持联系,也希望各位经常来逛逛。有反馈就在下面评论吧。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-sort-command-examples/
+
+作者:[Avishek Kumar][a]
+译者:[DongShuaike](https://github.com/DongShuaike)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/sort-command-linux/
diff --git a/published/201505/20150423 uperTuxKart 0.9 Released--The Best Racing Game on Linux Just Got Even Better.md b/published/201505/20150423 uperTuxKart 0.9 Released--The Best Racing Game on Linux Just Got Even Better.md
new file mode 100644
index 0000000000..70355325b6
--- /dev/null
+++ b/published/201505/20150423 uperTuxKart 0.9 Released--The Best Racing Game on Linux Just Got Even Better.md
@@ -0,0 +1,35 @@
+SuperTuxKart 0.9 已发行 —— Linux 中最好的竞速类游戏越来越棒了!
+================================================================================
+**热门竞速类游戏 SuperTuxKart 的新版本已经[打包发行][1]登陆下载服务器**
+
+
+
+*Super Tux Kart 0.9 发行海报*
+
+SuperTuxKart 0.9 相较前一版本做了巨大的升级,内部运行着刚出炉的新引擎(有个炫酷的名字叫‘Antarctica(南极洲)’),目的是要呈现更加炫酷的图形环境,从阴影到场景的纵深,外加卡丁车更好的物理效果。
+
+突出的图形表现也增加了对显卡的要求。SuperTuxKart 开发人员给玩家的建议是,要有图像处理能力比得上(或者,想要完美的话,要超过) Intel HD Graphics 3000, NVIDIA GeForce 8600 或 AMD Radeon HD 3650 的显卡。
+
+### 其他改变 ###
+
+SuperTuxKart 0.9 中与图像的改善同样吸引人眼球的是一对**全新赛道**,新的卡丁车,新的在线账户可以记录和分享**全新推出的成就系统**里赢得的徽章,以及大量的改装和涂装的微调。
+
+点击播放下面的官方发行视频,看看基于调色器的 STK 0.9 所散发的光辉吧。(youtube 视频:https://www.youtube.com/0FEwDH7XU9Q )
+
+Ubuntu 用户可以从项目网站上下载新发行版已编译的二进制文件。
+
+- [下载 SuperTuxKart 0.9][2]
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/04/supertuxkart-0-9-released
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[H-mudcup](https://github.com/H-mudcup)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:http://supertuxkart.blogspot.co.uk/2015/04/supertuxkart-09-released.html
+[2]:http://supertuxkart.sourceforge.net/Downloads
diff --git a/published/201505/20150429 Docker 1.6 Released--How to Upgrade on Fedora or CentOS.md b/published/201505/20150429 Docker 1.6 Released--How to Upgrade on Fedora or CentOS.md
new file mode 100644
index 0000000000..6b6141211f
--- /dev/null
+++ b/published/201505/20150429 Docker 1.6 Released--How to Upgrade on Fedora or CentOS.md
@@ -0,0 +1,167 @@
+如何在Fedora / CentOS上面升级Docker 1.6
+=============================================================================
+Docker,一个流行的将软件打包的开源容器平台,已经有了新的1.6版,增加了许多新的特性。该版本主要更新了Docker Registry、Engine、 Swarm、 Compose 和 Machine等方面。这次发布旨在提升性能、改善开发者和系统管理员的体验。让我们来快速看看有哪些新特性吧。
+
+**Docker Registry (2.0)**是一项推送Docker镜像用于存储和分享的服务,因为面临加载下的体验问题而经历了架构的改变。它仍然向后兼容。Docker Registry的编写语言现在从Python改为Google的Go语言了,以提升性能。与Docker Engine 1.6结合后,拉取镜像的能力更快了。早先的镜像是队列式输送的,而现在是并行的啦。
+
+**Docker Engine (1.6)**相比之前的版本有很大的提高。目前支持容器与镜像的标签。通过标签,你可以附加用户自定义的元数据到镜像和容器上,而镜像和容器反过来可以被其他工具使用。标签对正在运行的应用是不可见的,可以用来加速搜索容器和镜像。
+
+Windows版本的Docker客户端可以连接到远程的运行在linux上的Docker Engine。
+
+Docker目前支持日志驱动API,这允许我们发送容器日志给系统如Syslog,或者第三方。这将会使得系统管理员受益。
+
+**Swarm (0.2)**是一个Docker集群工具,可以将一个Docker主机池转换为一个虚拟主机。在新特性里,容器甚至被放在了可用的节点上。通过添加更多的Docker命令,努力支持完整的Docker API。将来,使用第三方驱动来集群会成为可能。
+
+**Compose (1.2)** 是一个Docker里定义和运行复杂应用的工具, 也得到了升级。在新版本里,可以创建多个子文件,而不是用一个没有结构的文件描述一个多容器应用。
+
+通过**Machine (0.2)**,我们可以很容易地在本地计算机、云和数据中心上搭建Docker主机。新的发布版本为开发者提供了一个相对干净地驱动界面来编写驱动。Machine集中控制供给,而不是每个独立的驱动。增加了新的命令,可以用来生成主机的TLS证书,以提高安全性。
+
+### 在Fedora / CentOS 上的升级指导 ###
+
+在这一部分里,我们将会学习如何在Fedora和CentOS上升级已有的docker到最新版本。请注意,目前的Docker仅运行在64位的架构上,Fedora和CentOS都源于RedHat,命令的使用是差不多相同的,除了在Fedora20和CentOS6.5里Docker包被叫做“docker-io”。
+
+如果你系统之前没有安装Docker,使用下面命令安装:
+
+ "yum install docker-io" – on Fedora20 / CentOS6.5
+
+ "yum install docker" - on Fedora21 / CentOS7
+
+在升级之前,备份一下docker镜像和容器卷是个不错的主意。
+
+参考[“将文件系统打成 tar 包”][1]与[“卷备份、恢复或迁移”][2],获取更多信息。
+
+目前,测试系统安装了Docker1.5。样例输出显示是来自一个Fedora20的系统。
+
+验证当前系统安装的Docker版本
+
+ [root@TestNode1 ~]#sudo docker -v
+
+ Docker version 1.5.0, build a8a31ef/1.5.0
+
+如果Docker正在运行,先停掉。
+
+ [root@TestNode1 ~]# sudo systemctl stop docker
+
+使用yum update升级到最新版,但是写这篇文章的时候,仓库并不是最新版本(1.6),因此你需要使用二进制的升级方法。
+
+ [root@TestNode1 ~]#sudo yum -y update docker-io
+
+ No packages marked for update
+
+ [root@TestNode1 ~]#sudo wget https://get.docker.com/builds/Linux/x86_64/docker-latest -O /usr/bin/docker
+
+ --2015-04-19 13:40:48-- https://get.docker.com/builds/Linux/x86_64/docker-latest
+
+ Resolving get.docker.com (get.docker.com)... 162.242.195.82
+
+ Connecting to get.docker.com (get.docker.com)|162.242.195.82|:443... connected.
+
+ HTTP request sent, awaiting response... 200 OK
+
+ Length: 15443598 (15M) [binary/octet-stream]
+
+ Saving to: /usr/bin/docker
+
+ 100%[======================================>] 15,443,598 8.72MB/s in 1.7s
+
+ 2015-04-19 13:40:50 (8.72 MB/s) - /usr/bin/docker saved
+
+检查更新后的版本
+
+ [root@TestNode1 ~]#sudo docker -v
+
+ Docker version 1.6.0, build 4749651
+
+重启docker服务
+
+ [root@TestNode1 ~]# sudo systemctl start docker
+
+确认Docker在运行
+
+ [root@TestNode1 ~]# docker images
+
+ REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
+
+ fedora latest 834629358fe2 3 months ago 241.3 MB
+
+ [root@TestNode1 ~]# docker run fedora /bin/echo Hello World
+
+ Hello World
+
+CentOS安装时需要**注意**,在CentOS上安装完Docker后,当你试图启动Docker服务的时候,你可能会得到错误的信息,如下所示:
+
+ docker.service - Docker Application Container Engine
+
+ Loaded: loaded (/usr/lib/systemd/system/docker.service; disabled)
+
+ Active: failed (Result: exit-code) since Mon 2015-04-20 03:24:24 EDT; 6h ago
+
+ Docs: http://docs.docker.com
+
+ Process: 21069 ExecStart=/usr/bin/docker -d $OPTIONS $DOCKER_STORAGE_OPTIONS $DOCKER_NETWORK_OPTIONS $ADD_REGISTRY $BLOCK_REGISTRY $INSECURE_REGISTRY (code=exited, status=127)
+
+ Main PID: 21069 (code=exited, status=127)
+
+ Apr 20 03:24:24 centos7 systemd[1]: Starting Docker Application Container E.....
+
+ Apr 20 03:24:24 centos7 docker[21069]: time="2015-04-20T03:24:24-04:00" lev...)"
+
+ Apr 20 03:24:24 centos7 docker[21069]: time="2015-04-20T03:24:24-04:00" lev...)"
+
+ Apr 20 03:24:24 centos7 docker[21069]: /usr/bin/docker: relocation error: /...ce
+
+ Apr 20 03:24:24 centos7 systemd[1]: docker.service: main process exited, co.../a
+
+ Apr 20 03:24:24 centos7 systemd[1]: Failed to start Docker Application Cont...e.
+
+ Apr 20 03:24:24 centos7 systemd[1]: Unit docker.service entered failed state.
+
+这是一个已知的bug([https://bugzilla.redhat.com/show_bug.cgi?id=1207839][3]),需要将设备映射升级到最新。
+
+ [root@centos7 ~]# rpm -qa device-mapper
+
+ device-mapper-1.02.84-14.el7.x86_64
+
+ [root@centos7 ~]# yum update device-mapper
+
+ [root@centos7 ~]# rpm -qa device-mapper
+
+ device-mapper-1.02.93-3.el7.x86_64
+
+ [root@centos7 ~]# systemctl start docker
+
+### 总结 ###
+
+尽管docker技术出现时间不长,但很快就变得非常流行了。它使得开发者的生活变得轻松,运维团队可以快速独立地创建和部署应用。通过该公司的发布,Docker的快速更新,产品质量的提升,满足用户需求,未来对于Docker来说一片光明。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/docker-1-6-features-upgrade-fedora-centos/
+
+作者:[B N Poornima][a]
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bnpoornima/
+[1]:http://docs.docker.com/reference/commandline/cli/#export
+[2]:http://docs.docker.com/userguide/dockervolumes/#backup-restore-or-migrate-data-volumes
+[3]:https://bugzilla.redhat.com/show_bug.cgi?id=1207839
+[4]:
+[5]:
+[6]:
+[7]:
+[8]:
+[9]:
+[10]:
+[11]:
+[12]:
+[13]:
+[14]:
+[15]:
+[16]:
+[17]:
+[18]:
+[19]:
+[20]:
diff --git a/published/201505/20150429 Synfig Studio 1.0--Open Source Animation Gets Serious.md b/published/201505/20150429 Synfig Studio 1.0--Open Source Animation Gets Serious.md
new file mode 100644
index 0000000000..a216674d9b
--- /dev/null
+++ b/published/201505/20150429 Synfig Studio 1.0--Open Source Animation Gets Serious.md
@@ -0,0 +1,38 @@
+Synfig Studio 1.0:开源动画动真格的了
+================================================================================
+
+
+**现在可以下载 Synfig Studio 这个自由、开源的2D动画软件的全新版本了。 **
+
+在这个跨平台的软件首次发行一年之后,Synfig Studio 1.0 带着一套全新改进过的功能,实现它所承诺的“创造电影级的动画的工业级解决方案”。
+
+在众多功能之上的是一个改进过的用户界面,据项目开发者说那是个用起来‘更简单’、‘更直观’的界面。客户端添加了新的**单窗口模式**,让界面更整洁,而且**使用了最新的 GTK3 库重制**。
+
+在功能方面有几个值得注意的变化,包括新加的全功能骨骼系统。
+
+这套**关节和转轴的‘骨骼’构架**非常适合2D剪纸动画,再配上这个版本新加的复杂的变形控制系统或是 Synfig 受欢迎的‘关键帧自动插入’(即:帧到帧之间的变形)应该会变得非常有效率的。(youtube视频 https://www.youtube.com/M8zW1qCq8ng )
+
+新的无损剪切工具,摩擦力效果和对逐帧位图动画的支持,可能会有助于释放开源动画师们的创造力,更别说新加的用于同步动画的时间线和声音的声效层!
+
+### 下载 Synfig Studio 1.0 ###
+
+Synfig Studio 并不是任何人都能用的工具套件,这最新发行版的最新一批改进应该能吸引一些动画制作者试一试这个软件。
+
+如果你想看看开源动画制作软件是什么样的,你可以通过下面的链接直接从工程的 Sourceforge 页下载一个适用于 Ubuntu 的最新版本的安装器。
+
+- [下载 Synfig 1.0 (64bit) .deb 安装器][1]
+- [下载 Synfig 1.0 (32bit) .deb 安装器][2]
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/04/synfig-studio-new-release-features
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[H-mudcup](https://github.com/H-mudcup)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_amd64.deb/download
+[2]:http://sourceforge.net/projects/synfig/files/releases/1.0/linux/synfigstudio_1.0_x86.deb/download
diff --git a/published/201505/20150429 web caching basics terminology http headers and caching strategies.md b/published/201505/20150429 web caching basics terminology http headers and caching strategies.md
new file mode 100644
index 0000000000..52e4e4e01f
--- /dev/null
+++ b/published/201505/20150429 web caching basics terminology http headers and caching strategies.md
@@ -0,0 +1,181 @@
+Web缓存基础:术语、HTTP报头和缓存策略
+=====================================================================
+
+### 简介
+
+对于您的站点的访问者来说,智能化的内容缓存是提高用户体验最有效的方式之一。缓存,或者对之前的请求的临时存储,是HTTP协议实现中最核心的内容分发策略之一。分发路径中的组件均可以缓存内容来加速后续的请求,这受控于对该内容所声明的缓存策略。
+
+在这份指南中,我们将讨论一些Web内容缓存的基本概念。这主要包括如何选择缓存策略以保证互联网范围内的缓存能够正确的处理您的内容。我们将谈一谈缓存带来的好处、副作用以及不同的策略能带来的性能和灵活性的最大结合。
+
+###什么是缓存(caching)?
+
+缓存(caching)是一个描述存储可重用资源以便加快后续请求的行为的术语。有许多不同类型的缓存,每种都有其自身的特点,应用程序缓存和内存缓存由于其对特定回复的加速,都很常用。
+
+这份指南的主要讲述的Web缓存是一种不同类型的缓存。Web缓存是HTTP协议的一个核心特性,它能最小化网络流量,并且提升用户所感知的整个系统响应速度。内容从服务器到浏览器的传输过程中,每个层面都可以找到缓存的身影。
+
+Web缓存根据特定的规则缓存相应HTTP请求的响应。对于缓存内容的后续请求便可以直接由缓存满足而不是重新发送请求到Web服务器。
+
+###好处
+
+有效的缓存技术不仅可以帮助用户,还可以帮助内容的提供者。缓存对内容分发带来的好处有:
+
+- **减少网络开销**:内容可以在从内容提供者到内容消费者网络路径之间的许多不同的地方被缓存。当内容在距离内容消费者更近的地方被缓存时,由于缓存的存在,请求将不会消耗额外的网络资源。
+- **加快响应速度**:由于并不是必须通过整个网络往返,缓存可以使内容的获得变得更快。缓存放在距用户更近的地方,例如浏览器缓存,使得内容的获取几乎是瞬时的。
+- **在同样的硬件上提高速度**:对于保存原始内容的服务器来说,更多的性能可以通过允许激进的缓存策略从硬件上压榨出来。内容拥有者们可以利用分发路径上某个强大的服务器来应对特定内容负载的冲击。
+- **网络中断时内容依旧可用**:使用某种策略,缓存可以保证在原始服务器变得不可用时,相应的内容对用户依旧可用。
+
+###术语
+
+在面对缓存时,您可能对一些经常遇到的术语可能不太熟悉。一些常见的术语如下:
+
+- **原始服务器**:原始服务器是内容的原始存放地点。如果您是Web服务器管理员,它就是您所管理的机器。它负责为任何不能从缓存中得到的内容进行回复,并且负责设置所有内容的缓存策略。
+- **缓存命中率**:一个缓存的有效性依照缓存的命中率进行度量。它是可以从缓存中得到数据的请求数与所有请求数的比率。缓存命中率高意味着有很高比例的数据可以从缓存中获得。这通常是大多数管理员想要的结果。
+- **新鲜度**:新鲜度用来描述一个缓存中的项目是否依旧适合返回给客户端。缓存中的内容只有在由缓存策略指定的新鲜期内才会被返回。
+- **过期内容**:缓存中根据缓存策略的新鲜期设置已过期的内容。过期的内容被标记为“陈旧”。通常,过期内容不能用于回复客户端的请求。必须重新从原始服务器请求新的内容或者至少验证缓存的内容是否仍然准确。
+- **校验**:缓存中的过期内容可以验证是否有效以便刷新过期时间。验证过程包括联系原始服务器以检查缓存的数据是否依旧代表了最近的版本。
+- **失效**:失效是依据过期日期从缓存中移除内容的过程。当内容在原始服务器上已被改变时就必须这样做,缓存中过期的内容会导致客户端发生问题。
+
+还有许多其他的缓存术语,不过上面的这些应该能帮助您开始。
+
+###什么能被缓存?
+
+某些特定的内容比其他内容更容易被缓存。对大多数站点来说,一些适合缓存的内容如下:
+
+- Logo和商标图像
+- 普通的不变化的图像(例如,导航图标)
+- CSS样式表
+- 普通的Javascript文件
+- 可下载的内容
+- 媒体文件
+
+这些文件更倾向于不经常改变,所以长时间的对它们进行缓存能获得好处。
+
+一些项目在缓存中必须加以注意:
+
+- HTML页面
+- 会替换改变的图像
+- 经常修改的Javascript和CSS文件
+- 需要有认证后的cookies才能访问的内容
+
+一些内容从来不应该被缓存:
+
+- 与敏感信息相关的资源(银行数据,等)
+- 用户相关且经常更改的数据
+
+除上面的通用规则外,通常您需要指定一些规则以便于更好地缓存不同种类的内容。例如,如果登录的用户都看到的是同样的网站视图,就应该在任何地方缓存这个页面。如果登录的用户会在一段时间内看到站点中用户特定的视图,您应该让用户的浏览器缓存该数据而不应让任何中介节点缓存该视图。
+
+###Web内容缓存的位置
+
+Web内容会在整个分发路径中的许多不同的位置被缓存:
+
+- **浏览器缓存**:Web浏览器自身会维护一个小型缓存。典型地,浏览器使用一种策略指示缓存最重要的内容。这可能是用户相关的内容或可能会再次请求且下载代价较高。
+- **中间缓存代理**:任何在客户端和您的基础架构之间的服务器都可以按期望缓存一些内容。这些缓存可能由ISP(网络服务提供者)或者其他独立组织提供。
+- **反向缓存**:您的服务器基础架构可以为后端的服务实现自己的缓存。如果实现了缓存,那么便可以在处理请求的位置返回相应的内容而不用每次请求都使用后端服务。
+
+上面的这些位置通常都可以根据它们自身的缓存策略和内容源的缓存策略缓存一些相应的内容。
+
+###缓存头部
+
+缓存策略依赖于两个不同的因素。所缓存的实体本身需要决定是否应该缓存可接受的内容。它可以只缓存部分可以缓存的内容,但不能缓存超过限制的内容。
+
+缓存行为主要由缓存策略决定,而缓存策略由内容拥有者设置。这些策略主要通过特定的HTTP头部来清晰地表达。
+
+经过几个不同HTTP协议的变化,出现了一些不同的针对缓存方面的头部,它们的复杂度各不相同。下面列出了那些你也许应该注意的:
+
+- **`Expires`**:尽管使用范围相当有限,但`Expires`头部是非常简洁明了的。通常它设置一个未来的时间,内容会在此时间过期。这时,任何对同样内容的请求都应该回到原始服务器处。这个头部或许仅仅最适合回退模式(fall back)。
+- **`Cache-Control`**:这是`Expires`的一个更加现代化的替换物。它已被很好的支持,且拥有更加灵活的实现。在大多数案例中,它比`Expires`更好,但同时设置两者的值也无妨。稍后我们将讨论您可以设置的`Cache-Control`的详细选项。
+- **`ETag`**:`ETag`用于缓存验证。源服务器可以在首次服务一个内容时为该内容提供一个独特的`ETag`。当一个缓存需要验证这个内容是否即将过期,他会将相应的`ETag`发送回服务器。源服务器或者告诉缓存内容是一致的,或者发送更新后的内容(带着新的`ETag`)。
+- **`Last-Modified`**:这个头部指明了相应的内容最后一次被修改的时间。它可能会作为保证内容新鲜度的验证策略的一部分被使用。
+- **`Content-Length`**:尽管并没有在缓存中明确涉及,`Content-Length`头部在设置缓存策略时很重要。某些软件如果不提前获知内容的大小以留出足够空间,则会拒绝缓存该内容。
+- **`Vary`**:缓存系统通常使用请求的主机和路径作为存储该资源的键。当判断一个请求是否是请求同样内容时,`Vary`头部可以被用来提醒缓存系统需要注意另一个附加头部。它通常被用来告诉缓存系统同样注意`Accept-Encoding`头部,以便缓存系统能够区分压缩和未压缩的内容。
+
+### Vary头部的隐语
+
+`Vary`头部提供给您存储同一个内容的不同版本的能力,代价是降低了缓存的容量。
+
+在使用`Accept-Encoding`时,设置`Vary`头部允许明确区分压缩和未压缩的内容。这在服务某些不能处理压缩数据的浏览器时很重要,它可以保证基本的可用性。`Vary`的一个典型的值是`Accept-Encoding`,它只有两到三个可选的值。
+
+一开始看上去`User-Agent`这样的头部可以用于区分移动浏览器和桌面浏览器,以便您的站点提供差异化的服务。但`User-Agent`字符串是非标准的,结果将会造成在中间缓存中保存同一内容的许多不同版本的缓存,这会导致缓存命中率的降低。`Vary`头部应该谨慎使用,尤其是您不具备在您控制的中间缓存中使请求标准化的能力(也许可以,比如您可以控制CDN的话)。
+
+###缓存控制标志怎样影响缓存
+
+上面我们提到了`Cache-Control`头部如何被用与现代缓存策略标准。能够通过这个头部设定许多不同的缓存指令,多个不同的指令通过逗号分隔。
+
+一些您可以使用的指示内容缓存策略的`Cache-Control`的选项如下:
+
+- **`no-cache`**:这个指令指示所有缓存的内容在新的请求到达时必须先重新验证,再发送给客户端。这条指令实际将内容立刻标记为过期的,但允许通过验证手段重新验证以避免重新下载整个内容。
+- **`no-store`**:这条指令指示缓存的内容不能以任何方式被缓存。它适合在回复敏感信息时设置。
+- **`public`**:它将内容标记为公有的,这意味着它能被浏览器和其他任何中间节点缓存。通常,对于使用了HTTP验证的请求,其回复被默认标记为`private`。`public`标记将会覆盖这个设置。
+- **`private`**:它将内容标记为私有的。私有数据可以被用户的浏览器缓存,但*不能*被任何中间节点缓存。它通常用于用户相关的数据。
+- **`max-age`**:这个设置指示了缓存内容的最大生存期,它在最大生存期后必须在源服务器处被验证或被重新下载。在现代浏览器中这个选项大体上取代了`Expires`头部,浏览器也将其作为决定内容的新鲜度的基础。这个选项的值以秒为单位表示,最大可以表示一年的新鲜期(31536000秒)。
+- **`s-maxage`**:这个选项非常类似于`max-age`,它指明了内容能够被缓存的时间。区别是这个选项只在中间节点的缓存中有效。结合这两个选项可以构建更加灵活的缓存策略。
+- **`must-revalidate`**:它指明了由`max-age`、`s-maxage`或`Expires`头部指明的新鲜度信息必须被严格的遵守。它避免了缓存的数据在网络中断等类似的场景中被使用。
+- **`proxy-revalidate`**:它和上面的选项有着一样的作用,但只应用于中间的代理节点。在这种情况下,用户的浏览器可以在网络中断时使用过期内容,但中间缓存内容不能用于此目的。
+- **`no-transform`**:这个选项告诉缓存在任何情况下都不能因为性能的原因修改接收到的内容。这意味着,缓存不允许压缩接收到的内容(没有从原始服务器处接收过压缩版本的该内容)并发送。
+
+这些选项能够以不同的方式结合以获得不同的缓存行为。一些互斥的值如下:
+
+- `no-cache`,`no-store`以及由其他前面未提到的选项指明的常用的缓存行为
+- `public`和`private`
+
+如果`no-store`和`no-cache`都被设置,那么`no-store`会取代`no-cache`。对于非授权的请求的回复,`public`是隐含的设置。对于授权的请求的回复,`private`选项是隐含的。他们可以通过在`Cache-Control`头部中指明相应的相反的选项以覆盖。
+
+###开发一种缓存策略
+
+在理想情况下,任何内容都可以被尽可能缓存,而您的服务器只需要偶尔的提供一些验证内容即可。但这在现实中很少发生,因此您应该尝试设置一些明智的缓存策略,以在长期缓存和站点改变的需求间达到平衡。
+
+### 常见问题
+
+在许多情况中,由于内容被产生的方式(如根据每个用户动态的产生)或者内容的特性(例如银行的敏感数据),这些内容不应该被缓存。另一些许多管理员在设置缓存时可能面对的问题是外部缓存的数据未过期,但新版本的数据已经产生。
+
+这些都是经常遇到的问题,它们会影响缓存的性能和您提供的数据的准确性。然而,我们可以通过开发提前预见这些问题的缓存策略来缓解这些问题。
+
+### 一般性建议
+
+尽管您的实际情况会指导您选择的缓存策略,但是下面的建议能帮助您获得一些合理的决定。
+
+在您担心使用哪一个特定的头部之前,有一些特定的步骤可以帮助您提高您的缓存命中率。一些建议如下:
+
+- **为图像、CSS和共享的内容建立特定的文件夹**:将内容放到特定的文件夹内使得您可以方便的从您的站点中的任何页面引用这些内容。
+- **使用同样的URL来表示同样的内容**:由于缓存使用内容请求中的主机名和路径作为键,因此应保证您的所有页面中的该内容的引用方式相同,前一个建议能让这点更加容易做到。
+- **尽可能使用CSS图像拼接**:对于像图标和导航等内容,使用CSS图像拼接能够减少渲染您页面所需要的请求往返,并且允许对拼接缓存很长一段时间。
+- **尽可能将主机脚本和外部资源本地化**:如果您使用Javascript脚本和其他外部资源,如果上游没有提供合适的缓存头部,那么您应考虑将这些内容放在您自己的服务器上。您应该注意上游的任何更新,以便更新本地的拷贝。
+- **对缓存内容收集文件摘要**:静态的内容比如CSS和Javascript文件等通常比较适合收集文件摘要。这意味着为文件名增加一个独特的标志符(通常是这个文件的哈希值)可以在文件修改后绕开缓存保证新的内容被重新获取。有很多工具可以帮助您创建文件摘要并且修改HTML文档中的引用。
+
+对于不同的文件正确地选择不同的头部这件事,下面的内容可以作为一般性的参考:
+
+- **允许所有的缓存存储一般内容**:静态内容以及非用户相关的内容应该在分发链的所有节点被缓存。这使得中间节点可以将该内容回复给多个用户。
+- **允许浏览器缓存用户相关的内容**:对于每个用户的数据,通常在用户自己的浏览器中缓存是可以被接受且有益的。缓存在用户自身的浏览器能够使得用户在接下来的浏览中能够瞬时读取,但这些内容不适合在任何中间代理节点缓存。
+- **将时间敏感的内容作为特例**:如果您的数据是时间敏感的,那么相对上面两条参考,应该将这些数据作为特例,以保证过期的数据不会在关键的情况下被使用。例如,您的站点有一个购物车,它应该立刻反应购物车里面的物品。依据内容的特点,可以在`Cache-Control`头部中使用`no-cache`或`no-store`选项。
+- **总是提供验证器**:验证器使得过期的内容可以无需重新下载而得到刷新。设置`ETag`和`Last-Modified`头部将允许缓存向原始服务器验证内容,并在内容未修改时刷新该内容新鲜度以减少负载。
+- **对于支持的内容设置长的新鲜期**:为了更加有效的利用缓存,一些作为支持性的内容应该被设置较长的新鲜期。这通常比较适合图像和CSS等由用户请求用来渲染HTML页面的内容。和文件摘要一起,设置延长的新鲜期将允许缓存长时间的存储这些资源。如果资源发生改变,修改的文件摘要将会使缓存的数据无效并触发对新的内容的下载。那时,新的支持的内容会继续被缓存。
+- **对父内容设置短的新鲜期**:为了使得前面的模式正常工作,容器类的内容应该相应的设置短的新鲜期,或者设置不全部缓存。这通常是在其他协助内容中使用的HTML页面。这个HTML页面将会被频繁的下载,使得它能快速的响应改变。支持性的内容因此可以被尽量缓存。
+
+关键之处便在于达到平衡,一方面可以尽量的进行缓存,另一方面为未来保留当改变发生时从而改变整个内容的机会。您的站点应该同时具有:
+
+- 尽量缓存的内容
+- 拥有短的新鲜期的缓存内容,可以被重新验证
+- 完全不被缓存的内容
+
+这样做的目的便是将内容尽可能的移动到第一个分类(尽量缓存)中的同时,维持可以接受的缓存命中率。
+
+结论
+----
+
+花时间确保您的站点使用了合适的缓存策略将对您的站点产生重要的影响。缓存使得您可以在保证服务同样内容的同时减少带宽的使用。您的服务器因此可以靠同样的硬件处理更多的流量。或许更重要的是,客户们能在您的网站中获得更快的体验,这会使得他们更愿意频繁的访问您的站点。尽管有效的Web缓存并不是银弹,但设置合适的缓存策略会使您以最小的代价获得可观的收获。
+
+---
+
+via: https://www.digitalocean.com/community/tutorials/web-caching-basics-terminology-http-headers-and-caching-strategies
+
+作者: [Justin Ellingwood](https://www.digitalocean.com/community/users/jellingwood)
+译者:[wwy-hust](https://github.com/wwy-hust)
+校对:[wxy](https://github.com/wxy)
+推荐:[royaso](https://github.com/royaso)
+
+
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+
+
diff --git a/published/201505/20150504 How To Install Visual Studio Code On Ubuntu.md b/published/201505/20150504 How To Install Visual Studio Code On Ubuntu.md
new file mode 100644
index 0000000000..b3bb071dc5
--- /dev/null
+++ b/published/201505/20150504 How To Install Visual Studio Code On Ubuntu.md
@@ -0,0 +1,63 @@
+在Ubuntu中安装Visual Studio Code
+================================================================================
+
+
+微软令人意外地[发布了Visual Studio Code][1],并支持主要的桌面平台,当然包括linux。如果你是一名需要在ubuntu工作的web开发人员,你可以**非常轻松的安装Visual Studio Code**。
+
+我将要使用[Ubuntu Make][2]来安装Visual Studio Code。Ubuntu Make,就是以前的Ubuntu开发者工具中心,是一个命令行工具,帮助用户快速安装各种开发工具、语言和IDE。也可以使用Ubuntu Make轻松[安装Android Studio][3] 和其他IDE,如Eclipse。本文将展示**如何在Ubuntu中使用Ubuntu Make安装Visual Studio Code**。(译注:也可以直接去微软官网下载安装包)
+
+### 安装微软Visual Studio Code ###
+
+开始之前,首先需要安装Ubuntu Make。虽然Ubuntu Make存在Ubuntu15.04官方库中,**但是需要Ubuntu Make 0.7以上版本才能安装Visual Studio**。所以,需要通过官方PPA更新到最新的Ubuntu Make。此PPA支持Ubuntu 14.04, 14.10 和 15.04。
+
+注意,**仅支持64位版本**。
+
+打开终端,使用下列命令,通过官方PPA来安装Ubuntu Make:
+
+ sudo add-apt-repository ppa:ubuntu-desktop/ubuntu-make
+ sudo apt-get update
+ sudo apt-get install ubuntu-make
+
+安装Ubuntu Make完后,接着使用下列命令安装Visual Studio Code:
+
+ umake web visual-studio-code
+
+安装过程中,将会询问安装路径,如下图:
+
+
+
+在抛出一堆要求和条件后,它会询问你是否确认安装Visual Studio Code。输入‘a’来确定:
+
+
+
+确定之后,安装程序会开始下载并安装。安装完成后,你可以发现Visual Studio Code 图标已经出现在了Unity启动器上。点击图标开始运行!下图是Ubuntu 15.04 Unity的截图:
+
+
+
+### 卸载Visual Studio Code###
+
+卸载Visual Studio Code,同样使用Ubuntu Make命令。如下:
+
+ umake web visual-studio-code --remove
+
+如果你不打算使用Ubuntu Make,也可以通过微软官方下载安装文件。
+
+- [下载Visual Studio Code Linux版][4]
+
+怎样!是不是超级简单就可以安装Visual Studio Code,这都归功于Ubuntu Make。我希望这篇文章能帮助到你。如果您有任何问题或建议,欢迎给我留言。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-visual-studio-code-ubuntu/
+
+作者:[Abhishek][a]
+译者:[Vic020/VicYu](http://vicyu.net)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:https://linux.cn/article-5376-1.html
+[2]:https://wiki.ubuntu.com/ubuntu-make
+[3]:http://itsfoss.com/install-android-studio-ubuntu-linux/
+[4]:https://code.visualstudio.com/Download
diff --git a/published/201505/20150505 Bodhi Linux Introduces Moksha Desktop.md b/published/201505/20150505 Bodhi Linux Introduces Moksha Desktop.md
new file mode 100644
index 0000000000..dcb724e7b1
--- /dev/null
+++ b/published/201505/20150505 Bodhi Linux Introduces Moksha Desktop.md
@@ -0,0 +1,40 @@
+Bodhi Linux 将引入 Moksha 桌面
+================================================================================
+
+
+基于Ubuntu的轻量级Linux发行版[Bodhi Linux][1]致力于构建其自家的桌面环境,这个全新桌面环境被称之为Moksha(梵文意为‘完全自由’)。Moksha将替换其原来的[Enlightenment桌面环境][2]。
+
+### 为何用Moksha替换Englightenment? ###
+
+Bodhi Linux的Jeff Hoogland最近[表示][3]了他对新版Enlightenment的不满。直到E17,Enlightenment都十分稳定,并且能满足轻量级Linux的部署需求。而E18则到处都充满了问题,Bodhi Linux只好弃之不用了。
+
+虽然最新的[Bodhi Linux 3.0发行版][4]仍然使用了E19作为其桌面(除传统模式外,这意味着,对于旧的硬件,仍然会使用E17),Jeff对E19也十分不满。他说道:
+
+> 除了性能问题外,对于我个人而言,E19并没有给我带来与E17下相同的工作流程,因为它移除了很多E17的特性。鉴于此,我不得不将我所有的3台Bodhi计算机桌面改成E17——这3台机器都是我高端的了。这不由得让我想到,我们还有多少现存的Bodhi用户也怀着和我同样的感受,所以,我[在我们的用户论坛上开启一个与此相关的讨论][5]。
+
+### Moksha是E17桌面的延续 ###
+
+Moksha将会是Bodhi所热衷的E17桌面的延续。Jeff进一步提到:
+
+> 我们将从整合所有Bodhi修改开始。多年来我们一直都只是给源代码打补丁,并修复桌面所带有的问题。如果该工作完成,我们将开始移植一些E18和E19引入的更为有用的特性,最后,我们将引入一些我们认为会改善最终用户体验的东西。
+
+### Moksha何时发布? ###
+
+下一个Bodhi更新将会是Bodhi 3.1.0,就在今年八月。这个新版本将为所有其默认安装镜像带来Moksha。让我们拭目以待,看看Moksha是否是一个好的决定。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/bodhi-linux-introduces-moksha-desktop/
+
+作者:[Abhishek][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://www.bodhilinux.com/
+[2]:https://www.enlightenment.org/
+[3]:http://www.bodhilinux.com/2015/04/28/introducing-the-moksha-desktop/
+[4]:http://itsfoss.com/bodhi-linux-3/
+[5]:http://forums.bodhilinux.com/index.php?/topic/12322-e17-vs-e19-which-are-you-using-and-why/
diff --git a/published/201505/20150506 How to Securely Store Passwords and Api Keys Using Vault.md b/published/201505/20150506 How to Securely Store Passwords and Api Keys Using Vault.md
new file mode 100644
index 0000000000..e2073d0b18
--- /dev/null
+++ b/published/201505/20150506 How to Securely Store Passwords and Api Keys Using Vault.md
@@ -0,0 +1,164 @@
+如何使用Vault安全的存储密码和API密钥
+=======================================================================
+Vault是用来安全的获取秘密信息的工具,它可以保存密码、API密钥、证书等信息。Vault提供了一个统一的接口来访问秘密信息,其具有健壮的访问控制机制和丰富的事件日志。
+
+对关键信息的授权访问是一个困难的问题,尤其是当有许多用户角色,并且用户请求不同的关键信息时,例如用不同权限登录数据库的登录配置,用于外部服务的API密钥,SOA通信的证书等。当保密信息由不同的平台进行管理,并使用一些自定义的配置时,情况变得更糟,因此,安全的存储、管理审计日志几乎是不可能的。但Vault为这种复杂情况提供了一个解决方案。
+
+### 突出特点 ###
+
+**数据加密**:Vault能够在不存储数据的情况下对数据进行加密、解密。开发者们便可以存储加密后的数据而无需开发自己的加密技术,Vault还允许安全团队自定义安全参数。
+
+**安全密码存储**:Vault在将秘密信息(API密钥、密码、证书)存储到持久化存储之前对数据进行加密。因此,如果有人偶尔拿到了存储的数据,这也没有任何意义,除非加密后的信息能被解密。
+
+**动态密码**:Vault可以随时为AWS、SQL数据库等类似的系统产生密码。比如,如果应用需要访问AWS S3 桶,它向Vault请求AWS密钥对,Vault将给出带有租期的所需秘密信息。一旦租用期过期,这个秘密信息就不再存储。
+
+**租赁和更新**:Vault给出的秘密信息带有租期,一旦租用期过期,它便立刻收回秘密信息,如果应用仍需要该秘密信息,则可以通过API更新租用期。
+
+**撤销**:在租用期到期之前,Vault可以撤销一个秘密信息或者一个秘密信息树。
+
+### 安装Vault ###
+
+有两种方式来安装使用Vault。
+
+**1. 预编译的Vault二进制** 能用于所有的Linux发行版,下载地址如下,下载之后,解压并将它放在系统PATH路径下,以方便调用。
+
+- [下载预编译的二进制 Vault (32-bit)][1]
+- [下载预编译的二进制 Vault (64-bit)][2]
+- [下载预编译的二进制 Vault (ARM)][3]
+
+
+
+*下载相应的预编译的Vault二进制版本。*
+
+
+
+*解压下载到本地的二进制版本。*
+
+祝贺你!您现在可以使用Vault了。
+
+
+
+**2. 从源代码编译**是另一种在系统中安装Vault的方式。在安装Vault之前需要安装GO和GIT。
+
+在 **Redhat系统中安装GO** 使用下面的指令:
+
+ sudo yum install go
+
+在 **Debin系统中安装GO** 使用下面的指令:
+
+ sudo apt-get install golang
+
+或者
+
+ sudo add-apt-repository ppa:gophers/go
+
+ sudo apt-get update
+
+ sudo apt-get install golang-stable
+
+在 **Redhat系统中安装GIT** 使用下面的命令:
+
+ sudo yum install git
+
+在 **Debian系统中安装GIT** 使用下面的命令:
+
+ sudo apt-get install git
+
+一旦GO和GIT都已被安装好,我们便可以开始从源码编译安装Vault。
+
+> 将下列的Vault仓库拷贝至GOPATH
+
+ https://github.com/hashicorp/vault
+
+> 测试下面的文件是否存在,如果它不存在,那么Vault没有被克隆到合适的路径。
+
+ $GOPATH/src/github.com/hashicorp/vault/main.go
+
+> 执行下面的指令来编译Vault,并将二进制文件放到系统bin目录下。
+
+ make dev
+
+
+
+### 一份Vault入门教程 ###
+
+我们已经编制了一份Vault的官方交互式教程,并带有它在SSH上的输出信息。
+
+**概述**
+
+这份教程包括下列步骤:
+
+- 初始化并启封您的Vault
+- 在Vault中对您的请求授权
+- 读写秘密信息
+- 密封您的Vault
+
+#### **初始化您的Vault**
+
+首先,我们需要为您初始化一个Vault的工作实例。在初始化过程中,您可以配置Vault的密封行为。简单起见,现在使用一个启封密钥来初始化Vault,命令如下:
+
+ vault init -key-shares=1 -key-threshold=1
+
+您会注意到Vault在这里输出了几个密钥。不要清除您的终端,这些密钥在后面的步骤中会使用到。
+
+
+
+#### **启封您的Vault**
+
+当一个Vault服务器启动时,它是密封的状态。在这种状态下,Vault被配置为知道物理存储在哪里及如何存取它,但不知道如何对其进行解密。Vault使用加密密钥来加密数据。这个密钥由"主密钥"加密,主密钥不保存。解密主密钥需要入口密钥。在这个例子中,我们使用了一个入口密钥来解密这个主密钥。
+
+ vault unseal
+
+
+
+####**为您的请求授权**
+
+在执行任何操作之前,连接的客户端必须是被授权的。授权的过程是检验一个人或者机器是否如其所申明的那样具有正确的身份。这个身份用在向Vault发送请求时。为简单起见,我们将使用在步骤2中生成的root令牌,这个信息可以回滚终端屏幕看到。使用一个客户端令牌进行授权:
+
+ vault auth
+
+
+
+####**读写保密信息**
+
+现在Vault已经被设置妥当,我们可以开始读写默认挂载的秘密后端里面的秘密信息了。写在Vault中的秘密信息首先被加密,然后被写入后端存储中。后端存储机制绝不会看到未加密的信息,并且也没有在Vault之外解密的需要。
+
+ vault write secret/hello value=world
+
+当然,您接下来便可以读这个保密信息了:
+
+ vault read secret/hello
+
+
+
+####**密封您的Vault**
+
+还有一个用I来密封Vault的API。它将丢掉现在的加密密钥并需要另一个启封过程来恢复它。密封仅需要一个拥有root权限的操作者。这是一种罕见的"打破玻璃过程"的典型部分。
+
+这种方式中,如果检测到一个入侵,Vault数据将会立刻被锁住,以便最小化损失。如果不能访问到主密钥碎片的话,就不能再次获取数据。
+
+ vault seal
+
+
+
+这便是入门教程的结尾。
+
+### 总结 ###
+
+Vault是一个非常有用的应用,它提供了一个可靠且安全的存储关键信息的方式。另外,它在存储前加密关键信息、审计日志维护、以租期的方式获取秘密信息,且一旦租用期过期它将立刻收回秘密信息。Vault是平台无关的,并且可以免费下载和安装。要发掘Vault的更多信息,请访问其[官方网站][4]。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/how-tos/secure-secret-store-vault/
+
+作者:[Aun Raza][a]
+译者:[wwy-hust](https://github.com/wwy-hust)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunrz/
+[1]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_386.zip
+[2]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_amd64.zip
+[3]:https://dl.bintray.com/mitchellh/vault/vault_0.1.0_linux_arm.zip
+[4]:https://vaultproject.io/
diff --git a/published/201505/20150506 Linux FAQs with Answers--How to configure a Linux bridge with Network Manager on Ubuntu.md b/published/201505/20150506 Linux FAQs with Answers--How to configure a Linux bridge with Network Manager on Ubuntu.md
new file mode 100644
index 0000000000..b1ff96e30b
--- /dev/null
+++ b/published/201505/20150506 Linux FAQs with Answers--How to configure a Linux bridge with Network Manager on Ubuntu.md
@@ -0,0 +1,86 @@
+Linux 有问必答:如何在Ubuntu上配置网桥
+===============================================================================
+> **Question**: 我需要在我的Ubuntu主机上建立一个Linux网桥,共享一个网卡给其他一些虚拟主机或在主机上创建的容器。我目前正在Ubuntu上使用网络管理器(Network Manager),所以最好>能使用网络管理器来配置一个网桥。我该怎么做?
+
+网桥是一个硬件装备,用来将两个或多个数据链路层(OSI七层模型中第二层)互联,以使得不同网段上的网络设备可以互相访问。当你想要互联一个主机里的多个虚拟机器或者以太接口时,就需要在Linux主机里有一个类似桥接的概念。这里使用的是一种软网桥。
+
+有很多的方法来配置一个Linux网桥。举个例子,在一个无外接显示/键盘的服务器环境里,你可以使用[brct][1]手动地配置一个网桥。而在桌面环境下,在网络管理器里也支持网桥设置。那就让我们测试一下如何用网络管理器配置一个网桥吧。
+
+### 要求 ###
+
+为了避免[任何问题][2],建议你的网络管理器版本为0.9.9或者更高,它用在 Ubuntu 15.04或者更新的版本。
+
+ $ apt-cache show network-manager | grep Version
+
+----------
+
+ Version: 0.9.10.0-4ubuntu15.1
+ Version: 0.9.10.0-4ubuntu15
+
+### 创建一个网桥 ###
+
+使用网络管理器创建网桥最简单的方式就是通过nm-connection-editor。这款GUI(图形用户界面)的工具允许你傻瓜式地配置一个网桥。
+
+首先,启动nm-connection-editor。
+
+ $ nm-connection-editor
+
+该编辑器的窗口会显示给你一个列表,列出目前配置好的网络连接。点击右上角的“添加”按钮,创建一个网桥。
+
+
+
+接下来,选择“Bridge”(网桥)作为连接类型。
+
+
+
+现在,开始配置网桥,包括它的名字和所桥接的连接。如果没有创建过其他网桥,那么默认的网桥接口会被命名为bridge0。
+
+回顾一下,创建网桥的目的是为了通过网桥共享你的以太网卡接口,所以你需要添加以太网卡接口到网桥。在图形界面添加一个新的“桥接的连接”可以实现上述目的。点击“Add”按钮。
+
+
+
+选择“以太网”作为连接类型。
+
+
+
+在“设备的 MAC 地址”区域,选择你想要从属于网桥的接口。本例中,假设该接口是eth0。
+
+
+
+点击“常规”标签,并且选中两个复选框,分别是“当其可用时自动连接到该网络”和“所有用户都可以连接到该网络”。
+
+
+
+切换到“IPv4 设置”标签,为网桥配置DHCP或者是静态IP地址。注意,你应该为从属的以太网卡接口eth0使用相同的IPv4设定。本例中,我们假设eth0是用过DHCP配置的。因此,此处选择“自动(DHCP)”。如果eth0被指定了一个静态IP地址,那么你也应该指定相同的IP地址给网桥。
+
+
+
+最后,保存网桥的设置。
+
+现在,你会看见一个新增的网桥连接被创建在“网络连接”窗口里。因为已经从属与网桥,以前配置好的有线连接 eth0 就不再需要了,所以去删除原来的有线连接吧。
+
+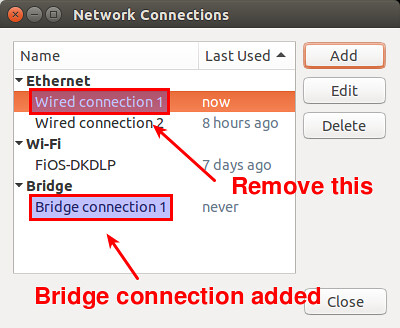
+
+这时候,网桥连接会被自动激活。从指定给eth0的IP地址被网桥接管起,你将会暂时丢失一下连接。当IP地址赋给了网桥,你将会通过网桥连接回你的以太网卡接口。你可以通过“Network”设置确认一下。
+
+
+
+同时,检查可用的接口。提醒一下,网桥接口必须已经取代了任何你的以太网卡接口拥有的IP地址。
+
+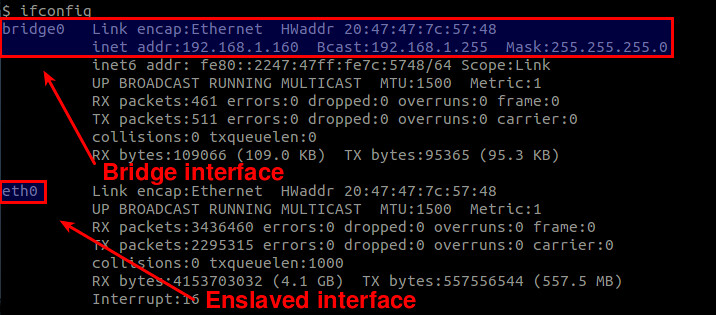
+
+就这么多了,现在,网桥已经可以用了。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/configure-linux-bridge-network-manager-ubuntu.html
+
+作者:[Dan Nanni][a]
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://xmodulo.com/how-to-configure-linux-bridge-interface.html
+[2]:https://bugs.launchpad.net/ubuntu/+source/network-manager/+bug/1273201
diff --git a/published/201505/20150506 Linux FAQs with Answers--How to install autossh on Linux.md b/published/201505/20150506 Linux FAQs with Answers--How to install autossh on Linux.md
new file mode 100644
index 0000000000..3fa2cf8a86
--- /dev/null
+++ b/published/201505/20150506 Linux FAQs with Answers--How to install autossh on Linux.md
@@ -0,0 +1,76 @@
+Linux有问必答:如何安装autossh
+================================================================================
+> **提问**: 我打算在linux上安装autossh,我应该怎么做呢?
+
+[autossh][1] 是一款开源工具,可以帮助管理SSH会话、自动重连和停止转发流量。autossh会假定目标主机已经设定[无密码SSH登陆][2],以便autossh可以重连断开的SSH会话而不用用户操作。
+
+只要你建立[反向SSH隧道][3]或者[挂载基于SSH的远程文件夹][4],autossh迟早会派上用场。基本上只要需要维持SSH会话,autossh肯定是有用的。
+
+
+
+下面有许多linux发行版autossh的安装方法。
+
+### Debian 或 Ubuntu 系统 ###
+
+autossh已经加入基于Debian系统的基础库,所以可以很方便的安装。
+
+ $ sudo apt-get install autossh
+
+### Fedora 系统 ###
+
+Fedora库同样包含autossh包,使用yum安装。
+
+ $ sudo yum install autossh
+
+### CentOS 或 RHEL 系统 ###
+
+CentOS/RHEL 6 或早期版本, 需要开启第三库[Repoforge库][5], 然后才能使用yum安装.
+
+ $ sudo yum install autossh
+
+CentOS/RHEL 7以后,autossh 已经不在Repoforge库中. 你需要从源码编译安装(例子在下面)。
+
+### Arch Linux 系统 ###
+
+ $ sudo pacman -S autossh
+
+### Debian 或 Ubuntu 系统中从源码编译安装###
+
+如果你想要使用最新版本的autossh,你可以自己编译源码安装
+
+ $ sudo apt-get install gcc make
+ $ wget http://www.harding.motd.ca/autossh/autossh-1.4e.tgz
+ $ tar -xf autossh-1.4e.tgz
+ $ cd autossh-1.4e
+ $ ./configure
+ $ make
+ $ sudo make install
+
+### CentOS, Fedora 或 RHEL 系统中从源码编译安装###
+
+在CentOS/RHEL 7以后,autossh不在是预编译包。所以你不得不从源码编译安装。
+
+ $ sudo yum install wget gcc make
+ $ wget http://www.harding.motd.ca/autossh/autossh-1.4e.tgz
+ $ tar -xf autossh-1.4e.tgz
+ $ cd autossh-1.4e
+ $ ./configure
+ $ make
+ $ sudo make install
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-autossh-linux.html
+
+作者:[Dan Nanni][a]
+译者:[Vic020/VicYu](http://vicyu.net)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://www.harding.motd.ca/autossh/
+[2]:https://linux.cn/article-5444-1.html
+[3]:http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
+[4]:http://xmodulo.com/how-to-mount-remote-directory-over-ssh-on-linux.html
+[5]:http://xmodulo.com/how-to-set-up-rpmforge-repoforge-repository-on-centos.html
diff --git a/published/201505/20150507 Command Line Tool to Monitor Linux Containers Performance.md b/published/201505/20150507 Command Line Tool to Monitor Linux Containers Performance.md
new file mode 100644
index 0000000000..161e030c11
--- /dev/null
+++ b/published/201505/20150507 Command Line Tool to Monitor Linux Containers Performance.md
@@ -0,0 +1,185 @@
+监控 Linux 容器性能的命令行神器
+================================================================================
+ctop是一个新的基于命令行的工具,它可用于在容器层级监控进程。容器通过利用控制器组(cgroup)的资源管理功能,提供了操作系统层级的虚拟化环境。该工具从cgroup收集与内存、CPU、块输入输出的相关数据,以及拥有者、开机时间等元数据,并以人性化的格式呈现给用户,这样就可以快速对系统健康状况进行评估。基于所获得的数据,它可以尝试推测下层的容器技术。ctop也有助于在低内存环境中检测出谁在消耗大量的内存。
+
+### 功能 ###
+
+ctop的一些功能如下:
+
+- 收集CPU、内存和块输入输出的度量值
+- 收集与拥有者、容器技术和任务统计相关的信息
+- 通过任意栏对信息排序
+- 以树状视图显示信息
+- 折叠/展开cgroup树
+- 选择并跟踪cgroup/容器
+- 选择显示数据刷新的时间窗口
+- 暂停刷新数据
+- 检测基于systemd、Docker和LXC的容器
+- 基于Docker和LXC的容器的高级特性
+ - 打开/连接shell以进行深度诊断
+ - 停止/杀死容器类型
+
+### 安装 ###
+
+**ctop**是由Python写成的,因此,除了需要Python 2.6或其更高版本外(带有内建的光标支持),别无其它外部依赖。推荐使用Python的pip进行安装,如果还没有安装pip,请先安装,然后使用pip安装ctop。
+
+*注意:本文样例来自Ubuntu(14.10)系统*
+
+ $ sudo apt-get install python-pip
+
+使用pip安装ctop:
+
+ poornima@poornima-Lenovo:~$ sudo pip install ctop
+
+ [sudo] password for poornima:
+
+ Downloading/unpacking ctop
+
+ Downloading ctop-0.4.0.tar.gz
+
+ Running setup.py (path:/tmp/pip_build_root/ctop/setup.py) egg_info for package ctop
+
+ Installing collected packages: ctop
+
+ Running setup.py install for ctop
+
+ changing mode of build/scripts-2.7/ctop from 644 to 755
+
+ changing mode of /usr/local/bin/ctop to 755
+
+ Successfully installed ctop
+
+ Cleaning up...
+
+如果不选择使用pip安装,你也可以使用wget直接从github安装:
+
+ poornima@poornima-Lenovo:~$ wget https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py -O ctop
+
+ --2015-04-29 19:32:53-- https://raw.githubusercontent.com/yadutaf/ctop/master/cgroup_top.py
+
+ Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 199.27.78.133
+
+ Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|199.27.78.133|:443... connected.
+
+ HTTP request sent, awaiting response... 200 OK Length: 27314 (27K) [text/plain]
+
+ Saving to: ctop
+
+ 100%[======================================>] 27,314 --.-K/s in 0s
+
+ 2015-04-29 19:32:59 (61.0 MB/s) - ctop saved [27314/27314]
+
+----------
+
+ poornima@poornima-Lenovo:~$ chmod +x ctop
+
+如果cgroup-bin包没有安装,你可能会碰到一个错误消息,你可以通过安装需要的包来解决。
+
+ poornima@poornima-Lenovo:~$ ./ctop
+
+ [ERROR] Failed to locate cgroup mountpoints.
+
+ poornima@poornima-Lenovo:~$ sudo apt-get install cgroup-bin
+
+下面是ctop的输出样例:
+
+
+
+*ctop屏幕*
+
+### 用法选项 ###
+
+ ctop [--tree] [--refresh=] [--columns=] [--sort-col=] [--follow=] [--fold=, ...] ctop (-h | --help)
+
+当你进入ctop屏幕,可使用上(↑)和下(↓)箭头键在容器间导航。点击某个容器就选定了该容器,按q或Ctrl+C退出该容器。
+
+现在,让我们来看看上面列出的那一堆选项究竟是怎么用的吧。
+
+**-h / --help - 显示帮助信息**
+
+ poornima@poornima-Lenovo:~$ ctop -h
+ Usage: ctop [options]
+
+ Options:
+ -h, --help show this help message and exit
+ --tree show tree view by default
+ --refresh=REFRESH Refresh display every
+ --follow=FOLLOW Follow cgroup path
+ --columns=COLUMNS List of optional columns to display. Always includes
+ 'name'
+ --sort-col=SORT_COL Select column to sort by initially. Can be changed
+ dynamically.
+
+
+**--tree - 显示容器的树形视图**
+
+默认情况下,会显示列表视图
+
+当你进入ctop窗口,你可以使用F5按钮在树状/列表视图间切换。
+
+**--fold= - 在树形视图中折叠名为 \ 的 cgroup 路径**
+
+该选项需要与 --tree 选项组合使用。
+
+例子: ctop --tree --fold=/user.slice
+
+
+
+*'ctop --fold'的输出*
+
+在ctop窗口中,使用+/-键来展开或折叠子cgroup。
+
+注意:在写本文时,pip仓库中还没有最新版的ctop,还不支持命令行的‘--fold’选项
+
+**--follow= - 跟踪/高亮 cgroup 路径**
+
+例子: ctop --follow=/user.slice/user-1000.slice
+
+正如你在下面屏幕中所见到的那样,带有“/user.slice/user-1000.slice”路径的cgroup被高亮显示,这让用户易于跟踪,就算显示位置变了也一样。
+
+
+
+*'ctop --follow'的输出*
+
+你也可以使用‘f’按钮来让高亮的行跟踪选定的容器。默认情况下,跟踪是关闭的。
+
+**--refresh= - 按指定频率刷新显示,默认1秒**
+
+这对于按每用户需求来显示改变刷新率时很有用。使用‘p’按钮可以暂停刷新并选择文本。
+
+**--columns= - 限定只显示选定的列。'name' 需要是第一个字段,其后跟着其它字段。默认情况下,字段包括:owner, processes,memory, cpu-sys, cpu-user, blkio, cpu-time**
+
+例子: ctop --columns=name,owner,type,memory
+
+
+
+*'ctop --column'的输出*
+
+**-sort-col= - 按指定的列排序。默认使用 cpu-user 排序**
+
+例子: ctop --sort-col=blkio
+
+如果有Docker和LXC支持的额外容器,跟踪选项也是可用的:
+
+ press 'a' - 接驳到终端输出
+
+ press 'e' - 打开容器中的一个 shell
+
+ press 's' - 停止容器 (SIGTERM)
+
+ press 'k' - 杀死容器 (SIGKILL)
+
+目前 Jean-Tiare Le Bigot 还在积极开发 [ctop][1] 中,希望我们能在该工具中见到像本地 top 命令一样的特性 :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/how-tos/monitor-linux-containers-performance/
+
+作者:[B N Poornima][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bnpoornima/
+[1]:https://github.com/yadutaf/ctop
diff --git a/published/201505/20150511 OpenSSL command line Root and Intermediate CA including OCSP, CRL and revocation.md b/published/201505/20150511 OpenSSL command line Root and Intermediate CA including OCSP, CRL and revocation.md
new file mode 100644
index 0000000000..9bd388f67c
--- /dev/null
+++ b/published/201505/20150511 OpenSSL command line Root and Intermediate CA including OCSP, CRL and revocation.md
@@ -0,0 +1,406 @@
+建立你自己的 CA 服务:OpenSSL 命令行 CA 操作快速指南
+================================================================================
+
+这些是关于使用 OpenSSL 生成证书授权(CA)、中间证书授权和末端证书的速记随笔,内容包括 OCSP、CRL 和 CA 颁发者信息,以及指定颁发和有效期限等。
+
+我们将建立我们自己的根 CA,我们将使用根 CA 来生成一个中间 CA 的例子,我们将使用中间 CA 来签署末端用户证书。
+
+### 根 CA ###
+
+创建根 CA 授权目录并切换到该目录:
+
+ mkdir ~/SSLCA/root/
+ cd ~/SSLCA/root/
+
+为我们的根 CA 生成一个8192位长的 SHA-256 RSA 密钥:
+
+ openssl genrsa -aes256 -out rootca.key 8192
+
+样例输出:
+
+ Generating RSA private key, 8192 bit long modulus
+ .........++
+ ....................................................................................................................++
+ e is 65537 (0x10001)
+
+如果你想要用密码保护该密钥,请添加 `-aes256` 选项。
+
+创建自签名根 CA 证书 `ca.crt`;你需要为你的根 CA 提供一个身份:
+
+ openssl req -sha256 -new -x509 -days 1826 -key rootca.key -out rootca.crt
+
+样例输出:
+
+ You are about to be asked to enter information that will be incorporated
+ into your certificate request.
+ What you are about to enter is what is called a Distinguished Name or a DN.
+ There are quite a few fields but you can leave some blank
+ For some fields there will be a default value,
+ If you enter '.', the field will be left blank.
+ -----
+ Country Name (2 letter code) [AU]:NL
+ State or Province Name (full name) [Some-State]:Zuid Holland
+ Locality Name (eg, city) []:Rotterdam
+ Organization Name (eg, company) [Internet Widgits Pty Ltd]:Sparkling Network
+ Organizational Unit Name (eg, section) []:Sparkling CA
+ Common Name (e.g. server FQDN or YOUR name) []:Sparkling Root CA
+ Email Address []:
+
+创建一个存储 CA 序列的文件:
+
+ touch certindex
+ echo 1000 > certserial
+ echo 1000 > crlnumber
+
+放置 CA 配置文件,该文件持有 CRL 和 OCSP 末端的存根。
+
+ # vim ca.conf
+ [ ca ]
+ default_ca = myca
+
+ [ crl_ext ]
+ issuerAltName=issuer:copy
+ authorityKeyIdentifier=keyid:always
+
+ [ myca ]
+ dir = ./
+ new_certs_dir = $dir
+ unique_subject = no
+ certificate = $dir/rootca.crt
+ database = $dir/certindex
+ private_key = $dir/rootca.key
+ serial = $dir/certserial
+ default_days = 730
+ default_md = sha1
+ policy = myca_policy
+ x509_extensions = myca_extensions
+ crlnumber = $dir/crlnumber
+ default_crl_days = 730
+
+ [ myca_policy ]
+ commonName = supplied
+ stateOrProvinceName = supplied
+ countryName = optional
+ emailAddress = optional
+ organizationName = supplied
+ organizationalUnitName = optional
+
+ [ myca_extensions ]
+ basicConstraints = critical,CA:TRUE
+ keyUsage = critical,any
+ subjectKeyIdentifier = hash
+ authorityKeyIdentifier = keyid:always,issuer
+ keyUsage = digitalSignature,keyEncipherment,cRLSign,keyCertSign
+ extendedKeyUsage = serverAuth
+ crlDistributionPoints = @crl_section
+ subjectAltName = @alt_names
+ authorityInfoAccess = @ocsp_section
+
+ [ v3_ca ]
+ basicConstraints = critical,CA:TRUE,pathlen:0
+ keyUsage = critical,any
+ subjectKeyIdentifier = hash
+ authorityKeyIdentifier = keyid:always,issuer
+ keyUsage = digitalSignature,keyEncipherment,cRLSign,keyCertSign
+ extendedKeyUsage = serverAuth
+ crlDistributionPoints = @crl_section
+ subjectAltName = @alt_names
+ authorityInfoAccess = @ocsp_section
+
+ [alt_names]
+ DNS.0 = Sparkling Intermidiate CA 1
+ DNS.1 = Sparkling CA Intermidiate 1
+
+ [crl_section]
+ URI.0 = http://pki.sparklingca.com/SparklingRoot.crl
+ URI.1 = http://pki.backup.com/SparklingRoot.crl
+
+ [ocsp_section]
+ caIssuers;URI.0 = http://pki.sparklingca.com/SparklingRoot.crt
+ caIssuers;URI.1 = http://pki.backup.com/SparklingRoot.crt
+ OCSP;URI.0 = http://pki.sparklingca.com/ocsp/
+ OCSP;URI.1 = http://pki.backup.com/ocsp/
+
+如果你需要设置某个特定的证书生效/过期日期,请添加以下内容到`[myca]`:
+
+ # format: YYYYMMDDHHMMSS
+ default_enddate = 20191222035911
+ default_startdate = 20181222035911
+
+### 创建中间 CA###
+
+生成中间 CA (名为 intermediate1)的私钥:
+
+ openssl genrsa -out intermediate1.key 4096
+
+生成中间 CA 的 CSR:
+
+ openssl req -new -sha256 -key intermediate1.key -out intermediate1.csr
+
+样例输出:
+
+ You are about to be asked to enter information that will be incorporated
+ into your certificate request.
+ What you are about to enter is what is called a Distinguished Name or a DN.
+ There are quite a few fields but you can leave some blank
+ For some fields there will be a default value,
+ If you enter '.', the field will be left blank.
+ -----
+ Country Name (2 letter code) [AU]:NL
+ State or Province Name (full name) [Some-State]:Zuid Holland
+ Locality Name (eg, city) []:Rotterdam
+ Organization Name (eg, company) [Internet Widgits Pty Ltd]:Sparkling Network
+ Organizational Unit Name (eg, section) []:Sparkling CA
+ Common Name (e.g. server FQDN or YOUR name) []:Sparkling Intermediate CA
+ Email Address []:
+
+ Please enter the following 'extra' attributes
+ to be sent with your certificate request
+ A challenge password []:
+ An optional company name []:
+
+确保中间 CA 的主体(CN)和根 CA 不同。
+
+用根 CA 签署 中间 CA 的 CSR:
+
+ openssl ca -batch -config ca.conf -notext -in intermediate1.csr -out intermediate1.crt
+
+样例输出:
+
+ Using configuration from ca.conf
+ Check that the request matches the signature
+ Signature ok
+ The Subject's Distinguished Name is as follows
+ countryName :PRINTABLE:'NL'
+ stateOrProvinceName :ASN.1 12:'Zuid Holland'
+ localityName :ASN.1 12:'Rotterdam'
+ organizationName :ASN.1 12:'Sparkling Network'
+ organizationalUnitName:ASN.1 12:'Sparkling CA'
+ commonName :ASN.1 12:'Sparkling Intermediate CA'
+ Certificate is to be certified until Mar 30 15:07:43 2017 GMT (730 days)
+
+ Write out database with 1 new entries
+ Data Base Updated
+
+生成 CRL(同时采用 PEM 和 DER 格式):
+
+ openssl ca -config ca.conf -gencrl -keyfile rootca.key -cert rootca.crt -out rootca.crl.pem
+
+ openssl crl -inform PEM -in rootca.crl.pem -outform DER -out rootca.crl
+
+每次使用该 CA 签署证书后,请生成 CRL。
+
+如果你需要撤销该中间证书:
+
+ openssl ca -config ca.conf -revoke intermediate1.crt -keyfile rootca.key -cert rootca.crt
+
+### 配置中间 CA ###
+
+为该中间 CA 创建一个新文件夹,然后进入该文件夹:
+
+ mkdir ~/SSLCA/intermediate1/
+ cd ~/SSLCA/intermediate1/
+
+从根 CA 拷贝中间证书和密钥:
+
+ cp ~/SSLCA/root/intermediate1.key ./
+ cp ~/SSLCA/root/intermediate1.crt ./
+
+创建索引文件:
+
+ touch certindex
+ echo 1000 > certserial
+ echo 1000 > crlnumber
+
+创建一个新的 `ca.conf` 文件:
+
+ # vim ca.conf
+ [ ca ]
+ default_ca = myca
+
+ [ crl_ext ]
+ issuerAltName=issuer:copy
+ authorityKeyIdentifier=keyid:always
+
+ [ myca ]
+ dir = ./
+ new_certs_dir = $dir
+ unique_subject = no
+ certificate = $dir/intermediate1.crt
+ database = $dir/certindex
+ private_key = $dir/intermediate1.key
+ serial = $dir/certserial
+ default_days = 365
+ default_md = sha1
+ policy = myca_policy
+ x509_extensions = myca_extensions
+ crlnumber = $dir/crlnumber
+ default_crl_days = 365
+
+ [ myca_policy ]
+ commonName = supplied
+ stateOrProvinceName = supplied
+ countryName = optional
+ emailAddress = optional
+ organizationName = supplied
+ organizationalUnitName = optional
+
+ [ myca_extensions ]
+ basicConstraints = critical,CA:FALSE
+ keyUsage = critical,any
+ subjectKeyIdentifier = hash
+ authorityKeyIdentifier = keyid:always,issuer
+ keyUsage = digitalSignature,keyEncipherment
+ extendedKeyUsage = serverAuth
+ crlDistributionPoints = @crl_section
+ subjectAltName = @alt_names
+ authorityInfoAccess = @ocsp_section
+
+ [alt_names]
+ DNS.0 = example.com
+ DNS.1 = example.org
+
+ [crl_section]
+ URI.0 = http://pki.sparklingca.com/SparklingIntermidiate1.crl
+ URI.1 = http://pki.backup.com/SparklingIntermidiate1.crl
+
+ [ocsp_section]
+ caIssuers;URI.0 = http://pki.sparklingca.com/SparklingIntermediate1.crt
+ caIssuers;URI.1 = http://pki.backup.com/SparklingIntermediate1.crt
+ OCSP;URI.0 = http://pki.sparklingca.com/ocsp/
+ OCSP;URI.1 = http://pki.backup.com/ocsp/
+
+修改 `[alt_names]` 部分,添加你需要的主体备选名。如果你不需要主体备选名,请移除该部分包括`subjectAltName = @alt_names`的行。
+
+如果你需要设置一个指定的生效/到期日期,请添加以下内容到 `[myca]`:
+
+ # format: YYYYMMDDHHMMSS
+ default_enddate = 20191222035911
+ default_startdate = 20181222035911
+
+生成一个空白 CRL(同时以 PEM 和 DER 格式):
+
+ openssl ca -config ca.conf -gencrl -keyfile rootca.key -cert rootca.crt -out rootca.crl.pem
+
+ openssl crl -inform PEM -in rootca.crl.pem -outform DER -out rootca.crl
+
+### 生成末端用户证书 ###
+
+我们使用这个新的中间 CA 来生成一个末端用户证书,请重复以下操作来使用该 CA 为每个用户签署。
+
+ mkdir enduser-certs
+
+生成末端用户的私钥:
+
+ openssl genrsa -out enduser-certs/enduser-example.com.key 4096
+
+生成末端用户的 CSR:
+
+ openssl req -new -sha256 -key enduser-certs/enduser-example.com.key -out enduser-certs/enduser-example.com.csr
+
+样例输出:
+
+ You are about to be asked to enter information that will be incorporated
+ into your certificate request.
+ What you are about to enter is what is called a Distinguished Name or a DN.
+ There are quite a few fields but you can leave some blank
+ For some fields there will be a default value,
+ If you enter '.', the field will be left blank.
+ -----
+ Country Name (2 letter code) [AU]:NL
+ State or Province Name (full name) [Some-State]:Noord Holland
+ Locality Name (eg, city) []:Amsterdam
+ Organization Name (eg, company) [Internet Widgits Pty Ltd]:Example Inc
+ Organizational Unit Name (eg, section) []:IT Dept
+ Common Name (e.g. server FQDN or YOUR name) []:example.com
+ Email Address []:
+
+ Please enter the following 'extra' attributes
+ to be sent with your certificate request
+ A challenge password []:
+ An optional company name []:
+
+使用中间 CA 签署末端用户的 CSR:
+
+ openssl ca -batch -config ca.conf -notext -in enduser-certs/enduser-example.com.csr -out enduser-certs/enduser-example.com.crt
+
+样例输出:
+
+ Using configuration from ca.conf
+ Check that the request matches the signature
+ Signature ok
+ The Subject's Distinguished Name is as follows
+ countryName :PRINTABLE:'NL'
+ stateOrProvinceName :ASN.1 12:'Noord Holland'
+ localityName :ASN.1 12:'Amsterdam'
+ organizationName :ASN.1 12:'Example Inc'
+ organizationalUnitName:ASN.1 12:'IT Dept'
+ commonName :ASN.1 12:'example.com'
+ Certificate is to be certified until Mar 30 15:18:26 2016 GMT (365 days)
+
+ Write out database with 1 new entries
+ Data Base Updated
+
+生成 CRL(同时以 PEM 和 DER 格式):
+
+ openssl ca -config ca.conf -gencrl -keyfile intermediate1.key -cert intermediate1.crt -out intermediate1.crl.pem
+
+ openssl crl -inform PEM -in intermediate1.crl.pem -outform DER -out intermediate1.crl
+
+每次你使用该 CA 签署证书后,都需要生成 CRL。
+
+如果你需要撤销该末端用户证书:
+
+ openssl ca -config ca.conf -revoke enduser-certs/enduser-example.com.crt -keyfile intermediate1.key -cert intermediate1.crt
+
+样例输出:
+
+ Using configuration from ca.conf
+ Revoking Certificate 1000.
+ Data Base Updated
+
+通过连接根证书和中间证书来创建证书链文件。
+
+ cat ../root/rootca.crt intermediate1.crt > enduser-certs/enduser-example.com.chain
+
+发送以下文件给末端用户:
+
+ enduser-example.com.crt
+ enduser-example.com.key
+ enduser-example.com.chain
+
+你也可以让末端用户提供他们自己的 CSR,而只发送给他们这个 .crt 文件。不要把它从服务器删除,否则你就不能撤销了。
+
+### 校验证书 ###
+
+你可以对证书链使用以下命令来验证末端用户证书:
+
+ openssl verify -CAfile enduser-certs/enduser-example.com.chain enduser-certs/enduser-example.com.crt
+ enduser-certs/enduser-example.com.crt: OK
+
+你也可以针对 CRL 来验证。首先,将 PEM 格式的 CRL 和证书链相连接:
+
+ cat ../root/rootca.crt intermediate1.crt intermediate1.crl.pem > enduser-certs/enduser-example.com.crl.chain
+
+验证证书:
+
+ openssl verify -crl_check -CAfile enduser-certs/enduser-example.com.crl.chain enduser-certs/enduser-example.com.crt
+
+没有撤销时的输出:
+
+ enduser-certs/enduser-example.com.crt: OK
+
+撤销后的输出如下:
+
+ enduser-certs/enduser-example.com.crt: CN = example.com, ST = Noord Holland, C = NL, O = Example Inc, OU = IT Dept
+ error 23 at 0 depth lookup:certificate revoked
+
+--------------------------------------------------------------------------------
+
+via: https://raymii.org/s/tutorials/OpenSSL_command_line_Root_and_Intermediate_CA_including_OCSP_CRL%20and_revocation.html
+
+作者:Remy van Elst
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/201505/20150512 Guake 0.7.0 Released--A Drop-Down Terminal for Gnome Desktops.md b/published/201505/20150512 Guake 0.7.0 Released--A Drop-Down Terminal for Gnome Desktops.md
new file mode 100644
index 0000000000..421bc00a0b
--- /dev/null
+++ b/published/201505/20150512 Guake 0.7.0 Released--A Drop-Down Terminal for Gnome Desktops.md
@@ -0,0 +1,121 @@
+一个用于Gnome桌面的下拉式终端: Guake 0.7.0 发布
+================================================================================
+Linux的命令行是最好、最强大的东西,它使新手着迷,并为老手和极客的提供极其强大的功能。那些在服务器和生产环境下工作的人早已认识到了这个事实。有趣的是,Linux终端是Linus Torvald在1991年写内核时实现的第一批功能之一。
+
+终端是个强大的工具,由于它没有什么可调整的部分,所以十分可靠。终端介于控制台环境和GUI环境之间。终端自身作为一个GUI程序,运行在桌面环境下。有许多终端是适用于特定的桌面环境的,其它的则是通用的。Terminator, Konsole, Gnome-Terminal, Terminology, XFCE terminal, xterm都是些常用的终端模拟器。
+
+您可以从下面的链接中获得一份使用最广泛的终端模拟器的列表。
+
+- [20 Useful Terminals for Linux][1]
+
+前几日上网时,我偶遇了名为‘Guake’的终端程序,它是用于gnome的终端模拟器。尽管这并不是我第一次听到Guake。实际上,我在大约一年前便知道了这个应用程序,但不知怎么搞的,我那时没有写写Guake,再后来我便渐渐忘掉了Guake,直到我再一次听到Guake。所以,最终,这篇文章诞生了。我将给你讲讲Guake的功能,在Debian、Ubuntu、Fedora上的安装过程以及一些测试。
+
+#### 什么是Guake? ####
+
+Guake是应用于Gnome环境的下拉式终端。主要由Python编写,使用了一些C,它以GPL2+许可证发布,适用于Linux以及类似的系统。Guake的灵感来源于电脑游戏Quake(雷神之锤)中的终端,Quake的终端能通过按下特定按键(默认为F12)从屏幕上滑下来,并在按下同样的键后滑上去。
+
+值得注意的是,Guake并不是第一个这样的应用。Yakuake(Yet Another Kuake)是一个运行于KDE的终端模拟器,Tilda是一个用GTK+写成的终端模拟器。它们的灵感都来自于雷神之锤那上下滑动的终端。
+
+#### Guake的功能 ####
+
+- 轻量级
+- 简单而优雅
+- 功能众多
+- 强大
+- 美观
+- 将终端平滑地集成于GUI中
+- 在按下预定义的键后出现/消失
+- 支持热键、标签、透明化背景,这使得它适合所有Gnome用户
+- 可配置各种方面
+- 包括许多颜色的调色板
+- 设定透明度的快捷方式
+- 通过Guake配置,可在启动时运行一个脚本
+- 可以在多个显示器上运行
+
+Guake 0.7.0最近发布,它带来了一些修正以及上面提到的一些功能。完整的版本历史和源代码包可以在[这里][2]找到。
+
+### 在Linux中安装Guake终端 ###
+
+如果您对从源码编译Guake感兴趣,您可以从上面的链接处下载Guake,并在安装前进行编译。
+
+然而Guake可以在许多的发行版中通过添加额外的仓库来安装。这里,我们将在Debian、Ubuntu、Linux Mint和Fedora下安装Guake。
+
+首先从仓库获取最新的软件包列表,并从默认的仓库安装Guake,如下所示:
+
+ ---------------- 在 Debian, Ubuntu 和 Linux Mint 上 ----------------
+ $ sudo apt-get update
+ $ apt-get install guake
+
+----------
+
+ ---------------- 在 Fedora 19 及其以后版本 ----------------
+ # yum update
+ # yum install guake
+
+安装后,可以从另一个终端中启动Guake:
+
+ $ guake
+
+在启动它后,便可以在Gnome桌面中使用F12(默认配置)来拉下、收回终端。
+
+看起来非常漂亮,尤其是透明背景。滑下来...滑上去...滑下来...滑上去...执行命令,打开另一个标签,执行命令,滑上去...滑下来...(作者已沉迷其中)
+
+
+
+*Guake实战*
+
+如果您的壁纸或活动窗口的颜色和Guake的颜色有些不搭。您可以改变您的壁纸,减少透明度或者改变Guake的颜色。
+
+下一步便是进入Guake的配置,根据每个人的需求修改设置。可以通过应用菜单或者下面的命令来运行Guake的配置。
+
+ $ guake --preferences
+
+
+
+*Guake终端配置*
+
+设置滚动
+
+
+
+*Guake滚动配置*
+
+外观设置 - 在这里您可以修改文字颜色和背景色以及透明度。
+
+
+
+*外观设置*
+
+键盘快捷键 - 在这里您可以修改Guake显示的开关快捷键。
+
+
+
+*键盘快捷键*
+
+兼容性设置 - 基本上不必设置它。
+
+
+
+*兼容性设置*
+
+### 结论 ###
+
+这个项目即不是太年轻也不是太古老,因此它已经达到了一定的成熟度,足够可靠,可以开箱即用。像我这样需要在GUI和终端间频繁切换的人来说,Guake是一个福利。我不需要管理一个多余的窗口,频繁的打开和关闭,使用tab在大量打开的应用程序中寻找终端或切换到不同的工作区来管理终端,现在我需要的只有F12。
+
+我认为对任何同时使用GUI和终端的Linux用户来说,Guake都是必须的工具。同样的,我会向任何想要在系统中结合使用GUI和终端的人推荐它,因为它既平滑又没有任何障碍。
+
+上面就是我要说的全部了。如果在安装和使用时有任何问题,请告诉我,我们会帮助您。也请您告诉我您使用Guake的经验。在下面的评论区反馈您宝贵的经验。点赞和分享以帮助我们宣传。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-guake-terminal-ubuntu-mint-fedora/
+
+作者:[Avishek Kumar][a]
+译者:[wwy-hust](https://github.com/wwy-hust)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/linux-terminal-emulators/
+[2]:https://github.com/Guake/guake/releases/tag/0.7.0
diff --git a/published/201505/20150515 New to Linux 5 Apps You Didn't Know You Were Missing.md b/published/201505/20150515 New to Linux 5 Apps You Didn't Know You Were Missing.md
new file mode 100644
index 0000000000..1d34cda0f4
--- /dev/null
+++ b/published/201505/20150515 New to Linux 5 Apps You Didn't Know You Were Missing.md
@@ -0,0 +1,105 @@
+初来乍到Linux? 你需要知道的5款好应用
+================================================================================
+
+
+当你刚刚迈入linux的世界时,你会立马动身开始使用那些知名的浏览器、云客户端、音乐播放器、邮件客户端,也许还有图形编辑器,对吗?可是,你却错过了几个非常重要的生产工具。这里将介绍给你5个应该安装的不容错过的应用。
+
+### [Synergy][1] ###
+
+Synergy 简直就是多桌面用户的福音。这是一个开源软件,它可以让你用一个鼠标和键盘跨越几台电脑、显示器和操作系统。在桌面之间切换鼠标和键盘非常简单,你只要把鼠标从一个桌面的边缘移向另一个桌面即可。
+
+
+
+当你第一次打开 Synergy,它会引导你完成设置。你的主桌面就是你将与其它桌面共享输入设备的那个。将主桌面设为服务端,将其它桌面设置为客户端。
+
+
+
+Synergy 在互连的各个桌面间维持同一张粘贴板。它也将锁屏功能融合到了一起,例如,你可以跳过锁屏一次登录到所有桌面。你可以在 **Edit 菜单的 Setting** 下调整更多的设置,比如设置密码或者将 Synergy 设置成开机自启动。
+
+(LCTT 译注:这是个[自由而开源][15]的好软件,但是如果你从它的网站下载,由于商业支持的缘故,是需要付费的;当然你可以自己[下载源代码并编译][15]。)
+
+### [BasKet Note Pads][2] ###
+
+从某种意义上来讲,用 BasKet Note Pads,就像把你的大脑刻画进计算机里一样。它把我们不经意间的想法记录下来,然后任由我们去把它们组织起来。你可以在各种任务中用到 BasKet Note Pads,比如记录笔记、制作脑图、记录代办事项、保存链接、管理你的发现、或者追踪项目数据。
+
+在 BasKet Note Pads 中,每个放到一个区域的主要的想法或项目被称作一个篮子(basket)。你可以进一步拆分,成一个或多个子篮或者兄弟篮。篮子进一步分成笔记,这些零零碎碎的笔记组成了一个项目。你可以自由组织它们,给它们打标签,和筛选它们。
+
+该应用的双面板结构的左侧以树形结构显示了你创建的所有篮子。
+
+
+
+BasKet Note Pads 第一次用起来可能有点复杂,但是如果你经常用它的话,你会觉得相当顺手。当你暂时不用它时,它会退出到系统托盘,方便你下次快速打开它。
+
+如果在 Linux 上想要一个[更简单的笔记本替代品][3]?可以试试[Springseed][4]。
+
+### [Caffeine(咖啡因)][5]###
+
+你怎样确保你的电脑不会在放一部[精彩的电影][6]中途突然休眠呢?Caffeine 会帮助你解决这个问题。当然,你并不需要为你的电脑泡一杯咖啡。你只需要安装一个轻量级的指示器 —— Caffeine。只要当前你是全屏模式,它就会禁用你的屏幕保护程序、锁屏程序,让你的电脑不会因为没有在任务中而进入睡眠模式。
+
+[点击下载][7]安装最新版本的 Caffeine。如果你想以[PPA的方式][8]安装,使用如下命令:
+
+ $ sudo add-apt-repository ppa:caffeine-developers/ppa
+ $ sudo apt-get update
+ $ sudo apt-get install caffeine
+
+如果你的Ubuntu版本是14.10或者15.04(或者其它衍生版本),你还需要安装下面的依赖包:
+
+ $ sudo apt-get install libappindicator3-1 gir1.2-appindicator3-0.1
+
+完成安装以后,将**Caffeine指示器**设置成开机自启动,这样可以使指示器显示在系统托盘里。你可以右键点击托盘图标打开应用的关联菜单,来开启或关闭Caffeine,
+
+
+
+### Easystroke ###
+
+Easystroke 是一个将[鼠标潜力][9]开发出来的应用。通过一系列的设置,用鼠标、触摸屏、手写笔的手势来完成敲击键盘、执行命令和滚动屏幕等通用操作。在 Easystroke 里能够设置的手势相当多,而且当你看到应用的界面时,你会发现应用的引导非常清晰。
+
+
+
+选择一个你喜欢的鼠标键开始设置手势。如果你喜欢,你还可以设置辅助功能键。通过Perferences>Behavior>Gesture Button 来设置。现在到**Action**选项卡里面,把你最常用的动作记录成手势吧。
+
+
+
+在 Preferences 和 Advanced 选项卡中,你可以做一些其它的调整,比如将 EasyStroke 设置成自动启动,在系统托盘中显示图标,改变滚动速度。
+
+### Guake ###
+
+我把我最喜欢的应用放在最后。Guake 是根据第一人称射击视屏游戏 [Quake][10] 模仿而来的下拉式命令行终端。不管你是否在[学习命令行终端][11],或者是有一定的基础,Guake 都可以将终端变得更加方便。你可以一键将它呼出,也可以一键将它隐藏。
+
+就像下面这张图,当打开时,Guake 的界面会覆盖在当前的屏幕上。你可以在终端中右键点击,调出 Preference 来改变 Guake 的界面,滚动方式,快捷键等等。
+
+
+
+如果[你的桌面][12]是 KDE,你可以选择一个类似的工具——[Yakuake][13].
+
+### 写下你最喜欢的Linux新发现!###
+
+还有更多[超级实用的 Linux 应用][14]等待被发现。放心,我们将一直关注,并把它们带到你们的生活中。
+
+哪一个应用是你最喜欢研究的呢?哪一个是你觉得必不可少的呢?在评论里告诉给我们吧。
+
+--------------------------------------------------------------------------------
+
+via: http://www.makeuseof.com/tag/new-linux-5-apps-didnt-know-missing/
+
+作者:[Akshata][a]
+译者:[sevenot](https://github.com/sevenot)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.makeuseof.com/tag/author/akshata/
+[1]:http://synergy-project.org/
+[2]:http://basket.kde.org/
+[3]:http://www.makeuseof.com/tag/try-these-3-beautiful-note-taking-apps-that-work-offline/
+[4]:http://getspringseed.com/
+[5]:https://launchpad.net/caffeine
+[6]:http://www.makeuseof.com/tag/popular-apps-movies-according-google/
+[7]:http://ppa.launchpad.net/caffeine-developers/ppa/ubuntu/pool/main/c/caffeine/
+[8]:http://www.makeuseof.com/tag/ubuntu-ppa-technology-explained/
+[9]:http://www.makeuseof.com/tag/4-astounding-linux-mouse-hacks/
+[10]:http://en.wikipedia.org/wiki/Quake_%28video_game%29
+[11]:http://www.makeuseof.com/tag/4-ways-teach-terminal-commands-linux-si/
+[12]:http://www.makeuseof.com/tag/10-top-linux-desktop-environments-available/
+[13]:https://yakuake.kde.org/
+[14]:http://www.makeuseof.com/tag/linux-treasures-x-sublime-native-linux-apps-will-make-want-switch/
diff --git a/published/201505/20150518 Linux FAQs with Answers--How to block specific user agents on nginx web server.md b/published/201505/20150518 Linux FAQs with Answers--How to block specific user agents on nginx web server.md
new file mode 100644
index 0000000000..16bc2060fb
--- /dev/null
+++ b/published/201505/20150518 Linux FAQs with Answers--How to block specific user agents on nginx web server.md
@@ -0,0 +1,115 @@
+Linux有问必答:nginx网络服务器上如何阻止特定用户代理(UA)
+================================================================================
+> **问题**: 我注意到有一些机器人经常访问我的nginx驱动的网站,并且进行一些攻击性的扫描,导致消耗掉了我的网络服务器的大量资源。我一直尝试着通过用户代理符串来阻挡这些机器人。我怎样才能在nginx网络服务器上阻挡掉特定的用户代理呢?
+
+现代互联网滋生了大量各种各样的恶意机器人和网络爬虫,比如像恶意软件机器人、垃圾邮件程序或内容刮刀,这些恶意工具一直偷偷摸摸地扫描你的网站,干些诸如检测潜在网站漏洞、收获电子邮件地址,或者只是从你的网站偷取内容。大多数机器人能够通过它们的“用户代理”签名字符串来识别。
+
+作为第一道防线,你可以尝试通过将这些机器人的用户代理字符串添加入robots.txt文件来阻止这些恶意软件机器人访问你的网站。但是,很不幸的是,该操作只针对那些“行为良好”的机器人,这些机器人被设计遵循robots.txt的规范。许多恶意软件机器人可以很容易地忽略掉robots.txt,然后随意扫描你的网站。
+
+另一个用以阻挡特定机器人的途径,就是配置你的网络服务器,通过特定的用户代理字符串拒绝要求提供内容的请求。本文就是说明如何**在nginx网络服务器上阻挡特定的用户代理**。
+
+### 在Nginx中将特定用户代理列入黑名单 ###
+
+要配置用户代理阻挡列表,请打开你的网站的nginx配置文件,找到`server`定义部分。该文件可能会放在不同的地方,这取决于你的nginx配置或Linux版本(如,`/etc/nginx/nginx.conf`,`/etc/nginx/sites-enabled/`,`/usr/local/nginx/conf/nginx.conf`,`/etc/nginx/conf.d/`)。
+
+ server {
+ listen 80 default_server;
+ server_name xmodulo.com;
+ root /usr/share/nginx/html;
+
+ ....
+ }
+
+在打开该配置文件并找到 `server` 部分后,添加以下 if 声明到该部分内的某个地方。
+
+ server {
+ listen 80 default_server;
+ server_name xmodulo.com;
+ root /usr/share/nginx/html;
+
+ # 大小写敏感的匹配
+ if ($http_user_agent ~ (Antivirx|Arian) {
+ return 403;
+ }
+
+ #大小写无关的匹配
+ if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
+ return 403;
+ }
+
+ ....
+ }
+
+如你所想,这些 if 声明使用正则表达式匹配了任意不良用户字符串,并向匹配的对象返回403 HTTP状态码。
+`$http_user_agent`是HTTP请求中的一个包含有用户代理字符串的变量。‘~’操作符针对用户代理字符串进行大小写敏感匹配,而‘~*’操作符则进行大小写无关匹配。‘|’操作符是逻辑或,因此,你可以在 if 声明中放入众多的用户代理关键字,然后将它们全部阻挡掉。
+
+在修改配置文件后,你必须重新加载nginx以激活阻挡:
+
+ $ sudo /path/to/nginx -s reload
+
+你可以通过使用带有 “--user-agent” 选项的 wget 测试用户代理阻挡。
+
+ $ wget --user-agent "malicious bot" http://
+
+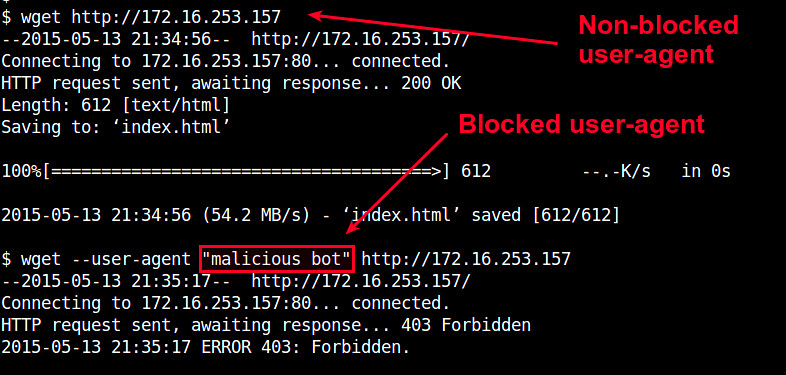
+
+### 管理Nginx中的用户代理黑名单 ###
+
+目前为止,我已经展示了在nginx中如何阻挡一些用户代理的HTTP请求。如果你有许多不同类型的网络爬虫机器人要阻挡,又该怎么办呢?
+
+由于用户代理黑名单会增长得很大,所以将它们放在nginx的server部分不是个好点子。取而代之的是,你可以创建一个独立的文件,在该文件中列出所有被阻挡的用户代理。例如,让我们创建/etc/nginx/useragent.rules,并定义以下面的格式定义所有被阻挡的用户代理的图谱。
+
+ $ sudo vi /etc/nginx/useragent.rules
+
+----------
+
+ map $http_user_agent $badagent {
+ default 0;
+ ~*malicious 1;
+ ~*backdoor 1;
+ ~*netcrawler 1;
+ ~Antivirx 1;
+ ~Arian 1;
+ ~webbandit 1;
+ }
+
+与先前的配置类似,‘~*’将匹配以大小写不敏感的方式匹配关键字,而‘~’将使用大小写敏感的正则表达式匹配关键字。“default 0”行所表达的意思是,任何其它文件中未被列出的用户代理将被允许。
+
+接下来,打开你的网站的nginx配置文件,找到里面包含 http 的部分,然后添加以下行到 http 部分某个位置。
+
+ http {
+ .....
+ include /etc/nginx/useragent.rules
+ }
+
+注意,该 include 声明必须出现在 server 部分之前(这就是为什么我们将它添加到了 http 部分里)。
+
+现在,打开nginx配置定义你的服务器的部分,添加以下 if 声明:
+
+ server {
+ ....
+
+ if ($badagent) {
+ return 403;
+ }
+
+ ....
+ }
+
+最后,重新加载nginx。
+
+ $ sudo /path/to/nginx -s reload
+
+现在,任何包含有`/etc/nginx/useragent.rules`中列出的关键字的用户代理将被nginx自动禁止。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/block-specific-user-agents-nginx-web-server.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/published/201505/20150518 Linux FAQs with Answers--How to fix 'fatal error--security or pam_modules.h--No such file or directory'.md b/published/201505/20150518 Linux FAQs with Answers--How to fix 'fatal error--security or pam_modules.h--No such file or directory'.md
new file mode 100644
index 0000000000..6ede2366a8
--- /dev/null
+++ b/published/201505/20150518 Linux FAQs with Answers--How to fix 'fatal error--security or pam_modules.h--No such file or directory'.md
@@ -0,0 +1,33 @@
+如何修复 “fatal error: security/pam_modules.h: No such file or directory”
+================================================================================
+> **问题**: 我尝试在 [某某 Linux 发行版] 上编译程序,但是出现下面的编译错误:
+>
+> "pam_otpw.c:27:34: fatal error: security/pam_modules.h: No such file or directory"
+>
+> 我怎样才能修复这个错误?
+
+缺失的头文件 'security/pam_modules.h' 是 libpam 开发版的一部分,一个 PAM(Pluggable Authentication Modules:插入式验证模块)库。因此要修复这个错误,你需要安装 libpam 开发包,如下所示。
+
+对于 Debian、 Ubuntu 或者 Linux Mint:
+
+ $ sudo apt-get install libpam0g-dev
+
+对与 CentOS、 Fedora 或者 RHEL:
+
+ $ sudo yum install gcc pam-devel
+
+现在验证缺失的头文件是否安装到了 /usr/include/security。
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/fatal-error-security-pam-modules.html
+
+作者:[Dan Nanni][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
\ No newline at end of file
diff --git a/published/201505/20150521 Microsoft Open-Sources The Windows Communication Foundation.md b/published/201505/20150521 Microsoft Open-Sources The Windows Communication Foundation.md
new file mode 100644
index 0000000000..bf071f9c5d
--- /dev/null
+++ b/published/201505/20150521 Microsoft Open-Sources The Windows Communication Foundation.md
@@ -0,0 +1,26 @@
+微软开源了WCF框架
+================================================================================
+微软于今日(2015/5/20)宣布了针对 .NET Core 重大开源:WCF(Windows Communication Foundation)。
+
+如[MSDN][1]中的描述:“WCF是一个构建面向服务应用的框架。使用WCF,你可以从一个服务终端给另一个发送异步消息。服务终端可以是托管在IIS中连续可用的服务的一部分,也可以是托管在某个程序上的服务。服务终端可以是请求服务端数据的客户端。消息可以是一个字符或者XML,也可以是复杂的二进制流。”
+
+它的[代码放在GitHub][2],“包含了Window桌面中完整WCF框架的一部分,它支持已经可用于构建Window Store上的WCF应用的库。这些主要是基于客户端,方便移动设备和中间层服务器使用WCF进行通信。”
+
+更多的关于微软开源 WCF 的细节查看[dotNETFoundation.org blog][3]的公告。
+
+WCF听上去有点像Linux中用于进程/服务之间的进程间通讯的D-BUS。
+
+--------------------------------------------------------------------------------
+
+via: http://www.phoronix.com/scan.php?page=news_item&px=Microsoft-Open-Source-WCF
+
+作者:[Michael Larabel][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.michaellarabel.com/
+[1]:https://msdn.microsoft.com/en-us/library/ms731082%28v=vs.110%29.aspx
+[2]:https://github.com/dotnet/wcf
+[3]:http://www.dotnetfoundation.org/blog/wcf-is-open-source
\ No newline at end of file
diff --git a/published/201505/20150527 Ubuntu Community Council Asks the Kubuntu Project Leader to Step Down.md b/published/201505/20150527 Ubuntu Community Council Asks the Kubuntu Project Leader to Step Down.md
new file mode 100644
index 0000000000..a47014fc9b
--- /dev/null
+++ b/published/201505/20150527 Ubuntu Community Council Asks the Kubuntu Project Leader to Step Down.md
@@ -0,0 +1,33 @@
+Ubuntu 社区委员会要求 Kubuntu 项目领导人下台
+================================================================================
+> 而Jonathan Riddell拒绝从Kubuntu领导人位置退出
+
+
+
+**这一切刚刚发生。一名Debian开发者以及Kubuntu委员会成员 Scott Kitterman 决定公开一些电子邮件,邮件披露了Ubuntu 社区委员会成员要求 Jonathan Riddell 从 Kubuntu 项目领导人位置退出的过程。**
+
+Jonathan Riddell 是 KDE 以及 Kubuntu 的一名开发者,多年来也是 Ubuntu 社区的一名重要成员。从 Scott Kitterman [今天曝光的社区邮件往来][1]中来看,Jonathan Riddell 被指责对 Ubuntu 以及 Kubuntu 社区的一些成员咄咄逼人和挑衅。
+
+长话短说,经过多轮邮件往来之后,Ubuntu 社区委员会的最终决定是让 Jonathan Riddell 退出他在 Ubuntu 以及Kubuntu 社区的领导人位置至少12个月,但仍可以像其他成员一样参与讨论。这个决定同时也得到了 Canonical 和Ubuntu 的创始人 Mark Shuttleworth 的支持。
+
+“很遗憾写下了讨论这个我们觉得对 Ubuntu 社区有着消极影响的问题的邮件。长期以来,Jonathan Riddell 变得越来越难以交往。Jonathan 提出了有效的问题及关注,但当收到他不赞同的答案时,他的反应就不那么让人愉快了。”在 Ubuntu 社区委员会发出的第一封认为 Jonathan Riddell 行为“不友好”的邮件中这么写道。
+
+### Jonathan Riddell拒绝从Kubuntu领导人位置退出 ###
+
+从今天 Scott Kitterman 披露邮件往来,并决定在博客上写第二篇博文来看,表明了他想从他在 Ubuntu 和 Kubuntu 的位置退出,这表明 Jonathan Riddell 可能拒绝从 Kubuntu 领导人位置退出。
+
+正如预料之中,Kubuntu 社区委员会的成员们支持 Jonathan Riddell,并且回击了 Ubuntu 社区委员会罢免 Kubuntu 项目领导人的决定。“我要感谢所有在 Kubuntu 委员会投票再次肯定我的 Kubuntu 成员。”,Jonathan Riddell 在[他的博客][2]上写道,“希望 Kubuntu 能够继续走下去,我也计划和我深爱的社区伙伴们一起为 15.10 发布而努力。”
+
+--------------------------------------------------------------------------------
+
+via: http://news.softpedia.com/news/Ubuntu-Community-Council-Asks-the-Kubuntu-Project-Leader-to-Step-Down-482384.shtml
+
+作者:[Marius Nestor][a]
+译者:[alim0x](https://github.com/alim0x)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/marius-nestor
+[1]:https://skitterman.wordpress.com/
+[2]:http://jriddell.org/
diff --git a/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--4.md b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--4.md
new file mode 100644
index 0000000000..b6d7ae7f10
--- /dev/null
+++ b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--4.md
@@ -0,0 +1,190 @@
+安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(四)
+================================================================================
+### 17. 安装 Webmin ###
+
+Webmin 是基于 Web 的 Linux 配置工具。它像一个中央系统,用于配置各种系统设置,比如用户、磁盘分配、服务以及 HTTP 服务器、Apache、MySQL 等的配置。
+
+ # wget http://prdownloads.sourceforge.net/webadmin/webmin-1.740-1.noarch.rpm
+ # rpm -ivh webmin-*.rpm
+
+
+
+*安装 Webmin*
+
+安装完 webmin 后,你会在终端上得到一个消息,提示你用 root 密码在端口 10000 登录你的主机 (http://ip-address:10000)。 如果运行的是无接口的服务器你可以转发端口然后从有接口的服务器上访问它。(LCTT 译注:无接口[headless]服务器指没有访问接口或界面的服务器,在此次场景,指的是是出于内网的服务器,可采用外网/路由器映射来访问该端口)
+
+### 18. 启用第三方库 ###
+
+添加不受信任的库并不是一个好主意,尤其是在生产环境中,这可能导致致命的问题。但仅作为例子在这里我们会添加一些社区证实可信任的库,以安装第三方工具和软件包。
+
+为企业版 Linux(EPEL)库添加额外的软件包。
+
+ # yum install epel-release
+
+添加社区企业版 Linux (Community Enterprise Linux)库:
+
+ # rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
+
+
+
+*安装 Epel 库*
+
+**注意!** 添加第三方库的时候尤其需要注意。
+
+### 19. 安装 7-zip 工具 ###
+
+在最小化安装 CentOS 时你并没有获得类似 unzip 或者 untar 的工具。我们可以选择根据需要来安装每个工具,或一个能处理所有格式的工具。7-zip 就是一个能压缩和解压所有已知类型文件的工具。
+
+ # yum install p7zip
+
+
+
+*安装 7zip 工具*
+
+**注意**: 该软件包从 Fedora EPEL 7 的库中下载和安装。
+
+### 20. 安装 NTFS-3G 驱动 ###
+
+NTFS-3G,一个很小但非常有用的 NTFS 驱动,在大部分类 UNIX 发行版上都可用。它对于挂载和访问 Windows NTFS 文件系统很有用。尽管也有其它可用的替代品,比如 Tuxera,但 NTFS-3G 是使用最广泛的。
+
+ # yum install ntfs-3g
+
+
+
+*安装 NTFS-3G 用于挂载 Windows 分区*
+
+ntfs-3g 安装完成之后,你可以使用以下命令挂载 Windows NTFS 分区(我的 Windows 分区是 /dev/sda5)。
+
+ # mount -ro ntfs-3g /dev/sda5 /mnt
+ # cd /mnt
+ # ls -l
+
+### 21. 安装 Vsftpd FTP 服务器 ###
+
+VSFTPD 表示 Very Secure File Transfer Protocol Daemon,是用于类 UNIX 系统的 FTP 服务器。它是现今最高效和安全的 FTP 服务器之一。
+
+ # yum install vsftpd
+
+
+
+*安装 Vsftpd FTP*
+
+编辑配置文件 ‘/etc/vsftpd/vsftpd.conf’ 用于保护 vsftpd。
+
+ # vi /etc/vsftpd/vsftpd.conf
+
+编辑一些值并使其它行保留原样,除非你知道自己在做什么。
+
+ anonymous_enable=NO
+ local_enable=YES
+ write_enable=YES
+ chroot_local_user=YES
+
+你也可以更改端口号,记得让 vsftpd 端口通过防火墙。
+
+ # firewall-cmd --add-port=21/tcp
+ # firewall-cmd --reload
+
+下一步重启 vsftpd 并启用开机自动启动。
+
+ # systemctl restart vsftpd
+ # systemctl enable vsftpd
+
+### 22. 安装和配置 sudo ###
+
+sudo 通常被称为 super do 或者 suitable user do,是一个类 UNIX 操作系统中用其它用户的安全权限执行程序的软件。让我们来看看怎样配置 sudo。
+
+ # visudo
+
+这会打开 /etc/sudoers 并进行编辑
+
+
+
+*sudoers 文件*
+
+1. 给一个已经创建好的用户(比如 tecmint)赋予所有权限(等同于 root)。
+
+ tecmint ALL=(ALL) ALL
+
+2. 如果给一个已经创建好的用户(比如 tecmint)赋予除了重启和关闭服务器以外的所有权限(等同于 root)。
+
+ 首先,再一次打开文件并编辑如下内容:
+
+ cmnd_Alias nopermit = /sbin/shutdown, /sbin/reboot
+
+ 然后,用逻辑操作符(!)添加该别名。
+
+ tecmint ALL=(ALL) ALL,!nopermit
+
+3. 如果准许一个组(比如 debian)运行一些 root 权限命令,比如(增加或删除用户)。
+
+ cmnd_Alias permit = /usr/sbin/useradd, /usr/sbin/userdel
+
+ 然后,给组 debian 增加权限。
+
+ debian ALL=(ALL) permit
+
+### 23. 安装并启用 SELinux ###
+
+SELinux 表示 Security-Enhanced Linux,是内核级别的安全模块。
+
+ # yum install selinux-policy
+
+
+
+*安装 SElinux 策略*
+
+查看 SELinux 当前模式。
+
+ # getenforce
+
+
+
+*查看 SELinux 模式*
+
+输出是 Enforcing,意味着 SELinux 策略已经生效。
+
+如果需要调试,可以临时设置 selinux 模式为允许。不需要重启。
+
+ # setenforce 0
+
+调试完了之后再次设置 selinux 为强制模式,无需重启。
+
+ # setenforce 1
+
+(LCTT 译注:在生产环境中,SELinux 固然会提升安全,但是也确实会给应用部署和运行带来不少麻烦。具体是否部署,需要根据情况而定。)
+
+### 24. 安装 Rootkit Hunter ###
+
+Rootkit Hunter,简写为 RKhunter,是在 Linux 系统中扫描 rootkits 和其它可能有害攻击的程序。
+
+ # yum install rkhunter
+
+
+
+*安装 Rootkit Hunter*
+
+在 Linux 中,从脚本文件以计划作业的形式运行 rkhunter 或者手动扫描有害攻击。
+
+ # rkhunter --check
+
+
+
+*扫描 rootkits*
+
+
+
+*RootKit 扫描结果*
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/4/
+
+作者:[Avishek Kumar][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
\ No newline at end of file
diff --git a/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--5.md b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--5.md
new file mode 100644
index 0000000000..446d6c663d
--- /dev/null
+++ b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--5.md
@@ -0,0 +1,140 @@
+安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(五)
+================================================================================
+### 25. 安装 Linux Malware Detect (LMD) ###
+
+Linux Malware Detect (LMD) 是 GNU GPLv2 协议下发布的开源 Linux 恶意程序扫描器,它是特别为面临威胁的主机环境所设计的。LMD 完整的安装、配置以及使用方法可以查看:
+
+- [安装 LMD 并和 ClamAV 一起使用作为反病毒引擎][1]
+
+### 26. 用 Speedtest-cli 测试服务器带宽 ###
+
+speedtest-cli 是用 python 写的用于测试网络下载和上传带宽的工具。关于 speedtest-cli 工具的完整安装和使用请阅读我们的文章[用命令行查看 Linux 服务器带宽][2]
+
+### 27. 配置 Cron 任务 ###
+
+这是最广泛使用的软件工具之一。它是一个任务调度器,比如,现在安排一个以后可以自动运行的作业。它用于未处理记录的日志和维护,以及其它日常工作,比如常规备份。所有的调度都写在文件 /etc/crontab 中。
+
+crontab 文件包含下面的 6 个域:
+
+ 分 时 日期 月份 星期 命令
+ (0-59) (0-23) (1-31) (1/jan-12/dec) (0-6/sun-sat) Command/script
+
+
+
+*Crontab 域*
+
+要在每天 04:30 运行一个 cron 任务(比如运行 /home/$USER/script.sh)。
+
+ 分 时 日期 月份 星期 命令
+ 30 4 * * * speedtest-cli
+
+就把下面的条目增加到 crontab 文件 ‘/etc/crontab/’。
+
+ 30 4 * * * /home/$user/script.sh
+
+把上面一行增加到 crontab 之后,它会在每天的 04:30 am 自动运行,输出取决于脚本文件的内容。另外脚本也可以用命令代替。关于更多 cron 任务的例子,可以阅读[Linux 上的 11 个 Cron 任务例子][3]
+
+### 28. 安装 Owncloud ###
+
+Owncloud 是一个基于 HTTP 的数据同步、文件共享和远程文件存储应用。更多关于安装 owncloud 的内容,你可以阅读这篇文章:[在 Linux 上创建个人/私有云存储][4]
+
+### 29. 启用 Virtualbox 虚拟化 ###
+
+虚拟化是创建虚拟操作系统、硬件和网络的过程,是当今最热门的技术之一。我们会详细地讨论如何安装和配置虚拟化。
+
+我们的最小化 CentOS 服务器是一个无用户界面服务器(LCTT 译注:无用户界面[headless]服务器指没有监视器和鼠标键盘等外设的服务器)。我们通过安装下面的软件包,让它可以托管虚拟机,虚拟机可通过 HTTP 访问。
+
+ # yum groupinstall 'Development Tools' SDL kernel-devel kernel-headers dkms
+
+
+
+*安装开发工具*
+
+更改工作目录到 ‘/etc/yum.repos.d/’ 并下载 VirtualBox 库。
+
+ # wget -q http://download.virtualbox.org/virtualbox/debian/oracle_vbox.asc
+
+安装刚下载的密钥。
+
+ # rpm --import oracle_vbox.asc
+
+升级并安装 VirtualBox。
+
+ # yum update && yum install virtualbox-4.3
+
+下一步,下载和安装 VirtualBox 扩展包。
+
+ # wget http://download.virtualbox.org/virtualbox/4.3.12/Oracle_VM_VirtualBox_Extension_Pack-4.3.12-93733.vbox-extpack
+ # VBoxManage extpack install Oracle_VM_VirtualBox_Extension_Pack-4.3.12-93733.vbox-extpack
+
+
+
+*安装 VirtualBox 扩展包*
+
+
+
+*正在安装 VirtualBox 扩展包*
+
+添加用户 ‘vbox’ 用于管理 VirtualBox 并把它添加到组 vboxusers 中。
+
+ # adduser vbox
+ # passwd vobx
+ # usermod -G vboxusers vbox
+
+安装 HTTPD 服务器。
+
+ # yum install httpd
+
+安装 PHP (支持 soap 扩展)。
+
+ # yum install php php-devel php-common php-soap php-gd
+
+下载 phpVirtualBox(一个 PHP 写的开源的 VirtualBox 用户界面)。
+
+ # wget http://sourceforge.net/projects/phpvirtualbox/files/phpvirtualbox-4.3-1.zip
+
+解压 zip 文件并把解压后的文件夹复制到 HTTP 工作目录。
+
+ # unzip phpvirtualbox-4.*.zip
+ # cp phpvirtualbox-4.3-1 -R /var/www/html
+
+下一步,重命名文件 /var/www/html/phpvirtualbox/config.php-example 为 var/www/html/phpvirtualbox/config.php。
+
+ # mv config.php.example config.php
+
+打开配置文件并添加我们上一步创建的 ‘username ’ 和 ‘password’。
+
+ # vi config.php
+
+最后,重启 VirtualBox 和 HTTP 服务器。
+
+ # service vbox-service restart
+ # service httpd restart
+
+转发端口并从一个有用户界面的服务器上访问它。
+
+ http://192.168.0.15/phpvirtualbox-4.3-1/
+
+
+
+*登录 PHP Virtualbox*
+
+
+
+*PHP Virtualbox 面板*
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/things-to-do-after-minimal-rhel-centos-7-installation/5/
+
+作者:[Avishek Kumar][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:https://linux.cn/article-5156-1.html
+[2]:https://linux.cn/article-3796-1.html
+[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
+[4]:https://linux.cn/article-2494-1.html
\ No newline at end of file
diff --git a/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--6.md b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--6.md
new file mode 100644
index 0000000000..c2c00c95a6
--- /dev/null
+++ b/published/201505/30 Things to Do After Minimal RHEL or CentOS 7 Installation--6.md
@@ -0,0 +1,86 @@
+安装完最小化 RHEL/CentOS 7 后需要做的 30 件事情(六)
+================================================================================
+### 30. 用密码保护 GRUB ###
+
+用密码保护你的 boot 引导程序这样你就可以在启动时获得额外的安全保障。同时你也可以在实物层面获得保护。通过在引导时给 GRUB 加锁防止任何无授权访问来保护你的服务器。
+
+首先备份两个文件,这样如果有任何错误出现,你可以有回滚的选择。备份 ‘/etc/grub2/grub.cfg’ 为 ‘/etc/grub2/grub.cfg.old’。
+
+ # cp /boot/grub2/grub.cfg /boot/grub2/grub.cfg.old
+
+同样,备份 ‘/etc/grub.d/10\_linux’ 为 ‘/etc/grub.d/10\_linux.old’。
+
+ # cp /etc/grub.d/10_linux /etc/grub.d/10_linux.old
+
+打开文件 ‘/etc/grub.d/10\_linux’ 并在文件末尾添加下列行。
+
+ cat <”和流索引)文件:
+
+ [root@localhost ~]# blablabla 1> output.txt
+ -bash: blablabla: command not found
+
+在本例中,我们试着重定向流1(**stdout**)到名为output.txt的文件。让我们来看对该文件内容所做的事情吧,使用cat命令可以做这事:
+
+ [root@localhost ~]# cat output.txt
+ [root@localhost ~]#
+
+看起来似乎是空的。好吧,现在让我们来重定向流2(**stderr**):
+
+ [root@localhost ~]# blablabla 2> error.txt
+ [root@localhost ~]#
+
+好吧,我们看到牢骚话没了。让我们检查一下那个文件:
+
+ [root@localhost ~]# cat error.txt
+ -bash: blablabla: command not found
+ [root@localhost ~]#
+
+果然如此!我们看到,所有牢骚话都被记录到errors.txt文件里头去了。
+
+有时候,命令会同时产生**stdout**和**stderr**。要重定向它们到不同的文件,我们可以使用以下语句:
+
+ command 1>out.txt 2>err.txt
+
+要缩短一点语句,我们可以忽略“1”,因为默认情况下**stdout**会被重定向:
+
+ command >out.txt 2>err.txt
+
+好吧,让我们试试做些“坏事”。让我们用rm命令把file1和folder1给删了吧:
+
+ [root@localhost ~]# rm -vf folder1 file1 > out.txt 2>err.txt
+
+现在来检查以下输出文件:
+
+ [root@localhost ~]# cat out.txt
+ removed `file1'
+ [root@localhost ~]# cat err.txt
+ rm: cannot remove `folder1': Is a directory
+ [root@localhost ~]#
+
+正如我们所看到的,不同的流被分离到了不同的文件。有时候,这也不是很方便,因为我们想要查看出现错误时,在某些操作前面或后面所连续发生的事情。要实现这一目的,我们可以重定向两个流到同一个文件:
+
+ command >>out_err.txt 2>>out_err.txt
+
+注意:请注意,我使用“>>”替代了“>”。它允许我们附加到文件,而不是覆盖文件。
+
+我们也可以重定向一个流到另一个:
+
+ command >out_err.txt 2>&1
+
+让我来解释一下吧。所有命令的标准输出将被重定向到out_err.txt,错误输出将被重定向到流1(上面已经解释过了),而该流会被重定向到同一个文件。让我们看这个实例:
+
+ [root@localhost ~]# rm -fv folder2 file2 >out_err.txt 2>&1
+ [root@localhost ~]# cat out_err.txt
+ rm: cannot remove `folder2': Is a directory
+ removed `file2'
+ [root@localhost ~]#
+
+看着这些组合的输出,我们可以将其说明为:首先,**rm**命令试着将folder2删除,而它不会成功,因为linux要求**-r**键来允许**rm**命令删除文件夹,而第二个file2会被删除。通过为**rm**提供**-v**(详情)键,我们让rm命令告诉我们每个被删除的文件或文件夹。
+
+这些就是你需要知道的,关于重定向的几乎所有内容了。我是说几乎,因为还有一个更为重要的重定向工具,它称之为“管道”。通过使用|(管道)符号,我们通常重定向**stdout**流。
+
+比如说,我们有这样一个文本文件:
+
+ [root@localhost ~]# cat text_file.txt
+ This line does not contain H e l l o word
+ This lilne contains Hello
+ This also containd Hello
+ This one no due to HELLO all capital
+ Hello bash world!
+
+而我们需要找到其中某些带有“Hello”的行,Linux中有个**grep**命令可以完成该工作:
+
+ [root@localhost ~]# grep Hello text_file.txt
+ This lilne contains Hello
+ This also containd Hello
+ Hello bash world!
+ [root@localhost ~]#
+
+当我们有个文件,想要在里头搜索的时候,这用起来很不错。当如果我们需要在另一个命令的输出中查找某些东西,这又该怎么办呢?是的,当然,我们可以重定向输出到文件,然后再在文件里头查找:
+
+ [root@localhost ~]# fdisk -l>fdisk.out
+ [root@localhost ~]# grep "Disk /dev" fdisk.out
+ Disk /dev/sda: 8589 MB, 8589934592 bytes
+ Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
+ Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
+ [root@localhost ~]#
+
+如果你打算grep一些双引号引起来带有空格的内容呢!
+
+注意:fdisk命令显示关于Linux操作系统磁盘驱动器的信息。
+
+就像我们看到的,这种方式很不方便,因为我们不一会儿就把临时文件空间给搞乱了。要完成该任务,我们可以使用管道。它们允许我们重定向一个命令的**stdout**到另一个命令的**stdin**流:
+
+ [root@localhost ~]# fdisk -l | grep "Disk /dev"
+ Disk /dev/sda: 8589 MB, 8589934592 bytes
+ Disk /dev/mapper/VolGroup-lv_root: 7205 MB, 7205814272 bytes
+ Disk /dev/mapper/VolGroup-lv_swap: 855 MB, 855638016 bytes
+ [root@localhost ~]#
+
+如你所见,我们不需要任何临时文件就获得了相同的结果。我们把**fdisk stdout**重定向到了**grep stdin**。
+
+**注意** : 管道重定向总是从左至右的。
+
+还有几个其它重定向,但是我们将把它们放在后面讲。
+
+### 在shell中显示自定义信息 ###
+
+正如我们所知道的,通常,与shell的交流以及shell内的交流是以对话的方式进行的。因此,让我们创建一些真正的脚本吧,这些脚本也会和我们讲话。这会让你学到一些简单的命令,并对脚本的概念有一个更好的理解。
+
+假设我们是某个公司的总服务台经理,我们想要创建某个shell脚本来注册呼叫信息:电话号码、用户名以及问题的简要描述。我们打算把这些信息存储到普通文本文件data.txt中,以便今后统计。脚本它自己就是以对话的方式工作,这会让总服务台的工作人员的小日子过得轻松点。那么,首先我们需要显示提问。对于显示信息,我们可以用echo和printf命令。这两个都是用来显示信息的,但是printf更为强大,因为我们可以通过它很好地格式化输出,我们可以让它右对齐、左对齐或者为信息留出专门的空间。让我们从一个简单的例子开始吧。要创建文件,请使用你惯用的文本编辑器(kate,nano,vi,……),然后创建名为note.sh的文件,里面写入这些命令:
+
+ echo "Phone number ?"
+
+### 如何运行/执行脚本? ###
+
+在保存文件后,我们可以使用bash命令来运行,把我们的文件作为它的参数:
+
+ [root@localhost ~]# bash note.sh
+ Phone number ?
+
+实际上,这样来执行脚本是很不方便的。如果不使用**bash**命令作为前缀来执行,会更舒服一些。要让脚本可执行,我们可以使用**chmod**命令:
+
+ [root@localhost ~]# ls -la note.sh
+ -rw-r--r--. 1 root root 22 Apr 23 20:52 note.sh
+ [root@localhost ~]# chmod +x note.sh
+ [root@localhost ~]# ls -la note.sh
+ -rwxr-xr-x. 1 root root 22 Apr 23 20:52 note.sh
+ [root@localhost ~]#
+
+
+
+**注意** : ls命令显示了当前文件夹内的文件。通过添加-la键,它会显示更多文件信息。
+
+如我们所见,在**chmod**命令执行前,脚本只有读(r)和写(w)权限。在执行**chmod +x**后,它就获得了执行(x)权限。(关于权限的更多细节,我会在下一篇文章中讲述。)现在,我们只需这么来运行:
+
+ [root@localhost ~]# ./note.sh
+ Phone number ?
+
+在脚本名前,我添加了 ./ 组合。.(点)在unix世界中意味着当前位置(当前文件夹),/(斜线)是文件夹分隔符。(在Windows系统中,我们使用反斜线 \ 表示同样功能)所以,这整个组合的意思是说:“从当前文件夹执行note.sh脚本”。我想,如果我用完整路径来运行这个脚本的话,你会更加清楚一些:
+
+ [root@localhost ~]# /root/note.sh
+ Phone number ?
+ [root@localhost ~]#
+
+它也能工作。
+
+如果所有linux用户都有相同的默认shell,那就万事OK。如果我们只是执行该脚本,默认的用户shell就会用于解析脚本内容并运行命令。不同的shell的语法、内部命令等等有着一丁点不同,所以,为了保证我们的脚本会使用**bash**,我们应该添加**#!/bin/bash**到文件首行。这样,默认的用户shell将调用**/bin/bash**,而只有在那时候,脚本中的命令才会被执行:
+
+ [root@localhost ~]# cat note.sh
+ #!/bin/bash
+ echo "Phone number ?"
+
+直到现在,我们才100%确信**bash**会用来解析我们的脚本内容。让我们继续。
+
+### 读取输入 ###
+
+在显示信息后,脚本会等待用户回答。有个**read**命令用来接收用户的回答:
+
+ #!/bin/bash
+ echo "Phone number ?"
+ read phone
+
+在执行后,脚本会等待用户输入,直到用户按[ENTER]键结束输入:
+
+ [root@localhost ~]# ./note.sh
+ Phone number ?
+ 12345 <--- 这儿是我输入的内容
+ [root@localhost ~]#
+
+你输入的所有东西都会被存储到变量**phone**中,要显示变量的值,我们同样可以使用**echo**命令:
+
+ [root@localhost ~]# cat note.sh
+ #!/bin/bash
+ echo "Phone number ?"
+ read phone
+ echo "You have entered $phone as a phone number"
+ [root@localhost ~]# ./note.sh
+ Phone number ?
+ 123456
+ You have entered 123456 as a phone number
+ [root@localhost ~]#
+
+在**bash** shell中,一般我们使用**$**(美元)符号来表明这是一个变量,除了读入到变量和其它为数不多的时候才不用这个$(将在今后说明)。
+
+好了,现在我们准备添加剩下的问题了:
+
+ #!/bin/bash
+ echo "Phone number?"
+ read phone
+ echo "Name?"
+ read name
+ echo "Issue?"
+ read issue
+ [root@localhost ~]# ./note.sh
+ Phone number?
+ 123
+ Name?
+ Jim
+ Issue?
+ script is not working.
+ [root@localhost ~]#
+
+### 使用流重定向 ###
+
+太完美了!剩下来就是重定向所有东西到文件data.txt了。作为字段分隔符,我们将使用/(斜线)符号。
+
+**注意** : 你可以选择任何你认为是最好的分隔符,但是确保文件内容不会包含这些符号在内,否则它会导致在文本行中产生额外字段。
+
+别忘了使用“>>”来代替“>”,因为我们想要将输出内容附加到文件末!
+
+ [root@localhost ~]# tail -2 note.sh
+ read issue
+ echo "$phone/$name/$issue">>data.txt
+ [root@localhost ~]# ./note.sh
+ Phone number?
+ 987
+ Name?
+ Jimmy
+ Issue?
+ Keybord issue.
+ [root@localhost ~]# cat data.txt
+ 987/Jimmy/Keybord issue.
+ [root@localhost ~]#
+
+**注意** : **tail**命令显示了文件的最后的**n**行。
+
+搞定。让我们再来运行一次看看:
+
+ [root@localhost ~]# ./note.sh
+ Phone number?
+ 556
+ Name?
+ Janine
+ Issue?
+ Mouse was broken.
+ [root@localhost ~]# cat data.txt
+ 987/Jimmy/Keybord issue.
+ 556/Janine/Mouse was broken.
+ [root@localhost ~]#
+
+我们的文件在增长,让我们在每行前面加个日期吧,这对于今后摆弄这些统计数据时会很有用。要实现这功能,我们可以使用date命令,并指定某种格式,因为我不喜欢默认格式:
+
+ [root@localhost ~]# date
+ Thu Apr 23 21:33:14 EEST 2015 <---- date命令的默认输出
+ [root@localhost ~]# date "+%Y.%m.%d %H:%M:%S"
+ 2015.04.23 21:33:18 <---- 格式化后的输出
+
+有几种方式可以读取命令的输出到变量,在这种简单的情况下,我们将使用`(是反引号,不是单引号,和波浪号~在同一个键位):
+
+ [root@localhost ~]# cat note.sh
+ #!/bin/bash
+ now=`date "+%Y.%m.%d %H:%M:%S"`
+ echo "Phone number?"
+ read phone
+ echo "Name?"
+ read name
+ echo "Issue?"
+ read issue
+ echo "$now/$phone/$name/$issue">>data.txt
+ [root@localhost ~]# ./note.sh
+ Phone number?
+ 123
+ Name?
+ Jim
+ Issue?
+ Script hanging.
+ [root@localhost ~]# cat data.txt
+ 2015.04.23 21:38:56/123/Jim/Script hanging.
+ [root@localhost ~]#
+
+嗯…… 我们的脚本看起来有点丑啊,让我们来美化一下。如果你要手动读取**read**命令,你会发现read命令也可以显示一些信息。要实现该功能,我们应该使用-p键加上信息:
+
+ [root@localhost ~]# cat note.sh
+ #!/bin/bash
+ now=`date "+%Y.%m.%d %H:%M:%S"`
+ read -p "Phone number: " phone
+ read -p "Name: " name
+ read -p "Issue: " issue
+ echo "$now/$phone/$name/$issue">>data.txt
+
+你可以直接从控制台查找到各个命令的大量有趣的信息,只需输入:**man read, man echo, man date, man ……**
+
+同意吗?它看上去是舒服多了!
+
+ [root@localhost ~]# ./note.sh
+ Phone number: 321
+ Name: Susane
+ Issue: Mouse was stolen
+ [root@localhost ~]# cat data.txt
+ 2015.04.23 21:38:56/123/Jim/Script hanging.
+ 2015.04.23 21:43:50/321/Susane/Mouse was stolen
+ [root@localhost ~]#
+
+光标在消息的后面(不是在新的一行中),这有点意思。(LCTT 译注:如果用 echo 命令输出显示的话,可以用 -n 参数来避免换行。)
+
+### 循环 ###
+
+是时候来改进我们的脚本了。如果用户一整天都在接电话,如果每次都要去运行,这岂不是很麻烦?让我们让这些活动都永无止境地循环去吧:
+
+ [root@localhost ~]# cat note.sh
+ #!/bin/bash
+ while true
+ do
+ read -p "Phone number: " phone
+ now=`date "+%Y.%m.%d %H:%M:%S"`
+ read -p "Name: " name
+ read -p "Issue: " issue
+ echo "$now/$phone/$name/$issue">>data.txt
+ done
+
+我已经交换了**read phone**和**now=`date`**行的位置。这是因为我想要在输入电话号码后再获得时间。如果我把它放在循环的首行,那么循环一次后,变量 now 就会在数据存储到文件中后马上获得时间。而这并不好,因为下一次呼叫可能在20分钟后,甚至更晚。
+
+ [root@localhost ~]# ./note.sh
+ Phone number: 123
+ Name: Jim
+ Issue: Script still not works.
+ Phone number: 777
+ Name: Daniel
+ Issue: I broke my monitor
+ Phone number: ^C
+ [root@localhost ~]# cat data.txt
+ 2015.04.23 21:38:56/123/Jim/Script hanging.
+ 2015.04.23 21:43:50/321/Susane/Mouse was stolen
+ 2015.04.23 21:47:55/123/Jim/Script still not works.
+ 2015.04.23 21:48:16/777/Daniel/I broke my monitor
+ [root@localhost ~]#
+
+注意: 要从无限循环中退出,你可以按[Ctrl]+[C]键。Shell会显示\^表示Ctrl键。
+
+### 使用管道重定向 ###
+
+让我们添加更多功能到我们的“弗兰肯斯坦(Frankenstein)”,我想要脚本在每次呼叫后显示某个统计数据。比如说,我想要查看各个号码呼叫了我几次。对于这个,我们应该cat文件data.txt:
+
+ [root@localhost ~]# cat data.txt
+ 2015.04.23 21:38:56/123/Jim/Script hanging.
+ 2015.04.23 21:43:50/321/Susane/Mouse was stolen
+ 2015.04.23 21:47:55/123/Jim/Script still not works.
+ 2015.04.23 21:48:16/777/Daniel/I broke my monitor
+ 2015.04.23 22:02:14/123/Jimmy/New script also not working!!!
+ [root@localhost ~]#
+
+现在,所有输出我们都可以重定向到**cut**命令,让**cut**来把每行切成一块一块(我们使用分隔符“/”),然后打印第二个字段:
+
+ [root@localhost ~]# cat data.txt | cut -d"/" -f2
+ 123
+ 321
+ 123
+ 777
+ 123
+ [root@localhost ~]#
+
+现在,我们可以把这个输出重定向打另外一个命令**sort**:
+
+ [root@localhost ~]# cat data.txt | cut -d"/" -f2|sort
+ 123
+ 123
+ 123
+ 321
+ 777
+ [root@localhost ~]#
+
+然后只留下唯一的行。要统计唯一条目,只需添加**-c**键到**uniq**命令:
+
+ [root@localhost ~]# cat data.txt | cut -d"/" -f2 | sort | uniq -c
+ 3 123
+ 1 321
+ 1 777
+ [root@localhost ~]#
+
+只要把这个添加到我们的循环的最后:
+
+ #!/bin/bash
+ while true
+ do
+ read -p "Phone number: " phone
+ now=`date "+%Y.%m.%d %H:%M:%S"`
+ read -p "Name: " name
+ read -p "Issue: " issue
+ echo "$now/$phone/$name/$issue">>data.txt
+ echo "===== We got calls from ====="
+ cat data.txt | cut -d"/" -f2 | sort | uniq -c
+ echo "--------------------------------"
+ done
+
+运行:
+
+ [root@localhost ~]# ./note.sh
+ Phone number: 454
+ Name: Malini
+ Issue: Windows license expired.
+ ===== We got calls from =====
+ 3 123
+ 1 321
+ 1 454
+ 1 777
+ --------------------------------
+ Phone number: ^C
+
+
+
+当前场景贯穿了几个熟知的步骤:
+
+- 显示消息
+- 获取用户输入
+- 存储值到文件
+- 处理存储的数据
+
+但是,如果用户有点责任心,他有时候需要输入数据,有时候需要统计,或者可能要在存储的数据中查找一些东西呢?对于这些事情,我们需要使用switches/cases,并知道怎样来很好地格式化输出。这对于在shell中“画”表格的时候很有用。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-shell-script/guide-start-learning-shell-scripting-scratch/
+
+作者:[Petras Liumparas][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/petrasl/
diff --git a/published/20150506 How to Setup OpenERP (Odoo) on CentOS 7.x.md b/published/20150506 How to Setup OpenERP (Odoo) on CentOS 7.x.md
new file mode 100644
index 0000000000..0035432ecb
--- /dev/null
+++ b/published/20150506 How to Setup OpenERP (Odoo) on CentOS 7.x.md
@@ -0,0 +1,112 @@
+如何在CentOS 7.x中安装OpenERP(Odoo)
+================================================================================
+各位好,这篇教程关于的是如何在CentOS 7中安装Odoo(就是我们所知的OpenERP)。你是不是在考虑为你的业务安装一个不错的ERP(企业资源规划)软件?那么OpenERP就是你寻找的最好的程序,因为它是一款为你的商务提供杰出特性的自由开源软件。
+
+[OpenERP][1]是一款自由开源的传统的OpenERP(企业资源规划),它包含了开源CRM、网站构建、电子商务、项目管理、计费账务、POS、人力资源、市场、生产、采购管理以及其它模块用于提高效率及销售。Odoo中的应用可以作为独立程序使用,它们也可以无缝集成到一起,因此你可以在安装几个程序来得到一个全功能的开源ERP。
+
+因此,下面是在你的CentOS上安装OpenERP的步骤。
+
+### 1. 安装 PostgreSQL ###
+
+首先,首先我们需要更新CentOS 7的软件包来确保是最新的包,补丁和安全更新。要更新我们的系统,我们要在shell下运行下面的命令。
+
+ # yum clean all
+ # yum update
+
+现在我们要安装PostgreSQL,因为OpenERP使用PostgreSQL作为它的数据库。要安装它,我们需要运行下面的命令。
+
+ # yum install postgresql postgresql-server postgresql-libs
+
+
+
+安装完成后,我们需要用下面的命令初始化数据库。
+
+ # postgresql-setup initdb
+
+
+
+我们接着设置PostgreSQL来使它每次开机启动。
+
+ # systemctl enable postgresql
+ # systemctl start postgresql
+
+因为我们还没有为用户“postgresql”设置密码,我们现在设置。
+
+ # su - postgres
+ $ psql
+ postgres=# \password postgres
+ postgres=# \q
+ # exit
+
+
+
+### 2. 设置Odoo仓库 ###
+
+在初始化数据库初始化完成后,我们要添加 EPEL(企业版Linux的额外包)到我们的CentOS中。Odoo(或者OpenERP)依赖的Python运行时环境以及其他包没有包含在标准仓库中。这样我们要为企业版Linux添加额外的包仓库支持来解决Odoo所需要的依赖。要安装完成,我们需要运行下面的命令。
+
+ # yum install epel-release
+
+
+
+现在,安装EPEL后,我们现在使用yum-config-manager添加Odoo(OpenERP)的仓库。
+
+ # yum install yum-utils
+
+ # yum-config-manager --add-repo=https://nightly.odoo.com/8.0/nightly/rpm/odoo.repo
+
+
+
+### 3. 安装Odoo 8 (OpenERP) ###
+
+在CentOS 7中添加Odoo 8(OpenERP)的仓库后。我们使用下面的命令来安装Odoo 8(OpenERP)。
+
+ # yum install -y odoo
+
+上面的命令会安装odoo以及必须的依赖的包。
+
+
+
+现在我们使用下面的命令在每次启动后启动Odoo服务。
+
+ # systemctl enable odoo
+ # systemctl start odoo
+
+
+
+### 4. 打开防火墙 ###
+
+因为Odoo使用8069端口,我们需要在防火墙中允许远程访问。我们使用下面的命令来在防火墙中允许8069端口访问。
+
+ # firewall-cmd --zone=public --add-port=8069/tcp --permanent
+ # firewall-cmd --reload
+
+
+
+**注意:默认情况下只有本地才允许连接数据库。如果我们要允许PostgreSQL的远程访问,我们需要在pg_hba.conf添加下面图片中一行**
+
+ # nano /var/lib/pgsql/data/pg_hba.conf
+
+
+
+### 5. Web接口 ###
+
+我们已经在CentOS 7中安装了最新的Odoo 8(OpenERP),我们可以在浏览器中输入`http://ip-address:8069`来访问Odoo。 接着,我们要做的第一件事就是创建一个新的数据库和新的密码。注意,主密码默认是‘admin’。接着,我们可以在面板中输入用户名和密码。
+
+
+
+### 总结 ###
+
+Odoo 8(OpenERP)是世界上最好的开源ERP程序。OpenERP是由许多模块组成的针对商务和公司的完整ERP程序,我们已经把它安装好了。因此,如果你有任何问题、建议、反馈请在下面的评论栏写下。谢谢你!享受OpenERP(Odoo 8)吧 :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/setup-openerp-odoo-centos-7/
+
+作者:[Arun Pyasi][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://www.odoo.com/
diff --git a/published/20150506 Linux FAQs with Answers--How to disable entering password for default keyring to unlock on Ubuntu desktop.md b/published/20150506 Linux FAQs with Answers--How to disable entering password for default keyring to unlock on Ubuntu desktop.md
new file mode 100644
index 0000000000..fb67d3dd34
--- /dev/null
+++ b/published/20150506 Linux FAQs with Answers--How to disable entering password for default keyring to unlock on Ubuntu desktop.md
@@ -0,0 +1,55 @@
+Linux有问必答:Ubuntu桌面上如何禁用默认的密钥环解锁提示
+================================================================================
+>**问题**:当我启动我的Ubuntu桌面时,出现了一个弹出对话框,要求我输入密码来解锁默认的密钥环。我怎样才能禁用这个“解锁默认密钥环”弹出窗口,并自动解锁我的密钥环?
+
+密钥环是一个以加密方式存储你的登录信息的本地数据库。各种桌面应用(如浏览器、电子邮件客户端)使用密钥环来安全地存储并管理你的登录凭证、机密、密码、证书或密钥。对于那些需要检索存储在密钥环中的信息的应用程序,需要解锁该密钥环。
+
+Ubuntu桌面所使用的GNOME密钥环被整合到了桌面登录中,该密钥环会在你验证进入桌面后自动解锁。但是,如果你设置了自动登录桌面或者是从休眠中唤醒,你默认的密钥环仍然可能“被锁定”的。在这种情况下,你会碰到这一提示:
+
+>“输入密码来解锁密钥环‘默认密钥环’。某个应用想要访问密钥环‘默认密钥环’,但它被锁定了。”
+>
+
+
+如果你想要避免在每次弹出对话框出现时输入密码来解锁默认密钥环,那么你可以这样做。
+
+在做之前,请先了解禁用密码提示后可能出现的结果。通过自动解锁默认密钥环,你可以让任何使用你桌面的人无需知道你的密码而能获取你的密钥环(以及存储在密钥环中的任何信息)。
+
+### 禁用默认密钥环解锁密码 ###
+
+打开Dash,然后输入“password”来启动“密码和密钥”应用。
+
+
+
+或者,使用seahorse命令从命令行启动图形界面。
+
+ $ seahorse
+
+在左侧面板中,右击“默认密钥环”,并选择“修改密码”。
+
+
+
+输入你的当前登录密码。
+
+
+
+在设置“默认”密钥环新密码的密码框中留空。
+
+
+
+在询问是否不加密存储密码对话框中点击“继续”。
+
+
+
+搞定。从今往后,那个该死的解锁密钥环提示对话框再也不会来烦你了。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/disable-entering-password-unlock-default-keyring.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/published/20150511 Open Source History--Why Did Linux Succeed.md b/published/20150511 Open Source History--Why Did Linux Succeed.md
new file mode 100644
index 0000000000..76b6d03ebe
--- /dev/null
+++ b/published/20150511 Open Source History--Why Did Linux Succeed.md
@@ -0,0 +1,73 @@
+开源旧事:Linux为什么能成功?
+================================================================================
+> Linux,这个始于1991年由Linus Torvalds开发的类Unix操作系统内核已经成为开源世界的中心,人们不禁追问为什么Linux成功了,而包括GNU HURD和BSD在内的那么多相似的项目却失败了?
+
+
+
+自由软件和开源世界的发展史中最令人不解的问题之一是为什么Linux取得了如此辉煌的成功,然而其它同样尝试打造自由开源、类Unix操作系统内核的项目却没能那么成功?这个问题难以回答,但我总结了一些原因,在下面与大家分享。
+
+不过,首先得明确:当我谈论Linux是一个巨大的成功时所表达的含义。我这样说是相对于其它类Unix操作系统内核的,后者中一些是开源的,一些不是,而且它们繁荣发展的时期是Linux诞生的时期。[GNU][1]的HURD,一个发起于[1991年5月][1]的Free(自由)的内核,便是其中之一。其它的包括现在大部分人都没听说过的Unix,比如由加州大学伯克利分校开发出来的BSD的各种各样Unix衍生版,由微软主导的Unix系统Xenix,包括Minix在内的学术版本Unix,和在AT&T赞助下开发的最初的Unix。在更早的数十年内,它对于学术界和商业界的计算发展至关重要,但到19世纪90年代就已经几乎已经消失在人们的视野里。
+
+#### 相关阅读 ####
+
+- [开源旧事:黑客文化和黑客伦理的起源追踪][3]
+- [Unix和个人计算机:重新诠释Linux起源][4]
+
+此外,得说明的是,我这里说的是内核,而不是完整的操作系统。在很大程度上,Linux内核的成功归功于GNU整个项目。GNU这个项目产生了一套至关重要的工具,包括编译器、调试器和BASH shell的实现,这些对于构建一个类Unix操作系统是必需的。但是GNU的开发者们从没开发出一个HURD内核的可行版本(尽管他们仍在[不懈努力中][5])。相反,Linux呈现出来的则是一个将GNU各个部分紧密连接在一起的内核,尽管这超出了GNU的初衷。
+
+因此,值得人们去追问为什么Linux,一个由Linus Torvalds这个芬兰的无名程序员于1991年——和HURD同一年——发起的内核,能够经受考验并发展壮大?在当时的大环境下,很多拥有强力商业支持的、由当时炙手可热的黑客领头的类Unix内核都没能够发展起来。为了说明这个问题,我找到了一些和这个问题相关的解释。为此我研究了自由软件和开源世界的发展史,和不同解释的优缺点。
+
+### Linux采用去中心化的开发方式 ###
+
+这个观点来源于Eric S. Raymond的文章,“[大教堂与市集][6]”和其相关资料。这些资料验证了一种情形:当大量的贡献者以一种去中心化的组织结构持续不断地协同合作时,软件开发的效率最佳。Linux的开发证明了这一点,与之相反的是,比如,GNU HURD采用了一种相对更集中化的方法来管理代码开发。其结果如同Raymond所言,显然在十年的时间里都没能成功构建出一个完整的操作系统。
+
+在一定程度上,这个解释有道理,但仍有一些明显的不足。举例来说,Torvalds在指导Linux代码开发过程中毫无争议地承担起一个更加有权威的角色,他可以决定接受或拒绝代码,这一点并非Raymond和其他人所想的那样。其次,这个观点不能解释除了没能开发出一个可行的系统内核外GNU仍然成功地生产出那么多优秀的软件。如果只有去中心化的开发方式才能很好地指导开源软件世界里的项目,那么GNU所有的编程工作都应该是徒劳无功的,但事实并非如此。
+
+### Linux是实用型的,而GNU是空想型的 ###
+
+个人而言,我觉得这个说法是最引人注目的,即Linux之所发展得如此迅速是因为它的创建者是一个实用主义者,他起初只是想写一个内核,使其能够在他家里的电脑上运行一个裁剪过的Unix操作系统,而不是成为以改变世界为目标的自由软件的一部分,而后者正是GNU项目的一贯目标。
+
+然而,这个解释仍然有一些不能完全让人信服的地方。特别是,尽管Torvalds本人信奉实用主义的原则,但无论以前还是现在,并非所有参与到他的项目中的成员都和他一样信奉这一原则。尽管如此,Linux仍然取得了成功。
+
+而且,如果实用主义是Linux持续发展的关键,那么就要再问一遍:为什么GNU除了没能开发出一个内核外还是成功地开发出这么多有用的工具?如果拥有某一种对软件的坚定政治信仰是追求成功的项目路上的绊脚石,那么GNU早应该是一个彻头彻尾的失败者,而不会是一个开发了那么多如今依然为IT世界提供坚实基础的优秀软件包的开拓者。
+
+最后(但并不是最不重要),许多诞生于19世纪80年代末期和90年代初期的Unix变体,尤其是一些BSD分支,都是实用主义的产物。它们的开发者们致力于开发出可以自由分享而不是受到高昂商业证书限制的Unix变体,但他们对于编程或者共享代码并非完全局限于意识形态。Torvalds同样如此,因此很难说Linux和成功和其它Unix项目的失败是意识形态在作怪。
+
+### 操作系统设计 ###
+
+当谈到Linux的成功时,不可忽视的是Linux和其它Unix变体之间的诸多技术差异。Richard Stallman,GNU项目的创始人,在一封给我的电子邮件中解释了为什么HURD的开发进度频频滞后:“GNU Hurd确实不是一次实用上的成功。部分原因是它的基本设计使它像是一个研究项目。(我之所以选择这样的设计,是考虑到这是快速实现一个可用内核的捷径。)”
+
+就Torvalds独自编写出Linux的所有代码这点而言,Linux也有别于其它Unix变体。当他在1991年8月[第一次发布Linux][7]时他的一个初衷就是拥有一个属于他自己的Unix,而不用别人的代码。这点特性使得Linux区别于同时期的大部分Unix变体,后者一般是从AT&T Unix或伯克利的BSD中衍生出基础代码。
+
+我并不是一个计算机科学家,所以我没有资格去评判是否Linux代码就优于其他Unix代码,以此来解释Linux的成功。虽然这并不能解释Linux和其它Unix内核在文化和人员上的不同,但这个观点对我来说解释得通,因为似乎在理解Linux成功这一点上操作系统设计比代码更加重要。
+
+### Linux背后的社区提供了有力支持 ###
+
+Stallman也写到Linux成功的“主要原因”是“Torvalds使Linux成为一个自由软件,所以相比Hurd有更多来自社区的支持涌入Linux的发展中。”但这对于Linux的成长轨迹并非是一个完美的解释,因为它不能说明为什么自由软件的开发者们追随了Torvalds而不是HURD或其它某个Unix,但它仍然点明了这种变化是Linux盛行的很大一部分原因。
+
+对于自由软件社区决定支持Linux有一个更全面的理由可以用来解释为什么开发者们这么做。起初,Linux只是一个默默无闻的小项目,以任何标准来衡量,它比同时期其它的一些尝试创建一个更加自由的Unix,比如NET BSD和386/BSD,都要显得微不足道。同样,最初并不清楚Linux和自由软件运动的目标是否一致。创建伊始,Torvalds只是在一份防止Linux不被商业使用的证书下发布了Linux。至于后来他为了保护源代码的开放性转向使用GNU的通用公开证书则是后话了。
+
+所以,这些就是我所找到的Linux作为一个开源操作系统之所以取得成功的解释,可以肯定Linux的成就在某些方面(但比如桌面版的Linux从未成为它的支持者希望成为的样子)已经是可以衡量的成功。总之,Linux业已与其它任何类Unix操作系统不同的方式成为了计算机世界的基石。也许源于BSD的苹果公司的OS X和iOS系统也很接近这一点,但它们没有在其它方面像Linux影响互联网一样扮演着如此重要的中心角色。
+
+对于为什么Linux能成为现在的样子,或者为什么它在Unix世界的竞争对手们几乎全部变得默默无闻的问题,你有其它的想法吗?如果有,我很乐意听到你的想法。(诚然,BSD的变体如今仍有一批追随者,而一些商用的Unix对于[Red Hat][8](RHT)为[他们的用户提供支持][9]来说也仍然十分重要。但这些Unix中没有一个能够像Linux一样几乎征服了从Web服务器到智能手机的每一个领域。)
+
+--------------------------------------------------------------------------------
+
+via: http://thevarguy.com/open-source-application-software-companies/050415/open-source-history-why-did-linux-succeed
+
+作者:[Christopher Tozzi][a]
+译者:[KayGuoWhu](https://github.com/KayGuoWhu)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://thevarguy.com/author/christopher-tozzi
+[1]:http://gnu.org/
+[2]:http://www.gnu.org/software/hurd/history/hurd-announce
+[3]:http://thevarguy.com/open-source-application-software-companies/042915/open-source-history-tracing-origins-hacker-culture-and-ha
+[4]:http://thevarguy.com/open-source-application-software-companies/042715/unix-and-personal-computers-reinterpreting-origins-linux
+[5]:http://thevarguy.com/open-source-application-software-companies/042015/30-years-hurd-lives-gnu-updates-open-source-
+[6]:http://www.catb.org/esr/writings/cathedral-bazaar/cathedral-bazaar/
+[7]:https://groups.google.com/forum/#!topic/comp.os.minix/dlNtH7RRrGA[1-25]
+[8]:http://www.redhat.com/
+[9]:http://thevarguy.com/open-source-application-software-companies/032614/red-hat-grants-certification-award-unix-linux-migration-a
\ No newline at end of file
diff --git a/published/20150512 How To Run Docker Client Inside Windows OS.md b/published/20150512 How To Run Docker Client Inside Windows OS.md
new file mode 100644
index 0000000000..050ed636f3
--- /dev/null
+++ b/published/20150512 How To Run Docker Client Inside Windows OS.md
@@ -0,0 +1,110 @@
+如何在 Windows 操作系统中运行 Docker 客户端
+================================================================================
+
+大家好,今天我们来了解一下 Windows 操作系统中的 Docker 以及在其中安装 Docker Windows 客户端的知识。Docker 引擎使用 Linux 特有的内核特性,因此不能通过 Windows 内核运行,所以,(在 Windows 上)Docker 引擎创建了一个小的虚拟系统运行 Linux 并利用它的资源和内核。这样,Windows Docker 客户端就可以用这个虚拟的 Docker 引擎来构建、运行以及管理 Docker 容器。有个叫 Boot2Docker 的团队开发了一个同名的应用程序,它创建了一个虚拟机来运行基于[Tiny Core Linux][1]特制的小型 Linux,来在 Windows 上运行 [Docker][2] 容器。它完全运行在内存中,需要大约 27M 内存并能在 5秒 (因人而异) 内启动。因此,在用于 Windows 的 Docker 引擎被开发出来之前,我们在 Windows 机器里只能运行 Linux 容器。
+
+下面是安装 Docker 客户端并在上面运行容器的简单步骤。
+
+### 1. 下载 Boot2Docker ###
+
+在我们开始安装之前,我们需要 Boot2Docker 的可执行文件。可以从 [它的 Github][3] 下载最新版本的 Boot2Docker。在这篇指南中,我们从网站中下载版本 v1.6.1。我们从那网页中用我们喜欢的浏览器或者下载管理器下载了名为 [docker-install.exe][4] 的文件。
+
+
+
+### 2. 安装 Boot2Docker ###
+
+现在我们运行安装文件,它会安装 Window Docker 客户端、用于 Windows 的 Git(MSYS-git)、VirtualBox、Boot2Docker Linux ISO 以及 Boot2Docker 管理工具,这些对于开箱即用地运行全功能的 Docker 引擎都至关重要。
+
+
+
+### 3. 运行 Boot2Docker ###
+
+
+
+安装完成必要的组件之后,我们从桌面上的“Boot2Docker Start”快捷方式启动 Boot2Docker。它会要求你输入以后用于验证的 SSH 密钥。然后会启动一个配置好的用于管理在虚拟机中运行的 Docker 的 unix shell。
+
+
+
+为了检查是否正确配置,运行下面的 docker version 命令。
+
+ docker version
+
+
+
+### 4. 运行 Docker ###
+
+由于 **Boot2Docker Start** 自动启动了一个已经正确设置好环境变量的 shell,我们可以马上开始使用 Docker。**请注意,如果我们要将 Boot2Docker 作为一个远程 Docker 守护进程,那么不要在 docker 命令之前加 sudo。**
+
+现在,让我们来试试 **hello-world** 例子镜像,它会下载 hello-world 镜像,运行并输出 "Hello from Docker" 信息。
+
+ $ docker run hello-world
+
+
+
+### 5. 使用命令提示符(CMD) 运行 Docker###
+
+现在,如果你想开始用命令提示符使用 Docker,你可以打开命令提示符(CMD.exe)。由于 Boot2Docker 要求 ssh.exe 在 PATH 中,我们需要在命令提示符中输入以下命令使得 %PATH% 环境变量中包括 Git 安装目录下的 bin 文件夹。
+
+ set PATH=%PATH%;"c:\Program Files (x86)\Git\bin"
+
+
+
+运行上面的命令之后,我们可以在命令提示符中运行 **boot2docker start** 启动 Boot2Docker 虚拟机。
+
+ boot2docker start
+
+
+
+**注意**: 如果你看到 machine does no exist 的错误信息,就运行 **boot2docker init** 命令。
+
+然后复制上图中控制台标出命令到 cmd.exe 中为控制台窗口设置环境变量,然后我们就可以像平常一样运行 docker 容器了。
+
+### 6. 使用 PowerShell 运行 Docker ###
+
+为了能在 PowerShell 中运行 Docker,我们需要启动一个 PowerShell 窗口并添加 ssh.exe 到 PATH 变量。
+
+ $Env:Path = "${Env:Path};c:\Program Files (x86)\Git\bin"
+
+运行完上面的命令,我们还需要运行
+
+ boot2docker start
+
+
+
+这会打印用于设置环境变量连接到虚拟机内部运行的 Docker 的 PowerShell 命令。我们只需要在 PowerShell 中运行这些命令就可以和平常一样运行 docker 容器。
+
+### 7. 用 PUTTY 登录 ###
+
+Boot2Docker 会在%USERPROFILE%\.ssh 目录生成和使用用于登录的公共和私有密钥,我们也需要使用这个文件夹中的私有密钥。私有密钥需要转换为 PuTTY 的格式。我们可以通过 puttygen.exe 实现。
+
+我们需要打开 puttygen.exe 并从 %USERPROFILE%\.ssh\id_boot2docker 中导入("File"->"Load" 菜单)私钥,然后点击 "Save Private Key"。然后用保存的文件通过 PuTTY 用 docker@127.0.0.1:2022 登录。
+
+### 8. Boot2Docker 选项 ###
+
+Boot2Docker 管理工具提供了一些命令,如下所示。
+
+ $ boot2docker
+
+ Usage: boot2docker.exe [] {help|init|up|ssh|save|down|poweroff|reset|restart|config|status|info|ip|shellinit|delete|download|upgrade|version} []
+
+### 总结 ###
+
+通过 Docker Windows 客户端使用 Docker 很有趣。Boot2Docker 管理工具是一个能使任何 Docker 容器能像在 Linux 主机上平滑运行的很棒的应用程序。如果你更仔细的话,你会发现 boot2docker 默认用户的用户名是 docker,密码是 tcuser。最新版本的 boot2docker 设置了一个 host-only 的网络适配器提供访问容器的端口。一般来说是 192.168.59.103,但可以通过 VirtualBox 的 DHCP 实现改变。
+
+如果你有任何问题、建议、反馈,请在下面的评论框中写下来然后我们可以改进或者更新我们的内容。非常感谢!Enjoy:-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/run-docker-client-inside-windows-os/
+
+作者:[Arun Pyasi][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:http://tinycorelinux.net/
+[2]:https://www.docker.io/
+[3]:https://github.com/boot2docker/windows-installer/releases/latest
+[4]:https://github.com/boot2docker/windows-installer/releases/download/v1.6.1/docker-install.exe
\ No newline at end of file
diff --git a/published/20150512 Linux FAQs with Answers--How to view torrent file content on Linux.md b/published/20150512 Linux FAQs with Answers--How to view torrent file content on Linux.md
new file mode 100644
index 0000000000..8f2a9c2ecd
--- /dev/null
+++ b/published/20150512 Linux FAQs with Answers--How to view torrent file content on Linux.md
@@ -0,0 +1,63 @@
+Linux有问必答:Linux上如何查看种子文件的内容
+================================================================================
+> **问题**: 我从网站上下载了一个torrent(种子)文件。Linux上有没有工具让我查看torrent文件的内容?例如,我想知道torrent里面都包含什么文件。
+
+torrent文件(也就是扩展名为**.torrent**的文件)是BitTorrent元数据文件,里面存储了BitTorrent客户端用来从BitTorrent点对点网络下载共享文件的信息(如,追踪器URL、文件列表、大小、校验和、创建日期等)。在单个torrent文件里面,可以列出一个或多个文件用于共享。
+
+torrent文件内容由BEncode编码为BitTorrent数据序列化格式,因此,要查看torrent文件的内容,你需要相应的解码器。
+
+事实上,任何图形化的BitTorrent客户端(如Transmission或uTorrent)都带有BEncode解码器,所以,你可以用它们直接打开来查看torrent文件的内容。然而,如果你不想要使用BitTorrent客户端来检查torrent文件,你可以试试这个命令行torrent查看器,它叫[dumptorrent][1]。
+
+**dumptorrent**命令可以使用内建的BEncode解码器打印出torrent文件的详细信息(如,文件名、大小、跟踪器URL、创建日期、信息散列等等)。
+
+### 安装DumpTorrent到Linux ###
+
+要安装dumptorrent到Linux,你可以从源代码来构建它。
+
+在Debian、Ubuntu或Linux Mint上:
+
+ $ sudo apt-get install gcc make
+ $ wget http://downloads.sourceforge.net/project/dumptorrent/dumptorrent/1.2/dumptorrent-1.2.tar.gz
+ $ tar -xvf dumptorrent-1.2.tar.gz
+ $ cd dumptorrent-1.2
+ $ make
+ $ sudo cp dumptorrent /usr/local/bin
+
+在CentOS、Fedora或RHEL上:
+
+ $ sudo yum install gcc make
+ $ wget http://downloads.sourceforge.net/project/dumptorrent/dumptorrent/1.2/dumptorrent-1.2.tar.gz
+ $ tar -xvf dumptorrent-1.2.tar.gz
+ $ cd dumptorrent-1.2
+ $ make
+ $ sudo cp dumptorrent /usr/local/bin
+
+确保你的搜索路径 PATH 中[包含][2]了/usr/local/bin。
+
+### 查看torrent的内容 ###
+
+要检查torrent的内容,只需要运行dumptorrent,并将torrent文件作为参数执行。这会打印出torrent的概要,包括文件名、大小和跟踪器URL。
+
+ $ dumptorrent
+
+
+
+要查看torrent的完整内容,请添加“-v”选项。它会打印更多关于torrent的详细信息,包括信息散列、片长度、创建日期、创建者,以及完整的声明列表。
+
+ $ dumptorrent -v
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/view-torrent-file-content-linux.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://dumptorrent.sourceforge.net/
+[2]:http://ask.xmodulo.com/change-path-environment-variable-linux.html
diff --git a/published/20150521 Will Ubuntu Linux Hit 200 Million Users This Year.md b/published/20150521 Will Ubuntu Linux Hit 200 Million Users This Year.md
new file mode 100644
index 0000000000..e06a6e98bb
--- /dev/null
+++ b/published/20150521 Will Ubuntu Linux Hit 200 Million Users This Year.md
@@ -0,0 +1,38 @@
+Ubuntu会在今年达到2亿用户么?
+================================================================================
+距离Mark Shuttleworth表达他的目标“在4年内Ubuntu的用户达到2亿”已经过去了四年零两周。尽管Ubuntu的用户数量在过去的四年中一直在上升,但这个目标目前并未实现,并且看起来不会在今年年底实现。
+
+那是2011年5月在[UDS 布达佩斯][1],Shuttleworth表示Ubuntu将在4年内达到2亿用户。
+
+
+
+上一次我听到Ubuntu有“1千万”用户,但是并没有任何可靠的报道表明Ubuntu的用户数接近2亿。来自Valve最近的统计表明相比于Windows和OS X的用户[使用Linux的游戏用户的比重少于1%][2]。大多数基于Web计量和其他统计方式的数据倾向于表明Linux的用户总数只占很少的部分。
+
+撇开桌面版不谈,Ubuntu在过去的四年来至少在云和服务器部署方面得到了大量的占有率,并且被证明是Red Hat Enterprise的有力竞争者。Ubuntu还证明了它对基于ARM的硬件十分友好。当Mark在四年前提出他的目标时,他可能考虑到Ubuntu Phone/Touch会比目前的状况更好。可是Ubuntu Phone/Touch目前仅仅在欧洲和[中国][3]可用,并且[Ubuntu Touch软件依旧在成熟的路上][4],[仍需要大量的关键应用程序方面的工作][5]等。
+
+
+
+距离Canonical宣布[Ubuntu不久将登陆5%的PC][6]也已过去了3年。5%的目标是全球的PC装机量,但哪怕再过3年,我依旧很难相信这个目标会实现。至少在美国和欧洲,我仍难以在实体店看到Ubuntu作为预装的系统,主要的网络零售商/OEM厂商仍倾向于在特定的PC型号中提供Linux,比如Chrome OS、Android设备。
+
+另一个由开源社区提出的高傲地、落空的目标便是[GNOME将在2010年占有全球桌面市场10%的份额][7]。五年了,没有任何迹象表明他们接近了那10%的里程碑。
+
+在今天,您认为Ubuntu用户有多少呢?在未来的几年里,Ubuntu(或者Linux)的用户会有多大增长呢?通过评论来与我们分享您的想法吧。
+
+--------------------------------------------------------------------------------
+
+via: http://www.phoronix.com/scan.php?page=news_item&px=2015-200-Million-Goal-Retro
+
+作者:[Michael Larabel][a]
+译者:[wwy-hust](https://github.com/wwy-hust)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.michaellarabel.com/
+[1]:http://www.phoronix.com/vr.php?view=16002
+[2]:http://www.phoronix.com/scan.php?page=news_item&px=Steam-April-2015-1-Drop
+[3]:http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-MX4-In-China
+[4]:http://www.phoronix.com/scan.php?page=news_item&px=Ubuntu-Calculator-Reboot
+[5]:http://www.phoronix.com/scan.php?page=news_item&px=MTgzOTM
+[6]:http://www.phoronix.com/scan.php?page=news_item&px=MTA5ODM
+[7]:https://www.phoronix.com/scan.php?page=news_item&px=Nzg1Mw
\ No newline at end of file
diff --git a/published/20150604 Ubuntu's Juju Now Supports systemd and Google Cloud Platform.md b/published/20150604 Ubuntu's Juju Now Supports systemd and Google Cloud Platform.md
new file mode 100644
index 0000000000..952b673c41
--- /dev/null
+++ b/published/20150604 Ubuntu's Juju Now Supports systemd and Google Cloud Platform.md
@@ -0,0 +1,29 @@
+Ubuntu下的Juju现在支持systemd和Google Cloud Platform了
+================================================================================
+> Juju已经更新到1.23.3了
+
+**Cononical旗下的Ubuntu认证公共云总监Udi Nachmany宣布了juju新版本的发布,一个开源的、解决方案驱动的Ubuntu下的协同工具。**
+
+根据[声明][1]和官方[发布公告][2],Juju 1.23.3是一个主要版本,它打包了那些你想要在云上扩展和管理的包,而不需太多操作。
+
+Juju 1.23.3显著的功能是包含了对GCE的支持,支持systemd初始化系统,支持Ubuntu 15.04(Vivid Vervet),新的好玩的功能和对受限网络的代理支持。
+
+另外,juju的发布带来了一个新的样式恢复、新的消息、新的块和实验性地支持Service Leader Elections,还有Ubuntu MAS和AWS上的LXC容器和KVM实例。
+
+Udi Nachmany说:“在一个相关告示中,如果你正在使用Google云平台,你可能已经注意到了Google最近发布了云启动器。如果你观察的足够仔细,你也会注意到你可以使用这个非常友好的UI来启动你的Ubuntu虚拟机。”
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://linux.softpedia.com/blog/Ubuntu-s-Juju-Now-Supports-systemd-and-Google-Cloud-Platform-483279.shtml
+
+作者:[Marius Nestor][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/marius-nestor
+[1]:http://insights.ubuntu.com/2015/06/03/juju-support-for-google-cloud-platform/
+[2]:https://jujucharms.com/docs/devel/reference-release-notes
diff --git a/sources/news/20141219 Google Cloud offers streamlined Ubuntu for Docker use.md b/sources/news/20141219 Google Cloud offers streamlined Ubuntu for Docker use.md
deleted file mode 100644
index c63c4a78f2..0000000000
--- a/sources/news/20141219 Google Cloud offers streamlined Ubuntu for Docker use.md
+++ /dev/null
@@ -1,43 +0,0 @@
-Google Cloud offers streamlined Ubuntu for Docker use
-================================================================================
-> Ubuntu Core provides a minimal Lightweight Linux environment for running containers
-
-Google has adopted for use in its cloud a streamlined version of the Canonical Ubuntu Linux distribution tweaked to run Docker and other containers.
-
-Ubuntu Core was designed to provide only the essential components for running Linux workloads in the cloud. An [early preview edition][1] of it, which Canonical calls "Snappy," was released last week. The new edition jettisoned many of the libraries and programs usually found in general use Linux distributions that were unnecessary for cloud use.
-
-[ [Get started with Docker][2] using this step-by-step guide to the red-hot open source framework. | Get the latest insight on the tech news that matters from [InfoWorld's Tech Watch blog][3]. ]
-
-The Google Compute Engine (GCE) [joins Microsoft Azure][4] in supporting the fresh distribution.
-
-According to Canonical, Ubuntu Core should provide users with an easy way to deploy Docker, an [increasingly lightweight virtualization container][4] that allows users to quickly spin up workloads and easily move them around, even across different cloud providers.
-
-Google has been an ardent supporter of Docker and container-based virtualization itself. In June, the company [released as open source its software for managing containers][5], called Kubernetes.
-
-The design of Ubuntu Core is similar to another Linux distribution, CoreOS, [first released a year ago][7].
-
-Developed in part by two ex-Rackspace engineers, [CoreOS][8] is a lightweight Linux distribution designed to work in clustered, highly scalable environments favored by companies that do much or all of their business on the Web.
-
-CoreOS was quickly adopted by many cloud providers, including Microsoft Azure, Amazon Web Services, DigitalOcean and Google Compute Engine.
-
-Like CoreOS, Ubuntu Core offers an expedited process for updating components, reducing the amount of time that an administrator would need to manually manage them.
-如同Coreos一样,Ubuntu内核提供了一个快速引擎来更新组件
---------------------------------------------------------------------------------
-
-via: http://www.infoworld.com/article/2860401/cloud-computing/google-cloud-offers-streamlined-ubuntu-for-docker-use.html
-
-作者:[Joab Jackson][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.infoworld.com/author/Joab-Jackson/
-[1]:http://www.ubuntu.com/cloud/tools/snappy
-[2]:http://www.infoworld.com/article/2607941/linux/how-to--get-started-with-docker.html
-[3]:http://www.infoworld.com/blog/infoworld-tech-watch/
-[4]:http://www.ubuntu.com/cloud/tools/snappy
-[5]:http://www.itworld.com/article/2695383/open-source-tools/docker-all-geared-up-for-the-enterprise.html
-[6]:http://www.itworld.com/article/2695501/cloud-computing/google-unleashes-docker-management-tools.html
-[7]:http://www.itworld.com/article/2696116/open-source-tools/coreos-linux-does-away-with-the-upgrade-cycle.html
-[8]:https://coreos.com/using-coreos/
diff --git a/sources/news/20150130 LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever.md b/sources/news/20150130 LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever.md
deleted file mode 100644
index 3718ee58a6..0000000000
--- a/sources/news/20150130 LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever.md
+++ /dev/null
@@ -1,38 +0,0 @@
-LibreOffice 4.4 Released as the Most Beautiful LibreOffice Ever
-----
-*The developer has made a lot of UI improvements*
-
-
-
-The Document Foundation has just announced that a new major update has been released for LibreOffice and it brings important UI improvements, enough for them to call this the most beautiful version ever.
-
-The Document Foundation doesn't usually make the UI the main focus of an update, but now the developers are saying that this is the most beautiful release made so far and that says a lot. Fortunately, this version is not just about interface fixes and there are plenty of other major improvements that should really provide a very good reason to get LibreOffice 4.4.
-
-LibreOffice has been gaining quite a lot of fans and users, and the past couple of years have been very successful. The office suite is implemented by default in most of the important Linux distributions out there and it was adopted by numerous administrations and companies across the world. LibreOffice is proving to be a difficult adversary for Microsoft's Office and each new version makes it even better.
-LibreOffice 4.4 brings a lot of new features
-
-If we move aside all the improvements made to the interface, we're still left with a ton of fixes and changes. The Document Foundation takes its job very seriously and all upgrades really improve the users' experience tremendously.
-
-"LibreOffice 4.4 has got a lot of UX and design love, and in my opinion is the most beautiful ever. We have completed the dialog conversion, redesigned menu bars, context menus, toolbars, status bars and rulers to make them much more useful. The Sifr monochrome icon theme is extended and now the default on OS X. We also developed a new Color Selector, improved the Sidebar to integrate more smoothly with menus, and reworked many user interface details to follow today’s UX trends," [says Jan "Kendy" Holesovsky](1), a member of the Membership Committee and the leader of the design team.
-
-Some of the other improvements include much better support for OOXML file formats, the source code has been "groomed" and cleaned after a Coverity Scan analysis, digital signatures for exported PDF files, improved import filters for Microsoft Visio, Microsoft Publisher and AbiWord files, and Microsoft Works spreadsheets, and much more.
-
-For now, the PPA doesn't have the latest version, but that should change soon. For the time being, you can download the [LibreOffice 4.4](2) source packages from Softpedia, if you want to compile them yourself.
-
---------------------------------------------------------------------------------
-
-via:http://news.softpedia.com/news/LibreOffice-4-4-Releases-As-the-Most-Beautiful-LibreOffice-Ever-471575.shtml
-
-本文发布时间:29 Jan 2015, 14:16 GMT
-
-作者:[Silviu Stahie][a]
-
-译者:[译者ID](https://github.com/译者ID)
-
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/silviu-stahie
-[1]:http://blog.documentfoundation.org/2015/01/29/libreoffice-4-4-the-most-beautiful-libreoffice-ever/
-[2]:http://linux.softpedia.com/get/Office/Office-Suites/LibreOffice-60713.shtml
\ No newline at end of file
diff --git a/sources/news/20150130 OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10.md b/sources/news/20150130 OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10.md
deleted file mode 100644
index 552f98e3f2..0000000000
--- a/sources/news/20150130 OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10.md
+++ /dev/null
@@ -1,33 +0,0 @@
-OpenJDK 7 Vulnerabilities Closed in Ubuntu 14.04 and Ubuntu 14.10
-----
-*Users have been advised to upgrade as soon as possible*
-
-##Canonical published details about a new OpenJDK 7 version has been pushed to the Ubuntu 14.04 LTS and Ubuntu 14.10 repositories. This update fixes a number of problems and various vulnerabilities.
-
-The Ubuntu maintainers have upgraded the OpenJDK packages in the repositories and numerous fixes have been implemented. This is an important update and it covers a few libraries.
-
-"Several vulnerabilities were discovered in the OpenJDK JRE related to information disclosure, data integrity and availability. An attacker could
-exploit these to cause a denial of service or expose sensitive data over the network,” reads the security notice.
-
-Also, "a vulnerability was discovered in the OpenJDK JRE related to information disclosure and integrity. An attacker could exploit this to
-expose sensitive data over the network."
-
-These are just a couple of the vulnerabilities identified and corrected by the developer and implemented by the maintainers/., and for a more detailed description of the problems, you can see Canonical's security notification. Users have been advised to upgrade their systems as soon as possible.
-
-The flaws can be fixed if you upgrade your system to the latest openjdk-7-related packages specific to each distribution. To apply the patch, users will have to run the Update Manager application. In general, a standard system update will make all the necessary changes. All Java-related applications will have to be restarted.
-
---------------------------------------------------------------------------------
-
-via:http://linux.softpedia.com/blog/OpenJDK-7-Vulnerabilities-Closed-in-Ubuntu-14-04-and-Ubuntu-14-10-471605.shtml
-
-本文发布时间:29 Jan 2015, 16:53 GMT
-
-作者:[Silviu Stahie][a]
-
-译者:[译者ID](https://github.com/译者ID)
-
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/silviu-stahie
\ No newline at end of file
diff --git a/sources/news/20150131 WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux.md b/sources/news/20150131 WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux.md
deleted file mode 100644
index 3d132079a4..0000000000
--- a/sources/news/20150131 WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux.md
+++ /dev/null
@@ -1,49 +0,0 @@
-WordPress Can Be Used to Leverage Critical Ghost Flaw in Linux
------
-*Users are advised to apply available patches immediately*
-
-
-
-**The vulnerability revealed this week by security researchers at Qualys, who dubbed it [Ghost](1), could be taken advantage of through WordPress or other PHP applications to compromise web servers.**
-
-The glitch is a buffer overflow that can be triggered by an attacker to gain command execution privileges on a Linux machine. It is present in the glibc’s “__nss_hostname_digits_dots()” function that can be used by the “gethostbyname()” function.
-
-##PHP applications can be used to exploit the glitch
-
-Marc-Alexandre Montpas at Sucuri says that the problem is significant because these functions are used in plenty of software and server-level mechanism.
-
-“An example of where this could be a big issue is within WordPress itself: it uses a function named wp_http_validate_url() to validate every pingback’s post URL,” which is carried out through the “gethostbyname()” function wrapper used by PHP applications, he writes in a blog post on Wednesday.
-
-An attacker could use this method to introduce a malicious URL designed to trigger the vulnerability on the server side and thus obtain access to the machine.
-
-In fact, security researchers at Trustwave created [proof-of-concept](2) code that would cause the buffer overflow using the pingback feature in WordPress.
-
-##Multiple Linux distributions are affected
-
-Ghost is present in glibc versions up to 2.17, which was made available in May 21, 2013. The latest version of glibc is 2.20, available since September 2014.
-
-However, at that time it was not promoted as a security fix and was not included in many Linux distributions, those offering long-term support (LTS) in particular.
-
-Among the impacted operating systems are Debian 7 (wheezy), Red Hat Enterprise Linux 6 and 7, CentOS 6 and 7, Ubuntu 12.04. Luckily, Linux vendors have started to distribute updates with the fix that mitigates the risk. Users are advised to waste no time downloading and applying them.
-
-In order to demonstrate the flaw, Qualys has created an exploit that allowed them remote code execution through the Exim email server. The security company said that it would not release the exploit until the glitch reached its half-life, meaning that the number of the affected systems has been reduced by 50%.
-
-Vulnerable application in Linux are clockdiff, ping and arping (under certain conditions), procmail, pppd, and Exim mail server.
-
---------------------------------------------------------------------------------
-
-via:http://news.softpedia.com/news/WordPress-Can-Be-Used-to-Leverage-Critical-Ghost-Flaw-in-Linux-471730.shtml
-
-本文发布时间:30 Jan 2015, 17:36 GMT
-
-作者:[Ionut Ilascu][a]
-
-译者:[译者ID](https://github.com/译者ID)
-
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
-[1]:http://news.softpedia.com/news/Linux-Systems-Affected-by-14-year-old-Vulnerability-in-Core-Component-471428.shtml
-[2]:http://blog.spiderlabs.com/2015/01/ghost-gethostbyname-heap-overflow-in-glibc-cve-2015-0235.html
diff --git a/sources/news/20150202 The Pirate Bay Is Now Back Online.md b/sources/news/20150202 The Pirate Bay Is Now Back Online.md
deleted file mode 100644
index acde800ad8..0000000000
--- a/sources/news/20150202 The Pirate Bay Is Now Back Online.md
+++ /dev/null
@@ -1,38 +0,0 @@
-The Pirate Bay Is Now Back Online
-------
-*The website was closed for about seven weeks*
-
-##After being [raided](1) by the police almost two months ago, (in)famous torrent website The Pirate Bay is now back online. Those who thought the website will never return will be either disappointed or happy given that The Pirate Bay seems to live once again.
-
-In order to celebrate its coming back, The Pirate Bay admins have posted a Phoenix bird on the front page, which signifies the fact that the website can't be killed only damaged.
-
-About two weeks after The Pirate Bay was raided the domain miraculously came back to life. Soon after a countdown appeared on the temporary homepage of The Pirate Bay indicating that the website is almost ready for a comeback.
-
-The countdown hinted to February 1, as the possible date for The Pirate Bay's comeback, but it looks like those who manage the website manage to pull it out one day earlier.
-
-Beginning today, those who have accounts on The Pirate Bay can start downloading the torrents they want. Other than the Phoenix on the front page there are no other messages that might point to the resurrection The Pirate Bay except for the fact that it's now operational.
-
-Admins of the website said a few weeks ago they will find ways to manage and optimize The Pirate Bay, so that there will be minimal chances for the website to be closed once again. Let's see how it lasts this time.
-
-##Another version of The Pirate Bay may be launched soon
-
-In related news, one of the members of the original staff was dissatisfied with the decisions made by the majority regarding some of the changes made in the way admins interact with the website.
-
-He told [Torrentfreak](2) earlier this week that he, along with a few others, will open his version of The Pirate Bay, which they claim will be the "real" one.
-
-------
-via:http://news.softpedia.com/news/The-Pirate-Bay-Is-Now-Back-Online-471802.shtml
-
-本文发布时间:31 Jan 2015, 22:49 GMT
-
-作者:[Cosmin Vasile][a]
-
-译者:[译者ID](https://github.com/译者ID)
-
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/cosmin-vasile
-[1]:http://news.softpedia.com/news/The-Pirate-Bay-Is-Down-December-9-2014-466987.shtml
-[2]:http://torrentfreak.com/pirate-bay-back-online-150131/
\ No newline at end of file
diff --git a/sources/news/20150205 Debian Forked over systemd--Birth of Devuan GNU or Linux Distribution.md b/sources/news/20150205 Debian Forked over systemd--Birth of Devuan GNU or Linux Distribution.md
deleted file mode 100644
index 89299a55d5..0000000000
--- a/sources/news/20150205 Debian Forked over systemd--Birth of Devuan GNU or Linux Distribution.md
+++ /dev/null
@@ -1,98 +0,0 @@
-Debian Forked over systemd: Birth of Devuan GNU/Linux Distribution
-================================================================================
-Debian GNU/Linux distribution is one of the oldest Linux distribution that is currently in working state. init used to be the default central management and configuration platform for Linux operating system before systemd emerged. Systemd from the date of its release has been very much controversial.
-
-Sooner or later it has replaced init on most of the Linux distribution. Debian remained no exception and Debian 8 codename JESSIE will be having systemd by default. The Debian adaptation of systemd in replacement of init caused polarization. This led to forking of Debian and hence Devuan GNU/Linux distribution born.
-
-Devuan project started with the primary goal to put back nit and remove controversial systemd. A lot of Linux Distribution are based on Debian or a derivative of Debian and one does not simply fork Debian. Debian will always attract developers.
-
-### What Devuan is all About? ###
-
-Devuan in Italian (pronounced Devone in English) suggests “Don’t panic and keep forking Debian”, for Init-Freedom lovers. Developers see Devuan as the beginning of a process which aims at base distribution and is able to protect the freedom of developers and community.
-
-
-
-Debian Forked over systemd: Birth of Devuan Linux
-
-Devuan project priority includes – interoperability, diversity and backward compatibility. It will derive its own installer and repos from Debian and modify where ever required. If everything works smooth by the mid of 2015 users can switch to Devuan from Debian 7 and start using devuan repos.
-
-The process of switching will fairly remain as simple as upgrading a Debian installation. The project will be as minimal as possible and completely in accordance of UNIX philosophy – “Doing one thing and doing it well”. The targeted users of Devuan will be System Admins, Developers and users having experience of Debian.
-
-The project started by italian developers has raised a fund of 4.5k€ (EUR) in the year 2014. They have moved distro infrastructure from GitHub to GitLab, progress on Loginkit (systemd Logind replaced), discussing Logo and other important aspects useful in long run.
-
-A few of the Logos are in discussion now are shown in the picture.
-
-
-
-Devuan Logo Proposals
-
-Have a look at them here at: [http://without-systemd.org/wiki/index.php/Category:Logo][1]
-
-The unrest over systemd that gave birth to Devuan is good or bad? Lets have a look.
-
-### Is Devuan fork a good thing? ###
-
-Well! difficult to answer that forking such a huge distro is really going to be of any good. A (group of) developer(s) who initially were working with Debian got unsatisfied with systemd and forked it.
-
-Now the actual number of developers working on Debian/Systemd decreased which is going to affect the productivity of both the projects. Now the same number of developers are working on two different projects.
-
-What you think would be the fate of Devuan as well as Debian project? Won’t it hinder the progress of either distro and Linux in the long run?
-
-Please give your [comments][2] about Devuan project.
-
-注:如果可以在发布文章的时候发布一个调查,就把下面这段发成一个调查,如果不行,就直接嵌入js代码
-
-
-
-Do you think systemd for Debian is
-
-Good
-Bad
-Don't Know
-Don't Care
-Other:
-
-VoteView ResultsPolldaddy.com
-
-
-**Do you really feel that Debian with systemd will have a bad fate as depicted below**
-
-
-
-Strip SystmeD
-
-Time to wait for Devuan 1.0 and lets see what it could contain.
-
-### Conclusion ###
-
-All the major Linux Distributions Like Fedora, RedHat, openSUSE, SUSE Enterprise, Arch, Megia have already switched to Systemd, Ubuntu and Debian are in the way to replace init with systemd. Only Gentoo and Slack till date have shown no interest in systemd but who knows someday even Gentoo and slack too started moving in the same direction.
-
-The reputation of Debian as a Linux Distro is something very few have reached the mark. It is blessed by some hundreds of developers and millions of users. The actual question is what percentage of users and developers were not comfortable with systemd. If the percentage is really high then what led debian to switch to systemd. Had it moved against the wishes of its users and developers. If this is the case the chance of success of devuan is pretty fair. Well how many developers put long hours of code punching for the project.
-
-Hope the fate of this project will not be something like those distros which once was started with high degree of passion and enthusiasm and later the developers got uninterested.
-
-Post Script : Linus Torvalds do not mind systemd that much.
-
-**If you need Devuan, then join and support it now!**
-
-Development : [https://git.devuan.org][3]
-Donations : [https://devuan.org/donate.html][4]
-Discussions : [https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng][5]
-Devuan Developers : onelove@devuan.org
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/
-
-作者:[Avishek Kumar][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/avishek/
-[1]:http://without-systemd.org/wiki/index.php/Category:Logo
-[2]:http://www.tecmint.com/debian-forked-over-systemd-birth-of-devuan-linux/#comments
-[3]:https://git.devuan.org/
-[4]:https://devuan.org/donate.html
-[5]:https://mailinglists.dyne.org/cgi-bin/mailman/listinfo/dng
\ No newline at end of file
diff --git a/sources/news/20150207 BQ and Canonical Officially Launch Aquaris E4.5 Ubuntu Edition, the First Ubuntu Phone.md b/sources/news/20150207 BQ and Canonical Officially Launch Aquaris E4.5 Ubuntu Edition, the First Ubuntu Phone.md
deleted file mode 100644
index 02b147abd9..0000000000
--- a/sources/news/20150207 BQ and Canonical Officially Launch Aquaris E4.5 Ubuntu Edition, the First Ubuntu Phone.md
+++ /dev/null
@@ -1,45 +0,0 @@
-BQ and Canonical Officially Launch Aquaris E4.5 Ubuntu Edition, the First Ubuntu Phone
-------
-*Everything you need to know about Aquaris E4.5*
-
-##BQ and Canonical have officially announced the new Aquaris E4.5 Ubuntu Edition and the fact that the phone will be available in the coming weeks through a series of flash sales.
-
-Information about the imminent launch of BQ Ubuntu phone has been around for some time and now it the two companies seem to have decided to make it official. This is the first device powered by Ubuntu Touch and a lot of people will be paying very close attention to what is happening in the mobile world.
-
-Ubuntu Touch is the latest operating system from Canonical and it's a brand new experience that aims to be very different from what users can find right now on the market, and that includes systems like Jola or Firefox OS. The OS has been in the works for more than two years and it's a system designed to work on all kind of devices, across the hardware spectrum.
-
-##Who is BQ and why has Canonical chosen them?
-
-When Mark Shuttleworth announced the two partners for the launch of Ubuntu Touch, BQ and Meizu, most of the people watching asked the same question. Who? BQ is not a very big company, but it's a young company and it has already started to penetrate the European market with some interesting devices. In many ways, they are doing the same thing companies like Meizu or Xiaomi are trying and succeeded in China: to offer devices that are interesting and different from what everyone else is doing.
-
-Many Ubuntu fans have questioned Canonical’s decision of choosing small companies and not big ones, but they are trying to do the same thing as the just-mentioned hardware makers. They want to offer an operating system radically different from what everyone else is doing. It's easy to understand why the goals of Canonical and BQ are actually one and the same.
-
-##What is Ubuntu Touch?
-
-The new operating system developed by Canonical embraces the fact that people are now swiping a lot more than they are tapping. Smartphones are no longer something new and everyone can understand how to swipe and get things done on a phone. Ubuntu devs have taken this to a whole new level. The operating system has no buttons, with the exception of the regular power and volume buttons. Everything is done with swiped gestures, from all sides of the screen.
-
-Also, Ubuntu Touch brings a new concept to the market, that of scopes. There is no longer a home screen, just scopes defined by the user to expand the experience. For example, you can have a Music scope that aggregates all your music sources on a single screen. It's a different way of looking at your smartphone, but this is built for people who crave a new experience. Don't worry, regular apps still exist, but they are differently integrated.
-
-
-
-"As any kind of content can be presented via Scopes - they provide developers an easy path for their creations to be integral to the device experience. It is simple to create new Scopes via an easy to use UI toolkit with much lower development and maintenance costs than traditional apps. Canonical and BQ have worked with a host of partners to ensure that there is a wealth of interesting, relevant and dynamic content available at launch, with more content partners to follow," said Cristian Parrino, VP Mobile at Canonical.
-
-##BQ’s Aquaris E4.5 Ubuntu Edition hardware specs
-
-First of all, it's important to know that Aquaris E4.5 Ubuntu Edition is a dual-sim phone and it comes unlocked so that everyone can use it with their network. It boasts a MediaTek Quad-Core Cortex A7 processor running at up to 1.3 GHz, a 4.5-inch screen, 1GB RAM, rear camera with high-quality BSI sensors, Largan lens, and autofocus with dual flash(8MP), and front camera with 5MP.
-
-It's also worth mentioning that several operators in Europe, including 3 Sweden, amena.com, giffgaff, and Portugal Telecom have decided to provide SIM bundles at purchase. The price is €169.90 ($191).
-
-So, are you ready to buy the Aquaris E4.5 Ubuntu Edition?
-
---------------------------------------------------------------------------------
-
-via: http://news.softpedia.com/news/BQ-and-Canonical-Officially-Launch-Aquaris-E4-5-Ubuntu-Edition-472397.shtml
-
-作者:[Silviu Stahie][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/silviu-stahie
\ No newline at end of file
diff --git a/sources/share/20140804 Group Test--Linux Text Editors.md b/sources/share/20140804 Group Test--Linux Text Editors.md
deleted file mode 100644
index b1f2846a0e..0000000000
--- a/sources/share/20140804 Group Test--Linux Text Editors.md
+++ /dev/null
@@ -1,318 +0,0 @@
-Group Test: Linux Text Editors
-================================================================================
-> Mayank Sharma tests five supercharged text editors that can crunch more than just words.
-
-If you’ve been using Linux long, you know that whether you want to edit an app’s configuration file, hack together a shell script, or write/review bits of code, the likes of LibreOffice just won’t cut it. Although the words mean almost the same thing, you don’t need a word processor for these tasks; you need a text editor.
-
-In this group test we’ll be looking at five humble text editors that are more than capable of heavy-lifting texting duties. They can highlight syntax and auto-indent code just as effortlessly as they can spellcheck documents. You can use them to record macros and manage code snippets just as easily as you can copy/paste plain text.
-
-Some simple text editors even exceed their design goals thanks to plugins that infuse them with capabilities to rival text-centric apps from other genres. They can take on the duties of a source code editor and even an Integrated Development Environment.
-
-Two of most popular and powerful plain text editors are Emacs and Vim. However, we didn’t include them in this group test for a couple of reasons. Firstly, if you are using either, congratulations: you don’t need to switch. Secondly, both of these have a steep learning curve, especially to the GUI-oriented desktop generation who have access to alternatives that are much more inviting.
-
-### The contenders: ###
-
-#### Gedit ####
-
-- URL:http://projects.gnome.org/gedit/
-- Version: 3.10
-- Licence: GPL
-- Is Gnome’s default text editor up to the challenge?
-
-#### Kate ####
-
-- URL: www.kate-editor.org
-- Version: 3.11
-- Licence: LGPL/GPL
-- Will Kate challenge fate?
-
-#### Sublime Text ####
-
-- URL: www.sublimetext.com
-- Version: 2.0.2
-- Licence: Proprietary
-- Proprietary software in the land of free with the heart of gold.
-
-#### UltraEdit ####
-
-- URL: www.ultraedit.com
-- Version: 4.1.0.4
-- Licence: Proprietary
-- Does it do enough to justify its price?
-
-#### jEdit ####
-
-- URL: www.jedit.org
-- Version: 5.1.0
-- Licence: GPL
-- Will the Java-based editor spoil the party for the rest?
-
-
-There’s a fine balance between stuffing an app with features and exposing all of them to the user. Geddit keeps most of its features hidden.
-
-### The crucial criteria ###
-
-All the tools, except Gedit and jEdit, were installed on Fedora and Ubuntu via their recommended installation method. The former already shipped with the default Gnome desktop and the latter stubbornly refused to install on Fedora. Since these are relatively simple apps, they have no esoteric dependencies, the only exception being jEdit, which requires Oracle Java.
-
-Thanks to the continued efforts of both Gnome and KDE, all editors look great and function properly irrespective of the desktop environment they are running on. That not only rules it out as an evaluation criterion, it also means that you are no longer bound by the tools that ship with your favourite desktop environment.
-
-In addition to their geekier functionality, we also tested all our candidates for general-purpose text editing. However, they are not designed to mimic all the functionality of a modern-day word processor and weren’t evaluated as such.
-
-
-
-Kate can double up as a versatile can capable integrated development environment (IDE).
-
-### Programming language support ###
-
-UltraEdit does syntax highlighting, can fold code and has project management capabilities. There’s also a function list, which is supposed to list all the functions in the source file, but it didn’t work for any of our test code files. UltraEdit also supports HTML5, and has a HTML toolbar with which you can add commonly-used HTML tags.
-
-Even Gnome’s default text editor, Gedit, has several code-oriented features such as bracket matching, automatic indentation, and will also highlight syntax for various programming languages including C, C++, Java, HTML, XML, Python, Perl, and many others.
-
-If you’re looking for more programming assistance, look at Sublime and Kate. Sublime supports several programming languages and (as well as the popular ones) is able to highlight syntax for C#, D, Dylan, Erlang, Groovy, Haskell, Lisp, Lua, MATLAB, OCaml, R, and even SQL. If that isn’t enough for you, you can download add-ons to support even more languages.
-
-Furthermore, its syntax highlighting ability offers several customisable options. The app will also match braces, to ensure they are all properly rounded off, and the auto-complete function in Sublime works with variables created by the user.
-
-Just like Komodo IDE, sublime also displays a scrollable preview of the full source code, which is really handy for navigating long code files and lets you jump between different parts of the file.
-
-One of the best features of Sublime is its ability to run code for certain languages like C++, Python, Ruby, etc from within the editor itself, assuming of course you have the compiler and other build system tools installed on your computer. This helps save time and eliminates the need to switch out to the command line.
-
-You can also enable the build system in Kate with plugins. Furthermore, you can add a simple front-end to the GDB debugger. Kate will work with Git, Subversion and Mercurial version control systems, and also provides some functionality for project management.
-
-It does all this in addition to highlighting syntax for over 180 languages, along with other assistance like bracket matching, auto-completion and auto-indentation. It also supports code folding and can even collapse functions within a program.
-
-The only disappointment is jEdit, which bills itself as a programmer’s text editor, but it struggled with other basic functions such as code folding and wouldn’t even suggest or complete functions.
-
-**Verdict:**
-
-- Gedit:3/5
-- Kate:5/5
-- Sublime:5/5
-- UltraEdit3/5
-- jEdit:1/5
-
-
-
-If you don’t like Sublime’s Charcoal appearance, you can choose one of the other 22 themes included with ti.
-
-### Keyboard control ###
-
-Users of an advanced text editor expect to control and operate it exclusively via the keyboard. Furthermore, some apps even allow their users to further customise the key bindings for the shortcuts.
-
-You can easily work with Gedit using its extensive keyboard shortcut keys. There are keys for working with and editing files as well as invoke tools for common tasks such as spellchecking a document. You can access a list of default shortcut keys from within the app, but there’s no graphical way to customise them. Similarly, to customise the keybindings in Sublime, you need to make modifications in its XML keymap files. Sublime has been criticised for its lack of a graphical interface to define keyboard shortcuts, but long-term users have defended the current file-based mechanism, which gives them more control.
-
-UltraEdit is proud of its “everything is customisable” motto, which it extend to keyboard shortcuts. You can define custom hotkeys for navigating the menus and also define your own multi-key key-mappings for accessing its plethora of functions.
-
-In addition to its fully customisable keyboard shortcuts, jEdit also has pre-defined keymaps for Emacs. Kate is equally impressive in this respect. It has an easily accessible window to customise the key bindings. You can change the default keys, as well as define alternate ones. Furthermore, Kate also has a Vi mode which will let users operate Kate using Vi keys.
-
-**Verdict:**
-
-- Gedit:2/5
-- Kate:5/5
-- Sublime:3/5
-- UltraEdit:4/5
-- jEdit:5/5
-
-### Snippets and macros ###
-
-Macros help you cut down the time spent on editing and organising data by automating repetitive steps, while Snippets of code extend a similar functionality to programmers by creating reusable chunks of source code. Both have the ability to save you time.
-
-The vanilla Gedit installation doesn’t have either of these functionalities, but you can enable them via separate plugins. While the Snippets plugin ships with Gedit, you’ll have to manually download and install the macro plugin (it’s called gedit-macropy and is hosted on GitHub) before you can enable it from within Gedit.
-
-Kate takes the same plugins route to enable the snippets feature. Once added, the plugin also adds a repository of snippets for PHP, Bash and Java. You can display the list of snippets in the sidebar for easier access. Right-click on a snippet to edit its contents as well as its shortcut key combination. However, very surprisingly, it doesn’t support macros – despite repeated hails from users since 2002!
-
-jEdit too has a plugin for enabling snippets. But it can record macros from user actions and you can also write them in the BeanShell scripting language (BeanShell supports scripted objects as simple method closures like those in Perl and JavaScript). jEdit also has a plugin that will download several macros from jEdit’s website.
-
-Sublime ships with inbuilt ability to create both snippets and macros, and ships with several snippets of frequently used functions for most popular programming languages.
-
-Snippets in UltraEdit are called Smart Templates and just like with Sublime you can insert them based upon the kind of source file you’re editing. To complement the Macro recording function, UltraEdit also has an integrated javascript-based scripting language to automate tasks. You can also download user-submitted macros and scripts from the editor’s website.
-
-**Verdict:**
-
-- Gedit:3/5
-- Kate:1/5
-- Sublime:5/5
-- UltraEdit:5/5
-- jEdit:5/5
-
-
-
-UltraEdit’s UI is highly configurable — you can customise the layout of the toolbars and menus just as easily as you can change many other aspects.
-
-### Ease of use ###
-
-Unlike a bare-bones text editor, the text editors in this feature are brimming with features to accommodate a wide range of users — from document writers to programmers. Instead of stripping features from the apps, their developers are looking for avenues to add more functionality.
-
-Although at first glance most apps in this group test have a very similar layout, upon closer inspection, you’ll notice several usability differences. We have a weak spot for apps that expose their functionality and features by making judicious use of the user interface, instead of just overwhelming the user.
-
-### Gedit: 4/5 ###
-
-Gedit wears a very vanilla look. It has an easy interface with minimal menus and buttons. This is a two-edged sword though, as some users might fail to realise its true potential.
-
-The app can open multiple files in tabs that can be rearranged and moved between windows. Users can optionally enable panels on the side and bottom for displaying a file browser and the output of a tool enabled by a plugin. The app will detect when an open file is modified by another application and offers to reload that file.
-
-The UI has been given a major overhaul in the latest version of the app yet to make its way into Gnome. However it isn’t yet stable, and while it maintains all features, several plugins that interact with the menu will need to be updated.
-
-### Kate: 5/5 ###
-
-Although a major part of its user interface resembles Gedit, Kate tucks in tabs at either side and its menus are much fuller. The app is approachable and invites users to explore other features.
-
-Kate can transparently open and save files over all protocols supported by KDE’s KIO including HTTP, FTP, SSH, SMB and WebDAV. You can use the app to work with multiple files at the same time. But unlike the traditional horizontal tab switching bar in most app, Kate has tabs on either side of the screen. The left sidebar will display an index of open files. Programmers who need to see different parts of the same file at the same time will also appreciate its ability to split the interface horizontally as well as vertically.
-
-### Sublime: 5/5 ###
-
-Sublime lets you view up to four files at the same time in various arrangements. There’s also a full-screen distraction free mode that just displays the file and the menu, for when you’re in the zone.
-
-The editor also has a minimap on the right, which is useful for navigating long files. The app ships with several snippets for popular functions in several programming languages, which makes it very usable for developers. Another neat editing feature, whether you are working with text documents or code, is the ability to swap and shuffle selections.
-
-### UltraEdit: 3/5 ###
-
-UltraEdit’s interface is loaded with several toolbars at the top and bottom of the interface. Along with the tabs to switch between documents, panes on either side and the gutter area, these leave little room for the editor window.
-
-Web developers working with HTML files have lots of assistance at their fingertips. You can also access remote files via FTP and SFTP. Advanced features such as recording a macro and comparing files are also easily accessible.
-
-Using the app’s Preferences window you can tweak various aspects of the app, including the colour scheme and other features like syntax highlighting.
-
-### jEdit: 3/5 ###
-
-In terms of usability, one of the first red-flags was jEdit’s inability to install on RPM-based distros. Navigating the editor takes some getting used to, since its menus aren’t in the same order as in other popular apps and some have names that won’t be familiar to the average desktop user. However, the app include detailed inbuilt help, which will help ease the learning curve.
-
-jEdit highlights the current line you are on and enables you to split windows in multiple viewing modes. You can easily install and manage plugins from within the app, and in addition to full macros, jEdit also lets you record quick temporary ones.
-
-
-
-Thanks to its Java underpinnings, jEdit doesn’t really feel at home on any desktop environment
-
-### Availability and support ###
-
-There are several similarities between Gedit and Kate. Both apps take advantage of their respective parent project, Gnome and KDE, and are bundled with several mainstream distros. Yet both projects are cross-platform and have Windows and Mac OS X ports as well as native Linux versions.
-
-Gedit is hosted on Gnome’s web infrastructure and has a brief user guide, information about the various plugins, and the usual channels of getting in touch including a mailing list and IRC channel. You’ll also find usage information on the websites of other Gnome-based distros such as Ubuntu. Similarly, Kate gets the benefit of KDE’s resources and hosts detailed user information as well as a mailing list and IRC channel. You can access their respective user guides offline from within the app as well.
-
-UltraEdit is also available for Windows and Mac OS X besides Linux, and has detailed user guides on getting started, though there’s none included within the app. To assist users, UltraEdit hosts a database of frequently asked questions, a bunch of power tips that have detailed information about several specific features, and users can engage with one another other on forum boards. Additionally, paid users can also seek support from the developers via email.
-
-Sublime supports the same number of platforms, however you don’t need to buy a separate licence for each platform. The developer keeps users abreast with ongoing development via a blog and also participates actively in the hosted forums. The highlight of the project’s support infrastructure is the freely available detailed tutorial and video course. Sublime is lovely.
-
-Because it’s written in Java, jEdit is available on several platforms. On its website you’ll find a detailed user guide and links to documentation of some plugins. However, there are no avenues for users to engage with other users or the developer.
-
-**Verdict:**
-
-- Gedit: 4/5
-- Kate: 4/5
-- Sublime: 5/5
-- UltraEdit: 3/5
-- jEdit: 2/5
-
-### Add-on and plugins ###
-
-Different users have different requirements, and a single lightweight app can only do as much. This is where plugins come into the picture. The apps rely on these small pluggable widgets to extend their feature set and be of use to even more number of users.
-
-The one exception is UltraEdit. The app has no third-party plugins, but its developers do point out that third-party tools such as HtmlTidy are already installed with UltraEdit.
-
-Gedit ships with a number of plugins installed, and you can download more with the gedit-plugins package. The project’s website also points to several third-party plugins based on their compatibility with the Gedit versions.
-
-Three useful plugins for programmers are Code Comment, Terminal Plugin, which adds a terminal in the bottom panel, and the Session Saver. The Session Saver is really useful when you’re working on a project with multiple files. You can open all the files in tabs, save your session and when you restore it with a single click it’ll open all the files in the same tab order as you saved them.
-
-Similarly, you can extend Kate by adding plugins using its built-in plugin manager. In addition to the impressive projects plugins, some others that will be of use to developers include an embedded terminal, ability to compile and debug code and execute SQL queries on databases.
-
-Plugins for Sublime are written in Python, and the text editor includes a tool called Package Control, which is a little bit like apt-get in that it enables the user to find, install, upgrade and remove plugin packages. With plugins, you can bring the Git version control to Sublime, as well as the JSLint tool to improve JavaScript. The Sublime Linter plugin is a must have for coders and will point out any errors in your code.
-
-jEdit boasts the most impressive plugin infrastructure. The app has over 200 plugins, which can be browsed in the dedicated site of their own. The website lists plugins under various categories such as File Management, Version Control, Text, etc. You’ll find lots of plugins housed under each category.
-
-Some of the best plugins are the Android plugin, which provides utilities to work on Android projects; the TomcatSwitch plugin, using which you can create and control an external Jakarta Tomcat server process; and the Vimulator plugin, for Vi-like capabilities. You can install these plugins using jEdit’s using its plugin manager.
-
-**Verdict**
-
-- Gedit: 3/5
-- Kate: 4/5
-- Sublime: 4/5
-- UltraEdit: 1/5
-- jEdit: 5/5
-
-### Plain ol’ text editing ###
-
-Despite all their powerful extra-curricular activities that might even displace full-blown apps across several genres, there will be times when you just need to use these text editing behemoths to read, write, or edit plain and simple text. While you can use all of them to enter text, we are evaluating them for access to common text-editing conveniences.
-
-Gedit which is Gnome’s default text editor, supports an undo and redo mechanism as well as search and replace. It can spellcheck documents in multiple languages and can also access and edit remote files using Gnome GVFS libraries.
-
-You can spellcheck documents with Kate as well, which also lets you perform a Google search on any highlighted text. It’s also got a line modification system which visually alerts users of lines which have modified and unsaved changes in a file. In addition, it enables users to set bookmarks within a file to ease navigation of lengthy documents.
-
-Sublime has a wide selection of editing commands, such as indenting text and formatting paragraphs. Its auto-save feature helps prevent users from losing their work. Advanced users will appreciate the regex-based recursive find and replace feature, as well as the ability to select multiple non-contiguous spans of text and act on them collectively.
-
-UltraEdit also enables the use of regular expressions for its search and replace feature and can edit remote files via FTP. One unique feature of jEdit is its support for an unlimited number of clipboard which it calls registers. You can copy snippets of text to these registers which are available across editing sessions.
-
-**Verdict:**
-
-- Gedit: 4/5
-- Kate: 5/5
-- Sublime: 5/5
-- UltraEdit: 4/5
-- jEdit: 4/5
-
-### Our verdict ###
-
-All the editors in this feature are good enough to replace your existing text editor for editing text files and tweaking configuration files. In fact, chances are they’ll even double up as your IDE. These apps are chock full of bells and whistles, and their developers aren’t thinking of stripping features, but adding more and more and more.
-
-At the tail end of this test we have jEdit. Not only does it insist on using the proprietary Oracle Java Runtime Environment, it failed to install on our Fedora machine, and the developer doesn’t actively engage with its users.
-
-UltraEdit does little better. This commercial proprietary tool focuses on web developers, and doesn’t offer anything to non-developer power users that makes it worth recommending over free software alternatives.
-
-On the third podium position we have Gedit. There’s nothing inherently wrong with Gnome’s default editor, but despite all its positive aspects, it’s simply outclassed by Sublime and Kate. Out of the box, Kate is a more versatile editor than Gedit, and outscores Gnome’s default editor even after taking their respective plugin systems into consideration.
-
-Both Sublime and Kate are equally good. They performed equally well in most of our tests. Whatever ground it lost to Sublime for not supporting macros, it gained for its keyboard friendliness and its ease of use in defining custom keybindings.
-
-Kate’s success can be drawn from the fact that it offers the maximum number of features with minimal learning curve. Just fire it up and use it as a simple text editor, or easily edit configuration file with syntax highlighting, or even use it to collaborate and work on a complex programming project thanks to its project management capabilities.
-
-We aren’t pitching Kate to replace a full-blown integrated development environment such as [insert your favourite specialised tool here]. But it’s an ideal all-rounder and a perfect stepping stone to a specialised tool.
-
-Kate is designed for moments when you need something that’s quick to respond, doesn’t overwhelm you with its interface and is just as useful as something that might otherwise be overkill.
-
-### 1st Kate ###
-
-- Licence LGPL/GPL Version 3.11
-- www.kate-editor.org
-- The ultimate mild-mannered text editor with super powers.
-- Kate is one of the best apps to come out of the KDE project.
-
-### 2nd Sublime Text ###
-
-- Licence Proprietary Version 2.0.2
-- www.sublimetext.com
-- A professionally done text editor that’s worth every penny – easy to use, full of features and it looks great.
-
-### 3rd Gedit ###
-
-- Licence GPL Version 3.10
-- http://projects.gnome.org/gedit
-- Gets it done from Gnome. It’s a wonderful text editor and does an admirable job, but the competition here is too great.
-
-### 4th UltraEdit ###
-
-- Licence Proprietary Version 4.1.0.4
-- www.ultraedit.com
-- Focuses on bundling conveniences for web developers without offering anything special for general users.
-
-### 5th jEdit ###
-
-- Licence GPL Version 5.1.0
-- www.jedit.org
-- A lack of support, lack of working on Fedora and a lack of looking nice relegate jEdit to the bottom slot.
-
-### You may also wish to try… ###
-
-The default text editor that ships with your distro will also be able to assist you with some advanced tasks. There’s KDE’s KWrite and Raspbian’s Nano, for instance. KWrite inherits some of Kate’s features thanks to KDE’s katepart component, and Nano has sprung back into limelight thanks to its availability for Raspberry Pi.
-
-If you wish to follow the steps of Linux gurus, you could always try the revered text editors Emacs and Vim. First time users who want to get a taste for the power of Vim might want to consider gVim, which exposes Vim’s power via a graphical interface.
-
-Besides jEdit and Kate, there are other editors that mimic the usability of veteran advanced editors like Emacs and Vim, such as the JED editor and Joe’s Own Editor, both of which have an emulation mode for Emacs. On the other hand, if you are looking for lightweight code editors check out Bluefish and Geany. They exist to fill the niche between text editors and full-fledged integrated development platforms.
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxvoice.com/text-editors/
-
-作者:[Ben Everard][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.linuxvoice.com/author/ben_everard/
\ No newline at end of file
diff --git a/sources/share/20141013 Compact Text Editors Great for Remote Editing and Much More.md b/sources/share/20141013 Compact Text Editors Great for Remote Editing and Much More.md
index 42b2700b49..b54a7b158f 100644
--- a/sources/share/20141013 Compact Text Editors Great for Remote Editing and Much More.md
+++ b/sources/share/20141013 Compact Text Editors Great for Remote Editing and Much More.md
@@ -1,4 +1,5 @@
-(translating by runningwater)
+translating by wwy-hust
+
Compact Text Editors Great for Remote Editing and Much More
================================================================================
A text editor is software used for editing plain text files. This type of software has many different uses including modifying configuration files, writing programming language source code, jotting down thoughts, or even making a grocery list. Given that editors can be used for such a diverse range of activities, it is worth spending the time finding an editor that best suites your preferences.
@@ -217,4 +218,4 @@ via: http://www.linuxlinks.com/article/20141011073917230/TextEditors.html
[2]:http://www.vim.org/
[3]:http://ne.di.unimi.it/
[4]:http://www.gnu.org/software/zile/
-[5]:http://nano-editor.org/
\ No newline at end of file
+[5]:http://nano-editor.org/
diff --git a/sources/share/20141106 Exaile 3.4.1 Overview--A Feature-Complete GNOME Music Player.md b/sources/share/20141106 Exaile 3.4.1 Overview--A Feature-Complete GNOME Music Player.md
deleted file mode 100644
index cd650fca22..0000000000
--- a/sources/share/20141106 Exaile 3.4.1 Overview--A Feature-Complete GNOME Music Player.md
+++ /dev/null
@@ -1,75 +0,0 @@
-Exaile 3.4.1 Overview – A Feature-Complete GNOME Music Player
-================================================================================
-**Exaile** has been a bit quiet in the past two years with maybe only one or two stable releases, but nevertheless, it’s one of the full-featured music players for GNOME which are on par with applications like [Rhythmbox][1] or [Banshee][2] in terms of features. However, over the past two months a new stable release, 3.4, has been put out under the slogan “We’re not dead yet”, as well as an incremental 3.4.1 release, which shipped on November 1. To be honest, Exaile has so many features that I could go on writing a lot more than an article to cover them all, so let’s have a look at some of the most notable ones.
-
-
-
-[Exaile][3] is a GTK2-based music player written in Python which fits well into GNOME, has an interface which pretty much resembles the one of the old Amarok 1.4 or actual Clementine, and ships with some great features. The interface is composed mainly of two panels, both with support for tabs. The left panel provides access to the collection, Internet radio, smart and custom playlists, file browser, podcasts, Group Tagger and lyrics while the main area of the window is taken by the playlists (with multiple, tabbed playlist support) and control buttons.
-
-Exaile’s interface is very similar to the one of Clementine or Amarok 1.4 and the tabs on the left can be shown or hidden:
-
-
-
-Version 3.4 shipped with a big number of major new features and changes while 3.4.1 was a small bug fix release. The major new features in 3.4 include new plugins like Icecast, Lyricsmania, Playlist Analyzer, Soma.fm, a new, simpler plugin API. Changes were done to the user interface and the general behavior as well, with the possibility to show playlists in multiple panels, close left panels, better BPM UI integration.
-
-The first time it starts you can add music folders to the collection – you can also choose to add directories and enable or disable monitoring or scanning them at start-up:
-
-
-
-Exaile’s features are practically countless. You can organize your music in a collection, listen to podcasts, set song ratings, edit tags, view file properties, queue tracks, view lyrics and covers, sort the playlist by a huge number of criteria, change playback behavior or appearance style.
-
-Equalizer, cover manager and listening to Internet radio:
-
-
-
-Local album covers are detected automatically and can be shown in full size, with the possibility to zoom in or out:
-
-
-
-The preferences window allows to configure various aspects of Exaile, including enable or disable plugins, appearance, system tray integration, or playback. The appearance settings will allow you to change the tabs placement, show/hide the tab bar, enable or disable transparency, or disable the start-up splash screen.
-
-
-
-
-
-The system tray integration offers a menu to quickly play/pause songs, set a song rating or change the way the playlist handles playback (shuffle, repeat or dynamic).
-
-
-
-
-
-The countless features in Exaile I believe make it the perfect choice as a music player, especially for GNOME users. Any user should be satisfied with the wealth of options and the highly configurable approach.
-
-### Install Exaile 3.4.1 in Ubuntu 14.04 and 14.10 ###
-
-Compiling and installing from source should be pretty straightforward. First, get the dependencies:
-
- sudo apt-get build-dep exaile
- sudo apt-get install python-gst0.10
-
-Download the source tarball from the [downloads page][4] (direct link [here][5]), then uncompress it:
-
- tar -xf exaile-3.4.1.tar.gz
-
-Change the working directory to exaile-3.4.1 and issue the following commands:
-
- make
- sudo make install
-
-The binary will be installed as **/usr/local/bin/exaile**.
-
---------------------------------------------------------------------------------
-
-via: http://www.tuxarena.com/2014/11/exaile-3-4-1-overview-a-feature-complete-gnome-music-player/
-
-作者:Craciun Dan
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:https://wiki.gnome.org/Apps/Rhythmbox
-[2]:http://banshee.fm/
-[3]:http://www.exaile.org/
-[4]:http://www.exaile.org/download/
-[5]:https://github.com/exaile-dev/exaile/archive/3.4.1.tar.gz
\ No newline at end of file
diff --git a/sources/share/20141127 11 Useful Utilities To Supercharge Your Ubuntu Experience.md b/sources/share/20141127 11 Useful Utilities To Supercharge Your Ubuntu Experience.md
deleted file mode 100644
index e947762b7c..0000000000
--- a/sources/share/20141127 11 Useful Utilities To Supercharge Your Ubuntu Experience.md
+++ /dev/null
@@ -1,154 +0,0 @@
-11 Useful Utilities To Supercharge Your Ubuntu Experience
-================================================================================
-**Whether you’re a relative novice or a seasoned pro, we all want to get the most from our operating system. Ubuntu, like most modern OSes, has more to offer than what is presented at first blush.**
-
-From tweaking and refining the look, behaviour and performance of the Unity desktop to performing system maintenance, there are a huge array of useful utilities and apps that can help **tune Ubuntu to meet your needs in no time**.
-
-Caveat time: Ubuntu has always shipped with ‘sane defaults’ — options that just work — out of the box. These defaults are well suited for the majority of people. They’re tested, accepted and recommended.
-
-But one size doesn’t fit all. For the tinkerers and experimenters among us the default experience is a starting point from which to tailor.
-
-So, without any more waffle, here is a set of 11 nifty utilities to help you supercharge your Ubuntu experience.
-
-### Unity Tweak Tool ###
-
-
-
-I’ll kick off this list with the big one: **Unity Tweak** Tool. The kitchen sink of customisation, Unity Tweak Tool offers a comprehensive set of system tweaks tuned for Ubuntu and the Unity desktop.
-
-It’s stuffed full of switches, toggles and control, letting you configure everything from the way Unity looks to the way it behaves. Use it to **quickly and easily change the GTK theme and icon set**, set up hot corners, adjust launcher size, add or remove workspaces, and — notably — enable Unity’s elusive ‘minimise on click’ feature.
-
-Free and readily available from the Software Center, Unity Tweak Tool is one well worth keeping in your back pocket.
-
-### Unity Privacy Indicator ###
-
-
-
-Privacy. A big, big issue and rightly so. But the topic is often shaded rather than binary; you may be happy to let some data or habits, say apps you frequently open, be logged locally, but not be ok with the searches you make in the Dash being ferried to a third-party server (however anonymous that data may be).
-
-[Privacy Indicator][1] is a useful tool to help you stay abreast of what files, folders and services are being accessed, logged and recce’d on the Ubuntu desktop.
-
-With a quick click on the ‘eye’ icon added to the desktop panel you can:
-
-- Toggle Online Search Results, Zeitgeist, HUD Logging & GeoIP
-- Quick access to clean Zeitgeist, F2, Recent Files, etc.
-- Options to show/hide desktop icons and name in the panel
-
-The latter two options may seem a little misplaced in this app but have less obvious privacy implications for those who take screenshots or screen share.
-
-- [Download Indicator Privacy (.deb)][2]
-
-### Unity Folders ###
-
-
-
-**Android, iOS, OS X, Chrome OS, and GNOME Shell have app folders, and so can Unity with a nifty third-party app. **
-
-“Unity Folders” allows you to organise apps on the Unity Launcher into handy folders — think ‘games’, ‘office’, ‘social‘, etc. You get quick access to your favourite apps without needing to open the Dash, which may suit your workflow.
-
-Each ‘folder’ is, actually, an application that opens up and positions itself near the origin point. But the overall effect is one that looks like an OS X style stack or an Android folder popover.
-
-Folder icons can be customised or auto-generated based on the applications tucked up inside. Existing folders can be edited, rearranged, rename and re-other stuff, too.
-
-- Create as many folders as you like
-- Choose custom or auto-generated folder icon
-- 3 folder layouts to choose from
-- Set custom icons for apps added to folders
-- Edit existing folders
-
-- Unity Folders Website
-
-### Caffeine ###
-
-A staple for many of us, and not just in our drinks, Caffeine offers a fast, silent way to stop your screensaver or lock-screen kicking in. The degree of usefulness will depend on your circumstances (read: quirks of your system), and though it’s not quite as user friendly as it once was, it’s still worth [checking out][3].
-
-### System Monitor Indicator ###
-
-
-
-If you’re a stat hound who likes to keep tabs on apps, processes and hardware status, Linux makes it easy. From Conky Configs to Terminal Commands — there’s no shortage of ways to monitor your CPU usage, network traffic or GPU temperature.
-
-But by far my favourite is System **Monitor Indicator** – also known as indicator-multiload — available from the Ubuntu Software Center. It has a host of configuration options, too.
-
-- [Click to Install ‘System Load Indicator’ on Ubuntu][4]
-
-### Power Saving Tools for Linux Laptops ###
-
-
-
-**TLP**
-
-Linux distributions don’t have the best reputation when it comes to power efficiency on portable devices.
-
-If your own Linux laptop can barely get you from the sofa to the kitchen before needing a recharge, there are some tools you can try.
-
-TLP is one of the most popular automated background tool promising to prolong battery life of laptops running Linux. It does this by adjusting the settings and behaviour of system processes and hardware, such as enabling Wi-Fi power saving mode, runtime power management of PCI bus devices, and processor frequency scaling.
-
-It’s available to [install on Ubuntu 14.04 LTS and later using the dedicated TLP PPA][5] and comes with a ‘catch-all’ config to get you started. The more advanced users among you can dive in and manually adjust the settings to suit your own hardware, something that a [thorough guide on the TLP wiki][6] makes easy.
-
-**Laptop Mode Tools**
-
-If TLP sounds a little too complex — and there’s no shame if it does — there’s a simpler alternative: **Laptop Mode Tools**. This package is available to install from the Ubuntu Software Center and keeps the tweaks made to a set of sane defaults (Wi-Fi, Bluetooth, etc.).
-
-Laptop Mode Tools cannot be installed at the same time as TLP.
-
-- [Laptop Mode Tools in Ubuntu Software Center][7]
-
-### Intel Graphics Installer ###
-
-
-
-The Intel Graphics Installer tool is a must-have for those running Intel graphics hardware who want the best performance they can get. It makes finding and installing the latest Intel GPU drivers a painless, fuss-free affair — no PPAs or Terminal kung foo needed.
-
-- [Download Intel Graphics Installer for Linux 0.7][8]
-
-### Hardware Stats ###
-
-
-
-If you plan on upgrading your PC or replacing a worn-out part you’ll need to get some specific hardware details, such as RAM type, CPU socket set or what PCI slots are available.
-
-**I-Nex** makes unearthing this, and host of other detailed system stats, easy. Use it to find your motherboard model number, RAM stepping, S.M.A.R.T. status and…well, pretty much anything else you can think of!
-
-- [Learn More About I-Nex on Launchpad][9]
-
-### Disk Space Visualizer ###
-
-
-
-In this age of 1TB hard drives we might not need to be as prudent with disk space as we once were. But for those of using a smallish SSD, running multiple partitions or working in a virtual machine with a fixed-size virtual disk, there’ll be times when freeing up a bit of extra space is required.
-
-GNOME Disks, installed in Ubuntu by default, makes finding the biggest space-gobbling culprits easy. Ideal for locating hidden logs, caches, and media files.
-
-### BleachBit (Cruft Cleaner) ###
-
-
-
-Windows users will be familiar with applications like CCleaner, which scan for and clean out junk files, empty folders, bloated caches, and obsolete packages. For a a similarly quick and effortless click n’ clean solution on Ubuntu try **BleachBit**.
-
-It is a powerful tool, so do pay attention to what you’re cleaning. Don’t aimlessly check every box; not everything that it can clean needs to be. Play it smart; when in doubt, leave it out.
-
-- [Install BleachBit from Ubuntu Software Center][10]
-
-Got a favourite system utility of your own? Let others know about it in the comments.
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2014/11/useful-tools-for-ubuntu-do-you-use-them
-
-作者:[Joey-Elijah Sneddon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/117485690627814051450/?rel=author
-[1]:http://www.florian-diesch.de/software/indicator-privacy/index.html
-[2]:http://www.florian-diesch.de/software/indicator-privacy/dist/indicator-privacy_0.04-1_all.deb
-[3]:http://www.omgubuntu.co.uk/2014/05/stop-ubuntu-sleeping-caffeine
-[4]:apt://indicator-mulitload
-[5]:https://launchpad.net/~linrunner/+archive/ubuntu/tlp/+packages
-[6]:http://linrunner.de/en/tlp/docs/tlp-configuration.html
-[7]:https://apps.ubuntu.com/cat/applications/laptop-mode-tools/
-[8]:https://01.org/linuxgraphics/downloads/2014/intelr-graphics-installer-linux-1.0.7
-[9]:https://launchpad.net/i-nex
-[10]:https://apps.ubuntu.com/cat/applications/bleachbit/
diff --git a/sources/share/20141204 Intense Gameplay--Try these 13 Roguelike games.md b/sources/share/20141204 Intense Gameplay--Try these 13 Roguelike games.md
deleted file mode 100644
index 14ce0991d0..0000000000
--- a/sources/share/20141204 Intense Gameplay--Try these 13 Roguelike games.md
+++ /dev/null
@@ -1,404 +0,0 @@
-Intense Gameplay? Try these 13 Roguelike games
-================================================================================
-Roguelike is a sub-genre of role-playing games. It literally means "a game like Rogue". Rogue is a dungeon crawling video game first released in 1980, standing out for being fiendishly addictive. Its goal was to retrieve the Amulet of Yendor, hidden deep in the 26th level, and ascend back to the top.
-
-There is no exact definition of a roguelike, but this type of game typically has the following characteristics:
-
-- High fantasy narrative background
-- Procedural level generation. Most of the game world is generated by the game for every new gameplay session. This is meant to encourage replayability
-- Turn-based dungeon exploration and combat
-- Tile-based graphics that are randomly generated
-- Random conflict outcomes
-- Permanent death death works realistically, once you're gone, you're gone
-- High difficulty
-
-This article compiles a good selection of roguelike games available for Linux. If you enjoy intense, addictive gameplay, try these 13 games. Don't be put off by the primitive graphics, you'll soon forget the visuals once you get immersed. All of them are available to download without charge, and almost all are released under an open source license.
-
-----------
-
-
-
-
-
-Dungeon Crawl Stone Soup is an open-source, single-player, role-playing roguelike game of exploration and treasure-hunting in dungeons filled with dangerous and unfriendly monsters in a quest to rescue the mystifyingly fabulous Orb of Zot.
-
-Dungeon Crawl Stone Soup is a continuation of Linley's Dungeon Crawl. It is openly developed and invites participation from the Crawl community.
-
-Dungeon Crawl has superb, deep tactical gameplay, innovative magic and religion systems, and a grand variety of monsters to fight. Crawl is also one of the hardest roguelikes to beat. When you finally beat the game and write your victory post on rec.games.roguelike.misc, you know you have achieved something.
-
-Features include:
-
-- Well-rounded, deep tactically rich roguelike
-- Hand-drawn maps
-- Numerous portal vaults
-- Slick interface
-- Innovative magic and religion systems
-- Wide range of Gods, Characters, Items, and Smart Monsters
-
-- Website: [crawl.develz.org][1]
-- Developer: Stone Soup devteam
-- License: Crawl General Public License
-- Version Number: 0.15.2
-
-----------
-
-
-
-
-
-Dwarf Fortress is a single-player fantasy game, similar to NetHack. You can control a dwarven outpost or an adventurer in a randomly generated, persistent world.
-
-The game features three modes of play (Dwarf Fortress, Adventurer and Legends modes), a distinct, randomly-generated world (complete with terrain, wildlife and legends), gruesome combat mechanics and vicious schools of carp.
-
-Features include:
-
-
-- The world persists as long as you like, over many games, recording historical events and tracking changes
-- Command your dwarves as they search for wealth in the mountain
- - Craft treasures and furniture from many materials and improve these objects with precious metals, jewels and more
- - Defend yourself against attacks from hostile civilizations, the wilderness and the depths
- - Support the nobility as they make demands of your populace
- - Keep your dwarves happy and read their thoughts as they work and relax
- - Z coordinate allows you to dig out fortresses with multiple levels. Build towers or conquer the depths
- - Build floodgates to divert water for farming or to drown your adversaries
-- Play an adventurer and explore, quest for glory or seek vengeance
- - Meet adversaries from previous games
- - Recruit people in towns to come with you on your journey
- - Explore without cumbersome plot restrictions
- - Seamlessly wander the world -up to 197376 x 197376 squares total -or travel more rapidly on the region map
- - Accept quests from the town and civilization leaders
- - Retire and meet your old characters. Bring them along on an adventure with a new character or reactivate them and play directly
- - Z coordinate allows you to move seamlessly between dungeon levels and scale structures fighting adversaries above and below
-- The combat model uses skills, body parts, wrestling, charging and dodging between squares, bleeding, pain, nausea, and much more
-- A dynamic weather model tracks wind, humidity and air masses to create fronts, clouds, rain storms and blizzards
-- Over two hundred rock and mineral types are incorporated into the world, placed in their proper geological environments
-- Add new creatures, weapons, plants, metals and other objects via modifiable text files
-- Extended ASCII character set rendered in 16 colors (including black) as well as 8 background colors (including black)
-
-- Website: [www.bay12games.com/dwarves/][2]
-- Developer: Tarn Adams
-- License: Freeware
-- Version Number: 0.40.19
-
-----------
-
-
-
-
-
-Ancient Domains of Mystery (ADOM) is a rogue-like game which has been in development since 1994.
-
-It is a single-user game featuring the exploration of a dungeon complex. You control a fictional character described by race, class, attributes, skills, and equipment. This fictional character is trying to achieve a specific goal (see below) and succeed in a difficult quest. To fulfill the quest, you have to explore previously undiscovered tunnels and dungeons, fight hideous monsters, uncover long forgotten secrets, and find treasures of all kind.
-
-During the game, you explore dungeon levels which are randomly generated each game. You might also encounter certain special levels, which present a particular challenge or are built around a certain theme.
-
-Features include:
-
-- Huge game world with hundreds of locations such as towns, randomized dungeons, elemental temples, graveyards, ancient ruins, towers and other secrets
-- Loads of races (dwarves, drakelings, mist elves, hurthlings, orcs, trolls, ratlings and many others) and even more classes (fighters, elementalists, assassins, chaos knights, duelists and much more) allowing for infinite play styles
-- Hundreds of monsters and items, many with enhanced random features
-- A corruption system forcing you to balance lust for power with fear of damnation
-- Spells, prayers, mindcraft, alchemy, crafting and more
-- Dozens of quests and branching story lines
-- Numerous wildly different endings that might alter reality itself
-
-- Website: [www.adom.de][3]
-- Developer: Thomas Biskup
-- License: Postcardware
-- Version Number: 1.20 Prelease 20
-
-----------
-
-
-
-
-
-Tales of Maj’Eyal (ToME) is a free, open source roguelike RPG, featuring tactical turn-based combat and advanced character building. It is written as a module that runs in T-Engine 4.0.
-
-This is the Age of Ascendancy, after over ten thousand years of strife, pain and chaos the known world is at last at relative peace. The Spellblaze last effects are now tamed, the land slowly heals itself and the civilisations rebuild themselves after the Age of Pyre.
-
-Features include:
-
-- Suitable for gamers without any rogueline experience
-- Supports both graphical tiles and ASCII mode
-- Over 40 abilities available on some characters
-- Talent system
-- Combat engine
-- Online persistent stat/achievement tracking
-- IRC chat client
-- Expandable and moddable
-- Atmospheric music
-- Unlock new races, classes, starting points, playmodes and features
-
-- Website: [te4.org][4]
-- Developer: ToME Development Team
-- License: GNU GPL v3.0
-- Version Number: 1.2.5
-
-----------
-
-
-
-
-
-Cataclysm is an open source post-apocalyptic roguelike, set in the countryside of fictional New England after a devastating plague of monsters and zombies. It is a continuation of Whale's original Cataclysm, which expands it with numerous new creatures, buildings, gameplay mechanics and many other features.
-
-While some have described it as a "zombie game", there's far more to Cataclysm than that. Struggle to survive in a harsh, persistent, procedurally generated world. Scavenge the remnants of a dead civilization for for food, equipment, or, if you're lucky, a vehicle with a full tank of gas to get you the hell out of Dodge. Fight to defeat or escape from a wide variety of powerful monstrosities, from zombies to giant insects to killer robots and things far stranger and deadlier, and against the others like yourself, that want what you have...
-
-Cataclysm is very different from most roguelikes in many ways. Rather than being set in a vertical, linear dungeon, it is set in an unbounded, 3D world. This means that exploration plays a much bigger role than in most roguelikes, and the game is much less linear. As the map is so huge, it is actually completely persistant between games. If you die, and start a new character, your new game will be set in the same game world as your last. Like in many roguelikes, you will be able to loot the dead bodies of previous characters; unlike most roguelikes, you will also be able to retrace their steps completely, and any dramatic changes made to the world will persist into your next game.
-
-Features include:
-
-
-- Detailed character creation, with a plethora of traits to choose
-- Defense mode, a coffeebreak mode with fast-paced combat
-- Bionics; Similar to the magic system in many games
-- Mutations, both positive and negative
-- Unbounded, fully randomized world map that is persistent between characters
-- Item crafting
- - New recipes may be acquired by honing your knowledge through practice or learning from books
-- Realistic fire, smoke, and other dynamic map effects
-- A day/night cycle with the need to sleep. Use caffeine to stay awake longer if you must but be aware this is not healthy
-- Over 300 item types, including a multitude of real-world guns, drugs, and tools
- - Many drugs are addictive, and will require continuous use to avoid withdrawal effects.
-- Ability to board doors and windows, construct traps and fortify your home base to prevent a rude awakening by a zombie
-- Ability to construct your own wooden constructions, including walls and a roof
-- Ability to drive around in vehicles found in the post-apocalyptic landscape
- - These can be modified to your needs, or you could even build one from scratch
-- A temperature system, being too cold or too hot is quite hazardous
-- Preliminary tile support
-- WorldGen options, and versatile editing methods
--
-- Website: [en.cataclysmdda.com][5]
-- Authors: Kevin Granade and others
-- License: Creative Commons Attribution-ShareAlike 3.0 Unported License
-- Version Number: 0.B
-
-----------
-
-
-
-
-
-Goblin Hack is an open source roguelike OpenGL-based smooth-scrolling ASCII graphics game. The game is inspired by the likes of NetHack, but faster with fewer keys.
-
-Goblin Hack has a simple interface that appears to appeal to players of all ages, and fires their imagination in today's world of over-rendered games.
-
-Players can choose one of several classes before being thrown into the first floor of a randomized, ongoing dungeon.
-
-Features include:
-
-- Impressive graphics (compared with many other roguelike games)
-- Simple interface
-- Choose one of several classes before being thrown into the first floor of a randomized, ongoing dungeon
-- Manually save the game
-
-- Website: [goblinhack.sourceforge.net][6], [github.com/goblinhack/goblinhack][7]
-- Authors: Neil McGill
-- License: GNU GPL v2
-- Version Number: 1.19
-
-----------
-
-
-
-
-
-Super Lotsa Added Stuff Hack - Extended Magic (SLASH'EM) is a role-playing game where you control a single character. SLASH'EM is a variant of NetHack. It also has an interface and gameplay similar to Rogue, ADOM, Anghand and NetHack. You control the actions through the keyboard and view the world from an overhead perspective.
-
-The problem: The Amulet of Yendor has been stolen. Not only that but it appears that the Wizard of Yendor (not a nice person), who took the amulet, is hiding in the Dungeons of Doom (not a friendly place).
-
-Features include:
-
-- Offers extra features, monsters, and items
-- Novel features inlude the Monk class and Sokoban levels
-- The main dungeon is much larger than in NetHack
-
-- Website: [www.slashem.org][8]
-- Developer: The Slash'EM development team
-- License: MIT License, NetHack General Public License
-- Version Number: 0.0.7E7F3
-
-----------
-
-
-
-
-
-NetHack is a wonderfully silly, yet quite addictive Dungeons and Dragons-style adventure game. The "net" element references that its development has been coordinated through the Internet. The "hack" element refers to a genre of role-playing games known as hack and slash for their focus on combat.
-
-In NetHack you play the part of a fierce fighter, wizard, or any of many other classes, fighting your way down to retrieve the Amulet of Yendor (try saying THAT one backwards!) for your god. On the way, you might encounter a quantum mechanic or two, or perhaps a microscopic space fleet, or -- if you're REALLY lucky -- the Ravenous Bugblatter Beast of Traal.
-
-Features include:
-
-- 45-50 levels, most of which are randomly generated
-- Variety of items: weapons, armour, scrolls, potions, rings, gems, and an assortment of tools such as keys and lamps
-- Blessings and curses
-- Permadeath: expired characters cannot be revived without having made backup copies of the actual save files
-- Interfaces:
- - Console
- - Graphical, using X, Qt toolkit or GNOME libraries
-
-- Website: [www.nethack.org][9]
-- Developer: The NetHack DevTeam
-- License: NetHack General Public License
-- Version Number: 3.4.3
-
-----------
-
-
-
-
-
-Ascii Sector is a free space combat/exploration/trading game which is based on the classic computer game Wing Commander: Privateer released by Origin Systems in 1993.
-
-In Ascii Sector, you start with a simple spaceship and can then accept missions or trade goods to earn enough money to upgrade your ship or buy a new one. You can engage in deadly fights both in space, on the ground and on board spaceships, and using the Ascii Sector scripting language, you can create your own quests for the game or have fun with other players' quests.
-
-Features include:
-
-- Uses the ANSI character set for the graphics
-- Real depth to the gameplay
-- Offers a wide variety of bases, missions, commodities and ships
-- Ships include: Broadsword, Centurion, Demon, Dralthi, Drayman, Galaxy, Gladius, Gothri, Kamekh, Nexus, Orion, Paradign, Stileto, Talon, Tarsus, and Ulysses
-- Four quadrants: Alizarin, Crimson, Mauve, and Viridian
-- Downloadable quests
-- Scripting of quests
-- Ascii Sector quest language, create your own stories in the Ascii Sector universe
-- NPCs on planets can be attacked and robbed
-- Persistent fleets that can move around, change control of systems, engage enemy fleets, head back for repairs and rebuilds
-- Ships whose systems have been disabled can be boarded
-- Download high quality music files
-
-- Website: [www.asciisector.net][10]
-- Developer: Christian Knudsen
-- License: Freeware
-- Version Number: 0.7.1.4
-
-----------
-
-
-
-
-
-Angband is a free, single-player graphical dungeon exploration game that uses ASCII characters where you take the role of an adventurer, exploring a deep dungeon, fighting monsters, and acquiring the best weaponry you can, in preparation for a final battle with Morgoth, the Lord of Darkness. It has been in development since the 1990s.
-
-Angband is along the lines of Rogue and NetHack. It is derived from the games Moria and Umoria, which were in turn based on Rogue. It is often described as a "roguelike" game because the look and feel of the game is still quite similar to Rogue. Many of these new creatures and objects are drawn from the writings of J.R.R Tolkien, although some of the monsters come straight from classical mythology, Dungeons & Dragons, Rolemaster, or the minds of the orginal Angband coders.
-
-Features include:
-
-- 100 level dungeon
-- New levels are randomly generated
-- Choose to be a human, half-elf, elf, hobbit, gnome, dwarf, half-orc, half-troll, dunadan, high-elf, or kobold
-- Artifacts
-- Spellcasting
-- Monsters
-- Monster pits
-- Monster nests
-
-- Website: [rephial.org][11]
-- Developer: Angband Development Team
-- License: GNU GPL v2
-- Version Number: 3.5.0
-
-----------
-
-
-
-
-
-UnNetHack is a fork of NetHack. NetHack was first released in 1987, and is considered by many gamers to be one of the best gaming experiences the computing world offers.
-
-Features include:
-
-
-- Adds a number of enhancements to NetHack such as additional monsters, more levels, a few new objects, additional dangers, more challenging gameplay, and most importantly more entertainment than vanilla NetHack
-- Tutorial to help new players get started
-
-- Website: [sourceforge.net/apps/trac/unnethack][12]
-- Authors: Patric Mueller
-- License: Nethack General Public License
-- Version Number: 5.1.0
-
-----------
-
-
-
-
-
-Hydra Slayer is an open source Roguelike game focused on slaying Hydras. It is inspired by Greek mythology, Dungeon Crawl, MathRL seven day roguelike, and some mathematical puzzles about brave heroes slaying many headed beasts.
-
-Features include:
-
-- Unique gameplay mechanics
-- A theme which mixes Greek mythology and mathematics
-- Traditional roguelike ASCII graphics, or tiles/3D display
-- 5 player character races with very distinct tactics, strengths and weaknesses
-- 28 enemy types:
- - 10 basic types of elemental hydras (each of them has two special variations)
- - 8 types of special enemies
- - Harmless mushrooms for strategic advantage
-- 28 types of equipment (not counting material and size/power variations)
-- 15 weapon materials
-- 18 types of non-equipment items
-- 3 game geometries to choose
-- 8 level topologies (including the Mobius strip and Klein bottle)
-- 11 level generators
-- 2 endings
-
-- Website: [www.roguetemple.com/z/hydra][13]
-- Developer: Zeno Rogue
-- License: GNU GPL v2
-- Version Number: 16.1
-
-----------
-
-
-
-
-
-Brogue is an open source Roguelike game for Mac OS X, Windows, Linux, iOS and Android.
-
-Brogue is a direct descendant of Rogue, a dungeon crawling video game first developed by Michael Toy and Glenn Wichman around 1980. Unlike other popular modern roguelikes, Brogue favors simplicity over complexity, while trying to ensure that the interactions between components are interesting and varied.
-
-The goal of the game is to travel to the 26th subterranean floor of the dungeon, retrieve the Amulet of Yendor and return with it to the surface. For the truly skillful who desire further challenge, depths below 26 contain three lumenstones each, items which confer an increased score upon victory.
-
-Brogue is a challenging game, but still great fun to play. Try not to be disheartened by the difficulty of the game; with some application, Brogue will become very addictive.
-
-Features include:
-
-- Favors simplicity over complexity
-- User-friendly features
-- Compared with Rogue, Brogue has a more sophisticated level generation
-- XP and levelling system removed
-- Traps, protecting items
-- Additional monster types and magical items
-
-- Website: [sites.google.com/site/broguegame][14]
-- Authors: Brian Walker
-- License: GNU Affero GPL
-- Version Number: 1.7.3
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxlinks.com/article/201412031524381/RoguelikeGames.html
-
-作者:Frazer Kline
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://crawl.develz.org/
-[2]:http://www.bay12games.com/dwarves/index.html
-[3]:http://www.adom.de/
-[4]:http://te4.org/
-[5]:http://en.cataclysmdda.com/
-[6]:http://goblinhack.sourceforge.net/
-[7]:https://github.com/goblinhack/goblinhack
-[8]:http://www.slashem.org/
-[9]:http://www.nethack.org/
-[10]:http://www.asciisector.net/
-[11]:http://rephial.org/
-[12]:http://sourceforge.net/apps/trac/unnethack/
-[13]:http://www.roguetemple.com/z/hydra/
-[14]:https://sites.google.com/site/broguegame/
\ No newline at end of file
diff --git a/sources/share/20150114 What is a good IDE for C or C++ on Linux.md b/sources/share/20150114 What is a good IDE for C or C++ on Linux.md
deleted file mode 100644
index 9560ce6ee1..0000000000
--- a/sources/share/20150114 What is a good IDE for C or C++ on Linux.md
+++ /dev/null
@@ -1,83 +0,0 @@
-What is a good IDE for C/C++ on Linux
-================================================================================
-"A real coder doesn't use an IDE, a real coder uses [insert a text editor name here] with such and such plugins." We all heard that somewhere. Yet, as much as one can agree with that statement, an IDE remains quite useful. An IDE is easy to set up and use out of the box. Hence there is no better way to start coding a project from scratch. So for this post, let me present you with my list of good IDEs for C/C++ on Linux. Why is C/C++ specifically? Because C is my favorite language, and we need to start somewhere. Also note that there are in general a lot of ways to code in C, so in order to trim down the list, I only selected "real out-of-the-box IDE", not text editors like Gedit or Vim pumped with [plugins][1]. Not that this alternative is bad in any way, just that the list will go on forever if I include text editors.
-
-### 1. Code::Blocks ###
-
-
-
-Starting all out with my personal favorite, [Code::Blocks][2] is a simple and fast IDE for C/C++ exclusively. Like any respectable IDE, it integrates syntax highlighting, bookmarking, word completion, project management, and a debugger. Where it shines is via its simple plugin system which adds indispensable tools like Valgrind and CppCheck, and less indispensable like a Tetris mini-game. But my reason for liking it particularly is for its coherent set of handy shortcuts, and the large number of options that never feel too overwhelming.
-
-### 2. Eclipse ###
-
-
-
-I know that I said only "real out-of-the-box IDE" and not a text editor pumped with plugins, but [Eclipse][3] is a "real out-of-the-box IDE." It's just that Eclipse needs a little [plugin][4] (or a variant) to code in C. So I technically did not contradict myself. And it would have been impossible to make an IDE list without mentioning the behemoth that is Eclipse. Like it or not, Eclipse remains a great tool to code in Java. And thanks to the [CDT Project][5], it is possible to program in C/C++ too. You will benefit from all the power of Eclipse and its traditional features like word completion, code outline, code generator, and advanced refactoring. What it lacks in my opinion is the lightness of Code::Blocks. It is still very heavy and takes time to load. But if your machine can take it, or if you are a hardcore Eclipse fan, it is a very safe option.
-
-### 3. Geany ###
-
-
-
-With a lot less features but a lot more flexibility, [Geany][6] is at the opposite of Eclipse. But what it lacks (like a debugger for example), Geany makes it up with nice little features: a space for note taking, creation from template, code outline, customizable shortcuts, and plugins management. Geany is still closer to an extensive text editor than an IDE here. However I keep it in the list for its lightness and its well designed interface.
-
-### 4. MonoDevelop ###
-
-
-
-Another monster to add to the list, [MonoDevelop][7] has a very unique feel derived from its look and interface. I personally love its project management and its integrated version control system. The plugin system is also pretty amazing. But for some reason, all the options and the support for all kind of programming languages make it feel a bit overwhelming to me. It remains a great tool that I used many times in the past, but just not my number one when dealing with "simplistic" C.
-
-### 5. Anjuta ###
-
-
-
-With a very strong "GNOME feeling" attached to it, [Anjuta][8]'s appearance is a hit or miss. I tend to see it as an advanced version of Geany with a debugger included, but the interface is actually a lot more elaborate. I do enjoy the tab system to switch between the project, folders, and code outline view. I would have liked maybe a bit more shortcuts to move around in a file. However, it is a good tool, and offers outstanding compilation and build options, which can support the most specific needs.
-
-### 6. Komodo Edit ###
-
-
-
-I was not very familiar with [Komodo Edit][9], but after trying it a few days, it surprised me with many many good things. First, the tab-based navigation is always appreciable. Then the fancy looking code outline reminds me a lot of Sublime Text. Furthermore, the macro system and the file comparator make Komodo Edit very practical. Its plugin library makes it almost perfect. "Almost" because I do not find the shortcuts as nice as in other IDEs. Also, I would enjoy more specific C/C++ tools, and this is typically the flaw of general IDEs. Yet, very enjoyable software.
-
-### 7. NetBeans ###
-
-
-
-Just like Eclipse, impossible to avoid this beast. With navigation via tabs, project management, code outline, change history tracking, and a plethora of tools, [NetBeans][10] might be the most complete IDE out there. I could list for half a page all of its amazing features. But that will tip you off too easily about its main disadvantage, it might be too big. As great as it is, I prefer plugin based software because I doubt that anyone will need both Git and Mercurial integration for the same project. Call me crazy. But if you have the patience to master all of its options, you will be pretty much become the master of IDEs everywhere.
-
-### 8. KDevelop ###
-
-
-
-For all KDE fans out there, [KDevelop][11] might be the answer to your prayers. With a lot of configuration options, KDevelop is yours if you manage to seize it. Call me superficial but I never really got past the interface. But it's too bad for me as the editor itself packs quite a punch with a lot of navigation options and customizable shortcuts. The debugger is also very advanced and will take a bit of practice to master. However, this patience will be rewarded with this very flexible IDE's full power. And it gets special credits for its amazing embedded documentation.
-
-### 9. CodeLite ###
-
-
-
-Finally, last for not least, [CodeLite][12] shows that you can take a traditional formula and still get something with its own feeling attached to it. If the interface really reminded me of Code::Blocks and Anjuta at first, I was just blown away by the extensive plugin library. Whether you want to diff a file, insert a copyright block, define an abbreviation, or push your work on Git, there is a plugin for you. If I had to nitpick, I would say that it lacks a few navigation shortcuts for my taste, but that's really it.
-
-To conclude, I hope that this list had you discover new IDEs for coding in your favorite language. While Code::Blocks remains my favorite, it has some serious challengers. Also we are far from covering all the ways to code in C/C++ using an IDE on Linux. So if you have another one to propose, let us know in the comments. Also if you would like me to cover IDEs for a different language next, also let us know in the comment section.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/good-ide-for-c-cpp-linux.html
-
-作者:[Adrien Brochard][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/adrien
-[1]:http://xmodulo.com/turn-vim-full-fledged-ide.html
-[2]:http://www.codeblocks.org/
-[3]:https://eclipse.org/
-[4]:http://xmodulo.com/how-to-set-up-c-cpp-development-environment-in-eclipse.html
-[5]:https://eclipse.org/cdt/
-[6]:http://www.geany.org/
-[7]:http://www.monodevelop.com/
-[8]:http://anjuta.org/
-[9]:http://komodoide.com/komodo-edit/
-[10]:https://netbeans.org/
-[11]:https://www.kdevelop.org/
-[12]:http://codelite.org/
\ No newline at end of file
diff --git a/sources/share/20150119 Cutegram--A Better Telegram Client For GNU or Linux.md b/sources/share/20150119 Cutegram--A Better Telegram Client For GNU or Linux.md
deleted file mode 100644
index 7a051be4fc..0000000000
--- a/sources/share/20150119 Cutegram--A Better Telegram Client For GNU or Linux.md
+++ /dev/null
@@ -1,76 +0,0 @@
-Cutegram: A Better Telegram Client For GNU/Linux
-================================================================================
-No need for a introduction to **Telegram**, right? Telegram is a popular free Instant messenger application that can be used to chat with your friends all over the world. Unlike Whatsapp, Telegram is free forever, no ads, no subscription fees. And, the Telegram client is open source too. Telegram is available for many different platforms, including Linux, Android, iOS, Windows Phone, Windows, and Mac OS X. The messages which are sending using telegram are highly encrypted and self-destructive. It is very secure, and there is no limit on the size of your media and chats.
-
-You can install and use Telegram desktop on your Debian/Ubuntu systems as mentioned in [our previous tutorial][1]. However, a new telegram client called **Cutegram** is available now to make your chat experience more fun and easy.
-
-### What is Cutegram? ###
-
-Cutegram is a free and opensource telegram clients for GNU/Linux focusing on user friendly, compatibility with Linux desktop environments and easy to use. Cutegram using Qt5, QML, libqtelegram, libappindication, AsemanQtTools technologies and Faenza icons and Twitter emojies graphic sets. It’s free and released under GPLv3 license.
-
-### Install Cutegram ###
-
-Head over to the Cutegram homepage and download the latest version of your distribution’s choice. As I use Ubuntu 64 bit, I downloaded the .deb file.
-
- wget http://aseman.co/downloads/cutegram/cutegram_1.0.2-1-amd64.deb
-
-Now, Install Cutegram as shown below.
-
- sudo apt-get install gdebi
- sudo gdebi cutegram_1.0.2-1-amd64.deb
-
-For other distributions, run the following commands.
-
-**64bit:**
-
- wget http://aseman.co/downloads/cutegram/cutegram-1.0.2-linux-x64-installer.run
-
-**32 bit:**
-
- wget http://aseman.co/downloads/cutegram/cutegram-1.0.2-linux-installer.run
-
-Set executable permission:
-
- chmod + cutegram-1.0.2-linux*.run
-
-And, install it as shown below.
-
- sudo ./cutegram-1.0.2-linux*.run
-
-### Usage ###
-
-Launch Cutegram either from Menu or Unity dash. From the login screen, select your country, and enter your mobile number, finally click **Login**.
-
-
-
-A code will be sent to your mobile number. Enter the code and click **Sign in**.
-
-
-
-There you go.
-
-
-
-Start Chatting!
-
-
-
-And, you can set a profile picture, start new chat/group chat, or secret chat from using the buttons on the left pane.
-
-Stay happy! Cheers!!
-
-For more details, check the [Cutegram website][2].
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/cutegram-better-telegram-client-gnulinux/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/sk/
-[1]:http://www.unixmen.com/install-telegram-desktop-via-ppa/
-[2]:http://aseman.co/en/products/cutegram/
\ No newline at end of file
diff --git a/sources/share/20150126 CD Audio Grabbers--Graphical Based.md b/sources/share/20150126 CD Audio Grabbers--Graphical Based.md
deleted file mode 100644
index 5dcfa26cca..0000000000
--- a/sources/share/20150126 CD Audio Grabbers--Graphical Based.md
+++ /dev/null
@@ -1,128 +0,0 @@
-CD Audio Grabbers - Graphical Based
-================================================================================
-CD audio grabbers are designed to extract ("rip") the raw digital audio (in a format commonly called CDDA) from a compact disc to a file or other output. This type of software enables a user to encode the digital audio into a variety of formats, and download and upload disc info from freedb, an internet compact disc database.
-
-Is copying CDs legal? Under US copyright law, converting an original CD to digital files for personal use has been cited as qualifying as 'fair use'. However, US copyright law does not explicitly allow or forbid making copies of a personally-owned audio CD, and case law has not yet established what specific scenarios are permitted as fair use. The copyright position is much clearer in the UK. From 2014 it become legal for UK citizens to make copies of CDs, MP3s, DVD, Blu-rays and e-books. This only applies if the individual owns the physical media being ripped, and the copy is made only for their own private use. For other countries in the European Union, member nations can allow a private copy exception too.
-
-If you are not sure what the position is for the country you live in, please check your local copyright law to make sure that you are on the right side of the law before using the software featured in this two page article.
-
-To some extent, it may seem a bit of a chore to rip CDs. Streaming services like Spotify and Google Play Music offer access to a huge library of music in a convenient form, and without having to rip your CD collection. However, if you already have a large CD collection, it is still desirable to be able to convert your CDs to enjoy on mobile devices like smartphones, tablets, and portable MP3 players.
-
-This two page article highlights my favorite audio CD grabbers. I pick the best four graphical audio grabbers, and the best four console audio grabbers. All of the utilities are released under an open source license.
-
-----------
-
-
-
-
-
-fre:ac is an open source audio converter and CD ripper that supports a wide range of popular formats and encoders. The utility currently converts between MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats. It comes with several different presents for the LAME encoder.
-
-#### Features include: ####
-
-- Easy to learn and use
-- Converter for MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats
-- Integrated CD ripper with CDDB/freedb title database support
-- Multi-core optimized encoders to speed up conversions on modern PCs
-- Full Unicode support for tags and file names
-- Easy to learn and use, still offers expert options when you need them
-- Joblists
-- Can use Winamp 2 input plugins
-- Multilingual user interface available in 41 languages
-
-- Website: [freac.org][1]
-- Developer: Robert Kausch
-- License: GNU GPL v2
-- Version Number: 20141005
-
-----------
-
-
-
-
-
-Audex is an easy to use open source audio CD ripping application. Whilst it is in a fairly early stage of development, this KDE desktop tool is stable, slick and simple to use.
-
-The assistant is able to create profiles for LAME, OGG Vorbis (oggenc), FLAC, FAAC (AAC/MP4) and RIFF WAVE. Beyond the assistant you can define your own profile, which means, that Audex works together with commmand line encoders in general.
-
-#### Features include: ####
-
-- Extract with CDDA Paranoia
-- Extract and encode run parallel
-- Filename editing with local and remote CDDB/FreeDB database
-- Submit new entries to CDDB/FreeDB database
-- Metadata correction tools like capitalize etc
-- Multi-profile extraction (with one commandline-encoder per profile)
-- Fetch covers from the internet and store them in the database
-- Create playlists, cover and template-based-info files in target directory
-- Create extraction and encoding protocols
-- Transfer files to a FTP-server
-- Internationalization support
-
-- Website: [kde.maniatek.com/audex][2]
-- Developer: Marco Nelles
-- License: GNU GPL v3
-- Version Number: 0.79
-
-----------
-
-
-
-
-
-Sound Juicer is a lean CD ripper using GTK+ and GStreamer. It extracts audio from CDs and converts it into audio files. Sound Juicer can also play audio tracks directly from the CD, offering a preview before ripping.
-
-It supports any audio codec supported by a GStreamer plugin, including MP3, Ogg Vorbis, FLAC, and uncompressed PCM formats.
-
-It is an established part of the GNOME desktop environment.
-
-#### Features include: ####
-
-- Automatic track tagging via CDDB
-- Encoding to ogg / vorbis, FLAC and raw WAV
-- Easy to configure encoding path
-- Multiple genres
-- Internationalization support
-
-- Website: [burtonini.com][3]
-- Developer: Ross Burton
-- License: GNU GPL v2
-- Version Number: 3.14
-
-----------
-
-
-
-
-
-ripperX is an open source graphical interface for ripping CD audio tracks and encoding them to Ogg, MP2, MP3, or FLAC formats. It's goal is to be easy to use, requiring only a few mouse clicks to convert an entire album. It supports CDDB lookups for album and track information.
-
-It uses cdparanoia to convert (i.e. "rip") CD audio tracks to WAV files, and then calls the Vorbis/Ogg encoder oggenc to convert the WAV to an OGG file. It can also call flac to perform lossless compression on the WAV file, resulting in a FLAC file.
-
-#### Features include: ####
-
-- Very simple to use
-- Rip audio CD tracks into WAV, MP3, OGG, or FLAC files
-- Supports CDDB lookups
-- Supports ID3v2 tags
-- Pause the ripping process
-
-- Website: [sourceforge.net/projects/ripperx][4]
-- Developer: Marc André Tanner
-- License: MIT/X Consortium License
-- Version Number: 2.8.0
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
-
-作者:Frazer Kline
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://www.freac.org/
-[2]:http://kde.maniatek.com/audex/
-[3]:http://burtonini.com/blog/computers/sound-juicer
-[4]:http://sourceforge.net/projects/ripperx/
\ No newline at end of file
diff --git a/sources/share/20150128 Meet Vivaldi--A New Web Browser Built for Power Users.md b/sources/share/20150128 Meet Vivaldi--A New Web Browser Built for Power Users.md
deleted file mode 100644
index c55a5fabe7..0000000000
--- a/sources/share/20150128 Meet Vivaldi--A New Web Browser Built for Power Users.md
+++ /dev/null
@@ -1,60 +0,0 @@
-Meet Vivaldi — A New Web Browser Built for Power Users
-================================================================================
-
-
-**A brand new web browser has arrived this week that aims to meet the needs of power users — and it’s already available for Linux.**
-
-Vivaldi is the name of this new browser and it has been launched as a tech preview (read: a beta without the responsibility) for 64-bit Linux machines, Windows and Mac. It is built — shock — on the tried-and-tested open-source frameworks of Chromium, Blink and Google’s open-source V8 JavaScript engine (among other projects).
-
-Does the world really want another browser? Vivaldi, the brain child of former Opera Software CEO Jon von Tetzchner, is less concerned about want and more about need.
-
-Vivaldi is being built with the sort of features that keyboard preferring tab addicts need. It is not being pitched at users who find Firefox perplexing or whose sole criticism of Chrome is that it moved the bookmarks button.
-
-That’s not tacky marketing spiel either. Despite the ‘technical preview’ badge it comes with, Vivaldi is already packed with features that demonstrate its power user slant.
-
-Plenty of folks feel left behind and underserved by the simplified, paired back offerings other software companies are producing. Vivaldi, even at this early juncture, looks well placed to succeed in winning them over.
-
-### Vivaldi Features ###
-
-A few of Vivaldi’s key features already present include:
-
-
-
-**Quick Commands** (Ctrl + Q) is an in-app HUD that lets you quickly filter through settings, options and features, be it opening a bookmark or hiding the status bar, using your keyboard. No clicks needed.
-
-**Tab Stacks** let you clean up your workspace by grouping separate tabs into one, and then using a keyboard command or the tab preview picker to switch between them.
-
-
-
-A collapsible **side panel** that houses extra features (just like old Opera) including a (not yet working) mail client, contacts, bookmarks browser and note taking section that lets you take and annotate screenshots.
-
-A bunch of other features are on offer too, including customizable keyboard shortcuts, a tabs bar that can be set on any edge of the browser (or hidden entirely), privacy options and a speed dial with folders.
-
-### Opera Mark II ###
-
-
-
-It’s not a leap to see Vivaldi as the true successor to Opera post-Presto (Opera’s old, proprietary rendering engine). Opera (which also pushed out a minor new update today) has split out many of its “power user” features as it chases a lighter, more manageable set of features.
-
-Vivaldi wants to pick up the baggage Opera has been so keen to offload. And while that might not help it grab marketshare it will see it grab the attention of power users, many of whom will no doubt already be using Linux.
-
-### Download ###
-
-Interested in taking it for a spin? You can. Vivaldi is available to download for Windows, Mac and 64-bit Linux distributions. On the latter you have a choice of Debian or RPM installer.
-
-Bear in mind that it’s not finished and that more features (including extensions, sync and more) are planned for future builds.
-
-- [Download Vivaldi Tech Preview for Linux][1]
-
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2015/01/vivaldi-web-browser-linux-download-power-users
-
-作者:[Joey-Elijah Sneddon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/117485690627814051450/?rel=author
-[1]:https://vivaldi.com/#Download
\ No newline at end of file
diff --git a/sources/share/20150407 10 Truly Amusing Easter Eggs in Linux.md b/sources/share/20150407 10 Truly Amusing Easter Eggs in Linux.md
new file mode 100644
index 0000000000..3ab7f47b79
--- /dev/null
+++ b/sources/share/20150407 10 Truly Amusing Easter Eggs in Linux.md
@@ -0,0 +1,154 @@
+10 Truly Amusing Easter Eggs in Linux
+================================================================================
+
+The programmer working on Adventure slipped a secret feature into the game. Instead of getting upset about it, Atari decided to give these sorts of “secret features” a name -- “Easter Eggs” because… you know… you hunt for them. Image credit: Wikipedia.
+
+Back in 1979, a video game was being developed for the Atari 2600 -- [Adventure][1].
+
+The programmer working on Adventure slipped a secret feature into the game which, when the user moved an “invisible square” to a particular wall, allowed entry into a “secret room”. That room contained a simple phrase: “Created by [Warren Robinett][2]”.
+
+Atari had a policy against putting author credits in their games, so this intrepid programmer put his John Hancock on the game by being, well, sneaky. Atari only found out about the “secret room” after Warren Robinett had left the company. Instead of getting upset about it, Atari decided to give these sorts of “secret features” a name -- “Easter Eggs” because… you know… you hunt for them -- and declared that they would be putting more of these “Easter Eggs” in future games.
+
+This wasn’t the first such “hidden feature” built into a piece of software (that distinction goes to an operating system for the [PDP-10][3] from 1966, but this was the first time it was given a name. And it was the first time it really grabbed the attention of most computer users and gamers.
+
+Linux (and Linux related software) has not been left out. Some truly amusing Easter Eggs have been created for our beloved operating system over the years. Here are some of my personal favorites -- with how to achieve them.
+
+You’ll notice, rather quickly, that most of these are experienced via a terminal. That’s on purpose. Because terminals are cool. [I should also take this moment to say that if you try to run an application I list, and you do not have it installed, it will not work. You should install it first. Because… computers.]
+
+### Arch : Pac-Man in pacman ###
+
+We’re going to start with one just for the [Arch Linux][4] fans out there. You can add a [Pac-Man][5]-esque character to your progress bars in “[pacman][6]” (the Arch package manager). Why this isn’t enabled by default is beyond me.
+
+To do this you’ll want to edit “/etc/pacman.conf” in your favorite text editor. Under the “# Misc options” section, remove the “#” in front of “Color” and add the line “ILoveCandy”. Because Pac-Man loves candy.
+
+That’s it! Next time you fire up a terminal and run pacman, you’ll help the little yellow guy get some lunch (or at least some candy).
+
+### GNU Emacs : Tetris and such ###
+
+
+I don’t like emacs. Not even a little bit. But it does play Tetris.
+
+I have a confession to make: I don’t like [emacs][7]. Not even a little bit.
+
+Some things fill my heart with gladness. Some things take away all my sadness. Some things ease my troubles. That’s [not what emacs does][8].
+
+But it does play Tetris. And that’s not nothing. Here’s how:
+
+Step 1) Launch emacs. (When in doubt, type “emacs”.)
+
+Step 2) Hit Escape then X on your keyboard.
+
+Step 3) Type “tetris” and hit Enter.
+
+Bored of Tetris? Try “pong”, “snake” and a whole host of other little games (and novelties). Take a look in “/usr/share/emacs/*/lisp/play” for the full list.
+
+### Animals Saying Things ###
+
+The Linux world has a long and glorious history of animals saying things in a terminal. Here are the ones that are the most important to know by heart.
+
+On a Debian-based distro? Try typing “apt-get moo".
+
+
+apt-get moo
+
+Simple, sure. But it’s a talking cow. So we like it. Then try “aptitude moo”. It will inform you that “There are no Easter Eggs in this program”.
+
+If there’s one thing you should know about [aptitude][9], it’s that it’s a dirty, filthy liar. If aptitude were wearing pants, the fire could be seen from space. Add a “-v” option to that same command. Keep adding more v’s until you force aptitude to come clean.
+
+
+I think we can all agree, that this is probably the most important feature in aptitude.
+
+I think we can all agree, that this is probably the most important feature in aptitude. But what if you want to put your own words into the mouth of a cow? That’s where “cowsay” comes in.
+
+And, don’t let the name “cowsay” fool you. You can put words into so much more than just a cow. Like an elephant, Calvin, Beavis and even the Ghostbusters logo. Just do a “cowsay -l” from the terminal to get a complete list of options.
+
+
+You can put words into so much more than just a cow.
+
+Want to get really tricky? You can pipe the output of other applications into cowsay. Try “fortune | cowsay”. Lots of fun can be had.
+
+### Sudo Insult Me Please ###
+
+Raise your hand if you’ve always wanted your computer to insult you when you do something wrong. Hell. I know I have. Try this:
+
+Type “sudo visudo” to open the “sudoers” file. In the top of that file you’ll likely see a few lines that start with “Defaults”. At the bottom of that list add “Defaults insults” and save the file.
+
+Now, whenever you mistype your sudo password, your system will lob insults at you. Confidence boosting phrases such as “Listen, burrito brains, I don’t have time to listen to this trash.”, “Are you on drugs?” and “You’re mind just hasn’t been the same since the electro-shocks, has it?”.
+
+This one has the side-effect of being a rather fun thing to set on a co-worker's computer.
+
+### Firefox is cheeky ###
+
+Here’s one that isn’t done from the Terminal! Huzzah!
+
+Open up Firefox. In the URL bar type “about:about”. That will give you a list of all of the “about” pages in Firefox. Nothing too fancy there, right?
+
+Now try “about:mozilla” and you’ll be greeted with a quote from the “[Book of Mozilla][10]” -- the holy book of web browsing. One of my other favorites, “about:robots”, is also quite excellent.
+
+
+The “Book of Mozilla” -- the holy book of web browsing.
+
+### Carefully Crafted Calendar Concoctions ###
+
+Tired of the boring old [Gregorian Calendar][11]? Ready to mix things up a little bit? Try typing “ddate”. This will print the current date on the [Discordian Calendar][12]. You will be greeted by something that looks like this:
+
+“Today is Sweetmorn, the 18th day of Discord in the YOLD 3181”
+
+I hear what you’re saying, “But, this isn’t an Easter Egg!” Shush. I’ll call it an Easter Egg if I want to.
+
+### Instant l33t Hacker Mode ###
+
+Want to feel like you’re a super-hacker from a movie? Try setting nmap into “[Script Kiddie][13]” mode (by adding “-oS”) and all of the output will be rendered in the most 3l33t [h@x0r-y way][14] possible.
+
+Example: “nmap -oS - google.com”
+
+Do it. You know you want to. Angelina Jolie would be [super impressed][15].
+
+### The lolcat Rainbow ###
+
+Having awesome Easter Eggs and goodies in your Linux terminal is fine and dandy… but what if you want it to have a little more… pizazz? Enter: lolcat. Take the text output of any program and pipe it through lolcat to super-duper-rainbow-ize it.
+
+
+Take the text output of any program and pipe it through lolcat to super-duper-rainbow-ize it.
+
+### Cursor Chasing Critter ###
+
+
+“Oneko” -- the Linux port of the classic “Neko”.
+
+“Oneko” -- the Linux port of the classic “[Neko][16]”.
+And that brings us to “oneko” -- the Linux port of the classic “Neko”. Basically a little cat that chases your cursor around the screen.
+
+While this may not qualify as an “Easter Egg” in the strictest sense of the word, it’s still fun. And it feels Easter Egg-y.
+
+You can also use different options (such as “oneko -dog”) to use a little dog instead of a cat and a few other tweaks and options. Lots of possibilities for annoying co-workers with this one.
+
+There you have it! A list of my favorite Linux Easter Eggs (and things of that ilk). Feel free to add your own favorite in the comments section below. Because this is the Internet. And you can do that sort of thing.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linux.com/news/software/applications/820944-10-truly-amusing-linux-easter-eggs-
+
+作者:[Bryan Lunduke][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linux.com/community/forums/person/56734
+[1]:http://en.wikipedia.org/wiki/Adventure_(Atari_2600)
+[2]:http://en.wikipedia.org/wiki/Warren_Robinett
+[3]:http://en.wikipedia.org/wiki/PDP-10
+[4]:http://en.wikipedia.org/wiki/Arch_Linux
+[5]:http://en.wikipedia.org/wiki/Pac-Man
+[6]:http://www.linux.com/news/software/applications/820944-10-truly-amusing-linux-easter-eggs-#Pacman
+[7]:http://en.wikipedia.org/wiki/GNU_Emacs
+[8]:https://www.youtube.com/watch?v=AQ4NAZPi2js
+[9]:https://wiki.debian.org/Aptitude
+[10]:http://en.wikipedia.org/wiki/The_Book_of_Mozilla
+[11]:http://en.wikipedia.org/wiki/Gregorian_calendar
+[12]:http://en.wikipedia.org/wiki/Discordian_calendar
+[13]:http://nmap.org/book/output-formats-script-kiddie.html
+[14]:http://nmap.org/book/output-formats-script-kiddie.html
+[15]:https://www.youtube.com/watch?v=Ql1uLyuWra8
+[16]:http://en.wikipedia.org/wiki/Neko_%28computer_program%29
diff --git a/sources/share/20150527 3 Open Source Python Shells.md b/sources/share/20150527 3 Open Source Python Shells.md
new file mode 100644
index 0000000000..c510096670
--- /dev/null
+++ b/sources/share/20150527 3 Open Source Python Shells.md
@@ -0,0 +1,99 @@
+3 Open Source Python Shells
+================================================================================
+Python is a high-level, general-purpose, structured, powerful, open source programming language that is used for a wide variety of programming tasks. It features a fully dynamic type system and automatic memory management, similar to that of Scheme, Ruby, Perl, and Tcl, avoiding many of the complexities and overheads of compiled languages. The language was created by Guido van Rossum in 1991, and continues to grow in popularity.
+
+Python is a very useful and popular computer language. One of the benefits of using an interpreted language such as Python is exploratory programming with its interactive shell. You can try out code without having to write a script. But there are limitations with the Python shell. Fortunately, there are some excellent alternative Python shells that extend on the basic shell. They each offer an excellent interactive Python experience.
+
+----------
+
+### bpython ###
+
+
+
+bpython is a fancy interface to the Python interpreter for Linux, BSD, OS X and Windows.
+
+The idea is to provide the user with all the features in-line, much like modern IDEs, but in a simple, lightweight package that can be run in a terminal window.
+
+bpython doesn't seek to create anything new or groundbreaking. Instead, it brings together a few neat ideas and focuses on practicality and usefulness.
+
+Features include:
+
+- In-line syntax highlighting - uses Pygments for lexing the code as you type, and colours appropriately
+- Readline-like autocomplete with suggestions displayed as you type
+- Expected parameter list for any Python function - seeks to display a list of parameters for any function you call
+- "Rewind" function to pop the last line of code from memory and re-evaluate
+- Send the code you've entered off to a pastebin
+- Save the code you've entered to a file
+- Auto-indentation
+- Python 3 support
+
+- Website: [www.bpython-interpreter.org][1]
+- Developer: Bob Farrell and contributors
+- License: MIT License
+- Version Number: 0.14.1
+
+----------
+
+### IPython ###
+
+
+
+IPython is an enhanced interactive Python shell. It provides a rich toolkit to help you make the most out of using Python interactively.
+
+IPython can be used as a replacement for the standard Python shell, or it can be used as a complete working environment for scientific computing (like Matlab or Mathematica) when paired with the standard Python scientific and numerical tools. It supports dynamic object introspections, numbered input/output prompts, a macro system, session logging, session restoring, complete system shell access, verbose and colored traceback reports, auto-parentheses, auto-quoting, and is embeddable in other Python programs.
+
+Features include:
+
+- Powerful interactive shells (terminal and Qt-based)
+- A browser-based notebook with support for code, rich text, mathematical expressions, inline plots and other rich media
+- Support for interactive data visualization and use of GUI toolkits
+- Flexible, embeddable interpreters to load into your own projects
+- Easy to use, high performance tools for parallel computing
+
+- Website: [ipython.org][2]
+- Developer: The IPython Development Team
+- License: BSD
+- Version Number: 3.1
+
+----------
+
+### DreamPie ###
+
+
+
+DreamPie is a Python shell which is designed to be reliable and fun.
+
+DreamPie can use just about any Python interpreter (Jython, IronPython, PyPy).
+
+Features include:
+
+- New concept for an interactive shell: the window is divided into the history box, which lets you view previous commands and their output, and the code box, where you write your code. This allows you to edit any amount of code, just like in your favorite editor, and execute it when it's ready. You can also copy code from anywhere, edit it and run it instantly
+- The Copy code only command will copy the code you want to keep, so you can save it in a file. The code is already formatted nicely with a four-space indentation
+- Automatic completion of attributes and file names
+- Automatically displays function arguments and documentation
+- Keeps your recent results in the result history, for later use
+- Can automatically fold long outputs, so you can concentrate on what's important
+- Save the history of the session as an HTML file, for future reference. You can then load the history file into DreamPie, and quickly redo previous commands
+- Automatically adds parentheses and optionally quotes when you press space after functions and methods. For example, type execfile fn and get execfile("fn")
+- Supports interactive plotting with matplotlib
+- Xupport for Python 2.5, Python 2.6, Python 3.1, Jython 2.5, IronPython 2.6, and PyPy
+- Extremely fast and responsive.
+
+- Website: [www.dreampie.org][3]
+- Developer: Noam Yorav-Raphael
+- License: GNU GPL v3
+- Version Number: 1.2.1
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxlinks.com/article/20150523032756576/PythonShells.html
+
+作者:Frazer Kline
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:http://www.bpython-interpreter.org/
+[2]:http://ipython.org/
+[3]:http://www.dreampie.org/
\ No newline at end of file
diff --git a/sources/share/20150527 Animated Wallpaper Adds Live Backgrounds To Linux Distros.md b/sources/share/20150527 Animated Wallpaper Adds Live Backgrounds To Linux Distros.md
new file mode 100644
index 0000000000..92eff36326
--- /dev/null
+++ b/sources/share/20150527 Animated Wallpaper Adds Live Backgrounds To Linux Distros.md
@@ -0,0 +1,113 @@
+Animated Wallpaper Adds Live Backgrounds To Linux Distros
+================================================================================
+**We know a lot of you love having a stylish Ubuntu desktop to show off.**
+
+
+
+Live Wallpaper
+
+And as Linux makes it so easy to create a stunning workspace with a minimal effort, that’s understandable!
+
+Today, we’re highlighting — [re-highlighting][2] for those of you with long memories — a free, open-source tool that can add extra bling your OS screenshots and screencasts.
+
+It’s called **Live Wallpaper** and (as you can probably guess) it will replace the standard static desktop background with an animated alternative powered by OpenGL.
+
+And the best bit: it can be installed in Ubuntu very easily.
+
+### Animated Wallpaper Themes ###
+
+
+
+Live Wallpaper is not the only app of this type, but it is one of the the best.
+
+It comes with a number of different themes out of the box.
+
+These range from the subtle (‘noise’) to frenetic (‘nexus’), and caters to everything in between. There’s even the obligatory clock wallpaper inspired by the welcome screen of the Ubuntu Phone:
+
+- Circles — Clock inspired by Ubuntu Phone with ‘evolving circle’ aura
+- Galaxy — Spinning galaxy that can be resized/repositioned
+- Gradient Clock — A polar clock overlaid on basic gradient
+- Nexus — Brightly colored particles fire across screen
+- Noise — A bokeh design similar to the iOS dynamic wallpaper
+- Photoslide — Grid of photos from folder (default ~/Photos) animate in/out
+
+Live Wallpaper is **fully open-source** so there’s nothing to stop imaginative artists with the know-how (and patience) from creating some slick themes of their own.
+
+### Settings & Features ###
+
+
+
+Each theme can be configured or customised in some way, though certain themes have more options than others.
+
+For example, in Nexus (pictured above) you can change the number and colour of the the pulse particles, their size, and their frequency.
+
+The preferences app also provides a set of **general options** that will apply to all themes. These include:
+
+- Setting live wallpaper to run on log-in
+- Setting a custom background that the animation sits on
+- Adjusting the FPS (including option to show FPS on screen)
+- Specifying the multi-monitor behaviour
+
+With so many options available it should be easy to create a background set up that suits you.
+
+### Drawbacks ###
+
+#### No Desktop Icons ####
+
+You can’t add, open or edit files or folders on the desktop while Live Wallpaper is ‘On’.
+
+The Preferences app does list an option that will, supposedly, let you do this. It may work on really older releases but in our testing, on Ubuntu 14.10, it does nothing.
+
+One workaround that seems to work for some users of the app on Ubuntu is setting a .png image as the custom background. It doesn’t have to be a transparent .png, simply a .png.
+
+#### Resource Usage ####
+
+Animated wallpapers use more system resources than standard background images.
+
+We’re not talking about 50% load at all times —at least not with this app in our testing— but those on low-power devices and laptops will want to use apps like this cautiously. Use a [system monitoring tool][2] to keep an eye on CPU and GPU load.
+
+#### Quitting the app ####
+
+The biggest “bug” for me is the absolute lack of “quit” option.
+
+Sure, the animated wallpaper can be turned off from the Indicator Applet and the Preferences tool but quitting the app entirely, quitting the indicator applet? Nope. To do that I have to use the ‘pkill livewallpaper’ command in the Terminal.
+
+### How to Install Live Wallpaper in Ubuntu 14.04 LTS + ###
+
+
+
+To install Live Wallpaper in Ubuntu 14.04 LTS and above you will first need to add the official PPA for the app to your Software Sources.
+
+The quickest way to do this is using the Terminal:
+
+ sudo add-apt-repository ppa:fyrmir/livewallpaper-daily
+
+ sudo apt-get update && sudo apt-get install livewallpaper
+
+You should also install the indicator applet, which lets you quickly and easily turn on/off the animated wallpaper and switch theme from the menu area, and the GUI settings tool so that you can configure each theme based on your tastes.
+
+ sudo apt-get install livewallpaper-config livewallpaper-indicator
+
+When everything has installed you will be able to launch the app and its preferences tool from the Unity Dash.
+
+
+
+Annoyingly, the Indicator Applet won’t automatically open after you install it. It does add itself to the start up list, so a quick log out > log in will get it to show.
+
+### Summary ###
+
+If you fancy breathing life into a dull desktop, give it a spin — and let us know what you think of it and what animated wallpapers you’d love to see added!
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/05/animated-wallpaper-adds-live-backgrounds-to-linux-distros
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:http://www.omgubuntu.co.uk/2012/11/live-wallpaper-for-ubuntu
+[2]:http://www.omgubuntu.co.uk/2011/11/5-system-monitoring-tools-for-ubuntu
\ No newline at end of file
diff --git a/sources/share/20150604 12 Globally Recognized Linux Certifications.md b/sources/share/20150604 12 Globally Recognized Linux Certifications.md
new file mode 100644
index 0000000000..4ec185770b
--- /dev/null
+++ b/sources/share/20150604 12 Globally Recognized Linux Certifications.md
@@ -0,0 +1,173 @@
+translating wi-cuckoo
+12 Globally Recognized Linux Certifications
+================================================================================
+Hi everyone, today we'll learn about some of the very precious globally recognized Linux Certifications. Linux Certifications are the certification programme hosted by different Linux Professional Institutes across the globe. Linux Certifications allows Linux Professionals to get easily enrolled with the Linux related jobs in servers, companies, etc. Linux Certifications enables how much a person is expertise in that respective field of Linux. There are pretty many Linux Professional Institutes providing different Linux Certifications. But there are some few well recognized Linux Certification Programmes running across the globe which are at high priority while getting a job in companies where we need to manage servers, virtualizations, installations, configurations, application support and other stuffs with Linux Operating System. With the increment of servers running Linux Operating System throughout the globe, the demand of Linux Professional are increasing. For better authenticated and authorized Linux Professional, better and renowned Certifications are always at higher priority by the companies across the globe.
+
+Here are some globally recognized Linux Certifications that we'll discuss about.
+
+### 1. CompTIA Linux+ ###
+
+CompTIA Linux+ is a Linux Certification programme hosted by LPI "Linux Professional Institute" providing knowledge all over the world. It provides knowledge on Linux which enables to produce a bunch of Linux related Professional jobs like Linux Administrators, Junior Network Administrators, Systems Administrators, Linux Database Administrators and Web Administrators. If anyone is aware of installing and maintaining Linux Operating System, this course will help to meet the certification requirements and prepare for the exam by providing with a broad awareness of Linux operating systems. The main objective of CompTIA Linux+ Certification by LPI is to provide the certificate holders enough knowledge on a critical knowledge of installation, operation, administration and troubleshooting devices. We can earn three industry-recognized certifications for the cost, time, and effort of one, by completing the CompTIA Linux+ powered by LPI certification, we can automatically receive the **LPI LPIC-1** and the **SUSE Certified Linux Administrator (CLA)** certifications.
+
+- **Certification Codes** : LX0-103 and LX0-104 (launches March 30, 2015) OR LX0-101 and LX0-102
+- Number of questions: 60 questions per exam
+- Type of Questions: Multiple choice
+- Length of test period: 90 minutes
+- Prerequisites: A+, Network+ and at least 12 months of Linux administration experience
+- Passing score: 500 (on a scale of 200-800)
+- Languages: English. Coming soon on German, Portuguese (Brazilian), Traditional Chinese, Spanish.
+- Validity: Valid till 3 Years after certified.
+
+**Note**: Exams from different series cannot be combined. If you start with LX0-101, you MUST take LX0-102 to complete your certification. The same applies for the LX0-103 and LX0-104 series. The LX0-103 and LX0-104 series is an update to the LX0-101 and LX0-102 series.
+
+### 2. LPIC ###
+
+LPIC stands for Linux Professional Institute Certification which is a Linux certification programme by Linux Professional Institute. It is a multi level certification program which requires passing of a number (usually two) certification exams for each level. There are three levels of certification which includes Junior Level Certification **LPIC-1**, Advanced Level Certification **LPIC-2** and Senior Level Certification **LPIC-3**. The first two certification aims on **Linux System Administration** whereas the final certification aims on several specialties including Virtualization and Security. To become **LPIC-3** certified, a candidate with an active **LPIC-1** and **LPIC-2** certification must pass at least one of 300 Mixed Environment, 303 Security and 304 Virtualization and High Availability. LPIC-1 certification is designed in such a way that the certification holder will be able to install, maintain, configure tasks running Linux with command line interface with basic networking where as LPIC-2 certification validates candidate to administer small to medium–sized mixed networks. LPIC-3 certification is designed for enterprise-level Linux professional and represents the highest level of professional, distribution-neutral Linux certification within the industry.
+
+- **Certification Codes** : LPIC-1 (101 and 102), LPIC-2 (201 and 202) and LPIC-3 (300, 303 or 304)
+- Type of Questions: 60 Multiple choice questions
+- Length of Test Period: 90 minutes
+- Prerequisites: None, Linux Essentials is recommended
+- Passing Score: 500 (on a scale of 200-800)
+- Languages: LPIC-1: English, German, Italian, Portuguese (Brazilian), Spanish (Modern), Chinese (Simplified), Chinese (Traditional), Japanese
+- LPIC-2: English, German, Portuguese (Brazilian), Japanese
+- LPIC-3: English, Japanese
+- Validity: Valid till 5 years of Retirement.
+
+### 3. Oracle Linux OCA ###
+
+Oracle Certified Associate (OCA) is designed for the individuals who are interested for a strong foundation of knowledge to implement and administer the Oracle Linux Operating System. This certification expertise individuals on the Oracle Linux distribution that's fully optimized for Oracle products and for running on Oracle's engineered systems including Oracle Exadata Database Machine, Oracle Exalytics In-Memory Machine, Oracle Exalogic Elastic Cloud, and Oracle Database Appliance. Oracle Linux's Unbreakable Enterprise Kernel delivers extreme performance, advanced scalability and reliability for enterprise applications. The OCA certification covers objectives such as managing local disk devices, managing file systems, installing and removing Solaris packages and patches, performing system boot procedures and system processes. It is initial step in achievement of flagship of OCP credential. This certification was formerly known as Sun Certified Solaris Associate (SCSAS).
+
+- **Certification Codes** : OCA
+- Type of Questions: 75 Multiple choice questions
+- Length of Test Period: 120 minutes
+- Prerequisites: None
+- Passing Score: 64%
+- Validity: Never Expires
+
+### 4. Oracle Linux OCP ###
+
+Oracle Certified Professional (OCP) is the certification provided by Oracle Corporation for Oracle Linux which covers more advanced knowledge and skills of an Oracle Linux Administrator. It covers knowledge such as configuring network interfaces, managing swap configurations, crash dumps, managing applications, databases and core files. OCP certification is benchmark of technical expertise and professional skill needed for developing, implementing, and managing applications, middleware and databases widely in enterprise. Job opportunities for Oracle Linux OCP are increased depending on job market and economy. It is designed such a way that the certificate holder has the ability to perform security administration, prepare Oracle Linux system for Oracle database, troubleshoot problems and perform corrective action, install software packages, installing and configuring kernel modules, maintain swap space, perform User and Group administration, creating file systems, configuring logical volume manager (LVM), file sharing services and more.
+
+- **Certification Codes** : OCP
+- Type of Questions: 60 to 80 Multiple choice questions
+- Length of Test Period: 120 minutes
+- Prerequisites: Oracle Linux OCA
+- Passing Score: 64%
+- Validity: Never Expires
+
+### 5. RHCSA ###
+
+RHCSA is a certification programme by Red Hat Incorporation as Red Hat Certified System Administrator. RHCSAs are the person who has the skill, and ability to perform core system administrations in the renowned Red Hat Linux environments. It is an initial entry-level certification programme that focuses on actual competencies at system administration, including installation and configuration of a Red Hat Linux system and attaching it to a live network running network services. A Red Hat Certified System Administrator (RHCSA) is able to understand and use essential tools for handling files, directories, command-line environments, and documentation, operate running systems, including booting into different run levels, identifying processes, starting and stopping virtual machines, and controlling services, configure local storage using partitions and logical volumes, create and configure file systems and file system attributes, such as permissions, encryption, access control lists, and network file systemsm, deploy, configure, and maintain systems, including software installation, update, and core services, manage users and groups, including use of a centralized directory for authentication, security, including basic firewall and SELinux configuration. One should be RHCSA certified to gain RHCE and other certifications.
+
+- **Certification Codes** : RHCSA
+- Course Codes: RH124, RH134 and RH199
+- Exam Codes: EX200
+- Length of Test Period: 21-22 hours depending on the elective course choosen.
+- Prerequisites: None. Better if has some fundamental knowledge of Linux.
+- Passing Score: 210 out of 300 points (70%)
+- Validity: 3 years
+
+### 6. RHCE ###
+
+RHCE, also known as Red Hat Certified Engineer is a mid to advanced level certification programme for Red Hat Certified System Administrator (RHCSA) who wants to acquire additional skills and knowledge required of a senior system administrator responsible for Red Hat Enterprise Linux. RHCE has the ability, knowledge and skills of configuring static routes, packet filtering, and network address translation, setting kernel runtime parameters, configuring an Internet Small Computer System Interface (iSCSI) initiator, producing and delivering reports on system utilization, using shell scripting to automate system maintenance tasks, configuring system logging, including remote logging, system to provide networking services including HTTP/HTTPS, File Transfer Protocol (FTP), network file system (NFS), server message block (SMB), Simple Mail Transfer Protocol (SMTP), secure shell (SSH) and Network Time Protocol (NTP) and more. RHCSAs who wish to earn a more senior-level credential and who have completed System Administration I, II, and II, or who have completed the RHCE Rapid Track Course is recommended to go for RHCE certification.
+
+- **Certification Codes** : RHCE
+- Course Codes: RH124, RH134, RH254 and RH199
+- Exam Codes: EX200 and EX300
+- Length of Test Period: 21-22 hours depending on the elective course choosen.
+- Prerequisites: A RHCSA credential
+- Passing Score: 210 out of 300 (70%)
+- Validity: 3 years
+
+### 7. RHCA ###
+
+RHCA stands for Red Hat Certified Architect which is a certification programme by Red Hat Incorporation. It focuses on actual competencies at system administration, including installation and configuration of a Red Hat Linux system and attaching it to a live network running network services. RHCA is the highest level of certification of all the Red Hat Certifications. Candidates are required to choose the concentration they wish to focus on or can choose any combination of eligible Red Hat certifications to create a custom concentration of their own. There are three main concentration Datacenter, Cloud and Application Platform. RHCA with the concentration of Datacenter has the skills and ability to work, manage a datacenter whereas with the concentration of Cloud has the ability create, configure and manage private, hybrid clouds, cloud application platforms, flexible storage solutions using Red Hat Enterprise Linux Platform. RHCA with the concentration of Application Platform includes skills like installing, configuring and managing Red Hat JBoss Enterprise Application Platform and applications, cloud application platforms and hybrid cloud environments with OpenShift Enterprise by Red Hat and federating data from multiple sources using Red Hat JBoss Data Virtualization.
+
+- **Certification Codes** : RHCA
+- Course Codes: CL210,CL220,CL280, RH236, RH318,RH401,RH413, RH436,RH442,JB248 and JB450
+- Exam Codes: EX333, EX401, EX423 or EX318, EX436 and EX442
+- Length of Test Period: 21-22 hours depending on the elective course choosen.
+- Prerequisites: Active RHCE credential
+- Passing Score: 210 out of 300 (70%)
+- Validity: 3 years
+
+### 8. SUSE CLA ###
+
+SUSE Certified Linux Administrator (SUSE CLA) is a initialcertification by SUSE which focuses on daily administration tasks in SUSE Linux Enterprise Server environments. To gain SUSE CLA certification, it is not necessary to perform the course work, one has to pass the examination to get certified. SUSE CLA are capable and has skills to use Linux Desktop, locate and use help resources, manage Linux File System, work with the Linux Shell and Command Line, install SLE 11 SP22, manage system installation, hardware, backup and recovery, administer Linux with YaST, linux processes and services, storage, configure network, remote access, monitor SLE 11 SP2, automate tasks and manage user access and security. We can gain dual certificates of SUSE CLA and LPIC-1 and CompTIA Linux powered by LPI as SUSE, Linux Professional Institute and CompTIA have teamed up to offer you the chance to earn three Linux certifications.
+
+- **Certification Codes** : SUSE CLA
+- Course Codes: 3115, 3116
+- Exam Codes: 050-720, 050-710
+- Type of Questions: multiple choice exams
+- Length of Test Period: 90 minutes
+- Prerequisites: None
+- Passing Score: 512
+
+### 9. SUSE CLP ###
+
+SUSE Certified Linux Professional (CLP) is a certification programme for the one who is interested to gain more seniority and professionalism in SUSE Linux Enterprise Servers. SUSE CLP is the next step after receiving the SUSE CLA certificate. One should pass the examination and should have certification of CLA to gain the certification of CLP thought the candidate has passed the examination of CLP. SUSE CLP certified person has the skills and ability of installing and configuring SUSE Linux Enterprise Server 11 systems, maintaining the file system, managing softwarepackages, processes, printing, configuring fundamental network services, samba, web servers, using IPv6 and creating and running bash shell scripts.
+
+- **Certification Codes** : SUSE CLP
+- Course Codes: 3115, 3116 and 3117
+- Exam Codes: 050-721, 050-697
+- Type of Test: hands on
+- Length of Test Period: 180 minute practicum
+- Prerequisites: SUSE CLA Certified
+
+### 10. SUSE CLE ###
+
+SUSE Certified Linux Engineer (CLE) is an engineer level advanced certification for those candidates who have passed the examination of CLE. To acquire a CLE certificate, one should gain the certificates of SUSE CLA and SUSE CLP. The candidate gaining the CLE certification has the skills of architecting complex SUSE Linux Enterprise Server environments. CLE certified person has the skill to configure fundamental networking services, manage printing, configure and use Open LDAP, samba, web servers, IPv6, perform Health Check and Performance Tuning, create and execute Shell Scripts, deploy SUSE Linux Enterprise, virtualization with Xen and more.
+
+- **Certification Codes** : SUSE CLE
+- Course Codes: 3107
+- Exam Codes: 050-723
+- Type of Test: hands on
+- Length of Test Period: 120 minute practicum
+- Prerequisites: SUSE CLP 10 or 11 Certified
+
+### 11. LFCS ###
+
+Linux Foundation Certified System Admin (LFCS) certified candidates possesses knowledge on the use of Linux and using Linux with the terminal environment. LFCS is a certification programme by Linux Foundation for system administrators and engineers working with the Linux operating system. The Linux Foundation collaborated with industry experts and the Linux kernel community to identify the core domains and the critical skills, knowledge and abilities applicable for the certification. LFCS certified candidates has the skills, knowledge and ability of editing and manipulating text files on the command line, managing and troubleshooting File Systems and Storage, assembling partitions as LVM devices, configuring SWAP partitions, managing networked filesystems, managing user accounts, permissions and ownerships, maintaining security, creating and executing bash shell scripts, installing, upgrading, removing software packages and more.
+
+- **Certification Codes** : LFCS
+- Course Codes: LFS201, LFS220 (Optional)
+- Exam Codes: LFCS exam
+- Length of Test Period: 2 hours
+- Prerequisites: None.
+- Passing Score: 74%
+- Languages: English
+- Validity: 2 years
+
+### 12. LFCE ###
+
+Linux Foundation Certified Engineer (LFCE), a certification for Linux Engineers by Linux Foundation. LFCE certified candidates possesses a wider range of skills on Linux than LFCS. It is a engineer-level advanced certification programme. The LFCE certified candidates possesses skills and abilities of Network Administraton like configuring network services, configuring packet filtering, monitor network performance, IP traffics, configuring filesystems and file services, network filesystems, install, update packages from the repositories, managing network security, configuring iptables, http services, proxy servers, email servers and many more. It is believed that LFCE is pretty difficult to pass and study than LFCS as its advanced engineering level certification programme.
+
+- **Certification Codes** : LFCE
+- Course Codes: LFS230
+- Exam Codes: LFCE exam
+- Length of Test Period: 2 hours
+- Prerequisites: LFCS certified.
+- Passing Score: 72%
+- Languages: English
+- Validity: 2 years
+
+### Facts we found (This is only our views) ###
+
+Recent surveys conducted on different top recruitment agency, says 80% of linux job profile preferred Redhat certification. If you are a student / newbie and want to learn linux then we prefer Linux Foundation Certifications as its getting much popular or CompTIA Linux would be also a choice. If you already know oracle or suse or working on their products then would prefer oracle / suse linux or if you working in an company these certification might enhance your career growth :-)
+
+### Conclusion ###
+
+There are thousands of big companies in this world running servers and mainframes running Linux Operating System, to handle, configure and work on those servers there is always a need of highly qualified and certified Linux Technical/Professional. These globally recognized Linux certificates has a big role of someones career in Linux. The companies around the world running Linux and wanting Linux Engineers, System Administrators and ethusiasts chooses one who has gained certificates and has good score in the related field of Linux. Globally recognized certifications are highly essential for excellence in the profession and career in Linux, so preparing best for the examination and getting the certification is a good choice for building career in Linux. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/12-globally-recognized-linux-certifications/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
diff --git a/sources/share/20150604 Read about The Document Foundation achievements in 2014--download the Annual Report.md b/sources/share/20150604 Read about The Document Foundation achievements in 2014--download the Annual Report.md
new file mode 100644
index 0000000000..28b0a76083
--- /dev/null
+++ b/sources/share/20150604 Read about The Document Foundation achievements in 2014--download the Annual Report.md
@@ -0,0 +1,34 @@
+sevenot translating
+Read about The Document Foundation achievements in 2014: download the Annual Report!
+================================================================================
+
+
+TDF ReportThe Document Foundation (TDF) is proud to announce its 2014 Annual Report, which can be downloaded from the following link: [http://tdf.io/report2014][1] (3.2 MB PDF). The version with HD images can be downloaded from [http://tdf.io/report2014hq][2] (15.9 MB PDF).
+
+TDF Annual Report starts with a Review of 2014, with highlights about TDF and LibreOffice, and a summary of financials and budget.
+
+Community, Projects & Events covers the LibreOffice Conference 2014 in Bern, Certification, Website and QA, Hackfests in Brussels, Gran Canaria, Paris, Boston and Tolouse, Native-Language Projects, Infrastructure, Documentation, Marketing and Design.
+
+Software, Development & Code reports about the activities of the Engineering Steering Committee, LibreOffice Development, the Document Liberation Project and LibreOffice on Android.
+
+The last section focuses on People, starting with Top Contributors, followed by TDF Staff, the Board of Directors and the Membership Committee, the Board of Trustees, or the body of TDF Members, and the Advisory Board.
+
+TDF 2014 Annual Report has been edited by Sophie Gautier, Alexander Werner, Christian Lohmaier, Florian Effenberger, Italo Vignoli and Robinson Tryon, and designed by Barak Paz, with the help of the fantastic LibreOffice community.
+
+To allow the widest distribution of the document, this is released with a CC BY 3.0 DE License, unless otherwise noted, to TDF Members and free software advocates worldwide.
+
+[The German version of TDF Annual Report is available from [http://tdf.io/bericht2014][3]].
+
+--------------------------------------------------------------------------------
+
+via: http://blog.documentfoundation.org/2015/06/03/read-about-the-document-foundation-achievements-in-2014-download-the-annual-report/
+
+作者:italovignoli
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[1]:https://wiki.documentfoundation.org/File:TDF2014AnnualReport.pdf
+[2]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportHQ.pdf
+[3]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportDE.pdf
\ No newline at end of file
diff --git a/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md b/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md
deleted file mode 100644
index fc1c708b14..0000000000
--- a/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md
+++ /dev/null
@@ -1,97 +0,0 @@
-Upstream and Downstream: why packaging takes time
-================================================================================
-Here in the KDE office in Barcelona some people spend their time on purely upstream KDE projects and some of us are primarily interested in making distros work which mean our users can get all the stuff we make. I've been asked why we don't just automate the packaging and go and do more productive things. One view of making on a distro like Kubuntu is that its just a way to package up the hard work done by others to take all the credit. I don't deny that, but there's quite a lot to the packaging of all that hard work, for a start there's a lot of it these days.
-
-"KDE" used to be released once every nine months or less frequently. But yesterday I released the [first bugfix update to Plasma][1], to make that happen I spent some time on Thursday with David making the [first update to Frameworks 5][2]. But Plasma 5 is still a work in progress for us distros, let's not forget about [KDE SC 4.13.3][3] which Philip has done his usual spectacular job of updating in the 14.04 LTS archive or [KDE SC 4.14 betas][4] which Scarlett has been packaging for utopic and backporting to 14.04 LTS. KDE SC used to be 20 tars, now it's 169 and over 50 langauge packs.
-
-### Patches ###
-
-If we were packaging it without any automation as used to be done it would take an age but of course we do automate the repetative tasks, the [KDE SC 4.13.97 status][5] page shows all the packages and highlights obvious problems. But with 169 tars even running the automated script takes a while, then you have to fix any patches that no longer apply. We have [policies][6] to disuade having patches, any patches should be upstream in KDE or on their way upstream, but sometimes it's unavoidable that we have some to maintain which often need small changes for each upstream release.
-
-### Symbols ###
-
-Much of what we package are libraries and if one small bit changes in the library, any applications which use that library will crash. This is ABI and the rules for [binary compatibility][7] in C++ are nuts. Not infrequently someone in KDE will alter a library ABI without realising. So we maintain symbol files to list all the symbols, these can often feel like more trouble than they're worth because they need updated when a new version of GCC produces different symbols or when symbols disappear and on investigation they turn out to be marked private and nobody will be using them anyway, but if you miss a change and apps start crashing as nearly happened in KDE PIM last week then people get grumpy.
-
-### Copyright ###
-
-Debian, and so Ubuntu, documents the copyright licence of every files in every package. This is a very slow and tedious job but it's important that it's done both upstream and downstream because it you don't people won't want to use your software in a commercial setting and at worst you could end up in court. So I maintain the [licensing policy][8] and not infrequently have to fix bits which are incorrectly or unclearly licenced and answer questions such as today I was reviewing whether a kcm in frameworks had to be LGPL licenced for Eike. We write a copyright file for every package and again this can feel like more trouble than its worth, there's no easy way to automate it but by some readings of the licence texts it's necessary to comply with them and it's just good practice. It also means that if someone starts making claims like requiring licencing for already distributed binary packages I'm in an informed position to correct such nonsense.
-
-### Descriptions ###
-
-When we were packaging KDE Frameworks from scratch we had to find a descirption of each Framework. Despite policies for metadata some were quite underdescribed so we had to go and search for a sensible descirption for them. Infact not infrequently we'll need to use a new library which doesn't even have a sensible paragraph describing what it does. We need to be able to make a package show something of a human face.
-
-### Multiarch ###
-
-A recent addition to the world of .deb packaging is [MultiArch][9] which allows i386 packages to be installed on amd64 computers as well as some even more obscure combinations (powerpc on ppcel64 anyone?). This lets you run Skype on your amd64 computer without messy cludges like the ia32-libs package. However it needs quite a lot of attention from packagers of libraries marking which packages are multiarch, which depend on other multiarch or arch independent packages and even after packaging KDE Frameworks I'm not entirely comfortable with doing it.
-
-### Splitting up Packages ###
-
-We spend lots of time splitting up packages. When say Calligra gets released it's all in one big tar but you don't want all of it on your system because you just want to write a letter in Calligra Words and Krita has lots of image and other data files which take up lots of space you don't care for. So for each new release we have to work out which of the installed files go into which .deb package. It takes time and even worse occationally we can get it wrong but if you don't want heaps of stuff on your computer you don't need then it needs to be done. It's also needed for library upgrades, if there's a new version of libfoo and not all the programs have been ported to it then you can install libfoo1 and libfoo2 on the same system without problems. That's not possible with distros which don't split up packages.
-
-One messy side effect of this is that when a file moves from one .deb to another .deb made by the same sources, maybe Debian chose to split it another way and we want to follow them, then it needs a Breaks/Replaces/Conflicts added. This is a pretty messy part of .deb packaging, you need to specify which version it Breaks/Replaces/Conflicts and depending on the type of move you need to specify some combination of these three fields but even experienced packages seem to be unclear on which. And then if a backport (with files in original places) is released which has a newer version than the version you specify in the Breaks/Replaces/Conflicts it just refuses to install and stops half way through installing until a new upload is made which updates the Breaks/Replaces/Conflicts version in the packaging. I'd be interested in how this is solved in the RPM world.
-
-### Debian Merges ###
-
-Ubuntu is forked from Debian and to piggy back on their work (and add our own bugs while taking the credit) we merge in Debian's packaging at the start of each cycle. This is fiddly work involving going through the diff (and for patches that's often a diff of a diff) and changelog to work out why each alternation was made. Then we merge them together, it takes time and it's error prone but it's what allows Ubuntu to be one of the most up to date distros around even while much of the work gone into maintaining universe packages not part of some flavour has slowed down.
-
-### Stable Release Updates ###
-
-You have Kubuntu 14.04 LTS but you want more? You want bugfixes too? Oh but you want them without the possibility of regressions? Ubuntu has quite strict definition of what's allowed in after an Ubuntu release is made, this is because once upon a time someone uploaded a fix for X which had the side effect of breaking X on half the installs out there. So for any updates to get into the archive they can only be for certain packages with a track record of making bug fix releases without sneaking in new features or breaking bits. They need to be tested, have some time passed to allow for wider testing, be tested again using the versions compiled in Launchpad and then released. KDE makes bugfix releases of KDE SC every month and we update them in the latest stable and LTS releases as [4.13.3 was this week][10]. But it's not a process you can rush and will take a couple of weeks usually. That 4.13.3 update was even later then usual because we were busy with Plasma 5 and whatnot. And it's not perfect, a bug in Baloo did get through with 4.13.2. But it would be even worse if we did rush it.
-
-### Backports ###
-
-Ah but you want new features too? We don't allow in new features into the normal updates because they will have more chance of having regressions. That's why we make backports, either in the kubuntu-ppa/backports archive or in the ubuntu backports archive. This involves running the package through another automation script to change whever needs changed for the backport then compiling it all, testing it and releasing it. Maintaining and running that backport script is quite faffy so sending your thanks is always appreciated.
-
-We have an allowance to upload new bugfix (micro releases) of KDE SC to the ubuntu archive because KDE SC has a good track record of fixing things and not breaking them. When we come to wanting to update Plasma we'll need to argue for another allowance. One controvertial issue in KDE Frameworks is that there's no bugfix releases, only monthly releases with new features. These are unlikely to get into the Ubuntu archive, we can try to argue the case that with automated tests and other processes the quality is high enough, but it'll be a hard sell.
-
-### Crack of the Day ###
-
-Project Neon provides packages of daily builds of parts of KDE from Git. And there's weekly ISOs that are made from this too. These guys rock. The packages are monolithic and install in /opt to be able to live alongside your normal KDE software.
-
-### Co-installability ###
-
-You should be able to run KDELibs 4 software on a Plasma 5 desktop. I spent quite a bit of time ensuring this is possible by having no overlapping files in kdelibs/kde-runtime and kde frameworks and some parts of Plasma. This wasn't done primarily for Kubuntu, many of the files could have been split out into .deb packages that could be shared between KDELibs 4 and Plasma 5, but other disros which just installs packages in a monolithic style benefitted. Some projects like Baloo didn't ensure they were co-installable, fine for Kubuntu as we can separate the libraries that need to be coinstalled from the binaries, but other distros won't be so happy.
-
-### Automated Testing ###
-
-Increasingly KDE software comes with its own test suite. Test suites are something that has been late coming to free software (and maybe software in general) but now it's here we can have higher confidence that the software is bug free. We run these test suites as part of the package compilation process and not infrequently find that the test suite doesn't run, I've been told that it's not expected for packagers to use it in the past. And of course tests fail.
-
-### Obscure Architectures ###
-
-In Ubuntu we have some obscure architectures. 64-bit Arm is likely to be a useful platform in the years to come. I'm not sure why we care about 64-bit powerpc, I can only assume someone has paid Canonical to care about it. Not infrequently we find software compiles fine on normal PCs but breaks on these obscure platforms and we need to debug why they is. This can be a slow process on ARM which takes an age to do anything, or very slow where I don't even have access to a machine to test on, but it's all part of being part of a distro with many use-cases.
-
-### Future Changes ###
-
-At Kubuntu we've never shared infrstructure with Debian despite having 99% the same packaging. This is because Ubuntu to an extent defines itself as being the technical awesomeness of Debian with smoother processes. But for some time Debian has used git while we've used the slower bzr (it was an early plan to make Ubuntu take over the world of distributed revision control with Bzr but then Git came along and turned out to be much faster even if harder to get your head around) and they've also moved to team maintainership so at last we're planning [shared repositories][11]. That'll mean many changes in our scripts but should remove much of the headache of merges each cycle.
-
-There's also a proposal to [move our packaging to daily builds][12] so we won't have to spend a lot of time updating packaging at every release. I'm skeptical if the hassle of the infrastructure for this plus fixing packaging problems as they occur each day will be less work than doing it for each release but it's worth a try.
-
-### ISO Testing ###
-
-Every 6 months we make an Ubuntu release (which includes all the flavours of which Ubuntu [Unity] is the flagship and Kubuntu is the most handsome) and there's alphas and betas before that which all need to be tested to ensure they actually install and run. Some of the pain of this has reduced since we've done away with the alternative (text debian-installer) images but we're nowhere near where Ubuntu [Unity] or OpenSUSE is with OpenQA where there are automated installs running all the time in various setups and some magic detects problems. I'd love to have this set up.
-
-I'd welcome comments on how any workflow here can be improved or how it compares to other distributions. It takes time but in Kubuntu we have a good track record of contributing fixes upstream and we all are part of KDE as well as Kubuntu. As well as the tasks I list above about checking copyright or co-installability I do Plasma releases currently, I just saw Harald do a Phonon release and Scott's just applied for a KDE account for fixes to PyKDE. And as ever we welcome more people to join us, we're in #kubuntu-devel where free hugs can be found, and we're having a whole day of Kubuntu love at Akademy.
-
---------------------------------------------------------------------------------
-
-via: https://blogs.kde.org/2014/08/13/upstream-and-downstream-why-packaging-takes-time
-
-作者:[Jonathan Riddell][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://blogs.kde.org/users/jriddell
-[1]:https://dot.kde.org/2014/08/12/first-bugfix-update-plasma-5
-[2]:https://dot.kde.org/2014/08/07/kde-frameworks-5.1
-[3]:http://www.kubuntu.org/news/kde-sc-4.13.3
-[4]:https://dot.kde.org/2014/07/18/kde-ships-july-updates-and-second-beta-applications-and-platform-414
-[5]:http://qa.kubuntu.co.uk/ninjas-status/build_status_4.13.97_utopic.html
-[6]:https://community.kde.org/Kubuntu/Policies
-[7]:https://techbase.kde.org/Policies/Binary_Compatibility_Issues_With_C++
-[8]:https://techbase.kde.org/Policies/Licensing_Policy
-[9]:https://help.ubuntu.com/community/MultiArch
-[10]:http://www.kubuntu.org/news/kde-sc-4.13.3
-[11]:http://lists.alioth.debian.org/pipermail/pkg-kde-talk/2014-August/001934.html
-[12]:https://lists.ubuntu.com/archives/kubuntu-devel/2014-August/008651.html
\ No newline at end of file
diff --git a/sources/talk/20141211 Open source all over the world.md b/sources/talk/20141211 Open source all over the world.md
index 175d870cb7..bd306edd5a 100644
--- a/sources/talk/20141211 Open source all over the world.md
+++ b/sources/talk/20141211 Open source all over the world.md
@@ -1,6 +1,3 @@
-////translating by yupmoon
-
-
Open source all over the world
================================================================================

diff --git a/sources/talk/20141217 Docker and the Integrated Open Source Company.md b/sources/talk/20141217 Docker and the Integrated Open Source Company.md
deleted file mode 100644
index 5a98324135..0000000000
--- a/sources/talk/20141217 Docker and the Integrated Open Source Company.md
+++ /dev/null
@@ -1,81 +0,0 @@
-Docker and the Integrated Open Source Company
-================================================================================
-It’s been a long time since an open source project has gotten as much buzz and attention as Docker. The easiest way to explain the concept is, well, to look at the logo of the eponymous1 company that created and manages the project:
-
-
-
-The reference in the logo is to shipping containers, one of the most important inventions of the 20th century. Actually, the word “invention” is not quite right: the idea of putting bulk goods into consistently-sized boxes goes back at least a few hundred years.[2][1] What changed the world was the standardization of containers by a trucking magnate named Malcom McLean and Keith Tantlinger, his head engineer. Tantlinger developed much of the technology undergirding the intermodal container, especially its corner casting and Twistlock mechanism that allowed the containers to be stacked on ships, transported by trucks, and moved by crane. More importantly, Tantlinger convinced McLean to release the patented design for anyone to copy without license, knowing that the technology would only be valuable if it were deployed in every port and on every transport ship in the world. Tantlinger, to put it in software terms, open-sourced the design.
-
-Shipping containers really are a perfect metaphor for what Docker is building: standardized containers for applications.
-
-
-- Just as the idea of a container wasn’t invented by Tantlinger, Docker is building on a concept that has been around for quite a while. Companies like Oracle, HP, and IBM have used containers for many years, and Google especially has a very similar implementation to Docker that they use for internal projects. Docker, though, by being open source and [community-centric][2], offers the promise of standardization
-- It doesn’t matter what is inside of a shipping container; the container itself will fit on any ship, truck, or crane in the world. Similarly, it doesn’t matter what app (and associated files, frameworks, dependencies, etc.) is inside of a docker container; the container will run on any Linux distribution and, more importantly, just about every cloud provider including AWS, Azure, Google Cloud Platform, Rackspace, etc.
-- When you move abroad, you can literally have a container brought to your house, stick in your belongings, and then have the entire thing moved to a truck to a crane to a ship to your new country. Similarly, containers allow developers to build and test an application on their local machine and have confidence that the application will behave the exact same way when it is pushed out to a server. Because everything is self-contained, the developer does not need to worry about there being different frameworks, versions, and other dependencies in the various places the application might be run
-
-The implications of this are far-reaching: not only do containers make it easier to manage the lifecycle of an application, they also (theoretically) commoditize cloud services through the age-old hope of “write once run anywhere.” More importantly, at least for now, docker containers offer the potential of being far more efficient than virtual machines. Relative to a container, using virtual machines is like using a car transport ship to move cargo: each unique entity on the ship is self-powered, which means a lot of wasted resources (those car engines aren’t very useful while crossing the ocean). Similarly, each virtual machine has to deal with the overhead of its own OS; containers, on the other hand, all share the same OS resulting in huge efficiency gains.[3][4]
-
-In short, Docker is a really big deal from a technical perspective. What excites me, though, is that the company is also innovating when it comes to their business model.
-
-----------
-
-The problem with monetizing open source is self-evident: if the software is freely available, what exactly is worth paying for? And, unlike media, you can’t exactly stick an advertisement next to some code!
-
-For many years the default answer has been to “be like Red Hat.” Red Hat is the creator and maintainer of the Red Hat Enterprise Linux (RHEL) distribution, which, like all Linux distributions, is freely available.[4][5] Red Hat, however, makes money by offering support, training, a certification program, etc. for enterprises looking to use their software. It is very much a traditional enterprise model – make money on support! – just minus the up-front license fees.
-
-This sort of business is certainly still viable; Hortonworks is [set to IPO][3] with a similar model based on Hadoop, albeit at a much lower valuation than it received during its last VC round. That doesn’t surprise me: I don’t think this is a particularly great model from a business perspective.
-
-To understand why it’s useful to think about there being three distinct parts of any company that is based on open source: the open source project itself, any value-added software built on top of that project, and the actual means of making money:
-
-
-
-*There are three parts of an open source business: the project itself, the value-added software on top of that project, and the means of monetization*
-
-The problem with the “Red Hat” model is the complete separation of all three of these parts: Red Hat doesn’t control the core project (Linux), and their value-added software (RHEL) is free, leaving their money-making support program to stand alone. To the company’s credit they have pulled this model off, but I think a big reason is because utilizing Linux was so much more of a challenge back in the 90s.[5][11] I highly doubt Red Hat could successfully build a similar business from scratch today.
-
-
-
-*The three parts of Red Hat’s business are separate and more difficult for the company to control and monetize*
-
-GitHub, the repository hosting service, is exploring what is to my mind a more compelling model. GitHub’s value-added software is a hosting service based on Git, an open-source project designed by Linux creator Linus Torvalds. Crucially, GitHub is seeking to monetize that hosting service directly, both through a SaaS model and through an on-premise enterprise offering[6][6]. This means that, in comparison to Red Hat, there is one less place to disintermediate GitHub: you can’t get their value-added software (for private projects – public is free) unless you’re willing to pay.
-
-
-
-*While GitHub does not control Git, their value-added software and means of monetization are unified, making the latter much easier and more sustainable*
-
-Docker takes the GitHub model a step further: the company controls everything from the open source project itself to the value-added software (DockerHub) built on top of that, and, just last week, [announced a monetization model][7] that is very similar to GitHub’s enterprise offering. Presuming Docker continues its present momentum and finds success with this enterprise offering, they have the potential to be a fully integrated open source software company: project, value-added software, and monetization all rolled into one.
-
-
-
-*Docker controls all the parts of their business: they are a fully integrated open source company.*
-
-This is exciting, and, to be honest, a little scary. What is exciting is that very few movements have had such a profound effect as open source software, and not just on the tech industry. Open source products are responsible for end user products like this blog; more importantly, open source technologies have enabled exponentially more startups to get off the ground with minimal investment, vastly accelerating the rate of innovation and iteration in tech.[7][8] The ongoing challenge for any open source project, though, is funding, and Docker’s business model is a potentially sustainable solution not just for Docker but for future open source technologies.
-
-That said, if Docker is successful, over the long run commercial incentives will steer the Docker open source project in a way that benefits Docker the company, which may not be what is best for the community broadly. That is what is scary about this: might open source in the long run be subtly corrupted by this business model? The makers of CoreOS, a stripped-down Linux distribution that is a perfect complement for Docker, [argued that was the case][9] last week:
-
-> We thought Docker would become a simple unit that we can all agree on. Unfortunately, a simple re-usable component is not how things are playing out. Docker now is building tools for launching cloud servers, systems for clustering, and a wide range of functions: building images, running images, uploading, downloading, and eventually even overlay networking, all compiled into one monolithic binary running primarily as root on your server. The standard container manifesto was removed. We should stop talking about Docker containers, and start talking about the Docker Platform. It is not becoming the simple composable building block we had envisioned.
-
-This, I suppose, is the beauty of open source: if you disagree, fork, which is essentially what CoreOS did, launching their own “Rocket” container.[8][10] It also shows that Docker’s business model – and any business model that contains open source – will never be completely defensible: there will always be a disintermediation point. I suspect, though, that Rocket will fail and Docker’s momentum will continue: the logic of there being one true container is inexorable, and Docker has already built up quite a bit of infrastructure and – just maybe – a business model to make it sustainable.
-
---------------------------------------------------------------------------------
-
-via: http://stratechery.com/2014/docker-integrated-open-source-company/
-
-作者:[Ben Thompson][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://stratechery.com/category/about/
-[1]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:1:1300
-[2]:https://github.com/docker/docker
-[3]:http://blogs.wsj.com/digits/2014/12/01/ipo-bound-hortonworks-drops-out-of-billion-dollar-startup-club/
-[4]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:2:1300
-[5]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:3:1300
-[6]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:5:1300
-[7]:http://blog.docker.com/2014/12/docker-announces-docker-hub-enterprise/
-[8]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:6:1300
-[9]:https://coreos.com/blog/rocket/
-[10]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:7:1300
-[11]:http://stratechery.com/2014/docker-integrated-open-source-company/#fn:4:1300
\ No newline at end of file
diff --git a/sources/talk/20141219 2015 will be the year Linux takes over the enterprise and other predictions.md b/sources/talk/20141219 2015 will be the year Linux takes over the enterprise and other predictions.md
index 4718480b82..0d2b26cc98 100644
--- a/sources/talk/20141219 2015 will be the year Linux takes over the enterprise and other predictions.md
+++ b/sources/talk/20141219 2015 will be the year Linux takes over the enterprise and other predictions.md
@@ -1,5 +1,3 @@
-translating by barney-ro
-
2015 will be the year Linux takes over the enterprise (and other predictions)
================================================================================
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
diff --git a/sources/talk/20141224 The Curious Case of the Disappearing Distros.md b/sources/talk/20141224 The Curious Case of the Disappearing Distros.md
index 5efa2f4d1f..b9fc7875d7 100644
--- a/sources/talk/20141224 The Curious Case of the Disappearing Distros.md
+++ b/sources/talk/20141224 The Curious Case of the Disappearing Distros.md
@@ -117,4 +117,4 @@ via: http://www.linuxinsider.com/story/The-Curious-Case-of-the-Disappearing-Dist
[5]:http://ledgersmbdev.blogspot.com/
[6]:http://www.ledgersmb.org/
[7]:http://www.novell.com/linux
-[8]:http://www.redhat.com/
\ No newline at end of file
+[8]:http://www.redhat.com/
diff --git a/sources/talk/20150112 Linus Tells Wired Leap Second Irrelevant.md b/sources/talk/20150112 Linus Tells Wired Leap Second Irrelevant.md
deleted file mode 100644
index ee1516c474..0000000000
--- a/sources/talk/20150112 Linus Tells Wired Leap Second Irrelevant.md
+++ /dev/null
@@ -1,29 +0,0 @@
-Linus Tells Wired Leap Second Irrelevant
-================================================================================
-
-
-Two larger publications today featured Linux and the effect of the upcoming leap second. The Register today said that the leap second effects of the past are no longer an issue. Coincidentally, Wired talked to Linus Torvalds about the same issue today as well.
-
-**Linus Torvalds** spoke with Wired's Robert McMillan about the approaching leap second due to be added in June. The Register said the last leap second in 2012 took out Mozilla, StumbleUpon, Yelp, FourSquare, Reddit and LinkedIn as well as several major airlines and travel reservation services that ran Linux. Torvalds told Wired today that the kernel is patched and he doesn't expect too many issues this time around. [He said][1], "Just take the leap second as an excuse to have a small nonsensical party for your closest friends. Wear silly hats, get a banner printed, and get silly drunk. That’s exactly how relevant it should be to most people."
-
-**However**, The Register said not everyone agrees with Torvalds' sentiments. They quote Daily Mail saying, "The year 2015 will have an extra second — which could wreak havoc on the infrastructure powering the Internet," then remind us of the Y2K scare that ended up being a non-event. The Register's Gavin [Clarke concluded][2]:
-
-> No reason the Penguins were caught sans pants.
-
-> Now they've gone belt and braces.
-
-The take-away is: move along, nothing to see here.
-
---------------------------------------------------------------------------------
-
-via: http://ostatic.com/blog/linus-tells-wired-leap-second-irrelevant
-
-作者:[Susan Linton][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://ostatic.com/member/susan-linton
-[1]:http://www.wired.com/2015/01/torvalds_leapsecond/
-[2]:http://www.theregister.co.uk/2015/01/09/leap_second_bug_linux_hysteria/
\ No newline at end of file
diff --git a/sources/talk/20150119 Linus Torvalds responds to Ars about diversity niceness in open source.md b/sources/talk/20150119 Linus Torvalds responds to Ars about diversity niceness in open source.md
deleted file mode 100644
index b98e27eacf..0000000000
--- a/sources/talk/20150119 Linus Torvalds responds to Ars about diversity niceness in open source.md
+++ /dev/null
@@ -1,44 +0,0 @@
-Linus Torvalds responds to Ars about diversity, niceness in open source
-================================================================================
-> Acknowledges diversity factors, says "we're different in so many other ways."
-
-
-See, sometimes Linus isn't flicking people off.
-
-Athanasios Kasampalis
-
-On Thursday, Linux legend Linus Torvalds sent a lengthy statement to Ars Technica responding to [statements he made in Auckland, New Zealand earlier that day about diversity and "niceness"][2] in the open source sector.
-
-"What I wanted to say [at the keynote]—and clearly must have done very badly—is that one of the great things about open source is exactly the fact that different people are so different," Torvalds wrote via e-mail. "I think people sometimes look at it as being just 'programmers,' which is not true. It's about all the people who are more oriented toward commercial things, too. It's about all those people who are interested in legal issues—and the social ones, too!"
-
-Torvalds spoke to what he thought was a larger concept of "diversity" than what has been mentioned a lot in recent stories on the topic, including economic disparity, language, and culture (even between neighboring European countries). "There's a lot of talk about gender and sexual preferences and race, but we're different in so many other ways, too," he wrote.
-
-"'Open source' as a term and as a movement hasn't been about 'you have to be a believer,'" Torvalds added. "It's not a religion. It's not an 'us vs them' thing. We've been able to work with all those 'evil commercial interests' and companies who also do proprietary software. And I think that was one of the things that the Linux community (and others—don't get me wrong, it's not unique to us) did and does well."
-
-Torvalds also talked about progress since the GPL vs. BSD "flame wars" from the '80s and early '90s, saying that the open source movement brought more technology and less "ideology" to the sector. "Which is not to say that a lot of people aren't around because they believe it's the 'ethical' thing to do (I do myself too)," Torvalds added, "but you don't have to believe that, and you can just do it because it's the most fun, or the most efficient way to do technology development."
-
-### “This ‘you have to be nice’ seems very popular in the US” ###
-
-He then sent a second e-mail to Ars about the topic of "niceness" that came up during the keynote. He said that his return to his Auckland hotel was delayed by "like three hours" because of hallway conversations about this very topic.
-
-"I don't know where you happen to be based, but this 'you have to be nice' seems to be very popular in the US," Torvalds continued, calling the concept an "ideology."
-
-"The same way we have developers and marketing people and legal people who speak different languages, I think we can have some developers who are used to—and prefer—a more confrontational style, and still **also** have people who don't," he wrote.
-
-He lambasted the "brainstorming" model of having a criticism-free bubble to bounce ideas off of. "Maybe it works for some people, but I happen to simply not believe in it," he said. "I'd rather be really confrontational, and bad ideas should be [taken] down aggressively. Even good ideas need to be vigorously defended."
-
-"Maybe it's just because I like arguing," Torvalds added. "I'm just not a huge believer in politeness and sensitivity being preferable over bluntly letting people know your feelings. But I also understand that other people are driven away by cursing and crass language when it all gets a bit too carried away." To that point, Torvalds said that the open source movement might simply need more "people who are good at mediating," as opposed to asking developers to calm their own tone or attitude.
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/business/2015/01/linus-torvalds-responds-to-ars-about-diversity-niceness-in-open-source/
-
-作者:[Sam Machkovech][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://arstechnica.com/author/samred/
-[1]:https://secure.flickr.com/photos/12693492@N04/1338136415/in/photolist-33fikv-3jXFce-3ALpLy-4m6Shj-4pADUg-4pHwcW-4rNTR7-4GMhKc-4HM2qp-4JSHKa-4PomQo-4SKxMo-58LBYf-5iVNX6-5tXbB8-5xi67A-5A8rRc-5C8fAT-5Ccxjw-5EcYvx-5UoNTc-5UoVJK-5Uti6q-5UuiX2-5UuE2B-5UyEJu-5UyHMf-5UyJ2G-5UFbXP-5UFg8Z-5UFhwV-5UKDkG-5UKDP9-5UTHGv-5XM2s2-5YFmLu-65N31L-6pSwh7-6trmfx-6H2uZP-6JVV4V-71qkot-71BBbk-72vuYo-73j9yB-79aQ2a-79bfqe-79EKPH-79EXvD-79PuG5-7a4BxF
-[2]:http://arstechnica.com/business/2015/01/linus-torvalds-on-why-he-isnt-nice-i-dont-care-about-you/
\ No newline at end of file
diff --git a/sources/talk/20150119 Ubuntu 15.04 Finally Lets You Set Menus ToAlways Show.md b/sources/talk/20150119 Ubuntu 15.04 Finally Lets You Set Menus ToAlways Show.md
deleted file mode 100644
index 346937d2b9..0000000000
--- a/sources/talk/20150119 Ubuntu 15.04 Finally Lets You Set Menus ToAlways Show.md
+++ /dev/null
@@ -1,41 +0,0 @@
-Ubuntu 15.04 Finally Lets You Set Menus To ‘Always Show’
-================================================================================
-**If you hate the way that Unity’s global menus fade out of view after you mouse away, Ubuntu 15.04 has a little extra to win you around.**
-
-
-
-The latest build of Unity for Ubuntu 15.04, currently sitting in the ‘proposed’ channel, offers an option to **make app menus visible in Ubuntu**.
-
-No fading, no timeout, no missing menus.
-
-The drawback for now is that it can currently only be enabled through a dconf switch and not a regular user-facing option.
-
-I’d hope (if not expect) that an option to set the feature is added to the Ubuntu System Settings > Appearance section as development continues.
-
-Right now, if you’re on Ubuntu 15.04 and have the “Proposed” update channel enabled, you should find this switch waiting in **com > canonical > unity >** ‘always show menus’.
-
-### Better Late Than Never? ###
-
-Developers plan to backport the option to Ubuntu 14.04 LTS in the next SRU (assuming nothing unexpected crops up during testing).
-
-Locally Integrated Menus (LIM) debuted in Ubuntu 14.04 LTS to much appreciation, being widely seen as the best compromise between those who liked the simplicity of the “hidden” approach and those who disliked the mouse and trackpad aerobics using it required.
-
-While locally integrated menus brought us half way to silencing the criticisms levelled at this aspect of Unity, the default “fade in/fade out” behaviour left an itch unscratched.
-
-The past few releases of Ubuntu has seen proactive addressing of concerns and issues experienced by its earlier UX decisions. After several years on the ‘to do’ list [we finally got Locally Integrated Menus last year][1], as well as an unsupported [option to minimise and restore apps to the Unity Launcher][2] by clicking on their icon.
-
-A year on from that we finally get an option to make application menus always show, no matter where our mouse is. Better late than never, right?
-
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2015/01/ubuntu-15-04-always-show-menu-bar-option
-
-作者:[Joey-Elijah Sneddon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/117485690627814051450/?rel=author
-[1]:http://www.omgubuntu.co.uk/2014/02/locally-integrated-menus-ubuntu-14-04
-[2]:http://www.omgubuntu.co.uk/2014/03/minimize-click-launcher-option-ubuntu-14-04
\ No newline at end of file
diff --git a/sources/talk/20150122 How are C data types “supported directly by most computers”.md b/sources/talk/20150122 How are C data types “supported directly by most computers”.md
deleted file mode 100644
index 0b57189252..0000000000
--- a/sources/talk/20150122 How are C data types “supported directly by most computers”.md
+++ /dev/null
@@ -1,53 +0,0 @@
-How are C data types “supported directly by most computers”?
----------
-
-#Q:
-
-I am reading K&R's *The C Programming Language*” and came across this statement [Introduction, p. 3]:
-
->Because the data types and control structures provided by C are supported directly by most computers, the run-time library required to implement self-contained programs is tiny.
-
-What does the bolded statement mean? Is there an example of a data type or a control structure that isn't supported directly by a computer?
-
-#A:
-
-Yes, there are data types not directly supported.
-
-On many embedded systems, there is no hardware floating point unit. So, when you write code like this:
-
-```C
-float x = 1.0f, y = 2.0f;
-return x + y;
-```
-
-It gets translated into something like this:
-
-```C
-unsigned x = 0x3f800000, y = 0x40000000;
-return _float_add(x, y);
-```
-
-Then the compiler or standard library has to supply an implementation of `_float_add()`, which takes up memory on your embedded system. If you're counting bytes on a really tiny system, this can add up.
-
-Another common example is 64-bit integers (`long long` in the C standard since 1999), which are not directly supported by 32-bit systems. Old SPARC systems didn't support integer multiplication, so multiplication had to be supplied by the runtime. There are other examples.
-
-##Other languages
-
-By comparison, other languages have more complicated primitives.
-
-For example, a Lisp symbol requires a lot of runtime support, just like tables in Lua, strings in Python, arrays in Fortran, et cetera. The equivalent types in C are usually either not part of the standard library at all (no standard symbols or tables) or they are much simpler and don't require much runtime support (arrays in C are basically just pointers, nul-terminated strings are almost as simple).
-
-##Control structures
-
-A notable control structure missing from C is exception handling. Nonlocal exit is limited to `setjmp()` and `longjmp()`, which just save and restore certain parts of processor state. By comparison, the C++ runtime has to walk the stack and call destructors and exception handlers.
-
-----
-via:[stackoverflow](http://stackoverflow.com/questions/27977522/how-are-c-data-types-supported-directly-by-most-computers/27977605#27977605)
-
-作者:[Dietrich Epp][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://stackoverflow.com/users/82294/dietrich-epp
\ No newline at end of file
diff --git a/sources/talk/20150122 Top 10 FOSS legal developments of 2014.md b/sources/talk/20150122 Top 10 FOSS legal developments of 2014.md
deleted file mode 100644
index a97e4910c6..0000000000
--- a/sources/talk/20150122 Top 10 FOSS legal developments of 2014.md
+++ /dev/null
@@ -1,72 +0,0 @@
-Top 10 FOSS legal developments of 2014
-================================================================================
-
-
-Image by : opensource.com
-
-The year 2014 continued the trend of the increasing importance of legal issues for the FOSS community. Continuing [the tradition of looking back][1] over the top ten legal developments in FOSS, my selection of the top ten issues for 2014 is as follows:
-
-### 1. Courts interpret General Public License version 2 (GPLv2) ###
-
-The GPLv2 continues to be the most widely used and most important license for free and open source software. Black Duck Software estimates that 16 billion lines of code are licensed under the GPLv2. Despite its importance, the GPLv2 has been the subject of very few court decisions, and virtually all of the most important terms of the GPLv2 have not been interpreted by courts. This lack of court decisions is about to change due to the five interrelated cases arising from an attempt by Versata Software, Inc. (Versata) to terminate its software license to Ameriprise Financial, Inc. Versata’s product included software licensed by Ximpleware, Inc. (Ximpleware) under the GPLv2, but Versata had not complied with the terms of the GPLv2. Ximpleware sued Versata and eight of its customers for both copyright and patent infringement. (For a more detailed description of the facts [read this article][2].) This dispute is important because Ximpleware is the first commercial enforcer of the GPLv2 in which the courts are likely to issue decisions and Ximpleware is seeking monetary damages rather than compliance.
-
-### 2. GPL guides ###
-
-Two of the most important organizations enforcing the GPL family of licenses recently provided [guidance on compliance][3]: On October 31, the Software Freedom Law Center published the second version of their Practical Guide to GPL Compliance. Several days later, the Software Conservancy and the Free Software Foundation published the first version of their guide, the Copyleft, and the GNU General Public License: [A Comprehensive Tutorial and Guide][4]. These guides are required reading for anyone managing FOSS.
-
-### 3. EU Commission (EC) to revise FOSS policy ###
-
-Governments are one of the most important users of software but have had a mixed record in using and contributing to FOSS (free and open source software). The EC recently announced that it intends to remove the barriers that may hinder code contributions to FOSS projects. In particular, the EC wants to clarify legal aspects, including intellectual property rights, copyright, and which author or authors to name when submitting code to the upstream repositories. Pierre Damas, Head of Sector at the Directorate General for IT, [hopes that such clarification][5] will motivate many of the EC’s software developers and functionaries to promote the use of FOSS at the EC.
-
-### 4. Validation of FOSS business model by Hortonworks IPO ###
-
-Hortonworks provides services and support for the Hadoop data analysis software managed by the Apache Software Foundation. Hortonworks is one of three venture backed companies based on the Hadoop software. Hortonworks went public this fall and immediately rose 65% in share price, valuing the company at over $1 billion. The market for Hadoop products, software, and services is projected to reach $50.2 billion in 2020, up from $1.5 billion in 2012.
-
-### 5. Core Infrastructure Initiative ###
-
-The Linux Foundation put together [a consortium of companies][6] to support the many smaller open source projects that are critical to software ecosystem, such as OpenSSL. This effort was a response to the Heartbleed problem with OpenSSL in 2013, which I described in last year’s summary. This consortium is a great example of the ability of the FOSS community to come together to solve community problems.
-
-### 6. Linux SCO case terminated again ###
-
-The lawsuit by Santa Cruz Operations, Inc. (SCO) against IBM claiming that Linux includes Unix code was once a potentially major challenge to FOSS. Despite losing its suit against Novell, the bankruptcy court allowed SCO to continue its suit against IBM. I thought this case [had been concluded in 2008][7], but Judge Nuffer appears to have put the case to rest on December 15, 2014. He dismissed the case against IBM based on the decisions in the Novell case (although SCO could still appeal once again):
-
-*It is further ORDERED that, with respect to all remaining claims and counterclaims, SCO is bound by, and may not here re-litigate, the rulings in the Novell Judgment that Novell (not SCO) owns the copyrights to the pre-1996 UNIX source code, and that Novell waived SCO’s contract claims against IBM for alleged breaches of the licensing agreements pursuant to which IBM licensed such source code.*
-
-### 7. FOSS trademark issues ###
-
-The use of trademarks in FOSS projects continues to raise issues. This year brought the settlement of the dispute over the “Python” mark between the Python Software Foundation and Veber, a small hosting company in the UK. Veber had decided to use "Python" in branding certain of its products and services. In addition, the OpenStack Foundation is working through the application of trademarks to the OpenStack project through its [DefCore committee][8].
-
-### 8. Use of FOSS by commercial companies expands ###
-
-We have discussed in the past how many large companies are using FOSS as an explicit strategy to build their software. Jim Zemlin, Executive Director of the Linux Foundation, has described this strategic use of FOSS as external “research and development.” His conclusions are supported by Gartner who noted that “the top tech companies are still spending tens of billions of dollars on software research and development, the smart ones are leveraging open source for 80 percent of the code and spending their money on the remaining 20 percent, which represents their program’s ‘special sauce.’” The scope of this trend was emphasized by Microsoft’s announcement that it was “open sourcing” the .NET software framework (this software is used by millions of developers to build and operate websites and other large online applications).
-
-### 9. Rockstar Consortium threat evaporates ###
-
-The Rockstar Consortium was formed by Microsoft, Blackberry, Ericsson, Sony, and Apple to exploit the 6,000 patents from Nortel Networks. The Rockstar Consortium sued Google for infringement of the Android operating system. This litigation was aimed at fundamental functions of the Android operating system and could have had a significant effect on the Android ecosystem. The Rockstar Consortium settled its litigation with Google this year, but then sold 4,000 of its patents to RPX, the patent defense firm (financed by a number of companies as well as RPX). The remaining patents were distributed to the members of the Rockstar Consortium.
-
-### 10. Android litigation ###
-
-The litigation surrounding Android continued this year, with significant developments in the patent litigation between Apple Computer, Inc. (Apple) and Samsung Electronics, Inc. (Samsung) and the copyright litigation over the Java APIs between Oracle Corporation (Oracle) and Google, Inc. (Google). Apple and Samsung have agreed to end patent disputes in nine countries, but they will continue the litigation in the US. As I stated last year, the Rockstar Consortium was a wild card in this dispute. However, the Rockstar Consortium settled its litigation with Google this year and sold off its patents, so it will no longer be a risk to the Android ecosystem.
-
-The copyright litigation regarding the copyrightability of the Java APIs was brought back to life by the Court of Appeals for the Federal Circuit (CAFC) decision which overturned [the District Court decision][9]. The District Court had found that Google was not liable for copyright infringement for its admitted copying of the Java APIs: the court found that the Java APIs were either not copyrightable or their use by Google was protected by various defenses to copyright. The CAFC overturned both the decision and the analysis and remanded the case to the District Court for a review of the fair use defense raised by Google. Subsequently, Google filed an appeal to the Supreme Court. The impact of a finding that Google was liable for copyright infringement in this case would have a dramatic effect on Android and, depending on the reasoning, would have a ripple effect across the interpretation of the scope of the “copyleft” terms of the GPL family of licenses which use APIs.
-
---------------------------------------------------------------------------------
-
-via: http://opensource.com/law/15/1/top-foss-legal-developments-2014
-
-作者:[Mark Radcliffe][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://opensource.com/users/mradcliffe
-[1]:http://lawandlifesiliconvalley.com/blog/?p=853
-[2]:http://opensource.com/law/14/12/gplv2-court-decisions-versata
-[3]:http://www.softwarefreedom.org/resources/
-[4]:http://www.copyleft.org/guide/
-[5]:https://joinup.ec.europa.eu/community/osor/news/european-commission-update-its-open-source-policy
-[6]:http://www.linuxfoundation.org/programs/core-infrastructure-initiative
-[7]:http://lawandlifesiliconvalley.com/blog/?m=200812
-[8]:https://wiki.openstack.org/wiki/Governance/CoreDefinition
-[9]:http://law.justia.com/cases/federal/appellate-courts/cafc/13-1021/13-1021-2014-05-09.html
\ No newline at end of file
diff --git a/sources/talk/20150122 Top 10 open source projects of 2014.md b/sources/talk/20150122 Top 10 open source projects of 2014.md
deleted file mode 100644
index edc81938d6..0000000000
--- a/sources/talk/20150122 Top 10 open source projects of 2014.md
+++ /dev/null
@@ -1,126 +0,0 @@
-Top 10 open source projects of 2014
-================================================================================
-
-
-Image credits : [CC0 Public Domain][1], modifications by Jen Wike Huger
-
-Every year we collect the best of the best open source projects covered on Opensource.com. [Last year's list of 10 projects][2] guided people working and interested in tech throughout 2014. Now, we're setting you up for 2015 with a brand new list of accomplished open source projects.
-
-Some faces are new. Some have been around and just keep rocking it. Let's dive in!
-
-## Top 10 open source projects in 2014 ##
-
-### Docker ###
-
-[application container platform][3]
-
-"In the same way that power management and virtualisation has allowed us to get maximum engineering benefit from our server utilisation, the problem of how to really solve first world problems in virtualisation has remained prevalent. Docker's open sourcing in 2013 can really align itself with these pivotal moments in the evolution of open source—providing the extensible building blocks allowing us as engineers and architects to extend distributed platforms like never before." —Richard Morrell, [Senior software engineer Petazzoni on the breathtaking growth of Docker][4].
-
-**Interview**: VP of Services for Docker talks to Jodi Biddle in [Why is Docker the new craze in virtualization and cloud computing?][5] "I think it's the lightweight nature of Docker combined with the workflow. It's fast, easy to use and a developer-centric DevOps-ish tool. Its mission is basically: make it easy to package and ship code." —James Turnbull.
-
-### Kubernetes ###
-
-[orchestration system for containers][6]
-
-"One of the projects you're starting to hear a lot about in the orchestration space is [Kubernetes][7], which came out of Google's internal container work. It aims to provide features such as high availability and replication, service discovery, and service aggregation." —Gordon Haff, [Open source accelerating the pace of software][8].
-
-### Taiga ###
-
-[project management platform][9]
-
-"It’s almost always the case that the project management tool doesn’t reflect the actual project scenario. One solution to this is using a tool that is intuitive and fits alongside the developer's normal workflow. Additionally, a tool that is quick to update and attracts users to use it. [Taiga][10] is an open source project management tool that aims to solve the basic problem of software usability." —Nitish Tiwari, [Taiga, a new open source project management tool with focus on usability][11].
-
-### Apache Mesos ###
-
-[cluster manager][12]
-
-"[Apache Mesos][13] is a cluster manager that provides efficient resource isolation and sharing across distributed applications or frameworks. It sits between the application layer and the operating system and makes it easier to deploy and manage applications in large-scale clustered environments more efficiently. It can run many applications on a dynamically shared pool of nodes. Prominent users of Mesos include Twitter, Airbnb, MediaCrossing, Xogito and Categorize. —Sachin P Bappalige, [Open source datacenter computing with Apache Mesos][14].
-
-Interview: Head of Open Source at Twitter talks to Jason Hibbets in [Scale like Twitter with Apache Mesos][15]. "As of today, Twitter has over 270 million active users which produces 500+ million tweets a day, up to 150k+ tweets per second, and more than 100TB+ of compressed data per day. Architecturally, Twitter is mostly composed of services, mostly written in the open source project [Finagle][16], representing the core nouns of the platform such as the user service, timeline service, and so on. Mesos allows theses services to scale to tens of thousands of bare-metal machines and leverage a shared pool of servers across data centers." —Chris Aniszczyk
-
-### OpenStack ###
-
-[cloud computing platform][17]
-
-"As OpenStack continues to mature and slowly make its way into production environments, the focus on the user is continuing to grow. And so, to better meet the needs of users, the community is working hard to get users to meet the next step of engagement by highlighting those users who are change agents both in their organization and within the OpenStack community at large: the superusers." —Jason Baker, [What is an OpenStack superuser][18]?
-
-**Interview**: Infrastructure manager at CERN talks to Jason Hibbets in [How OpenStack powers the research at CERN][19]. "At CERN, the European Organization for Nuclear Research physicists and engineers are probing the fundamental structure of the universe. In order to do this, we use some of the world's largest and most complex scientific instruments such as the Large Hadron Collider, a 27 KM ring 100m underground on the border between France and Switzerland. OpenStack provides the infrastructure cloud which is used to provide much of the compute resources for this processing." —Tim Bell.
-
-### Ansible ###
-
-[IT automation tool][20]
-
-"A lot of what I want to do is enable people to not only have more free time for beer, but to have more free time for their own projects, their own ideas, and to do new an interesting things." —[Michael DeHaan, Making your IT infrastructure boring with Ansible][21].
-
-**Interview**: CTO of Ansible talks to Jen Krieger in [Behind the scenes with CTO Michael DeHaan of Ansible][22]. "I like to quote Star Trek 2 a lot. We definitely optimize for 'the needs of the many'. I know Spock dies after he says that, but he does get to come back." —Michael DeHaan
-
-### ownCloud ###
-
-[cloud storage tool][23]
-
-"I was looking for an easy way how to have all my online storage services, such as Google Drive and Dropbox, integrated with my Linux desktop without using some nasty hack, and I finally have a solution that works. I'm here to share it with you. This is not rocket science really, all I did was a little bit of documentation reading, and a couple of clicks." —Jiri Folta, [Using ownCloud to integrate Dropbox, Google Drive, and more in Gnome][24].
-
-**Listed**: Top 5 open source alternatives: "ownCloud does most everything that the proprietary names do and it keeps control of your information in your hands." —Scott Nesbitt, [Five open source alternatives to popular web apps][25].
-
-### Apache Hadoop ###
-
-[framework for big data][26]
-
-"Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0." —Sachin P Bappalige, [An introduction to Apache Hadoop for big data][27].
-
-### Drupal ###
-
-[content management system (CMS)][28]
-
-"When it was released in 2011, Drupal 7 was the most accessible open source content management system (CMS) available. I expect that this will be true until the release of Drupal 8. Web accessibility requires constant vigilance and will be something that will always need attention in any piece of software striving to meet the Web Content Accessibility Guidelines (WCAG) 2.0 guidelines." —Mike Gifford, [Drupal 8's accessibility advantage][29].
-
-### OpenDaylight ###
-
-[foundation for software defined networking][30]
-
-"We are seeing more and more that the networking functions traditionally done in the datacenter by dedicated, almost exclusively proprietary hardware and software combinations, are now being defined through software. Leading that charge within the open source community has been the [OpenDaylight Project][31], a collaborative project through the [Linux Foundation][32] working to define the needs which software defined networking may fill and coordinating the efforts of individuals and companies worldwide to create an open source solution to software defined networking (SDN)." —Jason Baker, [Define your network in software with OpenDaylight][33].
-
---------------------------------------------------------------------------------
-
-via: http://opensource.com/business/14/12/top-10-open-source-projects-2014
-
-作者:[Jen Wike Huger][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://opensource.com/users/jen-wike
-[1]:http://pixabay.com/en/lightbulb-lamp-light-hotspot-336193/
-[2]:http://opensource.com/life/13/12/top-open-source-projects-2013
-[3]:https://www.docker.com/
-[4]:http://opensource.com/business/14/7/interview-jerome-petazzoni-docker
-[5]:https://opensource.com/business/14/7/why-docker-new-craze-virtualization-and-cloud-computing
-[6]:http://kubernetes.io/
-[7]:https://cloud.google.com/compute/docs/containers
-[8]:http://opensource.com/business/14/11/open-source-accelerating-pace-software
-[9]:https://taiga.io/
-[10]:https://github.com/taigaio
-[11]:https://opensource.com/business/14/10/taiga-open-source-project-management-tool
-[12]:http://mesos.apache.org/
-[13]:http://mesos.apache.org/
-[14]:https://opensource.com/business/14/9/open-source-datacenter-computing-apache-mesos
-[15]:https://opensource.com/business/14/8/interview-chris-aniszczyk-twitter-apache-mesos
-[16]:https://twitter.github.io/finagle/
-[17]:http://www.openstack.org/
-[18]:https://opensource.com/business/14/5/what-is-openstack-superuser
-[19]:https://opensource.com/business/14/10/interview-tim-bell-cern-it-operating-systems
-[20]:http://www.ansible.com/home
-[21]:https://opensource.com/business/14/12/ansible-it-infrastructure
-[22]:https://opensource.com/business/14/10/interview-michael-dehaan-ansible
-[23]:http://owncloud.org/
-[24]:https://opensource.com/life/14/12/using-owncloud-integrate-dropbox-google-drive-gnome
-[25]:https://opensource.com/life/14/10/five-open-source-alternatives-popular-web-apps
-[26]:http://hadoop.apache.org/
-[27]:http://opensource.com/life/14/8/intro-apache-hadoop-big-data
-[28]:https://www.drupal.org/
-[29]:http://opensource.com/business/14/5/new-release-drupal-8-accessibility-advantage
-[30]:http://www.opendaylight.org/
-[31]:http://www.opendaylight.org/
-[32]:http://www.linuxfoundation.org/
-[33]:http://opensource.com/business/14/5/defining-your-network-software-opendaylight
diff --git a/sources/talk/20150124 Why does C++ promote an int to a float when a float cannot represent all int values.md b/sources/talk/20150124 Why does C++ promote an int to a float when a float cannot represent all int values.md
deleted file mode 100644
index 25a2dc6daf..0000000000
--- a/sources/talk/20150124 Why does C++ promote an int to a float when a float cannot represent all int values.md
+++ /dev/null
@@ -1,43 +0,0 @@
-Why does C++ promote an int to a float when a float cannot represent all int values?
----------
-
-#Q:
-
-Say I have the following:
-
-```C
-int i = 23;
-float f = 3.14;
-if (i == f) // do something
-```
-
-The i will be promoted to a float and the two float numbers will be compared, but can a float represent all int values? Why not promote both the int and the float to a double?
-
-#A:
-
-When `int` is promoted to `unsigned` in the integral promotions, negative values are also lost (which leads to such fun as `0u < -1` being true).
-
-Like most mechanisms in C (that are inherited in C++), the usual arithmetic conversions should be understood in terms of hardware operations. The makers of C were very familiar with the assembly language of the machines with which they worked, and they wrote C to make immediate sense to themselves and people like themselves when writing things that would until then have been written in assembly (such as the UNIX kernel).
-
-Now, processors, as a rule, do not have mixed-type instructions (add float to double, compare int to float, etc.) because it would be a huge waste of real estate on the wafer -- you'd have to implement as many times more opcodes as you want to support different types. That you only have instructions for "add int to int," "compare float to float", "multiply unsigned with unsigned" etc. makes the usual arithmetic conversions necessary in the first place -- they are a mapping of two types to the instruction family that makes most sense to use with them.
-
-From the point of view of someone who's used to writing low-level machine code, if you have mixed types, the assembler instructions you're most likely to consider in the general case are those that require the least conversions. This is particularly the case with floating points, where conversions are runtime-expensive, and particularly back in the early 1970s, when C was developed, computers were slow, and when floating point calculations were done in software. This shows in the usual arithmetic conversions -- only one operand is ever converted (with the single exception of `long/unsigned int`, where the `long` may be converted to `unsigned long`, which does not require anything to be done on most machines. Perhaps not on any where the exception applies).
-
-So, the usual arithmetic conversions are written to do what an assembly coder would do most of the time: you have two types that don't fit, convert one to the other so that it does. This is what you'd do in assembler code unless you had a specific reason to do otherwise, and to people who are used to writing assembler code and do have a specific reason to force a different conversion, explicitly requesting that conversion is natural. After all, you can simply write
-
-```C
-if((double) i < (double) f)
-```
-
-It is interesting to note in this context, by the way, that `unsigned` is higher in the hierarchy than `int`, so that comparing `int` with `unsigned` will end in an unsigned comparison (hence the `0u < -1` bit from the beginning). I suspect this to be an indicator that people in olden times considered `unsigned` less as a restriction on `int` than as an extension of its value range: We don't need the sign right now, so let's use the extra bit for a larger value range. You'd use it if you had reason to expect that an `int` would overflow -- a much bigger worry in a world of 16-bit ints.
-
-----
-via:[stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
-
-作者:[wintermute][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://stackoverflow.com/users/4301306/wintermute
\ No newline at end of file
diff --git a/sources/talk/20150127 Windows 10 versus Linux.md b/sources/talk/20150127 Windows 10 versus Linux.md
deleted file mode 100644
index e2cdfc14c1..0000000000
--- a/sources/talk/20150127 Windows 10 versus Linux.md
+++ /dev/null
@@ -1,31 +0,0 @@
-Windows 10 versus Linux
-================================================================================
-
-
-Windows 10 seemed to dominate the headlines today, even in many Linux circles. Leading the pack is Brian Fagioli at betanews.com saying Windows 10 is ringing the death knell for Linux desktops. Microsoft announced today that Windows 10 will be free for loyal Windows users and Steven J. Vaughan-Nichols said it's the newest Open Source company. Then Matt Hartley compares Windows 10 to Ubuntu and Jesse Smith reviews Windows 10 from a Linux user's perspective.
-
-**Windows 10** was the talk around water coolers today with Microsoft's [announcement][1] that it would be free for Windows 7 and up users. Here in Linuxland, that didn't go unnoticed. Brian Fagioli at betanews.com, a self-proclaimed Linux fan, said today, "Windows 10 closes the door entirely. The year of the Linux desktop will never happen. Rest in peace." [Fagioli explained][2] that Microsoft listened to user complaints and not only addressed them but improved way beyond that. He said Linux missed the boat by failing to capitalize on the Windows 8 unpopularity and ultimate failure. Then he concluded that we on the fringe must accept our "shattered dreams" thanks to Windows 10.
-
-**H**owever, Jesse Smith, of Distrowatch.com fame, said Microsoft isn't making it easy to find the download, but it is possible and he did it. The installer was simple enough except for the partitioner, which was quite limited and almost scary. After finally getting into Windows 10, Smith said the layout was "sparce" without a lot of the distractions folks hated about 7. The menu is back and the start screen is gone. A new package manager looks a lot like Ubuntu's and Android's according to Smith, but requires an online Microsoft account to use. [Smith concludes][3] in part, "Windows 10 feels like a beta for an early version of Android, a consumer operating system that is designed to be on-line all the time. It does not feel like an operating system I would use to get work done."
-
-**S**mith's [full article][4] compares Windows 10 to Linux quite a bit, but Matt Hartley today posted an actual Windows 10 vs Linux report. [He said][5] both installers were straightforward and easy Windows still doesn't dual boot easily and Windows provides encryption by default but Ubuntu offers it as an option. At the desktop Hartley said Windows 10 "is struggling to let go of its Windows 8 roots." He thought the Windows Store looks more polished than Ubuntu's but didn't really like the "tile everything" approach to newly installed apps. In conclusion, Hartley said, "The first issue is that it's going to be a free upgrade for a lot of Windows users. This means the barrier to entry and upgrade is largely removed. Second, it seems this time Microsoft has really buckled down on listening to what their users want."
-
-**S**teven J. Vaughan-Nichols today said that Microsoft is the newest Open Source company; not because it's going to be releasing Windows 10 as a free upgrade but because Microsoft is changing itself from a software company to a software as a service company. And, according to Vaughan-Nichols, Microsoft needs Open Source to do it. They've been working on it for years beginning with Novell/SUSE. Not only that, they've been releasing software as Open Source as well (whatever the motives). [Vaughan-Nichols concluded][6], "Most people won't see it, but Microsoft -- yes Microsoft -- has become an open-source company."
-
---------------------------------------------------------------------------------
-
-via: http://ostatic.com/blog/windows-10-versus-linux
-
-作者:[Susan Linton][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://ostatic.com/member/susan-linton
-[1]:https://news.google.com/news/section?q=microsoft+windows+10+free&ie=UTF-8&oe=UTF-8
-[2]:http://betanews.com/2015/01/25/windows-10-is-the-final-nail-in-the-coffin-for-the-linux-desktop/
-[3]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
-[4]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
-[5]:http://www.datamation.com/open-source/windows-vs-linux-the-2015-version-1.html
-[6]:http://www.zdnet.com/article/microsoft-the-open-source-company/
\ No newline at end of file
diff --git a/sources/talk/20150203 9 Best IDEs and Code Editors for JavaScript Users.md b/sources/talk/20150203 9 Best IDEs and Code Editors for JavaScript Users.md
deleted file mode 100644
index 83f5f11293..0000000000
--- a/sources/talk/20150203 9 Best IDEs and Code Editors for JavaScript Users.md
+++ /dev/null
@@ -1,82 +0,0 @@
-9 Best IDEs and Code Editors for JavaScript Users
-================================================================================
-Web designing and developing is one of the trending sectors in the recent times, where more and more peoples started to search for their career opportunities. But, Getting the right opportunity as a web developer or graphic designer is not just a piece of cake for everyone, It certainly requires a strong mind presence as well as right skills to find the find the right job. There are a lot of websites available today which can help you to get the right job description according to your knowledge. But still if you want to achieve something in this sector you must have some excellent skills like working with different platforms, IDEs and various other tools too.
-
-Talking about the different platforms and IDEs used for various languages for different purposes, gone is the time when we learn just one IDE and get the optimum solutions for our web design projects easily. Today we are living in the modern lifestyle where competition is getting more and more tough on every single day. Same is the case with the IDEs, IDE is basically a powerful client application for creating and deploying applications. Today we are going to share some best javascript IDE for web designers and developers.
-
-Please visit this list of best code editors for javascript user and share your thought with us.
-
-### 1) [Spket][1] ###
-
-**Spket IDE** is powerful toolkit for JavaScript and XML development. The powerful editor for JavaScript, XUL/XBL and Yahoo! Widget development. The JavaScript editor provides features like code completion, syntax highlighting and content outline that helps developers productively create efficient JavaScript code.
-
-
-
-### 2) [Ixedit][2] ###
-
-IxEdit is a JavaScript-based interaction design tool for the web. With IxEdit, designers can practice DOM-scripting without coding to change, add, move, or transform elements dynamically on your web pages.
-
-
-
-### 3) [Komodo Edit][3] ###
-
-Komode is free and powerful code editor for Javascript and other programming languages.
-
-
-
-### 4) [EpicEditor][4] ###
-
-EpicEditor is an embeddable JavaScript Markdown editor with split fullscreen editing, live previewing, automatic draft saving, offline support, and more. For developers, it offers a robust API, can be easily themed, and allows you to swap out the bundled Markdown parser with anything you throw at it.
-
-
-
-### 5) [codepress][5] ###
-
-CodePress is web-based source code editor with syntax highlighting written in JavaScript that colors text in real time while it’s being typed in the browser.
-
-
-
-### 6) [ACe][6] ###
-
-Ace is an embeddable code editor written in JavaScript. It matches the features and performance of native editors such as Sublime, Vim and TextMate. It can be easily embedded in any web page and JavaScript application.
-
-
-
-### 7) [scripted][7] ###
-
-Scripted is a fast and lightweight code editor with an initial focus on JavaScript editing. Scripted is a browser based editor and the editor itself is served from a locally running Node.js server instance.
-
-
-
-### 8) [Netbeans][8] ###
-
-This is another more impressive and useful code editors for javascript and other programming languages.
-
-
-
-### 9) [Webstorm][9] ###
-
-This is the smartest ID for javascript. WebStorm is a lightweight yet powerful IDE, perfectly equipped for complex client-side development and server-side development with Node.js.
-
-
-
---------------------------------------------------------------------------------
-
-via: http://devzum.com/2015/01/31/9-best-ides-and-code-editors-for-javascript-users/
-
-作者:[vikas][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://devzum.com/author/vikas/
-[1]:http://spket.com/
-[2]:http://www.ixedit.com/
-[3]:http://komodoide.com/komodo-edit/
-[4]:http://oscargodson.github.io/EpicEditor/
-[5]:http://codepress.sourceforge.net/
-[6]:http://ace.c9.io/#nav=about
-[7]:https://github.com/scripted-editor/scripted
-[8]:https://netbeans.org/
-[9]:http://www.jetbrains.com/webstorm/
\ No newline at end of file
diff --git a/sources/talk/20150205 GHOST--Another Security Bug Hits Linux, But is it That Bad.md b/sources/talk/20150205 GHOST--Another Security Bug Hits Linux, But is it That Bad.md
deleted file mode 100644
index 90923c1aae..0000000000
--- a/sources/talk/20150205 GHOST--Another Security Bug Hits Linux, But is it That Bad.md
+++ /dev/null
@@ -1,34 +0,0 @@
-GHOST: Another Security Bug Hits Linux, But is it That Bad?
-================================================================================
-> GHOST, a newly announced security vulnerability that affects Linux servers and other systems that use the open source glibc library, is not as dangerous to data privacy as the Shellshock or Heartbleed bugs.
-
-
-
-Heartbleed is not even a year behind us, and the open source world has been hit with another major security vulnerability in the form of [GHOST][1], which involves holes in the Linux glibc library. This time, though, the actual danger may not live up to the hype.
-
-The GHOST vulnerability, which was announced last week by security researchers at [Qualys][2], resides in the gethostbyname*() functions of the glibc library. glibc is one of the core building blocks of most Linux systems, and gethostbyname*(), which resolves domain names into IP addresses, is widely used in open source applications.
-
-Attackers can exploit the GHOST security hole to create a buffer overflow, making it possible to execute any kind of code they want and do all sorts of nasty things.
-
-All of the above suggests that GHOST is bad news indeed. Fortunately for the open source community, however, the actual risk appears small. As TrendMicro [points out][3], the bug that makes the exploit possible has been fixed in glibc since May 2013, meaning that any Linux servers or PCs running more recent versions of the software are safe from attack.
-
-In addition, gethostbyname*() has been superseded by newer glibc functions that can better handle modern networking environments. Those include ones that use the IPv6 protocol, which gethostbyname*() doesn't support. As a result, newer applications often don't use the gethostbyname*() functions, and are not at risk.
-
-And perhaps most importantly, there's currently no known way of executing GHOST attacks through the Web. That greatly reduces opportunities for using this vulnerability to steal the data of unsuspecting users or otherwise wreak havoc.
-
-All in all, then, GHOST doesn't seem like a vulnerability that will prove as serious as Heartbleed or Shellshock, two other recent security problems that affected widely used open source software.
-
---------------------------------------------------------------------------------
-
-via: http://thevarguy.com/open-source-application-software-companies/020415/ghost-another-security-bug-hits-linux-it-bad
-
-作者:[Christopher Tozzi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://thevarguy.com/author/christopher-tozzi
-[1]:https://community.qualys.com/blogs/laws-of-vulnerabilities/2015/01/27/the-ghost-vulnerability
-[2]:http://qualys.com/
-[3]:http://blog.trendmicro.com/trendlabs-security-intelligence/not-so-spooky-linux-ghost-vulnerability/
\ No newline at end of file
diff --git a/sources/talk/20150205 LinuxQuestions Survey Results Surface Top Open Source Projects.md b/sources/talk/20150205 LinuxQuestions Survey Results Surface Top Open Source Projects.md
deleted file mode 100644
index c591faafcd..0000000000
--- a/sources/talk/20150205 LinuxQuestions Survey Results Surface Top Open Source Projects.md
+++ /dev/null
@@ -1,32 +0,0 @@
-LinuxQuestions Survey Results Surface Top Open Source Projects
-================================================================================
-
-
-Many people in the Linux community look forward to the always highly detailed and reliable results of the annual surveys from LinuxQuestions.org. As [Susan covered in detail in this post][1], this year's [results][2], focused on what readers at the site deem to be the best open source projects, are now available. Most of the people at LinuxQuestions are expert-level users who are on the site to answer questions from newer Linux users.
-
-In addition to the summary results that Susan provided in her post, below you'll find a graphical snapshot of what the experts took note of on the open source front.
-
-You can get a very nice graphical summary of the findings from the LinuxQuestions survey [here][3]. Here is a snapshot of the site's determination of the best Linux distributions, where Mint and Slackware fare quite well:
-
-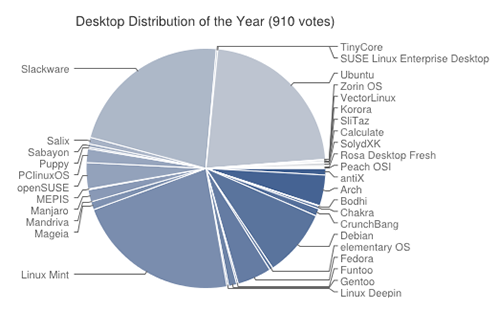
-
-And below is a snapshot of the site's determination of the best cloud projects. Notably, the LinuxQuestions crowd gives very high praise to ownCloud. Definiitely check into the full results of the survey at the site, see [Susan's summary][4] of winners, and check out all the good graphics [here][5].
-
-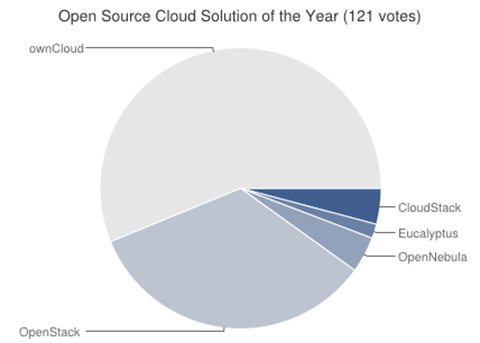
-
---------------------------------------------------------------------------------
-
-via: http://ostatic.com/blog/linuxquestions-survey-results-surface-top-open-source-projects
-
-作者:[Sam Dean][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://ostatic.com/member/samdean
-[1]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
-[2]:http://www.linuxquestions.org/questions/linux-news-59/2014-linuxquestions-org-members-choice-award-winners-4175532948/
-[3]:http://www.linuxquestions.org/questions/2014mca.php
-[4]:http://ostatic.com/blog/lq-members-choice-award-winners-announced
-[5]:http://www.linuxquestions.org/questions/2014mca.php
\ No newline at end of file
diff --git a/sources/talk/20150304 No reboot patching comes to Linux 4.0.md b/sources/talk/20150304 No reboot patching comes to Linux 4.0.md
new file mode 100644
index 0000000000..6333fea9a7
--- /dev/null
+++ b/sources/talk/20150304 No reboot patching comes to Linux 4.0.md
@@ -0,0 +1,58 @@
+No reboot patching comes to Linux 4.0
+================================================================================
+> **Summary**:With the new Linux 4.0 kernel, you'll need to reboot Linux less often than ever.
+
+With [Linux 4.0][1], you may never need to reboot your operating system again.
+
+
+Using Linux means never having to reboot. -- SUSE
+
+One reason to love Linux on your servers or in your data-center is that you so seldom needed to reboot it. True, critical patches require a reboot, but you could go months without rebooting. Now, with the latest changes to the Linux kernel you may be able to go years between reboots.
+
+This is actually a feature that was available in Linux in 2009 thanks to a program called [Ksplice][2]. This program compares the original and patched kernels and then uses a customized kernel module to patch the new code into the running kernel. Each Ksplice-enabled kernel comes with a special set of flags for each function that will be patched. The [Ksplice process][3] then watches for a moment when the code for the function being patched isn't in use, and ta-da, the patch is made and your server runs on.
+
+[Oracle acquired Ksplice][4] in 2011, and kept it just for its own [Oracle Linux][5], a [Red Hat Enterprise Linux (RHEL)][6] clone, and as a RHEL subscription service. That left all the other enterprise and server Linux back where they started.
+
+Then [KernelCare released a service that could provide bootless patches][7] for most enterprise Linux distros. This program use proprietary software and is only available as a service with a monthly fee. That was a long way from satisfying many Linux system administrators.
+
+So, [Red Hat][8] and [SUSE][9] both started working on their own purely open-source means of giving Linux the ability to keep running even while critical patches were being installed. Red Hat's program was named [kpatch][10], while SUSE' is named [kGraft][11].
+
+The two companies took different approaches. Kpatch issues a stop_machine() command. After that it looks at the stack of existing processes using [ftrace][12] and, if the patch can be made safely, it redirects the running code to the patched functions and then removes the now outdated code.
+
+Kgraft also uses ftrace, but it works on the thread level. When an old function is called it makes sure the thread reaches a point that it can switch to the new function.
+
+While the end result is the same, the operating system keeps running while patches are made, there are significant differences in performance. Kpatch takes from one to forty milliseconds, while kGraft might take several minutes but there's never even a millisecond of down time.
+
+At the Linux Plumbers Conference in October 2014, the two groups got together and started work on a way to [patch Linux without rebooting that combines the best of both programs][13]. Essentially, what they ended up doing was putting both kpatch and kGraft in the 4.0 Linux kernel.
+
+Jiri Kosina, a SUSE software engineer and Linux kernel developer, explained, that live-patching in the Linux kernel will "provides a basic infrastructure for function "live patching" (i.e. code redirection), including API [application programming interface] for kernel modules containing the actual patches, and API/ABI [application binary interface] for userspace to be able to operate on the patches. This is "relatively simple and minimalistic, as it's making use of existing kernel infrastructure (namely ftrace) as much as possible. It's also self-contained, in a sense that it doesn't hook itself in any other kernel subsystem (it doesn't even touch any other code)."
+
+The release candidate for Linux 4.0 is now out. Kosina stated that "It's now implemented for x86 only as a reference architecture, but support for powerpc, s390 and arm is already in the works." And, indeed, the source code for these architectures is already in the [Live Patching Git code][14].
+
+Simply having the code in there is just the start. Your Linux distribution will have to support it with patches that can make use of it. With both Red Hat and SUSE behind it, live patching will soon be the default in all serious business Linux distributions.
+
+--------------------------------------------------------------------------------
+
+via: http://www.zdnet.com/article/no-reboot-patching-comes-to-linux-4-0/#ftag=RSSbaffb68
+
+作者:[Steven J. Vaughan-Nichols][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.zdnet.com/meet-the-team/us/sjvn/
+[1]:http://www.zdnet.com/article/linux-kernel-turns-over-release-odometer-to-4-0/
+[2]:http://www.computerworld.com/article/2466389/open-source-tools/never-reboot-again-with-linux-and-ksplice.html
+[3]:http://www.ksplice.com/
+[4]:http://www.zdnet.com/article/oracle-acquires-zero-downtime-linux-upgrade-software/
+[5]:http://www.oracle.com/us/technologies/linux/overview/index.html
+[6]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
+[7]:http://www.zdnet.com/article/kernelcare-new-no-reboot-linux-patching-system/
+[8]:http://www.redhat.com/
+[9]:http://www.suse.com/
+[10]:http://rhelblog.redhat.com/2014/02/26/kpatch/
+[11]:http://www.zdnet.com/article/suse-gets-live-patching/
+[12]:http://elinux.org/Ftrace
+[13]:http://linuxplumbersconf.org/2014/wp-content/uploads/2014/10/LPC2014_LivePatching.txt
+[14]:https://kernel.googlesource.com/pub/scm/linux/kernel/git/jikos/livepatching/+/9ec0de0ee0c9f0ffe4f72da9158194121cc22807
\ No newline at end of file
diff --git a/sources/talk/20150309 Comparative Introduction To FreeBSD For Linux Users.md b/sources/talk/20150309 Comparative Introduction To FreeBSD For Linux Users.md
new file mode 100644
index 0000000000..d29a75cb69
--- /dev/null
+++ b/sources/talk/20150309 Comparative Introduction To FreeBSD For Linux Users.md
@@ -0,0 +1,98 @@
+Comparative Introduction To FreeBSD For Linux Users
+================================================================================
+
+
+### Introduction ###
+
+BSD was originally derived from UNIX and currently, there are various number of Unix-like operating systems descended from the BSD. While, FreeBSD is the most widely used open source Berkeley Software Distribution (BSD distribution). As it is implicitly said it is a free and open source Unix-like-operating system and a public server platform. FreeBSD source code is generally released under a permissive BSD license. It is true that it has similarities with Linux but we cannot deny that they differs in other points.
+
+The remainder of this article is organized as follows: the description of FreeBSD will be treated in our first section. The similarities between FreeBSD and Linux will be briefly described in the second section. While their differences will be discussed in the third section. And a comparison of their features will be summarized in our last section.
+
+### FreeBSD description ###
+
+#### History ####
+
+- The first version of FreeBSD was released in 1993, while its first CD-ROM distributed was FreeBSD1.0 on December 1993. Then, FreeBSD 2.1.0 was released in 1995 which gained the satisfaction of all users. Actually, many IT companies use FreeBSD and are satisfied where we can list those companies: IBM, Nokia, NetApp and Juniper Networks.
+
+#### License ####
+
+- Concerning its license, FreeBSD is released under various source licenses. Its newest code called Kernel is released under the two-clause BSD license, offering the possibility to use and redistribute FreeBSD with absolute freedom. Other codes are released three- and four-clause BSD license and some others are released under GPL and CDDL.
+
+#### Users ####
+
+- One of the important feature of FreeBSD, we can mention the various categories of its users. In fact, it is possible to use FreeBSD as a mail server, web server, FTP server and as a router due to the significant set of server-related software accompanied with it. Furthermore, ARM, PowerPC and MIPS are supported by FreeBSD so it is possible to use x86 and s86-64.
+
+### FreeBSD and Linux similarities ###
+
+FreeBSD and Linux are two free and open source systems. Indeed, their users can easily check and modify the source code with an absolute freedom. To add, FreeBSD and Linux, both of them are derived from Unix.-like because they have a kernel, internals, and libraries programmed using algorithms derived from historic AT&T Unix. While FreeBSD’s roots are similar to Unix systems, Linux is released as a free Unix-like option. Various tools and applications can be found either in FreeBSD or in Linux in fact, they almost share the same functionality.
+
+Furthermore, FreeBSD can run big number of Linux applications. It has a Linux compatibility layer that can be installed. This Linux compatibility layer can be installed while compiling FreeBSD with AAC Compact Linux or downloading compiled FreeBSD systems with a Linux compatibility program such as: aac_linux.ko. Which is not the same case with Linux, Linux cannot run FreeBSD software.
+
+At the end, we can mention that both of them have the same goal but have also some differences which we will outline in the next section.
+
+### FreeBSD and Linux differences ###
+
+Currently, no criteria of choice between FreeBSD and Linux is clear for most users. Since, they share almost the same applications. Those two operating systems are as mentioned previously UNIX-like.
+
+In this section, we will list the most important differences of those two systems.
+
+#### License ####
+
+- The first difference point between those two compared systems consist on their license. To start by Linux license, it is released under the GPL license which offers the possibility to view, distribute and change the source code with an absolute freedom. The GPL license helps users to prevent the distribution of binary-only source. Which is the case with FreeBSD, which is licensed under BSD license. This kind of license is more restrictive and easily allows the distribution of binary-only source. The BSD license is more permissive that the GPL since no derivative work is required to maintain the licensing terms. Means any user can use, distribute and modify the code without need to have the previous version of code before changing made. They only need to have the original license of BSD.
+- Depending on the needs of each user, a selection can be made between those two types of license. Starting by BSD license which is more preferred by many users due to its special features. In fact, this license gives the possibility to sell each software licensed under it and retain the source code. Passing now to the GPL license, which requires some care of each user has a software released under it.
+- To be able to choose between those two software, it is required to understand the licensing of both of them to more understand the methodology used in their development, to distinguish between their features and know which one will fit user’s need.
+
+#### Control ####
+
+- Since FreeBSD and Linux are released under two different type of license, the Linux Torvalds control the Linux kernel which is not the same case with FreeBSD which is not controlled. Personally, I prefer to use FreeBSD instead of Linux since it is an absolute free software, no control permission exists. But it is not enough there is other differences between Linux and FreeBSD, help you to choose between both of them. As an advice don’t choose one of them, follow us and then give us your choice.
+
+#### Operating system ####
+
+- Linux concentrates only on the kernel system which is not the case with FreeBSD while the whole operating system is maintained. The kernel and a set of software, some of them are developed by the FreeBSD team, are maintained as one unit. Indeed, the FreeBSD developers have the possibility to manage the essential operating systems remotely and efficiently.
+- With Linux, there is some difficulties while managing a system. Since, the different components maintained will be from different sources so the Linux developers need to assemble them into groups having the same functionality.
+- FreeBSD and Linux both of them give the possibility to have a big set of optional software and distributions but they differ on the way they are managed. With FreeBSD, they are managed together while with Linux they will be maintained separately.
+
+#### Hardware support ####
+
+- Concerning the hardware support, Linux is better than FreeBSD. It doesn’t mean that FreeBSD hasn’t the capability to support hardware as Linux. They differ just on the manner. It depends on your need as usual. So if you are searching for the newest solution, the FreeBSD will fit your needs but if you are looking for greatest graphs, it is better to use Linux.
+
+#### FreeBSD origin Vs Linux origin ####
+
+- The origin of each system is also another point of distinction between both of them. As I said previously Linux is an alternative of the operating system Unix, written by Linus Trovalds and assisted by a special group of hackers across the Net. Linux has all the needed features in a modern Unix, such as virtual memory, shared libraries, demand loading, proper memory management and many others. It is released under the General Public License.
+- FreeBSD also shared many important features of its Unix heritage. FreeBSD as a type of the Berkeley Software Distribution, the distribution of the Unix developed at the University of California. The most important reason under developing BSD is to replace the AT&T operating system by an open source alternative giving the user the ability to use BSD without carry about the obtaining of the AT&T license.
+- The problem of licensing, is the most important worry of developers. They try to offer the maximum open source clone of Unix. Which influences the choice of users regarding the degree of open source of each system as FreeBSD gives more freedom than Linux regarding its use since it is released under BSD license.
+
+#### Supported Package ####
+
+- From the user’s perspective, another difference between our two compared systems, is their availability and support of the packaged software and source installed software. The Linux distributions provide just the pre-compiled binary packages which is not the same case with FreeBSD, which has the pre-built packages and the build system for the compilation and installation through their available open source. Due to its ports, FreeBSD gives you the possibility to choose between the default making of pre-compiled packages and your ability to customize your software while it is compiled.
+- Those ports enable you to build all the software available with FreeBSD. Furthermore, there is an hierarchy of organization all of them due to the directories /usr/ports where you can find the location of the source files and some documentation about the way to use FreeBSD correctly.
+- The ports as mentioned give the possibility produce the packages version of software. Instead of having just the pre-compiled packages using Linux, FreeBSD gives you the possibility to have the source-built and the pre-packages software. You can manage your system using the two installation methods.
+
+#### FreeBSD Vs Linux common Tools ####
+
+- A huge number of common tools are available while using FreeBSD and are fully own made by the FreeBSD team. In contrast, the Linux tools are from the GNU that is why there is some control during their usage.
+- The fact that FreeBSD is released under BSD license is so beneficial and useful. Since, you have the ability to maintain the core operating system, control the development of these applications. Same of those tools are similar to BSD and Unix tools from where they were derived which is not the same case with GNU suite, which want to just make them less backwards compatible.
+
+#### The Standard Shell ####
+
+- The tcsh shell is used by default with FreeBSD. Which is an evaluated version fo csh. Since, the FreeBSD is released under the BSD license, it is not recommended to use the bash shell which is a GNU component. The only difference between bash and tcsh shell consists on the scripting feature which can’t be made by tcsh. Indeed, the sh shell is more recommended for the FreeBSD use since it is more reliable and prevents some issues of scripting can be occurred using the tcsh or csh shell.
+
+#### A More Stratified Filesystem ####
+
+- As it was mentioned previously, base operating system and optional components can be easily distinguished using the FreeBSD system. Which causes some specification of their organization. In Linux, /bin, /sbin, /usr/bin, or usr/sbin are the directories for executable systems. With FreeBSD it is not the case. There are some additional specifications concerning their organization. The base system are putted in one of the directories mentioned above while the ports and packages are placed in /usr/local/bin or /usr/local/sbin. This methodology helps to recognize and distinguish between an application considered as a base system or a port.
+
+### Conclusion ###
+
+FreeBSD and Linux those two free and open source systems, share various similarities but they also differ in several points. The list giving above isn’t given to say that one of them is better than the other. In fact, FreeBSD and Linux, each one of them has its features and specifications that make it a special regarding the other. And you what is your opinion? Have you already used one on them or both? If yes what is your feedback and if no after reading our description what do you think? Sound off and give us and the fellow readers your opinion.
+
+--------------------------------------------------------------------------------
+
+via: https://www.unixmen.com/comparative-introduction-freebsd-linux-users/
+
+作者:[anismaj][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://www.unixmen.com/author/anis/
\ No newline at end of file
diff --git a/sources/talk/20150320 Revealed--The best and worst of Docker.md b/sources/talk/20150320 Revealed--The best and worst of Docker.md
new file mode 100644
index 0000000000..1e188d6cba
--- /dev/null
+++ b/sources/talk/20150320 Revealed--The best and worst of Docker.md
@@ -0,0 +1,66 @@
+Revealed: The best and worst of Docker
+================================================================================
+
+Credit: [Shutterstock][1]
+
+> Docker experts talk about the good, the bad, and the ugly of the ubiquitous application container system
+
+No question about it: Docker's app container system has made its mark and become a staple in many IT environments. With its accelerating adoption, it's bound to stick around for a good long time.
+
+But there's no end to the debate about what Docker's best for, where it falls short, or how to most sensibly move it forward without alienating its existing users or damaging its utility. Here, we've turned to a few of the folks who have made Docker their business to get their takes on Docker's good, bad, and ugly sides.
+
+### The good ###
+
+One hardly expects Steve Francia, chief of operations of the Docker open source project, to speak of Docker in anything less than glowing terms. When asked by email about Docker's best attributes, he didn't disappoint: "I think the best thing about Docker is that it enables people, enables developers, enables users to very easily run an application anywhere," he said. "It's almost like the Holy Grail of development in that you can run an application on your desktop, and the exact same application without any changes can run on the server. That's never been done before."
+
+Alexis Richardson of [Weaveworks][2], a virtual networking product, praised Docker for enabling simplicity. "Docker offers immense potential to radically simplify and speed up how software gets built," he replied in an email. "This is why it has delivered record-breaking initial mind share and traction."
+
+Bob Quillin, CEO of [StackEngine][3], which makes Docker management and automation solutions, noted in an email that Docker (the company) has done a fine job of maintaining Docker's (the product) appeal to its audience. "Docker has been best at delivering strong developer support and focused investment in its product," he wrote. "Clearly, they know they have to keep the momentum, and they are doing that by putting intense effort into product functionality." He also mentioned that Docker's commitment to open source has accelerated adoption by "[allowing] people to build around their features as they are being built."
+
+Though containerization itself isn't new, as Rob Markovich of IT monitoring-service makers [Moogsoft][4] pointed out, Docker's implementation makes it new. "Docker is considered a next-generation virtualization technology given its more modern, lightweight form [of containerization]," he wrote in an email. "[It] brings an opportunity for an order-of-magnitude leap forward for software development teams seeking to deploy code faster."
+
+### The bad ###
+
+What's less appealing about Docker boils down to two issues: the complexity of using the product, and the direction of the company behind it.
+
+Samir Ghosh, CEO of enterprise PaaS outfit [WaveMaker][5], gave Docker a thumbs-up for simplifying the complex scripting typically needed for continuous delivery. That said, he added, "That doesn't mean Docker is simple. Implementing Docker is complicated. There are a lot of supporting technologies needed for things like container management, orchestration, app stack packaging, intercontainer networking, data snapshots, and so on."
+
+Ghosh noted the ones who feel the most of that pain are enterprises that want to leverage Docker for continuous delivery, but "it's even more complicated for enterprises that have diverse workloads, various app stacks, heterogenous infrastructures, and limited resources, not to mention unique IT needs for visibility, control and security."
+
+Complexity also becomes an issue in troubleshooting and analysis, and Markovich cited the fact that Docker provides application abstraction as the reason why. "It is nearly impossible to relate problems with application performance running on Docker to the performance of the underlying infrastructure domains," he said in an email. "IT teams are going to need visibility -- a new class of monitoring and analysis tools that can correlate across and relate how everything is working up and down the Docker stack, from the applications down to the private or public infrastructure."
+
+Quillin is most concerned about Docker's direction vis-à-vis its partner community: "Where will Docker make money, and where will their partners? If [Docker] wants to be the next VMware, it will need to take a page out of VMware's playbook in how to build and support a thriving partner ecosystem.
+
+"Additionally, to drive broader adoption, especially in the enterprise, Docker needs to start acting like a market leader by releasing more fully formed capabilities that organizations can count on, versus announcements of features with 'some assembly required,' that don't exist yet, or that require you to 'submit a pull request' to fix it yourself."
+
+Francia pointed to Docker's rapid ascent for creating its own difficulties. "[Docker] caught on so quickly that there's definitely places that we're focused on to add some features that a lot of users are looking forward to."
+
+One such feature, he noted, was having a GUI. "Right now to use Docker," he said, "you have to be comfortable with the command line. There's no visual interface to using Docker. Right now it's all command line-based. And we know if we want to really be as successful as we think we can be, we need to be more approachable and a lot of people when they see a command line, it's a bit intimidating for a lot of users."
+
+### The future ###
+
+In that last respect, Docker recently started to make advances. Last week it [bought the startup Kitematic][6], whose product gave Docker a convenient GUI on Mac OS X (and will eventually do the same for Windows). Another acqui-hire, [SocketPlane][7], is being spun in to work on Docker's networking.
+
+What remains to be seen is whether Docker's proposed solutions to its problems will be adopted, or whether another party -- say, [Red Hat][8] -- will provide a more immediately useful solution for enterprise customers who can't wait around for the chips to stop falling.
+
+"Good technology is hard and takes time to build," said Richardson. "The big risk is that expectations spin wildly out of control and customers are disappointed."
+
+--------------------------------------------------------------------------------
+
+via: http://www.infoworld.com/article/2896895/application-virtualization/best-and-worst-about-docker.html
+
+作者:[Serdar Yegulalp][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
+[1]:http://shutterstock.com/
+[2]:http://weave.works/
+[3]:http://stackengine.com/
+[4]:http://www.moogsoft.com/
+[5]:http://www.wavemaker.com/
+[6]:http://www.infoworld.com/article/2896099/application-virtualization/dockers-new-acquisition-does-containers-on-the-desktop.html
+[7]:http://www.infoworld.com/article/2892916/application-virtualization/docker-snaps-up-socketplane-to-fix-networking-flaws.html
+[8]:http://www.infoworld.com/article/2895804/application-virtualization/red-hat-wants-to-do-for-containers-what-its-done-for-linux.html
\ No newline at end of file
diff --git a/sources/talk/20150410 10 Top Distributions in Demand to Get Your Dream Job.md b/sources/talk/20150410 10 Top Distributions in Demand to Get Your Dream Job.md
new file mode 100644
index 0000000000..0e3e611ea4
--- /dev/null
+++ b/sources/talk/20150410 10 Top Distributions in Demand to Get Your Dream Job.md
@@ -0,0 +1,149 @@
+10 Top Distributions in Demand to Get Your Dream Job
+================================================================================
+We are coming up with a series of five articles which aims at making you aware of the top skills which will help you in getting yours dream job. In this competitive world you can not rely on one skill. You need to have balanced set of skills. There is no measure of a balanced skill set except a few conventions and statistics which changes from time-to-time.
+
+The below article and remaining to follow is the result of close study of job boards, posting and requirements of various IT Companies across the globe of last three months. The statistics keeps on changing as the demand and market changes. We will try our best to update the list when there is any major changes.
+The Five articles of this series are…
+
+- 10 Distributions in Demand to Get Your Dream Job
+- [10 Famous IT Skills in Demand That Will Get You Hired][1]
+- 10 Programming Skills That Will Help You to Get Dream Job
+- 10 IT Networking Protocols Skills to Land Your Dream Job
+- 10 Professional Certifications in Demand That Will Get You Hired
+
+### 1. Windows ###
+
+The operating System developed by Microsoft not only dominates the PC market but it is also the most sought OS skill from job perspective irrespective of all the odds and criticism that follows. It has shown a growth in demand which equals to 0.1% in the last quarter.
+
+Latest Stable Release : Windows 8.1
+
+### 2. Red Hat Enterprise Linux ###
+
+Red Hat Enterprise Linux is a commercial Linux Distribution developed by Red Hat Inc. It is one of the Most widely used Linux distribution specially in corporates and production. It comes at number two having a overall growth in demand which equals to 17% in the last quarter.
+
+Latest Stable Release : RedHat Enterprise Linux 7.1
+
+### 3. Solaris ###
+
+The UNIX Operating System developed by Sun Microsystems and now owned by Oracle Inc. comes at number three. It has shown a growth in demand which equals to 14% in the last quarter.
+
+Latest Stable Release : Oracle Solaris 10 1/13
+
+### 4. AIX ###
+
+Advanced Interactive eXecutive is a Proprietary Unix Operating System by IBM stands at number four. It has shown a growth in demand which equals to 11% in the last quarter.
+
+Latest Stable Release : AIX 7
+
+### 5. Android ###
+
+One of the most widely used open source operating system designed specially for mobile, tablet computers and wearable gadgets is now owned by Google Inc. comes at number five. It has shown a growth in demand which equals to 4% in the last quarter.
+
+Latest Stable Release : Android 5.1 aka Lollipop
+
+### 6. CentOS ###
+
+Community Enterprise Operating System is a Linux distribution derived from RedHat Enterprise Linux. It comes at sixth position in the list. Market has shown a growth in demand which is nearly 22% for CentOS, in the last quarter.
+
+Latest Stable Release : CentOS 7
+
+### 7. Ubuntu ###
+
+The Linux Operating System designed for Humans and designed by Canonicals Ltd. Ubuntu comes at position seventh. It has shown a growth in demand which equals to 11% in the last quarter.
+Latest Stable Release :
+
+- Ubuntu 14.10 (9 months security and maintenance update).
+- Ubuntu 14.04.2 LTS
+
+### 8. Suse ###
+
+Suse is a Linux operating System owned by Novell. The Linux distribution is famous for YaST configuration tool. It comes at position eight. It has shown a growth in demand which equals to 8% in the last quarter.
+
+Latest Stable Release : 13.2
+
+### 9. Debian ###
+
+The very famous Linux Operating System, mother of 100’s of Distro and closest to GNU comes at number nine. It has shown a decline in demand which is nearly 9% in the last quarter.
+
+Latest Stable Release : Debian 7.8
+
+### 10. HP-UX ###
+
+The Proprietary UNIX Operating System designed by Hewlett-Packard comes at number ten. It has shown a decline in the last quarter by 5%.
+
+Latest Stable Release : 11i v3 Update 13
+
+注:表格数据--不需要翻译--开始
+
+
+
+
+
+
+
1
+
Windows
+
0.1% +
+
+
+
2
+
RedHat
+
17% +
+
+
+
3
+
Solaris
+
14% +
+
+
+
4
+
AIX
+
11% +
+
+
+
5
+
Android
+
4% +
+
+
+
6
+
CentOS
+
22% +
+
+
+
7
+
Ubuntu
+
11% +
+
+
+
8
+
Suse
+
8% +
+
+
+
9
+
Debian
+
9% -
+
+
+
10
+
HP-UX
+
5% -
+
+
+
+注:表格数据--不需要翻译--结束
+
+That’s all for now. I’ll be coming up with the next article of this series very soon. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/
+
+作者:[Avishek Kumar][a]
+译者:[weychen](https://github.com/weychen)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/top-distributions-in-demand-to-get-your-dream-job/www.tecmint.com/famous-it-skills-in-demand-that-will-get-you-hired/
diff --git a/sources/talk/The history of Android/13 - The history of Android.md b/sources/talk/The history of Android/13 - The history of Android.md
deleted file mode 100644
index 31f5cd7eb4..0000000000
--- a/sources/talk/The history of Android/13 - The history of Android.md
+++ /dev/null
@@ -1,104 +0,0 @@
-【translating】The history of Android
-================================================================================
-
-
-### Android 2.1, update 1—the start of an endless war ###
-
-Google was a major launch partner for the first iPhone—the company provided Google Maps, Search, and YouTube for Apple’s mobile operating system. At the time, Google CEO Eric Schmidt was a member of Apple’s board of directors. In fact, during the original iPhone presentation, [Schmidt was the first person on stage][] after Steve Jobs, and he joked that the two companies were so close they could merge into “AppleGoo."
-
-While Google was developing Android, the relationship between the two companies slowly became contentious. Still, Google largely kept Apple happy by keeping key iPhone features, like pinch zoom, out of Android. The Nexus One, though, was the first slate-style Android flagship without a keyboard, which gave the device the same form factor as the iPhone. Combined with the newer software and Google branding, this was the last straw for Apple. According to Walter Isaacson’s biography on Steve Jobs, after seeing the Nexus One in January 2010, the Apple CEO was furious, saying "I will spend my last dying breath if I need to, and I will spend every penny of Apple's $40 billion in the bank, to right this wrong... I'm going to destroy Android, because it's a stolen product. I'm willing to go thermonuclear war on this."
-
-All of this happened behind closed doors, only coming out years after the Nexus One was released. The public first caught wind of this growing rift between Google and Apple when, a month after the release of Android 2.1, an update shipped for the Nexus One called “[2.1 update 1.][2]" The updated added one feature, something iOS long held over the head of Android: pinch-zoom.
-
-While Android supported multi-touch APIs since version 2.0, the default operating system apps stayed clear of this useful feature at the behest of Jobs. After reconciliation meetings over the Nexus One failed, there was no longer a reason to keep pinch zoom out of Android. Google pushed all their chips into the middle of the table, hit the update button, and was finally “all-in" with Android.
-
-With pinch zoom enabled in Google Maps, the Browser, and the Gallery, the Google-Apple smartphone war was on. In the coming years, the two companies would become bitter enemies. A month after the pinch zoom update, Apple went on the warpath, suing everyone and everything that used Android. HTC, Motorola, and Samsung were all brought to court, and some of them are still in court. Schmidt resigned from Apple’s board of directors. Google Maps and YouTube were kicked off of the iPhone, and Apple even started a rival mapping service. Today, the two players that were almost "AppleGoo" compete in smartphones, tablets, laptops, movies, TV shows, music, books, apps, e-mail, productivity software, browsers, personal assistants, cloud storage, mobile advertising, instant messaging, mapping, and set-top-boxes... and soon the two will be competing in car computers, wearables, mobile payments, and living room gaming.
-
-### Android 2.2 Froyo—faster and Flash-ier ###
-
-[Android 2.2][3] came out four months after the release of 2.1, in May 2010. Froyo featured major under-the-hood improvements for Android, all made in the name of speed. The biggest addition was just-in-time (JIT) compilation. JIT automatically converted java bytecode into native code at runtime, which led to drastic performance improvements across the board.
-
-The Browser got a performance boost, too, thanks to the integration of the V8 javascript engine from Chrome. This was the first of many features the Android browser would borrow from Chrome, and eventually the stock browser would be completely replaced by a mobile version of Chrome. Until that day came, though, the Android team needed to ship a browser. Pulling in Chrome parts was an easy way to upgrade.
-
-While Google was focusing on making its platform faster, Apple was making its platform bigger. Google's rival released the 10-inch iPad a month earlier, ushering in the modern era of tablets. While some large Froyo and Gingerbread tablets were released, Google's official response—Android 3.0 Honeycomb and the Motorola Xoom—would not arrive for nine months.
-
-
-Froyo added a two-icon dock at the bottom and universal search.
-Photo by Ron Amadeo
-
-The biggest change on the Froyo homescreen was the new dock at the bottom, which filled the previously empty space to the left and right of the app drawer with phone and browser icons. Both of these icons were custom-designed white versions of the stock icons, and they were not user-configurable.
-
-The default layout removed all the icons, and it only stuck the new tips widget on the screen, which directed you to click on the launcher icon to access your apps. The Google Search widget gained a Google logo which doubled as a button. Tapping it would open the search interface and allow you to restrict a search by Web, apps, or contacts.
-
-
-The downloads page showing the “update all" button, the Flash app, a flash-powered site where anything is possible, and the “move to SD" button.
-Photo by [Ryan Paul][4]
-
-Some of the best additions to Froyo were more download controls for the Android Market. There was now an “Update all" button pinned to the bottom of the Downloads page. Google also added an automatic updating feature, which would automatically install apps as long as the permissions hadn't changed; automatic updating was off by default, though.
-
-The second picture shows Adobe Flash Player, which was exclusive to Froyo. The app plugged in to the browser and allowed for a “full Web" experience. In 2010, this meant pages heavy with Flash navigation and video. Flash was one of Android's big differentiators compared to the iPhone. Steve Jobs started a holy war against Flash, declaring it an obsolete, buggy piece of software, and Apple would not allow it on iOS. So Android picked up the Flash ball and ran with it, giving users the option of having a semi-workable implementation on Android.
-
-At the time, Flash could bring even a desktop computer to its knees, so keeping it on all the time on a mobile phone delivered terrible performance. To fix this, Flash on Android's browser could be set to "on-demand"—Flash content would not load until users clicked on the Flash placeholder icon. Flash support would last on Android until 4.1, when Adobe gave up and killed the project. Ultimately Flash never really worked well on Android. The lack of Flash on the iPhone, the most popular mobile device, pushed the Internet to eventually dump the platform.
-
-The last picture shows the newly added ability to move apps to the SD card, which, in an era when phones came with 512MB of internal storage, was sorely needed.
-
-
-The car app and camera app. The camera could now rotate.
-Photo by Ron Amadeo
-
-The camera app was finally updated to support portrait mode. The camera settings were moved out of the drawer and into a semi-transparent strip of buttons next to the shutter button and other controls. This new design seemed to take a lot of inspiration from the Cooliris Gallery app, with transparent, springy speech bubble popups. It was quite strange to see the high-tech Cooliris-style UI design grafted on to the leather-bound camera app—the aesthetics didn't match at all.
-
-
-The semi-broken Facebook app is a good example of the common 2x3 navigation page. Google Goggles was included but also broken.
-Photo by Ron Amadeo
-
-Unlike the Facebook client included in Android 2.0 and 2.1, the 2.2 version still sort of works and can sign in to Facebook's servers. The Facebook app is a good example of Google's design guidelines for apps at the time, which suggested having a navigational page consisting of a 3x2 grid of icons as the main page of an app.
-
-This was Google's first standardized attempt at getting navigational elements out of the menu button and onto the screen, where users could find them. This design was usable, but it added an extra roadblock between launching an app and using an app. Google would later realize that when users launch an app, it was a better idea to show them content instead of an interstitial navigational screen. In Facebook for instance, opening to the news feed would be much more appropriate. And later app designs would relegate navigation to a second-tier location—first as tabs at the top of the screen, and later Google would settle on the "Navigation Drawer," a slide-out panel containing all the locations in an app.
-
-Also packed in with Froyo was Google Goggles, a visual search app which would try to identify the subject of a picture. It was useful for identifying works of art, landmarks, and barcodes, but not much else. These first two setup screens, along with the camera interface, are all that work in the app anymore. Today, you can't actually complete a search with a client this old. There wasn't much to see anyway; it was a camera interface that returned a search results page.
-
-
-The Twitter app, which was an animation-filled collaboration between Google and Twitter.
-Photo by Ron Amadeo
-
-Froyo included the first Android Twitter app, which was actually a collaboration between Google and Twitter. At the time, a Twitter app was one of the big holes in Android's app lineup. Developers favored the iPhone, and with Apple's head start and stringent design requirements, the App Store's app selection was far superior to Android's. But Google needed a Twitter app, so it teamed up with the company to get the first version out the door.
-
-This represented Google's newer design language, which meant it had an interstitial navigation page and a "tech-demo" approach to animations. The Twitter app was even more heavy-handed with animation effects than the Cooliris Gallery—everything moved all the time. The clouds at the top and bottom of every page continually scrolled at varying speeds, and the Twitter bird at the bottom flapped its wings and moved its head left and right.
-
-The Twitter app actually featured an early precursor to the Action Bar, a persistent strip of top-aligned controls that was introduced in Android 3.0 . Along the top of every screen was a blue bar containing the Twitter logo and buttons like search, refresh, and compose tweet. The big difference between this and the later action bars was that the Twitter/Google design lacks an "Up" button in the top right corner, and it actually uses an entire second bar to show your current location within the app. In the second picture above, you can see a whole bar dedicated to the location label "Tweets" (and, of course, the continuously scrolling clouds). The Twitter logo in the second bar acted as another navigational element, sometimes showing additional drill down areas within the current section and sometimes showing the entire top-level shortcut group.
-
-The 2.3 Tweet stream didn't look much different from what it does today, save for the hidden action buttons (reply, retweet, etc), which were all under the right-aligned arrow buttons. They popped up in a speech bubble menu that looked just like the navigational popup. The faux-action bar was doing serious work on the create tweet page. It housed the twitter logo, remaining character count, and buttons to attach a picture, take a picture, and a contact mention button.
-
-The Twitter app even came with a pair of home screen widgets. The big one took up eight slots and gave you a compose bar, update button, one tweet, and left and right arrows to view more tweets. The little one showed a tweet and reply button. Tapping on the compose bar on the large widget immediately launched the main "Create Tweet," rendering the "update" button worthless.
-
-
-Google Talk and the new USB dialog.
-Photo by Ron Amadeo
-
-Elsewhere, Google Talk (and the unpictured SMS app) changed from a dark theme to a light theme, which made both of them look a lot closer to the current, modern apps. The USB storage screen that popped up when you plugged into a computer changed from a simple dialog box to a full screen interface. Instead of a text-only design, the screen now had a mutant Android/USB-stick hybrid.
-
-While Android 2.2 didn’t feature much in the way of user-facing features, a major UI overhaul was coming in the next two versions. Before all the UI work, though, Google wanted to revamp the core of Android. Android 2.2 accomplished that.
-
-----------
-
-
-
-[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
-
-[@RonAmadeo][t]
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/
-
-译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://www.youtube.com/watch?v=9hUIxyE2Ns8#t=3016
-[2]:http://arstechnica.com/gadgets/2010/02/googles-nexus-one-gets-multitouch/
-[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
-[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
-[a]:http://arstechnica.com/author/ronamadeo
-[t]:https://twitter.com/RonAmadeo
diff --git a/sources/talk/The history of Android/14 - The history of Android.md b/sources/talk/The history of Android/14 - The history of Android.md
deleted file mode 100644
index 3377527026..0000000000
--- a/sources/talk/The history of Android/14 - The history of Android.md
+++ /dev/null
@@ -1,84 +0,0 @@
-alim0x translating
-
-The history of Android
-================================================================================
-### Voice Actions—a supercomputer in your pocket ###
-
-In August 2010, a new feature “[Voice Actions][1]" launched in the Android Market as part of the Voice Search app. Voice Actions allowed users to issue voice commands to their phone, and Android would try to interpret them and do something smart. Something like "Navigate to [address]" would fire up Google Maps and start turn-by-turn navigation to your stated destination. You could also send texts or e-mails, make a call, open a Website, get directions, or view a location on a map—all just by speaking.
-
-注:youtube视频地址
-
-
-Voice Actions was the culmination of a new app design philosophy for Google. Voice Actions was the most advanced voice control software for its time, and the secret was that Google wasn’t doing any computing on the device. In general, voice recognition was very CPU intensive. In fact, many voice recognition programs still have a “speed versus accuracy" setting, where users can choose how long they are willing to wait for the voice recognition algorithms to work—more CPU power means better accuracy.
-
-Google’s innovation was not bothering to do the voice recognition computing on the phone’s limited processor. When a command was spoken, the user’s voice was packaged up and shipped out over the Internet to Google’s cloud servers. There, Google’s farm of supercomputers pored over the message, interpreted it, and shipped it back to the phone. It was a long journey, but the Internet was finally fast enough to accomplish something like this in a second or two.
-
-Many people throw the phrase “cloud computing" around to mean “anything that is stored on a server," but this was actual cloud computing. Google was doing hardcore compute operations in the cloud, and because it is throwing a ridiculous amount of CPU power at the problem, the only limit to the voice recognition accuracy is the algorithms themselves. The software didn't need to be individually “trained" by each user, because everyone who used Voice Actions was training it all the time. Using the power of the Internet, Android put a supercomputer in your pocket, and, compared to existing solutions, moving the voice recognition workload from a pocket-sized computer to a room-sized computer greatly increased accuracy.
-
-Voice recognition had been a project of Google’s for some time, and it all started with an 800 number. [1-800-GOOG-411][1] was a free phone information service that Google launched in April 2007. It worked just like 411 information services had for years—users could call the number and ask for a phone book lookup—but Google offered it for free. No humans were involved in the lookup process, the 411 service was powered by voice recognition and a text-to-speech engine. Voice Actions was only possible after three years of the public teaching Google how to hear.
-
-Voice recognition was a great example of Google’s extremely long-term thinking—the company wasn't afraid to invest in a project that wouldn’t become a commercial product for several years. Today, voice recognition powers products all across Google. It’s used for voice input in the Google Search app, Android’s voice typing, and on Google.com. It’s also the primary input interface for Google Glass and [Android Wear][2].
-
-The company even uses it beyond input. Google's voice recognition technology is used to transcribe YouTube videos, which powers automatic closed captioning for the hearing impaired. The transcription is even indexed by Google, so you can search for words that were said in the video. Voice is the future of many products, and this long-term planning has led Google to be one of the few major tech companies with an in-house voice recognition service. Most other voice recognition products, like Apple’s Siri and Samsung devices, are forced to use—and pay a license fee for—voice recognition from Nuance.
-
-With the computer hearing system up and running, Google is applying this strategy to computer vision next. That's why things like Google Goggles, Google Image Search, and [Project Tango][3] exist. Just like the days of GOOG-411, these projects are in the early stages. When [Google's robot division][4] gets off the ground with a real robot, it will need to see and hear, and Google's computer vision and hearing projects will likely give the company a head start.
-
-
-The Nexus S, the first Nexus phone made by Samsung.
-
-### Android 2.3 Gingerbread—the first major UI overhaul ###
-
-Gingerbread was released in December 2010, a whopping seven months after the release of 2.2. The wait was worth it, though, as Android 2.3 changed just about every screen in the OS. It was the first major overhaul since the initial formation of Android in version 0.9. 2.3 would kick off a series of continual revamps in an attempt to turn Android from an ugly duckling into something that was capable of holding its own—aesthetically—against the iPhone.
-
-And speaking of Apple, six months earlier, the company released the iPhone 4 and iOS 4, which added multitasking and Facetime video chat. Microsoft was finally back in the game, too. The company jumped into the modern smartphone era with the launch of Windows Phone 7 in November 2010.
-
-Android 2.3 focused a lot on the interface design, but with no direction or design documents, many apps ended up getting a new bespoke theme. Some apps went with a flatter, darker theme, some used a gradient-filled, bubbly dark theme, and others went with a high-contrast white and green look. While it wasn't cohesive, Gingerbread accomplished the goal of modernizing nearly every part of the OS. It was a good thing, too, because the next phone version of Android wouldn’t arrive until nearly a year later.
-
-Gingerbread’s launch device was the Nexus S, Google’s second flagship device and the first Nexus manufactured by Samsung. While today we are used to new CPU models every year, back then that wasn't the case. The Nexus S had a 1GHz Cortex A8 processor, just like the Nexus One. The GPU was slightly faster, and that was it in the speed department. It was a little bigger than the Nexus One, with a 4-inch, 800×480 AMOLED display.
-
-Spec wise, the Nexus S might seem like a tame upgrade, but it was actually home to a lot of firsts for Android. The Nexus S was Google’s first flagship to shun a MicroSD slot, shipping with 16GB on-board memory. The Nexus One had only 512MB of storage, but it had a MicroSD slot. Removing the SD slot simplified storage management for users—there was just one pool now—but hurt expandability for power users. It was also Google's first phone to have NFC, a special chip in the back of the phone that could transfer information when touched to another NFC chip. For now, the Nexus S could only read NFC tags—it couldn't send data.
-
-Thanks to some upgrades in Gingerbread, the Nexus S was one of the first Android phones to ship without a hardware D-Pad or trackball. The Nexus S was now down to just the power, volume, and the four navigation buttons. The Nexus S was also a precursor to the [crazy curved-screen phones][6] of today, as Samsung outfitted the Nexus S with a piece of slightly curved glass.
-
-
-Gingerbread changed the status bar and wallpaper, and it added a bunch of new icons.
-Photo by Ron Amadeo
-
-An upgraded "Nexus" live wallpaper was released as an exclusive addition to the Nexus S. It was basically the same idea as the Nexus One version, with its animated streaks of light. On the Nexus S, the "grid" design was removed and replaced with a wavy blue/gray background. The dock at the bottom was given square corners and colored icons.
-
-
-The new notification panel and menu.
-Photo by Ron Amadeo
-
-The status bar was finally overhauled from the version that first debuted in 0.9. The bar was changed from a white gradient to flat black, and all the icons were redrawn in gray and green. Just about everything looked crisper and more modern thanks to the sharp-angled icon design and higher resolution. The strangest decisions were probably the removal of the time period from the status bar clock and the confusing shade of gray that was used for the signal bars. Despite gray being used for many status bar icons, and there being four gray bars in the above screenshot, Android was actually indicating no cellular signal. Green bars would indicate a signal, gray bars indicated “empty" signal slots.
-
-The green status bar icons in Gingerbread also doubled as a status indicator of network connectivity. If you had a working connection to Google's servers, the icons would be green, if there was no connection to Google, the icons turned white. This let you easily identify the connectivity status of your connection while you were out and about.
-
-The notification panel was changed from the aging Android 1.5 design. Again, we saw a UI piece that changed from a light theme to a dark theme, getting a dark gray header, black background, and black-on-gray text.
-
-The menu was darkened too, changing from a white background to a black one with a slight transparency. The contrast between the menu icons and the background wasn’t as strong as it should be, because the gray icons are the same color as they were on the white background. Requiring a color change would mean every developer would have to make new icons, so Google went with the preexisting gray color on black. This was a change at the system level, so this new menu would show up in every app.
-
-----------
-
-
-
-[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
-
-[@RonAmadeo][t]
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/
-
-译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://arstechnica.com/gadgets/2010/08/google-beefs-up-voice-search-mobile-sync/
-[2]:http://arstechnica.com/business/2007/04/google-rolls-out-free-411-service/
-[3]:http://arstechnica.com/gadgets/2014/03/in-depth-with-android-wear-googles-quantum-leap-of-a-smartwatch-os/
-[4]:http://arstechnica.com/gadgets/2014/02/googles-project-tango-is-a-smartphone-with-kinect-style-computer-vision/
-[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
-[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
-[a]:http://arstechnica.com/author/ronamadeo
-[t]:https://twitter.com/RonAmadeo
diff --git a/sources/talk/The history of Android/15 - The history of Android.md b/sources/talk/The history of Android/15 - The history of Android.md
index 078e106d1c..9ca4176245 100644
--- a/sources/talk/The history of Android/15 - The history of Android.md
+++ b/sources/talk/The history of Android/15 - The history of Android.md
@@ -1,3 +1,5 @@
+alim0x translating
+
The history of Android
================================================================================
@@ -83,4 +85,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
[a]:http://arstechnica.com/author/ronamadeo
-[t]:https://twitter.com/RonAmadeo
\ No newline at end of file
+[t]:https://twitter.com/RonAmadeo
diff --git a/sources/tech/20141114 How To Use Emoji Anywhere With Twitter's Open Source Library.md b/sources/tech/20141114 How To Use Emoji Anywhere With Twitter's Open Source Library.md
deleted file mode 100644
index e043210cf6..0000000000
--- a/sources/tech/20141114 How To Use Emoji Anywhere With Twitter's Open Source Library.md
+++ /dev/null
@@ -1,91 +0,0 @@
-How To Use Emoji Anywhere With Twitter's Open Source Library
-================================================================================
-> Embed them in webpages and other projects via GitHub.
-
-
-
-Emoji, tiny characters from Japan that convey emotions through images, have already conquered the world of cellphone text messaging.
-
-Now, you can post them everywhere else in the virtual world, too. Twitter has just [open-sourced][1] its emoji library so you can use them for your own websites, apps, and projects.
-
-This will require a little bit of heavy lifting. Unicode has recognized and even standardized the emoji alphabet, but emoji still [aren’t fully compliant with all Web browsers][2], meaning they'll show up as “tofu,” or blank boxes, most of the time. When Twitter wanted to make emoji available, the social network teamed up with a company called [Icon Factory][3] to render browser imitations of the text message symbols. As a result, Twitter says there’s been lots of demand for access to its emoji.
-
-Now, you can clone Twitter’s entire library on [GitHub][4] to use in your development projects. Here’s how to do that, and how to make emoji easier to use after you do.
-
-### Obtain Unicode Support For Emoji ###
-
-Unicode is an international encoding standard that assigns a string of characters to any symbol, letter, or digit people want to use online. In other words, it’s the missing link between how you read text on a computer, and how the computer reads text. For example, while you are looking at an empty space between these words, the computer sees “&mbsp.”
-
-Unicode even has its own [primitive emoji][5] that can be read in the browser without any effort on your part. For example while you see a ♥, your computer is decoding the string “2665.”
-
-To use Twitter’s emoji library in most cases, you simply need to add a script inside the section of your HTML page:
-
-
-
-This grants your project access to the JavaScript library that contains the hundreds of emoji that work on Twitter. However, creating a document with simply this script isn’t going to make emoji appear on your site. You also need to actually insert some emoji!
-
-In the section, paste a few of the emoji strings you can find in Twitter’s [preview.html source code][6]. I used 🎹 and 🏁 without really knowing how they'd appear in the browser window. Yeah, you’ll have to just paste and guess. You can already see the problem we're going to fix in section two.
-
-However, through some trial and error, you can turn a raw HTML file that looks like this—
-
-
-
-—into a webpage that looks something like this:
-
-
-
-### Convert Emoji Into Readable Language ###
-
-Twitter’s solution is all well and good for making a site or app emoji compliant. But if you want to be able to easily insert your favorite emoji at will via HTML, you’re going to need an easier solution than memorizing all those Unicode strings.
-
-That’s where programmer Elle Kasai’s [Twemoji Awesome][7] styles come in.
-
-By adding Elle’s open-source stylesheet to any webpage, you can use English words to understand which emoji you’re inserting. So if you want a heart emoji to show up, you can simply type this :
-
-
-
-In order to do this, let’s download Elle’s project with the “Download ZIP” button on GitHub.
-
-Next, let’s make a new folder on the desktop. Inside this folder, we’ll put emoji.html—the raw HTML file I showed you before, and also Elle’s [twemoji-awesome.css][8].
-
-We’ll need the HTML file to acknowledge the CSS file, so in the section of the html page you’ll want to add a link from the css file:
-
-
-
-Once you put this in, you can delete Twitter's script from before. Elle's styles each link to the Unicode string for the relevant emoji, so you no longer have to.
-
-Now, go down to the body section and add a few emoji. I used , , and .
-
-You'll end up with something like this:
-
-
-
-Save and view your creation in the browser:
-
-
-
-Ta-da! Not only have you gotten a basic webpage to support emoji in the browser, you’ve also made it easy to do. Feel free to check out this tutorial on [my GitHub][9] for actual files you can clone instead of screenshots.
-
-Lead image via [Get Emoji][10]; screenshots by Lauren Orsini
-
---------------------------------------------------------------------------------
-
-via: http://readwrite.com/2014/11/12/how-to-use-emoji-in-the-browser-window
-
-作者:[Lauren Orsini][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://readwrite.com/author/lauren-orsini
-[1]:https://blog.twitter.com/2014/open-sourcing-twitter-emoji-for-everyone
-[2]:http://www.unicode.org/reports/tr51/full-emoji-list.html
-[3]:https://twitter.com/iconfactory
-[4]:https://github.com/twitter/twemoji
-[5]:http://www.unicode.org/reports/tr51/full-emoji-list.html
-[6]:https://github.com/twitter/twemoji/blob/gh-pages/preview.html
-[7]:http://ellekasai.github.io/twemoji-awesome/
-[8]:https://github.com/ellekasai/twemoji-awesome/blob/gh-pages/twemoji-awesome.css
-[9]:https://github.com/laurenorsini/Emoji-Everywhere
-[10]:http://getemoji.com/
diff --git a/sources/tech/20141203 Undelete Files on Linux Systems.md b/sources/tech/20141203 Undelete Files on Linux Systems.md
deleted file mode 100644
index d0fa7f6a98..0000000000
--- a/sources/tech/20141203 Undelete Files on Linux Systems.md
+++ /dev/null
@@ -1,118 +0,0 @@
-Undelete Files on Linux Systems
-================================================================================
-Often times, a computer user will delete a needed file accidentally and not have an easy way to regain or recreate the file. Thankfully, files can be undeleted. When a user deletes a file, it is not gone, only hidden for some time. Here is how it all works. On a filesystem, the system has what is called a file allocation list. This list keeps track of what files are where on the storage unit (hard-drive, MicroSD card, flash-drive, etc.). When a file is deleted, the filesystem will perform one of two tasks on the allocation table. The file's entry on the file allocation table marked as "free space" or the file's entry on the list is erased and then the space is marked as free. Now, if a file needs to be placed on the storage unit, the operating system will put the file in the space marked as empty. After the new file is written to the "empty space", the deleted file is now gone forever. When a deleted file is to be recovered, the user must not manipulate any files because if the "empty space" is used, then the file can never be retrieved.
-
-### How do undelete programs work? ###
-
-The majority of filesystems only mark the space as empty. With these filesystems, the undelete program looks at the file allocation list and copies the deleted file to another storage unit. If the files were copied to the same storage unit, then the user could lose other deleted files that are needed.
-
-Rarely do filesystems erase the allocation table entry. If a filesystem does, this is how an undelete program undeletes the file. The program searches the storage unit for file headers. All files have a specific string of code that is at the very beginning of the file. This is called a magic number. For example, the magic number of a compiled JAVA class is the hex number "CAFEBABE". So, an undelete program would find "CAFEBABE" and copy that file to another storage unit. Some undelete programs can look for a specific file type. The user may want a PDF, so the program searches for the hex magic number "25504446" which is the ASCII code for "%PDF". Other undelete programs search for all magic numbers. Then, the user can select which deleted files to recover.
-
-If a part of the file has been written over, then the whole file will be corrupted. The file can usually be recovered, but the contents will be useless. For instance, recovering a corrupted JPEG file will be pointless because the image viewer will not be able to generate an image from the file. So, the user has the file, but the file is useless.
-
-### Device Locations: ###
-
-Before we continue, here is some information that will aid in directing the undelete utilities to the correct storage unit. All devices are in the /dev/ folder. The name of each device (not the name that the admin gave each partition or device) that is given by the system follows a predictable scheme. The second partition on the first SATA hard-drive would be sda2. The first letter indicates the storage type, in this case SATA, but an "s" could also mean SCSI, FireWire, or USB. The second letter "d" means disk. The third letter indicates the device number, so an "a" would be the first SATA and a "b" would be the second. The number displays the partition. To name the whole device with all partitions type the letters without the number. For this example that would be sda. Other possible letters "h" as the first letter. This means PATA hard-drive (IDE). As some examples of this scheme, a user has a computer with one SATA hard-drive (sda). The drive has four partitions - sda1, sda2, sda3, and sda4. The user deletes the third one, but sda4 remains sda4 until sda4 is reformatted. The user then plugs in a usb memory card (sdb) with one partition - sdb1. The user then adds a IDE hard-drive with one partition - hda1. Next, the user adds a SCSI hard-drive - sdc1. Then, the user removes the USB memory card (sdb). Now, the SCSI remains sdc, but if the SCSI is removed and added back, it will be sdb. Even though other storage device existed, the IDE drive will have the "a" because it is the first IDE drive. IDE devices are numbered separately from SCSI, SATA, FireWire, and USB devices.
-
-### Recovery: ###
-
-Each undelete program has different abilities, features, and support for various filesystems. Below are some instructions for using TestDisk to recover files on a set of filesystems.
-
-**FAT16, FAT32, exFAT (FAT64), NTFS, and ext2/3/4:**
-
-TestDisk is an open-source, free program that works on Linux, *BSD, SunOS, Mac OS X, DOS, and Windows. TestDisk can be found here: [http://www.cgsecurity.org/wiki/TestDisk][1]. TestDisk can also be installed by typing "sudo apt-get install testdisk". TestDisk has many abilities, but this article is concerned with undeleting files.
-
-Open TestDisk in a terminal using root privileges by typing “sudo testdisk”.
-
-Now, the TestDisk command-line application will execute. The terminal appearance will change. TestDisk asks the user if it can keep logs. This is entirely up to the user. If the user is recovering files from the system storage, then do not keep a log. The choices are "Create", "Append", and "No Log". If the user wants a log, it is kept in that user's home folder.
-
-
-
-In the following screen, the storage devices are listed using the /dev/* method. For my system, the system's storage unit is /dev/sda. This means that my storage unit is a SATA hard-drive (sd) and it is the first hard-drive (a). The size of each storage unit is displayed in Gigabytes. Use the up and down arrows to select a storage device and hit enter.
-
-
-
-The next screen displays a list of partition table (also called partition map) types. Just as there is the file allocation table for files, there is a table for the partitions. Partitions are dividers on a storage device. For instance, on almost all Linux systems there is at least two partitions - EXT3/4 and Swap. Each partition table will be briefly described. TestDisk does not support all partition tables, so this is not a complete list.
-
-
-
-- **Intel** - This partition table is very common on Windows systems and many Linux systems. This table is also know as MBR.
-- **EFI GPT** - This is usually used with Linux systems. This partition map is most recommended for Linux because the concept of logical/extended partitions does not apply to GPT (GUID Partition Table) tables. This means that a Linux user can multiboot many forms of Linux with one Linux OS on each partition. There are other advantages to using GPT, but that is beyond this article.
-- **Humax** - Humax maps are used with device made by the South Korean company Humax.
-- **Mac** - The Apple Partition Map (APM) is used by Apple devices.
-- **None** - Some devices do not have a partition table. For instance, many Subor game consoles do not use a partition map. If a user tried to undelete a file on these devices thinking that the partition map was one of the other choices, the user will be confused by the fact that TestDisk does not find any filesystem or files.
-- **Sun** - The Sun partition table is used by Sun systems.
-- **Xbox** - The Xbox uses the Xbox partition map for its storage devices.
-
-If a user selects "Xbox" even though their system uses GPT, TestDisk will not be able to find a partition or filesystem. If it does, then it will guess incorrectly. (The image below displays the output when the incorrect partition type)
-
-
-
-Once the user picks the correct choice for their device, on the next screen, select "Advanced".
-
-
-
-Now, the user should see a list of all of their filesystems/partitions on the storage unit. If the user had chosen the wrong partition map, then here is where they will know if they made the incorrect selection. If there are no errors, highlight the partition that contains the deleted file by placing the text-based cursor on it. Use the left and right arrows to highlight "List" on the bottom of the terminal. Now, hit enter.
-
-
-
-A new screen is displayed with a list of files and folders. The whitish files are current files that are not deleted. The red files have been deleted. On the far right column is the files' names. The next column over to the left is the creation date of the file. One column over to the left again is the files' sizes in bytes. To the far left is a column with dashes, "d"s, "r"s, "w"s, and "x"s. These are the file permissions. A "d" indicates that the item is a directory. The rest of the permission syntax is irrelevant to this article. The item on the top of the file list titled "." means the current directory. The second object titled ".." means go up one directory, so a user can move up a directory by selecting this line. For an example, I will go into the directory "Xaiml_Dataset". The folder is nearly full of deleted files. I will undelete "computers.xaiml" by pressing "c" on the keyboard. I am now asked to select a destination directory. Of course, I will put it on another partition. I am in my home folder, and I press "c". It does not matter what folder is highlighted. The current folder is the destination directory. Now, I am back to the list of files. At the top of the screen is a message that says "Copy Done!". In my home folder is a folder called "Xaiml_Dataset", and inside is the Xaiml file. If I press "c" on more deleted files, they will be placed in the new folder without a****g me for a destination.
-
-
-
-
-
-
-
-When finished press "q" repeatedly until the normal terminal is seen. The folder "Xaiml_Dataset" can only be accessed by the root. To fix this, use root privileges to change the folder permissions and the contained files. After that, the files have been recovered and accessible to the user.
-
-### ReiserFS: ###
-
-To undelete a file from a ReiserFS filesystem, make a backup of all of the files on the partition because this method can cause the file to be lost if something goes wrong. Next, execute the following command where DEVICE is the device in the form sda2. Some files will be put in the lost+found directory and other will remain where they were before deletion.
-
- reiserfsck --rebuild-tree --scan-whole-partition /dev/DEVICE
-
-### Recover Deleted File that is Open in a Program: ###
-
-Assume a user accidentally deletes a file that a program has open. The file of the hard-drive was deleted, but the program is using a copy of the file that is on the RAM. Thankfully, there are two easy solutions.
-
-If the program has save capabilities like a text editor, the user can resave the file. Thus, the file editor will write the file to the hard-drive.
-
-Assume that this is an MP3 file in a music player. The music player cannot save the MP3 file. This task requires a little more time than the previous situation. Unfortunately, this method does not work on all systems and applications. To begin, type the following command.
-
- lsof -c smplayer | grep mp3
-
-This command LiSts all of the Open Files used by Smplayer. This list is piped (given) to grep which searches for mp3. The output looks like the following.
-
- smplayer 10037 collier mp3 169r 8,1 676376 1704294 /usr/bin/smplayer
-
-Now, type the following command to recover the file directly from the RAM (on Linux systems, /proc/ is the RAM) and copy it to a folder of choice. The "cp" is the copy command. The 10037 number comes from the process number given in the output. The 169 is the file descriptor shown in the output. The "~/Music/" is the destination directory. Lastly, "music.mp3" is the file name that the user wants for the file.
-
- cp /proc/10037/fd/169 ~/Music/music.mp3
-
-### Real Deletion: ###
-
-To make for sure that a file can never be recovered, use a command that "wipes" the hard-drive. Wiping the hard-drive means writing meaningless data to the disk. For example, many wiping programs write zeros, random letters, or random data to the hard-drive. No space is taken up or lost. The wiping program just overwrites the "empty space". If the storage unit is ever full of files with no free space remaining, then all of the previously deleted files will be gone.
-
-The purpose of wiping hard-drives is to make sure that private data is never seen. For illustration, a company may order new computers. The manager decides to sell the old computers. However, there is concern that the new owners may view company secrets or customer information like credit card numbers and addresses. Thankfully, a computer technician in the company can wipe the hard-drives before selling the old computers.
-
-To install secure-delete, a wiping program, type "sudo apt-get install secure-delete". This installs a set of four commands that make sure that deleted files are never recovered.
-
-- srm - permanently delete a file. Usage: srm -f ./secret_file.txt
-- sfill - wipe the free space. Usage: sfill -f /mount/point/of/partition
-- sswap - wipe swap space. Usage: sswap -f /dev/SWAP_DEVICE
-
-If computers were to truly delete a file selected for deletion, then more time would be required to perform the task. It is quick and easy to mark some space as free, but to make the file gone forever requires time. Wiping a storage unit, for instance, takes a few hours to complete (depending on storage size). Overall, the current system works well because even when a user empties the recycle bin, they still have another chance to change their mind.
-
---------------------------------------------------------------------------------
-
-via: http://www.linux.org/threads/undelete-files-on-linux-systems.4316/
-
-作者:[DevynCJohnson][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.linux.org/members/devyncjohnson.4843/
-[1]:http://www.cgsecurity.org/wiki/TestDisk
\ No newline at end of file
diff --git a/sources/tech/20141205 How to configure a syslog server with rsyslog on Linux.md b/sources/tech/20141205 How to configure a syslog server with rsyslog on Linux.md
deleted file mode 100644
index e55c028ecd..0000000000
--- a/sources/tech/20141205 How to configure a syslog server with rsyslog on Linux.md
+++ /dev/null
@@ -1,156 +0,0 @@
-translating by coloka...
-
-How to configure a syslog server with rsyslog on Linux
-================================================================================
-A syslog server represents a central log monitoring point on a network, to which all kinds of devices including Linux or Windows servers, routers, switches or any other hosts can send their logs over network. By setting up a syslog server, you can filter and consolidate logs from different hosts and devices into a single location, so that you can view and archive important log messages more easily.
-
-On most Linux distributions, **rsyslog** is the standard syslog daemon that comes pre-installed. Configured in a client/server architecture, **rsyslog** can play both roles; as a syslog server **rsyslog** can gather logs from other devices, and as a syslog client, **rsyslog** can transmit its internal logs to a remote syslog server.
-
-In this tutorial, we cover how to configure a centralized syslog server using **rsyslog** on Linux. Before we go into the details, it is instructive to go over syslog standard first.
-
-### Basic of Syslog Standard ###
-
-When logs are collected with syslog mechanism, three important things must be taken into consideration:
-
-- **Facility level**: what type of processes to monitor
-- **Severity (priority) level**: what type of log messages to collect
-- **Destination**: where to send or record log messages
-
-Let's take a look at how the configuration is defined in more detail.
-
-The facility levels define a way to categorize internal system processes. Some of the common standard facilities in Linux are:
-
-- **auth**: messages related to authentication (login)
-- **cron**: messages related to scheduled processes or applications
-- **daemon**: messages related to daemons (internal servers)
-- **kernel**: messages related to the kernel
-- **mail**: messages related to internal mail servers
-- **syslog**: messages related to the syslog daemon itself
-- **lpr**: messages related to print servers
-- **local0 - local7**: messages defined by user (local7 is usually used by Cisco and Windows servers)
-
-The severity (priority) levels are standardized, and defined by using standard abbreviation and an assigned number with number 7 being the highest level of all. These levels are:
-
-- emerg: Emergency - 0
-- alert: Alerts - 1
-- crit: Critical - 2
-- err: Errors - 3
-- warn: Warnings - 4
-- notice: Notification - 5
-- info: Information - 6
-- debug: Debugging - 7
-
-Finally, the destination statement enforces a syslog client to perform one of three following tasks: (1) save log messages on a local file, (2) route them to a remote syslog server over TCP/UDP, or (3) send them to stdout such as a console.
-
-In rsyslog, syslog configuration is structured based on the following schema.
-
- [facility-level].[severity-level] [destination]
-
-### Configure Rsyslog on Linux ###
-
-Now that we understand syslog, it's time to configure a Linux server as a central syslog server using rsyslog. We will also see how to configure a Windows based system as a syslog client to send internal logs to the syslog server.
-
-#### Step One: Initial System Requirements ####
-
-To set up a Linux host as a central log server, we need to create a separate /var partition, and allocate a large enough disk size or create a LVM special volume group. That way, the syslog server will be able to sustain the exponential growth of collected logs over time.
-
-#### Step Two: Enable Rsyslog Daemon ####
-
-rsyslog daemon comes pre-installed on modern Linux distributions, but is not enabled by default. To enable rsyslog daemon to receive external messages, edit its configuration file located in /etc/rsyslog.conf.
-
-Once the file is opened for editing, search and uncomment the below two lines by removing the # sign from the beginning of lines.
-
- $ModLoad imudp
- $UDPServerRun 514
-
-This will enable rsyslog daemon to receive log messages on UDP port 514. UDP is way faster than TCP, but does not provide reliability on data flow the same way as TCP does. If you need to reliable delivery, you can enable TCP by uncommenting the following lines.
-
- $ModLoad imtcp
- $InputTCPServerRun 514
-
-Note that both TCP and UDP can be set on the server simultaneously to listen on TCP/UDP connections.
-
-#### Step Three: Create a Template for Log Receipt ####
-
-In the next step we need to create a template for remote messages, and tell rsyslog daemon how to record messages received from other client machines.
-
-Open /etc/rsyslog.conf with a text editor, and append the following template before the GLOBAL DIRECTIVES block:
-
- $template RemoteLogs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log" *
- *.* ?RemoteLogs
- & ~
-
-This template needs a little explanation. The $template RemoteLogs directive ("RemoteLogs" string can be changed to any other descriptive name) forces rsyslog daemon to write log messages to separate local log files in /var/log/, where log file names are defined based on the hostname of the remote sending machine as well as the remote application that generated the logs. The second line ("*.* ?RemoteLogs") implies that we apply RemoteLogs template to all received logs.
-
-The "& ~" sign represents a redirect rule, and is used to tell rsyslog daemon to stop processing log messages further, and not write them locally. If this redirection is not used, all the remote messages would be also written on local log files besides the log files described above, which means they would practically be written twice. Another consequence of using this rule is that the syslog server's own log messages would only be written to dedicated files named after machine's hostname.
-
-If you want, you can direct log messages with a specific facility or severity level to this new template using the following schema.
-
- [facility-level].[severity-level] ?RemoteLogs
-
-For example:
-
-Direct all internal authentication messages of all priority levels to RemoteLogs template:
-
- authpriv.* ?RemoteLogs
-
-Direct informational messages generated by all system processes, except mail, authentication and cron messages to RemoteLogs template:
-
- *.info,mail.none,authpriv.none,cron.none ?RemoteLogs
-
-If we want all received messages from remote clients written to a single file named after their IP address, you can use the following template. We assign a new name "IpTemplate" to this template.
-
- $template IpTemplate,"/var/log/%FROMHOST-IP%.log"
- *.* ?IpTemplate
- & ~
-
-After we have enabled rsyslog daemon and edited its configuration file, we need to restart the daemon.
-
-On Debian, Ubuntu or CentOS/RHEL 6:
-
- $ sudo service rsyslog restart
-
-On Fedora or CentOS/RHEL 7:
-
- $ sudo systemctl restart rsyslog
-
-We can verify that rsyslog daemon is functional by using netstat command.
-
- $ sudo netstat -tulpn | grep rsyslog
-
-The output should look like the following in case rsyslog daemon listens on UDP port.
-
- udp 0 0 0.0.0.0:514 0.0.0.0:* 551/rsyslogd
- udp6 0 0 :::514 :::* 551/rsyslogd
-
-If rsyslog daemon is set up to listen on TCP connections, the output should look like this.
-
- tcp 0 0 0.0.0.0:514 0.0.0.0:* LISTEN 1891/rsyslogd
- tcp6 0 0 :::514 :::* LISTEN 1891/rsyslogd
-
-#### Send Windows Logs to a Remote Rsyslog Server ####
-
-To forward a Windows based client's log messages to our rsyslog server, we need a Windows syslog agent. While there are a multitude of syslog agents that can run on Windows, we can use [Datagram SyslogAgent][1], which is a freeware program.
-
-After downloading and installing the syslog agent, we need to configure it to run as a service. Specify the protocol though which it will send data, the IP address and port of a remote rsyslog server, and what type of event logs should be transmitted as follows.
-
-
-
-After we have set up all the configurations, we can start the service and watch the log files on the central rsyslog server using tailf command line utility.
-
-### Conclusion ###
-
-By creating a central rsyslog server that can collect log files of local or remote hosts, we can get a better idea on what is going on internally in their systems, and can debug their problems more easily should any of them become unresponsive or crash.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/configure-syslog-server-linux.html
-
-作者:[Caezsar M][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/caezsar
-[1]:http://www.syslogserver.com/download.html
\ No newline at end of file
diff --git a/sources/tech/20141219 What is good audio editing software on Linux.md b/sources/tech/20141219 What is good audio editing software on Linux.md
index d9228b4eda..ccc6a0883b 100644
--- a/sources/tech/20141219 What is good audio editing software on Linux.md
+++ b/sources/tech/20141219 What is good audio editing software on Linux.md
@@ -1,8 +1,7 @@
-Translating by ly0
-
-Linux下一些蛮不错的音频编辑软件
+What is good audio editing software on Linux
================================================================================
-无论你是一个业余的音乐家或者仅仅是一个上课撸教授音的学,你总是需要和录音打交道。如果你有很长的时间仅仅用Mac干这种事情,那么可以和这个过程说拜拜了,现在Linux也可以干同样的事情。简而言之,这里有一个简单但是不错的音频编辑软件列表,来满足你对不同任务和需求。
+
+Whether you are an amateur musician or just a student recording his professor, you need to edit and work with audio recordings. If for a long time such task was exclusively attributed to Macintosh, this time is over, and Linux now has what it takes to do the job. In short, here is a non-exhaustive list of good audio editing software, fit for different tasks and needs.
### 1. Audacity ###
diff --git a/sources/tech/20141226 Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM.md b/sources/tech/20141226 Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM.md
deleted file mode 100644
index 651952ec1d..0000000000
--- a/sources/tech/20141226 Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM.md
+++ /dev/null
@@ -1,265 +0,0 @@
-Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM
-================================================================================
-**TL;DR In a local, Vagrant-based environment HHVM lost, probably due to a bug; it’s still investigated with the help of the HHVM guys! However on a DigitalOcean 4GB box it beat even the latest build of PHP-NG!**
-
-
-
-**Update: Please take a look at the results at the end of the article! They reflect the power of HHVM better (after the JIT warmup), for some reason we cannot get these results with all setups though.
-
-The tests below were done in a Vagrant/VVV environment, the results are still interesting, it might be a bug in HHVM or the Vagrant setup that’s preventing it from kicking into high speed, we’re investigating the issue with the HHVM guys.**
-
-If you remember we [wrote an article a good couple of months ago][1] when WordPress 3.9 came out that HHVM was fully supported beginning with that release, and we were all happy about it. The initial benchmark results showed HHVM to be far more superior than the Zend engine that’s currently powering all PHP builds. Then the problems came:
-
-- HHVM can only be run as one user, which means less security (in shared environments)
-- HHVM does not restart itself after it crashes, and unfortunately it still does that quite often
-- HHVM uses a lot of memory right from the start, and yes, it per-request memory usage will be lower once you scale compared to PHP-FPM
-
-Obviously you have to compromise based on your (or rather your sites’) needs but is it worth it? How much of a performance gain can you expect by switching to HHVM?
-
-At Kinsta we really like to test everything new and generally optimize everything to provide the best environment to our clients. Today I finally took the time to set up a test environment and do some tests to compare a couple of different builds with a fresh out of the box WordPress install and one that has a bunch of content added plus runs WooCommerce! To measure the script running time I simply added the
-
-
-
-line before the /body tag of the footer.php’s.
-
-**Note:
-Previously this section contained benchmarks made with Vagrant/Virtualbox/Ubuntu14.04 however for some reason HHVM was really underperforming, probably due to a bug or a limitation of the virtualized environment. We feel that these test results do not reflect the reality so we re-run the tests on a cloud server and consider these valid.**
-
-Here are the exact setup details of the environment:
-
-- DigitalOcean 4GB droplet (2 CPU cores, 4GB RAM)
-- Ubuntu 14.04, MariaDB10
-- Test site: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
-- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
-
-**Without further ado, these were my test results, the lower the better, values in seconds:**
-
-### DigitalOcean 4GB droplet ###
-
-Seconds, 10 runs, lower the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-It looks like that PHP-NG achieves its peak performance after the first run! HHVM needs a couple more reloads, but their performance seems to be almost equal! I can’t wait until PHP-NG is merged into the master! :)
-
-Hits in a minute, higher the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-**PHP 5.5.15 OpCache Disabled**
-
-- Transactions: **236 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.03 secs
-- Data transferred: 2.40 MB
-- Response time: 2.47 secs
-- Transaction rate: 4.00 trans/sec
-- Throughput: 0.04 MB/sec
-- Concurrency: 9.87
-- Successful transactions: 236
-- Failed transactions: 0
-- Longest transaction: 4.44
-- Shortest transaction: 0.48
-
-**PHP 5.5.15 OpCache Enabled**
-
-- Transactions: **441 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.55 secs
-- Data transferred: 4.48 MB
-- Response time: 1.34 secs
-- Transaction rate: 7.41 trans/sec
-- Throughput: 0.08 MB/sec
-- Concurrency: 9.91
-- Successful transactions: 441
-- Failed transactions: 0
-- Longest transaction: 2.19
-- Shortest transaction: 0.64
-
-**PHP 5.6 RC2 OpCache Disabled**
-
-- Transactions: **207 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.87 secs
-- Data transferred: 2.10 MB
-- Response time: 2.80 secs
-- Transaction rate: 3.46 trans/sec
-- Throughput: 0.04 MB/sec
-- Concurrency: 9.68
-- Successful transactions: 207
-- Failed transactions: 0
-- Longest transaction: 3.65
-- Shortest transaction: 0.54
-
-**PHP 5.6 RC2 OpCache Enabled**
-
-- Transactions: **412 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.03 secs
-- Data transferred: 4.18 MB
-- Response time: 1.42 secs
-- Transaction rate: 6.98 trans/sec
-- Throughput: 0.07 MB/sec
-- Concurrency: 9.88
-- Successful transactions: 412
-- Failed transactions: 0
-- Longest transaction: 1.93
-- Shortest transaction: 0.34
-
-**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)**
-
-- Transactions: **955 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.69 secs
-- Data transferred: 9.18 MB
-- Response time: 0.62 secs
-- Transaction rate: 16.00 trans/sec
-- Throughput: 0.15 MB/sec
-- Concurrency: 9.94
-- Successful transactions: 955
-- Failed transactions: 0
-- Longest transaction: 0.85
-- Shortest transaction: 0.23
-
-**PHP-NG OpCache Enabled (built: Jul 29 2014 )**
-
-- Transactions: **849 hits**
-- Availability: 100.00 %
-- Elapsed time: 59.88 secs
-- Data transferred: 8.63 MB
-- Response time: 0.70 secs
-- Transaction rate: 14.18 trans/sec
-- Throughput: 0.14 MB/sec
-- Concurrency: 9.94
-- Successful transactions: 849
-- Failed transactions: 0
-- Longest transaction: 1.06
-- Shortest transaction: 0.13
-
-----------
-
-**Note:
-These are the previous test results, they’re faulty. I left them here for future reference but please do NOT consider these values a truthful representation!**
-
-Here are the exact setup details of the environment:
-
-- Apple MacBook Pro mid-2011 (Intel Core i7 2 GHz 4 cores, 4GB RAM, 256GB Ocz Vertex 3 MI)
-- Current Varying Vagrant Vagrants build with Ubuntu 14.04, nginx 1.6.x, mysql 5.5.x, etc.
-- Test site 1: WordPress 3.9.1 bare minimum
-- Test site 2: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
-- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
-
-**Default Theme, Default WordPress 3.9.1, PHP 5.5.9-1ubuntu4.3 (with OpCache 7.0.3)**
-
-**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Disabled) ###
-
-**Faulty results. Please read the note above**! Seconds, 10 runs, lower the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Enabled) ###
-
-**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-**Siege
-parameters: 10 concurrent users for 1 minute: siege -c 10 -b -t 1M**
-
-**Faulty results. Please read the note above!** Hits in a minute, higher the better.
-
-这里有一个canvas的数据,发布的时候需要截一个图
-
-**PHP5.5 OpCache Disabled (PHP 5.5.15-1+deb.sury.org~trusty+1)Faulty results. Please read the note above!**
-
-- Transactions: 35 hits
-- Availability: 100.00 %
-- Elapsed time: 59.04 secs
-- Data transferred: 2.03 MB
-- Response time: 14.56 secs
-- Transaction rate: 0.59 trans/sec
-- Throughput: 0.03 MB/sec
-- Concurrency: 8.63
-- Successful transactions: 35
-- Failed transactions: 0
-- Longest transaction: 18.73
-- Shortest transaction: 5.80
-
-**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)Faulty results. Please read the note above!**
-
-- Transactions: 44 hits
-- Availability: 100.00 %
-- Elapsed time: 59.53 secs
-- Data transferred: 0.42 MB
-- Response time: 12.00 secs
-- Transaction rate: 0.74 trans/sec
-- Throughput: 0.01 MB/sec
-- Concurrency: 8.87
-- Successful transactions: 44
-- Failed transactions: 0
-- Longest transaction: 13.40
-- Shortest transaction: 2.65
-
-**PHP5.5 OpCache Enabled (PHP 5.5.15-1+deb.sury.org~trusty+1 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
-
-- Transactions: 100 hits
-- Availability: 100.00 %
-- Elapsed time: 59.30 secs
-- Data transferred: 5.81 MB
-- Response time: 5.69 secs
-- Transaction rate: 1.69 trans/sec
-- Throughput: 0.10 MB/sec
-- Concurrency: 9.60
-- Successful transactions: 100
-- Failed transactions: 0
-- Longest transaction: 7.25
-- Shortest transaction: 2.82
-
-**PHP5.6 OpCache Enabled (PHP 5.6.0RC2 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
-
-- Transactions: 103 hits
-- Availability: 100.00 %
-- Elapsed time: 59.99 secs
-- Data transferred: 5.98 MB
-- Response time: 5.51 secs
-- Transaction rate: 1.72 trans/sec
-- Throughput: 0.10 MB/sec
-- Concurrency: 9.45
-- Successful transactions: 103
-- Failed transactions: 0
-- Longest transaction: 6.87
-- Shortest transaction: 2.52
-
-**PHP-NG OpCache Enabled (20140718-git-6cc487d)Faulty results. Please read the note above!**
-
-- Transactions: 124 hits
-- Availability: 100.00 %
-- Elapsed time: 59.32 secs
-- Data transferred: 7.19 MB
-- Response time: 4.58 secs
-- Transaction rate: 2.09 trans/sec
-- Throughput: 0.12 MB/sec
-- Concurrency: 9.57
-- Successful transactions: 124
-- Failed transactions: 0
-- Longest transaction: 6.86
-- Shortest transaction: 2.24
-
-**What do you think about this test? Did I miss something? What would you like to see in the next benchmarking article? Please leave your comment below!**
-
---------------------------------------------------------------------------------
-
-via: https://kinsta.com/blog/real-world-wordpress-benchmarks-with-php5-5-php5-6-php-ng-and-hhvm/
-
-作者:[Mark Gavalda][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://kinsta.com/blog/author/kinstadmin/
-[1]:https://kinsta.com/blog/hhvm-and-wordpress/
\ No newline at end of file
diff --git a/sources/tech/20141229 4 Steps to Setup Local Repository in Ubuntu using APT-mirror.md b/sources/tech/20141229 4 Steps to Setup Local Repository in Ubuntu using APT-mirror.md
deleted file mode 100644
index 121f496d6a..0000000000
--- a/sources/tech/20141229 4 Steps to Setup Local Repository in Ubuntu using APT-mirror.md
+++ /dev/null
@@ -1,126 +0,0 @@
-ideas4u is translating!
-4 Steps to Setup Local Repository in Ubuntu using APT-mirror
-================================================================================
-Today we will show you how to setup a local repository in your Ubuntu PC or Ubuntu Server straight from the official Ubuntu repository. There are a lot benefit of creating a local repository in your computer if you have a lot of computers to install software, security updates and fixes often in all systems, then having a local Ubuntu repository is an efficient way. Because all required packages are downloaded over the fast LAN connection from your local server, so that it will save your Internet bandwidth and reduces the annual cost of Internet..
-
-You can setup a local repository of Ubuntu in your local PC or server using many tools, but we'll featuring about APT-Mirror in this tutorial. Here, we'll be mirroring packages from the default mirror to our Local Server or PC and we'll need at least **120 GB** or more free space in your local or external hard drive. It can be configured through a **HTTP** or **FTP** server to share its software packages with local system clients.
-
-We'll need to install Apache Web Server and APT-Mirror to get our stuffs working out of the box. Here are the steps below to configure a working local repository:
-
-### 1. Installing Required Packages ###
-
-First of all, we are going to pull whole packages from the public repository of Ubuntu package server and save them in our local Ubuntu server hard disk.
-
-We'll first install a web server to host our local repository. We'll install Apache web server but you can install any web server you wish, web server are necessary for the http protocol. You can additionally install FTP servers like proftpd, vsftpd,etc if you need to configure for ftp protocols and Rsync for rsync protocols.
-
- $ sudo apt-get install apache2
-
-And then we'll need to install apt-mirror:
-
- $ sudo apt-get install apt-mirror
-
-
-
-**Note: As I have already mentioned that we'll need at least 120 GBs free space to get all the packages mirrored or download.**
-
-### 2. Configuring APT-Mirror ###
-
-Now create a directory on your harddisk to save all packages. For example, let us create a directory called “/linoxide”. We are going to save all packages in this directory:
-
- $ sudo mkdir /linoxide
-
-
-
-Now, open the file **/etc/apt/mirror.list** file
-
- $ sudo nano /etc/apt/mirror.list
-
-
-
-Copy the below lines of configuration to mirror.list and edit as your requirements.
-
- ############# config ##################
- #
- set base_path /linoxide
- #
- # set mirror_path $base_path/mirror
- # set skel_path $base_path/skel
- # set var_path $base_path/var
- # set cleanscript $var_path/clean.sh
- # set defaultarch
- # set postmirror_script $var_path/postmirror.sh
- # set run_postmirror 0
- set nthreads 20
- set _tilde 0
- #
- ############# end config ##############
-
- deb http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
- deb http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
- deb http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
- #deb http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
- #deb http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
-
- deb-src http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
- deb-src http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
- deb-src http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
- #deb-src http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
- #deb-src http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
-
- clean http://archive.ubuntu.com/ubuntu
-
-
-
-**Note: You can replace the above official mirror server url by the nearest one, you can get your nearest server by visiting the page [Ubuntu Mirror Server][1]. If you are not in hurry and can wait for the mirroring, you can go with the default official one.**
-
-Here, we are going to mirror package repository of the latest and greatest LTS release of Ubuntu ie. Ubuntu 14.04 LTS (Trusty Tahr) so, we have configured trusty. If you need to mirror of Saucy or other version of Ubuntu, please edit it as its codename.
-
-Now, we'll have to run apt-mirror which will now get/mirror all the packages in the repository.
-
- sudo apt-mirror
-
-It will take time to download all the packages from the Ubuntu Server which depends upon the connection speed and performance with respect to you and the mirror server. I have interrupted the download as I have already done that...
-
-
-
-### 3.Configuring Web Server ###
-
-To be able to access the repo from other computers you need a webserver. You can also do it via ftp but I choose to use a webserver as I mentioned in above step 1. So, we are now gonna configure Apache Server:
-
-We will create a symlink from our local repo's directory to a directory ubuntu in the hosting directory of Apache ie /var/www/ubuntu
-
- $ sudo ln -s /linoxide /var/www/ubuntu
- $ sudo service apache2 start
-
-
-
-The above command will allow us to browse our Mirrored Repo from our localhost ie http://127.0.0.1 by default.
-
-### 4. Configuring Client Side ###
-
-Finally, we need to add repository source in other computers which will fetch the packages and repository from our computer. To do that, we'll need to edit /etc/apt/sources.list and add the following lines.
-
- $ sudo nano /etc/apt/sources.list
-
-Add this line in /etc/apt/sources.list and save.
-
- deb http://192.168.0.100/ubuntu/ trusty main restricted universe
-
-**Note: here 192.168.0.100 is the LAN IP address of our server computer, you need to replace that with yours.**
-
- $ sudo apt-get update
-
-Finally, we are done. Now you can install the required packages using sudo apt-get install packagename from your local Ubuntu repository with high speed download and with low bandwidth.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/setup-local-repository-ubuntu/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:https://launchpad.net/ubuntu/+archivemirrors
diff --git a/sources/tech/20150104 How to set up a cross-platform backup server on Linux with BackupPC.md b/sources/tech/20150104 How to set up a cross-platform backup server on Linux with BackupPC.md
deleted file mode 100644
index 48df08fa3b..0000000000
--- a/sources/tech/20150104 How to set up a cross-platform backup server on Linux with BackupPC.md
+++ /dev/null
@@ -1,134 +0,0 @@
-How to set up a cross-platform backup server on Linux with BackupPC
-================================================================================
-Just in case you haven't been able to tell from my earlier posts on [backupninja][1] and [backup-manager][2], I am a big backup fan. When it comes to backup, I'd rather have too much than not enough, because if the need arises, you will be grateful that you took the time and effort to generate extra copies of your important data.
-
-In this post, I will introduce you to [BackupPC][3], a cross-platform backup server software which can perform pull backup of Linux, Windows and MacOS client hosts over network. BackupPC adds a number of features that make managing backups an almost fun thing to do.
-
-### Features of BackupPC ###
-
-BackupPC comes with a robust web interface that allows you to collect and manage backups of other remote client hosts in a centralized fashion. Using the web interface, you can examine logs and configuration files, start/cancel/schedule backups of other remote hosts, and visualize current status of backup tasks. You can also browse through archived files and restore individual files or entire jobs from backup archives very easily. To restore individual single files, you can download them from any previous backup directly from the web interface. As if this weren't enough, no special client-side software is needed for client hosts. On Windows clients, the native SMB protocol is used, whereas on *nix clients, you will use `rsync` or tar over SSH, RSH or NFS.
-
-### Installing BackupPC ###
-
-On Debian, Ubuntu and their derivatives, run the following command.
-
- # aptitude install backuppc
-
-On Fedora, use `yum` command. Note the case sensitive package name.
-
-On CentOS/RHEL 6, first enable [EPEL repository][4]. On CentOS/RHEL 7, enable [Nux Dextop][5] repository instead. Then go ahead with `yum` command:
-
- # yum install BackupPC
-
-As usual, both package management systems will take care of dependency resolution automatically. In addition, as part of the installation process, you may be asked to configure, or reconfigure the web server that will be used for the graphical user interface. The following screenshot is from a Debian system:
-
-
-
-Select your choice by pressing the space bar, and then move to Ok with the tab key and hit ENTER.
-
-You will then be presented with the following screen informing you that an administrative user account 'backuppc', along with its corresponding password (which can be changed later if desired), has been created to manage BackupPC. Note that both a HTTP user account and a regular Linux account of the same name 'backuppc' will be created with an identical password. The former is needed to access BackupPC's protected web interface, while the latter is needed to perform backup using rsync over SSH.
-
-
-
-You can change the default password for the HTTP user 'backuppc' with the following command:
-
- # htpasswd /path/to/hash/file backuppc
-
-As for a regular 'backuppc' [Linux][6] user account, use passwd command to change its default password.
-
- # passwd backuppc
-
-Note that the installation process creates the web and the program's configuration files automatically.
-
-### Launching BackupPC and Configuring Backups ###
-
-To start, open a browser window and point to http:///backuppc/. When prompted, enter the default HTTP user credentials that were supplied to you earlier. If the authentication succeeds, you will be taken to the main page of the web interface.
-
-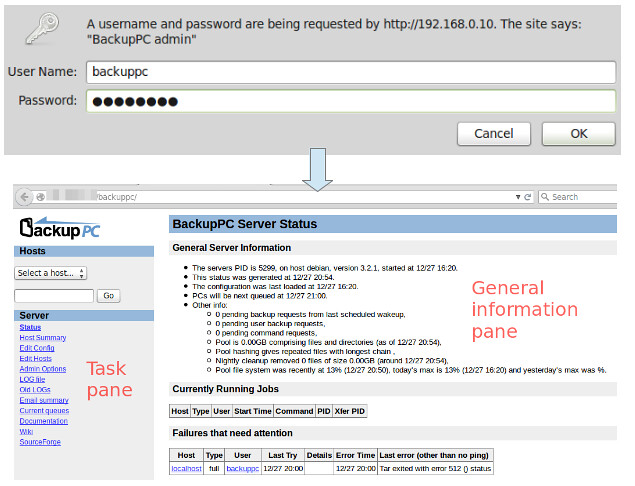
-
-Most likely the first thing that you will want to do is add a new client host to back up. Go to "Edit Hosts" in the Task pane. We will add two client hosts:
-
-- Host #1: CentOS 7 [IP 192.168.0.17]
-- Host #2: Windows 7 [IP 192.168.0.103]
-
-We will back up the CentOS host using rsync over SSH and the Windows host using SMB. Prior to performing the backup, we need to set up [key-based authentication][7] to our CentOS host and a shared folder in our Windows machine.
-
-Here are the instructions for setting up key-based authentication for a remote CentOS host. We create the 'backuppc' user's RSA key pair, and transfer its public key to the root account of the CentOS host.
-
- # usermod -s /bin/bash backuppc
- # su - backuppc
- # ssh-keygen -t rsa
- # ssh-copy-id root@192.168.0.17
-
-When prompted, type yes and enter root's password for 192.168.0.17.
-
-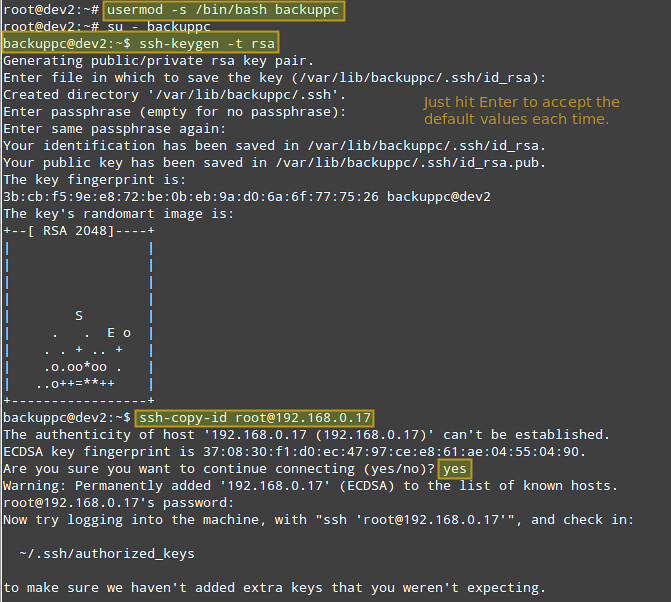
-
-You will need root access for a remote CentOS host to grant write access to all its file system in case of restoring a backup of files or directories owned by root.
-
-Once the CentOS and Windows hosts are ready, add them to BackupPC using the web interface:
-
-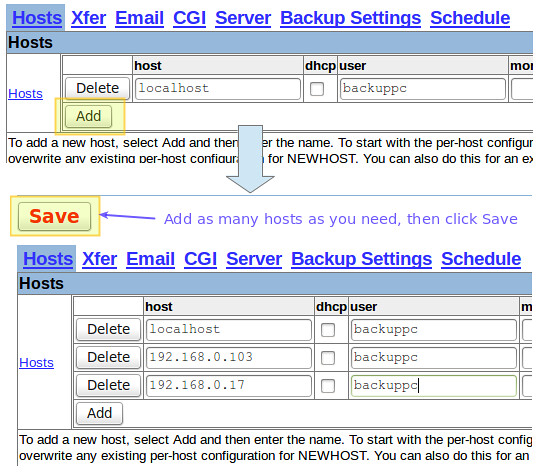
-
-The next step consists of modifying each host's backup settings:
-
-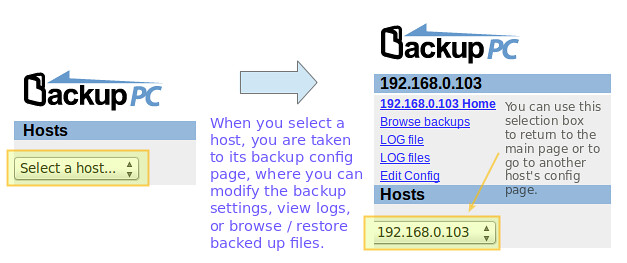
-
-The following image shows the configuration for the backup of the Windows machine:
-
-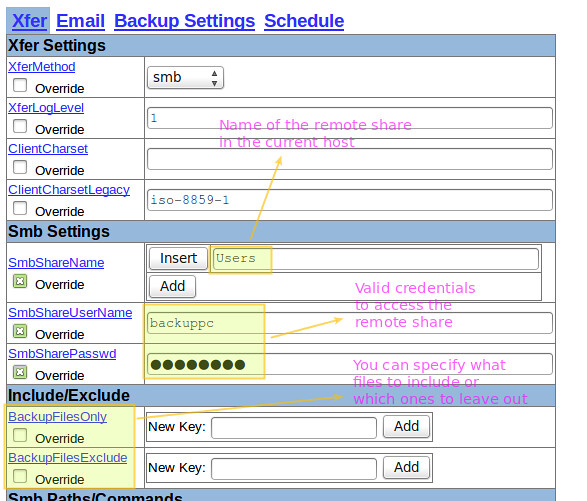
-
-And the following screenshot shows the settings for the backup of the CentOS box:
-
-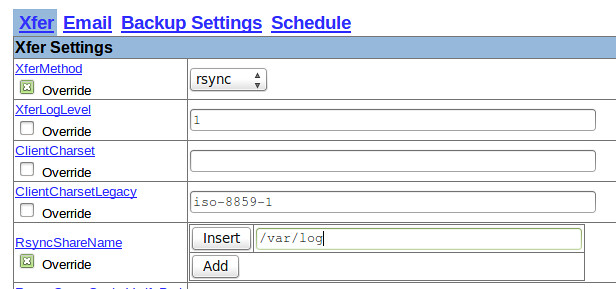
-
-### Starting a Backup ###
-
-To start each backup, go to each host's settings, and then click "Start Full Backup":
-
-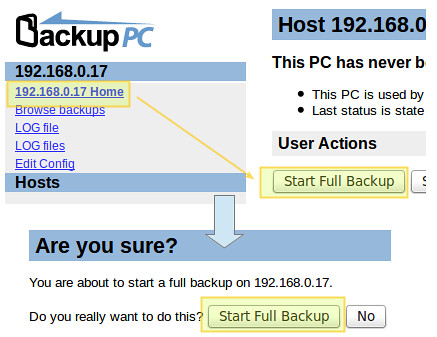
-
-At any time, you can view the status of the process by clicking on the host's home as shown in the image above. If it fails for some reason, a link to a page with the error message(s) will appear in the host menu as well. When a backup completes successfully, a directory with the host's name or IP address is created under /var/lib/backuppc/pc in the server:
-
-
-
-Feel free to browse those directories for the files from the command line, but there is an easier way to look for those files and restore them.
-
-### Restoring Backup ###
-
-To view the files that have been saved, go to "Browse backups" under each host's main menu. You can visualize the directories and files at a glance, and select those that you want to restore. Alternatively, you can click on files to open them with the default program, or right click and choose Save link as to download it to the machine where you're working at the time:
-
-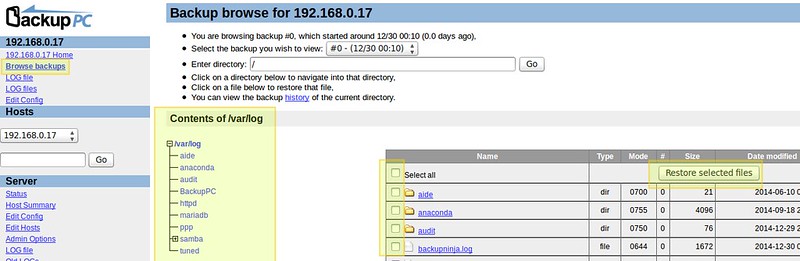
-
-If you want, you can download a zip or tar file containing the backup's contents:
-
-
-
-or just restore the file(s):
-
-
-
-### Conclusion ###
-
-There is a saying that goes, "the simpler, the better", and that is just what BackupPC has to offer. In BackupPC, you will not only find a backup tool but also a very versatile interface to manage your backups of several operating systems without needing any client-side application. I believe that's more than reason enough for you to give it at least a try.
-
-Feel free to leave your comments and questions, if you have any, using the form below. I am always happy to hear what readers have to say!
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/backuppc-cross-platform-backup-server-linux.html
-
-作者:[Gabriel Cánepa][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/gabriel
-[1]:http://xmodulo.com/backup-debian-system-backupninja.html
-[2]:http://xmodulo.com/linux-backup-manager.html
-[3]:http://backuppc.sourceforge.net/
-[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
-[5]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
-[6]:http://xmodulo.com/recommend/linuxguide
-[7]:http://xmodulo.com/how-to-enable-ssh-login-without.html
\ No newline at end of file
diff --git a/sources/tech/20150108 Interface (NICs) Bonding in Linux using nmcli.md b/sources/tech/20150108 Interface (NICs) Bonding in Linux using nmcli.md
deleted file mode 100644
index fa02f19ce6..0000000000
--- a/sources/tech/20150108 Interface (NICs) Bonding in Linux using nmcli.md
+++ /dev/null
@@ -1,136 +0,0 @@
-Interface (NICs) Bonding in Linux using nmcli
-================================================================================
-Today, we'll learn how to perform Interface (NICs) bonding in our CentOS 7.x using nmcli (Network Manager Command Line Interface).
-
-NICs (Interfaces) bonding is a method for linking **NICs** together logically to allow fail-over or higher throughput. One of the ways to increase the network availability of a server is by using multiple network interfaces. The Linux bonding driver provides a method for aggregating multiple network interfaces into a single logical bonded interface. It is a new implementation that does not affect the older bonding driver in linux kernel; it offers an alternate implementation.
-
-**NIC bonding is done to provide two main benefits for us:**
-
-1. **High bandwidth**
-1. **Redundancy/resilience**
-
-Now lets configure NICs bonding in CentOS 7. We'll need to decide which interfaces that we would like to configure a Team interface.
-
-run **ip link** command to check the available interface in the system.
-
- $ ip link
-
-
-
-Here we are using **eno16777736** and **eno33554960** NICs to create a team interface in **activebackup** mode.
-
-Use **nmcli** command to create a connection for the network team interface,with the following syntax.
-
- # nmcli con add type team con-name CNAME ifname INAME [config JSON]
-
-Where **CNAME** will be the name used to refer the connection ,**INAME** will be the interface name and **JSON** (JavaScript Object Notation) specifies the runner to be used.**JSON** has the following syntax:
-
- '{"runner":{"name":"METHOD"}}'
-
-where **METHOD** is one of the following: **broadcast, activebackup, roundrobin, loadbalance** or **lacp**.
-
-### 1. Creating Team Interface ###
-
-Now let us create the team interface. here is the command we used to create the team interface.
-
- # nmcli con add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'
-
-
-
-run **# nmcli con show** command to verify the team configuration.
-
- # nmcli con show
-
-
-
-### 2. Adding Slave Devices ###
-
-Now lets add the slave devices to the master team0. here is the syntax for adding the slave devices.
-
- # nmcli con add type team-slave con-name CNAME ifname INAME master TEAM
-
-Here we are adding **eno16777736** and **eno33554960** as slave devices for **team0** interface.
-
- # nmcli con add type team-slave con-name team0-port1 ifname eno16777736 master team0
-
- # nmcli con add type team-slave con-name team0-port2 ifname eno33554960 master team0
-
-
-
-Verify the connection configuration using **#nmcli con show** again. now we could see the slave configuration.
-
- #nmcli con show
-
-
-
-### 3. Assigning IP Address ###
-
-All the above command will create the required configuration files under **/etc/sysconfig/network-scripts/**.
-
-Lets assign an IP address to this team0 interface and enable the connection now. Here is the command to perform the IP assignment.
-
- # nmcli con mod team0 ipv4.addresses "192.168.1.24/24 192.168.1.1"
- # nmcli con mod team0 ipv4.method manual
- # nmcli con up team0
-
-
-
-### 4. Verifying the Bonding ###
-
-Verify the IP address information in **#ip add show team0** command.
-
- #ip add show team0
-
-
-
-Now lets check the **activebackup** configuration functionality using the **teamdctl** command.
-
- # teamdctl team0 state
-
-
-
-Now lets disconnect the active port and check the state again. to confirm whether the active backup configuration is working as expected.
-
- # nmcli dev dis eno33554960
-
-
-
-disconnected the active port and now check the state again using **#teamdctl team0 state**.
-
- # teamdctl team0 state
-
-
-
-Yes its working cool !! we will connect the disconnected connection back to team0 using the following command.
-
- #nmcli dev con eno33554960
-
-
-
-We have one more command called **teamnl** let us show some options with **teamnl** command.
-
-to check the ports in team0 run the following command.
-
- # teamnl team0 ports
-
-
-
-Display currently active port of **team0**.
-
- # teamnl team0 getoption activeport
-
-
-
-Hurray, we have successfully configured NICs bonding :-) Please share feedback if any.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-command/interface-nics-bonding-linux/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
\ No newline at end of file
diff --git a/sources/tech/20150112 What are useful command-line network monitors on Linux.md b/sources/tech/20150112 What are useful command-line network monitors on Linux.md
deleted file mode 100644
index f17e45cbf4..0000000000
--- a/sources/tech/20150112 What are useful command-line network monitors on Linux.md
+++ /dev/null
@@ -1,135 +0,0 @@
-What are useful command-line network monitors on Linux
-================================================================================
-Network monitoring is a critical IT function for businesses of all sizes. The goal of network monitoring can vary. For example, the monitoring activity can be part of long-term network provisioning, security protection, performance troubleshooting, network usage accounting, and so on. Depending on its goal, network monitoring is done in many different ways, such as performing packet-level sniffing, collecting flow-level statistics, actively injecting probes into the network, parsing server logs, etc.
-
-While there are many dedicated network monitoring systems capable of 24/7/365 monitoring, you can also leverage command-line network monitors in certain situations, where a dedicated monitor is an overkill. If you are a system admin, you are expected to have hands-on experience with some of well known CLI network monitors. Here is a list of **popular and useful command-line network monitors on Linux**.
-
-### Packet-Level Sniffing ###
-
-In this category, monitoring tools capture individual packets on the wire, dissect their content, and display decoded packet content or packet-level statistics. These tools conduct network monitoring from the lowest level, and as such, can possibly do the most fine-grained monitoring at the cost of network I/O and analysis efforts.
-
-1. **dhcpdump**: a comman-line DHCP traffic sniffer capturing DHCP request/response traffic, and displays dissected DHCP protocol messages in a human-friendly format. It is useful when you are troubleshooting DHCP related issues.
-
-2. **[dsniff][1]**: a collection of command-line based sniffing, spoofing and hijacking tools designed for network auditing and penetration testing. They can sniff various information such as passwords, NSF traffic, email messages, website URLs, and so on.
-
-3. **[httpry][2]**: an HTTP packet sniffer which captures and decode HTTP requests and response packets, and display them in a human-readable format.
-
-4. **IPTraf**: a console-based network statistics viewer. It displays packet-level, connection-level, interface-level, protocol-level packet/byte counters in real-time. Packet capturing can be controlled by protocol filters, and its operation is full menu-driven.
-
-
-
-5. **[mysql-sniffer][3]**: a packet sniffer which captures and decodes packets associated with MySQL queries. It displays the most frequent or all queries in a human-readable format.
-
-6. **[ngrep][4]**: grep over network packets. It can capture live packets, and match (filtered) packets against regular expressions or hexadecimal expressions. It is useful for detecting and storing any anomalous traffic, or for sniffing particular patterns of information from live traffic.
-
-7. **[p0f][5]**: a passive fingerprinting tool which, based on packet sniffing, reliably identifies operating systems, NAT or proxy settings, network link types and various other properites associated with an active TCP connection.
-
-8. **pktstat**: a command-line tool which analyzes live packets to display connection-level bandwidth usages as well as descriptive information of protocols involved (e.g., HTTP GET/POST, FTP, X11).
-
-
-
-9. **Snort**: an intrusion detection and prevention tool which can detect/prevent a variety of backdoor, botnets, phishing, spyware attacks from live traffic based on rule-driven protocol analysis and content matching.
-
-10. **tcpdump**: a command-line packet sniffer which is capable of capturing nework packets on the wire based on filter expressions, dissect the packets, and dump the packet content for packet-level analysis. It is widely used for any kinds of networking related troubleshooting, network application debugging, or [security][6] monitoring.
-
-11. **tshark**: a command-line packet sniffing tool that comes with Wireshark GUI program. It can capture and decode live packets on the wire, and show decoded packet content in a human-friendly fashion.
-
-### Flow-/Process-/Interface-Level Monitoring ###
-
-In this category, network monitoring is done by classifying network traffic into flows, associated processes or interfaces, and collecting per-flow, per-process or per-interface statistics. Source of information can be libpcap packet capture library or sysfs kernel virtual filesystem. Monitoring overhead of these tools is low, but packet-level inspection capabilities are missing.
-
-12. **bmon**: a console-based bandwidth monitoring tool which shows various per-interface information, including not-only aggregate/average RX/TX statistics, but also a historical view of bandwidth usage.
-
-
-
-13. **[iftop][7]**: a bandwidth usage monitoring tool that can shows bandwidth usage for individual network connections in real time. It comes with ncurses-based interface to visualize bandwidth usage of all connections in a sorted order. It is useful for monitoring which connections are consuming the most bandwidth.
-
-14. **nethogs**: a process monitoring tool which offers a real-time view of upload/download bandwidth usage of individual processes or programs in an ncurses-based interface. This is useful for detecting bandwidth hogging processes.
-
-15. **netstat**: a command-line tool that shows various statistics and properties of the networking stack, such as open TCP/UDP connections, network interface RX/TX statistics, routing tables, protocol/socket statistics. It is useful when you diagnose performance and resource usage related problems of the networking stack.
-
-16. **[speedometer][8]**: a console-based traffic monitor which visualizes the historical trend of an interface's RX/TX bandwidth usage with ncurses-drawn bar charts.
-
-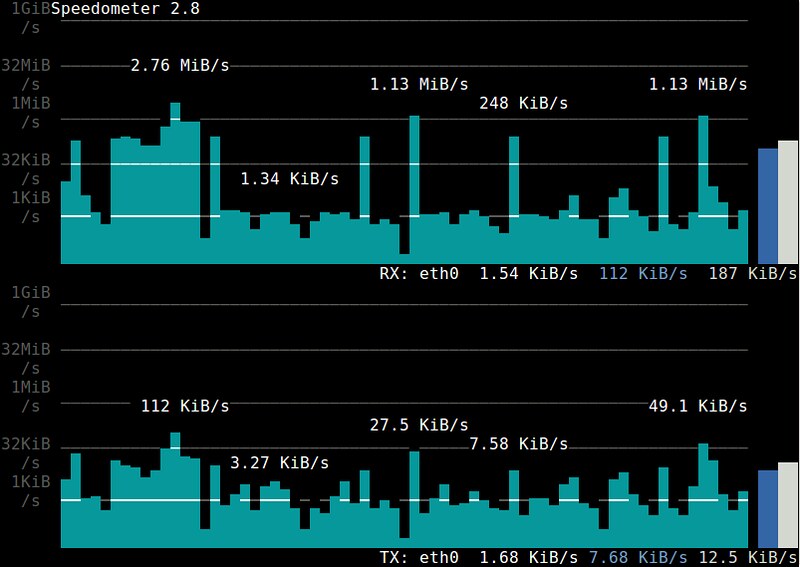
-
-17. **[sysdig][9]**: a comprehensive system-level debugging tool with a unified interface for investigating different Linux subsystems. Its network monitoring module is capable of monitoring, either online or offline, various per-process/per-host networking statistics such as bandwidth usage, number of connections/requests, etc.
-
-18. **tcptrack**: a TCP connection monitoring tool which displays information of active TCP connections, including source/destination IP addresses/ports, TCP state, and bandwidth usage.
-
-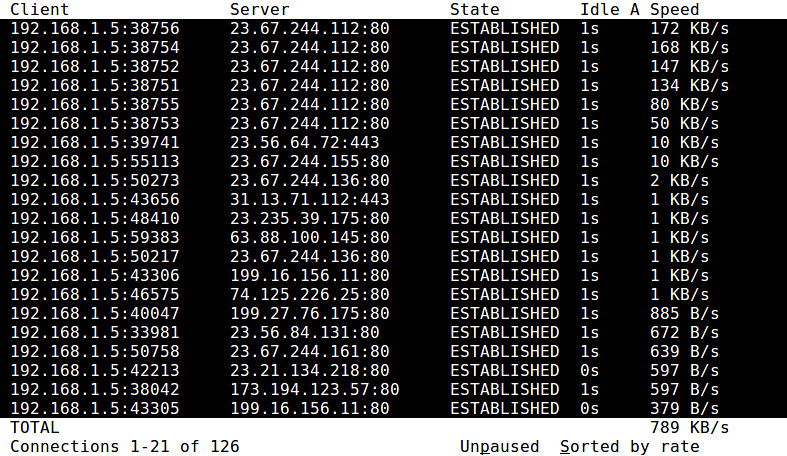
-
-19. **vnStat**: a command-line traffic monitor which maintains a historical view of RX/TX bandwidh usage (e.g., current, daily, monthly) on a per-interface basis. Running as a background daemon, it collects and stores interface statistics on bandwidth rate and total bytes transferred.
-
-### Active Network Monitoring ###
-
-Unlike passive monitoring tools presented so far, tools in this category perform network monitoring by actively "injecting" probes into the network and collecting corresponding responses. Monitoring targets include routing path, available bandwidth, loss rates, delay, jitter, system settings or vulnerabilities, and so on.
-
-20. **[dnsyo][10]**: a DNS monitoring tool which can conduct DNS lookup from open resolvers scattered across more than 1,500 different networks. It is useful when you check DNS propagation or troubleshoot DNS configuration.
-
-21. **[iperf][11]**: a TCP/UDP bandwidth measurement utility which can measure maximum available bandwidth between two end points. It measures available bandwidth by having two hosts pump out TCP/UDP probe traffic between them either unidirectionally or bi-directionally. It is useful when you test the network capacity, or tune the parameters of network stack. A variant called [netperf][12] exists with more features and better statistics.
-
-22. **[netcat][13]/socat**: versatile network debugging tools capable of reading from, writing to, or listen on TCP/UDP sockets. They are often used alongside with other programs or scripts for backend network transfer or port listening.
-
-23. **nmap**: a command-line port scanning and network discovery utility. It relies on a number of TCP/UDP based scanning techniques to detect open ports, live hosts, or existing operating systems on the local network. It is useful when you audit local hosts for vulnerabilities or build a host map for maintenance purpose. [zmap][14] is an alernative scanning tool with Internet-wide scanning capability.
-
-24. ping: a network testing tool which works by exchaning ICMP echo and reply packets with a remote host. It is useful when you measure round-trip-time (RTT) delay and loss rate of a routing path, as well as test the status or firewall rules of a remote system. Variations of ping exist with fancier interface (e.g., [noping][15]), multi-protocol support (e.g., [hping][16]) or parallel probing capability (e.g., [fping][17]).
-
-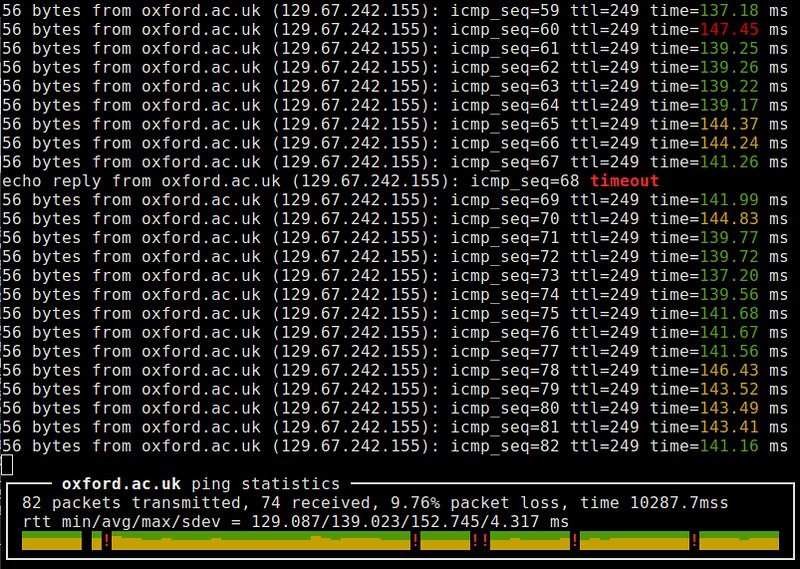
-
-25. **[sprobe][18]**: a command-line tool that heuristically infers the bottleneck bandwidth between a local host and any arbitrary remote IP address. It uses TCP three-way handshake tricks to estimate the bottleneck bandwidth. It is useful when troubleshooting wide-area network performance and routing related problems.
-
-26. **traceroute**: a network discovery tool which reveals a layer-3 routing/forwarding path from a local host to a remote host. It works by sending TTL-limited probe packets and collecting ICMP responses from intermediate routers. It is useful when troubleshooting slow network connections or routing related problems. Variations of traceroute exist with better RTT statistics (e.g., [mtr][19]).
-
-### Application Log Parsing ###
-
-In this category, network monitoring is targeted at a specific server application (e.g., web server or database server). Network traffic generated or consumed by a server application is monitored by analyzing its log file. Unlike network-level monitors presented in earlier categories, tools in this category can analyze and monitor network traffic from application-level.
-
-27. **[GoAccess][20]**: a console-based interactive viewer for Apache and Nginx web server traffic. Based on access log analysis, it presents a real-time statistics of a number of metrics including daily visits, top requests, client operating systems, client locations, client browsers, in a scrollable view.
-
-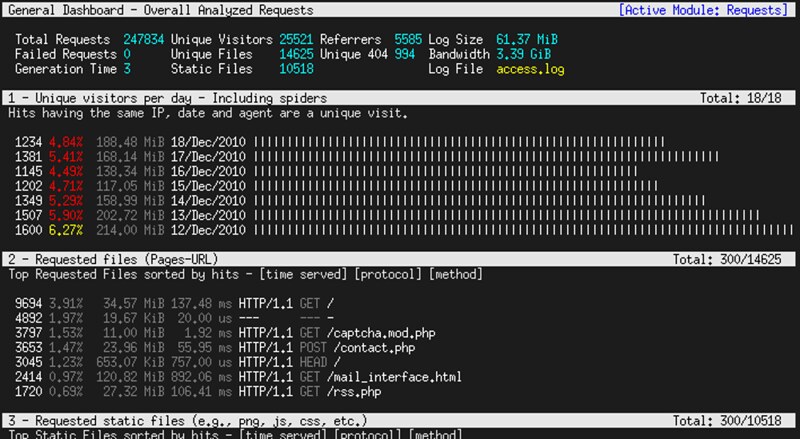
-
-28. **[mtop][21]**: a command-line MySQL/MariaDB server moniter which visualizes the most expensive queries and current database server load. It is useful when you optimize MySQL server performance and tune server configurations.
-
-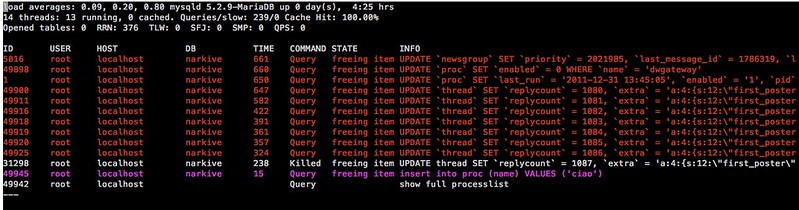
-
-29. **[ngxtop][22]**: a traffic monitoring tool for Nginx and Apache web server, which visualizes web server traffic in a top-like interface. It works by parsing a web server's access log file and collecting traffic statistics for individual destinations or requests.
-
-### Conclusion ###
-
-In this article, I presented a wide variety of command-line network monitoring tools, ranging from the lowest packet-level monitors to the highest application-level network monitors. Knowing which tool does what is one thing, and choosing which tool to use is another, as any single tool cannot be a universal solution for your every need. A good system admin should be able to decide which tool is right for the circumstance at hand. Hopefully the list helps with that.
-
-You are always welcome to improve the list with your comment!
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
-
-作者:[Dan Nanni][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/nanni
-[1]:http://www.monkey.org/~dugsong/dsniff/
-[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
-[3]:https://github.com/zorkian/mysql-sniffer
-[4]:http://ngrep.sourceforge.net/
-[5]:http://lcamtuf.coredump.cx/p0f3/
-[6]:http://xmodulo.com/recommend/firewallbook
-[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
-[8]:https://excess.org/speedometer/
-[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
-[10]:http://xmodulo.com/check-dns-propagation-linux.html
-[11]:https://iperf.fr/
-[12]:http://www.netperf.org/netperf/
-[13]:http://xmodulo.com/useful-netcat-examples-linux.html
-[14]:https://zmap.io/
-[15]:http://noping.cc/
-[16]:http://www.hping.org/
-[17]:http://fping.org/
-[18]:http://sprobe.cs.washington.edu/
-[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
-[20]:http://goaccess.io/
-[21]:http://mtop.sourceforge.net/
-[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
\ No newline at end of file
diff --git a/sources/tech/20150114 How to Configure Chroot Environment in Ubuntu 14.04.md b/sources/tech/20150114 How to Configure Chroot Environment in Ubuntu 14.04.md
deleted file mode 100644
index 540789d367..0000000000
--- a/sources/tech/20150114 How to Configure Chroot Environment in Ubuntu 14.04.md
+++ /dev/null
@@ -1,147 +0,0 @@
-[bazz2222222]
-How to Configure Chroot Environment in Ubuntu 14.04
-================================================================================
-There are many instances when you may wish to isolate certain applications, user, or environments within a Linux system. Different operating systems have different methods of achieving isolation, and in Linux, a classic way is through a `chroot` environment.
-
-In this guide, we'll show you step wise on how to setup an isolated environment using chroot in order to create a barrier between your regular operating system and a contained environment. This is mainly useful for testing purposes. We will teach you the steps on an **Ubuntu 14.04** VPS instance.
-
-Most system administrators will benefit from knowing how to accomplish a quick and easy chroot environment and it is a valuable skill to have.
-
-### The chroot environment ###
-
-A chroot environment is an operating system call that will change the root location temporarily to a new folder. Typically, the operating system's conception of the root directory is the actual root located at "/". However, with `chroot`, you can specify another directory to serve as the top-level directory for the duration of a chroot.
-
-Any applications that are run from within the `chroot` will be unable to see the rest of the operating system in principle.
-
-#### Advantages of Chroot Environment ####
-
-> - Test applications without the risk of compromising the entire host system.
->
-> - From the security point of view, whatever happens in the chroot environment won't affect the host system (not even under root user).
->
-> - A different operating system running in the same hardware.
-
-For instance, it allows you to build, install, and test software in an environment that is separated from your normal operating system. It could also be used as a method of **running 32-bit applications in a 64-bit environment**.
-
-But while chroot environments will certainly make additional work for an unprivileged user, they should be considered a hardening feature instead of a security feature, meaning that they attempt to reduce the number of attack vectors instead of creating a full solution. If you need full isolation, consider a more complete solution, such as Linux containers, Docker, vservers, etc.
-
-### Debootstrap and Schroot ###
-
-The necessary packages to setup the chroot environment are **debootstrap** and **schroot**, which are available in the ubuntu repository. The schroot command is used to setup the chroot environment.
-
-**Debootstrap** allows you to install a new fresh copy of any Debian (or debian-based) system from a repository in a directory with all the basic commands and binaries needed to run a basic instance of the operating system.
-
-The **schroot** allows access to chroots for normal users using the same mechanism, but with permissions checking and allowing additional automated setup of the chroot environment, such as mounting additional filesystems and other configuration tasks.
-
-These are the steps to implement this functionality in Ubuntu 14.04 LTS:
-
-### 1. Installing the Packages ###
-
-Firstly, We're gonna install debootstrap and schroot in our host Ubuntu 14.04 LTS.
-
- $ sudo apt-get install debootstrap
- $ sudo apt-get install schroot
-
-### 2. Configuring Schroot ###
-
-Now that we have the appropriate tools, we just need to specify a directory that we want to use as our chroot environment. We will create a directory called linoxide in our root directory to setup chroot there:
-
- sudo mkdir /linoxide
-
-We have to configure schroot to suit our needs in the configuration file .we will modify the schroot configuration file with the information we require to get configured.
-
- sudo nano /etc/schroot/schroot.conf
-
-We are on an Ubuntu 14.04 LTS (Trusty Tahr) system currently, but let's say that we want to test out some packages available on Ubuntu 13.10, code named "Saucy Salamander". We can do that by creating an entry that looks like this:
-
- [saucy]
- description=Ubuntu Saucy
- location=/linoxide
- priority=3
- users=arun
- root-groups=root
-
-
-
-Modify the values of the configuration parameters in the above example to fit your system:
-
-### 3. Installing 32 bit Ubuntu with debootstrap ###
-
-Debootstrap downloads and installs a minimal operating system inside your **chroot environment**. You can install any debian-based distro of your choice, as long as you have a repository available.
-
-Above, we placed the chroot environment under the directory **/linoxide** and this is the root directory of the chroot environment. So we'll need to run debootstrap inside that directory which we have already created:
-
- cd /linoxide
- sudo debootstrap --variant=buildd --arch amd64 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
- sudo chroot /linoxide /debootstrap/debootstrap --second-stage
-
-You can replace amd64 in --arch as i386 or other bit OS you wanna setup available in the repository. You can replace the mirror http://archive.ubuntu.com/ubuntu/ above as the one closest, you can get the closest one from the official [Ubuntu Mirror Page][1].
-
-**Note: You will need to add --foreign above 3rd line command if you choose to setup i386 bit OS choot in your 64 bit Host Ubuntu as:**
-
- sudo debootstrap --variant=buildd --foreign --arch i386 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
-
-It takes some time (depending on your bandwidth) to download, install and configure the complete system. It takes about 500 MBs for a minimal installation.
-
-### 4. Finallizing the chroot environment ###
-
-After the system is installed, we'll need to do some final configurations to make sure the system functions correctly. First, we'll want to make sure our host `fstab` is aware of some pseudo-systems in our guest.
-
- sudo nano /etc/fstab
-
-Add the below lines like these to the bottom of your fstab:
-
- proc /linoxide/proc proc defaults 0 0
- sysfs /linoxide/sys sysfs defaults 0 0
-
-Save and close the file.
-
-Now, we're going to need to mount these filesystems within our guest:
-
- $ sudo mount proc /linoxide/proc -t proc
- $sudo mount sysfs /linoxide/sys -t sysfs
-
-We'll also want to copy our /etc/hosts file so that we will have access to the correct network information:
-
- $ sudo cp /etc/hosts /linoxide/etc/hosts
-
-Finally, You can list the available chroot environments using the schroot command.
-
- $ schroot -l
-
-We can enter the chroot environment through a command like this:
-
- $ sudo chroot /linoxide/ /bin/bash
-
-You can test the chroot environment by checking the version of distributions installed.
-
- # lsb_release -a
- # uname -a
-
-To finish this tutorial, in order to run a graphic application from the chroot, you have to export the DISPLAY environment variable.
-
- $ DISPLAY=:0.0 ./apps
-
-Here, we have successfully installed Chrooted Ubuntu 13.10(Saucy Salamander) in your host Ubuntu 14.04 LTS (Trusty Tahr).
-
-You can exit chroot environment successfully by running the commands below:
-
- # exit
-
-Afterwards, we need to unmount our proc and sys filesystems:
-
- $ sudo umount /test/proc
- $ sudo umount /test/sys
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:https://launchpad.net/ubuntu/+archivemirrors
diff --git a/sources/tech/20150115 Get back your privacy and control.md b/sources/tech/20150115 Get back your privacy and control.md
deleted file mode 100644
index 915e3b073e..0000000000
--- a/sources/tech/20150115 Get back your privacy and control.md
+++ /dev/null
@@ -1,1114 +0,0 @@
-zpl1025
-Get back your privacy and control over your data in just a few hours: build your own cloud for you and your friends
-================================================================================
-40'000+ searches over 8 years! That's my Google Search history. How about yours? (you can find out for yourself [here][1]) With so many data points across such a long time, Google has a very precise idea of what you've been interested in, what's been on your mind, what you are worried about, and how that all changed over the years since you first got that Google account.
-
-### Some of the most personal pieces of your identity are stored on servers around the world beyond your control ###
-
-Let's say you've been a Gmail user between 2006 and 2013 like me, meaning you received 30'000+ emails and wrote about 5000 emails over that 7 year period. Some of the emails you sent or received are very personal, maybe so personal that you probably wouldn't like even some family members or close friends to go through them systematically. Maybe you also drafted a few emails that you never sent because you changed your mind at the last minute. But even if you never sent them, these emails are still stored somewhere on a server. As a result, it's fair to say that Google servers know more about your personal life than your closest friends or your family.
-
-Statistically, it's a safe bet to consider that you've got a smartphone. You can barely use the phone without using the contacts app which stores your contacts in Google Contact on Google servers by default. So not only does Google know about your emails, but also about your offline contacts: who you like to call, who calls you, whom you text, and what you text them about. You don't have to take my word for it, you can verify for yourself by taking a look at the permissions you gave apps such as the Google Play Service to read the list of people that called you and the SMS you got. Do you also use the calendar app that comes with your phone? Unless you explicitly opted out while setting up your calendar, this means that Google knows precisely what you're up to, at every time of the day, day after day, year after year. The same applies if you chose an iPhone over an Android phone, except Apple gets to know about your correspondance, contacts and schedule instead of Google.
-
-Do you also take great care to keep the contacts in your directory up-to-date, updating your friend's, colleagues's and and family's email addresses and phone numbers when they move to a new job or change carrier? That gives Google an extraordinarily accurate, up-to-date picture of your social network. And you love the GPS of your smartphone which you use a lot together with Google Maps. This means Google not only knows what you do from your calendar but also where you are, where you live, where you work. And by correlating GPS location data across users, Google can also tell with whom you may socializing with right now.
-
-### Your daily habit of handing out your most personal information will impact your life in a way that no one can even forsee ###
-
-To summarize, if you are an average internet user, Google has up-to-date, in-depth information about your interests, worries, passions, questions, over almost 10 years. It has a collection of some of your most personal messages (emails, SMS), an hour-by-hour detail of your daily activities and location, and a high-quality picture of your social network. Such an intimate knowledge of you likely goes beyond what your closest friends, family, or your sweetheart know of you.
-
-It wouldn't come to mind to give this mass of deeply personal information to complete strangers, for instance by putting it all on a USB key and leaving it on a table in a random cafe with a note saying 'Personal data of Olivier Martin, use as you please'. Who knows who might find it and what they would do with it? Yet, we have no problem handing in core pieces of your identity to strangers at IT companies with a strong interest in our data (that's how they make their bread) and [world-class experts in data analysis][2], perhaps just because it happens by default without us thinking about it when we hit that green 'Accept' button.
-
-With so much high-quality information, over the years, Google may well get to know you better than you can ever hope to know yourself: heck, crawling through my digital past right now, I can't remember having written half of the emails I sent five years ago. I am surprised and pleased to rediscover my interest in marxism back in 2005 and my joining [ATTAC][3] (an organization which strives to limit speculation and improve social justice by taxing financial transactions) the next year. And god knows why I was so much into dancing shoes back in 2007. These is pretty harmless information (you wouldn't have expected me to reveal something embarassing here, would you? ;-). But by connecting the dots between high-quality data over different aspects of your life (what, when, with whom, where, ...) over such time spans, one may extrapolate predictive statements about you. For instance, from the shopping habits of a 17-year-old girl, supermarkets can tell that she is pregnant before her dad even hears about it ([true story][4]). Who knows what will become possible with high-quality data the like Google has, which goes well beyond shopping habits? By connecting the dots, maybe one can predict how your tastes or political views will change in the coming years. Today, [companies you have never heard of claim to have 500 data points about you][5], including religion, sexual orientation and political views. Speaking of politics, what if you decide to go into politics in 10 years from now? Your life may change, your views too, and you may even forget, but Google won't. Will you have to worry that your opponent is in touch with someone who has access to your data at Google and can dig up something embarassing on you from those bottomless wells of personal data you gave away over the years? How long until Google or Facebook get hacked [just like Sony was recently hacked][6] and all your personal data end up in the public sphere forever?
-
-One of the reason most of us have entrusted our personal data to these companies is that they provide their services for free. But how free is it really? The value of the average Google account varies depending on the method used to estimate it: [1000 USD/year][7] accounts for the amount of time you invest in writing emails, while the value of your account for the advertisement industry is somewhere between [220 USD/year][8] and [500 USD/year][9]. So the service is not exactly free: you pay for it through advertisement and the yet unknown uses that our data may find in the future.
-
-I've been writing about Google mostly because that's the company I've entrusted most of my digital identify to so far and hence the one I know best. But I may well have written Apple or Facebook. These companies truly changed the world with their fantastic advances in design, engineering and services we love(d) to use, every day. But it doesn't mean we should stack up all our most personal data in their servers and entrust them with our digital lives: the potential for harm is just too large.
-
-### Claim back your privacy and that of people you care for in just 5h ###
-
-It does not have to be this way. You can live in the 21st century, have a smartphone, use email and GPS on daily basis, and still retain your privacy. All you need to do is get back control over your personal data: emails, calendar, contacts, files, etc.. The [Prism-Break.org][10] website lists software that help controlling the fate of your personal data. Beyond these options, the safest and most powerful way to get back control over your personal data is to host your cloud yourself, by building your own server. But you may just not have the time and energy to research how exactly to do that and make it work smoothly.
-
-That's where the present article fits in. In just 5 hours, we will set up a server to host your emails, contacts, calendars and files for you, your friends and your family. The server is designed to act as a hub or cloud for your personal data, so that you always retain full control over it. The data will automatically be synchronized between your PC/laptop, your phone and your tablet. Essentially, **we will set up a system that replaces Gmail, Google Drive / Dropbox, Google Contacts, Google Calendar and Picasa**.
-
-Just doing this for yourself will already be a big step. But then, a significant fraction of your personal information will still leak out and end up on some servers in the silicon valley, just because so many of the people you interact with every day use Gmail and have smartphones. So it's a good idea to have some of the people you are closest to join the adventure.
-
-We will build a system that
-
-- **supports an arbitrary number of domains and users**. This makes it easy to share your server with family and friends, so that they get control over their personal data too and can share the cost of the server with you. The people sharing your server can use their own domain name or share yours.
-- **lets you send and receive your emails from any network** upon successfully logging in onto the server. This way, you can send your emails from any of your email addresses, from any device (PC, phone, tablet), and any network (at home, at work, from a public network, ...)
-- **encrypts network traffic** when sending and receiving emails so people you don't trust won't fish out your password and won't be able to read your private emails.
-- **offers state-of-the-art antispam**, combining black lists of known spammers, automatic greylisting, and adaptative spam filtering. Re-training the adaptative spam filter if an email is misclassified is simply done by moving spam in or out of the Junk/Spam folder. Also, the server will contribute to community-based spam fighting efforts.
-- **requires just a few minutes of maintenance once in a while**, basically to install security updates and briefly check the server logs. Adding a new email address boils down to adding one record to a database. Apart from that, you can just forget about it and live your life. I set up the system described in this article 14 months ago and the thing has just been running smoothly since then. So I completely forgot about it, until I recently smiled at the thought that casually pressing the 'Check email' button of my phone caused electrons to travel all the way to Iceland (where my server sits) and back.
-
-To go through this article, you'll need a minimum of technical capabilities. If you know what is the difference between SMTP and IMAP, what is a DNS, and have a basic understanding of TCP/IP, you know enough to follow through. You will also need a basic working knowledge of Unix (working with files from the command line, basic system administration). And you'll need a total of 5 hours of time to set it up.
-
-Here's an overview what we will do:
-
-- [Get a Virtual Private Server, a domain name, and set them up][11]
-- [Set up postfix and dovecot to send and receive email][12]
-- [Prevent SPAM from reaching your INBOX][13]
-- [Make sure the emails you send get through spam filters][14]
-- [Host calendars, contacts, files with Owncloud and set up webmail][15]
-- [Sync your devices to the cloud][16]
-
-### This article was inspired by and builds upon previous work ###
-
-This article draws heavily from two other articles, namely [Xavier Claude][17]'s and [Drew Crawford][18]'s introduction to email self-hosting.
-
-The article includes all the features of Xavier's and Draw's articles, except from three features that Drew had and which I didn't need, namely push support for email (I like to check email only when I decide to, otherwise I get distracted all the time), fulltext search in email (which I don't have a use for), and storing emails in an encrypted form (my emails and data are not critical to the point that I have to encrypt them locally on the server). If you need any of these features, feel free to just add them by following to the respective section of Drew's article, which is compatible with the present one.
-
-Compared to Xavier's and Drew's work, the present article improves on several aspects:
-
-- it fixes bugs and typos based on my experience with Drew's article and the numerous comments on his original article. I also went through the present article, setting up the server from scratch several times to replicate it and make sure it would work right out of the box.
-- low maintenance: compared to Xavier's work, the present article adds support for multiple email domains on the server. It does so by requiring the minimum amount of server maintenance possible: basically, to add a domain or a user, just add one row to a mysql table and that's it (no need to add sieve scripts, ...).
-- I added webmail.
-- I added a section on setting up a cloud, to host not just your emails but also your files, your addressbook / contacts (emails, phone numbers, birthdays, ...), calendars and pictures for use across your devices.
-
-### Get a Virtual Private Server, a domain name, and set them up ###
-
-Let's start by setting the basic infrastructure: our virtual private server and our domain name.
-
-I've had an excellent experience with the Virtual Private Servers (VPS) of [1984.is][19] and [Linode][20]. In this article, we will use **Debian Wheezy**, for which both 1984 and Linode provide ready-made images to deploy on your VPS. I like 1984 because the servers are hosted in Iceland which run exclusively on renewable energy (geothermical and hydropower) and hence does not contribute to the climate change, unlike [the coal power plants on which most US-based datacenters currently run on][21]. Also, they put emphasis on [civil liberties, transparency, freedom][22] and [Free Software][23].
-
-It could be a good idea to start a file to store the various passwords we will need to set on the server (user accounts, mail accounts, cloud accounts, database accounts). It's definitely a good idea to encrypt this file (maybe with [GnuPG][24]), so that it won't be too easy to attack your server even if the computer you use to set up your server gets stolen or compromised.
-
-For registering a domain name, I've been using the services of [gandi][25] for over 10 years now, also with satisfaction. For this article, we will set up a zone with the name **jhausse.net**. We then add a host named **cloud.jhausse.net** to it, set the MX record to that host. While you're at it, set short Time To Lives (TTL) to your records like 300 seconds so that you'll be able to make changes to your zone and test the result rapidly while you're setting up the server.
-
-Finally, set the PTR record (reverse DNS) so that the IP address of the host maps back to its name. If you don't understand the previous sentence, read [this article][26] to get the background. If you use Linode, you can set the PTR record in the control panel in the Remote Access section. With 1984, contact the tech support who will help you with it.
-
-On the server, we will start by adding a non-privledged user, so that we don't end up working as root all the time. Also, to log in as root will require an extra layer of security.
-
- adduser roudy
-
-Then, in **/etc/ssh/sshd_config**, we set
-
- PermitRootLogin no
-
-and reload the ssh server
-
- service ssh reload
-
-Then, we'll need to change the hostname of the server. Edit **/etc/hostname** so that it has just a single line with your hostname, in our case
-
- cloud
-
-Then, edit the ssh server's public key files **/etc/ssh/ssh_host_rsa_key.pub, /etc/ssh/ssh_host_dsa_key.pub, /etc/ssh/ssh_host_ecdsa_key.pub** so that the end of the file reflects your hostname, or instance **root@cloud**. Then restart the system to make sure the hostname is fixed wherever is should be
-
- reboot
-
-We will update the system and remove services we don't need to reduce the risk of remote attacks.
-
- apt-get update
- apt-get dist-upgrade
- service exim4 stop
- apt-get remove exim4 rpcbind
- apt-get autoremove
- apt-get install vim
-
-I like to use vim for editing config files remotely. For this, it helps to automatically turn on syntax highlighting. We do so by adding
-
- syn on
-
-to **~/.vimrc**.
-
-### Set up postfix and dovecot to send and receive email ###
-
- apt-get install postfix postfix-mysql dovecot-core dovecot-imapd dovecot-mysql mysql-server dovecot-lmtpd postgrey
-
-In the [Postfix][27] configuration menu, we select **Internet Site**, and set the system mail name to **jhausse.net**.
-
-We will now set up a database to store the list of domains hosted on our server, the list of users for each of these domains (together with their password), and a list of mail aliases (to forward email from a given address to another one).
-
- mysqladmin -p create mailserver
- mysql -p mailserver
- mysql> GRANT SELECT ON mailserver.* TO 'mailuser'@'localhost' IDENTIFIED BY 'mailuserpass';
- mysql> FLUSH PRIVILEGES;
- mysql> CREATE TABLE `virtual_domains` (
- `id` int(11) NOT NULL auto_increment,
- `name` varchar(50) NOT NULL,
- PRIMARY KEY (`id`)
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- mysql> CREATE TABLE `virtual_users` (
- `id` int(11) NOT NULL auto_increment,
- `domain_id` int(11) NOT NULL,
- `password` varchar(106) NOT NULL,
- `email` varchar(100) NOT NULL,
- PRIMARY KEY (`id`),
- UNIQUE KEY `email` (`email`),
- FOREIGN KEY (domain_id) REFERENCES virtual_domains(id) ON DELETE CASCADE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- mysql> CREATE TABLE `virtual_aliases` (
- `id` int(11) NOT NULL auto_increment,
- `domain_id` int(11) NOT NULL,
- `source` varchar(100) NOT NULL,
- `destination` varchar(100) NOT NULL,
- PRIMARY KEY (`id`),
- FOREIGN KEY (domain_id) REFERENCES virtual_domains(id) ON DELETE CASCADE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-
-We will host the **jhausse.net** domain. If there are other domains you'd like to host, you can also add them. We also set up a postmaster address for each domain, which forwards to **roudy@jhausse.net**.
-
- mysql> INSERT INTO virtual_domains (`name`) VALUES ('jhausse.net');
- mysql> INSERT INTO virtual_domains (`name`) VALUES ('otherdomain.net');
- mysql> INSERT INTO virtual_aliases (`domain_id`, `source`, `destination`) VALUES ('1', 'postmaster', 'roudy@jhausse.net');
- mysql> INSERT INTO virtual_aliases (`domain_id`, `source`, `destination`) VALUES ('2', 'postmaster', 'roudy@jhausse.net');
-
-We now add a locally hosted email account **roudy@jhausse.net**. First, we generate a password hash for it:
-
- doveadm pw -s SHA512-CRYPT
-
-and then add the hash to the database
-
- mysql> INSERT INTO `mailserver`.`virtual_users` (`domain_id`, `password`, `email`) VALUES ('1', '$6$YOURPASSWORDHASH', 'roudy@jhausse.net');
-
-Now that our list of domains, aliases and users are in place, we will set up postfix (SMTP server, for outgoing mail). Replace the contents of **/etc/postfix/main.cf** with the following:
-
- myhostname = cloud.jhausse.net
- myorigin = /etc/mailname
- mydestination = localhost.localdomain, localhost
- mynetworks_style = host
-
- # We disable relaying in the general case
- smtpd_recipient_restrictions = permit_mynetworks, reject_unauth_destination
- # Requirements on servers that contact us: we verify the client is not a
- # known spammer (reject_rbl_client) and use a graylist mechanism
- # (postgrey) to help reducing spam (check_policy_service)
- smtpd_client_restrictions = permit_mynetworks, reject_rbl_client zen.spamhaus.org, check_policy_service inet:127.0.0.1:10023
- disable_vrfy_command = yes
- inet_interfaces = all
- smtpd_banner = $myhostname ESMTP $mail_name (Debian/GNU)
- biff = no
- append_dot_mydomain = no
- readme_directory = no
-
- # TLS parameters
- smtpd_tls_cert_file=/etc/ssl/certs/cloud.crt
- smtpd_tls_key_file=/etc/ssl/private/cloud.key
- smtpd_use_tls=yes
- smtpd_tls_auth_only = yes
- smtp_tls_security_level=may
- smtp_tls_loglevel = 1
- smtpd_tls_loglevel = 1
- smtpd_tls_received_header = yes
- smtpd_tls_session_cache_database = btree:${data_directory}/smtpd_scache
- smtp_tls_session_cache_database = btree:${data_directory}/smtp_scache
-
- # Delivery
- alias_maps = hash:/etc/aliases
- alias_database = hash:/etc/aliases
- message_size_limit = 50000000
- recipient_delimiter = +
-
- # The next lines are useful to set up a backup MX for myfriendsdomain.org
- # relay_domains = myfriendsdomain.org
- # relay_recipient_maps =
-
- # Virtual domains
- virtual_transport = lmtp:unix:private/dovecot-lmtp
- virtual_mailbox_domains = mysql:/etc/postfix/mysql-virtual-mailbox-domains.cf
- virtual_mailbox_maps = mysql:/etc/postfix/mysql-virtual-mailbox-maps.cf
- virtual_alias_maps = mysql:/etc/postfix/mysql-virtual-alias-maps.cf
- local_recipient_maps = $virtual_mailbox_maps
-
-Now we need to teach postfix to figure out which domains we would like him to accept emails for using the database we just set up. Create a new file **/etc/postfix/mysql-virtual-mailbox-domains.cf** and add the following:
-
- user = mailuser
- password = mailuserpass
- hosts = 127.0.0.1
- dbname = mailserver
- query = SELECT 1 FROM virtual_domains WHERE name='%s'
-
-We teach postfix to find out whether a given email account exists by creating **/etc/postfix/mysql-virtual-mailbox-maps.cf** with the following content
-
- user = mailuser
- password = mailuserpass
- hosts = 127.0.0.1
- dbname = mailserver
- query = SELECT 1 FROM virtual_users WHERE email='%s'
-
-Finally, postfix will use **/etc/postfix/mysql-virtual-alias-maps.cf** to look up mail aliases
-
- user = mailuser
- password = mailuserpass
- hosts = 127.0.0.1
- dbname = mailserver
- query = SELECT virtual_aliases.destination as destination FROM virtual_aliases, virtual_domains WHERE virtual_aliases.source='%u' AND virtual_aliases.domain_id = virtual_domains.id AND virtual_domains.name='%d'
-
-With all this in place, it is now time to test if postfix can query our database properly. We can do this using **postmap**:
-
- postmap -q jhausse.net mysql:/etc/postfix/mysql-virtual-mailbox-domains.cf
- postmap -q roudy@jhausse.net mysql:/etc/postfix/mysql-virtual-mailbox-maps.cf
- postmap -q postmaster@jhausse.net mysql:/etc/postfix/mysql-virtual-alias-maps.cf
- postmap -q bob@jhausse.net mysql:/etc/postfix/mysql-virtual-alias-maps.cf
-
-If you set up everything properly, the first two queries should return 1, the third query should return **roudy@jhausse.net** and the last one should return nothing at all.
-
-Now, let's set up dovecot (the IMAP server, to fetch incoming mail on the server from our devices). Edit **/etc/dovecot/dovecot.conf** to set the following parameters:
-
- # Enable installed protocol
- # !include_try /usr/share/dovecot/protocols.d/*.protocol
- protocols = imap lmtp
-
-which will only enable imap (to let us fetch emails) and lmtp (which postfix will use to pass incoming emails to dovecot). Edit **/etc/dovecot/conf.d/10-mail.conf** to set the following parameters:
-
- mail_location = maildir:/var/mail/%d/%n
- [...]
- mail_privileged_group = mail
- [...]
- first_valid_uid = 0
-
-which will store emails in /var/mail/domainname/username. Note that these settings are spread at different locations in the file, and are sometimes already there for us to set: we just need to comment them out. The other settings which are already in the file, you can leave as is. We will have to do the same to update settings in many more files in the remaining of this article. In **/etc/dovecot/conf.d/10-auth.conf**, set the parameters:
-
- disable_plaintext_auth = yes
- auth_mechanisms = plain
- #!include auth-system.conf.ext
- !include auth-sql.conf.ext
-
-In **/etc/dovecot/conf.d/auth-sql.conf.ext**, set the following parameters:
-
- passdb {
- driver = sql
- args = /etc/dovecot/dovecot-sql.conf.ext
- }
- userdb {
- driver = static
- args = uid=mail gid=mail home=/var/mail/%d/%n
- }
-
-where we just taught dovecot that users have their emails in /var/mail/domainname/username and to look up passwords from the database we just created. Now we still need to teach dovecot how exactly to use the database. To do so, put the following into **/etc/dovecot/dovecot-sql.conf.ext**:
-
- driver = mysql
- connect = host=localhost dbname=mailserver user=mailuser password=mailuserpass
- default_pass_scheme = SHA512-CRYPT
- password_query = SELECT email as user, password FROM virtual_users WHERE email='%u';
-
-We now fix permissions on config files
-
- chown -R mail:dovecot /etc/dovecot
- chmod -R o-rwx /etc/dovecot
-
-Almost there! We just need to edit a couple files more. In **/etc/dovecot/conf.d/10-master.conf**, set the following parameters:
-
- service imap-login {
- inet_listener imap {
- #port = 143
- port = 0
- }
- inet_listener imaps {
- port = 993
- ssl = yes
- }
- }
-
- service pop3-login {
- inet_listener pop3 {
- #port = 110
- port = 0
- }
- inet_listener pop3s {
- #port = 995
- #ssl = yes
- port = 0
- }
- }
-
- service lmtp {
- unix_listener /var/spool/postfix/private/dovecot-lmtp {
- mode = 0666
- group = postfix
- user = postfix
- }
- user = mail
- }
-
- service auth {
- unix_listener auth-userdb {
- mode = 0600
- user = mail
- #group =
- }
-
- # Postfix smtp-auth
- unix_listener /var/spool/postfix/private/auth {
- mode = 0666
- user = postfix
- group = postfix
- }
-
- # Auth process is run as this user.
- #user = $default_internal_user
- user = dovecot
- }
-
- service auth-worker {
- user = mail
- }
-
-Note that we set ports for all services but imaps to 0, which effectively disables them. Then, in **/etc/dovecot/conf.d/15-lda.conf**, specify an email address for the postmaster:
-
- postmaster_address = postmaster@jhausse.net
-
-Last but not least, we need to generate a pair of public and private key for the server, which we will use both in dovecot and postfix:
-
- openssl req -new -newkey rsa:4096 -x509 -days 365 -nodes -out "/etc/ssl/certs/cloud.crt" -keyout "/etc/ssl/private/cloud.key"
-
-Make sure that you specify your the Fully Qualified Domain Name (FQDN) of the server, in our case:
-
- Common Name (e.g. server FQDN or YOUR name) []:cloud.jhausse.net
-
-If you don't, our clients may complain that the server name in the SSL certificate does not match the name of the server they are connecting to. We tell dovecot to use these keys by setting the following parameters in **/etc/dovecot/conf.d/10-ssl.conf**:
-
- ssl = required
- ssl_cert = : Relay access denied
-
-That's good: had the server accepted the mail, it would have meant that we set up postfix as an open relay for all the spammers of the world and beyhond to use. Instead of the 'Relay access denied' message, you may instead get the message
-
- 554 5.7.1 Service unavailable; Client host [87.68.61.119] blocked using zen.spamhaus.org; http://www.spamhaus.org/query/bl?ip=87.68.61.119
-
-This means that you are trying to contact the server from an IP address that is considered as a spammer's address. I got this message while trying to connect to the server through my regular Internet Service Provider (ISP). To fix this issue, you can try to connect from another host, maybe another server you have access to through SSH. Alternatively, you can reconfigure Postfix's **main.cf** not to use Spamhaus's RBL, reload postfix, and verify that the above test works. In both cases, it's important that you find a solution that works for you because we'll test other things in a minute. If you chose to reconfigure Postfix not to use RBLs, don't forget to put the RBLs back in and to reload postfix after finishing the article to avoid getting more spam than necessary.
-
-Now let's try to send a valid email by SMTP on port 25, which regular mail servers use to talk to each other:
-
- openssl s_client -connect cloud.jhausse.net:25 -starttls smtp
- EHLO cloud.jhausse.net
- MAIL FROM:youremail@domain.com
- rcpt to:roudy@jhausse.net
-
-to which the server should respond
-
- Client host rejected: Greylisted, see http://postgrey.schweikert.ch/help/jhausse.net.html
-
-which shows that [postgrey][28] is working as it should. What postgrey does it to reject emails with a temporary error if the sender has never been seen before. The technical rules of email require email servers to try to deliver the email again. After five minutes, postgrey will accept the email. Legit email servers around the world will try repeatidly to redeliver the email to us, but most spammers won't. So, wait for 5 minutes, try to send the email again using the command above, and verify that postfix now accepts the email.
-
-Afterwards, we'll check that we can fetch the two emails that we just sent ourselves by talking IMAP to dovecot:
-
- openssl s_client -crlf -connect cloud.jhausse.net:993
- 1 login roudy@jhausse.net "mypassword"
- 2 LIST "" "*"
- 3 SELECT INBOX
- 4 UID fetch 1:1 (UID RFC822.SIZE FLAGS BODY.PEEK[])
- 5 LOGOUT
-
-where you should replace mypassword with the password you set for this email account. If that works, we basically have a functional email server which can receive our incoming emails, and from which we get retreive these emails from our devices (PC/laptop, tablets, phones, ...). But we can't give it our emails to send unless we send them from the server itself. We'll now allow postfix to forward our emails, but only upon successful authentification, that is after it could make sure that the email comes from someone who has a valid account on the server. To do so, we'll open a special, SSL-only, SASL-authentified email submission service. Set the following parameters in **/etc/postfix/master.cf**:
-
- submission inet n - - - - smtpd
- -o syslog_name=postfix/submission
- -o smtpd_tls_security_level=encrypt
- -o smtpd_sasl_auth_enable=yes
- -o smtpd_client_restrictions=permit_sasl_authenticated,reject
- -o smtpd_sasl_type=dovecot
- -o smtpd_sasl_path=private/auth
- -o smtpd_sasl_security_options=noanonymous
- -o smtpd_recipient_restrictions=permit_sasl_authenticated,reject_non_fqdn_recipient,reject_unauth_destination
-
-and reload postfix
-
- service postfix reload
-
-Now, let's try to use this service from a different machine than than the server, to verify postfix will now relay our emails and nobody else's:
-
- openssl s_client -connect cloud.jhausse.net:587 -starttls smtp
- EHLO cloud.jhausse.net
-
-Notice the '250-AUTH PLAIN' capabilities advertized by server, which doesn't appear when we connect to port 25.
-
- MAIL FROM:asdf@jkl.net
- rcpt to:bob@gmail.com
- 554 5.7.1 : Relay access denied
- QUIT
-
-That's good, postfix won't relay our emails if he doesn't know us. So let's authentify ourselves first. To do so, we first need to generate an authentification string:
-
- echo -ne '\000roudy@jhausse.net\000mypassword'|base64
-
-and let's try to send emails through the server again:
-
- openssl s_client -connect cloud.jhausse.net:587 -starttls smtp
- EHLO cloud.jhausse.net
- AUTH PLAIN DGplYW5AMTk4NGNsb3VQLm5ldAA4bmFmNGNvNG5jOA==
- MAIL FROM:asdf@jkl.net
- rcpt to:bob@gmail.com
-
-which postfix should now accept. To complete the test, let's verify that our virtual aliases work by sending an email to postmaster@jhausse.net and making sure it goes to roudy@jhausse.net:
-
- telnet cloud.jhausse.net 25
- EHLO cloud.jhausse.net
- MAIL FROM:youremail@domain.com
- rcpt to:postmaster@jhausse.net
- data
- Subject: Virtual alias test
-
- Dear postmaster,
- Long time no hear! I hope your MX is working smoothly and securely.
- Yours sincerely, Roudy
- .
- QUIT
-
-Let's check the mail made it all the way to the right inbox:
-
- openssl s_client -crlf -connect cloud.jhausse.net:993
- 1 login roudy@jhausse.net "mypassword"
- 2 LIST "" "*"
- 3 SELECT INBOX
- * 2 EXISTS
- * 2 RECENT
- 4 LOGOUT
-
-At this point, we have a functional email server, both for incoming and outgoing mails. We can set up our devices to use it.
-
-PS: did you remember to [try sending an email to an account hosted by the server through port 25][29] again, to verify that you are not longer blocked by postgrey?
-
-### Prevent SPAM from reaching your INBOX ###
-
-For the sake of SPAM filtering, we already have Realtime BlackLists (RBLs) and greylisting (postgrey) in place. We'll now take our spam fighting capabilities up a notch by adding adaptative spam filtering. This means we'll add artificial intelligence to our email server, so that it can learn from experience what is spam and what is not. We will use [dspam][30] for that.
-
- apt-get install dspam dovecot-antispam postfix-pcre dovecot-sieve
-
-dovecot-antispam is a package that allows dovecot to retrain the spam filter if we find an email that is misclassified by dspam. Basically, all we need to do is to move emails in or out of the Junk/Spam folder. dovecot-antispam will then take care of calling dspam to retrain the filter. As for postfix-pcre and dovecot-sieve, we will use them respectively to pass incoming emails through the spam filter and to automatically move spam to the user's Junk/Spam folder.
-
-In **/etc/dspam/dspam.conf**, set the following parameters to these values:
-
- TrustedDeliveryAgent "/usr/sbin/sendmail"
- UntrustedDeliveryAgent "/usr/lib/dovecot/deliver -d %u"
- Tokenizer osb
- IgnoreHeader X-Spam-Status
- IgnoreHeader X-Spam-Scanned
- IgnoreHeader X-Virus-Scanner-Result
- IgnoreHeader X-Virus-Scanned
- IgnoreHeader X-DKIM
- IgnoreHeader DKIM-Signature
- IgnoreHeader DomainKey-Signature
- IgnoreHeader X-Google-Dkim-Signature
- ParseToHeaders on
- ChangeModeOnParse off
- ChangeUserOnParse full
- ServerPID /var/run/dspam/dspam.pid
- ServerDomainSocketPath "/var/run/dspam/dspam.sock"
- ClientHost /var/run/dspam/dspam.sock
-
-Then, in **/etc/dspam/default.prefs**, change the following parameters to:
-
- spamAction=deliver # { quarantine | tag | deliver } -> default:quarantine
- signatureLocation=headers # { message | headers } -> default:message
- showFactors=on
-
-Now we need to connect dspam to postfix and dovecot by adding these two lines at the end of **/etc/postfix/master.cf**:
-
- dspam unix - n n - 10 pipe
- flags=Ru user=dspam argv=/usr/bin/dspam --deliver=innocent,spam --user $recipient -i -f $sender -- $recipient
- dovecot unix - n n - - pipe
- flags=DRhu user=mail:mail argv=/usr/lib/dovecot/deliver -f ${sender} -d ${recipient}
-
-Now we will tell postfix to filter every new email that gets submitted to the server on port 25 (normal SMTP traffic) through dspam, except if the email is submitted from the server itself (permit_mynetworks). Note that the emails we submit to postfix with SASL authentication won't be filtered through dspam either, as we set up a separate submission service for those in the previous section. Edit **/etc/postfix/main.cf** to change the **smtpd_client_restrictions** to the following:
-
- smtpd_client_restrictions = permit_mynetworks, reject_rbl_client zen.spamhaus.org, check_policy_service inet:127.0.0.1:10023, check_client_access pcre:/etc/postfix/dspam_filter_access
-
-At the end of the file, also also add:
-
- # For DSPAM, only scan one mail at a time
- dspam_destination_recipient_limit = 1
-
-We now need to specify the filter we defined. Basically, we will tell postfix to send all emails (/./) to dspam through a unix socket. Create a new file **/etc/postfix/dspam_filter_access** and put the following line into it:
-
- /./ FILTER dspam:unix:/run/dspam/dspam.sock
-
-That's it for the postfix part. Now let's set up dovecot for spam filtering. In **/etc/dovecot/conf.d/20-imap.conf**, edit the **imap mail_plugins** plugins parameter such that:
-
- mail_plugins = $mail_plugins antispam
-
-and add a section for lmtp:
-
- protocol lmtp {
- # Space separated list of plugins to load (default is global mail_plugins).
- mail_plugins = $mail_plugins sieve
- }
-
-We now configure the dovecot-antispam plugin. Edit **/etc/dovecot/conf.d/90-plugin.conf** to add the following content to the plugin section:
-
- plugin {
- ...
- # Antispam (DSPAM)
- antispam_backend = dspam
- antispam_allow_append_to_spam = YES
- antispam_spam = Junk;Spam
- antispam_trash = Trash;trash
- antispam_signature = X-DSPAM-Signature
- antispam_signature_missing = error
- antispam_dspam_binary = /usr/bin/dspam
- antispam_dspam_args = --user;%u;--deliver=;--source=error
- antispam_dspam_spam = --class=spam
- antispam_dspam_notspam = --class=innocent
- antispam_dspam_result_header = X-DSPAM-Result
- }
-
-and in **/etc/dovecot/conf.d/90-sieve.conf**, specify a default sieve script which will apply to all users of the server:
-
- sieve_default = /etc/dovecot/default.sieve
-
-What is sieve and why do we need a default script for all users? Sieve lets us automatize tasks on the IMAP server. In our case, we won't all emails identified as spam to be put in the Junk folder instead of in the Inbox. We would like this to be the default behavior for all users on the server; that's why we just set this script as default script. Let's create this script now, by creating a new file **/etc/dovecot/default.sieve** with the following content:
-
- require ["regex", "fileinto", "imap4flags"];
- # Catch mail tagged as Spam, except Spam retrained and delivered to the mailbox
- if allof (header :regex "X-DSPAM-Result" "^(Spam|Virus|Bl[ao]cklisted)$",
- not header :contains "X-DSPAM-Reclassified" "Innocent") {
- # Mark as read
- # setflag "\\Seen";
- # Move into the Junk folder
- fileinto "Junk";
- # Stop processing here
- stop;
- }
-
-Now we need to compile this script so that dovecot can run it. We also need to give it appropriate permissions.
-
- cd /etc/dovecot
- sievec .
- chown mail.dovecot default.siev*
- chmod 0640 default.sieve
- chmod 0750 default.svbin
-
-Finally, we need to fix permissions on two postfix config files that dspam needs to read from:
-
- chmod 0644 /etc/postfix/dynamicmaps.cf /etc/postfix/main.cf
-
-That's it! Let's restart dovecot and postfix
-
- service dovecot restart
- service postfix restart
-
-and test the antispam, by contacting the server from a remote host (e.g. the computer we are using to set the server):
-
- openssl s_client -connect cloud.jhausse.net:25 -starttls smtp
- EHLO cloud.jhausse.net
- MAIL FROM:youremail@domain.com
- rcpt to:roudy@jhausse.net
- DATA
- Subject: DSPAM test
-
- Hi Roudy, how'd you like to eat some ham tonight? Yours, J
- .
- QUIT
-
-Let's check if the mail arrived:
-
- openssl s_client -crlf -connect cloud.jhausse.net:993
- 1 login roudy@jhausse.net "mypassword"
- 2 LIST "" "*"
- 3 SELECT INBOX
- 4 UID fetch 3:3 (UID RFC822.SIZE FLAGS BODY.PEEK[])
-
-Which should return something the email with a collection of flag set by SPAM which look like this:
-
- X-DSPAM-Result: Innocent
- X-DSPAM-Processed: Sun Oct 5 16:25:48 2014
- X-DSPAM-Confidence: 1.0000
- X-DSPAM-Probability: 0.0023
- X-DSPAM-Signature: 5431710c178911166011737
- X-DSPAM-Factors: 27,
- Received*Postfix+with, 0.40000,
- Received*with+#+id, 0.40000,
- like+#+#+#+ham, 0.40000,
- some+#+tonight, 0.40000,
- Received*certificate+requested, 0.40000,
- Received*client+certificate, 0.40000,
- Received*for+roudy, 0.40000,
- Received*Sun+#+#+#+16, 0.40000,
- Received*Sun+#+Oct, 0.40000,
- Received*roudy+#+#+#+Oct, 0.40000,
- eat+some, 0.40000,
- Received*5+#+#+16, 0.40000,
- Received*cloud.jhausse.net+#+#+#+id, 0.40000,
- Roudy+#+#+#+to, 0.40000,
- Received*Oct+#+16, 0.40000,
- to+#+#+ham, 0.40000,
- Received*No+#+#+requested, 0.40000,
- Received*jhausse.net+#+#+Oct, 0.40000,
- Received*256+256, 0.40000,
- like+#+#+some, 0.40000,
- Received*ESMTPS+id, 0.40000,
- how'd+#+#+to, 0.40000,
- tonight+Yours, 0.40000,
- Received*with+cipher, 0.40000
- 5 LOGOUT
-
-Good! You now have adaptive spam filtering set up for the users of your server. Of course, each user will need to train the filter in the first few weeks. To train a message as spam, just move it to a folder called "Spam" or "Junk" using any of your devices (PC, tablet, phone). Otherwise it'll be trained as ham.
-
-### Make sure the emails you send get through spam filters ###
-
-Our goal in this section will be to make our mail server appear as clean as possible to the world and to make it harder for spammers to send emails in our name. As a side-effect, this will help us get our emails through the spam filters of other mail servers.
-
-#### Sender Policy Framework ####
-
-Sender Policy Framework (SPF) is a record that your add to your zone which declares which mail servers on the whole internet can send emails for your domain name. Setting it up is very easy, use the SPF wizard at [microsoft.com][31] to generate your SPF record, and then add it to your zone as a TXT record. It will look like this:
-
- jhausse.net. 300 IN TXT v=spf1 mx mx:cloud.jhausse.net -all
-
-#### Reverse PTR ####
-
-We discussed this point [earlier][32] in this article, it's a good idea that you set up the reverse DNS for your server correctly, so that doing a reverse lookup on the IP address of your server returns the actual name of your server.
-
-#### OpenDKIM ####
-
-When we activate [OpenDKIM][33], postfix will sign every outgoing email using a cryptographic key. We will then deposit that key in our zone, on the DNS. That way, every mail server in the world will be able to verify if the email actually came from us, or if it was forged by a spammer. Let's install opendkim:
-
- apt-get install opendkim opendkim-tools
-
-And set it up by editing **/etc/opendkim.conf** so that it looks like this:
-
- ##
- ## opendkim.conf -- configuration file for OpenDKIM filter
- ##
- Canonicalization relaxed/relaxed
- ExternalIgnoreList refile:/etc/opendkim/TrustedHosts
- InternalHosts refile:/etc/opendkim/TrustedHosts
- KeyTable refile:/etc/opendkim/KeyTable
- LogWhy Yes
- MinimumKeyBits 1024
- Mode sv
- PidFile /var/run/opendkim/opendkim.pid
- SigningTable refile:/etc/opendkim/SigningTable
- Socket inet:8891@localhost
- Syslog Yes
- SyslogSuccess Yes
- TemporaryDirectory /var/tmp
- UMask 022
- UserID opendkim:opendkim
-
-We'll need a couple of additional files which we will store in **/etc/opendkim**:
-
- mkdir -pv /etc/opendkim/
- cd /etc/opendkim/
-
-Let's create a new file **/etc/opendkim/TrustedHosts** with the following content
-
- 127.0.0.1
-
-and a new file called **/etc/opendkim/KeyTable** with the following content
-
- cloudkey jhausse.net:mail:/etc/opendkim/mail.private
-
-This tells OpenDKIM that we want to use an encryption key named 'cloudkey' whose contents can be found in /etc/opendkim/mail.private. We will create another file named **/etc/opendkim/SigningTable** and add the following line:
-
- *@jhausse.net cloudkey
-
-which tells OpenDKIM that every emails of the jhausse.net domain should be signed using the key 'cloudkey'. If we have other domains which we want to sign, we can add them here too.
-
-The next step is to generate that key and fix permissions on OpenDKIM's config files.
-
- opendkim-genkey -r -s mail [-t]
- chown -Rv opendkim:opendkim /etc/opendkim
- chmod 0600 /etc/opendkim/*
- chmod 0700 /etc/opendkim
-
-At first, it's a good idea to use the -t which will signal to other mail servers that you are just in testing mode, and that they shouldn't discard emails based on your OpenDKIM signature (yet). You can get your OpenDKIM key from the mail.txt file:
-
- cat mail.txt
-
-and then add it to your zone file as TXT record, which should look like this
-
- mail._domainkey.cloud1984.net. 300 IN TXT v=DKIM1; k=rsa; p=MIGfMA0GCSqG...
-
-Finally, we need to tell postfix to sign outgoing emails. At the end of /etc/postfix/main.cf, add:
-
- # Now for OpenDKIM: we'll sign all outgoing emails
- smtpd_milters = inet:127.0.0.1:8891
- non_smtpd_milters = $smtpd_milters
- milter_default_action = accept
-
-And reload the corresponding services
-
- service postfix reload
- service opendkim restart
-
-Now let's test if our OpenDKIM public key can be found and matches the private key:
-
- opendkim-testkey -d jhausse.net -s mail -k mail.private -vvv
-
-which should return
-
- opendkim-testkey: key OK
-
-For this, you may need to wait a bit until the name server has reloaded the zone (on Linode, this happens every 15min). You can use **dig** to check if the zone was reloaded yet.
-
-If this works, let's test if other servers can validate our OpenDKIM signatures and SPF record. To do this, we can use [Brandon Checkett's email test][34]. To send an email to a test address given to us on [Brandon's webpage][34], we can run the following command on the server
-
- mail -s CloudCheck ihAdmTBmUH@www.brandonchecketts.com
-
-On Brandon's webpage, you should then see **result = pass** in the 'DKIM Signature' section, and **Result: pass** in the 'SPF Information' section. If our emails pass this test, just regenerate an OpenDKIM key without the -t switch, upload the new key to the zone file, and retest to still if it still passes the tests. If so, congrats! You just successfully set up OpenDKIM and SPF on your server!
-
-### Host calendars, contacts, files with Owncloud and set up a webmail with Roundcube ###
-
-Now that we have a top-notch email server, let's add to it the possibility to store your contacts, calendars, and files in the cloud. These are services that the [Owncloud][35] provides out of the box. While we're at it, we'll also set up a webmail, so you can check email even if you're travelling without electronics, or in case your phone and laptop run out of battery.
-
-Installing Owncloud is straighforward and is well described [here][36]. On Debian, it boils down to adding the owncloud repository to your apt sources, downloading owncloud's release key and adding it to your apt keyring, and then installing owncloud itself using apt-get:
-
- echo 'deb http://download.opensuse.org/repositories/isv:/ownCloud:/community/Debian_7.0/ /' >> /etc/apt/sources.list.d/owncloud.list
- wget http://download.opensuse.org/repositories/isv:ownCloud:community/Debian_6.0/Release.key
- apt-key add - < Release.key
- apt-get update
- apt-get install apache2 owncloud roundcube
-
-When prompted for it, choose **dbconfig** and then say you want **roundcube** to use **mysql**. Then, provide the mysql root password and set a good password for the roundcube mysql user. Then, edit the roundcube config file **/etc/roundcube/main.inc.php** so that logging in on roundcube will default to using your IMAP server:
-
- $rcmail_config['default_host'] = 'ssl://localhost';
- $rcmail_config['default_port'] = 993;
-
-Now we will set up the apache2 webserver with SSL so that we can talk to Owncloud and Roundcube using encryption for our passwords and data. Let's turn on Apache's ssl module:
-
- a2enmod ssl
-
-and edit **/etc/apache2/ports.conf** to set the following parameters:
-
-NameVirtualHost *:80
-Listen 80
-ServerName www.jhausse.net
-
-
- # If you add NameVirtualHost *:443 here, you will also have to change
- # the VirtualHost statement in /etc/apache2/sites-available/default-ssl
- # to
- # Server Name Indication for SSL named virtual hosts is currently not
- # supported by MSIE on Windows XP.
- NameVirtualHost *:443
- Listen 443
-
-
-
- Listen 443
-
-
-We'll set up a default website for encrypted connections to the webserver as **https://www.jhausse.net** under **/var/www**. Edit **/etc/apache2/sites-available/default-ssl**:
-
-
- ServerAdmin webmaster@localhost
-
- DocumentRoot /var/www
- ServerName www.jhausse.net
- [...]
-
- Deny from all
-
- [...]
- SSLCertificateFile /etc/ssl/certs/cloud.crt
- SSLCertificateKeyFile /etc/ssl/private/cloud.key
- [...]
-
-
-and let's also set up a website for unencrypted connections to **http://www.jhausse.net** under **/var/www**. Edit **/etc/apache2/sites-available/default**:
-
-
- DocumentRoot /var/www
- ServerName www.jhausse.net
- [...]
-
- Deny from all
-
-
-
-That way, we can serve pages for www.jhausse.net by putting them in /var/www. The 'Deny from all' directive prevents access to Owncloud through www.jhausse.net: we will set it up to access it through **https://cloud.jhausse.net** instead.
-
-We will now set up the webmail (roundcube) so that it will be accessed through **https://webmail.jhausse.net**. Edit **/etc/apache2/sites-available/roundcube** to have the following content:
-
-
-
- ServerAdmin webmaster@localhost
-
- DocumentRoot /var/lib/roundcube
- # The host name under which you'd like to access the webmail
- ServerName webmail.jhausse.net
-
- Options FollowSymLinks
- AllowOverride None
-
-
- ErrorLog ${APACHE_LOG_DIR}/error.log
-
- # Possible values include: debug, info, notice, warn, error, crit,
- # alert, emerg.
- LogLevel warn
-
- CustomLog ${APACHE_LOG_DIR}/ssl_access.log combined
-
- # SSL Engine Switch:
- # Enable/Disable SSL for this virtual host.
- SSLEngine on
-
- # do not allow unsecured connections
- # SSLRequireSSL
- SSLCipherSuite HIGH:MEDIUM
-
- # A self-signed (snakeoil) certificate can be created by installing
- # the ssl-cert package. See
- # /usr/share/doc/apache2.2-common/README.Debian.gz for more info.
- # If both key and certificate are stored in the same file, only the
- # SSLCertificateFile directive is needed.
- SSLCertificateFile /etc/ssl/certs/cloud.crt
- SSLCertificateKeyFile /etc/ssl/private/cloud.key
-
- # Those aliases do not work properly with several hosts on your apache server
- # Uncomment them to use it or adapt them to your configuration
- Alias /program/js/tiny_mce/ /usr/share/tinymce/www/
-
- # Access to tinymce files
-
- Options Indexes MultiViews FollowSymLinks
- AllowOverride None
- Order allow,deny
- allow from all
-
-
-
- Options +FollowSymLinks
- # This is needed to parse /var/lib/roundcube/.htaccess. See its
- # content before setting AllowOverride to None.
- AllowOverride All
- order allow,deny
- allow from all
-
-
- # Protecting basic directories:
-
- Options -FollowSymLinks
- AllowOverride None
-
-
-
- Options -FollowSymLinks
- AllowOverride None
- Order allow,deny
- Deny from all
-
-
-
- Options -FollowSymLinks
- AllowOverride None
- Order allow,deny
- Deny from all
-
-
-
- SSLOptions +StdEnvVars
-
-
- SSLOptions +StdEnvVars
-
- # SSL Protocol Adjustments:
- # The safe and default but still SSL/TLS standard compliant shutdown
- # approach is that mod_ssl sends the close notify alert but doesn't wait for
- # the close notify alert from client. When you need a different shutdown
- # approach you can use one of the following variables:
- # o ssl-unclean-shutdown:
- # This forces an unclean shutdown when the connection is closed, i.e. no
- # SSL close notify alert is send or allowed to received. This violates
- # the SSL/TLS standard but is needed for some brain-dead browsers. Use
- # this when you receive I/O errors because of the standard approach where
- # mod_ssl sends the close notify alert.
- # o ssl-accurate-shutdown:
- # This forces an accurate shutdown when the connection is closed, i.e. a
- # SSL close notify alert is send and mod_ssl waits for the close notify
- # alert of the client. This is 100% SSL/TLS standard compliant, but in
- # practice often causes hanging connections with brain-dead browsers. Use
- # this only for browsers where you know that their SSL implementation
- # works correctly.
- # Notice: Most problems of broken clients are also related to the HTTP
- # keep-alive facility, so you usually additionally want to disable
- # keep-alive for those clients, too. Use variable "nokeepalive" for this.
- # Similarly, one has to force some clients to use HTTP/1.0 to workaround
- # their broken HTTP/1.1 implementation. Use variables "downgrade-1.0" and
- # "force-response-1.0" for this.
- BrowserMatch "MSIE [2-6]" \
- nokeepalive ssl-unclean-shutdown \
- downgrade-1.0 force-response-1.0
- # MSIE 7 and newer should be able to use keepalive
- BrowserMatch "MSIE [17-9]" ssl-unclean-shutdown
-
-
-
-and declare the server in your DNS, for instance:
-
- webmail.jhausse.net. 300 IN CNAME cloud.jhausse.net.
-
-Now let's enable these three websites
-
- a2ensite default default-ssl roundcube
- service apache2 restart
-
-and the webmail, accessible under **https://webmail.jhausse.net**, should basically work. Log in using the full email (e.g. roudy@jhausse.net) and the password you set in mailserver DB at the beginning of this article. The first time you connect, the browser will warn you that the certificate was not signed by a certification authority. That's fine, just add an exception.
-
-Last but not least, we will create a virtual host for owncloud by putting the following content in **/etc/apache2/sites-available/owncloud**:
-
-
-
- ServerAdmin webmaster@localhost
-
- DocumentRoot /var/www/owncloud
- ServerName cloud.jhausse.net
-
- Options FollowSymLinks
- AllowOverride None
-
-
- Options Indexes FollowSymLinks MultiViews
- AllowOverride All
- Order allow,deny
- allow from all
-
-
- ScriptAlias /cgi-bin/ /usr/lib/cgi-bin/
-
- AllowOverride None
- Options +ExecCGI -MultiViews +SymLinksIfOwnerMatch
- Order allow,deny
- Allow from all
-
-
- ErrorLog ${APACHE_LOG_DIR}/error.log
-
- # Possible values include: debug, info, notice, warn, error, crit,
- # alert, emerg.
- LogLevel warn
-
- CustomLog ${APACHE_LOG_DIR}/ssl_access.log combined
-
- # SSL Engine Switch:
- # Enable/Disable SSL for this virtual host.
- SSLEngine on
-
- # do not allow unsecured connections
- # SSLRequireSSL
- SSLCipherSuite HIGH:MEDIUM
- SSLCertificateFile /etc/ssl/certs/cloud.crt
- SSLCertificateKeyFile /etc/ssl/private/cloud.key
-
-
- SSLOptions +StdEnvVars
-
-
- SSLOptions +StdEnvVars
-
-
- BrowserMatch "MSIE [2-6]" \
- nokeepalive ssl-unclean-shutdown \
- downgrade-1.0 force-response-1.0
- # MSIE 7 and newer should be able to use keepalive
- BrowserMatch "MSIE [17-9]" ssl-unclean-shutdown
-
-
-
-and activate owncloud by running
-
- a2ensite owncloud
- service apache2 reload
-
-Then go ahead an configure owncloud by connecting to **https://cloud.jhausse.net/** in a web browswer.
-
-That's it! Now you've got your own Google Drive, Calendar, Contacts, Dropbox, and Gmail! Enjoy your freshly recovered privacy! :-)
-
-### Sync your devices to the cloud ###
-
-To sync your emails, you can just use your favorite email client: the standard email program on Android or iOS, [k9mail][37], or Thunderbird on your PC. Or you can also use the webmail we set up.
-
-How to sync your calendar and contacts with the cloud is described in the doc of owncloud. On Android, I'm using the CalDAV-Sync and CardDAV-Sync apps which act as bridges between the Android calendar and contacts apps of the phone and the owncloud server.
-
-For files, there is an Android app called Owncloud to access your files from your phone and automatically upload pictures and videos you take to your cloud. Accessing your files on the your Mac/PC is easy and [well described in the Owncloud documentation][38].
-
-### Last tips ###
-
-During the first few weeks, it's a good idea to monitor **/var/log/syslog** and **/var/log/mail.log** on a daily basis and make sure everything everything is running smoothly. It's important to do so before you invite others (friends, family, ...) to be hosted on your server; you might loose their trust in self-hosting for good if they trust you with their data and the server suddently becomes unavailable.
-
-To add another email user, just add a row to the **virtual_users** table of the **mailserver** DB.
-
-To add a domain, just add a row to the **virtual_domains** table. Then update **/etc/opendkim/SigningTable** to get outgoing emails signed, upload the OpenDKIM key to the zone, and reload OpenDKIM.
-
-Owncloud has its own user DB which can be managed by logging in in Owncloud as administrator.
-
-Finally, it's important to think in advance of a solution in case your server becomes temporarily unavailable. For instance, where would your mails go until your server returns? One solution would be to find a friend who can act as your backup MX, while you act as his backup MX (see the **relay_domains** and **relay_recipient_maps** setting in Postfix's **main.cf** file). Similarly, what if your server is compromised and a malicious individual erases all your files there? For that, it's important to think of a regular backup system. Linode offers backups as an option. On 1984.is, I set up a basic but sufficient automatic backup system using on crontabs and scp.
-
---------------------------------------------------------------------------------
-
-via: https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/
-
-作者:[Roudy Jhausse ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:aboutlinux@free.fr
-[1]:https://history.google.com/history/
-[2]:http://research.google.com/workatgoogle.html
-[3]:http://www.attac.org/
-[4]:http://www.nytimes.com/2012/02/19/magazine/shopping-habits.html?pagewanted=all
-[5]:http://vimeo.com/ondemand/termsandconditions
-[6]:http://www.techtimes.com/articles/21670/20141208/sony-pictures-hack-nightmare-week-celebs-data-leak-and-threatening-emails-to-employees.htm
-[7]:http://blog.backupify.com/2012/07/25/what-is-my-gmail-account-really-worth/
-[8]:http://adage.com/article/digital/worth-facebook-google/293042/
-[9]:http://vimeo.com/ondemand/termsandconditions
-[10]:https://prism-break.org/en/
-[11]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#VPS
-[12]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#mail
-[13]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#dspam
-[14]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#SPF
-[15]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#owncloud
-[16]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#sync
-[17]:http://linuxfr.org/news/heberger-son-courriel
-[18]:http://sealedabstract.com/code/nsa-proof-your-e-mail-in-2-hours/
-[19]:http://www.1984.is/
-[20]:http://www.linode.com/
-[21]:http://www.greenpeace.org/international/Global/international/publications/climate/2012/iCoal/HowCleanisYourCloud.pdf
-[22]:http://www.1984.is/about/
-[23]:http://www.fsf.org/
-[24]:https://www.gnupg.org/
-[25]:http://www.gandi.net/
-[26]:http://www.codinghorror.com/blog/2010/04/so-youd-like-to-send-some-email-through-code.html
-[27]:http://www.postfix.org/
-[28]:http://postgrey.schweikert.ch/
-[29]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#testPort25
-[30]:http://dspam.sourceforge.net/
-[31]:http://www.microsoft.com/mscorp/safety/content/technologies/senderid/wizard/
-[32]:https://www.howtoforge.com/tutorial/build-your-own-cloud-on-debian-wheezy/#PTR
-[33]:http://opendkim.org/opendkim-README
-[34]:http://www.brandonchecketts.com/emailtest.php
-[35]:http://owncloud.org/
-[36]:http://owncloud.org/install/
-[37]:https://code.google.com/p/k9mail/
-[38]:http://doc.owncloud.org/server/7.0/user_manual/files/files.html
diff --git a/sources/tech/20150119 How to Install Cherokee Lightweight Web Server on Ubuntu 14.04.md b/sources/tech/20150119 How to Install Cherokee Lightweight Web Server on Ubuntu 14.04.md
deleted file mode 100644
index 1e2ba90d6e..0000000000
--- a/sources/tech/20150119 How to Install Cherokee Lightweight Web Server on Ubuntu 14.04.md
+++ /dev/null
@@ -1,87 +0,0 @@
-How to Install Cherokee Lightweight Web Server on Ubuntu 14.04
-================================================================================
-**Cherokee** is an free and open source high performance, lightweight, full-featured web server and running on major platform (Linux, Mac OS X, Solaris, and BSD). It is compatible with TLS/SSL,FastCGI, SCGI, PHP, uWSGI, SSI, CGI, LDAP, HTTP proxying, video streaming, content caching, traffic shaping, virtual hosts, Apache compatible log files, and load balancing.
-
-Today we'll explains how to install and configure the Light Weight Cherokeeweb server on Ubuntu Server edition 14.04 LTS (Trusty) and should also work with 12.04, 12.10 and 13. 04, just skip the modification of source list.
-
-Step by step install and configure the Cherokee web server on Ubuntu Server edition
-
-### 1. Updating Ubuntu Package Index ###
-
-First, Login into Ubuntu Server and make sure your ubuntu server update, run the following commands one by one, and install any available updates:
-
- sudo apt-get update
-
- sudo apt-get upgrade
-
-### 2. Adding PPA ###
-
-Add the PPA cherokee webserver. by running the following commands
-
- sudo add-apt-repository ppa:cherokee-webserver
-
- sudo apt-get update
-
-Now, only for servers running Ubuntu 14.04 LTS (Trusty) follow this step below
-
- cd /etc/apt/sources.list.d
-
- nano cherokee-webserver-ppa-trusty.list
-
- replace:
-
- deb http://ppa.launchpad.net/cherokee-webserver/ppa/ubuntu trusty main
-
- to:
-
- deb http://ppa.launchpad.net/cherokee-webserver/ppa/ubuntu saucy main
-
-**then again run:**
-
- sudo apt-get update
-
-### 3. Installing Cherokee Web Server using apt-get ###
-
-Enter the following command to install the Cherokee web server including Module SSL
-
- sudo apt-get install cherokee cherokee-admin cherokee-doc libcherokee-mod-libssl libcherokee-mod-streaming libcherokee-mod-rrd
-
-### 4. Configuring Cherokee ###
-
- sudo service cherokee start
-
-The best part about using its Web Server is being able to manage all of its configurations through a simple to use web interface. This interface, known as cherokee-admin, is the recommended means of administering cherokee web server through web browser. Start cherokee-admin by running the following command:
-
- sudo cherokee-admin
-
-**Note: The cherokee-admin will display the administration user name, One-time Password and administration web interface.**
-
-**Note down your One-Time password. You will need this when you login to its admin web interface.**
-
-By default, cherokee-admin can only accessed from localhost. If you need to access the admin for other network address using the parameter ‘**-b**’. If you doesn’t mention any ip address, it will automatically listen to all network interfaces. Then you can connect to cherokee-admin from other network address.
-
- sudo cherokee-admin -b
-
-If you need to access its admin from specific network address
-
- sudo cherokee-admin -b 192.168.1.102
-
-### 5. Browse your Cherokee Admin Panel ###
-
-Now you can access the administration panel from you favorite browser by typing http://hostname_or_IP:9090/ for me its http://127.0.0.1:9090/, it will appear on your browser like this:
-
-
-
-Hurray, we have successfully installed and configured Cherokee Web Server in our Ubuntu Server.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/install-cherokee-lightweight-web-server-ubuntu-14-04/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
\ No newline at end of file
diff --git a/sources/tech/20150119 How to Remember and Restore Running Applications on Next Logon.md b/sources/tech/20150119 How to Remember and Restore Running Applications on Next Logon.md
deleted file mode 100644
index 457d6788e2..0000000000
--- a/sources/tech/20150119 How to Remember and Restore Running Applications on Next Logon.md
+++ /dev/null
@@ -1,97 +0,0 @@
-How to Remember and Restore Running Applications on Next Logon
-================================================================================
-You have made some apps running in your Ubuntu and don't want to stop the process, just managed your windows and opened your stuffs needed to work. Then, something else demands your attention or you have battery low in your machine and you have to shut down. No worries. You can have Ubuntu remember all your running applications and restore them the next time you log in.
-
-Now, to make our Ubuntu remember the applications you have running in our current session and restore them the next time our log in, We will use the dconf-editor. This tool replaces the gconf-editor available in previous versions of Ubuntu but is not available by default. To install the dconf-editor, you need to run sudo apt-get install dconf-editor.
-
- $ sudo apt-get install dconf-tools
-
-Once the dconf-editor is installed, you can open dconf-editor from Application Menu. Or you can run it from terminal or run command (alt+f2):
-
- $ dconf-editor
-
-In the “dconf Editor” window, click the right arrow next to “org” in the left pane to expand that branch of the tree.
-
-
-
-Under “org”, click the right arrow next to “gnome.”
-
-
-
-Under “gnome,” click “gnome-session”. In the right pane, select the “auto-save-session” check box to turn on the option.
-
-
-
-After you check or tick it, close the “Dconf Editor” by clicking the close button (X) in the upper-left corner of the window which is by default.
-
-
-
-The next time you log out and log back in, all of your running applications will be restored.
-
-Hurray, we have successfully configured our Ubuntu 14.04 LTS "Trusty" to remember automatically running applications from our last session.
-
-Now, on this same tutorial, we'll gonna also learn **how to enable hibernation in our Ubuntu 14.04 LTS**:
-
-Before getting started, press Ctrl+ALt+T on your keyboard to open the terminal. When it opens, run:
-
- sudo pm-hibernate
-
-After your computer turns off, switch it back on. Did your open applications re-open? If hibernate doesn’t work, check if your swap partition is at least as large as your available RAM.
-
-You can check your Swap Area Partition Size from System Monitor, you can get it from the App Menu or run command in terminal.
-
- $ gnome-system-monitor
-
-### Enable Hibernate in System Tray Menu: ###
-
-The indicator-session was updated to use logind instead of upower. Hibernate is disabled by default in both upower and logind.
-
-To re-enable hibernate, run the commands below one by one to edit the config file:
-
- sudo -i
-
- cd /var/lib/polkit-1/localauthority/50-local.d/
-
- gedit com.ubuntu.enable-hibernate.pkla
-
-**Tips: if the config file does not work for you, try another one by changing /var/lib to /etc in the code.**
-
-Copy and paste below lines into the file and save it.
-
- [Re-enable hibernate by default in upower]
- Identity=unix-user:*
- Action=org.freedesktop.upower.hibernate
- ResultActive=yes
-
- [Re-enable hibernate by default in logind]
- Identity=unix-user:*
- Action=org.freedesktop.login1.hibernate
- ResultActive=yes
-
-Restart your computer and done.
-
-### Hibernate your laptop when lid is closed: ###
-
-1.Edit “/etc/systemd/logind.conf” via command:
-
- $ sudo nano /etc/systemd/logind.conf
-
-2. Change the line **#HandleLidSwitch=suspend to HandleLidSwitch=hibernate** and save the file.
-
-3. Run command below or just restart your computer to apply changes:
-
- $ sudo restart systemd-logind
-
-That’s it. Enjoy! Now, we have both dconf and hibernation on :) Now, your Ubuntu will completely remember your opened apps and stuffs.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/ubuntu-how-to/remember-running-applications-ubuntu/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
\ No newline at end of file
diff --git a/sources/tech/20150119 Unity Greeter Badges Brings Missing Session Icons to Ubuntu Login Screen.md b/sources/tech/20150119 Unity Greeter Badges Brings Missing Session Icons to Ubuntu Login Screen.md
deleted file mode 100644
index 1aac09e11a..0000000000
--- a/sources/tech/20150119 Unity Greeter Badges Brings Missing Session Icons to Ubuntu Login Screen.md
+++ /dev/null
@@ -1,58 +0,0 @@
-‘Unity Greeter Badges’ Brings Missing Session Icons to Ubuntu Login Screen
-================================================================================
-
-
-**A new package available in Ubuntu 15.04 solves a petty gripe I have with the Unity Greeter: the lack of branded icons for alternative desktop sessions like Cinnamon.**
-
-I know it’s a minor quibble; it’s a visual paper cut with minimal impact for most. But the inconsistency niggles me because Ubuntu ships with icons for a number of sessions, including Unity, GNOME and KDE. Other DEs, including some of its own flavors like Xubuntu, default to showing a plain white dot in the session switcher list and the main user pod.
-
-The inconsistency these dots create jars, even if it is only for a fleeting moment, not just in design. It’s in usability too. Branded glyphs are helpful in letting us know what session we’re about to log in to.
-
-For instance, can you tell what session this is?
-
-
-
-Budgie? Maybe MATE? Could be Cinnamon…I’d have to click on it and check first.
-
-It doesn’t have to be this way. The Unity Greeter is built such that the developers of desktop environments can ship badges that appear in the Greeter (and some do). But in many cases, like MATE whose packages are imported from upstream Debian, the inclination to carry an “Ubuntu-specific patch” is either not desirable or not possible.
-
-### A Solution Is Badged ###
-
-Experienced Debian maintainer [Doug Torrance][1] has a solution to fix this usability paper cut. Rather than rely on desktop makers themselves to add branded badges to their packages, and rather than burden Ubuntu with the responsibility of maintaining it, Torrance has created a separate ‘unity-greeter-badges’ package to house them.
-
-In assuming responsibility for providing the session glyphs directly, this package ensure that new and old window managers, session and desktops alike are catered for.
-
-Among the 30 or so desktop environments it bundles new session badges for are:
-
-- Xubuntu
-- Cinnamon
-- MATE
-- Cairo-Dock
-- Xmonad
-- Awesome
-- OpenBox
-- Pantheon
-
-The best part is that ‘**Unity-Greeter-Badges**’ has been accepted into Ubuntu 15.04. That means Torrance’s package will be available to install directly, no PPAs or downloads needed. In not being part of a core package like the Unity Greeter it can be updated with newer icons in a more efficient and timely manner.
-
-If you’re running Ubuntu 15.04 you will find the package available to install from the Software Center in the coming days.
-
-Don’t want to wait until 15.04? Torrance has made .deb installers for Ubuntu 14.04 LTS and Ubuntu 14.10 users.
-
-- [Download unity-greeter-badges for Ubuntu 14.04][2]
-- [Download unity-greeter-badges for Ubuntu 14.10][3]
-
---------------------------------------------------------------------------------
-
-via: http://www.omgubuntu.co.uk/2015/01/unity-greeter-badges-brings-missing-session-icons-ubuntu-login-screen
-
-作者:[Joey-Elijah Sneddon][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:https://plus.google.com/117485690627814051450/?rel=author
-[1]:https://launchpad.net/~profzoom
-[2]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.04.1_all.deb
-[3]:https://launchpad.net/~profzoom/+archive/ubuntu/misc/+files/unity-greeter-badges_0.1-0ubuntu1%7E201412111501%7Eubuntu14.10.1_all.deb
\ No newline at end of file
diff --git a/sources/tech/20150121 How to Monitor Network Usage with nload in Linux.md b/sources/tech/20150121 How to Monitor Network Usage with nload in Linux.md
deleted file mode 100644
index afbfa4eab6..0000000000
--- a/sources/tech/20150121 How to Monitor Network Usage with nload in Linux.md
+++ /dev/null
@@ -1,206 +0,0 @@
-How to Monitor Network Usage with nload in Linux
-================================================================================
-nload is a free linux utility that can help the linux user or sysadmin to monitor network traffic and bandwidth usage in real time by providing two simple graphs: one per incoming traffic and one for outgoing traffic.
-
-I really like to use **nload** to display information on my screen about the current download speed, the total incoming traffic, and the average download speed. The graphs reported by nload tool are very easy to interpret and what is the most important thing they are very helpful.
-
-According to the manual pages it monitors all network devices by default, but you can easily specify the device you want to monitor and also switch between different network devices using the arrow keys. There are many options avaliable such as -t to determine refresh interval of the display in milliseconds (the default value of interval is 500), -m to show multiple devices at the same time(traffic graphs are not shown when this option is used), -u to set the type of unit used for the display of traffic numbers and many others that we are going to explore and practise in this tutorial.
-
-### How to install nload on your linux machine ###
-
-**Ubuntu** and **Fedora** users can easily install nload from the default repositories.
-
-Install nload on Ubuntu by using the following command.
-
- sudo apt-get install nload
-
-Install nload on Fedora by using the following command.
-
- sudo yum install nload
-
-What about **CentOS** users? Just type the following command on your machine and you will get nload installed.
-
- sudo yum install nload
-
-The following command will help you to install nload on OpenBSD systems.
-
- sudo pkg_add -i nload
-
-A very effective way to install software on linux machine is to compile by source as you can download and install the latest version which usually means better performance, cool features and less bugs.
-
-### How to install nload from source ###
-
-The first thing you need to do before installing nload from source you need to download it and to do this I like to use the wget uility which is available by default on many linux machines. This free utility helps linux users to download files from the web in a non-interactive way and has support for the following protocols.
-
-- HTTP
-- HTTPS
-- FTP
-
-Change directory to **/tmp** by using the following command.
-
- cd /tmp
-
-Now type the following command in your terminal to download the latest version of nload on your linux machine.
-
- wget http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
-
-If you don't like to use the linux wget utility you can easily download it from the [official][1] source by just a mouse click.
-
-The download will finish in no time as it is a small software. The next step is to untar the file you downloaded with the help of the **tar** utility.
-
-The tar archiving utility can be used to store and extract files from a tape or disk archive. There are many options available in this tool but we need the followings to perform our operation:
-
-1. **-x** to extract files from an archive
-1. **-v** to run in verbose mode
-1. **-f** to specify the files
-
-For example:
-
- tar xvf example.tar
-
-Now that you learned how to use the tar utility I am very sure you know how to untar .tar archives from the commandline.
-
- tar xvf nload-0.7.4.tar.gz
-
-Then use the cd command to change directory to nload*.
-
- cd nload*
-
-It looks like this on my system.
-
- oltjano@baby:/tmp/nload-0.7.4$
-
-Now run the command
-
- ./configure
-
-to to configure the package for your system.
-
- ./configure
-
-Alot of stuff is going to be displayed on your screen. The following screenshot demonstrates how it is going to look like.
-
-
-
-Then compile the nload with the following command.
-
- make
-
-
-
-And finally install nload on your linux machine with the following command.
-
- sudo make install
-
-
-
-Now that the installation of nload is finished it is time for you to learn how to use it.
-
-### How to use nload ###
-
-I like to explore so type the following command on your terminal.
-
- nload
-
-What do you see?
-
-I get the following.
-
-
-
-As you can see from the above screenshot I get information on:
-
-### Incoming Traffic ###
-
-#### Current download speed ####
-
-
-
-#### Average download speed ####
-
-
-
-#### Minimum download speed ####
-
-
-
-#### Maximum download speed ####
-
-
-
-#### Total incoming traffic in bytes by default ####
-
-
-
-### Outgoing Traffic ###
-
-The same goes for outgoing traffic.
-
-#### Some useful options of nload ####
-
-Use the option
-
- -u
-
-to set set the type of unit used for the display of traffic numbers.
-
-The following command will help you to use the MBit/s unit.
-
- nload -u m
-
-The following screenshot shows the result of the above command.
-
-
-
-Try the following command and see the results.
-
- nload -u g
-
-
-
-There is also the option **-U**. According to the manual pages it is same as the option -u but only for an amount of data. I tested this option and to be honest it very helpful when you want to check the total amount of traffic be it incoming or outgoing.
-
- nload -U G
-
-
-
-As you can see from the above screenshot the command **nload -U G** helps to display the total amount of data (incoming or outgoing) in Gbyte.
-
-Another useful option I like to use with nload is the option **-t**. This option is used to refresh interval of display in milliseconds which is 500 by default.
-
-I like to experiment a little by using the following command.
-
- nload -t 130
-
-So what the above command does is that it sets the display to refresh every 130 milliseconds. It is recommended to no specify refresh intervals shorter than about 100 milliseconds as nload will generate reports with mistakes during the calculations.
-
-Another option is **-a**. It is used when you want to set the length in seconds of the time window for average calculation which is 300 seconds by default.
-
-What if you want to monitor a specific network device? It is very easy to do that, just specify the device or the list of devices you want to monitor like shown below.
-
- nload wlan0
-
-
-
-The following syntax can help to monitor specific multiple devices.
-
- nload [options] device1 device2 devicen
-
-For example use the following command to monitor eth0 and wlan0.
-
- nload wlan0 eth0
-
-And if you run the command nload without any option it will monitor all auto-detected devices, you can display graphs for each one of them by using the right and left arrow keys.
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/monitoring-2/monitor-network-usage-nload/
-
-作者:[Oltjano Terpollari][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/oltjano/
-[1]:http://www.roland-riegel.de/nload/nload-0.7.4.tar.gz
\ No newline at end of file
diff --git a/sources/tech/20150121 How to apply image effects to pictures on Raspberry Pi.md b/sources/tech/20150121 How to apply image effects to pictures on Raspberry Pi.md
deleted file mode 100644
index 920f542832..0000000000
--- a/sources/tech/20150121 How to apply image effects to pictures on Raspberry Pi.md
+++ /dev/null
@@ -1,69 +0,0 @@
-How to apply image effects to pictures on Raspberry Pi
-================================================================================
-Like a common pocket camera which has a built-in function to add various effects on captured photos, [Raspberry Pi camera board][1] ("raspi cam") can actually do the same. With the help of raspistill camera control options, we can add the image effects function like we have in a pocket camera.
-
-There are [three comman-line applications][2] which can be utilized for [taking videos or pictures][3] with raspi cam, and one of them is the raspistill application. The raspistill tool offers various camera control options such as sharpness, contrast, brightness, saturation, ISO, exposure, automatic white balance (AWB), image effects.
-
-In this article I will show how to apply exposure, AWB, and other image effects with raspistill while capturing pictures using raspi cam. To automate the process, I wrote a simple Python script which takes pictures and automatically applies a series of image effects to the pictures. The raspi cam documentation describes available types of the exposure, AWB, and image effects. In total, the raspi cam offers 16 types of image effects, 12 types of exposure, and 10 types of AWB values.
-
-The simple Python script looks like the following.
-
- #!/usb/bin/python
- import os
- import time
- import subprocess
- list_ex=['auto','night']
- list_awb=['auto','cloud',flash']
- list_ifx=['blur','cartoon','colourswap','emboss','film','gpen','hatch','negative','oilpaint','posterise','sketch','solarise','watercolour']
- x=0
- for ex in list_ex:
- for awb in list_awb:
- for ifx in list_ifx:
- x=x+1
- filename='img_'+ex+'_'+awb+'_'+ifx+'.jpg'
- cmd='raspistill -o '+filename+' -n -t 1000 -ex '+ex+' -awb '+awb+' -ifx '+ifx+' -w 640 -h 480'
- pid=subprocess.call(cmd,shell=True)
- print "["+str(x)+"]-"+ex+"_"+awb+"_"+ifx+".jpg"
- time.sleep(0.25)
- print "End of image capture"
-
-The Python script operates as follows. First, create three array/list variable for the exposure, AWB and image effects. In the example, we use 2 types of exposure, 3 types of AWB, and 13 types of image effects values. Then make nested loops for applying the value of the three variables that we have. Inside the nested loop, execute the raspistill application. We specify (1) the output filename; (2) exposure value; (3) AWB value; (4) image effect value; (5) the time to take a photo, which is set to 1 second; and (6) the size of the photo, which is set to 640x480px. This Python script will create 78 different versions of a captured photo with a combination of 2 types of exposure, 3 types of AWB, and 13 types of image effects.
-
-To execute the Python script, simply type:
-
- $ python name_of_this_script.py
-
-Here is the first round of the sample result.
-
-
-
-### Bonus ###
-
-For those who are more interested, there is another way to access and control the raspi cam besides raspistill. [Picamera][4] a pure Python interface which provides APIs for accessing and controlling raspi cam, so that one can build a complex program for utilizing raspi cam according to their needs. If you are skilled at Python, picamera is a good feature-complete interface for implementing your raspi cam project. The picamera interface is included by default in the recent image of Raspbian. If your [Raspberry Pi][5] operating system is not new or not Raspbian, you can install it on your system as follows.
-
-First, install pip on your system by following [this guideline][6].
-
-Then, install picamera as follows.
-
- $ sudo pip install picamera
-
-Refer to the [official documentation][7] on how to use picamera.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/apply-image-effects-pictures-raspberrypi.html
-
-作者:[Kristophorus Hadiono][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/kristophorus
-[1]:http://xmodulo.com/go/picam
-[2]:http://www.raspberrypi.org/documentation/usage/camera/raspicam/
-[3]:http://xmodulo.com/install-raspberry-pi-camera-board.html
-[4]:https://pypi.python.org/pypi/picamera
-[5]:http://xmodulo.com/go/raspberrypi
-[6]:http://ask.xmodulo.com/install-pip-linux.html
-[7]:http://picamera.readthedocs.org/
\ No newline at end of file
diff --git a/sources/tech/20150122 Linux FAQs with Answers--How to use yum to download a RPM package without installing it.md b/sources/tech/20150122 Linux FAQs with Answers--How to use yum to download a RPM package without installing it.md
deleted file mode 100644
index f1663888c8..0000000000
--- a/sources/tech/20150122 Linux FAQs with Answers--How to use yum to download a RPM package without installing it.md
+++ /dev/null
@@ -1,56 +0,0 @@
-Linux FAQs with Answers--How to use yum to download a RPM package without installing it
-================================================================================
-> **Question**: I want to download a RPM package from Red Hat's standard repositories. Can I use yum command to download a RPM package without installing it?
-
-yum is the default package manager for Red Hat based systems, such as CentOS, Fedora or RHEL. Using yum, you can install or update a RPM package while resolving its package dependencies automatically. What if you want to download a RPM package without installing it on the system? For example, you may want to archive some RPM packages for later use or to install them on another machine.
-
-Here is how to download a RPM package from yum repositories.
-
-### Method One: Yum ###
-
-The yum command itself can be used to download a RPM package. The standard yum command offers '--downloadonly' option for this purpose.
-
- $ sudo yum install --downloadonly
-
-By default, a downloaded RPM package will be saved in:
-
- /var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
-
-In the above, [repository] is the name of the repository (e.g., base, fedora, updates) from which the package is downloaded.
-
-If you want to download a package to a specific directory (e.g., /tmp):
-
- $ sudo yum install --downloadonly --downloaddir=/tmp
-
-Note that if a package to download has any unmet dependencies, yum will download all dependent packages as well. None of them will be installed.
-
-One important thing is that on CentOS/RHEL 6 or earlier, you will need to install a separate yum plugin (called yum-plugin-downloadonly) to be able to use '--downloadonly' command option:
-
- $ sudo yum install yum-plugin-downloadonly
-
-Without this plugin, you will get the following error with yum:
-
- Command line error: no such option: --downloadonly
-
-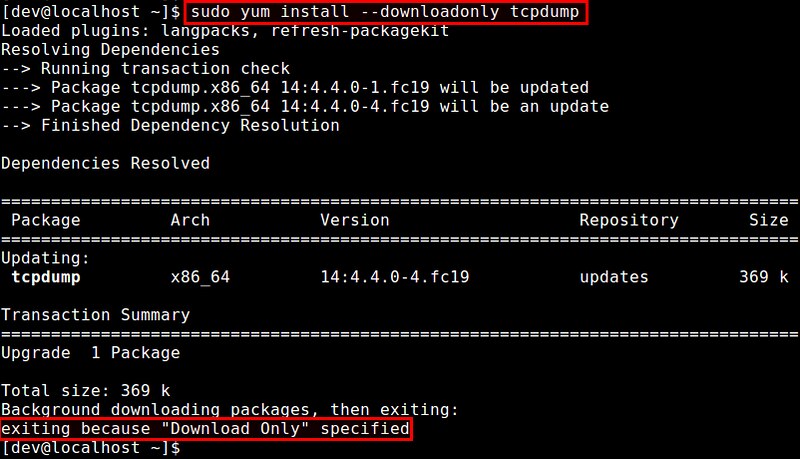
-
-### Method Two: Yumdownloader ###
-
-Another method to download a RPM package is via a dedicated package downloader tool called yumdownloader. This tool is part of yum-utils package which contains a suite of helper tools for yum package manager.
-
- $ sudo yum install yum-utils
-
-To download a RPM package:
-
- $ sudo yumdownloader
-
-The downloaded package will be saved in the current directory. You need to use root privilege because yumdownloader will update package index files during downloading. Unlike yum command above, none of the dependent package(s) will be downloaded.
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/yum-download-rpm-package.html
-
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
\ No newline at end of file
diff --git a/sources/tech/20150123 How to make a file immutable on Linux.md b/sources/tech/20150123 How to make a file immutable on Linux.md
deleted file mode 100644
index 7d46d1de68..0000000000
--- a/sources/tech/20150123 How to make a file immutable on Linux.md
+++ /dev/null
@@ -1,74 +0,0 @@
-Translating by Medusar
-
-How to make a file immutable on Linux
-================================================================================
-Suppose you want to write-protect some important files on Linux, so that they cannot be deleted or tampered with by accident or otherwise. In other cases, you may want to prevent certain configuration files from being overwritten automatically by software. While changing their ownership or permission bits on the files by using chown or chmod is one way to deal with this situation, this is not a perfect solution as it cannot prevent any action done with root privilege. That is when chattr comes in handy.
-
-chattr is a Linux command which allows one to set or unset attributes on a file, which are separate from the standard (read, write, execute) file permission. A related command is lsattr which shows which attributes are set on a file. While file attributes managed by chattr and lsattr are originally supported by EXT file systems (EXT2/3/4) only, this feature is now available on many other native Linux file systems such as XFS, Btrfs, ReiserFS, etc.
-
-In this tutorial, I am going to demonstrate how to use chattr to make files immutable on Linux.
-
-chattr and lsattr commands are a part of e2fsprogs package which comes pre-installed on all modern Linux distributions.
-
-Basic syntax of chattr is as follows.
-
- $ chattr [-RVf] [operator][attribute(s)] files...
-
-The operator can be '+' (which adds selected attributes to attribute list), '-' (which removes selected attributes from attribute list), or '=' (which forces selected attributes only).
-
-Some of available attributes are the following.
-
-- **a**: can be opened in append mode only.
-- **A**: do not update atime (file access time).
-- **c**: automatically compressed when written to disk.
-- **C**: turn off copy-on-write.
-- **i**: set immutable.
-- **s**: securely deleted with automatic zeroing.
-
-### Immutable Attribute ###
-
-To make a file immutable, you can add "immutable" attribute to the file as follows. For example, to write-protect /etc/passwd file:
-
- $ sudo chattr +i /etc/passwd
-
-Note that you must use root privilege to set or unset "immutable" attribute on a file. Now verify that "immutable" attribute is added to the file successfully.
-
- $ lsattr /etc/passwd
-
-Once the file is set immutable, this file is impervious to change for any user. Even the root cannot modify, remove, overwrite, move or rename the file. You will need to unset the immutable attribute before you can tamper with the file again.
-
-To unset the immutable attribute, use the following command:
-
- $ sudo chattr -i /etc/passwd
-
-
-
-If you want to make a whole directory (e.g., /etc) including all its content immutable at once recursively, use "-R" option:
-
- $ sudo chattr -R +i /etc
-
-### Append Only Attribute ###
-
-Another useful attribute is "append-only" attribute which forces a file to grow only. You cannot overwrite or delete a file with "append-only" attribute set. This attribute can be useful when you want to prevent a log file from being cleared by accident.
-
-Similar to immutable attribute, you can turn a file into "append-only" mode by:
-
- $ sudo chattr +a /var/log/syslog
-
-Note that when you copy an immutable or append-only file to another file, those attributes will not be preserved on the newly created file.
-
-### Conclusion ###
-
-In this tutorial, I showed how to use chattr and lsattr commands to manage additional file attributes to prevent (accidental or otherwise) file tampering. Beware that you cannot rely on chattr as a security measure as one can easily undo immutability. One possible way to address this limitation is to restrict the availability of chattr command itself, or drop kernel capability CAP_LINUX_IMMUTABLE. For more details on chattr and available attributes, refer to its man page.
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/make-file-immutable-linux.html
-
-作者:[Dan Nanni][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/nanni
diff --git a/sources/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md b/sources/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md
deleted file mode 100644
index db03257941..0000000000
--- a/sources/tech/20150126 Improve system performance by moving your log files to RAM Using Ramlog.md
+++ /dev/null
@@ -1,112 +0,0 @@
-Improve system performance by moving your log files to RAM Using Ramlog
-================================================================================
-Ramlog act as a system daemon. On startup it creates ramdisk, it copies files from /var/log into ramdisk and mounts ramdisk as /var/log. All logs after that will be updated on ramdisk. Logs on harddrive are kept in folder /var/log.hdd which is updated when ramlog is restarted or stopped. On shutdown it saves log files back to harddisk so logs are consistent. Ramlog 2.x is using tmpfs by default, ramfs and kernel ramdisk are suppored as well. Program rsync is used for log synchronization.
-
-Note: Logs not saved to harddrive are lost in case of power outage or kernel panic.
-
-Install ramlog if you have enough of free memory and you want to keep your logs on ramdisk. It is good for notebook users, for systems with UPS or for systems running from flash -- to save some write cycles.
-
-How it works and what it does:
-
-1.Ramlog starts among the first daemons (it depends on other daemons you have installed).
-
-2.Directory /var/log.hdd is created and hardlinked to /var/log.
-
-3.In case tmpfs (default) or ramfs is used, it is mounted over /var/log
-
-If kernel ramdisk is used, ramdisk created in /dev/ram9 and it is mounted to /var/log, by default ramlog takes all ramdisk memory specified by kernel argument "ramdisk_size".
-
-5.All other daemons are started and all logs are updated in ramdisk. Logrotate works on ramdisk as well.
-
-6.In case ramlog is restarted (by default it is one time per day), directory /var/log.hdd is synchronized with /var/log using rsync. Frequency of the automatic log saves can be controller via cron, by default, the ramlog file is placed into /etc/cron.daily
-
-7.On shutdown ramlog shuts among the last daemons.
-
-8. During ramlog stop phase files from /var/log.hdd are synchronized with /var/log
-Then /var/log is unmounted, /var/log.hdd is unmounted as well and empty directory /var/log.hdd is deleted.
-
-**Note:- This article is for advanced users only**
-
-### Install Ramlog in Ubuntu ###
-
-First you need to download the .deb package from [here][1] using the following command
-
- wget http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
-
-Now you should be having ramlog_2.0.0_all.deb package install this package using the following command
-
- sudo dpkg -i ramlog_2.0.0_all.deb
-
-This will complete the installation now you need to run the following commands
-
- sudo update-rc.d ramlog start 2 2 3 4 5 . stop 99 0 1 6 .
-
-#Now update sysklogd in init levels, so it is stopped properly before ramlog is stopped:
-
- sudo update-rc.d -f sysklogd remove
-
- sudo update-rc.d sysklogd start 10 2 3 4 5 . stop 90 0 1 6 .
-
-Now you need to restart your system
-
- sudo reboot
-
-After rebooting you need to run ‘ramlog getlogsize' to determine the size of your actual /var/log.Add about 40% to that number to ensure your ramdisk has sufficient size -- this will be the ramdisk size
-
-Edit your boot manager config file such as /etc/grub.conf, /boot/grub/menu.lst or /etc/lilo.conf and add update the actual kernel by adding kernel paramter ‘ramdisk_size=xxx' where xxx is calculated ramdisk size
-
-### Configuring Ramlog ###
-
-Ramlog configuration file is located in /etc/default/ramlog on deb based systems and you can set there below variables:
-
-Variable (with default value):
-
-Description:
-
- RAMDISKTYPE=0
- # Values:
- # 0 -- tmpfs (can be swapped) -- default
- # 1 -- ramfs (no max size in older kernels,
- # cannot be swapped, not SELinux friendly)
- # 2 -- old kernel ramdisk
- TMPFS_RAMFS_SIZE=
- #Maximum size of memory to be used by tmpfs or ramfs.
- # The value can be percentage of total RAM or size in megabytes -- for example:
- # TMPFS_RAMFS_SIZE=40%
- # TMPFS_RAMFS_SIZE=100m
- # Empty value means default tmpfs/ramfs size which is 50% of total RAM.
- # For more options please check ‘man mount', section ‘Mount options for tmpfs'
- # (btw -- ramfs supports size limit in newer kernels
- # as well despite man says there are no mount options)
- # It has only effect if RAMDISKTYPE=0 or 1
- KERNEL_RAMDISK_SIZE=MAX
- #Kernel ramdisk size in kilobytes or MAX to use entire ramdisk.
- #It has only effect if RAMDISKTYPE=2
- LOGGING=1
- # 0=off, 1=on Logs can be found in /var/log/ramdisk
- LOGNAME=ramlog
- # name of the ramlog log file (makes sense if LOGGING=1)
- VERBOSE=1
- # 0=off, 1=on (if 1, teststartstop puts detials
- # to the logs and it is called after start or stop fails)
-
-### How to uninstall Ubuntu ###
-
-Open the terminal and run the following command
-
- sudo dpkg -P ramlog
-
-Note: If ramlog was running before you uninstalled it, you should reboot your box to finish uninstallation procedure.
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-files-to-ram-using-ramlog.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
-[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
\ No newline at end of file
diff --git a/sources/tech/20150126 Installing Cisco Packet tracer in Linux.md b/sources/tech/20150126 Installing Cisco Packet tracer in Linux.md
deleted file mode 100644
index edac7a7490..0000000000
--- a/sources/tech/20150126 Installing Cisco Packet tracer in Linux.md
+++ /dev/null
@@ -1,197 +0,0 @@
-Installing Cisco Packet tracer in Linux
-================================================================================
-
-
-### What is Cisco Packet tracer ? ###
-
-**Cisco Packet tracer** is a powerful network simulator tool which used to trained while we do some Cisco certifications. It provide us good Interface view for every router’s, and networking devices which with many options same as using the physical machines we can use unlimited devices in a network. We can create multiple network in single project to get trained like a professionals. packet tracer will provide us with simulated application layer protocols such as **HTTP**, **DNS**, Routing with **RIP**, **OSPF**, **EIGRP** etc.
-
-Now it has been released including **ASA 5505 firewall** with command line configurations. Packet tracer available commonly for Windows, but not for Linux distributions. Here we can download and get install Cisco package tracer.
-
-#### Newly released version of Cisco packet tracer: ####
-
-The next Cisco Packet Tracer version will be Cisco Packet Tracer 6.2 currently it’s under development.
-
-### My Environment Setup: ###
-
-**Hostname** : desktop1.unixmen.com
-
-**IP address** : 192.168.0.167
-
-**Operating system** : Ubuntu 14.04 LTS Desktop
-
- # hostname
-
- # ifconfig | grep inet
-
- # lsb_release -a
-
-
-
-### Step 1: First we need to download the Cisco Packet tracer. ###
-
-To download Packet Tracer from official website we need to have a token, sign into Cisco NetSpace and select CCNA > Cisco Packet Tracer from the Offerings menu to start the download. If we don’t have a token you can get from below link which i have uploaded in Dropbox.
-
-Official Website: [https://www.netacad.com/][1]
-
-Many of them don’t have a token to download packet tracer. For that i have uploaded it in dropbox you can get packet tracer from below URL.
-
-[Download Cisco Packet Tracer 6.1.1][2]
-
-
-
-### Step 2: Install Java: ###
-
-To get install packet tracer we need to have install Java, To get install java we can use the default or add the PPA repository and update the package cache to get install java.
-
-Install the default jre using
-
- # sudo apt-get install default-jre
-
-
-
-(or)
-
-Use the below step to get install Java Run-time and set the Environment.
-
-Download Java from official website : [Download Java][3]
-
- # tar -zxvf jre-8u31-linux-x64.tar.gz
-
- # sudo mkdir -p /usr/lib/jvm
-
- # sudo mv -v jre1.8.0_31 /usr/lib/jvm/
-
- # cd /usr/lib/jvm/
-
- # sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jre1.8.0_31/bin/java" 1
-
- # sudo update-alternatives --set "java" "/usr/lib/jvm/jre1.8.0_31/bin/java"
-
-Set the environment for java by editing the profile file and add the location. While we adding in profile file java will available for every user’s in our machine.
-
- # sudo vi /etc/profile
-
-Add the following entries to the bottom of your /etc/profile file:
-
- export JAVA_HOME=/usr/lib/jvm/jre1.8.0_31
- export PATH=$PATH:/usr/java/jre1.8.0_31/bin
-
-Run the below command to activate java path immediately.
-
- # . /etc/profile
-
-Check for the Java version and Environment:
-
- # echo $JAVA_HOME
-
- # java -version
-
-
-
-### Step 3: Enable 32bit architecture support: ###
-
-For Packet tracer we need some of 32bit packages. To get install 32bit packages we need to install some of dependencies using below commands.
-
- # sudo dpkg --add-architecture i386
- # sudo apt-get update
-
-
-
- # sudo apt-get install libc6:i386
-
- # sudo apt-get install lib32z1 lib32ncurses5 lib32bz2-1.0
-
- # sudo apt-get install libnss3-1d:i386 libqt4-qt3support:i386 libssl1.0.0:i386 libqtwebkit4:i386 libqt4-scripttools:i386
-
-
-
-### Step 4: Extract and install the package: ###
-
-Extract the downloaded package using tar command.
-
- # mv Cisco\ Packet\ Tracer\ 6.1.1\ Linux.tar.gz\?dl\=0 Cisco_Packet_tracer.tar.gz
-
- # tar -zxvf Cisco_Packet_tracer.tar.gz
-
-
-
-Navigate to the extracted directory
-
- # cd PacketTracer611Student
-
-Now it’s time to start the installation , Installation is very simple and just take few seconds.
-
- # sudo ./install
-
-
-
-
-
-To working with Package tracer we need to set the environment for that Cisco have provided the environment script, We need to run the script using root user to set the environment variable.
-
- # sudo ./set_ptenv.sh
-
-
-
-That’s it for installation step’s. next we need to create a Desktop Icon for Packet tracer.
-
-Create the Desktop Icon by creating desktop file under.
-
- # sudo su
-
- # cd /usr/share/applications
-
- # sudo vim packettracer.desktop
-
-
-
-Append the Below content to the file using vim editor or your favourite one.
-
- [Desktop Entry]
- Name= Packettracer
- Comment=Networking
- GenericName=Cisco Packettracer
- Exec=/opt/packettracer/packettracer
- Icon=/usr/share/icons/packettracer.jpeg
- StartupNotify=true
- Terminal=false
- Type=Application
-
-Save and quit using wq!
-
-
-
-### Step 5: Run the packet tracer ###
-
- # sudo packettracer
-
-That’s it we have successfully installed the packet tracer in Linux, These above steps are suitable for every debian based Linux distributions.
-
-
-
-
-
-### Resources ###
-
-Home page:[Netacad][4]
-
-### Conclusion: ###
-
-Here we have seen how to install packet tracer in Linux distribution, Hope you have find a way to get install your favorite Simulator in Linux.
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/installing-cisco-packet-tracer-linux/
-
-作者:[babin][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/babin/
-[1]:https://www.netacad.com/
-[2]:https://www.dropbox.com/s/5evz8gyqqvq3o3v/Cisco%20Packet%20Tracer%206.1.1%20Linux.tar.gz?dl=0
-[3]:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
-[4]:https://www.netacad.com/
\ No newline at end of file
diff --git a/sources/tech/20150126 iptraf--A TCP or UDP Network Monitoring Utility.md b/sources/tech/20150126 iptraf--A TCP or UDP Network Monitoring Utility.md
deleted file mode 100644
index f39d53a47d..0000000000
--- a/sources/tech/20150126 iptraf--A TCP or UDP Network Monitoring Utility.md
+++ /dev/null
@@ -1,66 +0,0 @@
-Ping -- Translating
-
-iptraf: A TCP/UDP Network Monitoring Utility
-================================================================================
-[iptraf][1] is an ncurses-based IP LAN monitor that generates various network statistics including TCP info, UDP counts, ICMP and OSPF information, Ethernet load info, node stats, IP checksum errors, and others.
-
-Its ncurses-based user interface also saves users from remembering command line switches.
-
-### Features ###
-
-- An IP traffic monitor that shows information on the IP traffic passing over your network. Includes TCP flag information, packet and byte counts, ICMP details, OSPF packet types.
-- General and detailed interface statistics showing IP, TCP, UDP, ICMP, non-IP and other IP packet counts, IP checksum errors, interface activity, packet size counts.
-- A TCP and UDP service monitor showing counts of incoming and outgoing packets for common TCP and UDP application ports
-- A LAN statistics module that discovers active hosts and shows statistics showing the data activity on them
-- TCP, UDP, and other protocol display filters, allowing you to view only traffic you’re interested in.
-- Logging
-- Supports Ethernet, FDDI, ISDN, SLIP, PPP, and loopback interface types.
-- Utilizes the built-in raw socket interface of the Linux kernel, allowing it to be used over a wide range of supported network cards.
-- Full-screen, menu-driven operation.
-
-To install
-
-### Ubuntu and it’s derivatives ###
-
- sudo apt-get install iptraf
-
-### Arch Linux and Its derivatives ###
-
- sudo pacman -S iptra
-
-### Fedora and its derivatives ###
-
- sudo yum install iptraf
-
-### Usage ###
-
-If the **iptraf** command is issued without any command-line options, the program comes up in interactive mode, with the various facilities accessed through the main menu.
-
-
-
-Menu for easy navigation.
-
-
-
-Selecting interfaces to monitor.
-
-
-
-Traffic from interface **ppp0**
-
-
-
-Enjoy!
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
-
-作者:[Enock Seth Nyamador][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/seth/
-[1]:http://iptraf.seul.org/about.html
diff --git a/sources/tech/20150128 Docker-1 Moving to Docker.md b/sources/tech/20150128 Docker-1 Moving to Docker.md
deleted file mode 100644
index 1c1d4b78cc..0000000000
--- a/sources/tech/20150128 Docker-1 Moving to Docker.md
+++ /dev/null
@@ -1,82 +0,0 @@
-Translating by mtunique
-Moving to Docker
-================================================================================
-
-
-[TL;DR] This is the first post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment. If you want, you can skip the intro (this post) and head directly to the technical topics (links at the bottom of the page).
-
-----------
-
-In the last month I've been strggling with devops. This is my very personal story and experience in trying to streamline a deployment process of a Raila app with Docker.
-
-When I started my company – [Touchware][1] – in 2012 I was a lone developer. Things were small, uncomplicated, they didn't require a lot of maintenance, nor they needed to scale all that much. During the course of last year though, we grew quite a lot (we are now a team of 10 people) and our server-side applications and API grew both in terms of scope and scale.
-
-### Step 1 - Heroku ###
-
-We still are a very small team and we need to make things going and run as smoothly as possible. When we looked for possible solutions, we decided to stick with something that would have removed from our shoulders the burden of managing hardware. Since we develop mainly Rails based applications and Heroku has a great support for RoR and various kind of DBs and cached (Postgres / Mongo / Redis etc.), the smartest choice seemed to be going with [Heroku][2]. And that's what we did.
-
-Heroku has a great support and great documentation and deploying apps is just so snappy! Only problem is, when you start growing, you need to have piles of cash around to pay the bills. Not the best deal, really.
-
-### Step 2 - Dokku ###
-
-In a rush to try and cut the costs, we decided to try with Dokku. [Dokku][3], quoting the Github repo is a
-
-> Docker powered mini-Heroku in around 100 lines of Bash
-
-We launched some instances on [DigitalOcean][4] with Dokku pre-installed and we gave it spin. Dokku is very much like Heroku, but when you have complex applications for whom you need to twear params, or where you need certain dependencies, it's just not gonna work out. We had an app where we needed to apply multiple transformations on images and we couldn't find a way to install the correct version of imagemagick into the dokku-based Docker container that was hosting our Rails app. We still have a couple of very simple apps that are running on Dokku, but we had to move some of them back to Heroku.
-
-### Step 3 - Docker ###
-
-A couple of months ago, since the problem of devops and managing production apps was resurfacing, I decided to try out [Docker][5]. Docker, in simple terms, allows developers to containerize applications and to ease the deployment. Since a Docker container basically has all the dependencies it needs to run your app, if everything runs fine on your laptop, you can be sure it'll also run like a champ in production on a remote server, be it an AWS E2C instance or a VPS on DigitalOcean.
-
-Docker IMHO is particularly interesting for the following reasons:
-
-- it promotes modularization and separation of concerns: you need to start thinking about your apps in terms of logical components (load balancer: 1 container, DB: 1 container, webapp: 1 container etc.);
-- it's very flexible in terms of deployment options: containers can be deployed to a wide variety of HW and can be easily redeployed to different servers / providers;
-- it allows for a very fine grained tuning of your app environment: you build the images your containers runs from, so you have plenty of options for configuring your environment exactly as you would like to.
-
-There are howerver some downsides:
-
-- the learning curve is quite steep (this is probably a very personal problem, but I'm talking as a software dev and not as a skilled operations professional);
-- setup is not simple, especially if you want to have a private registry / repository (more about this later).
-
-Following are some tips I put together during the course of the last week with the findings of someone that is new to the game.
-
-----------
-
-In the following articles we'll see how to setup a semi-automated Docker based deployment system.
-
-- [Setting up a private Docker registry][6]
-- [Configuring a Rails app for semi-automated deployment][7]
-
---------------------------------------------------------------------------------
-
-via: http://cocoahunter.com/2015/01/23/docker-1/
-
-作者:[Michelangelo Chasseur][a]
-译者:[mtunique](https://github.com/mtunique)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://cocoahunter.com/author/michelangelo/
-[1]:http://www.touchwa.re/
-[2]:http://cocoahunter.com/2015/01/23/docker-1/www.heroku.com
-[3]:https://github.com/progrium/dokku
-[4]:http://cocoahunter.com/2015/01/23/docker-1/www.digitalocean.com
-[5]:http://www.docker.com/
-[6]:http://cocoahunter.com/2015/01/23/docker-2/
-[7]:http://cocoahunter.com/2015/01/23/docker-3/
-[8]:
-[9]:
-[10]:
-[11]:
-[12]:
-[13]:
-[14]:
-[15]:
-[16]:
-[17]:
-[18]:
-[19]:
-[20]:
diff --git a/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md b/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md
deleted file mode 100644
index 9a9341b4b7..0000000000
--- a/sources/tech/20150128 Docker-2 Setting up a private Docker registry.md
+++ /dev/null
@@ -1,241 +0,0 @@
-Setting up a private Docker registry
-================================================================================
-
-
-[TL;DR] This is the second post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
-
-- [First part][1]: where I talk about the process we went thru before approaching Docker;
-- [Third pard][2]: where I show how to automate the entire process of building images and deploying a Rails app with Docker.
-
-----------
-
-Why would ouy want ot set up a provate registry? Well, for starters, Docker Hub only allows you to have one free private repo. Other companies are beginning to offer similar services, but they are all not very cheap. In addition, if you need to deploy production ready applications built with Docker, you might not want to publish those images on the public Docker Hub.
-
-This is a very pragmatic approach to dealing with the intricacies of setting up a private Docker registry. For the tutorial we will be using a small 512MB instance on DigitalOcean (from now on DO). I also assume you already know the basics of Docker since I will be concentrating on some more complicated stuff.
-
-### Local set up ###
-
-First of all you need to install **boot2docker** and docker CLI. If you already have your basic Docker environment up and running, you can just skip to the next section.
-
-From the terminal run the following command[1][3]:
-
- brew install boot2docker docker
-
-If everything is ok[2][4], you will now be able to start the VM inside which Docker will run with the following command:
-
- boot2docker up
-
-Follow the instructions, copy and paste the export commands that boot2docker will print in the terminal. If you now run `docker ps` you should be greeted by the following line
-
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
-
-Ok, Docker is ready to go. This will be enough for the moment. Let's go back to setting up the registry.
-
-### Creating the server ###
-
-Log into you DO account and create a new Droplet by selecting an image with Docker pre-installed[^n].
-
-
-
-You should receive your root credentials via email. Log into your instance and run `docker ps` to see if eveything is ok.
-
-### Setting up AWS S3 ###
-
-We are going to use Amazon Simple Storage Service (S3) as the storage layer for our registry / repository. We will need to create a bucket and user credentials to allow our docker container accessoing it.
-
-Login into your AWS account (if you don't have one you can set one up at [http://aws.amazon.com/][5]) and from the console select S3 (Simple Storage Service).
-
-
-
-Click on **Create Bucket**, enter a unique name for your bucket (and write it down, we're gonna need it later), then click on **Create**.
-
-
-
-That's it! We're done setting up the storage part.
-
-### Setup AWS access credentials ###
-
-We are now going to create a new user. Go back to your AWS console and select IAM (Identity & Access Management).
-
-
-
-In the dashboard, on the left side of the webpage, you should click on Users. Then select **Create New Users**.
-
-You should be presented with the following screen:
-
-
-
-Enter a name for your user (e.g. docker-registry) and click on Create. Write down (or download the csv file with) your Access Key and Secret Access Key that we'll need when running the Docker container. Go back to your users list and select the one you just created.
-
-Under the Permission section, click on Attach User Policy. In the next screen, you will be presented with multiple choices: select Custom Policy.
-
-
-
-Here's the content of the custom policy:
-
- {
- "Version": "2012-10-17",
- "Statement": [
- {
- "Sid": "SomeStatement",
- "Effect": "Allow",
- "Action": [
- "s3:*"
- ],
- "Resource": [
- "arn:aws:s3:::docker-registry-bucket-name/*",
- "arn:aws:s3:::docker-registry-bucket-name"
- ]
- }
- ]
- }
-
-This will allow the user (i.e. the registry) to manage (read/write) content on the bucket (make sure to use the bucket name you previously defined when setting up AWS S3). To sum it up: when you'll be pushing Docker images from your local machine to your repository, the server will be able to upload them to S3.
-
-### Installing the registry ###
-
-Now let's head back to our DO server and SSH into it. We are going to use[^n] one of the [official Docker registry images][6].
-
-Let's start our registry with the following command:
-
- docker run \
- -e SETTINGS_FLAVOR=s3 \
- -e AWS_BUCKET=bucket-name \
- -e STORAGE_PATH=/registry \
- -e AWS_KEY=your_aws_key \
- -e AWS_SECRET=your_aws_secret \
- -e SEARCH_BACKEND=sqlalchemy \
- -p 5000:5000 \
- --name registry \
- -d \
- registry
-
-Docker should pull the required fs layers from the Docker Hub and eventually start the daemonised container.
-
-### Testing the registry ###
-
-If everything worked out, you should now be able to test the registry by pinging it and by searching its content (though for the time being it's still empty).
-
-Our registry is very basic and it does not provide any means of authentication. Since there are no easy ways of adding authentication (at least none that I'm aware of that are easy enough to implment in order to justify the effort), I've decided that the easiest way of querying / pulling / pushing the registry is an unsecure (over HTTP) connection tunneled thru SSH.
-
-Opening an SSH tunnel from your local machine is straightforward:
-
- ssh -N -L 5000:localhost:5000 root@your_registry.com
-
-The command is tunnelling connections over SSH from port 5000 of the registry server (which is the one we exposed with the `docker run` command in the previous paragraph) to port 5000 on the localhost.
-
-If you now browse to the following address [http://localhost:5000/v1/_ping][7] you should get the following very simple response
-
- {}
-
-This just means that the registry is working correctly. You can also list the whole content of the registry by browsing to [http://localhost:5000/v1/search][8] that will get you a similar response:
-
- {
- "num_results": 2,
- "query": "",
- "results": [
- {
- "description": "",
- "name": "username/first-repo"
- },
- {
- "description": "",
- "name": "username/second-repo"
- }
- ]
- }
-
-### Building an image ###
-
-Let's now try and build a very simple Docker image to test our newly installed registry. On your local machine, create a Dockerfile with the following content[^n]:
-
- # Base image with ruby 2.2.0
- FROM ruby:2.2.0
-
- MAINTAINER Michelangelo Chasseur
-
-...and build it:
-
- docker build -t localhost:5000/username/repo-name .
-
-The `localhost:5000` part is especially important: the first part of the name of a Docker image will tell the `docker push` command the endpoint towards which we are trying to push our image. In our case, since we are connecting to our remote private registry via an SSH tunnel, `localhost:5000` represents exactly the reference to our registry.
-
-If everything works as expected, when the command returns, you should be able to list your newly created image with the `docker images` command. Run it and see it for yourself.
-
-### Pushing to the registry ###
-
-Now comes the trickier part. It took a me a while to realize what I'm about to describe, so just be patient if you don't get it the first time you read and try to follow along. I know that all this stuff will seem pretty complicated (and it would be if you didn't automate the process), but I promise in the end it will all make sense. In the next post I will show a couple of shell scripts and Rake tasks that will automate the whole process and will let you deploy a Rails to your registry app with a single easy command.
-
-The docker command you are running from your terminal is actually using the boot2docker VM to run the containers and do all the magic stuff. So when we run a command like `docker push some_repo` what is actually happening is that it's the boot2docker VM that is reacing out for the registry, not our localhost.
-
-This is an extremely important point to understand: in order to push the Docker image to the remote private registry, the SSH tunnel needs to be established from the boot2docker VM and not from your local machine.
-
-There are a couple of ways to go with it. I will show you the shortest one (which is not probably the easiest to understand, but it's the one that will let us automate the process with shell scripts).
-
-First of all though we need to sort one last thing with SSH.
-
-### Setting up SSH ###
-
-Let's add our boot2docker SSH key to our remote server (registry) known hosts. We can do so using the ssh-copy-id utility that you can install with the following command shouldn't you already have it:
-
- brew install ssh-copy-id
-
-Then run:
-
- ssh-copy-id -i /Users/username/.ssh/id_boot2docker root@your-registry.com
-
-Make sure to substitute `/Users/username/.ssh/id_boot2docker` with the correct path of your ssh key.
-
-This will allow us to connect via SSH to our remote registry without being prompted for the password.
-
-Finally let's test it out:
-
- boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &" &
-
-To break things out a little bit:
-
-- `boot2docker ssh` lets you pass a command as a parameter that will be executed by the boot2docker VM;
-- the final `&` indicates that we want our command to be executed in the background;
-- `ssh -o 'StrictHostKeyChecking no' -i /Users/michelangelo/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@registry.touchwa.re &` is the actual command our boot2docker VM will run;
- - the `-o 'StrictHostKeyChecking no'` will make sure that we are not prompted with security questions;
- - the `-i /Users/michelangelo/.ssh/id_boot2docker` indicates which SSH key we want our VM to use for authentication purposes (note that this should be the key you added to your remote registry in the previous step);
- - finally we are opening a tunnel on mapping port 5000 to localhost:5000.
-
-### Pulling from another server ###
-
-You should now be able to push your image to the remote registry by simply issuing the following command:
-
- docker push localhost:5000/username/repo_name
-
-In the [next post][9] we'll se how to automate some of this stuff and we'll containerize a real Rails application. Stay tuned!
-
-P.S. Please use the comments to let me know of any inconsistencies or fallacies in my tutorial. Hope you enjoyed it!
-
-1. I'm also assuming you are running on OS X.
-1. For a complete list of instructions to set up your docker environment and requirements, please visit [http://boot2docker.io/][10]
-1. Select Image > Applications > Docker 1.4.1 on 14.04 at the time of this writing.
-1. [https://github.com/docker/docker-registry/][11]
-1. This is just a stub, in the next post I will show you how to bundle a Rails application into a Docker container.
-
---------------------------------------------------------------------------------
-
-via: http://cocoahunter.com/2015/01/23/docker-2/
-
-作者:[Michelangelo Chasseur][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://cocoahunter.com/author/michelangelo/
-[1]:http://cocoahunter.com/2015/01/23/docker-1/
-[2]:http://cocoahunter.com/2015/01/23/docker-3/
-[3]:http://cocoahunter.com/2015/01/23/docker-2/#fn:1
-[4]:http://cocoahunter.com/2015/01/23/docker-2/#fn:2
-[5]:http://aws.amazon.com/
-[6]:https://registry.hub.docker.com/_/registry/
-[7]:http://localhost:5000/v1/_ping
-[8]:http://localhost:5000/v1/search
-[9]:http://cocoahunter.com/2015/01/23/docker-3/
-[10]:http://boot2docker.io/
-[11]:https://github.com/docker/docker-registry/
\ No newline at end of file
diff --git a/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md b/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md
deleted file mode 100644
index f450361a68..0000000000
--- a/sources/tech/20150128 Docker-3 Automated Docker-based Rails deployments.md
+++ /dev/null
@@ -1,253 +0,0 @@
-Automated Docker-based Rails deployments
-================================================================================
-
-
-[TL;DR] This is the third post in a series of 3 on how my company moved its infrastructure from PaaS to Docker based deployment.
-
-- [First part][1]: where I talk about the process we went thru before approaching Docker;
-- [Second part][2]: where I explain how setting up a private registry for in house secure deployments.
-
-----------
-
-In this final part we will see how to automate the whole deployment process with a real world (though very basic) example.
-
-### Basic Rails app ###
-
-Let's dive into the topic right away and bootstrap a basic Rails app. For the purpose of this demonstration I'm going to use Ruby 2.2.0 and Rails 4.1.1
-
-From the terminal run:
-
- $ rvm use 2.2.0
- $ rails new && cd docker-test
-
-Let's create a basic controller:
-
- $ rails g controller welcome index
-
-...and edit `routes.rb` so that the root of the project will point to our newly created welcome#index method:
-
- root 'welcome#index'
-
-Running `rails s` from the terminal and browsing to [http://localhost:3000][3] should bring you to the index page. We're not going to make anything fancier to the app, it's just a basic example to prove that when we'll build and deploy the container everything is working.
-
-### Setup the webserver ###
-
-We are going to use Unicorn as our webserver. Add `gem 'unicorn'` and `gem 'foreman'` to the Gemfile and bundle it up (run `bundle install` from the command line).
-
-Unicorn needs to be configured when the Rails app launches, so let's put a **unicorn.rb** file inside the **config** directory. [Here is an example][4] of a Unicorn configuration file. You can just copy & paste the content of the Gist.
-
-Let's also add a Procfile with the following content inside the root of the project so that we will be able to start the app with foreman:
-
- web: bundle exec unicorn -p $PORT -c ./config/unicorn.rb
-
-If you now try to run the app with **foreman start** everything should work as expected and you should have a running app on [http://localhost:5000][5]
-
-### Building a Docker image ###
-
-Now let's build the image inside which our app is going to live. In the root of our Rails project, create a file named **Dockerfile** and paste in it the following:
-
- # Base image with ruby 2.2.0
- FROM ruby:2.2.0
-
- # Install required libraries and dependencies
- RUN apt-get update && apt-get install -qy nodejs postgresql-client sqlite3 --no-install-recommends && rm -rf /var/lib/apt/lists/*
-
- # Set Rails version
- ENV RAILS_VERSION 4.1.1
-
- # Install Rails
- RUN gem install rails --version "$RAILS_VERSION"
-
- # Create directory from where the code will run
- RUN mkdir -p /usr/src/app
- WORKDIR /usr/src/app
-
- # Make webserver reachable to the outside world
- EXPOSE 3000
-
- # Set ENV variables
- ENV PORT=3000
-
- # Start the web app
- CMD ["foreman","start"]
-
- # Install the necessary gems
- ADD Gemfile /usr/src/app/Gemfile
- ADD Gemfile.lock /usr/src/app/Gemfile.lock
- RUN bundle install --without development test
-
- # Add rails project (from same dir as Dockerfile) to project directory
- ADD ./ /usr/src/app
-
- # Run rake tasks
- RUN RAILS_ENV=production rake db:create db:migrate
-
-Using the provided Dockerfile, let's try and build an image with the following command[1][7]:
-
- $ docker build -t localhost:5000/your_username/docker-test .
-
-And again, if everything worked out correctly, the last line of the long log output should read something like:
-
- Successfully built 82e48769506c
- $ docker images
- REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
- localhost:5000/your_username/docker-test latest 82e48769506c About a minute ago 884.2 MB
-
-Let's try and run the container!
-
- $ docker run -d -p 3000:3000 --name docker-test localhost:5000/your_username/docker-test
-
-You should be able to reach your Rails app running inside the Docker container at port 3000 of your boot2docker VM[2][8] (in my case [http://192.168.59.103:3000][6]).
-
-### Automating with shell scripts ###
-
-Since you should already know from the previous post3 how to push your newly created image to a private regisitry and deploy it on a server, let's skip this part and go straight to automating the process.
-
-We are going to define 3 shell scripts and finally tie it all together with rake.
-
-### Clean ###
-
-Every time we build our image and deploy we are better off always clean everything. That means the following:
-
-- stop (if running) and restart boot2docker;
-- remove orphaned Docker images (images that are without tags and that are no longer used by your containers).
-
-Put the following into a **clean.sh** file in the root of your project.
-
- echo Restarting boot2docker...
- boot2docker down
- boot2docker up
-
- echo Exporting Docker variables...
- sleep 1
- export DOCKER_HOST=tcp://192.168.59.103:2376
- export DOCKER_CERT_PATH=/Users/user/.boot2docker/certs/boot2docker-vm
- export DOCKER_TLS_VERIFY=1
-
- sleep 1
- echo Removing orphaned images without tags...
- docker images | grep "" | awk '{print $3}' | xargs docker rmi
-
-Also make sure to make the script executable:
-
- $ chmod +x clean.sh
-
-### Build ###
-
-The build process basically consists in reproducing what we just did before (docker build). Create a **build.sh** script at the root of your project with the following content:
-
- docker build -t localhost:5000/your_username/docker-test .
-
-Make the script executable.
-
-### Deploy ###
-
-Finally, create a **deploy.sh** script with this content:
-
- # Open SSH connection from boot2docker to private registry
- boot2docker ssh "ssh -o 'StrictHostKeyChecking no' -i /Users/username/.ssh/id_boot2docker -N -L 5000:localhost:5000 root@your-registry.com &" &
-
- # Wait to make sure the SSH tunnel is open before pushing...
- echo Waiting 5 seconds before pushing image.
-
- echo 5...
- sleep 1
- echo 4...
- sleep 1
- echo 3...
- sleep 1
- echo 2...
- sleep 1
- echo 1...
- sleep 1
-
- # Push image onto remote registry / repo
- echo Starting push!
- docker push localhost:5000/username/docker-test
-
-If you don't understand what's going on here, please make sure you've read thoroughfully [part 2][9] of this series of posts.
-
-Make the script executable.
-
-### Tying it all together with rake ###
-
-Having 3 scripts would now require you to run them individually each time you decide to deploy your app:
-
-1. clean
-1. build
-1. deploy / push
-
-That wouldn't be much of an effort, if it weren't for the fact that developers are lazy! And lazy be it, then!
-
-The final step to wrap things up, is tying the 3 parts together with rake.
-
-To make things even simpler you can just append a bunch of lines of code to the end of the already present Rakefile in the root of your project. Open the Rakefile file - pun intended :) - and paste the following:
-
- namespace :docker do
- desc "Remove docker container"
- task :clean do
- sh './clean.sh'
- end
-
- desc "Build Docker image"
- task :build => [:clean] do
- sh './build.sh'
- end
-
- desc "Deploy Docker image"
- task :deploy => [:build] do
- sh './deploy.sh'
- end
- end
-
-Even if you don't know rake syntax (which you should, because it's pretty awesome!), it's pretty obvious what we are doing. We have declared 3 tasks inside a namespace (docker).
-
-This will create the following 3 tasks:
-
-- rake docker:clean
-- rake docker:build
-- rake docker:deploy
-
-Deploy is dependent on build, build is dependent on clean. So every time we run from the command line
-
- $ rake docker:deploy
-
-All the script will be executed in the required order.
-
-### Test it ###
-
-To see if everything is working, you just need to make a small change in the code of your app and run
-
- $ rake docker:deploy
-
-and see the magic happening. Once the image has been uploaded (and the first time it could take quite a while), you can ssh into your production server and pull (thru an SSH tunnel) the docker image onto the server and run. It's that easy!
-
-Well, maybe it takes a while to get accustomed to how everything works, but once it does, it's almost (almost) as easy as deploying with Heroku.
-
-P.S. As always, please let me have your ideas. I'm not sure this is the best, or the fastest, or the safest way of doing devops with Docker, but it certainly worked out for us.
-
-- make sure to have **boot2docker** up and running.
-- If you don't know your boot2docker VM address, just run `$ boot2docker ip`
-- if you don't, you can read it [here][10]
-
---------------------------------------------------------------------------------
-
-via: http://cocoahunter.com/2015/01/23/docker-3/
-
-作者:[Michelangelo Chasseur][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://cocoahunter.com/author/michelangelo/
-[1]:http://cocoahunter.com/docker-1
-[2]:http://cocoahunter.com/2015/01/23/docker-2/
-[3]:http://localhost:3000/
-[4]:https://gist.github.com/chasseurmic/0dad4d692ff499761b20
-[5]:http://localhost:5000/
-[6]:http://192.168.59.103:3000/
-[7]:http://cocoahunter.com/2015/01/23/docker-3/#fn:1
-[8]:http://cocoahunter.com/2015/01/23/docker-3/#fn:2
-[9]:http://cocoahunter.com/2015/01/23/docker-2/
-[10]:http://cocoahunter.com/2015/01/23/docker-2/
\ No newline at end of file
diff --git a/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md b/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md
deleted file mode 100644
index 92ac657b5a..0000000000
--- a/sources/tech/20150202 How to Bind Apache Tomcat to IPv4 in Centos or Redhat.md
+++ /dev/null
@@ -1,79 +0,0 @@
-How to Bind Apache Tomcat to IPv4 in Centos / Redhat
-================================================================================
-Hi all, today we'll learn how to bind tomcat to ipv4 in CentOS 7 Linux Distribution.
-
-**Apache Tomcat** is an open source web server and servlet container developed by the [Apache Software Foundation][1]. It implements the Java Servlet, JavaServer Pages (JSP), Java Unified Expression Language and Java WebSocket specifications from Sun Microsystems and provides a web server environment for Java code to run in.
-
-Binding Tomcat to IPv4 is necessary if we have our server not working due to the default binding of our tomcat server to IPv6. As we know IPv6 is the modern way of assigning IP address to a device and is not in complete practice these days but may come into practice in soon future. So, currently we don't need to switch our tomcat server to IPv6 due to no use and we should bind it to IPv4.
-
-Before thinking to bind to IPv4, we should make sure that we've got tomcat installed in our CentOS 7. Here's is a quick tutorial on [how to install tomcat 8 in CentOS 7.0 Server][2].
-
-### 1. Switching to user tomcat ###
-
-First of all, we'll gonna switch user to **tomcat** user. We can do that by running **su - tomcat** in a shell or terminal.
-
- # su - tomcat
-
-
-
-### 2. Finding Catalina.sh ###
-
-Now, we'll First Go to bin directory inside the directory of Apache Tomcat installation which is usually under **/usr/share/apache-tomcat-8.0.x/bin/** where x is sub version of the Apache Tomcat Release. In my case, its **/usr/share/apache-tomcat-8.0.18/bin/** as I have version 8.0.18 installed in my CentOS 7 Server.
-
- $ cd /usr/share/apache-tomcat-8.0.18/bin
-
-**Note: Please replace 8.0.18 to the version of Apache Tomcat installed in your system. **
-
-Inside the bin folder, there is a script file named catalina.sh . Thats the script file which we'll gonna edit and add a line of configuration which will bind tomcat to IPv4 . You can see that file by running **ls** into a terminal or shell.
-
- $ ls
-
-
-
-### 3. Configuring Catalina.sh ###
-
-Now, we'll add **JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"** to that scripting file catalina.sh at the end of the file as shown in the figure below. We can edit the file using our favorite text editing software like nano, vim, etc. Here, we'll gonna use nano.
-
- $ nano catalina.sh
-
-
-
-Then, add to the file as shown below:
-
-**JAVA_OPTS= "$JAVA_OPTS -Djava.net.preferIPv4Stack=true -Djava.net.preferIPv4Addresses"**
-
-
-
-Now, as we've added the configuration to the file, we'll now save and exit nano.
-
-### 4. Restarting ###
-
-Now, we'll restart our tomcat server to get our configuration working. We'll need to first execute shutdown.sh and then startup.sh .
-
- $ ./shutdown.sh
-
-Now, well run execute startup.sh as:
-
- $ ./startup.sh
-
-
-
-This will restart our tomcat server and the configuration will be loaded which will ultimately bind the server to IPv4.
-
-### Conclusion ###
-
-Hurray, finally we'have got our tomcat server bind to IPv4 running in our CentOS 7 Linux Distribution. Binding to IPv4 is easy and is necessary if your Tomcat server is bind to IPv6 which will infact will make your tomcat server not working as IPv6 is not used these days and may come into practice in coming future. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/bind-apache-tomcat-ipv4-centos/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:http://www.apache.org/
-[2]:http://linoxide.com/linux-how-to/install-tomcat-8-centos-7/
\ No newline at end of file
diff --git a/sources/tech/20150202 How to create and show a presentation from the command line on Linux.md b/sources/tech/20150202 How to create and show a presentation from the command line on Linux.md
deleted file mode 100644
index d80b385544..0000000000
--- a/sources/tech/20150202 How to create and show a presentation from the command line on Linux.md
+++ /dev/null
@@ -1,186 +0,0 @@
-How to create and show a presentation from the command line on Linux
-================================================================================
-When you prepare a talk for audience, the first thing that will probably come to your mind is shiny presentation charts filled with fancy diagrams, graphics and animation effects. Fine. No one can deny the power of visually charming presentation. However, not all presentations need to be Ted talk quality. Often times, the purpose of a presentation is to convey specific information, which can easily be done with textual messages. In such cases, your time can be better spent on gathering information and checking facts, rather than searching for good-looking graphics from Google Image.
-
-In the world of Linux, you can do presentation in several different ways, e.g., Impress for multimedia-rich content, [Impress.js][1] for stunning visualization, Beamer for hardcore LaTex users, and so on. If you are looking for a simple means to create and show a textual presentation, look no further. [mdp][2] can get the job done for you.
-
-### What is Mdp? ###
-
-mdp is an ncurses-based command-line presentation tool for Linux. What I like about mdp is its [markdown][3] support, which makes it easy to create slides with familiar markdown format. Naturally, it becomes painless to publish the slides in HTML format as well. Another plus is its support for UTF-8 character encoding, which comes in handy when showing non-English characters (e.g., Greek or Cyrillic alphabets).
-
-### Install Mdp on Linux ###
-
-Installation of mdp is mostly painless due to its light dependency requirement (i.e., ncursesw).
-
-#### Debian, Ubuntu or their derivatives ####
-
- $ sudo apt-get install git gcc make libncursesw5-dev
- $ git clone https://github.com/visit1985/mdp.git
- $ cd mdp
- $ make
- $ sudo make install
-
-#### Fedora or CentOS/RHEL ####
-
- $ sudo yum install git gcc make ncurses-devel
- $ git clone https://github.com/visit1985/mdp.git
- $ cd mdp
- $ make
- $ sudo make install
-
-#### Arch Linux ####
-
-On Arch Linux, you can easily install mdp from [AUR][4].
-
-### Create a Presentation from the Command Line ###
-
-Once you installed mdp, you can easily create a presentation by using your favorite text editor. If you are familiar with markdown, it will take no time to master mdp. For those of you who are not familiar with markdown, starting with an example is the best way to learn mdp.
-
-Here is a 6-page sample presentation for your reference.
-
- %title: Sample Presentation made with mdp (Xmodulo.com)
- %author: Dan Nanni
- %date: 2015-01-28
-
- -> This is a slide title <-
- =========
-
- -> mdp is a command-line based presentation tool with markdown support. <-
-
- *_Features_*
-
- * Multi-level headers
- * Code block formatting
- * Nested quotes
- * Nested list
- * Text highlight and underline
- * Citation
- * UTF-8 special characters
-
- -------------------------------------------------
-
- -> # Example of nested list <-
-
- This is an example of multi-level headers and a nested list.
-
- # first-level title
-
- second-level
- ------------
-
- - *item 1*
- - sub-item 1
- - sub-sub-item 1
- - sub-sub-item 2
- - sub-sub-item 3
- - sub-item 2
-
- -------------------------------------------------
-
- -> # Example of code block formatting <-
-
- This example shows how to format a code snippet.
-
- 1 /* Hello World program */
- 2
- 3 #include
- 4
- 5 int main()
- 6 {
- 7 printf("Hello World");
- 8 return 0;
- 9 }
-
- This example shows inline code: `sudo reboot`
-
- -------------------------------------------------
-
- -> # Example of nested quotes <-
-
- This is an example of nested quotes.
-
- # three-level nested quotes
-
- > This is the first-level quote.
- >> This is the second-level quote
- >> and continues.
- >>> *This is the third-level quote, and so on.*
-
- -------------------------------------------------
-
- -> # Example of citations <-
-
- This example shows how to place a citation inside a presentation.
-
- This tutorial is published at [Xmodulo](http://xmodulo.com)
-
- You are welcome to connect with me at [LinkedIn](http://www.linkedin.com/in/xmodulo)
-
- Pretty cool, huh?
-
- -------------------------------------------------
-
- -> # Example of UTF-8 special characters <-
-
- This example shows UTF-8 special characters.
-
- ae = ä, oe = ö, ue = ü, ss = ß
- alpha = ?, beta = ?, upsilon = ?, phi = ?
- Omega = ?, Delta = ?, Sigma = ?
-
- ???????????
- ?rectangle?
- ???????????
-
-### Show a Presentation from the Command Line ###
-
-Once you save the above code as slide.md text file, you can show the presentation by simply running:
-
- $ mdp slide.md
-
-You can navigate the presentation by pressing Enter/Space/Page-Down/Down-Arrow (next slide), Backspace/Page-Up/Up-Arrow (previous slide), Home (first slide), End (last slide), or numeric-N (N-th slide).
-
-The title of the presentation appears on top of each slide, and your name and page number are shown at the bottom.
-
-
-
-This is an example of a nested list and multi-level headers.
-
-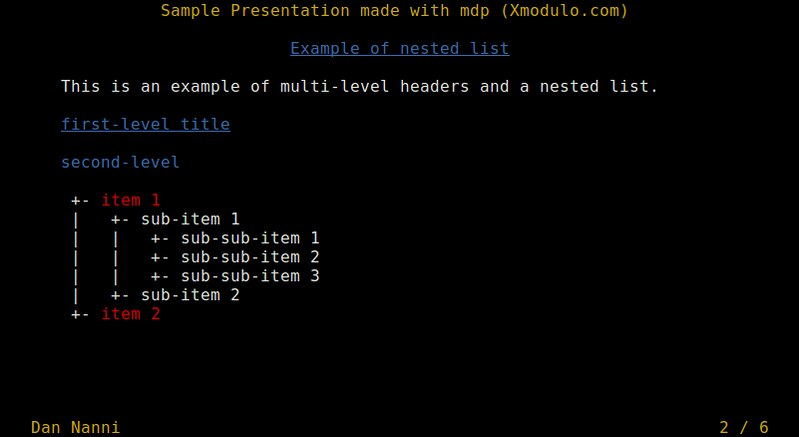
-
-This is an example of a code snippet and inline code.
-
-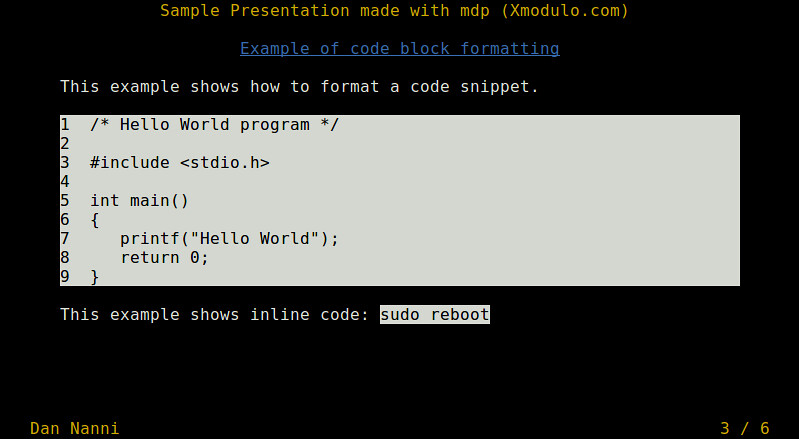
-
-This is an example of nested quotes.
-
-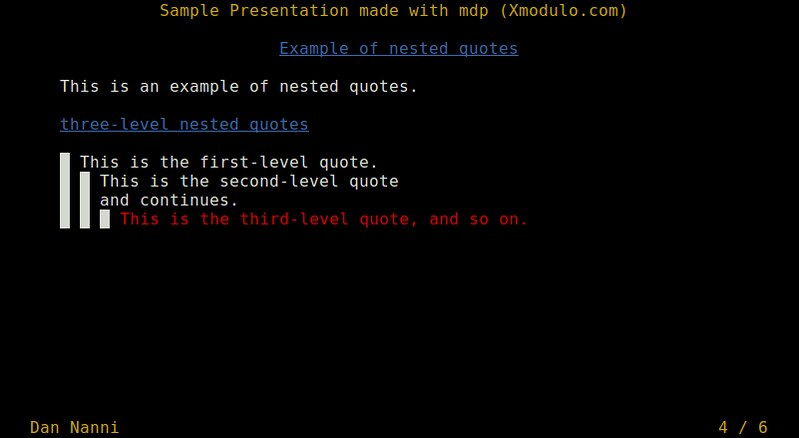
-
-This is an example of placing citations.
-
-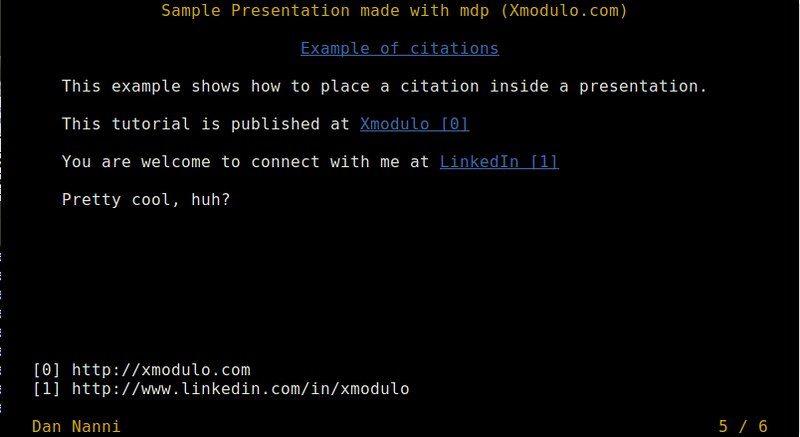
-
-This is an example of UTF-8 special characters.
-
-
-
-### Summary ###
-
-In this tutorial, I showed you how to use mdp to create and show a presentation from the command line. Its markdown compatibility saves us the trouble and hassle of having to learn any new formatting, which is an advantage compared to [tpp][5], another command-line presentation tool. Due to its limitations, mdp may not qualify as your default presentation tool, but there should be definitely a use case for that. What do you think of mdp? Do you prefer something else?
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/presentation-command-line-linux.html
-
-作者:[Dan Nanni][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/nanni
-[1]:http://bartaz.github.io/impress.js/
-[2]:https://github.com/visit1985/mdp
-[3]:http://daringfireball.net/projects/markdown/
-[4]:https://aur.archlinux.org/packages/mdp-git/
-[5]:http://www.ngolde.de/tpp.html
\ No newline at end of file
diff --git a/sources/tech/20150203 How To Install KDE Plasma 5.2 In Ubuntu 14.10.md b/sources/tech/20150203 How To Install KDE Plasma 5.2 In Ubuntu 14.10.md
deleted file mode 100644
index cd1a5eb525..0000000000
--- a/sources/tech/20150203 How To Install KDE Plasma 5.2 In Ubuntu 14.10.md
+++ /dev/null
@@ -1,60 +0,0 @@
-How To Install KDE Plasma 5.2 In Ubuntu 14.10
-================================================================================
-
-
-[KDE][1] Plasma 5.2 has been [released][2] and in this post we shall see how to install KDE Plasma 5.2 in Ubuntu 14.10.
-
-Ubuntu’s default desktop environment Unity is beautiful and packs quite some feature. But if you ask any experienced Linux user about desktop customization, his answer will be KDE. KDE is boss when it comes to customization and its popularity can be guessed that Ubuntu has an official KDE flavor, known as [Kubuntu][3].
-
-A good thing about Ubuntu (or any other Linux OS for that matter) is that it doesn’t bind you with one particular desktop environment. You can always install additional desktop environments and choose to switch between them while keeping several desktop environments at the same time. Earlier, we have seen the installation of following desktop environments:
-
-- [How to install Mate desktop in Ubuntu 14.04][4]
-- [How to install Cinnamon in Ubuntu 14.04][5]
-- [How to install Budgie desktop in Ubuntu 14.04][6]
-- [How to install GNOME Shell in Ubuntu 14.04][7]
-
-And today we shall see how to install KDE Plasma in Ubuntu 14.10.
-
-### Install KDE Plasma 5.2 in Ubuntu 14.04 ###
-
-Before you go on installing Plasma on Ubuntu 14.10, you should know that it will download around one GB of data. So consider your network speed and data package (if any) before opting for KDE installation. The PPA we are going to use for installing Plasma is the official PPA provided by the KDE community. Use the commands below in terminal:
-
- sudo apt-add-repository ppa:kubuntu-ppa/next-backports
- sudo apt-get update
- sudo apt-get dist-upgrade
- sudo apt-get install kubuntu-plasma5-desktop plasma-workspace-wallpapers
-
-During the installation, it will as you to choose the default display manager. I chose the default LightDM. Once installed, restart the system. At the login, click on the Ubuntu symbol beside the login field. In here, select Plasma.
-
-
-
-You’ll be logged in to KDE Plasma now. Here is a quick screenshot of how KDE Plasma 5.2 looks like in Ubuntu 14.10:
-
-
-
-### Remove KDE Plasma from Ubuntu ###
-
-If you want to revert the changes, use the following commands to get rid of KDE Plasma from Ubuntu 14.10.
-
- sudo apt-get install ppa-purge
- sudo apt-get remove kubuntu-plasma5-desktop
- sudo ppa-purge ppa:kubuntu-ppa/next
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/install-kde-plasma-ubuntu-1410/
-
-作者:[Abhishek][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:https://www.kde.org/
-[2]:https://dot.kde.org/2015/01/27/plasma-52-beautiful-and-featureful
-[3]:http://www.kubuntu.org/
-[4]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
-[5]:http://itsfoss.com/install-cinnamon-24-ubuntu-1404/
-[6]:http://itsfoss.com/install-budgie-desktop-ubuntu-1404/
-[7]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
\ No newline at end of file
diff --git a/sources/tech/20150203 Linux FAQs with Answers--How to fix 'Your profile could not be opened correctly' on Google Chrome.md b/sources/tech/20150203 Linux FAQs with Answers--How to fix 'Your profile could not be opened correctly' on Google Chrome.md
deleted file mode 100644
index 8d5c4b02ca..0000000000
--- a/sources/tech/20150203 Linux FAQs with Answers--How to fix 'Your profile could not be opened correctly' on Google Chrome.md
+++ /dev/null
@@ -1,52 +0,0 @@
-> Vic
-
-Linux FAQs with Answers--How to fix “Your profile could not be opened correctly” on Google Chrome
-================================================================================
-> **Question**: When I open Google Chrome web browser on my Linux box, I have several pop-up messages saying "Your profile could not be opened correctly." This error happens every time I open Google Chrome. How can I solve this error?
-
-When you see an error message saying "Your profile could not be opened correctly" on your Google Chrome web browser," that is because somehow your profile data on Google Chrome got corrupted. This can happen while you upgrade your Google Chrome browser manually on Linux.
-
-
-
-Depending on exactly which file got corrupted, you can try one of these methods.
-
-### Method One ###
-
-Close all your Chrome browser windows/tabs.
-
-Go to ~/.config/google-chrome/Default, and remove/rename "Web Data" file as below.
-
- $ cd ~/.config/google-chrome/Default
- $ rm "Web Data"
-
-Re-open Google Chrome browser.
-
-### Method Two ###
-
-Close all your Chrome browser windows/tabs.
-
-Go to ~/.config/google-chrome/"Profile 1", and rename "History" file as below.
-
- $ cd ~/.config/google-chrome/"Profile 1"
- $ mv History History.bak
-
-Re-open Google Chrome browser.
-
-### Method Three ###
-
-If the problem still persists, you can remove the Default profile folder (~/.config/google-chrome/Default) altogether. Note that by doing so, you will lose all previously opened Google tabs, imported bookmarks, browsing history, sign-in data, etc.
-
-Before removing it, first close all your Chrome browser windows/tabs.
-
- $ rm -rf ~/.config/google-chrome/Default
-
-After restarting Google Chrome, the folder ~/.config/google-chrome/Default will automatically be re-generated.
-
---------------------------------------------------------------------------------
-
-via: http://ask.xmodulo.com/your-profile-could-not-be-opened-correctly-google-chrome.html
-
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md b/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md
deleted file mode 100644
index a042cba174..0000000000
--- a/sources/tech/20150205 25 Linux Shell Scripting interview Questions & Answers.md
+++ /dev/null
@@ -1,377 +0,0 @@
-25 Linux Shell Scripting interview Questions & Answers
-================================================================================
-### Q:1 What is Shell Script and why it is required ? ###
-
-Ans: A Shell Script is a text file that contains one or more commands. As a system administrator we often need to issue number of commands to accomplish the task, we can add these all commands together in a text file (Shell Script) to complete daily routine task.
-
-### Q:2 What is the default login shell and how to change default login shell for a specific user ? ###
-
-Ans: In Linux like Operating system “/bin/bash” is the default login shell which is assigned while user creation. We can change default shell using the “chsh” command . Example is shown below :
-
- # chsh -s
- # chsh linuxtechi -s /bin/sh
-
-### Q:3 What are the different type of variables used in a shell Script ? ###
-
-Ans: In a shell script we can use two types of variables :
-
-- System defined variables
-- User defined variables
-
-System defined variables are defined or created by Operating System(Linux) itself. These variables are generally defined in Capital Letters and can be viewed by “**set**” command.
-
-User defined variables are created or defined by system users and the values of variables can be viewed by using the command “`echo $`”
-
-### Q:4 How to redirect both standard output and standard error to the same location ? ###
-
-Ans: There two method to redirect std output and std error to the same location:
-
-Method:1 2>&1 (# ls /usr/share/doc > out.txt 2>&1 )
-
-Method:2 &> (# ls /usr/share/doc &> out.txt )
-
-### Q:5 What is the Syntax of “nested if statement” in shell scripting ? ###
-
-Ans : Basic Syntax is shown below :
-
- if [ Condition ]
- then
- command1
- command2
- …..
- else
- if [ condition ]
- then
- command1
- command2
- ….
- else
- command1
- command2
- …..
- fi
- fi
-
-### Q:6 What is the use of “$?” sign in shell script ? ###
-
-Ans:While writing a shell script , if you want to check whether previous command is executed successfully or not , then we can use “$?” with if statement to check the exit status of previous command. Basic example is shown below :
-
- root@localhost:~# ls /usr/bin/shar
- /usr/bin/shar
- root@localhost:~# echo $?
- 0
-
-If exit status is 0 , then command is executed successfully
-
- root@localhost:~# ls /usr/bin/share
-
- ls: cannot access /usr/bin/share: No such file or directory
- root@localhost:~# echo $?
- 2
-
-If the exit status is other than 0, then we can say command is not executed successfully.
-
-### Q:7 How to compare numbers in Linux shell Scripting ? ###
-
-Ans: test command is used to compare numbers in if-then statement. Example is shown below :
-
- #!/bin/bash
- x=10
- y=20
-
- if [ $x -gt $y ]
- then
- echo “x is greater than y”
- else
- echo “y is greater than x”
- fi
-
-### Q:8 What is the use of break command ? ###
-
-Ans: The break command is a simple way to escape out of a loop in progress. We can use the break command to exit out from any loop, including while and until loops.
-
-### Q:9 What is the use of continue command in shell scripting ? ###
-
-Ans The continue command is identical to break command except it causes the present iteration of the loop to exit, instead of the entire loop. Continue command is useful in some scenarios where error has occurred but we still want to execute the next commands of the loop.
-
-### Q:10 Tell me the Syntax of “Case statement” in Linux shell scripting ? ###
-
-Ans: The basic syntax is shown below :
-
- case word in
- value1)
- command1
- command2
- …..
- last_command
- !!
- value2)
- command1
- command2
- ……
- last_command
- ;;
- esac
-
-### Q:11 What is the basic syntax of while loop in shell scripting ? ###
-
-Ans: Like the for loop, the while loop repeats its block of commands a number of times. Unlike the for loop, however, the while loop iterates until its while condition is no longer true. The basic syntax is :
-
- while [ test_condition ]
- do
- commands…
- done
-
-### Q:12 How to make a shell script executable ? ###
-
-Ans: Using the chmod command we can make a shell script executable. Example is shown below :
-
- # chmod a+x myscript.sh
-
-### Q:13 What is the use of “#!/bin/bash” ? ###
-
-Ans: #!/bin/bash is the first of a shell script , known as shebang , where # symbol is called hash and ‘!’ is called as bang. It shows that command to be executed via /bin/bash.
-
-### Q:14 What is the syntax of for loop in shell script ? ###
-
-Ans: Basic Syntax of for loop is given below :
-
- for variables in list_of_items
- do
- command1
- command2
- ….
- last_command
- done
-
-### Q:15 How to debug a shell script ? ###
-
-Ans: A shell script can be debug if we execute the script with ‘-x’ option ( sh -x myscript.sh). Another way to debug a shell script is by using ‘-nv’ option ( sh -nv myscript.sh).
-
-### Q:16 How compare the strings in shell script ? ###
-
-Ans: test command is used to compare the text strings. The test command compares text strings by comparing each character in each string.
-
-### Q:17 What are the Special Variables set by Bourne shell for command line arguments ? ###
-
-Ans: The following table lists the special variables set by the Bourne shell for command line arguments .
-
-注:表格部分
-
-
-
-
-
-
-
-
Special Variables
-
-
-
Holds
-
-
-
-
-
$0
-
-
-
Name of the Script from the command line
-
-
-
-
-
$1
-
-
-
First Command-line argument
-
-
-
-
-
$2
-
-
-
Second Command-line argument
-
-
-
-
-
…..
-
-
-
…….
-
-
-
-
-
$9
-
-
-
Ninth Command line argument
-
-
-
-
-
$#
-
-
-
Number of Command line arguments
-
-
-
-
-
$*
-
-
-
All Command-line arguments, separated with spaces
-
-
-
-
-
-### Q:18 How to test files in a shell script ? ###
-
-Ans: test command is used to perform different test on the files. Basic test are listed below :
-
-注:表格部分
-
-
-
-
-
-
-
-
Test
-
-
-
Usage
-
-
-
-
-
-d file_name
-
-
-
Returns true if the file exists and is a directory
-
-
-
-
-
-e file_name
-
-
-
Returns true if the file exists
-
-
-
-
-
-f file_name
-
-
-
Returns true if the file exists and is a regular file
-
-
-
-
-
-r file_name
-
-
-
Returns true if the file exists and have read permissions
-
-
-
-
-
-s file_name
-
-
-
Returns true if the file exists and is not empty
-
-
-
-
-
-w file_name
-
-
-
Returns true if the file exists and have write permissions
-
-
-
-
-
-x file_name
-
-
-
Returns true if the file exists and have execute permissions
-
-
-
-
-
-### Q:19 How to put comments in your shell script ? ###
-
-Ans: Comments are the messages to yourself and for other users that describe what a script is supposed to do and how its works.To put comments in your script, start each comment line with a hash sign (#) . Example is shown below :
-
- #!/bin/bash
- # This is a command
- echo “I am logged in as $USER”
-
-### Q:20 How to get input from the terminal for shell script ? ###
-
-Ans: ‘read’ command reads in data from the terminal (using keyboard). The read command takes in whatever the user types and places the text into the variable you name. Example is shown below :
-
- # vi /tmp/test.sh
-
- #!/bin/bash
- echo ‘Please enter your name’
- read name
- echo “My Name is $name”
-
- # ./test.sh
- Please enter your name
- LinuxTechi
- My Name is LinuxTechi
-
-### Q:21 How to unset or de-assign variables ? ###
-
-Ans: ‘unset’ command is used to de-assign or unset a variable. Syntax is shown below :
-
- # unset
-
-### Q:22 How to perform arithmetic operation ? ###
-
-Ans: There are two ways to perform arithmetic operations :
-
-1. Using `expr` command (# expr 5 + 2 )
-2. using a dollar sign and square brackets ( `$[ operation ]` ) Example : test=$[16 + 4] ; test=$[16 + 4]
-
-### Q:23 Basic Syntax of do-while statement ? ###
-
-Ans: The do-while statement is similar to the while statement but performs the statements before checking the condition statement. The following is the format for the do-while statement:
-
- do
- {
- statements
- } while (condition)
-
-### Q:24 How to define functions in shell scripting ? ###
-
-Ans: A function is simply a block of of code with a name. When we give a name to a block of code, we can then call that name in our script, and that block will be executed. Example is shown below :
-
- $ diskusage () { df -h ; }
-
-### Q:25 How to use bc (bash calculator) in a shell script ? ###
-
-Ans: Use the below Syntax to use bc in shell script.
-
- variable=`echo “options; expression” | bc`
-
---------------------------------------------------------------------------------
-
-via: http://www.linuxtechi.com/linux-shell-scripting-interview-questions-answers/
-
-作者:[Pradeep Kumar][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.linuxtechi.com/author/pradeep/
\ No newline at end of file
diff --git a/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md b/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md
deleted file mode 100644
index 3eaba972f8..0000000000
--- a/sources/tech/20150205 How To Install or Configure VNC Server On CentOS 7.0.md
+++ /dev/null
@@ -1,161 +0,0 @@
-How To Install / Configure VNC Server On CentOS 7.0
-================================================================================
-Hi there, this tutorial is all about how to install or setup [VNC][1] Server on your very CentOS 7. This tutorial also works fine in RHEL 7. In this tutorial, we'll learn what is VNC and how to install or setup [VNC Server][1] on CentOS 7
-
-As we know, most of the time as a system administrator we are managing our servers over the network. It is very rare that we will need to have a physical access to any of our managed servers. In most cases all we need is to SSH remotely to do our administration tasks. In this article we will configure a GUI alternative to a remote access to our CentOS 7 server, which is VNC. VNC allows us to open a remote GUI session to our server and thus providing us with a full graphical interface accessible from any remote location.
-
-VNC server is a Free and Open Source Software which is designed for allowing remote access to the Desktop Environment of the server to the VNC Client whereas VNC viewer is used on remote computer to connect to the server .
-
-**Some Benefits of VNC server are listed below:**
-
- Remote GUI administration makes work easy & convenient.
- Clipboard sharing between host CentOS server & VNC-client machine.
- GUI tools can be installed on the host CentOS server to make the administration more powerful
- Host CentOS server can be administered through any OS having the VNC-client installed.
- More reliable over ssh graphics and RDP connections.
-
-So, now lets start our journey towards the installation of VNC Server. We need to follow the steps below to setup and to get a working VNC.
-
-First of all we'll need a working Desktop Environment (X-Windows), if we don't have a working GUI Desktop Environment (X Windows) running, we'll need to install it first.
-
-**Note: The commands below must be running under root privilege. To switch to root please execute "sudo -s" under a shell or terminal without quotes("")**
-
-### 1. Installing X-Windows ###
-
-First of all to install [X-Windows][2] we'll need to execute the below commands in a shell or terminal. It will take few minutes to install its packages.
-
- # yum check-update
- # yum groupinstall "X Window System"
-
-
-
- #yum install gnome-classic-session gnome-terminal nautilus-open-terminal control-center liberation-mono-fonts
-
-
-
- # unlink /etc/systemd/system/default.target
- # ln -sf /lib/systemd/system/graphical.target /etc/systemd/system/default.target
-
-
-
- # reboot
-
-After our machine restarts, we'll get a working CentOS 7 Desktop.
-
-Now, we'll install VNC Server on our machine.
-
-### 2. Installing VNC Server Package ###
-
-Now, we'll install VNC Server package in our CentOS 7 machine. To install VNC Server, we'll need to execute the following command.
-
- # yum install tigervnc-server -y
-
-
-
-### 3. Configuring VNC ###
-
-Then, we'll need to create a configuration file under **/etc/systemd/system/** directory. We can copy the **vncserver@:1.service** file from example file from **/lib/systemd/system/vncserver@.service**
-
- # cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
-
-
-
-Now we'll open **/etc/systemd/system/vncserver@:1.service** in our favorite text editor (here, we're gonna use **nano**). Then find the below lines of text in that file and replace with your username. Here, in my case its linoxide so I am replacing with linoxide and finally looks like below.
-
- ExecStart=/sbin/runuser -l -c "/usr/bin/vncserver %i"
- PIDFile=/home//.vnc/%H%i.pid
-
-TO
-
- ExecStart=/sbin/runuser -l linoxide -c "/usr/bin/vncserver %i"
- PIDFile=/home/linoxide/.vnc/%H%i.pid
-
-If you are creating for root user then
-
- ExecStart=/sbin/runuser -l root -c "/usr/bin/vncserver %i"
- PIDFile=/root/.vnc/%H%i.pid
-
-
-
-Now, we'll need to reload our systemd.
-
- # systemctl daemon-reload
-
-Finally, we'll create VNC password for the user . To do so, first you'll need to be sure that you have sudo access to the user, here I will login to user "linoxide" then, execute the following. To login to linoxide we'll run "**su linoxide" without quotes** .
-
- # su linoxide
- $ sudo vncpasswd
-
-
-
-**Make sure that you enter passwords more than 6 characters.**
-
-### 4. Enabling and Starting the service ###
-
-To enable service at startup ( Permanent ) execute the commands shown below.
-
- $ sudo systemctl enable vncserver@:1.service
-
-Then, start the service.
-
- $ sudo systemctl start vncserver@:1.service
-
-### 5. Allowing Firewalls ###
-
-We'll need to allow VNC services in Firewall now.
-
- $ sudo firewall-cmd --permanent --add-service vnc-server
- $ sudo systemctl restart firewalld.service
-
-
-
-Now you can able to connect VNC server using IP and Port ( Eg : ip-address:1 )
-
-### 6. Connecting the machine with VNC Client ###
-
-Finally, we are done installing VNC Server. No, we'll wanna connect the server machine and remotely access it. For that we'll need a VNC Client installed in our computer which will only enable us to remote access the server machine.
-
-
-
-You can use VNC client like [Tightvnc viewer][3] and [Realvnc viewer][4] to connect Server.
-To connect with additional users create files with different ports, please go to step 3 to configure and add a new user and port, You'll need to create **vncserver@:2.service** and replace the username in config file and continue the steps by replacing service name for different ports. **Please make sure you logged in as that particular user for creating vnc password**.
-
-VNC by itself runs on port 5900. Since each user will run their own VNC server, each user will have to connect via a separate port. The addition of a number in the file name tells VNC to run that service as a sub-port of 5900. So in our case, arun's VNC service will run on port 5901 (5900 + 1) and further will run on 5900 + x. Where, x denotes the port specified when creating config file **vncserver@:x.service for the further users**.
-
-We'll need to know the IP Address and Port of the server to connect with the client. IP addresses are the unique identity number of the machine. Here, my IP address is 96.126.120.92 and port for this user is 1. We can get the public IP address by executing the below command in a shell or terminal of the machine where VNC Server is installed.
-
- # curl -s checkip.dyndns.org|sed -e 's/.*Current IP Address: //' -e 's/<.*$//'
-
-### Conclusion ###
-
-Finally, we installed and configured VNC Server in the machine running CentOS 7 / RHEL 7 (Red Hat Enterprises Linux) . VNC is the most easy FOSS tool for the remote access and also a good alternative to Teamviewer Remote Access. VNC allows a user with VNC client installed to control the machine with VNC Server installed. Here are some commands listed below that are highly useful in VNC . Enjoy !!
-
-#### Additional Commands : ####
-
-- To stop VNC service .
-
- # systemctl stop vncserver@:1.service
-
-- To disable VNC service from startup.
-
- # systemctl disable vncserver@:1.service
-
-- To stop firewall.
-
- # systemctl stop firewalld.service
-
---------------------------------------------------------------------------------
-
-via: http://linoxide.com/linux-how-to/install-configure-vnc-server-centos-7-0/
-
-作者:[Arun Pyasi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://linoxide.com/author/arunp/
-[1]:http://en.wikipedia.org/wiki/Virtual_Network_Computing
-[2]:http://en.wikipedia.org/wiki/X_Window_System
-[3]:http://www.tightvnc.com/
-[4]:https://www.realvnc.com/
\ No newline at end of file
diff --git a/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md b/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md
deleted file mode 100644
index b5bbc69a3b..0000000000
--- a/sources/tech/20150205 How To Use Smartphones Like Weather Conky In Linux.md
+++ /dev/null
@@ -1,84 +0,0 @@
-How To Use Smartphones Like Weather Conky In Linux
-================================================================================
-
-
-Smartphones have those sleek weather widgets that blend in to the display. Thanks to Flair Weather Conky, you can get **smartphone like weather display on your Linux desktop**. We will be using a GUI tool [Conky Manager to easily manage Conky in Linux][1]. Let’s first see how to install Conky Manager in Ubuntu 14.10, 14.04, Linux Mint 17 and other Linux distributions.
-
-### Install Conky Manager ###
-
-Open a terminal and use the following commands:
-
- sudo add-apt-repository ppa:teejee2008/ppa
- sudo apt-get update
- sudo apt-get install conky-manager
-
-You can read this article on [how to use Conky Manager in Linux][1].
-
-### Make sure curl is installed ###
-
-Do make sure that [curl][2] is installed. Use the following command:
-
- sudo apt-get install curl
-
-### Download Flair Weather Conky ###
-
-Get the Flair Weather Conky script from the link below:
-
-- [Download Flair Weather Conky Script][3]
-
-### Using Flair Weather Conky script in Conky Manager ###
-
-#### Step 1: ####
-
-Same as you install themes in Ubuntu 14.04, you should have a .conky directory in your Home folder. If you use command line, I don’t need to tell you how to find that. For beginners, go to your Home directory from File manager and press Ctrl+H to [show hidden files in Ubuntu][4]. Look for .conky folder here. If there is no such folder, make one.
-
-#### Step 2: ####
-
-In the .conky directory, extract the downloaded Flair Weather file. Do note that by default it is extracted to .conky directory itself. So go in this directory and get the Flair Weather folder out of it and paste it to actual .conky directory.
-
-#### Step 3: ####
-
-Flair Weather uses Yahoo and it doesn’t recognize your location automatically. You’ll need to manually edit it. Go to [Yahoo Weather][5] and get the location of id of your city by typing your city/pin code. You can get the location id from the URL.
-
-
-
-#### Step 4: ####
-
-Open Conky Manager. It should be able to read the newly installed Conky script. There are two variants, dark and light, available. You can choose whichever you prefer. You can should see the conky displayed on the desktop as soon as you select it.
-
-Default location in Flair Weather is set to Melbourne. You’ll have to manually edit the conky.
-
-
-
-#### Step 5: ####
-
-In the screenshot above, you can see the option to edit the selected conky. In the editor opened, look for location or WOEID. Change it with the location code you got in step 3. Now restart the Conky.
-
-
-
-In the same place, if you replace C by F, the unit of temperature will be changed to Fahrenheit from Celsius. Don’t forget to restart the Conky to see the changes made.
-
-#### Give it a try ####
-
-In this article we actually learned quite few things. We saw how we can use any Conky script easily, how to edit the scripts and how to use Conky Manager for various purposes. I hope you find it useful.
-
-A word of caution, Ubuntu 14.10 users might see overlapped time numerals. Please make the developer ware of any such issues.
-
-I have already shown you the screenshot of how the Flair Weather conky looked in my system. Time for you to try this and flaunt your desktop.
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/weather-conky-linux/
-
-作者:[Abhishek][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://itsfoss.com/conky-gui-ubuntu-1304/
-[2]:http://www.computerhope.com/unix/curl.htm
-[3]:http://speedracker.deviantart.com/art/Flair-Weather-Conky-Made-for-Conky-Manager-510130311
-[4]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
-[5]:https://weather.yahoo.com/
\ No newline at end of file
diff --git a/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md b/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md
deleted file mode 100644
index 62eee8521c..0000000000
--- a/sources/tech/20150205 zBackup--A versatile deduplicating backup tool.md
+++ /dev/null
@@ -1,63 +0,0 @@
-zBackup – A versatile deduplicating backup tool
-================================================================================
-zbackup is a globally-deduplicating backup tool, based on the ideas found in rsync. Feed a large .tar into it, and it will store duplicate regions of it only once, then compress and optionally encrypt the result. Feed another .tar file, and it will also re-use any data found in any previous backups. This way only new changes are stored, and as long as the files are not very different, the amount of storage required is very low. Any of the backup files stored previously can be read back in full at any time.
-
-### zBackup Features ###
-
-Parallel LZMA or LZO compression of the stored data
-Built-in AES encryption of the stored data
-Possibility to delete old backup data
-Use of a 64-bit rolling hash, keeping the amount of soft collisions to zero
-Repository consists of immutable files. No existing files are ever modified
-Written in C++ only with only modest library dependencies
-Safe to use in production
-Possibility to exchange data between repos without recompression
-
-### Install zBackup in ubuntu ###
-
-Open the terminal and run the following command
-
- sudo apt-get install zbackup
-
-### Using zBackup ###
-
-zbackup init initializes a backup repository for the backup files to be stored.
-
- zbackup init [--non-encrypted] [--password-file ~/.my_backup_password ] /my/backup/repo
-
-zbackup backup backups a tar file generated by tar c to the repository initialized using zbackup init
-
- zbackup [--password-file ~/.my_backup_password ] [--threads number_of_threads ] backup /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'`
-
-zbackup restore restores the backup file to a tar file.
-
- zbackup [--password-file ~/.my_backup_password [--cache-size cache_size_in_mb restore /my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` > /my/precious/backup-restored.tar
-
-### Available Options ###
-
-- -non-encrypted -- Do not encrypt the backup repository.
-- --password-file ~/.my_backup_password -- Use the password file specified at ~/.my_backup_password to encrypt the repository and backup file, or to decrypt the backup file.
-- --threads number_of_threads -- Limit the partial LZMA compression to number_of_threads needed. Recommended for 32-bit architectures.
-- --cache-size cache_size_in_mb -- Use the cache size provided by cache_size_in_mb to speed up the restoration process.
-
-### zBackup files ###
-
-~/.my_backup_password Used to encrypt the repository and backup file, or to decrypt the backup file. See zbackup for further details.
-
-/my/backup/repo The directory used to hold the backup repository.
-
-/my/precious/restored-tar The tar used for restoring the backup.
-
-/my/backup/repo/backups/backup-`date ‘+%Y-%m-%d'` Specifies the backup file.
-
---------------------------------------------------------------------------------
-
-via: http://www.ubuntugeek.com/zbackup-a-versatile-deduplicating-backup-tool.html
-
-作者:[ruchi][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.ubuntugeek.com/author/ubuntufix
\ No newline at end of file
diff --git a/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md b/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md
new file mode 100644
index 0000000000..58a0841280
--- /dev/null
+++ b/sources/tech/20150209 How to access Feedly RSS feed from the command line on Linux.md
@@ -0,0 +1,106 @@
+How to access Feedly RSS feed from the command line on Linux
+================================================================================
+In case you didn't know, [Feedly][1] is one of the most popular online news aggregation services. It offers seamlessly unified news reading experience across desktops, Android and iOS devices via browser extensions and mobile apps. Feedly took on the demise of Google Reader in 2013, quickly gaining a lot of then Google Reader users. I was one of them, and Feedly has remained my default RSS reader since then.
+
+While I appreciate the sleek interface of Feedly's browser extensions and mobile apps, there is yet another way to access Feedly: Linux command-line. That's right. You can access Feedly's news feed from the command line. Sounds geeky? Well, at least for system admins who live on headless servers, this can be pretty useful.
+
+Enter [Feednix][2]. This open-source software is a Feedly's unofficial command-line client written in C++. It allows you to browse Feedly's news feed in ncurses-based terminal interface. By default, Feednix is linked with a console-based browser called w3m to allow you to read articles within a terminal environment. You can choose to read from your favorite web browser though.
+
+In this tutorial, I am going to demonstrate how to install and configure Feednix to access Feedly from the command line.
+
+### Install Feednix on Linux ###
+
+You can build Feednix from the source using the following instructions. At the moment, the "Ubuntu-stable" branch of the official Github repository has the most up-to-date code. So let's use this branch to build it.
+
+As prerequisites, you will need to install a couple of development libraries, as well as w3m browser.
+
+#### Debian, Ubuntu or Linux Mint ####
+
+ $ sudo apt-get install git automake g++ make libncursesw5-dev libjsoncpp-dev libcurl4-gnutls-dev w3m
+ $ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
+ $ cd Feednix
+ $ ./autogen.sh
+ $ ./configure
+ $ make
+ $ sudo make install
+
+#### Fedora ####
+
+ $ sudo yum groupinstall "C Development Tools and Libraries"
+ $ sudo yum install gcc-c++ git automake make ncurses-devel jsoncpp-devel libcurl-devel w3m
+ $ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
+ $ cd Feednix
+ $ ./autogen.sh
+ $ ./configure
+ $ make
+ $ sudo make install
+
+Arch Linux
+
+On Arch Linux, you can easily install Feednix from [AUR][3].
+
+### Configure Feednix for the First Time ###
+
+After installing it, launch Feednix as follows.
+
+ $ feednix
+
+The first time you run Feednix, it will pop up a web browser window, where you need to sign up to create a Feedly's user ID and its corresponding developer access token. If you are running Feednix in a desktop-less environment, open a web browser on another computer, and go to https://feedly.com/v3/auth/dev.
+
+
+
+Once you sign in, you will see your Feedly user ID generated.
+
+
+
+To retrieve an access token, you need to follow the token link sent to your email address in your browser. Only then will you see the window showing your user ID, access token, and its expiration date. Be aware that access token is quite long (more than 200 characters). The token appears in a horizontally scrollable text box, so make sure to copy the whole access token string.
+
+
+
+Paste your user ID and access token into the Feednix' command-line prompt.
+
+ [Enter User ID] >> XXXXXX
+ [Enter token] >> YYYYY
+
+After successful authentication, you will see an initial Feednix screen with two panes. The left-side "Categories" pane shows a list of news categories, while the right-side "Posts" pane displays a list of news articles in the current category.
+
+
+
+### Read News in Feednix ###
+
+Here I am going to briefly describe how to access Feedly via Feednix.
+
+#### Navigate Feednix ####
+
+As I mentioned, the top screen of Feednix consists of two panes. To switch focus between the two panes, use TAB key. To move up and down the list within a pane, use 'j' and 'k' keys, respectively. These keyboard shorcuts are obviously inspired by Vim text editor.
+
+#### Read an Article ####
+
+To read a particular article, press 'o' key at the current article. It will invoke w2m browser, and load the article inside the browser. Once you are done reading, press 'q' to quit the browser, and come back to Feednix. If your environment can open a web browser, you can press 'O' to load an article on your default web browser such as Firefox.
+
+
+
+#### Subscribe to a News Feed ####
+
+You can add any arbitrary RSS news feed to your Feedly account from Feednix interface. To do so, simply press 'a' key. This will show "[ENTER FEED]:" prompt at the bottom of the screen. After typing the RSS feed, go ahead and fill in the name of the feed and its preferred category.
+
+
+
+#### Summary ####
+
+As you can see, Feednix is a quite convenient and easy-to-use command-line RSS reader. If you are a command-line junkie as well as a regular Feedly user, Feednix is definitely worth trying. I have been communicating with the creator of Feednix, Jarkore, to troubleshoot some issue. As far as I can tell, he is very active in responding to bug reports and fixing bugs. I encourage you to try out Feednix and let him know your feedback.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/feedly-rss-feed-command-line-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:https://feedly.com/
+[2]:https://github.com/Jarkore/Feednix
+[3]:https://aur.archlinux.org/packages/feednix/
\ No newline at end of file
diff --git a/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md b/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md
new file mode 100644
index 0000000000..127f10affc
--- /dev/null
+++ b/sources/tech/20150209 Install OpenQRM Cloud Computing Platform In Debian.md
@@ -0,0 +1,149 @@
+Install OpenQRM Cloud Computing Platform In Debian
+================================================================================
+### Introduction ###
+
+**openQRM** is a web-based open source Cloud computing and datacenter management platform that integrates flexibly with existing components in enterprise data centers.
+
+It supports the following virtualization technologies:
+
+- KVM,
+- XEN,
+- Citrix XenServer,
+- VMWare ESX,
+- LXC,
+- OpenVZ.
+
+The Hybrid Cloud Connector in openQRM supports a range of private or public cloud providers to extend your infrastructure on demand via **Amazon AWS**, **Eucalyptus** or **OpenStack**. It, also, automates provisioning, virtualization, storage and configuration management, and it takes care of high-availability. A self-service cloud portal with integrated billing system enables end-users to request new servers and application stacks on-demand.
+
+openQRM is available in two different flavours such as:
+
+- Enterprise Edition
+- Community Edition
+
+You can view the difference between both editions [here][1].
+
+### Features ###
+
+- Private/Hybrid Cloud Computing Platform;
+- Manages physical and virtualized server systems;
+- Integrates with all major open and commercial storage technologies;
+- Cross-platform: Linux, Windows, OpenSolaris, and *BSD;
+- Supports KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ and VirtualBox;
+- Support for Hybrid Cloud setups using additional Amazon AWS, Eucalyptus, Ubuntu UEC cloud resources;
+- Supports P2V, P2P, V2P, V2V Migrations and High-Availability;
+- Integrates with the best Open Source management tools – like puppet, nagios/Icinga or collectd;
+- Over 50 plugins for extended features and integration with your infrastructure;
+- Self-Service Portal for end-users;
+- Integrated billing system.
+
+### Installation ###
+
+Here, we will install openQRM in Ubuntu 14.04 LTS. Your server must atleast meet the following requirements.
+
+- 1 GB RAM;
+- 100 GB Hdd;
+- Optional: Virtualization enabled (VT for Intel CPUs or AMD-V for AMD CPUs) in Bios.
+
+First, install make package to compile openQRM source package.
+
+ sudo apt-get update
+ sudo apt-get upgrade
+ sudo apt-get install make
+
+Then, run the following commands one by one to install openQRM.
+
+Download the latest available version [from here][2].
+
+ wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
+
+ tar -xvzf openqrm-community-5.1.tgz
+
+ cd openqrm-community-5.1/src/
+
+ sudo make
+
+ sudo make install
+
+ sudo make start
+
+During installation, you’ll be asked to update the php.ini file.
+
+
+
+Enter mysql root user password.
+
+
+
+Re-enter password:
+
+
+
+Select the mail server configuration type.
+
+
+
+If you’re not sure, select Local only. In our case, I go with **Local only** option.
+
+
+
+Enter your system mail name, and finally enter the Nagios administration password.
+
+
+
+The above commands will take long time depending upon your Internet connection to download all packages required to run openQRM. Be patient.
+
+Finally, you’ll get the openQRM configuration URL along with username and password.
+
+
+
+### Configuration ###
+
+After installing openQRM, open up your web browser and navigate to the URL: **http://ip-address/openqrm**.
+
+For example, in my case http://192.168.1.100/openqrm.
+
+The default username and password is: **openqrm/openqrm**.
+
+
+
+Select a network card to use for the openQRM management network.
+
+
+
+Select a database type. In our case, I selected mysql.
+
+
+
+Now, configure the database connection and initialize openQRM. Here, I use **openQRM** as database name, and user as **root** and debian as password for the database. Be mindful that you should enter the mysql root user password that you have created while installing openQRM.
+
+
+
+Congratulations!! openQRM has been installed and configured.
+
+
+
+### Update openQRM ###
+
+To update openQRM at any time run the following command:
+
+ cd openqrm/src/
+ make update
+
+What we have done so far is just installed and configured openQRM in our Ubuntu server. For creating, running Virtual Machines, managing Storage, integrating additional systems and running your own private Cloud, I suggest you to read the [openQRM Administrator Guide][3].
+
+That’s all now. Cheers! Happy weekend!!
+
+--------------------------------------------------------------------------------
+
+via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
+
+作者:[SK][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.unixmen.com/author/sk/
+[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
+[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
+[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
\ No newline at end of file
diff --git a/sources/tech/20150225 How to make remote incremental backup of LUKS-encrypted disk or partition.md b/sources/tech/20150225 How to make remote incremental backup of LUKS-encrypted disk or partition.md
new file mode 100644
index 0000000000..64e872c4b7
--- /dev/null
+++ b/sources/tech/20150225 How to make remote incremental backup of LUKS-encrypted disk or partition.md
@@ -0,0 +1,80 @@
+How to make remote incremental backup of LUKS-encrypted disk/partition
+================================================================================
+Some of us have our hard drives at home or on a [VPS][1] encrypted by [Linux Unified Key Setup (LUKS)][2] for security reasons, and these drives can quickly grow to tens or hundreds of GBs in size. So while we enjoy the security of our LUKS device, we may start to think about a possible remote backup solution. For secure off-site backup, we will need something that operates at the block level of the encrypted LUKS device, and not at the un-encrypted file system level. So in the end we find ourselves in a situation where we will need to transfer the entire LUKS device (let's say 200GB for example) each time we want to make a backup. Clearly not feasible. How can we deal with this problem?
+
+### A Solution: Bdsync ###
+
+This is when a brilliant open-source tool called [Bdsync][3] (thanks to Rolf Fokkens) comes to our rescue. As the name implies, Bdsync can synchronize "block devices" over network. For fast synchronization, Bdsync generates and compares MD5 checksums of blocks in the local/remote block devices, and sync only the differences. What rsync can do at the file system level, Bdsync can do it at the block device level. Naturally, it works with encrypted LUKS devices as well. Pretty neat!
+
+Using Bdsync, the first-time backup will copy the entire LUKS block device to a remote host, so it will take a lot of time to finish. However, after that initial backup, if we make some new files on the LUKS device, the second backup will be finished quickly because we will need to copy only that blocks which have been changed. Classic incremental backup at play!
+
+### Install Bdsync on Linux ###
+
+Bdsync is not included in the standard repositories of [Linux][4] distributions. Thus you need to build it from the source. Use the following distro-specific instructions to install Bdsync and its man page on your system.
+
+#### Debian, Ubuntu or Linux Mint ####
+
+ $ sudo apt-get install git gcc libssl-dev
+ $ git clone https://github.com/TargetHolding/bdsync.git
+ $ cd bdsync
+ $ make
+ $ sudo cp bdsync /usr/local/sbin
+ $ sudo mkdir -p /usr/local/man/man1
+ $ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
+
+#### Fedora or CentOS/RHEL ####
+
+ $ sudo yum install git gcc openssl-devel
+ $ git clone https://github.com/TargetHolding/bdsync.git
+ $ cd bdsync
+ $ make
+ $ sudo cp bdsync /usr/local/sbin
+ $ sudo mkdir -p /usr/local/man/man1
+ $ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
+
+### Perform Off-site Incremental Backup of LUKS-Encrypted Device ###
+
+I assume that you have already provisioned a LUKS-encrypted block device as a backup source (e.g., /dev/LOCDEV). I also assume that you have a remote host where the source device will be backed up (e.g., as /dev/REMDEV).
+
+You need to access the root account on both systems, and set up [password-less SSH access][5] from the local host to a remote host. Finally, you need to install Bdsync on both hosts.
+
+To initiate a remote backup process on the local host, we execute the following command as the root:
+
+ # bdsync "ssh root@remote_host bdsync --server" /dev/LOCDEV /dev/REMDEV | gzip > /some_local_path/DEV.bdsync.gz
+
+Some explanations are needed here. Bdsync client will open an SSH connection to the remote host as the root, and execute Bdsync client with --server option. As clarified, /dev/LOCDEV is our source LUKS block device on the local host, and /dev/REMDEV is the target block device on the remote host. They could be /dev/sda (for an entire disk) or /dev/sda2 (for a single partition). The output of the local Bdsync client is then piped to gzip, which creates DEV.bdsync.gz (so-called binary patch file) in the local host.
+
+The first time you run the above command, it will take very long time, depending on your Internet/LAN speed and the size of /dev/LOCDEV. Remember that you must have two block devices (/dev/LOCDEV and /dev/REMDEV) with the same size.
+
+The next step is to copy the generated patch file from the local host to the remote host. Using scp is one possibility:
+
+ # scp /some_local_path/DEV.bdsync.gz root@remote_host:/remote_path
+
+The final step is to execute the following command on the remote host, which will apply the patch file to /dev/REMDEV:
+
+ # gzip -d < /remote_path/DEV.bdsync.gz | bdsync --patch=/dev/DSTDEV
+
+I recommend doing some tests with small partitions (without any important data) before deploying Bdsync with real data. After you fully understand how the entire setup works, you can start backing up real data.
+
+### Conclusion ###
+
+In conclusion, we showed how to use Bdsync to perform incremental backups for LUKS devices. Like rsync, only a fraction of data, not the entire LUKS device, is needed to be pushed to an off-site backup site at each backup, which saves bandwidth and backup time. Rest assured that all the data transfer is secured by SSH or SCP, on top of the fact that the device itself is encrypted by LUKS. It is also possible to improve this setup by using a dedicated user (instead of the root) who can run bdsync. We can also use bdsync for ANY block device, such as LVM volumes or RAID disks, and can easily set up Bdsync to back up local disks on to USB drives as well. As you can see, its possibility is limitless!
+
+Feel free to share your thought.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/remote-incremental-backup-luks-encrypted-disk-partition.html
+
+作者:[Iulian Murgulet][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/iulian
+[1]:http://xmodulo.com/go/digitalocean
+[2]:http://xmodulo.com/how-to-create-encrypted-disk-partition-on-linux.html
+[3]:http://bdsync.rolf-fokkens.nl/
+[4]:http://xmodulo.com/recommend/linuxbook
+[5]:http://xmodulo.com/how-to-enable-ssh-login-without.html
\ No newline at end of file
diff --git a/sources/tech/20150225 How to set up IPv6 BGP peering and filtering in Quagga BGP router.md b/sources/tech/20150225 How to set up IPv6 BGP peering and filtering in Quagga BGP router.md
new file mode 100644
index 0000000000..cae05670ba
--- /dev/null
+++ b/sources/tech/20150225 How to set up IPv6 BGP peering and filtering in Quagga BGP router.md
@@ -0,0 +1,258 @@
+How to set up IPv6 BGP peering and filtering in Quagga BGP router
+================================================================================
+In the previous tutorials, we demonstrated how we can set up a [full-fledged BGP router][1] and configure [prefix filtering][2] with Quagga. In this tutorial, we are going to show you how we can set up IPv6 BGP peering and advertise IPv6 prefixes through BGP. We will also demonstrate how we can filter IPv6 prefixes advertised or received by using prefix-list and route-map features.
+
+### Topology ###
+
+For this tutorial, we will be considering the following topology.
+
+
+
+Service providers A and B want to establish an IPv6 BGP peering between them. Their IPv6 and AS information is as follows.
+
+- Peering IP block: 2001:DB8:3::/64
+- Service provider A: AS 100, 2001:DB8:1::/48
+- Service provider B: AS 200, 2001:DB8:2::/48
+
+### Installing Quagga on CentOS/RHEL ###
+
+If Quagga has not already been installed, we can install it using yum.
+
+ # yum install quagga
+
+On CentOS/RHEL 7, the default SELinux policy, which prevents /usr/sbin/zebra from writing to its configuration directory, can interfere with the setup procedure we are going to describe. Thus we want to disable this policy as follows. Skip this step if you are using CentOS/RHEL 6.
+
+ # setsebool -P zebra_write_config 1
+
+### Creating Configuration Files ###
+
+After installation, we start the configuration process by creating the zebra/bgpd configuration files.
+
+ # cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
+ # cp /usr/share/doc/quagga-XXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
+
+Next, enable auto-start of these services.
+
+**On CentOS/RHEL 6:**
+
+ # service zebra start; service bgpd start
+ # chkconfig zebra on; chkconfig bgpd on
+
+**On CentOS/RHEL 7:**
+
+ # systemctl start zebra; systemctl start bgpd
+ # systemctl enable zebra; systmectl enable bgpd
+
+Quagga provides a built-in shell called vtysh, whose interface is similar to those of major router vendors such as Cisco or Juniper. Launch vtysh command shell:
+
+ # vtysh
+
+The prompt will be changed to:
+
+ router-a#
+
+or
+
+ router-b#
+
+In the rest of the tutorials, these prompts indicate that you are inside vtysh shell of either router.
+
+### Specifying Log File for Zebra ###
+
+Let's configure the log file for Zebra, which will be helpful for debugging.
+
+First, enter the global configuration mode by typing:
+
+ router-a# configure terminal
+
+The prompt will be changed to:
+
+ router-a(config)#
+
+Now specify log file location. Then exit the configuration mode:
+
+ router-a(config)# log file /var/log/quagga/quagga.log
+ router-a(config)# exit
+
+Save configuration permanently by:
+
+ router-a# write
+
+### Configuring Interface IP Addresses ###
+
+Let's now configure the IP addresses for Quagga's physical interfaces.
+
+First, we check the available interfaces from inside vtysh.
+
+ router-a# show interfaces
+
+----------
+
+ Interface eth0 is up, line protocol detection is disabled
+ ## OUTPUT TRUNCATED ###
+ Interface eth1 is up, line protocol detection is disabled
+ ## OUTPUT TRUNCATED ##
+
+Now we assign necessary IPv6 addresses.
+
+ router-a# conf terminal
+ router-a(config)# interface eth0
+ router-a(config-if)# ipv6 address 2001:db8:3::1/64
+ router-a(config-if)# interface eth1
+ router-a(config-if)# ipv6 address 2001:db8:1::1/64
+
+We use the same method to assign IPv6 addresses to router-B. I am summarizing the configuration below.
+
+ router-b# show running-config
+
+----------
+
+ interface eth0
+ ipv6 address 2001:db8:3::2/64
+
+ interface eth1
+ ipv6 address 2001:db8:2::1/64
+
+Since the eth0 interface of both routers are in the same subnet, i.e., 2001:DB8:3::/64, you should be able to ping from one router to another. Make sure that you can ping successfully before moving on to the next step.
+
+ router-a# ping ipv6 2001:db8:3::2
+
+----------
+
+ PING 2001:db8:3::2(2001:db8:3::2) 56 data bytes
+ 64 bytes from 2001:db8:3::2: icmp_seq=1 ttl=64 time=3.20 ms
+ 64 bytes from 2001:db8:3::2: icmp_seq=2 ttl=64 time=1.05 ms
+
+### Phase 1: IPv6 BGP Peering ###
+
+In this section, we will configure IPv6 BGP between the two routers. We start by specifying BGP neighbors in router-A.
+
+ router-a# conf t
+ router-a(config)# router bgp 100
+ router-a(config-router)# no auto-summary
+ router-a(config-router)# no synchronization
+ router-a(config-router)# neighbor 2001:DB8:3::2 remote-as 200
+
+Next, we define the address family for IPv6. Within the address family section, we will define the network to be advertised, and activate the neighbors as well.
+
+ router-a(config-router)# address-family ipv6
+ router-a(config-router-af)# network 2001:DB8:1::/48
+ router-a(config-router-af)# neighbor 2001:DB8:3::2 activate
+
+We will go through the same configuration for router-B. I'm providing the summary of the configuration.
+
+ router-b# conf t
+ router-b(config)# router bgp 200
+ router-b(config-router)# no auto-summary
+ router-b(config-router)# no synchronization
+ router-b(config-router)# neighbor 2001:DB8:3::1 remote-as 100
+ router-b(config-router)# address-family ipv6
+ router-b(config-router-af)# network 2001:DB8:2::/48
+ router-b(config-router-af)# neighbor 2001:DB8:3::1 activate
+
+If all goes well, an IPv6 BGP session should be up between the two routers. If not already done, please make sure that necessary ports (TCP 179) are [open in your firewall][3].
+
+We can check IPv6 BGP session information using the following commands.
+
+**For BGP summary:**
+
+ router-a# show bgp ipv6 unicast summary
+
+**For BGP advertised routes:**
+
+ router-a# show bgp ipv6 neighbors advertised-routes
+
+**For BGP received routes:**
+
+ router-a# show bgp ipv6 neighbors routes
+
+
+
+### Phase 2: Filtering IPv6 Prefixes ###
+
+As we can see from the above output, the routers are advertising their full /48 IPv6 prefix. For demonstration purposes, we will consider the following requirements.
+
+- Router-B will advertise one /64 prefix, one /56 prefix, as well as one full /48 prefix.
+- Router-A will accept any IPv6 prefix owned by service provider B, which has a netmask length between /56 and /64.
+
+We are going to filter the prefix as required, using prefix-list and route-map in router-A.
+
+
+
+#### Modifying prefix advertisement for Router-B ####
+
+Currently, router-B is advertising only one /48 prefix. We will modify router-B's BGP configuration so that it advertises additional /56 and /64 prefixes as well.
+
+ router-b# conf t
+ router-b(config)# router bgp 200
+ router-b(config-router)# address-family ipv6
+ router-b(config-router-af)# network 2001:DB8:2::/56
+ router-b(config-router-af)# network 2001:DB8:2::/64
+
+We will verify that all prefixes are received at router-A.
+
+
+
+Great! As we are receiving all prefixes in router-A, we will move forward and create prefix-list and route-map entries to filter these prefixes.
+
+#### Creating Prefix-List ####
+
+As described in the [previous tutorial][4], prefix-list is a mechanism that is used to match an IP address prefix with a subnet length. Once a matched prefix is found, we can apply filtering or other actions to the matched prefix. To meet our requirements, we will go ahead and create a necessary prefix-list entry in router-A.
+
+ router-a# conf t
+ router-a(config)# ipv6 prefix-list FILTER-IPV6-PRFX permit 2001:DB8:2::/56 le 64
+
+The above commands will create a prefix-list entry named 'FILTER-IPV6-PRFX' which will match any prefix in the 2001:DB8:2:: pool with a netmask between 56 and 64.
+
+#### Creating and Applying Route-Map ####
+
+Now that the prefix-list entry is created, we will create a corresponding route-map rule which uses the prefix-list entry.
+
+ router-a# conf t
+ router-a(config)# route-map FILTER-IPV6-RMAP permit 10
+ router-a(config-route-map)# match ipv6 address prefix-list FILTER-IPV6-PRFX
+
+The above commands will create a route-map rule named 'FILTER-IPV6-RMAP'. This rule will permit IPv6 addresses matched by the prefix-list 'FILTER-IPV6-PRFX' that we have created earlier.
+
+Remember that a route-map rule is only effective when it is applied to a neighbor or an interface in a certain direction. We will apply the route-map in the BGP neighbor configuration. As the filter is meant for inbound prefixes, we apply the route-map in the inbound direction.
+
+ router-a# conf t
+ router-a(config)# router bgp 100
+ router-a(config-router)# address-family ipv6
+ router-a(config-router-af)# neighbor 2001:DB8:3::2 route-map FILTER-IPV6-RMAP in
+
+Now when we check the routes received at router-A, we should see only two prefixes that are allowed.
+
+
+
+**Note**: You may need to reset the BGP session for the route-map to take effect.
+
+All IPv6 BGP sessions can be restarted using the following command:
+
+ router-a# clear bgp ipv6 *
+
+I am summarizing the configuration of both routers so you get a clear picture at a glance.
+
+
+
+### Summary ###
+
+To sum up, this tutorial focused on how to set up BGP peering and filtering using IPv6. We showed how to advertise IPv6 prefixes to a neighboring BGP router, and how to filter the prefixes advertised or received are advertised. Note that the process described in this tutorial may affect production networks of a service provider, so please use caution.
+
+Hope this helps.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
+
+作者:[Sarmed Rahman][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://xmodulo.com/centos-bgp-router-quagga.html
+[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
+[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
+[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
\ No newline at end of file
diff --git a/sources/tech/20150227 Fix Minimal BASH like line editing is supported GRUB Error In Linux.md b/sources/tech/20150227 Fix Minimal BASH like line editing is supported GRUB Error In Linux.md
new file mode 100644
index 0000000000..88b742d4f9
--- /dev/null
+++ b/sources/tech/20150227 Fix Minimal BASH like line editing is supported GRUB Error In Linux.md
@@ -0,0 +1,86 @@
+Fix Minimal BASH like line editing is supported GRUB Error In Linux
+================================================================================
+The other day when I [installed Elementary OS in dual boot with Windows][1], I encountered a Grub error at the reboot time. I was presented with command line with error message:
+
+**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
+
+
+
+Indeed this is not an error specific to Elementary OS. It is a common [Grub][2] error that could occur with any Linux OS be it Ubuntu, Fedora, Linux Mint etc.
+
+In this post we shall see **how to fix this “minimal BASH like line editing is supported” Grub error in Ubuntu** based Linux systems.
+
+> You can read this tutorial to fix similar and more frequent issue, [error: no such partition grub rescue in Linux][3].
+
+### Prerequisites ###
+
+To fix this issue, you would need the followings:
+
+- A live USB or disk of the same OS and same version
+- A working internet connection in the live session
+
+Once you make sure that you have the prerequisites, let’s see how to fix the black screen of death for Linux (if I can call it that ;)).
+
+### How to fix this “minimal BASH like line editing is supported” Grub error in Ubuntu based Linux ###
+
+I know that you might point out that this Grub error is not exclusive to Ubuntu or Ubuntu based Linux distributions, then why am I putting emphasis on the world Ubuntu? The reason is, here we will take an easy way out and use a tool called **Boot Repair** to fix our problem. I am not sure if this tool is available for other distributions like Fedora. Without wasting anymore time, let’s see how to solve minimal BASH like line editing is supported Grub error.
+
+### Step 1: Boot in lives session ###
+
+Plug in the live USB and boot in to the live session.
+
+### Step 2: Install Boot Repair ###
+
+Once you are in the lives session, open the terminal and use the following commands to install Boot Repair:
+
+ sudo add-apt-repository ppa:yannubuntu/boot-repair
+ sudo apt-get update
+ sudo apt-get install boot-repair
+
+Note: Follow this tutorial to [fix failed to fetch cdrom apt-get update cannot be used to add new CD-ROMs error][4], if you encounter it while running the above command.
+
+### Step 3: Repair boot with Boot Repair ###
+
+Once you installed Boot Repair, run it from the command line using the following command:
+
+ boot-repair &
+
+Actually things are pretty straight forward from here. You just need to follow the instructions provided by Boot Repair tool. First, click on **Recommended repair** option in the Boot Repair.
+
+
+
+It will take couple of minutes for Boot Repair to analyze the problem with boot and Grub. Afterwards, it will provide you some commands to use in the command line. Copy the commands one by one in terminal. For me it showed me a screen like this:
+
+
+
+It will do some processes after you enter these commands:
+
+
+
+Once the process finishes, it will provide you a URL which consists of the logs of the boot repair. If your boot issue is not fixed even now, you can go to the forum or mail to the dev team and provide them the URL as a reference. Cool, isn’t it?
+
+
+
+After the boot repair finishes successfully, shutdown your computer, remove the USB and boot again. For me it booted successfully but added two additional lines in the Grub screen. Something which was not of importance to me as I was happy to see the system booting normally again.
+
+
+
+### Did it work for you? ###
+
+So this is how I fixed **minimal BASH like line editing is supported Grub error in Elementary OS Freya**. How about you? Did it work for you? Feel free to ask a question or drop a suggestion in the comment box below.
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux/
+
+作者:[Abhishek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://itsfoss.com/guide-install-elementary-os-luna/
+[2]:http://www.gnu.org/software/grub/
+[3]:http://itsfoss.com/solve-error-partition-grub-rescue-ubuntu-linux/
+[4]:http://itsfoss.com/fix-failed-fetch-cdrom-aptget-update-add-cdroms/
\ No newline at end of file
diff --git a/sources/tech/20150316 How to Test Your Internet Speed Bidirectionally from Command Line Using 'Speedtest-CLI' Tool.md b/sources/tech/20150316 How to Test Your Internet Speed Bidirectionally from Command Line Using 'Speedtest-CLI' Tool.md
new file mode 100644
index 0000000000..a0c77c21f9
--- /dev/null
+++ b/sources/tech/20150316 How to Test Your Internet Speed Bidirectionally from Command Line Using 'Speedtest-CLI' Tool.md
@@ -0,0 +1,132 @@
+How to Test Your Internet Speed Bidirectionally from Command Line Using ‘Speedtest-CLI’ Tool
+================================================================================
+We always need to check the speed of the Internet connection at home and office. What we do for this? Go to websites like Speedtest.net and begin test. It loads JavaScript in the web browser and then select best server based upon ping and output the result. It also uses a Flash player to produce graphical results.
+
+What about headless server, where isn’t any web based browser and the main point is, most of the servers are headless. The another bottleneck of such web browser based speed testing is that, you can’t schedule the speed testing at regular interval. Here comes an application “Speedtest-cli” that removes such bottlenecks and let you test the speed of Internet connection from command line.
+
+#### What is Speedtest-cli ####
+
+The application is basically a script developed in Python programming Language. It measures Internet Bandwidth speed bidirectionally. It used speedtest.net infrastructure to measure the speed. Speedtest-cli is able to list server based upon physical distance, test against specific server, and gives you URL to share the result of your internet speed test.
+
+To install latest speedtest-cli tool in Linux systems, you must have Python 2.4-3.4 or higher version installed on the system.
+
+### Install speedtest-cli in Linux ###
+
+There are two ways to install speedtest-cli tool. The first method involves the use of `python-pip` package while the second method is to download the Python script, make it executable and run, here I will cover both ways….
+
+#### Install speedtest-cli Using pythin-pip ####
+
+First you need to install `python-pip` package, then afterwards you can install the speedtest-cli tool using pip command as shown below.
+
+ $ sudo apt-get install python-pip
+ $ sudo pip install speedtest-cli
+
+To upgrade speedtest-cli, at later stage, use.
+
+ $ sudo pip install speedtest-cli --upgrade
+
+#### Install speedtest-cli Using Python Script ####
+
+First download the python script from github using wget command, unpack the downloaded file (master.zip) and extract it..
+
+ $ wget https://github.com/sivel/speedtest-cli/archive/master.zip
+ $ unzip master.zip
+
+After extracting the file, go to the extracted directory `speedtest-cli-master` and make the script file executable.
+
+ $ cd speedtest-cli-master/
+ $ chmod 755 speedtest_cli.py
+
+Next, move the executable to `/usr/bin` folder, so that you don’t need to type the full path everytime.
+
+ $ sudo mv speedtest_cli.py /usr/bin/
+
+### Testing Internet Connection Speed with speedtest-cli ###
+
+**1. To test Download and Upload speed of your internet connection, run the `speedtest-cli` command without any argument as shown below.**
+
+ $ speedtest_cli.py
+
+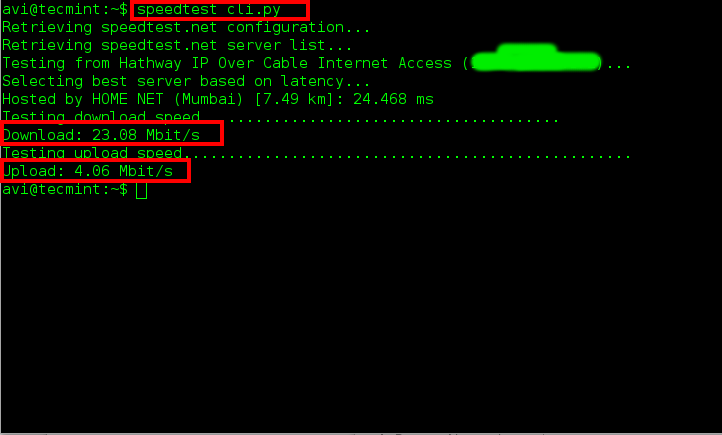
+Test Download Upload Speed in Linux
+
+**2. To check the speed result in bytes in place of bits.**
+
+ $ speedtest_cli.py --bytes
+
+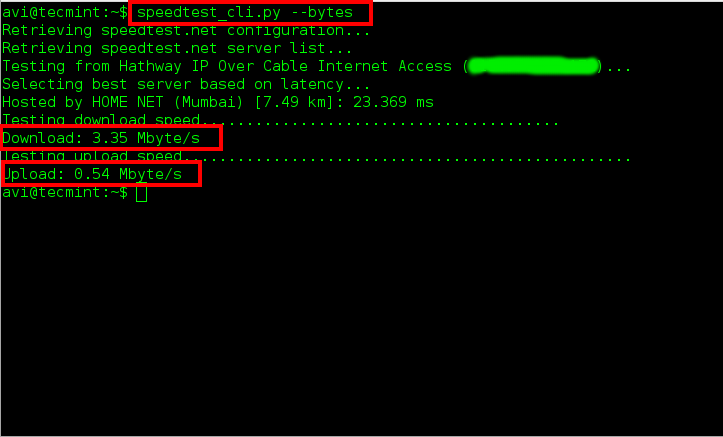
+Test Internet Speed in Bytes
+
+**3. Share your bandwidth speed with your friends or family. You are provided with a link that can be used to download an image.**
+
+
+Share Internet Speed Results
+
+The following picture is a sample speed test result generated using above command.
+
+
+Speed Test Results
+
+**4. Don’t need any additional information other than Ping, Download and upload?**
+
+ $ speedtest_cli.py --simple
+
+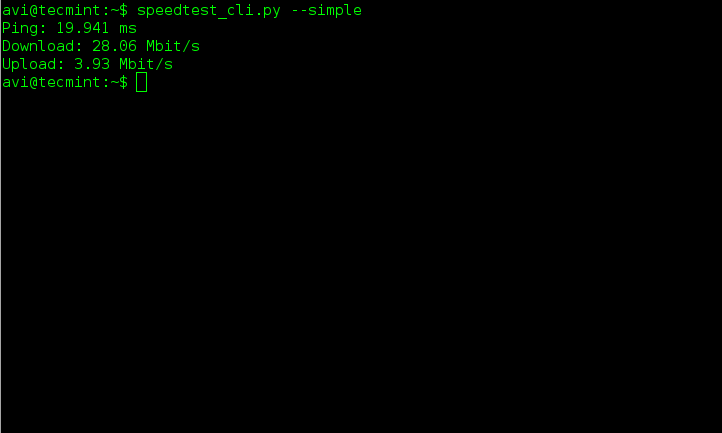
+Test Ping Download Upload Speed
+
+**5. List the `speedtest.net` server based upon physical distance. The distance in km is mentioned.**
+
+ $ speedtest_cli.py --list
+
+
+Check Speedtest.net Servers
+
+**6. The last stage generated a huge list of servers sorted on the basis of distance. How to get desired output? Say I only want to see the speedtest.net server located in Mumbai (India).**
+
+ $ speedtest_cli.py --list | grep -i Mumbai
+
+
+Check Nearest Server
+
+**7. Test connection speed against a specific server. Use Server Id generated in example 5 and example 6 in above.**
+
+ $ speedtest_cli.py --server [server ID]
+ $ speedtest_cli.py --server [5060] ## Here server ID 5060 is used in the example.
+
+
+Test Connection Against Server
+
+**8. To check the version number and help of `speedtest-cli` tool.**
+
+ $ speedtest_cli.py --version
+
+
+Check SpeedCli Version
+
+ $ speedtest_cli.py --help
+
+
+SpeedCli Help
+
+**Note:** Latency reported by tool is not its goal and one should not rely on it. The relative latency values output is responsible for server selected to be tested against. CPU and Memory capacity will influence the result to certain extent.
+
+### Conclusion ###
+
+The tool is must for system administrators and developers. A simple script which runs without any issue. I must say that the application is wonderful, lightweight and do what it promises. I disliked Speedtest.net for the reason it was using flash, but speedtest-cli gave me a reason to love them.
+
+speedtest_cli is a third party application and should not be used to automatically record the bandwidth speed. Speedtest.net is used by millions of users and it is a good idea to [Set Your Own Speedtest Mini Server][1].
+
+That’s all for now, till then stay tuned and connected to Tecmint. Don’t forget to give your valuable feedback in the comments below. Like and share us and help us get spread.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/check-internet-speed-from-command-line-in-linux/
+
+作者:[Avishek Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/speedtest-mini-server-to-test-bandwidth-speed/
diff --git a/sources/tech/20150318 How to Manage and Use LVM (Logical Volume Management) in Ubuntu.md b/sources/tech/20150318 How to Manage and Use LVM (Logical Volume Management) in Ubuntu.md
new file mode 100644
index 0000000000..ecfb639d54
--- /dev/null
+++ b/sources/tech/20150318 How to Manage and Use LVM (Logical Volume Management) in Ubuntu.md
@@ -0,0 +1,268 @@
+How to Manage and Use LVM (Logical Volume Management) in Ubuntu
+================================================================================
+
+
+In our [previous article we told you what LVM is and what you may want to use it for][1], and today we are going to walk you through some of the key management tools of LVM so you will be confident when setting up or expanding your installation.
+
+As stated before, LVM is a abstraction layer between your operating system and physical hard drives. What that means is your physical hard drives and partitions are no longer tied to the hard drives and partitions they reside on. Rather, the hard drives and partitions that your operating system sees can be any number of separate hard drives pooled together or in a software RAID.
+
+To manage LVM there are GUI tools available but to really understand what is happening with your LVM configuration it is probably best to know what the command line tools are. This will be especially useful if you are managing LVM on a server or distribution that does not offer GUI tools.
+
+Most of the commands in LVM are very similar to each other. Each valid command is preceded by one of the following:
+
+- Physical Volume = pv
+- Volume Group = vg
+- Logical Volume = lv
+
+The physical volume commands are for adding or removing hard drives in volume groups. Volume group commands are for changing what abstracted set of physical partitions are presented to your operating in logical volumes. Logical volume commands will present the volume groups as partitions so that your operating system can use the designated space.
+
+### Downloadable LVM Cheat Sheet ###
+
+To help you understand what commands are available for each prefix we made a LVM cheat sheet. We will cover some of the commands in this article, but there is still a lot you can do that won’t be covered here.
+
+All commands on this list will need to be run as root because you are changing system wide settings that will affect the entire machine.
+
+
+
+### How to View Current LVM Information ###
+
+The first thing you may need to do is check how your LVM is set up. The s and display commands work with physical volumes (pv), volume groups (vg), and logical volumes (lv) so it is a good place to start when trying to figure out the current settings.
+
+The display command will format the information so it’s easier to understand than the s command. For each command you will see the name and path of the pv/vg and it should also give information about free and used space.
+
+
+
+The most important information will be the PV name and VG name. With those two pieces of information we can continue working on the LVM setup.
+
+### Creating a Logical Volume ###
+
+Logical volumes are the partitions that your operating system uses in LVM. To create a logical volume we first need to have a physical volume and volume group. Here are all of the steps necessary to create a new logical volume.
+
+#### Create physical volume ####
+
+We will start from scratch with a brand new hard drive with no partitions or information on it. Start by finding which disk you will be working with. (/dev/sda, sdb, etc.)
+
+> Note: Remember all of the commands will need to be run as root or by adding ‘sudo’ to the beginning of the command.
+
+ fdisk -l
+
+If your hard drive has never been formatted or partitioned before you will probably see something like this in the fdisk output. This is completely fine because we are going to create the needed partitions in the next steps.
+
+
+
+Our new disk is located at /dev/sdb so lets use fdisk to create a new partition on the drive.
+
+There are a plethora of tools that can create a new partition with a GUI, [including Gparted][2], but since we have the terminal open already, we will use fdisk to create the needed partition.
+
+From a terminal type the following commands:
+
+ fdisk /dev/sdb
+
+This will put you in a special fdisk prompt.
+
+
+
+Enter the commands in the order given to create a new primary partition that uses 100% of the new hard drive and is ready for LVM. If you need to change the partition size or want multiple partions I suggest using GParted or reading about fdisk on your own.
+
+**Warning: The following steps will format your hard drive. Make sure you don’t have any information on this hard drive before following these steps.**
+
+- n = create new partition
+- p = creates primary partition
+- 1 = makes partition the first on the disk
+
+Push enter twice to accept the default first cylinder and last cylinder.
+
+
+
+To prepare the partition to be used by LVM use the following two commands.
+
+- t = change partition type
+- 8e = changes to LVM partition type
+
+Verify and write the information to the hard drive.
+
+- p = view partition setup so we can review before writing changes to disk
+- w = write changes to disk
+
+
+
+After those commands, the fdisk prompt should exit and you will be back to the bash prompt of your terminal.
+
+Enter pvcreate /dev/sdb1 to create a LVM physical volume on the partition we just created.
+
+You may be asking why we didn’t format the partition with a file system but don’t worry, that step comes later.
+
+
+
+#### Create volume Group ####
+
+Now that we have a partition designated and physical volume created we need to create the volume group. Luckily this only takes one command.
+
+ vgcreate vgpool /dev/sdb1
+
+
+
+Vgpool is the name of the new volume group we created. You can name it whatever you’d like but it is recommended to put vg at the front of the label so if you reference it later you will know it is a volume group.
+
+#### Create logical volume ####
+
+To create the logical volume that LVM will use:
+
+ lvcreate -L 3G -n lvstuff vgpool
+
+
+
+The -L command designates the size of the logical volume, in this case 3 GB, and the -n command names the volume. Vgpool is referenced so that the lvcreate command knows what volume to get the space from.
+
+#### Format and Mount the Logical Volume ####
+
+One final step is to format the new logical volume with a file system. If you want help choosing a Linux file system, read our [how to that can help you choose the best file system for your needs][3].
+
+ mkfs -t ext3 /dev/vgpool/lvstuff
+
+
+
+Create a mount point and then mount the volume somewhere you can use it.
+
+ mkdir /mnt/stuff
+ mount -t ext3 /dev/vgpool/lvstuff /mnt/stuff
+
+
+
+#### Resizing a Logical Volume ####
+
+One of the benefits of logical volumes is you can make your shares physically bigger or smaller without having to move everything to a bigger hard drive. Instead, you can add a new hard drive and extend your volume group on the fly. Or if you have a hard drive that isn’t used you can remove it from the volume group to shrink your logical volume.
+
+There are three basic tools for making physical volumes, volume groups, and logical volumes bigger or smaller.
+
+Note: Each of these commands will need to be preceded by pv, vg, or lv depending on what you are working with.
+
+- resize – can shrink or expand physical volumes and logical volumes but not volume groups
+- extend – can make volume groups and logical volumes bigger but not smaller
+- reduce – can make volume groups and logical volumes smaller but not bigger
+
+Let’s walk through an example of how to add a new hard drive to the logical volume “lvstuff” we just created.
+
+#### Install and Format new Hard Drive ####
+
+To install a new hard drive follow the steps above to create a new partition and add change it’s partition type to LVM (8e). Then use pvcreate to create a physical volume that LVM can recognize.
+
+#### Add New Hard Drive to Volume Group ####
+
+To add the new hard drive to a volume group you just need to know what your new partition is, /dev/sdc1 in our case, and the name of the volume group you want to add it to.
+
+This will add the new physical volume to the existing volume group.
+
+ vgextend vgpool /dev/sdc1
+
+
+
+#### Extend Logical Volume ####
+
+To resize the logical volume we need to say how much we want to extend by size instead of by device. In our example we just added a 8 GB hard drive to our 3 GB vgpool. To make that space usable we can use lvextend or lvresize.
+
+ lvextend -L8G /dev/vgpool/lvstuff
+
+
+
+While this command will work you will see that it will actually resize our logical volume to 8 GB instead of adding 8 GB to the existing volume like we wanted. To add the last 3 available gigabytes you need to use the following command.
+
+ lvextend -L+3G /dev/vgpool/lvstuff
+
+
+
+Now our logical volume is 11 GB in size.
+
+#### Extend File System ####
+
+The logical volume is 11 GB but the file system on that volume is still only 3 GB. To make the file system use the entire 11 GB available you have to use the command resize2fs. Just point resize2fs to the 11 GB logical volume and it will do the magic for you.
+
+ resize2fs /dev/vgpool/lvstuff
+
+
+
+**Note: If you are using a different file system besides ext3/4 please see your file systems resize tools.**
+
+#### Shrink Logical Volume ####
+
+If you wanted to remove a hard drive from a volume group you would need to follow the above steps in reverse order and use lvreduce and vgreduce instead.
+
+1. resize file system (make sure to move files to a safe area of the hard drive before resizing)
+1. reduce logical volume (instead of + to extend you can also use – to reduce by size)
+1. remove hard drive from volume group with vgreduce
+
+#### Backing up a Logical Volume ####
+
+Snapshots is a feature that some newer advanced file systems come with but ext3/4 lacks the ability to do snapshots on the fly. One of the coolest things about LVM snapshots is your file system is never taken offline and you can have as many as you want without taking up extra hard drive space.
+
+
+
+When LVM takes a snapshot, a picture is taken of exactly how the logical volume looks and that picture can be used to make a copy on a different hard drive. While a copy is being made, any new information that needs to be added to the logical volume is written to the disk just like normal, but changes are tracked so that the original picture never gets destroyed.
+
+To create a snapshot we need to create a new logical volume with enough free space to hold any new information that will be written to the logical volume while we make a backup. If the drive is not actively being written to you can use a very small amount of storage. Once we are done with our backup we just remove the temporary logical volume and the original logical volume will continue on as normal.
+
+#### Create New Snapshot ####
+
+To create a snapshot of lvstuff use the lvcreate command like before but use the -s flag.
+
+ lvcreate -L512M -s -n lvstuffbackup /dev/vgpool/lvstuff
+
+
+
+Here we created a logical volume with only 512 MB because the drive isn’t being actively used. The 512 MB will store any new writes while we make our backup.
+
+#### Mount New Snapshot ####
+
+Just like before we need to create a mount point and mount the new snapshot so we can copy files from it.
+
+ mkdir /mnt/lvstuffbackup
+ mount /dev/vgpool/lvstuffbackup /mnt/lvstuffbackup
+
+
+
+#### Copy Snapshot and Delete Logical Volume ####
+
+All you have left to do is copy all of the files from /mnt/lvstuffbackup/ to an external hard drive or tar it up so it is all in one file.
+
+**Note: tar -c will create an archive and -f will say the location and file name of the archive. For help with the tar command use man tar in the terminal.**
+
+ tar -cf /home/rothgar/Backup/lvstuff-ss /mnt/lvstuffbackup/
+
+
+
+Remember that while the backup is taking place all of the files that would be written to lvstuff are being tracked in the temporary logical volume we created earlier. Make sure you have enough free space while the backup is happening.
+
+Once the backup finishes, unmount the volume and remove the temporary snapshot.
+
+ umount /mnt/lvstuffbackup
+ lvremove /dev/vgpool/lvstuffbackup/
+
+
+
+#### Deleting a Logical Volume ####
+
+To delete a logical volume you need to first make sure the volume is unmounted, and then you can use lvremove to delete it. You can also remove a volume group once the logical volumes have been deleted and a physical volume after the volume group is deleted.
+
+Here are all the commands using the volumes and groups we’ve created.
+
+ umount /mnt/lvstuff
+ lvremove /dev/vgpool/lvstuff
+ vgremove vgpool
+ pvremove /dev/sdb1 /dev/sdc1
+
+
+
+That should cover most of what you need to know to use LVM. If you’ve got some experience on the topic, be sure to share your wisdom in the comments.
+
+--------------------------------------------------------------------------------
+
+via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
+
+译者:[runningwater](https://github.com/runningwater)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
+[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
+[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
\ No newline at end of file
diff --git a/sources/tech/20150318 How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots.md b/sources/tech/20150318 How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots.md
new file mode 100644
index 0000000000..883c5e3203
--- /dev/null
+++ b/sources/tech/20150318 How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots.md
@@ -0,0 +1,68 @@
+
+How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots
+================================================================================
+
+
+Ubuntu’s installer offers an easy “Use LVM” checkbox. The description says it enables Logical Volume Management so you can take snapshots and more easily resize your hard disk partitions — here’s how to do that.
+
+LVM is a technology that’s similar to [RAID arrays][1] or [Storage Spaces on Windows][2] in some ways. While this technology is particularly useful on servers, it can be used on desktop PCs, too.
+
+### Should You Use LVM With Your New Ubuntu Installation? ###
+
+The first question is whether you even want to use LVM with your Ubuntu installation. Ubuntu makes this easy to enable with a quick click, but this option isn’t enabled by default. As the installer says, this allows you to resize partitions, create snapshots, merge multiple disks into a single logical volume, and so on — all while the system is running. Unlike with typical partitions, you don’t have to shut down your system, boot from a live CD or USB drive, and [resize your partitions while they aren’t in use][3].
+
+To be perfectly honest, the average Ubuntu desktop user probably won’t realize whether they’re using LVM or not. But, if you want to do more advanced things later, LVM can help. LVM is potentially more complex, which could cause problems if you need to recover your data later — especially if you’re not that experienced with it. There shouldn’t be a noticeable performance penalty here — LVM is implemented right down in the Linux kernel.
+
+
+
+### Logical Volume Management Explained ###
+
+We’re previously [explained what LVM is][4]. In a nutshell, it provides a layer of abstraction between your physical disks and the partitions presented to your operating system. For example, your computer might have two hard drives inside it, each 1 TB in size. You’d have to have at least two partitions on these disks, and each of these partitions would be 1 TB in size.
+
+LVM provides a layer of abstraction over this. Instead of the traditional partition on a disk, LVM would treat the disks as two separate “physical volumes” after you initialize them. You could then create “logical volumes” based on these physical volumes. For example, you could combine those two 1 TB disks into a single 2 TB partition. Your operating system would just see a 2 TB volume, and LVM would deal with everything in the background. A group of physical volumes and logical volumes is known as a “volume group.” A typical system will just have a single volume group.
+
+This layer of abstraction makes it possibly to easily resize partitions, combine multiple disks into a single volume, and even take “snapshots” of a partition’s file system while it’s running, all without unmounting it.
+
+Note that merging multiple disks into a single volume can be a bad idea if you’re not creating backups. It’s like with RAID 0 — if you combine two 1 TB volumes into a single 2 TB volume, you could lose important data on the volume if just one of your hard disks fails. Backups are crucial if you go this route.
+
+### Graphical Utilities for Managing Your LVM Volumes ###
+
+Traditionally, [LVM volumes are managed with Linux terminal commands][5].These will work for you on Ubuntu, but there’s an easier, graphical method anyone can take advantage of. If you’re a Linux user used to using GParted or a similar partition manager, don’t bother — GParted doesn’t have support for LVM disks.
+
+Instead, you can use the Disks utility included along with Ubuntu for this. This utility is also known as GNOME Disk Utility, or Palimpsest. Launch it by clicking the icon on the dash, searching for Disks, and pressing Enter. Unlike GParted, the Disks utility will display your LVM partitions under “Other Devices,” so you can format them and adjust other options if you need to. This utility will also work from a live CD or USB drive, too.
+
+
+
+Unfortunately, the Disks utility doesn’t include support for taking advantage of LVM’s most powerful features. There’s no options for managing your volume groups, extending partitions, or taking snapshots. You could do that from the terminal, but you don’t have to. Instead, you can open the Ubuntu Software Center, search for LVM, and install the Logical Volume Management tool. You could also just run the **sudo apt-get install system-config-lvm** command in a terminal window. After it’s installed, you can open the Logical Volume Management utility from the dash.
+
+This graphical configuration tool was made by Red Hat. It’s a bit dated, but it’s the only graphical way to do this stuff without resorting to terminal commands.
+
+Let’s say you wanted to add a new physical volume to your volume group. You’d open the tool, select the new disk under Uninitialized Entries, and click the “Initialize Entry” button. You’d then find the new physical volume under Unallocated Volumes, and you could use the “Add to existing Volume Group” button to add it to the “ubuntu-vg” volume group Ubuntu created during the installation process.
+
+
+
+The volume group view shows you a visual overview of your physical volumes and logical volumes. Here, we have two physical partitions across two separate hard drives. We have a swap partition and a root partition, just as Ubuntu sets up its partitioning scheme by default. Because we’ve added a second physical partition from another drive, there’s now a good chunk of unused space.
+
+
+
+To expand a logical partition into the physical space, you could select it under Logical View, click Edit Properties, and modify the size to grow the partition. You could also shrink it from here.
+
+
+
+The other options in system-config-lvm allow you to set up snapshots and mirroring. You probably won’t need these features on a typical desktop, but they’re available graphically here. Remember, you can also [do all of this with terminal commands][6].
+
+--------------------------------------------------------------------------------
+
+via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://www.howtogeek.com/162676/how-to-use-multiple-disks-intelligently-an-introduction-to-raid/
+[2]:http://www.howtogeek.com/109380/how-to-use-windows-8s-storage-spaces-to-mirror-combine-drives/
+[3]:http://www.howtogeek.com/114503/how-to-resize-your-ubuntu-partitions/
+[4]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
+[5]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
+[6]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
\ No newline at end of file
diff --git a/sources/tech/20150331 How to set up remote desktop on Linux VPS using x2go.md b/sources/tech/20150331 How to set up remote desktop on Linux VPS using x2go.md
new file mode 100644
index 0000000000..d89c91832e
--- /dev/null
+++ b/sources/tech/20150331 How to set up remote desktop on Linux VPS using x2go.md
@@ -0,0 +1,137 @@
+How to set up remote desktop on Linux VPS using x2go
+================================================================================
+As everything is moved to the cloud, virtualized remote desktop becomes increasingly popular in the industry as a way to enhance employee's productivity. Especially for those who need to roam constantly across multiple locations and devices, remote desktop allows them to stay connected seamlessly to their work environment. Remote desktop is attractive for employers as well, achieving increased agility and flexibility in work environments, lower IT cost due to hardware consolidation, desktop security hardening, and so on.
+
+In the world of Linux, of course there is no shortage of choices for settings up remote desktop environment, with many protocols (e.g., RDP, RFB, NX) and server/client implementations (e.g., [TigerVNC][1], RealVNC, FreeNX, x2go, X11vnc, TeamViewer) available.
+
+Standing out from the pack is [X2Go][2], an open-source (GPLv2) implementation of NX-based remote desktop server and client. In this tutorial, I am going to demonstrate **how to set up remote desktop environment for [Linux VPS][3] using X2Go**.
+
+### What is X2Go? ###
+
+The history of X2Go goes back to NoMachine's NX technology. The NX remote desktop protocol was designed to deal with low bandwidth and high latency network connections by leveraging aggressive compression and caching. Later, NX was turned into closed-source while NX libraries were made GPL-ed. This has led to open-source implementation of several NX-based remote desktop solutions, and one of them is X2Go.
+
+What benefits does X2Go bring to the table, compared to other solutions such as VNC? X2Go inherits all the advanced features of NX technology, so naturally it works well over slow network connections. Besides, X2Go boasts of an excellent track record of ensuring security with its built-in SSH-based encryption. No longer need to set up an SSH tunnel [manually][4]. X2Go comes with audio support out of box, which means that music playback at the remote desktop is delivered (via PulseAudio) over network, and fed into local speakers. On usability front, an application that you run on remote desktop can be seamlessly rendered as a separate window on your local desktop, giving you an illusion that the application is actually running on the local desktop. As you can see, these are some of [its powerful features][5] lacking in VNC based solutions.
+
+### X2GO's Desktop Environment Compatibility ###
+
+As with other remote desktop servers, there are [known compatibility issues][6] for X2Go server. Desktop environments like KDE3/4, Xfce, MATE and LXDE are the most friendly to X2Go server. However, your mileage may vary with other desktop managers. For example, the later versions of GNOME 3, KDE5, Unity are known to be not compatible with X2Go. If the desktop manager of your remote host is compatible with X2Go, you can follow the rest of the tutorial.
+
+### Install X2Go Server on Linux ###
+
+X2Go consists of remote desktop server and client components. Let's start with X2Go server installation. I assume that you already have an X2Go-compatible desktop manager up and running on a remote host, where we will be installing X2Go server.
+
+Note that X2Go server component does not have a separate service that needs to be started upon boot. You just need to make sure that SSH service is up and running.
+
+#### Ubuntu or Linux Mint: ####
+
+Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
+
+ $ sudo add-apt-repository ppa:x2go/stable
+ $ sudo apt-get update
+ $ sudo apt-get install x2goserver x2goserver-xsession
+
+#### Debian (Wheezy): ####
+
+ $ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
+ $ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
+ $ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
+ $ sudo apt-get update
+ $ sudo apt-get install x2goserver x2goserver-xsession
+
+#### Fedora: ####
+
+ $ sudo yum install x2goserver x2goserver-xsession
+
+#### CentOS/RHEL: ####
+
+Enable [EPEL respository][7] first, and then run:
+
+ $ sudo yum install x2goserver x2goserver-xsession
+
+### Install X2Go Client on Linux ###
+
+On a local host where you will be connecting to remote desktop, install X2GO client as follows.
+
+#### Ubuntu or Linux Mint: ####
+
+Configure X2Go PPA repository. X2Go PPA is available for Ubuntu 14.04 and higher.
+
+ $ sudo add-apt-repository ppa:x2go/stable
+ $ sudo apt-get update
+ $ sudo apt-get install x2goclient
+
+Debian (Wheezy):
+
+ $ sudo apt-key adv --recv-keys --keyserver keys.gnupg.net E1F958385BFE2B6E
+ $ sudo sh -c "echo deb http://packages.x2go.org/debian wheezy main > /etc/apt/sources.list.d/x2go.list"
+ $ sudo sh -c "echo deb-src http://packages.x2go.org/debian wheezy main >> /etc/apt/sources.list.d/x2go.list"
+ $ sudo apt-get update
+ $ sudo apt-get install x2goclient
+
+#### Fedora: ####
+
+ $ sudo yum install x2goclient
+
+CentOS/RHEL:
+
+Enable EPEL respository first, and then run:
+
+ $ sudo yum install x2goclient
+
+### Connect to Remote Desktop with X2Go Client ###
+
+Now it's time to connect to your remote desktop. On the local host, simply run the following command or use desktop launcher to start X2Go client.
+
+ $ x2goclient
+
+Enter the remote host's IP address and SSH user name. Also, specify session type (i.e., desktop manager of a remote host).
+
+
+
+If you want, you can customize other things (by pressing other tabs), like connection speed, compression, screen resolution, and so on.
+
+
+
+
+
+When you initiate a remote desktop connection, you will be asked to log in. Type your SSH login and password.
+
+
+
+Upon successful login, you will see the remote desktop screen.
+
+
+
+If you want to test X2Go's seamless window feature, choose "Single application" as session type, and specify the path to an executable on the remote host. In this example, I choose Dolphin file manager on a remote KDE host.
+
+
+
+Once you are successfully connected, you will see a remote application window open on your local desktop, not the entire remote desktop screen.
+
+
+
+### Conclusion ###
+
+In this tutorial, I demonstrated how to set up X2Go remote desktop on [Linux VPS][8] instance. As you can see, the whole setup process is pretty much painless (if you are using a right desktop environment). While there are some desktop-specific quirkiness, X2Go is a solid remote desktop solution which is secure, feature-rich, fast, and free.
+
+What feature is the most appealing to you in X2Go? Please share your thought.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/x2go-remote-desktop-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://ask.xmodulo.com/centos-remote-desktop-vps.html
+[2]:http://wiki.x2go.org/
+[3]:http://xmodulo.com/go/digitalocean
+[4]:http://xmodulo.com/how-to-set-up-vnc-over-ssh.html
+[5]:http://wiki.x2go.org/doku.php/doc:newtox2go
+[6]:http://wiki.x2go.org/doku.php/doc:de-compat
+[7]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
+[8]:http://xmodulo.com/go/digitalocean
diff --git a/sources/tech/20150401 ZMap Documentation.md b/sources/tech/20150401 ZMap Documentation.md
new file mode 100644
index 0000000000..d2aa316c1f
--- /dev/null
+++ b/sources/tech/20150401 ZMap Documentation.md
@@ -0,0 +1,743 @@
+ZMap Documentation
+================================================================================
+1. Getting Started with ZMap
+1. Scanning Best Practices
+1. Command Line Arguments
+1. Additional Information
+ 1. TCP SYN Probe Module
+ 1. ICMP Echo Probe Module
+ 1. UDP Probe Module
+ 1. Configuration Files
+ 1. Verbosity
+ 1. Results Output
+ 1. Blacklisting
+ 1. Rate Limiting and Sampling
+ 1. Sending Multiple Probes
+1. Extending ZMap
+ 1. Sample Applications
+ 1. Writing Probe and Output Modules
+
+----------
+
+### Getting Started with ZMap ###
+
+ZMap is designed to perform comprehensive scans of the IPv4 address space or large portions of it. While ZMap is a powerful tool for researchers, please keep in mind that by running ZMap, you are potentially scanning the ENTIRE IPv4 address space at over 1.4 million packets per second. Before performing even small scans, we encourage users to contact their local network administrators and consult our list of scanning best practices.
+
+By default, ZMap will perform a TCP SYN scan on the specified port at the maximum rate possible. A more conservative configuration that will scan 10,000 random addresses on port 80 at a maximum 10 Mbps can be run as follows:
+
+ $ zmap --bandwidth=10M --target-port=80 --max-targets=10000 --output-file=results.csv
+
+Or more concisely specified as:
+
+ $ zmap -B 10M -p 80 -n 10000 -o results.csv
+
+ZMap can also be used to scan specific subnets or CIDR blocks. For example, to scan only 10.0.0.0/8 and 192.168.0.0/16 on port 80, run:
+
+ zmap -p 80 -o results.csv 10.0.0.0/8 192.168.0.0/16
+
+If the scan started successfully, ZMap will output status updates every one second similar to the following:
+
+ 0% (1h51m left); send: 28777 562 Kp/s (560 Kp/s avg); recv: 1192 248 p/s (231 p/s avg); hits: 0.04%
+ 0% (1h51m left); send: 34320 554 Kp/s (559 Kp/s avg); recv: 1442 249 p/s (234 p/s avg); hits: 0.04%
+ 0% (1h50m left); send: 39676 535 Kp/s (555 Kp/s avg); recv: 1663 220 p/s (232 p/s avg); hits: 0.04%
+ 0% (1h50m left); send: 45372 570 Kp/s (557 Kp/s avg); recv: 1890 226 p/s (232 p/s avg); hits: 0.04%
+
+These updates provide information about the current state of the scan and are of the following form: %-complete (est time remaining); packets-sent curr-send-rate (avg-send-rate); recv: packets-recv recv-rate (avg-recv-rate); hits: hit-rate
+
+If you do not know the scan rate that your network can support, you may want to experiment with different scan rates or bandwidth limits to find the fastest rate that your network can support before you see decreased results.
+
+By default, ZMap will output the list of distinct IP addresses that responded successfully (e.g. with a SYN ACK packet) similar to the following. There are several additional formats (e.g. JSON and Redis) for outputting results as well as options for producing programmatically parsable scan statistics. As wells, additional output fields can be specified and the results can be filtered using an output filter.
+
+ 115.237.116.119
+ 23.9.117.80
+ 207.118.204.141
+ 217.120.143.111
+ 50.195.22.82
+
+We strongly encourage you to use a blacklist file, to exclude both reserved/unallocated IP space (e.g. multicast, RFC1918), as well as networks that request to be excluded from your scans. By default, ZMap will utilize a simple blacklist file containing reserved and unallocated addresses located at `/etc/zmap/blacklist.conf`. If you find yourself specifying certain settings, such as your maximum bandwidth or blacklist file every time you run ZMap, you can specify these in `/etc/zmap/zmap.conf` or use a custom configuration file.
+
+If you are attempting to troubleshoot scan related issues, there are several options to help debug. First, it is possible can perform a dry run scan in order to see the packets that would be sent over the network by adding the `--dryrun` flag. As well, it is possible to change the logging verbosity by setting the `--verbosity=n` flag.
+
+----------
+
+### Scanning Best Practices ###
+
+We offer these suggestions for researchers conducting Internet-wide scans as guidelines for good Internet citizenship.
+
+- Coordinate closely with local network administrators to reduce risks and handle inquiries
+- Verify that scans will not overwhelm the local network or upstream provider
+- Signal the benign nature of the scans in web pages and DNS entries of the source addresses
+- Clearly explain the purpose and scope of the scans in all communications
+- Provide a simple means of opting out and honor requests promptly
+- Conduct scans no larger or more frequent than is necessary for research objectives
+- Spread scan traffic over time or source addresses when feasible
+
+It should go without saying that scan researchers should refrain from exploiting vulnerabilities or accessing protected resources, and should comply with any special legal requirements in their jurisdictions.
+
+----------
+
+### Command Line Arguments ###
+
+#### Common Options ####
+
+These options are the most common options when performing a simple scan. We note that some options are dependent on the probe module or output module used (e.g. target port is not used when performing an ICMP Echo Scan).
+
+
+**-p, --target-port=port**
+
+TCP port number to scan (e.g. 443)
+
+**-o, --output-file=name**
+
+Write results to this file. Use - for stdout
+
+**-b, --blacklist-file=path**
+
+File of subnets to exclude, in CIDR notation (e.g. 192.168.0.0/16), one-per line. It is recommended you use this to exclude RFC 1918 addresses, multicast, IANA reserved space, and other IANA special-purpose addresses. An example blacklist file is provided in conf/blacklist.example for this purpose.
+
+#### Scan Options ####
+
+**-n, --max-targets=n**
+
+Cap the number of targets to probe. This can either be a number (e.g. `-n 1000`) or a percentage (e.g. `-n 0.1%`) of the scannable address space (after excluding blacklist)
+
+**-N, --max-results=n**
+
+Exit after receiving this many results
+
+**-t, --max-runtime=secs**
+
+Cap the length of time for sending packets
+
+**-r, --rate=pps**
+
+Set the send rate in packets/sec
+
+**-B, --bandwidth=bps**
+
+Set the send rate in bits/second (supports suffixes G, M, and K (e.g. `-B 10M` for 10 mbps). This overrides the `--rate` flag.
+
+**-c, --cooldown-time=secs**
+
+How long to continue receiving after sending has completed (default=8)
+
+**-e, --seed=n**
+
+Seed used to select address permutation. Use this if you want to scan addresses in the same order for multiple ZMap runs.
+
+**--shards=n**
+
+Split the scan up into N shards/partitions among different instances of zmap (default=1). When sharding, `--seed` is required
+
+**--shard=n**
+
+Set which shard to scan (default=0). Shards are indexed in the range [0, N), where N is the total number of shards. When sharding `--seed` is required.
+
+**-T, --sender-threads=n**
+
+Threads used to send packets (default=1)
+
+**-P, --probes=n**
+
+Number of probes to send to each IP (default=1)
+
+**-d, --dryrun**
+
+Print out each packet to stdout instead of sending it (useful for debugging)
+
+#### Network Options ####
+
+**-s, --source-port=port|range**
+
+Source port(s) to send packets from
+
+**-S, --source-ip=ip|range**
+
+Source address(es) to send packets from. Either single IP or range (e.g. 10.0.0.1-10.0.0.9)
+
+**-G, --gateway-mac=addr**
+
+Gateway MAC address to send packets to (in case auto-detection does not work)
+
+**-i, --interface=name**
+
+Network interface to use
+
+#### Probe Options ####
+
+ZMap allows users to specify and write their own probe modules for use with ZMap. Probe modules are responsible for generating probe packets to send, and processing responses from hosts.
+
+**--list-probe-modules**
+
+List available probe modules (e.g. tcp_synscan)
+
+**-M, --probe-module=name**
+
+Select probe module (default=tcp_synscan)
+
+**--probe-args=args**
+
+Arguments to pass to probe module
+
+**--list-output-fields**
+
+List the fields the selected probe module can send to the output module
+
+#### Output Options ####
+
+ZMap allows users to specify and write their own output modules for use with ZMap. Output modules are responsible for processing the fieldsets returned by the probe module, and outputing them to the user. Users can specify output fields, and write filters over the output fields.
+
+**--list-output-modules**
+
+List available output modules (e.g. tcp_synscan)
+
+**-O, --output-module=name**
+
+Select output module (default=csv)
+
+**--output-args=args**
+
+Arguments to pass to output module
+
+**-f, --output-fields=fields**
+
+Comma-separated list of fields to output
+
+**--output-filter**
+
+Specify an output filter over the fields defined by the probe module
+
+#### Additional Options ####
+
+**-C, --config=filename**
+
+Read a configuration file, which can specify any other options.
+
+**-q, --quiet**
+
+Do not print status updates once per second
+
+**-g, --summary**
+
+Print configuration and summary of results at the end of the scan
+
+**-v, --verbosity=n**
+
+Level of log detail (0-5, default=3)
+
+**-h, --help**
+
+Print help and exit
+
+**-V, --version**
+
+Print version and exit
+
+----------
+
+### Additional Information ###
+
+#### TCP SYN Scans ####
+
+When performing a TCP SYN scan, ZMap requires a single target port and supports specifying a range of source ports from which the scan will originate.
+
+**-p, --target-port=port**
+
+TCP port number to scan (e.g. 443)
+
+**-s, --source-port=port|range**
+
+Source port(s) for scan packets (e.g. 40000-50000)
+
+**Warning!** ZMap relies on the Linux kernel to respond to SYN/ACK packets with RST packets in order to close connections opened by the scanner. This occurs because ZMap sends packets at the Ethernet layer in order to reduce overhead otherwise incurred in the kernel from tracking open TCP connections and performing route lookups. As such, if you have a firewall rule that tracks established connections such as a netfilter rule similar to `-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT`, this will block SYN/ACK packets from reaching the kernel. This will not prevent ZMap from recording responses, but it will prevent RST packets from being sent back, ultimately using up a connection on the scanned host until your connection times out. We strongly recommend that you select a set of unused ports on your scanning host which can be allowed access in your firewall and specifying this port range when executing ZMap, with the `-s` flag (e.g. `-s '50000-60000'`).
+
+#### ICMP Echo Request Scans ####
+
+While ZMap performs TCP SYN scans by default, it also supports ICMP echo request scans in which an ICMP echo request packet is sent to each host and the type of ICMP response received in reply is denoted. An ICMP scan can be performed by selecting the icmp_echoscan scan module similar to the following:
+
+ $ zmap --probe-module=icmp_echoscan
+
+#### UDP Datagram Scans ####
+
+ZMap additionally supports UDP probes, where it will send out an arbitrary UDP datagram to each host, and receive either UDP or ICMP Unreachable responses. ZMap supports four different methods of setting the UDP payload through the --probe-args command-line option. These are 'text' for ASCII-printable payloads, 'hex' for hexadecimal payloads set on the command-line, 'file' for payloads contained in an external file, and 'template' for payloads that require dynamic field generation. In order to obtain the UDP response, make sure that you specify 'data' as one of the fields to report with the -f option.
+
+The example below will send the two bytes 'ST', a PCAnwywhere 'status' request, to UDP port 5632.
+
+ $ zmap -M udp -p 5632 --probe-args=text:ST -N 100 -f saddr,data -o -
+
+The example below will send the byte '0x02', a SQL Server 'client broadcast' request, to UDP port 1434.
+
+ $ zmap -M udp -p 1434 --probe-args=hex:02 -N 100 -f saddr,data -o -
+
+The example below will send a NetBIOS status request to UDP port 137. This uses a payload file that is included with the ZMap distribution.
+
+ $ zmap -M udp -p 1434 --probe-args=file:netbios_137.pkt -N 100 -f saddr,data -o -
+
+The example below will send a SIP 'OPTIONS' request to UDP port 5060. This uses a template file that is included with the ZMap distribution.
+
+ $ zmap -M udp -p 1434 --probe-args=file:sip_options.tpl -N 100 -f saddr,data -o -
+
+UDP payload templates are still experimental. You may encounter crashes when more using more than one send thread (-T) and there is a significant decrease in performance compared to static payloads. A template is simply a payload file that contains one or more field specifiers enclosed in a ${} sequence. Some protocols, notably SIP, require the payload to reflect the source and destination of the packet. Other protocols, such as portmapper and DNS, contain fields that should be randomized per request or risk being dropped by multi-homed systems scanned by ZMap.
+
+The payload template below will send a SIP OPTIONS request to every destination:
+
+ OPTIONS sip:${RAND_ALPHA=8}@${DADDR} SIP/2.0
+ Via: SIP/2.0/UDP ${SADDR}:${SPORT};branch=${RAND_ALPHA=6}.${RAND_DIGIT=10};rport;alias
+ From: sip:${RAND_ALPHA=8}@${SADDR}:${SPORT};tag=${RAND_DIGIT=8}
+ To: sip:${RAND_ALPHA=8}@${DADDR}
+ Call-ID: ${RAND_DIGIT=10}@${SADDR}
+ CSeq: 1 OPTIONS
+ Contact: sip:${RAND_ALPHA=8}@${SADDR}:${SPORT}
+ Content-Length: 0
+ Max-Forwards: 20
+ User-Agent: ${RAND_ALPHA=8}
+ Accept: text/plain
+
+In the example above, note that line endings are \r\n and the end of this request must contain \r\n\r\n for most SIP implementations to correcly process it. A working example is included in the examples/udp-payloads directory of the ZMap source tree (sip_options.tpl).
+
+The following template fields are currently implemented:
+
+
+- **SADDR**: Source IP address in dotted-quad format
+- **SADDR_N**: Source IP address in network byte order
+- **DADDR**: Destination IP address in dotted-quad format
+- **DADDR_N**: Destination IP address in network byte order
+- **SPORT**: Source port in ascii format
+- **SPORT_N**: Source port in network byte order
+- **DPORT**: Destination port in ascii format
+- **DPORT_N**: Destination port in network byte order
+- **RAND_BYTE**: Random bytes (0-255), length specified with =(length) parameter
+- **RAND_DIGIT**: Random digits from 0-9, length specified with =(length) parameter
+- **RAND_ALPHA**: Random mixed-case letters from A-Z, length specified with =(length) parameter
+- **RAND_ALPHANUM**: Random mixed-case letters from A-Z and digits from 0-9, length specified with =(length) parameter
+
+### Configuration Files ###
+
+ZMap supports configuration files instead of requiring all options to be specified on the command-line. A configuration can be created by specifying one long-name option and the value per line such as:
+
+ interface "eth1"
+ source-ip 1.1.1.4-1.1.1.8
+ gateway-mac b4:23:f9:28:fa:2d # upstream gateway
+ cooldown-time 300 # seconds
+ blacklist-file /etc/zmap/blacklist.conf
+ output-file ~/zmap-output
+ quiet
+ summary
+
+ZMap can then be run with a configuration file and specifying any additional necessary parameters:
+
+ $ zmap --config=~/.zmap.conf --target-port=443
+
+### Verbosity ###
+
+There are several types of on-screen output that ZMap produces. By default, ZMap will print out basic progress information similar to the following every 1 second. This can be disabled by setting the `--quiet` flag.
+
+ 0:01 12%; send: 10000 done (15.1 Kp/s avg); recv: 144 143 p/s (141 p/s avg); hits: 1.44%
+
+ZMap also prints out informational messages during scanner configuration such as the following, which can be controlled with the `--verbosity` argument.
+
+ Aug 11 16:16:12.813 [INFO] zmap: started
+ Aug 11 16:16:12.817 [DEBUG] zmap: no interface provided. will use eth0
+ Aug 11 16:17:03.971 [DEBUG] cyclic: primitive root: 3489180582
+ Aug 11 16:17:03.971 [DEBUG] cyclic: starting point: 46588
+ Aug 11 16:17:03.975 [DEBUG] blacklist: 3717595507 addresses allowed to be scanned
+ Aug 11 16:17:03.975 [DEBUG] send: will send from 1 address on 28233 source ports
+ Aug 11 16:17:03.975 [DEBUG] send: using bandwidth 10000000 bits/s, rate set to 14880 pkt/s
+ Aug 11 16:17:03.985 [DEBUG] recv: thread started
+
+ZMap also supports printing out a grep-able summary at the end of the scan, similar to below, which can be invoked with the `--summary` flag.
+
+ cnf target-port 443
+ cnf source-port-range-begin 32768
+ cnf source-port-range-end 61000
+ cnf source-addr-range-begin 1.1.1.4
+ cnf source-addr-range-end 1.1.1.8
+ cnf maximum-packets 4294967295
+ cnf maximum-runtime 0
+ cnf permutation-seed 0
+ cnf cooldown-period 300
+ cnf send-interface eth1
+ cnf rate 45000
+ env nprocessors 16
+ exc send-start-time Fri Jan 18 01:47:35 2013
+ exc send-end-time Sat Jan 19 00:47:07 2013
+ exc recv-start-time Fri Jan 18 01:47:35 2013
+ exc recv-end-time Sat Jan 19 00:52:07 2013
+ exc sent 3722335150
+ exc blacklisted 572632145
+ exc first-scanned 1318129262
+ exc hit-rate 0.874102
+ exc synack-received-unique 32537000
+ exc synack-received-total 36689941
+ exc synack-cooldown-received-unique 193
+ exc synack-cooldown-received-total 1543
+ exc rst-received-unique 141901021
+ exc rst-received-total 166779002
+ adv source-port-secret 37952
+ adv permutation-gen 4215763218
+
+### Results Output ###
+
+ZMap can produce results in several formats through the use of **output modules**. By default, ZMap only supports **csv** output, however support for **redis** and **json** can be compiled in. The results sent to these output modules may be filtered using an **output filter**. The fields the output module writes are specified by the user. By default, ZMap will return results in csv format and if no output file is specified, ZMap will not produce specific results. It is also possible to write your own output module; see Writing Output Modules for information.
+
+**-o, --output-file=p**
+
+File to write output to
+
+**-O, --output-module=p**
+
+Invoke a custom output module
+
+
+**-f, --output-fields=p**
+
+Comma-separated list of fields to output
+
+**--output-filter=filter**
+
+Specify an output filter over fields for a given probe
+
+**--list-output-modules**
+
+Lists available output modules
+
+**--list-output-fields**
+
+List available output fields for a given probe
+
+#### Output Fields ####
+
+ZMap has a variety of fields it can output beyond IP address. These fields can be viewed for a given probe module by running with the `--list-output-fields` flag.
+
+ $ zmap --probe-module="tcp_synscan" --list-output-fields
+ saddr string: source IP address of response
+ saddr-raw int: network order integer form of source IP address
+ daddr string: destination IP address of response
+ daddr-raw int: network order integer form of destination IP address
+ ipid int: IP identification number of response
+ ttl int: time-to-live of response packet
+ sport int: TCP source port
+ dport int: TCP destination port
+ seqnum int: TCP sequence number
+ acknum int: TCP acknowledgement number
+ window int: TCP window
+ classification string: packet classification
+ success int: is response considered success
+ repeat int: is response a repeat response from host
+ cooldown int: Was response received during the cooldown period
+ timestamp-str string: timestamp of when response arrived in ISO8601 format.
+ timestamp-ts int: timestamp of when response arrived in seconds since Epoch
+ timestamp-us int: microsecond part of timestamp (e.g. microseconds since 'timestamp-ts')
+
+To select which fields to output, any combination of the output fields can be specified as a comma-separated list using the `--output-fields=fields` or `-f` flags. Example:
+
+ $ zmap -p 80 -f "response,saddr,daddr,sport,seq,ack,in_cooldown,is_repeat,timestamp" -o output.csv
+
+#### Filtering Output ####
+
+Results generated by a probe module can be filtered before being passed to the output module. Filters are defined over the output fields of a probe module. Filters are written in a simple filtering language, similar to SQL, and are passed to ZMap using the **--output-filter** option. Output filters are commonly used to filter out duplicate results, or to only pass only sucessful responses to the output module.
+
+Filter expressions are of the form ``. The type of `` must be either a string or unsigned integer literal, and match the type of ``. The valid operations for integer comparisons are `= !=, <, >, <=, >=`. The operations for string comparisons are =, !=. The `--list-output-fields` flag will print what fields and types are available for the selected probe module, and then exit.
+
+Compound filter expressions may be constructed by combining filter expressions using parenthesis to specify order of operations, the `&&` (logical AND) and `||` (logical OR) operators.
+
+**Examples**
+
+Write a filter for only successful, non-duplicate responses
+
+ --output-filter="success = 1 && repeat = 0"
+
+Filter for packets that have classification RST and a TTL greater than 10, or for packets with classification SYNACK
+
+ --output-filter="(classification = rst && ttl > 10) || classification = synack"
+
+#### CSV ####
+
+The csv module will produce a comma-separated value file of the output fields requested. For example, the following command produces the following CSV in a file called `output.csv`.
+
+ $ zmap -p 80 -f "response,saddr,daddr,sport,seq,ack,in_cooldown,is_repeat,timestamp" -o output.csv
+
+----------
+
+ response, saddr, daddr, sport, dport, seq, ack, in_cooldown, is_repeat, timestamp
+ synack, 159.174.153.144, 10.0.0.9, 80, 40555, 3050964427, 3515084203, 0, 0,2013-08-15 18:55:47.681
+ rst, 141.209.175.1, 10.0.0.9, 80, 40136, 0, 3272553764, 0, 0,2013-08-15 18:55:47.683
+ rst, 72.36.213.231, 10.0.0.9, 80, 56642, 0, 2037447916, 0, 0,2013-08-15 18:55:47.691
+ rst, 148.8.49.150, 10.0.0.9, 80, 41672, 0, 1135824975, 0, 0,2013-08-15 18:55:47.692
+ rst, 50.165.166.206, 10.0.0.9, 80, 38858, 0, 535206863, 0, 0,2013-08-15 18:55:47.694
+ rst, 65.55.203.135, 10.0.0.9, 80, 50008, 0, 4071709905, 0, 0,2013-08-15 18:55:47.700
+ synack, 50.57.166.186, 10.0.0.9, 80, 60650, 2813653162, 993314545, 0, 0,2013-08-15 18:55:47.704
+ synack, 152.75.208.114, 10.0.0.9, 80, 52498, 460383682, 4040786862, 0, 0,2013-08-15 18:55:47.707
+ synack, 23.72.138.74, 10.0.0.9, 80, 33480, 810393698, 486476355, 0, 0,2013-08-15 18:55:47.710
+
+#### Redis ####
+
+The redis output module allows addresses to be added to a Redis queue instead of being saved to file which ultimately allows ZMap to be incorporated with post processing tools.
+
+**Heads Up!** ZMap does not build with Redis support by default. If you are building ZMap from source, you can build with Redis support by running CMake with `-DWITH_REDIS=ON`.
+
+### Blacklisting and Whitelisting ###
+
+ZMap supports both blacklisting and whitelisting network prefixes. If ZMap is not provided with blacklist or whitelist parameters, ZMap will scan all IPv4 addresses (including local, reserved, and multicast addresses). If a blacklist file is specified, network prefixes in the blacklisted segments will not be scanned; if a whitelist file is provided, only network prefixes in the whitelist file will be scanned. A whitelist and blacklist file can be used in coordination; the blacklist has priority over the whitelist (e.g. if you have whitelisted 10.0.0.0/8 and blacklisted 10.1.0.0/16, then 10.1.0.0/16 will not be scanned). Whitelist and blacklist files can be specified on the command-line as follows:
+
+**-b, --blacklist-file=path**
+
+File of subnets to blacklist in CIDR notation, e.g. 192.168.0.0/16
+
+**-w, --whitelist-file=path**
+
+File of subnets to limit scan to in CIDR notation, e.g. 192.168.0.0/16
+
+Blacklist files should be formatted with a single network prefix in CIDR notation per line. Comments are allowed using the `#` character. Example:
+
+ # From IANA IPv4 Special-Purpose Address Registry
+ # http://www.iana.org/assignments/iana-ipv4-special-registry/iana-ipv4-special-registry.xhtml
+ # Updated 2013-05-22
+
+ 0.0.0.0/8 # RFC1122: "This host on this network"
+ 10.0.0.0/8 # RFC1918: Private-Use
+ 100.64.0.0/10 # RFC6598: Shared Address Space
+ 127.0.0.0/8 # RFC1122: Loopback
+ 169.254.0.0/16 # RFC3927: Link Local
+ 172.16.0.0/12 # RFC1918: Private-Use
+ 192.0.0.0/24 # RFC6890: IETF Protocol Assignments
+ 192.0.2.0/24 # RFC5737: Documentation (TEST-NET-1)
+ 192.88.99.0/24 # RFC3068: 6to4 Relay Anycast
+ 192.168.0.0/16 # RFC1918: Private-Use
+ 192.18.0.0/15 # RFC2544: Benchmarking
+ 198.51.100.0/24 # RFC5737: Documentation (TEST-NET-2)
+ 203.0.113.0/24 # RFC5737: Documentation (TEST-NET-3)
+ 240.0.0.0/4 # RFC1112: Reserved
+ 255.255.255.255/32 # RFC0919: Limited Broadcast
+
+ # From IANA Multicast Address Space Registry
+ # http://www.iana.org/assignments/multicast-addresses/multicast-addresses.xhtml
+ # Updated 2013-06-25
+
+ 224.0.0.0/4 # RFC5771: Multicast/Reserved
+
+If you are looking to scan only a random portion of the internet, checkout Sampling, instead of using whitelisting and blacklisting.
+
+**Heads Up!** The default ZMap configuration uses the blacklist file at `/etc/zmap/blacklist.conf`, which contains locally scoped address space and reserved IP ranges. The default configuration can be changed by editing `/etc/zmap/zmap.conf`.
+
+### Rate Limiting and Sampling ###
+
+By default, ZMap will scan at the fastest rate that your network adaptor supports. In our experiences on commodity hardware, this is generally around 95-98% of the theoretical speed of gigabit Ethernet, which may be faster than your upstream provider can handle. ZMap will not automatically adjust its send-rate based on your upstream provider. You may need to manually adjust your send-rate to reduce packet drops and incorrect results.
+
+**-r, --rate=pps**
+
+Set maximum send rate in packets/sec
+
+**-B, --bandwidth=bps**
+
+Set send rate in bits/sec (supports suffixes G, M, and K). This overrides the --rate flag.
+
+ZMap also allows random sampling of the IPv4 address space by specifying max-targets and/or max-runtime. Because hosts are scanned in a random permutation generated per scan instantiation, limiting a scan to n hosts will perform a random sampling of n hosts. Command-line options:
+
+**-n, --max-targets=n**
+
+Cap number of targets to probe
+
+**-N, --max-results=n**
+
+Cap number of results (exit after receiving this many positive results)
+
+**-t, --max-runtime=s**
+
+Cap length of time for sending packets (in seconds)
+
+**-s, --seed=n**
+
+Seed used to select address permutation. Specify the same seed in order to scan addresses in the same order for different ZMap runs.
+
+For example, if you wanted to scan the same one million hosts on the Internet for multiple scans, you could set a predetermined seed and cap the number of scanned hosts similar to the following:
+
+ zmap -p 443 -s 3 -n 1000000 -o results
+
+In order to determine which one million hosts were going to be scanned, you could run the scan in dry-run mode which will print out the packets that would be sent instead of performing the actual scan.
+
+ zmap -p 443 -s 3 -n 1000000 --dryrun | grep daddr
+ | awk -F'daddr: ' '{print $2}' | sed 's/ |.*//;'
+
+### Sending Multiple Packets ###
+
+ZMap supports sending multiple probes to each host. Increasing this number both increases scan time and hosts reached. However, we find that the increase in scan time (~100% per additional probe) greatly outweighs the increase in hosts reached (~1% per additional probe).
+
+**-P, --probes=n**
+
+The number of unique probes to send to each IP (default=1)
+
+----------
+
+### Sample Applications ###
+
+ZMap is designed for initiating contact with a large number of hosts and finding ones that respond positively. However, we realize that many users will want to perform follow-up processing, such as performing an application level handshake. For example, users who perform a TCP SYN scan on port 80 might want to perform a simple GET request and users who scan port 443 may be interested in completing a TLS handshake.
+
+#### Banner Grab ####
+
+We have included a sample application, banner-grab, with ZMap that enables users to receive messages from listening TCP servers. Banner-grab connects to the provided servers, optionally sends a message, and prints out the first message received from the server. This tool can be used to fetch banners such as HTTP server responses to specific commands, telnet login prompts, or SSH server strings.
+
+This example finds 1000 servers listening on port 80, and sends a simple GET request to each, storing their base-64 encoded responses in http-banners.out
+
+ $ zmap -p 80 -N 1000 -B 10M -o - | ./banner-grab-tcp -p 80 -c 500 -d ./http-req > out
+
+For more details on using `banner-grab`, see the README file in `examples/banner-grab`.
+
+**Heads Up!** ZMap and banner-grab can have significant performance and accuracy impact on one another if run simultaneously (as in the example). Make sure not to let ZMap saturate banner-grab-tcp's concurrent connections, otherwise banner-grab will fall behind reading stdin, causing ZMap to block on writing stdout. We recommend using a slower scanning rate with ZMap, and increasing the concurrency of banner-grab-tcp to no more than 3000 (Note that > 1000 concurrent connections requires you to use `ulimit -SHn 100000` and `ulimit -HHn 100000` to increase the maximum file descriptors per process). These parameters will of course be dependent on your server performance, and hit-rate; we encourage developers to experiment with small samples before running a large scan.
+
+#### Forge Socket ####
+
+We have also included a form of banner-grab, called forge-socket, that reuses the SYN-ACK sent from the server for the connection that ultimately fetches the banner. In `banner-grab-tcp`, ZMap sends a SYN to each server, and listening servers respond with a SYN+ACK. The ZMap host's kernel receives this, and sends a RST, as no active connection is associated with that packet. The banner-grab program must then create a new TCP connection to the same server to fetch data from it.
+
+In forge-socket, we utilize a kernel module by the same name, that allows us to create a connection with arbitrary TCP parameters. This enables us to suppress the kernel's RST packet, and instead create a socket that will reuse the SYN+ACK's parameters, and send and receive data through this socket as we would any normally connected socket.
+
+To use forge-socket, you will need the forge-socket kernel module, available from [github][1]. You should git clone `git@github.com:ewust/forge_socket.git` in the ZMap root source directory, and then cd into the forge_socket directory, and run make. Install the kernel module with `insmod forge_socket.ko` as root.
+
+You must also tell the kernel not to send RST packets. An easy way to disable RST packets system wide is to use **iptables**. `iptables -A OUTPUT -p tcp -m tcp --tcp-flgas RST,RST RST,RST -j DROP` as root will do this, though you may also add an optional --dport X to limit this to the port (X) you are scanning. To remove this after your scan completes, you can run `iptables -D OUTPUT -p tcp -m tcp --tcp-flags RST,RST RST,RST -j DROP` as root.
+
+Now you should be able to build the forge-socket ZMap example program. To run it, you must use the **extended_file** ZMap output module:
+
+ $ zmap -p 80 -N 1000 -B 10M -O extended_file -o - | \
+ ./forge-socket -c 500 -d ./http-req > ./http-banners.out
+
+See the README in `examples/forge-socket` for more details.
+
+----------
+
+### Writing Probe and Output Modules ###
+
+ZMap can be extended to support different types of scanning through **probe modules** and additional types of results **output through** output modules. Registered probe and output modules can be listed through the command-line interface:
+
+**--list-probe-modules**
+
+Lists installed probe modules
+
+**--list-output-modules**
+
+Lists installed output modules
+
+#### Output Modules ####
+
+ZMap output and post-processing can be extended by implementing and registering **output modules** with the scanner. Output modules receive a callback for every received response packet. While the default provided modules provide simple output, these modules are also capable of performing additional post-processing (e.g. tracking duplicates or outputting numbers in terms of AS instead of IP address)
+
+Output modules are created by defining a new output_module struct and registering it in [output_modules.c][2]:
+
+ typedef struct output_module {
+ const char *name; // how is output module referenced in the CLI
+ unsigned update_interval; // how often is update called in seconds
+
+ output_init_cb init; // called at scanner initialization
+ output_update_cb start; // called at the beginning of scanner
+ output_update_cb update; // called every update_interval seconds
+ output_update_cb close; // called at scanner termination
+
+ output_packet_cb process_ip; // called when a response is received
+
+ const char *helptext; // Printed when --list-output-modules is called
+
+ } output_module_t;
+
+Output modules must have a name, which is how they are referenced on the command-line and generally implement `success_ip` and oftentimes `other_ip` callback. The process_ip callback is called for every response packet that is received and passed through the output filter by the current **probe module**. The response may or may not be considered a success (e.g. it could be a TCP RST). These callbacks must define functions that match the `output_packet_cb` definition:
+
+ int (*output_packet_cb) (
+
+ ipaddr_n_t saddr, // IP address of scanned host in network-order
+ ipaddr_n_t daddr, // destination IP address in network-order
+
+ const char* response_type, // send-module classification of packet
+
+ int is_repeat, // {0: first response from host, 1: subsequent responses}
+ int in_cooldown, // {0: not in cooldown state, 1: scanner in cooldown state}
+
+ const u_char* packet, // pointer to struct iphdr of IP packet
+ size_t packet_len // length of packet in bytes
+ );
+
+An output module can also register callbacks to be executed at scanner initialization (tasks such as opening an output file), start of the scan (tasks such as documenting blacklisted addresses), during regular intervals during the scan (tasks such as progress updates), and close (tasks such as closing any open file descriptors). These callbacks are provided with complete access to the scan configuration and current state:
+
+ int (*output_update_cb)(struct state_conf*, struct state_send*, struct state_recv*);
+
+which are defined in [output_modules.h][3]. An example is available at [src/output_modules/module_csv.c][4].
+
+#### Probe Modules ####
+
+Packets are constructed using probe modules which allow abstracted packet creation and response classification. ZMap comes with two scan modules by default: `tcp_synscan` and `icmp_echoscan`. By default, ZMap uses `tcp_synscan`, which sends TCP SYN packets, and classifies responses from each host as open (received SYN+ACK) or closed (received RST). ZMap also allows developers to write their own probe modules for use with ZMap, using the following API.
+
+Each type of scan is implemented by developing and registering the necessary callbacks in a `send_module_t` struct:
+
+ typedef struct probe_module {
+ const char *name; // how scan is invoked on command-line
+ size_t packet_length; // how long is probe packet (must be static size)
+
+ const char *pcap_filter; // PCAP filter for collecting responses
+ size_t pcap_snaplen; // maximum number of bytes for libpcap to capture
+
+ uint8_t port_args; // set to 1 if ZMap requires a --target-port be
+ // specified by the user
+
+ probe_global_init_cb global_initialize; // called once at scanner initialization
+ probe_thread_init_cb thread_initialize; // called once for each thread packet buffer
+ probe_make_packet_cb make_packet; // called once per host to update packet
+ probe_validate_packet_cb validate_packet; // called once per received packet,
+ // return 0 if packet is invalid,
+ // non-zero otherwise.
+
+ probe_print_packet_cb print_packet; // called per packet if in dry-run mode
+ probe_classify_packet_cb process_packet; // called by receiver to classify response
+ probe_close_cb close; // called at scanner termination
+
+ fielddef_t *fields // Definitions of the fields specific to this module
+ int numfields // Number of fields
+
+ } probe_module_t;
+
+At scanner initialization, `global_initialize` is called once and can be utilized to perform any necessary global configuration or initialization. However, `global_initialize` does not have access to the packet buffer which is thread-specific. Instead, `thread_initialize` is called at the initialization of each sender thread and is provided with access to the buffer that will be used for constructing probe packets along with global source and destination values. This callback should be used to construct the host agnostic packet structure such that only specific values (e.g. destination host and checksum) need to be be updated for each host. For example, the Ethernet header will not change between headers (minus checksum which is calculated in hardware by the NIC) and therefore can be defined ahead of time in order to reduce overhead at scan time.
+
+The `make_packet` callback is called for each host that is scanned to allow the **probe module** to update host specific values and is provided with IP address values, an opaque validation string, and probe number (shown below). The probe module is responsible for placing as much of the verification string into the probe, in such a way that when a valid response is returned by a server, the probe module can verify that it is present. For example, for a TCP SYN scan, the tcp_synscan probe module can use the TCP source port and sequence number to store the validation string. Response packets (SYN+ACKs) will contain the expected values in the destination port and acknowledgement number.
+
+ int make_packet(
+ void *packetbuf, // packet buffer
+ ipaddr_n_t src_ip, // source IP in network-order
+ ipaddr_n_t dst_ip, // destination IP in network-order
+ uint32_t *validation, // validation string to place in probe
+ int probe_num // if sending multiple probes per host,
+ // this will be which probe number for this
+ // host we are currently sending
+ );
+
+Scan modules must also define `pcap_filter`, `validate_packet`, and `process_packet`. Only packets that match the PCAP filter will be considered by the scanner. For example, in the case of a TCP SYN scan, we only want to investigate TCP SYN/ACK or TCP RST packets and would utilize a filter similar to `tcp && tcp[13] & 4 != 0 || tcp[13] == 18`. The `validate_packet` function will be called for every packet that fulfills this PCAP filter. If the validation returns non-zero, the `process_packet` function will be called, and will populate a fieldset using fields defined in `fields` with data from the packet. For example, the following code processes a packet for the TCP synscan probe module.
+
+ void synscan_process_packet(const u_char *packet, uint32_t len, fieldset_t *fs)
+ {
+ struct iphdr *ip_hdr = (struct iphdr *)&packet[sizeof(struct ethhdr)];
+ struct tcphdr *tcp = (struct tcphdr*)((char *)ip_hdr
+ + (sizeof(struct iphdr)));
+
+ fs_add_uint64(fs, "sport", (uint64_t) ntohs(tcp->source));
+ fs_add_uint64(fs, "dport", (uint64_t) ntohs(tcp->dest));
+ fs_add_uint64(fs, "seqnum", (uint64_t) ntohl(tcp->seq));
+ fs_add_uint64(fs, "acknum", (uint64_t) ntohl(tcp->ack_seq));
+ fs_add_uint64(fs, "window", (uint64_t) ntohs(tcp->window));
+
+ if (tcp->rst) { // RST packet
+ fs_add_string(fs, "classification", (char*) "rst", 0);
+ fs_add_uint64(fs, "success", 0);
+ } else { // SYNACK packet
+ fs_add_string(fs, "classification", (char*) "synack", 0);
+ fs_add_uint64(fs, "success", 1);
+ }
+ }
+
+--------------------------------------------------------------------------------
+
+via: https://zmap.io/documentation.html
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:https://github.com/ewust/forge_socket/
+[2]:https://github.com/zmap/zmap/blob/v1.0.0/src/output_modules/output_modules.c
+[3]:https://github.com/zmap/zmap/blob/master/src/output_modules/output_modules.h
+[4]:https://github.com/zmap/zmap/blob/master/src/output_modules/module_csv.c
diff --git a/sources/tech/20150410 7 Command Line Tools for Browsing Websites and Downloading Files in Linux.md b/sources/tech/20150410 7 Command Line Tools for Browsing Websites and Downloading Files in Linux.md
new file mode 100644
index 0000000000..d291f34511
--- /dev/null
+++ b/sources/tech/20150410 7 Command Line Tools for Browsing Websites and Downloading Files in Linux.md
@@ -0,0 +1,152 @@
+7 Command Line Tools for Browsing Websites and Downloading Files in Linux
+================================================================================
+In the last article, we have covered few useful tools like ‘rTorrent‘, ‘wget‘, ‘cURL‘, ‘w3m‘, and ‘Elinks‘. We got lots of response to cover few other tools of same genre, if you’ve missed the first part you can go through it..
+
+- [5 Command Line Tools for Downloading Files and Browsing Websites][1]
+
+This article aims at making you aware of several other Linux command Line browsing and downloading applications, which will help you to browse and download files within the Linux shell.
+
+### 1. links ###
+
+Links is an open source web browser written in C programming Language. It is available for all major platforms viz., Linux, Windows, OS X and OS/2. This browser is text based as well as graphical. The text based links web browser is shipped by most of the standard Linux distributions by default. If links is not installed in your system by default you may install it from the repo. Elinks is a fork of links.
+
+ # apt-get install links
+ # yum install links
+
+After installing links, you can browse any websites within the terminal as shown below in the screen cast..
+
+ # links www.tecmint.com
+
+Use UP and DOWN arrow keys to navigate. Right arrow Key on a link will redirect you to that link and Left arrow key will bring you back to the last page. To QUIT press q.
+
+Here is how it seems to access Tecmint using links tool.
+
+
+
+If you are interested in installing GUI of links, you may need to download latest source tarball (i.e. version 2.9) from [http://links.twibright.com/download/][2].
+
+Alternatively, you may use following wget command to download and install as suggested below.
+
+ # wget http://links.twibright.com/download/links-2.9.tar.gz
+ # tar -xvf links-2.9.tar.gz
+ # cd links-2.9
+ # ./configure –enable-graphics
+ # make
+ # make install
+
+**Note**: You need to install packages (libpng, libjpeg, TIFF library, SVGAlib, XFree86, C Compiler and make), if not already installed to successfully compile the package.
+
+### 2. links2 ###
+
+Links2 is a graphical web browser version of Twibright Labs Links web browser. This browser has support for mouse and clicks. Designed specially for speed without any CSS support, fairly good HTML and JavaScript support with limitations.
+
+To install links2.
+
+ # apt-get install links2
+ # yum install links2
+
+### 3. lynx ###
+
+A text based web browser released under GNU GPLv2 license and written in ISO C. lynx is highly configurable web browser and Savior for many SYSAdmin. It has the reputation of being the oldest web browser that is being used and still actively developed.
+
+To install lynx.
+
+ # apt-get install lynx
+ # yum install lynx
+
+After installing lynx, type the following command to browse the website as shown below in the screen cast..
+
+ # lynx www.tecmint.com
+
+
+
+If you are interested in knowing a bit more about links and lynx web browser, you may like to visit the below link:
+
+- [Web Browsing with Lynx and Links Command Line Tools][3]
+
+### 4. youtube-dl ###
+
+youtube-dl is a platform independent application which can be used to download videos from youtube and a few other sites. Written primarily in python and released under GNU GPL License, the application works out of the box. (Since youtube don’t allow you to download videos, it may be illegal to use it. Check the laws before you start using this.)
+
+To install youtube-dl.
+
+ # apt-get install youtube-dl
+ # yum install youtube-dl
+
+After installing, try to download files from the Youtube site, as shown in the below screen cast.
+
+ # youtube-dl https://www.youtube.com/watch?v=ql4SEy_4xws
+
+
+
+If you are interested in knowing more about youtube-dl you may like to visit the below link:
+
+- [YouTube-DL – A Command Line Youtube Video Downloader for Linux][4]
+
+### 5. fetch ###
+
+It is a command utility for unix-like operating system that is used for URL retrieval. It supports a lot of options like fetching ipv4 only address, ipv6 only address, no redirect, exit after successful file retrieval request, retry, etc.
+
+Fetch can be Downloaded and installed from the link below
+
+- [http://sourceforge.net/projects/fetch/?source=typ_redirect][5]
+
+But before you compile and run it, you should install HTTP Fetcher. Download HTTP Fetcher from the link below.
+
+- [http://sourceforge.net/projects/http-fetcher/?source=typ_redirect][6]
+
+### 6. Axel ###
+
+Axel is a command-line based download accelerator for Linux. Axel makes it possible to download a file at much faster speed through single connection request for multiple copies of files in small chunks through multiple http and ftp connections.
+
+To install Axel.
+
+ # apt-get install axel
+ # yum install axel
+
+After axel installed, you may use following command to download any given file, as shown in the screen cast.
+
+ # axel http://mirror.cse.iitk.ac.in/archlinux/iso/2015.04.01/archlinux-2015.04.01-dual.iso
+
+
+
+### 7. aria2 ###
+
+aria2 is a command-line based download utility that is lightweight and support multi-protocol (HTTP, HTTPS, FTP, BitTorrent and Metalink). It can use metalinks files to simultaneously download ISO files from more than one server. It can serve as a Bit torrent client as well.
+
+To install aria2.
+
+ # apt-get install aria2
+ # yum install aria2
+
+Once aria2 installed, you can fire up the following command to download any given file…
+
+ # aria2c http://cdimage.debian.org/debian-cd/7.8.0/multi-arch/iso-cd/debian-7.8.0-amd64-i386-netinst.iso
+
+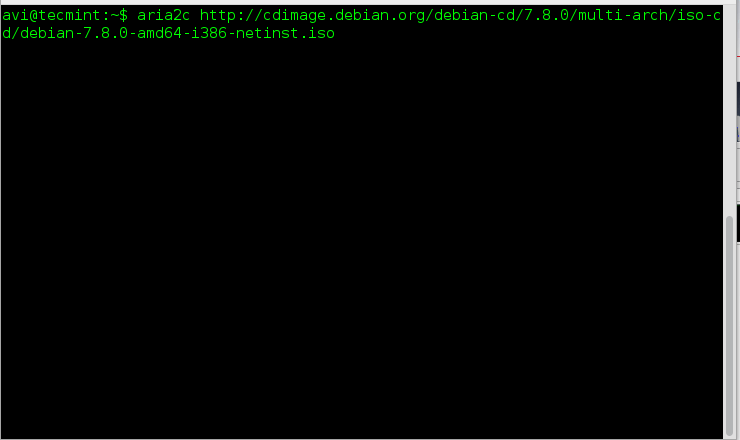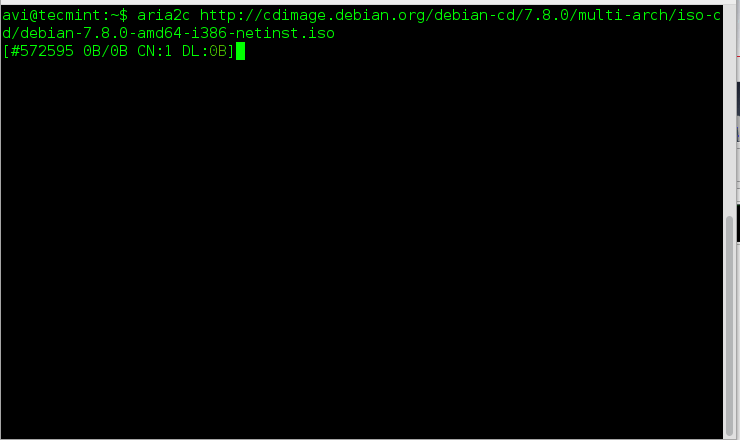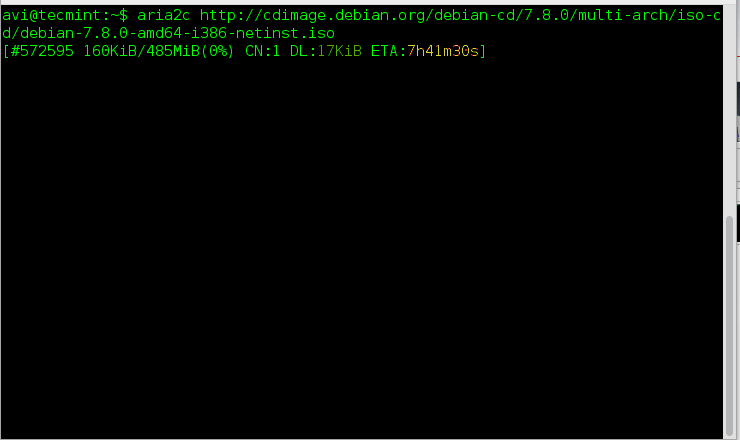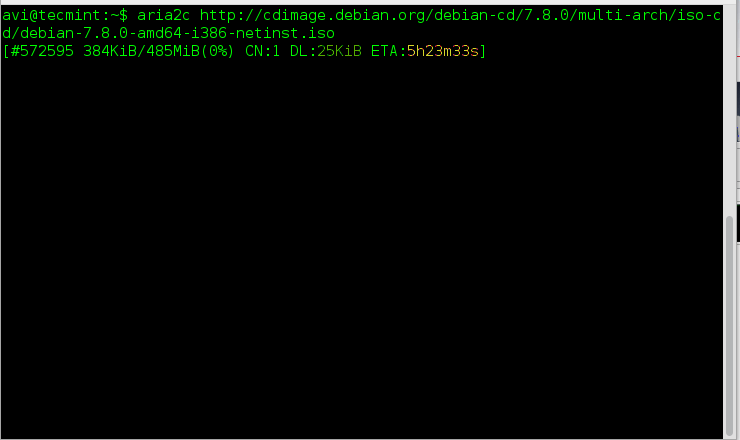
+Aria2: Command Line Download Manager for Linux
+
+If you’re interested to know more at aria2 and their switches, read the following article.
+
+- [Aria2 – A Multi-Protocol Command-Line Download Manager for Linux][7]
+
+That’s all for now. I’ll be here again with another interesting topic you people will love to read. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your valuable feedback in the comments below. Like and share us and help us get spread.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/command-line-web-browser-download-file-in-linux/
+
+作者:[Avishek Kumar][a]
+译者:[wangjiezhe](https://github.com/wangjiezhe)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/linux-command-line-tools-for-downloading-files/
+[2]:http://links.twibright.com/download/
+[3]:http://www.tecmint.com/command-line-web-browsers/
+[4]:http://www.tecmint.com/install-youtube-dl-command-line-video-download-tool/
+[5]:http://sourceforge.net/projects/fetch/?source=typ_redirect
+[6]:http://sourceforge.net/projects/http-fetcher/?source=typ_redirect
+[7]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
diff --git a/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md b/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
new file mode 100644
index 0000000000..2a8bdb2fbd
--- /dev/null
+++ b/sources/tech/20150410 How to Install and Configure Multihomed ISC DHCP Server on Debian Linux.md
@@ -0,0 +1,159 @@
+How to Install and Configure Multihomed ISC DHCP Server on Debian Linux
+================================================================================
+Dynamic Host Control Protocol (DHCP) offers an expedited method for network administrators to provide network layer addressing to hosts on a constantly changing, or dynamic, network. One of the most common server utilities to offer DHCP functionality is ISC DHCP Server. The goal of this service is to provide hosts with the necessary network information to be able to communicate on the networks in which the host is connected. Information that is typically served by this service can include: DNS server information, network address (IP), subnet mask, default gateway information, hostname, and much more.
+
+This tutorial will cover ISC-DHCP-Server version 4.2.4 on a Debian 7.7 server that will manage multiple virtual local area networks (VLAN) but can very easily be applied to a single network setup as well.
+
+The test network that this server was setup on has traditionally relied on a Cisco router to manage the DHCP address leases. The network currently has 12 VLANs needing to be managed by one centralized server. By moving this responsibility to a dedicated server, the router can regain resources for more important tasks such as routing, access control lists, traffic inspection, and network address translation.
+
+The other benefit to moving DHCP to a dedicated server will, in a later guide, involve setting up Dynamic Domain Name Service (DDNS) so that new host’s host-names will be added to the DNS system when the host requests a DHCP address from the server.
+
+### Step 1: Installing and Configuring ISC DHCP Server ###
+
+1. To start the process of creating this multi-homed server, the ISC software needs to be installed via the Debian repositories using the ‘apt‘ utility. As with all tutorials, root or sudo access is assumed. Please make the appropriate modifications to the following commands.
+
+ # apt-get install isc-dhcp-server [Installs the ISC DHCP Server software]
+ # dpkg --get-selections isc-dhcp-server [Confirms successful installation]
+ # dpkg -s isc-dhcp-server [Alternative confirmation of installation]
+
+
+
+2. Now that the server software is confirmed installed, it is now necessary to configure the server with the network information that it will need to hand out. At the bare minimum, the administrator needs to know the following information for a basic DHCP scope:
+
+- The network addresses
+- The subnet masks
+- The range of addresses to be dynamically assigned
+
+Other useful information to have the server dynamically assign includes:
+
+- Default gateway
+- DNS server IP addresses
+- The Domain Name
+- Host name
+- Network Broadcast addresses
+
+These are merely a few of the many options that the ISC DHCP server can handle. To get a complete list as well as a description of each option, enter the following command after installing the package:
+
+ # man dhcpd.conf
+
+3. Once the administrator has concluded all the necessary information for this server to hand out it is time to configure the DHCP server as well as the necessary pools. Before creating any pools or server configurations though, the DHCP service must be configured to listen on one of the server’s interfaces.
+
+On this particular server, a NIC team has been setup and DHCP will listen on the teamed interfaces which were given the name `'bond0'`. Be sure to make the appropriate changes given the server and environment in which everything is being configured. The defaults in this file are okay for this tutorial.
+
+
+
+This line will instruct the DHCP service to listen for DHCP traffic on the specified interface(s). At this point, it is time to modify the main configuration file to enable the DHCP pools on the necessary networks. The main configuration file is located at /etc/dhcp/dhcpd.conf. Open the file with a text editor to begin:
+
+ # nano /etc/dhcp/dhcpd.conf
+
+This file is the configuration for the DHCP server specific options as well as all of the pools/hosts one wishes to configure. The top of the file starts of with a ‘ddns-update-style‘ clause and for this tutorial it will remain set to ‘none‘ however in a future article, Dynamic DNS will be covered and ISC-DHCP-Server will be integrated with BIND9 to enable host name to IP address updates.
+
+4. The next section is typically the area where and administrator can configure global network settings such as the DNS domain name, default lease time for IP addresses, subnet-masks, and much more. Again to know more about all the options be sure to read the man page for the dhcpd.conf file.
+
+ # man dhcpd.conf
+
+For this server install, there were a couple of global network options that were configured at the top of the configuration file so that they wouldn’t have to be implemented in every single pool created.
+
+
+
+Lets take a moment to explain some of these options. While they are configured globally in this example, all of them can be configured on a per pool basis as well.
+
+- option domain-name “comptech.local”; – All hosts that this DHCP server hosts, will be a member of the DNS domain name “comptech.local”
+- option domain-name-servers 172.27.10.6; DHCP will hand out DNS server IP of 172.27.10.6 to all of the hosts on all of the networks it is configured to host.
+- option subnet-mask 255.255.255.0; – The subnet mask handed out to every network will be a 255.255.255.0 or a /24
+- default-lease-time 3600; – This is the time in seconds that a lease will automatically be valid. The host can re-request the same lease if time runs out or if the host is done with the lease, they can hand the address back early.
+- max-lease-time 86400; – This is the maximum amount of time in seconds a lease can be held by a host.
+- ping-check true; – This is an extra test to ensure that the address the server wants to assign out isn’t in use by another host on the network already.
+- ping-timeout; – This is how long in second the server will wait for a response to a ping before assuming the address isn’t in use.
+- ignore client-updates; For now this option is irrelevant since DDNS has been disabled earlier in the configuration file but when DDNS is operating, this option will ignore a hosts to request to update its host-name in DNS.
+
+5. The next line in this file is the authoritative DHCP server line. This line means that if this server is to be the server that hands out addresses for the networks configured in this file, then uncomment the authoritative stanza.
+
+This server will be the only authority on all the networks it manages so the global authoritative stanza was un-commented by removing the ‘#’ in front of the keyword authoritative.
+
+
+Enable ISC Authoritative
+
+By default the server is assumed to NOT be an authority on the network. The rationale behind this is security. If someone unknowingly configures the DHCP server improperly or on a network they shouldn’t, it could cause serious connectivity issues. This line can also be used on a per network basis. This means that if the server is not the entire network’s DHCP server, the authoritative line can instead be used on a per network basis rather than in the global configuration as seen in the above screen-shot.
+
+6. The next step is to configure all of the DHCP pools/networks that this server will manage. For brevities sake, this guide will only walk through one of the pools configured. The administrator will need to have gathered all of the necessary network information (ie domain name, network addresses, how many addresses can be handed out, etc).
+
+For this pool the following information was obtained from the network administrator: network id of 172.27.60.0, subnet mask of 255.255.255.0 or a /24, the default gateway for the subnet is 172.27.60.1, and a broadcast address of 172.27.60.255.
+This information is important to building the appropriate network stanza in the dhcpd.conf file. Without further ado, let’s open the configuration file again using a text editor and then add the new network to the server. This must be done with root/sudo!
+
+ # nano /etc/dhcp/dhcpd.conf
+
+
+Configure DHCP Pools and Networks
+
+This is the sample created to hand out IP addresses to a network that is used for the creation of VMWare virtual practice servers. The first line indicates the network as well as the subnet mask for that network. Then inside the brackets are all the options that the DHCP server should provide to hosts on this network.
+
+The first stanza, range 172.27.60.50 172.27.60.254;, is the range of dynamically assignable addresses that the DHCP server can hand out to hosts on this network. Notice that the first 49 addresses aren’t in the pool and can be assigned statically to hosts if needed.
+
+The second stanza, option routers 172.27.60.1; , hands out the default gateway address for all hosts on this network.
+
+The last stanza, option broadcast-address 172.27.60.255;, indicates what the network’s broadcast address. This address SHOULD NOT be a part of the range stanza as the broadcast address can’t be assigned to a host.
+
+Some pointers, be sure to always end the option lines with a semi-colon (;) and always make sure each network created is enclosed in curly braces { }.
+
+7. If there are more networks to create, continue creating them with their appropriate options and then save the text file. Once all configurations have been completed, the ISC-DHCP-Server process will need to be restarted in order to apply the new changes. This can be accomplished with the following command:
+
+ # service isc-dhcp-server restart
+
+This will restart the DHCP service and then the administrator can check to see if the server is ready for DHCP requests several different ways. The easiest is to simply see if the server is listening on port 67 via the [lsof command][1]:
+
+ # lsof -i :67
+
+
+Check DHCP Listening Port
+
+This output indicates that the DHCPD (DHCP Server daemon) is running and listening on port 67. Port 67 in this output was actually converted to ‘bootps‘ due to a port number mapping for port 67 in /etc/services file.
+
+This is very common on most systems. At this point, the server should be ready for network connectivity and can be confirmed by connecting a machine to the network and having it request a DHCP address from the server.
+
+### Step 2: Testing Client Connectivity ###
+
+8. Most systems now-a-days are using Network Manager to maintain network connections and as such the device should be pre-configured to pull DHCP when the interface is active.
+
+However on machines that aren’t using Network Manager, it may be necessary to manually attempt to pull a DHCP address. The next few steps will show how to do this as well as how to see whether the server is handing out addresses.
+
+The ‘[ifconfig][2]‘ utility can be used to check an interface’s configuration. The machine used to test the DHCP server only has one network adapter and it is called ‘eth0‘.
+
+ # ifconfig eth0
+
+
+Check Network Interface IP Address
+
+From this output, this machine currently doesn’t have an IPv4 address, great! Let’s instruct this machine to reach out to the DHCP server and request an address. This machine has the DHCP client utility known as ‘dhclient‘ installed. The DHCP client utility may very from system to system.
+
+ # dhclient eth0
+
+
+Request IP Address from DHCP
+
+Now the `'inet addr:'` field shows an IPv4 address that falls within the scope of what was configured for the 172.27.60.0 network. Also notice that the proper broadcast address was handed out as well as subnet mask for this network.
+
+Things are looking promising but let’s check the server to see if it was actually the place where this machine received this new IP address. To accomplish this task, the server’s system log file will be consulted. While the entire log file may contain hundreds of thousands of entries, only a few are necessary for confirming that the server is working properly. Rather than using a full text editor, this time a utility known as ‘tail‘ will be used to only show the last few lines of the log file.
+
+ # tail /var/log/syslog
+
+
+Check DHCP Logs
+
+Voila! The server recorded handing out an address to this host (HRTDEBXENSRV). It is a safe assumption at this point that the server is working as intended and handing out the appropriate addresses for the networks that it is an authority. At this point the DHCP server is up and running. Configure the other networks, troubleshoot, and secure as necessary.
+
+Enjoy the newly functioning ISC-DHCP-Server and tune in later for more Debian tutorials. In the not too distant future there will be an article on Bind9 and DDNS that will tie into this article.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
+
+作者:[Rob Turner][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/robturner/
+[1]:http://www.tecmint.com/10-lsof-command-examples-in-linux/
+[2]:http://www.tecmint.com/ifconfig-command-examples/
\ No newline at end of file
diff --git a/sources/tech/20150410 How to run Ubuntu Snappy Core on Raspberry Pi 2.md b/sources/tech/20150410 How to run Ubuntu Snappy Core on Raspberry Pi 2.md
new file mode 100644
index 0000000000..4b49e3acca
--- /dev/null
+++ b/sources/tech/20150410 How to run Ubuntu Snappy Core on Raspberry Pi 2.md
@@ -0,0 +1,89 @@
+How to run Ubuntu Snappy Core on Raspberry Pi 2
+================================================================================
+The Internet of Things (IoT) is upon us. In a couple of years some of us might ask ourselves how we ever survived without it, just like we question our past without cellphones today. Canonical is a contender in this fast growing, but still wide open market. The company wants to claim their stakes in IoT just as they already did for the cloud. At the end of January, the company launched a small operating system that goes by the name of [Ubuntu Snappy Core][1] which is based on Ubuntu Core.
+
+Snappy, the new component in the mix, represents a package format that is derived from DEB, is a frontend to update the system that lends its idea from atomic upgrades used in CoreOS, Red Hat's Atomic and elsewhere. As soon as the Raspberry Pi 2 was marketed, Canonical released Snappy Core for that plattform. The first edition of the Raspberry Pi was not able to run Ubuntu because Ubuntu's ARM images use the ARMv7 architecture, while the first Raspberry Pis were based on ARMv6. That has changed now, and Canonical, by releasing a RPI2-Image of Snappy Core, took the opportunity to make clear that Snappy was meant for the cloud and especially for IoT.
+
+Snappy also runs on other platforms like Amazon EC2, Microsofts Azure, and Google's Compute Engine, and can also be virtualized with KVM, Virtualbox, or Vagrant. Canonical has embraced big players like Microsoft, Google, Docker or OpenStack and, at the same time, also included small projects from the maker scene as partners. Besides startups like Ninja Sphere and Erle Robotics, there are board manufacturers like Odroid, Banana Pro, Udoo, PCDuino and Parallella as well as Allwinner. Snappy Core will also run in routers soon to help with the poor upgrade policy that vendors perform.
+
+In this post, let's see how we can test Ubuntu Snappy Core on Raspberry Pi 2.
+
+The image for Snappy Core for the RPI2 can be downloaded from the [Raspberry Pi website][2]. Unpacked from the archive, the resulting image should be [written to an SD card][3] of at least 8 GB. Even though the OS is small, atomic upgrades and the rollback function eat up quite a bit of space. After booting up your Raspberry Pi 2 with Snappy Core, you can log into the system with the default username and password being 'ubuntu'.
+
+
+
+sudo is already configured and ready for use. For security reasons you should change the username with:
+
+ $ sudo usermod -l
+
+Alternatively, you can add a new user with the command `adduser`.
+
+Due to the lack of a hardware clock on the RPI, that the Snappy Core image does not take account of, the image has a small bug that will throw a lot of errors when processing commands. It is easy to fix.
+
+To find out if the bug affects you, use the command:
+
+ $ date
+
+If the output is "Thu Jan 1 01:56:44 UTC 1970", you can fix it with:
+
+ $ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
+
+adapted to your actual time.
+
+
+
+Now you might want to check if there are any updates available. Note that the usual commands:
+
+ $ sudo apt-get update && sudo apt-get distupgrade
+
+will not get you very far though, as Snappy uses its own simplified package management system which is based on dpkg. This makes sense, as Snappy will run on a lot of embedded appliances, and you want things to be as simple as possible.
+
+Let's dive into the engine room for a minute to understand how things work with Snappy. The SD card you run Snappy on has three partitions besides the boot partition. Two of those house a duplicated file system. Both of those parallel file systems are permanently mounted as "read only", and only one is active at any given time. The third partition holds a partial writable file system and the users persistent data. With a fresh system, the partition labeled 'system-a' holds one complete file system, called a core, leaving the parallel partition still empty.
+
+
+
+If we run the following command now:
+
+ $ sudo snappy update
+
+the system will install the update as a complete core, similar to an image, on 'system-b'. You will be asked to reboot your device afterwards to activate the new core.
+
+After the reboot, run the following command to check if your system is up to date and which core is active.
+
+ $ sudo snappy versions -a
+
+After rolling out the update and rebooting, you should see that the core that is now active has changed.
+
+As we have not installed any apps yet, the following command:
+
+ $ sudo snappy update ubuntu-core
+
+would have been sufficient, and is the way if you want to upgrade just the underlying OS. Should something go wrong, you can rollback by:
+
+ $ sudo snappy rollback ubuntu-core
+
+which will take you back to the system's state before the update.
+
+
+
+Speaking of apps, they are what makes Snappy useful. There are not that many at this point, but the IRC channel #snappy on Freenode is humming along nicely and with a lot of people involved, the Snappy App Store gets new apps added on a regular basis. You can visit the shop by pointing your browser to http://:4200, and you can install apps right from the shop and then launch them with http://webdm.local in your browser. Building apps yourself for Snappy is not all that hard, and [well documented][4]. You can also port DEB packages into the snappy format quite easily.
+
+
+
+Ubuntu Snappy Core, due to the limited number of available apps, is not overly useful in a productive way at this point in time, although it invites us to dive into the new Snappy package format and play with atomic upgrades the Canonical way. Since it is easy to set up, this seems like a good opportunity to learn something new.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
+
+作者:[Ferdinand Thommes][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/ferdinand
+[1]:http://www.ubuntu.com/things
+[2]:http://www.raspberrypi.org/downloads/
+[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
+[4]:https://developer.ubuntu.com/en/snappy/
\ No newline at end of file
diff --git a/sources/tech/20150504 How to access a Linux server behind NAT via reverse SSH tunnel.md b/sources/tech/20150504 How to access a Linux server behind NAT via reverse SSH tunnel.md
new file mode 100644
index 0000000000..b67f5aee26
--- /dev/null
+++ b/sources/tech/20150504 How to access a Linux server behind NAT via reverse SSH tunnel.md
@@ -0,0 +1,130 @@
+How to access a Linux server behind NAT via reverse SSH tunnel
+================================================================================
+You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
+
+### What is Reverse SSH Tunneling? ###
+
+One alternative to SSH port forwarding is **reverse SSH tunneling**. The concept of reverse SSH tunneling is simple. For this, you will need another host (so-called "relay host") outside your restrictive home network, which you can connect to via SSH from where you are. You could set up a relay host using a [VPS instance][1] with a public IP address. What you do then is to set up a persistent SSH tunnel from the server in your home network to the public relay host. With that, you can connect "back" to the home server from the relay host (which is why it's called a "reverse" tunnel). As long as the relay host is reachable to you, you can connect to your home server wherever you are, or however restrictive your NAT or firewall is in your home network.
+
+
+
+### Set up a Reverse SSH Tunnel on Linux ###
+
+Let's see how we can create and use a reverse SSH tunnel. We assume the following. We will be setting up a reverse SSH tunnel from homeserver to relayserver, so that we can SSH to homeserver via relayserver from another computer called clientcomputer. The public IP address of **relayserver** is 1.1.1.1.
+
+On homeserver, open an SSH connection to relayserver as follows.
+
+ homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
+
+Here the port 10022 is any arbitrary port number you can choose. Just make sure that this port is not used by other programs on relayserver.
+
+The "-R 10022:localhost:22" option defines a reverse tunnel. It forwards traffic on port 10022 of relayserver to port 22 of homeserver.
+
+With "-fN" option, SSH will go right into the background once you successfully authenticate with an SSH server. This option is useful when you do not want to execute any command on a remote SSH server, and just want to forward ports, like in our case.
+
+After running the above command, you will be right back to the command prompt of homeserver.
+
+Log in to relayserver, and verify that 127.0.0.1:10022 is bound to sshd. If so, that means a reverse tunnel is set up correctly.
+
+ relayserver~$ sudo netstat -nap | grep 10022
+
+----------
+
+ tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
+
+Now from any other computer (e.g., clientcomputer), log in to relayserver. Then access homeserver as follows.
+
+ relayserver~$ ssh -p 10022 homeserver_user@localhost
+
+One thing to take note is that the SSH login/password you type for localhost should be for homeserver, not for relayserver, since you are logging in to homeserver via the tunnel's local endpoint. So do not type login/password for relayserver. After successful login, you will be on homeserver.
+
+### Connect Directly to a NATed Server via a Reverse SSH Tunnel ###
+
+While the above method allows you to reach **homeserver** behind NAT, you need to log in twice: first to **relayserver**, and then to **homeserver**. This is because the end point of an SSH tunnel on relayserver is binding to loopback address (127.0.0.1).
+
+But in fact, there is a way to reach NATed homeserver directly with a single login to relayserver. For this, you will need to let sshd on relayserver forward a port not only from loopback address, but also from an external host. This is achieved by specifying **GatewayPorts** option in sshd running on relayserver.
+
+Open /etc/ssh/sshd_conf of **relayserver** and add the following line.
+
+ relayserver~$ vi /etc/ssh/sshd_conf
+
+----------
+
+ GatewayPorts clientspecified
+
+Restart sshd.
+
+Debian-based system:
+
+ relayserver~$ sudo /etc/init.d/ssh restart
+
+Red Hat-based system:
+
+ relayserver~$ sudo systemctl restart sshd
+
+Now let's initiate a reverse SSH tunnel from homeserver as follows.
+homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
+
+Log in to relayserver and confirm with netstat command that a reverse SSH tunnel is established successfully.
+
+ relayserver~$ sudo netstat -nap | grep 10022
+
+----------
+
+ tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
+
+Unlike a previous case, the end point of a tunnel is now at 1.1.1.1:10022 (relayserver's public IP address), not 127.0.0.1:10022. This means that the end point of the tunnel is reachable from an external host.
+
+Now from any other computer (e.g., clientcomputer), type the following command to gain access to NATed homeserver.
+
+ clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
+
+In the above command, while 1.1.1.1 is the public IP address of relayserver, homeserver_user must be the user account associated with homeserver. This is because the real host you are logging in to is homeserver, not relayserver. The latter simply relays your SSH traffic to homeserver.
+
+### Set up a Persistent Reverse SSH Tunnel on Linux ###
+
+Now that you understand how to create a reverse SSH tunnel, let's make the tunnel "persistent", so that the tunnel is up and running all the time (regardless of temporary network congestion, SSH timeout, relay host rebooting, etc.). After all, if the tunnel is not always up, you won't be able to connect to your home server reliably.
+
+For a persistent tunnel, I am going to use a tool called autossh. As the name implies, this program allows you to automatically restart an SSH session should it breaks for any reason. So it is useful to keep a reverse SSH tunnel active.
+
+As the first step, let's set up [passwordless SSH login][2] from homeserver to relayserver. That way, autossh can restart a broken reverse SSH tunnel without user's involvement.
+
+Next, [install autossh][3] on homeserver where a tunnel is initiated.
+
+From homeserver, run autossh with the following arguments to create a persistent SSH tunnel destined to relayserver.
+
+ homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
+
+The "-M 10900" option specifies a monitoring port on relayserver which will be used to exchange test data to monitor an SSH session. This port should not be used by any program on relayserver.
+
+The "-fN" option is passed to ssh command, which will let the SSH tunnel run in the background.
+
+The "-o XXXX" options tell ssh to:
+
+- Use key authentication, not password authentication.
+- Automatically accept (unknown) SSH host keys.
+- Exchange keep-alive messages every 60 seconds.
+- Send up to 3 keep-alive messages without receiving any response back.
+
+The rest of reverse SSH tunneling related options remain the same as before.
+
+If you want an SSH tunnel to be automatically up upon boot, you can add the above autossh command in /etc/rc.local.
+
+### Conclusion ###
+
+In this post, I talked about how you can use a reverse SSH tunnel to access a Linux server behind a restrictive firewall or NAT gateway from outside world. While I demonstrated its use case for a home network, you must be careful when applying it for corporate networks. Such a tunnel can be considered as a breach of a corporate policy, as it circumvents corporate firewalls and can expose corporate networks to outside attacks. There is a great chance it can be misused or abused. So always remember its implication before setting it up.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/go/digitalocean
+[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
+[3]:http://ask.xmodulo.com/install-autossh-linux.html
diff --git a/sources/tech/20150515 How to Install Percona Server on CentOS 7.md b/sources/tech/20150515 How to Install Percona Server on CentOS 7.md
new file mode 100644
index 0000000000..03affe787e
--- /dev/null
+++ b/sources/tech/20150515 How to Install Percona Server on CentOS 7.md
@@ -0,0 +1,188 @@
+How to Install Percona Server on CentOS 7
+================================================================================
+In this article we are going to learn about percona server, an opensource drop-in replacement for MySQL and also for MariaDB. The InnoDB database engine make it very attractive and a good alternative if you need performance, reliability and a cost efficient solution
+
+In the following sections I am going to cover the installation of the percona server on the CentOS 7, I will also cover the steps needed to make backup of your current data, configuration and how to restore your backup.
+
+### Table of contents ###
+
+1. What is and why use percona
+1. Backup your databases
+1. Remove previous SQL server
+1. Installing Percona binaries
+1. Configuring Percona
+1. Securing your environment
+1. Restore your backup
+
+### 1. What is and why use Percona ###
+
+Percona is an opensource alternative to the MySQL and MariaDB databases, it's a fork of the MySQL with many improvements and unique features that makes it more reliable, powerful and faster than MySQL, and yet is fully compatible with it, you can even use replication between Oracle's MySQL and Percona.
+
+#### Features exclusive to Percona ####
+
+- Partitioned Adaptive Hash Search
+- Fast Checksum Algorithm
+- Buffer Pool Pre-Load
+- Support for FlashCache
+
+#### MySQL Enterprise and Percona specific features ####
+
+- Import Tables From Different Servers
+- PAM authentication
+- Audit Log
+- Threadpool
+
+Now that you are pretty excited to see all these good things together, we are going show you how to install and do basic configuration of Percona Server.
+
+### 2. Backup your databases ###
+
+The following, command creates a mydatabases.sql file with the SQL commands to recreate/restore salesdb and employeedb databases, replace the databases names to reflect your setup, skip if this is a brand new setup
+
+ mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
+
+Copy the current configuration file, you can also skip this in fresh setups
+
+ cp my.cnf my.cnf.bkp
+
+### 3. Remove your previous SQL Server ###
+
+Stop the MySQL/MariaDB if it's running.
+
+ systemctl stop mysql.service
+
+Uninstall MariaDB and MySQL
+
+ yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
+
+Move / Rename the MariaDB files in **/var/lib/mysql**, it's a safer and faster than just removing, it's like a 2nd level instant backup. :)
+
+ mv /var/lib/mysql /var/lib/mysql_mariadb
+
+### 4. Installing Percona binaries ###
+
+You can choose from a number of options on how to install Percona, in a CentOS system it's generally a better idea to use yum or RPM, so these are the way that are covered by this article, compiling and install from sources are not covered by this article.
+
+Installing from Yum repository:
+
+First you need to set the Percona's Yum repository with this:
+
+ yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
+
+And then install Percona with:
+
+ yum install Percona-Server-client-56 Percona-Server-server-56
+
+The above command installs Percona server and clients, shared libraries, possibly Perl and perl modules such as DBI::MySQL, if that are not already installed, and also other dependencies as needed.
+
+Installing from RPM package:
+
+We can download all rpm packages with the help of wget:
+
+ wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
+
+And with rpm utility, you install all the packages once:
+
+ rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
+
+Note the backslash '\' on the end of the sentences on the above commands, if you install individual packages, remember that to met dependencies, the shared package must be installed before client and client before server.
+
+### 5. Configuring Percona Server ###
+
+#### Restoring previous configuration ####
+
+As we are moving from MariaDB, you can just restore the backup of my.cnf file that you made in earlier steps.
+
+ cp /etc/my.cnf.bkp /etc/my.cnf
+
+#### Creating a new my.cnf ####
+
+If you need a new configuration file that fit your needs or if you don't have made a copy of my.cnf, you can use this wizard, it will generate for you, through simple steps.
+
+Here is a sample my.cnf file that comes with Percona-Server package
+
+ # Percona Server template configuration
+
+ [mysqld]
+ #
+ # Remove leading # and set to the amount of RAM for the most important data
+ # cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
+ # innodb_buffer_pool_size = 128M
+ #
+ # Remove leading # to turn on a very important data integrity option: logging
+ # changes to the binary log between backups.
+ # log_bin
+ #
+ # Remove leading # to set options mainly useful for reporting servers.
+ # The server defaults are faster for transactions and fast SELECTs.
+ # Adjust sizes as needed, experiment to find the optimal values.
+ # join_buffer_size = 128M
+ # sort_buffer_size = 2M
+ # read_rnd_buffer_size = 2M
+ datadir=/var/lib/mysql
+ socket=/var/lib/mysql/mysql.sock
+
+ # Disabling symbolic-links is recommended to prevent assorted security risks
+ symbolic-links=0
+
+ [mysqld_safe]
+ log-error=/var/log/mysqld.log
+ pid-file=/var/run/mysqld/mysqld.pid
+
+After making your my.cnf file fit your needs, it's time to start the service:
+
+ systemctl restart mysql.service
+
+If everything goes fine, your server is now up and ready to ready to receive SQL commands, you can try the following command to check:
+
+ mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
+
+If you can't start the service, you can look for a reason in **/var/log/mysql/mysqld.log** this file is set by the **log-error** option in my.cnf's **[mysqld_safe]** session.
+
+ tail /var/log/mysql/mysqld.log
+
+You can also take a look in a file inside **/var/lib/mysql/** with name in the form of **[hostname].err** as the following example:
+
+ tail /var/lib/mysql/centos7.err
+
+If this also fail in show what is wrong, you can also try strace:
+
+ yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
+
+The above command is extremely verbous and it's output is quite low level but can show you the reason you can't start service in most times.
+
+### 6. Securing your environment ###
+
+Ok, you now have your RDBMS ready to receive SQL queries, but it's not a good idea to put your precious data on a server without minimum security, it's better to make it safer with mysql_secure_instalation, this utility helps in removing unused default features, also set the root main password and make access restrictions for using this user.
+Just invoke it by the shell and follow instructions on the screen.
+
+ mysql_secure_install
+
+### 7. Restore your backup ###
+
+If you are coming from a previous setup, now you can restore your databases, just use mysqldump once again.
+
+ mysqldump -u root -p < mydatabases.sql
+
+Congratulations, you just installed Percona on your CentOS Linux, your server is now fully ready for use; You can now use your service as it was MySQL, and your services are fully compatible with it.
+
+### Conclusion ###
+
+There is a lot of things to configure in order to achieve better performance, but here is some straightforward options to improve your setup. When using innodb engine it's also a good idea to set the **innodb_file_per_table** option **on**, it gonna distribute table indexes in a file per table basis, it means that each table have it's own index file, it makes the overall system, more robust and easier to repair.
+
+Other option to have in mind is the **innodb_buffer_pool_size** option, InnoDB should have large enough to your datasets, and some value **between 70% and 80%** of the total available memory should be reasonable.
+
+By setting the **innodb-flush-method** to **O_DIRECT** you disable write cache, if you have **RAID**, this should be set to improved performance as this cache is already done in a lower level.
+
+If your data is not that critical and you don't need fully **ACID** compliant transactions, you can adjust to 2 the option **innodb_flush_log_at_trx_commit**, this will also lead to improved performance.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/percona-server-centos-7/
+
+作者:[Carlos Alberto][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/carlosal/
\ No newline at end of file
diff --git a/sources/tech/20150515 Install 'Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity.md b/sources/tech/20150515 Install 'Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity.md
new file mode 100644
index 0000000000..5731cd69f4
--- /dev/null
+++ b/sources/tech/20150515 Install 'Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity.md
@@ -0,0 +1,181 @@
+FSSlc translating
+
+Install ‘Tails 1.4′ Linux Operating System to Preserve Privacy and Anonymity
+================================================================================
+In this Internet world and the world of Internet we perform most of our task online be it Ticket booking, Money transfer, Studies, Business, Entertainment, Social Networking and what not. We spend a major part of our time online daily. It has been getting hard to remain anonymous with each passing day specially when backdoors are being planted by organizations like NSA (National Security Agency) who are putting their nose in between every thing that we come across online. We have least or no privacy online. All the searches are logged upon the basis of user Internet surfing activity and machine activity.
+
+A wonderful browser from Tor project is used by millions which help us surfing the web anonymously however it is not difficult to trace your browsing habits and hence tor alone is not the guarantee of your safety online. You may like to check Tor features and installation instructions here:
+
+- [Anonymous Web Browsing using Tor][1]
+
+There is a operating system named Tails by Tor Projects. Tails (The Amnesic Incognito Live System) is a live operating system, based on Debian Linux distribution, which mainly focused on preserving privacy and anonymity on the web while browsing internet, means all it’s outgoing connection are forced to pass through the Tor and direct (non-anonymous) requests are blocked. The system is designed to run from any boot-able media be it USB stick or DVD.
+
+The latest stable release of Tails OS is 1.4 which was released on May 12, 2015. Powered by open source Monolithic Linux Kernel and built on top of Debian GNU/Linux Tails aims at Personal Computer Market and includes GNOME 3 as default user Interface.
+
+#### Features of Tails OS 1.4 ####
+
+- Tails is a free operating system, free as in beer and free as in speech.
+- Built on top of Debian/GNU Linux. The most widely used OS that is Universal.
+- Security Focused Distribution.
+- Windows 8 camouflage.
+- Need not to be installed and browse Internet anonymously using Live Tails CD/DVD.
+- Leave no trace on the computer, while tails is running.
+- Advanced cryptographic tools used to encrypt everything that concerns viz., files, emails, etc.
+- Sends and Receive traffic through tor network.
+- In true sense it provides privacy for anyone, anywhere.
+- Comes with several applications ready to be used from Live Environment.
+- All the softwares comes per-configured to connect to INTERNET only through Tor network.
+- Any application that tries to connect to Internet without Tor Network is blocked, automatically.
+- Restricts someone who is watching what sites you visit and restricts sites to learn your geographical location.
+- Connect to websites that are blocked and/or censored.
+- Designed specially not to use space used by parent OS even when there is free swap space.
+- The whole OS loads on RAM and is flushed when we reboot/shutdown. Hence no trace of running.
+- Advanced security implementation by encrypting USB disk, HTTPS ans Encrypt and sign emails and documents.
+
+#### What can you expect in Tails 1.4 ####
+
+- Tor Browser 4.5 with a security Slider.
+- Tor Upgraded to version 0.2.6.7.
+- Several Security holes fixed.
+- Many of the bug fixed and patches applied to Applications like curl, OpenJDK 7, tor Network, openldap, etc.
+
+To get a complete list of change logs you may visit [HERE][2]
+
+**Note**: It is strongly recommended to upgrade to Tails 1.4, if you’re using any older version of Tails.
+
+#### Why should I use Tails Operating System ####
+
+You need Tails because you need:
+
+- Freedom from network surveillance
+- Defend freedom, privacy and confidentiality
+- Security aka traffic analysis
+
+This tutorial will walk through the installation of Tails 1.4 OS with a short review.
+
+### Tails 1.4 Installation Guide ###
+
+1. To download the latest Tails OS 1.4, you may use wget command to download directly.
+
+ $ wget http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
+
+Alternatively you may download Tails 1.4 Direct ISO image or use a Torrent Client to pull the iso image file for you. Here is the link to both downloads:
+
+- [tails-i386-1.4.iso][3]
+- [tails-i386-1.4.torrent][4]
+
+2. After downloading, verify ISO Integrity by matching SHA256 checksum with the SHA256SUM provided on the official website..
+
+ $ sha256sum tails-i386-1.4.iso
+
+ 339c8712768c831e59c4b1523002b83ccb98a4fe62f6a221fee3a15e779ca65d
+
+If you are interested in knowing OpenPGP, checking Tails signing key against Debian keyring and anything related to Tails cryptographic signature, you may like to point your browser [HERE][5].
+
+3. Next you need to write the image to USB stick or DVD ROM. You may like to check the article, [How to Create Live Bootable USB][6] for details on how to make a flash drive bootable and write ISO to it.
+
+4. Insert the Tails OS Bootable flash drive or DVD ROM in the disk and boot from it (select from BIOS to boot). The first screen – two options to select from ‘Live‘ and ‘Live (failsafe)‘. Select ‘Live‘ and press Enter.
+
+
+Tails Boot Menu
+
+5. Just before login. You have two options. Click ‘More Options‘ if you want to configure and set advanced options else click ‘No‘.
+
+
+Tails Welcome Screen
+
+6. After clicking Advanced option, you need to setup root password. This is important if you want to upgrade it. This root password is valid till you shutdown/reboot the machine.
+
+Also you may enable Windows Camouflage, if you want to run this OS on a public place, so that it seems as you are running Windows 8 operating system. Good option indeed! Is not it? Also you have a option to configure Network and Mac Address. Click ‘Login‘ when done!.
+
+
+Tails OS Configuration
+
+7. This is Tails GNU/Linux OS camouflaged by Windows Skin.
+
+
+Tails Windows Look
+
+8. It will start Tor Network in the background. Check the Notification on the top-right corner of the screen – Tor is Ready / You are now connected to the Internet.
+
+Also check what it contains under Internet Menu. Notice – It has Tor Browser (safe) and Unsafe Web Browser (Where incoming and outgoing data don’t pass through TOR Network) along with other applications.
+
+
+Tails Menu and Tools
+
+9. Click Tor and check your IP Address. It confirms my physical location is not shared and my privacy is intact.
+
+
+Check Privacy on Tails
+
+10. You may Invoke Tails Installer to clone & Install, Clone & Upgrade and Upgrade from ISO.
+
+
+Tails Installer Options
+
+11. The other option was to select Tor without any advanced option, just before login (Check step #5 above).
+
+
+Tails Without Advance Option
+
+12. You will get log-in to Gnome3 Desktop Environment.
+
+
+Tails Gnome Desktop
+
+13. If you click to Launch Unsafe browser in Camouflage or without Camouflage, you will be notified.
+
+
+Tails Browsing Notification
+
+If you do, this is what you get in a Browser.
+
+
+Tails Browsing Alert
+
+#### Is Tails for me? ####
+
+To get the above question answered, first answer a few question.
+
+- Do you need your privacy to be intact while you are online?
+- Do you want to remain hidden from Identity thieves?
+- Do you want somebody to put your nose in between your private chat online?
+- Do you really want to show your geographical location to anybody there?
+- Do you carry out banking transactions online?
+- Are you happy with the censorship by government and ISP?
+
+If the answer to any of the above question is ‘YES‘ you preferably need Tails. If answer to all the above question is ‘NO‘ you perhaps don’t need it.
+
+To know more about Tails? Point your browser to user Documentation : [https://tails.boum.org/doc/index.en.html][7]
+
+### Conclusion ###
+
+Tails is an OS which is must for those who work in an unsafe environment. An OS focused on security yet contains bundles of Application – Gnome Desktop, Tor, Firefox (Iceweasel), Network Manager, Pidgin, Claws mail, Liferea feed addregator, Gobby, Aircrack-ng, I2P.
+
+It also contain several tools for Encryption and Privacy Under the Hood, viz., LUKS, GNUPG, PWGen, Shamir’s Secret Sharing, Virtual Keyboard (against Hardware Keylogging), MAT, KeePassX Password Manager, etc.
+
+That’s all for now. Keep Connected to Tecmint. Share your thoughts on Tails GNU/Linux Operating System. What do you think about the future of the Project? Also test it Locally and let us know your experience.
+
+You may run it in [Virtualbox][8] as well. Remember Tails loads the whole OS in RAM hence give enough RAM to run Tails in VM.
+
+I tested in 1GB Environment and it worked without lagging. Thanks to all our readers for their Support. In making Tecmint a one place for all Linux related stuffs your co-operation is needed. Kudos!
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-tails-1-4-linux-operating-system-to-preserve-privacy-and-anonymity/
+
+作者:[Avishek Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
+[2]:https://tails.boum.org/news/version_1.4/index.en.html
+[3]:http://dl.amnesia.boum.org/tails/stable/tails-i386-1.4/tails-i386-1.4.iso
+[4]:https://tails.boum.org/torrents/files/tails-i386-1.4.torrent
+[5]:https://tails.boum.org/download/index.en.html#verify
+[6]:http://www.tecmint.com/install-linux-from-usb-device/
+[7]:https://tails.boum.org/doc/index.en.html
+[8]:http://www.tecmint.com/install-virtualbox-on-redhat-centos-fedora/
diff --git a/sources/tech/20150518 How to set up a Replica Set on MongoDB.md b/sources/tech/20150518 How to set up a Replica Set on MongoDB.md
new file mode 100644
index 0000000000..07e16dafc1
--- /dev/null
+++ b/sources/tech/20150518 How to set up a Replica Set on MongoDB.md
@@ -0,0 +1,182 @@
+How to set up a Replica Set on MongoDB
+================================================================================
+MongoDB has become the most famous NoSQL database on the market. MongoDB is document-oriented, and its scheme-free design makes it a really attractive solution for all kinds of web applications. One of the features that I like the most is Replica Set, where multiple copies of the same data set are maintained by a group of mongod nodes for redundancy and high availability.
+
+This tutorial describes how to configure a Replica Set on MonoDB.
+
+The most common configuration for a Replica Set involves one primary and multiple secondary nodes. The replication will then be initiated from the primary toward the secondaries. Replica Sets can not only provide database protection against unexpected hardware failure and service downtime, but also improve read throughput of database clients as they can be configured to read from different nodes.
+
+### Set up the Environment ###
+
+In this tutorial, we are going to set up a Replica Set with one primary and two secondary nodes.
+
+
+
+In order to implement this lab, we will use three virtual machines (VMs) running on VirtualBox. I am going to install Ubuntu 14.04 on the VMs, and install official packages for Mongodb.
+
+I am going to set up a necessary environment on one VM instance, and then clone it to the other two VM instances. Thus pick one VM named master, and perform the following installations.
+
+First, we need to add the MongoDB key for apt:
+
+ $ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
+
+Then we need to add the official MongoDB repository to our source.list:
+
+ $ sudo su
+ # echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
+
+Let's update repositories and install MongoDB.
+
+ $ sudo apt-get update
+ $ sudo apt-get install -y mongodb-org
+
+Now let's make some changes in /etc/mongodb.conf.
+
+ auth = true
+ dbpath=/var/lib/mongodb
+ logpath=/var/log/mongodb/mongod.log
+ logappend=true
+ keyFile=/var/lib/mongodb/keyFile
+ replSet=myReplica
+
+The first line is to make sure that we are going to have authentication on our database. keyFile is to set up a keyfile that is going to be used by MongoDB to replicate between nodes. replSet sets up the name of our replica set.
+
+Now we are going to create our keyfile, so that it can be in all our instances.
+
+ $ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
+
+This will create keyfile that contains a MD5 string, but it has some noise that we need to clean up before using it in MongoDB. Use the following command to clean it up:
+
+ $ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
+
+What grep command does is to print MD5 string with no spaces or other characters that we don't want.
+
+Now we are going to make the keyfile ready for use:
+
+ $ sudo cp keyFile /var/lib/mongodb
+ $ sudo chown mongodb:nogroup keyFile
+ $ sudo chmod 400 keyFile
+
+Now we have our Ubuntu VM ready to be cloned. Power it off, and clone it to the other VMs.
+
+
+
+I name the cloned VMs secondary1 and secondary2. Make sure to reinitialize the MAC address of cloned VMs and clone full disks.
+
+
+
+All three VM instances should be on the same network to communicate with each other. For this, we are going to attach all three VMs to "Internet Network".
+
+It is recommended that each VM instances be assigned a static IP address, as opposed to DHCP IP address, so that the VMs will not lose connectivity among themselves when a DHCP server assigns different IP addresses to them.
+
+Let's edit /etc/networks/interfaces of each VM as follows.
+
+On primary:
+
+ auto eth1
+ iface eth1 inet static
+ address 192.168.50.2
+ netmask 255.255.255.0
+
+On secondary1:
+
+ auto eth1
+ iface eth1 inet static
+ address 192.168.50.3
+ netmask 255.255.255.0
+
+On secondary2:
+
+ auto eth1
+ iface eth1 inet static
+ address 192.168.50.4
+ netmask 255.255.255.0
+
+Another file that needs to be set up is /etc/hosts, because we don't have DNS. We need to set the hostnames in /etc/hosts.
+
+On primary:
+
+ 127.0.0.1 localhost primary
+ 192.168.50.2 primary
+ 192.168.50.3 secondary1
+ 192.168.50.4 secondary2
+
+On secondary1:
+
+ 127.0.0.1 localhost secondary1
+ 192.168.50.2 primary
+ 192.168.50.3 secondary1
+ 192.168.50.4 secondary2
+
+On secondary2:
+
+ 127.0.0.1 localhost secondary2
+ 192.168.50.2 primary
+ 192.168.50.3 secondary1
+ 192.168.50.4 secondary2
+
+Check connectivity among themselves by using ping command:
+
+ $ ping primary
+ $ ping secondary1
+ $ ping secondary2
+
+### Set up a Replica Set ###
+
+After verifying connectivity among VMs, we can go ahead and create the admin user so that we can start working on the Replica Set.
+
+On primary node, open /etc/mongodb.conf, and comment out two lines that start with auth and replSet:
+
+ dbpath=/var/lib/mongodb
+ logpath=/var/log/mongodb/mongod.log
+ logappend=true
+ #auth = true
+ keyFile=/var/lib/mongodb/keyFile
+ #replSet=myReplica
+
+Restart mongod daemon.
+
+ $ sudo service mongod restart
+
+Create an admin user after conencting to MongoDB:
+
+ > use admin
+ > db.createUser({
+ user:"admin",
+ pwd:"
+ })
+ $ sudo service mongod restart
+
+Connect to MongoDB and use these commands to add secondary1 and secondary2 to our Replicat Set.
+
+ > use admin
+ > db.auth("admin","myreallyhardpassword")
+ > rs.initiate()
+ > rs.add ("secondary1:27017")
+ > rs.add("secondary2:27017")
+
+Now that we have our Replica Set, we can start working on our project. Consult the [official driver documentation][1] to see how to connect to a Replica Set. In case you want to query from shell, you have to connect to primary instance to insert or query the database. Secondary nodes will not let you do that. If you attempt to access the database on a secondary node, you will get this error message:
+
+ myReplica:SECONDARY>
+ myReplica:SECONDARY> show databases
+ 2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
+ at Error ()
+ at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
+ at shellHelper.show (src/mongo/shell/utils.js:630:33)
+ at shellHelper (src/mongo/shell/utils.js:524:36)
+ at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
+
+I hope you find this tutorial useful. You can use Vagrant to automate your local environments and help you code faster.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/setup-replica-set-mongodb.html
+
+作者:[Christopher Valerio][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/valerio
+[1]:http://docs.mongodb.org/ecosystem/drivers/
\ No newline at end of file
diff --git a/sources/tech/20150522 Analyzing Linux Logs.md b/sources/tech/20150522 Analyzing Linux Logs.md
new file mode 100644
index 0000000000..38d5b4636e
--- /dev/null
+++ b/sources/tech/20150522 Analyzing Linux Logs.md
@@ -0,0 +1,182 @@
+translating by zhangboyue
+Analyzing Linux Logs
+================================================================================
+There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
+
+We’ll show you first how to do this yourself on the command line using several different tools and then show you how a log management tool can automate much of the grunt work and make this so much more streamlined.
+
+### Searching with Grep ###
+
+Searching for text is the most basic way to find what you’re looking for. The most common tool for searching text is [grep][1]. This command line tool, available on most Linux distributions, allows you to search your logs using regular expressions. A regular expression is a pattern written in a special language that can identify matching text. The simplest pattern is to put the string you’re searching for surrounded by quotes
+
+#### Regular Expressions ####
+
+Here’s an example to find authentication logs for “user hoover” on an Ubuntu system:
+
+ $ grep "user hoover" /var/log/auth.log
+ Accepted password for hoover from 10.0.2.2 port 4792 ssh2
+ pam_unix(sshd:session): session opened for user hoover by (uid=0)
+ pam_unix(sshd:session): session closed for user hoover
+
+It can be hard to construct regular expressions that are accurate. For example, if we searched for a number like the port “4792” it could also match timestamps, URLs, and other undesired data. In the below example for Ubuntu, it matched an Apache log that we didn’t want.
+
+ $ grep "4792" /var/log/auth.log
+ Accepted password for hoover from 10.0.2.2 port 4792 ssh2
+ 74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972HTTP/1.0" 404 545 "-" "-”
+
+#### Surround Search ####
+
+Another useful tip is that you can do surround search with grep. This will show you what happened a few lines before or after a match. It can help you debug what lead up to a particular error or problem. The B flag gives you lines before, and A gives you lines after. For example, we can see that when someone failed to login as an admin, they also failed the reverse mapping which means they might not have a valid domain name. This is very suspicious!
+
+ $ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
+ Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
+ Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
+ Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
+ Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
+ Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
+
+#### Tail ####
+
+You can also pair grep with [tail][2] to get the last few lines of a file, or to follow the logs and print them in real time. This is useful if you are making interactive changes like starting a server or testing a code change.
+
+ $ tail -f /var/log/auth.log | grep 'Invalid user'
+ Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
+ Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
+
+A full introduction on grep and regular expressions is outside the scope of this guide, but [Ryan’s Tutorials][3] include more in-depth information.
+
+Log management systems have higher performance and more powerful searching abilities. They often index their data and parallelize queries so you can quickly search gigabytes or terabytes of logs in seconds. In contrast, this would take minutes or in extreme cases hours with grep. Log management systems also use query languages like [Lucene][4] which offer an easier syntax for searching on numbers, fields, and more.
+
+### Parsing with Cut, AWK, and Grok ###
+
+#### Command Line Tools ####
+
+Linux offers several command line tools for text parsing and analysis. They are great if you want to quickly parse a small amount of data but can take a long time to process large volumes of data
+
+#### Cut ####
+
+The [cut][5] command allows you to parse fields from delimited logs. Delimiters are characters like equal signs or commas that break up fields or key value pairs.
+
+Let’s say we want to parse the user from this log:
+
+ pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
+
+We can use the cut command like this to get the text after the eighth equal sign. This example is on an Ubuntu system:
+
+ $ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
+ root
+ hoover
+ root
+ nagios
+ nagios
+
+#### AWK ####
+
+Alternately, you can use [awk][6], which offers more powerful features to parse out fields. It offers a scripting language so you can filter out nearly everything that’s not relevant.
+
+For example, let’s say we have the following log line on an Ubuntu system and we want to extract the username that failed to login:
+
+ Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
+
+Here’s how you can use the awk command. First, put a regular expression /sshd.*invalid user/ to match the sshd invalid user lines. Then print the ninth field using the default delimiter of space using { print $9 }. This outputs the usernames.
+
+ $ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
+ guest
+ admin
+ info
+ test
+ ubnt
+
+You can read more about how to use regular expressions and print fields in the [Awk User’s Guide][7].
+
+#### Log Management Systems ####
+
+Log management systems make parsing easier and enable users to quickly analyze large collections of log files. They can automatically parse standard log formats like common Linux logs or web server logs. This saves a lot of time because you don’t have to think about writing your own parsing logic when troubleshooting a system problem.
+
+Here you can see an example log message from sshd which has each of the fields remoteHost and user parsed out. This is a screenshot from Loggly, a cloud-based log management service.
+
+
+
+You can also do custom parsing for non-standard formats. A common tool to use is [Grok][8] which uses a library of common regular expressions to parse raw text into structured JSON. Here is an example configuration for Grok to parse kernel log files inside Logstash:
+
+ filter{
+ grok {
+ match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
+ }
+ }
+
+And here is what the parsed output looks like from Grok:
+
+
+
+### Filtering with Rsyslog and AWK ###
+
+Filtering allows you to search on a specific field value instead of doing a full text search. This makes your log analysis more accurate because it will ignore undesired matches from other parts of the log message. In order to search on a field value, you need to parse your logs first or at least have a way of searching based on the event structure.
+
+#### How to Filter on One App ####
+
+Often, you just want to see the logs from just one application. This is easy if your application always logs to a single file. It’s more complicated if you need to filter one application among many in an aggregated or centralized log. Here are several ways to do this:
+
+1. Use the rsyslog daemon to parse and filter logs. This example writes logs from the sshd application to a file named sshd-messages, then discards the event so it’s not repeated elsewhere. You can try this example by adding it to your rsyslog.conf file.
+
+ :programname, isequal, “sshd” /var/log/sshd-messages
+ &~
+
+2. Use command line tools like awk to extract the values of a particular field like the sshd username. This example is from an Ubuntu system.
+
+ $ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
+ guest
+ admin
+ info
+ test
+ ubnt
+
+3. Use a log management system that automatically parses your logs, then click to filter on the desired application name. Here is a screenshot showing the syslog fields in a log management service called Loggly. We are filtering on the appName “sshd” as indicated by the Venn diagram icon.
+
+
+
+#### How to Filter on Errors ####
+
+One of the most common thing people want to see in their logs is errors. Unfortunately, the default syslog configuration doesn’t output the severity of errors directly, making it difficult to filter on them.
+
+There are two ways you can solve this problem. First, you can modify your rsyslog configuration to output the severity in the log file to make it easier to read and search. In your rsyslog configuration you can add a [template][9] with pri-text such as the following:
+
+ "<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
+
+This example gives you output in the following format. You can see that the severity in this message is err.
+
+ : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
+
+You can use awk or grep to search for just the error messages. In this example for Ubuntu, we’re including some surrounding syntax like the . and the > which match only this field.
+
+ $ grep '.err>' /var/log/auth.log
+ : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
+
+Your second option is to use a log management system. Good log management systems automatically parse syslog messages and extract the severity field. They also allow you to filter on log messages of a certain severity with a single click.
+
+Here is a screenshot from Loggly showing the syslog fields with the error severity highlighted to show we are filtering for errors:
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
+
+作者:[Jason Skowronski][a] [Amy Echeverri][b] [ Sadequl Hussain][c]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linkedin.com/in/jasonskowronski
+[b]:https://www.linkedin.com/in/amyecheverri
+[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
+[1]:http://linux.die.net/man/1/grep
+[2]:http://linux.die.net/man/1/tail
+[3]:http://ryanstutorials.net/linuxtutorial/grep.php
+[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
+[5]:http://linux.die.net/man/1/cut
+[6]:http://linux.die.net/man/1/awk
+[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
+[8]:http://logstash.net/docs/1.4.2/filters/grok
+[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
diff --git a/sources/tech/20150526 20 Useful Terminal Emulators for Linux.md b/sources/tech/20150526 20 Useful Terminal Emulators for Linux.md
new file mode 100644
index 0000000000..436b28f79f
--- /dev/null
+++ b/sources/tech/20150526 20 Useful Terminal Emulators for Linux.md
@@ -0,0 +1,301 @@
+Translating by ZTinoZ
+20 Useful Terminal Emulators for Linux
+================================================================================
+A Terminal emulator is a computer program that reproduces a video terminal within some other display structure. In other words the Terminal emulator has an ability to make a dumb machine appear like a client computer networked to the server. The terminal emulator allows an end user to access console as well as its applications such as text user interface and command line interface.
+
+
+
+20 Linux Terminal Emulators
+
+You may find huge number of terminal emulators to choose from this open source world. Some of them offers large range of features while others offers less features. To give a better understanding to the quality of software that are available, we have gathered a list of marvelous terminal emulator for Linux. Each title provides its description and feature along with screenshot of the software with relevant download link.
+
+### 1. Terminator ###
+
+Terminator is an advanced and powerful terminal emulator which supports multiple terminals windows. This emulator is fully customizable. You can change the size, colour, give different shapes to the terminal. Its very user friendly and fun to use.
+
+#### Features of Terminator ####
+
+- Customize your profiles and colour schemes, set the size to fit your needs.
+- Use plugins to get even more functionality.
+- Several key-shortcuts are available to speed up common activities.
+- Split the terminal window into several virtual terminals and re-size them as needed.
+
+
+
+Terminator Terminal
+
+- [Terminator Homepage][1]
+- [Download and Installation Instructions][2]
+
+### 2. Tilda ###
+
+Tilda is a stylish drop-down terminal based on GTK+. With the help of a single key press you can launch a new or hide Tilda window. However, you can add colors of your choice to change the look of the text and Terminal background.
+
+#### Features of Tilda ####
+
+ Interface with Highly customization option.
+ You can set the transparency level for Tilda window.
+ Excellent built-in colour schemes.
+
+
+
+Tilda Terminal
+
+- [Tilda Homepage][3]
+
+### 3. Guake ###
+
+Guake is a python based drop-down terminal created for the GNOME Desktop Environment. It is invoked by pressing a single keystroke, and can make it hidden by pressing same keystroke again. Its design was determined from FPS (First Person Shooter) games such as Quake and one of its main target is be easy to reach.
+
+Guake is very much similar to Yakuaka and Tilda, but it’s an experiment to mix the best of them into a single GTK-based program. Guake has been written in python from scratch using a little piece in C (global hotkeys stuff).
+
+
+
+Guake Terminal
+
+- [Guake Homepage][4]
+
+### 4. Yakuake ###
+
+Yakuake (Yet Another Kuake) is a KDE based drop-down terminal emulator very much similar to Guake terminal emulator in functionality. It’s design was inspired from fps consoles games such as Quake.
+
+Yakuake is basically a KDE application, which can be easily installed on KDE desktop, but if you try to install Yakuake in GNOME desktop, it will prompt you to install huge number of dependency packages.
+
+#### Yakuake Features ####
+
+- Fluently turn down from the top of your screen
+- Tabbed interface
+- Configurable dimensions and animation speed
+- Customizable
+
+
+
+Yakuake Terminal
+
+- [Yakuake Homepage][5]
+
+### 5. ROXTerm ###
+
+ROXterm is yet another lightweight terminal emulator designed to provide similar features to gnome-terminal. It was originally constructed to have lesser footprints and faster start-up time by not using the Gnome libraries and by using a independent applet to bring the configuration interface (GUI), but over the time it’s role has shifted to bringing a higher range of features for power users.
+
+However, it is more customizable than gnome-terminal and anticipated more at “power” users who make excessive use of terminals. It is easily integrated with GNOME desktop environment and provides features like drag & drop of items into terminal.
+
+
+
+Roxterm Terminal
+
+- [ROXTerm Homepage][6]
+
+### 6. Eterm ###
+
+Eterm is a lightest color terminal emulator designed as a replacement for xterm. It is developed with a Freedom of Choice ideology, leaving as much power, flexibility, and freedom as workable in the hands of the user.
+
+
+
+Eterm Terminal
+
+- [Eterm Homepage][7]
+
+### 7. Rxvt ###
+
+Rxvt stands for extended virtual terminal is a color terminal emulator application for Linux intended as an xterm replacement for power users who don’t need to have a feature such as Tektronix 4014 emulation and toolkit-style configurability.
+
+
+
+Rxvt Terminal
+
+- [Rxvt Homepage][8]
+
+### 8. Wterm ###
+
+Wterm is a another light weight color terminal emulator based on rxvt project. It includes features such as background images, transparency, reverse transparency and an considerable set or runtime options are accessible resulting in a very high customizable terminal emulator.
+
+
+
+wterm Terminal
+
+- [Wterm Homepage][9]
+
+### 9. LXTerminal ###
+
+LXTerminal is a default VTE-based terminal emulator for LXDE (Lightweight X Desktop Environment) without any unnecessary dependency. The terminal has got some nice features such as.
+LXTerminal Features
+
+- Multiple tabs support
+- Supports common commands like cp, cd, dir, mkdir, mvdir.
+- Feature to hide the menu bar for saving space
+- Change the color scheme.
+
+
+
+lxterminal Terminal
+
+- [LXTerminal Homepage][10]
+
+### 10. Konsole ###
+
+Konsole is yet another powerful KDE based free terminal emulator was originally created by Lars Doelle.
+Konsole Features
+
+- Multiple Tabbed terminals.
+- Translucent backgrounds.
+- Support for Split-view mode.
+- Directory and SSH bookmarking.
+- Customizable color schemes.
+- Customizable key bindings.
+- Notification alerts about activity in a terminal.
+- Incremental search
+- Support for Dolphin file manager
+- Export of output in plain text or HTML format.
+
+
+
+Konsole Terminal
+
+- [Konsole Homepage][11]
+
+### 11. TermKit ###
+
+TermKit is a elegant terminal that aims to construct aspects of the GUI with the command line based application using WebKit rendering engine mostly used in web browsers like Google Chrome and Chromium. TermKit is originally designed for Mac and Windows, but due to TermKit fork by Floby which you can now able to install it under Linux based distributions and experience the power of TermKit.
+
+
+
+TermKit Terminal
+
+- [TermKit Homepage][12]
+
+12. st
+
+st is a simple terminal implementation for X Window.
+
+
+
+st terminal
+
+- [st Homepage][13]
+
+### 13. Gnome-Terminal ###
+
+GNOME terminal is a built-in terminal emulator for GNOME desktop environment developed by Havoc Pennington and others. It allow users to run commands using a real Linux shell while remaining on the on the GNOME environment. GNOME Terminal emulates the xterm terminal emulator and brings a few similar features.
+
+The Gnome terminal supports multiple profiles, where users can able to create multiple profiles for his/her account and can customize configuration options such as fonts, colors, background image, behavior, etc. per account and define a name to each profile. It also supports mouse events, url detection, multiple tabs, etc.
+
+
+
+Gnome Terminal
+
+- [Gnome Terminal][14]
+
+### 14. Final Term ###
+
+Final Term is a open source stylish terminal emulator that has some exciting capabilities and handy features into one single beautiful interface. It is still under development, but provides significant features such as Semantic text menus, Smart command completion, GUI terminal controls, Omnipotent keybindings, Color support and many more. The following animated screen grab demonstrates some of their features. Please click on image to view demo.
+
+
+
+FinalTerm Terminal
+
+- [Final Term][15]
+
+### 15. Terminology ###
+
+Terminology is yet another new modern terminal emulator created for the Enlightenment desktop, but also can be used in different desktop environments. It has some awesome unique features, which do not have in any other terminal emulator.
+
+Apart features, terminology offers even more things that you wouldn’t assume from a other terminal emulators, like preview thumbnails of images, videos and documents, it also allows you to see those files directly from Terminology.
+
+You can watch a following demonstrations video created by the Terminology developer (the video quality isn’t clear, but still it’s enough to get the idea about Terminology).
+
+
+
+- [Terminology][16]
+
+### 16. Xfce4 terminal ###
+
+Xfce terminal is a lightweight modern and easy to use terminal emulator specially designed for Xfce desktop environment. The latest release of xfce terminal has some new cool features such as search dialog, tab color changer, drop-down console like Guake or Yakuake and many more.
+
+
+
+Xfce Terminal
+
+- [Xfce4 Terminal][17]
+
+### 17. xterm ###
+
+The xterm application is a standard terminal emulator for the X Window System. It maintain DEC VT102 and Tektronix 4014 compatible terminals for applications that can’t use the window system directly.
+
+
+
+xterm Terminal
+
+- [xterm][18]
+
+### 18. LilyTerm ###
+
+The LilyTerm is a another less known open source terminal emulator based off of libvte that desire to be fast and lightweight. LilyTerm also include some key features such as:
+
+- Support for tabbing, coloring and reordering tabs
+- Ability to manage tabs through keybindings
+- Support for background transparency and saturation.
+- Support for user specific profile creation.
+- Several customization options for profiles.
+- Extensive UTF-8 support.
+
+
+
+Lilyterm Terminal
+
+- [LilyTerm][19]
+
+### 19. Sakura ###
+
+The sakura is a another less known Unix style terminal emulator developed for command line purpose as well as text-based terminal programs. Sakura is based on GTK and livte and provides not more advanced features but some customization options such as multiple tab support, custom text color, font and background images, speedy command processing and few more.
+
+
+
+Sakura Terminal
+
+- [Sakura][20]
+
+### 20. rxvt-unicode ###
+
+The rxvt-unicode (also known as urxvt) is a yet another highly customizable, lightweight and fast terminal emulator with xft and unicode support was developed by Marc Lehmann. It got some outstanding features such as support for international language via Unicode, the ability to display multiple font types and support for Perl extensions.
+
+
+
+rxvt unicode
+
+- [rxvt-unicode][21]
+
+If you know any other capable Linux terminal emulators that I’ve not included in the above list, please do share with me using our comment section.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-terminal-emulators/
+
+作者:[Ravi Saive][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/admin/
+[1]:https://launchpad.net/terminator
+[2]:http://www.tecmint.com/terminator-a-linux-terminal-emulator-to-manage-multiple-terminal-windows/
+[3]:http://tilda.sourceforge.net/tildaabout.php
+[4]:https://github.com/Guake/guake
+[5]:http://extragear.kde.org/apps/yakuake/
+[6]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
+[7]:http://www.eterm.org/
+[8]:http://sourceforge.net/projects/rxvt/
+[9]:http://sourceforge.net/projects/wterm/
+[10]:http://wiki.lxde.org/en/LXTerminal
+[11]:http://konsole.kde.org/
+[12]:https://github.com/unconed/TermKit
+[13]:http://st.suckless.org/
+[14]:https://help.gnome.org/users/gnome-terminal/stable/
+[15]:http://finalterm.org/
+[16]:http://www.enlightenment.org/p.php?p=about/terminology
+[17]:http://docs.xfce.org/apps/terminal/start
+[18]:http://invisible-island.net/xterm/
+[19]:http://lilyterm.luna.com.tw/
+[20]:https://launchpad.net/sakura
+[21]:http://software.schmorp.de/pkg/rxvt-unicode
diff --git a/sources/tech/20150527 How to Create Own Online Shopping Store Using 'OpenCart' in Linux.md b/sources/tech/20150527 How to Create Own Online Shopping Store Using 'OpenCart' in Linux.md
new file mode 100644
index 0000000000..ad673a03e0
--- /dev/null
+++ b/sources/tech/20150527 How to Create Own Online Shopping Store Using 'OpenCart' in Linux.md
@@ -0,0 +1,225 @@
+How to Create Own Online Shopping Store Using “OpenCart” in Linux
+================================================================================
+In the Internet world we are doing everything using a computer. Electronic Commerce aka e-commerce is one one of them. E-Commerce is nothing new and it started in the early days of ARPANET, where ARPANET used to arrange sale between students of Massachusetts Institute of Technology and Stanford Artificial Intelligence Laboratory.
+
+These days there are some 100’s of E-Commerce site viz., Flipcart, eBay, Alibaba, Zappos, IndiaMART, Amazon, etc. Have you thought of making your own Amazon and Flipcart like web-based Application Server? If yes! This article is for you.
+
+Opencart is a free and open source E-Commerce Application written in PHP, which can be used to develop a shopping cart system similar to Amazon and Flipcart. If you want to sell your products online or want to serve your customers even when you are closed Opencart is for you. You can build a successful online store (for online merchants) using reliable and professional Opencart Application.
+
+### OpenCart Web Panel Demo ###
+
+- Store Front – [http://demo.opencart.com/][1]
+- Admin Login – [http://demo.opencart.com/admin/][2]
+
+ ------------------ Admin Login ------------------
+ Username: demo
+ Password: demo
+
+#### Features of Opencart ####
+
+Opencart is an application that meets all the requirements of an online merchant. It has all the features (see below) using which you can make your own E-Commerce Website.
+
+- It is a Free (as in beer) and Open Source (as in speech) Application released under GNU GPL License.
+- Everything is well documented, means you don’t need to Google and shout for help.
+- Free Life time support and updates.
+- Unlimited number of categories, Products and manufacturer supported.
+- Everything is Template based.
+- Multi-Language and Multi-Currency Supported. It ensures your product gets a global reach.
+- Built-in Product Review and Rating Features.
+- Downloadable Products (viz., ebook) supported.
+- Automatic Image Resizing supported.
+- Features like Multi tax Rates (as in various country), Viewing Related Products, Information Page, Shipping Weight Calculation, Availing Discount Coupons, etc are well implemented by default.
+- Built-in Backup and Restore tools.
+- Well implemented SEO.
+- Invoice Printing, Error Log and sales report are supported as well.
+
+#### System Requirements ####
+
+- Web Server (Apache HTTP Server Preferred)
+- PHP (5.2 and above).
+- Database (MySQLi Preferred but I am using MariaDB).
+
+#### Required PHP Libraries and Modules ####
+
+These extensions must be installed and enabled on your system to install Opencart properly on the web server.
+
+- Curl
+- Zip
+- Zlib
+- GD Library
+- Mcrypt
+- Mbstrings
+
+### Step 1: Installing Apache, PHP and MariaDB ###
+
+1. As I said, OpenCart requires certain technical requirements such as Apache, PHP with extensions and Database (MySQL or MariaDB) to be installed on the system, in order to run Opencart properly.
+
+Let’s install Apache, PHP and MariaDB using following Command.
+
+**Install Apache**
+
+ # apt-get install apache2 (On Debian based Systems)
+ # yum install httpd (On RedHat based Systems)
+
+**Install PHP and Extensions**
+
+ # apt-get install php5 libapache2-mod-php5 php5-curl php5-mcrypt (On Debian based Systems)
+ # yum install php php-mysql php5-curl php5-mcrypt (On RedHat based Systems)
+
+**Install MariaDB**
+
+ # apt-get install mariadb-server mariadb-client (On Debian based Systems)
+ # yum install mariadb-server mariadb (On RedHat based Systems)
+
+2. After installing all the above required things, you can start the Apache and MariaDB services using following commands.
+
+ ------------------- On Debian based Systems -------------------
+ # systemctl restart apache2.service
+ # systemctl restart mariadb.service
+
+----------
+
+ ------------------- On RedHat based Systems -------------------
+ # systemctl restart httpd.service
+ # systemctl restart mariadb.service
+
+### Step 2: Downloading and Setting OpenCart ###
+
+3. The most recent version of OpenCart (2.0.2.0) can be obtained from [OpenCart website][3] or directly from github.
+
+Alternatively, you may use following wget command to download the latest version of OpenCart directly from github repository as shown below.
+
+ # wget https://github.com/opencart/opencart/archive/master.zip
+
+4. After downloading zip file, copy to Apache Working directory (i.e. /var/www/html) and unzip the master.zip file.
+
+ # cp master.zip /var/www/html/
+ # cd /var/www/html
+ # unzip master.zip
+
+5. After extracting ‘master.zip‘ file, cd to extracted directory and move the content of upload directory to the root of the application folder (opencart-master).
+
+ # cd opencart-master
+ # mv -v upload/* ../opencart-master/
+
+6. Now you need to rename or copy OpenCart configuration files as shown below.
+
+ # cp /var/www/html/opencart-master/admin/config-dist.php /var/www/html/opencart-master/admin/config.php
+ # cp /var/www/html/opencart-master/config-dist.php /var/www/html/opencart-master/config.php
+
+7. Next, set correct Permissions to the files and folders of /var/www/html/opencart-master. You need to provide RWX permission to all the files and folders there, recursively.
+
+ # chmod 777 -R /var/www/html/opencart-master
+
+**Important**: Setting permission 777 may be dangerous, so as soon as you finish setting up everything, revert back to permission 755 recursively on the above folder.
+
+### Step 3: Creating OpenCart Database ###
+
+8. Next step is to create a database (say opencartdb) for the E-Commerce site to store data on the database. Connect to databaser server and create a database, user and grant correct privileges on the user to have full control over the database.
+
+ # mysql -u root -p
+ CREATE DATABASE opencartdb;
+ CREATE USER 'opencartuser'@'localhost' IDENTIFIED BY 'mypassword';
+ GRANT ALL PRIVILEDGES ON opencartdb.* TO 'opencartuser'@'localhost' IDENTIFIED by 'mypassword';
+
+### Step 4: OpenCart Web Installation ###
+
+9. Once everything set correctly, navigate to the web browser and type `http://` to access the OpenCart web installation.
+
+Click ‘CONTINUE‘ to Agree the License Agreement.
+
+
+
+Accept OpenCart License
+
+10. The next screen is Pre-installation Server Setup Check, to see that the server has all the required modules are installed properly and have correct permission on the OpenCart files.
+
+If any red marks are highlighted on #1 or #2, that means you need to install those components properly on the server to meet web server requirements.
+
+If there are any red marks on #3 or #4, that means there is issue with your files. If everything is correctly configured you should see all green marks are visible (as seen below), you may press “Continue“.
+
+
+
+Server Requirement Check
+
+11. On the next screen enter your Database Credentials like Database Driver, Hostname, User-name, Password, database. You should not touch db_port and Prefix, until and unless you know what you are doing.
+
+Also Enter User_name, Password and Email Address for Administrative account. Note these credentials will be used for logging in to Opencart Admin Panel as root, so keep it safe. Click continue when done!
+
+
+
+OpenCart Database Details
+
+12. The next screen shows message like “Installation Complete” with the Tag Line Ready to Start Selling. Also it warns to delete the installation directory, as everything required to setup using this directory has been accomplished.
+
+
+
+OpenCart Installation Completes
+
+To Remove install directory, you may like to run the below command.
+
+ # rm -rf /var/www/html/opencart-master/install
+
+### Step 4: Access OpenCart Web and Admin ###
+
+13. Now point your browser to `http:///opencart-master/` and you would see something like the below screenshot.
+
+
+
+OpenCart Product Showcase
+
+14. In order to login to Opencart Admin Panel, point your browser to http:///opencart-master/admin and fill the Admin Credentials you input, while setting it up.
+
+
+
+OpenCart Admin Login
+
+15. If everything ok! You should be able to see the Admin Dashboard of Opencart.
+
+
+
+OpenCart Dashboard
+
+Here in Admin Dashboard you may set up a lots of options like categories, product, options, Manufacturers, Downloads, Review, Information, Extension Installer, Shipping, Payment options, order totals, gift voucher, Paypal, Coupons, Affiliates, marketing, mails, Design and Settings, Error logs, in-built analytics and what not.
+
+#### What after testing the tools? ####
+
+If you have already tested the Application and finds it customizable, flexible, Rock Solid, Easy to maintain and use, you may need a good hosting provider to host OpenCart application, that remains live 24X7 support. Though there are a lot of options for hosting providers we recommend Hostgator.
+
+Hostgator is a Domain Registrant and Hosting Provider that is very well known for the service and feature it provides. It Provides you with UNLIMITED Disk Space, UNLIMITED Bandwidth, Easy to install (1-click install script), 99.9% Uptime, Award winning 24x7x365 Technical Support and 45 days money back guarantee, which means if you didn’t like the product and service you get your money back within 45 days of purchasing and mind it 45 days is a long time to Test.
+
+So if you have something to sell you can do it for free (by free I mean, Think of the cost you would spend on getting a physical store and then compare it with virtual store setting-up cost. You will feel its free).
+
+**Note**: When you buy hosting (and/or Domain) from Hostgator you will get a **Flat 25% OFF**. This offer is valid only for the readers of Tecmint Site.
+
+All you have to do is to Enter Promocode “**TecMint025**” during the payment of hosting. For reference see the preview of payment screen with promo code.
+
+
+
+[Sign up for Hostgator][4] (Coupon code: TecMint025)
+
+**Note**: Also worth mentioning, that for each hosting you buy from Hostgator to host OpenCart, we will get a small amount of commission, just to keep Tecmint Live (by Paying Bandwidth and hosting charges of server).
+
+So If you buy it using the above code, you get discount and we will get a small amount. Also note that you won’t pay anything extra, infact you will be paying 25% less on total bill.
+
+### Conclusion ###
+
+OpenCart is an application that performs out-of-the box. It is easy to install and you have the option to choose best suited templates, add your products and you become an online merchant.
+
+A lots of community made extensions(free and paid) makes it rich. It is a wonderful application for those who want to setup a virtual store and remain accessible to their customer 24X7. Let me know yours experience with the application. Any suggestion and feedback is welcome as well.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/create-e-commerce-online-shopping-store-using-opencart-in-linux/
+
+作者:[Avishek Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://demo.opencart.com/
+[2]:http://demo.opencart.com/admin/
+[3]:http://www.opencart.com/index.php?route=download/download/
+[4]:http://secure.hostgator.com/%7Eaffiliat/cgi-bin/affiliates/clickthru.cgi?id=tecmint
\ No newline at end of file
diff --git a/sources/tech/20150527 How to edit your documents collaboratively on Linux.md b/sources/tech/20150527 How to edit your documents collaboratively on Linux.md
new file mode 100644
index 0000000000..91d2bf6441
--- /dev/null
+++ b/sources/tech/20150527 How to edit your documents collaboratively on Linux.md
@@ -0,0 +1,122 @@
+How to edit your documents collaboratively on Linux
+================================================================================
+> "Developed many years before by some high-strung, compulsive assistant, the Bulletin was simply a Word document that lived in a shared folder both Emily and I could access. Only one of us could open it at a time and add a new message, thought, or question to the itemized list. Then we'd print out the updated version and place it on the clipboard that sat on the shelf over my desk, removing the old ones as we went." ("The Devil Wears Prada" by Lauren Weisberger)
+
+Even today such a "collaborative editing" is in use where only one person can open a shared file, make changes to it, and then inform others about what and when was modified.
+
+ONLYOFFICE is an open source online office suite integrated with different management tools for documents, emails, events, tasks and client relations.
+
+Using ONLYOFFICE office suite, a group of people can edit text, spreadsheet or presentation within a browser simultaneously. Leave comments directly in their document and interact with each other using the integrated chat. And, finally, save the document as a PDF file for further printing. As an added bonus, it gives the possibility to view the document history and restore the previous revision/version if needed.
+
+In this tutorial, I will describe how to deploy your own online office suite using [ONLYOFFICE Free Edition][1], an ONLYOFFICE self-hosted version distributed under GNU AGPL v3.
+
+### Installing ONLYOFFICE on Linux ###
+
+ONLYOFFICE installation requires the presence of mono (version 4.0.0 or later), nodejs, libstdc++6, nginx and mysql-server in your Linux system. To simplify the installation process and avoid dependency errors, I install ONLYOFFICE using Docker. In this case there is only one dependency to be installed - [Docker][2].
+
+Just to remind, Docker is an open-source project that automates the deployment of applications inside software containers. If Docker is not available on your Linux system, install it first by referring to Docker installation instructions for [Debian-based][3] or [Red-Hat based][4] systems.
+
+Note that you will need Docker 1.4.1 or later. To check the installed Docker version, use the following command.
+
+ $ docker version
+
+To try ONLYOFFICE inside a Docker container, simply execute the following commands:
+
+ $ sudo docker run -i -t -d --name onlyoffice-document-server onlyoffice/documentserver
+ $ sudo docker run -i -t -d -p 80:80 -p 443:443 --link onlyoffice-document-server:document_server onlyoffice/communityserver
+
+These commands will download the [official ONLYOFFICE Docker image][5] with all dependencies needed for its correct work.
+
+It's also possible to install [ONLYOFFICE Online Editors][6] separately on a Linux server, and easily integrate it into your website or cloud application via API provided.
+
+### Running a Self-Hosted Online Office ###
+
+To open your online office, enter localhost (http://IP-Address/) in the address bar of your browser. The Welcome page will open:
+
+
+
+Enter a password and specify the email address you will use to access your office the next time.
+
+### Editing Your Documents Online ###
+
+First, click the Documents link to open **the My Documents** folder.
+
+
+
+#### STEP 1. Select a Document to Edit ####
+
+To create a new document right there, click on the **Create** button in the upper left corner, and choose the file type from the drop-down list. To edit a file stored on your hard disk drive, upload it to **Documents** clicking the **Upload** button next to **Create** button.
+
+
+
+#### STEP 2. Share your Document ####
+
+Use the **Share** button to the right side if you are in the **My Documents** folder, or follow **File >> Document Info ... >> Change Access Rights** if you are inside your document.
+
+In the opened **Sharing Settings** window, click on the **People outside portal** link on the left, open the access to the document, and give full access to it by enabling the **Full Access** radio button.
+
+Finally, choose a way to share the link to your document, send it via email or one of the available social networks: Google+, Facebook, or Twitter.
+
+
+
+#### STEP 3. Start the Collaborative Editing ####
+
+To start co-editing the document, the invited person just needs to follow the provided link.
+
+The text passages edited by your co-editors will be automatically marked with dashed lines of different colors.
+
+
+
+As soon as one of your collaborators saves his/her changes, you will see a note appearing in the left upper corner of the top toolbar, indicating that there areupdates.
+
+
+
+To save your changes and get updates, click on the **Save** icon. All the updates will then be highlighted.
+
+
+
+#### STEP 4. Interact with your Co-editors ####
+
+To leave some comments, select a text passage with the mouse, right-click on it and, and choose the **Add comment** option from the context menu.
+
+
+
+To interact with co-editors in real time, use the integrated chat instead. All the users who currently edit the document will be listed on the **Chat** panel. To open it, click on the **Chat** icon at the left-side bar. To start a discussion, enter your message into an appropriate field on the **Chat** panel.
+
+
+
+### Useful Tips ###
+
+As final notes, here are some useful tips for you to take full advantage of ONLYOFFICE.
+
+#### Tip #1. Editing your Docs from Cloud Storage Services, Like ownCloud ####
+
+If you store your documents in other web resources like Box, Dropbox, Google Drive, OneDrive, SharePoint or ownCloud, you can easily synchronize them with the ONLYOFFICE.
+
+In the opened 'Documents' module, click one of the icons under the **Add the account** caption: Google, Box, DropBox, OneDrive, ownCloud or 'Add account', and enter the requested data.
+
+#### Tip #2. Editing Your Docs on iPad ####
+
+To add some changes to your document on the go, I use ONLYOFFICE Documents app for iPad. You can download and install it from [iTune][7], then you need to enter your ONLYOFFICE portal address, email and password to access your documents. The feature set is almost the same.
+
+To evaluate ONLYOFFICE Online Editors features, you can use the [cloud version][8] for personal use.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/edit-documents-collaboratively-linux.html
+
+作者:[Tatiana Kochedykova][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/tatiana
+[1]:http://www.onlyoffice.org/
+[2]:http://xmodulo.com/recommend/dockerbook
+[3]:http://xmodulo.com/manage-linux-containers-docker-ubuntu.html
+[4]:http://xmodulo.com/docker-containers-centos-fedora.html
+[5]:https://registry.hub.docker.com/u/onlyoffice/communityserver/
+[6]:http://onlyoffice.org/sources#document
+[7]:https://itunes.apple.com/us/app/onlyoffice-documents/id944896972
+[8]:https://personal.onlyoffice.com/
\ No newline at end of file
diff --git a/sources/tech/20150527 Howto Manage Host Using Docker Machine in a VirtualBox.md b/sources/tech/20150527 Howto Manage Host Using Docker Machine in a VirtualBox.md
new file mode 100644
index 0000000000..ea827ec74e
--- /dev/null
+++ b/sources/tech/20150527 Howto Manage Host Using Docker Machine in a VirtualBox.md
@@ -0,0 +1,113 @@
+Howto Manage Host Using Docker Machine in a VirtualBox
+================================================================================
+Hi all, today we'll learn how to create and manage a Docker host using Docker Machine in a VirtualBox. Docker Machine is an application that helps to create Docker hosts on our computer, on cloud providers and inside our own data center. It provides easy solution for creating servers, installing Docker on them and then configuring the Docker client according the users configuration and requirements. This API works for provisioning Docker on a local machine, on a virtual machine in the data center, or on a public cloud instance. Docker Machine is supported on Windows, OSX, and Linux and is available for installation as one standalone binary. It enables us to take full advantage of ecosystem partners providing Docker-ready infrastructure, while still accessing everything through the same interface. It makes people able to deploy the docker containers in the respective platform pretty fast and in pretty easy way with just a single command.
+
+Here are some easy and simple steps that helps us to deploy docker containers using Docker Machine.
+
+### 1. Installing Docker Machine ###
+
+Docker Machine supports awesome on every Linux Operating System. First of all, we'll need to download the latest version of Docker Machine from the [Github site][1] . Here, we'll use curl to download the latest version of Docker Machine ie 0.2.0 .
+
+**For 64 Bit Operating System**
+
+ # curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
+
+**For 32 Bit Operating System**
+
+ # curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
+
+After downloading the latest release of Docker Machine, we'll make the file named **docker-machine** under **/usr/local/bin/** executable using the command below.
+
+ # chmod +x /usr/local/bin/docker-machine
+
+After doing the above, we'll wanna ensure that we have successfully installed docker-machine. To check it, we can run the docker-machine -v which will give output of the version of docker-machine installed in our system.
+
+ # docker-machine -v
+
+
+
+To enable Docker commands on our machines, make sure to install the Docker client as well by running the command below.
+
+ # curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
+ # chmod +x /usr/local/bin/docker
+
+### 2. Creating VirualBox VM ###
+
+After we have successfully installed Docker Machine in our Linux running machine, we'll definitely wanna go for creating a Virtual Machine using VirtualBox. To get started, we need to run docker-machine create command followed by --driver flag with string as virtualbox as we are trying to deploy docker inside of Virtual Box running VM and the final argument is the name of the machine, here we have machine name as "linux". This command will download [boot2docker][2] iso which is a light-weighted linux distribution based on Tiny Core Linux with the Docker daemon installed and will create and start a VirtualBox VM with Docker running as mentioned above.
+
+To do so, we'll run the following command in a terminal or shell in our box.
+
+ # docker-machine create --driver virtualbox linux
+
+
+
+Now, to check whether we have successfully create a Virtualbox running Docker or not, we'll run the command **docker-machine** ls as shown below.
+
+ # docker-machine ls
+
+
+
+If the host is active, we can see * under the ACTIVE column in the output as shown above.
+
+### 3. Setting Environment Variables ###
+
+Now, we'll need to make docker talk with the machine. We can do that by running docker-machine env and then the machine name, here we have named **linux** as above.
+
+ # eval "$(docker-machine env linux)"
+ # docker ps
+
+This will set environment variables that the Docker client will read which specify the TLS settings. Note that we'll need to do this every time we reboot our machine or start a new tab. We can see what variables will be set by running the following command.
+
+ # docker-machine env linux
+
+ export DOCKER_TLS_VERIFY=1
+ export DOCKER_CERT_PATH=/Users//.docker/machine/machines/dev
+ export DOCKER_HOST=tcp://192.168.99.100:2376
+
+### 4. Running Docker Containers ###
+
+Finally, after configuring the environment variables and Virtual Machine, we are able to run docker containers in the host running inside the Virtual Machine. To give it a test, we'll run a busybox container out of it run running **docker run busybox** command with **echo hello world** so that we can get the output of the container.
+
+ # docker run busybox echo hello world
+
+
+
+### 5. Getting Docker Host's IP ###
+
+We can get the IP Address of the running Docker Host's using the **docker-machine ip** command. We can see any exposed ports that are available on the Docker host’s IP address.
+
+ # docker-machine ip
+
+
+
+### 6. Managing the Hosts ###
+
+Now we can manage as many local VMs running Docker as we desire by running docker-machine create command again and again as mentioned in above steps
+
+If you are finished working with the running docker, we can simply run **docker-machine stop** command to stop the whole hosts which are Active and if wanna start again, we can run **docker-machine start**.
+
+ # docker-machine stop
+ # docker-machine start
+
+You can also specify a host to stop or start using the host name as an argument.
+
+ $ docker-machine stop linux
+ $ docker-machine start linux
+
+### Conclusion ###
+
+Finally, we have successfully created and managed a Docker host inside a VirtualBox using Docker Machine. Really, Docker Machine enables people fast and easy to create, deploy and manage Docker hosts in different platforms as here we are running Docker hosts using Virtualbox platform. This virtualbox driver API works for provisioning Docker on a local machine, on a virtual machine in the data center. Docker Machine ships with drivers for provisioning Docker locally with Virtualbox as well as remotely on Digital Ocean instances whereas more drivers are in the work for AWS, Azure, VMware, and other infrastructure. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/host-virtualbox-docker-machine/
+
+作者:[Arun Pyasi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://github.com/docker/machine/releases
+[2]:https://github.com/boot2docker/boot2docker
\ No newline at end of file
diff --git a/sources/tech/20150528 11 pointless but awesome Linux terminal tricks.md b/sources/tech/20150528 11 pointless but awesome Linux terminal tricks.md
new file mode 100644
index 0000000000..74baa5fb5b
--- /dev/null
+++ b/sources/tech/20150528 11 pointless but awesome Linux terminal tricks.md
@@ -0,0 +1,108 @@
+Translating by goreliu ...
+
+11 pointless but awesome Linux terminal tricks
+================================================================================
+Here are some great Linux terminal tips and tricks, each one as pointless as it is awesome.
+
+
+
+### All work and no play... ###
+
+Linux is one of the most astoundingly functional and utilitarian Operating Systems around when it comes to working from the command line. Need to perform a particular task? Odds are there is an application or script you can use to get it done. Right from the terminal. But, as they say in the good book, "All work and no play make Jack really bored or something." So here is a collection of my favorite pointless, stupid, annoying or amusing things that you can do right in your Linux Terminal.
+
+
+
+### Give the terminal an attitude ###
+
+Step 1) Type "sudo visudo".
+
+Step 2) At the bottom of the "Defaults" (near the top of the file) add, on a new line, "Defaults insults".
+
+Step 3) Save the file.
+
+"What did I just do to my computer?" you may be asking yourself. Something wonderful. Now, whenever you issue a sudo command and misstype your password, your computer will call you names. My favorite: "Listen, burrito brains, I don't have time to listen to this trash."
+
+
+
+### apt-get moo ###
+
+That screenshot you see? That's what typing "apt-get moo" (on a Debian-based system) does. That's it. Don't go looking for this to do something fancy. It won't. That, I kid you not, is it. But it's one of the most commonly known little Easter eggs on Linux. So I include it here, right near the beginning, so I won't get 5,000 emails telling me I missed it in this list.
+
+
+
+### aptitude moo ###
+
+A bit more entertaining is aptitude's take on "moo." Type "aptitude moo" (on Ubuntu and the like) and you'll be corrected about thinking "moo" would do anything. But you know better. Try the same command again, this time with an optional "-v" attribute. Don't stop there. Add v's, one at a time, until aptitude gives you what you want.
+
+
+
+### Arch: Put Pac-Man in pacman ###
+
+This is one just for the Arch-lovers out there. The de facto package manager, pacman, is pretty fantastic already. Let's make it even better.
+
+Step 1) Open "/etc/pacman.conf".
+
+Step 2) In the "# Misc options", remove the "#" from in front of "Color".
+
+Step 3) Add "ILoveCandy".
+
+Now the progress for installing new packages, in pacman, will include a little tiny Pac-Man. Which should really just be the default anyway.
+
+
+
+### Cowsay! ###
+
+Making aptitude moo is neat, I guess, but you really can't use it for much. Enter "cowsay." It does what you think. You make a cow say things. Anything you like. And it's not even limited to cows. Calvin, Beavis, and the Ghostbusters logo are all available in full ASCII art glory – type "cowsay -l" for a full list of what's available in this, Linux's most powerful tool. Remember that, like most great terminal applications, you can pipe the output from other applications straight into cowsay (ala "fortune | cowsay").
+
+
+
+### Become an 3l33t h@x0r ###
+
+Typing "nmap" isn't something one typically needs to do on a day-to-day basis. But when one does need to "whip out the nmap," one wants to look as l33t as humanly possible. Add a "-oS" to any nmap command (such as "nmap -oS - google.com"). Bam. You're now in what is officially known as "[Script Kiddie Mode][1]." Angelina Jolie and Keanu Reeves would be proud.
+
+
+
+### Getting all Discordian ddate ###
+
+If you've ever been sitting around thinking, "Hey! I want today's date to be written in an essentially useless, but whimsical, way"…try typing "ddate". Results like "Today is Setting Orange, the 72nd day of Discord in the YOLD 3181," can really spice up your server logs.
+
+Note: Technically, this is a real thing called the [Discordian Calendar][2], used (in theory) by the followers of [Discordianism][3]. Which means I probably offended somebody. Or maybe not. I'm not really sure. Either way, ddate is a handy tool in any office.
+
+
+
+### I See Colors Everywhere! ###
+
+Tired of boring old text? Looking to spruce things up and show the world your true style? lolcat. Install it. Use it. Everywhere. It takes any text input and turns it into a rainbow of wonder and enchantment. Piping text into lolcat (ala "fortune | lolcat") is sure to liven up any party.
+
+
+
+### The Steam Locomotive ###
+
+Animated ASCII art steam locomotive in your terminal. You want this. You need this. Install and run "sl". Use "sl -l" for a tiny version. Or, if you want to really spend some time on this, "sl-h". This is the full train, including passenger cars.
+
+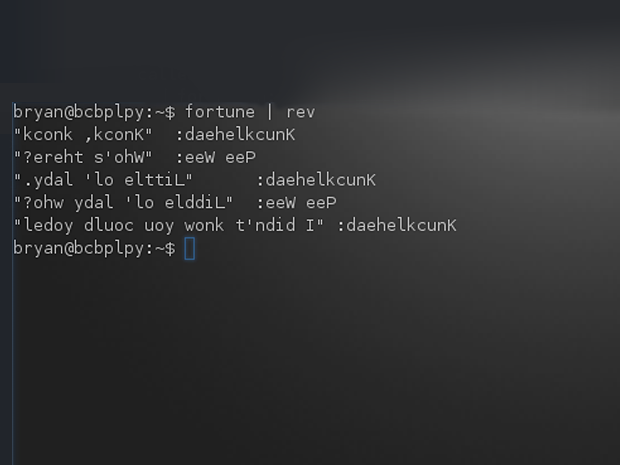
+
+### Reverse any text ###
+
+Pipe the output of any text into "rev" and it will reverse the text. "fortune | rev" gives you a fortune. In reverse. Which is, as odd as it may seem, not a misfortune.
+
+
+
+### The Matrix is still cool, right? ###
+
+Want your terminal to do that scrolling text, l33t, Matrix-y thing? "cmatrix" is your friend. You can even have it output different colors, which is snazzy. Learn how by typing "man cmatrix". Or, better yet, "man cmatrix | lolcat". Which, really, is the most pointless (but wonderful) thing you can do in the Linux Terminal. So that's where I leave you.
+
+--------------------------------------------------------------------------------
+
+via: http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html
+
+作者:[Bryan Lunduke][a]
+译者:[goreliu](https://github.com/goreliu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.networkworld.com/author/Bryan-Lunduke/
+[1]:http://nmap.org/book/output-formats-script-kiddie.html
+[2]:http://en.wikipedia.org/wiki/Discordian_calendar
+[3]:http://en.wikipedia.org/wiki/Discordianism
\ No newline at end of file
diff --git a/sources/tech/20150604 Nishita Agarwal Shares Her Interview Experience on Linux 'iptables' Firewall.md b/sources/tech/20150604 Nishita Agarwal Shares Her Interview Experience on Linux 'iptables' Firewall.md
new file mode 100644
index 0000000000..2ba7334580
--- /dev/null
+++ b/sources/tech/20150604 Nishita Agarwal Shares Her Interview Experience on Linux 'iptables' Firewall.md
@@ -0,0 +1,207 @@
+Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
+================================================================================
+Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
+
+
+
+All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
+
+> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
+
+Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
+
+### 1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used? ###
+
+> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
+>
+> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
+
+### 2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line? ###
+
+> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
+
+### 3. What are the basic differences between between iptables and firewalld? ###
+
+> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
+
+### 4. Would you replace iptables with firewalld on all your servers, if given a chance? ###
+
+> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
+
+### 5. You seems confident with iptables and the plus point is even we are using iptables on our server. ###
+
+What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
+
+> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
+>
+> Nat Table
+> Mangle Table
+> Filter Table
+> Raw Table
+>
+> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
+>
+> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
+>
+> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
+>
+> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
+
+### 6. What are the target values (that can be specified in target) in iptables and what they do, be brief! ###
+
+> **Answer** : Following are the target values that we can specify in target in iptables:
+>
+> ACCEPT : Accept Packets
+> QUEUE : Paas Package to user space (place where application and drivers reside)
+> DROP : Drop Packets
+> RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
+
+
+### 7. Lets move to the technical aspects of iptables, by technical I means practical. ###
+
+How will you Check iptables rpm that is required to install iptables in CentOS?.
+
+> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
+>
+> # rpm -qa iptables
+>
+> iptables-1.4.21-13.el7.x86_64
+>
+> If you need to install it, you may do yum to get it.
+>
+> # yum install iptables-services
+
+### 8. How to Check and ensure if iptables service is running? ###
+
+> **Answer** : To check the status of iptables, you may run the following command on the terminal.
+>
+> # service status iptables [On CentOS 6/5]
+> # systemctl status iptables [On CentOS 7]
+>
+> If it is not running, the below command may be executed.
+>
+> ---------------- On CentOS 6/5 ----------------
+> # chkconfig --level 35 iptables on
+> # service iptables start
+>
+> ---------------- On CentOS 7 ----------------
+> # systemctl enable iptables
+> # systemctl start iptables
+>
+> We may also check if the iptables module is loaded or not, as:
+>
+> # lsmod | grep ip_tables
+
+### 9. How will you review the current Rules defined in iptables? ###
+
+> **Answer** : The current rules in iptables can be review as simple as:
+>
+> # iptables -L
+>
+> Sample Output
+>
+> Chain INPUT (policy ACCEPT)
+> target prot opt source destination
+> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
+> ACCEPT icmp -- anywhere anywhere
+> ACCEPT all -- anywhere anywhere
+> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
+> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+>
+> Chain FORWARD (policy ACCEPT)
+> target prot opt source destination
+> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+>
+> Chain OUTPUT (policy ACCEPT)
+> target prot opt source destination
+
+### 10. How will you flush all iptables rules or a particular chain? ###
+
+> **Answer** : To flush a particular iptables chain, you may use following commands.
+>
+>
+> # iptables --flush OUTPUT
+>
+> To Flush all the iptables rules.
+>
+> # iptables --flush
+
+### 11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7) ###
+
+> **Answer** : The above scenario can be achieved simply by running the below command.
+>
+> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
+>
+> We may include standard slash or subnet mask in the source as:
+>
+> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
+> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
+
+### 12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables. ###
+
+> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:To ACCEPT tcp packets for ssh service (port 22).
+>
+> # iptables -A INPUT -s -p tcp - -dport -j ACCEPT
+>
+> To REJECT tcp packets for ssh service (port 22).
+>
+> # iptables -A INPUT -s -p tcp - -dport -j REJECT
+>
+> To DENY tcp packets for ssh service (port 22).
+>
+>
+> # iptables -A INPUT -s -p tcp - -dport -j DENY
+>
+> To DROP tcp packets for ssh service (port 22).
+>
+>
+> # iptables -A INPUT -s -p tcp - -dport -j DROP
+
+### 13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do? ###
+
+> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
+>
+> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
+>
+> The written rules can be checked using the below command.
+>
+> # iptables -L
+>
+> Chain INPUT (policy ACCEPT)
+> target prot opt source destination
+> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
+> ACCEPT icmp -- anywhere anywhere
+> ACCEPT all -- anywhere anywhere
+> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
+> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
+>
+> Chain FORWARD (policy ACCEPT)
+> target prot opt source destination
+> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
+>
+> Chain OUTPUT (policy ACCEPT)
+> target prot opt source destination
+
+**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
+
+As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
+
+Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
+
+Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com.
+
+Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
+
+作者:[Avishek Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 01--Reviewing Essential Commands and System Documentation.md b/sources/tech/RHCSA Series/RHCSA Series--Part 01--Reviewing Essential Commands and System Documentation.md
new file mode 100644
index 0000000000..9b32c93453
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 01--Reviewing Essential Commands and System Documentation.md
@@ -0,0 +1,313 @@
+RHCSA Series: Reviewing Essential Commands & System Documentation – Part 1
+================================================================================
+RHCSA (Red Hat Certified System Administrator) is a certification exam from Red Hat company, which provides an open source operating system and software to the enterprise community, It also provides support, training and consulting services for the organizations.
+
+
+
+RHCSA Exam Preparation Guide
+
+RHCSA exam is the certification obtained from Red Hat Inc, after passing the exam (codename EX200). RHCSA exam is an upgrade to the RHCT (Red Hat Certified Technician) exam, and this upgrade is compulsory as the Red Hat Enterprise Linux was upgraded. The main variation between RHCT and RHCSA is that RHCT exam based on RHEL 5, whereas RHCSA certification is based on RHEL 6 and 7, the courseware of these two certifications are also vary to a certain level.
+
+This Red Hat Certified System Administrator (RHCSA) is essential to perform the following core system administration tasks needed in Red Hat Enterprise Linux environments:
+
+- Understand and use necessary tools for handling files, directories, command-environments line, and system-wide / packages documentation.
+- Operate running systems, even in different run levels, identify and control processes, start and stop virtual machines.
+- Set up local storage using partitions and logical volumes.
+- Create and configure local and network file systems and its attributes (permissions, encryption, and ACLs).
+- Setup, configure, and control systems, including installing, updating and removing software.
+- Manage system users and groups, along with use of a centralized LDAP directory for authentication.
+- Ensure system security, including basic firewall and SELinux configuration.
+
+To view fees and register for an exam in your country, check the [RHCSA Certification page][1].
+
+To view fees and register for an exam in your country, check the RHCSA Certification page.
+
+In this 15-article RHCSA series, titled Preparation for the RHCSA (Red Hat Certified System Administrator) exam, we will going to cover the following topics on the latest releases of Red Hat Enterprise Linux 7.
+
+- Part 1: Reviewing Essential Commands & System Documentation
+- Part 2: How to Perform File and Directory Management in RHEL 7
+- Part 3: How to Manage Users and Groups in RHEL 7
+- Part 4: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps
+- Part 5: Process Management in RHEL 7: boot, shutdown, and everything in between
+- Part 6: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage
+- Part 7: Using ACLs (Access Control Lists) and Mounting Samba / NFS Shares
+- Part 8: Securing SSH, Setting Hostname and Enabling Network Services
+- Part 9: Installing, Configuring and Securing a Web and FTP Server
+- Part 10: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs
+- Part 11: Firewall Essentials and Control Network Traffic Using FirewallD and Iptables
+- Part 12: Automate RHEL 7 Installations Using ‘Kickstart’
+- Part 13: RHEL 7: What is SELinux and how it works?
+- Part 14: Use LDAP-based authentication in RHEL 7
+- Part 15: Virtualization in RHEL 7: KVM and Virtual machine management
+
+In this Part 1 of the RHCSA series, we will explain how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation.
+
+
+
+RHCSA: Reviewing Essential Linux Commands – Part 1
+
+#### Prerequisites: ####
+
+At least a slight degree of familiarity with basic Linux commands such as:
+
+- [cd command][2] (change directory)
+- [ls command][3] (list directory)
+- [cp command][4] (copy files)
+- [mv command][5] (move or rename files)
+- [touch command][6] (create empty files or update the timestamp of existing ones)
+- rm command (delete files)
+- mkdir command (make directory)
+
+The correct usage of some of them are anyway exemplified in this article, and you can find further information about each of them using the suggested methods in this article.
+
+Though not strictly required to start, as we will be discussing general commands and methods for information search in a Linux system, you should try to install RHEL 7 as explained in the following article. It will make things easier down the road.
+
+- [Red Hat Enterprise Linux (RHEL) 7 Installation Guide][7]
+
+### Interacting with the Linux Shell ###
+
+If we log into a Linux box using a text-mode login screen, chances are we will be dropped directly into our default shell. On the other hand, if we login using a graphical user interface (GUI), we will have to open a shell manually by starting a terminal. Either way, we will be presented with the user prompt and we can start typing and executing commands (a command is executed by pressing the Enter key after we have typed it).
+
+Commands are composed of two parts:
+
+- the name of the command itself, and
+- arguments
+
+Certain arguments, called options (usually preceded by a hyphen), alter the behavior of the command in a particular way while other arguments specify the objects upon which the command operates.
+
+The type command can help us identify whether another certain command is built into the shell or if it is provided by a separate package. The need to make this distinction lies in the place where we will find more information about the command. For shell built-ins we need to look in the shell’s man page, whereas for other binaries we can refer to its own man page.
+
+
+
+Check Shell built in Commands
+
+In the examples above, cd and type are shell built-ins, while top and less are binaries external to the shell itself (in this case, the location of the command executable is returned by type).
+
+Other well-known shell built-ins include:
+
+- [echo command][8]: Displays strings of text.
+- [pwd command][9]: Prints the current working directory.
+
+
+
+More Built in Shell Commands
+
+**exec command**
+
+Runs an external program that we specify. Note that in most cases, this is better accomplished by just typing the name of the program we want to run, but the exec command has one special feature: rather than create a new process that runs alongside the shell, the new process replaces the shell, as can verified by subsequent.
+
+ # ps -ef | grep [original PID of the shell process]
+
+When the new process terminates, the shell terminates with it. Run exec top and then hit the q key to quit top. You will notice that the shell session ends when you do, as shown in the following screencast:
+
+注:youtube视频
+
+
+**export command**
+
+Exports variables to the environment of subsequently executed commands.
+
+**history Command**
+
+Displays the command history list with line numbers. A command in the history list can be repeated by typing the command number preceded by an exclamation sign. If we need to edit a command in history list before executing it, we can press Ctrl + r and start typing the first letters associated with the command. When we see the command completed automatically, we can edit it as per our current need:
+
+注:youtube视频
+
+
+This list of commands is kept in our home directory in a file called .bash_history. The history facility is a useful resource for reducing the amount of typing, especially when combined with command line editing. By default, bash stores the last 500 commands you have entered, but this limit can be extended by using the HISTSIZE environment variable:
+
+
+
+Linux history Command
+
+But this change as performed above, will not be persistent on our next boot. In order to preserve the change in the HISTSIZE variable, we need to edit the .bashrc file by hand:
+
+ # for setting history length see HISTSIZE and HISTFILESIZE in bash(1)
+ HISTSIZE=1000
+
+**Important**: Keep in mind that these changes will not take effect until we restart our shell session.
+
+**alias command**
+
+With no arguments or with the -p option prints the list of aliases in the form alias name=value on standard output. When arguments are provided, an alias is defined for each name whose value is given.
+
+With alias, we can make up our own commands or modify existing ones by including desired options. For example, suppose we want to alias ls to ls –color=auto so that the output will display regular files, directories, symlinks, and so on, in different colors:
+
+ # alias ls='ls --color=auto'
+
+
+
+Linux alias Command
+
+**Note**: That you can assign any name to your “new command” and enclose as many commands as desired between single quotes, but in that case you need to separate them by semicolons, as follows:
+
+ # alias myNewCommand='cd /usr/bin; ls; cd; clear'
+
+**exit command**
+
+The exit and logout commands both terminate the shell. The exit command terminates any shell, but the logout command terminates only login shells—that is, those that are launched automatically when you initiate a text-mode login.
+
+If we are ever in doubt as to what a program does, we can refer to its man page, which can be invoked using the man command. In addition, there are also man pages for important files (inittab, fstab, hosts, to name a few), library functions, shells, devices, and other features.
+
+#### Examples: ####
+
+- man uname (print system information, such as kernel name, processor, operating system type, architecture, and so on).
+- man inittab (init daemon configuration).
+
+Another important source of information is provided by the info command, which is used to read info documents. These documents often provide more information than the man page. It is invoked by using the info keyword followed by a command name, such as:
+
+ # info ls
+ # info cut
+
+In addition, the /usr/share/doc directory contains several subdirectories where further documentation can be found. They either contain plain-text files or other friendly formats.
+
+Make sure you make it a habit to use these three methods to look up information for commands. Pay special and careful attention to the syntax of each of them, which is explained in detail in the documentation.
+
+**Converting Tabs into Spaces with expand Command**
+
+Sometimes text files contain tabs but programs that need to process the files don’t cope well with tabs. Or maybe we just want to convert tabs into spaces. That’s where the expand tool (provided by the GNU coreutils package) comes in handy.
+
+For example, given the file NumbersList.txt, let’s run expand against it, changing tabs to one space, and display on standard output.
+
+ # expand --tabs=1 NumbersList.txt
+
+
+
+Linux expand Command
+
+The unexpand command performs the reverse operation (converts spaces into tabs).
+
+**Display the first lines of a file with head and the last lines with tail**
+
+By default, the head command followed by a filename, will display the first 10 lines of the said file. This behavior can be changed using the -n option and specifying a certain number of lines.
+
+ # head -n3 /etc/passwd
+ # tail -n3 /etc/passwd
+
+
+
+Linux head and tail Command
+
+One of the most interesting features of tail is the possibility of displaying data (last lines) as the input file grows (tail -f my.log, where my.log is the file under observation). This is particularly useful when monitoring a log to which data is being continually added.
+
+Read More: [Manage Files Effectively using head and tail Commands][10]
+
+**Merging Lines with paste**
+
+The paste command merges files line by line, separating the lines from each file with tabs (by default), or another delimiter that can be specified (in the following example the fields in the output are separated by an equal sign).
+
+ # paste -d= file1 file2
+
+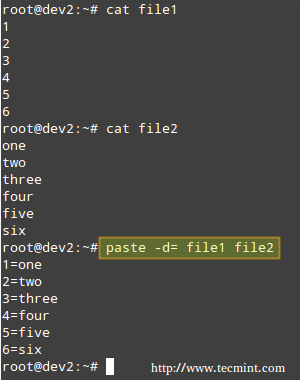
+
+Merge Files in Linux
+
+**Breaking a file into pieces using split command**
+
+The split command is used split a file into two (or more) separate files, which are named according to a prefix of our choosing. The splitting can be defined by size, chunks, or number of lines, and the resulting files can have a numeric or alphabetic suffixes. In the following example, we will split bash.pdf into files of size 50 KB (-b 50KB), using numeric suffixes (-d):
+
+ # split -b 50KB -d bash.pdf bash_
+
+
+
+Split Files in Linux
+
+You can merge the files to recreate the original file with the following command:
+
+ # cat bash_00 bash_01 bash_02 bash_03 bash_04 bash_05 > bash.pdf
+
+**Translating characters with tr command**
+
+The tr command can be used to translate (change) characters on a one-by-one basis or using character ranges. In the following example we will use the same file2 as previously, and we will change:
+
+- lowercase o’s to uppercase,
+- and all lowercase to uppercase
+
+ # cat file2 | tr o O
+ # cat file2 | tr [a-z] [A-Z]
+
+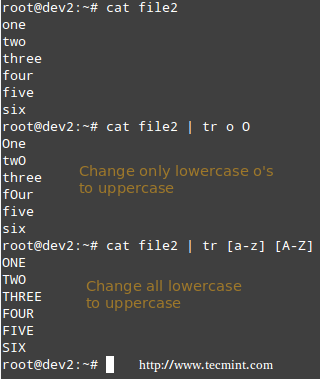
+
+Translate Characters in Linux
+
+**Reporting or deleting duplicate lines with uniq and sort command**
+
+The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files).
+
+By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option. Please note how the output returned by sort and uniq change as we change the key field in the following example:
+
+ # cat file3
+ # sort file3 | uniq
+ # sort -k2 file3 | uniq
+ # sort -k3 file3 | uniq
+
+
+
+Remove Duplicate Lines in Linux
+
+**Extracting text with cut command**
+
+The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b), characters (-c), or fields (-f).
+
+When using cut based on fields, the default field separator is a tab, but a different separator can be specified by using the -d option.
+
+ # cut -d: -f1,3 /etc/passwd # Extract specific fields: 1 and 3 in this case
+ # cut -d: -f2-4 /etc/passwd # Extract range of fields: 2 through 4 in this example
+
+
+
+Extract Text From a File in Linux
+
+Note that the output of the two examples above was truncated for brevity.
+
+**Reformatting files with fmt command**
+
+fmt is used to “clean up” files with a great amount of content or lines, or with varying degrees of indentation. The new paragraph formatting defaults to no more than 75 characters wide. You can change this with the -w (width) option, which set the line length to the specified number of characters.
+
+For example, let’s see what happens when we use fmt to display the /etc/passwd file setting the width of each line to 100 characters. Once again, output has been truncated for brevity.
+
+ # fmt -w100 /etc/passwd
+
+
+
+File Reformatting in Linux
+
+**Formatting content for printing with pr command**
+
+pr paginates and displays in columns one or more files for printing. In other words, pr formats a file to make it look better when printed. For example, the following command:
+
+ # ls -a /etc | pr -n --columns=3 -h "Files in /etc"
+
+Shows a listing of all the files found in /etc in a printer-friendly format (3 columns) with a custom header (indicated by the -h option), and numbered lines (-n).
+
+
+
+File Formatting in Linux
+
+### Summary ###
+
+In this article we have discussed how to enter and execute commands with the correct syntax in a shell prompt or terminal, and explained how to find, inspect, and use system documentation. As simple as it seems, it’s a large first step in your way to becoming a RHCSA.
+
+If you would like to add other commands that you use on a periodic basis and that have proven useful to fulfill your daily responsibilities, feel free to share them with the world by using the comment form below. Questions are also welcome. We look forward to hearing from you!
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:https://www.redhat.com/en/services/certification/rhcsa
+[2]:http://www.tecmint.com/cd-command-in-linux/
+[3]:http://www.tecmint.com/ls-command-interview-questions/
+[4]:http://www.tecmint.com/advanced-copy-command-shows-progress-bar-while-copying-files/
+[5]:http://www.tecmint.com/rename-multiple-files-in-linux/
+[6]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
+[7]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
+[8]:http://www.tecmint.com/echo-command-in-linux/
+[9]:http://www.tecmint.com/pwd-command-examples/
+[10]:http://www.tecmint.com/view-contents-of-file-in-linux/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 02--How to Perform File and Directory Management.md b/sources/tech/RHCSA Series/RHCSA Series--Part 02--How to Perform File and Directory Management.md
new file mode 100644
index 0000000000..7566862597
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 02--How to Perform File and Directory Management.md
@@ -0,0 +1,322 @@
+RHCSA Series: How to Perform File and Directory Management – Part 2
+================================================================================
+In this article, RHCSA Part 2: File and directory management, we will review some essential skills that are required in the day-to-day tasks of a system administrator.
+
+
+
+RHCSA: Perform File and Directory Management – Part 2
+
+### Create, Delete, Copy, and Move Files and Directories ###
+
+File and directory management is a critical competence that every system administrator should possess. This includes the ability to create / delete text files from scratch (the core of each program’s configuration) and directories (where you will organize files and other directories), and to find out the type of existing files.
+
+The [touch command][1] can be used not only to create empty files, but also to update the access and modification times of existing files.
+
+
+
+touch command example
+
+You can use `file [filename]` to determine a file’s type (this will come in handy before launching your preferred text editor to edit it).
+
+
+
+file command example
+
+and `rm [filename]` to delete it.
+
+
+
+rm command example
+
+As for directories, you can create directories inside existing paths with `mkdir [directory]` or create a full path with `mkdir -p [/full/path/to/directory].`
+
+
+
+mkdir command example
+
+When it comes to removing directories, you need to make sure that they’re empty before issuing the `rmdir [directory]` command, or use the more powerful (handle with care!) `rm -rf [directory]`. This last option will force remove recursively the `[directory]` and all its contents – so use it at your own risk.
+
+### Input and Output Redirection and Pipelining ###
+
+The command line environment provides two very useful features that allows to redirect the input and output of commands from and to files, and to send the output of a command to another, called redirection and pipelining, respectively.
+
+To understand those two important concepts, we must first understand the three most important types of I/O (Input and Output) streams (or sequences) of characters, which are in fact special files, in the *nix sense of the word.
+
+- Standard input (aka stdin) is by default attached to the keyboard. In other words, the keyboard is the standard input device to enter commands to the command line.
+- Standard output (aka stdout) is by default attached to the screen, the device that “receives” the output of commands and display them on the screen.
+- Standard error (aka stderr), is where the status messages of a command is sent to by default, which is also the screen.
+
+In the following example, the output of `ls /var` is sent to stdout (the screen), as well as the result of ls /tecmint. But in the latter case, it is stderr that is shown.
+
+
+
+Input and Output Example
+
+To more easily identify these special files, they are each assigned a file descriptor, an abstract representation that is used to access them. The essential thing to understand is that these files, just like others, can be redirected. What this means is that you can capture the output from a file or script and send it as input to another file, command, or script. This will allow you to store on disk, for example, the output of commands for later processing or analysis.
+
+To redirect stdin (fd 0), stdout (fd 1), or stderr (fd 2), the following operators are available.
+
+注:表格
+
+
+
+
+
+
Redirection Operator
+
Effect
+
+
+
>
+
Redirects standard output to a file containing standard output. If the destination file exists, it will be overwritten.
+
+
+
>>
+
Appends standard output to a file.
+
+
+
2>
+
Redirects standard error to a file containing standard output. If the destination file exists, it will be overwritten.
+
+
+
2>>
+
Appends standard error to the existing file.
+
+
+
&>
+
Redirects both standard output and standard error to a file; if the specified file exists, it will be overwritten.
+
+
+
<
+
Uses the specified file as standard input.
+
+
+
<>
+
The specified file is used for both standard input and standard output.
+
+
+
+
+As opposed to redirection, pipelining is performed by adding a vertical bar `(|)` after a command and before another one.
+
+Remember:
+
+- Redirection is used to send the output of a command to a file, or to send a file as input to a command.
+- Pipelining is used to send the output of a command to another command as input.
+
+#### Examples Of Redirection and Pipelining ####
+
+**Example 1: Redirecting the output of a command to a file**
+
+There will be times when you will need to iterate over a list of files. To do that, you can first save that list to a file and then read that file line by line. While it is true that you can iterate over the output of ls directly, this example serves to illustrate redirection.
+
+ # ls -1 /var/mail > mail.txt
+
+
+
+Redirect output of command tot a file
+
+**Example 2: Redirecting both stdout and stderr to /dev/null**
+
+In case we want to prevent both stdout and stderr to be displayed on the screen, we can redirect both file descriptors to `/dev/null`. Note how the output changes when the redirection is implemented for the same command.
+
+ # ls /var /tecmint
+ # ls /var/ /tecmint &> /dev/null
+
+
+
+Redirecting stdout and stderr ouput to /dev/null
+
+#### Example 3: Using a file as input to a command ####
+
+While the classic syntax of the [cat command][2] is as follows.
+
+ # cat [file(s)]
+
+You can also send a file as input, using the correct redirection operator.
+
+ # cat < mail.txt
+
+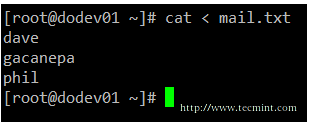
+
+cat command example
+
+#### Example 4: Sending the output of a command as input to another ####
+
+If you have a large directory or process listing and want to be able to locate a certain file or process at a glance, you will want to pipeline the listing to grep.
+
+Note that we use to pipelines in the following example. The first one looks for the required keyword, while the second one will eliminate the actual `grep command` from the results. This example lists all the processes associated with the apache user.
+
+ # ps -ef | grep apache | grep -v grep
+
+
+
+Send output of command as input to another
+
+### Archiving, Compressing, Unpacking, and Uncompressing Files ###
+
+If you need to transport, backup, or send via email a group of files, you will use an archiving (or grouping) tool such as [tar][3], typically used with a compression utility like gzip, bzip2, or xz.
+
+Your choice of a compression tool will be likely defined by the compression speed and rate of each one. Of these three compression tools, gzip is the oldest and provides the least compression, bzip2 provides improved compression, and xz is the newest and provides the best compression. Typically, files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively.
+
+注:表格
+
+
+
+
+
+
+
Command
+
Abbreviation
+
Description
+
+
+
–create
+
c
+
Creates a tar archive
+
+
+
–concatenate
+
A
+
Appends tar files to an archive
+
+
+
–append
+
r
+
Appends non-tar files to an archive
+
+
+
–update
+
u
+
Appends files that are newer than those in an archive
+
+
+
–diff or –compare
+
d
+
Compares an archive to files on disk
+
+
+
–list
+
t
+
Lists the contents of a tarball
+
+
+
–extract or –get
+
x
+
Extracts files from an archive
+
+
+
+
+注:表格
+
+
+
+
+
+
+
Operation modifier
+
Abbreviation
+
Description
+
+
+
—directory dir
+
C
+
Changes to directory dir before performing operations
+
+
+
—same-permissions and —same-owner
+
p
+
Preserves permissions and ownership information, respectively.
+
+
+
–verbose
+
v
+
Lists all files as they are read or extracted; if combined with –list, it also displays file sizes, ownership, and timestamps
+
+
+
—exclude file
+
—
+
Excludes file from the archive. In this case, file can be an actual file or a pattern.
+
+
+
—gzip or —gunzip
+
z
+
Compresses an archive through gzip
+
+
+
–bzip2
+
j
+
Compresses an archive through bzip2
+
+
+
–xz
+
J
+
Compresses an archive through xz
+
+
+
+
+#### Example 5: Creating a tarball and then compressing it using the three compression utilities ####
+
+You may want to compare the effectiveness of each tool before deciding to use one or another. Note that while compressing small files, or a few files, the results may not show much differences, but may give you a glimpse of what they have to offer.
+
+ # tar cf ApacheLogs-$(date +%Y%m%d).tar /var/log/httpd/* # Create an ordinary tarball
+ # tar czf ApacheLogs-$(date +%Y%m%d).tar.gz /var/log/httpd/* # Create a tarball and compress with gzip
+ # tar cjf ApacheLogs-$(date +%Y%m%d).tar.bz2 /var/log/httpd/* # Create a tarball and compress with bzip2
+ # tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* # Create a tarball and compress with xz
+
+
+
+tar command examples
+
+#### Example 6: Preserving original permissions and ownership while archiving and when ####
+
+If you are creating backups from users’ home directories, you will want to store the individual files with the original permissions and ownership instead of changing them to that of the user account or daemon performing the backup. The following example preserves these attributes while taking the backup of the contents in the `/var/log/httpd` directory:
+
+ # tar cJf ApacheLogs-$(date +%Y%m%d).tar.xz /var/log/httpd/* --same-permissions --same-owner
+
+### Create Hard and Soft Links ###
+
+In Linux, there are two types of links to files: hard links and soft (aka symbolic) links. Since a hard link represents another name for an existing file and is identified by the same inode, it then points to the actual data, as opposed to symbolic links, which point to filenames instead.
+
+In addition, hard links do not occupy space on disk, while symbolic links do take a small amount of space to store the text of the link itself. The downside of hard links is that they can only be used to reference files within the filesystem where they are located because inodes are unique inside a filesystem. Symbolic links save the day, in that they point to another file or directory by name rather than by inode, and therefore can cross filesystem boundaries.
+
+The basic syntax to create links is similar in both cases:
+
+ # ln TARGET LINK_NAME # Hard link named LINK_NAME to file named TARGET
+ # ln -s TARGET LINK_NAME # Soft link named LINK_NAME to file named TARGET
+
+#### Example 7: Creating hard and soft links ####
+
+There is no better way to visualize the relation between a file and a hard or symbolic link that point to it, than to create those links. In the following screenshot you will see that the file and the hard link that points to it share the same inode and both are identified by the same disk usage of 466 bytes.
+
+On the other hand, creating a hard link results in an extra disk usage of 5 bytes. Not that you’re going to run out of storage capacity, but this example is enough to illustrate the difference between a hard link and a soft link.
+
+
+
+Difference between a hard link and a soft link
+
+A typical usage of symbolic links is to reference a versioned file in a Linux system. Suppose there are several programs that need access to file fooX.Y, which is subject to frequent version updates (think of a library, for example). Instead of updating every single reference to fooX.Y every time there’s a version update, it is wiser, safer, and faster, to have programs look to a symbolic link named just foo, which in turn points to the actual fooX.Y.
+
+Thus, when X and Y change, you only need to edit the symbolic link foo with a new destination name instead of tracking every usage of the destination file and updating it.
+
+### Summary ###
+
+In this article we have reviewed some essential file and directory management skills that must be a part of every system administrator’s tool-set. Make sure to review other parts of this series as well in order to integrate these topics with the content covered in this tutorial.
+
+Feel free to let us know if you have any questions or comments. We are always more than glad to hear from our readers.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/file-and-directory-management-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
+[2]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
+[3]:http://www.tecmint.com/18-tar-command-examples-in-linux/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 03--How to Manage Users and Groups in RHEL 7.md b/sources/tech/RHCSA Series/RHCSA Series--Part 03--How to Manage Users and Groups in RHEL 7.md
new file mode 100644
index 0000000000..be78c87e3a
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 03--How to Manage Users and Groups in RHEL 7.md
@@ -0,0 +1,248 @@
+RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
+================================================================================
+Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.
+
+
+
+RHCSA: User and Group Management – Part 3
+
+### Managing User Accounts ###
+
+To add a new user account to a RHEL 7 server, you can run either of the following two commands as root:
+
+ # adduser [new_account]
+ # useradd [new_account]
+
+When a new user account is added, by default the following operations are performed.
+
+- His/her home directory is created (`/home/username` unless specified otherwise).
+- These `.bash_logout`, `.bash_profile` and `.bashrc` hidden files are copied inside the user’s home directory, and will be used to provide environment variables for his/her user session. You can explore each of them for further details.
+- A mail spool directory is created for the added user account.
+- A group is created with the same name as the new user account.
+
+The full account summary is stored in the `/etc/passwd `file. This file holds a record per system user account and has the following format (fields are separated by a colon):
+
+ [username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
+
+- These two fields `[username]` and `[Comment]` are self explanatory.
+- The second filed ‘x’ indicates that the account is secured by a shadowed password (in `/etc/shadow`), which is used to logon as `[username]`.
+- The fields `[UID]` and `[GID]` are integers that shows the User IDentification and the primary Group IDentification to which `[username]` belongs, equally.
+
+Finally,
+
+- The `[Home directory]` shows the absolute location of `[username]’s` home directory, and
+- `[Default shell]` is the shell that is commit to this user when he/she logins into the system.
+
+Another important file that you must become familiar with is `/etc/group`, where group information is stored. As it is the case with `/etc/passwd`, there is one record per line and its fields are also delimited by a colon:
+
+ [Group name]:[Group password]:[GID]:[Group members]
+
+where,
+
+- `[Group name]` is the name of group.
+- Does this group use a group password? (An “x” means no).
+- `[GID]`: same as in `/etc/passwd`.
+- `[Group members]`: a list of users, separated by commas, that are members of each group.
+
+After adding an account, at anytime, you can edit the user’s account information using usermod, whose basic syntax is:
+
+ # usermod [options] [username]
+
+Read Also:
+
+- [15 ‘useradd’ Command Examples][1]
+- [15 ‘usermod’ Command Examples][2]
+
+#### EXAMPLE 1: Setting the expiry date for an account ####
+
+If you work for a company that has some kind of policy to enable account for a certain interval of time, or if you want to grant access to a limited period of time, you can use the `--expiredate` flag followed by a date in YYYY-MM-DD format. To verify that the change has been applied, you can compare the output of
+
+ # chage -l [username]
+
+before and after updating the account expiry date, as shown in the following image.
+
+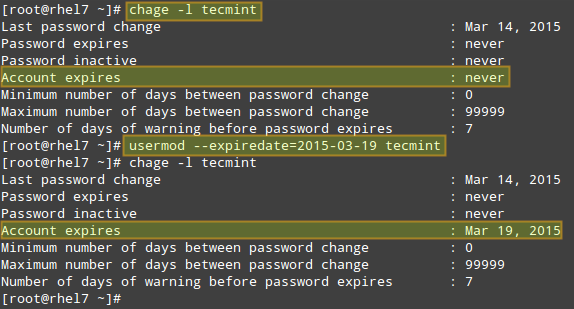
+
+Change User Account Information
+
+#### EXAMPLE 2: Adding the user to supplementary groups ####
+
+Besides the primary group that is created when a new user account is added to the system, a user can be added to supplementary groups using the combined -aG, or –append –groups options, followed by a comma separated list of groups.
+
+#### EXAMPLE 3: Changing the default location of the user’s home directory and / or changing its shell ####
+
+If for some reason you need to change the default location of the user’s home directory (other than /home/username), you will need to use the -d, or –home options, followed by the absolute path to the new home directory.
+
+If a user wants to use another shell other than bash (for example, sh), which gets assigned by default, use usermod with the –shell flag, followed by the path to the new shell.
+
+#### EXAMPLE 4: Displaying the groups an user is a member of ####
+
+After adding the user to a supplementary group, you can verify that it now actually belongs to such group(s):
+
+ # groups [username]
+ # id [username]
+
+The following image depicts Examples 2 through 4:
+
+
+
+Adding User to Supplementary Group
+
+In the example above:
+
+ # usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
+
+To remove a user from a group, omit the `--append` switch in the command above and list the groups you want the user to belong to following the `--groups` flag.
+
+#### EXAMPLE 5: Disabling account by locking password ####
+
+To disable an account, you will need to use either the -l (lowercase L) or the –lock option to lock a user’s password. This will prevent the user from being able to log on.
+
+#### EXAMPLE 6: Unlocking password ####
+
+When you need to re-enable the user so that he can log on to the server again, use the -u or the –unlock option to unlock a user’s password that was previously blocked, as explained in Example 5 above.
+
+ # usermod --unlock tecmint
+
+The following image illustrates Examples 5 and 6:
+
+
+
+Lock Unlock User Account
+
+#### EXAMPLE 7: Deleting a group or an user account ####
+
+To delete a group, you’ll want to use groupdel, whereas to delete a user account you will use userdel (add the –r switch if you also want to delete the contents of its home directory and mail spool):
+
+ # groupdel [group_name] # Delete a group
+ # userdel -r [user_name] # Remove user_name from the system, along with his/her home directory and mail spool
+
+If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
+
+### Listing, Setting and Changing Standard ugo/rwx Permissions ###
+
+The well-known [ls command][3] is one of the best friends of any system administrator. When used with the -l flag, this tool allows you to view a list a directory’s contents in long (or detailed) format.
+
+However, this command can also be applied to a single file. Either way, the first 10 characters in the output of `ls -l` represent each file’s attributes.
+
+The first char of this 10-character sequence is used to indicate the file type:
+
+- – (hyphen): a regular file
+- d: a directory
+- l: a symbolic link
+- c: a character device (which treats data as a stream of bytes, i.e. a terminal)
+- b: a block device (which handles data in blocks, i.e. storage devices)
+
+The next nine characters of the file attributes, divided in groups of three from left to right, are called the file mode and indicate the read (r), write(w), and execute (x) permissions granted to the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”), respectively.
+
+While the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run.
+
+File permissions are changed with the chmod command, whose basic syntax is as follows:
+
+ # chmod [new_mode] file
+
+where new_mode is either an octal number or an expression that specifies the new permissions. Feel free to use the mode that works best for you in each case. Or perhaps you already have a preferred way to set a file’s permissions – so feel free to use the method that works best for you.
+
+The octal number can be calculated based on the binary equivalent, which can in turn be obtained from the desired file permissions for the owner of the file, the owner group, and the world.The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence means 0. For example:
+
+
+
+File Permissions
+
+To set the file’s permissions as indicated above in octal form, type:
+
+ # chmod 744 myfile
+
+Please take a minute to compare our previous calculation to the actual output of `ls -l` after changing the file’s permissions:
+
+
+
+Long List Format
+
+#### EXAMPLE 8: Searching for files with 777 permissions ####
+
+As a security measure, you should make sure that files with 777 permissions (read, write, and execute for everyone) are avoided like the plague under normal circumstances. Although we will explain in a later tutorial how to more effectively locate all the files in your system with a certain permission set, you can -by now- combine ls with grep to obtain such information.
+
+In the following example, we will look for file with 777 permissions in the /etc directory only. Note that we will use pipelining as explained in [Part 2: File and Directory Management][4] of this RHCSA series:
+
+ # ls -l /etc | grep rwxrwxrwx
+
+
+
+Find All Files with 777 Permission
+
+#### EXAMPLE 9: Assigning a specific permission to all users ####
+
+Shell scripts, along with some binaries that all users should have access to (not just their corresponding owner and group), should have the execute bit set accordingly (please note that we will discuss a special case later):
+
+ # chmod a+x script.sh
+
+**Note**: That we can also set a file’s mode using an expression that indicates the owner’s rights with the letter `u`, the group owner’s rights with the letter `g`, and the rest with `o`. All of these rights can be represented at the same time with the letter `a`. Permissions are granted (or revoked) with the `+` or `-` signs, respectively.
+
+
+
+Set Execute Permission on File
+
+A long directory listing also shows the file’s owner and its group owner in the first and second columns, respectively. This feature serves as a first-level access control method to files in a system:
+
+
+
+Check File Owner and Group
+
+To change file ownership, you will use the chown command. Note that you can change the file and group ownership at the same time or separately:
+
+ # chown user:group file
+
+**Note**: That you can change the user or group, or the two attributes at the same time, as long as you don’t forget the colon, leaving user or group blank if you want to update the other attribute, for example:
+
+ # chown :group file # Change group ownership only
+ # chown user: file # Change user ownership only
+
+#### EXAMPLE 10: Cloning permissions from one file to another ####
+
+If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
+
+ # chown --reference=ref_file file
+
+where the owner and group of ref_file will be assigned to file as well:
+
+
+
+Clone File Ownership
+
+### Setting Up SETGID Directories for Collaboration ###
+
+Should you need to grant access to all the files owned by a certain group inside a specific directory, you will most likely use the approach of setting the setgid bit for such directory. When the setgid bit is set, the effective GID of the real user becomes that of the group owner.
+
+Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory.
+
+ # chmod g+s [filename]
+
+To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
+
+ # chmod 2755 [directory]
+
+### Conclusion ###
+
+A solid knowledge of user and group management, along with standard and special Linux permissions, when coupled with practice, will allow you to quickly identify and troubleshoot issues with file permissions in your RHEL 7 server.
+
+I assure you that as you follow the steps outlined in this article and use the system documentation (as explained in [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) you will master this essential competence of system administration.
+
+Feel free to let us know if you have any questions or comments using the form below.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/add-users-in-linux/
+[2]:http://www.tecmint.com/usermod-command-examples/
+[3]:http://www.tecmint.com/ls-interview-questions/
+[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
+[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 04--Editing Text Files with Nano and Vim or Analyzing text with grep and regexps.md b/sources/tech/RHCSA Series/RHCSA Series--Part 04--Editing Text Files with Nano and Vim or Analyzing text with grep and regexps.md
new file mode 100644
index 0000000000..1529fecf2e
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 04--Editing Text Files with Nano and Vim or Analyzing text with grep and regexps.md
@@ -0,0 +1,254 @@
+RHCSA Series: Editing Text Files with Nano and Vim / Analyzing text with grep and regexps – Part 4
+================================================================================
+Every system administrator has to deal with text files as part of his daily responsibilities. That includes editing existing files (most likely configuration files), or creating new ones. It has been said that if you want to start a holy war in the Linux world, you can ask sysadmins what their favorite text editor is and why. We are not going to do that in this article, but will present a few tips that will be helpful to use two of the most widely used text editors in RHEL 7: nano (due to its simplicity and easiness of use, specially to new users), and vi/m (due to its several features that convert it into more than a simple editor). I am sure that you can find many more reasons to use one or the other, or perhaps some other editor such as emacs or pico. It’s entirely up to you.
+
+
+
+RHCSA: Editing Text Files with Nano and Vim – Part 4
+
+### Editing Files with Nano Editor ###
+
+To launch nano, you can either just type nano at the command prompt, optionally followed by a filename (in this case, if the file exists, it will be opened in edition mode). If the file does not exist, or if we omit the filename, nano will also be opened in edition mode but will present a blank screen for us to start typing:
+
+
+
+Nano Editor
+
+As you can see in the previous image, nano displays at the bottom of the screen several functions that are available via the indicated shortcuts (^, aka caret, indicates the Ctrl key). To name a few of them:
+
+- Ctrl + G: brings up the help menu with a complete list of functions and descriptions:Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
+- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
+
+
+
+Nano Editor Help Menu
+
+- Ctrl + O: saves changes made to a file. It will let you save the file with the same name or a different one. Then press Enter to confirm.
+
+
+
+Nano Editor Save Changes Mode
+
+- Ctrl + X: exits the current file. If changes have not been saved, they are discarded.
+- Ctrl + R: lets you choose a file to insert its contents into the present file by specifying a full path.
+
+
+
+Nano: Insert File Content to Parent File
+
+will insert the contents of /etc/passwd into the current file.
+
+- Ctrl + K: cuts the current line.
+- Ctrl + U: paste.
+- Ctrl + C: cancels the current operation and places you at the previous screen.
+
+To easily navigate the opened file, nano provides the following features:
+
+- Ctrl + F and Ctrl + B move the cursor forward or backward, whereas Ctrl + P and Ctrl + N move it up or down one line at a time, respectively, just like the arrow keys.
+- Ctrl + space and Alt + space move the cursor forward and backward one word at a time.
+
+Finally,
+
+- Ctrl + _ (underscore) and then entering X,Y will take you precisely to Line X, column Y, if you want to place the cursor at a specific place in the document.
+
+
+
+Navigate to Line Numbers in Nano
+
+The example above will take you to line 15, column 14 in the current document.
+
+If you can recall your early Linux days, specially if you came from Windows, you will probably agree that starting off with nano is the best way to go for a new user.
+
+### Editing Files with Vim Editor ###
+
+Vim is an improved version of vi, a famous text editor in Linux that is available on all POSIX-compliant *nix systems, such as RHEL 7. If you have the chance and can install vim, go ahead; if not, most (if not all) the tips given in this article should also work.
+
+One of vim’s distinguishing features is the different modes in which it operates:
+
+
+- Command mode will allow you to browse through the file and enter commands, which are brief and case-sensitive combinations of one or more letters. If you need to repeat one of them a certain number of times, you can prefix it with a number (there are only a few exceptions to this rule). For example, yy (or Y, short for yank) copies the entire current line, whereas 4yy (or 4Y) copies the entire current line along with the next three lines (4 lines in total).
+- In ex mode, you can manipulate files (including saving a current file and running outside programs or commands). To enter ex mode, we must type a colon (:) starting from command mode (or in other words, Esc + :), directly followed by the name of the ex-mode command that you want to use.
+- In insert mode, which is accessed by typing the letter i, we simply enter text. Most keystrokes result in text appearing on the screen.
+- We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key.
+
+Let’s see how we can perform the same operations that we outlined for nano in the previous section, but now with vim. Don’t forget to hit the Enter key to confirm the vim command!
+
+To access vim’s full manual from the command line, type :help while in command mode and then press Enter:
+
+
+
+vim Edito Help Menu
+
+The upper section presents an index list of contents, with defined sections dedicated to specific topics about vim. To navigate to a section, place the cursor over it and press Ctrl + ] (closing square bracket). Note that the bottom section displays the current file.
+
+1. To save changes made to a file, run any of the following commands from command mode and it will do the trick:
+
+ :wq!
+ :x!
+ ZZ (yes, double Z without the colon at the beginning)
+
+2. To exit discarding changes, use :q!. This command will also allow you to exit the help menu described above, and return to the current file in command mode.
+
+3. Cut N number of lines: type Ndd while in command mode.
+
+4. Copy M number of lines: type Myy while in command mode.
+
+5. Paste lines that were previously cutted or copied: press the P key while in command mode.
+
+6. To insert the contents of another file into the current one:
+
+ :r filename
+
+For example, to insert the contents of `/etc/fstab`, do:
+
+
+
+Insert Content of File in vi Editor
+
+7. To insert the output of a command into the current document:
+
+ :r! command
+
+For example, to insert the date and time in the line below the current position of the cursor:
+
+
+
+Insert Time an Date in vi Editor
+
+In another article that I wrote for, ([Part 2 of the LFCS series][1]), I explained in greater detail the keyboard shortcuts and functions available in vim. You may want to refer to that tutorial for further examples on how to use this powerful text editor.
+
+### Analyzing Text with Grep and Regular Expressions ###
+
+By now you have learned how to create and edit files using nano or vim. Say you become a text editor ninja, so to speak – now what? Among other things, you will also need how to search for regular expressions inside text.
+
+A regular expression (also known as “regex” or “regexp“) is a way of identifying a text string or pattern so that a program can compare the pattern against arbitrary text strings. Although the use of regular expressions along with grep would deserve an entire article on its own, let us review the basics here:
+
+**1. The simplest regular expression is an alphanumeric string (i.e., the word “svm”) or two (when two are present, you can use the | (OR) operator):**
+
+ # grep -Ei 'svm|vmx' /proc/cpuinfo
+
+The presence of either of those two strings indicate that your processor supports virtualization:
+
+
+
+Regular Expression Example
+
+**2. A second kind of a regular expression is a range list, enclosed between square brackets.**
+
+For example, `c[aeiou]t` matches the strings cat, cet, cit, cot, and cut, whereas `[a-z]` and `[0-9]` match any lowercase letter or decimal digit, respectively. If you want to repeat the regular expression X certain number of times, type `{X}` immediately following the regexp.
+
+For example, let’s extract the UUIDs of storage devices from `/etc/fstab`:
+
+ # grep -Ei '[0-9a-f]{8}-([0-9a-f]{4}-){3}[0-9a-f]{12}' -o /etc/fstab
+
+
+
+Extract String from a File
+
+The first expression in brackets `[0-9a-f]` is used to denote lowercase hexadecimal characters, and `{8}` is a quantifier that indicates the number of times that the preceding match should be repeated (the first sequence of characters in an UUID is a 8-character long hexadecimal string).
+
+The parentheses, the `{4}` quantifier, and the hyphen indicate that the next sequence is a 4-character long hexadecimal string, and the quantifier that follows `({3})` denote that the expression should be repeated 3 times.
+
+Finally, the last sequence of 12-character long hexadecimal string in the UUID is retrieved with `[0-9a-f]{12}`, and the -o option prints only the matched (non-empty) parts of the matching line in /etc/fstab.
+
+**3. POSIX character classes.**
+
+注:表格
+
+
+
+
+
+
Character Class
+
Matches…
+
+
+
[[:alnum:]]
+
Any alphanumeric [a-zA-Z0-9] character
+
+
+
[[:alpha:]]
+
Any alphabetic [a-zA-Z] character
+
+
+
[[:blank:]]
+
Spaces or tabs
+
+
+
[[:cntrl:]]
+
Any control characters (ASCII 0 to 32)
+
+
+
[[:digit:]]
+
Any numeric digits [0-9]
+
+
+
[[:graph:]]
+
Any visible characters
+
+
+
[[:lower:]]
+
Any lowercase [a-z] character
+
+
+
[[:print:]]
+
Any non-control characters
+
+
+
[[:space:]]
+
Any whitespace
+
+
+
[[:punct:]]
+
Any punctuation marks
+
+
+
[[:upper:]]
+
Any uppercase [A-Z] character
+
+
+
[[:xdigit:]]
+
Any hex digits [0-9a-fA-F]
+
+
+
[:word:]
+
Any letters, numbers, and underscores [a-zA-Z0-9_]
+
+
+
+
+For example, we may be interested in finding out what the used UIDs and GIDs (refer to [Part 2][2] of this series to refresh your memory) are for real users that have been added to our system. Thus, we will search for sequences of 4 digits in /etc/passwd:
+
+ # grep -Ei [[:digit:]]{4} /etc/passwd
+
+
+
+Search For a String in File
+
+The above example may not be the best case of use of regular expressions in the real world, but it clearly illustrates how to use POSIX character classes to analyze text along with grep.
+
+### Conclusion ###
+
+In this article we have provided some tips to make the most of nano and vim, two text editors for the command-line users. Both tools are supported by extensive documentation, which you can consult in their respective official web sites (links given below) and using the suggestions given in [Part 1][3] of this series.
+
+#### Reference Links ####
+
+- [http://www.nano-editor.org/][4]
+- [http://www.vim.org/][5]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/rhcsa-exam-how-to-use-nano-vi-editors/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/vi-editor-usage/
+[2]:http://www.tecmint.com/file-and-directory-management-in-linux/
+[3]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
+[4]:http://www.nano-editor.org/
+[5]:http://www.vim.org/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 05--Process Management in RHEL 7--Boot Shutdown and Everything in Between.md b/sources/tech/RHCSA Series/RHCSA Series--Part 05--Process Management in RHEL 7--Boot Shutdown and Everything in Between.md
new file mode 100644
index 0000000000..2befb7bc55
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 05--Process Management in RHEL 7--Boot Shutdown and Everything in Between.md
@@ -0,0 +1,216 @@
+RHCSA Series: Process Management in RHEL 7: Boot, Shutdown, and Everything in Between – Part 5
+================================================================================
+We will start this article with an overall and brief revision of what happens since the moment you press the Power button to turn on your RHEL 7 server until you are presented with the login screen in a command line interface.
+
+
+
+Linux Boot Process
+
+**Please note that:**
+
+1. the same basic principles apply, with perhaps minor modifications, to other Linux distributions as well, and
+2. the following description is not intended to represent an exhaustive explanation of the boot process, but only the fundamentals.
+
+### Linux Boot Process ###
+
+1. The POST (Power On Self Test) initializes and performs hardware checks.
+
+2. When the POST finishes, the system control is passed to the first stage boot loader, which is stored on either the boot sector of one of the hard disks (for older systems using BIOS and MBR), or a dedicated (U)EFI partition.
+
+3. The first stage boot loader then loads the second stage boot loader, most usually GRUB (GRand Unified Boot Loader), which resides inside /boot, which in turn loads the kernel and the initial RAM–based file system (also known as initramfs, which contains programs and binary files that perform the necessary actions needed to ultimately mount the actual root filesystem).
+
+4. We are presented with a splash screen that allows us to choose an operating system and kernel to boot:
+
+
+
+Boot Menu Screen
+
+5. The kernel sets up the hardware attached to the system and once the root filesystem has been mounted, launches process with PID 1, which in turn will initialize other processes and present us with a login prompt.
+
+Note: That if we wish to do so at a later time, we can examine the specifics of this process using the [dmesg command][1] and filtering its output using the tools that we have explained in previous articles of this series.
+
+
+
+Login Screen and Process PID
+
+In the example above, we used the well-known ps command to display a list of current processes whose parent process (or in other words, the process that started them) is systemd (the system and service manager that most modern Linux distributions have switched to) during system startup:
+
+ # ps -o ppid,pid,uname,comm --ppid=1
+
+Remember that the -o flag (short for –format) allows you to present the output of ps in a customized format to suit your needs using the keywords specified in the STANDARD FORMAT SPECIFIERS section in man ps.
+
+Another case in which you will want to define the output of ps instead of going with the default is when you need to find processes that are causing a significant CPU and / or memory load, and sort them accordingly:
+
+ # ps aux --sort=+pcpu # Sort by %CPU (ascending)
+ # ps aux --sort=-pcpu # Sort by %CPU (descending)
+ # ps aux --sort=+pmem # Sort by %MEM (ascending)
+ # ps aux --sort=-pmem # Sort by %MEM (descending)
+ # ps aux --sort=+pcpu,-pmem # Combine sort by %CPU (ascending) and %MEM (descending)
+
+
+
+Customize ps Command Output
+
+### An Introduction to SystemD ###
+
+Few decisions in the Linux world have caused more controversies than the adoption of systemd by major Linux distributions. Systemd’s advocates name as its main advantages the following facts:
+
+Read Also: [The Story Behind ‘init’ and ‘systemd’][2]
+
+1. Systemd allows more processing to be done in parallel during system startup (as opposed to older SysVinit, which always tends to be slower because it starts processes one by one, checks if one depends on another, and then waits for daemons to launch so more services can start), and
+
+2. It works as a dynamic resource management in a running system. Thus, services are started when needed (to avoid consuming system resources if they are not being used) instead of being launched without a valid reason during boot.
+
+3. Backwards compatibility with SysVinit scripts.
+
+Systemd is controlled by the systemctl utility. If you come from a SysVinit background, chances are you will be familiar with:
+
+- the service tool, which -in those older systems- was used to manage SysVinit scripts, and
+- the chkconfig utility, which served the purpose of updating and querying runlevel information for system services.
+- shutdown, which you must have used several times to either restart or halt a running system.
+
+The following table shows the similarities between the use of these legacy tools and systemctl:
+
+注:表格
+
+
+
+
+
+
+
Legacy tool
+
Systemctl equivalent
+
Description
+
+
+
service name start
+
systemctl start name
+
Start name (where name is a service)
+
+
+
service name stop
+
systemctl stop name
+
Stop name
+
+
+
service name condrestart
+
systemctl try-restart name
+
Restarts name (if it’s already running)
+
+
+
service name restart
+
systemctl restart name
+
Restarts name
+
+
+
service name reload
+
systemctl reload name
+
Reloads the configuration for name
+
+
+
service name status
+
systemctl status name
+
Displays the current status of name
+
+
+
service –status-all
+
systemctl
+
Displays the status of all current services
+
+
+
chkconfig name on
+
systemctl enable name
+
Enable name to run on startup as specified in the unit file (the file to which the symlink points). The process of enabling or disabling a service to start automatically on boot consists in adding or removing symbolic links inside the /etc/systemd/system directory.
+
+
+
chkconfig name off
+
systemctl disable name
+
Disables name to run on startup as specified in the unit file (the file to which the symlink points)
+
+
+
chkconfig –list name
+
systemctl is-enabled name
+
Verify whether name (a specific service) is currently enabled
+
+
+
chkconfig –list
+
systemctl –type=service
+
Displays all services and tells whether they are enabled or disabled
+
+
+
shutdown -h now
+
systemctl poweroff
+
Power-off the machine (halt)
+
+
+
shutdown -r now
+
systemctl reboot
+
Reboot the system
+
+
+
+
+Systemd also introduced the concepts of units (which can be either a service, a mount point, a device, or a network socket) and targets (which is how systemd manages to start several related process at the same time, and can be considered -though not equal- as the equivalent of runlevels in SysVinit-based systems.
+
+### Summing Up ###
+
+Other tasks related with process management include, but may not be limited to, the ability to:
+
+**1. Adjust the execution priority as far as the use of system resources is concerned of a process:**
+
+This is accomplished through the renice utility, which alters the scheduling priority of one or more running processes. In simple terms, the scheduling priority is a feature that allows the kernel (present in versions => 2.6) to allocate system resources as per the assigned execution priority (aka niceness, in a range from -20 through 19) of a given process.
+
+The basic syntax of renice is as follows:
+
+ # renice [-n] priority [-gpu] identifier
+
+In the generic command above, the first argument is the priority value to be used, whereas the other argument can be interpreted as process IDs (which is the default setting), process group IDs, user IDs, or user names. A normal user (other than root) can only modify the scheduling priority of a process he or she owns, and only increase the niceness level (which means taking up less system resources).
+
+
+
+Process Scheduling Priority
+
+**2. Kill (or interrupt the normal execution) of a process as needed:**
+
+In more precise terms, killing a process entitles sending it a signal to either finish its execution gracefully (SIGTERM=15) or immediately (SIGKILL=9) through the [kill or pkill commands][3].
+
+The difference between these two tools is that the former is used to terminate a specific process or a process group altogether, while the latter allows you to do the same based on name and other attributes.
+
+In addition, pkill comes bundled with pgrep, which shows you the PIDs that will be affected should pkill be used. For example, before running:
+
+ # pkill -u gacanepa
+
+It may be useful to view at a glance which are the PIDs owned by gacanepa:
+
+ # pgrep -l -u gacanepa
+
+
+
+Find PIDs of User
+
+By default, both kill and pkill send the SIGTERM signal to the process. As we mentioned above, this signal can be ignored (while the process finishes its execution or for good), so when you seriously need to stop a running process with a valid reason, you will need to specify the SIGKILL signal on the command line:
+
+ # kill -9 identifier # Kill a process or a process group
+ # kill -s SIGNAL identifier # Idem
+ # pkill -s SIGNAL identifier # Kill a process by name or other attributes
+
+### Conclusion ###
+
+In this article we have explained the basics of the boot process in a RHEL 7 system, and analyzed some of the tools that are available to help you with managing processes using common utilities and systemd-specific commands.
+
+Note that this list is not intended to cover all the bells and whistles of this topic, so feel free to add your own preferred tools and commands to this article using the comment form below. Questions and other comments are also welcome.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/rhcsa-exam-boot-process-and-process-management/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/dmesg-commands/
+[2]:http://www.tecmint.com/systemd-replaces-init-in-linux/
+[3]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
\ No newline at end of file
diff --git a/sources/tech/RHCSA Series/RHCSA Series--Part 06--Using 'Parted' and 'SSM' to Configure and Encrypt System Storage.md b/sources/tech/RHCSA Series/RHCSA Series--Part 06--Using 'Parted' and 'SSM' to Configure and Encrypt System Storage.md
new file mode 100644
index 0000000000..474b707d23
--- /dev/null
+++ b/sources/tech/RHCSA Series/RHCSA Series--Part 06--Using 'Parted' and 'SSM' to Configure and Encrypt System Storage.md
@@ -0,0 +1,269 @@
+RHCSA Series: Using ‘Parted’ and ‘SSM’ to Configure and Encrypt System Storage – Part 6
+================================================================================
+In this article we will discuss how to set up and configure local system storage in Red Hat Enterprise Linux 7 using classic tools and introducing the System Storage Manager (also known as SSM), which greatly simplifies this task.
+
+
+
+RHCSA: Configure and Encrypt System Storage – Part 6
+
+Please note that we will present this topic in this article but will continue its description and usage on the next one (Part 7) due to vastness of the subject.
+
+### Creating and Modifying Partitions in RHEL 7 ###
+
+In RHEL 7, parted is the default utility to work with partitions, and will allow you to:
+
+- Display the current partition table
+- Manipulate (increase or decrease the size of) existing partitions
+- Create partitions using free space or additional physical storage devices
+
+It is recommended that before attempting the creation of a new partition or the modification of an existing one, you should ensure that none of the partitions on the device are in use (`umount /dev/partition`), and if you’re using part of the device as swap you need to disable it (`swapoff -v /dev/partition`) during the process.
+
+The easiest way to do this is to boot RHEL in rescue mode using an installation media such as a RHEL 7 installation DVD or USB (Troubleshooting → Rescue a Red Hat Enterprise Linux system) and Select Skip when you’re prompted to choose an option to mount the existing Linux installation, and you will be presented with a command prompt where you can start typing the same commands as shown as follows during the creation of an ordinary partition in a physical device that is not being used.
+
+
+
+RHEL 7 Rescue Mode
+
+To start parted, simply type.
+
+ # parted /dev/sdb
+
+Where `/dev/sdb` is the device where you will create the new partition; next, type print to display the current drive’s partition table:
+
+
+
+Creat New Partition
+
+As you can see, in this example we are using a virtual drive of 5 GB. We will now proceed to create a 4 GB primary partition and then format it with the xfs filesystem, which is the default in RHEL 7.
+
+You can choose from a variety of file systems. You will need to manually create the partition with mkpart and then format it with mkfs.fstype as usual because mkpart does not support many modern filesystems out-of-the-box.
+
+In the following example we will set a label for the device and then create a primary partition `(p)` on `/dev/sdb`, which starts at the 0% percentage of the device and ends at 4000 MB (4 GB):
+
+
+
+Label Partition Name
+
+Next, we will format the partition as xfs and print the partition table again to verify that changes were applied:
+
+ # mkfs.xfs /dev/sdb1
+ # parted /dev/sdb print
+
+
+
+Format Partition as XFS Filesystem
+
+For older filesystems, you could use the resize command in parted to resize a partition. Unfortunately, this only applies to ext2, fat16, fat32, hfs, linux-swap, and reiserfs (if libreiserfs is installed).
+
+Thus, the only way to resize a partition is by deleting it and creating it again (so make sure you have a good backup of your data!). No wonder the default partitioning scheme in RHEL 7 is based on LVM.
+
+To remove a partition with parted:
+
+ # parted /dev/sdb print
+ # parted /dev/sdb rm 1
+
+
+
+Remove or Delete Partition
+
+### The Logical Volume Manager (LVM) ###
+
+Once a disk has been partitioned, it can be difficult or risky to change the partition sizes. For that reason, if we plan on resizing the partitions on our system, we should consider the possibility of using LVM instead of the classic partitioning system, where several physical devices can form a volume group that will host a defined number of logical volumes, which can be expanded or reduced without any hassle.
+
+In simple terms, you may find the following diagram useful to remember the basic architecture of LVM.
+
+
+
+Basic Architecture of LVM
+
+#### Creating Physical Volumes, Volume Group and Logical Volumes ####
+
+Follow these steps in order to set up LVM using classic volume management tools. Since you can expand this topic reading the [LVM series on this site][1], I will only outline the basic steps to set up LVM, and then compare them to implementing the same functionality with SSM.
+
+**Note**: That we will use the whole disks `/dev/sdb` and `/dev/sdc` as PVs (Physical Volumes) but it’s entirely up to you if you want to do the same.
+
+**1. Create partitions `/dev/sdb1` and `/dev/sdc1` using 100% of the available disk space in /dev/sdb and /dev/sdc:**
+
+ # parted /dev/sdb print
+ # parted /dev/sdc print
+
+
+
+Create New Partitions
+
+**2. Create 2 physical volumes on top of /dev/sdb1 and /dev/sdc1, respectively.**
+
+ # pvcreate /dev/sdb1
+ # pvcreate /dev/sdc1
+
+
+
+Create Two Physical Volumes
+
+Remember that you can use pvdisplay /dev/sd{b,c}1 to show information about the newly created PVs.
+
+**3. Create a VG on top of the PV that you created in the previous step:**
+
+ # vgcreate tecmint_vg /dev/sd{b,c}1
+
+
+
+Create Volume Group
+
+Remember that you can use vgdisplay tecmint_vg to show information about the newly created VG.
+
+**4. Create three logical volumes on top of VG tecmint_vg, as follows:**
+
+ # lvcreate -L 3G -n vol01_docs tecmint_vg [vol01_docs → 3 GB]
+ # lvcreate -L 1G -n vol02_logs tecmint_vg [vol02_logs → 1 GB]
+ # lvcreate -l 100%FREE -n vol03_homes tecmint_vg [vol03_homes → 6 GB]
+
+
+
+Create Logical Volumes
+
+Remember that you can use lvdisplay tecmint_vg to show information about the newly created LVs on top of VG tecmint_vg.
+
+**5. Format each of the logical volumes with xfs (do NOT use xfs if you’re planning on shrinking volumes later!):**
+
+ # mkfs.xfs /dev/tecmint_vg/vol01_docs
+ # mkfs.xfs /dev/tecmint_vg/vol02_logs
+ # mkfs.xfs /dev/tecmint_vg/vol03_homes
+
+**6. Finally, mount them:**
+
+ # mount /dev/tecmint_vg/vol01_docs /mnt/docs
+ # mount /dev/tecmint_vg/vol02_logs /mnt/logs
+ # mount /dev/tecmint_vg/vol03_homes /mnt/homes
+
+#### Removing Logical Volumes, Volume Group and Physical Volumes ####
+
+**7. Now we will reverse the LVM implementation and remove the LVs, the VG, and the PVs:**
+
+ # lvremove /dev/tecmint_vg/vol01_docs
+ # lvremove /dev/tecmint_vg/vol02_logs
+ # lvremove /dev/tecmint_vg/vol03_homes
+ # vgremove /dev/tecmint_vg
+ # pvremove /dev/sd{b,c}1
+
+**8. Now let’s install SSM and we will see how to perform the above in ONLY 1 STEP!**
+
+ # yum update && yum install system-storage-manager
+
+We will use the same names and sizes as before:
+
+ # ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 /mnt/docs /dev/sd{b,c}1
+ # ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 /mnt/logs /dev/sd{b,c}1
+ # ssm create -n vol03_homes -p tecmint_vg --fstype ext4 /mnt/homes /dev/sd{b,c}1
+
+Yes! SSM will let you:
+
+- initialize block devices as physical volumes
+- create a volume group
+- create logical volumes
+- format LVs, and
+- mount them using only one command
+
+**9. We can now display the information about PVs, VGs, or LVs, respectively, as follows:**
+
+ # ssm list dev
+ # ssm list pool
+ # ssm list vol
+
+
+
+Check Information of PVs, VGs, or LVs
+
+**10. As we already know, one of the distinguishing features of LVM is the possibility to resize (expand or decrease) logical volumes without downtime.**
+
+Say we are running out of space in vol02_logs but have plenty of space in vol03_homes. We will resize vol03_homes to 4 GB and expand vol02_logs to use the remaining space:
+
+ # ssm resize -s 4G /dev/tecmint_vg/vol03_homes
+
+Run ssm list pool again and take note of the free space in tecmint_vg:
+
+
+
+Check Volume Size
+
+Then do:
+
+ # ssm resize -s+1.99 /dev/tecmint_vg/vol02_logs
+
+**Note**: that the plus sign after the -s flag indicates that the specified value should be added to the present value.
+
+**11. Removing logical volumes and volume groups is much easier with ssm as well. A simple,**
+
+ # ssm remove tecmint_vg
+
+will return a prompt asking you to confirm the deletion of the VG and the LVs it contains:
+
+
+
+Remove Logical Volume and Volume Group
+
+### Managing Encrypted Volumes ###
+
+SSM also provides system administrators with the capability of managing encryption for new or existing volumes. You will need the cryptsetup package installed first:
+
+ # yum update && yum install cryptsetup
+
+Then issue the following command to create an encrypted volume. You will be prompted to enter a passphrase to maximize security:
+
+ # ssm create -s 3G -n vol01_docs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/docs /dev/sd{b,c}1
+ # ssm create -s 1G -n vol02_logs -p tecmint_vg --fstype ext4 --encrypt luks /mnt/logs /dev/sd{b,c}1
+ # ssm create -n vol03_homes -p tecmint_vg --fstype ext4 --encrypt luks /mnt/homes /dev/sd{b,c}1
+
+Our next task consists in adding the corresponding entries in /etc/fstab in order for those logical volumes to be available on boot. Rather than using the device identifier (/dev/something).
+
+We will use each LV’s UUID (so that our devices will still be uniquely identified should we add other logical volumes or devices), which we can find out with the blkid utility:
+
+ # blkid -o value UUID /dev/tecmint_vg/vol01_docs
+ # blkid -o value UUID /dev/tecmint_vg/vol02_logs
+ # blkid -o value UUID /dev/tecmint_vg/vol03_homes
+
+In our case:
+
+
+
+Find Logical Volume UUID
+
+Next, create the /etc/crypttab file with the following contents (change the UUIDs for the ones that apply to your setup):
+
+ docs UUID=ba77d113-f849-4ddf-8048-13860399fca8 none
+ logs UUID=58f89c5a-f694-4443-83d6-2e83878e30e4 none
+ homes UUID=92245af6-3f38-4e07-8dd8-787f4690d7ac none
+
+And insert the following entries in /etc/fstab. Note that device_name (/dev/mapper/device_name) is the mapper identifier that appears in the first column of /etc/crypttab.
+
+ # Logical volume vol01_docs:
+ /dev/mapper/docs /mnt/docs ext4 defaults 0 2
+ # Logical volume vol02_logs
+ /dev/mapper/logs /mnt/logs ext4 defaults 0 2
+ # Logical volume vol03_homes
+ /dev/mapper/homes /mnt/homes ext4 defaults 0 2
+
+Now reboot (systemctl reboot) and you will be prompted to enter the passphrase for each LV. Afterwards you can confirm that the mount operation was successful by checking the corresponding mount points:
+
+
+
+Verify Logical Volume Mount Points
+
+### Conclusion ###
+
+In this tutorial we have started to explore how to set up and configure system storage using classic volume management tools and SSM, which also integrates filesystem and encryption capabilities in one package. This makes SSM an invaluable tool for any sysadmin.
+
+Let us know if you have any questions or comments – feel free to use the form below to get in touch with us!
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/rhcsa-exam-create-format-resize-delete-and-encrypt-partitions-in-linux/
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
\ No newline at end of file
diff --git a/translated/share/20150429 What are good command line HTTP clients.md b/translated/share/20150429 What are good command line HTTP clients.md
new file mode 100644
index 0000000000..fa9ef01c54
--- /dev/null
+++ b/translated/share/20150429 What are good command line HTTP clients.md
@@ -0,0 +1,110 @@
+什么是好的命令行HTTP客户端?
+==============================================================================
+整体大于各部分之和,这是引自希腊哲学家和科学家的亚里士多德的名言。这句话特别切中Linux。在我看来,Linux最强大的地方之一就是它的协作性。Linux的实用性并不仅仅源自大量的开源程序(命令行)。相反,其协作性来自于这些程序的综合利用,有时是结合更大型的应用。
+
+Unix哲学引发了一场“软件工具”的运动,关注开发简洁,基础,干净,模块化和扩展性好的代码,并可以运用于其他的项目。这种哲学为许多的Linux项目留下了一个重要的元素。
+
+好的开源开发者写程序为了确保该程序尽可能运行正确,同时能与其他程序很好地协作。目标就是使用者拥有一堆方便的工具,每一个力求干不止一件事。许多程序能独立工作得很好。
+
+这篇文章讨论3个开源命令行HTTP客户端。这些客户端可以让你使用命令行从互联网上下载文件。但同时,他们也可以用于许多有意思的地方,如测试,调式和与HTTP服务器或网络应用互动。对于HTTP架构师和API设计人员来说,使用命令行操作HTTP是一个值得花时间学习的技能。如果你需要来回使用API,HTTPie和cURL,这没什么价值。
+
+-------------
+
+
+
+
+
+HTTPie(发音 aych-tee-tee-pie)是一款开源命令行HTTP客户端。它是一个命令行界面,类cURL的工具。
+
+该软件的目标是使得与网络服务器的交互尽可能的人性化。其提供了一个简单的http命令,允许使用简单且自然的语句发送任意的HTTP请求,并显示不同颜色的输出。HTTPie可以用于测试,调式和与HTTP服务器的一般交互。
+
+#### 功能包括:####
+
+- 可表达,直观的语句
+- 格式化,颜色区分的终端输出
+- 内建JSON支持
+- 表单和文件上传
+- HTTPS,代理和认证
+- 任意数据请求
+- 自定义标题 (此处header不确定是否特别意义)
+- 持久会话
+- 类Wget下载
+- Python 2.6,2.7和3.x支持
+- Linux,Mac OS X 和 Windows支持
+- 支持插件
+- 帮助文档
+- 测试覆盖 (直译有点别扭)
+
+- 网站:[httpie.org][1]
+- 开发者: Jakub Roztočil
+- 证书: 开源
+- 版本号: 0.9.2
+
+----------
+
+
+
+
+
+cURL是一个开源命令行工具,用于使用URL语句传输数据,支持DICT, FILE, FTP, FTPS, GOPHER, HTTP, HTTPS,IMAP, IMAPS, LDAP, LDAPS, POP3, POP3S, RTMP, RTSP, SCP, SFTP, SMTP, SMTPS, TELNET和TFTP。
+
+cURL支持SSL证书,HTTP POST,HTTP PUT,FTP上传,HTTP基于表单上传,代理,缓存,用户名+密码认证(Basic, Digest, NTLM, Negotiate, kerberos...),文件传输恢复, 代理通道和一些其他实用窍门的总线负载。(这里的名词我不明白其专业意思)
+
+#### 功能包括:####
+
+- 配置文件支持
+- 一个单独命令行多个URL
+- “globbing”漫游支持: [0-13],{one, two, three}
+- 一个命令上传多个文件
+- 自定义最大传输速度
+- 重定向标准错误输出
+- Metalink支持
+
+- 网站: [curl.haxx.se][2]
+- 开发者: Daniel Stenberg
+- 证书: MIT/X derivate license
+- 版本号: 7.42.0
+
+----------
+
+
+
+
+
+Wget是一个从网络服务器获取信息的开源软件。其名字源于World Wide Web 和 get。Wget支持HTTP,HTTPS和FTP协议,同时也通过HTTP代理获取信息。
+
+Wget可以根据HTML页面的链接,创建远程网络站点的本地版本,是完全重造源站点的目录结构。这种方式被冠名“recursive downloading。”
+
+Wget已经设计可以加快低速或者不稳定的网络连接。
+
+功能包括:
+
+- 使用REST和RANGE恢复中断的下载
+- 使用文件名
+- 多语言的基于NLS的消息文件
+- 选择性地转换下载文档里地绝对链接为相对链接,使得下载文档可以本地相互链接
+- 在大多数类UNIX操作系统和微软Windows上运行
+- 支持HTTP代理
+- 支持HTTP数据缓存
+- 支持持续地HTTP连接
+- 无人照管/后台操作
+- 当远程对比时,使用本地文件时间戳来决定是否需要重新下载文档 (mirroring没想出合适的表达)
+
+- 站点: [www.gnu.org/software/wget/][3]
+- 开发者: Hrvoje Niksic, Gordon Matzigkeit, Junio Hamano, Dan Harkless, and many others
+- 证书: GNU GPL v3
+- 版本号: 1.16.3
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxlinks.com/article/20150425174537249/HTTPclients.html
+
+作者:Frazer Kline
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://httpie.org/
+[2]:http://curl.haxx.se/
+[3]:https://www.gnu.org/software/wget/
diff --git a/translated/share/20150515 This Ubuntu App Applies Instagram Style Filters to Your Photos.md b/translated/share/20150515 This Ubuntu App Applies Instagram Style Filters to Your Photos.md
new file mode 100644
index 0000000000..ae5e6df6eb
--- /dev/null
+++ b/translated/share/20150515 This Ubuntu App Applies Instagram Style Filters to Your Photos.md
@@ -0,0 +1,74 @@
+一个Ubuntu中给你的照片加Instagram风格滤镜的程序
+================================================================================
+**在Ubuntu中寻找一个给你的照片加Instagram风格的滤镜程序么?**
+
+拿起你的自拍棒跟着这个来。
+
+
+XnRetro是一个照片编辑应用
+
+### XnRetro 照片编辑器 ###
+
+**XnRetro** 是一个可以让你快速给你照片添加“类Instagram”效果的程序。
+
+你知道我说的这些效果:划痕、噪点、框架、过处理、复古和怀旧色调(因为在这个数字时代,我们必须知道无尽的自拍不能称为怀旧的自己。)
+
+无论你认为这些效果是愚蠢的艺术价值或者创作的捷径,这些滤镜非常流行切可以帮助那些平平照片添加个性。
+
+
+#### XnRetro的功能 ####
+
+**XnRetro有下面那些功能**
+
+- 20色彩滤镜
+- 15中光效果(虚化、泄露等等)
+- 28框架和边框
+- 5中插图 (带力度控制)
+- Image adjustments for contrast, gamma, saturation, etc
+- 对比度、伽马、饱和度等图像调整
+- 矩形修剪选项
+
+
+灯光效果调整
+
+你可以(理论上)编辑。jpg或者.png文件并且直接在app中等想到社交媒体上。
+
+我说“理论”上的意思是保存.jpg图像无法正常在linux版的程序上工作(你可以保存.png的图像)。相似的,大多数内置的社交链接失效或者无法导出。
+
+要使用**15中光影效果**你需要在XnRetro的‘light’文件夹下重新保存.jpg文件成.png文件。编辑‘light.xml’来匹配新的文件名,点击保存那没灯光效果就可以没有问题的加载进XnRetro了。
+
+> ‘用户友好的XnRetro很难打败-一旦你用顺之后。’
+
+**XnRetro值得安装么?**
+
+XnRetro并不是完美的。它看上去很丑、很难正确的安装并且已经纪念没有更新了。
+
+它还可以使用,输了保存.jpg文件外。同时也是那些像Gimp或者Shotwell的那些‘正规’图片调整工具的一个灵活替代品。
+
+While web apps and Chrome Apps¹ like [Pixlr Touch Up][1] and [Polarr][2] offer similar features you may be looking for a truly native solution.
+虽然web应用和Chrome Apps¹像[Pixlr Touch Up][1] 和 [Polarr][2]提供另外相似的功能,而你也许正在寻找真正原生的解决方案。
+
+对于此,用户友好带有容易使用滤镜的XnRetro很难被打败。
+
+### 下载Ubuntu下的XnRetro ###
+
+XnRetro没有可用的.deb安装包。它以二进制文件的形式发型,这意味着你需要每次双击程序来运行。它也只有32位的版本。
+
+你可以使用下面的XnRetro下载链接。下载完成后你需要解压压缩包并进入。双击里面的‘xnretro’程序。
+
+- [下载Linux版XnRetro (32位, tar.gz)][3]
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/05/instagram-photo-filters-ubuntu-desktop-app
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:http://www.omgchrome.com/?s=pixlr
+[2]:http://www.omgchrome.com/the-best-chrome-apps-of-2014/
+[3]:http://www.xnview.com/en/xnretro/#downloads
diff --git a/translated/share/20150527 How to Develop Own Custom Linux Distribution From Scratch.md b/translated/share/20150527 How to Develop Own Custom Linux Distribution From Scratch.md
new file mode 100644
index 0000000000..059f07b195
--- /dev/null
+++ b/translated/share/20150527 How to Develop Own Custom Linux Distribution From Scratch.md
@@ -0,0 +1,65 @@
+��δ����Լ���Linux���а�
+================================================================================
+���Ƿ�����������Լ���Linux���а棿ÿ��Linux�û�������ʹ��Linux�Ĺ����ж������һ�������Լ��ķ��а棬����һ�Ρ���Ҳ�����⣬��Ϊһ��Linux������Ҳ���ǹ�����һ���Լ���Linux���а档����һ��Linux���а汻����Linux From Scratch (LFS)��
+
+�ڿ�ʼ֮ǰ�����ܽ���һЩLFS�����ݣ����£�
+
+### 1. ��Щ��Ҫ���������Լ���Linux���а����Ӧ���˽����һ��Linux���а棨������ζ�Ŵ�ͷ��ʼ��������һ�����е�Linux���а�IJ�ͬ ###
+
+�����ֻ�����������Ļ��ʾ�����Ƶ�¼�Լ�ӵ�и��õ������ʹ�����顣������ѡ���κ�һ��Linux���а沢�Ұ�������ϲ�ý��и��Ի����á����⣬���������ù��߿���������
+
+������������б�����ļ���boot-loaders���ںˣ���ѡ��ʲô�ñ�����������Ȼ�������Լ�������һ�ж�������ô����ҪLinux From Scratch (LFS)��
+
+**ע��**�������ֻ��Ҫ����Linuxϵͳ����������飬���ָ�ϲ��ʺ��������������������һ��Linux���а棬�������˽���ô��ʼ�Լ�һЩ��������Ϣ����ô���ָ������Ϊ����д��
+
+### 2. ����һ��Linux���а棨LFS���ĺô� ###
+
+- �����˽�Linuxϵͳ���ڲ���������
+- ��������һ��������Ӧ�������ϵͳ
+- ��������ϵͳ��LFS������dz����գ���Ϊ���Ըð���/���ð���ʲôӵ�о��Ե��ƿ�
+- ��������ϵͳ��LFS���ڰ�ȫ���ϻ����
+
+### 3. ����һ��Linux���а棨LFS���Ļ��� ###
+
+����һ��Linuxϵͳ��ζ�Ž�������Ҫ�Ķ�������һ���ұ���֮������Ҫ������ġ����ĺ�ʱ�䡣��������Ҫһ�����õ�Linuxϵͳ���㹻�Ĵ��̿ռ�������Linuxϵͳ��
+
+### 4. ��Ȥ���ǣ�Gentoo/GNU Linux��ij����������ӽ���LFS��Gentoo��LFS������ȫ��Դ�����Ķ��Ƶ�Linuxϵͳ ###
+
+### 5. ��Ӧ����һ���о����Linux�û����Ա����������������൱���˽⣬�����Ǹ�shell�ű���ר�ҡ��˽�һ�ű�����ԣ�C��ã�����ʹ����������Щ������������һ�����֣�ֻҪ����һ�������ѧϰ�ߣ����Ժܿ������֪ʶ����Ҳ���Կ�ʼ������Ҫ���Dz�Ҫ��LFS�����ж�ʧ�������顣 ###
+
+����������ᶨ�����»���LFS���е�һ��ʱ������
+
+### 6. ��������Ҫһ��һ����ָ��������һ��Linux��LFS�Ǵ���Linux�Ĺٷ�ָ�ϡ����ǵĴ��վ��tradepubҲΪ���ǵĶ���������LFS��ָ�ϣ���ͬ������ѵġ� ###
+
+�����Դ��������������Linux From Scratch���鼮��
+
+[][1]
+
+����: [Linux From Scratch][1]
+
+### ���ڣ�Linux From Scratch ###
+
+�Ȿ������LFS����Ŀ��ͷ��Gerard Beekmans�����ģ���Matthew Burgess��Bruse Dubbs���༭�����˶���LFS��Ŀ�������쵼�ˡ��Ȿ�����ݺܹ㷺����338ҳ����
+
+�������ݰ���������LFS��������������Linux��LFS�������������ű���ʹLFS����������¼�����к���������֪����LFS��Ŀ�����ж�����
+
+�Ȿ�黹�����˱���һ������Ԥ��ʱ�䡣Ԥ����ʱ���Ա����һ������ʱ����Ϊ�ο������еĶ���������������ķ�ʽ���֣���������������˵��
+
+������г�ԣ��ʱ�䲢�������Թ����Լ���Linux���а����Ȥ����ô�����Բ������������������飨������أ��Ļ��ᡣ����Ҫ���ģ����������Ȿ����һ��������Linuxϵͳ���κ�Linux���а棬�㹻�Ĵ��̿ռ伴�ɣ��п�ʼ�������Լ���Linuxϵͳ��ʱ������顣
+
+���Linuxʹ�����ԣ���������Լ����ֹ���һ���Լ���Linux���а棬������ֽ���Ӧ��֪����ȫ���ˣ���������Ϣ�����Բο��������ӵ����е����ݡ�
+
+�������˽����Ķ�/ʹ���Ȿ��ľ������Ȿ�꾡��LFSָ�ϵ�ʹ���Ƿ��㹻��������Ѿ�������һ��LFS����������ǵĶ���һЩ���飬��ӭ���Ժͷ�����
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/create-custom-linux-distribution-from-scratch/
+
+���ߣ�[Avishek Kumar][a]
+���ߣ�[wwy-hust](https://github.com/wwy-hust)
+У�ԣ�[У����ID](https://github.com/У����ID)
+
+������ [LCTT](https://github.com/LCTT/TranslateProject) ԭ�����룬[Linux�й�](https://linux.cn/) �����Ƴ�
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://tecmint.tradepub.com/free/w_linu01/prgm.cgi
diff --git a/translated/share/20150603 Arc Is a Gorgeous GTK Theme for Linux Desktops.md b/translated/share/20150603 Arc Is a Gorgeous GTK Theme for Linux Desktops.md
new file mode 100644
index 0000000000..14dd88ef70
--- /dev/null
+++ b/translated/share/20150603 Arc Is a Gorgeous GTK Theme for Linux Desktops.md
@@ -0,0 +1,55 @@
+Arc是一个很棒的Linux桌面的GTK主题
+================================================================================
+
+
+距离本站上次推荐的GTK主题已经过了很久了。
+
+但是看到上面的Arc后,需要纠正这点了。
+
+我们不能不提到它。
+
+### Arc GTK主题 ###
+
+
+
+Transparency. Not to everyones’ taste.
+透明并不符合每个人的口味
+
+Arc是一个扁平化主题并有微妙的配色并部分选中的窗口透明,就像GTK的顶拦和Nautilus的侧边栏。
+
+
+它的效果不像我们之前的主题那样将程序渲染的像躲猫猫那样混乱。像OSX Yosemite,效果用的不变多但是很好。
+
+随之的图标集(称为Vertex)同样可用。
+
+**是的它支持Unity**
+
+Arc主题支持基于GTK3和GTK2桌面环境,包含Gnome Shell(当然)和标准的Ubuntu Unity。
+
+它也可以很好地与轻量级的Budgie和elementary的Pantheon桌面以及也可以工作在Cinnamon上。
+
+
+
+Arc中的开关、滑块和小挂件。
+
+它并不容易下载与安装- *understatement klaxon* - 因为它还在密集开发中。
+
+
+安装包需要GTK 3.14或者更新,这意味着Ubuntu 14.04 LTS和14.10的用户无法使用了。
+
+那些使用Ubuntu 15.04的用户可以使用这个主题。你还不能添加ppa或者双击.deb包。如果你喜欢你看见的你需要卷起你的袖子并查看github上的编译指导。
+
+- [Github中Arc安装指导][1]
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2015/06/arc-gtk-theme
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:https://github.com/horst3180/Arc-theme
diff --git a/translated/share/20150603 Here's How to Install the Beautiful Arc GTK+ Flat Theme on Linux.md b/translated/share/20150603 Here's How to Install the Beautiful Arc GTK+ Flat Theme on Linux.md
new file mode 100644
index 0000000000..f8d1c56d41
--- /dev/null
+++ b/translated/share/20150603 Here's How to Install the Beautiful Arc GTK+ Flat Theme on Linux.md
@@ -0,0 +1,61 @@
+如何在Linux中安装漂亮的扁平化Arc GTK+主题
+================================================================================
+> 易于看懂的每步都有的教程
+
+**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版见荣发。[这个主题叫Arc][1]。**
+
+开始讲细节之前,我建议你快速地看一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该意识到它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
+
+同样、Arc主题的开发者提醒我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
+
+### 要求和安装指导 ###
+
+要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对Fedora的pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对Fedora的gtk-murrine-engine)。
+
+Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续一步。
+
+ git clone https://github.com/horst3180/arc-theme --depth 1 && cd arc-theme
+ git fetch --tags
+ git checkout $(git describe --tags `git rev-list --tags --max-count=1`)
+ ./autogen.sh --prefix=/usr
+ sudo make install
+
+就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具或者如果你使用Unity可以使用Unity Tweak工具来激活主题。玩得开心也不要忘了在下面的评论栏里留下你的截图。
+
+
+
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://news.softpedia.com/news/Here-s-How-to-Install-the-Beautiful-Arc-GTK-plus-Flat-Theme-on-Linux-483143.shtml
+
+作者:[Marius Nestor][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/marius-nestor
+[1]:https://github.com/horst3180/Arc-theme
+[2]:
+[3]:
+[4]:
+[5]:
+[6]:
+[7]:
+[8]:
+[9]:
+[10]:
+[11]:
+[12]:
+[13]:
+[14]:
+[15]:
+[16]:
+[17]:
+[18]:
+[19]:
+[20]:
diff --git a/translated/talk/20150520 Is Linux Better than OS X GNU Open Source and Apple in History.md b/translated/talk/20150520 Is Linux Better than OS X GNU Open Source and Apple in History.md
new file mode 100644
index 0000000000..667a951f39
--- /dev/null
+++ b/translated/talk/20150520 Is Linux Better than OS X GNU Open Source and Apple in History.md
@@ -0,0 +1,57 @@
+Linux比Mac OS X更好吗?历史中的GNU,开源和Apple
+==============================================================================
+> 自由软件/开源社区与Apple之间的争论可以回溯到上世纪80年代,当时Linux的创始人称Mac OS X的核心就是"一个废物",还有其他一些软件历史上的轶事。
+
+
+
+开源拥护者们与微软之间有着很长,而且摇摆的关系。每个人都知道这个。但是,在许多方面,自由或者开源软件的支持者们与Apple之间的紧张关系则更加突出——尽管这很少受到媒体的关注。
+
+需要说明的是,并不是所有的开源拥护者都厌恶苹果。Anecdotally(待译),我已经见过很多Linux的黑客玩弄iPhones和iPads。实际上,许多Linux用户是十分喜欢Apple的OS X系统的,以至于他们[创造了很多Linux的发行版][1],都设计得看起来像OS X。(顺便说下,[北朝鲜政府][2]就这样做了。)
+
+但是Mac的信徒与企鹅——即Linux社区(未提及自由与开源软件世界的小众群体)的信徒之间的关系,并不一直是完全的和谐。并且这绝不是一个新的现象,在我研究Linux历史和开源基金会的时候就发现了。
+
+### GNU vs. Apple ###
+
+这场战争将回溯到至少上世界80年代后期。1988年6月,Richard Stallman发起了[GNU][3]项目,希望建立一个完全自由的类Unix操作系统,其源代码讲会免费共享,[[强烈指责][4]Apple对[Hewlett-Packard][5](HPQ)和[Microsoft][6](MSFT)的诉讼,称Apple的声明中,说别人对Macintosh操作系统的界面和体验的抄袭是不正确。如果Apple流行,GNU警告到,这家公司“将会借助大众的新力量终结掉自由软件,而自由软件可以成为商业软件的替代品。”
+
+那个时候,GNU对抗Apple的诉讼(这意味着,十分讽刺的是,GNU正在支持Microsoft,尽管当时的情况不一样),通过发布["让你的律师远离我的电脑”按钮][7]。同时呼吁GNU的支持者们抵制Apple,警告如果Macintoshes看起来是不错的计算机,但Apple一旦赢得了诉讼就会给市场带来垄断,这会极大地提高计算机的售价。
+
+Apple最终[输掉了诉讼][8],但是直到1994年之后,GNU才[撤销对Apple的抵制][9]。这期间,GNU一直不断指责Apple。在上世纪90年代早期甚至之后,GNU开始发展GNU软件项目,可以在其他个人电脑平台包括MS-DOS上使用。[GNU 宣称][10],除非Apple停止在计算机领域垄断的野心,让用户界面可以模仿Macintosh的一些东西,否则“我们不会提供任何对Apple机器的支持。”(因此讽刺的是一大堆软件都开发了OS X和类Unix系统的版本,于是Apple在90年代后期介绍这些软件来自GNU。但是那是另外的故事了。)
+
+### Trovalds on Jobs ###
+
+除去他对大多数发行版比较自由放任的态度,Liuns Trovalds,Linux内核的创造者,相较于Stallman和GNU过去对Apple的态度没有多一点仁慈。在他2001年出版的书"Just For Fun: The Story of an Accidental Revolutionary"中,Trovalds描述到与Steve Jobs的一个会面,大约是1997年收到后者的邀请去讨论Mac OS X,Apple正在开发,但还没有公开发布。
+
+"基本上,Jobs一开始就试图告诉我在桌面上的玩家就两个,Microsoft和Apple,而且他认为我能为Linux做的最好的事,就是从了Apple,努力让开源用户站到Mac OS X后面去"Trovalds写道。
+
+这次谈判显然让Trovalds很不爽。争吵的一点集中在Trovalds对Mach技术上的藐视,对于Apple正在用于构建新的OS X操作系统的内核,Trovalds称其“一推废物。它包含了所有你能做到的设计错误,并且甚至打算只弥补一小部分。”
+
+但是更令人不快的是,显然是Jobs在开发OS X时入侵开源的方式(OS X的核心里上有很多开源程序):“他有点贬低了结构的瑕疵:谁在乎基础操作系统,真正的low-core东西是不是开源,如果你有Mac层在最上面,这不是开源?”
+
+一切的一切,Trovalds总结到,Jobs“并没有使用太多争论。他仅仅很简单地说着,胸有成竹地认为我会对与Apple合作感兴趣”。“他没有任何线索,不能去想像还会有人并不关心Mac市场份额的增长。我认为他真的感到惊讶了,当我表现出对Mac的市场有多大,或者Microsoft市场有多大的可怜的关心时。”
+
+当然,Trovalds并没有对所有Linux用户说起。他对于OS X和Apple的看法从2001年开始就渐渐软化了。但实际上,早在2000年,Linux社区的领导角色表现出对Apple和其高层的傲慢的深深的鄙视,可以看出一些重要的东西,关于Apple和开源/自由软件世界的矛盾是多么的根深蒂固。
+
+从以上两则历史上的花边新闻中,可以看到关于Apple产品价值的重大争议,即是否该公司致力于提升软硬件的质量,或者仅仅是借市场的小聪明获利,后者会让Apple产品卖出更多的钱,**********(该处不知如何翻译)。但是不管怎样,我会暂时置身讨论之外。
+
+--------------------------------------------------------------------------------
+
+via: http://thevarguy.com/open-source-application-software-companies/051815/linux-better-os-x-gnu-open-source-and-apple-
+
+作者:[Christopher Tozzi][a]
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://thevarguy.com/author/christopher-tozzi
+[1]:https://www.linux.com/news/software/applications/773516-the-mac-ifying-of-the-linux-desktop/
+[2]:http://thevarguy.com/open-source-application-software-companies/010615/north-koreas-red-star-linux-os-made-apples-image
+[3]:http://gnu.org/
+[4]:https://www.gnu.org/bulletins/bull5.html
+[5]:http://www.hp.com/
+[6]:http://www.microsoft.com/
+[7]:http://www.duntemann.com/AppleSnakeButton.jpg
+[8]:http://www.freibrun.com/articles/articl12.htm
+[9]:https://www.gnu.org/bulletins/bull18.html#SEC6
+[10]:https://www.gnu.org/bulletins/bull12.html
diff --git a/translated/talk/The history of Android/13 - The history of Android.md b/translated/talk/The history of Android/13 - The history of Android.md
new file mode 100644
index 0000000000..8929f55064
--- /dev/null
+++ b/translated/talk/The history of Android/13 - The history of Android.md
@@ -0,0 +1,104 @@
+安卓编年史
+================================================================================
+
+
+### Android 2.1, update 1——无尽战争的开端 ###
+
+谷歌是第一代iPhone的主要合作伙伴——公司为苹果的移动操作系统提供了谷歌地图,搜索,以及Youtube。在那时,谷歌CEO埃里克·施密特是苹果的董事会成员之一。实际上,在最初的苹果发布会上,施密特是在史蒂夫·乔布斯[之后第一个登台的人][1],他还开玩笑说两家公司如此接近,都可以合并成“AppleGoo”了。
+
+当谷歌开发安卓的时候,两家公司间的关系慢慢变得充满争吵。然而,谷歌很大程度上还是通过拒iPhone关键特性于安卓门外,如双指缩放,来取悦苹果。尽管如此,Nexus One是第一部不带键盘的直板安卓旗舰机,设备被赋予了和iPhone相同的外观因素。Nexus One结合了新软件和谷歌的品牌,这是压倒苹果的最后一根稻草。根据沃尔特·艾萨克森为史蒂夫·乔布斯写的传记,2010年1月在看到了Nexus One之后,这个苹果的CEO震怒了,说道:“如果需要的话我会用尽最后一口气,以及花光苹果在银行里的400亿美元,来纠正这个错误……我要摧毁安卓,因为它完全是偷窃来的产品。我愿意为此进行核战争。”
+
+所有的这些都在秘密地发生,仅在Nexus One发布后的几年后才公诸于众。公众们最早在安卓2.1——推送给Nexus One的一个称作“[2.1 update 1][2]”的更新,发布后一个月左右捕捉到谷歌和苹果间愈演愈烈的分歧气息。这个更新添加了一个功能,正是iOS一直居于安卓之上的功能:双指缩放。
+
+尽管安卓从2.0版本开始就支持多点触控API了,默认的系统应用在乔布斯的命令下依然和这项实用的功能划清界限。在关于Nexus One的和解会议谈崩了之后,谷歌再也没有理由拒双指缩放于安卓门外了。谷歌给设备推送了更新,安卓终于补上了不足之处。
+
+随着谷歌地图,浏览器以及相册中双指缩放的全面启用,谷歌和苹果的智能手机战争也就此拉开序幕。在接下来的几年中,两家公司会变成死敌。双指缩放更新的一个月后,苹果开始了他的征途,起诉了所有使用安卓的公司。HTC,摩托罗拉以及三星都被告上法庭,直到现在都还有一些诉讼还没解决。施密特辞去了苹果董事会的职务。谷歌地图和Youtube被从iPhone中移除,苹果甚至开始打造自己的地图服务。今天,这两位选手几乎是“AppleGoo”竞赛的唯一选手,涉及领域十分广:智能手机,平板,笔记本,电影,TV秀,音乐,书籍,应用,邮件,生产力工具,浏览器,个人助理,云存储,移动广告,即时通讯,地图以及机顶盒……以及不久他们将会在汽车智能,穿戴设备,移动支付,以及客厅娱乐等进行竞争。
+
+### Android 2.2 Froyo——更快更华丽 ###
+
+[安卓2.2][3]在2010年5月,也就是2.1发布后的四个月后亮相。Froyo(冻酸奶)的亮点主要是底层优化,只为更快的速度。Froyo最大的改变是增加了JIT编译。JIT自动在运行时将java字节码转换为原生码,这会给系统全面带来显著的性能改善。
+
+浏览器同样得到了性能改善,这要感谢来自Chrome的V8 Javascript引擎的整合。这是安卓浏览器从Chrome借鉴的许多特性中的第一个,最终系统内置的浏览器会被移动版Chrome彻底替代掉。在那之前,安卓团队还是需要发布一个浏览器。从Chrome借鉴特性是条升级的捷径。
+
+在谷歌专注于让它的平台更快的同时,苹果正在让它的平台更全面。谷歌的竞争对手在一个月前发布了10英寸的iPad,先行进入了平板时代。尽管有些搭载Froyo和Gingerbread的安卓平板发布,谷歌的官方回应——安卓3.0 Honeycomb(蜂巢)以及摩托罗拉Xoom——在9个月后才来到。
+
+
+Froyo底部添加了双图标停靠栏以及全局搜索。
+Ron Amadeo供图
+
+Froyo主屏幕最大的变化是底部的新停靠栏,电话和浏览器图标填充了先前抽屉按钮左右的空白空间。这些新图标都是现有图标的定制白色版本,并且用户没办法自己设置图标。
+
+默认布局移除了所有图标,屏幕上只留下一个使用提示小部件,引导你点击启动器图标以访问你的应用。谷歌搜索小部件得到了一个谷歌logo,同时也是个按钮。点击它可以打开一个搜索界面,你可以限制搜索范围在互联网,应用或是联系人之内。
+
+
+下载页面有了“更新所有”按钮,Flash应用,一个flash驱动的一切皆有可能的网站,以及“移动到SD”按钮。
+[Ryan Paul][4]供图
+
+还有一些优秀的新功能加入了Froyo,安卓市场加入了更多的下载控制。有个新的“更新所有”按钮固定在了下载页面底部。谷歌还添加了自动更新特性,只要应用权限没有改变就能够自动安装应用;尽管如此,自动更新默认是关闭的。
+
+第二张图展示了Adobe Flash播放器,它是Froyo独占的。这个应用作为插件加入了浏览器,让浏览器能够有“完整的网络”体验。在2010年,这意味着网页充满了Flash导航和视频。Flash是安卓相比于iPhone最大的不同之一。史蒂夫·乔布斯展开了一场对抗Flash的圣战,声称它是一个被淘汰的,充满bug的软件,并且苹果不会在iOS上允许它的存在。所以安卓接纳了Flash并且让它在安卓上运行,给予用户在安卓上拥有半可用的flash实现。
+
+在那时,Flash甚至能够让桌面电脑崩溃,所以在移动设备上一直保持打开状态会带来可怕的体验。为了解决这个问题,安卓浏览器上的Flash可以设置为“按需打开”——除非用户点击Flash占位图标,否则不会加载Flash内容。对Flash的支持将会持续到安卓4.1,Adobe在那时放弃并且结束了这个项目。Flash归根到底从未在安卓上完美运行过。而Flash在iPhone这个最流行的移动设备上的缺失,推动了互联网最终放弃了这个平台。
+
+最后一张图片显示的是新增的移动应用到SD卡功能,在那个手机只有512MB内置存储的时代,这个功能十分的必要的。
+
+
+驾驶模式应用。相机现在可以旋转了。
+Ron Amadeo供图
+
+相机应用终于更新支持纵向模式了。相机设置被从抽屉中移出,变成一条半透明的按钮带,放在了快门按钮和其他控制键旁边。这个新设计看起来从Cooliris相册中获得了许多灵感,有着半透明,有弹性的聊天气泡弹出窗口。看到更现代的Cooliris风格UI设计被嫁接到皮革装饰的相机应用确实十分奇怪——从审美上来说一点都不搭。
+
+
+半残缺的Facebook应用是个常见的2x3导航页面的优秀范例。谷歌Goggles被包含了进来但同样是残缺的。
+Ron Amadeo供图
+
+不像在安卓2.0和2.1中包含的Facebook客户端,2.2版本的仍然部分能够工作并且登陆Facebook服务器。Facebook应用是个谷歌那时候设计指南的优秀范例,它建议应用拥有一个含有3x2图标方阵的导航页并作为应用主页。
+
+这是谷歌的第一个标准化尝试,将导航元素从菜单按钮里移到屏幕上,因为用户找不到它们。这个设计很实用,但它在打开应用和使用应用之间增加了额外的障碍。谷歌不久后湖意识到当用户打开一个应用,显示应用内容而不是中间导航页是个更好的主意。以Facebook为例,打开应用直接打开信息订阅会更合适。并且不久后应用设计将会把导航降级到二层位置——先是作为顶部的标签之一,后来谷歌放在了“导航抽屉”,一个含有应用所有功能位置的滑出式面板。
+
+还有个预装到Froyo的是谷歌Goggles,一个视觉搜索应用,它会尝试辨别图片上的主体。它在辨别艺术品,地标以及条形码时很实用,但差不多也就这些了。最先的两个设置屏幕,以及相机界面,这是应用里唯一现在还能运行的了。由于客户端太旧了,实际上你如今并不能完成一个搜索。应用里也没什么太多可看的,也就一个会返回搜索结果页的相机界面而已。
+
+
+Twitter应用,一个充满动画的谷歌和Twitter的合作成果。
+Ron Amadeo供图
+
+Froyo拥有第一个安卓Twitter应用,实际上它是谷歌和Twitter的合作成果。那时,一个Twitter应用是安卓应用阵容里的大缺憾。开发者们更偏爱iPhone,加上苹果占领先机和严格的设计要求,App Store里可选择的应用远比安卓的有优势。但是谷歌需要一个Twitter应用,所以它和Twitter合作组建团队让第一个版本问世。
+
+这个应用代表了谷歌的新设计语言,这以为着它有个中间导航页以及对动画要求的“技术演示”。Twitter应用甚至比Cooliris相册用的动画效果还多——所有东西一直都在动。所有页面顶部和底部的云朵以不同速度持续滚动,底部的Twitter小鸟拍动它的翅膀并且左右移动它的头。
+
+Twitter应用实际上有点Action Bar早期前身的特性,一条顶部对齐的连续控制条在安卓3.0中被引入。沿着所有屏幕的顶部有条拥有Twitter标志和像搜索,刷新和新tweet这样的按钮的蓝色横栏。它和后来的Action Bar之间大的区别在于Twitter/谷歌这里的设计的右上角缺少“上一级”按钮,实际上它在应用里用了完整的第二个栏位显示你当前所在位置。在上面的第二张图里,你可以看到整条带有“Tweets”标签的专用于显示位置的栏(当然,还有持续滚动的云朵)。第二个栏的Twitter标志扮演着另一个导航元素,有时候在当前部分显示额外的下拉区域,有时候显示整个顶级快捷方式集合。
+
+2.3Tweet流看起来和今天的并没有什么不同,除了隐藏的操作按钮(回复,转推等),都在右对齐的箭头按钮里。它们弹出来是一个聊天气泡菜单,看起来就像导航弹窗。仿action bar在新tweet页面有重要作用。它安置着twitter标志,剩余字数统计,以及添加照片,拍照,以及提到联系人按钮。
+
+Twitter应用甚至还有一对主屏幕小部件,大号的那个占据8格,给你新建栏,更新按钮,一条tweet,以及左右箭头来查看更多tweet。小号的显示一条tweet以及回复按钮。点击大号小部件的新建栏立即打开了“新Tweet”主窗口,这让“更新”按钮变得没有价值。
+
+
+Google Talk和新USB对话框。
+Ron Amadeo供图
+
+其他部分,Google Talk(以及没有截图的短信应用)从暗色主题变成了浅色主题,这让它们看起来和现在的更接近现在的,更现代的应用。USB存储界面会在你设备接入电脑的时候从一个简单的对话框进入全屏界面。这个界面现在有个一个异形安卓机器人/USB闪存盘混合体,而不是之前的纯文字设计。
+
+尽管安卓2.2在用户互动方式上没有什么新特性,但大的UI调整会在下两个版本到来。然而在所有的UI工作之前,谷歌希望先改进安卓的核心部分。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/13/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://www.youtube.com/watch?v=9hUIxyE2Ns8#t=3016
+[2]:http://arstechnica.com/gadgets/2010/02/googles-nexus-one-gets-multitouch/
+[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
+[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/talk/The history of Android/14 - The history of Android.md b/translated/talk/The history of Android/14 - The history of Android.md
new file mode 100644
index 0000000000..ce808f63da
--- /dev/null
+++ b/translated/talk/The history of Android/14 - The history of Android.md
@@ -0,0 +1,82 @@
+安卓编年史
+================================================================================
+### 语音操作——口袋里的超级电脑 ###
+
+2010年8月,作为语音搜索应用的一项新功能,“[语音命令][1]”登陆了安卓市场。语音命令允许用户向他们的手机发出语音命令,然后安卓会试着去理解他们并完成任务。像“导航至[地址]”这样的命令会打开谷歌地图并且开始逐向导航至你所陈述的目的地。你还可以仅仅通过语音来发送短信或电子邮件,拨打电话,打开网站,获取方向,或是在地图上查看一个地点。
+
+注:youtube视频地址
+
+
+语音命令是谷歌新应用设计哲学的顶峰。语音命令是那时候最先进的语音控制软件,秘密在于谷歌并不在设备上做任运算。一般来说,语音识别是对CPU的密集任务要求。实际上,许多语音识别程序仍然有“速度与准确性”设置,用户可以选择他们愿意为语音识别算法运行等待的时间——更多的CPU处理意味着更加准确。
+
+谷歌的创新在于没有劳烦手机上能力有限的处理器来进行语音识别运算。当说出一个命令时,用户的声音会被打包并通过互联网发送到谷歌云服务器。在那里,谷歌超算中心的超级计算机分析并解释语音,然后发送回手机。这是很长的一段旅程,但互联网最终还是有足够快的速度在一两秒内完成像这样的任务。
+
+很多人抛出词语“云计算”来表达“所有东西都被存储在服务器上”,但这才是真正的云计算。谷歌在云端进行这些巨量的运算操作,又因为在这个问题上投入了看似荒唐的CPU资源数目,所以语音识别准确性的唯一限制就是算法本身了。软件不需要由每个用户独立“训练”,因为所有使用语音操作的人无时不刻都在训练它。借助互联网的力量,安卓在你的口袋里放了一部超级电脑,同时相比于已有的解决方案,把语音识别这个工作量从口袋大小的电脑转移到房间大小的电脑上大大提高了准确性。
+
+语音识别作为谷歌的项目已经有一段时间了,它的出现都是因为一个800号码。[1-800-GOOG-411][2]是个谷歌从2007年4月起开通的免费电话信息服务。它就像411信息服务一样工作了多年——用户可以拨打这个号码询问电话号码——但是谷歌免费提供这项服务。查询过程中没有人工的干预,411服务由语音识别和文本语音转换引擎驱动。语音命令就是人们教谷歌如何去听之后三年才有实现的可能。
+
+语音识别是谷歌长远思考的极佳范例——公司并不怕在一个可能成不了商业产品的项目上投资多年。今天,语音识别驱动的产品遍布谷歌。它被用在谷歌搜索应用的输入,安卓的语音输入,以及Google.com。同时它还是Google Glass和[Android Wear][3]的默认输入界面。
+
+谷歌甚至还在输入之外的地方使用语音识别。谷歌的语音识别技术被用在了转述Youtube视频上,它能自动生成字幕供听障用户观看。生成的字幕甚至被谷歌做成了索引,所以你可以搜索某句话在视频的哪里说过。语音是许多产品的未来,并且这项长期计划将谷歌带入了屈指可数的拥有自家语音识别服务的公司行列。大部分其它的语音识别产品,像苹果的Siri和三星设备,被迫使用——并且为其支付了授权费——Nuance的语音识别。
+
+在计算机听觉系统设立运行之后,谷歌下一步将把这项策略应用到计算机视觉上。这就是为什么像Google Goggles,Google图像搜索和[Project Tango][4]这样的项目存在的原因。就像GOOG-411的那段日子,这些项目还处在早期阶段。当[谷歌的机器人部门][5]造出了机器人,它会需要看和听,谷歌的计算机视觉和听觉项目会给谷歌一个先机。
+
+
+Nexus S,第一部三星制造的Nexus手机。
+
+### Android 2.3 Gingerbread——第一次UI大变 ###
+
+Gingerbread(姜饼人)发布于2010年12月,这已是2.2发布整整七个月之后了。尽管如此,等待是值得的,因为安卓2.3整个系统的每个界面几乎都改变了。这是从安卓0.9最初的样式以来第一次重大的更新。2.3开始了一系列持续的改进,试着将安卓从丑陋的小鸭子变成能承载它自己的合适的样子——从美学角度——来对抗iPhone。
+
+说到苹果,六个月前,它发布了iPhone 4和iOS 4,新增了多任务处理和Facetime视频聊天。微软同样也终于重返这场游戏。微软在2010年11月发布了Windows Phone 7,也进入了智能手机时代。
+
+安卓2.3在界面设计上投入了很多精力,但是由于缺乏方向或设计文档,许多应用仅仅止步于获得了一个新的定制主题而已。一些应用用了更扁平的暗色主题,一些用了充满渐变,活泼的暗色主题,其他应用则是高对比度的白色和绿色组合。尽管2.3并没有做到风格统一,Gingerbread还是完成了让系统几乎每个部分变得更现代化的任务。这同样是件好事,因为下一个手机版安卓要在将近一年后才到来。
+
+Gingerbread的首发设备是Nexus S,谷歌的第二部旗舰设备,并且是第一部由三星生产的Nexus设备。尽管今天我们已经习惯了每年都有更新型号的CPU,那时候可不是这个样子。Nexus S有个1GHz Cortex A8处理器,和Nexus One是一样的。GPU从速度来说略微有所变快。Nexus S稍微比Nexus One大一点,拥有800×480分辨率的AMOLED显示屏。
+
+从参数上来说,Nexus S看起来只是个平淡无奇的升级,但他确实开了安卓的许多先河。Nexus S是谷歌第一部没有MicroSD卡槽的旗舰,板载16GB存储。Nexus One只有512MB存储空间,但它有MicroSD卡槽。移除SD卡槽为用户简化了存储管理——现在只有一个存储地点了——但是影响了高级用户的扩展能力。它是谷歌第一部带有NFC的手机,手机背面的一个特殊芯片能够在和其他NFC芯片接触时传输数据。Nexus S暂时只能读取NFC标签,而不能发送数据。
+
+托Gingerbread中一些升级的福,Nexus S是第一部不带有硬件十字方向键或轨迹球安卓手机之一。Nexus S缩减到只有电源,音量以及四个导航键。Nexus S同时还是如今[疯狂的曲面手机][6]的先驱,因为三星给Nexus S配备了一块略微有些弯曲的玻璃。
+
+
+Gingerbread更改了状态栏和壁纸,并且添加了许多新图标。
+Ron Amadeo供图
+
+升级过的“Nexus”动态壁纸作为Nexus S的独占发布。这个壁纸基本上和Nexus One的一样,带有带动画轨迹的光点。在Nexus S上,去除了方阵设计,取而代之的是波浪形的蓝/灰色背景。底部dock有了直角和彩色图标。
+
+
+新通知面板和菜单。
+Ron Amadeo供图
+
+状态栏自0.9的首次登场以来终于得到了重制。状态栏从白色渐变变成纯黑,所有图标重绘成了灰色和绿色。所有东西看起来都更加清爽和现代,这要感谢锐角图标设计和高分辨率。最奇怪的决定可能是从状态栏时钟移除了时间段显示以及信号强度那令人疑惑的灰色。尽管灰色被用在状态栏的许多图标上,而且上面截图有四格灰色信号,安卓实际上指示的是没有信号。绿色格表示信号强度,灰色格指示的是“空”信号格。
+
+Gingerbread的状态栏图标同时还作为网络连接的状态指示。如果你的设备连接到了谷歌的服务器,图标会变绿,如果没有谷歌的连接,图标会是白色的。这让你可以在外出时轻松了解你的网络连接状态。
+
+通知面板的设计从安卓1.5的设计改进而来。我们看到UI部分再次从浅色主题变为暗色主题,有个深灰色顶部,黑色背景以及在灰色底色上的黑色文本。
+
+菜单颜色同样变深了,背景从白色变成了带点透明的黑色。菜单图标和背景的对比并没有它应该有的那么强烈,因为灰色图标的颜色和它们在白色背景上的时候是一样的。要求改变颜色意味着每个开发者都得制作新的图标,所以谷歌在黑色背景上使用了先前就有的灰色。这是系统级别的改变,所以这个新菜单会出现在每个应用中。
+
+----------
+
+
+
+[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
+
+[@RonAmadeo][t]
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/14/
+
+译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2010/08/google-beefs-up-voice-search-mobile-sync/
+[2]:http://arstechnica.com/business/2007/04/google-rolls-out-free-411-service/
+[3]:http://arstechnica.com/gadgets/2014/03/in-depth-with-android-wear-googles-quantum-leap-of-a-smartwatch-os/
+[4]:http://arstechnica.com/gadgets/2014/02/googles-project-tango-is-a-smartphone-with-kinect-style-computer-vision/
+[5]:http://arstechnica.com/gadgets/2013/12/google-robots-former-android-chief-will-lead-google-robotics-division/
+[6]:http://arstechnica.com/gadgets/2013/12/lg-g-flex-review-form-over-even-basic-function/
+[a]:http://arstechnica.com/author/ronamadeo
+[t]:https://twitter.com/RonAmadeo
diff --git a/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md b/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md
deleted file mode 100644
index 17da6a9508..0000000000
--- a/translated/tech/20141127 dupeGuru--Find And Remove Duplicate Files Instantly From Hard Drive.md
+++ /dev/null
@@ -1,105 +0,0 @@
-dupeGuru - 直接从硬盘中查找并移除重复文件
-================================================================================
-
-### 简介 ###
-
-对我们来说,磁盘被装满是一个较大的困扰。无论我们如何小心谨慎,我们总可能将相同的文件复制到多个不同的地方,或者在不知情的情况下,重复下载了同一个文件。因此,迟早你会看到“磁盘已满”的错误提示,若此时我们确实需要一些磁盘空间来存储重要数据,以上情形无疑是最糟糕的。假如你确信自己的系统中有重复文件,那么 **dupeGuru** 可能会帮助到你。
-
-dupeGuru 团队也开发了名为 **dupeGuru 音乐版** 的应用来移除重复的音乐文件,和名为 **dupeGuru 图片版** 的应用来移除重复的图片文件。
-
-### 1. dupeGuru (标准版) ###
-
-对于那些不熟悉 [dupeGuru][1] 的人来说,它是一个免费,开源,跨平台的应用,其用途是在系统中查找和移除重复文件。它可以在 Linux, Windows, 和 Mac OS X 等平台下使用。通过使用一个快速的模糊匹配算法,它可以在几分钟内找到重复文件。同时,你还可以调整 dupeGuru 使它去精确查找特定文件类型的重复文件,以及从你想删除的文件中,消除特定的某些文件。它支持英语、 法语、 德语、 中文 (简体)、 捷克语、 意大利语、亚美尼亚语、 俄语、乌克兰语、巴西语和越南语。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru ####
-
-dupeGuru 开发者已经构建了一个 Ubuntu PPA (Personal Package Archives)来简化安装过程。为了安装 dupeGuru,依次在终端中键入以下命令:
-
-```
-sudo apt-add-repository ppa:hsoft/ppa
-sudo apt-get update
-sudo apt-get install dupeguru-se
-```
-
-### 使用 ###
-
-使用非常简单,可从 Unity 面板或菜单中启动 dupeGuru 。
-
-
-
-点击位于底部的 `+` 按钮来添加你想扫描的文件目录。点击 `扫描` 按钮开始查找重复文件。
-
-
-
-一旦所选目录中含有重复文件,则它将在窗口中展示重复文件。正如你所看到的,在下面的截图中,我的下载目录中有一个重复文件。
-
-
-
-现在,你可以决定下一步如何操作。你可以删除这个重复的文件,或者对它进行重命名,抑或是 复制/移动 这个文件到另一个位置。为此,选定该重复文件,或 在菜单栏中选定写有“**仅显示重复**”选项 ,如果你选择了“**仅显示重复**”选项,则只有重复文件在窗口中可见,这样你便可以轻易地选择并删除这些文件。点击“操作”下拉菜单,最后选择你将执行的操作。在这里,我只想删除重复文件,所以我选择了“移动标记文件到垃圾箱”这个选项。
-
-
-
-接着,点击“继续”选项来移除重复文件。
-
-
-
-### 2. dupeGuru 音乐版 ###
-
-[dupeGuru 音乐版][2] 或 简称 dupeGuru ME ,它的功能与 dupeGuru 类似。它拥有 dupeGuru 的所有功能,但它包含更多的信息列 (如比特率,持续时间,标签等)和更多的扫描类型(如带有字段的文件名,标签以及音频内容)。同 dupeGuru 一样, dupeGuru ME 也运行在 Linux, Windows, 和 Mac OS X 中。
-
-它支持众多的格式,诸如 MP3, WMA, AAC (iTunes 格式), OGG, FLAC, 即失真率较少的 AAC 和 WMA 格式等。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru ME ####
-
-现在,我们不必再添加任何 PPA,因为在前面的步骤中,我们已经进行了添加。所以在终端中键入以下命令来安装它:
-
-```
-sudo apt-get install dupeguru-me
-```
-
-### 使用 ###
-
-你可以从 Unity 面板或菜单中启动它。dupeGuru ME 的使用方法,操作界面和外观与正常的 dupeGuru 类似。添加你想扫描的目录并选择你想执行的操作。重复的音乐文件就会被删除。
-
-
-
-### 3. dupeGuru 图片版 ###
-
-[dupeGuru 图片版][3],或简称为 duepGuru PE,是一个在你的电脑中查找重复图片的工具。它与 dupeGuru 类似,但独具匹配重复图片的功能。dupeGuru PE 可运行在 Linux, Windows, 和 Mac OS X 中。
-
-dupeGuru PE 支持 JPG, PNG, TIFF, GIF 和 BMP 等图片格式。所有的这些格式可以被同时比较。Mac OS X 版的 dupeGuru PE 还支持 PSD 和 RAW (CR2 和 NEF) 格式。
-
-#### 在 Ubuntu 14.10/14.04/13.10/13.04/12.04 中安装 dupeGuru PE ####
-
-由于我们已经添加了 PPA, 我们也不必为 dupeGuru PE 添加 PPA。只需运行如下命令来安装它。
-
-```
-sudo apt-get install dupeguru-pe
-```
-
-#### 使用 ####
-
-就使用方法,操作界面和外观而言,它与 dupeGuru ,dupeGuru ME 类似。我就纳闷为什么开发者为不同的类别开发了不同的版本。我想如果开发一个结合以上三个版本功能的应用,或许会更好。
-
-启动它,添加你想扫描的目录,并选择你想执行的操作。就这样,你的重复文件将消失。
-
-
-
-如若因为任何的安全问题而不能移除某些重复文件,请记下这些文件的位置,通过终端或文件管理器来手动删除它们。
-
-欢呼吧!
-
---------------------------------------------------------------------------------
-
-via: http://www.unixmen.com/dupeguru-find-remove-duplicate-files-instantly-hard-drive/
-
-作者:[SK][a]
-译者:[FSSlc](https://github.com/FSSlc)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.unixmen.com/author/sk/
-[1]:http://www.hardcoded.net/dupeguru/
-[2]:http://www.hardcoded.net/dupeguru_me/
-[3]:http://www.hardcoded.net/dupeguru_pe/
diff --git a/translated/tech/20141211 How to use matplotlib for scientific plotting on Linux.md b/translated/tech/20141211 How to use matplotlib for scientific plotting on Linux.md
deleted file mode 100644
index 29c03c4c91..0000000000
--- a/translated/tech/20141211 How to use matplotlib for scientific plotting on Linux.md
+++ /dev/null
@@ -1,158 +0,0 @@
-+在Linux中使用matplotlib进行科学画图
-+================================================================================
-+
-+如果你想要在Linxu中获得一个高效、自动化、高质量的科学画图的解决方案,那就要考虑一下使用matplotlib库了。Matplotlib是基于python的开源科学测绘包,版权基于python软件基金许可证。大量的文档和例子,整合在Python和Numpy科学计处包中,其自动化性能是少数几个为什么这个包是在Linux环境中进行科学画图的可靠选择。这个教程将提供几个用matplotlib画图的例子。
-+
-+###特性###
-+-
-+-众多的画图类型,如:bar,box,contour,histogram,scatter,line plots....
-+-基于python的语法
-+-集成Numpy科学计算包
-+-可定制的画图格式(axes scales,tick positions, tick labels...)
-+-可定制文本(字体,大小,位置...)
-+-TeX 格式化(等式,符号,希腊字体...)
-+-与IPython相兼容
-+-自动化 -用Python 的循环迭代生成图片
-+-保存所绘图片格式为图片文件,如:png,pdf,ps,eps,svg等
-+
-+
-+基于Python语法的matplotlib通过许多自身特性和高效工作流基础进行表现。
-+世面上有许多用于绘制高质量图的科学绘图包,但是这些包允许你直接在你的Python代码中去使用吗?
-+除那以外,这些包允许你创建可以保存为图片文件的图片吗?
-+Matplotlib允许你完成所有的这些任务。
-+你可以期望着节省你的时间,从于使用你能够花更多的时间在如何创建更多的图片。
-+
-+###安装###
-+ 安装Python和Numpy包是使用Matplotlib的前提,安装Numpy的指引请见该链接。[here][1].
-+
-+
-+可以通过如下命令在Debian或Ubuntu中安装Matplotlib:
-+
-+ $ sudo apt-get install python-matplotlib
-+
-+
-+在Fedora或CentOS/RHEL环境则可用如下命令:
-+ $ sudo yum install python-matplotlib
-+
-+
-+###Matplotlib 例子###
-+
-+该教程会提供几个绘图例子演示如何使用matplotlib:
-+-离散和线性画图
-+-柱状图画图
-+-饼状图
-+
-+在这些例子中我们将用Python脚本来执行Mapplotlib命令。注意numpy和matplotlib模块需要通过import命令在脚本中进行导入。
-+在命令空间中,np指定为nuupy模块的引用,plt指定为matplotlib.pyplot的引用:
-+ import numpy as np
-+ import matplotlib.pyplot as plt
-+
-+
-+###例1:离散和线性图###
-+
-+第一个脚本,script1.py 完成如下任务:
-+
-+-创建3个数据集(xData,yData1和yData2)
-+-创建一个宽8英寸、高6英寸的图(赋值1)
-+-设置图画的标题、x轴标签、y轴标签(字号均为14)
-+-绘制第一个数据集:yData1为xData数据集的函数,用圆点标识的离散蓝线,标识为"y1 data"
-+-绘制第二个数据集:yData2为xData数据集的函数,采用红实线,标识为"y2 data"
-+-把图例放置在图的左上角
-+-保存图片为PNG格式文件
-+
-+script1.py的内容如下:
-+ import numpy as np
-+ import matplotlib.pyplot as plt
-+
-+ xData = np.arange(0, 10, 1)
-+ yData1 = xData.__pow__(2.0)
-+ yData2 = np.arange(15, 61, 5)
-+ plt.figure(num=1, figsize=(8, 6))
-+ plt.title('Plot 1', size=14)
-+ plt.xlabel('x-axis', size=14)
-+ plt.ylabel('y-axis', size=14)
-+ plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
-+ plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
-+ plt.legend(loc='upper left')
-+ plt.savefig('images/plot1.png', format='png')
-+
-+
-+所画之图如下:
-+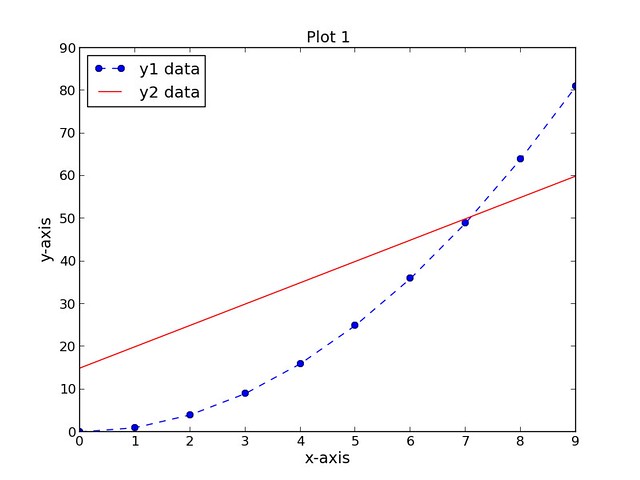
-+
-+
-+###例2:柱状图###
-+
-+第二个脚本,script2.py 完成如下任务:
-+
-+-创建一个包含1000个随机样本的正态分布数据集。
-+-创建一个宽8英寸、高6英寸的图(赋值1)
-+-设置图的标题、x轴标签、y轴标签(字号均为14)
-+-用samples这个数据集画一个40个柱状,边从-10到10的柱状图
-+-添加文本,用TeX格式显示希腊字母mu和sigma(字号为16)
-+-保存图片为PNG格式。
-+
-+script2.py代码如下:
-+ import numpy as np
-+ import matplotlib.pyplot as plt
-+
-+ mu = 0.0
-+ sigma = 2.0
-+ samples = np.random.normal(loc=mu, scale=sigma, size=1000)
-+ plt.figure(num=1, figsize=(8, 6))
-+ plt.title('Plot 2', size=14)
-+ plt.xlabel('value', size=14)
-+ plt.ylabel('counts', size=14)
-+ plt.hist(samples, bins=40, range=(-10, 10))
-+ plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
-+ plt.savefig('images/plot2.png', format='png')
-+
-+
-+结果见如下链接:
-+
-+
-+
-+###例3:饼状图###
-+
-+第三个脚本,script3.py 完成如下任务:
-+
-+-创建一个包含5个整数的列表
-+-创建一个宽6英寸、高6英寸的图(赋值1)
-+-添加一个长宽比为1的轴图
-+-设置图的标题(字号为14)
-+-用data列表画一个包含标签的饼状图
-+-保存图为PNG格式
-+
-+脚本script3.py的代码如下:
-+ import numpy as np
-+ import matplotlib.pyplot as plt
-+
-+ data = [33, 25, 20, 12, 10]
-+ plt.figure(num=1, figsize=(6, 6))
-+ plt.axes(aspect=1)
-+ plt.title('Plot 3', size=14)
-+ plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
-+ plt.savefig('images/plot3.png', format='png')
-+
-+
-+结果如下链接所示:
-+
-+
-+
-+###总结###
-+ 这个教程提供了几个用matplotlib科学画图包进行画图的例子,Matplotlib是在Linux环境中用于解决科学画图的绝佳方案,表现在其无缝地和Python、Numpy连接,自动化能力,和提供多种自定义的高质量的画图产品。[here][2].
-+
-+matplotlib包的文档和例子详见:
-+--------------------------------------------------------------------------------
-+
-+via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
-+
-+作者:[Joshua Reed][a]
-+译者:[ideas4u](https://github.com/ideas4u)
-+校对:[校对者ID](https://github.com/校对者ID)
-+
-+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-+
-+[a]:http://xmodulo.com/author/joshua
-+[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
-+[2]:http://matplotlib.org/
diff --git a/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md b/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md
deleted file mode 100644
index b5dc4c34a7..0000000000
--- a/translated/tech/20150104 How to debug a C or C++ program with Nemiver debugger.md
+++ /dev/null
@@ -1,126 +0,0 @@
-使用Nemiver调试器找出C/C++程序中的bug
-================================================================================
-
-如果你读过[my post on GDB][1],你就会明白我认为一个调试器对一段C/C++程序来说意味着多么的重要和有用。然而,如果一个像GDB的命令行对你而言听起来更像一个问题而不是一个解决方案,那么你也许会对Nemiver更感兴趣。[Nemiver][2] 是一款基于GTK+的独立图形化用于C/C++程序的调试器,同时它以GDB作为其后端。最令人佩服的是其速度和稳定性,Nemiver时一个非常可靠,具备许多优点的调试工具。
-
-### Nemiver的安装 ###
-
-基于Debian发行版,它的安装时非常直接简单如下:
-
- $ sudo apt-get install nemiver
-
-在Arch Linux中安装如下:
-
- $ sudo pacman -S nemiver
-
-在Fedora中安装如下:
-
- $ sudo yum install nemiver
-
-如果你选择自己变异,[GNOME website][3]中最新源码包可用。
-
-最令人欣慰的是,它能够很好地与GNOME环境像结合。
-
-### Nemiver的基本用法 ###
-
-启动Nemiver的命令:
-
- $ nemiver
-
-你也可以通过执行一下命令来启动:
-
- $ nemiver [path to executable to debug]
-
-你会注意到如果在调试模式下执行编译(-g标志表示GCC)将会更有帮助。
-
-还有一个优点是Nemiver的快速加载,所以你应该可以马上看到主屏幕的默认布局。
-
-
-
-
-
-
-
-默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:
-
-
-
-- Next line (mapped to F6)
-- Step inside a function (F7)
-- Step out of a function (Shift+F7)
-- 下一行 (映射到F6)
-- 执行内部行数(F7)
-- 执行外部函数(Shift+F7) ## 我不确定这个保留哪个都翻译出来了 ##
-
-但是由于我个人的喜好是“Run to cursor(运行至光标)”,该选项使你的程序运行精确至你光标下的行,并且默认映射到F11.
-
-下一步,断点通常是容易使用的。最快捷的方式是使用F8设置一个断点在相应的行。但是Nemiver也有一个更富在的菜单在“Debug”项,这允许你在一个特定的函数,行数,二进制位置文件的位置,或者类似一个异常,分支或者exec的事件。
-
-
-
-
-你也可以通过追踪来查看一个变量。在“Debug”选项,你可以通过命名来匹配一个表达式来检查。然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能虽然我从未因为浓厚的兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,将鼠标放置在相应位置时不生效的。如果想要让它更好地工作,Nemiver是可以看到结构并给所有成员的变量赋值。
-
-
-
-
-谈到方便地访问信息,我也非常欣赏这个程序的平面布局。默认情况下,代码在上个部分,标签在下半部分。这授予你访问中断输出、文本追踪、断点列表、注册地址、内存映射和变量控制。但是注意到在“Edit”“Preferences”“Layout”下你可以选择不同的布局,包括动态修改。
-
-
-
-
-
-
-自然而然,一旦你设置了所有短点,观察点和布局,您可以在“File”下很方便地保存以免你不小心关掉Nemiver。
-
-
-### Nemiver的高级用法 ###
-
-
-到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始喝调试一个简单的程序需要什么。如果你有更高的药求,特别是对于一些更佳复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
-
-
-#### 调试一个正在运行的进程 ####
-
-
-Nemiver允许你连接到一个正在运行的进程进行调试。在“File”菜单,你可以过滤出正在运行的进程,并连接到这个进程。
-
-
-
-
-#### 通过TCP连接远程调试一个程序 ####
-
-Nemiver支持远程调试,当你在一台远程机器设置一个轻量级调试服务器,你可以通过调试服务器启动Nemiver从另一台机器去调试承载远程服务器上的目标。如果出于某些原因,你不能在远程机器上吗很好地驾驭Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库的地址和端口。
-
-
-
-#### 使用你的GDB二进制进行调试 ####
-
-如果你想自行通过Nemiver进行编译,你可以在“Edit(编辑)”“Preferences(首选项)”“Debug(调试)”下给GDB制定一个新的位置。如果你想在Nemiver使用GDB的定制版本,那么这个选项对你来说是非常实用的。
-
-
-#### 循序一个子进程或者父进程 ####
-
-Nemiver是可以兼容一个子进程或者附近成的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
-
-
-
-总而言之,Nemiver大概是我最喜欢的没有IDE的调试程序。在我看来,它甚至可以击败GDB,并且[命令行][4]程序对我本身来说更接地气。所以,如果你从未使用过的话,我会强烈推荐你使用。我只能庆祝我们团队背后给了我这么一个可靠、稳定的程序。
-
-你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/debug-program-nemiver-debugger.html
-
-作者:[Adrien Brochard][a]
-译者:[disylee](https://github.com/disylee)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://xmodulo.com/author/adrien
-[1]:http://xmodulo.com/gdb-command-line-debugger.html
-[2]:https://wiki.gnome.org/Apps/Nemiver
-[3]:https://download.gnome.org/sources/nemiver/0.9/
-[4]:http://xmodulo.com/recommend/linuxclibook
diff --git a/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md b/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md
deleted file mode 100644
index 20b6715d38..0000000000
--- a/translated/tech/20150105 How To Install Kodi 14 (XBMC) In Ubuntu 14.04 and Linux Mint 17.md
+++ /dev/null
@@ -1,51 +0,0 @@
-Ubuntu14.04或Mint17如何安装Kodi14(XBMC)
-================================================================================
-
-
-[Kodi][1],原名就是大名鼎鼎的XBMC,发布[最新版本14][2],命名为Helix。感谢官方XMBC提供的PPA,现在可以很简单地在Ubuntu14.04中安装了。
-
-Kodi是一个优秀的自由和开源的(GPL)媒体中心软件,支持所有平台,如Windows, Linux, Mac, Android等。此软件拥有全屏幕的媒体中心,可以管理所有音乐和视频,不单支持本地文件还支持网络播放,如Tube,[Netflix][3], Hulu, Amazon Prime和其他串流服务商。
-
-### Ubuntu 14.04, 14.10 和 Linux Mint 17 中安装XBMC 14 Kodi Helix ###
-
-再次感谢官方的PPA,让我们可以轻松安装Kodi 14。
-支持Ubuntu 14.04, Ubuntu 12.04, Linux Mint 17, Pinguy OS 14.04, Deepin 2014, LXLE 14.04, Linux Lite 2.0, Elementary OS and 其他基于Ubuntu的Linux 发行版。
-打开终端(Ctrl+Alt+T)然后使用下列命令。
-
- sudo add-apt-repository ppa:team-xbmc/ppa
- sudo apt-get update
- sudo apt-get install kodi
-
-需要下载大约100MB,在我的观点这不是很大。若需安装解码插件,使用下列命令:
-
- sudo apt-get install kodi-audioencoder-* kodi-pvr-*
-
-#### 从Ubuntu中移除Kodi 14 ####
-
-从系统中移除Kodi 14 ,使用下列命令:
-
- sudo apt-get remove kodi
-
-同样也应该移除PPA软件源:
-
- sudo add-apt-repository --remove ppa:team-xbmc/ppa
-
-我希望这个简单的文章可以帮助到你,在Ubuntu, Linux Mint 和其他 Linux版本中轻松安装Kodi 14。
-你怎么发现Kodi 14 Helix?
-你有没有使用其他的什么媒体中心?
-可以在下面的评论区分享你的观点。
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/install-kodi-14-xbmc-in-ubuntu-14-04-linux-mint-17/
-
-作者:[Abhishek][a]
-译者:[Vic020/VicYu](http://www.vicyu.net)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://kodi.tv/
-[2]:http://kodi.tv/kodi-14-0-helix-unwinds/
-[3]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
diff --git a/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md b/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md
deleted file mode 100644
index b9fe775752..0000000000
--- a/translated/tech/20150105 How To Install Winusb In Ubuntu 14.04.md
+++ /dev/null
@@ -1,47 +0,0 @@
-如何在Ubuntu 14.04 中安装Winusb
-================================================================================
-
-
-[WinUSB][1]是一款简单的且有用的工具,可以让你从Windows ISO镜像或者DVD中创建USB安装盘。它结合了GUI和命令行,你可以根据你的喜好决定使用哪种。
-
-在本篇中我们会展示**如何在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
-
-### 在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB ###
-
-直到Ubuntu 13.10, WinUSBu一直都在积极开发,且在官方PPA中可以找到。这个PPA还没有为Ubuntu 14.04 和14.10更新,但是二进制文件仍旧可在更新版本的Ubuntu和Linux Mint中运行。基于[基于你使用的系统是32位还是64位的][2],使用下面的命令来下载二进制文件:
-
-打开终端,并在32位的系统下使用下面的命令:
-
- wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_i386.deb
-
-对于64位的系统,使用下面的命令:
-
- wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_amd64.deb
-
-一旦你下载了正确的二进制包,你可以用下面的命令安装WinUSB:
-
- sudo dpkg -i winusb*
-
-不要担心在你安装WinUSB时看见错误。使用这条命令修复依赖:
-
- sudo apt-get -f install
-
-之后,你就可以在Unity Dash中查找WinUSB并且用它在Ubuntu 14.04 中创建Windows的live USB了。
-
-
-
-我希望这篇文章能够帮到你**在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
-
---------------------------------------------------------------------------------
-
-via: http://itsfoss.com/install-winusb-in-ubuntu-14-04/
-
-作者:[Abhishek][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://itsfoss.com/author/Abhishek/
-[1]:http://en.congelli.eu/prog_info_winusb.html
-[2]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
\ No newline at end of file
diff --git a/translated/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md b/translated/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md
new file mode 100644
index 0000000000..1f645595b7
--- /dev/null
+++ b/translated/tech/20150211 Protect Apache Against Brute Force or DDoS Attacks Using Mod_Security and Mod_evasive Modules.md
@@ -0,0 +1,271 @@
+在Apache中使用Mod_Security和Mod_evasive来抵御暴力破解和DDos攻击
+================================================================================
+对于那些托管主机或者需要将您的主机暴露在因特网中的人来说,保证您的系统在面对攻击时安全是一个重要的事情。
+
+mod_security(一个开源的可以无缝接入Web服务器的用于Web应用入侵检测和防护的引擎)和mod_evasive是两个在服务器端对抗暴力破解和(D)Dos攻击的非常重要的工具。
+
+mod_evasive,如它的名字一样,在受攻击时提供避实就虚的功能,它像一个雨伞一样保护Web服务器免受那些威胁。
+
+
+
+安装Mod_Security和Mod_Evasive来保护Apache
+
+在这篇文章中我们将讨论如何安装、配置以及在RHEL/CentOS6、7和Fedora 21-15上将它们整合到Apache。另外,我们会模拟攻击以便验证服务器做出了正确的反应。
+
+以上以您的系统中安装有LAMP服务器为基础,所以,如果您没有安装,请先阅读下面链接的文章再开始阅读本文。
+
+- [在RHEL/CentOS 7中安装LAMP][1]
+
+如果您在运行RHEL/CentOS 7或Fedora 21,您还需要安装iptables作为默认[防火墙][2]前端以取代firewalld。这样做是为了在RHEL/CentOS 7或Fedora 21中使用同样的工具。
+
+### 步骤 1: 在RHEL/CentOS 7和Fedora 21上安装Iptables防火墙 ###
+
+用下面的命令停止和禁用firewalld:
+
+ # systemctl stop firewalld
+ # systemctl disable firewalld
+
+
+禁用firewalld服务
+
+接下来在使能iptables之前安装iptables-services包:
+
+ # yum update && yum install iptables-services
+ # systemctl enable iptables
+ # systemctl start iptables
+ # systemctl status iptables
+
+
+安装Iptables防火墙
+
+### 步骤 2: 安装Mod_Security和Mod_evasive ###
+
+另外,在安装LAMP后,您还需要在RHEL/CentOS 7/6中[开启EPEL仓库][3]来安装这两个包。Fedora用户不需要开启这个仓库,因为epel已经是Fedora项目的一部分了。
+
+ # yum update && yum install mod_security mod_evasive
+
+当安装结束后,您会在/etc/httpd/conf.d下找到两个工具的配置文件。
+
+ # ls -l /etc/httpd/conf.d
+
+
+mod_security + mod_evasive 配置文件
+
+现在,为了整合这两个模块到Apache,并在启动时加载它们。请确保下面几行出现在mod_evasive.conf和mod_security.conf的顶层部分,它们分别为:
+
+ LoadModule evasive20_module modules/mod_evasive24.so
+ LoadModule security2_module modules/mod_security2.so
+
+请注意modules/mod_security2.so和modules/mod_evasive24.so都是从/etc/httpd到模块源文件的相对路径。您可以通过列出/etc/httpd/modules的内容来验证(如果需要的话,修改它):
+
+ # cd /etc/httpd/modules
+ # pwd
+ # ls -l | grep -Ei '(evasive|security)'
+
+
+验证mod_security + mod_evasive模块
+
+接下来重启Apache并且核实它已加载了mod_evasive和mod_security:
+
+ # service httpd restart [在RHEL/CentOS 6和Fedora 20-18上]
+ # systemctl restart httpd [在RHEL/CentOS 7和Fedora 21上]
+
+----------
+
+ [输出已加载的静态模块和动态模块列表]
+
+ # httpd -M | grep -Ei '(evasive|security)'
+
+
+检查mod_security + mod_evasive模块已加载
+
+### 步骤 3: 安装一个核心规则集并且配置Mod_Security ###
+
+简单来说,一个核心规则集(即CRS)为web服务器提供特定状况下如何反应的指令。mod_security的开发者们提供了一个免费的CRS,叫做OWASP([开放Web应用安全项目])ModSecurity CRS,可以从下面的地址下载和安装。
+
+1. 下载OWASP CRS到为之创建的目录
+
+ # mkdir /etc/httpd/crs-tecmint
+ # cd /etc/httpd/crs-tecmint
+ # wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
+
+
+下载mod_security核心规则
+
+2. 解压CRS文件并修改文件夹名称
+
+ # tar xzf master
+ # mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
+
+
+解压mod_security核心规则
+
+3. 现在,是时候配置mod_security了。将同样的规则文件(owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example)拷贝至另一个没有.example扩展的文件。
+
+ # cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
+
+并通过将下面的几行插入到web服务器的主配置文件/etc/httpd/conf/httpd.conf来告诉Apache将这个文件和该模块放在一起使用。如果您选择解压打包文件到另一个文件夹,那么您需要修改Include的路径:
+
+
+ Include crs-tecmint/owasp-modsecurity-crs/modsecurity_crs_10_setup.conf
+ Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
+
+
+最后,建议您在/etc/httpd/modsecurity.d目录下创建自己的配置文件,在那里我们可以用我们自定义的文件夹(接下来的示例中,我们会将其命名为tecmint.conf)而无需修改CRS文件的目录。这样做能够在CRSs发布新版本时更加容易的升级。
+
+
+ SecRuleEngine On
+ SecRequestBodyAccess On
+ SecResponseBodyAccess On
+ SecResponseBodyMimeType text/plain text/html text/xml application/octet-stream
+ SecDataDir /tmp
+
+
+您可以在[SpiderLabs的ModSecurity GitHub][5]仓库中参考关于mod_security目录的更完整的解释。
+
+### 步骤 4: 配置Mod_Evasive ###
+
+mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。与mod_security不同,由于在包升级时没有规则来更新,因此我们不需要独立的文件来添加自定义指令。
+
+默认的mod_evasive.conf开启了下列的目录(注意这个文件被详细的注释了,因此我们剔掉了注释以重点显示配置指令):
+
+
+ DOSHashTableSize 3097
+ DOSPageCount 2
+ DOSSiteCount 50
+ DOSPageInterval 1
+ DOSSiteInterval 1
+ DOSBlockingPeriod 10
+
+
+这些指令的解释:
+
+- DOSHashTableSize: 这个指令指明了哈希表的大小,它用来追踪基于IP地址的活动。增加这个数字将使查询站点访问历史变得更快,但如果被设置的太高则会影响整体性能。
+- DOSPageCount: 在DOSPageInterval间隔内可由一个用户发起的面向特定的URI(例如,一个Apache托管的文件)的同一个请求的数量。
+- DOSSiteCount: 类似DOSPageCount,但涉及到整个站点总共有多少的请求可以在DOSSiteInterval间隔内被发起。
+- DOSBlockingPeriod: 如果一个用户超过了DOSSPageCount的限制或者DOSSiteCount,他的源IP地址将会在DOSBlockingPeriod期间内被加入黑名单。在DOSBlockingPeriod期间,任何从这个IP地址发起的请求将会遭遇一个403禁止错误。
+
+尽可能的试验这些值,以使您的web服务器有能力处理特定大小的负载。
+
+**一个小警告**: 如果这些值设置的不合适,则您会蒙受阻挡合法用户的风险。
+
+您也许想考虑下其他有用的指令:
+
+#### DOSEmailNotify ####
+
+如果您运行有一个邮件服务器,您可以通过Apache发送警告消息。注意,如果SELinux已开启,您需要授权apache用户SELinux的权限来发送email。您可以通过下面的命令来授予权限:
+
+ # setsebool -P httpd_can_sendmail 1
+
+接下来,将这个指令和其他指令一起加入到mod_evasive.conf文件。
+
+ DOSEmailNotify you@yourdomain.com
+
+如果这个值被合适的设置并且您的邮件服务器在正常的运行,则当一个IP地址被加入黑名单时,会有一封邮件被发送到相应的地址。
+
+#### DOSSystemCommand ####
+
+它需要一个有效的系统命令作为参数,
+
+ DOSSystemCommand
+
+这个指令指定当一个IP地址被加入黑名单时执行的命令。它通常结合shell脚本来使用,在脚本中添加一条防火墙规则来阻挡某个IP进一步的连接。
+
+**写一个shell脚本在防火墙阶段处理IP黑名单**
+
+当一个IP地址被加入黑名单,我们需要阻挡它进一步的连接。我们需要下面的shell脚本来执行这个任务。在/usr/local/bin下创建一个叫做scripts-tecmint的文件夹(或其他的名字),以及一个叫做ban_ip.sh的文件。
+
+ #!/bin/sh
+ # 由mod_evasive检测出,将被阻挡的IP地址
+ IP=$1
+ # iptables的完整路径
+ IPTABLES="/sbin/iptables"
+ # mod_evasive锁文件夹
+ MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
+ # 添加下面的防火墙规则 (阻止所有从$IP流入的流量)
+ $IPTABLES -I INPUT -s $IP -j DROP
+ # 为了未来的检测,移除锁文件
+ rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
+
+我们的DOSSystemCommand指令应该是这样的:
+
+ DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
+
+上面一行的%s代表了由mod_evasive检测到的攻击IP地址。
+
+**将apache用户添加到sudoers文件**
+
+请注意,如果您不给予apache用户以无需终端和密码的方式运行我们脚本(关键就是这个脚本)的权限,则这一切都不起作用。通常,您只需要以root权限键入visudo来存取/etc/sudoers文件,接下来添加下面的两行即可:
+
+ apache ALL=NOPASSWD: /usr/local/bin/scripts-tecmint/ban_ip.sh
+ Defaults:apache !requiretty
+
+
+添加Apache用户到Sudoers
+
+**重要**: 作为默认的安全策略,您只能在终端中运行sudo。由于这个时候我们需要在没有tty的时候运行sudo,我们像下面图片中那样必须注释掉下面这一行:
+
+ #Defaults requiretty
+
+
+为Sudo禁用tty
+
+最后,重启web服务器:
+
+ # service httpd restart [在RHEL/CentOS 6和Fedora 20-18上]
+ # systemctl restart httpd [在RHEL/CentOS 7和Fedora 21上]
+
+### 步骤4: 在Apache上模拟DDos攻击 ###
+
+有许多工具可以在您的服务器上模拟外部的攻击。您可以google下“tools for simulating ddos attacks”来找一找相关的工具。
+
+注意,您(也只有您)将负责您模拟所造成的结果。请不要考虑向不在您网络中的服务器发起模拟攻击。
+
+假如您想对一个由别人托管的VPS做这些事情,您需要向您的托管商发送适当的警告或就那样的流量通过他们的网络获得允许。Tecmint.com不会为您的行为负责!
+
+另外,仅从一个主机发起一个Dos攻击的模拟无法代表真实的攻击。为了模拟真实的攻击,您需要使用许多客户端在同一时间将您的服务器作为目标。
+
+我们的测试环境由一个CentOS 7服务器[IP 192.168.0.17]和一个Windows组成,在Windows[IP 192.168.0.103]上我们发起攻击:
+
+
+确认主机IP地址
+
+请播放下面的视频,并跟从列出的步骤来模拟一个Dos攻击:
+
+注:youtube视频,发布的时候不行做个链接吧
+
+
+然后攻击者的IP将被iptables阻挡:
+
+
+阻挡攻击者的IP地址
+
+### 结论 ###
+
+在开启mod_security和mod_evasive的情况下,模拟攻击会导致CPU和RAM用量在源IP地址被加入黑名单之前出现短暂几秒的使用峰值。如果没有这些模块,模拟攻击绝对会很快将服务器击溃,并使服务器在攻击期间无法提供服务。
+
+我们很高兴听见您打算使用(或已经使用过)这些工具。我们期望得到您的反馈,所以,请在留言处留下您的评价和问题,谢谢!
+
+### 参考链接 ###
+
+- [https://www.modsecurity.org/][6]
+- [http://www.zdziarski.com/blog/?page_id=442][7]
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
+
+作者:[Gabriel Cánepa][a]
+译者:[wwy-hust](https://github.com/wwy-hust)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/install-lamp-in-centos-7/
+[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
+[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
+[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
+[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
+[6]:https://www.modsecurity.org/
+[7]:http://www.zdziarski.com/blog/?page_id=442
\ No newline at end of file
diff --git a/translated/tech/20150504 How to Install and Configure 'PowerDNS' (with MariaDB) and 'PowerAdmin' in RHEL or CentOS 7.md b/translated/tech/20150504 How to Install and Configure 'PowerDNS' (with MariaDB) and 'PowerAdmin' in RHEL or CentOS 7.md
new file mode 100644
index 0000000000..0f7bc3d62f
--- /dev/null
+++ b/translated/tech/20150504 How to Install and Configure 'PowerDNS' (with MariaDB) and 'PowerAdmin' in RHEL or CentOS 7.md
@@ -0,0 +1,422 @@
+RHEL/CentOS 7中安装并配置‘PowerDNS’(与MariaDB搭配)和‘PowerAdmin’
+================================================================================
+PowerDNS是一个运行在许多Linux/Unix衍生版上的DNS服务器,它可以使用不同的后端进行配置,包括BIND类型的区域文件、相关的数据库,或者负载均衡/失效转移算法。它也可以被配置成一台DNS递归器,作为服务器上的一个独立进程运行。
+
+PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以获得的版本是3.4.3。我推荐安装EPEL仓库中提供的那一个,因为该版本已经在CentOS和Fedora中测试过。那样,你也可以在今后很容易地更新PowerDNS。
+
+本文倾向于向你演示如何安装并配置以MariaDB作为后端的PowerDNS和
+出于本文的写作目的,我将使用以下服务器:
+
+ 主机名: centos7.localhost
+ IP地址: 192.168.0.102
+
+### 步骤 1: 安装带有MariaDB后端的PowerDNS ###
+
+#### 1. 首先,你需要为你的系统启用EPEL仓库,只需使用: ####
+
+ # yum install epel-release.noarch
+
+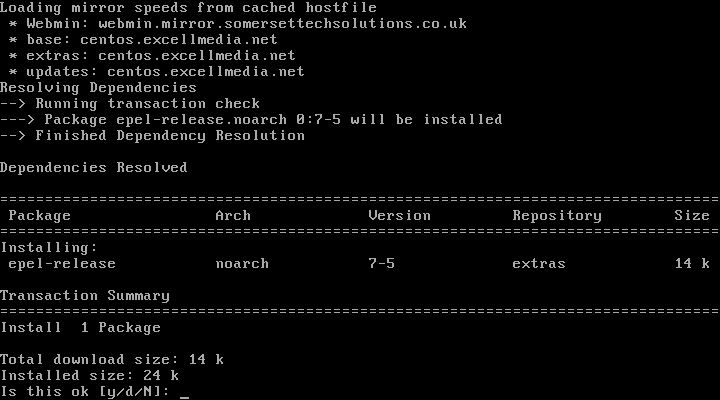
+启用Epel仓库
+
+#### 2. 下一步是安装MariaDB服务器。运行以下命令即可达成: ####
+
+ # yum -y install mariadb-server mariadb
+
+
+安装MariaDB服务器
+
+#### 3. 接下来,我们将配置并启用MySQL,并设置开机启动: ####
+
+ # systemctl enable mariadb.service
+ # systemctl start mariadb.service
+
+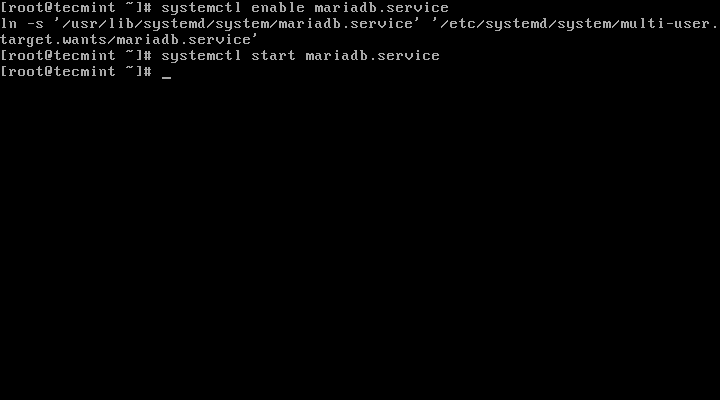
+启用MariaDB开机启动
+
+#### 4. 由于MySQL服务正在运行,我们将为MariaDB设置密码进行安全加固,运行以下命令: ####
+
+ # mysql_secure_installation
+
+#### 按照指示做 ####
+
+ /bin/mysql_secure_installation: line 379: find_mysql_client: command not found
+
+ NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB
+ SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!
+
+ In order to log into MariaDB to secure it, we'll need the current
+ password for the root user. If you've just installed MariaDB, and
+ you haven't set the root password yet, the password will be blank,
+ so you should just press enter here.
+
+ Enter current password for root (enter for none): Press ENTER
+ OK, successfully used password, moving on...
+
+ Setting the root password ensures that nobody can log into the MariaDB
+ root user without the proper authorisation.
+
+ Set root password? [Y/n] y
+ New password: ← Set New Password
+ Re-enter new password: ← Repeat Above Password
+ Password updated successfully!
+ Reloading privilege tables..
+ ... Success!
+
+
+ By default, a MariaDB installation has an anonymous user, allowing anyone
+ to log into MariaDB without having to have a user account created for
+ them. This is intended only for testing, and to make the installation
+ go a bit smoother. You should remove them before moving into a
+ production environment.
+
+ Remove anonymous users? [Y/n] y ← Choose “y” to disable that user
+ ... Success!
+
+ Normally, root should only be allowed to connect from 'localhost'. This
+ ensures that someone cannot guess at the root password from the network.
+
+ Disallow root login remotely? [Y/n] n ← Choose “n” for no
+ ... skipping.
+
+ By default, MariaDB comes with a database named 'test' that anyone can
+ access. This is also intended only for testing, and should be removed
+ before moving into a production environment.
+
+ Remove test database and access to it? [Y/n] y ← Choose “y” for yes
+ - Dropping test database...
+ ... Success!
+ - Removing privileges on test database...
+ ... Success!
+
+ Reloading the privilege tables will ensure that all changes made so far
+ will take effect immediately.
+
+ Reload privilege tables now? [Y/n] y ← Choose “y” for yes
+ ... Success!
+
+ Cleaning up...
+
+ All done! If you've completed all of the above steps, your MariaDB
+ installation should now be secure.
+
+ Thanks for using MariaDB!
+
+#### 5. MariaDB配置成功后,我们可以继续去安装PowerDNS。运行以下命令即可轻易完成: ####
+
+ # yum -y install pdns pdns-backend-mysql
+
+
+安装带有MariaDB后端的PowerDNS
+
+#### 6. PowerDNS的配置文件位于`/etc/pdns/pdns`,在编辑之前,我们将为PowerDNS服务配置一个MySQL数据库。首先,我们将连接到MySQL服务器并创建一个名为powerdns的数据库: ####
+
+ # mysql -u root -p
+ MariaDB [(none)]> CREATE DATABASE powerdns;
+
+
+创建PowerDNS数据库
+
+#### 7. 接下来,我们将创建一个名为powerdns的数据库用户: ####
+
+ MariaDB [(none)]> GRANT ALL ON powerdns.* TO 'powerdns'@'localhost' IDENTIFIED BY ‘tecmint123’;
+ MariaDB [(none)]> GRANT ALL ON powerdns.* TO 'powerdns'@'centos7.localdomain' IDENTIFIED BY 'tecmint123';
+ MariaDB [(none)]> FLUSH PRIVILEGES;
+
+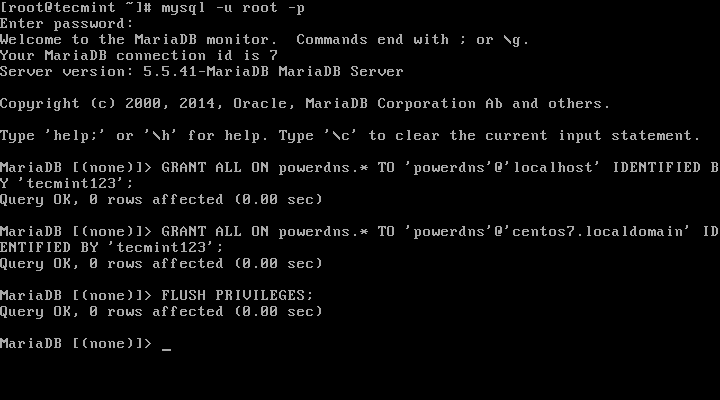
+创建PowerDNS用户
+
+**注意**: 请将“tecmint123”替换为你想要设置的实际密码。
+
+#### 8. 我们继续创建PowerDNS要使用的数据库表。像堆积木一样执行以下这些: ####
+
+ MariaDB [(none)]> USE powerdns;
+ MariaDB [(none)]> CREATE TABLE domains (
+ id INT auto_increment,
+ name VARCHAR(255) NOT NULL,
+ master VARCHAR(128) DEFAULT NULL,
+ last_check INT DEFAULT NULL,
+ type VARCHAR(6) NOT NULL,
+ notified_serial INT DEFAULT NULL,
+ account VARCHAR(40) DEFAULT NULL,
+ primary key (id)
+ );
+
+
+创建用于PowerDNS的表域
+
+ MariaDB [(none)]> CREATE UNIQUE INDEX name_index ON domains(name);
+ MariaDB [(none)]> CREATE TABLE records (
+ id INT auto_increment,
+ domain_id INT DEFAULT NULL,
+ name VARCHAR(255) DEFAULT NULL,
+ type VARCHAR(6) DEFAULT NULL,
+ content VARCHAR(255) DEFAULT NULL,
+ ttl INT DEFAULT NULL,
+ prio INT DEFAULT NULL,
+ change_date INT DEFAULT NULL,
+ primary key(id)
+ );
+
+
+创建用于PowerDNS的索引域
+
+ MariaDB [(none)]> CREATE INDEX rec_name_index ON records(name);
+ MariaDB [(none)]> CREATE INDEX nametype_index ON records(name,type);
+ MariaDB [(none)]> CREATE INDEX domain_id ON records(domain_id);
+
+
+创建索引记录
+
+ MariaDB [(none)]> CREATE TABLE supermasters (
+ ip VARCHAR(25) NOT NULL,
+ nameserver VARCHAR(255) NOT NULL,
+ account VARCHAR(40) DEFAULT NULL
+ );
+
+
+创建表的超主
+
+你现在可以输入以下命令退出MySQL控制台:
+
+ MariaDB [(none)]> quit;
+
+#### 9. 最后,我们可以继续以MySQL作为后台的方式配置PowerDNS。请打开PowerDNS的配置文件: ####
+
+ # vim /etc/pdns/pdns.conf
+
+在该文件中查找像下面这样的行:
+
+ #################################
+ # launch Which backends to launch and order to query them in
+ #
+ # launch=
+
+在这后面放置以下代码:
+
+ launch=gmysql
+ gmysql-host=localhost
+ gmysql-user=powerdns
+ gmysql-password=user-pass
+ gmysql-dbname=powerdns
+
+修改“user-pass”为你先前设置的实际密码,配置如下:
+
+
+配置PowerDNS
+
+保存修改并退出。
+
+#### 10. 现在,我们将启动并添加PowerDNS到系统开机启动列表: ####
+
+ # systemctl enable pdns.service
+ # systemctl start pdns.service
+
+
+启用并启动PowerDNS
+
+到这一步,你的PowerDNS服务器已经起来并运行了。要获取更多关于PowerDNS的信息,你可以参考手册[http://downloads.powerdns.com/documentation/html/index.html][1]
+
+### 步骤 2: 安装PowerAdmin来管理PowerDNS ###
+
+#### 11. 现在,我们将安装PowerAdmin——一个友好的网页接口PowerDNS服务器管理器。由于它是用PHP写的,我们将需要安装PHP和一台网络服务器(Apache): ####
+
+ # yum install httpd php php-devel php-gd php-imap php-ldap php-mysql php-odbc php-pear php-xml php-xmlrpc php-mbstring php-mcrypt php-mhash gettext
+
+
+安装Apache PHP
+
+PowerAdmin也需要两个PEAR包:
+
+ # yum -y install php-pear-DB php-pear-MDB2-Driver-mysql
+
+
+安装Pear
+
+你也可以参考一下文章了解CentOS 7中安装LAMP堆栈的完整指南:
+
+- [CentOS 7中安装LAMP][2]
+
+安装完成后,我们将需要启动并设置Apache开机启动:
+
+ # systemctl enable httpd.service
+ # systemctl start httpd.service
+
+
+启用Apache开机启动
+
+#### 12. 由于已经满足PowerAdmin的所有系统要求,我们可以继续下载软件包。因为Apache默认的网页目录位于/var/www/html/,我们将下载软件包到这里。 ####
+
+ # cd /var/www/html/
+ # wget http://downloads.sourceforge.net/project/poweradmin/poweradmin-2.1.7.tgz
+ # tar xfv poweradmin-2.1.7.tgz
+
+
+下载PowerAdmin
+
+#### 13. 现在,我们可以启动PowerAdmin的网页安装器了,只需打开: ####
+
+ http://192.168.0.102/poweradmin-2.1.7/install/
+
+这会进入安装过程的第一步:
+
+
+选择安装语言
+
+上面的页面会要求你为PowerAdmin选择语言,请选择你想要使用的那一个,然后点击“进入步骤 2”按钮。
+
+#### 14. 安装器需要PowerDNS数据库: ####
+
+
+PowerDNS数据库
+
+#### 15. 因为我们已经创建了一个,所以我们可以继续进入下一步。你会被要求提供先前配置的数据库详情,你也需要为Poweradmin设置管理员密码: ####
+
+
+输入PowerDNS数据库配置
+
+#### 16. 输入这些信息后,进入步骤 4。你将创建为Poweradmin创建一个受限用户。这里你需要输入的字段是: ####
+
+- 用户名 - PowerAdmin用户名。
+- 密码 – 上述用户的密码。
+- 注册人 - 当创建SOA记录而你没有制定注册人时,该值会被使用。
+- 辅助域名服务器 – 该值在创建新的DNS区域时会被用于作为主域名服务器。
+
+
+PowerDNS配置设置
+
+#### 17. 在下一步中,Poweradmin会要求你在数据库表中创建新的受限数据库用户,它会提供你需要在MySQL控制台输入的代码: ####
+
+
+创建新的数据库用户
+
+#### 18. 现在打开终端并运行: ####
+
+ # mysql -u root -p
+
+提供你的密码并执行由Poweradmin提供的代码:
+
+ MariaDB [(none)]> GRANT SELECT, INSERT, UPDATE, DELETE
+ ON powerdns.*
+ TO 'powermarin'@'localhost'
+ IDENTIFIED BY '123qweasd';
+
+
+为用户授予Mysql权限
+
+#### 19. 现在,回到浏览器中并继续下一步。安装器将尝试创建配置文件到/var/www/html/poweradmin-2.1.7/inc。 ####
+
+文件名是config.inc.php。为防止该脚本没有写权限,你可以手动复制这些内容到上述文件中:
+
+
+配置PowerDNS设置
+
+#### 20. 现在,进入最后页面,该页面会告知你安装已经完成以及如何访问安装好的Poweradmin: ####
+
+
+PowerDNS安装完成
+
+你可以通过运行以下命令来启用其他动态DNS提供商的URL:
+
+ # cp install/htaccess.dist .htaccess
+
+出于该目的,你将需要在Apache的配置中启用mod_rewrite。
+
+#### 21. 现在,需要移除从Poweradmin的根目录中移除“install”文件夹,这一点很重要。使用以下命令: ####
+
+ # rm -fr /var/www/html/poweradmin/install/
+
+在此之后,你可以通过以下方式访问PowerAdmin:
+
+ http://192.168.0.102/poweradmin-2.1.7/
+
+
+PowerDNS登录
+
+在登录后,你应该会看到Poweradmin的主页:
+
+
+PowerDNS仪表盘
+
+到这里,安装已经完成了,你也可以开始管理你的DNS区域了。
+
+### 步骤 3: PowerDNS中添加、编辑和删除DNS区域 ###
+
+#### 22. 要添加新的主区域,只需点击“添加主区域”: ####
+
+
+添加主区域
+
+在下一页中,你需要填写一些东西:
+
+- 域 – 你要添加区域的域。
+- 所有者 – 设置DNS区域的所有者。
+- 模板 – DNS模板 – 留空。
+- DNSSEC – Donany名称系统安全扩展(可选——检查你是否需要)。
+
+点击“添加区域”按钮来添加DNS区域。
+
+
+主DNS区域
+
+现在,你可以点击“首页”链接回到Poweradmin的首页。要查看所有现存的DNS区域,只需转到“列出区域”:
+
+
+检查区域列表
+
+你现在应该看到一个可用DNS区域列表:
+
+
+检查DNS区域列表
+
+#### 23. 要编辑现存DNS区域或者添加新的记录,点击编辑图标: ####
+
+
+编辑DNS区域
+
+在接下来的页面,你会看到你选择的DNS区域的条目:
+
+
+主DNS区域条目
+
+#### 24. 在此处添加新的DNS区域,你需要设置以下信息: ####
+
+- 名称 – 条目名称。只需添加域/子域的第一部分,Poweradmin会添加剩下的。
+- 类型 – 选择记录类型。
+- 优先级 – 记录优先级。
+- TTL – 存活时间,以秒计算。
+
+出于本文目的,我将为子域new.example.com添加一个A记录用于解析IP地址192.168.0.102,设置存活时间为14400秒:
+
+
+添加新DNS记录
+
+最后,点击“添加记录”按钮。
+
+#### 25. 如果你想要删除DNS区域,你可以回到“列出区域”页面,然后点击你想要删除的DNS区域旁边“垃圾桶”图标: ####
+
+
+删除DNS区域
+
+Poweradmin将问你是否确定想要删除DNS区域。只需点击“是”来完成删除。
+
+如要获取更多关于怎样创建、编辑和删除区域的说明,你可以参与Poweradmin的文档:
+
+[https://github.com/poweradmin/poweradmin/wiki/Documentation][3]
+
+我希望你已经发现本文很有趣,也很有用。一如既往,如果你有问题或要发表评论,请别犹豫,在下面评论区提交你的评论吧。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-powerdns-poweradmin-mariadb-in-centos-rhel/
+
+作者:[Marin Todorov][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/marintodorov89/
+[1]:http://downloads.powerdns.com/documentation/html/index.html
+[2]:http://www.tecmint.com/install-lamp-in-centos-7/
+[3]:https://github.com/poweradmin/poweradmin/wiki/Documentation
diff --git a/translated/tech/20150504 Useful Commands to Create Commandline Chat Server and Remove Unwanted Packages in Linux.md b/translated/tech/20150504 Useful Commands to Create Commandline Chat Server and Remove Unwanted Packages in Linux.md
new file mode 100644
index 0000000000..cd90e2bfb7
--- /dev/null
+++ b/translated/tech/20150504 Useful Commands to Create Commandline Chat Server and Remove Unwanted Packages in Linux.md
@@ -0,0 +1,177 @@
+Linux中,创建聊天服务器、移除冗余软件包的实用命令
+=============================================================================
+这里,我们来看Linux命令行实用技巧的下一个部分。如果你错过了Linux Tracks之前的文章,可以从这里找到。
+
+- [5 Linux Command Line Tracks][1]
+
+本篇中,我们将会介绍6个命令行小技巧,包括使用Netcat命令创建Linux命令行聊天,从某个命令的输出中对某一列做加法,移除Debian和CentOS上多余的包,从命令行中获取本地与远程的IP地址,在终端获得彩色的输出与解码各样的颜色,最后是Linux命令行里井号标签的使用。让我们来一个一个地看一下。
+
+
+6个实用的命令行技巧
+
+### 1. 创建Linux命令行聊天服务 ###
+我们大家使用聊天服务都有很长一段时间了。对于Google Chat,Hangout,Facebook Chat,Whatsapp,Hike和其他一些应用与集成的聊天服务,我们都很熟悉了。那你知道Linux的nc命令可以使你的Linux盒子变成一个聊天服务器,而仅仅只需要一行命令吗。什么是nc命令,它又是怎么工作的呢?
+
+nc是Linux netcat命令的旧版。nc就像瑞士军刀一样,内建呢大量的功能。nc可用做调式工具,调查工具,使用TCP/UDP读写网络连接,DNS正向/反向检查。
+
+nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使用任何闲置的端口和任何本地网络源地址。
+
+使用nc命令(在192.168.0.7的服务器上)创建一个命令行即时信息传输服务器。
+
+ $ nc -l -vv 11119
+
+对上述命令的解释。
+
+- -v : 表示 Verbose
+- -vv : 更多的 Verbose
+- -p : 本地端口号
+
+你可以用任何其他的本地端口号替换11119。
+
+接下来在客户端机器(IP地址:192.168.0.15),运行下面的命令初始化聊天会话(信息传输服务正在运行)。
+
+ $ nc 192.168.0.7:11119
+
+
+
+**注意**:你可以按下ctrl+c终止会话,同时nc聊天是一个一对一的服务。
+
+### 2. Linux中如何统计某一列的总值 ###
+
+如何统计在终端里,某个命令的输出中,其中一列的数值总和,
+
+‘ls -l’命令的输出。
+
+ $ ls -l
+
+
+
+注意到第二列代表软连接的数量,第五列则是文件的大小。假设我们需要汇总第五列的数值。
+
+仅仅列出第五列的内容。我们会使用‘awk’命令做到这点。‘$5’即代表第五列。
+
+ $ ls -l | awk '{print $5}'
+
+
+
+现在,通过管道连接,使用awk打印出第五列数值的总和。
+
+ $ ls -l | awk '{print $5}' | awk '{total = total + $1}END{print total}'
+
+
+
+### 在Linux里如何移除废弃包 ###
+
+废弃包是指那些作为其他包的依赖而被安装,但是当源包被移除之后就不再需要的包。
+
+假设我们安装了gtprogram,依赖是gtdependency。除非我们安装了gtdependency,否则安装不了gtprogram。
+
+当我们移除gtprogram的时候,默认并不会移除gtdependency。并且如果我们不移除gtdependency的话,它就会遗留下来成为废弃包,与其他任何包再无联系。
+
+ # yum autoremove [On RedHat Systems]
+
+
+
+ # apt-get autoremove [On Debian Systems]
+
+
+
+你应该经常移除废弃包,保持Linux机器仅仅加载一些需要的东西。
+
+### 4. 如何获得Linux服务器本地的与公网的IP地址 ###
+
+为了获得本地IP地址,运行下面的一行脚本。
+
+ $ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
+
+你必须安装了ifconfig,如果没有,使用apt或者yum工具安装需要的包。这里我们将会管道连接ifconfig的输出,并且结合grep命令找到包含“intel addr:”的字符串。
+
+我们知道对于输出本地IP地址,ifconfig命令足够用了。但是ifconfig生成了许多的输出,而我们关注的地方仅仅是本地IP地址,不是其他的。
+
+ # ifconfig | grep "inet addr:"
+
+
+
+尽管目前的输出好多了,但是我们需要过滤出本地的IP地址,不含其他东西。针对这个,我们将会使用awk打印出第二列输出,通过管道连接上述的脚本。
+
+ # ifconfig | grep “inet addr:” | awk '{print $2}'
+
+
+
+上面图片清楚的表示,我们已经很大程度上自定义了输出,当仍然不是我们想要的。本地环路地址 127.0.0.1 仍然在结果中。
+
+我们可以使用grep的-v选项,这样会打印出不匹配给定参数的其他行。每个机器都有同样的环路地址 127.0.0.1,所以使用grep -v打印出不包含127.0.0.1的行,通过管道连接前面的脚本。
+
+ # ifconfig | grep "inet addr" | awk '{print $2}' | grep -v '127.0.0.1'
+
+
+
+我们差不多得到想要的输出了,仅仅需要从开头替换掉字符串`(addr:)`。我们将会使用cut命令单独打印出第二列。一二列之间并不是用tab分割,而是`(:)`,所以我们需要使用到域分割符选项`(-d)`,通过管道连接上面的输出。
+
+ # ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
+
+
+
+最后!期望的结果出来了。
+
+### 5.如何在Linux终端彩色输出 ###
+
+你可能在终端看见过彩色的输出。同时你也可能知道在终端里允许/禁用彩色输出。如果都不知道的话,里可以参考下面的步骤。
+
+在Linux中,每个用户都有`'.bashrc'`文件,被用来管理你的终端输出。打开并且编辑该文件,用你喜欢的编辑器。注意一下,这个文件是隐藏的(文件开头为点的代表隐藏文件)。
+
+ $ vi /home/$USER/.bashrc
+
+确保以下的行没有被注释掉。ie.,行开头没有#。
+
+ if [ -x /usr/bin/dircolors ]; then
+ test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dirc$
+ alias ls='ls --color=auto'
+ #alias dir='dir --color=auto'
+ #alias vdir='vdir --color=auto'
+
+ alias grep='grep --color=auto'
+ alias fgrep='fgrep --color=auto'
+ alias egrep='egrep --color=auto'
+ fi
+
+
+
+完成后!保存并退出。为了让改动生效,需要注销账户后再次登录。
+
+现在,你会看见列出的文件和文件夹名字有着不同的颜色,根据文件类型来决定。为了解码颜色,可以运行下面的命令。
+
+ $ dircolors -p | less
+
+
+
+### 6.如何用井号标记和Linux命令和脚本 ###
+
+我们一直在Twitter,Facebook和Google Plus(可能是其他我们没有提到的地方)上使用井号标签。那些井号标签使得其他人搜索一个标签更加容易。可是很少人知道,我们可以在Linux命令行使用井号标签。
+
+我们已经知道配置文件里的`#`,在大多数的编程语言中,这个符号被用作注释行,即不被执行。
+
+运行一个命令,然后为这个命令创建一个井号标签,这样之后我们就可以找到它。假设我们有一个很长的脚本,就上面第四点被执行的命令。现在为它创建一个井号标签。我们知道ifconfig可以被sudo或者root执行,因此用root来执行。
+
+ # ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d: #myip
+
+上述脚本被’mytag‘给标记了。现在在reverse-i-search(按下ctrl+r)搜索一下这个标签,在终端里,并输入’mytag‘。你可以从这里开始执行。
+
+
+
+你可以创建很多的井号标签,为每个命令,之后使用reverse-i-search找到它。
+
+目前就这么多了。我们一直在辛苦的工作,创造有趣的,有知识性的内容给你。你觉得我们是如何工作的呢?欢迎咨询任何问题。你可以在下面评论。保持联络!Kudox。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-commandline-chat-server-and-remove-unwanted-packages/
+
+作者:[Avishek Kumar][a]
+译者:[wi-cuckoo](https://github.com/wi-cuckoo)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/5-linux-command-line-tricks/
diff --git a/translated/tech/20150505 How to Manage 'Systemd' Services and Units Using 'Systemctl' in Linux.md b/translated/tech/20150505 How to Manage 'Systemd' Services and Units Using 'Systemctl' in Linux.md
new file mode 100644
index 0000000000..a78dc01820
--- /dev/null
+++ b/translated/tech/20150505 How to Manage 'Systemd' Services and Units Using 'Systemctl' in Linux.md
@@ -0,0 +1,579 @@
+在Linux中使用‘Systemctl’管理‘Systemd’服务和单元
+================================================================================
+Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
+
+Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
+
+在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有位数不多的几个尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
+
+
+使用Systemctl管理Linux服务
+
+本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
+
+### Systemd初体验和Systemctl基础 ###
+
+#### 1. 首先检查你的系统中是否安装有systemd并确定当前安装的版本 ####
+
+ # systemd --version
+
+ systemd 215
+ +PAM +AUDIT +SELINUX +IMA +SYSVINIT +LIBCRYPTSETUP +GCRYPT +ACL +XZ -SECCOMP -APPARMOR
+
+上例中很清楚地表明,我们安装了215版本的systemd。
+
+#### 2. 检查systemd和systemctl的二进制文件和库文件的安装位置 ####
+
+ # whereis systemd
+ systemd: /usr/lib/systemd /etc/systemd /usr/share/systemd /usr/share/man/man1/systemd.1.gz
+
+
+ # whereis systemctl
+ systemctl: /usr/bin/systemctl /usr/share/man/man1/systemctl.1.gz
+
+#### 3. 检查systemd是否运行 ####
+
+ # ps -eaf | grep [s]ystemd
+
+ root 1 0 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd --switched-root --system --deserialize 23
+ root 444 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-journald
+ root 469 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-udevd
+ root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind
+ dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
+
+**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-
+
+a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(如 -eaf)。
+
+也请注意上例中后随的方括号和样例剩余部分。方括号表达式是grep的字符类表达式的一部分。
+
+#### 4. 分析systemd启动进程 ####
+
+ # systemd-analyze
+ Startup finished in 487ms (kernel) + 2.776s (initrd) + 20.229s (userspace) = 23.493s
+
+#### 5. 分析启动时各个进程花费的时间 ####
+
+ # systemd-analyze blame
+
+ 8.565s mariadb.service
+ 7.991s webmin.service
+ 6.095s postfix.service
+ 4.311s httpd.service
+ 3.926s firewalld.service
+ 3.780s kdump.service
+ 3.238s tuned.service
+ 1.712s network.service
+ 1.394s lvm2-monitor.service
+ 1.126s systemd-logind.service
+ ....
+
+#### 6. 分析启动时的关键链 ####
+
+ # systemd-analyze critical-chain
+
+ The time after the unit is active or started is printed after the "@" character.
+ The time the unit takes to start is printed after the "+" character.
+
+ multi-user.target @20.222s
+ └─mariadb.service @11.657s +8.565s
+ └─network.target @11.168s
+ └─network.service @9.456s +1.712s
+ └─NetworkManager.service @8.858s +596ms
+ └─firewalld.service @4.931s +3.926s
+ └─basic.target @4.916s
+ └─sockets.target @4.916s
+ └─dbus.socket @4.916s
+ └─sysinit.target @4.905s
+ └─systemd-update-utmp.service @4.864s +39ms
+ └─auditd.service @4.563s +301ms
+ └─systemd-tmpfiles-setup.service @4.485s +69ms
+ └─rhel-import-state.service @4.342s +142ms
+ └─local-fs.target @4.324s
+ └─boot.mount @4.286s +31ms
+ └─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d19608096
+ └─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4
+
+**重要**:Systemctl接受服务(.service),挂载点(.mount),套接口(.socket)和设备(.device)作为单元。
+
+#### 7. 列出所有可用单元 ####
+
+ # systemctl list-unit-files
+
+ UNIT FILE STATE
+ proc-sys-fs-binfmt_misc.automount static
+ dev-hugepages.mount static
+ dev-mqueue.mount static
+ proc-sys-fs-binfmt_misc.mount static
+ sys-fs-fuse-connections.mount static
+ sys-kernel-config.mount static
+ sys-kernel-debug.mount static
+ tmp.mount disabled
+ brandbot.path disabled
+ .....
+
+#### 8. 列出所有运行中单元 ####
+
+ # systemctl list-units
+
+ UNIT LOAD ACTIVE SUB DESCRIPTION
+ proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary Executable File Formats File Syste
+ sys-devices-pc...0-1:0:0:0-block-sr0.device loaded active plugged VBOX_CD-ROM
+ sys-devices-pc...:00:03.0-net-enp0s3.device loaded active plugged PRO/1000 MT Desktop Adapter
+ sys-devices-pc...00:05.0-sound-card0.device loaded active plugged 82801AA AC'97 Audio Controller
+ sys-devices-pc...:0:0-block-sda-sda1.device loaded active plugged VBOX_HARDDISK
+ sys-devices-pc...:0:0-block-sda-sda2.device loaded active plugged LVM PV Qzyo3l-qYaL-uRUa-Cjuk-pljo-qKtX-VgBQ8
+ sys-devices-pc...0-2:0:0:0-block-sda.device loaded active plugged VBOX_HARDDISK
+ sys-devices-pl...erial8250-tty-ttyS0.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS0
+ sys-devices-pl...erial8250-tty-ttyS1.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS1
+ sys-devices-pl...erial8250-tty-ttyS2.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS2
+ sys-devices-pl...erial8250-tty-ttyS3.device loaded active plugged /sys/devices/platform/serial8250/tty/ttyS3
+ sys-devices-virtual-block-dm\x2d0.device loaded active plugged /sys/devices/virtual/block/dm-0
+ sys-devices-virtual-block-dm\x2d1.device loaded active plugged /sys/devices/virtual/block/dm-1
+ sys-module-configfs.device loaded active plugged /sys/module/configfs
+ ...
+
+#### 9. 列出所有失败单元 ####
+
+ # systemctl --failed
+
+ UNIT LOAD ACTIVE SUB DESCRIPTION
+ kdump.service loaded failed failed Crash recovery kernel arming
+
+ LOAD = Reflects whether the unit definition was properly loaded.
+ ACTIVE = The high-level unit activation state, i.e. generalization of SUB.
+ SUB = The low-level unit activation state, values depend on unit type.
+
+ 1 loaded units listed. Pass --all to see loaded but inactive units, too.
+ To show all installed unit files use 'systemctl list-unit-files'.
+
+#### 10. 检查某个单元(cron.service)是否启用 ####
+
+ # systemctl is-enabled crond.service
+
+ enabled
+
+#### 11. 检查某个单元或服务是否运行 ####
+
+ # systemctl status firewalld.service
+
+ firewalld.service - firewalld - dynamic firewall daemon
+ Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled)
+ Active: active (running) since Tue 2015-04-28 16:27:55 IST; 34min ago
+ Main PID: 549 (firewalld)
+ CGroup: /system.slice/firewalld.service
+ └─549 /usr/bin/python -Es /usr/sbin/firewalld --nofork --nopid
+
+ Apr 28 16:27:51 tecmint systemd[1]: Starting firewalld - dynamic firewall daemon...
+ Apr 28 16:27:55 tecmint systemd[1]: Started firewalld - dynamic firewall daemon.
+
+### 使用Systemctl控制并管理服务 ###
+
+#### 12. 列出所有服务(包括启用的和禁用的) ####
+
+ # systemctl list-unit-files --type=service
+
+ UNIT FILE STATE
+ arp-ethers.service disabled
+ auditd.service enabled
+ autovt@.service disabled
+ blk-availability.service disabled
+ brandbot.service static
+ collectd.service disabled
+ console-getty.service disabled
+ console-shell.service disabled
+ cpupower.service disabled
+ crond.service enabled
+ dbus-org.fedoraproject.FirewallD1.service enabled
+ ....
+
+#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(httpd.service)状态 ####
+
+ # systemctl start httpd.service
+ # systemctl restart httpd.service
+ # systemctl stop httpd.service
+ # systemctl reload httpd.service
+ # systemctl status httpd.service
+
+ httpd.service - The Apache HTTP Server
+ Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled)
+ Active: active (running) since Tue 2015-04-28 17:21:30 IST; 6s ago
+ Process: 2876 ExecStop=/bin/kill -WINCH ${MAINPID} (code=exited, status=0/SUCCESS)
+ Main PID: 2881 (httpd)
+ Status: "Processing requests..."
+ CGroup: /system.slice/httpd.service
+ ├─2881 /usr/sbin/httpd -DFOREGROUND
+ ├─2884 /usr/sbin/httpd -DFOREGROUND
+ ├─2885 /usr/sbin/httpd -DFOREGROUND
+ ├─2886 /usr/sbin/httpd -DFOREGROUND
+ ├─2887 /usr/sbin/httpd -DFOREGROUND
+ └─2888 /usr/sbin/httpd -DFOREGROUND
+
+ Apr 28 17:21:30 tecmint systemd[1]: Starting The Apache HTTP Server...
+ Apr 28 17:21:30 tecmint httpd[2881]: AH00558: httpd: Could not reliably determine the server's fully q...ssage
+ Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server.
+ Hint: Some lines were ellipsized, use -l to show in full.
+
+**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会不会从终端获取到任何输出内容,只有status命令可以打印输出。
+
+#### 14. 如何激活服务并在启动时启用或禁用服务(系统启动时自动启动服务) ####
+
+ # systemctl is-active httpd.service
+ # systemctl enable httpd.service
+ # systemctl disable httpd.service
+
+#### 15. 如何屏蔽(让它不能启动)或显示服务(httpd.service) ####
+
+ # systemctl mask httpd.service
+ ln -s '/dev/null' '/etc/systemd/system/httpd.service'
+
+ # systemctl unmask httpd.service
+ rm '/etc/systemd/system/httpd.service'
+
+#### 16. 使用systemctl命令杀死服务 ####
+
+ # systemctl kill httpd
+ # systemctl status httpd
+
+ httpd.service - The Apache HTTP Server
+ Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled)
+ Active: failed (Result: exit-code) since Tue 2015-04-28 18:01:42 IST; 28min ago
+ Main PID: 2881 (code=exited, status=0/SUCCESS)
+ Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec"
+
+ Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:29 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:39 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:49 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 17:37:59 tecmint systemd[1]: httpd.service: Got notification message from PID 2881, but recepti...bled.
+ Apr 28 18:01:42 tecmint systemd[1]: httpd.service: control process exited, code=exited status=226
+ Apr 28 18:01:42 tecmint systemd[1]: Unit httpd.service entered failed state.
+ Hint: Some lines were ellipsized, use -l to show in full.
+
+### 使用Systemctl控制并管理挂载点 ###
+
+#### 17. 列出所有系统挂载点 ####
+
+ # systemctl list-unit-files --type=mount
+
+ UNIT FILE STATE
+ dev-hugepages.mount static
+ dev-mqueue.mount static
+ proc-sys-fs-binfmt_misc.mount static
+ sys-fs-fuse-connections.mount static
+ sys-kernel-config.mount static
+ sys-kernel-debug.mount static
+ tmp.mount disabled
+
+#### 18. 挂载、卸载、重新挂载、重载系统挂载点并检查系统中挂载点状态 ####
+
+ # systemctl start tmp.mount
+ # systemctl stop tmp.mount
+ # systemctl restart tmp.mount
+ # systemctl reload tmp.mount
+ # systemctl status tmp.mount
+
+ tmp.mount - Temporary Directory
+ Loaded: loaded (/usr/lib/systemd/system/tmp.mount; disabled)
+ Active: active (mounted) since Tue 2015-04-28 17:46:06 IST; 2min 48s ago
+ Where: /tmp
+ What: tmpfs
+ Docs: man:hier(7)
+
+ http://www.freedesktop.org/wiki/Software/systemd/APIFileSystems
+
+ Process: 3908 ExecMount=/bin/mount tmpfs /tmp -t tmpfs -o mode=1777,strictatime (code=exited, status=0/SUCCESS)
+
+ Apr 28 17:46:06 tecmint systemd[1]: Mounting Temporary Directory...
+ Apr 28 17:46:06 tecmint systemd[1]: tmp.mount: Directory /tmp to mount over is not empty, mounting anyway.
+ Apr 28 17:46:06 tecmint systemd[1]: Mounted Temporary Directory.
+
+#### 19. 在启动时激活、启用或禁用挂载点(系统启动时自动挂载) ####
+
+ # systemctl is-active tmp.mount
+ # systemctl enable tmp.mount
+ # systemctl disable tmp.mount
+
+#### 20. 在Linux中屏蔽(让它不能启动)或显示挂载点 ####
+
+ # systemctl mask tmp.mount
+
+ ln -s '/dev/null' '/etc/systemd/system/tmp.mount'
+
+ # systemctl unmask tmp.mount
+
+ rm '/etc/systemd/system/tmp.mount'
+
+### 使用Systemctl控制并管理套接口 ###
+
+#### 21. 列出所有可用系统套接口 ####
+
+ # systemctl list-unit-files --type=socket
+
+ UNIT FILE STATE
+ dbus.socket static
+ dm-event.socket enabled
+ lvm2-lvmetad.socket enabled
+ rsyncd.socket disabled
+ sshd.socket disabled
+ syslog.socket static
+ systemd-initctl.socket static
+ systemd-journald.socket static
+ systemd-shutdownd.socket static
+ systemd-udevd-control.socket static
+ systemd-udevd-kernel.socket static
+
+ 11 unit files listed.
+
+#### 22. 在Linux中启动、重启、停止、重载套接口并检查其状态####
+
+ # systemctl start cups.socket
+ # systemctl restart cups.socket
+ # systemctl stop cups.socket
+ # systemctl reload cups.socket
+ # systemctl status cups.socket
+
+ cups.socket - CUPS Printing Service Sockets
+ Loaded: loaded (/usr/lib/systemd/system/cups.socket; enabled)
+ Active: active (listening) since Tue 2015-04-28 18:10:59 IST; 8s ago
+ Listen: /var/run/cups/cups.sock (Stream)
+
+ Apr 28 18:10:59 tecmint systemd[1]: Starting CUPS Printing Service Sockets.
+ Apr 28 18:10:59 tecmint systemd[1]: Listening on CUPS Printing Service Sockets.
+
+#### 23. 在启动时激活套接口,并启用或禁用它(系统启动时自启动) ####
+
+ # systemctl is-active cups.socket
+ # systemctl enable cups.socket
+ # systemctl disable cups.socket
+
+#### 24. 屏蔽(使它不能启动)或显示套接口 ####
+
+ # systemctl mask cups.socket
+ ln -s '/dev/null' '/etc/systemd/system/cups.socket'
+
+ # systemctl unmask cups.socket
+ rm '/etc/systemd/system/cups.socket'
+
+### 服务的CPU利用率(分配额) ###
+
+#### 25. 获取当前某个服务的CPU分配额(如httpd) ####
+
+ # systemctl show -p CPUShares httpd.service
+
+ CPUShares=1024
+
+**注意**:各个服务的默认CPU分配份额=1024,你可以增加/减少某个进程的CPU分配份额。
+
+#### 26. 将某个服务(httpd.service)的CPU分配份额限制为2000 CPUShares/ ####
+
+ # systemctl set-property httpd.service CPUShares=2000
+ # systemctl show -p CPUShares httpd.service
+
+ CPUShares=2000
+
+**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
+
+ # vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf
+
+ [Service]
+ CPUShares=2000
+
+#### 27. 检查某个服务的所有配置细节 ####
+
+ # systemctl show httpd
+
+ Id=httpd.service
+ Names=httpd.service
+ Requires=basic.target
+ Wants=system.slice
+ WantedBy=multi-user.target
+ Conflicts=shutdown.target
+ Before=shutdown.target multi-user.target
+ After=network.target remote-fs.target nss-lookup.target systemd-journald.socket basic.target system.slice
+ Description=The Apache HTTP Server
+ LoadState=loaded
+ ActiveState=active
+ SubState=running
+ FragmentPath=/usr/lib/systemd/system/httpd.service
+ ....
+
+#### 28. 分析某个服务(httpd)的关键链 ####
+
+ # systemd-analyze critical-chain httpd.service
+
+ The time after the unit is active or started is printed after the "@" character.
+ The time the unit takes to start is printed after the "+" character.
+
+ httpd.service +142ms
+ └─network.target @11.168s
+ └─network.service @9.456s +1.712s
+ └─NetworkManager.service @8.858s +596ms
+ └─firewalld.service @4.931s +3.926s
+ └─basic.target @4.916s
+ └─sockets.target @4.916s
+ └─dbus.socket @4.916s
+ └─sysinit.target @4.905s
+ └─systemd-update-utmp.service @4.864s +39ms
+ └─auditd.service @4.563s +301ms
+ └─systemd-tmpfiles-setup.service @4.485s +69ms
+ └─rhel-import-state.service @4.342s +142ms
+ └─local-fs.target @4.324s
+ └─boot.mount @4.286s +31ms
+ └─systemd-fsck@dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.service @4.092s +149ms
+ └─dev-disk-by\x2duuid-79f594ad\x2da332\x2d4730\x2dbb5f\x2d85d196080964.device @4.092s
+
+#### 29. 获取某个服务(httpd)的依赖性列表 ####
+
+ # systemctl list-dependencies httpd.service
+
+ httpd.service
+ ├─system.slice
+ └─basic.target
+ ├─firewalld.service
+ ├─microcode.service
+ ├─rhel-autorelabel-mark.service
+ ├─rhel-autorelabel.service
+ ├─rhel-configure.service
+ ├─rhel-dmesg.service
+ ├─rhel-loadmodules.service
+ ├─paths.target
+ ├─slices.target
+ │ ├─-.slice
+ │ └─system.slice
+ ├─sockets.target
+ │ ├─dbus.socket
+ ....
+
+#### 30. 按等级列出控制组 ####
+
+ # systemd-cgls
+
+ ├─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 23
+ ├─user.slice
+ │ └─user-0.slice
+ │ └─session-1.scope
+ │ ├─2498 sshd: root@pts/0
+ │ ├─2500 -bash
+ │ ├─4521 systemd-cgls
+ │ └─4522 systemd-cgls
+ └─system.slice
+ ├─httpd.service
+ │ ├─4440 /usr/sbin/httpd -DFOREGROUND
+ │ ├─4442 /usr/sbin/httpd -DFOREGROUND
+ │ ├─4443 /usr/sbin/httpd -DFOREGROUND
+ │ ├─4444 /usr/sbin/httpd -DFOREGROUND
+ │ ├─4445 /usr/sbin/httpd -DFOREGROUND
+ │ └─4446 /usr/sbin/httpd -DFOREGROUND
+ ├─polkit.service
+ │ └─721 /usr/lib/polkit-1/polkitd --no-debug
+ ....
+
+#### 31. 按CPU、内存、输入和输出列出控制组 ####
+
+ # systemd-cgtop
+
+ Path Tasks %CPU Memory Input/s Output/s
+
+ / 83 1.0 437.8M - -
+ /system.slice - 0.1 - - -
+ /system.slice/mariadb.service 2 0.1 - - -
+ /system.slice/tuned.service 1 0.0 - - -
+ /system.slice/httpd.service 6 0.0 - - -
+ /system.slice/NetworkManager.service 1 - - - -
+ /system.slice/atop.service 1 - - - -
+ /system.slice/atopacct.service 1 - - - -
+ /system.slice/auditd.service 1 - - - -
+ /system.slice/crond.service 1 - - - -
+ /system.slice/dbus.service 1 - - - -
+ /system.slice/firewalld.service 1 - - - -
+ /system.slice/lvm2-lvmetad.service 1 - - - -
+ /system.slice/polkit.service 1 - - - -
+ /system.slice/postfix.service 3 - - - -
+ /system.slice/rsyslog.service 1 - - - -
+ /system.slice/system-getty.slice/getty@tty1.service 1 - - - -
+ /system.slice/systemd-journald.service 1 - - - -
+ /system.slice/systemd-logind.service 1 - - - -
+ /system.slice/systemd-udevd.service 1 - - - -
+ /system.slice/webmin.service 1 - - - -
+ /user.slice/user-0.slice/session-1.scope 3 - - - -
+
+### 控制系统运行等级 ###
+
+#### 32. 启动系统救援模式 ####
+
+ # systemctl rescue
+
+ Broadcast message from root@tecmint on pts/0 (Wed 2015-04-29 11:31:18 IST):
+
+ The system is going down to rescue mode NOW!
+
+#### 33. 进入紧急模式 ####
+
+ # systemctl emergency
+
+ Welcome to emergency mode! After logging in, type "journalctl -xb" to view
+ system logs, "systemctl reboot" to reboot, "systemctl default" to try again
+ to boot into default mode.
+
+#### 34. 列出当前使用的运行等级 ####
+
+ # systemctl get-default
+
+ multi-user.target
+
+#### 35. 启动运行等级5,即图形模式 ####
+
+ # systemctl isolate runlevel5.target
+ OR
+ # systemctl isolate graphical.target
+
+#### 36. 启动运行等级3,即多用户模式(命令行) ####
+
+ # systemctl isolate runlevel3.target
+ OR
+ # systemctl isolate multiuser.target
+
+#### 36. 设置多用户模式或图形模式为默认运行等级 ####
+
+ # systemctl set-default runlevel3.target
+
+ # systemctl set-default runlevel5.target
+
+#### 37. 重启、停止、挂起、休眠系统或使系统进入混合睡眠 ####
+
+ # systemctl reboot
+
+ # systemctl halt
+
+ # systemctl suspend
+
+ # systemctl hibernate
+
+ # systemctl hybrid-sleep
+
+对于不知运行等级为何物的人,说明如下。
+
+- Runlevel 0 : 关闭系统
+- Runlevel 1 : 救援?维护模式
+- Runlevel 3 : 多用户,无图形系统
+- Runlevel 4 : 多用户,无图形系统
+- Runlevel 5 : 多用户,图形化系统
+- Runlevel 6 : 关闭并重启机器
+
+到此为止吧。保持连线,进行评论。别忘了在下面的评论中为我们提供一些有价值的反馈哦。喜欢我们、与我们分享,求扩散。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
+
+作者:[Avishek Kumar][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
diff --git a/translated/tech/20150506 Linux FAQs with Answers--How to install Shrew Soft IPsec VPN client on Linux.md b/translated/tech/20150506 Linux FAQs with Answers--How to install Shrew Soft IPsec VPN client on Linux.md
new file mode 100644
index 0000000000..abe1d3943d
--- /dev/null
+++ b/translated/tech/20150506 Linux FAQs with Answers--How to install Shrew Soft IPsec VPN client on Linux.md
@@ -0,0 +1,98 @@
+Linux有问必答——Linux上如何安装Shrew Soft IPsec VPN
+================================================================================
+> **Question**: I need to connect to an IPSec VPN gateway. For that, I'm trying to use Shrew Soft VPN client, which is available for free. How can I install Shrew Soft VPN client on [insert your Linux distro]?
+> **问题**:我需要连接到一个IPSec VPN网关,鉴于此,我尝试使用Shrew Soft VPN客户端,它是一个免费版本。我怎样才能安装Shrew Soft VPN客户端到[插入你的Linux发行版]?
+
+市面上有许多商业VPN网关,同时附带有他们自己的专有VPN客户端软件。虽然也有许多开源的VPN服务器/客户端备选方案,但它们通常缺乏复杂的IPsec支持,比如互联网密钥交换(IKE),这是一个标准的IPsec协议,用于加固VPN密钥交换和验证安全。Shrew Soft VPN是一个免费的IPsec VPN客户端,它支持多种验证方法、密钥交换、加密以及防火墙穿越选项。
+
+下面介绍如何安装Shrew Soft VPN客户端到Linux平台。
+
+首先,从[官方站点][1]下载它的源代码。
+
+### 安装Shrew VPN客户端到Debian, Ubuntu或者Linux Mint ###
+
+Shrew Soft VPN客户端图形界面要求使用Qt 4.x。所以,作为依赖,你需要安装其开发文件。
+
+ $ sudo apt-get install cmake libqt4-core libqt4-dev libqt4-gui libedit-dev libssl-dev checkinstall flex bison
+ $ wget https://www.shrew.net/download/ike/ike-2.2.1-release.tbz2
+ $ tar xvfvj ike-2.2.1-release.tbz2
+ $ cd ike
+ $ cmake -DCMAKE_INSTALL_PREFIX=/usr -DQTGUI=YES -DETCDIR=/etc -DNATT=YES .
+ $ make
+ $ sudo make install
+ $ cd /etc/
+ $ sudo mv iked.conf.sample iked.conf
+
+### 安装Shrew VPN客户端到CentOS, Fedora或者RHEL ###
+
+与基于Debian的系统类似,在编译前你需要安装一堆依赖包,包括Qt4。
+
+ $ sudo yum install qt-devel cmake gcc-c++ openssl-devel libedit-devel flex bison
+ $ wget https://www.shrew.net/download/ike/ike-2.2.1-release.tbz2
+ $ tar xvfvj ike-2.2.1-release.tbz2
+ $ cd ike
+ $ cmake -DCMAKE_INSTALL_PREFIX=/usr -DQTGUI=YES -DETCDIR=/etc -DNATT=YES .
+ $ make
+ $ sudo make install
+ $ cd /etc/
+ $ sudo mv iked.conf.sample iked.conf
+
+在基于Red Hat的系统中,最后一步需要用文本编辑器打开/etc/ld.so.conf文件,并添加以下行。
+
+ $ sudo vi /etc/ld.so.conf
+
+----------
+
+ include /usr/lib/
+
+重新加载运行时绑定的共享库文件,以容纳新安装的共享库:
+
+ $ sudo ldconfig
+
+### 启动Shrew VPN客户端 ###
+
+首先,启动IKE守护进程(iked)。该守护进作为VPN客户端程通过IKE协议与远程主机经由IPSec通信。
+
+ $ sudo iked
+
+
+
+现在,启动qikea,它是一个IPsec VPN客户端前端。该GUI应用允许你管理远程站点配置并初始化VPN连接。
+
+
+
+要创建一个新的VPN配置,点击“添加”按钮,然后填入VPN站点配置。创建配置后,你可以通过点击配置来初始化VPN连接。
+
+
+
+### 故障排除 ###
+
+1. 我在运行iked时碰到了如下错误。
+
+ iked: error while loading shared libraries: libss_ike.so.2.2.1: cannot open shared object file: No such file or directory
+
+要解决该问题,你需要更新动态链接器来容纳libss_ike库。对于此,请添加库文件的位置路径到/etc/ld.so.conf文件中,然后运行ldconfig命令。
+
+ $ sudo ldconfig
+
+验证libss_ike是否添加到了库路径:
+
+ $ ldconfig -p | grep ike
+
+----------
+
+ libss_ike.so.2.2.1 (libc6,x86-64) => /lib/libss_ike.so.2.2.1
+ libss_ike.so (libc6,x86-64) => /lib/libss_ike.so
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-shrew-soft-ipsec-vpn-client-linux.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:https://www.shrew.net/download/ike
diff --git a/translated/tech/20150507 Install uGet Download Manager 2.0 in Debian Ubuntu Linux Mint and Fedora.md b/translated/tech/20150507 Install uGet Download Manager 2.0 in Debian Ubuntu Linux Mint and Fedora.md
new file mode 100644
index 0000000000..d5c2fc98f5
--- /dev/null
+++ b/translated/tech/20150507 Install uGet Download Manager 2.0 in Debian Ubuntu Linux Mint and Fedora.md
@@ -0,0 +1,134 @@
+在 Debian, Ubuntu, Linux Mint 及 Fedora 中安装 uGet 下载管理器 2.0
+================================================================================
+在经历了一段漫长的开发期后,期间发布了超过 11 个开发版本,最终 uGet 项目小组高兴地宣布 uGet 的最新稳定版本 uGet 2.0 已经可以下载使用了。最新版本包含许多吸引人的特点,例如一个新的设定对话框,改进了 aria2 插件对 BitTorrent 和 Metalink 协议的支持,同时对位于横栏中的 uGet RSS 信息提供了更好的支持,其他特点包括:
+
+- 一个新的 “检查更新” 按钮,提醒您有关新的发行版本的信息;
+- 增添新的语言支持并升级了现有的语言;
+- 增加了一个新的 “信息横栏” ,允许开发者轻松地向所有的用户提供有关 uGet 的信息;
+- 通过对文档、提交反馈和错误报告等内容的链接,增强了帮助菜单;
+- 将 uGet 下载管理器集成到了 Linux 平台下的两个主要的浏览器 Firefox 和 Google Chrome 中;
+- 改进了对 Firefox 插件 ‘FlashGot’ 的支持;
+
+### 何为 uGet ###
+
+uGet (先前名为 UrlGfe) 是一个开源,免费,且极其强大的基于 GTK 的多平台下载管理器应用程序,它用 C 语言写就,在 GPL 协议下发布。它提供了一大类的功能,如恢复先前的下载任务,支持多重下载,使用一个独立的配置来支持分类,剪贴板监视,下载队列,从 HTML 文件中导出 URL 地址,集成在 Firefox 中的 Flashgot 插件中,使用集成在 uGet 中的 aria2(一个命令行下载管理器) 来下载 torrent 和 metalink 文件。
+
+我已经在下面罗列出了 uGet 下载管理器的所有关键特点,并附带了详细的解释。
+
+#### uGet 下载管理器的关键特点 ####
+
+- 下载队列: 可以将你的下载任务放入一个队列中。当某些下载任务完成后,将会自动开始下载队列中余下的文件;
+- 恢复下载: 假如在某些情况下,你的网络中断了,不要担心,你可以从先前停止的地方继续下载或重新开始;
+- 下载分类: 支持多种分类来管理下载;
+- 剪贴板监视: 将要下载的文件类型复制到剪贴板中,便会自动弹出下载提示框以下载刚才复制的文件;
+- 批量下载: 允许你轻松地一次性下载多个文件;
+- 支持多种协议: 允许你轻松地使用 aria2 命令行插件通过 HTTP, HTTPS, FTP, BitTorrent 及 Metalink 等协议下载文件;
+- 多连接: 使用 aria2 插件,每个下载同时支持多达 20 个连接;
+- 支持 FTP 登录或匿名 FTP 登录: 同时支持使用用户名和密码来登录 FTP 或匿名 FTP ;
+- 队列下载: 新增队列下载,现在你可以对你的所有下载进行安排调度;
+- 通过 FlashGot 与 FireFox 集成: 与作为一个独立支持的 Firefox 插件的 FlashGot 集成,从而可以处理单个或大量的下载任务;
+- CLI 界面或虚拟终端支持: 提供命令行或虚拟终端选项来下载文件;
+- 自动创建目录: 假如你提供了一个先前并不存在的保存路径,uGet 将会自动创建这个目录;
+- 下载历史管理: 跟踪记录已下载和已删除的下载任务的条目,每个列表支持 9999 个条目,比当前默认支持条目数目更早的条目将会被自动删除;
+- 多语言支持: uGet 默认使用英语,但它可支持多达 23 种语言;
+- Aria2 插件: uGet 集成了 Aria2 插件,来为 aria2 提供更友好的 GUI 界面;
+
+如若你想了解更加完整的特点描述,请访问 uGet 官方的 [特点页面][1].
+
+### 在 Debian, Ubuntu, Linux Mint 及 Fedora 中安装 uGet ###
+
+uGet 开发者在 Linux 平台下的各种软件仓库中添加了 uGet 的最新版本,所以你可以在你使用的 Linux 发行版本下使用受支持的软件仓库来安装或升级 uGet 。
+
+当前,一些 Linux 发行版本下的 uGet 可能不是最新的,但你可以到 [uGet 下载页面][2] 去了解你所用发行版本的支持状态,在那里选择你喜爱的发行版本来了解更多的信息。
+
+#### 在 Debian 下 ####
+
+在 Debian 的测试版本 (Jessie) 和不稳定版本 (Sid) 中,你可以在一个可信赖的基础上,使用官方的软件仓库轻易地安装和升级 uGet 。
+
+ $ sudo apt-get update
+ $ sudo apt-get install uget
+
+#### 在 Ubuntu 和 Linux Mint 下 ####
+
+在 Ubuntu 和 Linux Mint 下,你可以使用官方的 PPA `ppa:plushuang-tw/uget-stable` 安装和升级 uGet ,通过使用这个 PPA,你可以自动地与最新版本保持同步。
+
+ $ sudo add-apt-repository ppa:plushuang-tw/uget-stable
+ $ sudo apt-get update
+ $ sudo apt-get install uget
+
+#### 在 Fedora 下 ####
+
+在 Fedora 20 – 21 下,最新版本的 uGet(2.0) 可以从官方软件仓库中获得,从这些软件仓库中安装是非常值得信赖的。
+
+ $ sudo yum install uget
+
+**注**: 在旧版本的 Debian, Ubuntu, Linux Mint 和 Fedora 下,用户也可以安装 uGet , 但可获取的版本为 1.10.4 。假如你期待使用升级版本(例如 2.0 版本),你需要升级你的系统并添加 uGet 的 PPA 以此来获取最新的稳定版本。
+
+### 安装 aria2 插件 ###
+
+[aria2][3] 是一个卓越的命令行下载管理应用,在 uGet 中它作为一个 aria2 插件,为 uGet 增添了更为强大的功能,如下载 toorent,metalinks 文件,支持多种协议和多来源下载等功能。
+
+默认情况下,uGet 在当今大多数的 Linux 系统中使用 `curl` 来作为后端,但 aria2 插件将 curl 替换为 aria2 来作为 uGet 的后端。
+
+aria2 是一个单独的软件包,需要独立安装。你可以在你的 Linux 发行版本下,使用受支持的软件仓库来轻易地安装 aria2 的最新版本,或根据 [下载 aria2 页面][4] 来安装它,该页面详细解释了在各个发行版本中如何安装 aria2 。
+
+#### 在 Debian, Ubuntu 和 Linux Mint 下 ####
+
+利用下面的命令,使用 aria2 的个人软件仓库来安装最新版本的 aria2 :
+
+ $ sudo add-apt-repository ppa:t-tujikawa/ppa
+ $ sudo apt-get update
+ $ sudo apt-get install aria2
+
+#### 在 Fedora 下 ####
+
+Fedora 的官方软件仓库中已经添加了 aria2 软件包,所以你可以轻易地使用下面的 yum 命令来安装它:
+
+ $ sudo yum install aria2
+
+#### 开启 uGet ####
+
+为了启动 uGet,从桌面菜单的搜索栏中键入 "uGet"。可参考如下的截图:
+
+
+开启 uGet 下载管理器
+
+
+uGet 版本: 2.0
+
+#### 在 uGet 中激活 aria2 插件 ####
+
+为了激活 aria2 插件, 从 uGet 菜单接着到 `编辑 –> 设置 –> 插件` , 从下拉菜单中选择 "aria2"。
+
+
+为 uGet 启用 Aria2 插件
+
+### uGet 2.0 截图赏析 ###
+
+
+使用 Aria2 下载文件
+
+
+使用 uGet 下载 Torrent 文件
+
+
+使用 uGet 进行批量下载
+
+针对其他 Linux 发行版本和 Windows 平台的 RPM 包和 uGet 的源文件都可以在 uGet 的[下载页面][5] 下找到。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-uget-download-manager-in-linux/
+
+作者:[Ravi Saive][a]
+译者:[FSSlc](https://github.com/FSSlc)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/admin/
+[1]:http://uget.visuex.com/features
+[2]:http://ugetdm.com/downloads
+[3]:http://www.tecmint.com/install-aria2-a-multi-protocol-command-line-download-manager-in-rhel-centos-fedora/
+[4]:http://ugetdm.com/downloads-aria2
+[5]:http://ugetdm.com/downloads
\ No newline at end of file
diff --git a/translated/tech/20150511 Fix Various Update Errors In Ubuntu 14.04.md b/translated/tech/20150511 Fix Various Update Errors In Ubuntu 14.04.md
new file mode 100644
index 0000000000..3780b4f948
--- /dev/null
+++ b/translated/tech/20150511 Fix Various Update Errors In Ubuntu 14.04.md
@@ -0,0 +1,151 @@
+修复Ubuntu 14.04中各种更新错误
+================================================================================
+
+
+在Ubuntu更新中,谁没有碰见个错误?在Ubuntu和其它基于Ubuntu的Linux发行版中,更新错误很常见,也为数不少。这些错误出现的原因多种多样,修复起来也很简单。在本文中,我们将见到Ubuntu中各种类型频繁发生的更新错误以及它们的修复方法。
+
+### 合并列表问题 ###
+
+当你在终端中运行更新命令时,你可能会碰到这个错误“[合并列表错误][1]”,就像下面这样:
+
+> E:Encountered a section with no Package: header,
+>
+> E:Problem with MergeList /var/lib/apt/lists/archive.ubuntu.com_ubuntu_dists_precise_universe_binary-i386_Packages,
+>
+> E:The package lists or status file could not be parsed or opened.’
+
+可以使用以下命令来修复该错误:
+
+ sudo rm -r /var/lib/apt/lists/*
+ sudo apt-get clean && sudo apt-get update
+
+### 下载仓库信息失败 -1 ###
+
+实际上,有两种类型的[下载仓库信息失败错误][2]。如果你的错误是这样的:
+
+> W:Failed to fetch bzip2:/var/lib/apt/lists/partial/in.archive.ubuntu.com_ubuntu_dists_oneiric_restricted_binary-i386_Packages Hash Sum mismatch,
+>
+> W:Failed to fetch bzip2:/var/lib/apt/lists/partial/in.archive.ubuntu.com_ubuntu_dists_oneiric_multiverse_binary-i386_Packages Hash Sum mismatch,
+>
+> E:Some index files failed to download. They have been ignored, or old ones used instead
+
+那么,你可以用以下命令修复:
+
+ sudo rm -rf /var/lib/apt/lists/*
+ sudo apt-get update
+
+### 下载仓库信息失败 -2 ###
+
+下载仓库信息失败的另外一种类型是由于PPA过时导致的。通常,当你运行更新管理器,并看到这样的错误时:
+
+
+
+你可以运行sudo apt-get update来查看哪个PPA更新失败,你可以把它从源列表中删除。你可以按照这个截图指南来[修复下载仓库信息失败错误][3]。
+
+### 下载包文件失败错误 ###
+
+一个类似的错误是[下载包文件失败错误][4],像这样:
+
+
+
+该错误很容易修复,只需修改软件源为主服务器即可。转到软件和更新,在那里你可以修改下载服务器为主服务器:
+
+
+
+### 部分更新错误 ###
+
+在终端中运行更新会出现[部分更新错误][5]:
+
+> Not all updates can be installed
+>
+> Run a partial upgrade, to install as many updates as possible
+
+在终端中运行以下命令来修复该错误:
+
+ sudo apt-get install -f
+
+### 加载共享库时发生错误 ###
+
+该错误更多是安装错误,而不是更新错误。如果尝试从源码安装程序,你可能会碰到这个错误:
+
+> error while loading shared libraries:
+>
+> cannot open shared object file: No such file or directory
+
+该错误可以通过在终端中运行以下命令来修复:
+
+ sudo /sbin/ldconfig -v
+
+你可以在这里查找到更多详细内容[加载共享库时发生错误][6]。
+
+### 无法获取锁/var/cache/apt/archives/lock ###
+
+在另一个程序在使用APT时,会发生该错误。假定你正在Ubuntu软件中心安装某个东西,然后你又试着在终端中运行apt。
+
+> E: Could not get lock /var/cache/apt/archives/lock – open (11: Resource temporarily unavailable)
+>
+> E: Unable to lock directory /var/cache/apt/archives/
+
+通常,只要你把所有其它使用apt的程序关了,这个问题就会好的。但是,如果问题持续,可以使用以下命令:
+
+ sudo rm /var/lib/apt/lists/lock
+
+如果上面的命令不起作用,可以试试这个命令:
+
+ sudo killall apt-get
+
+关于该错误的更多信息,可以在[这里][7]找到。
+
+### GPG错误: 下列签名无法验证 ###
+
+在添加一个PPA时,可能会导致以下错误[GPG错误: 下列签名无法验证][8],这通常发生在终端中运行更新时:
+
+> W: GPG error: http://repo.mate-desktop.org saucy InRelease: The following signatures couldn’t be verified because the public key is not available: NO_PUBKEY 68980A0EA10B4DE8
+
+我们所要做的,就是获取系统中的这个公钥,从信息中获取密钥号。在上述信息中,密钥号为68980A0EA10B4DE8。该密钥可通过以下方式使用:
+
+ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 68980A0EA10B4DE8
+
+在添加密钥后,再次运行更新就没有问题了。
+
+### BADSIG错误 ###
+
+另外一个与签名相关的Ubuntu更新错误是[BADSIG错误][9],它看起来像这样:
+
+> W: A error occurred during the signature verification. The repository is not updated and the previous index files will be used. GPG error: http://extras.ubuntu.com precise Release: The following signatures were invalid: BADSIG 16126D3A3E5C1192 Ubuntu Extras Archive Automatic Signing Key
+>
+> W: GPG error: http://ppa.launchpad.net precise Release:
+>
+> The following signatures were invalid: BADSIG 4C1CBC1B69B0E2F4 Launchpad PPA for Jonathan French W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/precise/Release
+
+要修复该BADSIG错误,请在终端中使用以下命令:
+
+ sudo apt-get clean
+ cd /var/lib/apt
+ sudo mv lists oldlist
+ sudo mkdir -p lists/partial
+ sudo apt-get clean
+ sudo apt-get update
+
+本文汇集了你可能会碰到的**Ubuntu更新错误**,我希望这会对你处理这些错误有所帮助。你在Ubuntu中是否也碰到过其它更新错误呢?请在下面的评论中告诉我,我会试着写个快速指南。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/fix-update-errors-ubuntu-1404/
+
+作者:[Abhishek][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://itsfoss.com/how-to-fix-problem-with-mergelist/
+[2]:http://itsfoss.com/solve-ubuntu-error-failed-to-download-repository-information-check-your-internet-connection/
+[3]:http://itsfoss.com/failed-to-download-repository-information-ubuntu-13-04/
+[4]:http://itsfoss.com/fix-failed-download-package-files-error-ubuntu/
+[5]:http://itsfoss.com/fix-partial-upgrade-error-elementary-os-luna-quick-tip/
+[6]:http://itsfoss.com/solve-open-shared-object-file-quick-tip/
+[7]:http://itsfoss.com/fix-ubuntu-install-error/
+[8]:http://itsfoss.com/solve-gpg-error-signatures-verified-ubuntu/
+[9]:http://itsfoss.com/solve-badsig-error-quick-tip/
diff --git a/translated/tech/20150512 45 Zypper Commands to Manage 'Suse' Linux Package Management.md b/translated/tech/20150512 45 Zypper Commands to Manage 'Suse' Linux Package Management.md
new file mode 100644
index 0000000000..efa807f2f3
--- /dev/null
+++ b/translated/tech/20150512 45 Zypper Commands to Manage 'Suse' Linux Package Management.md
@@ -0,0 +1,767 @@
+45 个用于 ‘Suse‘ Linux 包管理的 Zypper 命令
+======================================================================
+SUSE( Software and System Entwicklung,即软件和系统开发。其中‘entwicklung‘是德语,意为开发)Linux是 Novell 公司在 Linux 内核基础上发布的操作系统。SUSE Linux 有两个发行分支。其中之一名为 OpenSUSE,这是一款自由而且免费的操作系统。该系统由开源社区开发维护,支持一些最新版本的应用软件,其最新的稳定版本为 13.2。
+
+另外一个分支是SUSE Linux 企业版。该分支是一个为企业及商业化产品设计的 Linux 发行版,包含了大量的企业应用以及适用于商业产品生产环境的特性。其最新的稳定版本为 12。
+
+以下的链接包含了安装企业版 SUSE Linux 服务器的详细信息。
+
+- [如何安装企业版 SUSE Linux 12][1]
+
+Zypper 和 Yast 是 SUSE Linux 平台上的软件包管理工具,他们的底层使用了 RPM(译者注:RPM 最初指 Redhat Pacakge Manager ,现普遍解释为递归短语 RPM Package Manager 的缩写)。
+
+Yast(Yet another Setup Tool )是 OpenSUSE 以及企业版 SUSE 上用于系统管理、设置和配置的工具。
+
+Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUSE Linux上的软件以及进行系统更新。ZYpp为Zypper和Yast提供底层支持。
+
+本文将介绍实际应用中常见的一些Zypper命令。这些命令用来进行安装、更新、删除等任何软件包管理器所能够胜任的工作。
+
+**重要** : 切记所有的这些指令都将在系统全局范围内产生影响,所以必须以 root 身份执行,否则命令将失败。
+
+### 获取基本的 Zypper 帮助信息 ###
+
+1. 不带任何选项的执行 zypper, 将输出该命令的全局选项以及子命令列表(译者注:全局选项,global option,控制台命令的输入分为可选参数和位置参数两大类。按照习惯,一般可选参数称为选项'option',而位置参数称为参数 'argument')。
+
+
%> zypper help install
+ install (in) [options] {capability | rpm_file_uri}
+
+ Install packages with specified capabilities or RPM files with specified
+ location. A capability is NAME[.ARCH][OP], where OP is one
+ of <, <=, =, >=, >.
+
+ Command options:
+ --from Select packages from the specified repository.
+ -r, --repo Load only the specified repository.
+ -t, --type Type of package (package, patch, pattern, product, srcpackage).
+ Default: package.
+ -n, --name Select packages by plain name, not by capability.
+ -C, --capability Select packages by capability.
+ -f, --force Install even if the item is already installed (reinstall),
+ downgraded or changes vendor or architecture.
+ --oldpackage Allow to replace a newer item with an older one.
+ Handy if you are doing a rollback. Unlike --force
+ it will not enforce a reinstall.
+ --replacefiles Install the packages even if they replace files from other,
+ already installed, packages. Default is to treat file conflicts
+ as an error. --download-as-needed disables the fileconflict check.
+ ......
+
+3. 安装之前搜索一个安转包(以 gnome-desktop 为例 )
+
+
# zypper se gnome-desktop
+
+ Retrieving repository 'openSUSE-13.2-Debug' metadata ............................................................[done]
+ Building repository 'openSUSE-13.2-Debug' cache .................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ......................................................... [done]
+ Building repository 'openSUSE-13.2-Non-Oss' cache ...............................................................[done]
+ Retrieving repository 'openSUSE-13.2-Oss' metadata ..............................................................[done]
+ Building repository 'openSUSE-13.2-Oss' cache ...................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Update' metadata ...........................................................[done]
+ Building repository 'openSUSE-13.2-Update' cache ................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Update-Non-Oss' metadata ...................................................[done]
+ Building repository 'openSUSE-13.2-Update-Non-Oss' cache ........................................................[done]
+ Loading repository data...
+ Reading installed packages...
+
+ S | Name | Summary | Type
+ --+---------------------------------------+-----------------------------------------------------------+-----------
+ | gnome-desktop2-lang | Languages for package gnome-desktop2 | package
+ | gnome-desktop2 | The GNOME Desktop API Library | package
+ | libgnome-desktop-2-17 | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-10 | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-devel | The GNOME Desktop API Library -- Development Files | package
+ | libgnome-desktop-3_0-common | The GNOME Desktop API Library -- Common data files | package
+ | gnome-desktop-debugsource | Debug sources for package gnome-desktop | package
+ | gnome-desktop-sharp2-debugsource | Debug sources for package gnome-desktop-sharp2 | package
+ | gnome-desktop2-debugsource | Debug sources for package gnome-desktop2 | package
+ | libgnome-desktop-2-17-debuginfo | Debug information for package libgnome-desktop-2-17 | package
+ | libgnome-desktop-3-10-debuginfo | Debug information for package libgnome-desktop-3-10 | package
+ | libgnome-desktop-3_0-common-debuginfo | Debug information for package libgnome-desktop-3_0-common | package
+ | libgnome-desktop-2-17-debuginfo-32bit | Debug information for package libgnome-desktop-2-17 | package
+ | libgnome-desktop-3-10-debuginfo-32bit | Debug information for package libgnome-desktop-3-10 | package
+ | gnome-desktop-sharp2 | Mono bindings for libgnome-desktop | package
+ | libgnome-desktop-2-devel | The GNOME Desktop API Library -- Development Files | packag
+ | gnome-desktop-lang | Languages for package gnome-desktop | package
+ | libgnome-desktop-2-17-32bit | The GNOME Desktop API Library | package
+ | libgnome-desktop-3-10-32bit | The GNOME Desktop API Library | package
+ | gnome-desktop | The GNOME Desktop API Library | srcpackage
+
+4. 获取一个模式包的信息(以 lamp_server 为例)。
+
+
%> zypper info -t pattern lamp_server
+
+ Loading repository data...
+ Reading installed packages...
+
+
+ Information for pattern lamp_server:
+ ------------------------------------
+ Repository: openSUSE-13.2-Update
+ Name: lamp_server
+ Version: 20141007-5.1
+ Arch: x86_64
+ Vendor: openSUSE
+ Installed: No
+ Visible to User: Yes
+ Summary: Web and LAMP Server
+ Description:
+ Software to set up a Web server that is able to serve static, dynamic, and interactive content (like a Web shop). This includes Apache HTTP Server, the database management system MySQL,
+ and scripting languages such as PHP, Python, Ruby on Rails, or Perl.
+ Contents:
+
+ S | Name | Type | Dependency
+ --+-------------------------------+---------+-----------
+ | apache2-mod_php5 | package |
+ | php5-iconv | package |
+ i | patterns-openSUSE-base | package |
+ i | apache2-prefork | package |
+ | php5-dom | package |
+ | php5-mysql | package |
+ i | apache2 | package |
+ | apache2-example-pages | package |
+ | mariadb | package |
+ | apache2-mod_perl | package |
+ | php5-ctype | package |
+ | apache2-doc | package |
+ | yast2-http-server | package |
+ | patterns-openSUSE-lamp_server | package |
%> zypper ref
+ Repository 'openSUSE-13.2-0' is up to date.
+ Repository 'openSUSE-13.2-Debug' is up to date.
+ Repository 'openSUSE-13.2-Non-Oss' is up to date.
+ Repository 'openSUSE-13.2-Oss' is up to date.
+ Repository 'openSUSE-13.2-Update' is up to date.
+ Repository 'openSUSE-13.2-Update-Non-Oss' is up to date.
+ All repositories have been refreshed.
+
+10. 刷新一个指定的软件库(以 'repo-non-oss' 为例 )。
+
+
%> zypper refresh repo-non-oss
+ Repository 'openSUSE-13.2-Non-Oss' is up to date.
+ Specified repositories have been refreshed.
+
+11. 强制更新一个软件库(以 'repo-non-oss' 为例 )。
+
+
%> zypper ref -f repo-non-oss
+ Forcing raw metadata refresh
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ............................................................[done]
+ Forcing building of repository cache
+ Building repository 'openSUSE-13.2-Non-Oss' cache ............................................................[done]
+ Specified repositories have been refreshed.
%> zypper mr -rk -p 85 repo-non-oss
+ Repository 'repo-non-oss' priority has been left unchanged (85)
+ Nothing to change for repository 'repo-non-oss'.
+
+15. 对所有的软件库关闭 rpm 文件缓存。
+
+
%> zypper mr -Ka
+ RPM files caching has been disabled for repository 'openSUSE-13.2-0'.
+ RPM files caching has been disabled for repository 'repo-debug'.
+ RPM files caching has been disabled for repository 'repo-debug-update'.
+ RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been disabled for repository 'repo-non-oss'.
+ RPM files caching has been disabled for repository 'repo-oss'.
+ RPM files caching has been disabled for repository 'repo-source'.
+ RPM files caching has been disabled for repository 'repo-update'.
+ RPM files caching has been disabled for repository 'repo-update-non-oss'.
+
+16. 对所有的软件库开启 rpm 文件缓存。
+
zypper mr -ka
+ RPM files caching has been enabled for repository 'openSUSE-13.2-0'.
+ RPM files caching has been enabled for repository 'repo-debug'.
+ RPM files caching has been enabled for repository 'repo-debug-update'.
+ RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been enabled for repository 'repo-non-oss'.
+ RPM files caching has been enabled for repository 'repo-oss'.
+ RPM files caching has been enabled for repository 'repo-source'.
+ RPM files caching has been enabled for repository 'repo-update'.
+ RPM files caching has been enabled for repository 'repo-update-non-oss'.
+
+17. 关闭远程库的rpm 文件缓存
+
%> zypper mr -Kt
+ RPM files caching has been disabled for repository 'repo-debug'.
+ RPM files caching has been disabled for repository 'repo-debug-update'.
+ RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been disabled for repository 'repo-non-oss'.
+ RPM files caching has been disabled for repository 'repo-oss'.
+ RPM files caching has been disabled for repository 'repo-source'.
+ RPM files caching has been disabled for repository 'repo-update'.
+ RPM files caching has been disabled for repository 'repo-update-non-oss'.
+
+18. 开启远程软件库的 rpm 文件缓存。
+
%> zypper mr -kt
+ RPM files caching has been enabled for repository 'repo-debug'.
+ RPM files caching has been enabled for repository 'repo-debug-update'.
+ RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
+ RPM files caching has been enabled for repository 'repo-non-oss'.
+ RPM files caching has been enabled for repository 'repo-oss'.
+ RPM files caching has been enabled for repository 'repo-source'.
+ RPM files caching has been enabled for repository 'repo-update'.
+ RPM files caching has been enabled for repository 'repo-update-non-oss'.
%>zypper in 'gcc<5.1'
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 13 NEW packages are going to be installed:
+ cpp cpp48 gcc gcc48 libasan0 libatomic1-gcc49 libcloog-isl4 libgomp1-gcc49 libisl10 libitm1-gcc49 libmpc3 libmpfr4 libtsan0-gcc49
+
+ 13 new packages to install.
+ Overall download size: 14.5 MiB. Already cached: 0 B After the operation, additional 49.4 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+24. 为特定的CPU架构安装软件包(以兼容 i586 的 gcc 为例)。
+
+
%> zypper in gcc.i586
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 13 NEW packages are going to be installed:
+ cpp cpp48 gcc gcc48 libasan0 libatomic1-gcc49 libcloog-isl4 libgomp1-gcc49 libisl10 libitm1-gcc49 libmpc3 libmpfr4 libtsan0-gcc49
+
+ 13 new packages to install.
+ Overall download size: 14.5 MiB. Already cached: 0 B After the operation, additional 49.4 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+ Retrieving package libasan0-4.8.3+r212056-2.2.4.x86_64 (1/13), 74.2 KiB (166.9 KiB unpacked)
+ Retrieving: libasan0-4.8.3+r212056-2.2.4.x86_64.rpm .......................................................................................................................[done (79.2 KiB/s)]
+ Retrieving package libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64 (2/13), 14.3 KiB ( 26.1 KiB unpacked)
+ Retrieving: libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm ...............................................................................................................[done (55.3 KiB/s)]
%> zypper in 'gcc.i586<5.1'
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 13 NEW packages are going to be installed:
+ cpp cpp48 gcc gcc48 libasan0 libatomic1-gcc49 libcloog-isl4 libgomp1-gcc49 libisl10 libitm1-gcc49 libmpc3 libmpfr4 libtsan0-gcc49
+
+ 13 new packages to install.
+ Overall download size: 14.4 MiB. Already cached: 129.5 KiB After the operation, additional 49.4 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+ In cache libasan0-4.8.3+r212056-2.2.4.x86_64.rpm (1/13), 74.2 KiB (166.9 KiB unpacked)
+ In cache libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (2/13), 14.3 KiB ( 26.1 KiB unpacked)
+ In cache libgomp1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (3/13), 41.1 KiB ( 90.7 KiB unpacked)
+
+26. 从指定的软件库里面安装一个软件包,例如从 amarok 中安装 libxine。
+
%> zypper in amarok upd:libxine1
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+ The following 202 NEW packages are going to be installed:
+ amarok bundle-lang-kde-en clamz cups-libs enscript fontconfig gdk-pixbuf-query-loaders ghostscript-fonts-std gptfdisk gstreamer gstreamer-plugins-base hicolor-icon-theme
+ hicolor-icon-theme-branding-openSUSE htdig hunspell hunspell-tools icoutils ispell ispell-american kde4-filesystem kdebase4-runtime kdebase4-runtime-branding-openSUSE kdelibs4
+ kdelibs4-branding-openSUSE kdelibs4-core kdialog libakonadi4 l
+ .....
+
+27. 通过指定软件包的名字安装软件包。
+
+
%> zypper in -n git
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 35 NEW packages are going to be installed:
+ cvs cvsps fontconfig git git-core git-cvs git-email git-gui gitk git-svn git-web libserf-1-1 libsqlite3-0 libXft2 libXrender1 libXss1 perl-Authen-SASL perl-Clone perl-DBD-SQLite perl-DBI
+ perl-Error perl-IO-Socket-SSL perl-MLDBM perl-Net-Daemon perl-Net-SMTP-SSL perl-Net-SSLeay perl-Params-Util perl-PlRPC perl-SQL-Statement perl-Term-ReadKey subversion subversion-perl tcl
+ tk xhost
+
+ The following 13 recommended packages were automatically selected:
+ git-cvs git-email git-gui gitk git-svn git-web perl-Authen-SASL perl-Clone perl-MLDBM perl-Net-Daemon perl-Net-SMTP-SSL perl-PlRPC perl-SQL-Statement
+
+ The following package is suggested, but will not be installed:
+ git-daemon
+
+ 35 new packages to install.
+ Overall download size: 15.6 MiB. Already cached: 0 B After the operation, additional 56.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
+
%> zypper in php5*
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ Problem: php5-5.6.1-18.1.x86_64 requires smtp_daemon, but this requirement cannot be provided
+ uninstallable providers: exim-4.83-3.1.8.x86_64[openSUSE-13.2-0]
+ postfix-2.11.0-5.2.2.x86_64[openSUSE-13.2-0]
+ sendmail-8.14.9-2.2.2.x86_64[openSUSE-13.2-0]
+ exim-4.83-3.1.8.i586[repo-oss]
+ msmtp-mta-1.4.32-2.1.3.i586[repo-oss]
+ postfix-2.11.0-5.2.2.i586[repo-oss]
+ sendmail-8.14.9-2.2.2.i586[repo-oss]
+ exim-4.83-3.1.8.x86_64[repo-oss]
+ msmtp-mta-1.4.32-2.1.3.x86_64[repo-oss]
+ postfix-2.11.0-5.2.2.x86_64[repo-oss]
+ sendmail-8.14.9-2.2.2.x86_64[repo-oss]
+ postfix-2.11.3-5.5.1.i586[repo-update]
+ postfix-2.11.3-5.5.1.x86_64[repo-update]
+ Solution 1: Following actions will be done:
+ do not install php5-5.6.1-18.1.x86_64
+ do not install php5-pear-Auth_SASL-1.0.6-7.1.3.noarch
+ do not install php5-pear-Horde_Http-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Image-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Kolab_Format-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Ldap-2.0.1-6.1.3.noarch
+ do not install php5-pear-Horde_Memcache-2.0.1-7.1.3.noarch
+ do not install php5-pear-Horde_Mime-2.0.2-6.1.3.noarch
+ do not install php5-pear-Horde_Oauth-2.0.0-6.1.3.noarch
+ do not install php5-pear-Horde_Pdf-2.0.1-6.1.3.noarch
+ ....
+
+29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包
+
+
%> zypper in -t pattern lamp_server
+ ading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 29 NEW packages are going to be installed:
+ apache2 apache2-doc apache2-example-pages apache2-mod_perl apache2-prefork patterns-openSUSE-lamp_server perl-Data-Dump perl-Encode-Locale perl-File-Listing perl-HTML-Parser
+ perl-HTML-Tagset perl-HTTP-Cookies perl-HTTP-Daemon perl-HTTP-Date perl-HTTP-Message perl-HTTP-Negotiate perl-IO-HTML perl-IO-Socket-SSL perl-libwww-perl perl-Linux-Pid
+ perl-LWP-MediaTypes perl-LWP-Protocol-https perl-Net-HTTP perl-Net-SSLeay perl-Tie-IxHash perl-TimeDate perl-URI perl-WWW-RobotRules yast2-http-server
+
+ The following NEW pattern is going to be installed:
+ lamp_server
+
+ The following 10 recommended packages were automatically selected:
+ apache2 apache2-doc apache2-example-pages apache2-mod_perl apache2-prefork perl-Data-Dump perl-IO-Socket-SSL perl-LWP-Protocol-https perl-TimeDate yast2-http-server
+
+ 29 new packages to install.
+ Overall download size: 7.2 MiB. Already cached: 1.2 MiB After the operation, additional 34.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+
+30. 使用一行命令安转一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
+
+
# zypper in nano -vi
+ Loading repository data...
+ Reading installed packages...
+ '-vi' not found in package names. Trying capabilities.
+ Resolving package dependencies...
+
+ The following 2 NEW packages are going to be installed:
+ nano nano-lang
+
+ The following package is going to be REMOVED:
+ vim
+
+ The following recommended package was automatically selected:
+ nano-lang
+
+ 2 new packages to install, 1 to remove.
+ Overall download size: 550.0 KiB. Already cached: 0 B After the operation, 463.3 KiB will be freed.
+ Continue? [y/n/? shows all options] (y):
+ ...
+
+31. 使用 zypper 安装 rpm 软件包。
+
+
%> zypper in teamviewer*.rpm
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following 24 NEW packages are going to be installed:
+ alsa-oss-32bit fontconfig-32bit libasound2-32bit libexpat1-32bit libfreetype6-32bit libgcc_s1-gcc49-32bit libICE6-32bit libjpeg62-32bit libpng12-0-32bit libpng16-16-32bit libSM6-32bit
+ libuuid1-32bit libX11-6-32bit libXau6-32bit libxcb1-32bit libXdamage1-32bit libXext6-32bit libXfixes3-32bit libXinerama1-32bit libXrandr2-32bit libXrender1-32bit libXtst6-32bit
+ libz1-32bit teamviewer
+
+ The following recommended package was automatically selected:
+ alsa-oss-32bit
+
+ 24 new packages to install.
+ Overall download size: 41.2 MiB. Already cached: 0 B After the operation, additional 119.7 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+ ..
zypper up apache2 openssh
+ Loading repository data...
+ Reading installed packages...
+ No update candidate for 'apache2-2.4.10-19.1.x86_64'. The highest available version is already installed.
+ No update candidate for 'openssh-6.6p1-5.1.3.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+35. 安装一个软件库,例如 ariadb,如果该库存在则更新之。
+
+
%> zypper in mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
%> zypper si mariadb
+ Reading installed packages...
+ Loading repository data...
+ Resolving package dependencies...
+
+ The following 36 NEW packages are going to be installed:
+ autoconf automake bison cmake cpp cpp48 gcc gcc48 gcc48-c++ gcc-c++ libaio-devel libarchive13 libasan0 libatomic1-gcc49 libcloog-isl4 libedit-devel libevent-devel libgomp1-gcc49 libisl10
+ libitm1-gcc49 libltdl7 libmpc3 libmpfr4 libopenssl-devel libstdc++48-devel libtool libtsan0-gcc49 m4 make ncurses-devel pam-devel readline-devel site-config tack tcpd-devel zlib-devel
+
+ The following source package is going to be installed:
+ mariadb
+
+ 36 new packages to install, 1 source package.
+ Overall download size: 71.5 MiB. Already cached: 129.5 KiB After the operation, additional 183.9 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+37. 仅为某一个软件包安装源文件,例如 mariadb
+
+
%> zypper in -D mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+38. 仅为某一个软件包安装依赖关系,例如 mariadb
+
+
%> zypper si -d mariadb
+ Reading installed packages...
+ Loading repository data...
+ Resolving package dependencies...
+
+ The following 36 NEW packages are going to be installed:
+ autoconf automake bison cmake cpp cpp48 gcc gcc48 gcc48-c++ gcc-c++ libaio-devel libarchive13 libasan0 libatomic1-gcc49 libcloog-isl4 libedit-devel libevent-devel libgomp1-gcc49 libisl10
+ libitm1-gcc49 libltdl7 libmpc3 libmpfr4 libopenssl-devel libstdc++48-devel libtool libtsan0-gcc49 m4 make ncurses-devel pam-devel readline-devel site-config tack tcpd-devel zlib-devel
+
+ The following package is recommended, but will not be installed due to conflicts or dependency issues:
+ readline-doc
+
+ 36 new packages to install.
+ Overall download size: 33.7 MiB. Already cached: 129.5 KiB After the operation, additional 144.3 MiB will be used.
+ Continue? [y/n/? shows all options] (y): y
+
+#### Zypper in Scripts and Applications ####
+
+39. 安装一个软件包,并且在安装过程中跳过与用户的交互, 例如 mariadb。
+
+
%> zypper --non-interactive in mariadb
+ Loading repository data...
+ Reading installed packages...
+ 'mariadb' is already installed.
+ No update candidate for 'mariadb-10.0.13-2.6.1.x86_64'. The highest available version is already installed.
+ Resolving package dependencies...
+
+ Nothing to do.
+
+40. 卸载一个软件包,并且在卸载过程中跳过与用户的交互,例如 mariadb
+
+
%> zypper --non-interactive rm mariadb
+ Loading repository data...
+ Reading installed packages...
+ Resolving package dependencies...
+
+ The following package is going to be REMOVED:
+ mariadb
+
+ 1 package to remove.
+ After the operation, 71.8 MiB will be freed.
+ Continue? [y/n/? shows all options] (y): y
+ (1/1) Removing mariadb-10.0.13-2.6.1 .............................................................................[done]
%> zypper --quiet in mariadb
+ The following NEW package is going to be installed:
+ mariadb
+
+ 1 new package to install.
+ Overall download size: 0 B. Already cached: 7.8 MiB After the operation, additional 71.8 MiB will be used.
+ Continue? [y/n/? shows all options] (y):
+ ...
# zypper dist-upgrade
+ You are about to do a distribution upgrade with all enabled repositories. Make sure these repositories are compatible before you continue. See 'man zypper' for more information about this command.
+ Building repository 'openSUSE-13.2-0' cache .....................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Debug' metadata ............................................................[done]
+ Building repository 'openSUSE-13.2-Debug' cache .................................................................[done]
+ Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ..........................................................[done]
+ Building repository 'openSUSE-13.2-Non-Oss' cache ...............................................................[done]
+
+正文至此结束。希望本文可以帮助读者尤其是新手们管理SUSE Linux系统和服务器。如果您觉得某些比较重要的命令被作者漏掉了,请在评论部分写下您的返回,作者将根据评论对文章进行更新。保持联络,保持评论,多谢支持。
+
+--------------------------------------------------------------------------------
+
+原文地址: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
+
+作者:[Avishek Kumar][a]
+译者:[张博约](https://github.com/zhangboyue)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/installation-of-suse-linux-enterprise-server-12/
diff --git a/translated/tech/20150512 A Shell Script to Monitor Network, Disk Usage, Uptime, Load Average and RAM Usage in Linux.md b/translated/tech/20150512 A Shell Script to Monitor Network, Disk Usage, Uptime, Load Average and RAM Usage in Linux.md
new file mode 100644
index 0000000000..58eb9f18ca
--- /dev/null
+++ b/translated/tech/20150512 A Shell Script to Monitor Network, Disk Usage, Uptime, Load Average and RAM Usage in Linux.md
@@ -0,0 +1,96 @@
+Linux中用于监控网络、磁盘使用、开机时间、平均负载和内存使用率的shell脚本
+================================================================================
+系统管理员的任务真的很艰难,因为他/她必须监控服务器、用户、日志,还得创建备份,等等等等。对于大多数重复性的任务,大多数管理员都会写一个自动化脚本来日复一日重复这些任务。这里,我们已经写了一个shell脚本给大家,用来自动化完成系统管理员所要完成的常规任务,这可能在多数情况下,尤其是对于新手而言十分有用,他们能通过该脚本获取到大多数的他们想要的信息,包括系统、网络、用户、负载、内存、主机、内部IP、外部IP、开机时间等。
+
+我们已经注意并进行了格式化输出(在一定程度上哦)。此脚本不包含任何恶意内容,并且它能以普通用户帐号运行。事实上,我们也推荐你以普通用户运行该脚本,而不是root。
+
+
+监控Linux系统健康的Shell脚本
+
+你可以通过给Tecmint和脚本作者合适的积分,获得自由使用/修改/再分发下面代码的权利。我们已经试着在一定程度上自定义了输出结果,除了要求的输出内容外,其它内容都不会生成。我们也已经试着使用了那些Linux系统中通常不使用的变量,这些变量可能也是自由代码。
+
+#### 最小系统要求 ####
+
+你所需要的一切,就是一台正常运转的Linux盒子。
+
+#### 依赖性 ####
+
+对于一个标准的Linux发行版,使用此包时没有任何依赖。此外,该脚本不需要root权限来执行。但是,如果你想要安装,则必须输入一次root密码。
+
+#### 安全性 ####
+
+我们也关注到了系统安全问题,所以在安装此包时,不需要安装任何额外包,也不需要root访问权限来运行。此外,源代码是采用Apache 2.0许可证发布的,这意味着只要你保留Tecmint的版权,你可以自由地编辑、修改并再分发该代码。
+
+### 如何安装和运行脚本? ###
+
+首先,使用[wget命令][1]下载监控脚本`“tecmint_monitor.sh”`,给它赋予合适的执行权限。
+
+ # wget http://tecmint.com/wp-content/scripts/tecmint_monitor.sh
+ # chmod 755 tecmint_monitor.sh
+
+强烈建议你以普通用户身份安装该脚本,而不是root。安装过程中会询问root密码,并且在需要的时候安装必要的组件。
+
+要安装`“tecmint_monitor.sh”`脚本,只需像下面这样使用-i(安装)选项就可以了。
+
+ /tecmint_monitor.sh -i
+
+在提示你输入root密码时输入该密码。如果一切顺利,你会看到像下面这样的安装成功信息。
+
+ Password:
+ Congratulations! Script Installed, now run monitor Command
+
+安装完毕后,你可以通过在任何位置,以任何用户调用命令`‘monitor’`来运行该脚本。如果你不喜欢安装,你需要在每次运行时输入路径。
+
+ # ./Path/to/script/tecmint_monitor.sh
+
+现在,以任何用户从任何地方运行monitor命令,就是这么简单:
+
+ $ monitor
+
+
+
+你一运行命令,就会获得下面这些各种各样和系统相关的信息:
+
+- 互联网连通性
+- 操作系统类型
+- 操作系统名称
+- 操作系统版本
+- 架构
+- 内核版本
+- 主机名
+- 内部IP
+- 外部IP
+- 域名服务器
+- 已登录用户
+- 内存使用率
+- 交换分区使用率
+- 磁盘使用率
+- 平均负载
+- 系统开机时间
+
+使用-v(版本)开关来检查安装的脚本的版本。
+
+ $ monitor -v
+
+ tecmint_monitor version 0.1
+ Designed by Tecmint.com
+ Released Under Apache 2.0 License
+
+### 小结 ###
+
+该脚本在一些机器上可以开机即用,这一点我已经检查过。相信对于你而言,它也会正常工作。如果你们发现了什么毛病,可以在评论中告诉我。这个脚本还不是结束,这仅仅是个开始。从这里开始,你可以将它提升到任何等级。如果你想要编辑脚本,将它带入一个更深的层次,尽管随意去做吧,别忘了给我们合适的积分,也别忘了把你更新后的脚本拿出来和我们分享哦,这样,我们也能通过给你合适的积分来更新此文。
+
+别忘了和我们分享你的想法或者脚本,我们会在这儿帮助你。谢谢你们给予的所有挚爱。保持连线,不要走开哦。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/linux-server-health-monitoring-script/
+
+作者:[Avishek Kumar][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/10-wget-command-examples-in-linux/
diff --git a/translated/tech/20150515 Basic Networking Commands with Docker Containers.md b/translated/tech/20150515 Basic Networking Commands with Docker Containers.md
new file mode 100644
index 0000000000..d4b90aa7f2
--- /dev/null
+++ b/translated/tech/20150515 Basic Networking Commands with Docker Containers.md
@@ -0,0 +1,106 @@
+关于Docker容器的基础网络命令
+================================================================================
+各位好,今天我们将学习一些Docker容器的基础命令。Docker是一个提供了开放平台来打包、发布并以一个轻量级容器运行任意程序的开放平台。它没有语言支持、框架或者打包系统的限制,可在任何时间、任何地方在小到家用电脑大到高端服务器上运行。这使得在部署和扩展网络应用、数据库和终端服务时不依赖于特定的栈或者提供商。Docker注定是用于网络的如它正应用于数据中心、ISP和越来越多的网络服务。
+
+因此,这里有一些你在管理Docker容器的时候会用到的一些命令。
+
+### 1. 找到Docker接口 ###
+
+Docker默认会创建一个名为docker0的网桥接口来连接外部的世界。docker容器运行时直接连接到网桥接口docker0。默认上,docker会分配172.17.42.1/16给docker0,它是所有运行容器ip地址的子网。得到Docker接口的ip地址非常简单。要找出docker0网桥接口和连接到网桥上的docker容器,我们可以在终端或者安装了docker的shell中运行ip命令。
+
+ # ip a
+
+
+
+### 2. 得到Docker容器的ip地址 ###
+
+如我们上面读到的,docker在主机中创建了一个叫docker0的网桥接口。如我们创建一个心的docker容器一样,它自动被默认分配了一个在子网范围内的ip地址。因此,要检测运行中的Docker容器的ip地址,我们需要进入一个正在运行的容器并用下面的命令检查ip地址。首先,我们运行一个新的容器并进入。如果你已经有一个正在运行的容器,你可以跳过这个步骤。
+
+ # docker run -it ubuntu
+
+现在,我们可以运行ip a来得到容器的ip地址了。
+
+ # ip a
+
+
+
+### 3. 映射暴露的端口 ###
+
+要映射配置在Dockerfile的暴露端口,我们只需用下面带上-P标志的命令。这会打开docker容器的随机端口并映射到Dockerfile中定义的端口。下面是使用-P来打开/映射定义的端口的例子。
+
+ # docker run -itd -P httpd
+
+
+
+上面的命令会映射Dockerfile中定义的httpd 80端口到容器的端口上。我们用下面的命令来查看正在运行的容器暴露的端口。
+
+ # docker ps
+
+并且可以用下面的curl命令来检查。
+
+ # curl http://localhost:49153
+
+
+
+### 4. 映射到特定的端口上 ###
+
+我们也可以映射暴露端口或者docker容器端口到我们指定的端口上。要实现这个,我们用-p标志来定义我们的需要。这里是我们的一个例子。
+
+ # docker run -itd -p 8080:80 httpd
+
+上面的命令会映射8080端口到80上。我们可以运行curl来检查这点。
+
+ # curl http://localhost:8080
+
+
+
+### 5. 创建自己的网桥 ###
+
+要给容器创建一个自定义的IP地址,在本篇中我们会创建一个名为bro的新网桥。要分配需要的ip地址,我们需要在运行docker的主机中运行下面的命令。
+
+ # stop docker.io
+ # ip link add br0 type bridge
+ # ip addr add 172.30.1.1/20 dev br0
+ # ip link set br0 up
+ # docker -d -b br0
+
+
+
+创建完docker网桥之后,我们要让docker的守护进程知道它。
+
+ # echo 'DOCKER_OPTS="-b=br0"' >> /etc/default/docker
+ # service docker.io start
+
+
+
+到这里,桥接后的接口将会分配给容器新的在桥接子网内的ip地址。
+
+### 6. 链接到另外一个容器上 ###
+
+我们可以用Dokcer连接一个容器到另外一个上。我们可以在不容的容器上运行不同的程序,并且相互连接或链接。链接允许容器间相互连接并安全地从一个容器上传输信息给另一个容器。要做到这个,我们可以使用--link标志。首先,我们使用--name标志来表示training/postgres镜像。
+
+ # docker run -d --name db training/postgres
+
+
+
+完成之后,我们将容器db与training/webapp链接来形成新的叫web的容器。
+
+ # docker run -d -P --name web --link db:db training/webapp python app.py
+
+
+
+### 总结 ###
+
+Docker网络很神奇也好玩,因为有我们可以对docker容器做很多事情。这里有些简单和基础的我们可以把玩docker网络命令。docker的网络是非常高级的。我们可以用它做很多事情。如果你有任何的问题、建议、反馈请在下面的评论栏写下来以便于我们我们可以提升或者更新文章的内容。谢谢! 玩得开心!:-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/networking-commands-docker-containers/
+
+作者:[Arun Pyasi][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
diff --git a/translated/tech/20150518 10 Amazing and Mysterious Uses of Symbol or Operator in Linux Commands.md b/translated/tech/20150518 10 Amazing and Mysterious Uses of Symbol or Operator in Linux Commands.md
new file mode 100644
index 0000000000..4225cf9bb4
--- /dev/null
+++ b/translated/tech/20150518 10 Amazing and Mysterious Uses of Symbol or Operator in Linux Commands.md
@@ -0,0 +1,193 @@
+10����!��������Linux�������¾��˺�������÷�
+================================================================================
+`'!'`������Linux�в��������������ţ���������������ʷ�����¼��ȡ��������ĵ�ִ��֮ǰ���е�����������������Ѿ���Bash Shell�о���ȷ�еؼ�顣������û���Թ������������ڱ��Shell�����С��������ǽ�����Linux�������з���`'!'`�Ǿ��˺�������÷���
+
+### 1. ʹ�����ִ���ʷ�����б�����һ��������ִ�� ###
+
+��Ҳ��û����ʶ�������Դ���ʷ�����б���֮ǰ�Ѿ�ִ�е���������ҳ�һ�������С����ȣ�ͨ��"history"�������֮ǰ�������š�
+
+ $ history
+
+
+
+���ڣ�ֻ��Ҫʹ����ʷ�����������ʾ�ڸ�����ǰ������ֱ�����������������磬����һ����`history`����б����1551�����
+
+ $ !1551
+
+
+
+���������Ϊ1551����������������[top����][1]���������ˡ�����ͨ��ID����ִ��֮ǰ������ķ�ʽ�����ã�����������Щ����ܳ�������¡���ֻ��Ҫʹ��**![history������������]**����Ե�������
+
+### 2. ����֮ǰ�ĵ����ڶ��������߸������ ###
+
+����������һ�ַ�ʽ������֮ǰִ�е����ͨ��ʹ��-1�����������-2���������ڶ������-7�����������߸�����ȡ�
+
+����ʹ��history���������ִ�й���������б���history�����ִ�к��б�Ҫ����Ϊ������ͨ������ȷ��û��`rm command > file`�������ᵼ��Σ�յ����������ִ�е������������ڰ˸�����ʮ�����
+
+ $ history
+ $ !-6
+ $ !-8
+ $ !-10
+
+
+ͨ�������������֮ǰִ�е�����
+
+### 3. ����������ݲ������Է���������µ����� ###
+
+����Ҫ��ʾ`/home/$USER/Binary/firefox`�ļ��е����ݣ������ִ�У�
+
+ $ ls /home/$USER/Binary/firefox
+
+������������ʶ����Ӧ��ִ��'ls -l'���鿴�ĸ��ļ��ǿ�ִ���ļ��������Ӧ������������������ô�������Ҳ���Ҫ���ҽ���Ҫ���µ������д������IJ��������ƣ�
+
+ $ ls -l !$
+
+����`!$`�������ִ�е�����IJ������ݵ�����µ������С�
+
+
+����һ������IJ������ݸ�������
+
+### 4. ���ʹ��!���������������IJ��� ###
+
+����˵�������洴����һ���ı��ļ�file1.txt��
+
+ $ touch /home/avi/Desktop/1.txt
+
+Ȼ����cp������ʹ�þ���·������������`/home/avi/Downloads`��
+
+ $ cp /home/avi/Desktop/1.txt /home/avi/downloads
+
+���ڣ����Ǹ�cp�������������������һ����`/home/avi/Desktop/1.txt`���ڶ�����`/home/avi/Downloads`�������Ƿֱ������ǣ�ʹ��`echo [arguments]`����ӡ������ͬ�IJ�����
+
+ $ echo "1st Argument is : !^"
+ $ echo "2nd Argument is : !cp:2"
+
+ע���һ����������ʹ��`"!^"`���д�ӡ��������������ͨ��`"![������]:[�������]"`��ӡ��
+
+������������У���һ��������`cp`���ڶ�������Ҳ��Ҫ����ӡ�������`"!cp:2"`������κ��������xyz����ʱ��5��������������Ҫ��õ��ĸ�������������ʹ��`"!xyz:4"`�����еIJ���������ͨ��`"!*"`����á�
+
+
+�������������IJ���
+
+### 5. �Թؼ���Ϊ����ִ���ϸ������� ###
+
+���ǿ����Թؼ���Ϊ����ִ���ϴ�ִ�е�������Դ���������������⣺
+
+ $ ls /home > /dev/null [����1]
+ $ ls -l /home/avi/Desktop > /dev/null [����2]
+ $ ls -la /home/avi/Downloads > /dev/null [����3]
+ $ ls -lA /usr/bin > /dev/null [����4]
+
+��������ʹ����ͬ�������ls�������в�ͬ�Ŀ��غͲ�ͬ�IJ����ļ��С����ң����ǻ���������ݵ�`/dev/null`�����Dz�δ�������������ն����ɺܸɾ���
+
+�����Թؼ���Ϊ����ִ���ϸ������
+
+ $ ! ls [����1]
+ $ ! ls -l [����2]
+ $ ! ls -la [����3]
+ $ ! ls -lA [����4]
+
+���������������淢��������ʹ�ùؼ���`ls`��ִ�������Ѿ�ִ�й������
+
+
+�Թؼ���Ϊ����ִ������
+
+### 6. !!������������ ###
+
+������ʹ��`(!!)`����/�����ϸ����е������������һЩ��/�����������ϸ�������Ҹ���չʾһЩʵ���龳��
+
+������������һ�нű�������ҵ�˽��IP�������ִ���ˣ�
+
+ $ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/
+
+���ţ���ͻȻ��������Ҫ������ű�������ض���һ��ip.txt���ļ�����ˣ��Ҹ���ô���أ��Ҹ�����������������ض���һ���ļ�ô��һ���Ľ��������ʹ�����ϵ�����������`'> ip.txt'`��������ض����ļ���
+
+ $ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/ > ip.txt
+
+�������л������"���ϵ�����"�����ڣ��������������������������������һ�нű���
+
+ $ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
+
+һ��������������ű���Bash��ʾ���㷵���˴�����Ϣ`"bash: ifconfig: command not found"`��ԭ���Ѳ£��������˱�Ӧ��rootȨ�����е����
+
+���ԣ���ô����أ����Ǻ�����root�û���¼�����ٴμ�����������������ϵ�����Ҳ�������ˡ���ˣ�������Ҫ����`"!!"`��ȥ�����ţ�������Ϊ�Ǹ��û������ϸ����
+
+ $ su -c "!!" root
+
+����su�������л���root�û��ģ�`-c`������ij�û������ض����������Ҫ�IJ�����`!!`���������滻Ϊ�ϴ����е�����Եģ�����Ҫ�ṩroot���롣
+
+
+!!������������
+
+��ͨ����������龰��ʹ��`!!`��
+
+1.��������ͨ�û�������apt-get����ͨ���յ���ʾ˵��û��Ȩ����ִ�С�
+
+ $ apt-get upgrade && apt-get dist-upgrade
+
+�ðɣ��д������ģ�ʹ��������������ɹ���ִ��...
+
+ $ su -c !!
+
+ͬ���������ڣ�
+
+ $ service apache2 start
+ ��
+ $ /etc/init.d/apache2 start
+ ��
+ $ systemctl start apache2
+
+��ͨ�û�������Ȩִ����Щ�������������У�
+
+ $ su -c 'service apache2 start'
+ ��
+ $ su -c '/etc/init.d/apache2 start'
+ ��
+ $ su -c 'systemctl start apache2'
+
+### 7.����һ��Ӱ�����г���![FILE_NAME]���ļ����� ###
+
+`!`�����ǣ��������Գ���`'!'`����ļ������е��ļ�/��չִ�����
+
+A.���ļ����Ƴ������ļ���2.txt���⡣
+
+ $ rm !(2.txt)
+
+B.���ļ����Ƴ����е��ļ����ͣ�pdf���ͳ��⡣
+
+ $ rm !(*.pdf)
+
+### 8.���ij���ļ��У�����/home/avi/Tecmint���Ƿ���ڣ�����ӡ ###
+
+�������ʹ��`'! -d'`����֤�ļ����Ƿ���ڣ����ļ��в�����ʱ����ʹ��������AND������`(&&)`���д�ӡ�����ļ��д���ʱ����ʹ��OR������`(||)`���д�ӡ��
+
+���ϣ���`[ ! -d /home/avi/Tecmint ]`�����Ϊ0ʱ������ִ��AND������������ݣ���������ִ��OR����`(||)`��������ݡ�
+
+ $ [ ! -d /home/avi/Tecmint ] && printf '\nno such /home/avi/Tecmint directory exist\n' || printf '\n/home/avi/Tecmint directory exist\n'
+
+### 9.���ij�ļ����Ƿ���ڣ�������������˳������� ###
+
+���������������������ﵱ�������ļ��в�����ʱ����������˳���
+
+ $ [ ! -d /home/avi/Tecmint ] && exit
+
+### 10.�������home�ļ����ڲ�����һ���ļ��У��ȷ�˵test�������� ###
+
+���ǽű������е�һ�����õ�ʵ�֣����������ļ��в�����ʱ������һ����
+
+ [ ! -d /home/avi/Tecmint ] && mkdir /home/avi/Tecmint
+
+�����ȫ���ˡ������֪����ż����������ֵ���˽��`'!'`ʹ�÷����������ڷ����ĵط��������Ὠ�顣������ϵ��
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/mysterious-uses-of-symbol-or-operator-in-linux-commands/
+
+���ߣ�[Avishek Kumar][a]
+���ߣ�[wwy-hust](https://github.com/wwy-hust)
+У�ԣ�[У����ID](https://github.com/У����ID)
+
+������ [LCTT](https://github.com/LCTT/TranslateProject) ԭ�����룬[Linux�й�](https://linux.cn/) �����Ƴ�
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/12-top-command-examples-in-linux/
diff --git a/translated/tech/20150518 70 Expected Shell Scripting Interview Questions and Answers.md b/translated/tech/20150518 70 Expected Shell Scripting Interview Questions and Answers.md
new file mode 100644
index 0000000000..b5ccd63e0a
--- /dev/null
+++ b/translated/tech/20150518 70 Expected Shell Scripting Interview Questions and Answers.md
@@ -0,0 +1,399 @@
+70 个可能的 Shell 脚本面试问题及解答
+================================================================================
+我们为你的面试准备选择了 70 个可能的 shell 脚面问题及解答。了解脚本或至少知道基础知识对系统管理员来说至关重要,它也有助于你在工作环境中自动完成很多任务。在过去的几年里,我们注意到所有的 linux 工作职位都要求脚本技能。
+
+### 1) 如何向脚本传递参数 ? ###
+
+./script argument
+
+**例子** : 显示文件名称脚本
+
+./show.sh file1.txt
+
+ cat show.sh
+ #!/bin/bash
+ cat $1
+
+### 2) 如何在脚本中使用参数 ? ###
+
+第一个参数: $1,
+第二个参数 : $2
+
+例子 : 脚本会复制文件(arg1) 到目标地址(arg2)
+
+./copy.sh file1.txt /tmp/
+
+ cat copy.sh
+ #!/bin/bash
+ cp $1 $2
+
+### 3) 如何计算传递进来的参数 ? ###
+
+$#
+
+### 4) 如何在脚本中获取脚本名称 ? ###
+
+$0
+
+### 5) 如何检查之前的命令是否运行成功 ? ###
+
+$?
+
+### 6) 如何获取文件的最后一行 ? ###
+
+tail -1
+
+### 7) 如何获取文件的第一行 ? ###
+
+head -1
+
+### 8) 如何获取一个文件每一行的第三个元素 ? ###
+
+awk '{print $3}'
+
+### 9) 假如第一个等于 FIND,如何获取文件中每行的第二个元素 ###
+
+awk '{ if ($1 == "FIND") print $2}'
+
+### 10) 如何调试 bash 脚本 ###
+
+Add -xv to #!/bin/bash
+
+例子
+
+#!/bin/bash –xv
+
+### 11) 举例如何写一个函数 ? ###
+
+function example {
+echo "Hello world!"
+}
+
+### 12) 如何向 string 添加 string ? ###
+
+V1="Hello"
+V2="World"
+V3=$V1+$V2
+echo $V3
+
+Output
+
+Hello+World
+
+### 13) 如何进行两个整数相加 ? ###
+
+V1=1
+V2=2
+V3=$V1+$V2
+echo $V3
+
+Output
+3
+
+### 14) 如何检查文件系统中是否存在某个文件 ? ###
+
+if [ -f /var/log/messages ]
+then
+echo "File exists"
+fi
+
+### 15) 写出 shell 脚本中所有循环语法 ? ###
+
+#### for loop : ####
+
+for i in $( ls ); do
+echo item: $i
+done
+
+#### while loop : ####
+
+#!/bin/bash
+COUNTER=0
+while [ $COUNTER -lt 10 ]; do
+echo The counter is $COUNTER
+let COUNTER=COUNTER+1
+done
+
+#### untill oop : ####
+
+#!/bin/bash
+COUNTER=20
+until [ $COUNTER -lt 10 ]; do
+echo COUNTER $COUNTER
+let COUNTER-=1
+done
+
+### 16) 每个脚本开始的 #!/bin/sh 或 #!/bin/bash 表示什么意思 ? ###
+
+这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python
+
+### 17) 如何获取文本文件的第 10 行 ? ###
+
+head -10 file|tail -1
+
+### 18) bash 脚本文件的第一个符号是什么 ###
+
+#
+
+### 19) 命令:[ -z "" ] && echo 0 || echo 1 的输出是什么 ###
+
+0
+
+### 20) 命令 “export” 有什么用 ? ###
+
+使变量在子 shell 中公有
+
+### 21) 如何在后台运行脚本 ? ###
+
+在脚本后面添加 “&”
+
+### 22) "chmod 500 script" 做什么 ? ###
+
+使脚本所有者拥有可执行权限
+
+### 23) ">" 做什么 ? ###
+
+重定向输出流到文件或另一个流。
+
+### 24) & 和 && 有什么区别 ###
+
+& - 希望脚本在后台运行的时候使用它
+&& - 当第一个脚本成功完成才执行命令/脚本的时候使用它
+
+### 25) 什么时候要在 [ condition ] 之前使用 “if” ? ###
+
+当条件满足时需要运行多条命令的时候。
+
+### 26) 命令: name=John && echo 'My name is $name' 的输出是什么 ###
+
+My name is $name
+
+### 27) bash shell 脚本中哪个符号用于注释 ? ###
+
+#
+
+### 28) 命令: echo ${new:-variable} 的输出是什么 ###
+
+variable
+
+### 29) ' 和 " 引号有什么区别 ? ###
+
+' - 当我们不希望把变量转换为值的时候使用它。
+" - 会计算所有变量的值并用值代替。
+
+### 30) 如何在脚本文件中重定向标准输入输出流到 log.txt 文件 ? ###
+
+在脚本文件中添加 "exec >log.txt 2>&1" 命令
+
+### 31) 如何只用 echo 命令获取 string 变量的一部分 ? ###
+
+echo ${variable:x:y}
+x - 起始位置
+y - 长度
+例子:
+variable="My name is Petras, and I am developer."
+echo ${variable:11:6} # 会显示 Petras
+
+### 32) 如果给定字符串 variable="User:123:321:/home/dir" 如何只用 echo 命令获取 home_dir ? ###
+
+echo ${variable#*:*:*:}
+或
+echo ${variable##*:}
+
+### 33) 如何从上面的字符串中获取 “User” ? ###
+
+echo ${variable%:*:*:*}
+或
+echo ${variable%%:*}
+
+### 34) 如何使用 awk 列出 UID 小于 100 的用户 ? ###
+
+awk -F: '$3<100' /etc/passwd
+
+### 35) 写程序为用户计算主组数目并显示次数和组名 ###
+
+cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
+do
+{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
+done
+
+### 36) 如何在 bash shell 中更改标注域分隔符为 ":" ? ###
+
+IFS=":"
+
+### 37) 如何获取变量长度 ? ###
+
+${#variable}
+
+### 38) 如何打印变量的最后 5 个字符 ? ###
+
+echo ${variable: -5}
+
+### 39) ${variable:-10} 和 ${variable: -10} 有什么区别? ###
+
+${variable:-10} - 如果之前没有给 variable 赋值则输出 10
+${variable: -10} - 输出 variable 的最后 10 个字符
+
+### 40) 如何只用 echo 命令替换字符串的一部分 ? ###
+
+echo ${variable//pattern/replacement}
+
+### 41) 哪个命令将命令替换为大写 ? ###
+
+tr '[:lower:]' '[:upper:]'
+
+### 42) 如何计算本地用户数目 ? ###
+
+wc -l /etc/passwd|cut -d" " -f1
+或者
+cat /etc/passwd|wc -l
+
+### 43) 不用 wc 命令如何计算字符串中的单词数目 ? ###
+
+set ${string}
+echo $#
+
+### 44) "export $variable" 或 "export variable" 哪个正确 ? ###
+
+export variable
+
+### 45) 如何列出第二个字母是 a 或 b 的文件 ? ###
+
+ls -d ?[ab]*
+
+### 46) 如何将整数 a 加到 b 并赋值给 c ? ###
+
+c=$((a+b))
+或
+c=`expr $a + $b`
+或
+c=`echo "$a+$b"|bc`
+
+### 47) 如何去除字符串中的所有空格 ? ###
+
+echo $string|tr -d " "
+
+### 48) 重写命令输出变量转换为复数的句子: item="car"; echo "I like $item" ? ###
+
+item="car"; echo "I like ${item}s"
+
+### 49) 写出输出数字 0 到 100 中 3 的倍数(0 3 6 9 …)的命令 ? ###
+
+for i in {0..100..3}; do echo $i; done
+或
+for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
+
+### 50) 如何打印传递给脚本的所有参数 ? ###
+
+echo $*
+或
+echo $@
+
+### 51) [ $a == $b ] 和 [ $a -eq $b ] 有什么区别 ###
+
+[ $a == $b ] - 用于字符串比较
+[ $a -eq $b ] - 用于数字比较
+
+### 52) = 和 == 有什么区别 ###
+
+= - 用于为变量复制
+== - 用于字符串比较
+
+### 53) 写出测试 $a 是否大于 12 的命令 ? ###
+
+[ $a -gt 12 ]
+
+### 54) 写出测试 $b 是否小于等于 12 的命令 ? ###
+
+[ $b -le 12 ]
+
+### 55) 如何检查字符串是否以字母 "abc" 开头 ? ###
+
+[[ $string == abc* ]]
+
+### 56) [[ $string == abc* ]] 和 [[ $string == "abc*" ]] 有什么区别 ###
+
+[[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
+[[ $string == "abc* " ]] - 检查字符串是否完全等于 abc*
+
+### 57) 如何列出以 ab 或 xy 开头的用户名 ? ###
+
+egrep "^ab|^xy" /etc/passwd|cut -d: -f1
+
+### 58) bash 中 $! 表示什么意思 ? ###
+
+后台最近命令的 PID
+
+### 59) $? 表示什么意思 ? ###
+
+前台最近命令的结束状态
+
+### 60) 如何输出当前 shell 的 PID ? ###
+
+echo $$
+
+### 61) 如何获取传递给脚本的参数数目 ? ###
+
+echo $#
+
+### 62) $* 和 $@ 有什么区别 ###
+
+$* - 以一个字符串形式输出所有传递到脚本的参数
+$@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
+
+### 63) 如何在 bash 中定义数组 ? ###
+
+array=("Hi" "my" "name" "is")
+
+### 64) 如何打印数组的第一个元素 ? ###
+
+echo ${array[0]}
+
+### 65) 如何打印数组的所有元素 ? ###
+
+echo ${array[@]}
+
+### 66) 如何输出所有数组索引 ? ###
+
+echo ${!array[@]}
+
+### 67) 如何移除数组中索引为 2 的元素 ? ###
+
+unset array[2]
+
+### 68) 如何在数组中添加 id 为 333 的元素 ? ###
+
+array[333]="New_element"
+
+### 69) shell 脚本如何获取输入的值 ? ###
+
+a) 通过参数
+
+./script param1 param2
+
+b) 通过 read 命令
+
+read -p "Destination backup Server : " desthost
+
+### 70) 在脚本中如何使用 "expect" ? ###
+
+/usr/bin/expect << EOD
+spawn rsync -ar ${line} ${desthost}:${destpath}
+expect "*?assword:*"
+send "${password}\r"
+expect eof
+EOD
+
+好运 !! 如果你有任何疑问或者问题需要解答都可以在下面的评论框中写下来。让我们知道这对你的面试有所帮助:-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-shell-script/shell-scripting-interview-questions-answers/
+
+作者:[Petras Liumparas][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/petrasl/
\ No newline at end of file
diff --git a/translated/tech/20150518 Linux FAQs with Answers--How to fix '404 Not Found' error with 'apt-get update' on old Ubuntu.md b/translated/tech/20150518 Linux FAQs with Answers--How to fix '404 Not Found' error with 'apt-get update' on old Ubuntu.md
new file mode 100644
index 0000000000..9880f7953f
--- /dev/null
+++ b/translated/tech/20150518 Linux FAQs with Answers--How to fix '404 Not Found' error with 'apt-get update' on old Ubuntu.md
@@ -0,0 +1,45 @@
+Linux有问必答——在旧的Ubuntu上如何修复“apt-get update”的“404 Not Found”错误
+================================================================================
+> **问题**: 我的PC上安装了旧版的Ubuntu 13.04(急切的浣熊)。当我在上面运行“sudo apt-get update”时,它丢给了我一大堆“404 Not Found”错误,结果是我不能使用apt-get或aptitude来安装或更新任何软件包了。由于该错误的原因,我甚至不能将它升级到更新的版本。我怎样才能修复这个问题啊?
+>
+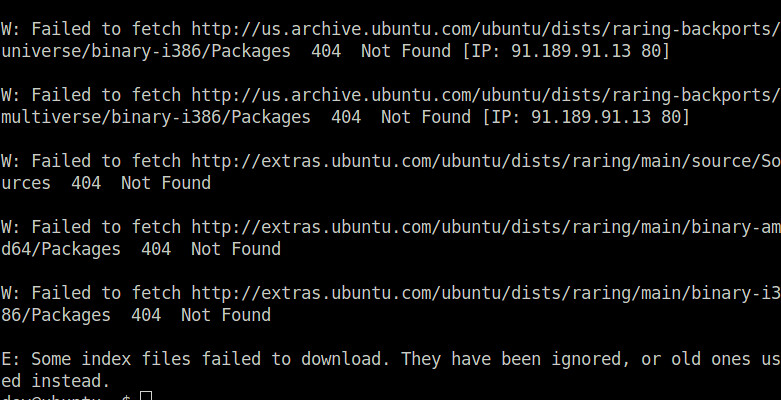
+
+每个Ubuntu版本都有生命结束周期(EOL)时间;常规的Ubuntu发行版提供18个月的支持,而LTS(长期支持)版本则长达3年(服务器版本)和5年(桌面版本)。当某个Ubuntu版本达到生命结束周期时,其仓库就不能再访问了,你也不能再从Canonical获取任何维护更新和安全补丁。在撰写本文时,Ubuntu 13.04(急切的浣熊)已经达到了它的生命结束周期。
+
+如果你所使用的Ubuntu系统已经被结束生命周期,你就会从apt-get或aptitude得到以下404错误,因为它的仓库已经被遗弃了。
+
+ W: Failed to fetch http://us.archive.ubuntu.com/ubuntu/dists/raring-backports/multiverse/binary-i386/Packages 404 Not Found [IP: 91.189.91.13 80]
+
+ W: Failed to fetch http://extras.ubuntu.com/ubuntu/dists/raring/main/binary-amd64/Packages 404 Not Found
+
+ W: Failed to fetch http://security.ubuntu.com/ubuntu/dists/raring-security/universe/binary-i386/Packages 404 Not Found [IP: 91.189.88.149 80]
+
+ E: Some index files failed to download. They have been ignored, or old ones used instead
+
+对于那些还在使用旧版本Ubuntu的用户,Canonical维护了一个old-releases.ubuntu.com的网站,这里包含了结束生命周期的仓库归档。因此,当Canonical对你安装的Ubuntu版本结束支持时,你需要将仓库切换到old-releases.ubuntu.com(除非你在结束生命周期之前想要升级)。
+
+这里,通过切换到旧版本仓库提供了一个快速修复“404 Not Found”错误的便捷方式。
+
+首先,使用旧版本仓库替换main/security仓库,就像下面这样。
+
+ $ sudo sed -i -r 's/([a-z]{2}\.)?archive.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
+ $ sudo sed -i -r 's/security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list
+
+然后,使用文本编辑器打开/etc/apt/sources.list,并查找extras.ubuntu.com。该仓库也不再支持Ubuntu 13.04了,所以你需要使用“#”号将extras.ubuntu.com注释掉。
+
+ #deb http://extras.ubuntu.com/ubuntu raring main
+ #deb-src http://extras.ubuntu.com/ubuntu raring main
+
+现在,你应该可以在旧版不受支持的Ubuntu上安装或更新软件包了。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/404-not-found-error-apt-get-update-ubuntu.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/translated/tech/20150518 Linux FAQs with Answers--How to fix 'Encountered a section with no Package--header' error on Raspbian.md b/translated/tech/20150518 Linux FAQs with Answers--How to fix 'Encountered a section with no Package--header' error on Raspbian.md
new file mode 100644
index 0000000000..54e0f393d1
--- /dev/null
+++ b/translated/tech/20150518 Linux FAQs with Answers--How to fix 'Encountered a section with no Package--header' error on Raspbian.md
@@ -0,0 +1,31 @@
+Linux 有问必答--如何修复 Raspbian 上的 “Encountered a section with no Package: header” 错误
+================================================================================
+> **问题**: 我在 Raspberry Pi 上安装新版的 Rasbian。但当我使用 sudo apt-get update 命令更新 APT 软件包索引的时候,它抛出下面的错误:
+
+ E: Encountered a section with no Package: header
+ E: Problem with MergeList /var/lib/dpkg/status
+ E: The package lists or status file could not be parsed or opened.
+
+> 之后我不能在 Raspbian 上安装任何软件包。我怎样才能解决这个错误?
+
+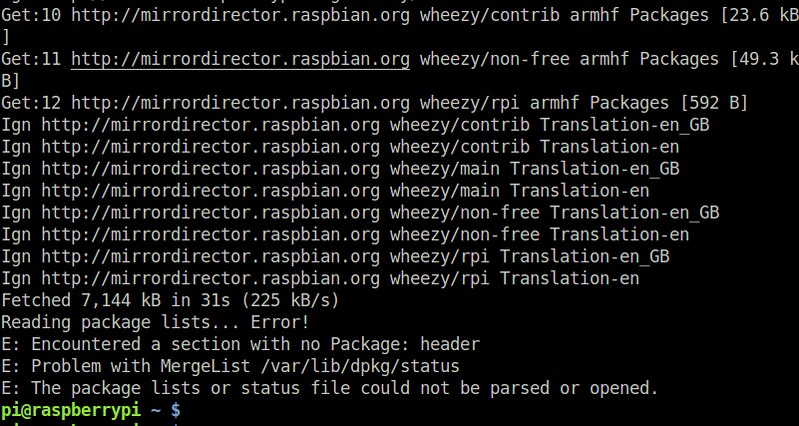
+
+错误说 "Problem with MergeList /var/lib/dpkg/status" 表示由于某些原因状态文件损坏了,因此无法解释。这个状态文件包括了已经安装的 deb 软件包的信息,因此需要小心备份。
+
+在这种情况下,由于这是新安装的 Raspbian,你可以安全地删除状态文件,然后用下面的命令重新生成。
+
+ $ sudo rm /var/lib/dpkg/status
+ $ sudo touch /var/lib/dpkg/status
+ $ sudo apt-get update
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/encountered-section-with-no-package-header-error.html
+
+作者:[Dan Nanni][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
\ No newline at end of file
diff --git a/translated/tech/20150518 Linux FAQs with Answers--How to view threads of a process on Linux.md b/translated/tech/20150518 Linux FAQs with Answers--How to view threads of a process on Linux.md
new file mode 100644
index 0000000000..a91a2b3ed3
--- /dev/null
+++ b/translated/tech/20150518 Linux FAQs with Answers--How to view threads of a process on Linux.md
@@ -0,0 +1,57 @@
+Linux有问必答——Linux上如何查看某个进程的线程
+================================================================================
+> **问题**: 我的程序创建并在它里头执行了多个线程,我怎样才能在该程序创建线程后监控其中单个线程?我想要看到带有它们名称的单个线程详细情况(如,CPU/内存使用率)。
+
+线程是现代操作系统上进行并行执行的一个流行的编程方面的抽象概念。当一个程序内有多个线程被叉分出用以执行多个流时,这些线程就会在它们之间共享特定的资源(如,内存地址空间、打开的文件),以使叉分开销最小化,并避免大量花销IPC(进程间通信)频道。这些功能让线程在并发执行时成为一个高效的机制。
+
+在Linux中,程序中创建的线程(也称为轻量级进程,LWP)会具有和程序的PID相同的“线程组ID”。然后,各个线程会获得其自身的线程ID(TID)。对于Linux内核调度器而言,线程不过是恰好共享特定资源的标准的进程。经典的命令行工具,如ps或top,都可以用来显示线程级别的信息,默认情况下它们会显示进程级别的信息。
+
+这里提供了**在Linux上显示某个进程的线程**的几种方式。
+
+### 方法一:PS ###
+
+在ps命令中,“-T”选项可以开启线程查看。下面的命令列出了由进程号为的进程创建的所有线程。
+
+ $ ps -T -p
+
+
+
+“SID”栏表示线程ID,而“CMD”栏则显示了线程名称。
+
+### 方法二: Top ###
+
+top命令可以实时显示各个线程情况。要在top输出中开启线程查看,请调用top命令的“-H”选项,该选项会列出所有Linux线程。在top运行时,你也可以通过按“H”键将线程查看模式切换为开或关。
+
+ $ top -H
+
+
+
+要让top输出某个特定进程并检查该进程内运行的线程状况:
+
+ $ top -H -p
+
+
+
+### 方法三: Htop ###
+
+一个对用户更加友好的方式是,通过htop查看单个进程的线程,它是一个基于ncurses的交互进程查看器。该程序允许你在树状视图中监控单个独立线程。
+
+要在htop中启用线程查看,请开启htop,然后按来进入htop的设置菜单。选择“设置”栏下面的“显示选项”,然后开启“树状视图”和“显示自定义线程名”选项。按退出设置。
+
+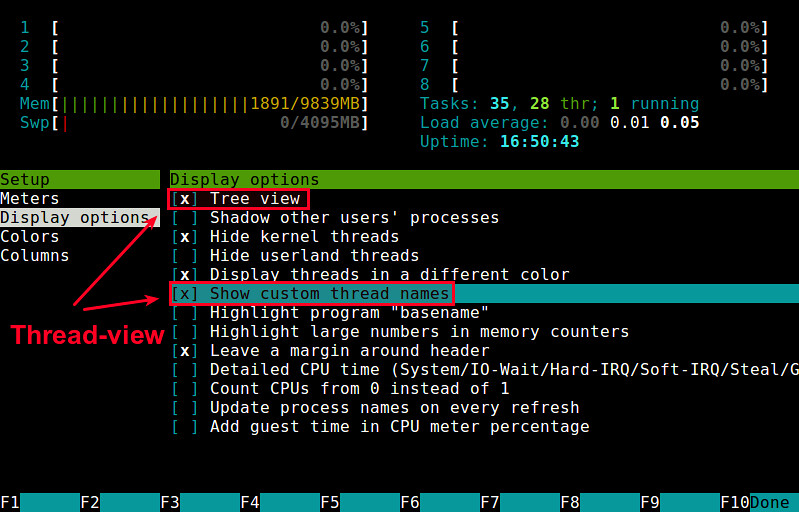
+
+现在,你就会看到下面这样单个进程的线程视图。
+
+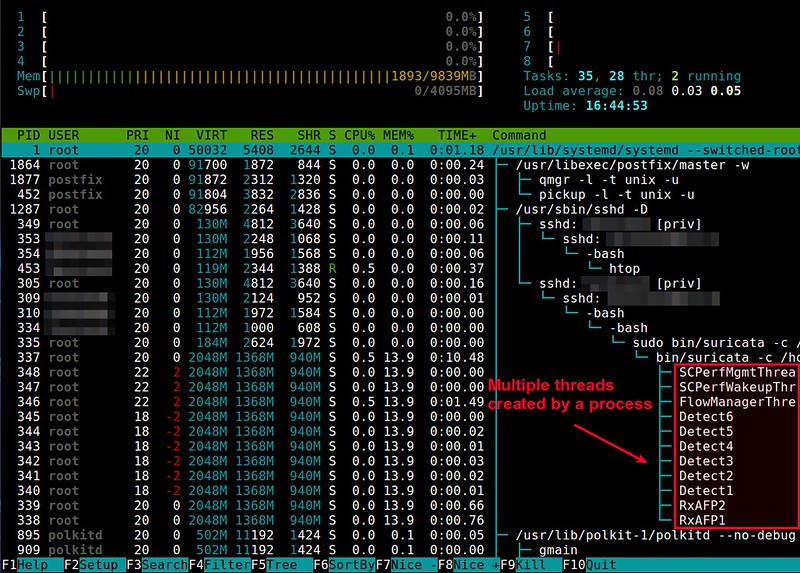
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/view-threads-process-linux.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
diff --git a/translated/tech/20150518 Linux FAQs with Answers--What is the Apache error log location on Linux.md b/translated/tech/20150518 Linux FAQs with Answers--What is the Apache error log location on Linux.md
new file mode 100644
index 0000000000..c43ac481e7
--- /dev/null
+++ b/translated/tech/20150518 Linux FAQs with Answers--What is the Apache error log location on Linux.md
@@ -0,0 +1,81 @@
+Linux有问必答——Linux上Apache错误日志的位置在哪里?
+================================================================================
+> **问题**: 我尝试着解决我 Linux 系统上的 Apache 网络服务器的错误,Apache的错误日志文件放在[你的 Linux 版本]的哪个位置呢?
+
+错误日志和访问日志文件为系统管理员提供了有用的信息,比如,为网络服务器排障,[保护][1]系统不受各种各样的恶意活动侵犯,或者只是进行[各种各样的][2][分析][3]以监控 HTTP 服务器。根据你网络服务器配置的不同,其错误/访问日志可能放在你系统中不同位置。
+
+本文可以帮助你**找到Linux上的Apache错误日志**。
+
+
+
+### Debian,Ubuntu或Linux Mint上的Apache错误日志位置 ###
+
+#### 默认的错误日志 ####
+
+在基于Debian的Linux上,系统范围的Apache错误日志默认位置是**/var/log/apache2/error.log**。默认位置可以通过编辑Apache的配置文件进行修改。
+
+#### 自定义的错误日志 ####
+
+要找到自定义的错误日志位置,请用文本编辑器打开 /etc/apache2/apache2.conf,然后查找以 ErrorLog 开头的行,该行指定了自定义的 Apache 错误日志文件的位置。例如,在未经修改的 Apache 配置文件中可以找到以下行:
+
+ ErrorLog ${APACHE_LOG_DIR}/error.log
+
+在本例中,该位置使用 APACHE_LOG_DIR 环境变量进行配置,该变量在 /etc/apache2/envvars 中已被定义。
+
+ export APACHE_LOG_DIR=/var/log/apache2$SUFFIX
+
+在实际情况中, ErrorLog 可能会指向你 Linux 系统中任意路径。
+
+#### 使用虚拟主机自定义的错误日志 ####
+
+如果在 Apache 网络服务器中使用了虚拟主机, ErrorLog 指令可能会在虚拟主机容器内指定,在这种情况下,上面所说的系统范围的错误日志位置将被忽略。
+
+启用了虚拟主机后,各个虚拟主机可以定义其自身的自定义错误日志位置。要找出某个特定虚拟主机的错误日志位置,你可以打开 /etc/apache2/sites-enabled/.conf,然后查找 ErrorLog 指令,该指令会显示站点指定的错误日志文件。
+
+### CentOS,Fedora或RHEL上的Apache错误日志位置 ###
+
+#### 默认的错误日志 ####
+
+在基于 Red Hat 的Linux中,系统范围的 Apache 错误日志文件默认被放置在**/var/log/httpd/error_log**。该默认位置可以通过修改 Apache 配置文件进行自定义。
+
+#### 自定义的错误日志 ####
+
+要找出 Apache 错误日志的自定义位置,请用文本编辑器打开 /etc/httpd/conf/httpd.conf,然后查找 ServerRoot,该参数显示了 Apache 服务器目录树的顶层,日志文件和配置都位于该目录树中。例如:
+
+ ServerRoot "/etc/httpd"
+
+现在,查找 ErrorLog 开头的行,该行指出了 Apache 网络服务器将错误日志写到了哪里去。注意,指定的位置是 ServerRoot 值的相对位置。例如:
+
+ ErrorLog "log/error_log"
+
+结合上面的两个指令,可以获得完整的错误日志路径,默认情况下该路径就是 /etc/httpd/logs/error_log。在全新安装的Apache中,这是一个到 /var/log/httpd/error_log 的符号链接。
+
+在实际情况中, ErrorLog 可能指向你 Linux 系统中的任意位置。
+
+#### 使用虚拟主机自定义的错误日志 ####
+
+如果你启用了虚拟主机,你可以通过检查 /etc/httpd/conf/httpd.conf(或其它任何定义了虚拟主机的文件)来找到各个虚拟主机的错误日志位置。在独立的虚拟主机部分查找 ErrorLog。如,在下面的虚拟主机部分,错误日志的位置是 /var/www/xmodulo.com/logs/error_log。
+
+
+ ServerAdmin webmaster@xmodulo.com
+ DocumentRoot /var/www/xmodulo.com/public_html
+ ServerName www.xmodulo.com
+ ServerAlias xmodulo.com
+ ErrorLog /var/www/xmodulo.com/logs/error_log
+ CustomLog /var/www/xmodulo.com/logs/access_log
+
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/apache-error-log-location-linux.html
+
+作者:[Dan Nanni][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://xmodulo.com/configure-fail2ban-apache-http-server.html
+[2]:http://xmodulo.com/interactive-apache-web-server-log-analyzer-linux.html
+[3]:http://xmodulo.com/sql-queries-apache-log-files-linux.html
diff --git a/translated/tech/20150520 How to Use Docker Machine with a Cloud Provider.md b/translated/tech/20150520 How to Use Docker Machine with a Cloud Provider.md
new file mode 100644
index 0000000000..acf052d493
--- /dev/null
+++ b/translated/tech/20150520 How to Use Docker Machine with a Cloud Provider.md
@@ -0,0 +1,148 @@
+如何在云服务提供商的机器使用Docker Machine
+================================================================================
+大家好,今天我们来学习如何使用Docker Machine在各种云服务提供商的平台部署Docker。Docker Machine是一个可以帮助我们在自己的电脑、云服务提供商的机器以及我们数据中心的机器上创建Docker机器的应用程序。它为创建服务器、在服务器中安装Docker、根据用户需求配置Docker客户端提供了简单的解决方案。驱动API对本地机器、数据中心的虚拟机或者公用云机器都适用。Docker Machine支持Windows、OSX和Linux,并且提供一个独立的二进制文件,可以直接使用。它让我们可以充分利用支持Docker的基础设施的生态环境合作伙伴,并且使用相同的接口进行访问。它让人们可以使用一个命令来简单而迅速地在不同的云平台部署Docker容器。
+
+
+### 1. 安装Docker Machine ###
+
+Docker Machine可以很好地支持每一种Linux发行版。首先,我们需要从Github网站下载最新版本的。这里我们使用curl来下载目前最新0.2.0版本的Docker Machine。
+
+在64位操作系统运行:
+
+ # curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
+
+在32位操作系统运行:
+
+ # curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
+
+下载最新版本的Docker Machine并将docker-machine文件放到了/usr/local/bin/后,添加执行权限:
+
+ # chmod +x /usr/local/bin/docker-machine
+
+完成如上操作后,我们需要确认已经成功安装docker-machine了。可以运行如下命令检查,它会输出系统中docker-machine的版本:
+
+ # docker-machine -v
+
+
+
+另外机器上需要有docker命令,可以使用如下命令安装:
+
+ # curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
+ # chmod +x /usr/local/bin/docker
+
+### 2. 创建机器 ###
+
+在自己的Linux机器上安装好了Docker Machine之后,我们想要将一个docker虚拟机部署到云服务器上。Docker Machine支持几个流行的云平台,如igital Ocean、Amazon Web Services(AWS)、Microsoft Azure、Google Cloud Computing等等,所以我们可以在不同的平台使用相同的接口来部署Docker。本文中我们会使用digitalocean驱动在Digital Ocean的服务器上部署Docker,--driver选项指定digitalocean驱动,--digitalocean-access-token选项指定[Digital Ocean Control Panel][1]提供的API Token,命令最后的是我们创建的Docker虚拟机的机器名。运行如下命令:
+
+ # docker-machine create --driver digitalocean --digitalocean-access-token linux-dev
+
+ # eval "$(docker-machine env linux-dev)"
+
+
+
+**注意**: 这里linux-dev是我们将要创建的机器的名称。``是一个安全key,可以在Digtal Ocean Control Panel生成。要找到这个key,我们只需要登录到我们的Digital Ocean Control Panel,然后点击API,再点击Generate New Token,填写一个名称,选上Read和Write。然后我们就会得到一串十六进制的key,那就是``,简单地替换到上边的命令中即可。
+
+运行如上命令后,我们可以在Digital Ocean Droplet Panel中看到一个具有默认配置的droplet已经被创建出来了。
+
+
+
+简便起见,docker-machine会使用默认配置来部署Droplet。我们可以通过增加选项来定制我们的Droplet。这里是一些digitalocean相关的选项,我们可以使用它们来覆盖Docker Machine所使用的默认配置。
+
+ --digitalocean-image "ubuntu-14-04-x64" 是选择Droplet的镜像
+ --digitalocean-ipv6 enable 是启用IPv6网络支持
+ --digitalocean-private-networking enable 是启用专用网络
+ --digitalocean-region "nyc3" 是选择部署Droplet的区域
+ --digitalocean-size "512mb" 是选择内存大小和部署的类型
+
+如果你想在其他云服务使用docker-machine,并且想覆盖默认的配置,可以运行如下命令来获取Docker Mackine默认支持的对每种平台适用的参数。
+
+ # docker-machine create -h
+
+### 3. 选择活跃机器 ###
+
+部署Droplet后,我们想马上运行一个Docker容器,但在那之前,我们需要检查下活跃机器是否是我们需要的机器。可以运行如下命令查看。
+
+ # docker-machine ls
+
+
+
+ACTIVE一列有“*”标记的是活跃机器。
+
+现在,如果我们想将活跃机器切换到需要的机器,运行如下命令:
+
+ # docker-machine active linux-dev
+
+**注意**:这里,linux-dev是机器名,我们打算激活这个机器,并且在其中运行Docker容器。
+
+### 4. 运行一个Docker容器 ###
+
+现在,我们已经选择了活跃机器,就可以运行Docker容器了。可以测试一下,运行一个busybox容器来执行`echo hello word`命令,这样就可以得到输出:
+
+ # docker run busybox echo hello world
+
+注意:如果你试图在一个装有32位操作系统的宿主机部署Docker容器,使用SSH来运行docker是个好办法。这样你就可以简单跳过这一步,直接进入下一步。
+
+### 5. SSH到Docker机器中 ###
+
+如果我们想在机器或者Droplet上控制之前部署的Docker机器,可以使用docker-machine ssh命令来SSH到机器上:
+
+ # docker-machine ssh
+
+
+
+SSH到机器上之后,我们可以在上边运行任何Docker容器。这里我们运行一个nginx:
+
+ # docker run -itd -p 80:80 nginx
+
+操作完毕后,我们需要运行exit命令来退出Droplet或者服务器。
+
+ # exit
+
+### 5. 删除机器 ###
+
+删除在运行的机器以及它的所有镜像和容器,我们可以使用docker-machine rm命令:
+
+ # docker-machine rm linux-dev
+
+
+
+使用docker-machine ls命令检查是否成功删除了:
+
+ # docker-machine ls
+
+
+
+### 6. 在不使用驱动的情况新增一个机器 ###
+
+我们可以在不使用驱动的情况往Docker增加一台机器,只需要一个URL。它可以使用一个已有机器的别名,所以我们就不需要每次在运行docker命令时输入完整的URL了。
+
+ $ docker-machine create --url=tcp://104.131.50.36:2376 custombox
+
+### 7. 管理机器 ###
+
+如果你已经让Docker运行起来了,可以使用简单的**docker-machine stop**命令来停止所有正在运行的机器,如果需要再启动的话可以运行**docker-machine start**:
+
+ # docker-machine stop
+ # docker-machine start
+
+你也可以使用如下命令来使用机器名作为参数来将其停止或启动:
+
+ $ docker-machine stop linux-dev
+ $ docker-machine start linux-dev
+
+### 总结 ###
+
+Docker Machine是一个非常棒的工具,可以使用Docker容器快速地部署服务。文中我们使用Digital Ocean Platform作演示,但Docker Machine还支持其他平台,如Amazon Web Service、Google Cloud Computing。使用Docker Machine,快速、安全地在几种不同平台部署Docker容器变得很简单了。因为Docker Machine还是Beta版本,不建议在生产环境使用。如果你有任何问题、建议、反馈,请在下方的评论框中写下来,我们会改进或者更新我们的内容。谢谢!享受吧 :-)
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/use-docker-machine-cloud-provider/
+
+作者:[Arun Pyasi][a]
+译者:[goreliu](https://github.com/goreliu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/arunp/
+[1]:https://cloud.digitalocean.com/settings/applications
\ No newline at end of file
diff --git a/translated/tech/20150520 How to Use tmpfs on RHEL or CentOS 7.0.md b/translated/tech/20150520 How to Use tmpfs on RHEL or CentOS 7.0.md
new file mode 100644
index 0000000000..7f3e37b3fe
--- /dev/null
+++ b/translated/tech/20150520 How to Use tmpfs on RHEL or CentOS 7.0.md
@@ -0,0 +1,64 @@
+如何在RHEL/CentOS 7.0中使用tmpfs
+================================================================================
+ 7中的tmpfs,这是一个将所有文件和文件夹写到虚拟内存中而不是实际写到磁盘中的虚拟文件系统。这意味中tmpfs中所有的内容都是临时的,在取消挂载、系统重启或者电源切断后内容都将会丢失。技术的角度上来说,tmpfs将搜有的内容放在内核内部缓存中并且会增大或者缩小来容纳文件并可从交换空间中交换处不需要的页。
+
+CentOS默认使用tmpfs做的事可用df -h命令的输出来看:
+
+ # df –h
+
+
+
+/dev - 含有针对所有设备的设备文件的目录
+/dev/shm – 包含共享内存分配
+/run - 用于系统日志
+/sys/fs/cgroup - 用于cgrpups, 一个针对特定进程限制、管制和审计资源利用的内核特性
+
+/tmp目录, 你可以用下面的两种方法来做到:
+
+### 使用systemctl来在/tmp中启用tmpfs ###
+
+你可以使用systemctl命令在tmp目录启用tmpfs, 首先用下面的命令来检查这个特性是否可用:
+
+ # systemctl is-enabled tmp.mount
+
+这会显示当先的状态,你可以使用下面的命令来启用它:
+
+ # systemctl enable tmp.mount
+
+
+
+这会控制/tmp目录并挂载tmpfs。
+
+### 手动挂载/tmp/文件系统 ###
+
+你可以在/etc/fstab中添加下面这行在/tmp挂载tmpfs。
+
+ tmpfs /tmp tmpfs size=512m 0 0
+
+接着运行这条命令
+
+ # mount –a
+
+
+
+这应该就会在df -h中显示tmpfs了,同样也会在你下次重启是会自动挂载。
+
+### 立即创建tmpfs ###
+
+如果由于一些原因,你写昂立即创建tmpfs,你可以使用下面的命令:
+
+ # mount -t tmpfs -o size=1G tmpfs /mnt/mytmpfs
+
+当然你可以在size选项中指定你希望的大小和希望的挂载点,只要记住是有效的目录就行了。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/file-system/use-tmpfs-rhel-centos-7-0/
+
+作者:[Adrian Dinu][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/adriand/
diff --git a/translated/tech/20150520 How to compile and install wxWidgets on Ubuntu or Debian or Linux Mint.md b/translated/tech/20150520 How to compile and install wxWidgets on Ubuntu or Debian or Linux Mint.md
new file mode 100644
index 0000000000..1f733207f3
--- /dev/null
+++ b/translated/tech/20150520 How to compile and install wxWidgets on Ubuntu or Debian or Linux Mint.md
@@ -0,0 +1,167 @@
+如何在Ubuntu/Debian/Linux Mint中编译和安装wxWidgets
+================================================================================
+### wxWidgets ###
+
+wxWidgets是一个程序开发框架/库, 允许你在Windows、Mac、Linux中使用相同的代码跨平台开发。
+
+它主要用C++写成,但也可以与其他语言绑定比如Python、Perl、Ruby。
+
+本教程中我将向你展示如何在基于Debian的linux中如Ubuntu和Linux Mint中编译wxwidgets 3.0+。
+
+从源码编译wxWidgets并不困难,仅仅需要几分钟。
+
+库可以按不同的方式来编译,比如静态或者动态库。
+
+### 1. 下载 wxWidgets ###
+
+第一步你需要从[wxwidgets.org][1]下载wxWidgets源码文件。
+
+做完后,解压到目录。
+
+### 2. 设置编译环境 ###
+
+要编译wxwidgets,我们需要一些工具包括C++编译器, 在Linux上是g++。所有这些可以通过apt-get工具从仓库中安装。
+
+我们还需要wxWidgets依赖的GTK开发库。
+
+ $ sudo apt-get install libgtk-3-dev build-essential checkinstall
+
+>checkinstall工具允许我们为wxwidgets创建一个安装包,这样之后就可以轻松的使用包管理器来卸载。
+
+### 3. 编译 wxWidgets ###
+
+进入到wxWidgets解压后的目录。为了保持清洁,创建一个编译用的目录。
+
+ $ mkdir gtk-build
+ $ cd gtk-build/
+
+现在运行configure和make命令。每个将花费一些时间来完成。
+
+ $ ../configure --disable-shared --enable-unicode
+ $ make
+
+"--disable-shared"选项将会编译静态库而不是动态库。
+
+make命令完成后,编译也成功了。是时候安装wxWidgets到正确的目录。
+
+更多信息请参考install.txt和readme.txt,这可在wxwidgets中的/docs/gtk/目录下找到。
+
+### 4. 安装 checkinstall ###
+
+现在我们不使用"make install"命令,我们使用checkinstall命令来创建一个wxwidgets的deb安装包。运行命令:
+
+ $ sudo checkinstall
+
+checkinstall会询问几个问题,请保证在提问后提供一个版本号,否则将会失败。
+
+完成这一切后,wxWidgets就安装好了,deb文件也会创建在相同的目录下。
+
+### 5. 追踪安装的文件 ###
+
+如果你想要检查文件安装的位置,使用dpkg命令后面跟上checkinstall提供的报名。
+
+ $ dpkg -L package_name
+ /.
+ /usr
+ /usr/local
+ /usr/local/lib
+ /usr/local/lib/libwx_baseu-3.0.a
+ /usr/local/lib/libwx_gtk3u_propgrid-3.0.a
+ /usr/local/lib/libwx_gtk3u_html-3.0.a
+ /usr/local/lib/libwxscintilla-3.0.a
+ /usr/local/lib/libwx_gtk3u_ribbon-3.0.a
+ /usr/local/lib/libwx_gtk3u_stc-3.0.a
+ /usr/local/lib/libwx_gtk3u_qa-3.0.a
+ /usr/local/lib/libwx_baseu_net-3.0.a
+ /usr/local/lib/libwxtiff-3.0.a
+
+### 6. 编译示例 ###
+
+编译wxWidgets完成后就可以马上编译示例程序了。在相同的目录下,一个新的sample目录已经创建了。
+
+进入它并运行下面的命令
+
+ $ compile samples
+ $ cd samples/
+ $ make
+
+make命令完成后,进入sampl子目录,这里就有一个可以马上运行的Demo程序了。
+
+### 7. 编译你的第一个程序 ###
+
+你完成编译demo程序后,可以写你自己的程序来编译了。这个也很简单。
+
+假设你用的是C++这样你可以使用编辑器的高亮特性。比如gedit、kate、kwrite等等。或者用全功能的IDE像Geany、Codelite、Codeblocks等等。
+
+然而你的第一个程序只需要用一个文本编辑器来快速完成。
+
+这里就是
+
+ #include
+
+ class Simple : public wxFrame
+ {
+ public:
+ Simple(const wxString& title)
+ : wxFrame(NULL, wxID_ANY, title, wxDefaultPosition, wxSize(250, 150))
+ {
+ Centre();
+ }
+ };
+
+ class MyApp : public wxApp
+ {
+ public:
+ bool OnInit()
+ {
+ Simple *simple = new Simple(wxT("Simple"));
+ simple->Show(true);
+ return true;
+ }
+ };
+
+ wxIMPLEMENT_APP(MyApp);
+
+现在保存并用下面的命令编译。
+
+ # compile
+ $ g++ basic.cpp `wx-config --cxxflags --libs std` -o program
+
+ # run
+ $ ./program
+
+#### 和非标准的库一起编译 ####
+
+面展示的wx-config命令默认只支持标准的库。如果你使用的是Aui库,那么你需要指定额外用到的库。
+
+ $ g++ code.cpp `wx-config --cxxflags --libs std,aui` -o program
+
+更多的信息参考这里[这里][2]。
+
+### 资源 ###
+
+下载wxWidgets的源码和帮助
+[https://www.wxwidgets.org/downloads/][3]
+
+wxWidgets编译的wiki页面
+[https://wiki.wxwidgets.org/Compiling_and_getting_started][4]
+
+使用wxWidgets最新版本(3.0+)的事项
+[https://wiki.wxwidgets.org/Updating_to_the_Latest_Version_of_wxWidgets][5]
+
+--------------------------------------------------------------------------------
+
+via: http://www.binarytides.com/install-wxwidgets-ubuntu/
+
+作者:[Silver Moon][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117145272367995638274/posts
+[1]:https://www.wxwidgets.org/downloads/
+[2]:https://wiki.wxwidgets.org/Updating_to_the_Latest_Version_of_wxWidgets#The_wx-config_script
+[3]:https://www.wxwidgets.org/downloads/
+[4]:https://wiki.wxwidgets.org/Compiling_and_getting_started
+[5]:https://wiki.wxwidgets.org/Updating_to_the_Latest_Version_of_wxWidgets
diff --git a/translated/tech/20150520 Shell Script to Backup Files or Directories Using rsync.md b/translated/tech/20150520 Shell Script to Backup Files or Directories Using rsync.md
new file mode 100644
index 0000000000..639e58ede9
--- /dev/null
+++ b/translated/tech/20150520 Shell Script to Backup Files or Directories Using rsync.md
@@ -0,0 +1,170 @@
+Shell脚本:使用rsync备份文件/目录
+================================================================================
+本文,我们带来了shell脚本,用来使用rsync命令将你本地Linux机器上的文件/目录备份到远程Linux服务器上。使用该脚本实施备份会是一个交互的方式,你需要提供远程备份服务器的主机名/ip地址和文件夹位置。我们保留了一个独立文件,在这个文件中你需要提供需要备份的文件/目录。我们添加了两个脚本,**第一个脚本**在每次拷贝完一个文件后询问密码(如果你启用了ssh验证密钥,那么就不会询问密码),而第二个脚本中,则只会提示一次输入密码。
+
+我们打算备份bckup.txt,dataconfig.txt,docs和orcledb。
+
+ [root@Fedora21 tmp]# ls -l
+ total 12
+ -rw-r--r--. 1 root root 0 May 15 10:43 bckrsync.sh
+ -rw-r--r--. 1 root root 0 May 15 10:44 bckup.txt
+ -rw-r--r--. 1 root root 0 May 15 10:46 dataconfig.txt
+ drwxr-xr-x. 2 root root 4096 May 15 10:45 docs
+ drwxr-xr-x. 2 root root 4096 May 15 10:44 oracledb
+
+该文件包含了备份文件/目录的详情
+
+ [root@Fedora21 tmp]# cat /tmp/bckup.txt
+ /tmp/oracledb
+ /tmp/dataconfig.txt
+ /tmp/docs
+ [root@Fedora21 tmp]#
+
+### 脚本 1: ###
+
+ #!/bin/bash
+
+ #We will save path to backup file in variable
+ backupf='/tmp/bckup.txt'
+
+ #Next line just prints message
+ echo "Shell Script Backup Your Files / Directories Using rsync"
+
+ #next line check if entered value is not null, and if null it will reask user to enter Destination Server
+ while [ x$desthost = "x" ]; do
+
+ #next line prints what userd should enter, and stores entered value to variable with name desthost
+ read -p "Destination backup Server : " desthost
+
+ #next line finishes while loop
+ done
+
+ #next line check if entered value is not null, and if null it will reask user to enter Destination Path
+ while [ x$destpath = "x" ]; do
+
+ #next line prints what userd should enter, and stores entered value to variable with name destpath
+ read -p "Destination Folder : " destpath
+
+ #next line finishes while loop
+ done
+
+ #Next line will start reading backup file line by line
+ for line in `cat $backupf`
+
+ #and on each line will execute next
+ do
+
+ #print message that file/dir will be copied
+ echo "Copying $line ... "
+ #copy via rsync file/dir to destination
+
+ rsync -ar "$line" "$desthost":"$destpath"
+
+ #this line just print done
+ echo "DONE"
+
+ #end of reading backup file
+ done
+
+#### 运行带有输出结果的脚本 ####
+
+ [root@Fedora21 tmp]# ./bckrsync.sh
+ Shell Script Backup Your Files / Directories Using rsync
+ Destination backup Server : 104.*.*.41
+ Destination Folder : /tmp
+ Copying /tmp/oracledb ...
+ The authenticity of host '104.*.*.41 (104.*.*.41)' can't be established.
+ ECDSA key fingerprint is 96:11:61:17:7f:fa:......
+ Are you sure you want to continue connecting (yes/no)? yes
+ Warning: Permanently added '104.*.*.41' (ECDSA) to the list of known hosts.
+ root@104.*.*.41's password:
+ DONE
+ Copying /tmp/dataconfig.txt ...
+ root@104.*.*.41's password:
+ DONE
+ Copying /tmp/docs ...
+ root@104.*.*.41's password:
+ DONE
+ [root@Fedora21 tmp]#
+
+### 脚本 2: ###
+
+ #!/bin/bash
+
+ #We will save path to backup file in variable
+ backupf='/tmp/bckup.txt'
+
+ #Next line just prints message
+ echo "Shell Script Backup Your Files / Directories Using rsync"
+
+ #next line check if entered value is not null, and if null it will reask user to enter Destination Server
+ while [ x$desthost = "x" ]; do
+
+ #next line prints what userd should enter, and stores entered value to variable with name desthost
+ read -p "Destination backup Server : " desthost
+
+ #next line finishes while loop
+ done
+
+ #next line check if entered value is not null, and if null it will reask user to enter Destination Path
+ while [ x$destpath = "x" ]; do
+
+ #next line prints what userd should enter, and stores entered value to variable with name destpath
+ read -p "Destination Folder : " destpath
+
+ #next line finishes while loop
+ done
+
+ #next line check if entered value is not null, and if null it will reask user to enter password
+ while [ x$password = "x" ]; do
+ #next line prints what userd should enter, and stores entered value to variable with name password. #To hide password we are using -s key
+ read -sp "Password : " password
+ #next line finishes while loop
+ done
+
+ #Next line will start reading backup file line by line
+ for line in `cat $backupf`
+
+ #and on each line will execute next
+ do
+
+ #print message that file/dir will be copied
+ echo "Copying $line ... "
+ #we will use expect tool to enter password inside script
+ /usr/bin/expect << EOD
+ #next line set timeout to -1, recommended to use
+ set timeout -1
+ #copy via rsync file/dir to destination, using part of expect — spawn command
+
+ spawn rsync -ar ${line} ${desthost}:${destpath}
+ #as result of previous command we expect “password” promtp
+ expect "*?assword:*"
+ #next command enters password from script
+ send "${password}\r"
+ #next command tells that we expect end of file (everything finished on remote server)
+ expect eof
+ #end of expect pard
+ EOD
+ #this line just print done
+ echo "DONE"
+
+ #end of reading backup file
+ done
+
+#### 运行第二个带有输出结果的脚本的屏幕截图 ####
+
+
+
+希望这些脚本对你备份会有帮助!!
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-shell-script/shell-script-backup-files-directories-rsync/
+
+作者:[Yevhen Duma][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/yevhend/
diff --git a/translated/tech/20150521 Linux FAQs with Answers--How to change system proxy settings from the command line on Ubuntu desktop.md b/translated/tech/20150521 Linux FAQs with Answers--How to change system proxy settings from the command line on Ubuntu desktop.md
new file mode 100644
index 0000000000..526de3549e
--- /dev/null
+++ b/translated/tech/20150521 Linux FAQs with Answers--How to change system proxy settings from the command line on Ubuntu desktop.md
@@ -0,0 +1,71 @@
+Linux 有问必答--如何在桌面版 Ubuntu 中用命令行更改系统代理设置
+================================================================================
+> **问题**: 我经常需要在桌面版 Ubuntu 中更改系统代理设置,但我不想通过繁琐的 GUI 菜单链:"系统设置" -> "网络" -> "网络代理"。在命令行中有更方便的方法更改桌面版的代理设置吗?
+
+在桌面版 Ubuntu 中,它的桌面环境设置,包括系统代理设置,都存储在 DConf 数据库,这是简单的键值对存储。如果你想通过系统设置菜单修改桌面属性,更改会持久保存在后端的 DConf 数据库。在 Ubuntu 中更改 DConf 数据库有基于图像用户界面和非图形用户界面的两种方式。系统设置或者 dconf-editor 是访问 DConf 数据库的图形方法,而 gsettings 或 dconf 就是能更改数据库的命令行工具。
+
+下面介绍如何用 gsettings 从命令行更改系统代理设置。
+
+
+
+gsetting 读写特定 Dconf 设置的基本用法如下:
+
+更改 DConf 设置:
+
+ $ gsettings set
+
+读取 DConf 设置:
+
+ $ gsettings get
+
+### 通过命令行更改系统代理设置为手动 ###
+
+桌面版 Ubuntu 中下面的命令会更改 HTTP 代理设置为 "my.proxy.com:8000"。
+
+ $ gsettings set org.gnome.system.proxy.http host 'my.proxy.com'
+ $ gsettings set org.gnome.system.proxy.http port 8000
+ $ gsettings set org.gnome.system.proxy mode 'manual'
+
+如果你还想更改 HTTPS/FTP 代理为手动,用这些命令:
+
+ $ gsettings set org.gnome.system.proxy.https host 'my.proxy.com'
+ $ gsettings set org.gnome.system.proxy.https port 8000
+ $ gsettings set org.gnome.system.proxy.ftp host 'my.proxy.com'
+ $ gsettings set org.gnome.system.proxy.ftp port 8000
+
+更改套接字主机设置为手动:
+
+ $ gsettings set org.gnome.system.proxy.socks host 'my.proxy.com'
+ $ gsettings set org.gnome.system.proxy.socks port 8000
+
+上面的更改都只适用于当前的桌面用户。如果你想在系统范围内使用代理设置更改,在 gsettings 命令面前添加 sudo。例如:
+
+ $ sudo gsettings set org.gnome.system.proxy.http host 'my.proxy.com'
+ $ sudo gsettings set org.gnome.system.proxy.http port 8000
+ $ sudo gsettings set org.gnome.system.proxy mode 'manual'
+
+### 在命令行中更改系统代理设置为自动 ###
+
+如果你正在使用 [自动配置代理][1] (proxy auto configuration,PAC),输入以下命令更改为 PAC。
+
+ $ gsettings set org.gnome.system.proxy mode 'auto'
+ $ gsettings set org.gnome.system.proxy autoconfig-url http://my.proxy.com/autoproxy.pac
+
+### 在命令行中清除系统代理设置 ###
+
+最后,清除所有 手动/自动 代理设置,还原为无代理设置:
+
+ $ gsettings set org.gnome.system.proxy mode 'none'
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/change-system-proxy-settings-command-line-ubuntu-desktop.html
+
+作者:[Dan Nanni][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:http://xmodulo.com/how-to-set-up-proxy-auto-config-on-ubuntu-desktop.html
\ No newline at end of file
diff --git a/translated/tech/20150521 Linux FAQs with Answers--How to install Unity Tweak Tool on Ubuntu desktop.md b/translated/tech/20150521 Linux FAQs with Answers--How to install Unity Tweak Tool on Ubuntu desktop.md
new file mode 100644
index 0000000000..def6860616
--- /dev/null
+++ b/translated/tech/20150521 Linux FAQs with Answers--How to install Unity Tweak Tool on Ubuntu desktop.md
@@ -0,0 +1,42 @@
+Linux 有问必答--如何在桌面版 Ubuntu 中安装 Unity Tweak Tool
+================================================================================
+> **问题**: 我试着给刚安装的桌面版 Ubuntu 自定制桌面。我想使用 Unity Tweak Tool。我怎样才能在 Ubuntu 上安装 Unity Tweak Tool 呢?
+
+[Unity Tweak Tool][1] 是个流行的 Unity 桌面自定制工具。顾名思义,该工具只适用于 Ubuntu 的默认桌面环境(例如,基于 Unity 的 GNOME 桌面)。这个多功能的工具允许你通过非常直观和简单易用的图形用户界面自定义多种 Unity 桌面特性。它的菜单看起来类似于 Ubuntu 的官方系统设置,但它的桌面自定制能力远远超过默认的系统设置。通过使用 Unity Tweak Tool,你可以自定制外观、行为以及很多桌面组件的配置,例如工作区、窗口、图标、主题、光标、字体、滑动、热键等等。如果你是 Unity 桌面用户,Unity Tweak Tool 一定是个必不可少的应用程序。
+
+
+
+尽管 Unity Tweak Tool 是桌面版 Ubuntu 的重要工具,并没有在桌面版 Ubuntu 中预安装。为了能自定制 Unity 桌面,下面介绍一下如何在桌面版 Ubuntu 中安装 Unity Tweak Tool。
+
+### 在 Ubuntu 13.04 或更高版本中安装 Unity Tweak Tool ###
+
+从 Ubuntu 13.04 开始, Ubuntu 的基础库中就有 Unity Tweak Tool 了。因此它的安装非常简单:
+
+ $ sudo apt-get install unity-tweak-tool
+
+启动 Unity Tweak Tool:
+
+ $ unity-tweak-tool
+
+如果你想使用最新版本的 Unity Tweak Tool,你可以从它的 PPA 中安装(如下所述)。
+
+### 在 Ubuntu 12.10 中安装 Unity Tweak Tool ###
+
+注意,Unity Tweak Tool 要求 Ubuntu 12.10 或更高的版本。如果你想着 Ubuntu 上安装它,你可以安装下面方法使用 PPA。当你想测试最新的开发版的时候这个 PPA 库也非常有用。
+
+ $ sudo add-apt-repository ppa:freyja-dev/unity-tweak-tool-daily
+ $ sudo apt-get update
+ $ sudo apt-get install unity-tweak-tool
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/install-unity-tweak-tool-ubuntu-desktop.html
+
+作者:[Dan Nanni][a]
+译者:[ictlyh](https://github.com/ictlyh)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
+[1]:https://launchpad.net/unity-tweak-tool
\ No newline at end of file
diff --git a/translated/tech/20150525 Linux ntopng--Network Monitoring Tool Installation Screenshots.md b/translated/tech/20150525 Linux ntopng--Network Monitoring Tool Installation Screenshots.md
new file mode 100644
index 0000000000..dc039ba551
--- /dev/null
+++ b/translated/tech/20150525 Linux ntopng--Network Monitoring Tool Installation Screenshots.md
@@ -0,0 +1,189 @@
+Linux ntopng——网络监控工具的安装(附截图)
+================================================================================
+当今世界,人们的计算机都相互连接,互联互通。小到你的家庭局域网(LAN),大到最大的一个被我们称为的——互联网。当你管理一台联网的计算机时,你就是在管理最关键的组件之一。由于大多数开发出的应用程序都基于网络,网络就连接起了这些关键点。
+
+这就是为什么我们需要网络监控工具。最好的网络监控工具之一,它叫作ntop。来自[维基百科][1]的知识“ntop是一个网络探测器,它以与top显示进程般类似的方式显示网络使用率。在交互模式中,它显示了用户终端上的网络状态。在网页模式中,它作为网络服务器,创建网络状态的HTML转储文件。它支持NetFlow/sFlowemitter/collector,这是一个基于HTTP的客户端界面,用于创建ntop为中心的监控应用和RRD用于持续地存储通信数据”
+
+15年后的今天,你将见到ntopng——下一代ntop。
+
+### ntopng是什么 ###
+
+Ntopng是一个基于网页的高速通信分析器和流量收集器。Ntopng基于ntop,它运行于所有Unix平台、MacOS X和Windows。
+
+### 特性 ###
+
+从[ntopng网站][2]上,我们可以看到他们说它有众多的特性。这里列出了其中一些:
+
+- 按各种协议对网络通信排序
+- 显示网络通信和IPv4/v6激活的主机
+- 持续不断以RRD格式存储定位主机的通信数据到磁盘
+- 通过nDPI,ntop的DPI框架,发现应用协议
+- 显示各种协议间的IP通信分布
+- 分析IP通信,并根据源/目的地址进行排序
+- 显示IP通信子网的矩阵(谁在和谁通信?)
+- 报告按协议类型排序的IP协议使用率
+- 生成HTML5/AJAX网络通信数据
+
+### 安装 ###
+
+Ntop为CentOS和**基于64位**Ubuntu预编译好了包,你可以在[他们的下载页面][3]找到这些包。对于32位操作系统,你必须从源代码编译。本文在**CentOS 6.4 32位**版本上**测试过**。但是,它也可以在其它基于CentOS/RedHat的Linux版本上工作。让我们开始吧。
+
+#### 先决条件 ####
+
+#### 开发工具 ####
+
+你必须确保你安装了编译ntopng所需的所有开发工具,要安装开发工具,你可以使用yum命令:
+
+ # yum groupinstall ‘Development Tools’
+
+#### 安装TCL ####
+
+ # yum install tcl
+
+#### 安装libpcap ####
+
+ # yum install libpcap libcap-devel
+
+#### 安装Redis ####
+
+ # wget http://redis.googlecode.com/files/redis-2.6.13.tar.gz
+ # tar zxfv redis-2.6.13.tar.gz
+ # cd redis-2.6.13
+ # make 32bit
+ # make test
+ # make install
+
+### 安装ntopng ###
+
+#### 方法 1 : ####
+
+ # wget http://sourceforge.net/projects/ntop/files/ntopng/ntopng-1.1_6932.tgz/download
+ # tar zxfv ntopng-1.1_6932.tgz
+ # cd ntopng-1.1_6932
+ # ./configure
+ # make
+ # make install
+
+#### 方法 2 : ####
+
+在我的CentOS 6.4上,我使用方法 1时收到了一个错误消息,错误消息内容如下:
+
+ ./third-party/LuaJIT-2.0.2/src/libluajit.a : could not read symbols : File in wrong format
+
+所以,我**切换**到了**SVN**来安装。对于此方法,需要联网,步骤如下:
+
+ # svn co https://svn.ntop.org/svn/ntop/trunk/ntopng/
+ # ./autogen.sh
+ # ./configure
+ # make
+ # make install
+
+*由于ntopng是一个基于网页的应用,你的系统必须安装有工作良好的网络服务器*
+
+### 为ntopng创建配置文件 ###
+
+如果一切都已安装完毕,那么我们该来运行它了。默认情况下,如果我们在./configure这一步没有明确修改安装文件夹的话,redis和ntopng将安装到/usr/local/文件夹。接下来,我们需要为ntopng创建配置文件。在本文中,我们使用vi作为文本编辑器。你也可以使用你所中意的文本编辑器来创建ntopng的配置文件。
+
+ # cd /usr/local/etc
+ # mkdir ntopng
+ # cd ntopng
+ # vi ntopng.start
+
+ 放入这些行:
+ --local-network “10.0.2.0/24”
+ --interface 1
+
+ # vi ntopng.pid
+
+ 放入该行:
+ -G=/var/run/ntopng.pid
+
+保存这些文件,然后继续下一步。
+
+### 运行ntopng ###
+
+我们假定你已正确安装了网络服务器,那么下一步就是运行redis服务器。
+
+ # /usr/local/bin/redis-server
+
+
+
+然后,**运行**ntopng
+
+ # /usr/local/bin/ntopng
+
+
+
+### 测试ntopng ###
+
+现在,你可以通过访问[http://yourserver.name:3000][4]来测试ntopng应用,你将会看到ntopng登录页面。首次登录,你可以使用用户‘**admin**’和密码‘**admin**’。
+
+
+
+仪表盘相当简洁。当你登入后,你将看到关于最高流量通信者页面。
+
+
+
+如果你点击右侧顶部的**流量菜单**,ntopng将会显示活动流量的更多细节。
+
+
+
+在**主机菜单**上,你可以看到连接到流的所有主机
+
+
+
+如果你点击**主机 > 交互**,ntop将显示一个漂亮的主机间的交互信息图表。
+
+
+
+**仪表盘菜单**组成部分:
+
+#### 顶级主机(发送+接收) ####
+
+
+
+#### 顶级应用协议 ####
+
+
+
+**界面菜单**将引领你进入更多内部菜单。
+包菜单将给你显示包的分布大小。
+
+
+
+**协议菜单**将为你显示使用了多少协议及其使用百分比。
+
+
+
+
+
+你也可以通过使用**历史活跃度菜单**查看活跃度
+
+
+
+
+
+最后一项要点是,你也可以通过顶部右侧区域的**设置菜单**(齿轮图标的那一个)管理哪些用户可以访问ntopng。
+
+
+
+Ntopng为你提供了一个范围宽广的时间线,从5分钟到1年都可以。你只需要点击你想要现实的时间线。图标本身是可以点击的,你可以点击它来进行缩放。
+
+当然,ntopng能做的事比上面图片中展示的还要多得多。你也可以将定位和电子地图服务整合进来。在ntopng自己的网站上,有已付费的模块可供使用,如nprobe可以扩展ntopng可以提供给你的信息。更多关于ntopng的信息,你可以访问[ntopng网站][5]。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/monitoring-2/ntopng-network-monitoring-tool/
+
+作者:[Pungki Arianto][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/pungki/
+[1]:http://en.wikipedia.org/wiki/Ntop
+[2]:http://www.ntop.org/products/ntop/
+[3]:http://www.nmon.net/packages/
+[4]:http://yourserver.name:3000/
+[5]:http://www.ntop.org/
diff --git a/translated/tech/20150527 3 Useful Hacks Every Linux User Must Know.md b/translated/tech/20150527 3 Useful Hacks Every Linux User Must Know.md
new file mode 100644
index 0000000000..25c1ef3e3d
--- /dev/null
+++ b/translated/tech/20150527 3 Useful Hacks Every Linux User Must Know.md
@@ -0,0 +1,78 @@
+每个Linux用户都应该知道的3个有用技巧
+================================================================================
+Linux世界充满了乐趣,我们越深入进去,就会发现越多有趣的事物。我们会努力给你提供一些小技巧,让你和其他人有所不同,下面就是我们准备的3个小技巧。
+
+### 1. 如何在不使用Cron的情况调度Linux下的作业 ###
+在Linux下,调度一个作业/命令可以缩写为Cron。当我们需要调度一个作业时,我们会使用Cron,但你知道我们在不使用Cron的情况也可以调度一个在将来时间运行的作业吗?你可以按照如下建议操作……
+
+每5秒钟运行一个命令(date)然后将结果写入到一个文件(data.txt)。为了实现这一点,我们可以直接在命令提示符运行如下单行脚本。
+
+ $ while true; do date >> date.txt ; sleep 5 ; done &
+
+上述脚本的解释:
+
+- `while true` :让脚本进入一个条件总为真的循环中,也就是制造一个死循环,将里边的命令一遍遍地重复运行。
+- `do` :`do`是`while`语句中的关键字,它之后的命令会被执行,在它后边可以放置一个或一系列命令。
+- `date >> date.txt` :运行date命令,并将其输出写入到data.txt文件中。注意我们使用`>>`,而不是`>`。
+- `>>` :对文件(date.txt)进行追加写的操作,这样每次运行命令后,输出内容会被追加到文件中。如果使用`>`的话,则会一遍遍地覆盖之前的内容。
+- `sleep 5` :让脚本处于5秒睡眠状态,然后再运行之后的命令。注意这里的时间单位只能用秒。也就是说如果你想让命令每6分钟运行一次,你应该使用`sleep 360`。
+- `done` :`while`循环语句块结束的标记。
+- `&` :将整个进程放到后台运行。
+
+类似地,我们可以这样运行任何脚本。下边的例子是每100秒运行一个名为`script_name.sh`的脚本。
+
+另外值得一提的是上边的脚本文件必须处于当前目录中,否则需要使用完整路径(`/home/$USER/…/script_name.sh`)。实现如上功能的单行脚本如下:
+
+ $ while true; do /bin/sh script_name.sh ; sleep 100 ; done &
+
+**总结**:上述的单行脚本并不是Cron的替代品,因为Cron工具支持众多选项,更加灵活,可定制性也更高。然而如果我们想运行某些测试,比如I/O评测,上述的单行脚本也管用。
+
+还可以参考:[11 Linux Cron Job Scheduling Examples][1]
+
+### 2. 如何不使用clear命令清空终端的内容 ###
+
+你如何清空终端的内容?你可能会认为这是一个傻问题。好吧,大家都清楚可以使用`clear`命令。如果养成使用`ctrl + l`快捷键的习惯,我们会节省大量时间。
+
+`Ctrl + l`快捷键的效果和`clear`命令一样。所以下一次你就可以使用`ctrl + l`来清空终端的内容了。
+
+**总结**:因为`ctrl + l`是一个快捷键,我们不可以在脚本中使用。所以如果我们需要在脚本中清空屏幕内容,还是需要使用`clear`命令。但我能想到的所有其他情况,`ctrl + l`都更加有效。
+
+### 3. 运行一个命令,然后自动回到当前的工作目录 ###
+
+这是一个很多人可能不知道的令人吃惊的技巧。你可能想运行任何一个命令,然后再回到当前目录。你只需要将命令放在一个圆括号里。
+
+我们来看一个例子:
+
+ avi@deb:~$ (cd /home/avi/Downloads/)
+
+#### 示例输出 ####
+
+ avi@deb:~
+
+它首先会cd到Downloads目录,然后又回到了之前的家目录。也许你认为里边的命令根本没有执行,或者是出了某种错误,因为从命令提示符看不出任何变化。让我们简单修改一下这个命令:
+
+ avi@deb:~$ (cd /home/avi/Downloads/ && ls -l)
+
+#### 示例输出 ####
+
+ -rw-r----- 1 avi avi 54272 May 3 18:37 text1.txt
+ -rw-r----- 1 avi avi 54272 May 3 18:37 text2.txt
+ -rw-r----- 1 avi avi 54272 May 3 18:37 text3.txt
+ avi@deb:~$
+
+在上述命令中,它首先进入Downloads目录,然后列出文件内容,最后又回到了当前目录。并且它证明了命令成功执行了。你可以在括号中包含任何命令,执行完都会顺利返回到当前目录。
+
+这就是全部内容了,如果你知道任何类似的Linux技巧,你可以在文章下面的评论框中分享给我们,不要忘记将本文和朋友分享 :)
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/useful-linux-hacks-commands/
+
+作者:[Avishek Kumar][a]
+译者:[goreliu](https://github.com/goreliu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
\ No newline at end of file
diff --git a/translated/tech/20150527 How To Check Laptop CPU Temperature In Ubuntu.md b/translated/tech/20150527 How To Check Laptop CPU Temperature In Ubuntu.md
new file mode 100644
index 0000000000..ace8999edb
--- /dev/null
+++ b/translated/tech/20150527 How To Check Laptop CPU Temperature In Ubuntu.md
@@ -0,0 +1,83 @@
+如何在Ubuntu中检查笔记本CPU的温度
+================================================================================
+
+
+笔记本过热是最近一个常见的问题。监控硬件温度或许可以帮助你诊断笔记本为什么会过热。本篇中,我们会**了解如何在Ubuntu中检查CPU的温度**。
+
+我们将使用一个GUI工具[Psensor][1],它允许你在Linux中监控硬件温度。用Psensor你可以:
+
+- 监控cpu和主板的温度
+- 监控NVidia GPU的文档
+- 监控硬盘的温度
+- 监控风扇的速度
+- 监控CPU的利用率
+
+Psensor最新的版本同样提供了Ubuntu中的指示小程序,这样使得在Ubuntu中监控温度变得更加容易。你可以选择在面板的右上角显示温度。它还会在温度上过阈值后通知。
+
+
+### 如何在Ubuntu 15.04 和 14.04中安装Psensor ###
+
+在安装Psensor前,你需要安装和配置[lm-sensors][2],一个用于硬件监控的命令行工具。如果你想要测量磁盘温度,你还需要安装[hddtemp][3]。要安装这些工具,运行下面的这些命令:
+
+ sudo apt-get install lm-sensors hddtemp
+
+接着开始检测硬件传感器:
+
+ sudo sensors-detect
+
+要确保已经工作,运行下面的命令:
+
+ sensors
+
+它会给出下面这样的输出:
+
+ acpitz-virtual-0
+ Adapter: Virtual device
+ temp1: +43.0°C (crit = +98.0°C)
+
+ coretemp-isa-0000
+ Adapter: ISA adapter
+ Physical id 0: +44.0°C (high = +100.0°C, crit = +100.0°C)
+ Core 0: +41.0°C (high = +100.0°C, crit = +100.0°C)
+ Core 1: +40.0°C (high = +100.0°C, crit = +100.0°C)
+
+如果一切看上去没问题,使用下面的命令安装Psensor:
+
+ sudo apt-get install psensor
+
+安装完成后,在Unity Dash中运行程序。第一次运行时,你应该配置Psensor该监控什么状态。
+
+
+
+### 在面板显示温度 ###
+
+如果你想要在面板中显示温度,进入**Sensor Preferences**:
+
+
+
+在 **Application Indicator** 菜单下,选择你想要显示温度的组件并勾上 **Display sensor in the label** 选项。
+
+
+
+### 每次启动启动Psensor ###
+
+进入 **Preferences->Startup** 并选择 **Launch on session startup** 使每次启动时启动Psensor。
+
+
+
+就是这样。你所要做的就是在这里监控CPU温度。你可以时刻注意并帮助你找出使计算机过热的进程。
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/check-laptop-cpu-temperature-ubuntu/
+
+作者:[Abhishek][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://wpitchoune.net/blog/psensor/
+[2]:http://www.lm-sensors.org/
+[3]:https://wiki.archlinux.org/index.php/Hddtemp
diff --git a/translated/tech/20150527 How to Kill Linux Processes or Unresponsive Applications Using 'xkill' Command.md b/translated/tech/20150527 How to Kill Linux Processes or Unresponsive Applications Using 'xkill' Command.md
new file mode 100644
index 0000000000..20211ab6bf
--- /dev/null
+++ b/translated/tech/20150527 How to Kill Linux Processes or Unresponsive Applications Using 'xkill' Command.md
@@ -0,0 +1,93 @@
+如何使用xkill命令傻点Linux进程/未响应的程序
+================================================================================
+我们如何在Linux中杀掉一个资源/进程?很明显我们会找出资源的pid然后用kill命令。
+
+更准确一点,我们可以找到资源(这里就是terminal)的PID:
+
+ $ ps -A | grep -i terminal
+
+ 6228 ? 00:00:00 gnome-terminal
+
+上面的输出中,‘6288’就是进程(gnome-terminal)的pid, 使用下面的命令来杀掉进程。
+
+ $ kill 6228
+
+kill命令会发送一个信号给该pid的进程。
+
+另外一个方法是我们可以使用pkill命令,它可以基于进程的名字或者其他的属性来杀掉进程。同样我们要杀掉一个叫terminal的进程可以这么做:
+
+ $ pkill terminal
+
+**注意**: pkill命令后面进程名的长度不大于15个字符
+
+pkill看上去更加容易上手,因为你你不用找出进程的pid。但是如果你要对系统做更好的控制,那么没有什么可以打败'kill'。使用kill命令可以更好地审视你要杀掉的进程。
+
+我们已经有一篇覆盖了[kill、pkill和killall命令][1]间细节的指导了。
+
+对于那些运行X Server的人而言,有另外一个工具称为xkill可以将进程从X Window中杀掉而不必传递它的名字或者pid。
+
+xkill工具强制X server关闭于它客户端之间的联系,这可以让X resource关闭这个客户端。xkill是X11工具集中一个非常容易上手的杀掉无用窗口的工具。
+
+它支持的选项如在同时运行多个X Server时使用-display选项后面跟上显示号连接到指定的X server,使用-all(并不建议)杀掉所有在屏幕上的所遇顶层窗口,同时将帧(-frame)也计算在内。
+
+要得到所有的客户端你可以运行:
+
+ $ xlsclients
+
+#### 示例输出 ####
+
+ ' ' /usr/lib/libreoffice/program/soffice
+ deb gnome-shell
+ deb Docky
+ deb google-chrome-stable
+ deb soffice
+ deb gnome-settings-daemon
+ deb gnome-terminal-server
+
+如果后面没有跟上资源id,xkill会将鼠标指针变成一个特殊符号,类似于“X”。只需在你要杀掉的窗口上点击,它就会杀掉它与server端的通信,这个程序就被杀掉了。
+
+
+ $ xkill
+
+
+
+使用xkill杀掉进程
+
+需要注意的是xkill并不能保证它的通信会被成功杀掉/退出。大多数程序会在与服务端的通信被关闭后杀掉。然而仍有少部分会继续运行。
+
+需要指出的点是:
+
+- 这个工具只能在X11 server运行的时候才能使用,因为这是X11工具的一部分。
+- 不要在你杀掉一个资源而它没有完全退出时而困惑。
+- 这不是kill的替代品
+
+**我需要在linux命令行中使用xkill么**
+
+不是,你不必在命令行中运行xkill。你可以设置一个快捷键,并用它来调用xkill。
+
+下面是如何在典型的gnome3桌面中设置键盘快捷键。
+
+进入设置-> 选择键盘。点击'+'并添加一个名字和命令。点击点击新条目并按下你想要的组合键。我的是Ctrl+Alt+Shift+x。
+
+
+
+Gnome 设置
+
+
+
+添加快捷键
+
+下次你要杀掉X资源只要用组合键就行了(Ctrl+Alt+Shift+x),你看到你的鼠标变成x了。点击想要杀掉的x资源就行了。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/kill-processes-unresponsive-programs-in-ubuntu/
+
+作者:[Avishek Kumar][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/how-to-kill-a-process-in-linux/
diff --git a/translated/tech/20150527 Linux FAQs with Answers--How to mount an LVM partition on Linux.md b/translated/tech/20150527 Linux FAQs with Answers--How to mount an LVM partition on Linux.md
new file mode 100644
index 0000000000..391769edc2
--- /dev/null
+++ b/translated/tech/20150527 Linux FAQs with Answers--How to mount an LVM partition on Linux.md
@@ -0,0 +1,89 @@
+Linux有问必答 -- 如何在Linux中挂载LVM分区
+================================================================================
+> **提问**: 我有一个USB盘包含了LVM分区。 我想要在Linux中访问这些LVM分区。我该如何在Linux中挂载LVM分区?
+
+】LVM是逻辑卷管理工具,它允许你使用逻辑卷和卷组的概念来管理磁盘空间。使用LVM相比传统分区最大的好处是弹性地位用户和程序分配空间而不用考虑每个物理磁盘的大小。
+
+在LVM中,那些创建了逻辑分区的物理存储是传统的分区(比如:/dev/sda2,/dev/sdb1)。这些分区必须被初始化位“物理卷”并被标签(如,“Linux LVM”)来使它们可以在LVM中使用。一旦分区被标记被LVM分区,你不能直接用mount命令挂载。
+
+如果你尝试挂载一个LVM分区(比如/dev/sdb2), 你会得到下面的错误。
+
+ $ mount /dev/sdb2 /mnt
+
+----------
+
+ mount: unknown filesystem type 'LVM2_member'
+
+
+
+要正确地挂载LVM分区,你必须挂载分区创建的“逻辑分区”。下面就是如何做的。
+
+=首先,用下面的命令检查可用的卷组:
+
+ $ sudo pvs
+
+----------
+
+ PV VG Fmt Attr PSize PFree
+ /dev/sdb2 vg_ezsetupsystem40a8f02fadd0 lvm2 a-- 237.60g 0
+
+
+
+物理卷的名字和卷组的名字分别在PV和VG列的下面。本例中,只有一个创建在dev/sdb2下的组“vg_ezsetupsystem40a8f02fadd0”。
+
+接下来检查卷组中存在的逻辑卷,使用lvdisplay命令:
+
+ $ sudo lvdisplay
+
+使用lvdisplay显示了可用卷的信息(如:设备名、卷名、卷大小等等)。
+
+ $ sudo lvdisplay /dev/vg_ezsetupsystem40a8f02fadd0
+
+----------
+
+ --- Logical volume ---
+ LV Path /dev/vg_ezsetupsystem40a8f02fadd0/lv_root
+ LV Name lv_root
+ VG Name vg_ezsetupsystem40a8f02fadd0
+ LV UUID imygta-P2rv-2SMU-5ugQ-g99D-A0Cb-m31eet
+ LV Write Access read/write
+ LV Creation host, time livecd.centos, 2015-03-16 18:38:18 -0400
+ LV Status available
+ # open 0
+ LV Size 50.00 GiB
+ Current LE 12800
+ Segments 1
+ Allocation inherit
+ Read ahead sectors auto
+ - currently set to 256
+ Block device 252:0
+
+
+
+如果你想要挂载一个特定的逻辑卷,使用“LV Path”下面的设备名(如:/dev/vg_ezsetupsystem40a8f02fadd0/lv_home)。
+
+ $ sudo mount /dev/vg_ezsetupsystem40a8f02fadd0/lv_home /mnt
+
+你可以用mount命令不带任何参数检查挂载状态,这会显示所有已挂载的文件系统。
+
+ $ mount
+
+
+
+如果你想在每次启动时自动挂载逻辑卷,在/etc/fstab中添加下面的行,你可以指定卷的文件系统类型(如 ext4),它可以从mount命令的输出中找。
+
+ /dev/vg_ezsetupsystem40a8f02fadd0/lv_home /mnt ext4 defaults 0 0
+
+现在逻辑卷会在每次启动时挂载到/mnt。
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/mount-lvm-partition-linux.html
+
+作者:[Dan Nanni][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ask.xmodulo.com/author/nanni
\ No newline at end of file
diff --git a/translated/tech/20150528 27 'DNF' Fork of Yum Commands for RPM Package Management in Linux.md b/translated/tech/20150528 27 'DNF' Fork of Yum Commands for RPM Package Management in Linux.md
new file mode 100644
index 0000000000..48dd213d68
--- /dev/null
+++ b/translated/tech/20150528 27 'DNF' Fork of Yum Commands for RPM Package Management in Linux.md
@@ -0,0 +1,287 @@
+27��Linux���������������ߡ�DNF����Yum�ķ�֧��������
+================================================================================
+DNF��Dandified YUM�ǻ���RPM�ķ��а����һ���������������ߡ���������Fedora 18�г��֣�������������е�Fedora 22�������[YUM����][1]��
+
+
+
+DNF�����ڸ���YUM��ƿ���������ܡ��ڴ�ռ�á�����������ٶȺ������������档DNFʹ��RPM��libsolv��hawkey����а���������������δԤװ��CentOS��RHEL 7�У���������ͨ��yum��װ����ͬʱʹ�ö��ߡ�
+
+��Ҳ�����Ķ��������DNF����Ϣ��
+
+- [ʹ��DNFȡ��Yum�����ԭ��][2]
+
+���µ�DNF�ȶ��汾��2015��5��11�շ�����1.0����д��ƪ����֮ǰ���������Լ�����DNF֮ǰ�汾����Ҫ��Python��д������GPL v2����֤������
+
+### ��װDNF ###
+
+����Fedora 22�ٷ��Ѿ����ɵ���DNF����DNF������RHEL/CentOS 7��Ĭ�ϲֿ��С�
+
+Ϊ����RHEL/CentOSϵͳ�а�װDNF������Ҫ���Ȱ�װ�Ϳ���epel-release�ֿ⡣
+
+ # yum install epel-release
+ ��
+ # yum install epel-release -y
+
+���ܲ���������ʹ��yumʱ����'-y'ѡ���Ϊ��û��ǿ���ʲô����װ������ϵͳ�С���������Դ˲������⣬��������ʹ��'-y'ѡ�����Զ����İ�װ�������û���Ԥ��
+
+��������ʹ��yum�����epel-realease�ֿⰲװDNF����
+
+ # yum install dnf
+
+����װ��dnf���һ�����չʾ27��ʵ�õ�dnf��������ӣ��Ա����������Ч�Ĺ�������RPM���ķ��а档
+
+### 1. ���DNF�汾 ###
+
+�������ϵͳ�ϰ�װ��DNF�汾��
+
+ # dnf --version
+
+
+
+### 2. �г�������DNF�ֿ� ###
+
+dnf�����е�'repolist'ѡ���ʾ��ϵͳ�����п����IJֿ⡣
+
+ # dnf repolist
+
+
+
+### 3. �г����п����رյ�DNF�ֿ� ###
+
+'repolist all'ѡ���ʾ��ϵͳ�����п���/�رյIJֿ⡣
+
+ # dnf repolist all
+
+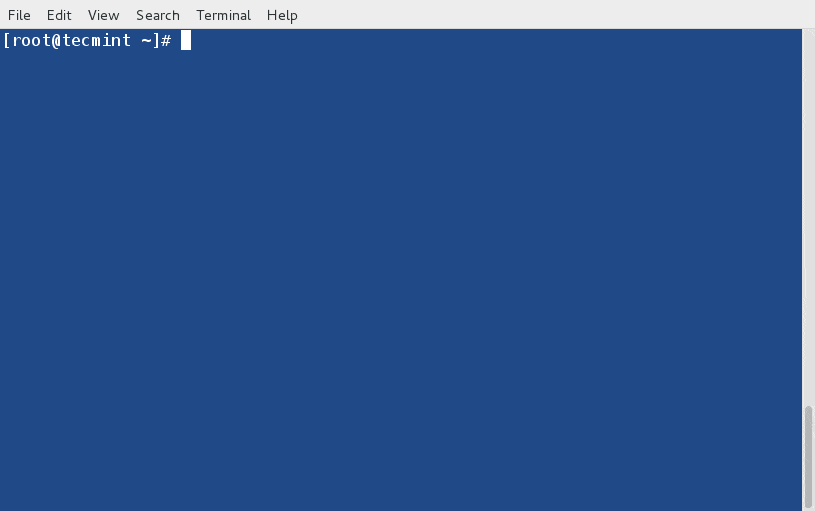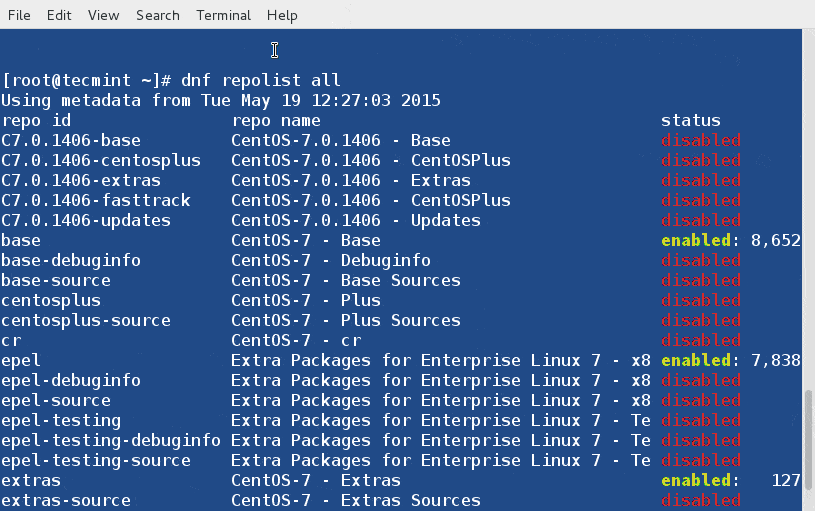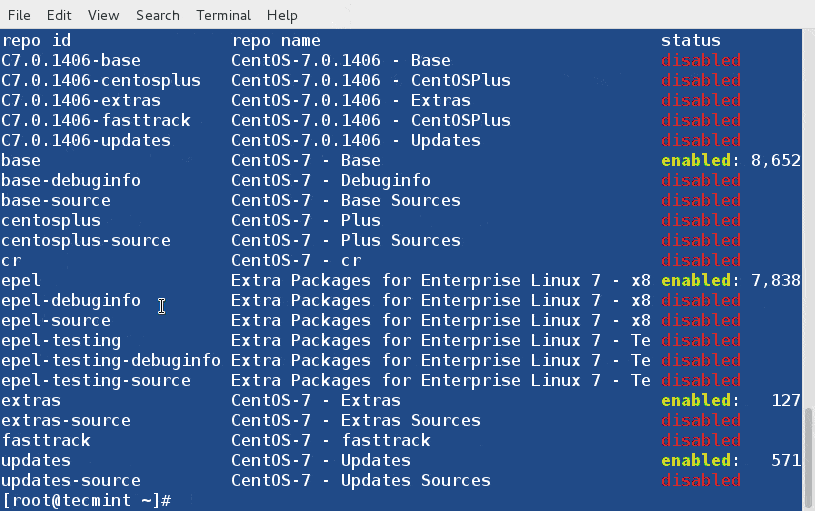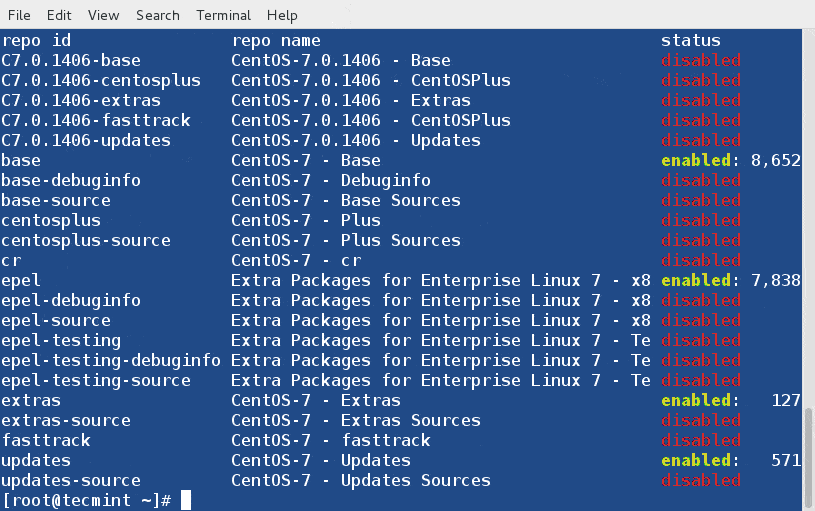
+
+### 4. ��DNF�г����п��õ����Ѱ�װ�������� ###
+
+'dnf list'����г����вֿ������п��õ�����������Linuxϵͳ���Ѱ�װ����������
+
+ # dnf list
+
+
+
+### 5. ��DNF�г������Ѱ�װ�������� ###
+
+����'dnf list'����г����вֿ������п��õ����������Ѱ�װ����������Ȼ��������һ��ʹ��'list installed'ѡ�ֻ�г��Ѱ�װ����������
+
+ # dnf list installed
+
+
+
+### 6. ��DNF�г����п��õ������� ###
+
+���Ƶģ�������'list available'ѡ���г����п����IJֿ������п��õ���������
+
+ # dnf list available
+
+
+
+### 7. ʹ��DNF���������� ###
+
+�������̫������밲װ�������������֣���������£�������ʹ��'search'ѡ��������ƥ����ַ������磬nano�����ַ�������������
+
+ # dnf search nano
+
+
+
+### 8. �鿴�ĸ��������ṩ��ij���ļ�/�������������� ###
+
+dnf��ѡ��'provides'�ܲ����ṩ��ij���ļ�/�����������������������磬������������Ǹ��������ṩ����ϵͳ�е�'/bin/bash'�ļ�������ʹ�����������
+
+ # dnf provides /bin/bash
+
+
+
+### 9. ʹ��DNF���һ������������ϸ��Ϣ ###
+
+��������ڰ�װһ��������ǰ֪��������ϸ��Ϣ��������ʹ��'info'�����һ������������ϸ��Ϣ�����磺
+
+ # dnf info nano
+
+
+
+### 10. ʹ��DNF��װ������ ###
+
+�밲װһ����nano����������ֻ������������������Ϊnano�Զ��Ľ���Ͱ�װ���е�������
+
+ # dnf install nano
+
+
+
+### 11. ʹ��DNF����һ�������� ###
+
+������ֻ�����һ���ض��İ������磬systemd�����ұ���ϵͳ��ʣ�����������䡣
+
+ # dnf update systemd
+
+
+
+### 12. ʹ��DNF���ϵͳ���� ###
+
+���ϵͳ�а�װ�������������ĸ��¿��Լ�ʹ��dnf���У�
+
+ # dnf check-update
+
+
+
+### 13. ʹ��DNF��װϵͳ�����е������� ###
+
+������ʹ���������������������ϵͳ�������Ѱ�װ����������
+
+ # dnf update
+ ��
+ # dnf upgrade
+
+
+
+### 14. ʹ��DNF���Ƴ�/ɾ��һ�������� ###
+
+��������dnf������ʹ��'remove'��'erase'ѡ�����Ƴ��κβ���Ҫ����������
+
+ # dnf remove nano
+ ��
+ # dnf erase nano
+
+
+
+### 15. ʹ��DNF�Ƴ����������õ���������Orphan Packages�� ###
+
+��ЩΪ������������װ������������Ӧ�ij���ɾ����㲻����Ҫ�ˡ������ù������������������ɾ����
+
+ # dnf autoremove
+
+
+
+### 16. ʹ��DNF�Ƴ������������ ###
+
+������ʹ��dnfʱ�������������ڵ�ͷ���Ͳ��������������ǻᵼ�´������ǿ���ʹ��������������������������Ͱ���Զ�̰���Ϣ��ͷ����
+
+ # dnf clean all
+
+
+
+### 17. ����ض�DNF����İ��� ###
+
+��������Ҫ�ض���DNF����İ��������磬clean��������ͨ��������������õ���
+
+ # dnf help clean
+
+
+
+### 18. �г�����DNF�������ѡ�� ###
+
+Ҫ��ʾ����dnf�������ѡ�ֻ��Ҫ��
+
+ # dnf help
+
+
+
+### 19. �鿴DNF����ʷ��¼ ###
+
+�����Ե���'dnf history'���鿴�Ѿ�ִ�й���dnf������б��������������֪��ʲô����װ/�Ƴ��Լ�ʱ�����
+
+ # dnf history
+
+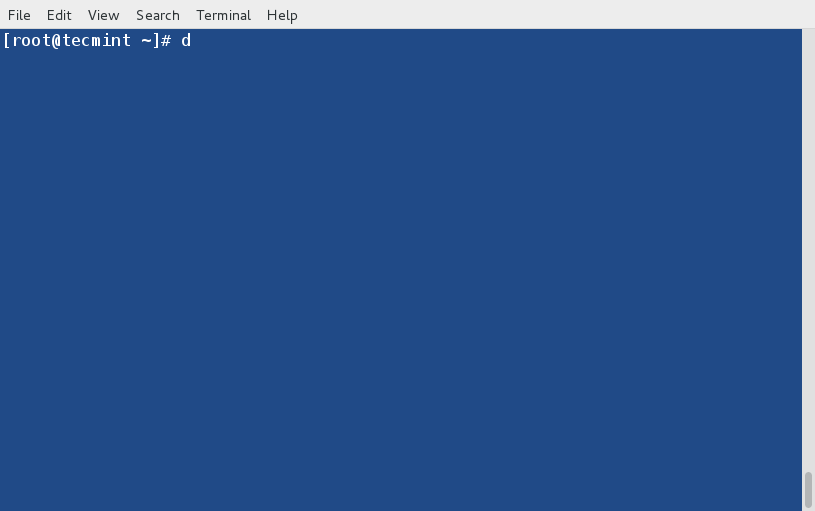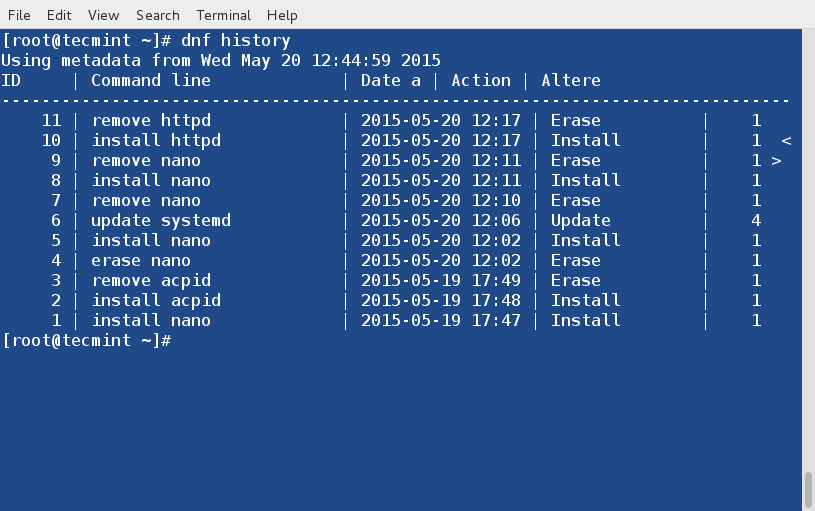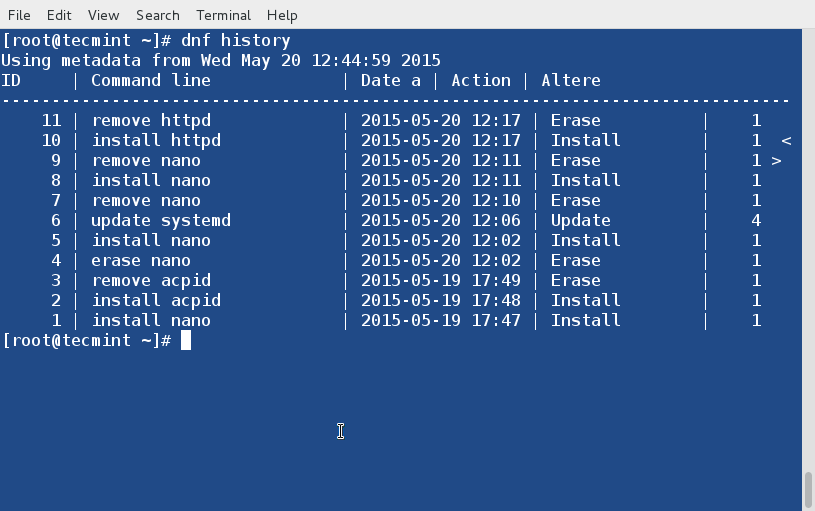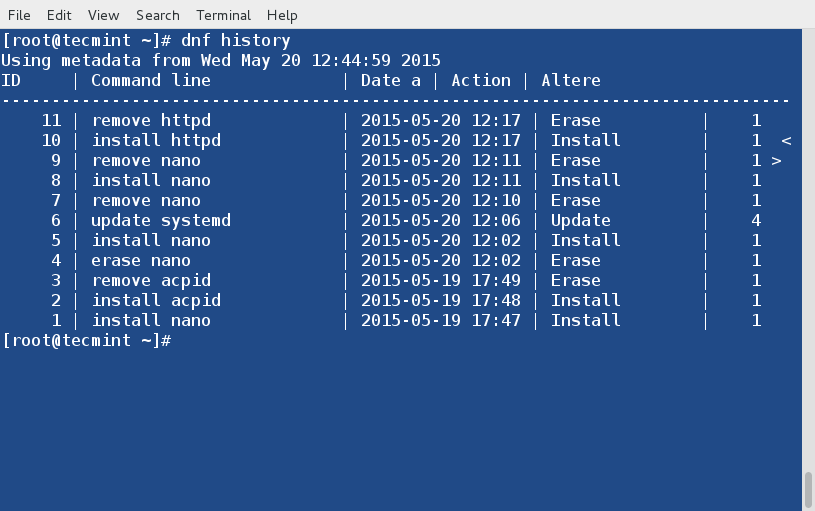
+
+### 20. ��ʾ������������ ###
+
+'dnf grouplist'������Դ�ӡ���п��õĻ��Ѱ�װ�������������û��ʲô������������г�������֪���������顣
+
+ # dnf grouplist
+
+
+
+### 21. ʹ��DNF��װһ���������� ###
+
+Ҫ��װһ�����������������һ����������飨���磬Educational Softaware����ֻ��Ҫִ�У�
+
+ # dnf groupinstall 'Educational Software'
+
+
+
+### 22. ����һ���������� ###
+
+����ͨ�����������������һ���������飨���磬Educational Software����
+
+ # dnf groupupdate 'Educational Software'
+
+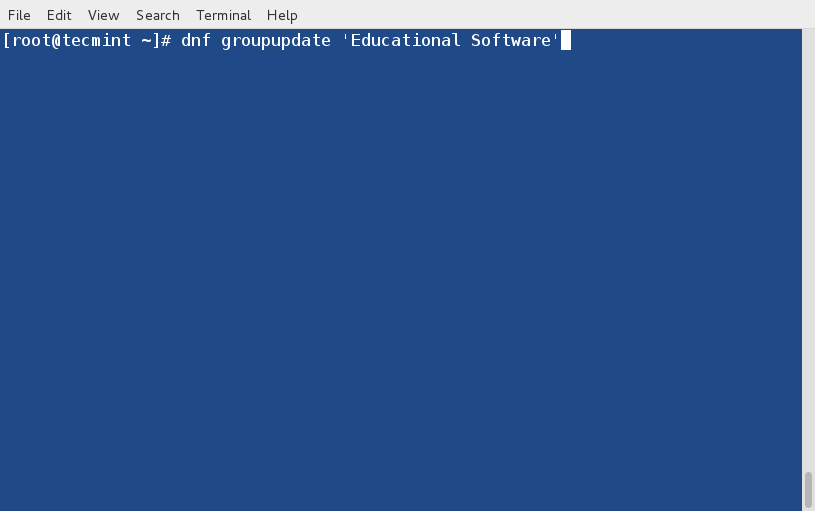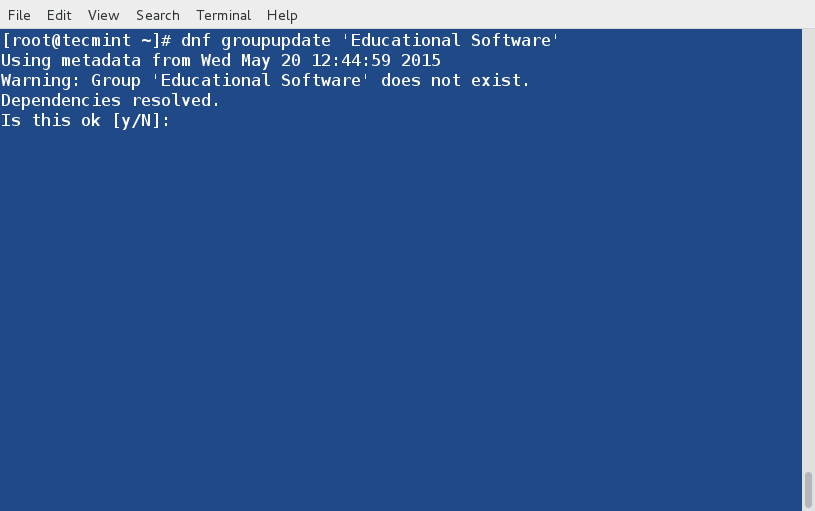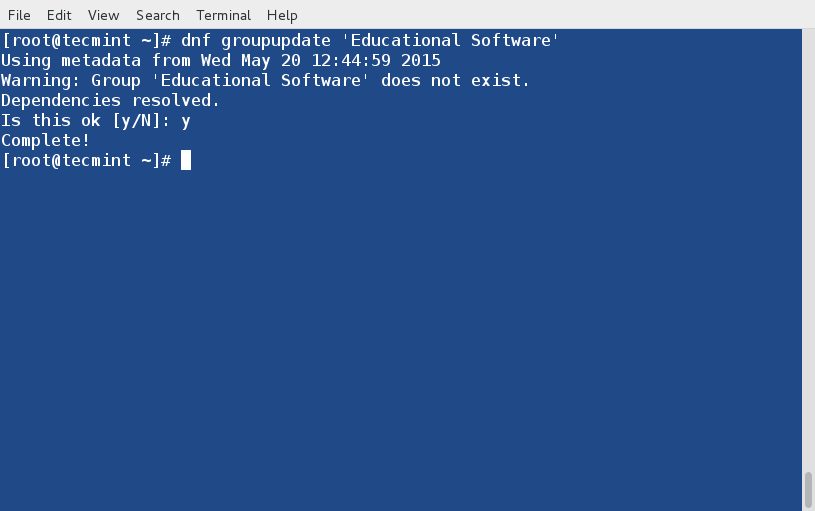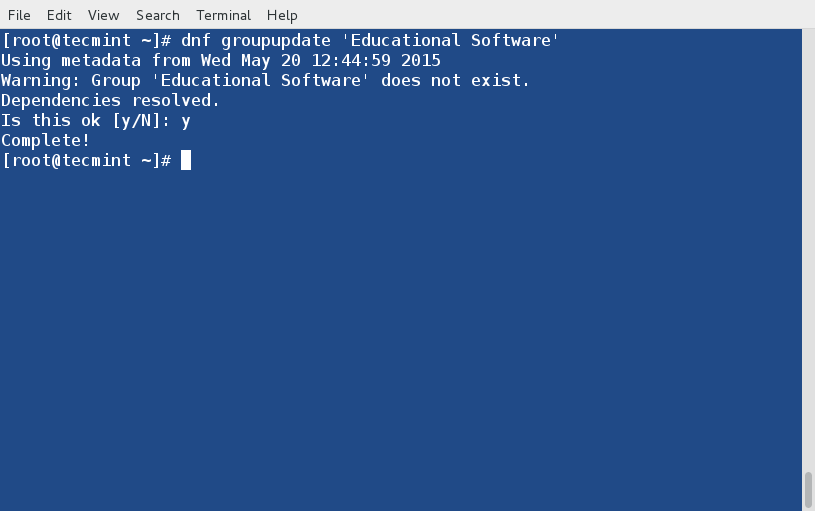
+
+### 23. �Ƴ�һ���������� ###
+
+����ʹ��������������Ƴ�һ���������飨���磬Educational Software����
+
+ # dnf groupremove 'Educational Software'
+
+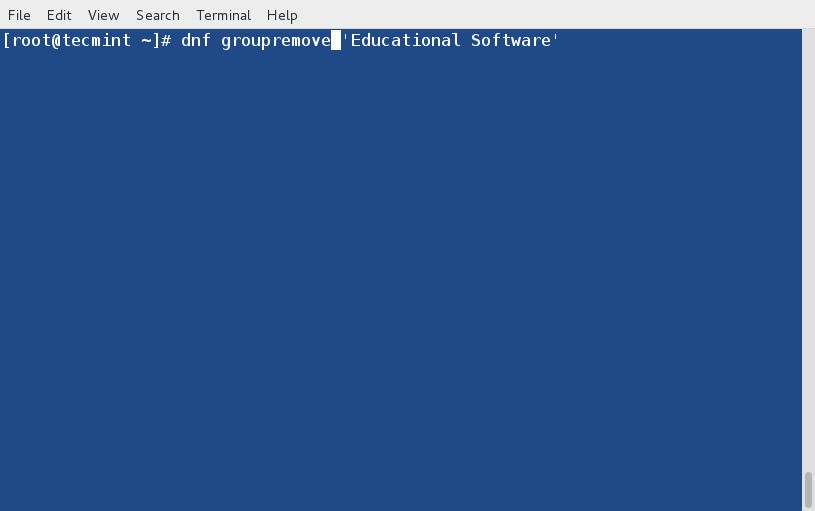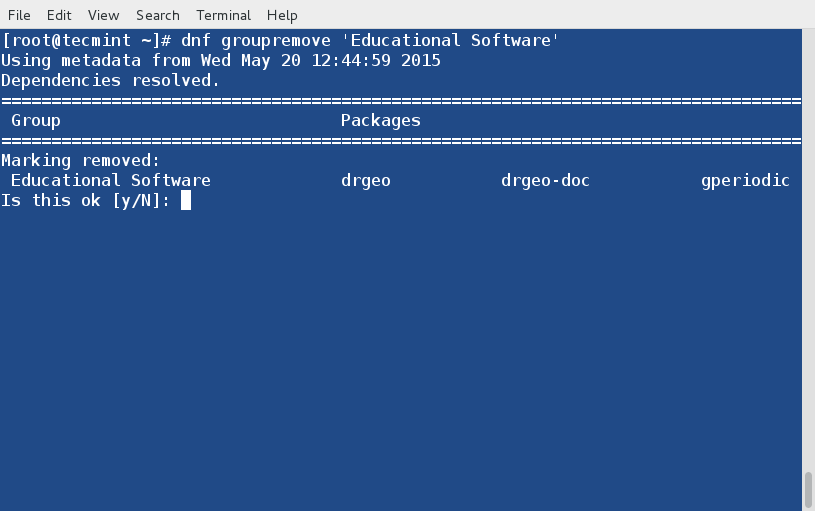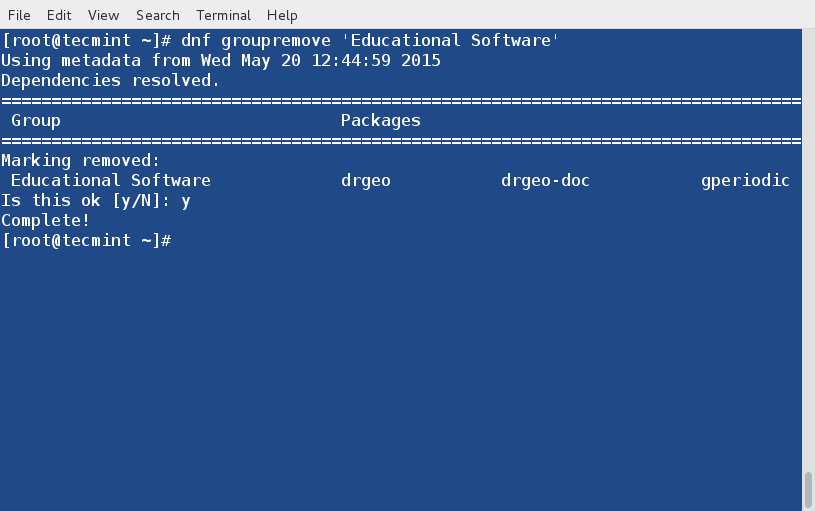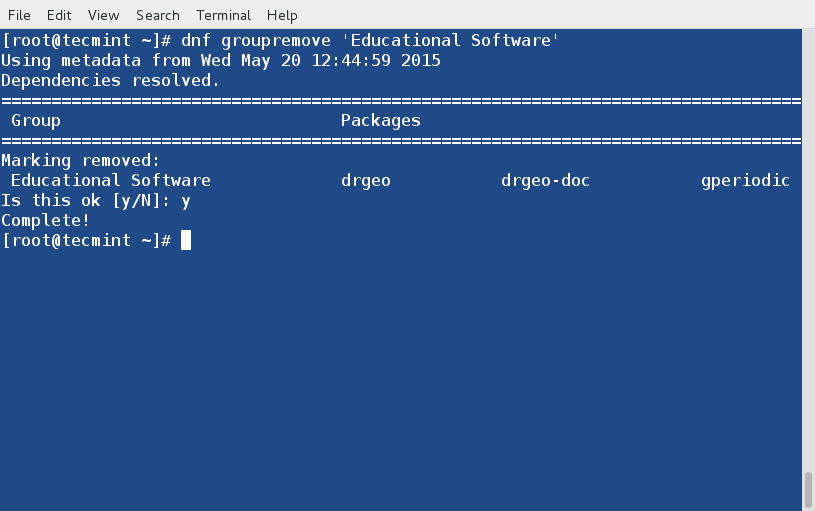
+
+### 24. ��ij���ض��IJֿⰲװһ�������� ###
+
+DNF���Դ��κ��ض��IJֿⰲװһ�������������磬phpmyadmin����
+
+ # dnf --enablerepo=epel install phpmyadmin
+
+
+
+### 25. ���Ѱ�װ��������ͬ�����ȶ����а� ###
+
+'dnf distro-sync'��ͬ�������Ѱ�װ�������������п����IJֿ���������ȶ��汾�����û����������ѡ�����ͬ�������Ѱ�װ����������
+
+ # dnf distro-sync
+
+
+
+### 26. ���°�װһ�������� ###
+
+'dnf reinstall nano'������°�װһ���Ѿ���װ�������������磬nano����
+
+ # dnf reinstall nano
+
+
+
+### 27. ����һ�������� ###
+
+ѡ��'downgrade'����ʹһ�������������磬acpid�����˵��Ͱ汾��
+
+ # dnf downgrade acpid
+
+ʾ�����
+
+ Using metadata from Wed May 20 12:44:59 2015
+ No match for available package: acpid-2.0.19-5.el7.x86_64
+ Error: Nothing to do.
+
+**�ҵĹ۲�**��dnf���ᰴԤ�����������һ����������������Ϊһ��bug���ύ��
+
+### ���� ###
+
+DNF��YUM���������������Ʒ�����������Զ��������о����Linuxϵͳ����Ա���������Ĺ��������磺
+
+- `--skip-broken`����DNFʶ�𣬲���DNF��û����������
+- ���������ܻ�����dnf provides������Ҳû��'resolvedep'�����ˡ�
+- û��'deplist'������������������������
+- ���ų�һ���ֿ���ζ�������в������ų��òֿ⣬����yum�У��ų�һ���ֿ�ֻ�ڰ�װ��������ʱ���ų����ǡ�
+
+����Linux�û�����Linux��̬ϵͳ�����������⡣����[Systemd�滻��init system][3]v������DNF���ڲ��ú��滻YUM��������Fedora 22����������RHEL��CentOS��
+
+����ô���أ��Dz��Ƿ��а������Linux��̬ϵͳ����ע���û������ڳ������û�Ը����㣵ķ���ǰ���أ�IT��ҵ��������һ�仰 - �����û�л���ΪʲôҪ���أ�����System V��YUM��û�л���
+
+���������ƪ���µ�ȫ���ˡ������·������������˽����ı����뷨�����ͷ����������Ǵ�����лл��
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
+
+���ߣ�[Avishek Kumar][a]
+���ߣ�[wwy-hust](https://github.com/wwy-hust)
+У�ԣ�[У����ID](https://github.com/У����ID)
+
+������ [LCTT](https://github.com/LCTT/TranslateProject) ԭ�����룬[Linux�й�](https://linux.cn/) �����Ƴ�
+
+[a]:http://www.tecmint.com/author/avishek/
+[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
+[2]:http://www.tecmint.com/dnf-next-generation-package-management-utility-for-linux/
+[3]:http://www.tecmint.com/systemd-replaces-init-in-linux/
diff --git a/translated/tech/20150528 Things To Do After Installing Fedora 22.md b/translated/tech/20150528 Things To Do After Installing Fedora 22.md
new file mode 100644
index 0000000000..172c7612ae
--- /dev/null
+++ b/translated/tech/20150528 Things To Do After Installing Fedora 22.md
@@ -0,0 +1,113 @@
+安装Fedora 22后要做的事
+================================================================================
+Fedora 22,Red Hat操作系统的社区开发版的最新成员,已经于2015年5月26日发布了。这个令人神圣的Fedora发行版充斥着各种炒作和预期,Fedora 22推出了大量的重大变化。
+
+就初始化进程而言,Systemd还是个新生儿,但它已经准备好替换脆弱的sysvinit这个一直是Linux生态系统一部分的模块。另外一个用户会碰到的重大改变存在于基本仓库的python版本中,这里提供了两种不同口味的python版本2.x和3.x分线,各个都有其不同的癖好和优点。所以,那些偏好2.x口味的用户可能想要安装他们喜爱的python版本。自从Fedora 18开始被打扮得更加时髦的Yum安装器也被设置来替换过时陈旧的YUM安装器后。Fedora也已最后决定,现在是时候用DNF来替换YUM了。
+### 1) 安装VLC媒体播放器 ###
+
+Fedora 22默认自带了媒体播放器viz gnome视频播放器(前身是totem)。如果你对此不感冒,那么我们可以跳过这一步继续往前走。但是,如果你像我一样,偏好使用最广泛的VLC,那么就去从RPMFusion仓库安装吧。安装方法如下:
+
+ sudo dnf install vlc -y
+
+### 2) 配置RPMFusion仓库 ###
+
+正如我已经提到过的,Fedora的意识形态很是严谨,它不会自带任何非自由组件。官方仓库不会提供一些包含有非自由组件的基本软件,比如像多媒体编码。因此,安装一些第三方仓库很有必要,这些仓库会为我们提供一些基本的软件。幸运的是,RPMFusion仓库前来拯救我们了。
+
+ $ sudo dnf install --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-22.noarch.rpm
+
+### 3) 安装多媒体编码 ###
+
+刚刚我们说过,一些多媒体编码和插件不会随Fedora一起发送。现在,有谁想仅仅是因为专有编码而错过他们最爱的节目和电影?试试这个吧:
+
+ $ sudo dnf install gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-ugly gstreamer-ffmpeg gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer-plugins-base-tools gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-good gstreamer1-plugins-base gstreamer1
+
+### 4) 更新系统 ###
+
+Fedora是一个尖端的发行版,因此它会持续发布更新用以修复系统中出现的错误和漏洞。因而,保持系统更新到最新,是个不错的做法。
+
+ $ sudo dnf update -y
+
+### 5) 卸载你不需要的软件 ###
+
+Fedora预装了一些大多数用户可以利用的包,但是对于更高级的用户,你可能意识到你并不需要它。要移除你不需要的包相当容易,只需使用以下命令——我选择卸载rhythmbox,因为我知道我不会用到它:
+
+ $ sudo dnf remove rhythmbox
+
+### 6) 安装Adobe Flash ###
+
+我们都希望Adobe Flash不要再存在了,因为它并不被认为是最安全的,或者资源利用最好的,但是暂时先让它待着吧。Fedora 22安装Adobe Flash的唯一途径是从Adobe安装官方RPM,就像下面这样。
+
+你可以从[这里][1]下载RPM。下载完后,你可以直接右击并像下面这样打开:
+
+
+
+右击并选择“用软件安装打开”
+
+然后,只需在弹出窗口中点击安装:
+
+
+
+点击“安装”来完成从Adobe安装自定义RPM的过程
+
+该过程完成后,“安装”按钮会变成“移除”,而此时安装也完成了。如果在此过程中你的浏览器开着,会提示你先把它关掉或在安装完成后重启以使修改生效。
+
+### 7) 用Gnome Boxes加速虚拟机 ###
+
+你刚刚安装了Fedora,你也很是喜欢,但是出于某些私人原因,你也许仍然需要Windows,或者你只是想玩玩另外一个Linux发行版。不管哪种情况,你都可以使用Gnome Boxes来简单地创建一个虚拟机或使用一个live发行版,Fedora 22提供了该软件。遵循以下步骤,使用你所选的ISO来开始吧!谁知道呢,也许你可以检验一下某个[Fedora Spin][2]。
+
+首先,打开Gnome Boxes,然后在顶部左边选择“新建”:
+
+
+
+点击“新建”来开始添加一个新虚拟机的进程吧。
+
+接下来,点击打开文件并选择一个ISO:
+
+
+
+在选择选择了选择文件或ISO后,选择你的ISO。这里,我已经安装了一个Debian ISO。
+
+最后,自定义VM设置或使用默认,然后点击“创建”。VM会以默认方式启动,可用的VM会在Gnome Boxes以小缩略图的方式显示。
+
+
+
+自定义设置为你所选择的,或者也可以保持默认。完成后,点击“创建”,VM就一切就绪了。
+
+### 8) 安装Google Chrome ###
+
+Firefox被包含在Fedora 22中,但是就跟大多数软件一样,每个人都有他们自己的选择。如果你所喜爱的浏览器恰好是Google Chrome,你可以使用和上面安装Adobe Flash Player类似的指令。然而,很明显,你得使用来自Google的任何你所下载的版本的RPM。最新的版本通常可以在[这里][3]找到。
+
+### 9) 添加社交媒体和其它在线帐号 ###
+
+Gnome自带有不错的内建功能用于容纳帐号相关的东西,像Facebook,Google以及其它在线帐号。你可以通过主Gnome设置应用访问在线帐号设置。然后,只需点击在线帐号,并添加你所选择的帐号。如果你要添加一个帐号,比如像Google,你可以用它来作为默认帐号,用来完成诸如发送邮件、日历提醒、相片和文档交互,以及诸如此类的更多事情。
+
+### 10) 安装KDE或另一个桌面环境 ###
+
+我们中的某些人不喜欢Gnome,那也没问题。在终端中运行以下命令来安装KDE所需的一切来替换它。这些指令也可以用以安装xfce、lxde或其它桌面环境。
+
+ $ sudo dnf install @kde-desktop
+
+安装完成后,登出。当你点击你的用户名时,注意那个表示设置的小齿轮。点击它,然后选择“Plasma”。当你再次登录时,一个全新的KDE桌面就会欢迎你。
+
+
+
+刚刚安装到Fedora 22上的Plasma环境
+
+### 尾声 ###
+
+就是这样了,一切就绪。使用新系统吧,试试新东西。如果你找不到与你喜好相关的东西,linux赋予你自由修改它的权利。Fedora自带有最新的Gnome Shell作为其桌面环境,如果你觉得太臃肿而不喜欢,那么试试KDE或一些轻量级的DE,像Cinnamon、xfce之类。愿你的Fedora之旅十分开心并且没有困扰。!!
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-how-to/things-do-after-installing-fedora-22/
+
+作者:[Jonathan DeMasi][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/jonathande/
+[1]:https://get.adobe.com/flashplayer/
+[2]:http://spins.fedoraproject.org/
+[3]:https://www.google.com/intl/en/chrome/browser/desktop/index.html
diff --git a/translated/tech/20150601 How to monitor Linux servers with SNMP and Cacti.md b/translated/tech/20150601 How to monitor Linux servers with SNMP and Cacti.md
new file mode 100644
index 0000000000..cc76945bd8
--- /dev/null
+++ b/translated/tech/20150601 How to monitor Linux servers with SNMP and Cacti.md
@@ -0,0 +1,181 @@
+使用SNMP和Cacti监控Linux服务器
+================================================================================
+SNMP(或者叫简单网络管理协议)用于收集设备内部发生的数据,如负载、磁盘状态、带宽之类。像Cacti这样的网络监控工具用这些数据来生成图标以达到监控的目的。
+
+在一个典型的Cacti和SNMP部署中,会有一台或多台启用了SNMP的设备,以及一台独立的用来从那些设备收集SNMP回馈的监控服务器。请记住,所有需要监控的设备必须启用SNMP。在本教程中,出于演示目的,我们将在同一台Linux服务器上配置Cacti和SNMP。
+
+### 在Debian或Ubuntu上配置SNMP ###
+
+要安装SNMP代理(snmpd)到基于Debian的系统,请运行以下命令:
+
+ root@server:~# apt-get install snmpd
+
+然后,如下编辑配置文件。
+
+ root@server:~# vim /etc/snmp/snmpd.conf
+
+----------
+
+ # this will make snmpd listen on all interfaces
+ agentAddress udp:161
+
+ # a read only community 'myCommunity' and the source network is defined
+ rocommunity myCommunity 172.17.1.0/24
+
+ sysLocation Earth
+ sysContact email@domain.tld
+
+在编辑完配置文件后,重启snmpd。
+
+ root@server:~# service snmpd restart
+
+### 在CentOS或RHEL上配置SNMP ###
+
+要安装SNMP工具和库,请运行以下命令。
+
+ root@server:~# sudo yum install net-snmp
+
+然后,如下编辑SNMP配置文件。
+
+ root@server:~# vim /etc/snmp/snmpd.conf
+
+----------
+
+ # A user 'myUser' is being defined with the community string 'myCommunity' and source network 172.17.1.0/24
+ com2sec myUser 172.17.1.0/24 myCommunity
+
+ # myUser is added into the group 'myGroup' and the permission of the group is defined
+ group myGroup v1 myUser
+ group myGroup v2c myUser
+ view all included .1
+ access myGroup "" any noauth exact all all none
+
+----------
+
+ root@server:~# service snmpd restart
+ root@server:~# chkconfig snmpd on
+
+重启snmpd服务,然后添加到启动服务列表。
+
+### 测试SNMP ###
+
+SNMP可以通过运行snmpwalk命令进行测试。如果SNMP已经配置成功,该命令会生成大量输出。
+
+ root@server:~# snmpwalk -c myCommunity 172.17.1.44 -v1
+
+----------
+
+ iso.3.6.1.2.1.1.1.0 = STRING: "Linux mrtg 3.5.0-17-generic #28-Ubuntu SMP Tue Oct 9 19:31:23 UTC 2012 x86_64"
+ iso.3.6.1.2.1.1.2.0 = OID: iso.3.6.1.4.1.8072.3.2.10
+ iso.3.6.1.2.1.1.3.0 = Timeticks: (2097) 0:00:20.97
+
+ ~~ OUTPUT TRUNCATED ~~
+
+ iso.3.6.1.2.1.92.1.1.2.0 = Gauge32: 1440
+ iso.3.6.1.2.1.92.1.2.1.0 = Counter32: 1
+ iso.3.6.1.2.1.92.1.2.2.0 = Counter32: 0
+ iso.3.6.1.2.1.92.1.3.1.1.2.7.100.101.102.97.117.108.116.1 = Timeticks: (1) 0:00:00.01
+ iso.3.6.1.2.1.92.1.3.1.1.3.7.100.101.102.97.117.108.116.1 = Hex-STRING: 07 DD 0B 12 00 39 27 00 2B 06 00
+
+### 配置带有SNMP的Cacti ###
+
+在本教程中,我们将在同一台Linux服务器上设置Cacti和SNMP。所以,去[安装Cacti][2]到刚刚配置SNMP的Linux服务器上吧。
+
+安装完后,Cacti网页接口可以通过“http://172.17.1.44/cacti”来访问,当然,在你的环境中,请将IP地址换成你的服务器的地址。
+
+
+
+
+
+安装过程中Cacti的路径一般都是正确的,但是如有必要,请再次检查以下。
+
+
+
+在首次安装过程中,Cacti默认的用户名和密码是“admin”和“admin”。在首次登录后会强制你修改密码。
+
+
+
+### 添加设备到Cacti并管理 ###
+
+Cacti将根据先前配置的SNMP字符串注册设备。在本教程中,我们将只添加启用了SNMP的本地服务器。
+
+要添加设备,我们必须以管理员登录,然后转到Cacti管理员面板中的控制台。点击控制台 > 设备。
+
+
+
+那里可能已经有一个名为‘localhost’的设备。我们不需要它,因为我们要创建全新的图表。我们可以将该设备从列表中删除,使用“添加”按钮来添加新设备。
+
+
+
+接下来,我们设置设备参数。
+
+
+
+由于设备已经添加,我们来指定想要创建的图表模板。你可以在该页的最后章节中找到本节内容。
+
+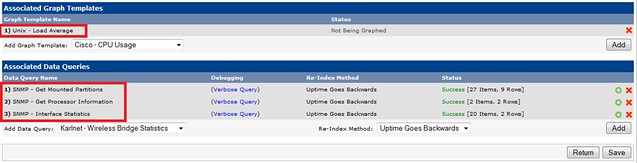
+
+然后,我们继续来创建图表。
+
+
+
+这里,我们创建用于平均负载、RAM和硬盘、处理器的图表。
+
+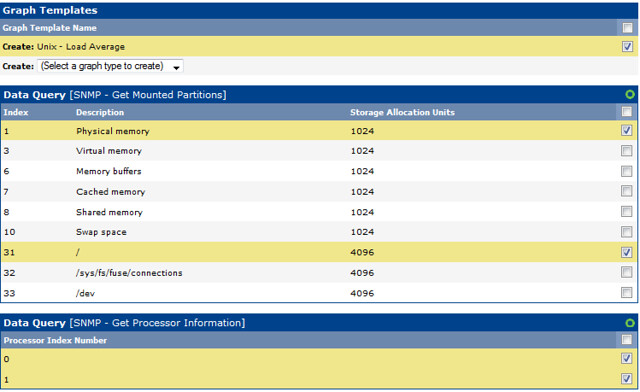
+
+### 接口图表和64位计数器 ###
+
+默认情况下,Cacti在SNMP查询中使用32位计数器。32位计数器对于大多数带宽图表而言已经足够了,但是对于超过100Mbps的带宽,它就无能为力了。如果已经知道带宽会超过100Mbps,建议你使用64位计数器。使用64位计数器一点也不麻烦。
+
+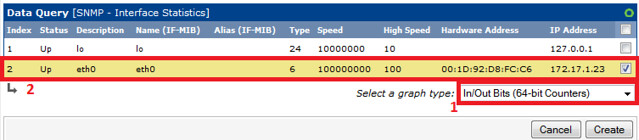
+
+**注意**: Cacti会花费大约15分钟来产生新图表,除了耐心等待,你别无选择。
+
+### 创建图表树 ###
+
+这些截图展示了如何创建图表树,以及如何添加图表到这些树中。
+
+
+
+
+
+
+
+
+
+我们可以验证图表树中的图表。
+
+
+
+### 用户管理 ###
+
+最后,我们创建一个只具有查看我们刚创建的图表权限的用户。Cacti内建了用户管理系统,而且是高度可定制的。
+
+
+
+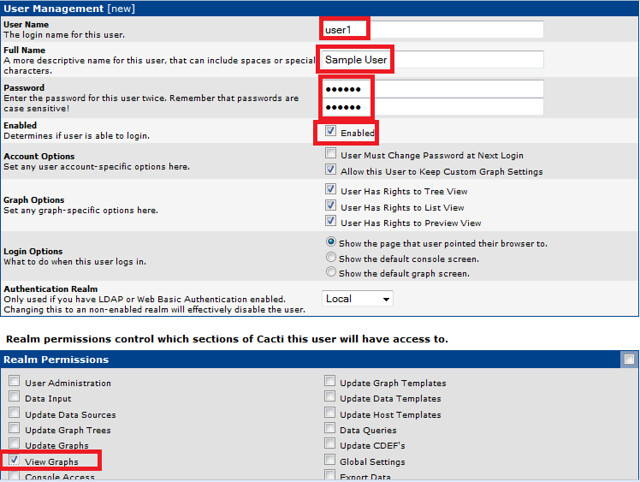
+
+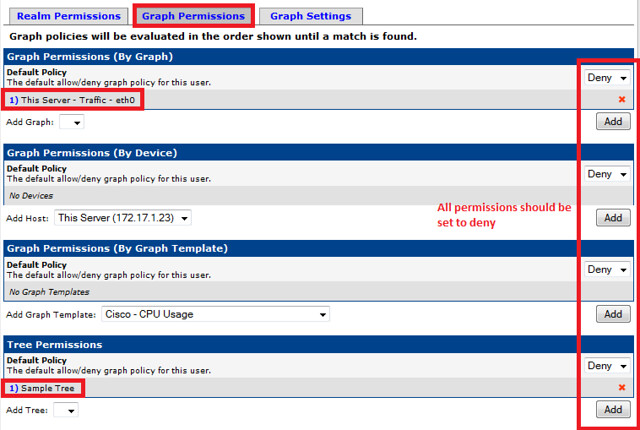
+
+在完成这些步骤后,我们可以使用‘user1’来登录进去,并验证只有该用户可以查看该图表。
+
+
+
+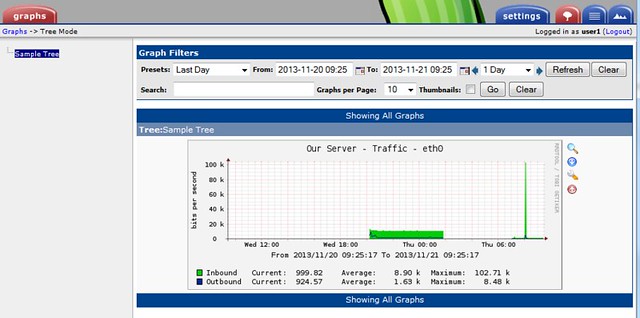
+
+至此,我们在网络监控系统中部署了一台Cacti服务器。Cacti服务器比较稳定,可以处理大量图表而不会出问题。
+
+希望本文对你有所帮助。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/monitor-linux-servers-snmp-cacti.html
+
+作者:[Sarmed Rahman][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://xmodulo.com/install-configure-cacti-linux.html
diff --git a/translated/tech/20150601 How to monitor common services with Nagios.md b/translated/tech/20150601 How to monitor common services with Nagios.md
new file mode 100644
index 0000000000..2898a57ad0
--- /dev/null
+++ b/translated/tech/20150601 How to monitor common services with Nagios.md
@@ -0,0 +1,269 @@
+如何用Nagios监控服务
+================================================================================
+Nagios内置了很多脚本来监控服务。本篇会使用其中一些来检查通用服务如MySql、Apache、DNS等等。
+
+为了保证本篇集中在系统监控,我们不会配置hostgroup或者模板,它们已经在 [前面的教程][1]中覆盖了,它们可以满足这些条件了。
+
+### 在命令行中运行Nagios ###
+
+通常建议在添加到Nagios前现在命令行中运行Nagios服务检测脚本。它会给出执行是否成功以及脚本的输出将会看上去的样子。
+
+这些脚本存储在 /etc/nagios-plugins/config/ ,可执行文件在 /usr/lib/nagios/plugins/。
+
+下面就是该怎么做
+
+ root@nagios:~# cd /etc/nagios-plugins/config/
+
+提供的脚本包含了语法帮助。示例包含了部分输出。
+
+ root@nagios:~# cat /etc/nagios-plugins/config/tcp_udp.cfg
+
+----------
+
+ # 'check_tcp' command definition
+ define command{
+ command_name check_tcp
+ command_line /usr/lib/nagios/plugins/check_tcp -H '$HOSTADDRESS$' -p '$ARG1$'
+
+了解了语法,TCP 80端口可以用下面的方法检查。
+
+ root@nagios:~# /usr/lib/nagios/plugins/check_tcp -H 10.10.10.1 -p 80
+
+----------
+
+ TCP OK - 0.000 second response time on port 80|time=0.000222s;;;0.000000;10.000000
+
+### 示例拓扑 ###
+
+本片中使用下面三台服务器。每台服务器运行多个通用服务。Nagios服务器现在运行的是Ubuntu。
+
+- Server 1 (10.10.10.1) : MySQL, Apache2
+- Server 2 (10.10.10.2) : Postfix, Apache2
+- Server 3 (10.10.10.3): DNS
+
+首先,服务器被定义在了Nagios中。
+
+ root@nagios:~# vim /etc/nagios3/conf.d/example.cfg
+
+----------
+
+ define host{
+ use generic-host
+ host_name test-server-1
+ alias test-server-1
+ address 10.10.10.1
+ }
+
+ define host{
+ use generic-host
+ host_name test-server-2
+ alias test-server-2
+ address 10.10.10.2
+ }
+
+ define host{
+ use generic-host
+ host_name test-server-3
+ alias test-server-3
+ address 10.10.10.3
+ }
+
+### 监控MySQL服务 ###
+
+#### MySQL 监控需要 ####
+
+- 通过检查3306端口来检测MySQL是否运行中。
+- 检测特定的数据库'testDB'是否可用。
+
+#### MySQL 服务器设置 ####
+
+开始检测MySQL时,需要记住MySQL默认只监听回环接口127.0.0.1。这增加了数据库的安全。手动调节需要告诉MySQL该监听什么其他接口。下面是该怎么做。
+
+这个设置在所有的MySQL服务器上已经做了。
+
+ root@nagios:~# vim /etc/mysql/my.cnf
+
+下面这行被注释掉了来监听所有接口。
+
+ #bind-address = 127.0.0.1
+
+同样,MySQL将不会运行任何主机来连接到它。在本机和任意主机都创建了用户‘nagios’。这个用户接着在所有的数据库中被授予所有的权限,这将在会用在监控中。
+
+下面的设置对所有的MySQL服务器都已经设置。
+
+ root@nagios:~# mysql -u root –p
+ ## MySQL root password here ##
+
+'nagios@localhost'用户在MySQL服务器中创建了。
+
+ mysql> CREATE USER 'nagios'@'localhost' IDENTIFIED BY 'nagios-pass';
+ mysql> GRANT ALL PRIVILEGES ON *.* TO 'nagios'@'localhost';
+
+'nagios@any-host'用户创建了。
+
+ mysql> CREATE USER 'nagios'@'%' IDENTIFIED BY 'nagios-pass';
+ mysql> GRANT ALL PRIVILEGES ON *.* TO 'nagios'@'%';
+
+ mysql> FLUSH PRIVILEGES;
+
+这使MySQL监听所有的接口,同样接受来自用户'nagios'的进入链接。
+
+请注意,这种变化可能有安全隐患,所以需要说几句话:
+
+- 这个设置将会暴露MySQL给所有的接口,包括WAN。确保只有合法的网络访问是非常重要的。应该使用防火墙和TCP封装器等过滤器。
+- MySQL用户‘nagios’的密码应该非常强。如果只有几台Nagios服务器,那么应该创建'nagios@servername'用户而不是任意用户的'nagios@%'。
+
+#### 对MySQL的NAgios配置 ####
+
+用下面的来做一些调整。
+
+ root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
+
+----------
+
+ define service{
+ use generic-service
+ host_name test-server-1
+ ;hostgroup can be used instead as well
+
+ service_description Check MYSQL via TCP port
+ check_command check_tcp!3306
+ }
+
+ define service{
+ use generic-service
+ host_name test-server-1
+ ;hostgroup can be used instead as well
+
+ service_description Check availability of database 'testDB'
+ check_command check_mysql_database!nagios!nagios-pass!testDB
+ ;check_mysql!userName!userPassword!databaseName
+ }
+
+这样,Nagios就可以同时监控MySQL服务器和数据库的可用性。
+
+### 监控Apache服务器 ###
+
+Nagios同样也可以监控Apache服务。
+
+#### Apache监控需要 ####
+
+- 监控apache是否可用
+
+这个任务非常简单因为Nagios有一个内置命令。
+
+ root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
+
+----------
+
+ define service{
+ use generic-service
+ host_name test-server-1, test-server-2
+ service_description Check Apache Web Server
+ check_command check_http
+ }
+
+现在就非常简单了。
+
+### 监控DNS服务 ###
+
+Nagios通过向DNS服务器查询一个完全合格域名(FQDN),或者使用dig工具来查询。默认用于FQDN的是www.google.com,但是这个可以按需改变。按照下面的文件修改来完成这个任务。
+
+ root@nagios:~# vim /etc/nagios-plugins/config/dns.cfg
+
+----------
+
+ ## The -H portion can be modified to replace Google ##
+ define command{
+ command_name check_dns
+ command_line /usr/lib/nagios/plugins/check_dns -H www.google.com -s '$HOSTADDRESS$'
+ }
+
+编辑下面的行。
+
+ root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
+
+----------
+
+ ## Nagios asks server-3 to resolve the IP for google.com ##
+ define service{
+ use generic-service
+ host_name test-server-3
+ service_description Check DNS
+ check_command check_dns
+ }
+
+ ## Nagios asks server-3 to dig google.com ##
+ define service{
+ use generic-service
+ host_name test-server-3
+ service_description Check DNS via dig
+ check_command check_dig!www.google.com
+ }
+
+### 监控邮件服务器 ###
+
+Nagios可以监控不同的邮件服务组件如SMTP、POP、IMAP和mailq。之前提过,server-2设置了后缀邮件服务。Nagios将被配置来监控SMTP和邮件队列。
+
+
+ root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
+
+----------
+
+ define service{
+ use generic-service
+ host_name test-server-2
+ service_description Check SMTP
+ check_command check_smtp
+ }
+
+ define service{
+ use generic-service
+ host_name test-server-2
+ service_description Check Mail Queue
+ check_command check_mailq_postfix!50!100
+ ;warning at 50, critical at 100
+ }
+
+下面的截屏显示了目前配置监控服务的概览。
+
+
+
+### 基于端口自定义监控程序 ###
+
+让我们假设下面的自定义程序同样运行在网络中,监听一个特定的端口。
+
+- 测试1号服务器:自定义程序(TCP端口 12345)
+
+过一些小的调整,Nagios也可以帮助监控这个程序。
+
+ root@nagios:~# vim /etc/nagios3/conf.d/services_nagios2.cfg
+
+----------
+
+ define service{
+ use generic-service
+ host_name test-server-1
+ service_description Check server 1 custom application
+ check_command check_tcp!12345
+ }
+
+在完结之前,Nagios可以监控网络很多其他的方面。存储在/etc/nagios-plugins/config/中的脚本为Nagios很棒的能力。
+
+
+一些Nagios提供的脚本被限制在本地服务器。例子包含服务负载、进程并发数量、登录用户数量。这些检查可以提供Nagios服务器内有用的信息。
+
+希望这篇有用。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/monitor-common-services-nagios.html
+
+作者:[Sarmed Rahman][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://xmodulo.com/install-configure-nagios-linux.html
\ No newline at end of file
diff --git a/translated/tech/20150602 Howto Configure OpenVPN Server-Client on Ubuntu 15.04.md b/translated/tech/20150602 Howto Configure OpenVPN Server-Client on Ubuntu 15.04.md
new file mode 100644
index 0000000000..5b6c2fc6bd
--- /dev/null
+++ b/translated/tech/20150602 Howto Configure OpenVPN Server-Client on Ubuntu 15.04.md
@@ -0,0 +1,305 @@
+Ubuntu 15.04上配置OpenVPN服务器-客户端
+================================================================================
+虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
+
+
+
+[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
+
+OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
+
+OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
+
+### 服务器端配置 ###
+
+首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
+
+ sudo apt-get install openvpn
+
+然后,我们必须配置一个密钥对,这可以通过默认的“openssl”工具完成。但是,这种方式十分难。这也是我们使用“easy-rsa”来实现此目的的原因。接下来的命令会将“easy-rsa”安装到系统中。
+
+ sudo apt-get unstall easy-rsa
+
+**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
+
+开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
+
+ mkdir /etc/openvpn/easy-rsa
+ cp -r /usr/share/easy-rsa /etc/openvpn/easy-rsa
+ mv /etc/openvpn/easy-rsa/easy-rsa /etc/openvpn/easy-rsa/2.0
+
+然后进入到该目录
+
+ cd /etc/openvpn/easy-rsa/2.0
+
+这里,我们开启了一个密钥生成进程。
+
+首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
+
+ export KEY_COUNTRY="US"
+ export KEY_PROVINCE="CA"
+ export KEY_CITY="SanFrancisco"
+ export KEY_ORG="Fort-Funston"
+ export KEY_EMAIL="my@myhost.mydomain"
+ export KEY_OU=server
+
+希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
+
+其次,我们需要拷贝openssl配置。另外一个版本已经有现成的配置文件,如果你没有特定要求,你可以使用它的上一个版本。这里是1.0.0版本。
+
+ cp openssl-1.0.0.cnf openssl.cnf
+
+第三,我们需要加载环境变量,这些变量已经在前面一步中编辑好了。
+
+ source ./vars
+
+生成密钥的最后一步准备工作是清空旧的证书和密钥,以及生成新密钥的序列号和索引文件。可以通过以下命令完成。
+
+ ./clean-all
+
+现在,我们完成了准备工作,准备好启动生成进程了。让我们先来生成证书。
+
+ ./build-ca
+
+在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
+
+ Generating a 2048 bit RSA private key
+ .............................................+++
+ ...................................................................................................+++
+ writing new private key to 'ca.key'
+ -----
+ You are about to be asked to enter information that will be incorporated
+ into your certificate request.
+ What you are about to enter is what is called a Distinguished Name or a DN.
+ There are quite a few fields but you can leave some blank
+ For some fields there will be a default value,
+ If you enter '.', the field will be left blank.
+ -----
+ Country Name (2 letter code) [US]:
+ State or Province Name (full name) [CA]:
+ Locality Name (eg, city) [SanFrancisco]:
+ Organization Name (eg, company) [Fort-Funston]:
+ Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
+ Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
+ Name [EasyRSA]:
+ Email Address [me@myhost.mydomain]:
+
+接下来,我们需要生成一个服务器密钥
+
+ ./build-key-server server
+
+该命令的对话如下:
+
+ Generating a 2048 bit RSA private key
+ ........................................................................+++
+ ............................+++
+ writing new private key to 'server.key'
+ -----
+ You are about to be asked to enter information that will be incorporated
+ into your certificate request.
+ What you are about to enter is what is called a Distinguished Name or a DN.
+ There are quite a few fields but you can leave some blank
+ For some fields there will be a default value,
+ If you enter '.', the field will be left blank.
+ -----
+ Country Name (2 letter code) [US]:
+ State or Province Name (full name) [CA]:
+ Locality Name (eg, city) [SanFrancisco]:
+ Organization Name (eg, company) [Fort-Funston]:
+ Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
+ Common Name (eg, your name or your server's hostname) [server]:
+ Name [EasyRSA]:
+ Email Address [me@myhost.mydomain]:
+
+ Please enter the following 'extra' attributes
+ to be sent with your certificate request
+ A challenge password []:
+ An optional company name []:
+ Using configuration from /etc/openvpn/easy-rsa/2.0/openssl-1.0.0.cnf
+ Check that the request matches the signature
+ Signature ok
+ The Subject's Distinguished Name is as follows
+ countryName :PRINTABLE:'US'
+ stateOrProvinceName :PRINTABLE:'CA'
+ localityName :PRINTABLE:'SanFrancisco'
+ organizationName :PRINTABLE:'Fort-Funston'
+ organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
+ commonName :PRINTABLE:'server'
+ name :PRINTABLE:'EasyRSA'
+ emailAddress :IA5STRING:'me@myhost.mydomain'
+ Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
+ Sign the certificate? [y/n]:y
+ 1 out of 1 certificate requests certified, commit? [y/n]y
+ Write out database with 1 new entries
+ Data Base Updated
+
+这里,最后两个关于“签署证书”和“提交”的问题,我们必须回答“yes”。
+
+现在,我们已经有了证书和服务器密钥。下一步,就是去省城Diffie-Hellman密钥。执行以下命令,耐心等待。在接下来的几分钟内,我们将看到许多点和加号。
+
+ ./build-dh
+
+该命令的输出样例如下
+
+ Generating DH parameters, 2048 bit long safe prime, generator 2
+ This is going to take a long time
+ ................................+................
+
+在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
+
+ openvpn --genkey --secret keys/ta.key
+
+现在,生成完毕,我们可以移动所有生成的文件到最后的位置中。
+
+ cp -r /etc/openvpn/easy-rsa/2.0/keys/ /etc/openvpn/
+
+最后,我们来创建OpenVPN配置文件。让我们从样例中拷贝过来吧:
+
+ cp /usr/share/doc/openvpn/examples/sample-config-files/server.conf.gz /etc/openvpn/
+ cd /etc/openvpn
+ gunzip -d /etc/openvpn/server.conf.gz
+
+然后编辑
+
+ vim /etc/openvpn/server.conf
+
+我们需要指定密钥的自定义路径
+
+ ca /etc/openvpn/keys/ca.crt
+ cert /etc/openvpn/keys/server.crt
+ key /etc/openvpn/keys/server.key # This file should be kept secret
+ dh /etc/openvpn/keys/dh2048.pem
+
+一切就绪。在重启OpenVPN后,服务器端配置就完成了。
+
+ service openvpn restart
+
+### Unix的客户端配置 ###
+
+假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
+
+ cd /etc/openvpn/easy-rsa/2.0
+
+加载环境变量
+
+ source vars
+
+然后创建客户端密钥
+
+ ./build-key client
+
+我们将看到一个与先前关于服务器密钥生成部分的章节描述一样的对话,填入客户端的实际信息。
+
+如果需要密码保护密钥,你需要运行另外一个命令,命令如下
+
+ ./build-key-pass client
+
+在此种情况下,在建立VPN连接时,会提示你输入密码。
+
+现在,我们需要将以下文件从服务器拷贝到客户端/etc/openvpn/keys/文件夹。
+
+服务器文件列表:
+
+- ca.crt,
+- dh2048.pem,
+- client.crt,
+- client.key,
+- ta.key.
+
+在此之后,我们转到客户端,准备配置文件。配置文件位于/etc/openvpn/client.conf,内容如下
+
+ dev tun
+ proto udp
+
+ # IP and Port of remote host with OpenVPN server
+ remote 111.222.333.444 1194
+
+ resolv-retry infinite
+
+ ca /etc/openvpn/keys/ca.crt
+ cert /etc/openvpn/keys/client.crt
+ key /etc/openvpn/keys/client.key
+ tls-client
+ tls-auth /etc/openvpn/keys/ta.key 1
+ auth SHA1
+ cipher BF-CBC
+ remote-cert-tls server
+ comp-lzo
+ persist-key
+ persist-tun
+
+ status openvpn-status.log
+ log /var/log/openvpn.log
+ verb 3
+ mute 20
+
+在此之后,我们需要重启OpenVPN以接受新配置。
+
+ service openvpn restart
+
+好了,客户端配置完成。
+
+### 安卓客户端配置 ###
+
+安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
+
+- configuration file (.ovpn),
+- ca.crt,
+- dh2048.pem,
+- client.crt,
+- client.key.
+
+客户端密钥生成方式和先前章节所述的一样。
+
+配置文件内容如下
+
+ client tls-client
+ dev tun
+ proto udp
+
+ # IP and Port of remote host with OpenVPN server
+ remote 111.222.333.444 1194
+
+ resolv-retry infinite
+ nobind
+ ca ca.crt
+ cert client.crt
+ key client.key
+ dh dh2048.pem
+ persist-tun
+ persist-key
+
+ verb 3
+ mute 20
+
+所有这些文件我们必须移动我们设备的SD卡上。
+
+然后,我们需要安装[OpenVPN连接][2]。
+
+接下来,配置过程很是简单:
+
+ open setting of OpenVPN and select Import options
+ select Import Profile from SD card option
+ in opened window go to folder with prepared files and select .ovpn file
+ application offered us to create a new profile
+ tap on the Connect button and wait a second
+
+搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
+
+### 尾声 ###
+
+虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15-04/
+
+作者:[Ivan Zabrovskiy][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/ivanz/
+[1]:https://openvpn.net/
+[2]:https://play.google.com/store/apps/details?id=net.openvpn.openvpn
diff --git a/translated/tech/20150603 Installing Ruby on Rails using rbenv on Ubuntu 15.04.md b/translated/tech/20150603 Installing Ruby on Rails using rbenv on Ubuntu 15.04.md
new file mode 100644
index 0000000000..65ff38744e
--- /dev/null
+++ b/translated/tech/20150603 Installing Ruby on Rails using rbenv on Ubuntu 15.04.md
@@ -0,0 +1,151 @@
+在Ubuntu 15.04中安装RUby on Rails
+================================================================================
+本篇我们会学习如何用rbenv在Ubuntu 15.04中安装Ruby on Rails。我们选择Ubuntu作为操作系统因为Ubuntu是Linux发行版中自带很多包和完整文档的操作系统,因此我认为这是正确的选择。如果你不想安装最新的Ubuntu,你可以从[下载iso文件][1]开始。
+
+### 安装 Ruby ###
+
+我们要做的第一件事是更新Ubuntu包并且为Ruby安装一些依赖。
+
+ sudo apt-get update
+ sudo apt-get install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev python-software-properties libffi-dev
+
+有三种方法来安装Ruby比如rbenv,rvm和从源码安装。每种都有各自的好处,但是这些天开发者们更倾向使用rbenv而不是rvm和源码来安装。我们将安装最新的Ruby版本,2.2.2。
+
+用rbenv来安装只有简单的两步。第一步安装rbenv接着是ruby-build:
+
+ cd
+ git clone git://github.com/sstephenson/rbenv.git .rbenv
+ echo 'eval "$(rbenv init -)"' >> ~/.bashrc
+ exec $SHELL
+
+ git clone git://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build
+ echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc
+ exec $SHELL
+
+ git clone https://github.com/sstephenson/rbenv-gem-rehash.git ~/.rbenv/plugins/rbenv-gem-rehash
+
+ rbenv install 2.2.2
+ rbenv global 2.2.2
+ ruby -v
+
+我们需要安装Bundler但是我们要在安装之前告诉rubygems不要为每个包本地安装文档。
+
+ echo "gem: --no-ri --no-rdoc" > ~/.gemrc
+ gem install bundler
+
+### 配置 GIT ###
+
+配置git之前,你要创建一个github账号,你可以注册[git][2]。我们需要git作为版本控制系统,因此我们要设置来匹配github账号。
+
+用户的github账号来代替下面的**Name** 和 **Email address** 。
+
+ git config --global color.ui true
+ git config --global user.name "YOUR NAME"
+ git config --global user.email "YOUR@EMAIL.com"
+ ssh-keygen -t rsa -C "YOUR@EMAIL.com"
+
+接下来用新生成的ssh key添加到github账号中。这样你需要复制下面命令的输出并[粘贴在这][3]。
+
+ cat ~/.ssh/id_rsa.pub
+
+如果你做完了,检查是否已经成功。
+
+ ssh -T git@github.com
+
+你应该得到下面这样的信息。
+
+ Hi excid3! You've successfully authenticated, but GitHub does not provide shell access.
+
+### 安装 Rails ###
+
+我们需要安装javascript运行时,像NodeJS因为这些天Rails带来很多依赖。这样我们可以结合并缩小你的javascript来提供一个更快的生产环境。
+
+我们需要添加PPA来安装nodeJS。
+
+ sudo add-apt-repository ppa:chris-lea/node.js
+ sudo apt-get update
+ sudo apt-get install nodejs
+
+如果在更新是晕倒了问题,你可以试试这个命令:
+
+ # Note the new setup script name for Node.js v0.12
+ curl -sL https://deb.nodesource.com/setup_0.12 | sudo bash -
+
+ # Then install with:
+ sudo apt-get install -y nodejs
+
+下一步,用这个命令:
+
+ gem install rails -v 4.2.1
+
+因为我们正在使用rbenv,用下面的命令来安装rails。
+
+ rbenv rehash
+
+要确保rails已经正确安炸u哪个,你可以运行rails -v,显示如下:
+
+ rails -v
+ # Rails 4.2.1
+
+如果你得到的是不同的结果可能是环境没有设置正确。
+
+### 设置 MySQL ###
+
+或许你已经熟悉MySQL了,你可以从Ubuntu的仓库中安装MySQL的客户端与服务端。你可以在安装时设置root用户密码。这个信息将来会进入你rails程序的database.yml文件中、用下面的命令来安装mysql。
+
+ sudo apt-get install mysql-server mysql-client libmysqlclient-dev
+
+安装libmysqlclient-dev用于提供在设置rails程序时,rails在连接mysql所需要用到的用于编译mysql2 gem的文件。
+
+### 最后一步 ###
+
+让我们尝试创建你的第一个rails程序:
+
+ # Use MySQL
+
+ rails new myapp -d mysql
+
+ # Move into the application directory
+
+ cd myapp
+
+ # Create Database
+
+ rake db:create
+
+ rails server
+
+访问http://localhost:3000来访问你的新网站。现在你的电脑上已经可以构建rails程序了。
+
+
+
+如果你在创建数据库时遇到了“Access denied for user 'root'@'localhost' (Using password: NO)”这个错误信息,你需要更新你的config/database.yml文件来匹配数据库的**用户名**和**密码**。
+
+ # Edit your database.yml in config folder
+
+ nano config/database.yml
+
+接着输入MySql root用户的密码。
+
+
+
+退出 (Ctrl+X)并保存。
+
+### 总结 ###
+
+Rails是用Ruby写的, 也就是随着rails一起使用的编程语言。在Ubuntu 15.04中Ruby on Rails可以用rbenv、 rvm和源码的方式来安装。本篇我们使用的是rbenv方式并用了MySQL作为数据库。有任何的问题或建议,请在评论栏指出。
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/ubuntu-how-to/installing-ruby-rails-using-rbenv-ubuntu-15-04/
+
+作者:[Obet][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/obetp/
+[1]:http://release.ubuntu.com/15.04
+[2]:http://github.com
+[3]:https://github.com/settings/ssh
diff --git a/translated/tech/20150604 How To Install Unity 8 Desktop Preview In Ubuntu.md b/translated/tech/20150604 How To Install Unity 8 Desktop Preview In Ubuntu.md
new file mode 100644
index 0000000000..bf1c3ea0bb
--- /dev/null
+++ b/translated/tech/20150604 How To Install Unity 8 Desktop Preview In Ubuntu.md
@@ -0,0 +1,77 @@
+Ubuntu中安装Unity 8桌面预览版
+================================================================================
+
+
+如果你一直关注新闻,那么Ubuntu将会切换到[Mir显示服务器][1],并随同发布[Unity 8][2]桌面。然而,在尚未确定Unity 8是否会在[Ubuntu 15.10 Willy Werewolf][3]中部署到Mir上之前,提供了一个Unity 8的预览版本供你体验和测试。通过官方PPA,可以很容地**安装Unity 8到Ubuntu 14.04,14.10和15.04中**。
+
+到目前为止,开发者已经可以通过[ISO][4]获得该Unity 8预览来进行测试。但是Canonical已经通过[LXC容器][5]发布了。通过该方法,你可以获取Unity 8桌面会话,让它作为任何一个桌面环境运行在Mir显示服务器上。就像你[在Ubuntu中安装Mate桌面][6],然后从LightDm登录屏幕选择桌面会话一样。
+
+好奇?想要试试Unity 8?让我们来看怎样安装它吧。
+
+**注意: 它是一个实验性预览,可能不是所有人都可以让它正确工作的。**
+
+### 安装Unity 8桌面到Ubuntu ###
+
+下面是安装并使用Unity 8的步骤:
+
+#### 步骤 1: 安装Unity 8到Ubuntu 12.04和14.04 ####
+
+如果你真运行着Ubuntu 12.04和14.04,那么你必须使用官方PPA来安装Unity 8。使用以下命令进行安装:
+
+ sudo apt-add-repository ppa:unity8-desktop-session-team/unity8-preview-lxc
+ sudo apt-get update
+ sudo apt-get upgrade
+ sudo apt-get install unity8-lxc
+
+#### 步骤 1: 安装Unity 8到Ubuntu 14.10和15.04 ####
+
+如果你真运行着Ubuntu 14.10或15.04,那么Unity 8 LXC已经在源中准备好。你只需要运行以下命令:
+
+ sudo apt-get update
+ sudo apt-get install unity8-lxc
+
+#### 步骤 2: 设置Unity 8桌面预览LXC ####
+
+安装Unity 8 LXC后,该对它进行设置,下面的命令就可达到目的:
+
+ sudo unity8-lxc-setup
+
+它将花费一些时间来设置,所以,给点耐心吧。它会下载ISO,然后解压缩,接着完整最后一些必要的设置来让它工作。它也会安装一个LightDM的轻度修改版本。这一切都搞定后,需要重启。
+
+#### 步骤 3: 选择Unity 8 ####
+
+重启后,在登录屏幕,点击你的登录旁边的Ubuntu图标:
+
+
+
+你应该可以在这看到Unity 8的选项,选择它:
+
+
+
+### 卸载Unity 8 LXC ###
+
+如果你发现Unity 8毛病太多,或者你不喜欢它,那么你可以以相同的方式切换会默认Unity版本。此外,你也可以通过下面的命令移除Unity 8:
+
+ sudo apt-get remove unity8-lxc
+
+该命令会将Unity 8选项从LightDM屏幕移除,但是配置仍然保留着。
+
+以上就是你在Ubuntu中安装嗲有Mir的Unity 8的全部过程,试玩后请分享你关于Unity 8的想法哦!
+
+--------------------------------------------------------------------------------
+
+via: http://itsfoss.com/install-unity-8-desktop-ubuntu/
+
+作者:[Abhishek][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/abhishek/
+[1]:http://en.wikipedia.org/wiki/Mir_%28software%29
+[2]:https://wiki.ubuntu.com/Unity8Desktop
+[3]:http://itsfoss.com/ubuntu-15-10-codename/
+[4]:https://wiki.ubuntu.com/Unity8DesktopIso
+[5]:https://wiki.ubuntu.com/Unity8inLXC
+[6]:http://itsfoss.com/install-mate-desktop-ubuntu-14-04/
diff --git a/translated/tech/20150604 How to access SQLite database in Perl.md b/translated/tech/20150604 How to access SQLite database in Perl.md
new file mode 100644
index 0000000000..76cc1f01f0
--- /dev/null
+++ b/translated/tech/20150604 How to access SQLite database in Perl.md
@@ -0,0 +1,171 @@
+如何用Perl访问SQLite数据库
+================================================================================
+SQLite是一个零配置,无服务端,基于文件的事务文件系统。由于它的轻量级,自包含和紧凑的设计,所以当你想要集成数据库到你的程序中时,SQLite是一个非常流行的选择。在这篇文章中,我会展示如何用Perl脚本来创建和访问SQLite数据库。我演示的Perl代码片段是完整的,所以你可以很简单地修改并集成到你的项目中。
+
+
+
+### 访问SQLite的准备 ###
+
+我会使用SQLite DBI Perl驱动来连接到SQLite3。因此你需要在Linux中安装它(和SQLite3一起)。
+
+**Debian、 Ubuntu 或者 Linux Mint**
+
+ $ sudo apt-get install sqlite3 libdbd-sqlite3-perl
+
+**CentOS、 Fedora 或者 RHEL**
+
+ $ sudo yum install sqlite perl-DBD-SQLite
+
+安装后,你可以检查SQLite驱动可以通过下面的脚本访问到。
+
+ #!/usr/bin/perl
+
+ my @drv = DBI->available_drivers();
+ print join("\n", @drv), "\n";
+
+如果你运行脚本,你应该会看见下面的输出。
+
+ DBM
+ ExampleP
+ File
+ Gofer
+ Proxy
+ SQLite
+ Sponge
+
+### Perl SQLite 访问示例 ###
+
+下面就是Perl访问SQLite的示例。这个Perl脚本会演示下面这些SQLite数据库的常规管理。
+
+- 创建和连接SQLite数据库
+- 在SQLite数据库中创建新表
+- 在表中插入行
+- 在表中搜索和迭代行
+- 在表中更新行
+- 在表中删除行
+
+ use DBI;
+ use strict;
+
+ # define database name and driver
+ my $driver = "SQLite";
+ my $db_name = "xmodulo.db";
+ my $dbd = "DBI:$driver:dbname=$db_name";
+
+ # sqlite does not have a notion of username/password
+ my $username = "";
+ my $password = "";
+
+ # create and connect to a database.
+ # this will create a file named xmodulo.db
+ my $dbh = DBI->connect($dbd, $username, $password, { RaiseError => 1 })
+ or die $DBI::errstr;
+ print STDERR "Database opened successfully\n";
+
+ # create a table
+ my $stmt = qq(CREATE TABLE IF NOT EXISTS NETWORK
+ (ID INTEGER PRIMARY KEY AUTOINCREMENT,
+ HOSTNAME TEXT NOT NULL,
+ IPADDRESS INT NOT NULL,
+ OS CHAR(50),
+ CPULOAD REAL););
+ my $ret = $dbh->do($stmt);
+ if($ret < 0) {
+ print STDERR $DBI::errstr;
+ } else {
+ print STDERR "Table created successfully\n";
+ }
+
+ # insert three rows into the table
+ $stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
+ VALUES ('xmodulo', 16843009, 'Ubuntu 14.10', 0.0));
+ $ret = $dbh->do($stmt) or die $DBI::errstr;
+
+ $stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
+ VALUES ('bert', 16843010, 'CentOS 7', 0.0));
+ $ret = $dbh->do($stmt) or die $DBI::errstr;
+
+ $stmt = qq(INSERT INTO NETWORK (HOSTNAME,IPADDRESS,OS,CPULOAD)
+ VALUES ('puppy', 16843011, 'Ubuntu 14.10', 0.0));
+ $ret = $dbh->do($stmt) or die $DBI::errstr;
+
+ # search and iterate row(s) in the table
+ $stmt = qq(SELECT id, hostname, os, cpuload from NETWORK;);
+ my $obj = $dbh->prepare($stmt);
+ $ret = $obj->execute() or die $DBI::errstr;
+
+ if($ret < 0) {
+ print STDERR $DBI::errstr;
+ }
+ while(my @row = $obj->fetchrow_array()) {
+ print "ID: ". $row[0] . "\n";
+ print "HOSTNAME: ". $row[1] ."\n";
+ print "OS: ". $row[2] ."\n";
+ print "CPULOAD: ". $row[3] ."\n\n";
+ }
+
+ # update specific row(s) in the table
+ $stmt = qq(UPDATE NETWORK set CPULOAD = 50 where OS='Ubuntu 14.10';);
+ $ret = $dbh->do($stmt) or die $DBI::errstr;
+
+ if( $ret < 0 ) {
+ print STDERR $DBI::errstr;
+ } else {
+ print STDERR "A total of $ret rows updated\n";
+ }
+
+ # delete specific row(s) from the table
+ $stmt = qq(DELETE from NETWORK where ID=2;);
+ $ret = $dbh->do($stmt) or die $DBI::errstr;
+
+ if($ret < 0) {
+ print STDERR $DBI::errstr;
+ } else {
+ print STDERR "A total of $ret rows deleted\n";
+ }
+
+ # quit the database
+ $dbh->disconnect();
+ print STDERR "Exit the database\n";
+
+上面的Perl脚本运行成功后会创建一个叫“xmodulo.db”的数据库文件,并会有下面的输出。
+
+ Database opened successfully
+ Table created successfully
+ ID: 1
+ HOSTNAME: xmodulo
+ OS: Ubuntu 14.10
+ CPULOAD: 0
+
+ ID: 2
+ HOSTNAME: bert
+ OS: CentOS 7
+ CPULOAD: 0
+
+ ID: 3
+ HOSTNAME: puppy
+ OS: Ubuntu 14.10
+ CPULOAD: 0
+
+ A total of 2 rows updated
+ A total of 1 rows deleted
+ Exit the database
+
+### 错误定位 ###
+
+如果你尝试没有安装SQLite DBI驱动的情况下使用Perl访问SQLite的话,你会遇到下面的错误。你必须按开始说的安装DBI驱动。
+
+ Can't locate DBI.pm in @INC (@INC contains: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5 .) at ./script.pl line 3.
+ BEGIN failed--compilation aborted at ./script.pl line 3.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/access-sqlite-database-perl.html
+
+作者:[Dan Nanni][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
 +
+