mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
4aed32d8ec
64
published/20151013 DFileManager--Cover Flow File Manager.md
Normal file
64
published/20151013 DFileManager--Cover Flow File Manager.md
Normal file
@ -0,0 +1,64 @@
|
||||
DFileManager:封面流(CoverFlow)文件管理器
|
||||
================================================================================
|
||||
|
||||
这个一个 Ubuntu 标准软件仓库中缺失的像宝石般的、有着其独特的功能的文件管理器。这是 DFileManager 在推特中的宣称。
|
||||
|
||||
有一个不好回答的问题,如何知道到底有多少个 Linux 的开源软件?好奇的话,你可以在 Shell 里输入如下命令:
|
||||
|
||||
~$ for f in /var/lib/apt/lists/*Packages; do printf '%5d %s\n' $(grep '^Package: ' "$f" | wc -l) ${f##*/} done | sort -rn
|
||||
|
||||
在我的 Ubuntu 15.04 系统上,产生结果如下:
|
||||
|
||||

|
||||
|
||||
正如上面的截图所示,在 Universe 仓库中,大约有39000个包,在 main 仓库中大约有8500个包。这听起来很多。但是这些包括了开源应用、工具、库,有很多不是由 Ubuntu 开发者打包的。更重要的是,有很多重要的软件不在库中,只能通过源代码编译。DFileManager 就是这样一个软件。它是仍处在开发早期的一个基于 QT 的跨平台文件管理器。QT提供单一源码下的跨平台可移植性。
|
||||
|
||||
现在还没有二进制文件包,用户需要编译源代码才行。对于一些工具来说,这个可能会产生很大的问题,特别是如果这个应用依赖于某个复杂的依赖库,或者需要与已经安装在系统中的软件不兼容的某个版本。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
幸运的是,DFileManager 非常容易编译。对于我的老 Ubutnu 机器来说,在开发者网站上的安装介绍提供了大部分的重要步骤,不过少量的基础包没有列出(为什么总是这样?虽然许多库会让文件系统变得一团糟!)。在我的系统上,从github 下载源代码并且编译这个软件,我在 Shell 里输入了以下命令:
|
||||
|
||||
~$ sudo apt-get install qt5-default qt5-qmake libqt5x11extras5-dev
|
||||
~$ git clone git://git.code.sf.net/p/dfilemanager/code dfilemanager-code
|
||||
~$ cd dfilemananger-code
|
||||
~$ mkdir build
|
||||
~$ cd build
|
||||
~$ cmake ../ -DCMAKE_INSTALL_PREFIX=/usr
|
||||
~$ make
|
||||
~$ sudo make install
|
||||
|
||||
你可以通过在shell中输入如下命令来启动它:
|
||||
|
||||
~$ dfm
|
||||
|
||||
下面是运行中的 DFileManager,完全展示了其最吸引人的地方:封面流(Cover Flow)视图。可以在当前文件夹的项目间滑动,提供了一个相当有吸引力的体验。这是看图片的理想选择。这个文件管理器酷似 Finder(苹果操作系统下的默认文件管理器),可能会吸引你。
|
||||
|
||||

|
||||
|
||||
### 特点: ###
|
||||
|
||||
- 4种视图:图标、详情、列视图和封面流
|
||||
- 按位置和设备归类书签
|
||||
- 标签页
|
||||
- 简单的搜索和过滤
|
||||
- 自定义文件类型的缩略图,包括多媒体文件
|
||||
- 信息栏可以移走
|
||||
- 单击打开文件和目录
|
||||
- 可以排队 IO 操作
|
||||
- 记住每个文件夹的视图属性
|
||||
- 显示隐藏文件
|
||||
|
||||
DFileManager 不是 KDE 的 Dolphin 的替代品,但是能做相同的事情。这个是一个真正能够帮助人们的浏览文件的文件管理器。还有,别忘了反馈信息给开发者,任何人都可以做出这样的贡献。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://gofk.tumblr.com/post/131014089537/dfilemanager-cover-flow-file-manager-a-real-gem
|
||||
|
||||
作者:[gofk][a]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://gofk.tumblr.com/
|
||||
@ -0,0 +1,32 @@
|
||||
黑客们成功地在土豆上安装了 Linux !
|
||||
================================================================================
|
||||
|
||||
来自荷兰阿姆斯特丹的消息称,LinuxOnAnything.nl 网站的黑客们成功地在土豆上安装了 Linux!这是该操作系统第一次在根用蔬菜(root vegetable)上安装成功(LCTT 译注:root vetetable,一语双关,root 在 Linux 是指超级用户)。
|
||||
|
||||

|
||||
|
||||
“土豆没有 CPU,内存和存储器,这真的是个挑战,” Linux On Anything (LOA) 小组的 Johan Piest 说。“显然我们不能使用一个像 Fedora 或 Ubuntu 这些体量较大的发行版,所以我们用的是 Damn Small Linux。”
|
||||
|
||||
在尝试了几周之后,LOA 小组的的同学们弄出了一个适合土豆的 Linux 内核,这玩艺儿上面可以用 vi 来编辑小的文本文件。这个 Linux 通过一个小型的 U 盘加载到土豆上,并通过一组红黑线以二进制的方式向这个土豆发送命令。
|
||||
|
||||
LOA 小组是一个不断壮大的黑客组织的分支;这个组织致力于将 Linux 安装到所有物体上;他们先是将 Linux 装到Gameboy 和 iPod 等电子产品上,不过最近他们在挑战一些高难度的东西,譬如将Linux安装到灯泡和小狗身上!
|
||||
|
||||
LOA 小组在与另一个黑客小组 Stuttering Monarchs 竞赛,看谁先拿到土豆这一分。“土豆是一种每个人都会接触到的蔬菜,它的用途就像 Linux 一样极其广泛。无论你是想煮捣烹炸还是别的都可以” Piest 说道,“你也许认为我们完成这个挑战是为了获得某些好处,而我们只是追求逼格而已。”
|
||||
|
||||
LOA 是第一个将 Linux 安装到一匹设德兰矮种马上的小组,但这五年来竞争愈演愈烈,其它黑客小组的进度已经反超了他们。
|
||||
|
||||
“我们本来可以成为在饼干上面安装 Linux 的第一个小组,但是那群来自挪威的混蛋把我们击败了。” Piest 说。
|
||||
|
||||
第一个成功安装了 Linux 的蔬菜是一头卷心菜,它是由一个土耳其的一个黑客小组完成的。
|
||||
|
||||
(好啦——是不是已经目瞪口呆,事实上,这是一篇好几年前的恶搞文,你看出来了吗?哈哈哈哈)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.bbspot.com/news/2008/12/linux-on-a-potato.html
|
||||
|
||||
作者:[Brian Briggs](briggsb@bbspot.com)
|
||||
译者:[StdioA](https://github.com/StdioA), [hittlle](https://github.com/hittlle)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,6 +1,7 @@
|
||||
在 Ubuntu 15.10 上为单个网卡设置多个 IP 地址
|
||||
================================================================================
|
||||
有时候你可能想在你的网卡上使用多个 IP 地址。遇到这种情况你会怎么办呢?买一个新的网卡并分配一个新的 IP?不,这没有必要(至少在小网络中)。现在我们可以在 Ubuntu 系统中为一个网卡分配多个 IP 地址。想知道怎么做到的?跟着我往下看,其实并不难。
|
||||
|
||||
有时候你可能想在你的网卡上使用多个 IP 地址。遇到这种情况你会怎么办呢?买一个新的网卡并分配一个新的 IP?不,没有这个必要(至少在小型网络中)。现在我们可以在 Ubuntu 系统中为一个网卡分配多个 IP 地址。想知道怎么做到的?跟着我往下看,其实并不难。
|
||||
|
||||
这个方法也适用于 Debian 以及它的衍生版本。
|
||||
|
||||
@ -12,7 +13,7 @@
|
||||
|
||||
sudo ip addr
|
||||
|
||||
**事例输出:**
|
||||
**样例输出:**
|
||||
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
@ -31,7 +32,7 @@
|
||||
|
||||
sudo ifconfig
|
||||
|
||||
**事例输出:**
|
||||
**样例输出:**
|
||||
|
||||
enp0s3 Link encap:Ethernet HWaddr 08:00:27:2a:03:4b
|
||||
inet addr:192.168.1.103 Bcast:192.168.1.255 Mask:255.255.255.0
|
||||
@ -50,7 +51,7 @@
|
||||
collisions:0 txqueuelen:0
|
||||
RX bytes:38793 (38.7 KB) TX bytes:38793 (38.7 KB)
|
||||
|
||||
正如你在上面看到的,我的网卡名称是 **enp0s3**,它的 IP 地址是 **192.168.1.103**。
|
||||
正如你在上面输出中看到的,我的网卡名称是 **enp0s3**,它的 IP 地址是 **192.168.1.103**。
|
||||
|
||||
现在让我们来为网卡添加一个新的 IP 地址,例如说 **192.168.1.104**。
|
||||
|
||||
@ -73,7 +74,7 @@
|
||||
inet6 fe80::a00:27ff:fe2a:34e/64 scope link
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
类似地,你可以添加想要的任意多的 IP 地址。
|
||||
类似地,你可以添加任意数量的 IP 地址,只要你想要。
|
||||
|
||||
让我们 ping 一下这个 IP 地址验证一下。
|
||||
|
||||
@ -108,7 +109,7 @@
|
||||
|
||||
可以看到已经没有了!!
|
||||
|
||||
也许你已经知道,你重启系统后会丢失这些设置。那么怎么设置才能永久有效呢?这也很简单。
|
||||
正如你所知,重启系统后这些设置会失效。那么怎么设置才能永久有效呢?这也很简单。
|
||||
|
||||
### 添加永久 IP 地址 ###
|
||||
|
||||
@ -138,7 +139,7 @@ Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
|
||||
|
||||
sudo nano /etc/network/interfaces
|
||||
|
||||
按照黑色字体标注的添加额外的 IP 地址。
|
||||
如下添加额外的 IP 地址。
|
||||
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
@ -154,7 +155,7 @@ Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
无需重启运行下面的命令使更改生效。
|
||||
运行下面的命令使更改无需重启即生效。
|
||||
|
||||
sudo ifdown enp0s3 && sudo ifup enp0s3
|
||||
|
||||
@ -182,7 +183,7 @@ Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
|
||||
DHCPACK of 192.168.1.103 from 192.168.1.1
|
||||
bound to 192.168.1.103 -- renewal in 35146 seconds.
|
||||
|
||||
**注意**:如果你从远程连接到服务器,把上面的两个命令放到**一行**中**非常重要**,因为第一个命令会断掉你的连接。而采用这种方式可以存活你的 ssh 会话。
|
||||
**注意**:如果你从远程连接到服务器,把上面的两个命令放到**一行**中**非常重要**,因为第一个命令会断掉你的连接。而采用这种方式可以保留你的 ssh 会话。
|
||||
|
||||
现在,让我们用下面的命令来检查一下是否添加了新的 IP:
|
||||
|
||||
@ -217,10 +218,9 @@ Ubuntu 系统的网卡配置文件是 **/etc/network/interfaces**。
|
||||
|
||||
想知道怎么给 CentOS/RHEL/Scientific Linux/Fedora 系统添加额外的 IP 地址,可以点击下面的链接。
|
||||
|
||||
注:此篇文章以前做过选题:20150205 Linux Basics--Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7.md
|
||||
- [Assign Multiple IP Addresses To Single Network Interface Card On CentOS 7][1]
|
||||
- [在CentOS 7上给一个网卡分配多个IP地址][1]
|
||||
|
||||
周末愉快!
|
||||
工作愉快!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -228,9 +228,9 @@ via: http://www.unixmen.com/assign-multiple-ip-addresses-to-one-interface-on-ubu
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.unixmen.com/linux-basics-assign-multiple-ip-addresses-single-network-interface-card-centos-7/
|
||||
[1]:https://linux.cn/article-5127-1.html
|
||||
@ -0,0 +1,131 @@
|
||||
如何在 Ubuntu 14/15 上配置 Apache Solr
|
||||
================================================================================
|
||||
|
||||
大家好,欢迎来阅读我们今天这篇 Apache Solr 的文章。简单的来说,Apache Solr 是一个最负盛名的开源搜索平台,配合运行在网站后端的 Apache Lucene,能够让你轻松创建搜索引擎来搜索网站、数据库和文件。它能够索引和搜索多个网站并根据搜索文本的相关内容返回搜索建议。
|
||||
|
||||
Solr 使用 HTTP 可扩展标记语言(XML),可以为 JSON、Python 和 Ruby 等提供应用程序接口(API)。根据Apache Lucene 项目所述,Solr 提供了非常多的功能,很受管理员们的欢迎:
|
||||
|
||||
- 全文检索
|
||||
- 分面导航(Faceted Navigation)
|
||||
- 拼写建议/自动完成
|
||||
- 自定义文档排序/排列
|
||||
|
||||
#### 前提条件: ####
|
||||
|
||||
在一个使用最小化安装包的全新 Ubuntu 14/15 系统上,你仅仅需要少量的准备,就开始安装 Apache Solor.
|
||||
|
||||
### 1)System Update 系统更新###
|
||||
|
||||
使用一个具有 sudo 权限的非 root 用户登录你的 Ubuntu 服务器,在接下来的所有安装和使用 Solr 的步骤中都会使用它。
|
||||
|
||||
登录成功后,使用下面的命令,升级你的系统到最新的更新及补丁:
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
### 2) 安装 JRE###
|
||||
|
||||
要安装 Solr,首先需要安装 JRE(Java Runtime Environment)作为基础环境,因为 solr 和 tomcat 都是基于Java.所以,我们需要安装最新版的 Java 并配置 Java 本地环境.
|
||||
|
||||
要想安装最新版的 Java 8,我们需要通过以下命令安装 Python Software Properties 工具包
|
||||
|
||||
$ sudo apt-get install python-software-properties
|
||||
|
||||
完成后,配置最新版 Java 8的仓库
|
||||
|
||||
$ sudo add-apt-repository ppa:webupd8team/java
|
||||
|
||||
现在你可以通过以下命令更新包源列表,使用‘apt-get’来安装最新版本的 Oracle Java 8。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install oracle-java8-installer
|
||||
|
||||
在安装和配置过程中,点击'OK'按钮接受 Java SE Platform 和 JavaFX 的 Oracle 二进制代码许可协议(Oracle Binary Code License Agreement)。
|
||||
|
||||
在安装完成后,运行下面的命令,检查是否安装成功以及查看安装的版本。
|
||||
|
||||
kash@solr:~$ java -version
|
||||
java version "1.8.0_66"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
|
||||
|
||||
执行结果表明我们已经成功安装了 Java,并达到安装 Solr 最基本的要求了,接着我们进行下一步。
|
||||
|
||||
### 安装 Solr###
|
||||
|
||||
有两种不同的方式可以在 Ubuntu 上安装 Solr,在本文中我们只用最新的源码包来演示源码安装。
|
||||
|
||||
要使用源码安装 Solr,先要从[官网][1]下载最新的可用安装包。复制以下链接,然后使用 'wget' 命令来下载。
|
||||
|
||||
$ wget http://www.us.apache.org/dist/lucene/solr/5.3.1/solr-5.3.1.tgz
|
||||
|
||||
运行下面的命令,将这个已归档的服务解压到 /bin 目录。
|
||||
|
||||
$ tar -xzf solr-5.3.1.tgz solr-5.3.1/bin/install_solr_service.sh --strip-components=2
|
||||
|
||||
运行脚本来启动 Solr 服务,这将会先创建一个 solr 的用户,然后将 Solr 安装成服务。
|
||||
|
||||
$ sudo bash ./install_solr_service.sh solr-5.3.1.tgz
|
||||
|
||||

|
||||
|
||||
使用下面的命令来检查 Solr 服务的状态。
|
||||
|
||||
$ service solr status
|
||||
|
||||

|
||||
|
||||
### 创建 Solr 集合: ###
|
||||
|
||||
我们现在可以使用 Solr 用户添加多个集合。就像下图所示的那样,我们只需要在命令行中指定集合名称和指定其配置集就可以创建多个集合了。
|
||||
|
||||
$ sudo su - solr -c "/opt/solr/bin/solr create -c myfirstcollection -n data_driven_schema_configs"
|
||||
|
||||

|
||||
|
||||
我们已经成功的为我们的第一个集合创建了新核心实例目录,并可以将数据添加到里面。要查看库中的默认模式文件,可以在这里找到: '/opt/solr/server/solr/configsets/data_driven_schema_configs/conf' 。
|
||||
|
||||
### 使用 Solr Web###
|
||||
|
||||
可以使用默认的端口8983连接 Apache Solr。打开浏览器,输入 http://your\_server\_ip:8983/solr 或者 http://your-domain.com:8983/solr. 确保你的防火墙允许8983端口.
|
||||
|
||||
http://172.25.10.171:8983/solr/
|
||||
|
||||

|
||||
|
||||
在 Solr 的 Web 控制台左侧菜单点击 'Core Admin' 按钮,你将会看见我们之前使用命令行方式创建的集合。你可以点击 'Add Core' 按钮来创建新的核心。
|
||||
|
||||

|
||||
|
||||
就像下图中所示,你可以选择某个集合并指向文档来向里面添加内容或从文档中查询数据。如下显示的那样添加指定格式的数据。
|
||||
|
||||
{
|
||||
"number": 1,
|
||||
"Name": "George Washington",
|
||||
"birth_year": 1989,
|
||||
"Starting_Job": 2002,
|
||||
"End_Job": "2009-04-30",
|
||||
"Qualification": "Graduation",
|
||||
"skills": "Linux and Virtualization"
|
||||
}
|
||||
|
||||
添加文件后点击 'Submit Document'按钮.
|
||||
|
||||

|
||||
|
||||
### 总结###
|
||||
|
||||
在 Ubuntu 上安装成功后,你就可以使用 Solr Web 接口插入或查询数据。如果你想通过 Solr 来管理更多的数据和文件,可以创建更多的集合。希望你能喜欢这篇文章并且希望它能够帮到你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-apache-solr-ubuntu-14-15/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[taichirain](https://github.com/taichirain)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://lucene.apache.org/solr/
|
||||
@ -1,61 +1,61 @@
|
||||
|
||||
如何在FreeBSD 10.2上安装Nginx作为Apache的反向代理
|
||||
如何在 FreeBSD 10.2 上安装 Nginx 作为 Apache 的反向代理
|
||||
================================================================================
|
||||
Nginx是一款免费的,开源的HTTP和反向代理服务器, 以及一个代理POP3/IMAP的邮件服务器. Nginx是一款高性能的web服务器,其特点是丰富的功能,简单的结构以及低内存的占用. 第一个版本由 Igor Sysoev在2002年发布,然而到现在为止很多大的科技公司都在使用,包括 Netflix, Github, Cloudflare, WordPress.com等等
|
||||
|
||||
在这篇教程里我们会 "**在freebsd 10.2系统上,安装和配置Nginx网络服务器作为Apache的反向代理**". Apache 会用PHP在8080端口上运行,并且我们需要在80端口配置Nginx的运行,用来接收用户/访问者的请求.如果网页的用户请求来自于浏览器的80端口, 那么Nginx会用Apache网络服务器和PHP来通过这个请求,并运行在8080端口.
|
||||
Nginx 是一款自由开源的 HTTP 和反向代理服务器,也可以用作 POP3/IMAP 的邮件代理服务器。Nginx 是一款高性能的 web 服务器,其特点是功能丰富,结构简单以及内存占用低。 第一个版本由 Igor Sysoev 发布于2002年,到现在有很多大型科技公司在使用,包括 Netflix、 Github、 Cloudflare、 WordPress.com 等等。
|
||||
|
||||
在这篇教程里我们会“**在 freebsd 10.2 系统上,安装和配置 Nginx 网络服务器作为 Apache 的反向代理**”。 Apache 将在8080端口上运行 PHP ,而我们会配置 Nginx 运行在80端口以接收用户/访问者的请求。如果80端口接收到用户浏览器的网页请求,那么 Nginx 会将该请求传递给运行在8080端口上的 Apache 网络服务器和 PHP。
|
||||
|
||||
#### 前提条件 ####
|
||||
|
||||
- FreeBSD 10.2.
|
||||
- Root 权限.
|
||||
- FreeBSD 10.2
|
||||
- Root 权限
|
||||
|
||||
### 步骤 1 - 更新系统 ###
|
||||
|
||||
使用SSH证书登录到你的FreeBSD服务器以及使用下面命令来更新你的系统 :
|
||||
使用 SSH 认证方式登录到你的 FreeBSD 服务器,使用下面命令来更新你的系统:
|
||||
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### 步骤 2 - 安装 Apache ###
|
||||
|
||||
Apache是现在使用范围最广的网络服务器以及开源的HTTP服务器.在FreeBSD里Apache是未被默认安装的, 但是我们可以直接从端口下载,或者解压包在"/usr/ports/www/apache24" 目录下,再或者直接从PKG命令的FreeBSD系统信息库安装。在本教程中,我们将使用PKG命令从FreeBSD的库中安装:
|
||||
Apache 是开源的、使用范围最广的 web 服务器。在 FreeBSD 里默认没有安装 Apache, 但是我们可以直接通过 /usr/ports/www/apache24 下的 ports 或软件包来安装,也可以直接使用 pkg 命令从 FreeBSD 软件库中安装。在本教程中,我们将使用 pkg 命令从 FreeBSD 软件库中安装:
|
||||
|
||||
pkg install apache24
|
||||
|
||||
### 步骤 3 - 安装 PHP ###
|
||||
|
||||
一旦成功安装Apache, 接着将会安装PHP并由一个用户处理一个PHP的文件请求. 我们将会用到如下的PKG命令来安装PHP :
|
||||
一旦成功安装 Apache,接着将会安装 PHP ,它来负责处理用户对 PHP 文件的请求。我们将会用到如下的 pkg 命令来安装 PHP:
|
||||
|
||||
pkg install php56 mod_php56 php56-mysql php56-mysqli
|
||||
|
||||
### 步骤 4 - 配置 Apache 和 PHP ###
|
||||
|
||||
一旦所有都安装好了, 我们将会配置Apache在8080端口上运行, 并让PHP与Apache一同工作. 为了配置Apache,我们可以编辑 "httpd.conf"这个配置文件, 然而PHP我们只需要复制PHP的配置文件 php.ini 在 "/usr/local/etc/"目录下.
|
||||
一旦所有都安装好了,我们将会配置 Apache 运行在8080端口上, 并让 PHP 与 Apache 一同工作。 要想配置Apache,我们可以编辑“httpd.conf”这个配置文件, 对于 PHP 我们只需要复制 “/usr/local/etc/”目录下的 PHP 配置文件 php.ini。
|
||||
|
||||
进入到 "/usr/local/etc/" 目录 并且复制 php.ini-production 文件到 php.ini :
|
||||
进入到“/usr/local/etc/”目录,并且复制 php.ini-production 文件到 php.ini :
|
||||
|
||||
cd /usr/local/etc/
|
||||
cp php.ini-production php.ini
|
||||
|
||||
下一步, 在Apache目录下通过编辑 "httpd.conf"文件来配置Apache :
|
||||
下一步,在 Apache 目录下通过编辑“httpd.conf”文件来配置 Apache:
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
端口配置在第 **52**行 :
|
||||
端口配置在第**52**行 :
|
||||
|
||||
Listen 8080
|
||||
|
||||
服务器名称配置在第 **219** 行:
|
||||
服务器名称配置在第**219**行:
|
||||
|
||||
ServerName 127.0.0.1:8080
|
||||
|
||||
在第 **277**行,如果目录需要,添加的DirectoryIndex文件,Apache将直接作用于它 :
|
||||
在第**277**行,添加 DirectoryIndex 文件,Apache 将用它来服务对目录的请求:
|
||||
|
||||
DirectoryIndex index.php index.html
|
||||
|
||||
在第 **287**行下,配置Apache通过添加脚本来支持PHP :
|
||||
在第**287**行下,配置 Apache ,添加脚本支持:
|
||||
|
||||
<FilesMatch "\.php$">
|
||||
SetHandler application/x-httpd-php
|
||||
@ -64,49 +64,49 @@ Apache是现在使用范围最广的网络服务器以及开源的HTTP服务器.
|
||||
SetHandler application/x-httpd-php-source
|
||||
</FilesMatch>
|
||||
|
||||
保存然后退出.
|
||||
保存并退出。
|
||||
|
||||
现在用sysrc命令,来添加Apache作为开机启动项目 :
|
||||
现在用 sysrc 命令,来添加 Apache 为开机启动项目:
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
|
||||
然后用下面的命令测试Apache的配置 :
|
||||
然后用下面的命令测试 Apache 的配置:
|
||||
|
||||
apachectl configtest
|
||||
|
||||
如果到这里都没有问题的话,那么就启动Apache吧 :
|
||||
如果到这里都没有问题的话,那么就启动 Apache 吧:
|
||||
|
||||
service apache24 start
|
||||
|
||||
如果全部完毕, 在"/usr/local/www/apache24/data" 目录下,创建一个phpinfo文件是验证PHP在Apache下完美运行的好方法 :
|
||||
如果全部完毕,在“/usr/local/www/apache24/data”目录下创建一个 phpinfo 文件来验证 PHP 在 Apache 下顺利运行:
|
||||
|
||||
cd /usr/local/www/apache24/data
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
现在就可以访问 freebsd 的服务器 IP : 192.168.1.123:8080/info.php.
|
||||
现在就可以访问 freebsd 的服务器 IP : 192.168.1.123:8080/info.php 。
|
||||
|
||||

|
||||
|
||||
Apache 是使用 PHP 在 8080端口下运行的.
|
||||
Apache 及 PHP 运行在 8080 端口。
|
||||
|
||||
### 步骤 5 - 安装 Nginx ###
|
||||
|
||||
Nginx 以低内存的占用作为一款高性能的web服务器以及反向代理服务器.在这个步骤里,我们将会使用Nginx作为Apache的反向代理, 因此让我们用pkg命令来安装它吧 :
|
||||
Nginx 可以以较低内存占用提供高性能的 Web 服务器和反向代理服务器。在这个步骤里,我们将会使用 Nginx 作为Apache 的反向代理,因此让我们用 pkg 命令来安装它吧:
|
||||
|
||||
pkg install nginx
|
||||
|
||||
### 步骤 6 - 配置 Nginx ###
|
||||
|
||||
一旦 Nginx 安装完毕, 在 "**nginx.conf**" 文件里,我们需要做一个新的配置文件来替换掉原来的nginx文件. 更改到 "/usr/local/etc/nginx/"目录下 并且默认备份到 nginx.conf 文件:
|
||||
一旦 Nginx 安装完毕,在“**nginx.conf**”文件里,我们需要做一个新的配置文件来替换掉原来的 nginx 配置文件。切换到“/usr/local/etc/nginx/”目录下,并且备份默认 nginx.conf 文件:
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mv nginx.conf nginx.conf.oroginal
|
||||
|
||||
现在就可以创建一个新的 nginx 配置文件了 :
|
||||
现在就可以创建一个新的 nginx 配置文件了:
|
||||
|
||||
nano -c nginx.conf
|
||||
|
||||
然后粘贴下面的配置:
|
||||
然后粘贴下面的配置:
|
||||
|
||||
user www;
|
||||
worker_processes 1;
|
||||
@ -164,14 +164,14 @@ Nginx 以低内存的占用作为一款高性能的web服务器以及反向代
|
||||
|
||||
}
|
||||
|
||||
保存退出.
|
||||
保存并退出。
|
||||
|
||||
下一步, 在nginx目录下面,创建一个 **proxy.conf** 文件,使其作为反向代理 :
|
||||
下一步,在 nginx 目录下面,创建一个 **proxy.conf** 文件,使其作为反向代理 :
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
nano -c proxy.conf
|
||||
|
||||
粘贴如下配置 :
|
||||
粘贴如下配置:
|
||||
|
||||
proxy_buffering on;
|
||||
proxy_redirect off;
|
||||
@ -186,27 +186,27 @@ Nginx 以低内存的占用作为一款高性能的web服务器以及反向代
|
||||
proxy_buffers 100 8k;
|
||||
add_header X-Cache $upstream_cache_status;
|
||||
|
||||
保存退出.
|
||||
保存并退出。
|
||||
|
||||
最后一步, 为 nginx 的高速缓存创建一个 "/var/nginx/cache"的新目录 :
|
||||
最后一步,为 nginx 的高速缓存创建一个“/var/nginx/cache”的新目录:
|
||||
|
||||
mkdir -p /var/nginx/cache
|
||||
|
||||
### 步骤 7 - 配置 Nginx 的虚拟主机 ###
|
||||
|
||||
在这个步骤里面,我们需要创建一个新的虚拟主机域 "saitama.me", 以跟文件 "/usr/local/www/saitama.me" 和日志文件一同放在 "/var/log/nginx" 目录下.
|
||||
在这个步骤里面,我们需要创建一个新的虚拟主机域“saitama.me”,其文档根目录为“/usr/local/www/saitama.me”,日志文件放在“/var/log/nginx”目录下。
|
||||
|
||||
我们必须做的第一件事情就是创建新的目录来存放虚拟主机文件, 在这里我们将用到一个"**vhost**"的新文件. 并创建它 :
|
||||
我们必须做的第一件事情就是创建新的目录来存放虚拟主机配置文件,我们创建的新目录名为“**vhost**”。创建它:
|
||||
|
||||
cd /usr/local/etc/nginx/
|
||||
mkdir vhost
|
||||
|
||||
创建好vhost 目录, 那么我们就进入这个目录并创建一个新的虚拟主机文件. 这里我取名为 "**saitama.conf**" :
|
||||
创建好 vhost 目录,然后我们就进入这个目录并创建一个新的虚拟主机文件。这里我取名为“**saitama.conf**”:
|
||||
|
||||
cd vhost/
|
||||
nano -c saitama.conf
|
||||
|
||||
粘贴如下虚拟主机的配置 :
|
||||
粘贴如下虚拟主机的配置:
|
||||
|
||||
server {
|
||||
# Replace with your freebsd IP
|
||||
@ -252,67 +252,67 @@ Nginx 以低内存的占用作为一款高性能的web服务器以及反向代
|
||||
|
||||
}
|
||||
|
||||
保存退出.
|
||||
保存并退出。
|
||||
|
||||
下一步, 为nginx和虚拟主机创建一个新的日志目录 "/var/log/" :
|
||||
下一步,为 nginx 和虚拟主机创建一个新的日志目录“/var/log/”:
|
||||
|
||||
mkdir -p /var/log/nginx/
|
||||
|
||||
如果一切顺利, 在文件的根目录下创建文件 saitama.me :
|
||||
如果一切顺利,在文件的根目录下创建目录 saitama.me 用作文档根:
|
||||
|
||||
cd /usr/local/www/
|
||||
mkdir saitama.me
|
||||
|
||||
### 步骤 8 - 测试 ###
|
||||
|
||||
在这个步骤里面,我们只是测试我们的nginx和虚拟主机的配置.
|
||||
在这个步骤里面,我们只是测试我们的 nginx 和虚拟主机的配置。
|
||||
|
||||
用如下命令测试nginx的配置 :
|
||||
用如下命令测试 nginx 的配置:
|
||||
|
||||
nginx -t
|
||||
|
||||
如果一切都没有问题, 用 sysrc 命令添加nginx为启动项,并且启动nginx和重启apache:
|
||||
如果一切都没有问题,用 sysrc 命令添加 nginx 为开机启动项,并且启动 nginx 和重启 apache:
|
||||
|
||||
sysrc nginx_enable=yes
|
||||
service nginx start
|
||||
service apache24 restart
|
||||
|
||||
一切完毕后, 在 saitama.me 目录下,添加一个新的phpinfo文件来验证php的正常运行 :
|
||||
一切完毕后,在 saitama.me 目录下,添加一个新的 phpinfo 文件来验证 php 的正常运行:
|
||||
|
||||
cd /usr/local/www/saitama.me
|
||||
echo "<?php phpinfo(); ?>" > info.php
|
||||
|
||||
然后便访问这个文档 : **www.saitama.me/info.php**.
|
||||
然后访问这个域名: **www.saitama.me/info.php**。
|
||||
|
||||

|
||||
|
||||
Nginx 作为Apache的反向代理正在运行了,PHP也同样在进行工作了.
|
||||
Nginx 作为 Apache 的反向代理运行了,PHP 也同样工作了。
|
||||
|
||||
这是另一种结果 :
|
||||
这是另一个结果:
|
||||
|
||||
Test .html 文件无缓存.
|
||||
测试无缓存的 .html 文件。
|
||||
|
||||
curl -I www.saitama.me
|
||||
|
||||

|
||||
|
||||
Test .css 文件只有三十天的缓存.
|
||||
测试有三十天缓存的 .css 文件。
|
||||
|
||||
curl -I www.saitama.me/test.css
|
||||
|
||||

|
||||
|
||||
Test .php 文件正常缓存 :
|
||||
测试缓存的 .php 文件:
|
||||
|
||||
curl -I www.saitama.me/info.php
|
||||
|
||||

|
||||
|
||||
全部完成.
|
||||
全部搞定。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
Nginx 是最广泛的 HTTP 和反向代理的服务器. 拥有丰富的高性能和低内存/RAM的使用功能. Nginx使用了太多的缓存, 我们可以在网络上缓存静态文件使得网页加速, 并且在用户需要的时候再缓存php文件. 这样Nginx 的轻松配置和使用,可以让它用作HTTP服务器 或者 apache的反向代理.
|
||||
Nginx 是最受欢迎的 HTTP 和反向代理服务器,拥有丰富的功能、高性能、低内存/RAM 占用。Nginx 也用于缓存, 我们可以在网络上缓存静态文件使得网页加速,并且缓存用户请求的 php 文件。 Nginx 容易配置和使用,可以将它用作 HTTP 服务器或者 apache 的反向代理。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -320,7 +320,7 @@ via: http://linoxide.com/linux-how-to/install-nginx-reverse-proxy-apache-freebsd
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[KnightJoker](https://github.com/KnightJoker)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,162 @@
|
||||
在 Debian Linux 上安装配置 ISC DHCP 服务器
|
||||
================================================================================
|
||||
|
||||
动态主机控制协议(Dynamic Host Control Protocol,DHCP)给网络管理员提供了一种便捷的方式,为不断变化的网络主机或是动态网络提供网络层地址。其中最常用的 DHCP 服务工具是 ISC DHCP Server。DHCP 服务的目的是给主机提供必要的网络信息以便能够和其他连接在网络中的主机互相通信。DHCP 服务提供的信息包括:DNS 服务器信息,网络地址(IP),子网掩码,默认网关信息,主机名等等。
|
||||
|
||||
本教程介绍运行在 Debian 7.7 上 4.2.4 版的 ISC-DHCP-Server 如何管理多个虚拟局域网(VLAN),也可以非常容易应用到单一网络上。
|
||||
|
||||
测试用的网络是通过思科路由器使用传统的方式来管理 DHCP 租约地址的。目前有 12 个 VLAN 需要通过集中式服务器来管理。把 DHCP 的任务转移到一个专用的服务器上,路由器可以收回相应的资源,把资源用到更重要的任务上,比如路由寻址,访问控制列表,流量监测以及网络地址转换等。
|
||||
|
||||
另一个将 DHCP 服务转移到专用服务器的好处,以后会讲到,它可以建立动态域名服务器(DDNS),这样当主机从服务器请求 DHCP 地址的时候,这样新主机的主机名就会被添加到 DNS 系统里面。
|
||||
|
||||
### 安装和配置 ISC DHCP 服务器###
|
||||
|
||||
1、使用 apt 工具用来安装 Debian 软件仓库中的 ISC 软件,来创建这个多宿主服务器。与其他教程一样需要使用 root 或者 sudo 访问权限。请适当的修改,以便使用下面的命令。(LCTT 译注:下面中括号里面是注释,使用的时候请删除,#表示使用的 root 权限)
|
||||
|
||||
# apt-get install isc-dhcp-server [安装 the ISC DHCP Server 软件]
|
||||
# dpkg --get-selections isc-dhcp-server [确认软件已经成功安装]
|
||||
# dpkg -s isc-dhcp-server [用另一种方式确认成功安装]
|
||||
|
||||
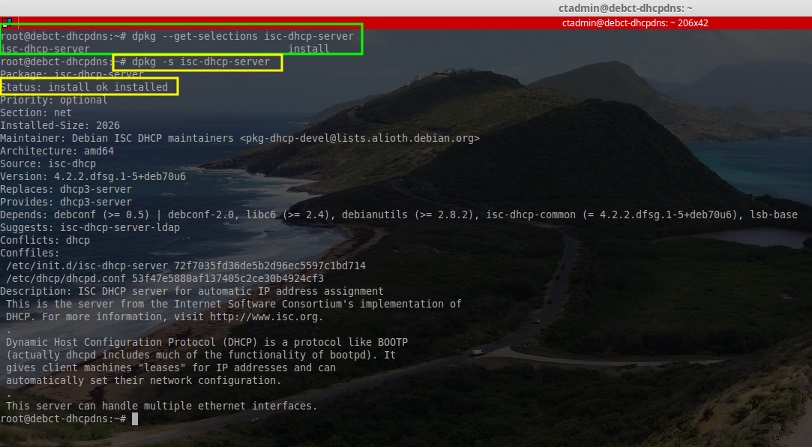
|
||||
|
||||
2、 确认服务软件已经安装完成,现在需要提供网络信息来配置服务器,这样服务器才能够根据我们的需要来分发网络信息。作为管理员最起码需要了解的 DHCP 信息如下:
|
||||
|
||||
- 网络地址
|
||||
- 子网掩码
|
||||
- 动态分配的地址范围
|
||||
|
||||
其他一些服务器动态分配的有用信息包括:
|
||||
|
||||
- 默认网关
|
||||
- DNS 服务器 IP 地址
|
||||
- 域名
|
||||
- 主机名
|
||||
- 网络广播地址
|
||||
|
||||
这只是能让 ISC DHCP 服务器处理的选项中非常少的一部分。如果你想查看所有选项及其描述需要在安装好软件后输入以下命令:
|
||||
|
||||
# man dhcpd.conf
|
||||
|
||||
3、 一旦管理员已经确定了这台服务器分发的所有必要信息,那么是时候配置服务器并且分配必要的地址池了。在配置任何地址池或服务器配置之前,必须配置 DHCP 服务器侦听这台服务器上面的一个接口。
|
||||
|
||||
在这台特定的服务器上,设置好网卡后,DHCP 会侦听名称名为`'bond0'`的接口。请适根据你的实际情况来更改服务器以及网络环境。下面的配置都是针对本教程的。
|
||||
|
||||

|
||||
|
||||
这行指定的是 DHCP 服务侦听接口(一个或多个)上的 DHCP 流量。修改主配置文件,分配适合的 DHCP 地址池到所需要的网络上。主配置文件在 /etc/dhcp/dhcpd.conf。用文本编辑器打开这个文件
|
||||
|
||||
# nano /etc/dhcp/dhcpd.conf
|
||||
|
||||
这个配置文件可以配置我们所需要的地址池/主机。文件顶部有 ‘ddns-update-style‘ 这样一句,在本教程中它设置为 ‘none‘。在以后的教程中会讲到动态 DNS,ISC-DHCP-Server 将会与 BIND9 集成,它能够使主机名更新指向到 IP 地址。
|
||||
|
||||
4、 接下来的部分是管理员配置全局网络设置,如 DNS 域名,默认的租约时间,IP地址,子网的掩码,以及其它。如果你想了解所有的选项,请阅读 man 手册中的 dhcpd.conf 文件,命令如下:
|
||||
|
||||
# man dhcpd.conf
|
||||
|
||||
对于这台服务器,我们需要在配置文件顶部配置一些全局网络设置,这样就不用到每个地址池中去单独设置了。
|
||||
|
||||
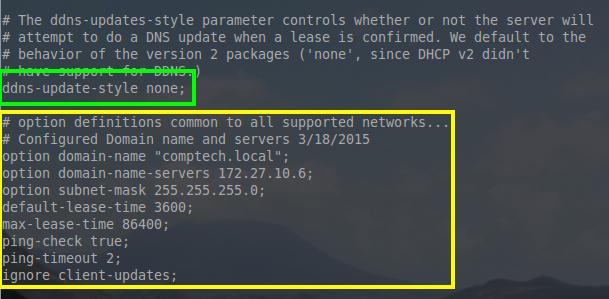
|
||||
|
||||
我们花一点时间来解释一下这些选项,在本教程中虽然它们是一些全局设置,但是也可以单独的为某一个地址池进行配置。
|
||||
|
||||
- option domain-name “comptech.local”; – 所有使用这台 DHCP 服务器的主机,都将成为 DNS 域 “comptech.local” 的一员
|
||||
|
||||
- option domain-name-servers 172.27.10.6; DHCP 向所有配置这台 DHCP 服务器的的网络主机分发 DNS 服务器地址为 172.27.10.6
|
||||
|
||||
- option subnet-mask 255.255.255.0; – 每个网络设备都分配子网掩码 255.255.255.0 或 /24
|
||||
|
||||
- default-lease-time 3600; – 默认有效的地址租约时间(单位是秒)。如果租约时间耗尽,那么主机可以重新申请租约。如果租约完成,那么相应的地址也将被尽快回收。
|
||||
|
||||
- max-lease-time 86400; – 这是一台主机所能租用的最大的租约时间(单位为秒)。
|
||||
|
||||
- ping-check true; – 这是一个额外的测试,以确保服务器分发出的网络地址不是当前网络中另一台主机已使用的网络地址。
|
||||
|
||||
- ping-timeout; – 在判断地址以前没有使用过前,服务器将等待 ping 响应多少秒。
|
||||
|
||||
- ignore client-updates; 现在这个选项是可以忽略的,因为 DDNS 在前面已在配置文件中已经被禁用,但是当 DDNS 运行时,这个选项会忽略主机更新其 DNS 主机名的请求。
|
||||
|
||||
5、 文件中下面一行是权威 DHCP 所在行。这行的意义是如果服务器是为文件中所配置的网络分发地址的服务器,那么取消对该权威关键字(authoritative stanza) 的注释。
|
||||
|
||||
通过去掉关键字 authoritative 前面的 ‘#’,取消注释全局权威关键字。这台服务器将是它所管理网络里面的唯一权威。
|
||||
|
||||

|
||||
|
||||
默认情况下服务器被假定为**不是**网络上的权威服务器。之所以这样做是出于安全考虑。如果有人因为不了解 DHCP 服务的配置,导致配置不当或配置到一个不该出现的网络里面,这都将带来非常严重的连接问题。这行还可用在每个网络中单独配置使用。也就是说如果这台服务器不是整个网络的 DHCP 服务器,authoritative 行可以用在每个单独的网络中,而不是像上面截图中那样的全局配置。
|
||||
|
||||
6、 这一步是配置服务器将要管理的所有 DHCP 地址池/网络。简短起见,本教程只讲到配置的地址池之一。作为管理员需要收集一些必要的网络信息(比如域名,网络地址,有多少地址能够被分发等等)
|
||||
|
||||
以下这个地址池所用到的信息都是管理员收集整理的:网络 ID 172.27.60.0, 子网掩码 255.255.255.0 或 /24, 默认子网网关 172.27.60.1,广播地址 172.27.60.255.0 。
|
||||
|
||||
以上这些信息对于构建 dhcpd.conf 文件中新网络非常重要。使用文本编辑器修改配置文件添加新网络进去,这里我们需要使用 root 或 sudo 访问权限。
|
||||
|
||||
# nano /etc/dhcp/dhcpd.conf
|
||||
|
||||

|
||||
|
||||
当前这个例子是给用 VMWare 创建的虚拟服务器分配 IP 地址。第一行显示是该网络的子网掩码。括号里面的内容是 DHCP 服务器应该提供给网络上面主机的所有选项。
|
||||
|
||||
第一行, range 172.27.60.50 172.27.60.254; 这一行显示的是,DHCP 服务在这个网络上能够给主机动态分发的地址范围。
|
||||
|
||||
第二行,option routers 172.27.60.1; 这里显示的是给网络里面所有的主机分发的默认网关地址。
|
||||
|
||||
最后一行, option broadcast-address 172.27.60.255; 显示当前网络的广播地址。这个地址不能被包含在要分发放的地址范围内,因为广播地址不能分配到一个主机上面。
|
||||
|
||||
必须要强调的是每行的结尾必须要用(;)来结束,所有创建的网络必须要在 {} 里面。
|
||||
|
||||
7、 如果要创建多个网络,继续创建完它们的相应选项后保存文本文件即可。配置完成以后如果有更改,ISC-DHCP-Server 进程需要重启来使新的更改生效。重启进程可以通过下面的命令来完成:
|
||||
|
||||
# service isc-dhcp-server restart
|
||||
|
||||
这条命令将重启 DHCP 服务,管理员能够使用几种不同的方式来检查服务器是否已经可以处理 dhcp 请求。最简单的方法是通过 [lsof 命令][1]来查看服务器是否在侦听67端口,命令如下:
|
||||
|
||||
# lsof -i :67
|
||||
|
||||

|
||||
|
||||
这里输出的结果表明 dhcpd(DHCP 服务守护进程)正在运行并且侦听67端口。由于在 /etc/services 文件中67端口的映射,所以输出中的67端口实际上被转换成了 “bootps”。
|
||||
|
||||
在大多数的系统中这是非常常见的,现在服务器应该已经为网络连接做好准备,我们可以将一台主机接入网络请求DHCP地址来验证服务是否正常。
|
||||
|
||||
### 测试客户端连接 ###
|
||||
|
||||
8、 现在许多系统使用网络管理器来维护网络连接状态,因此这个设备应该预先配置好的,只要对应的接口处于活跃状态就能够获取 DHCP。
|
||||
|
||||
然而当一台设备无法使用网络管理器时,它可能需要手动获取 DHCP 地址。下面的几步将演示怎样手动获取以及如何查看服务器是否已经按需要分发地址。
|
||||
|
||||
‘[ifconfig][2]‘工具能够用来检查接口的配置。这台被用来测试的 DHCP 服务器的设备,它只有一个网络适配器(网卡),这块网卡被命名为 ‘eth0‘。
|
||||
|
||||
# ifconfig eth0
|
||||
|
||||

|
||||
|
||||
从输出结果上看,这台设备目前没有 IPv4 地址,这样很便于测试。我们把这台设备连接到 DHCP 服务器并发出一个请求。这台设备上已经安装了一个名为 ‘dhclient‘ 的DHCP客户端工具。因为操作系统各不相同,所以这个客户端软件也是互不一样的。
|
||||
|
||||
# dhclient eth0
|
||||
|
||||

|
||||
|
||||
当前 `'inet addr:'` 字段中显示了属于 172.27.60.0 网络地址范围内的 IPv4 地址。值得欣慰的是当前网络还配置了正确的子网掩码并且分发了广播地址。
|
||||
|
||||
到这里看起来还都不错,让我们来测试一下,看看这台设备收到新 IP 地址是不是由服务器发出的。这里我们参照服务器的日志文件来完成这个任务。虽然这个日志的内容有几十万条,但是里面只有几条是用来确定服务器是否正常工作的。这里我们使用一个工具 ‘tail’,它只显示日志文件的最后几行,这样我们就可以不用拿一个文本编辑器去查看所有的日志文件了。命令如下:
|
||||
|
||||
# tail /var/log/syslog
|
||||
|
||||

|
||||
|
||||
OK!服务器记录表明它分发了一个地址给这台主机 (HRTDEBXENSRV)。服务器按预期运行,给它充当权威服务器的网络分发了适合的网络地址。至此 DHCP 服务器搭建成功并且运行。如果有需要你可以继续配置其他的网络,排查故障,确保安全。
|
||||
|
||||
在以后的Debian教程中我会讲一些新的 ISC-DHCP-Server 功能。有时间的话我将写一篇关于 Bind9 和 DDNS 的教程,融入到这篇文章里面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-and-configure-multihomed-isc-dhcp-server-on-debian-linux/
|
||||
|
||||
作者:[Rob Turner][a]
|
||||
译者:[ivo-wang](https://github.com/ivo-wang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/robturner/
|
||||
[1]:http://www.tecmint.com/10-lsof-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/ifconfig-command-examples/
|
||||
220
published/201512/20150917 A Repository with 44 Years of Unix Evolution.md
Executable file
220
published/201512/20150917 A Repository with 44 Years of Unix Evolution.md
Executable file
@ -0,0 +1,220 @@
|
||||
一个涵盖 Unix 44 年进化史的版本仓库
|
||||
=============================================================================
|
||||
|
||||
http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
This is an HTML rendering of a working paper draft that led to a publication. The publication should always be cited in preference to this draft using the following reference:
|
||||
|
||||
- **Diomidis Spinellis**. [A repository with 44 years of Unix evolution](http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html). In MSR '15: Proceedings of the 12th Working Conference on Mining Software Repositories, pages 13-16. IEEE, 2015. Best Data Showcase Award. ([doi:10.1109/MSR.2015.6](http://dx.doi.org/10.1109/MSR.2015.6))
|
||||
|
||||
This document is also available in [PDF format](http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.pdf).
|
||||
|
||||
The document's metadata is available in [BibTeX format](http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c-bibtex.html).
|
||||
|
||||
This material is presented to ensure timely dissemination of scholarly and technical work. Copyright and all rights therein are retained by authors or by other copyright holders. All persons copying this information are expected to adhere to the terms and constraints invoked by each author's copyright. In most cases, these works may not be reposted without the explicit permission of the copyright holder.
|
||||
|
||||
[Diomidis Spinellis Publications](http://www.dmst.aueb.gr/dds/pubs/)
|
||||
|
||||
© 2015 IEEE. Personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution to servers or lists, or to reuse any copyrighted component of this work in other works must be obtained from the IEEE.
|
||||
|
||||
### 摘要 ###
|
||||
|
||||
Unix 操作系统的进化历史,可以从一个版本控制仓库中窥见,时间跨度从 1972 年的 5000 行内核代码开始,到 2015 年成为一个含有 26,000,000 行代码的被广泛使用的系统。该仓库包含 659,000 条提交,和 2306 次合并。仓库部署了被普遍采用的 Git 系统用于储存其代码,并且在时下流行的 GitHub 上建立了存档。它由来自贝尔实验室(Bell Labs),伯克利大学(Berkeley University),386BSD 团队所开发的系统软件的 24 个快照综合定制而成,这包括两个老式仓库和一个开源 FreeBSD 系统的仓库。总的来说,可以确认其中的 850 位个人贡献者,更早些时候的一批人主要做基础研究。这些数据可以用于一些经验性的研究,在软件工程,信息系统和软件考古学领域。
|
||||
|
||||
### 1、介绍 ###
|
||||
|
||||
Unix 操作系统作为一个主要的工程上的突破而脱颖而出,得益于其模范的设计、大量的技术贡献、它的开发模型及广泛的使用。Unix 编程环境的设计已经被视为一个提供非常简洁、强大而优雅的设计 [[1][1]] 。在技术方面,许多对 Unix 有直接贡献的,或者因 Unix 而流行的特性就包括 [[2][2]] :用高级语言编写的可移植部署的内核;一个分层式设计的文件系统;兼容的文件,设备,网络和进程间 I/O;管道和过滤架构;虚拟文件系统;和作为普通进程的可由用户选择的不同 shell。很早的时候,就有一个庞大的社区为 Unix 贡献软件 [[3][3]] ,[[4][4],pp. 65-72] 。随时间流逝,这个社区不断壮大,并且以现在称为开源软件开发的方式在工作着 [[5][5],pp. 440-442] 。Unix 和其睿智的晚辈们也将 C 和 C++ 编程语言、分析程序和词法分析生成器(*yacc*,*lex*)、文档编制工具(*troff*,*eqn*,*tbl*)、脚本语言(*awk*,*sed*,*Perl*)、TCP/IP 网络、和配置管理系统(configuration management system)(*SCSS*,*RCS*,*Subversion*,*Git*)发扬广大了,同时也形成了现代互联网基础设施和网络的最大的部分。
|
||||
|
||||
幸运的是,一些重要的具有历史意义的 Unix 材料已经保存下来了,现在保持对外开放。尽管 Unix 最初是由相对严格的协议发行,但在早期的开发中,很多重要的部分是通过 Unix 的版权拥有者之一(Caldera International) (LCTT 译注:2002年改名为 SCO Group)以一个自由的协议发行。通过将这些部分再结合上由加州大学伯克利分校(University of California, Berkeley)和 FreeBSD 项目组开发或发布的开源软件,贯穿了从 1972 年六月二十日开始到现在的整个系统的开发。
|
||||
|
||||
通过规划和处理这些可用的快照以及或旧或新的配置管理仓库,将这些可用数据的大部分重建到一个新合成的 Git 仓库之中。这个仓库以数字的形式记录了过去44年来最重要的数字时代产物的详细的进化。下列章节描述了该仓库的结构和内容(第[2][6]节)、创建方法(第[3][7]节)和该如何使用(第[4][8]节)。
|
||||
|
||||
### 2、数据概览 ###
|
||||
|
||||
这 1GB 的 Unix 历史仓库可以从 [GitHub][9] 上克隆^[1][10] 。如今^[2][11] ,这个仓库包含来自 850 个贡献者的 659,000 个提交和 2,306 个合并。贡献者有来自贝尔实验室(Bell Labs)的 23 个员工,伯克利大学(Berkeley University)的计算机系统研究组(Computer Systems Research Group)(CSRG)的 158 个人,和 FreeBSD 项目的 660 个成员。
|
||||
|
||||
这个仓库的生命始于一个 *Epoch* 的标签,这里面只包含了证书信息和现在的 README 文件。其后各种各样的标签和分支记录了很多重要的时刻。
|
||||
|
||||
- *Research-VX* 标签对应来自贝尔实验室(Bell Labs)六个研究版本。从 *Research-V1* (4768 行 PDP-11 汇编代码)开始,到以 *Research-V7* (大约 324,000 行代码,1820 个 C 文件)结束。
|
||||
- *Bell-32V* 是第七个版本 Unix 在 DEC/VAX 架构上的移植。
|
||||
- *BSD-X* 标签对应伯克利大学(Berkeley University)释出的 15 个快照。
|
||||
- *386BSD-X* 标签对应该系统的两个开源版本,主要是 Lynne 和 William Jolitz 写的适用于 Intel 386 架构的内核代码。
|
||||
- *FreeBSD-release/X* 标签和分支标记了来自 FreeBSD 项目的 116 个发行版。
|
||||
|
||||
另外,以 *-Snapshot-Development* 为后缀的分支,表示该提交由来自一个以时间排序的快照文件序列而合成;而以一个 *-VCS-Development* 为后缀的标签,标记了有特定发行版出现的历史分支的时刻。
|
||||
|
||||
仓库的历史包含从系统开发早期的一些提交,比如下面这些。
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
Date: Mon Dec 2 18:18:02 1974 -0500
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
两个发布之间的合并代表着系统发生了进化,比如 BSD 3 的开发来自 BSD2 和 Unix 32/V,它在 Git 仓库里正是被表示为带两个父节点的图形节点。
|
||||
|
||||
更为重要的是,以这种方式构造的仓库允许 **git blame**,就是可以给源代码行加上注释,如版本、日期和它们第一次出现相关联的作者,这样可以知道任何代码的起源。比如说,检出 **BSD-4** 这个标签,并在内核的 *pipe.c* 文件上运行一下 git blame,就会显示出由 Ken Thompson 写于 1974,1975 和 1979年的代码行,和 Bill Joy 写于 1980 年的。这就可以自动(尽管计算上比较费事)检测出任何时刻出现的代码。
|
||||
|
||||
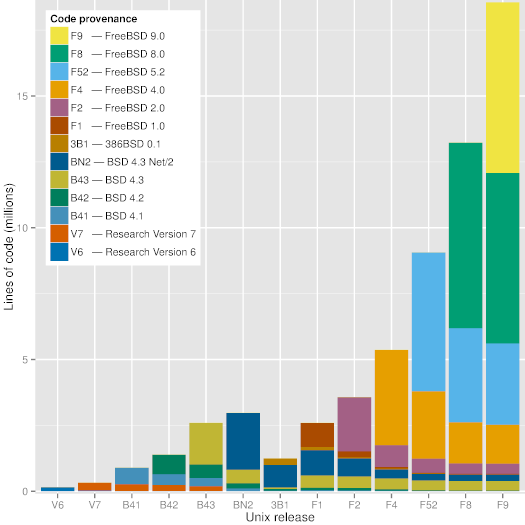
|
||||
|
||||
*图1:各个重大 Unix 发行版的代码来源*
|
||||
|
||||
如[上图][12]所示,现代版本的 Unix(FreeBSD 9)依然有相当部分的来自 BSD 4.3,BSD 4.3 Net/2 和 BSD 2.0 的代码块。有趣的是,这图片显示有部分代码好像没有保留下来,当时激进地要创造一个脱离于伯克利(386BSD 和 FreeBSD 1.0)所释出代码的开源操作系统。FreeBSD 9 中最古老的代码是一个 18 行的队列,在 C 库里面的 timezone.c 文件里,该文件也可以在第七版的 Unix 文件里找到,同样的名字,时间戳是 1979 年一月十日 - 36 年前。
|
||||
|
||||
### 3、数据收集和处理 ###
|
||||
|
||||
这个项目的目的是以某种方式巩固从数据方面说明 Unix 的进化,通过将其并入一个现代的版本仓库,帮助人们对系统进化的研究。项目工作包括收录数据,分类并综合到一个单独的 Git 仓库里。
|
||||
|
||||
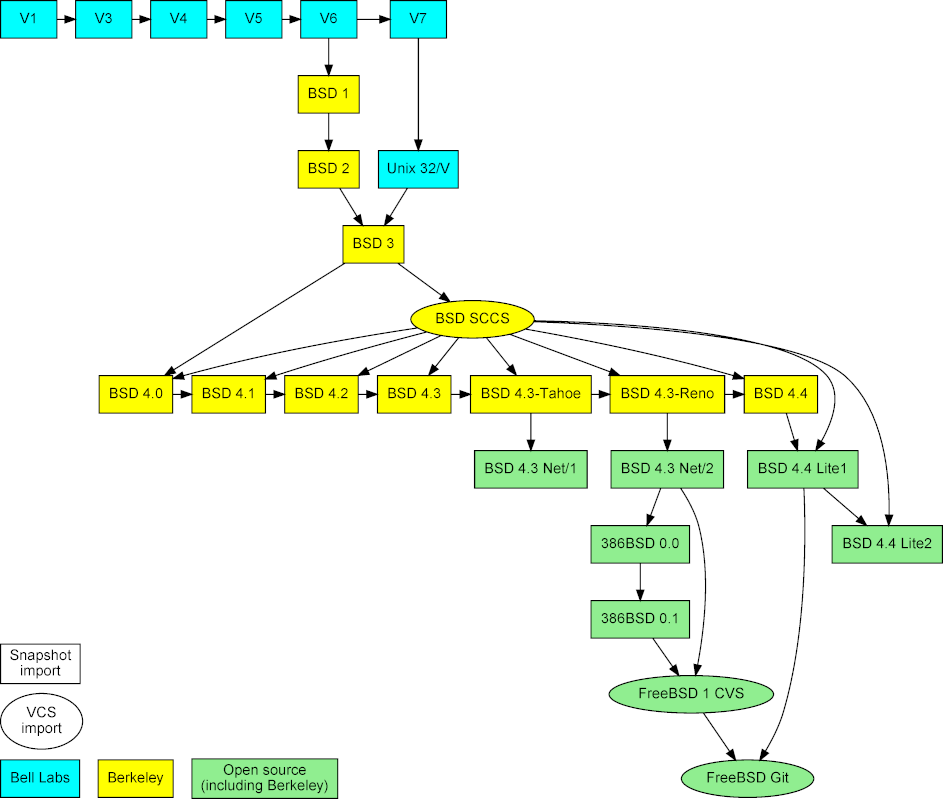
|
||||
|
||||
*图2:导入 Unix 快照、仓库及其合并*
|
||||
|
||||
项目以三种数据类型为基础(见[图2][13])。首先,早期发布版本的快照,获取自 [Unix 遗产社会归档(Unix Heritage Society archive)][14]^[3][15] 、包括了 CSRG 全部的源代码归档的 [CD-ROM 镜像][16]^[4][17] , [Oldlinux 网站][18]^[5][19] 和 [FreeBSD 归档][20]^[6][21] 。 其次,以前的和现在的仓库,即 CSRG SCCS [[6][22]] 仓库,FreeBSD 1 CVS 仓库,和[现代 FreeBSD 开发的 Git 镜像][23]^[7][24] 。前两个都是从和快照相同的来源获得的。
|
||||
|
||||
最后,也是最费力的数据源是 **初步研究(primary research)**。释出的快照并没有提供关于它们的源头和每个文件贡献者的信息。因此,这些信息片段需要通过初步研究(primary research)验证。至于作者信息主要通过作者的自传,研究论文,内部备忘录和旧文档扫描件;通过阅读并且自动处理源代码和帮助页面补充;通过与那个年代的人用电子邮件交流;在 *StackExchange* 网站上贴出疑问;查看文件的位置(在早期的内核版本的源代码,分为 `usr/sys/dmr` 和 `/usr/sys/ken` 两个位置);从研究论文和帮助手册披露的作者找到源代码,从一个又一个的发行版中获取。(有趣的是,第一和第二的研究版(Research Edition)帮助页面都有一个 “owner” 部分,列出了作者(比如,*Ken*)及对应的系统命令、文件、系统调用或库函数。在第四版中这个部分就没了,而在 BSD 发行版中又浮现了 “Author” 部分。)关于作者信息更为详细地写在了项目的文件中,这些文件被用于匹配源代码文件和它们的作者和对应的提交信息。最后,关于源代码库之间的合并信息是获取自[ NetBSD 项目所维护的 BSD 家族树][25]^[8][26] 。
|
||||
|
||||
作为本项目的一部分而开发的软件和数据文件,现在可以[在线获取][27]^[9][28] ,并且,如果有合适的网络环境,CPU 和磁盘资源,可以用来从头构建这样一个仓库。关于主要发行版的作者信息,都存储在本项目的 `author-path` 目录下的文件里。它们的内容中带有正则表达式的文件路径后面指出了相符的作者。可以指定多个作者。正则表达式是按线性处理的,所以一个文件末尾的匹配一切的表达式可以指定一个发行版的默认作者。为避免重复,一个以 `.au` 后缀的独立文件专门用于映射作者的识别号(identifier)和他们的名字及 email。这样一个文件为每个与该系统进化相关的社区都建立了一个:贝尔实验室(Bell Labs),伯克利大学(Berkeley University),386BSD 和 FreeBSD。为了真实性的需要,早期贝尔实验室(Bell Labs)发行版的 emails 都以 UUCP 注释(UUCP notation)方式列出(例如, `research!ken`)。FreeBSD 作者的识别映射,需要导入早期的 CVS 仓库,通过从如今项目的 Git 仓库里拆解对应的数据构建。总的来说,由 1107 行构成了注释作者信息的文件(828 个规则),并且另有 640 行用于映射作者的识别号到名字。
|
||||
|
||||
现在项目的数据源被编码成了一个 168 行的 `Makefile`。它包括下面的步骤。
|
||||
|
||||
**Fetching** 从远程站点复制和克隆大约 11GB 的镜像、归档和仓库。
|
||||
|
||||
**Tooling** 从 2.9 BSD 中为旧的 PDP-11 归档获取一个归档器,并调整它以在现代的 Unix 版本下编译;编译 4.3 BSD 的 *compress* 程序来解压 386BSD 发行版,这个程序不再是现代 Unix 系统的组成部分了。
|
||||
|
||||
**Organizing** 用 *tar* 和 *cpio* 解压缩包;合并第六个研究版的三个目录;用旧的 PDP-11 归档器解压全部一个 BSD 归档;挂载 CD-ROM 镜像,这样可以作为文件系统处理;合并第 8 和 62 的 386BSD 磁盘镜像为两个独立的文件。
|
||||
|
||||
**Cleaning** 恢复第一个研究版的内核源代码文件,这个可以通过 OCR 从打印件上得到近似其原始状态的的格式;给第七个研究版的源代码文件打补丁;移除发行后被添加进来的元数据和其他文件,为避免得到错误的时间戳信息;修复毁坏的 SCCS 文件;用一个定制的 Perl 脚本移除指定到多个版本的 CVS 符号、删除与现在冲突的 CVS *Attr* 文件、用 *cvs2svn* 将 CVS 仓库转换为 Git 仓库,以处理早期的 FreeBSD CVS 仓库。
|
||||
|
||||
在仓库再现(representation)中有一个很有意思的部分就是,如何导入那些快照,并以一种方式联系起来,使得 *git blame* 可以发挥它的魔力。快照导入到仓库是基于每个文件的时间戳作为一系列的提交实现的。当所有文件导入后,就被用对应发行版的名字给标记了。然后,可以删除那些文件,并开始导入下一个快照。注意 *git blame* 命令是通过回溯一个仓库的历史来工作的,并使用启发法(heuristics)来检测文件之间或文件内的代码移动和复制。因此,删除掉的快照间会产生中断,以防止它们之间的代码被追踪。
|
||||
|
||||
相反,在下一个快照导入之前,之前快照的所有文件都被移动到了一个隐藏的后备目录里,叫做 `.ref`(引用)。它们保存在那,直到下个快照的所有文件都被导入了,这时候它们就会被删掉。因为 `.ref` 目录下的每个文件都精确对应一个原始文件,*git blame* 可以知道多少源代码通过 `.ref` 文件从一个版本移到了下一个,而不用显示出 `.ref` 文件。为了更进一步帮助检测代码起源,同时增加再现(representation)的真实性,每个发行版都被再现(represented)为一个有增量文件的分支(*-Development*)与之前发行版之间的合并。
|
||||
|
||||
上世纪 80 年代时期,只有伯克利(Berkeley) 开发的文件的一个子集是用 SCCS 版本控制的。在那个期间,我们的统一仓库里包含了来自 SCCS 的提交和快照的增量文件的导入数据。对于每个发行版,可用最近的时间戳找到该 SCCS 提交,并被标记为一个与发行版增量导入分支的合并。这些合并可以在[图2][29] 的中间看到。
|
||||
|
||||
将各种数据资源综合到一个仓库的工作,主要是用两个脚本来完成的。一个 780 行的 Perl 脚本(`import-dir.pl`)可以从一个单独的数据源(快照目录、SCCS 仓库,或者 Git 仓库)中,以 *Git fast export* 格式导出(真实的或者综合的)提交历史。输出是一个简单的文本格式,Git 工具用这个来导入和导出提交。其他方面,这个脚本以一些东西为参数,如文件到贡献者的映射、贡献者登录名和他们的全名间的映射、哪个导入的提交会被合并、哪些文件要处理和忽略、以及“引用”文件的处理。一个 450 行的 Shell 脚本创建 Git 仓库,并调用带适当参数的 Perl 脚本,来导入 27 个可用的历史数据资源。Shell 脚本也会运行 30 个测试,比较特定标签的仓库和对应的数据源,核对查看的目录中出现的和没出现的,并回溯查看分支树和合并的数量,*git blame* 和 *git log* 的输出。最后,调用 *git* 作垃圾收集和仓库压缩,从最初的 6GB 降到分发的 1GB 大小。
|
||||
|
||||
### 4、数据使用 ###
|
||||
|
||||
该数据可以用于软件工程、信息系统和软件考古学(software archeology)领域的经验性研究。鉴于它从不间断而独一无二的存在了超过了 40 年,可以供软件进化和跨代更迭参考。从那时以来,处理速度已经成千倍地增长、存储容量扩大了百万倍,该数据同样可以用于软件和硬件技术交叉进化(co-evolution)的研究。软件开发从研究中心到大学,到开源社区的转移,可以用来研究组织文化对于软件开发的影响。该仓库也可以用于学习著名人物的实际编程,比如 Turing 奖获得者(Dennis Ritchie 和 Ken Thompson)和 IT 产业的大佬(Bill Joy 和 Eric Schmidt)。另一个值得学习的现象是代码的长寿,无论是单行的水平,或是作为那个时代随 Unix 发布的完整的系统(Ingres、 Lisp、 Pascal、 Ratfor、 Snobol、 TMP),和导致代码存活或消亡的因素。最后,因为该数据让 Git 感到了压力,底层的软件仓库存储技术达到了其极限,这会推动版本管理系统领域的工程进度。
|
||||
|
||||
|
||||
|
||||
*图3:Unix 发行版的代码风格进化*
|
||||
|
||||
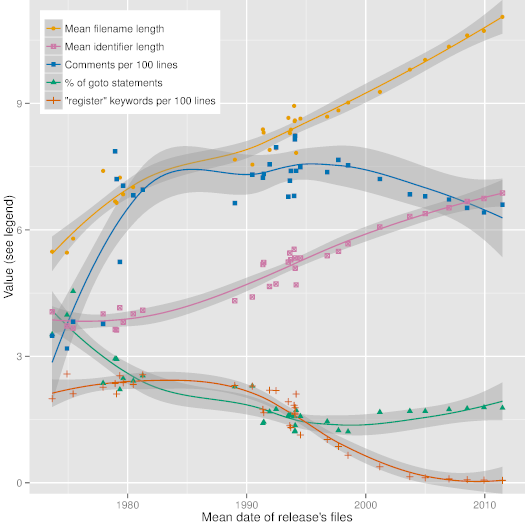
[图3][30] 根据 36 个主要 Unix 发行版描述了一些有趣的代码统计的趋势线(用 R 语言的局部多项式回归拟合函数生成),验证了代码风格和编程语言的使用在很长的时间尺度上的进化。这种进化是软硬件技术的需求和支持、软件构筑理论,甚至社会力量所驱动的。图片中的日期计算了出现在一个给定发行版中的所有文件的平均日期。正如可以从中看到,在过去的 40 年中,标示符和文件名字的长度已经稳步从 4 到 6 个字符增长到 7 到 11 个字符。我们也可以看到注释数量的少量稳步增加,以及 *goto* 语句的使用量减少,同时 *register* 这个类型修饰符的消失。
|
||||
|
||||
### 5、未来的工作 ###
|
||||
|
||||
可以做很多事情去提高仓库的正确性和有效性。创建过程以开源代码共享了,通过 GitHub 的拉取请求(pull request),可以很容易地贡献更多代码和修复。最有用的社区贡献将使得导入的快照文件的覆盖面增长,以便归属于某个具体的作者。现在,大约 90,000 个文件(在 160,000 总量之外)通过默认规则指定了作者。类似地,大约有 250 个作者(最初 FreeBSD 那些)仅知道其识别号。两个都列在了 build 仓库的 unmatched 目录里,欢迎贡献数据。进一步,BSD SCCS 和 FreeBSD CVS 的提交共享相同的作者和时间戳,这些可以结合成一个单独的 Git 提交。导入 SCCS 文件提交的支持会被添加进来,以便引入仓库对应的元数据。最后,也是最重要的,开源系统的更多分支会添加进来,比如 NetBSD、 OpenBSD、DragonFlyBSD 和 *illumos*。理想情况下,其他历史上重要的 Unix 发行版,如 System III、System V、 NeXTSTEP 和 SunOS 等的当前版权拥有者,也会在一个允许他们的合作伙伴使用仓库用于研究的协议下释出他们的系统。
|
||||
|
||||
### 鸣谢 ###
|
||||
|
||||
本文作者感谢很多付出努力的人们。 Brian W. Kernighan, Doug McIlroy 和 Arnold D. Robbins 在贝尔实验室(Bell Labs)的登录识别号方面提供了帮助。 Clem Cole, Era Erikson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze 和 Anatole Shaw 在 BSD 的登录识别号方面提供了帮助。BSD SCCS 的导入代码是基于 H. Merijn Brand 和 Jonathan Gray 的工作。
|
||||
|
||||
这次研究由欧盟 ( 欧洲社会基金(European Social Fund,ESF)) 和 希腊国家基金(Greek national funds)通过国家战略参考框架( National Strategic Reference Framework ,NSRF) 的 Operational Program " Education and Lifelong Learning" - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform ,共同出资赞助。
|
||||
|
||||
### 引用 ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
|
||||
[[2]][32]
|
||||
D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
|
||||
|
||||
[[3]][33]
|
||||
D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
|
||||
|
||||
[[4]][34]
|
||||
P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
|
||||
|
||||
[[5]][35]
|
||||
E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
|
||||
|
||||
[[6]][36]
|
||||
M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
|
||||
|
||||
----------
|
||||
|
||||
#### 脚注 ####
|
||||
|
||||
[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
|
||||
|
||||
[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
|
||||
|
||||
[3][40] - [http://www.tuhs.org/archive_sites.html][41]
|
||||
|
||||
[4][42] - [https://www.mckusick.com/csrg/][43]
|
||||
|
||||
[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
|
||||
|
||||
[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
|
||||
|
||||
[7][48] - [https://github.com/freebsd/freebsd][49]
|
||||
|
||||
[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
|
||||
|
||||
[9][52] - [https://github.com/dspinellis/unix-history-make][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
作者:Diomidis Spinellis
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
|
||||
[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
|
||||
[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
|
||||
[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
|
||||
[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
|
||||
[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
|
||||
[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
|
||||
[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
|
||||
[9]:https://github.com/dspinellis/unix-history-repo
|
||||
[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
|
||||
[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
|
||||
[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
|
||||
[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[14]:http://www.tuhs.org/archive_sites.html
|
||||
[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
|
||||
[16]:https://www.mckusick.com/csrg/
|
||||
[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
|
||||
[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
|
||||
[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
|
||||
[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
|
||||
[23]:https://github.com/freebsd/freebsd
|
||||
[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
|
||||
[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
|
||||
[27]:https://github.com/dspinellis/unix-history-make
|
||||
[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
|
||||
[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
|
||||
[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
|
||||
[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
|
||||
[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
|
||||
[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
|
||||
[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
|
||||
[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
|
||||
[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
|
||||
[38]:https://github.com/dspinellis/unix-history-repo
|
||||
[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
|
||||
[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
|
||||
[41]:http://www.tuhs.org/archive_sites.html
|
||||
[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
|
||||
[43]:https://www.mckusick.com/csrg/
|
||||
[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
|
||||
[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
|
||||
[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
|
||||
[49]:https://github.com/freebsd/freebsd
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
@ -1,19 +1,18 @@
|
||||
|
||||
提高 WordPress 性能的9个技巧
|
||||
深入浅出讲述提升 WordPress 性能的九大秘笈
|
||||
================================================================================
|
||||
|
||||
关于建站和 web 应用程序交付,WordPress 是全球最大的一个平台。全球大约 [四分之一][1] 的站点现在正在使用开源 WordPress 软件,包括 eBay, Mozilla, RackSpace, TechCrunch, CNN, MTV,纽约时报,华尔街日报。
|
||||
在建站和 web 应用程序交付方面,WordPress 是全球最大的一个平台。全球大约[四分之一][1] 的站点现在正在使用开源 WordPress 软件,包括 eBay、 Mozilla、 RackSpace、 TechCrunch、 CNN、 MTV、纽约时报、华尔街日报 等等。
|
||||
|
||||
WordPress.com,对于用户创建博客平台是最流行的,其也运行在WordPress 开源软件上。[NGINX powers WordPress.com][2]。许多 WordPress 用户刚开始在 WordPress.com 上建站,然后移动到搭载着 WordPress 开源软件的托管主机上;其中大多数站点都使用 NGINX 软件。
|
||||
最流行的个人博客平台 WordPress.com,其也运行在 WordPress 开源软件上。[而 NGINX 则为 WordPress.com 提供了动力][2]。在 WordPress.com 的用户当中,许多站点起步于 WordPress.com,然后换成了自己运行 WordPress 开源软件;它们中越来越多的站点也使用了 NGINX 软件。
|
||||
|
||||
WordPress 的吸引力是它的简单性,无论是安装启动或者对于终端用户的使用。然而,当使用量不断增长时,WordPress 站点的体系结构也存在一定的问题 - 这里几个方法,包括使用缓存以及组合 WordPress 和 NGINX,可以解决这些问题。
|
||||
WordPress 的吸引力源于其简单性,无论是对于最终用户还是安装架设。然而,当使用量不断增长时,WordPress 站点的体系结构也存在一定的问题 - 这里有几个方法,包括使用缓存,以及将 WordPress 和 NGINX 组合起来,可以解决这些问题。
|
||||
|
||||
在这篇博客中,我们提供了9个技巧来进行优化,以帮助你解决 WordPress 中一些常见的性能问题:
|
||||
在这篇博客中,我们提供了九个提速技巧来帮助你解决 WordPress 中一些常见的性能问题:
|
||||
|
||||
- [缓存静态资源][3]
|
||||
- [缓存动态文件][4]
|
||||
- [使用 NGINX][5]
|
||||
- [添加支持 NGINX 的链接][6]
|
||||
- [迁移到 NGINX][5]
|
||||
- [添加 NGINX 静态链接支持][6]
|
||||
- [为 NGINX 配置 FastCGI][7]
|
||||
- [为 NGINX 配置 W3_Total_Cache][8]
|
||||
- [为 NGINX 配置 WP-Super-Cache][9]
|
||||
@ -22,39 +21,39 @@ WordPress 的吸引力是它的简单性,无论是安装启动或者对于终
|
||||
|
||||
### 在 LAMP 架构下 WordPress 的性能 ###
|
||||
|
||||
大多数 WordPress 站点都运行在传统的 LAMP 架构下:Linux 操作系统,Apache Web 服务器软件,MySQL 数据库软件 - 通常是一个单独的数据库服务器 - 和 PHP 编程语言。这些都是非常著名的,广泛应用的开源工具。大多数人都将 WordPress “称为” LAMP,并且很容易寻求帮助和支持。
|
||||
大多数 WordPress 站点都运行在传统的 LAMP 架构下:Linux 操作系统,Apache Web 服务器软件,MySQL 数据库软件(通常是一个单独的数据库服务器)和 PHP 编程语言。这些都是非常著名的,广泛应用的开源工具。在 WordPress 世界里,很多人都用的是 LAMP,所以很容易寻求帮助和支持。
|
||||
|
||||
当用户访问 WordPress 站点时,浏览器为每个用户创建六到八个连接来运行 Linux/Apache 的组合。当用户请求连接时,每个页面的 PHP 文件开始飞速的从 MySQL 数据库争夺资源来响应请求。
|
||||
当用户访问 WordPress 站点时,浏览器为每个用户创建六到八个连接来连接到 Linux/Apache 上。当用户请求连接时,PHP 即时生成每个页面,从 MySQL 数据库获取资源来响应请求。
|
||||
|
||||
LAMP 对于数百个并发用户依然能照常工作。然而,流量突然增加是常见的并且 - 通常是 - 一件好事。
|
||||
LAMP 或许对于数百个并发用户依然能照常工作。然而,流量突然增加是常见的,并且通常这应该算是一件好事。
|
||||
|
||||
但是,当 LAMP 站点变得繁忙时,当同时在线的用户达到数千个时,它的瓶颈就会被暴露出来。瓶颈存在主要是两个原因:
|
||||
|
||||
1. Apache Web 服务器 - Apache 为每一个连接需要消耗大量资源。如果 Apache 接受了太多的并发连接,内存可能会耗尽,性能急剧降低,因为数据必须使用磁盘进行交换。如果以限制连接数来提高响应时间,新的连接必须等待,这也导致了用户体验变得很差。
|
||||
1. Apache Web 服务器 - Apache 的每个/每次连接需要消耗大量资源。如果 Apache 接受了太多的并发连接,内存可能会耗尽,从而导致性能急剧降低,因为数据必须交换到磁盘了。如果以限制连接数来提高响应时间,新的连接必须等待,这也导致了用户体验变得很差。
|
||||
|
||||
1. PHP/MySQL 的交互 - 总之,一个运行 PHP 和 MySQL 数据库服务器的应用服务器上每秒的请求量不能超过最大限制。当请求的数量超过最大连接数时,用户必须等待。超过最大连接数时也会增加所有用户的响应时间。超过其两倍以上时会出现明显的性能问题。
|
||||
1. PHP/MySQL 的交互 - 一个运行 PHP 和 MySQL 数据库服务器的应用服务器上每秒的请求量有一个最大限制。当请求的数量超过这个最大限制时,用户必须等待。超过这个最大限制时也会增加所有用户的响应时间。超过其两倍以上时会出现明显的性能问题。
|
||||
|
||||
LAMP 架构的网站一般都会出现性能瓶颈,这时就需要升级硬件了 - 加 CPU,扩大磁盘空间等等。当 Apache 和 PHP/MySQL 的架构负载运行后,在硬件上不断的提升无法保证对系统资源指数增长的需求。
|
||||
LAMP 架构的网站出现性能瓶颈是常见的情况,这时就需要升级硬件了 - 增加 CPU,扩大磁盘空间等等。当 Apache 和 PHP/MySQL 的架构超载后,在硬件上不断的提升却跟不上系统资源指数增长的需求。
|
||||
|
||||
最先取代 LAMP 架构的是 LEMP 架构 – Linux, NGINX, MySQL, 和 PHP。 (这是 LEMP 的缩写,E 代表着 “engine-x.” 的发音。) 我们在 [技巧 3][12] 中会描述 LEMP 架构。
|
||||
首选替代 LAMP 架构的是 LEMP 架构 – Linux, NGINX, MySQL, 和 PHP。 (这是 LEMP 的缩写,E 代表着 “engine-x.” 的发音。) 我们在 [技巧 3][12] 中会描述 LEMP 架构。
|
||||
|
||||
### 技巧 1. 缓存静态资源 ###
|
||||
|
||||
静态资源是指不变的文件,像 CSS,JavaScript 和图片。这些文件往往在网页的数据中占半数以上。页面的其余部分是动态生成的,像在论坛中评论,仪表盘的性能,或个性化的内容(可以看看Amazon.com 产品)。
|
||||
静态资源是指不变的文件,像 CSS,JavaScript 和图片。这些文件往往在网页的数据中占半数以上。页面的其余部分是动态生成的,像在论坛中评论,性能仪表盘,或个性化的内容(可以看看 Amazon.com 产品)。
|
||||
|
||||
缓存静态资源有两大好处:
|
||||
|
||||
- 更快的交付给用户 - 用户从他们浏览器的缓存或者从互联网上离他们最近的缓存服务器获取静态文件。有时候文件较大,因此减少等待时间对他们来说帮助很大。
|
||||
- 更快的交付给用户 - 用户可以从它们浏览器的缓存或者从互联网上离它们最近的缓存服务器获取静态文件。有时候文件较大,因此减少等待时间对它们来说帮助很大。
|
||||
|
||||
- 减少应用服务器的负载 - 从缓存中检索到的每个文件会让 web 服务器少处理一个请求。你的缓存越多,用户等待的时间越短。
|
||||
|
||||
要让浏览器缓存文件,需要早在静态文件中设置正确的 HTTP 首部。当看到 HTTP Cache-Control 首部时,特别设置了 max-age,Expires 首部,以及 Entity 标记。[这里][13] 有详细的介绍。
|
||||
要让浏览器缓存文件,需要在静态文件中设置正确的 HTTP 首部。看看 HTTP Cache-Control 首部,特别是设置了 max-age 参数,Expires 首部,以及 Entity 标记。[这里][13] 有详细的介绍。
|
||||
|
||||
当启用本地缓存然后用户请求以前访问过的文件时,浏览器首先检查该文件是否在缓存中。如果在,它会询问 Web 服务器该文件是否改变过。如果该文件没有改变,Web 服务器将立即响应一个304状态码(未改变),这意味着该文件没有改变,而不是返回状态码200 OK,然后继续检索并发送已改变的文件。
|
||||
当启用本地缓存,然后用户请求以前访问过的文件时,浏览器首先检查该文件是否在缓存中。如果在,它会询问 Web 服务器该文件是否改变过。如果该文件没有改变,Web 服务器将立即响应一个304状态码(未改变),这意味着该文件没有改变,而不是返回状态码200 OK 并检索和发送已改变的文件。
|
||||
|
||||
为了支持浏览器以外的缓存,可以考虑下面的方法,内容分发网络(CDN)。CDN 是一种流行且强大的缓存工具,但我们在这里不详细描述它。可以想一下 CDN 背后的支撑技术的实现。此外,当你的站点从 HTTP/1.x 过渡到 HTTP/2 协议时,CDN 的用处可能不太大;根据需要调查和测试,找到你网站需要的正确方法。
|
||||
要在浏览器之外支持缓存,可以考虑下面讲到的技巧,以及考虑使用内容分发网络(CDN)。CDN 是一种流行且强大的缓存工具,但我们在这里不详细描述它。在你实现了这里讲到的其它技术之后可以考虑 CDN。此外,当你的站点从 HTTP/1.x 过渡到 HTTP/2 协议时,CDN 的用处可能不太大;根据需要调查和测试,找到你网站需要的正确方法。
|
||||
|
||||
如果你转向 NGINX Plus 或开源的 NGINX 软件作为架构的一部分,建议你考虑 [技巧 3][14],然后配置 NGINX 缓存静态资源。使用下面的配置,用你 Web 服务器的 URL 替换 www.example.com。
|
||||
如果你转向 NGINX Plus 或将开源的 NGINX 软件作为架构的一部分,建议你考虑 [技巧 3][14],然后配置 NGINX 缓存静态资源。使用下面的配置,用你 Web 服务器的 URL 替换 www.example.com。
|
||||
|
||||
server {
|
||||
# substitute your web server's URL for www.example.com
|
||||
@ -86,63 +85,63 @@ LAMP 对于数百个并发用户依然能照常工作。然而,流量突然增
|
||||
|
||||
### 技巧 2. 缓存动态文件 ###
|
||||
|
||||
WordPress 是动态生成的网页,这意味着每次请求时它都要生成一个给定的网页(即使和前一次的结果相同)。这意味着用户随时获得的是最新内容。
|
||||
WordPress 动态地生成网页,这意味着每次请求时它都要生成一个给定的网页(即使和前一次的结果相同)。这意味着用户随时获得的是最新内容。
|
||||
|
||||
想一下,当用户访问一个帖子时,并在文章底部有用户的评论时。你希望用户能够看到所有的评论 - 即使评论刚刚发布。动态内容就是处理这种情况的。
|
||||
|
||||
但现在,当帖子每秒出现十几二十几个请求时。应用服务器可能每秒需要频繁生成页面导致其压力过大,造成延误。为了给用户提供最新的内容,每个访问理论上都是新的请求,因此他们也不得不在首页等待。
|
||||
但现在,当帖子每秒出现十几二十几个请求时。应用服务器可能每秒需要频繁生成页面导致其压力过大,造成延误。为了给用户提供最新的内容,每个访问理论上都是新的请求,因此它们不得不在原始出处等待很长时间。
|
||||
|
||||
为了防止页面由于负载过大变得缓慢,需要缓存动态文件。这需要减少文件的动态内容来提高整个系统的响应速度。
|
||||
为了防止页面由于不断提升的负载而变得缓慢,需要缓存动态文件。这需要减少文件的动态内容来提高整个系统的响应速度。
|
||||
|
||||
要在 WordPress 中启用缓存中,需要使用一些流行的插件 - 如下所述。WordPress 的缓存插件需要刷新页面,然后将其缓存短暂时间 - 也许只有几秒钟。因此,如果该网站每秒中只有几个请求,那大多数用户获得的页面都是缓存的副本。这也有助于提高所有用户的检索时间:
|
||||
要在 WordPress 中启用缓存中,需要使用一些流行的插件 - 如下所述。WordPress 的缓存插件会请求最新的页面,然后将其缓存短暂时间 - 也许只有几秒钟。因此,如果该网站每秒中会有几个请求,那大多数用户获得的页面都是缓存的副本。这也有助于提高所有用户的检索时间:
|
||||
|
||||
- 大多数用户获得页面的缓存副本。应用服务器没有做任何工作。
|
||||
- 用户很快会得到一个新的副本。应用服务器只需每隔一段时间刷新页面。当服务器产生一个新的页面(对于第一个用户访问后,缓存页过期),它这样做要快得多,因为它的请求不会超载。
|
||||
- 用户会得到一个之前的崭新副本。应用服务器只需每隔一段时间生成一个崭新页面。当服务器产生一个崭新页面(对于缓存过期后的第一个用户访问),它这样做要快得多,因为它的请求并没有超载。
|
||||
|
||||
你可以缓存运行在 LAMP 架构或者 [LEMP 架构][15] 上 WordPress 的动态文件(在 [技巧 3][16] 中说明了)。有几个缓存插件,你可以在 WordPress 中使用。这里有最流行的缓存插件和缓存技术,从最简单到最强大的:
|
||||
你可以缓存运行在 LAMP 架构或者 [LEMP 架构][15] 上 WordPress 的动态文件(在 [技巧 3][16] 中说明了)。有几个缓存插件,你可以在 WordPress 中使用。运用到了最流行的缓存插件和缓存技术,从最简单到最强大的:
|
||||
|
||||
- [Hyper-Cache][17] 和 [Quick-Cache][18] – 这两个插件为每个 WordPress 页面创建单个 PHP 文件。它支持的一些动态函数会绕过多个 WordPress 与数据库的连接核心处理,创建一个更快的用户体验。他们不会绕过所有的 PHP 处理,所以使用以下选项他们不能给出相同的性能提升。他们也不需要修改 NGINX 的配置。
|
||||
- [Hyper-Cache][17] 和 [Quick-Cache][18] – 这两个插件为每个 WordPress 页面创建单个 PHP 文件。它支持绕过多个 WordPress 与数据库的连接核心处理的一些动态功能,创建一个更快的用户体验。它们不会绕过所有的 PHP 处理,所以并不会如下面那些取得同样的性能提升。它们也不需要修改 NGINX 的配置。
|
||||
|
||||
- [WP Super Cache][19] – 最流行的 WordPress 缓存插件。它有许多功能,它的界面非常简洁,如下图所示。我们展示了 NGINX 一个简单的配置实例在 [技巧 7][20] 中。
|
||||
- [WP Super Cache][19] – 最流行的 WordPress 缓存插件。在它易用的界面易用上提供了许多功能,如下所示。我们在 [技巧 7][20] 中展示了一个简单的 NGINX 配置实例。
|
||||
|
||||
- [W3 Total Cache][21] – 这是第二大最受欢迎的 WordPress 缓存插件。它比 WP Super Cache 的功能更强大,但它有些配置选项比较复杂。一个 NGINX 的简单配置,请看 [技巧 6][22]。
|
||||
- [W3 Total Cache][21] – 这是第二流行的 WordPress 缓存插件。它比 WP Super Cache 的功能更强大,但它有些配置选项比较复杂。样例 NGINX 配置,请看 [技巧 6][22]。
|
||||
|
||||
- [FastCGI][23] – CGI 代表通用网关接口,在因特网上发送请求和接收文件。它不是一个插件只是一种能直接使用缓存的方法。FastCGI 可以被用在 Apache 和 Nginx 上,它也是最流行的动态缓存方法;我们在 [技巧 5][24] 中描述了如何配置 NGINX 来使用它。
|
||||
- [FastCGI][23] – CGI 的意思是通用网关接口( Common Gateway Interface),在因特网上发送请求和接收文件的一种通用方式。它不是一个插件,而是一种与缓存交互缓存的方法。FastCGI 可以被用在 Apache 和 Nginx 上,它也是最流行的动态缓存方法;我们在 [技巧 5][24] 中描述了如何配置 NGINX 来使用它。
|
||||
|
||||
这些插件的技术文档解释了如何在 LAMP 架构中配置它们。配置选项包括数据库和对象缓存;也包括使用 HTML,CSS 和 JavaScript 来构建 CDN 集成环境。对于 NGINX 的配置,请看列表中的提示技巧。
|
||||
这些插件和技术的文档解释了如何在典型的 LAMP 架构中配置它们。配置方式包括数据库和对象缓存;最小化 HTML、CSS 和 JavaScript;集成流行的 CDN 集成环境。对于 NGINX 的配置,请看列表中的提示技巧。
|
||||
|
||||
**注意**:WordPress 不能缓存用户的登录信息,因为它们的 WordPress 页面都是不同的。(对于大多数网站来说,只有一小部分用户可能会登录),大多数缓存不会对刚刚评论过的用户显示缓存页面,只有当用户刷新页面时才会看到他们的评论。若要缓存页面的非个性化内容,如果它对整体性能来说很重要,可以使用一种称为 [fragment caching][25] 的技术。
|
||||
**注意**:缓存不会用于已经登录的 WordPress 用户,因为他们的 WordPress 页面都是不同的。(对于大多数网站来说,只有一小部分用户可能会登录)此外,大多数缓存不会对刚刚评论过的用户显示缓存页面,因为当用户刷新页面时希望看到他们的评论。若要缓存页面的非个性化内容,如果它对整体性能来说很重要,可以使用一种称为 [碎片缓存(fragment caching)][25] 的技术。
|
||||
|
||||
### 技巧 3. 使用 NGINX ###
|
||||
|
||||
如上所述,当并发用户数超过某一值时 Apache 会导致性能问题 – 可能数百个用户同时使用。Apache 对于每一个连接会消耗大量的资源,因而容易耗尽内存。Apache 可以配置连接数的值来避免耗尽内存,但是这意味着,超过限制时,新的连接请求必须等待。
|
||||
如上所述,当并发用户数超过某一数量时 Apache 会导致性能问题 – 可能是数百个用户同时使用。Apache 对于每一个连接会消耗大量的资源,因而容易耗尽内存。Apache 可以配置连接数的值来避免耗尽内存,但是这意味着,超过限制时,新的连接请求必须等待。
|
||||
|
||||
此外,Apache 使用 mod_php 模块将每一个连接加载到内存中,即使只有静态文件(图片,CSS,JavaScript 等)。这使得每个连接消耗更多的资源,从而限制了服务器的性能。
|
||||
此外,Apache 为每个连接加载一个 mod_php 模块副本到内存中,即使只有服务于静态文件(图片,CSS,JavaScript 等)。这使得每个连接消耗更多的资源,从而限制了服务器的性能。
|
||||
|
||||
开始解决这些问题吧,从 LAMP 架构迁到 LEMP 架构 – 使用 NGINX 取代 Apache 。NGINX 仅消耗很少量的内存就能处理成千上万的并发连接数,所以你不必经历颠簸,也不必限制并发连接数。
|
||||
要解决这些问题,从 LAMP 架构迁到 LEMP 架构 – 使用 NGINX 取代 Apache 。NGINX 在一定的内存之下就能处理成千上万的并发连接数,所以你不必经历颠簸,也不必限制并发连接数到很小的数量。
|
||||
|
||||
NGINX 处理静态文件的性能也较好,它有内置的,简单的 [缓存][26] 控制策略。减少应用服务器的负载,你的网站的访问速度会更快,用户体验更好。
|
||||
NGINX 处理静态文件的性能也较好,它有内置的,容易调整的 [缓存][26] 控制策略。减少应用服务器的负载,你的网站的访问速度会更快,用户体验更好。
|
||||
|
||||
你可以在部署的所有 Web 服务器上使用 NGINX,或者你可以把一个 NGINX 服务器作为 Apache 的“前端”来进行反向代理 - NGINX 服务器接收客户端请求,将请求的静态文件直接返回,将 PHP 请求转发到 Apache 上进行处理。
|
||||
你可以在部署环境的所有 Web 服务器上使用 NGINX,或者你可以把一个 NGINX 服务器作为 Apache 的“前端”来进行反向代理 - NGINX 服务器接收客户端请求,将请求的静态文件直接返回,将 PHP 请求转发到 Apache 上进行处理。
|
||||
|
||||
对于动态页面的生成 - WordPress 核心体验 - 选择一个缓存工具,如 [技巧 2][27] 中描述的。在下面的技巧中,你可以看到 FastCGI,W3_Total_Cache 和 WP-Super-Cache 在 NGINX 上的配置示例。 (Hyper-Cache 和 Quick-Cache 不需要改变 NGINX 的配置。)
|
||||
对于动态页面的生成,这是 WordPress 核心体验,可以选择一个缓存工具,如 [技巧 2][27] 中描述的。在下面的技巧中,你可以看到 FastCGI,W3\_Total\_Cache 和 WP-Super-Cache 在 NGINX 上的配置示例。 (Hyper-Cache 和 Quick-Cache 不需要改变 NGINX 的配置。)
|
||||
|
||||
**技巧** 缓存通常会被保存到磁盘上,但你可以用 [tmpfs][28] 将缓存放在内存中来提高性能。
|
||||
|
||||
为 WordPress 配置 NGINX 很容易。按照这四个步骤,其详细的描述在指定的技巧中:
|
||||
为 WordPress 配置 NGINX 很容易。仅需四步,其详细的描述在指定的技巧中:
|
||||
|
||||
1.添加永久的支持 - 添加对 NGINX 的永久支持。此步消除了对 **.htaccess** 配置文件的依赖,这是 Apache 特有的。参见 [技巧 4][29]
|
||||
2.配置缓存 - 选择一个缓存工具并安装好它。可选择的有 FastCGI cache,W3 Total Cache, WP Super Cache, Hyper Cache, 和 Quick Cache。请看技巧 [5][30], [6][31], 和 [7][32].
|
||||
3.落实安全防范措施 - 在 NGINX 上采用对 WordPress 最佳安全的做法。参见 [技巧 8][33]。
|
||||
4.配置 WordPress 多站点 - 如果你使用 WordPress 多站点,在 NGINX 下配置子目录,子域,或多个域的结构。见 [技巧9][34]。
|
||||
1. 添加永久链接的支持 - 让 NGINX 支持永久链接。此步消除了对 **.htaccess** 配置文件的依赖,这是 Apache 特有的。参见 [技巧 4][29]。
|
||||
2. 配置缓存 - 选择一个缓存工具并安装好它。可选择的有 FastCGI cache,W3 Total Cache, WP Super Cache, Hyper Cache, 和 Quick Cache。请看技巧 [5][30]、 [6][31] 和 [7][32]。
|
||||
3. 落实安全防范措施 - 在 NGINX 上采用对 WordPress 最佳安全的做法。参见 [技巧 8][33]。
|
||||
4. 配置 WordPress 多站点 - 如果你使用 WordPress 多站点,在 NGINX 下配置子目录,子域,或多域名架构。见 [技巧9][34]。
|
||||
|
||||
### 技巧 4. 添加支持 NGINX 的链接 ###
|
||||
### 技巧 4. 让 NGINX 支持永久链接 ###
|
||||
|
||||
许多 WordPress 网站依靠 **.htaccess** 文件,此文件依赖 WordPress 的多个功能,包括永久支持,插件和文件缓存。NGINX 不支持 **.htaccess** 文件。幸运的是,你可以使用 NGINX 的简单而全面的配置文件来实现大部分相同的功能。
|
||||
许多 WordPress 网站依赖于 **.htaccess** 文件,此文件为 WordPress 的多个功能所需要,包括永久链接支持、插件和文件缓存。NGINX 不支持 **.htaccess** 文件。幸运的是,你可以使用 NGINX 的简单而全面的配置文件来实现大部分相同的功能。
|
||||
|
||||
你可以在使用 NGINX 的 WordPress 中通过在主 [server][36] 块下添加下面的 location 块中启用 [永久链接][35]。(此 location 块在其他代码示例中也会被包括)。
|
||||
你可以在你的主 [server][36] 块下添加下面的 location 块中为使用 NGINX 的 WordPress 启用 [永久链接][35]。(此 location 块在其它代码示例中也会被包括)。
|
||||
|
||||
**try_files** 指令告诉 NGINX 检查请求的 URL 在根目录下是作为文件(**$uri**)还是目录(**$uri/**),**/var/www/example.com/htdocs**。如果都不是,NGINX 将重定向到 **/index.php**,通过查询字符串参数判断是否作为参数。
|
||||
**try_files** 指令告诉 NGINX 检查请求的 URL 在文档根目录(**/var/www/example.com/htdocs**)下是作为文件(**$uri**)还是目录(**$uri/**) 存在的。如果都不是,NGINX 将重定向到 **/index.php**,并传递查询字符串参数作为参数。
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
@ -159,17 +158,17 @@ NGINX 处理静态文件的性能也较好,它有内置的,简单的 [缓存
|
||||
|
||||
### 技巧 5. 在 NGINX 中配置 FastCGI ###
|
||||
|
||||
NGINX 可以从 FastCGI 应用程序中缓存响应,如 PHP 响应。此方法可提供最佳的性能。
|
||||
NGINX 可以缓存来自 FastCGI 应用程序的响应,如 PHP 响应。此方法可提供最佳的性能。
|
||||
|
||||
对于开源的 NGINX,第三方模块 [ngx_cache_purge][37] 提供了缓存清除能力,需要手动编译,配置代码如下所示。NGINX Plus 已经包含了此代码的实现。
|
||||
对于开源的 NGINX,编译入第三方模块 [ngx\_cache\_purge][37] 可以提供缓存清除能力,配置代码如下所示。NGINX Plus 已经包含了它自己实现此代码。
|
||||
|
||||
当使用 FastCGI 时,我们建议你安装 [NGINX 辅助插件][38] 并使用下面的配置文件,尤其是要使用 **fastcgi_cache_key** 并且 location 块下要包括 **fastcgi_cache_purge**。当页面被发布或有改变时,甚至有新评论被发布时,该插件会自动清除你的缓存,你也可以从 WordPress 管理控制台手动清除。
|
||||
当使用 FastCGI 时,我们建议你安装 [NGINX 辅助插件][38] 并使用下面的配置文件,尤其是要注意 **fastcgi\_cache\_key** 的使用和包括 **fastcgi\_cache\_purge** 的 location 块。当页面发布或有改变时,有新评论被发布时,该插件会自动清除你的缓存,你也可以从 WordPress 管理控制台手动清除。
|
||||
|
||||
NGINX 的辅助插件还可以添加一个简短的 HTML 代码到你网页的底部,确认缓存是否正常并显示一些统计工作。(你也可以使用 [$upstream_cache_status][39] 确认缓存功能是否正常。)
|
||||
NGINX 的辅助插件还可以在你网页的底部添加一个简短的 HTML 代码,以确认缓存是否正常并显示一些统计数据。(你也可以使用 [$upstream\_cache\_status][39] 确认缓存功能是否正常。)
|
||||
|
||||
fastcgi_cache_path /var/run/nginx-cache levels=1:2
|
||||
fastcgi_cache_path /var/run/nginx-cache levels=1:2
|
||||
keys_zone=WORDPRESS:100m inactive=60m;
|
||||
fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
@ -181,7 +180,7 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
set $skip_cache 0;
|
||||
|
||||
# POST 请求和查询网址的字符串应该交给 PHP
|
||||
# POST 请求和带有查询参数的网址应该交给 PHP
|
||||
if ($request_method = POST) {
|
||||
set $skip_cache 1;
|
||||
}
|
||||
@ -196,7 +195,7 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
set $skip_cache 1;
|
||||
}
|
||||
|
||||
#用户不能使用缓存登录或缓存最近的评论
|
||||
#不要为登录用户或最近的评论者进行缓存
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+|wp-postpass
|
||||
|wordpress_no_cache|wordpress_logged_in") {
|
||||
set $skip_cache 1;
|
||||
@ -240,13 +239,13 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
}
|
||||
}
|
||||
|
||||
### 技巧 6. 为 NGINX 配置 W3_Total_Cache ###
|
||||
### 技巧 6. 为 NGINX 配置 W3\_Total\_Cache ###
|
||||
|
||||
[W3 Total Cache][40], 是 Frederick Townes 的 [W3-Edge][41] 下的, 是一个支持 NGINX 的 WordPress 缓存框架。其有众多选项配置,可以替代 FastCGI 缓存。
|
||||
[W3 Total Cache][40], 是 [W3-Edge][41] 的 Frederick Townes 出品的, 是一个支持 NGINX 的 WordPress 缓存框架。其有众多选项配置,可以替代 FastCGI 缓存。
|
||||
|
||||
缓存插件提供了各种缓存配置,还包括数据库和对象的缓存,对 HTML,CSS 和 JavaScript,可选择性的与流行的 CDN 整合。
|
||||
这个缓存插件提供了各种缓存配置,还包括数据库和对象的缓存,最小化 HTML、CSS 和 JavaScript,并可选与流行的 CDN 整合。
|
||||
|
||||
使用插件时,需要将其配置信息写入位于你的域的根目录的 NGINX 配置文件中。
|
||||
这个插件会通过写入一个位于你的域的根目录的 NGINX 配置文件来控制 NGINX。
|
||||
|
||||
server {
|
||||
server_name example.com www.example.com;
|
||||
@ -271,11 +270,11 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
### 技巧 7. 为 NGINX 配置 WP Super Cache ###
|
||||
|
||||
[WP Super Cache][42] 是由 Donncha O Caoimh 完成的, [Automattic][43] 上的一个 WordPress 开发者, 这是一个 WordPress 缓存引擎,它可以将 WordPress 的动态页面转变成静态 HTML 文件,以使 NGINX 可以很快的提供服务。它是第一个 WordPress 缓存插件,和其他的相比,它更专注于某一特定的领域。
|
||||
[WP Super Cache][42] 是由 Donncha O Caoimh 开发的, 他是 [Automattic][43] 的一个 WordPress 开发者, 这是一个 WordPress 缓存引擎,它可以将 WordPress 的动态页面转变成静态 HTML 文件,以使 NGINX 可以很快的提供服务。它是第一个 WordPress 缓存插件,和其它的相比,它更专注于某一特定的领域。
|
||||
|
||||
配置 NGINX 使用 WP Super Cache 可以根据你的喜好而进行不同的配置。以下是一个示例配置。
|
||||
|
||||
在下面的配置中,location 块中使用了名为 WP Super Cache 的超级缓存中部分配置来工作。代码的其余部分是根据 WordPress 的规则不缓存用户登录信息,不缓存 POST 请求,并对静态资源设置过期首部,再加上标准的 PHP 实现;这部分可以进行定制,来满足你的需求。
|
||||
在下面的配置中,带有名为 supercache 的 location 块是 WP Super Cache 特有的部分。 WordPress 规则的其余代码用于不缓存已登录用户的信息,不缓存 POST 请求,并对静态资源设置过期首部,再加上标准的 PHP 处理;这部分可以根据你的需求进行定制。
|
||||
|
||||
|
||||
server {
|
||||
@ -288,7 +287,7 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
set $cache_uri $request_uri;
|
||||
|
||||
# POST 请求和查询网址的字符串应该交给 PHP
|
||||
# POST 请求和带有查询字符串的网址应该交给 PHP
|
||||
if ($request_method = POST) {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
@ -305,13 +304,13 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
#用户不能使用缓存登录或缓存最近的评论
|
||||
#不对已登录用户和最近的评论者使用缓存
|
||||
if ($http_cookie ~* "comment_author|wordpress_[a-f0-9]+
|
||||
|wp-postpass|wordpress_logged_in") {
|
||||
set $cache_uri 'null cache';
|
||||
}
|
||||
|
||||
#当请求的文件存在时使用缓存,否则将请求转发给WordPress
|
||||
#当请求的文件存在时使用缓存,否则将请求转发给 WordPress
|
||||
location / {
|
||||
try_files /wp-content/cache/supercache/$http_host/$cache_uri/index.html
|
||||
$uri $uri/ /index.php;
|
||||
@ -346,7 +345,7 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
### 技巧 8. 为 NGINX 配置安全防范措施 ###
|
||||
|
||||
为了防止攻击,可以控制对关键资源的访问以及当机器超载时进行登录限制。
|
||||
为了防止攻击,可以控制对关键资源的访问并限制机器人对登录功能的过量攻击。
|
||||
|
||||
只允许特定的 IP 地址访问 WordPress 的仪表盘。
|
||||
|
||||
@ -365,14 +364,14 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
deny all;
|
||||
}
|
||||
|
||||
拒绝其他人访问 WordPress 的配置文件 **wp-config.php**。拒绝其他人访问的另一种方法是将该文件的一个目录移到域的根目录下。
|
||||
拒绝其它人访问 WordPress 的配置文件 **wp-config.php**。拒绝其它人访问的另一种方法是将该文件的一个目录移到域的根目录之上的目录。
|
||||
|
||||
# 拒绝其他人访问 wp-config.php
|
||||
# 拒绝其它人访问 wp-config.php
|
||||
location ~* wp-config.php {
|
||||
deny all;
|
||||
}
|
||||
|
||||
对 **wp-login.php** 进行限速来防止暴力攻击。
|
||||
对 **wp-login.php** 进行限速来防止暴力破解。
|
||||
|
||||
# 拒绝访问 wp-login.php
|
||||
location = /wp-login.php {
|
||||
@ -383,27 +382,27 @@ fastcgi_cache_key "$scheme$request_method$host$request_uri";
|
||||
|
||||
### 技巧 9. 配置 NGINX 支持 WordPress 多站点 ###
|
||||
|
||||
WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单个实例中允许你管理两个或多个网站。[WordPress.com][44] 运行的就是 WordPress 多站点,其主机为成千上万的用户提供博客服务。
|
||||
WordPress 多站点(WordPress Multisite),顾名思义,这个版本 WordPress 可以让你以单个实例管理两个或多个网站。[WordPress.com][44] 运行的就是 WordPress 多站点,其主机为成千上万的用户提供博客服务。
|
||||
|
||||
你可以从单个域的任何子目录或从不同的子域来运行独立的网站。
|
||||
|
||||
使用此代码块添加对子目录的支持。
|
||||
|
||||
# 在 WordPress 中添加支持子目录结构的多站点
|
||||
# 在 WordPress 多站点中添加对子目录结构的支持
|
||||
if (!-e $request_filename) {
|
||||
rewrite /wp-admin$ $scheme://$host$uri/ permanent;
|
||||
rewrite ^(/[^/]+)?(/wp-.*) $2 last;
|
||||
rewrite ^(/[^/]+)?(/.*\.php) $2 last;
|
||||
}
|
||||
|
||||
使用此代码块来替换上面的代码块以添加对子目录结构的支持,子目录名自定义。
|
||||
使用此代码块来替换上面的代码块以添加对子目录结构的支持,替换为你自己的子目录名。
|
||||
|
||||
# 添加支持子域名
|
||||
server_name example.com *.example.com;
|
||||
|
||||
旧版本(3.4以前)的 WordPress 多站点使用 readfile() 来提供静态内容。然而,readfile() 是 PHP 代码,它会导致在执行时性能会显著降低。我们可以用 NGINX 来绕过这个非必要的 PHP 处理。该代码片段在下面被(==============)线分割出来了。
|
||||
|
||||
# 避免 PHP readfile() 在 /blogs.dir/structure 子目录中
|
||||
# 避免对子目录中 /blogs.dir/ 结构执行 PHP readfile()
|
||||
location ^~ /blogs.dir {
|
||||
internal;
|
||||
alias /var/www/example.com/htdocs/wp-content/blogs.dir;
|
||||
@ -414,7 +413,7 @@ WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单
|
||||
|
||||
============================================================
|
||||
|
||||
# 避免 PHP readfile() 在 /files/structure 子目录中
|
||||
# 避免对子目录中 /files/ 结构执行 PHP readfile()
|
||||
location ~ ^(/[^/]+/)?files/(?.+) {
|
||||
try_files /wp-content/blogs.dir/$blogid/files/$rt_file /wp-includes/ms-files.php?file=$rt_file;
|
||||
access_log off;
|
||||
@ -424,7 +423,7 @@ WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单
|
||||
|
||||
============================================================
|
||||
|
||||
# WPMU 文件结构的子域路径
|
||||
# 子域路径的WPMU 文件结构
|
||||
location ~ ^/files/(.*)$ {
|
||||
try_files /wp-includes/ms-files.php?file=$1 =404;
|
||||
access_log off;
|
||||
@ -434,7 +433,7 @@ WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单
|
||||
|
||||
============================================================
|
||||
|
||||
# 地图博客 ID 在特定的目录下
|
||||
# 映射博客 ID 到特定的目录
|
||||
map $http_host $blogid {
|
||||
default 0;
|
||||
example.com 1;
|
||||
@ -444,15 +443,15 @@ WordPress 多站点,顾名思义,使用同一个版本的 WordPress 从单
|
||||
|
||||
### 结论 ###
|
||||
|
||||
可扩展性对许多站点的开发者来说是一项挑战,因为这会让他们在 WordPress 站点中取得成功。(对于那些想要跨越 WordPress 性能问题的新站点。)为 WordPress 添加缓存,并将 WordPress 和 NGINX 结合,是不错的答案。
|
||||
可扩展性对许多要让他们的 WordPress 站点取得成功的开发者来说是一项挑战。(对于那些想要跨越 WordPress 性能门槛的新站点而言。)为 WordPress 添加缓存,并将 WordPress 和 NGINX 结合,是不错的答案。
|
||||
|
||||
NGINX 不仅对 WordPress 网站是有用的。世界上排名前 1000,10,000和100,000网站中 NGINX 也是作为 [领先的 web 服务器][45] 被使用。
|
||||
NGINX 不仅用于 WordPress 网站。世界上排名前 1000、10000 和 100000 网站中 NGINX 也是 [遥遥领先的 web 服务器][45]。
|
||||
|
||||
欲了解更多有关 NGINX 的性能,请看我们最近的博客,[关于 10x 应用程序的 10 个技巧][46]。
|
||||
欲了解更多有关 NGINX 的性能,请看我们最近的博客,[让应用性能提升 10 倍的 10 个技巧][46]。
|
||||
|
||||
NGINX 软件有两个版本:
|
||||
|
||||
- NGINX 开源的软件 - 像 WordPress 一样,此软件你可以自行下载,配置和编译。
|
||||
- NGINX 开源软件 - 像 WordPress 一样,此软件你可以自行下载,配置和编译。
|
||||
- NGINX Plus - NGINX Plus 包括一个预构建的参考版本的软件,以及服务和技术支持。
|
||||
|
||||
想要开始,先到 [nginx.org][47] 下载开源软件并了解下 [NGINX Plus][48]。
|
||||
@ -463,7 +462,7 @@ via: https://www.nginx.com/blog/9-tips-for-improving-wordpress-performance-with-
|
||||
|
||||
作者:[Floyd Smith][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,15 @@
|
||||
|
||||
如何在树莓派2 B型上安装 FreeBSD
|
||||
如何在树莓派 2B 上安装 FreeBSD
|
||||
================================================================================
|
||||
|
||||
在树莓派2 B型上如何安装 FreeBSD 10 或 FreeBSD 11(current)?怎么在 Linux,OS X,FreeBSD 或类 Unix 操作系统上烧录 SD 卡?
|
||||
在树莓派 2B 上如何安装 FreeBSD 10 或 FreeBSD 11(current)?怎么在 Linux,OS X,FreeBSD 或类 Unix 操作系统上烧录 SD 卡?
|
||||
|
||||
在树莓派2 B型上安装 FreeBSD 10或 FreeBSD 11(current)很容易。使用 FreeBSD 操作系统可以打造一个非常易用的 Unix 服务器。FreeBSD-CURRENT 自2012年十一月以来一直支持树莓派,2015年三月份后也开始支持树莓派2了。在这个快速教程中我将介绍如何在 RPI2 上安装 FreeBSD 11 current arm 版。
|
||||
在树莓派 2B 上安装 FreeBSD 10 或 FreeBSD 11(current)很容易。使用 FreeBSD 操作系统可以打造一个非常易用的 Unix 服务器。FreeBSD-CURRENT 自2012年十一月以来一直支持树莓派,2015年三月份后也开始支持树莓派2了。在这个快速教程中我将介绍如何在树莓派 2B 上安装 FreeBSD 11 current arm 版。
|
||||
|
||||
### 1. 下载 FreeBSD-current 的 arm 镜像 ###
|
||||
|
||||
你可以 [访问这个页面来下载][1] 树莓派2的镜像。使用 wget 或 curl 命令来下载镜像:
|
||||
|
||||
|
||||
$ wget ftp://ftp.freebsd.org/pub/FreeBSD/snapshots/arm/armv6/ISO-IMAGES/11.0/FreeBSD-11.0-CURRENT-arm-armv6-RPI2-20151016-r289420.img.xz
|
||||
|
||||
或
|
||||
@ -45,52 +44,51 @@
|
||||
1024+0 records out
|
||||
1073741824 bytes transferred in 661.669584 secs (1622776 bytes/sec)
|
||||
|
||||
#### 使用 Linux/FreeBSD 或者 类 Unix 系统来烧录 FreeBSD-current ####
|
||||
#### 使用 Linux/FreeBSD 或者类 Unix 系统来烧录 FreeBSD-current ####
|
||||
|
||||
语法是这样:
|
||||
|
||||
$ dd if=FreeBSD-11.0-CURRENT-arm-armv6-RPI2-20151016-r289420.img of=/dev/sdb bs=1M
|
||||
|
||||
确保使用实际 SD 卡的设备名称来替换 /dev/sdb 。
|
||||
**确保使用实际的 SD 卡的设备名称来替换 /dev/sdb**(LCTT 译注:千万注意不要写错了)。
|
||||
|
||||
### 4. 引导 FreeBSD ###
|
||||
|
||||
在树莓派2 B型上插入 SD 卡。你需要连接键盘,鼠标和显示器。我使用的是 USB 转串口线来连接显示器的:
|
||||
在树莓派 2B 上插入 SD 卡。你需要连接键盘,鼠标和显示器。我使用的是 USB 转串口线来连接显示器的:
|
||||
|
||||

|
||||
|
||||
|
||||
图01 RPI 基于 USB 的串行连接
|
||||
*图01 基于树莓派 USB 的串行连接*
|
||||
|
||||
在下面的例子中,我使用 screen 命令来连接我的 RPI:
|
||||
|
||||
## Linux version ##
|
||||
## Linux 上 ##
|
||||
screen /dev/tty.USB0 115200
|
||||
|
||||
## OS X version ##
|
||||
## OS X 上 ##
|
||||
screen /dev/cu.usbserial 115200
|
||||
|
||||
## Windows user use Putty.exe ##
|
||||
## Windows 请使用 Putty.exe ##
|
||||
|
||||
FreeBSD RPI 启动输出样例:
|
||||
|
||||

|
||||
|
||||
图01: 在 RPi 2上引导 FreeBSD-current
|
||||
*图02: 在树莓派 2上引导 FreeBSD-current*
|
||||
|
||||
### 5. FreeBSD 在 RPi 2上的用户名和密码 ###
|
||||
|
||||
默认的密码是 freebsd/freebsd 和 root/root。
|
||||
|
||||
到此为止, FreeBSD-current 已经安装并运行在 RPi 2上。
|
||||
到此为止, FreeBSD-current 已经安装并运行在树莓派 2上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/how-to-install-freebsd-on-raspberry-pi-2-model-b/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
在 Ubuntu 15.10 上安装 PostgreSQL 9.4 和 phpPgAdmin
|
||||
在 Ubuntu 上安装世界上最先进的开源数据库 PostgreSQL 9.4 和 phpPgAdmin
|
||||
================================================================================
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
[PostgreSQL][1] 是一款强大的,开源对象关系型数据库系统。它支持所有的主流操作系统,包括 Linux、Unix(AIX、BSD、HP-UX,SGI IRIX、Mac OS、Solaris、Tru64) 以及 Windows 操作系统。
|
||||
[PostgreSQL][1] 是一款强大的,开源的,对象关系型数据库系统。它支持所有的主流操作系统,包括 Linux、Unix(AIX、BSD、HP-UX,SGI IRIX、Mac OS、Solaris、Tru64) 以及 Windows 操作系统。
|
||||
|
||||
下面是 **Ubuntu** 发起者 **Mark Shuttleworth** 对 PostgreSQL 的一段评价。
|
||||
|
||||
> PostgreSQL 真的是一款很好的数据库系统。刚开始我们使用它的时候,并不确定它能否胜任工作。但我错的太离谱了。它很强壮、快速,在各个方面都很专业。
|
||||
> PostgreSQL 是一款极赞的数据库系统。刚开始我们在 Launchpad 上使用它的时候,并不确定它能否胜任工作。但我是错了。它很强壮、快速,在各个方面都很专业。
|
||||
>
|
||||
> — Mark Shuttleworth.
|
||||
|
||||
@ -22,7 +22,7 @@
|
||||
|
||||
如果你需要其它的版本,按照下面那样先添加 PostgreSQL 仓库然后再安装。
|
||||
|
||||
**PostgreSQL apt 仓库** 支持 amd64 和 i386 架构的 Ubuntu 长期支持版(10.04、12.04 和 14.04),以及非长期支持版(14.04)。对于其它非长期支持版,该软件包虽然不能完全支持,但使用和 LTS 版本近似的也能正常工作。
|
||||
**PostgreSQL apt 仓库** 支持 amd64 和 i386 架构的 Ubuntu 长期支持版(10.04、12.04 和 14.04),以及非长期支持版(14.04)。对于其它非长期支持版,该软件包虽然没有完全支持,但使用和 LTS 版本近似的也能正常工作。
|
||||
|
||||
#### Ubuntu 14.10 系统: ####
|
||||
|
||||
@ -36,11 +36,11 @@
|
||||
|
||||
**注意**: 上面的库只能用于 Ubuntu 14.10。还没有升级到 Ubuntu 15.04 和 15.10。
|
||||
|
||||
**Ubuntu 14.04**,添加下面一行:
|
||||
对于 **Ubuntu 14.04**,添加下面一行:
|
||||
|
||||
deb http://apt.postgresql.org/pub/repos/apt/ trusty-pgdg main
|
||||
|
||||
**Ubuntu 12.04**,添加下面一行:
|
||||
对于 **Ubuntu 12.04**,添加下面一行:
|
||||
|
||||
deb http://apt.postgresql.org/pub/repos/apt/ precise-pgdg main
|
||||
|
||||
@ -48,8 +48,6 @@
|
||||
|
||||
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc
|
||||
|
||||
----------
|
||||
|
||||
sudo apt-key add -
|
||||
|
||||
更新软件包列表:
|
||||
@ -66,7 +64,7 @@
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
#### 事例输出: ####
|
||||
#### 示例输出: ####
|
||||
|
||||
psql (9.4.5)
|
||||
Type "help" for help.
|
||||
@ -87,7 +85,7 @@
|
||||
Enter it again:
|
||||
postgres=# \q
|
||||
|
||||
要安装 PostgreSQL Adminpack,在 postgresql 窗口输入下面的命令:
|
||||
要安装 PostgreSQL Adminpack 扩展,在 postgresql 窗口输入下面的命令:
|
||||
|
||||
sudo -u postgres psql postgres
|
||||
|
||||
@ -165,7 +163,7 @@
|
||||
#port = 5432
|
||||
[...]
|
||||
|
||||
取消改行的注释,然后设置你 postgresql 服务器的 IP 地址,或者设置为 ‘*’ 监听所有用户。你应该谨慎设置所有远程用户都可以访问 PostgreSQL。
|
||||
取消该行的注释,然后设置你 postgresql 服务器的 IP 地址,或者设置为 ‘*’ 监听所有用户。你应该谨慎设置所有远程用户都可以访问 PostgreSQL。
|
||||
|
||||
[...]
|
||||
listen_addresses = '*'
|
||||
@ -272,8 +270,6 @@
|
||||
|
||||
sudo systemctl restart postgresql
|
||||
|
||||
----------
|
||||
|
||||
sudo systemctl restart apache2
|
||||
|
||||
或者,
|
||||
@ -284,19 +280,19 @@
|
||||
|
||||
现在打开你的浏览器并导航到 **http://ip-address/phppgadmin**。你会看到以下截图。
|
||||
|
||||

|
||||

|
||||
|
||||
用你之前创建的用户登录。我之前已经创建了一个名为 “**senthil**” 的用户,密码是 “**ubuntu**”,因此我以 “senthil” 用户登录。
|
||||
|
||||

|
||||

|
||||
|
||||
然后你就可以访问 phppgadmin 面板了。
|
||||
|
||||

|
||||

|
||||
|
||||
用 postgres 用户登录:
|
||||
|
||||

|
||||

|
||||
|
||||
就是这样。现在你可以用 phppgadmin 可视化创建、删除或者更改数据库了。
|
||||
|
||||
@ -308,7 +304,7 @@ via: http://www.unixmen.com/install-postgresql-9-4-and-phppgadmin-on-ubuntu-15-1
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
黑客利用 Wi-Fi 攻击你的七种方法
|
||||
================================================================================
|
||||

|
||||
|
||||
### 黑客利用 Wi-Fi 侵犯你隐私的七种方法 ###
|
||||
|
||||
Wi-Fi — 啊,你是如此的方便,却又如此的危险!
|
||||
|
||||
这里给大家介绍一下通过Wi-Fi连接“慷慨捐赠”你的身份信息的七种方法和反制措施。
|
||||
|
||||

|
||||
|
||||
### 利用免费热点 ###
|
||||
|
||||
它们似乎无处不在,而且它们的数量会在[接下来四年里增加三倍][1]。但是它们当中很多都是不值得信任的,从你的登录凭证、email 甚至更加敏感的账户,都能被黑客用“嗅探器(sniffers)”软件截获 — 这种软件能截获到任何你通过该连接提交的信息。防止被黑客盯上的最好办法就是使用VPN(虚拟私有网virtual private network),它加密了你所输入的信息,因此能够保护你的数据隐私。
|
||||
|
||||

|
||||
|
||||
### 网上银行 ###
|
||||
|
||||
你可能认为没有人需要被提醒不要使用免费 Wi-Fi 来操作网上银行, 但网络安全厂商卡巴斯基实验室表示**[全球超过100家银行因为网络黑客而损失9亿美元][2]**,由此可见还是有很多人因此受害。如果你确信一家咖啡店的免费 Wi-Fi 是正规的,想要连接它,那么你应该向服务员确认网络名称。[其他人在店里用路由器设置一个开放的无线连接][3],并将它的网络名称设置成店名是一件相当简单的事。
|
||||
|
||||

|
||||
|
||||
### 始终开着 Wi-Fi 开关 ###
|
||||
|
||||
如果你手机的 Wi-Fi 开关一直开着的,你会自动被连接到一个不安全的网络中去,你甚至都没有意识到。你可以利用你手机中[基于位置的 Wi-Fi 功能][4],如果有这种功能的话,那它会在你离开你所保存的网络范围后自动关闭你的 Wi-Fi 开关并在你回去之后再次开启。
|
||||
|
||||

|
||||
|
||||
### 不使用防火墙 ###
|
||||
|
||||
防火墙是你的第一道抵御恶意入侵的防线,它能有效地让你的电脑网络保持通畅并阻挡黑客和恶意软件。你应该时刻开启它除非你的杀毒软件有它自己的防火墙。
|
||||
|
||||

|
||||
|
||||
### 浏览非加密网页 ###
|
||||
|
||||
说起来很难过,**[世界上排名前100万个网站中55%是不加密的][5]**,一个未加密的网站会让一切传输数据暴露在黑客的眼中。如果一个网页是安全的,你的浏览器则会有标明(比如说火狐浏览器是一把灰色的挂锁,Chrome 浏览器则是个绿锁图标)。但是即使是安全的网站不能让你免于被劫持的风险,他们能通过公共网络从你访问过的网站上窃取 cookies,无论是不是正规网站。
|
||||
|
||||

|
||||
|
||||
### 不更新你的安全防护软件 ###
|
||||
|
||||
如果你想要确保你自己的网络是受保护的,就更新路由器固件。你要做的就是进入你的路由器管理页面去检查,通常你能在厂商的官方网页上下载到最新的固件版本。
|
||||
|
||||

|
||||
|
||||
### 不保护你的家用 Wi-Fi ###
|
||||
|
||||
不用说,设置一个复杂的密码和更改无线连接的默认名都是非常重要的。你还可以过滤你的 MAC 地址来让你的路由器只识别那些确认过的设备。
|
||||
|
||||
本文作者 **Josh Althuser** 是一个开源支持者、网络架构师和科技企业家。在过去12年里,他花了很多时间去倡导使用开源软件来管理团队和项目,同时为网络应用程序提供企业级咨询并帮助它们把产品推向市场。你可以通过[他的推特][6]联系他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/3003170/mobile-security/7-ways-hackers-can-use-wi-fi-against-you.html
|
||||
|
||||
作者:[Josh Althuser][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/JoshAlthuser
|
||||
[1]:http://www.pcworld.com/article/243464/number_of_wifi_hotspots_to_quadruple_by_2015_says_study.html
|
||||
[2]:http://www.nytimes.com/2015/02/15/world/bank-hackers-steal-millions-via-malware.html?hp&action=click&pgtype=Homepage&module=first-column-region%C2%AEion=top-news&WT.nav=top-news&_r=3
|
||||
[3]:http://news.yahoo.com/blogs/upgrade-your-life/banking-online-not-hacked-182159934.html
|
||||
[4]:http://pocketnow.com/2014/10/15/should-you-leave-your-smartphones-wifi-on-or-turn-it-off
|
||||
[5]:http://www.cnet.com/news/chrome-becoming-tool-in-googles-push-for-encrypted-web/
|
||||
[6]:https://twitter.com/JoshAlthuser
|
||||
@ -1,8 +1,8 @@
|
||||
Linux 中如何从命令行访问 Dropbox
|
||||
Linux 中如何通过命令行访问 Dropbox
|
||||
================================================================================
|
||||
在当今这个多设备的环境下,云存储无处不在。无论身处何方,人们都想通过多种设备来从云存储中获取所需的内容。由于优雅的 UI 和完美的跨平台兼容性,Dropbox 已成为最为广泛使用的云存储服务。 Dropbox 的流行已引发了一系列官方或非官方 Dropbox 客户端的出现,它们支持不同的操作系统平台。
|
||||
在当今这个多设备的环境下,云存储无处不在。无论身处何方,人们都想通过多种设备来从云存储中获取所需的内容。由于拥有漂亮的 UI 和完美的跨平台兼容性,Dropbox 已成为最为广泛使用的云存储服务。 Dropbox 的流行已引发了一系列官方或非官方 Dropbox 客户端的出现,它们支持不同的操作系统平台。
|
||||
|
||||
当然 Linux 平台下也有着自己的 Dropbox 客户端: 既有命令行的,也有图形界面。[Dropbox Uploader][1] 是一个简单易用的 Dropbox 命令行客户端,它是用 BASH 脚本语言所编写的。在这篇教程中,我将描述 **在 Linux 中如何使用 Dropbox Uploader 通过命令行来访问 Dropbox**。
|
||||
当然 Linux 平台下也有着自己的 Dropbox 客户端: 既有命令行的,也有图形界面客户端。[Dropbox Uploader][1] 是一个简单易用的 Dropbox 命令行客户端,它是用 Bash 脚本语言所编写的(LCTT 译注:对,你没看错, 就是 Bash)。在这篇教程中,我将描述 **在 Linux 中如何使用 Dropbox Uploader 通过命令行来访问 Dropbox**。
|
||||
|
||||
### Linux 中安装和配置 Dropbox Uploader ###
|
||||
|
||||
@ -13,7 +13,7 @@ Linux 中如何从命令行访问 Dropbox
|
||||
|
||||
请确保你已经在系统中安装了 `curl`,因为 Dropbox Uploader 通过 curl 来运行 Dropbox 的 API。
|
||||
|
||||
要配置 Dropbox Uploader,只需运行 dropbox_uploader.sh 即可。当你第一次运行这个脚本时,它将询问你,以使得它可以访问你的 Dropbox 账户。
|
||||
要配置 Dropbox Uploader,只需运行 dropbox_uploader.sh 即可。当你第一次运行这个脚本时,它将请求得到授权以使得脚本可以访问你的 Dropbox 账户。
|
||||
|
||||
$ ./dropbox_uploader.sh
|
||||
|
||||
@ -88,7 +88,7 @@ via: http://xmodulo.com/access-dropbox-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,17 @@
|
||||
如何在 Ubuntu 15.04 / CentOS 7 上安装 Android Studio
|
||||
================================================================================
|
||||
随着最近几年智能手机的进步,安卓成为了最大的手机平台之一,也有很多免费的用于开发安卓应用的工具。Android Studio 是基于 [IntelliJ IDEA][1] 用于开发安卓应用的集成开发环境。它是 Google 2014 年发布的免费开源软件,继 Eclipse 之后成为主要的 IDE。
|
||||
随着最近几年智能手机的进步,安卓成为了最大的手机平台之一,在开发安卓应用中所用到的所有工具也都可以免费得到。Android Studio 是基于 [IntelliJ IDEA][1] 用于开发安卓应用的集成开发环境(IDE)。它是 Google 2014 年发布的免费开源软件,继 Eclipse 之后成为主要的 IDE。
|
||||
|
||||
在这篇文章,我们一起来学习如何在 Ubuntu 15.04 和 CentOS 7 上安装 Android Studio。
|
||||
|
||||
### 在 Ubuntu 15.04 上安装 ###
|
||||
|
||||
我们可以用两种方式安装 Android Studio。第一种是配置必须的库然后再安装它;另一种是从 Android 官方网站下载然后再本地编译安装。在下面的例子中,我们会使用命令行设置库并安装它。在继续下一步之前,我们需要确保我们已经安装了 JDK 1.6 或者更新版本。
|
||||
我们可以用两种方式安装 Android Studio。第一种是配置所需的库然后再安装它;另一种是从 Android 官方网站下载然后在本地编译安装。在下面的例子中,我们会使用命令行设置库并安装它。在继续下一步之前,我们需要确保我们已经安装了 JDK 1.6 或者更新版本。
|
||||
|
||||
这里,我打算安装 JDK 1.8。
|
||||
|
||||
$ sudo add-apt-repository ppa:webupd8team/java
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install oracle-java8-installer oracle-java8-set-default
|
||||
|
||||
验证 java 是否安装成功:
|
||||
@ -27,12 +25,11 @@
|
||||

|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install android-studio
|
||||
|
||||
上面的安装命令会在 /opt 目录下面安装 Android Studio。
|
||||
|
||||
现在,运行下面的命令启动安装窗口:
|
||||
现在,运行下面的命令启动安装向导:
|
||||
|
||||
$ /opt/android-studio/bin/studio.sh
|
||||
|
||||
@ -48,7 +45,7 @@
|
||||
|
||||

|
||||
|
||||
这一步之后就完成了 Android Studio 的安装。当你重启 Android Studio 时,你会看到下面的欢迎界面,从这里你可以开始用 Android Studio 工作了。
|
||||
这一步完成之后就结束了 Android Studio 的安装。当你重启 Android Studio 时,你会看到下面的欢迎界面,从这里你可以开始用 Android Studio 工作了。
|
||||
|
||||

|
||||
|
||||
@ -85,21 +82,14 @@
|
||||
|
||||
如果你安装 Android Studio 的时候看到任何类似 “unable-to-run-mksdcard-sdk-tool:” 的错误信息,你可能要在 CentOS 7 64 位系统中安装以下软件包:
|
||||
|
||||
glibc.i686
|
||||
|
||||
glibc-devel.i686
|
||||
|
||||
libstdc++.i686
|
||||
|
||||
zlib-devel.i686
|
||||
|
||||
ncurses-devel.i686
|
||||
|
||||
libX11-devel.i686
|
||||
|
||||
libXrender.i686
|
||||
|
||||
libXrandr.i686
|
||||
- glibc.i686
|
||||
- glibc-devel.i686
|
||||
- libstdc++.i686
|
||||
- zlib-devel.i686
|
||||
- ncurses-devel.i686
|
||||
- libX11-devel.i686
|
||||
- libXrender.i686
|
||||
- libXrandr.i686
|
||||
|
||||
通过从 [Android 网站][3] 下载 IDE 文件然后解压安装 studio 也是一样的。
|
||||
|
||||
@ -121,7 +111,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
虽然发布不到一年,但是 Android Studio 已经替代 Eclipse 成为了安装开发最主要的 IDE。它是唯一一个能支持之后 Google 提供的 Android SDKs 和其它 Android 特性的官方 IDE 工具。那么,你还在等什么呢?赶快安装 Android Studio 然后体验开发安装应用的乐趣吧。
|
||||
虽然发布不到一年,但是 Android Studio 已经替代 Eclipse 成为了 Android 的开发最主要的 IDE。它是唯一能支持 Google 之后将要提供的 Android SDK 和其它 Android 特性的官方 IDE 工具。那么,你还在等什么呢?赶快安装 Android Studio 来体验开发 Android 应用的乐趣吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -129,7 +119,7 @@ via: http://linoxide.com/tools/install-android-studio-ubuntu-15-04-centos-7/
|
||||
|
||||
作者:[B N Poornima][a]
|
||||
译者:[ictlyh](http://mutouxiaogui.cn/blog/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
eSpeak: Linux 文本转语音工具
|
||||
================================================================================
|
||||

|
||||
|
||||
[eSpeak][1]是一款 Linux 命令行工具,能把文本转换成语音。它是一款简洁的语音合成器,用C语言编写而成,它支持英语和其它多种语言。
|
||||
|
||||
eSpeak 从标准输入或者输入文件中读取文本。虽然语音输出与真人声音相去甚远,但是,在你项目需要的时候,eSpeak 仍不失为一个简便快捷的工具。
|
||||
|
||||
eSpeak 部分主要特性如下:
|
||||
|
||||
- 提供给 Linux 和 Windows 的命令行工具
|
||||
- 从文件或者标准输入中把文本读出来
|
||||
- 提供给其它程序使用的共享库版本
|
||||
- 为 Windows 提供 SAPI5 版本,所以它能用于 screen-readers 或者其它支持 Windows SAPI5 接口的程序
|
||||
- 可移植到其它平台,包括安卓,OSX等
|
||||
- 提供多种声音特性选择
|
||||
- 语音输出可保存为 [.WAV][2] 格式的文件
|
||||
- 配合 HTML 部分可支持 SSML(语音合成标记语言,[Speech Synthesis Markup Language][3])
|
||||
- 体积小巧,整个程序连同语言支持等占用小于2MB
|
||||
- 可以实现文本到音素编码(phoneme code)的转化,因此可以作为其它语音合成引擎的前端工具
|
||||
- 开发工具可用于生产和调整音素数据
|
||||
|
||||
### 安装 eSpeak ###
|
||||
|
||||
基于 Ubuntu 的系统中,在终端运行以下命令安装 eSpeak:
|
||||
|
||||
sudo apt-get install espeak
|
||||
|
||||
eSpeak 是一个古老的工具,我推测它应该能在其它众多 Linux 发行版中运行,比如 Arch,Fedora。使用 dnf,pacman 等命令就能轻松安装。
|
||||
|
||||
eSpeak 用法如下:输入 espeak 运行程序。输入字符按 enter 转换为语音输出(LCTT 译注:补充)。使用 Ctrl+C 来关闭运行中的程序。
|
||||
|
||||

|
||||
|
||||
还有一些其他的选项可用,可以通过程序帮助进行查看。
|
||||
|
||||
### GUI 版本:Gespeaker ###
|
||||
|
||||
如果你更倾向于使用 GUI 版本,可以安装 Gespeaker,它为 eSpeak 提供了 GTK 界面。
|
||||
|
||||
使用以下命令来安装 Gespeaker:
|
||||
|
||||
sudo apt-get install gespeaker
|
||||
|
||||
操作界面简明易用,你完全可以自行探索。
|
||||
|
||||

|
||||
|
||||
虽然这些工具在大多数计算任务下用不到,但是当你的项目需要把文本转换成语音时,使用 espeak 还是挺方便的。是否使用 espeak 这款语音合成器,选择权就交给你们啦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/espeak-text-speech-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[soooogreen](https://github.com/soooogreen)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://espeak.sourceforge.net/
|
||||
[2]:http://en.wikipedia.org/wiki/WAV
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
@ -0,0 +1,73 @@
|
||||
如何在 Ubuntu 中安装最新的 Arduino IDE 1.6.6
|
||||
================================================================================
|
||||

|
||||
|
||||
> 本篇教程会教你如何在当前的 Ubuntu 发行版中安装最新的 Arduino IDE 1.6.6。
|
||||
|
||||
开源的 Arduino IDE 发布了1.6.6,并带来了很多的改变。新的发布已经切换到 Java 8,它与 IDE 绑定并且用于编译所需。具体见 [发布说明][1]。
|
||||
|
||||
|
||||
|
||||
对于那些不想使用软件中心的 1.0.5 旧版本的人而言,你可以使用下面的步骤在所有的 Ubuntu 发行版中安装 Arduino。
|
||||
|
||||
> **请用正确版本号替换软件包的版本号**
|
||||
|
||||
**1、** 从下面的官方链接下载最新的包 **Linux 32-bit 或者 Linux 64-bit**。
|
||||
|
||||
- [https://www.arduino.cc/en/Main/Software][2]
|
||||
|
||||
如果不知道你系统的类型?进入系统设置->详细->概览。
|
||||
|
||||
**2、** 从Unity Dash、App Launcher 或者使用 Ctrl+Alt+T 打开终端。打开后,一个个运行下面的命令:
|
||||
|
||||
进入下载文件夹:
|
||||
|
||||
cd ~/Downloads
|
||||
|
||||

|
||||
|
||||
使用 tar 命令解压:
|
||||
|
||||
tar -xvf arduino-1.6.6-*.tar.xz
|
||||
|
||||

|
||||
|
||||
将解压后的文件移动到**/opt/**下:
|
||||
|
||||
sudo mv arduino-1.6.6 /opt
|
||||
|
||||

|
||||
|
||||
**3、** 现在 IDE 已经与最新的 Java 绑定使用了。但是最好为程序设置一个桌面图标/启动方式:
|
||||
|
||||
进入安装目录:
|
||||
|
||||
cd /opt/arduino-1.6.6/
|
||||
|
||||
在这个目录给 install.sh 可执行权限
|
||||
|
||||
chmod +x install.sh
|
||||
|
||||
最后运行脚本同时安装桌面快捷方式和启动图标:
|
||||
|
||||
./install.sh
|
||||
|
||||
下图中我用“&&”同时运行这三个命令:
|
||||
|
||||

|
||||
|
||||
最后从 Unity Dash、程序启动器或者桌面快捷方式运行 Arduino IDE。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/11/install-arduino-ide-1-6-6-ubuntu/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
[1]:https://www.arduino.cc/en/Main/ReleaseNotes
|
||||
[2]:https://www.arduino.cc/en/Main/Software
|
||||
@ -0,0 +1,41 @@
|
||||
可以在 Linux 下试试苹果编程语言 Swift
|
||||
================================================================================
|
||||

|
||||
|
||||
是的,你知道的,苹果编程语言 Swift 已经开源了。其实我们并不应该感到意外,因为[在六个月以前苹果就已经宣布了这个消息][1]。
|
||||
|
||||
苹果宣布推出开源 Swift 社区。一个专用于开源 Swift 社区的[新网站][2]已经就位,网站首页显示以下信息:
|
||||
|
||||
> 我们对 Swift 开源感到兴奋。在苹果推出了编程语言 Swift 之后,它很快成为历史上增长最快的语言之一。Swift 可以编写出难以置信的又快又安全的软件。目前,Swift 是开源的,你可以将这个最好的通用编程语言用在各种地方。
|
||||
|
||||
[swift.org][2] 这个网站将会作为一站式网站,它会提供各种资料的下载,包括各种平台,社区指南,最新消息,入门教程,为开源 Swift 做贡献的说明,文件和一些其他的指南。 如果你正期待着学习 Swift,那么必须收藏这个网站。
|
||||
|
||||
在苹果的这次宣布中,一个用于方便分享和构建代码的包管理器已经可用了。
|
||||
|
||||
对于所有的 Linux 使用者来说,最重要的是,源代码已经可以从 [Github][3]获得了.你可以从以下链接 Checkout 它:
|
||||
|
||||
- [苹果 Swift 源代码][3]
|
||||
|
||||
除此之外,对于 ubuntu 14.04 和 15.10 版本还有预编译的二进制文件。
|
||||
|
||||
- [ubuntu 系统的 Swift 二进制文件][4]
|
||||
|
||||
不要急着在产品环境中使用它们,因为这些都是开发分支而不适合于产品环境。因此现在应避免使用在产品环境中,一旦发布了 Linux 下 Swift 的稳定版本,我希望 ubuntu 会把它包含在 [umake][5]中,和 [Visual Studio Code][6] 放一起。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/swift-open-source-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/apple-open-sources-swift-programming-language-linux/
|
||||
[2]:https://swift.org/
|
||||
[3]:https://github.com/apple
|
||||
[4]:https://swift.org/download/#latest-development-snapshots
|
||||
[5]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[6]:http://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
@ -0,0 +1,66 @@
|
||||
如何深度定制 Ubuntu 面板的时间日期显示格式
|
||||
================================================================================
|
||||

|
||||
|
||||
尽管设置页面里已经有一些选项可以用了,这个快速教程会向你展示如何更加深入地自定义 Ubuntu 面板上的时间和日期指示器。
|
||||
|
||||
|
||||
|
||||
在开始之前,在 Ubuntu 软件中心搜索并安装 **dconf Editor**。然后启动该软件并按以下步骤执行:
|
||||
|
||||
**1、** 当 dconf Editor 启动后,导航至 **com -> canonical -> indicator -> datetime**。将 **time-format** 的值设置为 **custom**。
|
||||
|
||||
|
||||
|
||||
你也可以通过终端里的命令完成以上操作:
|
||||
|
||||
gsettings set com.canonical.indicator.datetime time-format 'custom'
|
||||
|
||||
**2、** 现在你可以通过编辑 **custom-time-format** 的值来自定义时间和日期的格式。
|
||||
|
||||
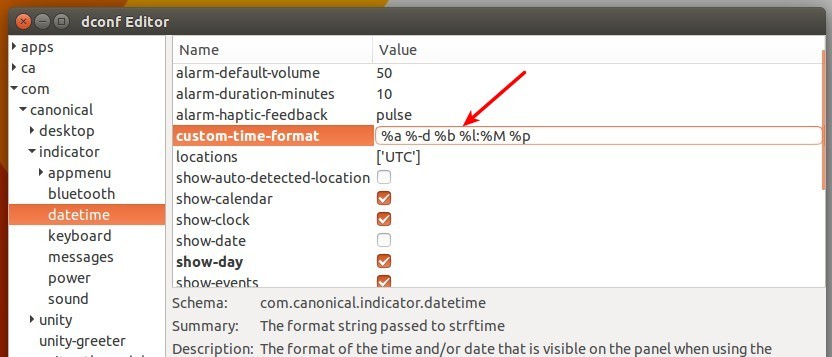
|
||||
|
||||
你也可以通过命令完成:(LCTT 译注:将 FORMAT_VALUE_HERE 替换为所需要的格式值)
|
||||
|
||||
gsettings set com.canonical.indicator.datetime custom-time-format 'FORMAT_VALUE_HERE'
|
||||
|
||||
以下是参数含义:
|
||||
|
||||
- %a = 星期名缩写
|
||||
- %A = 星期名完整拼写
|
||||
- %b = 月份名缩写
|
||||
- %B = 月份名完整拼写
|
||||
- %d = 每月的日期
|
||||
- %l = 小时 ( 1..12), %I = 小时 (01..12)
|
||||
- %k = 小时 ( 1..23), %H = 小时 (01..23)
|
||||
- %M = 分钟 (00..59)
|
||||
- %p = 午别,AM 或 PM, %P = am 或 pm.
|
||||
- %S = 秒 (00..59)
|
||||
|
||||
可以打开终端键入命令 `man date` 并执行以了解更多细节。
|
||||
|
||||
一些自定义时间日期显示格式值的例子:
|
||||
|
||||
**%a %H:%M %m/%d/%Y**
|
||||
|
||||

|
||||
|
||||
**%a %r %b %d or %a %I:%M:%S %p %b %d**
|
||||
|
||||
|
||||
|
||||
**%a %-d %b %l:%M %P %z**
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/12/time-date-format-ubuntu-panel/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[alim0x](https://github.com/alim0x)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
@ -1,11 +1,16 @@
|
||||
|
||||
在 Centos/RHEL 6.X 上安装 Wetty
|
||||
================================================================================
|
||||

|
||||
|
||||
Wetty 是什么?
|
||||
**Wetty 是什么?**
|
||||
|
||||
作为系统管理员,如果你是在 Linux 桌面下,你可能会使用一个软件来连接远程服务器,像 GNOME 终端(或类似的),如果你是在 Windows 下,你可能会使用像 Putty 这样的 SSH 客户端来连接,并同时可以在浏览器中查收邮件等做其他事情。
|
||||
Wetty = Web + tty
|
||||
|
||||
作为系统管理员,如果你是在 Linux 桌面下,你可以用它像一个 GNOME 终端(或类似的)一样来连接远程服务器;如果你是在 Windows 下,你可以用它像使用 Putty 这样的 SSH 客户端一样来连接远程,然后同时可以在浏览器中上网并查收邮件等其它事情。
|
||||
|
||||
(LCTT 译注:简而言之,这是一个基于 Web 浏览器的远程终端)
|
||||
|
||||

|
||||
|
||||
### 第1步: 安装 epel 源 ###
|
||||
|
||||
@ -16,6 +21,8 @@ Wetty 是什么?
|
||||
|
||||
# yum install epel-release git nodejs npm -y
|
||||
|
||||
(LCTT 译注:对,没错,是用 node.js 编写的)
|
||||
|
||||
### 第3步:在安装完依赖后,克隆 GitHub 仓库 ###
|
||||
|
||||
# git clone https://github.com/krishnasrinivas/wetty
|
||||
@ -31,13 +38,15 @@ Wetty 是什么?
|
||||
|
||||
### 第6步:为 Wetty 安装 HTTPS 证书 ###
|
||||
|
||||
# openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes (complete this)
|
||||
# openssl req -x509 -newkey rsa:2048 -keyout key.pem -out cert.pem -days 365 -nodes
|
||||
|
||||
### Step 7: 通过 HTTPS 来使用 Wetty ###
|
||||
(等待完成)
|
||||
|
||||
### 第7步:通过 HTTPS 来使用 Wetty ###
|
||||
|
||||
# nohup node app.js --sslkey key.pem --sslcert cert.pem -p 8080 &
|
||||
|
||||
### Step 8: 为 wetty 添加一个用户 ###
|
||||
### 第8步:为 wetty 添加一个用户 ###
|
||||
|
||||
# useradd <username>
|
||||
# Passwd <username>
|
||||
@ -45,7 +54,8 @@ Wetty 是什么?
|
||||
### 第9步:访问 wetty ###
|
||||
|
||||
http://Your_IP-Address:8080
|
||||
give the credential have created before for wetty and access
|
||||
|
||||
输入你之前为 wetty 创建的证书然后访问。
|
||||
|
||||
到此结束!
|
||||
|
||||
@ -55,7 +65,7 @@ via: http://www.unixmen.com/install-wetty-centosrhel-6-x/
|
||||
|
||||
作者:[Debojyoti Das][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,100 @@
|
||||
如何在 CentOS 上启用 软件集 Software Collections(SCL)
|
||||
================================================================================
|
||||
|
||||
红帽企业版 linux(RHEL)和它的社区版分支——CentOS,提供10年的生命周期,这意味着 RHEL/CentOS 的每个版本会提供长达10年的安全更新。虽然这么长的生命周期为企业用户提供了迫切需要的系统兼容性和可靠性,但也存在一个缺点:随着底层的 RHEL/CentOS 版本接近生命周期的结束,核心应用和运行时环境变得陈旧过时。例如 CentOS 6.5,它的生命周期结束时间是2020年11月30日,其所携带的 Python 2.6.6和 MySQL 5.1.73,以今天的标准来看已经非常古老了。
|
||||
|
||||
另一方面,在 RHEL/CentOS 上试图手动升级开发工具链和运行时环境存在使系统崩溃的潜在可能,除非所有依赖都被正确解决。通常情况下,手动升级都是不推荐的,除非你知道你在干什么。
|
||||
|
||||
[软件集(Software Collections)][1](SCL)源出现了,以帮助解决 RHEL/CentOS 下的这种问题。SCL 的创建就是为了给 RHEL/CentOS 用户提供一种以方便、安全地安装和使用应用程序和运行时环境的多个(而且可能是更新的)版本的方式,同时避免把系统搞乱。与之相对的是第三方源,它们可能会在已安装的包之间引起冲突。
|
||||
|
||||
最新的 SCL 提供了:
|
||||
|
||||
- Python 3.3 和 2.7
|
||||
- PHP 5.4
|
||||
- Node.js 0.10
|
||||
- Ruby 1.9.3
|
||||
- Perl 5.16.3
|
||||
- MariaDB 和 MySQL 5.5
|
||||
- Apache httpd 2.4.6
|
||||
|
||||
在这篇教程的剩余部分,我会展示一下如何配置 SCL 源,以及如何安装和启用 SCL 中的包。
|
||||
|
||||
### 配置 SCL 源
|
||||
|
||||
SCL 可用于 CentOS 6.5 及更新的版本。要配置 SCL 源,只需执行:
|
||||
|
||||
$ sudo yum install centos-release-SCL
|
||||
|
||||
要启用和运行 SCL 中的应用,你还需要安装下列包:
|
||||
|
||||
$ sudo yum install scl-utils-build
|
||||
|
||||
执行下面的命令可以查看 SCL 中可用包的完整列表:
|
||||
|
||||
$ yum --disablerepo="*" --enablerepo="scl" list available
|
||||
|
||||
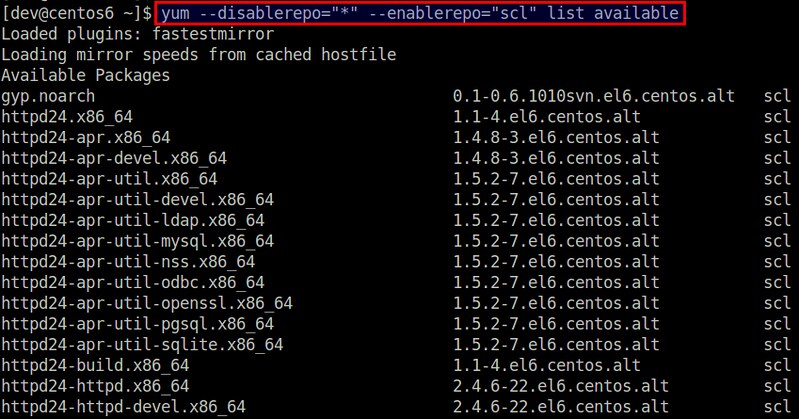
|
||||
|
||||
### 从 SCL 中安装和启用包
|
||||
|
||||
既然你已配置好了 SCL,你可以继续并从 SCL 中安装包了。
|
||||
|
||||
你可以搜索 SCL 中的包:
|
||||
|
||||
$ yum --disablerepo="*" --enablerepo="scl" search <keyword>
|
||||
|
||||
我们假设你要安装 Python 3.3。
|
||||
|
||||
继续,就像通常安装包那样使用 yum 安装:
|
||||
|
||||
$ sudo yum install python33
|
||||
|
||||
任何时候你都可以查看从 SCL 中安装的包的列表,只需执行:
|
||||
|
||||
$ scl --list
|
||||
|
||||
python33
|
||||
|
||||
SCL 的优点之一是安装其中的包不会覆盖任何系统文件,并且保证不会引起与系统中其它库和应用的冲突。
|
||||
|
||||
例如,如果在安装 python33 包后检查默认的 python 版本,你会发现默认的版本并没有改变:
|
||||
|
||||
$ python --version
|
||||
|
||||
Python 2.6.6
|
||||
|
||||
如果想使用一个已经安装的 SCL 包,你需要在每个命令中使用 `scl` 命令显式启用它(LCTT 译注:即想在哪条命令中使用 SCL 中的包,就得通过`scl`命令执行该命令)
|
||||
|
||||
$ scl enable <scl-package-name> <command>
|
||||
|
||||
例如,要针对`python`命令启用 python33 包:
|
||||
|
||||
$ scl enable python33 'python --version'
|
||||
|
||||
Python 3.3.2
|
||||
|
||||
如果想在启用 python33 包时执行多条命令,你可以像下面那样创建一个启用 SCL 的 bash 会话:
|
||||
|
||||
$ scl enable python33 bash
|
||||
|
||||
在这个 bash 会话中,默认的 python 会被切换为3.3版本,直到你输入`exit`,退出会话。
|
||||
|
||||

|
||||
|
||||
简而言之,SCL 有几分像 Python 的虚拟环境,但更通用,因为你可以为远比 Python 更多的应用启用/禁用 SCL 会话。
|
||||
|
||||
更详细的 SCL 指南,参考官方的[快速入门指南][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/enable-software-collections-centos.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[bianjp](https://github.com/bianjp)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://www.softwarecollections.org/
|
||||
[2]:https://www.softwarecollections.org/docs/
|
||||
@ -0,0 +1,76 @@
|
||||
Linux/Unix 桌面趣事:让桌面下雪
|
||||
================================================================================
|
||||
|
||||
在这个节日里感到孤独么?试一下 Xsnow 吧。它是一个可以在 Unix/Linux 桌面下下雪的应用。圣诞老人和他的驯鹿会在屏幕中奔跑,伴随着雪片让你感受到节日的感觉。
|
||||
|
||||
我第一次安装它还是在 13、4 年前。它最初是在 1984 年 Macintosh 系统中创造的。你可以用下面的方法来安装:
|
||||
|
||||
### 安装 xsnow ###
|
||||
|
||||
Debian/Ubuntu/Mint 用户用下面的命令:
|
||||
|
||||
$ sudo apt-get install xsnow
|
||||
|
||||
Freebsd 用户输入下面的命令:
|
||||
|
||||
# cd /usr/ports/x11/xsnow/
|
||||
# make install clean
|
||||
|
||||
或者尝试添加包:
|
||||
|
||||
# pkg_add -r xsnow
|
||||
|
||||
#### 其他发行版的方法 ####
|
||||
|
||||
1. Fedora/RHEL/CentOS 在 [rpmfusion][1] 仓库中找找。
|
||||
2. Gentoo 用户试下 Gentoo portage,也就是[emerge -p xsnow][2]
|
||||
3. Opensuse 用户使用 yast 搜索 xsnow
|
||||
|
||||
### 我该如何使用 xsnow? ###
|
||||
|
||||
打开终端(程序 > 附件 > 终端),输入下面的额命令启动 xsnow:
|
||||
|
||||
$ xsnow
|
||||
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
*图01: 在 Linux 和 Unix 桌面中显示雪花*
|
||||
|
||||
你可以设置背景为蓝色,并让它下白雪,输入:
|
||||
|
||||
$ xsnow -bg blue -sc snow
|
||||
|
||||
设置最大的雪片数量,并让它尽可能快地掉下,输入:
|
||||
|
||||
$ xsnow -snowflakes 10000 -delay 0
|
||||
|
||||
不要显示圣诞树和圣诞老人满屏幕地跑,输入:
|
||||
|
||||
$ xsnow -notrees -nosanta
|
||||
|
||||
关于 xsnow 更多的信息和选项,在命令行下输入 man xsnow 查看手册:
|
||||
|
||||
$ man xsnow
|
||||
|
||||
建议阅读
|
||||
|
||||
- 官网[下载 Xsnow][1]
|
||||
- 注意 [MS-Windows][2] 和 [Mac OS X][3] 版本有一次性的共享软件费用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/linux-unix-xsnow.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://rpmfusion.org/Configuration
|
||||
[2]:http://www.gentoo.org/doc/en/handbook/handbook-x86.xml?part=2&chap=1
|
||||
[3]:http://dropmix.xs4all.nl/rick/Xsnow/
|
||||
[4]:http://dropmix.xs4all.nl/rick/WinSnow/
|
||||
[5]:http://dropmix.xs4all.nl/rick/MacOSXSnow/
|
||||
@ -0,0 +1,41 @@
|
||||
Linux/Unix 桌面趣事:蒸汽火车
|
||||
================================================================================
|
||||
一个你[经常犯的错误][1]是把 ls 输入成了 sl。我已经设置了[一个别名][2],也就是 `alias sl=ls`。但是这样你也许就错过了这辆带汽笛的蒸汽小火车了。
|
||||
|
||||
sl 是一个搞笑软件或,也是一个 Unix 游戏。它会在你错误地把“ls”输入成“sl”(Steam Locomotive)后出现一辆蒸汽火车穿过你的屏幕。
|
||||
|
||||
### 安装 sl ###
|
||||
|
||||
在 Debian/Ubuntu 下输入下面的命令:
|
||||
|
||||
# apt-get install sl
|
||||
|
||||
它同样也在 Freebsd 和其他类Unix的操作系统上存在。
|
||||
|
||||
下面,让我们把 ls 输错成 sl:
|
||||
|
||||
$ sl
|
||||
|
||||

|
||||
|
||||
*图01: 如果你把 “ls” 输入成 “sl” ,蒸汽火车会穿过你的屏幕。*
|
||||
|
||||
它同样支持下面的选项:
|
||||
|
||||
- **-a** : 似乎发生了意外。你会为那些哭喊求助的人们感到难过。
|
||||
- **-l** : 显示小一点的火车
|
||||
- **-F** : 它居然飞走了
|
||||
- **-e** : 允许被 Ctrl+C 中断
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/tips/my-10-unix-command-line-mistakes.html
|
||||
[2]:http://bash.cyberciti.biz/guide/Create_and_use_aliases
|
||||
@ -1,10 +1,11 @@
|
||||
Linux / UNIX Desktop Fun: Terminal ASCII Aquarium
|
||||
Linux/Unix 桌面趣事:终端 ASCII 水族箱
|
||||
================================================================================
|
||||
You can now enjoy mysteries of the sea from the safety of your own terminal using ASCIIQuarium. It is an aquarium/sea animation in ASCII art created using perl.
|
||||
|
||||
### Install Term::Animation ###
|
||||
你可以在你的终端中使用 ASCIIQuarium 安全地欣赏海洋的神秘了。它是一个用 perl 写的 ASCII 艺术水族箱/海洋动画。
|
||||
|
||||
First, you need to install Perl module called Term-Animation. Open a command-line terminal (select Applications > Accessories > Terminal), and then type:
|
||||
### 安装 Term::Animation ###
|
||||
|
||||
首先你需要安装名为 Term-Animation 的perl模块。打开终端(选择程序 > 附件 > 终端),并输入:
|
||||
|
||||
$ sudo apt-get install libcurses-perl
|
||||
$ cd /tmp
|
||||
@ -14,9 +15,9 @@ First, you need to install Perl module called Term-Animation. Open a command-lin
|
||||
$ perl Makefile.PL && make && make test
|
||||
$ sudo make install
|
||||
|
||||
### Download and Install ASCIIQuarium ###
|
||||
### 下载安装 ASCIIQuarium ###
|
||||
|
||||
While still at bash prompt, type:
|
||||
接着在终端中输入:
|
||||
|
||||
$ cd /tmp
|
||||
$ wget http://www.robobunny.com/projects/asciiquarium/asciiquarium.tar.gz
|
||||
@ -25,36 +26,38 @@ While still at bash prompt, type:
|
||||
$ sudo cp asciiquarium /usr/local/bin
|
||||
$ sudo chmod 0755 /usr/local/bin/asciiquarium
|
||||
|
||||
### How do I view my ASCII Aquarium? ###
|
||||
### 我怎么观赏 ASCII 水族箱? ###
|
||||
|
||||
Simply type the following command:
|
||||
输入下面的命令:
|
||||
|
||||
$ /usr/local/bin/asciiquarium
|
||||
|
||||
OR
|
||||
或者
|
||||
|
||||
$ perl /usr/local/bin/asciiquarium
|
||||
|
||||
|
||||
|
||||
### Related media ###
|
||||
*ASCII 水族箱*
|
||||
|
||||
### 相关媒体 ###
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="596" height="335" frameborder="0" allowfullscreen="" src="//www.youtube.com/embed/MzatWgu67ok"></iframe>
|
||||
|
||||
[Video 01: ASCIIQuarium - Sea Animation on Linux / Unix Desktop][1]
|
||||
[视频01: ASCIIQuarium - Linux/Unix桌面上的海洋动画][1]
|
||||
|
||||
### Download: erminal ASCII Aquarium KDE and Mac OS X Version ###
|
||||
### 下载:ASCII Aquarium 的 KDE 和 Mac OS X 版本 ###
|
||||
|
||||
[Download asciiquarium][2]. If you're running Mac OS X, try a packaged [version][3] that will run out of the box. For KDE users, try a [KDE Screensaver][4] based on the Asciiquarium.
|
||||
[点此下载 asciiquarium][2]。如果你运行的是 Mac OS X,试下这个可以直接使用的已经打包好的[版本][3]。对于 KDE 用户,试试基于 Asciiquarium 的[KDE 屏幕保护程序][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/linux-unix-apple-osx-terminal-ascii-aquarium.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
Linux/Unix桌面趣事:显示器里的猫和老鼠
|
||||
================================================================================
|
||||
Oneko 是一个有趣的应用。它会把你的光标变成一只老鼠,并在后面创建一个可爱的小猫,并且始终追逐着老鼠光标。单词“neko”在日语中的意思是老鼠。它最初是一位日本人开发的 Macintosh 桌面附件。
|
||||
|
||||
### 安装 oneko ###
|
||||
|
||||
试下下面的命令:
|
||||
|
||||
$ sudo apt-get install oneko
|
||||
|
||||
示例输出:
|
||||
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following NEW packages will be installed:
|
||||
oneko
|
||||
0 upgraded, 1 newly installed, 0 to remove and 10 not upgraded.
|
||||
Need to get 38.6 kB of archives.
|
||||
After this operation, 168 kB of additional disk space will be used.
|
||||
Get:1 http://debian.osuosl.org/debian/ squeeze/main oneko amd64 1.2.sakura.6-7 [38.6 kB]
|
||||
Fetched 38.6 kB in 1s (25.9 kB/s)
|
||||
Selecting previously deselected package oneko.
|
||||
(Reading database ... 274152 files and directories currently installed.)
|
||||
Unpacking oneko (from .../oneko_1.2.sakura.6-7_amd64.deb) ...
|
||||
Processing triggers for menu ...
|
||||
Processing triggers for man-db ...
|
||||
Setting up oneko (1.2.sakura.6-7) ...
|
||||
Processing triggers for menu ...
|
||||
|
||||
FreeBSD 用户输入下面的命令安装 oneko:
|
||||
|
||||
# cd /usr/ports/games/oneko
|
||||
# make install clean
|
||||
|
||||
### 我该如何使用 oneko? ###
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
$ oneko
|
||||
|
||||
你可以把猫变成 “tora-neko”,一只像白老虎条纹的猫:
|
||||
|
||||
$ oneko -tora
|
||||
|
||||
### 不喜欢猫? ###
|
||||
|
||||
你可以用狗代替猫:
|
||||
|
||||
$ oneko -dog
|
||||
|
||||
下面可以用樱花代替猫:
|
||||
|
||||
$ oneko -sakura
|
||||
|
||||
用大道寺代替猫:
|
||||
|
||||
$ oneko -tomoyo
|
||||
|
||||
### 查看相关媒体 ###
|
||||
|
||||
这个教程同样也有视频格式:
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="596" height="335" frameborder="0" allowfullscreen="" src="http://www.youtube.com/embed/Nm3SkXThL0s"></iframe>
|
||||
|
||||
(Video.01: 示例 - 在 Linux 下安装和使用 oneko)
|
||||
|
||||
### 其他选项 ###
|
||||
|
||||
你可以传入下面的选项
|
||||
|
||||
1. **-tofocus**:让猫在获得焦点的窗口顶部奔跑。当获得焦点的窗口不在视野中时,猫像平常那样追逐老鼠。
|
||||
2. **-position 坐标** :指定X和Y来调整猫相对老鼠的位置
|
||||
3. **-rv**:将前景色和背景色对调
|
||||
4. **-fg 颜色** : 前景色 (比如 oneko -dog -fg red)。
|
||||
5. **-bg 颜色** : 背景色 (比如 oneko -dog -bg green)。
|
||||
6. 查看 oneko 的手册获取更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/open-source/oneko-app-creates-cute-cat-chasing-around-your-mouse/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,55 @@
|
||||
在 Linux 终端下看《星球大战》
|
||||
================================================================================
|
||||

|
||||
|
||||
《星球大战(Star Wars)》已经席卷世界。最新一期的 [《星球大战》系列, 《星球大战7:原力觉醒》,打破了有史以来的记录][1]。
|
||||
|
||||
虽然我不能帮你得到一张最新的《星球大战》的电影票,但我可以提供给你一种方式,看[星球大战第四集][2],它是非常早期的《星球大战》电影(1977 年)。
|
||||
|
||||
|
||||
不,它不会是高清,也不是蓝光版。相反,它将是 ASCII 版的《星球大战》第四集,你可以在 Linux 终端看它,这才是真正的极客的方式 :)
|
||||
|
||||
### 在 Linux 终端看星球大战 ###
|
||||
|
||||
打开一个终端,使用以下命令:
|
||||
|
||||
telnet towel.blinkenlights.nl
|
||||
|
||||
等待几秒钟,你可以在终端看到类似于以下这样的动画ASCII艺术:
|
||||
|
||||
(LCTT 译注:有时候会解析到效果更好 IPv6 版本上,如果你没有 IPv6 地址,可以重新连接试试;另外似乎线路不稳定,出现卡顿时稍等。)
|
||||
|
||||

|
||||
|
||||
它将继续播映……
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
要停止动画,按 ctrl +],在这之后输入 quit 来退出 telnet 程序。
|
||||
|
||||
### 更多有趣的终端 ###
|
||||
|
||||
事实上,看《星球大战》并不是你在 Linux 终端下唯一能做有趣的事情。您可以运行[终端里的列车][3]或[通过ASCII艺术得到Linux标志][4]。
|
||||
|
||||
希望你能享受在 Linux 下看《星球大战》。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/star-wars-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.gamespot.com/articles/star-wars-7-breaks-thursday-night-movie-opening-re/1100-6433246/
|
||||
[2]:http://www.imdb.com/title/tt0076759/
|
||||
[3]:http://itsfoss.com/ubuntu-terminal-train/
|
||||
[4]:http://itsfoss.com/display-linux-logo-in-ascii/
|
||||
@ -0,0 +1,164 @@
|
||||
如何在 CentOS 7 / Ubuntu 15.04 上安装 PHP 框架 Laravel
|
||||
================================================================================
|
||||
|
||||
大家好,这篇文章将要讲述如何在 CentOS 7 / Ubuntu 15.04 上安装 Laravel。如果你是一个 PHP Web 的开发者,你并不需要考虑如何在琳琅满目的现代 PHP 框架中选择,Laravel 是最轻松启动和运行的,它省时省力,能让你享受到 web 开发的乐趣。Laravel 信奉着一个普世的开发哲学,通过简单的指导创建出可维护代码具有最高优先级,你将保持着高速的开发效率,能够随时毫不畏惧更改你的代码来改进现有功能。
|
||||
|
||||
Laravel 安装并不繁琐,你只要跟着本文章一步步操作就能在 CentOS 7 或者 Ubuntu 15 服务器上安装。
|
||||
|
||||
### 1) 服务器要求 ###
|
||||
|
||||
在安装 Laravel 前需要安装一些它的依赖前提条件,主要是一些基本的参数调整,比如升级系统到最新版本,sudo 权限和安装依赖包。
|
||||
|
||||
当你连接到你的服务器时,请确保你能通以下命令能成功的使用 EPEL 仓库并且升级你的服务器。
|
||||
|
||||
#### CentOS-7 ####
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
|
||||
# yum update
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# apt-get install python-software-properties
|
||||
# add-apt-repository ppa:ondrej/php5
|
||||
|
||||
# apt-get update
|
||||
|
||||
# apt-get install -y php5 mcrypt php5-mcrypt php5-gd
|
||||
|
||||
### 2) 防火墙安装 ###
|
||||
|
||||
系统防火墙和 SELinux 设置对于用于产品应用安全来说非常重要,当你使用测试服务器的时候可以关闭防火墙,用以下命令行设置 SELinux 成宽容模式(permissive)来保证安装程序不受它们的影响。
|
||||
|
||||
# setenforce 0
|
||||
|
||||
### 3) Apache, MariaDB, PHP 安装 ###
|
||||
|
||||
Laravel 安装程序需要完成安装 LAMP 整个环境,需要额外安装 OpenSSL、PDO,Mbstring 和 Tokenizer 等 PHP 扩展。如果 LAMP 已经运行在你的服务器上你可以跳过这一步,直接确认一些必要的 PHP 插件是否安装好。
|
||||
|
||||
要安装完整 AMP 你需要在自己的服务器上运行以下命令。
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
# yum install httpd mariadb-server php56w php56w-mysql php56w-mcrypt php56w-dom php56w-mbstring
|
||||
|
||||
要在 CentOS 7 上实现 MySQL / Mariadb 服务开机自动启动,你需要运行以下命令。
|
||||
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
|
||||
#systemctl start mysqld
|
||||
#systemctl enable mysqld
|
||||
|
||||
在启动 MariaDB 服务之后,你需要运行以下命令配置一个足够安全的密码。
|
||||
|
||||
#mysql_secure_installation
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# apt-get install mysql-server apache2 libapache2-mod-php5 php5-mysql
|
||||
|
||||
### 4) 安装 Composer ###
|
||||
|
||||
在我们安装 Laravel 前,先让我们开始安装 composer。安装 composer 是安装 Laravel 的最重要步骤之一,因为 composer 能帮我们安装 Laravel 的各种依赖。
|
||||
|
||||
#### CentOS/Ubuntu ####
|
||||
|
||||
在 CentOS / Ubuntu 下运行以下命令来配置 composer 。
|
||||
|
||||
# curl -sS https://getcomposer.org/installer | php
|
||||
# mv composer.phar /usr/local/bin/composer
|
||||
# chmod +x /usr/local/bin/composer
|
||||
|
||||

|
||||
|
||||
### 5) 安装 Laravel ###
|
||||
|
||||
我们可以运行以下命令从 github 上下载 Laravel 的安装包。
|
||||
|
||||
# wget https://github.com/laravel/laravel/archive/develop.zip
|
||||
|
||||
运行以下命令解压安装包并且移动 document 的根目录。
|
||||
|
||||
# unzip develop.zip
|
||||
|
||||
# mv laravel-develop /var/www/
|
||||
|
||||
现在使用 compose 命令来安装目录下所有 Laravel 所需要的依赖。
|
||||
|
||||
# cd /var/www/laravel-develop/
|
||||
# composer install
|
||||
|
||||

|
||||
|
||||
### 6) 密钥 ###
|
||||
|
||||
为了加密服务器,我们使用以下命令来生成一个加密后的 32 位的密钥。
|
||||
|
||||
# php artisan key:generate
|
||||
|
||||
Application key [Lf54qK56s3qDh0ywgf9JdRxO2N0oV9qI] set successfully
|
||||
|
||||
现在把这个密钥放到 'app.php' 文件,如以下所示。
|
||||
|
||||
# vim /var/www/laravel-develop/config/app.php
|
||||
|
||||

|
||||
|
||||
### 7) 虚拟主机和所属用户 ###
|
||||
|
||||
在 composer 安装好后,分配 document 根目录的权限和所属用户,如下所示。
|
||||
|
||||
# chmod 775 /var/www/laravel-develop/app/storage
|
||||
|
||||
# chown -R apache:apache /var/www/laravel-develop
|
||||
|
||||
用任意一款编辑器打开 apache 服务器的默认配置文件,在文件最后加上虚拟主机配置。
|
||||
|
||||
# vim /etc/httpd/conf/httpd.conf
|
||||
|
||||
----------
|
||||
|
||||
ServerName laravel-develop
|
||||
DocumentRoot /var/www/laravel/public
|
||||
|
||||
start Directory /var/www/laravel
|
||||
AllowOverride All
|
||||
Directory close
|
||||
|
||||
现在我们用以下命令重启 apache 服务器,打开浏览器查看 localhost 页面。
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
### 8) Laravel 5 网络访问 ###
|
||||
|
||||
打开浏览器然后输入你配置的 IP 地址或者完整域名(Fully qualified domain name)你将会看到 Laravel 5 的默认页面。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Laravel 框架对于开发网页应用来说是一个绝好的的工具。所以,看了这篇文章你将学会在 Ubuntu 15 和 CentOS 7 上安装 Laravel, 之后你就可以使用这个超棒的 PHP 框架提供的各种功能和舒适便捷性来进行你的开发工作。
|
||||
|
||||
如果您有什么意见或者建议请在以下评论区中回复,我们将根据您宝贵的反馈来使我们的文章更加浅显易懂。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-laravel-php-centos-7-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
92
published/20151222 Turn Tor socks to http.md
Normal file
92
published/20151222 Turn Tor socks to http.md
Normal file
@ -0,0 +1,92 @@
|
||||
将 Tor socks 转换成 http 代理
|
||||
================================================================================
|
||||

|
||||
|
||||
你可以通过不同的 Tor 工具来使用 Tor 服务,如 Tor 浏览器、Foxyproxy 和其它东西,像 wget 和 aria2 这样的下载管理器不能直接使用 Tor socks 开始匿名下载,因此我们需要一些工具来将 Tor socks 转换成 http 代理,这样就能用它来下载了。
|
||||
|
||||
**注意**:本教程基于 Debian ,其他发行版会有些不同,因此如果你的发行版是基于 Debian 的,就可以直接使用下面的配置了。
|
||||
|
||||
### Polipo
|
||||
|
||||
这个服务会使用 8123 端口和 127.0.0.1 的 IP 地址,使用下面的命令来在计算机上安装 Polipo:
|
||||
|
||||
sudo apt install polipo
|
||||
|
||||
现在使用如下命令打开 Polipo 的配置文件:
|
||||
|
||||
sudo nano /etc/polipo/config
|
||||
|
||||
在文件最后加入下面的行:
|
||||
|
||||
proxyAddress = "::0"
|
||||
allowedClients = 192.168.1.0/24
|
||||
socksParentProxy = "localhost:9050"
|
||||
socksProxyType = socks5
|
||||
|
||||
用如下的命令来重启 Polipo:
|
||||
|
||||
sudo service polipo restart
|
||||
|
||||
现在 Polipo 已经安装好了!在匿名的世界里做你想做的吧!下面是使用的例子:
|
||||
|
||||
pdmt -l "link" -i 127.0.01 -p 8123
|
||||
|
||||
通过上面的命令 PDMT(Persian 下载器终端)会匿名地下载你的文件。
|
||||
|
||||
### Proxychains
|
||||
|
||||
在此服务中你可以设置使用 Tor 或者 Lantern 代理,但是在使用上它和 Polipo 和 Privoxy 有点不同,它不需要使用任何端口!使用下面的命令来安装:
|
||||
|
||||
sudo apt install proxychains
|
||||
|
||||
用这条命令来打开配置文件:
|
||||
|
||||
sudo nano /etc/proxychains.conf
|
||||
|
||||
现在添加下面的代码到文件底部,这里是 Tor 的端口和 IP:
|
||||
|
||||
socks5 127.0.0.1 9050
|
||||
|
||||
如果你在命令的前面加上“proxychains”并运行,它就能通过 Tor 代理来运行:
|
||||
|
||||
proxychains firefoxt
|
||||
proxychains aria2c
|
||||
proxychains wget
|
||||
|
||||
### Privoxy
|
||||
|
||||
Privoxy 使用 8118 端口,可以很轻松地通过 privoxy 包来安装:
|
||||
|
||||
sudo apt install privoxy
|
||||
|
||||
我们现在要修改配置文件:
|
||||
|
||||
sudo nano /etc/pivoxy/config
|
||||
|
||||
在文件底部加入下面的行:
|
||||
|
||||
forward-socks5 / 127.0.0.1:9050 .
|
||||
forward-socks4a / 127.0.0.1:9050 .
|
||||
forward-socks5t / 127.0.0.1:9050 .
|
||||
forward 192.168.*.*/ .
|
||||
forward 10.*.*.*/ .
|
||||
forward 127.*.*.*/ .
|
||||
forward localhost/ .
|
||||
|
||||
重启服务:
|
||||
|
||||
sudo service privoxy restart
|
||||
|
||||
服务已经好了!端口是 8118,IP 是 127.0.0.1,就尽情使用吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/turn-tor-socks-http/
|
||||
|
||||
作者:[Hossein heydari][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/hossein/
|
||||
@ -1,229 +0,0 @@
|
||||
Translating by H-mudcup
|
||||
Great Open Source Collaborative Editing Tools
|
||||
================================================================================
|
||||
In a nutshell, collaborative writing is writing done by more than one person. There are benefits and risks of collaborative working. Some of the benefits include a more integrated / co-ordinated approach, better use of existing resources, and a stronger, united voice. For me, the greatest advantage is one of the most transparent. That's when I need to take colleagues' views. Sending files back and forth between colleagues is inefficient, causes unnecessary delays and leaves people (i.e. me) unhappy with the whole notion of collaboration. With good collaborative software, I can share notes, data and files, and use comments to share thoughts in real-time or asynchronously. Working together on documents, images, video, presentations, and tasks is made less of a chore.
|
||||
|
||||
There are many ways to collaborate online, and it has never been easier. This article highlights my favourite open source tools to collaborate on documents in real time.
|
||||
|
||||
Google Docs is an excellent productivity application with most of the features I need. It serves as a collaborative tool for editing documents in real time. Documents can be shared, opened, and edited by multiple users simultaneously and users can see character-by-character changes as other collaborators make edits. While Google Docs is free for individuals, it is not open source.
|
||||
|
||||
Here is my take on the finest open source collaborative editors which help you focus on writing without interruption, yet work mutually with others.
|
||||
|
||||
----------
|
||||
|
||||
### Hackpad ###
|
||||
|
||||

|
||||
|
||||
Hackpad is an open source web-based realtime wiki, based on the open source EtherPad collaborative document editor.
|
||||
|
||||
Hackpad allows users to share your docs realtime and it uses color coding to show which authors have contributed to which content. It also allows in line photos, checklists and can also be used for coding as it offers syntax highlighting.
|
||||
|
||||
While Dropbox acquired Hackpad in April 2014, it is only this month that the software has been released under an open source license. It has been worth the wait.
|
||||
|
||||
Features include:
|
||||
|
||||
- Very rich set of functions, similar to those offered by wikis
|
||||
- Take collaborative notes, share data and files, and use comments to share your thoughts in real-time or asynchronously
|
||||
- Granular privacy permissions enable you to invite a single friend, a dozen teammates, or thousands of Twitter followers
|
||||
- Intelligent execution
|
||||
- Directly embed videos from popular video sharing sites
|
||||
- Tables
|
||||
- Syntax highlighting for most common programming languages including C, C#, CSS, CoffeeScript, Java, and HTML
|
||||
|
||||
- Website: [hackpad.com][1]
|
||||
- Source code: [github.com/dropbox/hackpad][2]
|
||||
- Developer: [Contributors][3]
|
||||
- License: Apache License, Version 2.0
|
||||
- Version Number: -
|
||||
|
||||
----------
|
||||
|
||||
### Etherpad ###
|
||||
|
||||

|
||||
|
||||
Etherpad is an open source web-based collaborative real-time editor, allowing authors to simultaneously edit a text document leave comments, and interact with others using an integrated chat.
|
||||
|
||||
Etherpad is implemented in JavaScript, on top of the AppJet platform, with the real-time functionality achieved using Comet streaming.
|
||||
|
||||
Features include:
|
||||
|
||||
- Well designed spartan interface
|
||||
- Simple text formatting features
|
||||
- "Time slider" - explore the history of a pad
|
||||
- Download documents in plain text, PDF, Microsoft Word, Open Document, and HTML
|
||||
- Auto-saves the document at regular, short intervals
|
||||
- Highly customizable
|
||||
- Client side plugins extend the editor functionality
|
||||
- Hundreds of plugins extend Etherpad including support for email notifications, pad management, authentication
|
||||
- Accessibility enabled
|
||||
- Interact with Pad contents in real time from within Node and from your CLI
|
||||
|
||||
- Website: [etherpad.org][4]
|
||||
- Source code: [github.com/ether/etherpad-lite][5]
|
||||
- Developer: David Greenspan, Aaron Iba, J.D. Zamfiresc, Daniel Clemens, David Cole
|
||||
- License: Apache License Version 2.0
|
||||
- Version Number: 1.5.7
|
||||
|
||||
----------
|
||||
|
||||
### Firepad ###
|
||||
|
||||

|
||||
|
||||
Firepad is an open source, collaborative text editor. It is designed to be embedded inside larger web applications with collaborative code editing added in only a few days.
|
||||
|
||||
Firepad is a full-featured text editor, with capabilities like conflict resolution, cursor synchronization, user attribution, and user presence detection. It uses Firebase as a backend, and doesn't need any server-side code. It can be added to any web app. Firepad can use either the CodeMirror editor or the Ace editor to render documents, and its operational transform code borrows from ot.js.
|
||||
|
||||
If you want to extend your web application capabilities by adding the simple document and code editor, Firepad is perfect.
|
||||
|
||||
Firepad is used by several editors, including the Atlassian Stash Realtime Editor, Nitrous.IO, LiveMinutes, and Koding.
|
||||
|
||||
Features include:
|
||||
|
||||
- True collaborative editing
|
||||
- Intelligent OT-based merging and conflict resolution
|
||||
- Support for both rich text and code editing
|
||||
- Cursor position synchronization
|
||||
- Undo / redo
|
||||
- Text highlighting
|
||||
- User attribution
|
||||
- Presence detection
|
||||
- Version checkpointing
|
||||
- Images
|
||||
- Extend Firepad through its API
|
||||
- Supports all modern browsers: Chrome, Safari, Opera 11+, IE8+, Firefox 3.6+
|
||||
|
||||
- Website: [www.firepad.io][6]
|
||||
- Source code: [github.com/firebase/firepad][7]
|
||||
- Developer: Michael Lehenbauer and the team at Firebase
|
||||
- License: MIT
|
||||
- Version Number: 1.1.1
|
||||
|
||||
----------
|
||||
|
||||
### OwnCloud Documents ###
|
||||
|
||||

|
||||
|
||||
ownCloud Documents is an ownCloud app to work with office documents alone and/or collaboratively. It allows up to 5 individuals to collaborate editing .odt and .doc files in a web browser.
|
||||
|
||||
ownCloud is a self-hosted file sync and share server. It provides access to your data through a web interface, sync clients or WebDAV while providing a platform to view, sync and share across devices easily.
|
||||
|
||||
Features include:
|
||||
|
||||
- Cooperative edit, with multiple users editing files simultaneously
|
||||
- Document creation within ownCloud
|
||||
- Document upload
|
||||
- Share and edit files in the browser, and then share them inside ownCloud or through a public link
|
||||
- ownCloud features like versioning, local syncing, encryption, undelete
|
||||
- Seamless support for Microsoft Word documents by way of transparent conversion of file formats
|
||||
|
||||
- Website: [owncloud.org][8]
|
||||
- Source code: [github.com/owncloud/documents][9]
|
||||
- Developer: OwnCloud Inc.
|
||||
- License: AGPLv3
|
||||
- Version Number: 8.1.1
|
||||
|
||||
----------
|
||||
|
||||
### Gobby ###
|
||||
|
||||

|
||||
|
||||
Gobby is a collaborative editor supporting multiple documents in one session and a multi-user chat. All users could work on the file simultaneously without the need to lock it. The parts the various users write are highlighted in different colours and it supports syntax highlighting of various programming and markup languages.
|
||||
|
||||
Gobby allows multiple users to edit the same document together over the internet in real-time. It integrates well with the GNOME environment. It features a client-server architecture which supports multiple documents in one session, document synchronisation on request, password protection and an IRC-like chat for communication out of band. Users can choose a colour to highlight the text they have written in a document.
|
||||
|
||||
A dedicated server called infinoted is also provided.
|
||||
|
||||
Features include:
|
||||
|
||||
- Full-fledged text editing capabilities including syntax highlighting using GtkSourceView
|
||||
- Real-time, lock-free collaborative text editing through encrypted connections (including PFS)
|
||||
- Integrated group chat
|
||||
- Local group undo: Undo does not affect changes of remote users
|
||||
- Shows cursors and selections of remote users
|
||||
- Highlights text written by different users with different colors
|
||||
- Syntax highlighting for most programming languages, auto indentation, configurable tab width
|
||||
- Zeroconf support
|
||||
- Encrypted data transfer including perfect forward secrecy (PFS)
|
||||
- Sessions can be password-protected
|
||||
- Sophisticated access control with Access Control Lists (ACLs)
|
||||
- Highly configurable dedicated server
|
||||
- Automatic saving of documents
|
||||
- Advanced search and replace options
|
||||
- Internationalisation
|
||||
- Full Unicode support
|
||||
|
||||
- Website: [gobby.github.io][10]
|
||||
- Source code: [github.com/gobby][11]
|
||||
- Developer: Armin Burgmeier, Philipp Kern and contributors
|
||||
- License: GNU GPLv2+ and ISC
|
||||
- Version Number: 0.5.0
|
||||
|
||||
----------
|
||||
|
||||
### OnlyOffice ###
|
||||
|
||||

|
||||
|
||||
ONLYOFFICE (formerly known as Teamlab Office) is a multifunctional cloud online office suite integrated with CRM system, document and project management toolset, Gantt chart and email aggregator.
|
||||
|
||||
It allows you to organize business tasks and milestones, store and share your corporate or personal documents, use social networking tools such as blogs and forums, as well as communicate with your team members via corporate IM.
|
||||
|
||||
Manage documents, projects, team and customer relations in one place. OnlyOffice combines text, spreadsheet and presentation editors that include features similar to Microsoft desktop editors (Word, Excel and PowerPoint), but then allow to co-edit, comment and chat in real time.
|
||||
|
||||
OnlyOffice is written in ASP.NET, based on HTML5 Canvas element, and translated to 21 languages.
|
||||
|
||||
Features include:
|
||||
|
||||
- As powerful as a desktop editor when working with large documents, paging and zooming
|
||||
- Document sharing in view / edit modes
|
||||
- Document embedding
|
||||
- Spreadsheet and presentation editors
|
||||
- Co-editing
|
||||
- Commenting
|
||||
- Integrated chat
|
||||
- Mobile applications
|
||||
- Gantt charts
|
||||
- Time management
|
||||
- Access right management
|
||||
- Invoicing system
|
||||
- Calendar
|
||||
- Integration with file storage systems: Google Drive, Box, OneDrive, Dropbox, OwnCloud
|
||||
- Integration with CRM, email aggregator and project management module
|
||||
- Mail server
|
||||
- Mail aggregator
|
||||
- Edit documents, spreadsheets and presentations of the most popular formats: DOC, DOCX, ODT, RTF, TXT, XLS, XLSX, ODS, CSV, PPTX, PPT, ODP
|
||||
|
||||
- Website: [www.onlyoffice.com][12]
|
||||
- Source code: [github.com/ONLYOFFICE/DocumentServer][13]
|
||||
- Developer: Ascensio System SIA
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 7.7
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150823085112605/CollaborativeEditing.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://hackpad.com/
|
||||
[2]:https://github.com/dropbox/hackpad
|
||||
[3]:https://github.com/dropbox/hackpad/blob/master/CONTRIBUTORS
|
||||
[4]:http://etherpad.org/
|
||||
[5]:https://github.com/ether/etherpad-lite
|
||||
[6]:http://www.firepad.io/
|
||||
[7]:https://github.com/firebase/firepad
|
||||
[8]:https://owncloud.org/
|
||||
[9]:http://github.com/owncloud/documents/
|
||||
[10]:https://gobby.github.io/
|
||||
[11]:https://github.com/gobby
|
||||
[12]:https://www.onlyoffice.com/free-edition.aspx
|
||||
[13]:https://github.com/ONLYOFFICE/DocumentServer
|
||||
@ -1,195 +0,0 @@
|
||||
Optimize Web Delivery with these Open Source Tools
|
||||
================================================================================
|
||||
Web proxy software forwards HTTP requests without modifying traffic in any way. They can be configured as a transparent proxy with no client-side configuration required. They can also be used as a reverse proxy front-end to websites; here the cache serves an unlimited number of clients for one or some web servers.
|
||||
|
||||
Web proxies are versatile tools. They have a wide variety of uses, from caching web, DNS and other lookups, to speeding up the delivery of a web server / reducing bandwidth consumption. Web proxy software can also harden security by filtering traffic and anonymizing connections, and offer media-range limitations. This software is used by high-profile, high-traffic websites such as The New York Times, The Guardian, and social media and content sites such as Twitter, Facebook, and Wikipedia.
|
||||
|
||||
Web caches have become a vital mechanism for optimising the amount of data that is delivered in a given period of time. Good web caches also help to minimise latency, serving pages as quickly as possible. This helps to prevent the end user from becoming impatient having to wait for content to be delivered. Web caches optimise the data flow between client and server. They also help to converse bandwidth by caching frequently-delivered content. If you need to reduce server load and improve delivery speed of your content, it is definitely worth exploring the benefits offered by web cache software.
|
||||
|
||||
To provide an insight into the quality of software available for Linux, I feature below 5 excellent open source web proxy tools. Some of the them are full-featured; a couple of them have very modest resource needs.
|
||||
|
||||
### Squid ###
|
||||
|
||||
Squid is a high-performance open source proxy caching server and web cache daemon. It supports FTP, Internet Gopher, HTTPS, TLS, and SSL. It handles all requests in a single, non-blocking, I/O-driven process over IPv4 or IPv6.
|
||||
|
||||
Squid consists of a main server program squid, a Domain Name System lookup program dnsserver, some optional programs for rewriting requests and performing authentication, together with some management and client tools.
|
||||
|
||||
Squid offers a rich access control, authorization and logging environment to develop web proxy and content serving applications.
|
||||
|
||||
Features include:
|
||||
|
||||
- Web proxy:
|
||||
- Caching to reduce access time and bandwidth use
|
||||
- Keeps meta data and especially hot objects cached in RAM
|
||||
- Caches DNS lookups
|
||||
- Supports non-blocking DNS lookups
|
||||
- Implements negative chacking of failed requests
|
||||
- Squid caches can be arranged in a hierarchy or mesh for additional bandwidth savings
|
||||
- Enforce site-usage policies with extensive access controls
|
||||
- Anonymize connections, such as disabling or changing specific header fields in a client's HTTP request
|
||||
- Reverse proxy
|
||||
- Media-range limitations
|
||||
- Supports SSL
|
||||
- Support for IPv6
|
||||
- Error Page Localization - error pages presented by Squid may now be localized per-request to match the visitors local preferred language
|
||||
- Connection Pinning (for NTLM Auth Passthrough) - a workaround which permits Web servers to use Microsoft NTLM Authentication instead of HTTP standard authentication through a web proxy
|
||||
- Quality of Service (QoS) Flow support
|
||||
- Select a TOS/Diffserv value to mark local hits
|
||||
- Select a TOS/Diffserv value to mark peer hits
|
||||
- Selectively mark only sibling or parent requests
|
||||
- Allows any HTTP response towards clients to have the TOS value of the response coming from the remote server preserved
|
||||
- Mask certain bits in the TOS received from the remote server, before copying the value to the TOS send towards clients
|
||||
- SSL Bump (for HTTPS Filtering and Adaptation) - Squid-in-the-middle decryption and encryption of CONNECT tunneled SSL traffic, using configurable client- and server-side certificates
|
||||
- eCAP Adaptation Module support
|
||||
- ICAP Bypass and Retry enhancements - ICAP is now extended with full bypass and dynamic chain routing to handle multiple adaptation services.
|
||||
- ICY streaming protocol support - commonly known as SHOUTcast multimedia streams
|
||||
- Dynamic SSL Certificate Generation
|
||||
- Support for the Internet Content Adaptation Protocol (ICAP)
|
||||
- Full request logging
|
||||
- Anonymize connections
|
||||
|
||||
- Website: [www.squid-cache.org][1]
|
||||
- Developer: National Laboratory for Applied Networking Research (NLANR) and Internet volunteers
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 4.0.1
|
||||
|
||||
### Privoxy ###
|
||||
|
||||
Privoxy (Privacy Enhancing Proxy) is a non-caching Web proxy with advanced filtering capabilities for enhancing privacy, modifying web page data and HTTP headers, controlling access, and removing ads and other obnoxious Internet junk. Privoxy has a flexible configuration and can be customized to suit individual needs and tastes. It supports both stand-alone systems and multi-user networks.
|
||||
|
||||
Privoxy uses the concept of actions in order to manipulate the data stream between the browser and remote sites.
|
||||
|
||||
Features include:
|
||||
|
||||
- Highly configurable - completely personalize your installation
|
||||
- Ad blocking
|
||||
- Cookie management
|
||||
- Supports "Connection: keep-alive". Outgoing connections can be kept alive independently from the client
|
||||
- Supports IPv6
|
||||
- Tagging which allows to change the behaviour based on client and server headers
|
||||
- Run as an "intercepting" proxy
|
||||
- Sophisticated actions and filters for manipulating both server and client headers
|
||||
- Can be chained with other proxies
|
||||
- Integrated browser-based configuration and control utility. Browser-based tracing of rule and filter effects. Remote toggling
|
||||
- Web page filtering (text replacements, removes banners based on size, invisible "web-bugs" and HTML annoyances, etc)
|
||||
- Modularized configuration that allows for standard settings and user settings to reside in separate files, so that installing updated actions files won't overwrite individual user settings
|
||||
- Support for Perl Compatible Regular Expressions in the configuration files, and a more sophisticated and flexible configuration syntax
|
||||
- GIF de-animation
|
||||
- Bypass many click-tracking scripts (avoids script redirection)
|
||||
- User-customizable HTML templates for most proxy-generated pages (e.g. "blocked" page)
|
||||
- Auto-detection and re-reading of config file changes
|
||||
- Most features are controllable on a per-site or per-location basis
|
||||
|
||||
- Website: [www.privoxy.org][2]
|
||||
- Developer: Fabian Keil (lead developer), David Schmidt, and many other contributors
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 3.4.2
|
||||
|
||||
### Varnish Cache ###
|
||||
|
||||
Varnish Cache is a web accelerator written with performance and flexibility in mind. It's modern architecture offers significantly better performance. It typically speeds up delivery with a factor of 300 - 1000x, depending on your architecture. Varnish stores web pages in memory so the web servers do not have to create the same web page repeatedly. The web server only recreates a page when it is changed. When content is served from memory this happens a lot faster then anything.
|
||||
|
||||
Additionally Varnish can serve web pages much faster then any application server is capable of - giving the website a significant speed enhancement.
|
||||
|
||||
For a cost-effective configuration, Varnish Cache uses between 1-16GB and a SSD disk.
|
||||
|
||||
Features include:
|
||||
|
||||
- Modern design
|
||||
- VCL - a very flexible configuration language. The VCL configuration is translated to C, compiled, loaded and executed giving flexibility and speed
|
||||
- Load balancing using both a round-robin and a random director, both with a per-backend weighting
|
||||
- DNS, Random, Hashing and Client IP based Directors
|
||||
- Load balance between multiple backends
|
||||
- Support for Edge Side Includes including stitching together compressed ESI fragments
|
||||
- Heavily threaded
|
||||
- URL rewriting
|
||||
- Cache multiple vhosts with a single Varnish
|
||||
- Log data is stored in shared memory
|
||||
- Basic health-checking of backends
|
||||
- Graceful handling of "dead" backends
|
||||
- Administered by a command line interface
|
||||
- Use In-line C to extend Varnish
|
||||
- Can be used on the same system as Apache
|
||||
- Run multiple Varnish on the same system
|
||||
- Support for HAProxy's PROXY protocol. This is a protocol adds a small header on each incoming TCP connection that describes who the real client is, added by (for example) an SSL terminating process
|
||||
- Warm and cold VCL states
|
||||
- Plugin support with Varnish Modules, called VMODs
|
||||
- Backends defined through VMODs
|
||||
- Gzip Compression and Decompression
|
||||
- HTTP Streaming Pass & Fetch
|
||||
- Saint and Grace mode. Saint Mode allows for unhealthy backends to be blacklisted for a period of time, preventing them from serving traffic when using Varnish as a load balancer. Grace mode allows Varnish to serve an expired version of a page or other asset in cases where Varnish is unable to retrieve a healthy response from the backend
|
||||
- Experimental support for Persistent Storage, without LRU eviction
|
||||
|
||||
- Website: [www.varnish-cache.org][3]
|
||||
- Developer: Varnish Software
|
||||
- License: FreeBSD
|
||||
- Version Number: 4.1.0
|
||||
|
||||
### Polipo ###
|
||||
|
||||
Polipo is an open source caching HTTP proxy which has modest resource needs.
|
||||
|
||||
It listens to requests for web pages from your browser and forwards them to web servers, and forwards the servers’ replies to your browser. In the process, it optimises and cleans up the network traffic. It is similar in spirit to WWWOFFLE, but the implementation techniques are more like the ones ones used by Squid.
|
||||
|
||||
Polipo aims at being a compliant HTTP/1.1 proxy. It should work with any web site that complies with either HTTP/1.1 or the older HTTP/1.0.
|
||||
|
||||
Features include:
|
||||
|
||||
- HTTP 1.1, IPv4 & IPv6, traffic filtering and privacy-enhancement
|
||||
- Uses HTTP/1.1 pipelining if it believes that the remote server supports it, whether the incoming requests are pipelined or come in simultaneously on multiple connections
|
||||
- Cache the initial segment of an instance if the download has been interrupted, and, if necessary, complete it later using Range requests
|
||||
- Upgrade client requests to HTTP/1.1 even if they come in as HTTP/1.0, and up- or downgrade server replies to the client's capabilities
|
||||
- Complete support for IPv6 (except for scoped (link-local) addresses)
|
||||
- Use as a bridge between the IPv4 and IPv6 Internets
|
||||
- Content-filtering
|
||||
- Can use a technique known as Poor Man's Multiplexing to reduce latency
|
||||
- SOCKS 4 and SOCKS 5 protocol support
|
||||
- HTTPS proxying
|
||||
- Behaves as a transparent proxy
|
||||
- Run Polipo together with Privoxy or tor
|
||||
|
||||
- Website: [www.pps.univ-paris-diderot.fr/~jch/software/polipo/][4]
|
||||
- Developer: Juliusz Chroboczek, Christopher Davis
|
||||
- License: MIT License
|
||||
- Version Number: 1.1.1
|
||||
|
||||
### Tinyproxy ###
|
||||
|
||||
Tinyproxy is a lightweight open source web proxy daemon. It is designed to be fast and yet small. It is useful for cases such as embedded deployments where a full featured HTTP proxy is required, but the system resources for a larger proxy are unavailable.
|
||||
|
||||
Tinyproxy is very useful in a small network setting, where a larger proxy would either be too resource intensive, or a security risk. One of the key features of Tinyproxy is the buffering connection concept. In effect, Tinyproxy will buffer a high speed response from a server, and then relay it to a client at the highest speed the client will accept. This feature greatly reduces the problems with sluggishness on the net.
|
||||
|
||||
Features:
|
||||
|
||||
- Easy to modify
|
||||
- Anonymous mode - allows specification of individual HTTP headers that should be allowed through, and which should be blocked
|
||||
- HTTPS support - Tinyproxy allows forwarding of HTTPS connections without modifying traffic in any way through the CONNECT method
|
||||
- Remote monitoring - access proxy statistics from afar, letting you know exactly how busy the proxy is
|
||||
- Load average monitoring - configure software to refuse connections after the server load reaches a certain point
|
||||
- Access control - configure to only allow connections from certain subnets or IP addresses
|
||||
- Secure - run without any special privileges, thus minimizing the chance of system compromise
|
||||
- URL based filtering - allows domain and URL-based black- and whitelisting
|
||||
- Transparent proxying - configure as a transparent proxy, so that a proxy can be used without any client-side configuration
|
||||
- Proxy chaining - use an upstream proxy server for outbound connections, instead of direct connections to the target server, creating a so-called proxy chain
|
||||
- Privacy features - restrict both what data comes to your web browser from the HTTP server (e.g., cookies), and to restrict what data is allowed through from your web browser to the HTTP server (e.g., version information)
|
||||
- Small footprint - the memory footprint is about 2MB with glibc, and the CPU load increases linearly with the number of simultaneous connections (depending on the speed of the connection). Tinyproxy can be run on an old machine without affecting performance
|
||||
|
||||
- Website: [banu.com/tinyproxy][5]
|
||||
- Developer: Robert James Kaes and contributors
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151101020309690/WebDelivery.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.squid-cache.org/
|
||||
[2]:http://www.privoxy.org/
|
||||
[3]:https://www.varnish-cache.org/
|
||||
[4]:http://www.pps.univ-paris-diderot.fr/%7Ejch/software/polipo/
|
||||
[5]:https://banu.com/tinyproxy/
|
||||
@ -1,3 +1,4 @@
|
||||
bazz2222222222222222222222222222222222222222222
|
||||
Review EXT4 vs. Btrfs vs. XFS
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,220 +0,0 @@
|
||||
19 Years of KDE History: Step by Step
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/1UG4lQOMBC4?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
### Introduction ###
|
||||
|
||||
KDE – one of most functional desktop environment ever. It’s open source and free for use. 19 years ago, 14 october 1996 german programmer Matthias Ettrich has started a development of this beautiful environment. KDE provides the shell and many applications for everyday using. Today KDE uses the hundred thousand peoples over the world on Unix and Windows operating system. 19 years – serious age for software projects. Time to return and see how it begin.
|
||||
|
||||
K Desktop Environment has some new aspects: new design, good look & feel, consistency, easy to use, powerful applications for typical desktop work and special use cases. Name “KDE” is an easy word hack with “Common Desktop Environment”, “K” – “Cool”. The first KDE version used proprietary Trolltech’s Qt framework (parent of Qt) with dual licensing: open source QPL(Q public license) and proprietary commercial license. In 2000 Trolltech released some Qt libraries under GPL; Qt 4.5 was released in LGPL 2.1. Since 2009 KDE is compiled for three products: Plasma Workspaces (Shell), KDE Applications, KDE Platform as KDE Software compilation.
|
||||
|
||||
### Releases ###
|
||||
|
||||
#### Pre-Release – 14 October 1996 ####
|
||||
|
||||

|
||||
|
||||
Kool Desktop Environment. Word “Kool” will be dropped in future. In the beginning, all components were released to the developer community separately without any coordinated timeframe throughout the overall project. First communication of KDE via mailing list, that was called kde@fiwi02.wiwi.uni-Tubingen.de.
|
||||
|
||||
#### KDE 1.0 – July 12, 1998 ####
|
||||
|
||||

|
||||
|
||||
This version received mixed reception. Many criticized the use of the Qt software framework – back then under the FreeQt license which was claimed to not be compatible with free software – and advised the use of Motif or LessTif instead. Despite that criticism, KDE was well received by many users and made its way into the first Linux distributions.
|
||||
|
||||

|
||||
|
||||
28 January 1999
|
||||
|
||||
An update, **K Desktop Environment 1.1**, was faster, more stable and included many small improvements. It also included a new set of icons, backgrounds and textures. Among this overhauled artwork was a new KDE logo by Torsten Rahn consisting of the letter K in front of a gear which is used in revised form to this day.
|
||||
|
||||
#### KDE 2.0 – October 23, 2000 ####
|
||||
|
||||

|
||||
|
||||
Major updates: * DCOP (Desktop COmmunication Protocol), a client-to-client communications protocol * KIO, an application I/O library. * KParts, a component object model * KHTML, an HTML 4.0 compliant rendering and drawing engine
|
||||
|
||||

|
||||
|
||||
26 February 2001
|
||||
|
||||
**K Desktop Environment 2.1** release inaugurated the media player noatun, which used a modular, plugin design. For development, K Desktop Environment 2.1 was bundled with KDevelop.
|
||||
|
||||

|
||||
|
||||
15 August 2001
|
||||
|
||||
The **KDE 2.2** release featured up to a 50% improvement in application startup time on GNU/Linux systems and increased stability and capabilities for HTML rendering and JavaScript; some new features in KMail.
|
||||
|
||||
#### KDE 3.0 – April 3, 2002 ####
|
||||
|
||||

|
||||
|
||||
K Desktop Environment 3.0 introduced better support for restricted usage, a feature demanded by certain environments such as kiosks, Internet cafes and enterprise deployments, which disallows the user from having full access to all capabilities of a piece of software.
|
||||
|
||||

|
||||
|
||||
28 January 2003
|
||||
|
||||
**K Desktop Environment 3.1** introduced new default window (Keramik) and icon (Crystal) styles as well as several feature enhancements.
|
||||
|
||||

|
||||
|
||||
3 February 2004
|
||||
|
||||
**K Desktop Environment 3.2** included new features, such as inline spell checking for web forms and emails, improved e-mail and calendaring support, tabs in Konqueror and support for Microsoft Windows desktop sharing protocol (RDP).
|
||||
|
||||

|
||||
|
||||
19 August 2004
|
||||
|
||||
**K Desktop Environment 3.3** focused on integrating different desktop components. Kontact was integrated with Kolab, a groupware application, and Kpilot. Konqueror was given better support for instant messaging contacts, with the capability to send files to IM contacts and support for IM protocols (e.g., IRC).
|
||||
|
||||

|
||||
|
||||
16 March 2005
|
||||
|
||||
**K Desktop Environment 3.4** focused on improving accessibility. The update added a text-to-speech system with support for Konqueror, Kate, KPDF, the standalone application KSayIt and text-to-speech synthesis on the desktop.
|
||||
|
||||

|
||||
|
||||
29 November 2005
|
||||
|
||||
**The K Desktop Environment 3.5** release added SuperKaramba, which provides integrated and simple-to-install widgets to the desktop. Konqueror was given an ad-block feature and became the second web browser to pass the Acid2 CSS test.
|
||||
|
||||
#### KDE SC 4.0 – January 11, 2008 ####
|
||||
|
||||

|
||||
|
||||
The majority of development went into implementing most of the new technologies and frameworks of KDE 4. Plasma and the Oxygen style were two of the biggest user-facing changes. Dolphin replaces Konqueror as file manager, Okular – default document viewer.
|
||||
|
||||

|
||||
|
||||
29 July 2008
|
||||
|
||||
**KDE 4.1** includes a shared emoticon theming system which is used in PIM and Kopete, and DXS, a service that lets applications download and install data from the Internet with one click. Also introduced are GStreamer, QuickTime 7, and DirectShow 9 Phonon backends. New applications: * Dragon Player * Kontact * Skanlite – software for scanners * Step – physics simulator * New games: Kdiamond, Kollision, KBreakout and others
|
||||
|
||||

|
||||
|
||||
27 January 2009
|
||||
|
||||
**KDE 4.2** is considered a significant improvement beyond KDE 4.1 in nearly all aspects, and a suitable replacement for KDE 3.5 for most users.
|
||||
|
||||

|
||||
|
||||
4 August 2009
|
||||
|
||||
**KDE 4.3** fixed over 10,000 bugs and implemented almost 2,000 feature requests. Integration with other technologies, such as PolicyKit, NetworkManager & Geolocation services, was another focus of this release.
|
||||
|
||||

|
||||
|
||||
9 February 2010
|
||||
|
||||
**KDE SC 4.4** is based on version 4.6 of the Qt 4 toolkit. New application – KAddressBook, first release of Kopete.
|
||||
|
||||

|
||||
|
||||
10 August 2010
|
||||
|
||||
**KDE SC 4.5** has some new features: integration of the WebKit library, an open-source web browser engine, which is used in major browsers such as Apple Safari and Google Chrome. KPackageKit replaced Kpackage.
|
||||
|
||||

|
||||
|
||||
26 January 2011
|
||||
|
||||
**KDE SC 4.6** has better OpenGL compositing along with the usual myriad of fixes and features.
|
||||
|
||||

|
||||
|
||||
27 July 2011
|
||||
|
||||
**KDE SC 4.7** has updated KWin with OpenGL ES 2.0 compatible, Qt Quick, Plasma Desktop with many enhancements and a lot of new functions in general applications. 12k bugs if fixed.
|
||||
|
||||

|
||||
|
||||
25 January 2012
|
||||
|
||||
**KDE SC 4.8**: better KWin performance and Wayland support, new design of Doplhin.
|
||||
|
||||

|
||||
|
||||
1 August 2012
|
||||
|
||||
**KDE SC 4.9**: several improvements to the Dolphin file manager, including the reintroduction of in-line file renaming, back and forward mouse buttons, improvement of the places panel and better usage of file metadata.
|
||||
|
||||

|
||||
|
||||
6 February 2013
|
||||
|
||||
**KDE SC 4.10**: many of the default Plasma widgets were rewritten in QML, and Nepomuk, Kontact and Okular received significant speed improvements.
|
||||
|
||||

|
||||
|
||||
14 August 2013
|
||||
|
||||
**KDE SC 4.11**: Kontact and Nepomuk received many optimizations. The first generation Plasma Workspaces entered maintenance-only development mode.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.12**: Kontact received substantial improvements, many small improvements.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.13**: Nepomuk semantic desktop search was replaced with KDE’s in house Baloo. KDE SC 4.13 was released in 53 different translations.
|
||||
|
||||

|
||||
|
||||
18 December 2013
|
||||
|
||||
**KDE SC 4.14**: he release primarily focused on stability, with numerous bugs fixed and few new features added. This was the final KDE SC 4 release.
|
||||
|
||||
#### KDE Plasma 5.0 – July 15, 2014 ####
|
||||
|
||||

|
||||
|
||||
KDE Plasma 5 – 5th generation of KDE. Massive impovements in design and system, new default theme – Breeze, complete migration to QML, better performance with OpenGL, better HiDPI displays support.
|
||||
|
||||

|
||||
|
||||
11 November 2014
|
||||
|
||||
**KDE Plasma 5.1**: Ported missing features from Plasma 4.
|
||||
|
||||

|
||||
|
||||
27 January 2015
|
||||
|
||||
**KDE Plasma 5.2**: New components: BlueDevil, KSSHAskPass, Muon, SDDM theme configuration, KScreen, GTK+ style configuration and KDecoration.
|
||||
|
||||

|
||||
|
||||
28 April 2015
|
||||
|
||||
**KDE Plasma 5.3**: Tech preview of Plasma Media Center. New Bluetooth and touchpad applets. Enhanced power management.
|
||||
|
||||

|
||||
|
||||
25 August 2015
|
||||
|
||||
**KDE Plasma 5.4**: Initial Wayland session, new QML-based audio volume applet, and alternative full-screen application launcher.
|
||||
|
||||
Big thanks to the [KDE][1] developers and community, Wikipedia for [descriptions][2] and all my readers. Be free and use the open source software like a KDE.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/kde-history/
|
||||
|
||||
作者:[Pavlo RudyiCategories][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://www.kde.org/
|
||||
[2]:https://en.wikipedia.org/wiki/KDE_Plasma_5
|
||||
@ -1,4 +1,3 @@
|
||||
sevenot translating
|
||||
A Linux User Using ‘Windows 10′ After More than 8 Years – See Comparison
|
||||
================================================================================
|
||||
Windows 10 is the newest member of windows NT family of which general availability was made on July 29, 2015. It is the successor of Windows 8.1. Windows 10 is supported on Intel Architecture 32 bit, AMD64 and ARMv7 processors.
|
||||
|
||||
@ -1,72 +0,0 @@
|
||||
14 tips for teaching open source development
|
||||
================================================================================
|
||||
Academia is an excellent platform for training and preparing the open source developers of tomorrow. In research, we occasionally open source software we write. We do this for two reasons. One, to promote the use of the tools we produce. And two, to learn more about the impact and issues other people face when using them. With this background of writing research software, I was tasked with redesigning the undergraduate software engineering course for second-year students at the University of Bradford.
|
||||
|
||||
It was a challenge, as I was faced with 80 students coming for different degrees, including IT, business computing, and software engineering, all in the same course. The hardest part was working with students with a wide range of programming experience levels. Traditionally, the course had involved allowing students to choose their own teams, tasking them with building a garage database system and then submitting a report in the end as part of the assessment.
|
||||
|
||||
I decided to redesign the course to give students insight into the process of working on real-world software teams. I divided the students into teams of five or six, based on their degrees and programming skills. The aim was to have an equal distribution of skills across the teams to prevent any unfair advantage of one team over another.
|
||||
|
||||
### The core lessons ###
|
||||
|
||||
The course format was updated to have both lectures and lab sessions. However, the lab session functioned as mentoring sessions, where instructors visited each team to ask for updates and see how the teams were progressing with the clients and the products. There were traditional lectures on project management, software testing, requirements engineering, and similar topics, supplemented by lab sessions and mentor meetings. These meetings allowed us to check up on students' progress and monitor whether they were following the software engineering methodologies taught in the lecture portion. Topics we taught this year included:
|
||||
|
||||
- Requirements engineering
|
||||
- How to interact with clients and other team members
|
||||
- Software methodologies, such as agile and extreme programming approaches
|
||||
- How to use different software engineering approaches and work through sprints
|
||||
- Team meetings and documentations
|
||||
- Project management and Gantt charts
|
||||
- UML diagrams and system descriptions
|
||||
- Code revisioning using Git
|
||||
- Software testing and bug tracking
|
||||
- Using open source libraries for their tools
|
||||
- Open source licenses and which one to use
|
||||
- Software delivery
|
||||
|
||||
Along with these lectures, we had a few guest speakers from the corporate world talk about their practices in software product deliveries. We also managed to get the university’s intellectual property lawyer to come and talk about IP issues surrounding software in the UK, and how to handle any intellectual properties issues in software.
|
||||
|
||||
### Collaboration tools ###
|
||||
|
||||
To make all of the above possible, a number of tools were introduced. Students were trained on how to use them for their projects. These included:
|
||||
|
||||
- Google Drive folders shared within the team and the tutor, to maintain documents and spreadsheets for project descriptions, requirements gathering, meeting minutes, and time tracking of the project. This was an extremely efficient way to monitor and also provide feedback straight into the folders for each team.
|
||||
- [Basecamp][1] for document sharing as well, and later in the course we considered this as a possible replacement for Google Drive.
|
||||
- Bug reporting tools such as [Mantis][2] again have a limited users for free reporting. Later Git itself was being used for bug reports n any tools by the testers in the teams
|
||||
- Remote videoconferencing tools were used as a number of clients were off-campus, and sometimes not even in the same city. The students were regularly using Skype to communicate with them, documenting their meetings and sometimes even recording them for later use.
|
||||
- A number of open source tool kits were also used for students' projects. The students were allowed to choose their own tool kits and languages based on the requirements of the projects. The only condition was that these have to be open source and could be installed in the university labs, which the technical staff was extremely supportive of.
|
||||
- In the end all teams had to deliver their projects to the client, including complete working version of the software, documentation, and open source licenses of their own choosing. Most of the teams chose the GPL version 3 license.
|
||||
|
||||
### Tips and lessons learned ###
|
||||
|
||||
In the end, it was a fun year and nearly all students did very well. Here are some of the lessons I learned which may help improve the course next year:
|
||||
|
||||
1. Give the students a wide variety of choice in projects that are interesting, such as game development or mobile application development, and projects with goals. Working with mundane database systems is not going to keep most students interested. Working with interesting projects, most students became self-learners, and were also helping others in their teams and outside to solve some common issues. The course also had a message list, where students were posting any issues they were encountering, in hopes of receiving advice from others. However, there was a drawback to this approach. The external examiners have advised us to go back to a style of one type of project, and one type of language to help narrow the assessment criteria for the students.
|
||||
1. Give students regular feedback on their performance at every stage. This could be done during the mentoring meetings with the teams, or at other stages, to help them improve the work for next time.
|
||||
1. Students are more than willing to work with clients from outside university! They look forward to working with external company representatives or people outside the university, just because of the new experience. They were all able to display professional behavior when interacting with their mentors, which put the instructors at ease.
|
||||
1. A lot of teams left developing unit testing until the end of the project, which from an extreme programming methodology standpoint was a serious no-no. Maybe testing should be included at the assessments of the various stages to help remind students that they need to be developing unit tests in parallel with the software.
|
||||
1. In the class of 80, there were only four girls, each working in different teams. I observed that boys were very ready to take on roles as team leads, assigning the most interesting code pieces to themselves and the girls were mostly following instructions or doing documentation. For some reason, the girls choose not to show authority or preferred not to code even when they were encouraged by a female instructor. This is still a major issue that needs to be addressed.
|
||||
1. There are different styles of documentation such as using UML, state diagrams, and others. Allow students to learn them all and merge with other courses during the year to improve their learning experience.
|
||||
1. Some students were very good developers, but some doing business computing had very little coding experience. The teams were encouraged to work together to prevent the idea that developer would get better marks than other team members if they were only doing meeting minutes or documentations. Roles were also encouraged to be rotated during mentoring sessions to see that everyone was getting a chance to learn how to program.
|
||||
1. Allowing the team to meet with the mentor every week was helpful in monitoring team activities. It also showed who was doing the most work. Usually students who were not participating in their groups would not come to meetings, and could be identified by the work being presented by other members every week.
|
||||
1. We encouraged students to attach licenses to their work and identify intellectual property issues when working with external libraries and clients. This allowed students to think out of the box and learn about real-world software delivery problems.
|
||||
1. Give students room to choose their own technologies.
|
||||
1. Having teaching assistants is key. Managing 80 students was very difficult, especially on the weeks when they were being assessed. Next year I would definitely have teaching assistants helping me with the teams.
|
||||
1. A supportive tech support for the lab is very important. The university tech support was extremely supportive of the course. Next year, they are talking about having virtual machines assigned to teams, so the teams can install any software on their own virtual machine as needed.
|
||||
1. Teamwork helps. Most teams exhibited a supportive nature to other team members, and mentoring also helped.
|
||||
1. Additional support from other staff members is a plus. As a new academic, I needed to learn from experience and also seek advice at multiple points on how to handle certain students and teams if I was confused on how to engage them with the course. Support from senior staff members was very encouraging to me.
|
||||
|
||||
In the end, it was a fun course—not only for the me as an instructor, but for the students as well. There were some issues with learning objectives and traditional grading schemes that still need to be ironed out to reduce the workload it produced on the instructors. For next year, I plan to keep this same format, but hope to come up with a better grading scheme and introduce more software tools that can help monitor project activities and code revisions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/education/15/9/teaching-open-source-development-undergraduates
|
||||
|
||||
作者:[Mariam Kiran][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/mariamkiran
|
||||
[1]:https://basecamp.com/
|
||||
[2]:https://www.mantisbt.org/
|
||||
@ -1,3 +1,5 @@
|
||||
For my dear RMS
|
||||
|
||||
30 Years of Free Software Foundation: Best Quotes of Richard Stallman
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
|
||||
@ -1,171 +0,0 @@
|
||||
20 Years of GIMP Evolution: Step by Step
|
||||
================================================================================
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" frameborder="0" allowfullscreen="" src="https://www.youtube.com/embed/PSJAzJ6mkVw?feature=oembed"></iframe>
|
||||
|
||||
[GIMP][1] (GNU Image Manipulation Program) – superb open source and free graphics editor. Development began in 1995 as students project of the University of California, Berkeley by Peter Mattis and Spencer Kimball. In 1997 the project was renamed in “GIMP” and became an official part of [GNU Project][2]. During these years the GIMP is one of the best graphics editor and platinum holy wars “GIMP vs Photoshop” – one of the most popular.
|
||||
|
||||
The first announce, 21.11.1995:
|
||||
|
||||
> From: Peter Mattis
|
||||
>
|
||||
> Subject: ANNOUNCE: The GIMP
|
||||
>
|
||||
> Date: 1995-11-21
|
||||
>
|
||||
> Message-ID: <48s543$r7b@agate.berkeley.edu>
|
||||
>
|
||||
> Newsgroups: comp.os.linux.development.apps,comp.os.linux.misc,comp.windows.x.apps
|
||||
>
|
||||
> The GIMP: the General Image Manipulation Program
|
||||
> ------------------------------------------------
|
||||
>
|
||||
> The GIMP is designed to provide an intuitive graphical interface to a
|
||||
> variety of image editing operations. Here is a list of the GIMP's
|
||||
> major features:
|
||||
>
|
||||
> Image viewing
|
||||
> -------------
|
||||
>
|
||||
> * Supports 8, 15, 16 and 24 bit color.
|
||||
> * Ordered and Floyd-Steinberg dithering for 8 bit displays.
|
||||
> * View images as rgb color, grayscale or indexed color.
|
||||
> * Simultaneously edit multiple images.
|
||||
> * Zoom and pan in real-time.
|
||||
> * GIF, JPEG, PNG, TIFF and XPM support.
|
||||
>
|
||||
> Image editing
|
||||
> -------------
|
||||
>
|
||||
> * Selection tools including rectangle, ellipse, free, fuzzy, bezier
|
||||
> and intelligent.
|
||||
> * Transformation tools including rotate, scale, shear and flip.
|
||||
> * Painting tools including bucket, brush, airbrush, clone, convolve,
|
||||
> blend and text.
|
||||
> * Effects filters (such as blur, edge detect).
|
||||
> * Channel & color operations (such as add, composite, decompose).
|
||||
> * Plug-ins which allow for the easy addition of new file formats and
|
||||
> new effect filters.
|
||||
> * Multiple undo/redo.
|
||||
|
||||
GIMP 0.54, 1996
|
||||
|
||||

|
||||
|
||||
GIMP 0.54 was required X11 displays, X-server and Motif 1.2 wigdets and supported 8, 15, 16 & 24 color depths with RGB & grayscale colors. Supported images format: GIF, JPEG, PNG, TIFF and XPM.
|
||||
|
||||
Basic functionality: rectangle, ellipse, free, fuzzy, bezier, intelligent selection tools, and rotate, scale, shear, clone, blend and flip images.
|
||||
|
||||
Extended tools: text operations, effects filters, tools for channel and colors manipulation, undo and redo operations. Since the first version GIMP support the plugin system.
|
||||
|
||||
GIMP 0.54 can be ran in Linux, HP-UX, Solaris, SGI IRIX.
|
||||
|
||||
### GIMP 0.60, 1997 ###
|
||||
|
||||

|
||||
|
||||
This is development release, not for all users. GIMP has the new toolkits – GDK (GIMP Drawing Kit) and GTK (GIMP Toolkit), Motif support is deprecated. GIMP Toolkit is also begin of the GTK+ cross-platform widget toolkit. New features:
|
||||
|
||||
- basic layers
|
||||
- sub-pixel sampling
|
||||
- brush spacing
|
||||
- improver airbrush
|
||||
- paint modes
|
||||
|
||||
### GIMP 0.99, 1997 ###
|
||||
|
||||

|
||||
|
||||
Since 0.99 version GIMP has the scripts add macros (Script-Fus) support. GTK and GDK with some improvements has now the new name – GTK+. Other improvements:
|
||||
|
||||
- support big images (rather than 100 MB)
|
||||
- new native format – XCF
|
||||
- new API – write plugins and extensions is easy
|
||||
|
||||
### GIMP 1.0, 1998 ###
|
||||
|
||||

|
||||
|
||||
GIMP and GTK+ was splitted into separate projects. The GIMP official website has
|
||||
reconstructed and contained new tutorials, plugins and documentation. New features:
|
||||
|
||||
- tile-based memory management
|
||||
- massive changes in plugin API
|
||||
- XFC format now support layers, guides and selections
|
||||
- web interface
|
||||
- online graphics generation
|
||||
|
||||
### GIMP 1.2, 2000 ###
|
||||
|
||||
New features:
|
||||
|
||||
- translation for non-english languages
|
||||
- fixed many bugs in GTK+ and GIMP
|
||||
- many new plugins
|
||||
- image map
|
||||
- new toolbox: resize, measure, dodge, burn, smugle, samle colorize and curve bend
|
||||
- image pipes
|
||||
- images preview before saving
|
||||
- scaled brush preview
|
||||
- recursive selection by path
|
||||
- new navigation window
|
||||
- drag’n’drop
|
||||
- watermarks support
|
||||
|
||||
### GIMP 2.0, 2004 ###
|
||||
|
||||

|
||||
|
||||
The biggest change – new GTK+ 2.x toolkit.
|
||||
|
||||
### GIMP 2.2, 2004 ###
|
||||
|
||||

|
||||
|
||||
Many bugfixes and drag’n’drop support.
|
||||
|
||||
### GIMP 2.4, 2007 ###
|
||||
|
||||

|
||||
|
||||
New features:
|
||||
|
||||
- better drag’n’drop support
|
||||
- Ti-Fu was replaced to Script-Fu – the new script interpreter
|
||||
- new plugins: photocopy, softglow, neon, cartoon, dog, glob and others
|
||||
|
||||
### GIMP 2.6, 2008 ###
|
||||
|
||||
New features:
|
||||
|
||||
- renew graphics interface
|
||||
- new select and tool
|
||||
- GEGL (GEneric Graphics Library) integration
|
||||
- “The Utility Window Hint” for MDI behavior
|
||||
|
||||
### GIMP 2.8, 2012 ###
|
||||
|
||||

|
||||
|
||||
New features:
|
||||
|
||||
- GUI has some visual changes
|
||||
- new save and export menu
|
||||
- renew text editor
|
||||
- layers group support
|
||||
- JPEG2000 and export to PDF support
|
||||
- webpage screenshot tool
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://tlhp.cf/20-years-of-gimp-evolution/
|
||||
|
||||
作者:[Pavlo Rudyi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://tlhp.cf/author/paul/
|
||||
[1]:https://gimp.org/
|
||||
[2]:http://www.gnu.org/
|
||||
@ -1,3 +1,4 @@
|
||||
translating by kylepeng93
|
||||
KDE vs GNOME vs XFCE Desktop
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -0,0 +1,96 @@
|
||||
What’s the Best File System for My Linux Install?
|
||||
================================================================================
|
||||

|
||||
|
||||
File systems: they’re not the most exciting things in the world, but important nonetheless. In this article we’ll go over the popular choices for file systems on Linux – what they’re about, what they can do, and who they’re for.
|
||||
|
||||
### Ext4 ###
|
||||
|
||||

|
||||
|
||||
If you’ve ever installed Linux before, chances are you’ve seen the “Ext4” during installation. There’s a good reason for that: it’s the file system of choice for just about every Linux distribution available right now. Sure, there are some that choose other options, but there’s no denying that Extended 4 is the file system of choice for almost all Linux users.
|
||||
|
||||
#### What can it do? ####
|
||||
|
||||
Extended 4 has all of the goodness that you’ve come to expect from past file system iterations (Ext2/Ext3) but with enhancements. There’s a lot to dig into, but here are the best parts of what Ext4 can do for you:
|
||||
|
||||
- file system journaling
|
||||
- journal checksums
|
||||
- multi-block file allocation
|
||||
- backwards compatibility support for Extended 2 and 3
|
||||
- persistent pre-allocation of free space
|
||||
- improved file system checking (over previous versions)
|
||||
- and of course, support for larger files
|
||||
|
||||
#### Who is it for? ####
|
||||
|
||||
Extended 4 is for those looking for a super-stable foundation to build upon, or for those looking for something that just works. This file system won’t snapshot your system; it doesn’t even have the greatest SSD support, but If your needs aren’t too extravagant, you’ll get along with it just fine.
|
||||
|
||||
### BtrFS ###
|
||||
|
||||

|
||||
|
||||
The B-tree file system (also known as butterFS) is a file system for Linux developed by Oracle. It’s a new file system and is in heavy development stages. The Linux community considers it unstable to use for some. The core principle of BtrFS is based around the principle of copy-on-write. **Copy on write** basically means that the system has one single copy of a bit of data before the data has been written. When the data has been written, a copy of it is made.
|
||||
|
||||
#### What can it do? ####
|
||||
|
||||
Besides supporting copy-on-write, BtrFS can do many other things – so many things, in fact, that it’d take forever to list everything. Here are the most notable features: The file system supports read-only snapshots, file cloning, subvolumes, transparent compression, offline file system check, in-place conversion from ext3 and 4 to Btrfs, online defragmentation, anew has support for RAID 0, RAID 1, RAID 5, RAID 6 and RAID 10.
|
||||
|
||||
#### Who is it for? ####
|
||||
|
||||
The developers of BtrFS have promised that this file system is the next-gen replacement for other file systems out there. That much is true, though it certainly is a work in progress. There are many killer features for advanced users and basic users alike (including great performance on SSDs). This file system is for those looking to get a little bit more out of their file system and who want to try the copy-on-write way of doing things.
|
||||
|
||||
### XFS ###
|
||||
|
||||

|
||||
|
||||
Developed and created by Silicon Graphics, XFS is a high-end file system that specializes in speed and performance. XFS does extremely well when it comes to parallel input and output because of its focus on performance. The XFS file system can handle massive amounts of data, so much in fact that some users of XFS have close to 300+ terabytes of data.
|
||||
|
||||
#### What can it do? ####
|
||||
|
||||
XFS is a well-tested data storage file system created for high performance operations. Its features include:
|
||||
|
||||
- striped allocation of RAID arrays
|
||||
- file system journaling
|
||||
- variable block sizes
|
||||
- direct I/O
|
||||
- guaranteed-rate I/O
|
||||
- snapshots
|
||||
- online defragmentation
|
||||
- online resizing
|
||||
|
||||
#### Who is it for? ####
|
||||
|
||||
XFS is for those looking for a rock-solid file solution. The file system has been around since 1993 and has only gotten better and better with time. If you have a home server and you’re perplexed on where you should go with storage, consider XFS. A lot of the features the file system comes with (like snapshots) could aid in your file storage system. It’s not just for servers, though. If you’re a more advanced user and you’re interested in a lot of what was promised in BtrFS, check out XFS. It does a lot of the same stuff and doesn’t have stability issues.
|
||||
|
||||
### Reiser4 ###
|
||||
|
||||

|
||||
|
||||
Reiser4, the successor to ReiserFS, is a file system created and developed by Namesys. The creation of Reiser4 was backed by the Linspire project as well as DARPA. What makes Reiser4 special is its multitude of transaction models. There isn’t one single way data can be written; instead, there are many.
|
||||
|
||||
#### What can it do? ####
|
||||
|
||||
Reiser4 has the unique ability to use different transaction models. It can use the copy-on-write model (like BtrFS), write-anywhere, journaling, and the hybrid transaction model. It has a lot of improvements upon ReiserFS, including better file system journaling via wandering logs, better support for smaller files, and faster handling of directories. Reiser4 has a lot to offer. There are a lot more features to talk about, but suffice it to say it’s a huge improvement over ReiserFS with tons of added features.
|
||||
|
||||
#### Who is it for? ####
|
||||
|
||||
Resier4 is for those looking to stretch one file system across multiple use-cases. Maybe you want to set up one machine with copy-on-write, another with write-anywhere, and another with hybrid transaction, and you don’t want to use different types of file systems to accomplish this task. Reiser4 is perfect for this type of use-case.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There are many file systems available on Linux. Each serves a unique purpose for unique users looking to solve different problems.This post focuses on the most popular choices for the platform. There is no doubt there are other choices out there for other use-cases.
|
||||
|
||||
What’s your favorite file system to use on Linux? Tell us why below!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-file-system-linux/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
66
sources/talk/20151227 Upheaval in the Debian Live project.md
Normal file
66
sources/talk/20151227 Upheaval in the Debian Live project.md
Normal file
@ -0,0 +1,66 @@
|
||||
While the event had a certain amount of drama surrounding it, the [announcement][1] of the end for the [Debian Live project][2] seems likely to have less of an impact than it first appeared. The loss of the lead developer will certainly be felt—and the treatment he and the project received seems rather baffling—but the project looks like it will continue in some form. So Debian will still have tools to create live CDs and other media going forward, but what appears to be a long-simmering dispute between project founder and leader Daniel Baumann and the Debian CD and installer teams has been "resolved", albeit in an unfortunate fashion.
|
||||
|
||||
The November 9 announcement from Baumann was titled "An abrupt End to Debian Live". In that message, he pointed to a number of different events over the nearly ten years since the [project was founded][3] that indicated to him that his efforts on Debian Live were not being valued, at least by some. The final straw, it seems, was an "intent to package" (ITP) bug [filed][4] by Iain R. Learmonth that impinged on the namespace used by Debian Live.
|
||||
|
||||
Given that one of the main Debian Live packages is called "live-build", the new package's name, "live-build-ng", was fairly confrontational in and of itself. Live-build-ng is meant to be a wrapper around the [vmdebootstrap][5] tool for creating live media (CDs and USB sticks), which is precisely the role Debian Live is filling. But when Baumann [asked][6] Learmonth to choose a different name for his package, he got an "interesting" [reply][7]:
|
||||
|
||||
```
|
||||
It is worth noting that live-build is not a Debian project, it is an external project that claims to be an official Debian project. This is something that needs to be fixed.
|
||||
There is no namespace issue, we are building on the existing live-config and live-boot packages that are maintained and bringing these into Debian as native projects. If necessary, these will be forks, but I'm hoping that won't have to happen and that we can integrate these packages into Debian and continue development in a collaborative manner.
|
||||
live-build has been deprecated by debian-cd, and live-build-ng is replacing it. In a purely Debian context at least, live-build is deprecated. live-build-ng is being developed in collaboration with debian-cd and D-I [Debian Installer].
|
||||
```
|
||||
|
||||
Whether or not Debian Live is an "official" Debian project (or even what "official" means in this context) has been disputed in the thread. Beyond that, though, Neil Williams (who is the maintainer of vmdebootstrap) [provided some][8] explanation for the switch away from Debian Live:
|
||||
|
||||
```
|
||||
vmdebootstrap is being extended explicitly to provide support for a replacement for live-build. This work is happening within the debian-cd team to be able to solve the existing problems with live-build. These problems include reliability issues, lack of multiple architecture support and lack of UEFI support. vmdebootstrap has all of these, we do use support from live-boot and live-config as these are out of the scope for vmdebootstrap.
|
||||
```
|
||||
|
||||
Those seem like legitimate complaints, but ones that could have been fixed within the existing project. Instead, though, something of a stealth project was evidently undertaken to replace live-build. As Baumann [pointed out][9], nothing was posted to the debian-live mailing list about the plans. The ITP was the first notice that anyone from the Debian Live project got about the plans, so it all looks like a "secret plan"—something that doesn't sit well in a project like Debian.
|
||||
|
||||
As might be guessed, there were multiple postings that supported Baumann's request to rename "live-build-ng", followed by many that expressed dismay at his decision to stop working on Debian Live. But Learmonth and Williams were adamant that replacing live-build is needed. Learmonth did [rename][10] live-build-ng to a perhaps less confrontational name: live-wrapper. He noted that his aim had been to add the new tool to the Debian Live project (and "bring the Debian Live project into Debian"), but things did not play out that way.
|
||||
|
||||
```
|
||||
I apologise to everyone that has been upset by the ITP bug. The software is not yet ready for use as a full replacement for live-build, and it was filed to let people know that the work was ongoing and to collect feedback. This sort of worked, but the feedback wasn't the kind I was looking for.
|
||||
```
|
||||
|
||||
The backlash could perhaps have been foreseen. Communication is a key aspect of free-software communities, so a plan to replace the guts of a project seems likely to be controversial—more so if it is kept under wraps. For his part, Baumann has certainly not been perfect—he delayed the "wheezy" release by [uploading an unsuitable syslinux package][11] and [dropped down][12] from a Debian Developer to a Debian Maintainer shortly thereafter—but that doesn't mean he deserves this kind of treatment. There are others involved in the project as well, of course, so it is not just Baumann who is affected.
|
||||
|
||||
One of those other people is Ben Armstrong, who has been something of a diplomat during the event and has tried to smooth the waters. He started with a [post][13] that celebrated the project and what Baumann and the team had accomplished over the years. As he noted, the [list of downstream projects][14] for Debian Live is quite impressive. In another post, he also [pointed out][15] that the project is not dead:
|
||||
|
||||
```
|
||||
If the Debian CD team succeeds in their efforts and produces a replacement that is viable, reliable, well-tested, and a suitable candidate to replace live-build, this can only be good for Debian. If they are doing their job, they will not "[replace live-build with] an officially improved, unreliable, little-tested alternative". I've seen no evidence so far that they operate that way. And in the meantime, live-build remains in the archive -- there is no hurry to remove it, so long as it remains in good shape, and there is not yet an improved successor to replace it.
|
||||
```
|
||||
|
||||
On November 24, Armstrong also [posted][16] an update (and to [his blog][17]) on Debian Live. It shows some good progress made in the two weeks since Baumann's exit; there are even signs of collaboration between the project and the live-wrapper developers. There is also a [to-do list][18], as well as the inevitable call for more help. That gives reason to believe that all of the drama surrounding the project was just a glitch—avoidable, perhaps, but not quite as dire as it might have seemed.
|
||||
|
||||
|
||||
---------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/665839/
|
||||
|
||||
作者:Jake Edge
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://lwn.net/Articles/666127/
|
||||
[2]: http://live.debian.net/
|
||||
[3]: https://www.debian.org/News/weekly/2006/08/
|
||||
[4]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=804315
|
||||
[5]: http://liw.fi/vmdebootstrap/
|
||||
[6]: https://lwn.net/Articles/666173/
|
||||
[7]: https://lwn.net/Articles/666176/
|
||||
[8]: https://lwn.net/Articles/666181/
|
||||
[9]: https://lwn.net/Articles/666208/
|
||||
[10]: https://lwn.net/Articles/666321/
|
||||
[11]: https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=699808
|
||||
[12]: https://nm.debian.org/public/process/14450
|
||||
[13]: https://lwn.net/Articles/666336/
|
||||
[14]: http://live.debian.net/project/downstream/
|
||||
[15]: https://lwn.net/Articles/666338/
|
||||
[16]: https://lwn.net/Articles/666340/
|
||||
[17]: http://syn.theti.ca/2015/11/24/debian-live-after-debian-live/
|
||||
[18]: https://wiki.debian.org/DebianLive/TODO
|
||||
@ -1,105 +0,0 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||

|
||||
Photo by Ron Amadeo
|
||||
|
||||
### Google Play and the return of direct-to-consumer device sales ###
|
||||
|
||||
On March 6, 2012, Google unified all of its content offerings under the banner of "Google Play." The Android Market became the Google Play Store, Google Books became Google Play Books, Google Music became Google Play Music, and Android Market Movies became Google Play Movies & TV. While the app interfaces didn't change much, all four content apps got new names and icons. Content purchased in the Play Store would be downloaded to the appropriate app, and the Play Store and Play content apps all worked together to provide a fairly organized content experience.
|
||||
|
||||
The Google Play update was Google's first big out-of-cycle update. Four packed-in apps were all changed without having to issue a system update—they were all updated through the Android Market/Play Store. Enabling out-of-cycle updates to individual apps was a big focus for Google, and being able to do an update like this was the culmination of an engineering effort that started in the Gingerbread era. Google had been working on "decoupling" the apps from the operating system and making everything portable enough to be distributed through the Android Market/Play Store.
|
||||
|
||||
While one or two apps (mostly Maps and Gmail) had previously lived on the Android Market, from here on you'll see a lot more significant updates that have nothing to do with an operating system release. System updates require the cooperation of OEMs and carriers, so they are difficult to push out to every user. Play Store updates are completely controlled by Google, though, providing the company a direct line to users' devices. For the launch of Google Play, the Android Market updated itself to the Google Play Store, and from there, Books, Music, and Movies were all issued Google Play-flavored updates.
|
||||
|
||||
The design of the Google Play apps was still all over the place. Each app looked and functioned differently, but for now, a cohesive brand was a good start. And removing "Android" from the branding was necessary because many services were available in the browser and could be used without touching an Android device at all.
|
||||
|
||||
In April 2012, Google started [selling devices though the Play Store again][1], reviving the direct-to-customer model it had experimented with for the launch of the Nexus One. While it was only two years after ending the Nexus One sales, Internet shopping was now more common place, and buying something before you could hold it didn't seem as crazy as it did in 2010.
|
||||
|
||||
Google also saw how price-conscious consumers became when faced with the Nexus One's $530 price tag. The first device for sale was an unlocked, GSM version of the Galaxy Nexus for $399. From there, price would go even lower. $350 has been the entry-level price for the last two Nexus smartphones, and 7-inch Nexus tablets would come in at only $200 to $220.
|
||||
|
||||
Today, the Play Store sells eight different Android devices, four Chromebooks, a thermostat, and tons of accessories, and the device store is the de-facto location for a new Google product launch. New phone launches are so popular, the site usually breaks under the load, and new Nexus phones sell out in a few hours.
|
||||
|
||||
### Android 4.1, Jelly Bean—Google Now points toward the future ###
|
||||
|
||||

|
||||
The Asus-made Nexus 7, Android 4.1's launch device.
|
||||
|
||||
With the release of Android 4.1, Jelly Bean in July 2012, Google settled into an Android release cadence of about every six months. The platform matured to the point where a release every three months was unnecessary, and the slower release cycle gave OEMs a chance to catch their breath. Unlike Honeycomb, point releases were now fairly major updates, with 4.1 bringing major UI and framework changes.
|
||||
|
||||
One of the biggest changes in Jelly Bean that you won't be able to see in screenshots is "Project Butter," the name for a concerted effort by Google's engineers to make Android animations run smoothly at 30FPS. Core changes were made, like Vsync and triple buffering, and individual animations were optimized so they could be drawn smoothly. Animation and scrolling smoothness had always been a weak point of Android when compared to iOS. After some work on both the core animation framework and on individual apps, Jelly Bean brought Android a lot closer to iOS' smoothness.
|
||||
|
||||
Along with Jelly Bean came the [Nexus][2] 7, a 7-inch tablet manufactured by Asus. Unlike the primarily horizontal Xoom, the Nexus 7 was meant to be used in portrait mode, like a large phone. The Nexus 7 showed that, after almost a year-and-a-half of ecosystem building, Google was ready to commit to the tablet market with a flagship device. Like the Nexus One and GSM Galaxy Nexus, the Nexus 7 was sold online directly by Google. While those earlier devices had shockingly high prices for consumers that were used to carrier subsidies, the Nexus 7 hit a mass market price point of only $200. The price bought you a device with a 7-inch, 1280x800 display, a quad core, 1.2 GHz Tegra 3 processor, 1GB of RAM, and 8GB of storage. The Nexus 7 was such a good value that many wondered if Google was making any money at all on its flagship tablet.
|
||||
|
||||
This smaller, lighter, 7-inch form factor would be a huge success for Google, and it put the company in the rare position of being an industry trendsetter. Apple, which started with a 10-inch iPad, was eventually forced to answer the Nexus 7 and tablets like it with the iPad Mini.
|
||||
|
||||

|
||||
4.1's new lock screen design, wallpaper, and the new on-press highlight on the system buttons.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The Tron look introduced in Honeycomb was toned down a little in Ice Cream Sandwich, and Jelly Bean took things a step further. It started removing blue from large chunks of the operating system. The hint was the on-press highlights on the system buttons, which changed from blue to gray.
|
||||
|
||||
|
||||
A composite image of the new app lineup and the new notification panel with expandable notifications.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The Notification panel was completely revamped, and we've finally arrived at the design used today in KitKat. The new panel extended to the top of the screen and covered the usual status icons, meaning the status bar was no longer visible when the panel was open. The time was prominently displayed in the top left corner, along with the date and a settings shortcut. The clear all notions button, which was represented by an "X" in Ice Cream Sandwich, changed to a stairstep icon, symbolizing the staggered sliding animation that cleared the notification panel. The bottom handle changed from a circle to a single line that ran the length of the notification panel. All the typography was changed—the notification panel now used bigger, thinner fonts for everything. This was another screen where the blue introduced in Ice Cream Sandwich and Honeycomb was removed. The notification panel was entirely gray now except for on-touch highlights.
|
||||
|
||||
There was new functionality in the panel, too. Notifications were now expandable and could show much more information than the previous two-line design. It now showed up to eight lines of text and could even show buttons at the bottom of the notification. The screenshot notification had a share button at the bottom, and you could call directly from a missed call notification, or you could snooze a ringing alarm all from the notification panel. New notifications were expanded by default, but as they piled up they would collapse back to the traditional size. Dragging down on a notification with two fingers would expand it.
|
||||
|
||||
|
||||
The new Google Search app, with Google Now cards, voice search, and text search.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The biggest feature addition to Jelly Bean for not only Android, but for Google as a whole, was the new version of the Google Search application. This introduced "Google Now," a predictive search feature. Google Now was displayed as several cards that sit below the search box, and it would offer results to searches Google thinks you care about. These were things like Google Maps searches for places you've recently looked at on your desktop computer or calendar appointment locations, the weather, and time at home while traveling.
|
||||
|
||||
The new Google Search app could, of course, be launched with the Google icon, but it could also be accessed from any screen with a swipe up from the system bar. Long pressing on the system bar brought up a ring that worked similarly to the lock screen ring. The card section scrolled vertically, and cards could be a swipe away if you didn't want to see them. Voice Search was a big part of the updates. Questions weren't just blindly entered into Google; if Google knew the answer, it would also talk back using a text-To-Speech engine. And old-school text searches were, of course, still supported. Just tap on the bar and start typing.
|
||||
|
||||
Google frequently called Google Now "the future of Google Search." Telling Google what you wanted wasn't good enough. Google wanted to know what you wanted before you did. Google Now put all of Google's data mining knowledge about you to work for you, and it was the company's biggest advantage against rival search services like Bing. Smartphones knew more about you than any other device you own, so the service debuted on Android. But Google slowly worked Google Now into Chrome, and eventually it will likely end up on Google.com.
|
||||
|
||||
While the functionality was important, it became clear that Google Now was the most important design work to ever come out of the company, too. The white card aesthetic that this app introduced would become the foundation for Google's design of just about everything. Today, this card style is used in the Google Play Store and in all of the Play content apps, YouTube, Google Maps, Drive, Keep, Gmail, Google+, and many others. It's not just Android apps, either. Many of Google's desktop sites and iOS apps are inspired by this design. Design was historically one of Google's weak areas, but Google Now was the point where the company finally got its act together with a cohesive, company-wide design language.
|
||||
|
||||
|
||||
Yet another YouTube redesign. Information density went way down.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Another version, another YouTube redesign. This time the list view was primarily thumbnail-based, with giant images taking up most of the screen real estate. Information density tanked with the new list design. Before YouTube would display around six items per screen, now it could only display three.
|
||||
|
||||
YouTube was one of the first apps to add a sliding drawer to the left side of an app, a feature which would become a standard design style across Google's apps. The drawer has links for your account and channel subscriptions, which allowed Google to kill the tabs-on-top design.
|
||||
|
||||
|
||||
Google Play Service's responsibilities versus the rest of Android.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
### Google Play Services—fragmentation and making OS versions (nearly) obsolete ###
|
||||
|
||||
It didn't seem like a big deal at the time, but in September 2012, Google Play Services 1.0 was automatically pushed out to every Android phone running 2.2 and up. It added a few Google+ APIs and support for OAuth 2.0.
|
||||
|
||||
While this update might sound boring, Google Play Services would eventually grow to become an integral part of Android. Google Play Services acts as a shim between the normal apps and the installed Android OS, allowing Google to update or replace some core components and add APIs without having to ship out a new Android version.
|
||||
|
||||
With Play Services, Google had a direct line to the core of an Android phone without having to go through OEM updates and carrier approval processes. Google used Play Services to add an entirely new location system, a malware scanner, remote wipe capabilities, and new Google Maps APIs, all without shipping an OS update. Like we mentioned at the end of the Gingerbread section, thanks to all the "portable" APIs implemented in Play Services, Gingerbread can still download a modern version of the Play Store and many other Google Apps.
|
||||
|
||||
The other big benefit was compatibility with Android's user base. The newest release of an Android OS can take a very long time to get out to the majority of users, which means APIs that get tied to the latest version of the OS won't be any good to developers until the majority of the user base upgrades. Google Play Services is compatible with Froyo and above, which is 99 percent of active devices, and the updates pushed directly to phones through the Play Store. By including APIs in Google Play Services instead of Android, Google can push a new API out to almost all users in about a week. It's [a great solution][3] to many of the problems caused by version fragmentation.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/21/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://arstechnica.com/gadgets/2012/04/unlocked-samsung-galaxy-nexus-can-now-be-purchased-from-google/
|
||||
[2]:http://arstechnica.com/gadgets/2012/07/divine-intervention-googles-nexus-7-is-a-fantastic-200-tablet/
|
||||
[3]:http://arstechnica.com/gadgets/2013/09/balky-carriers-and-slow-oems-step-aside-google-is-defragging-android/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Android 4.2, Jelly Bean—new Nexus devices, new tablet interface ###
|
||||
|
||||
@ -1,8 +1,12 @@
|
||||
taichirain 翻译中
|
||||
|
||||
5 great Raspberry Pi projects for the classroom
|
||||
5 伟大的树莓派项目教室
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
图片来源 : opensource.com
|
||||
|
||||
### 1. Minecraft Pi ###
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy Translating
|
||||
|
||||
6 creative ways to use ownCloud
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,79 +0,0 @@
|
||||
6 useful LibreOffice extensions
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : Opensource.com
|
||||
|
||||
LibreOffice is the best free office suite around, and as such has been adopted by all major Linux distributions. Although LibreOffice is already packed with features, it can be extended by using specific add-ons, called extensions.
|
||||
|
||||
The main LibreOffice extensions website is [extensions.libreoffice.org][1]. Extensions are tools that can be added or removed independently from the main installation, and may add new functionality or make existing functionality easier to use.
|
||||
|
||||
### 1. MultiFormatSave ###
|
||||
|
||||
MultiFormatSave lets users save a document in the OpenDocument, Microsoft Office (old and new), and/or PDF formats simultaneously, according to user settings. This extension is extremely useful during the migration from Microsoft Office document formats to the [Open Document Format][2] standard, because it offers the option to save in both flavors: ODF for interoperability, and Microsoft Office for compatibility with all users sticking to legacy formats. This makes the migration process softer, and easier to administer.
|
||||
|
||||
**[Download MultiFormatSave][3]**
|
||||
|
||||
|
||||
|
||||
### 2. Alternative dialog Find & Replace for Writer (AltSearch) ###
|
||||
|
||||
This extension adds many new features to Writer's find & replace function: searched or replaced text can contain one or more paragraphs; multiple search and replacement in one step; searching: Bookmarks, Notes, Text fields, Cross-references and Reference marks to their content, name or mark and their inserting; searching and inserting Footnote and Endnote; searching object of Table, Pictures and Text frames according to their name; searching out manual page and column break and their set up or deactivation; and searching similarly formatted text, according to cursor point. It is also possible to save and load search and replacement parameters, and execute the batch on several opened documents at the same time.
|
||||
|
||||
**[Download Alternative dialog Find & Replace for Writer (AltSearch)][4]**
|
||||
|
||||
|
||||
|
||||
### 3. Pepito Cleaner ###
|
||||
|
||||
Pepito Cleaner is an extension of LibreOffice created to quickly resolve the most common formatting mistakes of old scans, PDF imports, and every digital text file. By clicking the Pepito Cleaner icon on the LibreOffice toolbar, users will open a window that will analyze the document and show the results broken down by category. This is extremely useful when converting PDF documents to ODF, as it cleans all the cruft left in place by the automatic process.
|
||||
|
||||
**[Download Pepito Cleaner][5]**
|
||||
|
||||
|
||||
|
||||
### 4. ImpressRunner ###
|
||||
|
||||
Impress Runner is a simple extension that transforms an [Impress][6] presentation into an auto-running file. The extension adds two icons, to set and remove the autostart function, which can also be added manually by editing the File | Properties | Custom Properties menu, and adding the term autostart in one of the first four text fields. This extension is especially useful for booths at conferences and events, where the slides are supposed to run unattended.
|
||||
|
||||
**[Download ImpressRunner][7]**
|
||||
|
||||
### 5. Export as Images ###
|
||||
|
||||
The Export as Images extension adds a File menu entry export as Images... in Impress and [Draw][8], to export all slides or pages as images in JPG, PNG, GIF, BMP, and TIFF format, and allows users to choose a file name for exported images, the image size, and other parameters.
|
||||
|
||||
**[Download Export as Images][9]**
|
||||
|
||||
|
||||
|
||||
### 6. Anaphraseus ###
|
||||
|
||||
Anaphraseus is a CAT (Computer-Aided Translation) tool for creating, managing, and using bilingual Translation Memories. Anaphraseus is a LibreOffice macro set available as an extension or a standalone document. Originally, Anaphraseus was developed to work with the Wordfast format, but it can also export and import files in TMX format. Anaphraseus main features are: text segmentation, fuzzy search in Translation Memory, terminology recognition, and TMX Export/Import (OmegaT translation memory format).
|
||||
|
||||
**[Download Anaphraseus][10]**
|
||||
|
||||
|
||||
|
||||
Do you have a favorite LibreOffice extension to recommend? Let us know about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/6-useful-libreoffice-extensions
|
||||
|
||||
作者:[Italo Vignoli][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/italovignoli
|
||||
[1]:http://extensions.libreoffice.org/
|
||||
[2]:http://www.opendocumentformat.org/
|
||||
[3]:http://extensions.libreoffice.org/extension-center/multisave-1
|
||||
[4]:http://extensions.libreoffice.org/extension-center/alternative-dialog-find-replace-for-writer
|
||||
[5]:http://pepitoweb.altervista.org/pepito_cleaner/index.php
|
||||
[6]:https://www.libreoffice.org/discover/impress/
|
||||
[7]:http://extensions.libreoffice.org/extension-center/impressrunner
|
||||
[8]:https://www.libreoffice.org/discover/draw/
|
||||
[9]:http://extensions.libreoffice.org/extension-center/export-as-images
|
||||
[10]:http://anaphraseus.sourceforge.net/
|
||||
@ -1,79 +0,0 @@
|
||||
Top 5 open source community metrics to track
|
||||
================================================================================
|
||||

|
||||
|
||||
So you decided to use metrics to track your free, open source software (FOSS) community. Now comes the big question: Which metrics should I be tracking?
|
||||
|
||||
To answer this question, you must have an idea of what information you need. For example, you may want to know about the sustainability of the project community. How quickly does the community react to problems? How is the community attracting, retaining, or losing contributors? Once you decide which information you need, you can figure out which traces of community activity are available to provide it. Fortunately, FOSS projects following an open development model tend to leave loads of public data in their software development repositories, which can be analyzed to gather useful data.
|
||||
|
||||
In this article, I'll introduce metrics that help provide a multi-faceted view of your project community.
|
||||
|
||||
### 1. Activity ###
|
||||
|
||||
The overall activity of the community and how it evolves over time is a useful metric for all open source communities. Activity provides a first view of how much the community is doing, and can be used to track different kinds of activity. For example, the number of commits gives a first idea about the volume of the development effort. The number of tickets opened provides insight into how many bugs are reported or new features are proposed. The number of messages in mailing lists or posts in forums gives an idea of how much discussion is being held in public.
|
||||
|
||||
|
||||
|
||||
Number of commits and number of merged changes after code review in the OpenStack project, as found in the [OpenStack Activity Dashboard][1]. Evolution over time (weekly data).
|
||||
|
||||
### 2. Size ###
|
||||
|
||||
The size of the community is the number of people participating in it, but, depending on the kind of participation, size numbers may vary. Usually you're interested in active contributors, which is good news. Active people may leave traces in the repositories of the project, which means you can count contributors who are active in producing code by looking at the **Author** field in git repositories, or count people participating in the resolution of tickets by looking at who is contributing to them.
|
||||
|
||||
This basic idea of activity" (somebody did something) can be extended in many ways. One common way to track activity is to look at how many people did a sizable chunk of the activity. Generally most of a project's code contributions, for example, are from a small fraction of the people in the project's community. Knowing about that fraction helps provide an idea of the core group (i.e., the people who help lead the community).
|
||||
|
||||
|
||||
|
||||
Number of authors and number of posters in mailing lists in the Xen project, as found in the [Xen Project Development Dashboard][2]. Evolution over time (monthly data).
|
||||
|
||||
### 3. Performance ###
|
||||
|
||||
So far, I have focused on measuring quantities of activities and contributors. You also can analyze how processes and people are performing. For example, you can measure how long processes take to finish. Time to resolve or close tickets shows how the project is reacting to new information that requires action, such as fixing a reported bug or implementing a requested new feature. Time spent in code review—from the moment when a change to the code is proposed to the moment it is accepted—shows how long upgrading a proposed change to the quality standards expected by the community takes.
|
||||
|
||||
Other metrics deal with how well the project is coping with pending work, such as the ratio of new to closed tickets, or the backlog of still non-completed code reviews. Those parameters tell us, for example, whether or not the resources put into solving issues is enough.
|
||||
|
||||
|
||||
|
||||
Ratio of tickets closed by tickets opened, and ratio of change proposals accepted or abandoned by new change proposals per quarter. OpenStack project, as shown in the [OpenStack Development Report, 2015-Q3][3] (PDF).
|
||||
|
||||
### 4. Demographics ###
|
||||
|
||||
Communities change as contributors move in and out. Depending on how people enter and leave a community over time, the age (time since members joined the community) of the community varies. The [community aging chart][4] nicely illustrates these exchanges over time. The chart is structured as a set of horizontal bars, two per "generation" of people joining the community. For each generation, the attracted bar shows how many new people joined the community during the corresponding period of time. The retained bar shows how many people are still active in the community.
|
||||
|
||||
The relationship between the two bars for each generation is the retention rate: the fraction of people of that generation who are still in the project. The complete set of attracted bars show how attractive the project was in the past. And the complete set of the retention bars shows the current age structure of the community.
|
||||
|
||||
|
||||
|
||||
Community aging chart for the Eclipse community, as shown in the [Eclipse Development Dashboard][5]. Generations are defined every six months.
|
||||
|
||||
### 5. Diversity ###
|
||||
|
||||
Diversity is an important factor in the resiliency of communities. In general, the more diverse communities are—in terms of people or organizations participating—the more resilient they are. For example, when a company decides to leave a FOSS community, the potential problems the departure may cause are much smaller if its employees were contributing 5% of the work rather than 85%.
|
||||
|
||||
The [Pony Factor][6], a term defined by [Daniel Gruno][7] for the minimum number of developers performing 50% of the commits. Based on the Pony Factor, the Elephant Factor is the minimum number of companies whose employees perform 50% of the commits. Both numbers provide an indication of how many people or companies the community depends on.
|
||||
|
||||
|
||||
|
||||
Pony and Elephant Factor for several FOSS projects in the area of cloud computing, as presented in [The quantitative state of the open cloud 2015][8] (slides).
|
||||
|
||||
There are many other metrics to help measure a community. When determing which metrics to collect, think about the goals of your community, and which metrics will help you reach them.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/15/12/top-5-open-source-community-metrics-track
|
||||
|
||||
作者:[Jesus M. Gonzalez-Barahona][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jgbarah
|
||||
[1]:http://activity.openstack.org/
|
||||
[2]:http://projects.bitergia.com/xen-project-dashboard/
|
||||
[3]:http://activity.openstack.org/dash/reports/2015-q3/pdf/2015-q3_OpenStack_report.pdf
|
||||
[4]:http://radar.oreilly.com/2014/10/measure-your-open-source-communitys-age-to-keep-it-healthy.html
|
||||
[5]:http://dashboard.eclipse.org/demographics.html
|
||||
[6]:https://ke4qqq.wordpress.com/2015/02/08/pony-factor-math/
|
||||
[7]:https://twitter.com/humbedooh
|
||||
[8]:https://speakerdeck.com/jgbarah/the-quantitative-state-of-the-open-cloud-2015-edition
|
||||
@ -1,203 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
A Repository with 44 Years of Unix Evolution
|
||||
================================================================================
|
||||
### Abstract ###
|
||||
|
||||
The evolution of the Unix operating system is made available as a version-control repository, covering the period from its inception in 1972 as a five thousand line kernel, to 2015 as a widely-used 26 million line system. The repository contains 659 thousand commits and 2306 merges. The repository employs the commonly used Git system for its storage, and is hosted on the popular GitHub archive. It has been created by synthesizing with custom software 24 snapshots of systems developed at Bell Labs, Berkeley University, and the 386BSD team, two legacy repositories, and the modern repository of the open source FreeBSD system. In total, 850 individual contributors are identified, the early ones through primary research. The data set can be used for empirical research in software engineering, information systems, and software archaeology.
|
||||
|
||||
### 1 Introduction ###
|
||||
|
||||
The Unix operating system stands out as a major engineering breakthrough due to its exemplary design, its numerous technical contributions, its development model, and its widespread use. The design of the Unix programming environment has been characterized as one offering unusual simplicity, power, and elegance [[1][1]]. On the technical side, features that can be directly attributed to Unix or were popularized by it include [[2][2]]: the portable implementation of the kernel in a high level language; a hierarchical file system; compatible file, device, networking, and inter-process I/O; the pipes and filters architecture; virtual file systems; and the shell as a user-selectable regular process. A large community contributed software to Unix from its early days [[3][3]], [[4][4],pp. 65-72]. This community grew immensely over time and worked using what are now termed open source software development methods [[5][5],pp. 440-442]. Unix and its intellectual descendants have also helped the spread of the C and C++ programming languages, parser and lexical analyzer generators (*yacc, lex*), document preparation tools (*troff, eqn, tbl*), scripting languages (*awk, sed, Perl*), TCP/IP networking, and configuration management systems (*SCCS, RCS, Subversion, Git*), while also forming a large part of the modern internet infrastructure and the web.
|
||||
|
||||
Luckily, important Unix material of historical importance has survived and is nowadays openly available. Although Unix was initially distributed with relatively restrictive licenses, the most significant parts of its early development have been released by one of its right-holders (Caldera International) under a liberal license. Combining these parts with software that was developed or released as open source software by the University of California, Berkeley and the FreeBSD Project provides coverage of the system's development over a period ranging from June 20th 1972 until today.
|
||||
|
||||
Curating and processing available snapshots as well as old and modern configuration management repositories allows the reconstruction of a new synthetic Git repository that combines under a single roof most of the available data. This repository documents in a digital form the detailed evolution of an important digital artefact over a period of 44 years. The following sections describe the repository's structure and contents (Section [II][6]), the way it was created (Section [III][7]), and how it can be used (Section [IV][8]).
|
||||
|
||||
### 2 Data Overview ###
|
||||
|
||||
The 1GB Unix history Git repository is made available for cloning on [GitHub][9].[1][10] Currently[2][11] the repository contains 659 thousand commits and 2306 merges from about 850 contributors. The contributors include 23 from the Bell Labs staff, 158 from Berkeley's Computer Systems Research Group (CSRG), and 660 from the FreeBSD Project.
|
||||
|
||||
The repository starts its life at a tag identified as *Epoch*, which contains only licensing information and its modern README file. Various tag and branch names identify points of significance.
|
||||
|
||||
- *Research-VX* tags correspond to six research editions that came out of Bell Labs. These start with *Research-V1* (4768 lines of PDP-11 assembly) and end with *Research-V7* (1820 mostly C files, 324kLOC).
|
||||
- *Bell-32V* is the port of the 7th Edition Unix to the DEC/VAX architecture.
|
||||
- *BSD-X* tags correspond to 15 snapshots released from Berkeley.
|
||||
- *386BSD-X* tags correspond to two open source versions of the system, with the Intel 386 architecture kernel code mainly written by Lynne and William Jolitz.
|
||||
- *FreeBSD-release/X* tags and branches mark 116 releases coming from the FreeBSD project.
|
||||
|
||||
In addition, branches with a *-Snapshot-Development* suffix denote commits that have been synthesized from a time-ordered sequence of a snapshot's files, while tags with a *-VCS-Development* suffix mark the point along an imported version control history branch where a particular release occurred.
|
||||
|
||||
The repository's history includes commits from the earliest days of the system's development, such as the following.
|
||||
|
||||
commit c9f643f59434f14f774d61ee3856972b8c3905b1
|
||||
Author: Dennis Ritchie <research!dmr>
|
||||
Date: Mon Dec 2 18:18:02 1974 -0500
|
||||
Research V5 development
|
||||
Work on file usr/sys/dmr/kl.c
|
||||
|
||||
Merges between releases that happened along the system's evolution, such as the development of BSD 3 from BSD 2 and Unix 32/V, are also correctly represented in the Git repository as graph nodes with two parents.
|
||||
|
||||
More importantly, the repository is constructed in a way that allows *git blame*, which annotates source code lines with the version, date, and author associated with their first appearance, to produce the expected code provenance results. For example, checking out the *BSD-4* tag, and running git blame on the kernel's *pipe.c* file will show lines written by Ken Thompson in 1974, 1975, and 1979, and by Bill Joy in 1980. This allows the automatic (though computationally expensive) detection of the code's provenance at any point of time.
|
||||
|
||||

|
||||
|
||||
Figure 1: Code provenance across significant Unix releases.
|
||||
|
||||
As can be seen in Figure [1][12], a modern version of Unix (FreeBSD 9) still contains visible chunks of code from BSD 4.3, BSD 4.3 Net/2, and FreeBSD 2.0. Interestingly, the Figure shows that code developed during the frantic dash to create an open source operating system out of the code released by Berkeley (386BSD and FreeBSD 1.0) does not seem to have survived. The oldest code in FreeBSD 9 appears to be an 18-line sequence in the C library file timezone.c, which can also be found in the 7th Edition Unix file with the same name and a time stamp of January 10th, 1979 - 36 years ago.
|
||||
|
||||
### 3 Data Collection and Processing ###
|
||||
|
||||
The goal of the project is to consolidate data concerning the evolution of Unix in a form that helps the study of the system's evolution, by entering them into a modern revision repository. This involves collecting the data, curating them, and synthesizing them into a single Git repository.
|
||||
|
||||

|
||||
|
||||
Figure 2: Imported Unix snapshots, repositories, and their mergers.
|
||||
|
||||
The project is based on three types of data (see Figure [2][13]). First, snapshots of early released versions, which were obtained from the [Unix Heritage Society archive][14],[3][15] the [CD-ROM images][16] containing the full source archives of CSRG,[4][17] the [OldLinux site][18],[5][19] and the [FreeBSD archive][20].[6][21] Second, past and current repositories, namely the CSRG SCCS [[6][22]] repository, the FreeBSD 1 CVS repository, and the [Git mirror of modern FreeBSD development][23].[7][24] The first two were obtained from the same sources as the corresponding snapshots.
|
||||
|
||||
The last, and most labour intensive, source of data was **primary research**. The release snapshots do not provide information regarding their ancestors and the contributors of each file. Therefore, these pieces of information had to be determined through primary research. The authorship information was mainly obtained by reading author biographies, research papers, internal memos, and old documentation scans; by reading and automatically processing source code and manual page markup; by communicating via email with people who were there at the time; by posting a query on the Unix *StackExchange* site; by looking at the location of files (in early editions the kernel source code was split into `usr/sys/dmr` and `/usr/sys/ken`); and by propagating authorship from research papers and manual pages to source code and from one release to others. (Interestingly, the 1st and 2nd Research Edition manual pages have an "owner" section, listing the person (e.g. *ken*) associated with the corresponding system command, file, system call, or library function. This section was not there in the 4th Edition, and resurfaced as the "Author" section in BSD releases.) Precise details regarding the source of the authorship information are documented in the project's files that are used for mapping Unix source code files to their authors and the corresponding commit messages. Finally, information regarding merges between source code bases was obtained from a [BSD family tree maintained by the NetBSD project][25].[8][26]
|
||||
|
||||
The software and data files that were developed as part of this project, are [available online][27],[9][28] and, with appropriate network, CPU and disk resources, they can be used to recreate the repository from scratch. The authorship information for major releases is stored in files under the project's `author-path` directory. These contain lines with a regular expressions for a file path followed by the identifier of the corresponding author. Multiple authors can also be specified. The regular expressions are processed sequentially, so that a catch-all expression at the end of the file can specify a release's default authors. To avoid repetition, a separate file with a `.au` suffix is used to map author identifiers into their names and emails. One such file has been created for every community associated with the system's evolution: Bell Labs, Berkeley, 386BSD, and FreeBSD. For the sake of authenticity, emails for the early Bell Labs releases are listed in UUCP notation (e.g. `research!ken`). The FreeBSD author identifier map, required for importing the early CVS repository, was constructed by extracting the corresponding data from the project's modern Git repository. In total the commented authorship files (828 rules) comprise 1107 lines, and there are another 640 lines mapping author identifiers to names.
|
||||
|
||||
The curation of the project's data sources has been codified into a 168-line `Makefile`. It involves the following steps.
|
||||
|
||||
**Fetching** Copying and cloning about 11GB of images, archives, and repositories from remote sites.
|
||||
|
||||
**Tooling** Obtaining an archiver for old PDP-11 archives from 2.9 BSD, and adjusting it to compile under modern versions of Unix; compiling the 4.3 BSD *compress* program, which is no longer part of modern Unix systems, in order to decompress the 386BSD distributions.
|
||||
|
||||
**Organizing** Unpacking archives using tar and *cpio*; combining three 6th Research Edition directories; unpacking all 1 BSD archives using the old PDP-11 archiver; mounting CD-ROM images so that they can be processed as file systems; combining the 8 and 62 386BSD floppy disk images into two separate files.
|
||||
|
||||
**Cleaning** Restoring the 1st Research Edition kernel source code files, which were obtained from printouts through optical character recognition, into a format close to their original state; patching some 7th Research Edition source code files; removing metadata files and other files that were added after a release, to avoid obtaining erroneous time stamp information; patching corrupted SCCS files; processing the early FreeBSD CVS repository by removing CVS symbols assigned to multiple revisions with a custom Perl script, deleting CVS *Attic* files clashing with live ones, and converting the CVS repository into a Git one using *cvs2svn*.
|
||||
|
||||
An interesting part of the repository representation is how snapshots are imported and linked together in a way that allows *git blame* to perform its magic. Snapshots are imported into the repository as sequential commits based on the time stamp of each file. When all files have been imported the repository is tagged with the name of the corresponding release. At that point one could delete those files, and begin the import of the next snapshot. Note that the *git blame* command works by traversing backwards a repository's history, and using heuristics to detect code moving and being copied within or across files. Consequently, deleted snapshots would create a discontinuity between them, and prevent the tracing of code between them.
|
||||
|
||||
Instead, before the next snapshot is imported, all the files of the preceding snapshot are moved into a hidden look-aside directory named `.ref` (reference). They remain there, until all files of the next snapshot have been imported, at which point they are deleted. Because every file in the `.ref` directory matches exactly an original file, *git blame* can determine how source code moves from one version to the next via the `.ref` file, without ever displaying the `.ref` file. To further help the detection of code provenance, and to increase the representation's realism, each release is represented as a merge between the branch with the incremental file additions (*-Development*) and the preceding release.
|
||||
|
||||
For a period in the 1980s, only a subset of the files developed at Berkeley were under SCCS version control. During that period our unified repository contains imports of both the SCCS commits, and the snapshots' incremental additions. At the point of each release, the SCCS commit with the nearest time stamp is found and is marked as a merge with the release's incremental import branch. These merges can be seen in the middle of Figure [2][29].
|
||||
|
||||
The synthesis of the various data sources into a single repository is mainly performed by two scripts. A 780-line Perl script (`import-dir.pl`) can export the (real or synthesized) commit history from a single data source (snapshot directory, SCCS repository, or Git repository) in the *Git fast export* format. The output is a simple text format that Git tools use to import and export commits. Among other things, the script takes as arguments the mapping of files to contributors, the mapping between contributor login names and their full names, the commit(s) from which the import will be merged, which files to process and which to ignore, and the handling of "reference" files. A 450-line shell script creates the Git repository and calls the Perl script with appropriate arguments to import each one of the 27 available historical data sources. The shell script also runs 30 tests that compare the repository at specific tags against the corresponding data sources, verify the appearance and disappearance of look-aside directories, and look for regressions in the count of tree branches and merges and the output of *git blame* and *git log*. Finally, *git* is called to garbage-collect and compress the repository from its initial 6GB size down to the distributed 1GB.
|
||||
|
||||
### 4 Data Uses ###
|
||||
|
||||
The data set can be used for empirical research in software engineering, information systems, and software archeology. Through its unique uninterrupted coverage of a period of more than 40 years, it can inform work on software evolution and handovers across generations. With thousandfold increases in processing speed and million-fold increases in storage capacity during that time, the data set can also be used to study the co-evolution of software and hardware technology. The move of the software's development from research labs, to academia, and to the open source community can be used to study the effects of organizational culture on software development. The repository can also be used to study how notable individuals, such as Turing Award winners (Dennis Ritchie and Ken Thompson) and captains of the IT industry (Bill Joy and Eric Schmidt), actually programmed. Another phenomenon worthy of study concerns the longevity of code, either at the level of individual lines, or as complete systems that were at times distributed with Unix (Ingres, Lisp, Pascal, Ratfor, Snobol, TMG), as well as the factors that lead to code's survival or demise. Finally, because the data set stresses Git, the underlying software repository storage technology, to its limits, it can be used to drive engineering progress in the field of revision management systems.
|
||||
|
||||

|
||||
|
||||
Figure 3: Code style evolution along Unix releases.
|
||||
|
||||
Figure [3][30], which depicts trend lines (obtained with R's local polynomial regression fitting function) of some interesting code metrics along 36 major releases of Unix, demonstrates the evolution of code style and programming language use over very long timescales. This evolution can be driven by software and hardware technology affordances and requirements, software construction theory, and even social forces. The dates in the Figure have been calculated as the average date of all files appearing in a given release. As can be seen in it, over the past 40 years the mean length of identifiers and file names has steadily increased from 4 and 6 characters to 7 and 11 characters, respectively. We can also see less steady increases in the number of comments and decreases in the use of the *goto* statement, as well as the virtual disappearance of the *register* type modifier.
|
||||
|
||||
### 5 Further Work ###
|
||||
|
||||
Many things can be done to increase the repository's faithfulness and usefulness. Given that the build process is shared as open source code, it is easy to contribute additions and fixes through GitHub pull requests. The most useful community contribution would be to increase the coverage of imported snapshot files that are attributed to a specific author. Currently, about 90 thousand files (out of a total of 160 thousand) are getting assigned an author through a default rule. Similarly, there are about 250 authors (primarily early FreeBSD ones) for which only the identifier is known. Both are listed in the build repository's unmatched directory, and contributions are welcomed. Furthermore, the BSD SCCS and the FreeBSD CVS commits that share the same author and time-stamp can be coalesced into a single Git commit. Support can be added for importing the SCCS file comment fields, in order to bring into the repository the corresponding metadata. Finally, and most importantly, more branches of open source systems can be added, such as NetBSD OpenBSD, DragonFlyBSD, and *illumos*. Ideally, current right holders of other important historical Unix releases, such as System III, System V, NeXTSTEP, and SunOS, will release their systems under a license that would allow their incorporation into this repository for study.
|
||||
|
||||
#### Acknowledgements ####
|
||||
|
||||
The author thanks the many individuals who contributed to the effort. Brian W. Kernighan, Doug McIlroy, and Arnold D. Robbins helped with Bell Labs login identifiers. Clem Cole, Era Eriksson, Mary Ann Horton, Kirk McKusick, Jeremy C. Reed, Ingo Schwarze, and Anatole Shaw helped with BSD login identifiers. The BSD SCCS import code is based on work by H. Merijn Brand and Jonathan Gray.
|
||||
|
||||
This research has been co-financed by the European Union (European Social Fund - ESF) and Greek national funds through the Operational Program "Education and Lifelong Learning" of the National Strategic Reference Framework (NSRF) - Research Funding Program: Thalis - Athens University of Economics and Business - Software Engineering Research Platform.
|
||||
|
||||
### References ###
|
||||
|
||||
[[1]][31]
|
||||
M. D. McIlroy, E. N. Pinson, and B. A. Tague, "UNIX time-sharing system: Foreword," *The Bell System Technical Journal*, vol. 57, no. 6, pp. 1899-1904, July-August 1978.
|
||||
|
||||
[[2]][32]
|
||||
D. M. Ritchie and K. Thompson, "The UNIX time-sharing system," *Bell System Technical Journal*, vol. 57, no. 6, pp. 1905-1929, July-August 1978.
|
||||
|
||||
[[3]][33]
|
||||
D. M. Ritchie, "The evolution of the UNIX time-sharing system," *AT&T Bell Laboratories Technical Journal*, vol. 63, no. 8, pp. 1577-1593, Oct. 1984.
|
||||
|
||||
[[4]][34]
|
||||
P. H. Salus, *A Quarter Century of UNIX*. Boston, MA: Addison-Wesley, 1994.
|
||||
|
||||
[[5]][35]
|
||||
E. S. Raymond, *The Art of Unix Programming*. Addison-Wesley, 2003.
|
||||
|
||||
[[6]][36]
|
||||
M. J. Rochkind, "The source code control system," *IEEE Transactions on Software Engineering*, vol. SE-1, no. 4, pp. 255-265, 1975.
|
||||
|
||||
----------
|
||||
|
||||
#### Footnotes: ####
|
||||
|
||||
[1][37] - [https://github.com/dspinellis/unix-history-repo][38]
|
||||
|
||||
[2][39] - Updates may add or modify material. To ensure replicability the repository's users are encouraged to fork it or archive it.
|
||||
|
||||
[3][40] - [http://www.tuhs.org/archive_sites.html][41]
|
||||
|
||||
[4][42] - [https://www.mckusick.com/csrg/][43]
|
||||
|
||||
[5][44] - [http://www.oldlinux.org/Linux.old/distributions/386BSD][45]
|
||||
|
||||
[6][46] - [http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/][47]
|
||||
|
||||
[7][48] - [https://github.com/freebsd/freebsd][49]
|
||||
|
||||
[8][50] - [http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree][51]
|
||||
|
||||
[9][52] - [https://github.com/dspinellis/unix-history-make][53]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#MPT78
|
||||
[2]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#RT78
|
||||
[3]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Rit84
|
||||
[4]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Sal94
|
||||
[5]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#Ray03
|
||||
[6]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:data
|
||||
[7]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:dev
|
||||
[8]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#sec:use
|
||||
[9]:https://github.com/dspinellis/unix-history-repo
|
||||
[10]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAB
|
||||
[11]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAC
|
||||
[12]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:provenance
|
||||
[13]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[14]:http://www.tuhs.org/archive_sites.html
|
||||
[15]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAD
|
||||
[16]:https://www.mckusick.com/csrg/
|
||||
[17]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAE
|
||||
[18]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[19]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAF
|
||||
[20]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[21]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAG
|
||||
[22]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#SCCS
|
||||
[23]:https://github.com/freebsd/freebsd
|
||||
[24]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAH
|
||||
[25]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[26]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAI
|
||||
[27]:https://github.com/dspinellis/unix-history-make
|
||||
[28]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFtNtAAJ
|
||||
[29]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:branches
|
||||
[30]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#fig:metrics
|
||||
[31]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITEMPT78
|
||||
[32]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERT78
|
||||
[33]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERit84
|
||||
[34]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESal94
|
||||
[35]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITERay03
|
||||
[36]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#CITESCCS
|
||||
[37]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAB
|
||||
[38]:https://github.com/dspinellis/unix-history-repo
|
||||
[39]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAC
|
||||
[40]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAD
|
||||
[41]:http://www.tuhs.org/archive_sites.html
|
||||
[42]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAE
|
||||
[43]:https://www.mckusick.com/csrg/
|
||||
[44]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAF
|
||||
[45]:http://www.oldlinux.org/Linux.old/distributions/386BSD
|
||||
[46]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAG
|
||||
[47]:http://ftp-archive.freebsd.org/pub/FreeBSD-Archive/old-releases/
|
||||
[48]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAH
|
||||
[49]:https://github.com/freebsd/freebsd
|
||||
[50]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAI
|
||||
[51]:http://ftp.netbsd.org/pub/NetBSD/NetBSD-current/src/share/misc/bsd-family-tree
|
||||
[52]:http://www.dmst.aueb.gr/dds/pubs/conf/2015-MSR-Unix-History/html/Spi15c.html#tthFrefAAJ
|
||||
[53]:https://github.com/dspinellis/unix-history-make
|
||||
@ -1,3 +1,4 @@
|
||||
translating By Bestony
|
||||
Remember sed and awk? All Linux admins should
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,63 +0,0 @@
|
||||
DFileManager: Cover Flow File Manager
|
||||
================================================================================
|
||||
A real gem of a file manager absent from the standard Ubuntu repositories but sporting a unique feature. That’s DFileManager in a twitterish statement.
|
||||
|
||||
A tricky question to answer is just how many open source Linux applications are available. Just out of curiosity, you can type at the shell:
|
||||
|
||||
~$ for f in /var/lib/apt/lists/*Packages; do printf ’%5d %s\n’ $(grep ’^Package: ’ “$f” | wc -l) ${f##*/} done | sort -rn
|
||||
|
||||
On my Ubuntu 15.04 system, it produces the following results:
|
||||
|
||||

|
||||
|
||||
As the screenshot above illustrates, there are approximately 39,000 packages in the Universe repository, and around 8,500 packages in the main repository. These numbers sound a lot. But there is a smorgasbord of open source applications, utilities, and libraries that don’t have an Ubuntu team generating a package. And more importantly, there are some real treasures missing from the repositories which can only be discovered by compiling source code. DFileManager is one such utility. It is a Qt based cross-platform file manager which is in an early stage of development. Qt provides single-source portability across all major desktop operating systems.
|
||||
|
||||
In the absence of a binary package, the user needs to compile the code. For some tools, this can be problematic, particularly if the application depends on any obscure libraries, or specific versions which may be incompatible with other software installed on a system.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Fortunately, DFileManager is simple to compile. The installation instructions on the developer’s website provide most of the steps necessary for my creaking Ubuntu box, but a few essential packages were missing (why is it always that way however many libraries clutter up your filesystem?) To prepare my system, download the source code from GitHub and then compile the software, I entered the following commands at the shell:
|
||||
|
||||
~$ sudo apt-get install qt5-default qt5-qmake libqt5x11extras5-dev
|
||||
~$ git clone git://git.code.sf.net/p/dfilemanager/code dfilemanager-code
|
||||
~$ cd dfilemananger-code
|
||||
~$ mkdir build
|
||||
~$ cd build
|
||||
~$ cmake ../ -DCMAKE_INSTALL_PREFIX=/usr
|
||||
~$ make
|
||||
~$ sudo make install
|
||||
|
||||
You can then start the application by typing at the shell:
|
||||
|
||||
~$ dfm
|
||||
|
||||
Here is a screenshot of DFileManager in action, with the main attraction in full view; the Cover Flow view. This offers the ability to slide through items in the current folder with an attractive feel. It’s ideal for viewing photos. The file manager bears a resemblance to Finder (the default file manager and graphical user interface shell used on all Macintosh operating systems), which may appeal to you.
|
||||
|
||||

|
||||
|
||||
### Features: ###
|
||||
|
||||
- 4 views: Icons, Details, Columns, and Cover Flow
|
||||
- Categorised bookmarks with Places and Devices
|
||||
- Tabs
|
||||
- Simple searching and filtering
|
||||
- Customizable thumbnails for filetypes including multimedia files
|
||||
- Information bar which can be undocked
|
||||
- Open folders and files with one click
|
||||
- Option to queue IO operations
|
||||
- Remembers some view properties for each folder
|
||||
- Show hidden files
|
||||
|
||||
DFileManager is not a replacement for KDE’s Dolphin, but do give it a go. It’s a file manager that really helps the user browse files. And don’t forget to give feedback to the developer; that’s a contribution anyone can offer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://gofk.tumblr.com/post/131014089537/dfilemanager-cover-flow-file-manager-a-real-gem
|
||||
|
||||
作者:[gofk][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://gofk.tumblr.com/
|
||||
@ -1,317 +0,0 @@
|
||||
How to Setup Drone - a Continuous Integration Service in Linux
|
||||
==============================================================
|
||||
|
||||
Are you tired of cloning, building, testing, and deploying codes time and again? If yes, switch to continuous integration. Continuous Integration aka CI is practice in software engineering of making frequent commits to the code base, building, testing and deploying as we go. CI helps to quickly integrate new codes into the existing code base. If this process is made automated, then this will speed up the development process as it reduces the time taken for the developer to build and test things manually. [Drone][1] is a free and open source project which provides an awesome environment of continuous integration service and is released under Apache License Version 2.0. It integrates with many repository providers like Github, Bitbucket and Google Code and has the ability to pull codes from the repositories enabling us to build the source code written in number of languages including PHP, Node, Ruby, Go, Dart, Python, C/C++, JAVA and more. It is made such a powerful platform cause it uses containers and docker technology for every build making users a complete control over their build environment with guaranteed isolation.
|
||||
|
||||
### 1. Installing Docker ###
|
||||
|
||||
First of all, we'll gonna install Docker as its the most vital element for the complete workflow of Drone. Drone does a proper utilization of docker for the purpose of building and testing application. This container technology speeds up the development of the applications. To install docker, we'll need to run the following commands with respective the distribution of linux. In this tutorial, we'll cover the steps with Ubuntu 14.04 and CentOS 7 linux distributions.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
To install Docker in Ubuntu, we can simply run the following commands in a terminal or console.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install docker.io
|
||||
|
||||
After the installation is done, we'll restart our docker engine using service command.
|
||||
|
||||
# service docker restart
|
||||
|
||||
Then, we'll make docker start automatically in every system boot.
|
||||
|
||||
# update-rc.d docker defaults
|
||||
|
||||
Adding system startup for /etc/init.d/docker ...
|
||||
/etc/rc0.d/K20docker -> ../init.d/docker
|
||||
/etc/rc1.d/K20docker -> ../init.d/docker
|
||||
/etc/rc6.d/K20docker -> ../init.d/docker
|
||||
/etc/rc2.d/S20docker -> ../init.d/docker
|
||||
/etc/rc3.d/S20docker -> ../init.d/docker
|
||||
/etc/rc4.d/S20docker -> ../init.d/docker
|
||||
/etc/rc5.d/S20docker -> ../init.d/docker
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
First, we'll gonna update every packages installed in our centos machine. We can do that by running the following command.
|
||||
|
||||
# sudo yum update
|
||||
|
||||
To install docker in centos, we can simply run the following commands.
|
||||
|
||||
# curl -sSL https://get.docker.com/ | sh
|
||||
|
||||
After our docker engine is installed in our centos machine, we'll simply start it by running the following systemd command as systemd is the default init system in centos 7.
|
||||
|
||||
# systemctl start docker
|
||||
|
||||
Then, we'll enable docker to start automatically in every system startup.
|
||||
|
||||
# systemctl enable docker
|
||||
|
||||
ln -s '/usr/lib/systemd/system/docker.service' '/etc/systemd/system/multi-user.target.wants/docker.service'
|
||||
|
||||
### 2. Installing SQlite Driver ###
|
||||
|
||||
It uses SQlite3 database server for storing its data and information by default. It will automatically create a database file named drone.sqlite under /var/lib/drone/ which will handle database schema setup and migration. To setup SQlite3 drivers, we'll need to follow the below steps.
|
||||
|
||||
#### On Ubuntu 14.04 ####
|
||||
|
||||
As SQlite3 is available on the default respository of Ubuntu 14.04, we'll simply install it by running the following apt command.
|
||||
|
||||
# apt-get install libsqlite3-dev
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
To install it on CentOS 7 machine, we'll need to run the following yum command.
|
||||
|
||||
# yum install sqlite-devel
|
||||
|
||||
### 3. Installing Drone ###
|
||||
|
||||
Finally, after we have installed those dependencies successfully, we'll now go further towards the installation of drone in our machine. In this step, we'll simply download the binary package of it from the official download link of the respective binary formats and then install them using the default package manager.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
We'll use wget to download the debian package of drone for ubuntu from the [official Debian file download link][2]. Here is the command to download the required debian package of drone.
|
||||
|
||||
# wget downloads.drone.io/master/drone.deb
|
||||
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.48.98
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.48.98|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7722384 (7.4M) [application/x-debian-package]
|
||||
Saving to: 'drone.deb'
|
||||
100%[======================================>] 7,722,384 1.38MB/s in 17s
|
||||
2015-11-06 14:09:28 (456 KB/s) - 'drone.deb' saved [7722384/7722384]
|
||||
|
||||
After its downloaded, we'll gonna install it with dpkg package manager.
|
||||
|
||||
# dpkg -i drone.deb
|
||||
|
||||
Selecting previously unselected package drone.
|
||||
(Reading database ... 28077 files and directories currently installed.)
|
||||
Preparing to unpack drone.deb ...
|
||||
Unpacking drone (0.3.0-alpha-1442513246) ...
|
||||
Setting up drone (0.3.0-alpha-1442513246) ...
|
||||
Your system ubuntu 14: using upstart to control Drone
|
||||
drone start/running, process 9512
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
In the machine running CentOS, we'll download the RPM package from the [official download link for RPM][3] using wget command as shown below.
|
||||
|
||||
# wget downloads.drone.io/master/drone.rpm
|
||||
|
||||
--2015-11-06 11:06:45-- http://downloads.drone.io/master/drone.rpm
|
||||
Resolving downloads.drone.io (downloads.drone.io)... 54.231.114.18
|
||||
Connecting to downloads.drone.io (downloads.drone.io)|54.231.114.18|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: 7763311 (7.4M) [application/x-redhat-package-manager]
|
||||
Saving to: ‘drone.rpm’
|
||||
100%[======================================>] 7,763,311 1.18MB/s in 20s
|
||||
2015-11-06 11:07:06 (374 KB/s) - ‘drone.rpm’ saved [7763311/7763311]
|
||||
|
||||
Then, we'll install the download rpm package using yum package manager.
|
||||
|
||||
# yum localinstall drone.rpm
|
||||
|
||||
### 4. Configuring Port ###
|
||||
|
||||
After the installation is completed, we'll gonna configure drone to make it workable. The configuration of drone is inside **/etc/drone/drone.toml** file. By default, drone web interface is exposed under port 80 which is the default port of http, if we wanna change it, we can change it by replacing the value under server block as shown below.
|
||||
|
||||
[server]
|
||||
port=":80"
|
||||
|
||||
### 5. Integrating Github ###
|
||||
|
||||
In order to run Drone we must setup at least one integration points between GitHub, GitHub Enterprise, Gitlab, Gogs, Bitbucket. In this tutorial, we'll only integrate github but if we wanna integrate other we can do that from the configuration file. In order to integrate github, we'll need to create a new application in our [github settings][4].
|
||||
|
||||

|
||||
|
||||
To create, we'll need to click on Register a New Application then fill out the form as shown in the following image.
|
||||
|
||||

|
||||
|
||||
We should make sure that **Authorization callback URL** looks like http://drone.linoxide.com/api/auth/github.com under the configuration of the application. Then, we'll click on Register application. After done, we'll note the Client ID and Client Secret key as we'll need to configure it in our drone configuration.
|
||||
|
||||

|
||||
|
||||
After thats done, we'll need to edit our drone configuration using a text editor by running the following command.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll find the [github] section and append the section with the above noted configuration as shown below.
|
||||
|
||||
[github]
|
||||
client="3dd44b969709c518603c"
|
||||
secret="4ee261abdb431bdc5e96b19cc3c498403853632a"
|
||||
# orgs=[]
|
||||
# open=false
|
||||
|
||||

|
||||
|
||||
### 6. Configuring SMTP server ###
|
||||
|
||||
If we wanna enable drone to send notifications via emails, then we'll need to specify the SMTP configuration of our SMTP server. If we already have an SMTP server, we can use its configuration but as we don't have an SMTP server, we'll need to install an MTA ie Postfix and then specify the SMTP configuration in the drone configuration.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
We can install postfix in ubuntu by running the following apt command.
|
||||
|
||||
# apt-get install postfix
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
We can install postfix in CentOS by running the following yum command.
|
||||
|
||||
# yum install postfix
|
||||
|
||||
After installing, we'll need to edit the configuration of our postfix configuration using a text editor.
|
||||
|
||||
# nano /etc/postfix/main.cf
|
||||
|
||||
Then, we'll need to replace the value of myhostname parameter to our FQDN ie drone.linoxide.com .
|
||||
|
||||
myhostname = drone.linoxide.com
|
||||
|
||||
Now, we'll gonna finally configure the SMTP section of our drone configuration file.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll find the [stmp] section and then we'll need to append the setting as follows.
|
||||
|
||||
[smtp]
|
||||
host = "drone.linoxide.com"
|
||||
port = "587"
|
||||
from = "root@drone.linoxide.com"
|
||||
user = "root"
|
||||
pass = "password"
|
||||
|
||||

|
||||
|
||||
Note: Here, **user** and **pass** parameters are strongly recommended to be changed according to one's user configuration.
|
||||
|
||||
### 7. Configuring Worker ###
|
||||
|
||||
As we know that drone utilizes docker for its building and testing task, we'll need to configure docker as the worker for our drone. To do so, we'll need to edit the [worker] section in the drone configuration file.
|
||||
|
||||
# nano /etc/drone/drone.toml
|
||||
|
||||
Then, we'll uncomment the following lines and append as shown below.
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
Here, we have set only 2 node which means the above configuration is capable of executing only 2 build at a time. In order to increase concurrency, we can increase the number of nodes.
|
||||
|
||||
[worker]
|
||||
nodes=[
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock",
|
||||
"unix:///var/run/docker.sock"
|
||||
]
|
||||
|
||||
Here, in the above configuration, drone is configured to process four builds at a time, using the local docker daemon.
|
||||
|
||||
### 8. Restarting Drone ###
|
||||
|
||||
Finally, after everything is done regarding the installation and configuration, we'll now start our drone server in our linux machine.
|
||||
|
||||
#### On Ubuntu ####
|
||||
|
||||
To start drone in our Ubuntu 14.04 machine, we'll simply run service command as the default init system of Ubuntu 14.04 is SysVinit.
|
||||
|
||||
# service drone restart
|
||||
|
||||
To make drone start automatically in every boot of the system, we'll run the following command.
|
||||
|
||||
# update-rc.d drone defaults
|
||||
|
||||
#### On CentOS ####
|
||||
|
||||
To start drone in CentOS machine, we'll simply run systemd command as CentOS 7 is shipped with systemd as init system.
|
||||
|
||||
# systemctl restart drone
|
||||
|
||||
Then, we'll enable drone to start automatically in every system boot.
|
||||
|
||||
# systemctl enable drone
|
||||
|
||||
### 9. Allowing Firewalls ###
|
||||
|
||||
As we know drone utilizes port 80 by default and we haven't changed the port, we'll gonna configure our firewall programs to allow port 80 (http) and be accessible from other machines in the network.
|
||||
|
||||
#### On Ubuntu 14.04 ####
|
||||
|
||||
Iptables is a popular firewall program which is installed in the ubuntu distributions by default. We'll make iptables to expose port 80 so that we can make our Drone web interface accessible in the network.
|
||||
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# /etc/init.d/iptables save
|
||||
|
||||
#### On CentOS 7 ####
|
||||
|
||||
As CentOS 7 has systemd installed by default, it contains firewalld running as firewall problem. In order to open the port 80 (http service) on firewalld, we'll need to execute the following commands.
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||
### 10. Accessing Web Interface ###
|
||||
|
||||
Now, we'll gonna open the web interface of drone using our favourite web browser. To do so, we'll need to point our web browser to our machine running drone in it. As the default port of drone is 80 and we have also set 80 in this tutorial, we'll simply point our browser to http://ip-address/ or http://drone.linoxide.com according to our configuration. After we have done that correctly, we'll see the first page of it having options to login into our dashboard.
|
||||
|
||||

|
||||
|
||||
As we have configured Github in the above step, we'll simply select github and we'll go through the app authentication process and after its done, we'll be forwarded to our Dashboard.
|
||||
|
||||

|
||||
|
||||
Here, it will synchronize all our github repository and will ask us to activate the repo which we want to build with drone.
|
||||
|
||||

|
||||
|
||||
After its activated, it will ask us to add a new file named .drone.yml in our repository and define the build process and configuration in that file like which image to fetch and which command/script to run while compiling, etc.
|
||||
|
||||
We'll need to configure our .drone.yml as shown below.
|
||||
|
||||
image: python
|
||||
script:
|
||||
- python helloworld.py
|
||||
- echo "Build has been completed."
|
||||
|
||||
After its done, we'll be able to build our application using the configuration YAML file .drone.yml in our drone appliation. All the commits made into the repository is synced in realtime. It automatically syncs the commit and changes made to the repository. Once the commit is made in the repository, build is automatically started in our drone application.
|
||||
|
||||

|
||||
|
||||
After the build is completed, we'll be able to see the output of the build with the output console.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, we learned to completely setup a workable Continuous Intergration platform with Drone. If we want, we can even get started with the services provided by the official Drone.io project. We can start with free service or paid service according to our requirements. It has changed the world of Continuous integration with its beautiful web interface and powerful bunches of features. It has the ability to integrate with many third party applications and deployment platforms. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/setup-drone-continuous-integration-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://drone.io/
|
||||
[2]:http://downloads.drone.io/master/drone.deb
|
||||
[3]:http://downloads.drone.io/master/drone.rpm
|
||||
[4]:https://github.com/settings/developers
|
||||
@ -1,133 +0,0 @@
|
||||
How to Configure Apache Solr on Ubuntu 14 / 15
|
||||
================================================================================
|
||||
Hello and welcome to our today's article on Apache Solr. The brief description about Apache Solr is that it is an Open Source most famous search platform with Apache Lucene at the back end for Web sites that enables you to easily create search engines which searches websites, databases and files. It can index and search multiple sites and return recommendations for related contents based on the searched text.
|
||||
|
||||
Solr works with HTTP Extensible Markup Language (XML) that offers application program interfaces (APIs) for Javascript Object Notation, Python, and Ruby. According to the Apache Lucene Project, Solr offers capabilities that have made it popular with administrators including it many featuring like:
|
||||
|
||||
- Full Text Search
|
||||
- Faceted Navigation
|
||||
- Snippet generation/highting
|
||||
- Spell Suggestion/Auto complete
|
||||
- Custom document ranking/ordering
|
||||
|
||||
#### Prerequisites: ####
|
||||
|
||||
On a fresh Linux Ubuntu 14/15 with minimal packages installed, you only have to take care of few prerequisites in order to install Apache Solr.
|
||||
|
||||
### 1)System Update ###
|
||||
|
||||
Login to your Ubuntu server with a non-root sudo user that will be used to perform all the steps to install and use Solr.
|
||||
|
||||
After successful login, issue the following command to update your system with latest updates and patches.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
### 2) JRE Setup ###
|
||||
|
||||
The Solr setup needs Java Runtime Environment to be installed on the system as its basic requirement because solr and tomcat both are the Java based applications. So, we need to install and configure its home environment with latest Java.
|
||||
|
||||
To install the latest version on Oracle Java 8, we need to install Python Software Properties using the below command.
|
||||
|
||||
$ sudo apt-get install python-software-properties
|
||||
|
||||
Upon completion, run the setup its the repository for the latest version of Java 8.
|
||||
|
||||
$ sudo add-apt-repository ppa:webupd8team/java
|
||||
|
||||
Now you are able to install the latest version of Oracle Java 8 with 'wget' by issuing the below commands to update the packages source list and then to install Java.
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
----------
|
||||
|
||||
$ sudo apt-get install oracle-java8-installer
|
||||
|
||||
Accept the Oracle Binary Code License Agreement for the Java SE Platform Products and JavaFX as you will be asked during the Java installation and configuration process by a click on the 'OK' button.
|
||||
|
||||
When the installation process complete, run the below command to test the successful installation of Java and check its version.
|
||||
|
||||
kash@solr:~$ java -version
|
||||
java version "1.8.0_66"
|
||||
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
|
||||
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)
|
||||
|
||||
The output indicates that we have successfully fulfilled the basic requirement of Solr by installing the Java. Now move to the next step to install Solr.
|
||||
|
||||
### Installing Solr ###
|
||||
|
||||
Installing Solr on Ubuntu can be done by using two different ways but in this article we prefer to install its latest package from the source.
|
||||
|
||||
To install Solr from its source, download its available package with latest version from there Official [Web Page][1], copy the link address and get it using 'wget' command.
|
||||
|
||||
$ wget http://www.us.apache.org/dist/lucene/solr/5.3.1/solr-5.3.1.tgz
|
||||
|
||||
Run the command below to extract the archived service into '/bin' folder.
|
||||
|
||||
$ tar -xzf solr-5.3.1.tgz solr-5.3.1/bin/install_solr_service.sh --strip-components=2
|
||||
|
||||
Then run the script to start Solr service that will creates a new 'solr' user and then installs solr as a service.
|
||||
|
||||
$ sudo bash ./install_solr_service.sh solr-5.3.1.tgz
|
||||
|
||||

|
||||
|
||||
To check the status of Solr service, you use the below command.
|
||||
|
||||
$ service solr status
|
||||
|
||||

|
||||
|
||||
### Creating Solr Collection: ###
|
||||
|
||||
Now we can create multiple collections using Solr user. To do so just run the below command by mentioning the name of the collection you want to create and by specifying its configuration set as shown.
|
||||
|
||||
$ sudo su - solr -c "/opt/solr/bin/solr create -c myfirstcollection -n data_driven_schema_configs"
|
||||
|
||||

|
||||
|
||||
We have successfully created the new core instance directory for our our first collection where we can add new data in it. To view its default schema file in directory '/opt/solr/server/solr/configsets/data_driven_schema_configs/conf' .
|
||||
|
||||
### Using Solr Web ###
|
||||
|
||||
Apache Solr can be accessible on the default port of Solr that 8983. Open your favorite browser and navigate to http://your_server_ip:8983/solr or http://your-domain.com:8983/solr. Make sure that the port is allowed in your firewall.
|
||||
|
||||
http://172.25.10.171:8983/solr/
|
||||
|
||||

|
||||
|
||||
From the Solr Web Console click on the 'Core Admin' button from the left bar, then you will see your first collection that we created earlier using CLI. While you can also create new cores by pointing on the 'Add Core' button.
|
||||
|
||||

|
||||
|
||||
You can also add the document and query from the document as shown in below image by selecting your particular collection and pointing the document. Add the data in the specified format as shown in the box.
|
||||
|
||||
{
|
||||
"number": 1,
|
||||
"Name": "George Washington",
|
||||
"birth_year": 1989,
|
||||
"Starting_Job": 2002,
|
||||
"End_Job": "2009-04-30",
|
||||
"Qualification": "Graduation",
|
||||
"skills": "Linux and Virtualization"
|
||||
}
|
||||
|
||||
After adding the document click on the 'Submit Document' button.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
You are now able to insert and query data using the Solr web interface after its successful installation on Ubuntu. Now add more collections and insert you own data and documents that you wish to put and manage through Solr. We hope you have got this article much helpful and enjoyed reading this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-apache-solr-ubuntu-14-15/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
[1]:http://lucene.apache.org/solr/
|
||||
@ -1,148 +0,0 @@
|
||||
How to Install Cockpit in Fedora / CentOS / RHEL/ Arch Linux
|
||||
================================================================================
|
||||
Cockpit is a free and open source server management software that makes us easy to administer our GNU/Linux servers via its beautiful web interface frontend. Cockpit helps make linux system administrator, system maintainers and DevOps easy to manage their server and to perform simple tasks, such as administering storage, inspecting journals, starting and stopping services and more. Its journal interface adds aroma in flower making people easy to switch between the terminal and web interface. And moreover, it makes easy to manage not only one server but several multiple networked servers from a single place at the same time with just a single click. It is very light weight and has easy to use web based interface. In this tutorial, we'll learn how we can setup Cockpit and use it to manage our server running Fedora, CentOS, Arch Linux and RHEL distributions as their operating system software. Some of the awesome benefits of Cockpit in our GNU/Linux servers are as follows:
|
||||
|
||||
1. It consist of systemd service manager for ease.
|
||||
1. It has a Journal log viewer to perform troubleshoots and log analysis.
|
||||
1. Storage setup including LVM was never easier before.
|
||||
1. Basic Network configuration can be applied with Cockpit
|
||||
1. We can easily add and remove local users and manage multiple servers.
|
||||
|
||||
### 1. Installing Cockpit ###
|
||||
|
||||
First of all, we'll need to setup Cockpit in our linux based server. In most of the distributions, the cockpit package is already available in their official repositories. Here, in this tutorial, we'll setup Cockpit in Fedora 22, CentOS 7, Arch Linux and RHEL 7 from their official repositories.
|
||||
|
||||
#### On CentOS / RHEL ####
|
||||
|
||||
Cockpit is available in the official repository of CenOS and RHEL. So, we'll simply install it using yum manager. To do so, we'll simply run the following command under sudo/root access.
|
||||
|
||||
# yum install cockpit
|
||||
|
||||

|
||||
|
||||
#### On Fedora 22/21 ####
|
||||
|
||||
Alike, CentOS, it is also available by default in Fedora's official repository, we'll simply install cockpit using dnf package manager.
|
||||
|
||||
# dnf install cockpit
|
||||
|
||||

|
||||
|
||||
#### On Arch Linux ####
|
||||
|
||||
Cockpit is currently not available in the official repository of Arch Linux but it is available in the Arch User Repository also know as AUR. So, we'll simply run the following yaourt command to install it.
|
||||
|
||||
# yaourt cockpit
|
||||
|
||||

|
||||
|
||||
### 2. Starting and Enabling Cockpit ###
|
||||
|
||||
After we have successfully installed it, we'll gonna start the cockpit server with our service/daemon manager. As of 2015, most of the linux distributions have adopted Systemd whereas some of the linux distributions still run SysVinit to manage daemon, but Cockpit uses systemd for almost everything from running daemons to services. So, we can only setup Cockpit in the latest releases of linux distributions running Systemd. In order to start Cockpit and make it start in every boot of the system, we'll need to run the following command in a terminal or a console.
|
||||
|
||||
# systemctl start cockpit
|
||||
|
||||
# systemctl enable cockpit.socket
|
||||
|
||||
Created symlink from /etc/systemd/system/sockets.target.wants/cockpit.socket to /usr/lib/systemd/system/cockpit.socket.
|
||||
|
||||
### 3. Allowing Firewall ###
|
||||
|
||||
After we have started our cockpit server and enable it to start in every boot, we'll now go for configuring firewall. As we have firewall programs running in our server, we'll need to allow ports in order to make cockpit accessible outside of the server.
|
||||
|
||||
#### On Firewalld ####
|
||||
|
||||
# firewall-cmd --add-service=cockpit --permanent
|
||||
|
||||
success
|
||||
|
||||
# firewall-cmd --reload
|
||||
|
||||
success
|
||||
|
||||

|
||||
|
||||
#### On Iptables ####
|
||||
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
|
||||
# service iptables save
|
||||
|
||||
### 4. Accessing Cockpit Web Interface ###
|
||||
|
||||
Next, we'll gonna finally access the Cockpit web interface using a web browser. We'll simply need to point our web browser to https://ip-address:9090 or https://server.domain.com:9090 according to the configuration. Here, in our tutorial, we'll gonna point our browser to https://128.199.114.17:9090 as shown in the image below.
|
||||
|
||||

|
||||
|
||||
We'll be displayed an SSL certification warning as we are using a self-signed SSL certificate. So, we'll simply ignore it and go forward towards the login page, in chrome/chromium, we'll need to click on Show Advanced and then we'll need to click on **Proceed to 128.199.114.17 (unsafe)** .
|
||||
|
||||

|
||||
|
||||
Now, we'll be asked to enter the login details in order to enter into the dashboard. Here, the username and password is the same as that of the login details we use to login to our linux server. After we enter the login details and click on Log In button, we will be welcomed into the Cockpit Dashboard.
|
||||
|
||||

|
||||
|
||||
Here, we'll see all the menu and visualization of CPU, Disk, Network, Storage usages of the server. We'll see the dashboard as shown above.
|
||||
|
||||
#### Services ####
|
||||
|
||||
To manage services, we'll need to click on Services button on the menu situated in the right side of the web page. Then, we'll see the services under 5 categories, Targets, System Services, Sockets, Timers and Paths.
|
||||
|
||||

|
||||
|
||||
#### Docker Containers ####
|
||||
|
||||
We can even manage docker containers with Cockpit. It is pretty easy to monitor and administer Docker containers with Cockpit. As docker isn't installed and running in our server, we'll need to click on Start Docker.
|
||||
|
||||

|
||||
|
||||
Cockpit will automatically install and run docker in our server. After its running, we see the following screen. Then, we can manage the docker images, containers as per our requirement.
|
||||
|
||||

|
||||
|
||||
#### Journal Log Viewer ####
|
||||
|
||||
Cockpit has a managed log viewer which separates the Errors, Warnings, Notices into different tabs. And we also have a tab All where we can see them all in a single place.
|
||||
|
||||

|
||||
|
||||
#### Networking ####
|
||||
|
||||
Under the networking section, we see two graphs in which there is the visualization of Sending and Receiving speed. And we can see there the list of available interfaces with option to Add Bond, Bridge, VLAN. If we need to configure an interface, we can do so by simply clicking on the interface name. Below everything, we can see the Journal Log Viewer for Networking.
|
||||
|
||||

|
||||
|
||||
#### Storage ####
|
||||
|
||||
Now, its easy with Cockpit to see the R/W speed of our hard disk. We can see the Journal log of the Storage in order to perform troubleshoot and fixes. A clear visualization bar of how much space is occupied is shown in the page. We can even Unmount, Format, Delete a partition of a Hard Disk and more. Features like creating RAID Device, Volume Group is also available in it.
|
||||
|
||||

|
||||
|
||||
#### Account Management ####
|
||||
|
||||
We can easily create new accounts with Cockpit Web Interface. The accounts created in it is applied to the system's user account. We can change password, specify roles, delete, rename user accounts with it.
|
||||
|
||||

|
||||
|
||||
#### Live Terminal ####
|
||||
|
||||
This is an awesome feature built-in with Cockpit. Yes, we can execute commands, do stuffs with the live terminal provided by Cockpit interface. This makes us really easy to switch between the web interface and terminal according to our need.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Cockpit is a good free and open source software developed by [Red Hat][1] for making the server management easy and simple. It is best for performing simple system administration tasks and is good for the new system administrators. It is still under pre-release as its stable release hasn't been released yet. So, it is not suitable for production. It is currently developed on the latest release of Fedora, CentOS, Arch Linux, RHEL where systemd is installed by default. If you are willing to install Cockpit in Ubuntu, you can get the PPA access but is currently outdated. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank You !
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-cockpit-fedora-centos-rhel-arch-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.redhat.com/
|
||||
@ -1,40 +0,0 @@
|
||||
Running a mainline kernel on a cellphone
|
||||
================================================================================
|
||||
|
||||
One of the biggest freedoms associated with free software is the ability to replace a program with an updated or modified version. Even so, of the many millions of people using Linux-powered phones, few are able to run a mainline kernel on those phones, even if they have the technical skills to do the replacement. The sad fact is that no mainstream phone available runs mainline kernels. A session at the 2015 Kernel Summit, led by Rob Herring, explored this problem and what might be done to address it.
|
||||
|
||||
When asked, most of the developers in the room indicated that they would prefer to be able to run mainline kernels on their phones — though a handful did say that they would rather not do so. Rob has been working on this problem for the last year and a half in support of Project Ara (mentioned in this article). But the news is not good.
|
||||
|
||||
There is, he said, too much out-of-tree code running on a typical handset; mainline kernels simply lack the drivers needed to make that handset work. A typical phone is running 1-3 million lines of out-of-tree code. Almost all of those phones are stuck on the 3.10 kernel — or something even older. There are all kinds of reasons for this, but the simple fact is that things seem to move too quickly in the handset world for the kernel community to keep up. Is that, he asked, something that we care about?
|
||||
|
||||
Tim Bird noted that the Nexus 1, one of the original Android phones, never ran a mainline kernel and never will. It broke the promise of open source, making it impossible for users to put a new kernel onto their devices. At this point, no phone supports that ability. Peter Zijlstra wondered about how much of that out-of-tree code was duplicated functionality from one handset to the next; Rob noted that he has run into three independently developed hotplug governors so far.
|
||||
|
||||
Dirk Hohndel suggested that few people care. Of the billion phones out there, he said, approximately 27 of them have owners who care about running mainline kernels. The rest just want to get the phone to work. Perhaps developers who are concerned about running mainline kernels are trying to solve the wrong problem.
|
||||
|
||||
Chris Mason said that handset vendors are currently facing the same sorts of problems that distributors dealt with many years ago. They are coping with a lot of inefficient, repeated, duplicated work. Once the distributors [Rob Herring] decided to put their work into the mainline instead of carrying it themselves, things got a lot better. The key is to help the phone manufacturers to realize that they can benefit in the same way; that, rather than pressure from users, is how the problem will be solved.
|
||||
|
||||
Grant Likely raised concerns about security in a world where phones cannot be upgraded. What we need is a real distribution market for phones. But, as long as the vendors are in charge of the operating software, phones will not be upgradeable. We have a big security mess coming, he said. Peter added that, with Stagefright, that mess is already upon us.
|
||||
|
||||
Ted Ts'o said that running mainline kernels is not his biggest concern. He would be happy if the phones on sale this holiday season would be running a 3.18 or 4.1 kernel, rather than being stuck on 3.10. That, he suggested, is a more solvable problem. Steve Rostedt said that would not solve the security problem, but Ted remarked that a newer kernel would at least make it easier to backport fixes. Grant replied that, one year from now, it would all just happen again; shipping newer kernels is just an incremental fix. Kees Cook added that there is not much to be gained from backporting fixes; the real problem is that there are no defenses from bugs (he would expand on this theme in a separate session later in the day).
|
||||
|
||||
Rob said that any kind of solution would require getting the vendors on board. That, though, will likely run into trouble with the sort of lockdown that vendors like to apply to their devices. Paolo Bonzini asked whether it would be possible to sue vendors over unfixed security vulnerabilities, especially when the devices are still under warranty. Grant said that upgradeability had to become a market requirement or it simply wasn't going to happen. It might be a nasty security issue that causes this to happen, or carriers might start requiring it. Meanwhile, kernel developers need to keep pushing in that direction. Rob noted that, beyond the advantages noted thus far, the ability to run mainline kernels would help developers to test and validate new features on Android devices.
|
||||
|
||||
Josh Triplett asked whether the community would be prepared to do what it would take if the industry were to come around to the idea of mainline kernel support. There would be lots of testing and validation of kernels on handsets required; Android Compatibility Test Suite failures would have to be treated as regressions. Rob suggested that this could be discussed next year, after the basic functionality is in place, but Josh insisted that, if the demand were to show up, we would have to be able to give a good answer.
|
||||
|
||||
Tim said that there is currently a big disconnect with the vendor world; vendors are not reporting or contributing anything back to the community at all. They are completely disconnected, so there is no forward progress ever. Josh noted that when vendors do report bugs with the old kernels they are using, the reception tends to be less than friendly. Arnd Bergmann said that what was needed was to get one of the big silicon vendors to commit to the idea and get its hardware to a point where running mainline kernels was possible; that would put pressure on the others. But, he added, that would require the existence of one free GPU driver that got shipped with the hardware — something that does not exist currently.
|
||||
|
||||
Rob put up a list of problem areas, but there was not much time for discussion of the particulars. WiFi drivers continue to be an issue, especially with the new features being added in the Android world. Johannes Berg agreed that the new features are an issue; the Android developers do not even talk about them until they ship with the hardware. Support for most of those features does eventually land in the mainline kernel, though.
|
||||
|
||||
As things wound down, Ben Herrenschmidt reiterated that the key was to get vendors to realize that working with the mainline kernel is in their own best interest; it saves work in the long run. Mark Brown said that, in past years when the kernel version shipped with Android moved forward more reliably, the benefits of working upstream were more apparent to vendors. Now that things seem to be stuck on 3.10, that pressure is not there in the same way. The session ended with developers determined to improve the situation, but without any clear plan for getting there.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/662147/
|
||||
|
||||
作者:[Jonathan Corbet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/KernelSummit2015/
|
||||
@ -1,175 +0,0 @@
|
||||
How to Install Laravel PHP Framework on CentOS 7 / Ubuntu 15.04
|
||||
================================================================================
|
||||
Hi All, In this article we are going to setup Laravel on CentOS 7 and Ubuntu 15.04. If you are a PHP web developer then you don't need to worry about of all modern PHP frameworks, Laravel is the easiest to get up and running that saves your time and effort and makes web development a joy. Laravel embraces a general development philosophy that sets a high priority on creating maintainable code by following some simple guidelines, you should be able to keep a rapid pace of development and be free to change your code with little fear of breaking existing functionality.
|
||||
|
||||
Laravel's PHP framework installation is not a big deal. You can simply follow the step by step guide in this article for your CentOS 7 or Ubuntu 15 server.
|
||||
|
||||
### 1) Server Requirements ###
|
||||
|
||||
Laravel depends upon a number of prerequisites that must be setup before installing it. Those prerequisites includes some basic tuning parameter of server like your system update, sudo rights and installation of required packages.
|
||||
|
||||
Once you are connected to your server make sure to configure the fully qualified domain name then run the commands below to enable EPEL Repo and update your server.
|
||||
|
||||
#### CentOS-7 ####
|
||||
|
||||
# yum install epel-release
|
||||
|
||||
----------
|
||||
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
|
||||
----------
|
||||
|
||||
# yum update
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# apt-get install python-software-properties
|
||||
# add-apt-repository ppa:ondrej/php5
|
||||
|
||||
----------
|
||||
|
||||
# apt-get update
|
||||
|
||||
----------
|
||||
|
||||
# apt-get install -y php5 mcrypt php5-mcrypt php5-gd
|
||||
|
||||
### 2) Firewall Setup ###
|
||||
|
||||
System Firewall and SELinux setup is an important part regarding the security of your applications in production. You can make firewall off if you are working on test server and keep SELinux to permissive mode using the below command, so that you installing setup won't be affected by it.
|
||||
|
||||
# setenforce 0
|
||||
|
||||
### 3) Apache, MariaDB, PHP Setup ###
|
||||
|
||||
Laravel installation requires a complete LAMP stack with OpenSSL, PDO, Mbstring and Tokenizer PHP Extensions. If you are already running LAMP server then you can skip this step to move on and just make sure that the required PHP extensions are installed.
|
||||
|
||||
To install AMP stack you can use the below commands on your respective server.
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
# yum install httpd mariadb-server php56w php56w-mysql php56w-mcrypt php56w-dom php56w-mbstring
|
||||
|
||||
To start and enable Apache web and MySQL/Mariadb services at bootup on CentOS 7 , we will use below commands.
|
||||
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
|
||||
----------
|
||||
|
||||
#systemctl start mysqld
|
||||
#systemctl enable mysqld
|
||||
|
||||
After starting MariaDB service, we will configure its secured password with below command.
|
||||
|
||||
#mysql_secure_installation
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# apt-get install mysql-server apache2 libapache2-mod-php5 php5-mysql
|
||||
|
||||
### 4) Install Composer ###
|
||||
|
||||
Now we are going to install composer that is one of the most important requirement before starting the Laravel installation that helps in installing Laravel's dependencies.
|
||||
|
||||
#### CentOS/Ubuntu ####
|
||||
|
||||
Run the below commands to setup 'composer' in CentOS/Ubuntu.
|
||||
|
||||
# curl -sS https://getcomposer.org/installer | php
|
||||
# mv composer.phar /usr/local/bin/composer
|
||||
# chmod +x /usr/local/bin/composer
|
||||
|
||||

|
||||
|
||||
### 5) Installing Laravel ###
|
||||
|
||||
Laravel's installation package can be downloaded from github using the command below.
|
||||
|
||||
# wget https://github.com/laravel/laravel/archive/develop.zip
|
||||
|
||||
To extract the archived package and move into the document root directory use below commands.
|
||||
|
||||
# unzip develop.zip
|
||||
|
||||
----------
|
||||
|
||||
# mv laravel-develop /var/www/
|
||||
|
||||
Now use the following compose command that will install all required dependencies for Laravel within its directory.
|
||||
|
||||
# cd /var/www/laravel-develop/
|
||||
# composer install
|
||||
|
||||

|
||||
|
||||
### 6) Key Encryption ###
|
||||
|
||||
For encrypter service, we will be generating a 32 digit encryption key using the command below.
|
||||
|
||||
# php artisan key:generate
|
||||
|
||||
Application key [Lf54qK56s3qDh0ywgf9JdRxO2N0oV9qI] set successfully
|
||||
|
||||
Now put this key into the 'app.php' file as shown below.
|
||||
|
||||
# vim /var/www/laravel-develop/config/app.php
|
||||
|
||||

|
||||
|
||||
### 7) Virtua Host and Ownership ###
|
||||
|
||||
After composer installation assign the permissions and apache user ownership to the document root directory as shown.
|
||||
|
||||
# chmod 775 /var/www/laravel-develop/app/storage
|
||||
|
||||
----------
|
||||
|
||||
# chown -R apache:apache /var/www/laravel-develop
|
||||
|
||||
Open the default configuration file of apache web server using any editor to add the following lines at the end file for new virtual host entry.
|
||||
|
||||
# vim /etc/httpd/conf/httpd.conf
|
||||
|
||||
----------
|
||||
|
||||
ServerName laravel-develop
|
||||
DocumentRoot /var/www/laravel/public
|
||||
|
||||
start Directory /var/www/laravel
|
||||
AllowOverride All
|
||||
Directory close
|
||||
|
||||
Now the time is to restart apache web server services as shown below and then open your web browser to check your localhost page.
|
||||
|
||||
#### CentOS ####
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||
#### Ubuntu ####
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
### 8) Laravel 5 Web Access ###
|
||||
|
||||
Open your web browser and give your server IP or Fully Qualified Domain name and you will see the default web page of Laravel 5 frame work.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Laravel Framework is a great tool to develop your web applications. So, at the end of this article you have learned its installation setup on Ubuntu 15 and CentOS 7 , Now start using this awesome PHP framework that provides you a lot of more features and comfort in your development work. Feel free to comment us back for your valuable suggestions an feedback to guide you in more specific and easiest way.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/install-laravel-php-centos-7-ubuntu-15-04/
|
||||
|
||||
作者:[Kashif][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,54 +0,0 @@
|
||||
NetworkManager and privacy in the IPv6 internet
|
||||
======================
|
||||
|
||||
IPv6 is gaining momentum. With growing use of the protocol concerns about privacy that were not initially anticipated arise. The Internet community actively publishes solutions to them. What’s the current state and how does NetworkManager catch up? Let’s figure out!
|
||||
|
||||

|
||||
|
||||
## The identity of a IPv6-connected host
|
||||
|
||||
The IPv6 enabled nodes don’t need a central authority similar to IPv4 [DHCP](https://tools.ietf.org/html/rfc2132) servers to configure their addresses. They discover the networks they are in and [complete the addresses themselves](https://tools.ietf.org/html/rfc4862) by generating the host part. This makes the network configuration simpler and scales better to larger networks. However, there’s some drawbacks to this approach. Firstly, the node needs to ensure that its address doesn’t collide with an address of any other node on the network. Secondly, if the node uses the same host part of the address in every network it enters then its movement can be tracked and the privacy is at risk.
|
||||
|
||||
Internet Engineering Task Force (IETF), the organization behind the Internet standards, [acknowledged this problem](https://tools.ietf.org/html/draft-iesg-serno-privacy-00) and recommends against use of hardware serial numbers to identify the node in the network.
|
||||
|
||||
But what does the actual implementation look like?
|
||||
|
||||
The problem of address uniqueness is addressed with [Duplicate Address Detection](https://tools.ietf.org/html/rfc4862#section-5.4) (DAD) mechanism. When a node creates an address for itself it first checks whether another node uses the same address using the [Neighbor Discovery Protocol](https://tools.ietf.org/html/rfc4861) (a mechanism not unlike IPv4 [ARP](https://tools.ietf.org/html/rfc826) protocol). When it discovers the address is already used, it must discard it.
|
||||
|
||||
The other problem (privacy) is a bit harder to solve. An IP address (be it IPv4 or IPv6) address consists of a network part and the host part. The host discovers the relevant network parts and is supposed generate the host part. Traditionally it just uses an Interface Identifier derived from the network hardware’s (MAC) address. The MAC address is set at manufacturing time and can uniquely identify the machine. This guarantees the address is stable and unique. That’s a good thing for address collision avoidance but a bad thing for privacy. The host part remaining constant in different network means that the machine can be uniquely identified as it enters different networks. This seemed like non-issue at the time the protocol was designed, but the privacy concerns arose as the IPv6 gained popularity. Fortunately, there’s a solution to this problem.
|
||||
|
||||
## Enter privacy extensions
|
||||
|
||||
It’s no secret that the biggest problem with IPv4 is that the addresses are scarce. This is no longer true with IPv6 and in fact an IPv6-enabled host can use addresses quite liberally. There’s absolutely nothing wrong with having multiple IPv6 addresses attached to the same interface. On the contrary, it’s a pretty standard situation. At the very minimum each node has an address that is used for contacting nodes on the same hardware link called a link-local address. When the network contains a router that connects it to other networks in the internet, a node has an address for every network it’s directly connected to. If a host has more addresses in the same network the node accepts incoming traffic for all of them. For the outgoing connections which, of course, reveal the address to the remote host, the kernel picks the fittest one. But which one is it?
|
||||
|
||||
With privacy extensions enabled, as defined by [RFC4941](https://tools.ietf.org/html/rfc4941), a new address with a random host part is generated every now and then. The newest one is used for new outgoing connections while the older ones are deprecated when they’re unused. This is a nifty trick — the host does not reveal the stable address as it’s not used for outgoing connections, but still accepts connections to it from the hosts that are aware of it.
|
||||
|
||||
There’s a downside to this. Certain applications tie the address to the user identity. Consider a web application that issues a HTTP Cookie for the user during the authentication but only accepts it for the connections that come from the address that conducted the authentications. As the kernel generates a new temporary address, the server would reject the requests that use it, effectively logging the user out. It could be argued that the address is not an appropriate mechanism for establishing user’s identity but that’s what some real-world applications do.
|
||||
|
||||
## Privacy stable addressing to the rescue
|
||||
|
||||
Another approach would be needed to cope with this. There’s a need for an address that is unique (of course), stable for a particular network but still changes when user enters another network so that tracking is not possible. The RFC7217 introduces a mechanism that provides exactly this.
|
||||
|
||||
Creation of a privacy stable address relies on a pseudo-random key that’s only known the host itself and never revealed to other hosts in the network. This key is then hashed using a cryptographically secure algorithm along with values specific for a particular network connection. It includes an identifier of the network interface, the network prefix and possibly other values specific to the network such as the wireless SSID. The use of the secret key makes it impossible to predict the resulting address for the other hosts while the network-specific data causes it to be different when entering a different network.
|
||||
|
||||
This also solves the duplicate address problem nicely. The random key makes collisions unlikely. If, in spite of this, a collision occurs then the hash can be salted with a DAD failure counter and a different address can be generated instead of failing the network connectivity. Now that’s clever.
|
||||
|
||||
Using privacy stable address doesn’t interfere with the privacy extensions at all. You can use the [RFC7217](https://tools.ietf.org/html/rfc7217) stable address while still employing the RFC4941 temporary addresses at the same time.
|
||||
|
||||
## Where does NetworkManager stand?
|
||||
|
||||
We’ve already enabled the privacy extensions with the release NetworkManager 1.0.4. They’re turned on by default; you can control them with ipv6.ip6-privacy property.
|
||||
|
||||
With the release of NetworkManager 1.2, we’re adding the stable privacy addressing. It’s supposed to address the situations where the privacy extensions don’t make the cut. The use of the feature is controlled with the ipv6.addr-gen-mode property. If it’s set to stable-privacy then stable privacy addressing is used. Setting it to “eui64” or not setting it at all preserves the traditional default behavior.
|
||||
|
||||
Stay tuned for NetworkManager 1.2 release in early 2016! If you want to try the bleeding-edge snapshot, give Fedora Rawhide a try. It will eventually become Fedora 24.
|
||||
|
||||
*I’d like to thank Hannes Frederic Sowa for a valuable feedback. The article would make less sense without his corrections. Hannes also created the in-kernel implementation of the RFC7217 mechanism which can be used when the networking is not managed by NetworkManager.*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blogs.gnome.org/lkundrak/2015/12/03/networkmanager-and-privacy-in-the-ipv6-internet/
|
||||
作者:[Lubomir Rintel]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,65 +0,0 @@
|
||||
How to Customize Time & Date Format in Ubuntu Panel
|
||||
================================================================================
|
||||

|
||||
|
||||
This quick tutorial is going to show you how to customize your Time & Date indicator in Ubuntu panel, though there are already a few options available in the settings page.
|
||||
|
||||

|
||||
|
||||
To get started, search for and install **dconf Editor** in Ubuntu Software Center. Then launch the software and follow below steps:
|
||||
|
||||
**1.** When dconf Editor launches, navigate to **com -> canonical -> indicator -> datetime**. Set the value of **time-format** to **custom**.
|
||||
|
||||

|
||||
|
||||
You can also do this via a command in terminal:
|
||||
|
||||
gsettings set com.canonical.indicator.datetime time-format 'custom'
|
||||
|
||||
**2.** Now you can customize the Time & Date format by editing the value of **custom-time-format**.
|
||||
|
||||

|
||||
|
||||
You can also do this via command:
|
||||
|
||||
gsettings set com.canonical.indicator.datetime custom-time-format 'FORMAT_VALUE_HERE'
|
||||
|
||||
Interpreted sequences are:
|
||||
|
||||
- %a = abbreviated weekday name
|
||||
- %A = full weekday name
|
||||
- %b = abbreviated month name
|
||||
- %B = full month name
|
||||
- %d = day of month
|
||||
- %l = hour ( 1..12), %I = hour (01..12)
|
||||
- %k = hour ( 1..23), %H = hour (01..23)
|
||||
- %M = minute (00..59)
|
||||
- %p = AM or PM, %P = am or pm.
|
||||
- %S = second (00..59)
|
||||
- open terminal and run command `man date` to get more details.
|
||||
|
||||
Some examples:
|
||||
|
||||
custom time format value: **%a %H:%M %m/%d/%Y**
|
||||
|
||||

|
||||
|
||||
**%a %r %b %d or %a %I:%M:%S %p %b %d**
|
||||
|
||||

|
||||
|
||||
**%a %-d %b %l:%M %P %z**
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ubuntuhandbook.org/index.php/2015/12/time-date-format-ubuntu-panel/
|
||||
|
||||
作者:[Ji m][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ubuntuhandbook.org/index.php/about/
|
||||
@ -1,268 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
How to Install Bugzilla with Apache and SSL on FreeBSD 10.2
|
||||
================================================================================
|
||||
Bugzilla is open source web base application for bug tracker and testing tool, develop by mozilla project, and licensed under Mozilla Public License. It is used by high tech company like mozilla, redhat and gnome. Bugzilla was originally created by Terry Weissman in 1998. It written in perl, use MySQL as the database back-end. It is a server software designed to help you manage software development. Bugzilla has a lot of features, optimized database, excellent security, advanced search tool, integrated with email capabilities etc.
|
||||
|
||||
In this tutorial we will install bugzilla 5.0 with apache for the web server, and enable SSL for it. Then install mysql51 as the database system on freebsd 10.2.
|
||||
|
||||
#### Prerequisite ####
|
||||
|
||||
FreeBSD 10.2 - 64bit.
|
||||
Root privileges.
|
||||
|
||||
### Step 1 - Update System ###
|
||||
|
||||
Log in to the freebsd server with ssl login, and update the repository database :
|
||||
|
||||
sudo su
|
||||
freebsd-update fetch
|
||||
freebsd-update install
|
||||
|
||||
### Step 2 - Install and Configure Apache ###
|
||||
|
||||
In this step we will install apache from the freebsd repositories with pkg command. Then configure apache by editing file "httpd.conf" on apache24 directory, configure apache to use SSL, and CGI support.
|
||||
|
||||
Install apache with pkg command :
|
||||
|
||||
pkg install apache24
|
||||
|
||||
Go to the apache directory and edit the file "httpd.conf" with nanao editor :
|
||||
|
||||
cd /usr/local/etc/apache24
|
||||
nano -c httpd.conf
|
||||
|
||||
Uncomment the list line below :
|
||||
|
||||
#Line 70
|
||||
LoadModule authn_socache_module libexec/apache24/mod_authn_socache.so
|
||||
|
||||
#Line 89
|
||||
LoadModule socache_shmcb_module libexec/apache24/mod_socache_shmcb.so
|
||||
|
||||
# Line 117
|
||||
LoadModule expires_module libexec/apache24/mod_expires.so
|
||||
|
||||
#Line 141 to enabling SSL
|
||||
LoadModule ssl_module libexec/apache24/mod_ssl.so
|
||||
|
||||
# Line 162 for cgi support
|
||||
LoadModule cgi_module libexec/apache24/mod_cgi.so
|
||||
|
||||
# Line 174 to enable mod_rewrite
|
||||
LoadModule rewrite_module libexec/apache24/mod_rewrite.so
|
||||
|
||||
# Line 219 for the servername configuration
|
||||
ServerName 127.0.0.1:80
|
||||
|
||||
Save and exit.
|
||||
|
||||
Next, we need to install mod perl from freebsd repository, and then enable it :
|
||||
|
||||
pkg install ap24-mod_perl2
|
||||
|
||||
To enable mod_perl, edit httpd.conf and add to the "Loadmodule" line below :
|
||||
|
||||
nano -c httpd.conf
|
||||
|
||||
Add line below :
|
||||
|
||||
# Line 175
|
||||
LoadModule perl_module libexec/apache24/mod_perl.so
|
||||
|
||||
Save and exit.
|
||||
|
||||
And before start apache, add it to start at boot time with sysrc command :
|
||||
|
||||
sysrc apache24_enable=yes
|
||||
service apache24 start
|
||||
|
||||
### Step 3 - Install and Configure MySQL Database ###
|
||||
|
||||
We will use mysql51 for the database back-end, and it is support for perl module for mysql. Install mysql51 with pkg command below :
|
||||
|
||||
pkg install p5-DBD-mysql51 mysql51-server mysql51-client
|
||||
|
||||
Now we must add mysql to the boot time, and then start and configure the root password for mysql.
|
||||
|
||||
Run command below to do it all :
|
||||
|
||||
sysrc mysql_enable=yes
|
||||
service mysql-server start
|
||||
mysqladmin -u root password aqwe123
|
||||
|
||||
Note :
|
||||
|
||||
mysql password : aqwe123
|
||||
|
||||

|
||||
|
||||
Next, we will log in to the mysql shell with user root and password that we've configured above, then we will create new database and user for bugzilla installation.
|
||||
|
||||
Log in to the mysql shell with command below :
|
||||
|
||||
mysql -u root -p
|
||||
password: aqwe123
|
||||
|
||||
Add the database :
|
||||
|
||||
create database bugzilladb;
|
||||
create user bugzillauser@localhost identified by 'bugzillauser@';
|
||||
grant all privileges on bugzilladb.* to bugzillauser@localhost identified by 'bugzillauser@';
|
||||
flush privileges;
|
||||
\q
|
||||
|
||||

|
||||
|
||||
Database for bugzilla is created, database "bugzilladb" with user "bugzillauser" and password "bugzillauser@".
|
||||
|
||||
### Step 4 - Generate New SSL Certificate ###
|
||||
|
||||
Generate new self signed ssl certificate on directory "ssl" for bugzilla site.
|
||||
|
||||
Go to the apache24 directory and create new directory "ssl" on it :
|
||||
|
||||
cd /usr/local/etc/apache24/
|
||||
mkdir ssl; cd ssl
|
||||
|
||||
Next, generate the certificate file with openssl command, then change the permission of the certificate file :
|
||||
|
||||
sudo openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout /usr/local/etc/apache24/ssl/bugzilla.key -out /usr/local/etc/apache24/ssl/bugzilla.crt
|
||||
chmod 600 *
|
||||
|
||||
### Step 5 - Configure Virtualhost ###
|
||||
|
||||
We will install bugzilla on directory "/usr/local/www/bugzilla", so we must create new virtualhost configuration for it.
|
||||
|
||||
Go to the apache directory and create new directory called "vhost" for virtualhost file :
|
||||
|
||||
cd /usr/local/etc/apache24/
|
||||
mkdir vhost; cd vhost
|
||||
|
||||
Now create new file "bugzilla.conf" for the virtualhost file :
|
||||
|
||||
nano -c bugzilla.conf
|
||||
|
||||
Paste configuration below :
|
||||
|
||||
<VirtualHost *:80>
|
||||
ServerName mybugzilla.me
|
||||
ServerAlias www.mybuzilla.me
|
||||
DocumentRoot /usr/local/www/bugzilla
|
||||
Redirect permanent / https://mybugzilla.me/
|
||||
</VirtualHost>
|
||||
|
||||
Listen 443
|
||||
<VirtualHost _default_:443>
|
||||
ServerName mybugzilla.me
|
||||
DocumentRoot /usr/local/www/bugzilla
|
||||
|
||||
ErrorLog "/var/log/mybugzilla.me-error_log"
|
||||
CustomLog "/var/log/mybugzilla.me-access_log" common
|
||||
|
||||
SSLEngine On
|
||||
SSLCertificateFile /usr/local/etc/apache24/ssl/bugzilla.crt
|
||||
SSLCertificateKeyFile /usr/local/etc/apache24/ssl/bugzilla.key
|
||||
|
||||
<Directory "/usr/local/www/bugzilla">
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
DirectoryIndex index.cgi index.html
|
||||
AllowOverride Limit FileInfo Indexes Options
|
||||
Require all granted
|
||||
</Directory>
|
||||
</VirtualHost>
|
||||
|
||||
Save and exit.
|
||||
|
||||
If all is done, create new directory for bugzilla installation and then enable the bugzilla virtualhost by adding the virtualhost configuration to httpd.conf file.
|
||||
|
||||
Run command below on "apache24" directory :
|
||||
|
||||
mkdir -p /usr/local/www/bugzilla
|
||||
cd /usr/local/etc/apache24/
|
||||
nano -c httpd.conf
|
||||
|
||||
In the end of the line, add configuration below :
|
||||
|
||||
Include etc/apache24/vhost/*.conf
|
||||
|
||||
Save and exit.
|
||||
|
||||
Now test the apache configuration with "apachectl" command and restart it :
|
||||
|
||||
apachectl configtest
|
||||
service apache24 restart
|
||||
|
||||
### Step 6 - Install Bugzilla ###
|
||||
|
||||
We can install bugzilla manually by downloading the source, or install it from freebsd repository. In this step we will install bugzilla from freebsd repository with pkg command :
|
||||
|
||||
pkg install bugzilla50
|
||||
|
||||
If it's done, go to the bugzilla installation directory and install all perl module that needed by bugzilla.
|
||||
|
||||
cd /usr/local/www/bugzilla
|
||||
./install-module --all
|
||||
|
||||
Wait it until all is finished, it is take the time.
|
||||
|
||||
Next, generate the configuration file "localconfig" by executing "checksetup.pl" file on bugzilla installation directory.
|
||||
|
||||
./checksetup.pl
|
||||
|
||||
You will see the error message about the database configuration, so edit the file "localconfig" with nano editor :
|
||||
|
||||
nano -c localconfig
|
||||
|
||||
Now add the database that was created on step 3.
|
||||
|
||||
#Line 57
|
||||
$db_name = 'bugzilladb';
|
||||
|
||||
#Line 60
|
||||
$db_user = 'bugzillauser';
|
||||
|
||||
#Line 67
|
||||
$db_pass = 'bugzillauser@';
|
||||
|
||||
Save and exit.
|
||||
|
||||
Then run "checksetup.pl" again :
|
||||
|
||||
./checksetup.pl
|
||||
|
||||
You will be prompt about mail and administrator account, fill all of it with your email, user and password.
|
||||
|
||||

|
||||
|
||||
In the last, we need to change the owner of the installation directory to user "www", then restart apache with service command :
|
||||
|
||||
cd /usr/local/www/
|
||||
chown -R www:www bugzilla
|
||||
service apache24 restart
|
||||
|
||||
Now Bugzilla is installed, you can see it by visiting mybugzilla.me and you will be redirect to the https connection.
|
||||
|
||||
Bugzilla home page.
|
||||
|
||||

|
||||
|
||||
Bugzilla admin panel.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Bugzilla is web based application help you to manage the software development. It is written in perl and use MySQL as the database system. Bugzilla used by mozilla, redhat, gnome etc for help their software development. Bugzilla has a lot of features and easy to configure and install.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-apache-ssl-freebsd-10-2/
|
||||
|
||||
作者:[Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arulm/
|
||||
@ -1,452 +0,0 @@
|
||||
su-kaiyao translating
|
||||
|
||||
Getting started with Docker by Dockerizing this Blog
|
||||
======================
|
||||
>This article covers the basic concepts of Docker and how to Dockerize an application by creating a custom Dockerfile
|
||||
>Written by Benjamin Cane on 2015-12-01 10:00:00
|
||||
|
||||
Docker is an interesting technology that over the past 2 years has gone from an idea, to being used by organizations all over the world to deploy applications. In today's article I am going to cover how to get started with Docker by "Dockerizing" an existing application. The application in question is actually this very blog!
|
||||
|
||||
## What is Docker
|
||||
|
||||
Before we dive into learning the basics of Docker let's first understand what Docker is and why it is so popular. Docker, is an operating system container management tool that allows you to easily manage and deploy applications by making it easy to package them within operating system containers.
|
||||
|
||||
### Containers vs. Virtual Machines
|
||||
|
||||
Containers may not be as familiar as virtual machines but they are another method to provide **Operating System Virtualization**. However, they differ quite a bit from standard virtual machines.
|
||||
|
||||
Standard virtual machines generally include a full Operating System, OS Packages and eventually an Application or two. This is made possible by a Hypervisor which provides hardware virtualization to the virtual machine. This allows for a single server to run many standalone operating systems as virtual guests.
|
||||
|
||||
Containers are similar to virtual machines in that they allow a single server to run multiple operating environments, these environments however, are not full operating systems. Containers generally only include the necessary OS Packages and Applications. They do not generally contain a full operating system or hardware virtualization. This also means that containers have a smaller overhead than traditional virtual machines.
|
||||
|
||||
Containers and Virtual Machines are often seen as conflicting technology, however, this is often a misunderstanding. Virtual Machines are a way to take a physical server and provide a fully functional operating environment that shares those physical resources with other virtual machines. A Container is generally used to isolate a running process within a single host to ensure that the isolated processes cannot interact with other processes within that same system. In fact containers are closer to **BSD Jails** and `chroot`'ed processes than full virtual machines.
|
||||
|
||||
### What Docker provides on top of containers
|
||||
|
||||
Docker itself is not a container runtime environment; in fact Docker is actually container technology agnostic with efforts planned for Docker to support [Solaris Zones](https://blog.docker.com/2015/08/docker-oracle-solaris-zones/) and [BSD Jails](https://wiki.freebsd.org/Docker). What Docker provides is a method of managing, packaging, and deploying containers. While these types of functions may exist to some degree for virtual machines they traditionally have not existed for most container solutions and the ones that existed, were not as easy to use or fully featured as Docker.
|
||||
|
||||
Now that we know what Docker is, let's start learning how Docker works by first installing Docker and deploying a public pre-built container.
|
||||
|
||||
## Starting with Installation
|
||||
As Docker is not installed by default step 1 will be to install the Docker package; since our example system is running Ubuntu 14.0.4 we will do this using the Apt package manager.
|
||||
|
||||
```
|
||||
# apt-get install docker.io
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following extra packages will be installed:
|
||||
aufs-tools cgroup-lite git git-man liberror-perl
|
||||
Suggested packages:
|
||||
btrfs-tools debootstrap lxc rinse git-daemon-run git-daemon-sysvinit git-doc
|
||||
git-el git-email git-gui gitk gitweb git-arch git-bzr git-cvs git-mediawiki
|
||||
git-svn
|
||||
The following NEW packages will be installed:
|
||||
aufs-tools cgroup-lite docker.io git git-man liberror-perl
|
||||
0 upgraded, 6 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 7,553 kB of archives.
|
||||
After this operation, 46.6 MB of additional disk space will be used.
|
||||
Do you want to continue? [Y/n] y
|
||||
```
|
||||
|
||||
To check if any containers are running we can execute the `docker` command using the `ps` option.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
The `ps` function of the `docker` command works similar to the Linux `ps `command. It will show available Docker containers and their current status. Since we have not started any Docker containers yet, the command shows no running containers.
|
||||
|
||||
## Deploying a pre-built nginx Docker container
|
||||
One of my favorite features of Docker is the ability to deploy a pre-built container in the same way you would deploy a package with `yum` or `apt-get`. To explain this better let's deploy a pre-built container running the nginx web server. We can do this by executing the `docker` command again, however, this time with the `run` option.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
The `run` function of the `docker` command tells Docker to find a specified Docker image and start a container running that image. By default, Docker containers run in the foreground, meaning when you execute `docker run` your shell will be bound to the container's console and the process running within the container. In order to launch this Docker container in the background I included the `-d` (**detach**) flag.
|
||||
|
||||
By executing `docker ps` again we can see the nginx container running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 nginx:latest nginx -g 'daemon off 4 seconds ago Up 3 seconds 443/tcp, 80/tcp desperate_lalande
|
||||
```
|
||||
|
||||
In the above output we can see the running container `desperate_lalande` and that this container has been built from the `nginx:latest image`.
|
||||
|
||||
### Docker Images
|
||||
Images are one of Docker's key features and is similar to a virtual machine image. Like virtual machine images, a Docker image is a container that has been saved and packaged. Docker however, doesn't just stop with the ability to create images. Docker also includes the ability to distribute those images via Docker repositories which are a similar concept to package repositories. This is what gives Docker the ability to deploy an image like you would deploy a package with `yum`. To get a better understanding of how this works let's look back at the output of the `docker run` execution.
|
||||
|
||||
```
|
||||
# docker run -d nginx
|
||||
Unable to find image 'nginx' locally
|
||||
```
|
||||
|
||||
The first message we see is that `docker` could not find an image named nginx locally. The reason we see this message is that when we executed `docker run` we told Docker to startup a container, a container based on an image named **nginx**. Since Docker is starting a container based on a specified image it needs to first find that image. Before checking any remote repository Docker first checks locally to see if there is a local image with the specified name.
|
||||
|
||||
Since this system is brand new there is no Docker image with the name nginx, which means Docker will need to download it from a Docker repository.
|
||||
|
||||
```
|
||||
Pulling repository nginx
|
||||
5c82215b03d1: Download complete
|
||||
e2a4fb18da48: Download complete
|
||||
58016a5acc80: Download complete
|
||||
657abfa43d82: Download complete
|
||||
dcb2fe003d16: Download complete
|
||||
c79a417d7c6f: Download complete
|
||||
abb90243122c: Download complete
|
||||
d6137c9e2964: Download complete
|
||||
85e566ddc7ef: Download complete
|
||||
69f100eb42b5: Download complete
|
||||
cd720b803060: Download complete
|
||||
7cc81e9a118a: Download complete
|
||||
```
|
||||
|
||||
This is exactly what the second part of the output is showing us. By default, Docker uses the [Docker Hub](https://hub.docker.com/) repository, which is a repository service that Docker (the company) runs.
|
||||
|
||||
Like GitHub, Docker Hub is free for public repositories but requires a subscription for private repositories. It is possible however, to deploy your own Docker repository, in fact it is as easy as `docker run registry`. For this article we will not be deploying a custom registry service.
|
||||
|
||||
### Stopping and Removing the Container
|
||||
Before moving on to building a custom Docker container let's first clean up our Docker environment. We will do this by stopping the container from earlier and removing it.
|
||||
|
||||
To start a container we executed `docker` with the `run` option, in order to stop this same container we simply need to execute the `docker` with the `kill` option specifying the container name.
|
||||
|
||||
```
|
||||
# docker kill desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
If we execute `docker ps` again we will see that the container is no longer running.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
```
|
||||
|
||||
However, at this point we have only stopped the container; while it may no longer be running it still exists. By default, `docker ps` will only show running containers, if we add the `-a` (all) flag it will show all containers running or not.
|
||||
|
||||
```
|
||||
# docker ps -a
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
f6d31ab01fc9 5c82215b03d1 nginx -g 'daemon off 4 weeks ago Exited (-1) About a minute ago desperate_lalande
|
||||
```
|
||||
|
||||
In order to fully remove the container we can use the `docker` command with the `rm` option.
|
||||
|
||||
```
|
||||
# docker rm desperate_lalande
|
||||
desperate_lalande
|
||||
```
|
||||
|
||||
While this container has been removed; we still have a **nginx** image available. If we were to re-run `docker run -d nginx` again the container would be started without having to fetch the nginx image again. This is because Docker already has a saved copy on our local system.
|
||||
|
||||
To see a full list of local images we can simply run the `docker` command with the `images` option.
|
||||
|
||||
```
|
||||
# docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
|
||||
nginx latest 9fab4090484a 5 days ago 132.8 MB
|
||||
```
|
||||
|
||||
## Building our own custom image
|
||||
At this point we have used a few basic Docker commands to start, stop and remove a common pre-built image. In order to "Dockerize" this blog however, we are going to have to build our own Docker image and that means creating a **Dockerfile**.
|
||||
|
||||
With most virtual machine environments if you wish to create an image of a machine you need to first create a new virtual machine, install the OS, install the application and then finally convert it to a template or image. With Docker however, these steps are automated via a Dockerfile. A Dockerfile is a way of providing build instructions to Docker for the creation of a custom image. In this section we are going to build a custom Dockerfile that can be used to deploy this blog.
|
||||
|
||||
### Understanding the Application
|
||||
Before we can jump into creating a Dockerfile we first need to understand what is required to deploy this blog.
|
||||
|
||||
The blog itself is actually static HTML pages generated by a custom static site generator that I wrote named; **hamerkop**. The generator is very simple and more about getting the job done for this blog specifically. All the code and source files for this blog are available via a public [GitHub](https://github.com/madflojo/blog) repository. In order to deploy this blog we simply need to grab the contents of the GitHub repository, install **Python** along with some **Python** modules and execute the `hamerkop` application. To serve the generated content we will use **nginx**; which means we will also need **nginx** to be installed.
|
||||
|
||||
So far this should be a pretty simple Dockerfile, but it will show us quite a bit of the [Dockerfile Syntax](https://docs.docker.com/v1.8/reference/builder/). To get started we can clone the GitHub repository and creating a Dockerfile with our favorite editor; `vi` in my case.
|
||||
|
||||
```
|
||||
# git clone https://github.com/madflojo/blog.git
|
||||
Cloning into 'blog'...
|
||||
remote: Counting objects: 622, done.
|
||||
remote: Total 622 (delta 0), reused 0 (delta 0), pack-reused 622
|
||||
Receiving objects: 100% (622/622), 14.80 MiB | 1.06 MiB/s, done.
|
||||
Resolving deltas: 100% (242/242), done.
|
||||
Checking connectivity... done.
|
||||
# cd blog/
|
||||
# vi Dockerfile
|
||||
```
|
||||
|
||||
### FROM - Inheriting a Docker image
|
||||
The first instruction of a Dockerfile is the `FROM` instruction. This is used to specify an existing Docker image to use as our base image. This basically provides us with a way to inherit another Docker image. In this case we will be starting with the same **nginx** image we were using before, if we wanted to start with a blank slate we could use the **Ubuntu** Docker image by specifying `ubuntu:latest`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
```
|
||||
|
||||
In addition to the `FROM` instruction, I also included a `MAINTAINER` instruction which is used to show the Author of the Dockerfile.
|
||||
|
||||
As Docker supports using `#` as a comment marker, I will be using this syntax quite a bit to explain the sections of this Dockerfile.
|
||||
|
||||
### Running a test build
|
||||
Since we inherited the **nginx** Docker image our current Dockerfile also inherited all the instructions within the [Dockerfile](https://github.com/nginxinc/docker-nginx/blob/08eeb0e3f0a5ee40cbc2bc01f0004c2aa5b78c15/Dockerfile) used to build that **nginx** image. What this means is even at this point we are able to build a Docker image from this Dockerfile and run a container from that image. The resulting image will essentially be the same as the **nginx** image but we will run through a build of this Dockerfile now and a few more times as we go to help explain the Docker build process.
|
||||
|
||||
In order to start the build from a Dockerfile we can simply execute the `docker` command with the **build** option.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 23.6 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Running in c97f36450343
|
||||
---> 60a44f78d194
|
||||
Removing intermediate container c97f36450343
|
||||
Successfully built 60a44f78d194
|
||||
```
|
||||
|
||||
In the above example I used the `-t` (**tag**) flag to "tag" the image as "blog". This essentially allows us to name the image, without specifying a tag the image would only be callable via an **Image ID** that Docker assigns. In this case the **Image ID** is `60a44f78d194` which we can see from the `docker` command's build success message.
|
||||
|
||||
In addition to the `-t` flag, I also specified the directory `/root/blog`. This directory is the "build directory", which is the directory that contains the Dockerfile and any other files necessary to build this container.
|
||||
|
||||
Now that we have run through a successful build, let's start customizing this image.
|
||||
|
||||
### Using RUN to execute apt-get
|
||||
The static site generator used to generate the HTML pages is written in **Python** and because of this the first custom task we should perform within this `Dockerfile` is to install Python. To install the Python package we will use the Apt package manager. This means we will need to specify within the Dockerfile that `apt-get update` and `apt-get install python-dev` are executed; we can do this with the `RUN` instruction.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
```
|
||||
|
||||
In the above we are simply using the `RUN` instruction to tell Docker that when it builds this image it will need to execute the specified `apt-get` commands. The interesting part of this is that these commands are only executed within the context of this container. What this means is even though `python-dev` and `python-pip` are being installed within the container, they are not being installed for the host itself. Or to put it simplier, within the container the `pip` command will execute, outside the container, the `pip` command does not exist.
|
||||
|
||||
It is also important to note that the Docker build process does not accept user input during the build. This means that any commands being executed by the `RUN` instruction must complete without user input. This adds a bit of complexity to the build process as many applications require user input during installation. For our example, none of the commands executed by `RUN` require user input.
|
||||
|
||||
### Installing Python modules
|
||||
With **Python** installed we now need to install some Python modules. To do this outside of Docker, we would generally use the `pip` command and reference a file within the blog's Git repository named `requirements.txt`. In an earlier step we used the `git` command to "clone" the blog's GitHub repository to the `/root/blog` directory; this directory also happens to be the directory that we have created the `Dockerfile`. This is important as it means the contents of the Git repository are accessible to Docker during the build process.
|
||||
|
||||
When executing a build, Docker will set the context of the build to the specified "build directory". This means that any files within that directory and below can be used during the build process, files outside of that directory (outside of the build context), are inaccessible.
|
||||
|
||||
In order to install the required Python modules we will need to copy the `requirements.txt` file from the build directory into the container. We can do this using the `COPY` instruction within the `Dockerfile`.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
```
|
||||
|
||||
Within the `Dockerfile` we added 3 instructions. The first instruction uses `RUN` to create a `/build/` directory within the container. This directory will be used to copy any application files needed to generate the static HTML pages. The second instruction is the `COPY` instruction which copies the `requirements.txt` file from the "build directory" (`/root/blog`) into the `/build` directory within the container. The third is using the `RUN` instruction to execute the `pip` command; installing all the modules specified within the `requirements.txt` file.
|
||||
|
||||
`COPY` is an important instruction to understand when building custom images. Without specifically copying the file within the Dockerfile this Docker image would not contain the requirements.txt file. With Docker containers everything is isolated, unless specifically executed within a Dockerfile a container is not likely to include required dependencies.
|
||||
|
||||
### Re-running a build
|
||||
Now that we have a few customization tasks for Docker to perform let's try another build of the blog image again.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Running in bde05cf1e8fe
|
||||
---> f4b66e09fa61
|
||||
Removing intermediate container bde05cf1e8fe
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
Removing intermediate container 9aa8ff43f4b0
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Running in c50b15ddd8b1
|
||||
Downloading/unpacking jinja2 (from -r /build/requirements.txt (line 1))
|
||||
Downloading/unpacking PyYaml (from -r /build/requirements.txt (line 2))
|
||||
<truncated to reduce noise>
|
||||
Successfully installed jinja2 PyYaml mistune markdown MarkupSafe
|
||||
Cleaning up...
|
||||
---> abab55c20962
|
||||
Removing intermediate container c50b15ddd8b1
|
||||
Successfully built abab55c20962
|
||||
```
|
||||
|
||||
From the above build output we can see the build was successful, but we can also see another interesting message;` ---> Using cache`. What this message is telling us is that Docker was able to use its build cache during the build of this image.
|
||||
|
||||
#### Docker build cache
|
||||
|
||||
When Docker is building an image, it doesn't just build a single image; it actually builds multiple images throughout the build processes. In fact we can see from the above output that after each "Step" Docker is creating a new image.
|
||||
|
||||
```
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> cef11c3fb97c
|
||||
```
|
||||
|
||||
The last line from the above snippet is actually Docker informing us of the creating of a new image, it does this by printing the **Image ID**; `cef11c3fb97c`. The useful thing about this approach is that Docker is able to use these images as cache during subsequent builds of the **blog** image. This is useful because it allows Docker to speed up the build process for new builds of the same container. If we look at the example above we can actually see that rather than installing the `python-dev` and `python-pip` packages again, Docker was able to use a cached image. However, since Docker was unable to find a build that executed the `mkdir` command, each subsequent step was executed.
|
||||
|
||||
The Docker build cache is a bit of a gift and a curse; the reason for this is that the decision to use cache or to rerun the instruction is made within a very narrow scope. For example, if there was a change to the `requirements.txt` file Docker would detect this change during the build and start fresh from that point forward. It does this because it can view the contents of the `requirements.txt` file. The execution of the `apt-get` commands however, are another story. If the **Apt** repository that provides the Python packages were to contain a newer version of the python-pip package; Docker would not be able to detect the change and would simply use the build cache. This means that an older package may be installed. While this may not be a major issue for the `python-pip` package it could be a problem if the installation was caching a package with a known vulnerability.
|
||||
|
||||
For this reason it is useful to periodically rebuild the image without using Docker's cache. To do this you can simply specify `--no-cache=True` when executing a Docker build.
|
||||
|
||||
## Deploying the rest of the blog
|
||||
With the Python packages and modules installed this leaves us at the point of copying the required application files and running the `hamerkop` application. To do this we will simply use more `COPY` and `RUN` instructions.
|
||||
|
||||
```
|
||||
## Dockerfile that generates an instance of http://bencane.com
|
||||
|
||||
FROM nginx:latest
|
||||
MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
|
||||
## Install python and pip
|
||||
RUN apt-get update
|
||||
RUN apt-get install -y python-dev python-pip
|
||||
|
||||
## Create a directory for required files
|
||||
RUN mkdir -p /build/
|
||||
|
||||
## Add requirements file and run pip
|
||||
COPY requirements.txt /build/
|
||||
RUN pip install -r /build/requirements.txt
|
||||
|
||||
## Add blog code nd required files
|
||||
COPY static /build/static
|
||||
COPY templates /build/templates
|
||||
COPY hamerkop /build/
|
||||
COPY config.yml /build/
|
||||
COPY articles /build/articles
|
||||
|
||||
## Run Generator
|
||||
RUN /build/hamerkop -c /build/config.yml
|
||||
```
|
||||
|
||||
Now that we have the rest of the build instructions, let's run through another build and verify that the image builds successfully.
|
||||
|
||||
```
|
||||
# docker build -t blog /root/blog/
|
||||
Sending build context to Docker daemon 19.52 MB
|
||||
Sending build context to Docker daemon
|
||||
Step 0 : FROM nginx:latest
|
||||
---> 9fab4090484a
|
||||
Step 1 : MAINTAINER Benjamin Cane <ben@bencane.com>
|
||||
---> Using cache
|
||||
---> 8e0f1899d1eb
|
||||
Step 2 : RUN apt-get update
|
||||
---> Using cache
|
||||
---> 78b36ef1a1a2
|
||||
Step 3 : RUN apt-get install -y python-dev python-pip
|
||||
---> Using cache
|
||||
---> ef4f9382658a
|
||||
Step 4 : RUN mkdir -p /build/
|
||||
---> Using cache
|
||||
---> f4b66e09fa61
|
||||
Step 5 : COPY requirements.txt /build/
|
||||
---> Using cache
|
||||
---> cef11c3fb97c
|
||||
Step 6 : RUN pip install -r /build/requirements.txt
|
||||
---> Using cache
|
||||
---> abab55c20962
|
||||
Step 7 : COPY static /build/static
|
||||
---> 15cb91531038
|
||||
Removing intermediate container d478b42b7906
|
||||
Step 8 : COPY templates /build/templates
|
||||
---> ecded5d1a52e
|
||||
Removing intermediate container ac2390607e9f
|
||||
Step 9 : COPY hamerkop /build/
|
||||
---> 59efd1ca1771
|
||||
Removing intermediate container b5fbf7e817b7
|
||||
Step 10 : COPY config.yml /build/
|
||||
---> bfa3db6c05b7
|
||||
Removing intermediate container 1aebef300933
|
||||
Step 11 : COPY articles /build/articles
|
||||
---> 6b61cc9dde27
|
||||
Removing intermediate container be78d0eb1213
|
||||
Step 12 : RUN /build/hamerkop -c /build/config.yml
|
||||
---> Running in fbc0b5e574c5
|
||||
Successfully created file /usr/share/nginx/html//2011/06/25/checking-the-number-of-lwp-threads-in-linux
|
||||
Successfully created file /usr/share/nginx/html//2011/06/checking-the-number-of-lwp-threads-in-linux
|
||||
<truncated to reduce noise>
|
||||
Successfully created file /usr/share/nginx/html//archive.html
|
||||
Successfully created file /usr/share/nginx/html//sitemap.xml
|
||||
---> 3b25263113e1
|
||||
Removing intermediate container fbc0b5e574c5
|
||||
Successfully built 3b25263113e1
|
||||
```
|
||||
|
||||
### Running a custom container
|
||||
With a successful build we can now start our custom container by running the `docker` command with the `run` option, similar to how we started the nginx container earlier.
|
||||
|
||||
```
|
||||
# docker run -d -p 80:80 --name=blog blog
|
||||
5f6c7a2217dcdc0da8af05225c4d1294e3e6bb28a41ea898a1c63fb821989ba1
|
||||
```
|
||||
|
||||
Once again the `-d` (**detach**) flag was used to tell Docker to run the container in the background. However, there are also two new flags. The first new flag is `--name`, which is used to give the container a user specified name. In the earlier example we did not specify a name and because of that Docker randomly generated one. The second new flag is `-p`, this flag allows users to map a port from the host machine to a port within the container.
|
||||
|
||||
The base **nginx** image we used exposes port 80 for the HTTP service. By default, ports bound within a Docker container are not bound on the host system as a whole. In order for external systems to access ports exposed within a container the ports must be mapped from a host port to a container port using the `-p` flag. The command above maps port 80 from the host, to port 80 within the container. If we wished to map port 8080 from the host, to port 80 within the container we could do so by specifying the ports in the following syntax `-p 8080:80`.
|
||||
|
||||
From the above command it appears that our container was started successfully, we can verify this by executing `docker ps`.
|
||||
|
||||
```
|
||||
# docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
d264c7ef92bd blog:latest nginx -g 'daemon off 3 seconds ago Up 3 seconds 443/tcp, 0.0.0.0:80->80/tcp blog
|
||||
```
|
||||
|
||||
## Wrapping up
|
||||
|
||||
At this point we now have a running custom Docker container. While we touched on a few Dockerfile instructions within this article we have yet to discuss all the instructions. For a full list of Dockerfile instructions you can checkout [Docker's reference page](https://docs.docker.com/v1.8/reference/builder/), which explains the instructions very well.
|
||||
|
||||
Another good resource is their [Dockerfile Best Practices page](https://docs.docker.com/engine/articles/dockerfile_best-practices/) which contains quite a few best practices for building custom Dockerfiles. Some of these tips are very useful such as strategically ordering the commands within the Dockerfile. In the above examples our Dockerfile has the `COPY` instruction for the `articles` directory as the last `COPY` instruction. The reason for this is that the `articles` directory will change quite often. It's best to put instructions that will change oftenat the lowest point possible within the Dockerfile to optimize steps that can be cached.
|
||||
|
||||
In this article we covered how to start a pre-built container and how to build, then deploy a custom container. While there is quite a bit to learn about Docker this article should give you a good idea on how to get started. Of course, as always if you think there is anything that should be added drop it in the comments below.
|
||||
|
||||
--------------------------------------
|
||||
via:http://bencane.com/2015/12/01/getting-started-with-docker-by-dockerizing-this-blog/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+bencane%2FSAUo+%28Benjamin+Cane%29
|
||||
|
||||
作者:Benjamin Cane
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,49 +0,0 @@
|
||||
Fix: Cannot establish FTP connection to an SFTP server
|
||||
================================================================================
|
||||
### Problem ###
|
||||
|
||||
The other day I had to connect to my web server. I use [FileZilla][1] for connecting to FTP servers. When I entered the hostname and password and tried to connect to the FTP server, it gave me the following error:
|
||||
|
||||
> Error: Cannot establish FTP connection to an SFTP server. Please select proper protocol.
|
||||
>
|
||||
> Error: Critical error: Could not connect to server
|
||||
|
||||

|
||||
|
||||
### Reason ###
|
||||
|
||||
By reading the error message itself made me realize my mistake. I was trying to establish an [FTP][2] connection with an [SFTP][3] server. Clearly, I was not using the correct protocol (which should have been SFTP and not FTP).
|
||||
|
||||
As you can see in the picture above, FileZilla defaults to FTP protocol.
|
||||
|
||||
### Solution for “Cannot establish FTP connection to an SFTP server” ###
|
||||
|
||||
Solution is simple. Use SFTP protocol instead of FTP. The one problem you might face is to know how to change the protocol to SFTP. This is where I am going to help you.
|
||||
|
||||
In FileZilla menu, go to **File->Site Manager**.
|
||||
|
||||

|
||||
|
||||
In the Site Manager, go in General tab and select SFTP in Protocol. Also fill in the host server, port number, user password etc.
|
||||
|
||||

|
||||
|
||||
I hope you can handle things from here onward.
|
||||
|
||||
I hope this quick tutorial helped you to fix “Cannot establish FTP connection to an SFTP server. Please select proper protocol.” problem. In related articles, you can read this post to [know how to set up FTP server in Linux][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-establish-ftp-connection-sftp-server/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://filezilla-project.org/
|
||||
[2]:https://en.wikipedia.org/wiki/File_Transfer_Protocol
|
||||
[3]:https://en.wikipedia.org/wiki/SSH_File_Transfer_Protocol
|
||||
[4]:http://itsfoss.com/set-ftp-server-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc translating
|
||||
|
||||
How to block network traffic by country on Linux
|
||||
================================================================================
|
||||
As a system admin who maintains production Linux servers, there are circumstances where you need to **selectively block or allow network traffic based on geographic locations**. For example, you are experiencing denial-of-service attacks mostly originating from IP addresses registered with a particular country. You want to block SSH logins from unknown foreign countries for security reasons. Your company has a distribution right to online videos, which requires it to legally stream to particular countries only. You need to prevent any local host from uploading documents to any non-US remote cloud storage due to geo-restriction company policies.
|
||||
|
||||
@ -1,105 +0,0 @@
|
||||
How to enable Software Collections (SCL) on CentOS
|
||||
================================================================================
|
||||
Red Hat Enterprise Linux (RHEL) and its community fork, CentOS, offer 10-year life cycle, meaning that each version of RHEL/CentOS is updated with security patches for up to 10 years. While such long life cycle guarantees much needed system compatibility and reliability for enterprise users, a downside is that core applications and run-time environments grow antiquated as the underlying RHEL/CentOS version becomes close to end-of-life (EOF). For example, CentOS 6.5, whose EOL is dated to November 30th 2020, comes with python 2.6.6 and MySQL 5.1.73, which are already pretty old by today's standard.
|
||||
|
||||
On the other hand, attempting to manually upgrade development toolchains and run-time environments on RHEL/CentOS may potentially break your system unless all dependencies are resolved correctly. Under normal circumstances, manual upgrade is not recommended unless you know what you are doing.
|
||||
|
||||
The [Software Collections][1] (SCL) repository came into being to help with RHEL/CentOS users in this situation. The SCL is created to provide RHEL/CentOS users with a means to easily and safely install and use multiple (and potentially more recent) versions of applications and run-time environments "without" messing up the existing system. This is in contrast to other third party repositories which could cause conflicts among installed packages.
|
||||
|
||||
The latest SCL offers:
|
||||
|
||||
- Python 3.3 and 2.7
|
||||
- PHP 5.4
|
||||
- Node.js 0.10
|
||||
- Ruby 1.9.3
|
||||
- Perl 5.16.3
|
||||
- MariaDB and MySQL 5.5
|
||||
- Apache httpd 2.4.6
|
||||
|
||||
In the rest of the tutorial, let me show you how to set up the SCL repository and how to install and enable the packages from the SCL.
|
||||
|
||||
### Set up the Software Collections (SCL) Repository ###
|
||||
|
||||
The SCL is available on CentOS 6.5 and later. To set up the SCL, simply run:
|
||||
|
||||
$ sudo yum install centos-release-SCL
|
||||
|
||||
To enable and run applications from the SCL, you also need to install the following package.
|
||||
|
||||
$ sudo yum install scl-utils-build
|
||||
|
||||
You can browse a complete list of packages available from the SCL repository by running:
|
||||
|
||||
$ yum --disablerepo="*" --enablerepo="scl" list available
|
||||
|
||||

|
||||
|
||||
### Install and Enable a Package from the SCL ###
|
||||
|
||||
Now that you have set up the SCL, you can go ahead and install any package from the SCL.
|
||||
|
||||
You can search for SCL packages with:
|
||||
|
||||
$ yum --disablerepo="*" --enablerepo="scl" search <keyword>
|
||||
|
||||
Let's say you want to install python 3.3.
|
||||
|
||||
Go ahead and install it as usual with yum:
|
||||
|
||||
$ sudo yum install python33
|
||||
|
||||
At any time you can check the list of packages you installed from the SCL by running:
|
||||
|
||||
$ scl --list
|
||||
|
||||
----------
|
||||
|
||||
python33
|
||||
|
||||
A nice thing about the SCL is that installing a package from the SCL does NOT overwrite any system files, and is guaranteed to not cause any conflicts with other system libraries and applications.
|
||||
|
||||
For example, if you check the default python version after installing python33, you will see that the default version is still the same:
|
||||
|
||||
$ python --version
|
||||
|
||||
----------
|
||||
|
||||
Python 2.6.6
|
||||
|
||||
If you want to try an installed SCL package, you need to explicitly enable it "on a per-command basis" using scl:
|
||||
|
||||
$ scl enable <scl-package-name> <command>
|
||||
|
||||
For example, to enable python33 package for python command:
|
||||
|
||||
$ scl enable python33 'python --version'
|
||||
|
||||
----------
|
||||
|
||||
Python 3.3.2
|
||||
|
||||
If you want to run multiple commands while enabling python33 package, you can actually create an SCL-enabled bash session as follows.
|
||||
|
||||
$ scl enable python33 bash
|
||||
|
||||
Within this bash session, the default python will be switched to 3.3 until you type exit and kill the session.
|
||||
|
||||

|
||||
|
||||
In short, the SCL is somewhat similar to the virtualenv of Python, but is more general in that you can enable/disable SCL sessions for a far greater number of applications than just Python.
|
||||
|
||||
For more detailed instructions on the SCL, refer to the official [quick start guide][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/enable-software-collections-centos.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://www.softwarecollections.org/
|
||||
[2]:https://www.softwarecollections.org/docs/
|
||||
@ -1,75 +0,0 @@
|
||||
Linux / UNIX Desktop Fun: Let it Snow On Your Desktop
|
||||
================================================================================
|
||||
Feeling lonely this holiday season? Try Xsnow. This little app will let it snow on the Unix / Linux desktop. Santa and his reindeer will complete your festive season feeling with moving snowflakes on your desktop, with Santa Claus running all over the screen.
|
||||
|
||||
I first installed this 13 or 14 years ago. It was was originally created for Macintosh systems in 1984. You can install it as follows:
|
||||
|
||||
### Install xsnow ###
|
||||
|
||||
Debian / Ubuntu / Mint users type the following command:
|
||||
|
||||
$ sudo apt-get install xsnow
|
||||
|
||||
Freebsd users type the following command to install the same:
|
||||
|
||||
# cd /usr/ports/x11/xsnow/
|
||||
# make install clean
|
||||
|
||||
OR, try to add the package:
|
||||
|
||||
# pkg_add -r xsnow
|
||||
|
||||
#### A Note About Other Distros ####
|
||||
|
||||
1. Fedora / RHEL / CentOS Linux desktop users may find the package using [rpmfusion][1] repo.
|
||||
1. Gentoo user try Gentoo portage i.e. [emerge -p xsnow][2]
|
||||
1. OpenSuse Linux user try Yast and search for xsnow.
|
||||
|
||||
### How Do I Use xsnow? ###
|
||||
|
||||
Open a command-line terminal (select Applications > Accessories > Terminal), and then type the following to starts xsnow:
|
||||
|
||||
$ xsnow
|
||||
|
||||
Sample outputs:
|
||||
|
||||

|
||||
|
||||
Fig.01: Snow for your Linux and Unix desktop systems
|
||||
|
||||
You can set the background to a blue color and lets it snow white, type:
|
||||
|
||||
$ xsnow -bg blue -sc snow
|
||||
|
||||
To set the maximum number of snowflakes and runs as fast as possible, type:
|
||||
|
||||
$ xsnow -snowflakes 10000 -delay 0
|
||||
|
||||
Do not display the trees and Santa Claus running all over the screen, enter:
|
||||
|
||||
$ xsnow -notrees -nosanta
|
||||
|
||||
For more information about xsnow and other options, please see the manual page by typing man xsnow from the command line:
|
||||
|
||||
$ man xsnow
|
||||
|
||||
Recommended readings:
|
||||
|
||||
- [Download Xsnow][1] from the official site.
|
||||
- Please note that [MS-Windows][2] and [Mac OS X version][3] attracts one time shareware fee.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/linux-unix-xsnow.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://rpmfusion.org/Configuration
|
||||
[2]:http://www.gentoo.org/doc/en/handbook/handbook-x86.xml?part=2&chap=1
|
||||
[3]:http://dropmix.xs4all.nl/rick/Xsnow/
|
||||
[4]:http://dropmix.xs4all.nl/rick/WinSnow/
|
||||
[5]:http://dropmix.xs4all.nl/rick/MacOSXSnow/
|
||||
@ -1,39 +0,0 @@
|
||||
Linux / UNIX Desktop Fun: Steam Locomotive
|
||||
================================================================================
|
||||
One of the most [common mistake][1] is typing sl instead of ls command. I actually set [an alias][2] i.e. alias sl=ls; but then you may miss out the steam train with whistle.
|
||||
|
||||
sl is a joke software or classic UNIX game. It is a steam locomotive runs across your screen if you type "sl" (Steam Locomotive) instead of "ls" by mistake.
|
||||
|
||||
### Install sl ###
|
||||
|
||||
Type the following command under Debian / Ubuntu Linux, enter:
|
||||
|
||||
# apt-get install sl
|
||||
|
||||
It is also available on FreeBSD and other UNIX like operating systems. Next, mistyped ls command as sl:
|
||||
|
||||
$ sl
|
||||
|
||||

|
||||
|
||||
Fig.01: Run steam locomotive across the screen if you type "sl" instead of "ls"
|
||||
|
||||
It also supports the following options:
|
||||
|
||||
- **-a** : An accident seems to happen. You'll feel pity for people who cry for help.
|
||||
- **-l** : shows little one.
|
||||
- **-F** : It flies.
|
||||
- **-e** : Allow interrupt by Ctrl+C.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/tips/displays-animations-when-accidentally-you-type-sl-instead-of-ls.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/tips/my-10-unix-command-line-mistakes.html
|
||||
[2]:http://bash.cyberciti.biz/guide/Create_and_use_aliases
|
||||
@ -1,89 +0,0 @@
|
||||
Linux / Unix Desktop Fun: Cat And Mouse Chase All Over Your Screen
|
||||
================================================================================
|
||||
Oneko is a little fun app. It will change your cursor into mouse and creates a little cute cat and the cat start chasing around your mouse cursor. The word "neko" means "cat" in Japanese and it was originally written by a Japanese author as a Macintosh desktop accessory.
|
||||
|
||||
### Install oneko ###
|
||||
|
||||
Type the following command:
|
||||
|
||||
$ sudo apt-get install oneko
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
The following NEW packages will be installed:
|
||||
oneko
|
||||
0 upgraded, 1 newly installed, 0 to remove and 10 not upgraded.
|
||||
Need to get 38.6 kB of archives.
|
||||
After this operation, 168 kB of additional disk space will be used.
|
||||
Get:1 http://debian.osuosl.org/debian/ squeeze/main oneko amd64 1.2.sakura.6-7 [38.6 kB]
|
||||
Fetched 38.6 kB in 1s (25.9 kB/s)
|
||||
Selecting previously deselected package oneko.
|
||||
(Reading database ... 274152 files and directories currently installed.)
|
||||
Unpacking oneko (from .../oneko_1.2.sakura.6-7_amd64.deb) ...
|
||||
Processing triggers for menu ...
|
||||
Processing triggers for man-db ...
|
||||
Setting up oneko (1.2.sakura.6-7) ...
|
||||
Processing triggers for menu ...
|
||||
|
||||
FreeBSD unix user type the following command to install oneko:
|
||||
|
||||
# cd /usr/ports/games/oneko
|
||||
# make install clean
|
||||
|
||||
### How do I use oneko? ###
|
||||
|
||||
Simply type the following command:
|
||||
|
||||
$ oneko
|
||||
|
||||
You can make cat into "tora-neko", a cat wite tiger-like stripe:
|
||||
|
||||
$ oneko -tora
|
||||
|
||||
### Not a cat person? ###
|
||||
|
||||
You can run a dog instead of a cat:
|
||||
|
||||
$ oneko -dog
|
||||
|
||||
The followin will runs Sakura Kinomoto instead of a cat:
|
||||
|
||||
$ oneko -sakura
|
||||
|
||||
Runs Tomoyo Daidouji instead of a cat:
|
||||
|
||||
$ oneko -tomoyo
|
||||
|
||||
### Check out related media ###
|
||||
|
||||
This tutorial also available in video format:
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="596" height="335" frameborder="0" allowfullscreen="" src="http://www.youtube.com/embed/Nm3SkXThL0s"></iframe>
|
||||
|
||||
(Video.01: Demo - Install and use oneko under Linux)
|
||||
|
||||
### Other options ###
|
||||
|
||||
You can pass the following options:
|
||||
|
||||
1. **-tofocus** : Makes cat run to and on top of focus window. When focus window is not in sight, cat chases mouse as usually.
|
||||
1. **-position geometry** : Specify X and Y offsets in pixels to adjust position of cat relative to mouse pointer./li>
|
||||
1. **-rv** : Reverse background color and foreground color.
|
||||
1. **-fg color** : Foreground color (e.g., oneko -dog -fg red).
|
||||
1. **-bg color** : Background color (e.g., oneko -dog -bg green).
|
||||
1. See oneko man page for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/open-source/oneko-app-creates-cute-cat-chasing-around-your-mouse/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,3 +1,4 @@
|
||||
翻译中
|
||||
Linux / Unix Desktop Fun: Text Mode ASCII-art Box and Comment Drawing
|
||||
================================================================================
|
||||
Boxes command is a text filter and a little known tool that can draw any kind of ASCII art box around its input text or code for fun and profit. You can quickly create email signatures, or create regional comments in any programming language. This command was intended to be used with the vim text editor, but can be tied to any text editor which supports filters, as well as from the command line as a standalone tool.
|
||||
@ -190,7 +191,7 @@ See also
|
||||
via: http://www.cyberciti.biz/tips/unix-linux-draw-any-kind-of-boxes-around-text-editor.html
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[zky001](https://github.com/zky001)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,7 @@
|
||||
translating by ezio
|
||||
|
||||
|
||||
|
||||
Securi-Pi: Using the Raspberry Pi as a Secure Landing Point
|
||||
================================================================================
|
||||
|
||||
|
||||
631
sources/tech/20151220 GCC-Inline-Assembly-HOWTO.md
Normal file
631
sources/tech/20151220 GCC-Inline-Assembly-HOWTO.md
Normal file
@ -0,0 +1,631 @@
|
||||
translate by zky001
|
||||
* * *
|
||||
|
||||
# GCC-Inline-Assembly-HOWTO
|
||||
v0.1, 01 March 2003.
|
||||
* * *
|
||||
|
||||
_This HOWTO explains the use and usage of the inline assembly feature provided by GCC. There are only two prerequisites for reading this article, and that’s obviously a basic knowledge of x86 assembly language and C._
|
||||
|
||||
* * *
|
||||
|
||||
## 1. Introduction.
|
||||
|
||||
## 1.1 Copyright and License.
|
||||
|
||||
Copyright (C)2003 Sandeep S.
|
||||
|
||||
This document is free; you can redistribute and/or modify this under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
|
||||
|
||||
This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
|
||||
|
||||
## 1.2 Feedback and Corrections.
|
||||
|
||||
Kindly forward feedback and criticism to [Sandeep.S](mailto:busybox@sancharnet.in). I will be indebted to anybody who points out errors and inaccuracies in this document; I shall rectify them as soon as I am informed.
|
||||
|
||||
## 1.3 Acknowledgments.
|
||||
|
||||
I express my sincere appreciation to GNU people for providing such a great feature. Thanks to Mr.Pramode C E for all the helps he did. Thanks to friends at the Govt Engineering College, Trichur for their moral-support and cooperation, especially to Nisha Kurur and Sakeeb S. Thanks to my dear teachers at Govt Engineering College, Trichur for their cooperation.
|
||||
|
||||
Additionally, thanks to Phillip, Brennan Underwood and colin@nyx.net; Many things here are shamelessly stolen from their works.
|
||||
|
||||
* * *
|
||||
|
||||
## 2. Overview of the whole thing.
|
||||
|
||||
We are here to learn about GCC inline assembly. What this inline stands for?
|
||||
|
||||
We can instruct the compiler to insert the code of a function into the code of its callers, to the point where actually the call is to be made. Such functions are inline functions. Sounds similar to a Macro? Indeed there are similarities.
|
||||
|
||||
What is the benefit of inline functions?
|
||||
|
||||
This method of inlining reduces the function-call overhead. And if any of the actual argument values are constant, their known values may permit simplifications at compile time so that not all of the inline function’s code needs to be included. The effect on code size is less predictable, it depends on the particular case. To declare an inline function, we’ve to use the keyword `inline` in its declaration.
|
||||
|
||||
Now we are in a position to guess what is inline assembly. Its just some assembly routines written as inline functions. They are handy, speedy and very much useful in system programming. Our main focus is to study the basic format and usage of (GCC) inline assembly functions. To declare inline assembly functions, we use the keyword `asm`.
|
||||
|
||||
Inline assembly is important primarily because of its ability to operate and make its output visible on C variables. Because of this capability, "asm" works as an interface between the assembly instructions and the "C" program that contains it.
|
||||
|
||||
* * *
|
||||
|
||||
## 3. GCC Assembler Syntax.
|
||||
|
||||
GCC, the GNU C Compiler for Linux, uses **AT&T**/**UNIX** assembly syntax. Here we’ll be using AT&T syntax for assembly coding. Don’t worry if you are not familiar with AT&T syntax, I will teach you. This is quite different from Intel syntax. I shall give the major differences.
|
||||
|
||||
1. Source-Destination Ordering.
|
||||
|
||||
The direction of the operands in AT&T syntax is opposite to that of Intel. In Intel syntax the first operand is the destination, and the second operand is the source whereas in AT&T syntax the first operand is the source and the second operand is the destination. ie,
|
||||
|
||||
"Op-code dst src" in Intel syntax changes to
|
||||
|
||||
"Op-code src dst" in AT&T syntax.
|
||||
|
||||
2. Register Naming.
|
||||
|
||||
Register names are prefixed by % ie, if eax is to be used, write %eax.
|
||||
|
||||
3. Immediate Operand.
|
||||
|
||||
AT&T immediate operands are preceded by ’$’. For static "C" variables also prefix a ’$’. In Intel syntax, for hexadecimal constants an ’h’ is suffixed, instead of that, here we prefix ’0x’ to the constant. So, for hexadecimals, we first see a ’$’, then ’0x’ and finally the constants.
|
||||
|
||||
4. Operand Size.
|
||||
|
||||
In AT&T syntax the size of memory operands is determined from the last character of the op-code name. Op-code suffixes of ’b’, ’w’, and ’l’ specify byte(8-bit), word(16-bit), and long(32-bit) memory references. Intel syntax accomplishes this by prefixing memory operands (not the op-codes) with ’byte ptr’, ’word ptr’, and ’dword ptr’.
|
||||
|
||||
Thus, Intel "mov al, byte ptr foo" is "movb foo, %al" in AT&T syntax.
|
||||
|
||||
5. Memory Operands.
|
||||
|
||||
In Intel syntax the base register is enclosed in ’[’ and ’]’ where as in AT&T they change to ’(’ and ’)’. Additionally, in Intel syntax an indirect memory reference is like
|
||||
|
||||
section:[base + index*scale + disp], which changes to
|
||||
|
||||
section:disp(base, index, scale) in AT&T.
|
||||
|
||||
One point to bear in mind is that, when a constant is used for disp/scale, ’$’ shouldn’t be prefixed.
|
||||
|
||||
Now we saw some of the major differences between Intel syntax and AT&T syntax. I’ve wrote only a few of them. For a complete information, refer to GNU Assembler documentations. Now we’ll look at some examples for better understanding.
|
||||
|
||||
> `
|
||||
>
|
||||
> <pre>+------------------------------+------------------------------------+
|
||||
> | Intel Code | AT&T Code |
|
||||
> +------------------------------+------------------------------------+
|
||||
> | mov eax,1 | movl $1,%eax |
|
||||
> | mov ebx,0ffh | movl $0xff,%ebx |
|
||||
> | int 80h | int $0x80 |
|
||||
> | mov ebx, eax | movl %eax, %ebx |
|
||||
> | mov eax,[ecx] | movl (%ecx),%eax |
|
||||
> | mov eax,[ebx+3] | movl 3(%ebx),%eax |
|
||||
> | mov eax,[ebx+20h] | movl 0x20(%ebx),%eax |
|
||||
> | add eax,[ebx+ecx*2h] | addl (%ebx,%ecx,0x2),%eax |
|
||||
> | lea eax,[ebx+ecx] | leal (%ebx,%ecx),%eax |
|
||||
> | sub eax,[ebx+ecx*4h-20h] | subl -0x20(%ebx,%ecx,0x4),%eax |
|
||||
> +------------------------------+------------------------------------+
|
||||
> </pre>
|
||||
>
|
||||
> `
|
||||
|
||||
* * *
|
||||
|
||||
## 4. Basic Inline.
|
||||
|
||||
The format of basic inline assembly is very much straight forward. Its basic form is
|
||||
|
||||
`asm("assembly code");`
|
||||
|
||||
Example.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>asm("movl %ecx %eax"); /* moves the contents of ecx to eax */
|
||||
> __asm__("movb %bh (%eax)"); /*moves the byte from bh to the memory pointed by eax */
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
You might have noticed that here I’ve used `asm` and `__asm__`. Both are valid. We can use `__asm__` if the keyword `asm` conflicts with something in our program. If we have more than one instructions, we write one per line in double quotes, and also suffix a ’\n’ and ’\t’ to the instruction. This is because gcc sends each instruction as a string to **as**(GAS) and by using the newline/tab we send correctly formatted lines to the assembler.
|
||||
|
||||
Example.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> __asm__ ("movl %eax, %ebx\n\t"
|
||||
> "movl $56, %esi\n\t"
|
||||
> "movl %ecx, $label(%edx,%ebx,$4)\n\t"
|
||||
> "movb %ah, (%ebx)");
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
If in our code we touch (ie, change the contents) some registers and return from asm without fixing those changes, something bad is going to happen. This is because GCC have no idea about the changes in the register contents and this leads us to trouble, especially when compiler makes some optimizations. It will suppose that some register contains the value of some variable that we might have changed without informing GCC, and it continues like nothing happened. What we can do is either use those instructions having no side effects or fix things when we quit or wait for something to crash. This is where we want some extended functionality. Extended asm provides us with that functionality.
|
||||
|
||||
* * *
|
||||
|
||||
## 5. Extended Asm.
|
||||
|
||||
In basic inline assembly, we had only instructions. In extended assembly, we can also specify the operands. It allows us to specify the input registers, output registers and a list of clobbered registers. It is not mandatory to specify the registers to use, we can leave that head ache to GCC and that probably fit into GCC’s optimization scheme better. Anyway the basic format is:
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ( assembler template
|
||||
> : output operands /* optional */
|
||||
> : input operands /* optional */
|
||||
> : list of clobbered registers /* optional */
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
The assembler template consists of assembly instructions. Each operand is described by an operand-constraint string followed by the C expression in parentheses. A colon separates the assembler template from the first output operand and another separates the last output operand from the first input, if any. Commas separate the operands within each group. The total number of operands is limited to ten or to the maximum number of operands in any instruction pattern in the machine description, whichever is greater.
|
||||
|
||||
If there are no output operands but there are input operands, you must place two consecutive colons surrounding the place where the output operands would go.
|
||||
|
||||
Example:
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ("cld\n\t"
|
||||
> "rep\n\t"
|
||||
> "stosl"
|
||||
> : /* no output registers */
|
||||
> : "c" (count), "a" (fill_value), "D" (dest)
|
||||
> : "%ecx", "%edi"
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Now, what does this code do? The above inline fills the `fill_value` `count` times to the location pointed to by the register `edi`. It also says to gcc that, the contents of registers `eax` and `edi` are no longer valid. Let us see one more example to make things more clearer.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>
|
||||
> int a=10, b;
|
||||
> asm ("movl %1, %%eax;
|
||||
> movl %%eax, %0;"
|
||||
> :"=r"(b) /* output */
|
||||
> :"r"(a) /* input */
|
||||
> :"%eax" /* clobbered register */
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here what we did is we made the value of ’b’ equal to that of ’a’ using assembly instructions. Some points of interest are:
|
||||
|
||||
* "b" is the output operand, referred to by %0 and "a" is the input operand, referred to by %1.
|
||||
* "r" is a constraint on the operands. We’ll see constraints in detail later. For the time being, "r" says to GCC to use any register for storing the operands. output operand constraint should have a constraint modifier "=". And this modifier says that it is the output operand and is write-only.
|
||||
* There are two %’s prefixed to the register name. This helps GCC to distinguish between the operands and registers. operands have a single % as prefix.
|
||||
* The clobbered register %eax after the third colon tells GCC that the value of %eax is to be modified inside "asm", so GCC won’t use this register to store any other value.
|
||||
|
||||
When the execution of "asm" is complete, "b" will reflect the updated value, as it is specified as an output operand. In other words, the change made to "b" inside "asm" is supposed to be reflected outside the "asm".
|
||||
|
||||
Now we may look each field in detail.
|
||||
|
||||
## 5.1 Assembler Template.
|
||||
|
||||
The assembler template contains the set of assembly instructions that gets inserted inside the C program. The format is like: either each instruction should be enclosed within double quotes, or the entire group of instructions should be within double quotes. Each instruction should also end with a delimiter. The valid delimiters are newline(\n) and semicolon(;). ’\n’ may be followed by a tab(\t). We know the reason of newline/tab, right?. Operands corresponding to the C expressions are represented by %0, %1 ... etc.
|
||||
|
||||
## 5.2 Operands.
|
||||
|
||||
C expressions serve as operands for the assembly instructions inside "asm". Each operand is written as first an operand constraint in double quotes. For output operands, there’ll be a constraint modifier also within the quotes and then follows the C expression which stands for the operand. ie,
|
||||
|
||||
"constraint" (C expression) is the general form. For output operands an additional modifier will be there. Constraints are primarily used to decide the addressing modes for operands. They are also used in specifying the registers to be used.
|
||||
|
||||
If we use more than one operand, they are separated by comma.
|
||||
|
||||
In the assembler template, each operand is referenced by numbers. Numbering is done as follows. If there are a total of n operands (both input and output inclusive), then the first output operand is numbered 0, continuing in increasing order, and the last input operand is numbered n-1\. The maximum number of operands is as we saw in the previous section.
|
||||
|
||||
Output operand expressions must be lvalues. The input operands are not restricted like this. They may be expressions. The extended asm feature is most often used for machine instructions the compiler itself does not know as existing ;-). If the output expression cannot be directly addressed (for example, it is a bit-field), our constraint must allow a register. In that case, GCC will use the register as the output of the asm, and then store that register contents into the output.
|
||||
|
||||
As stated above, ordinary output operands must be write-only; GCC will assume that the values in these operands before the instruction are dead and need not be generated. Extended asm also supports input-output or read-write operands.
|
||||
|
||||
So now we concentrate on some examples. We want to multiply a number by 5\. For that we use the instruction `lea`.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ("leal (%1,%1,4), %0"
|
||||
> : "=r" (five_times_x)
|
||||
> : "r" (x)
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here our input is in ’x’. We didn’t specify the register to be used. GCC will choose some register for input, one for output and does what we desired. If we want the input and output to reside in the same register, we can instruct GCC to do so. Here we use those types of read-write operands. By specifying proper constraints, here we do it.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ("leal (%0,%0,4), %0"
|
||||
> : "=r" (five_times_x)
|
||||
> : "0" (x)
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Now the input and output operands are in the same register. But we don’t know which register. Now if we want to specify that also, there is a way.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ("leal (%%ecx,%%ecx,4), %%ecx"
|
||||
> : "=c" (x)
|
||||
> : "c" (x)
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
In all the three examples above, we didn’t put any register to the clobber list. why? In the first two examples, GCC decides the registers and it knows what changes happen. In the last one, we don’t have to put `ecx` on the c lobberlist, gcc knows it goes into x. Therefore, since it can know the value of `ecx`, it isn’t considered clobbered.
|
||||
|
||||
## 5.3 Clobber List.
|
||||
|
||||
Some instructions clobber some hardware registers. We have to list those registers in the clobber-list, ie the field after the third ’**:**’ in the asm function. This is to inform gcc that we will use and modify them ourselves. So gcc will not assume that the values it loads into these registers will be valid. We shoudn’t list the input and output registers in this list. Because, gcc knows that "asm" uses them (because they are specified explicitly as constraints). If the instructions use any other registers, implicitly or explicitly (and the registers are not present either in input or in the output constraint list), then those registers have to be specified in the clobbered list.
|
||||
|
||||
If our instruction can alter the condition code register, we have to add "cc" to the list of clobbered registers.
|
||||
|
||||
If our instruction modifies memory in an unpredictable fashion, add "memory" to the list of clobbered registers. This will cause GCC to not keep memory values cached in registers across the assembler instruction. We also have to add the **volatile** keyword if the memory affected is not listed in the inputs or outputs of the asm.
|
||||
|
||||
We can read and write the clobbered registers as many times as we like. Consider the example of multiple instructions in a template; it assumes the subroutine _foo accepts arguments in registers `eax` and `ecx`.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> asm ("movl %0,%%eax;
|
||||
> movl %1,%%ecx;
|
||||
> call _foo"
|
||||
> : /* no outputs */
|
||||
> : "g" (from), "g" (to)
|
||||
> : "eax", "ecx"
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
## 5.4 Volatile ...?
|
||||
|
||||
If you are familiar with kernel sources or some beautiful code like that, you must have seen many functions declared as `volatile` or `__volatile__` which follows an `asm` or `__asm__`. I mentioned earlier about the keywords `asm` and `__asm__`. So what is this `volatile`?
|
||||
|
||||
If our assembly statement must execute where we put it, (i.e. must not be moved out of a loop as an optimization), put the keyword `volatile` after asm and before the ()’s. So to keep it from moving, deleting and all, we declare it as
|
||||
|
||||
`asm volatile ( ... : ... : ... : ...);`
|
||||
|
||||
Use `__volatile__` when we have to be verymuch careful.
|
||||
|
||||
If our assembly is just for doing some calculations and doesn’t have any side effects, it’s better not to use the keyword `volatile`. Avoiding it helps gcc in optimizing the code and making it more beautiful.
|
||||
|
||||
In the section `Some Useful Recipes`, I have provided many examples for inline asm functions. There we can see the clobber-list in detail.
|
||||
|
||||
* * *
|
||||
|
||||
## 6. More about constraints.
|
||||
|
||||
By this time, you might have understood that constraints have got a lot to do with inline assembly. But we’ve said little about constraints. Constraints can say whether an operand may be in a register, and which kinds of register; whether the operand can be a memory reference, and which kinds of address; whether the operand may be an immediate constant, and which possible values (ie range of values) it may have.... etc.
|
||||
|
||||
## 6.1 Commonly used constraints.
|
||||
|
||||
There are a number of constraints of which only a few are used frequently. We’ll have a look at those constraints.
|
||||
|
||||
1. **Register operand constraint(r)**
|
||||
|
||||
When operands are specified using this constraint, they get stored in General Purpose Registers(GPR). Take the following example:
|
||||
|
||||
`asm ("movl %%eax, %0\n" :"=r"(myval));`
|
||||
|
||||
Here the variable myval is kept in a register, the value in register `eax` is copied onto that register, and the value of `myval` is updated into the memory from this register. When the "r" constraint is specified, gcc may keep the variable in any of the available GPRs. To specify the register, you must directly specify the register names by using specific register constraints. They are:
|
||||
|
||||
> `
|
||||
>
|
||||
> <pre>+---+--------------------+
|
||||
> | r | Register(s) |
|
||||
> +---+--------------------+
|
||||
> | a | %eax, %ax, %al |
|
||||
> | b | %ebx, %bx, %bl |
|
||||
> | c | %ecx, %cx, %cl |
|
||||
> | d | %edx, %dx, %dl |
|
||||
> | S | %esi, %si |
|
||||
> | D | %edi, %di |
|
||||
> +---+--------------------+
|
||||
> </pre>
|
||||
>
|
||||
> `
|
||||
|
||||
2. **Memory operand constraint(m)**
|
||||
|
||||
When the operands are in the memory, any operations performed on them will occur directly in the memory location, as opposed to register constraints, which first store the value in a register to be modified and then write it back to the memory location. But register constraints are usually used only when they are absolutely necessary for an instruction or they significantly speed up the process. Memory constraints can be used most efficiently in cases where a C variable needs to be updated inside "asm" and you really don’t want to use a register to hold its value. For example, the value of idtr is stored in the memory location loc:
|
||||
|
||||
`asm("sidt %0\n" : :"m"(loc));`
|
||||
|
||||
3. **Matching(Digit) constraints**
|
||||
|
||||
In some cases, a single variable may serve as both the input and the output operand. Such cases may be specified in "asm" by using matching constraints.
|
||||
|
||||
`asm ("incl %0" :"=a"(var):"0"(var));`
|
||||
|
||||
We saw similar examples in operands subsection also. In this example for matching constraints, the register %eax is used as both the input and the output variable. var input is read to %eax and updated %eax is stored in var again after increment. "0" here specifies the same constraint as the 0th output variable. That is, it specifies that the output instance of var should be stored in %eax only. This constraint can be used:
|
||||
|
||||
* In cases where input is read from a variable or the variable is modified and modification is written back to the same variable.
|
||||
* In cases where separate instances of input and output operands are not necessary.
|
||||
|
||||
The most important effect of using matching restraints is that they lead to the efficient use of available registers.
|
||||
|
||||
Some other constraints used are:
|
||||
|
||||
1. "m" : A memory operand is allowed, with any kind of address that the machine supports in general.
|
||||
2. "o" : A memory operand is allowed, but only if the address is offsettable. ie, adding a small offset to the address gives a valid address.
|
||||
3. "V" : A memory operand that is not offsettable. In other words, anything that would fit the `m’ constraint but not the `o’constraint.
|
||||
4. "i" : An immediate integer operand (one with constant value) is allowed. This includes symbolic constants whose values will be known only at assembly time.
|
||||
5. "n" : An immediate integer operand with a known numeric value is allowed. Many systems cannot support assembly-time constants for operands less than a word wide. Constraints for these operands should use ’n’ rather than ’i’.
|
||||
6. "g" : Any register, memory or immediate integer operand is allowed, except for registers that are not general registers.
|
||||
|
||||
Following constraints are x86 specific.
|
||||
|
||||
1. "r" : Register operand constraint, look table given above.
|
||||
2. "q" : Registers a, b, c or d.
|
||||
3. "I" : Constant in range 0 to 31 (for 32-bit shifts).
|
||||
4. "J" : Constant in range 0 to 63 (for 64-bit shifts).
|
||||
5. "K" : 0xff.
|
||||
6. "L" : 0xffff.
|
||||
7. "M" : 0, 1, 2, or 3 (shifts for lea instruction).
|
||||
8. "N" : Constant in range 0 to 255 (for out instruction).
|
||||
9. "f" : Floating point register
|
||||
10. "t" : First (top of stack) floating point register
|
||||
11. "u" : Second floating point register
|
||||
12. "A" : Specifies the `a’ or `d’ registers. This is primarily useful for 64-bit integer values intended to be returned with the `d’ register holding the most significant bits and the `a’ register holding the least significant bits.
|
||||
|
||||
## 6.2 Constraint Modifiers.
|
||||
|
||||
While using constraints, for more precise control over the effects of constraints, GCC provides us with constraint modifiers. Mostly used constraint modifiers are
|
||||
|
||||
1. "=" : Means that this operand is write-only for this instruction; the previous value is discarded and replaced by output data.
|
||||
2. "&" : Means that this operand is an earlyclobber operand, which is modified before the instruction is finished using the input operands. Therefore, this operand may not lie in a register that is used as an input operand or as part of any memory address. An input operand can be tied to an earlyclobber operand if its only use as an input occurs before the early result is written.
|
||||
|
||||
The list and explanation of constraints is by no means complete. Examples can give a better understanding of the use and usage of inline asm. In the next section we’ll see some examples, there we’ll find more about clobber-lists and constraints.
|
||||
|
||||
* * *
|
||||
|
||||
## 7. Some Useful Recipes.
|
||||
|
||||
Now we have covered the basic theory about GCC inline assembly, now we shall concentrate on some simple examples. It is always handy to write inline asm functions as MACRO’s. We can see many asm functions in the kernel code. (/usr/src/linux/include/asm/*.h).
|
||||
|
||||
1. First we start with a simple example. We’ll write a program to add two numbers.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>int main(void)
|
||||
> {
|
||||
> int foo = 10, bar = 15;
|
||||
> __asm__ __volatile__("addl %%ebx,%%eax"
|
||||
> :"=a"(foo)
|
||||
> :"a"(foo), "b"(bar)
|
||||
> );
|
||||
> printf("foo+bar=%d\n", foo);
|
||||
> return 0;
|
||||
> }
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here we insist GCC to store foo in %eax, bar in %ebx and we also want the result in %eax. The ’=’ sign shows that it is an output register. Now we can add an integer to a variable in some other way.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> __asm__ __volatile__(
|
||||
> " lock ;\n"
|
||||
> " addl %1,%0 ;\n"
|
||||
> : "=m" (my_var)
|
||||
> : "ir" (my_int), "m" (my_var)
|
||||
> : /* no clobber-list */
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
This is an atomic addition. We can remove the instruction ’lock’ to remove the atomicity. In the output field, "=m" says that my_var is an output and it is in memory. Similarly, "ir" says that, my_int is an integer and should reside in some register (recall the table we saw above). No registers are in the clobber list.
|
||||
|
||||
2. Now we’ll perform some action on some registers/variables and compare the value.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre> __asm__ __volatile__( "decl %0; sete %1"
|
||||
> : "=m" (my_var), "=q" (cond)
|
||||
> : "m" (my_var)
|
||||
> : "memory"
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here, the value of my_var is decremented by one and if the resulting value is `0` then, the variable cond is set. We can add atomicity by adding an instruction "lock;\n\t" as the first instruction in assembler template.
|
||||
|
||||
In a similar way we can use "incl %0" instead of "decl %0", so as to increment my_var.
|
||||
|
||||
Points to note here are that (i) my_var is a variable residing in memory. (ii) cond is in any of the registers eax, ebx, ecx and edx. The constraint "=q" guarantees it. (iii) And we can see that memory is there in the clobber list. ie, the code is changing the contents of memory.
|
||||
|
||||
3. How to set/clear a bit in a register? As next recipe, we are going to see it.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>__asm__ __volatile__( "btsl %1,%0"
|
||||
> : "=m" (ADDR)
|
||||
> : "Ir" (pos)
|
||||
> : "cc"
|
||||
> );
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here, the bit at the position ’pos’ of variable at ADDR ( a memory variable ) is set to `1` We can use ’btrl’ for ’btsl’ to clear the bit. The constraint "Ir" of pos says that, pos is in a register, and it’s value ranges from 0-31 (x86 dependant constraint). ie, we can set/clear any bit from 0th to 31st of the variable at ADDR. As the condition codes will be changed, we are adding "cc" to clobberlist.
|
||||
|
||||
4. Now we look at some more complicated but useful function. String copy.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>static inline char * strcpy(char * dest,const char *src)
|
||||
> {
|
||||
> int d0, d1, d2;
|
||||
> __asm__ __volatile__( "1:\tlodsb\n\t"
|
||||
> "stosb\n\t"
|
||||
> "testb %%al,%%al\n\t"
|
||||
> "jne 1b"
|
||||
> : "=&S" (d0), "=&D" (d1), "=&a" (d2)
|
||||
> : "0" (src),"1" (dest)
|
||||
> : "memory");
|
||||
> return dest;
|
||||
> }
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
The source address is stored in esi, destination in edi, and then starts the copy, when we reach at **0**, copying is complete. Constraints "&S", "&D", "&a" say that the registers esi, edi and eax are early clobber registers, ie, their contents will change before the completion of the function. Here also it’s clear that why memory is in clobberlist.
|
||||
|
||||
We can see a similar function which moves a block of double words. Notice that the function is declared as a macro.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>#define mov_blk(src, dest, numwords) \
|
||||
> __asm__ __volatile__ ( \
|
||||
> "cld\n\t" \
|
||||
> "rep\n\t" \
|
||||
> "movsl" \
|
||||
> : \
|
||||
> : "S" (src), "D" (dest), "c" (numwords) \
|
||||
> : "%ecx", "%esi", "%edi" \
|
||||
> )
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Here we have no outputs, so the changes that happen to the contents of the registers ecx, esi and edi are side effects of the block movement. So we have to add them to the clobber list.
|
||||
|
||||
5. In Linux, system calls are implemented using GCC inline assembly. Let us look how a system call is implemented. All the system calls are written as macros (linux/unistd.h). For example, a system call with three arguments is defined as a macro as shown below.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>#define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
|
||||
> type name(type1 arg1,type2 arg2,type3 arg3) \
|
||||
> { \
|
||||
> long __res; \
|
||||
> __asm__ volatile ( "int $0x80" \
|
||||
> : "=a" (__res) \
|
||||
> : "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
|
||||
> "d" ((long)(arg3))); \
|
||||
> __syscall_return(type,__res); \
|
||||
> }
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
Whenever a system call with three arguments is made, the macro shown above is used to make the call. The syscall number is placed in eax, then each parameters in ebx, ecx, edx. And finally "int 0x80" is the instruction which makes the system call work. The return value can be collected from eax.
|
||||
|
||||
Every system calls are implemented in a similar way. Exit is a single parameter syscall and let’s see how it’s code will look like. It is as shown below.
|
||||
|
||||
> `
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> <pre>{
|
||||
> asm("movl $1,%%eax; /* SYS_exit is 1 */
|
||||
> xorl %%ebx,%%ebx; /* Argument is in ebx, it is 0 */
|
||||
> int $0x80" /* Enter kernel mode */
|
||||
> );
|
||||
> }
|
||||
> </pre>
|
||||
>
|
||||
> * * *
|
||||
>
|
||||
> `
|
||||
|
||||
The number of exit is "1" and here, it’s parameter is 0\. So we arrange eax to contain 1 and ebx to contain 0 and by `int $0x80`, the `exit(0)` is executed. This is how exit works.
|
||||
|
||||
* * *
|
||||
|
||||
## 8. Concluding Remarks.
|
||||
|
||||
This document has gone through the basics of GCC Inline Assembly. Once you have understood the basic concept it is not difficult to take steps by your own. We saw some examples which are helpful in understanding the frequently used features of GCC Inline Assembly.
|
||||
|
||||
GCC Inlining is a vast subject and this article is by no means complete. More details about the syntax’s we discussed about is available in the official documentation for GNU Assembler. Similarly, for a complete list of the constraints refer to the official documentation of GCC.
|
||||
|
||||
And of-course, the Linux kernel use GCC Inline in a large scale. So we can find many examples of various kinds in the kernel sources. They can help us a lot.
|
||||
|
||||
If you have found any glaring typos, or outdated info in this document, please let us know.
|
||||
|
||||
* * *
|
||||
|
||||
## 9. References.
|
||||
|
||||
1. [Brennan’s Guide to Inline Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html)
|
||||
2. [Using Assembly Language in Linux](http://linuxassembly.org/articles/linasm.html)
|
||||
3. [Using as, The GNU Assembler](http://www.gnu.org/manual/gas-2.9.1/html_mono/as.html)
|
||||
4. [Using and Porting the GNU Compiler Collection (GCC)](http://gcc.gnu.org/onlinedocs/gcc_toc.html)
|
||||
5. [Linux Kernel Source](http://ftp.kernel.org/)
|
||||
|
||||
* * *
|
||||
via: http://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html
|
||||
|
||||
作者:[Sandeep.S](mailto:busybox@sancharnet.in) 译者:[zky001](https://github.com/zky001) 校对:[]()
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
68
sources/tech/20151227 Ubuntu Touch, three years later.md
Normal file
68
sources/tech/20151227 Ubuntu Touch, three years later.md
Normal file
@ -0,0 +1,68 @@
|
||||
Back in early 2013, your editor [dedicated a sacrificial handset][2] to the testing of the then-new Ubuntu Touch distribution. At that time, things were so unbaked that the distribution came with mocked-up data for unready apps; it even came with a set of fake tweets. Nearly three years later, it seemed time to give Ubuntu Touch another try on another sacrificial device. This distribution has certainly made some progress in those years, but, sadly, it still seems far from being a competitive offering in this space.
|
||||
In particular, your editor tested version 16.04r3 from the testing channel on a Nexus 4 handset. The Nexus 4 is certainly past its prime at the end of 2015, but it still functions as a credible Android device. It is, in any case, the only phone handset on [the list of supported devices][1] other than the three that were sold (in locations far from your editor's home) with Ubuntu Touch pre-installed. It is a bit discouraging that Ubuntu Touch is not supported on a more recent device; the Nexus 4 was discontinued over two years ago.
|
||||
|
||||
People who are accustomed to putting strange systems on Nexus devices know the drill fairly well: unlock the bootloader, install a new recovery image if necessary, then use the **fastboot** tool to flash a new image. Ubuntu Touch does not work that way; instead, one must use a set of tools available only on the Ubuntu desktop distribution. Your editor's current menagerie of systems does not include any of those, but, fortunately, running the Ubuntu 15.10 distribution off a USB drive works just fine. It must be said, though, that Ubuntu appears not to have gotten the memo regarding high-DPI laptop displays; 15.10 is an exercise in eyestrain on such a device.
|
||||
|
||||
Once the requisite packages have been installed, the **ubuntu-device-flash** command can be used to install Ubuntu Touch on the phone. It finds the installation image wherever Canonical hides them (it's not obvious where that is) and puts it onto the phone; the process, on the Nexus 4, took about three hours — a surprisingly long time. Among other things, it installs a Ubuntu-specific recovery image, regardless of whether that should be necessary or not. The installation takes up about 4.5GB of space on the device. At the end, the phone reboots and comes up with the Ubuntu Touch lock screen, which has changed little in the last three years. The first boot takes a discouragingly long time, but subsequent reboots are faster, perhaps faster than Android on the same device.
|
||||
|
||||
Alas, that's about the only thing that is faster than Android. The phone starts sluggish and gets worse as time goes on. At one point it took a solid minute to get the dialer screen up on the running device. Scrolling can be jerky and unpleasant to work with. At least once, the phone bogged down to the point that there was little alternative to shutting it down and starting over.
|
||||
|
||||
Logging into the device over the USB connection offers some clues as to why that might be. There were no less than 258 processes running on the system. A number of them have "evolution" in their name, which is never a good sign even on a heftier system. Daemons like NetworkManager and pulseaudio are running. In general, Ubuntu Touch seems to have a large number of relatively large moving parts, leading, seemingly, to memory pressure and a certain amount of thrashing.
|
||||
|
||||
Three years ago, Ubuntu Touch was built on an Android chassis. There are still bits of Android that show up here and there (it uses binder, for example), but a number of those components have been replaced. This release runs an Android-derived kernel that identifies itself as "3.4.0-7 #39-Ubuntu". 3.4.0 was released in May 2012, so it is getting a bit long in the tooth; the 3.4.0 number suggests this kernel hasn't even gotten the stable updates that followed that release. Finding the source for the kernel in this distribution is not easy; it must almost certainly be hidden somewhere in this Gerrit repository, but your editor ran out of time while trying to find it. The SurfaceFlinger display manager has been replaced by Ubuntu's own Mir, with Unity providing the interface. Upstart is the init system, despite the fact that Ubuntu has moved to systemd on desktop systems.
|
||||
|
||||
When one moves beyond the command-line interface and starts playing with the touchscreen, one finds that the basics of the interface resemble what was demonstrated three years ago. Swiping from the left edge brings the [Overview screen] Unity icon bar (but no longer switches to a home screen; the "home screen" concept doesn't really seem to exist anymore). Swiping from the right will either switch to another application or produce an overview of running applications; it's not clear how it decides which. The overview provides a cute oblique view of the running applications; it's sufficient to choose one, but seems somewhat wasteful of screen space. Swiping up from the bottom produces an application-specific menu — usually.
|
||||
|
||||
![][3]
|
||||
|
||||
|
||||
The swipe gestures work well enough once one gets used to them, but there is scope for confusion. The camera app, for example, will instruct the user to "swipe left for photo roll," but, unless one is careful to avoid [Swipe left] the right edge of the screen, that gesture will yield the overview screen instead. One can learn subtleties like "swipes involving the edge" and "swipes avoiding the edge," but one could argue that such an interface is more difficult than it needs to be and less discoverable than it could be.
|
||||
|
||||
![][4]
|
||||
|
||||
Speaking of the camera app, it takes pictures as one might expect, and it has gained a high-dynamic-range mode in recent years. It still has no support for stitching together photos in a panorama or "photo sphere" mode, though.
|
||||
|
||||
![][5]
|
||||
|
||||
The base distribution comes with a fairly basic set of apps. Many of them appear to be interfaces to an associated web page; the Amazon, GMail, and Facebook apps, for example. Something called "Shorts" appears to be an RSS reader, though it seems impervious to the addition of arbitrary feeds. There is a terminal app, but it prompts for a password — a bit surprising [Terminal emulator] given that no password had ever been supplied for the device (it turns out that one should use the screen-lock PIN here). It's not clear that this extra level of "security" is helpful, given that the user involved is already able to install, launch, and run applications on the device, but so it goes.
|
||||
|
||||
Despite the presence of all those evolution processes, there is no IMAP-capable email app; there are also no mapping apps. There is a rudimentary web browser with Ubuntu branding; it appears that this browser is based on Chromium. The weather app is limited to a few dozen hardwired locations worldwide; the closest supported location to LWN headquarters was Houston, which, one assumes, is unlikely to be dealing with the foot of snow your editor had to shovel while partway through this article. One suspects we would have heard about that.
|
||||
|
||||
![][6]
|
||||
|
||||
Inevitably, there is a store from which one can obtain other apps. There are, for example, a couple of seemingly capable, OpenStreetMap-based mapping apps there, including one that claims turn-by-turn navigation, but nothing requiring GPS access worked in your editor's tests. Games abound, of course, but [Maps] there is little in the way of apps that are well known in the Android or iOS worlds. The store will refuse to allow the installation of apps until one creates a "Ubuntu One" account; that is unfortunate, but most Android users never get anywhere near that far before having to create or supply a Google account.
|
||||
|
||||
![][7]
|
||||
|
||||
Canonical puts a fair amount of energy into promoting its "scopes," which are said to be better than apps for the aggregation of content. In truth, they seem to just be another type of app with a focus on gathering information from more than one source. Although, with "branded scopes," the "more than one source" part is often deliberately put by the wayside. Your editor played around with scopes for a while, but, in truth, could not find what was supposed to make them special.
|
||||
|
||||
Permissions management in Ubuntu Touch resembles that found in recent Android releases: the user will be prompted the first time an application tries to exercise a specific privilege. As with Android, the number of [Permissions request] actions requiring privilege is relatively small, and "connect to any arbitrary site on the Internet" is not among them. Access to location information or the camera, though, will generate a prompt. There is also, again as with Android, a way to control which applications are allowed to place notifications on the screen.
|
||||
|
||||
Ubuntu Touch still seems to drain the battery far more quickly than Android does on the same device. Indeed, it is barely able to get through the night while sitting idle. There is a cute battery app that offers a couple of "ways to reduce battery use," but it lacks Android's ability to say which apps are actually draining the battery (though, it must be said, that information from Android is often less helpful than one might hope).
|
||||
|
||||
![][8]
|
||||
|
||||
The keyboard now has proper multi-lingual support (though there is no visual indication of which language is currently in effect) and, as with Android, one can switch between languages on the fly. It offers word suggestions, does [Keyboard] spelling correction, and all the usual things. One missing feature, though, is "swipe" typing which, your editor has found, can speed the process of inputting text on a small keyboard considerably. There is also no voice input; no major loss from your editor's point of view, but others will probably see that differently.
|
||||
|
||||
There is a lot to like in Ubuntu Touch. There is some appeal to running something that looks like a proper Linux system, even if it still has a number of Ubuntu-specific components. One does not get the sense that the device is watching quite as closely as Android devices do, though it's not entirely clear, for example, what happens with location data or where it might be stored. In any case, a Ubuntu device clearly has more free software on it than most alternatives do; there is no proprietary "play services" layer maintaining control over the system.
|
||||
|
||||
Sadly, though, this distribution still is not up to the capabilities and the performance of the big alternatives. Switching to Ubuntu Touch means settling for a much slower system, running on a severely limited set of devices, with a relative scarcity of apps to choose from. Your editor would very much like to see a handset distribution that is more free and more open than the alternatives, but that distribution must also be competitive with those alternatives, and that does not seem to be the case here. Unless Canonical can find a way to close the performance and feature gaps with Android, it seems unlikely to have much hope of achieving uptake that is within a few orders of magnitude of Android's.
|
||||
|
||||
--------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/667983/
|
||||
|
||||
作者:Jonathan Corbet
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://developer.ubuntu.com/en/start/ubuntu-for-devices/devices/
|
||||
[2]: https://lwn.net/Articles/540138/
|
||||
[3]: https://static.lwn.net/images/2015/utouch/overview-sm.png
|
||||
[4]: https://static.lwn.net/images/2015/utouch/camera-swipe-sm.png
|
||||
[5]: https://static.lwn.net/images/2015/utouch/terminal.png
|
||||
[6]: https://static.lwn.net/images/2015/utouch/gps-sm.png
|
||||
[7]: https://static.lwn.net/images/2015/utouch/camera-perm.png
|
||||
[8]: https://static.lwn.net/images/2015/utouch/schifo.png
|
||||
236
sources/tech/20151229 Grub 2--Heal your bootloader.md
Normal file
236
sources/tech/20151229 Grub 2--Heal your bootloader.md
Normal file
@ -0,0 +1,236 @@
|
||||
翻译中。。。。。
|
||||
Grub 2: Heal your bootloader
|
||||
================================================================================
|
||||
**There are few things as irritating as a broken bootloader. Get the best out of Grub 2 and keep it shipshape.**
|
||||
|
||||
Why do this?
|
||||
|
||||
- Grub 2 is the most popular bootloader that’s used by almost every Linux distribution.
|
||||
- A bootloader is a vital piece of software, but they are susceptible to damage.
|
||||
- Grub 2 is an expansive and flexible boot loader that offers various customisable options.
|
||||
|
||||
The Grub 2 Linux bootloader is a wonderful and versatile piece of software. While it isn’t the only bootloader out there, it’s the most popular and almost all the leading desktop distros use it. The job of the Grub bootloader is twofold. First, it displays a menu of all installed operating systems on a computer and invites you to pick one. Second, Grub loads the Linux kernel if you choose a Linux operating system from the boot menu.
|
||||
|
||||
As you can see, if you use Linux, you can’t escape the bootloader. Yet it’s one the least understood components inside a Linux distro. In this tutorial we’ll familiarise you with some of Grub 2’s famed versatility and equip you with the skills to help yourself when you have a misbehaving bootloader.
|
||||
|
||||
The most important parts of Grub 2 are a bunch of text files and a couple of scripts. The first piece to know is **/etc/default/grub**. This is the text file in which you can set the general configuration variables and other characteristics of the Grub 2 menu (see box titled “Common user settings”).
|
||||
|
||||
The other important aspect of Grub 2 is the **/etc/grub.d** folder. All the scripts that define each menu entry are housed there. The names of these scripts must have a two-digit numeric prefix. Its purpose is to define the order in which the scripts are executed and the order of the corresponding entries when the Grub 2 menu is built. The **00_header** file is read first, which parses the **/etc/default/grub** configuration file. Then come the entries for the Linux kernels in the **10_linux** file. This script creates one regular and one recovery menu entry for each kernel in the default **/boot** partition.
|
||||
|
||||
This script is followed by others for third-party apps such as **30_os-prober** and **40_custom**. The **os-prober** script creates entries for kernels and other operating systems found on other partitions. It can recognise Linux, Windows, BSD and Mac OS X installations. If your hard disk layout is too exotic for the **os-prober** script to pick up an installed distro, you can add it to the **40_custom** file (see the “Add custom entries” box).
|
||||
|
||||
**Grub** 2 does not require you to manually maintain your boot options’ configuration file: instead it generates the **/boot/grub/grub.cfg** file with the **grub2-mkconfig** command. This utility will parse the scripts in the **/etc/grub.d** directory and the **/etc/default/grub** settings file to define your setup.
|
||||
|
||||
Graphical boot repair
|
||||
|
||||
A vast majority of Grub 2 issues can easily be resolved with the touch of a button thanks to the Boot Repair app. This nifty little application has an intuitive user interface and can scan and comprehend various kinds of disk layouts and partitioning schemes, and can sniff out and correctly identify operating system installations inside them. The utility works on traditional computers with a Master Boot Record (MBR) as well as the newer UEFI computers with the UID Partition Table (GPT) layout.
|
||||
|
||||
The easiest way to use Boot Repair is to install it inside a Live Ubuntu session. Fire up an Ubuntu Live distro on a machine with a broken bootloader and install Boot Repair by first adding its PPA repository with
|
||||
|
||||
sudo add-apt-repository ppa:yannubuntu/Boot Repair
|
||||
|
||||
Then refresh the list of repositories with
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
before installing the app with
|
||||
|
||||
sudo apt-get install -y Boot Repair
|
||||
|
||||
Fire up the tool once it’s installed. The app will scan your hard disk before displaying its interface, which is made up of a couple of buttons. To follow the advice of the tool, simply press the Recommended Repair button, which should fix most broken bootloaders. After it’s restored your bootloader, the tool also spits out a small URL which you should note. The URL contains a detailed summary of your disks, including your partitions along with the contents of important Grub 2 files including **/etc/default/grub** and **boot/grub/grub.cfg**. If the tool hasn’t been able to fix your bootloader, you can share the URL on your distro’s forum boards to allow others to understand your disk layout and offer suggestions.
|
||||
|
||||
|
||||
|
||||
**Boot Repair also lets you customise Grub 2’s options.**
|
||||
|
||||
#### Bootloader bailout ####
|
||||
|
||||
Grub 2 boot problems can leave the system in several states. The text on the display where you’d expect the bootloader menu gives an indication of the current state of the system. If the system stops booting at the **grub>** prompt, it means the Grub 2 modules were loaded but it couldn’t find the **grub.cfg** file. This is the full Grub 2 command shell and you can do quite a bit here to help yourself. If you see the **grub rescue>** prompt, it means that the bootloader couldn’t find the Grub 2 modules nor could it find any of your boot files. However, if your screen just displays the word ‘GRUB’, it means the bootloader has failed to find even the most basic information that’s usually contained in the Master Boot Record.
|
||||
|
||||
You can correct these Grub failures either by using a live CD or from Grub 2’s command shell. If you’re lucky and your bootloader drops you at the **grub>** prompt, you have the power of the Grub 2 shell at your disposal to correct any errors.
|
||||
|
||||
The next few commands work with both **grub>** and **grub rescue>**. The **set pager=1** command invokes the pager, which prevents text from scrolling off the screen. You can also use the **ls** command which lists all partitions that Grub sees, like this:
|
||||
|
||||
grub> ls
|
||||
(hd0) (hd0,msdos5) (hd0,msdos6) (hd1,msdos1)
|
||||
|
||||
As you can see, the command also lists the partition table scheme along with the partitions.
|
||||
|
||||
You can also use the **ls** command on each partition to find your root filesystem:
|
||||
|
||||
grub> ls (hd0,5)/
|
||||
lost+found/ var/ etc/ media/ bin/ initrd.gz
|
||||
boot/ dev/ home/ selinux/ srv/ tmp/ vmlinuz
|
||||
|
||||
You can drop the **msdos** bit from the name of the partition. Also, if you miss the trailing slash and instead say **ls (hd0,5)** you’ll get information about the partition including its filesystem type, total size, and last modification time. If you have multiple partitions, read the contents of the **/etc/issue** file with the **cat** command to identify the distro, such as **cat (hd0,5)/etc/issue**.
|
||||
|
||||
Assuming you find the root filesystem you’re looking for inside **(hd0,5)**, make sure that it contains the /**boot/grub** directory and the Linux kernel image you wish to boot into, such as **vmlinuz-3.13.0-24-generic**. Now type the following:
|
||||
|
||||
grub> set root=(hd0,5)
|
||||
grub> linux /boot/vmlinuz-3.13.0-24-generic root=/dev/sda5
|
||||
grub> initrd /boot/initrd.img-3.13.0-24-generic
|
||||
|
||||
The first command points Grub to the partition housing the distro we wish to boot into. The second command then tells Grub the location of the kernel image inside the partition as well as the location of the root filesystem. The final line sets the location of the initial ramdisk file. You can use tab autocompletion to fill in the name of the kernel and the initrd, which will save you a lot of time and effort.
|
||||
|
||||
Once you’ve keyed these in, type **boot** at the next **grub>** prompt and Grub will boot into the specified operating system.
|
||||
|
||||
Things are a little different if you’re at the **grub rescue>** prompt. Since the bootloader hasn’t been able to find and load any of the required modules, you’ll have to insert them manually:
|
||||
|
||||
grub rescue> set root=(hd0,5)
|
||||
grub rescue> insmod (hd0,5)/boot/grub/normal.mod
|
||||
grub rescue> normal
|
||||
grub> insmod linux
|
||||
|
||||
As you can see, just like before, after we use the **ls** command to hunt down the Linux partition, we mark it with the **set** command. We then insert the **normal** module, which when activated will return us to the standard **grub>** mode. The next command then inserts the linux module in case it hasn’t been loaded. Once this module has been loaded you can proceed to point the boot loader to the kernel image and initrd files just as before and round off the procedure with the **boot** command to bring up the distro.
|
||||
|
||||
Once you’ve successfully booted into the distro, don’t forget to regenerate a new configuration file for Grub with the
|
||||
|
||||
grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
command. You’ll also have to install a copy of the bootloader into the MBR with the
|
||||
|
||||
sudo grub2-install /dev/sda
|
||||
|
||||
command.
|
||||
|
||||

|
||||
|
||||
**To disable a script under the /etc/grub.d, all you need to do is remove the executable bit, for example with chmod -x /etc/grub.d/20_memtest86+ which will remove the ‘Memory Test’ option from the menu.**
|
||||
|
||||
### Grub 2 and UEFI ###
|
||||
|
||||
UEFI-enabled machines (more or less, any machine sold in the last couple of years) have added another layer of complexity to debugging a broken **Grub 2** bootloader. While the procedure for restoring a **Grub 2** install on a UEFI machine isn’t much different than it is on a non-UEFI machine, the newer firmware handles things differently, which results in mixed restoration results.
|
||||
|
||||
On a UEFI-based system, you do not install anything in the MBR. Instead you install a Linux EFI bootloader in the EFI System Partition (ESP) and set it as the EFI’s default boot program using a tool such as **efibootmgr** for Linux, or **bcdedit** for Windows.
|
||||
|
||||
As things stand now, the Grub 2 bootloader should be installed properly when installing any major desktop Linux distro, which will happily coexist with Windows 8. However, if you end up with a broken bootloader, you can restore the machine with a live distro. When you boot the live medium, make sure you boot it in the UEFI mode. The computer’s boot menu will have two boot options for each removable drive – a vanilla option and an option tagged with UEFI. Use the latter to expose the EFI variables in **/sys/firmware/efi/**.
|
||||
|
||||
From the live environment, mount the root filesystem of the broken installation as mentioned in the tutorial. You’ll also have to mount the ESP partition. Assuming it’s **/dev/sda1**, you can mount it with
|
||||
|
||||
sudo mount /dev/sda1 /mnt/boot/efi
|
||||
|
||||
Then load the **efivars** module with **modprobe efivars** before chrooting into the installed distribution as shown in the tutorial.
|
||||
|
||||
Here on, if you’re using Fedora, reinstall the bootloader with the
|
||||
|
||||
yum reinstall grub2-efi shim
|
||||
|
||||
command followed by
|
||||
|
||||
grub2-mkconfig -o /boot/grub2/grub.cfg
|
||||
|
||||
to generate the new configuration file. Ubuntu users can do this with
|
||||
|
||||
apt-get install --reinstall grub-efi-amd64
|
||||
|
||||
With the bootloader in place, exit chroot, unmount all partitions and reboot to the Grub 2 menu.
|
||||
|
||||
#### Dude, where’s my Grub? ####
|
||||
|
||||
The best thing about Grub 2 is that you can reinstall it whenever you want. So if you lose the Grub 2 bootloader, say when another OS like Windows replaces it with its own bootloader, you can restore Grub within a few steps with the help of a live distro. Assuming you’ve installed a distro on **/dev/sda5**, you can reinstall Grub by first creating a mount directory for the distro with
|
||||
|
||||
sudo mkdir -p /mnt/distro
|
||||
|
||||
and then mounting the partition with
|
||||
|
||||
mount /dev/sda5 /mnt/distro
|
||||
|
||||
You can then reinstall Grub with
|
||||
|
||||
grub2-install --root-directory=/mnt/distro /dev/sda
|
||||
|
||||
This command will rewrite the MBR information on the **/dev/sda** device, point to the current Linux installation and rewrite some Grub 2 files such as **grubenv** and **device.map**.
|
||||
|
||||
Another common issue pops up on computers with multiple distros. When you install a new Linux distro, its bootloader should pick up the already installed distros. In case it doesn’t, just boot into the newly installed distro and run
|
||||
|
||||
grub2-mkconfig
|
||||
|
||||
Before running the command, make sure that the root partitions of the distros missing from the boot menu are mounted. If the distro you wish to add has **/root** and **/home** on separate partitions, only mount the partition that contains /root, before running the **grub2-mkconfig** command.
|
||||
|
||||
While Grub 2 will be able to pick most distros, trying to add a Fedora installation from within Ubuntu requires one extra step. If you’ve installed Fedora with its default settings, the distro’s installer would have created LVM partitions. In this case, you’ll first have to install the **lvm2** driver using the distro’s package management system, such as with
|
||||
|
||||
sudo apt-get install lvm2
|
||||
|
||||
before Grub 2’s **os-prober** script can find and add Fedora to the boot menu.
|
||||
|
||||
### Common user settings ###
|
||||
|
||||
Grub 2 has lots of configuration variables. Here are some of the common ones that you’re most likely to modify in the **/etc/default/grub** file. The **GRUB_DEFAULT** variable specifies the default boot entry. It will accept a numeric value such as 0, which denotes the first entry, or “saved” which will point it to the selected option from the previous boot. The **GRUB_TIMEOUT** variable specifies the delay before booting the default menu entry and the **GRUB_CMDLINE_LINUX** variable lists the parameters that are passed on the kernel command line for all Linux menu entries.
|
||||
|
||||
If the **GRUB_DISABLE_RECOVERY** variable is set to **true**, the recovery mode menu entries will not be generated. These entries boot the distro into single-user mode from where you can repair your system with command line tools. Also useful is the **GRUB_GFXMODE** variable, which specifies the resolution of the text shown in the menu. The variable can take any value supported by your graphics card.
|
||||
|
||||
|
||||
|
||||
**Grub 2 has a command line, which you can invoke by pressing C at the bootloader menu.**
|
||||
|
||||
#### Thorough fix ####
|
||||
|
||||
If the **grub2-install** command didn’t work for you, and you still can’t boot into Linux, you’ll need to completely reinstall and reconfigure the bootloader. For this task, we’ll use the venerable **chroot** utility to change the run environment from that of the live CD to the Linux install we want to recover. You can use any Linux live CD for this purpose as long as it has the **chroot** tool. However, make sure the live medium is for the same architecture as the architecture of the installation on the hard disk. So if you wish to **chroot** to a 64-bit installation you must use an amd64 live distro.
|
||||
|
||||
After you’ve booted the live distro, the first order of business is to check the partitions on the machine. Use **fdisk -l** to list all the partitions on the disk and make note of the partition that holds the Grub 2 installation that you want to fix.
|
||||
|
||||
Let’s assume we wish to restore the bootloader from the distro installed in **/dev/sda5**. Fire up a terminal and mount it with:
|
||||
|
||||
sudo mount /dev/sda5 /mnt
|
||||
|
||||
Now you’ll have to bind the directories that the Grub 2 bootloader needs access to in order to detect other operating systems:
|
||||
|
||||
$ sudo mount --bind /dev /mnt/dev
|
||||
$ sudo mount --bind /dev/pts /mnt/dev/pts
|
||||
$ sudo mount --bind /proc /mnt/proc
|
||||
$ sudo mount --bind /sys /mnt/sys
|
||||
|
||||
We’re now all set to leave the live environment and enter into the distro installed inside the **/dev/sda5** partition via **chroot**:
|
||||
|
||||
$ sudo chroot /mnt /bin/bash
|
||||
|
||||
You’re now all set to install, check, and update Grub. Just like before, use the
|
||||
|
||||
sudo grub2-install /dev/sda
|
||||
|
||||
command to reinstall the bootloader. Since the **grub2-install** command doesn’t touch the **grub.cfg** file, we’ll have to create it manually with
|
||||
|
||||
sudo grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
That should do the trick. You now have a fresh copy of Grub 2 with a list of all the operating systems and distros installed on your machine. Before you can restart the computer, you’ll have to exit the chrooted system and unmount all the partitions in the following order:
|
||||
|
||||
$ exit
|
||||
$ sudo umount /mnt/sys
|
||||
$ sudo umount /mnt/proc
|
||||
$ sudo umount /mnt/dev/pts
|
||||
$ sudo umount /mnt/dev
|
||||
$ sudo umount /mnt
|
||||
|
||||
You can now safely reboot the machine, which should be back under Grub 2’s control, and the bootloader under yours!
|
||||
|
||||
### Add custom entries ###
|
||||
|
||||
If you wish to add an entry to the bootloader menu, you should add a boot stanza to the **40_custom** script. You can, for example, use it to display an entry to boot a Linux distro installed on a removable USB drive. Assuming your USB drive is **sdb1**, and the vmlinuz kernel image and the initrd files are under the root (/) directory, add the following to the **40_custom** file:
|
||||
|
||||
menuentry “Linux on USB” {
|
||||
set root=(hd1,1)
|
||||
linux /vmlinuz root=/dev/sdb1 ro quiet splash
|
||||
initrd /initrd.img
|
||||
}
|
||||
|
||||
For more accurate results, instead of device and partition names you can use their UUIDs, such as
|
||||
|
||||
set root=UUID=54f22dd7-eabe
|
||||
|
||||
Use
|
||||
|
||||
sudo blkid
|
||||
|
||||
to find the UUIDs of all the connected drives and partitions. You can also add entries for any distros on your disk that weren’t picked up by the os-prober script, as long as you know where the distro’s installed and the location of its kernel and initrd image files.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxvoice.com/grub-2-heal-your-bootloader/
|
||||
|
||||
作者:[Mayank Sharma][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxvoice.com/author/mayank/
|
||||
@ -0,0 +1,110 @@
|
||||
translating by fw8899
|
||||
What is good stock portfolio management software on Linux
|
||||
================================================================================
|
||||
If you are investing in the stock market, you probably understand the importance of a sound portfolio management plan. The goal of portfolio management is to come up with the best investment plan tailored for you, considering your risk tolerance, time horizon and financial goals. Given its importance, no wonder there are no shortage of commercial portfolio management apps and stock market monitoring software, each touting various sophisticated portfolio performance tracking and reporting capabilities.
|
||||
|
||||
For those of you Linux aficionados who are looking for a **good open-source portfolio management tool** to manage and track your stock portfolio on Linux, I would highly recommend a Java-based portfolio manager called [JStock][1]. If you are not a big Java fan, you might be turned off by the fact that JStock runs on a heavyweight JVM. At the same time I am sure many people will appreciate the fact that JStock is instantly accessible on every Linux platform with JRE installed. No hoops to jump through to make it work on your Linux environment.
|
||||
|
||||
The day is gone when "open-source" means "cheap" or "subpar". Considering that JStock is just a one-man job, JStock is impressively packed with many useful features as a portfolio management tool, and all that credit goes to Yan Cheng Cheok! For example, JStock supports price monitoring via watchlists, multiple portfolios, custom/built-in stock indicators and scanners, support for 27 different stock markets and cross-platform cloud backup/restore. JStock is available on multiple platforms (Linux, OS X, Android and Windows), and you can save and restore your JStock portfolios seamlessly across different platforms via cloud backup/restore.
|
||||
|
||||
Sounds pretty neat, huh? Now I am going to show you how to install and use JStock in more detail.
|
||||
|
||||
### Install JStock on Linux ###
|
||||
|
||||
Since JStock is written in Java, you must [install JRE][2] to run it. Note that JStock requires JRE 1.7 or higher. If your JRE version does not meet this requirement, JStock will fail with the following error.
|
||||
|
||||
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
|
||||
|
||||
Once you install JRE on your Linux, download the latest JStock release from the official website, and launch it as follows.
|
||||
|
||||
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
|
||||
$ unzip jstock-1.0.7.13-bin.zip
|
||||
$ cd jstock
|
||||
$ chmod +x jstock.sh
|
||||
$ ./jstock.sh
|
||||
|
||||
In the rest of the tutorial, let me demonstrate several useful features of JStock.
|
||||
|
||||
### Monitor Stock Price Movements via Watchlist ###
|
||||
|
||||
On JStock you can monitor stock price movement and automatically get notified by creating one or more watchlists. In each watchlist, you can add multiple stocks you are interested in. Then add your alert thresholds under "Fall Below" and "Rise Above" columns, which correspond to minimum and maximum stock prices you want to set, respectively.
|
||||
|
||||
|
||||
|
||||
For example, if you set minimum/maximum prices of AAPL stock to $102 and $115.50, you will be alerted via desktop notifications if the stock price goes below $102 or moves higher than $115.50 at any time.
|
||||
|
||||
You can also enable email alert option, so that you will instead receive email notifications for such price events. To enable email alerts, go to "Options" menu. Under "Alert" tab, turn on "Send message to email(s)" box, and enter your Gmail account. Once you go through Gmail authorization steps, JStock will start sending email alerts to that Gmail account (and optionally CC to any third-party email address).
|
||||
|
||||
|
||||
|
||||
### Manage Multiple Portfolios ###
|
||||
|
||||
JStock allows you to manage multiple portfolios. This feature is useful if you are using multiple stock brokers. You can create a separate portfolio for each broker and manage your buy/sell/dividend transactions on a per-broker basis. You can switch different portfolios by choosing a particular portfolio under "Portfolio" menu. The following screenshot shows a hypothetical portfolio.
|
||||
|
||||
|
||||
|
||||
Optionally you can enable broker fee option, so that you can enter any broker fees, stamp duty and clearing fees for each buy/sell transaction. If you are lazy, you can enable fee auto-calculation and enter fee schedules for each brokering firm from the option menu beforehand. Then JStock will automatically calculate and enter fees when you add transactions to your portfolio.
|
||||
|
||||
|
||||
|
||||
### Screen Stocks with Built-in/Custom Indicators ###
|
||||
|
||||
If you are doing any technical analysis on stocks, you may want to screen stocks based on various criteria (so-called "stock indicators"). For stock screening, JStock offers several [pre-built technical indicators][3] that capture upward/downward/reversal trends of individual stocks. The following is a list of available indicators.
|
||||
|
||||
- Moving Average Convergence Divergence (MACD)
|
||||
- Relative Strength Index (RSI)
|
||||
- Money Flow Index (MFI)
|
||||
- Commodity Channel Index (CCI)
|
||||
- Doji
|
||||
- Golden Cross, Death Cross
|
||||
- Top Gainers/Losers
|
||||
|
||||
To install any pre-built indicator, go to "Stock Indicator Editor" tab on JStock. Then click on "Install" button in the right-side panel. Choose "Install from JStock server" option, and then install any indicator(s) you want.
|
||||
|
||||

|
||||
|
||||
Once one or more indicators are installed, you can scan stocks using them. Go to "Stock Indicator Scanner" tab, click on "Scan" button at the bottom, and choose any indicator.
|
||||
|
||||

|
||||
|
||||
Once you select the stocks to scan (e.g., NYSE, NASDAQ), JStock will perform scan, and show a list of stocks captured by the indicator.
|
||||
|
||||

|
||||
|
||||
Besides pre-built indicators, you can also define custom indicator(s) on your own with a GUI-based indicator editor. The following example screens for stocks whose current price is less than or equal to its 60-day average price.
|
||||
|
||||

|
||||
|
||||
### Cloud Backup and Restore between Linux and Android JStock ###
|
||||
|
||||
Another nice feature of JStock is cloud backup and restore. JStock allows you to save and restore your portfolios/watchlists via Google Drive, and this features works seamlessly across different platforms (e.g., Linux and Android). For example, if you saved your JStock portfolios to Google Drive on Android, you can restore them on Linux version of JStock.
|
||||
|
||||

|
||||
|
||||
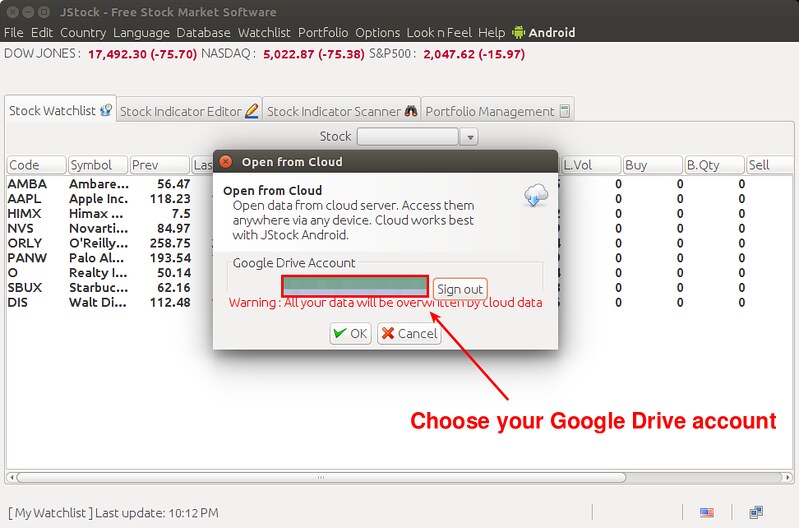
|
||||
|
||||
If you don't see your portfolios/watchlists after restoring from Google Drive, make sure that your country is correctly set under "Country" menu.
|
||||
|
||||
JStock Android free version is available from [Google Play store][4]. You will need to upgrade to premium version for one-time payment if you want to use its full features (e.g., cloud backup, alerts, charts). I think the premium version is definitely worth it.
|
||||
|
||||
|
||||
|
||||
As a final note, I should mention that its creator, Yan Cheng Cheok, is pretty active in JStock development, and quite responsive in addressing any bugs. Kudos to him!
|
||||
|
||||
What do you think of JStock as portfolio tracking software?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/stock-portfolio-management-software-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://jstock.org/
|
||||
[2]:http://ask.xmodulo.com/install-java-runtime-linux.html
|
||||
[3]:http://jstock.org/ma_indicator.html
|
||||
[4]:https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui
|
||||
@ -1,3 +1,4 @@
|
||||
Being translated by hittlle......
|
||||
Part 10 - LFCS: Understanding & Learning Basic Shell Scripting and Linux Filesystem Troubleshooting
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new initiative whose purpose is to allow individuals everywhere (and anywhere) to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||
@ -1,387 +0,0 @@
|
||||
Part 2 - LFCS: How to Install and Use vi/vim as a Full Text Editor
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification in order to help individuals from all over the world to verify they are capable of doing basic to intermediate system administration tasks on Linux systems: system support, first-hand troubleshooting and maintenance, plus intelligent decision-making to know when it’s time to raise issues to upper support teams.
|
||||
|
||||

|
||||
|
||||
Learning VI Editor in Linux
|
||||
|
||||
Please take a look at the below video that explains The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 2 of a 10-tutorial series, here in this part, we will cover the basic file editing operations and understanding modes in vi/m editor, that are required for the LFCS certification exam.
|
||||
|
||||
### Perform Basic File Editing Operations Using vi/m ###
|
||||
|
||||
Vi was the first full-screen text editor written for Unix. Although it was intended to be small and simple, it can be a bit challenging for people used exclusively to GUI text editors, such as NotePad++, or gedit, to name a few examples.
|
||||
|
||||
To use Vi, we must first understand the 3 modes in which this powerful program operates, in order to begin learning later about the its powerful text-editing procedures.
|
||||
|
||||
Please note that most modern Linux distributions ship with a variant of vi known as vim (“Vi improved”), which supports more features than the original vi does. For that reason, throughout this tutorial we will use vi and vim interchangeably.
|
||||
|
||||
If your distribution does not have vim installed, you can install it as follows.
|
||||
|
||||
- Ubuntu and derivatives: aptitude update && aptitude install vim
|
||||
- Red Hat-based distributions: yum update && yum install vim
|
||||
- openSUSE: zypper update && zypper install vim
|
||||
|
||||
### Why should I want to learn vi? ###
|
||||
|
||||
There are at least 2 good reasons to learn vi.
|
||||
|
||||
1. vi is always available (no matter what distribution you’re using) since it is required by POSIX.
|
||||
|
||||
2. vi does not consume a considerable amount of system resources and allows us to perform any imaginable tasks without lifting our fingers from the keyboard.
|
||||
|
||||
In addition, vi has a very extensive built-in manual, which can be launched using the :help command right after the program is started. This built-in manual contains more information than vi/m’s man page.
|
||||
|
||||

|
||||
|
||||
vi Man Pages
|
||||
|
||||
#### Launching vi ####
|
||||
|
||||
To launch vi, type vi in your command prompt.
|
||||
|
||||

|
||||
|
||||
Start vi Editor
|
||||
|
||||
Then press i to enter Insert mode, and you can start typing. Another way to launch vi/m is.
|
||||
|
||||
# vi filename
|
||||
|
||||
Which will open a new buffer (more on buffers later) named filename, which you can later save to disk.
|
||||
|
||||
#### Understanding Vi modes ####
|
||||
|
||||
1. In command mode, vi allows the user to navigate around the file and enter vi commands, which are brief, case-sensitive combinations of one or more letters. Almost all of them can be prefixed with a number to repeat the command that number of times.
|
||||
|
||||
For example, yy (or Y) copies the entire current line, whereas 3yy (or 3Y) copies the entire current line along with the two next lines (3 lines in total). We can always enter command mode (regardless of the mode we’re working on) by pressing the Esc key. The fact that in command mode the keyboard keys are interpreted as commands instead of text tends to be confusing to beginners.
|
||||
|
||||
2. In ex mode, we can manipulate files (including saving a current file and running outside programs). To enter this mode, we must type a colon (:) from command mode, directly followed by the name of the ex-mode command that needs to be used. After that, vi returns automatically to command mode.
|
||||
|
||||
3. In insert mode (the letter i is commonly used to enter this mode), we simply enter text. Most keystrokes result in text appearing on the screen (one important exception is the Esc key, which exits insert mode and returns to command mode).
|
||||
|
||||

|
||||
|
||||
vi Insert Mode
|
||||
|
||||
#### Vi Commands ####
|
||||
|
||||
The following table shows a list of commonly used vi commands. File edition commands can be enforced by appending the exclamation sign to the command (for example, <b.:q! enforces quitting without saving).
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="290">
|
||||
</colgroup>
|
||||
<colgroup width="781">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#999999" height="19" align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Key command</span></b></td>
|
||||
<td bgcolor="#999999" align="LEFT" style="border: 1px solid #000000;"><b><span style="font-size: small;"> Description</span></b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> h or left arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go one character to the left</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> j or down arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go down one line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> k or up arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go up one line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> l (lowercase L) or right arrow</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go one character to the right</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> H</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the top of the screen</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> L</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the bottom of the screen</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> G</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the end of the file</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> w</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Move one word to the right</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> b</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Move one word to the left</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> 0 (zero)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the beginning of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> ^</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the first nonblank character on the current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> $</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go to the end of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> Ctrl-B</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go back one screen</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> Ctrl-F</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Go forward one screen</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> i</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> I (uppercase i)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert at the beginning of the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> J (uppercase j)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Join current line with the next one (move next line up)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> a</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Append after the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> o (lowercase O)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Creates a blank line after the current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> O (uppercase o)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Creates a blank line before the current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> r</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Replace the character at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> R</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Overwrite at the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> x</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Delete the character at the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> X</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Delete the character immediately before (to the left) of the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> dd</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Cut (for later pasting) the entire current line</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> D</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Cut from the current cursor position to the end of the line (this command is equivalent to d$)</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> yX</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Give a movement command X, copy (yank) the appropriate number of characters, words, or lines from the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> yy or Y</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Yank (copy) the entire current line</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Paste after (next line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> P</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Paste before (previous line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> . (period)</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Repeat the last command</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> u</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Undo the last command</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> U</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Undo the last command in the last line. This will work as long as the cursor is still on the line.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> n</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Find the next match in a search</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> N</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Find the previous match in a search</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :n</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Next file; when multiple files are specified for editing, this commands loads the next file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :e file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Load file in place of the current file.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :r file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Insert the contents of file after (next line) the current cursor position</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :q</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Quit without saving changes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :w file</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Write the current buffer to file. To append to an existing file, use :w >> file.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000000;"><span style="font-family: Courier New;"> :wq</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Write the contents of the current file and quit. Equivalent to x! and ZZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000000;"> :r! command</td>
|
||||
<td align="LEFT" style="border: 1px solid #000000;"> Execute command and insert output after (next line) the current cursor position.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Vi Options ####
|
||||
|
||||
The following options can come in handy while running vim (we need to add them in our ~/.vimrc file).
|
||||
|
||||
# echo set number >> ~/.vimrc
|
||||
# echo syntax on >> ~/.vimrc
|
||||
# echo set tabstop=4 >> ~/.vimrc
|
||||
# echo set autoindent >> ~/.vimrc
|
||||
|
||||
|
||||
|
||||
vi Editor Options
|
||||
|
||||
- set number shows line numbers when vi opens an existing or a new file.
|
||||
- syntax on turns on syntax highlighting (for multiple file extensions) in order to make code and config files more readable.
|
||||
- set tabstop=4 sets the tab size to 4 spaces (default value is 8).
|
||||
- set autoindent carries over previous indent to the next line.
|
||||
|
||||
#### Search and replace ####
|
||||
|
||||
vi has the ability to move the cursor to a certain location (on a single line or over an entire file) based on searches. It can also perform text replacements with or without confirmation from the user.
|
||||
|
||||
a). Searching within a line: the f command searches a line and moves the cursor to the next occurrence of a specified character in the current line.
|
||||
|
||||
For example, the command fh would move the cursor to the next instance of the letter h within the current line. Note that neither the letter f nor the character you’re searching for will appear anywhere on your screen, but the character will be highlighted after you press Enter.
|
||||
|
||||
For example, this is what I get after pressing f4 in command mode.
|
||||
|
||||

|
||||
|
||||
Search String in Vi
|
||||
|
||||
b). Searching an entire file: use the / command, followed by the word or phrase to be searched for. A search may be repeated using the previous search string with the n command, or the next one (using the N command). This is the result of typing /Jane in command mode.
|
||||
|
||||
|
||||
|
||||
Vi Search String in File
|
||||
|
||||
c). vi uses a command (similar to sed’s) to perform substitution operations over a range of lines or an entire file. To change the word “old” to “young” for the entire file, we must enter the following command.
|
||||
|
||||
:%s/old/young/g
|
||||
|
||||
**Notice**: The colon at the beginning of the command.
|
||||
|
||||
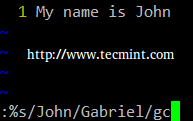
|
||||
|
||||
Vi Search and Replace
|
||||
|
||||
The colon (:) starts the ex command, s in this case (for substitution), % is a shortcut meaning from the first line to the last line (the range can also be specified as n,m which means “from line n to line m”), old is the search pattern, while young is the replacement text, and g indicates that the substitution should be performed on every occurrence of the search string in the file.
|
||||
|
||||
Alternatively, a c can be added to the end of the command to ask for confirmation before performing any substitution.
|
||||
|
||||
:%s/old/young/gc
|
||||
|
||||
Before replacing the original text with the new one, vi/m will present us with the following message.
|
||||
|
||||
|
||||
|
||||
Replace String in Vi
|
||||
|
||||
- y: perform the substitution (yes)
|
||||
- n: skip this occurrence and go to the next one (no)
|
||||
- a: perform the substitution in this and all subsequent instances of the pattern.
|
||||
- q or Esc: quit substituting.
|
||||
- l (lowercase L): perform this substitution and quit (last).
|
||||
- Ctrl-e, Ctrl-y: Scroll down and up, respectively, to view the context of the proposed substitution.
|
||||
|
||||
#### Editing Multiple Files at a Time ####
|
||||
|
||||
Let’s type vim file1 file2 file3 in our command prompt.
|
||||
|
||||
# vim file1 file2 file3
|
||||
|
||||
First, vim will open file1. To switch to the next file (file2), we need to use the :n command. When we want to return to the previous file, :N will do the job.
|
||||
|
||||
In order to switch from file1 to file3.
|
||||
|
||||
a). The :buffers command will show a list of the file currently being edited.
|
||||
|
||||
:buffers
|
||||
|
||||
|
||||
|
||||
Edit Multiple Files
|
||||
|
||||
b). The command :buffer 3 (without the s at the end) will open file3 for editing.
|
||||
|
||||
In the image above, a pound sign (#) indicates that the file is currently open but in the background, while %a marks the file that is currently being edited. On the other hand, a blank space after the file number (3 in the above example) indicates that the file has not yet been opened.
|
||||
|
||||
#### Temporary vi buffers ####
|
||||
|
||||
To copy a couple of consecutive lines (let’s say 4, for example) into a temporary buffer named a (not associated with a file) and place those lines in another part of the file later in the current vi section, we need to…
|
||||
|
||||
1. Press the ESC key to be sure we are in vi Command mode.
|
||||
|
||||
2. Place the cursor on the first line of the text we wish to copy.
|
||||
|
||||
3. Type “a4yy to copy the current line, along with the 3 subsequent lines, into a buffer named a. We can continue editing our file – we do not need to insert the copied lines immediately.
|
||||
|
||||
4. When we reach the location for the copied lines, use “a before the p or P commands to insert the lines copied into the buffer named a:
|
||||
|
||||
- Type “ap to insert the lines copied into buffer a after the current line on which the cursor is resting.
|
||||
- Type “aP to insert the lines copied into buffer a before the current line.
|
||||
|
||||
If we wish, we can repeat the above steps to insert the contents of buffer a in multiple places in our file. A temporary buffer, as the one in this section, is disposed when the current window is closed.
|
||||
|
||||
### Summary ###
|
||||
|
||||
As we have seen, vi/m is a powerful and versatile text editor for the CLI. Feel free to share your own tricks and comments below.
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][1]
|
||||
- [Why get a Linux Foundation Certification?][2]
|
||||
- [Register for the LFCS exam][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/vi-editor-usage/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[3]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,382 +0,0 @@
|
||||
Part 3 - LFCS: How to Archive/Compress Files & Directories, Setting File Attributes and Finding Files in Linux
|
||||
================================================================================
|
||||
Recently, the Linux Foundation started the LFCS (Linux Foundation Certified Sysadmin) certification, a brand new program whose purpose is allowing individuals from all corners of the globe to have access to an exam, which if approved, certifies that the person is knowledgeable in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-level troubleshooting and analysis, plus the ability to decide when to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 3
|
||||
|
||||
Please watch the below video that gives the idea about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 3 of a 10-tutorial series, here in this part, we will cover how to archive/compress files and directories, set file attributes, and find files on the filesystem, that are required for the LFCS certification exam.
|
||||
|
||||
### Archiving and Compression Tools ###
|
||||
|
||||
A file archiving tool groups a set of files into a single standalone file that we can backup to several types of media, transfer across a network, or send via email. The most frequently used archiving utility in Linux is tar. When an archiving utility is used along with a compression tool, it allows to reduce the disk size that is needed to store the same files and information.
|
||||
|
||||
#### The tar utility ####
|
||||
|
||||
tar bundles a group of files together into a single archive (commonly called a tar file or tarball). The name originally stood for tape archiver, but we must note that we can use this tool to archive data to any kind of writeable media (not only to tapes). Tar is normally used with a compression tool such as gzip, bzip2, or xz to produce a compressed tarball.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# tar [options] [pathname ...]
|
||||
|
||||
Where … represents the expression used to specify which files should be acted upon.
|
||||
|
||||
#### Most commonly used tar commands ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="150">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="351">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b>Long option</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>Abbreviation</b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b>Description</b></td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –create</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> c</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Creates a tar archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –concatenate</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> A</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends tar files to an archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –append</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> r</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends files to the end of an archive</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –update</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> u</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Appends files newer than copy in archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –diff or –compare</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> d</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Find differences between archive and file system</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"> –file archive</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> f</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Use archive file or device ARCHIVE</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –list</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> t</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Lists the contents of a tarball</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –extract or –get</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> x</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Extracts files from an archive</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
#### Normally used operation modifiers ####
|
||||
|
||||
注:表格
|
||||
<table cellspacing="0" border="0">
|
||||
<colgroup width="162">
|
||||
</colgroup>
|
||||
<colgroup width="109">
|
||||
</colgroup>
|
||||
<colgroup width="743">
|
||||
</colgroup>
|
||||
<tbody>
|
||||
<tr class="alt">
|
||||
<td bgcolor="#999999" height="18" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Long option</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Abbreviation</span></b></td>
|
||||
<td bgcolor="#999999" align="CENTER" style="border: 1px solid #000001;"><b><span style="font-family: Droid Sans;">Description</span></b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –directory dir</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> C</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Changes to directory dir before performing operations</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –same-permissions</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> p</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Preserves original permissions</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="38" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verbose</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> v</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Lists all files read or extracted. When this flag is used along with –list, the file sizes, ownership, and time stamps are displayed.</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –verify</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> W</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Verifies the archive after writing it</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude file</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> —</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Excludes file from the archive</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="18" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –exclude=pattern</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> X</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Droid Sans;"> Exclude files, given as a PATTERN</span></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"> –gzip or –gunzip</td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> z</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through gzip</td>
|
||||
</tr>
|
||||
<tr class="alt">
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –bzip2</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> j</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through bzip2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td height="20" align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> –xz</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"><span style="font-family: Consolas;"> J</span></td>
|
||||
<td align="LEFT" style="border: 1px solid #000001;"> Processes an archive through xz</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
Gzip is the oldest compression tool and provides the least compression, while bzip2 provides improved compression. In addition, xz is the newest but (usually) provides the best compression. This advantages of best compression come at a price: the time it takes to complete the operation, and system resources used during the process.
|
||||
|
||||
Normally, tar files compressed with these utilities have .gz, .bz2, or .xz extensions, respectively. In the following examples we will be using these files: file1, file2, file3, file4, and file5.
|
||||
|
||||
**Grouping and compressing with gzip, bzip2 and xz**
|
||||
|
||||
Group all the files in the current working directory and compress the resulting bundle with gzip, bzip2, and xz (please note the use of a regular expression to specify which files should be included in the bundle – this is to prevent the archiving tool to group the tarballs created in previous steps).
|
||||
|
||||
# tar czf myfiles.tar.gz file[0-9]
|
||||
# tar cjf myfiles.tar.bz2 file[0-9]
|
||||
# tar cJf myfile.tar.xz file[0-9]
|
||||
|
||||

|
||||
|
||||
Compress Multiple Files
|
||||
|
||||
**Listing the contents of a tarball and updating / appending files to the bundle**
|
||||
|
||||
List the contents of a tarball and display the same information as a long directory listing. Note that update or append operations cannot be applied to compressed files directly (if you need to update or append a file to a compressed tarball, you need to uncompress the tar file and update / append to it, then compress again).
|
||||
|
||||
# tar tvf [tarball]
|
||||
|
||||
|
||||
|
||||
List Archive Content
|
||||
|
||||
Run any of the following commands:
|
||||
|
||||
# gzip -d myfiles.tar.gz [#1]
|
||||
# bzip2 -d myfiles.tar.bz2 [#2]
|
||||
# xz -d myfiles.tar.xz [#3]
|
||||
|
||||
Then
|
||||
|
||||
# tar --delete --file myfiles.tar file4 (deletes the file inside the tarball)
|
||||
# tar --update --file myfiles.tar file4 (adds the updated file)
|
||||
|
||||
and
|
||||
|
||||
# gzip myfiles.tar [ if you choose #1 above ]
|
||||
# bzip2 myfiles.tar [ if you choose #2 above ]
|
||||
# xz myfiles.tar [ if you choose #3 above ]
|
||||
|
||||
Finally,
|
||||
|
||||
# tar tvf [tarball] #again
|
||||
|
||||
and compare the modification date and time of file4 with the same information as shown earlier.
|
||||
|
||||
**Excluding file types**
|
||||
|
||||
Suppose you want to perform a backup of user’s home directories. A good sysadmin practice would be (may also be specified by company policies) to exclude all video and audio files from backups.
|
||||
|
||||
Maybe your first approach would be to exclude from the backup all files with an .mp3 or .mp4 extension (or other extensions). What if you have a clever user who can change the extension to .txt or .bkp, your approach won’t do you much good. In order to detect an audio or video file, you need to check its file type with file. The following shell script will do the job.
|
||||
|
||||
#!/bin/bash
|
||||
# Pass the directory to backup as first argument.
|
||||
DIR=$1
|
||||
# Create the tarball and compress it. Exclude files with the MPEG string in its file type.
|
||||
# -If the file type contains the string mpeg, $? (the exit status of the most recently executed command) expands to 0, and the filename is redirected to the exclude option. Otherwise, it expands to 1.
|
||||
# -If $? equals 0, add the file to the list of files to be backed up.
|
||||
tar X <(for i in $DIR/*; do file $i | grep -i mpeg; if [ $? -eq 0 ]; then echo $i; fi;done) -cjf backupfile.tar.bz2 $DIR/*
|
||||
|
||||

|
||||
|
||||
Exclude Files in tar
|
||||
|
||||
**Restoring backups with tar preserving permissions**
|
||||
|
||||
You can then restore the backup to the original user’s home directory (user_restore in this example), preserving permissions, with the following command.
|
||||
|
||||
# tar xjf backupfile.tar.bz2 --directory user_restore --same-permissions
|
||||
|
||||

|
||||
|
||||
Restore Files from Archive
|
||||
|
||||
**Read Also:**
|
||||
|
||||
- [18 tar Command Examples in Linux][1]
|
||||
- [Dtrx – An Intelligent Archive Tool for Linux][2]
|
||||
|
||||
### Using find Command to Search for Files ###
|
||||
|
||||
The find command is used to search recursively through directory trees for files or directories that match certain characteristics, and can then either print the matching files or directories or perform other operations on the matches.
|
||||
|
||||
Normally, we will search by name, owner, group, type, permissions, date, and size.
|
||||
|
||||
#### Basic syntax: ####
|
||||
|
||||
# find [directory_to_search] [expression]
|
||||
|
||||
**Finding files recursively according to Size**
|
||||
|
||||
Find all files (-f) in the current directory (.) and 2 subdirectories below (-maxdepth 3 includes the current working directory and 2 levels down) whose size (-size) is greater than 2 MB.
|
||||
|
||||
# find . -maxdepth 3 -type f -size +2M
|
||||
|
||||
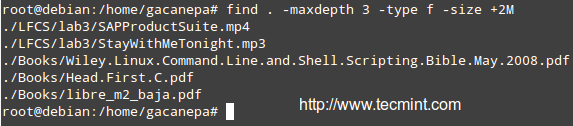
|
||||
|
||||
Find Files Based on Size
|
||||
|
||||
**Finding and deleting files that match a certain criteria**
|
||||
|
||||
Files with 777 permissions are sometimes considered an open door to external attackers. Either way, it is not safe to let anyone do anything with files. We will take a rather aggressive approach and delete them! (‘{}‘ + is used to “collect” the results of the search).
|
||||
|
||||
# find /home/user -perm 777 -exec rm '{}' +
|
||||
|
||||

|
||||
|
||||
Find Files with 777Permission
|
||||
|
||||
**Finding files per atime or mtime**
|
||||
|
||||
Search for configuration files in /etc that have been accessed (-atime) or modified (-mtime) more (+180) or less (-180) than 6 months ago or exactly 6 months ago (180).
|
||||
|
||||
Modify the following command as per the example below:
|
||||
|
||||
# find /etc -iname "*.conf" -mtime -180 -print
|
||||
|
||||

|
||||
|
||||
Find Modified Files
|
||||
|
||||
- Read Also: [35 Practical Examples of Linux ‘find’ Command][3]
|
||||
|
||||
### File Permissions and Basic Attributes ###
|
||||
|
||||
The first 10 characters in the output of ls -l are the file attributes. The first of these characters is used to indicate the file type:
|
||||
|
||||
- – : a regular file
|
||||
- -d : a directory
|
||||
- -l : a symbolic link
|
||||
- -c : a character device (which treats data as a stream of bytes, i.e. a terminal)
|
||||
- -b : a block device (which handles data in blocks, i.e. storage devices)
|
||||
|
||||
The next nine characters of the file attributes are called the file mode and represent the read (r), write (w), and execute (x) permissions of the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”).
|
||||
|
||||
Whereas the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run, while in a directory it allows the same to be cd’ed into it.
|
||||
|
||||
File permissions are changed with the chmod command, whose basic syntax is as follows:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
Where new_mode is either an octal number or an expression that specifies the new permissions.
|
||||
|
||||
The octal number can be converted from its binary equivalent, which is calculated from the desired file permissions for the owner, the group, and the world, as follows:
|
||||
|
||||
The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence equates to 0. For example:
|
||||
|
||||

|
||||
|
||||
File Permissions
|
||||
|
||||
To set the file’s permissions as above in octal form, type:
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
You can also set a file’s mode using an expression that indicates the owner’s rights with the letter u, the group owner’s rights with the letter g, and the rest with o. All of these “individuals” can be represented at the same time with the letter a. Permissions are granted (or revoked) with the + or – signs, respectively.
|
||||
|
||||
**Revoking execute permission for a shell script to all users**
|
||||
|
||||
As we explained earlier, we can revoke a certain permission prepending it with the minus sign and indicating whether it needs to be revoked for the owner, the group owner, or all users. The one-liner below can be interpreted as follows: Change mode for all (a) users, revoke (–) execute permission (x).
|
||||
|
||||
# chmod a-x backup.sh
|
||||
|
||||
Granting read, write, and execute permissions for a file to the owner and group owner, and read permissions for the world.
|
||||
|
||||
When we use a 3-digit octal number to set permissions for a file, the first digit indicates the permissions for the owner, the second digit for the group owner and the third digit for everyone else:
|
||||
|
||||
- Owner: (r=22 + w=21 + x=20 = 7)
|
||||
- Group owner: (r=22 + w=21 + x=20 = 7)
|
||||
- World: (r=22 + w=0 + x=0 = 4),
|
||||
|
||||
# chmod 774 myfile
|
||||
|
||||
In time, and with practice, you will be able to decide which method to change a file mode works best for you in each case. A long directory listing also shows the file’s owner and its group owner (which serve as a rudimentary yet effective access control to files in a system):
|
||||
|
||||

|
||||
|
||||
Linux File Listing
|
||||
|
||||
File ownership is changed with the chown command. The owner and the group owner can be changed at the same time or separately. Its basic syntax is as follows:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
Where at least user or group need to be present.
|
||||
|
||||
**Few Examples**
|
||||
|
||||
Changing the owner of a file to a certain user.
|
||||
|
||||
# chown gacanepa sent
|
||||
|
||||
Changing the owner and group of a file to an specific user:group pair.
|
||||
|
||||
# chown gacanepa:gacanepa TestFile
|
||||
|
||||
Changing only the group owner of a file to a certain group. Note the colon before the group’s name.
|
||||
|
||||
# chown :gacanepa email_body.txt
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
As a sysadmin, you need to know how to create and restore backups, how to find files in your system and change their attributes, along with a few tricks that can make your life easier and will prevent you from running into future issues.
|
||||
|
||||
I hope that the tips provided in the present article will help you to achieve that goal. Feel free to add your own tips and ideas in the comments section for the benefit of the community. Thanks in advance!
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][4]
|
||||
- [Why get a Linux Foundation Certification?][5]
|
||||
- [Register for the LFCS exam][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/18-tar-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/dtrx-an-intelligent-archive-extraction-tar-zip-cpio-rpm-deb-rar-tool-for-linux/
|
||||
[3]:http://www.tecmint.com/35-practical-examples-of-linux-find-command/
|
||||
[4]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[5]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[6]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,191 +0,0 @@
|
||||
Part 4 - LFCS: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
================================================================================
|
||||
Last August, the Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a shiny chance for system administrators to show, through a performance-based exam, that they can perform overall operational support of Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation – if needed – to other support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 4
|
||||
|
||||
Please aware that Linux Foundation certifications are precise, totally based on performance and available through an online portal anytime, anywhere. Thus, you no longer have to travel to a examination center to get the certifications you need to establish your skills and expertise.
|
||||
|
||||
Please watch the below video that explains The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 4 of a 10-tutorial series, here in this part, we will cover the Partitioning storage devices, Formatting filesystems and Configuring swap partition, that are required for the LFCS certification exam.
|
||||
|
||||
### Partitioning Storage Devices ###
|
||||
|
||||
Partitioning is a means to divide a single hard drive into one or more parts or “slices” called partitions. A partition is a section on a drive that is treated as an independent disk and which contains a single type of file system, whereas a partition table is an index that relates those physical sections of the hard drive to partition identifications.
|
||||
|
||||
In Linux, the traditional tool for managing MBR partitions (up to ~2009) in IBM PC compatible systems is fdisk. For GPT partitions (~2010 and later) we will use gdisk. Each of these tools can be invoked by typing its name followed by a device name (such as /dev/sdb).
|
||||
|
||||
#### Managing MBR Partitions with fdisk ####
|
||||
|
||||
We will cover fdisk first.
|
||||
|
||||
# fdisk /dev/sdb
|
||||
|
||||
A prompt appears asking for the next operation. If you are unsure, you can press the ‘m‘ key to display the help contents.
|
||||
|
||||

|
||||
|
||||
fdisk Help Menu
|
||||
|
||||
In the above image, the most frequently used options are highlighted. At any moment, you can press ‘p‘ to display the current partition table.
|
||||
|
||||

|
||||
|
||||
Show Partition Table
|
||||
|
||||
The Id column shows the partition type (or partition id) that has been assigned by fdisk to the partition. A partition type serves as an indicator of the file system, the partition contains or, in simple words, the way data will be accessed in that partition.
|
||||
|
||||
Please note that a comprehensive study of each partition type is out of the scope of this tutorial – as this series is focused on the LFCS exam, which is performance-based.
|
||||
|
||||
**Some of the options used by fdisk as follows:**
|
||||
|
||||
You can list all the partition types that can be managed by fdisk by pressing the ‘l‘ option (lowercase l).
|
||||
|
||||
Press ‘d‘ to delete an existing partition. If more than one partition is found in the drive, you will be asked which one should be deleted.
|
||||
|
||||
Enter the corresponding number, and then press ‘w‘ (write modifications to partition table) to apply changes.
|
||||
|
||||
In the following example, we will delete /dev/sdb2, and then print (p) the partition table to verify the modifications.
|
||||
|
||||

|
||||
|
||||
fdisk Command Options
|
||||
|
||||
Press ‘n‘ to create a new partition, then ‘p‘ to indicate it will be a primary partition. Finally, you can accept all the default values (in which case the partition will occupy all the available space), or specify a size as follows.
|
||||
|
||||

|
||||
|
||||
Create New Partition
|
||||
|
||||
If the partition Id that fdisk chose is not the right one for our setup, we can press ‘t‘ to change it.
|
||||
|
||||

|
||||
|
||||
Change Partition Name
|
||||
|
||||
When you’re done setting up the partitions, press ‘w‘ to commit the changes to disk.
|
||||
|
||||

|
||||
|
||||
Save Partition Changes
|
||||
|
||||
#### Managing GPT Partitions with gdisk ####
|
||||
|
||||
In the following example, we will use /dev/sdb.
|
||||
|
||||
# gdisk /dev/sdb
|
||||
|
||||
We must note that gdisk can be used either to create MBR or GPT partitions.
|
||||
|
||||

|
||||
|
||||
Create GPT Partitions
|
||||
|
||||
The advantage of using GPT partitioning is that we can create up to 128 partitions in the same disk whose size can be up to the order of petabytes, whereas the maximum size for MBR partitions is 2 TB.
|
||||
|
||||
Note that most of the options in fdisk are the same in gdisk. For that reason, we will not go into detail about them, but here’s a screenshot of the process.
|
||||
|
||||

|
||||
|
||||
gdisk Command Options
|
||||
|
||||
### Formatting Filesystems ###
|
||||
|
||||
Once we have created all the necessary partitions, we must create filesystems. To find out the list of filesystems supported in your system, run.
|
||||
|
||||
# ls /sbin/mk*
|
||||
|
||||

|
||||
|
||||
Check Filesystems Type
|
||||
|
||||
The type of filesystem that you should choose depends on your requirements. You should consider the pros and cons of each filesystem and its own set of features. Two important attributes to look for in a filesystem are.
|
||||
|
||||
- Journaling support, which allows for faster data recovery in the event of a system crash.
|
||||
- Security Enhanced Linux (SELinux) support, as per the project wiki, “a security enhancement to Linux which allows users and administrators more control over access control”.
|
||||
|
||||
In our next example, we will create an ext4 filesystem (supports both journaling and SELinux) labeled Tecmint on /dev/sdb1, using mkfs, whose basic syntax is.
|
||||
|
||||
# mkfs -t [filesystem] -L [label] device
|
||||
or
|
||||
# mkfs.[filesystem] -L [label] device
|
||||
|
||||
|
||||
|
||||
Create ext4 Filesystems
|
||||
|
||||
### Creating and Using Swap Partitions ###
|
||||
|
||||
Swap partitions are necessary if we need our Linux system to have access to virtual memory, which is a section of the hard disk designated for use as memory, when the main system memory (RAM) is all in use. For that reason, a swap partition may not be needed on systems with enough RAM to meet all its requirements; however, even in that case it’s up to the system administrator to decide whether to use a swap partition or not.
|
||||
|
||||
A simple rule of thumb to decide the size of a swap partition is as follows.
|
||||
|
||||
Swap should usually equal 2x physical RAM for up to 2 GB of physical RAM, and then an additional 1x physical RAM for any amount above 2 GB, but never less than 32 MB.
|
||||
|
||||
So, if:
|
||||
|
||||
M = Amount of RAM in GB, and S = Amount of swap in GB, then
|
||||
|
||||
If M < 2
|
||||
S = M *2
|
||||
Else
|
||||
S = M + 2
|
||||
|
||||
Remember this is just a formula and that only you, as a sysadmin, have the final word as to the use and size of a swap partition.
|
||||
|
||||
To configure a swap partition, create a regular partition as demonstrated earlier with the desired size. Next, we need to add the following entry to the /etc/fstab file (X can be either b or c).
|
||||
|
||||
/dev/sdX1 swap swap sw 0 0
|
||||
|
||||
Finally, let’s format and enable the swap partition.
|
||||
|
||||
# mkswap /dev/sdX1
|
||||
# swapon -v /dev/sdX1
|
||||
|
||||
To display a snapshot of the swap partition(s).
|
||||
|
||||
# cat /proc/swaps
|
||||
|
||||
To disable the swap partition.
|
||||
|
||||
# swapoff /dev/sdX1
|
||||
|
||||
For the next example, we’ll use /dev/sdc1 (=512 MB, for a system with 256 MB of RAM) to set up a partition with fdisk that we will use as swap, following the steps detailed above. Note that we will specify a fixed size in this case.
|
||||
|
||||

|
||||
|
||||
Create Swap Partition
|
||||
|
||||

|
||||
|
||||
Enable Swap Partition
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Creating partitions (including swap) and formatting filesystems are crucial in your road to Sysadminship. I hope that the tips given in this article will guide you to achieve your goals. Feel free to add your own tips & ideas in the comments section below, for the benefit of the community.
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][1]
|
||||
- [Why get a Linux Foundation Certification?][2]
|
||||
- [Register for the LFCS exam][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[2]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[3]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,232 +0,0 @@
|
||||
Part 5 - LFCS: How to Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
================================================================================
|
||||
The Linux Foundation launched the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is allowing individuals from all corners of the globe to get certified in basic to intermediate system administration tasks for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus smart decision-making when it comes to raising issues to upper support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 5
|
||||
|
||||
The following video shows an introduction to The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This post is Part 5 of a 10-tutorial series, here in this part, we will explain How to mount/unmount local and network filesystems in linux, that are required for the LFCS certification exam.
|
||||
|
||||
### Mounting Filesystems ###
|
||||
|
||||
Once a disk has been partitioned, Linux needs some way to access the data on the partitions. Unlike DOS or Windows (where this is done by assigning a drive letter to each partition), Linux uses a unified directory tree where each partition is mounted at a mount point in that tree.
|
||||
|
||||
A mount point is a directory that is used as a way to access the filesystem on the partition, and mounting the filesystem is the process of associating a certain filesystem (a partition, for example) with a specific directory in the directory tree.
|
||||
|
||||
In other words, the first step in managing a storage device is attaching the device to the file system tree. This task can be accomplished on a one-time basis by using tools such as mount (and then unmounted with umount) or persistently across reboots by editing the /etc/fstab file.
|
||||
|
||||
The mount command (without any options or arguments) shows the currently mounted filesystems.
|
||||
|
||||
# mount
|
||||
|
||||

|
||||
|
||||
Check Mounted Filesystem
|
||||
|
||||
In addition, mount is used to mount filesystems into the filesystem tree. Its standard syntax is as follows.
|
||||
|
||||
# mount -t type device dir -o options
|
||||
|
||||
This command instructs the kernel to mount the filesystem found on device (a partition, for example, that has been formatted with a filesystem type) at the directory dir, using all options. In this form, mount does not look in /etc/fstab for instructions.
|
||||
|
||||
If only a directory or device is specified, for example.
|
||||
|
||||
# mount /dir -o options
|
||||
or
|
||||
# mount device -o options
|
||||
|
||||
mount tries to find a mount point and if it can’t find any, then searches for a device (both cases in the /etc/fstab file), and finally attempts to complete the mount operation (which usually succeeds, except for the case when either the directory or the device is already being used, or when the user invoking mount is not root).
|
||||
|
||||
You will notice that every line in the output of mount has the following format.
|
||||
|
||||
device on directory type (options)
|
||||
|
||||
For example,
|
||||
|
||||
/dev/mapper/debian-home on /home type ext4 (rw,relatime,user_xattr,barrier=1,data=ordered)
|
||||
|
||||
Reads:
|
||||
|
||||
dev/mapper/debian-home is mounted on /home, which has been formatted as ext4, with the following options: rw,relatime,user_xattr,barrier=1,data=ordered
|
||||
|
||||
**Mount Options**
|
||||
|
||||
Most frequently used mount options include.
|
||||
|
||||
- async: allows asynchronous I/O operations on the file system being mounted.
|
||||
- auto: marks the file system as enabled to be mounted automatically using mount -a. It is the opposite of noauto.
|
||||
- defaults: this option is an alias for async,auto,dev,exec,nouser,rw,suid. Note that multiple options must be separated by a comma without any spaces. If by accident you type a space between options, mount will interpret the subsequent text string as another argument.
|
||||
- loop: Mounts an image (an .iso file, for example) as a loop device. This option can be used to simulate the presence of the disk’s contents in an optical media reader.
|
||||
- noexec: prevents the execution of executable files on the particular filesystem. It is the opposite of exec.
|
||||
- nouser: prevents any users (other than root) to mount and unmount the filesystem. It is the opposite of user.
|
||||
- remount: mounts the filesystem again in case it is already mounted.
|
||||
- ro: mounts the filesystem as read only.
|
||||
- rw: mounts the file system with read and write capabilities.
|
||||
- relatime: makes access time to files be updated only if atime is earlier than mtime.
|
||||
- user_xattr: allow users to set and remote extended filesystem attributes.
|
||||
|
||||
**Mounting a device with ro and noexec options**
|
||||
|
||||
# mount -t ext4 /dev/sdg1 /mnt -o ro,noexec
|
||||
|
||||
In this case we can see that attempts to write a file to or to run a binary file located inside our mounting point fail with corresponding error messages.
|
||||
|
||||
# touch /mnt/myfile
|
||||
# /mnt/bin/echo “Hi there”
|
||||
|
||||

|
||||
|
||||
Mount Device Read Write
|
||||
|
||||
**Mounting a device with default options**
|
||||
|
||||
In the following scenario, we will try to write a file to our newly mounted device and run an executable file located within its filesystem tree using the same commands as in the previous example.
|
||||
|
||||
# mount -t ext4 /dev/sdg1 /mnt -o defaults
|
||||
|
||||

|
||||
|
||||
Mount Device
|
||||
|
||||
In this last case, it works perfectly.
|
||||
|
||||
### Unmounting Devices ###
|
||||
|
||||
Unmounting a device (with the umount command) means finish writing all the remaining “on transit” data so that it can be safely removed. Note that if you try to remove a mounted device without properly unmounting it first, you run the risk of damaging the device itself or cause data loss.
|
||||
|
||||
That being said, in order to unmount a device, you must be “standing outside” its block device descriptor or mount point. In other words, your current working directory must be something else other than the mounting point. Otherwise, you will get a message saying that the device is busy.
|
||||
|
||||
|
||||
|
||||
Unmount Device
|
||||
|
||||
An easy way to “leave” the mounting point is typing the cd command which, in lack of arguments, will take us to our current user’s home directory, as shown above.
|
||||
|
||||
### Mounting Common Networked Filesystems ###
|
||||
|
||||
The two most frequently used network file systems are SMB (which stands for “Server Message Block”) and NFS (“Network File System”). Chances are you will use NFS if you need to set up a share for Unix-like clients only, and will opt for Samba if you need to share files with Windows-based clients and perhaps other Unix-like clients as well.
|
||||
|
||||
Read Also
|
||||
|
||||
- [Setup Samba Server in RHEL/CentOS and Fedora][1]
|
||||
- [Setting up NFS (Network File System) on RHEL/CentOS/Fedora and Debian/Ubuntu][2]
|
||||
|
||||
The following steps assume that Samba and NFS shares have already been set up in the server with IP 192.168.0.10 (please note that setting up a NFS share is one of the competencies required for the LFCE exam, which we will cover after the present series).
|
||||
|
||||
#### Mounting a Samba share on Linux ####
|
||||
|
||||
Step 1: Install the samba-client samba-common and cifs-utils packages on Red Hat and Debian based distributions.
|
||||
|
||||
# yum update && yum install samba-client samba-common cifs-utils
|
||||
# aptitude update && aptitude install samba-client samba-common cifs-utils
|
||||
|
||||
Then run the following command to look for available samba shares in the server.
|
||||
|
||||
# smbclient -L 192.168.0.10
|
||||
|
||||
And enter the password for the root account in the remote machine.
|
||||
|
||||

|
||||
|
||||
Mount Samba Share
|
||||
|
||||
In the above image we have highlighted the share that is ready for mounting on our local system. You will need a valid samba username and password on the remote server in order to access it.
|
||||
|
||||
Step 2: When mounting a password-protected network share, it is not a good idea to write your credentials in the /etc/fstab file. Instead, you can store them in a hidden file somewhere with permissions set to 600, like so.
|
||||
|
||||
# mkdir /media/samba
|
||||
# echo “username=samba_username” > /media/samba/.smbcredentials
|
||||
# echo “password=samba_password” >> /media/samba/.smbcredentials
|
||||
# chmod 600 /media/samba/.smbcredentials
|
||||
|
||||
Step 3: Then add the following line to /etc/fstab file.
|
||||
|
||||
# //192.168.0.10/gacanepa /media/samba cifs credentials=/media/samba/.smbcredentials,defaults 0 0
|
||||
|
||||
Step 4: You can now mount your samba share, either manually (mount //192.168.0.10/gacanepa) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
|
||||
|
||||

|
||||
|
||||
Mount Password Protect Samba Share
|
||||
|
||||
#### Mounting a NFS share on Linux ####
|
||||
|
||||
Step 1: Install the nfs-common and portmap packages on Red Hat and Debian based distributions.
|
||||
|
||||
# yum update && yum install nfs-utils nfs-utils-lib
|
||||
# aptitude update && aptitude install nfs-common
|
||||
|
||||
Step 2: Create a mounting point for the NFS share.
|
||||
|
||||
# mkdir /media/nfs
|
||||
|
||||
Step 3: Add the following line to /etc/fstab file.
|
||||
|
||||
192.168.0.10:/NFS-SHARE /media/nfs nfs defaults 0 0
|
||||
|
||||
Step 4: You can now mount your nfs share, either manually (mount 192.168.0.10:/NFS-SHARE) or by rebooting your machine so as to apply the changes made in /etc/fstab permanently.
|
||||
|
||||
|
||||
|
||||
Mount NFS Share
|
||||
|
||||
### Mounting Filesystems Permanently ###
|
||||
|
||||
As shown in the previous two examples, the /etc/fstab file controls how Linux provides access to disk partitions and removable media devices and consists of a series of lines that contain six fields each; the fields are separated by one or more spaces or tabs. A line that begins with a hash mark (#) is a comment and is ignored.
|
||||
|
||||
Each line has the following format.
|
||||
|
||||
<file system> <mount point> <type> <options> <dump> <pass>
|
||||
|
||||
Where:
|
||||
|
||||
- <file system>: The first column specifies the mount device. Most distributions now specify partitions by their labels or UUIDs. This practice can help reduce problems if partition numbers change.
|
||||
- <mount point>: The second column specifies the mount point.
|
||||
- <type>: The file system type code is the same as the type code used to mount a filesystem with the mount command. A file system type code of auto lets the kernel auto-detect the filesystem type, which can be a convenient option for removable media devices. Note that this option may not be available for all filesystems out there.
|
||||
- <options>: One (or more) mount option(s).
|
||||
- <dump>: You will most likely leave this to 0 (otherwise set it to 1) to disable the dump utility to backup the filesystem upon boot (The dump program was once a common backup tool, but it is much less popular today.)
|
||||
- <pass>: This column specifies whether the integrity of the filesystem should be checked at boot time with fsck. A 0 means that fsck should not check a filesystem. The higher the number, the lowest the priority. Thus, the root partition will most likely have a value of 1, while all others that should be checked should have a value of 2.
|
||||
|
||||
**Mount Examples**
|
||||
|
||||
1. To mount a partition with label TECMINT at boot time with rw and noexec attributes, you should add the following line in /etc/fstab file.
|
||||
|
||||
LABEL=TECMINT /mnt ext4 rw,noexec 0 0
|
||||
|
||||
2. If you want the contents of a disk in your DVD drive be available at boot time.
|
||||
|
||||
/dev/sr0 /media/cdrom0 iso9660 ro,user,noauto 0 0
|
||||
|
||||
Where /dev/sr0 is your DVD drive.
|
||||
|
||||
### Summary ###
|
||||
|
||||
You can rest assured that mounting and unmounting local and network filesystems from the command line will be part of your day-to-day responsibilities as sysadmin. You will also need to master /etc/fstab. I hope that you have found this article useful to help you with those tasks. Feel free to add your comments (or ask questions) below and to share this article through your network social profiles.
|
||||
Reference Links
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mount-filesystem-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/setup-samba-server-using-tdbsam-backend-on-rhel-centos-6-3-5-8-and-fedora-17-12/
|
||||
[2]:http://www.tecmint.com/how-to-setup-nfs-server-in-linux/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,3 +1,4 @@
|
||||
[Translating by cposture 15-12-31]
|
||||
Part 6 - LFCS: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
================================================================================
|
||||
Recently, the Linux Foundation launched the LFCS (Linux Foundation Certified Sysadmin) certification, a shiny chance for system administrators everywhere to demonstrate, through a performance-based exam, that they are capable of performing overall operational support on Linux systems: system support, first-level diagnosing and monitoring, plus issue escalation, when required, to other support teams.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by Flowsnow
|
||||
|
||||
Part 7 - LFCS: Managing System Startup Process and Services (SysVinit, Systemd and Upstart)
|
||||
================================================================================
|
||||
A couple of months ago, the Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, an exciting new program whose aim is allowing individuals from all ends of the world to get certified in performing basic to intermediate system administration tasks on Linux systems. This includes supporting already running systems and services, along with first-hand problem-finding and analysis, plus the ability to decide when to raise issues to engineering teams.
|
||||
|
||||
@ -1,330 +0,0 @@
|
||||
Part 8 - LFCS: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
================================================================================
|
||||
Last August, the Linux Foundation started the LFCS certification (Linux Foundation Certified Sysadmin), a brand new program whose purpose is to allow individuals everywhere and anywhere take an exam in order to get certified in basic to intermediate operational support for Linux systems, which includes supporting running systems and services, along with overall monitoring and analysis, plus intelligent decision-making to be able to decide when it’s necessary to escalate issues to higher level support teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 8
|
||||
|
||||
Please have a quick look at the following video that describes an introduction to the Linux Foundation Certification Program.
|
||||
|
||||
注:youtube视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
This article is Part 8 of a 10-tutorial long series, here in this section, we will guide you on how to manage users and groups permissions in Linux system, that are required for the LFCS certification exam.
|
||||
|
||||
Since Linux is a multi-user operating system (in that it allows multiple users on different computers or terminals to access a single system), you will need to know how to perform effective user management: how to add, edit, suspend, or delete user accounts, along with granting them the necessary permissions to do their assigned tasks.
|
||||
|
||||
### Adding User Accounts ###
|
||||
|
||||
To add a new user account, you can run either of the following two commands as root.
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
When a new user account is added to the system, the following operations are performed.
|
||||
|
||||
1. His/her home directory is created (/home/username by default).
|
||||
|
||||
2. The following hidden files are copied into the user’s home directory, and will be used to provide environment variables for his/her user session.
|
||||
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
|
||||
3. A mail spool is created for the user at /var/spool/mail/username.
|
||||
|
||||
4. A group is created and given the same name as the new user account.
|
||||
|
||||
**Understanding /etc/passwd**
|
||||
|
||||
The full account information is stored in the /etc/passwd file. This file contains a record per system user account and has the following format (fields are delimited by a colon).
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- Fields [username] and [Comment] are self explanatory.
|
||||
- The x in the second field indicates that the account is protected by a shadowed password (in /etc/shadow), which is needed to logon as [username].
|
||||
- The [UID] and [GID] fields are integers that represent the User IDentification and the primary Group IDentification to which [username] belongs, respectively.
|
||||
- The [Home directory] indicates the absolute path to [username]’s home directory, and
|
||||
- The [Default shell] is the shell that will be made available to this user when he or she logins the system.
|
||||
|
||||
**Understanding /etc/group**
|
||||
|
||||
Group information is stored in the /etc/group file. Each record has the following format.
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
- [Group name] is the name of group.
|
||||
- An x in [Group password] indicates group passwords are not being used.
|
||||
- [GID]: same as in /etc/passwd.
|
||||
- [Group members]: a comma separated list of users who are members of [Group name].
|
||||
|
||||

|
||||
|
||||
Add User Accounts
|
||||
|
||||
After adding an account, you can edit the following information (to name a few fields) using the usermod command, whose basic syntax of usermod is as follows.
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
**Setting the expiry date for an account**
|
||||
|
||||
Use the –expiredate flag followed by a date in YYYY-MM-DD format.
|
||||
|
||||
# usermod --expiredate 2014-10-30 tecmint
|
||||
|
||||
**Adding the user to supplementary groups**
|
||||
|
||||
Use the combined -aG, or –append –groups options, followed by a comma separated list of groups.
|
||||
|
||||
# usermod --append --groups root,users tecmint
|
||||
|
||||
**Changing the default location of the user’s home directory**
|
||||
|
||||
Use the -d, or –home options, followed by the absolute path to the new home directory.
|
||||
|
||||
# usermod --home /tmp tecmint
|
||||
|
||||
**Changing the shell the user will use by default**
|
||||
|
||||
Use –shell, followed by the path to the new shell.
|
||||
|
||||
# usermod --shell /bin/sh tecmint
|
||||
|
||||
**Displaying the groups an user is a member of**
|
||||
|
||||
# groups tecmint
|
||||
# id tecmint
|
||||
|
||||
Now let’s execute all the above commands in one go.
|
||||
|
||||
# usermod --expiredate 2014-10-30 --append --groups root,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||

|
||||
|
||||
usermod Command Examples
|
||||
|
||||
Read Also:
|
||||
|
||||
- [15 useradd Command Examples in Linux][1]
|
||||
- [15 usermod Command Examples in Linux][2]
|
||||
|
||||
For existing accounts, we can also do the following.
|
||||
|
||||
**Disabling account by locking password**
|
||||
|
||||
Use the -L (uppercase L) or the –lock option to lock a user’s password.
|
||||
|
||||
# usermod --lock tecmint
|
||||
|
||||
**Unlocking user password**
|
||||
|
||||
Use the –u or the –unlock option to unlock a user’s password that was previously blocked.
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
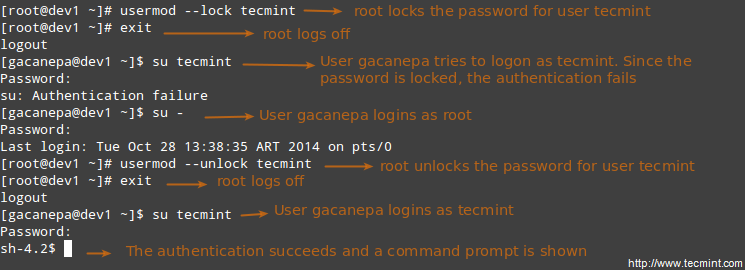
|
||||
|
||||
Lock User Accounts
|
||||
|
||||
**Creating a new group for read and write access to files that need to be accessed by several users**
|
||||
|
||||
Run the following series of commands to achieve the goal.
|
||||
|
||||
# groupadd common_group # Add a new group
|
||||
# chown :common_group common.txt # Change the group owner of common.txt to common_group
|
||||
# usermod -aG common_group user1 # Add user1 to common_group
|
||||
# usermod -aG common_group user2 # Add user2 to common_group
|
||||
# usermod -aG common_group user3 # Add user3 to common_group
|
||||
|
||||
**Deleting a group**
|
||||
|
||||
You can delete a group with the following command.
|
||||
|
||||
# groupdel [group_name]
|
||||
|
||||
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
|
||||
|
||||
### Linux File Permissions ###
|
||||
|
||||
Besides the basic read, write, and execute permissions that we discussed in [Setting File Attributes – Part 3][3] of this series, there are other less used (but not less important) permission settings, sometimes referred to as “special permissions”.
|
||||
|
||||
Like the basic permissions discussed earlier, they are set using an octal file or through a letter (symbolic notation) that indicates the type of permission.
|
||||
Deleting user accounts
|
||||
|
||||
You can delete an account (along with its home directory, if it’s owned by the user, and all the files residing therein, and also the mail spool) using the userdel command with the –remove option.
|
||||
|
||||
# userdel --remove [username]
|
||||
|
||||
#### Group Management ####
|
||||
|
||||
Every time a new user account is added to the system, a group with the same name is created with the username as its only member. Other users can be added to the group later. One of the purposes of groups is to implement a simple access control to files and other system resources by setting the right permissions on those resources.
|
||||
|
||||
For example, suppose you have the following users.
|
||||
|
||||
- user1 (primary group: user1)
|
||||
- user2 (primary group: user2)
|
||||
- user3 (primary group: user3)
|
||||
|
||||
All of them need read and write access to a file called common.txt located somewhere on your local system, or maybe on a network share that user1 has created. You may be tempted to do something like,
|
||||
|
||||
# chmod 660 common.txt
|
||||
OR
|
||||
# chmod u=rw,g=rw,o= common.txt [notice the space between the last equal sign and the file name]
|
||||
|
||||
However, this will only provide read and write access to the owner of the file and to those users who are members of the group owner of the file (user1 in this case). Again, you may be tempted to add user2 and user3 to group user1, but that will also give them access to the rest of the files owned by user user1 and group user1.
|
||||
|
||||
This is where groups come in handy, and here’s what you should do in a case like this.
|
||||
|
||||
**Understanding Setuid**
|
||||
|
||||
When the setuid permission is applied to an executable file, an user running the program inherits the effective privileges of the program’s owner. Since this approach can reasonably raise security concerns, the number of files with setuid permission must be kept to a minimum. You will likely find programs with this permission set when a system user needs to access a file owned by root.
|
||||
|
||||
Summing up, it isn’t just that the user can execute the binary file, but also that he can do so with root’s privileges. For example, let’s check the permissions of /bin/passwd. This binary is used to change the password of an account, and modifies the /etc/shadow file. The superuser can change anyone’s password, but all other users should only be able to change their own.
|
||||
|
||||

|
||||
|
||||
passwd Command Examples
|
||||
|
||||
Thus, any user should have permission to run /bin/passwd, but only root will be able to specify an account. Other users can only change their corresponding passwords.
|
||||
|
||||
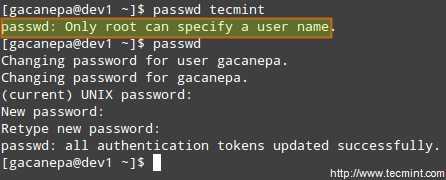
|
||||
|
||||
Change User Password
|
||||
|
||||
**Understanding Setgid**
|
||||
|
||||
When the setgid bit is set, the effective GID of the real user becomes that of the group owner. Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory. You will most likely use this approach whenever members of a certain group need access to all the files in a directory, regardless of the file owner’s primary group.
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
**Setting the SETGID in a directory**
|
||||
|
||||

|
||||
|
||||
Add Setgid to Directory
|
||||
|
||||
**Understanding Sticky Bit**
|
||||
|
||||
When the “sticky bit” is set on files, Linux just ignores it, whereas for directories it has the effect of preventing users from deleting or even renaming the files it contains unless the user owns the directory, the file, or is root.
|
||||
|
||||
# chmod o+t [directory]
|
||||
|
||||
To set the sticky bit in octal form, prepend the number 1 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 1755 [directory]
|
||||
|
||||
Without the sticky bit, anyone able to write to the directory can delete or rename files. For that reason, the sticky bit is commonly found on directories, such as /tmp, that are world-writable.
|
||||
|
||||
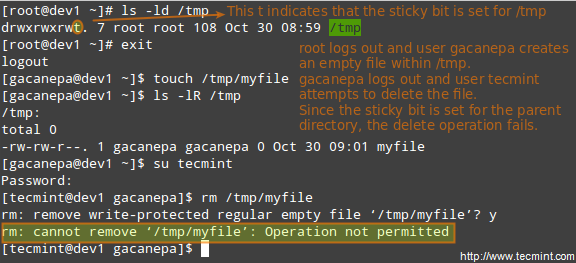
|
||||
|
||||
Add Stickybit to Directory
|
||||
|
||||
### Special Linux File Attributes ###
|
||||
|
||||
There are other attributes that enable further limits on the operations that are allowed on files. For example, prevent the file from being renamed, moved, deleted, or even modified. They are set with the [chattr command][4] and can be viewed using the lsattr tool, as follows.
|
||||
|
||||
# chattr +i file1
|
||||
# chattr +a file2
|
||||
|
||||
After executing those two commands, file1 will be immutable (which means it cannot be moved, renamed, modified or deleted) whereas file2 will enter append-only mode (can only be open in append mode for writing).
|
||||
|
||||
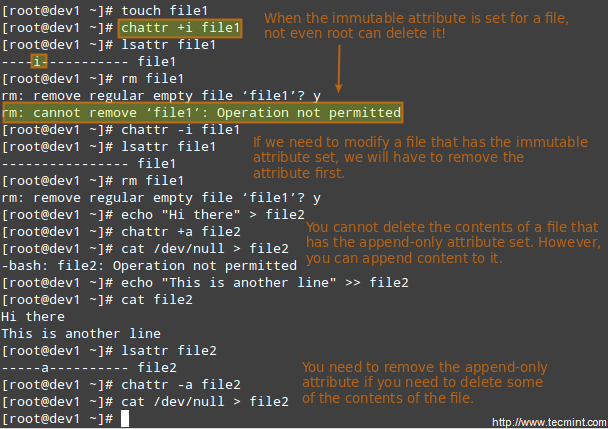
|
||||
|
||||
Chattr Command to Protect Files
|
||||
|
||||
### Accessing the root Account and Using sudo ###
|
||||
|
||||
One of the ways users can gain access to the root account is by typing.
|
||||
|
||||
$ su
|
||||
|
||||
and then entering root’s password.
|
||||
|
||||
If authentication succeeds, you will be logged on as root with the current working directory as the same as you were before. If you want to be placed in root’s home directory instead, run.
|
||||
|
||||
$ su -
|
||||
|
||||
and then enter root’s password.
|
||||
|
||||
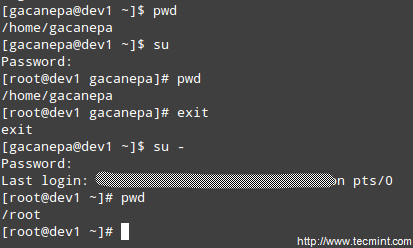
|
||||
|
||||
Enable Sudo Access on Users
|
||||
|
||||
The above procedure requires that a normal user knows root’s password, which poses a serious security risk. For that reason, the sysadmin can configure the sudo command to allow an ordinary user to execute commands as a different user (usually the superuser) in a very controlled and limited way. Thus, restrictions can be set on a user so as to enable him to run one or more specific privileged commands and no others.
|
||||
|
||||
- Read Also: [Difference Between su and sudo User][5]
|
||||
|
||||
To authenticate using sudo, the user uses his/her own password. After entering the command, we will be prompted for our password (not the superuser’s) and if the authentication succeeds (and if the user has been granted privileges to run the command), the specified command is carried out.
|
||||
|
||||
To grant access to sudo, the system administrator must edit the /etc/sudoers file. It is recommended that this file is edited using the visudo command instead of opening it directly with a text editor.
|
||||
|
||||
# visudo
|
||||
|
||||
This opens the /etc/sudoers file using vim (you can follow the instructions given in [Install and Use vim as Editor – Part 2][6] of this series to edit the file).
|
||||
|
||||
These are the most relevant lines.
|
||||
|
||||
Defaults secure_path="/usr/sbin:/usr/bin:/sbin"
|
||||
root ALL=(ALL) ALL
|
||||
tecmint ALL=/bin/yum update
|
||||
gacanepa ALL=NOPASSWD:/bin/updatedb
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
Let’s take a closer look at them.
|
||||
|
||||
Defaults secure_path="/usr/sbin:/usr/bin:/sbin:/usr/local/bin"
|
||||
|
||||
This line lets you specify the directories that will be used for sudo, and is used to prevent using user-specific directories, which can harm the system.
|
||||
|
||||
The next lines are used to specify permissions.
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
- The first ALL keyword indicates that this rule applies to all hosts.
|
||||
- The second ALL indicates that the user in the first column can run commands with the privileges of any user.
|
||||
- The third ALL means any command can be run.
|
||||
|
||||
tecmint ALL=/bin/yum update
|
||||
|
||||
If no user is specified after the = sign, sudo assumes the root user. In this case, user tecmint will be able to run yum update as root.
|
||||
|
||||
gacanepa ALL=NOPASSWD:/bin/updatedb
|
||||
|
||||
The NOPASSWD directive allows user gacanepa to run /bin/updatedb without needing to enter his password.
|
||||
|
||||
%admin ALL=(ALL) ALL
|
||||
|
||||
The % sign indicates that this line applies to a group called “admin”. The meaning of the rest of the line is identical to that of an regular user. This means that members of the group “admin” can run all commands as any user on all hosts.
|
||||
|
||||
To see what privileges are granted to you by sudo, use the “-l” option to list them.
|
||||
|
||||

|
||||
|
||||
Sudo Access Rules
|
||||
|
||||
### Summary ###
|
||||
|
||||
Effective user and file management skills are essential tools for any system administrator. In this article we have covered the basics and hope you can use it as a good starting to point to build upon. Feel free to leave your comments or questions below, and we’ll respond quickly.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/compress-files-and-finding-files-in-linux/
|
||||
[4]:http://www.tecmint.com/chattr-command-examples/
|
||||
[5]:http://www.tecmint.com/su-vs-sudo-and-how-to-configure-sudo-in-linux/
|
||||
[6]:http://www.tecmint.com/vi-editor-usage/
|
||||
@ -1,156 +0,0 @@
|
||||
bazz2
|
||||
Learn with Linux: Learning Music
|
||||
================================================================================
|
||||

|
||||
|
||||
[Linux 学习系列][1]的所有文章:
|
||||
|
||||
- [Linux 教学之教你练打字][2]
|
||||
- [Linux 教学之物理模拟][3]
|
||||
- [Linux 教学之教你玩音乐][4]
|
||||
- [Linux 教学之两款地理软件][5]
|
||||
- [Linux 教学之掌握数学][6]
|
||||
|
||||
引言:Linux 提供大量的教学软件和工具,面向各个年级段以及年龄段,提供大量学科的练习实践,其中大多数是可以与用户进行交互的。本“Linux 教学”系列就来介绍一些教学软件。
|
||||
|
||||
Learning music is a great pastime. Training your ears to identify scales and chords and mastering an instrument or your own voice requires lots of practise and could become difficult. Music theory is extensive. There is much to memorize, and to turn it into a “skill” you will need diligence. Linux offers exceptional software to help you along your musical journey. They will not help you become a professional musician instantly but could ease the process of learning, being a great aide and reference point.
|
||||
|
||||
### Gnu Solfège ###
|
||||
|
||||
[Solfège][7] is a popular music education method that is used in all levels of music education all around the world. Many popular methods (like the Kodály method) use Solfège as their basis. GNU Solfège is a great software aimed more at practising Solfège than learning it. It assumes the student has already acquired the basics and wishes to practise what they have learned.
|
||||
|
||||
As the developer states on the GNU website:
|
||||
|
||||
> “When you study music on high school, college, music conservatory, you usually have to do ear training. Some of the exercises, like sight singing, is easy to do alone [sic]. But often you have to be at least two people, one making questions, the other answering. […] GNU Solfège tries to help out with this. With Solfege you can practise the more simple and mechanical exercises without the need to get others to help you. Just don’t forget that this program only touches a part of the subject.”
|
||||
|
||||
The software delivers its promise; you can practise essentially everything with audible and visual aids.
|
||||
|
||||
GNU solfege is in the Debian (therefore Ubuntu) repositories. To get it just type the following command into a terminal:
|
||||
|
||||
sudo apt-get install solfege
|
||||
|
||||
When it loads, you find yourself on a simple starting screen/
|
||||
|
||||

|
||||
|
||||
The number of options is almost overwhelming. Most of the links will open sub-categories
|
||||
|
||||

|
||||
|
||||
from where you can select individual exercises.
|
||||
|
||||

|
||||
|
||||
There are practice sessions and tests. Both will be able to play the tones through any connected MIDI device or just your sound card’s MIDI player. The exercises often have visual notation and the ability to play back the sequence slowly.
|
||||
|
||||
One important note about Solfège is that under Ubuntu you might not be able to hear anything with the default setup (unless you have a MIDI device connected). If that is the case, head over to “File -> Preferences,” select sound setup and choose the appropriate option for your system (choosing ALSA would probably work in most cases).
|
||||
|
||||

|
||||
|
||||
Solfège could be very helpful for your daily practise. Use it regularly and you will have trained your ear before you can sing do-re-mi.
|
||||
|
||||
### Tete (ear trainer) ###
|
||||
|
||||
[Tete][8] (This ear trainer ‘ere) is a Java application for simple, yet efficient, [ear training][9]. It helps you identify a variety of scales by playing thhm back under various circumstances, from different roots and on different MIDI sounds. [Download it from SourceForge][10]. You then need to unzip the downloaded file.
|
||||
|
||||
unzip Tete-*
|
||||
|
||||
Enter the unpacked directory:
|
||||
|
||||
cd Tete-*
|
||||
|
||||
Assuming you have Java installed in your system, you can run the java file with
|
||||
|
||||
java -jar Tete-[your version]
|
||||
|
||||
(To autocomplete the above command, just press the Tab key after typing “Tete-“.)
|
||||
|
||||
Tete has a simple, one-page interface with everything on it.
|
||||
|
||||

|
||||
|
||||
You can choose to play scales (see above), chords,
|
||||
|
||||

|
||||
|
||||
or intervals.
|
||||
|
||||

|
||||
|
||||
You can “fine tune” your experience with various options including the midi instrument’s sound, what note to start from, ascending or descending scales, and how slow/fast the playback should be. Tete’s SourceForge page includes a very useful tutorial that explains most aspects of the software.
|
||||
|
||||
### JalMus ###
|
||||
|
||||
Jalmus is a Java-based keyboard note reading trainer. It works with attached MIDI keyboards or with the on-screen virtual keyboard. It has many simple lessons and exercises to train in music reading. Unfortunately, its development has been discontinued since 2013, but the software appears to still be functional.
|
||||
|
||||
To get Jalmus, head over to the [sourceforge page][11] of its last version (2.3) to get the Java installer, or just type the following command into a terminal:
|
||||
|
||||
wget http://garr.dl.sourceforge.net/project/jalmus/Jalmus-2.3/installjalmus23.jar
|
||||
|
||||
Once the download finishes, load the installer with
|
||||
|
||||
java -jar installjalmus23.jar
|
||||
|
||||
You will be guided through a simple Java-based installer that was made for cross-platform installation.
|
||||
|
||||
Jalmus’s main screen is plain.
|
||||
|
||||

|
||||
|
||||
You can find lessons of varying difficulty in the Lessons menu. It ranges from very simple ones, where one notes swims in from the left, and the corresponding key lights up on the on screen keyboard …
|
||||
|
||||

|
||||
|
||||
… to difficult ones with many notes swimming in from the right, and you are required to repeat the sequence on your keyboard.
|
||||
|
||||

|
||||
|
||||
Jalmus also includes exercises of note reading single notes, which are very similar to the lessons, only without the visual hints, where your score will be displayed after you finished. It also aids rhythm reading of varying difficulty, where the rhythm is both audible and visually marked. A metronome (audible and visual) aids in the understanding
|
||||
|
||||

|
||||
|
||||
and score reading where multiple notes will be played
|
||||
|
||||

|
||||
|
||||
All these options are configurable; you can switch features on and off as you like.
|
||||
|
||||
All things considered, Jalmus probably works best for rhythm training. Although it was not necessarily its intended purpose, the software really excelled in this particular use-case.
|
||||
|
||||
### Notable mentions ###
|
||||
|
||||
#### TuxGuitar ####
|
||||
|
||||
For guitarists, [TuxGuitar][12] works much like Guitar Pro on Windows (and it can also read guitar-pro files).
|
||||
PianoBooster
|
||||
|
||||
[Piano Booster][13] can help with piano skills. It is designed to play MIDI files, which you can play along with on an attached keyboard, watching the core roll past on the screen.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Linux offers many great tools for learning, and if your particular interest is music, your will not be left without software to aid your practice. Surely there are many more excellent software tools available for music students than were mentioned above. Do you know of any? Please let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-learning-music/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
[7]:https://en.wikipedia.org/wiki/Solf%C3%A8ge
|
||||
[8]:http://tete.sourceforge.net/index.shtml
|
||||
[9]:https://en.wikipedia.org/wiki/Ear_training
|
||||
[10]:http://sourceforge.net/projects/tete/files/latest/download
|
||||
[11]:http://sourceforge.net/projects/jalmus/files/Jalmus-2.3/
|
||||
[12]:http://tuxguitar.herac.com.ar/
|
||||
[13]:http://www.linuxlinks.com/article/20090517041840856/PianoBooster.html
|
||||
@ -1,121 +0,0 @@
|
||||
Learn with Linux: Learning to Type
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Typing is taken for granted by many people; today being keyboard savvy often comes as second nature. Yet how many of us still type with two fingers, even if ever so fast? Once typing was taught in schools, but slowly the art of ten-finger typing is giving way to two thumbs.
|
||||
|
||||
The following two applications can help you master the keyboard so that your next thought does not get lost while your fingers catch up. They were chosen for their simplicity and ease of use. While there are some more flashy or better looking typing apps out there, the following two will get the basics covered and offer the easiest way to start out.
|
||||
|
||||
### TuxType (or TuxTyping) ###
|
||||
|
||||
TuxType is for children. Young students can learn how to type with ten fingers with simple lessons and practice their newly-acquired skills in fun games.
|
||||
|
||||
Debian and derivatives (therefore all Ubuntu derivatives) should have TuxType in their standard repositories. To install simply type
|
||||
|
||||
sudo apt-get install tuxtype
|
||||
|
||||
The application starts with a simple menu screen featuring Tux and some really bad midi music (Fortunately the sound can be turned off easily with the icon in the lower left corner.).
|
||||
|
||||

|
||||
|
||||
The top two choices, “Fish Cascade” and “Comet Zap,” represent typing games, but to start learning you need to head over to the lessons.
|
||||
|
||||
There are forty simple built-in lessons to choose from. Each one of these will take a letter from the keyboard and make the student practice while giving visual hints, such as which finger to use.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
For more advanced practice, phrase typing is also available, although for some reason this is hidden under the options menu.
|
||||
|
||||

|
||||
|
||||
The games are good for speed and accuracy as the player helps Tux catch falling fish
|
||||
|
||||

|
||||
|
||||
or zap incoming asteroids by typing the words written over them.
|
||||
|
||||

|
||||
|
||||
Besides being a fun way to practice, these games teach spelling, speed, and eye-to-hand coordination, as you must type while also watching the screen, building a foundation for touch typing, if taken seriously.
|
||||
|
||||
### GNU typist (gtype) ###
|
||||
|
||||
For adults and more experienced typists, there is GNU Typist, a console-based application developed by the GNU project.
|
||||
|
||||
GNU Typist will also be carried by most Debian derivatives’ main repos. Installing it is as easy as typing
|
||||
|
||||
sudo apt-get install gtype
|
||||
|
||||
You will probably not find it in the Applications menu; insteaad you should start it from a terminal window.
|
||||
|
||||
gtype
|
||||
|
||||
The main menu is simple, no-nonsense and frill-free, yet it is evident how much the software has to offer. Typing lessons of all levels are immediately accessible.
|
||||
|
||||

|
||||
|
||||
The lessons are straightforward and detailed.
|
||||
|
||||

|
||||
|
||||
The interactive practice sessions offer little more than highlighting your mistakes. Instead of flashy visuals you have to chance to focus on practising. At the end of each lesson you get some simple statistics of how you’ve been doing. If you make too many mistakes, you cannot proceed until you can pass the level.
|
||||
|
||||

|
||||
|
||||
While the basic lessons only require you to repeat some characters, more advanced drills will have the practitioner type either whole sentences,
|
||||
|
||||

|
||||
|
||||
where of course the three percent error margin means you are allowed even fewer mistakes,
|
||||
|
||||

|
||||
|
||||
or some drills aiming to achieve certain goals, as in the “Balanced keyboard drill.”
|
||||
|
||||

|
||||
|
||||
Simple speed drills have you type quotes,
|
||||
|
||||

|
||||
|
||||
while more advanced ones will make you write longer texts taken from classics.
|
||||
|
||||

|
||||
|
||||
If you’d prefer a different language, more lessons can also be loaded as command line arguments.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
If you care to hone your typing skills, Linux has great software to offer. The two basic, yet feature-rich, applications discussed above will cater to most aspiring typists’ needs. If you use or know of another great typing application, please don’t hesitate to let us know below in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
@ -1,103 +0,0 @@
|
||||
Learn with Linux: Two Geography Apps
|
||||
================================================================================
|
||||

|
||||
|
||||
This article is part of the [Learn with Linux][1] series:
|
||||
|
||||
- [Learn with Linux: Learning to Type][2]
|
||||
- [Learn with Linux: Physics Simulation][3]
|
||||
- [Learn with Linux: Learning Music][4]
|
||||
- [Learn with Linux: Two Geography Apps][5]
|
||||
- [Learn with Linux: Master Your Math with These Linux Apps][6]
|
||||
|
||||
Linux offers great educational software and many excellent tools to aid students of all grades and ages in learning and practicing a variety of topics, often interactively. The “Learn with Linux” series of articles offers an introduction to a variety of educational apps and software.
|
||||
|
||||
Geography is an interesting subject, used by many of us day to day, often without realizing. But when you fire up GPS, SatNav, or just Google maps, you are using the geographical data provided by this software with the maps drawn by cartographists. When you hear about a certain country in the news or hear financial data being recited, these all fall under the umbrella of geography. And you have some great Linux software to study and practice these, whether it is for school or your own improvement.
|
||||
|
||||
### Kgeography ###
|
||||
|
||||
There are only two geography-related applications readily available in most Linux repositories, and both of these are KDE applications, in fact part of the KDE Educatonal project. Kgeography uses simple color-coded maps of any selected country.
|
||||
|
||||
To install kegeography just type
|
||||
|
||||
sudo apt-get install kgeography
|
||||
|
||||
into a terminal window of any Ubuntu-based distribution.
|
||||
|
||||
The interface is very basic. You are first presented with a picker menu that lets you choose an area map.
|
||||
|
||||

|
||||
|
||||
On the map you can display the name and capital of any given territory by clicking on it,
|
||||
|
||||

|
||||
|
||||
and test your knowledge in different quizzes.
|
||||
|
||||

|
||||
|
||||
It is an interactive way to test your basic geographical knowledge and could be an excellent tool to help you prepare for exams.
|
||||
|
||||
### Marble ###
|
||||
|
||||
Marble is a somewhat more advanced software, offering a global view of the world without the need of 3D acceleration.
|
||||
|
||||

|
||||
|
||||
To get Marble, type
|
||||
|
||||
sudo apt-get install marble
|
||||
|
||||
into a terminal window of any Ubuntu-based distribution.
|
||||
|
||||
Marble focuses on cartography, its main view being that of an atlas.
|
||||
|
||||

|
||||
|
||||
You can have different projections, like Globe or Mercator displayed as defaults, with flat and other exotic views available from a drop-down menu. The surfaces include the basic Atlas view, a full-fledged offline map powered by OpenStreetMap,
|
||||
|
||||

|
||||
|
||||
satellite view (by NASA),
|
||||
|
||||

|
||||
|
||||
and political and even historical maps of the world, among others.
|
||||
|
||||

|
||||
|
||||
Besides providing great offline maps with different skins and varying amount of data, Marble offers other types of information as well. You can switch on and off various offline info-boxes
|
||||
|
||||

|
||||
|
||||
and online services from the menu.
|
||||
|
||||

|
||||
|
||||
An interesting online service is Wikipedia integration. Clicking on the little Wiki logos will bring up a pop-up featuring detailed information about the selected places.
|
||||
|
||||

|
||||
|
||||
The software also includes options for location tracking, route planning, and searching for locations, among other great and useful features. If you enjoy cartography, Marble offers hours of fun exploring and learning.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Linux offers many great educational applications, and the subject of geography is no exception. With the above two programs you can learn a lot about our globe and test your knowledge in a fun and interactive manner.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/linux-geography-apps/
|
||||
|
||||
作者:[Attila Orosz][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/attilaorosz/
|
||||
[1]:https://www.maketecheasier.com/series/learn-with-linux/
|
||||
[2]:https://www.maketecheasier.com/learn-to-type-in-linux/
|
||||
[3]:https://www.maketecheasier.com/linux-physics-simulation/
|
||||
[4]:https://www.maketecheasier.com/linux-learning-music/
|
||||
[5]:https://www.maketecheasier.com/linux-geography-apps/
|
||||
[6]:https://www.maketecheasier.com/learn-linux-maths/
|
||||
@ -1,3 +1,4 @@
|
||||
(translating by runningwater)
|
||||
Grep From Files and Display the File Name
|
||||
================================================================================
|
||||
How do I grep from a number of files and display the file name only?
|
||||
@ -61,7 +62,7 @@ Sample outputs:
|
||||
via: http://www.cyberciti.biz/faq/grep-from-files-and-display-the-file-name/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,43 +0,0 @@
|
||||
|
||||
苹果编程语言Swift开始支持Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
苹果也开源了?是的,苹果编程语言Swift已经开源了。其实我们并不应该感到意外,因为[在六个月以前苹果就已经宣布了这个消息][1]。
|
||||
|
||||
苹果宣布这周将推出开源Swift社区。一个专用于开源Swift社区的[新网站][2]已经就位,网站首页显示以下信息:
|
||||
|
||||
> 我们对Swift开源感到兴奋。在苹果推出了编程语言Swift之后,它很快成为历史上增长最快的语言之一。Swift可以编写出难以置信的又快又安全的软件。目前,Swift是开源的,你能帮助做出随处可用的最好的通用编程语言。
|
||||
|
||||
[swift.org][2]这个网站将会作为一站式网站,它会提供各种资料的下载,包括各种平台,社区指南,最新消息,入门教程,贡献开源Swift的说明,文件和一些其他的指南。 如果你正期待着学习Swift,那么必须收藏这个网站。
|
||||
|
||||
在苹果的这次宣布中,一个用于方便分享和构建代码的包管理器已经可用了。
|
||||
|
||||
对于所有的Linux使用者来说,最重要的是,源代码已经可以从[Github][3]获得了.你可以从以下链接Checkout它:
|
||||
Most important of all for Linux users, the source code is now available at [Github][3]. You can check it out from the link below:
|
||||
|
||||
- [苹果Swift源代码][3]
|
||||
|
||||
除此之外,对于ubuntu 14.04和15.10版本还有预编译的二进制文件。
|
||||
|
||||
- [ubuntu系统的Swift二进制文件][4]
|
||||
|
||||
不要急着去使用它们,因为这些都是发展分支而且不适合于专用机器。因此现在避免使用,一旦发布了Linux下Swift的稳定版本,我希望ubuntu会把它包含在[umake][5]中靠近[Visual Studio][6]的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/swift-open-source-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://itsfoss.com/apple-open-sources-swift-programming-language-linux/
|
||||
[2]:https://swift.org/
|
||||
[3]:https://github.com/apple
|
||||
[4]:https://swift.org/download/#latest-development-snapshots
|
||||
[5]:https://wiki.ubuntu.com/ubuntu-make
|
||||
[6]:http://itsfoss.com/install-visual-studio-code-ubuntu/
|
||||
@ -0,0 +1,228 @@
|
||||
优秀的开源合作编辑工具
|
||||
================================================================================
|
||||
一句话,合作编著就是多个人进行编著。合作有好处也有风险。好处包括更加全面/协调的方式,更好的利用现有资源和一个更加有力的、团结的声音。对于我来说,最大的好处是极大的透明度。那是当我需要采纳同事的观点。同事之间来来回回地传文件效率非常低,导致不必要的延误还让人(比如,我)对整个合作这件事都感到不满意。有个好的合作软件,我就能实时地或异步地分享笔记,数据和文件,并用评论来分享自己的想法。这样在文档、图片、视频、演示文稿上合作就不会那么的琐碎而无聊。
|
||||
|
||||
有很多种方式能在线进行合作,简直不能更简便了。这篇文章表明了我最喜欢的开源实时文档合作编辑工具。
|
||||
|
||||
Google Docs 是个非常好的高效应用,有着大部分我所需要的功能。它可以作为一个实时地合作编辑文档的工具提供服务。文档可以被分享、打开并被多位用户同时编辑,用户还能看见其他合作者一个字母一个字母的编辑过程。虽然 Google Docs 对个人是免费的,但并不开源。
|
||||
|
||||
下面是我带来的最棒的开源合作编辑器,它们能帮你不被打扰的集中精力进行写作,而且是和其他人协同完成。
|
||||
|
||||
----------
|
||||
|
||||
### Hackpad ###
|
||||
|
||||

|
||||
|
||||
Hackpad 是个开源的基于网页的实时 wiki,基于开源 EtherPad 合作文档编辑器。
|
||||
|
||||
Hackpad 允许用户实时分享你的文档,它还用彩色编码显示各个作者分别贡献了哪部分。它还允许插入图片、清单,由于提供了语法高亮功能,它还能用来写代码。
|
||||
|
||||
当2014年4月 Dropbox 获得了 Hackpad 后,这款软件就以开源的形式在本月发行。让我们经历的等待非常值得。
|
||||
|
||||
特性:
|
||||
|
||||
- 有类似 wiki 所提供的,一套非常完善的功能
|
||||
- 实时或者异步地记合作笔记,共享数据和文件,或用评论分享你们的想法
|
||||
- 细致的隐私许可让你可以邀请单个朋友,一个十几人的团队或者上千的 Twitter 粉丝
|
||||
- 智能执行
|
||||
- 直接从流行的视频分享网站上插入视频
|
||||
- 表格
|
||||
- 可对使用广泛的包括 C, C#, CSS, CoffeeScript, Java, 以及 HTML 在内的编程语言进行语法高亮
|
||||
|
||||
- 网站:[hackpad.com][1]
|
||||
- 源代码:[github.com/dropbox/hackpad][2]
|
||||
- 开发者:[Contributors][3]
|
||||
- 许可:Apache License, Version 2.0
|
||||
- 版本号: -
|
||||
|
||||
----------
|
||||
|
||||
### Etherpad ###
|
||||
|
||||

|
||||
|
||||
Etherpad 是个基于网页的开源实时合作编辑器,允许多个作者同时编辑一个文本文档,写评论,并与其他作者用群聊方式进行交流。
|
||||
|
||||
Etherpad 是用 JavaScript 运行的,在 AppJet 平台的顶端,通过 Comet 流实现实时的功能。
|
||||
|
||||
特性:
|
||||
|
||||
- 尽心设计的斯巴达界面
|
||||
- 简单的格式化文本功能
|
||||
- “滑动时间轴”——浏览一个工程历史版本
|
||||
- 可以下载纯文本、 PDF、微软的 Word 文档、Open Document 和 HTML 格式的文档
|
||||
- 每隔一段很短的时间就会自动保存
|
||||
- 可个性化程度高
|
||||
- 有客户端插件可以扩展编辑的功能
|
||||
- 几百个支持 Etherpad 的扩展包括支持 email 提醒,pad 管理,授权
|
||||
- 可访问性开启
|
||||
- 可从 Node 里或通过 CLI(命令行界面)和 Pad 目录实时交互
|
||||
|
||||
- 网站: [etherpad.org][4]
|
||||
- 源代码:[github.com/ether/etherpad-lite][5]
|
||||
- 开发者:David Greenspan, Aaron Iba, J.D. Zamfiresc, Daniel Clemens, David Cole
|
||||
- 许可:Apache License, Version 2.0
|
||||
- 版本号: 1.5.7
|
||||
|
||||
----------
|
||||
|
||||
### Firepad ###
|
||||
|
||||

|
||||
|
||||
Firepad 是个开源的合作文本编辑器。它的设计目的是被嵌入到更大的网页应用中对几天内新加入的代码进行批注。
|
||||
|
||||
Firepad 是个全功能的文本编辑器,有解决冲突,光标同步,用户属性,用户在线状态检测功能。它使用 Firebase 作为后台,而且不需要任何服务器端的代码。他可以被加入到任何网页应用中。Firepad 可以使用 CodeMirror 编辑器或者 Ace 编辑器提交文本,它的操作转换代码是从 ot.js 上借鉴的。
|
||||
|
||||
如果你想要通过添加简单的文档和代码编辑器来扩展你的网页应用能力,Firepad 最适合不过了。
|
||||
|
||||
Firepad 已被多个编辑器使用,包括Atlassian Stash Realtime Editor、Nitrous.IO、LiveMinutes 和 Koding。
|
||||
|
||||
特性:
|
||||
|
||||
- 纯正的合作编辑
|
||||
- 基于 OT 的智能合并及解决冲突
|
||||
- 支持多种格式的文本和代码的编辑
|
||||
- 光标位置同步
|
||||
- 撤销/重做
|
||||
- 文本高亮
|
||||
- 用户属性
|
||||
- 在线检测
|
||||
- 版本检查点
|
||||
- 图片
|
||||
- 通过它的 API 拓展 Firepad
|
||||
- 支持所有现代浏览器:Chrome、Safari、Opera 11+、IE8+、Firefox 3.6+
|
||||
|
||||
- 网站: [www.firepad.io][6]
|
||||
- 源代码:[github.com/firebase/firepad][7]
|
||||
- 开发者:Michael Lehenbauer and the team at Firebase
|
||||
- 许可:MIT
|
||||
- 版本号:1.1.1
|
||||
|
||||
----------
|
||||
|
||||
### OwnCloud Documents ###
|
||||
|
||||

|
||||
|
||||
ownCloud Documents 是个可以单独并/或合作进行办公室文档编辑 ownCloud 应用。它允许最多5个人同时在网页浏览器上合作进行编辑 .odt 和 .doc 文件。
|
||||
|
||||
ownCloud 是个自托管文件同步和分享服务器。他通过网页界面,同步客户端或 WebDAV 提供你数据的使用权,同时提供一个容易在设备间进行浏览、同步和分享的平台。
|
||||
|
||||
特性:
|
||||
|
||||
- 合作编辑,多个用户同时进行文件编辑
|
||||
- 在 ownCloud 里创建文档
|
||||
- 上传文档
|
||||
- 在浏览器里分享和编辑文件,然后在 ownCloud 内部或通过公共链接进行分享这些文件
|
||||
- 有类似 ownCloud 的功能,如版本管理、本地同步、加密、恢复被删文件
|
||||
- 通过透明转换文件格式的方式无缝支持微软 Word 文档
|
||||
|
||||
- 网站:[owncloud.org][8]
|
||||
- 源代码: [github.com/owncloud/documents][9]
|
||||
- 开发者:OwnCloud Inc.
|
||||
- 许可:AGPLv3
|
||||
- 版本号:8.1.1
|
||||
|
||||
----------
|
||||
|
||||
### Gobby ###
|
||||
|
||||

|
||||
|
||||
Gobby 是个支持在一个会话内进行多个用户聊天并打开多个文档的合作编辑器。所有的用户都能同时在文件上进行工作,无需锁定。不同用户编写的部分用不同颜色高亮显示,它还支持多个编程和标记语言的语法高亮。
|
||||
|
||||
Gobby 允许多个用户在互联网上实时共同编辑同一个文档。他很好的整合了 GNOME 环境。它拥有一个客户端-服务端结构,这让它能支持一个会话开多个文档,文档同步请求,密码保护和 IRC 式的聊天方式可以在多个频道进行交流。用户可以选择一个颜色对他们在文档中编写的文本进行高亮。
|
||||
|
||||
还供有一个叫做 infinoted 的专用服务器。
|
||||
|
||||
特性:
|
||||
|
||||
- 成熟的文本编辑能力包括使用 GtkSourceView 的语法高亮功能
|
||||
- 实时、无需锁定、通过加密(包括PFS)连接的合作文本编辑
|
||||
- 整合了群聊
|
||||
- 本地组撤销:撤销不会影响远程用户的修改
|
||||
- 显示远程用户的光标和选择区域
|
||||
- 用不同颜色高亮不同用户编写的文本
|
||||
- 适用于大多数编程语言的语法高亮,自动缩进,可配置 tab 宽度
|
||||
- 零冲突
|
||||
- 加密数据传输包括完美的正向加密(PFS)
|
||||
- 会话可被密码保护
|
||||
- 通过 Access Control Lists (ACLs) 进行精密的权限保护
|
||||
- 高度个性化的专用服务器
|
||||
- 自动保存文档
|
||||
- 先进的查找和替换功能
|
||||
- 国际化
|
||||
- 完整的 Unicode 支持
|
||||
|
||||
- 网站:[gobby.github.io][10]
|
||||
- 源代码: [github.com/gobby][11]
|
||||
- 开发者: Armin Burgmeier, Philipp Kern and contributors
|
||||
- 许可: GNU GPLv2+ and ISC
|
||||
- 版本号:0.5.0
|
||||
|
||||
----------
|
||||
|
||||
### OnlyOffice ###
|
||||
|
||||

|
||||
|
||||
ONLYOFFICE(从前叫 Teamlab Office)是个多功能云端在线办公套件,整合了 CRM(客户关系管理)系统、文档和项目管理工具箱、甘特图以及邮件整合器
|
||||
|
||||
它能让你整理商业任务和时间表,保存并分享你的合作或个人文档,使用网络社交工具如博客和论坛,还可以和你的队员通过团队的即时聊天工具进行交流。
|
||||
|
||||
能在同一个地方管理文档、项目、团队和顾客关系。OnlyOffice 结合了文本,电子表格和电子幻灯片编辑器,他们的功能跟微软桌面应用(Word、Excel 和 PowerPoint)的功能相同。但是他允许实时进行合作编辑、评论和聊天。
|
||||
|
||||
OnlyOffice 是用 ASP.NET 编写的,基于 HTML5 Canvas 元素,并且被翻译成21种语言。
|
||||
|
||||
特性:
|
||||
|
||||
- 当在大文档里工作、翻页和缩放时,它能与桌面应用一样强大
|
||||
- 文档可以在浏览/编辑模式下分享
|
||||
- 文档嵌入
|
||||
- 电子表格和电子幻灯片编辑器
|
||||
- 合作编辑
|
||||
- 评论
|
||||
- 群聊
|
||||
- 移动应用
|
||||
- 甘特图
|
||||
- 时间管理
|
||||
- 权限管理
|
||||
- Invoicing 系统
|
||||
- 日历
|
||||
- 整合了文件保存系统:Google Drive、Box、OneDrive、Dropbox、OwnCloud
|
||||
- 整合了 CRM、电子邮件整合器和工程管理模块
|
||||
- 邮件服务器
|
||||
- 邮件整合器
|
||||
- 可以编辑流行格式的文档、电子表格和电子幻灯片:DOC、DOCX、ODT、RTF、TXT、XLS、XLSX、ODS、CSV、PPTX、PPT、ODP
|
||||
|
||||
- 网站:[www.onlyoffice.com][12]
|
||||
- 源代码:[github.com/ONLYOFFICE/DocumentServer][13]
|
||||
- 开发者:Ascensio System SIA
|
||||
- 许可:GNU GPL v3
|
||||
- 版本号:7.7
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150823085112605/CollaborativeEditing.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://hackpad.com/
|
||||
[2]:https://github.com/dropbox/hackpad
|
||||
[3]:https://github.com/dropbox/hackpad/blob/master/CONTRIBUTORS
|
||||
[4]:http://etherpad.org/
|
||||
[5]:https://github.com/ether/etherpad-lite
|
||||
[6]:http://www.firepad.io/
|
||||
[7]:https://github.com/firebase/firepad
|
||||
[8]:https://owncloud.org/
|
||||
[9]:http://github.com/owncloud/documents/
|
||||
[10]:https://gobby.github.io/
|
||||
[11]:https://github.com/gobby
|
||||
[12]:https://www.onlyoffice.com/free-edition.aspx
|
||||
[13]:https://github.com/ONLYOFFICE/DocumentServer
|
||||
@ -0,0 +1,195 @@
|
||||
使用开源工具优化Web响应
|
||||
================================================================================
|
||||
Web代理软件转发HTTP请求时并不会改变数据流量。它们经过配置后,可以免客户端配置,作为透明代理。它们还可以作为网站反向代理的前端;缓存服务器在此能支撑一台或多台web服务器为海量用户提供服务。
|
||||
|
||||
网站代理功能多样,有着宽泛的用途:从页面缓存、DNS和其他查询,到加速web服务器响应、降低带宽消耗。代理软件广泛用于大型高访问量的网站,比如纽约时报、卫报, 以及社交媒体网站如Twitter、Facebook和Wikipedia。
|
||||
|
||||
页面缓存已经成为优化单位时间内所能吞吐的数据量的至关重要的机制。好的Web缓存还能降低延迟,尽可能快地响应页面,让终端用户不至于因等待内容的时间过久而失去耐心。它们还能将频繁访问的内容缓存起来以节省带宽。如果你需要降低服务器负载并改善网站内容响应速度,那缓存软件能带来的好处就绝对值得探索一番。
|
||||
|
||||
为深入探查Linux下可用的相关软件的质量,我列出了下边5个优秀的开源web代理工具。它们中有些功能完备强大,也有几个只需很低的资源就能运行。
|
||||
|
||||
### Squid ###
|
||||
|
||||
Squid是一个高性能、开源的代理缓存和Web缓存服务器,支持FTP、Internet Gopher、HTTPS和SSL等多种协议。它通过一个非阻塞,I/O事件驱动的单一进程处理所有IPV4或IPV6上的请求。
|
||||
|
||||
Squid由一个主服务程序squid,和DNS查询程序dnsserver,另外还有可选的请求重写、执行认证程序组件,及一些管理和客户端工具构成。
|
||||
|
||||
Squid提供了丰富的访问控制、认证和日志环境, 用于开发web代理和内容服务网站应用。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- Web代理:
|
||||
- 通过缓存来降低访问时间和带宽使用
|
||||
- 将元数据和特别热的对象缓存到内存中
|
||||
- 缓存DNS查询
|
||||
- 支持非阻塞的DNS查询
|
||||
- 实现了失败请求的未果缓存
|
||||
- Squid缓存可架设为层次结构,或网状结构以节省额外的带宽
|
||||
- 通过可扩展的访问控制来执行网站使用条款
|
||||
- 隐匿请求,如禁用或修改客户端HTTP请求头特定属性
|
||||
- 反向代理
|
||||
- 媒体范围限制
|
||||
- 支持SSL
|
||||
- 支持IPv6
|
||||
- 错误页面的本地化 - Squid可以根据访问者的语言选项对每个请求展示本地化的错误页面
|
||||
- 连接Pinning(用于NTLM Auth Passthrough) - 一种通过Web代理,允许Web服务器使用Microsoft NTLM安全认证替代HTTP标准认证的方案
|
||||
- 支持服务质量 (QoS, Quality of Service) 流
|
||||
- 选择一个TOS/Diffserv值来标记本地命中
|
||||
- 选择一个TOS/Diffserv值来标记邻居命中
|
||||
- 选择性地仅标记同级或上级请求
|
||||
- 允许任意发往客户端的HTTP响应保持由远程服务器处响应的TOS值
|
||||
- 对收到的远程服务器的TOS值,在复制之前对指定位进行掩码操作,再发送到客户端
|
||||
- SSL Bump (用于HTTPS过滤和适配) - Squid-in-the-middle,在CONNECT方式的SSL隧道中,用配置化的客户端和服务器端证书,对流量进行解密和加密
|
||||
- 支持适配模块
|
||||
- ICAP旁路和重试增强 - 通过完全的旁路和动态链式路由扩展ICAP,来处理多多个适应性服务。
|
||||
- 支持ICY流式协议 - 俗称SHOUTcast多媒体流
|
||||
- 动态SSL证书生产
|
||||
- 支持ICAP协议(Internet Content Adaptation Protocol)
|
||||
- 完整的请求日志记录
|
||||
- 匿名连接
|
||||
|
||||
- 网站: [www.squid-cache.org][1]
|
||||
- 开发: 美国国家应用网络研究实验室和网络志愿者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 4.0.1
|
||||
|
||||
### Privoxy ###
|
||||
|
||||
Privoxy(Privacy Enhancing Proxy)是一个非缓存类Web代理软件,它自带的高级过滤功能用来增强隐私保护,修改页面内容和HTTP头部信息,访问控制,以及去除广告和其它招人反感的互联网垃圾。Privoxy的配置非常灵活,能充分定制已满足各种各样的需求和偏好。它支持单机和多用户网络两种模式。
|
||||
|
||||
Privoxy使用Actions规则来处理浏览器和远程站点间的数据流。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- 高度配置化
|
||||
- 广告拦截
|
||||
- Cookie管理
|
||||
- 支持"Connection: keep-alive"。可以无视客户端配置而保持持久连接
|
||||
- 支持IPv6
|
||||
- 标签化,允许按照客户端和服务器的请求头进行处理
|
||||
- 作为拦截代理器运行
|
||||
- 巧妙的手段和过滤机制用来处理服务器和客户端的HTTP头部
|
||||
- 可以与其他代理软件链式使用
|
||||
- 整合了基于浏览器的配置和控制工具,能在线跟踪规则和过滤效果,可远程开关
|
||||
- 页面过滤(文本替换、根据尺寸大小删除广告栏, 隐藏的"web-bugs"元素和HTML容错等)
|
||||
- 模块化的配置使得标准配合和用户配置可以存放于不同文件中,这样安装更新就不会覆盖用户的个性化设置
|
||||
- 配置文件支持Perl兼容的正则表达式,以及更为精妙和灵活的配置语法
|
||||
- GIF去动画
|
||||
- 旁路处理大量click-tracking脚本(避免脚本重定向)
|
||||
- 大多数代理生成的页面(例如 "访问受限" 页面)可由用户自定义HTML模板
|
||||
- 自动监测配置文件的修改并重新读取
|
||||
- 最大特点是可以基于每个站点或每个位置来进行控制
|
||||
|
||||
- 网站: [www.privoxy.org][2]
|
||||
- 开发: Fabian Keil(开发领导者), David Schmidt, 和众多其他贡献者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 3.4.2
|
||||
|
||||
### Varnish Cache ###
|
||||
|
||||
Varnish Cache是一个为性能和灵活性而生的web加速器。它新颖的架构设计能带来显著的性能提升。根据你的架构,通常情况下它能加速响应速度300-1000倍。Varnish将页面存储到内存,这样web服务器就无需重复地创建相同的页面,只需要在页面发生变化后重新生成。页面内容直接从内存中访问,当然比其他方式更快。
|
||||
|
||||
此外Varnish能大大提升响应web页面的速度,用任何应用服务器都能使网站访问速度大幅度地提升。
|
||||
|
||||
按按经验,Varnish Cache比较经济的配置是1-16GB内存+SSD固态硬盘。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- 新颖的设计
|
||||
- VCL - 非常灵活的配置语言。VCL配置转换成C,然后编译、加载、运行,灵活且高效
|
||||
- 能使用round-robin轮询和随机分发两种方式来负载均衡,两种方式下后端服务器都可以设置权重
|
||||
- 基于DNS、随机、散列和客户端IP的分发器
|
||||
- 多台后端主机间的负载均衡
|
||||
- 支持Edge Side Includes,包括拼装压缩后的ESI片段
|
||||
- 多线程并发
|
||||
- URL重写
|
||||
- 单Varnish缓存多个虚拟主机
|
||||
- 日志数据存储在共享内存中
|
||||
- 基本的后端服务器健康检查
|
||||
- 优雅地处理后端服务器“挂掉”
|
||||
- 命令行界面的管理控制台
|
||||
- 使用内联C来扩展Varnish
|
||||
- 可以与Apache用在相同的系统上
|
||||
- 单系统可运行多个Varnish
|
||||
- 支持HAProxy代理协议。该协议在每个收到的TCP请求,例如SSL终止过程中,附加小段头信息,以记录客户端的真实地址
|
||||
- 冷热VCL状态
|
||||
- 用名为VMODs的Varnish模块来提供插件扩展
|
||||
- 通过VMODs定义后端主机
|
||||
- Gzip压缩及解压
|
||||
- HTTP流通过和获取
|
||||
- 神圣模式和优雅模式。用Varnish作为负载均衡器,神圣模式下可以将不稳定的后端服务器在一段时间内打入黑名单,阻止它们继续提供流量服务。优雅模式允许Varnish在获取不到后端服务器状态良好的响应时,提供已过期版本的页面或其它内容。
|
||||
- 实验性支持持久化存储,无需LRU缓存淘汰
|
||||
|
||||
- 网站: [www.varnish-cache.org][3]
|
||||
- 开发: Varnish Software
|
||||
- 授权: FreeBSD
|
||||
- 版本号: 4.1.0
|
||||
|
||||
### Polipo ###
|
||||
|
||||
Polipo是一个开源的HTTP缓存代理,只需要非常低的资源开销。
|
||||
|
||||
它监听来自浏览器的web页面请求,转发到web服务器,然后将服务器的响应转发到浏览器。在此过程中,它能优化和整形网络流量。从本质来讲Polipo与WWWOFFLE很相似,但其实现技术更接近于Squid。
|
||||
|
||||
Polipo最开始的目标是作为一个兼容HTTP/1.1的代理,理论它能在任何兼容HTTP/1.1或更早的HTTP/1.0的站点上运行。
|
||||
|
||||
其特性包括:
|
||||
|
||||
- HTTP 1.1、IPv4 & IPv6、流量过滤和隐私保护增强
|
||||
- 如确认远程服务器支持,则无论收到的请求是管道处理过的还是在多个连接上同时收到的,都使用HTTP/1.1管道
|
||||
- 下载被中断时缓存起始部分,当需要续传时用区间请求来完成下载
|
||||
- 将HTTP/1.0的客户端请求升级为HTTP/1.1,然后按照客户端支持的级别进行升级或降级后回复
|
||||
- 全面支持IPv6 (作用域(链路本地)地址除外)
|
||||
- 作为IPv4和IPv6网络的网桥
|
||||
- 内容过滤
|
||||
- 能使用Poor Man多路复用技术降低延迟
|
||||
- 支持SOCKS 4和SOCKS 5协议
|
||||
- HTTPS代理
|
||||
- 扮演透明代理的角色
|
||||
- 可以与Privoxy或tor一起运行
|
||||
|
||||
- 网站: [www.pps.univ-paris-diderot.fr/~jch/software/polipo/][4]
|
||||
- 开发: Juliusz Chroboczek, Christopher Davis
|
||||
- 授权: MIT License
|
||||
- 版本号: 1.1.1
|
||||
|
||||
### Tinyproxy ###
|
||||
|
||||
Tinyproxy是一个轻量级的开源web代理守护进程,其设计目标是快而小。它适用于需要完整HTTP代理特性,但系统资源又不足以运行大型代理的场景,比如嵌入式部署。
|
||||
|
||||
Tinyproxy对小规模网络非常有用,这样的场合下大型代理会使系统资源紧张,或有安全风险。Tinyproxy的一个关键特性是其缓冲连接的理念。实质上Tinyproxy服务器的响应进行了高速缓冲,然后按照客户端能够处理的最高速度进行响应。该特性极大的降低了网络延滞带来的问题。
|
||||
|
||||
特性:
|
||||
|
||||
- 易于修改
|
||||
- 隐匿模式 - 定义哪些HTTP头允许通过,哪些又会被拦截
|
||||
- 支持HTTPS - Tinyproxy允许通过CONNECT方法转发HTTPS连接,任何情况下都不会修改数据流量
|
||||
- 远程监控 - 远程访问代理统计数据,让你能清楚了解代理服务当前的忙碌状态
|
||||
- 平均负载监控 - 通过配置,当服务器的负载接近一定值后拒绝新连接
|
||||
- 访问控制 - 通过配置,仅允许指定子网或IP地址的访问
|
||||
- 安全 - 运行无需额外权限,减小了系统受到威胁的概率
|
||||
- 基于URL的过滤 - 允许基于域和URL的黑白名单
|
||||
- 透明代理 - 配位为透明代理,这样客户端就无需任何配置
|
||||
- 代理链 - 来流量出口处采用上游代理服务器,而不是直接转发到目标服务器,创建我们所说的代理链
|
||||
- 隐私特性 - 限制允许从浏览器收到的来自HTTP服务器的数据(例如cookies),同时限制允许通过的从浏览器到HTTP服务器的数据(例如版本信息)
|
||||
- 低开销 - 使用glibc内存开销只有2MB,CPU负载按并发连接数线性增长(取决于网络连接速度)。 Tinyproxy可以运行在老旧的机器上而无需担心性能问题。
|
||||
|
||||
- 网站: [banu.com/tinyproxy][5]
|
||||
- 开发: Robert James Kaes和其他贡献者
|
||||
- 授权: GNU GPL v2
|
||||
- 版本号: 1.8.3
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20151101020309690/WebDelivery.html
|
||||
|
||||
译者:[fw8899](https://github.com/fw8899)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.squid-cache.org/
|
||||
[2]:http://www.privoxy.org/
|
||||
[3]:https://www.varnish-cache.org/
|
||||
[4]:http://www.pps.univ-paris-diderot.fr/%7Ejch/software/polipo/
|
||||
[5]:https://banu.com/tinyproxy/
|
||||
@ -1,69 +0,0 @@
|
||||
黑客利用Wi-Fi侵犯你隐私的七种方法
|
||||
================================================================================
|
||||

|
||||
|
||||
### 黑客利用Wi-Fi侵犯你隐私的七种方法 ###
|
||||
|
||||
Wi-Fi — 既然方便又危险的东西!这里给大家介绍一下通过Wi-Fi连接泄露身份信息的七种方法和预防措施。
|
||||
|
||||

|
||||
|
||||
### 利用免费热点 ###
|
||||
|
||||
它们似乎无处不在,而且它们的数量会在[下一个四年里增加四倍][1]。但是它们当中很多都是不值得信任的,从你的登录凭证、email甚至更加敏感的账户,都能被黑客用一款名叫“sniffers”的软件截获 — 这款软件能截获到任何你通过该连接提交的信息。防止被黑客盯上的最好办法就是使用VPN(virtual private network),它能保护你的数据隐私它会加密你所输入的信息。
|
||||
|
||||

|
||||
|
||||
### 网上银行 ###
|
||||
|
||||
你可能认为没有人需要自己被提醒不要使用免费Wi-Fi来操作网上银行, 但网络安全厂商卡巴斯基实验室表示[全球超过100家银行因为网络黑客而损失9亿美元][2],由此可见还是有很多人因此受害。如果你真的想要在一家咖吧里使用免费真实的Wi-Fi,那么你应该向服务员确认网络名称。[在店里用路由器设置一个开放的无线连接][3]并将它的网络名称设置成店名是一件相当简单的事。
|
||||
|
||||

|
||||
|
||||
### 始终开着Wi-Fi开关 ###
|
||||
|
||||
如果你手机的Wi-Fi开关一直开着的,你会自动被连接到一个不安全的网络中去,你甚至都没有意识到。你可以利用你手机的[基于位置的Wi-Fi功能][4],如果它是可用的,那它会在你离开你所保存的网络范围后自动关闭你的Wi-Fi开关并在你回去之后再次开启。
|
||||
|
||||

|
||||
|
||||
### 不使用防火墙 ###
|
||||
|
||||
防火墙是你的第一道抵御恶意入侵的防线,它能有效地让你的电脑网络通畅并阻挡黑客和恶意软件。你应该时刻开启它除非你的杀毒软件有它自己的防火墙。
|
||||
|
||||

|
||||
|
||||
### 浏览非加密网页 ###
|
||||
|
||||
说起来很难过,[世界上排名前100万个网站中55%是不加密的][5],一个未加密的网站则会让传输的数据暴露在黑客的眼下。如果一个网页是安全的,你的浏览器则会有标明(比如说火狐浏览器是一把绿色的挂锁、Chrome蓝旗则是个绿色的图标)。但是一个安全的网站不能让你免于被劫持的风险,它能通过公共网络从你访问过的网站上窃取cookies,无论是不是正当网站与否。
|
||||
|
||||

|
||||
|
||||
### 不更新你的安全防护软件 ###
|
||||
|
||||
如果你想要确保你自己的网络是受保护的,就更新的路由器固件。你要做的就是进入你的路由器管理页面去检查,通常你能在厂商的官方网页上下载到最新的固件版本。
|
||||
|
||||

|
||||
|
||||
### 不保护你的家用Wi-Fi ###
|
||||
|
||||
不用说,设置一个复杂的密码和更改无线连接的默认名都是非常重要的。你还可以过滤你的MAC地址来让你的路由器只承认那些确认过的设备。
|
||||
|
||||
**Josh Althuser**是一个开源支持者、网络架构师和科技企业家。在过去12年里,他花了很多时间去倡导使用开源软件来管理团队和项目,同时为网络应用程序提供企业级咨询并帮助它们走向市场。你可以联系[他的推特][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/3003170/mobile-security/7-ways-hackers-can-use-wi-fi-against-you.html
|
||||
|
||||
作者:[Josh Althuser][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/JoshAlthuser
|
||||
[1]:http://www.pcworld.com/article/243464/number_of_wifi_hotspots_to_quadruple_by_2015_says_study.html
|
||||
[2]:http://www.nytimes.com/2015/02/15/world/bank-hackers-steal-millions-via-malware.html?hp&action=click&pgtype=Homepage&module=first-column-region%C2%AEion=top-news&WT.nav=top-news&_r=3
|
||||
[3]:http://news.yahoo.com/blogs/upgrade-your-life/banking-online-not-hacked-182159934.html
|
||||
[4]:http://pocketnow.com/2014/10/15/should-you-leave-your-smartphones-wifi-on-or-turn-it-off
|
||||
[5]:http://www.cnet.com/news/chrome-becoming-tool-in-googles-push-for-encrypted-web/
|
||||
[6]:https://twitter.com/JoshAlthuser
|
||||
@ -1,64 +0,0 @@
|
||||
eSpeak: Linux文本转语音工具
|
||||
================================================================================
|
||||

|
||||
|
||||
[eSpeak][1]是Linux的命令行工具,能把文本转变成语音。这是一款用C语言写就的精致的语音合成器,提供英语和其它多种语言支持。
|
||||
|
||||
eSpeak从标准输入或者输入文件中读取文本。虽然语音输出与真人声音相去甚远,但是,在你项目有用得到的地方,eSpeak仍不失为一个精致快捷的工具。
|
||||
|
||||
eSpeak部分主要特性如下:
|
||||
|
||||
- 为Linux和Windows准备的命令行工具
|
||||
- 从文件或者标准输入中把文本读出来
|
||||
- 提供给其它程序使用的共享库版本
|
||||
- 为Windows提供SAPI5版本,在screen-readers或者其它支持Windows SAPI5接口程序的支持下,eSpeak仍然能正常使用
|
||||
- 可移植到其它平台,包括安卓,OSX等
|
||||
- 多种特色声音提供选择
|
||||
- 语音输出可保存为[.WAV][2]格式的文件
|
||||
- 部分SSML([Speech Synthesis Markup Language][3])能为HTML所支持
|
||||
- 体积小巧,整个程序包括语言支持等占用不足2MB
|
||||
- 可以实现文本到音素编码的转化,能被其它语音合成引擎吸纳为前端工具
|
||||
- 可作为生成和调制音素数据的开发工具
|
||||
|
||||
### 安装eSpeak ###
|
||||
|
||||
基于Ubuntu的系统中,在终端运行以下命令安装eSpeak:
|
||||
|
||||
sudo apt-get install espeak
|
||||
|
||||
eSpeak is an old tool and I presume that it should be available in the repositories of other Linux distributions such as Arch Linux, Fedora etc. You can install eSpeak easily using dnf, pacman etc.eSpeak是一个古老的工具,我推测它应该能在其它众多Linux发行版如Arch,Fedora中运行。使用dnf,pacman等命令就能轻易安装。
|
||||
|
||||
eSpeak用法如下:输入espeak按enter键运行程序。输入字符按enter转换为语音输出(译补)。使用Ctrl+C来关闭运行中的程序。
|
||||
|
||||

|
||||
|
||||
还有其它可以的选项,可以通过程序帮助进行查看。
|
||||
|
||||
### GUI版本:Gespeaker ###
|
||||
|
||||
如果你更倾向于使用GUI版本,可以安装Gespeaker,它为eSpeak提供了GTK界面。
|
||||
|
||||
使用以下命令来安装Gespeaker:
|
||||
|
||||
sudo apt-get install gespeaker
|
||||
|
||||
操作接口简明易用,你完全可以自行探索。
|
||||
|
||||

|
||||
|
||||
虽然这个工具不能为大部分计算所用,但是当你的项目需要把文本转换成语音,espeak还是挺方便使用的。需则用之吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/espeak-text-speech-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/soooogreen)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://espeak.sourceforge.net/
|
||||
[2]:http://en.wikipedia.org/wiki/WAV
|
||||
[3]:http://en.wikipedia.org/wiki/Speech_Synthesis_Markup_Language
|
||||
@ -0,0 +1,209 @@
|
||||
# 19年KDE进化历程
|
||||
注:youtube 视频
|
||||
<iframe width="660" height="371" src="https://www.youtube.com/embed/1UG4lQOMBC4?feature=oembed" frameborder="0" allowfullscreen></iframe>
|
||||
|
||||
## 概述
|
||||
KDE – 史上功能最强大的桌面环境之一; 开源且免费。19年前,1996年10月14日,德国程序员 Matthias Ettrich 开始了编写这个美观的桌面环境。KDE提供了诸如shell以及其他很多日常使用的程序。今日,KDE被成千上万人在 Unix 和 Windows 上使用。19年----一个对软件项目而言极为漫长的年岁。现在是时候让我们回到最初,看看这一切从哪里开始了。
|
||||
|
||||
K Desktop Environment(KDE)有很多创新之处:新设计,美观,连贯性,易于使用,对普通用户和专业用户都足够强大的应用库。"KDE"这个名字是对单词"通用桌面环境"(Common Desktop Environment)玩的一个简单谐音游戏,"K"----"Cool"。 第一代KDE在双证书授权下使用了有专利的 Trolltech's Qt 框架 (现Qt的前身),这两个许可证分别是 open source QPL(Q public license) 和 商业专利许可证(proprietary commercial license)。在2000年 Trolltech 让一部分 Qt 软件库开始发布在 GPL 证书下; Qt 4.5 发布在了 LGPL 2.1 许可证下。自2009起 KDE 桌面环境由三部分构成:Plasma Workspaces (作Shell),KDE 应用,作为 KDE Software 编译的 KDE Platform.
|
||||
|
||||
## 各发布版本
|
||||
### Pre-Release – 1996年10月14日
|
||||

|
||||
|
||||
当时名称为 Kool Desktop Environment;"Kool"这个单词在很快就被弃用了。最初,所有KDE的组件都是被单独发布在开发社区里的,他们之间没有任何环绕大项目的组装配合。开发组邮件列表中的第一封通信是发往kde@fiwi02.wiwi.uni-Tubingen.de 的邮件。
|
||||
|
||||
### KDE 1.0 – 1998年7月12日
|
||||

|
||||
|
||||
这个版本受到了颇有争议的反馈。很多人反对使用Qt框架----当时的 FreeQt 许可证和自由软件许可证并不兼容----并建议开发组使用 Motif 或者 LessTif 替代。尽管有着这些反对声,KDE 仍然被很多用户所青睐,并且成功作为第一个Linux发行版的环境被集成了进去。(made its way into the first Linux distributions)
|
||||
|
||||

|
||||
|
||||
1999年1月28日
|
||||
|
||||
一次升级,**K Desktop Environment 1.1**,更快,更稳定的同时加入了很多小升级。这个版本同时也加入了很多新的图标,背景,外观文理。和这些全面翻新同时出现的还有 Torsten Rahn 绘制的全新KDE图标----齿轮前的3个K字母;这个图标的修改版也一直沿用至今。
|
||||
|
||||
### KDE 2.0 – 2000年10月23日
|
||||

|
||||
|
||||
重大更新:_ DCOP (Desktop COmmunication Protocol),一个端到端的通信协议 _ KIO,一个应用程序I/O库 _ KParts,组件对象模板 _ KHTML,一个符合 HTML 4.0 标准的图像绘制引擎。
|
||||
|
||||

|
||||
|
||||
2001年2月26日
|
||||
|
||||
**K Desktop Environment 2.1** 首次发布了媒体播放器 noatun,noatun使用了先进的模组-插件设计。为了便利开发者,K Desktop Environment 2.1 打包了 KDevelop
|
||||
|
||||

|
||||
|
||||
2001年8月15日
|
||||
|
||||
**KDE 2.2**版本在GNU/Linux上加快了50%的应用启动速度,同时提高了稳定性和 HTML、JavaScript的解析性能,同时还增加了一些 KMail 的功能。
|
||||
|
||||
### KDE 3.0 – 2002年4月3日
|
||||

|
||||
|
||||
K Desktop Environment 3.0 加入了更好的限制使用功能,这个功能在网咖,企业公用电脑上被广泛需求。
|
||||
|
||||

|
||||
|
||||
2003年1月28日
|
||||
|
||||
**K Desktop Environment 3.1** 加入了新的默认窗口(Keramik)和图标样式(Crystal)和其他一些改进。
|
||||
|
||||

|
||||
|
||||
2004年2月3日
|
||||
|
||||
**K Desktop Environment 3.2** 加入了诸如网页表格,书写邮件中拼写检查的新功能;补强了邮件和日历功能。完善了Konqueror 中的标签机制和对 Microsoft Windows 桌面共享协议的支持。
|
||||
|
||||

|
||||
|
||||
2004年8月19日
|
||||
|
||||
**K Desktop Environment 3.3** 侧重于组合不同的桌面组件。Kontact 被放进了群件应用Kolab 并与 Kpilot 结合。Konqueror 的加入让KDE有了更好的 IM 交流功能,比如支持发送文件,以及其他 IM 协议(如IRC)的支持。
|
||||
|
||||

|
||||
|
||||
2005年3月16日
|
||||
|
||||
**K Desktop Environment 3.4** 侧重于提高易用性。这次更新为Konqueror,Kate,KPDF加入了文字-语音转换功能;也在桌面系统中加入了独立的 KSayIt 文字-语音转换软件。
|
||||
|
||||

|
||||
|
||||
2005年11月29日
|
||||
|
||||
**The K Desktop Environment 3.5** 发布加入了 SuperKaramba,为桌面环境提供了易于安装的插件机制。 desktop. Konqueror 加入了广告屏蔽功能并成为了有史以来第二个通过Acid2 CSS 测试的浏览器。
|
||||
|
||||
### KDE SC 4.0 – 2008年1月11日
|
||||

|
||||
|
||||
大部分开组投身于把最新的技术和开发框架整合进 KDE 4 当中。Plasma 和 Oxygen 是两次最大的用户界面风格变更。同时,Dolphin 替代 Konqueror 成为默认文件管理器,Okular 成为了默认文档浏览器。
|
||||
|
||||

|
||||
|
||||
2008年7月29日
|
||||
|
||||
**KDE 4.1** 引入了一个在 PIM 和 Kopete 中使用的表情主题系统;引入了可以让用户便利地从互联网上一键下载数据的DXS。同时引入了 GStreamer,QuickTime,和 DirectShow 9 Phonon 后台。加入了新应用如:_ Dragon Player _ Kontact _ Skanlite – 扫描仪软件,_ Step – 物理模拟软件 * 新游戏: Kdiamond,Kollision,KBreakout 和更多......
|
||||
|
||||

|
||||
|
||||
2009年1月27日
|
||||
|
||||
**KDE 4.2** 被认为是在已经极佳的 KDE 4.1 基础上的又一次全面超越,同时也成为了大多数用户替换旧 3.5 版本的完美选择。
|
||||
|
||||

|
||||
|
||||
2009年8月4日
|
||||
|
||||
**KDE 4.3** 修复了超过10,000个 bugs,同时加入了让近2,000个被用户需求的功能。整合一些新的技术例如:PolicyKit,NetworkManage & Geolocation services 等也是这个版本的一大重点。
|
||||
|
||||

|
||||
|
||||
2010年2月9日
|
||||
|
||||
**KDE SC 4.4** 基础 Qt 4 开框架的 4.6 版本,新的应用 KAddressBook 被加入,同时也是is based on version 4.6 of the Qt 4 toolkit. New application – KAddressBook,Kopete首次发布。
|
||||
|
||||

|
||||
|
||||
2010年8月10日
|
||||
|
||||
**KDE SC 4.5** 增加了一些新特性:整合了 WebKit 库----一个开源的浏览器引擎库,现在也被在 Apple Safari 和 Google Chrome 中广泛使用。KPackageKit 替换了 Kpackage。
|
||||
|
||||

|
||||
|
||||
2011年1月26日
|
||||
|
||||
**KDE SC 4.6** 加强了 OpenGl 的性能,同时照常更新了无数bug和小改进。
|
||||
|
||||

|
||||
|
||||
2011年7月27日
|
||||
|
||||
**KDE SC 4.7** 升级 KWin 以兼容 OpenGL ES 2.0 ,更新了 Qt Quick,Plasma Desktop 中在应用里普遍使用的新特性 1.2万个bug被修复。
|
||||
|
||||

|
||||
|
||||
2012年1月25日
|
||||
|
||||
**KDE SC 4.8**: 更好的 KWin 性能与 Wayland 支持,更新了 Doplhin 的外观设计。
|
||||
|
||||

|
||||
|
||||
2012年8月1日
|
||||
|
||||
**KDE SC 4.9**: 向 Dolphin 文件管理器增加了一些更新,比如加入了实时文件重命名,鼠标辅助按钮支持,更好的位置标签和更多文件分类管理功能。
|
||||
|
||||

|
||||
|
||||
2013年2月6日
|
||||
|
||||
**KDE SC 4.10**: 很多 Plasma 插件使用 QML 重写; Nepomuk,Kontact 和 Okular 得到了很大程度的性能和功能提升。
|
||||
|
||||

|
||||
|
||||
2013年8月14日
|
||||
|
||||
**KDE SC 4.11**: Kontact 和 Nepomuk 有了很大的优化。 第一代 Plasma Workspaces 进入了仅有维护而没有新生开发的软件周期。
|
||||
|
||||

|
||||
|
||||
2013年12月18日
|
||||
|
||||
**KDE SC 4.12**: Kontact 得到了极大的提升。
|
||||
|
||||

|
||||
|
||||
2014年4月16日
|
||||
|
||||
**KDE SC 4.13**: Nepomuk 语义搜索功能替代了桌面上的原有的Baloo搜索。 KDE SC 4.13 发布了53个语言版本。
|
||||
|
||||

|
||||
|
||||
2014年8月20日
|
||||
|
||||
**KDE SC 4.14**: 这个发布版本侧重于稳定性提升:大量的bug修复和小更新。这是最后一个 KDE SC 4 发布版本。
|
||||
|
||||
### KDE Plasma 5.0 – 2014年7月15日
|
||||

|
||||
|
||||
KDE Plasma 5 – 第五代 KDE。大幅改进了设计和系统,新的默认主题 ---- Breeze,完全迁移到了 QML,更好的 OpenGL 性能,更完美的 HiDPI (高分辨率)显示支持。
|
||||
|
||||

|
||||
|
||||
2014年11月11日
|
||||
|
||||
**KDE Plasma 5.1**:加入了Plasma 4里原先没有补完的功能。
|
||||
|
||||

|
||||
|
||||
2015年1月27日
|
||||
|
||||
**KDE Plasma 5.2**:新组件:BlueDevil,KSSHAskPass,Muon,SDDM 主题设置,KScreen,GTK+ 样式设置 和 KDecoration.
|
||||
|
||||

|
||||
|
||||
2015年4月28日
|
||||
|
||||
**KDE Plasma 5.3**:Plasma Media Center 技术预览。新的蓝牙和触摸板小程序;改良了电源管理。
|
||||
|
||||

|
||||
|
||||
2015年8月25日
|
||||
|
||||
**KDE Plasma 5.4**:Wayland 登场,新的基于 QML 的音频管理程序,交替式全屏程序显示。
|
||||
|
||||
万分感谢 [KDE][1] 开发者和社区及Wikipedia 为书写 [概述][2] 带来的帮助,同时,感谢所有读者。希望大家保持自由精神(be free)并继续支持如同 KDE 一样的开源的自由软件发展。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://tlhp.cf/kde-history/](https://tlhp.cf/kde-history/)
|
||||
|
||||
作者:[Pavlo RudyiCategories][a] 译者:[jerryling315](https://github.com/jerryling315) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://www.kde.org/
|
||||
[2]: https://en.wikipedia.org/wiki/KDE_Plasma_5
|
||||
[a]: https://tlhp.cf/author/paul/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user