mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
4a2411782d
@ -1,16 +1,6 @@
|
||||
如何在 Debian 中使用 badIPs.com 保护你的服务器并通过 Fail2ban 报告 IP
|
||||
使用 badIPs.com 保护你的服务器,并通过 Fail2ban 报告恶意 IP
|
||||
============================================================
|
||||
|
||||
### 文章导航
|
||||
|
||||
1. [使用 badIPs 列表][4]
|
||||
1. [定义安全等级和类别][1]
|
||||
2. [创建脚本][5]
|
||||
3. [使用 Fail2ban 向 badIPs 报告 IP][6]
|
||||
1. [Fail2ban >= 0.8.12][2]
|
||||
2. [Fail2ban < 0.8.12][3]
|
||||
4. [你的 IP 报告统计信息][7]
|
||||
|
||||
这篇指南向你介绍使用 badips 滥用追踪器(abuse tracker) 和 Fail2ban 保护你的服务器或计算机的步骤。我已经在 Debian 8 Jessie 和 Debian 7 Wheezy 系统上进行了测试。
|
||||
|
||||
**什么是 badIPs?**
|
||||
@ -21,158 +11,177 @@ BadIps 是通过 [fail2ban][8] 报告为不良 IP 的列表。
|
||||
|
||||
### 使用 badIPs 列表
|
||||
|
||||
### 定义安全等级和类别
|
||||
#### 定义安全等级和类别
|
||||
|
||||
你可以通过使用 REST API 获取 IP 地址列表。
|
||||
|
||||
当你使用 GET 请求获取 URL:[https://www.badips.com/get/categories][9] 后,你就可以看到服务中现有的所有不同类别。
|
||||
|
||||
* 第二步,决定适合你的等级。
|
||||
参考 badips 应该有所帮助(我个人使用 scope=3):
|
||||
* 如果你想要编译统计信息或者将数据用于实验目的,那么你应该用等级 0 开始。
|
||||
* 如果你想用防火墙保护你的服务器或者网站,使用等级 2。可能也要和你的结果相结合,尽管它们可能没有超过 0 或 1 的等级。
|
||||
* 当你使用 GET 请求获取 URL:[https://www.badips.com/get/categories][9] 后,你就可以看到服务中现有的所有不同类别。
|
||||
* 第二步,决定适合你的等级。 参考 badips 应该有所帮助(我个人使用 `scope = 3`):
|
||||
* 如果你想要编译一个统计信息模块或者将数据用于实验目的,那么你应该用等级 0 开始。
|
||||
* 如果你想用防火墙保护你的服务器或者网站,使用等级 2。可能也要和你的结果相结合,尽管它们可能没有超过 0 或 1 的情况。
|
||||
* 如果你想保护一个网络商店、或高流量、赚钱的电子商务服务器,我推荐你使用值 3 或 4。当然还是要和你的结果相结合。
|
||||
* 如果你是偏执狂,那就使用 5。
|
||||
|
||||
现在你已经有了两个变量,通过把它们两者连接起来获取你的链接。
|
||||
|
||||
```
|
||||
http://www.badips.com/get/list/{{SERVICE}}/{{LEVEL}}
|
||||
```
|
||||
|
||||
注意:像我一样,你可以要求所有服务。在这种情况下把服务的名称改为 “any”。
|
||||
注意:像我一样,你可以获取所有服务。在这种情况下把服务的名称改为 `any`。
|
||||
|
||||
最终的 URL 就是:
|
||||
|
||||
```
|
||||
https://www.badips.com/get/list/any/3
|
||||
```
|
||||
|
||||
### 创建脚本
|
||||
|
||||
所有都完成了之后,我们就会创建一个简单的脚本。
|
||||
|
||||
1. 把你的列表放到一个临时文件。
|
||||
2. 在 iptables 中创建一个 chain(只需要一次)。(译者注:iptables 可能包括多个表(tables),表可能包括多个链(chains),链可能包括多个规则(rules))
|
||||
3. 把所有链接的数据(旧条目)刷到 chain。
|
||||
4. 把每个 IP 连接到新的 chain。
|
||||
5. 完成后,阻塞所有链接到 chain 的 INPUT / OUTPUT /FORWARD。
|
||||
6. 删除我们的临时文件。
|
||||
1、 把你的列表放到一个临时文件。
|
||||
|
||||
2、 在 iptables 中创建一个链(chain)(只需要创建一次)。(LCTT 译注:iptables 可能包括多个表(tables),表可能包括多个链(chains),链可能包括多个规则(rules))
|
||||
|
||||
3、 把所有链接到该链的数据(旧条目)刷掉。
|
||||
|
||||
4、 把每个 IP 链接到这个新的链。
|
||||
|
||||
5、 完成后,阻塞所有链接到该链的 INPUT / OUTPUT /FORWARD 请求。
|
||||
|
||||
6、 删除我们的临时文件。
|
||||
|
||||
为此,我们创建脚本:
|
||||
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
```
|
||||
cd /home/<user>/
|
||||
vi myBlacklist.sh
|
||||
```
|
||||
|
||||
把以下内容输入到文件。
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
### based on this version http://www.timokorthals.de/?p=334
|
||||
### adapted by Stéphane T.
|
||||
|
||||
#!/bin/sh
|
||||
# based on this version http://www.timokorthals.de/?p=334
|
||||
# adapted by Stéphane T.
|
||||
|
||||
_ipt=/sbin/iptables # iptables 路径(应该是对的)
|
||||
_input=badips.db # 数据库的名称(会用这个名称下载)Name of database (will be downloaded with this name)
|
||||
_pub_if=eth0 # 连接到网络的设备(执行 $ifconfig 获取)Device which is connected to the internet (ex. $ifconfig for that)
|
||||
_droplist=droplist # iptables 中 chain 的名称(只有当你已经有这么一个名称的 chain 时才修改它)Name of chain in iptables (Only change this if you have already a chain with this name)
|
||||
_level=3 # Blog(译者注:Bad log)等级:不怎么坏(0)、确认坏(3)、相当坏(5)(从 www.badips.com 获取详情)Blog level: not so bad/false report (0) over confirmed bad (3) to quite aggressive (5) (see www.badips.com for that)
|
||||
_service=any # 记录日志的服务(从 www.badips.com 获取详情)Logged service (see www.badips.com for that)
|
||||
|
||||
# 获取不良 IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### 设置我们的黑名单 ###
|
||||
# 首先刷盘
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
# 创建新的 chain
|
||||
# 首次运行时取消下面一行的注释
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
# 过滤掉注释和空行
|
||||
# 保存每个 ip 到 $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
# 添加到 $_droplist
|
||||
_ipt=/sbin/iptables ### iptables 路径(应该是这个)
|
||||
_input=badips.db ### 数据库的名称(会用这个名称下载)
|
||||
_pub_if=eth0 ### 连接到互联网的设备(执行 $ifconfig 获取)
|
||||
_droplist=droplist ### iptables 中链的名称(如果你已经有这么一个名称的链,你就换另外一个)
|
||||
_level=3 ### Blog(LCTT 译注:Bad log)等级:不怎么坏(0)、确认坏(3)、相当坏(5)(从 www.badips.com 获取详情)
|
||||
_service=any ### 记录日志的服务(从 www.badips.com 获取详情)
|
||||
|
||||
# 获取不良 IPs
|
||||
wget -qO- http://www.badips.com/get/list/${_service}/$_level > $_input || { echo "$0: Unable to download ip list."; exit 1; }
|
||||
|
||||
### 设置我们的黑名单 ###
|
||||
### 首先清除该链
|
||||
$_ipt --flush $_droplist
|
||||
|
||||
### 创建新的链
|
||||
### 首次运行时取消下面一行的注释
|
||||
# $_ipt -N $_droplist
|
||||
|
||||
### 过滤掉注释和空行
|
||||
### 保存每个 ip 到 $ip
|
||||
for ip in `cat $_input`
|
||||
do
|
||||
### 添加到 $_droplist
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j LOG --log-prefix "Drop Bad IP List "
|
||||
$_ipt -A $_droplist -i ${_pub_if} -s $ip -j DROP
|
||||
done
|
||||
|
||||
# 最后,插入或者追加我们的黑名单列表
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
# 删除你的临时文件
|
||||
rm $_input
|
||||
exit 0
|
||||
done
|
||||
|
||||
### 最后,插入或者追加到我们的黑名单列表
|
||||
$_ipt -I INPUT -j $_droplist
|
||||
$_ipt -I OUTPUT -j $_droplist
|
||||
$_ipt -I FORWARD -j $_droplist
|
||||
|
||||
完成这些后,你应该创建一个 cronjob 定期更新我们的黑名单。
|
||||
### 删除你的临时文件
|
||||
rm $_input
|
||||
exit 0
|
||||
```
|
||||
|
||||
完成这些后,你应该创建一个定时任务定期更新我们的黑名单。
|
||||
|
||||
为此,我使用 crontab 在每天晚上 11:30(在我的延迟备份之前) 运行脚本。
|
||||
|
||||
crontab -e
|
||||
|
||||
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
```
|
||||
23 30 * * * /home/<user>/myBlacklist.sh #Block BAD IPS
|
||||
```
|
||||
|
||||
别忘了更改脚本的权限:
|
||||
|
||||
````
|
||||
chmod + x myBlacklist.sh
|
||||
```
|
||||
|
||||
现在终于完成了,你的服务器/计算机应该更安全了。
|
||||
|
||||
你也可以像下面这样手动运行脚本:
|
||||
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
```
|
||||
cd /home/<user>/
|
||||
./myBlacklist.sh
|
||||
```
|
||||
|
||||
它可能要花费一些时间,因此期间别中断脚本。事实上,耗时取决于最后一行。
|
||||
它可能要花费一些时间,因此期间别中断脚本。事实上,耗时取决于该脚本的最后一行。
|
||||
|
||||
### 使用 Fail2ban 向 badIPs 报告 IP 地址
|
||||
|
||||
在本篇指南的第二部分,我会向你展示如何通过使用 Fail2ban 向 badips.com 网站报告不良 IP 地址。
|
||||
|
||||
### Fail2ban >= 0.8.12
|
||||
#### Fail2ban >= 0.8.12
|
||||
|
||||
通过 Fail2ban 完成报告。取决于你 Fail2ban 的版本,你要使用本章的第一或第二节。
|
||||
|
||||
如果你 fail2ban 的版本是 0.8.12 或更新版本。
|
||||
|
||||
fail2ban-server --version
|
||||
```
|
||||
fail2ban-server --version
|
||||
```
|
||||
|
||||
在每个你要报告的类别中,添加一个action。
|
||||
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
在每个你要报告的类别中,添加一个 action。
|
||||
|
||||
```
|
||||
[ssh]
|
||||
enabled = true
|
||||
action = iptables-multiport
|
||||
badips[category=ssh]
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry= 6
|
||||
```
|
||||
|
||||
正如你看到的,类别是 SSH,从 ([https://www.badips.com/get/categories][11]) 查找正确类别。
|
||||
|
||||
### Fail2ban < 0.8.12
|
||||
#### Fail2ban < 0.8.12
|
||||
|
||||
如果版本是 0.8.12 之前,你需要新建一个 action。你可以从 [https://www.badips.com/asset/fail2ban/badips.conf][12] 下载。
|
||||
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
```
|
||||
wget https://www.badips.com/asset/fail2ban/badips.conf -O /etc/fail2ban/action.d/badips.conf
|
||||
```
|
||||
|
||||
在上面的 badips.conf 中,你可以像前面那样激活每个类别,也可以全局启用它:
|
||||
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
```
|
||||
cd /etc/fail2ban/
|
||||
vi jail.conf
|
||||
```
|
||||
|
||||
```
|
||||
[DEFAULT]
|
||||
...
|
||||
|
||||
[DEFAULT]
|
||||
|
||||
...
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
|
||||
banaction = iptables-multiport
|
||||
badips
|
||||
```
|
||||
|
||||
现在重启 fail2ban - 从现在开始它就应该开始报告了。
|
||||
|
||||
@ -180,21 +189,21 @@ chmod + x myBlacklist.sh
|
||||
|
||||
### 你的 IP 报告统计信息
|
||||
|
||||
最后一步 - 没那么有用。你可以创建一个密钥。
|
||||
如果你想看你的数据,这一步就很有帮助。
|
||||
最后一步 - 没那么有用。你可以创建一个密钥。 但如果你想看你的数据,这一步就很有帮助。
|
||||
|
||||
复制/粘贴下面的命令,你的控制台中就会出现一个 JSON 响应。
|
||||
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
```
|
||||
wget https://www.badips.com/get/key -qO -
|
||||
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
```
|
||||
|
||||
{
|
||||
"err":"",
|
||||
"suc":"new key 5f72253b673eb49fc64dd34439531b5cca05327f has been set.",
|
||||
"key":"5f72253b673eb49fc64dd34439531b5cca05327f"
|
||||
}
|
||||
|
||||
|
||||
到[badips][13] 网站,输入你的 “key” 并点击 “statistics”。
|
||||
到 [badips][13] 网站,输入你的 “key” 并点击 “statistics”。
|
||||
|
||||
现在你就可以看到不同类别的统计信息。
|
||||
|
||||
@ -204,7 +213,7 @@ via: https://www.howtoforge.com/tutorial/protect-your-server-computer-with-badip
|
||||
|
||||
作者:[Stephane T][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Windows 木马黑进嵌入式设备来安装 Mirai
|
||||
Windows 木马攻破嵌入式设备来安装 Mirai 恶意软件
|
||||
============================================================
|
||||
|
||||
> 木马尝试使用出厂默认凭证对不同协议进行身份验证,如果成功则会部署 Mirai 僵尸程序。
|
||||
@ -31,7 +31,7 @@ Doctor Web 发现的新木马被称为 [Trojan.Mirai.1][23],从它可以看到
|
||||
|
||||
via: http://www.csoonline.com/article/3168357/security/windows-trojan-hacks-into-embedded-devices-to-install-mirai.html
|
||||
|
||||
作者:[ Lucian Constantin][a]
|
||||
作者:[Lucian Constantin][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
Arrive On Time With NTP -- Part 1: Usage Overview
|
||||
============================================================
|
||||
|
||||

|
||||
In this first of a three-part series, Chris Binnie looks at why NTP services are essential to a happy infrastructure.[Used with permission][1]
|
||||
|
||||
Few services on the Internet can claim to be so critical in nature as time. Subtle issues which affect the timekeeping of your systems can sometimes take a day or two to be realized, and they are almost always unwelcome because of the knock-on effects they cause.
|
||||
|
||||
Consider as an example that your backup server loses connectivity to your Network Time Protocol (NTP) server and, over a period of a few days, introduces several hours of clock skew. Your colleagues arrive at work at 9am as usual only to find the bandwidth-intensive backups consuming all the network resources meaning that they can barely even log into their workstations to start their day’s work until the backup has finished.
|
||||
|
||||
In this first of a three-part series, I’ll provide brief overview of NTP to help prevent such disasters. From the timestamps on your emails to remembering when you started your shift at work, NTP services are essential to a happy infrastructure.
|
||||
|
||||
You might consider that the really important NTP servers (from which other servers pick up their clock data) are at the bottom of an inverted pyramid and referred to as Stratum 1 servers (also known as “primary” servers). These servers speak directly to national time services (known as Stratum 0, which might be devices such as atomic clocks or GPS clocks, for example). There are a number of ways of communicating with them securely, via satellite or radio, for example.
|
||||
|
||||
Somewhat surprisingly, it’s reasonably common for even large enterprises to connect to Stratum 2 servers (or “secondary” servers) as opposed to primary servers. Stratum 2 servers, as you’d expect, synchronize directly with Stratum 1 servers. If you consider that a corporation might have their own onsite NTP servers (at least two, usually three, for resilience) then these would be Stratum 3 servers. As a result, such a corporation’s Stratum 3 servers would then connect upstream to predefined secondary servers and dutifully pass the time onto its many client and server machines as an accurate reflection of the current time.
|
||||
|
||||
A simple design component of NTP is that it works on the premise -- thanks to the large geographical distances travelled by Internet traffic -- that round-trip times (of when a packet was sent and how many seconds later it was received) are sensibly taken into account before trusting to a time as being entirely accurate. There’s a lot more to setting a computer’s clock than you might at first think, if you don’t believe me, then [this fascinating web page][3] is well worth looking at.
|
||||
|
||||
At the risk of revisiting the point, NTP is so key to making sure your infrastructure functions as expected that the Stratum servers to which your NTP servers connect to fuel your internal timekeeping must be absolutely trusted and additionally offer redundancy. There’s an informative list of the Stratum 1 servers available at the [main NTP site][4].
|
||||
|
||||
As you can see from that list, some NTP Stratum 1 servers run in a “ClosedAccount” state; these servers can’t be used without prior consent. However, as long as you adhere to their usage guidelines, “OpenAccess” servers are indeed open for polling. Any “RestrictedAccess” servers can sometimes be limited due to a maximum number of clients or a minimum poll interval. Additionally, these are sometimes only available to certain types of organizations, such as academia.
|
||||
|
||||
### Respect My Authority
|
||||
|
||||
On a public NTP server, you are likely to find that the usage guidelines follow several rules. Let’s have a look at some of them now.
|
||||
|
||||
The “iburst” option involves a client sending a number of packets (eight packets rather than the usual single packet) to an NTP server should it not respond during at a standard polling interval. If, after shouting loudly at the NTP server a few times within a short period of time, a recognized response isn’t forthcoming, then the local time is not changed.
|
||||
|
||||
Unlike “iburst” the “burst” option is not commonly allowed (so don’t use it!) as per the general rules for NTP servers. That option instead sends numerous packets (eight again apparently) at each polling interval and also when the server is available. If you are continually throwing packets at higher-up Stratum servers even when they are responding normally, you may get blacklisted for using the “burst” option.
|
||||
|
||||
Clearly, how often you connect to a server makes a difference to its load (and the negligible amount of bandwidth used). These settings can be configured locally using the “minpoll” and “maxpoll” options. However, to follow the connecting rules on to an NTP server, you shouldn’t generally alter the the defaults of 64 seconds and 1024 seconds, respectively.
|
||||
|
||||
Another, far from tacit, rule is that clients should always respect Kiss-Of-Death (KOD) messages generated by those servers from which they request time. If an NTP server doesn’t want to respond to a particular request, similar to certain routing and firewalling techniques, then it’s perfectly possible for it to simply discard or blackhole any associated packets.
|
||||
|
||||
In other words, the recipient server of these unwanted packets takes on no extra load to speak of and simply drops the traffic that it doesn’t think it should serve a response to. As you can imagine, however, this isn’t always entirely helpful, and sometimes it’s better to politely ask the client to cease and desist, rather than ignoring the requests. For this reason, there’s a specific packet type called the KOD packet. Should a client be sent an unwelcome KOD packet then it should then remember that particular server as having responded with an access-denied style marker.
|
||||
|
||||
If it’s not the first KOD packet received from back the server, then the client assumes that there is a rate-limiting condition (or something similar) present on the server. It’s common at this stage for the client to write to its local logs, noting the less-than-satisfactory outcome of the transaction with that particular server, if you ever need to troubleshoot such a scenario.
|
||||
|
||||
Bear in mind that, for obvious reasons, it’s key that your NTP’s infrastructure be dynamic. Thus, it’s important not to hard-code IP addresses into your NTP config. By using DNS names, individual servers can fall off the network and the service can still be maintained, IP address space can be reallocated and simple load balancing (with a degree of resilience) can be introduced.
|
||||
|
||||
Let’s not forget that we also need to consider that the exponential growth of the Internet of Things (IoT), eventually involving billions of new devices, will mean a whole host of equipment will need to keep its wristwatches set to the correct time. Should a hardware vendor inadvertently (or purposely) configure their devices to only communicate with one provider’s NTP servers (or even a single server) then there can be -- and have been in the past -- very unwelcome issues.
|
||||
|
||||
As you might imagine, as more units of hardware are purchased and brought online, the owner of the NTP infrastructure is likely to be less than grateful for the associated fees that they are incurring without any clear gain. This scenario is far from being unique to the realms of fantasy. Ongoing headaches -- thanks to NTP traffic forcing a provider’s infrastructure to creak -- have been seen several times over the last few years.
|
||||
|
||||
In the next two articles, I’ll look at some important NTP configuration options and examine server setup.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -1,67 +0,0 @@
|
||||
5 Open Source Software Defined Networking Projects to Know
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
SDN is beginning to redefine corporate networking; here are five open source projects you should know.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
Throughout 2016, Software Defined Networking (SDN) continued to rapidly evolve and gain maturity. We are now beyond the conceptual phase of open source networking, and the companies that were assessing the potential of these projects two years ago have begun enterprise deployments. As has been predicted for several years, SDN is beginning to redefine corporate networking.
|
||||
|
||||
Market researchers are essentially unanimous on the topic. IDC published[ a study][3] of the SDN market earlier this year and predicted a 53.9 percent CAGR from 2014 through 2020, at which point the market will be valued at $12.5 billion. In addition, the Technology Trends 2016 report ranked SDN as the best technology investment for 2016.
|
||||
|
||||
"Cloud computing and the 3rd Platform have driven the need for SDN, which will represent a market worth more than $12.5 billion in 2020\. Not surprisingly, the value of SDN will accrue increasingly to network-virtualization software and to SDN applications, including virtualized network and security services. Large enterprises are now realizing the value of SDN in the datacenter, but ultimately, they will also recognize its applicability across the WAN to branch offices and to the campus network," said[ Rohit Mehra][4], Vice President of Network Infrastructure at IDC.
|
||||
|
||||
The Linux Foundation recently[ ][5]announced the release of its 2016 report[ "Guide to the Open Cloud: Current Trends and Open Source Projects."][6] This third annual report provides a comprehensive look at the state of open cloud computing, and includes a section on unikernels. You can[ download the report][7] now, and one of the first things to notice is that it aggregates and analyzes research, illustrating how trends in containers, unikernels, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series, we are looking at various categories and providing extra insight on how the areas are evolving. Below, you’ll find several important SDN projects and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
### Software-Defined Networking
|
||||
|
||||
[ONOS][8]
|
||||
|
||||
Open Network Operating System (ONOS), a Linux Foundation project, is a software-defined networking OS for service providers that has scalability, high availability, high performance and abstractions to create apps and services. [ONOS on GitHub][9]
|
||||
|
||||
[OpenContrail][10]
|
||||
|
||||
OpenContrail is Juniper Networks’ open source network virtualization platform for the cloud. It provides all the necessary components for network virtualization: SDN controller, virtual router, analytics engine, and published northbound APIs. Its REST API configures and gathers operational and analytics data from the system. [OpenContrail on GitHub][11]
|
||||
|
||||
[OpenDaylight][12]
|
||||
|
||||
OpenDaylight, an OpenDaylight Foundation project at The Linux Foundation, is a programmable, software-defined networking platform for service providers and enterprises. Based on a microservices architecture, it enables network services across a spectrum of hardware in multivendor environments. [OpenDaylight on GitHub][13]
|
||||
|
||||
[Open vSwitch][14]
|
||||
|
||||
Open vSwitch, a Linux Foundation project, is a production-quality, multilayer virtual switch. It’s designed for massive network automation through programmatic extension, while still supporting standard management interfaces and protocols including NetFlow, sFlow, IPFIX, RSPAN, CLI, LACP, and 802.1ag. It supports distribution across multiple physical servers similar to VMware’s vNetwork distributed vswitch or Cisco’s Nexus 1000V. [OVS on GitHub][15]
|
||||
|
||||
[OPNFV][16]
|
||||
|
||||
Open Platform for Network Functions Virtualization (OPNFV), a Linux Foundation project, is a reference NFV platform for enterprise and service provider networks. It brings together upstream components across compute, storage and network virtualization in order create an end-to-end platform for NFV applications. [OPNFV on Bitergia][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/5-open-source-software-defined-networking-projects-know
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-defined-networkingjpg-0
|
||||
[3]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[4]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[5]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[6]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[7]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[8]:http://onosproject.org/
|
||||
[9]:https://github.com/opennetworkinglab/onos
|
||||
[10]:http://www.opencontrail.org/
|
||||
[11]:https://github.com/Juniper/contrail-controller
|
||||
[12]:https://www.opendaylight.org/
|
||||
[13]:https://github.com/opendaylight
|
||||
[14]:http://openvswitch.org/
|
||||
[15]:https://github.com/openvswitch/ovs
|
||||
[16]:https://www.opnfv.org/
|
||||
[17]:http://projects.bitergia.com/opnfv/browser/
|
||||
@ -1,130 +0,0 @@
|
||||
wcnnbdk1 translating
|
||||
### Basics of network protocol analyzer Wireshark On Linux
|
||||
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Installation][4]
|
||||
* [2. Basic Configuration][5]
|
||||
* [2.1. Layout][1]
|
||||
* [2.2. Toolbars][2]
|
||||
* [2.3. Functionality][3]
|
||||
* [3. Capture][6]
|
||||
* [4. Reading Data][7]
|
||||
* [5. Closing Thoughts][8]
|
||||
|
||||
Wireshark is just one of the valuable tools provided by Kali Linux. Like the others, it can be used for either positive or negative purposes. Of course, this guide will cover monitoring _your own_ network traffic to detect any potentially unwanted activity.
|
||||
|
||||
Wireshark is incredibly powerful, and it can appear daunting at first, but it serves the single purpose of monitoring network traffic, and all of those many options that it makes available only serve to enhance it's monitoring ability.
|
||||
|
||||
### Installation
|
||||
|
||||
Kali ships with Wireshark. However, the `wireshark-gtk` package provides a nicer interface that makes working with Wireshark a much friendlier experience. So, the first step in using Wireshark is installing the `wireshark-gtk` package.
|
||||
```
|
||||
# apt install wireshark-gtk
|
||||
```
|
||||
Don't worry if you're running Kali on a live medium. It'll still work.
|
||||
|
||||
### Basic Configuration
|
||||
|
||||
Before you do anything else, it's probably best to set Wireshark up the way you will be most comfortable using it. Wireshark offers a number of different layouts as well as options that configure the program's behavior. Despite their numbers, using them is fairly straightforward.
|
||||
|
||||
Start out by opening Wireshark-gtk. Make sure it is the GTK version. They are listed separately by Kali.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
### Layout
|
||||
|
||||
By default, Wireshark has three sections stacked on top of one another. The top section is the list of packets. The middle section is the packet details. The bottom section contains the raw packet bytes. For most uses, the top two are much more useful than the last, but can still be great information for more advanced users.
|
||||
|
||||
The sections can be expanded and contracted, but that stacked layout isn't for everyone. You can alter it in Wireshark's "Preferences" menu. To get there, click on "Edit" then "Preferences..." at the bottom of the drop down. That will open up a new window with more options. Click on "Layout" under "User Interface" on the side menu.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
You will now see different available layout options. The illustrations across the top allow you to select the positioning of the different panes, and the radio button selectors allow you to select the data that will go in each pane.
|
||||
|
||||
The tab below, labelled "Columns," allows you to select which columns will be displayed by Wireshark in the list of packets. Select only the ones with the data you need, or leave them all checked.
|
||||
|
||||
### Toolbars
|
||||
|
||||
There isn't too much that you can do with the toolbars in Wireshark, but if you want to customize them, you can find some useful setting on the same "Layout" menu as the pane arrangement tools in the last section. There are toolbar options directly below the pane options that allow you to change how the toolbars and toolbar items are displayed.
|
||||
|
||||
You can also customize which toolbars are displayed under the "View" menu by checking and unchecking them.
|
||||
|
||||
### Functionality
|
||||
|
||||
The majority of the controls for altering how Wireshark captures packets are collected can be found under "Capture" in "Options."
|
||||
|
||||
The top "Capture" section of the window allows you to select which networking interfaces Wireshark should monitor. This could differ greatly depending on your system and how it's configured. Just be sure to check the right boxes to get the right data. Virtual machines and their accompanying networks will show up in this list. There will also be multiple options for multiple network interface cards.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Directly below the listing of network interfaces are two options. One allows you to select all interfaces. The other allows you to enable or disable promiscuous mode. This allows your computer to monitor the traffic of all other computers on the selected network. If you are trying to monitor your whole network, this is the option you want.
|
||||
|
||||
**WARNING:** using promiscuous mode on a network that you do not own or have permission to monitor is illegal!
|
||||
|
||||
On the bottom left of the screen are the "Display Options" and "Name Resolution" sections. For "Display Options," it's probably a good idea to leave all three checked. If you want to uncheck them, it's okay, but "Update list of packets in real time" should probably remain checked at all times.
|
||||
|
||||
Under "Name Resolution" you can pick your preference. Having more options checked will create more requests and clutter up your packet list. Checking for MAC resolutions is a good idea to see the brand of the networking hardware being used. It helps you identify which machines and interfaces are interacting.
|
||||
|
||||
### Capture
|
||||
|
||||
Capture is at the core of Wireshark. It's primary purpose is it monitor and record traffic on a specified network. It does this, in its most basic form, very simply. Of course, more configuration and options can be used to utilize more of Wireshark's power. This intro section, though, will be sticking to the most basic recording.
|
||||
|
||||
To start a new capture, press the new live capture button. It should look like a blue shark fin.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
While capturing, Wireshark will gather all of the packet data that it can and record it. Depending on your settings, you should see new packets coming in on the "Packet Listing" pane. You can click on each one you find interesting and investigate in real time, or you can simply walk away and let Wireshark run.
|
||||
|
||||
When you're done, press the red square "Stop" button. Now, you can choose to either save or discard your capture. To save, you can click on "File" then "Save" or "Save as."
|
||||
|
||||
### Reading Data
|
||||
|
||||
Wireshark aims to provide you with all of the data that you will need. In doing so, it collects a large amount of data related to the network packets that it is monitoring. It tries to make this data less daunting by breaking it down in collapsible tabs. Each tab corresponds to a piece of the request data tied to the packet.
|
||||
|
||||
The tabs are stacked in order from lowest level to highest level. The top tab will always contain data on the bytes contained in the packet. The lowest tab will vary. In the case of an HTTP request, it will contain the HTTP information. The majority of packets that you encounter will be TCP data, and that will be the bottom tab.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Each tab contains data relevant data for that part of the packet. An HTTP packet will contain information pertaining to the type of request, the web browser used, IP address of the server, language, and encoding data. A TCP packet will contain information on which ports are being used on both the client and server as well as flags being used for the TCP handshake process.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
The other upper fields will contain less information that will interest most users. There is a tab containing information on whether or not the packet was transferred via IPv4 or IPv6 as well as the IP addresses of the client and the server. Another tab provides the MAC address information for both the client machine and the router or gateway used to access the internet.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
Even with just these basics, you can see how powerful of a tool Wireshark can be. Monitoring your network traffic can help to stop cyber attacks or just improve connection speeds. It can also help you chase down problem applications. The next Wireshark guide will explore the options available for filtering packets with Wireshark.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
[1]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-1-layout
|
||||
[2]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-2-toolbars
|
||||
[3]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-3-functionality
|
||||
[4]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h1-installation
|
||||
[5]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-basic-configuration
|
||||
[6]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h3-capture
|
||||
[7]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h4-reading-data
|
||||
[8]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,62 @@
|
||||
用 NTP 把控时间 -- 第一部分:使用概览
|
||||
============================================================
|
||||
|
||||

|
||||
这系列共三部分,首先,Chirs Binnie考量了一个令人愉快的基础建设中 NTP 服务的重要性。[经许可使用][1]
|
||||
|
||||
鲜有网络服务器在计时方面称得上是标准。影响你系统的时间计时的小问题可能花了一两天被发现,这样的不速之客通常会引起连锁效应。
|
||||
|
||||
设想你的备份服务器与网络时间协议(NTP)断开连接,过了几天,引起几小时的时间扭曲。你的同事照常九点上班,发现 bandwidth-intensive 类型的备份服务器消耗了所有网络资源,这也就意味着他们在备份完成之前几乎不能登录工作台开始他们的日常工作。
|
||||
|
||||
这系列共三部分,首先,我将提供简要介绍 NTP 防止这种困境的发生。从邮件的时间戳到记录你工作的进展,NTP 服务对于一个令人愉快的基础建设是如此重要。
|
||||
|
||||
想想非常重要的 NTP 服务器 (其他服务器时间数据来源) 是倒置金字塔的底部,与第1层的服务器(也被称为“主要”服务器)相关。这些服务器(0层,是原子钟和GPS钟之类的装置)与自然时间直接交互。安全沟通的方法很多,例如通过卫星或者无线电。
|
||||
|
||||
令人惊讶的是,几乎所有的大型企业都会连接二层服务器(或“次级”服务器)而是不主服务器。如你所料,二层服务器和一层直接同步。如果你觉得大公司可能有自己的本地 NTP 服务器(至少两个,通常三个,为了恢复),这样就会有三层服务器。结果,第3层服务器将连接上层去预定义次级服务器,负责任地传递时间给客户端和服务器作为当前时间的精确反馈。
|
||||
|
||||
简单设计构成的 NTP 工作前提是——多亏了英特网通路走过大量地理距离——在信任时间完全准确之前,来回时间(包什么时候发出和多少秒后被收到)都会被清楚记录。设置电脑时间比你想象的要多做很多,如果你不信我,那[这神奇的网站][3]值得一看。
|
||||
|
||||
由于有重复访问节点的风险,NTP 如此关键以至于 NTP 与层次服务器之间的连接被期望必须确保内部计时完全被信赖并且能提供额外信息。有一个有用的 Stratum 1 服务器列表在 [主 NTP 站点][4].
|
||||
|
||||
正如你在列表所见,一些 NTP 一层服务器以“ClosedAccount”状态运行;这些服务器需要提前同意才可以使用。但是只要你完全按照他们的使用引导做,“OpenAccess” 服务一定会为了轮询开放。每个 “RestrictedAccess” 服务有时候会因为大量客户端访问或者少数轮询间隙而受限。另外有时候会专供某种类型的组织,例如学术界。
|
||||
|
||||
### 尊重我的权威
|
||||
|
||||
在公共 NTP 服务器上,你可能发现使用引导遵从某些规则。现在让我们看看其中一些。
|
||||
|
||||
“iburst” 选项作用是客户端发送一定数量的包(八个包而不是通常的一个)给 NTP 服务器,轮询间隔会没有应答。
|
||||
如果在短时间内呼叫 NTP 服务器几次,没有出现可辨识的应答,那么本地时间没有变化。
|
||||
|
||||
不像 “iburst” ,按照 NTP 服务器的规则, “burst” 选项一般不允许使用(所以不要用它!)。这个选项不仅在探询间隙发送大量包(明显又是八个),而且也会在能正常使用时这样做。如果你在高层服务器持续发送包,甚至是它们在正常应答时,你可能会因为使用 “burst” 选项而被拉黑。
|
||||
|
||||
显然,你连接服务器的频率影响了它加载的速度(和少量带宽使用)。使用“minpoll”和“maxpoll”选项可以本地设置。然而,根据连接 NTP 服务器的规则,你不应该分别修改默认的 64 秒和 1024 秒。
|
||||
|
||||
此外,需要提出的是客户应该重视请求时间的服务器发出的 Kiss-Of-Death (KOD) 消息。如果 NTP 服务器不想反馈特殊请求,类似于路由和防火墙技术,那么它极有可能遗弃或吞没每个相关的包。
|
||||
|
||||
换句话说,接受异常数据的服务器交互不需要额外的负载而且几乎不消耗流量以至于它认为这不值得回应。你就可以想象,这很无力,有时候礼貌地问客户是否中止或停止比忽略请求更为有效。因此,这种特别的包类型叫做 KOD 包。不受欢迎的 KOD 包被传送给客户端,然后记住这特别的拒绝访问标志。
|
||||
|
||||
如果收到不止一个服务器反馈的 KOD 包,客户端会猜想服务器上发生了流量限速的情况(或类似的)。客户端一般会写入本地日志,使用特别服务器差强人意的处理结果,如果你需要分析解决方案。
|
||||
|
||||
牢记, NTP 服务器的动态基础建设明显是关键。因此,不要给你的 NTP 配置硬编码 IP 地址。通过使用 DNS 域名,独立服务器衰减网络,服务仍能继续进行,IP 地址空间能被重新分配并且可引入简单的负载均衡(具有一定程度的弹性)。
|
||||
|
||||
请别忘了我们也需要考虑呈指数增长的物联网(IoT),最终将包括数以亿万计的新装置,意味着设备的主机需要保持正确时间。硬件卖家无意(或有意)设置他们的设备只能与一个提供者的(甚至一个) NTP 服务器连接将成为过去,变成非常不受欢迎的问题。
|
||||
|
||||
你可能会想象,随着更多的硬件单元被在线购进,NTP 基础设施的拥有者大概不会为相关费用感激,因为他们正被没有实际收入所困扰。这方案远非在奇幻领域独树一帜。正当头疼 -- 感谢 NTP 通路提供的基本设置强制停止 -- 过去几年里已遇多次。
|
||||
|
||||
在下面两篇文章里,我将着重于一些重要的 NTP 配置和测试服务器启动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/arrive-time-ntp-part-1-usage-overview
|
||||
|
||||
作者:[CHRIS BINNIE][a]
|
||||
译者:[译者ID](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/chrisbinnie
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/files/images/ntp-timejpg
|
||||
[3]:http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm
|
||||
[4]:http://support.ntp.org/bin/view/Servers/StratumOneTimeServers
|
||||
@ -0,0 +1,67 @@
|
||||
5 个要了解的开源软件定义网络项目
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
SDN 开始重新定义企业网络。这里有五个应该知道的开源项目。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
纵观整个 2016 年,软件定义网络(SDN)持续快速发展并变得成熟。我们现在已经超出了开源网络的概念阶段,两年前评估这些项目潜力的公司已经开始了企业部署。如几年来所预测的,SDN 正在开始重新定义企业网络。
|
||||
|
||||
这与市场研究人员的观点基本上是一致的。IDC 在今年早些时候公布了 SDN 市场的[一份研究][3],它预计从 2014 年到 2020 年 SDN 的年均复合增长率为 53.9%,届时市场价值将达到 125 亿美元。此外,“Technology Trends 2016” 报告中将 SDN 列为 2016 年最佳技术投资。
|
||||
|
||||
IDC 网络基础设施副总裁,[Rohit Mehra][4] 说:“云计算和第三方平台推动了 SDN 的需求,这将在 2020 年代表一个价值超过 125 亿美元的市场。毫无疑问的是 SDN 的价值将越来越多地渗透到网络虚拟化软件和 SDN 应用中,包括虚拟化网络和安全服务,大型企业在数据中心实现 SDN 的价值,但它们最终会认识到其在分支机构和校园网络中的广泛应用。“
|
||||
|
||||
Linux 基金会最近[发布][5]了其 2016 年度报告[“开放云指南:当前趋势和开源项目”][6]。其中第三份年度报告全面介绍了开放云计算的状态,并包含关于 unikernel 的部分。你现在可以[下载报告][7]了,首先要注意的是汇总和分析研究,说明了容器、unikernel等的趋势是如何重塑云计算的。该报告提供了对当今开放云环境中心的分类项目的描述和链接。
|
||||
|
||||
在本系列中,我们会研究各种类别,并提供关于这些领域如何发展的更多见解。下面,你会看到几个重要的 SDN 项目及其所带来的影响,以及 GitHub 仓库的链接,这些都是从 Open Cloud 指南中收集的:
|
||||
|
||||
### 软件定义网络
|
||||
|
||||
[ONOS][8]
|
||||
|
||||
开放网络操作系统(ONOS)是一个 Linux 基金会项目,它是一个给服务提供商的软件定义网络操作系统,它具有可扩展性、高可用性、高性能和抽象功能来创建应用程序和服务。[ONOS 的 GitHub 地址][9]
|
||||
|
||||
[OpenContrail][10]
|
||||
|
||||
OpenContrail 是 Juniper Networks 的云开源网络虚拟化平台。它提供网络虚拟化的所有必要组件:SDN 控制器、虚拟路由器、分析引擎和已发布的上层 API。其 REST API 配置并收集来自系统的操作和分析数据。[OpenContrail 的 GitHub 地址][11]
|
||||
|
||||
[OpenDaylight][12]
|
||||
|
||||
OpenDaylight 是 Linux 基金会的一个 OpenDaylight Foundation 项目,它是一个可编程的、提供给服务提供商和企业的软件定义网络平台。它基于微服务架构,可以在多供应商环境中的一系列硬件上实现网络服务。[OpenDaylight 的 GitHub 地址][13]
|
||||
|
||||
[Open vSwitch][14]
|
||||
|
||||
Open vSwitch 是一个 Linux 基金会项目,具有生产级别质量的多层虚拟交换机。它通过程序化扩展设计用于大规模网络自动化,同时还支持标准管理接口和协议,包括 NetFlow、sFlow、IPFIX、RSPAN、CLI、LACP 和 802.1ag。它支持类似 VMware 的分布式 vNetwork 或者 Cisco Nexus 1000V 那样跨越多个物理服务器分发。[OVS 在 GitHub 的地址][15]
|
||||
|
||||
[OPNFV][16]
|
||||
|
||||
网络功能虚拟化开放平台 (OPNFV) 是 Linux 基金会项目,它用于企业和服务提供商网络的 NFV 平台。它汇集了计算、存储和网络虚拟化方面的上游组件以创建 NFV 程序的端到端平台。[OPNFV 在 Bitergia 上的地址][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/5-open-source-software-defined-networking-projects-know
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/software-defined-networkingjpg-0
|
||||
[3]:https://www.idc.com/getdoc.jsp?containerId=prUS41005016
|
||||
[4]:http://www.idc.com/getdoc.jsp?containerId=PRF003513
|
||||
[5]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[6]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[7]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[8]:http://onosproject.org/
|
||||
[9]:https://github.com/opennetworkinglab/onos
|
||||
[10]:http://www.opencontrail.org/
|
||||
[11]:https://github.com/Juniper/contrail-controller
|
||||
[12]:https://www.opendaylight.org/
|
||||
[13]:https://github.com/opendaylight
|
||||
[14]:http://openvswitch.org/
|
||||
[15]:https://github.com/openvswitch/ovs
|
||||
[16]:https://www.opnfv.org/
|
||||
[17]:http://projects.bitergia.com/opnfv/browser/
|
||||
@ -0,0 +1,128 @@
|
||||
### 网络协议分析器 Wireshark 在 Linux 下使用的基础知识
|
||||
|
||||
目录
|
||||
|
||||
* * [1. 安装][4]
|
||||
* [2. 基础配置][5]
|
||||
* [2.1. 布局][1]
|
||||
* [2.2. 工具条][2]
|
||||
* [2.3. 功能][3]
|
||||
* [3. 抓包][6]
|
||||
* [4. 读取数据][7]
|
||||
* [5. 结语][8]
|
||||
|
||||
Wireshark 是 Kali 中预置的众多有价值工具中的一种。与其它工具一样,它可以被用于积极的目的同样也可以被用于消极的目的。当然,本文将会介绍如何追踪你自己的网络流量来发现潜在的非正常活动。
|
||||
|
||||
Wireshark 相当的强大,当你第一次见到它的时候可能会被它吓到,但是它的目的始终就只有一个那就是追踪网络流量,并且它所实现的所有选项都只为了加强它追踪流量的能力。
|
||||
|
||||
### 安装
|
||||
|
||||
Kali 中预置了 Wireshark 。不过,`wireshark-gtk` 包提供了一个更好的界面使你在使用 Wireshark 的时候会有更友好的体验。因此,在使用 Wireshark 前的第一步是安装 `wireshark-gtk` 这个包。
|
||||
```
|
||||
# apt install wireshark-gtk
|
||||
```
|
||||
如果你的 Kali 是从 live 介质上运行的也不需要担心,依然有效。(这里的 live 没有想出怎么翻比较合适)
|
||||
|
||||
|
||||
### 基础配置
|
||||
|
||||
在你使用 Wireshark 之前,将它设置成你使用起来最舒适的状态可能是最好的。Wireshark 提供了许多不同的布局方案和选项来配置程序的行为。尽管数量很多,但是使用起来是相当直接明确的。
|
||||
|
||||
从启动 Wireshark-gtk 开始。需要确定启动的是 GTK 版本的。在 Kali 中他们是被分别列出的。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
### 布局
|
||||
|
||||
默认情况下,Wireshark 的信息展示分为三块内容每一块都叠在另一块上方。(这里的三部分指的是展示抓包信息的时候的那三块内容,本段配图没有展示,配图 4, 5, 6 的设置不是默认设置,与这里的描述不符)最上方的一块是所抓包的列表。中间的一块是包的详细信息。最下面那块中包含的是包的原始字节信息。通常来说,上面的两块中的信息比最下面的那块有用的多,但是对于资深用户来说这块内容仍然是重要信息。
|
||||
|
||||
每一块都是可以缩放的,可并不是每一个人都必须使用这样叠起来的布局方式。你可以在 Wireshark 的“选项(Preferences)”菜单中进行更改。这个位置就位于“编辑(Edit)”菜单下的“选项”菜单的最下方。这个选项会打开一个有更多选项的新窗口。单击侧边菜单中“用户界面(User Interface)”下的“布局(Layout)”选项。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
你将会看到一些不同的布局方案。上方的图示可以让你选择不同的面板位置布局方案,下面的单选框可以让你选择不同面板中的数据内容。
|
||||
|
||||
下面那个标记为“列”的标签可以让你选择哪些所抓取包的信息来展示。选择那些你需要的数据信息,或者全部展示。
|
||||
|
||||
### 工具条
|
||||
|
||||
对于 Wireshark 的工具条能做的设置不是太多,但是如果你想设置的话,你依然在前文中提到的“布局”菜单中的窗口管理工具下方找到一些有用的设置选项。那些能让你配置工具条和工具条中条目的选项就在窗口选项下方。
|
||||
|
||||
你还可以在“视图(View)”菜单下勾选来配置工具条的显示内容。
|
||||
|
||||
### 功能
|
||||
|
||||
主要的用来控制 Wireshark 抓包的控制选项基本都集中在“捕捉(Capture)”菜单下的“选项(Options)”选项中。
|
||||
|
||||
在开启的窗口中最上方的部分可以让你选择 Wireshark 来监控某个具体的网络接口。(这里的翻译是依照下面的配图默认了读者打开了前一段中的选项窗口,按照这句的捕捉菜单来翻的话感觉怪怪的,因为捕捉菜单下还有一个接口选项可能会有点弄不清)这部分可能会由于你系统的配置不同而会有相当大的不同。要记得查看正确的接口才能获得正确的数据。(将这里的 boxes 翻译成前一句提到的接口,不知是否合适)虚拟机和伴随它们一起的网络接口也同样会在这个列表里显示。同样也会有多种不同的选项对应这多种不同的网络接口。
|
||||
|
||||

|
||||
|
||||
|
||||
在网络接口列表的下方是两个选项。其中一个选项是全选所有的接口。另一个选项用来选择是否开启混杂模式。这个选项可以使你的计算机监控到所选网络上的所有的计算机。(这个描述可能有问题吧,因为这个混杂模式只是可以捕获那些由于目的IP或者MAC地址非本机而会被自动丢弃的数据包吧)如果你想监控你所在的整个网络,这个选项是你所需要的。
|
||||
|
||||
**注意:** 在一个不属于你或者不拥有权限的网络上使用混杂模式来监控是非法的!
|
||||
|
||||
在窗口下方的右侧是“显示选项”和“名称解析”选项块。对于“显示选项”来说,三个选项全选可能就是一个很好的选择了。当然你也可以取消选择,但是最好还是保留选择“实时更新抓包列表”。
|
||||
|
||||
在“名称解析”中你也可以设置你的偏好。这里的选项会产生附加的请求因此选得越多就会有越多的请求产生使你的抓取的包列表显得杂乱。把 MAC 解析选项选上是个好主意,那样就可以知道所使用的网络硬件的品牌了。这可以帮助你来确定你是在与哪台设备上的哪个接口进行交互。
|
||||
|
||||
### 抓包
|
||||
|
||||
抓包是 Wireshark 的核心功能。监控和记录特定网络上的流量就是它最初产生的目的。使用它最基本的方式来作这个抓包的工作是相当简单方便的。当然,越多的配置和选项就越可以充分利用 Wireshark 的力量。这里的介绍的关注点依然还是它最基本的记录方式。
|
||||
|
||||
按下那个看起来像蓝色鲨鱼鳍的新建实时抓包按钮就可以开始抓包了。(在我的 Debian 上它是绿色的)
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
在抓包的过程中,Wireshark 会收集所有它能收集到的包的数据并且记录下来。如果没有更改过相关设置的话,在抓包的过程中你会看见不断的有新的包进入到“包列表”面板中。你可以实时的查看你认为有趣的包,或者就让 Wireshark 运行着,同时你可以做一些其它的事情。
|
||||
|
||||
当你完成了,按下红色的正方形“停止”按钮就可以了。现在,你可以选择是否要保存这些所抓取的数据了。要保存的话,你可以使用“文件”菜单下的“保存”或者是“另存为”选项。
|
||||
|
||||
### 读取数据
|
||||
|
||||
Wireshark 的目标是向你提供你所需要的所有数据。这样做时,它会在它监控的网络上收集大量的与网络包相关的数据。它使用可折叠的标签来展示这些数据使得这些数据看起来没有那么吓人。每一个标签都对应于网络包中一部分的请求数据。
|
||||
|
||||
这些标签是按照从最底层到最高层一层层堆起来的。顶部标签总是包含数据包中包含的字节的数据。(这句没理解,机翻的,不知是否合适)最下方的标签可能会是多种多样的。在下图的例子中是一个 HTTP 请求,它会包含 HTTP 的信息。您遇到的大多数数据包将是TCP数据,HTTP 请求数据展示在底部标签页中。(这句我理解的是,前半句讲的是总体上的抓取的数据包类型,后半句讲的是下图中展示的那个数据包的信息和在它右侧的点开的 HTTP 请求标签页)
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
每一个标签页都包含了抓取包中对应部分的相关数据。一个 HTTP 包可能会包含与请求类型相关的信息,如所使用的网络浏览器,服务器的 IP 地址,语言,编码方式等的数据。一个 TCP 包会包含服务器与客户端使用的端口信息和 TCP 三次握手过程中的标志位信息。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
在上方的其它标签中所包含的信息对于大多数用户来说其中只有少量的信息是有用的。(这一句的处理不知是否合适)其中一个标签中包含了数据包是通过 IPv4 或者 IPv6 传输的信息与客户端和服务器端的 IP 地址。另一个标签中包含了客户端与路由器或者网关接入因特网的 MAC 地址的信息。(这里有点不太明白作者说的接入因特网是什么意思,MAC地址只到下一台机器啊似乎跟是否接入因特网没有什么关系啊)
|
||||
|
||||
### 结语
|
||||
|
||||
即使只使用这些基础选项与配置,你依然可以发现 Wireshark 会是一个多么强大的工具。监控你的网络流量可以帮助你识别,终止网络攻击或者提升连接速度。它也可以帮你找到问题应用。下一篇 Wireshark 指南我们将会一起探索 Wireshark 的包过滤选项。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/wcnnbdk1)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux
|
||||
[1]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-1-layout
|
||||
[2]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-2-toolbars
|
||||
[3]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-3-functionality
|
||||
[4]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h1-installation
|
||||
[5]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h2-basic-configuration
|
||||
[6]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h3-capture
|
||||
[7]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h4-reading-data
|
||||
[8]:https://linuxconfig.org/basic-of-network-protocol-analyzer-wireshark-on-linux#h5-closing-thoughts
|
||||
@ -3,7 +3,8 @@
|
||||
|
||||

|
||||
|
||||
如果你正在寻找一种简单的方法来管理包含容器的 Linux 服务器,那么你应该看看 Cockpit。[Creative Commons Zero][6]
|
||||
如果你正在寻找一种简单的方法来管理包含容器的 Linux 服务器,那么你应该看看 Cockpit。
|
||||
[Creative Commons Zero][6]
|
||||
|
||||
如果你管理着一台 Linux 服务器,那么你可能正在寻找一个可靠的管理工具。为了这个你可能已经看了 [Webmin][14] 和 [cPanel][15] 这类软件。但是,如果你正在寻找一种简单的方法来管理还包括 Docker 的 Linux 服务器,那么有一个工具可以用于这个需求:[Cockpit][16]。
|
||||
|
||||
@ -25,7 +26,7 @@
|
||||
|
||||
* 查看系统服务和日志文件
|
||||
|
||||
Cockpit 可以安装在 [Debian][17]、[Red Hat][18]、[CentOS] [19]、[Arch Linux][20] 和 [Ubuntu][21] 之上。在这里,我将使用一台已经安装了 Docker 的 Ubuntu 16.04 服务器来安装系统。
|
||||
Cockpit 可以安装在 [Debian][17]、[Red Hat][18]、[CentOS][19]、[Arch Linux][20] 和 [Ubuntu][21] 之上。在这里,我将使用一台已经安装了 Docker 的 Ubuntu 16.04 服务器来安装系统。
|
||||
|
||||
在上面的功能列表中,其中最突出的是容器管理。为什么?因为它使安装和管理容器变得非常简单。事实上,你可能很难找到更好的容器管理解决方案。
|
||||
因此,让我们来安装这个方案并看看它的使用是多么简单。
|
||||
@ -65,7 +66,7 @@ sudo systemctl enable cockpit
|
||||
|
||||

|
||||
|
||||
图 1:Cockpit 登录页面。[授权使用][1]
|
||||
*图 1:Cockpit 登录页面。[授权使用][1]*
|
||||
|
||||
在 Ubuntu 中使用 Cockpit 有个警告。Cockpit 中的很多任务需要管理员权限。如果你使用标准用户登录,则无法使用 Docker 等一些工具。 要解决这个问题,你可以在 Ubuntu 上启用 root 用户。但这并不总是一个好主意。通过启用 root 帐户,你将绕过多年来一直存在的安全系统。但是,为了本文,我将使用以下两个命令启用 root 用户:
|
||||
|
||||
@ -75,7 +76,7 @@ sudo passwd root
|
||||
sudo passwd -u root
|
||||
```
|
||||
|
||||
注意,请确保你给 root 帐户一个强壮的密码。
|
||||
注意,请确保给 root 帐户一个强壮的密码。
|
||||
|
||||
你想恢复这个修改的话,你只需输入下面的命令:
|
||||
|
||||
@ -85,13 +86,13 @@ sudo passwd -l root
|
||||
|
||||
在其他发行版(如 CentOS 和 Red Hat)中,你可以使用用户名 _root_ 和 root 密码登录 Cockpit,而无需像上面那样需要额外的步骤。
|
||||
|
||||
如果你还在犹豫启用 root 用户,则可以始终在服务终端拉取镜像(使用命令 _docker pull IMAGE_NAME _, 这里的 _IMAGE_NAME_ 是你要拉取的镜像)。这会将镜像添加到你的 docker 服务器中,然后可以通过普通用户进行管理。唯一需要注意的是,普通用户必须使用以下命令将自己添加到 Docker 组:
|
||||
如果你对启用 root 用户感到担心,则可以在服务终端拉取镜像(使用命令 _docker pull IMAGE_NAME _, 这里的 _IMAGE_NAME_ 是你要拉取的镜像)。这会将镜像添加到你的 docker 服务器中,然后可以通过普通用户进行管理。唯一需要注意的是,普通用户必须使用以下命令将自己添加到 Docker 组:
|
||||
|
||||
```
|
||||
sudo usermod -aG docker USER
|
||||
```
|
||||
|
||||
USER 是实际添加到组的用户名。在你完成后,重新登出并登入,接着使用下面的命令重启 Docker:
|
||||
其中,USER 是实际添加到组的用户名。在你完成后,重新登出并登入,接着使用下面的命令重启 Docker:
|
||||
|
||||
```
|
||||
sudo service docker restart
|
||||
@ -99,27 +100,26 @@ sudo service docker restart
|
||||
|
||||
现在常规用户可以启动并停止 Docker 镜像/容器而无需启用 root 用户了。唯一一点是用户不能通过 Cockpit 界面添加新的镜像。
|
||||
|
||||
使用 Cockpit
|
||||
### 使用 Cockpit
|
||||
|
||||
一旦你登录后,你可以看到 Cockpit 的主界面(图 2)。
|
||||
|
||||
|
||||

|
||||
|
||||
图 2:Cockpit 主界面。[授权使用][2]
|
||||
*图 2:Cockpit 主界面。[授权使用][2]*
|
||||
|
||||
你可以通过每个栏目来检查服务器的状态,与用户合作等,但是我们想要直接进入容器。单击 “Containers” 那栏以显示当前运行的以及可用的镜像(图3)。
|
||||
|
||||

|
||||
|
||||
图 3:使用 Cockpit 管理容器难以置信地简单。[授权使用][3]
|
||||
*图 3:使用 Cockpit 管理容器难以置信地简单。[授权使用][3]*
|
||||
|
||||
要启动一个镜像,只要找到镜像并点击关联的启动按钮。在弹出的窗口中(图 4),你可以在点击运行之前查看所有镜像的信息(并根据需要调整)。
|
||||
|
||||
|
||||

|
||||
|
||||
图 4: 使用 Cockpit 运行 Docker 镜像。[授权使用][4]
|
||||
*图 4: 使用 Cockpit 运行 Docker 镜像。[授权使用][4]*
|
||||
|
||||
镜像运行后,你可以点击它查看状态,并可以停止、重启、删除示例。你也可以点击修改资源限制并接着调整内存限制还有(或者)CPU 优先级。
|
||||
|
||||
@ -129,13 +129,13 @@ sudo service docker restart
|
||||
|
||||

|
||||
|
||||
图 5:使用 Cockpit 添加最新的官方构建 CentOS 镜像到 Docker 中。[Used with permission][5]
|
||||
*图 5:使用 Cockpit 添加最新的官方构建 CentOS 镜像到 Docker 中。[授权使用][5]*
|
||||
|
||||
镜像下载完后,那它就在 Docker 中可用了,并可以通过 Cockpit 运行。
|
||||
|
||||
### 如它获取那样简单
|
||||
### 如获取它那样简单
|
||||
|
||||
管理 Docker 并不容易。是的,在 Ubuntu 上运行 Cockpit 会有一个警告,但如果这是你唯一的选择,那么还有办法让它工作。在 Cockpit 的帮助下,你不仅可以轻松管理 Docker 镜像,也可以在任何可以访问 Linux 服务器的 web 浏览器上进行。请享受这个新发现的容易使用 Docker 的方法。
|
||||
管理 Docker 并不容易。是的,在 Ubuntu 上运行 Cockpit 会有一个警告,但如果这是你唯一的选择,那么还有办法让它工作。在 Cockpit 的帮助下,你不仅可以轻松管理 Docker 镜像,也可以在任何可以访问 Linux 服务器的 web 浏览器上这样做。请享受这个新发现的容易使用 Docker 的方法。
|
||||
|
||||
_在 Linux Foundation 以及 edX 中通过免费的 ["Introduction to Linux"][13] 课程学习 Linux。_
|
||||
|
||||
@ -145,7 +145,7 @@ via: https://www.linux.com/learn/intro-to-linux/2017/3/make-container-management
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,20 +1,19 @@
|
||||
如何在现有的 Linux 系统上添加新的磁盘
|
||||
============================================================
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分,或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
|
||||
作为一个系统管理员,我们会有这样的一些需求:作为升级服务器容量的一部分、或者有时出现磁盘故障时更换磁盘,我们需要将新的硬盘配置到现有服务器。
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 **RHEL/CentOS** 或者 **Debian/Ubuntu Linux** 系统的步骤。
|
||||
|
||||
在这篇文章中,我会向你逐步介绍添加新硬盘到现有 RHEL/CentOS 或者 Debian/Ubuntu Linux 系统的步骤。
|
||||
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]
|
||||
**推荐阅读:** [如何将超过 2TB 的新硬盘添加到现有 Linux][1]。
|
||||
|
||||
重要:请注意这篇文章的目的只是告诉你如何创建新的分区,而不包括分区扩展或者其它选项。
|
||||
|
||||
我使用 [fdisk 工具][2] 完成这些配置。
|
||||
|
||||
我已经添加了一块 20GB 容量的硬盘,挂载到了 `/data` 分区。
|
||||
我已经添加了一块 **20GB** 容量的硬盘,挂载到了 `/data` 分区。
|
||||
|
||||
fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
**fdisk** 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行工具。
|
||||
|
||||
```
|
||||
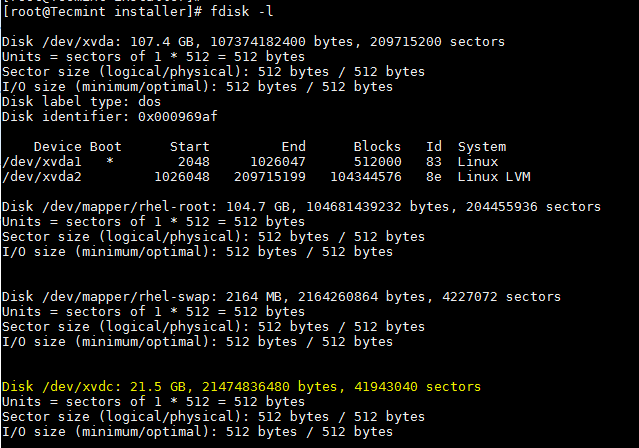
# fdisk -l
|
||||
@ -26,7 +25,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||

|
||||
][3]
|
||||
|
||||
查看 Linux 分区详情
|
||||
*查看 Linux 分区详情*
|
||||
|
||||
添加了 20GB 容量的硬盘后,`fdisk -l` 的输出像下面这样。
|
||||
|
||||
@ -37,9 +36,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][4]
|
||||
|
||||
查看新分区详情
|
||||
*查看新分区详情*
|
||||
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
新添加的磁盘显示为 `/dev/xvdc`。如果我们添加的是物理磁盘,基于磁盘类型它会显示为类似 `/dev/sda`。这里我使用的是虚拟磁盘。
|
||||
|
||||
要在特定硬盘上分区,例如 `/dev/xvdc`。
|
||||
|
||||
@ -47,7 +46,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
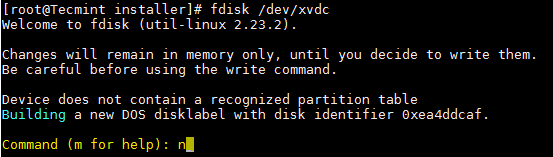
# fdisk /dev/xvdc
|
||||
```
|
||||
|
||||
常用 fdisk 命令。
|
||||
常用的 fdisk 命令。
|
||||
|
||||
* `n` - 创建分区
|
||||
* `p` - 打印分区表
|
||||
@ -61,7 +60,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][5]
|
||||
|
||||
在 Linux上创建新分区
|
||||
*在 Linux 上创建新分区*
|
||||
|
||||
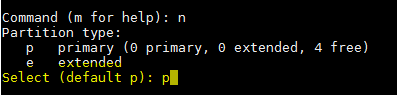
创建主分区或者扩展分区。默认情况下我们最多可以有 4 个主分区。
|
||||
|
||||
@ -69,7 +68,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][6]
|
||||
|
||||
创建主分区
|
||||
*创建主分区*
|
||||
|
||||
按需求输入分区编号。推荐使用默认的值 `1`。
|
||||
|
||||
@ -77,7 +76,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
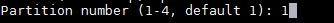
|
||||
][7]
|
||||
|
||||
分配分区编号
|
||||
*分配分区编号*
|
||||
|
||||
输入第一个扇区的大小。如果是一个新的磁盘,通常选择默认值。如果你是在同一个磁盘上创建第二个分区,我们需要在前一个分区的最后一个扇区的基础上加 `1`。
|
||||
|
||||
@ -85,7 +84,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
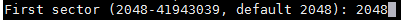
|
||||
][8]
|
||||
|
||||
为分区分配扇区
|
||||
*为分区分配扇区*
|
||||
|
||||
输入最后一个扇区或者分区大小的值。通常推荐输入分区的大小。总是添加前缀 `+` 以防止值超出范围错误。
|
||||
|
||||
@ -93,7 +92,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
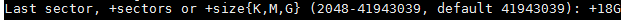
|
||||
][9]
|
||||
|
||||
分配分区大小
|
||||
*分配分区大小*
|
||||
|
||||
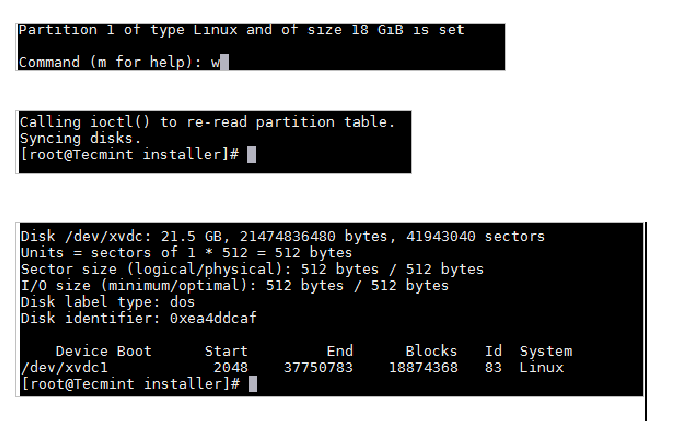
保存更改并退出。
|
||||
|
||||
@ -101,9 +100,9 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][10]
|
||||
|
||||
保存分区更改
|
||||
*保存分区更改*
|
||||
|
||||
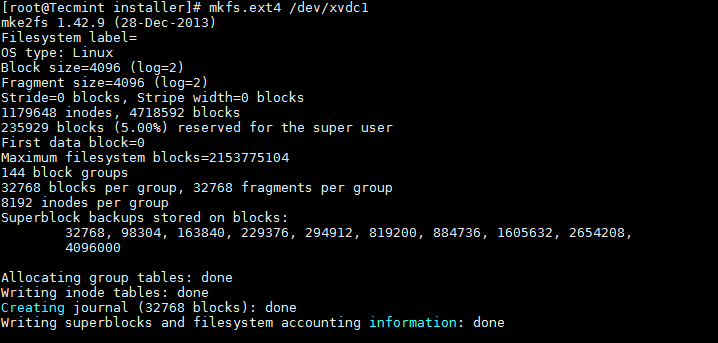
现在使用 mkfs 命令格式化磁盘。
|
||||
现在使用 **mkfs** 命令格式化磁盘。
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/xvdc1
|
||||
@ -112,7 +111,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
][11]
|
||||
|
||||
格式化新分区
|
||||
*格式化新分区*
|
||||
|
||||
格式化完成后,按照下面的命令挂载分区。
|
||||
|
||||
@ -130,7 +129,7 @@ fdisk 是一个在 Linux 系统上用于显示和管理硬盘和分区命令行
|
||||
|
||||
现在你知道如何使用 [fdisk 命令][12] 在新磁盘上创建分区并挂载了。
|
||||
|
||||
当处理分区、尤其是编辑已配置磁盘的时候我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
当处理分区、尤其是编辑已配置磁盘的时候,我们需要格外的小心。请分享你的反馈和建议吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user