mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
This commit is contained in:
commit
4a117be8bc
published
20140510 Managing Digital Files (e.g., Photographs) in Files and Folders.md20180706 Building a Messenger App- OAuth.md20180906 What a shell dotfile can do for you.md20190214 The Earliest Linux Distros- Before Mainstream Distros Became So Popular.md20190301 Guide to Install VMware Tools on Linux.md20190320 Move your dotfiles to version control.md20190404 How writers can get work done better with Git.md20190513 Blockchain 2.0 - Introduction To Hyperledger Fabric -Part 10.md20190614 What is a Java constructor.md20190627 RPM packages explained.md20190701 Learn how to Record and Replay Linux Terminal Sessions Activity.md20190719 Buying a Linux-ready laptop.md
201908
20171113 IT disaster recovery- Sysadmins vs. natural disasters - HPE.md20171216 Sysadmin 101- Troubleshooting.md20180104 How allowing myself to be vulnerable made me a better leader.md20180116 Command Line Heroes- Season 1- OS Wars.md20180119 Two great uses for the cp command Bash shortcuts.md20180131 How to test Webhooks when youre developing locally.md20180622 Use LVM to Upgrade Fedora.md20180720 A brief history of text-based games and open source.md20180727 4 Ways to Customize Xfce and Give it a Modern Look.md20180928 Quiet log noise with Python and machine learning.md20181011 Exploring the Linux kernel- The secrets of Kconfig-kbuild.md20181029 Create animated, scalable vector graphic images with MacSVG.md20181029 DF-SHOW - A Terminal File Manager Based On An Old DOS Application.md20181030 Podman- A more secure way to run containers.md20181202 How To Customize The GNOME 3 Desktop.md20181213 Podman and user namespaces- A marriage made in heaven.md20181220 Getting started with Prometheus.md20181222 How to detect automatically generated emails.md20190225 How to Install VirtualBox on Ubuntu -Beginner-s Tutorial.md20190304 How to Install MongoDB on Ubuntu.md20190315 How To Parse And Pretty Print JSON With Linux Commandline Tools.md20190318 Let-s try dwm - dynamic window manager.md20190429 How To Turn On And Shutdown The Raspberry Pi -Absolute Beginner Tip.md20190505 Blockchain 2.0 - An Introduction To Hyperledger Project (HLP) -Part 8.md20190510 Check storage performance with dd.md20190611 What is a Linux user.md20190613 Continuous integration testing for the Linux kernel.md20190617 How To Check Linux Package Version Before Installing It.md20190705 Enable ‘Tap to click- on Ubuntu Login Screen -Quick Tip.md20190706 Install NetData Performance Monitoring Tool On Linux.md20190709 How to install Elasticsearch and Kibana on Linux.md20190711 What is a golden image.md20190715 Understanding software design patterns.md20190715 What is POSIX- Richard Stallman explains.md20190720 How to Upgrade Debian 9 (Stretch) to Debian 10 (Buster) via Command Line.md20190724 3 types of metric dashboards for DevOps teams.md20190725 How to transition into a career as a DevOps engineer.md20190725 Introduction to GNU Autotools.md20190726 Manage your passwords with Bitwarden and Podman.md20190729 Command line quick tips- More about permissions.md20190729 Top 8 Things to do after Installing Debian 10 (Buster).md20190730 How to create a pull request in GitHub.md20190730 OpenHMD- Open Source Project for VR Development.md20190731 Bash aliases you can-t live without.md20190801 5 Free Partition Managers for Linux.md20190801 Bash Script to Send a Mail When a New User Account is Created in System.md20190802 Linux Smartphone Librem 5 is Available for Preorder.md20190802 Use Postfix to get email from your Fedora system.md20190803 The fastest open source CPU ever, Facebook shares AI algorithms fighting harmful content, and more news.md20190805 4 cool new projects to try in COPR for August 2019.md20190805 Find The Linux Distribution Name, Version And Kernel Details.md20190805 GameMode - A Tool To Improve Gaming Performance On Linux.md20190805 How To Add ‘New Document- Option In Right Click Context Menu In Ubuntu 18.04.md20190805 How To Find Hardware Specifications On Linux.md20190805 How To Set Up Time Synchronization On Ubuntu.md20190805 How To Verify ISO Images In Linux.md20190806 Microsoft finds Russia-backed attacks that exploit IoT devices.md20190806 Unboxing the Raspberry Pi 4.md20190808 Find Out How Long Does it Take To Boot Your Linux System.md20190808 How to manipulate PDFs on Linux.md20190809 Copying files in Linux.md20190809 Use a drop-down terminal for fast commands in Fedora.md20190811 How to measure the health of an open source community.md20190812 How Hexdump works.md20190812 How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS.md20190814 How to Reinstall Ubuntu in Dual Boot or Single Boot Mode.md20190815 Fix ‘E- The package cache file is corrupted, it has the wrong hash- Error In Ubuntu.md20190815 How To Change Linux Console Font Type And Size.md20190815 How To Fix -Kernel driver not installed (rc--1908)- VirtualBox Error In Ubuntu.md20190815 How To Set up Automatic Security Update (Unattended Upgrades) on Debian-Ubuntu.md20190815 How To Setup Multilingual Input Method On Ubuntu.md20190815 SSLH - Share A Same Port For HTTPS And SSH.md20190817 GNOME and KDE team up on the Linux desktop, docs for Nvidia GPUs open up, a powerful new way to scan for firmware vulnerabilities, and more news.md20190817 LiVES Video Editor 3.0 is Here With Significant Improvements.md20190820 A guided tour of Linux file system types.md20190823 How to Delete Lines from a File Using the sed Command.md20190823 Managing credentials with KeePassXC.md20190825 Happy birthday to the Linux kernel- What-s your favorite release.md20190825 How to Install Ansible (Automation Tool) on Debian 10 (Buster).md20190827 A dozen ways to learn Python.md20190830 11 surprising ways you use Linux every day.md
20190805 How to Install and Configure PostgreSQL on Ubuntu.md20190809 Mutation testing is the evolution of TDD.md20190822 A Raspberry Pi Based Open Source Tablet is in Making and it-s Called CutiePi.md20190823 The lifecycle of Linux kernel testing.md20190824 How to compile a Linux kernel in the 21st century.md20190826 Introduction to the Linux chown command.md20190830 How to Install Linux on Intel NUC.md@ -0,0 +1,619 @@
|
||||
数码文件与文件夹收纳术(以照片为例)
|
||||
======
|
||||
|
||||

|
||||
|
||||
- 更新 2014-05-14:增加了一些具体实例
|
||||
- 更新 2015-03-16:根据照片的 GPS 坐标过滤图片
|
||||
- 更新 2016-08-29:以新的 `filetags --filter` 替换已经过时的 `show-sel.sh` 脚本
|
||||
- 更新 2017-08-28: geeqier 视频缩略图的邮件评论
|
||||
- 更新 2018-03-06:增加了 Julian Kahnert 的链接
|
||||
- 更新 2018-05-06:增加了作者在 2018 Linuxtage Graz 大会上 45 分钟演讲的视频
|
||||
- 更新 2018-06-05:关于 metadata 的邮件回复
|
||||
- 更新 2018-07-22:移动文件夹结构的解释到一篇它自己的文章中
|
||||
- 更新 2019-07-09:关于在文件名中避免使用系谱和字符的邮件回复
|
||||
|
||||
每当度假或去哪游玩时我就会化身为一个富有激情的摄影师。所以,过去的几年中我积累了许多的 [JPEG][1] 文件。这篇文章中我会介绍我是如何避免 [供应商锁定][2](LCTT 译注:<ruby>供应商锁定<rt>vendor lock-in</rt></ruby>,原为经济学术语,这里引申为避免过于依赖某一服务平台)造成受限于那些临时性的解决方案及数据丢失。相反,我更倾向于使用那些可以让我**投入时间和精力打理,并能长久使用**的解决方案。
|
||||
|
||||
这一(相当长的)攻略 **并不仅仅适用于图像文件**:我将进一步阐述像是文件夹结构、文件的命名规则等等许多领域的事情。因此,这些规范适用于我所能接触到的所有类型的文件。
|
||||
|
||||
在我开始传授我的方法之前,我们应该先就我将要介绍方法的达成一个共识,那就是我们是否有相同的需求。如果你对 [raw 图像格式][3]十分推崇,将照片存储在云端或其他你信赖的地方(对我而言可能不会),那么你可能不会认同这篇文章将要描述的方式了。请根据你的情况来灵活做出选择。
|
||||
|
||||
### 我的需求
|
||||
|
||||
对于 **将照片(或视频)从我的数码相机中导出到电脑里**,我只需要将 SD 卡插到我的电脑里并调用 `fetch-workflow` 软件。这一步也完成了**图像软件的预处理**以适用于我的文件命名规范(下文会具体论述),同时也可以将图片旋转至正常的方向(而不是横着)。
|
||||
|
||||
这些文件将会被存入到我的摄影收藏文件夹 `$HOME/tmp/digicam/`。在这一文件夹中我希望能**遍历我的图像和视频文件**,以便于**整理/删除、重命名、添加/移除标签,以及将一系列相关的文件移动到相应的文件夹中**。
|
||||
|
||||
在完成这些以后,我将会**浏览包含图像/电影文件集的文件夹**。在极少数情况下,我希望**在独立的图像处理工具**(比如 [GIMP][4])中打开一个图像文件。如果仅是为了**旋转 JPEG 文件**,我想找到一个快速的方法,不需要图像处理工具,并且是[以无损的方式][5]旋转 JPEG 图像。
|
||||
|
||||
我的数码相机支持用 [GPS][6] 坐标标记图像。因此,我需要一个方法来**对单个文件或一组文件可视化 GPS 坐标**来显示我走过的路径。
|
||||
|
||||
我想拥有的另一个好功能是:假设你在威尼斯度假时拍了几百张照片。每一个都很漂亮,所以你每张都舍不得删除。另一方面,你可能想把一组更少的照片送给家里的朋友。而且,在他们嫉妒的爆炸之前,他们可能只希望看到 20 多张照片。因此,我希望能够**定义并显示一组特定的照片子集**。
|
||||
|
||||
就独立性和**避免锁定效应**而言,我不想使用那种一旦公司停止产品或服务就无法使用的工具。出于同样的原因,由于我是一个注重隐私的人,**我不想使用任何基于云的服务**。为了让自己对新的可能性保持开放的心态,我不希望只在一个特定的操作系统平台才可行的方案上倾注全部的精力。**基本的东西必须在任何平台上可用**(查看、导航、……),而**全套需求必须可以在 GNU/Linux 上运行**,对我而言,我选择 Debian GNU/Linux。
|
||||
|
||||
在我传授当前针对上述大量需求的解决方案之前,我必须解释一下我的一般文件夹结构和文件命名约定,我也使用它来命名数码照片。但首先,你必须认清一个重要的事实:
|
||||
|
||||
#### iPhoto、Picasa,诸如此类应被认为是有害的
|
||||
|
||||
管理照片集的软件工具确实提供了相当酷的功能。它们提供了一个良好的用户界面,并试图为你提供满足各种需求的舒适的工作流程。
|
||||
|
||||
对它们我确实遇到了很多大问题。它们几乎对所有东西都使用专有的存储格式:图像文件、元数据等等。当你打算在几年内换一个不同的软件,这是一个大问题。相信我:总有一天你会因为多种原因而**更换软件**。
|
||||
|
||||
如果你现在正打算更换相应的工具,你会意识到 iPhoto 或 Picasa 是分别存储原始图像文件和你对它们所做的所有操作的(旋转图像、向图像文件添加描述/标签、裁剪等等)。如果你不能导出并重新导入到新工具,那么**所有的东西都将永远丢失**。而无损的进行转换和迁移几乎是不可能的。
|
||||
|
||||
我不想在一个会锁住我工作的工具上投入任何精力。**我也拒绝把自己绑定在任何专有工具上**。我是一个过来人,希望你们吸取我的经验。
|
||||
|
||||
这就是我在文件名中保留时间戳、图像描述或标记的原因。文件名是永久性的,除非我手动更改它们。当我把照片备份或复制到 U 盘或其他操作系统时,它们不会丢失。每个人都能读懂。任何未来的系统都能够处理它们。
|
||||
|
||||
### 我的文件命名规范
|
||||
|
||||
这里有一个我在 [2018 Linuxtage Graz 大会][44]上做的[演讲][45],其中详细阐述了我的在本文中提到的想法和工作流程。
|
||||
|
||||
- [Grazer Linuxtage 2018 - The Advantages of File Name Conventions and Tagging](https://youtu.be/rckSVmYCH90)
|
||||
- [备份视频托管在 media.CCC.de](https://media.ccc.de/v/GLT18_-_321_-_en_-_g_ap147_004_-_201804281550_-_the_advantages_of_file_name_conventions_and_tagging_-_karl_voit)
|
||||
|
||||
我所有的文件都与一个特定的日期或时间有关,根据所采用的 [ISO 8601][7] 规范,我采用的是**日期戳**或**时间戳**
|
||||
|
||||
带有日期戳和两个标签的示例文件名:`2014-05-09 Budget export for project 42 -- finance company.csv`。
|
||||
|
||||
带有时间戳(甚至包括可选秒)和两个标签的示例文件名:`2014-05-09T22.19.58 Susan presenting her new shoes -- family clothing.jpg`。
|
||||
|
||||
由于我使用的 ISO 时间戳冒号不适用于 Windows [NTFS 文件系统][8],因此,我用点代替冒号,以便将小时与分钟(以及可选的秒)区别开来。
|
||||
|
||||
如果是**持续的一段日期或时间**,我会将两个日期戳或时间戳用两个减号分开:`2014-05-09--2014-05-13 Jazz festival Graz -- folder tourism music.pdf`。
|
||||
|
||||
文件名中的时间/日期戳的优点是,除非我手动更改它们,否则它们保持不变。当通过某些不处理这些元数据的软件进行处理时,包含在文件内容本身中的元数据(如 [Exif][9])往往会丢失。此外,使用这样的日期/时间戳开始的文件名可以确保文件按时间顺序显示,而不是按字母顺序显示。字母表是一种[完全人工的排序顺序][10],对于用户定位文件通常不太实用。
|
||||
|
||||
当我想将**标签**关联到文件名时,我将它们放在原始文件名和[文件名扩展名][11]之间,中间用空格、两个减号和两端额外的空格分隔 ` -- `。我的标签是小写的英文单词,不包含空格或特殊字符。有时,我可能会使用 `quantifiedself` 或 `usergenerated` 这样的连接词。我[倾向于选择一般类别][12],而不是太过具体的描述标签。我在 Twitter [hashtags][13]、文件名、文件夹名、书签、诸如此类的博文等诸如此类地地方重用这些标签。
|
||||
|
||||
标签作为文件名的一部分有几个优点。通过使用常用的桌面搜索引擎,你可以在标签的帮助下定位文件。文件名称中的标签不会因为复制到不同的存储介质上而丢失。当系统使用与文件名之外的存储位置(如:元数据数据库、[点文件][14]、[备用数据流][15]等)存储元信息通常会发生丢失。
|
||||
|
||||
当然,通常在文件和文件夹名称中,**请避免使用特殊字符**、变音符、冒号等。尤其是在不同操作系统平台之间同步文件时。
|
||||
|
||||
我的**文件夹名命名约定**与文件的相应规范相同。
|
||||
|
||||
注意:由于 [Memacs][17] 的 [filenametimestamp][16] 模块的聪明之处,所有带有日期/时间戳的文件和文件夹都出现在我的 Org 模式的日历(日程)上的同一天/同一时间。这样,我就能很好地了解当天发生了什么,包括我拍的所有照片。
|
||||
|
||||
### 我的一般文件夹结构
|
||||
|
||||
在本节中,我将描述我的主文件夹中最重要的文件夹。注意:这可能在将来的被移动到一个独立的页面。或许不是。让我们等着瞧 :-) (LCTT 译注:后来这一节已被作者扩展并移动到另外一篇[文章](https://karl-voit.at/folder-hierarchy/)。)
|
||||
|
||||
很多东西只有在一定的时间内才会引起人们的兴趣。这些内容包括快速浏览其内容的下载、解压缩文件以检查包含的文件、一些有趣的小内容等等。对于**临时的东西**,我有 `$HOME/tmp/` 子层次结构。新照片放在 `$HOME/tmp/digicam/` 中。我从 CD、DVD 或 USB 记忆棒临时复制的东西放在 `$HOME/tmp/fromcd/` 中。每当软件工具需要用户文件夹层次结构中的临时数据时,我就使用 `$HOME/tmp/Tools/`作为起点。我经常使用的文件夹是 `$HOME/tmp/2del/`:`2del` 的意思是“随时可以删除”。例如,我所有的浏览器都使用这个文件夹作为默认的下载文件夹。如果我需要在机器上腾出空间,我首先查看这个 `2del` 文件夹,用于删除内容。
|
||||
|
||||
与上面描述的临时文件相比,我当然也想将文件**保存更长的时间**。这些文件被移动到我的 `$HOME/archive/` 子层次结构中。它有几个子文件夹用于备份、我想保留的 web 下载类、我要存档的二进制文件、可移动媒体(CD、DVD、记忆棒、外部硬盘驱动器)的索引文件,和一个稍后(寻找一个合适的的目标文件夹)存档的文件夹。有时,我太忙或没有耐心的时候将文件妥善整理。是的,那就是我,我甚至有一个名为“现在不要烦我”的文件夹。这对你而言是否很怪?:-)
|
||||
|
||||
我的归档中最重要的子层次结构是 `$HOME/archive/events_memories/` 及其子文件夹 `2014/`、`2013/`、`2012/` 等等。正如你可能已经猜到的,每个年份有一个**子文件夹**。其中每个文件中都有单个文件和文件夹。这些文件是根据我在前一节中描述的文件名约定命名的。文件夹名称以 [ISO 8601][7] 日期标签 “YYYY-MM-DD” 开头,后面跟着一个具有描述性的名称,如 `$HOME/archive/events_memories/2014/2014-05-08 Business marathon with/`。在这些与日期相关的文件夹中,我保存着各种与特定事件相关的文件:照片、(扫描的)pdf 文件、文本文件等等。
|
||||
|
||||
对于**共享数据**,我设置一个 `$HOME/share/` 子层次结构。这是我的 Dropbox 文件夹,我用各种各样的方法(比如 [unison][18])来分享数据。我也在我的设备之间共享数据:家里的 Mac Mini、家里的 GNU/Linux 笔记本、Android 手机,root-server(我的个人云),工作用的 Windows 笔记本。我不想在这里详细说明我的同步设置。如果你想了解相关的设置,可以参考另一篇相关的文章。:-)
|
||||
|
||||
在我的 `$HOME/templates_tags/` 子层次结构中,我保存了各种**模板文件**([LaTeX][19]、脚本、…),插图和**徽标**,等等。
|
||||
|
||||
我的 **Org 模式** 文件,主要是保存在 `$HOME/org/`。我练习记忆力,不会解释我有多喜欢 [Emacs/Org 模式][20] 以及我从中获益多少。你可能读过或听过我详细描述我用它做的很棒的事情。具体可以在我的博客上查找 [我的 Emacs 标签][21],在 Twitter 上查找 [hashtag #orgmode][22]。
|
||||
|
||||
以上就是我最重要的文件夹子层次结构设置方式。
|
||||
|
||||
### 我的工作流程
|
||||
|
||||
哒哒哒,在你了解了我的文件夹结构和文件名约定之后,下面是我当前的工作流程和工具,我使用它们来满足我前面描述的需求。
|
||||
|
||||
请注意,**你必须知道你在做什么**。我这里的示例及文件夹路径和更多**只适用我的机器或我的环境**。**你必须采用相应的**路径、文件名等来满足你的需求!
|
||||
|
||||
#### 工作流程:将文件从 SD 卡移动到笔记本电脑、旋转人像图像,并重命名文件
|
||||
|
||||
当我想把数据从我的数码相机移到我的 GNU/Linux 笔记本上时,我拿出它的 mini SD 存储卡,把它放在我的笔记本上。然后它会自动挂载在 `/media/digicam` 上。
|
||||
|
||||
然后,调用 [getdigicamdata][23]。它做了如下几件事:它将文件从 SD 卡移动到一个临时文件夹中进行处理。原始文件名会转换为小写字符。所有的人像照片会使用 [jhead][24] 旋转。同样使用 jhead,我从 Exif 头的时间戳中生成文件名称中的时间戳。使用 [date2name][25],我也将时间戳添加到电影文件中。处理完所有这些文件后,它们将被移动到新的数码相机文件的目标文件夹: `$HOME/tmp/digicam/tmp/`。
|
||||
|
||||
#### 工作流程:文件夹索引、查看、重命名、删除图像文件
|
||||
|
||||
为了快速浏览我的图像和电影文件,我喜欢使用 GNU/Linux 上的 [geeqie][26]。这是一个相当轻量级的图像浏览器,它具有其他文件浏览器所缺少的一大优势:我可以添加通过键盘快捷方式调用的外部脚本/工具。通过这种方式,我可以通过任意外部命令扩展这个图像浏览器的特性。
|
||||
|
||||
基本的图像管理功能是内置在 geeqie:浏览我的文件夹层次结构、以窗口模式或全屏查看图像(快捷键 `f`)、重命名文件名、删除文件、显示 Exif 元数据(快捷键 `Ctrl-e`)。
|
||||
|
||||
在 OS X 上,我使用 [Xee][27]。与 geeqie 不同,它不能通过外部命令进行扩展。不过,基本的浏览、查看和重命名功能也是可用的。
|
||||
|
||||
#### 工作流程:添加和删除标签
|
||||
|
||||
我创建了一个名为 [filetags][28] 的 Python 脚本,用于向单个文件以及一组文件添加和删除标记。
|
||||
|
||||
对于数码照片,我使用标签,例如,`specialL` 用于我认为适合桌面背景的风景图片,`specialP` 用于我想展示给其他人的人像照片,`sel` 用于筛选,等等。
|
||||
|
||||
##### 使用 geeqie 初始设置 filetags
|
||||
|
||||
向 geeqie 添加 `filetags` 是一个手动步骤:“Edit > Preferences > Configure Editors ...”,然后创建一个附加条目 `New`。在这里,你可以定义一个新的桌面文件,如下所示:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetags
|
||||
GenericName=filetags
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*add-tags.desktop*
|
||||
|
||||
封装脚本 `vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh` 是必须的,因为我想要弹出一个新的终端,以便添加标签到我的文件:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --interactive "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetags-interactive-adding-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
在 geeqie 中,你可以在 “Edit > Preferences > Preferences ... > Keyboard”。我将 `t` 与 `filetags` 命令相关联。
|
||||
|
||||
这个 `filetags` 脚本还能够从单个文件或一组文件中删除标记。它基本上使用与上面相同的方法。唯一的区别是 `filetags` 脚本额外的 `--remove` 参数:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetags-remove
|
||||
GenericName=filetags-remove
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetags-interactive-removing-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*remove-tags.desktop*
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --interactive --remove "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetags-interactive-removing-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
为了删除标签,我创建了一个键盘快捷方式 `T`。
|
||||
|
||||
##### 在 geeqie 中使用 filetags
|
||||
|
||||
当我在 geeqie 文件浏览器中浏览图像文件时,我选择要标记的文件(一到多个)并按 `t`。然后,一个小窗口弹出,要求我提供一个或多个标签。用回车确认后,这些标签被添加到文件名中。
|
||||
|
||||
删除标签也是一样:选择多个文件,按下 `T`,输入要删除的标签,然后按回车确认。就是这样。几乎没有[给文件添加或删除标签的更简单的方法了][29]。
|
||||
|
||||
#### 工作流程:改进的使用 appendfilename 重命名文件
|
||||
|
||||
##### 不使用 appendfilename
|
||||
|
||||
重命名一组大型文件可能是一个冗长乏味的过程。对于 `2014-04-20T17.09.11_p1100386.jpg` 这样的原始文件名,在文件名中添加描述的过程相当烦人。你将按 `Ctrl-r` (重命名)在 geeqie 中打开文件重命名对话框。默认情况下,原始名称(没有文件扩展名的文件名称)被标记。因此,如果不希望删除/覆盖文件名(但要追加),则必须按下光标键 `→`。然后,光标放在基本名称和扩展名之间。输入你的描述(不要忘记以空格字符开始),并用回车进行确认。
|
||||
|
||||
##### 在 geeqie 使中用 appendfilename
|
||||
|
||||
使用 [appendfilename][30],我的过程得到了简化,可以获得将文本附加到文件名的最佳用户体验:当我在 geeqie 中按下 `a`(附加)时,会弹出一个对话框窗口,询问文本。在回车确认后,输入的文本将放置在时间戳和可选标记之间。
|
||||
|
||||
例如,当我在 `2014-04-20T17.09.11_p1100386.jpg` 上按下 `a`,然后键入`Pick-nick in Graz` 时,文件名变为 `2014-04-20T17.09.11_p1100386 Pick-nick in Graz.jpg`。当我再次按下 `a` 并输入 `with Susan` 时,文件名变为 `2014-04-20T17.09.11_p1100386 Pick-nick in Graz with Susan.jpg`。当文件名添加标记时,附加的文本前将附加标记分隔符。
|
||||
|
||||
这样,我就不必担心覆盖时间戳或标记。重命名的过程对我来说变得更加有趣!
|
||||
|
||||
最好的部分是:当我想要将相同的文本添加到多个选定的文件中时,也可以使用 `appendfilename`。
|
||||
|
||||
##### 在 geeqie 中初始设置 appendfilename
|
||||
|
||||
添加一个额外的编辑器到 geeqie: “Edit > Preferences > Configure Editors ... > New”。然后输入桌面文件定义:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=appendfilename
|
||||
GenericName=appendfilename
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-appendfilename-interactive-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*appendfilename.desktop*
|
||||
|
||||
同样,我也使用了一个封装脚本,它将为我打开一个新的终端:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=90x5+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/appendfilename/appendfilename.py "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-appendfilename-interactive-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
#### 工作流程:播放电影文件
|
||||
|
||||
在 GNU/Linux 上,我使用 [mplayer][31] 回放视频文件。由于 geeqie 本身不播放电影文件,所以我必须创建一个设置,以便在 mplayer 中打开电影文件。
|
||||
|
||||
##### 在 geeqie 中初始设置 mplayer
|
||||
|
||||
我已经使用 [xdg-open][32] 将电影文件扩展名关联到 mplayer。因此,我只需要为 geeqie 创建一个通用的“open”命令,让它使用 `xdg-open` 打开任何文件及其关联的应用程序。
|
||||
|
||||
在 geeqie 中,再次访问 “Edit > Preferences > Configure Editors ...” 添加“open”的条目:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=open
|
||||
GenericName=open
|
||||
Comment=
|
||||
Exec=/usr/bin/xdg-open %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
hidden=false
|
||||
NOMimeType=*;
|
||||
MimeType=image/*;video/*
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*open.desktop*
|
||||
|
||||
当你也将快捷方式 `o` (见上文)与 geeqie 关联时,你就能够打开与其关联的应用程序的视频文件(和其他文件)。
|
||||
|
||||
##### 使用 xdg-open 打开电影文件(和其他文件)
|
||||
|
||||
在上面的设置过程之后,当你的 geeqie 光标位于文件上方时,你只需按下 `o` 即可。就是如此简洁。
|
||||
|
||||
#### 工作流程:在外部图像编辑器中打开
|
||||
|
||||
我不太希望能够在 GIMP 中快速编辑图像文件。因此,我添加了一个快捷方式 `g`,并将其与外部编辑器 “"GNU Image Manipulation Program" (GIMP)” 关联起来,geeqie 已经默认创建了该外部编辑器。
|
||||
|
||||
这样,只需按下 `g` 就可以在 GIMP 中打开当前图像。
|
||||
|
||||
#### 工作流程:移动到存档文件夹
|
||||
|
||||
现在我已经在我的文件名中添加了注释,我想将单个文件移动到 `$HOME/archive/events_memories/2014/`,或者将一组文件移动到这个文件夹中的新文件夹中,如 `$HOME/archive/events_memories/2014/2014-05-08 business marathon after show - party`。
|
||||
|
||||
通常的方法是选择一个或多个文件,并用快捷方式 `Ctrl-m` 将它们移动到文件夹中。
|
||||
|
||||
何等繁复无趣之至!
|
||||
|
||||
因此,我(再次)编写了一个 Python 脚本,它为我完成了这项工作:[move2archive][33](简写为:` m2a `),需要一个或多个文件作为命令行参数。然后,出现一个对话框,我可以在其中输入一个可选文件夹名。当我不输入任何东西而是按回车,文件被移动到相应年份的文件夹。当我输入一个类似 `Business-Marathon After-Show-Party` 的文件夹名称时,第一个图像文件的日期戳被附加到该文件夹(`$HOME/archive/events_memories/2014/2014-05-08 Business-Marathon After-Show-Party`),然后创建该文件夹,并移动文件。
|
||||
|
||||
再一次,我在 geeqie 中选择一个或多个文件,按 `m`(移动),或者只按回车(没有特殊的子文件夹),或者输入一个描述性文本,这是要创建的子文件夹的名称(可选不带日期戳)。
|
||||
|
||||
**没有一个图像管理工具像我的带有 appendfilename 和 move2archive 的 geeqie 一样可以通过快捷键快速且有趣的完成工作。**
|
||||
|
||||
##### 在 geeqie 里初始化 m2a 的相关设置
|
||||
|
||||
同样,向 geeqie 添加 `m2a` 是一个手动步骤:“Edit > Preferences > Configure Editors ...”,然后创建一个附加条目“New”。在这里,你可以定义一个新的桌面文件,如下所示:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=move2archive
|
||||
GenericName=move2archive
|
||||
Comment=Moving one or more files to my archive folder
|
||||
Exec=/home/vk/src/misc/vk-m2a-interactive-wrapper-with-gnome-terminal.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*m2a.desktop*
|
||||
|
||||
封装脚本 `vk-m2a-interactive-wrapper-with-gnome-terminal.sh` 是必要的,因为我想要弹出一个新的终端窗口,以便我的文件进入我指定的目标文件夹:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=157x56+330+5 \
|
||||
--tab-with-profile=big \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/m2a/m2a.py --pauseonexit "${@}"
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-m2a-interactive-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
在 geeqie 中,你可以在 “Edit > Preferences > Preferences ... > Keyboard” 将 `m` 与 `m2a` 命令相关联。
|
||||
|
||||
#### 工作流程:旋转图像(无损)
|
||||
|
||||
通常,我的数码相机会自动将人像照片标记为人像照片。然而,在某些特定的情况下(比如从装饰图案上方拍照),我的相机会出错。在那些**罕见的情况下**,我必须手动修正方向。
|
||||
|
||||
你必须知道,JPEG 文件格式是一种有损格式,应该只用于照片,而不是计算机生成的东西,如屏幕截图或图表。以傻瓜方式旋转 JPEG 图像文件通常会解压/可视化图像文件、旋转生成新的图像,然后重新编码结果。这将导致生成的图像[比原始图像质量差得多][5]。
|
||||
|
||||
因此,你应该使用无损方法来旋转 JPEG 图像文件。
|
||||
|
||||
再一次,我添加了一个“外部编辑器”到 geeqie:“Edit > Preferences > Configure Editors ... > New”。在这里,我添加了两个条目:使用 [exiftran][34],一个用于旋转 270 度(即逆时针旋转 90 度),另一个用于旋转 90 度(顺时针旋转 90 度):
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Version=1.0
|
||||
Type=Application
|
||||
Name=Losslessly rotate JPEG image counterclockwise
|
||||
|
||||
# call the helper script
|
||||
TryExec=exiftran
|
||||
Exec=exiftran -p -2 -i -g %f
|
||||
|
||||
# Desktop files that are usable only in Geeqie should be marked like this:
|
||||
Categories=X-Geeqie;
|
||||
OnlyShowIn=X-Geeqie;
|
||||
|
||||
# Show in menu "Edit/Orientation"
|
||||
X-Geeqie-Menu-Path=EditMenu/OrientationMenu
|
||||
|
||||
MimeType=image/jpeg;
|
||||
```
|
||||
|
||||
*rotate-270.desktop*
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Version=1.0
|
||||
Type=Application
|
||||
Name=Losslessly rotate JPEG image clockwise
|
||||
|
||||
# call the helper script
|
||||
TryExec=exiftran
|
||||
Exec=exiftran -p -9 -i -g %f
|
||||
|
||||
# Desktop files that are usable only in Geeqie should be marked like this:
|
||||
Categories=X-Geeqie;
|
||||
OnlyShowIn=X-Geeqie;
|
||||
|
||||
# Show in menu "Edit/Orientation"
|
||||
X-Geeqie-Menu-Path=EditMenu/OrientationMenu
|
||||
|
||||
# It can be made verbose
|
||||
# X-Geeqie-Verbose=true
|
||||
|
||||
MimeType=image/jpeg;
|
||||
```
|
||||
|
||||
*rotate-90.desktop*
|
||||
|
||||
我创建了 geeqie 快捷键 `[`(逆时针方向)和 `]`(顺时针方向)。
|
||||
|
||||
#### 工作流程:可视化 GPS 坐标
|
||||
|
||||
我的数码相机有一个 GPS 传感器,它在 JPEG 文件的 Exif 元数据中存储当前的地理位置。位置数据以 [WGS 84][35] 格式存储,如 `47, 58, 26.73; 16, 23, 55.51`(纬度;经度)。这一方式可读性较差,我期望:要么是地图,要么是位置名称。因此,我向 geeqie 添加了一些功能,这样我就可以在 [OpenStreetMap][36] 上看到单个图像文件的位置: `Edit > Preferences > Configure Editors ... > New`。
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=vkphotolocation
|
||||
GenericName=vkphotolocation
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vkphotolocation.sh %F
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/bmp;image/gif;image/jpeg;image/jpg;image/pjpeg;image/png;image/tiff;image/x-bmp;image/x-gray;image/x-icb;image/x-ico;image/x-png;image/x-portable-anymap;image/x-portable-bitmap;image/x-portable-graymap;image/x-portable-pixmap;image/x-xbitmap;image/x-xpixmap;image/x-pcx;image/svg+xml;image/svg+xml-compressed;image/vnd.wap.wbmp;
|
||||
```
|
||||
|
||||
*photolocation.desktop*
|
||||
|
||||
这调用了我的名为 `vkphotolocation.sh` 的封装脚本,它使用 [ExifTool][37] 以 [Marble][38] 能够读取和可视化的适当格式提取该坐标:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
IMAGEFILE="${1}"
|
||||
IMAGEFILEBASENAME=`basename ${IMAGEFILE}`
|
||||
|
||||
COORDINATES=`exiftool -c %.6f "${IMAGEFILE}" | awk '/GPS Position/ { print $4 " " $6 }'`
|
||||
|
||||
if [ "x${COORDINATES}" = "x" ]; then
|
||||
zenity --info --title="${IMAGEFILEBASENAME}" --text="No GPS-location found in the image file."
|
||||
else
|
||||
/usr/bin/marble --latlon "${COORDINATES}" --distance 0.5
|
||||
fi
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vkphotolocation.sh*
|
||||
|
||||
映射到键盘快捷键 `G`,我可以快速地得到**单个图像文件的位置的地图定位**。
|
||||
|
||||
当我想将多个 JPEG 图像文件的**位置可视化为路径**时,我使用 [GpsPrune][39]。我无法挖掘出 GpsPrune 将一组文件作为命令行参数的方法。正因为如此,我必须手动启动 GpsPrune,用 “File > Add photos”选择一组文件或一个文件夹。
|
||||
|
||||
通过这种方式,我可以为每个 JPEG 位置在 OpenStreetMap 地图上获得一个点(如果配置为这样)。通过单击这样一个点,我可以得到相应图像的详细信息。
|
||||
|
||||
如果你恰好在国外拍摄照片,可视化 GPS 位置对**在文件名中添加描述**大有帮助!
|
||||
|
||||
#### 工作流程:根据 GPS 坐标过滤照片
|
||||
|
||||
这并非我的工作流程。为了完整起见,我列出该工作流对应工具的特性。我想做的就是从一大堆图片中寻找那些在一定区域内(范围或点 + 距离)的照片。
|
||||
|
||||
到目前为止,我只找到了 [DigiKam][40],它能够[根据矩形区域进行过滤][41]。如果你知道其他工具,请将其添加到下面的评论或给我写一封电子邮件。
|
||||
|
||||
#### 工作流程:显示给定集合的子集
|
||||
|
||||
如上面的需求所述,我希望能够对一个文件夹中的文件定义一个子集,以便将这个小集合呈现给其他人。
|
||||
|
||||
工作流程非常简单:我向选择的文件添加一个标记(通过 `t`/`filetags`)。为此,我使用标记 `sel`,它是 “selection” 的缩写。在标记了一组文件之后,我可以按下 `s`,它与一个脚本相关联,该脚本只显示标记为 `sel` 的文件。
|
||||
|
||||
当然,这也适用于任何标签或标签组合。因此,用同样的方法,你可以得到一个适当的概述,你的婚礼上的所有照片都标记着“教堂”和“戒指”。
|
||||
|
||||
很棒的功能,不是吗?:-)
|
||||
|
||||
##### 初始设置 filetags 以根据标签和 geeqie 过滤
|
||||
|
||||
你必须定义一个额外的“外部编辑器”,“ Edit > Preferences > Configure Editors ... > New”:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Name=filetag-filter
|
||||
GenericName=filetag-filter
|
||||
Comment=
|
||||
Exec=/home/vk/src/misc/vk-filetag-filter-wrapper-with-gnome-terminal.sh
|
||||
Icon=
|
||||
Terminal=true
|
||||
Type=Application
|
||||
Categories=Application;Graphics;
|
||||
hidden=false
|
||||
MimeType=image/*;video/*;image/mpo;image/thm
|
||||
Categories=X-Geeqie;
|
||||
```
|
||||
|
||||
*filter-tags.desktop*
|
||||
|
||||
再次调用我编写的封装脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
/usr/bin/gnome-terminal \
|
||||
--geometry=85x15+330+5 \
|
||||
--hide-menubar \
|
||||
-x /home/vk/src/filetags/filetags.py --filter
|
||||
|
||||
#end
|
||||
```
|
||||
|
||||
*vk-filetag-filter-wrapper-with-gnome-terminal.sh*
|
||||
|
||||
带有参数 `--filter` 的 `filetags` 基本上完成的是:用户被要求输入一个或多个标签。然后,当前文件夹中所有匹配的文件都使用[符号链接][42]链接到 `$HOME/.filetags_tagfilter/`。然后,启动了一个新的 geeqie 实例,显示链接的文件。
|
||||
|
||||
在退出这个新的 geeqie 实例之后,你会看到进行选择的旧的 geeqie 实例。
|
||||
|
||||
#### 用一个真实的案例来总结
|
||||
|
||||
哇哦, 这是一篇很长的博客文章。你可能已经忘了之前的概述。总结一下我在(扩展了标准功能集的) geeqie 中可以做的事情,我有一个很酷的总结:
|
||||
|
||||
快捷键 | 功能
|
||||
--- | ---
|
||||
`m` | 移到归档(m2a)
|
||||
`o` | 打开(针对非图像文件)
|
||||
`a` | 在文件名里添加字段
|
||||
`t` | 文件标签(添加)
|
||||
`T` | 文件标签(删除)
|
||||
`s` | 文件标签(排序)
|
||||
`g` | gimp
|
||||
`G` | 显示 GPS 信息
|
||||
`[` | 无损的逆时针旋转
|
||||
`]` | 无损的顺时针旋转
|
||||
`Ctrl-e` | EXIF 图像信息
|
||||
`f` | 全屏显示
|
||||
|
||||
文件名(包括它的路径)的部分及我用来操作该部分的相应工具:
|
||||
|
||||
```
|
||||
/this/is/a/folder/2014-04-20T17.09 Picknick in Graz -- food graz.jpg
|
||||
[ move2archive ] [ date2name ] [appendfilename] [ filetags ]
|
||||
```
|
||||
|
||||
在实践中,我按照以下步骤将照片从相机保存到存档:我将 SD 存储卡放入计算机的 SD 读卡器中。然后我运行 [getdigicamdata.sh][23]。完成之后,我在 geeqie 中打开 `$HOME/tmp/digicam/tmp/`。我浏览了一下照片,把那些不成功的删除了。如果有一个图像的方向错误,我用 `[` 或 `]` 纠正它。
|
||||
|
||||
在第二步中,我向我认为值得评论的文件添加描述 (`a`)。每当我想添加标签时,我也这样做:我快速地标记所有应该共享相同标签的文件(`Ctrl + 鼠标点击`),并使用 [filetags][28](`t`)进行标记。
|
||||
|
||||
要合并来自给定事件的文件,我选中相应的文件,将它们移动到年度归档文件夹中的 `event-folder`,并通过在 [move2archive][33](`m`)中键入事件描述,其余的(非特殊的文件夹)无需声明事件描述由 `move2archive` (`m`)直接移动到年度归档中。
|
||||
|
||||
结束我的工作流程,我删除了 SD 卡上的所有文件,把它从操作系统上弹出,然后把它放回我的数码相机里。
|
||||
|
||||
以上。
|
||||
|
||||
因为这种工作流程几乎不需要任何开销,所以评论、标记和归档照片不再是一项乏味的工作。
|
||||
|
||||
### 最后
|
||||
|
||||
所以,这是一个详细描述我关于照片和电影的工作流程的叙述。你可能已经发现了我可能感兴趣的其他东西。所以请不要犹豫,请使用下面的链接留下评论或电子邮件。
|
||||
|
||||
我也希望得到反馈,如果我的工作流程适用于你。并且,如果你已经发布了你的工作流程或者找到了其他人工作流程的描述,也请留下评论!
|
||||
|
||||
及时行乐,莫让错误的工具或低效的方法浪费了我们的人生!
|
||||
|
||||
### 其他工具
|
||||
|
||||
阅读关于[本文中关于 gThumb 的部分][43]。
|
||||
|
||||
当你觉得你以上文中所叙述的符合你的需求时,请根据相关的建议来选择对应的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/managing-digital-photographs/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/Jpeg
|
||||
[2]:http://en.wikipedia.org/wiki/Vendor_lock-in
|
||||
[3]:https://en.wikipedia.org/wiki/Raw_image_format
|
||||
[4]:http://www.gimp.org/
|
||||
[5]:http://petapixel.com/2012/08/14/why-you-should-always-rotate-original-jpeg-photos-losslessly/
|
||||
[6]:https://en.wikipedia.org/wiki/Gps
|
||||
[7]:https://en.wikipedia.org/wiki/Iso_date
|
||||
[8]:https://en.wikipedia.org/wiki/Ntfs
|
||||
[9]:https://en.wikipedia.org/wiki/Exif
|
||||
[10]:http://www.isisinform.com/reinventing-knowledge-the-medieval-controversy-of-alphabetical-order/
|
||||
[11]:https://en.wikipedia.org/wiki/File_name_extension
|
||||
[12]:http://karl-voit.at/tagstore/en/papers.shtml
|
||||
[13]:https://en.wikipedia.org/wiki/Hashtag
|
||||
[14]:https://en.wikipedia.org/wiki/Dot-file
|
||||
[15]:https://en.wikipedia.org/wiki/NTFS#Alternate_data_streams_.28ADS.29
|
||||
[16]:https://github.com/novoid/Memacs/blob/master/docs/memacs_filenametimestamps.org
|
||||
[17]:https://github.com/novoid/Memacs
|
||||
[18]:http://www.cis.upenn.edu/~bcpierce/unison/
|
||||
[19]:https://github.com/novoid/LaTeX-KOMA-template
|
||||
[20]:http://orgmode.org/
|
||||
[21]:http://karl-voit.at/tags/emacs
|
||||
[22]:https://twitter.com/search?q%3D%2523orgmode&src%3Dtypd
|
||||
[23]:https://github.com/novoid/getdigicamdata.sh
|
||||
[24]:http://www.sentex.net/%3Ccode%3Emwandel/jhead/
|
||||
[25]:https://github.com/novoid/date2name
|
||||
[26]:http://geeqie.sourceforge.net/
|
||||
[27]:http://xee.c3.cx/
|
||||
[28]:https://github.com/novoid/filetag
|
||||
[29]:http://karl-voit.at/tagstore/
|
||||
[30]:https://github.com/novoid/appendfilename
|
||||
[31]:http://www.mplayerhq.hu
|
||||
[32]:https://wiki.archlinux.org/index.php/xdg-open
|
||||
[33]:https://github.com/novoid/move2archive
|
||||
[34]:http://manpages.ubuntu.com/manpages/raring/man1/exiftran.1.html
|
||||
[35]:https://en.wikipedia.org/wiki/WGS84#A_new_World_Geodetic_System:_WGS_84
|
||||
[36]:http://www.openstreetmap.org/
|
||||
[37]:http://www.sno.phy.queensu.ca/~phil/exiftool/
|
||||
[38]:http://userbase.kde.org/Marble/Tracking
|
||||
[39]:http://activityworkshop.net/software/gpsprune/
|
||||
[40]:https://en.wikipedia.org/wiki/DigiKam
|
||||
[41]:https://docs.kde.org/development/en/extragear-graphics/digikam/using-kapp.html#idp7659904
|
||||
[42]:https://en.wikipedia.org/wiki/Symbolic_link
|
||||
[43]:http://karl-voit.at/2017/02/19/gthumb
|
||||
[44]:https://glt18.linuxtage.at
|
||||
[45]:https://glt18-programm.linuxtage.at/events/321.html
|
||||
444
published/20180706 Building a Messenger App- OAuth.md
Normal file
444
published/20180706 Building a Messenger App- OAuth.md
Normal file
@ -0,0 +1,444 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (PsiACE)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11510-1.html)
|
||||
[#]: subject: (Building a Messenger App: OAuth)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-oauth/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
构建一个即时消息应用(二):OAuth
|
||||
======
|
||||
|
||||
[上一篇:模式](https://linux.cn/article-11396-1.html)。
|
||||
|
||||
在这篇帖子中,我们将会通过为应用添加社交登录功能进入后端开发。
|
||||
|
||||
社交登录的工作方式十分简单:用户点击链接,然后重定向到 GitHub 授权页面。当用户授予我们对他的个人信息的访问权限之后,就会重定向回登录页面。下一次尝试登录时,系统将不会再次请求授权,也就是说,我们的应用已经记住了这个用户。这使得整个登录流程看起来就和你用鼠标单击一样快。
|
||||
|
||||
如果进一步考虑其内部实现的话,过程就会变得复杂起来。首先,我们需要注册一个新的 [GitHub OAuth 应用][2]。
|
||||
|
||||
这一步中,比较重要的是回调 URL。我们将它设置为 `http://localhost:3000/api/oauth/github/callback`。这是因为,在开发过程中,我们总是在本地主机上工作。一旦你要将应用交付生产,请使用正确的回调 URL 注册一个新的应用。
|
||||
|
||||
注册以后,你将会收到“客户端 id”和“安全密钥”。安全起见,请不要与任何人分享他们 👀
|
||||
|
||||
顺便让我们开始写一些代码吧。现在,创建一个 `main.go` 文件:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"database/sql"
|
||||
"fmt"
|
||||
"log"
|
||||
"net/http"
|
||||
"net/url"
|
||||
"os"
|
||||
"strconv"
|
||||
|
||||
"github.com/gorilla/securecookie"
|
||||
"github.com/joho/godotenv"
|
||||
"github.com/knq/jwt"
|
||||
_ "github.com/lib/pq"
|
||||
"github.com/matryer/way"
|
||||
"golang.org/x/oauth2"
|
||||
"golang.org/x/oauth2/github"
|
||||
)
|
||||
|
||||
var origin *url.URL
|
||||
var db *sql.DB
|
||||
var githubOAuthConfig *oauth2.Config
|
||||
var cookieSigner *securecookie.SecureCookie
|
||||
var jwtSigner jwt.Signer
|
||||
|
||||
func main() {
|
||||
godotenv.Load()
|
||||
|
||||
port := intEnv("PORT", 3000)
|
||||
originString := env("ORIGIN", fmt.Sprintf("http://localhost:%d/", port))
|
||||
databaseURL := env("DATABASE_URL", "postgresql://root@127.0.0.1:26257/messenger?sslmode=disable")
|
||||
githubClientID := os.Getenv("GITHUB_CLIENT_ID")
|
||||
githubClientSecret := os.Getenv("GITHUB_CLIENT_SECRET")
|
||||
hashKey := env("HASH_KEY", "secret")
|
||||
jwtKey := env("JWT_KEY", "secret")
|
||||
|
||||
var err error
|
||||
if origin, err = url.Parse(originString); err != nil || !origin.IsAbs() {
|
||||
log.Fatal("invalid origin")
|
||||
return
|
||||
}
|
||||
|
||||
if i, err := strconv.Atoi(origin.Port()); err == nil {
|
||||
port = i
|
||||
}
|
||||
|
||||
if githubClientID == "" || githubClientSecret == "" {
|
||||
log.Fatalf("remember to set both $GITHUB_CLIENT_ID and $GITHUB_CLIENT_SECRET")
|
||||
return
|
||||
}
|
||||
|
||||
if db, err = sql.Open("postgres", databaseURL); err != nil {
|
||||
log.Fatalf("could not open database connection: %v\n", err)
|
||||
return
|
||||
}
|
||||
defer db.Close()
|
||||
if err = db.Ping(); err != nil {
|
||||
log.Fatalf("could not ping to db: %v\n", err)
|
||||
return
|
||||
}
|
||||
|
||||
githubRedirectURL := *origin
|
||||
githubRedirectURL.Path = "/api/oauth/github/callback"
|
||||
githubOAuthConfig = &oauth2.Config{
|
||||
ClientID: githubClientID,
|
||||
ClientSecret: githubClientSecret,
|
||||
Endpoint: github.Endpoint,
|
||||
RedirectURL: githubRedirectURL.String(),
|
||||
Scopes: []string{"read:user"},
|
||||
}
|
||||
|
||||
cookieSigner = securecookie.New([]byte(hashKey), nil).MaxAge(0)
|
||||
|
||||
jwtSigner, err = jwt.HS256.New([]byte(jwtKey))
|
||||
if err != nil {
|
||||
log.Fatalf("could not create JWT signer: %v\n", err)
|
||||
return
|
||||
}
|
||||
|
||||
router := way.NewRouter()
|
||||
router.HandleFunc("GET", "/api/oauth/github", githubOAuthStart)
|
||||
router.HandleFunc("GET", "/api/oauth/github/callback", githubOAuthCallback)
|
||||
router.HandleFunc("GET", "/api/auth_user", guard(getAuthUser))
|
||||
|
||||
log.Printf("accepting connections on port %d\n", port)
|
||||
log.Printf("starting server at %s\n", origin.String())
|
||||
addr := fmt.Sprintf(":%d", port)
|
||||
if err = http.ListenAndServe(addr, router); err != nil {
|
||||
log.Fatalf("could not start server: %v\n", err)
|
||||
}
|
||||
}
|
||||
|
||||
func env(key, fallbackValue string) string {
|
||||
v, ok := os.LookupEnv(key)
|
||||
if !ok {
|
||||
return fallbackValue
|
||||
}
|
||||
return v
|
||||
}
|
||||
|
||||
func intEnv(key string, fallbackValue int) int {
|
||||
v, ok := os.LookupEnv(key)
|
||||
if !ok {
|
||||
return fallbackValue
|
||||
}
|
||||
i, err := strconv.Atoi(v)
|
||||
if err != nil {
|
||||
return fallbackValue
|
||||
}
|
||||
return i
|
||||
}
|
||||
```
|
||||
|
||||
安装依赖项:
|
||||
|
||||
```
|
||||
go get -u github.com/gorilla/securecookie
|
||||
go get -u github.com/joho/godotenv
|
||||
go get -u github.com/knq/jwt
|
||||
go get -u github.com/lib/pq
|
||||
ge get -u github.com/matoous/go-nanoid
|
||||
go get -u github.com/matryer/way
|
||||
go get -u golang.org/x/oauth2
|
||||
```
|
||||
|
||||
我们将会使用 `.env` 文件来保存密钥和其他配置。请创建这个文件,并保证里面至少包含以下内容:
|
||||
|
||||
```
|
||||
GITHUB_CLIENT_ID=your_github_client_id
|
||||
GITHUB_CLIENT_SECRET=your_github_client_secret
|
||||
```
|
||||
|
||||
我们还要用到的其他环境变量有:
|
||||
|
||||
* `PORT`:服务器运行的端口,默认值是 `3000`。
|
||||
* `ORIGIN`:你的域名,默认值是 `http://localhost:3000/`。我们也可以在这里指定端口。
|
||||
* `DATABASE_URL`:Cockroach 数据库的地址。默认值是 `postgresql://root@127.0.0.1:26257/messenger?sslmode=disable`。
|
||||
* `HASH_KEY`:用于为 cookie 签名的密钥。没错,我们会使用已签名的 cookie 来确保安全。
|
||||
* `JWT_KEY`:用于签署 JSON <ruby>网络令牌<rt>Web Token</rt></ruby>的密钥。
|
||||
|
||||
因为代码中已经设定了默认值,所以你也不用把它们写到 `.env` 文件中。
|
||||
|
||||
在读取配置并连接到数据库之后,我们会创建一个 OAuth 配置。我们会使用 `ORIGIN` 信息来构建回调 URL(就和我们在 GitHub 页面上注册的一样)。我们的数据范围设置为 “read:user”。这会允许我们读取公开的用户信息,这里我们只需要他的用户名和头像就够了。然后我们会初始化 cookie 和 JWT 签名器。定义一些端点并启动服务器。
|
||||
|
||||
在实现 HTTP 处理程序之前,让我们编写一些函数来发送 HTTP 响应。
|
||||
|
||||
```
|
||||
func respond(w http.ResponseWriter, v interface{}, statusCode int) {
|
||||
b, err := json.Marshal(v)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not marshal response: %v", err))
|
||||
return
|
||||
}
|
||||
w.Header().Set("Content-Type", "application/json; charset=utf-8")
|
||||
w.WriteHeader(statusCode)
|
||||
w.Write(b)
|
||||
}
|
||||
|
||||
func respondError(w http.ResponseWriter, err error) {
|
||||
log.Println(err)
|
||||
http.Error(w, http.StatusText(http.StatusInternalServerError), http.StatusInternalServerError)
|
||||
}
|
||||
```
|
||||
|
||||
第一个函数用来发送 JSON,而第二个将错误记录到控制台并返回一个 `500 Internal Server Error` 错误信息。
|
||||
|
||||
### OAuth 开始
|
||||
|
||||
所以,用户点击写着 “Access with GitHub” 的链接。该链接指向 `/api/oauth/github`,这将会把用户重定向到 github。
|
||||
|
||||
```
|
||||
func githubOAuthStart(w http.ResponseWriter, r *http.Request) {
|
||||
state, err := gonanoid.Nanoid()
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not generte state: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
stateCookieValue, err := cookieSigner.Encode("state", state)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not encode state cookie: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
http.SetCookie(w, &http.Cookie{
|
||||
Name: "state",
|
||||
Value: stateCookieValue,
|
||||
Path: "/api/oauth/github",
|
||||
HttpOnly: true,
|
||||
})
|
||||
http.Redirect(w, r, githubOAuthConfig.AuthCodeURL(state), http.StatusTemporaryRedirect)
|
||||
}
|
||||
```
|
||||
|
||||
OAuth2 使用一种机制来防止 CSRF 攻击,因此它需要一个“状态”(`state`)。我们使用 `Nanoid()` 来创建一个随机字符串,并用这个字符串作为状态。我们也把它保存为一个 cookie。
|
||||
|
||||
### OAuth 回调
|
||||
|
||||
一旦用户授权我们访问他的个人信息,他将会被重定向到这个端点。这个 URL 的查询字符串上将会包含状态(`state`)和授权码(`code`): `/api/oauth/github/callback?state=&code=`。
|
||||
|
||||
```
|
||||
const jwtLifetime = time.Hour * 24 * 14
|
||||
|
||||
type GithubUser struct {
|
||||
ID int `json:"id"`
|
||||
Login string `json:"login"`
|
||||
AvatarURL *string `json:"avatar_url,omitempty"`
|
||||
}
|
||||
|
||||
type User struct {
|
||||
ID string `json:"id"`
|
||||
Username string `json:"username"`
|
||||
AvatarURL *string `json:"avatarUrl"`
|
||||
}
|
||||
|
||||
func githubOAuthCallback(w http.ResponseWriter, r *http.Request) {
|
||||
stateCookie, err := r.Cookie("state")
|
||||
if err != nil {
|
||||
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
|
||||
return
|
||||
}
|
||||
|
||||
http.SetCookie(w, &http.Cookie{
|
||||
Name: "state",
|
||||
Value: "",
|
||||
MaxAge: -1,
|
||||
HttpOnly: true,
|
||||
})
|
||||
|
||||
var state string
|
||||
if err = cookieSigner.Decode("state", stateCookie.Value, &state); err != nil {
|
||||
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
|
||||
return
|
||||
}
|
||||
|
||||
q := r.URL.Query()
|
||||
|
||||
if state != q.Get("state") {
|
||||
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
|
||||
t, err := githubOAuthConfig.Exchange(ctx, q.Get("code"))
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not fetch github token: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
client := githubOAuthConfig.Client(ctx, t)
|
||||
resp, err := client.Get("https://api.github.com/user")
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not fetch github user: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
var githubUser GithubUser
|
||||
if err = json.NewDecoder(resp.Body).Decode(&githubUser); err != nil {
|
||||
respondError(w, fmt.Errorf("could not decode github user: %v", err))
|
||||
return
|
||||
}
|
||||
defer resp.Body.Close()
|
||||
|
||||
tx, err := db.BeginTx(ctx, nil)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not begin tx: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
var user User
|
||||
if err = tx.QueryRowContext(ctx, `
|
||||
SELECT id, username, avatar_url FROM users WHERE github_id = $1
|
||||
`, githubUser.ID).Scan(&user.ID, &user.Username, &user.AvatarURL); err == sql.ErrNoRows {
|
||||
if err = tx.QueryRowContext(ctx, `
|
||||
INSERT INTO users (username, avatar_url, github_id) VALUES ($1, $2, $3)
|
||||
RETURNING id
|
||||
`, githubUser.Login, githubUser.AvatarURL, githubUser.ID).Scan(&user.ID); err != nil {
|
||||
respondError(w, fmt.Errorf("could not insert user: %v", err))
|
||||
return
|
||||
}
|
||||
user.Username = githubUser.Login
|
||||
user.AvatarURL = githubUser.AvatarURL
|
||||
} else if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query user by github ID: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if err = tx.Commit(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not commit to finish github oauth: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
exp := time.Now().Add(jwtLifetime)
|
||||
token, err := jwtSigner.Encode(jwt.Claims{
|
||||
Subject: user.ID,
|
||||
Expiration: json.Number(strconv.FormatInt(exp.Unix(), 10)),
|
||||
})
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not create token: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
expiresAt, _ := exp.MarshalText()
|
||||
|
||||
data := make(url.Values)
|
||||
data.Set("token", string(token))
|
||||
data.Set("expires_at", string(expiresAt))
|
||||
|
||||
http.Redirect(w, r, "/callback?"+data.Encode(), http.StatusTemporaryRedirect)
|
||||
}
|
||||
```
|
||||
|
||||
首先,我们会尝试使用之前保存的状态对 cookie 进行解码。并将其与查询字符串中的状态进行比较。如果它们不匹配,我们会返回一个 `418 I'm teapot`(未知来源)错误。
|
||||
|
||||
接着,我们使用授权码生成一个令牌。这个令牌被用于创建 HTTP 客户端来向 GitHub API 发出请求。所以最终我们会向 `https://api.github.com/user` 发送一个 GET 请求。这个端点将会以 JSON 格式向我们提供当前经过身份验证的用户信息。我们将会解码这些内容,一并获取用户的 ID、登录名(用户名)和头像 URL。
|
||||
|
||||
然后我们将会尝试在数据库上找到具有该 GitHub ID 的用户。如果没有找到,就使用该数据创建一个新的。
|
||||
|
||||
之后,对于新创建的用户,我们会发出一个将用户 ID 作为主题(`Subject`)的 JSON 网络令牌,并使用该令牌重定向到前端,查询字符串中一并包含该令牌的到期日(`Expiration`)。
|
||||
|
||||
这一 Web 应用也会被用在其他帖子,但是重定向的链接会是 `/callback?token=&expires_at=`。在那里,我们将会利用 JavaScript 从 URL 中获取令牌和到期日,并通过 `Authorization` 标头中的令牌以 `Bearer token_here` 的形式对 `/api/auth_user` 进行 GET 请求,来获取已认证的身份用户并将其保存到 localStorage。
|
||||
|
||||
### Guard 中间件
|
||||
|
||||
为了获取当前已经过身份验证的用户,我们设计了 Guard 中间件。这是因为在接下来的文章中,我们会有很多需要进行身份认证的端点,而中间件将会允许我们共享这一功能。
|
||||
|
||||
```
|
||||
type ContextKey struct {
|
||||
Name string
|
||||
}
|
||||
|
||||
var keyAuthUserID = ContextKey{"auth_user_id"}
|
||||
|
||||
func guard(handler http.HandlerFunc) http.HandlerFunc {
|
||||
return func(w http.ResponseWriter, r *http.Request) {
|
||||
var token string
|
||||
if a := r.Header.Get("Authorization"); strings.HasPrefix(a, "Bearer ") {
|
||||
token = a[7:]
|
||||
} else if t := r.URL.Query().Get("token"); t != "" {
|
||||
token = t
|
||||
} else {
|
||||
http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
|
||||
return
|
||||
}
|
||||
|
||||
var claims jwt.Claims
|
||||
if err := jwtSigner.Decode([]byte(token), &claims); err != nil {
|
||||
http.Error(w, http.StatusText(http.StatusUnauthorized), http.StatusUnauthorized)
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
ctx = context.WithValue(ctx, keyAuthUserID, claims.Subject)
|
||||
|
||||
handler(w, r.WithContext(ctx))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
首先,我们尝试从 `Authorization` 标头或者是 URL 查询字符串中的 `token` 字段中读取令牌。如果没有找到,我们需要返回 `401 Unauthorized`(未授权)错误。然后我们将会对令牌中的申明进行解码,并使用该主题作为当前已经过身份验证的用户 ID。
|
||||
|
||||
现在,我们可以用这一中间件来封装任何需要授权的 `http.handlerFunc`,并且在处理函数的上下文中保有已经过身份验证的用户 ID。
|
||||
|
||||
```
|
||||
var guarded = guard(func(w http.ResponseWriter, r *http.Request) {
|
||||
authUserID := r.Context().Value(keyAuthUserID).(string)
|
||||
})
|
||||
```
|
||||
|
||||
### 获取认证用户
|
||||
|
||||
```
|
||||
func getAuthUser(w http.ResponseWriter, r *http.Request) {
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
|
||||
var user User
|
||||
if err := db.QueryRowContext(ctx, `
|
||||
SELECT username, avatar_url FROM users WHERE id = $1
|
||||
`, authUserID).Scan(&user.Username, &user.AvatarURL); err == sql.ErrNoRows {
|
||||
http.Error(w, http.StatusText(http.StatusTeapot), http.StatusTeapot)
|
||||
return
|
||||
} else if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query auth user: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
user.ID = authUserID
|
||||
|
||||
respond(w, user, http.StatusOK)
|
||||
}
|
||||
```
|
||||
|
||||
我们使用 Guard 中间件来获取当前经过身份认证的用户 ID 并查询数据库。
|
||||
|
||||
这一部分涵盖了后端的 OAuth 流程。在下一篇帖子中,我们将会看到如何开始与其他用户的对话。
|
||||
|
||||
- [源代码][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[PsiACE](https://github.com/PsiACE)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
|
||||
[2]: https://github.com/settings/applications/new
|
||||
[3]: https://github.com/nicolasparada/go-messenger-demo
|
||||
277
published/20180906 What a shell dotfile can do for you.md
Normal file
277
published/20180906 What a shell dotfile can do for you.md
Normal file
@ -0,0 +1,277 @@
|
||||
Shell 点文件可以为你做点什么
|
||||
======
|
||||
|
||||
> 了解如何使用配置文件来改善你的工作环境。
|
||||
|
||||

|
||||
|
||||
不要问你可以为你的 shell <ruby>点文件<rt>dotfile</rt></ruby>做什么,而是要问一个 shell 点文件可以为你做什么!
|
||||
|
||||
我一直在操作系统领域里面打转,但是在过去的几年中,我的日常使用的一直是 Mac。很长一段时间,我都在使用 Bash,但是当几个朋友开始把 [zsh][1] 当成宗教信仰时,我也试试了它。我没用太长时间就喜欢上了它,几年后,我越发喜欢它做的许多小事情。
|
||||
|
||||
我一直在使用 zsh(通过 [Homebrew][2] 提供,而不是由操作系统安装的)和 [Oh My Zsh 增强功能][3]。
|
||||
|
||||
本文中的示例是我的个人 `.zshrc`。大多数都可以直接用在 Bash 中,我觉得不是每个人都依赖于 Oh My Zsh,但是如果不用的话你的工作量可能会有所不同。曾经有一段时间,我同时为 zsh 和 Bash 维护一个 shell 点文件,但是最终我还是放弃了我的 `.bashrc`。
|
||||
|
||||
### 不偏执不行
|
||||
|
||||
如果你希望在各个操作系统上使用相同的点文件,则需要让你的点文件聪明点。
|
||||
|
||||
```
|
||||
### Mac 专用
|
||||
if [[ "$OSTYPE" == "darwin"* ]]; then
|
||||
# Mac 专用内容在此
|
||||
```
|
||||
|
||||
例如,我希望 `Alt + 箭头键` 将光标按单词移动而不是单个空格。为了在 [iTerm2][4](我的首选终端)中实现这一目标,我将此代码段添加到了 `.zshrc` 的 Mac 专用部分:
|
||||
|
||||
```
|
||||
### Mac 专用
|
||||
if [[ "$OSTYPE" == "darwin"* ]]; then
|
||||
### Mac 用于 iTerm2 的光标命令;映射 ctrl+arrows 或 alt+arrows 来快速移动
|
||||
bindkey -e
|
||||
bindkey '^[[1;9C' forward-word
|
||||
bindkey '^[[1;9D' backward-word
|
||||
bindkey '\e\e[D' backward-word
|
||||
bindkey '\e\e[C' forward-word
|
||||
fi
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “We're all mad here” 是电影《爱丽丝梦游仙境》中,微笑猫对爱丽丝讲的一句话:“我们这儿全都是疯的”。)
|
||||
|
||||
### 在家不工作
|
||||
|
||||
虽然我开始喜欢我的 Shell 点文件了,但我并不总是想要家用计算机上的东西与工作的计算机上的东西一样。解决此问题的一种方法是让补充的点文件在家中使用,而不是在工作中使用。以下是我的实现方式:
|
||||
|
||||
```
|
||||
if [[ `egrep 'dnssuffix1|dnssuffix2' /etc/resolv.conf` ]]; then
|
||||
if [ -e $HOME/.work ]
|
||||
source $HOME/.work
|
||||
else
|
||||
echo "This looks like a work machine, but I can't find the ~/.work file"
|
||||
fi
|
||||
fi
|
||||
```
|
||||
|
||||
在这种情况下,我根据我的工作 dns 后缀(或多个后缀,具体取决于你的情况)来提供(`source`)一个可以使我的工作环境更好的单独文件。
|
||||
|
||||
(LCTT 译注:标题 “What about Bob?” 是 1991 年的美国电影《天才也疯狂》。)
|
||||
|
||||
### 你该这么做
|
||||
|
||||
现在可能是放弃使用波浪号(`~`)表示编写脚本时的主目录的好时机。你会发现在某些上下文中无法识别它。养成使用环境变量 `$HOME` 的习惯,这将为你节省大量的故障排除时间和以后的工作。
|
||||
|
||||
如果你愿意,合乎逻辑的扩展是应该包括特定于操作系统的点文件。
|
||||
|
||||
(LCTT 译注:标题 “That thing you do” 是 1996 年由汤姆·汉克斯执导的喜剧片《挡不住的奇迹》。)
|
||||
|
||||
### 别指望记忆
|
||||
|
||||
我写了那么多 shell 脚本,我真的再也不想写脚本了。并不是说 shell 脚本不能满足我大部分时间的需求,而是我发现写 shell 脚本,可能只是拼凑了一个胶带式解决方案,而不是永久地解决问题。
|
||||
|
||||
同样,我讨厌记住事情,在我的整个职业生涯中,我经常不得不在一天之中就彻彻底底地改换环境。实际的结果是这些年来,我不得不一再重新学习很多东西。(“等等……这种语言使用哪种 for 循环结构?”)
|
||||
|
||||
因此,每隔一段时间我就会觉得自己厌倦了再次寻找做某事的方法。我改善生活的一种方法是添加别名。
|
||||
|
||||
对于任何一个使用操作系统的人来说,一个常见的情况是找出占用了所有磁盘的内容。不幸的是,我从来没有记住过这个咒语,所以我做了一个 shell 别名,创造性地叫做 `bigdirs`:
|
||||
|
||||
```
|
||||
alias bigdirs='du --max-depth=1 2> /dev/null | sort -n -r | head -n20'
|
||||
```
|
||||
|
||||
虽然我可能不那么懒惰,并实际记住了它,但是,那不太 Unix ……
|
||||
|
||||
(LCTT 译注:标题 “Memory, all alone in the moonlight” 是一手英文老歌。)
|
||||
|
||||
### 输错的人们
|
||||
|
||||
使用 shell 别名改善我的生活的另一种方法是使我免于输入错误。我不知道为什么,但是我已经养成了这种讨厌的习惯,在序列 `ea` 之后输入 `w`,所以如果我想清除终端,我经常会输入 `cleawr`。不幸的是,这对我的 shell 没有任何意义。直到我添加了这个小东西:
|
||||
|
||||
```
|
||||
alias cleawr='clear'
|
||||
```
|
||||
|
||||
在 Windows 中有一个等效但更好的命令 `cls`,但我发现自己会在 Shell 也输入它。看到你的 shell 表示抗议真令人沮丧,因此我添加:
|
||||
|
||||
```
|
||||
alias cls='clear'
|
||||
```
|
||||
|
||||
是的,我知道 `ctrl + l`,但是我从不使用它。
|
||||
|
||||
(LCTT 译注:标题 “Typos, and the people who love them” 可能来自某部电影。)
|
||||
|
||||
### 要自娱自乐
|
||||
|
||||
工作压力很大。有时你需要找点乐子。如果你的 shell 不知道它显然应该执行的命令,则可能你想直接让它耸耸肩!你可以使用以下功能执行此操作:
|
||||
|
||||
```
|
||||
shrug() { echo "¯\_(ツ)_/¯"; }
|
||||
```
|
||||
|
||||
如果还不行,也许你需要掀桌不干了:
|
||||
|
||||
```
|
||||
fliptable() { echo "(╯°□°)╯ ┻━┻"; } # 掀桌,用法示例: fsck -y /dev/sdb1 || fliptable
|
||||
```
|
||||
|
||||
想想看,当我想掀桌子时而我不记得我给它起了个什么名字,我会有多沮丧和失望,所以我添加了更多的 shell 别名:
|
||||
|
||||
```
|
||||
alias flipdesk='fliptable'
|
||||
alias deskflip='fliptable'
|
||||
alias tableflip='fliptable'
|
||||
```
|
||||
|
||||
而有时你需要庆祝一下:
|
||||
|
||||
```
|
||||
disco() {
|
||||
echo "(•_•)"
|
||||
echo "<) )╯"
|
||||
echo " / \ "
|
||||
echo ""
|
||||
echo "\(•_•)"
|
||||
echo " ( (>"
|
||||
echo " / \ "
|
||||
echo ""
|
||||
echo " (•_•)"
|
||||
echo "<) )>"
|
||||
echo " / \ "
|
||||
}
|
||||
```
|
||||
|
||||
通常,我会将这些命令的输出通过管道传递到 `pbcopy`,并将其粘贴到我正在使用的相关聊天工具中。
|
||||
|
||||
我从一个我关注的一个叫 “Command Line Magic” [@ climagic][5] 的 Twitter 帐户得到了下面这个有趣的函数。自从我现在住在佛罗里达州以来,我很高兴看到我这一生中唯一的一次下雪:
|
||||
|
||||
```
|
||||
snow() {
|
||||
clear;while :;do echo $LINES $COLUMNS $(($RANDOM%$COLUMNS));sleep 0.1;done|gawk '{a[$3]=0;for(x in a) {o=a[x];a[x]=a[x]+1;printf "\033[%s;%sH ",o,x;printf "\033[%s;%sH*\033[0;0H",a[x],x;}}'
|
||||
}
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Amuse yourself” 是 1936 年的美国电影《自娱自乐》)
|
||||
|
||||
### 函数的乐趣
|
||||
|
||||
我们已经看到了一些我使用的函数示例。由于这些示例中几乎不需要参数,因此可以将它们作为别名来完成。 当比一个短句更长时,我出于个人喜好使用函数。
|
||||
|
||||
在我职业生涯的很多时期我都运行过 [Graphite][6],这是一个开源、可扩展的时间序列指标解决方案。 在很多的情况下,我需要将度量路径(用句点表示)转换到文件系统路径(用斜杠表示),反之亦然,拥有专用于这些任务的函数就变得很有用:
|
||||
|
||||
```
|
||||
# 在 Graphite 指标和文件路径之间转换很有用
|
||||
function dottoslash() {
|
||||
echo $1 | sed 's/\./\//g'
|
||||
}
|
||||
function slashtodot() {
|
||||
echo $1 | sed 's/\//\./g'
|
||||
}
|
||||
```
|
||||
|
||||
在我的另外一段职业生涯里,我运行了很多 Kubernetes。如果你对运行 Kubernetes 不熟悉,你需要编写很多 YAML。不幸的是,一不小心就会编写了无效的 YAML。更糟糕的是,Kubernetes 不会在尝试应用 YAML 之前对其进行验证,因此,除非你应用它,否则你不会发现它是无效的。除非你先进行验证:
|
||||
|
||||
```
|
||||
function yamllint() {
|
||||
for i in $(find . -name '*.yml' -o -name '*.yaml'); do echo $i; ruby -e "require 'yaml';YAML.load_file(\"$i\")"; done
|
||||
}
|
||||
```
|
||||
|
||||
因为我厌倦了偶尔破坏客户的设置而让自己感到尴尬,所以我写了这个小片段并将其作为提交前挂钩添加到我所有相关的存储库中。在持续集成过程中,类似的内容将非常有帮助,尤其是在你作为团队成员的情况下。
|
||||
|
||||
(LCTT 译注:哦抱歉,我不知道这个标题的出处。)
|
||||
|
||||
### 手指不听话
|
||||
|
||||
我曾经是一位出色的盲打打字员。但那些日子已经一去不回。我的打字错误超出了我的想象。
|
||||
|
||||
在各种时期,我多次用过 Chef 或 Kubernetes。对我来说幸运的是,我从未同时使用过这两者。
|
||||
|
||||
Chef 生态系统的一部分是 Test Kitchen,它是加快测试的一组工具,可通过命令 `kitchen test` 来调用。Kubernetes 使用 CLI 工具 `kubectl` 进行管理。这两个命令都需要几个子命令,并且这两者都不会特别顺畅地移动手指。
|
||||
|
||||
我没有创建一堆“输错别名”,而是将这两个命令别名为 `k`:
|
||||
|
||||
```
|
||||
alias k='kitchen test $@'
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
alias k='kubectl $@'
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Oh, fingers, where art thou?” 演绎自《O Brother, Where Art Thou?》,这是 2000 年美国的一部电影《逃狱三王》。)
|
||||
|
||||
### 分裂与合并
|
||||
|
||||
我职业生涯的后半截涉及与其他人一起编写更多代码。我曾在许多环境中工作过,在这些环境中,我们在帐户中复刻了存储库副本,并将拉取请求用作审核过程的一部分。当我想确保给定存储库的复刻与父版本保持最新时,我使用 `fetchupstream`:
|
||||
|
||||
```
|
||||
alias fetchupstream='git fetch upstream && git checkout master && git merge upstream/master && git push'
|
||||
```
|
||||
|
||||
(LCTT 译注:标题 “Timesplitters” 是一款视频游戏《时空分裂者》。)
|
||||
|
||||
### 颜色之荣耀
|
||||
|
||||
我喜欢颜色。它可以使 `diff` 之类的东西更易于使用。
|
||||
|
||||
```
|
||||
alias diff='colordiff'
|
||||
```
|
||||
|
||||
我觉得彩色的手册页是个巧妙的技巧,因此我合并了以下函数:
|
||||
|
||||
```
|
||||
# 彩色化手册页,来自:
|
||||
# http://boredzo.org/blog/archives/2016-08-15/colorized-man-pages-understood-and-customized
|
||||
man() {
|
||||
env \
|
||||
LESS_TERMCAP_md=$(printf "\e[1;36m") \
|
||||
LESS_TERMCAP_me=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_se=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_so=$(printf "\e[1;44;33m") \
|
||||
LESS_TERMCAP_ue=$(printf "\e[0m") \
|
||||
LESS_TERMCAP_us=$(printf "\e[1;32m") \
|
||||
man "$@"
|
||||
}
|
||||
```
|
||||
|
||||
我喜欢命令 `which`,但它只是告诉你正在运行的命令在文件系统中的位置,除非它是 Shell 函数才能告诉你更多。在多个级联的点文件之后,有时会不清楚函数的定义位置或作用。事实证明,`whence` 和 `type` 命令可以帮助解决这一问题。
|
||||
|
||||
```
|
||||
# 函数定义在哪里?
|
||||
whichfunc() {
|
||||
whence -v $1
|
||||
type -a $1
|
||||
}
|
||||
```
|
||||
|
||||
(LCTT 译注:标题“Mine eyes have seen the glory of the coming of color” 演绎自歌曲 《Mine Eyes Have Seen The Glory Of The Coming Of The Lord》)
|
||||
|
||||
### 总结
|
||||
|
||||
希望本文对你有所帮助,并能激发你找到改善日常使用 Shell 的方法。这些方法不必庞大、新颖或复杂。它们可能会解决一些微小但频繁的摩擦、创建捷径,甚至提供减少常见输入错误的解决方案。
|
||||
|
||||
欢迎你浏览我的 [dotfiles 存储库][7],但我要警示你,这样做可能会花费很多时间。请随意使用你认为有帮助的任何东西,并互相取长补短。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/shell-dotfile
|
||||
|
||||
作者:[H.Waldo Grunenwald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gwaldo
|
||||
[1]: http://www.zsh.org/
|
||||
[2]: https://brew.sh/
|
||||
[3]: https://github.com/robbyrussell/oh-my-zsh
|
||||
[4]: https://www.iterm2.com/
|
||||
[5]: https://twitter.com/climagic
|
||||
[6]: https://github.com/graphite-project/
|
||||
[7]: https://github.com/gwaldo/dotfiles
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11420-1.html)
|
||||
[#]: subject: (The Earliest Linux Distros: Before Mainstream Distros Became So Popular)
|
||||
[#]: via: (https://itsfoss.com/earliest-linux-distros/)
|
||||
[#]: author: (Avimanyu Bandyopadhyay https://itsfoss.com/author/avimanyu/)
|
||||
|
||||
主流发行版之前的那些最早的 Linux 发行版
|
||||
======
|
||||
|
||||
> 在这篇回溯历史的文章中,我们尝试回顾一些最早的 Linux 发行版是如何演变的,并形成我们今天所知道的发行版的。
|
||||
|
||||
![][1]
|
||||
|
||||
在这里,我们尝试探讨了第一个 Linux 内核问世后,诸如 Red Hat、Debian、Slackware、SUSE、Ubuntu 等诸多流行的发行版的想法是如何产生的。
|
||||
|
||||
随着 1991 年 Linux 最初以内核的形式发布,今天我们所知道的发行版在世界各地众多合作者的帮助下得以创建 shell、库、编译器和相关软件包,从而使其成为一个完整的操作系统。
|
||||
|
||||
### 1、第一个已知的“发行版”是由 HJ Lu 创建的
|
||||
|
||||
Linux 发行版这种方式可以追溯到 1992 年,当时可以用来访问 Linux 的第一个已知的类似发行版的工具是由 HJ Lu 发布的。它由两个 5.25 英寸软盘组成:
|
||||
|
||||
![Linux 0.12 Boot and Root Disks | Photo Credit][2]
|
||||
|
||||
* LINUX 0.12 BOOT DISK:“启动”磁盘用来先启动系统。
|
||||
* LINUX 0.12 ROOT DISK:第二个“根”磁盘,用于在启动后获取命令提示符以访问 Linux 文件系统。
|
||||
|
||||
要在硬盘上安装 LINUX 0.12,必须使用十六进制编辑器来编辑其主启动记录(MBR),这是一个非常复杂的过程,尤其是在那个时代。
|
||||
|
||||
> 感觉太怀旧了?
|
||||
>
|
||||
> 你可以[安装 cool-retro-term 应用程序][3],它可以为你提供 90 年代计算机的复古外观的 Linux 终端。
|
||||
|
||||
### 2、MCC Interim Linux
|
||||
|
||||
![MCC Linux 0.99.14, 1993 | Image Credit][4]
|
||||
|
||||
MCC Interim Linux 最初由英格兰曼彻斯特计算中心的 Owen Le Blanc 与 “LINUX 0.12” 同年发布,它是针对普通用户的第一个 Linux 发行版,它具有菜单驱动的安装程序和最终用户/编程工具。它也是以软盘集的形式,可以将其安装在系统上以提供基于文本的基本环境。
|
||||
|
||||
MCC Interim Linux 比 0.12 更加易于使用,并且在硬盘驱动器上的安装过程更加轻松和类似于现代方式。它不需要使用十六进制编辑器来编辑 MBR。
|
||||
|
||||
尽管它于 1992 年 2 月首次发布,但自当年 11 月以来也可以通过 FTP 下载。
|
||||
|
||||
### 3、TAMU Linux
|
||||
|
||||
![TAMU Linux | Image Credit][5]
|
||||
|
||||
TAMU Linux 由 Texas A&M 的 Aggies 与 Texas A&M Unix & Linux 用户组于 1992 年 5 月开发,被称为 TAMU 1.0A。它是第一个提供 X Window System 的 Linux 发行版,而不仅仅是基于文本的操作系统。
|
||||
|
||||
### 4、Softlanding Linux System (SLS)
|
||||
|
||||
![SLS Linux 1.05, 1994 | Image Credit][6]
|
||||
|
||||
他们的口号是“DOS 伞降的温柔救援”!SLS 由 Peter McDonald 于 1992 年 5 月发布。SLS 在其时代得到了广泛的使用和流行,并极大地推广了 Linux 的思想。但是由于开发人员决定更改发行版中的可执行格式,因此用户停止使用它。
|
||||
|
||||
当今社区最熟悉的许多流行发行版是通过 SLS 演变而成的。其中两个是:
|
||||
|
||||
* Slackware:它是最早的 Linux 发行版之一,由 Patrick Volkerding 于 1993 年创建。Slackware 基于 SLS,是最早的 Linux 发行版之一。
|
||||
* Debian:由 Ian Murdock 发起,Debian 在从 SLS 模型继续发展之后于 1993 年发布。我们今天知道的非常流行的 Ubuntu 发行版基于 Debian。
|
||||
|
||||
### 5、Yggdrasil
|
||||
|
||||
![LGX Yggdrasil Fall 1993 | Image Credit][7]
|
||||
|
||||
Yggdrasil 于 1992 年 12 月发行,是第一个产生 Live Linux CD 想法的发行版。它是由 Yggdrasil 计算公司开发的,该公司由位于加利福尼亚州伯克利的 Adam J. Richter 创立。它可以在系统硬件上自动配置自身,即“即插即用”功能,这是当今非常普遍且众所周知的功能。Yggdrasil 后来的版本包括一个用于在 Linux 中运行任何专有 MS-DOS CD-ROM 驱动程序的黑科技。
|
||||
|
||||
![Yggdrasil’s Plug-and-Play Promo | Image Credit][8]
|
||||
|
||||
他们的座右铭是“我们其余人的免费软件”。
|
||||
|
||||
### 6、Mandriva
|
||||
|
||||
在 90 年代后期,有一个非常受欢迎的发行版 [Mandriva][9],该发行版于 1998 年首次发行,是通过将法国的 Mandrake Linux 发行版与巴西的 Conectiva Linux 发行版统一起来形成的。它的发布寿命为 18 个月,会对 Linux 和系统软件进行更新,并且每年都会发布基于桌面的更新。它还有带有 5 年支持的服务器版本。现在是 [Open Mandriva][10]。
|
||||
|
||||
如果你在 Linux 发行之初就用过更多的怀旧发行版,请在下面的评论中与我们分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/earliest-linux-distros/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/earliest-linux-distros.png?resize=800%2C450&ssl=1
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-0.12-Floppies.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/cool-retro-term/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/MCC-Interim-Linux-0.99.14-1993.jpg?fit=800%2C600&ssl=1
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/TAMU-Linux.jpg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/SLS-1.05-1994.jpg?ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/LGX_Yggdrasil_CD_Fall_1993.jpg?fit=781%2C800&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Yggdrasil-Linux-Summer-1994.jpg?ssl=1
|
||||
[9]: https://en.wikipedia.org/wiki/Mandriva_Linux
|
||||
[10]: https://www.openmandriva.org/
|
||||
134
published/20190301 Guide to Install VMware Tools on Linux.md
Normal file
134
published/20190301 Guide to Install VMware Tools on Linux.md
Normal file
@ -0,0 +1,134 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11467-1.html)
|
||||
[#]: subject: (Guide to Install VMware Tools on Linux)
|
||||
[#]: via: (https://itsfoss.com/install-vmware-tools-linux)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
在 Linux 上安装 VMware 工具
|
||||
======
|
||||
|
||||
> VMware 工具通过允许你共享剪贴板和文件夹以及其他东西来提升你的虚拟机体验。了解如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具。
|
||||
|
||||
![如何在 Linux 上安装 VMware 工具][4]
|
||||
|
||||
在先前的教程中,你学习了[在 Ubuntu 上安装 VMware 工作站][1]。你还可以通过安装 VMware 工具进一步提升你的虚拟机功能。
|
||||
|
||||
如果你已经在 VMware 上安装了一个访客机系统,你必须要注意 [VMware 工具][2]的要求 —— 尽管并不完全清楚到底有什么要求。
|
||||
|
||||
在本文中,我们将要强调 VMware 工具的重要性、所提供的特性,以及在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具的方法。
|
||||
|
||||
### VMware 工具:概览及特性
|
||||
|
||||
![在 Ubuntu 上安装 VMware 工具][3]
|
||||
|
||||
出于显而易见的理由,虚拟机(你的访客机系统)并不能做到与宿主机上的表现完全一致。在其性能和操作上会有特定的限制。那就是为什么引入 VMware 工具的原因。
|
||||
|
||||
VMware 工具以一种高效的形式在提升了其性能的同时,也可以帮助管理访客机系统。
|
||||
|
||||
#### VMware 工具到底负责什么?
|
||||
|
||||
你大致知道它可以做什么,但让我们探讨一下细节:
|
||||
|
||||
* 同步访客机系统与宿主机系统间的时间以简化操作
|
||||
* 提供从宿主机系统向访客机系统传递消息的能力。比如说,你可以复制文字到剪贴板,并将它轻松粘贴到你的访客机系统
|
||||
* 在访客机系统上启用声音
|
||||
* 提升访客机视频分辨率
|
||||
* 修正错误的网络速度数据
|
||||
* 减少不合适的色深
|
||||
|
||||
在访客机系统上安装了 VMware 工具会给它带来显著改变,但是它到底包含了什么特性才解锁或提升这些功能的呢?让我们来看看……
|
||||
|
||||
#### VMware 工具:核心特性细节
|
||||
|
||||
![用 VMware 工具在宿主机系统与访客机系统间共享剪切板][5]
|
||||
|
||||
如果你不想知道它包含什么来启用这些功能的话,你可以跳过这部分。但是为了好奇的读者,让我们简短地讨论它一下:
|
||||
|
||||
**VMware 设备驱动:** 它具体取决于操作系统。大多数主流操作系统都默认包含了设备驱动,因此你不必另外安装它。这主要涉及到内存控制驱动、鼠标驱动、音频驱动、网卡驱动、VGA 驱动以及其它。
|
||||
|
||||
**VMware 用户进程:** 这是这里真正有意思的地方。通过它你获得了在访客机和宿主机间复制粘贴和拖拽的能力。基本上,你可以从宿主机复制粘贴文本到虚拟机,反之亦然。
|
||||
|
||||
你同样也可以拖拽文件。此外,在你未安装 SVGA 驱动时它会启用鼠标指针的释放/锁定。
|
||||
|
||||
**VMware 工具生命周期管理:** 嗯,我们会在下面看看如何安装 VMware 工具,但是这个特性帮你在虚拟机中轻松安装/升级 VMware 工具。
|
||||
|
||||
**共享文件夹**:除了这些。VMware 工具同样允许你在访客机与宿主机系统间共享文件夹。
|
||||
|
||||
![使用 VMware 工具在访客机与宿机系统间共享文件][6]
|
||||
|
||||
当然,它的效果同样取决于访客机系统。例如在 Windows 上你通过 Unity 模式运行虚拟机上的程序并从宿主机系统上操作它。
|
||||
|
||||
### 如何在 Ubuntu 和其它 Linux 发行版上安装 VMware 工具
|
||||
|
||||
**注意:** 对于 Linux 操作系统,你应该已经安装好了“Open VM 工具”,大多数情况下免除了额外安装 VMware 工具的需要。
|
||||
|
||||
大部分时候,当你安装了访客机系统时,如果操作系统支持 [Easy Install][7] 的话你会收到软件更新或弹窗告诉你要安装 VMware 工具。
|
||||
|
||||
Windows 和 Ubuntu 都支持 Easy Install。因此如果你使用 Windows 作为你的宿主机或尝试在 Ubuntu 上安装 VMware 工具,你应该会看到一个和弹窗消息差不多的选项来轻松安装 VMware 工具。这是它应该看起来的样子:
|
||||
|
||||
![安装 VMware 工具的弹窗][8]
|
||||
|
||||
这是搞定它最简便的办法。因此当你配置虚拟机时确保你有一个通畅的网络连接。
|
||||
|
||||
如果你没收到任何弹窗或者选项来轻松安装 VMware 工具。你需要手动安装它。以下是如何去做:
|
||||
|
||||
1. 运行 VMware Workstation Player。
|
||||
2. 从菜单导航至 “Virtual Machine -> Install VMware tools”。如果你已经安装了它并想修复安装,你会看到 “Re-install VMware tools” 这一选项出现。
|
||||
3. 一旦你点击了,你就会看到一个虚拟 CD/DVD 挂载在访客机系统上。
|
||||
4. 打开该 CD/DVD,并复制粘贴那个 tar.gz 文件到任何你选择的区域并解压,这里我们选择“桌面”作为解压目的地。
|
||||
|
||||
![][9]
|
||||
5. 在解压后,运行终端并通过输入以下命令导航至里面的文件夹:
|
||||
|
||||
```
|
||||
cd Desktop/VMwareTools-10.3.2-9925305/vmware-tools-distrib
|
||||
```
|
||||
|
||||
你需要检查文件夹与路径名,这取决于版本与解压目的地,名字可能会改变。
|
||||
|
||||
![][10]
|
||||
|
||||
用你的存储位置(如“下载”)替换“桌面”,如果你安装的也是 10.3.2 版本,其它的保持一样即可。
|
||||
6. 现在仅需输入以下命令开始安装:
|
||||
|
||||
```
|
||||
sudo ./vmware-install.pl -d
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
你会被询问密码以获得安装权限,输入密码然后应当一切都搞定了。
|
||||
|
||||
到此为止了,你搞定了。这系列步骤应当适用于几乎大部分基于 Ubuntu 的访客机系统。如果你想要在 Ubuntu 服务器上或其它系统安装 VMware 工具,步骤应该类似。
|
||||
|
||||
### 总结
|
||||
|
||||
在 Ubuntu Linux 上安装 VMware 工具应该挺简单。除了简单办法,我们也详述了手动安装的方法。如果你仍需帮助或者对安装有任何建议,在评论区评论让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-vmware-tools-linux
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[2]: https://kb.vmware.com/s/article/340
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-downloading.jpg?fit=800%2C531&ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/03/install-vmware-tools-linux.png?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-features.gif?resize=800%2C500&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-shared-folder.jpg?fit=800%2C660&ssl=1
|
||||
[7]: https://docs.vmware.com/en/VMware-Workstation-Player-for-Linux/15.0/com.vmware.player.linux.using.doc/GUID-3F6B9D0E-6CFC-4627-B80B-9A68A5960F60.html
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools.jpg?fit=800%2C481&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-extraction.jpg?fit=800%2C564&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-folder.jpg?fit=800%2C487&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmware-tools-installation-ubuntu.jpg?fit=800%2C492&ssl=1
|
||||
125
published/20190320 Move your dotfiles to version control.md
Normal file
125
published/20190320 Move your dotfiles to version control.md
Normal file
@ -0,0 +1,125 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11419-1.html)
|
||||
[#]: subject: (Move your dotfiles to version control)
|
||||
[#]: via: (https://opensource.com/article/19/3/move-your-dotfiles-version-control)
|
||||
[#]: author: (Matthew Broberg https://opensource.com/users/mbbroberg)
|
||||
|
||||
把“点文件”放到版本控制中
|
||||
======
|
||||
|
||||
> 通过在 GitLab 或 GitHub 上分享你的点文件,可以在整个系统上备份或同步你的自定义配置。
|
||||
|
||||

|
||||
|
||||
通过隐藏文件集(称为<ruby>点文件<rt>dotfile</rt></ruby>)来定制操作系统是个非常棒的想法。在这篇 [Shell 点文件可以为你做点什么][1]中,H. "Waldo" Grunenwald 详细介绍了为什么以及如何设置点文件的细节。现在让我们深入探讨分享它们的原因和方式。
|
||||
|
||||
### 什么是点文件?
|
||||
|
||||
“<ruby>点文件<rt>dotfile</rt></ruby>”是指我们计算机中四处漂泊的配置文件。这些文件通常在文件名的开头以 `.` 开头,例如 `.gitconfig`,并且操作系统通常在默认情况下将其隐藏。例如,当我在 MacOS 上使用 `ls -a` 时,它才会显示所有可爱的点文件,否则就不会显示这些点文件。
|
||||
|
||||
```
|
||||
dotfiles on master
|
||||
➜ ls
|
||||
README.md Rakefile bin misc profiles zsh-custom
|
||||
|
||||
dotfiles on master
|
||||
➜ ls -a
|
||||
. .gitignore .oh-my-zsh README.md zsh-custom
|
||||
.. .gitmodules .tmux Rakefile
|
||||
.gemrc .global_ignore .vimrc bin
|
||||
.git .gvimrc .zlogin misc
|
||||
.gitconfig .maid .zshrc profiles
|
||||
```
|
||||
|
||||
如果看一下用于 Git 配置的 `.gitconfig`,我能看到大量的自定义配置。我设置了帐户信息、终端颜色首选项和大量别名,这些别名可以使我的命令行界面看起来就像我的一样。这是 `[alias]` 块的摘录:
|
||||
|
||||
```
|
||||
87 # Show the diff between the latest commit and the current state
|
||||
88 d = !"git diff-index --quiet HEAD -- || clear; git --no-pager diff --patch-with-stat"
|
||||
89
|
||||
90 # `git di $number` shows the diff between the state `$number` revisions ago and the current state
|
||||
91 di = !"d() { git diff --patch-with-stat HEAD~$1; }; git diff-index --quiet HEAD -- || clear; d"
|
||||
92
|
||||
93 # Pull in remote changes for the current repository and all its submodules
|
||||
94 p = !"git pull; git submodule foreach git pull origin master"
|
||||
95
|
||||
96 # Checkout a pull request from origin (of a github repository)
|
||||
97 pr = !"pr() { git fetch origin pull/$1/head:pr-$1; git checkout pr-$1; }; pr"
|
||||
```
|
||||
|
||||
由于我的 `.gitconfig` 有 200 多行的自定义设置,我无意于在我使用的每一台新计算机或系统上重写它,其他人肯定也不想这样。这是分享点文件变得越来越流行的原因之一,尤其是随着社交编码网站 GitHub 的兴起。正式提倡分享点文件的文章是 Zach Holman 在 2008 年发表的《[点文件意味着被复刻][2]》。其前提到今天依然如此:我想与我自己、与点文件新手,以及那些分享了他们的自定义配置从而教会了我很多知识的人分享它们。
|
||||
|
||||
### 分享点文件
|
||||
|
||||
我们中的许多人拥有多个系统,或者知道硬盘变化无常,因此我们希望备份我们精心策划的自定义设置。那么我们如何在环境之间同步这些精彩的文件?
|
||||
|
||||
我最喜欢的答案是分布式版本控制,最好是可以为我处理繁重任务的服务。我经常使用 GitHub,随着我对 GitLab 的使用经验越来越丰富,我肯定会一如既往地继续喜欢它。任何一个这样的服务都是共享你的信息的理想场所。要自己设置的话可以这样做:
|
||||
|
||||
1. 登录到你首选的基于 Git 的服务。
|
||||
2. 创建一个名为 `dotfiles` 的存储库。(将其设置为公开!分享即关爱。)
|
||||
3. 将其克隆到你的本地环境。(你可能需要设置 Git 配置命令来克隆存储库。GitHub 和 GitLab 都会提示你需要运行的命令。)
|
||||
4. 将你的点文件复制到该文件夹中。
|
||||
5. 将它们符号链接回到其目标文件夹(最常见的是 `$HOME`)。
|
||||
6. 将它们推送到远程存储库。
|
||||
|
||||
|
||||
|
||||
上面的步骤 4 是这项工作的关键,可能有些棘手。无论是使用脚本还是手动执行,工作流程都是从 `dotfiles` 文件夹符号链接到点文件的目标位置,以便对点文件的任何更新都可以轻松地推送到远程存储库。要对我的 `.gitconfig` 文件执行此操作,我要输入:
|
||||
|
||||
```
|
||||
$ cd dotfiles/
|
||||
$ ln -nfs .gitconfig $HOME/.gitconfig
|
||||
```
|
||||
|
||||
添加到符号链接命令的标志还具有其他一些用处:
|
||||
|
||||
* `-s` 创建符号链接而不是硬链接。
|
||||
* `-f` 在发生错误时继续做其他符号链接(此处不需要,但在循环中很有用)
|
||||
* `-n` 避免符号链接到一个符号链接文件(等同于其他版本的 `ln` 的 `-h` 标志)
|
||||
|
||||
如果要更深入地研究可用参数,可以查看 IEEE 和开放小组的 [ln 规范][3]以及 [MacOS 10.14.3] [4] 上的版本。自从其他人的点文件中拉取出这些标志以来,我才发现了这些标志。
|
||||
|
||||
你还可以使用一些其他代码来简化更新,例如我从 [Brad Parbs][6] 复刻的 [Rakefile][5]。另外,你也可以像 Jeff Geerling [在其点文件中][7]那样,使它保持极其简单的状态。他使用[此 Ansible 剧本][8]对文件进行符号链接。这样使所有内容保持同步很容易:你可以从点文件的文件夹中进行 cron 作业或偶尔进行 `git push`。
|
||||
|
||||
### 简单旁注:什么不能分享
|
||||
|
||||
在继续之前,值得注意的是你不应该添加到共享的点文件存储库中的内容 —— 即使它以点开头。任何有安全风险的东西,例如 `.ssh/` 文件夹中的文件,都不是使用此方法分享的好选择。确保在在线发布配置文件之前仔细检查配置文件,并再三检查文件中没有 API 令牌。
|
||||
|
||||
### 我应该从哪里开始?
|
||||
|
||||
如果你不熟悉 Git,那么我[有关 Git 术语的文章][9]和常用命令[备忘清单][10]将会帮助你继续前进。
|
||||
|
||||
还有其他超棒的资源可帮助你开始使用点文件。多年前,我就发现了 [dotfiles.github.io][11],并继续使用它来更广泛地了解人们在做什么。在其他人的点文件中隐藏了许多秘传知识。花时间浏览一些,大胆地将它们添加到自己的内容中。
|
||||
|
||||
我希望这是让你在计算机上拥有一致的点文件的快乐开端。
|
||||
|
||||
你最喜欢的点文件技巧是什么?添加评论或在 Twitter 上找我 [@mbbroberg][12]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/move-your-dotfiles-version-control
|
||||
|
||||
作者:[Matthew Broberg][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mbbroberg
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11417-1.html
|
||||
[2]: https://zachholman.com/2010/08/dotfiles-are-meant-to-be-forked/
|
||||
[3]: http://pubs.opengroup.org/onlinepubs/9699919799/utilities/ln.html
|
||||
[4]: https://www.unix.com/man-page/FreeBSD/1/ln/
|
||||
[5]: https://github.com/mbbroberg/dotfiles/blob/master/Rakefile
|
||||
[6]: https://github.com/bradp/dotfiles
|
||||
[7]: https://github.com/geerlingguy/dotfiles
|
||||
[8]: https://github.com/geerlingguy/mac-dev-playbook
|
||||
[9]: https://opensource.com/article/19/2/git-terminology
|
||||
[10]: https://opensource.com/downloads/cheat-sheet-git
|
||||
[11]: http://dotfiles.github.io/
|
||||
[12]: https://twitter.com/mbbroberg?lang=en
|
||||
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11499-1.html)
|
||||
[#]: subject: (How writers can get work done better with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/write-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/noreplyhttps://opensource.com/users/seth)
|
||||
|
||||
用 Git 帮助写作者更好地完成工作
|
||||
======
|
||||
|
||||
> 如果你是一名写作者,你也能从使用 Git 中受益。在我们的系列文章中了解有关 Git 鲜为人知的用法。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天我们来看看写作者如何使用 Git 更好的地完成工作。
|
||||
|
||||
### 写作者的 Git
|
||||
|
||||
有些人写小说,也有人撰写学术论文、诗歌、剧本、技术手册或有关开源的文章。许多人都在做一些各种写作。相同的是,如果你是一名写作者,或许能从使用 Git 中受益。尽管 Git 是著名的计算机程序员所使用的高度技术性工具,但它也是现代写作者的理想之选,本文将向你演示如何改变你的书写方式以及为什么要这么做的原因。
|
||||
|
||||
但是,在谈论 Git 之前,重要的是先谈谈“副本”(或者叫“内容”,对于数字时代而言)到底是什么,以及为什么它与你的交付*媒介*不同。这是 21 世纪,大多数写作者选择的工具是计算机。尽管计算机看似擅长将副本的编辑和布局等过程结合在一起,但写作者还是(重新)发现将内容与样式分开是一个好主意。这意味着你应该在计算机上像在打字机上而不是在文字处理器中进行书写。以计算机术语而言,这意味着以*纯文本*形式写作。
|
||||
|
||||
### 以纯文本写作
|
||||
|
||||
这个假设曾经是毫无疑问的:你知道自己的写作所要针对的市场,你可以为书籍、网站或软件手册等不同市场编写内容。但是,近来各种市场趋于扁平化:你可能决定在纸质书中使用为网站编写的内容,并且纸质书可能会在以后发布 EPUB 版本。对于你的内容的数字版本,读者才是最终控制者:他们可以在你发布内容的网站上阅读你的文字,也可以点击 Firefox 出色的[阅读视图][3],还可能会打印到纸张上,或者可能会使用 Lynx 将网页转储到文本文件中,甚至可能因为使用屏幕阅读器而根本看不到你的内容。
|
||||
|
||||
你只需要逐字写下你的内容,而将交付工作留给发布者。即使你是自己发布,将字词作为写作作品的一种源代码也是一种更聪明、更有效的工作方式,因为在发布时,你可以使用相同的源(你的纯文本)生成适合你的目标输出(用于打印的 PDF、用于电子书的 EPUB、用于网站的 HTML 等)。
|
||||
|
||||
用纯文本编写不仅意味着你不必担心布局或文本样式,而且也不再需要专门的工具。无论是手机或平板电脑上的基本的记事本应用程序、计算机附带的文本编辑器,还是从互联网上下载的免费编辑器,任何能够产生文本内容的工具对你而言都是有效的“文字处理器”。无论你身在何处或在做什么,几乎可以在任何设备上书写,并且所生成的文本可以与你的项目完美集成,而无需进行任何修改。
|
||||
|
||||
而且,Git 专门用来管理纯文本。
|
||||
|
||||
### Atom 编辑器
|
||||
|
||||
当你以纯文本形式书写时,文字处理程序会显得过于庞大。使用文本编辑器更容易,因为文本编辑器不会尝试“有效地”重组输入内容。它使你可以将脑海中的单词输入到屏幕中,而不会受到干扰。更好的是,文本编辑器通常是围绕插件体系结构设计的,这样应用程序本身很基础(它用来编辑文本),但是你可以围绕它构建一个环境来满足你的各种需求。
|
||||
|
||||
[Atom][4] 编辑器就是这种设计理念的一个很好的例子。这是一个具有内置 Git 集成的跨平台文本编辑器。如果你不熟悉纯文本格式,也不熟悉 Git,那么 Atom 是最简单的入门方法。
|
||||
|
||||
#### 安装 Git 和 Atom
|
||||
|
||||
首先,请确保你的系统上已安装 Git。如果运行 Linux 或 BSD,则 Git 在软件存储库或 ports 树中可用。你使用的命令将根据你的发行版而有所不同。例如在 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf install git
|
||||
```
|
||||
|
||||
你也可以下载并安装适用于 [Mac][5] 和 [Windows][6] 的 Git。
|
||||
|
||||
你不需要直接使用 Git,因为 Atom 会充当你的 Git 界面。下一步是安装 Atom。
|
||||
|
||||
如果你使用的是 Linux,请通过软件安装程序或适当的命令从软件存储库中安装 Atom,例如:
|
||||
|
||||
```
|
||||
$ sudo dnf install atom
|
||||
```
|
||||
|
||||
Atom 当前没有在 BSD 上构建。但是,有很好的替代方法,例如 [GNU Emacs][7]。对于 Mac 和 Windows 用户,可以在 [Atom 网站][4]上找到安装程序。
|
||||
|
||||
安装完成后,启动 Atom 编辑器。
|
||||
|
||||
#### 快速指导
|
||||
|
||||
如果要使用纯文本和 Git,则需要适应你的编辑器。Atom 的用户界面可能比你习惯的更加动态。实际上,你可以将它视为 Firefox 或 Chrome,而不是文字处理程序,因为它具有可以根据需要打开或关闭的选项卡和面板,甚至还可以安装和配置附件。尝试全部掌握 Atom 如许之多的功能是不切实际的,但是你至少可以知道有什么功能。
|
||||
|
||||
当打开 Atom 时,它将显示一个欢迎屏幕。如果不出意外,此屏幕很好地介绍了 Atom 的选项卡式界面。你可以通过单击 Atom 窗口顶部选项卡上的“关闭”图标来关闭欢迎屏幕,并使用“文件 > 新建文件”创建一个新文件。
|
||||
|
||||
使用纯文本格式与使用文字处理程序有点不同,因此这里有一些技巧,以人可以理解的方式编写内容,并且 Git 和计算机可以解析,跟踪和转换。
|
||||
|
||||
#### 用 Markdown 书写
|
||||
|
||||
如今,当人们谈论纯文本时,大多是指 Markdown。Markdown 与其说是格式,不如说是样式,这意味着它旨在为文本提供可预测的结构,以便计算机可以检测自然的模式并智能地转换文本。Markdown 有很多定义,但是最好的技术定义和备忘清单在 [CommonMark 的网站][8]上。
|
||||
|
||||
```
|
||||
# Chapter 1
|
||||
|
||||
This is a paragraph with an *italic* word and a **bold** word in it.
|
||||
And it can even reference an image.
|
||||
|
||||

|
||||
```
|
||||
|
||||
从示例中可以看出,Markdown 读起来感觉不像代码,但可以将其视为代码。如果你遵循 CommonMark 定义的 Markdown 规范,那么一键就可以可靠地将 Markdown 的文字转换为 .docx、.epub、.html、MediaWiki、.odt、.pdf、.rtf 和各种其他的格式,而*不会*失去格式。
|
||||
|
||||
你可以认为 Markdown 有点像文字处理程序的样式。如果你曾经为出版社撰写过一套样式来控制章节标题及其样式,那基本上就是一回事,除了不是从下拉菜单中选择样式以外,你需要给你的文字添加一些小记号。对于任何习惯“以文字交谈”的现代阅读者来说,这些表示法都是很自然的,但是在呈现文本时,它们会被精美的文本样式替换掉。实际上,这就是文字处理程序在后台秘密进行的操作。文字处理器显示粗体文本,但是如果你可以看到使文本变为粗体的生成代码,则它与 Markdown 很像(实际上,它是更复杂的 XML)。使用 Markdown 可以消除这种代码和样式之间的阻隔,一方面看起来更可怕一些,但另一方面,你可以在几乎所有可以生成文本的东西上书写 Markdown 而不会丢失任何格式信息。
|
||||
|
||||
Markdown 文件流行的文件扩展名是 .md。如果你使用的平台不知道 .md 文件是什么,则可以手动将该扩展名与 Atom 关联,或者仅使用通用的 .txt 扩展名。文件扩展名不会更改文件的性质。它只会改变你的计算机决定如何处理它的方式。Atom 和某些平台足够聪明,可以知道该文件是纯文本格式,无论你给它以什么扩展名。
|
||||
|
||||
#### 实时预览
|
||||
|
||||
Atom 具有 “Markdown 预览” 插件,该插件可以向你显示正在编写的纯文本 Markdown 及其(通常)呈现的方式。
|
||||
|
||||
![Atom's preview screen][9]
|
||||
|
||||
要激活此预览窗格,请选择“包 > Markdown 预览 > 切换预览” 或按 `Ctrl + Shift + M`。
|
||||
|
||||
此视图为你提供了两全其美的方法。无需承担为你的文本添加样式的负担就可以写作,而你也可以看到一个通用的示例外观,至少是以典型的数字化格式显示文本的外观。当然,关键是你无法控制文本的最终呈现方式,因此不要试图调整 Markdown 来强制以某种方式显示呈现的预览。
|
||||
|
||||
#### 每行一句话
|
||||
|
||||
你的高中写作老师不会看你的 Markdown。
|
||||
|
||||
一开始它不那么自然,但是在数字世界中,保持每行一个句子更有意义。Markdown 会忽略单个换行符(当你按下 `Return` 或 `Enter` 键时),并且只在单个空行之后才会创建一个新段落。
|
||||
|
||||
![Writing in Atom][10]
|
||||
|
||||
每行写一个句子的好处是你的工作更容易跟踪。也就是说,假如你在段落的开头更改了一个单词,如果更改仅限于一行而不是一个长的段落中的一个单词,那么 Atom、Git 或任何应用程序很容易以有意义的方式突出显示该更改。换句话说,对一个句子的更改只会影响该句子,而不会影响整个段落。
|
||||
|
||||
你可能会想:“许多文字处理器也可以跟踪更改,它们可以突出显示已更改的单个单词。”但是这些修订跟踪器绑定在该字处理器的界面上,这意味着你必须先打开该字处理器才能浏览修订。在纯文本工作流程中,你可以以纯文本形式查看修订,这意味着无论手头有什么,只要该设备可以处理纯文本(大多数都可以),就可以进行编辑或批准编辑。
|
||||
|
||||
诚然,写作者通常不会考虑行号,但它对于计算机有用,并且通常是一个很好的参考点。默认情况下,Atom 为文本文档的行进行编号。按下 `Enter` 键或 `Return` 键后,一*行*就是一行。
|
||||
|
||||
![Writing in Atom][11]
|
||||
|
||||
如果(在 Atom 的)一行的行号中有一个点而不是一个数字,则表示它是上一行折叠的一部分,因为它超出了你的屏幕。
|
||||
|
||||
#### 主题
|
||||
|
||||
如果你是一个在意视觉形象的人,那么你可能会非常注重自己的写作环境。即使你使用普通的 Markdown 进行编写,也并不意味着你必须使用程序员的字体或在使你看起来像码农的黑窗口中进行书写。修改 Atom 外观的最简单方法是使用[主题包][12]。主题设计人员通常将深色主题与浅色主题区分开,因此你可以根据需要使用关键字“Dark”或“Light”进行搜索。
|
||||
|
||||
要安装主题,请选择“编辑 > 首选项”。这将在 Atom 界面中打开一个新标签页。是的,标签页可以用于处理文档*和*用于配置及控制面板。在“设置”标签页中,单击“安装”类别。
|
||||
|
||||
在“安装”面板中,搜索要安装的主题的名称。单击搜索字段右侧的“主题”按钮,以仅搜索主题。找到主题后,单击其“安装”按钮。
|
||||
|
||||
![Atom's themes][13]
|
||||
|
||||
要使用已安装的主题或根据喜好自定义主题,请导航至“设置”标签页中的“主题”类别中。从下拉菜单中选择要使用的主题。更改会立即进行,因此你可以准确了解主题如何影响你的环境。
|
||||
|
||||
你也可以在“设置”标签的“编辑器”类别中更改工作字体。Atom 默认采用等宽字体,程序员通常首选这种字体。但是你可以使用系统上的任何字体,无论是衬线字体、无衬线字体、哥特式字体还是草书字体。无论你想整天盯着什么字体都行。
|
||||
|
||||
作为相关说明,默认情况下,Atom 会在其屏幕上绘制一条垂直线,以提示编写代码的人员。程序员通常不想编写太长的代码行,因此这条垂直线会提醒他们不要写太长的代码行。不过,这条竖线对写作者而言毫无意义,你可以通过禁用 “wrap-guide” 包将其删除。
|
||||
|
||||
要禁用 “wrap-guide” 软件包,请在“设置”标签中选择“折行”类别,然后搜索 “wrap-guide”。找到该程序包后,单击其“禁用”按钮。
|
||||
|
||||
#### 动态结构
|
||||
|
||||
创建长文档时,我发现每个文件写一个章节比在一个文件中写整本书更有意义。此外,我不会以明显的语法 ` chapter-1.md` 或 `1.example.md` 来命名我的章节,而是以章节标题或关键词(例如 `example.md`)命名。为了将来为自己提供有关如何编写本书的指导,我维护了一个名为 `toc.md` (用于“目录”)的文件,其中列出了各章的(当前)顺序。
|
||||
|
||||
我这样做是因为,无论我多么相信第 6 章都不可能出现在第 1 章之前,但在我完成整本书之前,几乎难以避免我会交换一两个章节的顺序。我发现从一开始就保持动态变化可以帮助我避免重命名混乱,也可以帮助我避免僵化的结构。
|
||||
|
||||
### 在 Atom 中使用 Git
|
||||
|
||||
每位写作者的共同点是两件事:他们为流传而写作,而他们的写作是一段旅程。你不能一坐下来写作就完成了最终稿件。顾名思义,你有一个初稿。该草稿会经过修订,你会仔细地将每个修订保存一式两份或三份的备份,以防万一你的文件损坏了。最终,你得到了所谓的最终草稿,但很有可能你有一天还会回到这份最终草稿,要么恢复好的部分,要么修改坏的部分。
|
||||
|
||||
Atom 最令人兴奋的功能是其强大的 Git 集成。无需离开 Atom,你就可以与 Git 的所有主要功能进行交互,跟踪和更新项目、回滚你不喜欢的更改、集成来自协作者的更改等等。最好的学习方法就是逐步学习,因此这是在一个写作项目中从始至终在 Atom 界面中使用 Git 的方法。
|
||||
|
||||
第一件事:通过选择 “视图 > 切换 Git 标签页” 来显示 Git 面板。这将在 Atom 界面的右侧打开一个新标签页。现在没什么可看的,所以暂时保持打开状态就行。
|
||||
|
||||
#### 建立一个 Git 项目
|
||||
|
||||
你可以认为 Git 被绑定到一个文件夹。Git 目录之外的任何文件夹都不知道 Git,而 Git 也不知道外面。Git 目录中的文件夹和文件将被忽略,直到你授予 Git 权限来跟踪它们为止。
|
||||
|
||||
你可以通过在 Atom 中创建新的项目文件夹来创建 Git 项目。选择 “文件 > 添加项目文件夹”,然后在系统上创建一个新文件夹。你创建的文件夹将出现在 Atom 窗口的左侧“项目面板”中。
|
||||
|
||||
#### Git 添加文件
|
||||
|
||||
右键单击你的新项目文件夹,然后选择“新建文件”以在项目文件夹中创建一个新文件。如果你要导入文件到新项目中,请右键单击该文件夹,然后选择“在文件管理器中显示”,以在系统的文件查看器中打开该文件夹(Linux 上为 Dolphin 或 Nautilus,Mac 上为 Finder,在 Windows 上是 Explorer),然后拖放文件到你的项目文件夹。
|
||||
|
||||
在 Atom 中打开一个项目文件(你创建的空文件或导入的文件)后,单击 Git 标签中的 “<ruby>创建存储库<rt>Create Repository</rt></ruby>” 按钮。在弹出的对话框中,单击 “<ruby>初始化<rt>Init</rt></ruby>” 以将你的项目目录初始化为本地 Git 存储库。 Git 会将 `.git` 目录(在系统的文件管理器中不可见,但在 Atom 中可见)添加到项目文件夹中。不要被这个愚弄了:`.git` 目录是 Git 管理的,而不是由你管理的,因此一般你不要动它。但是在 Atom 中看到它可以很好地提醒你正在由 Git 管理的项目中工作。换句话说,当你看到 `.git` 目录时,就有了修订历史记录。
|
||||
|
||||
在你的空文件中,写一些东西。你是写作者,所以输入一些单词就行。你可以随意输入任何一组单词,但要记住上面的写作技巧。
|
||||
|
||||
按 `Ctrl + S` 保存文件,该文件将显示在 Git 标签的 “<ruby>未暂存的改变<rt>Unstaged Changes</rt></ruby>” 部分中。这意味着该文件存在于你的项目文件夹中,但尚未提交给 Git 管理。通过单击 Git 选项卡右上方的 “<ruby>暂存全部<rt>Stage All</rt></ruby>” 按钮,以允许 Git 跟踪这些文件。如果你使用过带有修订历史记录的文字处理器,则可以将此步骤视为允许 Git 记录更改。
|
||||
|
||||
#### Git 提交
|
||||
|
||||
你的文件现在已暂存。这意味着 Git 知道该文件存在,并且知道自上次 Git 知道该文件以来,该文件已被更改。
|
||||
|
||||
Git 的<ruby>提交<rt>commit</rt></ruby>会将你的文件发送到 Git 的内部和永久存档中。如果你习惯于文字处理程序,这就类似于给一个修订版命名。要创建一个提交,请在 Git 选项卡底部的“<ruby>提交<rt>Commit</rt></ruby>”消息框中输入一些描述性文本。你可能会感到含糊不清或随意写点什么,但如果你想在将来知道进行修订的原因,那么输入一些有用的信息会更有用。
|
||||
|
||||
第一次提交时,必须创建一个<ruby>分支<rt>branch</rt></ruby>。Git 分支有点像另外一个空间,它允许你从一个时间轴切换到另一个时间轴,以进行你可能想要也可能不想要永久保留的更改。如果最终喜欢该更改,则可以将一个实验分支合并到另一个实验分支,从而统一项目的不同版本。这是一个高级过程,不需要先学会,但是你仍然需要一个活动分支,因此你必须为首次提交创建一个分支。
|
||||
|
||||
单击 Git 选项卡最底部的“<ruby>分支<rt>Branch</rt></ruby>”图标,以创建新的分支。
|
||||
|
||||
![Creating a branch][14]
|
||||
|
||||
通常将第一个分支命名为 `master`,但不是必须如此;你可以将其命名为 `firstdraft` 或任何你喜欢的名称,但是遵守当地习俗有时会使谈论 Git(和查找问题的答案)变得容易一些,因为你会知道有人提到 “master” 时,它们的真正意思是“主干”而不是“初稿”或你给分支起的什么名字。
|
||||
|
||||
在某些版本的 Atom 上,UI 也许不会更新以反映你已经创建的新分支。不用担心,做了提交之后,它会创建分支(并更新 UI)。按下 “<ruby>提交<rt>Commit</rt></ruby>” 按钮,无论它显示的是 “<ruby>创建脱离的提交<rt>Create detached commit</rt></ruby>” 还是 “<ruby>提交到主干<rt>Commit to master</rt></ruby>。
|
||||
|
||||
提交后,文件的状态将永久保留在 Git 的记忆之中。
|
||||
|
||||
#### 历史记录和 Git 差异
|
||||
|
||||
一个自然而然的问题是你应该多久做一次提交。这并没有正确的答案。使用 `Ctrl + S` 保存文件和提交到 Git 是两个单独的过程,因此你会一直做这两个过程。每当你觉得自己已经做了重要的事情或打算尝试一个可能会被干掉的疯狂的新想法时,你可能都会想要做次提交。
|
||||
|
||||
要了解提交对工作流程的影响,请从测试文档中删除一些文本,然后在顶部和底部添加一些文本。再次提交。 这样做几次,直到你在 Git 标签的底部有了一小段历史记录,然后单击其中一个提交以在 Atom 中查看它。
|
||||
|
||||
![Viewing differences][15]
|
||||
|
||||
查看过去的提交时,你会看到三种元素:
|
||||
|
||||
1. 绿色文本是该提交中已被添加到文档中的内容。
|
||||
2. 红色文本是该提交中已从文档中删除的内容。
|
||||
3. 其他所有文字均未做更改。
|
||||
|
||||
#### 远程备份
|
||||
|
||||
使用 Git 的优点之一是,按照设计它是分布式的,这意味着你可以将工作提交到本地存储库,并将所做的更改推送到任意数量的服务器上进行备份。你还可以从这些服务器中拉取更改,以便你碰巧正在使用的任何设备始终具有最新更改。
|
||||
|
||||
为此,你必须在 Git 服务器上拥有一个帐户。有几种免费的托管服务,其中包括 GitHub,这个公司开发了 Atom,但奇怪的是 GitHub 不是开源的;而 GitLab 是开源的。相比私有软件,我更喜欢开源,在本示例中,我将使用 GitLab。
|
||||
|
||||
如果你还没有 GitLab 帐户,请注册一个帐户并开始一个新项目。项目名称不必与 Atom 中的项目文件夹匹配,但是如果匹配,则可能更有意义。你可以将项目保留为私有,在这种情况下,只有你和任何一个你给予了明确权限的人可以访问它,或者,如果你希望该项目可供任何互联网上偶然发现它的人使用,则可以将其公开。
|
||||
|
||||
不要将 README 文件添加到项目中。
|
||||
|
||||
创建项目后,它将为你提供有关如何设置存储库的说明。如果你决定在终端中或通过单独的 GUI 使用 Git,这是非常有用的信息,但是 Atom 的工作流程则有所不同。
|
||||
|
||||
单击 GitLab 界面右上方的 “<ruby>克隆<rt>Clone</rt></ruby>” 按钮。这显示了访问 Git 存储库必须使用的地址。复制 “SSH” 地址(而不是 “https” 地址)。
|
||||
|
||||
在 Atom 中,点击项目的 `.git` 目录,然后打开 `config` 文件。将下面这些配置行添加到该文件中,调整 `url` 值的 `seth/example.git` 部分以匹配你自己独有的地址。
|
||||
|
||||
```
|
||||
[remote "origin"]
|
||||
url = git@gitlab.com:seth/example.git
|
||||
fetch = +refs/heads/*:refs/remotes/origin/*
|
||||
[branch "master"]
|
||||
remote = origin
|
||||
merge = refs/heads/master
|
||||
```
|
||||
|
||||
在 Git 标签的底部,出现了一个新按钮,标记为 “<ruby>提取<rt>Fetch</rt></ruby>”。由于你的服务器是全新的服务器,因此没有可供你提取的数据,因此请右键单击该按钮,然后选择“<ruby>推送<rt>Push</rt></ruby>”。这会将你的更改推送到你的 GitLab 帐户,现在你的项目已备份到 Git 服务器上。
|
||||
|
||||
你可以在每次提交后将更改推送到服务器。它提供了即刻的异地备份,并且由于数据量通常很少,因此它几乎与本地保存一样快。
|
||||
|
||||
### 撰写而 Git
|
||||
|
||||
Git 是一个复杂的系统,不仅对修订跟踪和备份有用。它还支持异步协作并鼓励实验。本文介绍了一些基础知识,但还有更多关于 Git 的文章和整本的书,以及如何使用它使你的工作更高效、更具弹性和更具活力。 从使用 Git 完成小任务开始,使用的次数越多,你会发现自己提出的问题就越多,最终你将学到的技巧越多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/write-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/noreplyhttps://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/write-hand_0.jpg?itok=Uw5RJD03 (Writing Hand)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://support.mozilla.org/en-US/kb/firefox-reader-view-clutter-free-web-pages
|
||||
[4]: http://atom.io
|
||||
[5]: https://git-scm.com/download/mac
|
||||
[6]: https://git-scm.com/download/win
|
||||
[7]: http://gnu.org/software/emacs
|
||||
[8]: https://commonmark.org/help/
|
||||
[9]: https://opensource.com/sites/default/files/uploads/atom-preview.jpg (Atom's preview screen)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/atom-para.jpg (Writing in Atom)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/atom-linebreak.jpg (Writing in Atom)
|
||||
[12]: https://atom.io/themes
|
||||
[13]: https://opensource.com/sites/default/files/uploads/atom-theme.jpg (Atom's themes)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/atom-branch.jpg (Creating a branch)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/git-diff.jpg (Viewing differences)
|
||||
[16]: mailto:git@gitlab.com
|
||||
@ -0,0 +1,73 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11461-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – Introduction To Hyperledger Fabric [Part 10])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
区块链 2.0:Hyperledger Fabric 介绍(十)
|
||||
======
|
||||
|
||||
![Hyperledger Fabric][1]
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
[Hyperledger 项目][2] 是一个伞形组织,包括许多正在开发的不同模块和系统。在这些子项目中,最受欢迎的是 “Hyperledger Fabric”。这篇博文将探讨一旦区块链系统开始大量使用到主流,将使 Fabric 在不久的将来成为几乎不可或缺的功能。最后,我们还将快速了解开发人员和爱好者们需要了解的有关 Hyperledger Fabric 技术的知识。
|
||||
|
||||
### 起源
|
||||
|
||||
按照 Hyperledger 项目的常规方式,Fabric 由其核心成员之一 IBM “捐赠”给该组织,而 IBM 以前是该组织的主要开发者。由 IBM 共享的这个技术平台在 Hyperledger 项目中进行了联合开发,来自 100 多个成员公司和机构为之做出了贡献。
|
||||
|
||||
目前,Fabric 正处于 LTS 版本的 v1.4,该版本已经发展很长一段时间,并且被视为企业管理业务数据的解决方案。Hyperledger 项目的核心愿景也必然会渗透到 Fabric 中。Hyperledger Fabric 系统继承了所有企业级的可扩展功能,这些功能已深深地刻入到 Hyperledger 组织旗下所有的项目当中。
|
||||
|
||||
### Hyperledger Fabric 的亮点
|
||||
|
||||
Hyperledger Fabric 提供了多种功能和标准,这些功能和标准围绕着支持快速开发和模块化体系结构的使命而构建。此外,与竞争对手(主要是瑞波和[以太坊][3])相比,Fabric 明确用于封闭和[许可区块链][4]。它们的核心目标是开发一套工具,这些工具将帮助区块链开发人员创建定制的解决方案,而不是创建独立的生态系统或产品。
|
||||
|
||||
Hyperledger Fabric 的一些亮点如下:
|
||||
|
||||
#### 许可区块链系统
|
||||
|
||||
这是一个 Hyperledger Fabric 与其他平台(如以太坊和瑞波)差异很大的地方。默认情况下,Fabric 是一种旨在实现私有许可的区块链的工具。此类区块链不能被所有人访问,并且其中致力于达成共识或验证交易的节点将由中央机构进行选择。这对于某些应用(例如银行和保险)可能很重要,在这些应用中,交易必须由中央机构而不是参与者来验证。
|
||||
|
||||
#### 机密和受控的信息流
|
||||
|
||||
Fabric 内置了权限系统,该权限系统将视情况限制特定组或某些个人中的信息流。与公有区块链不同,在公有区块链中,任何运行节点的人都可以对存储在区块链中的数据进行复制和选择性访问,而 Fabric 系统的管理员可以选择谁能访问共享的信息,以及访问的方式。与现有竞争产品相比,它还有以更好的安全性标准对存储的数据进行加密的子系统。
|
||||
|
||||
#### 即插即用架构
|
||||
|
||||
Hyperledger Fabric 具有即插即用类型的体系结构。可以选择实施系统的各个组件,而开发人员看不到用处的系统组件可能会被废弃。Fabric 采取高度模块化和可定制的方式进行开发,而不是一种与其竞争对手采用的“一种方法适应所有需求”的方式。对于希望快速构建精益系统的公司和公司而言,这尤其有吸引力。这与 Fabric 和其它 Hyperledger 组件的互操作性相结合,意味着开发人员和设计人员现在可以使用各种标准化工具,而不必从其他来源提取代码并随后进行集成。它还提供了一种相当可靠的方式来构建健壮的模块化系统。
|
||||
|
||||
#### 智能合约和链码
|
||||
|
||||
运行在区块链上的分布式应用程序称为[智能合约][5]。虽然智能合约这个术语或多或少与以太坊平台相关联,但<ruby>链码<rt>chaincode</rt></ruby>是 Hyperledger 阵营中为其赋予的名称。链码应用程序除了拥有 DApp 中有的所有优点之外,使 Hyperledger 与众不同的是,该应用程序的代码可以用多种高级编程语言编写。它本身支持 [Go][6] 和 JavaScript,并且在与适当的编译器模块集成后还支持许多其它编程语言。尽管这一事实在此时可能并不代表什么,但这意味着,如果可以将现有人才用于正在进行的涉及区块链的项目,从长远来看,这有可能为公司节省数十亿美元的人员培训和管理费用。开发人员可以使用自己喜欢的语言进行编码,从而在 Hyperledger Fabric 上开始构建应用程序,而无需学习或培训平台特定的语言和语法。这提供了 Hyperledger Fabric 当前竞争对手无法提供的灵活性。
|
||||
|
||||
### 总结
|
||||
|
||||
* Hyperledger Fabric 是一个后端驱动程序平台,是一个主要针对需要区块链或其它分布式账本技术的集成项目。因此,除了次要的脚本功能外,它不提供任何面向用户的服务。(认可以为它更像是一种脚本语言。)
|
||||
* Hyperledger Fabric 支持针对特定用例构建侧链。如果开发人员希望将一组用户或参与者隔离到应用程序的特定部分或功能,则可以通过侧链来实现。侧链是衍生自主要父代的区块链,但在其初始块之后形成不同的链。产生新链的块将不受新链进一步变化的影响,即使将新信息添加到原始链中,新链也将保持不变。此功能将有助于扩展正在开发的平台,并引入用户特定的和案例特定的处理功能。
|
||||
* 前面的功能还意味着并非所有用户都会像通常对公有链所期望的那样拥有区块链中所有数据的“精确”副本。参与节点将具有仅与之相关的数据副本。例如,假设有一个类似于印度的 PayTM 的应用程序,该应用程序具有钱包功能以及电子商务功能。但是,并非所有的钱包用户都使用 PayTM 在线购物。在这种情况下,只有活跃的购物者将在 PayTM 电子商务网站上拥有相应的交易链,而钱包用户将仅拥有存储钱包交易的链的副本。这种灵活的数据存储和检索体系结构在扩展时非常重要,因为大量的单链区块链已经显示出会增加处理交易的前置时间。这样可以保持链的精简和分类。
|
||||
|
||||
我们将在以后的文章中详细介绍 Hyperledger Project 下的其他模块。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-introduction-to-hyperledger-fabric/
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/05/Hyperledger-Fabric-720x340.png
|
||||
[2]: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
[3]: https://www.ostechnix.com/blockchain-2-0-what-is-ethereum/
|
||||
[4]: https://www.ostechnix.com/blockchain-2-0-public-vs-private-blockchain-comparison/
|
||||
[5]: https://www.ostechnix.com/blockchain-2-0-explaining-smart-contracts-and-its-types/
|
||||
[6]: https://www.ostechnix.com/install-go-language-linux/
|
||||
151
published/20190614 What is a Java constructor.md
Normal file
151
published/20190614 What is a Java constructor.md
Normal file
@ -0,0 +1,151 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (laingke)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11478-1.html)
|
||||
[#]: subject: (What is a Java constructor?)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-java-constructor)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
什么是 Java 构造器?
|
||||
======
|
||||
|
||||
> 构造器是编程的强大组件。使用它们来释放 Java 的全部潜力。
|
||||
|
||||

|
||||
|
||||
在开源、跨平台编程领域,Java 无疑(?)是无可争议的重量级语言。尽管有许多[伟大的跨平台][2][框架][3],但很少有像 [Java][4] 那样统一和直接的。
|
||||
|
||||
当然,Java 也是一种非常复杂的语言,具有自己的微妙之处和惯例。Java 中与<ruby>构造器<rt> constructor</rt></ruby>有关的最常见问题之一是:它们是什么,它们的作用是什么?
|
||||
|
||||
简而言之:构造器是在 Java 中创建新<ruby>对象<rt>object</rt></ruby>时执行的操作。当 Java 应用程序创建一个你编写的类的实例时,它将检查构造器。如果(该类)存在构造器,则 Java 在创建实例时将运行构造器中的代码。这几句话中包含了大量的技术术语,但是当你看到它的实际应用时就会更加清楚,所以请确保你已经[安装了 Java][5] 并准备好进行演示。
|
||||
|
||||
### 没有使用构造器的开发日常
|
||||
|
||||
如果你正在编写 Java 代码,那么你已经在使用构造器了,即使你可能不知道它。Java 中的所有类都有一个构造器,因为即使你没有创建构造器,Java 也会在编译代码时为你生成一个。但是,为了进行演示,请忽略 Java 提供的隐藏构造器(因为默认构造器不添加任何额外的功能),并观察没有显式构造器的情况。
|
||||
|
||||
假设你正在编写一个简单的 Java 掷骰子应用程序,因为你想为游戏生成一个伪随机数。
|
||||
|
||||
首先,你可以创建骰子类来表示一个骰子。你玩了很久[《龙与地下城》][6],所以你决定创建一个 20 面的骰子。在这个示例代码中,变量 `dice` 是整数 20,表示可能的最大掷骰数(一个 20 边骰子的掷骰数不能超过 20)。变量 `roll` 是最终的随机数的占位符,`rand` 用作随机数种子。
|
||||
|
||||
```
|
||||
import java.util.Random;
|
||||
|
||||
public class DiceRoller {
|
||||
private int dice = 20;
|
||||
private int roll;
|
||||
private Random rand = new Random();
|
||||
```
|
||||
|
||||
接下来,在 `DiceRoller` 类中创建一个函数,以执行计算机模拟模子滚动所必须采取的步骤:从 `rand` 中获取一个整数并将其分配给 `roll`变量,考虑到 Java 从 0 开始计数但 20 面的骰子没有 0 值的情况,`roll` 再加 1 ,然后打印结果。
|
||||
|
||||
```
|
||||
import java.util.Random;
|
||||
|
||||
public class DiceRoller {
|
||||
private int dice = 20;
|
||||
private int roll;
|
||||
private Random rand = new Random();
|
||||
```
|
||||
|
||||
最后,产生 `DiceRoller` 类的实例并调用其关键函数 `Roller`:
|
||||
|
||||
```
|
||||
// main loop
|
||||
public static void main (String[] args) {
|
||||
System.out.printf("You rolled a ");
|
||||
|
||||
DiceRoller App = new DiceRoller();
|
||||
App.Roller();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
只要你安装了 Java 开发环境(如 [OpenJDK][10]),你就可以在终端上运行你的应用程序:
|
||||
|
||||
```
|
||||
$ java dice.java
|
||||
You rolled a 12
|
||||
```
|
||||
|
||||
在本例中,没有显式构造器。这是一个非常有效和合法的 Java 应用程序,但是它有一点局限性。例如,如果你把游戏《龙与地下城》放在一边,晚上去玩一些《快艇骰子》,你将需要六面骰子。在这个简单的例子中,更改代码不会有太多的麻烦,但是在复杂的代码中这不是一个现实的选择。解决这个问题的一种方法是使用构造器。
|
||||
|
||||
### 构造函数的作用
|
||||
|
||||
这个示例项目中的 `DiceRoller` 类表示一个虚拟骰子工厂:当它被调用时,它创建一个虚拟骰子,然后进行“滚动”。然而,通过编写一个自定义构造器,你可以让掷骰子的应用程序询问你希望模拟哪种类型的骰子。
|
||||
|
||||
大部分代码都是一样的,除了构造器接受一个表示面数的数字参数。这个数字还不存在,但稍后将创建它。
|
||||
|
||||
```
|
||||
import java.util.Random;
|
||||
|
||||
public class DiceRoller {
|
||||
private int dice;
|
||||
private int roll;
|
||||
private Random rand = new Random();
|
||||
|
||||
// constructor
|
||||
public DiceRoller(int sides) {
|
||||
dice = sides;
|
||||
}
|
||||
```
|
||||
|
||||
模拟滚动的函数保持不变:
|
||||
|
||||
```
|
||||
public void Roller() {
|
||||
roll = rand.nextInt(dice);
|
||||
roll += 1;
|
||||
System.out.println (roll);
|
||||
}
|
||||
```
|
||||
|
||||
代码的主要部分提供运行应用程序时提供的任何参数。这的确会是一个复杂的应用程序,你需要仔细解析参数并检查意外结果,但对于这个例子,唯一的预防措施是将参数字符串转换成整数类型。
|
||||
|
||||
```
|
||||
public static void main (String[] args) {
|
||||
System.out.printf("You rolled a ");
|
||||
DiceRoller App = new DiceRoller( Integer.parseInt(args[0]) );
|
||||
App.Roller();
|
||||
}
|
||||
```
|
||||
|
||||
启动这个应用程序,并提供你希望骰子具有的面数:
|
||||
|
||||
```
|
||||
$ java dice.java 20
|
||||
You rolled a 10
|
||||
$ java dice.java 6
|
||||
You rolled a 2
|
||||
$ java dice.java 100
|
||||
You rolled a 44
|
||||
```
|
||||
|
||||
构造器已接受你的输入,因此在创建类实例时,会将 `sides` 变量设置为用户指定的任何数字。
|
||||
|
||||
构造器是编程的功能强大的组件。练习用它们来解开了 Java 的全部潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-java-constructor
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[laingke](https://github.com/laingke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/build_structure_tech_program_code_construction.png?itok=nVsiLuag
|
||||
[2]: https://opensource.com/resources/python
|
||||
[3]: https://opensource.com/article/17/4/pyqt-versus-wxpython
|
||||
[4]: https://opensource.com/resources/java
|
||||
[5]: https://openjdk.java.net/install/index.html
|
||||
[6]: https://opensource.com/article/19/5/free-rpg-day
|
||||
[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+random
|
||||
[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||
[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||
[10]: https://openjdk.java.net/
|
||||
[11]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+integer
|
||||
313
published/20190627 RPM packages explained.md
Normal file
313
published/20190627 RPM packages explained.md
Normal file
@ -0,0 +1,313 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11452-1.html)
|
||||
[#]: subject: (RPM packages explained)
|
||||
[#]: via: (https://fedoramagazine.org/rpm-packages-explained/)
|
||||
[#]: author: (Ankur Sinha "FranciscoD" https://fedoramagazine.org/author/ankursinha/)
|
||||
|
||||
RPM 包初窥
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
也许,Fedora 社区追求其[促进自由和开源的软件及内容的使命][2]的最著名的方式就是开发 [Fedora 软件发行版][3]了。因此,我们将很大一部分的社区资源用于此任务也就不足为奇了。这篇文章总结了这些软件是如何“打包”的,以及使之成为可能的基础工具,如 `rpm` 之类。
|
||||
|
||||
### RPM:最小的软件单元
|
||||
|
||||
可供用户选择的“版本”和“风味版”([spins][4] / [labs][5] / [silverblue][6])其实非常相似。它们都是由各种软件组成的,这些软件经过混合和搭配,可以很好地协同工作。它们之间的不同之处在于放入其中的具体工具不同。这种选择取决于它们所针对的用例。所有这些的“版本”和“风味版”基本组成单位都是 RPM 软件包文件。
|
||||
|
||||
RPM 文件是类似于 ZIP 文件或 tarball 的存档文件。实际上,它们使用了压缩来减小存档文件的大小。但是,除了文件之外,RPM 存档中还包含有关软件包的元数据。可以使用 `rpm` 工具查询:
|
||||
|
||||
```
|
||||
$ rpm -q fpaste
|
||||
fpaste-0.3.9.2-2.fc30.noarch
|
||||
|
||||
$ rpm -qi fpaste
|
||||
Name : fpaste
|
||||
Version : 0.3.9.2
|
||||
Release : 2.fc30
|
||||
Architecture: noarch
|
||||
Install Date: Tue 26 Mar 2019 08:49:10 GMT
|
||||
Group : Unspecified
|
||||
Size : 64144
|
||||
License : GPLv3+
|
||||
Signature : RSA/SHA256, Thu 07 Feb 2019 15:46:11 GMT, Key ID ef3c111fcfc659b9
|
||||
Source RPM : fpaste-0.3.9.2-2.fc30.src.rpm
|
||||
Build Date : Thu 31 Jan 2019 20:06:01 GMT
|
||||
Build Host : buildhw-07.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : https://pagure.io/fpaste
|
||||
Bug URL : https://bugz.fedoraproject.org/fpaste
|
||||
Summary : A simple tool for pasting info onto sticky notes instances
|
||||
Description :
|
||||
It is often useful to be able to easily paste text to the Fedora
|
||||
Pastebin at http://paste.fedoraproject.org and this simple script
|
||||
will do that and return the resulting URL so that people may
|
||||
examine the output. This can hopefully help folks who are for
|
||||
some reason stuck without X, working remotely, or any other
|
||||
reason they may be unable to paste something into the pastebin
|
||||
|
||||
$ rpm -ql fpaste
|
||||
/usr/bin/fpaste
|
||||
/usr/share/doc/fpaste
|
||||
/usr/share/doc/fpaste/README.rst
|
||||
/usr/share/doc/fpaste/TODO
|
||||
/usr/share/licenses/fpaste
|
||||
/usr/share/licenses/fpaste/COPYING
|
||||
/usr/share/man/man1/fpaste.1.gz
|
||||
```
|
||||
|
||||
安装 RPM 软件包后,`rpm` 工具可以知道具体哪些文件被添加到了系统中。因此,删除该软件包也会删除这些文件,并使系统保持一致状态。这就是为什么要尽可能地使用 `rpm` 安装软件,而不是从源代码安装软件的原因。
|
||||
|
||||
### 依赖关系
|
||||
|
||||
如今,完全独立的软件已经非常罕见。甚至 [fpaste][7],连这样一个简单的单个文件的 Python 脚本,都需要安装 Python 解释器。因此,如果系统未安装 Python(几乎不可能,但有可能),则无法使用 `fpaste`。用打包者的术语来说,“Python 是 `fpaste` 的**运行时依赖项**。”
|
||||
|
||||
构建 RPM 软件包时(本文不讨论构建 RPM 的过程),生成的归档文件中包括了所有这些元数据。这样,与 RPM 软件包归档文件交互的工具就知道必须要安装其它的什么东西,以便 `fpaste` 可以正常工作:
|
||||
|
||||
```
|
||||
$ rpm -q --requires fpaste
|
||||
/usr/bin/python3
|
||||
python3
|
||||
rpmlib(CompressedFileNames) <= 3.0.4-1
|
||||
rpmlib(FileDigests) <= 4.6.0-1
|
||||
rpmlib(PayloadFilesHavePrefix) <= 4.0-1
|
||||
rpmlib(PayloadIsXz) <= 5.2-1
|
||||
|
||||
$ rpm -q --provides fpaste
|
||||
fpaste = 0.3.9.2-2.fc30
|
||||
|
||||
$ rpm -qi python3
|
||||
Name : python3
|
||||
Version : 3.7.3
|
||||
Release : 3.fc30
|
||||
Architecture: x86_64
|
||||
Install Date: Thu 16 May 2019 18:51:41 BST
|
||||
Group : Unspecified
|
||||
Size : 46139
|
||||
License : Python
|
||||
Signature : RSA/SHA256, Sat 11 May 2019 17:02:44 BST, Key ID ef3c111fcfc659b9
|
||||
Source RPM : python3-3.7.3-3.fc30.src.rpm
|
||||
Build Date : Sat 11 May 2019 01:47:35 BST
|
||||
Build Host : buildhw-05.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : https://www.python.org/
|
||||
Bug URL : https://bugz.fedoraproject.org/python3
|
||||
Summary : Interpreter of the Python programming language
|
||||
Description :
|
||||
Python is an accessible, high-level, dynamically typed, interpreted programming
|
||||
language, designed with an emphasis on code readability.
|
||||
It includes an extensive standard library, and has a vast ecosystem of
|
||||
third-party libraries.
|
||||
|
||||
The python3 package provides the "python3" executable: the reference
|
||||
interpreter for the Python language, version 3.
|
||||
The majority of its standard library is provided in the python3-libs package,
|
||||
which should be installed automatically along with python3.
|
||||
The remaining parts of the Python standard library are broken out into the
|
||||
python3-tkinter and python3-test packages, which may need to be installed
|
||||
separately.
|
||||
|
||||
Documentation for Python is provided in the python3-docs package.
|
||||
|
||||
Packages containing additional libraries for Python are generally named with
|
||||
the "python3-" prefix.
|
||||
|
||||
$ rpm -q --provides python3
|
||||
python(abi) = 3.7
|
||||
python3 = 3.7.3-3.fc30
|
||||
python3(x86-64) = 3.7.3-3.fc30
|
||||
python3.7 = 3.7.3-3.fc30
|
||||
python37 = 3.7.3-3.fc30
|
||||
```
|
||||
|
||||
### 解决 RPM 依赖关系
|
||||
|
||||
虽然 `rpm` 知道每个归档文件所需的依赖关系,但不知道在哪里找到它们。这是设计使然:`rpm` 仅适用于本地文件,必须具体告知它们的位置。因此,如果你尝试安装单个 RPM 软件包,则 `rpm` 找不到该软件包的运行时依赖项时就会出错。本示例尝试安装从 Fedora 软件包集中下载的软件包:
|
||||
|
||||
```
|
||||
$ ls
|
||||
python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
|
||||
$ rpm -qpi python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
Name : python3-elephant
|
||||
Version : 0.6.2
|
||||
Release : 3.fc30
|
||||
Architecture: noarch
|
||||
Install Date: (not installed)
|
||||
Group : Unspecified
|
||||
Size : 2574456
|
||||
License : BSD
|
||||
Signature : (none)
|
||||
Source RPM : python-elephant-0.6.2-3.fc30.src.rpm
|
||||
Build Date : Fri 14 Jun 2019 17:23:48 BST
|
||||
Build Host : buildhw-02.phx2.fedoraproject.org
|
||||
Relocations : (not relocatable)
|
||||
Packager : Fedora Project
|
||||
Vendor : Fedora Project
|
||||
URL : http://neuralensemble.org/elephant
|
||||
Bug URL : https://bugz.fedoraproject.org/python-elephant
|
||||
Summary : Elephant is a package for analysis of electrophysiology data in Python
|
||||
Description :
|
||||
Elephant - Electrophysiology Analysis Toolkit Elephant is a package for the
|
||||
analysis of neurophysiology data, based on Neo.
|
||||
|
||||
$ rpm -qp --requires python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
python(abi) = 3.7
|
||||
python3.7dist(neo) >= 0.7.1
|
||||
python3.7dist(numpy) >= 1.8.2
|
||||
python3.7dist(quantities) >= 0.10.1
|
||||
python3.7dist(scipy) >= 0.14.0
|
||||
python3.7dist(six) >= 1.10.0
|
||||
rpmlib(CompressedFileNames) <= 3.0.4-1
|
||||
rpmlib(FileDigests) <= 4.6.0-1
|
||||
rpmlib(PartialHardlinkSets) <= 4.0.4-1
|
||||
rpmlib(PayloadFilesHavePrefix) <= 4.0-1
|
||||
rpmlib(PayloadIsXz) <= 5.2-1
|
||||
|
||||
$ sudo rpm -i ./python3-elephant-0.6.2-3.fc30.noarch.rpm
|
||||
error: Failed dependencies:
|
||||
python3.7dist(neo) >= 0.7.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
|
||||
python3.7dist(quantities) >= 0.10.1 is needed by python3-elephant-0.6.2-3.fc30.noarch
|
||||
```
|
||||
|
||||
理论上,你可以下载 `python3-elephant` 所需的所有软件包,并告诉 `rpm` 它们都在哪里,但这并不方便。如果 `python3-neo` 和 `python3-quantities` 还有其它的运行时要求怎么办?很快,这种“依赖链”就会变得相当复杂。
|
||||
|
||||
#### 存储库
|
||||
|
||||
幸运的是,有了 `dnf` 和它的朋友们,可以帮助解决此问题。与 `rpm` 不同,`dnf` 能感知到**存储库**。存储库是程序包的集合,带有告诉 `dnf` 这些存储库包含什么内容的元数据。所有 Fedora 系统都带有默认启用的默认 Fedora 存储库:
|
||||
|
||||
```
|
||||
$ sudo dnf repolist
|
||||
repo id repo name status
|
||||
fedora Fedora 30 - x86_64 56,582
|
||||
fedora-modular Fedora Modular 30 - x86_64 135
|
||||
updates Fedora 30 - x86_64 - Updates 8,573
|
||||
updates-modular Fedora Modular 30 - x86_64 - Updates 138
|
||||
updates-testing Fedora 30 - x86_64 - Test Updates 8,458
|
||||
```
|
||||
|
||||
在 Fedora 快速文档中有[这些存储库][8]以及[如何管理][9]它们的更多信息。
|
||||
|
||||
`dnf` 可用于查询存储库以获取有关它们包含的软件包信息。它还可以在这些存储库中搜索软件,或从中安装/卸载/升级软件包:
|
||||
|
||||
```
|
||||
$ sudo dnf search elephant
|
||||
Last metadata expiration check: 0:05:21 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
============================================================================== Name & Summary Matched: elephant ==============================================================================
|
||||
python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
|
||||
python3-elephant.noarch : Elephant is a package for analysis of electrophysiology data in Python
|
||||
|
||||
$ sudo dnf list \*elephant\*
|
||||
Last metadata expiration check: 0:05:26 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
Available Packages
|
||||
python3-elephant.noarch 0.6.2-3.fc30 updates-testing
|
||||
python3-elephant.noarch 0.6.2-3.fc30 updates
|
||||
```
|
||||
|
||||
#### 安装依赖项
|
||||
|
||||
现在使用 `dnf` 安装软件包时,它将*解决*所有必需的依赖项,然后调用 `rpm` 执行该事务操作:
|
||||
|
||||
```
|
||||
$ sudo dnf install python3-elephant
|
||||
Last metadata expiration check: 0:06:17 ago on Sun 23 Jun 2019 14:33:38 BST.
|
||||
Dependencies resolved.
|
||||
==============================================================================================================================================================================================
|
||||
Package Architecture Version Repository Size
|
||||
==============================================================================================================================================================================================
|
||||
Installing:
|
||||
python3-elephant noarch 0.6.2-3.fc30 updates-testing 456 k
|
||||
Installing dependencies:
|
||||
python3-neo noarch 0.8.0-0.1.20190215git49b6041.fc30 fedora 753 k
|
||||
python3-quantities noarch 0.12.2-4.fc30 fedora 163 k
|
||||
Installing weak dependencies:
|
||||
python3-igor noarch 0.3-5.20150408git2c2a79d.fc30 fedora 63 k
|
||||
|
||||
Transaction Summary
|
||||
==============================================================================================================================================================================================
|
||||
Install 4 Packages
|
||||
|
||||
Total download size: 1.4 M
|
||||
Installed size: 7.0 M
|
||||
Is this ok [y/N]: y
|
||||
Downloading Packages:
|
||||
(1/4): python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch.rpm 222 kB/s | 63 kB 00:00
|
||||
(2/4): python3-elephant-0.6.2-3.fc30.noarch.rpm 681 kB/s | 456 kB 00:00
|
||||
(3/4): python3-quantities-0.12.2-4.fc30.noarch.rpm 421 kB/s | 163 kB 00:00
|
||||
(4/4): python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch.rpm 840 kB/s | 753 kB 00:00
|
||||
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||
Total 884 kB/s | 1.4 MB 00:01
|
||||
Running transaction check
|
||||
Transaction check succeeded.
|
||||
Running transaction test
|
||||
Transaction test succeeded.
|
||||
Running transaction
|
||||
Preparing : 1/1
|
||||
Installing : python3-quantities-0.12.2-4.fc30.noarch 1/4
|
||||
Installing : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
|
||||
Installing : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
|
||||
Installing : python3-elephant-0.6.2-3.fc30.noarch 4/4
|
||||
Running scriptlet: python3-elephant-0.6.2-3.fc30.noarch 4/4
|
||||
Verifying : python3-elephant-0.6.2-3.fc30.noarch 1/4
|
||||
Verifying : python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch 2/4
|
||||
Verifying : python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch 3/4
|
||||
Verifying : python3-quantities-0.12.2-4.fc30.noarch 4/4
|
||||
|
||||
Installed:
|
||||
python3-elephant-0.6.2-3.fc30.noarch python3-igor-0.3-5.20150408git2c2a79d.fc30.noarch python3-neo-0.8.0-0.1.20190215git49b6041.fc30.noarch python3-quantities-0.12.2-4.fc30.noarch
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
请注意,`dnf` 甚至还安装了`python3-igor`,而它不是 `python3-elephant` 的直接依赖项。
|
||||
|
||||
### DnfDragora:DNF 的一个图形界面
|
||||
|
||||
尽管技术用户可能会发现 `dnf` 易于使用,但并非所有人都这样认为。[Dnfdragora][10] 通过为 `dnf` 提供图形化前端来解决此问题。
|
||||
|
||||
![dnfdragora (version 1.1.1-2 on Fedora 30) listing all the packages installed on a system.][11]
|
||||
|
||||
从上面可以看到,dnfdragora 似乎提供了 `dnf` 的所有主要功能。
|
||||
|
||||
Fedora 中还有其他工具也可以管理软件包,GNOME 的“<ruby>软件<rt>Software</rt></ruby>”和“<ruby>发现<rt>Discover</rt></ruby>”就是其中两个。GNOME “软件”仅专注于图形应用程序。你无法使用这个图形化前端来安装命令行或终端工具,例如 `htop` 或 `weechat`。但是,GNOME “软件”支持安装 `dnf` 所不支持的 [Flatpak][12] 和 Snap 应用程序。它们是针对不同目标受众的不同工具,因此提供了不同的功能。
|
||||
|
||||
这篇文章仅触及到了 Fedora 软件的生命周期的冰山一角。本文介绍了什么是 RPM 软件包,以及使用 `rpm` 和 `dnf` 的主要区别。
|
||||
|
||||
在以后的文章中,我们将详细介绍:
|
||||
|
||||
* 创建这些程序包所需的过程
|
||||
* 社区如何测试它们以确保它们正确构建
|
||||
* 社区用来将其给到社区用户的基础设施
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/rpm-packages-explained/
|
||||
|
||||
作者:[Ankur Sinha "FranciscoD"][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/ankursinha/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/06/rpm.png-816x345.jpg
|
||||
[2]: https://docs.fedoraproject.org/en-US/project/#_what_is_fedora_all_about
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://spins.fedoraproject.org/
|
||||
[5]: https://labs.fedoraproject.org/
|
||||
[6]: https://silverblue.fedoraproject.org/
|
||||
[7]: https://src.fedoraproject.org/rpms/fpaste
|
||||
[8]: https://docs.fedoraproject.org/en-US/quick-docs/repositories/
|
||||
[9]: https://docs.fedoraproject.org/en-US/quick-docs/adding-or-removing-software-repositories-in-fedora/
|
||||
[10]: https://src.fedoraproject.org/rpms/dnfdragora
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/06/dnfdragora-1024x558.png
|
||||
[12]: https://fedoramagazine.org/getting-started-flatpak/
|
||||
@ -1,48 +1,50 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11429-1.html)
|
||||
[#]: subject: (Learn how to Record and Replay Linux Terminal Sessions Activity)
|
||||
[#]: via: (https://www.linuxtechi.com/record-replay-linux-terminal-sessions-activity/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
Learn how to Record and Replay Linux Terminal Sessions Activity
|
||||
在 Linux 上记录和重放终端会话活动
|
||||
======
|
||||
|
||||
Generally, all Linux administrators use **history** command to track which commands were executed in previous sessions, but there is one limitation of history command is that it doesn’t store the command’s output. There can be some scenarios where we want to check commands output of previous session and want to compare it with current session. Apart from this, there are some situations where we are troubleshooting the issues on Linux production boxes and want to save all terminal session activities for future reference, so in such cases script command become handy.
|
||||
通常,Linux 管理员们都使用 `history` 命令来跟踪在先前的会话中执行过哪些命令,但是 `history` 命令的局限性在于它不存储命令的输出。在某些情况下,我们要检查上一个会话的命令输出,并希望将其与当前会话进行比较。除此之外,在某些情况下,我们正在对 Linux 生产环境中的问题进行故障排除,并希望保存所有终端会话活动以供将来参考,因此在这种情况下,`script` 命令就变得很方便。
|
||||
|
||||
<https://www.linuxtechi.com/wp-content/uploads/2019/06/Record-linux-terminal-session-activity.jpg>
|
||||

|
||||
|
||||
Script is a command line tool which is used to capture or record your Linux server terminal sessions activity and later the recorded session can be replayed using scriptreplay command. In this article we will demonstrate how to install script command line tool and how to record Linux server terminal session activity and then later we will see how the recorded session can be replayed using **scriptreplay** command.
|
||||
`script` 是一个命令行工具,用于捕获/记录你的 Linux 服务器终端会话活动,以后可以使用 `scriptreplay` 命令重放记录的会话。在本文中,我们将演示如何安装 `script` 命令行工具以及如何记录 Linux 服务器终端会话活动,然后,我们将看到如何使用 `scriptreplay` 命令来重放记录的会话。
|
||||
|
||||
### Installation of Script tool on RHEL 7/ CentOS 7
|
||||
### 安装 script 工具
|
||||
|
||||
Script command is provided by the rpm package “**util-linux**”, in case it is not installed on your CentOS 7 / RHEL 7 system , run the following yum command,
|
||||
#### 在 RHEL 7/ CentOS 7 上安装 script 工具
|
||||
|
||||
`script` 命令由 RPM 包 `util-linux` 提供,如果你没有在你的 CentOS 7 / RHEL 7 系统上安装它,运行下面的 `yum` 安装它:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# yum install util-linux -y
|
||||
```
|
||||
|
||||
**On RHEL 8 / CentOS 8**
|
||||
#### 在 RHEL 8 / CentOS 8 上安装 script 工具
|
||||
|
||||
Run the following dnf command to install script utility on RHEL 8 and CentOS 8 system,
|
||||
运行下面的 `dnf` 命令来在 RHEL 8 / CentOS 8 上安装 `script` 工具:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# dnf install util-linux -y
|
||||
```
|
||||
|
||||
**Installation of Script tool on Debian based systems (Ubuntu / Linux Mint)**
|
||||
#### 在基于 Debian 的系统(Ubuntu / Linux Mint)上安装 script 工具
|
||||
|
||||
Execute the beneath apt-get command to install script utility
|
||||
运行下面的 `apt-get` 命令来安装 `script` 工具:
|
||||
|
||||
```
|
||||
root@linuxtechi ~]# apt-get install util-linux -y
|
||||
```
|
||||
|
||||
### How to Use script utility
|
||||
### 如何使用 script 工具
|
||||
|
||||
Use of script command is straight forward, type script command on terminal then hit enter, it will start capturing your current terminal session activities inside a file called “**typescript**”
|
||||
直接使用 `script` 命令,在终端上键入 `script` 命令,然后按回车,它将开始在名为 `typescript` 的文件中捕获当前的终端会话活动。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script
|
||||
@ -50,7 +52,7 @@ Script started, file is typescript
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
To stop recording the session activities, type exit command and hit enter.
|
||||
要停止记录会话活动,请键入 `exit` 命令,然后按回车:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# exit
|
||||
@ -59,23 +61,23 @@ Script done, file is typescript
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Syntax of Script command:
|
||||
`script` 命令的语法格式:
|
||||
|
||||
```
|
||||
~ ] # script {options} {file_name}
|
||||
~] # script {options} {file_name}
|
||||
```
|
||||
|
||||
Different options used in script command,
|
||||
能在 `script` 命令中使用的不同选项:
|
||||
|
||||
![options-script-command][1]
|
||||
|
||||
Let’s start recording of your Linux terminal session by executing script command and then execute couple of command like ‘**w**’, ‘**route -n**’ , ‘[**df -h**][2]’ and ‘**free-h**’, example is shown below
|
||||
让我们开始通过执行 `script` 命令来记录 Linux 终端会话,然后执行诸如 `w`,`route -n`,`df -h` 和 `free -h`,示例如下所示:
|
||||
|
||||
![script-examples-linux-server][3]
|
||||
|
||||
As we can see above, terminal session logs are saved in the file “typescript”
|
||||
正如我们在上面看到的,终端会话日志保存在文件 `typescript` 中:
|
||||
|
||||
Now view the contents of typescript file using [cat][4] / vi command,
|
||||
现在使用 `cat` / `vi` 命令查看 `typescript` 文件的内容,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# ls -l typescript
|
||||
@ -85,11 +87,11 @@ Now view the contents of typescript file using [cat][4] / vi command,
|
||||
|
||||
![typescript-file-content-linux][5]
|
||||
|
||||
Above confirms that whatever commands we execute on terminal that have been saved inside the file “typescript”
|
||||
以上内容确认了我们在终端上执行的所有命令都已保存在 `typescript` 文件中。
|
||||
|
||||
### Use Custom File name in script command
|
||||
### 在 script 命令中使用定制文件名
|
||||
|
||||
Let’s assume we want to use our customize file name to script command, so specify the file name after script command, in the below example we are using a file name “session-log-(current-date-time).txt”
|
||||
假设我们要使用自定义文件名来执行 `script` 命令,可以在 `script` 命令后指定文件名。在下面的示例中,我们使用的文件名为 `session-log-(当前日期时间).txt`。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script sessions-log-$(date +%d-%m-%Y-%T).txt
|
||||
@ -97,7 +99,7 @@ Script started, file is sessions-log-21-06-2019-01:37:39.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now run the commands and then type exit,
|
||||
现在运行该命令并输入 `exit`:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# exit
|
||||
@ -106,9 +108,9 @@ Script done, file is sessions-log-21-06-2019-01:37:39.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Append the commands output to script file
|
||||
### 附加命令输出到 script 记录文件
|
||||
|
||||
Let assume script command had already recorded the commands output to a file called session-log.txt file and now we want to append output of new sessions commands output to this file, then use “**-a**” command in script command
|
||||
假设 `script` 命令已经将命令输出记录到名为 `session-log.txt` 的文件中,现在我们想将新会话命令的输出附加到该文件中,那么可以在 `script` 命令中使用 `-a` 选项。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -a sessions-log.txt
|
||||
@ -129,11 +131,11 @@ Script done, file is sessions-log.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
To view updated session’s logs, use “cat session-log.txt ”
|
||||
要查看更新的会话记录,使用 `cat session-log.txt` 命令。
|
||||
|
||||
### Capture commands output to script file without interactive shell
|
||||
### 无需 shell 交互而捕获命令输出到 script 记录文件
|
||||
|
||||
Let’s assume we want to capture commands output to a script file, then use **-c** option, example is shown below,
|
||||
假设我们要捕获命令的输出到会话记录文件,那么使用 `-c` 选项,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -c "uptime && hostname && date" root-session.txt
|
||||
@ -145,9 +147,9 @@ Script done, file is root-session.txt
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Run script command in quiet mode
|
||||
### 以静默模式运行 script 命令
|
||||
|
||||
To run script command in quiet mode use **-q** option, this option will suppress the script started and script done message, example is shown below,
|
||||
要以静默模式运行 `script` 命令,请使用 `-q` 选项,该选项将禁止 `script` 的启动和完成消息,示例如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script -c "uptime && date" -q root-session.txt
|
||||
@ -156,11 +158,13 @@ Fri Jun 21 02:01:10 EDT 2019
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Record Timing information to a file and capture commands output to a separate file, this can be achieved in script command by passing timing file (**–timing**) , example is shown below,
|
||||
要将时序信息记录到文件中并捕获命令输出到单独的文件中,这可以通过在 `script` 命令中传递时序文件(`-timing`)实现,示例如下所示:
|
||||
|
||||
Syntax:
|
||||
语法格式:
|
||||
|
||||
~ ]# script -t <timing-file-name> {file_name}
|
||||
```
|
||||
~ ]# script -t <timing-file-name> {file_name}
|
||||
```
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# script --timing=timing.txt session.log
|
||||
@ -185,23 +189,23 @@ Script done, file is session.log
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Replay recorded Linux terminal session activity
|
||||
### 重放记录的 Linux 终端会话活动
|
||||
|
||||
Now replay the recorded terminal session activities using scriptreplay command,
|
||||
现在,使用 `scriptreplay` 命令重放录制的终端会话活动。
|
||||
|
||||
**Note:** Scriptreplay is also provided by rpm package “**util-linux**”. Scriptreplay command requires timing file to work.
|
||||
注意:`scriptreplay` 也由 RPM 包 `util-linux` 提供。`scriptreplay` 命令需要时序文件才能工作。
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# scriptreplay --timing=timing.txt session.log
|
||||
```
|
||||
|
||||
Output of above command would be something like below,
|
||||
上面命令的输出将如下所示,
|
||||
|
||||
<https://www.linuxtechi.com/wp-content/uploads/2019/06/scriptreplay-linux.gif>
|
||||
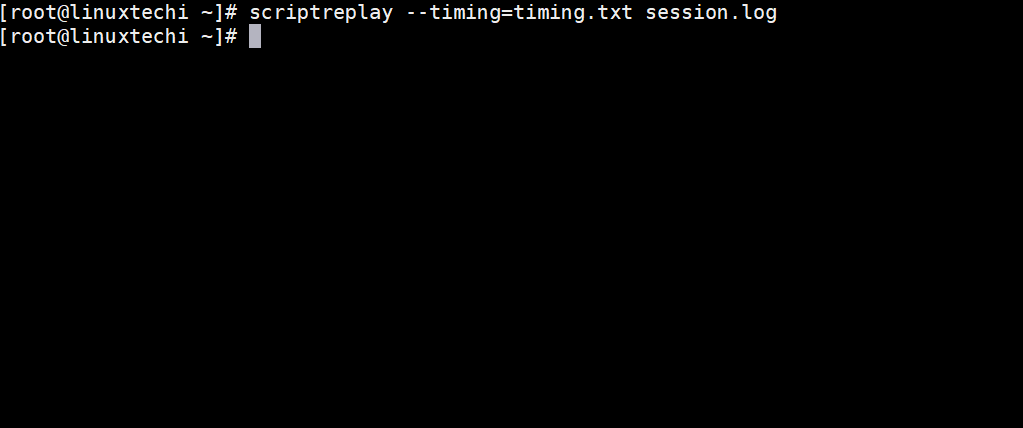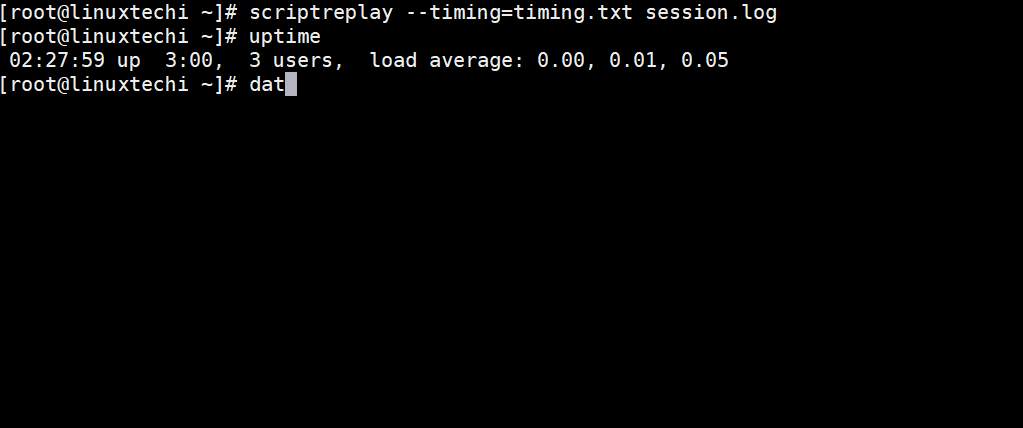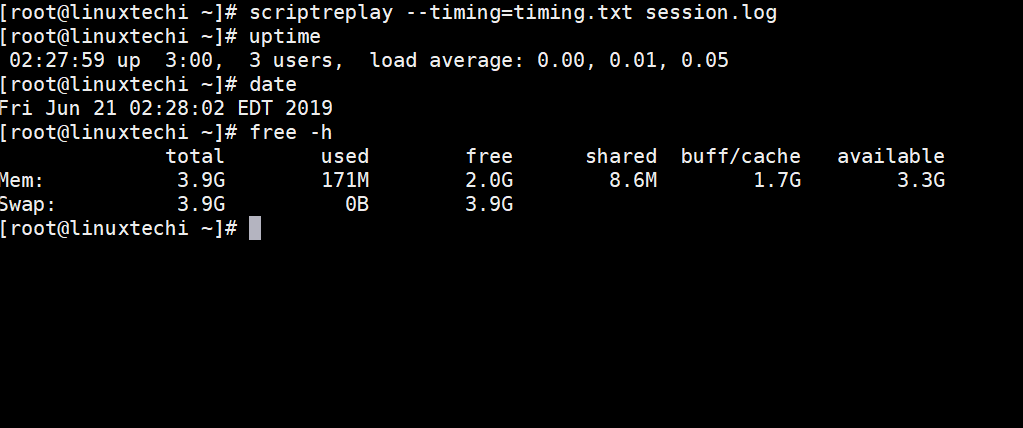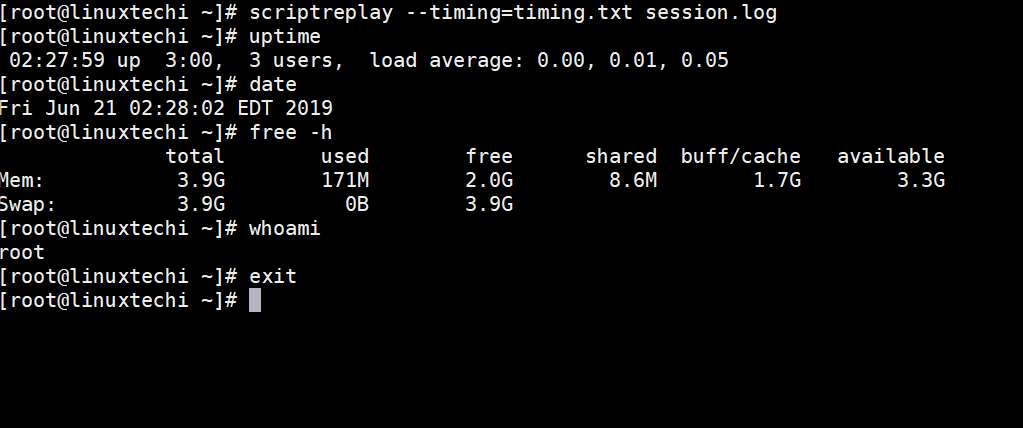
|
||||
|
||||
### Record all User’s Linux terminal session activities
|
||||
### 记录所有用户的 Linux 终端会话活动
|
||||
|
||||
There are some business critical Linux servers where we want keep track on all users activity, so this can be accomplished using script command, place the following content in /etc/profile file ,
|
||||
在某些关键业务的 Linux 服务器上,我们希望跟踪所有用户的活动,这可以使用 `script` 命令来完成,将以下内容放在 `/etc/profile` 文件中,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/profile
|
||||
@ -218,22 +222,22 @@ fi
|
||||
……………………………………………………
|
||||
```
|
||||
|
||||
Save & exit the file.
|
||||
保存文件并退出。
|
||||
|
||||
Create the session directory under /var/log folder,
|
||||
在 `/var/log` 文件夹下创建 `session` 目录:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mkdir /var/log/session
|
||||
```
|
||||
|
||||
Assign the permissions to session folder,
|
||||
给该文件夹指定权限:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# chmod 777 /var/log/session/
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now verify whether above code is working or not. Login to ordinary user to linux server, in my I am using pkumar user,
|
||||
现在,验证以上代码是否有效。在我正在使用 `pkumar` 用户的情况下,登录普通用户到 Linux 服务器:
|
||||
|
||||
```
|
||||
~ ] # ssh root@linuxtechi
|
||||
@ -263,13 +267,13 @@ Login as root and view user’s linux terminal session activity
|
||||
|
||||
![Session-output-file-linux][6]
|
||||
|
||||
We can also use scriptreplay command to replay user’s terminal session activities,
|
||||
我们还可以使用 `scriptreplay` 命令来重放用户的终端会话活动:
|
||||
|
||||
```
|
||||
[root@linuxtechi session]# scriptreplay --timing session.pkumar.19785.21-06-2019-04\:34\:05.timing session.pkumar.19785.21-06-2019-04\:34\:05
|
||||
```
|
||||
|
||||
That’s all from this tutorial, please do share your feedback and comments in the comments section below.
|
||||
以上就是本教程的全部内容,请在下面的评论部分中分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -277,8 +281,8 @@ via: https://www.linuxtechi.com/record-replay-linux-terminal-sessions-activity/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
82
published/20190719 Buying a Linux-ready laptop.md
Normal file
82
published/20190719 Buying a Linux-ready laptop.md
Normal file
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11436-1.html)
|
||||
[#]: subject: (Buying a Linux-ready laptop)
|
||||
[#]: via: (https://opensource.com/article/19/7/linux-laptop)
|
||||
[#]: author: (Ricardo Berlasso https://opensource.com/users/rgb-es)
|
||||
|
||||
我买了一台 Linux 笔记本
|
||||
======
|
||||
|
||||
> Tuxedo 让买一台开箱即用的 Linux 笔记本变得容易。
|
||||
|
||||

|
||||
|
||||
最近,我开始使用我买的 Linux 笔记本计算机 Tuxedo Book BC1507。十年前,如果有人告诉我,十年后我可以从 [System76][2]、[Slimbook][3] 和 [Tuxedo][4] 等公司购买到高质量的“企鹅就绪”的笔记本电脑。我可能会发笑。好吧,现在我也在笑,但是很开心!
|
||||
|
||||
除了为免费/自由开源软件(FLOSS)设计计算机之外,这三家公司最近[宣布][5]都试图通过切换到[Coreboot][6]来消除专有的 BIOS 软件。
|
||||
|
||||
### 买一台
|
||||
|
||||
Tuxedo Computers 是一家德国公司,生产支持 Linux 的笔记本电脑。实际上,如果你要使用其他的操作系统,则它的价格会更高。
|
||||
|
||||
购买他们的计算机非常容易。Tuxedo 提供了许多付款方式:不仅包括信用卡,而且还包括 PayPal 甚至银行转帐(LCTT 译注:我们需要支付宝和微信支付……此外,要国际配送,还需要支付运输费和清关费用等)。只需在 Tuxedo 的网页上填写银行转帐表格,公司就会给你发送银行信息。
|
||||
|
||||
Tuxedo 可以按需构建每台计算机,只需选择基本模型并浏览下拉菜单以选择不同的组件,即可轻松准确地选择所需内容。页面上有很多信息可以指导你进行购买。
|
||||
|
||||
如果你选择的 Linux 发行版与推荐的发行版不同,则 Tuxedo 会进行“网络安装”,因此请准备好网络电缆以完成安装,也可以将你首选的镜像文件刻录到 USB 盘上。我通过外部 DVD 阅读器来安装刻录了 openSUSE Leap 15.1 安装程序的 DVD,但是你可用你自己的方式。
|
||||
|
||||
我选择的型号最多可以容纳两个磁盘:一个 SSD,另一个可以是 SSD 或常规硬盘。由于已经超出了我的预算,因此我决定选择传统的 1TB 磁盘并将 RAM 增加到 16GB。该处理器是具有四个内核的第八代 i5。我选择了背光西班牙语键盘、1920×1080/96dpi 屏幕和 SD 卡读卡器。总而言之,这是一个很棒的系统。
|
||||
|
||||
如果你对默认的英语或德语键盘感觉满意,甚至可以要求在 Meta 键上印上一个企鹅图标!我需要的西班牙语键盘则不提供此选项。
|
||||
|
||||
### 收货并开箱使用
|
||||
|
||||
付款完成后仅六个工作日,完好包装的计算机就十分安全地到达了我家。打开计算机包装并解锁电池后,我准备好开始浪了。
|
||||
|
||||
![Tuxedo Book BC1507][7]
|
||||
|
||||
*我的(物理)桌面上的新玩具。*
|
||||
|
||||
该电脑的设计确实很棒,而且感觉扎实。即使此型号的外壳不是铝制的(LCTT 译注:他们有更好看的铝制外壳的型号),也可以保持凉爽。风扇真的很安静,气流像许多其他笔记本电脑一样导向后边缘,而不是流向侧面。电池可提供数小时的续航时间。BIOS 中的一个名为 FlexiCharger 的选项会在达到一定百分比后停止为电池充电,因此在插入电源长时间工作时,无需卸下电池。
|
||||
|
||||
键盘真的很舒适,而且非常安静。甚至触摸板按键也很安静!另外,你可以轻松调整背光键盘上的光强度。
|
||||
|
||||
最后,很容易访问笔记本电脑中的每个组件,因此可以毫无问题地对计算机进行更新或维修。Tuxedo 甚至送了几个备用螺丝!
|
||||
|
||||
### 结语
|
||||
|
||||
经过一个月的频繁使用,我对该系统感到非常满意。它完全满足了我的要求,并且一切都很完美。
|
||||
|
||||
因为它们通常是高端系统,所以包含 Linux 的计算机往往比较昂贵。如果你将 Tuxedo 或 Slimbook 电脑的价格与更知名品牌的类似规格的价格进行比较,价格相差无几。如果你想要一台使用自由软件的强大系统,请毫不犹豫地支持这些公司:他们所提供的物有所值。
|
||||
|
||||
请在评论中让我们知道你在 Tuxedo 和其他“企鹅友好”公司的经历。
|
||||
|
||||
* * *
|
||||
|
||||
本文基于 Ricardo 的博客 [From Mind to Type][9] 上发表的“ [我的新企鹅笔记本电脑:Tuxedo-Book-BC1507][8]”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/linux-laptop
|
||||
|
||||
作者:[Ricardo Berlasso][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rgb-es
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22 (Penguin with green background)
|
||||
[2]: https://system76.com/
|
||||
[3]: https://slimbook.es/en/
|
||||
[4]: https://www.tuxedocomputers.com/
|
||||
[5]: https://www.tuxedocomputers.com/en/Infos/News/Tuxedo-Computers-stands-for-Free-Software-and-Security-.tuxedo
|
||||
[6]: https://coreboot.org/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/tuxedo-600_0.jpg (Tuxedo Book BC1507)
|
||||
[8]: https://frommindtotype.wordpress.com/2019/06/17/my-new-penguin-ready-laptop-tuxedo-book-bc1507/
|
||||
[9]: https://frommindtotype.wordpress.com/
|
||||
@ -0,0 +1,156 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11272-1.html)
|
||||
[#]: subject: (A brief history of text-based games and open source)
|
||||
[#]: via: (https://opensource.com/article/18/7/interactive-fiction-tools)
|
||||
[#]: author: (Jason Mclntosh https://opensource.com/users/jmac)
|
||||
|
||||
互动小说及其开源简史
|
||||
======
|
||||
|
||||
> 了解开源如何促进互动小说的成长和发展。
|
||||
|
||||

|
||||
|
||||
<ruby>[互动小说技术基金会][1]<rt>Interactive Fiction Technology Foundation</rt></ruby>(IFTF) 是一个非营利组织,致力于保护和改进那些用来生成我们称之为<ruby>互动小说<rt>interactive fiction</rt></ruby>的数字艺术形式的技术。当 Opensource.com 的一位社区版主提出一篇关于 IFTF、它支持的技术与服务,以及它如何与开源相交织的文章时,我发现这对于我讲了数几十年的开源故事来说是个新颖的视角。互动小说的历史比<ruby>自由及开源软件<rt>Free and Open Source Software</rt></ruby>(FOSS)运动的历史还要长,但同时也与之密切相关。希望你们能喜欢我在这里的分享。
|
||||
|
||||
### 定义和历史
|
||||
|
||||
对于我来说,互动小说这个术语涵盖了读者主要通过文本与之交互的任何视频游戏或数字化艺术作品。这个术语起源于 20 世纪 80 年代,当时由语法解析器驱动的文本冒险游戏确立了什么是家用电脑娱乐,在美国主要以 [魔域][2]、[银河系漫游指南][3] 和 [Infocom][4] 公司的其它佳作为代表。在 20 世纪 90 年代,它的主流商业价值被挖掘殆尽,但在线爱好者社区接过了该传统,继续发布这类游戏和游戏创建工具。
|
||||
|
||||
在四分之一个世纪之后的今天,互动小说包括了品种繁多并且妙趣橫生的作品,如从充满谜题的文字冒险游戏到衍生改良的超文本类型。定期举办的在线竞赛和节日为品鉴和试玩新作品提供了个好地方---英语互动小说世界每年都会举办一些活动,包括 [Spring Thing][5] 和 [IFComp][6]。后者是自 1995 年以来现代互动小说的核心活动,这也使它成为在同类型活动中持续举办时间最长的游戏展示活动。[IFComp 从 2017 年开始的评选和排名记录][7] 显示了如今基于文本的游戏在形式、风格和主题方面的惊人多样性。
|
||||
|
||||
(作者注:以上我特指英语,因为可能出于写作方面的技术原因,互动小说社区倾向于按语言进行区分。例如也有 [法语][8] 或 [意大利语][9] 的互动小说年度活动,我就听说过至少一届的中文互动小说节。幸运的是,这些边界易于打破。在我管理 IFComp 的四年中,我们很欢迎来自国际社区的所有英语翻译工作。)
|
||||
|
||||
![“假冒的猴子”游戏截图][11]
|
||||
|
||||
*在解释器 Lectrote 上启动 Emily Short 的“假冒的猴子”新游戏(二者皆为开源软件)。*
|
||||
|
||||
此外由于互动小说专注于文本,它为玩家和作者都提供了最方便的平台。几乎所有能阅读数字化文本的人(包括能通过文字转语音软件等辅助技术阅读的用户)都能玩大部分的互动小说作品。同样,互动小说的创作对所有愿意学习和使用其工具和技术的作家开放。
|
||||
|
||||
这使我们了解了互动小说与开源的长期关系,以及从它的全盛时期以来,对于艺术形式可用性的积极影响。接下来我将概述当代开源互动小说创建工具,并讨论共享源代码的互动小说作品古老且有点稀奇的传统。
|
||||
|
||||
### 开源互动小说工具的世界
|
||||
|
||||
一些开发平台(其中大部分是开源的)可用于创建传统的语法解析器驱动互动小说,其中用户可通过输入命令(如 `向北走`、`拾取提灯`、`收养小猫` 或 `向 Zoe 询问量子机械学`)来与游戏世界交互。20 世纪 90 年代初期出现了几个<ruby>适于魔改<rt>hacker-friendly</rt></ruby>的语法解析器游戏开发工具,其中目前还在使用的有 [TADS][12]、[Alan][13] 和 [Quest][14],它们都是开源的,并且后两者兼容 FOSS 许可证。
|
||||
|
||||
其中最出名的是 [Inform][15],1993 年 Graham Nelson 发布了第一个版本,目前由 Nelson 领导的一个团队进行维护。Inform 的源代码是不太寻常的半开源:Inform 6 是前一个主要版本,[它通过 Artistic 许可证开放源码][16]。这其中蕴涵着比我们所看到的更直接的相关性,因为它专有的 Inform 7 将 Inform 6 作为其核心,可以让它在将作品编译为机器码之前,将其 [杰出的自然语言语法][17] (LCTT 译注:此链接已遗失)翻译为其前一代的那种更类似 C 的代码。
|
||||
|
||||
![inform 7 集成式开发环境截图][19]
|
||||
|
||||
*Inform 7 集成式开发环境,打开了文档以及一个示例项目*
|
||||
|
||||
Inform 游戏运行在虚拟机上,这是 Infocom 时代的遗留产物。当时的发行者为了让同一个游戏可以运行在 Apple II、Commodore 4、Atari 800 以及其它种类的“[家用计算机][20]”上,将虚拟机作为解决方案。这些原本流行的操作系统中只有少数至今仍存在,但 Inform 的虚拟机使得它创建的作品能够通过 Inform 解释器运行在任何的计算机上。这些虚拟机包括相对现代的 [Glulx][21],或者通过对 Infocom 过去的虚拟机进行逆向工程克隆得到的可爱的古董 [Z-machine][22]。现在,流行的跨平台解释器包括如 [lectrote][23] 和 [Gargoyle][24] 等桌面程序,以及如 [Quixe][25] 和 [Parchment][26] 等基于浏览器的程序。以上所有均为开源软件。
|
||||
|
||||
如其它的流行开源项目一样,如果 Inform 的发展进程随着它的成熟而逐渐变缓,它为我们留下的最重要的财富就是其活跃透明的生态环境。对于 Inform 来说,(这些财富)包括前面提到的解释器、[一套语言扩展][27](通常混合使用 Inform 6 和 Inform 7 写成),当然也包括所有用它们写成并分享于全世界的作品,有的时候也包括那些源代码。(在这篇文章的后半部分我会回到这个话题)
|
||||
|
||||
互动小说创建工具发明于 21 世纪,力求在传统的语法解析器之外探索一种新的玩家交互方式,即创建任何现代 Web 浏览器都能加载的超文本驱动作品。其中的领头羊是 [Twine][28],原本由 Klimas 在 2009 年开发,目前是 [GNU 许可证开源项目][29],有许多贡献者正在积极开发。(事实上,[Twine][30] 的开源软件血统可追溯到 [TiddlyWiki][31],Klimas 的项目最初是从该项目衍生而来的)
|
||||
|
||||
对于互动小说开发来说,Twine 代表着一系列最开放及最可用的方法。由于它天生的 FOSS 属性,它将其输出渲染为一个自包含的网站,不依赖于需要进一步特殊解析的机器码,而是使用开放并且成熟的 HTML、CSS 和 JavaScript 标准。作为一个创建工具,Twine 能够根据创建者的技能等级,展示出与之相匹配的复杂度。拥有很少或没有编程知识的用户能够创建简单但是可玩的互动小说作品,但那些拥有更多编码和设计技能(包括通过开发 Twine 游戏获得的技能提升)的用户能够创建更复杂的项目。这也难怪近几年 Twine 在教育领域的曝光率和流行度有不小的提升。
|
||||
|
||||
另一些值得注意的开源互动小说开发项目包括由 Ian Millington 开发的以 MIT 许可证发布的 [Undum][32],以及由 Dan Fabulich 和 [Choice of Games][34] 团队开发的 [ChoiceScript][33],两者也专注于将 Web 浏览器作为游戏平台。除了以上专用的开发系统以外,基于 Web 的互动小说也呈现给我们以开源作品的丰富、变幻的生态。比如 Furkle 的 [Twine 扩展工具集][35],以及 Liza Daly 为自己的互动小说游戏创建的名为 [Windrift][36] 的 JavaScript 框架。
|
||||
|
||||
### 程序、游戏,以及游戏程序
|
||||
|
||||
Twine 受益于 [一个致力于提供支持的长期 IFTF 计划][37],公众可以为其维护和发展提供资助。IFTF 还直接支持两个长期公共服务:IFComp 和<ruby>互动小说归档<rt>IF Archive</rt></ruby>,这两个服务都依赖并回馈开源软件和技术。
|
||||
|
||||
![Harmonia 开场截图][39]
|
||||
|
||||
*由 Liza Daly 开发的“Harmonia”的开场画面,该游戏使用 Windrift 开源互动小说创建框架创建。*
|
||||
|
||||
自 2014 年以来,用于运行 IFComp 网站的基于 Perl 和 JavaScript 的应用程序一直是 [一个共享源代码项目][40],它反映了 [互动小说特有子组件使用的 FOSS 许可证是个大杂烩][41],其中包括那些可以让以语法解析器驱动的竞争项目在 Web 浏览器中运行的各式各样的代码库。在 1992 年上线并 [在 2017 年成为一个 IFTF 项目][43] 的 <ruby>[互动小说归档][42]<rt>IF Archive</rt></ruby>,是一套完全基于古老且稳定的互联网标准的镜像仓库,只使用了 [一点开源 Pyhon 脚本][44] 用来处理索引。
|
||||
|
||||
### 最后,也是最有趣的部分,让我们聊聊开源文字游戏
|
||||
|
||||
互动小说归档的主体 [由游戏组成][45],当然,是那些历经岁月的游戏。它们反映了数十年来不断发展的游戏设计趋势和互动小说工具发展。
|
||||
|
||||
许多互动小说作品都共享其源代码,要快速找到它们的快速很简单 —— [在 IFDB 中搜索标签 “source available”][46]。IFDB 是另一个长期运行的互动小说社区服务,由 TADS 的创立者 Mike Roberts 私人运营。对更加简单的界面感到舒适的用户,也可以浏览互动小说归档的 [games/source 目录][47],该目录按开发平台和编写语言对内容运行分组(也有很多作品,由于太繁杂或太古老而无法分类,只能浮于顶级目录)。
|
||||
|
||||
对这些代码共享游戏随机抽取的几个样本,揭示了一个有趣的窘境:与更广阔的开源软件世界不同,互动小说社区缺少一种普遍认同的方式来授权它生成的所有代码。与软件工具(包括我们用来创建互动小说的所有工具)不同的是,从字面意思上讲,交互式小说游戏是一件艺术作品。这意味着,将面向软件的开源许可证用于交互式小说游戏,并不会比将其用于其它像散文或诗歌作品更适合。但同样,互动小说游戏也是一个软件,它展示了创建者希望合法地与世界分享的源代码模式和技术。一个拥有开源意识的互动小说创建者会怎么做呢?
|
||||
|
||||
有些游戏通过将其代码放到公共领域来解决这一问题,或者通过明确的许可证,亦或者如 [42 年前由 Crowther 和 Woods 开发的“<ruby>冒险之旅<rt>Adventure</rt></ruby>”][48] 一样通过社区发布。一些人试图将其中的不同部分分开,应用他们自己的许可证,允许免费复用游戏公开的业务逻辑,但禁止针对其散文内容的再创作。这是我在开源自己的游戏 <ruby>[莺巢][49]<rt>The Warbler’s Nest</rt></ruby> 时采取的策略。天知道这是否能在法律上站得住脚,但我当时没有更好的主意。
|
||||
|
||||
当然,你会发现一些作品对所有部分使用单一的许可证,而不介意反对者。一个突出的例子就是 [Emily Short 的史诗作品“<ruby>假冒的猴子<rt>Counterfeit Monkey</rt></ruby>”][50],其全部采用 Creative Commons 4.0 许可证发布。[CC 对其应用于代码感到不满][51],但你可以认为 [Inform 7 源码这种不寻常的散文风格特性][52] 至少比传统的软件项目更适合 CC 许可证。
|
||||
|
||||
### 接下来要做什么呢,冒险者?
|
||||
|
||||
如果你希望开始探索互动小说的世界,这里有几个链接可供你参考:
|
||||
|
||||
+ 如上所述,[IFDB][53] 和[互动小说归档][54]都提供了可浏览的界面,用于浏览超过 40 年价值的互动小说作品。其中大部分可以在 Web 浏览器中玩,但有些需要额外的解释器程序。IFDB 能帮助你找到并安装它们。[IFComp 的年度结果页面][55]展现了另一个视图,帮助你了解最佳的免费和归档可用作品。
|
||||
+ [互动小说技术基金会][56]是一个非营利组织,主要帮助并支持 Twine、IFComp 和互动小说归档的发展,以及提升互动小说的无障碍功能、探索互动小说在教育领域中的应用等等。加入其[邮件列表][57],可以接收 IFTF 的每月资讯,浏览其[博客][58],亦或浏览[一些主题商品][59]。
|
||||
+ 在今年的早些时候,John Paul Wohlscheid 写了这篇[关于开源互动小说工具][60]的文章。它涵盖了一些这里没有提及的平台,所以如果你还想了解更多,请看一看这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/interactive-fiction-tools
|
||||
|
||||
作者:[Jason Mclntosh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jmac
|
||||
[1]:http://iftechfoundation.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Zork
|
||||
[3]:https://en.wikipedia.org/wiki/The_Hitchhiker%27s_Guide_to_the_Galaxy_(video_game)
|
||||
[4]:https://en.wikipedia.org/wiki/Infocom
|
||||
[5]:http://www.springthing.net/
|
||||
[6]:http://ifcomp.org/
|
||||
[7]:https://ifcomp.org/comp/2017
|
||||
[8]:http://www.fiction-interactive.fr/
|
||||
[9]:http://www.oldgamesitalia.net/content/marmellata-davventura-2018
|
||||
[10]:/file/403396
|
||||
[11]:https://opensource.com/sites/default/files/uploads/monkey.png (counterfeit monkey game screenshot)
|
||||
[12]:http://tads.org/
|
||||
[13]:https://www.alanif.se/
|
||||
[14]:http://textadventures.co.uk/quest/
|
||||
[15]:http://inform7.com/
|
||||
[16]:https://github.com/DavidKinder/Inform6
|
||||
[17]:http://inform7.com/learn/man/RB_4_1.html#e307
|
||||
[18]:/file/403386
|
||||
[19]:https://opensource.com/sites/default/files/uploads/inform.png (inform 7 IDE screenshot)
|
||||
[20]:https://www.youtube.com/watch?v=bu55q_3YtOY
|
||||
[21]:http://ifwiki.org/index.php/Glulx
|
||||
[22]:http://ifwiki.org/index.php/Z-machine
|
||||
[23]:https://github.com/erkyrath/lectrote
|
||||
[24]:https://github.com/garglk/garglk/
|
||||
[25]:http://eblong.com/zarf/glulx/quixe/
|
||||
[26]:https://github.com/curiousdannii/parchment
|
||||
[27]:https://github.com/i7/extensions
|
||||
[28]:http://twinery.org/
|
||||
[29]:https://github.com/klembot/twinejs
|
||||
[30]:https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
|
||||
[31]:https://tiddlywiki.com/
|
||||
[32]:https://github.com/idmillington/undum
|
||||
[33]:https://github.com/dfabulich/choicescript
|
||||
[34]:https://www.choiceofgames.com/
|
||||
[35]:https://github.com/furkle
|
||||
[36]:https://github.com/lizadaly/windrift
|
||||
[37]:http://iftechfoundation.org/committees/twine/
|
||||
[38]:/file/403391
|
||||
[39]:https://opensource.com/sites/default/files/uploads/harmonia.png (Harmonia opening screen shot)
|
||||
[40]:https://github.com/iftechfoundation/ifcomp
|
||||
[41]:https://github.com/iftechfoundation/ifcomp/blob/master/LICENSE.md
|
||||
[42]:https://www.ifarchive.org/
|
||||
[43]:http://blog.iftechfoundation.org/2017-06-30-iftf-is-adopting-the-if-archive.html
|
||||
[44]:https://github.com/iftechfoundation/ifarchive-ifmap-py
|
||||
[45]:https://www.ifarchive.org/indexes/if-archiveXgames
|
||||
[46]:http://ifdb.tads.org/search?sortby=ratu&searchfor=%22source+available%22
|
||||
[47]:https://www.ifarchive.org/indexes/if-archiveXgamesXsource.html
|
||||
[48]:http://ifdb.tads.org/viewgame?id=fft6pu91j85y4acv
|
||||
[49]:https://github.com/jmacdotorg/warblers-nest/
|
||||
[50]:https://github.com/i7/counterfeit-monkey
|
||||
[51]:https://creativecommons.org/faq/#can-i-apply-a-creative-commons-license-to-software
|
||||
[52]:https://github.com/i7/counterfeit-monkey/blob/master/Counterfeit%20Monkey.materials/Extensions/Counterfeit%20Monkey/Liquids.i7x
|
||||
[53]:http://ifdb.tads.org/
|
||||
[54]:https://ifarchive.org/
|
||||
[55]:https://ifcomp.org/comp/last_comp
|
||||
[56]:http://iftechfoundation.org/
|
||||
[57]:http://iftechfoundation.org/cgi-bin/mailman/listinfo/friends
|
||||
[58]:http://blog.iftechfoundation.org/
|
||||
[59]:http://blog.iftechfoundation.org/2017-12-20-the-iftf-gift-shop-is-now-open.html
|
||||
[60]:https://itsfoss.com/create-interactive-fiction/
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11268-1.html)
|
||||
[#]: subject: (Podman and user namespaces: A marriage made in heaven)
|
||||
[#]: via: (https://opensource.com/article/18/12/podman-and-user-namespaces)
|
||||
[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
|
||||
|
||||
Podman 和用户名字空间:天作之合
|
||||
======
|
||||
|
||||
> 了解如何使用 Podman 在单独的用户空间运行容器。
|
||||
|
||||

|
||||
|
||||
[Podman][1] 是 [libpod][2] 库的一部分,使用户能够管理 pod、容器和容器镜像。在我的上一篇文章中,我写过将 [Podman 作为一种更安全的运行容器的方式][3]。在这里,我将解释如何使用 Podman 在单独的用户命名空间中运行容器。
|
||||
|
||||
作为分离容器的一个很棒的功能,我一直在思考<ruby>[用户命名空间][4]<rt>user namespace</rt></ruby>,它主要是由 Red Hat 的 Eric Biederman 开发的。用户命名空间允许你指定用于运行容器的用户标识符(UID)和组标识符(GID)映射。这意味着你可以在容器内以 UID 0 运行,在容器外以 UID 100000 运行。如果容器进程逃逸出了容器,内核会将它们视为以 UID 100000 运行。不仅如此,任何未映射到用户命名空间的 UID 所拥有的文件对象都将被视为 `nobody` 所拥有(UID 是 `65534`, 由 `kernel.overflowuid` 指定),并且不允许容器进程访问,除非该对象可由“其他人”访问(即世界可读/可写)。
|
||||
|
||||
如果你拥有一个权限为 [660][5] 的属主为“真实” `root` 的文件,而当用户命名空间中的容器进程尝试读取它时,会阻止它们访问它,并且会将该文件视为 `nobody` 所拥有。
|
||||
|
||||
### 示例
|
||||
|
||||
以下是它是如何工作的。首先,我在 `root` 拥有的系统中创建一个文件。
|
||||
|
||||
```
|
||||
$ sudo bash -c "echo Test > /tmp/test"
|
||||
$ sudo chmod 600 /tmp/test
|
||||
$ sudo ls -l /tmp/test
|
||||
-rw-------. 1 root root 5 Dec 17 16:40 /tmp/test
|
||||
```
|
||||
|
||||
接下来,我将该文件卷挂载到一个使用用户命名空间映射 `0:100000:5000` 运行的容器中。
|
||||
|
||||
```
|
||||
$ sudo podman run -ti -v /tmp/test:/tmp/test:Z --uidmap 0:100000:5000 fedora sh
|
||||
# id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
# ls -l /tmp/test
|
||||
-rw-rw----. 1 nobody nobody 8 Nov 30 12:40 /tmp/test
|
||||
# cat /tmp/test
|
||||
cat: /tmp/test: Permission denied
|
||||
```
|
||||
|
||||
上面的 `--uidmap` 设置告诉 Podman 在容器内映射一系列的 5000 个 UID,从容器外的 UID 100000 开始的范围(100000-104999)映射到容器内 UID 0 开始的范围(0-4999)。在容器内部,如果我的进程以 UID 1 运行,则它在主机上为 100001。
|
||||
|
||||
由于实际的 `UID=0` 未映射到容器中,因此 `root` 拥有的任何文件都将被视为 `nobody` 所拥有。即使容器内的进程具有 `CAP_DAC_OVERRIDE` 能力,也无法覆盖此种保护。`DAC_OVERRIDE` 能力使得 root 的进程能够读/写系统上的任何文件,即使进程不是 `root` 用户拥有的,也不是全局可读或可写的。
|
||||
|
||||
用户命名空间的功能与宿主机上的功能不同。它们是命名空间的功能。这意味着我的容器的 root 只在容器内具有功能 —— 实际上只有该范围内的 UID 映射到内用户命名空间。如果容器进程逃逸出了容器,则它将没有任何非映射到用户命名空间的 UID 之外的功能,这包括 `UID=0`。即使进程可能以某种方式进入另一个容器,如果容器使用不同范围的 UID,它们也不具备这些功能。
|
||||
|
||||
请注意,SELinux 和其他技术还限制了容器进程破开容器时会发生的情况。
|
||||
|
||||
### 使用 podman top 来显示用户名字空间
|
||||
|
||||
我们在 `podman top` 中添加了一些功能,允许你检查容器内运行的进程的用户名,并标识它们在宿主机上的真实 UID。
|
||||
|
||||
让我们首先使用我们的 UID 映射运行一个 `sleep` 容器。
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:100000:5000 -d fedora sleep 1000
|
||||
```
|
||||
|
||||
现在运行 `podman top`:
|
||||
|
||||
```
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 100000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
注意 `podman top` 报告用户进程在容器内以 `root` 身份运行,但在宿主机(`HUSER`)上以 UID 100000 运行。此外,`ps` 命令确认 `sleep` 过程以 UID 100000 运行。
|
||||
|
||||
现在让我们运行第二个容器,但这次我们将选择一个单独的 UID 映射,从 200000 开始。
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:200000:5000 -d fedora sleep 1000
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 200000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
200000 23644 23632 1 08:08 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
请注意,`podman top` 报告第二个容器在容器内以 `root` 身份运行,但在宿主机上是 UID=200000。
|
||||
|
||||
另请参阅 `ps` 命令,它显示两个 `sleep` 进程都在运行:一个为 100000,另一个为 200000。
|
||||
|
||||
这意味着在单独的用户命名空间内运行容器可以在进程之间进行传统的 UID 分离,而这从一开始就是 Linux/Unix 的标准安全工具。
|
||||
|
||||
### 用户名字空间的问题
|
||||
|
||||
几年来,我一直主张用户命名空间应该作为每个人应该有的安全工具,但几乎没有人使用过。原因是没有任何文件系统支持,也没有一个<ruby>移动文件系统<rt>shifting file system</rt></ruby>。
|
||||
|
||||
在容器中,你希望在许多容器之间共享**基本**镜像。上面的每个示例中使用了 Fedora 基本镜像。Fedora 镜像中的大多数文件都由真实的 `UID=0` 拥有。如果我在此镜像上使用用户名称空间 `0:100000:5000` 运行容器,默认情况下它会将所有这些文件视为 `nobody` 所拥有,因此我们需要移动所有这些 UID 以匹配用户名称空间。多年来,我想要一个挂载选项来告诉内核重新映射这些文件 UID 以匹配用户命名空间。上游内核存储开发人员还在继续研究,在此功能上已经取得一些进展,但这是一个难题。
|
||||
|
||||
由于由 Nalin Dahyabhai 领导的团队开发的自动 [chown][6] 内置于[容器/存储][7]中,Podman 可以在同一镜像上使用不同的用户名称空间。当 Podman 使用容器/存储,并且 Podman 在新的用户命名空间中首次使用一个容器镜像时,容器/存储会 “chown”(如,更改所有权)镜像中的所有文件到用户命名空间中映射的 UID 并创建一个新镜像。可以把它想象成一个 `fedora:0:100000:5000` 镜像。
|
||||
|
||||
当 Podman 在具有相同 UID 映射的镜像上运行另一个容器时,它使用“预先 chown”的镜像。当我在`0:200000:5000` 上运行第二个容器时,容器/存储会创建第二个镜像,我们称之为 `fedora:0:200000:5000`。
|
||||
|
||||
请注意,如果你正在执行 `podman build` 或 `podman commit` 并将新创建的镜像推送到容器注册库,Podman 将使用容器/存储来反转该移动,并将推送所有文件属主变回真实 UID=0 的镜像。
|
||||
|
||||
这可能会导致在新的 UID 映射中创建容器时出现真正的减速,因为 `chown` 可能会很慢,具体取决于镜像中的文件数。此外,在普通的 [OverlayFS][8] 上,镜像中的每个文件都会被复制。普通的 Fedora 镜像最多可能需要 30 秒才能完成 `chown` 并启动容器。
|
||||
|
||||
幸运的是,Red Hat 内核存储团队(主要是 Vivek Goyal 和 Miklos Szeredi)在内核 4.19 中为 OverlayFS 添加了一项新功能。该功能称为“仅复制元数据”。如果使用 `metacopy=on` 选项来挂载层叠文件系统,则在更改文件属性时,它不会复制较低层的内容;内核会创建新的 inode,其中包含引用指向较低级别数据的属性。如果内容发生变化,它仍会复制内容。如果你想试用它,可以在 Red Hat Enterprise Linux 8 Beta 中使用此功能。
|
||||
|
||||
这意味着容器 `chown` 可能在两秒钟内发生,并且你不会倍增每个容器的存储空间。
|
||||
|
||||
这使得像 Podman 这样的工具在不同的用户命名空间中运行容器是可行的,大大提高了系统的安全性。
|
||||
|
||||
### 前瞻
|
||||
|
||||
我想向 Podman 添加一个新选项,比如 `--userns=auto`,它会为你运行的每个容器自动选择一个唯一的用户命名空间。这类似于 SELinux 与单独的多类别安全(MCS)标签一起使用的方式。如果设置环境变量 `PODMAN_USERNS=auto`,则甚至不需要设置该选项。
|
||||
|
||||
Podman 最终允许用户在不同的用户名称空间中运行容器。像 [Buildah][9] 和 [CRI-O][10] 这样的工具也可以利用用户命名空间。但是,对于 CRI-O,Kubernetes 需要了解哪个用户命名空间将运行容器引擎,上游正在开发这个功能。
|
||||
|
||||
在我的下一篇文章中,我将解释如何在用户命名空间中将 Podman 作为非 root 用户运行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/podman-and-user-namespaces
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://podman.io/
|
||||
[2]: https://github.com/containers/libpod
|
||||
[3]: https://linux.cn/article-11261-1.html
|
||||
[4]: http://man7.org/linux/man-pages/man7/user_namespaces.7.html
|
||||
[5]: https://chmodcommand.com/chmod-660/
|
||||
[6]: https://en.wikipedia.org/wiki/Chown
|
||||
[7]: https://github.com/containers/storage
|
||||
[8]: https://en.wikipedia.org/wiki/OverlayFS
|
||||
[9]: https://buildah.io/
|
||||
[10]: http://cri-o.io/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11282-1.html)
|
||||
[#]: subject: (How to Install VirtualBox on Ubuntu [Beginner’s Tutorial])
|
||||
[#]: via: (https://itsfoss.com/install-virtualbox-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 上安装 VirtualBox
|
||||
======
|
||||
|
||||
> 本新手教程解释了在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||

|
||||
|
||||
Oracle 公司的自由开源产品 [VirtualBox][1] 是一款出色的虚拟化工具,专门用于桌面操作系统。与另一款虚拟化工具 [Linux 上的 VMWare Workstation][2] 相比起来,我更喜欢它。
|
||||
|
||||
你可以使用 VirtualBox 等虚拟化软件在虚拟机中安装和使用其他操作系统。
|
||||
|
||||
例如,你可以[在 Windows 上的 VirtualBox 中安装 Linux][3]。同样地,你也可以[用 VirtualBox 在 Linux 中安装 Windows][4]。
|
||||
|
||||
你也可以用 VirtualBox 在你当前的 Linux 系统中安装别的 Linux 发行版。事实上,这就是我用它的原因。如果我听说了一个不错的 Linux 发行版,我会在虚拟机上测试它,而不是安装在真实的系统上。当你想要在安装之前尝试一下别的发行版时,用虚拟机会很方便。
|
||||
|
||||
![Linux installed inside Linux using VirtualBox][5]
|
||||
|
||||
*安装在 Ubuntu 18.04 内的 Ubuntu 18.10*
|
||||
|
||||
在本新手教程中,我将向你展示在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 VirtualBox
|
||||
|
||||
这里提出的安装方法也适用于其他基于 Debian 和 Ubuntu 的 Linux 发行版,如 Linux Mint、elementar OS 等。
|
||||
|
||||
#### 方法 1:从 Ubuntu 仓库安装 VirtualBox
|
||||
|
||||
**优点**:安装简便
|
||||
|
||||
**缺点**:较旧版本
|
||||
|
||||
在 Ubuntu 上下载 VirtualBox 最简单的方法可能是从软件中心查找并下载。
|
||||
|
||||
![VirtualBox in Ubuntu Software Center][6]
|
||||
|
||||
*VirtualBox 在 Ubuntu 软件中心提供*
|
||||
|
||||
你也可以使用这条命令从命令行安装:
|
||||
|
||||
```
|
||||
sudo apt install virtualbox
|
||||
```
|
||||
|
||||
然而,如果[在安装前检查软件包版本][7],你会看到 Ubuntu 仓库提供的 VirtualBox 版本已经很老了。
|
||||
|
||||
举个例子,在写下本教程时 VirtualBox 的最新版本是 6.0,但是在软件中心提供的是 5.2。这意味着你无法获得[最新版 VirtualBox ][8]中引入的新功能。
|
||||
|
||||
#### 方法 2:使用 Oracle 网站上的 Deb 文件安装 VirtualBox
|
||||
|
||||
**优点**:安装简便,最新版本
|
||||
|
||||
**缺点**:不能更新
|
||||
|
||||
如果你想要在 Ubuntu 上使用 VirtualBox 的最新版本,最简单的方法就是[使用 Deb 文件][9]。
|
||||
|
||||
Oracle 为 VirtiualBox 版本提供了开箱即用的二进制文件。如果查看其下载页面,你将看到为 Ubuntu 和其他发行版下载 deb 安装程序的选项。
|
||||
|
||||
![VirtualBox Linux Download][10]
|
||||
|
||||
你只需要下载 deb 文件并双击它即可安装。就是这么简单。
|
||||
|
||||
- [下载 virtualbox for Ubuntu](https://www.virtualbox.org/wiki/Linux_Downloads)
|
||||
|
||||
然而,这种方法的问题在于你不能自动更新到最新的 VirtualBox 版本。唯一的办法是移除现有版本,下载最新版本并再次安装。不太方便,是吧?
|
||||
|
||||
#### 方法 3:用 Oracle 的仓库安装 VirtualBox
|
||||
|
||||
**优点**:自动更新
|
||||
|
||||
**缺点**:安装略微复杂
|
||||
|
||||
现在介绍的是命令行安装方法,它看起来可能比较复杂,但与前两种方法相比,它更具有优势。你将获得 VirtualBox 的最新版本,并且未来它还将自动更新到更新的版本。我想那就是你想要的。
|
||||
|
||||
要通过命令行安装 VirtualBox,请在你的仓库列表中添加 Oracle VirtualBox 的仓库。添加 GPG 密钥以便你的系统信任此仓库。现在,当你安装 VirtualBox 时,它会从 Oracle 仓库而不是 Ubuntu 仓库安装。如果发布了新版本,本地 VirtualBox 将跟随一起更新。让我们看看怎么做到这一点:
|
||||
|
||||
首先,添加仓库的密钥。你可以通过这一条命令下载和添加密钥:
|
||||
|
||||
```
|
||||
wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
```
|
||||
|
||||
> Mint 用户请注意:
|
||||
|
||||
> 下一步只适用于 Ubuntu。如果你使用的是 Linux Mint 或其他基于 Ubuntu 的发行版,请将命令行中的 `$(lsb_release -cs)` 替换成你当前版本所基于的 Ubuntu 版本。例如,Linux Mint 19 系列用户应该使用 bionic,Mint 18 系列用户应该使用 xenial,像这样:
|
||||
|
||||
> ```
|
||||
> sudo add-apt-repository “deb [arch=amd64] <http://download.virtualbox.org/virtualbox/debian> **bionic** contrib“`
|
||||
> ```
|
||||
|
||||
现在用以下命令来将 Oracle VirtualBox 仓库添加到仓库列表中:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb [arch=amd64] http://download.virtualbox.org/virtualbox/debian $(lsb_release -cs) contrib"
|
||||
```
|
||||
|
||||
如果你有读过我的文章[检查 Ubuntu 版本][11],你大概知道 `lsb_release -cs` 将打印你的 Ubuntu 系统的代号。
|
||||
|
||||
**注**:如果你看到 “[add-apt-repository command not found][12]” 错误,你需要下载 `software-properties-common` 包。
|
||||
|
||||
现在你已经添加了正确的仓库,请通过此仓库刷新可用包列表并安装 VirtualBox:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt install virtualbox-6.0
|
||||
```
|
||||
|
||||
**提示**:一个好方法是输入 `sudo apt install virtualbox-` 并点击 `tab` 键以查看可用于安装的各种 VirtualBox 版本,然后通过补全命令来选择其中一个版本。
|
||||
|
||||
![Install VirtualBox via terminal][13]
|
||||
|
||||
### 如何从 Ubuntu 中删除 VirtualBox
|
||||
|
||||
现在你已经学会了如何安装 VirtualBox,我还想和你提一下删除它的步骤。
|
||||
|
||||
如果你是从软件中心安装的,那么删除它最简单的方法是从软件中心下手。你只需要在[已安装的应用程序列表][14]中找到它,然后单击“删除”按钮。
|
||||
|
||||
另一种方式是使用命令行:
|
||||
|
||||
```
|
||||
sudo apt remove virtualbox virtualbox-*
|
||||
```
|
||||
|
||||
请注意,这不会删除你用 VirtualBox 安装的操作系统关联的虚拟机和文件。这并不是一件坏事,因为你可能希望以后或在其他系统中使用它们是安全的。
|
||||
|
||||
### 最后…
|
||||
|
||||
我希望你能在以上方法中选择一种安装 VirtualBox。我还将在另一篇文章中写到如何有效地使用 VirtualBox。目前,如果你有点子、建议或任何问题,请随时在下面发表评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-virtualbox-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.virtualbox.org
|
||||
[2]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://itsfoss.com/install-windows-10-virtualbox-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/linux-inside-linux-virtualbox.png?resize=800%2C450&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-ubuntu-software-center.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/know-program-version-before-install-ubuntu/
|
||||
[8]: https://itsfoss.com/oracle-virtualbox-release/
|
||||
[9]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-download.jpg?resize=800%2C433&ssl=1
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://itsfoss.com/add-apt-repository-command-not-found/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-virtualbox-ubuntu-terminal.png?resize=800%2C165&ssl=1
|
||||
[14]: https://itsfoss.com/list-installed-packages-ubuntu/
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zionfuo)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11275-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:Hyperledger 项目简介(八)
|
||||
======
|
||||
|
||||
![Introduction To Hyperledger Project][1]
|
||||
|
||||
一旦一个新技术平台在积极发展和商业利益方面达到了一定程度的受欢迎程度,全球的主要公司和小型的初创企业都急于抓住这块蛋糕。在当时 Linux 就是这样的一个平台。一旦实现了其应用程序的普及,个人、公司和机构就开始对其表现出兴趣,到 2000 年,Linux 基金会就成立了。
|
||||
|
||||
Linux 基金会旨在通过赞助他们的开发团队来将 Linux 作为一个平台来标准化和发展。Linux 基金会是一个由软件和 IT 巨头([如微软、甲骨文、三星、思科、 IBM 、英特尔等][7])支持的非营利组织。这不包括为改进该平台而提供服务的数百名个人开发者。多年来,Linux 基金会已经在旗下开展了许多项目。**Hyperledger** 项目是迄今为止发展最快的项目。
|
||||
|
||||
在将技术推进至可用且有用的方面上,这种联合主导的开发具有很多优势。为大型项目提供开发标准、库和所有后端协议既昂贵又耗费资源,而且不会从中产生丝毫收入。因此,对于公司来说,通过支持这些组织来汇集他们的资源来开发常见的那些 “烦人” 部分是有很意义的,以及随后完成这些标准部分的工作以简单地即插即用和定制他们的产品。除了这种模型的经济性之外,这种合作努力还产生了标准,使其容易使用和集成到优秀的产品和服务中。
|
||||
|
||||
上述联盟模式,在曾经或当下的创新包括 WiFi(Wi-Fi 联盟)、移动电话等标准。
|
||||
|
||||
### Hyperledger 项目(HLP)简介
|
||||
|
||||
Hyperledger 项目(HLP)于 2015 年 12 月由 Linux 基金会启动,目前是其孵化的增长最快的项目之一。它是一个<ruby>伞式组织<rt>umbrella organization</rt></ruby>,用于合作开发和推进基于[区块链][2]的分布式账本技术 (DLT) 的工具和标准。支持该项目的主要行业参与者包括 IBM、英特尔 和 SAP Ariba [等][3]。HLP 旨在为个人和公司创建框架,以便根据需要创建共享和封闭的区块链,以满足他们自己的需求。其设计原则是开发一个专注于隐私和未来可审计性的全球可部署、可扩展、强大的区块链平台。[^2] 同样要注意的是大多数提出的区块链及其框架。
|
||||
|
||||
### 开发目标和构造:即插即用
|
||||
|
||||
虽然面向企业的平台有以太坊联盟之类的产品,但根据定义,HLP 是面向企业的,并得到行业巨头的支持,他们在 HLP 旗下的许多模块中做出贡献并进一步发展。HLP 还孵化开发的周边项目,并这些创意项目推向公众。HLP 的成员贡献了他们自己的力量,例如 IBM 为如何协作开发贡献了他们的 Fabric 平台。该代码库由 IBM 在其项目组内部研发,并开源出来供所有成员使用。
|
||||
|
||||
这些过程使得 HLP 中的模块具有高度灵活的插件框架,这将支持企业环境中的快速开发和部署。此外,默认情况下,其他对比的平台是开放的<ruby>免许可链<rt>permission-less blockchain</rt></ruby>或是<ruby>公有链<rt>public blockchain</rt></ruby>,甚至可以将它们应用到特定应用当中。HLP 模块本身支持该功能。
|
||||
|
||||
有关公有链和私有链的差异和用例更多地涵盖在[这篇][4]比较文章当中。
|
||||
|
||||
根据该项目执行董事 Brian Behlendorf 的说法,Hyperledger 项目的使命有四个。
|
||||
|
||||
分别是:
|
||||
|
||||
1. 创建企业级 DLT 框架和标准,任何人都可以移植以满足其特定的行业或个人需求。
|
||||
2. 创建一个强大的开源社区来帮助生态系统发展。
|
||||
3. 促进所述的生态系统的行业成员(如成员公司)的参与。
|
||||
4. 为 HLP 社区提供中立且无偏见的基础设施,以收集和分享相关的更新和发展。
|
||||
|
||||
可以在这里访问[原始文档][5]。
|
||||
|
||||
### HLP 的架构
|
||||
|
||||
HLP 由 12 个项目组成,这些项目被归类为独立的模块,每个项目通常都是结构化的,可以独立开发其模块的。在孵化之前,首先对它们的能力和活力进行研究。该组织的任何成员都可以提出附加建议。在项目孵化后,就会进行积极开发,然后才会推出。这些模块之间的互操作性具有很高的优先级,因此这些组之间的定期通信由社区维护。目前,这些项目中有 4 个被归类为活跃项目。被标为活跃意味着它们已经准备好使用,但还没有准备好发布主要版本。这 4 个模块可以说是推动区块链革命的最重要或相当基本的模块。稍后,我们将详细介绍各个模块及其功能。然而,Hyperledger Fabric 平台的简要描述,可以说是其中最受欢迎的。
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
Hyperledger Fabric 是一个完全开源的、基于区块链的许可 (非公开) DLT 平台,设计时考虑了企业的使用。该平台提供了适合企业环境的功能和结构。它是高度模块化的,允许开发人员在不同的共识协议、链上代码协议([智能合约][6])或身份管理系统等中进行选择。这是一个基于区块链的许可平台,它利用身份管理系统,这意味着参与者将知道彼此在企业环境中的身份。Fabric 允许以各种主流编程语言 (包括 Java、Javascript、Go 等) 开发智能合约(“<ruby>链码<rt>chaincode</rt></ruby>”,是 Hyperledger 团队使用的术语)。这使得机构和企业可以利用他们在该领域的现有人才,而无需雇佣或重新培训开发人员来开发他们自己的智能合约。与标准订单验证系统相比,Fabric 还使用<ruby>执行顺序验证<rt>execute-order-validate</rt></ruby>系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。Fabric 的其他功能还有可插拔性能、身份管理系统、数据库管理系统、共识平台等,这些功能使它在竞争中保持领先地位。
|
||||
|
||||
### 结论
|
||||
|
||||
诸如 Hyperledger Fabric 平台这样的项目能够在主流用例中更快地采用区块链技术。Hyperledger 社区结构本身支持开放治理原则,并且由于所有项目都是作为开源平台引导的,因此这提高了团队在履行承诺时表现出来的安全性和责任感。
|
||||
|
||||
由于此类项目的主要应用涉及与企业合作及进一步开发平台和标准,因此 Hyperledger 项目目前在其他类似项目前面处于有利地位。
|
||||
|
||||
[^2]: E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zionfuo](https://github.com/zionfuo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
|
||||
[2]: https://linux.cn/article-10650-1.html
|
||||
[3]: https://www.hyperledger.org/members
|
||||
[4]: https://linux.cn/article-11080-1.html
|
||||
[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
|
||||
[6]: https://linux.cn/article-10956-1.html
|
||||
[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11285-1.html)
|
||||
[#]: subject: (How to transition into a career as a DevOps engineer)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
|
||||
[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
|
||||
|
||||
如何转职为 DevOps 工程师
|
||||
======
|
||||
|
||||
> 无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
|
||||
|
||||

|
||||
|
||||
DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为 [DevOps 工程师][2]。
|
||||
|
||||
### 让自己沉浸其中
|
||||
|
||||
首先学习 [DevOps][3] 的基本原理、实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章、观看 YouTube 视频、参加当地小组聚会或者会议 —— 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
|
||||
|
||||
### 考虑你的背景
|
||||
|
||||
如果你有从事技术工作的经历,例如软件开发人员、系统工程师、系统管理员、网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(LCTT 译注:STEM 是<ruby>科学<rt>Science</rt></ruby>、<ruby>技术<rt>Technology</rt></ruby>、<ruby>工程<rt>Engineering</rt></ruby>和<ruby>数学<rt>Math</rt></ruby>四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
|
||||
|
||||
DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
|
||||
|
||||
* **偏向于开发(Dev)的 DevOps 工程师**,在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD)、共享仓库、云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
|
||||
* **偏向于运维技术(Ops)的 DevOps 工程师**,可以与系统工程师或系统管理员相比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队实现手动流程的自动化,并提高人员和技术系统的效率。这可能意味着分解遗留代码,并用不太繁琐的自动化脚本来运行相同的命令,或者可能意味着安装、配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教团队如何利用 CI / CD 和其他 DevOps 实践来帮助他们。
|
||||
* **网站可靠性工程师(SRE)**,就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展、高可用且可靠的软件系统。
|
||||
|
||||
在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
|
||||
|
||||
### 要学习的技术
|
||||
|
||||
DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师需要使用和理解的基本技术开始。
|
||||
|
||||
#### 操作系统
|
||||
|
||||
操作系统是一切运行的地方,拥有相关的基础知识十分重要。[Linux][4] 是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地中断,并在此过程中学习。
|
||||
|
||||
#### 脚本
|
||||
|
||||
接下来,选择一门语言来学习脚本编程。有很多语言可供选择,包括 Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是遵循面向对象编程(OOP)的准则编写的,可用于 Web 开发、软件开发以及创建桌面 GUI 和业务应用程序。
|
||||
|
||||
#### 云
|
||||
|
||||
学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务、Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员、运维人员,甚至面向业务的部门的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2、S3 和 VPC 开始,然后看看你从其中想学到什么。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
如果你对 DevOps 的软件开发充满热情,请继续提高你的编程技能。DevOps 中的一些优秀和常用的编程语言和你用于脚本编程的相同:Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
|
||||
|
||||
#### 容器
|
||||
|
||||
最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
|
||||
|
||||
#### 其他的呢?
|
||||
|
||||
如果你缺乏开发经验,你依然可以通过对自动化的热情,提高效率,与他人协作以及改进自己的工作来[参与 DevOps][3]。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务、平台即服务、云平台和 Linux 会非常有用。你可能会设置工具并学习如何构建具有弹性和容错能力的系统,并在编写代码时利用它们。
|
||||
|
||||
### 找一份 DevOps 的工作
|
||||
|
||||
求职过程会有所不同,具体取决于你是否一直从事技术工作,是否正在进入 DevOps 领域,或者是刚开始职业生涯的毕业生。
|
||||
|
||||
#### 如果你已经从事技术工作
|
||||
|
||||
如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你能通过和其他的团队一起工作来重新掌握技能吗?尝试跟随其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践、工具和技术中学习,你将能在面试时展示相关知识从而占据有利位置。关键是要诚实,不要担心失败。大多数招聘主管都明白你并不知道所有的答案;如果你能展示你一直在学习的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
|
||||
|
||||
#### 如果你刚开始职业生涯
|
||||
|
||||
申请雇用初级 DevOps 工程师的公司的空缺机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
|
||||
|
||||
然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 会聘请应届毕业生并且对其进行 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并充分了解它在财富 500 强公司环境中的运用方式。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 —— MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
|
||||
|
||||
### 总结
|
||||
|
||||
转职成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
|
||||
|
||||
作者:[Conor Delanbanque][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
|
||||
[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
|
||||
[3]: https://opensource.com/resources/devops
|
||||
[4]: https://opensource.com/resources/linux
|
||||
[5]: https://opensource.com/resources/python
|
||||
[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
[7]: https://www.mthreealumni.com/
|
||||
@ -1,32 +1,32 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11270-1.html)
|
||||
[#]: subject: (Find The Linux Distribution Name, Version And Kernel Details)
|
||||
[#]: via: (https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-kernel-details/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Find The Linux Distribution Name, Version And Kernel Details
|
||||
查找 Linux 发行版名称、版本和内核详细信息
|
||||
======
|
||||
|
||||
![Find The Linux Distribution Name, Version And Kernel Details][1]
|
||||
|
||||
This guide explains how to find the Linux distribution name, version and Kernel details. If your Linux system has GUI mode, you can find these details easily from the System’s Settings. But in CLI mode, it is bit difficult for beginners to find out such details. No problem! Here I have given a few command line methods to find the Linux system information. There could be many, but these methods will work on most Linux distributions.
|
||||
本指南介绍了如何查找 Linux 发行版名称、版本和内核详细信息。如果你的 Linux 系统有 GUI 界面,那么你可以从系统设置中轻松找到这些信息。但在命令行模式下,初学者很难找到这些详情。没有问题!我这里给出了一些命令行方法来查找 Linux 系统信息。可能有很多,但这些方法适用于大多数 Linux 发行版。
|
||||
|
||||
### 1\. Find Linux distribution name, version
|
||||
### 1、查找 Linux 发行版名称、版本
|
||||
|
||||
There are many methods to find out what OS is running on in your VPS.
|
||||
有很多方法可以找出 VPS 中运行的操作系统。
|
||||
|
||||
##### Method 1:
|
||||
#### 方法 1:
|
||||
|
||||
Open your Terminal and run the following command:
|
||||
打开终端并运行以下命令:
|
||||
|
||||
```
|
||||
$ cat /etc/*-release
|
||||
```
|
||||
|
||||
**Sample output from CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
CentOS Linux release 7.0.1406 (Core)
|
||||
@ -45,7 +45,7 @@ CentOS Linux release 7.0.1406 (Core)
|
||||
CentOS Linux release 7.0.1406 (Core)
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
@ -66,29 +66,29 @@ VERSION_CODENAME=bionic
|
||||
UBUNTU_CODENAME=bionic
|
||||
```
|
||||
|
||||
##### Method 2:
|
||||
#### 方法 2:
|
||||
|
||||
The following command will also get your distribution details.
|
||||
以下命令也能获取你发行版的详细信息。
|
||||
|
||||
```
|
||||
$ cat /etc/issue
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Ubuntu 18.04.2 LTS \n \l
|
||||
```
|
||||
|
||||
##### Method 3:
|
||||
#### 方法 3:
|
||||
|
||||
The following command will get you the distribution details in Debian and its variants like Ubuntu, Linux Mint etc.
|
||||
以下命令能在 Debian 及其衍生版如 Ubuntu、Linux Mint 上获取发行版详细信息。
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
@ -98,87 +98,73 @@ Release: 18.04
|
||||
Codename: bionic
|
||||
```
|
||||
|
||||
### 2\. Find Linux Kernel details
|
||||
### 2、查找 Linux 内核详细信息
|
||||
|
||||
##### Method 1:
|
||||
#### 方法 1:
|
||||
|
||||
To find out your Linux kernel details, run the following command from your Terminal.
|
||||
要查找 Linux 内核详细信息,请在终端运行以下命令。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
```
|
||||
|
||||
**Sample output in CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
Linux server.ostechnix.lan 3.10.0-123.9.3.el7.x86_64 #1 SMP Thu Nov 6 15:06:03 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
**Sample output in Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Linux ostechnix 4.18.0-25-generic #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
Or,
|
||||
或者,
|
||||
|
||||
```
|
||||
$ uname -mrs
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linux 4.18.0-25-generic x86_64
|
||||
```
|
||||
|
||||
Where,
|
||||
这里,
|
||||
|
||||
* **Linux** – Kernel name
|
||||
* **4.18.0-25-generic** – Kernel version
|
||||
* **x86_64** – System hardware architecture (i.e 64 bit system)
|
||||
* `Linux` – 内核名
|
||||
* `4.18.0-25-generic` – 内核版本
|
||||
* `x86_64` – 系统硬件架构(即 64 位系统)
|
||||
|
||||
|
||||
|
||||
For more details about uname command, refer the man page.
|
||||
有关 `uname` 命令的更多详细信息,请参考手册页。
|
||||
|
||||
```
|
||||
$ man uname
|
||||
```
|
||||
|
||||
##### Method 2:
|
||||
#### 方法2:
|
||||
|
||||
From your Terminal, run the following command:
|
||||
在终端中,运行以下命令:
|
||||
|
||||
```
|
||||
$ cat /proc/version
|
||||
```
|
||||
|
||||
**Sample output from CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
Linux version 3.10.0-123.9.3.el7.x86_64 ([email protected]) (gcc version 4.8.2 20140120 (Red Hat 4.8.2-16) (GCC) ) #1 SMP Thu Nov 6 15:06:03 UTC 2014
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Linux version 4.18.0-25-generic ([email protected]) (gcc version 7.4.0 (Ubuntu 7.4.0-1ubuntu1~18.04.1)) #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
* [**How To Find Linux System Details Using inxi**][2]
|
||||
* [**Neofetch – Display Linux system Information In Terminal**][3]
|
||||
* [**How To Find Hardware And Software Specifications In Ubuntu**][4]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
These are few ways to find find out a Linux distribution’s name, version and Kernel details. Hope you find it useful.
|
||||
这些是查找 Linux 发行版的名称、版本和内核详细信息的几种方法。希望你觉得它有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -186,14 +172,11 @@ via: https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2015/08/Linux-Distribution-Name-Version-Kernel-720x340.png
|
||||
[2]: https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/
|
||||
[3]: https://www.ostechnix.com/neofetch-display-linux-systems-information/
|
||||
[4]: https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/
|
||||
228
published/201908/20190812 How Hexdump works.md
Normal file
228
published/201908/20190812 How Hexdump works.md
Normal file
@ -0,0 +1,228 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (0x996)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11288-1.html)
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Hexdump 如何工作
|
||||
======
|
||||
|
||||
> Hexdump 能帮助你查看二进制文件的内容。让我们来学习 Hexdump 如何工作。
|
||||
|
||||

|
||||
|
||||
Hexdump 是个用十六进制、十进制、八进制数或 ASCII 码显示二进制文件内容的工具。它是个用于检查的工具,也可用于[数据恢复][2]、逆向工程和编程。
|
||||
|
||||
### 学习基本用法
|
||||
|
||||
Hexdump 让你毫不费力地得到输出结果,依你所查看文件的尺寸,输出结果可能会非常多。本文中我们会创建一个 1x1 像素的 PNG 文件。你可以用图像处理应用如 [GIMP][3] 或 [Mtpaint][4] 来创建该文件,或者也可以在终端内用 [ImageMagick][5] 创建。
|
||||
|
||||
用 ImagiMagick 生成 1x1 像素 PNG 文件的命令如下:
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
你可以用 `file` 命令确认此文件是 PNG 格式:
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
你可能好奇 `file` 命令是如何判断文件是什么类型。巧的是,那正是 `hexdump` 将要揭示的原理。眼下你可以用你常用的图像查看软件来看看你的单一像素图片(它看上去就像这样:`.`),或者你可以用 `hexdump` 查看文件内部:
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
透过一个你以前可能从未用过的视角,你所见的是该示例 PNG 文件的内容。它和你在图像查看软件中看到的是完全一样的数据,只是用一种你或许不熟悉的方式编码。
|
||||
|
||||
### 提取熟悉的字符串
|
||||
|
||||
尽管默认的数据输出结果看上去毫无意义,那并不意味着其中没有有价值的信息。你可以用 `--canonical` 选项将输出结果,或至少是其中可翻译的部分,翻译成更加熟悉的字符集:
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
在右侧的列中,你看到的是和左侧一样的数据,但是以 ASCII 码展现的。如果你仔细看,你可以从中挑选出一些有用的信息,如文件格式(PNG)以及文件创建、修改日期和时间(向文件底部寻找一下)。
|
||||
|
||||
`file` 命令通过头 8 个字节获取文件类型。程序员会参考 [libpng 规范][6] 来知晓需要查看什么。具体而言,那就是你能在该图像文件的头 8 个字节中看到的字符串 `PNG`。这个事实显而易见,因为它揭示了 `file` 命令是如何知道要报告的文件类型。
|
||||
|
||||
你也可以控制 `hexdump` 显示多少字节,这在处理大于一个像素的文件时很实用:
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
`hexdump` 不只限于查看 PNG 或图像文件。你也可以用 `hexdump` 查看你日常使用的二进制文件,如 [ls][7]、[rsync][8],或你想检查的任何二进制文件。
|
||||
|
||||
### 用 hexdump 实现 cat 命令
|
||||
|
||||
阅读 PNG 规范的时候你可能会注意到头 8 个字节中的数据与 `hexdump` 提供的结果看上去不一样。实际上,那是一样的数据,但以一种不同的转换方式展现出来。所以 `hexdump` 的输出是正确的,但取决于你在寻找的信息,其输出结果对你而言不总是直接了当的。出于这个原因,`hexdump` 有一些选项可供用于定义格式和转化其转储的原始数据。
|
||||
|
||||
转换选项可以很复杂,所以用无关紧要的东西练习会比较实用。下面这个简易的介绍,通过重新实现 [cat][9] 命令来演示如何格式化 `hexdump` 的输出。首先,对一个文本文件运行 `hexdump` 来查看其原始数据。通常你可以在硬盘上某处找到 <ruby>[GNU 通用许可证][10]<rt>GNU General Public License</rt></ruby>(GPL)的一份拷贝,也可以用你手头的任何文本文件。你的输出结果可能不同,但下面是如何在你的系统中找到一份 GPL(或至少其部分)的拷贝:
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
对其运行 `hexdump`:
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
如果该文件输出结果很长,用 `--length`(或短选项 `-n`)来控制输出长度使其易于管理。
|
||||
|
||||
原始数据对你而言可能没什么意义,但你已经知道如何将其转换为 ASCII 码:
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
这个输出结果有帮助但太累赘且难于阅读。要将 `hexdump` 的输出结果转换为其选项不支持的其他格式,可组合使用 `--format`(或 `-e`)和专门的格式代码。用来自定义格式的代码和 `printf` 命令使用的类似,所以如果你熟悉 `printf` 语句,你可能会觉得 `hexdump` 自定义格式不难学会。
|
||||
|
||||
在 `hexdump` 中,字符串 `%_p` 告诉 `hexdump` 用你系统的默认字符集输出字符。`--format` 选项的所有格式符号必须以*单引号*包括起来:
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
这次的输出好些了,但依然不方便阅读。传统上 UNIX 文本文件假定 80 个字符的输出宽度(因为很久以前显示器一行只能显示 80 个字符)。
|
||||
|
||||
尽管这个输出结果未被自定义格式限制输出宽度,你可以用附加选项强制 `hexdump` 一次处理 80 字节。具体而言,通过 80 除以 1 这种形式,你可以告诉 `hexdump` 将 80 字节作为一个单元对待:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在该文件被分割成 80 字节的块处理,但没有任何换行。你可以用 `\n` 字符自行添加换行,在 UNIX 中它代表换行:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在你已经(大致上)用 `hexdump` 自定义格式实现了 `cat` 命令。
|
||||
|
||||
### 控制输出结果
|
||||
|
||||
实际上自定义格式是让 `hexdump` 变得有用的方法。现在你已经(至少是原则上)熟悉 `hexdump` 自定义格式,你可以让 `hexdump -n 8` 的输出结果跟 `libpng` 官方规范中描述的 PNG 文件头相匹配了。
|
||||
|
||||
首先,你知道你希望 `hexdump` 以 8 字节的块来处理 PNG 文件。此外,你可能通过识别这些整数从而知道 PNG 格式规范是以十进制数表述的,根据 `hexdump` 文档,十进制用 `%d` 来表示:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
你可以在每个整数后面加个空格使输出结果变得完美:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
现在输出结果跟 PNG 规范完美匹配了。
|
||||
|
||||
### 好玩又有用
|
||||
|
||||
Hexdump 是个迷人的工具,不仅让你更多地领会计算机如何处理和转换信息,而且让你了解文件格式和编译的二进制文件如何工作。日常工作时你可以随机地试着对不同文件运行 `hexdump`。你永远不知道你会发现什么样的信息,或是什么时候具有这种洞察力会很实用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11283-1.html)
|
||||
[#]: subject: (How To Fix “Kernel driver not installed (rc=-1908)” VirtualBox Error In Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-virtualbox-error-in-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -26,7 +26,7 @@ where: suplibOsInit what: 3 VERR_VM_DRIVER_NOT_INSTALLED (-1908) - The support d
|
||||
|
||||
![][2]
|
||||
|
||||
Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误
|
||||
*Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误*
|
||||
|
||||
我点击了 OK 关闭消息框,然后在后台看到了另一条消息。
|
||||
|
||||
@ -45,7 +45,7 @@ IMachine {85cd948e-a71f-4289-281e-0ca7ad48cd89}
|
||||
|
||||
![][3]
|
||||
|
||||
启动期间虚拟机意外终止,退出代码为 1(0x1)
|
||||
*启动期间虚拟机意外终止,退出代码为 1(0x1)*
|
||||
|
||||
我不知道该先做什么。我运行以下命令来检查是否有用。
|
||||
|
||||
@ -61,7 +61,7 @@ modprobe: FATAL: Module vboxdrv not found in directory /lib/modules/5.0.0-23-gen
|
||||
|
||||
仔细阅读这两个错误消息后,我意识到我应该更新 Virtualbox 程序。
|
||||
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 **“virtualbox-dkms”** 包:
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 `virtualbox-dkms` 包:
|
||||
|
||||
```
|
||||
$ sudo apt install virtualbox-dkms
|
||||
@ -82,7 +82,7 @@ via: https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-vi
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11274-1.html)
|
||||
[#]: subject: (A guided tour of Linux file system types)
|
||||
[#]: via: (https://www.networkworld.com/article/3432990/a-guided-tour-of-linux-file-system-types.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Linux 文件系统类型导览
|
||||
======
|
||||
|
||||
> Linux 文件系统多年来在不断发展,让我们来看一下文件系统类型。
|
||||
|
||||

|
||||
|
||||
虽然对于普通用户来说可能并不明显,但在过去十年左右的时间里,Linux 文件系统已经发生了显著的变化,这使它们能够更好对抗损坏和性能问题。
|
||||
|
||||
如今大多数 Linux 系统使用名为 ext4 的文件系统。 “ext” 代表“<ruby>扩展<rt>extended</rt></ruby>”,“4” 表示这是此文件系统的第 4 代。随着时间的推移添加的功能包括:能够提供越来越大的文件系统(目前大到 1,000,000 TiB)和更大的文件(高达 16 TiB),更抗系统崩溃,更少碎片(将单个文件分散为存在多个位置的块)以提高性能。
|
||||
|
||||
ext4 文件系统还带来了对性能、可伸缩性和容量的其他改进。实现了元数据和日志校验和以增强可靠性。时间戳现在可以跟踪纳秒级变化,以便更好地对文件打戳(例如,文件创建和最后更新时间)。并且,在时间戳字段中增加了两个位,2038 年的问题(存储日期/时间的字段将从最大值翻转到零)已被推迟到了 400 多年之后(到 2446)。
|
||||
|
||||
### 文件系统类型
|
||||
|
||||
要确定 Linux 系统上文件系统的类型,请使用 `df` 命令。下面显示的命令中的 `-T` 选项显示文件系统类型。 `-h` 显示“易读的”磁盘大小。换句话说,调整报告的单位(如 M 和 G),使人们更好地理解。
|
||||
|
||||
```
|
||||
$ df -hT | head -10
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
udev devtmpfs 2.9G 0 2.9G 0% /dev
|
||||
tmpfs tmpfs 596M 1.5M 595M 1% /run
|
||||
/dev/sda1 ext4 110G 50G 55G 48% /
|
||||
/dev/sdb2 ext4 457G 642M 434G 1% /apps
|
||||
tmpfs tmpfs 3.0G 0 3.0G 0% /dev/shm
|
||||
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
|
||||
/dev/loop0 squashfs 89M 89M 0 100% /snap/core/7270
|
||||
/dev/loop2 squashfs 142M 142M 0 100% /snap/hexchat/42
|
||||
```
|
||||
|
||||
请注意,`/`(根)和 `/apps` 的文件系统都是 ext4,而 `/dev` 是 devtmpfs 文件系统(一个由内核填充的自动化设备节点)。其他的文件系统显示为 tmpfs(驻留在内存和/或交换分区中的临时文件系统)和 squashfs(只读压缩文件系统的文件系统,用于快照包)。
|
||||
|
||||
还有 proc 文件系统,用于存储正在运行的进程的信息。
|
||||
|
||||
```
|
||||
$ df -T /proc
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
proc proc 0 0 0 - /proc
|
||||
```
|
||||
|
||||
当你在整个文件系统中游览时,可能会遇到许多其他文件系统类型。例如,当你移动到目录中并想了解它的文件系统时,可以运行以下命令:
|
||||
|
||||
```
|
||||
$ cd /dev/mqueue; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
mqueue mqueue 0 0 0 - /dev/mqueue
|
||||
$ cd /sys; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
sysfs sysfs 0 0 0 - /sys
|
||||
$ cd /sys/kernel/security; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
securityfs securityfs 0 0 0 - /sys/kernel/security
|
||||
```
|
||||
|
||||
与其他 Linux 命令一样,这里的 `.` 代表整个文件系统的当前位置。
|
||||
|
||||
这些和其他独特的文件系统提供了一些特殊功能。例如,securityfs 提供支持安全模块的文件系统。
|
||||
|
||||
Linux 文件系统需要能够抵抗损坏,能够承受系统崩溃并提供快速、可靠的性能。由几代 ext 文件系统和新一代专用文件系统提供的改进使 Linux 系统更易于管理和更可靠。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432990/a-guided-tour-of-linux-file-system-types.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/guided-tour-on-the-flaker_people-in-horse-drawn-carriage_germany-by-andreas-lehner-flickr-100808681-large.jpg
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,404 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hello-wn)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11276-1.html)
|
||||
[#]: subject: (How to Delete Lines from a File Using the sed Command)
|
||||
[#]: via: (https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何使用 sed 命令删除文件中的行
|
||||
======
|
||||
|
||||

|
||||
|
||||
Sed 代表<ruby>流编辑器<rt>Stream Editor</rt></ruby>,常用于 Linux 中基本的文本处理。`sed` 命令是 Linux 中的重要命令之一,在文件处理方面有着重要作用。可用于删除或移动与给定模式匹配的特定行。
|
||||
|
||||
它还可以删除文件中的特定行,它能够从文件中删除表达式,文件可以通过指定分隔符(例如逗号、制表符或空格)进行标识。
|
||||
|
||||
本文列出了 15 个使用范例,它们可以帮助你掌握 `sed` 命令。
|
||||
|
||||
如果你能理解并且记住这些命令,在你需要使用 `sed` 时,这些命令就能派上用场,帮你节约很多时间。
|
||||
|
||||
注意:为了方便演示,我在执行 `sed` 命令时,不使用 `-i` 选项(因为这个选项会直接修改文件内容),被移除了行的文件内容将打印到 Linux 终端。
|
||||
|
||||
但是,如果你想在实际环境中从源文件中删除行,请在 `sed` 命令中使用 `-i` 选项。
|
||||
|
||||
演示之前,我创建了 `sed-demo.txt` 文件,并添加了以下内容和相应行号以便更好地理解。
|
||||
|
||||
```
|
||||
# cat sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 1) 如何删除文件的第一行?
|
||||
|
||||
使用以下语法删除文件首行。
|
||||
|
||||
`N` 表示文件中的第 N 行,`d` 选项在 `sed` 命令中用于删除一行。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
sed 'Nd' file
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第一行。
|
||||
|
||||
```
|
||||
# sed '1d' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 2) 如何删除文件的最后一行?
|
||||
|
||||
使用以下语法删除文件最后一行。
|
||||
|
||||
`$` 符号表示文件的最后一行。
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的最后一行。
|
||||
|
||||
```
|
||||
# sed '$d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
```
|
||||
|
||||
### 3) 如何删除指定行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 3 行。
|
||||
|
||||
```
|
||||
# sed '3d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 4) 如何删除指定范围内的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 5 到 7 行。
|
||||
|
||||
```
|
||||
# sed '5,7d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 5) 如何删除多行内容?
|
||||
|
||||
`sed` 命令能够删除给定行的集合。
|
||||
|
||||
本例中,下面的 `sed` 命令删除了第 1 行、第 5 行、第 9 行和最后一行。
|
||||
|
||||
```
|
||||
# sed '1d;5d;9d;$d' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
```
|
||||
|
||||
### 5a) 如何删除指定范围以外的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中第 3 到 6 行范围以外的所有行。
|
||||
|
||||
```
|
||||
# sed '3,6!d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
```
|
||||
|
||||
### 6) 如何删除空行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的空行。
|
||||
|
||||
```
|
||||
# sed '/^$/d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 7) 如何删除包含某个模式的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 模式的行。
|
||||
|
||||
```
|
||||
# sed '/System/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 8) 如何删除包含字符串集合中某个字符串的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 或 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '/System\|Linux/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 9) 如何删除以指定字符开头的行?
|
||||
|
||||
为了测试,我创建了 `sed-demo-1.txt` 文件,并添加了以下内容。
|
||||
|
||||
```
|
||||
# cat sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除以 `R` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^R/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `R` 或者 `F` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^[RF]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
### 10) 如何删除以指定字符结尾的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/m$/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `x` 或者 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/[xm]$/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 11) 如何删除所有大写字母开头的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有大写字母开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[A-Z]/d' sed-demo-1.txt
|
||||
|
||||
debian
|
||||
ubuntu
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
### 12) 如何删除指定范围内匹配模式的行?
|
||||
|
||||
使用以下 `sed` 命令删除第 1 到 6 行中包含 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '1,6{/Linux/d;}' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 13) 如何删除匹配模式的行及其下一行?
|
||||
|
||||
使用以下 `sed` 命令删除包含 `System` 表达式的行以及它的下一行。
|
||||
|
||||
```
|
||||
# sed '/System/{N;d;}' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 14) 如何删除包含数字的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有包含数字的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除所有以数字开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[0-9]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除所有以数字结尾的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]$/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
2 - Manjaro
|
||||
```
|
||||
|
||||
### 15) 如何删除包含字母的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有包含字母的行。
|
||||
|
||||
```
|
||||
# sed '/[A-Za-z]/d' sed-demo-1.txt
|
||||
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hello-wn](https://github.com/hello-wn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
116
published/201908/20190823 Managing credentials with KeePassXC.md
Normal file
116
published/201908/20190823 Managing credentials with KeePassXC.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11278-1.html)
|
||||
[#]: subject: (Managing credentials with KeePassXC)
|
||||
[#]: via: (https://fedoramagazine.org/managing-credentials-with-keepassxc/)
|
||||
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||
|
||||
使用 KeePassXC 管理凭据
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[上一篇文章][2]我们讨论了使用服务器端技术的密码管理工具。这些工具非常有趣而且适合云安装。在本文中,我们将讨论 KeePassXC,这是一个简单的多平台开源软件,它使用本地文件作为数据库。
|
||||
|
||||
这种密码管理软件的主要优点是简单。无需服务器端技术专业知识,因此可供任何类型的用户使用。
|
||||
|
||||
### 介绍 KeePassXC
|
||||
|
||||
KeePassXC 是一个开源的跨平台密码管理器:它是作为 KeePassX 的一个分支开始开发的,这是个不错的产品,但开发不是非常活跃。它使用 256 位密钥的 AES 算法将密钥保存在加密数据库中,这使得在云端设备(如 pCloud 或 Dropbox)中保存数据库相当安全。
|
||||
|
||||
除了密码,KeePassXC 还允许你在加密皮夹中保存各种信息和附件。它还有一个有效的密码生成器,可以帮助用户正确地管理他的凭据。
|
||||
|
||||
### 安装
|
||||
|
||||
这个程序在标准的 Fedora 仓库和 Flathub 仓库中都有。不幸的是,在沙箱中运行的程序无法使用浏览器集成,所以我建议通过 dnf 安装程序:
|
||||
|
||||
```
|
||||
sudo dnf install keepassxc
|
||||
```
|
||||
|
||||
### 创建你的皮夹
|
||||
|
||||
要创建新数据库,有两个重要步骤:
|
||||
|
||||
* 选择加密设置:默认设置相当安全,增加转换轮次也会增加解密时间。
|
||||
* 选择主密钥和额外保护:主密钥必须易于记忆(如果丢失它,你的皮夹就会丢失!)而足够强大,一个至少有 4 个随机单词的密码可能是一个不错的选择。作为额外保护,你可以选择密钥文件(请记住:你必须始终都有它,否则无法打开皮夹)和/或 YubiKey 硬件密钥。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
数据库文件将保存到文件系统。如果你想与其他计算机/设备共享,可以将它保存在 U 盘或 pCloud 或 Dropbox 等云存储中。当然,如果你选择云存储,建议使用特别强大的主密码,如果有额外保护则更好。
|
||||
|
||||
### 创建你的第一个条目
|
||||
|
||||
创建数据库后,你可以开始创建第一个条目。对于 Web 登录,请在“条目”选项卡中输入用户名、密码和 URL。你可以根据个人策略指定凭据的到期日期,也可以通过按右侧的按钮下载网站的 favicon 并将其关联为条目的图标,这是一个很好的功能。
|
||||
|
||||
![][5]
|
||||
|
||||
![][6]
|
||||
|
||||
KeePassXC 还提供了一个很好的密码/口令生成器,你可以选择长度和复杂度,并检查对暴力攻击的抵抗程度:
|
||||
|
||||
![][7]
|
||||
|
||||
### 浏览器集成
|
||||
|
||||
KeePassXC 有一个适用于所有主流浏览器的扩展。该扩展允许你填写所有已指定 URL 条目的登录信息。
|
||||
|
||||
必须在 KeePassXC(工具菜单 -> 设置)上启用浏览器集成,指定你要使用的浏览器:
|
||||
|
||||
![][8]
|
||||
|
||||
安装扩展后,必须与数据库建立连接。要执行此操作,请按扩展按钮,然后按“连接”按钮:如果数据库已打开并解锁,那么扩展程序将创建关联密钥并将其保存在数据库中,该密钥对于浏览器是唯一的,因此我建议对它适当命名:
|
||||
|
||||
![][9]
|
||||
|
||||
当你打开 URL 字段中的登录页并且数据库是解锁的,那么这个扩展程序将为你提供与该页面关联的所有凭据:
|
||||
|
||||
![][10]
|
||||
|
||||
通过这种方式,你可以通过 KeePassXC 获取互联网凭据,而无需将其保存在浏览器中。
|
||||
|
||||
### SSH 代理集成
|
||||
|
||||
KeePassXC 的另一个有趣功能是与 SSH 集成。如果你使用 ssh 代理,KeePassXC 能够与之交互并添加你上传的 ssh 密钥到条目中。
|
||||
|
||||
首先,在常规设置(工具菜单 -> 设置)中,你必须启用 ssh 代理并重启程序:
|
||||
|
||||
![][11]
|
||||
|
||||
此时,你需要以附件方式上传你的 ssh 密钥对到条目中。然后在 “SSH 代理” 选项卡中选择附件下拉列表中的私钥,此时会自动填充公钥。不要忘记选择上面的两个复选框,以便在数据库打开/解锁时将密钥添加到代理,并在数据库关闭/锁定时删除:
|
||||
|
||||
![][12]
|
||||
|
||||
现在打开和解锁数据库,你可以使用皮夹中保存的密钥登录 ssh。
|
||||
|
||||
唯一的限制是可以添加到代理的最大密钥数:ssh 服务器默认不接受超过 5 次登录尝试,出于安全原因,建议不要增加此值。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-credentials-with-keepassxc/
|
||||
|
||||
作者:[Marco Sarti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/msarti/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/keepassxc-816x345.png
|
||||
[2]: https://linux.cn/article-11181-1.html
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-33-27.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-48-21.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-30-07.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-43-11.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-49-22.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-48-09.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-05-57.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-13-29.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-47-21.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-46-35.png
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11271-1.html)
|
||||
[#]: subject: (Happy birthday to the Linux kernel: What's your favorite release?)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-favorite-release)
|
||||
[#]: author: (Lauren Pritchett https://opensource.com/users/lauren-pritchett)
|
||||
|
||||
Linux 内核生日快乐 —— 那么你喜欢哪个版本?
|
||||
======
|
||||
|
||||
> 自从第一个 Linux 内核发布已经过去 28 年了。自 1991 年以来发布了几十个 Linux 内核版本,你喜欢的是哪个?投个票吧!
|
||||
|
||||
![][1]
|
||||
|
||||
让我们回到 1991 年 8 月,那个创造历史的时间。科技界经历过许多关键时刻,这些时刻仍在影响着我们。在那个 8 月,Tim Berners-Lee 宣布了一个名为<ruby>万维网<rt>World Wide Web</rt></ruby>的有趣项目,并推出了第一个网站;超级任天堂在美国发布,为所有年龄段的孩子们开启了新的游戏篇章;在赫尔辛基大学,一位名叫 Linus Torvalds 的学生向同好们询问(1991 年 8 月 25 日)了他作为[业余爱好][3]开发的新免费操作系统的反馈。那时 Linux 内核诞生了。
|
||||
|
||||
如今,我们可以浏览超过 15 亿个网站,在我们的电视机上玩另外五种任天堂游戏机,并维护着六个长期 Linux 内核。以下是我们的一些作者对他们最喜欢的 Linux 内核版本所说的话。
|
||||
|
||||
“引入模块的那个版本(1.2 吧?)。这是 Linux 迈向成功的未来的重要一步。” - Milan Zamazal
|
||||
|
||||
“2.6.9,因为它是我 2006 年加入 Red Hat 时的版本(在 RHEL4 中)。但我也更钟爱 2.6.18(RHEL5)一点,因为它在大规模部署的、我们最大客户(Telco, FSI)的关键任务工作负载中使用。它还带来了我们最大的技术变革之一:虚拟化(Xen 然后是 KVM)。” - Herve Lemaitre
|
||||
|
||||
“4.10。(虽然我不知道如何衡量这一点)。” - Ivan Bazulic
|
||||
|
||||
“Fedora 30 附带的新内核修复了我的 Thinkpad Yoga 笔记本电脑的挂起问题;挂起功能现在可以完美运行。我是一个笨人,只是忍受这个问题而从未试着提交错误报告,所以我特别感谢这项工作,我知道一定会解决这个问题。” - MáirínDuffy
|
||||
|
||||
“2.6.16 版本将永远在我的心中占有特殊的位置。这是我负责将其转换为在 hertz neverlost gps 系统上运行的第一个内核。我负责这项为那个设备构建内核和根文件系统的工作,对我来说这真的是一个奇迹时刻。我们在初次发布后多次更新了内核,但我想我必须还是推选那个最初版本,不过,我对于它的热爱没有任何技术原因,这纯属感性选择 =)” - Michael McCune
|
||||
|
||||
“我最喜欢的 Linux 内核版本是 2.4.0 系列,它集成了对 USB、LVM 和 ext3 的支持。ext3 是第一个具有日志支持的主流 Linux 文件系统,其从 2.4.15 内核可用。我使用的第一个内核版本是 2.2.13。” - Sean Nelson
|
||||
|
||||
“也许是 2.2.14,因为它是在我安装的第一个 Linux 上运行的版本(Mandrake Linux 7.0,在 2000 IIRC)。它也是我第一个需要重新编译以让我的视频卡或我的调制解调器(记不清了)工作的版本。” - GermánPulido
|
||||
|
||||
“我认为最新的一个!但我有段时间使用实时内核扩展来进行音频制作。” - Mario Torre
|
||||
|
||||
*在 Linux 内核超过 [52 个的版本][2]当中,你最喜欢哪一个?参加我们的调查并在评论中告诉我们原因。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-favorite-release
|
||||
|
||||
作者:[Lauren Pritchett][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/luis-ibanezhttps://opensource.com/users/mhayden
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_anniversary_celebreate_tux.jpg?itok=JOE-yXus
|
||||
[2]: http://phb-crystal-ball.org/
|
||||
[3]: http://lkml.iu.edu/hypermail/linux/kernel/1908.3/00457.html
|
||||
@ -0,0 +1,194 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11286-1.html)
|
||||
[#]: subject: (How to Install Ansible (Automation Tool) on Debian 10 (Buster))
|
||||
[#]: via: (https://www.linuxtechi.com/install-ansible-automation-tool-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 Debian 10 上安装 Ansible
|
||||
======
|
||||
|
||||
在如今的 IT 领域,自动化一个是热门话题,每个组织都开始采用自动化工具,像 Puppet、Ansible、Chef、CFEngine、Foreman 和 Katello。在这些工具中,Ansible 是几乎所有 IT 组织中管理 UNIX 和 Linux 系统的首选。在本文中,我们将演示如何在 Debian 10 Sever 上安装和使用 Ansible。
|
||||
|
||||
![Ansible-Install-Debian10][2]
|
||||
|
||||
我的实验室环境:
|
||||
|
||||
* Debian 10 – Ansible 服务器/ 控制节点 – 192.168.1.14
|
||||
* CentOS 7 – Ansible 主机 (Web 服务器)– 192.168.1.15
|
||||
* CentOS 7 – Ansible 主机(DB 服务器)– 192.169.1.17
|
||||
|
||||
我们还将演示如何使用 Ansible 服务器管理 Linux 服务器
|
||||
|
||||
### 在 Debian 10 Server 上安装 Ansible
|
||||
|
||||
我假设你的 Debian 10 中有一个拥有 root 或 sudo 权限的用户。在我这里,我有一个名为 `pkumar` 的本地用户,它拥有 sudo 权限。
|
||||
|
||||
Ansible 2.7 包存在于 Debian 10 的默认仓库中,在命令行中运行以下命令安装 Ansible,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
```
|
||||
|
||||
运行以下命令验证 Ansible 版本,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
要安装最新版本的 Ansible 2.8,首先我们必须设置 Ansible 仓库。
|
||||
|
||||
一个接一个地执行以下命令,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu bionic main" | sudo tee -a /etc/apt/sources.list
|
||||
root@linuxtechi:~$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 使用 Ansible 管理 Linux 服务器
|
||||
|
||||
请参考以下步骤,使用 Ansible 控制器节点管理 Linux 类的服务器,
|
||||
|
||||
#### 步骤 1:在 Ansible 服务器及其主机之间交换 SSH 密钥
|
||||
|
||||
在 Ansible 服务器生成 ssh 密钥并在 Ansible 主机之间共享密钥。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo -i
|
||||
root@linuxtechi:~# ssh-keygen
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
```
|
||||
|
||||
#### 步骤 2:创建 Ansible 主机清单
|
||||
|
||||
安装 Ansible 后会自动创建 `/etc/ansible/hosts`,在此文件中我们可以编辑 Ansible 主机或其客户端。我们还可以在家目录中创建自己的 Ansible 主机清单,
|
||||
|
||||
运行以下命令在我们的家目录中创建 Ansible 主机清单。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi $HOME/hosts
|
||||
[Web]
|
||||
192.168.1.15
|
||||
|
||||
[DB]
|
||||
192.168.1.17
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
注意:在上面的主机文件中,我们也可以使用主机名或 FQDN,但为此我们必须确保 Ansible 主机可以通过主机名或者 FQDN 访问。
|
||||
|
||||
#### 步骤 3:测试和使用默认的 Ansible 模块
|
||||
|
||||
Ansible 附带了许多可在 `ansible` 命令中使用的默认模块,示例如下所示。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# ansible -i <host_file> -m <module> <host>
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* `-i ~/hosts`:包含 Ansible 主机列表
|
||||
* `-m`:在之后指定 Ansible 模块,如 ping 和 shell
|
||||
* `<host>`:我们要运行 Ansible 模块的 Ansible 主机
|
||||
|
||||
使用 Ansible ping 模块验证 ping 连接,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping all
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping Web
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping DB
|
||||
```
|
||||
|
||||
命令输出如下所示:
|
||||
|
||||
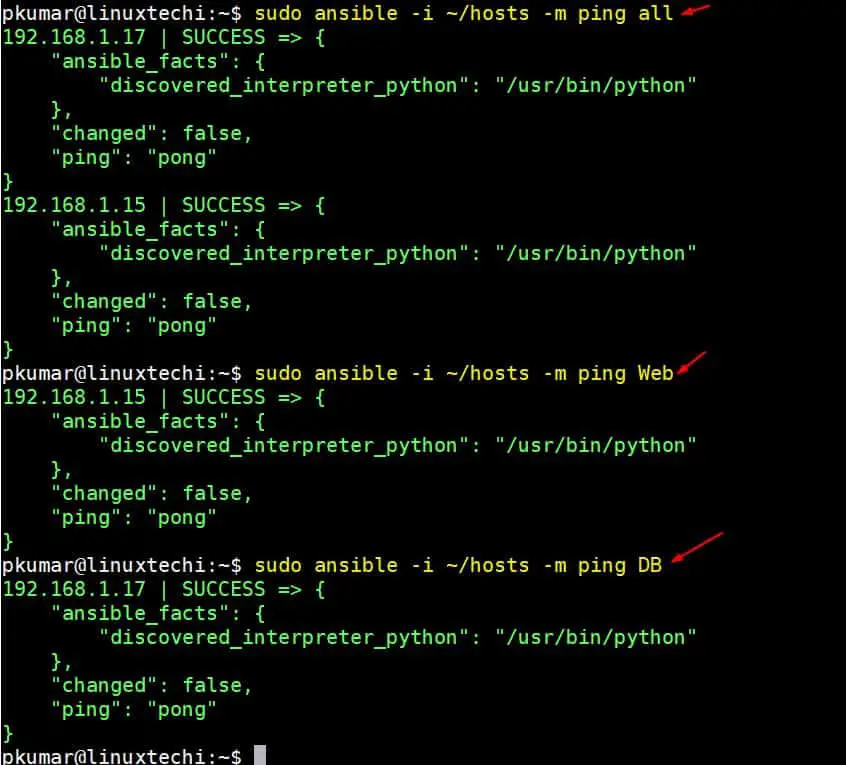
|
||||
|
||||
使用 shell 模块在 Ansible 主机上运行 shell 命令
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
ansible -i <hosts_file> -m shell -a <shell_commands> <host>
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime" all
|
||||
192.168.1.17 | CHANGED | rc=0 >>
|
||||
01:48:34 up 1:07, 3 users, load average: 0.00, 0.01, 0.05
|
||||
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:48:39 up 1:07, 3 users, load average: 0.00, 0.01, 0.04
|
||||
|
||||
root@linuxtechi:~$
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime ; df -Th / ; uname -r" Web
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:52:03 up 1:11, 3 users, load average: 0.12, 0.07, 0.06
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/centos-root xfs 13G 1017M 12G 8% /
|
||||
3.10.0-327.el7.x86_64
|
||||
|
||||
root@linuxtechi:~$
|
||||
```
|
||||
|
||||
上面的命令输出表明我们已成功设置 Ansible 控制器节点。
|
||||
|
||||
让我们创建一个安装 nginx 的示例剧本,下面的剧本将在所有服务器上安装 nginx,这些服务器是 Web 主机组的一部分,但在这里,我的主机组下只有一台 centos 7 机器。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi nginx.yaml
|
||||
---
|
||||
- hosts: Web
|
||||
tasks:
|
||||
- name: Install latest version of nginx on CentOS 7 Server
|
||||
yum: name=nginx state=latest
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
现在使用以下命令执行剧本。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible-playbook -i ~/hosts nginx.yaml
|
||||
```
|
||||
|
||||
上面命令的输出类似下面这样,
|
||||
|
||||
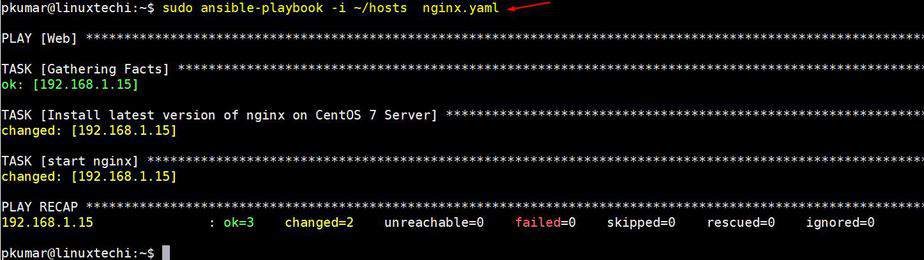
|
||||
|
||||
这表明 Ansible 剧本成功执行了。
|
||||
|
||||
本文就是这些了,请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-ansible-automation-tool-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
|
||||
102
published/201908/20190827 A dozen ways to learn Python.md
Normal file
102
published/201908/20190827 A dozen ways to learn Python.md
Normal file
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11280-1.html)
|
||||
[#]: subject: (A dozen ways to learn Python)
|
||||
[#]: via: (https://opensource.com/article/19/8/dozen-ways-learn-python)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
学习 Python 的 12 个方式
|
||||
======
|
||||
|
||||
> 这些资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||

|
||||
|
||||
Python 是世界上[最受欢迎的][2]编程语言之一,它受到了全世界各地的开发者和创客的欢迎。大多数 Linux 和 MacOS 计算机都预装了某个版本的 Python,现在甚至一些 Windows 计算机供应商也开始安装 Python 了。
|
||||
|
||||
也许你尚未学会它,想学习但又不知道在哪里入门。这里的 12 个资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||
### 课程、书籍、文章和文档
|
||||
|
||||
1、[Python 软件基金会][3]提供了出色的信息和文档,可帮助你迈上编码之旅。请务必查看 [Python 入门指南][4]。它将帮助你得到最新版本的 Python,并提供有关编辑器和开发环境的有用提示。该组织还有可以来进一步指导你的[优秀文档][5]。
|
||||
|
||||
2、我的 Python 旅程始于[海龟模块][6]。我首先在 Bryson Payne 的《[教你的孩子编码][7]》中找到了关于 Python 和海龟的内容。这本书是一个很好的资源,购买这本书可以让你看到几十个示例程序,这将激发你的编程好奇心。Payne 博士还在 [Udemy][8] 上以相同的名称开设了一门便宜的课程。
|
||||
|
||||
3、Payne 博士的书激起了我的好奇心,我渴望了解更多。这时我发现了 Al Sweigart 的《[用 Python 自动化无聊的东西][9]》。你可以购买这本书,也可以使用它的在线版本,它与印刷版完全相同且可根据知识共享许可免费获得和分享。Al 的这本书让我学习到了 Python 的基础知识、函数、列表、字典和如何操作字符串等等。这是一本很棒的书,我已经购买了许多本捐赠给了当地图书馆。Al 还提供 [Udemy][10] 课程;使用他的网站上的优惠券代码,只需 10 美元即可参加。
|
||||
|
||||
4、Eric Matthes 撰写了《[Python 速成][11]》,这是由 No Starch Press 出版的 Python 的逐步介绍(如同上面的两本书)。Matthes 还有一个很棒的[伴侣网站][12],其中包括了如何在你的计算机上设置 Python 以及一个用以简化学习曲线的[速查表][13]。
|
||||
|
||||
5、[Python for Everybody][14] 是另一个很棒的 Python 学习资源。该网站可以免费访问 [Charles Severance][15] 的 Coursera 和 edX 认证课程的资料。该网站分为入门、课程和素材等部分,其中 17 个课程按从安装到数据可视化的主题进行分类组织。Severance([@drchuck on Twitter][16]),是密歇根大学信息学院的临床教授。
|
||||
|
||||
6、[Seth Kenlon][17],我们 Opensource.com 的 Python 大师,撰写了大量关于 Python 的文章。Seth 有很多很棒的文章,包括“[用 JSON 保存和加载 Python 数据][18]”,“[用 Python 学习面向对象编程][19]”,“[在 Python 游戏中用 Pygame 放置平台][20]”,等等。
|
||||
|
||||
### 在设备上使用 Python
|
||||
|
||||
7、最近我对 [Circuit Playground Express][21] 非常感兴趣,这是一个运行 [CircuitPython][22] 的设备,CircuitPython 是为微控制器设计的 Python 编程语言的子集。我发现 Circuit Playground Express 和 CircuitPython 是向学生介绍 Python(以及一般编程)的好方法。它的制造商 Adafruit 有一个很好的[系列教程][23],可以让你快速掌握 CircuitPython。
|
||||
|
||||
8、[BBC:Microbit][24] 是另一种入门 Python 的好方法。你可以学习如何使用 [MicroPython][25] 对其进行编程,这是另一种用于编程微控制器的 Python 实现。
|
||||
|
||||
9、学习 Python 的文章如果没有提到[树莓派][26]单板计算机那是不完整的。一旦你有了[舒适][27]而强大的树莓派,你就可以在 Opensource.com 上找到[成吨的][28]使用它的灵感,包括“[7 个值得探索的树莓派项目][29]”,“[在树莓派上复活 Amiga][30]”,和“[如何使用树莓派作为 VPN 服务器][31]”。
|
||||
|
||||
10、许多学校为学生提供了 iOS 设备以支持他们的教育。在尝试帮助这些学校的老师和学生学习用 Python 编写代码时,我发现了 [Trinket.io][32]。Trinket 允许你在浏览器中编写和执行 Python 3 代码。 Trinket 的 [Python 入门][33]教程将向你展示如何在 iOS 设备上使用 Python。
|
||||
|
||||
### 播客
|
||||
|
||||
11、我喜欢在开车的时候听播客,我在 Kelly Paredes 和 Sean Tibor 的 [Teaching Python][34] 播客上找到了大量的信息。他们的内容很适合教育领域。
|
||||
|
||||
12、如果你正在寻找一些更通用的东西,我推荐 Michael Kennedy 的 [Talk Python to Me][35] 播客。它提供了有关 Python 及相关技术的最佳信息。
|
||||
|
||||
你学习 Python 最喜欢的资源是什么?请在评论中分享。
|
||||
|
||||
计算机编程可能是一个有趣的爱好,正如我以前在 Apple II 计算机上编程时所学到的……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dozen-ways-learn-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_code_screen_display.jpg?itok=2HMTzqz0 (Code on a screen)
|
||||
[2]: https://insights.stackoverflow.com/survey/2019#most-popular-technologies
|
||||
[3]: https://www.python.org/
|
||||
[4]: https://www.python.org/about/gettingstarted/
|
||||
[5]: https://docs.python.org/3/
|
||||
[6]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[7]: https://opensource.com/education/15/9/review-bryson-payne-teach-your-kids-code
|
||||
[8]: https://www.udemy.com/teach-your-kids-to-code/
|
||||
[9]: https://automatetheboringstuff.com/
|
||||
[10]: https://www.udemy.com/automate/?couponCode=PAY_10_DOLLARS
|
||||
[11]: https://nostarch.com/pythoncrashcourse2e
|
||||
[12]: https://ehmatthes.github.io/pcc/
|
||||
[13]: https://ehmatthes.github.io/pcc/cheatsheets/README.html
|
||||
[14]: https://www.py4e.com/
|
||||
[15]: http://www.dr-chuck.com/dr-chuck/resume/bio.htm
|
||||
[16]: https://twitter.com/drchuck/
|
||||
[17]: https://opensource.com/users/seth
|
||||
[18]: https://linux.cn/article-11133-1.html
|
||||
[19]: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
[20]: https://linux.cn/article-10902-1.html
|
||||
[21]: https://opensource.com/article/19/7/circuit-playground-express
|
||||
[22]: https://circuitpython.org/
|
||||
[23]: https://learn.adafruit.com/welcome-to-circuitpython
|
||||
[24]: https://opensource.com/article/19/8/getting-started-bbc-microbit
|
||||
[25]: https://micropython.org/
|
||||
[26]: https://www.raspberrypi.org/
|
||||
[27]: https://projects.raspberrypi.org/en/pathways/getting-started-with-raspberry-pi
|
||||
[28]: https://opensource.com/sitewide-search?search_api_views_fulltext=Raspberry%20Pi
|
||||
[29]: https://opensource.com/article/19/3/raspberry-pi-projects
|
||||
[30]: https://opensource.com/article/19/3/amiga-raspberry-pi
|
||||
[31]: https://opensource.com/article/19/6/raspberry-pi-vpn-server
|
||||
[32]: https://trinket.io/
|
||||
[33]: https://docs.trinket.io/getting-started-with-python#/welcome/where-we-ll-go
|
||||
[34]: https://www.teachingpython.fm/
|
||||
[35]: https://talkpython.fm/
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11289-1.html)
|
||||
[#]: subject: (11 surprising ways you use Linux every day)
|
||||
[#]: via: (https://opensource.com/article/19/8/everyday-tech-runs-linux)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
你可能意识不到的使用 Linux 的 11 种方式
|
||||
======
|
||||
|
||||
> 什么技术运行在 Linux 上?你可能会惊讶于日常生活中使用 Linux 的频率。
|
||||
|
||||

|
||||
|
||||
现在 Linux 几乎可以运行每样东西,但很多人都没有意识到这一点。有些人可能知道 Linux,可能听说过超级计算机运行着这个操作系统。根据 [Top500][2],Linux 现在驱动着世界上最快的 500 台计算机。你可以转到他们的网站并[搜索“Linux”][3]自己查看一下结果。
|
||||
|
||||
### NASA 运行在 Linux 之上
|
||||
|
||||
你可能不知道 Linux 为 NASA(美国国家航空航天局)提供支持。NASA 的 [Pleiades][4] 超级计算机运行着 Linux。由于操作系统的可靠性,国际空间站六年前[从 Windows 切换到了 Linux][5]。NASA 甚至最近给国际空间站部署了三台[运行着 Linux][6] 的“Astrobee”机器人。
|
||||
|
||||
### 电子书运行在 Linux 之上
|
||||
|
||||
我读了很多书,我的首选设备是亚马逊 Kindle Paperwhite,它运行 Linux(虽然大多数人完全没有意识到这一点)。如果你使用亚马逊的任何服务,从[亚马逊弹性计算云(Amazon EC2)][7] 到 Fire TV,你就是在 Linux 上运行。当你问 Alexa 现在是什么时候,或者你最喜欢的运动队得分时,你也在使用 Linux,因为 Alexa 由 [Fire OS][8](基于 Android 的操作系统)提供支持。实际上,[Android][9] 是由谷歌开发的用于移动手持设备的 Linux,而且占据了当今移动电话的[76% 的市场][10]。
|
||||
|
||||
### 电视运行在 Linux 之上
|
||||
|
||||
如果你有一台 [TiVo][11],那么你也在运行 Linux。如果你是 Roku 用户,那么你也在使用 Linux。[Roku OS][12] 是专为 Roku 设备定制的 Linux 版本。你可以选择使用在 Linux 上运行的 Chromecast 看流媒体。不过,Linux 不只是为机顶盒和流媒体设备提供支持。它也可能运行着你的智能电视。LG 使用 webOS,它是基于 Linux 内核的。Panasonic 使用 Firefox OS,它也是基于 Linux 内核的。三星、菲利普斯以及更多厂商都使用基于 Linux 的操作系统支持其设备。
|
||||
|
||||
### 智能手表和平板电脑运行在 Linux 之上
|
||||
|
||||
如果你拥有智能手表,它可能正在运行 Linux。世界各地的学校系统一直在实施[一对一系统][13],让每个孩子都有自己的笔记本电脑。越来越多的机构为学生配备了 Chromebook。这些轻巧的笔记本电脑使用 [Chrome OS][14],它基于 Linux。
|
||||
|
||||
### 汽车运行在 Linux 之上
|
||||
|
||||
你驾驶的汽车可能正在运行 Linux。 [汽车级 Linux(AGL)][15] 是一个将 Linux 视为汽车标准代码库的项目,它列入了丰田、马自达、梅赛德斯-奔驰和大众等汽车制造商。你的[车载信息娱乐(IVI)][16]系统也可能运行 Linux。[GENIVI 联盟][17]在其网站称,它开发了“用于集成在集中连接的车辆驾驶舱中的操作系统和中间件的标准方法”。
|
||||
|
||||
### 游戏运行在 Linux 之上
|
||||
|
||||
如果你是游戏玩家,那么你可能正在使用 [SteamOS][18],这是一个基于 Linux 的操作系统。此外,如果你使用 Google 的众多服务,那么你也运行在 Linux上。
|
||||
|
||||
### 社交媒体运行在 Linux 之上
|
||||
|
||||
当你刷屏和评论时,你可能会意识到这些平台正在做的很多工作。也许 Instagram、Facebook、YouTube 和 Twitter 都在 Linux 上运行并不令人惊讶。
|
||||
|
||||
此外,社交媒体的新浪潮,去中心化的联合社区的联盟节点,如 [Mastodon][19]、[GNU Social][20]、[Nextcloud][21](类似 Twitter 的微博平台)、[Pixelfed][22](分布式照片共享)和[Peertube][23](分布式视频共享)至少默认情况下在 Linux 上运行。由于开源,它们可以在任何平台上运行,这本身就是一个强大的优先级。
|
||||
|
||||
### 商业和政务运行在 Linux 之上
|
||||
|
||||
与五角大楼一样,纽约证券交易所也在 Linux 上运行。美国联邦航空管理局每年处理超过 1600 万次航班,他们在 Linux 上运营。美国国会图书馆、众议院、参议院和白宫都使用 Linux。
|
||||
|
||||
### 零售运行在 Linux 之上
|
||||
|
||||
最新航班座位上的娱乐系统很可能在 Linux 上运行。你最喜欢的商店的 POS 机可能正运行在 Linux 上。基于 Linux 的 [Tizen OS][24] 为智能家居和其他智能设备提供支持。许多公共图书馆现在在 [Evergreen][25] 和 [Koha][26] 上托管他们的综合图书馆系统。这两个系统都在 Linux 上运行。
|
||||
|
||||
### Apple 运行在 Linux 之上
|
||||
|
||||
如果你是使用 [iCloud][27] 的 iOS 用户,那么你也在使用运行在 Linux 上的系统。Apple 公司的网站在 Linux 上运行。如果你想知道在 Linux 上运行的其他网站,请务必使用 [Netcraft][28] 并检查“该网站运行在什么之上?”的结果。
|
||||
|
||||
### 路由器运行在 Linux 之上
|
||||
|
||||
在你家里将你连接到互联网的路由器可能正运行在 Linux 上。如果你当前的路由器没有运行 Linux 而你想改变它,那么这里有一个[优秀的方法][29]。
|
||||
|
||||
如你所见,Linux 从许多方面为今天的世界提供动力。还有什么运行在 Linux 之上的东西是人们还没有意识到的?请让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/everyday-tech-runs-linux
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/truck_steering_wheel_drive_car_kubernetes.jpg?itok=0TOzve80 (Truck steering wheel and dash)
|
||||
[2]: https://www.top500.org/
|
||||
[3]: https://www.top500.org/statistics/sublist/
|
||||
[4]: https://www.nas.nasa.gov/hecc/resources/pleiades.html
|
||||
[5]: https://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[6]: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20180003515.pdf
|
||||
[7]: https://aws.amazon.com/amazon-linux-ami/
|
||||
[8]: https://en.wikipedia.org/wiki/Fire_OS
|
||||
[9]: https://en.wikipedia.org/wiki/Android_(operating_system)
|
||||
[10]: https://gs.statcounter.com/os-market-share/mobile/worldwide/
|
||||
[11]: https://tivo.pactsafe.io/legal.html#open-source-software
|
||||
[12]: https://en.wikipedia.org/wiki/Roku
|
||||
[13]: https://en.wikipedia.org/wiki/One-to-one_computing
|
||||
[14]: https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[15]: https://opensource.com/life/16/8/agl-provides-common-open-code-base
|
||||
[16]: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
|
||||
[17]: https://www.genivi.org/faq
|
||||
[18]: https://store.steampowered.com/steamos/
|
||||
[19]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[20]: https://www.gnu.org/software/social/
|
||||
[21]: https://apps.nextcloud.com/apps/social
|
||||
[22]: https://pixelfed.org/
|
||||
[23]: https://joinpeertube.org/en/
|
||||
[24]: https://wiki.tizen.org/Devices
|
||||
[25]: https://evergreen-ils.org/
|
||||
[26]: https://koha-community.org/
|
||||
[27]: https://toolbar.netcraft.com/site_report?url=https://www.icloud.com/
|
||||
[28]: https://www.netcraft.com/
|
||||
[29]: https://opensource.com/life/16/6/why-i-built-my-own-linux-router
|
||||
@ -0,0 +1,257 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lnrCoder)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11480-1.html)
|
||||
[#]: subject: (How to Install and Configure PostgreSQL on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/install-postgresql-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 上安装和配置 PostgreSQL
|
||||
======
|
||||
|
||||
> 本教程中,你将学习如何在 Ubuntu Linux 上安装和使用开源数据库 PostgreSQL。
|
||||
|
||||
[PostgreSQL][1] (又名 Postgres) 是一个功能强大的自由开源的关系型数据库管理系统 ([RDBMS][2]) ,其在可靠性、稳定性、性能方面获得了业内极高的声誉。它旨在处理各种规模的任务。它是跨平台的,而且是 [macOS Server][3] 的默认数据库。
|
||||
|
||||
如果你喜欢简单易用的 SQL 数据库管理器,那么 PostgreSQL 将是一个正确的选择。PostgreSQL 对标准的 SQL 兼容的同时提供了额外的附加特性,同时还可以被用户大量扩展,用户可以添加数据类型、函数并执行更多的操作。
|
||||
|
||||
之前我曾论述过 [在 Ubuntu 上安装 MySQL][4]。在本文中,我将向你展示如何安装和配置 PostgreSQL,以便你随时可以使用它来满足你的任何需求。
|
||||
|
||||
![][5]
|
||||
|
||||
### 在 Ubuntu 上安装 PostgreSQL
|
||||
|
||||
PostgreSQL 可以从 Ubuntu 主存储库中获取。然而,和许多其它开发工具一样,它可能不是最新版本。
|
||||
|
||||
首先在终端中使用 [apt 命令][7] 检查 [Ubuntu 存储库][6] 中可用的 PostgreSQL 版本:
|
||||
|
||||
```
|
||||
apt show postgresql
|
||||
```
|
||||
|
||||
在我的 Ubuntu 18.04 中,它显示 PostgreSQL 的可用版本是 10(10+190 表示版本 10)而 PostgreSQL 版本 11 已经发布。
|
||||
|
||||
```
|
||||
Package: postgresql
|
||||
Version: 10+190
|
||||
Priority: optional
|
||||
Section: database
|
||||
Source: postgresql-common (190)
|
||||
Origin: Ubuntu
|
||||
```
|
||||
|
||||
根据这些信息,你可以自主决定是安装 Ubuntu 提供的版本还是还是获取 PostgreSQL 的最新发行版。
|
||||
|
||||
我将向你介绍这两种方法:
|
||||
|
||||
#### 方法一:通过 Ubuntu 存储库安装 PostgreSQL
|
||||
|
||||
在终端中,使用以下命令安装 PostgreSQL:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install postgresql postgresql-contrib
|
||||
```
|
||||
|
||||
根据提示输入你的密码,依据于你的网速情况,程序将在几秒到几分钟安装完成。说到这一点,随时检查 [Ubuntu 中的各种网络带宽][8]。
|
||||
|
||||
> 什么是 postgresql-contrib?
|
||||
|
||||
> postgresql-contrib 或者说 contrib 包,包含一些不属于 PostgreSQL 核心包的实用工具和功能。在大多数情况下,最好将 contrib 包与 PostgreSQL 核心一起安装。
|
||||
|
||||
#### 方法二:在 Ubuntu 中安装最新版本的 PostgreSQL 11
|
||||
|
||||
要安装 PostgreSQL 11, 你需要在 `sources.list` 中添加官方 PostgreSQL 存储库和证书,然后从那里安装它。
|
||||
|
||||
不用担心,这并不复杂。 只需按照以下步骤。
|
||||
|
||||
首先添加 GPG 密钥:
|
||||
|
||||
```
|
||||
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
|
||||
```
|
||||
|
||||
现在,使用以下命令添加存储库。如果你使用的是 Linux Mint,则必须手动替换你的 Mint 所基于的 Ubuntu 版本号:
|
||||
|
||||
```
|
||||
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ `lsb_release -cs`-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
|
||||
```
|
||||
|
||||
现在一切就绪。使用以下命令安装 PostgreSQL:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install postgresql postgresql-contrib
|
||||
```
|
||||
|
||||
> PostgreSQL GUI 应用程序
|
||||
|
||||
> 你也可以安装用于管理 PostgreSQL 数据库的 GUI 应用程序(pgAdmin):
|
||||
|
||||
> `sudo apt install pgadmin4`
|
||||
|
||||
### PostgreSQL 配置
|
||||
|
||||
你可以通过执行以下命令来检查 PostgreSQL 是否正在运行:
|
||||
|
||||
```
|
||||
service postgresql status
|
||||
```
|
||||
|
||||
通过 `service` 命令,你可以启动、关闭或重启 `postgresql`。输入 `service postgresql` 并按回车将列出所有选项。现在,登录该用户。
|
||||
|
||||
默认情况下,PostgreSQL 会创建一个拥有所权限的特殊用户 `postgres`。要实际使用 PostgreSQL,你必须先登录该账户:
|
||||
|
||||
```
|
||||
sudo su postgres
|
||||
```
|
||||
|
||||
你的提示符会更改为类似于以下的内容:
|
||||
|
||||
```
|
||||
postgres@ubuntu-VirtualBox:/home/ubuntu$
|
||||
```
|
||||
|
||||
现在,使用 `psql` 来启动 PostgreSQL Shell:
|
||||
|
||||
```
|
||||
psql
|
||||
```
|
||||
|
||||
你应该会看到如下提示符:
|
||||
|
||||
```
|
||||
postgress=#
|
||||
```
|
||||
|
||||
你可以输入 `\q` 以退出,输入 `\?` 获取帮助。
|
||||
|
||||
要查看现有的所有表,输入如下命令:
|
||||
|
||||
```
|
||||
\l
|
||||
```
|
||||
|
||||
输出内容类似于下图所示(单击 `q` 键退出该视图):
|
||||
|
||||
![PostgreSQL Tables][10]
|
||||
|
||||
使用 `\du` 命令,你可以查看 PostgreSQL 用户:
|
||||
|
||||
![PostgreSQLUsers][11]
|
||||
|
||||
你可以使用以下命令更改任何用户(包括 `postgres`)的密码:
|
||||
|
||||
```
|
||||
ALTER USER postgres WITH PASSWORD 'my_password';
|
||||
```
|
||||
|
||||
**注意:**将 `postgres` 替换为你要更改的用户名,`my_password` 替换为所需要的密码。另外,不要忘记每条命令后面的 `;`(分号)。
|
||||
|
||||
建议你另外创建一个用户(不建议使用默认的 `postgres` 用户)。为此,请使用以下命令:
|
||||
|
||||
```
|
||||
CREATE USER my_user WITH PASSWORD 'my_password';
|
||||
```
|
||||
|
||||
运行 `\du`,你将看到该用户,但是,`my_user` 用户没有任何的属性。来让我们给它添加超级用户权限:
|
||||
|
||||
```
|
||||
ALTER USER my_user WITH SUPERUSER;
|
||||
```
|
||||
|
||||
你可以使用以下命令删除用户:
|
||||
|
||||
```
|
||||
DROP USER my_user;
|
||||
```
|
||||
|
||||
要使用其他用户登录,使用 `\q` 命令退出,然后使用以下命令登录:
|
||||
|
||||
```
|
||||
psql -U my_user
|
||||
```
|
||||
|
||||
你可以使用 `-d` 参数直接连接数据库:
|
||||
|
||||
```
|
||||
psql -U my_user -d my_db
|
||||
```
|
||||
|
||||
你可以使用其他已存在的用户调用 PostgreSQL。例如,我使用 `ubuntu`。要登录,从终端执行以下命名:
|
||||
|
||||
```
|
||||
psql -U ubuntu -d postgres
|
||||
```
|
||||
|
||||
**注意:**你必须指定一个数据库(默认情况下,它将尝试将你连接到与登录的用户名相同的数据库)。
|
||||
|
||||
如果遇到如下错误:
|
||||
|
||||
```
|
||||
psql: FATAL: Peer authentication failed for user "my_user"
|
||||
```
|
||||
|
||||
确保以正确的用户身份登录,并使用管理员权限编辑 `/etc/postgresql/11/main/pg_hba.conf`:
|
||||
|
||||
```
|
||||
sudo vim /etc/postgresql/11/main/pg_hba.conf
|
||||
```
|
||||
|
||||
**注意:**用你的版本替换 `11`(例如 `10`)。
|
||||
|
||||
对如下所示的一行进行替换:
|
||||
|
||||
```
|
||||
local all postgres peer
|
||||
```
|
||||
|
||||
替换为:
|
||||
|
||||
```
|
||||
local all postgres md5
|
||||
```
|
||||
|
||||
然后重启 PostgreSQL:
|
||||
|
||||
```
|
||||
sudo service postgresql restart
|
||||
```
|
||||
|
||||
使用 PostgreSQL 与使用其他 SQL 类型的数据库相同。由于本文旨在帮助你进行初步的设置,因此不涉及具体的命令。不过,这里有个 [非常有用的要点][12] 可供参考! 另外, 手册(`man psql`)和 [文档][13] 也非常有用。
|
||||
|
||||
### 总结
|
||||
|
||||
阅读本文有望指导你完成在 Ubuntu 系统上安装和准备 PostgreSQL 的过程。如果你不熟悉 SQL,你应该阅读 [基本的 SQL 命令][15]。
|
||||
|
||||
如果你有任何问题或疑惑,请随时在评论部分提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-postgresql-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lnrCoder](https://github.com/lnrCoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.postgresql.org/
|
||||
[2]: https://www.codecademy.com/articles/what-is-rdbms-sql
|
||||
[3]: https://www.apple.com/in/macos/server/
|
||||
[4]: https://itsfoss.com/install-mysql-ubuntu/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-postgresql-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[6]: https://itsfoss.com/ubuntu-repositories/
|
||||
[7]: https://itsfoss.com/apt-command-guide/
|
||||
[8]: https://itsfoss.com/network-speed-monitor-linux/
|
||||
[9]: https://itsfoss.com/fix-gvfsd-smb-high-cpu-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_tables.png?fit=800%2C303&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/postgresql_users.png?fit=800%2C244&ssl=1
|
||||
[12]: https://gist.github.com/Kartones/dd3ff5ec5ea238d4c546
|
||||
[13]: https://www.postgresql.org/docs/manuals/
|
||||
[14]: https://itsfoss.com/sync-any-folder-with-dropbox/
|
||||
[15]: https://itsfoss.com/basic-sql-commands/
|
||||
273
published/20190809 Mutation testing is the evolution of TDD.md
Normal file
273
published/20190809 Mutation testing is the evolution of TDD.md
Normal file
@ -0,0 +1,273 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11468-1.html)
|
||||
[#]: subject: (Mutation testing is the evolution of TDD)
|
||||
[#]: via: (https://opensource.com/article/19/8/mutation-testing-evolution-tdd)
|
||||
[#]: author: (Alex Bunardzic https://opensource.com/users/alex-bunardzic)
|
||||
|
||||
变异测试是测试驱动开发(TDD)的演变
|
||||
======
|
||||
|
||||
> 测试驱动开发技术是根据大自然的运作规律创建的,变异测试自然成为 DevOps 演变的下一步。
|
||||
|
||||
![Ants and a leaf making the word "open"][1]
|
||||
|
||||
在 “[故障是无懈可击的开发运维中的一个特点][2]”,我讨论了故障在通过征求反馈来交付优质产品的过程中所起到的重要作用。敏捷 DevOps 团队就是用故障来指导他们并推动开发进程的。<ruby>[测试驱动开发][3]<rt>Test-driven development</rt></ruby>(TDD)是任何敏捷 DevOps 团队评估产品交付的[必要条件][4]。以故障为中心的 TDD 方法仅在与可量化的测试配合使用时才有效。
|
||||
|
||||
TDD 方法仿照大自然是如何运作的以及自然界在进化博弈中是如何产生赢家和输家为模型而建立的。
|
||||
|
||||
### 自然选择
|
||||
|
||||
![查尔斯·达尔文][5]
|
||||
|
||||
1859 年,<ruby>[查尔斯·达尔文][6]<rt>Charles Darwin</rt></ruby>在他的《<ruby>[物种起源][7]<rt>On the Origin of Species</rt></ruby>》一书中提出了进化论学说。达尔文的论点是,自然变异是由生物个体的自发突变和环境压力共同造成的。环境压力淘汰了适应性较差的生物体,而有利于其他适应性强的生物的发展。每个生物体的染色体都会发生变异,而这些自发的变异会携带给下一代(后代)。然后在自然选择下测试新出现的变异性 —— 当下存在的环境压力是由变异性的环境条件所导致的。
|
||||
|
||||
这张简图说明了调整适应环境条件的过程。
|
||||
|
||||
![环境压力对鱼类的影响][8]
|
||||
|
||||
*图1. 不同的环境压力导致自然选择下的不同结果。图片截图来源于[理查德·道金斯的一个视频][9]。*
|
||||
|
||||
该图显示了一群生活在自己栖息地的鱼。栖息地各不相同(海底或河床底部的砾石颜色有深有浅),每条鱼长的也各不相同(鱼身图案和颜色也有深有浅)。
|
||||
|
||||
这张图还显示了两种情况(即环境压力的两种变化):
|
||||
|
||||
1. 捕食者在场
|
||||
2. 捕食者不在场
|
||||
|
||||
在第一种情况下,在砾石颜色衬托下容易凸显出来的鱼被捕食者捕获的风险更高。当砾石颜色较深时,浅色鱼的数量会更少一些。反之亦然,当砾石颜色较浅时,深色鱼的数量会更少。
|
||||
|
||||
在第二种情况下,鱼完全放松下来进行交配。在没有捕食者和没有交配仪式的情况下,可以预料到相反的结果:在砾石背景下显眼的鱼会有更大的机会被选来交配并将其特性传递给后代。
|
||||
|
||||
### 选择标准
|
||||
|
||||
变异性在进行选择时,绝不是任意的、反复无常的、异想天开的或随机的。选择过程中的决定性因素通常是可以度量的。该决定性因素通常称为测试或目标。
|
||||
|
||||
一个简单的数学例子可以说明这一决策过程。(在该示例中,这种选择不是由自然选择决定的,而是由人为选择决定。)假设有人要求你构建一个小函数,该函数将接受一个正数,然后计算该数的平方根。你将怎么做?
|
||||
|
||||
敏捷 DevOps 团队的方法是快速验证失败。谦虚一点,先承认自己并不真的知道如何开发该函数。这时,你所知道的就是如何描述你想做的事情。从技术上讲,你已准备好进行单元测试。
|
||||
|
||||
“<ruby>单元测试<rt>unit test</rt></ruby>”描述了你的具体期望结果是什么。它可以简单地表述为“给定数字 16,我希望平方根函数返回数字 4”。你可能知道 16 的平方根是 4。但是,你不知道一些较大数字(例如 533)的平方根。
|
||||
|
||||
但至少,你已经制定了选择标准,即你的测试或你的期望值。
|
||||
|
||||
### 进行故障测试
|
||||
|
||||
[.NET Core][10] 平台可以演示该测试。.NET 通常使用 xUnit.net 作为单元测试框架。(要跟随进行这个代码示例,请安装 .NET Core 和 xUnit.net。)
|
||||
|
||||
打开命令行并创建一个文件夹,在该文件夹实现平方根解决方案。例如,输入:
|
||||
|
||||
```
|
||||
mkdir square_root
|
||||
```
|
||||
|
||||
再输入:
|
||||
|
||||
```
|
||||
cd square_root
|
||||
```
|
||||
|
||||
为单元测试创建一个单独的文件夹:
|
||||
|
||||
```
|
||||
mkdir unit_tests
|
||||
```
|
||||
|
||||
进入 `unit_tests` 文件夹下(`cd unit_tests`),初始化 xUnit 框架:
|
||||
|
||||
```
|
||||
dotnet new xunit
|
||||
```
|
||||
|
||||
现在,转到 `square_root` 下, 创建 `app` 文件夹:
|
||||
|
||||
```
|
||||
mkdir app
|
||||
cd app
|
||||
```
|
||||
|
||||
如果有必要的话,为你的代码创建一个脚手架:
|
||||
|
||||
```
|
||||
dotnet new classlib
|
||||
```
|
||||
|
||||
现在打开你最喜欢的编辑器开始编码!
|
||||
|
||||
在你的代码编辑器中,导航到 `unit_tests` 文件夹,打开 `UnitTest1.cs`。
|
||||
|
||||
将 `UnitTest1.cs` 中自动生成的代码替换为:
|
||||
|
||||
```
|
||||
using System;
|
||||
using Xunit;
|
||||
using app;
|
||||
|
||||
namespace unit_tests{
|
||||
|
||||
public class UnitTest1{
|
||||
Calculator calculator = new Calculator();
|
||||
|
||||
[Fact]
|
||||
public void GivenPositiveNumberCalculateSquareRoot(){
|
||||
var expected = 4;
|
||||
var actual = calculator.CalculateSquareRoot(16);
|
||||
Assert.Equal(expected, actual);
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
该单元测试描述了变量的**期望值**应该为 4。下一行描述了**实际值**。建议通过将输入值发送到称为`calculator` 的组件来计算**实际值**。对该组件的描述是通过接收数值来处理`CalculateSquareRoot` 信息。该组件尚未开发。但这并不重要,我们在此只是描述期望值。
|
||||
|
||||
最后,描述了触发消息发送时发生的情况。此时,判断**期望值**是否等于**实际值**。如果是,则测试通过,目标达成。如果**期望值**不等于**实际值**,则测试失败。
|
||||
|
||||
接下来,要实现称为 `calculator` 的组件,在 `app` 文件夹中创建一个新文件,并将其命名为`Calculator.cs`。要实现计算平方根的函数,请在此新文件中添加以下代码:
|
||||
|
||||
```
|
||||
namespace app {
|
||||
public class Calculator {
|
||||
public double CalculateSquareRoot(double number) {
|
||||
double bestGuess = number;
|
||||
return bestGuess;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在测试之前,你需要通知单元测试如何找到该新组件(`Calculator`)。导航至 `unit_tests` 文件夹,打开 `unit_tests.csproj` 文件。在 `<ItemGroup>` 代码块中添加以下代码:
|
||||
|
||||
```
|
||||
<ProjectReference Include="../app/app.csproj" />
|
||||
```
|
||||
|
||||
保存 `unit_test.csproj` 文件。现在,你可以运行第一个测试了。
|
||||
|
||||
切换到命令行,进入 `unit_tests` 文件夹。运行以下命令:
|
||||
|
||||
```
|
||||
dotnet test
|
||||
```
|
||||
|
||||
运行单元测试,会输出以下内容:
|
||||
|
||||
![单元测试失败后xUnit的输出结果][12]
|
||||
|
||||
*图2. 单元测试失败后 xUnit 的输出结果*
|
||||
|
||||
正如你所看到的,单元测试失败了。期望将数字 16 发送到 `calculator` 组件后会输出数字 4,但是输出(`Actual`)的是 16。
|
||||
|
||||
恭喜你!创建了第一个故障。单元测试为你提供了强有力的反馈机制,敦促你修复故障。
|
||||
|
||||
### 修复故障
|
||||
|
||||
要修复故障,你必须要改进 `bestGuess`。当下,`bestGuess` 仅获取函数接收的数字并返回。这不够好。
|
||||
|
||||
但是,如何找到一种计算平方根值的方法呢? 我有一个主意 —— 看一下大自然母亲是如何解决问题的。
|
||||
|
||||
### 效仿大自然的迭代
|
||||
|
||||
在第一次(也是唯一的)尝试中要得出正确值是非常难的(几乎不可能)。你必须允许自己进行多次尝试猜测,以增加解决问题的机会。允许多次尝试的一种方法是进行迭代。
|
||||
|
||||
要迭代,就要将 `bestGuess` 值存储在 `previousGuess` 变量中,转换 `bestGuess` 的值,然后比较两个值之间的差。如果差为 0,则说明问题已解决。否则,继续迭代。
|
||||
|
||||
这是生成任何正数的平方根的函数体:
|
||||
|
||||
```
|
||||
double bestGuess = number;
|
||||
double previousGuess;
|
||||
|
||||
do {
|
||||
previousGuess = bestGuess;
|
||||
bestGuess = (previousGuess + (number/previousGuess))/2;
|
||||
} while((bestGuess - previousGuess) != 0);
|
||||
|
||||
return bestGuess;
|
||||
```
|
||||
|
||||
该循环(迭代)将 `bestGuess` 值集中到设想的解决方案。现在,你精心设计的单元测试通过了!
|
||||
|
||||
![单元测试通过了][13]
|
||||
|
||||
*图 3. 单元测试通过了。*
|
||||
|
||||
### 迭代解决了问题
|
||||
|
||||
正如大自然母亲解决问题的方法,在本练习中,迭代解决了问题。增量方法与逐步改进相结合是获得满意解决方案的有效方法。该示例中的决定性因素是具有可衡量的目标和测试。一旦有了这些,就可以继续迭代直到达到目标。
|
||||
|
||||
### 关键点!
|
||||
|
||||
好的,这是一个有趣的试验,但是更有趣的发现来自于使用这种新创建的解决方案。到目前为止,`bestGuess` 从开始一直把函数接收到的数字作为输入参数。如果更改 `bestGuess` 的初始值会怎样?
|
||||
|
||||
为了测试这一点,你可以测试几种情况。 首先,在迭代多次尝试计算 25 的平方根时,要逐步细化观察结果:
|
||||
|
||||
![25 平方根的迭代编码][14]
|
||||
|
||||
*图 4. 通过迭代来计算 25 的平方根。*
|
||||
|
||||
以 25 作为 `bestGuess` 的初始值,该函数需要八次迭代才能计算出 25 的平方根。但是,如果在设计 `bestGuess` 初始值上犯下荒谬的错误,那将怎么办? 尝试第二次,那 100 万可能是 25 的平方根吗? 在这种明显错误的情况下会发生什么?你写的函数是否能够处理这种低级错误。
|
||||
|
||||
直接来吧。回到测试中来,这次以一百万开始:
|
||||
|
||||
![逐步求精法][15]
|
||||
|
||||
*图 5. 在计算 25 的平方根时,运用逐步求精法,以 100 万作为 bestGuess 的初始值。*
|
||||
|
||||
哇! 以一个荒谬的数字开始,迭代次数仅增加了两倍(从八次迭代到 23 次)。增长幅度没有你直觉中预期的那么大。
|
||||
|
||||
### 故事的寓意
|
||||
|
||||
啊哈! 当你意识到,迭代不仅能够保证解决问题,而且与你的解决方案的初始猜测值是好是坏也没有关系。 不论你最初理解得多么不正确,迭代过程以及可衡量的测试/目标,都可以使你走上正确的道路并得到解决方案。
|
||||
|
||||
图 4 和 5 显示了陡峭而戏剧性的燃尽图。一个非常错误的开始,迭代很快就产生了一个绝对正确的解决方案。
|
||||
|
||||
简而言之,这种神奇的方法就是敏捷 DevOps 的本质。
|
||||
|
||||
### 回到一些更深层次的观察
|
||||
|
||||
敏捷 DevOps 的实践源于人们对所生活的世界的认知。我们生活的世界存在不确定性、不完整性以及充满太多的困惑。从科学/哲学的角度来看,这些特征得到了<ruby>[海森堡的不确定性原理][16]<rt>Heisenberg's Uncertainty Principle</rt></ruby>(涵盖不确定性部分),<ruby>[维特根斯坦的逻辑论哲学][17]<rt>Wittgenstein's Tractatus Logico-Philosophicus</rt></ruby>(歧义性部分),<ruby>[哥德尔的不完全性定理][18]<rt>Gödel's incompleteness theorems</rt></ruby>(不完全性方面)以及<ruby>[热力学第二定律][19]<rt>Second Law of Thermodynamics</rt></ruby>(无情的熵引起的混乱)的充分证明和支持。
|
||||
|
||||
简而言之,无论你多么努力,在尝试解决任何问题时都无法获得完整的信息。因此,放下傲慢的姿态,采取更为谦虚的方法来解决问题对我们会更有帮助。谦卑会给为你带来巨大的回报,这个回报不仅是你期望的一个解决方案,还会有它的副产品。
|
||||
|
||||
### 总结
|
||||
|
||||
大自然在不停地运作,这是一个持续不断的过程。大自然没有总体规划。一切都是对先前发生的事情的回应。 反馈循环是非常紧密的,明显的进步/倒退都是逐步实现的。大自然中随处可见,任何事物的都在以一种或多种形式逐步完善。
|
||||
|
||||
敏捷 DevOps 是工程模型逐渐成熟的一个非常有趣的结果。DevOps 基于这样的认识,即你所拥有的信息总是不完整的,因此你最好谨慎进行。获得可衡量的测试(例如,假设、可测量的期望结果),进行简单的尝试,大多数情况下可能失败,然后收集反馈,修复故障并继续测试。除了同意每个步骤都必须要有可衡量的假设/测试之外,没有其他方法。
|
||||
|
||||
在本系列的下一篇文章中,我将仔细研究变异测试是如何提供及时反馈来推动实现结果的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/mutation-testing-evolution-tdd
|
||||
|
||||
作者:[Alex Bunardzic][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alex-bunardzic
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_520X292_openanttrail-2.png?itok=xhD3WmUd (Ants and a leaf making the word "open")
|
||||
[2]: https://opensource.com/article/19/7/failure-feature-blameless-devops
|
||||
[3]: https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[4]: https://www.merriam-webster.com/dictionary/conditio%20sine%20qua%20non
|
||||
[5]: https://opensource.com/sites/default/files/uploads/darwin.png (Charles Darwin)
|
||||
[6]: https://en.wikipedia.org/wiki/Charles_Darwin
|
||||
[7]: https://en.wikipedia.org/wiki/On_the_Origin_of_Species
|
||||
[8]: https://opensource.com/sites/default/files/uploads/environmentalconditions2.png (Environmental pressures on fish)
|
||||
[9]: https://www.youtube.com/watch?v=MgK5Rf7qFaU
|
||||
[10]: https://dotnet.microsoft.com/
|
||||
[11]: https://xunit.net/
|
||||
[12]: https://opensource.com/sites/default/files/uploads/xunit-output.png (xUnit output after the unit test run fails)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/unit-test-success.png (Unit test successful)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/iterating-square-root.png (Code iterating for the square root of 25)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/bestguess.png (Stepwise refinement)
|
||||
[16]: https://en.wikipedia.org/wiki/Uncertainty_principle
|
||||
[17]: https://en.wikipedia.org/wiki/Tractatus_Logico-Philosophicus
|
||||
[18]: https://en.wikipedia.org/wiki/G%C3%B6del%27s_incompleteness_theorems
|
||||
[19]: https://en.wikipedia.org/wiki/Second_law_of_thermodynamics
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11414-1.html)
|
||||
[#]: subject: (A Raspberry Pi Based Open Source Tablet is in Making and it’s Called CutiePi)
|
||||
[#]: via: (https://itsfoss.com/cutiepi-open-source-tab/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
CutiePi:正在开发中的基于树莓派的开源平板
|
||||
======
|
||||
|
||||
|
||||
|
||||
CutiePi 是一款 8 英寸的构建在树莓派上的开源平板。他们在[树莓派论坛][1]上宣布:现在,它只是一台原型机。
|
||||
|
||||
在本文中,你将了解有关 CutiePi 的规格、价格和可用性的更多详细信息。
|
||||
|
||||
它们使用一款定制的计算模块载版(CM3)来制造平板。[官网][2]提到使用定制 CM3 载板的目的是:
|
||||
|
||||
> 定制 CM3/CM3+ 载板是专为便携使用而设计,拥有增强的电源管理和锂聚合物电池电量监控功能。还可与指定的 HDMI 或 MIPI DSI 显示器配合使用。
|
||||
|
||||
因此,这使得该平板足够薄而且便携。
|
||||
|
||||
### CutiePi 规格
|
||||
|
||||
![CutiePi Board][3]
|
||||
|
||||
我惊讶地了解到它有 8 英寸的 IPS LCD 显示屏,这对新手而言是个好事。然而,你不会有一个真正高清的屏幕,因为官方宣称它的分辨率是 1280×800。
|
||||
|
||||
它还计划配备 4800 mAh 锂电池(原型机的电池为 5000 mAh)。嗯,对于平板来说,这不算坏。
|
||||
|
||||
连接性上包括支持 Wi-Fi 和蓝牙 4.0。此外,还有一个 USB Type-A 插口、6 个 GPIO 引脚和 microSD 卡插槽。
|
||||
|
||||
![CutiePi Specifications][4]
|
||||
|
||||
硬件与 [Raspbian OS][5] 官方兼容,用户界面采用 [Qt][6] 构建,以获得快速直观的用户体验。此外,除了内置应用外,它还将通过 XWayland 支持 Raspbian PIXEL 应用。
|
||||
|
||||
### CutiePi 源码
|
||||
|
||||
你可以通过分析所用材料的清单来猜测此平板的定价。CutiePi 遵循 100% 的开源硬件设计。因此,如果你觉得好奇,可以查看它的 [GitHub 页面][7],了解有关硬件设计和内容的详细信息。
|
||||
|
||||
### CutiePi 价格、发布日期和可用性
|
||||
|
||||
CutiePi 计划在 8 月进行[设计验证测试][8]批量 PCB。他们的目标是在 2019 年底推出最终产品。
|
||||
|
||||
官方预计,发售价大约在 $150-$250 左右。这只是一个近似的范围,还应该保有怀疑。
|
||||
|
||||
显然,即使产品听上去挺有希望,但价格将是它成功的一个主要因素。
|
||||
|
||||
### 总结
|
||||
|
||||
CutiePi 并不是第一个使用[像树莓派这样的单板计算机][9]来制作平板的项目。我们有即将推出的 [PineTab][10],它基于 Pine64 单板电脑。Pine 还有一种笔记本电脑,名为 [Pinebook][11]。
|
||||
|
||||
从原型来看,它确实是一个我们可以期望使用的产品。但是,预安装的应用和它将支持的应用可能会扭转局面。此外,考虑到价格估计,这听起来很有希望。
|
||||
|
||||
你觉得怎么样?让我们在下面的评论中知道你的想法,或者投个票。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cutiepi-open-source-tab/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.raspberrypi.org/forums/viewtopic.php?t=247380
|
||||
[2]: https://cutiepi.io/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-board.png?ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/cutiepi-specifications.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/raspberry-pi-os-desktop/
|
||||
[6]: https://en.wikipedia.org/wiki/Qt_%28software%29
|
||||
[7]: https://github.com/cutiepi-io/cutiepi-board
|
||||
[8]: https://en.wikipedia.org/wiki/Engineering_validation_test#Design_verification_test
|
||||
[9]: https://itsfoss.com/raspberry-pi-alternatives/
|
||||
[10]: https://www.pine64.org/pinetab/
|
||||
[11]: https://itsfoss.com/pinebook-pro/
|
||||
75
published/20190823 The lifecycle of Linux kernel testing.md
Normal file
75
published/20190823 The lifecycle of Linux kernel testing.md
Normal file
@ -0,0 +1,75 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11464-1.html)
|
||||
[#]: subject: (The lifecycle of Linux kernel testing)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-testing)
|
||||
[#]: author: (Major Hayden https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden)
|
||||
|
||||
Linux 内核测试的生命周期
|
||||
======
|
||||
|
||||
> 内核持续集成(CKI)项目旨在防止错误进入 Linux 内核。
|
||||
|
||||

|
||||
|
||||
在 [Linux 内核的持续集成测试][2] 一文中,我介绍了 <ruby>[内核持续集成][3]<rt>Continuous Kernel Integration</rt></ruby>(CKI)项目及其使命:改变内核开发人员和维护人员的工作方式。本文深入探讨了该项目的某些技术方面,以及这所有的部分是如何组合在一起的。
|
||||
|
||||
### 从一次更改开始
|
||||
|
||||
内核中每一项令人兴奋的功能、改进和错误都始于开发人员提出的更改。这些更改出现在各个内核存储库的大量邮件列表中。一些存储库关注内核中的某些子系统,例如存储或网络,而其它存储库关注内核的更多方面。 当开发人员向内核提出更改或补丁集时,或者维护者在存储库本身中进行更改时,CKI 项目就会付诸行动。
|
||||
|
||||
CKI 项目维护的触发器用于监视这些补丁集并采取措施。诸如 [Patchwork][4] 之类的软件项目通过将多个补丁贡献整合为单个补丁系列,使此过程变得更加容易。补丁系列作为一个整体历经 CKI 系统,并可以针对该系列发布单个报告。
|
||||
|
||||
其他触发器可以监视存储库中的更改。当内核维护人员合并补丁集、还原补丁或创建新标签时,就会触发。测试这些关键的更改可确保开发人员始终具有坚实的基线,可以用作编写新补丁的基础。
|
||||
|
||||
所有这些更改都会进入 GitLab CI 管道,并历经多个阶段和多个系统。
|
||||
|
||||
### 准备构建
|
||||
|
||||
首先要准备好要编译的源代码。这需要克隆存储库、打上开发人员建议的补丁集,并生成内核配置文件。这些配置文件具有成千上万个用于打开或关闭功能的选项,并且配置文件在不同的系统体系结构之间差异非常大。 例如,一个相当标准的 x86\_64 系统在其配置文件中可能有很多可用选项,但是 s390x 系统(IBM zSeries 大型机)的选项可能要少得多。在该大型机上,某些选项可能有意义,但在消费类笔记本电脑上没有任何作用。
|
||||
|
||||
内核进一步转换为源代码工件。该工件包含整个存储库(已打上补丁)以及编译所需的所有内核配置文件。 上游内核会打包成压缩包,而 Red Hat 的内核会生成下一步所用的源代码 RPM 包。
|
||||
|
||||
### 成堆的编译
|
||||
|
||||
编译内核会将源代码转换为计算机可以启动和使用的代码。配置文件描述了要构建的内容,内核中的脚本描述了如何构建它,系统上的工具(例如 GCC 和 glibc)完成构建。此过程需要一段时间才能完成,但是 CKI 项目需要针对四种体系结构快速完成:aarch64(64 位 ARM)、ppc64le(POWER)、s390x(IBM zSeries)和 x86\_64。重要的是,我们必须快速编译内核,以便使工作任务不会积压,而开发人员可以及时收到反馈。
|
||||
|
||||
添加更多的 CPU 可以大大提高速度,但是每个系统都有其局限性。CKI 项目在 OpenShift 的部署环境中的容器内编译内核;尽管 OpenShift 可以实现高伸缩性,但在部署环境中的可用 CPU 仍然是数量有限的。CKI 团队分配了 20 个虚拟 CPU 来编译每个内核。涉及到四个体系结构,这就涨到了 80 个 CPU!
|
||||
|
||||
另一个速度的提高来自 [ccache][5] 工具。内核开发进展迅速,但是即使在多个发布版本之间,内核的大部分仍保持不变。ccache 工具进行编译期间会在磁盘上缓存已构建的对象(整个内核的一小部分)。稍后再进行另一个内核编译时,ccache 会查找以前看到的内核的未更改部分。ccache 会从磁盘中提取缓存的对象并重新使用它。这样可以加快编译速度并降低总体 CPU 使用率。现在,耗时 20 分钟编译的内核在不到几分钟的时间内就完成了。
|
||||
|
||||
### 测试时间
|
||||
|
||||
内核进入最后一步:在真实硬件上进行测试。每个内核都使用 Beaker 在其原生体系结构上启动,并且开始无数次的测试以发现问题。一些测试会寻找简单的问题,例如容器问题或启动时的错误消息。其他测试则深入到各种内核子系统中,以查找系统调用、内存分配和线程中的回归问题。
|
||||
|
||||
大型测试框架,例如 [Linux Test Project][6](LTP),包含了大量测试,这些测试在内核中寻找麻烦的回归问题。其中一些回归问题可能会回滚关键的安全修复程序,并且进行测试以确保这些改进仍保留在内核中。
|
||||
|
||||
测试完成后,关键的一步仍然是:报告。内核开发人员和维护人员需要一份简明的报告,准确地告诉他们哪些有效、哪些无效以及如何获取更多信息。每个 CKI 报告都包含所用源代码、编译参数和测试输出的详细信息。该信息可帮助开发人员知道从哪里开始寻找解决问题的方法。此外,它还可以帮助维护人员在漏洞进入内核存储库之前知道何时需要保留补丁集以进行其他查看。
|
||||
|
||||
### 总结
|
||||
|
||||
CKI 项目团队通过向内核开发人员和维护人员提供及时、自动的反馈,努力防止错误进入 Linux 内核。这项工作通过发现导致内核错误、安全性问题和性能问题等易于找到的问题,使他们的工作更加轻松。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-testing
|
||||
|
||||
作者:[Major Hayden][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mhaydenhttps://opensource.com/users/mhaydenhttps://opensource.com/users/marcobravohttps://opensource.com/users/mhayden
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||
[2]: https://opensource.com/article/19/6/continuous-kernel-integration-linux
|
||||
[3]: https://cki-project.org/
|
||||
[4]: https://github.com/getpatchwork/patchwork
|
||||
[5]: https://ccache.dev/
|
||||
[6]: https://linux-test-project.github.io
|
||||
[7]: https://cki-project.org/posts/hackfest-agenda/
|
||||
[8]: https://www.linuxplumbersconf.org/
|
||||
@ -0,0 +1,212 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11427-1.html)
|
||||
[#]: subject: (How to compile a Linux kernel in the 21st century)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-21st-century)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在 21 世纪该怎样编译 Linux 内核
|
||||
======
|
||||
|
||||
> 也许你并不需要编译 Linux 内核,但你能通过这篇教程快速上手。
|
||||
|
||||

|
||||
|
||||
在计算机世界里,<ruby>内核<rt>kernel</rt></ruby>是处理硬件与一般系统之间通信的<ruby>低阶软件<rt>low-level software</rt></ruby>。除过一些烧录进计算机主板的初始固件,当你启动计算机时,内核让系统意识到它有一个硬盘驱动器、屏幕、键盘以及网卡。分配给每个部件相等时间(或多或少)使得图像、音频、文件系统和网络可以流畅甚至并行地运行。
|
||||
|
||||
然而,对于硬件的需求是源源不断的,随着发布的硬件越多,内核就必须纳入更多代码来保证那些硬件正常工作。得到具体的数字很困难,但是 Linux 内核无疑是硬件兼容性方面的顶级内核之一。Linux 操作着无数的计算机和移动电话、工业用途和爱好者使用的板级嵌入式系统(SoC)、RAID 卡、缝纫机等等。
|
||||
|
||||
回到 20 世纪(甚至是 21 世纪初期),对于 Linux 用户来说,在刚买到新的硬件后就需要下载最新的内核代码并编译安装才能使用这是不可理喻的。而现在你也很难见到 Linux 用户为了好玩而编译内核或通过高度专业化定制的硬件的方式赚钱。现在,通常已经不需要再编译 Linux 内核了。
|
||||
|
||||
这里列出了一些原因以及快速编译内核的教程。
|
||||
|
||||
### 更新当前的内核
|
||||
|
||||
无论你买了配备新显卡或 Wifi 芯片集的新品牌电脑还是给家里配备一个新的打印机,你的操作系统(称为 GNU+Linux 或 Linux,它也是该内核的名字)需要一个驱动程序来打开新部件(显卡、芯片集、打印机和其他任何东西)的信道。有时候当你插入某些新的设备时而你的电脑表示发现了它,这具有一定的欺骗性。别被骗到了,有时候那就够了,但更多的情况是你的操作系统仅仅是使用了通用的协议检测到安装了新的设备。
|
||||
|
||||
例如,你的计算机也许能够鉴别出新的网络打印机,但有时候那仅仅是因为打印机的网卡被设计成为了获得 DHCP 地址而在网络上标识自己。它并不意味着你的计算机知道如何发送文档给打印机进行打印。事实上,你可以认为计算机甚至不“知道”那台设备是一个打印机。它也许仅仅是显示网络有个设备在一个特定的地址上,并且该设备以一系列字符 “p-r-i-n-t-e-r” 标识自己而已。人类语言的便利性对于计算机毫无意义。计算机需要的是一个驱动程序。
|
||||
|
||||
内核开发者、硬件制造商、技术支持和爱好者都知道新的硬件会不断地发布。它们大多数都会贡献驱动程序,直接提交给内核开发团队以包含在 Linux 中。例如,英伟达显卡驱动程序通常都会写入 [Nouveau][2] 内核模块中,并且因为英伟达显卡很常用,它的代码都包含在任一个日常使用的发行版内核中(例如当下载 [Fedora][3] 或 [Ubuntu][4] 得到的内核)。英伟达也有不常用的地方,例如嵌入式系统中 Nouveau 模块通常被移除。对其他设备来说也有类似的模块:打印机得益于 [Foomatic][5] 和 [CUPS][6],无线网卡有 [b43、ath9k、wl][7] 模块等等。
|
||||
|
||||
发行版往往会在它们 Linux 内核的构建中包含尽可能多合理的驱动程序,因为他们想让你在接入新设备时不用安装驱动程序能够立即使用。对于大多数情况来说就是这样的,尤其是现在很多设备厂商都在资助自己售卖硬件的 Linux 驱动程序开发,并且直接将这些驱动程序提交给内核团队以用在通常的发行版上。
|
||||
|
||||
有时候,或许你正在运行六个月之前安装的内核,并配备了上周刚刚上市令人兴奋的新设备。在这种情况下,你的内核也许没有那款设备的驱动程序。好消息是经常会出现那款设备的驱动程序已经存在于最近版本的内核中,意味着你只要更新运行的内核就可以了。
|
||||
|
||||
通常,这些都是通过安装包管理软件完成的。例如在 RHEL、CentOS 和 Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo dnf update kernel
|
||||
```
|
||||
|
||||
在 Debian 和 Ubuntu 上,首先获取你当前内核的版本:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
4.4.186
|
||||
```
|
||||
|
||||
搜索新的版本:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt search linux-image
|
||||
```
|
||||
|
||||
安装找到的最新版本。在这个例子中,最新的版本是 5.2.4:
|
||||
|
||||
```
|
||||
$ sudo apt install linux-image-5.2.4
|
||||
```
|
||||
|
||||
内核更新后,你必须 [reboot][8] (除非你使用 kpatch 或 kgraft)。这时,如果你需要的设备驱动程序包含在最新的内核中,你的硬件就会正常工作。
|
||||
|
||||
### 安装内核模块
|
||||
|
||||
有时候一个发行版没有预计到用户会使用某个设备(或者该设备的驱动程序至少不足以包含在 Linux 内核中)。Linux 对于驱动程序采用模块化方式,因此尽管驱动程序没有编译进内核,但发行版可以推送单独的驱动程序包让内核去加载。尽管有些复杂但是非常有用,尤其是当驱动程序没有包含进内核中而是在引导过程中加载,或是内核中的驱动程序相比模块化的驱动程序过期时。第一个问题可以用 “initrd” 解决(初始化 RAM 磁盘),这一点超出了本文的讨论范围,第二点通过 “kmod” 系统解决。
|
||||
|
||||
kmod 系统保证了当内核更新后,所有与之安装的模块化驱动程序也得到更新。如果你手动安装一个驱动程序,你就体验不到 kmod 提供的自动化,因此只要能用 kmod 安装包,就应该选择它。例如,尽管英伟达驱动程序以 Nouveau 模块构建在内核中,但官方的驱动程序仅由英伟达发布。你可以去网站上手动安装英伟达旗下的驱动程序,下载 “.run” 文件,并运行提供的 shell 脚本,但在安装了新的内核之后你必须重复相同的过程,因为没有任何东西告诉包管理软件你手动安装了一个内核驱动程序。英伟达驱动着你的显卡,手动更新英伟达驱动程序通常意味着你需要通过终端来执行更新,因为没有显卡驱动程序将无法显示。
|
||||
|
||||
![Nvidia configuration application][9]
|
||||
|
||||
然而,如果你通过 kmod 包安装英伟达驱动程序,更新你的内核也会更新你的英伟达驱动程序。在 Fedora 和相关的发行版中:
|
||||
|
||||
```
|
||||
$ sudo dnf install kmod-nvidia
|
||||
```
|
||||
|
||||
在 Debian 和相关发行版上:
|
||||
|
||||
```
|
||||
$ sudo apt update
|
||||
$ sudo apt install nvidia-kernel-common nvidia-kernel-dkms nvidia-glx nvidia-xconfig nvidia-settings nvidia-vdpau-driver vdpau-va-driver
|
||||
```
|
||||
|
||||
这仅仅是一个例子,但是如果你真的要安装英伟达驱动程序,你也必须屏蔽掉 Nouveau 驱动程序。参考你使用发行版的文档获取最佳的步骤吧。
|
||||
|
||||
### 下载并安装驱动程序
|
||||
|
||||
不是所有的东西都包含在内核中,也不是所有的东西都可以作为内核模块使用。在某些情况下,你需要下载一个由供应商编写并绑定好的特殊驱动程序,还有一些情况,你有驱动程序,但是没有配置驱动程序的前端界面。
|
||||
|
||||
有两个常见的例子是 HP 打印机和 [Wacom][10] 数位板。如果你有一台 HP 打印机,你可能有能够和打印机通信的通用的驱动程序,甚至能够打印出东西。但是通用的驱动程序却不能为特定型号的打印机提供定制化的选项,例如双面打印、校对、纸盒选择等等。[HPLIP][11](HP Linux 成像和打印系统)提供了选项来进行任务管理、调整打印设置、选择可用的纸盒等等。
|
||||
|
||||
HPLIP 通常包含在包管理软件中;只要搜索“hplip”就行了。
|
||||
|
||||
![HPLIP in action][12]
|
||||
|
||||
同样的,电子艺术家主要使用的数位板 Wacom 的驱动程序通常也包含在内核中,但是例如调整压感和按键功能等设置只能通过默认包含在 GNOME 的图形控制面板访问。但也可以作为 KDE 上额外的程序包“kde-config-tablet”来访问。
|
||||
|
||||
这里也有几个类似的个别例子,例如内核中没有驱动程序,但是以 RPM 或 DEB 文件提供了可供下载并且通过包管理软件安装的 kmod 版本的驱动程序。
|
||||
|
||||
### 打上补丁并编译你的内核
|
||||
|
||||
即使在 21 世纪的未来主义乌托邦里,仍有厂商不够了解开源,没有提供可安装的驱动程序。有时候,一些公司为驱动程序提供开源代码,而需要你下载代码、修补内核、编译并手动安装。
|
||||
|
||||
这种发布方式和在 kmod 系统之外安装打包的驱动程序拥有同样的缺点:对内核的更新会破坏驱动程序,因为每次更换新的内核时都必须手动将其重新集成到内核中。
|
||||
|
||||
令人高兴的是,这种事情变得少见了,因为 Linux 内核团队在呼吁公司们与他们交流方面做得很好,并且公司们最终接受了开源不会很快消失的事实。但仍有新奇的或高度专业的设备仅提供了内核补丁。
|
||||
|
||||
官方上,对于你如何编译内核以使包管理器参与到升级系统如此重要的部分中,发行版有特定的习惯。这里有太多的包管理器,所以无法一一涵盖。举一个例子,当你使用 Fedora 上的工具例如 `rpmdev` 或 `build-essential`,Debian 上的 `devscripts`。
|
||||
|
||||
首先,像通常那样,找到你正在运行内核的版本:
|
||||
|
||||
```
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
在大多数情况下,如果你还没有升级过内核那么可以试试升级一下内核。搞定之后,也许你的问题就会在最新发布的内核中解决。如果你尝试后发现不起作用,那么你应该下载正在运行内核的源码。大多数发行版提供了特定的命令来完成这件事,但是手动操作的话,可以在 [kernel.org][13] 上找到它的源代码。
|
||||
|
||||
你必须下载内核所需的任何补丁。有时候,这些补丁对应具体的内核版本,因此请谨慎选择。
|
||||
|
||||
通常,或至少在人们习惯于编译内核的那时,都是拿到源代码并对 `/usr/src/linux` 打上补丁。
|
||||
|
||||
解压内核源码并打上需要的补丁:
|
||||
|
||||
```
|
||||
$ cd /usr/src/linux
|
||||
$ bzip2 --decompress linux-5.2.4.tar.bz2
|
||||
$ cd linux-5.2.4
|
||||
$ bzip2 -d ../patch*bz2
|
||||
```
|
||||
|
||||
补丁文件也许包含如何使用的教程,但通常它们都设计成在内核源码树的顶层可用来执行。
|
||||
|
||||
```
|
||||
$ patch -p1 < patch*example.patch
|
||||
```
|
||||
|
||||
当内核代码打上补丁后,你可以继续使用旧的配置来对打了补丁的内核进行配置。
|
||||
|
||||
```
|
||||
$ make oldconfig
|
||||
```
|
||||
|
||||
`make oldconfig` 命令有两个作用:它继承了当前的内核配置,并且允许你配置补丁带来的新的选项。
|
||||
|
||||
你或许需要运行 `make menuconfig` 命令,它启动了一个基于 ncurses 的菜单界面,列出了新的内核所有可能的选项。整个菜单可能看不过来,但是它是以旧的内核配置为基础的,你可以遍历菜单并且禁用掉你没有或不需要的硬件模块。另外,如果你知道自己有一些硬件没有包含在当前的配置中,你可以选择构建它,当作模块或者直接嵌入内核中。理论上,这些并不是必要的,因为你可以猜想,当前的内核运行良好只是缺少了补丁,当使用补丁的时候可能已经激活了所有设备所必要的选项。
|
||||
|
||||
下一步,编译内核和它的模块:
|
||||
|
||||
```
|
||||
$ make bzImage
|
||||
$ make modules
|
||||
```
|
||||
|
||||
这会产生一个叫作 `vmlinuz` 的文件,它是你的可引导内核的压缩版本。保存旧的版本并在 `/boot` 文件夹下替换为新的。
|
||||
|
||||
```
|
||||
$ sudo mv /boot/vmlinuz /boot/vmlinuz.nopatch
|
||||
$ sudo cat arch/x86_64/boot/bzImage > /boot/vmlinuz
|
||||
$ sudo mv /boot/System.map /boot/System.map.stock
|
||||
$ sudo cp System.map /boot/System.map
|
||||
```
|
||||
|
||||
到目前为止,你已经打上了补丁并且编译了内核和它的模块,你安装了内核,但你并没有安装任何模块。那就是最后的步骤:
|
||||
|
||||
```
|
||||
$ sudo make modules_install
|
||||
```
|
||||
|
||||
新的内核已经就位,并且它的模块也已经安装。
|
||||
|
||||
最后一步是更新你的引导程序,为了让你的计算机在加载 Linux 内核之前知道它的位置。GRUB 引导程序使这一过程变得相当简单:
|
||||
|
||||
```
|
||||
$ sudo grub2-mkconfig
|
||||
```
|
||||
|
||||
### 现实生活中的编译
|
||||
|
||||
当然,现在没有人手动执行这些命令。相反的,参考你的发行版,寻找发行版维护人员使用的开发者工具集修改内核的说明。这些工具集可能会创建一个集成所有补丁的可安装软件包,告诉你的包管理器来升级并更新你的引导程序。
|
||||
|
||||
### 内核
|
||||
|
||||
操作系统和内核都是玄学,但要理解构成它们的组件并不难。下一次你看到某个技术无法应用在 Linux 上时,深呼吸,调查可用的驱动程序,寻找一条捷径。Linux 比以前简单多了——包括内核。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-21st-century
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/migration_innovation_computer_software.png?itok=VCFLtd0q (and old computer and a new computer, representing migration to new software or hardware)
|
||||
[2]: https://nouveau.freedesktop.org/wiki/
|
||||
[3]: http://fedoraproject.org
|
||||
[4]: http://ubuntu.com
|
||||
[5]: https://wiki.linuxfoundation.org/openprinting/database/foomatic
|
||||
[6]: https://www.cups.org/
|
||||
[7]: https://wireless.wiki.kernel.org/en/users/drivers
|
||||
[8]: https://opensource.com/article/19/7/reboot-linux
|
||||
[9]: https://opensource.com/sites/default/files/uploads/nvidia.jpg (Nvidia configuration application)
|
||||
[10]: https://linuxwacom.github.io
|
||||
[11]: https://developers.hp.com/hp-linux-imaging-and-printing
|
||||
[12]: https://opensource.com/sites/default/files/uploads/hplip.jpg (HPLIP in action)
|
||||
[13]: https://www.kernel.org/
|
||||
131
published/20190826 Introduction to the Linux chown command.md
Normal file
131
published/20190826 Introduction to the Linux chown command.md
Normal file
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11416-1.html)
|
||||
[#]: subject: (Introduction to the Linux chown command)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-chown-command)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
chown 命令简介
|
||||
======
|
||||
|
||||
> 学习如何使用 chown 命令更改文件或目录的所有权。
|
||||
|
||||

|
||||
|
||||
Linux 系统上的每个文件和目录均由某个人拥有,拥有者可以完全控制更改或删除他们拥有的文件。除了有一个*拥有用户*外,文件还有一个*拥有组*。
|
||||
|
||||
你可以使用 `ls -l` 命令查看文件的所有权:
|
||||
|
||||
```
|
||||
[pablo@workstation Downloads]$ ls -l
|
||||
total 2454732
|
||||
-rw-r--r--. 1 pablo pablo 1934753792 Jul 25 18:49 Fedora-Workstation-Live-x86_64-30-1.2.iso
|
||||
```
|
||||
|
||||
该输出的第三和第四列是拥有用户和组,它们一起称为*所有权*。上面的那个 ISO 文件这两者都是 `pablo`。
|
||||
|
||||
所有权设置由 [chmod 命令][2]进行设置,控制允许谁可以执行读取、写入或运行的操作。你可以使用 `chown` 命令更改所有权(一个或两者)。
|
||||
|
||||
所有权经常需要更改。文件和目录一直存在在系统中,但用户不断变来变去。当文件和目录在系统中移动时,或从一个系统移动到另一个系统时,所有权也可能需要更改。
|
||||
|
||||
我的主目录中的文件和目录的所有权是我的用户和我的主要组,以 `user:group` 的形式表示。假设 Susan 正在管理 Delta 组,该组需要编辑一个名为 `mynotes` 的文件。你可以使用 `chown` 命令将该文件的用户更改为 `susan`,组更改为 `delta`:
|
||||
|
||||
```
|
||||
$ chown susan:delta mynotes
|
||||
ls -l
|
||||
-rw-rw-r--. 1 susan delta 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
当给该文件设置好了 Delta 组时,它可以分配回给我:
|
||||
|
||||
```
|
||||
$ chown alan mynotes
|
||||
$ ls -l mynotes
|
||||
-rw-rw-r--. 1 alan delta 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
给用户后添加冒号(`:`),可以将用户和组都分配回给我:
|
||||
|
||||
```
|
||||
$ chown alan: mynotes
|
||||
$ ls -l mynotes
|
||||
-rw-rw-r--. 1 alan alan 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
通过在组前面加一个冒号,可以只更改组。现在,`gamma` 组的成员可以编辑该文件:
|
||||
|
||||
```
|
||||
$ chown :gamma mynotes
|
||||
$ ls -l
|
||||
-rw-rw-r--. 1 alan gamma 0 Aug 1 12:04 mynotes
|
||||
```
|
||||
|
||||
`chown` 的一些附加参数都能用在命令行和脚本中。就像许多其他 Linux 命令一样,`chown` 有一个递归参数(`-R`),它告诉该命令进入目录以对其中的所有文件进行操作。没有 `-R` 标志,你就只能更改文件夹的权限,而不会更改其中的文件。在此示例中,假定目的是更改目录及其所有内容的权限。这里我添加了 `-v`(详细)参数,以便 `chown` 报告其工作情况:
|
||||
|
||||
```
|
||||
$ ls -l . conf
|
||||
.:
|
||||
drwxrwxr-x 2 alan alan 4096 Aug 5 15:33 conf
|
||||
|
||||
conf:
|
||||
-rw-rw-r-- 1 alan alan 0 Aug 5 15:33 conf.xml
|
||||
|
||||
$ chown -vR susan:delta conf
|
||||
changed ownership of 'conf/conf.xml' from alan:alan to susan:delta
|
||||
changed ownership of 'conf' from alan:alan to susan:delta
|
||||
```
|
||||
|
||||
根据你的角色,你可能需要使用 `sudo` 来更改文件的所有权。
|
||||
|
||||
在更改文件的所有权以匹配特定配置时,或者在你不知道所有权时(例如运行脚本时),可以使用参考文件(`--reference=RFILE`)。例如,你可以复制另一个文件(`RFILE`,称为参考文件)的用户和组,以撤消上面所做的更改。回想一下,点(`.`)表示当前的工作目录。
|
||||
|
||||
```
|
||||
$ chown -vR --reference=. conf
|
||||
```
|
||||
|
||||
### 报告更改
|
||||
|
||||
大多数命令都有用于控制其输出的参数。最常见的是 `-v`(`--verbose`)以启用详细信息,但是 `chown` 还具有 `-c`(`--changes`)参数来指示 `chown` 仅在进行更改时报告。`chown` 还会报告其他情况,例如不允许进行的操作。
|
||||
|
||||
参数 `-f`(`--silent`、`--quiet`)用于禁止显示大多数错误消息。在下一节中,我将使用 `-f` 和 `-c`,以便仅显示实际更改。
|
||||
|
||||
### 保持根目录
|
||||
|
||||
Linux 文件系统的根目录(`/`)应该受到高度重视。如果命令在此层级上犯了一个错误,则后果可能会使系统完全无用。尤其是在运行一个会递归修改甚至删除的命令时。`chown` 命令具有一个可用于保护和保持根目录的参数,它是 `--preserve-root`。如果在根目录中将此参数和递归一起使用,那么什么也不会发生,而是会出现一条消息:
|
||||
|
||||
```
|
||||
$ chown -cfR --preserve-root alan /
|
||||
chown: it is dangerous to operate recursively on '/'
|
||||
chown: use --no-preserve-root to override this failsafe
|
||||
```
|
||||
|
||||
如果不与 `--recursive` 结合使用,则该选项无效。但是,如果该命令由 `root` 用户运行,则 `/` 本身的权限将被更改,但其下的其他文件或目录的权限则不会更改:
|
||||
|
||||
```
|
||||
$ chown -c --preserve-root alan /
|
||||
chown: changing ownership of '/': Operation not permitted
|
||||
[root@localhost /]# chown -c --preserve-root alan /
|
||||
changed ownership of '/' from root to alan
|
||||
```
|
||||
|
||||
### 所有权即安全
|
||||
|
||||
文件和目录所有权是良好的信息安全性的一部分,因此,偶尔检查和维护文件所有权以防止不必要的访问非常重要。`chown` 命令是 Linux 安全命令集中最常见和最重要的命令之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-chown-command
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
|
||||
[2]: https://opensource.com/article/19/8/introduction-linux-chmod-command
|
||||
184
published/20190830 How to Install Linux on Intel NUC.md
Normal file
184
published/20190830 How to Install Linux on Intel NUC.md
Normal file
@ -0,0 +1,184 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (amwps290)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11477-1.html)
|
||||
[#]: subject: "How to Install Linux on Intel NUC"
|
||||
[#]: via: "https://itsfoss.com/install-linux-on-intel-nuc/"
|
||||
[#]: author: "Abhishek Prakash https://itsfoss.com/author/abhishek/"
|
||||
|
||||
在 Intel NUC 上安装 Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
在上周,我买了一台 [InteL NUC][1]。虽然它是如此之小,但它与成熟的桌面型电脑差别甚小。实际上,大部分的[基于 Linux 的微型 PC][2] 都是基于 Intel NUC 构建的。
|
||||
|
||||
我买了第 8 代 Core i3 处理器的“<ruby>准系统<rt>barebone</rt></ruby>” NUC。准系统意味着该设备没有 RAM、没有硬盘,显然也没有操作系统。我添加了一个 [Crucial 的 8 GB 内存条][3](大约 33 美元)和一个 [240 GB 的西数的固态硬盘][4](大约 45 美元)。
|
||||
|
||||
现在,我已经有了一台不到 400 美元的电脑。因为我已经有了一个电脑屏幕和键鼠套装,所以我没有把它们计算在内。
|
||||
|
||||
![在我的办公桌上放着一个崭新的英特尔 NUC NUC8i3BEH,后面有树莓派 4][5]
|
||||
|
||||
我买这个 Intel NUC 的主要原因就是我想在实体机上测试各种各样的 Linux 发行版。我已经有一个 [树莓派 4][6] 设备作为一个入门级的桌面系统,但它是一个 [ARM][7] 设备,因此,只有少数 Linux 发行版可用于树莓派上。(LCTT 译注:新发布的 Ubuntu 19.10 支持树莓派 4B)
|
||||
|
||||
*这个文章里的亚马逊链接是(原文的)受益连接。请参阅我们的[受益政策][8]。*
|
||||
|
||||
### 在 NUC 上安装 Linux
|
||||
|
||||
现在我准备安装 Ubuntu 18.04 长期支持版,因为我现在就有这个系统的安装文件。你也可以按照这个教程安装其他的发行版。在最重要的分区之前,前边的步骤都大致相同。
|
||||
|
||||
#### 第一步:创建一个 USB 启动盘
|
||||
|
||||
你可以在 Ubuntu 官网下载它的安装文件。使用另一个电脑去[创建一个 USB 启动盘][9]。你可以使用像 [Rufus][10] 和 [Etcher][11] 这样的软件。在 Ubuntu上,你可以使用默认的启动盘创建工具。
|
||||
|
||||
#### 第二步:确认启动顺序是正确的
|
||||
|
||||
将你的 USB 启动盘插入到你的电脑并开机。一旦你看到 “Intel NUC” 字样出现在你的屏幕上,快速的按下 `F2` 键进入到 BIOS 设置中。
|
||||
|
||||
![Intel NUC 的 BIOS 设置][12]
|
||||
|
||||
在这里,只是确认一下你的第一启动项是你的 USB 设备。如果不是,切换启动顺序。
|
||||
|
||||
如果你修改了一些选项,按 `F10` 键保存退出,否则直接按下 `ESC` 键退出 BIOS 设置。
|
||||
|
||||
#### 第三步:正确分区,安装 Linux
|
||||
|
||||
现在当机器重启的时候,你就可以看到熟悉的 Grub 界面,可以让你试用或者安装 Ubuntu。现在我们选择安装它。
|
||||
|
||||
开始的几个安装步骤非常简单,选择键盘的布局,是否连接网络还有一些其他简单的设置。
|
||||
|
||||
![在安装 Ubuntu Linux 时选择键盘布局][14]
|
||||
|
||||
你可能会使用常规安装,默认情况下会安装一些有用的应用程序。
|
||||
|
||||
![][15]
|
||||
|
||||
接下来的是要注意的部分。你有两种选择:
|
||||
|
||||
* “<ruby>擦除磁盘并安装 Ubuntu<rt>Erase disk and install Ubuntu</rt></ruby>”:最简单的选项,它将在整个磁盘上安装 Ubuntu。如果你只想在 Intel NUC 上使用一个操作系统,请选择此选项,Ubuntu 将负责剩余的工作。
|
||||
* “<ruby>其他选项<rt>Something else</rt></ruby>”:这是一个控制所有选择的高级选项。就我而言,我想在同一 SSD 上安装多个 Linux 发行版。因此,我选择了此高级选项。
|
||||
|
||||
![][16]
|
||||
|
||||
**如果你选择了“<ruby>擦除磁盘并安装 Ubuntu<rt>Erase disk and install Ubuntu</rt></ruby>”,点击“<ruby>继续<rt>Continue</rt></ruby>”,直接跳到第四步,**
|
||||
|
||||
如果你选择了高级选项,请按照下面剩下的部分进行操作。
|
||||
|
||||
选择固态硬盘,然后点击“<ruby>新建分区表<rt>New Partition Table</rt></ruby>”。
|
||||
|
||||
![][17]
|
||||
|
||||
它会给你显示一个警告。直接点击“<ruby>继续<rt>Continue</rt></ruby>”。
|
||||
|
||||
![][18]
|
||||
|
||||
现在你就可以看到你 SSD 磁盘里的空闲空间。我的想法是为 EFI bootloader 创建一个 EFI 系统分区。一个根(`/`)分区,一个主目录(`/home`)分区。这里我并没有创建[交换分区][19]。Ubuntu 会根据自己的需要来创建交换分区。我也可以通过[创建新的交换文件][32]来扩展交换分区。
|
||||
|
||||
我将在磁盘上保留近 200 GB 的可用空间,以便可以在此处安装其他 Linux 发行版。你可以将其全部用于主目录分区。保留单独的根分区和主目录分区可以在你需要重新安装系统时帮你保存里面的数据。
|
||||
|
||||
选择可用空间,然后单击加号以添加分区。
|
||||
|
||||
![][20]
|
||||
|
||||
一般来说,100MB 足够 EFI 的使用,但是某些发行版可能需要更多空间,因此我要使用 500MB 的 EFI 分区。
|
||||
|
||||
![][21]
|
||||
|
||||
接下来,我将使用 20GB 的根分区。如果你只使用一个发行版,则可以随意地将其增加到 40GB。
|
||||
|
||||
根目录(`/`)是系统文件存放的地方。你的程序缓存和你安装的程序将会有一些文件放在这个目录下边。我建议你可以阅读一下 [Linux 文件系统层次结构][22]来了解更多相关内容。
|
||||
|
||||
填入分区的大小,选择 Ext4 文件系统,选择 `/` 作为挂载点。
|
||||
|
||||
![][24]
|
||||
|
||||
接下来是创建一个主目录分区,我再说一下,如果你仅仅想使用一个 Linux 发行版。那就把剩余的空间都使用完吧。为主目录分区选择一个合适的大小。
|
||||
|
||||
主目录是你个人的文件,比如文档、图片、音乐、下载和一些其他的文件存储的地方。
|
||||
|
||||
![][25]
|
||||
|
||||
既然你创建好了 EFI 分区、根分区、主目录分区,那你就可以点击“<ruby>现在安装<rt>Install Now</rt></ruby>”按钮安装系统了。
|
||||
|
||||
![][26]
|
||||
|
||||
它将会提示你新的改变将会被写入到磁盘,点击“<ruby>继续<rt>Continue</rt></ruby>”。
|
||||
|
||||
![][27]
|
||||
|
||||
#### 第四步:安装 Ubuntu
|
||||
|
||||
事情到了这就非常明了了。现在选择你的分区或者以后选择也可以。
|
||||
|
||||
![][28]
|
||||
|
||||
接下来,输入你的用户名、主机名以及密码。
|
||||
|
||||
![][29]
|
||||
|
||||
看 7-8 分钟的幻灯片就可以安装完成了。
|
||||
|
||||
![][30]
|
||||
|
||||
一旦安装完成,你就可以重新启动了。
|
||||
|
||||
![][31]
|
||||
|
||||
当你重启的时候,你必须要移除你的 USB 设备,否则你将会再次进入安装系统的界面。
|
||||
|
||||
这就是在 Intel NUC 设备上安装 Linux 所需要做的一切。坦白说,你可以在其他任何系统上使用相同的过程。
|
||||
|
||||
### Intel NUC 和 Linux 在一起:如何使用它?
|
||||
|
||||
我非常喜欢 Intel NUC。它不占用太多的桌面空间,而且有足够的能力去取代传统的桌面型电脑。你可以将它的内存升级到 32GB。你也可以安装两个 SSD 硬盘。总之,它提供了一些配置和升级范围。
|
||||
|
||||
如果你想购买一个桌面型的电脑,我非常推荐你购买使用 [Intel NUC][1] 迷你主机。如果你不想自己安装系统,那么你可以购买一个[基于 Linux 的已经安装好的系统迷你主机][2]。
|
||||
|
||||
你是否已经有了一个 Intel NUC?有一些什么相关的经验?你有什么相关的意见与我们分享吗?可以在下面评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-linux-on-intel-nuc/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.amazon.com/Intel-NUC-Mainstream-Kit-NUC8i3BEH/dp/B07GX4X4PW?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B07GX4X4PW "Intel NUC"
|
||||
[2]: https://itsfoss.com/linux-based-mini-pc/
|
||||
[3]: https://www.amazon.com/Crucial-Single-PC4-19200-SODIMM-260-Pin/dp/B01BIWKP58?psc=1&SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01BIWKP58 "8GB RAM from Crucial"
|
||||
[4]: https://www.amazon.com/Western-Digital-240GB-Internal-WDS240G1G0B/dp/B01M9B2VB7?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B01M9B2VB7 "240 GB Western Digital SSD"
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/intel-nuc.jpg?resize=800%2C600&ssl=1
|
||||
[6]: https://itsfoss.com/raspberry-pi-4/
|
||||
[7]: https://en.wikipedia.org/wiki/ARM_architecture
|
||||
[8]: https://itsfoss.com/affiliate-policy/
|
||||
[9]: https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
|
||||
[10]: https://rufus.ie/
|
||||
[11]: https://www.balena.io/etcher/
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/boot-screen-nuc.jpg?ssl=1
|
||||
[13]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[14]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-1_tutorial.jpg?ssl=1
|
||||
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-2_tutorial.jpg?ssl=1
|
||||
[16]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-3_tutorial.jpg?ssl=1
|
||||
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-4_tutorial.jpg?ssl=1
|
||||
[18]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-5_tutorial.jpg?ssl=1
|
||||
[19]: https://itsfoss.com/swap-size/
|
||||
[20]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-6_tutorial.jpg?ssl=1
|
||||
[21]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-7_tutorial.jpg?ssl=1
|
||||
[22]: https://linuxhandbook.com/linux-directory-structure/
|
||||
[23]: https://itsfoss.com/share-folders-local-network-ubuntu-windows/
|
||||
[24]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-8_tutorial.jpg?ssl=1
|
||||
[25]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-9_tutorial.jpg?ssl=1
|
||||
[26]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-10_tutorial.jpg?ssl=1
|
||||
[27]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-11_tutorial.jpg?ssl=1
|
||||
[28]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-12_tutorial.jpg?ssl=1
|
||||
[29]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-13_tutorial.jpg?ssl=1
|
||||
[30]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-14_tutorial.jpg?ssl=1
|
||||
[31]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/install-ubuntu-linux-on-intel-nuc-15_tutorial.jpg?ssl=1
|
||||
[32]: https://itsfoss.com/create-swap-file-linux/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user