mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-16 22:42:21 +08:00
commit
496762ced5
13
.travis.yml
13
.travis.yml
@ -1,18 +1,27 @@
|
||||
language: c
|
||||
language: minimal
|
||||
install:
|
||||
- sudo apt-get install jq
|
||||
- git clone --depth=1 -b gh-pages https://github.com/LCTT/TranslateProject/ build && rm -rf build/.git
|
||||
script:
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" != "false" ]; then sh ./scripts/check.sh; fi'
|
||||
- 'if [ "$TRAVIS_PULL_REQUEST" = "false" ]; then sh ./scripts/badge.sh; fi'
|
||||
- 'if [ "$TRAVIS_EVENT_TYPE" = "cron" ]; then sh ./scripts/status.sh; fi'
|
||||
|
||||
branches:
|
||||
only:
|
||||
- master
|
||||
# - status
|
||||
except:
|
||||
- gh-pages
|
||||
git:
|
||||
submodules: false
|
||||
depth: false
|
||||
deploy:
|
||||
provider: pages
|
||||
skip_cleanup: true
|
||||
github_token: $GITHUB_TOKEN
|
||||
local_dir: build
|
||||
on:
|
||||
branch: master
|
||||
branch:
|
||||
- master
|
||||
# - status
|
||||
|
||||
90
README.md
90
README.md
@ -1,8 +1,8 @@
|
||||
|
||||

|
||||

|
||||

|
||||

|
||||
[](https://lctt.github.io/new)
|
||||
[](https://lctt.github.io/translating)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/translated)
|
||||
[](https://github.com/LCTT/TranslateProject/tree/master/published)
|
||||
|
||||
[](https://travis-ci.com/LCTT/TranslateProject)
|
||||
[](https://github.com/LCTT/TranslateProject/graphs/contributors)
|
||||
@ -11,7 +11,7 @@
|
||||
简介
|
||||
-------------------------------
|
||||
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
[LCTT](https://linux.cn/lctt/) 是“Linux 中国”([https://linux.cn/](https://linux.cn/))的翻译组,负责从国外优秀媒体翻译 Linux 相关的技术、资讯、杂文等内容。
|
||||
|
||||
LCTT 已经拥有几百名活跃成员,并欢迎更多的 Linux 志愿者加入我们的团队。
|
||||
|
||||
@ -31,14 +31,14 @@ LCTT 的组成
|
||||
加入我们
|
||||
-------------------------------
|
||||
|
||||
请首先加入翻译组的 QQ 群,群号是:198889102,加群时请说明是“志愿者”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
请首先加入翻译组的 QQ 群,群号是:**198889102**,加群时请说明是“*志愿者*”。加入后记得修改您的群名片为您的 GitHub 的 ID。
|
||||
|
||||
加入的成员,请先阅读 [WIKI 如何开始](https://github.com/LCTT/TranslateProject/wiki/01-如何开始)。
|
||||
|
||||
如何开始
|
||||
-------------------------------
|
||||
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
请阅读 [WIKI](https://github.com/LCTT/TranslateProject/wiki)。如需要协助,请在群内发问。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
@ -79,44 +79,52 @@ LCTT 的组成
|
||||
* 2018/08/17 提升 pityonline 为核心成员,担任校对,并接受他的建议采用 PR 审核模式。
|
||||
* 2018/09/10 [LCTT 五周年](https://linux.cn/article-9999-1.html)。
|
||||
* 2018/10/25 重构了 CI,感谢 vizv、lujun9972、bestony。
|
||||
* 2018/11/13 [成立了项目管理委员会(PMC)](https://linux.cn/article-10279-1.html),初始成员为:@wxy (主席)、@oska874、@lujun9972、@bestony、@pityonline、@geekpi、@qhwdw。
|
||||
|
||||
核心成员
|
||||
|
||||
项目管理委员及核心成员
|
||||
-------------------------------
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
LCTT 现由项目管理委员会(PMC)进行管理,成员如下:
|
||||
|
||||
- 组长 @wxy,
|
||||
- 选题 @oska874,
|
||||
- 选题 @lujun9972,
|
||||
- 技术 @bestony,
|
||||
- 校对 @jasminepeng,
|
||||
- 校对 @pityonline,
|
||||
- 钻石译者 @geekpi,
|
||||
- 钻石译者 @qhwdw,
|
||||
- 钻石译者 @GOLinux,
|
||||
- 核心成员 @GHLandy,
|
||||
- 核心成员 @martin2011qi,
|
||||
- 核心成员 @ictlyh,
|
||||
- 核心成员 @strugglingyouth,
|
||||
- 核心成员 @FSSlc,
|
||||
- 核心成员 @zpl1025,
|
||||
- 核心成员 @runningwater,
|
||||
- 核心成员 @bazz2,
|
||||
- 核心成员 @Vic020,
|
||||
- 核心成员 @alim0x,
|
||||
- 核心成员 @tinyeyeser,
|
||||
- 核心成员 @Locez,
|
||||
- 核心成员 @ucasFL,
|
||||
- 核心成员 @rusking,
|
||||
- 核心成员 @MjSeven
|
||||
- 前任选题 @DeadFire,
|
||||
- 前任校对 @reinoir222,
|
||||
- 前任校对 @PurlingNayuki,
|
||||
- 前任校对 @carolinewuyan,
|
||||
- 功勋成员 @vito-L,
|
||||
- 功勋成员 @willqian,
|
||||
- 功勋成员 @vizv,
|
||||
- 功勋成员 @dongfengweixiao,
|
||||
- 🎩 主席 @wxy
|
||||
- 🎩 选题 @oska874
|
||||
- 🎩 选题 @lujun9972
|
||||
- 🎩 技术 @bestony
|
||||
- 🎩 校对 @pityonline
|
||||
- 🎩 译者 @geekpi
|
||||
- 🎩 译者 @qhwdw
|
||||
|
||||
目前 LCTT 核心成员有:
|
||||
|
||||
- ❤️ 核心成员 @vizv
|
||||
- ❤️ 核心成员 @zpl1025
|
||||
- ❤️ 核心成员 @runningwater
|
||||
- ❤️ 核心成员 @FSSlc
|
||||
- ❤️ 核心成员 @Vic020
|
||||
- ❤️ 核心成员 @alim0x
|
||||
- ❤️ 核心成员 @martin2011qi
|
||||
- ❤️ 核心成员 @Locez
|
||||
- ❤️ 核心成员 @ucasFL
|
||||
- ❤️ 核心成员 @MjSeven
|
||||
|
||||
曾经做出了巨大贡献的核心成员,被列入荣誉榜:
|
||||
|
||||
- 🏆 前任选题 @DeadFire
|
||||
- 🏆 前任校对 @reinoir222
|
||||
- 🏆 前任校对 @PurlingNayuki
|
||||
- 🏆 前任校对 @carolinewuyan
|
||||
- 🏆 前任校对 @jasminepeng
|
||||
- 🏆 功勋成员 @tinyeyeser
|
||||
- 🏆 功勋成员 @vito-L
|
||||
- 🏆 功勋成员 @willqian
|
||||
- 🏆 功勋成员 @GOLinux
|
||||
- 🏆 功勋成员 @bazz2
|
||||
- 🏆 功勋成员 @ictlyh
|
||||
- 🏆 功勋成员 @dongfengweixiao
|
||||
- 🏆 功勋成员 @strugglingyouth
|
||||
- 🏆 功勋成员 @GHLandy
|
||||
- 🏆 功勋成员 @rusking
|
||||
|
||||
全部成员列表请参见: https://linux.cn/lctt-list/ 。
|
||||
|
||||
|
||||
@ -0,0 +1,401 @@
|
||||
学习 Linux/*BSD/Unix 的 30 个最佳在线文档
|
||||
======
|
||||
|
||||
手册页(man)是由系统管理员和 IT 技术开发人员写的,更多的是为了作为参考而不是教你如何使用。手册页对于已经熟悉使用 Linux、Unix 和 BSD 操作系统的人来说是非常有用的。如果你仅仅需要知道某个命令或者某个配置文件的格式那么你可以使用手册页,但是手册页对于 Linux 新手来说并没有太大的帮助。想要通过使用手册页来学习一些新东西不是一个好的选择。这里有将提供 30 个学习 Linux 和 Unix 操作系统的最佳在线网页文档。
|
||||
|
||||
![Dennis Ritchie and Ken Thompson working with UNIX PDP11][1]
|
||||
|
||||
值得一提的是,相对于 Linux,BSD 的手册页更好。
|
||||
|
||||
### #1:Red Hat Enterprise Linux(RHEL)
|
||||
|
||||
![Red hat Enterprise Linux 文档][2]
|
||||
|
||||
RHEL 是由红帽公司开发的面向商业市场的 Linux 发行版。红帽的文档是最好的文档之一,涵盖从 RHEL 的基础到一些高级主题比如安全、SELinux、虚拟化、目录服务器、服务器集群、JBOSS 应用程序服务器、高可用性集群(HPC)等。红帽的文档已经被翻译成 22 种语言,发布成多页面 HTML、单页面 HTML、PDF、EPUB 等文件格式。好消息同样的文档你可以用于 Centos 和 Scientific Linux(社区企业发行版)。这些文档随操作系统一起下载提供,也就是说当你没有网络的时候,你也可以使用它们。RHEL 的文档**涵盖从安装到配置器群的所有内容**。唯一的缺点是你需要成为付费用户。当然这对于企业公司来说是一件完美的事。
|
||||
|
||||
1. RHEL 文档:[HTML/PDF格式][3](LCTT 译注:**此链接**需要付费用户才可以访问)
|
||||
2. 是否支持论坛:只能通过红帽公司的用户网站提交支持案例。
|
||||
|
||||
#### 关于 CentOS Wiki 和论坛的说明
|
||||
|
||||
![Centos Linux Wiki][4]
|
||||
|
||||
CentOS(<ruby>社区企业操作系统<rt>Community ENTerprise Operating System</rt></ruby>)是由 RHEL 提供的自由源码包免费重建的。它为个人电脑或其它用途提供了可靠的、免费的企业级 Linux。你可以不用付出任何支持和认证费用就可以获得 RHEL 的稳定性。CentOS的 wiki 分为 Howto、技巧等等部分,链接如下:
|
||||
|
||||
1. 文档:[wiki 格式][87]
|
||||
2. 是否支持论坛:[是][88]
|
||||
|
||||
### #2:Arch 的 Wiki 和论坛
|
||||
|
||||
![Arch Linux wiki 和教程][5]
|
||||
|
||||
Arch linux 是一个独立开发的 Linux 操作系统,它有基于 wiki 网站形式的非常不错的文档。它是由 Arch 社区的一些用户共同协作开发出来的,并且允许任何用户添加或修改内容。这些文档教程被分为几类比如说优化、软件包管理、系统管理、X window 系统还有获取安装 Arch Linux 等。它的[官方论坛][7]在解决许多问题的时候也非常有用。它有总共 4 万多个注册用户、超过 1 百万个帖子。 该 wiki 包含一些 **其它 Linux 发行版也适用的通用信息**。
|
||||
|
||||
1. Arch 社区文档:[Wiki 格式][8]
|
||||
2. 是否支持论坛:[是][7]
|
||||
|
||||
### #3:Gentoo Linux Wiki 和论坛
|
||||
|
||||
![Gentoo Linux 手册和 Wiki][9]
|
||||
|
||||
Gentoo Linux 基于 Portage 包管理系统。Gentoo Linux 用户根据它们选择的配置在本地编译源代码。多数 Gentoo Linux 用户都会定制自己独有的程序集。 Gentoo Linux 的文档会给你一些有关 Gentoo Linux 操作系统的说明和一些有关安装、软件包、网络和其它等主要出现的问题的解决方法。Gentoo 有对你来说 **非常有用的论坛**,论坛中有超过 13 万 4 千的用户,总共发了有 5442416 个文章。
|
||||
|
||||
1. Gentoo 社区文档:[手册][10] 和 [Wiki 格式][11]
|
||||
2. 是否支持论坛:[是][12]
|
||||
|
||||
### #4:Ubuntu Wiki 和文档
|
||||
|
||||
![Ubuntu Linux Wiki 和论坛][14]
|
||||
|
||||
Ubuntu 是领先的台式机和笔记本电脑发行版之一。其官方文档由 Ubuntu 文档工程开发维护。你可以在从官方文档中查看大量的信息,比如如何开始使用 Ubuntu 的教程。最好的是,此处包含的这些信息也可用于基于 Debian 的其它系统。你可能会找到由 Ubuntu 的用户们创建的社区文档,这是一份有关 Ubuntu 的使用教程和技巧等。Ubuntu Linux 有着网络上最大的 Linux 社区的操作系统,它对新用户和有经验的用户均有助益。
|
||||
|
||||
1. Ubuntu 社区文档:[wiki 格式][15]
|
||||
2. Ubuntu 官方文档:[wiki 格式][16]
|
||||
3. 是否支持论坛:[是][17]
|
||||
|
||||
### #5:IBM Developer Works
|
||||
|
||||
![IBM: Linux 程序员和系统管理员用到的技术][18]
|
||||
|
||||
IBM Developer Works 为 Linux 程序员和系统管理员提供技术资源,其中包含数以百计的文章、教程和技巧来协助 Linux 程序员的编程工作和应用开发还有系统管理员的日常工作。
|
||||
|
||||
1. IBM 开发者项目文档:[HTML 格式][19]
|
||||
2. 是否支持论坛:[是][20]
|
||||
|
||||
### #6:FreeBSD 文档和手册
|
||||
|
||||
![Freebsd Documentation][21]
|
||||
|
||||
FreeBSD 的手册是由 <ruby>FreeBSD 文档项目<rt>FreeBSD Documentation Project</rt></ruby>所创建的,它介绍了 FreeBSD 操作系统的安装、管理和一些日常使用技巧等内容。FreeBSD 的手册页通常比 GNU Linux 的手册页要好一点。FreeBSD **附带有全部最新手册页的文档**。 FreeBSD 手册涵盖任何你想要的内容。手册包含一些通用的 Unix 资料,这些资料同样适用于其它的 Linux 发行版。FreeBSD 官方论坛会在你遇到棘手问题时给予帮助。
|
||||
|
||||
1. FreeBSD 文档:[HTML/PDF 格式][90]
|
||||
2. 是否支持论坛:[是][91]
|
||||
|
||||
### #7:Bash Hackers Wiki
|
||||
|
||||
![Bash Hackers wiki][22]
|
||||
|
||||
这是一个对于 bash 使用者来说非常好的资源。Bash 使用者的 wiki 是为了归纳所有类型的 GNU Bash 文档。这个项目的动力是为了提供可阅读的文档和资料来避免用户被迫一点一点阅读 Bash 的手册,有时候这是非常麻烦的。Bash Hackers Wiki 分为各个类,比如说脚本和通用资料、如何使用、代码风格、bash 命令格式和其它。
|
||||
|
||||
1. Bash 用户教程:[wiki 格式][23]
|
||||
|
||||
### #8:Bash 常见问题
|
||||
|
||||
![Bash 常见问题:一些有关 GNU/BASH 常见问题的解决方法][24]
|
||||
|
||||
这是一个为 bash 新手设计的一个 wiki。它收集了 IRC 网络的 #bash 频道里常见问题的解决方法,这些解决方法是由该频道的普通成员提供。当你遇到问题的时候不要忘了在 [BashPitfalls][25] 部分检索查找答案。这些常见问题的解决方法可能会倾向于 Bash,或者偏向于最基本的 Bourne Shell,这决定于是谁给出的答案。大多数情况会尽力提供可移植的(Bourne)和高效的(Bash,在适当情况下)的两类答案。
|
||||
|
||||
1. Bash 常见问题:[wiki 格式][26]
|
||||
|
||||
### #9: Howtoforge - Linux 教程
|
||||
|
||||
![Howtoforge][27]
|
||||
|
||||
博客作者 Falko 在 Howtoforge 上有一些非常不错的东西。这个网站提供了 Linux 关于各种各样主题的教程,比如说其著名的“最佳服务器系列”,网站将主题分为几类,比如说 web 服务器、linux 发行版、DNS 服务器、虚拟化、高可用性、电子邮件和反垃圾邮件、FTP 服务器、编程主题还有一些其它的内容。这个网站也支持德语。
|
||||
|
||||
1. Howtoforge: [html 格式][28]
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #10:OpenBSD 常见问题和文档
|
||||
|
||||
![OpenBSD 文档][29]
|
||||
|
||||
OpenBSD 是另一个基于 BSD 的类 Unix 计算机操作系统。OpenBSD 是由 NetBSD 项目分支而来。OpenBSD 因高质量的代码和文档、对软件许可协议的坚定立场和强烈关注安全问题而闻名。OpenBSD 的文档分为多个主题类别,比如说安装、包管理、防火墙设置、用户管理、网络、磁盘和磁盘阵列管理等。
|
||||
|
||||
1. OpenBSD:[html 格式][30]
|
||||
2. 是否支持论坛:否,但是可以通过 [邮件列表][31] 来咨询
|
||||
|
||||
### #11: Calomel - 开源研究和参考文档
|
||||
|
||||
![开源研究和参考文档][32]
|
||||
|
||||
这个极好的网站是专门作为开源软件和那些特别专注于 OpenBSD 的软件的文档来使用的。这是最简洁的引导网站之一,专注于高质量的内容。网站内容分为多个类,比如说 DNS、OpenBSD、安全、web 服务器、Samba 文件服务器、各种工具等。
|
||||
|
||||
1. Calomel 官网:[html 格式][33]
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #12:Slackware 书籍项目
|
||||
|
||||
![Slackware Linux 手册和文档][34]
|
||||
|
||||
Slackware Linux 是我的第一个 Linux 发行版。Slackware 是基于 Linux 内核的最早的发行版之一,也是当前正在维护的最古老的 Linux 发行版。 这个发行版面向专注于稳定性的高级用户。 Slackware 也是很少有的的“类 Unix” 的 Linux 发行版之一。官方的 Slackware 手册是为了让用户快速开始了解 Slackware 操作系统的使用方法而设计的。 这不是说它将包含发行版的每一个方面,而是为了说明它的实用性和给使用者一些有关系统的基础工作使用方法。手册分为多个主题,比如说安装、网络和系统配置、系统管理、包管理等。
|
||||
|
||||
1. Slackware Linux 手册:[html 格式][35]、pdf 和其它格式
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #13:Linux 文档项目(TLDP)
|
||||
|
||||
![Linux 学习网站和文档][36]
|
||||
|
||||
<ruby>Linux 文档项目<rt>Linux Documentation Project</rt></ruby>旨在给 Linux 操作系统提供自由、高质量文档。网站是由志愿者创建和维护的。网站分为具体主题的帮助、由浅入深的指南等。在此我想推荐一个非常好的[文档][37],这个文档既是一个教程也是一个 shell 脚本编程的参考文档,对于新用户来说这个 HOWTO 的[列表][38]也是一个不错的开始。
|
||||
|
||||
1. Linux [文档工程][39] 支持多种查阅格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #14:Linux Home Networking
|
||||
|
||||
![Linux Home Networking][40]
|
||||
|
||||
Linux Home Networking 是学习 linux 的另一个比较好的资源,这个网站包含了 Linux 软件认证考试的内容比如 RHCE,还有一些计算机培训课程。网站包含了许多主题,比如说网络、Samba 文件服务器、无线网络、web 服务器等。
|
||||
|
||||
1. Linux [home networking][41] 可通过 html 格式和 PDF(少量费用)格式查阅
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #15:Linux Action Show
|
||||
|
||||
![Linux 播客][42]
|
||||
|
||||
Linux Action Show(LAS) 是一个关于 Linux 的播客。这个网站是由 Bryan Lunduke、Allan Jude 和 Chris Fisher 共同管理的。它包含了 FOSS 的最新消息。网站内容主要是评论一些应用程序和 Linux 发行版。有时候也会发布一些和开源项目著名人物的采访视频。
|
||||
|
||||
1. Linux [action show][43] 支持音频和视频格式
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #16:Commandlinefu
|
||||
|
||||
![Commandlinefu 的最优 Unix / Linux 命令][45]
|
||||
|
||||
Commandlinefu 列出了各种有用或有趣的 shell 命令。这里所有命令都可以评论、讨论和投票(支持或反对)。对于所有 Unix 命令行用户来说是一个极好的资源。不要忘了查看[评选出来的最佳命令][44]。
|
||||
|
||||
1. [Commandlinefu][46] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #17:Debian 管理技巧和资源
|
||||
|
||||
![Debian Linux 管理: 系统管理员技巧和教程][48]
|
||||
|
||||
这个网站包含一些只和 Debian GNU/Linux 相关的主题、技巧和教程,特别是包含了关于系统管理的有趣和有用的信息。你可以在上面贡献文章、建议和问题。提交了之后不要忘记查看[最佳文章列表][47]里有没有你的文章。
|
||||
|
||||
1. Debian [系统管理][49] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #18: Catonmat - Sed、Awk、Perl 教程
|
||||
|
||||
![Sed 流编辑器、 Awk 文本处理工具、 Perl 语言教程][50]
|
||||
|
||||
这个网站是由博客作者 Peteris Krumins 维护的。主要关注命令行和 Unix 编程主题,比如说 sed 流编辑器、perl 语言、AWK 文本处理工具等。不要忘了查看 [sed 介绍][51]、sed 含义解释,还有命令行历史的[权威介绍][53]。
|
||||
|
||||
1. [catonmat][55] 支持 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #19:Debian GNU/Linux 文档和 Wiki
|
||||
|
||||
![Debian Linux 教程和 Wiki][56]
|
||||
|
||||
Debian 是另外一个 Linux 操作系统,其主要使用的软件以 GNU 许可证发布。Debian 因严格坚持 Unix 和自由软件的理念而闻名,它也是很受欢迎并且有一定影响力的 Linux 发行版本之一。 Ubuntu 等发行版本都是基于 Debian 的。Debian 项目以一种易于访问的形式提供给用户合适的文档。这个网站分为 Wiki、安装指导、常见问题、支持论坛几个模块。
|
||||
|
||||
1. Debian GNU/Linux [文档][57] 支持 html 和其它格式访问
|
||||
2. Debian GNU/Linux [wiki][58]
|
||||
3. 是否支持论坛:[是][59]
|
||||
|
||||
### #20:Linux Sea
|
||||
|
||||
Linux Sea 这本书提供了比较通俗易懂但充满技术(从最终用户角度来看)的 Linux 操作系统的介绍,使用 Gentoo Linux 作为例子。它既没有谈论 Linux 内核或 Linux 发行版的历史,也没有谈到 Linux 用户不那么感兴趣的细节。
|
||||
|
||||
1. Linux [sea][60] 支持 html 格式访问
|
||||
2. 是否支持论坛: 否
|
||||
|
||||
### #21:O'reilly Commons
|
||||
|
||||
![免费 Linux / Unix / Php / Javascript / Ubuntu 学习笔记][61]
|
||||
|
||||
O'reilly 出版社发布了不少 wiki 格式的文章。这个网站主要是为了给那些喜欢创作、参考、使用、修改、更新和修订来自 O'Reilly 或者其它来源的素材的社区提供资料。这个网站包含关于 Ubuntu、PHP、Spamassassin、Linux 等的免费书籍。
|
||||
|
||||
1. Oreilly [commons][62] 支持 Wiki 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #22:Ubuntu 袖珍指南
|
||||
|
||||
![Ubuntu 新手书籍][63]
|
||||
|
||||
这本书的作者是 Keir Thomas。这本指南(或者说是书籍)对于所有 ubuntu 用户来说都值得一读。这本书旨在向用户介绍 Ubuntu 操作系统和其所依赖的理念。你可以从官网下载这本书的 PDF 版本,也可以在亚马逊买印刷版。
|
||||
|
||||
1. Ubuntu [pocket guide][64] 支持 PDF 和印刷版本.
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #23: Linux: Rute User's Tutorial and Exposition
|
||||
|
||||
![GNU/LINUX system administration book][65]
|
||||
|
||||
这本书涵盖了 GNU/LINUX 系统管理,主要是对主流的发布版本比如红帽和 Debian 的说明,可以作为新用户的教程和高级管理员的参考。这本书旨在给出 Unix 系统的每个面的简明彻底的解释和实践性的例子。想要全面了解 Linux 的人都不需要再看了 —— 这里没有涉及的内容。
|
||||
|
||||
1. Linux: [Rute User's Tutorial and Exposition][66] 支持印刷版和 html 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #24:高级 Linux 编程
|
||||
|
||||
![高级 Linux 编程][67]
|
||||
|
||||
这本书是写给那些已经熟悉了 C 语言编程的程序员的。这本书采取一种教程式的方式来讲述大多数在 GNU/Linux 系统应用编程中重要的概念和功能特性。如果你是一个已经对 GNU/Linux 系统编程有一定经验的开发者,或者是对其它类 Unix 系统编程有一定经验的开发者,或者对 GNU/Linux 软件开发有兴趣,或者想要从非 Unix 系统环境转换到 Unix 平台并且已经熟悉了优秀软件的开发原则,那你很适合读这本书。另外,你会发现这本书同样适合于 C 和 C++ 编程。
|
||||
|
||||
1. [高级 Linux 编程][68] 支持印刷版和 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #25: LPI 101 Course Notes
|
||||
|
||||
![Linux 国际专业协会认证书籍][69]
|
||||
|
||||
LPIC 1、2、3 级是用于 Linux 系统管理员认证的。这个网站提供了 LPI 101 和 LPI 102 的测试训练。这些是根据 <ruby>GNU 自由文档协议<rt>GNU Free Documentation Licence</rt></ruby>(FDL)发布的。这些课程材料基于 Linux 国际专业协会的 LPI 101 和 102 考试的目标。这个课程是为了提供给你一些必备的 Linux 系统的操作和管理的技能。
|
||||
|
||||
1. LPI [训练手册][70] 支持 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #26: FLOSS 手册
|
||||
|
||||
![FLOSS Manuals is a collection of manuals about free and open source software][72]
|
||||
|
||||
FLOSS 手册是一系列关于自由和开源软件以及用于创建它们的工具和使用这些工具的社区的手册。社区的成员包含作者、编辑、设计师、软件开发者、积极分子等。这些手册中说明了怎样安装使用一些自由和开源软件,如何操作(比如设计和维持在线安全)开源软件,这其中也包含如何使用或支持自由软件和格式的自由文化服务手册。你也会发现关于一些像 VLC、 [Linux 视频编辑][71]、 Linux、 OLPC / SUGAR、 GRAPHICS 等软件的手册。
|
||||
|
||||
1. 你可以浏览 [FOSS 手册][73] 支持 Wiki 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #27:Linux 入门包
|
||||
|
||||
![Linux 入门包][74]
|
||||
|
||||
刚接触 Linux 这个美好世界?想找一个简单的入门方式?你可以下载一个 130 页的指南来入门。这个指南会向你展示如何在你的个人电脑上安装 Linux,如何浏览桌面,掌握最主流行的 Linux 程序和修复可能出现的问题的方法。
|
||||
|
||||
1. [Linux 入门包][75]支持 PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #28:Linux.com - Linux 信息来源
|
||||
|
||||
Linux.com 是 Linux 基金会的一个产品。这个网站上提供一些新闻、指南、教程和一些关于 Linux 的其它信息。利用全球 Linux 用户的力量来通知、写作、连接 Linux 的事务。
|
||||
|
||||
1. 在线访问 [Linux.com][76]
|
||||
2. 是否支持论坛:是
|
||||
|
||||
### #29: LWN
|
||||
|
||||
LWN 是一个注重自由软件及用于 Linux 和其它类 Unix 操作系统的软件的网站。这个网站有周刊、基本上每天发布的单独文章和文章的讨论对话。该网站提供有关 Linux 和 FOSS 相关的开发、法律、商业和安全问题的全面报道。
|
||||
|
||||
1. 在线访问 [lwn.net][77]
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### #30:Mac OS X 相关网站
|
||||
|
||||
与 Mac OS X 相关网站的快速链接:
|
||||
|
||||
* [Mac OS X 提示][78] —— 这个网站专用于苹果的 Mac OS X Unix 操作系统。网站有很多有关 Bash 和 Mac OS X 的使用建议、技巧和教程
|
||||
* [Mac OS 开发库][79] —— 苹果拥有大量和 OS X 开发相关的优秀系列内容。不要忘了看一看 [bash shell 脚本入门][80]
|
||||
* [Apple 知识库][81] - 这个有点像 RHN 的知识库。这个网站提供了所有苹果产品包括 OS X 相关的指南和故障报修建议。
|
||||
|
||||
### #30: NetBSD
|
||||
|
||||
(LCTT 译注:没错,又一个 30)
|
||||
|
||||
NetBSD 是另一个基于 BSD Unix 操作系统的自由开源操作系统。NetBSD 项目专注于系统的高质量设计、稳定性和性能。由于 NetBSD 的可移植性和伯克利式的许可证,NetBSD 常用于嵌入式系统。这个网站提供了一些 NetBSD 官方文档和各种第三方文档的链接。
|
||||
|
||||
1. 在线访问 [netbsd][82] 文档,支持 html、PDF 格式
|
||||
2. 是否支持论坛:否
|
||||
|
||||
### 你要做的事
|
||||
|
||||
这是我的个人列表,这可能并不完全是权威的,因此如果你有你自己喜欢的独特 Unix/Linux 网站,可以在下方参与评论分享。
|
||||
|
||||
// 图片来源: [Flickr photo][83] PanelSwitchman。一些连接是用户在我们的 Facebook 粉丝页面上建议添加的。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者和经验丰富的系统管理员以及 Linux 操作系统 / Unix shell 脚本的培训师。它曾与全球客户及各行各业合作,包括 IT、教育,国防和空间研究以及一些非营利部门。可以关注作者的 [Twitter][84]、[Facebook][85]、[Google+][86]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-documentations.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[ScarboroughCoral](https://github.com/ScarboroughCoral)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2011/12/unix-pdp11.jpg "Dennis Ritchie and Ken Thompson working with UNIX PDP11"
|
||||
[2]:https://www.cyberciti.biz/media/new/tips/2011/12/redhat-enterprise-linux-docs.png "Red hat Enterprise Linux Docs"
|
||||
[3]:https://access.redhat.com/documentation/en-us/
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2011/12/centos-linux-wiki.png "Centos Linux Wiki, Support, Documents"
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2011/12/arch-linux-wiki.png "Arch Linux wiki and tutorials "
|
||||
[6]:https://wiki.archlinux.org/index.php/Category:Networking_%28English%29
|
||||
[7]:https://bbs.archlinux.org/
|
||||
[8]:https://wiki.archlinux.org/
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2011/12/gentoo-linux-wiki1.png "Gentoo Linux Handbook and Wiki"
|
||||
[10]:http://www.gentoo.org/doc/en/handbook/
|
||||
[11]:https://wiki.gentoo.org
|
||||
[12]:https://forums.gentoo.org/
|
||||
[13]:http://gentoo-wiki.com
|
||||
[14]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-linux-wiki.png "Ubuntu Linux Wiki and Forums"
|
||||
[15]:https://help.ubuntu.com/community
|
||||
[16]:https://help.ubuntu.com/
|
||||
[17]:https://ubuntuforums.org/
|
||||
[18]:https://www.cyberciti.biz/media/new/tips/2011/12/ibm-devel.png "IBM: Technical for Linux programmers and system administrators"
|
||||
[19]:https://www.ibm.com/developerworks/learn/linux/index.html
|
||||
[20]:https://www.ibm.com/developerworks/community/forums/html/public?lang=en
|
||||
[21]:https://www.cyberciti.biz/media/new/tips/2011/12/freebsd-docs.png "Freebsd Documentation"
|
||||
[22]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-hackers-wiki.png "Bash hackers wiki for bash users"
|
||||
[23]:http://wiki.bash-hackers.org/doku.php
|
||||
[24]:https://www.cyberciti.biz/media/new/tips/2011/12/bash-faq.png "Bash FAQ: Answers to frequently asked questions about GNU/BASH"
|
||||
[25]:http://mywiki.wooledge.org/BashPitfalls
|
||||
[26]:https://mywiki.wooledge.org/BashFAQ
|
||||
[27]:https://www.cyberciti.biz/media/new/tips/2011/12/howtoforge.png "Howtoforge tutorials"
|
||||
[28]:https://howtoforge.com/
|
||||
[29]:https://www.cyberciti.biz/media/new/tips/2011/12/openbsd-faq.png "OpenBSD Documenation"
|
||||
[30]:https://www.openbsd.org/faq/index.html
|
||||
[31]:https://www.openbsd.org/mail.html
|
||||
[32]:https://www.cyberciti.biz/media/new/tips/2011/12/calomel_org.png "Open Source Research and Reference Documentation"
|
||||
[33]:https://calomel.org
|
||||
[34]:https://www.cyberciti.biz/media/new/tips/2011/12/slackware-linux-book.png "Slackware Linux Book and Documentation "
|
||||
[35]:http://www.slackbook.org/
|
||||
[36]:https://www.cyberciti.biz/media/new/tips/2011/12/tldp.png "Linux Learning Site and Documentation "
|
||||
[37]:http://tldp.org/LDP/abs/html/index.html
|
||||
[38]:http://tldp.org/HOWTO/HOWTO-INDEX/howtos.html
|
||||
[39]:http://tldp.org/
|
||||
[40]:https://www.cyberciti.biz/media/new/tips/2011/12/linuxhomenetworking.png "Linux Home Networking "
|
||||
[41]:http://www.linuxhomenetworking.com/
|
||||
[42]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-action-show.png "Linux Podcast "
|
||||
[43]:http://www.jupiterbroadcasting.com/show/linuxactionshow/
|
||||
[44]:https://www.commandlinefu.com/commands/browse/sort-by-votes
|
||||
[45]:https://www.cyberciti.biz/media/new/tips/2011/12/commandlinefu.png "The best Unix / Linux Commands "
|
||||
[46]:https://commandlinefu.com/
|
||||
[47]:https://www.debian-administration.org/hof
|
||||
[48]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-admin.png "Debian Linux Adminstration: Tips and Tutorial For Sys Admin"
|
||||
[49]:https://www.debian-administration.org/
|
||||
[50]:https://www.cyberciti.biz/media/new/tips/2011/12/catonmat.png "Sed, Awk, Perl Tutorials"
|
||||
[51]:http://www.catonmat.net/blog/worlds-best-introduction-to-sed/
|
||||
[52]:https://www.catonmat.net/blog/sed-one-liners-explained-part-one/
|
||||
[53]:https://www.catonmat.net/blog/the-definitive-guide-to-bash-command-line-history/
|
||||
[54]:https://www.catonmat.net/blog/awk-one-liners-explained-part-one/
|
||||
[55]:https://catonmat.net/
|
||||
[56]:https://www.cyberciti.biz/media/new/tips/2011/12/debian-wiki.png "Debian Linux Tutorials and Wiki"
|
||||
[57]:https://www.debian.org/doc/
|
||||
[58]:https://wiki.debian.org/
|
||||
[59]:https://www.debian.org/support
|
||||
[60]:http://swift.siphos.be/linux_sea/
|
||||
[61]:https://www.cyberciti.biz/media/new/tips/2011/12/orelly.png "Oreilly Free Linux / Unix / Php / Javascript / Ubuntu Books"
|
||||
[62]:http://commons.oreilly.com/wiki/index.php/O%27Reilly_Commons
|
||||
[63]:https://www.cyberciti.biz/media/new/tips/2011/12/ubuntu-guide.png "Ubuntu Book For New Users"
|
||||
[64]:http://ubuntupocketguide.com/
|
||||
[65]:https://www.cyberciti.biz/media/new/tips/2011/12/rute.png "GNU/LINUX system administration free book"
|
||||
[66]:https://web.archive.org/web/20160204213406/http://rute.2038bug.com/rute.html.gz
|
||||
[67]:https://www.cyberciti.biz/media/new/tips/2011/12/advanced-linux-programming.png "Download Advanced Linux Programming PDF version"
|
||||
[68]:https://github.com/MentorEmbedded/advancedlinuxprogramming
|
||||
[69]:https://www.cyberciti.biz/media/new/tips/2011/12/lpic.png "Download Linux Professional Institute Certification PDF Book"
|
||||
[70]:http://academy.delmar.edu/Courses/ITSC1358/eBooks/LPI-101.LinuxTrainingCourseNotes.pdf
|
||||
[71]://www.cyberciti.biz/faq/top5-linux-video-editing-system-software/
|
||||
[72]:https://www.cyberciti.biz/media/new/tips/2011/12/floss-manuals.png "Download manuals about free and open source software"
|
||||
[73]:https://flossmanuals.net/
|
||||
[74]:https://www.cyberciti.biz/media/new/tips/2011/12/linux-starter.png "New to Linux? Start Linux starter book [ PDF version ]"
|
||||
[75]:http://www.tuxradar.com/linuxstarterpack
|
||||
[76]:https://linux.com
|
||||
[77]:https://lwn.net/
|
||||
[78]:http://hints.macworld.com/
|
||||
[79]:https://developer.apple.com/library/mac/navigation/
|
||||
[80]:https://developer.apple.com/library/mac/#documentation/OpenSource/Conceptual/ShellScripting/Introduction/Introduction.html
|
||||
[81]:https://support.apple.com/kb/index?page=search&locale=en_US&q=
|
||||
[82]:https://www.netbsd.org/docs/
|
||||
[83]:https://www.flickr.com/photos/9479603@N02/3311745151/in/set-72157614479572582/
|
||||
[84]:https://twitter.com/nixcraft
|
||||
[85]:https://facebook.com/nixcraft
|
||||
[86]:https://plus.google.com/+CybercitiBiz
|
||||
[87]:https://wiki.centos.org/
|
||||
[88]:https://www.centos.org/forums/
|
||||
[90]: https://www.freebsd.org/docs.html
|
||||
[91]: https://forums.freebsd.org/
|
||||
108
published/20171108 Continuous infrastructure- The other CI.md
Normal file
108
published/20171108 Continuous infrastructure- The other CI.md
Normal file
@ -0,0 +1,108 @@
|
||||
持续基础设施:另一个 CI
|
||||
======
|
||||
|
||||
> 想要提升你的 DevOps 效率吗?将基础设施当成你的 CI 流程中的重要的一环。
|
||||
|
||||

|
||||
|
||||
持续交付(CD)和持续集成(CI)是 DevOps 的两个众所周知的方面。但在 CI 大肆流行的今天却忽略了另一个关键性的 "I":<ruby>基础设施<rt>infrastructure</rt></ruby>。
|
||||
|
||||
曾经有一段时间 “基础设施”就意味着<ruby>无头<rt>headless</rt></ruby>的黑盒子、庞大的服务器,和高耸的机架 —— 更不用说漫长的采购流程和对盈余负载的错误估计。后来到了虚拟机时代,把基础设施处理得很好,虚拟化 —— 以前的世界从未有过这样。我们不再需要管理实体的服务器。仅仅是简单的点击,我们就可以创建和销毁、开始和停止、升级和降级我们的服务器。
|
||||
|
||||
有一个关于银行的流行故事:它们实现了数字化,并且引入了在线表格,用户需要手动填写表格、打印,然后邮寄回银行(LCTT 译注:我真的遇到过有人问我这样的需求怎么办)。这就是我们今天基础设施遇到的情况:使用新技术来做和以前一样的事情。
|
||||
|
||||
在这篇文章中,我们会看到在基础设施管理方面的进步,将基础设施视为一个版本化的组件并试着探索<ruby>不可变服务器<rt>immutable server</rt></ruby>的概念。在后面的文章中,我们将了解如何使用开源工具来实现持续的基础设施。
|
||||
|
||||
![continuous infrastructure pipeline][2]
|
||||
|
||||
*实践中的持续集成流程*
|
||||
|
||||
这是我们熟悉的 CI,尽早发布、经常发布的循环流程。这个流程缺少一个关键的组件:基础设施。
|
||||
|
||||
突击小测试:
|
||||
|
||||
* 你怎样创建和升级你的基础设施?
|
||||
* 你怎样控制和追溯基础设施的改变?
|
||||
* 你的基础设施是如何与你的业务进行匹配的?
|
||||
* 你是如何确保在正确的基础设施配置上进行测试的?
|
||||
|
||||
要回答这些问题,就要了解<ruby>持续基础设施<rt>continuous infrastructure</rt></ruby>。把 CI 构建流程分为<ruby>代码持续集成<rt>continuous integration code</rt></ruby>(CIc)和<ruby>基础设施持续集成<rt>continuous integration infrastructure</rt></ruby>(CIi)来并行开发和构建代码和基础设施,再将两者融合到一起进行测试。把基础设施构建视为 CI 流程中的重要的一环。
|
||||
|
||||
![pipeline with infrastructure][4]
|
||||
|
||||
*包含持续基础设施的 CI 流程*
|
||||
|
||||
关于 CIi 定义的几个方面:
|
||||
|
||||
1. 代码
|
||||
|
||||
通过代码来创建基础设施架构,而不是通过安装。<ruby>基础设施如代码<rt>Infrastructure as code</rt></ruby>(IaC)是使用配置脚本创建基础设施的现代最流行的方法。这些脚本遵循典型的编码和单元测试周期(请参阅下面关于 Terraform 脚本的示例)。
|
||||
2. 版本
|
||||
|
||||
IaC 组件在源码仓库中进行版本管理。这让基础设施的拥有了版本控制的所有好处:一致性,可追溯性,分支和标记。
|
||||
3. 管理
|
||||
|
||||
通过编码和版本化的基础设施管理,你可以使用你所熟悉的测试和发布流程来管理基础设施的开发。
|
||||
|
||||
CIi 提供了下面的这些优势:
|
||||
|
||||
1. <ruby>一致性<rt>Consistency</rt></ruby>
|
||||
|
||||
版本化和标记化的基础设施意味着你可以清楚的知道你的系统使用了哪些组件和配置。这建立了一个非常好的 DevOps 实践,用来鉴别和管理基础设施的一致性。
|
||||
2. <ruby>可重现性<rt>Reproducibility</rt></ruby>
|
||||
|
||||
通过基础设施的标记和基线,重建基础设施变得非常容易。想想你是否经常听到这个:“但是它在我的机器上可以运行!”现在,你可以在本地的测试平台中快速重现类似生产环境,从而将环境像变量一样在你的调试过程中删除。
|
||||
3. <ruby>可追溯性<rt>Traceability</rt></ruby>
|
||||
|
||||
你是否还记得曾经有过多少次寻找到底是谁更改了文件夹权限的经历,或者是谁升级了 `ssh` 包?代码化的、版本化的,发布的基础设施消除了临时性变更,为基础设施的管理带来了可追踪性和可预测性。
|
||||
4. <ruby>自动化<rt>Automation</rt></ruby>
|
||||
|
||||
借助脚本化的基础架构,自动化是下一个合乎逻辑的步骤。自动化允许你按需创建基础设施,并在使用完成后销毁它,所以你可以将更多宝贵的时间和精力用在更重要的任务上。
|
||||
5. <ruby>不变性<rt>Immutability</rt></ruby>
|
||||
|
||||
CIi 带来了不可变基础设施等创新。你可以创建一个新的基础设施组件而不是通过升级(请参阅下面有关不可变设施的说明)。
|
||||
|
||||
持续基础设施是从运行基础环境到运行基础组件的进化。像处理代码一样,通过证实的 DevOps 流程来完成。对传统的 CI 的重新定义包含了缺少的那个 “i”,从而形成了连贯的 CD 。
|
||||
|
||||
**(CIc + CIi) = CI -> CD**
|
||||
|
||||
### 基础设施如代码 (IaC)
|
||||
|
||||
CIi 流程的一个关键推动因素是<ruby>基础设施如代码<rt>infrastructure as code</rt></ruby>(IaC)。IaC 是一种使用配置文件进行基础设施创建和升级的机制。这些配置文件像其他的代码一样进行开发,并且使用版本管理系统进行管理。这些文件遵循一般的代码开发流程:单元测试、提交、构建和发布。IaC 流程拥有版本控制带给基础设施开发的所有好处,如标记、版本一致性,和修改可追溯。
|
||||
|
||||
这有一个简单的 Terraform 脚本用来在 AWS 上创建一个双层基础设施的简单示例,包括虚拟私有云(VPC)、弹性负载(ELB),安全组和一个 NGINX 服务器。[Terraform][5] 是一个通过脚本创建和更改基础设施架构和开源工具。
|
||||
|
||||
![terraform script][7]
|
||||
|
||||
*Terraform 脚本创建双层架构设施的简单示例*
|
||||
|
||||
完整的脚本请参见 [GitHub][8]。
|
||||
|
||||
### 不可变基础设施
|
||||
|
||||
你有几个正在运行的虚拟机,需要更新安全补丁。一个常见的做法是推送一个远程脚本单独更新每个系统。
|
||||
|
||||
要是不更新旧系统,如何才能直接丢弃它们并部署安装了新安全补丁的新系统呢?这就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>。因为之前的基础设施是版本化的、标签化的,所以安装补丁就只是更新该脚本并将其推送到发布流程而已。
|
||||
|
||||
现在你知道为什么要说基础设施在 CI 流程中特别重要了吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/continuous-infrastructure-other-ci
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Jamskr](https://github.com/Jamskr)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gammay
|
||||
[1]:/file/376916
|
||||
[2]:https://opensource.com/sites/default/files/images/life-uploads/figure1.jpg (continuous infrastructure pipeline in use)
|
||||
[3]:/file/376921
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/figure2.jpg (CI pipeline with infrastructure)
|
||||
[5]:https://github.com/hashicorp/terraform
|
||||
[6]:/file/376926
|
||||
[7]:https://opensource.com/sites/default/files/images/life-uploads/figure3_0.png (sample terraform script)
|
||||
[8]:https://github.com/terraform-providers/terraform-provider-aws/tree/master/examples/two-tier
|
||||
@ -0,0 +1,869 @@
|
||||
编写你的第一行 HTML 代码,来帮助蝙蝠侠写一封情书
|
||||
======
|
||||
|
||||

|
||||
|
||||
在一个美好的夜晚,你的肚子拒绝消化你在晚餐吃的大块披萨,所以你不得不在睡梦中冲进洗手间。
|
||||
|
||||
在浴室里,当你在思考为什么会发生这种情况时,你听到一个来自通风口的低沉声音:“嘿,我是蝙蝠侠。”
|
||||
|
||||
这时,你会怎么做呢?
|
||||
|
||||
在你恐慌并处于关键时刻之前,蝙蝠侠说:“我需要你的帮助。我是一个超级极客,但我不懂 HTML。我需要用 HTML 写一封情书,你愿意帮助我吗?”
|
||||
|
||||
谁会拒绝蝙蝠侠的请求呢,对吧?所以让我们用 HTML 来写一封蝙蝠侠的情书。
|
||||
|
||||
### 你的第一个 HTML 文件
|
||||
|
||||
HTML 网页与你电脑上的其它文件一样。就同一个 .doc 文件以 MS Word 打开,.jpg 文件在图像查看器中打开一样,一个 .html 文件在浏览器中打开。
|
||||
|
||||
那么,让我们来创建一个 .html 文件。你可以在 Notepad 或其它任何编辑器中完成此任务,但我建议使用 VS Code。[在这里下载并安装 VS Code][2]。它是免费的,也是我唯一喜欢的微软产品。
|
||||
|
||||
在系统中创建一个目录,将其命名为 “HTML Practice”(不带引号)。在这个目录中,再创建一个名为 “Batman's Love Letter”(不带引号)的目录,这将是我们的项目根目录。这意味着我们所有与这个项目相关的文件都会在这里。
|
||||
|
||||
打开 VS Code,按下 `ctrl+n` 创建一个新文件,按下 `ctrl+s` 保存文件。切换到 “Batman's Love Letter” 文件夹并将其命名为 “loveletter.html”,然后单击保存。
|
||||
|
||||
现在,如果你在文件资源管理器中双击它,它将在你的默认浏览器中打开。我建议使用 Firefox 来进行 web 开发,但 Chrome 也可以。
|
||||
|
||||
让我们将这个过程与我们已经熟悉的东西联系起来。还记得你第一次拿到电脑吗?我做的第一件事是打开 MS Paint 并绘制一些东西。你在 Paint 中绘制一些东西并将其另存为图像,然后你可以在图像查看器中查看该图像。之后,如果要再次编辑该图像,你在 Paint 中重新打开它,编辑并保存它。
|
||||
|
||||
我们目前的流程非常相似。正如我们使用 Paint 创建和编辑图像一样,我们使用 VS Code 来创建和编辑 HTML 文件。就像我们使用图像查看器查看图像一样,我们使用浏览器来查看我们的 HTML 页面。
|
||||
|
||||
### HTML 中的段落
|
||||
|
||||
我们有一个空的 HTML 文件,以下是蝙蝠侠想在他的情书中写的第一段。
|
||||
|
||||
“After all the battles we fought together, after all the difficult times we saw together, and after all the good and bad moments we’ve been through, I think it’s time I let you know how I feel about you.”
|
||||
|
||||
复制这些到 VS Code 中的 loveletter.html。单击 “View -> Toggle Word Wrap (alt+z)” 自动换行。
|
||||
|
||||
保存并在浏览器中打开它。如果它已经打开,单击浏览器中的刷新按钮。
|
||||
|
||||
瞧!那是你的第一个网页!
|
||||
|
||||
我们的第一段已准备就绪,但这不是在 HTML 中编写段落的推荐方法。我们有一种特定的方法让浏览器知道一个文本是一个段落。
|
||||
|
||||
如果你用 `<p>` 和 `</p>` 来包裹文本,那么浏览器将识别 `<p>` 和 `</p>` 中的文本是一个段落。我们这样做:
|
||||
|
||||
```
|
||||
<p>After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.</p>
|
||||
```
|
||||
|
||||
通过在 `<p>` 和 `</p>`中编写段落,你创建了一个 HTML 元素。一个网页就是 HTML 元素的集合。
|
||||
|
||||
让我们首先来认识一些术语:`<p>` 是开始标签,`</p>` 是结束标签,“p” 是标签名称。元素开始和结束标签之间的文本是元素的内容。
|
||||
|
||||
### “style” 属性
|
||||
|
||||
在上面,你将看到文本覆盖屏幕的整个宽度。
|
||||
|
||||
我们不希望这样。没有人想要阅读这么长的行。让我们设定段落宽度为 550px。
|
||||
|
||||
我们可以通过使用元素的 `style` 属性来实现。你可以在其 `style` 属性中定义元素的样式(例如,在我们的示例中为宽度)。以下行将在 `p` 元素上创建一个空样式属性:
|
||||
|
||||
```
|
||||
<p style="">...</p>
|
||||
```
|
||||
|
||||
你看到那个空的 `""` 了吗?这就是我们定义元素外观的地方。现在我们要将宽度设置为 550px。我们这样做:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
After all the battles we fought together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
我们将 `width` 属性设置为 `550px`,用冒号 `:` 分隔,以分号 `;` 结束。
|
||||
|
||||
另外,注意我们如何将 `<p>` 和 `</p>` 放在单独的行中,文本内容用一个制表符缩进。像这样设置代码使其更具可读性。
|
||||
|
||||
### HTML 中的列表
|
||||
|
||||
接下来,蝙蝠侠希望列出他所钦佩的人的一些优点,例如:
|
||||
|
||||
```
|
||||
You complete my darkness with your light. I love:
|
||||
- the way you see good in the worst things
|
||||
- the way you handle emotionally difficult situations
|
||||
- the way you look at Justice
|
||||
I have learned a lot from you. You have occupied a special place in my heart over time.
|
||||
```
|
||||
|
||||
这看起来很简单。
|
||||
|
||||
让我们继续,在 `</p>` 下面复制所需的文本:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<p style="width:550px;">
|
||||
You complete my darkness with your light. I love:
|
||||
- the way you see good in the worse
|
||||
- the way you handle emotionally difficult situations
|
||||
- the way you look at Justice
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
```
|
||||
|
||||
保存并刷新浏览器。
|
||||
|
||||

|
||||
|
||||
哇!这里发生了什么,我们的列表在哪里?
|
||||
|
||||
如果你仔细观察,你会发现没有显示换行符。在代码中我们在新的一行中编写列表项,但这些项在浏览器中显示在一行中。
|
||||
|
||||
如果你想在 HTML(新行)中插入换行符,你必须使用 `<br>`。让我们来使用 `<br>`,看看它长什么样:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<p style="width:550px;">
|
||||
You complete my darkness with your light. I love: <br>
|
||||
- the way you see good in the worse <br>
|
||||
- the way you handle emotionally difficult situations <br>
|
||||
- the way you look at Justice <br>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
```
|
||||
|
||||
保存并刷新:
|
||||
|
||||

|
||||
|
||||
好的,现在它看起来就像我们想要的那样!
|
||||
|
||||
另外,注意我们没有写一个 `</br>`。有些标签不需要结束标签(它们被称为自闭合标签)。
|
||||
|
||||
还有一件事:我们没有在两个段落之间使用 `<br>`,但第二个段落仍然是从一个新行开始,这是因为 `<p>` 元素会自动插入换行符。
|
||||
|
||||
我们使用纯文本编写列表,但是有两个标签可以供我们使用来达到相同的目的:`<ul>` and `<li>`。
|
||||
|
||||
让我们解释一下名字的意思:ul 代表<ruby>无序列表<rt>Unordered List</rt></ruby>,li 代表<ruby>列表项目<rt>List Item</rt></ruby>。让我们使用它们来展示我们的列表:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
You complete my darkness with your light. I love:
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
```
|
||||
|
||||
在复制代码之前,注意差异部分:
|
||||
|
||||
* 我们删除了所有的 `<br>`,因为每个 `<li>` 会自动显示在新行中
|
||||
* 我们将每个列表项包含在 `<li>` 和 `</li>` 之间
|
||||
* 我们将所有列表项的集合包裹在 `<ul>` 和 `</ul>` 之间
|
||||
* 我们没有像 `<p>` 元素那样定义 `<ul>` 元素的宽度。这是因为 `<ul>` 是 `<p>` 的子节点,`<p>` 已经被约束到 550px,所以 `<ul>` 不会超出这个范围。
|
||||
|
||||
让我们保存文件并刷新浏览器以查看结果:
|
||||
|
||||
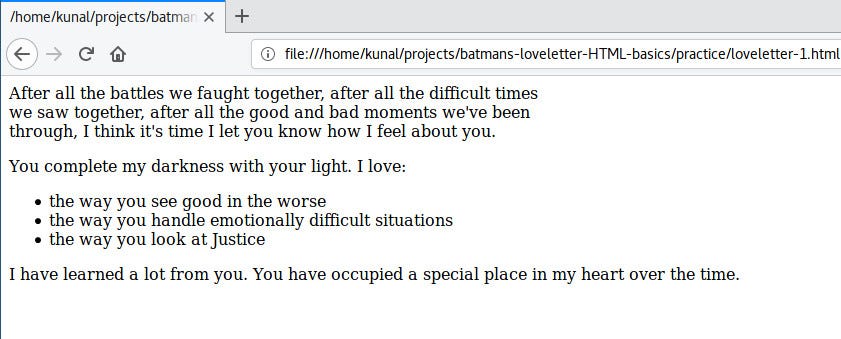
|
||||
|
||||
你会立即注意到在每个列表项之前显示了重点标志。我们现在不需要在每个列表项之前写 “-”。
|
||||
|
||||
经过仔细检查,你会注意到最后一行超出 550px 宽度。这是为什么?因为 HTML 不允许 `<ul>` 元素出现在 `<p>` 元素中。让我们将第一行和最后一行放在单独的 `<p>` 元素中:
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<ul style="width:550px;">
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
```
|
||||
|
||||
```
|
||||
<p style="width:550px;">
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
```
|
||||
|
||||
保存并刷新。
|
||||
|
||||
注意,这次我们还定义了 `<ul>` 元素的宽度。那是因为我们现在已经将 `<ul>` 元素放在了 `<p>` 元素之外。
|
||||
|
||||
定义情书中所有元素的宽度会变得很麻烦。我们有一个特定的元素用于此目的:`<div>` 元素。一个 `<div>` 元素就是一个通用容器,用于对内容进行分组,以便轻松设置样式。
|
||||
|
||||
让我们用 `<div>` 元素包装整个情书,并为其赋予宽度:550px 。
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
棒极了,我们的代码现在看起来简洁多了。
|
||||
|
||||
### HTML 中的标题
|
||||
|
||||
到目前为止,蝙蝠侠对结果很高兴,他希望在情书上标题。他想写一个标题: “Bat Letter”。当然,你已经看到这个名字了,不是吗?:D
|
||||
|
||||
你可以使用 `<h1>`、`<h2>`、`<h3>`、`<h4>`、`<h5>` 和 `<h6>` 标签来添加标题,`<h1>` 是最大的标题和最主要的标题,`<h6>` 是最小的标题。
|
||||
|
||||

|
||||
|
||||
让我们在第二段之前使用 `<h1>` 做主标题和一个副标题:
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<h1>Bat Letter</h1>
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
保存,刷新。
|
||||
|
||||
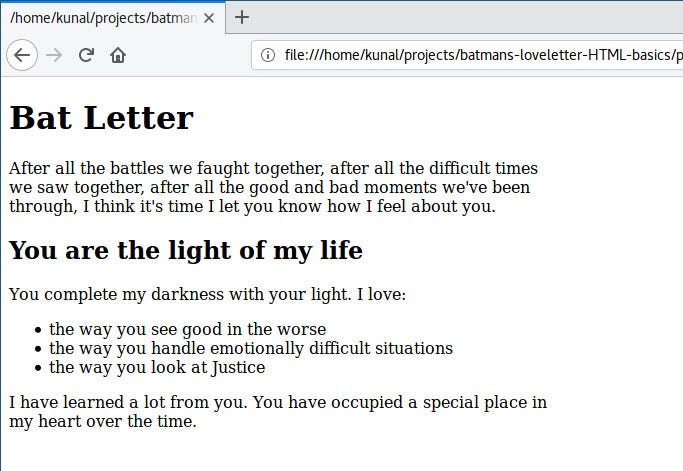
|
||||
|
||||
### HTML 中的图像
|
||||
|
||||
我们的情书尚未完成,但在继续之前,缺少一件大事:蝙蝠侠标志。你见过是蝙蝠侠的东西但没有蝙蝠侠的标志吗?
|
||||
|
||||
并没有。
|
||||
|
||||
所以,让我们在情书中添加一个蝙蝠侠标志。
|
||||
|
||||
在 HTML 中包含图像就像在一个 Word 文件中包含图像一样。在 MS Word 中,你到 “菜单 -> 插入 -> 图像 -> 然后导航到图像位置为止 -> 选择图像 -> 单击插入”。
|
||||
|
||||
在 HTML 中,我们使用 `<img>` 标签让浏览器知道我们需要加载的图像,而不是单击菜单。我们在 `src` 属性中写入文件的位置和名称。如果图像在项目根目录中,我们可以简单地在 `src` 属性中写入图像文件的名称。
|
||||
|
||||
在我们深入编码之前,从[这里][3]下载蝙蝠侠标志。你可能希望裁剪图像中的额外空白区域。复制项目根目录中的图像并将其重命名为 “bat-logo.jpeg”。
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<h1>Bat Letter</h1>
|
||||
<img src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
我们在第 3 行包含了 `<img>` 标签。这个标签也是一个自闭合的标签,所以我们不需要写 `</img>`。在 `src` 属性中,我们给出了图像文件的名称。这个名称应与图像名称完全相同,包括扩展名(.jpeg)及其大小写。
|
||||
|
||||
保存并刷新,查看结果。
|
||||
|
||||

|
||||
|
||||
该死的!刚刚发生了什么?
|
||||
|
||||
当使用 `<img>` 标签包含图像时,默认情况下,图像将以其原始分辨率显示。在我们的例子中,图像比 550px 宽得多。让我们使用 `style` 属性定义它的宽度:
|
||||
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<h1>Bat Letter</h1>
|
||||
<img src="bat-logo.jpeg" style="width:100%">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
你会注意到,这次我们定义宽度使用了 “%” 而不是 “px”。当我们在 “%” 中定义宽度时,它将占据父元素宽度的百分比。因此,100% 的 550px 将为我们提供 550px。
|
||||
|
||||
保存并刷新,查看结果。
|
||||
|
||||
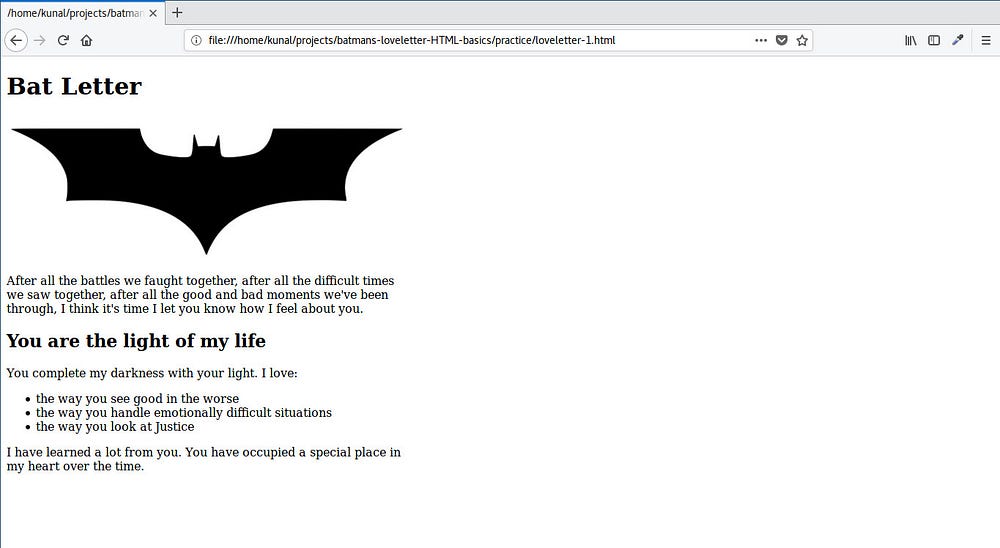
|
||||
|
||||
太棒了!这让蝙蝠侠的脸露出了羞涩的微笑 :)。
|
||||
|
||||
### HTML 中的粗体和斜体
|
||||
|
||||
现在蝙蝠侠想在最后几段中承认他的爱。他有以下文本供你用 HTML 编写:
|
||||
|
||||
“I have a confession to make
|
||||
|
||||
It feels like my chest _does_ have a heart. You make my heart beat. Your smile brings a smile to my face, your pain brings pain to my heart.
|
||||
|
||||
I don’t show my emotions, but I think this man behind the mask is falling for you.”
|
||||
|
||||
当阅读到这里时,你会问蝙蝠侠:“等等,这是给谁的?”蝙蝠侠说:
|
||||
|
||||
“这是给超人的。”
|
||||
|
||||

|
||||
|
||||
你说:哦!我还以为是给神奇女侠的呢。
|
||||
|
||||
蝙蝠侠说:不,这是给超人的,请在最后写上 “I love you Superman.”。
|
||||
|
||||
好的,我们来写:
|
||||
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<h1>Bat Letter</h1>
|
||||
<img src="bat-logo.jpeg" style="width:100%">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest does have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p>I love you Superman.</p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
这封信差不多完成了,蝙蝠侠另外想再做两次改变。蝙蝠侠希望在最后段落的第一句中的 “does” 一词是斜体,而 “I love you Superman” 这句话是粗体的。
|
||||
|
||||
我们使用 `<em>` 和 `<strong>` 以斜体和粗体显示文本。让我们来更新这些更改:
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
<h1>Bat Letter</h1>
|
||||
<img src="bat-logo.jpeg" style="width:100%">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
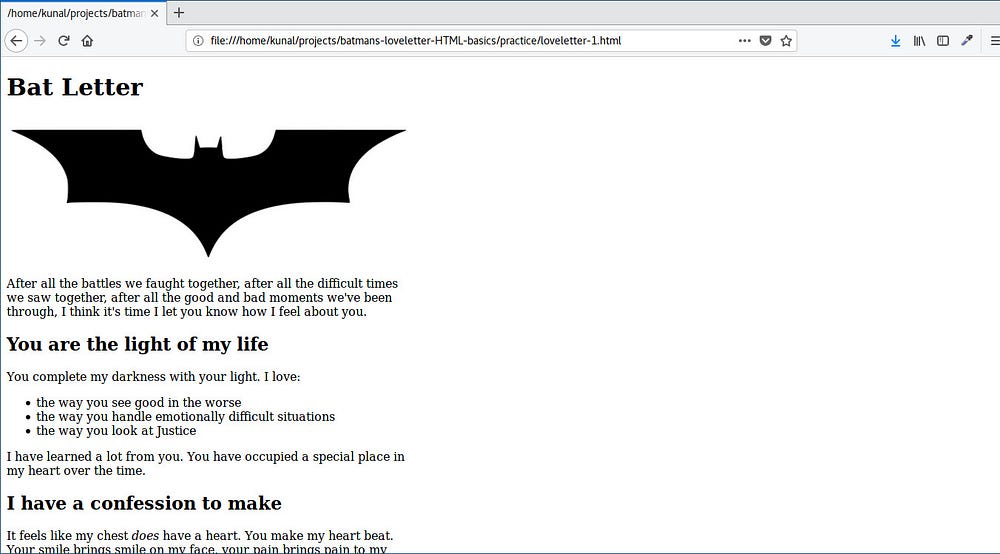
|
||||
|
||||
### HTML 中的样式
|
||||
|
||||
你可以通过三种方式设置样式或定义 HTML 元素的外观:
|
||||
|
||||
* 内联样式:我们使用元素的 `style` 属性来编写样式。这是我们迄今为止使用的,但这不是一个好的实践。
|
||||
* 嵌入式样式:我们在由 `<style>` 和 `</style>` 包裹的 “style” 元素中编写所有样式。
|
||||
* 链接样式表:我们在具有 .css 扩展名的单独文件中编写所有元素的样式。此文件称为样式表。
|
||||
|
||||
让我们来看看如何定义 `<div>` 的内联样式:
|
||||
|
||||
```
|
||||
<div style="width:550px;">
|
||||
```
|
||||
|
||||
我们可以在 `<style>` 和 `</style>` 里面写同样的样式:
|
||||
|
||||
```
|
||||
div{
|
||||
width:550px;
|
||||
}
|
||||
```
|
||||
|
||||
在嵌入式样式中,我们编写的样式是与元素分开的。所以我们需要一种方法来关联元素及其样式。第一个单词 “div” 就做了这样的活。它让浏览器知道花括号 `{...}` 里面的所有样式都属于 “div” 元素。由于这种语法确定要应用样式的元素,因此它称为一个选择器。
|
||||
|
||||
我们编写样式的方式保持不变:属性(`width`)和值(`550px`)用冒号(`:`)分隔,以分号(`;`)结束。
|
||||
|
||||
让我们从 `<div>` 和 `<img>` 元素中删除内联样式,将其写入 `<style>` 元素:
|
||||
|
||||
```
|
||||
<style>
|
||||
div{
|
||||
width:550px;
|
||||
}
|
||||
img{
|
||||
width:100%;
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
```
|
||||
<div>
|
||||
<h1>Bat Letter</h1>
|
||||
<img src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
保存并刷新,结果应保持不变。
|
||||
|
||||
但是有一个大问题,如果我们的 HTML 文件中有多个 `<div>` 和 `<img>` 元素该怎么办?这样我们在 `<style>` 元素中为 div 和 img 定义的样式就会应用于页面上的每个 div 和 img。
|
||||
|
||||
如果你在以后的代码中添加另一个 div,那么该 div 也将变为 550px 宽。我们并不希望这样。
|
||||
|
||||
我们想要将我们的样式应用于现在正在使用的特定 div 和 img。为此,我们需要为 div 和 img 元素提供唯一的 id。以下是使用 `id` 属性为元素赋予 id 的方法:
|
||||
|
||||
```
|
||||
<div id="letter-container">
|
||||
```
|
||||
|
||||
以下是如何在嵌入式样式中将此 id 用作选择器:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
注意 `#` 符号。它表示它是一个 id,`{...}` 中的样式应该只应用于具有该特定 id 的元素。
|
||||
|
||||
让我们来应用它:
|
||||
|
||||
```
|
||||
<style>
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
```
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
```
|
||||
|
||||
```
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
HTML 已经准备好了嵌入式样式。
|
||||
|
||||
但是,你可以看到,随着我们包含越来越多的样式,`<style></style>` 将变得很大。这可能很快会混乱我们的主 HTML 文件。
|
||||
|
||||
因此,让我们更进一步,通过将 `<style>` 标签内的内容复制到一个新文件来使用链接样式。
|
||||
|
||||
在项目根目录中创建一个新文件,将其另存为 “style.css”:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
我们不需要在 CSS 文件中写 `<style>` 和 `</style>`。
|
||||
|
||||
我们需要使用 HTML 文件中的 `<link>` 标签来将新创建的 CSS 文件链接到 HTML 文件。以下是我们如何做到这一点:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
```
|
||||
|
||||
我们使用 `<link>` 元素在 HTML 文档中包含外部资源,它主要用于链接样式表。我们使用的三个属性是:
|
||||
|
||||
* `rel`:关系。链接文件与文档的关系。具有 .css 扩展名的文件称为样式表,因此我们保留 rel=“stylesheet”。
|
||||
* `type`:链接文件的类型;对于一个 CSS 文件来说它是 “text/css”。
|
||||
* `href`:超文本参考。链接文件的位置。
|
||||
|
||||
link 元素的结尾没有 `</link>`。因此,`<link>` 也是一个自闭合的标签。
|
||||
|
||||
```
|
||||
<link rel="gf" type="cute" href="girl.next.door">
|
||||
```
|
||||
|
||||
如果只是得到一个女朋友,那么很容易:D
|
||||
|
||||
可惜没有那么简单,让我们继续前进。
|
||||
|
||||
这是我们 “loveletter.html” 的内容:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
```
|
||||
|
||||
“style.css” 内容:
|
||||
|
||||
```
|
||||
#letter-container{
|
||||
width:550px;
|
||||
}
|
||||
#header-bat-logo{
|
||||
width:100%;
|
||||
}
|
||||
```
|
||||
|
||||
保存文件并刷新,浏览器中的输出应保持不变。
|
||||
|
||||
### 一些手续
|
||||
|
||||
我们的情书已经准备好给蝙蝠侠,但还有一些正式的片段。
|
||||
|
||||
与其他任何编程语言一样,HTML 自出生以来(1990 年)经历过许多版本,当前版本是 HTML5。
|
||||
|
||||
那么,浏览器如何知道你使用哪个版本的 HTML 来编写页面呢?要告诉浏览器你正在使用 HTML5,你需要在页面顶部包含 `<!DOCTYPE html>`。对于旧版本的 HTML,这行不同,但你不需要了解它们,因为我们不再使用它们了。
|
||||
|
||||
此外,在之前的 HTML 版本中,我们曾经将整个文档封装在 `<html></html>` 标签内。整个文件分为两个主要部分:头部在 `<head></head>` 里面,主体在 `<body></body>` 里面。这在 HTML5 中不是必须的,但由于兼容性原因,我们仍然这样做。让我们用 `<Doctype>`, `<html>`、 `<head>` 和 `<body>` 更新我们的代码:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
主要内容在 `<body>` 里面,元信息在 `<head>` 里面。所以我们把 `<div>` 保存在 `<body>` 里面并加载 `<head>` 里面的样式表。
|
||||
|
||||
保存并刷新,你的 HTML 页面应显示与之前相同的内容。
|
||||
|
||||
### HTML 的标题
|
||||
|
||||
我发誓,这是最后一次改变。
|
||||
|
||||
你可能已经注意到选项卡的标题正在显示 HTML 文件的路径:
|
||||
|
||||
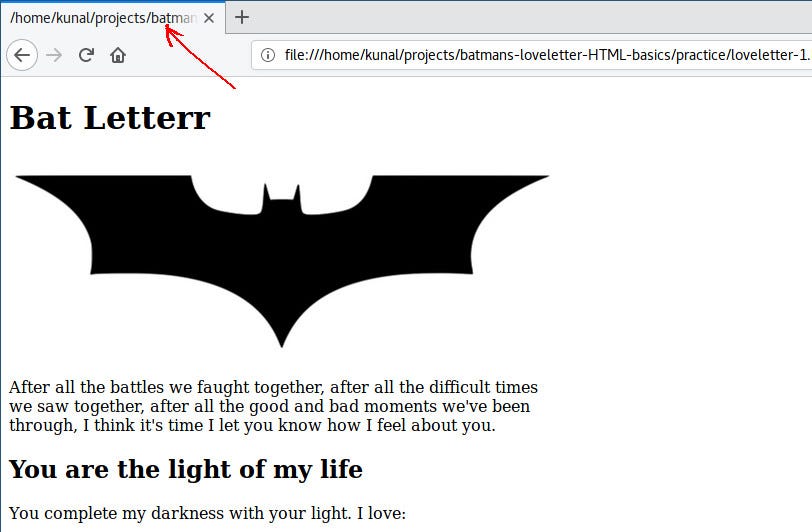
|
||||
|
||||
我们可以使用 `<title>` 标签来定义 HTML 文件的标题。标题标签也像链接标签一样在 `<head>` 内部。让我们我们在标题中加上 “Bat Letter”:
|
||||
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html>
|
||||
<head>
|
||||
<title>Bat Letter</title>
|
||||
<link rel="stylesheet" type="text/css" href="style.css">
|
||||
</head>
|
||||
<body>
|
||||
<div id="letter-container">
|
||||
<h1>Bat Letter</h1>
|
||||
<img id="header-bat-logo" src="bat-logo.jpeg">
|
||||
<p>
|
||||
After all the battles we faught together, after all the difficult times we saw together, after all the good and bad moments we've been through, I think it's time I let you know how I feel about you.
|
||||
</p>
|
||||
<h2>You are the light of my life</h2>
|
||||
<p>
|
||||
You complete my darkness with your light. I love:
|
||||
</p>
|
||||
<ul>
|
||||
<li>the way you see good in the worse</li>
|
||||
<li>the way you handle emotionally difficult situations</li>
|
||||
<li>the way you look at Justice</li>
|
||||
</ul>
|
||||
<p>
|
||||
I have learned a lot from you. You have occupied a special place in my heart over the time.
|
||||
</p>
|
||||
<h2>I have a confession to make</h2>
|
||||
<p>
|
||||
It feels like my chest <em>does</em> have a heart. You make my heart beat. Your smile brings smile on my face, your pain brings pain to my heart.
|
||||
</p>
|
||||
<p>
|
||||
I don't show my emotions, but I think this man behind the mask is falling for you.
|
||||
</p>
|
||||
<p><strong>I love you Superman.</strong></p>
|
||||
<p>
|
||||
Your not-so-secret-lover, <br>
|
||||
Batman
|
||||
</p>
|
||||
</div>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
保存并刷新,你将看到在选项卡上显示的是 “Bat Letter” 而不是文件路径。
|
||||
|
||||
蝙蝠侠的情书现在已经完成。
|
||||
|
||||
恭喜!你用 HTML 制作了蝙蝠侠的情书。
|
||||
|
||||

|
||||
|
||||
### 我们学到了什么
|
||||
|
||||
我们学习了以下新概念:
|
||||
|
||||
* 一个 HTML 文档的结构
|
||||
* 在 HTML 中如何写元素(`<p></p>`)
|
||||
* 如何使用 style 属性在元素内编写样式(这称为内联样式,尽可能避免这种情况)
|
||||
* 如何在 `<style>...</style>` 中编写元素的样式(这称为嵌入式样式)
|
||||
* 在 HTML 中如何使用 `<link>` 在单独的文件中编写样式并链接它(这称为链接样式表)
|
||||
* 什么是标签名称,属性,开始标签和结束标签
|
||||
* 如何使用 id 属性为一个元素赋予 id
|
||||
* CSS 中的标签选择器和 id 选择器
|
||||
|
||||
我们学习了以下 HTML 标签:
|
||||
|
||||
* `<p>`:用于段落
|
||||
* `<br>`:用于换行
|
||||
* `<ul>`、`<li>`:显示列表
|
||||
* `<div>`:用于分组我们信件的元素
|
||||
* `<h1>`、`<h2>`:用于标题和子标题
|
||||
* `<img>`:用于插入图像
|
||||
* `<strong>`、`<em>`:用于粗体和斜体文字样式
|
||||
* `<style>`:用于嵌入式样式
|
||||
* `<link>`:用于包含外部样式表
|
||||
* `<html>`:用于包裹整个 HTML 文档
|
||||
* `<!DOCTYPE html>`:让浏览器知道我们正在使用 HTML5
|
||||
* `<head>`:包裹元信息,如 `<link>` 和 `<title>`
|
||||
* `<body>`:用于实际显示的 HTML 页面的主体
|
||||
* `<title>`:用于 HTML 页面的标题
|
||||
|
||||
我们学习了以下 CSS 属性:
|
||||
|
||||
* width:用于定义元素的宽度
|
||||
* CSS 单位:“px” 和 “%”
|
||||
|
||||
朋友们,这就是今天的全部了,下一个教程中见。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:开发者 + 作者 | supersarkar.com | twitter.com/supersarkar
|
||||
|
||||
-------------
|
||||
|
||||
via: https://medium.freecodecamp.org/for-your-first-html-code-lets-help-batman-write-a-love-letter-64c203b9360b
|
||||
|
||||
作者:[Kunal Sarkar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@supersarkar
|
||||
[1]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[2]:https://code.visualstudio.com/
|
||||
[3]:https://www.pexels.com/photo/batman-black-and-white-logo-93596/
|
||||
[4]:http://supersarkar.com/
|
||||
@ -1,10 +1,11 @@
|
||||
12 条实用的 zypper 命令范例
|
||||
======
|
||||
zypper 是 Suse Linux 系统的包和补丁管理器,你可以根据下面的 12 条附带输出示例的实用范例来学习 zypper 命令的使用。
|
||||
|
||||
`zypper` 是 Suse Linux 系统的包和补丁管理器,你可以根据下面的 12 条附带输出示例的实用范例来学习 `zypper` 命令的使用。
|
||||
|
||||
![zypper 命令示例][1]
|
||||
|
||||
Suse Linux 使用 zypper 进行包管理,其是一个由 [ZYpp 包管理引擎][2]提供技术支持的包管理系统。在此篇文章中我们将分享 12 条附带输出示例的实用 zypper 命令,能帮助你处理日常的系统管理任务。
|
||||
Suse Linux 使用 `zypper` 进行包管理,其是一个由 [ZYpp 包管理引擎][2]提供的包管理系统。在此篇文章中我们将分享 12 条附带输出示例的实用 `zypper` 命令,能帮助你处理日常的系统管理任务。
|
||||
|
||||
不带参数的 `zypper` 命令将列出所有可用的选项,这比参考详细的 man 手册要容易上手得多。
|
||||
|
||||
@ -18,12 +19,12 @@ root@kerneltalks # zypper
|
||||
--help, -h 帮助
|
||||
--version, -V 输出版本号
|
||||
--promptids 输出 zypper 用户提示符列表
|
||||
--config, -c <file> 使用制定的配置文件来替代默认的
|
||||
--config, -c <file> 使用指定的配置文件来替代默认的
|
||||
--userdata <string> 在历史和插件中使用的用户自定义事务 id
|
||||
--quiet, -q 忽略正常输出,只打印错误信息
|
||||
--verbose, -v 增加冗长程度
|
||||
--color
|
||||
--no-color 是否启用彩色模式如果 tty 支持
|
||||
--no-color 是否启用彩色模式,如果 tty 支持的话
|
||||
--no-abbrev, -A 表格中的文字不使用缩写
|
||||
--table-style, -s 表格样式(整型)
|
||||
--non-interactive, -n 不询问任何选项,自动使用默认答案
|
||||
@ -43,7 +44,7 @@ root@kerneltalks # zypper
|
||||
--gpg-auto-import-keys 自动信任并导入新仓库的签名密钥
|
||||
--plus-repo, -p <URI> 使用附加仓库
|
||||
--plus-content <tag> 另外使用禁用的仓库来提供特定的关键词
|
||||
尝试 '--plus-content debug' 选项来启用仓库
|
||||
尝试使用 '--plus-content debug' 选项来启用仓库
|
||||
--disable-repositories 不从仓库中读取元数据
|
||||
--no-refresh 不刷新仓库
|
||||
--no-cd 忽略 CD/DVD 中的仓库
|
||||
@ -55,11 +56,11 @@ root@kerneltalks # zypper
|
||||
--disable-system-resolvables
|
||||
不读取已安装包
|
||||
|
||||
命令:
|
||||
命令:
|
||||
help, ? 打印帮助
|
||||
shell, sh 允许多命令
|
||||
|
||||
仓库管理:
|
||||
仓库管理:
|
||||
repos, lr 列出所有自定义仓库
|
||||
addrepo, ar 添加一个新仓库
|
||||
removerepo, rr 移除指定仓库
|
||||
@ -68,14 +69,14 @@ root@kerneltalks # zypper
|
||||
refresh, ref 刷新所有仓库
|
||||
clean 清除本地缓存
|
||||
|
||||
服务管理:
|
||||
服务管理:
|
||||
services, ls 列出所有自定义服务
|
||||
addservice, as 添加一个新服务
|
||||
modifyservice, ms 修改指定服务
|
||||
removeservice, rs 移除指定服务
|
||||
refresh-services, refs 刷新所有服务
|
||||
|
||||
软件管理:
|
||||
软件管理:
|
||||
install, in 安装包
|
||||
remove, rm 移除包
|
||||
verify, ve 确认包依赖的完整性
|
||||
@ -83,7 +84,7 @@ root@kerneltalks # zypper
|
||||
install-new-recommends, inr
|
||||
安装由已安装包建议一并安装的新包
|
||||
|
||||
更新管理:
|
||||
更新管理:
|
||||
update, up 更新已安装包至更新版本
|
||||
list-updates, lu 列出可用更新
|
||||
patch 安装必要的补丁
|
||||
@ -91,7 +92,7 @@ root@kerneltalks # zypper
|
||||
dist-upgrade, dup 进行发行版更新
|
||||
patch-check, pchk 检查补丁
|
||||
|
||||
查询:
|
||||
查询:
|
||||
search, se 查找符合匹配模式的包
|
||||
info, if 展示特定包的完全信息
|
||||
patch-info 展示特定补丁的完全信息
|
||||
@ -103,27 +104,28 @@ root@kerneltalks # zypper
|
||||
products, pd 列出所有可用的产品
|
||||
what-provides, wp 列出提供特定功能的包
|
||||
|
||||
包锁定:
|
||||
包锁定:
|
||||
addlock, al 添加一个包锁定
|
||||
removelock, rl 移除一个包锁定
|
||||
locks, ll 列出当前的包锁定
|
||||
cleanlocks, cl 移除无用的锁定
|
||||
|
||||
其他命令:
|
||||
其他命令:
|
||||
versioncmp, vcmp 比较两个版本字符串
|
||||
targetos, tos 打印目标操作系统 ID 字符串
|
||||
licenses 打印已安装包的证书和 EULAs 报告
|
||||
download 使用命令行下载指定 rpm 包到本地目录
|
||||
source-download 下载所有已安装包的源码 rpm 包到本地目录
|
||||
|
||||
子命令:
|
||||
子命令:
|
||||
subcommand 列出可用子命令
|
||||
|
||||
输入 'zypper help <command>' 来获得特定命令的帮助。
|
||||
```
|
||||
##### 如何使用 zypper 安装包
|
||||
|
||||
`zypper` 通过 `in` 或 `install` 开关来在你的系统上安装包。它的用法与 [yum package installation][3] 相同。你只需要提供包名作为参数,包管理器(此处是 zypper)就会处理所有的依赖并与你指定的包一并安装。
|
||||
### 如何使用 zypper 安装包
|
||||
|
||||
`zypper` 通过 `in` 或 `install` 子命令来在你的系统上安装包。它的用法与 [yum 软件包安装][3] 相同。你只需要提供包名作为参数,包管理器(此处是 `zypper`)就会处理所有的依赖并与你指定的包一并安装。
|
||||
|
||||
```
|
||||
# zypper install telnet
|
||||
@ -147,11 +149,11 @@ Checking for file conflicts: ...................................................
|
||||
|
||||
以上是我们安装 `telnet` 包时的输出,供你参考。
|
||||
|
||||
推荐阅读 : [在 YUM 和 APT 系统中安装包][3]
|
||||
推荐阅读:[在 YUM 和 APT 系统中安装包][3]
|
||||
|
||||
##### 如何使用 zypper 移除包
|
||||
### 如何使用 zypper 移除包
|
||||
|
||||
要在 Suse Linux 中擦除或移除包,使用 `zypper` 命令附带 `remove` 或 `rm` 开关。
|
||||
要在 Suse Linux 中擦除或移除包,使用 `zypper` 附带 `remove` 或 `rm` 子命令。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper rm telnet
|
||||
@ -167,13 +169,14 @@ After the operation, 113.3 KiB will be freed.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
(1/1) Removing telnet-1.2-165.63.x86_64 ..........................................................................................................................[done]
|
||||
```
|
||||
|
||||
我们在此处移除了先前安装的 telnet 包。
|
||||
|
||||
##### 使用 zypper 检查依赖或者认证已安装包的完整性
|
||||
### 使用 zypper 检查依赖或者认证已安装包的完整性
|
||||
|
||||
有时可以通过强制忽略依赖关系来安装软件包。`zypper` 使你能够扫描所有已安装的软件包并检查其依赖性。如果缺少任何依赖项,它将提供你安装或重新安装它的机会,从而保持已安装软件包的完整性。
|
||||
|
||||
使用附带 `verify` 或 `ve` 开关的 `zypper` 命令来检查已安装包的完整性。
|
||||
使用附带 `verify` 或 `ve` 子命令的 `zypper` 命令来检查已安装包的完整性。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper ve
|
||||
@ -184,9 +187,10 @@ Reading installed packages...
|
||||
|
||||
Dependencies of all installed packages are satisfied.
|
||||
```
|
||||
|
||||
在上面的输出中,你能够看到最后一行说明已安装包的所有依赖都已安装完全,并且无需更多操作。
|
||||
|
||||
##### 如何在 Suse Linux 中使用 zypper 下载包
|
||||
### 如何在 Suse Linux 中使用 zypper 下载包
|
||||
|
||||
`zypper` 提供了一种方法使得你能够将包下载到本地目录而不去安装它。你可以在其他具有同样配置的系统上使用这个已下载的软件包。包会被下载至 `/var/cache/zypp/packages/<repo>/<arch>/` 目录。
|
||||
|
||||
@ -206,13 +210,14 @@ total 52
|
||||
-rw-r--r-- 1 root root 53025 Feb 21 03:17 telnet-1.2-165.63.x86_64.rpm
|
||||
|
||||
```
|
||||
|
||||
你能看到我们使用 `zypper` 将 telnet 包下载到了本地。
|
||||
|
||||
推荐阅读 : [在 YUM 和 APT 系统中只下载包而不安装][4]
|
||||
推荐阅读:[在 YUM 和 APT 系统中只下载包而不安装][4]
|
||||
|
||||
##### 如何使用 zypper 列出可用包更新
|
||||
### 如何使用 zypper 列出可用包更新
|
||||
|
||||
`zypper` 允许你浏览已安装包的所有可用更新,以便你可以提前计划更新活动。使用 `list-updates` 或 `lu` 开关来显示已安装包的所有可用更新。
|
||||
`zypper` 允许你浏览已安装包的所有可用更新,以便你可以提前计划更新活动。使用 `list-updates` 或 `lu` 子命令来显示已安装包的所有可用更新。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lu
|
||||
@ -229,11 +234,12 @@ v | SLE-Module-Containers12-Updates | containerd | 0.2.5+gitr6
|
||||
v | SLES12-SP3-Updates | crash | 7.1.8-4.3.1 | 7.1.8-4.6.2 | x86_64
|
||||
v | SLES12-SP3-Updates | rsync | 3.1.0-12.1 | 3.1.0-13.10.1 | x86_64
|
||||
```
|
||||
|
||||
输出特意被格式化以便于阅读。每一列分别代表包所属仓库名称、包名、已安装版本、可用的更新版本和架构。
|
||||
|
||||
##### 在 Suse Linux 中列出和安装补丁
|
||||
### 在 Suse Linux 中列出和安装补丁
|
||||
|
||||
使用 `list-patches` 或 `lp` 开关来显示你的 Suse Linux 系统需要被应用的所有可用补丁。
|
||||
使用 `list-patches` 或 `lp` 子命令来显示你的 Suse Linux 系统需要被应用的所有可用补丁。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lp
|
||||
@ -260,9 +266,9 @@ Found 37 applicable patches:
|
||||
|
||||
你可以通过发出 `zypper patch` 命令安装所有需要的补丁。
|
||||
|
||||
##### 如何使用 zypper 更新包
|
||||
### 如何使用 zypper 更新包
|
||||
|
||||
要使用 zypper 更新包,使用 `update` 或 `up` 开关后接包名。在上述列出的更新命令中,我们知道在我们的服务器上 `rsync` 包更新可用。让我们现在来更新它吧!
|
||||
要使用 `zypper` 更新包,使用 `update` 或 `up` 子命令后接包名。在上述列出的更新命令中,我们知道在我们的服务器上 `rsync` 包更新可用。让我们现在来更新它吧!
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper update rsync
|
||||
@ -284,9 +290,9 @@ Checking for file conflicts: ...................................................
|
||||
(1/1) Installing: rsync-3.1.0-13.10.1.x86_64 .....................................................................................................................[done]
|
||||
```
|
||||
|
||||
##### 在 Suse Linux 上使用 zypper 查找包
|
||||
### 在 Suse Linux 上使用 zypper 查找包
|
||||
|
||||
如果你不确定包的全名也不要担心。你可以使用 zypper 附带 `se` 或 `search` 开关并提供查找字符串来查找包。
|
||||
如果你不确定包的全名也不要担心。你可以使用 `zypper` 附带的 `se` 或 `search` 子命令并提供查找字符串来查找包。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper se lvm
|
||||
@ -303,14 +309,15 @@ S | Name | Summary | Type
|
||||
| llvm-devel | Header Files for LLVM | package
|
||||
| lvm2 | Logical Volume Manager Tools | srcpackage
|
||||
i+ | lvm2 | Logical Volume Manager Tools | package
|
||||
| lvm2-devel | Development files for LVM2 | package
|
||||
|
||||
| lvm2-devel | Development files for LVM2 | package
|
||||
```
|
||||
在上述示例中我们查找了 `lvm` 字符串并得到了如上输出列表。你能在 zypper install/remove/update 命令中使用 `Name` 字段的名字。
|
||||
|
||||
##### 使用 zypper 检查已安装包信息
|
||||
在上述示例中我们查找了 `lvm` 字符串并得到了如上输出列表。你能在 `zypper install/remove/update` 命令中使用 `Name` 字段的名字。
|
||||
|
||||
### 使用 zypper 检查已安装包信息
|
||||
|
||||
你能够使用 `zypper` 检查已安装包的详细信息。`info` 或 `if` 子命令将列出已安装包的信息。它也可以显示未安装包的详细信息,在该情况下,`Installed` 参数将返回 `No` 值。
|
||||
|
||||
你能够使用 zypper 检查已安装包的详细信息。`info` 或 `if` 开关将列出已安装包的信息。它也可以显示未安装包的详细信息,在该情况下,`Installed` 参数将返回 `No` 值。
|
||||
```
|
||||
root@kerneltalks # zypper info rsync
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
@ -343,9 +350,9 @@ Description :
|
||||
for backups and mirroring and as an improved copy command for everyday use.
|
||||
```
|
||||
|
||||
##### 使用 zypper 列出仓库
|
||||
### 使用 zypper 列出仓库
|
||||
|
||||
使用 zypper 命令附带 `lr` 或 `repos` 开关列出仓库。
|
||||
使用 `zypper` 命令附带 `lr` 或 `repos` 子命令列出仓库。
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lr
|
||||
@ -364,7 +371,7 @@ Repository priorities are without effect. All enabled repositories share the sam
|
||||
|
||||
此处你需要检查 `enabled` 列来确定哪些仓库是已被启用的而哪些没有。
|
||||
|
||||
##### 在 Suse Linux 中使用 zypper 添加或移除仓库
|
||||
### 在 Suse Linux 中使用 zypper 添加或移除仓库
|
||||
|
||||
要添加仓库你需要仓库或 .repo 文件的 URI,否则你会遇到如下错误。
|
||||
|
||||
@ -390,16 +397,17 @@ Priority : 99 (default priority)
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
```
|
||||
|
||||
在 Suse 中使用附带 `addrepo` 或 `ar` 开关的 `zypper` 命令添加仓库,后接 URI 以及你需要提供一个别名。
|
||||
在 Suse 中使用附带 `addrepo` 或 `ar` 子命令的 `zypper` 命令添加仓库,后接 URI 以及你需要提供一个别名。
|
||||
|
||||
要在 Suse 中移除一个仓库,使用附带 `removerepo` 或 `rr` 子命令的 `zypper` 命令。
|
||||
|
||||
要在 Suse 中移除一个仓库,使用附带 `removerepo` 或 `rr` 开关的 `zypper` 命令。
|
||||
```
|
||||
root@kerneltalks # zypper removerepo nVidia-Driver-SLE12-SP3
|
||||
Removing repository 'nVidia-Driver-SLE12-SP3' ....................................................................................................................[done]
|
||||
Repository 'nVidia-Driver-SLE12-SP3' has been removed.
|
||||
```
|
||||
|
||||
##### 清除 zypper 本地缓存
|
||||
### 清除 zypper 本地缓存
|
||||
|
||||
使用 `zypper clean` 命令清除 zypper 本地缓存。
|
||||
|
||||
@ -414,7 +422,7 @@ via: https://kerneltalks.com/commands/12-useful-zypper-command-examples/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
在 Linux 命令行下进行时间管理
|
||||
======
|
||||
|
||||
> 学习如何在命令行下用这些方法自己组织待办事项。
|
||||
|
||||

|
||||
|
||||
关于如何在命令行下进行<ruby>时间管理<rt>getting things done</rt></ruby>(GTD)有很多讨论。不知有多少文章在讲使用 ls 晦涩的选项、配合 Sed 和 Awk 的一些神奇的正则表达式,以及用 Perl 解析一大堆的文本。但这些都不是问题的重点。
|
||||
|
||||
本文章是关于“[如何完成][1]”,在我们不需要图形桌面、网络浏览器或网络连接情况下,用命令行操作能实际完成事务的跟踪。为了达到这一点,我们将介绍四种跟踪待办事项的方式:纯文件文件、Todo.txt、TaskWarrior 和 Org 模式。
|
||||
|
||||
### 简单纯文本
|
||||
|
||||
![纯文本][3]
|
||||
|
||||
*我喜欢用 Vim,其实你也可以用 Nano。*
|
||||
|
||||
最直接管理你的待办事项的方式就是用纯文本文件来编辑。只需要打开一个空文件,每一行添加一个任务。当任务完成后,删除这一行。简单有效,无论你用它做什么都没关系。不过这个方法也有两个缺点,一但你删除一行并保存了文件,它就是永远消失了。如果你想知道本周或者上周都做了哪些事情,就成了问题。使用简单文本文件很方便却也容易导致混乱。
|
||||
|
||||
### Todo.txt: 纯文件的升级版
|
||||
|
||||
![todo.txt 截屏][5]
|
||||
|
||||
*整洁,有条理,易用*
|
||||
|
||||
这就是我们要说的 [Todo.txt][6] 文件格式和应用程序。安装很简单,可从 GitHub [下载][7]最新的版本解压后并执行命令 `sudo make install` 。
|
||||
|
||||
![安装 todo.txt][9]
|
||||
|
||||
*也可以从 Git 克隆一个。*
|
||||
|
||||
Todo.txt 可以很容易的增加新任务,并能显示任务列表和已完成任务的标记:
|
||||
|
||||
| 命令 | 说明 |
|
||||
| ------------- |:-------------|
|
||||
| `todo.sh add "某任务"` | 增加 “某任务” 到你的待办列表 |
|
||||
| `todo.sh ls` | 显示所有的任务 |
|
||||
| `todo.sh ls due:2018-02-15` | 显示2018-02-15之前的所有任务 |
|
||||
| `todo.sh do 3` | 标记任务3 为已完成任务 |
|
||||
|
||||
这个清单实际上仍然是纯文本,你可以用你喜欢的编辑器遵循[正确的格式][10]编辑它。
|
||||
|
||||
该应用程序同时也内置了一个强大的帮助系统。
|
||||
|
||||
![在 todo.txt 中语法高亮][12]
|
||||
|
||||
*你可以使用语法高亮的功能*
|
||||
|
||||
此外,还有许多附加组件可供选择,以及编写自己的附件组件规范。甚至有浏览器组件、移动设备应用程序和桌面应用程序支持 Todo.txt 的格式。
|
||||
|
||||
![GNOME extensions in todo.txt][14]
|
||||
|
||||
*GNOME的扩展组件*
|
||||
|
||||
Todo.txt 最大的缺点是缺少自动或内置的同步机制。大多数(不是全部)的浏览器扩展程序和移动应用程序需要用 Dropbox 实现桌面系统和应用程序直接的数据同步。如果你想内置同步机制,我们有……
|
||||
|
||||
### Taskwarrior: 现在我们用 Python 做事了
|
||||
|
||||
![Taskwarrior][25]
|
||||
|
||||
*花哨吗?*
|
||||
|
||||
[Taskwarrior][15] 是一个与 Todo.txt 有许多相同功能的 Python 工具。但不同的是它的数据保存在数据库里并具有内置的数据同步功能。它还可以跟踪即将要做的任务,可以提醒某个任务持续了多久,可以提醒你一些重要的事情应该马上去做。
|
||||
|
||||
![][26]
|
||||
|
||||
*看起来不错*
|
||||
|
||||
[安装][16] Taskwarrior 可以通过通过发行版自带的包管理器,或通过 Python 命令 `pip` 安装,或者用源码编译。用法也和 Todo.txt 的命令完全一样:
|
||||
|
||||
| 命令 | 说明 |
|
||||
| ------------- |:-------------|
|
||||
| `task add "某任务"` | 增加 “某任务” 到任务清单 |
|
||||
| `task list` | 列出所有任务 |
|
||||
| `task list due ``:today` | 列出截止今天的任务 |
|
||||
| `task do 3` | 标记编号是3的任务为完成状态 |
|
||||
|
||||
Taskwarrior 还有漂亮的文本用户界面。
|
||||
|
||||
![Taskwarrior in Vit][18]
|
||||
|
||||
*我喜欢 Vit, 它的设计灵感来自 Vim*
|
||||
|
||||
不同于 Todo.txt,Taskwarrior 可以和本地或远程服务器同步信息。如果你希望运行自己的同步服务器可以使用名为 `taskd` 的非常基本的服务器,如果不使用自己的服务器也有好几个可用服务器。
|
||||
|
||||
Taskwarriot 还拥有一个蓬勃发展的插件和扩展生态系统,以及移动和桌面系统的应用。
|
||||
|
||||
![GNOME in Taskwarrior ][20]
|
||||
|
||||
*在 GNOME 下的 Taskwarrior 看起来还是很漂亮的。*
|
||||
|
||||
Taskwarrior 有一个唯一的缺点,你是不能直接修改待办任务的,这和其他的工具不一样。你只能把任务清单按照格式导出,然后修改导出文件后,重新再导入,这样相对于编辑器直接编辑任务还是挺麻烦的。
|
||||
|
||||
谁能给我们带来最大的希望呢……
|
||||
|
||||
### Emacs Org 模式:牛X的任务收割机
|
||||
|
||||
![Org-mode][22]
|
||||
|
||||
*Emacs 啥都有*
|
||||
|
||||
Emacs [Org 模式][23] 是目前为止最强大、最灵活的开源待办事项管理器。它支持多文件、使用纯文本、高度可定制、自动识别日期、截止日期和任务计划。相对于我们这里介绍的其他工具,它的配置也更复杂一些。但是一旦配置好,它可以比其他工具完成更多功能。如果你是熟悉或者是 [Bullet Journals][24] 的粉丝,Org 模式可能是在桌面程序里最像[Bullet Journals][24] 的了。
|
||||
|
||||
Emacs 能运行,Org 模式就能运行,一些移动应用程序可以和它很好交互。但是不幸的是,目前没有桌面程序或浏览器插件支持 Org 模式。尽管如此,Org 模式仍然是跟踪待办事项最好的应用程序之一,因为它确实很强大。
|
||||
|
||||
### 选择适合自己的工具
|
||||
|
||||
最后,这些程序目的是帮助你跟踪待办事项,并确保不会忘记做某个事情。这些程序的基础功能都大同小异,那一款适合你取决于多种因素。有的人需要自带同步功能,有的人需要一个移动客户端,有的人要必须支持插件。不管你选择什么,请记住程序本身不会让你更有调理,但是可以帮助你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-to-done-agile-linux-command-line
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[1]:https://www.scruminc.com/getting-done/
|
||||
[3]:https://opensource.com/sites/default/files/u128651/plain-text.png (plaintext)
|
||||
[5]:https://opensource.com/sites/default/files/u128651/todo-txt.png (todo.txt screen)
|
||||
[6]:http://todotxt.org/
|
||||
[7]:https://github.com/todotxt/todo.txt-cli/releases
|
||||
[9]:https://opensource.com/sites/default/files/u128651/todo-txt-install.png (Installing todo.txt)
|
||||
[10]:https://github.com/todotxt/todo.txt
|
||||
[12]:https://opensource.com/sites/default/files/u128651/todo-txt-vim.png (Syntax highlighting in todo.txt)
|
||||
[14]:https://opensource.com/sites/default/files/u128651/tod-txt-gnome.png (GNOME extensions in todo.txt)
|
||||
[15]:https://taskwarrior.org/
|
||||
[16]:https://taskwarrior.org/download/
|
||||
[18]:https://opensource.com/sites/default/files/u128651/taskwarrior-vit.png (Taskwarrior in Vit)
|
||||
[20]:https://opensource.com/sites/default/files/u128651/taskwarrior-gnome.png (Taskwarrior on GNOME)
|
||||
[22]:https://opensource.com/sites/default/files/u128651/emacs-org-mode.png (Org-mode)
|
||||
[23]:https://orgmode.org/
|
||||
[24]:http://bulletjournal.com/
|
||||
[25]:https://opensource.com/sites/default/files/u128651/taskwarrior.png
|
||||
[26]:https://opensource.com/sites/default/files/u128651/taskwarrior-complains.png
|
||||
177
published/20180228 Emacs -2- Introducing org-mode.md
Normal file
177
published/20180228 Emacs -2- Introducing org-mode.md
Normal file
@ -0,0 +1,177 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Emacs #2: Introducing org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: (https://linux.cn/article-10312-1.html)
|
||||
|
||||
Emacs 系列(二):Org 模式介绍
|
||||
======
|
||||
|
||||
在我 Emacs 系列中的[第一篇文章][1]里,我介绍了我在用了几十年的 vim 后转向了 Emacs,Org 模式就是我为什么这样做的原因。
|
||||
|
||||
Org 模式的精简和高效真的震惊了我,它真的是个“杀手”应用。
|
||||
|
||||
### 所以,Org 模式到底是什么呢?
|
||||
|
||||
这是我昨天写的:
|
||||
|
||||
> 它是一个组织信息的平台,它的主页上这样写着:“一切都是纯文本:Org 模式用于记笔记、维护待办事项列表、计划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
这是事实,但并不是很准确。Org 模式是一个你用来组织事务的小工具。它有一些非常合理的默认设置,但也允许你自己定制。
|
||||
|
||||
主要突出在这几件事上:
|
||||
|
||||
* **维护待办事项列表**:项目可以分散在 Org 文件中,包含附件,有标签、截止日期、时间表。有一个方便的“日程”视图,显示需要做什么。项目也可以重复。
|
||||
* **编写文档**:Org 模式有个特殊的功能来生成 HTML、LaTeX、幻灯片(用 LaTeX beamer)和其他所有的格式。它也支持直接在缓冲区中运行和以 Emacs 所支持的的语言进行<ruby>文学编程<rt>literate programming</rt></ruby>。如果你想要深入了解这项功能的话,参阅[这篇文学式 DevOps 的文章][2]。而 [整个 Worg 网站][3] 是用 Org 模式开发的。
|
||||
* **记笔记**:对,它也能做笔记。通过全文搜索,文件的交叉引用(类似 wiki),UUID,甚至可以与其他的系统进行交互(通过 Message-ID 与 mu4e 交互,通过 ERC 的日志等等……)。
|
||||
|
||||
### 入门
|
||||
|
||||
我强烈建议去阅读 [Carsten Dominik 关于 Org 模式的一篇很棒的 Google 讲话][4]。那篇文章真的很赞。
|
||||
|
||||
在 Emacs 中带有 Org 模式,但如果你想要个比较新的版本的话,Debian 用户可以使用命令 `apt-get install org-mode` 来更新,或者使用 Emacs 的包管理系统命令 `M-x package-install RET org-mode RET`。
|
||||
|
||||
现在,你可能需要阅读一下 Org 模式的精简版教程中的[导读部分][5],特别注意,你要设置下[启动部分][6]中提到的那些键的绑定。
|
||||
|
||||
### 一份好的教程
|
||||
|
||||
我会给出一些好的教程和介绍的链接,但这篇文章不会是一篇教程。特别是在本文末尾,有两个很不错的视频链接。
|
||||
|
||||
### 我的一些配置
|
||||
|
||||
我将在这里记录下一些我的配置并介绍它的作用。你没有必要每行每句将它拷贝到你的配置中 —— 这只是一个参考,告诉你哪些可以配置,要怎么在手册中查找,或许只是一个“我现在该怎么做”的参考。
|
||||
|
||||
首先,我将 Emacs 的编码默认设置为 UTF-8。
|
||||
|
||||
```
|
||||
(prefer-coding-system 'utf-8)
|
||||
(set-language-environment "UTF-8")
|
||||
```
|
||||
|
||||
Org 模式中可以打开 URL。默认的,它会在 Firefox 中打开,但我喜欢用 Chromium。
|
||||
|
||||
```
|
||||
(setq browse-url-browser-function 'browse-url-chromium)
|
||||
```
|
||||
|
||||
我把基本的键的绑定和设为教程里的一样,再加上 `M-RET` 的操作的配置。
|
||||
|
||||
```
|
||||
(global-set-key "\C-cl" 'org-store-link)
|
||||
(global-set-key "\C-ca" 'org-agenda)
|
||||
(global-set-key "\C-cc" 'org-capture)
|
||||
(global-set-key "\C-cb" 'org-iswitchb)
|
||||
|
||||
(setq org-M-RET-may-split-line nil)
|
||||
```
|
||||
|
||||
|
||||
### 捕获配置
|
||||
|
||||
我可以在 Emacs 的任何模式中按 `C-c c`,按下后它就会[帮我捕获某些事][7],其中包括一个指向我正在处理事务的链接。
|
||||
|
||||
你可以通过定义[捕获模板][8]来配置它。我将保存两个日志文件,作为会议、电话等的通用记录。一个是私人用的,一个是办公用的。如果我按下 `C-c c j`,它就会帮我捕获为私人项. 下面包含 `%a` 的配置是表示我当前的位置(或是我使用 `C-c l` 保存的链接)的链接。
|
||||
|
||||
```
|
||||
(setq org-default-notes-file "~/org/tasks.org")
|
||||
(setq org-capture-templates
|
||||
'(
|
||||
("t" "Todo" entry (file+headline "inbox.org" "Tasks")
|
||||
"* TODO %?\n %i\n %u\n %a")
|
||||
("n" "Note/Data" entry (file+headline "inbox.org" "Notes/Data")
|
||||
"* %? \n %i\n %u\n %a")
|
||||
("j" "Journal" entry (file+datetree "~/org/journal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
("J" "Work-Journal" entry (file+datetree "~/org/wjournal.org")
|
||||
"* %?\nEntered on %U\n %i\n %a")
|
||||
))
|
||||
(setq org-irc-link-to-logs t)
|
||||
```
|
||||
|
||||
我喜欢通过 UUID 来建立链接,这让我在文件之间移动而不会破坏位置。当我要 Org 存储一个链接目标以便将来插入时,以下配置有助于生成 UUID。
|
||||
|
||||
```
|
||||
(require 'org-id)
|
||||
(setq org-id-link-to-org-use-id 'create-if-interactive)
|
||||
```
|
||||
|
||||
### 议程配置
|
||||
|
||||
我喜欢将星期天作为一周的开始,当我将某件事标记为完成时,我也喜欢记下时间。
|
||||
|
||||
```
|
||||
(setq org-log-done 'time)
|
||||
(setq org-agenda-start-on-weekday 0)
|
||||
```
|
||||
|
||||
### 文件归档配置
|
||||
|
||||
在这我将配置它,让它知道在议程中该使用哪些文件,而且在纯文本的搜索中添加一点点小功能。我喜欢保留一个通用的文件夹(我可以从其中移动或“重新归档”内容),然后将个人和工作项的任务、日志和知识库分开。
|
||||
|
||||
```
|
||||
(setq org-agenda-files (list "~/org/inbox.org"
|
||||
"~/org/email.org"
|
||||
"~/org/tasks.org"
|
||||
"~/org/wtasks.org"
|
||||
"~/org/journal.org"
|
||||
"~/org/wjournal.org"
|
||||
"~/org/kb.org"
|
||||
"~/org/wkb.org"
|
||||
))
|
||||
(setq org-agenda-text-search-extra-files
|
||||
(list "~/org/someday.org"
|
||||
"~/org/config.org"
|
||||
))
|
||||
|
||||
(setq org-refile-targets '((nil :maxlevel . 2)
|
||||
(org-agenda-files :maxlevel . 2)
|
||||
("~/org/someday.org" :maxlevel . 2)
|
||||
("~/org/templates.org" :maxlevel . 2)
|
||||
)
|
||||
)
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
### 外观配置
|
||||
|
||||
我喜欢一个较漂亮的的屏幕。在你开始习惯 Org 模式之后,你可以试试这个。
|
||||
|
||||
```
|
||||
(add-hook 'org-mode-hook
|
||||
(lambda ()
|
||||
(org-bullets-mode t)))
|
||||
(setq org-ellipsis "⤵")
|
||||
```
|
||||
|
||||
### 下一篇
|
||||
|
||||
希望这篇文章展示了 Org 模式的一些功能。接下来,我将介绍如何定制 `TODO` 关键字和标记、归档旧任务、将电子邮件转发到 Org 模式,以及如何使用 `git` 在不同电脑之间进行同步。
|
||||
|
||||
你也可以查看[本系列的所有文章列表][9]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9865-emacs-2-introducing-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10297-1.html
|
||||
[2]: http://www.howardism.org/Technical/Emacs/literate-devops.html
|
||||
[3]: https://orgmode.org/worg/
|
||||
[4]: https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]: https://orgmode.org/guide/Introduction.html#Introduction
|
||||
[6]: https://orgmode.org/guide/Activation.html#Activation
|
||||
[7]: https://orgmode.org/guide/Capture.html#Capture
|
||||
[8]: https://orgmode.org/guide/Capture-templates.html#Capture-templates
|
||||
[9]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
130
published/20180302 Emacs -3- More on org-mode.md
Normal file
130
published/20180302 Emacs -3- More on org-mode.md
Normal file
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (Emacs #3: More on org-mode)
|
||||
[#]: via: (https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode)
|
||||
[#]: author: (John Goerzen http://changelog.complete.org/archives/author/jgoerzen)
|
||||
[#]: url: (https://linux.cn/article-10327-1.html)
|
||||
|
||||
Emacs 系列(三): Org 模式的补充
|
||||
======
|
||||
|
||||
这是 [Emacs 和 Org 模式系列][1]的第三篇。
|
||||
|
||||
### Todo 的跟进及关键字
|
||||
|
||||
当你使用 Org 模式来跟进你的 TODO 时,它有多种状态。你可以用 `C-c C-t` 来快速切换状态。我将它设为这样:
|
||||
|
||||
```
|
||||
(setq org-todo-keywords '(
|
||||
(sequence "TODO(t!)" "NEXT(n!)" "STARTED(a!)" "WAIT(w@/!)" "OTHERS(o!)" "|" "DONE(d)" "CANCELLED(c)")
|
||||
))
|
||||
```
|
||||
|
||||
在这里,我设置了一个任务未完成的五种状态:`TODO`、`NEXT`、`STARTED`、`WAIT` 及 `OTHERS`。每一个状态都有单个字的快捷键(`t`、`n`、`a` 等)。管道符(`|`)之后的状态被认为是“完成”的状态。我有两个“完成”状态:`DONE`(已经完成)及 `CANCELLED`(还没完成,但由于其它的原因无法完成)。
|
||||
|
||||
`!` 的含义是记录某项更改为状态的时间。我不把这个添加到完成的状态,是因为它们已经被记录了。`@` 符号表示带理由的提示,所以当切换到 `WAIT` 时,Org 模式会问我为什么,并将这个添加到笔记中。
|
||||
|
||||
以下是项目状态发生变化的例子:
|
||||
|
||||
```
|
||||
** DONE This is a test
|
||||
CLOSED: [2018-03-02 Fri 03:05]
|
||||
|
||||
- State "DONE" from "WAIT" [2018-03-02 Fri 03:05]
|
||||
- State "WAIT" from "TODO" [2018-03-02 Fri 03:05] \\
|
||||
waiting for pigs to fly
|
||||
- State "TODO" from "NEXT" [2018-03-02 Fri 03:05]
|
||||
- State "NEXT" from "TODO" [2018-03-02 Fri 03:05]
|
||||
```
|
||||
|
||||
在这里,最新的项目在最上面。
|
||||
|
||||
### 议程模式,日程及期限
|
||||
|
||||
当你处在一个待办事项时,`C-c C-s` 或 `C-c C-d` 可以为其设置相应的日程或期限。这些都是在议程模式中的功能。它们的区别在于其意图和表现。日程是你希望在某个时候完成的事情,而期限是在某个特定的时间应该完成的事情。默认情况下,议程视图将在项目的截止日期前提醒你。
|
||||
|
||||
在此过程中,[议程视图][3]将显示即将出现的项目,提供了一种基于纯文本或标记搜索项目的方法,甚至可以进行跨多个文件处理项目的批量操作。我在本系列的[第 2 部分][4]中介绍了为议程模式配置。
|
||||
|
||||
### 标签
|
||||
|
||||
Org 模式当然也支持标签了。你可以通过 `C-c C-q` 快速的建立标签。
|
||||
|
||||
你可能会想为一些常用的标签设置快捷键。就像这样:
|
||||
|
||||
```
|
||||
(setq org-tag-persistent-alist
|
||||
'(("@phone" . ?p)
|
||||
("@computer" . ?c)
|
||||
("@websurfing" . ?w)
|
||||
("@errands" . ?e)
|
||||
("@outdoors" . ?o)
|
||||
("MIT" . ?m)
|
||||
("BIGROCK" . ?b)
|
||||
("CONTACTS" . ?C)
|
||||
("INBOX" . ?i)
|
||||
))
|
||||
```
|
||||
|
||||
你还可以按文件向该列表添加标记,也可以按文件为某些内容设置标记。我就在我的 `inbox.org` 和 `email.org` 文件中设置了一个 `INBOX` 的标签。然后我可以每天从日程视图中查看所有标记为 `INBOX` 的项目,像将它们重新归档到其他文件中的这样的简单操作将让它们去掉 `INBOX` 标记。
|
||||
|
||||
### 重新归档
|
||||
|
||||
“重新归档”就是在文件中或其他地方移动。它是使用标题来完成的。`C-c C-w` 就是做这个的。我设置成这样:
|
||||
|
||||
```
|
||||
(setq org-outline-path-complete-in-steps nil) ; Refile in a single go
|
||||
(setq org-refile-use-outline-path 'file)
|
||||
```
|
||||
|
||||
### 归档分类
|
||||
|
||||
一段时间后,你的文件就会被已经完成的事情弄得乱七八糟。Org 模式有一个[归档][6]特性,可以将主 `.org` 文件移到其他文件中,以备将来参考。如果你在 `git` 或其他软件中 有 Org 文件,你可能希望删除这些其他文件,因为无论如何都会在历史中拥有这些文件,但是我发现它们对于析取和搜索非常方便。
|
||||
|
||||
我会定期检查并归档文件中的所有内容。基于 [stackoverflow 的讨论][7],我有以下代码:
|
||||
|
||||
```
|
||||
(defun org-archive-done-tasks ()
|
||||
(interactive)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/DONE" 'file)
|
||||
(org-map-entries
|
||||
(lambda ()
|
||||
(org-archive-subtree)
|
||||
(setq org-map-continue-from (outline-previous-heading)))
|
||||
"/CANCELLED" 'file)
|
||||
)
|
||||
```
|
||||
|
||||
这基于[一个特定的答案][8] —— 你可以从评论那获得一些额外的提示。现在你可以运行 `M-x org-archive-done-tasks`,当前文件中所有标记为 `DONE` 或 `CANCELED` 的内容都将放到另一个文件中。
|
||||
|
||||
### 下一篇
|
||||
|
||||
我将通过讨论在 Org 模式中自动接受邮件以及在不同的机器上同步来对 Org 模式进行总结。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://changelog.complete.org/archives/9877-emacs-3-more-on-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://changelog.complete.org/archives/author/jgoerzen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://changelog.complete.org/archives/tag/emacs2018
|
||||
[2]: https://orgmode.org/guide/TODO-Items.html#TODO-Items
|
||||
[3]: https://orgmode.org/guide/Agenda-Views.html#Agenda-Views
|
||||
[4]: https://linux.cn/article-10312-1.html
|
||||
[5]: https://orgmode.org/guide/Tags.html#Tags
|
||||
[6]: https://orgmode.org/guide/Archiving.html#Archiving
|
||||
[7]: https://stackoverflow.com/questions/6997387/how-to-archive-all-the-done-tasks-using-a-single-command
|
||||
[8]: https://stackoverflow.com/a/27043756
|
||||
@ -0,0 +1,122 @@
|
||||
NASA 在开放科学方面做了些什么
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
最近我们刚为开设了一个新的“[科学类][2]”的文章分类。其中发表的最新一篇文章名为:[开源是怎样影响科学的][3]。在这篇文章中我们主要讨论了 [NASA][4] 的积极努力,这些努力包括他们通过开源实践来促进科学研究的积极作用。
|
||||
|
||||
### NASA 是怎样使用开源手段促进科学研究的
|
||||
|
||||
NASA 将他们的整个研究库对整个公共领域开放,这是一项[壮举][5]。
|
||||
|
||||
没错!每个人都能访问他们的整个研究库,并能从他们的研究中获益。
|
||||
|
||||
他们现已开放的资料可以大致分为以下三类:
|
||||
|
||||
* 开源 NASA
|
||||
* 开放 API
|
||||
* 开放数据
|
||||
|
||||
### 1、开源 NASA
|
||||
|
||||
这里有一份 [GitHub][7] 的联合创始人之一和执行总裁 [Chris Wanstrath][6] 的采访,他向我们介绍道,一切都是从很多年前开始的。
|
||||
|
||||
- [Chris Wanstrath on NASA, open source and Github](https://youtu.be/dUFzMe8GM3M)
|
||||
|
||||
该项目名为 “[code.nasa.gov][8]”,截至本文发表为止,NASA 已经[通过 GitHub 开源][9]了 365 个科学软件(LCTT 译注:本文原文发表于 2018/3/28,截止至本译文发布,已经有 454 个项目了)。对于一位热爱程序的开发者来说,即使一天研究一个软件,想把 NASA 的这些软件全部研究过来也要整整一年的时间。
|
||||
|
||||
即使你不是一位开发者,你也可以在这个门户网站浏览这个壮观的软件合集。
|
||||
|
||||
其中就有[阿波罗 11 号][10]的制导计算机的源代码。阿波罗 11 号空间飞行器[首次将两名人类带上月球][11],分别是 [Neil Armstrong][12] 和 [Edwin Aldrin][13] 。如果你对 Edwin Aldrin 感兴趣,可以点击[这里][14]了解更多。
|
||||
|
||||
#### NASA 开源代码促进会使用的开源代码许可
|
||||
|
||||
它们采用了几种[开源许可证][15],其分类如下:
|
||||
|
||||
- [Apache 许可证 2.0](https://www.apache.org/licenses/LICENSE-2.0)
|
||||
- [Nasa 开源许可证 3.0](https://opensource.org/licenses/NASA-1.3)
|
||||
- [GPL v3](https://www.gnu.org/licenses/gpl.html)
|
||||
- [MIT 许可证](https://en.wikipedia.org/wiki/MIT_License)
|
||||
|
||||
### 2、开放 API
|
||||
|
||||
开放 [API][16] 在推行开放科学中起到了很大作用。与[开源促进会][17]类似,对于 API,也有一个 [开放 API 促进会][18]。下面这张示意图可以告诉你 API 是怎样将应用程序和它的开发者连接起来的。
|
||||
|
||||
![][19]
|
||||
|
||||
记得点击这个[链接](https://sproutsocial.com/insights/what-is-an-api/)看看。链接内的文章使用了简单易懂的方法解读了 API ,文末总结了五大要点。
|
||||
|
||||
![][20]
|
||||
|
||||
这会让你感受到专有 API 和开放 API 会有多么大的不同。
|
||||
|
||||
![][22]
|
||||
|
||||
[NASA 的 Open API][23] 主要针对应用程序开发者,旨在显著改善数据的可访问性,也包括图片内容在内。该网站有一个实时编辑器,可供你调用[每日天文一图(APOD)][24] 的 API。
|
||||
|
||||
#### 3、开放数据
|
||||
|
||||
![][25]
|
||||
|
||||
在[我们发布的第一篇开放科学的文章][3]中,我们在“开放科学”段落下提到的三个国家 —— 法国、印度和美国的多种开放数据形式。NASA 有着类似的想法和行为。这种重要的意识形态已经被[多个国家][26]所接受。
|
||||
|
||||
[NASA 的开放数据门户][27]致力于开放,拥有不断增长的可供大众自由使用的开放数据。将数据集纳入到这个数据集对于任何研究活动来说都是必要且重要的。NASA 还在他们的门户网站上征集各方的数据需求,以一同收录在他们的数据库中。这一举措不仅是领先的、创新的,还顺应了[数据科学][28]、[AI 和深度学习][29]的趋势。
|
||||
|
||||
下面的视频讲的是学者和学生们是怎样通过大量研究得出对数据科学的定义的。这个过程十分的激动人心。瑞尔森大学罗杰斯商学院的 [Murtaza Haider 教授][30]在视频结尾中提到了开源的出现对数据科学的改变,尤其让是旧有的闭源方式逐渐变得开放。而这也确实成为了现实。
|
||||
|
||||
- [What is Data Science? Data Science 101](https://youtu.be/z1kPKBdYks4)
|
||||
|
||||
![][31]
|
||||
|
||||
现在任何人都能在 NASA 上征集数据。正如前面的视频中所说,NASA 的举措很大程度上与征集和分析优化数据有关。
|
||||
|
||||
![][32]
|
||||
|
||||
你只需要免费注册即可。考虑到论坛上的公开讨论以及数据集在可能存在的每一类分析领域中的重要性,这一举措在未来会有非常积极的影响,对数据的统计分析当然也会大幅进展。在之后的文章中我们还会具体讨论这些细节,还有它们和开源模式之间的相关性。
|
||||
|
||||
以上就是对 NASA 开放科学模式的一些探索成就,希望您能继续关注我们接下来的相关文章!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/nasa-open-science/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2018/03/tux-in-space.jpg
|
||||
[2]:https://itsfoss.com/category/science/
|
||||
[3]:https://itsfoss.com/open-source-impact-on-science/
|
||||
[4]:https://www.nasa.gov/
|
||||
[5]:https://futurism.com/free-science-nasa-just-opened-its-entire-research-library-to-the-public/
|
||||
[6]:http://chriswanstrath.com/
|
||||
[7]:https://github.com/
|
||||
[8]:http://code.nasa.gov
|
||||
[9]:https://github.com/open-source
|
||||
[10]:https://www.nasa.gov/mission_pages/apollo/missions/apollo11.html
|
||||
[11]:https://www.space.com/16758-apollo-11-first-moon-landing.html
|
||||
[12]:https://www.jsc.nasa.gov/Bios/htmlbios/armstrong-na.html
|
||||
[13]:https://www.jsc.nasa.gov/Bios/htmlbios/aldrin-b.html
|
||||
[14]:https://buzzaldrin.com/the-man/
|
||||
[15]:https://itsfoss.com/open-source-licenses-explained/
|
||||
[16]:https://en.wikipedia.org/wiki/Application_programming_interface
|
||||
[17]:https://opensource.org/
|
||||
[18]:https://www.openapis.org/
|
||||
[19]:https://itsfoss.com/wp-content/uploads/2018/03/api-bridge.jpeg
|
||||
[20]:https://itsfoss.com/wp-content/uploads/2018/03/open-api-diagram.jpg
|
||||
[21]:http://www.apiacademy.co/resources/api-strategy-lesson-201-private-apis-vs-open-apis/
|
||||
[22]:https://itsfoss.com/wp-content/uploads/2018/03/nasa-open-api-live-example.jpg
|
||||
[23]:https://api.nasa.gov/
|
||||
[24]:https://apod.nasa.gov/apod/astropix.html
|
||||
[25]:https://itsfoss.com/wp-content/uploads/2018/03/nasa-open-data-portal.jpg
|
||||
[26]:https://www.xbrl.org/the-standard/why/ten-countries-with-open-data/
|
||||
[27]:https://data.nasa.gov/
|
||||
[28]:https://en.wikipedia.org/wiki/Data_science
|
||||
[29]:https://www.kdnuggets.com/2017/07/ai-deep-learning-explained-simply.html
|
||||
[30]:https://www.ryerson.ca/tedrogersschool/bm/programs/real-estate-management/murtaza-haider/
|
||||
[31]:https://itsfoss.com/wp-content/uploads/2018/03/suggest-dataset-nasa-1.jpg
|
||||
[32]:https://itsfoss.com/wp-content/uploads/2018/03/suggest-dataset-nasa-2-1.jpg
|
||||
@ -0,0 +1,72 @@
|
||||
Emacs 系列(四):使用 Org 模式自动管理邮件及同步文档
|
||||
======
|
||||
|
||||
这是 [Emacs 和 Org 模式系列][4]的第四篇。
|
||||
|
||||
至今为止,你已经见识到了 Org 模式的强大和高效,如果你像我一样,你可能会想:
|
||||
|
||||
> “我真的很想让它在我所有的设备上同步。”
|
||||
|
||||
或者是说:
|
||||
|
||||
> “我能在 Org 模式中转发邮件吗?”
|
||||
|
||||
答案当然是肯定的,因为这就是 Emacs。
|
||||
|
||||
### 同步
|
||||
|
||||
由于 Org 模式只使用文本文件,所以使用任意工具都可以很容易地实现同步。我使用的是 git 的 `git-remote-gcrypt`。由于 `git-remote-gcrypt` 的一些限制,每台机器都倾向于推到自己的分支,并使用命令来控制。每台机器都会先合并其它所有的分支,然后再将合并后的结果推送到主干上。cron 作业可以实现将机器上的分支推送上去,而 elisp 会协调这一切 —— 确保在同步之前保存缓冲区,在同步之后从磁盘刷新缓冲区,等等。
|
||||
|
||||
这篇文章的代码有点多,所以我将把它链接到 github 上,而不是写在这里。
|
||||
|
||||
|
||||
我有一个用来存放我所有的 Org 模式的文件的目录 `$HOME/org`,在 `~/org` 目录下有个 [Makefile][2] 文件来处理同步。该文件定义了以下目标:
|
||||
|
||||
* `push`: 添加、提交和推送到以主机命名的分支上
|
||||
* `fetch`: 一个简单的 `git fetch` 操作
|
||||
* `sync`: 添加、提交和拉取远程的修改,合并,并(假设合并成功)将其推送到以主机命名的分支和主干上
|
||||
|
||||
现在,在我的用户 crontab 中有这个:
|
||||
|
||||
```
|
||||
*/15 * * * * make -C $HOME/org push fetch 2>&1 | logger --tag 'orgsync'
|
||||
```
|
||||
|
||||
[与之相关的 elisp 代码][3] 定义了一个快捷键(`C-c s`)来调用同步。多亏了 cronjob,只要文件被保存 —— 即使我没有在另一个机器上同步 —— 它们也会被拉取进来。
|
||||
|
||||
我发现这个设置非常好用。
|
||||
|
||||
### 用 Org 模式发邮件
|
||||
|
||||
在继续下去之前,首先要问自己一下:你真的需要它吗? 我用的是带有 [mu4e][4] 的 Org 模式,而且它集成的也很好;任何 Org 模式的任务都可以通过 `Message-id` 链接到电子邮件,这很理想 —— 它可以让一个人做一些事情,比如提醒他在一周内回复一条消息。
|
||||
|
||||
然而,Org 模式不仅仅只有提醒。它还是一个知识库、创作系统等,但是并不是我所有的邮件客户端都使用 mu4e。(注意:移动设备中有像 MobileOrg 这样的应用)。我并没有像我想的那样经常使用它,但是它有它的用途,所以我认为我也应该在这里记录它。
|
||||
|
||||
现在我不仅想处理纯文本电子邮件。我希望能够处理附件、HTML 邮件等。这听起来很快就有问题了 —— 但是通过使用 ripmime 和 pandoc 这样的工具,情况还不错。
|
||||
|
||||
第一步就是要用某些方法将获取到的邮件放入指定的文件夹下。扩展名、特殊用户等。然后我用一个 [fetchmail 配置][5] 来将它拉取下来并运行我自己的 [insorgmail][6] 脚本。
|
||||
|
||||
这个脚本就是处理所有有趣的部分了。它开始用 ripmime 处理消息,用 pandoc 将 HTML 的部分转换为 Org 模式的格式。 Org 模式的层次结构是用来尽可能最好地表示 email 的结构。使用 HTML 和其他工具时,email 可能会变得相当复杂,但我发现这对于我来说是可以接受的。
|
||||
|
||||
### 下一篇
|
||||
|
||||
我最后一篇关于 Org 模式的文章将讨论如何使用它来编写文档和准备幻灯片 —— 我发现自己对 Org 模式的使用非常满意,但这需要一些调整。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9898-emacs-4-automated-emails-to-org-mode-and-org-mode-syncing
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/
|
||||
[1]:https://changelog.complete.org/archives/tag/emacs2018
|
||||
[2]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/Makefile
|
||||
[3]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/emacs-config.org
|
||||
[4]:https://www.emacswiki.org/emacs/mu4e
|
||||
[5]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/fetchmailrc.orgmail
|
||||
[6]:https://github.com/jgoerzen/public-snippets/blob/master/emacs/org-tools/insorgmail
|
||||
@ -0,0 +1,221 @@
|
||||
如何在 Linux 中从一个 PDF 文件中移除密码
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天,我碰巧分享一个受密码保护的 PDF 文件给我的一个朋友。我知道这个 PDF 文件的密码,但是我不想透露密码。作为代替,我只想移除密码并发送文件给他。我开始在因特网上查找一些简单的方法来从 PDF 文件中移除密码保护。在快速 google 搜索后,在 Linux 中,我带来四种方法来从一个 PDF 文件中移除密码。有趣的事是,在几年以前我已经做过这事情但是我忘记了。如果你想知道,如何在 Linux 中从一个 PDF 文件移除密码,继续读!它是不难的。
|
||||
|
||||
### 在Linux中从一个PDF文件中移除密码
|
||||
|
||||
#### 方法 1 – 使用 Qpdf
|
||||
|
||||
**Qpdf** 是一个 PDF 转换软件,它被用于加密和解密 PDF 文件,转换 PDF 文件到其他等效的 PDF 文件。 Qpdf 在大多数 Linux 发行版中的默认存储库中是可用的,所以你可以使用默认的软件包安装它。
|
||||
|
||||
例如,Qpdf 可以被安装在 Arch Linux 和它的衍生版,使用 [pacman][1] ,像下面显示。
|
||||
|
||||
```
|
||||
$ sudo pacman -S qpdf
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install qpdf
|
||||
```
|
||||
|
||||
现在,让我们使用 qpdf 从一个 pdf 文件移除密码。
|
||||
|
||||
我有一个受密码保护的 PDF 文件,名为 `secure.pdf`。每当我打开这个文件时,它提示我输入密码来显示它的内容。
|
||||
|
||||
![][3]
|
||||
|
||||
我知道上面 PDF 文件的密码。然而,我不想与任何人共享密码。所以,我将要做的事是简单地移除 PDF 文件的密码,使用 Qpdf 功能带有下面的命令。
|
||||
|
||||
```
|
||||
$ qpdf --password='123456' --decrypt secure.pdf output.pdf
|
||||
```
|
||||
|
||||
相当简单,不是吗?是的,它是!这里,`123456` 是 `secure.pdf` 文件的密码。用你自己的密码替换。
|
||||
|
||||
#### 方法 2 – 使用 Pdftk
|
||||
|
||||
**Pdftk** 是另一个用于操作 PDF 文件的好软件。 Pdftk 可以做几乎所有的 PDF 操作,例如:
|
||||
|
||||
* 加密和解密 PDF 文件。
|
||||
* 合并 PDF 文档。
|
||||
* 整理 PDF 页扫描。
|
||||
* 拆分 PDF 页。
|
||||
* 旋转 PDF 文件或页。
|
||||
* 用 X/FDF 数据 填充 PDF 表单,和/或摧毁表单。
|
||||
* 从 PDF 表单中生成 PDF数据模板。
|
||||
* 应用一个背景水印,或一个前景印记。
|
||||
* 报告 PDF 度量标准、书签和元数据。
|
||||
* 添加/更新 PDF 书签或元数据。
|
||||
* 附加文件到 PDF 页,或 PDF 文档。
|
||||
* 解包 PDF 附件。
|
||||
* 拆解一个 PDF 文件到单页中。
|
||||
* 压缩和解压缩页流。
|
||||
* 修复破损的 PDF 文件。
|
||||
|
||||
Pddftk 在 AUR 中是可用的,所以你可以在 Arch Linux 和它的衍生版上使用任意 AUR 帮助程序安装它。
|
||||
|
||||
使用 [Pacaur][4]:
|
||||
|
||||
```
|
||||
$ pacaur -S pdftk
|
||||
```
|
||||
|
||||
使用 [Packer][5]:
|
||||
|
||||
```
|
||||
$ packer -S pdftk
|
||||
```
|
||||
|
||||
使用 [Trizen][6]:
|
||||
|
||||
```
|
||||
$ trizen -S pdftk
|
||||
```
|
||||
|
||||
使用 [Yay][7]:
|
||||
|
||||
```
|
||||
$ yay -S pdftk
|
||||
```
|
||||
|
||||
使用 [Yaourt][8]:
|
||||
|
||||
```
|
||||
$ yaourt -S pdftk
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上,运行:
|
||||
|
||||
```
|
||||
$ sudo apt-get instal pdftk
|
||||
```
|
||||
|
||||
在 CentOS、Fedora、Red Hat 上:
|
||||
|
||||
首先,安装 EPEL 仓库:
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
$ sudo dnf install epel-release
|
||||
```
|
||||
|
||||
然后,安装 PDFtk 应用程序,使用命令:
|
||||
|
||||
```
|
||||
$ sudo yum install pdftk
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
$ sudo dnf install pdftk
|
||||
```
|
||||
|
||||
一旦 pdftk 安装,你可以从一个 PDF 文档移除密码,使用命令:
|
||||
|
||||
```
|
||||
$ pdftk secure.pdf input_pw 123456 output output.pdf
|
||||
```
|
||||
|
||||
用你正确的密码替换 `123456`。这个命令解密 `secure.pdf` 文件,并创建一个相同的名为 `output.pdf` 的无密码保护的文件。
|
||||
|
||||
**参阅:**
|
||||
|
||||
- [How To Merge PDF Files In Command Line On Linux][9]
|
||||
- [How To Split or Extract Particular Pages From A PDF File][10]
|
||||
|
||||
#### 方法 3 – 使用 Poppler
|
||||
|
||||
**Poppler** 是一个基于 xpdf-3.0 代码库的 PDF 渲染库。它包含下列用于操作 PDF 文档的命令行功能集。
|
||||
|
||||
* `pdfdetach` – 列出或提取嵌入的文件。
|
||||
* `pdffonts` – 字体分析器。
|
||||
* `pdfimages` – 图片提取器。
|
||||
* `pdfinfo` – 文档信息。
|
||||
* `pdfseparate` – 页提取工具。
|
||||
* `pdfsig` – 核查数字签名。
|
||||
* `pdftocairo` – PDF 到 PNG/JPEG/PDF/PS/EPS/SVG 转换器,使用 Cairo 。
|
||||
* `pdftohtml` – PDF 到 HTML 转换器。
|
||||
* `pdftoppm` – PDF 到 PPM/PNG/JPEG 图片转换器。
|
||||
* `pdftops` – PDF 到 PostScript (PS) 转换器。
|
||||
* `pdftotext` – 文本提取。
|
||||
* `pdfunite` – 文档合并工具。
|
||||
|
||||
因这个指南的目的,我们仅使用 `pdftops` 功能。
|
||||
|
||||
在基于 Arch Linux 的发行版上,安装 Poppler,运行:
|
||||
|
||||
```
|
||||
$ sudo pacman -S poppler
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install poppler-utils
|
||||
```
|
||||
|
||||
在 RHEL、CentOS、Fedora 上:
|
||||
|
||||
```
|
||||
$ sudo yum install poppler-utils
|
||||
```
|
||||
|
||||
一旦 Poppler 安装,运行下列命令来解密密码保护的 PDF 文件,并创建一个新的相同的名为 `output.pdf` 的文件。
|
||||
|
||||
```
|
||||
$ pdftops -upw 123456 secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
再一次,用你的 pdf 密码替换 `123456` 。
|
||||
|
||||
正如你在上面方法中可能注意到,我们仅转换密码保护的名为 `secure.pdf` 的 PDF 文件到另一个相同的名为 `output.pdf` 的 PDF 文件。技术上讲,我们并没有真的从源文件中移除密码,作为代替,我们解密它,并保存它为另一个相同的没有密码保护的 PDF 文件。
|
||||
|
||||
#### 方法 4 – 打印到一个文件
|
||||
|
||||
这是在所有上面方法中的最简单的方法。你可以使用你存在的 PDF 查看器,例如 Atril 文档查看器、Evince 等等,并打印密码保护的 PDF 文件到另一个文件。
|
||||
|
||||
在你的 PDF 查看器应用程序中打开密码保护的文件。转到 “File - > Print” 。并在你选择的某个位置保存 PDF 文件。
|
||||
|
||||
![][2]
|
||||
|
||||
于是,这是全部。希望这是有用的。你知道/使用一些其它方法来从从 PDF 文件中移除密码保护吗?在下面的评价区让我们知道。
|
||||
|
||||
更多好东西来了。敬请期待!
|
||||
|
||||
谢谢!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:https://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-2.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-1.png
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[9]: https://www.ostechnix.com/how-to-merge-pdf-files-in-command-line-on-linux/
|
||||
[10]: https://www.ostechnix.com/extract-particular-pages-pdf-file/
|
||||
112
published/20180518 How to Manage Fonts in Linux.md
Normal file
112
published/20180518 How to Manage Fonts in Linux.md
Normal file
@ -0,0 +1,112 @@
|
||||
如何在 Linux 上管理字体
|
||||
======
|
||||
|
||||

|
||||
|
||||
我不仅写技术文档,还写小说。并且因为我对 GIMP 等工具感到满意,所以我也(LCTT 译注:此处应指使用 GIMP)为自己的书籍创作了封面(并为少数客户做了图形设计)。艺术创作取决于很多东西,包括字体。
|
||||
|
||||
虽然字体渲染已经在过去的几年里取得了长足进步,但它在 Linux 平台上仍是个问题。如果你在 Linux 和 macOS 平台上比较相同字体的外观,差别是显而易见的,尤其是你要盯着屏幕一整天的时候。虽然在 Linux 平台上尚未找到完美的字体渲染方案,但开源平台做的很好一件事的就是允许用户轻松地管理他们的字体。通过选择、添加、缩放和调整,你可以在 Linux 平台上相当轻松地使用字体。
|
||||
|
||||
此处,我将分享一些这些年来我的一些技巧,可以帮我在 Linux 上扩展“字体能力”。这些技巧将对那些在开源平台上进行艺术创作的人有特别的帮助。因为 Linux 平台上有非常多可用的桌面界面(每种界面以不同的方式处理字体),因此当桌面环境成为字体管理的中心时,我将主要聚焦在 GNOME 和 KDE 上。
|
||||
|
||||
话虽如此,让我们开始吧。
|
||||
|
||||
### 添加新字体
|
||||
|
||||
在相当长的一段时间里,我都是一个字体收藏家,甚至有些人会说我有些痴迷。从我使用 Linux 的早期开始,我就总是用相同的方法向我的桌面添加字体。有两种方法可以做到这一点:
|
||||
|
||||
* 使字体按用户可用;
|
||||
* 使字体在系统范围内可用。
|
||||
|
||||
因为我的桌面从没有其他用户(除了我自己),我只使用了按用户可用的字体设置。然而,我会向你演示如何完成这两种设置。首先,让我们来看一下如何向用户添加新字体。你首先要做的是找到字体文件,True Type 字体(TTF)和 Open Type 字体(OTF)都可以添加。我选择手动添加字体,也就是说,我在 `~/` 目录下新建了一个名为 `~/.fonts` 的隐藏目录。该操作可由以下命令完成:
|
||||
|
||||
```
|
||||
mkdir ~/.fonts
|
||||
```
|
||||
|
||||
当此文件夹新建完成,我将所有 TTF 和 OTF 字体文件移动到此文件夹中。也就是说,你在此文件夹中添加的所有字体都可以在已安装的应用中使用了。但是要记住,这些字体只会对这一个用户可用。
|
||||
|
||||
如果你想要使这个字体集合对所有用户可用,你可以如下操作:
|
||||
|
||||
1. 打开一个终端窗口;
|
||||
2. 切换路径到包含你所有字体的目录中;
|
||||
3. 使用 `sudo cp *.ttf *.TTF /usr/share/fonts/truetype/` 和 `sudo cp *.otf *.OTF /usr/share/fonts/opentype` 命令拷贝所有字体。
|
||||
|
||||
当下次用户登录时,他们就将可以使用所有这些漂亮的字体。
|
||||
|
||||
### 图形界面字体管理
|
||||
|
||||
在 Linux 上你有许多方式来管理你的字体,如何完成取决于你的桌面环境。让我们以 KDE 为例。使用以 KDE 作为桌面环境的 Kubuntu 18.04,你能够找到一个预装的字体管理工具。打开此工具,你就能轻松地添加、移除、启用或禁用字体(当然也包括获得所有已安装字体的详细信息)。这个工具也能让你轻松地针对每个用户或在系统范围内添加和删除字体。假如你想要为用户添加一个特定的字体,你需要下载该字体并打开“字体管理”工具。在此工具中(图 1),点击“个人字体”并点击“+”号添加按钮。
|
||||
|
||||
![添加字体][2]
|
||||
|
||||
*图 1: 在 KDE 中添加个人字体。*
|
||||
|
||||
导航至你的字体路径,选择它们,然后点击打开。你的字体就会被添加进了个人区域,并且立即可用(图 2)。
|
||||
|
||||
![KDE 字体管理][5]
|
||||
|
||||
*图 2: 使用 KDE 字体管理添加字体*
|
||||
|
||||
在 GNOME 中做同样的事需要安装一个应用。打开 GNOME 软件中心或者 Ubuntu 软件中心(取决于你使用的发行版)并搜索字体管理器。选择“字体管理器”并点击安装按钮。一但安装完成,你就可以从桌面菜单中启动它,然后让我们安装个人字体。下面是如何安装:
|
||||
|
||||
1. 从左侧窗格选择“用户”(图 3);
|
||||
2. 点击窗口顶部的 “+” 按钮;
|
||||
3. 浏览并选择已下载的字体;
|
||||
4. 点击“打开”。
|
||||
|
||||
![添加字体][7]
|
||||
|
||||
*图 3: 在 GNOME 中添加字体*
|
||||
|
||||
### 调整字体
|
||||
|
||||
首先你需要理解 3 个概念:
|
||||
|
||||
* **字体提示:** 使用数学指令调整字体轮廓显示,使其与光栅化网格对齐。
|
||||
* **抗锯齿:** 一种通过使曲线和斜线锯齿状边缘光滑化,提高数字图像真实性的技术。
|
||||
* **缩放因子:** 一个允许你倍增字体大小的缩放单元。也就是说如果你的字体是 12pt 并且缩放因子为 1,那么字体大小将会是 12pt。如果你的缩放因子为 2,那么字体将会是 24pt。
|
||||
|
||||
假设你已经安装好了你的字体,但它们看起来并不像你想的那么好。你将如何调整字体的外观?在 KDE 和 GNOME 中,你都可以做一些调整。在调整字体时需要考虑的一件事是,关于字体的口味是非常主观的。你也许会发现你只得不停地调整,直到你得到了看起来确实满意的字体(由你的需求和特殊口味决定)。让我们先看一下 KDE 下的情况吧。
|
||||
|
||||
打开“系统设置”工具并点击“字体”。在此节中,你不仅能切换不同字体,你也能够启用或配置抗锯齿或启用字体缩放因子(图 4)。
|
||||
|
||||
![配置字体][9]
|
||||
|
||||
*图 4: 在 KDE 中配置字体*
|
||||
|
||||
要配置抗锯齿,在下拉菜单中选择“启用”并点击“配置”。在结果窗口中(图 5),你可以配置“排除范围”、“子像素渲染类型”和“提示类型”。
|
||||
|
||||
一但你做了更改,点击“应用”。重启所有正在运行的程序,然后新的设置就会生效。
|
||||
|
||||
要在 GNOME 中这么做,你需要安装“字体管理器”或 GNOME Tweaks。在此处,GNOME Tweaks 是更好的工具。如果你打开 GNOME Dash 菜单但没有找到 Tweaks,打开 GNOME “软件”(或 Ubuntu “软件”)并安装 GNOME Tweaks。安装完毕,打开并点击“字体”,此处你可以配置提示、抗锯齿和缩放因子(图 6)。
|
||||
|
||||
![调整字体][11]
|
||||
|
||||
*图 6: 在 GNOME 中调整字体*
|
||||
|
||||
### 美化你的字体
|
||||
|
||||
以上便是使你的 Linux 字体尽可能漂亮的要旨。你可能得不到像 macOS 那样渲染的字体,但你一定可以提升字体外观。最后,你选择的字体会很大程度地影响视觉效果,因此请确保你安装的字体是干净并且完整适配的,否则你将输掉这次对抗。
|
||||
|
||||
通过 The Linux Foundation 和 edX 平台的免费课程 [初识 Linux][12] 了解更多关于 Linux 的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/5/how-manage-fonts-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[2]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_1.jpg?itok=7yTTe6o3 (adding fonts)
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_2.jpg?itok=_g0dyVYq (KDE Font Manager)
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_3.jpg?itok=8o884QKs (Adding fonts )
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_4.jpg?itok=QJpPzFED (Configuring fonts)
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/fonts_6.jpg?itok=4cQeIW9C (Tweaking fonts)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
210
published/20180523 How to dual-boot Linux and Windows.md
Normal file
210
published/20180523 How to dual-boot Linux and Windows.md
Normal file
@ -0,0 +1,210 @@
|
||||
如何实现 Linux + Windows 双系统启动
|
||||
=====
|
||||
> 设置你的计算机根据需要启动 Windows 10 或 Ubuntu 18.04。
|
||||
|
||||

|
||||
|
||||
尽管 Linux 是一个有着广泛的硬件和软件支持的操作系统,但事实上有时你仍需要使用 Windows,也许是因为有些不能在 Linux 下运行的重要软件。但幸运地是,双启动 Windows 和 Linux 是很简单的 —— 在这篇文章中我将会向你展示如何实现 Windows 10 + Ubuntu 18.04 双系统启动。
|
||||
|
||||
在你开始之前,确保你已经备份了你的电脑文件。虽然设置双启动过程不是非常复杂,但意外有可能仍会发生。所以花一点时间来备份你的重要文件以防混沌理论发挥作用。除了备份你的文件之外,考虑制作一份备份镜像也是个不错的选择,虽然这不是必需的且会变成一个更高级的过程。
|
||||
|
||||
### 要求
|
||||
|
||||
为了开始,你将需要以下 5 项东西:
|
||||
|
||||
#### 1、两个 USB 闪存盘(或者 DVD-R)
|
||||
|
||||
我推荐用 USB 闪存盘来安装 Windows 和 Ubuntu,因为他们比 DVD 更快。这通常是毋庸置疑的, 但是创建一个可启动的介质会抹除闪存盘上的一切东西。因此,确保闪存盘是空的或者其包含的文件是你不再需要的。
|
||||
|
||||
如果你的电脑不支持从 USB 启动,你可以创建 DVD 介质来代替。不幸的是,因为电脑上的 DVD 烧录软件似乎各有不同,所以我无法使用这一过程。然而,如果你的 DVD 烧录软件有从一个 ISO 镜像中烧录的选项,这个选项是你需要的。
|
||||
|
||||
#### 2、一份 Windows 10 许可证
|
||||
|
||||
如果你的电脑已经安装 Windows 10,那么许可证将会被安装到你的电脑中,所以你不需要担心在安装过程中输入它。如果你购买的是零售版,你应该拥有一个需要在安装过程中输入的产品密钥。
|
||||
|
||||
#### 3、Windows 10 介质创建工具
|
||||
|
||||
下载并运行 Windows 10 [介质创建工具][1]。一旦你运行这个工具,它将会引导你完成在一个 USB 或者 DVD-R 上创建 Windows 安装介质的所需步骤。注意:即使你已经安装了 Windows 10,创建一个可引导的介质也是一个不错的主意,万一刚好系统出错了且需要你重新安装。
|
||||
|
||||
#### 4、Ubuntu 18.04 安装介质
|
||||
|
||||
下载 [Ubuntu 18.04][2] ISO 镜像。
|
||||
|
||||
#### 5、Etcher 软件(用于制作一个可引导 Ubuntu 的 USB 驱动器)
|
||||
|
||||
用于为任何 Linux 发行版创建可启动的介质的工具,我推荐 [Etcher][3]。Etcher 可以在三大主流操作系统(Linux、MacOS 和 Windows)上运行且不会让你覆盖当前操作系统的分区。
|
||||
|
||||
一旦你下载完成并运行 Etcher,点击选择镜像并指向你在步骤 4 中下载的 Ubuntu ISO 镜像, 接下来,点击驱动器以选择你的闪存驱动器,然后点击 “Flash!” 开始将闪存驱动器转化为一个 Ubuntu 安装器的过程。 (如果你正使用一个 DVD-R,使用你电脑中的 DVD 烧录软件来完成此过程。)
|
||||
|
||||
### 安装 Windows 和 Ubuntu
|
||||
|
||||
你应该准备好了,此时,你应该完成以下操作:
|
||||
|
||||
* 备份你重要的文件
|
||||
* 创建 Windows 安装介质
|
||||
* 创建 Ubuntu 安装介质
|
||||
|
||||
有两种方法可以进行安装。首先,如果你已经安装了 Windows 10 ,你可以让 Ubuntu 安装程序调整分区大小,然后在空白区域上进行安装。或者,如果你尚未安装 Windows 10,你可以在安装过程中将它(Windows)安装在一个较小的分区上(下面我将描述如何去做)。第二种方法是首选的且出错率较低。很有可能你不会遇到任何问题,但是手动安装 Windows 并给它一个较小的分区,然后再安装 Ubuntu 是最简单的方法。
|
||||
|
||||
如果你的电脑上已经安装了 Windows 10,那么请跳过以下的 Windows 安装说明并继续安装 Ubuntu。
|
||||
|
||||
#### 安装 Windows
|
||||
|
||||
将创建的 Windows 安装介质插入你的电脑中并引导其启动。这如何做取决于你的电脑。但大多数有一个可以按下以显示启动菜单的快捷键。例如,在戴尔的电脑上就是 F12 键。如果闪存盘并未作为一个选项显示,那么你可能需要重新启动你的电脑。有时候,只有在启动电脑前插入介质才能使其显示出来。如果看到类似“请按任意键以从安装介质中启动”的信息,请按下任意一个键。然后你应该会看到如下的界面。选择你的语言和键盘样式,然后单击 “Next”。
|
||||
|
||||
![Windows 安装][5]
|
||||
|
||||
点击“现在安装”启动 Windows 安装程序。
|
||||
|
||||
![现在安装][6]
|
||||
|
||||
在下一个屏幕上,它会询问你的产品密钥。如果因你的电脑在出厂时已经安装了 Windows 10 而没有密钥的话,请选择“我没有一个产品密钥”。在安装完成后更新该密码后会自动激活。如果你有一个产品密钥,输入密钥并单击“下一步”。
|
||||
|
||||
![输入产品密钥][7]
|
||||
|
||||
选择你想要安装的 Windows 版本。如果你有一个零售版,封面标签(LCTT 译注:类似于 CPU 型号的 logo 贴标)会告诉你你有什么版本。否则,它通常在你的计算机的附带文档中可以找到。在大多数情况下,它要么是 Windows 10 家庭版或者 Windows 10 专业版。大多数带有 家庭版的电脑都有一个简单的标签,上面写着“Windows 10”,而专业版则会明确标明。
|
||||
|
||||
![选择 Windows 版本][10]
|
||||
|
||||
勾选复选框以接受许可协议,然后单击“下一步”。
|
||||
|
||||
![接受许可协议][12]
|
||||
|
||||
在接受协议后,你有两种可用的安装选项。选择第二个选项“自定义:只安装 Windows (高级)”。
|
||||
|
||||
![选择 Windows 的安装方式][14]
|
||||
|
||||
接下来应该会显示你当前的硬盘配置。
|
||||
|
||||
![硬盘配置][16]
|
||||
|
||||
你的结果可能看起来和我的不一样。我以前从来没有用过这个硬盘,所以它是完全未分配的。你可能会看到你当前操作系统的一个或多个分区。选中每个分区并移除它。(LCTT 译注:确保这些分区中没有你需要的数据!!)
|
||||
|
||||
此时,你的电脑屏幕将显示未分配的整个磁盘。创建一个新的分区以继续安装。
|
||||
|
||||
![创建一个新分区][18]
|
||||
|
||||
你可以看到我通过创建一个 81920MB 大小的分区(接近 160GB 的一半)将驱动器分成了一半(或者说接近一半)。给 Windows 至少 40GB,最好 64GB 或者更多。把剩下的硬盘留着不要分配,作为以后安装 Ubuntu 的分区。
|
||||
|
||||
你的结果应该看起来像这样:
|
||||
|
||||
![保留未分配空间的分区][20]
|
||||
|
||||
确认分区看起来合理,然后单击“下一步”。现在将开始安装 Windows。
|
||||
|
||||
![安装 Windows][22]
|
||||
|
||||
如果你的电脑成功地引导进入了 Windows 桌面环境,你就可以进入下一步了。
|
||||
|
||||
![Windows 桌面][24]
|
||||
|
||||
#### 安装 Ubuntu
|
||||
|
||||
无论你是已经安装了 Windows,还是完成了上面的步骤,现在你已经安装了 Windows。现在用你之前创建的 Ubuntu 安装介质来引导进入 Ubuntu。继续插入安装介质并从中引导你的电脑,同样,启动引导菜单的快捷键因计算机型号而异,因此如果你不确定,请查阅你的文档。如果一切顺利的话,当安装介质加载完成之后,你将会看到以下界面:
|
||||
|
||||
![Ubuntu 安装欢迎屏幕][26]
|
||||
|
||||
在这里,你可以选择 “尝试 Ubuntu” 或者 “安装 Ubuntu”。现在不要安装,相反,点击 “尝试 Ubuntu”。当完成加载之后,你应该可以看到 Ubuntu 桌面。
|
||||
|
||||
![Ubuntu 桌面][28]
|
||||
|
||||
通过单击“尝试 Ubuntu”,你已经选择在安装之前试用 Ubuntu。 在 Live 模式下,你可以试用 Ubuntu,确保在你安装之前一切正常。Ubuntu 能兼容大多数 PC 硬件,但最好提前测试一下。确保你可以访问互联网并可以正常播放音频和视频。登录 YouTube 播放视频是一次性完成所有这些工作的好方法(LCTT 译注:国情所限,这个方法在这里并不奏效)。如果你需要连接到无线网络,请单击屏幕右上角的网络图标。在那里,你可以找到一个无线网络列表并连接到你的无线网络。
|
||||
|
||||
准备好之后,双击桌面上的 “安装 Ubuntu 18.04 LTS” 图标启动安装程序。
|
||||
|
||||
选择要用于安装过程的语言,然后单击 “继续”。
|
||||
|
||||
![选择 Ubuntu 的语言][30]
|
||||
|
||||
接下来,选择键盘布局。完成后选择后,单击“继续”。
|
||||
|
||||
![选择 Ubuntu 的键盘][32]
|
||||
|
||||
在下面的屏幕上有一些选项。你可以选择一个正常安装或最小化安装。对大多数人来说,普通安装是理想的。高级用户可能想要默认安装应用程序比较少的最小化安装。此外,你还可以选择下载更新以及是否包含第三方软件和驱动程序。我建议同时检查这两个方框。完成后,单击“继续”。
|
||||
|
||||
![选择 Ubuntu 安装选项][34]
|
||||
|
||||
下一个屏幕将询问你是要擦除磁盘还是设置双启动。由于你是双启动,因此请选择“安装 Ubuntu,与 Windows 10共存”,单击“现在安装”。
|
||||
|
||||
![安装 Ubuntu,与 Windows 10共存][36]
|
||||
|
||||
可能会出现以下屏幕。如果你从头开始安装 Windows 并在磁盘上保留了未分区的空间,Ubuntu 将会自动在空白区域中自行设置分区,因此你将看不到此屏幕。如果你已经安装了 Windows 10 并且它占用了整个驱动器,则会出现此屏幕,并在顶部为你提供一个选择磁盘的选项。如果你只有一个磁盘,则可以选择从 Windows 窃取多少空间给 Ubuntu。你可以使用鼠标左右拖动中间的垂直线以从其中一个分区中拿走一些空间并给另一个分区,按照你自己想要的方式调整它,然后单击“现在安装”。
|
||||
|
||||
![分配驱动器空间][38]
|
||||
|
||||
你应该会看到一个显示 Ubuntu 计划将要做什么的确认屏幕,如果一切正常,请单击“继续”。
|
||||
|
||||
![确认屏幕][39]
|
||||
|
||||
Ubuntu 正在后台安装。不过,你仍需要进行一些配置。当 Ubuntu 试图找到你的位置时,你可以点击地图来缩小范围以确保你的时区和其他设置是正确的。
|
||||
|
||||
![选择地理位置][40]
|
||||
|
||||
接下来,填写用户账户信息:你的姓名、计算机名、用户名和密码。完成后单击“继续”。
|
||||
|
||||
![账户设置][41]
|
||||
|
||||
现在你就拥有它了,安装完成了。继续并重启你的电脑。
|
||||
|
||||
![Ubuntu 安装完成][42]
|
||||
|
||||
如果一切按计划进行,你应该会在计算机重新启动时看到类似的屏幕,选择 Ubuntu 或 Windows 10,其他选项是用于故障排除,所以我们一般不会选择进入其中。
|
||||
|
||||
![选择操作系统][43]
|
||||
|
||||
尝试启动并进入 Ubuntu 或 Windows 以测试是否安装成功并确保一切按预期地正常工作。如果没有问题,你已经在你的电脑上安装了 Windows 和 Ubuntu 。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/dual-boot-linux
|
||||
|
||||
作者:[Jay LaCroix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlacroix
|
||||
[1]:https://www.microsoft.com/en-us/software-download/windows10
|
||||
[2]:https://www.ubuntu.com/download/desktop
|
||||
[3]:http://www.etcher.io
|
||||
[4]:/file/397066
|
||||
[5]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_01.png "Windows setup"
|
||||
[6]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_02a.png
|
||||
[7]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_03.png "Enter product key"
|
||||
[9]:/file/397081
|
||||
[10]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_04.png "Select Windows version"
|
||||
[11]:/file/397086
|
||||
[12]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_05.png "Accept license terms"
|
||||
[13]:/file/397091
|
||||
[14]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_06.png "Select type of Windows installation"
|
||||
[15]:/file/397096
|
||||
[16]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_07.png "Hard drive configuration"
|
||||
[17]:/file/397101
|
||||
[18]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_08.png "Create a new partition"
|
||||
[19]:/file/397106
|
||||
[20]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_09.png "Leaving a partition with unallocated space"
|
||||
[21]:/file/397111
|
||||
[22]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_10.png "Installing Windows"
|
||||
[23]:/file/397116
|
||||
[24]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_11.png "Windows desktop"
|
||||
[25]:/file/397121
|
||||
[26]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_12.png "Ubuntu installation welcome screen"
|
||||
[27]:/file/397126
|
||||
[28]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_13.png "Ubuntu desktop"
|
||||
[29]:/file/397131
|
||||
[30]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_15.png "Select language in Ubuntu"
|
||||
[31]:/file/397136
|
||||
[32]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_16.png "Select keyboard in Ubuntu"
|
||||
[33]:/file/397141
|
||||
[34]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_17.png "Choose Ubuntu installation options"
|
||||
[35]:/file/397146
|
||||
[36]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_18.png "Install Ubuntu alongside Windows"
|
||||
[37]:/file/397151
|
||||
[38]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_18b.png "Allocate drive space"
|
||||
[39]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_19.png "Confirmation screen"
|
||||
[40]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_20.png "Select location"
|
||||
[41]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_21.png "Account setup"
|
||||
[42]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_22.png "Installation complete"
|
||||
[43]:https://opensource.com/sites/default/files/uploads/linux-dual-boot_23.png "Chose which OS to use"
|
||||
@ -0,0 +1,90 @@
|
||||
如何在 Linux 中为每个屏幕设置不同的壁纸
|
||||
======
|
||||
|
||||
> 如果你想在 Ubuntu 18.04 或任何其他 Linux 发行版上使用 GNOME、MATE 或 Budgie 桌面环境在多个显示器上显示不同的壁纸,这个小工具将帮助你实现这一点。
|
||||
|
||||
多显示器设置通常会在 Linux 上出现多个问题,但我不打算在本文中讨论这些问题。我有另外一篇关于 Linux 上多显示器支持的文章。
|
||||
|
||||
如果你使用多台显示器,也许你想为每台显示器设置不同的壁纸。我不确定其他 Linux 发行版和桌面环境,但是 [GNOME 桌面][1] 的 Ubuntu 本身并不提供此功能。
|
||||
|
||||
不要烦恼!在本教程中,我将向你展示如何使用 GNOME 桌面环境为 Linux 发行版上的每个显示器设置不同的壁纸。
|
||||
|
||||
### 在 Ubuntu 18.04 和其他 Linux 发行版上为每个显示器设置不同的壁纸
|
||||
|
||||
![Different wallaper on each monitor in Ubuntu][2]
|
||||
|
||||
我将使用一个名为 [HydraPaper][3] 的小工具在不同的显示器上设置不同的背景。HydraPaper 是一个基于 [GTK][4] 的应用,用于为 [GNOME 桌面环境][5]中的每个显示器设置不同的背景。
|
||||
|
||||
它还支持 [MATE][6] 和 [Budgie][7] 桌面环境。这意味着 Ubuntu MATE 和 [Ubuntu Budgie][8] 用户也可以从这个应用中受益。
|
||||
|
||||
#### 使用 FlatPak 在 Linux 上安装 HydraPaper
|
||||
|
||||
使用 [FlatPak][9] 可以轻松安装 HydraPaper。Ubuntu 18.04 已 经提供对 FlatPaks 的支持,所以你需要做的就是下载应用文件并双击在 GNOME 软件中心中打开它。
|
||||
|
||||
你可以参考这篇文章来了解如何在你的发行版[启用 FlatPak 支持][10]。启用 FlatPak 支持后,只需从 [FlatHub][11] 下载并安装即可。
|
||||
|
||||
- [下载 HydraPaper][12]
|
||||
|
||||
#### 使用 HydraPaper 在不同的显示器上设置不同的背景
|
||||
|
||||
安装完成后,只需在应用菜单中查找 HydraPaper 并启动应用。你将在此处看到“图片”文件夹中的图像,因为默认情况下,应用会从用户的“图片”文件夹中获取图像。
|
||||
|
||||
你可以添加自己的文件夹来保存壁纸。请注意,它不会递归地查找图像。如果你有嵌套文件夹,它将只显示顶部文件夹中的图像。
|
||||
|
||||
![Setting up different wallpaper for each monitor on Linux][13]
|
||||
|
||||
使用 HydraPaper 很简单。只需为每个显示器选择壁纸,然后单击顶部的应用按钮。你可以轻松地用 HDMI 标识来识别外部显示器。
|
||||
|
||||
![Setting up different wallpaper for each monitor on Linux][14]
|
||||
|
||||
你还可以将选定的壁纸添加到“收藏夹”以便快速访问。这样做会将“最喜欢的壁纸”从“壁纸”选项卡移动到“收藏夹”选项卡。
|
||||
|
||||
![Setting up different wallpaper for each monitor on Linux][15]
|
||||
|
||||
你不需要在每次启动时启动 HydraPaper。为不同的显示器设置不同的壁纸后,设置将被保存,即使重新启动后你也会看到所选择的壁纸。这当然是预期的行为,但我想特别提一下。
|
||||
|
||||
HydraPaper 的一大缺点在于它的设计工作方式。你可以看到,HydraPaper 将你选择的壁纸拼接成一张图像并将其拉伸到屏幕上,给人的印象是每个显示器上都有不同的背景。当你移除外部显示器时,这将成为一个问题。
|
||||
|
||||
例如,当我尝试使用没有外接显示器的笔记本电脑时,它向我展示了这样的背景图像。
|
||||
|
||||
![Dual Monitor wallpaper HydraPaper][16]
|
||||
|
||||
很明显,这不是我所期望的。
|
||||
|
||||
#### 你喜欢它吗?
|
||||
|
||||
HydraPaper 使得在不同的显示器上设置不同的背景变得很方便。它支持超过两个显示器和不同的显示器方向。只有所需功能的简单界面使其成为那些总是使用双显示器的人的理想应用。
|
||||
|
||||
如何在 Linux 上为不同的显示器设置不同的壁纸?你认为 HydraPaper 是值得安装的应用吗?
|
||||
|
||||
请分享您的观点,另外如果你看到这篇文章,请在各种社交媒体渠道上分享,如 Twitter 和 [Reddit][17]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/wallpaper-multi-monitor/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.gnome.org/
|
||||
[2]:https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/05/multi-monitor-wallpaper-setup.jpeg?w=800&ssl=1
|
||||
[3]:https://github.com/GabMus/HydraPaper
|
||||
[4]:https://www.gtk.org/
|
||||
[5]:https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
[6]:https://mate-desktop.org/
|
||||
[7]:https://budgie-desktop.org/home/
|
||||
[8]:https://itsfoss.com/ubuntu-budgie-18-review/
|
||||
[9]:https://flatpak.org
|
||||
[10]:https://flatpak.org/setup/
|
||||
[11]:https://flathub.org
|
||||
[12]:https://flathub.org/apps/details/org.gabmus.hydrapaper
|
||||
[13]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-2.jpeg?w=800&ssl=1
|
||||
[14]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-1.jpeg?w=799&ssl=1
|
||||
[15]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/05/different-wallpaper-each-monitor-hydrapaper-3.jpeg?w=799&ssl=1
|
||||
[16]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/05/hydra-paper-dual-monitor.jpeg?w=800&ssl=1
|
||||
[17]:https://www.reddit.com/r/LinuxUsersGroup/
|
||||
324
published/20180707 Version Control Before Git with CVS.md
Normal file
324
published/20180707 Version Control Before Git with CVS.md
Normal file
@ -0,0 +1,324 @@
|
||||
Git 前时代:使用 CVS 进行版本控制
|
||||
======
|
||||
|
||||
GitHub 网站发布于 2008 年。如果你的软件工程师职业生涯跟我一样,也是晚于此时间的话,Git 可能是你用过的唯一版本控制软件。虽然其陡峭的学习曲线和不直观地用户界面时常会遭人抱怨,但不可否认的是,Git 已经成为学习版本控制的每个人的选择。Stack Overflow 2015 年进行的开发者调查显示,69.3% 的被调查者在使用 Git,几乎是排名第二的 Subversion 版本控制系统使用者数量的两倍。[^1] 2015 年之后,也许是因为 Git 太受欢迎了,大家对此话题不再感兴趣,所以 Stack Overflow 停止了关于开发人员使用的版本控制系统的问卷调查。
|
||||
|
||||
GitHub 的发布时间距离 Git 自身发布时间很近。2005 年,Linus Torvalds 发布了 Git 的首个版本。现在的年经一代开发者可能很难想象“版本控制软件”一词所代表的世界并不仅仅只有 Git,虽然这样的世界诞生的时间并不长。除了 Git 外,还有很多可供选择。那时,开源开发者较喜欢 Subversion,企业和视频游戏公司使用 Perforce (到如今有些仍在用),而 Linux 内核项目依赖于名为 BitKeeper 的版本控制系统。
|
||||
|
||||
其中一些系统,特别是 BitKeeper,会让年经一代的 Git 用户感觉很熟悉,上手也很快,但大多数相差很大。除了 BitKeeper,Git 之前的版本控制系统都是以不同的架构模型为基础运行的。《[Version Control By Example][8]》一书的作者 Eric Sink 在他的书中对版本控制进行了分类,按其说法,Git 属于第三代版本控制系统,而大多数 Git 的前身,即流行于二十世纪九零年代和二十一世纪早期的系统,都属于第二代版本控制系统。[^2] 第三代版本控制系统是分布式的,第二代是集中式。你们以前大概都听过 Git 被描述为一款“分布式”版本控制系统。我一直都不明白分布式/集中式之间的区别,随后自己亲自安装了一款第二代的集中式版本控件系统,并做了相关实验,至少明白了一些。
|
||||
|
||||
我安装的版本系统是 CVS。CVS,即 “<ruby>并发版本系统<rt>Concurrent Versions System</rt></ruby>” 的缩写,是最初的第二代版本控制系统。大约十年间,它是最为流行的版本控制系统,直到 2000 年被 Subversion 所取代。即便如此,Subversion 被认为是 “更好的 CVS”,这更进一步突出了 CVS 在二十世纪九零年代的主导地位。
|
||||
|
||||
CVS 最早是由一位名叫 Dick Grune 的荷兰科学家在 1986 年开发的,当时有一个编译器项目,他正在寻找一种能与其学生合作的方法。[^3] CVS 最初仅仅只是一个包装了 RCS(<ruby>修订控制系统<rt>Revision Control System</rt></ruby>) 的 Shell 脚本集合,Grune 想改进这个第一代的版本控制系统。 RCS 是按悲观锁模式工作的,这意味着两个程序员不可以同时处理同一个文件。需要编辑一个文件话,首先得向 RCS 系统请求一个排它锁,锁定此文件直到完成编辑,如果你想编辑的文件有人正在编辑,你就必须等待。CVS 在 RCS 基础上改进,并把悲观锁模型替换成乐观锁模型,迎来了第二代版本控制系统的时代。现在,程序员可以同时编辑同一个文件、合并编辑部分,随后解决合并冲突问题。(后来接管 CVS 项目的工程师 Brian Berliner 于 1990 年撰写了一篇非常易读的关于 CVS 创新的 [论文][1]。)
|
||||
|
||||
从这个意义上来讲,CVS 与 Git 并无差异,因为 Git 也是运行于乐观锁模式的,但也仅仅只有此点相似。实际上,Linus Torvalds 开发 Git 时,他的一个指导原则是 WWCVSND,即 “<ruby>CVS 不能做的<rt>What Would CVS
|
||||
Not Do</rt></ruby>”。每当他做决策时,他都会力争选择那些在 CVS 设计里没有使用的功能选项。[^4] 所以即使 CVS 要早于 Git 十多年,但它对 Git 的影响是反面的。
|
||||
|
||||
我非常喜欢折腾 CVS。我认为要弄明白为什么 Git 的分布式特性是对以前的版本控制系统的极大改善的话,除了折腾 CVS 外,没有更好的办法。因此,我邀请你跟我一起来一段激动人心的旅程,并在接下来的十分钟内了解下这个近十年来无人使用的软件。(可以看看文末“修正”部分)
|
||||
|
||||
### CVS 入门
|
||||
|
||||
CVS 的安装教程可以在其 [项目主页][2] 上找到。MacOS 系统的话,可以使用 Homebrew 安装。
|
||||
|
||||
由于 CVS 是集中式的,所以它有客户端和服务端之区分,这种模式 Git 是没有的。两端分别有不同的可执行文件,其区别不太明显。但要开始使用 CVS 的话,即使只在你的本地机器上使用,也必须设置 CVS 的服务后端。
|
||||
|
||||
CVS 的后端,即所有代码的中央存储区,被叫做<ruby>存储库<rt> repository</rt></ruby>。在 Git 中每一个项目都有一个存储库,而 CVS 中一个存储库就包含所有的项目。尽管有办法保证一次只能访问一个项目,但一个中央存储库包含所有东西是改变不了的。
|
||||
|
||||
要在本地创建存储库的话,请运行 `init` 命令。你可以像如下所示在家目录创建,也可以在你本地的任何地方创建。
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox init
|
||||
```
|
||||
|
||||
CVS 允许你将选项传递给 `cvs` 命令本身或 `init` 子命令。出现在 `cvs` 命令之后的选项默认是全局的,而出现在子命令之后的是子命令特有选项。上面所示例子中,`-d` 标志是全局选项。在这儿是告诉 CVS 我们想要创建存储库路径在哪里,但一般 `-d` 标志指的是我们想要使用的且已经存在的存储库位置。一直使用 `-d` 标志很单调乏味,所以可以设置 `CVSROOT` 环境变量来代替。
|
||||
|
||||
因为我们只是在本地操作,所以仅仅使用 `-d` 参考来传递路径就可以,但也可以包含个主机名。
|
||||
|
||||
此命令在你的家目录创建了一个名叫 `sandbox` 的目录。 如果你列出 `sandbox` 内容,会发现下面包含有名为 `CVSROOT` 的目录。请不要把此目录与我们的环境变量混淆,它保存存储库的管理文件。
|
||||
|
||||
恭喜! 你刚刚创建了第一个 CVS 存储库。
|
||||
|
||||
### 检入代码
|
||||
|
||||
假设你决定留存下自己喜欢的颜色清单。因为你是一个有艺术倾向但很健忘的人,所以你键入颜色列表清单,并保存到一个叫 `favorites.txt` 的文件中:
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
我们也假设你把文件保存到一个叫 `colors` 的目录中。现在你想要把喜欢的颜色列表清单置于版本控制之下,因为从现在起的五十年间你会回顾下,随着时间的推移自己的品味怎么变化,这件事很有意思。
|
||||
|
||||
为此,你必须将你的目录导入为新的 CVS 项目。可以使用 `import` 命令:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox import -m "" colors colors initial
|
||||
N colors/favorites.txt
|
||||
|
||||
No conflicts created by this import
|
||||
```
|
||||
|
||||
这里我们再次使用 `-d` 标志来指定存储库的位置,其余的参数是传输给 `import` 子命令的。必须要提供一条消息,但这儿没必要,所以留空。下一个参数 `colors`,指定了存储库中新目录的名字,这儿给的名字跟检入的目录名称一致。最后的两个参数分别指定了 “vendor” 标签和 “release” 标签。我们稍后就会谈论标签。
|
||||
|
||||
我们刚将 `colors` 项目拉入 CVS 存储库。将代码引入 CVS 有很多种不同的方法,但这是 《[Pragmatic Version Control Using CVS][3]》 一书所推荐方法,这是一本关于 CVS 的程序员实用指导书籍。使用这种方法有点尴尬的就是你得重新<ruby>检出<rt>check out</rt></ruby>工作项目,即使已经存在有 `colors` 此项目了。不要使用该目录,首先删除它,然后从 CVS 中检出刚才的版本,如下示:
|
||||
|
||||
```
|
||||
$ cvs -d ~/sandbox co colors
|
||||
cvs checkout: Updating colors
|
||||
U colors/favorites.txt
|
||||
```
|
||||
|
||||
这个过程会创建一个新的目录,也叫做 `colors`。此目录里会发现你的源文件 `favorites.txt`,还有一个叫 `CVS` 的目录。这个 `CVS` 目录基本上与每个 Git 存储库的 `.git` 目录等价。
|
||||
|
||||
### 做出改动
|
||||
|
||||
准备旅行。
|
||||
|
||||
和 Git 一样,CVS 也有 `status` 命令:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.1.1.1 2018-07-06 19:27:54 -0400
|
||||
Repository revision: 1.1.1.1 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: fD7GYxt035GNg8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
到这儿事情开始陌生起来了。CVS 没有提交对象这一概念。如上示,有一个叫 “<ruby>提交标识符<rt>Commit Identifier</rt></ruby>” 的东西,但这可能是一个较新版本的标识,在 2003 年出版的《Pragmatic Version Control Using CVS》一书中并没有提到 “提交标识符” 这个概念。 (CVS 的最新版本于 2008 年发布的。[^5] )
|
||||
|
||||
在 Git 中,我们所谈论某文件版本其实是在谈论如 `commit 45de392` 相关的东西,而 CVS 中文件是独立版本化的。文件的第一个版本为 1.1 版本,下一个是 1.2 版本,依此类推。涉及分支时,会在后面添加扩展数字。因此你会看到如上所示的 `1.1.1.1` 的内容,这就是示例的版本号,即使我们没有创建分支,似乎默认的会给加上。
|
||||
|
||||
一个项目中会有很多的文件和很多次的提交,如果你运行 `cvs log` 命令(等同于 `git log`),会看到每个文件提交历史信息。同一个项目中,有可能一个文件处于 1.2 版本,一个文件处于 1.14 版本。
|
||||
|
||||
继续,我们对 1.1 版本的 `favorites.txt` 文件做些修改(LCTT 译注:原文此处示例有误):
|
||||
|
||||
```
|
||||
blue
|
||||
orange
|
||||
green
|
||||
cyan
|
||||
|
||||
definitely not yellow
|
||||
```
|
||||
|
||||
修改完成,就可以运行 `cvs diff` 来看看 CVS 发生了什么:
|
||||
|
||||
```
|
||||
$ cvs diff
|
||||
cvs diff: Diffing .
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.1.1.1
|
||||
diff -r1.1.1.1 favorites.txt
|
||||
3a4
|
||||
> cyan
|
||||
```
|
||||
|
||||
CVS 识别出我们我在文件中添加了一个包含颜色 “cyan” 的新行。(实际上,它说我们已经对 “RCS” 文件进行了更改;你可以看到,CVS 底层使用的还是 RCS。) 此差异指的是当前工作目录中的 `favorites.txt` 副本与存储库中 1.1.1.1 版本的文件之间的差异。
|
||||
|
||||
为了更新存储库中的版本,我们必须提交更改。Git 中,这个操作要好几个步骤。首先,暂存此修改,使其在索引中出现,然后提交此修改,最后,为了使此修改让其他人可见,我们必须把此提交推送到源存储库中。
|
||||
|
||||
而 CVS 中,只需要运行 `cvs commit` 命令就搞定一切。CVS 会汇集它所找到的变化,然后把它们放到存储库中:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Add cyan to favorites."
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.2; previous revision: 1.1
|
||||
```
|
||||
|
||||
我已经习惯了 Git,所以这种操作会让我感到十分恐惧。因为没有变更暂存区的机制,工作目录下任何你动过的东西都会一股脑给提交到公共存储库中。你有过因为不爽,私下里重写了某个同事不佳的函数实现,但仅仅只是自我宣泄一下并不想让他知道的时候吗?如果不小心提交上去了,就太糟糕了,他会认为你是个混蛋。在推送它们之前,你也不能对提交进行编辑,因为提交就是推送。还是你愿意花费 40 分钟的时间来反复运行 `git rebase -i` 命令,以使得本地提交历史记录跟数学证明一样清晰严谨?很遗憾,CVS 里不支持,结果就是,大家都会看到你没有先写测试用例。
|
||||
|
||||
不过,到现在我终于理解了为什么那么多人都觉得 Git 没必要搞那么复杂。对那些早已经习惯直接 `cvs commit` 的人来说,进行暂存变更和推送变更操作确实是毫无意义的差事。
|
||||
|
||||
人们常谈论 Git 是一个 “分布式” 系统,其中分布式与非分布式的主要区别为:在 CVS 中,无法进行本地提交。提交操作就是向中央存储库提交代码,所以没有网络连接,就无法执行操作,你本地的那些只是你的工作目录而已;在 Git 中,会有一个完完全全的本地存储库,所以即使断网了也可以无间断执行提交操作。你还可以编辑那些提交、回退、分支,并选择你所要的东西,没有任何人会知道他们必须知道的之外的东西。
|
||||
|
||||
因为提交是个大事,所以 CVS 用户很少做提交。提交会包含很多的内容修改,就像如今我们能在一个含有十次提交的拉取请求中看到的一样多。特别是在提交触发了 CI 构建和自动测试程序时如此。
|
||||
|
||||
现在我们运行 `cvs status`,会看到产生了文件的新版本:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Up-to-date
|
||||
|
||||
Working revision: 1.2 2018-07-06 21:18:59 -0400
|
||||
Repository revision: 1.2 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: pQx5ooyNk90wW8JA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
### 合并
|
||||
|
||||
如上所述,在 CVS 中,你可以同时编辑其他人正在编辑的文件。这是 CVS 对 RCS 的重大改进。当需要将更改的部分重新组合在一起时会发生什么?
|
||||
|
||||
假设你邀请了一些朋友来将他们喜欢的颜色添加到你的列表中。在他们添加的时候,你确定了不再喜欢绿色,然后把它从列表中删除。
|
||||
|
||||
当你提交更新的时候,会发现 CVS 报出了个问题:
|
||||
|
||||
```
|
||||
$ cvs commit -m "Remove green"
|
||||
cvs commit: Examining .
|
||||
cvs commit: Up-to-date check failed for `favorites.txt'
|
||||
cvs [commit aborted]: correct above errors first!
|
||||
```
|
||||
|
||||
这看起来像是朋友们首先提交了他们的变化。所以你的 `favorites.txt` 文件版本没有更新到存储库中的最新版本。此时运行 `cvs status` 就可以看到,本地的 `favorites.txt` 文件副本有一些本地变更且是 1.2 版本的,而存储库上的版本号是 1.3,如下示:
|
||||
|
||||
```
|
||||
$ cvs status
|
||||
cvs status: Examining .
|
||||
===================================================================
|
||||
File: favorites.txt Status: Needs Merge
|
||||
|
||||
Working revision: 1.2 2018-07-07 10:42:43 -0400
|
||||
Repository revision: 1.3 /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
Commit Identifier: 2oZ6n0G13bDaldJA
|
||||
Sticky Tag: (none)
|
||||
Sticky Date: (none)
|
||||
Sticky Options: (none)
|
||||
```
|
||||
|
||||
你可以运行 `cvs diff` 来了解 1.2 版本与 1.3 版本的确切差异:
|
||||
|
||||
```
|
||||
$ cvs diff -r HEAD favorites.txt
|
||||
Index: favorites.txt
|
||||
===================================================================
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.3
|
||||
diff -r1.3 favorites.txt
|
||||
3d2
|
||||
< green
|
||||
7,10d5
|
||||
<
|
||||
< pink
|
||||
< hot pink
|
||||
< bubblegum pink
|
||||
```
|
||||
|
||||
看来我们的朋友是真的喜欢粉红色,但好在他们编辑的是此文件的不同部分,所以很容易地合并此修改。跟 `git pull` 类似,只要运行 `cvs update` 命令,CVS 就可以为我们做合并操作,如下示:
|
||||
|
||||
```
|
||||
$ cvs update
|
||||
cvs update: Updating .
|
||||
RCS file: /Users/sinclairtarget/sandbox/colors/favorites.txt,v
|
||||
retrieving revision 1.2
|
||||
retrieving revision 1.3
|
||||
Merging differences between 1.2 and 1.3 into favorites.txt
|
||||
M favorites.txt
|
||||
```
|
||||
|
||||
此时查看 `favorites.txt` 文件内容的话,你会发现你的朋友对文件所做的更改已经包含进去了,你的修改也在里面。现在你可以自由的提交文件了,如下示:
|
||||
|
||||
```
|
||||
$ cvs commit
|
||||
cvs commit: Examining .
|
||||
/Users/sinclairtarget/sandbox/colors/favorites.txt,v <-- favorites.txt
|
||||
new revision: 1.4; previous revision: 1.3
|
||||
```
|
||||
|
||||
最终的结果就跟在 Git 中运行 `git pull --rebase` 一样。你的修改是添加在你朋友的修改之后的,所以没有 “合并提交” 这操作。
|
||||
|
||||
某些时候,对同一文件的修改可能导致冲突。例如,如果你的朋友把 “green” 修改成 “olive”,同时你完全删除 “green”,就会出现冲突。CVS 早期的时候,正是这种情况导致人们担心 CVS 不安全,而 RCS 的悲观锁机制可以确保此情况永不会发生。但 CVS 提供了一个安全保障机制,可以确保不会自动的覆盖任何人的修改。因此,当运行 `cvs update` 的时候,你必须告诉 CVS 想要保留哪些修改才能继续下一步操作。CVS 会标记文件的所有变更,这跟 Git 检测到合并冲突时所做的方式一样,然后,你必须手工编辑文件,选择需要保留的变更进行合并。
|
||||
|
||||
这儿需要注意的有趣事情就是在进行提交之前必须修复并合并冲突。这是 CVS 集中式特性的另一个结果。而在 Git 里,在推送本地的提交内容之前,你都不用担心合并冲突问题。
|
||||
|
||||
### 标记与分支
|
||||
|
||||
由于 CVS 没有易于寻址的提交对象,因此对变更集合进行分组的唯一方法就是对于特定的工作目录状态打个标记。
|
||||
|
||||
创建一个标记是很容易的:
|
||||
|
||||
```
|
||||
$ cvs tag VERSION_1_0
|
||||
cvs tag: Tagging .
|
||||
T favorites.txt
|
||||
```
|
||||
|
||||
稍后,运行 `cvs update` 命令并把标签传输给 `-r` 标志就可以把文件恢复到此状态,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r VERSION_1_0
|
||||
cvs update: Updating .
|
||||
U favorites.txt
|
||||
```
|
||||
|
||||
因为你需要一个标记来回退到早期的工作目录状态,所以 CVS 鼓励创建大量的抢先标记。例如,在重大的重构之前,你可以创建一个 `BEFORE_REFACTOR_01` 标记,如果重构出错,就可以使用此标记回退。你如果想生成整个项目的差异文件的话,也可以使用标记。基本上,如今我们惯常使用提交的哈希值完成的事情都必须在 CVS 中提前计划,因为你必须首先有个标签才行。
|
||||
|
||||
可以在 CVS 中创建分支。分支只是一种特殊的标记,如下示:
|
||||
|
||||
```
|
||||
$ cvs rtag -b TRY_EXPERIMENTAL_THING colors
|
||||
cvs rtag: Tagging colors
|
||||
```
|
||||
|
||||
这命令仅仅只是创建了分支(每个人都这样觉得吧),所以还需要使用 `cvs update` 命令来切换分支,如下示:
|
||||
|
||||
```
|
||||
$ cvs update -r TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
上面的命令就会把你的当前工作目录切换到新的分支,但《Pragmatic Version Control Using CVS》一书实际上是建议创建一个新的目录来房子你的新分支。估计,其作者发现在 CVS 里切换目录要比切换分支来得更简单吧。
|
||||
|
||||
此书也建议不要从现有分支创建分支,而只在主线分支(Git 中被叫做 `master`)上创建分支。一般来说,分支在 CVS 中主认为是 “高级” 技能。而在 Git 中,你几乎可以任性创建新分支,但 CVS 中要在真正需要的时候才能创建,比如发布项目。
|
||||
|
||||
稍后可以使用 `cvs update` 和 `-j` 标志将分支合并回主线:
|
||||
|
||||
```
|
||||
$ cvs update -j TRY_EXPERIMENTAL_THING
|
||||
```
|
||||
|
||||
### 感谢历史上的贡献者
|
||||
|
||||
2007 年,Linus Torvalds 在 Google 进行了一场关于 Git 的 [演讲][4](LCTT 译注:[已搬运][9])。当时 Git 是很新的东西,整场演讲基本上都是在说服满屋子都持有怀疑态度的程序员们:尽管 Git 是如此的与众不同,也应该使用 Git。如果没有看过这个视频的话,我强烈建议你去看看。Linus 是个有趣的演讲者,即使他有些傲慢。他非常出色地解释了为什么分布式的版本控制系统要比集中式的优秀。他的很多评论是直接针对 CVS 的。
|
||||
|
||||
Git 是一个 [相当复杂的工具][5]。学习起来是一个令人沮丧的经历,但也不断的给我惊喜:Git 还能做这样的事情。相比之下,CVS 简单明了,但是,许多我们认为理所当然的操作都做不了。想要对 Git 的强大功能和灵活性有全新的认识的话,就回过头来用用 CVS 吧,这是种很好的学习方式。这很好的诠释了为什么理解软件的开发历史可以让人受益匪浅。重拾过期淘汰的工具可以让我们理解今天所使用的工具后面所隐藏的哲理。
|
||||
|
||||
如果你喜欢此博文的话,每两周会有一次更新!请在 Twitter 上关注 [@TwoBitHistory][6] 或都通过 [RSS feed][7] 订阅,新博文出来会有通知。
|
||||
|
||||
### 修正
|
||||
|
||||
有人告诉我,有很多组织企业,特别是像做医疗设备软件等这种规避风险类的企业,仍在使用 CVS。这些企业中的程序员通过使用一些小技巧来解决 CVS 的限制,例如为几乎每个更改创建一个新分支以避免直接提交给 `HEAD`。 (感谢 Michael Kohne 指出这一点。)
|
||||
|
||||
[^1]: “2015 Developer Survey,” Stack Overflow, accessed July 7, 2018, https://insights.stackoverflow.com/survey/2015#tech-sourcecontrol.
|
||||
[^2]: Eric Sink, “A History of Version Control,” Version Control By Example, 2011, accessed July 7, 2018, https://ericsink.com/vcbe/html/history_of_version_control.html.
|
||||
[^3]: Dick Grune, “Concurrent Versions System CVS,” dickgrune.com, accessed July 7, 2018, https://dickgrune.com/Programs/CVS.orig/#History.
|
||||
[^4]: “Tech Talk: Linus Torvalds on Git,” YouTube, May 14, 2007, accessed July 7, 2018, https://www.youtube.com/watch?v=4XpnKHJAok8.
|
||||
[^5]: “Concurrent Versions System - News,” Savannah, accessed July 7, 2018, http://savannah.nongnu.org/news/?group=cvs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/07/07/cvs.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://docs.freebsd.org/44doc/psd/28.cvs/paper.pdf
|
||||
[2]: https://www.nongnu.org/cvs/
|
||||
[3]: http://shop.oreilly.com/product/9780974514000.do
|
||||
[4]: https://www.youtube.com/watch?v=4XpnKHJAok8
|
||||
[5]: https://xkcd.com/1597/
|
||||
[6]: https://twitter.com/TwoBitHistory
|
||||
[7]: https://twobithistory.org/feed.xml
|
||||
[8]: https://ericsink.com/vcbe/index.html
|
||||
[9]: https://v.qq.com/x/page/o0772kqh5iv.html
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (5 Firefox extensions to protect your privacy)
|
||||
[#]: via: (https://opensource.com/article/18/7/firefox-extensions-protect-privacy)
|
||||
[#]: author: ( Chris Short https://opensource.com/users/chrisshort)
|
||||
[#]: url: (https://linux.cn/article-10316-1.html)
|
||||
|
||||
5 个保护你隐私的 Firefox 扩展
|
||||
======
|
||||
> 用这些关注隐私的工具使你的浏览器免于泄露数据。
|
||||
|
||||

|
||||
|
||||
在<ruby>剑桥分析公司<rt>Cambridge Analytica</rt></ruby>这件事后,我仔细研究了我让 Facebook 渗透到我的网络生活的程度。由于我一般担心单点故障,我不是一个使用社交登录的人。我使用密码管理器为每个站点创建唯一的登录(你也应该这样做)。
|
||||
|
||||
我最担心的 Facebook 对我的数字生活的普遍侵扰。在深入了解剑桥分析公司这件事后,我几乎立即卸载了 Facebook 的移动程序。我还从 Facebook [断开了对所有应用、游戏和网站的连接][1]。是的,这将改变你在 Facebook 上的体验,但它也将保护您的隐私。作为一名有遍布全球朋友的人,保持 Facebook 的社交连接对我来说非常重要。
|
||||
|
||||
我还仔细审查了其他服务。我检查了 Google、Twitter、GitHub 以及任何未使用的连接应用。但我知道这还不够。我需要我的浏览器主动防止侵犯我隐私的行为。我开始研究如何做到最好。当然,我可以锁定浏览器,但是我需要使我用的网站和工具正常使用,同时试图防止它们泄露数据。
|
||||
|
||||
以下是五种可在使用浏览器时保护你隐私的工具。前三个扩展可用于 Firefox 和 Chrome,而后两个仅适用于 Firefox。
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
我已经使用 [Privacy Badger][2] 有一段时间了。其他内容或广告拦截器做得更好吗?也许。很多内容拦截器的问题在于它们的“付费显示”。这意味着他们有收费的“合作伙伴”白名单。这就站在了为什么存在内容拦截器这件事的对立面。Privacy Badger 是由电子前沿基金会 (EFF) 制作的,这是一家以捐赠为基础的商业模式的非营利实体。Privacy Badger 承诺从你的浏览习惯中学习,并且很少需要调整。例如,我只需将一些网站列入白名单。Privacy Badger 允许精确控制在哪些站点上启用哪些跟踪器。这是我无论在哪个浏览器必须安装的头号扩展。
|
||||
|
||||
### DuckDuckGo Privacy Essentials
|
||||
|
||||
搜索引擎 DuckDuckGo 通常有隐私意识。[DuckDuckGo Privacy Essentials][3] 适用于主流的移动设备和浏览器。它的独特之处在于它根据你提供的设置对网站进行评分。例如,即使启用了隐私保护,Facebook 也会获得 D。同时,[chrisshort.net][4] 在启用隐私保护时获得 B 和禁用时获得 C。如果你因任何原因不喜欢 EFF 或 Privacy Badger,我会推荐 DuckDuckGo Privacy Essentials(选择一个,而不是两个,因为它们基本上做同样的事情)。
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
[HTTPS Everywhere][5] 是 EFF 的另一个扩展。根据 HTTPS Everywhere 的说法,“网络上的许多网站都通过 HTTPS 提供一些有限的加密支持,但使它难以使用。例如,它们可能默认为未加密的 HTTP 或在加密的页面里面使用返回到未加密站点的链接。HTTPS Everywhere 扩展通过使用聪明的技术将对这些站点的请求重写为 HTTPS 来解决这些问题。“虽然许多网站和浏览器在实施 HTTPS 方面越来越好,但仍有很多网站仍需要帮助。HTTPS Everywhere 将尽力确保你的流量已加密。
|
||||
|
||||
### NoScript Security Suite
|
||||
|
||||
[NoScript Security Suite][6] 不适合胆小的人。虽然这个 Firefox 独有扩展“允许 JavaScript、Java、Flash 和其他插件只能由你选择的受信任网站执行”,但它并不能很好地确定你的选择。但是,毫无疑问,防止泄漏数据的可靠方法是不执行可能会泄露数据的代码。NoScript 通过其“基于白名单的抢占式脚本阻止”实现了这一点。这意味着你需要为尚未加入白名单的网站构建白名单。请注意,NoScript 仅适用于 Firefox。
|
||||
|
||||
### Facebook Container
|
||||
|
||||
[Facebook Container][7] 使 Firefox 成为我在使用 Facebook 时的唯一浏览器。 “Facebook Container 的工作原理是将你的 Facebook 身份隔离到一个单独的容器中,这使得 Facebook 更难以使用第三方 Cookie 跟踪你访问其他网站。” 这意味着 Facebook 无法窥探浏览器中其他地方发生的活动。 突然间,这些令人毛骨悚然的广告将停止频繁出现(假设你在移动设备上卸载了 Facebook 应用)。 在隔离的空间中使用 Facebook 将阻止任何额外的数据收集。 请记住,你已经提供了 Facebook 数据,而 Facebook Container 无法阻止这些数据被共享。
|
||||
|
||||
这些是我浏览器隐私的首选扩展。 你的是什么? 请在评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/firefox-extensions-protect-privacy
|
||||
|
||||
作者:[Chris Short][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/chrisshort
|
||||
[1]:https://www.facebook.com/help/211829542181913
|
||||
[2]:https://www.eff.org/privacybadger
|
||||
[3]:https://duckduckgo.com/app
|
||||
[4]:https://chrisshort.net
|
||||
[5]:https://www.eff.org/https-everywhere
|
||||
[6]:https://noscript.net/
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/facebook-container/
|
||||
@ -0,0 +1,95 @@
|
||||
GPaste:Gnome Shell 中优秀的剪贴板管理器
|
||||
======
|
||||
|
||||
[GPaste][1] 是一个剪贴板管理系统,它包含了库、守护程序以及命令行和 Gnome 界面(使用原生 Gnome Shell 扩展)。
|
||||
|
||||
剪贴板管理器能够跟踪你正在复制和粘贴的内容,从而能够访问以前复制的项目。GPaste 带有原生的 Gnome Shell 扩展,是那些寻找 Gnome 剪贴板管理器的人的完美补充。
|
||||
|
||||
[![GPaste Gnome Shell extension Ubuntu 18.04][2]][3]
|
||||
|
||||
*GPaste Gnome Shell扩展*
|
||||
|
||||
在 Gnome 中使用 GPaste,你只需单击顶部面板即可得到可配置的、可搜索的剪贴板历史记录。GPaste 不仅会记住你复制的文本,还能记住文件路径和图像(后者需要在设置中启用,因为默认情况下它被禁用)。
|
||||
|
||||
不仅如此,GPaste 还可以检测到增长的行,这意味着当检测到新文本是另一个文本的增长时,它会替换它,这对于保持剪贴板整洁非常有用。
|
||||
|
||||
在扩展菜单中,你可以暂停 GPaste 跟踪剪贴板,并从剪贴板历史记录或整个历史记录中删除项目。你还会发现一个启动 GPaste 用户界面窗口的按钮。
|
||||
|
||||
如果你更喜欢使用键盘,你可以使用快捷键从顶栏开启 GPaste 历史记录(`Ctrl + Alt + H`)或打开全部的 GPaste GUI(`Ctrl + Alt + G`)。
|
||||
|
||||
该工具还包含这些键盘快捷键(可以更改):
|
||||
|
||||
* 从历史记录中删除活动项目: `Ctrl + Alt + V`
|
||||
* 将活动项目显示为密码(在 GPaste 中混淆剪贴板条目): `Ctrl + Alt + S`
|
||||
* 将剪贴板同步到主选择: `Ctrl + Alt + O`
|
||||
* 将主选择同步到剪贴板:`Ctrl + Alt + P`
|
||||
* 将活动项目上传到 pastebin 服务:`Ctrl + Alt + U`
|
||||
|
||||
[![][4]][5]
|
||||
|
||||
*GPaste GUI*
|
||||
|
||||
GPaste 窗口界面提供可供搜索的剪贴板历史记录(包括清除、编辑或上传项目的选项)、暂停 GPaste 跟踪剪贴板的选项、重启 GPaste 守护程序,备份当前剪贴板历史记录,还有它的设置。
|
||||
|
||||
[![][6]][7]
|
||||
|
||||
*GPaste GUI*
|
||||
|
||||
在 GPaste 界面中,你可以更改以下设置:
|
||||
|
||||
* 启用或禁用 Gnome Shell 扩展
|
||||
* 将守护程序状态与扩展程序的状态同步
|
||||
* 主选区生效历史
|
||||
* 使剪贴板与主选区同步
|
||||
* 图像支持
|
||||
* 修整条目
|
||||
* 检测增长行
|
||||
* 保存历史
|
||||
* 历史记录设置,如最大历史记录大小、内存使用情况、最大文本长度等
|
||||
* 键盘快捷键
|
||||
|
||||
### 下载 GPaste
|
||||
|
||||
- [下载 GPaste](https://github.com/Keruspe/GPaste)
|
||||
|
||||
Gpaste 项目页面没有链接到任何 GPaste 二进制文件,它只有源码安装说明。非 Debian 或 Ubuntu 的 Linux 发行版的用户(你可以在下面找到 GPaste 安装说明)可以在各自的发行版仓库中搜索 GPaste。
|
||||
|
||||
不要将 GPaste 与 Gnome Shell 扩展网站上发布的 GPaste Integration 扩展混淆。这是一个使用 GPaste 守护程序的 Gnome Shell 扩展,它不再维护。内置于 GPaste 中的原生 Gnome Shell 扩展仍然维护。
|
||||
|
||||
#### 在 Ubuntu(18.04、16.04)或 Debian(Jessie 和更新版本)中安装 GPaste
|
||||
|
||||
对于 Debian,GPaste 可用于 Jessie 和更新版本,而对于 Ubuntu,GPaste 在 16.04 及更新版本的仓库中(因此可在 Ubuntu 18.04 Bionic Beaver 中使用)。
|
||||
|
||||
你可以使用以下命令在 Debian 或 Ubuntu 中安装 GPaste(守护程序和 Gnome Shell 扩展):
|
||||
|
||||
```
|
||||
sudo apt install gnome-shell-extensions-gpaste gpaste
|
||||
```
|
||||
|
||||
安装完成后,按下 `Alt + F2` 并输入 `r` 重新启动 Gnome Shell,然后按回车键。现在应该启用了 GPaste Gnome Shell 扩展,其图标应显示在顶部 Gnome Shell 面板上。如果没有,请使用 Gnome Tweaks(Gnome Tweak Tool)启用扩展。
|
||||
|
||||
[Debian][8] 和 [Ubuntu][9] 的 GPaste 3.28.0 中有一个错误,如果启用了图像支持选项会导致它崩溃,所以现在不要启用此功能。这在 GPaste 3.28.2 中被标记为[已修复][10],但 Debian 和 Ubuntu 仓库中尚未提供此包。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/gpaste-is-great-clipboard-manager-for.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://github.com/Keruspe/GPaste
|
||||
[2]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s400/gpaste-gnome-shell-extension-ubuntu1804.png (Gpaste Gnome Shell)
|
||||
[3]:https://2.bp.blogspot.com/-2ndArDBcrwY/W2gyhMc1kEI/AAAAAAAABS0/ZAe_onuGCacMblF733QGBX3XqyZd--WuACLcBGAs/s1600/gpaste-gnome-shell-extension-ubuntu1804.png
|
||||
[4]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s640/gpaste-gui_1.png
|
||||
[5]:https://2.bp.blogspot.com/-7FBRsZJvYek/W2gyvzmeRxI/AAAAAAAABS4/LhokMFSn8_kZndrNB-BTP4W3e9IUuz9BgCLcBGAs/s1600/gpaste-gui_1.png
|
||||
[6]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s640/gpaste-gui_2.png
|
||||
[7]:https://4.bp.blogspot.com/-047ShYc6RrQ/W2gyz5FCf_I/AAAAAAAABTA/-o6jaWzwNpsSjG0QRwRJ5Xurq_A6dQ0sQCLcBGAs/s1600/gpaste-gui_2.png
|
||||
[8]:https://packages.debian.org/buster/gpaste
|
||||
[9]:https://launchpad.net/ubuntu/+source/gpaste
|
||||
[10]:https://www.imagination-land.org/posts/2018-04-13-gpaste-3.28.2-released.html
|
||||
@ -1,13 +1,16 @@
|
||||
Systemd 定时器: 三种使用场景
|
||||
Systemd 定时器:三种使用场景
|
||||
======
|
||||
|
||||
> 继续 systemd 教程,这些特殊的例子可以展示给你如何更好的利用 systemd 定时器单元。
|
||||
|
||||

|
||||
|
||||
在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元][1]。不过,在我们开始讨论 socket 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
|
||||
在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元][1]。不过,在我们开始讨论 sockets 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
|
||||
|
||||
### 简单的类 _cron_ 行为
|
||||
### 简单的类 cron 行为
|
||||
|
||||
我每周都要去收集 [Debian popcon 数据][2],如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 cron 任务来完成的典型事例,但 systemd 定时器同样能做到:
|
||||
|
||||
我每周都要去收集 [Debian popcon 数据][2],如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 _cron_ 任务来完成的典型事例,但 systemd 定时器同样能做到:
|
||||
```
|
||||
# 类 cron 的 popcon.timer
|
||||
|
||||
@ -20,14 +23,14 @@ Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
实际的 _popcon.service_ 会执行一个常规的 _wget_ 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示“_在周四运行_”,`*-*-*` 表示“_具体年份、月份和日期无关紧要_”,这些可以翻译成“不管年月日,只在每周四运行”。
|
||||
实际的 `popcon.service` 会执行一个常规的 `wget` 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示 “在周四运行”,`*-*-*` 表示“具体年份、月份和日期无关紧要”,这些可以翻译成 “不管年月日,只在每周四运行”。
|
||||
|
||||
这样,你就设置了这个服务的运行时间。我选择在欧洲中部夏令时区的上午 5:30 左右运行,那个时候服务器不是很忙。
|
||||
|
||||
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 _anacron_ 一样的功能。
|
||||
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 anacron 一样的功能。
|
||||
|
||||
```
|
||||
# 具备类似 anacron 功能的 popcon.timer
|
||||
|
||||
@ -41,26 +44,26 @@ Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,_popcon.service_ 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
|
||||
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,`popcon.service` 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
|
||||
|
||||
到目前为止,就是这么直白。
|
||||
到目前为止,就是这么简单直白。
|
||||
|
||||
### 延迟执行
|
||||
|
||||
但是,我们提升一个档次,来“改进”这个[基于 systemd 的监控系统][3]。你应该记得,当你接入摄像头的时候,系统就会开始拍照。假设你并不希望它在你安装摄像头的时候拍下你的脸。你希望将拍照服务的启动时间向后推迟一两分钟,这样你就有时间接入摄像头,然后走到画框外面。
|
||||
|
||||
为了完成这件事,首先你要更改 Udev 规则,将它指向一个定时器:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
```
|
||||
|
||||
这个定时器看起来像这样:
|
||||
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
@ -73,10 +76,9 @@ Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 _picchanged.path_,它会[监视主图片的变化][4]。_picchanged.path_ 还会负责接触 _webcan.service_,这个实际用来拍照的服务。
|
||||
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 `picchanged.path`,它会[监视主图片的变化][4]。`picchanged.path` 还会负责接触 `webcan.service`,这个实际用来拍照的服务。
|
||||
|
||||
### 在每天的特定时刻启停 Minetest 服务器
|
||||
|
||||
@ -85,6 +87,7 @@ WantedBy= basic.target
|
||||
你有个为你的孩子设置的 Minetest 服务。不过,你还想要假装关心一下他们的教育和成长,要让他们做作业和家务活。所以你要确保 Minetest 只在每天晚上的一段时间内可用,比如五点到七点。
|
||||
|
||||
这个跟之前的“_在特定时间启动服务_”不太一样。写个定时器在下午五点启动服务很简单…:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
@ -97,12 +100,12 @@ Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
…可是编写一个对应的定时器,让它在特定时刻关闭服务,则需要更大剂量的横向思维。
|
||||
|
||||
我们从最明显的东西开始 —— 设置定时器:
|
||||
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
@ -115,16 +118,16 @@ Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
这里棘手的部分是如何去告诉 _stopminetest.service_ 去 —— 你知道的 —— 停止 Minetest. 我们无法从 _minetest.service_ 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
|
||||
这里棘手的部分是如何去告诉 `stopminetest.service` 去 —— 你知道的 —— 停止 Minetest. 我们无法从 `minetest.service` 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
|
||||
|
||||
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情_正相反_。如果你有一个 _b.service_ 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 _a.service_ 没有运行,则 _b.service_ 会运行它。同样,如果你的 _b.service_ 单元中有一行写着 `Conflicts= a.service`,那么在 _b.service_ 启动时,systemd 会停止 _a.service_.
|
||||
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情_正相反_。如果你有一个 `b.service` 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 `a.service` 没有运行,则 `b.service` 会运行它。同样,如果你的 `b.service` 单元中有一行写着 `Conflicts= a.service`,那么在 `b.service` 启动时,systemd 会停止 `a.service`.
|
||||
|
||||
这种机制用于两个服务在尝试同时控制同一资源时会发生冲突的场景,例如当两个服务要同时访问打印机的时候。通过在首选服务中设置 `Conflicts=`,你就可以确保它会覆盖掉最不重要的服务。
|
||||
|
||||
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 _minetest.service_:
|
||||
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 `minetest.service`:
|
||||
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
@ -135,12 +138,12 @@ Conflicts= minetest.service
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
_stopminetest.service_ 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 _minetest.service_.
|
||||
`stopminetest.service` 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 `minetest.service`.
|
||||
|
||||
在你完美的 Minetest 设置中,还有最后一点涟漪:你下班晚了,错过了服务器的开机时间,可当你开机的时候游戏时间还没结束,这该怎么办?`Persistent=` 指令(如上所述)在错过开始时间后仍然可以运行服务,但这个方案还是不行。如果你在早上十一点把服务器打开,它就会启动 Minetest,而这不是你想要的。你真正需要的是一个确保 systemd 只在晚上五到七点启动 Minetest 的方法:
|
||||
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
@ -153,12 +156,12 @@ Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “_在下午五到七点间的每分钟,运行 minetest.service_”
|
||||
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “在下午五到七点间的每分钟,运行 minetest.service”
|
||||
|
||||
不过还有一个问题:一旦 `minetest.service` 启动并运行,你会希望 `minetest.timer` 不要再次尝试运行它。你可以在 `minetest.service` 中包含一条 `Conflicts=` 指令:
|
||||
|
||||
不过还有一个问题:一旦 _minetest.service_ 启动并运行,你会希望 _minetest.timer_ 不要再次尝试运行它。你可以在 _minetest.service_ 中包含一条 `Conflicts=` 指令:
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
@ -175,19 +178,18 @@ ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
上面的 `Conflicts=` 指令会保证在 _minstest.service_ 成功运行后,_minetest.timer_ 就会立即停止。
|
||||
上面的 `Conflicts=` 指令会保证在 `minstest.service` 成功运行后,`minetest.timer` 就会立即停止。
|
||||
|
||||
现在,启用并启动 `minetest.timer`:
|
||||
|
||||
现在,启用并启动 _minetest.timer_:
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
而且,如果你在六点钟启动了服务器,_minetest.timer_ 会启用;到了五到七点,_minetest.timer_ 每分钟都会尝试启动 _minetest.service_. 不过,一旦 _minetest.service_ 开始运行,systemd 会停止 _minetest.timer_,因为它会与 _minetest.service_“冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
|
||||
而且,如果你在六点钟启动了服务器,`minetest.timer` 会启用;到了五到七点,`minetest.timer` 每分钟都会尝试启动 `minetest.service`。不过,一旦 `minetest.service` 开始运行,systemd 会停止 `minetest.timer`,因为它会与 `minetest.service` “冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
|
||||
|
||||
在首先启动某个服务时杀死启动它的计时器,这么做有点反直觉,但它是有效的。
|
||||
|
||||
@ -197,7 +199,7 @@ systemctl start minetest.timer
|
||||
|
||||
但是,这个系列文章的目的不是为任何具体问题提供最佳解决方案。它的目的是为了尽可能多地使用 systemd 来解决问题,甚至会到荒唐的程度。它的目的是展示大量的例子,来说明如何利用不同类型的单位及其包含的指令。我们的读者,也就是你,可以从这篇文章中找到所有这些的可实践范例。
|
||||
|
||||
尽管如此,我们还有一件事要做:下回中,我们会关注 _sockets_ 和 _targets_,然后我们将完成对 systemd 单元的介绍。
|
||||
尽管如此,我们还有一件事要做:下回中,我们会关注 sockets 和 targets,然后我们将完成对 systemd 单元的介绍。
|
||||
|
||||
你可以在 Linux 基金会和 edX 中,通过免费的 [Linux 介绍][5]课程中,学到更多关于 Linux 的知识。
|
||||
|
||||
@ -208,12 +210,12 @@ via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cas
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[1]:https://linux.cn/article-10182-1.html
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
@ -0,0 +1,73 @@
|
||||
混合软件开发角色效果更佳
|
||||
======
|
||||
|
||||
> 为什么在工程中混合角色对用户更好的三个原因。
|
||||
|
||||

|
||||
|
||||
大多数开源社区没有很多正式的角色。当然,也有一些固定人员帮助处理系统管理员任务、测试、编写文档以及翻译或开发代码。但开源社区的人员通常在不同的角色之间流动,往往同时履行几个角色的职责。
|
||||
|
||||
相反,大多数传统公司的团队成员都定义了角色,例如,负责文档、技术支持、质量检验和其他领域。
|
||||
|
||||
为什么开源社区采取共享角色的方法,更重要的是,这种协作方式如何影响产品和客户?
|
||||
|
||||
[Nextcloud][1] 采用了这种社区式的混合角色的做法,我们看到了我们的客户和用户受益颇多。
|
||||
|
||||
### 1、更好的产品测试
|
||||
|
||||
每个测试人员都会说测试是一项困难的工作。你需要了解工程师开发的产品,并且需要设计测试案例、执行测试案例并将结果返回给开发人员。完成该过程后,开发人员将进行更改,然后重复该过程,根据需要来回进行多次,直到任务完成。
|
||||
|
||||
在社区中,贡献者通常会对他们开发的项目负责,因此他们会对这些项目进行广泛的测试和记录,然后再将其交给用户。贴近项目的用户通常会与开发人员协作,帮助测试、翻译和编写文档。这将创建一个更紧密、更快的反馈循环,从而加快开发速度并提高质量。
|
||||
|
||||
当开发人员不断面对他们的工作结果时,会鼓励他们以最大限度地减少测试和调试的方式去书写。自动化测试是开发中的一个重要元素,反馈循环可以确保正确地完成操作:开发人员主观能动的来实现自动化 —— 而不过于简化也不过于复杂。当然,他们可能希望别人做更多的测试或自动化的测试,但当测试是正确的选择时,他们就会这样做。此外,他们还审查对方的代码,因为他们知道问题往往会在以后让他们付出代价。
|
||||
|
||||
因此,虽然我不认为放弃专用测试人员更好,但在没有社区志愿者进行测试的项目中,测试人员应该是开发人员,并密切嵌入到开发团队中。结果如何?客户得到的产品是由 100% 有动机的人测试和开发的,以确保它是稳定和可靠的。
|
||||
|
||||
### 2、开发和客户需求之间的密切协作
|
||||
|
||||
要使产品开发与客户需求保持一致是非常困难的。每个客户都有自己独特的需求,有长期和短期的因素需要考虑 —— 当然,作为一家公司,你对你的发展方向有想法。你如何整合所有这些想法和愿景?
|
||||
|
||||
公司通常会创建与工程和产品开发分开的角色,如产品管理、支持、质量检测等。这背后的想法是,人们在专攻的时候做得最好,工程师不应该为测试或支持等 “简单” 的任务而烦恼。
|
||||
|
||||
实际上,这种角色分离是一项削减成本的措施。它使管理层能够进行微观管理,并更能掌握全局,因为他们可以简单地进行产品管理,例如,确定路线图项目的优先次序。(它还创建了更多的会议!)
|
||||
|
||||
另一方面,在社区,“决定权在工作者手上”。开发人员通常也是用户(或由用户支付报酬),因此他们自然地与用户的需求保持一致。当用户帮助进行测试时(如上所述),开发人员会不断地与他们合作,因此双方都完全了解什么是可行的,什么是需要的。
|
||||
|
||||
这种开放的合作方式使用户和项目紧密协作。在没有管理层干涉和指手画脚的情况下,用户最迫切的需求可以迅速得到满足,因为工程师已经非常了解这些需求。
|
||||
|
||||
在 nextcloud 中,客户永远不需要解释两次,也不需要依靠初级支持团队成员将问题准确地传达给工程师。我们的工程师根据客户的实际需求不断调整他们的优先级。同时,基于对客户的深入了解,合作制定长期目标。
|
||||
|
||||
### 3、最佳支持
|
||||
|
||||
与专有的或 <ruby>[开放源核心][2]<rt>open core</rt></ruby>的供应商不同,开源供应商有强大的动力提供尽可能最好的支持:这是与其他公司在其生态系统中的关键区别。
|
||||
|
||||
为什么项目背后的推动者(比如 [Collabora][3] 在 [LibreOffice][4] 背后,[The Qt Company][5] 在 [Qt][6] 背后,或者 [Red Hat][7] 在 [RHEL][8] 背后)是客户支持的最佳来源呢?
|
||||
|
||||
当然是直接接触工程师。这些公司并不阻断来自工程团队的支持,而是为客户提供了获得工程师专业知识的机会。这有助于确保客户始终尽快获得最佳答案。虽然一些工程师可能比其他人在支持上花费更多的时间,但整个工程团队在客户成功方面发挥着作用。专有供应商可能会为客户提供一个专门的现场工程师,费用相当高,但一个开源公司,如 [OpenNMS][9] 可以在您的支持合同中提供相同级别的服务,即使您不是财富 500 强客户也是如此。
|
||||
|
||||
还有一个好处,那就是与测试和客户协作有关:共享角色可确保工程师每天处理客户问题和愿望,从而促使他们快速解决最常见的问题。他们还倾向于构建额外的工具和功能,以满足客户预期。
|
||||
|
||||
简单地说,将质量检测、支持、产品管理和其他工程角色合并为一个团队,可确保优秀开发人员的三大优点 —— <ruby>[从简、精益求精、高度自我要求][10]<rt>laziness,impatience,and hubris</rt></ruby> —— 与客户紧密保持一致。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/mixing-roles-engineering
|
||||
|
||||
作者:[Jos Poortvliet][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jospoortvliet
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Open_core
|
||||
[3]:https://www.collaboraoffice.com/
|
||||
[4]:https://www.libreoffice.org/
|
||||
[5]:https://www.qt.io/
|
||||
[6]:https://www.qt.io/developers/
|
||||
[7]:https://www.redhat.com/en
|
||||
[8]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[9]:https://www.opennms.org/en
|
||||
[10]:http://threevirtues.com/
|
||||
@ -1,23 +1,24 @@
|
||||
使用 MDwiki 将 Markdown 发布成 HTML
|
||||
======
|
||||
> 用这个有用工具从 Markdown 文件创建一个基础的网站。
|
||||
|
||||

|
||||
|
||||
有很多理由喜欢 Markdown,这是一门简单的语言,有易于学习的语法,它可以与任何文本编辑器一起使用。使用像 [Pandoc][1] 这样的工具,你可以将 Markdown 文本转换为[各种流行格式][2],包括 HTML。你还可以在 Web 服务器中自动执行转换过程。由 TimoDörr 创建的名为 [MDwiki][3]的 HTML5 和 JavaScript 应用可以将一堆 Markdown 文件在浏览器请求它们时转换为网站。MDwiki 网站包含一个操作指南和其他信息可帮助你入门:
|
||||
有很多理由喜欢 Markdown,这是一门简单的语言,有易于学习的语法,它可以与任何文本编辑器一起使用。使用像 [Pandoc][1] 这样的工具,你可以将 Markdown 文本转换为[各种流行格式][2],包括 HTML。你还可以在 Web 服务器中自动执行转换过程。由 TimoDörr 创建的名为 [MDwiki][3] 的 HTML5 和 JavaScript 应用可以将一堆 Markdown 文件在浏览器请求它们时转换为网站。MDwiki 网站包含一个操作指南和其他信息可帮助你入门:
|
||||
|
||||
![MDwiki site getting started][5]
|
||||
|
||||
Mdwiki 网站的样子。
|
||||
*Mdwiki 网站的样子。*
|
||||
|
||||
在 Web 服务器内部,基本的 MDwiki 站点如下所示:
|
||||
|
||||
![MDwiki site inside web server][7]
|
||||
|
||||
该站点的 web 服务器文件夹的样子
|
||||
*该站点的 web 服务器文件夹的样子*
|
||||
|
||||
我将此项目的 MDwiki HTML 文件重命名为 `START.HTML`。还有一个处理导航的 Markdown 文件和一个 JSON 文件来保存一些配置设置。其他的都是网站内容。
|
||||
|
||||
虽然整个网站设计被 MDwiki 固定了,但内容、样式和页面数量却没有。你可以在 [MDwiki 站点][8]查看由 MDwiki 生成的一系列不同站点。公平地说,MDwiki 网站缺乏网页设计师可以实现的视觉吸引力 - 但它们是功能性的,用户应该平衡其简单的外观与创建和编辑它们的速度和简易性。
|
||||
虽然整个网站设计被 MDwiki 固定了,但内容、样式和页面数量却没有。你可以在 [MDwiki 站点][8]查看由 MDwiki 生成的一系列不同站点。公平地说,MDwiki 网站缺乏网页设计师可以实现的视觉吸引力 —— 但它们是功能性的,用户应该平衡其简单的外观与创建和编辑它们的速度和简易性。
|
||||
|
||||
Markdown 有不同的风格,可以针对不同的特定目的扩展稳定的核心功能。MDwiki 使用 GitHub 风格 [Markdown][9],它为流行的编程语言添加了格式化代码块和语法高亮等功能,使其非常适合生成程序文档和教程。
|
||||
|
||||
@ -29,13 +30,14 @@ MDwiki 的默认配色方案并非适用于所有项目,但你可以将其替
|
||||
|
||||
![MDwiki screen with Bootswatch Superhero theme][12]
|
||||
|
||||
MDwiki 页面使用 Bootswatch Superhero 主题
|
||||
*MDwiki 页面使用 Bootswatch Superhero 主题*
|
||||
|
||||
MDwiki、Markdown 文件和静态图像可以用于许多目的。但是,你有时可能希望包含 JavaScript 幻灯片或反馈表单。Markdown 文件可以包含 HTML 代码,但将 Markdown 与 HTML 混合会让人感到困惑。一种解决方案是在单独的 HTML 文件中创建所需的功能,并将其显示在带有 iframe 标记的 Markdown 文件中。我从 [Twine Cookbook][13] 知道了这个想法,它是 Twine 交互式小说引擎的支持站点。Twine Cookbook 实际上并没有使用 MDwiki,但结合 Markdown 和 iframe 标签开辟了广泛的创作可能性。
|
||||
|
||||
这是一个例子:
|
||||
|
||||
此 HTML 将显示由 Markdown 文件中的 Twine 交互式小说引擎创建的 HTML 页面。
|
||||
|
||||
```
|
||||
<iframe height="400" src="sugarcube_dungeonmoving_example.html" width="90%"></iframe>
|
||||
```
|
||||
@ -53,7 +55,7 @@ via: https://opensource.com/article/18/8/markdown-html-publishing
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
48
published/20180904 Why schools of the future are open.md
Normal file
48
published/20180904 Why schools of the future are open.md
Normal file
@ -0,0 +1,48 @@
|
||||
为什么未来的学校是开放式的
|
||||
======
|
||||
> 一个学生对现代教育并不那么悲观的观点。
|
||||
|
||||

|
||||
|
||||
最近有些人和我说现代教育会是什么样子,我回答说:就像过去一百年一样。我们为什么会对我们的教育体系保持悲观态度呢?
|
||||
|
||||
这不是一个悲观的观点,而是一个务实的观点。任何花时间在学校的人都会有同样的感觉,我们对教导年轻人的方式固执地抵制变革。随着美国学校开始新的一年,大多数学生回到了桌子排成一排排的教室。教学环境主要以教师为中心,学生的进步由卡内基单位和 A-F 评分来衡量,而合作通常被认为是作弊。
|
||||
|
||||
我们从哪能够找到证据指出这种工业化模式正在产生所预想的结果?每个孩子都得到个人关注,以培养对学习的热爱,并发展出当今创新经济中茁壮成长所需的技能,我们很可能对现状非常满意。 但是,任何真实客观地看待当前的指标都表明要从基本开始改变。
|
||||
|
||||
但我的观点并非悲观。 事实上,非常乐观。
|
||||
|
||||
尽管我们可以很容易的阐述现代教育的问题所在,但我也知道一个例子,教育利益相关者愿意走出那些舒适的环境,并挑战这个对变革无动于衷的体系。教师要与同龄人进行更多的合作,并采取更多方式公开透明的对原型创意进行展示,从而为学生带来真正的创新 —— 而不是通过技术重新包装传统方法。管理员通过以社区为中心,基于项目的学习,实现更深入、更紧密的学习实际的应用程序 —— 不仅仅是在孤立的教室中“做项目”。 父母们想把学习的快乐回归到学校的文化,这些文化因强调考试而受到损害。
|
||||
|
||||
所有文化变革向来都不容易,特别是在面对任何考试成绩下降(无论统计意义如何重要)都面临政治反弹的环境中,因此人们不愿意承担风险。
|
||||
那么为什么我乐观地认为我们正在接近一个临界点,我们所需要的变化确实可以克服长期挫败它们的惯性呢?
|
||||
|
||||
因为在我们的现代时代,社会中还有其他东西在以前没有出现过:开放的精神,由数字技术催化。
|
||||
|
||||
想一想:如果你需要为即将到来的法国旅行学习基本的法语,你该怎么办? 您可以在当地社区学院注册一门课程或者从图书馆借书,但很有可能,您会用免费在线视频并了解旅行所需的基本知识。人类历史上从未有过免费的按需学习。事实上,人们可以参加麻省理工学院关于“[应用数学的专题:线性代数和变异微积分][1]的免费在线课程。报名参加吧!
|
||||
|
||||
为什么麻省理工学院、斯坦福大学和哈佛大学等学校提供免费课程? 为什么人们和公司愿意公开分享曾经严格控制的知识产权?为什么全球各地的人们都愿意花时间,无偿地帮助公民科学项目呢?
|
||||
|
||||
David Price 在他那本很棒的书《[开放:我们将如何在未来工作和学习][2]》中,清楚地描述了非正式的社交学习如何成为新的学习规范,尤其是习惯于能够及时获取他们需要的知识学习的年轻人。通过一系列案例研究,Price 清楚地描绘了当传统制度不适应这种新现实并因此变得越来越不相关时会发生什么。这是缺失的元素,它能让众包产生积极的颠覆性的影响。
|
||||
|
||||
Price 指出(以及人们现在对基层的要求)正是一场开放的运动,人们认识到开放式合作和自由交换思想已经破坏了从音乐到软件再到出版的生态系统。 而且,除了任何自上而下推动的“改革”之外,这种对开放性的期望有可能从根本上改变长期以来一直抵制变革的教育体系。事实上,开放精神的标志之一是,它期望知识的透明和公平民主化,造福所有人。那么,对于这样一种精神而言,还有什么生态系统能比试图让年轻人做好准备,继承这个世界、让这个世界变得更好呢?
|
||||
|
||||
当然,也有另一种悲观的声音说,我早期关于教育未来的预测可能确实是短期未来的教育状况。但我也非常乐观地认为,这种说法将被证明是错误的。 我知道我和许多其他志趣相投的教育工作者每天都在努力证明这是错误的。 当我们开始帮助我们的学校[转变为开放式组织][3] —— 从过时的传统模式过渡到更开放、灵活,响应每个学生和他们服务的社区需要的时候,你会加入我吗?
|
||||
|
||||
这是适合现代时代的真正教育模式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/9/modern-education-open-education
|
||||
|
||||
作者:[Ben Owens][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/engineerteacher
|
||||
[1]: https://ocw.mit.edu/courses/mechanical-engineering/2-035-special-topics-in-mathematics-with-applications-linear-algebra-and-the-calculus-of-variations-spring-2007/
|
||||
[2]: https://www.goodreads.com/book/show/18730272-open
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
116
published/20181004 Archiving web sites.md
Normal file
116
published/20181004 Archiving web sites.md
Normal file
@ -0,0 +1,116 @@
|
||||
对网站进行归档
|
||||
======
|
||||
|
||||
我最近深入研究了网站归档,因为有些朋友担心遇到糟糕的系统管理或恶意删除时失去对放在网上的内容的控制权。这使得网站归档成为系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难归档。本文介绍了对传统网站进行归档的过程,并阐述在面对最新流行单页面应用程序(SPA)的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动编码 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript、PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃、升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户这样的想法:希望网站基本上可以永久工作。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站归档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而镜像保存一个完整网站的命令却是错综复杂的:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[归档者的习惯做法][4],并以尽可能快的速度归档网站。大多数抓取工具都可以选择在两次抓取间暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “页面所需(LCTT 译注:单页面所需的所有元素)”,如样式表(CSS)、图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任何 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任何使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正轨。比如,在网站上有一段时间很流行日历块。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的归档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 噩梦
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指引很少被人遵循 —— 使用过 [NoScript][6] 或 [uMatrix][7] 等插件的人都知道。
|
||||
|
||||
传统的归档方法有时会以最愚蠢的方式失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在包含 的 JavaScript 末尾添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供归档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类归档时,这些脚本会加载失败,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为执行任意代码的虚拟机转化,依赖于纯 HTML 文件解析的归档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的归档者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件
|
||||
|
||||
在 <ruby>[互联网档案馆][9]<rt>Internet Archive</rt></ruby> 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (即 “ARChive”)文件格式,以提供一种聚合其归档工作所产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由<ruby>[国际互联网保护联盟][12]<rt>International Internet Preservation Consortium</rt></ruby>(IIPC)领导,据维基百科称,这是一个“*为了协调为未来而保护互联网内容的努力而成立的国际图书馆组织和其他组织*”;它的成员包括<ruby>美国国会图书馆<rt>US Library of Congress</rt></ruby>和互联网档案馆等。后者在其基于 Java 的 [Heritrix crawler][13](LCTT 译注:一种爬虫程序)内部使用了 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息、文件内容,以及其他元数据。方便的是,Wget 实际上提供了 `--warc` 参数来支持 WARC 格式。不幸的是,web 浏览器不能直接显示 WARC 文件,所以为了访问归档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像“<ruby>时光倒流机网站<rt>Wayback Machine</rt></ruby>”的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16]的 [1.0 规范不一致][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面所需(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来归档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂归档工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“*零散离群的归档者、程序员、作家以及演说家*”使用,他们致力于“*在历史永远丢失之前保存它们*”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其它零散的工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取一个社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。该团队使用的另一个工具是 [crocoite][27],它使用无头模式的 Chrome 浏览器来归档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。它工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将它们与我现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和归档的悲剧就是死数据。幸运的是,业余的归档者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,“互联网档案馆”看起来仍然在那里,并且 ArchiveTeam 显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
@ -1,89 +1,86 @@
|
||||
实验 3:用户环境
|
||||
Caffeinated 6.828:实验 3:用户环境
|
||||
======
|
||||
### 实验 3:用户环境
|
||||
|
||||
#### 简介
|
||||
### 简介
|
||||
|
||||
在本实验中,你将要实现一个基本的内核功能,要求它能够保护运行的用户模式环境(即:进程)。你将去增强这个 JOS 内核,去配置数据结构以便于保持对用户环境的跟踪、创建一个单一用户环境、将程序镜像加载到用户环境中、并将它启动运行。你也要写出一些 JOS 内核的函数,用来处理任何用户环境生成的系统调用,以及处理由用户环境引进的各种异常。
|
||||
|
||||
**注意:** 在本实验中,术语**_“环境”_** 和**_“进程”_** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
**注意:** 在本实验中,术语**“环境”** 和**“进程”** 是可互换的 —— 它们都表示同一个抽象概念,那就是允许你去运行的程序。我在介绍中使用术语**“环境”**而不是使用传统术语**“进程”**的目的是为了强调一点,那就是 JOS 的环境和 UNIX 的进程提供了不同的接口,并且它们的语义也不相同。
|
||||
|
||||
##### 预备知识
|
||||
#### 预备知识
|
||||
|
||||
使用 Git 去提交你自实验 2 以后的更改(如果有的话),获取课程仓库的最新版本,以及创建一个命名为 `lab3` 的本地分支,指向到我们的 lab3 分支上 `origin/lab3` :
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git commit -am 'changes to lab2 after handin'
|
||||
Created commit 734fab7: changes to lab2 after handin
|
||||
4 files changed, 42 insertions(+), 9 deletions(-)
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab3 origin/lab3
|
||||
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
|
||||
Switched to a new branch "lab3"
|
||||
athena% git merge lab2
|
||||
Merge made by recursive.
|
||||
kern/pmap.c | 42 +++++++++++++++++++
|
||||
1 files changed, 42 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
实验 3 包含一些你将探索的新源文件:
|
||||
|
||||
```c
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
inc/ env.h Public definitions for user-mode environments
|
||||
trap.h Public definitions for trap handling
|
||||
syscall.h Public definitions for system calls from user environments to the kernel
|
||||
lib.h Public definitions for the user-mode support library
|
||||
kern/ env.h Kernel-private definitions for user-mode environments
|
||||
env.c Kernel code implementing user-mode environments
|
||||
trap.h Kernel-private trap handling definitions
|
||||
trap.c Trap handling code
|
||||
trapentry.S Assembly-language trap handler entry-points
|
||||
syscall.h Kernel-private definitions for system call handling
|
||||
syscall.c System call implementation code
|
||||
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
|
||||
entry.S Assembly-language entry-point for user environments
|
||||
libmain.c User-mode library setup code called from entry.S
|
||||
syscall.c User-mode system call stub functions
|
||||
console.c User-mode implementations of putchar and getchar, providing console I/O
|
||||
exit.c User-mode implementation of exit
|
||||
panic.c User-mode implementation of panic
|
||||
user/ * Various test programs to check kernel lab 3 code
|
||||
```
|
||||
|
||||
另外,一些在实验 2 中的源文件在实验 3 中将被修改。如果想去查看有什么更改,可以运行:
|
||||
|
||||
```
|
||||
$ git diff lab2
|
||||
|
||||
$ git diff lab2
|
||||
```
|
||||
|
||||
你也可以另外去看一下 [实验工具指南][1],它包含了与本实验有关的调试用户代码方面的信息。
|
||||
|
||||
##### 实验要求
|
||||
#### 实验要求
|
||||
|
||||
本实验分为两部分:Part A 和 Part B。Part A 在本实验完成后一周内提交;你将要提交你的更改和完成的动手实验,在提交之前要确保你的代码通过了 Part A 的所有检查(如果你的代码未通过 Part B 的检查也可以提交)。只需要在第二周提交 Part B 的期限之前代码检查通过即可。
|
||||
|
||||
由于在实验 2 中,你需要做实验中描述的所有正则表达式练习,并且至少通过一个挑战(是指整个实验,不是每个部分)。写出详细的问题答案并张贴在实验中,以及一到两个段落的关于你如何解决你选择的挑战问题的详细描述,并将它放在一个名为 `answers-lab3.txt` 的文件中,并将这个文件放在你的 `lab` 目标的根目录下。(如果你做了多个问题挑战,你仅需要提交其中一个即可)不要忘记使用 `git add answers-lab3.txt` 提交这个文件。
|
||||
|
||||
##### 行内汇编语言
|
||||
#### 行内汇编语言
|
||||
|
||||
在本实验中你可能找到使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言("`asm`" 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
在本实验中你可能发现使用了 GCC 的行内汇编语言特性,虽然不使用它也可以完成实验。但至少你需要去理解这些行内汇编语言片段,这些汇编语言(`asm` 语句)片段已经存在于提供给你的源代码中。你可以在课程 [参考资料][2] 的页面上找到 GCC 行内汇编语言有关的信息。
|
||||
|
||||
#### Part A:用户环境和异常处理
|
||||
### Part A:用户环境和异常处理
|
||||
|
||||
新文件 `inc/env.h` 中包含了在 JOS 中关于用户环境的基本定义。现在就去阅读它。内核使用数据结构 `Env` 去保持对每个用户环境的跟踪。在本实验的开始,你将只创建一个环境,但你需要去设计 JOS 内核支持多环境;实验 4 将带来这个高级特性,允许用户环境去 `fork` 其它环境。
|
||||
|
||||
正如你在 `kern/env.c` 中所看到的,内核维护了与环境相关的三个全局变量:
|
||||
|
||||
```
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
|
||||
struct Env *envs = NULL; // All environments
|
||||
struct Env *curenv = NULL; // The current env
|
||||
static struct Env *env_free_list; // Free environment list
|
||||
```
|
||||
|
||||
一旦 JOS 启动并运行,`envs` 指针指向到一个数组,即数据结构 `Env`,它保存了系统中全部的环境。在我们的设计中,JOS 内核将同时支持最大值为 `NENV` 个的活动的环境,虽然在一般情况下,任何给定时刻运行的环境很少。(`NENV` 是在 `inc/env.h` 中用 `#define` 定义的一个常量)一旦它被分配,对于每个 `NENV` 可能的环境,`envs` 数组将包含一个数据结构 `Env` 的单个实例。
|
||||
@ -92,38 +89,38 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
|
||||
内核使用符号 `curenv` 来保持对任意给定时刻的 _当前正在运行的环境_ 进行跟踪。在系统引导期间,在第一个环境运行之前,`curenv` 被初始化为 `NULL`。
|
||||
|
||||
##### 环境状态
|
||||
#### 环境状态
|
||||
|
||||
数据结构 `Env` 被定义在文件 `inc/env.h` 中,内容如下:(在后面的实验中将添加更多的字段):
|
||||
|
||||
```c
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
struct Env {
|
||||
struct Trapframe env_tf; // Saved registers
|
||||
struct Env *env_link; // Next free Env
|
||||
envid_t env_id; // Unique environment identifier
|
||||
envid_t env_parent_id; // env_id of this env's parent
|
||||
enum EnvType env_type; // Indicates special system environments
|
||||
unsigned env_status; // Status of the environment
|
||||
uint32_t env_runs; // Number of times environment has run
|
||||
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
// Address space
|
||||
pde_t *env_pgdir; // Kernel virtual address of page dir
|
||||
};
|
||||
```
|
||||
|
||||
以下是数据结构 `Env` 中的字段简介:
|
||||
|
||||
* **env_tf**:
|
||||
* `env_tf`:
|
||||
这个结构定义在 `inc/trap.h` 中,它用于在那个环境不运行时保持它保存在寄存器中的值,即:当内核或一个不同的环境在运行时。当从用户模式切换到内核模式时,内核将保存这些东西,以便于那个环境能够在稍后重新运行时回到中断运行的地方。
|
||||
* **env_link**:
|
||||
* `env_link`:
|
||||
这是一个链接,它链接到在 `env_free_list` 上的下一个 `Env` 上。`env_free_list` 指向到列表上第一个空闲的环境。
|
||||
* **env_id**:
|
||||
* `env_id`:
|
||||
内核在数据结构 `Env` 中保存了一个唯一标识当前环境的值(即:使用数组 `envs` 中的特定槽位)。在一个用户环境终止之后,内核可能给另外的环境重新分配相同的数据结构 `Env` —— 但是新的环境将有一个与已终止的旧的环境不同的 `env_id`,即便是新的环境在数组 `envs` 中复用了同一个槽位。
|
||||
* **env_parent_id**:
|
||||
* `env_parent_id`:
|
||||
内核使用它来保存创建这个环境的父级环境的 `env_id`。通过这种方式,环境就可以形成一个“家族树”,这对于做出“哪个环境可以对谁做什么”这样的安全决策非常有用。
|
||||
* **env_type**:
|
||||
* `env_type`:
|
||||
它用于去区分特定的环境。对于大多数环境,它将是 `ENV_TYPE_USER` 的。在稍后的实验中,针对特定的系统服务环境,我们将引入更多的几种类型。
|
||||
* **env_status**:
|
||||
* `env_status`:
|
||||
这个变量持有以下几个值之一:
|
||||
* `ENV_FREE`:
|
||||
表示那个 `Env` 结构是非活动的,并且因此它还在 `env_free_list` 上。
|
||||
@ -135,59 +132,64 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
表示那个 `Env` 结构所代表的是一个当前活动的环境,但不是当前准备去运行的:例如,因为它正在因为一个来自其它环境的进程间通讯(IPC)而处于等待状态。
|
||||
* `ENV_DYING`:
|
||||
表示那个 `Env` 结构所表示的是一个僵尸环境。一个僵尸环境将在下一次被内核捕获后被释放。我们在实验 4 之前不会去使用这个标志。
|
||||
* **env_pgdir**:
|
||||
* `env_pgdir`:
|
||||
这个变量持有这个环境的内核虚拟地址的页目录。
|
||||
|
||||
|
||||
|
||||
就像一个 Unix 进程一样,一个 JOS 环境耦合了“线程”和“地址空间”的概念。线程主要由保存的寄存器来定义(`env_tf` 字段),而地址空间由页目录和 `env_pgdir` 所指向的页表所定义。为运行一个环境,内核必须使用保存的寄存器值和相关的地址空间去设置 CPU。
|
||||
|
||||
我们的 `struct Env` 与 xv6 中的 `struct proc` 类似。它们都在一个 `Trapframe` 结构中持有环境(即进程)的用户模式寄存器状态。在 JOS 中,单个的环境并不能像 xv6 中的进程那样拥有它们自己的内核栈。在这里,内核中任意时间只能有一个 JOS 环境处于活动中,因此,JOS 仅需要一个单个的内核栈。
|
||||
|
||||
##### 为环境分配数组
|
||||
#### 为环境分配数组
|
||||
|
||||
在实验 2 的 `mem_init()` 中,你为数组 `pages[]` 分配了内存,它是内核用于对页面分配与否的状态进行跟踪的一个表。你现在将需要去修改 `mem_init()`,以便于后面使用它分配一个与结构 `Env` 类似的数组,这个数组被称为 `envs`。
|
||||
|
||||
```markdown
|
||||
练习 1、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
```
|
||||
> **练习 1**、修改在 `kern/pmap.c` 中的 `mem_init()`,以用于去分配和映射 `envs` 数组。这个数组完全由 `Env` 结构分配的实例 `NENV` 组成,就像你分配的 `pages` 数组一样。与 `pages` 数组一样,由内存支持的数组 `envs` 也将在 `UENVS`(它的定义在 `inc/memlayout.h` 文件中)中映射用户只读的内存,以便于用户进程能够从这个数组中读取。
|
||||
|
||||
你应该去运行你的代码,并确保 `check_kern_pgdir()` 是没有问题的。
|
||||
|
||||
##### 创建和运行环境
|
||||
#### 创建和运行环境
|
||||
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
现在,你将在 `kern/env.c` 中写一些必需的代码去运行一个用户环境。因为我们并没有做一个文件系统,因此,我们将设置内核去加载一个嵌入到内核中的静态的二进制镜像。JOS 内核以一个 ELF 可运行镜像的方式将这个二进制镜像嵌入到内核中。
|
||||
|
||||
在实验 3 中,`GNUmakefile` 将在 `obj/user/` 目录中生成一些二进制镜像。如果你看到 `kern/Makefrag`,你将注意到一些奇怪的的东西,它们“链接”这些二进制直接进入到内核中运行,就像 `.o` 文件一样。在链接器命令行上的 `-b binary` 选项,将因此把它们链接为“原生的”不解析的二进制文件,而不是由编译器产生的普通的 `.o` 文件。(就链接器而言,这些文件压根就不是 ELF 镜像文件 —— 它们可以是任何东西,比如,一个文本文件或图片!)如果你在内核构建之后查看 `obj/kern/kernel.sym` ,你将会注意到链接器很奇怪的生成了一些有趣的、命名很费解的符号,比如像 `_binary_obj_user_hello_start`、`_binary_obj_user_hello_end`、以及 `_binary_obj_user_hello_size`。链接器通过改编二进制文件的命令来生成这些符号;这种符号为普通内核代码使用一种引入嵌入式二进制文件的方法。
|
||||
|
||||
在 `kern/init.c` 的 `i386_init()` 中,你将写一些代码在环境中运行这些二进制镜像中的一种。但是,设置用户环境的关键函数还没有实现;将需要你去完成它们。
|
||||
|
||||
```markdown
|
||||
练习 2、在文件 `env.c` 中,写完以下函数的代码:
|
||||
> **练习 2**、在文件 `env.c` 中,写完以下函数的代码:
|
||||
|
||||
* `env_init()`
|
||||
初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
* `env_setup_vm()`
|
||||
为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
* `region_alloc()`
|
||||
为一个新环境分配和映射物理内存
|
||||
* `load_icode()`
|
||||
你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
* `env_create()`
|
||||
使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
* `env_run()`
|
||||
在用户模式中开始运行一个给定的环境
|
||||
> * `env_init()`
|
||||
|
||||
> 初始化 `envs` 数组中所有的 `Env` 结构,然后把它们添加到 `env_free_list` 中。也称为 `env_init_percpu`,它通过配置硬件,在硬件上为 level 0(内核)权限和 level 3(用户)权限使用单独的段。
|
||||
|
||||
> * `env_setup_vm()`
|
||||
|
||||
在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
> 为一个新环境分配一个页目录,并初始化新环境的地址空间的内核部分。
|
||||
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
> * `region_alloc()`
|
||||
|
||||
中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
> 为一个新环境分配和映射物理内存
|
||||
|
||||
> * `load_icode()`
|
||||
|
||||
> 你将需要去解析一个 ELF 二进制镜像,就像引导加载器那样,然后加载它的内容到一个新环境的用户地址空间中。
|
||||
|
||||
> * `env_create()`
|
||||
|
||||
> 使用 `env_alloc` 去分配一个环境,并调用 `load_icode` 去加载一个 ELF 二进制
|
||||
|
||||
> * `env_run()`
|
||||
|
||||
> 在用户模式中开始运行一个给定的环境
|
||||
|
||||
> 在你写这些函数时,你可能会发现新的 cprintf 动词 `%e` 非常有用 -- 它可以输出一个错误代码的相关描述。比如:
|
||||
|
||||
> ```
|
||||
r = -E_NO_MEM;
|
||||
panic("env_alloc: %e", r);
|
||||
```
|
||||
|
||||
> 中 panic 将输出消息 "env_alloc: out of memory"。
|
||||
|
||||
下面是用户代码相关的调用图。确保你理解了每一步的用途。
|
||||
|
||||
* `start` (`kern/entry.S`)
|
||||
@ -200,107 +202,94 @@ JOS 内核在 `env_free_list` 上用数据结构 `Env` 保存了所有不活动
|
||||
* `env_run`
|
||||
* `env_pop_tf`
|
||||
|
||||
|
||||
|
||||
在完成以上函数后,你应该去编译内核并在 QEMU 下运行它。如果一切正常,你的系统将进入到用户空间并运行二进制的 `hello` ,直到使用 `int` 指令生成一个系统调用为止。在那个时刻将存在一个问题,因为 JOS 尚未设置硬件去允许从用户空间到内核空间的各种转换。当 CPU 发现没有系统调用中断的服务程序时,它将生成一个一般保护异常,找到那个异常并去处理它,还将生成一个双重故障异常,同样也找到它并处理它,并且最后会出现所谓的“三重故障异常”。通常情况下,你将随后看到 CPU 复位以及系统重引导。虽然对于传统的应用程序(在 [这篇博客文章][3] 中解释了原因)这是重大的问题,但是对于内核开发来说,这是一个痛苦的过程,因此,在打了 6.828 补丁的 QEMU 上,你将可以看到转储的寄存器内容和一个“三重故障”的信息。
|
||||
|
||||
我们马上就会去处理这些问题,但是现在,我们可以使用调试器去检查我们是否进入了用户模式。使用 `make qemu-gdb` 并在 `env_pop_tf` 处设置一个 GDB 断点,它是你进入用户模式之前到达的最后一个函数。使用 `si` 单步进入这个函数;处理器将在 `iret` 指令之后进入用户模式。然后你将会看到在用户环境运行的第一个指令,它将是在 `lib/entry.S` 中的标签 `start` 的第一个指令 `cmpl`。现在,在 `hello` 中的 `sys_cputs()` 的 `int $0x30` 处使用 `b *0x...`(关于用户空间的地址,请查看 `obj/user/hello.asm` )设置断点。这个指令 `int` 是系统调用去显示一个字符到控制台。如果到 `int` 还没有运行,那么可能在你的地址空间设置或程序加载代码时发生了错误;返回去找到问题并解决后重新运行。
|
||||
|
||||
##### 处理中断和异常
|
||||
#### 处理中断和异常
|
||||
|
||||
到目前为止,在用户空间中的第一个系统调用指令 `int $0x30` 已正式寿终正寝了:一旦处理器进入用户模式,将无法返回。因此,现在,你需要去实现基本的异常和系统调用服务程序,因为那样才有可能让内核从用户模式代码中恢复对处理器的控制。你所做的第一件事情就是彻底地掌握 x86 的中断和异常机制的使用。
|
||||
|
||||
```
|
||||
练习 3、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
```
|
||||
> **练习 3**、如果你对中断和异常机制不熟悉的话,阅读 80386 程序员手册的第 9 章(或 IA-32 开发者手册的第 5 章)。
|
||||
|
||||
在这个实验中,对于中断、异常、以其它类似的东西,我们将遵循 Intel 的术语习惯。由于如<ruby>异常<rt>exception</rt></ruby>、<ruby>陷阱<rt>trap</rt></ruby>、<ruby>中断<rt>interrupt</rt></ruby>、<ruby>故障<rt>fault</rt></ruby>和<ruby>中止<rt>abort</rt></ruby>这些术语在不同的架构和操作系统上并没有一个统一的标准,我们经常在特定的架构下(如 x86)并不去考虑它们之间的细微差别。当你在本实验以外的地方看到这些术语时,它们的含义可能有细微的差别。
|
||||
|
||||
##### 受保护的控制转移基础
|
||||
#### 受保护的控制转移基础
|
||||
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(CPL=0)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
异常和中断都是“受保护的控制转移”,它将导致处理器从用户模式切换到内核模式(`CPL=0`)而不会让用户模式的代码干扰到内核的其它函数或其它的环境。在 Intel 的术语中,一个中断就是一个“受保护的控制转移”,它是由于处理器以外的外部异步事件所引发的,比如外部设备 I/O 活动通知。而异常正好与之相反,它是由当前正在运行的代码所引发的同步的、受保护的控制转移,比如由于发生了一个除零错误或对无效内存的访问。
|
||||
|
||||
为了确保这些受保护的控制转移是真正地受到保护,处理器的中断/异常机制设计是:当中断/异常发生时,当前运行的代码不能随意选择进入内核的位置和方式。而是,处理器在确保内核能够严格控制的条件下才能进入内核。在 x86 上,有两种机制协同来提供这种保护:
|
||||
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
1. **中断描述符表** 处理器确保中断和异常仅能够导致内核进入几个特定的、由内核本身定义好的、明确的入口点,而不是去运行中断或异常发生时的代码。
|
||||
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
x86 允许最多有 256 个不同的中断或异常入口点去进入内核,每个入口点都使用一个不同的中断向量。一个向量是一个介于 0 和 255 之间的数字。一个中断向量是由中断源确定的:不同的设备、错误条件、以及应用程序去请求内核使用不同的向量生成中断。CPU 使用向量作为进入处理器的中断描述符表(IDT)的索引,它是内核设置的内核私有内存,GDT 也是。从这个表中的适当的条目中,处理器将加载:
|
||||
|
||||
* 将值加载到指令指针寄存器(EIP),指向内核代码设计好的,用于处理这种异常的服务程序。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 level 0。)
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
* 将值加载到代码段寄存器(CS),它包含运行权限为 0—1 级别的、要运行的异常服务程序。(在 JOS 中,所有的异常处理程序都运行在内核模式中,运行级别为 0。)
|
||||
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
2. **任务状态描述符表** 处理器在中断或异常发生时,需要一个地方去保存旧的处理器状态,比如,处理器在调用异常服务程序之前的 `EIP` 和 `CS` 的原始值,这样那个异常服务程序就能够稍后通过还原旧的状态来回到中断发生时的代码位置。但是对于已保存的处理器的旧状态必须被保护起来,不能被无权限的用户模式代码访问;否则代码中的 bug 或恶意用户代码将危及内核。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的 level 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
基于这个原因,当一个 x86 处理器产生一个中断或陷阱时,将导致权限级别的变更,从用户模式转换到内核模式,它也将导致在内核的内存中发生栈切换。有一个被称为 TSS 的任务状态描述符表规定段描述符和这个栈所处的地址。处理器在这个新栈上推送 `SS`、`ESP`、`EFLAGS`、`CS`、`EIP`、以及一个可选的错误代码。然后它从中断描述符上加载 `CS` 和 `EIP` 的值,然后设置 `ESP` 和 `SS` 去指向新的栈。
|
||||
|
||||
虽然 TSS 很大并且默默地为各种用途服务,但是 JOS 仅用它去定义当从用户模式到内核模式的转移发生时,处理器即将切换过去的内核栈。因为在 JOS 中的“内核模式”仅运行在 x86 的运行级别 0 权限上,当进入内核模式时,处理器使用 TSS 上的 `ESP0` 和 `SS0` 字段去定义内核栈。JOS 并不去使用 TSS 的任何其它字段。
|
||||
|
||||
|
||||
|
||||
##### 异常和中断的类型
|
||||
#### 异常和中断的类型
|
||||
|
||||
所有的 x86 处理器上的同步异常都能够产生一个内部使用的、介于 0 到 31 之间的中断向量,因此它映射到 IDT 就是条目 0-31。例如,一个页故障总是通过向量 14 引发一个异常。大于 31 的中断向量仅用于软件中断,它由 `int` 指令生成,或异步硬件中断,当需要时,它们由外部设备产生。
|
||||
|
||||
在这一节中,我们将扩展 JOS 去处理向量为 0-31 之间的、内部产生的 x86 异常。在下一节中,我们将完成 JOS 的 48(0x30)号软件中断向量,JOS 将(随意选择的)使用它作为系统调用中断向量。在实验 4 中,我们将扩展 JOS 去处理外部生成的硬件中断,比如时钟中断。
|
||||
|
||||
##### 一个示例
|
||||
#### 一个示例
|
||||
|
||||
我们把这些片断综合到一起,通过一个示例来巩固一下。我们假设处理器在用户环境下运行代码,遇到一个除零问题。
|
||||
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
1. 处理器去切换到由 TSS 中的 `SS0` 和 `ESP0` 定义的栈,在 JOS 中,它们各自保存着值 `GD_KD` 和 `KSTACKTOP`。
|
||||
2. 处理器在内核栈上推入异常参数,起始地址为 `KSTACKTOP`:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20 <---- ESP
|
||||
+--------------------+
|
||||
|
||||
```
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
|
||||
|
||||
3. 由于我们要处理一个除零错误,它将在 x86 上产生一个中断向量 0,处理器读取 IDT 的条目 0,然后设置 `CS:EIP` 去指向由条目描述的处理函数。
|
||||
4. 处理服务程序函数将接管控制权并处理异常,例如中止用户环境。
|
||||
|
||||
对于某些类型的 x86 异常,除了以上的五个“标准的”寄存器外,处理器还推入另一个包含错误代码的寄存器值到栈中。页故障异常,向量号为 14,就是一个重要的示例。查看 80386 手册去确定哪些异常推入一个错误代码,以及错误代码在那个案例中的意义。当处理器推入一个错误代码后,当从用户模式中进入内核模式,异常处理服务程序开始时的栈看起来应该如下所示:
|
||||
|
||||
```
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
+--------------------+ KSTACKTOP
|
||||
| 0x00000 | old SS | " - 4
|
||||
| old ESP | " - 8
|
||||
| old EFLAGS | " - 12
|
||||
| 0x00000 | old CS | " - 16
|
||||
| old EIP | " - 20
|
||||
| error code | " - 24 <---- ESP
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
##### 嵌套的异常和中断
|
||||
#### 嵌套的异常和中断
|
||||
|
||||
处理器能够处理来自用户和内核模式中的异常和中断。当收到来自用户模式的异常和中断时才会进入内核模式中,而且,在推送它的旧寄存器状态到栈中和通过 IDT 调用相关的异常服务程序之前,x86 处理器会自动切换栈。如果当异常或中断发生时,处理器已经处于内核模式中(`CS` 寄存器低位两个比特为 0),那么 CPU 只是推入一些值到相同的内核栈中。在这种方式中,内核可以优雅地处理嵌套的异常,嵌套的异常一般由内核本身的代码所引发。在实现保护时,这种功能是非常重要的工具,我们将在稍后的系统调用中看到它。
|
||||
|
||||
如果处理器已经处于内核模式中,并且发生了一个嵌套的异常,由于它并不需要切换栈,它也就不需要去保存旧的 `SS` 或 `ESP` 寄存器。对于不推入错误代码的异常类型,在进入到异常服务程序时,它的内核栈看起来应该如下图:
|
||||
|
||||
```
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
+--------------------+ <---- old ESP
|
||||
| old EFLAGS | " - 4
|
||||
| 0x00000 | old CS | " - 8
|
||||
| old EIP | " - 12
|
||||
+--------------------+
|
||||
```
|
||||
|
||||
对于需要推入一个错误代码的异常类型,处理器将在旧的 `EIP` 之后,立即推入一个错误代码,就和前面一样。
|
||||
|
||||
关于处理器的异常嵌套的功能,这里有一个重要的警告。如果处理器正处于内核模式时发生了一个异常,并且不论是什么原因,比如栈空间泄漏,都不会去推送它的旧的状态,那么这时处理器将不能做任何的恢复,它只是简单地重置。毫无疑问,内核应该被设计为禁止发生这种情况。
|
||||
|
||||
##### 设置 IDT
|
||||
#### 设置 IDT
|
||||
|
||||
到目前为止,你应该有了在 JOS 中为了设置 IDT 和处理异常所需的基本信息。现在,我们去设置 IDT 以处理中断向量 0-31(处理器异常)。我们将在本实验的稍后部分处理系统调用,然后在后面的实验中增加中断 32-47(设备 IRQ)。
|
||||
|
||||
@ -311,102 +300,94 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
你将要实现的完整的控制流如下图所描述:
|
||||
|
||||
```c
|
||||
IDT trapentry.S trap.c
|
||||
IDT trapentry.S trap.c
|
||||
|
||||
+----------------+
|
||||
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
| &handler1 |----> handler1: trap (struct Trapframe *tf)
|
||||
| | // do stuff {
|
||||
| | call trap // handle the exception/interrupt
|
||||
| | // ... }
|
||||
+----------------+
|
||||
| &handler2 |--------> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handler2 |----> handler2:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
.
|
||||
.
|
||||
.
|
||||
+----------------+
|
||||
| &handlerX |--------> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
| &handlerX |----> handlerX:
|
||||
| | // do stuff
|
||||
| | call trap
|
||||
| | // ...
|
||||
+----------------+
|
||||
```
|
||||
|
||||
每个异常或中断都应该在 `trapentry.S` 中有它自己的处理程序,并且 `trap_init()` 应该使用这些处理程序的地址去初始化 IDT。每个处理程序都应该在栈上构建一个 `struct Trapframe`(查看 `inc/trap.h`),然后使用一个指针调用 `trap()`(在 `trap.c` 中)到 `Trapframe`。`trap()` 接着处理异常/中断或派发给一个特定的处理函数。
|
||||
|
||||
```markdown
|
||||
练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
> 练习 4、编辑 `trapentry.S` 和 `trap.c`,然后实现上面所描述的功能。在 `trapentry.S` 中的宏 `TRAPHANDLER` 和 `TRAPHANDLER_NOEC` 将会帮你,还有在 `inc/trap.h` 中的 T_* defines。你需要在 `trapentry.S` 中为每个定义在 `inc/trap.h` 中的陷阱添加一个入口点(使用这些宏),并且你将有 t、o 提供的 `_alltraps`,这是由宏 `TRAPHANDLER`指向到它。你也需要去修改 `trap_init()` 来初始化 `idt`,以使它指向到每个在 `trapentry.S` 中定义的入口点;宏 `SETGATE` 将有助你实现它。
|
||||
|
||||
你的 `_alltraps` 应该:
|
||||
> 你的 `_alltraps` 应该:
|
||||
|
||||
1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
4. `call trap` (`trap` 能够返回吗?)
|
||||
> 1. 推送值以使栈看上去像一个结构 Trapframe
|
||||
> 2. 加载 `GD_KD` 到 `%ds` 和 `%es`
|
||||
> 3. `pushl %esp` 去传递一个指针到 Trapframe 以作为一个 trap() 的参数
|
||||
> 4. `call trap` (`trap` 能够返回吗?)
|
||||
|
||||
> 考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
|
||||
> 使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
|
||||
考虑使用 `pushal` 指令;它非常适合 `struct Trapframe` 的布局。
|
||||
.
|
||||
|
||||
使用一些在 `user` 目录中的测试程序来测试你的陷阱处理代码,这些测试程序在生成任何系统调用之前能引发异常,比如 `user/divzero`。在这时,你应该能够成功完成 `divzero`、`softint`、以有 `badsegment` 测试。
|
||||
> **小挑战!**目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
> 在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
> 1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
> 2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!目前,在 `trapentry.S` 中列出的 `TRAPHANDLER` 和他们安装在 `trap.c` 中可能有许多代码非常相似。清除它们。修改 `trapentry.S` 中的宏去自动为 `trap.c` 生成一个表。注意,你可以直接使用 `.text` 和 `.data` 在汇编器中切换放置其中的代码和数据。
|
||||
```
|
||||
|
||||
```markdown
|
||||
问题
|
||||
|
||||
在你的 `answers-lab3.txt` 中回答下列问题:
|
||||
|
||||
1. 为每个异常/中断设置一个独立的服务程序函数的目的是什么?(即:如果所有的异常/中断都传递给同一个服务程序,在我们的当前实现中能否提供这样的特性?)
|
||||
2. 你需要做什么事情才能让 `user/softint` 程序正常运行?评级脚本预计将会产生一个一般保护故障(trap 13),但是 `softint` 的代码显示为 `int $14`。为什么它产生的中断向量是 13?如果内核允许 `softint` 的 `int $14` 指令去调用内核页故障的服务程序(它的中断向量是 14)会发生什么事情?
|
||||
```
|
||||
|
||||
|
||||
本实验的 Part A 部分结束了。不要忘了去添加 `answers-lab3.txt` 文件,提交你的变更,然后在 Part A 作业的提交截止日期之前运行 `make handin`。
|
||||
|
||||
#### Part B:页故障、断点异常、和系统调用
|
||||
### Part B:页故障、断点异常、和系统调用
|
||||
|
||||
现在,你的内核已经有了最基本的异常处理能力,你将要去继续改进它,来提供依赖异常服务程序的操作系统原语。
|
||||
|
||||
##### 处理页故障
|
||||
#### 处理页故障
|
||||
|
||||
页故障异常,中断向量为 14(`T_PGFLT`),它是一个非常重要的东西,我们将通过本实验和接下来的实验来大量练习它。当处理器产生一个页故障时,处理器将在它的一个特定的控制寄存器(`CR2`)中保存导致这个故障的线性地址(即:虚拟地址)。在 `trap.c` 中我们提供了一个专门处理它的函数的一个雏形,它就是 `page_fault_handler()`,我们将用它来处理页故障异常。
|
||||
|
||||
```markdown
|
||||
练习 5、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite`、和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 make run- _x_ 或 make run- _x_ -nox 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 make run-hello-nox 去运行 the _hello_ user 程序。
|
||||
```
|
||||
> **练习 5**、修改 `trap_dispatch()` 将页故障异常派发到 `page_fault_handler()` 上。你现在应该能够成功测试 `faultread`、`faultreadkernel`、`faultwrite` 和 `faultwritekernel` 了。如果它们中的任何一个不能正常工作,找出问题并修复它。记住,你可以使用 `make run-x` 或 `make run-x-nox` 去重引导 JOS 进入到一个特定的用户程序。比如,你可以运行 `make run-hello-nox` 去运行 `hello` 用户程序。
|
||||
|
||||
下面,你将进一步细化内核的页故障服务程序,因为你要实现系统调用了。
|
||||
|
||||
##### 断点异常
|
||||
#### 断点异常
|
||||
|
||||
断点异常,中断向量为 3(`T_BRKPT`),它一般用在调试上,它在一个程序代码中插入断点,从而使用特定的 1 字节的 `int3` 软件中断指令来临时替换相应的程序指令。在 JOS 中,我们将稍微“滥用”一下这个异常,通过将它打造成一个伪系统调用原语,使得任何用户环境都可以用它来调用 JOS 内核监视器。如果我们将 JOS 内核监视认为是原始调试器,那么这种用法是合适的。例如,在 `lib/panic.c` 中实现的用户模式下的 `panic()` ,它在显示它的 `panic` 消息后运行一个 `int3` 中断。
|
||||
|
||||
```markdown
|
||||
练习 6、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
```
|
||||
> **练习 6**、修改 `trap_dispatch()`,让它在调用内核监视器时产生一个断点异常。你现在应该可以在 `breakpoint` 上成功完成测试。
|
||||
|
||||
```markdown
|
||||
小挑战!修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
.
|
||||
|
||||
可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
```
|
||||
> **小挑战!**修改 JOS 内核监视器,以便于你能够从当前位置(即:在 `int3` 之后,断点异常调用了内核监视器) '继续' 异常,并且因此你就可以一次运行一个单步指令。为了实现单步运行,你需要去理解 `EFLAGS` 寄存器中的某些比特的意义。
|
||||
|
||||
```markdown
|
||||
问题
|
||||
> 可选:如果你富有冒险精神,找一些 x86 反汇编的代码 —— 即通过从 QEMU 中、或从 GNU 二进制工具中分离、或你自己编写 —— 然后扩展 JOS 内核监视器,以使它能够反汇编,显示你的每步的指令。结合实验 1 中的符号表,这将是你写的一个真正的内核调试器。
|
||||
|
||||
3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
```
|
||||
.
|
||||
|
||||
> **问题**
|
||||
|
||||
##### 系统调用
|
||||
> 3. 在断点测试案例中,根据你在 IDT 中如何初始化断点条目的不同情况(即:你的从 `trap_init` 到 `SETGATE` 的调用),既有可能产生一个断点异常,也有可能产生一个一般保护故障。为什么?为了能够像上面的案例那样工作,你需要如何去设置它,什么样的不正确设置才会触发一个一般保护故障?
|
||||
|
||||
> 4. 你认为这些机制的意义是什么?尤其是要考虑 `user/softint` 测试程序的工作原理。
|
||||
|
||||
#### 系统调用
|
||||
|
||||
用户进程请求内核为它做事情就是通过系统调用来实现的。当用户进程请求一个系统调用时,处理器首先进入内核模式,处理器和内核配合去保存用户进程的状态,内核为了完成系统调用会运行有关的代码,然后重新回到用户进程。用户进程如何获得内核的关注以及它如何指定它需要的系统调用的具体细节,这在不同的系统上是不同的。
|
||||
|
||||
@ -414,45 +395,43 @@ x86 允许最多有 256 个不同的中断或异常入口点去进入内核,
|
||||
|
||||
应用程序将在寄存器中传递系统调用号和系统调用参数。通过这种方式,内核就不需要去遍历用户环境的栈或指令流。系统调用号将放在 `%eax` 中,而参数(最多五个)将分别放在 `%edx`、`%ecx`、`%ebx`、`%edi`、和 `%esi` 中。内核将在 `%eax` 中传递返回值。在 `lib/syscall.c` 中的 `syscall()` 中已为你编写了使用一个系统调用的汇编代码。你可以通过阅读它来确保你已经理解了它们都做了什么。
|
||||
|
||||
```markdown
|
||||
练习 7、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
> **练习 7**、在内核中为中断向量 `T_SYSCALL` 添加一个服务程序。你将需要去编辑 `kern/trapentry.S` 和 `kern/trap.c` 的 `trap_init()`。还需要去修改 `trap_dispatch()`,以便于通过使用适当的参数来调用 `syscall()` (定义在 `kern/syscall.c`)以处理系统调用中断,然后将系统调用的返回值安排在 `%eax` 中传递给用户进程。最后,你需要去实现 `kern/syscall.c` 中的 `syscall()`。如果系统调用号是无效值,确保 `syscall()` 返回值一定是 `-E_INVAL`。为确保你理解了系统调用的接口,你应该去阅读和掌握 `lib/syscall.c` 文件(尤其是行内汇编的动作),对于在 `inc/syscall.h` 中列出的每个系统调用都需要通过调用相关的内核函数来处理A。
|
||||
|
||||
在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 "`hello, world`",然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
> 在你的内核中运行 `user/hello` 程序(make run-hello)。它应该在控制台上输出 `hello, world`,然后在用户模式中产生一个页故障。如果没有产生页故障,可能意味着你的系统调用服务程序不太正确。现在,你应该有能力成功通过 `testbss` 测试。
|
||||
|
||||
.
|
||||
|
||||
> 小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
|
||||
> `sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
|
||||
> 在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
|
||||
> 最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
> ```
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
```
|
||||
|
||||
```markdown
|
||||
小挑战!使用 `sysenter` 和 `sysexit` 指令而不是使用 `int 0x30` 和 `iret` 来实现系统调用。
|
||||
> GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(`push`)和恢复(`pop`)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
`sysenter/sysexit` 指令是由 Intel 设计的,它的运行速度要比 `int/iret` 指令快。它使用寄存器而不是栈来做到这一点,并且通过假定了分段寄存器是如何使用的。关于这些指令的详细内容可以在 Intel 参考手册 2B 卷中找到。
|
||||
> 注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在 JOS 中添加对这些指令支持的最容易的方法是,在 `kern/trapentry.S` 中添加一个 `sysenter_handler`,在它里面保存足够多的关于用户环境返回、设置内核环境、推送参数到 `syscall()`、以及直接调用 `syscall()` 的信息。一旦 `syscall()` 返回,它将设置好运行 `sysexit` 指令所需的一切东西。你也将需要在 `kern/init.c` 中添加一些代码,以设置特殊模块寄存器(MSRs)。在 AMD 架构程序员手册第 2 卷的 6.1.2 节中和 Intel 参考手册的 2B 卷的 SYSENTER 上都有关于 MSRs 的很详细的描述。对于如何去写 MSRs,在[这里][4]你可以找到一个添加到 `inc/x86.h` 中的 `wrmsr` 的实现。
|
||||
> 在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
|
||||
最后,`lib/syscall.c` 必须要修改,以便于支持用 `sysenter` 来生成一个系统调用。下面是 `sysenter` 指令的一种可能的寄存器布局:
|
||||
|
||||
eax - syscall number
|
||||
edx, ecx, ebx, edi - arg1, arg2, arg3, arg4
|
||||
esi - return pc
|
||||
ebp - return esp
|
||||
esp - trashed by sysenter
|
||||
|
||||
GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的值。不要忘了同时去保存(push)和恢复(pop)你使用的其它寄存器,或告诉内联汇编器你正在使用它们。内联汇编器不支持保存 `%ebp`,因此你需要自己去增加一些代码来保存和恢复它们,返回地址可以使用一个像 `leal after_sysenter_label, %%esi` 的指令置入到 `%esi` 中。
|
||||
|
||||
注意,它仅支持 4 个参数,因此你需要保留支持 5 个参数的系统调用的旧方法。而且,因为这个快速路径并不更新当前环境的 trap 帧,因此,在我们添加到后续实验中的一些系统调用上,它并不适合。
|
||||
|
||||
在接下来的实验中我们启用了异步中断,你需要再次去评估一下你的代码。尤其是,当返回到用户进程时,你需要去启用中断,而 `sysexit` 指令并不会为你去做这一动作。
|
||||
```
|
||||
|
||||
##### 启动用户模式
|
||||
#### 启动用户模式
|
||||
|
||||
一个用户程序是从 `lib/entry.S` 的顶部开始运行的。在一些配置之后,代码调用 `lib/libmain.c` 中的 `libmain()`。你应该去修改 `libmain()` 以初始化全局指针 `thisenv`,使它指向到这个环境在数组 `envs[]` 中的 `struct Env`。(注意那个 `lib/entry.S` 中已经定义 `envs` 去指向到在 Part A 中映射的你的设置。)提示:查看 `inc/env.h` 和使用 `sys_getenvid`。
|
||||
|
||||
`libmain()` 接下来调用 `umain`,在 hello 程序的案例中,`umain` 是在 `user/hello.c` 中。注意,它在输出 "`hello, world`” 之后,它尝试去访问 `thisenv->env_id`。这就是为什么前面会发生故障的原因了。现在,你已经正确地初始化了 `thisenv`,它应该不会再发生故障了。如果仍然会发生故障,或许是因为你没有映射 `UENVS` 区域为用户可读取(回到前面 Part A 中 查看 `pmap.c`);这是我们第一次真实地使用 `UENVS` 区域)。
|
||||
|
||||
```markdown
|
||||
练习 8、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 "`hello, world`" 然后输出 "`i am environment 00001000`"。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去"退出"。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
```
|
||||
> **练习 8**、添加要求的代码到用户库,然后引导你的内核。你应该能够看到 `user/hello` 程序会输出 `hello, world` 然后输出 `i am environment 00001000`。`user/hello` 接下来会通过调用 `sys_env_destroy()`(查看`lib/libmain.c` 和 `lib/exit.c`)尝试去“退出”。由于内核目前仅支持一个用户环境,它应该会报告它毁坏了唯一的环境,然后进入到内核监视器中。现在你应该能够成功通过 `hello` 的测试。
|
||||
|
||||
##### 页故障和内存保护
|
||||
#### 页故障和内存保护
|
||||
|
||||
内存保护是一个操作系统中最重要的特性,通过它来保证一个程序中的 bug 不会破坏其它程序或操作系统本身。
|
||||
|
||||
@ -462,10 +441,8 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
对于内存保护,系统调用中有一个非常有趣的问题。许多系统调用接口让用户程序传递指针到内核中。这些指针指向用户要读取或写入的缓冲区。然后内核在执行系统调用时废弃这些指针。这样就有两个问题:
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
|
||||
1. 内核中的页故障可能比用户程序中的页故障多的多。如果内核在维护它自己的数据结构时发生页故障,那就是一个内核 bug,而故障服务程序将使整个内核(和整个系统)崩溃。但是当内核废弃了由用户程序传递给它的指针后,它就需要一种方式去记住那些废弃指针所导致的页故障其实是代表用户程序的。
|
||||
2. 一般情况下内核拥有比用户程序更多的权限。用户程序可以传递一个指针到系统调用,而指针指向的区域有可能是内核可以读取或写入而用户程序不可访问的区域。内核必须要非常小心,不能被废弃的这种指针欺骗,因为这可能导致泄露私有信息或破坏内核的完整性。
|
||||
|
||||
由于以上的原因,内核在处理由用户程序提供的指针时必须格外小心。
|
||||
|
||||
@ -473,32 +450,33 @@ GCC 的内联汇编器将自动保存你告诉它的直接加载进寄存器的
|
||||
|
||||
这样,内核在废弃一个用户提供的指针时就绝不会发生页故障。如果内核出现这种页故障,它应该崩溃并终止。
|
||||
|
||||
```markdown
|
||||
练习 9、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
> **练习 9**、如果在内核模式中发生一个页故障,修改 `kern/trap.c` 去崩溃。
|
||||
|
||||
提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
> 提示:判断一个页故障是发生在用户模式还是内核模式,去检查 `tf_cs` 的低位比特即可。
|
||||
|
||||
阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
> 阅读 `kern/pmap.c` 中的 `user_mem_assert` 并在那个文件中实现 `user_mem_check`。
|
||||
|
||||
修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
> 修改 `kern/syscall.c` 去常态化检查传递给系统调用的参数。
|
||||
|
||||
引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
> 引导你的内核,运行 `user/buggyhello`。环境将被毁坏,而内核将不会崩溃。你将会看到:
|
||||
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
> ```
|
||||
[00001000] user_mem_check assertion failure for va 00000001
|
||||
[00001000] free env 00001000
|
||||
Destroyed the only environment - nothing more to do!
|
||||
```
|
||||
|
||||
> 最后,修改在 `kern/kdebug.c` 中的 `debuginfo_eip`,在 `usd`、`stabs`、和 `stabstr` 上调用 `user_mem_check`。如果你现在运行 `user/breakpoint`,你应该能够从内核监视器中运行回溯,然后在内核因页故障崩溃前看到回溯进入到 `lib/libmain.c`。是什么导致了这个页故障?你不需要去修复它,但是你应该明白它是如何发生的。
|
||||
|
||||
注意,刚才实现的这些机制也同样适用于恶意用户程序(比如 `user/evilhello`)。
|
||||
|
||||
```
|
||||
练习 10、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
> **练习 10**、引导你的内核,运行 `user/evilhello`。环境应该被毁坏,并且内核不会崩溃。你应该能看到:
|
||||
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
> ```
|
||||
[00000000] new env 00001000
|
||||
...
|
||||
[00001000] user_mem_check assertion failure for va f010000c
|
||||
[00001000] free env 00001000
|
||||
```
|
||||
|
||||
**本实验到此结束。**确保你通过了所有的等级测试,并且不要忘记去写下问题的答案,在 `answers-lab3.txt` 中详细描述你的挑战练习的解决方案。提交你的变更并在 `lab` 目录下输入 `make handin` 去提交你的工作。
|
||||
@ -512,13 +490,13 @@ via: https://pdos.csail.mit.edu/6.828/2018/labs/lab3/
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/labguide.html
|
||||
[1]: https://linux.cn/article-10273-1.html
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labs/reference.html
|
||||
[3]: http://blogs.msdn.com/larryosterman/archive/2005/02/08/369243.aspx
|
||||
[4]: http://ftp.kh.edu.tw/Linux/SuSE/people/garloff/linux/k6mod.c
|
||||
@ -0,0 +1,147 @@
|
||||
如何用 Python 编写你喜爱的 R 函数
|
||||
======
|
||||
> R 还是 Python ? Python 脚本模仿易使用的 R 风格函数,使得数据统计变得简单易行。
|
||||
|
||||

|
||||
|
||||
“Python vs. R” 是数据科学和机器学习的现代战争之一。毫无疑问,近年来这两者发展迅猛,成为数据科学、预测分析和机器学习领域的顶级编程语言。事实上,根据 IEEE 最近的一篇文章,Python 已在 [最受欢迎编程语言排行榜][1] 中超越 C++ 成为排名第一的语言,并且 R 语言也稳居前 10 位。
|
||||
|
||||
但是,这两者之间存在一些根本区别。[R][2] 语言设计的初衷主要是作为统计分析和数据分析问题的快速原型设计的工具,另一方面,Python 是作为一种通用的、现代的面向对象语言而开发的,类似 C++ 或 Java,但具有更简单的学习曲线和更灵活的语言风格。因此,R 仍在统计学家、定量生物学家、物理学家和经济学家中备受青睐,而 Python 已逐渐成为日常脚本、自动化、后端 Web 开发、分析和通用机器学习框架的顶级语言,拥有广泛的支持基础和开源开发社区。
|
||||
|
||||
### 在 Python 环境中模仿函数式编程
|
||||
|
||||
[R 作为函数式编程语言的本质][3]为用户提供了一个极其简洁的用于快速计算概率的接口,还为数据分析问题提供了必不可少的描述统计和推论统计方法(LCTT 译注:统计学从功能上分为描述统计学和推论统计学)。例如,只用一个简洁的函数调用来解决以下问题难道不是很好吗?
|
||||
|
||||
* 如何计算数据向量的平均数 / 中位数 / 众数。
|
||||
* 如何计算某些服从正态分布的事件的累积概率。如果服<ruby>从泊松分布<rt>Poisson distribution</rt></ruby>又该怎样计算呢?
|
||||
* 如何计算一系列数据点的四分位距。
|
||||
* 如何生成服从学生 t 分布的一些随机数(LCTT 译注: 在概率论和统计学中,学生 t-分布(Student's t-distribution)可简称为 t 分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值)。
|
||||
|
||||
R 编程环境可以完成所有这些工作。
|
||||
|
||||
另一方面,Python 的脚本编写能力使分析师能够在各种分析流程中使用这些统计数据,具有无限的复杂性和创造力。
|
||||
|
||||
要结合二者的优势,你只需要一个简单的 Python 封装的库,其中包含与 R 风格定义的概率分布和描述性统计相关的最常用函数。 这使你可以非常快速地调用这些函数,而无需转到正确的 Python 统计库并理解整个方法和参数列表。
|
||||
|
||||
### 便于调用 R 函数的 Python 包装脚本
|
||||
|
||||
[我编写了一个 Python 脚本][4] ,用 Python 简单统计分析定义了最简洁和最常用的 R 函数。导入此脚本后,你将能够原生地使用这些 R 函数,就像在 R 编程环境中一样。
|
||||
|
||||
此脚本的目标是提供简单的 Python 函数,模仿 R 风格的统计函数,以快速计算密度估计和点估计、累积分布和分位数,并生成重要概率分布的随机变量。
|
||||
|
||||
为了延续 R 风格,脚本不使用类结构,并且只在文件中定义原始函数。因此,用户可以导入这个 Python 脚本,并在需要单个名称调用时使用所有功能。
|
||||
|
||||
请注意,我使用 mimic 这个词。 在任何情况下,我都声称要模仿 R 的真正的函数式编程范式,该范式包括深层环境设置以及这些环境和对象之间的复杂关系。 这个脚本允许我(我希望无数其他的 Python 用户)快速启动 Python 程序或 Jupyter 笔记本程序、导入脚本,并立即开始进行简单的描述性统计。这就是目标,仅此而已。
|
||||
|
||||
如果你已经写过 R 代码(可能在研究生院)并且刚刚开始学习并使用 Python 进行数据分析,那么你将很高兴看到并在 Jupyter 笔记本中以类似在 R 环境中一样使用一些相同的知名函数。
|
||||
|
||||
无论出于何种原因,使用这个脚本很有趣。
|
||||
|
||||
### 简单的例子
|
||||
|
||||
首先,只需导入脚本并开始处理数字列表,就好像它们是 R 中的数据向量一样。
|
||||
|
||||
```
|
||||
from R_functions import *
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
<more code, more statistics...>
|
||||
```
|
||||
|
||||
假设你想从数据向量计算 [Tuckey 五数][5]摘要。 你只需要调用一个简单的函数 `fivenum`,然后将向量传进去。 它将返回五数摘要,存在 NumPy 数组中。
|
||||
|
||||
```
|
||||
lst=[20,12,16,32,27,65,44,45,22,18]
|
||||
fivenum(lst)
|
||||
> array([12. , 18.5, 24.5, 41. , 65. ])
|
||||
```
|
||||
|
||||
或许你想要知道下面问题的答案:
|
||||
|
||||
> 假设一台机器平均每小时输出 10 件成品,标准偏差为 2。输出模式遵循接近正态的分布。 机器在下一个小时内输出至少 7 个但不超过 12 个单位的概率是多少?
|
||||
|
||||
答案基本上是这样的:
|
||||
|
||||
|
||||
|
||||
使用 `pnorm` ,你可以只用一行代码就能获得答案:
|
||||
|
||||
```
|
||||
pnorm(12,10,2)-pnorm(7,10,2)
|
||||
> 0.7745375447996848
|
||||
```
|
||||
|
||||
或者你可能需要回答以下问题:
|
||||
|
||||
> 假设你有一个不公平硬币,每次投它时有 60% 可能正面朝上。 你正在玩 10 次投掷游戏。 你如何绘制并给出这枚硬币所有可能的胜利数(从 0 到 10)的概率?
|
||||
|
||||
只需使用一个函数 `dbinom` 就可以获得一个只有几行代码的美观条形图:
|
||||
|
||||
```
|
||||
probs=[]
|
||||
import matplotlib.pyplot as plt
|
||||
for i in range(11):
|
||||
probs.append(dbinom(i,10,0.6))
|
||||
plt.bar(range(11),height=probs)
|
||||
plt.grid(True)
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 简单的概率计算接口
|
||||
|
||||
R 提供了一个非常简单直观的接口,可以从基本概率分布中快速计算。 接口如下:
|
||||
|
||||
* **d** 分布:给出点 **x** 处的密度函数值
|
||||
* **p** 分布:给出 **x** 点的累积值
|
||||
* **q** 分布:以概率 **p** 给出分位数函数值
|
||||
* **r** 分布:生成一个或多个随机变量
|
||||
|
||||
在我们的实现中,我们坚持使用此接口及其关联的参数列表,以便你可以像在 R 环境中一样执行这些函数。
|
||||
|
||||
### 目前已实现的函数
|
||||
|
||||
脚本中实现了以下 R 风格函数,以便快速调用。
|
||||
|
||||
* 平均数、中位数、方差、标准差
|
||||
* Tuckey 五数摘要、<ruby>四分位距<rt>interquartile range</rt></ruby>(IQR)
|
||||
* 矩阵的协方差或两个向量之间的协方差
|
||||
* 以下分布的密度、累积概率、分位数函数和随机变量生成:正态、均匀、二项式、<ruby>泊松<rt>Poisson</rt></ruby>、F、<ruby>学生 t<rt>Student's t</rt></ruby>、<ruby>卡方<rt>Chi-square</rt></ruby>、<ruby>贝塔<rt>beta</rt></ruby>和<ruby>伽玛<rt>gamma</rt></ruby>
|
||||
|
||||
### 进行中的工作
|
||||
|
||||
显然,这是一项正在进行的工作,我计划在此脚本中添加一些其他方便的R函数。 例如,在 R 中,单行命令 `lm` 可以为数字数据集提供一个简单的最小二乘拟合模型,其中包含所有必要的推理统计(P 值,标准误差等)。 这非常简洁! 另一方面,Python 中的标准线性回归问题经常使用 [Scikit-learn][6] 库来处理,此用途需要更多的脚本,所以我打算使用 Python 的 [statsmodels][7] 库合并这个单函数线性模型来拟合功能。
|
||||
|
||||
如果你喜欢这个脚本,并且愿意在工作中使用,请在 [GitHub 仓库][8]点个 star 或者 fork 帮助其他人找到它。 另外,你可以查看我其他的 [GitHub 仓库][9],了解 Python、R 或 MATLAB 中的有趣代码片段以及一些机器学习资源。
|
||||
|
||||
如果你有任何问题或想法要分享,请通过 [tirthajyoti [AT] gmail.com][10] 与我联系。 如果你像我一样热衷于机器学习和数据科学,请 [在 LinkedIn 上加我为好友][11]或者[在 Twitter 上关注我][12]。
|
||||
|
||||
本篇文章最初发表于[走向数据科学][13]。 请在 [CC BY-SA 4.0][14] 协议下转载。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/write-favorite-r-functions-python
|
||||
|
||||
作者:[Tirthajyoti Sarkar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[yongshouzhang](https://github.com/yongshouzhang)
|
||||
校对:[Flowsnow](https://github.com/Flowsnow)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tirthajyoti
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://spectrum.ieee.org/at-work/innovation/the-2018-top-programming-languages
|
||||
[2]: https://www.coursera.org/lecture/r-programming/overview-and-history-of-r-pAbaE
|
||||
[3]: http://adv-r.had.co.nz/Functional-programming.html
|
||||
[4]: https://github.com/tirthajyoti/StatsUsingPython/blob/master/R_Functions.py
|
||||
[5]: https://en.wikipedia.org/wiki/Five-number_summary
|
||||
[6]: http://scikit-learn.org/stable/
|
||||
[7]: https://www.statsmodels.org/stable/index.html
|
||||
[8]: https://github.com/tirthajyoti/StatsUsingPython
|
||||
[9]: https://github.com/tirthajyoti?tab=repositories
|
||||
[10]: mailto:tirthajyoti@gmail.com
|
||||
[11]: https://www.linkedin.com/in/tirthajyoti-sarkar-2127aa7/
|
||||
[12]: https://twitter.com/tirthajyotiS
|
||||
[13]: https://towardsdatascience.com/how-to-write-your-favorite-r-functions-in-python-11e1e9c29089
|
||||
[14]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
@ -0,0 +1,109 @@
|
||||
流量引导:网络世界的负载均衡解密
|
||||
======
|
||||
|
||||
> 均衡网络流量的常用技术,它们的优势和利弊权衡。
|
||||
|
||||

|
||||
|
||||
大型的多站点互联网系统,包括内容分发网络(CDN)和云服务提供商,用一些方法来均衡来访的流量。这篇文章我们讲一下常见的流量均衡设计,包括它们的技术手段和利弊权衡。
|
||||
|
||||
早期的云计算服务提供商,可以提供单一一台客户 Web 服务器,分配一个 IP 地址,然后用一个便于人读的域名配置一个 DNS 记录指向这个 IP 地址,再将 IP 地址通过边界网关协议(BGP)宣告出去,BGP 是在不同网络之间交换路由信息的标准方式。
|
||||
|
||||
这本身并不是负载均衡,但是能在冗余的多条网络路径中进行流量分发,而且可以利用网络技术让流量绕过不可用的网络,从而提高了可用性(也引起了[非对称路由][1]的现象)。
|
||||
|
||||
### 简单的 DNS 负载均衡
|
||||
|
||||
随着来自客户的流量变大,老板希望服务是高可用的。你上线第二台 web 服务器,它有自己独立的公网 IP 地址,然后你更新了 DNS 记录,把用户流量引到两台服务器上(内心希望它们均衡地提供服务)。在其中一台服务器出故障之前,这样做一直是没有问题的。假设你能很快地监测到故障,可以更新一下 DNS 配置(手动更新或者通过软件)删除解析到故障机器的记录。
|
||||
|
||||
不幸的是,因为 DNS 记录会被缓存,在客户端缓存和它们依赖的 DNS 服务器上的缓存失效之前,大约一半的请求会失败。DNS 记录都有一个几分钟或更长的生命周期(TTL),所以这种方式会对系统可用性造成严重的影响。
|
||||
|
||||
更糟糕的是,部分客户端会完全忽略 TTL,所以有一些请求会持续被引导到你的故障机器上。设置很短的 TTL 也不是个好办法,因为这意味着更高的 DNS 服务负载,还有更长的访问时延,因为客户端要做更多的 DNS 查询。如果 DNS 服务由于某种原因不可用了,那设置更短的 TTL 会让服务的访问量更快地下降,因为没那么多客户端有你网站 IP 地址的缓存了。
|
||||
|
||||
### 增加网络负载均衡
|
||||
|
||||
要解决上述问题,可以增加一对相互冗余的[四层][2](L4)网络负载均衡器,配置一样的虚拟 IP 地址(VIP)。均衡器可以是硬件的,也可以是像 [HAProxy][3] 这样的软件。域名的 DNS 记录指向 VIP,不再承担负载均衡的功能。
|
||||
|
||||
![Layer 4 load balancers balance connections across webservers.][5]
|
||||
|
||||
*四层负载均衡器能够均衡用户和两台 web 服务器的连接*
|
||||
|
||||
四层均衡器将网络流量均衡地引导至后端服务器。通常这是基于对 IP 数据包的五元组做散列(数学函数)来完成的,五元组包括:源地址、源端口、目的地址、目的端口、协议(比如 TCP 或 UDP)。这种方法是快速和高效的(还维持了 TCP 的基本属性),而且不需要均衡器维持每个连接的状态。(更多信息请阅读[谷歌发表的 Maglev 论文][6],这篇论文详细讨论了四层软件负载均衡器的实现细节。)
|
||||
|
||||
四层均衡器可以对后端服务做健康检查,只把流量分发到健康的机器上。和使用 DNS 做负载均衡不同的是,在某个后端 web 服务故障的时候,它可以很快地把流量重新分发到其他机器上,虽然故障机器的已有连接会被重置。
|
||||
|
||||
当后端服务器的能力不同时,四层均衡器可以根据权重做流量分发。它为运维人员提供了强大的能力和灵活性,而且硬件成本相对较小。
|
||||
|
||||
### 扩展到多站点
|
||||
|
||||
系统规模在持续增长。你的客户希望能一直使用服务,即使是数据中心发生故障的时候。所以你建设了一个新的数据中心,另外独立部署了一套服务和四层负载均衡器集群,仍然使用同样的 VIP。DNS 的设置不变。
|
||||
|
||||
两个站点的边缘路由器都把自己的地址空间宣告出去,包括 VIP 地址。发往该 VIP 的请求可能到达任何一个站点,取决于用户和系统之间的网络是如何连接的,以及各个网络的路由策略是如何配置的。这就是泛播。大部分时候这种机制可以很好的工作。如果一个站点出问题了,你可以停止通过 BGP 宣告 VIP 地址,客户的请求就会迅速地转移到另外一个站点去。
|
||||
|
||||
![Serving from multiple sites using anycast][8]
|
||||
|
||||
*多个站点使用泛播提供服务*
|
||||
|
||||
这种设置有一些问题。最大的问题是,不能控制请求流向哪个站点,或者限制某个站点的流量。也没有一个明确的方式把用户的请求转到距离他最近的站点(为了降低网络延迟),不过,网络协议和路由选路配置在大部分情况下应该能把用户请求路由到最近的站点。
|
||||
|
||||
### 控制多站点系统中的入站请求
|
||||
|
||||
为了维持稳定性,需要能够控制每个站点的流量大小。要实现这种控制,可以给每个站点分配不同的 VIP 地址,然后用简单的或者有权重的 DNS [轮询][9]来做负载均衡。
|
||||
|
||||
![Serving from multiple sites using a primary VIP][11]
|
||||
|
||||
*多站点提供服务,每个站点使用一个主 VIP,另外一个站点作为备份。基于能感知地理位置的 DNS。*
|
||||
|
||||
现在有两个问题。
|
||||
|
||||
第一、使用 DNS 均衡意味着会有被缓存的记录,如果你要快速重定向流量的话就麻烦了。
|
||||
|
||||
第二、用户每次做新的 DNS 查询,都可能连上任意一个站点,可能不是距离最近的。如果你的服务运行在分布广泛的很多站点上,用户会感受到响应时间有明显的变化,取决于用户和提供服务的站点之间有多大的网络延迟。
|
||||
|
||||
让每个站点都配置上其他所有站点的 VIP 地址,并宣告出去(因此也会包含故障的站点),这样可以解决第一个问题。有一些网络上的小技巧,比如备份站点宣告路由时,不像主站点使用那么具体的目的地址,这样可以保证每个 VIP 的主站点只要可用就会优先提供服务。这是通过 BGP 来实现的,所以我们应该可以看到,流量在 BGP 更新后的一两分钟内就开始转移了。
|
||||
|
||||
即使离用户最近的站点是健康而且有服务能力的,但是用户真正访问到的却不一定是这个站点,这个问题还没有很好的解决方案。很多大型的互联网服务利用 DNS 给不同地域的用户返回不同的解析结果,也能有一定的效果。不过,因为网络地址的结构和地理位置无关,一个地址段也可能会改变所在位置(例如,当一个公司重新规划网络时),而且很多用户可能使用了同一个 DNS 缓存服务器。所以这种方案有一定的复杂度,而且容易出错。
|
||||
|
||||
### 增加七层负载均衡
|
||||
|
||||
又过了一段时间,你的客户开始要更多的高级功能。
|
||||
|
||||
虽然四层负载均衡可以高效地在多个 web 服务器之间分发流量,但是它们只针对源地址、目标地址、协议和端口来操作,请求的内容是什么就不得而知了,所以很多高级功能在四层负载均衡上实现不了。而七层(L7)负载均衡知道请求的内容和结构,所以能做更多的事情。
|
||||
|
||||
七层负载均衡可以实现缓存、限速、错误注入,做负载均衡时可以感知到请求的代价(有些请求需要服务器花更多的时间去处理)。
|
||||
|
||||
七层负载均衡还可以基于请求的属性(比如 HTTP cookies)来分发流量,可以终结 SSL 连接,还可以帮助防御应用层的拒绝服务(DoS)攻击。规模大的 L7 负载均衡的缺点是成本 —— 处理请求需要更多的计算,而且每个活跃的请求都占用一些系统资源。在一个或者多个 L7 均衡器前面运行 L4 均衡器集群,对扩展规模有帮助。
|
||||
|
||||
### 结论
|
||||
|
||||
负载均衡是一个复杂的难题。除了上面说过的策略,还有不同的[负载均衡算法][13],用来实现负载均衡器的高可用技术、客户端负载均衡技术,以及最近兴起的服务网络等等。
|
||||
|
||||
核心的负载均衡模式随着云计算的发展而不断发展,而且,随着大型 web 服务商致力于让负载均衡技术更可控和更灵活,这项技术会持续发展下去。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/internet-scale-load-balancing
|
||||
|
||||
作者:[Laura Nolan][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauranolan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.noction.com/blog/bgp-and-asymmetric-routing
|
||||
[2]: https://en.wikipedia.org/wiki/Transport_layer
|
||||
[3]: https://www.haproxy.com/blog/failover-and-worst-case-management-with-haproxy/
|
||||
[4]: /file/412596
|
||||
[5]: https://opensource.com/sites/default/files/uploads/loadbalancing1_l4-network-loadbalancing.png "Layer 4 load balancers balance connections across webservers."
|
||||
[6]: https://ai.google/research/pubs/pub44824
|
||||
[7]: /file/412601
|
||||
[8]: https://opensource.com/sites/default/files/uploads/loadbalancing2_going-multisite.png "Serving from multiple sites using anycast"
|
||||
[9]: https://en.wikipedia.org/wiki/Round-robin_scheduling
|
||||
[10]: /file/412606
|
||||
[11]: https://opensource.com/sites/default/files/uploads/loadbalancing3_controlling-inbound-requests.png "Serving from multiple sites using a primary VIP"
|
||||
[12]: https://landing.google.com/sre/book/chapters/load-balancing-frontend.html
|
||||
[13]: https://medium.com/netflix-techblog/netflix-edge-load-balancing-695308b5548c
|
||||
[14]: https://www.usenix.org/conference/lisa18/presentation/suriar
|
||||
[15]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,37 +1,35 @@
|
||||
使用企业版 Docker 搭建自己的私有注册服务器
|
||||
使用 Docker 企业版搭建自己的私有注册服务器
|
||||
======
|
||||
|
||||
![docker trusted registry][1]
|
||||
|
||||
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub][2] 上拉取完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己的私有注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
|
||||
Docker 真的很酷,特别是和使用虚拟机相比,转移 Docker 镜像十分容易。如果你已准备好使用 Docker,那你肯定已从 [Docker Hub][2] 上拉取过完整的镜像。Docker Hub 是 Docker 的云端注册服务器服务,它包含成千上万个供选择的 Docker 镜像。如果你开发了自己的软件包并创建了自己的 Docker 镜像,那么你会想有自己私有的注册服务器。如果你有搭配着专有许可的镜像,或想为你的构建系统提供复杂的持续集成(CI)过程,则更应该拥有自己的私有注册服务器。
|
||||
|
||||
Docker 企业版包括 Docker Trusted Registry(译者注:DTR,Docker 可信注册服务器)。这是一个具有安全镜像管理功能的高可用的注册服务器,为了在你自己的数据中心或基于云端的架构上运行而构建。在接下来的几周,我们将了解 DTR 是提供安全、可重用且连续的[软件供应链][3]的一个关键组件。你可以通过我们的[免费托管小样][4]立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
|
||||
Docker 企业版包括 <ruby>Docker 可信注册服务器<rt>Docker Trusted Registry</rt></ruby>(DTR)。这是一个具有安全镜像管理功能的高可用的注册服务器,为在你自己的数据中心或基于云端的架构上运行而构建。在接下来,我们将了解到 DTR 是提供安全、可重用且连续的[软件供应链][3]的一个关键组件。你可以通过我们的[免费托管小样][4]立即开始使用,或者通过下载安装进行 30 天的免费试用。下面是开始自己安装的步骤。
|
||||
|
||||
## 配置 Docker 企业版
|
||||
### 配置 Docker 企业版
|
||||
|
||||
Docker Trusted Registry 在通用控制面板(UCP)上运行,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
|
||||
DTR 运行于通用控制面板(UCP)之上,所以开始前要安装一个单节点集群。如果你已经有了自己的 UCP 集群,可以跳过这一步。在你的 docker 托管主机上,运行以下命令:
|
||||
|
||||
```
|
||||
# 拉取并安装 UCP
|
||||
|
||||
docker run -it -rm -v /var/run/docker.sock:/var/run/docker.sock -name ucp docker/ucp:latest install
|
||||
```
|
||||
|
||||
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店][5]获取30天的免费试用版。
|
||||
当 UCP 启动并运行后,在安装 DTR 之前你还有几件事要做。针对刚刚安装的 UCP 实例,打开浏览器。在日志输出的末尾应该有一个链接。如果你已经有了 Docker 企业版的许可证,那就在这个界面上输入它吧。如果你还没有,可以访问 [Docker 商店][5]获取 30 天的免费试用版。
|
||||
|
||||
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行他们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击管理员设置 -> 集群配置并修改控制器端口,比如 5443。
|
||||
准备好许可证后,你可能会需要改变一下 UCP 运行的端口。因为这是一个单节点集群,DTR 和 UCP 可能会以相同的端口运行它们的 web 服务。如果你拥有不只一个节点的 UCP 集群,这就不是问题,因为 DTR 会寻找有所需空闲端口的节点。在 UCP 中,点击“管理员设置 -> 集群配置”并修改控制器端口,比如 5443。
|
||||
|
||||
## 安装 DTR
|
||||
### 安装 DTR
|
||||
|
||||
我们要安装一个简单的、单节点的 Docker Trusted Registry 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(译者注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
|
||||
我们要安装一个简单的、单节点的 DTR 实例。如果你要安装实际生产用途的 DTR,那么你会将其设置为高可用(HA)模式,即需要另一种存储介质,比如基于云端的对象存储或者 NFS(LCTT 译注:Network File System,网络文件系统)。因为目前安装的是一个单节点实例,我们依然使用默认的本地存储。
|
||||
|
||||
首先我们需要拉取 DTR 的 bootstrap 镜像。Boostrap 镜像是一个微小的独立安装程序,包括连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
|
||||
首先我们需要拉取 DTR 的 bootstrap 镜像。boostrap 镜像是一个微小的独立安装程序,包括了连接到 UCP 以及设置和启动 DTR 所需的所有容器、卷和逻辑网络。
|
||||
|
||||
使用命令:
|
||||
|
||||
```
|
||||
# 拉取并运行 DTR 引导程序
|
||||
|
||||
docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
```
|
||||
|
||||
@ -39,55 +37,42 @@ docker run -it -rm docker/dtr:latest install -ucp-insecure-tls
|
||||
|
||||
然后 DTR bootstrap 镜像会让你确定几项设置,比如 UCP 安装的 URL 地址以及管理员的用户名和密码。从拉取所有的 DTR 镜像到设置全部完成,只需要一到两分钟的时间。
|
||||
|
||||
## 保证一切安全
|
||||
### 保证一切安全
|
||||
|
||||
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便安全的与 DTR 通信。
|
||||
一切都准备好后,就可以向注册服务器推送或者从中拉取镜像了。在做这一步之前,让我们设置 TLS 证书,以便与 DTR 安全地通信。
|
||||
|
||||
在 Linux 上,我们可以使用以下命令(只需确保更改了 DTR_HOSTNAME 变量,来正确映射我们刚刚设置的 DTR):
|
||||
在 Linux 上,我们可以使用以下命令(只需确保更改了 `DTR_HOSTNAME` 变量,来正确映射我们刚刚设置的 DTR):
|
||||
|
||||
```
|
||||
# 从 DTR 拉取 CA 证书(如果 curl 不可用,你可以使用 wget)
|
||||
|
||||
DTR_HOSTNAME=< DTR 主机名>
|
||||
|
||||
curl -k https://$(DTR_HOSTNAME)/ca > $(DTR_HOSTNAME).crt
|
||||
|
||||
sudo mkdir /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
sudo cp $(DTR_HOSTNAME) /etc/docker/certs.d/$(DTR_HOSTNAME)
|
||||
|
||||
# 重启 docker 守护进程(在 Ubuntu 14.04 上,使用 `sudo service docker restart` 命令)
|
||||
|
||||
sudo systemctl restart docker
|
||||
```
|
||||
|
||||
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入设置 -> 守护进程,在 Insecure Registries(译者注:不安全的注册服务器)部分,输入你的 DTR 主机名。点击应用,docker 守护进程应在重启后可以良好使用。
|
||||
对于 Mac 和 Windows 版的 Docker,我们会以不同的方式安装客户端。转入“设置 -> 守护进程”,在“不安全的注册服务器”部分,输入你的 DTR 主机名。点击“应用”,docker 守护进程应在重启后可以良好使用。
|
||||
|
||||
## 推送和拉取镜像
|
||||
### 推送和拉取镜像
|
||||
|
||||
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 https://<Your DTR hostname> 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
|
||||
现在我们需要设置一个仓库来存放镜像。这和 Docker Hub 有一点不同,如果你做的 docker 推送仓库中不存在,它会自动创建一个。要创建一个仓库,在浏览器中打开 `https://<Your DTR hostname>` 并在出现登录提示时使用你的管理员凭据登录。如果你向 UCP 添加了许可证,则 DTR 会自动获取该许可证。如果没有,请现在确认上传你的许可证。
|
||||
|
||||
进入刚才的网页之后,点击`新建仓库`按钮来创建新的仓库。
|
||||
进入刚才的网页之后,点击“新建仓库”按钮来创建新的仓库。
|
||||
|
||||
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 `alpine`,点击`保存`(在 DTR 2.5 及更高版本中叫`创建`)。
|
||||
我们会创建一个用于存储 Alpine linux 的仓库,所以在名字输入处键入 “alpine”,点击“保存”(在 DTR 2.5 及更高版本中叫“创建”)。
|
||||
|
||||
现在我们回到 shell 界面输入以下命令:
|
||||
|
||||
```
|
||||
# 拉取 Alpine Linux 的最新版
|
||||
|
||||
docker pull alpine:latest
|
||||
|
||||
# 登入新的 DTR 实例
|
||||
|
||||
docker login <Your DTR hostname>
|
||||
|
||||
# 标记上 Alpine 使能推送其至你的 DTR
|
||||
|
||||
docker tag alpine:latest <Your DTR hostname>/admin/alpine:latest
|
||||
|
||||
# 向 DTR 推送镜像
|
||||
|
||||
docker push <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
@ -95,22 +80,19 @@ docker push <Your DTR hostname>/admin/alpine:latest
|
||||
|
||||
```
|
||||
# 从 DTR 中拉取镜像
|
||||
|
||||
docker pull <Your DTR hostname>/admin/alpine:latest
|
||||
```
|
||||
|
||||
DTR 具有许多优秀的镜像管理功能,例如图像缓存,镜像,扫描,签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
|
||||
|
||||
|
||||
DTR 具有许多优秀的镜像管理功能,例如镜像的缓存、映像、扫描、签名甚至自动化供应链策略。这些功能我们在后期的博客文章中更详细的探讨。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2018/01/dtr/
|
||||
|
||||
作者:[Patrick Devine;Rolf Neugebauer;Docker Core Engineering;Matt Bentley][a]
|
||||
作者:[Patrick Devine][a]
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
Emacs 系列(一):抛掉一切,投入 Emacs 和 Org 模式的怀抱
|
||||
======
|
||||
|
||||
我必须承认,在使用了几十年的 vim 后, 我被 [Emacs][1] 吸引了。
|
||||
|
||||
长期以来,我一直对如何组织安排事情感到沮丧。我也有用过 [GTD][2] 和 [ZTD][3] 之类的方法,但是像邮件或是大型文件这样的事务真的很难来组织安排。
|
||||
|
||||
我一直在用 Asana 处理任务,用 Evernote 做笔记,用 Thunderbird 处理邮件,把 ikiwiki 和其他的一些项目组合作为个人知识库,而且还在电脑的归档了各种文件。当我的新工作需要将 Slack 也加入进来时,我终于忍无可忍了。
|
||||
|
||||
许多 TODO 管理工具与电子邮件集成的很差。当你想做“提醒我在一周内回复这个邮件”之类的事时,很多时候是不可能的,因为这个工具不能以一种能够轻松回复的方式存储邮件。而这个问题在 Slack 上更为严重。
|
||||
|
||||
就在那时,我偶然发现了 [Carsten Dominik 在 Google Talk 上关于 Org 模式的讲话][4]。Carsten 是 Org 模式的作者,即便是这个讲话已经有 10 年了,但它仍然很具有参考价值。
|
||||
|
||||
我之前有用过 [Org 模式][5],但是每次我都没有真正的深入研究它,
|
||||
因为我当时的反应是“一个大纲编辑器?但我需要的是待办事项列表”。我就这么错过了它。但实际上 Org 模式就是我所需要的。
|
||||
|
||||
### 什么是 Emacs?什么是 Org 模式?
|
||||
|
||||
Emacs 最初是一个文本编辑器,现在依然是一个文本编辑器,而且这种传统无疑贯穿始终。但是说 Emacs 是个编辑器是很不公平的。
|
||||
|
||||
Emacs 更像一个平台或是工具包。你不仅可以用它来编辑源代码,而且配置 Emacs 本身也是编程,里面有很多模式。就像编写一个 Firefox 插件一样简单,只要几行代码,然后,模式里的操作就改变了。
|
||||
|
||||
Org 模式也一样。确实,它是一个大纲编辑器,但它真正所包含的不止如此。它是一个信息组织平台。它的网站上写着,“你可以用纯文本来记录你的生活:你可以用 Org 模式来记笔记,处理待办事项,规划项目和使用快速有效的纯文本系统编写文档。”
|
||||
|
||||
### 捕获
|
||||
|
||||
如果你读过基于 GTD 的生产力指南,那么他们强调的一件事就是毫不费力地获取项目。这个想法是,当某件事突然出现在你的脑海里时,把它迅速输入一个受信任的系统,这样你就可以继续做你正在做的事情。Org 模式有一个专门的捕获系统。我可以在 Emacs 的任何地方按下 `C-c c` 键,它就会空出一个位置来记录我的笔记。最关键的是,自动嵌入到笔记中的链接可以链接到我按下 `C-c c` 键时正在编辑的那一行。如果我正在编辑文件,它会链回到那个文件和我所在的行。如果我正在浏览邮件,它就会链回到那封邮件(通过邮件的 Message-Id,这样它就可以在任何一个文件夹中找到邮件)。聊天时也一样,甚至是当你在另一个 Org 模式中也可也这样。
|
||||
|
||||
这样我就可以做一个笔记,它会提醒我在一周内回复某封邮件,当我点击这个笔记中的链接时,它会在我的邮件阅读器中弹出这封邮件 —— 即使我随后将它从收件箱中存档。
|
||||
|
||||
没错,这正是我要找的!
|
||||
|
||||
### 工具套件
|
||||
|
||||
一旦你开始使用 Org 模式,很快你就会想将所有的事情都集成到里面。有可以从网络上捕获内容的浏览器插件,也有多个 Emacs 邮件或新闻阅读器与之集成,ERC(IRC 客户端)也不错。所以我将自己从 Thunderbird 和 mairix + mutt (用于邮件归档)换到了 mu4e,从 xchat + slack 换到了 ERC。
|
||||
|
||||
你可能不明白,我喜欢这些基于 Emacs 的工具,而不是具有相同功能的单独的工具。
|
||||
|
||||
一个小花絮:我又在使用离线 IMAP 了!我甚至在很久以前就用过 GNUS。
|
||||
|
||||
### 用一个 Emacs 进程来管理
|
||||
|
||||
我以前也经常使用 Emacs,那时,Emacs 是一个“大”的程序(现在显示电源状态的小程序占用的内存要比 Emacs 多)。当时存在在启动时间过长的问题,但是现在已经有连接到一个正在运行的 Emacs 进程的解决方法。
|
||||
|
||||
我喜欢用 Mod-p(一个 [xmonad][6] 中 [dzen][7] 菜单栏的快捷方式,但是在大多数传统的桌面环境中该功能的快捷键是 `Alt-F2`)来启动程序(LCTT 译注:xmonad 是一种平铺桌面;dzen 是 X11 窗口下管理消息、提醒和菜单的程序)。这个设置在不运行多个<ruby>[emacs 们](https://www.emacswiki.org/emacs/Emacsen)<rt>emacsen</rt></ruby>时很方便,因为这样就不会在试图捕获另一个打开的文件时出问题。这中方法很简单:创建一个叫 `em` 的脚本并将它放到我自己的环境变量中。就像这样:
|
||||
|
||||
```
|
||||
#!/bin/bash exec emacsclient -c -a "" "$@"
|
||||
```
|
||||
|
||||
如果没有 emacs 进程存在的话,就会创建一个新的 emacs 进程,否则的话就直接使用已存在的进程。这样做还有一个好处:`-nw` 之类的参数工作的很好,它实际上就像在 shell 提示符下输入 `emacs` 一样。它很适合用于设置 `EDITOR` 环境变量。
|
||||
|
||||
### 下一篇
|
||||
|
||||
接下来我将讨论我的使用情况,并展示以下的配置:
|
||||
|
||||
* Org 模式,包括计算机之间的同步、捕获、日程和待办事项、文件、链接、关键字和标记、各种导出(幻灯片)等。
|
||||
* mu4e,用于电子邮件,包括多个账户,bbdb 集成
|
||||
* ERC,用于 IRC 和即时通讯
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9861-emacs-1-ditching-a-bunch-of-stuff-and-moving-to-emacs-and-org-mode
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://www.gnu.org/software/emacs/
|
||||
[2]:https://gettingthingsdone.com/
|
||||
[3]:https://zenhabits.net/zen-to-done-the-simple-productivity-e-book/
|
||||
[4]:https://www.youtube.com/watch?v=oJTwQvgfgMM
|
||||
[5]:https://orgmode.org/
|
||||
[6]:https://wiki.archlinux.org/index.php/Xmonad_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
|
||||
[7]:http://robm.github.io/dzen/
|
||||
@ -1,26 +1,34 @@
|
||||
DevOps应聘者应该准备回答的20个问题
|
||||
DevOps 应聘者应该准备回答的 20 个问题
|
||||
======
|
||||
|
||||
> 想要建立一个积极,富有成效的工作环境? 在招聘过程中要专注于寻找契合点。
|
||||
|
||||

|
||||
聘请一个不合适的人代价是很高的。根据Link人力资源的首席执行官Jörgen Sundberg的统计,招聘,雇佣一名新员工将会花费公司$240,000之多,当你进行了一次不合适的招聘:
|
||||
* 你失去了他们所知道的。
|
||||
* 你失去了他们认识的人
|
||||
|
||||
聘请一个不合适的人[代价是很高的][1]。根据 Link 人力资源的首席执行官 Jörgen Sundberg 的统计,招聘、雇佣一名新员工将会花费公司$240,000 之多,当你进行了一次不合适的招聘:
|
||||
|
||||
* 你失去了他们的知识技能。
|
||||
* 你失去了他们的人脉。
|
||||
* 你的团队将可能进入到一个组织发展的震荡阶段
|
||||
* 你的公司将会面临组织破裂的风险
|
||||
|
||||
当你失去一名员工的时候,你就像丢失了公司图谱中的一块。同样值得一提的是另一端的疼痛。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
当你失去一名员工的时候,你就像丢失了公司版图中的一块。同样值得一提的是另一端的痛苦。应聘到一个错误工作岗位的员工会感受到很大的压力以及整个身心的不满意,甚至是健康问题。
|
||||
|
||||
另外一方面,当你招聘到合适的人时,新的员工将会:
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助驱动一个更长久的财务业绩,而且如果你在一个欢快的环境中工 作,你更有可能在生活中做的更好。
|
||||
|
||||
* 丰富公司现有的文化,使你的组织成为一个更好的工作场所。研究表明一个积极的工作文化能够帮助更长久推动财务业绩增长,而且如果你在一个欢快的环境中工作,你更有可能在生活中做的更好。
|
||||
* 热爱和你的组织在一起工作。当人们热爱他们所在做的,他们会趋向于做的更好。
|
||||
|
||||
招聘适合的或者加强现有的文化在DevOps和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工因应该能够帮助团队合作来充分发挥放大他们的价值同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
招聘以适合或加强现有的文化在 DevOps 和敏捷团多中是必不可少的。也就是说雇佣到一个能够鼓励积极合作的人,以便来自不同背景,有着不同目标和工作方式的团队能够在一起有效的工作。你新雇佣的员工应该能够帮助团队合作来充分发挥放大他们的价值,同时也能够增加员工的满意度以及平衡组织目标的冲突。他或者她应该能够通过明智的选择工具和工作流来促进你的组织,文化就是一切。
|
||||
|
||||
作为我们 2017 年 11 月发布的一篇文章 [DevOps 的招聘经理应该准备回答的 20 个问题][4] 的回应,这篇文章将会重点关注在如何招聘最适合的人。
|
||||
|
||||
作为我们2017年11月发布的一篇文章,[DevOps的招聘经理应该准备回答的20个问题][4],这篇文章将会重点关注在如何招聘最适合的人。
|
||||
### 为什么招聘走错了方向
|
||||
很多公司现在在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 职位公告栏。
|
||||
* 关注和所需才能符合的应聘者。
|
||||
很多公司现在用的典型的雇佣策略是基于人才过剩的基础上:
|
||||
|
||||
* 在职位公告栏发布招聘。
|
||||
* 关注具有所需才能的应聘者。
|
||||
* 尽可能找多的候选者。
|
||||
* 通过面试淘汰弱者。
|
||||
* 通过正式的面试淘汰更多的弱者。
|
||||
@ -30,37 +38,48 @@ DevOps应聘者应该准备回答的20个问题
|
||||

|
||||
|
||||
职位公告栏是有成千上万失业者人才过剩的经济大萧条时期发明的。在今天的求职市场上已经没有人才过剩了,然而我们仍然在使用基于此的招聘策略。
|
||||
|
||||

|
||||
|
||||
### 雇佣最合适的人员:运用文化和情感
|
||||
在人才过剩雇佣策略背后的思想是去设计工作岗位然后将人员安排进去。
|
||||
相反,做相反的事情:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想如此实现,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
**谁正在寻找一份工作?** 根据一份2016年对美国50,000名开发者的调查显示,[85.7%的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近[28.3%的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
**运用团队力量去发现和寻找潜力的雇员**。列如,戴安娜是你的团队中的一名开发者,她所提供的机会即使她已经从事编程很多年而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能,知识和智慧上要比HR所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
**雇员想要什么?**一份来自千禧年,婴儿潮实时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
在人才过剩雇佣策略背后的思想是设计工作岗位然后将人员安排进去。
|
||||
|
||||
反而应该反过来:寻找将会积极融入你的商业文化的人才,然后为他们寻找他们热爱的最合适的岗位。要想实现这样的目标,你必须能够围绕他们热情为他们创造工作岗位。
|
||||
|
||||
**谁正在寻找一份工作?** 根据一份 2016 年对美国 50000 名开发者的调查显示,[85.7% 的受访对象][5]要么对新的机会不感兴趣,要么对于寻找新工作没有积极性。在寻找工作的那部分中,有将近 [28.3% 的求职者][5]来自于朋友的推荐。如果你只是在那些在找工作的人中寻找人才,你将会错过高端的人才。
|
||||
|
||||
**运用团队力量去发现和寻找潜力的雇员**。例如,戴安娜是你的团队中的一名开发者,她所能提供的机会是,她已经[从事编程很多年][6]而且在期间已经结识了很多从事热爱他们所从事的工作的人。难道你不认为她所推荐的潜在员工在技能、知识和智慧上要比 HR 所寻找的要优秀吗?在要求戴安娜分享她同伴之前,通知她即将到来的使命任务,向她阐明你要雇佣潜在有探索精神的团队,描述在将来会需要的知识领域。
|
||||
|
||||
**雇员想要什么?**一份来自千禧年婴儿潮时期出生的人的对比综合性研究显示,20% 的人所想要的是相同的:
|
||||
|
||||
1. 对组织产生积极的影响
|
||||
2. 帮助解决社交或者环境上的挑战
|
||||
3. 和一群有动力的人一起工作
|
||||
|
||||
### 面试的挑战
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试多都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你竟会得到一个被推荐的机会。这又很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会
|
||||
|
||||
### 助你释放潜在雇员激情的20个问题
|
||||
面试应该是招聘者和应聘者双方为了寻找最合适的人才进行的一次双方之间的对话。将面试聚焦在企业文化和情感对话两个问题上:这个应聘者将会丰富你的企业文化并且会热爱和你在一起工作吗?你能够在工作中帮他们取得成功吗?
|
||||
|
||||
**对于招聘经理来说:** 每一次的面试都是你学习如何将自己的组织变得对未来的团队成员更有吸引力,并且每次积极的面试都可能是你发现人才(即使你不会雇佣)的机会。每个人都将会记得积极有效的面试的经历。即使他们不会被雇佣,他们将会和他们的朋友谈论这次经历,你会得到一个被推荐的机会。这有很大的好处:如果你无法吸引到这个人才,你也将会从中学习吸取经验并且改善。
|
||||
|
||||
**对面试者来说**:每次的面试都是你释放激情的机会。
|
||||
|
||||
### 助你释放潜在雇员激情的 20 个问题
|
||||
|
||||
1. 你热爱什么?
|
||||
2. “今天早晨我已经迫不及待的要去工作”你怎么看待这句话?
|
||||
2. “今天早晨我已经迫不及待的要去工作”,你怎么看待这句话?
|
||||
3. 你曾经最快乐的是什么?
|
||||
4. 你曾经解决问题的最典型的例子是什么,你是如何解决的?
|
||||
5. 你如何看待配对学习?
|
||||
6. 你到达办公室和离开办公室心里最先想到的是什么?
|
||||
7. 你如果你有一次改变你之前或者现在的共工作的一件事的机会,将会是什么事?
|
||||
8. 当你在这工作的时候,你最兴奋去学习什么?
|
||||
7. 你如果你有一次改变你之前或者现在的工作中的一件事的机会,将会是什么事?
|
||||
8. 当你在工作的时候,你最乐于去学习什么?
|
||||
9. 你的梦想是什么,你如何去实现?
|
||||
10. 你在学会如何去实现你的追求的时候想要或者需要什么?
|
||||
11. 你的价值观是什么?
|
||||
12. 你是如何坚守自己的价值观的?
|
||||
13. 平衡在你的生活中意味着什么?
|
||||
13. 在你的生活中平衡意味着什么?
|
||||
14. 你最引以为傲的工作交流能力是什么?为什么?
|
||||
15. 你最喜欢营造什么样的环境?
|
||||
16. 你喜欢别人怎样对待你?
|
||||
@ -70,14 +89,13 @@ DevOps应聘者应该准备回答的20个问题
|
||||
20. 如果你正在雇佣我,你将会问我什么问题?
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
构建满足用户需求的云环境的五个步骤
|
||||
======
|
||||
> 在投入时间和资金开发你的云环境之前,确认什么是你的用户所需要的。
|
||||
|
||||

|
||||
|
||||
无论你如何定义,云就是你的用户展现其在组织中的价值的另一个工具。当谈论新的范例或者技术(云是两者兼有)的时候很容易被它的新特性所分心。由一系列无止境的问题引发的对话能够很快的被发展为功能愿景清单,所有下面的这些都是你可能已经考虑到的:
|
||||
|
||||
* 是公有云、私有云还是混合云?
|
||||
* 会使用虚拟机还是容器,或者是两者?
|
||||
* 会提供自助服务吗?
|
||||
* 从开发到生产是完全自动的,还是它将需要手动操作?
|
||||
* 我们能以多块的速度做到?
|
||||
* 关于某某工具?
|
||||
|
||||
这样的清单还可以列举很多。
|
||||
|
||||
当开始 IT 现代化,或者数字转型,无论你是如何称呼的,通常方法是开始回答更高管理层的一些高层次问题,这种方法的结果是可以预想到的:失败。经过大范围的调研并且花费了数月的时间(如果不是几年的话)部署了这个最炫的新技术,而这个新的云技术却从未被使用过,而且陷入了荒废,直到它最终被丢弃或者遗忘在数据中心的一角和预算之中。
|
||||
|
||||
这是因为无论你交付的是什么工具,都不是用户所想要或者需要的。更加糟糕的是,它可能是一个单一的工具,而用户真正需要的是一系列工具 —— 能够随着时间推移,更换升级为更新的、更漂亮的工具,以更好地满足其需求。
|
||||
|
||||
### 专注于重要的事情
|
||||
|
||||
问题在于关注,传统上一直是关注于工具。但工具并不是要增加到组织价值中的东西;终端用户利用它做什么才是目的。你需要将你的注意力从创建云(例如技术和工具)转移到你的人员和用户身上。
|
||||
|
||||
事实上,除了使用工具的用户(而不是工具本身)是驱动价值的因素之外,聚焦注意力在用户身上也是有其它原因的。工具是给用户使用去解决他们的问题并允许他们创造价值的,所以这就导致了如果那些工具不能满足那些用户的需求,那么那些工具将不会被使用。如果你交付给你的用户的工具并不是他们喜欢的,他们将不会使用,这就是人类的人性行为。
|
||||
|
||||
数十年来,IT 产业只为用户提供一种解决方案,因为仅有一个或两个选择,用户是没有权力去改变的。现在情况已经不同了。我们现在生活在一个技术选择的世界中。不给用户一个选择的机会的情况将不会被接受的;他们在个人的科技生活中有选择,同时希望在工作中也有选择。现在的用户都是受过教育的并且知道将会有比你所提供的更好选择。
|
||||
|
||||
因此,在物理上的最安全的地点之外,没有能够阻止他们只做他们自己想要的东西的方法,我们称之为“影子 IT”。如果你的组织有如此严格的安全策略和承诺策略而不允许影子 IT,许多员工将会感到灰心丧气并且会离职去其他能提供更好机会的公司。
|
||||
|
||||
基于以上所有的原因,你必须牢记要首先和你的最终用户设计你的昂贵又费时的云项目。
|
||||
|
||||
### 创建满足用户需求的云五个步骤的过程
|
||||
|
||||
既然我们已经知道了为什么,接下来我们来讨论一下怎么做。你如何去为终端用户创建一个云?你怎样重新将你的注意力从技术转移到使用技术的用户身上?
|
||||
|
||||
根据以往的经验,我们知道最好的方法中包含两件重要的事情:从你的用户中得到及时的反馈,在创建中和用户进行更多的互动。
|
||||
|
||||
你的云环境将继续随着你的组织不断发展。下面的五个步骤将会帮助你创建满足用户需求的云环境。
|
||||
|
||||
#### 1、识别谁将是你的用户
|
||||
|
||||
在你开始询问用户问题之前,你首先必须识别谁将是你的新的云环境的用户。他们可能包括将在云上创建开发应用的开发者;也可能是运营、维护或者或者创建该云的运维团队;还可能是保护你的组织的安全团队。在第一次迭代时,将你的用户数量缩小至人数较少的小组防止你被大量的反馈所淹没,让你识别的每个小组指派两个代表(一个主要的一个辅助的)。这将使你的第一次交付在规模和时间上都很小。
|
||||
|
||||
#### 2、和你的用户面对面的交谈来收获有价值的输入。
|
||||
|
||||
获得反馈的最佳途径是和用户直接交谈。群发的邮件会自行挑选出受访者——如果你能收到回复的话。小组讨论会很有帮助的,但是当人们有个私密的、专注的对话者时,他们会比较的坦诚。
|
||||
|
||||
和你的第一批用户安排个面对面的个人的会谈,并且向他们询问以下的问题:
|
||||
|
||||
* 为了完成你的任务,你需要什么?
|
||||
* 为了完成你的任务,你想要什么?
|
||||
* 你现在最头疼的技术痛点是什么?
|
||||
* 你现在最头疼的政策或者流程痛点是哪个?
|
||||
* 关于解决你的需求、希望或痛点,你有什么建议?
|
||||
|
||||
这些问题只是指导性的,并不一定适合每个组织。你不应该只询问这些问题,他们应该导向更深层次的讨论。确保告诉用户他们任何所说的和被问的都被视作反馈,所有的反馈都是有帮助的,无论是消极的还是积极的。这些对话将会帮助你设置你的开发优先级。
|
||||
|
||||
收集这种个性化的反馈是保持初始用户群较小的另一个原因:这将会花费你大量的时间来和每个用户交流,但是我们已经发现这是相当值得付出的投入。
|
||||
|
||||
#### 3、设计并交付你的解决方案的第一个版本
|
||||
|
||||
一旦你收到初始用户的反馈,就是时候开始去设计并交付一部分的功能了。我们不推荐尝试一次性交付整个解决方案。设计和交付的时期要短;这可以避免你花费一年的时间去构建一个你*认为*正确的解决方案,而只会让你的用户拒绝它,因为对他们来说毫无用处。创建你的云所需要的工具取决于你的组织和它的特殊需求。只需确保你的解决方案是建立在用户的反馈的基础上的,你将功能小块化的交付并且要经常的去征求用户的反馈。
|
||||
|
||||
#### 4、询问用户对第一个版本的反馈
|
||||
|
||||
太棒了,现在你已经设计并向你的用户交付了你的炫酷的新的云环境的第一个版本!你并不是花费一整年去完成它而是将它处理成小的模块。为什么将其分为小的模块如此重要呢?因为你要回到你的用户组并且向他们收集关于你的设计和交付的功能。他们喜欢什么?不喜欢什么?你正确的处理了他们所关注的吗?是技术功能上很厉害,但系统进程或者策略方面仍然欠缺吗?
|
||||
|
||||
再重申一次,你要问的问题取决于你的组织;这里的关键是继续前一个阶段的讨论。毕竟你正在为用户创建云环境,所以确保它对用户来说是有用的并且能够有效利用每个人的时间。
|
||||
|
||||
#### 5、回到第一步。
|
||||
|
||||
这是一个迭代的过程。你的首次交付应该是快速而小规模的,而且以后的迭代也应该是这样的。不要期待仅仅按照这个流程完成了一次、两次甚至是三次就能完成。一旦你持续的迭代,你将会吸引更多的用户从而能够在这个过程中得到更好的回报。你将会从用户那里得到更多的支持。你能够迭代的更迅速并且更可靠。到最后,你将会通过改变你的流程来满足用户的需求。
|
||||
|
||||
用户是这个过程中最重要的一部分,但迭代是第二重要的因为它让你能够回到用户中进行持续沟通从而得到更多有用的信息。在每个阶段,记录哪些是有效的哪些没有起到应有的效果。要自省,要对自己诚实。我们所花费的时间提供了最有价值的了吗?如果不是,在下一个阶段尝试些不同的。在每次循环中不要花费太多时间的最重要的部分是,如果某部分在这次不起作用,你能够很容易的在下一次中调整它,直到你找到能够在你组织中起作用的方法。
|
||||
|
||||
### 这仅仅是开始
|
||||
|
||||
通过许多客户约见,从他们那里收集反馈,以及在这个领域的同行的经验,我们一次次的发现在创建云的时候最重要事就是和你的用户交谈。这似乎是很明显的,但很让人惊讶的是很多组织却偏离了这个方向去花费数月或者数年的时间去创建,然后最终发现它对终端用户甚至一点用处都没有。
|
||||
|
||||
现在你已经知道为什么你需要将你的注意力集中到终端用户身上并且在中心节点和用户一起的互动创建云。剩下的是我们所喜欢的部分,你自己去做的部分。
|
||||
|
||||
这篇文章是基于一篇作者在 [Red Hat Summit 2018][3] 上发表的文章“[为终端用户设计混合云,要么失败]”。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/5-steps-building-your-cloud-correctly
|
||||
|
||||
作者:[Cameron Wyatt][a], [Ian Teksbury][1]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cameronmwyatt
|
||||
[1]:https://opensource.com/users/itewk
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154225
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
@ -0,0 +1,214 @@
|
||||
如何使用 Emacs 创建 LaTeX 文档
|
||||
======
|
||||
> 这篇教程将带你遍历在 Emacs 使用强大的开源排版系统 LaTex 来创建文档的全过程。
|
||||
|
||||

|
||||
|
||||
一篇由 Aaron Cocker 写的很棒的文章 “[在 LaTeX 中创建文件的介绍][1]” 中,介绍了 [LaTeX 排版系统][3] 并描述了如何使用 [TeXstudio][4] 来创建 LaTeX 文档。同时,他也列举了一些很多用户觉得创建 LaTeX 文档很方便的编辑器。
|
||||
|
||||
[Greg Pittman][5] 对这篇文章的评论吸引了我:“当你第一次开始使用 LaTeX 时,他似乎是个很差劲的排版……” 事实也确实如此。LaTeX 包含了多种排版字体和调试,如果你漏了一个特殊的字符比如说感叹号,这会让很多用户感到沮丧,尤其是新手。在本文中,我将介绍如何使用 [GNU Emacs][6] 来创建 LaTeX 文档。
|
||||
|
||||
### 创建你的第一个文档
|
||||
|
||||
启动 Emacs:
|
||||
|
||||
```
|
||||
emacs -q --no-splash helloworld.org
|
||||
```
|
||||
|
||||
参数 `-q` 确保 Emacs 不会加载其他的初始化配置。参数 `--no-splash-screen` 防止 Emacs 打开多个窗口,确保只打开一个窗口,最后的参数 `helloworld.org` 表示你要创建的文件名为 `helloworld.org` 。
|
||||
|
||||
![Emacs startup screen][8]
|
||||
|
||||
*GNU Emacs 打开文件名为 helloworld.org 的窗口时的样子。*
|
||||
|
||||
现在让我们用 Emacs 添加一些 LaTeX 的标题吧:在菜单栏找到 “Org” 选项并选择 “Export/Publish”。
|
||||
|
||||
![template_flow.png][10]
|
||||
|
||||
*导入一个默认的模板*
|
||||
|
||||
在下一个窗口中,Emacs 同时提供了导入和导出一个模板。输入 `#`(“[#] Insert template”)来导入一个模板。这将会使光标跳转到一个带有 “Options category:” 提示的 mini-buffer 中。第一次你可能不知道这个类型的名字,但是你可以使用 `Tab` 键来查看所有的补全。输入 “default” 然后按回车,之后你就能看到如下的内容被插入了:
|
||||
|
||||
```
|
||||
#+TITLE: helloworld
|
||||
#+DATE: <2018-03-12 Mon>
|
||||
#+AUTHOR:
|
||||
#+EMAIL: makerpm@nubia
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:t todo:t |:t
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
#+DESCRIPTION:
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
#+KEYWORDS:
|
||||
#+LANGUAGE: en
|
||||
#+SELECT_TAGS: export
|
||||
```
|
||||
|
||||
根据自己的需求修改标题、日期、作者和 email。我自己的话是下面这样的:
|
||||
|
||||
```
|
||||
#+TITLE: Hello World! My first LaTeX document
|
||||
#+DATE: \today
|
||||
#+AUTHOR: Sachin Patil
|
||||
#+EMAIL: psachin@redhat.com
|
||||
```
|
||||
|
||||
我们目前还不想创建一个目录,所以要将 `toc` 的值由 `t` 改为 `nil`,具体如下:
|
||||
|
||||
```
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
```
|
||||
|
||||
现在让我们添加一个章节和段落吧。章节是由一个星号(`*`)开头。我们从 Aaron 的贴子(来自 [Lipsum Lorem Ipsum 生成器][11])复制一些文本过来:
|
||||
|
||||
```
|
||||
* Introduction
|
||||
|
||||
\paragraph{}
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Cras lorem
|
||||
nisi, tincidunt tempus sem nec, elementum feugiat ipsum. Nulla in
|
||||
diam libero. Nunc tristique ex a nibh egestas sollicitudin.
|
||||
|
||||
\paragraph{}
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum ligula felis,
|
||||
pulvinar a posuere id, luctus vitae leo. Sed ac imperdiet orci, non
|
||||
elementum leo. Nullam molestie congue placerat. Phasellus tempor et
|
||||
libero maximus commodo.
|
||||
```
|
||||
|
||||
|
||||
![helloworld_file.png][13]
|
||||
|
||||
*helloworld.org 文件*
|
||||
|
||||
|
||||
将内容修改好后,我们要把它导出为 PDF 格式。再次在 “Org” 的菜单选项中选择 “Export/Publish”,但是这次,要输入 `l`(“export to LaTeX”),紧跟着输入 `o`(“as PDF file and open”)。这次操作不止会打开 PDF 文件让你浏览,同时也会将文件保存为 `helloworld.pdf`,并保存在与 `helloworld.org` 的同一个目录下。
|
||||
|
||||
![org_to_pdf.png][15]
|
||||
|
||||
*将 helloworld.org 导出为 helloworld.pdf*
|
||||
|
||||
![org_and_pdf_file.png][17]
|
||||
|
||||
*打开 helloworld.pdf 文件*
|
||||
|
||||
你也可以按下 `Alt + x` 键,然后输入 `org-latex-export-to-pdf` 来将 org 文件导出为 PDF 文件。可以使用 `Tab` 键来自动补全命令。
|
||||
|
||||
Emacs 也会创建 `helloworld.tex` 文件来让你控制具体的内容。
|
||||
|
||||
![org_tex_pdf.png][19]
|
||||
|
||||
*Emacs 在三个不同的窗口中分别打开 LaTeX,org 和 PDF 文档。*
|
||||
|
||||
你可以使用命令来将 `.tex` 文件转换为 `.pdf` 文件:
|
||||
|
||||
```
|
||||
pdflatex helloworld.tex
|
||||
```
|
||||
|
||||
你也可以将 `.org` 文件输出为 HTML 或是一个简单的文本格式的文件。我最喜欢 `.org` 文件的原因是他们可以被推送到 [GitHub][20] 上,然后同 markdown 一样被渲染。
|
||||
|
||||
### 创建一个 LaTeX 的 Beamer 简报
|
||||
|
||||
现在让我们更进一步,通过少量的修改上面的文档来创建一个 LaTeX [Beamer][21] 简报,如下所示:
|
||||
|
||||
```
|
||||
#+TITLE: LaTeX Beamer presentation
|
||||
#+DATE: \today
|
||||
#+AUTHOR: Sachin Patil
|
||||
#+EMAIL: psachin@redhat.com
|
||||
#+OPTIONS: ':nil *:t -:t ::t <:t H:3 \n:nil ^:t arch:headline
|
||||
#+OPTIONS: author:t c:nil creator:comment d:(not "LOGBOOK") date:t
|
||||
#+OPTIONS: e:t email:nil f:t inline:t num:t p:nil pri:nil stat:t
|
||||
#+OPTIONS: tags:t tasks:t tex:t timestamp:t toc:nil todo:t |:t
|
||||
#+CREATOR: Emacs 25.3.1 (Org mode 8.2.10)
|
||||
#+DESCRIPTION:
|
||||
#+EXCLUDE_TAGS: noexport
|
||||
#+KEYWORDS:
|
||||
#+LANGUAGE: en
|
||||
#+SELECT_TAGS: export
|
||||
#+LATEX_CLASS: beamer
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
|
||||
|
||||
* Introduction
|
||||
*** Programming
|
||||
- Python
|
||||
- Ruby
|
||||
|
||||
*** Paragraph one
|
||||
|
||||
Lorem ipsum dolor sit amet, consectetur adipiscing
|
||||
elit. Cras lorem nisi, tincidunt tempus sem nec, elementum feugiat
|
||||
ipsum. Nulla in diam libero. Nunc tristique ex a nibh egestas
|
||||
sollicitudin.
|
||||
|
||||
*** Paragraph two
|
||||
|
||||
Mauris efficitur vitae ex id egestas. Vestibulum
|
||||
ligula felis, pulvinar a posuere id, luctus vitae leo. Sed ac
|
||||
imperdiet orci, non elementum leo. Nullam molestie congue
|
||||
placerat. Phasellus tempor et libero maximus commodo.
|
||||
|
||||
* Thanks
|
||||
*** Links
|
||||
- Link one
|
||||
- Link two
|
||||
```
|
||||
|
||||
我们给标题增加了三行:
|
||||
|
||||
```
|
||||
#+LATEX_CLASS: beamer
|
||||
#+BEAMER_THEME: Frankfurt
|
||||
#+BEAMER_INNER_THEME: rounded
|
||||
```
|
||||
|
||||
导出为 PDF,按下 `Alt + x` 键后输入 `org-beamer-export-to-pdf`。
|
||||
|
||||
![latex_beamer_presentation.png][23]
|
||||
|
||||
*用 Emacs 和 Org 模式创建的 Latex Beamer 简报*
|
||||
|
||||
希望你会爱上使用 Emacs 来创建 LaTex 和 Beamer 文档(注意:使用快捷键比用鼠标更快些)。Emacs 的 Org 模式提供了比我在这篇文章中说的更多的功能,你可以在 [orgmode.org][24] 获取更多的信息.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/how-create-latex-documents-emacs
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://opensource.com/article/17/6/introduction-latex
|
||||
[2]:https://opensource.com/users/aaroncocker
|
||||
[3]:https://www.latex-project.org
|
||||
[4]:http://www.texstudio.org/
|
||||
[5]:https://opensource.com/users/greg-p
|
||||
[6]:https://www.gnu.org/software/emacs/
|
||||
[7]:/file/392261
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/emacs_startup.png?itok=UnT4PgK5 (Emacs startup screen)
|
||||
[9]:/file/392266
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/insert_template_flow.png?itok=V_c2KipO (template_flow.png)
|
||||
[11]:https://www.lipsum.com/feed/html
|
||||
[12]:/file/392271
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/helloworld_file.png?itok=o8IX0TsJ (helloworld_file.png)
|
||||
[14]:/file/392276
|
||||
[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_to_pdf.png?itok=fNnC1Y-L (org_to_pdf.png)
|
||||
[16]:/file/392281
|
||||
[17]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_and_pdf_file.png?itok=HEhtw-cu (org_and_pdf_file.png)
|
||||
[18]:/file/392286
|
||||
[19]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/org_tex_pdf.png?itok=poZZV_tj (org_tex_pdf.png)
|
||||
[20]:https://github.com
|
||||
[21]:https://www.sharelatex.com/learn/Beamer
|
||||
[22]:/file/392291
|
||||
[23]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/latex_beamer_presentation.png?itok=rsPSeIuM (latex_beamer_presentation.png)
|
||||
[24]:https://orgmode.org/worg/org-tutorials/org-latex-export.html
|
||||
@ -0,0 +1,139 @@
|
||||
如何在终端中浏览 Stack Overflow
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们写了一篇关于 [SoCLI][1] 的文章,它是一个从命令行搜索和浏览 Stack Overflow 网站的 python 脚本。今天,我们将讨论一个名为 “how2” 的类似工具。它是一个命令行程序,可以从终端浏览 Stack Overflow。你可以如你在 [Google 搜索][2]中那样直接用英语查询,然后它会使用 Google 和 Stackoverflow API 来搜索给定的查询。它是使用 NodeJS 编写的自由开源程序。
|
||||
|
||||
### 使用 how2 从终端浏览 Stack Overflow
|
||||
|
||||
由于 `how2` 是一个 NodeJS 包,我们可以使用 Npm 包管理器安装它。如果你尚未安装 Npm 和 NodeJS,请参考以下指南。
|
||||
|
||||
在安装 Npm 和 NodeJS 后,运行以下命令安装 how2。
|
||||
|
||||
```
|
||||
$ npm install -g how2
|
||||
```
|
||||
|
||||
现在让我们看下如何使用这个程序浏览 Stack Overflow。使用 `how2` 搜索 Stack Overflow 站点的典型用法是:
|
||||
|
||||
```
|
||||
$ how2 <search-query>
|
||||
```
|
||||
|
||||
例如,我将搜索如何创建 tgz 存档。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
哎呀!我收到以下错误。
|
||||
|
||||
```
|
||||
/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59
|
||||
Transport.prototype.__proto__ = EventEmitter.prototype;
|
||||
^
|
||||
|
||||
TypeError: Cannot read property 'prototype' of undefined
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js:59:46)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
at Object.Module._extensions..js (internal/modules/cjs/loader.js:665:10)
|
||||
at Module.load (internal/modules/cjs/loader.js:566:32)
|
||||
at tryModuleLoad (internal/modules/cjs/loader.js:506:12)
|
||||
at Function.Module._load (internal/modules/cjs/loader.js:498:3)
|
||||
at Module.require (internal/modules/cjs/loader.js:598:17)
|
||||
at require (internal/modules/cjs/helpers.js:11:18)
|
||||
at Object.<anonymous> (/home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/stream.js:8:17)
|
||||
at Module._compile (internal/modules/cjs/loader.js:654:30)
|
||||
|
||||
```
|
||||
|
||||
我可能遇到了一个 bug。我希望它在未来版本中得到修复。但是,我在[这里][3]找到了一个临时方法。
|
||||
|
||||
|
||||
要临时修复此错误,你需要使用以下命令编辑 `transport.js`:
|
||||
|
||||
```
|
||||
$ vi /home/sk/.nvm/versions/node/v9.11.1/lib/node_modules/how2/node_modules/devnull/transports/transport.js
|
||||
```
|
||||
|
||||
此文件的实际路径将显示在错误输出中。用你自己的文件路径替换上述文件路径。然后找到以下行:
|
||||
|
||||
```
|
||||
var EventEmitter = process.EventEmitter;
|
||||
```
|
||||
|
||||
并用以下行替换它:
|
||||
|
||||
```
|
||||
var EventEmitter = require('events');
|
||||
```
|
||||
|
||||
按 `ESC` 并输入 `:wq` 以保存并退出文件。
|
||||
|
||||
现在再次搜索查询。
|
||||
|
||||
```
|
||||
$ how2 create archive tgz
|
||||
```
|
||||
|
||||
这是我的 Ubuntu 系统的示例输出。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你要查找的答案未显示在上面的输出中,请按**空格键**键开始交互式搜索,你可以通过它查看 Stack Overflow 站点中的所有建议问题和答案。
|
||||
|
||||
![][6]
|
||||
|
||||
使用向上/向下箭头在结果之间移动。得到正确的答案/问题后,点击空格键或回车键在终端中打开它。
|
||||
|
||||
![][7]
|
||||
|
||||
要返回并退出,请按 `ESC`。
|
||||
|
||||
**搜索特定语言的答案**
|
||||
|
||||
如果你没有指定语言,它**默认为 Bash** unix 命令行,并立即为你提供最可能的答案。你还可以将结果缩小到特定语言,例如 perl、python、c、Java 等。
|
||||
|
||||
例如,使用 `-l` 标志仅搜索与 “Python” 语言相关的查询,如下所示。
|
||||
|
||||
```
|
||||
$ how2 -l python linked list
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
要获得快速帮助,请输入:
|
||||
|
||||
```
|
||||
$ how2 -h
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
`how2` 是一个基本的命令行程序,它可以快速搜索 Stack Overflow 中的问题和答案,而无需离开终端,并且它可以很好地完成这项工作。但是,它只是 Stack overflow 的 CLI 浏览器。对于一些高级功能,例如搜索投票最多的问题,使用多个标签搜索查询,彩色界面,提交新问题和查看问题统计信息等,**SoCLI** 做得更好。
|
||||
|
||||
就是这些了。希望这篇文章有用。我将很快写一篇新的指南。在此之前,请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-browse-stack-overflow-from-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/search-browse-stack-overflow-website-commandline/
|
||||
[2]:https://www.ostechnix.com/google-search-navigator-enhance-keyboard-navigation-in-google-search/
|
||||
[3]:https://github.com/santinic/how2/issues/79
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-3.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/04/stack-overflow-4.png
|
||||
@ -0,0 +1,103 @@
|
||||
如何在 Anbox 上安装 Google Play 商店及启用 ARM 支持
|
||||
======
|
||||
|
||||
|
||||
|
||||
[Anbox][1] (Anroid in a Box)是一个自由开源工具,它允许你在 Linux 上运行 Android 应用程序。它的工作原理是在 LXC 容器中运行 Android 运行时环境,重新创建 Android 的目录结构作为可挂载的 loop 镜像,同时使用本机 Linux 内核来执行应用。
|
||||
|
||||
据其网站所述,它的主要特性是安全性、性能、集成和趋同(不同外形尺寸缩放)。
|
||||
|
||||
使用 Anbox,每个 Android 应用或游戏就像系统应用一样都在一个单独的窗口中启动,它们的行为或多或少类似于常规窗口,显示在启动器中,可以平铺等等。
|
||||
|
||||
默认情况下,Anbox 没有 Google Play 商店或 ARM 应用支持。要安装应用,你必须下载每个应用的 APK 并使用 `adb` 手动安装。此外,默认情况下不能使用 Anbox 安装 ARM 应用或游戏 —— 尝试安装 ARM 应用会显示以下错误:
|
||||
|
||||
```
|
||||
Failed to install PACKAGE.NAME.apk: Failure [INSTALL_FAILED_NO_MATCHING_ABIS: Failed to extract native libraries, res=-113]
|
||||
|
||||
```
|
||||
|
||||
你可以在 Anbox 中手动设置 Google Play 商店和 ARM 应用支持(通过 libhoudini),但这是一个非常复杂的过程。为了更容易地在 Anbox 上安装 Google Play 商店和 Google Play 服务,并让它支持 ARM 应用程序和游戏(使用 libhoudini),[geeks-r-us.de][2](文章是德语)上的人创建了一个自动执行这些任务的脚本。
|
||||
|
||||
在使用之前,我想明确指出,即使在集成 libhoudini 来支持 ARM 后,也并非所有 Android 应用和游戏都能在 Anbox 中运行。某些 Android 应用和游戏可能根本不会出现在 Google Play 商店中,而一些应用和游戏可能可以安装但无法使用。此外,某些应用可能无法使用某些功能。
|
||||
|
||||
### 安装 Google Play 商店并在 Anbox 上启用 ARM 应用/游戏支持
|
||||
|
||||
如果你的 Linux 桌面上尚未安装 Anbox,这些说明显然不起作用。如果你还没有,请按照[此处][7]的安装说明安装 Anbox。此外,请确保在安装 Anbox 之后,使用此脚本之前至少运行一次 `anbox.appmgr`,以避免遇到问题。另外,确保在执行下面的脚本时 Anbox 没有运行(我怀疑这是导致评论中提到的这个[问题][8]的原因)。
|
||||
|
||||
1、 安装所需的依赖项(wget、lzip、unzip 和 squashfs-tools)。
|
||||
|
||||
在 Debian、Ubuntu 或 Linux Mint 中,使用此命令安装所需的依赖项:
|
||||
|
||||
```
|
||||
sudo apt install wget lzip unzip squashfs-tools
|
||||
```
|
||||
|
||||
2、 下载并运行脚本,在 Anbox 上自动下载并安装 Google Play 商店(和 Google Play 服务)和 libhoudini(用于 ARM 应用/游戏支持)。
|
||||
|
||||
**警告:永远不要在不知道它做什么的情况下运行不是你写的脚本。在运行此脚本之前,请查看其[代码][4]。**
|
||||
|
||||
要下载脚本,使其可执行并在 Linux 桌面上运行,请在终端中使用以下命令:
|
||||
|
||||
```
|
||||
wget https://raw.githubusercontent.com/geeks-r-us/anbox-playstore-installer/master/install-playstore.sh
|
||||
chmod +x install-playstore.sh
|
||||
sudo ./install-playstore.sh
|
||||
```
|
||||
|
||||
3、要让 Google Play 商店在 Anbox 中运行,你需要启用 Google Play 商店和 Google Play 服务的所有权限
|
||||
|
||||
为此,请运行Anbox:
|
||||
|
||||
```
|
||||
anbox.appmgr
|
||||
```
|
||||
|
||||
然后进入“设置 > 应用 > Google Play 服务 > 权限”并启用所有可用权限。对 Google Play 商店也一样!
|
||||
|
||||
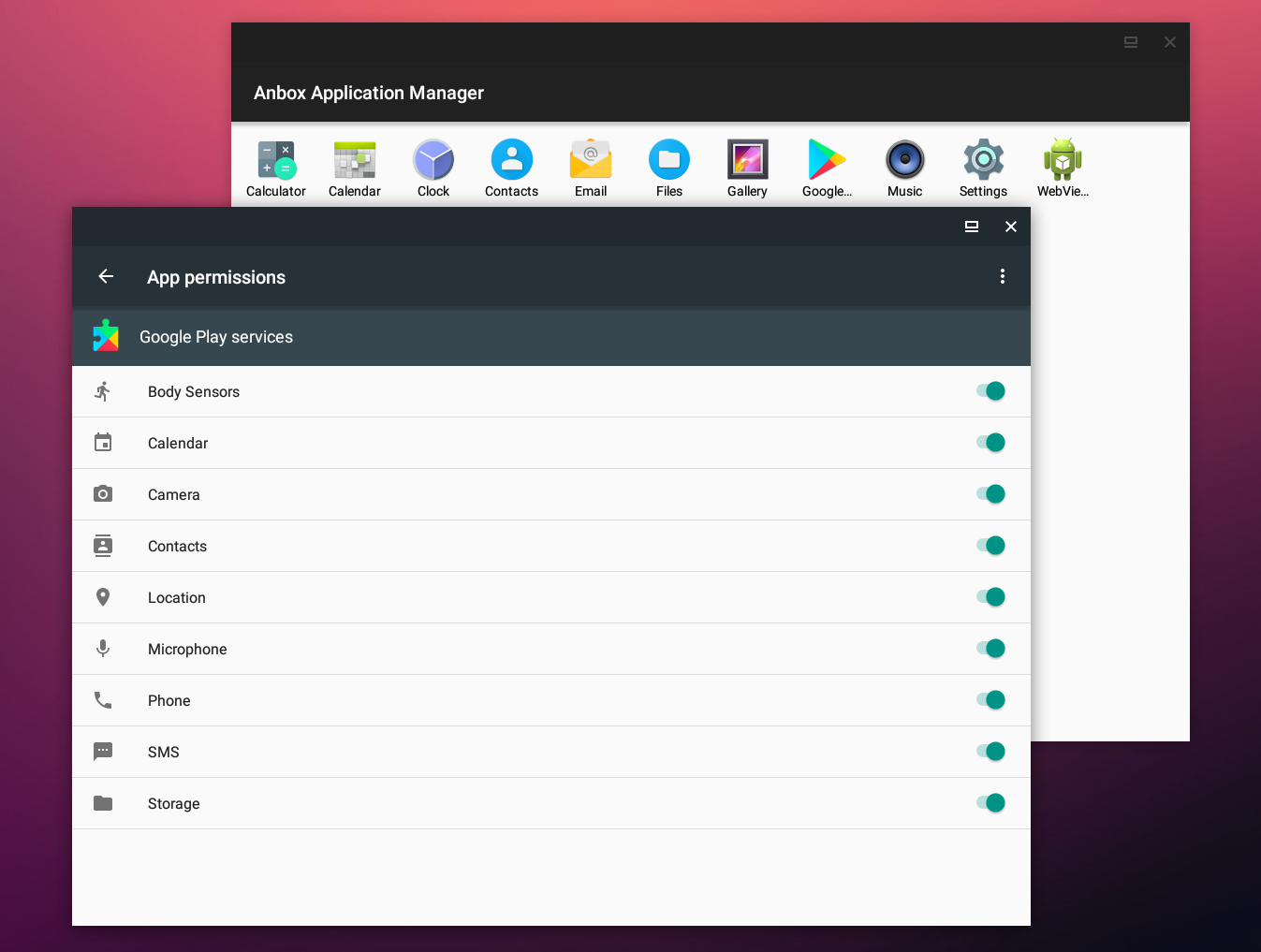
|
||||
|
||||
你现在应该可以使用 Google 帐户登录 Google Play 商店了。
|
||||
|
||||
如果未启用 Google Play 商店和 Google Play 服务的所有权限,你可能会在尝试登录 Google 帐户时可能会遇到问题,并显示以下错误消息:“Couldn't sign in. There was a problem communicating with Google servers. Try again later“,如你在下面的截图中看到的那样:
|
||||
|
||||
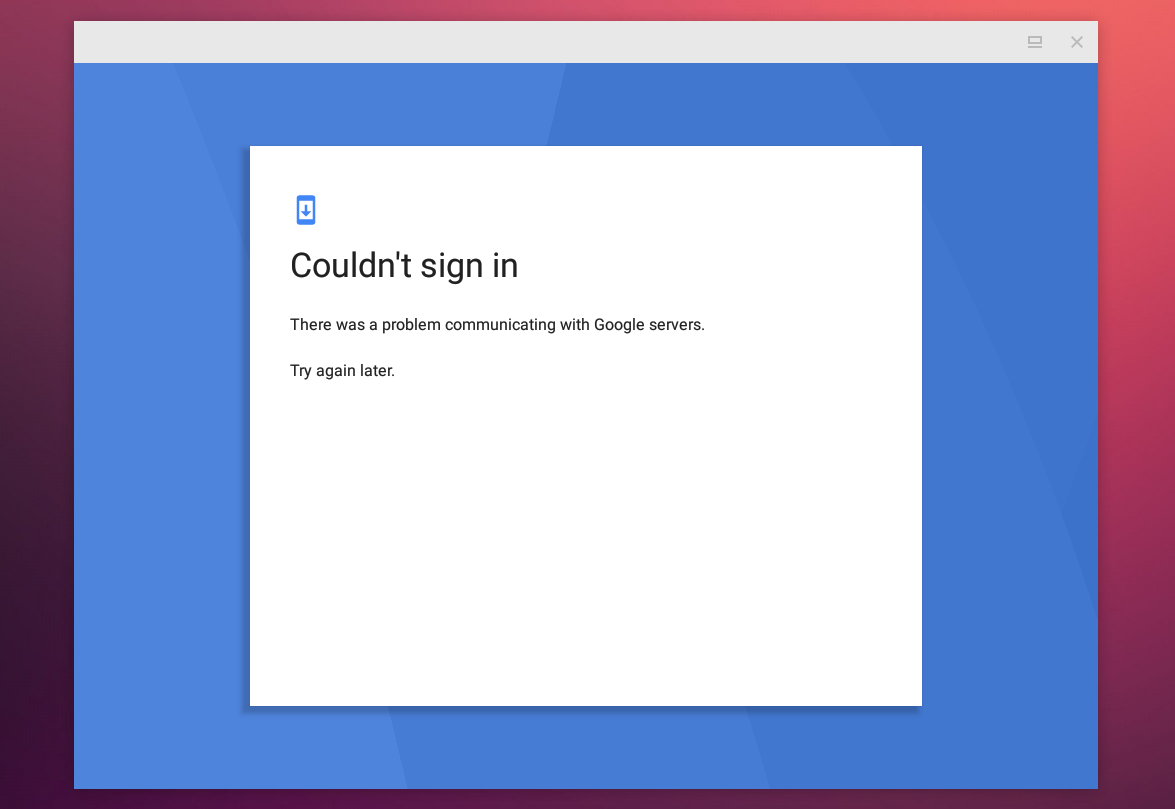
|
||||
|
||||
登录后,你可以停用部分 Google Play 商店/Google Play 服务权限。
|
||||
|
||||
**如果你在 Anbox 上登录 Google 帐户时遇到一些连接问题**,请确保 `anbox-bride.sh` 正在运行:
|
||||
|
||||
启动它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh start
|
||||
```
|
||||
重启它:
|
||||
|
||||
```
|
||||
sudo /snap/anbox/current/bin/anbox-bridge.sh restart
|
||||
```
|
||||
|
||||
根据[此用户][9]的说法,如果 Anbox 仍然存在连接问题,你可能还需要安装 dnsmasq 包。但是在我的 Ubuntu 18.04 桌面上不需要这样做。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://anbox.io/
|
||||
[2]:https://geeks-r-us.de/2017/08/26/android-apps-auf-dem-linux-desktop/
|
||||
[3]:https://github.com/geeks-r-us/anbox-playstore-installer/
|
||||
[4]:https://github.com/geeks-r-us/anbox-playstore-installer/blob/master/install-playstore.sh
|
||||
[5]:https://docs.anbox.io/userguide/install.html
|
||||
[6]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
[7]:https://github.com/anbox/anbox/blob/master/docs/install.md
|
||||
[8]:https://www.linuxuprising.com/2018/07/anbox-how-to-install-google-play-store.html?showComment=1533506821283#c4415289781078860898
|
||||
[9]:https://github.com/anbox/anbox/issues/118#issuecomment-295270113
|
||||
@ -0,0 +1,109 @@
|
||||
i3 窗口管理器使 Linux 更美好
|
||||
======
|
||||
|
||||
> 通过键盘操作的 i3 平铺窗口管理器使用 Linux 桌面。
|
||||
|
||||

|
||||
|
||||
Linux(和一般的开源软件)最美好的一点是自由 —— 可以在不同的替代方案中进行选择以满足我们的需求。
|
||||
|
||||
我使用 Linux 已经很长时间了,但我从来没有对可选用的桌面环境完全满意过。直到去年,[Xfce][1] 还是我认为在功能和性能之间的平和最接近满意的一个桌面环境。然后我发现了 [i3][2],这是一个改变了我的生活的惊人的软件。
|
||||
|
||||
i3 是一个平铺窗口管理器。窗口管理器的目标是控制窗口系统中窗口的外观和位置。窗口管理器通常用作功能齐全的桌面环境 (如 GONME 或 Xfce ) 的一部分,但也有一些可以用作独立的应用程序。
|
||||
|
||||
平铺式窗口管理器会自动排列窗口,以不重叠的方式占据整个屏幕。其他流行的平铺式窗口管理器还有 [wmii][3] 和 [xmonad][4] 。
|
||||
|
||||
![i3 tiled window manager screenshot][6]
|
||||
|
||||
*带有三个的 i3 屏幕截图*
|
||||
|
||||
为了获得更好的 Linux 桌面体验,以下是我使用和推荐 i3 窗口管理器的五个首要原因。
|
||||
|
||||
### 1、极简艺术
|
||||
|
||||
i3 速度很快。它既不冗杂、也不花哨。它的设计简单而高效。作为开发人员,我重视这些功能,因为我可以使用更多的功能以丰富我最喜欢的开发工具,或者使用容器或虚拟机在本地测试内容。
|
||||
|
||||
此外, i3 是一个窗口管理器,与功能齐全的桌面环境不同,它并不规定您应该使用的应用程序。您是否想使用 Xfce 的 Thunar 作为文件管理器?GNOME 的 gedit 去编辑文本? i3 并不在乎。选择对您的工作流最有意义的工具,i3 将以相同的方式管理它们。
|
||||
|
||||
### 2、屏幕实际使用面积
|
||||
|
||||
作为平铺式窗口管理器,i3 将自动 “平铺”,以不重叠的方式定位窗口,类似于在墙上放置瓷砖。因为您不需要担心窗口定位,i3 一般会更好地利用您的屏幕空间。它还可以让您更快地找到您需要的东西。
|
||||
|
||||
对于这种情况有很多有用的例子。例如,系统管理员可以打开多个终端来同时监视或在不同的远程系统上工作;开发人员可以使用他们最喜欢的 IDE 或编辑器和几个终端来测试他们的程序。
|
||||
|
||||
此外,i3 具有灵活性。如果您需要为特定窗口提供更多空间,请启用全屏模式或切换到其他布局,如堆叠或选项卡式(标签式)。
|
||||
|
||||
### 3、键盘式工作流程
|
||||
|
||||
i3 广泛使用键盘快捷键来控制环境的不同方面。其中包括打开终端和其他程序、调整大小和定位窗口、更改布局,甚至退出 i3。当您开始使用 i3 时,您需要记住其中的一些快捷方式才能使用,随着时间的推移,您会使用更多的快捷方式。
|
||||
|
||||
主要好处是,您不需要经常在键盘和鼠标之间切换。通过练习,您将提高工作流程的速度和效率。
|
||||
|
||||
例如, 要打开新的终端,请按 `<SUPER>+<ENTER>`。由于窗口是自动定位的,您可以立即开始键入命令。结合一个很好的终端文本编辑器(如 Vim)和一个以面向键盘的浏览器,形成一个完全由键盘驱动的工作流程。
|
||||
|
||||
在 i3 中,您可以为所有内容定义快捷方式。下面是一些示例:
|
||||
|
||||
* 打开终端
|
||||
* 打开浏览器
|
||||
* 更改布局
|
||||
* 调整窗口大小
|
||||
* 控制音乐播放器
|
||||
* 切换工作区
|
||||
|
||||
现在我已经习惯了这个工作形式,我已无法回到了常规的桌面环境。
|
||||
|
||||
### 4、灵活
|
||||
|
||||
i3 力求极简,使用很少的系统资源,但这并不意味着它不能变漂亮。i3 是灵活且可通过多种方式进行自定义以改善视觉体验。因为 i3 是一个窗口管理器,所以它没有提供启用自定义的工具,你需要外部工具来实现这一点。一些例子:
|
||||
|
||||
* 用 `feh` 定义桌面的背景图片。
|
||||
* 使用合成器管理器,如 `compton` 以启用窗口淡入淡出和透明度等效果。
|
||||
* 用 `dmenu` 或 `rofi` 以启用可从键盘快捷方式启动的可自定义菜单。
|
||||
* 用 `dunst` 用于桌面通知。
|
||||
|
||||
i3 是可完全配置的,您可以通过更新默认配置文件来控制它的各个方面。从更改所有键盘快捷键,到重新定义工作区的名称,再到修改状态栏,您都可以使 i3 以任何最适合您需要的方式运行。
|
||||
|
||||
![i3 with rofi menu and dunst desktop notifications][8]
|
||||
|
||||
*i3 与 `rofi` 菜单和 `dunst` 桌面通知。*
|
||||
|
||||
最后,对于更高级的用户,i3 提供了完整的进程间通信([IPC][9])接口,允许您使用偏好的语言来开发脚本或程序,以实现更多的自定义选项。
|
||||
|
||||
### 5、工作空间
|
||||
|
||||
在 i3 中,工作区是对窗口进行分组的一种简单方法。您可以根据您的工作流以不同的方式对它们进行分组。例如,您可以将浏览器放在一个工作区上,终端放在另一个工作区上,将电子邮件客户端放在第三个工作区上等等。您甚至可以更改 i3 的配置,以便始终将特定应用程序分配给它们自己的工作区。
|
||||
|
||||
切换工作区既快速又简单。像 i3 中的惯例,使用键盘快捷方式执行此操作。按 `<SUPER>+num` 切换到工作区 `num` 。如果您养成了始终将应用程序组的窗口分配到同一个工作区的习惯,则可以在它们之间快速切换,这使得工作区成为非常有用的功能。
|
||||
|
||||
此外,还可以使用工作区来控制多监视器环境,其中每个监视器都有个初始工作区。如果切换到该工作区,则切换到该监视器,而无需让手离开键盘。
|
||||
|
||||
最后,i3 中还有另一种特殊类型的工作空间:the scratchpad(便笺簿)。它是一个不可见的工作区,通过按快捷方式显示在其他工作区的中间。这是一种访问您经常使用的窗口或程序的方便方式,如电子邮件客户端或音乐播放器。
|
||||
|
||||
### 尝试一下吧
|
||||
|
||||
如果您重视简洁和效率,并且不惮于使用键盘,i3 就是您的窗口管理器。有人说是为高级用户准备的,但情况不一定如此。你需要学习一些基本的快捷方式来度过开始的阶段,不久就会越来越自然并且不假思索地使用它们。
|
||||
|
||||
这篇文章只是浅浅谈及了 i3 能做的事情。欲了解更多详情,请参阅 [i3 的文档][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/i3-tiling-window-manager
|
||||
|
||||
作者:[Ricardo Gerardi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lixinyuxx](https://github.com/lixinyuxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rgerardi
|
||||
[1]:https://xfce.org/
|
||||
[2]:https://i3wm.org/
|
||||
[3]:https://code.google.com/archive/p/wmii/
|
||||
[4]:https://xmonad.org/
|
||||
[5]:/file/406476
|
||||
[6]:https://opensource.com/sites/default/files/uploads/i3_screenshot.png "i3 tiled window manager screenshot"
|
||||
[7]:/file/405161
|
||||
[8]:https://opensource.com/sites/default/files/uploads/rofi_dunst.png "i3 with rofi menu and dunst desktop notifications"
|
||||
[9]:https://i3wm.org/docs/ipc.html
|
||||
[10]:https://i3wm.org/docs/userguide.html
|
||||
@ -0,0 +1,100 @@
|
||||
顶级 Linux 开发者推荐的编程书籍
|
||||
======
|
||||
|
||||

|
||||
|
||||
> 毫无疑问,Linux 是由那些拥有深厚计算机知识背景而且才华横溢的程序员发明的。让那些大名鼎鼎的 Linux 程序员向如今的开发者分享一些曾经带领他们登堂入室的好书和技术参考资料吧,你会不会也读过其中几本呢?
|
||||
|
||||
Linux,毫无争议的属于 21 世纪的操作系统。虽然 Linus Torvalds 在建立开源社区这件事上做了很多工作和社区决策,不过那些网络专家和开发者愿意接受 Linux 的原因还是因为它卓越的代码质量和高可用性。Torvalds 是个编程天才,同时必须承认他还是得到了很多其他同样极具才华的开发者的无私帮助。
|
||||
|
||||
就此我咨询了 Torvalds 和其他一些顶级 Linux 开发者,有哪些书籍帮助他们走上了成为顶级开发者的道路,下面请听我一一道来。
|
||||
|
||||
### 熠熠生辉的 C 语言
|
||||
|
||||
Linux 是在大约上世纪 90 年代开发出来的,与它一起问世的还有其他一些完成基础功能的开源软件。与此相应,那时的开发者使用的工具和语言反映了那个时代的印记,也就是说 C 语言。可能 [C 语言不再流行了][1],可对于很多已经建功立业的开发者来说,C 语言是他们的第一个在实际开发中使用的语言,这一点也在他们推选的对他们有着深远影响的书单中反映出来。
|
||||
|
||||
Torvalds 说,“你不应该再选用我那个时代使用的语言或者开发方式”,他的开发道路始于 BASIC,然后转向机器码(“甚至都不是汇编语言,而是真真正正的‘二进制’机器码”,他解释道),再然后转向汇编语言和 C 语言。
|
||||
|
||||
“任何人都不应该再从这些语言开始进入开发这条路了”,他补充道。“这些语言中的一些今天已经没有什么意义(如 BASIC 和机器语言)。尽管 C 还是一个主流语言,我也不推荐你从它开始。”
|
||||
|
||||
并不是他不喜欢 C。不管怎样,Linux 是用 [GNU C 语言][2]写就的。“我始终认为 C 是一个伟大的语言,它有着非常简单的语法,对于很多方向的开发都很合适,但是我怀疑你会遇到重重挫折,从你的第一个‘Hello World’程序开始到你真正能开发出能用的东西当中有很大一步要走”。他认为,用现在的标准,如果作为入门语言的话,从 C 语言开始的代价太大。
|
||||
|
||||
在他那个时代,Torvalds 的唯一选择的书就只能是 Brian W. Kernighan 和 Dennis M. Ritchie 合著的《<ruby>[C 编程语言,第二版][3]<rt>C Programming Language, 2nd Edition</rt></ruby>》,它在编程圈内也被尊称为 K&R。“这本书简单精炼,但是你要先有编程的背景才能欣赏它”,Torvalds 说到。
|
||||
|
||||
Torvalds 并不是唯一一个推荐 K&R 的开源开发者。以下几位也同样引用了这本他们认为值得推荐的书籍,他们有:Linux 和 Oracle 虚拟化开发副总裁 Wim Coekaerts;Linux 开发者 Alan Cox;Google 云 CTO Brian Stevens;Canonical 技术运营部副总裁 Pete Graner。
|
||||
|
||||
如果你今日还想同 C 语言较量一番的话,Samba 的共同创始人 Jeremy Allison 推荐《<ruby>[C 程序设计新思维][4]<rt>21st Century C: C Tips from the New School</rt></ruby>》。他还建议,同时也去阅读一本比较旧但是写的更详细的《<ruby>[C 专家编程][5]<rt>Expert C Programming: Deep C Secrets</rt></ruby>》和有着 20 年历史的《<ruby>[POSIX 多线程编程][6]<rt>Programming with POSIX Threads</rt></ruby>》。
|
||||
|
||||
### 如果不选 C 语言, 那选什么?
|
||||
|
||||
Linux 开发者推荐的书籍自然都是他们认为适合今时今日的开发项目的语言工具。这也折射了开发者自身的个人偏好。例如,Allison 认为年轻的开发者应该在《<ruby>[Go 编程语言][7]<rt>The Go Programming Language</rt></ruby>》和《<ruby>[Rust 编程][8]<rt>Rust with Programming Rust</rt></ruby>》的帮助下去学习 Go 语言和 Rust 语言。
|
||||
|
||||
但是超越编程语言来考虑问题也不无道理(尽管这些书传授了你编程技巧)。今日要做些有意义的开发工作的话,"要从那些已经完成了 99% 显而易见工作的框架开始,然后你就能围绕着它开始写脚本了", Torvalds 推荐了这种做法。
|
||||
|
||||
“坦率来说,语言本身远远没有围绕着它的基础架构重要”,他继续道,“可能你会从 Java 或者 Kotlin 开始,但那是因为你想为自己的手机开发一个应用,因此安卓 SDK 成为了最佳的选择,又或者,你对游戏开发感兴趣,你选择了一个游戏开发引擎来开始,而通常它们有着自己的脚本语言”。
|
||||
|
||||
这里提及的基础架构包括那些和操作系统本身相关的编程书籍。
|
||||
Garner 在读完了大名鼎鼎的 K&R 后又拜读了 W. Richard Steven 的《<ruby>[Unix 网络编程][10]<rt>Unix Network Programming</rt></ruby>》。特别是,Steven 的《<ruby>[TCP/IP 详解,卷1:协议][11]<rt>TCP/IP Illustrated, Volume 1: The Protocols</rt></ruby>》在出版了 30 年之后仍然被认为是必读之书。因为 Linux 开发很大程度上和[和网络基础架构有关][12],Garner 也推荐了很多 O'Reilly 在 [Sendmail][13]、[Bash][14]、[DNS][15] 以及 [IMAP/POP][16] 等方面的书。
|
||||
|
||||
Coekaerts 也是 Maurice Bach 的《<ruby>[UNIX 操作系统设计][17]<rt>The Design of the Unix Operation System</rt></ruby>》的书迷之一。James Bottomley 也是这本书的推崇者,作为一个 Linux 内核开发者,当 Linux 刚刚问世时 James 就用 Bach 的这本书所传授的知识将它研究了个底朝天。
|
||||
|
||||
### 软件设计知识永不过时
|
||||
|
||||
尽管这样说有点太局限在技术领域。Stevens 还是说到,“所有的开发者都应该在开始钻研语法前先研究如何设计,《<ruby>[设计心理学][18]<rt>The Design of Everyday Things</rt></ruby>》是我的最爱”。
|
||||
|
||||
Coekaerts 喜欢 Kernighan 和 Rob Pike 合著的《<ruby>[程序设计实践][19]<rt>The Practic of Programming</rt></ruby>》。这本关于设计实践的书当 Coekaerts 还在学校念书的时候还未出版,他说道,“但是我把它推荐给每一个人”。
|
||||
|
||||
不管何时,当你问一个长期从事于开发工作的开发者他最喜欢的计算机书籍时,你迟早会听到一个名字和一本书:Donald Knuth 和他所著的《<ruby>[计算机程序设计艺术(1-4A)][20]<rt>The Art of Computer Programming, Volumes 1-4A</rt></ruby>》。VMware 首席开源官 Dirk Hohndel,认为这本书尽管有永恒的价值,但他也承认,“今时今日并非极其有用”。(LCTT 译注:不代表译者观点)
|
||||
|
||||
### 读代码。大量的读。
|
||||
|
||||
编程书籍能教会你很多,也请别错过另外一个在开源社区特有的学习机会:《<ruby>[代码阅读方法与实践][21]<rt>Code Reading: The Open Source Perspective</rt></ruby>》。那里有不可计数的代码例子阐述如何解决编程问题(以及如何让你陷入麻烦……)。Stevens 说,谈到磨炼编程技巧,在他的书单里排名第一的“书”是 Unix 的源代码。
|
||||
|
||||
“也请不要忽略从他人身上学习的各种机会。” Cox 道,“我是在一个计算机俱乐部里和其他人一起学的 BASIC,在我看来,这仍然是一个学习的最好办法”,他从《<ruby>[精通 ZX81 机器码][22]<rt>Mastering machine code on your ZX81</rt></ruby>》这本书和 Honeywell L66 B 编译器手册里学习到了如何编写机器码,但是学习技术这点来说,单纯阅读和与其他开发者在工作中共同学习仍然有着很大的不同。
|
||||
|
||||
Cox 说,“我始终认为最好的学习方法是和一群人一起试图去解决你们共同关心的一些问题并从中找到快乐,这和你是 5 岁还是 55 岁无关”。
|
||||
|
||||
最让我吃惊的是这些顶级 Linux 开发者都是在非常底层级别开始他们的开发之旅的,甚至不是从汇编语言或 C 语言,而是从机器码开始开发。毫无疑问,这对帮助开发者理解计算机在非常微观的底层级别是怎么工作的起了非常大的作用。
|
||||
|
||||
那么现在你准备好尝试一下硬核 Linux 开发了吗?Greg Kroah-Hartman,这位 Linux 内核稳定分支的维护者,推荐了 Steve Oualline 的《<ruby>[实用 C 语言编程][23]<rt>Practical C Programming</rt></ruby>》和 Samuel harbison 与 Guy Steels 合著的《<ruby>[C 语言参考手册][24]<rt>C: A Reference Manual</rt></ruby>》。接下来请阅读<ruby>[如何进行 Linux 内核开发][25]<rt>HOWTO do Linux kernel development</rt></ruby>,到这时,就像 Kroah-Hartman 所说,你已经准备好启程了。
|
||||
|
||||
于此同时,还请你刻苦学习并大量编码,最后祝你在跟随顶级 Linux 开发者脚步的道路上好运相随。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/top-linux-developers-recommended-programming-books-1808.html
|
||||
|
||||
作者:[Steven Vaughan-Nichols][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/DavidChenLiang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/steven-j-vaughan-nichols.html
|
||||
[1]:https://www.codingdojo.com/blog/7-most-in-demand-programming-languages-of-2018/
|
||||
[2]:https://www.gnu.org/software/gnu-c-manual/
|
||||
[3]:https://amzn.to/2nhyjEO
|
||||
[4]:https://amzn.to/2vsL8k9
|
||||
[5]:https://amzn.to/2KBbWn9
|
||||
[6]:https://amzn.to/2M0rfeR
|
||||
[7]:https://amzn.to/2nhyrnMe
|
||||
[8]:http://shop.oreilly.com/product/0636920040385.do
|
||||
[9]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_linuxbooks_containerebook0818
|
||||
[10]:https://amzn.to/2MfpbyC
|
||||
[11]:https://amzn.to/2MpgrTn
|
||||
[12]:https://www.hpe.com/us/en/insights/articles/how-to-see-whats-going-on-with-your-linux-system-right-now-1807.html
|
||||
[13]:http://shop.oreilly.com/product/9780596510299.do
|
||||
[14]:http://shop.oreilly.com/product/9780596009656.do
|
||||
[15]:http://shop.oreilly.com/product/9780596100575.do
|
||||
[16]:http://shop.oreilly.com/product/9780596000127.do
|
||||
[17]:https://amzn.to/2vsCJgF
|
||||
[18]:https://amzn.to/2APzt3Z
|
||||
[19]:https://www.amazon.com/Practice-Programming-Addison-Wesley-Professional-Computing/dp/020161586X/ref=as_li_ss_tl?ie=UTF8&linkCode=sl1&tag=thegroovycorpora&linkId=e6bbdb1ca2182487069bf9089fc8107e&language=en_US
|
||||
[20]:https://amzn.to/2OknFsJ
|
||||
[21]:https://amzn.to/2M4VVL3
|
||||
[22]:https://amzn.to/2OjccJA
|
||||
[23]:http://shop.oreilly.com/product/9781565923065.do
|
||||
[24]:https://amzn.to/2OjzgrT
|
||||
[25]:https://www.kernel.org/doc/html/v4.16/process/howto.html
|
||||
File diff suppressed because it is too large
Load Diff
@ -3,11 +3,12 @@
|
||||
|
||||

|
||||
|
||||
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu][1] (container utilities 的简写) 是一个Python库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
|
||||
越来越多的开发人员使用容器开发和部署他们的应用。这意味着可以轻松地测试容器也变得很重要。[Conu][1] (container utilities 的简写) 是一个 Python 库,让你编写容器测试变得简单。本文向你介绍如何使用它测试容器。
|
||||
|
||||
### 开始吧
|
||||
|
||||
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
|
||||
首先,你需要一个容器程序来测试。为此,以下命令创建一个包含一个容器的 Dockerfile 和一个被容器伺服的 Flask 应用程序的文件夹。
|
||||
|
||||
```bash
|
||||
$ mkdir container_test
|
||||
$ cd container_test
|
||||
@ -15,22 +16,24 @@ $ touch Dockerfile
|
||||
$ touch app.py
|
||||
```
|
||||
|
||||
将以下代码复制到 app.py 文件中。这是惯常的基本 Flask 应用,它返回字符串“Hello Container World!”。
|
||||
将以下代码复制到 `app.py` 文件中。这是惯常的基本 Flask 应用,它返回字符串 “Hello Container World!”。
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
app = Flask(__name__)
|
||||
|
||||
@app.route('/')
|
||||
def hello_world():
|
||||
return 'Hello Container World!'
|
||||
return 'Hello Container World!'
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
app.run(debug=True,host='0.0.0.0')
|
||||
```
|
||||
|
||||
### 创建和构建测试容器
|
||||
|
||||
为了构建测试容器,将以下指令添加到 Dockerfile。
|
||||
|
||||
```dockerfile
|
||||
FROM registry.fedoraproject.org/fedora-minimal:latest
|
||||
RUN microdnf -y install python3-flask && microdnf clean all
|
||||
@ -39,6 +42,7 @@ CMD ["python3", "/srv/app.py"]
|
||||
```
|
||||
|
||||
然后使用 Docker CLI 工具构建容器。
|
||||
|
||||
```bash
|
||||
$ sudo dnf -y install docker
|
||||
$ sudo systemctl start docker
|
||||
@ -48,6 +52,7 @@ $ sudo docker build . -t flaskapp_container
|
||||
提示:只有在系统上未安装 Docker 时才需要前两个命令。
|
||||
|
||||
构建之后使用以下命令运行容器。
|
||||
|
||||
```bash
|
||||
$ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
|
||||
@ -56,17 +61,19 @@ $ sudo docker run -p 5000:5000 --rm flaskapp_container
|
||||
* Debugger PIN: 473-505-51
|
||||
```
|
||||
|
||||
最后,使用 curl 检查 Flask 应用程序是否在容器内正确运行:
|
||||
最后,使用 `curl` 检查 Flask 应用程序是否在容器内正确运行:
|
||||
|
||||
```bash
|
||||
$ curl http://127.0.0.1:5000
|
||||
Hello Container World!
|
||||
```
|
||||
|
||||
现在,flaskapp_container 正在运行并准备好进行测试,你可以使用 Ctrl+C 将其停止。
|
||||
现在,flaskapp_container 正在运行并准备好进行测试,你可以使用 `Ctrl+C` 将其停止。
|
||||
|
||||
### 创建测试脚本
|
||||
|
||||
在编写测试脚本之前,必须安装 conu。在先前创建的 container_test 目录中,运行以下命令。
|
||||
在编写测试脚本之前,必须安装 `conu`。在先前创建的 `container_test` 目录中,运行以下命令。
|
||||
|
||||
```bash
|
||||
$ python3 -m venv .venv
|
||||
$ source .venv/bin/activate
|
||||
@ -75,48 +82,48 @@ $ source .venv/bin/activate
|
||||
$ touch test_container.py
|
||||
```
|
||||
|
||||
然后将以下脚本复制并保存在 test_container.py 文件中。
|
||||
然后将以下脚本复制并保存在 `test_container.py` 文件中。
|
||||
|
||||
```python
|
||||
import conu
|
||||
|
||||
PORT = 5000
|
||||
|
||||
with conu.DockerBackend() as backend:
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
image = backend.ImageClass("flaskapp_container")
|
||||
options = ["-p", "5000:5000"]
|
||||
container = image.run_via_binary(additional_opts=options)
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
try:
|
||||
# Check that the container is running and wait for the flask application to start.
|
||||
assert container.is_running()
|
||||
container.wait_for_port(PORT)
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Run a GET request on / port 5000.
|
||||
http_response = container.http_request(path="/", port=PORT)
|
||||
|
||||
# Check the response status code is 200
|
||||
assert http_response.ok
|
||||
|
||||
# Get the response content
|
||||
response_content = http_response.content.decode("utf-8")
|
||||
|
||||
# Check that the "Hello Container World!" string is served.
|
||||
assert "Hello Container World!" in response_content
|
||||
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
# Get the logs from the container
|
||||
logs = [line for line in container.logs()]
|
||||
# Check the the Flask application saw the GET request.
|
||||
assert b'"GET / HTTP/1.1" 200 -' in logs[-1]
|
||||
|
||||
finally:
|
||||
container.stop()
|
||||
container.delete()
|
||||
```
|
||||
|
||||
#### 测试设置
|
||||
|
||||
这个脚本首先设置 conu 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp_container。
|
||||
这个脚本首先设置 `conu` 使用 Docker 作为后端来运行容器。然后它设置容器镜像以使用你在本教程第一部分中构建的 flaskapp_container。
|
||||
|
||||
下一步是配置运行容器所需的选项。在此示例中,Flask 应用在端口5000上提供内容。于是你需要暴露此端口并将其映射到主机上的同一端口。
|
||||
|
||||
@ -124,13 +131,13 @@ with conu.DockerBackend() as backend:
|
||||
|
||||
#### 测试方法
|
||||
|
||||
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 container.is_running 和 container.wait_for_port。这些方法可确保容器正在运行,并且服务在预设端口上可用。
|
||||
在测试容器之前,检查容器是否正在运行并准备就绪。示范脚本使用 `container.is_running` 和 `container.wait_for_port`。这些方法可确保容器正在运行,并且服务在预设端口上可用。
|
||||
|
||||
container.http_request 是 [request][2] 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject][3],因此可以轻松地访问响应的内容以进行测试。
|
||||
`container.http_request` 是 [request][2] 库的包装器,可以方便地在测试期间发送 HTTP 请求。这个方法返回[requests.Responseobject][3],因此可以轻松地访问响应的内容以进行测试。
|
||||
|
||||
Conu 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,container.logs 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
|
||||
`conu` 还可以访问容器日志。又一次,这在测试期间非常有用。在上面的示例中,`container.logs` 方法返回容器日志。你可以使用它们断言打印了特定日志,或者,例如在测试期间没有异常被引发。
|
||||
|
||||
Conu 提供了许多与容器接合的有用方法。[文档][4]中提供了完整的 API 列表。你还可以参考 [GitHub][5] 上提供的示例。
|
||||
`conu` 提供了许多与容器接合的有用方法。[文档][4]中提供了完整的 API 列表。你还可以参考 [GitHub][5] 上提供的示例。
|
||||
|
||||
运行本教程所需的所有代码和文件也可以在 [GitHub][6] 上获得。 对于想要进一步采用这个例子的读者,你可以看看使用 [pytest][7] 来运行测试并构建一个容器测试套件。
|
||||
|
||||
@ -141,7 +148,7 @@ via: https://fedoramagazine.org/test-containers-python-conu/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
222
published/201811/20180907 6.828 lab tools guide.md
Normal file
@ -0,0 +1,222 @@
|
||||
Caffeinated 6.828:实验工具指南
|
||||
======
|
||||
|
||||
熟悉你的环境对高效率的开发和调试来说是至关重要的。本文将为你简单概述一下 JOS 环境和非常有用的 GDB 和 QEMU 命令。话虽如此,但你仍然应该去阅读 GDB 和 QEMU 手册,来理解这些强大的工具如何使用。
|
||||
|
||||
### 调试小贴士
|
||||
|
||||
#### 内核
|
||||
|
||||
GDB 是你的朋友。使用 `qemu-gdb target`(或它的变体 `qemu-gdb-nox`)使 QEMU 等待 GDB 去绑定。下面在调试内核时用到的一些命令,可以去查看 GDB 的资料。
|
||||
|
||||
如果你遭遇意外的中断、异常、或三重故障,你可以使用 `-d` 参数要求 QEMU 去产生一个详细的中断日志。
|
||||
|
||||
调试虚拟内存问题时,尝试 QEMU 的监视命令 `info mem`(提供内存高级概述)或 `info pg`(提供更多细节内容)。注意,这些命令仅显示**当前**页表。
|
||||
|
||||
(在实验 4 以后)去调试多个 CPU 时,使用 GDB 的线程相关命令,比如 `thread` 和 `info threads`。
|
||||
|
||||
#### 用户环境(在实验 3 以后)
|
||||
|
||||
GDB 也可以去调试用户环境,但是有些事情需要注意,因为 GDB 无法区分开多个用户环境或区分开用户环境与内核环境。
|
||||
|
||||
你可以使用 `make run-name`(或编辑 `kern/init.c` 目录)来指定 JOS 启动的用户环境,为使 QEMU 等待 GDB 去绑定,使用 `run-name-gdb` 的变体。
|
||||
|
||||
你可以符号化调试用户代码,就像调试内核代码一样,但是你要告诉 GDB,哪个符号表用到符号文件命令上,因为它一次仅能够使用一个符号表。提供的 `.gdbinit` 用于加载内核符号表 `obj/kern/kernel`。对于一个用户环境,这个符号表在它的 ELF 二进制文件中,因此你可以使用 `symbol-file obj/user/name` 去加载它。不要从任何 `.o` 文件中加载符号,因为它们不会被链接器迁移进去(库是静态链接进 JOS 用户二进制文件中的,因此这些符号已经包含在每个用户二进制文件中了)。确保你得到了正确的用户二进制文件;在不同的二进制文件中,库函数被链接为不同的 EIP,而 GDB 并不知道更多的内容!
|
||||
|
||||
(在实验 4 以后)因为 GDB 绑定了整个虚拟机,所以它可以将时钟中断看作为一种控制转移。这使得从底层上不可能实现步进用户代码,因为一个时钟中断无形中保证了片刻之后虚拟机可以再次运行。因此可以使用 `stepi` 命令,因为它阻止了中断,但它仅可以步进一个汇编指令。断点一般来说可以正常工作,但要注意,因为你可能在不同的环境(完全不同的一个二进制文件)上遇到同一个 EIP。
|
||||
|
||||
### 参考
|
||||
|
||||
#### JOS makefile
|
||||
|
||||
JOS 的 GNUmakefile 包含了在各种方式中运行的 JOS 的许多假目标。所有这些目标都配置 QEMU 去监听 GDB 连接(`*-gdb` 目标也等待这个连接)。要在运行中的 QEMU 上启动它,只需要在你的实验目录中简单地运行 `gdb ` 即可。我们提供了一个 `.gdbinit` 文件,它可以在 QEMU 中自动指向到 GDB、加载内核符号文件、以及在 16 位和 32 位模式之间切换。退出 GDB 将关闭 QEMU。
|
||||
|
||||
* `make qemu`
|
||||
|
||||
在一个新窗口中构建所有的东西并使用 VGA 控制台和你的终端中的串行控制台启动 QEMU。想退出时,既可以关闭 VGA 窗口,也可以在你的终端中按 `Ctrl-c` 或 `Ctrl-a x`。
|
||||
* `make qemu-nox`
|
||||
|
||||
和 `make qemu` 一样,但仅使用串行控制台来运行。想退出时,按下 `Ctrl-a x`。这种方式在通过 SSH 拨号连接到 Athena 上时非常有用,因为 VGA 窗口会占用许多带宽。
|
||||
* `make qemu-gdb`
|
||||
|
||||
和 `make qemu` 一样,但它与任意时间被动接受 GDB 不同,而是暂停第一个机器指令并等待一个 GDB 连接。
|
||||
* `make qemu-nox-gdb`
|
||||
|
||||
它是 `qemu-nox` 和 `qemu-gdb` 目标的组合。
|
||||
* `make run-nam`
|
||||
|
||||
(在实验 3 以后)运行用户程序 _name_。例如,`make run-hello` 运行 `user/hello.c`。
|
||||
* `make run-name-nox`,`run-name-gdb`, `run-name-gdb-nox`
|
||||
|
||||
(在实验 3 以后)与 `qemu` 目标变量对应的 `run-name` 的变体。
|
||||
|
||||
makefile 也接受几个非常有用的变量:
|
||||
|
||||
* `make V=1 …`
|
||||
|
||||
详细模式。输出正在运行的每个命令,包括参数。
|
||||
* `make V=1 grade`
|
||||
|
||||
在评级测试失败后停止,并将 QEMU 的输出放入 `jos.out` 文件中以备检查。
|
||||
* `make QEMUEXTRA=' _args_ ' …`
|
||||
|
||||
指定传递给 QEMU 的额外参数。
|
||||
|
||||
#### JOS obj/
|
||||
|
||||
在构建 JOS 时,makefile 也产生一些额外的输出文件,这些文件在调试时非常有用:
|
||||
|
||||
* `obj/boot/boot.asm`、`obj/kern/kernel.asm`、`obj/user/hello.asm`、等等。
|
||||
|
||||
引导加载器、内核、和用户程序的汇编代码列表。
|
||||
* `obj/kern/kernel.sym`、`obj/user/hello.sym`、等等。
|
||||
|
||||
内核和用户程序的符号表。
|
||||
* `obj/boot/boot.out`、`obj/kern/kernel`、`obj/user/hello`、等等。
|
||||
|
||||
内核和用户程序链接的 ELF 镜像。它们包含了 GDB 用到的符号信息。
|
||||
|
||||
#### GDB
|
||||
|
||||
完整的 GDB 命令指南请查看 [GDB 手册][1]。下面是一些在 6.828 课程中非常有用的命令,它们中的一些在操作系统开发之外的领域几乎用不到。
|
||||
|
||||
* `Ctrl-c`
|
||||
|
||||
在当前指令处停止机器并打断进入到 GDB。如果 QEMU 有多个虚拟的 CPU,所有的 CPU 都会停止。
|
||||
* `c`(或 `continue`)
|
||||
|
||||
继续运行,直到下一个断点或 `Ctrl-c`。
|
||||
* `si`(或 `stepi`)
|
||||
|
||||
运行一个机器指令。
|
||||
* `b function` 或 `b file:line`(或 `breakpoint`)
|
||||
|
||||
在给定的函数或行上设置一个断点。
|
||||
* `b * addr`(或 `breakpoint`)
|
||||
|
||||
在 EIP 的 addr 处设置一个断点。
|
||||
* `set print pretty`
|
||||
|
||||
启用数组和结构的美化输出。
|
||||
* `info registers`
|
||||
|
||||
输出通用寄存器 `eip`、`eflags`、和段选择器。更多更全的机器寄存器状态转储,查看 QEMU 自己的 `info registers` 命令。
|
||||
* `x/ N x addr`
|
||||
|
||||
以十六进制显示虚拟地址 addr 处开始的 N 个词的转储。如果 N 省略,默认为 1。addr 可以是任何表达式。
|
||||
* `x/ N i addr`
|
||||
|
||||
显示从 addr 处开始的 N 个汇编指令。使用 `$eip` 作为 addr 将显示当前指令指针寄存器中的指令。
|
||||
* `symbol-file file`
|
||||
|
||||
(在实验 3 以后)切换到符号文件 file 上。当 GDB 绑定到 QEMU 后,它并不是虚拟机中进程边界内的一部分,因此我们要去告诉它去使用哪个符号。默认情况下,我们配置 GDB 去使用内核符号文件 `obj/kern/kernel`。如果机器正在运行用户代码,比如是 `hello.c`,你就需要使用 `symbol-file obj/user/hello` 去切换到 hello 的符号文件。
|
||||
|
||||
QEMU 将每个虚拟 CPU 表示为 GDB 中的一个线程,因此你可以使用 GDB 中所有的线程相关的命令去查看或维护 QEMU 的虚拟 CPU。
|
||||
|
||||
* `thread n`
|
||||
|
||||
GDB 在一个时刻只关注于一个线程(即:CPU)。这个命令将关注的线程切换到 n,n 是从 0 开始编号的。
|
||||
* `info threads`
|
||||
|
||||
列出所有的线程(即:CPU),包括它们的状态(活动还是停止)和它们在什么函数中。
|
||||
|
||||
|
||||
#### QEMU
|
||||
|
||||
QEMU 包含一个内置的监视器,它能够有效地检查和修改机器状态。想进入到监视器中,在运行 QEMU 的终端中按入 `Ctrl-a c` 即可。再次按下 `Ctrl-a c` 将切换回串行控制台。
|
||||
|
||||
监视器命令的完整参考资料,请查看 [QEMU 手册][2]。下面是 6.828 课程中用到的一些有用的命令:
|
||||
|
||||
* `xp/ N x paddr`
|
||||
|
||||
显示从物理地址 paddr 处开始的 N 个词的十六进制转储。如果 N 省略,默认为 1。这是 GDB 的 `x` 命令模拟的物理内存。
|
||||
* `info registers`
|
||||
|
||||
显示机器内部寄存器状态的一个完整转储。实践中,对于段选择器,这将包含机器的 _隐藏_ 段状态和局部、全局、和中断描述符表加任务状态寄存器。隐藏状态是在加载段选择器后,虚拟的 CPU 从 GDT/LDT 中读取的信息。下面是实验 1 中 JOS 内核处于运行中时的 CS 信息和每个字段的含义:
|
||||
|
||||
```c
|
||||
CS =0008 10000000 ffffffff 10cf9a00 DPL=0 CS32 [-R-]
|
||||
```
|
||||
|
||||
* `CS =0008`
|
||||
|
||||
代码选择器可见部分。我们使用段 0x8。这也告诉我们参考全局描述符表(0x8&4=0),并且我们的 CPL(当前权限级别)是 0x8&3=0。
|
||||
* `10000000`
|
||||
|
||||
这是段基址。线性地址 = 逻辑地址 + 0x10000000。
|
||||
* `ffffffff`
|
||||
|
||||
这是段限制。访问线性地址 0xffffffff 以上将返回段违规异常。
|
||||
* `10cf9a00`
|
||||
|
||||
段的原始标志,QEMU 将在接下来的几个字段中解码这些对我们有用的标志。
|
||||
* `DPL=0`
|
||||
|
||||
段的权限级别。一旦代码以权限 0 运行,它将就能够加载这个段。
|
||||
* `CS32`
|
||||
|
||||
这是一个 32 位代码段。对于数据段(不要与 DS 寄存器混淆了),另外的值还包括 `DS`,而对于本地描述符表是 `LDT`。
|
||||
* `[-R-]`
|
||||
|
||||
这个段是只读的。
|
||||
|
||||
* `info mem`
|
||||
|
||||
(在实验 2 以后)显示映射的虚拟内存和权限。比如:
|
||||
|
||||
```
|
||||
ef7c0000-ef800000 00040000 urw
|
||||
efbf8000-efc00000 00008000 -rw
|
||||
```
|
||||
|
||||
这告诉我们从 0xef7c0000 到 0xef800000 的 0x00040000 字节的内存被映射为读取/写入/用户可访问,而映射在 0xefbf8000 到 0xefc00000 之间的内存权限是读取/写入,但是仅限于内核可访问。
|
||||
|
||||
* `info pg`
|
||||
|
||||
(在实验 2 以后)显示当前页表结构。它的输出类似于 `info mem`,但与页目录条目和页表条目是有区别的,并且为每个条目给了单独的权限。重复的 PTE 和整个页表被折叠为一个单行。例如:
|
||||
|
||||
```
|
||||
VPN range Entry Flags Physical page
|
||||
[00000-003ff] PDE[000] -------UWP
|
||||
[00200-00233] PTE[200-233] -------U-P 00380 0037e 0037d 0037c 0037b 0037a ..
|
||||
[00800-00bff] PDE[002] ----A--UWP
|
||||
[00800-00801] PTE[000-001] ----A--U-P 0034b 00349
|
||||
[00802-00802] PTE[002] -------U-P 00348
|
||||
```
|
||||
|
||||
这里各自显示了两个页目录条目、虚拟地址范围 0x00000000 到 0x003fffff 以及 0x00800000 到 0x00bfffff。 所有的 PDE 都存在于内存中、可写入、并且用户可访问,而第二个 PDE 也是可访问的。这些页表中的第二个映射了三个页、虚拟地址范围 0x00800000 到 0x00802fff,其中前两个页是存在于内存中的、可写入、并且用户可访问的,而第三个仅存在于内存中,并且用户可访问。这些 PTE 的第一个条目映射在物理页 0x34b 处。
|
||||
|
||||
QEMU 也有一些非常有用的命令行参数,使用 `QEMUEXTRA` 变量可以将参数传递给 JOS 的 makefile。
|
||||
|
||||
* `make QEMUEXTRA='-d int' ...`
|
||||
|
||||
记录所有的中断和一个完整的寄存器转储到 `qemu.log` 文件中。你可以忽略前两个日志条目、“SMM: enter” 和 “SMM: after RMS”,因为这些是在进入引导加载器之前生成的。在这之后的日志条目看起来像下面这样:
|
||||
|
||||
```
|
||||
4: v=30 e=0000 i=1 cpl=3 IP=001b:00800e2e pc=00800e2e SP=0023:eebfdf28 EAX=00000005
|
||||
EAX=00000005 EBX=00001002 ECX=00200000 EDX=00000000
|
||||
ESI=00000805 EDI=00200000 EBP=eebfdf60 ESP=eebfdf28
|
||||
...
|
||||
```
|
||||
|
||||
第一行描述了中断。`4:` 只是一个日志记录计数器。`v` 提供了十六进程的向量号。`e` 提供了错误代码。`i=1` 表示它是由一个 `int` 指令(相对一个硬件产生的中断而言)产生的。剩下的行的意思很明显。对于一个寄存器转储而言,接下来看到的就是寄存器信息。
|
||||
|
||||
注意:如果你运行的是一个 0.15 版本之前的 QEMU,日志将写入到 `/tmp` 目录,而不是当前目录下。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://sourceware.org/gdb/current/onlinedocs/gdb/
|
||||
[2]: http://wiki.qemu.org/download/qemu-doc.html#pcsys_005fmonitor
|
||||
@ -1,34 +1,35 @@
|
||||
IssueHunt:一个新的开源软件打赏平台
|
||||
======
|
||||
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由和开源软件。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
|
||||
|
||||
我们已经写了一篇关于[开源资金平台][1]的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt][2] 。
|
||||
![IssueHunt][4]
|
||||
|
||||
许多开源开发者和公司都在努力解决的问题之一就是资金问题。社区中有一种假想,甚至是期望,必须免费提供自由开源软件(FOSS)。但即使是 FOSS 也需要资金来继续开发。如果我们不建立让软件持续开发的系统,我们怎能期待更高质量的软件?
|
||||
|
||||
我们已经写了一篇关于[开源资金平台][1]的文章来试图解决这个缺点,截至今年 7 月,市场上出现了一个新的竞争者,旨在帮助填补这个空白:[IssueHunt][2]。
|
||||
|
||||
### IssueHunt: 开源软件打赏平台
|
||||
|
||||
![IssueHunt website][3]
|
||||
|
||||
IssueHunt 提供了一种服务,支付自由开发者对开源代码的贡献。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
|
||||
IssueHunt 提供了一种服务,对自由开发者的开源代码贡献进行支付。它通过所谓的赏金来实现:给予解决特定问题的任何人财务奖励。这些奖励的资金来自任何愿意捐赠以修复任何特定 bug 或添加功能的人。
|
||||
|
||||
如果你想修复的某个开源软件存在问题,你可以根据自己选择的方式提供奖励金额。
|
||||
|
||||
想要自己的产品被争抢解决么?在 IssueHunt 上向任何解决问题的人提供奖金就好了。就这么简单。
|
||||
|
||||
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交 pull request,如果你的 pull request 被合并,那么你就会得到了钱。
|
||||
如果你是程序员,则可以浏览未解决的问题。解决这个问题(如果你可以的话),在 GitHub 存储库上提交拉取请求,如果你的拉取请求被合并,那么你就会得到了钱。
|
||||
|
||||
#### IssueHunt 最初是 Boostnote 的内部项目
|
||||
|
||||
![IssueHunt][4]
|
||||
|
||||
当笔记应用 [Boostnote][5] 背后的开发人员联系社区为他们的产品做出贡献时,该产品出现了。
|
||||
|
||||
在使用 IssueHunt 的前两年,Boostnote 通过数百名贡献者和压倒性的捐款收到了超过 8,400 个 Github star。
|
||||
|
||||
该产品非常成功,团队决定将其开放给社区的其他成员。
|
||||
|
||||
今天,[列表中在使用这个服务的项目][6]提供了数千美元的赏金。
|
||||
如今,[列表中在使用这个服务的项目][6]提供了数千美元的赏金。
|
||||
|
||||
Boostnote 号称有 [$2,800 的总赏金] [7],而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金][8]。
|
||||
Boostnote 号称有 [$2,800 的总赏金][7],而 Settings Sync,以前称为 Visual Studio Code Settings Sync,提供了[超过 $1,600 的赏金][8]。
|
||||
|
||||
还有其他服务提供类似于 IssueHunt 在此提供的内容。也许最引人注目的是 [Bountysource][9],它提供与 IssueHunt 类似的赏金服务,同时还提供类似于 [Librepay][10] 的订阅支付处理。
|
||||
|
||||
@ -36,7 +37,7 @@ Boostnote 号称有 [$2,800 的总赏金] [7],而 Settings Sync,以前称为
|
||||
|
||||
在撰写本文时,IssueHunt 还处于起步阶段,但我非常高兴看到这个项目在这些年里的成果。
|
||||
|
||||
我不了解你,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
|
||||
我不知道你会怎么看,但我非常乐意为 FOSS 付款。如果产品质量高,并为我的生活增添价值,那么我很乐意向开发者支付产品费用。特别是 FOSS 的开发者正在创造尊重我自由的产品。
|
||||
|
||||
话虽如此,我一定会关注 IssueHunt 的继续前进,我可以用自己的钱或者在需要贡献的地方传播这个它来支持社区。
|
||||
|
||||
@ -49,15 +50,15 @@ via: https://itsfoss.com/issuehunt/
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/phillip/
|
||||
[1]: https://itsfoss.com/open-source-funding-platforms/
|
||||
[2]: https://issuehunt.io
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/issuehunt-website.png
|
||||
[4]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/issuehunt.jpg
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt-website.png?w=799&ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/09/issuehunt.jpg?w=800&ssl=1
|
||||
[5]: https://itsfoss.com/boostnote-linux-review/
|
||||
[6]: https://issuehunt.io/repos
|
||||
[7]: https://issuehunt.io/repos/53266139
|
||||
@ -1,17 +1,17 @@
|
||||
将 Grails 与 jQuery 和 DataTables 一起使用
|
||||
在 Grails 中使用 jQuery 和 DataTables
|
||||
======
|
||||
|
||||
本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
|
||||
> 本文介绍如何构建一个基于 Grails 的数据浏览器来可视化复杂的表格数据。
|
||||
|
||||

|
||||
|
||||
我是 [Grails][1] 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据人。数据人经常需要_查看_数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails,[jQuery][2],以及 [DataTables jQuery 插件][3],我们可以制作出非常友好的表格数据浏览器。
|
||||
我是 [Grails][1] 的忠实粉丝。当然,我主要是热衷于利用命令行工具来探索和分析数据的数据从业人员。数据从业人员经常需要*查看*数据,这也意味着他们通常拥有优秀的数据浏览器。利用 Grails、[jQuery][2],以及 [DataTables jQuery 插件][3],我们可以制作出非常友好的表格数据浏览器。
|
||||
|
||||
[DataTables 网站][3]提供了许多“食谱风格”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript,HTML,以及偶尔出现的 [PHP][4]。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是虚构公司的员工的单个平面表数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
|
||||
[DataTables 网站][3]提供了许多“食谱式”的教程文档,展示了如何组合一些优秀的示例应用程序,这些程序包含了完成一些非常漂亮的东西所必要的 JavaScript、HTML,以及偶尔出现的 [PHP][4]。但对于那些宁愿使用 Grails 作为后端的人来说,有必要进行一些说明示教。此外,样本程序中使用的数据是一个虚构公司的员工的单个平面表格数据,因此处理这些复杂的表关系可以作为读者的一个练习项目。
|
||||
|
||||
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准 [Groovy][5]-fied Java Hibernate 标准。我已将代码托管在 [GitHub][6] 上方便大家访问,因此本文主要是对代码细节的解读。
|
||||
本文中,我们将创建具有略微复杂的数据结构和 DataTables 浏览器的 Grails 应用程序。我们将介绍 Grails 标准,它是 [Groovy][5] 式的 Java Hibernate 标准。我已将代码托管在 [GitHub][6] 上方便大家访问,因此本文主要是对代码细节的解读。
|
||||
|
||||
首先,你需要配置 Java,Groovy,Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim][7],本文也使用它们。为获得现代 Java,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit][8] (OpenJDK)(应该是 Java 8,9,10或11,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SKDMAN!][9]。
|
||||
首先,你需要配置 Java、Groovy、Grails 的使用环境。对于 Grails,我倾向于使用终端窗口和 [Vim][7],本文也使用它们。为获得现代的 Java 环境,建议下载并安装 Linux 发行版提供的 [Open Java Development Kit][8] (OpenJDK)(应该是 Java 8、9、10 或 11 之一,撰写本文时,我正在使用 Java 8)。从我的角度来看,获取最新的 Groovy 和 Grails 的最佳方法是使用 [SDKMAN!][9]。
|
||||
|
||||
从未尝试过 Grails 的读者可能需要做一些背景资料阅读。作为初学者,推荐文章 [创建你的第一个 Grails 应用程序][10]。
|
||||
|
||||
@ -34,7 +34,7 @@ grails create-domain-class com.nuevaconsulting.embrow.Employeecd embrowgrails cr
|
||||
|
||||
这种方式构建的域类没有属性,因此必须按如下方式编辑它们:
|
||||
|
||||
Position 域类:
|
||||
`Position` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -51,7 +51,7 @@ class Position {
|
||||
}com.Stringint startingstatic constraintsnullableblankstarting nullable
|
||||
```
|
||||
|
||||
Office 域类:
|
||||
`Office` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -72,7 +72,7 @@ class Office {
|
||||
}
|
||||
```
|
||||
|
||||
Enployee 域类:
|
||||
`Enployee` 域类:
|
||||
|
||||
```
|
||||
package com.nuevaconsulting.embrow
|
||||
@ -98,7 +98,7 @@ class Employee {
|
||||
}
|
||||
```
|
||||
|
||||
请注意,虽然 Position 和 Office 域类使用了预定义的 Groovy 类型 String 以及 int,但 Employee 域类定义了 Position 和 Office 字段(以及预定义的 Date)。这会导致创建数据库表,其中存储的 Employee 实例中包含了指向存储 Position 和 Office 实例表的引用或者外键。
|
||||
请注意,虽然 `Position` 和 `Office` 域类使用了预定义的 Groovy 类型 `String` 以及 `int`,但 `Employee` 域类定义了 `Position` 和 `Office` 字段(以及预定义的 `Date`)。这会导致创建数据库表,其中存储的 `Employee` 实例中包含了指向存储 `Position` 和 `Office` 实例表的引用或者外键。
|
||||
|
||||
现在你可以生成控制器,视图,以及其他各种测试组件:
|
||||
|
||||
@ -108,7 +108,7 @@ grails generate-all com.nuevaconsulting.embrow.Office
|
||||
grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.grails generateall com.grails generateall com.
|
||||
```
|
||||
|
||||
此时,你已经准备好基本的 create-read-update-delete(CRUD)应用程序。我在**grails-app/init/com/nuevaconsulting/BootStrap.groovy**中包含了一些基础数据来填充表格。
|
||||
此时,你已经准备好了一个基本的增删改查(CRUD)应用程序。我在 `grails-app/init/com/nuevaconsulting/BootStrap.groovy` 中包含了一些基础数据来填充表格。
|
||||
|
||||
如果你用如下命令来启动应用程序:
|
||||
|
||||
@ -116,43 +116,44 @@ grails generate-all com.nuevaconsulting.embrow.Employeegrails generateall com.gr
|
||||
grails run-app
|
||||
```
|
||||
|
||||
在浏览器输入**<http://localhost:8080/:>**,你将会看到如下界面:
|
||||
在浏览器输入 `http://localhost:8080/`,你将会看到如下界面:
|
||||
|
||||
![Embrow home screen][12]
|
||||
|
||||
Embrow 应用程序主界面。
|
||||
*Embrow 应用程序主界面。*
|
||||
|
||||
单击 OfficeController,会跳转到如下界面:
|
||||
单击 “OfficeController” 链接,会跳转到如下界面:
|
||||
|
||||
![Office list][14]
|
||||
|
||||
Office 列表
|
||||
*Office 列表*
|
||||
|
||||
注意,此表由 **OfficeController index** 生成,并由视图 `office/index.gsp` 显示。
|
||||
注意,此表由 `OfficeController` 的 `index` 方式生成,并由视图 `office/index.gsp` 显示。
|
||||
|
||||
同样,单击 **EmployeeController** 跳转到如下界面:
|
||||
同样,单击 “EmployeeController” 链接 跳转到如下界面:
|
||||
|
||||
![Employee controller][16]
|
||||
|
||||
employee controller
|
||||
*employee 控制器*
|
||||
|
||||
好吧,这很丑陋: Position 和 Office 链接是什么?
|
||||
|
||||
上面的命令 `generate-all` 生成的视图创建了一个叫 **index.gsp** 的文件,它使用 Grails <f:table/> 标签,该标签默认会显示类名(**com.nuevaconsulting.embrow.Position**)和持久化示例标识符(**30**)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可拍序列的一些非常简洁直观的东西。
|
||||
上面的命令 `generate-all` 生成的视图创建了一个叫 `index.gsp` 的文件,它使用 Grails `<f:table/>` 标签,该标签默认会显示类名(`com.nuevaconsulting.embrow.Position`)和持久化示例标识符(`30`)。这个操作可以自定义用来产生更好看的东西,并且自动生成链接,自动生成分页以及自动生成可排序列的一些非常简洁直观的东西。
|
||||
|
||||
但该员工信息浏览器功能也是有限的。例如,如果想查找 position 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,office 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
|
||||
但该员工信息浏览器功能也是有限的。例如,如果想查找 “position” 信息中包含 “dev” 的员工该怎么办?如果要组合排序,以姓氏为主排序关键字,“office” 为辅助排序关键字,该怎么办?或者,你需要将已排序的数据导出到电子表格或 PDF 文档以便通过电子邮件发送给无法访问浏览器的人,该怎么办?
|
||||
|
||||
jQuery DataTables 插件提供了这些所需的功能。允许你创建一个完成的表格数据浏览器。
|
||||
|
||||
### 创建员工信息浏览器视图和控制器的方法
|
||||
|
||||
要基于 jQuery DataTables 创建员工信息浏览器,你必须先完成以下两个任务:
|
||||
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
|
||||
|
||||
1. 创建 Grails 视图,其中包含启用 DataTable 所需的 HTML 和 JavaScript
|
||||
2. 给 Grails 控制器增加一个方法来控制新视图。
|
||||
|
||||
#### 员工信息浏览器视图
|
||||
|
||||
在目录 **embrow/grails-app/views/employee** 中,首先复制 **index.gsp** 文件,重命名为 **browser.gsp**:
|
||||
在目录 `embrow/grails-app/views/employee` 中,首先复制 `index.gsp` 文件,重命名为 `browser.gsp`:
|
||||
|
||||
```
|
||||
cd Projects
|
||||
@ -160,7 +161,7 @@ cd embrow/grails-app/views/employee
|
||||
cp gsp browser.gsp
|
||||
```
|
||||
|
||||
此刻,你自定义新的 **browser.gsp** 文件来添加相关的 jQuery DataTables 代码。
|
||||
此刻,你自定义新的 `browser.gsp` 文件来添加相关的 jQuery DataTables 代码。
|
||||
|
||||
通常,在可能的时候,我喜欢从内容提供商处获得 JavaScript 和 CSS;在下面这行后面:
|
||||
|
||||
@ -185,7 +186,7 @@ cp gsp browser.gsp
|
||||
<script type="text/javascript" charset="utf8" src="https://cdn.datatables.net/buttons/1.5.1/js/buttons.print.min.js "></script>
|
||||
```
|
||||
|
||||
然后删除 **index.gsp** 中提供数据分页的代码:
|
||||
然后删除 `index.gsp` 中提供数据分页的代码:
|
||||
|
||||
```
|
||||
<div id="list-employee" class="content scaffold-list" role="main">
|
||||
@ -253,7 +254,7 @@ $(this).html('<input type="text" size="15" placeholder="' + title + '?" />');
|
||||
});titletitletitletitletitle
|
||||
```
|
||||
|
||||
接下来,定义表模型。 这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 dom 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 Ajax 连接。 请注意,使用 Groovy GString 调用 Grails **createLink()** 的方法创建 URL,在 **EmployeeController** 中指向 **browserLister** 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
|
||||
接下来,定义表模型。这是提供所有表选项的地方,包括界面的滚动,而不是分页,根据 DOM 字符串提供的装饰,将数据导出为 CSV 和其他格式的能力,以及建立与服务器的 AJAX 连接。 请注意,使用 Groovy GString 调用 Grails `createLink()` 的方法创建 URL,在 `EmployeeController` 中指向 `browserLister` 操作。同样有趣的是表格列的定义。此信息将发送到后端,后端查询数据库并返回相应的记录。
|
||||
|
||||
```
|
||||
var table = $('#employee_dt').DataTable( {
|
||||
@ -302,7 +303,7 @@ that.search(this.value).draw();
|
||||
|
||||
|
||||
|
||||
这是另一个屏幕截图,显示了过滤和多列排序(寻找 position 包括字符 “dev” 的员工,先按 office 排序,然后按姓氏排序):
|
||||
这是另一个屏幕截图,显示了过滤和多列排序(寻找 “position” 包括字符 “dev” 的员工,先按 “office” 排序,然后按姓氏排序):
|
||||
|
||||
|
||||
|
||||
@ -314,37 +315,37 @@ that.search(this.value).draw();
|
||||
|
||||
|
||||
|
||||
好的,视图部分看起来非常简单; 因此,控制器必须做所有繁重的工作,对吧? 让我们来看看…
|
||||
好的,视图部分看起来非常简单;因此,控制器必须做所有繁重的工作,对吧? 让我们来看看……
|
||||
|
||||
#### 控制器 browserLister 操作
|
||||
|
||||
回想一下,我们看到过这个字符串
|
||||
回想一下,我们看到过这个字符串:
|
||||
|
||||
```
|
||||
"${createLink(controller: 'employee', action: 'browserLister')}"
|
||||
```
|
||||
|
||||
对于从 DataTables 模型中调用 Ajax 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()][17] 的方法实现的。这会最终产生一个指向 **EmployeeController** 的链接,位于:
|
||||
对于从 DataTables 模型中调用 AJAX 的 URL,是在 Grails 服务器上动态创建 HTML 链接,其 Grails 标记背后通过调用 [createLink()][17] 的方法实现的。这会最终产生一个指向 `EmployeeController` 的链接,位于:
|
||||
|
||||
```
|
||||
embrow/grails-app/controllers/com/nuevaconsulting/embrow/EmployeeController.groovy
|
||||
```
|
||||
|
||||
特别是控制器方法 **browserLister()**。我在代码中留了一些 print 语句,以便在运行时能够在终端看到中间结果。
|
||||
特别是控制器方法 `browserLister()`。我在代码中留了一些 `print` 语句,以便在运行时能够在终端看到中间结果。
|
||||
|
||||
```
|
||||
def browserLister() {
|
||||
// Applies filters and sorting to return a list of desired employees
|
||||
```
|
||||
|
||||
首先,打印出传递给 **browserLister()** 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
|
||||
首先,打印出传递给 `browserLister()` 的参数。我通常使用此代码开始构建控制器方法,以便我完全清楚我的控制器正在接收什么。
|
||||
|
||||
```
|
||||
println "employee browserLister params $params"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 **jqdtParams**的 Groovy 映射:
|
||||
接下来,处理这些参数以使它们更加有用。首先,jQuery DataTables 参数,一个名为 `jqdtParams` 的 Groovy 映射:
|
||||
|
||||
```
|
||||
def jqdtParams = [:]
|
||||
@ -363,7 +364,7 @@ println "employee dataTableParams $jqdtParams"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,列数据,一个名为 **columnMap**的 Groovy 映射:
|
||||
接下来,列数据,一个名为 `columnMap` 的 Groovy 映射:
|
||||
|
||||
```
|
||||
def columnMap = jqdtParams.columns.collectEntries { k, v ->
|
||||
@ -386,7 +387,7 @@ println "employee columnMap $columnMap"
|
||||
println()
|
||||
```
|
||||
|
||||
接下来,从 **columnMap** 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 **allColumnList**和 **orderList**:
|
||||
接下来,从 `columnMap` 中检索的所有列表,以及在视图中应如何排序这些列表,Groovy 列表分别称为 `allColumnList` 和 `orderList` :
|
||||
|
||||
```
|
||||
def allColumnList = columnMap.keySet() as List
|
||||
@ -395,7 +396,7 @@ def orderList = jqdtParams.order.collect { k, v -> [allColumnList[v.column as In
|
||||
println "employee orderList $orderList"
|
||||
```
|
||||
|
||||
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭; 在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 **createAlias** 以允许我们进入相关类别 Position 和 Office:
|
||||
我们将使用 Grails 的 Hibernate 标准实现来实际选择要显示的元素以及它们的排序和分页。标准要求过滤器关闭;在大多数示例中,这是作为标准实例本身的创建的一部分给出的,但是在这里我们预先定义过滤器闭包。请注意,在这种情况下,“date hired” 过滤器的相对复杂的解释被视为一年并应用于建立日期范围,并使用 `createAlias` 以允许我们进入相关类别 `Position` 和 `Office`:
|
||||
|
||||
```
|
||||
def filterer = {
|
||||
@ -424,14 +425,14 @@ def filterer = {
|
||||
}
|
||||
```
|
||||
|
||||
是时候应用上述内容了。第一步是获取分页代码所需的所有 Employee 实例的总数:
|
||||
是时候应用上述内容了。第一步是获取分页代码所需的所有 `Employee` 实例的总数:
|
||||
|
||||
```
|
||||
def recordsTotal = Employee.count()
|
||||
println "employee recordsTotal $recordsTotal"
|
||||
```
|
||||
|
||||
接下来,将过滤器应用于 Employee 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
|
||||
接下来,将过滤器应用于 `Employee` 实例以获取过滤结果的计数,该结果将始终小于或等于总数(同样,这是针对分页代码):
|
||||
|
||||
```
|
||||
def c = Employee.createCriteria()
|
||||
@ -467,7 +468,7 @@ def filterer = {
|
||||
|
||||
要完全清楚,JTable 中的分页代码管理三个计数:数据集中的记录总数,应用过滤器后得到的数字,以及要在页面上显示的数字(显示是滚动还是分页)。 排序应用于所有过滤的记录,并且分页应用于那些过滤的记录的块以用于显示目的。
|
||||
|
||||
接下来,处理命令返回的结果,在每行中创建指向 Employee,Position 和 Office 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
|
||||
接下来,处理命令返回的结果,在每行中创建指向 `Employee`、`Position` 和 `Office` 实例的链接,以便用户可以单击这些链接以获取相关实例的所有详细信息:
|
||||
|
||||
```
|
||||
def dollarFormatter = new DecimalFormat('$##,###.##')
|
||||
@ -490,14 +491,15 @@ def filterer = {
|
||||
}
|
||||
```
|
||||
|
||||
大功告成
|
||||
大功告成。
|
||||
|
||||
如果你熟悉 Grails,这可能看起来比你原先想象的要多,但这里没有火箭式的一步到位方法,只是很多分散的操作步骤。但是,如果你没有太多接触 Grails(或 Groovy),那么需要了解很多新东西 - 闭包,代理和构建器等等。
|
||||
|
||||
在那种情况下,从哪里开始? 最好的地方是了解 Groovy 本身,尤其是 [Groovy closures][18] 和 [Groovy delegates and builders][19]。然后再去阅读上面关于 Grails 和 Hibernate 条件查询的建议阅读文章。
|
||||
|
||||
### 结语
|
||||
|
||||
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
|
||||
jQuery DataTables 为 Grails 制作了很棒的表格数据浏览器。对视图进行编码并不是太棘手,但 DataTables 文档中提供的 PHP 示例提供的功能仅到此位置。特别是,它们不是用 Grails 程序员编写的,也不包含探索使用引用其他类(实质上是查找表)的元素的更精细的细节。
|
||||
|
||||
我使用这种方法制作了几个数据浏览器,允许用户选择要查看和累积记录计数的列,或者只是浏览数据。即使在相对适度的 VPS 上的百万行表中,性能也很好。
|
||||
|
||||
@ -512,7 +514,7 @@ via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -528,11 +530,11 @@ via: https://opensource.com/article/18/9/using-grails-jquery-and-datatables
|
||||
[9]: http://sdkman.io/
|
||||
[10]: http://guides.grails.org/creating-your-first-grails-app/guide/index.html
|
||||
[11]: https://opensource.com/file/410061
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png "Embrow home screen"
|
||||
[12]: https://opensource.com/sites/default/files/uploads/screen_1.png
|
||||
[13]: https://opensource.com/file/410066
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png "Office list screenshot"
|
||||
[14]: https://opensource.com/sites/default/files/uploads/screen_2.png
|
||||
[15]: https://opensource.com/file/410071
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png "Employee controller screenshot"
|
||||
[16]: https://opensource.com/sites/default/files/uploads/screen3.png
|
||||
[17]: https://gsp.grails.org/latest/ref/Tags/createLink.html
|
||||
[18]: http://groovy-lang.org/closures.html
|
||||
[19]: http://groovy-lang.org/dsls.html
|
||||
@ -1,7 +1,7 @@
|
||||
容器技术对 DevOps 的一些启发
|
||||
======
|
||||
|
||||
容器技术的使用支撑了目前 DevOps 三大主要实践:工作流,及时反馈,持续学习。
|
||||
> 容器技术的使用支撑了目前 DevOps 三大主要实践:工作流、及时反馈、持续学习。
|
||||
|
||||
|
||||
|
||||
@ -11,11 +11,11 @@
|
||||
|
||||
#### 容器中的工作流
|
||||
|
||||
每个容器都可以看成一个独立的运行环境,对于容器内部,不需要考虑外部的宿主环境、集群环境、以及其它基础设施。在容器内部,每个功能看起来都是以传统的方式运行。从外部来看,容器内运行的应用一般作为整个应用系统架构的一部分:比如 web API,web app 用户界面,数据库,任务执行,缓存系统,垃圾回收等。运维团队一般会限制容器的资源使用,并在此基础上建立完善的容器性能监控服务,从而降低其对基础设施或者下游其他用户的影响。
|
||||
每个容器都可以看成一个独立的运行环境,对于容器内部,不需要考虑外部的宿主环境、集群环境,以及其它基础设施。在容器内部,每个功能看起来都是以传统的方式运行。从外部来看,容器内运行的应用一般作为整个应用系统架构的一部分:比如 web API、web app 用户界面、数据库、任务执行、缓存系统、垃圾回收等。运维团队一般会限制容器的资源使用,并在此基础上建立完善的容器性能监控服务,从而降低其对基础设施或者下游其他用户的影响。
|
||||
|
||||
#### 现实中的工作流
|
||||
|
||||
那些跟“容器”一样业务功能独立的团队,也可以借鉴这种容器思维。因为无论是在现实生活中的工作流(代码发布、构建基础设施,甚至制造 [Spacely’s Sprockets][2] 等),还是技术中的工作流(开发、测试、运维、发布)都使用了这样的线性工作流,一旦某个独立的环节或者工作团队出现了问题,那么整个下游都会受到影响,虽然使用这种线性的工作流有效降低了工作耦合性。
|
||||
那些跟“容器”一样业务功能独立的团队,也可以借鉴这种容器思维。因为无论是在现实生活中的工作流(代码发布、构建基础设施,甚至制造 [《杰森一家》中的斯贝斯利太空飞轮][2] 等),还是技术中的工作流(开发、测试、运维、发布)都使用了这样的线性工作流,一旦某个独立的环节或者工作团队出现了问题,那么整个下游都会受到影响,虽然使用这种线性的工作流有效降低了工作耦合性。
|
||||
|
||||
#### DevOps 中的工作流
|
||||
|
||||
@ -23,7 +23,7 @@ DevOps 中的第一条原则,就是掌控整个执行链路的情况,努力
|
||||
|
||||
> 践行这样的工作流后,可以避免将一个已知缺陷带到工作流的下游,避免局部优化导致可能的全局性能下降,要不断探索如何优化工作流,持续加深对于系统的理解。
|
||||
|
||||
—— Gene Kim,[支撑 DevOps 的三个实践][3],IT 革命,2017.4.25
|
||||
> —— Gene Kim,《[支撑 DevOps 的三个实践][3]》,IT 革命,2017.4.25
|
||||
|
||||
### 反馈
|
||||
|
||||
@ -33,7 +33,7 @@ DevOps 中的第一条原则,就是掌控整个执行链路的情况,努力
|
||||
|
||||
#### 现实中的反馈
|
||||
|
||||
在现实中,从始至终同样也需要反馈。一个高效的处理流程中,及时的反馈能够快速地定位事情发生的时间。反馈的关键词是“快速”和“相关”。当一个团队被淹没在大量不相关的事件时,那些真正需要快速反馈的重要信息很容易被忽视掉,并向下游传递形成更严重的问题。想象下[如果露西和埃塞尔][6]能够很快地意识到:传送带太快了,那么制作出的巧克力可能就没什么问题了(尽管这样就不那么搞笑了)。
|
||||
在现实中,从始至终同样也需要反馈。一个高效的处理流程中,及时的反馈能够快速地定位事情发生的时间。反馈的关键词是“快速”和“相关”。当一个团队被淹没在大量不相关的事件时,那些真正需要快速反馈的重要信息很容易被忽视掉,并向下游传递形成更严重的问题。想象下[如果露西和埃塞尔][6]能够很快地意识到:传送带太快了,那么制作出的巧克力可能就没什么问题了(尽管这样就不那么搞笑了)。(LCTT 译注:露西和埃塞尔是上世纪 50 年代的著名黑白情景喜剧《我爱露西》中的主角)
|
||||
|
||||
#### DevOps 中的反馈
|
||||
|
||||
@ -41,7 +41,7 @@ DevOps 中的第二条原则,就是快速收集所有相关的有用信息,
|
||||
|
||||
> 快速的反馈对于提高技术的质量、可用性、安全性至关重要。
|
||||
|
||||
—— Gene Kim 及其他,DevOps 手册:如何在技术组织中创造世界级的敏捷性,可靠性和安全性,IT 革命,2016
|
||||
> —— Gene Kim 等人,《DevOps 手册:如何在技术组织中创造世界级的敏捷性,可靠性和安全性》,IT 革命,2016
|
||||
|
||||
### 持续学习
|
||||
|
||||
@ -71,7 +71,7 @@ DevOps 中的第二条原则,就是快速收集所有相关的有用信息,
|
||||
|
||||
> 实验和冒险让我们能够不懈地改进我们的工作,但也要求我们尝试之前未用过的工作方式。
|
||||
|
||||
—— Gene Kim 及其他,[凤凰计划:让你了解 IT、DevOps 以及如何取得商业成功][7],IT 革命,2013
|
||||
> —— Gene Kim 等人,《[凤凰计划:让你了解 IT、DevOps 以及如何取得商业成功][7]》,IT 革命,2013
|
||||
|
||||
### 容器技术带给 DevOps 的启迪
|
||||
|
||||
@ -84,7 +84,7 @@ via: https://opensource.com/article/18/9/containers-can-teach-us-devops
|
||||
作者:[Chris Hermansen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[littleji](https://github.com/littleji)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
使用 Pandoc 将你的书转换成网页和电子书
|
||||
======
|
||||
|
||||
通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
> 通过 Markdown 和 Pandoc,可以做到编写一次,发布两次。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我的 [Pandoc 简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。在我 [对 Pandoc 的简介][1] 一文中,我演示了如何把 Markdown 编写的文本转换为网页、幻灯片和 PDF。
|
||||
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书-- [面向对象思想的 GRASP 原则][3] 为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
在这篇后续文章中,我将深入探讨 [Pandoc][2],展示如何从同一个 Markdown 源文件生成网页和 ePub 格式的电子书。我将使用我即将发布的电子书《[面向对象思想的 GRASP 原则][3]》为例进行讲解,这本电子书正是通过以下过程创建的。
|
||||
|
||||
首先,我将解释这本书使用的文件结构,然后介绍如何使用 Pandoc 生成网页并将其部署在 GitHub 上;最后,我演示了如何生成对应的 ePub 格式电子书。
|
||||
|
||||
@ -15,7 +15,7 @@ Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为
|
||||
|
||||
### 设置图书结构
|
||||
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
我用 Markdown 语法完成了所有的写作,你也可以使用 HTML 标记,但是当 Pandoc 将 Markdown 转换为 ePub 文档时,引入的 HTML 标记越多,出现问题的风险就越高。我的书按照每章一个文件的形式进行组织,用 Markdown 的 `H1` 标记(`#`)声明每章的标题。你也可以在每个文件中放置多个章节,但将它们放在单独的文件中可以更轻松地查找内容并在以后进行更新。
|
||||
|
||||
元信息遵循类似的模式,每种输出格式都有自己的元信息文件。元信息文件定义有关文档的信息,例如要添加到 HTML 中的文本或 ePub 的许可证。我将所有 Markdown 文档存储在名为 `parts` 的文件夹中(这对于用来生成网页和 ePub 的 Makefile 非常重要)。下面以一个例子进行说明,让我们看一下目录,前言和关于本书(分为 `toc.md`、`preface.md` 和 `about.md` 三个文件)这三部分,为清楚起见,我们将省略其余的章节。
|
||||
|
||||
@ -48,60 +48,60 @@ author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
\```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
\```
|
||||
```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
```
|
||||
include-before:
|
||||
- |
|
||||
\```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
\```
|
||||
```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
\```
|
||||
---:
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
```
|
||||
---
|
||||
```
|
||||
|
||||
下面几个变量需要注意一下:
|
||||
|
||||
- `header-includes` 变量包含将要嵌入 `<head>` 标签的 HTML 文本。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与`|`对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我要求读者帮忙宣传我的书或给我打赏。
|
||||
- 调用变量后的下一行必须是 `- |`。再往下一行必须以与 `|` 对齐的三个反引号开始,否则 Pandoc 将无法识别。`{= html}` 告诉 Pandoc 其中的内容是原始文本,不应该作为 Markdown 处理。(为此,需要检查 Pandoc 中的 `raw_attribute` 扩展是否已启用。要进行此检查,键入 `pandoc --list-extensions | grep raw` 并确保返回的列表包含名为 `+ raw_html` 的项目,加号表示已启用。)
|
||||
- 变量 `include-before` 在网页开头添加一些 HTML 文本,此处我请求读者帮忙宣传我的书或给我打赏。
|
||||
- `include-after` 变量在网页末尾添加原始 HTML 文本,同时显示我的图书许可证。
|
||||
|
||||
这些只是其中一部分可用的变量,查看 HTML 中的模板变量(我的文章 [Pandoc简介][1] 中介绍了如何查看 LaTeX 的模版变量,查看 HTML 模版变量的过程是相同的)对其余变量进行了解。
|
||||
|
||||
#### 将网页分成多章
|
||||
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。 我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
网页可以作为一个整体生成,这会产生一个包含所有内容的长页面;也可以分成多章,我认为这样会更容易阅读。我将解释如何将网页划分为多章,以便读者不会被长网页吓到。
|
||||
|
||||
为了使网页易于在 GitHub Pages 上部署,需要创建一个名为 `docs` 的根文件夹(这是 GitHub Pages 默认用于渲染网页的根文件夹)。然后我们需要为 `docs` 下的每一章创建文件夹,将 HTML 内容放在各自的文件夹中,将文件内容放在名为 `index.html` 的文件中。
|
||||
|
||||
例如,`about.md` 文件将转换成名为 `index.html` 的文件,该文件位于名为 `about`(`about/index.html`)的文件夹中。这样,当用户键入 `http://<your-website.com>/about/` 时,文件夹中的 `index.html` 文件将显示在其浏览器中。
|
||||
|
||||
下面的 Makefile 将执行上述所有操作:
|
||||
下面的 `Makefile` 将执行上述所有操作:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
@ -149,6 +149,7 @@ clean:
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
根文件夹现在应该包含如下所示的文件结构:
|
||||
|
||||
```
|
||||
@ -200,7 +201,7 @@ stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
将以下内容添加到之前的 Makefile 中:
|
||||
将以下内容添加到之前的 `Makefile` 中:
|
||||
|
||||
```
|
||||
epub:
|
||||
@ -208,7 +209,7 @@ epub:
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 Makefile 将会这样调用:
|
||||
用于产生 ePub 格式图书的命令从 HTML 版本获取所有依赖项(每章的名称),向它们添加 Markdown 扩展,并在它们前面加上每一章的文件夹路径,以便让 Pandoc 知道如何进行处理。例如,如果 `$(DEPENDENCIES` 变量只包含 “前言” 和 “关于本书” 两章,那么 `Makefile` 将会这样调用:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
@ -226,18 +227,17 @@ Pandoc 将提取这两章的内容,然后进行组合,最后生成 ePub 格
|
||||
- HTML 图书:
|
||||
- 使用 Markdown 语法创建每章内容
|
||||
- 添加元信息
|
||||
- 创建一个 Makefile 将各个部分组合在一起
|
||||
- 创建一个 `Makefile` 将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
- ePub 电子书:
|
||||
- 使用之前创建的每一章内容
|
||||
- 添加新的元信息文件
|
||||
- 创建一个 Makefile 以将各个部分组合在一起
|
||||
- 创建一个 `Makefile` 以将各个部分组合在一起
|
||||
- 设置 GitHub Pages
|
||||
- 部署
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
@ -245,12 +245,12 @@ via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://opensource.com/article/18/9/intro-pandoc
|
||||
[1]: https://linux.cn/article-10228-1.html
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
@ -1,42 +1,42 @@
|
||||
|
||||
Greg Kroah-Hartman 解释内核社区如何保护 Linux
|
||||
============================================================
|
||||
Greg Kroah-Hartman 解释内核社区是如何使 Linux 安全的
|
||||
============
|
||||
|
||||

|
||||
内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。[Creative Commons Zero][2]
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高全世界最广泛使用的技术 — Linux 内核的安全性的重要程序越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
> 内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高这个世界上使用最广泛的技术 —— Linux 内核的安全性的重要性越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
|
||||
### bug 不可避免
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman [Linux 基金会][1]
|
||||
*Greg Kroah-Hartman [Linux 基金会][1]*
|
||||
|
||||
正如 Linus Torvalds 曾经说过,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是个软件就有 bug。
|
||||
正如 Linus Torvalds 曾经说过的,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是软件就有 bug。
|
||||
|
||||
Kroah-Hartman 说:“就算是 bug ,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
Kroah-Hartman 说:“就算是 bug,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
|
||||
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
|
||||
|
||||
Kroah Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
Kroah-Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
|
||||
Kroah Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
Kroah-Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah Hartman 说:“我们意识到,我们需要一些主动的缓减措施。因此我们需要加固内核。”
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah-Hartman 说:“我们意识到,我们需要一些主动的缓减措施,因此我们需要加固内核。”
|
||||
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商必须要启用这些新特性来让它们充分发挥作用。但他们并没有这么做。
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商们必须要启用这些新特性来让它们充分发挥作用,但他们并没有这么做。
|
||||
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长周期的支持,公司只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长期的支持,公司们只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核”。“我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 — SoC 制造商、运营商、等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核。……我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 —— SoC 制造商、运营商等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。”
|
||||
|
||||
好消息是,与消息电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod、和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
好消息是,与消费电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod 和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
|
||||
### Meltdown 和 Spectre
|
||||
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre 缺陷。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
|
||||
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
|
||||
|
||||
@ -57,7 +57,7 @@ via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-c
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||

|
||||
|
||||
几周前,Steam 宣布要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
之前,Steam [宣布][1]要给 Steam Play 增加一个新组件,用于支持在 Linux 平台上使用 Proton 来玩 Windows 的游戏,这个组件是 WINE 的一个分支。这个功能仍然处于测试阶段,且并非对所有游戏都有效。这里有一些关于 Steam 和 Proton 的细节。
|
||||
|
||||
据 Steam 网站称,测试版本中有以下这些新功能:
|
||||
|
||||
@ -13,29 +13,27 @@
|
||||
* 改进了对游戏控制器的支持,游戏自动识别所有 Steam 支持的控制器,比起游戏的原始版本,能够获得更多开箱即用的控制器兼容性。
|
||||
* 和 vanilla WINE 比起来,游戏的多线程性能得到了极大的提高。
|
||||
|
||||
|
||||
|
||||
### 安装
|
||||
|
||||
如果你有兴趣,想尝试一下 Steam 和 Proton。请按照下面这些简单的步骤进行操作。(请注意,如果你已经安装了最新版本的 Steam,可以忽略启用 Steam 测试版这个第一步。在这种情况下,你不再需要通过 Steam 测试版来使用 Proton。)
|
||||
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持22个游戏。
|
||||
打开 Steam 并登陆到你的帐户,这个截屏示例显示的是在使用 Proton 之前仅支持 22 个游戏。
|
||||
|
||||
![][3]
|
||||
|
||||
现在点击客户端顶部的 Steam 选项,这会显示一个下拉菜单。然后选择设置。
|
||||
现在点击客户端顶部的 “Steam” 选项,这会显示一个下拉菜单。然后选择“设置”。
|
||||
|
||||
![][4]
|
||||
|
||||
现在弹出了设置窗口,选择账户选项,并在 Beta participation 旁边,点击更改。
|
||||
现在弹出了设置窗口,选择“账户”选项,并在 “参与 Beta 测试” 旁边,点击“更改”。
|
||||
|
||||
![][5]
|
||||
|
||||
现在将 None 更改为 Steam Beta Update。
|
||||
现在将 “None” 更改为 “Steam Beta Update”。
|
||||
|
||||
![][6]
|
||||
|
||||
点击确定,然后系统会提示你重新启动。
|
||||
点击“确定”,然后系统会提示你重新启动。
|
||||
|
||||
![][7]
|
||||
|
||||
@ -43,11 +41,11 @@
|
||||
|
||||
![][8]
|
||||
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定有为提供支持的游戏使用 Stream Play 这个复选框,让所有的游戏都使用 Steam Play 进行运行,而不是 steam 中游戏特定的选项。兼容性工具应该是 Proton。
|
||||
在重新启动之后,返回到上面的设置窗口。这次你会看到一个新选项。确定勾选了“为提供支持的游戏使用 Stream Play” 、“让所有的游戏都使用 Steam Play 运行”,“使用这个工具替代 Steam 中游戏特定的选项”。这个兼容性工具应该就是 Proton。
|
||||
|
||||
![][9]
|
||||
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
Steam 客户端会要求你重新启动,照做,然后重新登录你的 Steam 账户,你的 Linux 的游戏库就能得到扩展了。
|
||||
|
||||
![][10]
|
||||
|
||||
@ -69,7 +67,7 @@ Steam 客户端会要求你重新启动,照做,然后重新登陆你的 Stea
|
||||
|
||||
![][16]
|
||||
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在下面这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
一些游戏可能会受到 Proton 测试性质的影响,在这个叫 Chantelise 游戏中,没有了声音并且帧率很低。请记住这个功能仍然在测试阶段,Fedora 不会对结果负责。如果你想要了解更多,社区已经创建了一个 Google 文档,这个文档里有已经测试过的游戏的列表。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -79,25 +77,25 @@ via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
作者:[Francisco J. Vergara Torres][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/patxi/
|
||||
[1]: https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561
|
||||
[2]: https://fedoramagazine.org/third-party-repositories-fedora/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-300x197.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-300x169.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-300x196.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4-300x272.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6-300x237.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7-300x126.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10-300x237.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-300x196.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-300x196.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-300x195.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-300x196.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-300x195.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-300x169.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-300x169.png
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-768x505.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-768x432.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-768x503.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-768x503.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-768x501.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-768x498.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-768x501.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-768x500.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-768x432.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-768x432.png
|
||||
[17]: https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831
|
||||
@ -30,6 +30,8 @@ Lisp 是怎么成为上帝的编程语言的
|
||||
> 我知道,上帝偏爱那一门
|
||||
|
||||
> 名字是四个字母的语言。
|
||||
|
||||
(LCTT 译注:参见 “四个字母”,参见:[四字神名](https://zh.wikipedia.org/wiki/%E5%9B%9B%E5%AD%97%E7%A5%9E%E5%90%8D),致谢 [no1xsyzy](https://github.com/LCTT/TranslateProject/issues/11320))
|
||||
|
||||
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种 “Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们[开始怂恿彼此,“在你死掉之前至少试一试 Lisp”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁)[^1] ,程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?—— 但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||
|
||||
@ -83,7 +85,7 @@ SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日
|
||||
|
||||
*SICP 封面上的画作。*
|
||||
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 微积分之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 演算之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||
|
||||
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智、复数的计算机程序,和计算机”的作品 [^19]。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“<ruby>程序性认识论<rt>procedural epistemology</rt></ruby>”的一种新表达方式 [^20]。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对论中一样关键 [^21]。都是些高深难懂的东西。
|
||||
|
||||
@ -97,7 +99,7 @@ SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日
|
||||
|
||||
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是保罗·格雷厄姆发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。保罗·格雷厄姆是 Y-Combinator 的联合创始人和《Hacker News》的创始者,他这几篇短文有很大的影响力。例如,在短文《<ruby>[胜于平庸][20]<rt>Beating the Averages</rt></ruby>》中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表理解。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表推导式。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如格雷厄姆之前在 2001 年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化” [^23]。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,麦卡锡写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优” [^24]。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
什么是 SRE?它和 DevOps 是怎么关联的?
|
||||
=====
|
||||
|
||||
大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
> 大型企业里 SRE 角色比较常见,不过小公司也需要 SRE。
|
||||
|
||||

|
||||
|
||||
虽然站点可靠性工程师(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
虽然<ruby>站点可靠性工程师<rt>site reliability engineer</rt></ruby>(SRE)角色在近几年变得流行起来,但是很多人 —— 甚至是软件行业里的 —— 还不知道 SRE 是什么或者 SRE 都干些什么。为了搞清楚这些问题,这篇文章解释了 SRE 的含义,还有 SRE 怎样关联 DevOps,以及在工程师团队规模不大的组织里 SRE 该如何工作。
|
||||
|
||||
### 什么是站点可靠性工程?
|
||||
|
||||
谷歌的几个工程师写的《 [SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
谷歌的几个工程师写的《[SRE:谷歌运维解密][1]》被认为是站点可靠性工程的权威书籍。谷歌的工程副总裁 Ben Treynor Sloss 在二十一世纪初[创造了这个术语][2]。他是这样定义的:“当你让软件工程师设计运维功能时,SRE 就产生了。”
|
||||
|
||||
虽然系统管理员从很久之前就在写代码,但是过去的很多时候系统管理团队是手动管理机器的。当时他们管理的机器可能有几十台或者上百台,不过当这个数字涨到了几千甚至几十万的时候,就不能简单的靠人去解决问题了。规模如此大的情况下,很明显应该用代码去管理机器(以及机器上运行的软件)。
|
||||
|
||||
@ -19,13 +19,13 @@
|
||||
|
||||
### SRE 和 DevOps
|
||||
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“devs”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
站点可靠性工程的核心,就是对 DevOps 范例的实践。[DevOps 的定义][3]有很多种方式。开发团队(“dev”)和运维(“ops”)团队相互分离的传统模式下,写代码的团队在将服务交付给用户使用之后就不再对服务状态负责了。开发团队“把代码扔到墙那边”让运维团队去部署和支持。
|
||||
|
||||
这种情况会导致大量失衡。开发和运维的目标总是不一致 —— 开发希望用户体验到“最新最棒”的代码,但是运维想要的是变更尽量少的稳定系统。运维是这样假定的,任何变更都可能引发不稳定,而不做任何变更的系统可以一直保持稳定。(减少软件的变更次数并不是避免故障的唯一因素,认识到这一点很重要。例如,虽然你的 web 应用保持不变,但是当用户数量涨到十倍时,服务可能就会以各种方式出问题。)
|
||||
|
||||
DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开发团队时刻都想把新代码部署上线,那么他们也必须对新代码引起的故障负责。就像亚马逊的 [Werner Vogels 说的][4]那样,“谁开发,谁运维”(生产环境)。但是开发人员已经有一大堆问题了。他们不断的被推动着去开发老板要的产品功能。再让他们去了解基础设施,包括如何部署、配置还有监控服务,这对他们的要求有点太多了。所以就需要 SRE 了。
|
||||
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师,图形设计师,前端工程师,后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署,配置,监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
开发一个 web 应用的时候经常是很多人一起参与。有用户界面设计师、图形设计师、前端工程师、后端工程师,还有许多其他工种(视技术选型的具体情况而定)。如何管理写好的代码也是需求之一(例如部署、配置、监控)—— 这是 SRE 的专业领域。但是,就像前端工程师受益于后端领域的知识一样(例如从数据库获取数据的方法),SRE 理解部署系统的工作原理,知道如何满足特定的代码或者项目的具体需求。
|
||||
|
||||
所以 SRE 不仅仅是“写代码的运维工程师”。相反,SRE 是开发团队的成员,他们有着不同的技能,特别是在发布部署、配置管理、监控、指标等方面。但是,就像前端工程师必须知道如何从数据库中获取数据一样,SRE 也不是只负责这些领域。为了提供更容易升级、管理和监控的产品,整个团队共同努力。
|
||||
|
||||
@ -37,7 +37,7 @@ DevOps 理念认为通过合并这两个岗位就能够消灭争论。如果开
|
||||
|
||||
让开发人员做 SRE 最显著的优点是,团队规模变大的时候也能很好的扩展。而且,开发人员将会全面地了解应用的特性。但是,许多初创公司的基础设施包含了各种各样的 SaaS 产品,这种多样性在基础设施上体现的最明显,因为连基础设施本身也是多种多样。然后你们在某个基础设施上引入指标系统、站点监控、日志分析、容器等等。这些技术解决了一部分问题,也增加了复杂度。开发人员除了要了解应用程序的核心技术(比如开发语言),还要了解上述所有技术和服务。最终,掌握所有的这些技术让人无法承受。
|
||||
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“ 三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
另一种方案是聘请专家专职做 SRE。他们专注于发布部署、配置管理、监控和指标,可以节省开发人员的时间。这种方案的缺点是,SRE 的时间必须分配给多个不同的应用(就是说 SRE 需要贯穿整个工程部门)。 这可能意味着 SRE 没时间对任何应用深入学习,然而他们可以站在一个能看到服务全貌的高度,知道各个部分是怎么组合在一起的。 这个“三万英尺高的视角”可以帮助 SRE 从系统整体上考虑,哪些薄弱环节需要优先修复。
|
||||
|
||||
有一个关键信息我还没提到:其他的工程师。他们可能很渴望了解发布部署的原理,也很想尽全力学会使用指标系统。而且,雇一个 SRE 可不是一件简单的事儿。因为你要找的是一个既懂系统管理又懂软件工程的人。(我之所以明确地说软件工程而不是说“能写代码”,是因为除了写代码之外软件工程还包括很多东西,比如编写良好的测试或文档。)
|
||||
|
||||
@ -54,7 +54,7 @@ via: https://opensource.com/article/18/10/sre-startup
|
||||
作者:[Craig Sebenik][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[BeliteX](https://github.com/belitex)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user