mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
commit
4966949151
@ -0,0 +1,230 @@
|
||||
Linux 包管理基础:apt、yum、dnf 和 pkg
|
||||
========================
|
||||
|
||||
![Package_Management_tw_mostov.png-307.8kB][1]
|
||||
|
||||
### 介绍
|
||||
|
||||
大多数现代的类 Unix 操作系统都提供了一种中心化的机制用来搜索和安装软件。软件通常都是存放在存储库中,并通过包的形式进行分发。处理包的工作被称为包管理。包提供了操作系统的基本组件,以及共享的库、应用程序、服务和文档。
|
||||
|
||||
包管理系统除了安装软件外,它还提供了工具来更新已经安装的包。包存储库有助于确保你的系统中使用的代码是经过审查的,并且软件的安装版本已经得到了开发人员和包维护人员的认可。
|
||||
|
||||
在配置服务器或开发环境时,我们最好了解下包在官方存储库之外的情况。某个发行版的稳定版本中的包有可能已经过时了,尤其是那些新的或者快速迭代的软件。然而,包管理无论对于系统管理员还是开发人员来说都是至关重要的技能,而已打包的软件对于主流 Linux 发行版来说也是一笔巨大的财富。
|
||||
|
||||
本指南旨在快速地介绍下在多种 Linux 发行版中查找、安装和升级软件包的基础知识,并帮助您将这些内容在多个系统之间进行交叉对比。
|
||||
|
||||
### 包管理系统:简要概述
|
||||
|
||||
大多数包系统都是围绕包文件的集合构建的。包文件通常是一个存档文件,它包含已编译的二进制文件和软件的其他资源,以及安装脚本。包文件同时也包含有价值的元数据,包括它们的依赖项,以及安装和运行它们所需的其他包的列表。
|
||||
|
||||
虽然这些包管理系统的功能和优点大致相同,但打包格式和工具却因平台而异:
|
||||
|
||||
| 操作系统 | 格式 | 工具 |
|
||||
| --- | --- | --- |
|
||||
| Debian | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| Ubuntu | `.deb` | `apt`, `apt-cache`, `apt-get`, `dpkg` |
|
||||
| CentOS | `.rpm` | `yum` |
|
||||
| Fedora | `.rpm` | `dnf` |
|
||||
| FreeBSD | Ports, `.txz` | `make`, `pkg` |
|
||||
|
||||
Debian 及其衍生版,如 Ubuntu、Linux Mint 和 Raspbian,它们的包格式是 `.deb`。APT 这款先进的包管理工具提供了大多数常见的操作命令:搜索存储库、安装软件包及其依赖项,并管理升级。在本地系统中,我们还可以使用 `dpkg` 程序来安装单个的 `deb` 文件,APT 命令作为底层 `dpkg` 的前端,有时也会直接调用它。
|
||||
|
||||
最近发布的 debian 衍生版大多数都包含了 `apt` 命令,它提供了一个简洁统一的接口,可用于通常由 `apt-get` 和 `apt-cache` 命令处理的常见操作。这个命令是可选的,但使用它可以简化一些任务。
|
||||
|
||||
CentOS、Fedora 和其它 Red Hat 家族成员使用 RPM 文件。在 CentOS 中,通过 `yum` 来与单独的包文件和存储库进行交互。
|
||||
|
||||
在最近的 Fedora 版本中,`yum` 已经被 `dnf` 取代,`dnf` 是它的一个现代化的分支,它保留了大部分 `yum` 的接口。
|
||||
|
||||
FreeBSD 的二进制包系统由 `pkg` 命令管理。FreeBSD 还提供了 `Ports` 集合,这是一个存在于本地的目录结构和工具,它允许用户获取源码后使用 Makefile 直接从源码编译和安装包。
|
||||
|
||||
### 更新包列表
|
||||
|
||||
大多数系统在本地都会有一个和远程存储库对应的包数据库,在安装或升级包之前最好更新一下这个数据库。另外,`yum` 和 `dnf` 在执行一些操作之前也会自动检查更新。当然你可以在任何时候对系统进行更新。
|
||||
|
||||
| 系统 | 命令 |
|
||||
| --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get update` |
|
||||
| | `sudo apt update` |
|
||||
| CentOS | `yum check-update` |
|
||||
| Fedora | `dnf check-update` |
|
||||
| FreeBSD Packages | `sudo pkg update` |
|
||||
| FreeBSD Ports | `sudo portsnap fetch update` |
|
||||
|
||||
### 更新已安装的包
|
||||
|
||||
在没有包系统的情况下,想确保机器上所有已安装的软件都保持在最新的状态是一个很艰巨的任务。你将不得不跟踪数百个不同包的上游更改和安全警报。虽然包管理器并不能解决升级软件时遇到的所有问题,但它确实使你能够使用一些命令来维护大多数系统组件。
|
||||
|
||||
在 FreeBSD 上,升级已安装的 ports 可能会引入破坏性的改变,有些步骤还需要进行手动配置,所以在通过 `portmaster` 更新之前最好阅读下 `/usr/ports/UPDATING` 的内容。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get upgrade` | 只更新已安装的包 |
|
||||
| | `sudo apt-get dist-upgrade` | 可能会增加或删除包以满足新的依赖项 |
|
||||
| | `sudo apt upgrade` | 和 `apt-get upgrade` 类似 |
|
||||
| | `sudo apt full-upgrade` | 和 `apt-get dist-upgrade` 类似 |
|
||||
| CentOS | `sudo yum update` | |
|
||||
| Fedora | `sudo dnf upgrade` | |
|
||||
| FreeBSD Packages | `sudo pkg upgrade` | |
|
||||
| FreeBSD Ports | `less /usr/ports/UPDATING` | 使用 `less` 来查看 ports 的更新提示(使用上下光标键滚动,按 q 退出)。 |
|
||||
| | `cd /usr/ports/ports-mgmt/portmaster && sudo make install && sudo portmaster -a` | 安装 `portmaster` 然后使用它更新已安装的 ports |
|
||||
|
||||
### 搜索某个包
|
||||
|
||||
大多数发行版都提供针对包集合的图形化或菜单驱动的工具,我们可以分类浏览软件,这也是一个发现新软件的好方法。然而,查找包最快和最有效的方法是使用命令行工具进行搜索。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache search search_string` | |
|
||||
| | `apt search search_string` | |
|
||||
| CentOS | `yum search search_string` | |
|
||||
| | `yum search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| Fedora | `dnf search search_string` | |
|
||||
| | `dnf search all search_string` | 搜索所有的字段,包括描述 |
|
||||
| FreeBSD Packages | `pkg search search_string` | 通过名字进行搜索 |
|
||||
| | `pkg search -f search_string` | 通过名字进行搜索并返回完整的描述 |
|
||||
| | `pkg search -D search_string` | 搜索描述 |
|
||||
| FreeBSD Ports | `cd /usr/ports && make search name=package` | 通过名字进行搜索 |
|
||||
| | `cd /usr/ports && make search key=search_string` | 搜索评论、描述和依赖 |
|
||||
|
||||
### 查看某个软件包的信息
|
||||
|
||||
在安装软件包之前,我们可以通过仔细阅读包的描述来获得很多有用的信息。除了人类可读的文本之外,这些内容通常包括像版本号这样的元数据和包的依赖项列表。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `apt-cache show package` | 显示有关包的本地缓存信息 |
|
||||
| | `apt show package` | |
|
||||
| | `dpkg -s package` | 显示包的当前安装状态 |
|
||||
| CentOS | `yum info package` | |
|
||||
| | `yum deplist package` | 列出包的依赖 |
|
||||
| Fedora | `dnf info package` | |
|
||||
| | `dnf repoquery --requires package` | 列出包的依赖 |
|
||||
| FreeBSD Packages | `pkg info package` | 显示已安装的包的信息 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && cat pkg-descr` | |
|
||||
|
||||
### 从存储库安装包
|
||||
|
||||
知道包名后,通常可以用一个命令来安装它及其依赖。你也可以一次性安装多个包,只需将它们全部列出来即可。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get install package` | |
|
||||
| | `sudo apt-get install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo apt-get install -y package` | 在 `apt` 提示是否继续的地方直接默认 `yes` |
|
||||
| | `sudo apt install package` | 显示一个彩色的进度条 |
|
||||
| CentOS | `sudo yum install package` | |
|
||||
| | `sudo yum install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo yum install -y package` | 在 `yum` 提示是否继续的地方直接默认 `yes` |
|
||||
| Fedora | `sudo dnf install package` | |
|
||||
| | `sudo dnf install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| | `sudo dnf install -y package` | 在 `dnf` 提示是否继续的地方直接默认 `yes` |
|
||||
| FreeBSD Packages | `sudo pkg install package` | |
|
||||
| | `sudo pkg install package1 package2 ...` | 安装所有列出来的包 |
|
||||
| FreeBSD Ports | `cd /usr/ports/category/port && sudo make install` | 从源码构建安装一个 port |
|
||||
|
||||
### 从本地文件系统安装一个包
|
||||
|
||||
对于一个给定的操作系统,有时有些软件官方并没有提供相应的包,那么开发人员或供应商将需要提供包文件的下载。你通常可以通过 web 浏览器检索这些包,或者通过命令行 `curl` 来检索这些信息。将包下载到目标系统后,我们通常可以通过单个命令来安装它。
|
||||
|
||||
在 Debian 派生的系统上,`dpkg` 用来处理单个的包文件。如果一个包有未满足的依赖项,那么我们可以使用 `gdebi` 从官方存储库中检索它们。
|
||||
|
||||
在 CentOS 和 Fedora 系统上,`yum` 和 `dnf` 用于安装单个的文件,并且会处理需要的依赖。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo dpkg -i package.deb` | |
|
||||
| | `sudo apt-get install -y gdebi && sudo gdebi package.deb` | 安装 `gdebi`,然后使用 `gdebi` 安装 `package.deb` 并处理缺失的依赖|
|
||||
| CentOS | `sudo yum install package.rpm` | |
|
||||
| Fedora | `sudo dnf install package.rpm` | |
|
||||
| FreeBSD Packages | `sudo pkg add package.txz` | |
|
||||
| | `sudo pkg add -f package.txz` | 即使已经安装的包也会重新安装 |
|
||||
|
||||
### 删除一个或多个已安装的包
|
||||
|
||||
由于包管理器知道给定的软件包提供了哪些文件,因此如果某个软件不再需要了,它通常可以干净利落地从系统中清除这些文件。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `sudo apt-get remove package` | |
|
||||
| | `sudo apt remove package` | |
|
||||
| | `sudo apt-get autoremove` | 删除不需要的包 |
|
||||
| CentOS | `sudo yum remove package` | |
|
||||
| Fedora | `sudo dnf erase package` | |
|
||||
| FreeBSD Packages | `sudo pkg delete package` | |
|
||||
| | `sudo pkg autoremove` | 删除不需要的包 |
|
||||
| FreeBSD Ports | `sudo pkg delete package` | |
|
||||
| | `cd /usr/ports/path_to_port && make deinstall` | 卸载 port |
|
||||
|
||||
### `apt` 命令
|
||||
|
||||
Debian 家族发行版的管理员通常熟悉 `apt-get` 和 `apt-cache`。较少为人所知的是简化的 `apt` 接口,它是专为交互式使用而设计的。
|
||||
|
||||
| 传统命令 | 等价的 `apt` 命令 |
|
||||
| --- | --- |
|
||||
| `apt-get update` | `apt update` |
|
||||
| `apt-get dist-upgrade` | `apt full-upgrade` |
|
||||
| `apt-cache search string` | `apt search string` |
|
||||
| `apt-get install package` | `apt install package` |
|
||||
| `apt-get remove package` | `apt remove package` |
|
||||
| `apt-get purge package` | `apt purge package` |
|
||||
|
||||
虽然 `apt` 通常是一个特定操作的快捷方式,但它并不能完全替代传统的工具,它的接口可能会随着版本的不同而发生变化,以提高可用性。如果你在脚本或 shell 管道中使用包管理命令,那么最好还是坚持使用 `apt-get` 和 `apt-cache`。
|
||||
|
||||
### 获取帮助
|
||||
|
||||
除了基于 web 的文档,请记住我们可以通过 shell 从 Unix 手册页(通常称为 man 页面)中获得大多数的命令。比如要阅读某页,可以使用 `man`:
|
||||
|
||||
```
|
||||
man page
|
||||
|
||||
```
|
||||
|
||||
在 `man` 中,你可以用箭头键导航。按 `/` 搜索页面内的文本,使用 `q` 退出。
|
||||
|
||||
| 系统 | 命令 | 说明 |
|
||||
| --- | --- | --- |
|
||||
| Debian / Ubuntu | `man apt-get` | 更新本地包数据库以及与包一起工作 |
|
||||
| | `man apt-cache` | 在本地的包数据库中搜索 |
|
||||
| | `man dpkg` | 和单独的包文件一起工作以及能查询已安装的包 |
|
||||
| | `man apt` | 通过更简洁,用户友好的接口进行最基本的操作 |
|
||||
| CentOS | `man yum` | |
|
||||
| Fedora | `man dnf` | |
|
||||
| FreeBSD Packages | `man pkg` | 和预先编译的二进制包一起工作 |
|
||||
| FreeBSD Ports | `man ports` | 和 Ports 集合一起工作 |
|
||||
|
||||
### 结论和进一步的阅读
|
||||
|
||||
本指南通过对多个系统间进行交叉对比概述了一下包管理系统的基本操作,但只涉及了这个复杂主题的表面。对于特定系统更详细的信息,可以参考以下资源:
|
||||
|
||||
* [这份指南][2] 详细介绍了 Ubuntu 和 Debian 的软件包管理。
|
||||
* 这里有一份 CentOS 官方的指南 [使用 yum 管理软件][3]
|
||||
* 这里有一个有关 Fedora 的 `dnf` 的 [wifi 页面][4] 以及一份有关 `dnf` [官方的手册][5]
|
||||
* [这份指南][6] 讲述了如何使用 `pkg` 在 FreeBSD 上进行包管理
|
||||
* 这本 [FreeBSD Handbook][7] 有一节讲述了[如何使用 Ports 集合][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.digitalocean.com/community/tutorials/package-management-basics-apt-yum-dnf-pkg
|
||||
|
||||
译者后记:
|
||||
|
||||
从经典的 `configure` && `make` && `make install` 三部曲到 `dpkg`,从需要手处理依赖关系的 `dpkg` 到全自动化的 `apt-get`,恩~,你有没有想过接下来会是什么?译者只能说可能会是 `Snaps`,如果你还没有听过这个东东,你也许需要关注下这个公众号了:**Snapcraft**
|
||||
|
||||
作者:[Brennen Bearnes][a]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.digitalocean.com/community/users/bpb
|
||||
|
||||
|
||||
[1]: http://static.zybuluo.com/apollomoon/g9kiere2xuo1511ls1hi9w9w/Package_Management_tw_mostov.png
|
||||
[2]:https://www.digitalocean.com/community/tutorials/ubuntu-and-debian-package-management-essentials
|
||||
[3]: https://www.centos.org/docs/5/html/yum/
|
||||
[4]: https://fedoraproject.org/wiki/Dnf
|
||||
[5]: https://dnf.readthedocs.org/en/latest/index.html
|
||||
[6]: https://www.digitalocean.com/community/tutorials/how-to-manage-packages-on-freebsd-10-1-with-pkg
|
||||
[7]:https://www.freebsd.org/doc/handbook/
|
||||
[8]: https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
[9]:https://www.freebsd.org/doc/handbook/ports-using.html
|
||||
@ -1,20 +1,20 @@
|
||||
响应式编程vs.响应式系统
|
||||
响应式编程与响应式系统
|
||||
============================================================
|
||||
|
||||
>在恒久的迷惑与过多期待的海洋中,登上一组简单响应式设计原则的小岛。
|
||||
> 在恒久的迷惑与过多期待的海洋中,登上一组简单响应式设计原则的小岛。
|
||||
|
||||
>
|
||||
|
||||

|
||||
|
||||
下载 Konrad Malawski 的免费电子书[《为什么选择响应式?企业应用中的基本原则》][5],深入了解更多响应式技术的知识与好处。
|
||||
> 下载 Konrad Malawski 的免费电子书[《为什么选择响应式?企业应用中的基本原则》][5],深入了解更多响应式技术的知识与好处。
|
||||
|
||||
自从2013年一起合作写了[《响应式宣言》][23]之后,我们看着响应式从一种几乎无人知晓的软件构建技术——当时只有少数几个公司的边缘项目使用了这一技术——最后成为中间件领域(middleware field)大佬们全平台战略中的一部分。本文旨在定义和澄清响应式各个方面的概念,方法是比较在_响应式编程_风格下,以及把_响应式系统_视作一个紧密整体的设计方法下写代码的不同。
|
||||
自从 2013 年一起合作写了[《响应式宣言》][23]之后,我们看着响应式从一种几乎无人知晓的软件构建技术——当时只有少数几个公司的边缘项目使用了这一技术——最后成为<ruby>中间件领域<rt>middleware field</rt></ruby>大佬们全平台战略中的一部分。本文旨在定义和澄清响应式各个方面的概念,方法是比较在_响应式编程_风格下和把_响应式系统_视作一个紧密整体的设计方法下编写代码的不同之处。
|
||||
|
||||
### 响应式是一组设计原则
|
||||
响应式技术目前成功的标志之一是“响应式”成为了一个热词,并且跟一些不同的事物与人联系在了一起——常常伴随着像“流(streaming)”,“轻量级(lightweight)”和“实时(real-time)”这样的词。
|
||||
|
||||
举个例子:当我们看到一支运动队时(像棒球队或者篮球队),我们一般会把他们看成一个个单独个体的组合,但是当他们之间碰撞不出火花,无法像一个团队一样高效地协作时,他们就会输给一个“更差劲”的队伍。从这篇文章的角度来看,响应式是一组设计原则,一种关于系统架构与设计的思考方式,一种关于在一个分布式环境下,当实现技术(implementation techniques),工具和设计模式都只是一个更大系统的一部分时如何设计的思考方式。
|
||||
响应式技术目前成功的标志之一是“<ruby>响应式<rt>reactive</rt></ruby>”成为了一个热词,并且跟一些不同的事物与人联系在了一起——常常伴随着像“<ruby>流<rt>streaming</rt></ruby>”、“<ruby>轻量级<rt>lightweight</rt></ruby>”和“<ruby>实时<rt>real-time</rt></ruby>”这样的词。
|
||||
|
||||
举个例子:当我们看到一支运动队时(像棒球队或者篮球队),我们一般会把他们看成一个个单独个体的组合,但是当他们之间碰撞不出火花,无法像一个团队一样高效地协作时,他们就会输给一个“更差劲”的队伍。从这篇文章的角度来看,响应式是一组设计原则,一种关于系统架构与设计的思考方式,一种关于在一个分布式环境下,当实现技术(implementation techniques)、工具和设计模式都只是一个更大系统的一部分时如何设计的思考方式。
|
||||
|
||||
这个例子展示了不经考虑地将一堆软件拼揍在一起——尽管单独来看,这些软件都很优秀——和响应式系统之间的不同。在一个响应式系统中,正是_不同组件(parts)间的相互作用_让响应式系统如此不同,它使得不同组件能够独立地运作,同时又一致协作从而达到最终想要的结果。
|
||||
|
||||
@ -28,62 +28,64 @@ _一个响应式系统_ 是一种架构风格(architectural style),它允许
|
||||
* 响应式编程(基于声明的事件的)
|
||||
* 函数响应式编程(FRP)
|
||||
|
||||
我们将检查这些做法与技术的意思,特别是前两个。更明确地说,我们会在使用它们的时候讨论它们,例如它们是怎么联系在一起的,从它们身上又能到什么样的好处——特别是在为多核、云或移动架构搭建系统的情境下。
|
||||
我们将调查这些做法与技术的意思,特别是前两个。更明确地说,我们会在使用它们的时候讨论它们,例如它们是怎么联系在一起的,从它们身上又能到什么样的好处——特别是在为多核、云或移动架构搭建系统的情境下。
|
||||
|
||||
让我们先来说一说函数响应式编程吧,以及我们在本文后面不再讨论它的原因。
|
||||
|
||||
### 函数响应式编程(FRP)
|
||||
|
||||
_函数响应式编程_,通常被称作_FRP_,是最常被误解的。FRP在二十年前就被Conal Elliott[精确地定义][24]了。但是最近这个术语却被错误地用来描述一些像Elm,Bacon.js的技术以及其它技术中的响应式插件(RxJava, Rx.NET, RxJS)。许多的库(libraries)声称他们支持FRP,事实上他们说的并非_响应式编程_,因此我们不会再进一步讨论它们。
|
||||
<ruby>函数响应式编程<rt>Functional reactive programming</rt></ruby>,通常被称作_FRP_,是最常被误解的。FRP在二十年前就被 Conal Elliott [精确地定义过了][24]了。但是最近这个术语却被错误地^脚注1 用来描述一些像 Elm、Bacon.js 的技术以及其它技术中的响应式插件(RxJava、Rx.NET、 RxJS)。许多的库(libraries)声称他们支持 FRP,事实上他们说的并非_响应式编程_,因此我们不会再进一步讨论它们。
|
||||
|
||||
### 响应式编程
|
||||
|
||||
_响应式编程_,不要把它跟_函数响应式编程_混淆了,它是异步编程下的一个子集,也是一种范式,在这种范式下,由新信息的有效性(availability)推动逻辑的前进,而不是让一条执行线程(a thread-of-execution)去推动控制流(control flow)。
|
||||
<ruby>响应式编程<rt>Reactive programming</rt></ruby>,不要把它跟_函数响应式编程_混淆了,它是异步编程下的一个子集,也是一种范式,在这种范式下,由新信息的有效性(availability)推动逻辑的前进,而不是让一条执行线程(a thread-of-execution)去推动控制流(control flow)。
|
||||
|
||||
它能够把问题分解为多个独立的步骤,这些独立的步骤可以以异步且非阻塞(non-blocking)的方式被执行,最后再组合在一起产生一条工作流(workflow)——它的输入和输出可能是非绑定的(unbounded)。
|
||||
|
||||
[“异步地(Asynchronous)”][25]被牛津词典定义为“不在同一时刻存在或发生”,在我们的语境下,它意味着一条消息或者一个事件可发生在任何时刻,有可能是在未来。这在响应式编程中是非常重要的一项技术,因为响应式编程允许[非阻塞式(non-blocking)]的执行方式——执行线程在竞争一块共享资源时不会因为阻塞(blocking)而陷入等待(防止执行线程在当前的工作完成之前执行任何其它操作),而是在共享资源被占用的期间转而去做其它工作。阿姆达尔定律(Amdahl's Law)[2][9]告诉我们,竞争是可伸缩性(scalability)最大的敌人,所以一个响应式系统应当在极少数的情况下才不得不做阻塞工作。
|
||||
[“异步地(Asynchronous)”][25]被牛津词典定义为“不在同一时刻存在或发生”,在我们的语境下,它意味着一条消息或者一个事件可发生在任何时刻,也有可能是在未来。这在响应式编程中是非常重要的一项技术,因为响应式编程允许[非阻塞式(non-blocking)]的执行方式——执行线程在竞争一块共享资源时不会因为阻塞(blocking)而陷入等待(为了防止执行线程在当前的工作完成之前执行任何其它操作),而是在共享资源被占用的期间转而去做其它工作。阿姆达尔定律(Amdahl's Law) ^脚注2 告诉我们,竞争是可伸缩性(scalability)最大的敌人,所以一个响应式系统应当在极少数的情况下才不得不做阻塞工作。
|
||||
|
||||
响应式编程一般是_事件驱动(event-driven)_ ,相比之下,响应式系统则是_消息驱动(message-driven)_ 的——事件驱动与消息驱动之间的差别会在文章后面阐明。
|
||||
|
||||
响应式编程库的应用程序接口(API)一般是以下二者之一:
|
||||
|
||||
* 基于回调的(Callback-based)——匿名的间接作用(side-effecting)回调函数被绑定在事件源(event sources)上,当事件被放入数据流(dataflow chain)中时,回调函数被调用。
|
||||
* 声明式的(Declarative)——通过函数的组合,通常是使用一些固定的函数,像 _map_, _filter_, _fold_ 等等。
|
||||
* 声明式的(Declarative)——通过函数的组合,通常是使用一些固定的函数,像 _map_、 _filter_、 _fold_ 等等。
|
||||
|
||||
大部分的库会混合这两种风格,一般还带有基于流(stream-based)的操作符(operators),像windowing, counts, triggers。
|
||||
大部分的库会混合这两种风格,一般还带有基于流(stream-based)的操作符(operators),像 windowing、 counts、 triggers。
|
||||
|
||||
说响应式编程跟[数据流编程(dataflow programming)][27]有关是很合理的,因为它强调的是_数据流_而不是_控制流_。
|
||||
|
||||
举几个为这种编程技术提供支持的的编程抽象概念:
|
||||
|
||||
* [Futures/Promises][10]——一个值的容器,具有读共享/写独占(many-read/single-write)的语义,即使变量尚不可用也能够添加异步的值转换操作。
|
||||
* 流(streams)-[响应式流][11]——无限制的数据处理流,支持异步,非阻塞式,支持多个源与目的的反压转换管道(back-pressured transformation pipelines)。
|
||||
* [数据流变量][12]——依赖于输入,过程(procedures)或者其它单元的单赋值变量(存储单元)(single assignment variables),它能够自动更新值的改变。其中一个应用例子是表格软件——一个单元的值的改变会像涟漪一样荡开,影响到所有依赖于它的函数,顺流而下地使它们产生新的值。
|
||||
* 流(streams) - [响应式流][11]——无限制的数据处理流,支持异步,非阻塞式,支持多个源与目的的反压转换管道(back-pressured transformation pipelines)。
|
||||
* [数据流变量][12]——依赖于输入、过程(procedures)或者其它单元的单赋值变量(single assignment variables)(存储单元),它能够自动更新值的改变。其中一个应用例子是表格软件——一个单元的值的改变会像涟漪一样荡开,影响到所有依赖于它的函数,顺流而下地使它们产生新的值。
|
||||
|
||||
在JVM中,支持响应式编程的流行库有Akka Streams、Ratpack、Reactor、RxJava和Vert.x等等。这些库实现了响应式编程的规范,成为JVM上响应式编程库之间的互通标准(standard for interoperability),并且根据它自身的叙述是“……一个为如何处理非阻塞式反压异步流提供标准的倡议”
|
||||
在 JVM 中,支持响应式编程的流行库有 Akka Streams、Ratpack、Reactor、RxJava 和 Vert.x 等等。这些库实现了响应式编程的规范,成为 JVM 上响应式编程库之间的互通标准(standard for interoperability),并且根据它自身的叙述是“……一个为如何处理非阻塞式反压异步流提供标准的倡议”。
|
||||
|
||||
响应式编程的基本好处是:提高多核和多CPU硬件的计算资源利用率;根据阿姆达尔定律以及引申的Günther的通用可伸缩性定律[3][13](Günther’s Universal Scalability Law),通过减少序列化点(serialization points)来提高性能。
|
||||
响应式编程的基本好处是:提高多核和多 CPU 硬件的计算资源利用率;根据阿姆达尔定律以及引申的 Günther 的通用可伸缩性定律(Günther’s Universal Scalability Law) ^脚注3 ,通过减少序列化点(serialization points)来提高性能。
|
||||
|
||||
另一个好处是开发者生产效率,传统的编程范式都尽力想提供一个简单直接的可持续的方法来处理异步非阻塞式计算和I/O。在响应式编程中,因活动(active)组件之间通常不需要明确的协作,从而也就解决了其中大部分的挑战。
|
||||
另一个好处是开发者生产效率,传统的编程范式都尽力想提供一个简单直接的可持续的方法来处理异步非阻塞式计算和 I/O。在响应式编程中,因活动(active)组件之间通常不需要明确的协作,从而也就解决了其中大部分的挑战。
|
||||
|
||||
响应式编程真正的发光点在于组件的创建跟工作流的组合。为了在异步执行上取得最大的优势,把[反压(back-pressure)][28]加进来是很重要,这样能避免过度使用,或者确切地说,无限度的消耗资源。
|
||||
响应式编程真正的发光点在于组件的创建跟工作流的组合。为了在异步执行上取得最大的优势,把[反压(back-pressure)][28]加进来是很重要,这样能避免过度使用,或者确切地说,避免无限度的消耗资源。
|
||||
|
||||
尽管如此,响应式编程在搭建现代软件上仍然非常有用,为了在更高层次上理解(reason about)一个系统,那么必须要使用到另一个工具:_响应式架构_——设计响应式系统的方法。此外,要记住编程范式有很多,而响应式编程仅仅只是其中一个,所以如同其它工具一样,响应式编程并不是万金油,它不意图适用于任何情况。
|
||||
尽管如此,响应式编程在搭建现代软件上仍然非常有用,为了在更高层次上理解(reason about)一个系统,那么必须要使用到另一个工具:<ruby>响应式架构<rt>reactive architecture</rt></ruby>——设计响应式系统的方法。此外,要记住编程范式有很多,而响应式编程仅仅只是其中一个,所以如同其它工具一样,响应式编程并不是万金油,它不意图适用于任何情况。
|
||||
|
||||
### 事件驱动 vs. 消息驱动
|
||||
如上面提到的,响应式编程——专注于短时间的数据流链条上的计算——因此倾向于_事件驱动_,而响应式系统——关注于通过分布式系统的通信和协作所得到的弹性和韧性——则是[_消息驱动的_][29][4][14](或者称之为 _消息式(messaging)_ 的)。
|
||||
|
||||
如上面提到的,响应式编程——专注于短时间的数据流链条上的计算——因此倾向于_事件驱动_,而响应式系统——关注于通过分布式系统的通信和协作所得到的弹性和韧性——则是[_消息驱动的_][29] ^脚注4(或者称之为 _消息式(messaging)_ 的)。
|
||||
|
||||
一个拥有长期存活的可寻址(long-lived addressable)组件的消息驱动系统跟一个事件驱动的数据流驱动模型的不同在于,消息具有固定的导向,而事件则没有。消息会有明确的(一个)去向,而事件则只是一段等着被观察(observe)的信息。另外,消息式(messaging)更适用于异步,因为消息的发送与接收和发送者和接收者是分离的。
|
||||
|
||||
响应式宣言中的术语表定义了两者之间[概念上的不同][30]:
|
||||
|
||||
> 一条消息就是一则被送往一个明确目的地的数据。一个事件则是达到某个给定状态的组件发出的一个信号。在一个消息驱动系统中,可寻址到的接收者等待消息的到来然后响应它,否则保持休眠状态。在一个事件驱动系统中,通知的监听者被绑定到消息源上,这样当消息被发出时它就会被调用。这意味着一个事件驱动系统专注于可寻址的事件源而消息驱动系统专注于可寻址的接收者。
|
||||
|
||||
分布式系统需要通过消息在网络上传输进行交流,以实现其沟通基础,与之相反,事件的发出则是本地的。在底层通过发送包裹着事件的消息来搭建跨网络的事件驱动系统的做法很常见。这样能够维持在分布式环境下事件驱动编程模型的相对简易性并且在某些特殊的和合理范围内的使用案例上工作得很好。
|
||||
分布式系统需要通过消息在网络上传输进行交流,以实现其沟通基础,与之相反,事件的发出则是本地的。在底层通过发送包裹着事件的消息来搭建跨网络的事件驱动系统的做法很常见。这样能够维持在分布式环境下事件驱动编程模型的相对简易性,并且在某些特殊的和合理的范围内的使用案例上工作得很好。
|
||||
|
||||
然而,这是有利有弊的:在编程模型的抽象性和简易性上得一分,在控制上就减一分。消息强迫我们去拥抱分布式系统的真实性和一致性——像局部错误(partial failures),错误侦测(failure detection),丢弃/复制/重排序 消息(dropped/duplicated/reordered messages),最后还有一致性,管理多个并发真实性等等——然后直面它们,去处理它们,而不是像过去无数次一样,藏在一个蹩脚的抽象面罩后——假装网络并不存在(例如EJB, [RPC][31], [CORBA][32], 和 [XA][33])。
|
||||
然而,这是有利有弊的:在编程模型的抽象性和简易性上得一分,在控制上就减一分。消息强迫我们去拥抱分布式系统的真实性和一致性——像局部错误(partial failures),错误侦测(failure detection),丢弃/复制/重排序 (dropped/duplicated/reordered )消息,最后还有一致性,管理多个并发真实性等等——然后直面它们,去处理它们,而不是像过去无数次一样,藏在一个蹩脚的抽象面罩后——假装网络并不存在(例如EJB、 [RPC][31]、 [CORBA][32] 和 [XA][33])。
|
||||
|
||||
这些在语义学和适用性上的不同在应用设计中有着深刻的含义,包括分布式系统的复杂性(complexity)中的 _弹性(resilience)_, _韧性(elasticity)_,_移动性(mobility)_,_位置透明性(location transparency)_ 和 _管理(management)_,这些在文章后面再进行介绍。
|
||||
这些在语义学和适用性上的不同在应用设计中有着深刻的含义,包括分布式系统的复杂性(complexity)中的 _弹性(resilience)_、 _韧性(elasticity)_、_移动性(mobility)_、_位置透明性(location transparency)_ 和 _管理(management)_,这些在文章后面再进行介绍。
|
||||
|
||||
在一个响应式系统中,特别是使用了响应式编程技术的,这样的系统中就即有事件也有消息——一个是用于沟通的强大工具(消息),而另一个则呈现现实(事件)。
|
||||
|
||||
@ -91,17 +93,17 @@ _响应式编程_,不要把它跟_函数响应式编程_混淆了,它是异
|
||||
|
||||
_响应式系统_ —— 如同在《响应式宣言》中定义的那样——是一组用于搭建现代系统——已充分准备好满足如今应用程序所面对的不断增长的需求的现代系统——的架构设计原则。
|
||||
|
||||
响应式系统的原则决对不是什么新东西,它可以被追溯到70和80年代Jim Gray和Pat Helland在[串级系统(Tandem System)][34]上和Joe aomstrong和Robert Virding在[Erland][35]上做出的重大工作。然而,这些人在当时都超越了时代,只有到了最近5-10年,技术行业才被不得不反思当前企业系统最好的开发实践活动并且学习如何将来之不易的响应式原则应用到今天这个多核、云计算和物联网的世界中。
|
||||
响应式系统的原则决对不是什么新东西,它可以被追溯到 70 和 80 年代 Jim Gray 和 Pat Helland 在[串级系统(Tandem System)][34] 上和 Joe aomstrong 和 Robert Virding 在 [Erland][35] 上做出的重大工作。然而,这些人在当时都超越了时代,只有到了最近 5 - 10 年,技术行业才被不得不反思当前企业系统最好的开发实践活动并且学习如何将来之不易的响应式原则应用到今天这个多核、云计算和物联网的世界中。
|
||||
|
||||
响应式系统的基石是_消息传递(message-passing)_ ,消息传递为两个组件之间创建一条暂时的边界,使得他们能够在 _时间_ 上分离——实现并发性——和 _空间(space)_ ——实现分布式(distribution)与移动性(mobility)。这种分离是两个组件完全[隔离(isolation)][36]以及实现 _弹性(resilience)_ 和 _韧性(elasticity)_ 基础的必需条件。
|
||||
响应式系统的基石是_消息传递(message-passing)_ ,消息传递为两个组件之间创建一条暂时的边界,使得它们能够在 _时间_ 上分离——实现并发性——和 _空间(space)_ ——实现分布式(distribution)与移动性(mobility)。这种分离是两个组件完全[隔离(isolation)][36]以及实现 _弹性(resilience)_ 和 _韧性(elasticity)_ 基础的必需条件。
|
||||
|
||||
### 从程序到系统
|
||||
|
||||
这个世界的连通性正在变得越来越高。我们构建 _程序_ ——为单个操作子计算某些东西的端到端逻辑——已经不如我们构建 _系统_ 来得多了。
|
||||
这个世界的连通性正在变得越来越高。我们不再构建 _程序_ ——为单个操作子来计算某些东西的端到端逻辑——而更多地在构建 _系统_ 了。
|
||||
|
||||
系统从定义上来说是复杂的——每一部分都包含多个组件,每个组件的自身或其子组件也可以是一个系统——这意味着软件要正常工作已经越来越依赖于其它软件。
|
||||
|
||||
我们今天构建的系统会在多个计算机上被操作,小型的或大型的,数量少的或数量多的,相近的或远隔半个地球的。同时,由于人们的生活正变得越来越依赖于系统顺畅运行的有效性,用户的期望也变得越得越来越难以满足。
|
||||
我们今天构建的系统会在多个计算机上操作,小型的或大型的,或少或多,相近的或远隔半个地球的。同时,由于人们的生活正变得越来越依赖于系统顺畅运行的有效性,用户的期望也变得越得越来越难以满足。
|
||||
|
||||
为了实现用户——和企业——能够依赖的系统,这些系统必须是 _灵敏的(responsive)_ ,这样无论是某个东西提供了一个正确的响应,还是当需要一个响应时响应无法使用,都不会有影响。为了达到这一点,我们必须保证在错误( _弹性_ )和欠载( _韧性_ )下,系统仍然能够保持灵敏性。为了实现这一点,我们把系统设计为 _消息驱动的_ ,我们称其为 _响应式系统_ 。
|
||||
|
||||
@ -109,36 +111,32 @@ _响应式系统_ —— 如同在《响应式宣言》中定义的那样——
|
||||
|
||||
弹性是与 _错误下_ 的灵敏性(responsiveness)有关的,它是系统内在的功能特性,是需要被设计的东西,而不是能够被动的加入系统中的东西。弹性是大于容错性的——弹性无关于故障退化(graceful degradation)——虽然故障退化对于系统来说是很有用的一种特性——与弹性相关的是与从错误中完全恢复达到 _自愈_ 的能力。这就需要组件的隔离以及组件对错误的包容,以免错误散播到其相邻组件中去——否则,通常会导致灾难性的连锁故障。
|
||||
|
||||
因此构建一个弹性的,自愈(self-healing)系统的关键是允许错误被:容纳,具体化为消息,发送给其他的(担当监管者的(supervisors))组件,从而在错误组件之外修复出一个安全环境。在这,消息驱动是其促成因素:远离高度耦合的、脆弱的深层嵌套的同步调用链,大家长期要么学会忍受其煎熬或直接忽略。解决的想法是将调用链中的错误管理分离,将客户端从处理服务端错误的责任中解放出来。
|
||||
因此构建一个弹性的、自愈(self-healing)系统的关键是允许错误被:容纳、具体化为消息,发送给其他的(担当监管者的(supervisors))组件,从而在错误组件之外修复出一个安全环境。在这,消息驱动是其促成因素:远离高度耦合的、脆弱的深层嵌套的同步调用链,大家长期要么学会忍受其煎熬或直接忽略。解决的想法是将调用链中的错误管理分离,将客户端从处理服务端错误的责任中解放出来。
|
||||
|
||||
### 响应式系统的韧性
|
||||
|
||||
[韧性(Elasticity)][37]是关于 _欠载下的灵敏性(responsiveness)_ 的——意味着一个系统的吞吐量在资源增加或减少时能够自动地相应增加或减少(scales up or down)(同样能够向内或外扩展(scales in or out))以满足不同的需求。这是利用云计算承诺的特性所必需的因素:使系统利用资源更加有效,成本效益更佳,对环境友好以及实现按次付费。
|
||||
|
||||
系统必须能够在不重写甚至不重新设置的情况下,适应性地——即无需介入自动伸缩——响应状态及行为,沟通负载均衡,故障转移(failover),以及升级。实现这些的就是 _位置透明性(location transparency)_ :使用同一个方法,同样的编程抽象,同样的语义,在所有向度中伸缩(scaling)系统的能力——从CPU核心到数据中心。
|
||||
系统必须能够在不重写甚至不重新设置的情况下,适应性地——即无需介入自动伸缩——响应状态及行为,沟通负载均衡,故障转移(failover),以及升级。实现这些的就是 _位置透明性(location transparency)_ :使用同一个方法,同样的编程抽象,同样的语义,在所有向度中伸缩(scaling)系统的能力——从 CPU 核心到数据中心。
|
||||
|
||||
如同《响应式宣言》所述:
|
||||
|
||||
> 一个极大地简化问题的关键洞见在于意识到我们都在使用分布式计算。无论我们的操作系统是运行在一个单一结点上(拥有多个独立的CPU,并通过QPI链接进行交流),还是在一个节点集群(cluster of nodes,独立的机器,通过网络进行交流)上。拥抱这个事实意味着在垂直方向上多核的伸缩与在水平方面上集群的伸缩并无概念上的差异。在空间上的解耦 [...],是通过异步消息传送以及运行时实例与其引用解耦从而实现的,这就是我们所说的位置透明性。
|
||||
> 一个极大地简化问题的关键洞见在于意识到我们都在使用分布式计算。无论我们的操作系统是运行在一个单一结点上(拥有多个独立的 CPU,并通过 QPI 链接进行交流),还是在一个节点集群(cluster of nodes)(独立的机器,通过网络进行交流)上。拥抱这个事实意味着在垂直方向上多核的伸缩与在水平方面上集群的伸缩并无概念上的差异。在空间上的解耦 [...],是通过异步消息传送以及运行时实例与其引用解耦从而实现的,这就是我们所说的位置透明性。
|
||||
|
||||
因此,不论接收者在哪里,我们都以同样的方式与它交流。唯一能够在语义上等同实现的方式是消息传送。
|
||||
|
||||
### 响应式系统的生产效率
|
||||
|
||||
既然大多数的系统生来即是复杂的,那么其中一个最重要的点即是保证一个系统架构在开发和维护组件时,最小程度地减低生产效率,同时将操作的 _偶发复杂性(accidental complexity_ 降到最低。
|
||||
既然大多数的系统生来即是复杂的,那么其中一个最重要的点即是保证一个系统架构在开发和维护组件时,最小程度地减低生产效率,同时将操作的 _偶发复杂性(accidental complexity)_ 降到最低。
|
||||
|
||||
这一点很重要,因为在一个系统的生命周期中——如果系统的设计不正确——系统的维护会变得越来越困难,理解、定位和解决问题所需要花费时间和精力会不断地上涨。
|
||||
|
||||
响应式系统是我们所知的最具 _生产效率_ 的系统架构(在多核、云及移动架构的背景下):
|
||||
|
||||
* 错误的隔离为组件与组件之间裹上[舱壁][15](译者注:当船遭到损坏进水时,舱壁能够防止水从损坏的船舱流入其他船舱),防止引发连锁错误,从而限制住错误的波及范围以及严重性。
|
||||
|
||||
* 错误的隔离为组件与组件之间裹上[舱壁][15](LCTT 译注:当船遭到损坏进水时,舱壁能够防止水从损坏的船舱流入其他船舱),防止引发连锁错误,从而限制住错误的波及范围以及严重性。
|
||||
* 监管者的层级制度提供了多个等级的防护,搭配以自我修复能力,避免了许多曾经在侦查(inverstigate)时引发的操作代价(cost)——大量的瞬时故障(transient failures)。
|
||||
|
||||
* 消息传送和位置透明性允许组件被卸载下线、代替或重新布线(rerouted)同时不影响终端用户的使用体验,并降低中断的代价、它们的相对紧迫性以及诊断和修正所需的资源。
|
||||
|
||||
* 复制减少了数据丢失的风险,减轻了数据检索(retrieval)和存储的有效性错误的影响。
|
||||
|
||||
* 韧性允许在使用率波动时保存资源,允许在负载很低时,最小化操作开销,并且允许在负载增加时,最小化运行中断(outgae)或紧急投入(urgent investment)伸缩性的风险。
|
||||
|
||||
因此,响应式系统使生成系统(creation systems)很好的应对错误、随时间变化的负载——同时还能保持低运营成本。
|
||||
@ -173,19 +171,19 @@ _响应式系统_ —— 如同在《响应式宣言》中定义的那样——
|
||||
|
||||
响应式编程在内部逻辑及数据流转换的组件层次上为开发者提高了生产率——通过性能与资源的有效利用实现。而响应式系统在构建 _原生云(cloud native)_ 和其它大型分布式系统的系统层次上为架构师及DevOps从业者提高了生产率——通过弹性与韧性。我们建议在响应式系统设计原则中结合响应式编程技术。
|
||||
|
||||
```
|
||||
1 参考Conal Elliott,FRP的发明者,见[这个演示][16][↩][17]
|
||||
2 [Amdahl 定律][18]揭示了系统理论上的加速会被一系列的子部件限制,这意味着系统在新的资源加入后会出现收益递减(diminishing returns)。 [↩][19]
|
||||
3 Neil Günter的[通用可伸缩性定律(Universal Scalability Law)][20]是理解并发与分布式系统的竞争与协作的重要工具,它揭示了当新资源加入到系统中时,保持一致性的开销会导致不好的结果。
|
||||
4 消息可以是同步的(要求发送者和接受者同时存在),也可以是异步的(允许他们在时间上解耦)。其语义上的区别超出本文的讨论范围。[↩][22]
|
||||
```
|
||||
|
||||
> 1. 参考Conal Elliott,FRP的发明者,见[这个演示][16]
|
||||
> 2. [Amdahl 定律][18]揭示了系统理论上的加速会被一系列的子部件限制,这意味着系统在新的资源加入后会出现收益递减(diminishing returns)。
|
||||
> 3. Neil Günter的[通用可伸缩性定律(Universal Scalability Law)][20]是理解并发与分布式系统的竞争与协作的重要工具,它揭示了当新资源加入到系统中时,保持一致性的开销会导致不好的结果。
|
||||
> 4. 消息可以是同步的(要求发送者和接受者同时存在),也可以是异步的(允许他们在时间上解耦)。其语义上的区别超出本文的讨论范围。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/reactive-programming-vs-reactive-systems
|
||||
|
||||
作者:[Jonas Bonér][a] , [Viktor Klang][b]
|
||||
作者:[Jonas Bonér][a], [Viktor Klang][b]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
399
published/20161220 TypeScript the missing introduction.md
Normal file
399
published/20161220 TypeScript the missing introduction.md
Normal file
@ -0,0 +1,399 @@
|
||||
一篇缺失的 TypeScript 介绍
|
||||
=============================================================
|
||||
|
||||
**下文是 James Henry([@MrJamesHenry][8])所提交的内容。我是 ESLint 核心团队的一员,也是 TypeScript 布道师。我正在和 Todd 在 [UltimateAngular][9] 平台上合作发布 Angular 和 TypeScript 的精品课程。**
|
||||
|
||||
> 本文的主旨是为了介绍我们是如何看待 TypeScript 的以及它在加强 JavaScript 开发中所起的作用。
|
||||
>
|
||||
> 我们也将尽可能地给出那些类型和编译方面的那些时髦词汇的准确定义。
|
||||
|
||||
TypeScript 强大之处远远不止这些,本篇文章无法涵盖,想要了解更多请阅读[官方文档][15],或者学习 [UltimateAngular 上的 TypeScript 课程][16] ,从初学者成为一位 TypeScript 高手。
|
||||
|
||||
### 背景
|
||||
|
||||
TypeScript 是个出乎意料强大的工具,而且它真的很容易掌握。
|
||||
|
||||
然而,TypeScript 可能比 JavaScript 要更为复杂一些,因为 TypeScript 可能向我们同时引入了一系列以前没有考虑过的 JavaScript 程序相关的技术概念。
|
||||
|
||||
每当我们谈论到类型、编译器等这些概念的时候,你会发现很快会变的不知所云起来。
|
||||
|
||||
这篇文章就是一篇为了解答你需要知道的许许多多不知所云的概念,来帮助你 TypeScript 快速入门的教程,可以让你轻松自如的应对这些概念。
|
||||
|
||||
### 关键知识的掌握
|
||||
|
||||
在 Web 浏览器中运行我们的代码这件事或许使我们对它是如何工作的产生一些误解,“它不用经过编译,是吗?”,“我敢肯定这里面是没有类型的...”
|
||||
|
||||
更有意思的是,上述的说法既是正确的也是不正确的,这取决于上下文环境和我们是如何定义这些概念的。
|
||||
|
||||
首先,我们要作的是明确这些。
|
||||
|
||||
#### JavaScript 是解释型语言还是编译型语言?
|
||||
|
||||
传统意义上,程序员经常将自己的程序编译之后运行出结果就认为这种语言是编译型语言。
|
||||
|
||||
> 从初学者的角度来说,编译的过程就是将我们自己编辑好的高级语言程序转换成机器实际运行的格式。
|
||||
|
||||
就像 Go 语言,可以使用 `go build` 的命令行工具编译 .go 的文件,将其编译成代码的低级形式,它可以直接执行、运行。
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
作为一个 JavaScript 程序员(这一刻,请先忽略我们对新一代构建工具和模块加载程序的热爱),我们在日常的 JavaScript 开发中并没有编译的这一基本步骤,
|
||||
|
||||
我们写一些 JavaScript 代码,把它放在浏览器的 `<script>` 标签中,它就能运行了(或者在服务端环境运行,比如:node.js)。
|
||||
|
||||
**好吧,因此 JavaScript 没有进行过编译,那它一定是解释型语言了,是吗?**
|
||||
|
||||
实际上,我们能够确定的一点是,JavaScript 不是我们自己编译的,现在让我们简单的回顾一个简单的解释型语言的例子,再来谈 JavaScript 的编译问题。
|
||||
|
||||
> 解释型计算机语言的执行的过程就像人们看书一样,从上到下、一行一行的阅读。
|
||||
|
||||
我们所熟知的解释型语言的典型例子是 bash 脚本。我们终端中的 bash 解释器逐行读取我们的命令并且执行它。
|
||||
|
||||
现在我们回到 JavaScript 是解释执行还是编译执行的讨论中,我们要将逐行读取和逐行执行程序分开理解(对“解释型”的简单理解),不要混在一起。
|
||||
|
||||
以此代码为例:
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello(){
|
||||
console.log("Hello")
|
||||
}
|
||||
```
|
||||
|
||||
这是真正意义上 JavaScript 输出 Hello 单词的程序代码,但是,在 `hello()` 在我们定义它之前就已经使用了这个函数,这是简单的逐行执行办不到的,因为 `hello()` 在第一行没有任何意义的,直到我们在第二行声明了它。
|
||||
|
||||
像这样在 JavaScript 是存在的,因为我们的代码实际上在执行之前就被所谓的“JavaScript 引擎”或者是“特定的编译环境”编译过,这个编译的过程取决于具体的实现(比如,使用 V8 引擎的 node.js 和 Chome 就和使用 SpiderMonkey 的 FireFox 就有所不同)。
|
||||
|
||||
在这里,我们不会在进一步的讲解编译型执行和解释型执行微妙之处(这里的定义已经很好了)。
|
||||
|
||||
> 请务必记住,我们编写的 JavaScript 代码已经不是我们的用户实际执行的代码了,即使是我们简单地将其放在 HTML 中的 `<script>` ,也是不一样的。
|
||||
|
||||
#### 运行时间 VS 编译时间
|
||||
|
||||
现在我们已经正确理解了编译和运行是两个不同的阶段,那“<ruby>运行阶段<rt>Run Time</rt></ruby>”和“<ruby>编译阶段<rt>Compile Time</rt></ruby>”理解起来也就容易多了。
|
||||
|
||||
编译阶段,就是我们在我们的编辑器或者 IDE 当中的代码转换成其它格式的代码的阶段。
|
||||
|
||||
运行阶段,就是我们程序实际执行的阶段,例如:上面的 `hello()` 函数就执行在“运行阶段”。
|
||||
|
||||
#### TypeScript 编译器
|
||||
|
||||
现在我们了解了程序的生命周期中的关键阶段,接下来我们可以介绍 TypeScript 编译器了。
|
||||
|
||||
TypeScript 编译器是帮助我们编写代码的关键。比如,我们不需将 JavaScript 代码包含到 `<script>` 标签当中,只需要通过 TypeScript 编译器传递它,就可以在运行程序之前得到改进程序的建议。
|
||||
|
||||
> 我们可以将这个新的步骤作为我们自己的个人“编译阶段”,这将在我们的程序抵达 JavaScript 主引擎之前,确保我们的程序是以我们预期的方式编写的。
|
||||
|
||||
它与上面 Go 语言的实例类似,但是 TypeScript 编译器只是基于我们编写程序的方式提供提示信息,并不会将其转换成低级的可执行文件,它只会生成纯 JavaScript 代码。
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
在[官方文档][23]中,有许多关于将 TypeScript 编译器以各种方式融入到你的现有工作流程中的文章。这些已经超出本文范围。
|
||||
|
||||
#### 动态类型与静态类型
|
||||
|
||||
就像对比编译程序与解释程序一样,动态类型与静态类型的对比在现有的资料中也是极其模棱两可的。
|
||||
|
||||
让我们先回顾一下我们在 JavaScript 中对于类型的理解。
|
||||
|
||||
我们的代码如下:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
我们如何给别人描述这段代码?
|
||||
|
||||
“我们声明了一个变量 `name`,它被分配了一个 “James” 的**字符串**,然后我们又申请了一个变量 `sum`,它被分配了一个**数字** 1 和**数字** 2 的求和的数值结果。”
|
||||
|
||||
即使在这样一个简单的程序中,我们也使用了两个 JavaScript 的基本类型:`String` 和 `Number`。
|
||||
|
||||
就像上面我们讲编译一样,我们不会陷入编程语言类型的学术细节当中,关键是要理解在 JavaScript 中类型表示的是什么,并扩展到 TypeScript 的类型的理解上。
|
||||
|
||||
从每夜拜读的最新 ECMAScript 规范中我们可以学到(LOL, JK - “wat’s an ECMA?”),它大量引用了 JavaScript 的类型及其用法。
|
||||
|
||||
直接引自官方规范:
|
||||
|
||||
> ECMAScript 语言的类型取决于使用 ECMAScript 语言的 ECMAScript 程序员所直接操作的值。
|
||||
>
|
||||
> ECMAScript 语言的类型有 Undefined、Null、Boolean、String、Symbol、Number 和 Object。
|
||||
|
||||
我们可以看到,JavaScript 语言有 7 种正式类型,其中我们在我们现在程序中使用了 6 种(Symbol 首次在 ES2015 中引入,也就是 ES6)。
|
||||
|
||||
现在我们来深入一点看上面的 JavaScript 代码中的 “name 和 sum”。
|
||||
|
||||
我们可以把我们当前被分配了字符串“James”的变量 `name` 重新赋值为我们的第二个变量 sum 的当前值,目前是数字 3。
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
该 `name` 变量开始“存有”一个字符串,但现在它“存有”一个数字。这凸显了 JavaScript 中变量和类型的基本特性:
|
||||
|
||||
“James” 值一直是字符串类型,而 `name` 变量可以分配任何类型的值。和 `sum` 赋值的情况相同,1 是一个数字类型,`sum` 变量可以分配任何可能的值。
|
||||
|
||||
> 在 JavaScript 中,值是具有类型的,而变量是可以随时保存任何类型的值。
|
||||
|
||||
这也恰好是一个“动态类型语言”的定义。
|
||||
|
||||
相比之下,我们可以将“静态类型语言”视为我们可以(也必须)将类型信息与特定变量相关联的语言:
|
||||
|
||||
```
|
||||
var name: string = ‘James’;
|
||||
```
|
||||
|
||||
在这段代码中,我们能够更好地显式声明我们对变量 `name` 的意图,我们希望它总是用作一个字符串。
|
||||
|
||||
你猜怎么着?我们刚刚看到我们的第一个 TypeScript 程序。
|
||||
|
||||
当我们<ruby>反思</rt>reflect</rt></ruby>我们自己的代码(非编程方面的双关语“反射”)时,我们可以得出的结论,即使我们使用动态语言(如 JavaScript),在几乎所有的情况下,当我们初次定义变量和函数参数时,我们应该有非常明确的使用意图。如果这些变量和参数被重新赋值为与我们原先赋值不同类型的值,那么有可能某些东西并不是我们预期的那样工作的。
|
||||
|
||||
> 作为 JavaScript 开发者,TypeScript 的静态类型注释给我们的一个巨大的帮助,它能够清楚地表达我们对变量的意图。
|
||||
|
||||
> 这种改进不仅有益于 TypeScript 编译器,还可以让我们的同事和将来的自己明白我们的代码。代码是用来读的。
|
||||
|
||||
### TypeScript 在我们的 JavaScript 工作流程中的作用
|
||||
|
||||
我们已经开始看到“为什么经常说 TypeScript 只是 JavaScript + 静态类型”的说法了。`: string` 对于我们的 `name` 变量就是我们所谓的“类型注释”,在编译时被使用(换句话说,当我们让代码通过 TypeScript 编译器时),以确保其余的代码符合我们原来的意图。
|
||||
|
||||
我们再来看看我们的程序,并添加显式注释,这次是我们的 `sum` 变量:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
如果我们使用 TypeScript 编译器编译这个代码,我们现在就会收到一个在 `name = sum` 这行的错误: `Type 'number' is not assignable to type 'string'`,我们的这种“偷渡”被警告,我们执行的代码可能有问题。
|
||||
|
||||
> 重要的是,如果我们想要继续执行,我们可以选择忽略 TypeScript 编译器的错误,因为它只是在将 JavaScript 代码发送给我们的用户之前给我们反馈的工具。
|
||||
|
||||
TypeScript 编译器为我们输出的最终 JavaScript 代码将与上述原始源代码完全相同:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
类型注释全部为我们自动删除了,现在我们可以运行我们的代码了。
|
||||
|
||||
> 注意:在此示例中,即使我们没有提供显式类型注释的 `: string` 和 `: number` ,TypeScript 编译器也可以为我们提供完全相同的错误 。
|
||||
|
||||
> TypeScript 通常能够从我们使用它的方式推断变量的类型!
|
||||
|
||||
#### 我们的源文件是我们的文档,TypeScript 是我们的拼写检查
|
||||
|
||||
对于 TypeScript 与我们的源代码的关系来说,一个很好的类比,就是拼写检查与我们在 Microsoft Word 中写的文档的关系。
|
||||
|
||||
这两个例子有三个关键的共同点:
|
||||
|
||||
1. **它能告诉我们写的东西的客观的、直接的错误:**
|
||||
* _拼写检查_:“我们已经写了字典中不存在的字”
|
||||
* _TypeScript_:“我们引用了一个符号(例如一个变量),它没有在我们的程序中声明”
|
||||
2. **它可以提醒我们写的可能是错误的:**
|
||||
* _拼写检查_:“该工具无法完全推断特定语句的含义,并建议重写”
|
||||
* _TypeScript_:“该工具不能完全推断特定变量的类型,并警告不要这样使用它”
|
||||
3. **我们的来源可以用于其原始目的,无论工具是否存在错误:**
|
||||
* _拼写检查_:“即使您的文档有很多拼写错误,您仍然可以打印出来,并把它当成文档使用”
|
||||
* _TypeScript_:“即使您的源代码具有 TypeScript 错误,它仍然会生成您可以执行的 JavaScript 代码”
|
||||
|
||||
### TypeScript 是一种可以启用其它工具的工具
|
||||
|
||||
TypeScript 编译器由几个不同的部分或阶段组成。我们将通过查看这些部分之一 The Parser(语法分析程序)来结束这篇文章,除了 TypeScript 已经为我们做的以外,它为我们提供了在其上构建其它开发工具的机会。
|
||||
|
||||
编译过程的“解析器步骤”的结果是所谓的抽象语法树,简称为 AST。
|
||||
|
||||
#### 什么是抽象语法树(AST)?
|
||||
|
||||
我们以普通文本形式编写我们的程序,因为这是我们人类与计算机交互的最好方式,让它们能够做我们想要的东西。我们并不是很擅长于手工编写复杂的数据结构!
|
||||
|
||||
然而,不管在哪种情况下,普通文本在编译器里面实际上是一个非常棘手的事情。它可能包含程序运作不必要的东西,例如空格,或者可能存在有歧义的部分。
|
||||
|
||||
因此,我们希望将我们的程序转换成数据结构,将数据结构全部映射为我们所使用的所谓“标记”,并将其插入到我们的程序中。
|
||||
|
||||
这个数据结构正是 AST!
|
||||
|
||||
AST 可以通过多种不同的方式表示,我使用 JSON 来看一看。
|
||||
|
||||
我们从这个极其简单的基本源代码来看:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
TypeScript 编译器的 Parser(语法分析程序)阶段的(简化后的)输出将是以下 AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
我们的 AST 中的对象称为节点。
|
||||
|
||||
#### 示例:在 VS Code 中重命名符号
|
||||
|
||||
在内部,TypeScript 编译器将使用 Parser 生成的 AST 来提供一些非常重要的事情,例如,发生在编译程序时的类型检查。
|
||||
|
||||
但它不止于此!
|
||||
|
||||
> 我们可以使用 AST 在 TypeScript 之上开发自己的工具,如代码美化工具、代码格式化工具和分析工具。
|
||||
|
||||
建立在这个 AST 代码之上的工具的一个很好的例子是:<ruby>语言服务器<rt>Language Server</rt></ruby>。
|
||||
|
||||
深入了解语言服务器的工作原理超出了本文的范围,但是当我们编写程序时,它能为我们提供一个绝对重量级别功能,就是“重命名符号”。
|
||||
|
||||
假设我们有以下源代码:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
经过代码审查和对完美的适当追求,我们决定应该改换我们的变量命名惯例;使用驼峰式命名方式,而不是我们当前正在使用这种蛇式命名。
|
||||
|
||||
在我们的代码编辑器中,我们一直以来可以选择多个相同的文本,并使用多个光标来一次更改它们。
|
||||
|
||||

|
||||
|
||||
当我们把程序也视作文本这样继续操作时,我们已经陷入了一个典型的陷阱中。
|
||||
|
||||
那个注释中我们不想修改的“name”单词,在我们的手动匹配中却被误选中了。我们可以看到在现实世界的应用程序中这样更改代码是有多危险。
|
||||
|
||||
正如我们在上面学到的那样,像 TypeScript 这样的东西在幕后生成一个 AST 的时候,与我们的程序不再像普通文本那样可以交互,每个标记在 AST 中都有自己的位置,而且它有很清晰的映射关系。
|
||||
|
||||
当我们右键单击我们的 `first_name` 变量时,我们可以在 VS Code 中直接“重命名符号”(TypeScript 语言服务器插件也可用于其他编辑器)。
|
||||
|
||||

|
||||
|
||||
非常好!现在我们的 `first_name` 变量是唯一需要改变的东西,如果需要的话,这个改变甚至会发生在我们项目中的多个文件中(与导出和导入的值一样)!
|
||||
|
||||
### 总结
|
||||
|
||||
哦,我们在这篇文章中已经讲了很多的内容。
|
||||
|
||||
我们把有关学术方面的规避开,围绕编译器和类型还有很多专业术语给出了通俗的定义。
|
||||
|
||||
我们对比了编译语言与解释语言、运行阶段与编译阶段、动态类型与静态类型,以及抽象语法树(AST)如何为我们的程序构建工具提供了更为优化的方法。
|
||||
|
||||
重要的是,我们提供了 TypeScript 作为我们 JavaScript 开发工具的一种思路,以及如何在其上构建更棒的工具,比如说作为重构代码的一种方式的重命名符号。
|
||||
|
||||
快来 UltimateAngular 平台上学习从初学者到 TypeScript 高手的课程吧,开启你的学习之旅!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:James Henry
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
10 个应当了解的 Unikernel 开源项目
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> unikernel 实质上是一个缩减的操作系统,它可以与应用程序结合成为一个 unikernel 程序,它通常在虚拟机中运行。下载《开放云指南》了解更多。
|
||||
|
||||
当涉及到操作系统、容器技术和 unikernel,趋势是朝着微型化发展。什么是 unikernel?unikernel 实质上是一个缩减的操作系统(特指 “unikernel”),它可以与应用程序结合成为一个 unikernel 程序, 它通常在虚拟机中运行。它们有时被称为库操作系统,因为它包含了使应用程序能够将硬件和网络协议与一组访问控制和网络层隔离的策略相结合使用的库。
|
||||
|
||||
在讨论云计算和 Linux 时容器常常会被提及,而 unikernel 也在做一些变革。容器和 unikernel 都不是新事物。在 20 世纪 90 年代就有类似 unikernel 的系统,如 Exokernel,而如今流行的 unikernel 系统则有 MirageOS 和 OSv。 Unikernel 程序可以独立使用并在异构环境中部署。它们可以促进专业化和隔离化服务,并被广泛用于在微服务架构中开发应用程序。
|
||||
|
||||
作为 unikernel 如何引起关注的一个例子,你可以看看 Docker 收购了[基于 Cambridge 的 Unikernel 系统][3],并且已在许多情况下在使用 unikernel。
|
||||
|
||||
unikernel,就像容器技术一样, 它剥离了非必需的的部分,因此它们对应用程序的稳定性、可用性以及安全性有非常积极的影响。在开源领域,它们也吸引了许多顶级,最具创造力的开发人员。
|
||||
|
||||
Linux 基金会最近[宣布][4]发布了其 2016 年度报告[开放云指南:当前趋势和开源项目指南][5]。这份第三年度的报告全面介绍了开放云计算的状况,并包含了一节关于 unikernel 的内容。你现在可以[下载该报告][6]。它汇总并分析研究、描述了容器、unikernel 的发展趋势,已经它们如何重塑云计算的。该报告提供了对当今开放云环境中心的各类项目的描述和链接。
|
||||
|
||||
在本系列文章中,我们将按类别分析指南中提到的项目,为整体类别的演变提供了额外的见解。下面, 你将看到几个重要 unikernel 项目的列表及其影响,以及它们的 GitHub 仓库的链接, 这些都是从开放云指南中收集到的:
|
||||
|
||||
### [ClickOS][7]
|
||||
|
||||
ClickOS 是 NEC 的高性能虚拟化软件中间件平台,用于构建于 MiniOS/MirageOS 之上网络功能虚拟化(NFV)
|
||||
|
||||
- [ClickOS 的 GitHub][8]
|
||||
|
||||
### [Clive][9]
|
||||
|
||||
Clive 是用 Go 编写的一个操作系统,旨在工作于分布式和云计算环境中。
|
||||
|
||||
### [HaLVM][10]
|
||||
|
||||
Haskell 轻量级虚拟机(HaLVM)是 Glasgow Haskell 编译器工具包的移植,它使开发人员能够编写可以直接在 Xen 虚拟机管理程序上运行的高级轻量级虚拟机。
|
||||
|
||||
- [HaLVM 的 GitHub][11]
|
||||
|
||||
### [IncludeOS][12]
|
||||
|
||||
IncludeOS 是在云中运行 C++ 服务的 unikernel 操作系统。它提供了一个引导加载程序、标准库以及运行服务的构建和部署系统。在 VirtualBox 或 QEMU 中进行测试,并在 OpenStack 上部署服务。
|
||||
|
||||
- [IncludeOS 的 GitHub][13]
|
||||
|
||||
### [Ling][14]
|
||||
|
||||
Ling 是一个用于构建超级可扩展云的 Erlang 平台,可直接运行在 Xen 虚拟机管理程序之上。它只运行三个外部库 (没有 OpenSSL),并且文件系统是只读的,以避免大多数攻击。
|
||||
|
||||
- [Ling 的 GitHub][15]
|
||||
|
||||
### [MirageOS][16]
|
||||
|
||||
MirageOS 是在 Linux 基金会的 Xen 项目下孵化的库操作系统。它使用 OCaml 语言构建的 unikernel 可以用于各种云计算和移动平台上安全的高性能网络应用。代码可以在诸如 Linux 或 MacOS X 等普通的操作系统上开发,然后编译成在 Xen 虚拟机管理程序下运行的完全独立的专用 Unikernel。
|
||||
|
||||
- [MirageOS 的 GitHub][17]
|
||||
|
||||
### [OSv][18]
|
||||
|
||||
OSv 是 Cloudius Systems 为云设计的开源操作系统。它支持用 Java、Ruby(通过 JRuby)、JavaScript(通过 Rhino 和 Nashorn)、Scala 等编写程序。它运行在 VMware、VirtualBox、KVM 和 Xen 虚拟机管理程序上。
|
||||
|
||||
- [OSV 的 GitHub][19]
|
||||
|
||||
### [Rumprun][20]
|
||||
|
||||
Rumprun 是一个可用于生产环境的 unikernel,它使用 rump 内核提供的驱动程序,添加了 libc 和应用程序环境,并提供了一个工具链,用于将现有的 POSIX-y 程序构建为 Rumprun unikernel。它适用于 KVM 和 Xen 虚拟机管理程序和裸机,并支持用 C、C ++、Erlang、Go、Java、JavaScript(Node.js)、Python、Ruby、Rust 等编写的程序。
|
||||
|
||||
- [Rumprun 的 GitHub][21]
|
||||
|
||||
### [Runtime.js][22]
|
||||
|
||||
Runtime.js 是用于在云上运行 JavaScript 的开源库操作系统(unikernel),它可以与应用程序捆绑在一起,并部署为轻量级和不可变的 VM 镜像。它基于 V8 JavaScript 引擎,并使用受 Node.js 启发的事件驱动和非阻塞 I/O 模型。KVM 是唯一支持的虚拟机管理程序。
|
||||
|
||||
- [Runtime.js 的 GitHub] [23]
|
||||
|
||||
### [UNIK][24]
|
||||
|
||||
Unik 是 EMC 推出的工具,可以将应用程序源编译为 unikernel(轻量级可引导磁盘镜像)而不是二进制文件。它允许应用程序在各种云提供商、嵌入式设备(IoT) 以及开发人员的笔记本或工作站上安全地部署,资源占用很少。它支持多种 unikernel 类型、处理器架构、管理程序和编排工具,包括 Cloud Foundry、Docker 和 Kubernetes。[Unik 的 GitHub] [25]
|
||||
|
||||
(题图:Pixabay)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-age-unikernel
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/unikernelsjpg-0
|
||||
[3]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[4]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[5]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[7]:http://cnp.neclab.eu/clickos/
|
||||
[8]:https://github.com/cnplab/clickos
|
||||
[9]:http://lsub.org/ls/clive.html
|
||||
[10]:https://galois.com/project/halvm/
|
||||
[11]:https://github.com/GaloisInc/HaLVM
|
||||
[12]:http://www.includeos.org/
|
||||
[13]:https://github.com/hioa-cs/IncludeOS
|
||||
[14]:http://erlangonxen.org/
|
||||
[15]:https://github.com/cloudozer/ling
|
||||
[16]:https://mirage.io/
|
||||
[17]:https://github.com/mirage/mirage
|
||||
[18]:http://osv.io/
|
||||
[19]:https://github.com/cloudius-systems/osv
|
||||
[20]:http://rumpkernel.org/
|
||||
[21]:https://github.com/rumpkernel/rumprun
|
||||
[22]:http://runtimejs.org/
|
||||
[23]:https://github.com/runtimejs/runtime
|
||||
[24]:http://dojoblog.emc.com/unikernels/unik-build-run-unikernels-easy/
|
||||
[25]:https://github.com/emc-advanced-dev/unik
|
||||
@ -0,0 +1,161 @@
|
||||
用 R 收集和映射推特数据的初学者向导
|
||||
============================================================
|
||||
|
||||
> 学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
|
||||
|
||||

|
||||
|
||||
当我开始学习 R ,我也需要学习如何出于研究的目的地收集推特数据并对其进行映射。尽管网上关于这个话题的信息很多,但我发觉难以理解什么与收集并映射推特数据相关。我不仅是个 R 新手,而且对各种教程中技术名词不熟悉。但尽管困难重重,我成功了!在这个教程里,我将以一种新手程序员都能看懂的方式来攻略如何收集推特数据并将至展现在地图中。
|
||||
|
||||
### 创建应用程序
|
||||
|
||||
如果你没有推特帐号,首先你需要 [注册一个][19]。然后,到 [apps.twitter.com][20] 创建一个允许你收集推特数据的应用程序。别担心,创建应用程序极其简单。你创建的应用程序会与推特应用程序接口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入推特 API 令其收集数据。只需确保不要请求太多,因为推特数据请求次数是有[限制][21] 的。
|
||||
|
||||
收集推文有两个可用的 API 。你若想做一次性的推文收集,那么使用 **REST API**. 若是想在特定时间内持续收集,可以用 **streaming API**。教程中我主要使用 REST API。
|
||||
|
||||
创建应用程序之后,前往 **Keys and Access Tokens** 标签。你需要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
|
||||
|
||||
### 收集推特数据
|
||||
|
||||
下一步是打开 R 准备写代码。对于初学者,我推荐使用 [RStudio][22],这是 R 的集成开发环境 (IDE) 。我发现 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 **[twitteR][8]**。
|
||||
|
||||
打开 RStudio 并新建 RScript。做好这些之后,你需要安装和加载 **twitteR** 包:
|
||||
|
||||
```
|
||||
install.packages("twitteR")
|
||||
#安装 TwitteR
|
||||
library (twitteR)
|
||||
#载入 TwitteR
|
||||
```
|
||||
|
||||
安装并载入 **twitteR** 包之后,你得输入上文提及的应用程序的 API 信息:
|
||||
|
||||
```
|
||||
api_key <- ""
|
||||
#在引号内放入你的 API key
|
||||
api_secret <- ""
|
||||
#在引号内放入你的 API secret token
|
||||
token <- ""
|
||||
#在引号内放入你的 token
|
||||
token_secret <- ""
|
||||
#在引号内放入你的 token secret
|
||||
```
|
||||
|
||||
接下来,连接推特访问 API:
|
||||
|
||||
```
|
||||
setup_twitter_oauth(api_key, api_secret, token, token_secret)
|
||||
```
|
||||
|
||||
我们来试试让推特搜索有关社区花园和农夫市场:
|
||||
|
||||
```
|
||||
tweets <- searchTwitter("community garden OR #communitygarden OR farmers market OR #farmersmarket", n = 200, lang = "en")
|
||||
```
|
||||
|
||||
这个代码意思是搜索前 200 篇 `(n = 200)` 英文 `(lang = "en")` 的推文, 包括关键词 `community garden` 或 `farmers market` 或任何提及这些关键词的话题标签。
|
||||
|
||||
推特搜索完成之后,在数据框中保存你的结果:
|
||||
|
||||
```
|
||||
tweets.df <-twListToDF(tweets)
|
||||
```
|
||||
|
||||
为了用推文创建地图,你需要收集的导出为 **.csv** 文件:
|
||||
|
||||
```
|
||||
write.csv(tweets.df, "C:\Users\YourName\Documents\ApptoMap\tweets.csv")
|
||||
#an example of a file extension of the folder in which you want to save the .csv file.
|
||||
```
|
||||
|
||||
运行前确保 **R** 代码已保存然后继续进行下一步。.
|
||||
|
||||
### 生成地图
|
||||
|
||||
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 **[Leaflet][9]** 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 [magrittr][23] 管道运算符 (`%>%`), 因为其语法自然,易于写代码。刚接触可能有点奇怪,但它确实降低了写代码的工作量。
|
||||
|
||||
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这些包:
|
||||
|
||||
```
|
||||
install.packages("leaflet")
|
||||
install.packages("maps")
|
||||
library(leaflet)
|
||||
library(maps)
|
||||
```
|
||||
|
||||
现在需要一个路径让 Leaflet 访问你的数据:
|
||||
|
||||
```
|
||||
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv", stringsAsFactors = FALSE)
|
||||
```
|
||||
|
||||
`stringAsFactors = FALSE` 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章["stringsAsFactors: An unauthorized biography"][24], 作者 Roger Peng)
|
||||
|
||||
是时候制作你的 Leaflet 地图了。我们将使用 **OpenStreetMap**基本地图来做你的地图:
|
||||
|
||||
```
|
||||
m <- leaflet(mymap) %>% addTiles()
|
||||
```
|
||||
|
||||
我们在基本地图上加个圈。对于 `lng` 和 `lat`,输入包含推文的经纬度的列名,并在前面加个`~`。 `~longitude` 和 `~latitude` 指向你的 **.csv** 文件中与列名:
|
||||
|
||||
```
|
||||
m %>% addCircles(lng = ~longitude, lat = ~latitude, popup = mymap$type, weight = 8, radius = 40, color = "#fb3004", stroke = TRUE, fillOpacity = 0.8)
|
||||
```
|
||||
|
||||
运行你的代码。会弹出网页浏览器并展示你的地图。这是我前面收集的推文的地图:
|
||||
|
||||
|
||||

|
||||
|
||||
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap [CC-BY-SA][5]
|
||||
|
||||
虽然你可能会对地图上的图文数量如此之小感到惊奇,通常只有 1% 的推文记录了地理编码。我收集了总数为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困扰,改变搜索关键词看看能不能得到更好的结果。
|
||||
|
||||
### 总结
|
||||
|
||||
对于初学者,把以上所有碎片结合起来,从推特数据生成一个 Leaflet 地图可能很艰难。 这个教程基于我完成这个任务的经验,我希望它能让你的学习过程变得更轻松。
|
||||
|
||||
(题图:[琼斯·贝克][14]. [CC BY-SA 4.0][15]. 来源: [Cloud][16], [Globe][17]. Both [CC0][18].)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Dorris Scott - Dorris Scott 是佐治亚大学的地理学博士生。她的研究重心是地理信息系统(GIS)、 地理数据科学、可视化和公共卫生。她的论文是在一个 GIS 系统接口将退伍军人福利医院的传统和非传统数据结合起来,帮助病人为他们的健康状况作出更为明朗的决定。
|
||||
|
||||
-----------------
|
||||
via: https://opensource.com/article/17/6/collecting-and-mapping-twitter-data-using-r
|
||||
|
||||
作者:[Dorris Scott][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dorrisscott
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://creativecommons.org/licenses/by-sa/2.0/
|
||||
[6]:https://opensource.com/file/356071
|
||||
[7]:https://opensource.com/article/17/6/collecting-and-mapping-twitter-data-using-r?rate=Rnu6Lf0Eqvepznw75VioNPWIaJQH39pZETBfu2ZI3P0
|
||||
[8]:https://cran.r-project.org/web/packages/twitteR/twitteR.pdf
|
||||
[9]:https://rstudio.github.io/leaflet
|
||||
[10]:https://werise.tech/sessions/2017/4/16/from-app-to-map-collecting-and-mapping-social-media-data-using-r?rq=social%20mapping
|
||||
[11]:https://werise.tech/
|
||||
[12]:https://twitter.com/search?q=%23WeRiseTech&src=typd
|
||||
[13]:https://opensource.com/user/145006/feed
|
||||
[14]:https://opensource.com/users/jason-baker
|
||||
[15]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[16]:https://pixabay.com/en/clouds-sky-cloud-dark-clouds-1473311/
|
||||
[17]:https://pixabay.com/en/globe-planet-earth-world-1015311/
|
||||
[18]:https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[19]:https://twitter.com/signup
|
||||
[20]:https://apps.twitter.com/
|
||||
[21]:https://dev.twitter.com/rest/public/rate-limiting
|
||||
[22]:https://www.rstudio.com/
|
||||
[23]:https://github.com/smbache/magrittr
|
||||
[24]:http://simplystatistics.org/2015/07/24/stringsasfactors-an-unauthorized-biography/
|
||||
[25]:https://opensource.com/users/dorrisscott
|
||||
@ -0,0 +1,91 @@
|
||||
CoreOS,一款 Linux 容器发行版
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> CoreOS,一款最新的 Linux 发行版本,支持自动升级内核软件,提供各集群间配置的完全控制。
|
||||
|
||||
关于使用哪个版本的 Linux 服务器系统的争论,常常是以这样的话题开始的:
|
||||
|
||||
> 你是喜欢基于 [Red Hat Enterprise Linux (RHEL)][1] 的 [CentOS][2] 或者 [Fedora][3],还是基于 [Debian][4] 的 [Ubuntu][5],抑或 [SUSE][6] 呢?
|
||||
|
||||
但是现在,一款名叫 [CoreOS 容器 Linux][7] 的 Linux 发行版加入了这场“圣战”。[这个最近在 Linode 服务器上提供的 CoreOS][8],和它的老前辈比起来,它使用了完全不同的实现方法。
|
||||
|
||||
你可能会感到不解,这里有这么多成熟的 Linux 发行版本,为什么要选择用 CoreOS ?借用 Linux 主干分支的维护者,也是 CoreOS 顾问的 Greg Kroah-Hartman 先生的一句话:
|
||||
|
||||
> CoreOS 可以控制发行版的升级(基于 ChromeOS 代码),并结合了 Docker 和潜在的核对/修复功能,这意味着不用停止或者重启你的相关进程,就可以[在线升级][9]。测试版本已经支持此功能,这是史无前例的。
|
||||
|
||||
当 Greg Kroah-Hartman 做出这段评价时,CoreOS 还处于 α 测试阶段,当时也许就是在硅谷的一个车库当中,[开发团队正在紧锣密鼓地开发此产品][10],但 CoreOS 不像最开始的苹果或者惠普,其在过去的四年当中一直稳步发展。
|
||||
|
||||
当我参加在旧金山举办的 [2017 CoreOS 大会][11]时,CoreOS 已经支持谷歌云、IBM、AWS 和微软的相关服务。现在有超过 1000 位开发人员参与到这个项目中,并为能够成为这个伟大产品的一员而感到高兴。
|
||||
|
||||
究其原因,CoreOS 从开始就是为容器而设计的轻量级 Linux 发行版,其起初是作为一个 [Docker][12] 平台,随着时间的推移, CoreOS 在容器方面走出了自己的道路,除了 Docker 之外,它也支持它自己的容器 [rkt][13] (读作 rocket )。
|
||||
|
||||
不像大多数其他的 Linux 发行版,CoreOS 没有包管理器,取而代之的是通过 Google ChromeOS 的页面自动进行软件升级,这样能提高在集群上运行的机器/容器的安全性和可靠性。不用通过系统管理员的干涉,操作系统升级组件和安全补丁可以定期推送到 CoreOS 容器。
|
||||
|
||||
你可以通过 [CoreUpdate 和它的 Web 界面][14]上来修改推送周期,这样你就可以控制你的机器何时更新,以及更新以多快的速度滚动分发到你的集群上。
|
||||
|
||||
CoreOS 通过一种叫做 [etcd][15] 的分布式配置服务来进行升级,etcd 是一种基于 [YAML][16] 的开源的分布式哈希存储系统,它可以为 Linux 集群容器提供配置共享和服务发现等功能。
|
||||
|
||||
此服务运行在集群上的每一台服务器上,当其中一台服务器需要下线升级时,它会发起领袖选举,以便服务器更新时整个Linux 系统和容器化的应用可以继续运行。
|
||||
|
||||
对于集群管理,CoreOS 之前采用的是 [fleet][17] 方法,这将 etcd 和 [systemd][18] 结合到分布式初始化系统中。虽然 fleet 仍然在使用,但 CoreOS 已经将 etcd 加入到 [Kubernetes][19] 容器编排系统构成了一个更加强有力的管理工具。
|
||||
|
||||
CoreOS 也可以让你定制其它的操作系统相关规范,比如用 [cloud-config][20] 的方式管理网络配置、用户账号和 systemd 单元等。
|
||||
|
||||
综上所述,CoreOS 可以不断地自行升级到最新版本,能让你获得从单独系统到集群等各种场景的完全控制。如 CoreOS 宣称的,你再也不用为了改变一个单独的配置而在每一台机器上运行 [Chef][21] 了。
|
||||
|
||||
假如说你想进一步的扩展你的 DevOps 控制,[CoreOS 能够轻松地帮助你部署 Kubernetes][22]。
|
||||
|
||||
CoreOS 从一开始就是构建来易于部署、管理和运行容器的。当然,其它的 Linux 发行版,比如 RedHat 家族的[原子项目][23]也可以达到类似的效果,但是对于那些发行版而言是以附加组件的方式出现的,而 CoreOS 从它诞生的第一天就是为容器而设计的。
|
||||
|
||||
当前[容器和 Docker 已经逐渐成为商业系统的主流][24],如果在可预见的未来中你要在工作中使用容器,你应该考虑下 CoreOS,不管你的系统是在裸机硬件上、虚拟机还是云上。
|
||||
|
||||
如果有任何关于 CoreOS 的观点或者问题,还请在评论栏中留言。如果你觉得这篇博客还算有用的话,还请分享一下~
|
||||
|
||||
---
|
||||
|
||||
关于博主:Steven J. Vaughan-Nichols 是一位经验丰富的 IT 记者,许多网站中都刊登有他的文章,包括 [ZDNet.com][25]、[PC Magazine][26]、[InfoWorld][27]、[ComputerWorld][28]、[Linux Today][29] 和 [eWEEK][30] 等。他拥有丰富的 IT 知识 - 而且他曾参加过智力竞赛节目 Jeopardy !他的相关观点都是自身思考的结果,并不代表 Linode 公司,我们对他做出的贡献致以最真诚的感谢。如果想知道他更多的信息,可以关注他的 Twitter [_@sjvn_][31]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[吴霄/toyijiu](https://github.com/toyijiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
[1]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[2]:https://www.centos.org/
|
||||
[3]:https://getfedora.org/
|
||||
[4]:https://www.debian.org/
|
||||
[5]:https://www.ubuntu.com/
|
||||
[6]:https://www.suse.com/
|
||||
[7]:https://coreos.com/os/docs/latest
|
||||
[8]:https://www.linode.com/docs/platform/use-coreos-container-linux-on-linode
|
||||
[9]:https://plus.google.com/+gregkroahhartman/posts/YvWFmPa9kVf
|
||||
[10]:https://www.wired.com/2013/08/coreos-the-new-linux/
|
||||
[11]:https://coreos.com/fest/
|
||||
[12]:https://www.docker.com/
|
||||
[13]:https://coreos.com/rkt
|
||||
[14]:https://coreos.com/products/coreupdate/
|
||||
[15]:https://github.com/coreos/etcd
|
||||
[16]:http://yaml.org/
|
||||
[17]:https://github.com/coreos/fleet
|
||||
[18]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[19]:https://kubernetes.io/
|
||||
[20]:https://coreos.com/os/docs/latest/cloud-config.html
|
||||
[21]:https://insights.hpe.com/articles/what-is-chef-a-primer-for-devops-newbies-1704.html
|
||||
[22]:https://blogs.dxc.technology/2017/06/08/coreos-moves-in-on-cloud-devops-with-kubernetes/
|
||||
[23]:http://www.projectatomic.io/
|
||||
[24]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[25]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[26]:http://www.pcmag.com/author-bio/steven-j.-vaughan-nichols
|
||||
[27]:http://www.infoworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[28]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[29]:http://www.linuxtoday.com/author/Steven+J.+Vaughan-Nichols/
|
||||
[30]:http://www.eweek.com/cp/bio/Steven-J.-Vaughan-Nichols/
|
||||
[31]:http://www.twitter.com/sjvn
|
||||
@ -0,0 +1,234 @@
|
||||
学习用 Python 编程时要避免的 3 个错误
|
||||
============================================================
|
||||
|
||||
> 这些错误会造成很麻烦的问题,需要数小时才能解决。
|
||||
|
||||

|
||||
|
||||
当你做错事时,承认错误并不是一件容易的事,但是犯错是任何学习过程中的一部分,无论是学习走路,还是学习一种新的编程语言都是这样,比如学习 Python。
|
||||
|
||||
为了让初学 Python 的程序员避免犯同样的错误,以下列出了我学习 Python 时犯的三种错误。这些错误要么是我长期以来经常犯的,要么是造成了需要几个小时解决的麻烦。
|
||||
|
||||
年轻的程序员们可要注意了,这些错误是会浪费一下午的!
|
||||
|
||||
### 1、 可变数据类型作为函数定义中的默认参数
|
||||
|
||||
这似乎是对的?你写了一个小函数,比如,搜索当前页面上的链接,并可选将其附加到另一个提供的列表中。
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
从表面看,这像是十分正常的 Python 代码,事实上它也是,而且是可以运行的。但是,这里有个问题。如果我们给 `add_to` 参数提供了一个列表,它将按照我们预期的那样工作。但是,如果我们让它使用默认值,就会出现一些神奇的事情。
|
||||
|
||||
试试下面的代码:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
可能你认为我们将看到:
|
||||
|
||||
```
|
||||
[3]
|
||||
[4]
|
||||
[5]
|
||||
```
|
||||
|
||||
但实际上,我们看到的却是:
|
||||
|
||||
```
|
||||
[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]
|
||||
```
|
||||
|
||||
为什么呢?如你所见,每次都使用的是同一个列表,输出为什么会是这样?在 Python 中,当我们编写这样的函数时,这个列表被实例化为函数定义的一部分。当函数运行时,它并不是每次都被实例化。这意味着,这个函数会一直使用完全一样的列表对象,除非我们提供一个新的对象:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
```
|
||||
[4, 3]
|
||||
```
|
||||
|
||||
答案正如我们所想的那样。要想得到这种结果,正确的方法是:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
或是在第一个例子中:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
这将在模块加载的时候移走实例化的内容,以便每次运行函数时都会发生列表实例化。请注意,对于不可变数据类型,比如[**元组**][7]、[**字符串**][8]、[**整型**][9],是不需要考虑这种情况的。这意味着,像下面这样的代码是非常可行的:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2、 可变数据类型作为类变量
|
||||
|
||||
这和上面提到的最后一个错误很相像。思考以下代码:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
这段代码看起来非常正常。我们有一个储存 URL 的对象。当我们调用 add_url 方法时,它会添加一个给定的 URL 到存储中。看起来非常正确吧?让我们看看实际是怎样的:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.com')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.hk')
|
||||
```
|
||||
|
||||
b.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
a.urls:
|
||||
|
||||
```
|
||||
['http://www.google.com', 'http://www.bbc.co.uk']
|
||||
```
|
||||
|
||||
等等,怎么回事?!我们想的不是这样啊。我们实例化了两个单独的对象 `a` 和 `b`。把一个 URL 给了 `a`,另一个给了 `b`。这两个对象怎么会都有这两个 URL 呢?
|
||||
|
||||
这和第一个错例是同样的问题。创建类定义时,URL 列表将被实例化。该类所有的实例使用相同的列表。在有些时候这种情况是有用的,但大多数时候你并不想这样做。你希望每个对象有一个单独的储存。为此,我们修改代码为:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
现在,当创建对象时,URL 列表被实例化。当我们实例化两个单独的对象时,它们将分别使用两个单独的列表。
|
||||
|
||||
### 3、 可变的分配错误
|
||||
|
||||
这个问题困扰了我一段时间。让我们做出一些改变,并使用另一种可变数据类型 - [**字典**][10]。
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
现在,假设我们想把这个字典用在别的地方,且保持它的初始数据完整。
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
简单吧?
|
||||
|
||||
现在,让我们看看原来那个我们不想改变的字典 `a`:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
哇等一下,我们再看看 **b**?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
等等,什么?有点乱……让我们回想一下,看看其它不可变类型在这种情况下会发生什么,例如一个**元组**:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
现在 `c` 是 `(2, 3)`,而 `d` 是 `(4, 5)`。
|
||||
|
||||
这个函数结果如我们所料。那么,在之前的例子中到底发生了什么?当使用可变类型时,其行为有点像 **C** 语言的一个指针。在上面的代码中,我们令 `b = a`,我们真正表达的意思是:`b` 成为 `a` 的一个引用。它们都指向 Python 内存中的同一个对象。听起来有些熟悉?那是因为这个问题与先前的相似。其实,这篇文章应该被称为「可变引发的麻烦」。
|
||||
|
||||
列表也会发生同样的事吗?是的。那么我们如何解决呢?这必须非常小心。如果我们真的需要复制一个列表进行处理,我们可以这样做:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
这将遍历并复制列表中的每个对象的引用,并且把它放在一个新的列表中。但是要注意:如果列表中的每个对象都是可变的,我们将再次获得它们的引用,而不是完整的副本。
|
||||
|
||||
假设在一张纸上列清单。在原来的例子中相当于,A 某和 B 某正在看着同一张纸。如果有个人修改了这个清单,两个人都将看到相同的变化。当我们复制引用时,每个人现在有了他们自己的清单。但是,我们假设这个清单包括寻找食物的地方。如果“冰箱”是列表中的第一个,即使它被复制,两个列表中的条目也都指向同一个冰箱。所以,如果冰箱被 A 修改,吃掉了里面的大蛋糕,B 也将看到这个蛋糕的消失。这里没有简单的方法解决它。只要你记住它,并编写代码的时候,使用不会造成这个问题的方式。
|
||||
|
||||
字典以相同的方式工作,并且你可以通过以下方式创建一个昂贵副本:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
再次说明,这只会创建一个新的字典,指向原来存在的相同的条目。因此,如果我们有两个相同的列表,并且我们修改字典 `a` 的一个键指向的可变对象,那么在字典 b 中也将看到这些变化。
|
||||
|
||||
可变数据类型的麻烦也是它们强大的地方。以上都不是实际中的问题;它们是一些要注意防止出现的问题。在第三个项目中使用昂贵复制操作作为解决方案在 99% 的时候是没有必要的。你的程序或许应该被改改,所以在第一个例子中,这些副本甚至是不需要的。
|
||||
|
||||
_编程快乐!在评论中可以随时提问。_
|
||||
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter 是一位充满激情的开源爱好者,在过去十年里一直在推广和使用开源产品。他从 Ubuntu 社区开始,在许多不同的领域自愿参与音频制作领域的研究工作。在职业经历方面,他起初作为公司的系统管理员,大部分时间在管理和建立数据中心,之后在 Red Hat 担任 CloudForms 产品的主要测试工程师。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage][a]
|
||||
译者:[polebug](https://github.com/polebug)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -0,0 +1,166 @@
|
||||
使用 Snapcraft 构建、测试并发布 Snap 软件包
|
||||
================================
|
||||
|
||||
snapcraft 是一个正在为其在 Linux 中的地位而奋斗的包管理系统,它为你重新设想了分发软件的方式。这套新的跨发行版的工具可以用来帮助你构建和发布 snap 软件包。接下来我们将会讲述怎么使用 CircleCI 2.0 来加速这个过程以及一些在这个过程中的可能遇到的问题。
|
||||
|
||||
### snap 软件包是什么?snapcraft 又是什么?
|
||||
|
||||
snap 是用于 Linux 发行版的软件包,它们在设计的时候吸取了像 Android 这样的移动平台和物联网设备上分发软件的经验教训。snapcraft 这个名字涵盖了 snap 和用来构建它们的命令行工具、这个 [snapcraft.io][1] 网站,以及在这些技术的支撑下构建的几乎整个生态系统。
|
||||
|
||||
snap 软件包被设计成用来隔离并封装整个应用程序。这些概念使得 snapcraft 提高软件安全性、稳定性和可移植性的目标得以实现,其中可移植性允许单个 snap 软件包不仅可以在 Ubuntu 的多个版本中安装,而且也可以在 Debian、Fedora 和 Arch 等发行版中安装。snapcraft 网站对其的描述如下:
|
||||
|
||||
> 为每个 Linux 桌面、服务器、云端或设备打包任何应用程序,并且直接交付更新。
|
||||
|
||||
### 在 CircleCI 2.0 上构建 snap 软件包
|
||||
|
||||
在 CircleCI 上使用 [CircleCI 2.0 语法][2] 来构建 snap 和在本地机器上基本相同。在本文中,我们将会讲解一个示例配置文件。如果您对 CircleCI 还不熟悉,或者想了解更多有关 2.0 的入门知识,您可以从 [这里][3] 开始。
|
||||
|
||||
### 基础配置
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
```
|
||||
|
||||
这个例子使用了 `machine` 执行器来安装用于管理运行 snap 的可执行程序 `snapd` 和制作 snap 的 `snapcraft` 工具。
|
||||
|
||||
由于构建过程需要使用比较新的内核,所以我们使用了 `machine` 执行器而没有用 `docker` 执行器。在这里,Linux v4.4 已经足够满足我们的需求了。
|
||||
|
||||
### 用户空间的依赖关系
|
||||
|
||||
上面的例子使用了 `machine` 执行器,它实际上是一个内核为 Linux v4.4 的 [Ubuntu 14.04 (Trusty) 虚拟机][4]。如果 Trusty 仓库可以满足你的 project/snap 构建依赖,那就没问题。如果你的构建依赖需要其他版本,比如 Ubuntu 16.04 (Xenial),我们仍然可以在 `machine` 执行器中使用 Docker 来构建我们的 snap 软件包 。
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
|
||||
这个例子中,我们再次在 `machine` 执行器的虚拟机中安装了 `snapd`,但是我们决定将 snapcraft 安装在 Ubuntu Xenial 镜像构建的 Docker 容器中,并使用它来构建我们的 snap。这样,在 `snapcraft` 运行的过程中就可以使用在 Ubuntu 16.04 中可用的所有 `apt` 包。
|
||||
|
||||
### 测试
|
||||
|
||||
在我们的[博客](https://circleci.com/blog/)、[文档](https://circleci.com/docs/)以及互联网上已经有很多讲述如何对软件代码进行单元测试的内容。搜索你的语言或者框架和单元测试或者 CI 可以找到大量相关的信息。在 CircleCI 上构建 snap 软件包,我们最终会得到一个 `.snap` 的文件,这意味着除了创造它的代码外我们还可以对它进行测试。
|
||||
|
||||
### 工作流
|
||||
|
||||
假设我们构建的 snap 软件包是一个 webapp,我们可以通过测试套件来确保构建的 snap 可以正确的安装和运行,我们也可以试着安装它或者使用 [Selenium][5] 来测试页面加载、登录等功能正常工作。但是这里有一个问题,由于 snap 是被设计成可以在多个 Linux 发行版上运行,这就需要我们的测试套件可以在 Ubuntu 16.04、Fedora 25 和 Debian 9 等发行版中可以正常运行。这个问题我们可以通过 CircleCI 2.0 的工作流来有效地解决。
|
||||
|
||||
工作流是在最近的 CircleCI 2.0 测试版中加入的,它允许我们通过特定的逻辑流程来运行离散的任务。这样,使用单个任务构建完 snap 后,我们就可以开始并行的运行 snap 的发行版测试任务,每个任务对应一个不同的发行版的 [Docker 镜像][6] (或者在将来,还会有其他可用的执行器)。
|
||||
|
||||
这里有一个简单的例子:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
在这个例子中首先构建了 snap,然后在四个不同的发行版上运行验收测试。如果所有的发行版都通过测试了,那么我们就可以运行发布 `job`,以便在将其推送到 snap 商店之前完成剩余的 snap 任务。
|
||||
|
||||
### 留着 .snap 包
|
||||
|
||||
为了测试我们在工作流示例中使用的 .snap 软件包,我们需要一种在构建的时候持久保存 snap 的方法。在这里我将提供两种方法:
|
||||
|
||||
1. **artifact** —— 在运行 `build` 任务的时候我们可以将 snaps 保存为一个 CircleCI 的 artifact(LCTT 译注:artifact 是 `snapcraft.yaml` 中的一个 `Plugin-specific` 关键字),然后在接下来的任务中检索它。CircleCI 工作流有自己处理共享 artifact 的方式,相关信息可以在 [这里][7] 找到。
|
||||
2. **snap 商店通道** —— 当发布 snap 软件包到 snap 商店时,有多种通道可供我们选择。将 snap 的主分支发布到 edge 通道以供内部或者用户测试已经成为一种常见做法。我们可以在 `build` 任务中完成这些工作,然后接下来的的任务就可以从 edge 通道来安装构建好的 snap 软件包。
|
||||
|
||||
第一种方法速度更快,并且它还可以在 snap 软包上传到 snap 商店供用户甚至是测试用户使用之前对 snap 进行验收测试。第二种方法的好处是我们可以从 snap 商店安装 snap,这也是 CI 运行期间的测试项之一。
|
||||
|
||||
### snap 商店的身份验证
|
||||
|
||||
[snapcraft-config-generator.py][8] 脚本可以生成商店证书并将其保存到 `.snapcraft/snapcraft.cfg` 中(注意:在运行公共脚本之前一定要对其进行检查)。如果觉得在你仓库中使用明文来保存这个文件不安全,你可以用 `base64` 编码该文件,并将其存储为一个[私有环境变量][9],或者你也可以对文件 [进行加密][10],并将密钥存储在一个私有环境变量中。
|
||||
|
||||
下面是一个示例,将商店证书放在一个加密的文件中,并在 `deploy` 环节中使用它将 snap 发布到 snap 商店中。
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
除了 `deploy` 任务之外,工作流示例同之前的一样, `deploy` 任务只有当验收测试任务通过时才会运行。
|
||||
|
||||
### 更多的信息
|
||||
|
||||
* Alan Pope 在 [论坛中发的帖子][11]:“popey” 是 Canonical 的员工,他在 snapcraft 的论坛上写了这篇文章,并启发作者写了这篇博文。
|
||||
* [snapcraft 网站][12]: snapcraft 官方网站。
|
||||
* [snapcraft 的 CircleCI Bug 报告][13]:在 Launchpad 上有一个开放的 bug 报告页面,用来改善 CircleCI 对 snapcraft 的支持。同时这将使这个过程变得更简单并且更“正式”。期待您的支持。
|
||||
* 怎么使用 CircleCI 构建 [Nextcloud][14] 的 snap:这里有一篇题为 [“复杂应用的持续验收测试”][15] 的博文,它同时也影响了这篇博文。
|
||||
|
||||
|
||||
这篇客座文章的作者是 Ricardo Feliciano —— CircleCi 的开发者传道士。如果您也有兴趣投稿,请联系 ubuntu-iot@canonical.com。原始文章可以从 [这里][18] 找到。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
译者简介:
|
||||
|
||||
> 常年混迹于 snapcraft.io,对 Ubuntu Core、snaps 和 snapcraft 有浓厚的兴趣,并致力于将这些还在快速发展的新技术通过翻译或原创的方式介绍到中文世界。有兴趣的小伙伴也可以关注译者个人的公众号: `Snapcraft`
|
||||
|
||||
作者:Ricardo Feliciano
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
|
||||
[1]: https://snapcraft.io/
|
||||
[2]:https://circleci.com/docs/2.0/
|
||||
[3]: https://circleci.com/docs/2.0/first-steps/
|
||||
[4]: https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[5]:http://www.seleniumhq.org/
|
||||
[6]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[7]: https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[8]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[9]: https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[10]: https://github.com/circleci/encrypted-files
|
||||
[11]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[12]:https://snapcraft.io/
|
||||
[13]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[14]:https://nextcloud.com/
|
||||
[15]: https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[16]:https://nextcloud.com/
|
||||
[17]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[18]: https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
[19]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
@ -0,0 +1,233 @@
|
||||
在 Ubuntu 16.04 Server 上安装 Zabbix
|
||||
============================================================
|
||||
|
||||
[][3]
|
||||
|
||||
### 监控服务器 - 什么是 Zabbix
|
||||
|
||||
[Zabbix][2] 是企业级开源分布式监控服务器解决方案。该软件能监控网络的不同参数以及服务器的完整性,还允许为任何事件配置基于电子邮件的警报。Zabbix 根据存储在数据库(例如 MySQL)中的数据提供报告和数据可视化功能。软件收集的每个测量指标都可以通过基于 Web 的界面访问。
|
||||
|
||||
Zabbix 根据 GNU 通用公共许可证版本 2(GPLv2)的条款发布,完全免费。
|
||||
|
||||
在本教程中,我们将在运行 MySQL、Apache 和 PHP 的 Ubuntu 16.04 server 上安装 Zabbix。
|
||||
|
||||
### 安装 Zabbix 服务器
|
||||
|
||||
首先,我们需要安装 Zabbix 所需的几个 PHP 模块:
|
||||
|
||||
```
|
||||
# apt-get install php7.0-bcmath php7.0-xml php7.0-mbstring
|
||||
```
|
||||
|
||||
Ubuntu 仓库中提供的 Zabbix 软件包已经过时了。使用官方 Zabbix 仓库安装最新的稳定版本。
|
||||
|
||||
通过执行以下命令来安装仓库软件包:
|
||||
|
||||
```
|
||||
$ wget http://repo.zabbix.com/zabbix/3.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_3.2-1+xenial_all.deb
|
||||
# dpkg -i zabbix-release_3.2-1+xenial_all.deb
|
||||
```
|
||||
|
||||
然后更新 `apt` 包源:
|
||||
|
||||
```
|
||||
# apt-get update
|
||||
```
|
||||
|
||||
现在可以安装带有 MySQL 支持和 PHP 前端的 Zabbix 服务器。执行命令:
|
||||
|
||||
```
|
||||
# apt-get install zabbix-server-mysql zabbix-frontend-php
|
||||
```
|
||||
|
||||
安装 Zabbix 代理:
|
||||
|
||||
```
|
||||
# apt-get install zabbix-agent
|
||||
```
|
||||
|
||||
Zabbix 现已安装。下一步是配置数据库来存储数据。
|
||||
|
||||
### 为 Zabbix 配置 MySQL
|
||||
|
||||
我们需要创建一个新的 MySQL 数据库,Zabbix 将用来存储收集的数据。
|
||||
|
||||
启动 MySQL shell:
|
||||
|
||||
```
|
||||
$ mysql -uroot -p
|
||||
```
|
||||
|
||||
接下来:
|
||||
|
||||
```
|
||||
mysql> CREATE DATABASE zabbix CHARACTER SET utf8 COLLATE utf8_bin;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
mysql> GRANT ALL PRIVILEGES ON zabbix.* TO zabbix@localhost IDENTIFIED BY 'usr_strong_pwd';
|
||||
Query OK, 0 rows affected, 1 warning (0.00 sec)
|
||||
|
||||
mysql> EXIT;
|
||||
Bye
|
||||
```
|
||||
|
||||
接下来,导入初始表和数据。
|
||||
|
||||
```
|
||||
# zcat /usr/share/doc/zabbix-server-mysql/create.sql.gz | mysql -uzabbix -p zabbix
|
||||
```
|
||||
|
||||
输入在 MySQL shell 中创建的 **zabbix** 用户的密码。
|
||||
|
||||
接下来,我们需要编辑 Zabbix 服务器配置文件,它是 `/etc/zabbix/zabbis_server.conf`:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/zabbix/zabbix_server.conf
|
||||
```
|
||||
|
||||
搜索文件的 `DBPassword` 部分:
|
||||
|
||||
```
|
||||
### Option: DBPassword
|
||||
# Database password. Ignored for SQLite.
|
||||
# Comment this line if no password is used.
|
||||
#
|
||||
# Mandatory: no
|
||||
# Default:
|
||||
# DBPassword=
|
||||
|
||||
```
|
||||
|
||||
取消注释 `DBPassword=` 这行,并添加在 MySQL 中创建的密码:
|
||||
|
||||
```
|
||||
DBPassword=usr_strong_pwd
|
||||
|
||||
```
|
||||
|
||||
接下来,查找 `DBHost=` 这行并取消注释。
|
||||
|
||||
保存并退出。
|
||||
|
||||
### 配置 PHP
|
||||
|
||||
我们需要配置 PHP 来使用 Zabbix。在安装过程中,安装程序在 `/etc/zabbix` 中创建了一个名为 `apache.conf` 的配置文件。打开此文件:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/zabbix/apache.conf
|
||||
```
|
||||
|
||||
此时,只需要取消注释 `date.timezone` 并设置正确的时区:
|
||||
|
||||
```
|
||||
|
||||
<IfModule mod_php7.c>
|
||||
php_value max_execution_time 300
|
||||
php_value memory_limit 128M
|
||||
php_value post_max_size 16M
|
||||
php_value upload_max_filesize 2M
|
||||
php_value max_input_time 300
|
||||
php_value always_populate_raw_post_data -1
|
||||
php_value date.timezone Europe/Rome
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
此时,重启 Apache 并启动 Zabbix Server 服务,使其能够在开机时启动:
|
||||
|
||||
```
|
||||
# systemctl restart apache2
|
||||
# systemctl start zabbix-server
|
||||
# systemctl enable zabbix-server
|
||||
```
|
||||
|
||||
用 `systemctl` 检查 Zabbix 状态:
|
||||
|
||||
```
|
||||
# systemctl status zabbix-server
|
||||
```
|
||||
|
||||
这个命令应该输出:
|
||||
|
||||
```
|
||||
â zabbix-server.service - Zabbix Server
|
||||
Loaded: loaded (/lib/systemd/system/zabbix-server.service; enabled; vendor pr
|
||||
Active: active (running) ...
|
||||
```
|
||||
|
||||
此时,Zabbix 的服务器端已经正确安装和配置了。
|
||||
|
||||
### 配置 Zabbix Web 前端
|
||||
|
||||
如介绍中所述,Zabbix 有一个基于 Web 的前端,我们将用于可视化收集的数据。但是,必须配置此接口。
|
||||
|
||||
使用 Web 浏览器,进入 URL `http://localhost/zabbix`。
|
||||
|
||||
|
||||
|
||||
点击 **Next step**
|
||||
|
||||
|
||||
|
||||
确保所有的值都是 **Ok**,然后再次单击 **Next step** 。
|
||||
|
||||
|
||||
|
||||
输入 MySQL **zabbix** 的用户密码,然后点击 **Next step**。
|
||||
|
||||
|
||||
|
||||
单击 **Next step** ,安装程序将显示具有所有配置参数的页面。再次检查以确保一切正确。
|
||||
|
||||
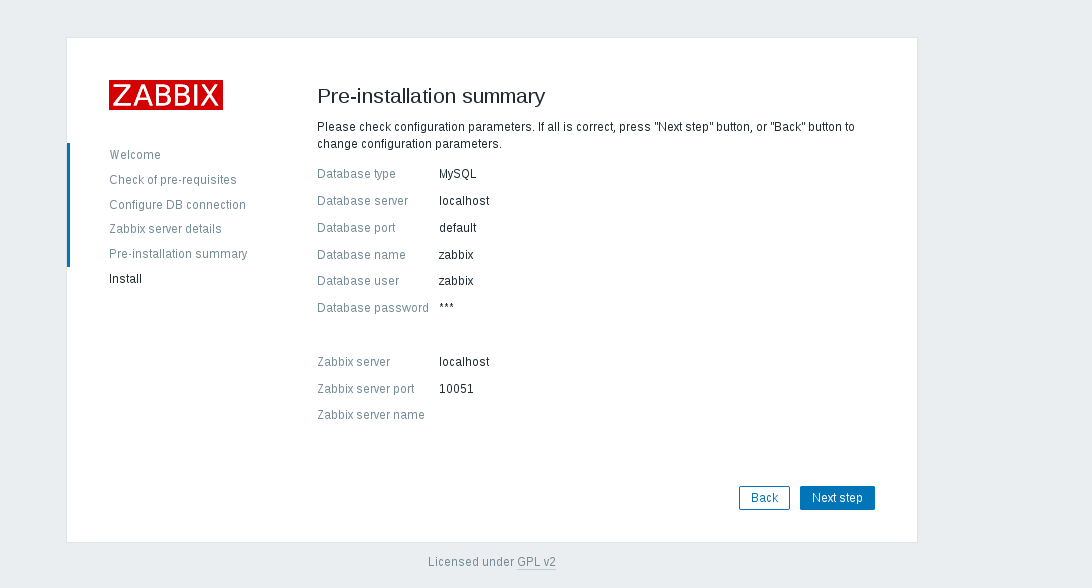
|
||||
|
||||
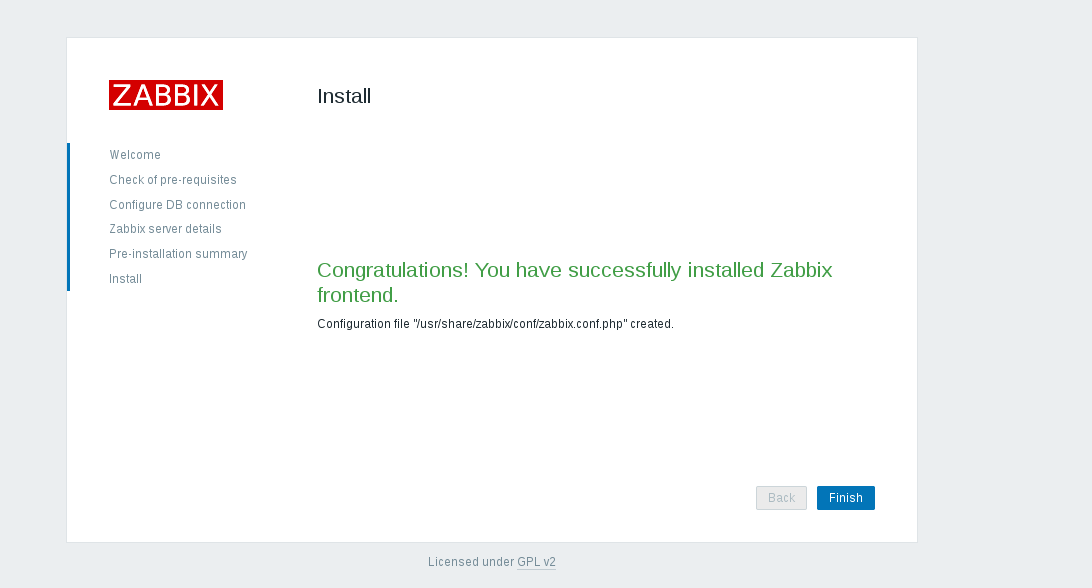
|
||||
|
||||
点击 **Next step** 进入最后一页。
|
||||
|
||||
点击完成以完成前端安装。默认用户名为 **Admin**,密码是 **zabbix**。
|
||||
|
||||
### Zabbix 服务器入门
|
||||
|
||||
|
||||
|
||||
使用上述凭证登录后,我们将看到 Zabbix 面板:
|
||||
|
||||
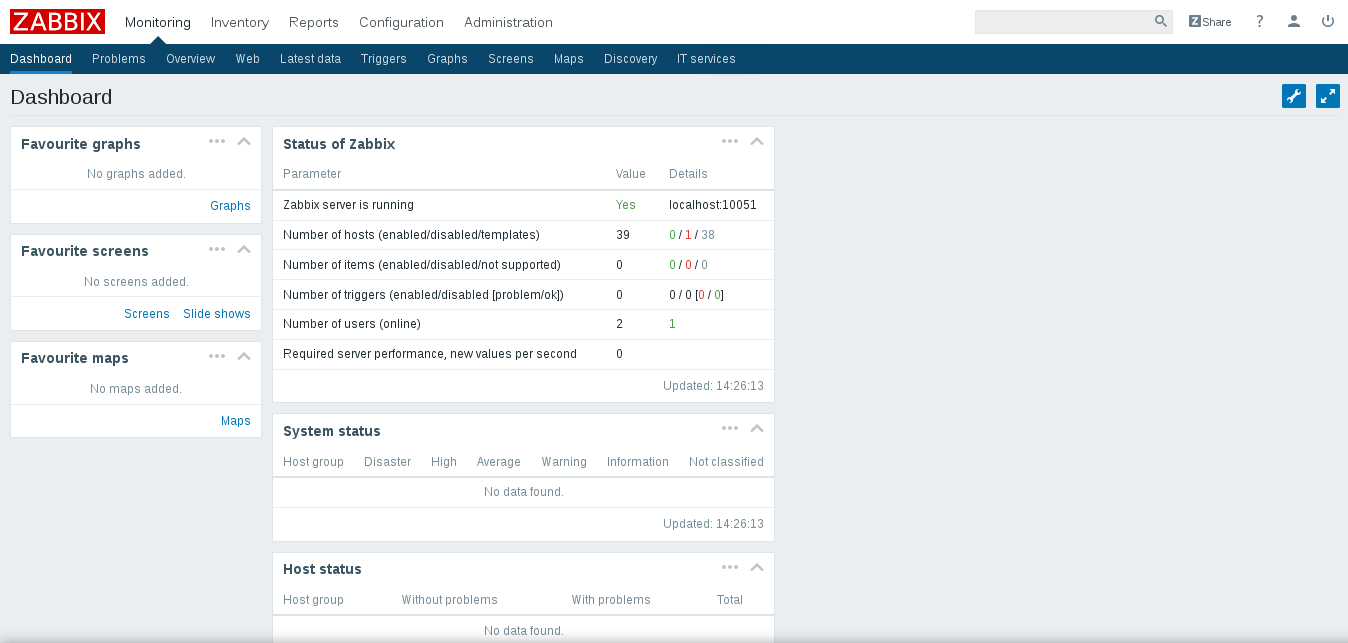
|
||||
|
||||
前往 **Administration -> Users**,了解已启用帐户的概况:
|
||||
|
||||
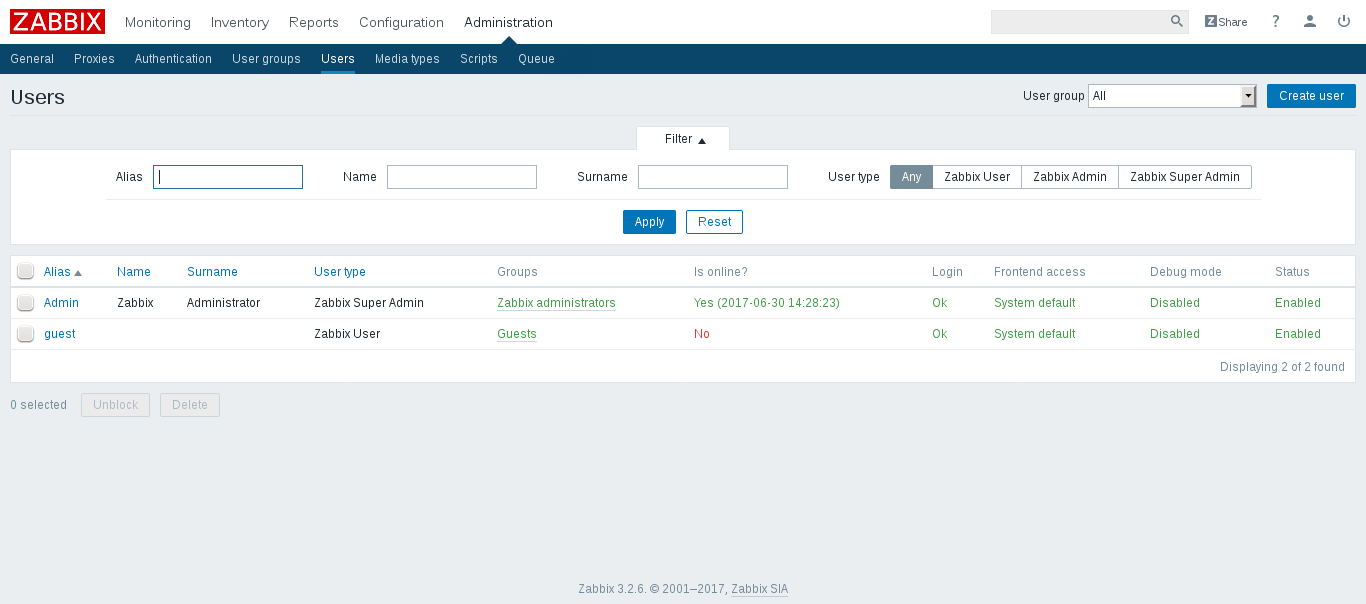
|
||||
|
||||
通过点击 **Create user** 创建一个新帐户。
|
||||
|
||||
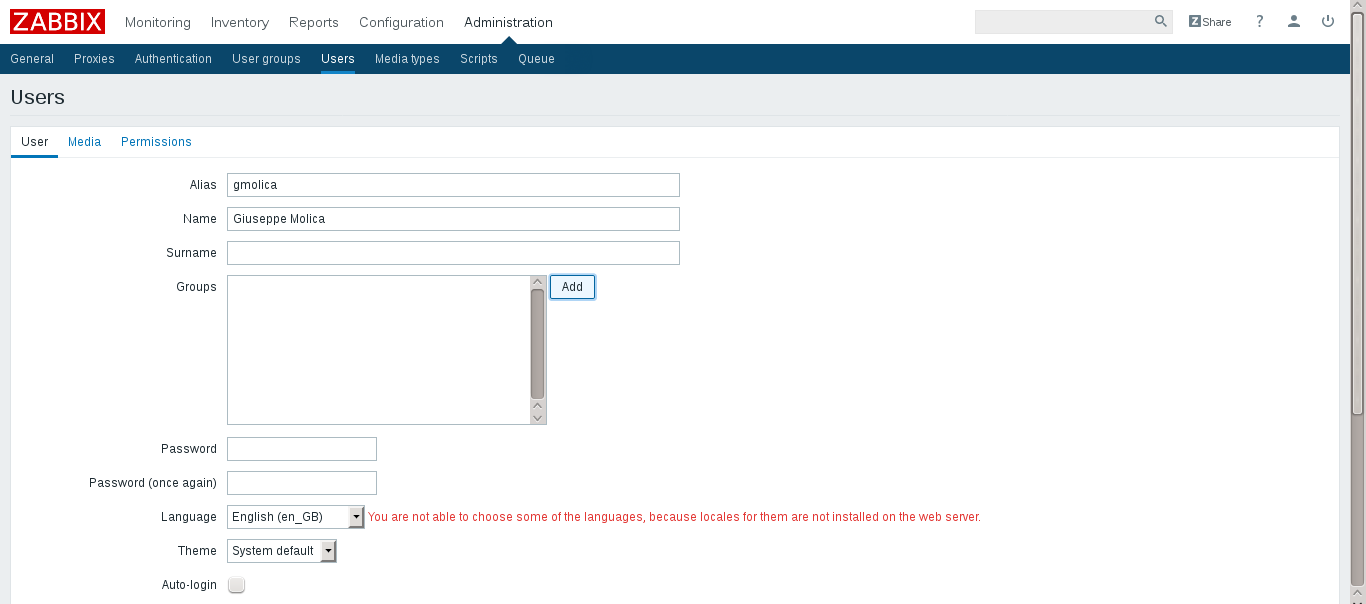
|
||||
|
||||
点击 **Groups** 中的 **Add**,然后选择一个组:
|
||||
|
||||
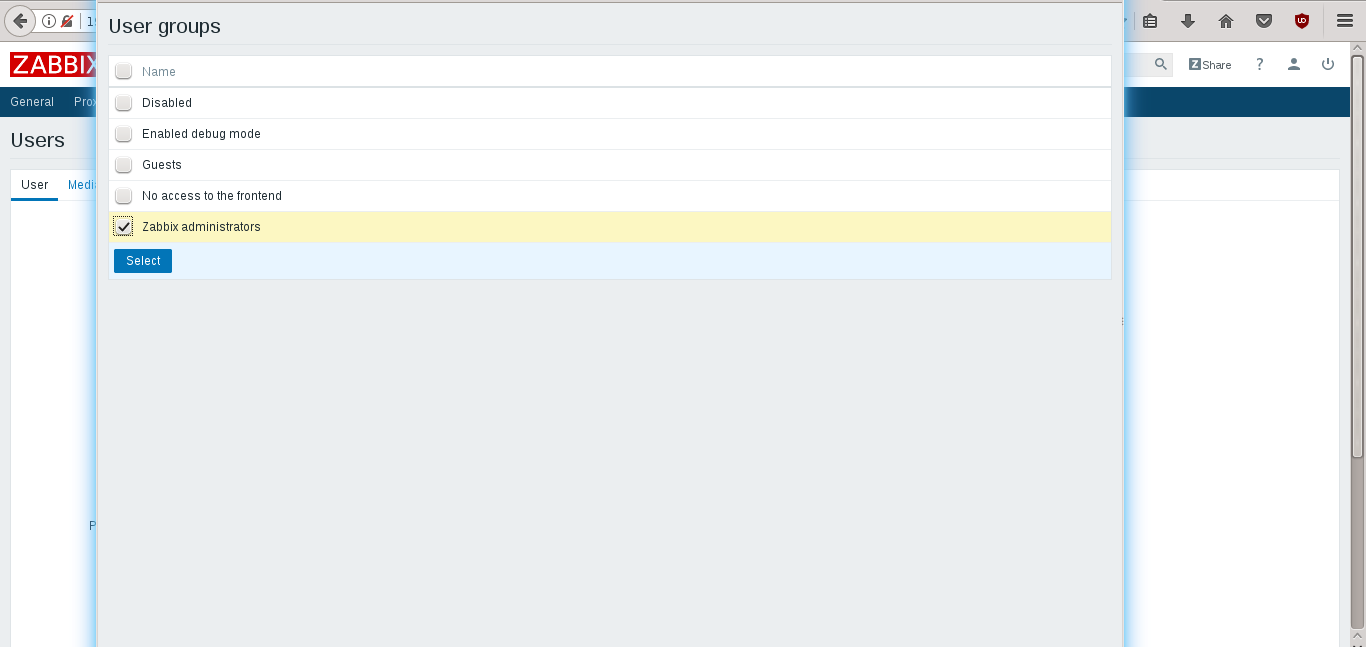
|
||||
|
||||
保存新用户凭证,它将显示在 **Administration -> Users** 面板中。
|
||||
|
||||
**请注意,在 Zabbix 中,主机的访问权限分配给用户组,而不是单个用户。**
|
||||
|
||||
### 总结
|
||||
|
||||
我们结束了 Zabbix Server 安装的教程。现在,监控基础设施已准备好完成其工作并收集有关需要在 Zabbix 配置中添加的服务器的数据。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/monitoring-server-install-zabbix-ubuntu-16-04/
|
||||
|
||||
作者:[Giuseppe Molica][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:http://www.zabbix.com/
|
||||
[3]:https://www.unixmen.com/wp-content/uploads/2017/06/zabbix_logo.png
|
||||
187
published/20170705 Two great uses for the cp command.md
Normal file
187
published/20170705 Two great uses for the cp command.md
Normal file
@ -0,0 +1,187 @@
|
||||
cp 命令两个高效的用法
|
||||
============================================================
|
||||
|
||||
> Linux 中高效的备份拷贝命令
|
||||
|
||||

|
||||
|
||||
在 Linux 上能使用鼠标点来点去的图形化界面是一件很美妙的事……但是如果你喜欢的开发交互环境和编译器是终端窗口、Bash 和 Vim,那你应该像我一样*经常*和终端打交道。
|
||||
|
||||
即使是不经常使用终端的人,如果对终端环境深入了解也能获益良多。举个例子—— `cp` 命令,据 [维基百科][12] 的解释,`cp` (意即 copy)命令是第一个版本的 [Unix][13] 系统的一部分。连同一组其它的命令 `ls`、`mv`、`cd`、`pwd`、`mkdir`、`vi`、`sh`、`sed` 和 `awk` ,还有提到的 `cp` 都是我在 1984 年接触 System V Unix 系统时所学习的命令之一。`cp` 命令最常见的用法是制作文件副本。像这样:
|
||||
|
||||
```
|
||||
cp sourcefile destfile
|
||||
```
|
||||
|
||||
在终端中执行此命令,上述命令将名为 `sourcefile` 的文件复制到名为 `destfile` 的文件中。如果在执行命令之前 `destfile` 文件不存在,那将会创建此文件,如果已经存在,那就会覆盖此文件。
|
||||
|
||||
这个命令我不知道自己用了多少次了(我也不想知道),但是我知道在我编写测试代码的时候,我经常用,为了保留当前正常的版本,而且又能继续修改,我会输入这个命令:
|
||||
|
||||
```
|
||||
cp test1.py test1.bak
|
||||
```
|
||||
|
||||
在过去的30多年里,我使用了无数次这个命令。另外,当我决定编写我的第二个版本的测试程序时,我会输入这个命令:
|
||||
|
||||
```
|
||||
cp test1.py test2.py
|
||||
```
|
||||
|
||||
这样就完成了修改程序的第一步。
|
||||
|
||||
我通常很少查看 `cp` 命令的参考文档,但是当我在备份我的图片文件夹的时候(在 GUI 环境下使用 “file” 应用),我开始思考“在 `cp` 命令中是否有个参数支持只复制新文件或者是修改过的文件。”果然,真的有!
|
||||
|
||||
### 高效用法 1:更新你的文件夹
|
||||
|
||||
比如说在我的电脑上有一个存放各种文件的文件夹,另外我要不时的往里面添加一些新文件,而且我会不时地修改一些文件,例如我手机里下载的照片或者是音乐。
|
||||
|
||||
假设我收集的这些文件对我而言都很有价值,我有时候会想做个拷贝,就像是“快照”一样将文件保存在其它媒体。当然目前有很多程序都支持备份,但是我想更为精确的将目录结构复制到可移动设备中,方便于我经常使用这些离线设备或者连接到其它电脑上。
|
||||
|
||||
`cp` 命令提供了一个易如反掌的方法。例子如下:
|
||||
|
||||
在我的 `Pictures` 文件夹下,我有这样一个文件夹名字为 `Misc`。为了方便说明,我把文件拷贝到 USB 存储设备上。让我们开始吧!
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r Misc /media/clh/4388-D5FE
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
上面的命令是我从按照终端窗口中完整复制下来的。对于有些人来说不是很适应这种环境,在我们输入命令或者执行命令之前,需要注意的是 `me@mydesktop:~/Pictures` 这个前缀,`me` 这个是当前用户,`mydesktop` 这是电脑名称,`~/Pictures` 这个是当前工作目录,是 `/home/me/Pictures` 完整路径的缩写。
|
||||
|
||||
我输入这个命令 `cp -r Misc /media/clh/4388-D5FE` 并执行后 ,拷贝 `Misc` 目录下所有文件(这个 `-r` 参数,全称 “recursive”,递归处理,意思为本目录下所有文件及子目录一起处理)到我的 USB 设备的挂载目录 `/media/clh/4388-D5FE`。
|
||||
|
||||
执行命令后回到之前的提示,大多数命令继承了 Unix 的特性,在命令执行后,如果没有任何异常什么都不显示,在任务结束之前不会显示像 “execution succeeded” 这样的提示消息。如果想获取更多的反馈,就使用 `-v` 参数让执行结果更详细。
|
||||
|
||||
下图中是我的 USB 设备中刚刚拷贝过来的文件夹 `Misc` ,里面总共有 9 张图片。
|
||||
|
||||

|
||||
|
||||
假设我要在原始拷贝路径下 `~/Pictures/Misc` 下添加一些新文件,就像这样:
|
||||
|
||||

|
||||
|
||||
现在我想只拷贝新的文件到我的存储设备上,我就使用 `cp` 的“更新”和“详细”选项。
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r -u -v Misc /media/clh/4388-D5FE
|
||||
'Misc/asunder.png' -> '/media/clh/4388-D5FE/Misc/asunder.png'
|
||||
'Misc/editing tags guayadeque.png' -> '/media/clh/4388-D5FE/Misc/editing tags guayadeque.png'
|
||||
'Misc/misc on usb.png' -> '/media/clh/4388-D5FE/Misc/misc on usb.png'
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
上面的第一行中是 `cp` 命令和具体的参数(`-r` 是“递归”, `-u` 是“更新”,`-v` 是“详细”)。接下来的三行显示被复制文件的信息,最后一行显示命令行提示符。
|
||||
|
||||
通常来说,参数 `-r` 也可用更详细的风格 `--recursive`。但是以简短的方式,也可以这么连用 `-ruv`。
|
||||
|
||||
### 高效用法 2:版本备份
|
||||
|
||||
回到一开始的例子中,我在开发的时候定期给我的代码版本进行备份。然后我找到了另一种更好用的 `cp` 参数。
|
||||
|
||||
假设我正在编写一个非常有用的 Python 程序,作为一个喜欢不断修改代码的开发者,我会在一开始编写一个程序简单版本,然后不停的往里面添加各种功能直到它能成功的运行起来。比方说我的第一个版本就是用 Python 程序打印出 “hello world”。这只有一行代码的程序就像这样:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
```
|
||||
|
||||
然后我将这个代码保存成文件命名为 `test1.py`。我可以这么运行它:
|
||||
|
||||
```
|
||||
me@desktop:~/Test$ python test1.py
|
||||
hello world
|
||||
me@desktop:~/Test$
|
||||
```
|
||||
|
||||
现在程序可以运行了,我想在添加新的内容之前进行备份。我决定使用带编号的备份选项,如下:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
所以,上面的做法是什么意思呢?
|
||||
|
||||
第一,这个 `--backup=numbered` 参数意思为“我要做个备份,而且是带编号的连续备份”。所以一个备份就是 1 号,第二个就是 2 号,等等。
|
||||
|
||||
第二,如果源文件和目标文件名字是一样的。通常我们使用 `cp` 命令去拷贝成自己,会得到这样的报错信息:
|
||||
|
||||
```
|
||||
cp: 'test1.py' and 'test1.py' are the same file
|
||||
```
|
||||
|
||||
在特殊情况下,如果我们想备份的源文件和目标文件名字相同,我们使用 `--force` 参数。
|
||||
|
||||
第三,我使用 `ls` (意即 “list”)命令来显示现在目录下的文件,名字为 `test1.py` 的是原始文件,名字为 `test1.py.~1~` 的是备份文件
|
||||
|
||||
假如现在我要加上第二个功能,在程序里加上另一行代码,可以打印 “Kilroy was here.”。现在程序文件 `test1.py` 的内容如下:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
print 'Kilroy was here'
|
||||
```
|
||||
|
||||
看到 Python 编程多么简单了吗?不管怎样,如果我再次执行备份的步骤,结果如下:
|
||||
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~ test1.py.~2~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
现在我有有两个备份文件: `test1.py.~1~` 包含了一行代码的程序,和 `test1.py.~2~` 包含两行代码的程序。
|
||||
|
||||
这个很好用的功能,我考虑做个 shell 函数让它变得更简单。
|
||||
|
||||
### 最后总结
|
||||
|
||||
第一,Linux 手册页,它在大多数桌面和服务器发行版都默认安装了,它提供了更为详细的使用方法和例子,对于 `cp` 命令,在终端中输入如下命令:
|
||||
|
||||
```
|
||||
man cp
|
||||
```
|
||||
|
||||
对于那些想学习如何使用这些命令,但不清楚如何使用的用户应该首先看一下这些说明,然后我建议创建一个测试目录和文件来尝试使用命令和选项。
|
||||
|
||||
第二,兴趣是最好的老师。在你最喜欢的搜索引擎中搜索 “linux shell tutorial”,你会获得很多有趣和有用的资源。
|
||||
|
||||
第三,你是不是在想,“为什么我要用这么麻烦的方法,图形化界面中有相同的功能,只用点击几下岂不是更简单?”,关于这个问题我有两个理由。首先,在我们工作中需要中断其他工作流程以及大量使用点击动作时,点击动作可就不简单了。其次,如果我们要完成流水线般的重复性工作,通过使用 shell 脚本和 shell 函数以及 shell 重命名等功能就能很轻松的实现。
|
||||
|
||||
你还知道关于 `cp` 命令其他更棒的使用方式吗?请在留言中积极回复哦~
|
||||
|
||||
(题图:Opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Chris Hermansen - 1978 年毕业于英国哥伦比亚大学后一直从事计算机相关职业,我从 2005 年开始一直使用 Linux、Solaris、SunOS,在那之前我就是 Unix 系统管理员了,在技术方面,我的大量的职业生涯都是在做数据分析,尤其是空间数据分析,我有大量的编程经验与数据分析经验,熟练使用 awk、Python、PostgreSQL、PostGIS 和 Groovy。
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
译者:[bigdimple](https://github.com/bigdimple)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/360601
|
||||
[7]:https://opensource.com/file/360606
|
||||
[8]:https://opensource.com/article/17/7/two-great-uses-cp-command?rate=87TiE9faHZRes_f4Gj3yQZXhZ-x7XovYhnhjrk3SdiM
|
||||
[9]:https://opensource.com/user/37806/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[11]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[12]:https://en.wikipedia.org/wiki/Cp_(Unix)
|
||||
[13]:https://en.wikipedia.org/wiki/Unix
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
[15]:https://opensource.com/users/clhermansen
|
||||
[16]:https://opensource.com/article/17/7/two-great-uses-cp-command#comments
|
||||
@ -0,0 +1,124 @@
|
||||
4 个 Linux 桌面上的轻量级图像浏览器
|
||||
============================================================
|
||||
|
||||
> 当你需要的不仅仅是一个基本的图像浏览器,而是一个完整的图像编辑器,请查看这些程序。
|
||||
|
||||

|
||||
|
||||
像大多数人一样,你计算机上可能有些照片和其他图像。而且,像大多数人一样,你可能想要经常查看那些图像和照片。
|
||||
|
||||
而启动一个 [GIMP][18] 或者 [Pinta][19] 这样的图片编辑器对于简单的浏览图片来说太笨重了。
|
||||
|
||||
另一方面,大多数 Linux 桌面环境中包含的基本图像查看器可能不足以满足你的需要。如果你想要一些更多的功能,但仍然希望它是轻量级的,那么看看这四个 Linux 桌面中的图像查看器,如果还不能满足你的需要,还有额外的选择。
|
||||
|
||||
### Feh
|
||||
|
||||
[Feh][20] 是我以前在老旧计算机上最喜欢的软件。它简单、朴实、用起来很好。
|
||||
|
||||
你可以从命令行启动 Feh:只将其指向图像或者包含图像的文件夹之后就行了。Feh 会快速加载,你可以通过鼠标点击或使用键盘上的向左和向右箭头键滚动图像。不能更简单了。
|
||||
|
||||
Feh 可能很轻量级,但它提供了一些选项。例如,你可以控制 Feh 的窗口是否具有边框,设置要查看的图像的最小和最大尺寸,并告诉 Feh 你想要从文件夹中的哪个图像开始浏览。
|
||||
|
||||

|
||||
|
||||
*Feh 的使用*
|
||||
|
||||
### Ristretto
|
||||
|
||||
如果你将 Xfce 作为桌面环境,那么你会熟悉 [Ristretto][21]。它很小、简单、并且非常有用。
|
||||
|
||||
怎么简单?你打开包含图像的文件夹,单击左侧的缩略图之一,然后单击窗口顶部的导航键浏览图像。Ristretto 甚至有幻灯片功能。
|
||||
|
||||
Ristretto 也可以做更多的事情。你可以使用它来保存你正在浏览的图像的副本,将该图像设置为桌面壁纸,甚至在另一个应用程序中打开它,例如,当你需要修改一下的时候。
|
||||
|
||||

|
||||
|
||||
*在 Ristretto 中浏览照片 *
|
||||
|
||||
### Mirage
|
||||
|
||||
表面上,[Mirage][22]有点平常,没什么特色,但它做着和其他优秀图片浏览器一样的事:打开图像,将它们缩放到窗口的宽度,并且可以使用键盘滚动浏览图像。它甚至可以使用幻灯片。
|
||||
|
||||
不过,Mirage 将让需要更多功能的人感到惊喜。除了其核心功能,Mirage 还可以调整图像大小和裁剪图像、截取屏幕截图、重命名图像,甚至生成文件夹中图像的 150 像素宽的缩略图。
|
||||
|
||||
如果这还不够,Mirage 还可以显示 [SVG 文件][23]。你甚至可以从[命令行][24]中运行。
|
||||
|
||||
|
||||

|
||||
|
||||
*使用 Mirage*
|
||||
|
||||
### Nomacs
|
||||
|
||||
[Nomacs][25] 显然是本文中最重量级的图像浏览器。它所呈现的那么多功能让人忽视了它的速度。它快捷而易用。
|
||||
|
||||
Nomacs 不仅仅可以显示图像。你还可以查看和编辑图像的[元数据][26],向图像添加注释,并进行一些基本的编辑,包括裁剪、调整大小、并将图像转换为灰度。Nomacs 甚至可以截图。
|
||||
|
||||
一个有趣的功能是你可以在桌面上运行程序的两个实例,并在这些实例之间同步图像。当需要比较两个图像时,[Nomacs 文档][27]中推荐这样做。你甚至可以通过局域网同步图像。我没有尝试通过网络进行同步,如果你做过可以分享下你的经验。
|
||||
|
||||
|
||||

|
||||
|
||||
*Nomacs 中的照片及其元数据*
|
||||
|
||||
### 其他一些值得一看的浏览器
|
||||
|
||||
如果这四个图像浏览器不符合你的需求,这里还有其他一些你可能感兴趣的。
|
||||
|
||||
**[Viewnior][11]** 自称是 “GNU/Linux 中的快速简单的图像查看器”,它很适合这个用途。它的界面干净整洁,Viewnior 甚至可以进行一些基本的图像处理。
|
||||
|
||||
如果你喜欢在命令行中使用,那么 **display** 可能是你需要的浏览器。 **[ImageMagick][12]** 和 **[GraphicsMagick][13]** 这两个图像处理软件包都有一个名为 display 的应用程序,这两个版本都有查看图像的基本和高级选项。
|
||||
|
||||
**[Geeqie][14]** 是更轻和更快的图像浏览器之一。但是,不要让它的简单误导你。它包含的功能有元数据编辑功能和其它浏览器所缺乏的查看相机 RAW 图像格式的功能。
|
||||
|
||||
**[Shotwell][15]** 是 GNOME 桌面的照片管理器。然而它不仅仅能浏览图像,而且 Shotwell 非常快速,并且非常适合显示照片和其他图形。
|
||||
|
||||
_在 Linux 桌面中你有最喜欢的一款轻量级图片浏览器么?请在评论区随意分享你的喜欢的浏览器_
|
||||
|
||||
(题图:[互联网存档图书图片][17]. 由 Opensource.com 修改。 CC BY-SA 4.0)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我是一名长期使用自由/开源软件的用户,并因为乐趣和收获写各种东西。我不会很严肃。你可以在这些网站上找到我:Twitter、Mastodon、GitHub。
|
||||
|
||||
via: https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/361216
|
||||
[7]:https://opensource.com/file/361231
|
||||
[8]:https://opensource.com/file/361221
|
||||
[9]:https://opensource.com/file/361226
|
||||
[10]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop?rate=UcKbaJQJAbLScWVu8qm9bqii7JMsIswjfcBHt3aRnEU
|
||||
[11]:http://siyanpanayotov.com/project/viewnior/
|
||||
[12]:https://www.imagemagick.org/script/display.php
|
||||
[13]:http://www.graphicsmagick.org/display.html
|
||||
[14]:http://geeqie.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[16]:https://opensource.com/user/14925/feed
|
||||
[17]:https://www.flickr.com/photos/internetarchivebookimages/14758810172/in/photolist-oubL5m-ocu2ck-odJwF4-oeq1na-odgZbe-odcugD-w7KHtd-owgcWd-oucGPe-oud585-rgBDNf-obLoQH-oePNvs-osVgEq-othPLM-obHcKo-wQR3KN-oumGqG-odnCyR-owgLg3-x2Zeyq-hMMxbq-oeRzu1-oeY49i-odumMM-xH4oJo-odrT31-oduJr8-odX8B3-obKG8S-of1hTN-ovhHWY-ow7Scj-ovfm7B-ouu1Hj-ods7Sg-qwgw5G-oeYz5D-oeXqFZ-orx8d5-hKPN4Q-ouNKch-our8E1-odvGSH-oweGTn-ouJNQQ-ormX8L-od9XZ1-roZJPJ-ot7Wf4
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://pinta-project.com/pintaproject/pinta/
|
||||
[20]:https://feh.finalrewind.org/
|
||||
[21]:https://docs.xfce.org/apps/ristretto/start
|
||||
[22]:http://mirageiv.sourceforge.net/
|
||||
[23]:https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[24]:http://mirageiv.sourceforge.net/docs-advanced.html#cli
|
||||
[25]:http://nomacs.org/
|
||||
[26]:https://iptc.org/standards/photo-metadata/photo-metadata/
|
||||
[27]:http://nomacs.org/synchronization/
|
||||
[28]:https://opensource.com/users/scottnesbitt
|
||||
[29]:https://opensource.com/users/scottnesbitt
|
||||
[30]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop#comments
|
||||
@ -0,0 +1,99 @@
|
||||
文件系统层次标准(FHS)简介
|
||||
============================================================
|
||||

|
||||
|
||||
当你好奇地看着系统的根目录(`/`)的时候,可能会发现自己有点不知所措。大多数三个字母的目录名称并没有告诉你它们是做什么的,如果你需要做出一些重要的修改,那就很难知道在哪里可以查看。
|
||||
|
||||
我想给那些没有深入了解过自己的根目录的人简单地介绍下它。
|
||||
|
||||
### 有用的工具
|
||||
|
||||
在我们开始之前,这里有几个需要熟悉的工具,它们可以让您随时挖掘那些您自己找到的有趣的东西。这些程序都不会对您的文件进行任何更改。
|
||||
|
||||
最有用的工具是 `ls` -- 它列出了使用完整路径或相对路径(即从当前目录开始的路径)作为参数给出的任何目录的内容。
|
||||
|
||||
```
|
||||
$ ls 路径
|
||||
```
|
||||
|
||||
当您进一步深入文件系统时,重复输入长路径可能会变得很麻烦,所以如果您想简化这一操作,可以用 `cd` 替换 `ls` 来更改当前的工作目录到该目录。与 `ls` 一样,只需将目录路径作为 `cd` 的参数。
|
||||
|
||||
```
|
||||
$ cd 路径
|
||||
```
|
||||
|
||||
如果您不确定某个文件是什么文件类型的,可以通过运行 `file` 并且将文件名作为 `file` 命令的参数。
|
||||
|
||||
```
|
||||
$ file 文件名
|
||||
```
|
||||
|
||||
最后,如果这个文件看起来像是适宜阅读的,那么用 `less` 来看看(不用担心文件有改变)。与最后一个工具一样,给出一个文件名作为参数来查看它。
|
||||
|
||||
```
|
||||
$ less 文件名
|
||||
```
|
||||
|
||||
完成文件翻阅后,点击 `q` 键退出,即可返回到您的终端。
|
||||
|
||||
### 根目录之旅
|
||||
|
||||
现在就开始我们的旅程。我将按照字母顺序介绍直接放在根目录下的目录。这里并没有介绍所有的目录,但到最后,我们会突出其中的亮点。
|
||||
|
||||
我们所有要遍历的目录的分类及功能都基于 Linux 的文件系统层次标准(FHS)。[Linux 基金会][4]维护的 Linux FHS 帮助发行版和程序的设计者和开发人员来规划他们的工具的各个组件应该存放的位置。
|
||||
|
||||
通过将各个程序的所有文件、二进制文件和帮助手册保存在一致的组织结构中,FHS 让对它们的学习、调试或修改更加容易。想象一下,如果不是使用 `man` 命令找到使用指南,那么你就得对每个程序分别寻找其手册。
|
||||
|
||||
按照字母顺序和结构顺序,我们从 `/bin` 开始。该目录是存放所有核心系统二进制文件的地方,其包含的命令可以在 shell (解释终端指令的程序)中使用。没有这个目录的内容,你的系统就基本没法使用。
|
||||
|
||||
接下来是 `/boot` 目录,它存储了您的计算机启动所需的所有东西。其中最重要的是引导程序和内核。引导程序是一个通过初始化一些基础工具,使引导过程得以继续的程序。在初始化结束时,引导程序会加载内核,内核允许计算机与所有其它硬件和固件进行接口。从这一点看,它可以使整个操作系统工作起来。
|
||||
|
||||
`/dev` 目录用于存储类似文件的对象来表示被系统识别为“设备”的各种东西。这里包括许多显式的设备,如计算机的硬件组件:键盘、屏幕、硬盘驱动器等。
|
||||
|
||||
此外,`/dev` 还包含被系统视为“设备”的数据流的伪文件。一个例子是流入和流出您的终端的数据,可以分为三个“流”。它读取的信息被称为“标准输入”。命令或进程的输出是“标准输出”。最后,被分类为调试信息的辅助性输出指向到“标准错误”。终端本身作为文件也可以在这里找到。
|
||||
|
||||
`/etc`(发音类似工艺商业网站 “Etsy”,如果你想让 Linux 老用户惊艳一下的话,囧),许多程序在这里存储它们的配置文件,用于改变它们的设置。一些程序存储这里的是默认配置的副本,这些副本将在修改之前复制到另一个位置。其它的程序在这里存储配置的唯一副本,并期望用户可以直接修改。为 root 用户保留的许多程序常用一种配置模式。
|
||||
|
||||
`/home` 目录是用户个人文件所在的位置。对于桌面用户来说,这是您花费大部分时间的地方。对于每个非特权用户,这里都有一个具有相应名称的目录。
|
||||
|
||||
`/lib` 是您的系统赖以运行的许多库的所在地。许多程序都会重复使用一个或多个功能或子程序,它们经常会出现在几十上百个程序中。所以,如果每个程序在其二进制文件中重复写它需要的每一个组件,结果会是产生出一些大而无当的程序,作为更好的替代方案,我们可以通过进行“库调用”来引用这些库中的一个或多个。
|
||||
|
||||
在 `/media` 目录中可以访问像 USB 闪存驱动器或摄像机这样的可移动媒体。虽然它并不是所有系统上都有,但在一些专注于直观的桌面系统中还是比较普遍的,如 Ubuntu。具有存储能力的媒体在此处被“挂载”,这意味着当设备中的原始位流位于 `/dev` 目录下时,用户通常可以在这里访问那些可交互的文件对象。
|
||||
|
||||
`/proc` 目录是一个动态显示系统数据的虚拟文件系统。这意味着系统可以即时地创建 `/proc` 的内容,用包含运行时生成的系统信息(如硬件统计信息)的文件进行填充。
|
||||
|
||||
`/tmp` 正如其名字,用于放置缓存数据等临时信息。这个目录不做其他更多的事情。
|
||||
|
||||
现代 Linux 系统上大多数程序的二进制文件保存在 `/usr` 目录中。为了统一包含二进制文件的各种目录,`/usr` 包含 `/bin`、`/sbin` 和 `/lib` 中的所有内容的副本。
|
||||
|
||||
最后,`/var` 里保存“<ruby>可变<rt>variable</rt></ruby>”长度的数据。这里的可变长度数据的类型通常是会累积的数据,就像日志和缓存一样。一个例子是你的内核保留的日志。
|
||||
|
||||
为了避免硬盘空间用尽和崩溃的情况,`/var` 内置了“日志旋转”功能,可删除旧信息,为新信息腾出空间,维持固定的最大大小。
|
||||
|
||||
### 结尾
|
||||
|
||||
正如我所说,这里介绍的绝对不是您在根目录中可以找到的一切,但是确定系统核心功能所在地是一个很好的开始,而且可以更深入地研究这些功能是什么。
|
||||
|
||||
所以,如果你不知道要学习什么,就可能有很多的想法。如果你想得到一个更好的想法,就在这些目录中折腾自己吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
自 2017 年以来 Jonathan Terrasi 一直是 ECT 新闻网的专栏作家。他的主要兴趣是计算机安全(特别是 Linux 桌面),加密和分析政治和时事。他是全职自由作家和音乐家。他的背景包括在芝加哥委员会发表的保卫人权法案文章中提供技术评论和分析。
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: http://www.linuxinsider.com/story/84658.html
|
||||
|
||||
作者:[Jonathan Terrasi][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxinsider.com/perl/mailit/?id=84658
|
||||
[1]:http://www.linuxinsider.com/story/84658.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84658
|
||||
[4]:http://www.linuxfoundation.org/
|
||||
@ -0,0 +1,159 @@
|
||||
Ubuntu Core:制作包含私有 snap 的工厂镜像
|
||||
========
|
||||
|
||||
这篇帖子是有关 [在 Ubuntu Core 开发 ROS 原型到成品][1] 系列的补充,用来回答我收到的一个问题: “我想做一个工厂镜像,但我不想使我的 snap 公开” 当然,这个问题和回答都不只是针对于机器人技术。在这篇帖子中,我将会通过两种方法来回答这个问题。
|
||||
|
||||
开始之前,你需要了解一些制作 Ubuntu Core 镜像的背景知识,如果你已经看过 [在 Ubuntu Core 开发 ROS 原型到成品[3] 系列文章(具体是第 5 部分),你就已经有了需要的背景知识,如果没有看过的话,可以查看有关 [制作你的 Ubuntu Core 镜像][5] 的教程。
|
||||
|
||||
如果你已经了解了最新的情况,并且当我说 “模型定义” 或者 “模型断言” 时知道我在谈论什么,那就让我们开始通过不同的方法使用私有 sanps 来制作 Ubuntu Core 镜像吧。
|
||||
|
||||
### 方法 1: 不要上传你的 snap 到商店
|
||||
|
||||
这是最简单的方法了。首先看一下这个有关模型定义的例子——`amd64-model.json`:
|
||||
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-test-snap"]
|
||||
}
|
||||
```
|
||||
|
||||
让我们将它转换成模型断言:
|
||||
|
||||
```
|
||||
$ cat amd64-model.json | snap sign -k my-key-name > amd64.model
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "my-key-name"
|
||||
4096-bit RSA key, ID 0B79B865, created 2016-01-01
|
||||
...
|
||||
```
|
||||
|
||||
获得模型断言:`amd64.model` 后,如果你现在就把它交给 `ubuntu-image` 使用,你将会碰钉子:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-test-snap
|
||||
error: cannot find snap "kyrofa-test-snap": snap not found
|
||||
COMMAND FAILED: snap prepare-image --channel=stable amd64.model /tmp/tmp6p453gk9/unpack
|
||||
```
|
||||
|
||||
实际上商店中并没有名为 `kyrofa-test-snap` 的 snap。这里需要重点说明的是:模型定义(以及转换后的断言)只包含了一系列的 snap 的名字。如果你在本地有个那个名字的 snap,即使它没有存在于商店中,你也可以通过 `--extra-snaps` 选项告诉 `ubuntu-image` 在断言中匹配这个名字来使用它:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable \
|
||||
--extra-snaps /path/to/kyrofa-test-snap_0.1_amd64.snap \
|
||||
amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Copying "/path/to/kyrofa-test-snap_0.1_amd64.snap" (kyrofa-test-snap)
|
||||
kyrofa-test-snap already prepared, skipping
|
||||
WARNING: "kyrofa-test-snap" were installed from local snaps
|
||||
disconnected from a store and cannot be refreshed subsequently!
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
|
||||
现在,在 snap 并没有上传到商店的情况下,你已经获得一个预装了私有 snap 的 Ubuntu Core 镜像(名为 `pc.img`)。但是这样做有一个很大的问题,ubuntu-image 会提示一个警告:不通过连接商店预装 snap 意味着你没有办法在烧录了这些镜像的设备上更新它。你只能通过制作新的镜像并重新烧录到设备的方式来更新它。
|
||||
|
||||
### 方法 2: 使用品牌商店
|
||||
|
||||
当你注册了一个商店账号并访问 [dashboard.snapcraft.io][6] 时,你其实是在标准的 Ubuntu 商店中查看你的 snap。如果你是在系统中新安装的 snapd,默认会从这个商店下载。虽然你可以在 Ubuntu 商店中发布私有的 snap,但是你[不能将它们预装到镜像中][7],因为只有你(以及你添加的合作者)才有权限去使用它。在这种情况下制作镜像的唯一方式就是公开发布你的 snap,然而这并不符合这篇帖子的目的。
|
||||
|
||||
对于这种用例,我们有所谓的 [品牌商店][8]。品牌商店仍然托管在 Ubuntu 商店里,但是它们是针对于某一特定公司或设备的一个定制的、专门的版本。品牌商店可以继承或者不继承标准的 Ubuntu 商店,品牌商店也可以选择开放给所有的开发者或者将其限制在一个特定的组内(保持私有正是我们想要的)。
|
||||
|
||||
请注意,这是一个付费功能。你需要 [申请一个品牌商店][9]。请求通过后,你将可以通过访问用户名下的 “stores you can access” 看到你的新商店。
|
||||
|
||||

|
||||
|
||||
在那里你可以看到多个有权使用的商店。最少的情况下也会有两个:标准的 Ubuntu 商店以及你的新的品牌商店。选择品牌商店(红框),进去后记录下你的商店 ID(蓝框):等下你将会用到它。
|
||||
|
||||

|
||||
|
||||
在品牌商店里注册名字或者上传 snap 和标准的商店使用的方法是一样的,只是它们现在是上传到你的品牌商店而不是标准的那个。如果你将品牌商店放在 unlisted 里面,那么这些 snap 对外部用户是不可见。但是这里需要注意的是第一次上传 snap 的时候需要通过 web 界面来操作。在那之后,你可以继续像往常一样使用 Snapcraft 来操作。
|
||||
|
||||
那么这些是如何改变的呢?我的 “kyrofal-store” 从 Ubuntu 商店继承了 snap,并且还包含一个发布在稳定通道中的 “kyrofa-bran-test-snap” 。这个 snap 在 Ubuntu 商店里是使用不了的,如果你去搜索它,你是找不到的:
|
||||
|
||||
```
|
||||
$ snap find kyrofa-branded
|
||||
The search "kyrofa-branded" returned 0 snaps
|
||||
```
|
||||
|
||||
但是使用我们前面记录的商店 ID,我们可以创建一个从品牌商店而不是 Ubuntu 商店下载 snap 的模型断言。我们只需要将 “store” 键添加到 JSON 文件中,就像这样:
|
||||
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-branded-test-snap"],
|
||||
"store": "ky<secret>ek"
|
||||
}
|
||||
```
|
||||
|
||||
使用方法 1 中的方式对它签名,然后我们就可以像这样很简单的制作一个预装有我们品牌商店私有 snap 的 Ubuntu Core 镜像:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-branded-test-snap
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
|
||||
现在,和方法 1 的最后一样,你获得了一个为工厂准备的 `pc.img`。并且使用这种方法制作的镜像中的所有 snap 都从商店下载的,这意味着它们将能像平常一样自动更新。
|
||||
|
||||
### 结论
|
||||
|
||||
到目前为止,做这个只有两种方法。当我开始写这篇帖子的时候,我想过可能还有第三种(将 snap 设置为私有然后使用它制作镜像),[但最后证明是不行的][12]。
|
||||
|
||||
另外,我们也收到很多内部部署或者企业商店的请求,虽然这样的产品还没有公布,但是商店团队正在从事这项工作。一旦可用,我将会写一篇有关它的文章。
|
||||
|
||||
希望能帮助到您!
|
||||
|
||||
---
|
||||
|
||||
关于作者
|
||||
|
||||
Kyle 是 Snapcraft 团队的一员,也是 Canonical 公司的常驻机器人专家,他专注于 snaps 和 snap 开发实践,以及 snaps 和 Ubuntu Core 的机器人技术实现。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/11/ubuntu-core-making-a-factory-image-with-private-snaps/
|
||||
|
||||
作者:[Kyle Fazzari][a]
|
||||
译者:[Snaplee](https://github.com/Snaplee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[2]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[3]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[4]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[5]: https://tutorials.ubuntu.com/tutorial/create-your-own-core-image
|
||||
[6]: https://dashboard.snapcraft.io/dev/snaps/
|
||||
[7]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps
|
||||
[8]: https://docs.ubuntu.com/core/en/build-store/index?_ga=2.103787520.1269328701.1501772209-778441655.1499262639
|
||||
[9]: https://docs.ubuntu.com/core/en/build-store/create
|
||||
[12]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps/1115
|
||||
[14]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
@ -3,17 +3,14 @@
|
||||
|
||||
[][2]
|
||||
|
||||
**Apache Hadoop** 软件库是一个框架,它允许使用简单的编程模型在计算机集群上对大型数据集进行分布式处理。Apache™ Hadoop® 是可靠、可扩展、分布式计算的开源软件。
|
||||
Apache Hadoop 软件库是一个框架,它允许使用简单的编程模型在计算机集群上对大型数据集进行分布式处理。Apache™ Hadoop® 是可靠、可扩展、分布式计算的开源软件。
|
||||
|
||||
该项目包括以下模块:
|
||||
|
||||
* **Hadoop Common**:支持其他 Hadoop 模块的常用工具
|
||||
|
||||
* **Hadoop 分布式文件系统 (HDFS™)**:分布式文件系统,可提供对应用程序数据的高吞吐量访问
|
||||
|
||||
* **Hadoop YARN**:作业调度和集群资源管理框架。
|
||||
|
||||
* **Hadoop MapReduce**:一个基于 YARN 的大型数据集并行处理系统。
|
||||
* Hadoop Common:支持其他 Hadoop 模块的常用工具。
|
||||
* Hadoop 分布式文件系统 (HDFS™):分布式文件系统,可提供对应用程序数据的高吞吐量访问支持。
|
||||
* Hadoop YARN:作业调度和集群资源管理框架。
|
||||
* Hadoop MapReduce:一个基于 YARN 的大型数据集并行处理系统。
|
||||
|
||||
本文将帮助你逐步在 CentOS 上安装 hadoop 并配置单节点 hadoop 集群。
|
||||
|
||||
@ -30,7 +27,7 @@ Java HotSpot(TM) 64-Bit Server VM (build 24.75-b04, mixed mode)
|
||||
|
||||
要安装或更新 Java,请参考下面逐步的说明。
|
||||
|
||||
第一步是从[ Oracle 官方网站][3]下载最新版本的 java。
|
||||
第一步是从 [Oracle 官方网站][3]下载最新版本的 java。
|
||||
|
||||
```
|
||||
cd /opt/
|
||||
@ -58,7 +55,7 @@ There are 3 programs which provide 'java'.
|
||||
Enter to keep the current selection[+], or type selection number: 3 [Press Enter]
|
||||
```
|
||||
|
||||
现在你可能还需要使用alternatives 命令设置 javac 和 jar 命令路径。
|
||||
现在你可能还需要使用 `alternatives` 命令设置 `javac` 和 `jar` 命令路径。
|
||||
|
||||
```
|
||||
alternatives --install /usr/bin/jar jar /opt/jdk1.7.0_79/bin/jar 2
|
||||
@ -69,27 +66,27 @@ alternatives --set javac /opt/jdk1.7.0_79/bin/javac
|
||||
|
||||
下一步是配置环境变量。使用以下命令正确设置这些变量。
|
||||
|
||||
* 设置 **JAVA_HOME** 变量
|
||||
设置 `JAVA_HOME` 变量:
|
||||
|
||||
```
|
||||
export JAVA_HOME=/opt/jdk1.7.0_79
|
||||
```
|
||||
|
||||
* 设置 **JRE_HOME** 变量
|
||||
设置 `JRE_HOME` 变量:
|
||||
|
||||
```
|
||||
export JRE_HOME=/opt/jdk1.7.0_79/jre
|
||||
```
|
||||
|
||||
* 设置 **PATH** 变量
|
||||
设置 `PATH` 变量:
|
||||
|
||||
```
|
||||
export PATH=$PATH:/opt/jdk1.7.0_79/bin:/opt/jdk1.7.0_79/jre/bin
|
||||
```
|
||||
|
||||
### 安装 **Apache Hadoop**
|
||||
### 安装 Apache Hadoop
|
||||
|
||||
设置好 java 环境后。开始安装 **Apache Hadoop**。
|
||||
设置好 java 环境后。开始安装 Apache Hadoop。
|
||||
|
||||
第一步是创建用于 hadoop 安装的系统用户帐户。
|
||||
|
||||
@ -98,7 +95,7 @@ useradd hadoop
|
||||
passwd hadoop
|
||||
```
|
||||
|
||||
现在你需要配置用户 hadoop 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
|
||||
现在你需要配置用户 `hadoop` 的 ssh 密钥。使用以下命令启用无需密码的 ssh 登录。
|
||||
|
||||
```
|
||||
su - hadoop
|
||||
@ -119,7 +116,7 @@ mv hadoop-2.6.0 hadoop
|
||||
|
||||
下一步是设置 hadoop 使用的环境变量。
|
||||
|
||||
编辑 **~/.bashrc**,并在文件末尾添加以下这些值。
|
||||
编辑 `~/.bashrc`,并在文件末尾添加以下这些值。
|
||||
|
||||
```
|
||||
export HADOOP_HOME=/home/hadoop/hadoop
|
||||
@ -138,7 +135,7 @@ export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
编辑 **$HADOOP_HOME/etc/hadoop/hadoop-env.sh** 并设置 **JAVA_HOME** 环境变量。
|
||||
编辑 `$HADOOP_HOME/etc/hadoop/hadoop-env.sh` 并设置 `JAVA_HOME` 环境变量。
|
||||
|
||||
```
|
||||
export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
@ -149,10 +146,10 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
首先编辑 hadoop 配置文件并进行以下更改。
|
||||
|
||||
```
|
||||
cd /home/hadoop/hadoop/etc/hadoop
|
||||
cd /home/hadoop/hadoop/etc/hadoop
|
||||
```
|
||||
|
||||
让我们编辑 core-site.xml。
|
||||
让我们编辑 `core-site.xml`。
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -163,7 +160,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
接着编辑 hdfs-site.xml:
|
||||
接着编辑 `hdfs-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -184,7 +181,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
并编辑 mapred-site.xml:
|
||||
并编辑 `mapred-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -195,7 +192,7 @@ export JAVA_HOME=/opt/jdk1.7.0_79/
|
||||
</configuration>
|
||||
```
|
||||
|
||||
最后编辑 yarn-site.xml:
|
||||
最后编辑 `yarn-site.xml`:
|
||||
|
||||
```
|
||||
<configuration>
|
||||
@ -220,7 +217,7 @@ start-dfs.sh
|
||||
start-yarn.sh
|
||||
```
|
||||
|
||||
要检查所有服务是否正常启动,请使用 “jps” 命令:
|
||||
要检查所有服务是否正常启动,请使用 `jps` 命令:
|
||||
|
||||
```
|
||||
jps
|
||||
@ -237,19 +234,19 @@ jps
|
||||
25807 NameNode
|
||||
```
|
||||
|
||||
现在,你可以在浏览器中访问 Hadoop 服务:**http://your-ip-address:8088/**。
|
||||
现在,你可以在浏览器中访问 Hadoop 服务:http://your-ip-address:8088/ 。
|
||||
|
||||
[][5]
|
||||
|
||||
谢谢!!!
|
||||
谢谢阅读!!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/setup-apache-hadoop-centos/
|
||||
|
||||
作者:[anismaj ][a]
|
||||
作者:[anismaj][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,296 @@
|
||||
Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
============================================================
|
||||
|
||||
本指南将向你介绍如何使用 Authconfig 在命令行中将无图形界面的 CentOS 7 服务器集成到 [Samba4 AD 域控制器][3]中。
|
||||
|
||||
这类设置提供了由 Samba 持有的单一集中式帐户数据库,允许 AD 用户通过网络基础设施对 CentOS 服务器进行身份验证。
|
||||
|
||||
#### 要求
|
||||
|
||||
1. [在 Ubuntu 上使用 Samba4 创建 AD 基础架构][1]
|
||||
2. [CentOS 7.3 安装指南][2]
|
||||
|
||||
### 步骤 1:为 Samba4 AD DC 配置 CentOS
|
||||
|
||||
1、 在开始将 CentOS 7 服务器加入 Samba4 DC 之前,你需要确保网络接口被正确配置为通过 DNS 服务查询域。
|
||||
|
||||
运行 `ip address` 命令列出你机器网络接口,选择要编辑的特定网卡,通过针对接口名称运行 `nmtui-edit` 命令(如本例中的 ens33),如下所示。
|
||||
|
||||
```
|
||||
# ip address
|
||||
# nmtui-edit ens33
|
||||
```
|
||||
|
||||
[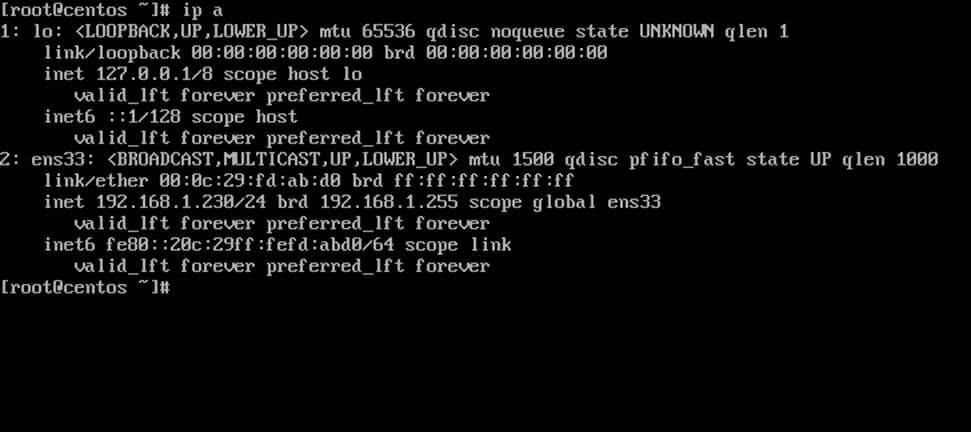][5]
|
||||
|
||||
*列出网络接口*
|
||||
|
||||
2、 打开网络接口进行编辑后,添加最适合 LAN 的静态 IPv4 配置,并确保为 DNS 服务器设置 Samba AD 域控制器 IP 地址。
|
||||
|
||||
另外,在搜索域中追加你的域的名称,并使用 [TAB] 键跳到确定按钮来应用更改。
|
||||
|
||||
当你仅对域 dns 记录使用短名称时, 已提交的搜索域保证域对应项会自动追加到 dns 解析 (FQDN) 中。
|
||||
|
||||
[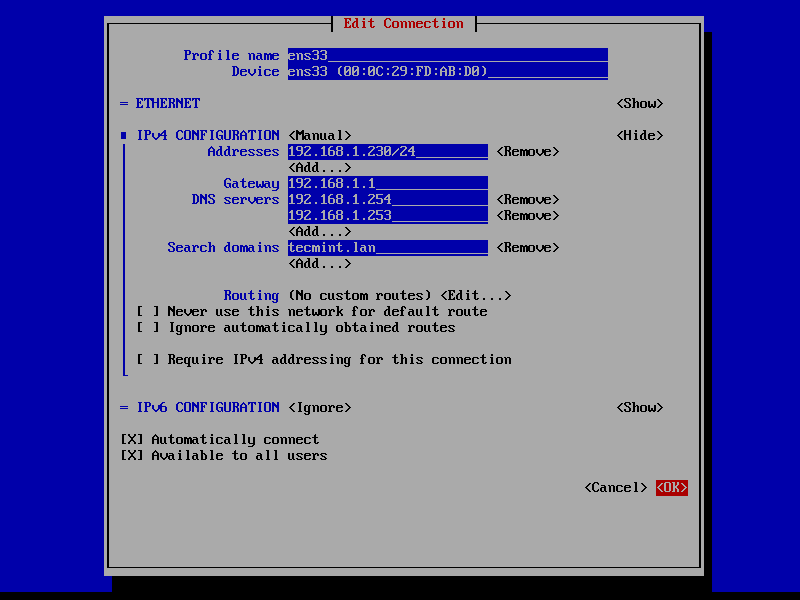][6]
|
||||
|
||||
*配置网络接口*
|
||||
|
||||
3、最后,重启网络守护进程以应用更改,并通过对域名和域控制器 ping 来测试 DNS 解析是否正确配置,如下所示。
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
# ping -c2 tecmint.lan
|
||||
# ping -c2 adc1
|
||||
# ping -c2 adc2
|
||||
```
|
||||
|
||||
[][7]
|
||||
|
||||
*验证域上的 DNS 解析*
|
||||
|
||||
4、 另外,使用下面的命令配置你的计算机主机名并重启机器应用更改。
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_hostname
|
||||
# init 6
|
||||
```
|
||||
|
||||
使用以下命令验证主机名是否正确配置。
|
||||
|
||||
```
|
||||
# cat /etc/hostname
|
||||
# hostname
|
||||
```
|
||||
|
||||
5、 最后,使用 root 权限运行以下命令,与 Samba4 AD DC 同步本地时间。
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate domain.tld
|
||||
```
|
||||
|
||||
[][8]
|
||||
|
||||
*与 Samba4 AD DC 同步时间*
|
||||
|
||||
### 步骤 2:将 CentOS 7 服务器加入到 Samba4 AD DC
|
||||
|
||||
6、 要将 CentOS 7 服务器加入到 Samba4 AD 中,请先用具有 root 权限的帐户在计算机上安装以下软件包。
|
||||
|
||||
```
|
||||
# yum install authconfig samba-winbind samba-client samba-winbind-clients
|
||||
```
|
||||
|
||||
7、 为了将 CentOS 7 服务器与域控制器集成,可以使用 root 权限运行 `authconfig-tui`,并使用下面的配置。
|
||||
|
||||
```
|
||||
# authconfig-tui
|
||||
```
|
||||
|
||||
首屏选择:
|
||||
|
||||
* 在 User Information 中:
|
||||
* Use Winbind
|
||||
* 在 Authentication 中使用[空格键]选择:
|
||||
* Use Shadow Password
|
||||
* Use Winbind Authentication
|
||||
* Local authorization is sufficient
|
||||
|
||||
[][9]
|
||||
|
||||
*验证配置*
|
||||
|
||||
8、 点击 Next 进入 Winbind 设置界面并配置如下:
|
||||
|
||||
* Security Model: ads
|
||||
* Domain = YOUR_DOMAIN (use upper case)
|
||||
* Domain Controllers = domain machines FQDN (comma separated if more than one)
|
||||
* ADS Realm = YOUR_DOMAIN.TLD
|
||||
* Template Shell = /bin/bash
|
||||
|
||||
[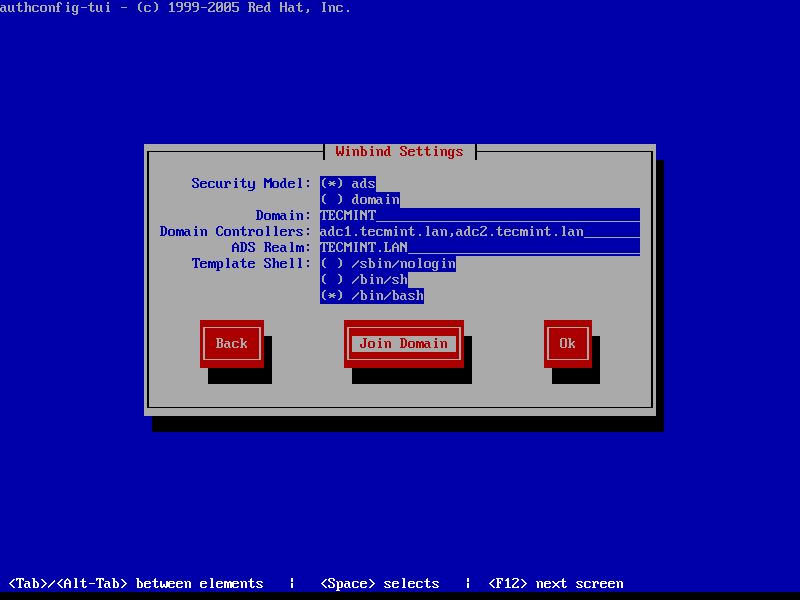][10]
|
||||
|
||||
*Winbind 设置*
|
||||
|
||||
9、 要加入域,使用 [tab] 键跳到 “Join Domain” 按钮,然后按[回车]键加入域。
|
||||
|
||||
在下一个页面,添加具有提升权限的 Samba4 AD 帐户的凭据,以将计算机帐户加入 AD,然后单击 “OK” 应用设置并关闭提示。
|
||||
|
||||
请注意,当你输入用户密码时,凭据将不会显示在屏幕中。在下面再次点击 OK,完成 CentOS 7 的域集成。
|
||||
|
||||
[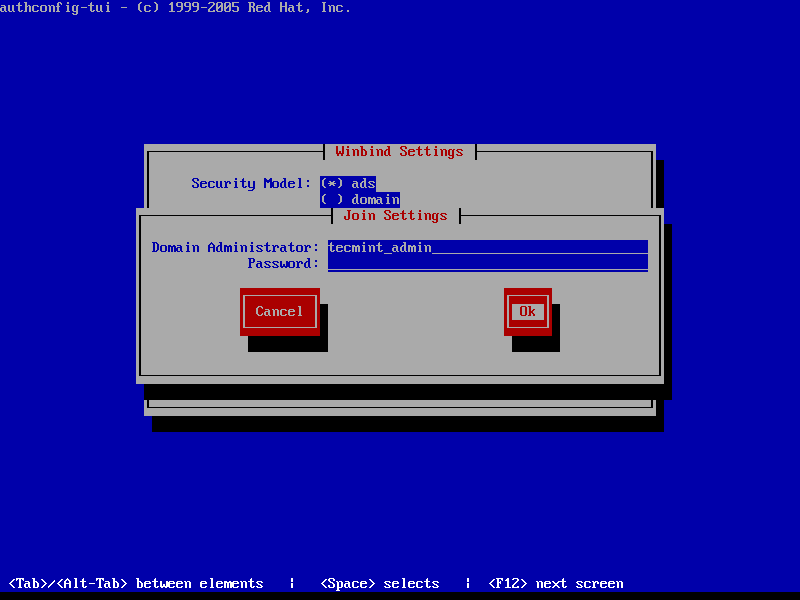][11]
|
||||
|
||||
*加入域到 Samba4 AD DC*
|
||||
|
||||
[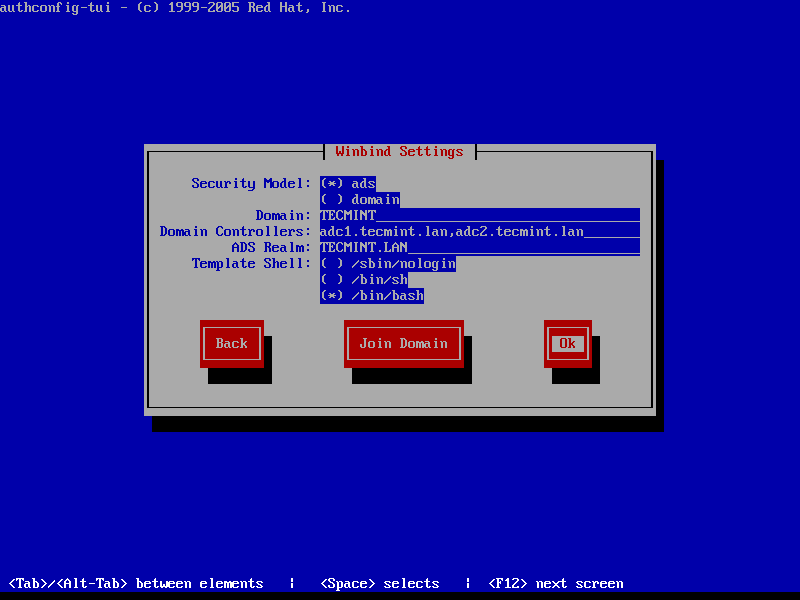][12]
|
||||
|
||||
*确认 Winbind 设置*
|
||||
|
||||
要强制将机器添加到特定的 Samba AD OU 中,请使用 hostname 命令获取计算机的完整名称,并使用机器名称在该 OU 中创建一个新的计算机对象。
|
||||
|
||||
将新对象添加到 Samba4 AD 中的最佳方法是已经集成到[安装了 RSAT 工具][13]的域的 Windows 机器上使用 ADUC 工具。
|
||||
|
||||
重要:加入域的另一种方法是使用 `authconfig` 命令行,它可以对集成过程进行广泛的控制。
|
||||
|
||||
但是,这种方法很容易因为其众多参数造成错误,如下所示。该命令必须输入一条长命令行。
|
||||
|
||||
```
|
||||
# authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --smbworkgroup=YOUR_DOMAIN --smbrealm YOUR_DOMAIN.TLD --smbservers=adc1.yourdomain.tld --krb5realm=YOUR_DOMAIN.TLD --enablewinbindoffline --enablewinbindkrb5 --winbindtemplateshell=/bin/bash--winbindjoin=domain_admin_user --update --enablelocauthorize --savebackup=/backups
|
||||
```
|
||||
|
||||
10、 机器加入域后,通过使用以下命令验证 winbind 服务是否正常运行。
|
||||
|
||||
```
|
||||
# systemctl status winbind.service
|
||||
```
|
||||
|
||||
11、 接着检查是否在 Samba4 AD 中成功创建了 CentOS 机器对象。从安装了 RSAT 工具的 Windows 机器使用 AD 用户和计算机工具,并进入到你的域计算机容器。一个名为 CentOS 7 Server 的新 AD 计算机帐户对象应该在右边的列表中。
|
||||
|
||||
12、 最后,使用文本编辑器打开 samba 主配置文件(`/etc/samba/smb.conf`)来调整配置,并在 `[global]` 配置块的末尾附加以下行,如下所示:
|
||||
|
||||
```
|
||||
winbind use default domain = true
|
||||
winbind offline logon = true
|
||||
```
|
||||
|
||||
[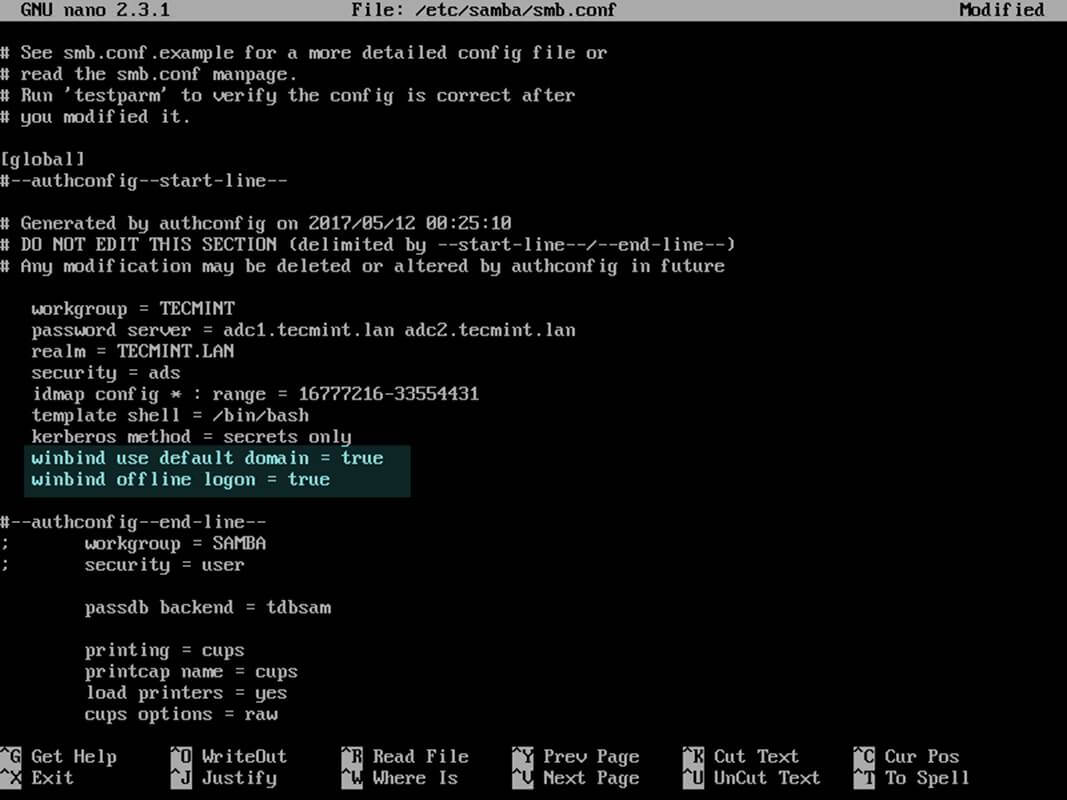][14]
|
||||
|
||||
*配置 Samba*
|
||||
|
||||
13、 为了在 AD 帐户首次登录时在机器上创建本地家目录,请运行以下命令:
|
||||
|
||||
```
|
||||
# authconfig --enablemkhomedir --update
|
||||
```
|
||||
|
||||
14、 最后,重启 Samba 守护进程使更改生效,并使用一个 AD 账户登陆验证域加入。AD 帐户的家目录应该会自动创建。
|
||||
|
||||
```
|
||||
# systemctl restart winbind
|
||||
# su - domain_account
|
||||
```
|
||||
|
||||
[][15]
|
||||
|
||||
*验证域加入*
|
||||
|
||||
15、 通过以下命令之一列出域用户或域组。
|
||||
|
||||
```
|
||||
# wbinfo -u
|
||||
# wbinfo -g
|
||||
```
|
||||
|
||||
[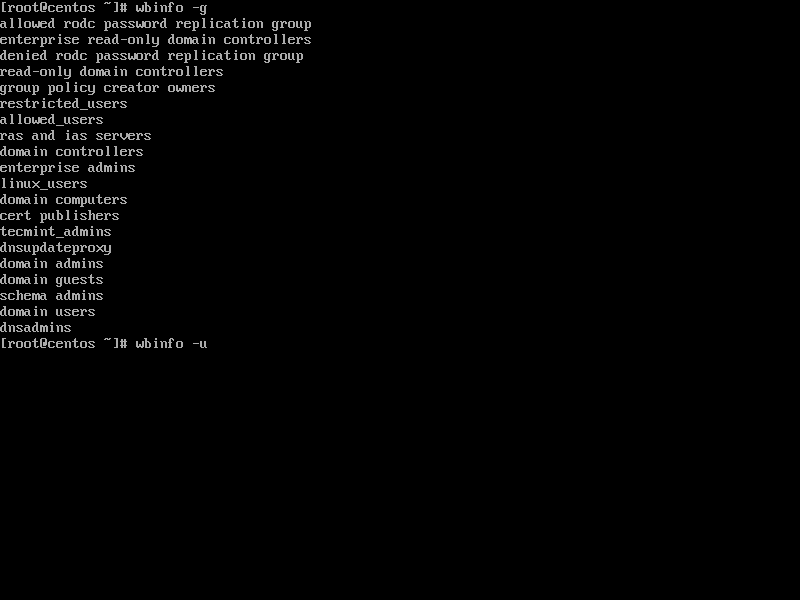][16]
|
||||
|
||||
*列出域用户和组*
|
||||
|
||||
16、 要获取有关域用户的信息,请运行以下命令。
|
||||
|
||||
```
|
||||
# wbinfo -i domain_user
|
||||
```
|
||||
|
||||
[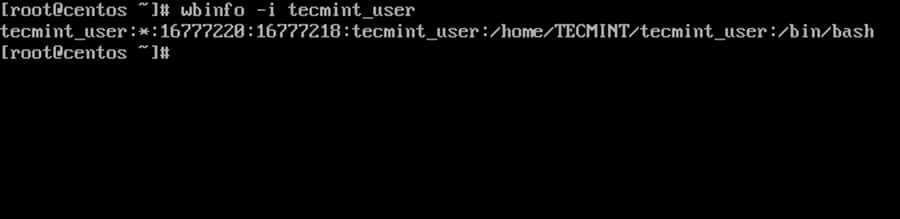][17]
|
||||
|
||||
*列出域用户信息*
|
||||
|
||||
17、 要显示域摘要信息,请使用以下命令。
|
||||
|
||||
```
|
||||
# net ads info
|
||||
```
|
||||
|
||||
[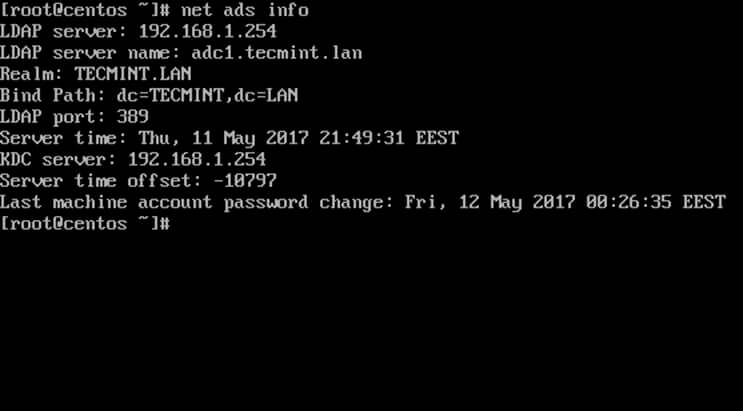][18]
|
||||
|
||||
*列出域摘要*
|
||||
|
||||
### 步骤 3:使用 Samba4 AD DC 帐号登录CentOS
|
||||
|
||||
18、 要在 CentOS 中与域用户进行身份验证,请使用以下命令语法之一。
|
||||
|
||||
```
|
||||
# su - ‘domain\domain_user’
|
||||
# su - domain\\domain_user
|
||||
```
|
||||
|
||||
或者在 samba 配置文件中设置了 `winbind use default domain = true` 参数的情况下,使用下面的语法。
|
||||
|
||||
```
|
||||
# su - domain_user
|
||||
# su - domain_user@domain.tld
|
||||
```
|
||||
|
||||
19、 要为域用户或组添加 root 权限,请使用 `visudocommand` 编辑 `sudoers` 文件,并添加以下截图所示的行。
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
|
||||
或者在 samba 配置文件中设置了 `winbind use default domain = true` 参数的情况下,使用下面的语法。
|
||||
|
||||
```
|
||||
domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
[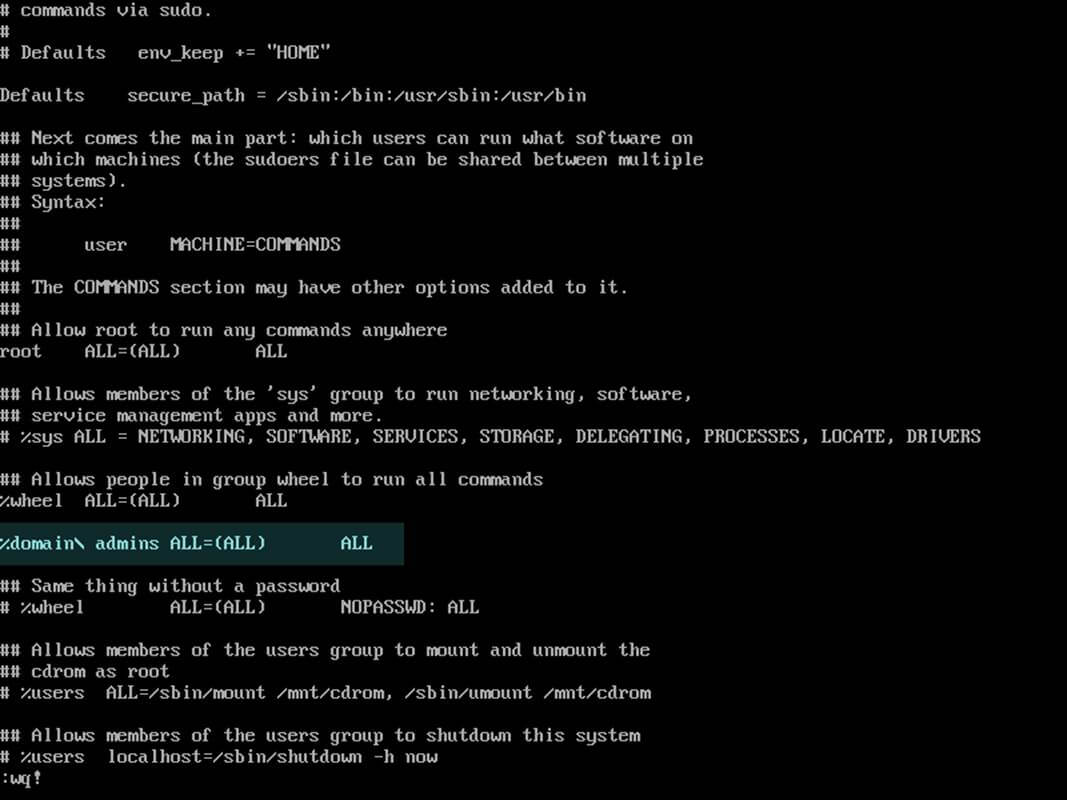][19]
|
||||
|
||||
*授予域用户 root 权限*
|
||||
|
||||
20、 针对 Samba4 AD DC 的以下一系列命令也可用于故障排除:
|
||||
|
||||
```
|
||||
# wbinfo -p #Ping domain
|
||||
# wbinfo -n domain_account #Get the SID of a domain account
|
||||
# wbinfo -t #Check trust relationship
|
||||
```
|
||||
|
||||
21、 要离开该域, 请使用具有提升权限的域帐户对你的域名运行以下命令。从 AD 中删除计算机帐户后, 重启计算机以在集成进程之前还原更改。
|
||||
|
||||
```
|
||||
# net ads leave -w DOMAIN -U domain_admin
|
||||
# init 6
|
||||
```
|
||||
|
||||
就是这样了!尽管此过程主要集中在将 CentOS 7 服务器加入到 Samba4 AD DC 中,但这里描述的相同步骤也适用于将 CentOS 服务器集成到 Microsoft Windows Server 2012 AD 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar - 我是一个电脑上瘾的家伙,开源和基于 linux 的系统软件的粉丝,在 Linux 发行版桌面、服务器和 bash 脚本方面拥有大约 4 年的经验。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://linux.cn/article-8065-1.html
|
||||
[2]:https://linux.cn/article-8048-1.html
|
||||
[3]:https://linux.cn/article-8065-1.html
|
||||
[4]:https://www.tecmint.com/ip-command-examples/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Network-Interfaces.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-DNS-Resolution-on-Domain.png
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/Sync-Time-with-Samba4-AD-DC.png
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Authentication-Configuration.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Winbind-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Domain-to-Samba4-AD-DC.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Winbind-Settings.png
|
||||
[13]:https://linux.cn/article-8097-1.html
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-Domain-Joining.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Users-and-Groups.png
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-User-Info.jpg
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Summary.jpg
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/07/Grant-Root-Privileges-on-Domain-Users.jpg
|
||||
[20]:https://www.tecmint.com/author/cezarmatei/
|
||||
[21]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,128 @@
|
||||
Fedora 26 助力云、服务器、工作站系统
|
||||
============================================================
|
||||
|
||||
|
||||
[Fedora 项目][4] 7 月份宣布推出 Fedora 26, 它是全面开放源代码的 Fedora 操作系统的最新版本。
|
||||
|
||||

|
||||
|
||||
Fedora Linux 是 Red Hat Enterprise Linux(RHEL)的社区版本。Fedora 26 包含一组基础包,形成针对不同用户的三个不同版本的基础。
|
||||
|
||||
Fedora <ruby>原子主机版<rt>Atomic Host Edition</rt></ruby> 是用于运行基于容器的工作的操作系统。Fedora <ruby>服务器版<rt>Server</rt></ruby>将 Fedora Server OS 安装在硬盘驱动器上。Fedora <ruby>工作站版<rt>Workstation</rt></ruby>是一款用于笔记本电脑和台式机的用户友好操作系统,它适用于广泛的用户 - 从业余爱好者和学生到企业环境中的专业人士。
|
||||
|
||||
所有这三个版本都有共同的基础和一些共同的优点。所有 Fedora 版本每年发行两次。
|
||||
|
||||
Fedora 项目是创新和新功能的测试基地。Fedora 项目负责人 Matthew Miller 说,有些特性将在即将发布的 RHEL 版本中实现。
|
||||
|
||||
他告诉 LinuxInsider:“Fedora 并没有直接参与这些产品化决策。Fedora 提供了许多想法和技术,它是 Red Hat Enterprise Linux 客户参与并提供反馈的好地方。”
|
||||
|
||||
### 强力的软件包
|
||||
|
||||
Fedora 开发人员更新和改进了所有三个版本的软件包。他们在 Fedora 26 中进行了许多错误修复和性能调整,以便在 Fedora 的用例中提供更好的用户体验。
|
||||
|
||||
这些安装包包括以下改进:
|
||||
|
||||
* 更新的编译器和语言,包括 GCC 7、Go 1.8、Python 3.6 和 Ruby 2.4;
|
||||
* DNF 2.0 是 Fedora 下一代包管理系统的最新版本,它与 Yum 的向后兼容性得到改善;
|
||||
* Anaconda 安装程序新的存储配置界面,可从设备和分区进行自下而上的配置;
|
||||
* Fedora Media Writer 更新,使用户可以为基于 ARM 的设备(如 Raspberry Pi)创建可启动 SD 卡。
|
||||
|
||||
[Endpoint Technologies Associates][5] 的总裁 Roger L. Kay 指出,云工具对于使用云的用户必不可少,尤其是程序员。
|
||||
|
||||
他对 LinuxInsider 表示:“Kubernetes 对于在混合云中编程感兴趣的程序员来说是至关重要的,这可能是目前业界更重要的发展之一。云,无论是公有云、私有云还是混合云 - 都是企业计算未来的关键。”
|
||||
|
||||
### Fedora 26 原子主机亮相
|
||||
|
||||
Linux 容器和容器编排引擎一直在普及。Fedora 26 原子主机提供了一个最小占用的操作系统,专门用于在裸机到云端的环境中运行基于容器的工作任务。
|
||||
|
||||
Fedora 26 原子主机更新大概每两周发布一次,这个时间表可以让用户及时跟上游创新。
|
||||
|
||||
Fedora 26 原子主机可用于 Amazon EC2 。OpenStack、Vagrant 镜像和标准安装程序 ISO 镜像可在 [Fedora 项目][6]网站上找到。
|
||||
|
||||
最小化的 Fedora 原子的容器镜像也在 Fedora 26 上首次亮相。
|
||||
|
||||
### 云托管
|
||||
|
||||
最新版本为 Fedora 26 原子主机提供了新功能和特性:
|
||||
|
||||
* 容器化的 Kubernetes 作为内置的 Kubernetes 二进制文件的替代品,使用户更容易地运行不同版本的容器编排引擎;
|
||||
* 最新版本的 rpm-ostree,其中包括支持直接 RPM 安装,重新加载命令和清理命令;
|
||||
* 系统容器,它提供了一种在容器中的 Fedora 原子主机上安装系统基础设施软件(如网络或 Kubernetes)的方法;
|
||||
* 更新版本的 Docker、Atomic和 Cockpit,用于增强容器构建,系统支持和负载监控。
|
||||
|
||||
根据 Fedora 项目的 Miller 所言,容器化的 Kubernetes 对于 Fedora 原子主机来说是重要的,有两个重要原因。
|
||||
|
||||
他解释说:“首先,它可以让我们从基础镜像中删除它,减小大小和复杂度。第二,在容器中提供它可以轻松地在不同版本中切换,而不会破环基础,或者为尚未准备好进行改变的人造成麻烦。”
|
||||
|
||||
### 服务器端服务
|
||||
|
||||
Fedora 26 服务器版为数据中心运营提供了一个灵活的多角色平台。它还允许用户自定义此版本的 Fedora 操作系统以满足其独特需求。
|
||||
|
||||
Fedora 26 服务器版的新功能包括 FreeIPA 4.5,它可以改进容器中运行的安全信息管理解决方案,以及 SSSD 文件缓存,以加快用户和组查询的速度。
|
||||
|
||||
Fedora 26 服务器版月底将增加称为 “Boltron” 的 Fedora 模块化技术预览。作为模块化操作系统,Boltron 使不同版本的不同应用程序能够在同一个系统上运行,这实质上允许将前沿运行时与稳定的数据库配合使用。
|
||||
|
||||
### 打磨工作站版
|
||||
|
||||
对于一般用户的新工具和功能之一是更新的 GNOME 桌面功能。开发将获得增强的生产力工具。
|
||||
|
||||
Fedora 26 工作站版附带 GNOME 3.24 和众多更新的功能调整。夜光根据时间细微地改变屏幕颜色,以减少对睡眠模式的影响。[LibreOffice][7] 5.3 是开源办公生产力套件的最新更新。
|
||||
|
||||
GNOME 3.24 提供了 Builder 和 Flatpak 的成熟版本,它为开发人员提供了更好的应用程序开发工具,它可以方便地访问各种系统,包括 Rust 和 Meson。
|
||||
|
||||
### 不只是为了开发
|
||||
|
||||
根据 [Azul Systems][8] 的首席执行官 Scott Sellers 的说法,更新的云工具将纳入针对企业用户的 Linux 发行版中。
|
||||
|
||||
他告诉 LinuxInsider:“云是新兴公司以及地球上一些最大的企业的主要开发和生产平台。”
|
||||
|
||||
Sellers说:“鉴于 Fedora 社区的前沿性质,我们预计在任何 Fedora 版本中都会强烈关注云技术,Fedora 26 不会不令人失望。”
|
||||
|
||||
他指出,Fedora 开发人员和用户社区的另一个特点就是 Fedora 团队在模块化方面所做的工作。
|
||||
|
||||
Sellers 说:“我们将密切关注这些实验功能。”
|
||||
|
||||
### 支持的升级方式
|
||||
|
||||
Sellers 说 Fedora 的用户超过其他 Linux 发行版的用户,很多都有兴趣升级到 Fedora 26,即使他们不是重度云端用户。
|
||||
|
||||
他说:“这个发行版的主要优点之一就是能提前看到先进的生产级别技术,这些最终将被整合到 RHEL 中。Fedora 26 的早期评论表明它非常稳定,修复了许多错误以及提升了性能。”
|
||||
|
||||
Fedora 的 Miller 指出,有兴趣从早期 Fedora 版本升级的用户可能比擦除现有系统安装 Fedora 26 更容易。Fedora 一次维护两个版本,中间还有一个月的重叠。
|
||||
|
||||
他说:“所以,如果你在用 Fedora 24,你应该在下个月升级。幸运的 Fedora 25 用户可以随时升级,这是 Fedora 快速滚动版本的优势之一。”
|
||||
|
||||
### 更快的发布
|
||||
|
||||
用户可以安排自己升级,而不是在发行版制作出来时进行升级。
|
||||
|
||||
也就是说,Fedora 23 或更早版本的用户应该尽快升级。社区不再为这些版本发布安全更新
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain 自 2003 年以来一直是 ECT 新闻网记者。他的主要重点领域是企业IT、Linux、和开源技术。他撰写了许多关于 Linux 发行版和其他开源软件的评论。发邮件联系 Jack
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84674.html
|
||||
|
||||
作者:[Jack M. Germain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:jack.germain@newsroom.ectnews.comm
|
||||
[1]:http://www.linuxinsider.com/story/84674.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84674
|
||||
[3]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[4]:https://getfedora.org/
|
||||
[5]:http://www.ndpta.com/
|
||||
[6]:https://getfedora.org/
|
||||
[7]:http://www.libreoffice.org/
|
||||
[8]:https://www.azul.com/
|
||||
[9]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[10]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
@ -0,0 +1,73 @@
|
||||
如何建模可以帮助你避免在 OpenStack 中遇到问题
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
_乐高的空客 A380-800模型。空客运行 OpenStack_
|
||||
|
||||
OpenStack 部署完就是一个 “<ruby>僵栈<rt>StuckStack</rt></ruby>”,一般出于技术原因,但有时是商业上的原因,它是无法在没有明显中断,也不花费时间和成本的情况下升级的。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,以及当时是怎么决定的与如今的大部分常识相符。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
|
||||
|
||||
### 没有魔法解决方案
|
||||
|
||||
如果你仍在寻找一个可以没有任何问题地升级你现有的 <ruby>僵栈<rt>StuckStack</rt></ruby> 的解决方案,那么我有坏消息给你:没有魔法解决方案,你最好集中精力建立一个标准化的平台,它可以有效地运营和轻松地升级。
|
||||
|
||||
廉价航空业已经表明,虽然乘客可能渴望最好的体验,可以坐在头等舱或者商务舱喝香槟,有足够的空间放松,但是大多数人会选择乘坐最便宜的,最终价值等式不要让他们付出更多的代价。工作负载是相同的。长期而言,工作负载将运行在最经济的平台上,因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心,并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售、实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但它现在还不重要,因为<ruby>成本模式<rt>cost model</rt></ruby>在当今世界无法生存。一些组织试图通过改用免费软件替代,而不改变自己的行为来解决这一问题。因此,他们发现,他们只是将成本从获取软件变到运营软件上。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
|
||||
### 什么是软件模型?
|
||||
|
||||
虽然许多年来,软件程序由许多对象、进程和服务而组成,但近年来,程序是普遍由许多单独的服务组成,它们高度分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
|
||||

|
||||
|
||||
_OpenStack 服务的简单演示_
|
||||
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理的还是虚拟的。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
|
||||

|
||||
|
||||
_Juju 建模 OpenStack 服务_
|
||||
|
||||
在 Juju 中,软件服务被定义为一种叫做 Charm 的东西。 Charms 是代码片段,它通常用 python 或 bash 编写,其中提供有关服务的信息 - 声明的接口、服务的安装方式、可连接的其他服务等。
|
||||
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如 [裸机即服务(MAAS)][3] 这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要,提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
|
||||
这种方法有两个不同的好处:1 - 通过创建一个模型,我们从底层硬件抽象出每个云服务。2 - 使用已知来源的标准化组件,通过迭代组合新的架构。这种一致性使我们能够使用相同的工具部署非常不同的云架构,运行和升级这些工具是安全的。
|
||||
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施,这将会导致进一步的兼容性问题。
|
||||
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 <ruby>僵栈<rt>StuckStack</rt></ruby>,那么虽然我们不能很容易地拯救它,但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
|
||||
### 即将举行的网络研讨会
|
||||
|
||||
如果你在旧版本的 OpenStack 中遇到问题,并且想要轻松升级 OpenStack 云并且无需停机,请观看我们的[在线点播研讨会][4],从 Newton 升级到 Ocata 的现场演示。
|
||||
|
||||
### 联系我们
|
||||
|
||||
如果你想了解有关迁移到 Canonical OpenStack 云的更多信息,请[联系][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
专注于 Ubuntu OpenStack 的云产品经理。以前在 MySQL 和 Red Hat 工作。喜欢摩托车,遇见使用 Ubuntu 和 Openstack 做有趣事的人。
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/markbaker/
|
||||
[1]:https://insights.ubuntu.com/author/markbaker/
|
||||
[2]:https://www.ubuntu.com/cloud/juju
|
||||
[3]:https://www.ubuntu.com/server/maas
|
||||
[4]:http://ubunt.eu/Bwe7kQ
|
||||
[5]:http://ubunt.eu/3OYs5s
|
||||
@ -0,0 +1,82 @@
|
||||
解密开放容器计划(OCI)规范
|
||||
============================================================
|
||||
|
||||
<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby>(OCI)宣布本周完成了容器运行时和镜像的第一版规范。OCI 在是 <ruby>Linux 基金会<rt>Linux Foundation</rt></ruby>支持下的容器解决方案标准化的成果。两年来,为了[建立这些规范][12]已经付出了大量的努力。 由此,让我们一起来回顾过去两年中出现的一些误区。
|
||||
|
||||

|
||||
|
||||
### 误区:OCI 是 Docker 的替代品
|
||||
|
||||
诚然标准非常重要,但它们远非一个完整的生产平台。 以万维网为例,它 25 年来一路演进,建立在诸如 TCP/IP 、HTTP 和 HTML 等可靠的核心标准之上。再以 TCP/IP 为例,当企业将 TCP/IP 合并为一种通用协议时,它推动了路由器行业,尤其是思科的发展。 然而,思科通过专注于在其路由平台上提供差异化的功能,而成为市场的领导者。我们认为 OCI 规范和 Docker 也是类似这样并行存在的。
|
||||
|
||||
[Docker 是一个完整的生产平台][13],提供了基于容器的开发、分发、安全、编排的一体化解决方案。Docker 使用了 OCI 规范,但它大约只占总代码的 5%,而且 Docker 平台只有一小部分涉及容器的运行时行为和容器镜像的布局。
|
||||
|
||||
### 误区:产品和项目已经通过了 OCI 规范认证
|
||||
|
||||
运行时和镜像规范本周刚发布 1.0 的版本。 而且 OCI 认证计划仍在开发阶段,所以企业在该认证正式推出之前(今年晚些时候),没法要求容器产品的合规性、一致性或兼容性。
|
||||
|
||||
OCI [认证工作组][14]目前正在制定标准,使容器产品和开源项目能够符合规范的要求。标准和规范对于实施解决方案的工程师很重要,但正式认证是向客户保证其正在使用的技术真正符合标准的唯一方式。
|
||||
|
||||
### 误区:Docker 不支持 OCI 规范的工作
|
||||
|
||||
Docker 很早就开始为 OCI 做贡献。 我们向 OCI 贡献了大部分的代码,作为 OCI 项目的维护者,为 OCI 运行时和镜像规范定义提供了积极有益的帮助。Docker 运行时和镜像格式在 2013 年开源发布之后,便迅速成为事实上的标准,我们认为将代码捐赠给中立的管理机构,对于避免容器行业的碎片化和鼓励行业创新将是有益的。我们的目标是提供一个可靠和标准化的规范,因此 Docker 提供了一个简单的容器运行时 runc 作为运行时规范工作的基础,后来又贡献了 Docker V2 镜像规范作为 OCI 镜像规范工作的基础。
|
||||
|
||||
Docker 的开发人员如 Michael Crosby 和 Stephen Day 从一开始就是这项工作的关键贡献者,确保能将 Docker 的托管和运行数十亿个容器镜像的经验带给 OCI。等认证工作组完成(制定认证规范的)工作后,Docker 将通过 OCI 认证将其产品展示出来,以证明 OCI 的一致性。
|
||||
|
||||
### 误区:OCI 仅用于 Linux 容器技术
|
||||
|
||||
因为 OCI 是由 <ruby>Linux 基金会<rt>Linux Foundation</rt></ruby> 负责制定的,所以很容易让人误解为 OCI 仅适用于 Linux 容器技术。 而实际上并非如此,尽管 Docker 技术源于 Linux 世界,但 Docker 也一直在与微软合作,将我们的容器技术、平台和工具带到 Windows Server 的世界。 此外,Docker 向 OCI 贡献的基础技术广泛适用于包括 Linux 、Windows 和 Solaris 在内的多种操作系统环境,涵盖了 x86、ARM 和 IBM zSeries 等多种架构环境。
|
||||
|
||||
### 误区:Docker 仅仅是 OCI 的众多贡献者之一
|
||||
|
||||
OCI 作为一个支持成员众多的开放组织,代表了容器行业的广度。 也就是说,它是一个小而专业的个人技术专家组,为制作初始规范的工作贡献了大量的时间和技术。 Docker 是 OCI 的创始成员,贡献了初始代码库,构成了运行时规范的基础和后来的参考实现。 同样地,Docker 也将 Docker V2 镜像规范贡献给 OCI 作为镜像规范的基础。
|
||||
|
||||
### 误区:CRI-O 是 OCI 项目
|
||||
|
||||
CRI-O 是<ruby>云计算基金会<rt>Cloud Native Computing Foundation</rt></ruby>(CNCF)的 Kubernetes 孵化器的开源项目 -- 它不是 OCI 项目。 它基于早期版本的 Docker 体系结构,而 containerd 是一个直接的 CNCF 项目,它是一个包括 runc 参考实现的更大的容器运行时。 containerd 负责镜像传输和存储、容器运行和监控,以及支持存储和网络附件等底层功能。 Docker 在五个最大的云提供商(阿里云、AWS、Google Cloud Platform(GCP)、IBM Softlayer 和 Microsoft Azure)的支持下,将 containerd 捐赠给了云计算基金会(CNCF),作为多个容器平台和编排系统的核心容器运行时。
|
||||
|
||||
### 误区:OCI 规范现在已经完成了
|
||||
|
||||
虽然首版容器运行时和镜像格式规范的发布是一个重要的里程碑,但还有许多工作有待完成。 OCI 一开始着眼于定义一个狭窄的规范:开发人员可以依赖于容器的运行时行为,防止容器行业碎片化,并且仍然允许在不断变化的容器域中进行创新。之后才将含容器镜像规范囊括其中。
|
||||
|
||||
随着工作组完成运行时行为和镜像格式的第一个稳定规范,新的工作考量也已经同步展开。未来的新特性将包括分发和签名等。 然而,OCI 的下一个最重要的工作是提供一个由测试套件支持的认证过程,因为第一个规范已经稳定了。
|
||||
|
||||
**在 Docker 了解更多关于 OCI 和开源的信息:**
|
||||
|
||||
* 阅读关于 [OCI v1.0 版本的运行时和镜像格式规范]的博文[1]
|
||||
* 访问 [OCI 的网站][2]
|
||||
* 访问 [Moby 项目网站][3]
|
||||
* 参加 [DockerCon Europe 2017][4]
|
||||
* 参加 [Moby Summit LA][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Stephen 是 Docker 开源项目总监。 他曾在 Hewlett-Packard Enterprise (惠普企业)担任董事和杰出技术专家。他的关于开源软件和商业的博客发布在 “再次违约”(http://stephesblog.blogs.com) 和网站 opensource.com 上。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/demystifying-open-container-initiative-oci-specifications/
|
||||
|
||||
作者:[Stephen][a]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications
|
||||
[2]:https://www.opencontainers.org/join
|
||||
[3]:http://mobyproject.org/
|
||||
[4]:https://europe-2017.dockercon.com/
|
||||
[5]:https://www.eventbrite.com/e/moby-summit-los-angeles-tickets-35930560273
|
||||
[6]:https://blog.docker.com/author/stephen-walli/
|
||||
[7]:https://blog.docker.com/tag/containerd/
|
||||
[8]:https://blog.docker.com/tag/cri-o/
|
||||
[9]:https://blog.docker.com/tag/linux-containers/
|
||||
[10]:https://blog.docker.com/tag/linux-foundation/
|
||||
[11]:https://blog.docker.com/tag/oci/
|
||||
[12]:https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications
|
||||
[13]:https://www.docker.com/
|
||||
[14]:https://github.com/opencontainers/certification
|
||||
@ -0,0 +1,95 @@
|
||||
OCI 发布容器运行时和镜像格式规范 V1.0
|
||||
============================================================
|
||||
|
||||
7 月 19 日是<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby>(OCI)的一个重要里程碑,OCI 发布了容器运行时和镜像规范的 1.0 版本,而 Docker 在这过去两年中一直充当着推动和引领的核心角色。我们的目标是为社区、客户以及更广泛的容器行业提供底层的标准。要了解这一里程碑的意义,我们先来看看 Docker 在开发容器技术行业标准方面的成长和发展历史。
|
||||
|
||||
### Docker 将运行时和镜像捐赠给 OCI 的历史回顾
|
||||
|
||||
Docker 的镜像格式和容器运行时在 2013 年作为开源项目发布后,迅速成为事实上的标准。我们认识到将其转交给中立管理机构管理,以加强创新和防止行业碎片化的重要性。我们与广泛的容器技术人员和行业领导者合作,成立了<ruby>开放容器项目<rt>Open Container Project</rt></ruby>来制定了一套容器标准,并在 Linux 基金会的支持下,于 2015 年 6 月在 Docker 大会(DockerCon)上推出。最终在那个夏天演变成为<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby> (OCI)。
|
||||
|
||||
Docker 贡献了 runc ,这是从 Docker 员工 [Michael Crosby][17] 的 libcontainer 项目中发展而来的容器运行时参考实现。 runc 是描述容器生命周期和运行时行为的运行时规范的基础。runc 被用在数千万个节点的生产环境中,这比任何其它代码库都要大一个数量级。runc 已经成为运行时规范的参考实现,并且随着项目的进展而不断发展。
|
||||
|
||||
在运行时规范制定工作开始近一年后,我们组建了一个新的工作组来制定镜像格式的规范。 Docker 将 Docker V2 镜像格式捐赠给 OCI 作为镜像规范的基础。通过这次捐赠,OCI 定义了构成容器镜像的数据结构(原始镜像)。定义容器镜像格式是一个至关重要的步骤,但它需要一个像 Docker 这样的平台通过定义和提供构建、管理和发布镜像的工具来实现它的价值。 例如,Dockerfile 等内容并不包括在 OCI 规范中。
|
||||
|
||||

|
||||
|
||||
### 开放容器标准化之旅
|
||||
|
||||
这个规范已经持续开发了两年。随着代码的重构,更小型的项目已经从 runc 参考实现中脱颖而出,并支持即将发布的认证测试工具。
|
||||
|
||||
有关 Docker 参与塑造 OCI 的详细信息,请参阅上面的时间轴,其中包括:创建 runc ,和社区一起更新、迭代运行时规范,创建 containerd 以便于将 runc 集成到 Docker 1.11 中,将 Docker V2 镜像格式贡献给 OCI 作为镜像格式规范的基础,并在 [containerd][18] 中实现该规范,使得该核心容器运行时同时涵盖了运行时和镜像格式标准,最后将 containerd 捐赠给了<ruby>云计算基金会<rt>Cloud Native Computing Foundation</rt></ruby>(CNCF),并于本月发布了更新的 1.0 alpha 版本。
|
||||
|
||||
维护者 [Michael Crosby][19] 和 [Stephen Day][20] 引导了这些规范的发展,并且为 v1.0 版本的实现提供了极大的帮助,另外 Alexander Morozov,Josh Hawn,Derek McGown 和 Aaron Lehmann 也贡献了代码,以及 Stephen Walli 参加了认证工作组。
|
||||
|
||||
Docker 仍然致力于推动容器标准化进程,在每个人都认可的层面建立起坚实的基础,使整个容器行业能够在依旧十分差异化的层面上进行创新。
|
||||
|
||||
### 开放标准只是一小块拼图
|
||||
|
||||
Docker 是一个完整的平台,用于创建、管理、保护和编排容器以及镜像。该项目的愿景始终是致力于成为支持开源组件的行业规范的基石,或着是容器解决方案的校准铅锤。Docker 平台正位于此层之上 -- 为客户提供从开发到生产的安全的容器管理解决方案。
|
||||
|
||||
OCI 运行时和镜像规范成为一个可靠的标准基础,允许和鼓励多样化的容器解决方案,同时它们不限制产品创新或遏制主要开发者。打一个比方,TCP/IP、HTTP 和 HTML 成为过去 25 年来建立万维网的可靠标准,其他公司可以继续通过这些标准的新工具、技术和浏览器进行创新。 OCI 规范也为容器解决方案提供了类似的规范基础。
|
||||
|
||||
开源项目也在为产品开发提供组件方面发挥着作用。containerd 项目就使用了 OCI 的 runc 参考实现,它负责镜像的传输和存储,容器运行和监控,以及支持存储和网络附件的等底层功能。containerd 项目已经被 Docker 捐赠给了 CNCF ,与其他重要项目一起支持云计算解决方案。
|
||||
|
||||
Docker 使用了 containerd 和其它自己的核心开源基础设施组件,如 LinuxKit,InfraKit 和 Notary 等项目来构建和保护 Docker 社区版容器解决方案。正在寻找一个能提供容器管理、安全性、编排、网络和更多功能的完整容器平台的用户和组织可以了解下 Docker Enterprise Edition 。
|
||||
|
||||

|
||||
|
||||
> 这张图强调了 OCI 规范提供了一个由容器运行时实现的标准层:containerd 和 runc。 要组装一个完整的像 Docker 这样具有完整容器生命周期和工作流程的容器平台,需要和许多其他的组件集成在一起:管理基础架构的 InfraKit,提供操作系统的 LinuxKit,交付编排的 SwarmKit,确保安全性的 Notary。
|
||||
|
||||
### OCI 下一步该干什么
|
||||
|
||||
随着运行时和镜像规范的发布,我们应该庆祝开发者的努力。开放容器计划的下一个关键工作是提供认证计划,以验证实现者的产品和项目确实符合运行时和镜像规范。[认证工作组][21] 已经组织了一个程序,结合了开发套件(developing suite)的[运行时][22]和[镜像][23]规范测试工具将展示产品应该如何参照标准进行实现。
|
||||
|
||||
同时,当前规范的开发者们正在考虑下一个最重要的容器技术领域。云计算基金会的通用容器网络接口开发工作已经正在进行中,支持镜像签署和分发的工作正也在 OCI 的考虑之中。
|
||||
|
||||
除了 OCI 及其成员,Docker 仍然致力于推进容器技术的标准化。 OCI 的使命是为用户和公司提供在开发者工具、镜像分发、容器编排、安全、监控和管理等方面进行创新的基准。Docker 将继续引领创新,不仅提供提高生产力和效率的工具,而且还通过授权用户,合作伙伴和客户进行创新。
|
||||
|
||||
**在 Docker 学习更过关于 OCI 和开源的信息:**
|
||||
|
||||
* 阅读 [OCI 规范的误区][1]
|
||||
* 访问 [开放容器计划的网站][2]
|
||||
* 访问 [Moby 项目网站][3]
|
||||
* 参加 [DockerCon Europe 2017][4]
|
||||
* 参加 [Moby Summit LA][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Patrick Chanezon是Docker Inc.技术人员。他的工作是帮助构建 Docker 。一个程序员和讲故事的人 (storyller),他在 Netscape 和 Sun 工作了10年的时间,又在Google,VMware 和微软工作了10年。他的主要职业兴趣是为这些奇特的双边市场“平台”建立和推动网络效应。他曾在门户网站,广告,电商,社交,Web,分布式应用和云平台上工作过。有关更多信息,请访问 linkedin.com/in/chanezon 和他的推特@chanezon。
|
||||
|
||||
------
|
||||
|
||||
via: https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications/
|
||||
|
||||
作者:[Patrick Chanezon][a]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/chanezon/
|
||||
[1]:https://linux.cn/article-8763-1.html
|
||||
[2]:https://www.opencontainers.org/join
|
||||
[3]:http://mobyproject.org/
|
||||
[4]:https://europe-2017.dockercon.com/
|
||||
[5]:https://www.eventbrite.com/e/moby-summit-los-angeles-tickets-35930560273
|
||||
[6]:https://blog.docker.com/author/chanezon/
|
||||
[7]:https://blog.docker.com/tag/cncf/
|
||||
[8]:https://blog.docker.com/tag/containerd/
|
||||
[9]:https://blog.docker.com/tag/containers/
|
||||
[10]:https://blog.docker.com/tag/docker/
|
||||
[11]:https://blog.docker.com/tag/docker-image-format/
|
||||
[12]:https://blog.docker.com/tag/docker-runtime/
|
||||
[13]:https://blog.docker.com/tag/infrakit/
|
||||
[14]:https://blog.docker.com/tag/linux-foundation/
|
||||
[15]:https://blog.docker.com/tag/oci/
|
||||
[16]:https://blog.docker.com/tag/open-containers/
|
||||
[17]:https://github.com/crosbymichael
|
||||
[18]:https://containerd.io/
|
||||
[19]:https://github.com/crosbymichael
|
||||
[20]:https://github.com/stevvooe
|
||||
[21]:https://github.com/opencontainers/certification
|
||||
[22]:https://github.com/opencontainers/runtime-tools
|
||||
[23]:https://github.com/opencontainers/image-tools
|
||||
@ -1,38 +1,38 @@
|
||||
Deploy Kubernetes cluster for Linux containers
|
||||
部署Kubernetes 容器集群
|
||||
在 Azure 中部署 Kubernetes 容器集群
|
||||
============================================================
|
||||
|
||||
在这个快速入门教程中,我们使用 Azure CLI 创建 Kubernetes 集群。 然后在集群上部署并运行由 Web 前端和 Redis 实例组成的多容器应用程序。 一旦部署完成,应用程序可以通过互联网访问。
|
||||
在这个快速入门教程中,我们使用 Azure CLI 创建一个 Kubernetes 集群,然后在集群上部署运行由 Web 前端和 Redis 实例组成的多容器应用程序。一旦部署完成,应用程序可以通过互联网访问。
|
||||
|
||||
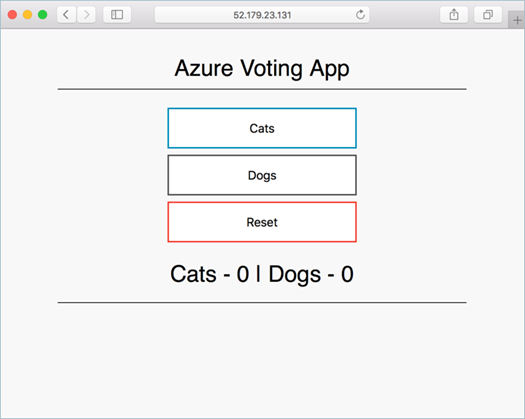
|
||||
|
||||
这个快速入门教程假设你已经基本了解了Kubernetes 的概念,有关 Kubernetes 的详细信息,请参阅[ Kubernetes 文档][3]。
|
||||
这个快速入门教程假设你已经基本了解了 Kubernetes 的概念,有关 Kubernetes 的详细信息,请参阅 [Kubernetes 文档][3]。
|
||||
|
||||
如果您没有 Azure 账号订阅,请在开始之前创建一个[免费帐户][4]。
|
||||
如果您没有 Azure 账号,请在开始之前创建一个[免费帐户][4]。
|
||||
|
||||
### 登陆Azure 云控制台
|
||||
### 登录 Azure 云控制台
|
||||
|
||||
Azure 云控制台是一个免费的 Bash shell ,你可以直接在 Azure 网站上运行。 它已经在你的账户中预先配置好了, 单击[ Azure 门户][5]右上角菜单上的 “Cloud Shell” 按钮;
|
||||
Azure 云控制台是一个免费的 Bash shell,你可以直接在 Azure 网站上运行。它已经在你的账户中预先配置好了, 单击 [Azure 门户][5]右上角菜单上的 “Cloud Shell” 按钮;
|
||||
|
||||
[][6]
|
||||
[][6]
|
||||
|
||||
该按钮启动一个交互式 shell,您可以使用它来运行本教程中的所有操作步骤。
|
||||
该按钮会启动一个交互式 shell,您可以使用它来运行本教程中的所有操作步骤。
|
||||
|
||||
[][7]
|
||||
[][7]
|
||||
|
||||
此快速入门教程所用的 Azure CLI 的版本最低要求为 2.0.4 。如果您选择在本地安装和使用 CLI 工具,请运行 `az --version` 来检查已安装的版本。 如果您需要安装或升级请参阅[安装 Azure CLI 2.0 ][8]。
|
||||
此快速入门教程所用的 Azure CLI 的版本最低要求为 2.0.4。如果您选择在本地安装和使用 CLI 工具,请运行 `az --version` 来检查已安装的版本。 如果您需要安装或升级请参阅[安装 Azure CLI 2.0 ][8]。
|
||||
|
||||
### 创建一个资源组
|
||||
|
||||
使用 [az group create][9] 命令创建一个资源组,一个 Azure 资源组是 Azure 资源部署和管理的逻辑组。
|
||||
使用 [az group create][9] 命令创建一个资源组,一个 Azure 资源组是指 Azure 资源部署和管理的逻辑组。
|
||||
|
||||
以下示例在 _eastus_ 位置中创建名为 _myResourceGroup_ 的资源组。
|
||||
以下示例在 _eastus_ 区域中创建名为 _myResourceGroup_ 的资源组。
|
||||
|
||||
```
|
||||
az group create --name myResourceGroup --location eastus
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -53,23 +53,21 @@ az group create --name myResourceGroup --location eastus
|
||||
|
||||
使用 [az acs create][10] 命令在 Azure 容器服务中创建 Kubernetes 集群。 以下示例使用一个 Linux 主节点和三个 Linux 代理节点创建一个名为 _myK8sCluster_ 的集群。
|
||||
|
||||
Azure CLICopyTry It
|
||||
|
||||
```
|
||||
az acs create --orchestrator-type=kubernetes --resource-group myResourceGroup --name=myK8sCluster --generate-ssh-keys
|
||||
|
||||
```
|
||||
几分钟后,命令将完成并返回有关该集群的json格式的信息。
|
||||
几分钟后,命令将完成并返回有关该集群的 json 格式的信息。
|
||||
|
||||
### 连接到 Kubernetes 集群
|
||||
|
||||
要管理 Kubernetes 群集,可以使用 Kubernetes 命令行工具 [kubectl][11]。
|
||||
|
||||
如果您使用 Azure CloudShell ,则已经安装了 kubectl 。 如果要在本地安装,可以使用 [az acs kubernetes install-cli][12] 命令。
|
||||
如果您使用 Azure CloudShell ,则已经安装了 kubectl 。如果要在本地安装,可以使用 [az acs kubernetes install-cli][12] 命令。
|
||||
|
||||
要配置 kubectl 连接到您的 Kubernetes 群集,请运行 [az acs kubernetes get-credentials][13] 命令下载凭据并配置 Kubernetes CLI 以使用它们。
|
||||
|
||||
|
||||
```
|
||||
az acs kubernetes get-credentials --resource-group=myResourceGroup --name=myK8sCluster
|
||||
|
||||
@ -83,7 +81,7 @@ kubectl get nodes
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -171,7 +169,7 @@ kubectl create -f azure-vote.yaml
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -188,15 +186,13 @@ service "azure-vote-front" created
|
||||
|
||||
要监控这个进程,使用 [kubectl get service][17] 命令时加上 `--watch` 参数。
|
||||
|
||||
Azure CLICopyTry It
|
||||
|
||||
```
|
||||
kubectl get service azure-vote-front --watch
|
||||
|
||||
```
|
||||
|
||||
Initially the EXTERNAL-IP for the _azure-vote-front_ service appears as _pending_ . Once the EXTERNAL-IP address has changed from _pending_ to an _IP address_ , use `CTRL-C` to stop the kubectl watch process.
|
||||
最初,_azure-vote-front_ 服务的 EXTERNAL-IP 显示为 _pending_ 。 一旦 EXTERNAL-IP 地址从 _pending_ 变成一个具体的IP地址,请使用 “CTRL-C” 来停止 kubectl 监视进程。
|
||||
最初,_azure-vote-front_ 服务的 EXTERNAL-IP 显示为 _pending_ 。 一旦 EXTERNAL-IP 地址从 _pending_ 变成一个具体的 IP 地址,请使用 “CTRL-C” 来停止 kubectl 监视进程。
|
||||
|
||||
```
|
||||
azure-vote-front 10.0.34.242 <pending> 80:30676/TCP 7s
|
||||
@ -204,7 +200,6 @@ azure-vote-front 10.0.34.242 52.179.23.131 80:30676/TCP 2m
|
||||
|
||||
```
|
||||
|
||||
You can now browse to the external IP address to see the Azure Vote App.
|
||||
现在你可以通过这个外网 IP 地址访问到 Azure Vote 这个应用了。
|
||||
|
||||

|
||||
@ -234,9 +229,9 @@ az group delete --name myResourceGroup --yes --no-wait
|
||||
|
||||
via: https://docs.microsoft.com/en-us/azure/container-service/kubernetes/container-service-kubernetes-walkthrough
|
||||
|
||||
作者:[neilpeterson ][a],[mmacy][b]
|
||||
作者:[neilpeterson][a],[mmacy][b]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wangs0622
|
||||
|
||||
Book review: Ours to Hack and to Own
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
翻译中 by WuXiao(toyijiu)
|
||||
|
||||
Education of a Programmer
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
【Translating by JanzenLiu】
|
||||
Beyond public key encryption
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by softpaopao
|
||||
|
||||
The problem with software before standards
|
||||
============================================================
|
||||
|
||||
|
||||
96
sources/tech/20160511 LEDE and OpenWrt.md
Normal file
96
sources/tech/20160511 LEDE and OpenWrt.md
Normal file
@ -0,0 +1,96 @@
|
||||
XYenChi is Translating
|
||||
LEDE and OpenWrt
|
||||
===================
|
||||
|
||||
The [OpenWrt][1] project is perhaps the most widely known Linux-based distribution for home WiFi routers and access points; it was spawned from the source code of the now-famous Linksys WRT54G router more than 12 years ago. In early May, the OpenWrt user community was thrown into a fair amount of confusion when a group of core OpenWrt developers [announced][2] that they were starting a spin-off (or, perhaps, a fork) of OpenWrt to be named the [Linux Embedded Development Environment][3] (LEDE). It was not entirely clear to the public why the split was taking place—and the fact that the LEDE announcement surprised a few other OpenWrt developers suggested trouble within the team.
|
||||
|
||||
The LEDE announcement was sent on May 3 by Jo-Philipp Wich to both the OpenWrt development list and the new LEDE development list. It describes LEDE as "a reboot of the OpenWrt community" and as "a spin-off of the OpenWrt project" seeking to create an embedded-Linux development community "with a strong focus on transparency, collaboration and decentralisation."
|
||||
|
||||
The rationale given for the reboot was that OpenWrt suffered from longstanding issues that could not be fixed from within—namely, regarding internal processes and policies. For instance, the announcement said, the number of developers is at an all-time low, but there is no process for on-boarding new developers (and, it seems, no process for granting commit access to new developers). The project infrastructure is unreliable (evidently, server outages over the past year have caused considerable strife within the project), the announcement said, but internal disagreements and single points of failure prevented fixing it. There is also a general lack of "communication, transparency and coordination" internally and from the project to the outside world. Finally, a few technical shortcomings were cited: inadequate testing, lack of regular builds, and poor stability and documentation.
|
||||
|
||||
The announcement goes on to describe how the LEDE reboot will address these issues. All communication channels will be made available for public consumption, decisions will be made by project-wide votes, the merge policy will be more relaxed, and so forth. A more detailed explanation of the new project's policies can be found on the [rules][4] page at the LEDE site. Among other specifics, it says that there will be only one class of committer (that is, no "core developer" group with additional privileges), that simple majority votes will settle decisions, and that any infrastructure managed by the project must have at least three operators with administrative access. On the LEDE mailing list, Hauke Mehrtens [added][5] that the project will make an effort to have patches sent upstream—a point on which OpenWrt has been criticized in the past, especially where the kernel is concerned.
|
||||
|
||||
In addition to Wich, the announcement was co-signed by OpenWrt contributors John Crispin, Daniel Golle, Felix Fietkau, Mehrtens, Matthias Schiffer, and Steven Barth. It ends with an invitation for others interested in participating to visit the LEDE site.
|
||||
|
||||
#### Reactions and questions
|
||||
|
||||
One might presume that the LEDE organizers expected their announcement to be met with some mixture of positive and negative reactions. After all, a close reading of the criticisms of the OpenWrt project in the announcement suggests that there were some OpenWrt project members that the LEDE camp found difficult to work with (the "single points of failure" or "internal disagreements" that prevented infrastructure fixes, for instance).
|
||||
|
||||
And, indeed, there were negative responses. OpenWrt co-founder Mike Baker [responded][6] with some alarm, disagreeing with all of the LEDE announcement's conclusions and saying "phrases such as a 'reboot' are both vague and misleading and the LEDE project failed to identify its true nature." Around the same time, someone disabled the @openwrt.org email aliases of those developers who signed the LEDE announcement; when Fietkau [objected][7], Baker [replied][8] that the accounts were "temporarily disabled" because "it's unclear if LEDE still represents OpenWrt." Imre Kaloz, another core OpenWrt member, [wrote][9]that "the LEDE team created most of that [broken] status quo" in OpenWrt that it was now complaining about.
|
||||
|
||||
But the majority of the responses on the OpenWrt list expressed confusion about the announcement. List members were not clear whether the LEDE team was going to [continue contributing][10] to OpenWrt or not, nor what the [exact nature][11] of the infrastructure and internal problems were that led to the split. Baker's initial response lamented the lack of public debate over the issues cited in the announcement: "We recognize the current OpenWrt project suffers from a number of issues," but "we hoped we had an opportunity to discuss and attempt to fix" them. Baker concluded:
|
||||
|
||||
We would like to stress that we do want to have an open discussion and resolve matters at hand. Our goal is to work with all parties who can and want to contribute to OpenWrt, including the LEDE team.
|
||||
|
||||
In addition to the questions over the rationale of the new project, some list subscribers expressed confusion as to whether LEDE was targeting the same uses cases as OpenWrt, given the more generic-sounding name of the new project. Furthermore, a number of people, such as Roman Yeryomin, [expressed confusion][12] as to why the issues demanded the departure of the LEDE team, particularly given that, together, the LEDE group constituted a majority of the active core OpenWrt developers. Some list subscribers, like Michael Richardson, were even unclear on [who would still be developing][13] OpenWrt.
|
||||
|
||||
#### Clarifications
|
||||
|
||||
The LEDE team made a few attempts to further clarify their position. In Fietkau's reply to Baker, he said that discussions about proposed changes within the OpenWrt project tended to quickly turn "toxic," thus resulting in no progress. Furthermore:
|
||||
|
||||
A critical part of many of these debates was the fact that people who were controlling critical pieces of the infrastructure flat out refused to allow other people to step up and help, even in the face of being unable to deal with important issues themselves in a timely manner.
|
||||
|
||||
This kind of single-point-of-failure thing has been going on for years, with no significant progress on resolving it.
|
||||
|
||||
Neither Wich nor Fietkau pointed fingers at specific individuals, although others on the list seemed to think that the infrastructure and internal decision-making problems in OpenWrt came down to a few people. Daniel Dickinson [stated][14] that:
|
||||
|
||||
My impression is that Kaloz (at least) holds infrastructure hostage to maintain control, and that the fundamental problem here is that OpenWrt is *not* democratic and ignores what people who were ones visibly working on openwrt want and overrides their wishes because he/they has/have the keys.
|
||||
|
||||
On the other hand, Luka Perkov [countered][15] that many OpenWrt developers wanted to switch from Subversion to Git, but that Fietkau was responsible for blocking that change.
|
||||
|
||||
What does seem clear is that the OpenWrt project has been operating with a governance structure that was not functioning as desired and, as a result, personality conflicts were erupting and individuals were able to disrupt or block proposed changes simply by virtue of there being no well-defined process. Clearly, that is not a model that works well in the long run.
|
||||
|
||||
On May 6, Crispin [wrote][16] to the OpenWrt list in a new thread, attempting to reframe the LEDE project announcement. It was not, he said, meant as a "hostile or disruptive" act, but to make a clean break from the dysfunctional structures of OpenWrt and start fresh. The matter "does not boil down to one single event, one single person or one single flamewar," he said. "We wanted to split with the errors we have done ourselves in the past and the wrong management decision that were made at times." Crispin also admitted that the announcement had not been handled well, saying that the LEDE team "messed up the politics of the launch."
|
||||
|
||||
Crispin's email did not seem to satisfy Kaloz, who [insisted][17] that Crispin (as release manager) and Fietkau (as lead developer) could simply have made any desirable changes within the OpenWrt project. But the discussion thread has subsequently gone silent; whatever happens next on either the LEDE or OpenWrt side remains to be seen.
|
||||
|
||||
#### Intent
|
||||
|
||||
For those still seeking further detail on what the LEDE team regarded as problematic within OpenWrt, there is one more source of information that can shed light on the issues. Prior to the public announcement, the LEDE organizers spent several weeks hashing out their plan, and IRC logs of the meetings have now been [published][18]. Of particular interest is the March 30 [meeting][19] that includes a detailed discussion of the project's goals.
|
||||
|
||||
Several specific complaints about OpenWrt's infrastructure are included, such as the shortcomings of the project's Trac issue tracker. It is swamped with incomplete bug reports and "me too" comments, Wich said, and as a result, few committers make use of it. In addition, people seem confused by the fact that bugs are also being tracked on GitHub, making it unclear where issues ought to be discussed.
|
||||
|
||||
The IRC discussion also tackles the development process itself. The LEDE team would like to implement several changes, starting with the use of staging trees that get merged into the trunk during a formal merge window, rather than the commit-directly-to-master approach employed by OpenWrt. The project would also commit to time-based releases and encourage user testing by only releasing binary modules that have successfully been tested, by the community rather than the core developers, on actual hardware.
|
||||
|
||||
Finally, the IRC discussion does make it clear that the LEDE team's intent was not to take OpenWrt by surprise with its announcement. Crispin suggested that LEDE be "semi public" at first and gradually be made more public. Wich noted that he wanted LEDE to be "neutral, professional and welcoming to OpenWrt to keep the door open for a future reintegration." The launch does not seem to have gone well on that front, which is unfortunate.
|
||||
|
||||
In an email, Fietkau added that the core OpenWrt developers had been suffering from bottlenecks on tasks like patch review and maintenance work that were preventing them from getting other work done—such as setting up download mirrors or improving the build system. In just the first few days after the LEDE announcement, he said, the team had managed to tackle the mirror and build-system tasks, which had languished for years.
|
||||
|
||||
A lot of what we did in LEDE was based on the experience with decentralizing the development of packages by moving it to GitHub and giving up a lot of control over how packages should be maintained. This ended up reducing our workload significantly and we got quite a few more active developers this way.
|
||||
|
||||
We really wanted to do something similar with the core development, but based on our experience with trying to make bigger changes we felt that we couldn't do this from within the OpenWrt project.
|
||||
|
||||
Fixing the infrastructure will reap other dividends, too, he said, such as an improved system for managing the keys used to sign releases. The team is considering a rule that imposes some conditions on non-upstream patches, such as requiring a description of the patch and an explanation of why it has not yet been sent upstream. He also noted that many of the remaining OpenWrt developers have expressed interest in joining LEDE, and that the parties involved are trying to figure out if they will re-merge the projects.
|
||||
|
||||
One would hope that LEDE's flatter governance model and commitment to better transparency will help it to find success in areas where OpenWrt has struggled. For the time being, sorting out the communication issues that plagued the initial announcement may prove to be a major hurdle. If that process goes well, though, LEDE and OpenWrt may find common ground and work together in the future. If not, then the two teams may each be forced to move forward with fewer resources than they had before, which may not be what developers or users want to see.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lwn.net/Articles/686767/
|
||||
|
||||
作者:[Nathan Willis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lwn.net/Articles/686767/
|
||||
[1]:https://openwrt.org/
|
||||
[2]:https://lwn.net/Articles/686180/
|
||||
[3]:https://www.lede-project.org/
|
||||
[4]:https://www.lede-project.org/rules.html
|
||||
[5]:http://lists.infradead.org/pipermail/lede-dev/2016-May/000080.html
|
||||
[6]:https://lwn.net/Articles/686988/
|
||||
[7]:https://lwn.net/Articles/686989/
|
||||
[8]:https://lwn.net/Articles/686990/
|
||||
[9]:https://lwn.net/Articles/686991/
|
||||
[10]:https://lwn.net/Articles/686995/
|
||||
[11]:https://lwn.net/Articles/686996/
|
||||
[12]:https://lwn.net/Articles/686992/
|
||||
[13]:https://lwn.net/Articles/686993/
|
||||
[14]:https://lwn.net/Articles/686998/
|
||||
[15]:https://lwn.net/Articles/687001/
|
||||
[16]:https://lwn.net/Articles/687003/
|
||||
[17]:https://lwn.net/Articles/687004/
|
||||
[18]:http://meetings.lede-project.org/lede-adm/2016/?C=M;O=A
|
||||
[19]:http://meetings.lede-project.org/lede-adm/2016/lede-adm.2016-03-30-11.05.log.html
|
||||
@ -0,0 +1,177 @@
|
||||
[Translating by Snapcrafter]
|
||||
Making your snaps available to the store using snapcraft
|
||||
============================================================
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
Now that Ubuntu Core has been officially released, it might be a good time to get your snaps into the Store!
|
||||
|
||||
**Delivery and Store Concepts **
|
||||
So let’s start with a refresher on what we have available on the Store side to manage your snaps.
|
||||
|
||||
Every time you push a snap to the store, the store will assign it a revision, this revision is unique in the store for this particular snap.
|
||||
|
||||
However to be able to push a snap for the first time, the name needs to be registered which is pretty easy to do given the name is not already taken.
|
||||
|
||||
Any revision on the store can be released to a number of channels which are defined conceptually to give your users the idea of a stability or risk level, these channel names are:
|
||||
|
||||
* stable
|
||||
|
||||
* candidate
|
||||
|
||||
* beta
|
||||
|
||||
* edge
|
||||
|
||||
Ideally anyone with a CI/CD process would push daily or on every source update to the edge channel. During this process there are two things to take into account.
|
||||
|
||||
The first thing to take into account is that at the beginning of the snapping process you will likely get started with a non confined snap as this is where the bulk of the work needs to happen to adapt to this new paradigm. With that in mind, your project gets started with a confinement set to devmode. This makes it possible to get going on the early phases of development and still get your snap into the store. Once everything is fully supported with the security model snaps work in, this confinement entry can be switched to strict. Given the confinement level of devmode this snap is only releasable on the edge and beta channels which hints your users on how much risk they are taking by going there.
|
||||
|
||||
So let’s say you are good to go on the confinement side and you start a CI/CD process against edge but you also want to make sure in some cases that early releases of a new iteration against master never make it to stable or candidate and for this we have a grade entry. If the grade of the snap is set to devel the store will never allow you to release to the most stable channels (stable and candidate). not be possible.
|
||||
|
||||
Somewhere along the way we might want to release a revision into beta which some users are more likely want to track on their side (which given good release management process should be to some level more usable than a random daily build). When that stage in the process is over but want people to keep getting updates we can choose to close the beta channel as we only plan to release to candidate and stable from a certain point in time, by closing this beta channel we will make that channel track the following open channel in the stability list, in this case it is candidate, if candidate is tracking stable whatever is in stable is what we will get.
|
||||
|
||||
**Enter Snapcraft**
|
||||
|
||||
So given all these concepts how do we get going with snapcraft, first of all we need to login:
|
||||
|
||||
```
|
||||
$ snapcraft login
|
||||
Enter your Ubuntu One SSO credentials.
|
||||
Email: sxxxxx.sxxxxxx@canonical.com
|
||||
Password: **************
|
||||
Second-factor auth: 123456
|
||||
```
|
||||
|
||||
After logging in we are ready to get our snap registered, for examples sake let’s say we wanted to register awesome-database, a fantasy snap we want to get started with:
|
||||
|
||||
```
|
||||
$ snapcraft register awesome-database
|
||||
We always want to ensure that users get the software they expect
|
||||
for a particular name.
|
||||
|
||||
If needed, we will rename snaps to ensure that a particular name
|
||||
reflects the software most widely expected by our community.
|
||||
|
||||
For example, most people would expect ‘thunderbird’ to be published by
|
||||
Mozilla. They would also expect to be able to get other snaps of
|
||||
Thunderbird as 'thunderbird-sergiusens'.
|
||||
|
||||
Would you say that MOST users will expect 'a' to come from
|
||||
you, and be the software you intend to publish there? [y/N]: y
|
||||
|
||||
You are now the publisher for 'awesome-database'
|
||||
```
|
||||
|
||||
So assuming we have the snap built already, all we have to do is push it to the store. Let’s take advantage of a shortcut and –release in the same command:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap --release edge
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 1 of 'awesome-database' created.
|
||||
|
||||
Channel Version Revision
|
||||
stable - -
|
||||
candidate - -
|
||||
beta - -
|
||||
edge 0.1 1
|
||||
|
||||
The edge channel is now open.
|
||||
```
|
||||
|
||||
If we try to release this to stable the store will block us:
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 1 stable
|
||||
Revision 1 (devmode) cannot target a stable channel (stable, grade: devel)
|
||||
```
|
||||
|
||||
We are safe from messing up and making this available to our faithful users. Now eventually we will push a revision worthy of releasing to the stable channel:
|
||||
|
||||
```
|
||||
$ snapcraft push awesome-databse_0.1_amd64.snap
|
||||
Uploading awesome-database_0.1_amd64.snap [=================] 100%
|
||||
Processing....
|
||||
Revision 10 of 'awesome-database' created.
|
||||
```
|
||||
|
||||
```
|
||||
Notice that the version is just a friendly identifier and what really matters is the revision number the store generates for us. Now let’s go ahead and release this to stable:
|
||||
```
|
||||
|
||||
```
|
||||
$ snapcraft release awesome-database 10 stable
|
||||
Channel Version Revision
|
||||
stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge 0.1 10
|
||||
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
In this last channel map view for the architecture we are working with, we can see that edge is going to be stuck on revision 10, and that beta and candidate will be following stable which is on revision 10\. For some reason we decide that we will focus on stability and make our CI/CD push to beta instead. This means that our edge channel will slightly fall out of date, in order to avoid things like this we can decide to close the channel:
|
||||
|
||||
```
|
||||
$ snapcraft close awesome-database edge
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
|
||||
The edge channel is now closed.
|
||||
```
|
||||
|
||||
In this current state, all channels are following the stable channel so people subscribed to candidate, beta and edge would be tracking changes to that channel. If revision 11 is ever pushed to stable only, people on the other channels would also see it.
|
||||
|
||||
This listing also provides us with a full architecture view, in this case we have only been working with amd64.
|
||||
|
||||
**Getting more information**
|
||||
|
||||
So some time passed and we want to know what was the history and status of our snap in the store. There are two commands for this, the straightforward one is to run status which will give us a familiar result:
|
||||
|
||||
```
|
||||
$ snapcraft status awesome-database
|
||||
Arch Channel Version Revision
|
||||
amd64 stable 0.1 10
|
||||
candidate ^ ^
|
||||
beta ^ ^
|
||||
edge ^ ^
|
||||
```
|
||||
|
||||
We can also get the full history:
|
||||
|
||||
```
|
||||
$ snapcraft history awesome-database
|
||||
Rev. Uploaded Arch Version Channels
|
||||
3 2016-09-30T12:46:21Z amd64 0.1 stable*
|
||||
...
|
||||
...
|
||||
...
|
||||
2 2016-09-30T12:38:20Z amd64 0.1 -
|
||||
1 2016-09-30T12:33:55Z amd64 0.1 -
|
||||
```
|
||||
|
||||
**Closing remarks**
|
||||
|
||||
I hope this gives an overview of the things you can do with the store and more people start taking advantage of it!
|
||||
|
||||
[Publish a snap][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2016/11/15/making-your-snaps-available-to-the-store-using-snapcraft/
|
||||
|
||||
作者:[Sergio Schvezov ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[1]:https://insights.ubuntu.com/author/sergio-schvezov/
|
||||
[2]:http://snapcraft.io/docs/build-snaps/publish
|
||||
@ -1,408 +0,0 @@
|
||||
[HaitaoBio](https://github.com/HaitaoBio)
|
||||
|
||||
TypeScript: the missing introduction
|
||||
============================================================
|
||||
|
||||
|
||||
**The following is a guest post by James Henry ([@MrJamesHenry][8]). I am a member of the ESLint Core Team, and a TypeScript evangelist. I am working with Todd on [UltimateAngular][9] to bring you more award-winning Angular and TypeScript courses.**
|
||||
|
||||
> The purpose of this article is to offer an introduction to how we can think about TypeScript, and its role in supercharging our **JavaScript** development.
|
||||
>
|
||||
> We will also try and come up with our own reasonable definitions for a lot of the buzzwords surrounding types and compilation.
|
||||
|
||||
There is huge amount of great stuff in the TypeScript project that we won’t be able to cover within the scope of this blog post. Please read the [official documentation][15] to learn more, and check out the [TypeScript courses over on UltimateAngular][16] to go from total beginner to TypeScript Pro!
|
||||
|
||||
### [Table of contents][17]
|
||||
|
||||
* [Background][10]
|
||||
* [Getting to grips with the buzzwords][11]
|
||||
* [JavaScript - interpreted or compiled?][1]
|
||||
* [Run Time vs Compile Time][2]
|
||||
* [The TypeScript Compiler][3]
|
||||
* [Dynamic vs Static Typing][4]
|
||||
* [TypeScript’s role in our JavaScript workflow][12]
|
||||
* [Our source file is our document, TypeScript is our Spell Check][5]
|
||||
* [TypeScript is a tool which enables other tools][13]
|
||||
* [What is an Abstract Syntax Tree (AST)?][6]
|
||||
* [Example: Renaming symbols in VS Code][7]
|
||||
* [Summary][14]
|
||||
|
||||
### [Background][18]
|
||||
|
||||
TypeScript is an amazingly powerful tool, and really quite easy to get started with.
|
||||
|
||||
It can, however, come across as more complex than it is, because it may simultaneously be introducing us to a whole host of technical concepts related to our JavaScript programs that we may not have considered before.
|
||||
|
||||
Whenever we stray into the area of talking about types, compilers, etc. things can get really confusing, really fast.
|
||||
|
||||
This article is designed as a “what you need to know” guide for a lot of these potentially confusing concepts, so that by the time you dive into the “Getting Started” style tutorials, you are feeling confident with the various themes and terminology that surround the topic.
|
||||
|
||||
### [Getting to grips with the buzzwords][19]
|
||||
|
||||
There is something about running our code in a web browser that makes us _feel_ differently about how it works. “It’s not compiled, right?”, “Well, I definitely know there aren’t any types…”
|
||||
|
||||
Things get even more interesting when we consider that both of those statements are both correct and incorrect at the same time - depending on the context and how you define some of these concepts.
|
||||
|
||||
As a first step, we are going to do exactly that!
|
||||
|
||||
#### [JavaScript - interpreted or compiled?][20]
|
||||
|
||||
Traditionally, developers will often think about a language being a “compiled language” when they are the ones responsible for compiling their own programs.
|
||||
|
||||
> In basic terms, when we compile a program we are converting it from the form we wrote it in, to the form it actually gets run in.
|
||||
|
||||
In a language like Golang, for example, you have a command line tool called `go build`which allows you to compile your `.go` file into a lower-level representation of the code, which can then be executed and run:
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
As authors of JavaScript (ignoring our love of new-fangled build tools and module loaders for a moment), we don’t have such a fundamental compilation step in our workflow.
|
||||
|
||||
We write some code, and load it up in a browser using a `<script>` tag (or a server-side environment such as node.js), and it just runs.
|
||||
|
||||
**Ok, so JavaScript isn’t compiled - it must be an interpreted language, right?**
|
||||
|
||||
Well, actually, all we have determined so far is that JavaScript is not something that we compile _ourselves_, but we’ll come back to this after we briefly look an example of an “interpreted language”.
|
||||
|
||||
> An interpreted computer program is one that is executed like a human reads a book, starting at the top and working down line-by-line.
|
||||
|
||||
The classic example of interpreted programs that we are already familiar with are bash scripts. The bash interpreter in our terminal reads our commands in line-by-line and executes them.
|
||||
|
||||
Now, if we return to thinking about JavaScript and whether or not it is interpreted or compiled, intuitively there are some things about it that just don’t add up when we think about reading and executing a program line-by-line (our simple definition of “interpreted”).
|
||||
|
||||
Take this code as an example:
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello() {
|
||||
console.log('Hello!');
|
||||
}
|
||||
```
|
||||
|
||||
This is perfectly valid JavaScript which will print the word “Hello!”, but we have used the `hello()` function before we have even defined it! A simple line-by-line execution of this program would just not be possible, because `hello()` on line 1 does not have any meaning until we reach its declaration on line 2.
|
||||
|
||||
The reason that this, and many other concepts like it, is possible in JavaScript is because our code is actually compiled by the so called “JavaScript engine”, or environment, before it is executed. The exact nature of this compilation process will depend on the specific implementation (e.g. V8, which powers node.js and Google Chrome, will behave slightly differently to SpiderMonkey, which is used by FireFox).
|
||||
|
||||
We will not dig any further into the subtleties of defining “compiled vs interpreted” here (there are a LOT).
|
||||
|
||||
> It’s useful to always keep in mind that the JavaScript code we write is already not the actual code that will be executed by our users, even when we simply have a `<script>` tag in an HTML document.
|
||||
|
||||
#### [Run Time vs Compile Time][21]
|
||||
|
||||
Now that we have properly introduced the idea that compiling a program and running a program are two distinct phases, the terms “Run Time” and “Compile Time” become a little easier to reason about.
|
||||
|
||||
When something happens at **Compile Time**, it is happening during the conversion of our code from what we wrote in our editor/IDE to some other form.
|
||||
|
||||
When something happens at **Run Time**, it is happening during the actual execution of our program. For example, our `hello()` function above is executed at “run time”.
|
||||
|
||||
#### [The TypeScript Compiler][22]
|
||||
|
||||
Now that we understand these key phases in the lifecycle of a program, we can introduce the **TypeScript compiler**.
|
||||
|
||||
The TypeScript compiler is at the core of how TypeScript is able to help us when we write our code. Instead of just including our JavaScript in a `<script>` tag, for example, we will first pass it through the TypeScript compiler so that it can give us helpful hints on how we can improve our program before it runs.
|
||||
|
||||
> We can think about this new step as our own personal “compile time”, which will help us ensure that our program is written in the way we intended, before it even reaches the main JavaScript engine.
|
||||
|
||||
It is a similar process to the one shown in the Golang example above, except that the TypeScript compiler just provides hints based on how we have written our program, and doesn’t turn it into a lower-level executable - it produces pure JavaScript.
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
There are many great posts about the different options for integrating the TypeScript compiler into your existing workflow, including the [official documentation][23]. It is beyond the scope of this article to go into those options here.
|
||||
|
||||
#### [Dynamic vs Static Typing][24]
|
||||
|
||||
Just like with “compiled vs interpreted” programs, the existing material on “dynamic vs static typing” can be incredibly confusing.
|
||||
|
||||
Let’s start by taking a step back and refreshing our memory on how much we _already_understand about types from our existing JavaScript code.
|
||||
|
||||
We have the following program:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
How would we describe this code to somebody?
|
||||
|
||||
“We have declared a variable called `name`, which is assigned the **string** of ‘James’, and we have declared the variable `sum`, which is assigned the value we get when we add the **number** `1` to the **number** `2`.”
|
||||
|
||||
Even in such a simple program, we have already highlighted two of JavaScript’s fundamental types: String and Number.
|
||||
|
||||
As with our introduction to compilation above, we are not going to get bogged down in the academic subtleties of types in programming languages - the key thing is understanding what it means for our JavaScript so that we can then extend it to properly understanding TypeScript.
|
||||
|
||||
We know from our traditional nightly ritual of reading the [latest ECMAScript specification][25]**(LOL, JK - “wat’s an ECMA?”)**, that it makes numerous references to types and their usage in JavaScript.
|
||||
|
||||
Taken directly from the official spec:
|
||||
|
||||
> An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language.
|
||||
>
|
||||
> The ECMAScript language types are Undefined, Null, Boolean, String, Symbol, Number, and Object.
|
||||
|
||||
We can see that the JavaScript language officially has 7 types, of which we have likely used 6 in just about every real-world program we have ever written (Symbol was first introduced in ES2015, a.k.a. ES6).
|
||||
|
||||
Now, let’s think a bit more deeply about our “name and sum” JavaScript program above.
|
||||
|
||||
We could take our `name` variable which is currently assigned the **string** ‘James’, and reassign it to the current value of our second variable `sum`, which is the **number** `3`.
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
The `name` variable started out “holding” a string, but now it holds a number. This highlights a fundamental quality of variables and types in JavaScript:
|
||||
|
||||
The _value_ ‘James’ is always one type - a string - but the `name` variable can be assigned any value, and therefore any type. The exact same is true in the case of the `sum`assignment: the _value_ `1` is always a number type, but the `sum` variable could be assigned any possible value.
|
||||
|
||||
> In JavaScript, it is _values_, not variables, which have types. Variables can hold any value, and therefore any _type_, at any time.
|
||||
|
||||
For our purposes, this also just so happens to be the very definition of a **“dynamically typed language”**!
|
||||
|
||||
By contrast, we can think of a **“statically typed language”** as being one in which we can (and very likely have to) associate type information with a particular variable:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
```
|
||||
|
||||
In this code, we are better able to explicitly declare our _intentions_ for the `name` variable - we want it to always be used as a string.
|
||||
|
||||
And guess what? We have just seen our first bit of TypeScript in action!
|
||||
|
||||
When we reflect on our own code (no programming pun intended), we can likely conclude that even when we are working with dynamic languages like JavaScript, in almost all cases we should have pretty clear intentions for the usage of our variables and function parameters when we first define them. If those variables and parameters are reassigned to hold values of _different_ types to ones we first assigned them to, it is possible that something is not working out as we planned.
|
||||
|
||||
> One great power that the static type annotations from TypeScript give us, as JavaScript authors, is the ability to clearly express our intentions for our variables.
|
||||
>
|
||||
> This improved clarity benefits not only the TypeScript compiler, but also our colleagues and future selves when they come to read and understand our code. Code is _read_ far more than it is written.
|
||||
|
||||
### [TypeScript’s role in our JavaScript workflow][26]
|
||||
|
||||
We have started to see why it is often said that TypeScript is just JavaScript + Static Types. Our so-called “type annotation” `: string` for our `name` variable is used by TypeScript at _compile time_ (in other words, when we pass our code through the TypeScript compiler) to make sure that the rest of the code is true to our original intention.
|
||||
|
||||
Let’s take a look at our program again, and add another explicit annotation, this time for our `sum` variable:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
If we let TypeScript take a look at this code for us, we will now get an error `Type 'number' is not assignable to type 'string'` for our `name = sum` assignment, and we are appropriately warned against shipping _potentially_ problematic code to be executed by our users.
|
||||
|
||||
> Importantly, we can choose to ignore errors from the TypeScript compiler if we want to, because it is just a tool which gives us feedback on our JavaScript code before we ship it to our users.
|
||||
|
||||
The final JavaScript code that the TypeScript compiler will output for us will look exactly the same as our original source above:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
The type annotations are all removed for us automatically, and we can now run our code.
|
||||
|
||||
> NOTE: In this example, the TypeScript Compiler would have been able to offer us the exact same error even if we hadn’t provided the explicit type annotations `: string` and `: number`.
|
||||
>
|
||||
> TypeScript is very often able to just _infer_ the type of a variable from the way we have used it!
|
||||
|
||||
#### [Our source file is our document, TypeScript is our Spell Check][27]
|
||||
|
||||
A great analogy for TypeScript’s relationship with our source code, is that of Spell Check’s relationship to a document we are writing in Microsoft Word, for example.
|
||||
|
||||
There are three key commonalities between the two examples:
|
||||
|
||||
1. **It can tell us when stuff we have written is objectively, flat-out wrong:**
|
||||
* _Spell Check_: “we have written a word that does not exist in the dictionary”
|
||||
* _TypeScript_: “we have referenced a symbol (e.g. a variable), which is not declared in our program”
|
||||
|
||||
2. **It can suggest that what we have written _might be_ wrong:**
|
||||
* _Spell Check_: “the tool is not able to fully infer the meaning of a particular clause and suggests rewriting it”
|
||||
* _TypeScript_: “the tool is not able to fully infer the type of a particular variable and warns against using it as is”
|
||||
|
||||
3. **Our source can be used for its original purpose, regardless of if there are errors from the tool or not:**
|
||||
* _Spell Check_: “even if your document has lots of Spell Check errors, you can still print it out and “use” it as document”
|
||||
* _TypeScript_: “even if your source code has TypeScript errors, it will still produce JavaScript code which you can execute”
|
||||
|
||||
### [TypeScript is a tool which enables other tools][28]
|
||||
|
||||
The TypeScript compiler is made up of a couple of different parts or phases. We are going to finish off this article by looking at how one of those parts - **the Parser** - offers us the chance to build _additional developer tools_ on top of what TypeScript already does for us.
|
||||
|
||||
The result of the “parser step” of the compilation process is what is called an **Abstract Syntax Tree**, or **AST** for short.
|
||||
|
||||
#### [What is an Abstract Syntax Tree (AST)?][29]
|
||||
|
||||
We write our programs in a free text form, as this is a great way for us humans to interact with our computers to get them to do the stuff we want them to. We are not so great at manually composing complex data structures!
|
||||
|
||||
However, free text is actually a pretty tricky thing to work with within a compiler in any kind of reasonable way. It may contain things which are unnecessary for the program to function, such as whitespace, or there may be parts which are ambiguous.
|
||||
|
||||
For this reason, we ideally want to convert our programs into a data structure which maps out all of the so-called “tokens” we have used, and where they slot into our program.
|
||||
|
||||
This data structure is exactly what an AST is!
|
||||
|
||||
An AST could be represented in a number of different ways, but let’s take a look at a quick example using our old buddy JSON.
|
||||
|
||||
If we have this incredibly basic source code:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
The (simplified) output of the TypeScript Compiler’s **Parser** phase will be the following AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The objects in our in our AST are called _nodes_.
|
||||
|
||||
#### [Example: Renaming symbols in VS Code][30]
|
||||
|
||||
Internally, the TypeScript Compiler will use the AST it has produced to power a couple of really important things such as the actual **Type Checking** that occurs when we compile our programs.
|
||||
|
||||
But it does not stop there!
|
||||
|
||||
> We can use the AST to develop our own tooling on top of TypeScript, such as linters, formatters, and analysis tools.
|
||||
|
||||
One great example of a tool built on top of this AST generation is the **Language Server**.
|
||||
|
||||
It is beyond the scope of this article to dive into how the Language Server works, but one absolutely killer feature that it enables for us when we write our programs is that of “renaming symbols”.
|
||||
|
||||
Let’s say that we have the following source code:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
After a _thorough_ code review and appropriate bikeshedding, it is decided that we should switch our variable naming convention to use camel case instead of the snake case we are currently using.
|
||||
|
||||
In our code editors, we have long been able to select multiple occurrences of the same text and use multiple cursors to change all of them at once - awesome!
|
||||
|
||||

|
||||
|
||||
Ah! We have fallen into one of the classic traps that appear when we continue to treat our programs as pieces of text.
|
||||
|
||||
The word “name” in our comment, which we did not want to change, got caught up in our manual matching process. We can see how risky such a strategy would be for code changes in a real-world application!
|
||||
|
||||
As we learned above, when something like TypeScript generates an AST for our program behind the scenes, it no longer has to interact with our program as if it were free text - each token has its own place in the AST, and its usage is clearly mapped.
|
||||
|
||||
We can take advantage of this directly in VS Code using the “rename symbol” option when we right click on our `first_name` variable (TypeScript Language Server plugins are available for other editors).
|
||||
|
||||

|
||||
|
||||
Much better! Now our `first_name` variable is the only thing that will be changed, and this change will even happen across multiple files in our project if applicable (as with exported and imported values)!
|
||||
|
||||
### [Summary][31]
|
||||
|
||||
Phew! We have covered a lot in this post.
|
||||
|
||||
We cut through all of the academic distractions to decide on practical definitions for a lot of the terminology that surrounds any discussion on compilers and types.
|
||||
|
||||
We looked at compiled vs interpreted languages, run time vs compile time, dynamic vs static typing, and how Abstract Syntax Trees give us a more optimal way to build tooling for our programs.
|
||||
|
||||
Importantly, we provided a way of thinking about TypeScript as a tool for our _JavaScript_development, and how it in turn can be built upon to offer even more amazing utilities, such as renaming symbols as a way of refactoring code.
|
||||
|
||||
Come join us over on [UltimateAngular][32] to continue the journey and go from total beginner to TypeScript Pro!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I'm Todd, I teach the world Angular through @UltimateAngular. Conference speaker and Developer Expert at Google.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:[Todd][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftoddmotto.com%2Ftypescript-the-missing-introduction%3Futm_source%3Djavascriptweekly%26utm_medium%3Demail&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=toddmotto&tw_p=followbutton
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
@ -1,94 +0,0 @@
|
||||
The Age of the Unikernel: 10 Projects to Know
|
||||
============================================================
|
||||
|
||||

|
||||
A unikernel is essentially a pared-down operating system that can pair with an application into a unikernel application, typically running within a virtual machine. Download the Guide to the Open Cloud to learn more.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
When it comes to operating systems, container technologies, and unikernels, the trend toward tiny continues. What is a unikernel? It is essentially a pared-down operating system (the unikernel) that can pair with an application into a unikernel application, typically running within a virtual machine. They are sometimes called library operating systems because they include libraries that enable applications to use hardware and network protocols in combination with a set of policies for access control and isolation of the network layer.
|
||||
|
||||
Containers often come to mind when discussion turns to cloud computing and Linux, but unikernels are doing transformative things, too. Neither containers nor unikernels are brand new. There were unikernel-like systems in the 1990s such as Exokernel, but today popular unikernels include MirageOS and OSv. Unikernel applications can be used independently and deployed across heterogeneous environments. They can facilitate specialized and isolated services and have become widely used for developing applications within a microservices architecture.
|
||||
|
||||
As an example of how unikernels are attracting attention, consider the fact that Docker purchased[ Cambridge-based Unikernel Systems][3], and has been working with unikernels in numerous scenarios.
|
||||
|
||||
Unikernels, like container technologies, strip away non-essentials and thus they have a very positive impact on application stability and availability, as well as security. They are also attracting many of the top, most creative developers on the open source scene.
|
||||
|
||||
The Linux Foundation recently[ announced][4] the release of its 2016 report[Guide to the Open Cloud: Current Trends and Open Source Projects.][5] This third annual report provides a comprehensive look at the state of open cloud computing and includes a section on unikernels. You can[ download the report][6] now. It aggregates and analyzes research, illustrating how trends in containers, unikernels, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series of articles, we are looking at the projects mentioned in the guide, by category, providing extra insights on how the overall category is evolving. Below, you’ll find a list of several important unikernels and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
[CLICKOS][7]
|
||||
|
||||
ClickOS is NEC’s high-performance, virtualized software middlebox platform for network function virtualization (NFV) built on top of MiniOS/ MirageOS. [ClickOS on GitHub][8]
|
||||
|
||||
[CLIVE][9]
|
||||
|
||||
Clive is an operating system written in Go and designed to work in distributed and cloud computing environments.
|
||||
|
||||
[HALVM][10]
|
||||
|
||||
The Haskell Lightweight Virtual Machine (HaLVM) is a port of the Glasgow Haskell Compiler toolsuite that enables developers to write high-level, lightweight virtual machines that can run directly on the Xen hypervisor. [HaLVM on GitHub][11]
|
||||
|
||||
[INCLUDEOS][12]
|
||||
|
||||
IncludeOS is a unikernel operating system for C++ services running in the cloud. It provides a bootloader, standard libraries and the build- and deployment system on which to run services. Test in VirtualBox or QEMU, and deploy services on OpenStack. [IncludeOS on GitHub][13]
|
||||
|
||||
[LING][14]
|
||||
|
||||
Ling is an Erlang platform for building super-scalable clouds that runs directly on top of the Xen hypervisor. It runs on only three external libraries — no OpenSSL — and the filesystem is read-only to remove the majority of attack vectors. [Ling on GitHub][15]
|
||||
|
||||
[MIRAGEOS][16]
|
||||
|
||||
MirageOS is a library operating system incubating under the Xen Project at The Linux Foundation. It uses the OCaml language to construct unikernels for secure, high-performance network applications across a variety of cloud computing and mobile platforms. Code can be developed on a normal OS such as Linux or MacOS X, and then compiled into a fully-standalone, specialised unikernel that runs under the Xen hypervisor.[ MirageOS on GitHub][17]
|
||||
|
||||
[OSV][18]
|
||||
|
||||
OSv is the open source operating system from Cloudius Systems designed for the cloud. It supports applications written in Java, Ruby (via JRuby), JavaScript (via Rhino and Nashorn), Scala, and others. And it runs on the VMware, VirtualBox, KVM, and Xen hypervisors. [OSv on GitHub][19]
|
||||
|
||||
[RUMPRUN][20]
|
||||
|
||||
Rumprun is a production-ready unikernel that uses the drivers offered by rump kernels, adds a libc and an application environment on top, and provides a toolchain with which to build existing POSIX-y applications as Rumprun unikernels. It works on KVM and Xen hypervisors and on bare metal and supports applications written in C, C++, Erlang, Go, Java, Javascript (Node.js), Python, Ruby, Rust, and more. [Rumprun on GitHub][21]
|
||||
|
||||
[RUNTIME.JS][22]
|
||||
|
||||
Runtime.js is an open source library operating system (unikernel) for the cloud that runs JavaScript, can be bundled up with an application and deployed as a lightweight and immutable VM image. It’s built on V8 JavaScript engine and uses event-driven and non- blocking I/O model inspired by Node.js. KVM is the only supported hypervisor. [Runtime.js on GitHub][23]
|
||||
|
||||
[UNIK][24]
|
||||
|
||||
Unik is EMC’s tool for compiling application sources into unikernels (lightweight bootable disk images) rather than binaries. It allows applications to be deployed securely and with minimal footprint across a variety of cloud providers, embedded devices (IoT), as well as a developer laptop or workstation. It supports multiple unikernel types, processor architectures, hypervisors and orchestration tools including Cloud Foundry, Docker, and Kubernetes. [Unik on GitHub][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-age-unikernel
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/unikernelsjpg-0
|
||||
[3]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[4]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[5]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[7]:http://cnp.neclab.eu/clickos/
|
||||
[8]:https://github.com/cnplab/clickos
|
||||
[9]:http://lsub.org/ls/clive.html
|
||||
[10]:https://galois.com/project/halvm/
|
||||
[11]:https://github.com/GaloisInc/HaLVM
|
||||
[12]:http://www.includeos.org/
|
||||
[13]:https://github.com/hioa-cs/IncludeOS
|
||||
[14]:http://erlangonxen.org/
|
||||
[15]:https://github.com/cloudozer/ling
|
||||
[16]:https://mirage.io/
|
||||
[17]:https://github.com/mirage/mirage
|
||||
[18]:http://osv.io/
|
||||
[19]:https://github.com/cloudius-systems/osv
|
||||
[20]:http://rumpkernel.org/
|
||||
[21]:https://github.com/rumpkernel/rumprun
|
||||
[22]:http://runtimejs.org/
|
||||
[23]:https://github.com/runtimejs/runtime
|
||||
[24]:http://dojoblog.emc.com/unikernels/unik-build-run-unikernels-easy/
|
||||
[25]:https://github.com/emc-advanced-dev/unik
|
||||
@ -1,3 +1,5 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
The End Of An Era: A Look Back At The Most Popular Solaris Milestones & News
|
||||
=================================
|
||||
|
||||
|
||||
@ -1,277 +0,0 @@
|
||||
Making the move from Scala to Go, and why we’re not going back
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
Here’s the story of why we chose to migrate from [Scala][1] to [Go,][2] and gradually rewrote part of our Scala codebase to Go. As a whole, Movio hosts a much broader and diverse set of opinions, so the “we” in this post accounts for Movio Cinema’s Red Squad only. Scala remains the primary language for some Squads at Movio.
|
||||
|
||||
### Why we loved Scala in the first place
|
||||
|
||||
What made Scala so attractive? This can easily be explained if you consider our backgrounds. Here's the succession of favorite languages over time for some of us:
|
||||
|
||||

|
||||
|
||||
As you can see, we largely came from the stateful procedural world.
|
||||
|
||||
With Scala coming onto the scene, functional programming gained hype and it really clicked with us. [Pure functions][3] made deterministic tests easy, and then [TDD][4] gained popularity and also spoke to our issues with software quality.
|
||||
|
||||
I think the first time I appreciated the positive aspects of having a strong type system was with Scala. Personally, coming from a myriad of PHP silent errors and whimsical behavior, it felt quite empowering to have the confidence that, supported by type-checking and a few well-thought-out tests, my code was doing what it was meant to. On top of that, it would keep doing what it was meant to do after refactoring, otherwise breaking the type-checking or the tests. Yes, Java gave you that as well but without the beauty of FP, and with all the baggage of the EE.
|
||||
|
||||
There are other elusive qualities that make Scala extremely sexy for nerds. It allows you to create your own operators or override existing ones, essentially being unary and binary functions with non-alphanumeric identifiers. You can also extend the compiler via macros (user-defined functions that are called by the compiler), and enrich a third-party library via implicit classes, also known as the "pimp my library" pattern.
|
||||
|
||||
But Scala wasn’t without its problems.
|
||||
|
||||
### Slow compilation
|
||||
|
||||
The slowness of the Scala compiler, an issue [acknowledged and thoroughly described][5] by Martin Odersky, was a source of constant frustration. Coupled with a big monolith and a complex dependency tree with a complicated resolving mechanism - and after years of great engineers babysitting it - adding a property on a model class in one of our core modules would still mean a coffee break, or a [sword fight.][6] Most importantly, it became rare to have acceptable coding feedback loop times (i.e. delays in between code-test-refactor iterations).
|
||||
|
||||
### Slow deployments
|
||||
|
||||
Slow compile times and a big monolith meant really slow CI and, in turn, lengthy deploys. Luckily, the smart engineers on Movio Cinema's Blue Squad were able to parallelize module tests on different nodes, bringing the overall CI times from more than an hour to as little as 20 minutes. This was a great success, but still an issue for agile deployments.
|
||||
|
||||
### Tooling
|
||||
|
||||
IDE support was poor. [Ensime's][7] troubles with multiple Scala version projects (different versions on different modules) made it impractical to support optimize imports, non-grep-based jump to definition, and the like. This meant that all open-source and community-driven IDEs (e.g. vim, Emacs, atom) would have less-than-ideal feature sets. The language seems too complex to make tooling for!
|
||||
|
||||
Even the more ambitious attempts at Scala integration struggled on multiple project builds, most notably Jetbrains' [Intellij Scala Plugin,][8]with jump-to-definition taking us to outdated JARs rather than the modified files. We've seen broken highlighting on code using advanced language features, too.
|
||||
|
||||
On the lighter side of things, we were able to identify exactly whether a programmer was using [IDEA][9] or [sbt][10] based purely on the loudness of their laptop fans. On a MacBook Pro, this is a real problem for anyone hoping to embark on an extended programming session away from a power outlet.
|
||||
|
||||
### Developments in the global Scala community (and non-Scala)
|
||||
|
||||
Criticism for object-oriented programming had been lingering in the office for some time, but it hadn’t reached mainstream status until someone shared [this blog post][11] by [Lawrence Krubner.][12] Since then, it has become easier to float the idea of alternative non-OOP languages. For example, at one stage there were several of us learning Haskell, among other experiments.
|
||||
|
||||
Though old news, the famous 2011 "Yammer moving away from Scala" [email from Coda Hale to the Scala team][13] started to make a lot of sense once our mindset shifted. Consider this quote:
|
||||
|
||||
_“A lot of this [complexity] has been waved away as something only library authors really need to know about, but when an library's API bubbles all of this up to the top (and since most of these features resolve specifics at the call site, they do), engineers need to have an accurate mental model of how these libraries work or they shift into cargo-culting snippets of code as magic talismans of functionality.”_
|
||||
|
||||
Since then, bigger players have followed, Twitter and [LinkedIn][14] being notable examples.
|
||||
|
||||
The following is a quote from Raffi Krikorian on Twitter:
|
||||
|
||||
_“What I would have done differently four years ago is use Java and not used Scala as part of this rewrite. [...] it would take an engineer two months before they're fully productive and writing Scala code.”_
|
||||
|
||||
[Paul Phillips'][15] departure from Scala's core team, and [his long talk][16] discussing it, painted a disturbing picture of the state of the language - one of stark contrast to the image we had.
|
||||
|
||||
For further disturbing literature, you can find the whole vanguard of the Scala community in [this JSON AST debate.][17] Reading this as it developed left some of us feeling like this:
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
### The need for an alternative
|
||||
|
||||
Until ‘Go’ came into the spotlight, though, there seemed to be no real alternative to Scala for us; there was simply no plausible option raising the bar. Consider this quote from the popular Coursera blog post ['Why we love Scala at Coursera':][19]
|
||||
|
||||
_“I personally found compilation and reload times pretty acceptable (not as tight as PHP's edit-test loop, but acceptable given the type-checking and other niceties we get with Scala).”_
|
||||
|
||||
And this other one from the same blog post:
|
||||
|
||||
_“Yes, scalac is slow. On the other hand, dynamic languages require you to incessantly re-run or test your code until you work out all the type errors, syntax errors and null dereferencing. I'd rather have a sip of coffee while scalac does all this work for me.”_
|
||||
|
||||
### Why ‘Go’ made sense
|
||||
|
||||
### It's simple to learn
|
||||
|
||||
It took some of us six months including some [after hours MOOCs,][20] to be able to get relatively comfortable with Scala. In contrast, we picked up ‘Go’ in two weeks. In fact, the first time I got to code some Go was at a [Code Retreat][21] about 10 months ago. I was able to code a very basic [Mario-like platform game!][22]
|
||||
|
||||
We've also feared that a lower-level language would force us to deal with an unnecessary layer of complexity that was hidden by high-level abstractions in Scala e.g. [Futures][23] hiding threads. Interestingly, what we've had to review were things like [signals,][24] [syscalls][25] and [mutexes,][26]which is actually not such a bad thing for so-called full-stack developers!
|
||||
|
||||
For the first time ever, we actually read [the language spec][27] when we’re unsure of how something works. That's how simple it is; the spec is readable! For my average-sized brain, this actually means a lot. Part of my frustration with Scala (and Java) was the feeling that I was never able to get the full context on a given problem domain, due to its complexity. An approachable and complete guide to the language strengthens my confidence in making assumptions while following a piece of code, and in justifying my decision-making rationale.
|
||||
|
||||
### Simpler code is more readable code
|
||||
|
||||
No map, no flatMap, no fold, no generics, no inheritance… Do we miss them? Perhaps we did, for about two weeks.
|
||||
|
||||
It’s hard to explain why it’s preferable to obtain expressiveness without actually ‘Go’ing through the experience yourself - pun intended. However, Russ Cox, Golang's Tech Lead, does a good job of it in the “Go Balance” section of [his 2015 keynote][28] at GopherCon.
|
||||
|
||||
As it turned out, more flexibility led to devs writing code that others actually struggled to understand. It would be tough to decide if one should feel ashamed for not being smart enough to grasp the logic, or annoyed at the unnecessary complexity. On the flip side, on a few occasions one would feel "special" for understanding and applying concepts that would be hard for others. Having this smartness disparity between devs is really bad for team dynamics, and complexity leads invariably to this.
|
||||
|
||||
In terms of code complexity, this wasn't just the case for our Squad; some very smart people have taken it (and continue to take it) to the extreme. The funny part is that, because dependency hell is so ubiquitous in Scala-land (which includes Java-land), we ended up using some of the projects that we deemed too complex for our codebase (e.g scalaz) via transitive dependencies.
|
||||
|
||||
Consider these randomly selected examples from some of the Scala libraries we've been using (and continue to maintain):
|
||||
|
||||
[Strong Syntax][29]
|
||||
(What is this file's purpose, without being a theoretical physicist?)
|
||||
|
||||
[Content Type][30]
|
||||
(broke Github's linter)
|
||||
|
||||
[Abstract Table][31]
|
||||
(Would you explain foreignKey's signature to me?)
|
||||
|
||||
While still on the Scala happiness train, we read [this post][32] with great curiosity (originally posted [here,][33] but site is now down). I find myself wholeheartedly agreeing with it today.
|
||||
|
||||
### Channels and goroutines have made our job so much easier
|
||||
|
||||
It's not just the fact that channels and goroutines are [cheaper in terms of resources,][34] compared to threadpool-based Futures and Promises, resources being memory and CPU. They are also easier to reason about when coding.
|
||||
|
||||
To clarify this point, I think that both languages and their different approaches can basically do the same job, and you can reach a point where you are equally comfortable working with either. Perhaps the fact that makes it simpler in ‘Go’ is that there's usually one limited set of tools to work with, which you use repeatedly and get a chance to master. With Scala, there are way too many options that evolve too frequently (and get superseded) to become proficient with.
|
||||
|
||||
### Case study
|
||||
|
||||
Recently, we've been struggling with an issue where we had to process some billing information.
|
||||
|
||||
The data came through a stream, and had to be persisted to a MariaDB database. As persisting directly was impractical due to the high rate of data consumption, we had to buffer and aggregate, and persist on buffer full or after a timeout.
|
||||
|
||||

|
||||
|
||||
First, we made the mistake of making the `persist` function [synchronized.][35] This guaranteed that buffer-full-based invocations would not run concurrently with timeout-based invocations. However, because the stream digest and the `persist` functions did run concurrently and manipulated the buffer, we had to further synchronize those functions to each other!
|
||||
|
||||
In the end, we resorted to the [Actor system,][36] as we had Akka in the module's dependencies anyway, and it did the job. We just had to ensure that adding to the buffer and clearing the buffer were messages processed by the same Actor, and would never run concurrently. This is just fine, but to get there we needed to; learn the Actor System, teach it to the newcomers, import those dependencies, have Akka properly configured in the code and in the configuration files, etc. Furthermore, the stream came from a Kafka Consumer, and in our wrapper we needed to provide a `digest` function for each consumed message that ran in a `Future`. Circumventing the issue of mixing Futures and Actors required extra head scratching time.
|
||||
|
||||
Enter channels.
|
||||
|
||||
```
|
||||
buffer := []kafkaMsg{}
|
||||
bufferSize := 100
|
||||
timeout := 100 * time.Millisecond
|
||||
|
||||
for {
|
||||
select {
|
||||
case kafkaMsg := <-channel:
|
||||
buffer = append(buffer, kafkaMsg)
|
||||
if len(buffer) >= bufferSize {
|
||||
persist()
|
||||
}
|
||||
case<-time.After(timeout):
|
||||
persist()
|
||||
}
|
||||
}
|
||||
|
||||
func persist() {
|
||||
insert(buffer)
|
||||
buffer = buffer[:0]
|
||||
}
|
||||
```
|
||||
|
||||
Done; Kafka sends to a channel. Consuming the stream and persisting the buffer never run concurrently, and a timer is reset to timeout 100 milliseconds after no messages received.
|
||||
|
||||
Further reading; a few more illustrative channel examples:
|
||||
|
||||
[Parallel processing with ordered output][37]
|
||||
|
||||
[A simple strategy for server-side backpressure][38]
|
||||
|
||||
### It compiles fast and runs fast
|
||||
|
||||
Go runs [very fast.][39]
|
||||
|
||||
Our Go microservices currently:
|
||||
|
||||
* Build in 5 seconds or less
|
||||
* Test in 1 or 2 seconds (including integration tests)
|
||||
* run in our CI infrastructure in less than half a minute (and we're looking into it, because that's unacceptable!), outputting a Docker container
|
||||
* Deploy (via Kubernetes) new containers in 10 seconds or less (key factor here being small images)
|
||||
|
||||
A feedback loop of one second on our daily struggle with computers has made us more productive and happy.
|
||||
|
||||
### Microservice panacea: from dev-done to deployed in less than a minute on cheap boxes
|
||||
|
||||
We've found that Go microservices are a great fit for distributed systems.
|
||||
|
||||
Consider how well it fits with the requirements:
|
||||
|
||||
* Tiny-sized containers: our average Go docker container is 16.5MB, vs 220MB for Scala
|
||||
* Low-memory footprint: mileage may vary; recently, we’ve had a major success when rewriting a crucial µs from Scala to Go and going from 4G to 300M for the worst-case scenario usage
|
||||
* Fast starts and fast shutdowns: just a binary; no need to start a VM
|
||||
|
||||
For us, the fatter Scala images not only meant more money spent on cloud bills, but crucially container orchestration delays. Re-scheduling a container on a different Kubernetes node requires pulling the image from a registry; the bigger the image, the more time it takes. Not to mention, pulling the latest image locally on our laptops!
|
||||
|
||||
### Last but not least: tooling
|
||||
|
||||
In the Red Squad, we have a very diverse choice of IDEs:
|
||||
|
||||

|
||||
|
||||
Go plays really well with all of them! Tools are also steadily improving over time, and new tools are created often.
|
||||
|
||||
My personal favourite item in our little ‘Go’ rebellion: for the first time ever, we make our own tooling!
|
||||
|
||||
Here's a selection of our open source projects we're currently using at work:
|
||||
|
||||
[kt][40]
|
||||
|
||||
Kafka tool for consuming, producing and getting info about Kafka topics; composes nicely with jq.
|
||||
|
||||
[kubemrr][41]
|
||||
|
||||
Kubernetes Mirror; bash/zsh autocompletion for kubectl parameters (e.g. pod names).
|
||||
|
||||
[sql][42]
|
||||
|
||||
MySQL pipe; sends queries to one, many or all your MySQL instances, local or remote, or behind SSH tunnels, and outputs conveniently for further processing. Composes nicely with [chart;][43] another tool we've written for quick ad-hoc charting.
|
||||
|
||||
[flowbro][44]
|
||||
|
||||
Real-time and after-the-fact visualization for Kafka-based distributed systems.
|
||||
|
||||
### So... Go all the things?
|
||||
|
||||
Not so fast. There's much we're not wise enough to comment on yet. Movio's use cases are only a subset of a very long and diverse list of requirements.
|
||||
|
||||
* Choose based on your use case. For example, if your main focus is around data science you might be better off with the Python stack
|
||||
* Depending on the ecosystem that you come from, a library that you’re using might not exist or not be as mature as in Java. For example, the Kafka maintainers are providing client libraries in Java, and the Go versions will naturally lag behind the JVM versions
|
||||
* Our microservices generally do one tiny specific thing; when we reach a certain level of complexity we usually spawn new microservices. Complex logic might be cumbersome to express with the simple tools that Go provides. So far, this has not been a problem for us
|
||||
|
||||
Golang is certainly a good fit for our squad! See how it “Goes” for you :P
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://movio.co/blog/migrate-Scala-to-Go/?utm_source=golangweekly&utm_medium=email
|
||||
|
||||
作者:[Mariano Gappa ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://movio.co/blog/author/mariano/
|
||||
[1]:https://www.scala-lang.org/
|
||||
[2]:https://golang.org/
|
||||
[3]:https://en.wikipedia.org/wiki/Pure_function
|
||||
[4]:https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[5]:http://stackoverflow.com/questions/3490383/java-compile-speed-vs-scala-compile-speed/3612212#3612212
|
||||
[6]:https://xkcd.com/303/
|
||||
[7]:https://github.com/ensime
|
||||
[8]:https://confluence.jetbrains.com/display/SCA/Scala+Plugin+for+IntelliJ+IDEA
|
||||
[9]:https://en.wikipedia.org/wiki/IntelliJ_IDEA
|
||||
[10]:http://www.scala-sbt.org/
|
||||
[11]:http://www.smashcompany.com/technology/object-oriented-programming-is-an-expensive-disaster-which-must-end
|
||||
[12]:https://twitter.com/krubne
|
||||
[13]:https://codahale.com/downloads/email-to-donald.txt
|
||||
[14]:https://www.quora.com/Is-LinkedIn-getting-rid-of-Scala/answer/Kevin-Scott
|
||||
[15]:https://github.com/paulp
|
||||
[16]:https://www.youtube.com/watch?v=TS1lpKBMkgg
|
||||
[17]:https://github.com/scala/slip/pull/28
|
||||
[18]:https://xkcd.com/386/
|
||||
[19]:https://building.coursera.org/blog/2014/02/18/why-we-love-scala-at-coursera/
|
||||
[20]:https://www.coursera.org/learn/progfun1
|
||||
[21]:http://movio.co/blog/tech-digest-global-day-of-coderetreat-2016/
|
||||
[22]:https://github.com/MarianoGappa/gomario
|
||||
[23]:http://docs.scala-lang.org/overviews/core/futures.html
|
||||
[24]:https://en.wikipedia.org/wiki/Unix_signa
|
||||
[25]:https://en.wikipedia.org/wiki/System_call
|
||||
[26]:https://en.wikipedia.org/wiki/Mutual_exclusion
|
||||
[27]:https://golang.org/ref/spec
|
||||
[28]:https://www.youtube.com/watch?v=XvZOdpd_9tc&t=3m25s
|
||||
[29]:https://github.com/scalaz/scalaz/blob/series/7.3.x/core/src/main/scala/scalaz/syntax/StrongSyntax.scala
|
||||
[30]:https://github.com/spray/spray/blob/master/spray-http/src/main/scala/spray/http/ContentType.scala
|
||||
[31]:https://github.com/slick/slick/blob/master/slick/src/main/scala/slick/lifted/AbstractTable.scala
|
||||
[32]:http://126kr.com/article/8sx2b2nrcc7
|
||||
[33]:http://jimplush.com/talk/2015/12/19/moving-a-team-from-scala-to-golang/
|
||||
[34]:https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
|
||||
[35]:https://docs.oracle.com/javase/tutorial/essential/concurrency/syncmeth.html
|
||||
[36]:http://doc.akka.io/docs/akka/current/general/actor-systems.html
|
||||
[37]:https://gist.github.com/MarianoGappa/a50c4a8a302b8378c08c4b0d947f0a33
|
||||
[38]:https://gist.github.com/MarianoGappa/00b8235deffab51271ea4177369cfe2e
|
||||
[39]:http://benchmarksgame.alioth.debian.org/u64q/go.html
|
||||
[40]:https://github.com/fgeller/kt
|
||||
[41]:https://github.com/mkokho/kubemrr
|
||||
[42]:https://github.com/MarianoGappa/sql
|
||||
[43]:https://github.com/MarianoGappa/chart
|
||||
[44]:https://github.com/MarianoGappa/flowbro
|
||||
[45]:https://movio.co/blog/author/mariano/
|
||||
[46]:https://movio.co/blog/category/technology/
|
||||
[47]:https://movio.co/blog/migrate-Scala-to-Go/?utm_source=golangweekly&utm_medium=email#disqus_thread
|
||||
@ -1,70 +0,0 @@
|
||||
translating by xllc
|
||||
|
||||
Performance made easy with Linux containers
|
||||
============================================================
|
||||
|
||||

|
||||
Image credits : CC0 Public Domain
|
||||
|
||||
Performance for an application determines how quickly your software can complete the intended task. It answers questions about the application, such as:
|
||||
|
||||
* Response time under peak load
|
||||
* Ease of use, supported functionality, and use cases compared to an alternative
|
||||
* Operational costs (CPU usage, memory needs, data throughput, bandwidth, etc.)
|
||||
|
||||
The value of this performance analysis extends beyond the estimation of the compute resources needed to serve the load or the number of application instances needed to meet the peak demand. Performance is clearly tied to the fundamentals of a successful business. It informs the overall user experience, including identifying what slows down customer-expected response times, improving customer stickiness by designing content delivery optimized to their bandwidth, choosing the best device, and ultimately helping enterprises grow their business.
|
||||
|
||||
### The problem
|
||||
|
||||
Of course, this is an oversimplification of the value of performance engineering for business services. To understand the challenges behind accomplishing what I've just described, let's make this real and just a little bit complicated.
|
||||
|
||||

|
||||
|
||||
Real-world applications are likely hosted on the cloud. An application could avail to very large (or conceptually infinite) amounts of compute resources. Its needs in terms of both hardware and software would be met via the cloud. The developers working on it would use the cloud-offered features for enabling faster coding and deployment. Cloud hosting doesn't come free, but the cost overhead is proportional to the resource needs of the application.
|
||||
|
||||
Outside of Search as a Service (SaaS), Platform as a Service (PaaS), Infrastructure as a Service (IaaS), and Load Balancing as a Service (LBaaS), which is when the cloud takes care of traffic management for this hosted app, a developer probably may also use one or more of these fast-growing cloud services:
|
||||
|
||||
* Security as a Service (SECaaS), which meets security needs for software and the user
|
||||
* Data as a Service (DaaS), which provides a user's data on demand for application
|
||||
* Logging as a Service (LaaS), DaaS's close cousin, which provides analytic metrics on delivery and usage of logs
|
||||
* Search as a Service (SaaS), which is for the analytics and big data needs of the app
|
||||
* Network as a Service (NaaS), which is for sending and receiving data across public networks
|
||||
|
||||
Cloud-powered services are also growing exponentially because they make writing complex apps easier for developers. In addition to the software complexity, the interplay of all these distributed components becomes more involved. The user base becomes more diverse. The list of requirements for the software becomes longer. The dependencies on other services becomes larger. Because of these factors, the flaws in this ecosystem can trigger a domino effect of performance problems.
|
||||
|
||||
For example, assume you have a well-written application that follows secure coding practices, is designed to meet varying load requirements, and is thoroughly tested. Assume also that you have the infrastructure and analytics work in tandem to support the basic performance requirements. What does it take to build performance standards into the implementation, design, and architecture of your system? How can the software keep up with evolving market needs and emerging technologies? How do you measure the key parameters to tune a system for optimal performance as it ages? How can the system be made resilient and self-recovering? How can you identify any underlying performance problems faster and resolved them sooner?
|
||||
|
||||
### Enter containers
|
||||
|
||||
Software [containers][2] backed with the merits of [microservices][3] design, or Service-oriented Architecture (SoA), improves performance because a system comprising of smaller, self-sufficient code blocks is easier to code and has cleaner, well-defined dependencies on other system components. It is easier to test and problems, including those around resource utilization and memory over-consumption, are more easily identified than in a giant monolithic architecture.
|
||||
|
||||
When scaling the system to serve increased load, the containerized applications replicate fast and easy. Security flaws are better isolated. Patches can be versioned independently and deployed fast. Performance monitoring is more targeted and the measurements are more reliable. You can also rewrite and "facelift" resource-intensive code pieces to meet evolving performance requirements.
|
||||
|
||||
Containers start fast and stop fast. They enable efficient resource utilization and far better process isolation than Virtual Machines (VMs). Containers do not have idle memory and CPU overhead. They allow for multiple applications to share a machine without the loss of data or performance. Containers make applications portable, so developers can build and ship apps to any server running Linux that has support for container technology, without worrying about performance penalties. Containers live within their means and abide by the quotas (examples include storage, compute, and object count quotas) as imposed by their cluster manager, such as Cloud Foundry's Diego, [Kubernetes][4], Apache Mesos, and Docker Swarm.
|
||||
|
||||
While containers show merit in performance, the coming wave of "serverless" computing, also known as Function as a Service (FaaS), is set to extend the benefits of containers. In the FaaS era, these ephemeral or short-lived containers will drive the benefits beyond application performance and translate directly to savings in overhead costs of hosting in the cloud. If the container does its job faster, then it lives for a shorter time, and the computation overload is purely on demand.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima is a Engineering Manager at Red Hat focussed on OpenShift Container Platform. Prior to Red Hat, Garima helped fuel innovation at Akamai Technologies & MathWorks Inc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -1,76 +0,0 @@
|
||||
cygmris is translating
|
||||
|
||||
# Filtering Packets In Wireshark on Kali Linux
|
||||
|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][1]
|
||||
|
||||
* [2. Boolean Expressions and Comparison Operators][2]
|
||||
|
||||
* [3. Filtering Capture][3]
|
||||
|
||||
* [4. Filtering Results][4]
|
||||
|
||||
* [5. Closing Thoughts][5]
|
||||
|
||||
### Introduction
|
||||
|
||||
Filtering allows you to focus on the exact sets of data that you are interested in reading. As you have seen, Wireshark collects _everything_ by default. That can get in the way of the specific data that you are looking for. Wireshark provides two powerful filtering tools to make targeting the exact data you need simple and painless.
|
||||
|
||||
There are two way that Wireshark can filter packets. It can filter an only collect certain packets, or the packet results can be filtered after they are collected. Of course, these can be used in conjunction with one another, and their respective usefulness is dependent on which and how much data is being collected.
|
||||
|
||||
### Boolean Expressions and Comparison Operators
|
||||
|
||||
Wireshark has plenty of built-in filters which work just great. Start typing in either of the filter fields, and you will see them autocomplete in. Most correspond to the more common distinctions that a user would make between packets. Filtering only HTTP requests would be a good example.
|
||||
|
||||
For everything else, Wireshark uses Boolean expressions and/or comparison operators. If you've ever done any kind of programming, you should be familiar with Boolean expressions. They are expressions that use "and," "or," and "not" to verify the truthfulness of a statement or expression. Comparison operators are much simpler. They just determine if two or more things are equal, greater, or less than one another.
|
||||
|
||||
### Filtering Capture
|
||||
|
||||
Before diving in to custom capture filters, take a look at the ones Wireshark already has built in. Click on the "Capture" tab on the top menu, and go to "Options." Below the available interfaces is the line where you can write your capture filters. Directly to its left is a button labeled "Capture Filter." Click on it, and you will see a new dialog box with a listing of pre-built capture filters. Look around and see what's there.
|
||||
|
||||

|
||||
|
||||
|
||||
At the bottom of that box, there is a small form for creating and saving hew capture filters. Press the "New" button to the left. It will create a new capture filter populated with filler data. To save the new filter, just replace the filler with the actual name and expression that you want and click "Ok." The filter will be saved and applied. Using this tool, you can write and save multiple different filters and have them ready to use again in the future.
|
||||
|
||||
Capture has it's own syntax for filtering. For comparison, it omits and equals symbol and uses `>` and for greater and less than. For Booleans, it relies on the words "and," "or," and "not."
|
||||
|
||||
If, for example, you only wanted to listen to traffic on port 80, you could use and expressions like this: `port 80`. If you only wanted to listen on port 80 from a specific IP, you would add that on. `port 80 and host 192.168.1.20` As you can see, capture filters have specific keywords. These keywords are used to tell Wireshark how to monitor packets and which ones to look at. For example, `host` is used to look at all traffic from an IP. `src` is used to look at traffic originating from that IP. `dst` in contrast, only watches incoming traffic to an IP. To watch traffic on a set of IPs or a network, use `net`.
|
||||
|
||||
### Filtering Results
|
||||
|
||||
The bottom menu bar on your layout is the one dedicated to filtering results. This filter doesn't change the data that Wireshark has collected, it just allows you to sort through it more easily. There is a text field for entering a new filter expression with a drop down arrow to review previously entered filters. Next to that is a button marked "Expression" and a few others for clearing and saving your current expression.
|
||||
|
||||
Click on the "Expression" button. You will see a small window with several boxes with options in them. To the left is the largest box with a huge list of items, each with additional collapsed sub-lists. These are all of the different protocols, fields, and information that you can filter by. There's no way to go through all of it, so the best thing to do is look around. You should notice some familiar options like HTTP, SSL, and TCP.
|
||||
|
||||

|
||||
|
||||
The sub-lists contain the different parts and methods that you can filter by. This would be where you'd find the methods for filtering HTTP requests by GET and POST.
|
||||
|
||||
You can also see a list of operators in the middle boxes. By selecting items from each column, you can use this window to create filters without memorizing every item that Wireshark can filter by. For filtering results, comparison operators use a specific set of symbols. `==` determines if two things are equal. `>`determines if one thing is greater than another, `<` finds if something is less. `>=` and `<=` are for greater than or equal to and less than or equal to respectively. They can be used to determine if packets contain the right values or filter by size. An example of using `==` to filter only HTTP GET requests like this: `http.request.method == "GET"`.
|
||||
|
||||
Boolean operators can chain smaller expressions together to evaluate based on multiple conditions. Instead of words like with capture, they use three basic symbols to do this. `&&` stands for "and." When used, both statements on either side of `&&` must be true in order for Wireshark to filter those packages. `||`signifies "or." With `||` as long as either expression is true, it will be filtered. If you were looking for all GET and POST requests, you could use `||` like this: `(http.request.method == "GET") || (http.request.method == "POST")`. `!` is the "not" operator. It will look for everything but the thing that is specified. For example, `!http` will give you everything but HTTP requests.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
Filtering Wireshark really allows you to efficiently monitor your network traffic. It takes some time to familiarize yourself with the options available and become used to the powerful expressions that you can create with filters. Once you do, though, you will be able to quickly collect and find exactly the network data the you are looking for without having to comb through long lists of packets or do a whole lot of work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -1,4 +1,3 @@
|
||||
yangmingming translating
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
Translating by CherryMill
|
||||
|
||||
penghuster is translating
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,119 @@
|
||||
ucasFL translating
|
||||
Know your Times Tables, but... do you know your "Hash Tables"?
|
||||
============================================================
|
||||
|
||||
Diving into the world of Hash Tables and understanding the underlying mechanics is _extremely_ interesting, and very rewarding. So lets get into it and get started from the beginning.
|
||||
|
||||
A Hash Table is a common data structure used in many modern day Software applications. It provides a dictionary-like functionality, giving you the ability to perform opertations such as inserting, removing and deleting items inside it. Let’s just say I want to find what the definition of what “Apple” is, and I know the defintion is stored in my defined Hash Table. I will query my Hash Table to give me a defintion. The _entry_ inside my Hash Table might look something like this `"Apple" => "A green fruit of fruity goodness"`. So, “Apple” is my _key_ and “A green fruit of fruity goodness” is my associated _value_ .
|
||||
|
||||
One more example just so we’re clear, take below the contents of a Hash Table:
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "solid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
I want to look up if _bread_ is a solid or liquid, So I will query the Hash Table to give me the associated value, and the table will return to me with “solid”. Ok so we got the generally gist of how it functions. Another important concept to note with Hash Tables is the fact that every key is unique. Let’s say tomorrow, I feel like having a bread milkshake (which is a _liquid_ ), we now need to update the Hash Table to reflect its change from solid to liquid! So we add the entry into the dictionary, the key : “bread” and the value : “liquid”. Can you spot what has changed in the table below?
|
||||
|
||||
|
||||
```
|
||||
1234
|
||||
```
|
||||
|
||||
```
|
||||
"bread" => "liquid""water" => "liquid""soup" => "liquid""corn chips" => "solid"
|
||||
```
|
||||
|
||||
|
||||
That’s right, bread has been updated to have the value “liquid”.
|
||||
|
||||
**Keys are unique**, my bread can’t be both a liquid and a solid. But what makes this data structure so special from the rest? Why not just use an [Array][1] instead? It depends on the nature of the problem. You may very well be better off using a Array for a particular problem, and that also brings me to the point, **choose the data structure that is most suited to your problem**. Example, If all you need to do is store a simple grocery list, an Array would do just fine. Consider the two problems below, each problem is very different in nature.
|
||||
|
||||
1. I need a grocery list of fruit
|
||||
|
||||
2. I need a grocery list of fruit and how much each it will cost me (per kilogram).
|
||||
|
||||
As you can see below, an Array might be a better choice for storing the fruit for the grocery list. But a Hash Table looks like a better choice for looking up the cost of each item.
|
||||
|
||||
|
||||
```
|
||||
123456789
|
||||
```
|
||||
|
||||
```
|
||||
//Example Array ["apple, "orange", "pear", "grape"] //Example Hash Table { "apple" : 3.05, "orange" : 5.5, "pear" : 8.4, "grape" : 12.4 }
|
||||
```
|
||||
|
||||
|
||||
There are literally so many oppurtunities to [use][2] Hash Tables.
|
||||
|
||||
### Time and what that means to you
|
||||
|
||||
[A brush up on time and space complexity][3].
|
||||
|
||||
On average it takes a Hash Table O(1) to search, insert and delete entries in the Hash Table. For the unaware, O(1) is spoken as “Big O 1” and represents constant time. Meaning that the running time to perform each operation is not dependent on the amount of data in the dataset. We can also _promise_ that for searching, inserting and deleting items will take constant time, “IF AND ONLY” IF the implementation of the Hash Table is done right. If it’s not, then it can be really slow _O(n)_ , especially if everything hashes to the same position/slot in the Hash Table.
|
||||
|
||||
### Building a good Hash Table
|
||||
|
||||
So far we now understand how to use a Hash Table, but what if we wanted to **build** one? Essentially what we need to do is map a string (eg. “dog”) to a **hash code** (a generated number), which maps to an index of an Array. You might ask, why not just go straight to using indexes? Why bother? Well this way it allows us to find out immediately where “dog” is located by quering directly for “dog”, `String name = Array["dog"] //name is "Lassy"`. But with using an index to look up the name, we could be in the likely situation that we do not know the index where the name is located. For example, `String name = Array[10] // name is now "Bob"` - that’s not my dog’s name! And that is the benefit of mapping the string to a hash code (which corresponds to an index of an Array). We can get the index of the Array by using the modulo operator with the size of the Hash Table, `index = hash_code % table_size`.
|
||||
|
||||
Another situation that we want to avoid is having two keys mapping to the same index, this is called a **hash collision** and they’re very likely to happen if the hash function is not properly implemented. But the truth is that every hash function _with more inputs than outputs_ there is some chance of collision. To demonstrate a simple collision take the following two function outputs below:
|
||||
|
||||
`int cat_idx = hashCode("cat") % table_size; //cat_idx is now equal to 1`
|
||||
|
||||
`int dog_idx = hashCode("dog") % table_size; //dog_idx is now also equal 1`
|
||||
|
||||
We can see that both Array indexes are now 1! And as such the values will overwrite each other because they are being written to the same index. Like if we tried to look up the value for “cat” it would then return “Lassy”. Not what we wanted after all. There are various methods of [resolving hash collisions][4], the more popular one is called **Chaining**. The idea with chaining is that there is a Linked List for each index of an Array. If a collision occurs, the value will be stored inside that Linked List. Thus in the previous example, we would get the value we requested, but it we would need to search a Linked List attached to the index 1 of the Array. Hashing with Chaining achieves O(1 + α) time where α is the load factor which can be represented as n/k, n being the number of entries in the Hash Table and k being the number of slots available in the Hash Table. But remember this only holds true if the keys that you give are particularly random (relying on [SUHA][5])).
|
||||
|
||||
This is a big assumption to make, as there is always a possibility that non-equal keys will hash to the same slot. One solution to this is to take the reliance of randomness away from what keys are given to the Hash Table, and put the randomness on how the keys will be hashed to increase the likeliness of _very few conflicts_ occuring. And this is known as…
|
||||
|
||||
### Universal Hashing
|
||||
|
||||
The concept is pretty simple, select _at random_ a hash function h from the set universal hash family to compute the hash code. So in other words, choose any random hash function to hash the key! And by following this method it provides a _very low_ probability that the hashes of two distinct keys will not be the same. I will keep this one short, but if you don’t trust me then trust [Mathematics][6] instead. Also another thing to watch out for is when implementing this method be careful of having a bad universal hash family. It can blow out the time and space complexity to O(U) where U is the size of the family. And where the challenge lies is finding a Hash family that does not take too much time to compute, and too much space to store.
|
||||
|
||||
### A Hash function of the Gods
|
||||
|
||||
The search for perfection is inevitable. What if we could construct a _Perfect hash function_ where we could just map things to a set of integers with absolutely _no collisions_ . Good news is we can do this, Well kind of.. but our data has to be static (which means no insertions/deletes/updates can assured constant time). One approach to achieve a perfect hash function is to use _2-Level Hashing_ , it is basically a combination of the last two ideas we previously discussed. It uses _Universal Hashing_ to select which hash function to use, and then combines it with _Chaining_ , but this time instead of using a Linked List data structure we use another Hash Table! Let’s see how this looks visually below:
|
||||
|
||||
[][8]
|
||||
|
||||
**But how does this work and how can we ensure no lookup collisions?**
|
||||
|
||||
Well it works in reverse to the [Birthday paradox][7]. It states that in a set of N randomly chosen people, some pair will have the same birthday. But if the number of days in a year far outwighs the number of people (squared) then there is a damn good possibility that no pair of people will share the same birthday. So how it relates is, for each chained Hash Table is the size of the first-level Hash Table _squared_ . That is if 2 elements happen to hash to the same slot, then the size of the chained Hash Table will be of size 4\. Most of the time the chained Tables will be very sparse/empty.
|
||||
|
||||
Repeat the following two steps to ensure no look up collisions,
|
||||
|
||||
* Select a hash from the universal hash family
|
||||
|
||||
* If we get a collision, then select another hash from the universal hash family.
|
||||
|
||||
Literally that is it, (Well.. for an O(N^2) space solution anyway). If space is a concern, then a different approach is obviously needed. But the great thing is that we will only ever have to do this process on average **twice**.
|
||||
|
||||
### Summing up
|
||||
|
||||
A Hash Table is only as good as it’s _Hash function_ . Deriving a _Perfect hash function_ is much harder to achieve without losing in particular areas such as functionality, time and space. I invite you to always consider Hash Tables when solving a problem as they offer great performance benefits and they can make a noticeable difference in the usability of your application. Hash Tables and Perfect hash functions are often used in Real-time programming applications. And have been widely implemented in algorithms around the world. Hash Tables are here to stay.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zeroequalsfalse.press/2017/02/20/hashtables/
|
||||
|
||||
作者:[Marty Jacobs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zeroequalsfalse.press/about
|
||||
[1]:https://en.wikipedia.org/wiki/Array_data_type
|
||||
[2]:https://en.wikipedia.org/wiki/Hash_table#Uses
|
||||
[3]:https://www.hackerearth.com/practice/basic-programming/complexity-analysis/time-and-space-complexity/tutorial/
|
||||
[4]:https://en.wikipedia.org/wiki/Hash_table#Collision_resolution
|
||||
[5]:https://en.wikipedia.org/wiki/SUHA_(computer_science
|
||||
[6]:https://en.wikipedia.org/wiki/Universal_hashing#Mathematical_guarantees
|
||||
[7]:https://en.wikipedia.org/wiki/Birthday_problem
|
||||
[8]:http://www.zeroequalsfalse.press/2017/02/20/hashtables/Diagram.png
|
||||
203
sources/tech/20170227 Ubuntu Core in LXD containers.md
Normal file
203
sources/tech/20170227 Ubuntu Core in LXD containers.md
Normal file
@ -0,0 +1,203 @@
|
||||
Translating By LHRchina
|
||||
|
||||
|
||||
Ubuntu Core in LXD containers
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
### What’s Ubuntu Core?
|
||||
|
||||
Ubuntu Core is a version of Ubuntu that’s fully transactional and entirely based on snap packages.
|
||||
|
||||
Most of the system is read-only. All installed applications come from snap packages and all updates are done using transactions. Meaning that should anything go wrong at any point during a package or system update, the system will be able to revert to the previous state and report the failure.
|
||||
|
||||
The current release of Ubuntu Core is called series 16 and was released in November 2016.
|
||||
|
||||
Note that on Ubuntu Core systems, only snap packages using confinement can be installed (no “classic” snaps) and that a good number of snaps will not fully work in this environment or will require some manual intervention (creating user and groups, …). Ubuntu Core gets improved on a weekly basis as new releases of snapd and the “core” snap are put out.
|
||||
|
||||
### Requirements
|
||||
|
||||
As far as LXD is concerned, Ubuntu Core is just another Linux distribution. That being said, snapd does require unprivileged FUSE mounts and AppArmor namespacing and stacking, so you will need the following:
|
||||
|
||||
* An up to date Ubuntu system using the official Ubuntu kernel
|
||||
|
||||
* An up to date version of LXD
|
||||
|
||||
### Creating an Ubuntu Core container
|
||||
|
||||
The Ubuntu Core images are currently published on the community image server.
|
||||
You can launch a new container with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc launch images:ubuntu-core/16 ubuntu-core
|
||||
Creating ubuntu-core
|
||||
Starting ubuntu-core
|
||||
```
|
||||
|
||||
The container will take a few seconds to start, first executing a first stage loader that determines what read-only image to use and setup the writable layers. You don’t want to interrupt the container in that stage and “lxc exec” will likely just fail as pretty much nothing is available at that point.
|
||||
|
||||
Seconds later, “lxc list” will show the container IP address, indicating that it’s booted into Ubuntu Core:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc list
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
| ubuntu-core | RUNNING | 10.90.151.104 (eth0) | 2001:470:b368:b2b5:216:3eff:fee1:296f (eth0) | PERSISTENT | 0 |
|
||||
+-------------+---------+----------------------+----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
You can then interact with that container the same way you would any other:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap list
|
||||
Name Version Rev Developer Notes
|
||||
core 16.04.1 394 canonical -
|
||||
pc 16.04-0.8 9 canonical -
|
||||
pc-kernel 4.4.0-45-4 37 canonical -
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
### Updating the container
|
||||
|
||||
If you’ve been tracking the development of Ubuntu Core, you’ll know that those versions above are pretty old. That’s because the disk images that are used as the source for the Ubuntu Core LXD images are only refreshed every few months. Ubuntu Core systems will automatically update once a day and then automatically reboot to boot onto the new version (and revert if this fails).
|
||||
|
||||
If you want to immediately force an update, you can do it with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap refresh
|
||||
pc-kernel (stable) 4.4.0-53-1 from 'canonical' upgraded
|
||||
core (stable) 16.04.1 from 'canonical' upgraded
|
||||
root@ubuntu-core:~# snap version
|
||||
snap 2.17
|
||||
snapd 2.17
|
||||
series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
And then reboot the system and check the snapd version again:
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# reboot
|
||||
root@ubuntu-core:~#
|
||||
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap version
|
||||
snap 2.21
|
||||
snapd 2.21
|
||||
series 16
|
||||
root@ubuntu-core:~#
|
||||
```
|
||||
|
||||
You can get an history of all snapd interactions with
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core snap changes
|
||||
ID Status Spawn Ready Summary
|
||||
1 Done 2017-01-31T05:14:38Z 2017-01-31T05:14:44Z Initialize system state
|
||||
2 Done 2017-01-31T05:14:40Z 2017-01-31T05:14:45Z Initialize device
|
||||
3 Done 2017-01-31T05:21:30Z 2017-01-31T05:22:45Z Refresh all snaps in the system
|
||||
```
|
||||
|
||||
### Installing some snaps
|
||||
|
||||
Let’s start with the simplest snaps of all, the good old Hello World:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install hello-world
|
||||
hello-world 6.3 from 'canonical' installed
|
||||
root@ubuntu-core:~# hello-world
|
||||
Hello World!
|
||||
```
|
||||
|
||||
And then move on to something a bit more useful:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install nextcloud
|
||||
nextcloud 11.0.1snap2 from 'nextcloud' installed
|
||||
```
|
||||
|
||||
Then hit your container over HTTP and you’ll get to your newly deployed Nextcloud instance.
|
||||
|
||||
If you feel like testing the latest LXD straight from git, you can do so with:
|
||||
|
||||
```
|
||||
stgraber@dakara:~$ lxc config set ubuntu-core security.nesting true
|
||||
stgraber@dakara:~$ lxc exec ubuntu-core bash
|
||||
root@ubuntu-core:~# snap install lxd --edge
|
||||
lxd (edge) git-c6006fb from 'canonical' installed
|
||||
root@ubuntu-core:~# lxd init
|
||||
Name of the storage backend to use (dir or zfs) [default=dir]:
|
||||
|
||||
We detected that you are running inside an unprivileged container.
|
||||
This means that unless you manually configured your host otherwise,
|
||||
you will not have enough uid and gid to allocate to your containers.
|
||||
|
||||
LXD can re-use your container's own allocation to avoid the problem.
|
||||
Doing so makes your nested containers slightly less safe as they could
|
||||
in theory attack their parent container and gain more privileges than
|
||||
they otherwise would.
|
||||
|
||||
Would you like to have your containers share their parent's allocation (yes/no) [default=yes]?
|
||||
Would you like LXD to be available over the network (yes/no) [default=no]?
|
||||
Would you like stale cached images to be updated automatically (yes/no) [default=yes]?
|
||||
Would you like to create a new network bridge (yes/no) [default=yes]?
|
||||
What should the new bridge be called [default=lxdbr0]?
|
||||
What IPv4 address should be used (CIDR subnet notation, “auto” or “none”) [default=auto]?
|
||||
What IPv6 address should be used (CIDR subnet notation, “auto” or “none”) [default=auto]?
|
||||
LXD has been successfully configured.
|
||||
```
|
||||
|
||||
And because container inception never gets old, lets run Ubuntu Core 16 inside Ubuntu Core 16:
|
||||
|
||||
```
|
||||
root@ubuntu-core:~# lxc launch images:ubuntu-core/16 nested-core
|
||||
Creating nested-core
|
||||
Starting nested-core
|
||||
root@ubuntu-core:~# lxc list
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
| nested-core | RUNNING | 10.71.135.21 (eth0) | fd42:2861:5aad:3842:216:3eff:feaf:e6bd (eth0) | PERSISTENT | 0 |
|
||||
+-------------+---------+---------------------+-----------------------------------------------+------------+-----------+
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you ever wanted to try Ubuntu Core, this is a great way to do it. It’s also a great tool for snap authors to make sure their snap is fully self-contained and will work in all environments.
|
||||
|
||||
Ubuntu Core is a great fit for environments where you want to ensure that your system is always up to date and is entirely reproducible. This does come with a number of constraints that may or may not work for you.
|
||||
|
||||
And lastly, a word of warning. Those images are considered as good enough for testing, but aren’t officially supported at this point. We are working towards getting fully supported Ubuntu Core LXD images on the official Ubuntu image server in the near future.
|
||||
|
||||
### Extra information
|
||||
|
||||
The main LXD website is at: [https://linuxcontainers.org/lxd][2] Development happens on Github at: [https://github.com/lxc/lxd][3]
|
||||
Mailing-list support happens on: [https://lists.linuxcontainers.org][4]
|
||||
IRC support happens in: #lxcontainers on irc.freenode.net
|
||||
Try LXD online: [https://linuxcontainers.org/lxd/try-it][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/02/27/ubuntu-core-in-lxd-containers/
|
||||
|
||||
作者:[Stéphane Graber ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/stgraber/
|
||||
[1]:https://insights.ubuntu.com/author/stgraber/
|
||||
[2]:https://linuxcontainers.org/lxd
|
||||
[3]:https://github.com/lxc/lxd
|
||||
[4]:https://lists.linuxcontainers.org/
|
||||
[5]:https://linuxcontainers.org/lxd/try-it
|
||||
@ -1,107 +0,0 @@
|
||||
# How to work around video and subtitle embed errors
|
||||
|
||||
|
||||
This is going to be a slightly weird tutorial. The background story is as follows. Recently, I created a bunch of [sweet][1] [parody][2] [clips][3] of the [Risitas y las paelleras][4] sketch, famous for its insane laughter by the protagonist, Risitas. As always, I had them uploaded to Youtube, but from the moment I decided on what subtitles to use to the moment when the videos finally became available online, there was a long and twisty journey.
|
||||
|
||||
In this guide, I would like to present several typical issues that you may encounter when creating your own media, mostly with subtitles and the subsequent upload to media sharing portals, specifically Youtube, and how you can work around those. After me.
|
||||
|
||||
### The background story
|
||||
|
||||
My software of choice for video editing is Kdenlive, which I started using when I created the most silly [Frankenstein][5] clip, and it's been my loyal companion ever since. Normally, I render files to WebM container, with VP8 video codec and Vorbis audio codec, because that's what Google likes. Indeed, I had no issues with the roughly 40 different clips I uploaded in the last seven odd years.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
However, after I completed my Risitas & Linux project, I was in a bit of a predicament. The video file and the subtitle file were still two separate entities, and I needed somehow to put them together. My original article for subtitles work mentions Avidemux and Handbrake, and both these are valid options.
|
||||
|
||||
However, I was not too happy with the output generated by either one of these, and for a variety of reasons, something was ever so slightly off. Avidemux did not handle the video codecs well, whereas Handbrake omitted a couple of lines of subtitle text from the final product, and the font was ugly. Solvable, but not the topic for today.
|
||||
|
||||
Therefore, I decided to use VideoLAN (VLC) to embed subtitles onto the video. There are several ways to do this. You can use the Media > Convert/Save option, but this one does not have everything we need. Instead, you should use Media > Stream, which comes with a more fully fledged wizard, and it also offers an editable summary of the transcoding options, which we DO need - see my [tutorial][6] on subtitles for this please.
|
||||
|
||||
### Errors!
|
||||
|
||||
The process of embedding subtitles is not trivial. You will most likely encounter several problems along the way. This guide should help you work around these so you can focus on your work and not waste time debugging weird software errors. Anyhow, here's a small but probable collection of issues you will face while working with subtitles in VLC. Trial & error, but also nerdy design.
|
||||
|
||||
### No playable streams
|
||||
|
||||
You have probably chosen weird output settings. You might want to double check you have selected the right video and audio codecs. Also, remember that some media players may not have all the codecs. Also, make sure you test on the system you want these clips to play.
|
||||
|
||||

|
||||
|
||||
### Subtitles overlaid twice
|
||||
|
||||
This can happen if you check the box that reads Use a subtitle file in the first step of the streaming media wizard. Just select the file you need and click Stream. Leave the box unchecked.
|
||||
|
||||

|
||||
|
||||
### No subtitle output is generated
|
||||
|
||||
This can happen for two main reasons. One, you have selected the wrong encapsulation format. Do make sure the subtitles are marked correctly on the profile page when you edit it before proceeding. If the format does not support subtitles, it might not work.
|
||||
|
||||

|
||||
|
||||
Two, you may have left the subtitle codec render enabled in the final output. You do not need this. You only need to overlay the subtitles onto the video clip. Please check the generated stream output string and delete an option that reads scodec=<something> before you click the Stream button.
|
||||
|
||||

|
||||
|
||||
### Missing codecs + workaround
|
||||
|
||||
This is a common [bug][7] due to how experimental codecs are implemented, and you will most likely see it if you choose the following profile: Video - H.264 + AAC (MP4). The file will be rendered, and if you selected subtitles, they will be overlaid, too, but without any audio. However, we can fix this with a hack.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
One possible hack is to start VLC from command line with the --sout-ffmpeg-strict=-2 option (might work). The other and more sureway workaround is to take the audio-less video but with the subtitles overlayed and re-render it through Kdenlive with the original project video render without subtitles as an audio source. Sounds complicated, so in detail:
|
||||
|
||||
* Move existing clips (containing audio) from video to audio. Delete the rest.
|
||||
|
||||
* Alternatively, use rendered WebM file as your audio source.
|
||||
|
||||
* Add new clip - the one we created with embedded subtitles AND no audio.
|
||||
|
||||
* Place the clip as new video.
|
||||
|
||||
* Render as WebM again.
|
||||
|
||||

|
||||
|
||||
Using other types of audio codecs will most likely work (e.g. MP3), and you will have a complete project with video, audio and subtitles. If you're happy that nothing is missing, you can now upload to Youtube. But then ...
|
||||
|
||||
### Youtube video manager & unknown format
|
||||
|
||||
If you're trying to upload a non-WebM clip (say MP4), you might get an unspecified error that your clip does not meet the media format requirements. I was not sure why VLC generated a non-Youtube-compliant file. However, again, the fix is easy. Use Kdenlive to recreate the video, and this should result in a file that has all the right meta fields and whatnot that Youtube likes. Back to my original story and the 40-odd clips created through Kdenlive this way.
|
||||
|
||||
P.S. If your clip has valid audio, then just re-run it through Kdenlive. If it does not, do the video/audio trick from before. Mute clips as necessary. In the end, this is just like overlay, except you're using the video source from one clip and audio from another for the final render. Job done.
|
||||
|
||||
### More reading
|
||||
|
||||
I do not wish to repeat myself or spam unnecessarily with links. I have loads of clips on VLC in the Software & Security section, so you might want to consult those. The earlier mentioned article on VLC & Subtitles has links to about half a dozen related tutorials, covering additional topics like streaming, logging, video rotation, remote file access, and more. I'm sure you can work the search engine like pros.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I hope you find this guide helpful. It covers a lot, and I tried to make it linear and simple and address as many pitfalls entrepreneuring streamers and subtitle lovers may face when working with VLC. It's all about containers and codecs, but also the fact there are virtually no standards in the media world, and when you go from one format to another, sometimes you may encounter corner cases.
|
||||
|
||||
If you do hit an error or three, the tips and tricks here should help you solve at least some of them, including unplayable streams, missing or duplicate subtitles, missing codecs and the wicked Kdenlive workaround, Youtube upload errors, hidden VLC command line options, and a few other extras. Quite a lot for a single piece of text, right. Luckily, all good stuff. Take care, children of the Internet. And if you have any other requests as to what next my future VLC articles should cover, do feel liberated enough to send an email.
|
||||
|
||||
Cheers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
||||
|
||||
作者:[Dedoimedo ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
[1]:https://www.youtube.com/watch?v=MpDdGOKZ3dg
|
||||
[2]:https://www.youtube.com/watch?v=KHG6fXEba0A
|
||||
[3]:https://www.youtube.com/watch?v=TXw5lRi97YY
|
||||
[4]:https://www.youtube.com/watch?v=cDphUib5iG4
|
||||
[5]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
||||
[6]:http://www.dedoimedo.com/computers/vlc-subtitles.html
|
||||
[7]:https://trac.videolan.org/vlc/ticket/6184
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中++++++++++++++
|
||||
++++++++++++++
|
||||
Getting started with Perl on the Raspberry Pi
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,310 +0,0 @@
|
||||
ucasFL translating
|
||||
|
||||
STUDY RUBY PROGRAMMING WITH OPEN-SOURCE BOOKS
|
||||
============================================================
|
||||
|
||||
### Open Source Ruby Books
|
||||
|
||||
Ruby is a general purpose, scripting, structured, flexible, fully object-oriented programming language developed by Yukihiro “Matz” Matsumoto. It features a fully dynamic type system, which means that the majority of its type checking is performed at run-time rather than at compilation. This stops programmers having to overly worry about integer and string types. Ruby has automatic memory management. The language shares many similar traits with Python, Perl, Lisp, Ada, Eiffel, and Smalltalk.
|
||||
|
||||
Ruby’s popularity was enhanced by the Ruby on Rails framework, a full-stack web framework which has been used to create many popular applications including Basecamp, GitHub, Shopify, Airbnb, Twitch, SoundCloud, Hulu, Zendesk, Square, and Highrise.
|
||||
|
||||
Ruby possesses a high portability running on Linux, Windows, Mac OS X, Cygwin, FreeBSD, NetBSD, OpenBSD, BSD/OS, Solaris, Tru64 UNIX, HP-UX, and many other operating systems. The TIOBE Programming Community index currently ranks Ruby in 12th place.
|
||||
|
||||
This compilation makes 9 strong recommendations. There are books here for beginner, intermediate, and advanced programmers. All of the texts are, of course, released under an open source license.
|
||||
|
||||
This article is part of [OSSBlog’s series of open source programming books][18].
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Best Practices][1]
|
||||
|
||||
By Gregory Brown (328 pages)
|
||||
|
||||
Ruby Best Practices is for programmers who want to use Ruby as experienced Rubyists do. Written by the developer of the Ruby project Prawn, this book explains how to design beautiful APIs and domain-specific languages with Ruby, as well as how to work with functional programming ideas and techniques that can simplify your code and make you more productive.
|
||||
|
||||
Ruby Best Practices is much more about how to go about solving problems in Ruby than it is about the exact solution you should use. The book is not targeted at the Ruby beginner, and will be of little use to someone new to programming. The book assumes a reasonable technical understanding of Ruby, and some experience in developing software with it.
|
||||
|
||||
The book is split into two parts, with eight chapters forming its core and three appendixes included as supplementary material.
|
||||
|
||||
This book provides a wealth of information on:
|
||||
|
||||
* Driving Code Through Tests – covers a number testing philosophies and techniques. Use mocks and stubs
|
||||
* Designing Beautiful APIs with special focus on Ruby’s secret powers: Flexible argument processing and code blocks
|
||||
* Mastering the Dynamic Toolkit showing developers how to build flexible interfaces, implementing per-object behaviour, extending and modifying pre-existing code, and building classes and modules programmatically
|
||||
* Text Processing and File Management focusing on regular expressions, working with files, the tempfile standard library, and text-processing strategies
|
||||
* Functional Programming Techniques highlighting modular code organisation, memoization, infinite lists, and higher-order procedures
|
||||
* Understand how and why things can go wrong explaining how to work with logger
|
||||
* Reduce Cultural Barriers by leveraging Ruby’s multilingual capabilities
|
||||
* Skillful Project Maintenance
|
||||
|
||||
The book is open source, released under the Creative Commons NC-SA license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [I Love Ruby][2]
|
||||
|
||||
By Karthikeyan A K (246 pages)
|
||||
|
||||
I Love Ruby explains fundamental concepts and techniques in greater depth than traditional introductions. This approach provides a solid foundation for writing useful, correct, maintainable, and efficient Ruby code.
|
||||
|
||||
Chapters cover:
|
||||
|
||||
* Variables
|
||||
* Strings
|
||||
* Comparison and Logic
|
||||
* Loops
|
||||
* Arrays
|
||||
* Hashes and Symbols
|
||||
* Ranges
|
||||
* Functions
|
||||
* Variable Scope
|
||||
* Classes & Objects
|
||||
* Rdoc
|
||||
* Modules and Mixins
|
||||
* Date and Time
|
||||
* Files
|
||||
* Proc, Lambdas and Blocks
|
||||
* Multi Threading
|
||||
* Exception Handling
|
||||
* Regular Expressions
|
||||
* Gems
|
||||
* Meta Programming
|
||||
|
||||
Permission is granted to copy, distribute and/or modify the book under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Programming Ruby – The Pragmatic Programmer’s Guide][3]
|
||||
|
||||
By David Thomas, Andrew Hunt (HTML)
|
||||
|
||||
Programming Ruby is a tutorial and reference for the Ruby programming language. Use Ruby, and you will write better code, be more productive, and make programming a more enjoyable experience.
|
||||
|
||||
Topics covered include:
|
||||
|
||||
* Classes, Objects and Variables
|
||||
* Containers, Blocks and Iterators
|
||||
* Standard Types
|
||||
* More about Methods
|
||||
* Expressions
|
||||
* Exceptions, Catch and Throw
|
||||
* Modules
|
||||
* Basic Input and Output
|
||||
* Threads and Processes
|
||||
* When Trouble Strikes
|
||||
* Ruby and its World, the Web, Tk, and Microsoft Windows
|
||||
* Extending Ruby
|
||||
* Reflection, ObjectSpace and Distributed Ruby
|
||||
* Standard Library
|
||||
* Object-Oriented Design Libraries
|
||||
* Network and Web Libraries
|
||||
* Embedded Documentation
|
||||
* Interactive Ruby Shell
|
||||
|
||||
The first edition of this book is released under the Open Publication License, v1.0 or later. An updated Second Edition of this book, covering Ruby 1.8 and including descriptions of all the new libraries is available, but is not released under a freely distributable license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Why’s (Poignant) Guide to Ruby][4]
|
||||
|
||||
By why the lucky stiff (176 pages)
|
||||
|
||||
Why’s (poignant) Guide to Ruby is an introductory book to the Ruby programming language. The book includes some wacky humour and goes off-topic on occasions. The book includes jokes that are known within the Ruby community as well as cartoon characters.
|
||||
|
||||
The contents of the book:
|
||||
|
||||
* About this book
|
||||
* Kon’nichi wa, Ruby
|
||||
* A Quick (and Hopefully Painless) Ride Through Ruby (with Cartoon Foxes): basic introduction to central Ruby concepts
|
||||
* Floating Little Leaves of Code: evaluation and values, hashes and lists
|
||||
* Them What Make the Rules and Them What Live the Dream: case/when, while/until, variable scope, blocks, methods, class definitions, class attributes, objects, modules, introspection in IRB, dup, self, rbconfig module
|
||||
* Downtown: metaprogramming, regular expressions
|
||||
* When You Wish Upon a Beard: send method, new methods in existing classes
|
||||
* Heaven’s Harp
|
||||
|
||||
This book is made available under the Creative Commons Attribution-ShareAlike License.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Hacking Guide][5]
|
||||
|
||||
By Minero Aoki – translated by Vincent Isambart and Clifford Escobar Caoille (HTML)
|
||||
|
||||
This book has the following goals:
|
||||
|
||||
* To have knowledge of the structure of Ruby
|
||||
* To gain knowledge about language processing systems in general
|
||||
* To acquire skills in reading source code
|
||||
|
||||
This book has four main parts:
|
||||
|
||||
* Objects
|
||||
* Syntactic analysis
|
||||
* Evaluation
|
||||
* Peripheral around the evaluator
|
||||
|
||||
Knowledge about the C language and the basics of object-oriented programming is needed to get the most from the book. This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike2.5 license.
|
||||
|
||||
The official support site of the original book is [i.loveruby.net/ja/rhg/][10]
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Book Of Ruby][6]
|
||||
|
||||
By How Collingbourne (425 pages)
|
||||
|
||||
The Book Of Ruby is a free in-depth tutorial to Ruby programming.
|
||||
|
||||
The Book Of Ruby is provided in the form of a PDF document in which each chapter is accompanied by ready-to-run source code for all the examples. There is also an Introduction which explains how to use the source code in Ruby In Steel or any other editor/IDE of your choice plus appendices and an index. It concentrates principally on version 1.8.x of the Ruby language.
|
||||
|
||||
The book is divided up into bite-sized chunks. Each chapter introduces a theme which is subdivided into sub-topics. Each programming topic is accompanied by one or more small self-contained, ready-to-run Ruby programs.
|
||||
|
||||
* Strings, Numbers, Classes, and Objects – getting and putting input, strings and embedded evaluation, numbers, testing a condition: if … then, local and global variables, classes and objects, instance variables, messages, methods and polymorphism, constructors, and inspecting objects
|
||||
* Class Hierarchies, Attributes, and Class Variables – superclasses and subclasses, passing arguments to the superclass, accessor methods, ‘set’ accessors, attribute readers and writers, calling methods of a superclass, and class variables
|
||||
* Strings and Ranges – user-defined string delimiters, backquotes, and more
|
||||
* Arrays and Hashes – shows how to create a list of objects
|
||||
* Loops and Iterators – for loops, blocks, while loops, while modifiers, and until loops
|
||||
* Conditional Statements – If..Then..Else, And..Or..Not, If..Elsif, unless, if and unless modifiers, and case statements
|
||||
* Methods – class methods, class variables, what are class methods for, ruby constructors, singleton methods, singleton classes, overriding methods and more
|
||||
* Passing Arguments and Returning Values – instance methods, class methods, singleton methods, returning values, returning multiple values, default and multiple arguments, assignment and parameter passing, and more
|
||||
* Exception Handling – covers rescue, ensure, else, error numbers, retry, and raise
|
||||
* Blocks, Procs, and Lambdas – explains why they are special to Ruby
|
||||
* Symbols – symbols and strings, symbols and variables, and why symbols should be used
|
||||
* Modules and Mixins
|
||||
* Files and IO – opening and closing files, files and directories, copying files, directory enquiries, a discursion into recursion, and sorting by size
|
||||
* YAML – includes nested sequences, saving YAML data and more
|
||||
* Marshal – offers an alternative way of saving and loading data
|
||||
* Regular Expressions – making matches, match groups, and more
|
||||
* Threads – shows you how to run more than one task at a time
|
||||
* Debugging and Testing – covers the interactive ruby shell (IRB.exe), debugging, and unit testing
|
||||
* Ruby on Rails – goes through a hands-on guide to create a blog
|
||||
* Dynamic Programming – self-modifying programs, eval magic, special types of eval, adding variables and methods, and more
|
||||
|
||||
The book is distributed by SapphireSteel Software – developers of the Ruby In Steel IDE for Visual Studio. Readers may copy or distribute the text and programs of The Book Of Ruby (free edition).
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Little Book Of Ruby][7]
|
||||
|
||||
By Huw Collingbourne (87 pages)
|
||||
|
||||
The Little Book of Ruby is a step-by-step tutorial to programming in Ruby. It guides the reader through the fundamentals of Ruby. It shares content with The Book of Ruby, but aims to be a simpler guide to the main features of Ruby.
|
||||
|
||||
Chapters cover:
|
||||
|
||||
* Strings and Methods – including embedded evaluation. Details the syntax to Ruby methods
|
||||
* Classes and Objects – explains how to create new types of objects
|
||||
* Class Hierarchies – a class which is a ‘special type ’ of some other class simply ‘inherits’ the features of that other class
|
||||
* Accessors, Attributes, Class Variables – accessor methods, attribute readers and writers, attributes create variables, calling methods of a superclass, and class variables are explored
|
||||
* Arrays – learn how to create a list of objects: arrays including multi-dimensional arrays,
|
||||
* Hashes – create, indexing into a hash, and hash operations are covered
|
||||
* Loops and Iterators – for loops, blocks, while loops, while modifiers, and until loops
|
||||
* Conditional Statements – If..Then..Else, And..Or..Not, If..Elsif, unless, if and unless modifiers, and case statements
|
||||
* Modules and Mixins – including module methods, modules as namespaces, module ‘instance methods’, included modules or ‘mixins’, including modules from files, and pre-defined modules
|
||||
* Saving Files, Moving on..
|
||||
|
||||
This book can be copied and distributed freely as long as the text is not modified and the copyright notice is retained.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Kestrels, Quirky Birds, and Hopeless Egocentricity][8]
|
||||
|
||||
By Reg “raganwald” Braithwaite (123 pages)
|
||||
|
||||
Kestrels, Quirky Birds, and Hopeless Egocentricity collects Reg “Raganwald” Braithwaite’s series of essays about Combinatory Logic, Method Combinators, and Ruby Meta-Programing into a convenient e-book.
|
||||
|
||||
The book provides a gentle introduction to Combinatory Logic, applied using the Ruby programming language. Combinatory Logic is a mathematical notation that is powerful enough to handle set theory and issues in computability.
|
||||
|
||||
In this book, the reader meets some of the standard combinators, and for each one the book explores some of its ramifications when writing programs using the Ruby programming language. In Combinatory Logic, combinators combine and alter each other, and the book’s Ruby examples focus on combining and altering Ruby code. From simple examples like the K Combinator and Ruby’s .tap method, the books works up to meta-programming with aspects and recursive combinators.
|
||||
|
||||
The book is published under the MIT license.
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Programming][9]
|
||||
|
||||
By Wikibooks.org (261 pages)
|
||||
|
||||
Ruby is an interpreted, object-oriented programming language.
|
||||
|
||||
The book is broken down into several sections and is intended to be read sequentially.
|
||||
|
||||
* Getting started – shows users how to install and begin using Ruby in an environment
|
||||
* Basic Ruby – explains the main features of the syntax of Ruby. It covers, amongst other things, strings, encoding, writing methods, classes and objects, and exceptions
|
||||
* Ruby Semantic reference
|
||||
* Built in classes
|
||||
* Available modules covers some of the standard library
|
||||
* Intermediate Ruby covers a selection of slightly more advanced topics
|
||||
|
||||
This book is published under the Creative Commons Attribution-ShareAlike 3.0 Unported license.
|
||||
|
||||
|
|
||||
|
||||
* * *
|
||||
|
||||
In no particular order, I’ll close with useful free-to-download Ruby programming books which are not released under an open source license.
|
||||
|
||||
* [Mr. Neighborly’s Humble Little Ruby Book][11] – an easy to read, easy to follow guide to all things Ruby.
|
||||
* [Introduction to Programming with Ruby][12] – learn the basic foundational building blocks of programming, starting from the very beginning
|
||||
* [Object Oriented Programming with Ruby][13] – learn the basic foundational building blocks of object oriented programming, starting from the very beginning
|
||||
* [Core Ruby Tools][14] – provides a short tour of four core Ruby tools: Gems, Ruby Version Managers, Bundler, and Rake.
|
||||
* [Learn Ruby the Hard Way, 3rd Edition][15] – a simple book designed to start your programming adventures
|
||||
* [Learn to Program][16] – by Chris Pine
|
||||
* [Ruby Essentials][17] – designed to provide a concise and easy to follow guide to learning Ruby.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/study-ruby-programming-with-open-source-books/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://github.com/practicingruby/rbp-book/tree/gh-pages/pdfs
|
||||
[2]:https://mindaslab.github.io/I-Love-Ruby/
|
||||
[3]:http://ruby-doc.com/docs/ProgrammingRuby/
|
||||
[4]:http://poignant.guide/
|
||||
[5]:http://ruby-hacking-guide.github.io/
|
||||
[6]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[7]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[8]:https://leanpub.com/combinators
|
||||
[9]:https://en.wikibooks.org/wiki/Ruby_Programming
|
||||
[10]:http://i.loveruby.net/ja/rhg/
|
||||
[11]:http://www.humblelittlerubybook.com/
|
||||
[12]:https://launchschool.com/books/ruby
|
||||
[13]:https://launchschool.com/books/oo_ruby
|
||||
[14]:https://launchschool.com/books/core_ruby_tools
|
||||
[15]:https://learnrubythehardway.org/book/
|
||||
[16]:https://pine.fm/LearnToProgram
|
||||
[17]:http://www.techotopia.com/index.php/Ruby_Essentials
|
||||
[18]:https://www.ossblog.org/opensourcebooks/
|
||||
@ -1,5 +1,3 @@
|
||||
tranlated by mudongliang
|
||||
|
||||
FEWER MALLOCS IN CURL
|
||||
===========================================================
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
Translating by ChauncyD
|
||||
translating-----geekpi
|
||||
|
||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,179 +0,0 @@
|
||||
XYenChi is translating
|
||||
A beginner's guide to collecting and mapping Twitter data using R
|
||||
============================================================
|
||||
|
||||
### Learn to use R's twitteR and leaflet packages, which allow you to map the location of tweets on any topic.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Jason Baker][14]. [CC BY-SA 4.0][15]. Source: [Cloud][16], [Globe][17]. Both [CC0][18].
|
||||
|
||||
When I started learning R, I also needed to learn how to collect Twitter data and map it for research purposes. Despite the wealth of information on the internet about this topic, I found it difficult to understand what was involved in collecting and mapping Twitter data. Not only was I was a novice to R, but I was also unfamiliar with the technical terms in the various tutorials. Despite these barriers, I was successful! In this tutorial, I will break down how to collect Twitter data and display it on a map in a way that even novice coders can understand.
|
||||
|
||||
Programming and development
|
||||
|
||||
* [New Python content][1]
|
||||
|
||||
* [Our latest JavaScript articles][2]
|
||||
|
||||
* [Recent Perl posts][3]
|
||||
|
||||
* [Red Hat Developers Blog][4]
|
||||
|
||||
### Create the app
|
||||
|
||||
If you don't have a Twitter account, the first thing you need to do is to [create one][19]. After that, go to [apps.twitter.com][20] to create an app that allows you to collect Twitter data. Don't worry, creating the app is extremely easy. The app you create will connect to the Twitter application program interface (API). Think of an API as an electronic personal assistant of sorts. You will be using the API to ask another program to do something for you. In this case, you will be connecting to the Twitter API and asking it to collect data. Just make sure you don't ask too much, because there is a [limit][21] on how many times you can request Twitter data.
|
||||
|
||||
There are two APIs that you can use to collect tweets. If you want to do a one-time collection of tweets, then you'll use the **REST API**. If you want to do a continuous collection of tweets for a specific time period, you'll use the **streaming API**. In this tutorial, I'll focus on using the REST API.
|
||||
|
||||
After you create your app, go to the **Keys and Access Tokens** tab. You will need the Consumer Key (API key), Consumer Secret (API secret), Access Token, and Access Token Secret to access your app in R.
|
||||
|
||||
### Collect the Twitter data
|
||||
|
||||
The next step is to open R and get ready to write code. For beginners, I recommend using [RStudio][22], the integrated development environment (IDE) for R. I find using RStudio helpful when I am troubleshooting or testing code. R has a package to access the REST API called **[twitteR][8]**.
|
||||
|
||||
Open RStudio and create a new RScript. Once you have done this, you will need to install and load the **twitteR** package:
|
||||
|
||||
```
|
||||
install.packages("twitteR")
|
||||
#installs TwitteR
|
||||
library (twitteR)
|
||||
#loads TwitteR
|
||||
```
|
||||
|
||||
Once you've installed and loaded the **twitteR** package, you will need to enter the your app's API information from the section above:
|
||||
|
||||
```
|
||||
api_key <- ""
|
||||
#in the quotes, put your API key
|
||||
api_secret <- ""
|
||||
#in the quotes, put your API secret token
|
||||
token <- ""
|
||||
#in the quotes, put your token
|
||||
token_secret <- ""
|
||||
#in the quotes, put your token secret
|
||||
```
|
||||
|
||||
Next, connect to Twitter to access the API:
|
||||
|
||||
```
|
||||
setup_twitter_oauth(api_key, api_secret, token, token_secret)
|
||||
```
|
||||
|
||||
Let's try doing a Twitter search about community gardens and farmers markets:
|
||||
|
||||
```
|
||||
tweets <- searchTwitter("community garden OR #communitygarden OR farmers market OR #farmersmarket", n = 200, lang = "en")
|
||||
```
|
||||
|
||||
This code simply says to search for the first 200 tweets **(n = 200)** in English **(lang = "en")**, which contain the terms **community garden** or **farmers market**or any hashtag mentioning these terms.
|
||||
|
||||
After you have done your Twitter search, save your results in a data frame:
|
||||
|
||||
```
|
||||
tweets.df <-twListToDF(tweets)
|
||||
```
|
||||
|
||||
To create a map with your tweets, you will need to export what you collected into a **.csv** file:
|
||||
|
||||
```
|
||||
write.csv(tweets.df, "C:\Users\YourName\Documents\ApptoMap\tweets.csv")
|
||||
#an example of a file extension of the folder in which you want to save the .csv file.
|
||||
```
|
||||
|
||||
Make sure you save your **R** code before running it and moving on to the next step.
|
||||
|
||||
### Create the map
|
||||
|
||||
Now that you have data, you can display it in a map. For this tutorial, we will make a basic app using the R package **[Leaflet][9]**, a popular JavaScript library for making interactive maps. Leaflet uses the [**magrittr**][23] pipe operator (**%>%**), which makes it easier to write code because the syntax is more natural. It might seem strange at first, but it does cut down on the amount of work you have to do when writing code.
|
||||
|
||||
For the sake of clarity, open a new R script in RStudio and install these packages:
|
||||
|
||||
```
|
||||
install.packages("leaflet")
|
||||
install.packages("maps")
|
||||
library(leaflet)
|
||||
library(maps)
|
||||
```
|
||||
|
||||
Now you need a way for Leaflet to access your data:
|
||||
|
||||
```
|
||||
read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv", stringsAsFactors = FALSE)
|
||||
```
|
||||
|
||||
**stringAsFactors = FALSE** means to keep the information as it is and not convert it into factors. (For information about factors, read the article ["stringsAsFactors: An unauthorized biography"][24], by Roger Peng.)
|
||||
|
||||
It's time to make your Leaflet map. You are going to use the **OpenStreetMap**base map for your map:
|
||||
|
||||
```
|
||||
m <- leaflet(mymap) %>% addTiles()
|
||||
```
|
||||
|
||||
Let's add circles to the base map. For **lng** and **lat**, enter the name of the columns that contain the latitude and longitude of your tweets followed by **~**. The **~longitude** and **~latitude** refer to the name of the columns in your **.csv** file:
|
||||
|
||||
```
|
||||
m %>% addCircles(lng = ~longitude, lat = ~latitude, popup = mymap$type, weight = 8, radius = 40, color = "#fb3004", stroke = TRUE, fillOpacity = 0.8)
|
||||
```
|
||||
|
||||
Run your code. A web browser should pop up and display your map. Here is a map of the tweets that I collected in the previous section:
|
||||
|
||||
### [leafletmap.jpg][6]
|
||||
|
||||

|
||||
|
||||
Map of tweets by location, Leaflet and OpenStreetMap, [CC-BY-SA][5]
|
||||
|
||||
<add here="" leafletmap.jpg=""></add>
|
||||
|
||||
Although you might be surprised with the small number of tweets on the map, typically only 1% of tweets are geocoded. I collected a total of 366 tweets, but only 10 (around 3% of total tweets) were geocoded. If you are having trouble getting geocoded tweets, change your search terms to see if you get a better result.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
For beginners, putting all the pieces together to create a Leaflet map from Twitter data can be overwhelming. This tutorial is based on my experiences doing this task, and I hope it makes the learning process easier for you.
|
||||
|
||||
_Dorris Scott will present this topic in a workshop, [From App to Map: Collecting and Mapping Social Media Data using R][10], at the [We Rise][11] Women in Tech Conference ([#WeRiseTech][12]) June 23-24 in Atlanta._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Dorris Scott - Dorris Scott is a PhD student in geography at the University of Georgia. Her research emphases are in Geographic Information Systems (GIS), geographic data science, visualization, and public health. Her dissertation is on combining traditional and non-traditional data about Veteran’s Affairs hospitals in a GIS interface to help patients make more informed decisions regarding their healthcare.
|
||||
|
||||
|
||||
-----------------
|
||||
via: https://opensource.com/article/17/6/collecting-and-mapping-twitter-data-using-r
|
||||
|
||||
作者:[Dorris Scott ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dorrisscott
|
||||
[1]:https://opensource.com/tags/python?src=programming_resource_menu
|
||||
[2]:https://opensource.com/tags/javascript?src=programming_resource_menu
|
||||
[3]:https://opensource.com/tags/perl?src=programming_resource_menu
|
||||
[4]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ&src=programming_resource_menu
|
||||
[5]:https://creativecommons.org/licenses/by-sa/2.0/
|
||||
[6]:https://opensource.com/file/356071
|
||||
[7]:https://opensource.com/article/17/6/collecting-and-mapping-twitter-data-using-r?rate=Rnu6Lf0Eqvepznw75VioNPWIaJQH39pZETBfu2ZI3P0
|
||||
[8]:https://cran.r-project.org/web/packages/twitteR/twitteR.pdf
|
||||
[9]:https://rstudio.github.io/leaflet
|
||||
[10]:https://werise.tech/sessions/2017/4/16/from-app-to-map-collecting-and-mapping-social-media-data-using-r?rq=social%20mapping
|
||||
[11]:https://werise.tech/
|
||||
[12]:https://twitter.com/search?q=%23WeRiseTech&src=typd
|
||||
[13]:https://opensource.com/user/145006/feed
|
||||
[14]:https://opensource.com/users/jason-baker
|
||||
[15]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[16]:https://pixabay.com/en/clouds-sky-cloud-dark-clouds-1473311/
|
||||
[17]:https://pixabay.com/en/globe-planet-earth-world-1015311/
|
||||
[18]:https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[19]:https://twitter.com/signup
|
||||
[20]:https://apps.twitter.com/
|
||||
[21]:https://dev.twitter.com/rest/public/rate-limiting
|
||||
[22]:https://www.rstudio.com/
|
||||
[23]:https://github.com/smbache/magrittr
|
||||
[24]:http://simplystatistics.org/2015/07/24/stringsasfactors-an-unauthorized-biography/
|
||||
[25]:https://opensource.com/users/dorrisscott
|
||||
@ -1,94 +0,0 @@
|
||||
The What, Why and Wow! Behind the CoreOS Container Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
#### Latest Linux distro automatically updates kernel software and gives full configuration control across clusters.
|
||||
|
||||
The usual debate over server Linux distributions begins with:
|
||||
|
||||
_Do you use a _ [_Red Hat Enterprise Linux (RHEL)_][1] _-based distribution, such as _ [_CentOS_][2] _ or _ [_Fedora_][3] _; a _ [_Debian_][4] _-based Linux like _ [_Ubuntu_][5] _; or _ [_SUSE_][6] _?_
|
||||
|
||||
But now, [CoreOS Container Linux][7] joins the fracas. [CoreOS, recently offered by Linode on its servers][8], takes an entirely different approach than its more conventional, elder siblings.
|
||||
|
||||
So, you may be asking yourself: “Why should I bother, when there are so many other solid Linux distros?” Well, I’ll let Greg Kroah-Hartman, the kernel maintainer for the Linux-stable branch and CoreOS advisor, start the conversation:
|
||||
|
||||
> (CoreOS) handles distro updates (based on the ChromeOS code) combined with Docker and potentially checkpoint/restore, (which) means that you might be [able to update the distro under your application without stopping/starting the process/container.][9] I’ve seen it happen in testing, and it’s scary [good].”
|
||||
|
||||
And that assessment came when CoreOS was in alpha. Back then, [CoreOS was being developed in — believe it or not — a Silicon Valley garage][10]. While CoreOS is no Apple or HPE, it’s grown considerably in the last four years.
|
||||
|
||||
When I checked in on them at 2017’s [CoreOS Fest][11] in San Francisco, CoreOS had support from Google Cloud, IBM, Amazon Web Services, and Microsoft. The project itself now has over a thousand contributors. They think they’re on to something good, and I agree.
|
||||
|
||||
Why? Because, CoreOS is a lightweight Linux designed from the get-go for running containers. It started as a [Docker][12] platform, but over time CoreOS has taken its own path to containers. It now supports both its own take on containers, [rkt][13] (pronounced rocket), and Docker.
|
||||
|
||||
Unlike most Linux distributions, CoreOS doesn’t have a package manager. Instead it takes a page from Google’s ChromeOS and automates software updates to ensure better security and reliability of machines and containers running on clusters. Both operating system updates and security patches are regularly pushed to CoreOS Container Linux machines without sysadmin intervention.
|
||||
|
||||
You control how often patches are pushed using [CoreUpdate, with its web-based interface][14]. This enables you to control when your machines update, and how quickly an update is rolled out across your cluster.
|
||||
|
||||
Specifically, CoreOS does this with the the distributed configuration service [etcd][15]. This is an open-source, distributed key value store based on [YAML][16]. Etcd provides shared configuration and service discovery for Container Linux clusters.
|
||||
|
||||
This service runs on each machine in a cluster. When one server goes down, say to update, it handles the leader election so that the overall Linux system and containerized applications keep running as each server is updated.
|
||||
|
||||
To handle cluster management, [CoreOS used to use fleet][17]. This ties together [systemd][18] and etcd into a distributed init system. While fleet is still around, CoreOS has joined etcd with [Kubernetes][19] container orchestration to form an even more powerful management tool.
|
||||
|
||||
CoreOS also enables you to declaratively customize other operating system specifications, such as network configuration, user accounts, and systemd units, with [cloud-config][20].
|
||||
|
||||
Put it all together and you have a Linux that’s constantly self-updating to the latest patches while giving you full control over its configuration from individual systems to thousand of container instances. Or, as CoreOS puts it, “You’ll never have to run [Chef ][21]on every machine in order to change a single config value ever again.”
|
||||
|
||||
Let’s say you want to expand your DevOps control even further. [CoreOS helps you there, too, by making it easy to deploy Kubernetes][22].
|
||||
|
||||
So, what does all this mean? CoreOS is built from the ground-up to make it easy to deploy, manage and run containers. Yes, other Linux distributions, such as the Red Hat family with [Project Atomic][23], also enable you to do this, but for these distributions, it’s an add-on. CoreOS was designed from day one for containers.
|
||||
|
||||
If you foresee using containers in your business — and you’d better because [Docker and containers are fast becoming _The Way_ to develop and run business applications][24] — then you must consider CoreOS Container Linux, no matter whether you’re running on bare-metal, virtual machines, or the cloud.
|
||||
|
||||
* * *
|
||||
|
||||
_Please feel free to share below any comments or insights about your experience with or questions about CoreOS. And if you found this blog useful, please consider sharing it through social media._
|
||||
|
||||
* * *
|
||||
|
||||
_About the blogger: Steven J. Vaughan-Nichols is a veteran IT journalist whose estimable work can be found on a host of channels, including _ [_ZDNet.com_][25] _, _ [_PC Magazine_][26] _, _ [_InfoWorld_][27] _, _ [_ComputerWorld_][28] _, _ [_Linux Today_][29] _ and _ [_eWEEK_][30] _. Steven’s IT expertise comes without parallel — he has even been a Jeopardy! clue. And while his views and cloud situations are solely his and don’t necessarily reflect those of Linode, we are grateful for his contributions. He can be followed on Twitter (_ [_@sjvn_][31] _)._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
[1]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[2]:https://www.centos.org/
|
||||
[3]:https://getfedora.org/
|
||||
[4]:https://www.debian.org/
|
||||
[5]:https://www.ubuntu.com/
|
||||
[6]:https://www.suse.com/
|
||||
[7]:https://coreos.com/os/docs/latest
|
||||
[8]:https://www.linode.com/docs/platform/use-coreos-container-linux-on-linode
|
||||
[9]:https://plus.google.com/+gregkroahhartman/posts/YvWFmPa9kVf
|
||||
[10]:https://www.wired.com/2013/08/coreos-the-new-linux/
|
||||
[11]:https://coreos.com/fest/
|
||||
[12]:https://www.docker.com/
|
||||
[13]:https://coreos.com/rkt
|
||||
[14]:https://coreos.com/products/coreupdate/
|
||||
[15]:https://github.com/coreos/etcd
|
||||
[16]:http://yaml.org/
|
||||
[17]:https://github.com/coreos/fleet
|
||||
[18]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[19]:https://kubernetes.io/
|
||||
[20]:https://coreos.com/os/docs/latest/cloud-config.html
|
||||
[21]:https://insights.hpe.com/articles/what-is-chef-a-primer-for-devops-newbies-1704.html
|
||||
[22]:https://blogs.dxc.technology/2017/06/08/coreos-moves-in-on-cloud-devops-with-kubernetes/
|
||||
[23]:http://www.projectatomic.io/
|
||||
[24]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[25]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[26]:http://www.pcmag.com/author-bio/steven-j.-vaughan-nichols
|
||||
[27]:http://www.infoworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[28]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[29]:http://www.linuxtoday.com/author/Steven+J.+Vaughan-Nichols/
|
||||
[30]:http://www.eweek.com/cp/bio/Steven-J.-Vaughan-Nichols/
|
||||
[31]:http://www.twitter.com/sjvn
|
||||
@ -1,228 +0,0 @@
|
||||
|
||||
translating by xllc
|
||||
|
||||
3 mistakes to avoid when learning to code in Python
|
||||
============================================================
|
||||
|
||||
### These errors created big problems that took hours to solve.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
It's never easy to admit when you do things wrong, but making errors is part of any learning process, from learning to walk to learning a new programming language, such as Python.
|
||||
|
||||
Here's a list of three things I got wrong when I was learning Python, presented so that newer Python programmers can avoid making the same mistakes. These are errors that either I got away with for a long time or that that created big problems that took hours to solve.
|
||||
|
||||
Take heed young coders, some of these mistakes are afternoon wasters!
|
||||
|
||||
### 1\. Mutable data types as default arguments in function definitions
|
||||
|
||||
It makes sense right? You have a little function that, let's say, searches for links on a current page and optionally appends it to another supplied list.
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=[]):
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
On the face of it, this looks like perfectly normal Python, and indeed it is. It works. But there are issues with it. If we supply a list for the **add_to** parameter, it works as expected. If, however, we let it use the default, something interesting happens.
|
||||
|
||||
Try the following code:
|
||||
|
||||
```
|
||||
def fn(var1, var2=[]):
|
||||
var2.append(var1)
|
||||
print var2
|
||||
|
||||
fn(3)
|
||||
fn(4)
|
||||
fn(5)
|
||||
```
|
||||
|
||||
You may expect that we would see:
|
||||
|
||||
**[3]
|
||||
[4]
|
||||
[5]**
|
||||
|
||||
But we actually see this:
|
||||
|
||||
**[3]
|
||||
[3, 4]
|
||||
[3, 4, 5]**
|
||||
|
||||
Why? Well, you see, the same list is used each time. In Python, when we write the function like this, the list is instantiated as part of the function's definition. It is not instantiated each time the function is run. This means that the function keeps using the exact same list object again and again, unless of course we supply another one:
|
||||
|
||||
```
|
||||
fn(3, [4])
|
||||
```
|
||||
|
||||
**[4, 3]**
|
||||
|
||||
Just as expected. The correct way to achieve the desired result is:
|
||||
|
||||
```
|
||||
def fn(var1, var2=None):
|
||||
if not var2:
|
||||
var2 = []
|
||||
var2.append(var1)
|
||||
```
|
||||
|
||||
Or, in our first example:
|
||||
|
||||
```
|
||||
def search_for_links(page, add_to=None):
|
||||
if not add_to:
|
||||
add_to = []
|
||||
new_links = page.search_for_links()
|
||||
add_to.extend(new_links)
|
||||
return add_to
|
||||
```
|
||||
|
||||
This moves the instantiation from module load time so that it happens every time the function runs. Note that for immutable data types, like [**tuples**][7], [**strings**][8], or [**ints**][9], this is not necessary. That means it is perfectly fine to do something like:
|
||||
|
||||
```
|
||||
def func(message="my message"):
|
||||
print message
|
||||
```
|
||||
|
||||
### 2\. Mutable data types as class variables
|
||||
|
||||
Hot on the heels of the last error is one that is very similar. Consider the following:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
This code looks perfectly normal. We have an object with a storage of URLs. When we call the **add_url** method, it adds a given URL to the store. Perfect right? Let's see it in action:
|
||||
|
||||
```
|
||||
a = URLCatcher()
|
||||
a.add_url('http://www.google.')
|
||||
b = URLCatcher()
|
||||
b.add_url('http://www.bbc.co.')
|
||||
```
|
||||
|
||||
**b.urls
|
||||
['[http://www.google.com][2]', '[http://www.bbc.co.uk][3]']**
|
||||
|
||||
**a.urls
|
||||
['[http://www.google.com][4]', '[http://www.bbc.co.uk][5]']**
|
||||
|
||||
Wait, what?! We didn't expect that. We instantiated two separate objects, **a** and **b**. **A** was given one URL and **b** the other. How is it that both objects have both URLs?
|
||||
|
||||
Turns out it's kinda the same problem as in the first example. The URLs list is instantiated when the class definition is created. All instances of that class use the same list. Now, there are some cases where this is advantageous, but the majority of the time you don't want to do this. You want each object to have a separate store. To do that, we would modify the code like:
|
||||
|
||||
```
|
||||
class URLCatcher(object):
|
||||
def __init__(self):
|
||||
self.urls = []
|
||||
|
||||
def add_url(self, url):
|
||||
self.urls.append(url)
|
||||
```
|
||||
|
||||
Now the URLs list is instantiated when the object is created. When we instantiate two separate objects, they will be using two separate lists.
|
||||
|
||||
### 3\. Mutable assignment errors
|
||||
|
||||
This one confused me for a while. Let's change gears a little and use another mutable datatype, the [**dict**][10].
|
||||
|
||||
```
|
||||
a = {'1': "one", '2': 'two'}
|
||||
```
|
||||
|
||||
Now let's assume we want to take that **dict** and use it someplace else, leaving the original intact.
|
||||
|
||||
```
|
||||
b = a
|
||||
|
||||
b['3'] = 'three'
|
||||
```
|
||||
|
||||
Simple eh?
|
||||
|
||||
Now let's look at our original dict, **a**, the one we didn't want to modify:
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Whoa, hold on a minute. What does **b** look like then?
|
||||
|
||||
```
|
||||
{'1': "one", '2': 'two', '3': 'three'}
|
||||
```
|
||||
|
||||
Wait what? But… let's step back and see what happens with our other immutable types, a **tuple** for instance:
|
||||
|
||||
```
|
||||
c = (2, 3)
|
||||
d = c
|
||||
d = (4, 5)
|
||||
```
|
||||
|
||||
Now **c** is:
|
||||
**(2, 3)**
|
||||
|
||||
While **d** is:
|
||||
**(4, 5)**
|
||||
|
||||
That functions as expected. So what happened in our example? When using mutable types, we get something that behaves a little more like a pointer from C. When we said **b = a** in the code above, what we really meant was: **b** is now also a reference to **a**. They both point to the same object in Python's memory. Sound familiar? That's because it's similar to the previous problems. In fact, this post should really have been called, "The Trouble with Mutables."
|
||||
|
||||
Does the same thing happen with lists? Yes. So how do we get around it? Well, we have to be very careful. If we really need to copy a list for processing, we can do so like:
|
||||
|
||||
```
|
||||
b = a[:]
|
||||
```
|
||||
|
||||
This will go through and copy a reference to each item in the list and place it in a new list. But be warned: If any objects in the list are mutable, we will again get references to those, rather than complete copies.
|
||||
|
||||
Imagine having a list on a piece of paper. In the original example, Person A and Person B are looking at the same piece of paper. If someone changes that list, both people will see the same changes. When we copy the references, each person now has their own list. But let's suppose that this list contains places to search for food. If "fridge" is first on the list, even when it is copied, both entries in both lists point to the same fridge. So if the fridge is modified by Person A, by say eating a large gateaux, Person B will also see that the gateaux is missing. There is no easy way around this. It is just something that you need to remember and code in a way that will not cause an issue.
|
||||
|
||||
Dicts function in the same way, and you can create this expensive copy by doing:
|
||||
|
||||
```
|
||||
b = a.copy()
|
||||
```
|
||||
|
||||
Again, this will only create a new dictionary pointing to the same entries that were present in the original. Thus, if we have two lists that are identical and we modify a mutable object that is pointed to by a key from dict 'a', the dict object present in dict 'b' will also see those changes.
|
||||
|
||||
The trouble with mutable data types is that they are powerful. None of the above are real problems; they are things to keep in mind to prevent issues. The expensive copy operations presented as solutions in the third item are unnecessary 99% of the time. Your program can and probably should be modified so that those copies are not even required in the first place.
|
||||
|
||||
_Happy coding! And feel free to ask questions in the comments._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Pete Savage - Peter is a passionate Open Source enthusiast who has been promoting and using Open Source products for the last 10 years. He has volunteered in many different areas, starting in the Ubuntu community, before moving off into the realms of audio production and later into writing. Career wise he spent much of his early years managing and building datacenters as a sysadmin, before ending up working for Red Hat as a Principal Quailty Engineer for the CloudForms product. He occasionally pops out a
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python
|
||||
|
||||
作者:[Pete Savage ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psav
|
||||
[1]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python?rate=SfClhaQ6tQsJdKM8-YTNG00w53fsncvsNWafwuJbtqs
|
||||
[2]:http://www.google.com/
|
||||
[3]:http://www.bbc.co.uk/
|
||||
[4]:http://www.google.com/
|
||||
[5]:http://www.bbc.co.uk/
|
||||
[6]:https://opensource.com/user/36026/feed
|
||||
[7]:https://docs.python.org/2/library/functions.html?highlight=tuple#tuple
|
||||
[8]:https://docs.python.org/2/library/string.html
|
||||
[9]:https://docs.python.org/2/library/functions.html#int
|
||||
[10]:https://docs.python.org/2/library/stdtypes.html?highlight=dict#dict
|
||||
[11]:https://opensource.com/users/psav
|
||||
[12]:https://opensource.com/article/17/6/3-things-i-did-wrong-learning-python#comments
|
||||
@ -1,173 +0,0 @@
|
||||
【Snaplee准备翻译】Build, test, and publish snap packages using snapcraft
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||
_This is a guest post by Ricardo Feliciano, Developer Evangelist at CircleCI. If you would like to contribute a guest post, please contact ubuntu-iot@canonical.com._
|
||||
|
||||
Snapcraft, the package management system fighting for its spot at the Linux table, re-imagines how you can deliver your software. A new set of cross-distro tools are available to help you build and publish “Snaps”. We’ll cover how to use CircleCI 2.0 to power this process and some potential gotchas along the way.
|
||||
|
||||
### What are snap packages? And Snapcraft?
|
||||
|
||||
**Snaps** are software packages for Linux distributions. They’re designed with lessons learned from delivering software on mobile platforms such as Android as well Internet of Things devices. **Snapcraft** is the name that encompasses Snaps and the command-line tool that builds them, [the website][9], and pretty much the entire ecosystem around the technologies that enables this.
|
||||
|
||||
Snap packages are designed to isolate and encapsulate an entire application. This concept enables Snapcraft’s goal of increasing security, stability, and portability of software allowing a single “snap” to be installed on not just multiple versions of Ubuntu, but Debian, Fedora, Arch, and more. Snapcraft’s description per their website:
|
||||
|
||||
“Package any app for every Linux desktop, server, cloud or device, and deliver updates directly.”
|
||||
|
||||
### Building a snap package on CircleCI 2.0
|
||||
|
||||
Building a snap on CircleCI is mostly the same as your local machine, wrapped with [CircleCI 2.0 syntax][10]. We’ll go through a sample config file in this post. If you’re not familiar with CircleCI or would like to know more about getting started with 2.0 specifically, you can start [here][11].
|
||||
|
||||
### Base Config
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
sudo snap install snapcraft --edge --classic
|
||||
/snap/bin/snapcraft
|
||||
|
||||
```
|
||||
|
||||
This example uses the `machine` executor to install `snapd`, the executable that allows you to manage snaps and enables the platform, as well as `snapcraft`, the tool for creating snaps.
|
||||
|
||||
The `machine` executor is used rather than the `docker` executor as we need a newer kernel for the build process. Linux 4.4 is available here, which is new enough for our purposes.
|
||||
|
||||
### Userspace dependencies
|
||||
|
||||
The example above uses the `machine` executor, which currently is [a VM with Ubuntu 14.04 (Trusty)][12] and the Linux v4.4 kernel. This is fine if your project/snap requires build dependencies available in the Trusty repositories. What if you need dependencies available in a different version, perhaps Ubuntu 16.04 (Xenial)? We can still use Docker within the `machine` executor to build our snap.
|
||||
|
||||
```
|
||||
version: 2
|
||||
jobs:
|
||||
build:
|
||||
machine: true
|
||||
working_directory: ~/project
|
||||
steps:
|
||||
- checkout
|
||||
- run:
|
||||
command: |
|
||||
sudo apt update && sudo apt install -y snapd
|
||||
docker run -v $(pwd):$(pwd) -t ubuntu:xenial sh -c "apt update -qq && apt install snapcraft -y && cd $(pwd) && snapcraft"
|
||||
|
||||
```
|
||||
|
||||
In this example, we again install `snapd` in the `machine` executor’s VM, but we decide to install Snapcraft and build our snap within a Docker container built with the Ubuntu Xenial image. All `apt` packages available in Ubuntu 16.04 will be available to `snapcraft` during the build.
|
||||
|
||||
### Testing
|
||||
|
||||
Unit testing your software’s code has been covered extensively in [our blog][13], [our docs][14], and around the Internet. Searching for your language/framework and unit testing or CI will turn up tons of information. Building a snap on CircleCI means we end with a `.snap` file which we can test in addition to the code that created it.
|
||||
|
||||
### Workflows
|
||||
|
||||
Let’s say the snap we built was a webapp. We can build a testing suite to make sure this snap installs and runs correctly. We could try installing the snap. We could run [Selenium][15] to make sure the proper pages load, logins, work, etc. Here’s the catch, snaps are designed to run on multiple Linux distros. That means we need to be able to run this test suite in Ubuntu 16.04, Fedora 25, Debian 9, etc. CircleCI 2.0’s Workflows can efficiently solve this.
|
||||
|
||||
[A recent addition][16] to the CircleCI 2.0 beta is Workflows. This allows us to run discrete jobs in CircleCI with a certain flow logic. In this case, **after** our snap is built, which would be a single job, we could then kick off snap distro testing jobs, running in parallel. One for each distro we want to test. Each of these jobs would be a different [Docker image][17] for that distro (or in the future, additional `executors` will be available).
|
||||
|
||||
Here’s simple example of what this might look like:
|
||||
|
||||
```
|
||||
workflows:
|
||||
version: 2
|
||||
build-test-and-deploy:
|
||||
jobs:
|
||||
- build
|
||||
- acceptance_test_xenial:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_fedora_25:
|
||||
requires:
|
||||
- build
|
||||
- acceptance_test_arch:
|
||||
requires:
|
||||
- build
|
||||
- publish:
|
||||
requires:
|
||||
- acceptance_test_xenial
|
||||
- acceptance_test_fedora_25
|
||||
- acceptance_test_arch
|
||||
|
||||
```
|
||||
|
||||
This setup builds the snap, and then runs acceptance tests on it with four different distros. If and when all distro builds pass, then we can run the publish `job` in order to finish up any remaining snap task before pushing it to the Snap Store.
|
||||
|
||||
### Persisting the .snap package
|
||||
|
||||
To test our `.snap` package in the workflows example, a way of persisting that file between builds is needed. I’ll mention two ways here.
|
||||
|
||||
1. **artifacts** – We could store the snap package as a CircleCI artifact during the `build`job. Then retrieve it within the following jobs. CircleCI Workflows has its own way of of handling sharing artifacts which can be found [here][1].
|
||||
|
||||
2. **snap store channels** – When publishing a snap to the Snap Store, there’s more than one `channel` to choose from. It’s becoming a common practice to publish the master branch of your snap to the `edge` channel for internal and/or user testing. This can be done in the `build` job, with the following jobs installing the snap from the edge channel.
|
||||
|
||||
The first method is faster to complete and has the advantage of being able to run acceptance tests on your snap before it hits the Snap Store and touches any user, even testing users. The second method has the advantage of install from the Snap Store being one of the test that is run during CI.
|
||||
|
||||
### Authenticating with the snap store
|
||||
|
||||
The script [snapcraft-config-generator.py][18] can generate the store credentials and save them to `.snapcraft/snapcraft.cfg` (note: always inspect public scripts before running them). You don’t want to store this file in plaintext in your repo (for security reasons). You can either base64 encode the file and store it as a [private environment variable][19] or you can [encrypt the file][20] and just store the key in a private environment variable.
|
||||
|
||||
Here’s an example of having the store credentials in an encrypted file, and using the creds in a `deploy` step to publish to the Snap Store:
|
||||
|
||||
```
|
||||
- deploy:
|
||||
name: Push to Snap Store
|
||||
command: |
|
||||
openssl aes-256-cbc -d -in .snapcraft/snapcraft.encrypted -out .snapcraft/snapcraft.cfg -k $KEY
|
||||
/snap/bin/snapcraft push *.snap
|
||||
|
||||
```
|
||||
|
||||
Instead of a deploy step, keeping with the Workflow examples from earlier, this could be a deploy job that only runs when and if the acceptance test jobs passed.
|
||||
|
||||
### More information
|
||||
|
||||
* Alan Pope’s [Forum Post][2]: “popey” is a Canonical employee and wrote the post in [Snapcraft’s Forum][3] that inspired this blog post
|
||||
|
||||
* [Snapcraft Website][4]: the official Snapcraft website
|
||||
|
||||
* [Snapcraft’s CircleCI Bug Report][5]: There is an open bug report on Launchpad to add support for CircleCI to Snapcraft. This will make this process a little easier and more “official”. Please add your support.
|
||||
|
||||
* How the [Nextcloud][6] snap is being built with CircleCI: a great blog post called [“Continuous acceptance tests for complex applications”][7]. Also influenced this blog post.
|
||||
|
||||
Original post [here][21]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2017/06/28/build-test-and-publish-snap-packages-using-snapcraft/
|
||||
|
||||
作者:[ Guest ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/guest/
|
||||
[1]:https://circleci.com/docs/2.0/workflows/#using-workspaces-to-share-artifacts-among-jobs
|
||||
[2]:https://forum.snapcraft.io/t/building-and-pushing-snaps-using-circleci/789
|
||||
[3]:https://forum.snapcraft.io/
|
||||
[4]:https://snapcraft.io/
|
||||
[5]:https://bugs.launchpad.net/snapcraft/+bug/1693451
|
||||
[6]:https://nextcloud.com/
|
||||
[7]:https://kyrofa.com/posts/continuous-acceptance-tests-for-complex-applications
|
||||
[8]:https://insights.ubuntu.com/author/guest/
|
||||
[9]:https://snapcraft.io/
|
||||
[10]:https://circleci.com/docs/2.0/
|
||||
[11]:https://circleci.com/docs/2.0/first-steps/
|
||||
[12]:https://circleci.com/docs/1.0/differences-between-trusty-and-precise/
|
||||
[13]:https://circleci.com/blog/
|
||||
[14]:https://circleci.com/docs/
|
||||
[15]:http://www.seleniumhq.org/
|
||||
[16]:https://circleci.com/blog/introducing-workflows-on-circleci-2-0/
|
||||
[17]:https://circleci.com/docs/2.0/building-docker-images/
|
||||
[18]:https://gist.github.com/3v1n0/479ad142eccdd17ad7d0445762dea755
|
||||
[19]:https://circleci.com/docs/1.0/environment-variables/#setting-environment-variables-for-all-commands-without-adding-them-to-git
|
||||
[20]:https://github.com/circleci/encrypted-files
|
||||
[21]:https://circleci.com/blog/build-test-publish-snap-packages?utm_source=insightsubuntu&utm_medium=syndicatedblogpost
|
||||
@ -1,219 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Monitoring Server: Install Zabbix on an Ubuntu 16.04 Server
|
||||
============================================================
|
||||
|
||||
[][3]
|
||||
|
||||
### Monitoring Server – What is Zabbix
|
||||
|
||||
[Zabbix][2] is an enterprise-class open source distributed monitoring server solution. The software monitors different parameters of a network and the integrity of a server, and also allows the configuration of email based alerts for any event. Zabbix offers reporting and data visualization features based on the data stored in a database (MySQL, for example). Every metric collected by the software is accessible through a web-based interface.
|
||||
|
||||
Zabbix is released under the terms of the GNU General Public License version 2 (GPLv2), totally free of cost.
|
||||
|
||||
In this tutorial we will install Zabbix on an Ubuntu 16.04 server running MySQL, Apache and PHP.
|
||||
|
||||
### Install the Zabbix Server
|
||||
|
||||
First, we’ll need to install a few PHP modules required by Zabbix:
|
||||
|
||||
```
|
||||
# apt-get install php7.0-bcmath php7.0-xml php7.0-mbstring
|
||||
```
|
||||
The Zabbix package available in the Ubuntu repositories is outdated. Use the official Zabbix repository to install the latest stable version.
|
||||
|
||||
Install the repository package by executing the following commands:
|
||||
|
||||
```
|
||||
$ wget http://repo.zabbix.com/zabbix/3.2/ubuntu/pool/main/z/zabbix-release/zabbix-release_3.2-1+xenial_all.deb
|
||||
# dpkg -i zabbix-release_3.2-1+xenial_all.deb
|
||||
```
|
||||
|
||||
Then update the `apt` packages source:
|
||||
|
||||
```
|
||||
# apt-get update
|
||||
```
|
||||
Now it’s possible to install Zabbix Server with MySQL support and the PHP front-end. Execute the command:
|
||||
```
|
||||
# apt-get install zabbix-server-mysql zabbix-frontend-php
|
||||
```
|
||||
|
||||
Install the Zabbix agent:
|
||||
|
||||
```
|
||||
# apt-get install zabbix-agent
|
||||
```
|
||||
|
||||
Zabbix is now installed. The next step is to configure a database for storing its data.
|
||||
|
||||
### Configure MySQL for Zabbix
|
||||
|
||||
We need to create a new MySQL database, in which Zabbix will store the collected data.
|
||||
|
||||
Start the MySQL shell:
|
||||
|
||||
```
|
||||
$ mysql -uroot -p
|
||||
```
|
||||
|
||||
Next:
|
||||
|
||||
```
|
||||
mysql> CREATE DATABASE zabbix CHARACTER SET utf8 COLLATE utf8_bin;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
|
||||
mysql> GRANT ALL PRIVILEGES ON zabbix.* TO zabbix@localhost IDENTIFIED BY 'usr_strong_pwd';
|
||||
Query OK, 0 rows affected, 1 warning (0.00 sec)
|
||||
|
||||
mysql> EXIT;
|
||||
Bye
|
||||
```
|
||||
|
||||
Next, import the initial schema and data.
|
||||
|
||||
```
|
||||
# zcat /usr/share/doc/zabbix-server-mysql/create.sql.gz | mysql -uzabbix -p zabbix
|
||||
```
|
||||
|
||||
Enter the password for the **zabbix** user created in the MySQL shell.
|
||||
|
||||
Next, we need to edit the Zabbix Server configuration file, which is `/etc/zabbix/zabbis_server.conf`:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/zabbix/zabbix_server.conf
|
||||
```
|
||||
|
||||
Search the `DBPassword` section of the file:
|
||||
|
||||
```
|
||||
### Option: DBPassword
|
||||
# Database password. Ignored for SQLite.
|
||||
# Comment this line if no password is used.
|
||||
#
|
||||
# Mandatory: no
|
||||
# Default:
|
||||
# DBPassword=
|
||||
|
||||
```
|
||||
|
||||
Uncomment the `DBPassword=` line and edit by adding the password created in MySQL:
|
||||
|
||||
```
|
||||
DBPassword=usr_strong_pwd
|
||||
|
||||
```
|
||||
|
||||
Next, look for the `DBHost=` line and uncomment it.
|
||||
|
||||
Save and exit.
|
||||
|
||||
### Configure PHP
|
||||
|
||||
We need to configure PHP for working with Zabbix. During the installation process, the installer created a configuration file in `/etc/zabbix`, named `apache.conf`. Open this file:
|
||||
|
||||
```
|
||||
# $EDITOR /etc/zabbix/apache.conf
|
||||
```
|
||||
|
||||
Here, right now, it’s necessary only to uncomment the `date.timezone` setting and set the correct timezone:
|
||||
|
||||
```
|
||||
|
||||
<IfModule mod_php7.c>
|
||||
php_value max_execution_time 300
|
||||
php_value memory_limit 128M
|
||||
php_value post_max_size 16M
|
||||
php_value upload_max_filesize 2M
|
||||
php_value max_input_time 300
|
||||
php_value always_populate_raw_post_data -1
|
||||
php_value date.timezone Europe/Rome
|
||||
</IfModule>
|
||||
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
|
||||
At this point, restart Apache and start the Zabbix Server service, enabling it for starting at boot time:
|
||||
|
||||
```
|
||||
# systemctl restart apache2
|
||||
# systemctl start zabbix-server
|
||||
# systemctl enable zabbix-server
|
||||
```
|
||||
Check the Zabbix status with `systemctl`:
|
||||
```
|
||||
# systemctl status zabbix-server
|
||||
```
|
||||
|
||||
This command should output:
|
||||
|
||||
```
|
||||
â zabbix-server.service - Zabbix Server
|
||||
Loaded: loaded (/lib/systemd/system/zabbix-server.service; enabled; vendor pr
|
||||
Active: active (running) ...
|
||||
```
|
||||
|
||||
At this point, the server-side part of Zabbix has been correctly installed and configured.
|
||||
|
||||
### Configure Zabbix Web Fronted
|
||||
|
||||
As mentioned in the introduction, Zabbix has a web-based front-end which we’ll use for visualizing collected data. However, this interface has to be configured.
|
||||
|
||||
With a web browser, go to URL `http://localhost/zabbix`.
|
||||
|
||||

|
||||
|
||||
Click on _**Next step**_
|
||||
|
||||

|
||||
|
||||
Be sure that all the values are **Ok**, and then click on _**Next step** _ again.
|
||||
|
||||

|
||||
Insert the MySQL **zabbix** user password, and then click on _**Next step**_ .
|
||||
|
||||

|
||||
|
||||
Click on _**Next step**_ , and the installer will show the following page with all the configuration parameters. Check again to ensure that everything is correct..
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Click **Next step** to proceed to the final screen.
|
||||
|
||||
Click finish to complete the front-end installation. The default user name is **Admin** with **zabbix **as the password.
|
||||
|
||||
### Getting Started with the Zabbix Server
|
||||
|
||||

|
||||
|
||||
After logging in with the above mentioned credentials, we will see the Zabbix dashboard:
|
||||

|
||||
Go on _Administration -> Users_ for an overview about enabled accounts
|
||||

|
||||
Create a new account by clicking on _**Create user**_
|
||||

|
||||
Click on **Add** in the **Groups** section and select one group
|
||||

|
||||
Save the new user credentials, and it will appear in the _Administration -> Users _ panel.**Note that in Zabbix access rights to hosts are assigned to user groups, not individual users.**
|
||||
|
||||
### Conclusion
|
||||
|
||||
This concludes the tutorial for the Zabbix Server installation. Now, the monitoring infrastructure is ready to do its job and collect data about servers that need to be added in the Zabbix configuration.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.unixmen.com/monitoring-server-install-zabbix-ubuntu-16-04/
|
||||
|
||||
作者:[Giuseppe Molica ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/tutan/
|
||||
[1]:https://www.unixmen.com/author/tutan/
|
||||
[2]:http://www.zabbix.com/
|
||||
[3]:https://www.unixmen.com/wp-content/uploads/2017/06/zabbix_logo.png
|
||||
@ -1,206 +0,0 @@
|
||||
【big_dimple翻译中】
|
||||
Two great uses for the cp command
|
||||
============================================================
|
||||
|
||||
### Linux's copy command makes quick work of making specialized backups.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Internet Archive [Book][10] [Images][11]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
The point-and-click graphical user interface available on Linux is a wonderful thing... but if your favorite interactive development environment consists of the terminal window, Bash, Vim, and your favorite language compiler, then, like me, you use the terminal _a lot_ .
|
||||
|
||||
But even people who generally avoid the terminal can benefit by being more aware of the riches that its environment offers. A case in point – the **cp** command. [According to Wikipedia][12], the **cp** (or copy) command was part of Version 1 of [Unix][13]. Along with a select group of other commands—**ls**, **mv**, **cd**, **pwd**, **mkdir**, **vi**, **sh**, **sed**, and **awk** come to mind—**cp** was one of my first few steps in System V Unix back in 1984\. The most common use of **cp** is to make a copy of a file, as in:
|
||||
|
||||
```
|
||||
cp sourcefile destfile
|
||||
```
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
issued at the command prompt in a terminal session. The above command copies the file named **sourcefile** to the file named **destfile**. If **destfile** doesn't exist before the command is issued, it's created; if it does exist, it's overwritten.
|
||||
|
||||
I don't know how many times I've used this command (maybe I don't want to know), but I do know that I often use it when I'm writing and testing code and I have a working version of something that I want to retain as-is before I move on. So, I have probably typed something like this:
|
||||
|
||||
```
|
||||
cp test1.py test1.bak
|
||||
```
|
||||
|
||||
at a command prompt at least a zillion times over the past 30+ years. Alternatively, I might have decided to move on to version 2 of my test program, in which case I may have typed:
|
||||
|
||||
```
|
||||
cp test1.py test2.py
|
||||
```
|
||||
|
||||
to accomplish the first step of that move.
|
||||
|
||||
This is such a common and simple thing to do that I have rarely ever looked at the reference documentation for **cp**. But, while backing up my Pictures folder (using the Files application in my GUI environment), I started thinking, "I wonder if there is an option to have **cp** copy over only new files or those that have changed?" And sure enough, there is!
|
||||
|
||||
### Great use #1: Updating a second copy of a folder
|
||||
|
||||
Let's say I have a folder on my computer that contains a collection of files. Furthermore, let's say that from time to time I put a new file into that collection. Finally, let's say that from time to time I might edit one of those files in some way. An example of such a collection might be the photos I download from my cellphone or my music files.
|
||||
|
||||
Assuming that this collection of files has some enduring value to me, I might occasionally want to make a copy of it—a kind of "snapshot" of it—to preserve it on some other media. Of course, there are many utility programs that exist for doing backups, but maybe I want to have this exact structure duplicated on a removable device that I generally store offline or even connect to another computer.
|
||||
|
||||
The **cp** command offers a dead-easy way to do this. Here's an example.
|
||||
|
||||
In my **Pictures** folder, I have a sub-folder called **Misc**. For illustrative purposes, I'm going to make a copy of it on a USB memory stick. Here we go!
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r Misc /media/clh/4388-D5FE
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
The above lines are copied as-is from my terminal window. For those who might not be fully comfortable with that environment, it's worth noting that **me @mydesktop:~/Pictures$** is the command prompt provided by the terminal before every command is entered and executed. It identifies the user (**me**), the computer (**mydesktop**), and the current working directory, in this case, **~/Pictures**, which is shorthand for **/home/me/Pictures**, that is, the **Pictures** folder in my home directory.
|
||||
|
||||
The command I've entered and executed, **cp -r Misc /media/clh/4388-D5FE**, copies the folder **Misc** and all its contents (the **-r**, or "recursive," option indicates the contents as well as the folder or file itself) into the folder **/media/clh/4388-D5FE**, which is where my USB stick is mounted.
|
||||
|
||||
Executing the command returned me to the original prompt. Like with most commands inherited from Unix, if the command executes without detecting any kind of anomalous result, it won't print out a message like "execution succeeded" before terminating. People who would like more feedback can use the **-v** option to make execution "verbose."
|
||||
|
||||
Below is an image of my new copy of **Misc** on the USB drive. There are nine JPEG files in the directory.
|
||||
|
||||
### [cp1_file_structure.png][6]
|
||||
|
||||

|
||||
|
||||
Suppose I add a few new files to the master copy of the directory **~/Pictures/Misc**, so now it looks like this:
|
||||
|
||||
### [cp2_new_files.png][7]
|
||||
|
||||

|
||||
|
||||
Now I want to copy over only the new files to my memory stick. For this I'll use the "update" and "verbose" options to **cp**:
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r -u -v Misc /media/clh/4388-D5FE
|
||||
'Misc/asunder.png' -> '/media/clh/4388-D5FE/Misc/asunder.png'
|
||||
'Misc/editing tags guayadeque.png' -> '/media/clh/4388-D5FE/Misc/editing tags guayadeque.png'
|
||||
'Misc/misc on usb.png' -> '/media/clh/4388-D5FE/Misc/misc on usb.png'
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
The first line above shows the **cp** command and its options (**-r** for "recursive", **-u** for "update," and **-v** for "verbose"). The next three lines show the files that are copied across. The last line shows the command prompt again.
|
||||
|
||||
Generally speaking, options such as **-r** can also be given in a more verbose fashion, such as **--recursive**. In brief form, they can also be combined, such as **-ruv**.
|
||||
|
||||
### Great use #2 – Making versioned backups
|
||||
|
||||
Returning to my initial example of making periodic backups of working versions of code in development, another really useful **cp** option I discovered while learning about update is backup.
|
||||
|
||||
Suppose I'm setting out to write a really useful Python program. Being a fan of iterative development, I might do so by getting a simple version of the program working first, then successively adding more functionality to it until it does the job. Let's say my first version just prints the string "hello world" using the Python print command. This is a one-line program that looks like this:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
```
|
||||
|
||||
and I've put that string in the file **test1.py**. I can run it from the command line as follows:
|
||||
|
||||
```
|
||||
me@desktop:~/Test$ python test1.py
|
||||
hello world
|
||||
me@desktop:~/Test$
|
||||
```
|
||||
|
||||
Now that the program is working, I want to make a backup of it before adding the next component. I decide to use the backup option with numbering, as follows:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
So, what does this all mean?
|
||||
|
||||
First, the **--backup=numbered** option says, "I want to do a backup, and I want successive backups to be numbered." So the first backup will be number 1, the second 2, and so on.
|
||||
|
||||
Second, note that the source file and destination file are the same. Normally, if we try to use the **cp** command to copy a file onto itself, we will receive a message like:
|
||||
|
||||
```
|
||||
cp: 'test1.py' and 'test1.py' are the same file
|
||||
```
|
||||
|
||||
In the special case where we are doing a backup and we want the same source and destination, we use the **--force** option.
|
||||
|
||||
Third, I used the **ls** (or "list") command to show that we now have a file called **test1.py**, which is the original, and another called **test1.py.~1~**, which is the backup file.
|
||||
|
||||
Suppose now that the second bit of functionality I want to add to the program is another print statement that prints the string "Kilroy was here." Now the program in file **test1.py**looks like this:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
print 'Kilroy was here'
|
||||
```
|
||||
|
||||
See how simple Python programming is? Anyway, if I again execute the backup step, here's what happens:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~ test1.py.~2~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
Now we have two backup files: **test1.py.~1~**, which contains the original one-line program, and **test1.py.~2~**, which contains the two-line program, and I can move on to adding and testing some more functionality.
|
||||
|
||||
This is such a useful thing to me that I am considering making a shell function to make it simpler.
|
||||
|
||||
### Three points to wrap this up
|
||||
|
||||
First, the Linux manual pages, installed by default on most desktop and server distros, provide details and occasionally useful examples of commands like **cp**. At the terminal, enter the command:
|
||||
|
||||
```
|
||||
man cp
|
||||
```
|
||||
|
||||
Such explanations can be dense and obscure to users just trying to learn how to use a command in the first place. For those inclined to persevere nevertheless, I suggest creating a test directory and files and trying the command and options out there.
|
||||
|
||||
Second, if a tutorial is of greater interest, the search string "linux shell tutorial" typed into your favorite search engine brings up a lot of interesting and useful resources.
|
||||
|
||||
Third, if you're wondering, "Why bother when the GUI typically offers the same functionality with point-and-click ease?" I have two responses. The first is that "point-and-click" isn't always that easy, especially when it disrupts another workflow and requires a lot of points and a lot of clicks to make it work. The second is that repetitive tasks can often be easily streamlined through the use of shell scripts, shell functions, and shell aliases.
|
||||
|
||||
Are you using the **cp** command in new or interesting ways? Let us know about them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Chris Hermansen - Engaged in computing since graduating from the University of British Columbia in 1978, I have been a full-time Linux user since 2005 and a full-time Solaris, SunOS and UNIX System V user before that. On the technical side of things, I have spent a great deal of my career doing data analysis; especially spatial data analysis. I have a substantial amount of programming experience in relation to data analysis, using awk, Python, PostgreSQL, PostGIS and lately Groovy.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
|
||||
作者:[ Chris Hermansen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/360601
|
||||
[7]:https://opensource.com/file/360606
|
||||
[8]:https://opensource.com/article/17/7/two-great-uses-cp-command?rate=87TiE9faHZRes_f4Gj3yQZXhZ-x7XovYhnhjrk3SdiM
|
||||
[9]:https://opensource.com/user/37806/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[11]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[12]:https://en.wikipedia.org/wiki/Cp_(Unix)
|
||||
[13]:https://en.wikipedia.org/wiki/Unix
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
[15]:https://opensource.com/users/clhermansen
|
||||
[16]:https://opensource.com/article/17/7/two-great-uses-cp-command#comments
|
||||
@ -1,144 +0,0 @@
|
||||
4 lightweight image viewers for the Linux desktop
|
||||
============================================================
|
||||
|
||||
### When you need more than a basic image viewer but less than a full image editor, check out these apps.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Internet Archive Book Images][17]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
Like most people, you probably have more than a few photos and other images on your computer. And, like most people, you probably like to take a peek at those images and photos every so often.
|
||||
|
||||
Firing up an editor like [GIMP][18] or [Pinta][19] is overkill for simply viewing images.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
On the other hand, the basic image viewer included with most Linux desktop environments might not be enough for your needs. If you want something with a few more features, but still want it to be lightweight, then take a closer look at these four image viewers for the Linux desktop, plus a handful of bonus options if they don't meet your needs.
|
||||
|
||||
### Feh
|
||||
|
||||
[Feh][20] is an old favorite from the days when I computed on older, slower hardware. It's simple, unadorned, and does what it's designed to do very well.
|
||||
|
||||
You drive Feh from the command line: just point it at an image or a folder containing images and away you go. Feh loads quickly, and you can scroll through a set of images with a mouse click or by using the left and right arrow keys on your keyboard. What could be simpler?
|
||||
|
||||
Feh might be light, but it offers some options. You can, for example, control whether Feh's window has a border, set the minimum and maximum sizes of the images you want to view, and tell Feh at which image in a folder you want to start viewing.
|
||||
|
||||
### [feh.png][6]
|
||||
|
||||

|
||||
|
||||
Feh in action
|
||||
|
||||
### Ristretto
|
||||
|
||||
If you've used Xfce as a desktop environment, you'll be familiar with [Ristretto][21]. It's small, simple, and very useful.
|
||||
|
||||
How simple? You open a folder containing images, click on one of the thumbnails on the left, and move through the images by clicking the navigation keys at the top of the window. Ristretto even has a slideshow feature.
|
||||
|
||||
Ristretto can do a bit more, too. You can use it to save a copy of an image you're viewing, set that image as your desktop wallpaper, and even open it in another application, for example, if you need to touch it up.
|
||||
|
||||
### [ristretto.png][7]
|
||||
|
||||

|
||||
|
||||
Viewing photos in Ristretto
|
||||
|
||||
### Mirage
|
||||
|
||||
On the surface, [Mirage][22] is kind of plain and nondescript. It does the same things just about every decent image viewer does: opens image files, scales them to the width of the window, and lets you scroll through a collection of images using your keyboard. It even runs slideshows.
|
||||
|
||||
Still, Mirage will surprise anyone who needs a little more from their image viewer. In addition to its core features, Mirage lets you resize and crop images, take screenshots, rename an image file, and even generate 150-pixel-wide thumbnails of the images in a folder.
|
||||
|
||||
If that wasn't enough, Mirage can display [SVG files][23]. You can even drive it [from the command line][24].
|
||||
|
||||
### [mirage.png][8]
|
||||
|
||||

|
||||
|
||||
Taking Mirage for a spin
|
||||
|
||||
### Nomacs
|
||||
|
||||
[Nomacs][25] is easily the heaviest of the image viewers described in this article. Its perceived bulk belies Nomacs' speed. It's quick and easy to use.
|
||||
|
||||
Nomacs does more than display images. You can also view and edit an image's [metadata][26], add notes to an image, and do some basic editing—including cropping, resizing, and converting the image to grayscale. Nomacs can even take screenshots.
|
||||
|
||||
One interesting feature is that you can run two instances of the application on your desktop and synchronize an image across those instances. The [Nomacs documentation][27]recommends this when you need to compare two images. You can even synchronize an image across a local area network. I haven't tried synchronizing across a network, but please share your experiences if you have.
|
||||
|
||||
### [nomacs.png][9]
|
||||
|
||||

|
||||
|
||||
A photo and its metadata in Nomacs
|
||||
|
||||
### A few other viewers worth looking at
|
||||
|
||||
If these four image viewers don't suit your needs, here are some others that might interest you.
|
||||
|
||||
**[Viewnior][11]** bills itself as a "fast and simple image viewer for GNU/Linux," and it fits that bill nicely. Its interface is clean and uncluttered, and Viewnior can even do some basic image manipulation.
|
||||
|
||||
If the command line is more your thing, then **display** might be the viewer for you. Both the **[ImageMagick][12]** and **[GraphicsMagick][13]** image manipulation packages have an application named display, and both versions have basic and advanced options for viewing images.
|
||||
|
||||
**[Geeqie][14]** is one of the lighter and faster image viewers out there. Don't let its simplicity fool you, though. It packs features, like metadata editing and viewing camera RAW image formats, that other viewers lack.
|
||||
|
||||
**[Shotwell][15]** is the photo manager for the GNOME desktop. While it does more than just view images, Shotwell is quite speedy and does a great job of displaying photos and other graphics.
|
||||
|
||||
_Do you have a favorite lightweight image viewer for the Linux desktop? Feel free to share your preferences by leaving a comment._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
cott Nesbitt - I'm a long-time user of free/open source software, and write various things for both fun and profit. I don't take myself too seriously. You can find me at these fine establishments on the web: Twitter, Mastodon, GitHub.
|
||||
|
||||
via: https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop
|
||||
|
||||
作者:[ Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/361216
|
||||
[7]:https://opensource.com/file/361231
|
||||
[8]:https://opensource.com/file/361221
|
||||
[9]:https://opensource.com/file/361226
|
||||
[10]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop?rate=UcKbaJQJAbLScWVu8qm9bqii7JMsIswjfcBHt3aRnEU
|
||||
[11]:http://siyanpanayotov.com/project/viewnior/
|
||||
[12]:https://www.imagemagick.org/script/display.php
|
||||
[13]:http://www.graphicsmagick.org/display.html
|
||||
[14]:http://geeqie.org/
|
||||
[15]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[16]:https://opensource.com/user/14925/feed
|
||||
[17]:https://www.flickr.com/photos/internetarchivebookimages/14758810172/in/photolist-oubL5m-ocu2ck-odJwF4-oeq1na-odgZbe-odcugD-w7KHtd-owgcWd-oucGPe-oud585-rgBDNf-obLoQH-oePNvs-osVgEq-othPLM-obHcKo-wQR3KN-oumGqG-odnCyR-owgLg3-x2Zeyq-hMMxbq-oeRzu1-oeY49i-odumMM-xH4oJo-odrT31-oduJr8-odX8B3-obKG8S-of1hTN-ovhHWY-ow7Scj-ovfm7B-ouu1Hj-ods7Sg-qwgw5G-oeYz5D-oeXqFZ-orx8d5-hKPN4Q-ouNKch-our8E1-odvGSH-oweGTn-ouJNQQ-ormX8L-od9XZ1-roZJPJ-ot7Wf4
|
||||
[18]:https://www.gimp.org/
|
||||
[19]:https://pinta-project.com/pintaproject/pinta/
|
||||
[20]:https://feh.finalrewind.org/
|
||||
[21]:https://docs.xfce.org/apps/ristretto/start
|
||||
[22]:http://mirageiv.sourceforge.net/
|
||||
[23]:https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
|
||||
[24]:http://mirageiv.sourceforge.net/docs-advanced.html#cli
|
||||
[25]:http://nomacs.org/
|
||||
[26]:https://iptc.org/standards/photo-metadata/photo-metadata/
|
||||
[27]:http://nomacs.org/synchronization/
|
||||
[28]:https://opensource.com/users/scottnesbitt
|
||||
[29]:https://opensource.com/users/scottnesbitt
|
||||
[30]:https://opensource.com/article/17/7/4-lightweight-image-viewers-linux-desktop#comments
|
||||
@ -1,3 +1,4 @@
|
||||
translating by sugarfillet
|
||||
Functional testing Gtk+ applications in C
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,297 +0,0 @@
|
||||
Integrate CentOS 7 to Samba4 AD from Commandline – Part 14
|
||||
============================================================
|
||||
|
||||
This guide will show you how you can integrate a CentOS 7 Server with no Graphical User Interface to [Samba4 Active Directory Domain Controller][3] from command line using Authconfig software.
|
||||
|
||||
This type of setup provides a single centralized account database held by Samba and allows the AD users to authenticate to CentOS server across the network infrastructure.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||
|
||||
2. [CentOS 7.3 Installation Guide][2]
|
||||
|
||||
### Step 1: Configure CentOS for Samba4 AD DC
|
||||
|
||||
1. Before starting to join CentOS 7 Server into a Samba4 DC you need to assure that the network interface is properly configured to query domain via DNS service.
|
||||
|
||||
Run [ip address][4] command to list your machine network interfaces and choose the specific NIC to edit by issuing nmtui-edit command against the interface name, such as ens33 in this example, as illustrated below.
|
||||
|
||||
```
|
||||
# ip address
|
||||
# nmtui-edit ens33
|
||||
```
|
||||
[][5]
|
||||
|
||||
List Network Interfaces
|
||||
|
||||
2. Once the network interface is opened for editing, add the static IPv4 configurations best suited for your LAN and make sure you setup Samba AD Domain Controllers IP addresses for the DNS servers.
|
||||
|
||||
Also, append the name of your domain in search domains filed and navigate to OK button using [TAB] key to apply changes.
|
||||
|
||||
The search domains filed assures that the domain counterpart is automatically appended by DNS resolution (FQDN) when you use only a short name for a domain DNS record.
|
||||
|
||||
[][6]
|
||||
|
||||
Configure Network Interface
|
||||
|
||||
3. Finally, restart the network daemon to apply changes and test if DNS resolution is properly configured by issuing series of ping commands against the domain name and domain controllers short names as shown below.
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
# ping -c2 tecmint.lan
|
||||
# ping -c2 adc1
|
||||
# ping -c2 adc2
|
||||
```
|
||||
[][7]
|
||||
|
||||
Verify DNS Resolution on Domain
|
||||
|
||||
4. Also, configure your machine hostname and reboot the machine to properly apply the settings by issuing the following commands.
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_hostname
|
||||
# init 6
|
||||
```
|
||||
|
||||
Verify if hostname was correctly applied with the below commands.
|
||||
|
||||
```
|
||||
# cat /etc/hostname
|
||||
# hostname
|
||||
```
|
||||
|
||||
5. Finally, sync local time with Samba4 AD DC by issuing the below commands with root privileges.
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate domain.tld
|
||||
```
|
||||
[][8]
|
||||
|
||||
Sync Time with Samba4 AD DC
|
||||
|
||||
### Step 2: Join CentOS 7 Server to Samba4 AD DC
|
||||
|
||||
6. To join CentOS 7 server to Samba4 Active Directory, first install the following packages on your machine from an account with root privileges.
|
||||
|
||||
```
|
||||
# yum install authconfig samba-winbind samba-client samba-winbind-clients
|
||||
```
|
||||
|
||||
7. In order to integrate CentOS 7 server to a domain controller run authconfig-tui graphical utility with root privileges and use the below configurations as described below.
|
||||
|
||||
```
|
||||
# authconfig-tui
|
||||
```
|
||||
|
||||
At the first prompt screen choose:
|
||||
|
||||
* On User Information:
|
||||
* Use Winbind
|
||||
|
||||
* On Authentication tab select by pressing [Space] key:
|
||||
* Use Shadow Password
|
||||
|
||||
* Use Winbind Authentication
|
||||
|
||||
* Local authorization is sufficient
|
||||
|
||||
[][9]
|
||||
|
||||
Authentication Configuration
|
||||
|
||||
8. Hit Next to continue to the Winbind Settings screen and configure as illustrated below:
|
||||
|
||||
* Security Model: ads
|
||||
|
||||
* Domain = YOUR_DOMAIN (use upper case)
|
||||
|
||||
* Domain Controllers = domain machines FQDN (comma separated if more than one)
|
||||
|
||||
* ADS Realm = YOUR_DOMAIN.TLD
|
||||
|
||||
* Template Shell = /bin/bash
|
||||
|
||||
[][10]
|
||||
|
||||
Winbind Settings
|
||||
|
||||
9. To perform domain joining navigate to Join Domain button using [tab] key and hit [Enter] key to join domain.
|
||||
|
||||
At the next screen prompt, add the credentials for a Samba4 AD account with elevated privileges to perform the machine account joining into AD and hit OK to apply settings and close the prompt.
|
||||
|
||||
Be aware that when you type the user password, the credentials won’t be shown in the password screen. On the remaining screen hit OK again to finish domain integration for CentOS 7 machine.
|
||||
|
||||
[][11]
|
||||
|
||||
Join Domain to Samba4 AD DC
|
||||
|
||||
[][12]
|
||||
|
||||
Confirm Winbind Settings
|
||||
|
||||
To force adding a machine into a specific Samba AD Organizational Unit, get your machine exact name using hostname command and create a new Computer object in that OU with the name of your machine.
|
||||
|
||||
The best way to add a new object into a Samba4 AD is by using ADUC tool from a Windows machine integrated into the domain with [RSAT tools installed][13] on it.
|
||||
|
||||
Important: An alternate method of joining a domain is by using authconfig command line which offers extensive control over the integration process.
|
||||
|
||||
However, this method is prone to errors do to its numerous parameters as illustrated on the below command excerpt. The command must be typed into a single long line.
|
||||
|
||||
```
|
||||
# authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --smbworkgroup=YOUR_DOMAIN --smbrealm YOUR_DOMAIN.TLD --smbservers=adc1.yourdomain.tld --krb5realm=YOUR_DOMAIN.TLD --enablewinbindoffline --enablewinbindkrb5 --winbindtemplateshell=/bin/bash--winbindjoin=domain_admin_user --update --enablelocauthorize --savebackup=/backups
|
||||
```
|
||||
|
||||
10. After the machine has been joined to domain, verify if winbind service is up and running by issuing the below command.
|
||||
|
||||
```
|
||||
# systemctl status winbind.service
|
||||
```
|
||||
|
||||
11. Then, check if CentOS machine object has been successfully created in Samba4 AD. Use AD Users and Computers tool from a Windows machine with RSAT tools installed and navigate to your domain Computers container. A new AD computer account object with name of your CentOS 7 server should be listed in the right plane.
|
||||
|
||||
12. Finally, tweak the configuration by opening samba main configuration file (/etc/samba/smb.conf) with a text editor and append the below lines at the end of the [global]configuration block as illustrated below:
|
||||
|
||||
```
|
||||
winbind use default domain = true
|
||||
winbind offline logon = true
|
||||
```
|
||||
[][14]
|
||||
|
||||
Configure Samba
|
||||
|
||||
13. In order to create local homes on the machine for AD accounts at their first logon run the below command.
|
||||
|
||||
```
|
||||
# authconfig --enablemkhomedir --update
|
||||
```
|
||||
|
||||
14. Finally, restart Samba daemon to reflect changes and verify domain joining by performing a logon on the server with an AD account. The home directory for the AD account should be automatically created.
|
||||
|
||||
```
|
||||
# systemctl restart winbind
|
||||
# su - domain_account
|
||||
```
|
||||
[][15]
|
||||
|
||||
Verify Domain Joining
|
||||
|
||||
15. List the domain users or domain groups by issuing one of the following commands.
|
||||
|
||||
```
|
||||
# wbinfo -u
|
||||
# wbinfo -g
|
||||
```
|
||||
[][16]
|
||||
|
||||
List Domain Users and Groups
|
||||
|
||||
16. To get info about a domain user run the below command.
|
||||
|
||||
```
|
||||
# wbinfo -i domain_user
|
||||
```
|
||||
[][17]
|
||||
|
||||
List Domain User Info
|
||||
|
||||
17. To display summary domain info issue the following command.
|
||||
|
||||
```
|
||||
# net ads info
|
||||
```
|
||||
[][18]
|
||||
|
||||
List Domain Summary
|
||||
|
||||
### Step 3: Login to CentOS with a Samba4 AD DC Account
|
||||
|
||||
18. To authenticate with a domain user in CentOS, use one of the following command line syntaxes.
|
||||
|
||||
```
|
||||
# su - ‘domain\domain_user’
|
||||
# su - domain\\domain_user
|
||||
```
|
||||
|
||||
Or use the below syntax in case winbind use default domain = true parameter is set to samba configuration file.
|
||||
|
||||
```
|
||||
# su - domain_user
|
||||
# su - domain_user@domain.tld
|
||||
```
|
||||
|
||||
19. In order to add root privileges for a domain user or group, edit sudoers file using visudocommand and add the following lines as illustrated on the below screenshot.
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
|
||||
Or use the below excerpt in case winbind use default domain = true parameter is set to samba configuration file.
|
||||
|
||||
```
|
||||
domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
[][19]
|
||||
|
||||
Grant Root Privileges on Domain Users
|
||||
|
||||
20. The following series of commands against a Samba4 AD DC can also be useful for troubleshooting purposes:
|
||||
|
||||
```
|
||||
# wbinfo -p #Ping domain
|
||||
# wbinfo -n domain_account #Get the SID of a domain account
|
||||
# wbinfo -t #Check trust relationship
|
||||
```
|
||||
|
||||
21. To leave the domain run the following command against your domain name using a domain account with elevated privileges. After the machine account has been removed from the AD, reboot the machine to revert changes before the integration process.
|
||||
|
||||
```
|
||||
# net ads leave -w DOMAIN -U domain_admin
|
||||
# init 6
|
||||
```
|
||||
|
||||
That’s all! Although this procedure is mainly focused on joining a CentOS 7 server to a Samba4 AD DC, the same steps described here are also valid for integrating a CentOS server into a Microsoft Windows Server 2012 Active Directory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[4]:https://www.tecmint.com/ip-command-examples/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Network-Interfaces.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-DNS-Resolution-on-Domain.png
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/Sync-Time-with-Samba4-AD-DC.png
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Authentication-Configuration.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Winbind-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Domain-to-Samba4-AD-DC.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Winbind-Settings.png
|
||||
[13]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-Domain-Joining.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Users-and-Groups.png
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-User-Info.jpg
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Summary.jpg
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/07/Grant-Root-Privileges-on-Domain-Users.jpg
|
||||
[20]:https://www.tecmint.com/author/cezarmatei/
|
||||
[21]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,138 +0,0 @@
|
||||
Fedora 26 Powers Up Cloud, Server, Workstation Systems
|
||||
============================================================
|
||||
|
||||
|
||||
[**What Every CSO Must Know About Open Source | Download the White Paper**][9]
|
||||
[][10]Flexera Software shares application security strategies for security and engineering teams to manage open source.
|
||||
**[Download Now!][3]**
|
||||
|
||||
The [Fedora Project][4] this week announced the general availability of Fedora 26, the latest version of the fully open source Fedora operating system.
|
||||
|
||||

|
||||
|
||||
Fedora Linux is the community version of Red Hat Enterprise Linux, or RHEL. Fedora 26 comprises a set of base packages that form the foundation of three distinct editions targeting different users.
|
||||
|
||||
Fedora Atomic Host edition is an operating system for running container-based workloads. Fedora Server edition installs the Fedora Server OS on a hard drive. Fedora Workstation edition is a user-friendly operating system for laptops and desktop computers, suitable for a broad range of users -- from hobbyists and students to professionals in corporate environments.
|
||||
|
||||
All three editions share a common base and some common strengths. All of the Fedora editions are released twice a year.
|
||||
|
||||
The Fedora Project is a testing ground for innovations and new features. Some will be implemented in upcoming releases of RHEL, said Matthew Miller, Fedora Project Leader.
|
||||
|
||||
"Fedora is not directly involved in those productization decisions," he told LinuxInsider. "Fedora provides a look at many ideas and technologies, and it is a great place for Red Hat Enterprise Linux customers to get involved and provide feedback."
|
||||
|
||||
### Package Power
|
||||
|
||||
The Fedora developers updated and improved the packages powering all three editions. They made numerous bug fixes and performance tweaks in Fedora 26 to provide an enhanced user experience across Fedora's use cases.
|
||||
|
||||
These packages include the following improvements:
|
||||
|
||||
* Updated compilers and languages, including GNU Compiler Collection 7, Go 1.8, Python 3.6 and Ruby 2.4;
|
||||
|
||||
* DNF 2.0, the latest version of Fedora's next-generation package management system with improved backward compatibility with Yum;
|
||||
|
||||
* A new storage configuration screen for the Anaconda installation program, which enables bottom-up configuration from devices and partitions; and
|
||||
|
||||
* Fedora Media Writer updates that enable users to create bootable SD cards for ARM-based devices, like Raspberry Pi.
|
||||
|
||||
The cloud tools are essential to users with a cloud presence, especially programmers, noted Roger L. Kay, president of [Endpoint Technologies Associates][5].
|
||||
|
||||
"Kubernetes is essential for programmers interested in writing from the hybrid cloud, which is arguably one of the more important developments in the industry at the moment," he told LinuxInsider. "Cloud -- public, private and hybrid -- is key to the future of enterprise computing."
|
||||
|
||||
### Fedora 26 Atomic Host Makeover
|
||||
|
||||
Linux containers and container orchestration engines have been expanding in popularity. Fedora 26 Atomic Host offers a minimal-footprint operating system tailored for running container-based workloads across environments, from bare metal to the cloud.
|
||||
|
||||
Fedora 26 Atomic Host updates are delivered roughly every two weeks, a schedule that lets users keep pace with upstream innovation.
|
||||
|
||||
Fedora 26 Atomic Host is available for Amazon EC2\. Images for OpenStack, Vagrant, and standard installer ISO images are available on the [Fedora Project][6]website.
|
||||
|
||||
A minimal Fedora Atomic container image also made its debut with Fedora 26.
|
||||
|
||||
### Cloud Hosting
|
||||
|
||||
The latest release brings new capabilities and features to Fedora 26 Atomic Host:
|
||||
|
||||
* Containerized Kubernetes as an alternative to built-in Kubernetes binaries, enabling users to run different versions of the container orchestration engine more easily;
|
||||
|
||||
* The latest version of rpm-ostree, which includes support for direct RPM install, a reload command, and a clean-up command;
|
||||
|
||||
* System Containers, which provide a way of installing system infrastructure software, like networking or Kubernetes, on Fedora Atomic Host in a container; and
|
||||
|
||||
* Updated versions of Docker, Atomic and Cockpit for enhanced container building, system support and workload monitoring.
|
||||
|
||||
Containerizing Kubernetes is important for Fedora Atomic Host for two big reasons, according to the Fedora Project's Miller.
|
||||
|
||||
"First, it lets us remove it from the base image, reducing the size and complexity there," he explained. "Second, providing it in a container makes it easy to swap in different versions without disrupting the base or causing trouble for people who are not ready for a change quite yet."
|
||||
|
||||
### Server-Side Services
|
||||
|
||||
Fedora 26 Server provides a flexible, multi-role platform for data center operations. It also allows users to customize this edition of the Fedora operating system to fit their unique needs.
|
||||
|
||||
New features for Fedora 26 Server include FreeIPA 4.5, which improves running the security information management solution in containers, and SSSD file caching to speed up the resolution of user and group queries.
|
||||
|
||||
Fedora 26 Server edition later this month will add a preview of Fedora's modularity technology delivered as "Boltron." As a modular operating system, Boltron enables different versions of different applications to run on the same system, essentially allowing for leading-edge runtimes to be paired with stable databases.
|
||||
|
||||
### Workstation Workout
|
||||
|
||||
Among the new tools and features for general users is updated GNOME desktop functionality. Devs will get enhanced productivity tools.
|
||||
|
||||
Fedora 26 Workstation comes with GNOME 3.24 and numerous updated functionality tweaks. Night Light subtly changes screen color based on time of day to reduce effect on sleep patterns. [LibreOffice][7] 5.3 is the latest update to the open source office productivity suite.
|
||||
|
||||
GNOME 3.24 provides mature versions of Builder and Flatpak to give devs better application development tools for easier access across the board to a variety of systems, including Rust and Meson.
|
||||
|
||||
### Not Just for Devs
|
||||
|
||||
The inclusion of updated cloud tools in a Linux distro targeting enterprise users is significant, according to Scott Sellers, CEO of [Azul Systems][8].
|
||||
|
||||
"The cloud is a primary development and production platform for emerging companies, as well as some of the largest enterprises on the planet," he told LinuxInsider.
|
||||
|
||||
"Given the cutting-edge nature of the Fedora community, we would expect a strong cloud focus in any Fedora release, and Fedora 26 does not disappoint," Sellers said.
|
||||
|
||||
The other feature set of immediate interest to the Fedora developer and user community is the work the Fedora team did in terms of modularity, he noted.
|
||||
|
||||
"We will be looking at these experimental features closely," Sellers said.
|
||||
|
||||
### Supportive Upgrade Path
|
||||
|
||||
Users of Fedora, more than users of other Linux distros, have a vested interest in upgrading to Fedora 26, even if they are not heavy cloud users, according to Sellers.
|
||||
|
||||
"One of the primary advantages of this distro is to get an early look at production-grade advanced technologies that [eventually] will be integrated into RHEL," he said. "Early reviews of Fedora 26 suggest that it is very stable, with lots of bug fixes as well as performance enhancements."
|
||||
|
||||
Users interested in upgrading from earlier Fedora editions may find an easier approach than wiping existing systems to install Fedora 26, noted Fedora's Miller. Fedora maintains two releases at a time, plus a month of overlap.
|
||||
|
||||
"So, if you are on Fedora 24, you should upgrade in the next month," he said. "Happy Fedora 25 users can take their time. This is one of the advantages of Fedora over fast-moving rolling releases."
|
||||
|
||||
### Faster Delivery
|
||||
|
||||
Users can schedule their own upgrades rather than having to take them when the distro makes them.
|
||||
|
||||
That said, users of Fedora 23 or earlier should upgrade soon. The community no longer produces security updates for those releases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Jack M. Germain has been an ECT News Network reporter since 2003. His main areas of focus are enterprise IT, Linux and open source technologies. He has written numerous reviews of Linux distros and other open source software. Email Jack.
|
||||
|
||||
|
||||
---------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/84674.html
|
||||
|
||||
作者:[ Jack M. Germain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:jack.germain@newsroom.ectnews.comm
|
||||
[1]:http://www.linuxinsider.com/story/84674.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84674
|
||||
[3]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[4]:https://getfedora.org/
|
||||
[5]:http://www.ndpta.com/
|
||||
[6]:https://getfedora.org/
|
||||
[7]:http://www.libreoffice.org/
|
||||
[8]:https://www.azul.com/
|
||||
[9]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
[10]:http://www.linuxinsider.com/story/84674.html?rss=1
|
||||
@ -1,122 +0,0 @@
|
||||
translating by flowsnow
|
||||
|
||||
THE BEST WAY TO LEARN DOCKER FOR FREE: PLAY-WITH-DOCKER (PWD)
|
||||
============================================================
|
||||
|
||||
|
||||
Last year at the Distributed System Summit in Berlin, Docker captains[ Marcos Nils][15] and[ Jonathan Leibiusky][16] started hacking on an in-browser solution to help people learn Docker. A few days later, [Play-with-docker][17] (PWD) was born.
|
||||
|
||||
PWD is a Docker playground which allows users to run Docker commands in a matter of seconds. It gives the experience of having a free Alpine Linux Virtual Machine in browser, where you can build and run Docker containers and even create clusters in[ Docker Swarm Mode][18]. Under the hood Docker-in-Docker (DinD) is used to give the effect of multiple VMs/PCs. In addition to the playground, PWD also includes a training site composed of a large set of Docker labs and quizzes from beginner to advanced level available at [training.play-with-docker.com][19].
|
||||
|
||||
In case you missed it, Marcos and Jonathan presented PWD during the last DockerCon Moby Cool Hack session. Watch the video below for a deep dive into the infrastructure and roadmaps.
|
||||
|
||||
|
||||
Over the past few months, the Docker team has been working closely with Marcos, Jonathan and other active members of the Docker community to add new features to the project and Docker labs to the training section.
|
||||
|
||||
### PWD: the Playground
|
||||
|
||||
Here is a quick recap of what’s new with the Docker playground:
|
||||
|
||||
##### 1\. PWD Docker Machine driver and SSH
|
||||
|
||||
As PWD success grew, the community started to ask if they could use PWD to run their own Docker workshops and trainings. So one of the first improvements made to the project was the creation of [PWD Docker machine driver][20], which allows users to create and manage their PWD hosts easily through their favorite terminal including the option to use ssh related commands. Here is how it works:
|
||||
|
||||

|
||||
|
||||
##### 2\. Adding support for file upload
|
||||
|
||||
Another cool feature brought to you by Marcos and Jonathan is the ability to upload your Dockerfile directly into your PWD windows with a simple drag and drop of your file in your PWD instance.
|
||||
|
||||

|
||||
|
||||
##### 3\. Templated session
|
||||
|
||||
In addition to file upload, PWD also has a feature which lets you spin up a 5 nodes swarm in a matter of seconds using predefined templates.
|
||||
|
||||
#####
|
||||

|
||||
|
||||
##### 4\. Showcasing your applications with Docker in a single click
|
||||
|
||||
Another cool feature that comes with PWD is its embeddable button that you can use in your sites to set up a PWD environment and deploy a compose stack right away and a [chrome extension][21] that adds the “Try in PWD” button to the most popular images in DockerHub. Here’s a short demo of the extension in action:
|
||||
|
||||

|
||||
|
||||
### PWD: the Training Site
|
||||
|
||||
A number of new labs are available on [training.play-with-docker.com][22]. Some notable highlights include two labs that were originally hands-on labs from DockerCon in Austin, and a couple that highlight new features that are stable in Docker 17.06CE:
|
||||
|
||||
* [Docker Networking Hands-on Lab][1]
|
||||
|
||||
* [Docker Orchstration Hands-on Lab][2]
|
||||
|
||||
* [Multi-stage builds][3]
|
||||
|
||||
* [Docker swarm config files][4]
|
||||
|
||||
All in all, there are now 36 labs, with more being added all the time. If you want to contribute a lab, check out the [GitHub repo][23] and get started.
|
||||
|
||||
### PWD: the Use Cases
|
||||
|
||||
With the traffic to the site and the feedback we’ve received, it’s fair to say that PWD has a lot of traction right now. Here are some of the most common use-cases:
|
||||
|
||||
* Try new features fast as it’s updated with the latest dev versions.
|
||||
|
||||
* Set up clusters in no-time and launch replicated services.
|
||||
|
||||
* Learn through it’s interactive tutorials: [training.play-with-docker.com][5].
|
||||
|
||||
* Give presentations at conferences and meetups.
|
||||
|
||||
* Allow to run advanced workshops that’d usually require complex setups, such as Jérôme’s [advanced Docker Orchestration workshop][6]
|
||||
|
||||
* Collaborate with community members to diagnose and detect issues.
|
||||
|
||||
Get involved with PWD:
|
||||
|
||||
* Contribute to [PWD by submitting PRs][7]
|
||||
|
||||
* Contribute to the [PWD training site][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介;
|
||||
|
||||
Victor is the Sr. Community Marketing Manager at Docker, Inc. He likes fine wines, chess and soccer in no particular order. Victor tweets at @vcoisne.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -1,76 +0,0 @@
|
||||
How modelling helps you avoid getting a stuck OpenStack
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
_Lego model of an Airbus A380-800\. Airbus run OpenStack_
|
||||
|
||||
A “StuckStack” is a deployment of OpenStack that usually, for technical but sometimes business reasons, is unable to be upgraded without significant disruption, time and expense. In the last post on this topic we discussed how many of these clouds became stuck and how the decisions made at the time were consistent with much of the prevailing wisdom of the day. Now, with OpenStack being 7 years old, the recent explosion of growth in container orchestration systems and more businesses starting to make use of cloud platforms, both public and private, OpenStack are under pressure.
|
||||
|
||||
### No magic solution
|
||||
|
||||
If you are still searching for a solution to upgrade your existing StuckStack in place without issues, then I have bad news for you: there are no magic solutions and you are best focusing your energy on building a standardised platform that can be operated efficiently and upgraded easily.
|
||||
|
||||
The low cost airlines industry has shown that whilst flyers may aspire to best of breed experience and sit in first or business class sipping champagne with plenty of space to relax, most will choose to fly in the cheapest seat as ultimately the value equation doesn’t warrant them paying more. Workloads are the same. Long term, workloads will run on the platform where it is most economic to run them as the business really doesn’t benefit from running on premium priced hardware or software.
|
||||
|
||||
Amazon, Microsoft, Google and other large scale public cloud players know this which is why they have built highly efficient data centres and used models to build, operate and scale their infrastructure. Enterprises have long followed a policy of using best of breed hardware and software infrastructure that is designed, built, marketed, priced, sold and implemented as first class experiences. The reality may not have always lived up to the promise but it matters not now anyway, as the cost model cannot survive in today’s world. Some organisations have tried to tackle this by switching to free software alternatives yet without a change in their own behaviour. Thus find that they are merely moving cost from software acquisition to software operation.The good news is that the techniques used by the large operators, who place efficient operations above all else, are available to organisations of all types now.
|
||||
|
||||
### What is a software model?
|
||||
|
||||
Whilst for many years software applications have been comprised of many objects, processes and services, in recent years it has become far more common for applications to be made up of many individual services that are highly distributed across servers in a data centre and across different data centres themselves.
|
||||
|
||||

|
||||
|
||||
_A simple representation of OpenStack Services_
|
||||
|
||||
Many services means many pieces of software to configure, manage and keep track of over many physical machines. Doing this at scale in a cost efficient way requires a model of how all the components are connected and how they map to physical resources. To build the model we need to have a library of software components, a means of defining how they connect with one another and a way to deploy them onto a platform, be it physical or virtual. At Canonical we recognised this several years ago and built [Juju][2], a generic software modelling tool that enables operators to compose complex software applications with flexible topologies, architectures and deployment targets from a catalogue of 100s of common software services.
|
||||
|
||||

|
||||
|
||||
_Juju modelling OpenStack Services_
|
||||
|
||||
In Juju, software services are defined in something called a Charm. Charms are pieces of code, typically written in python or bash that give information about the service – the interfaces declared, how the service is installed, what other services it can connect to etc.
|
||||
|
||||
Charms can be simple or complex depending on the level of intelligence you wish to give them. For OpenStack, Canonical, with help from the upstream OpenStack community, has developed a full set of Charms for the primary OpenStack services. The Charms represents the instructions for the model such that it can be deployed, operated scaled and replicated with ease. The Charms also define how to upgrade themselves including, where needed, the sequence in which to perform the upgrade and how to gracefully pause and resume services when required. By connecting Juju to a bare metal provisioning system such as [Metal As A Service (MAAS)][3] the logical model of OpenStack can is deployed to physical hardware. By default, the Charms will deploy services in LXC containers which gives greater flexibility to relocate services as required based on the cloud behaviour. Config is defined in the Charms or injected at deploy time by a 3rd party tool such as Puppet or Chef.
|
||||
|
||||
There are 2 distinct benefits from this approach: 1 – by creating a model we have abstracted each of the cloud services from the underlying hardware and 2: we have the means to compose new architectures through iterations using the standardised components from a known source. This consistency is what enables us to deploy very different cloud architectures using the same tooling, safe in the knowledge that we will be able to operate and upgrade them easily.
|
||||
|
||||
With hardware inventory being managed with a fully automated provisioning tool and software applications modelled, operators can scale infrastructure much more efficiently than using legacy enterprise techniques or building a bespoke system that deviates from core. Valuable development resources can be focused on innovating in the application space, bringing new software services online faster rather than altering standard, commodity infrastructure in a way which will create compatibility problems further down the line.
|
||||
|
||||
In the next post I’ll highlight some of the best practises for deploying a fully modelled OpenStack and how you can get going quickly. If you have an existing StuckStack then whilst we aren’t going to be able to rescue it that easily, we will be able to get you on a path to fully supported, efficient infrastructure with operations cost that compares to public cloud.
|
||||
|
||||
### Upcoming webinar
|
||||
|
||||
If you are stuck on an old version of OpenStack and want to upgrade your OpenStack cloud easily and without downtime, watch our [on-demand webinar][4] with live demo of an upgrade from Newton to Ocata.
|
||||
|
||||
### Contact us
|
||||
|
||||
If you would like to learn more about migrating to a Canonical OpenStack cloud, [get in touch][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Cloud Product Manager focused on Ubuntu OpenStack. Previously at MySQL and Red Hat. Likes motorcycles and meeting people who do interesting stuff with Ubuntu and OpenStack
|
||||
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/markbaker/
|
||||
[1]:https://insights.ubuntu.com/author/markbaker/
|
||||
[2]:https://www.ubuntu.com/cloud/juju
|
||||
[3]:https://www.ubuntu.com/server/maas
|
||||
[4]:http://ubunt.eu/Bwe7kQ
|
||||
[5]:http://ubunt.eu/3OYs5s
|
||||
@ -1,377 +0,0 @@
|
||||
Integrate Ubuntu to Samba4 AD DC with SSSD and Realm – Part 15
|
||||
============================================================
|
||||
|
||||
|
||||
This tutorial will guide you on how to join an Ubuntu Desktop machine into a Samba4 Active Directory domain with SSSD and Realmd services in order to authenticate users against an Active Directory.
|
||||
|
||||
#### Requirements:
|
||||
|
||||
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||
|
||||
### Step 1: Initial Configurations
|
||||
|
||||
1. Before starting to join Ubuntu into an Active Directory make sure the hostname is properly configured. Use hostnamectl command to set the machine name or manually edit /etc/hostname file.
|
||||
|
||||
```
|
||||
$ sudo hostnamectl set-hostname your_machine_short_hostname
|
||||
$ cat /etc/hostname
|
||||
$ hostnamectl
|
||||
```
|
||||
|
||||
2. On the next step, edit machine network interface settings and add the proper IP configurations and the correct DNS IP server addresses to point to the Samba AD domain controller as illustrated in the below screenshot.
|
||||
|
||||
If you have configured a DHCP server at your premises to automatically assign IP settings for your LAN machines with the proper AD DNS IP addresses then you can skip this step and move forward.
|
||||
|
||||
[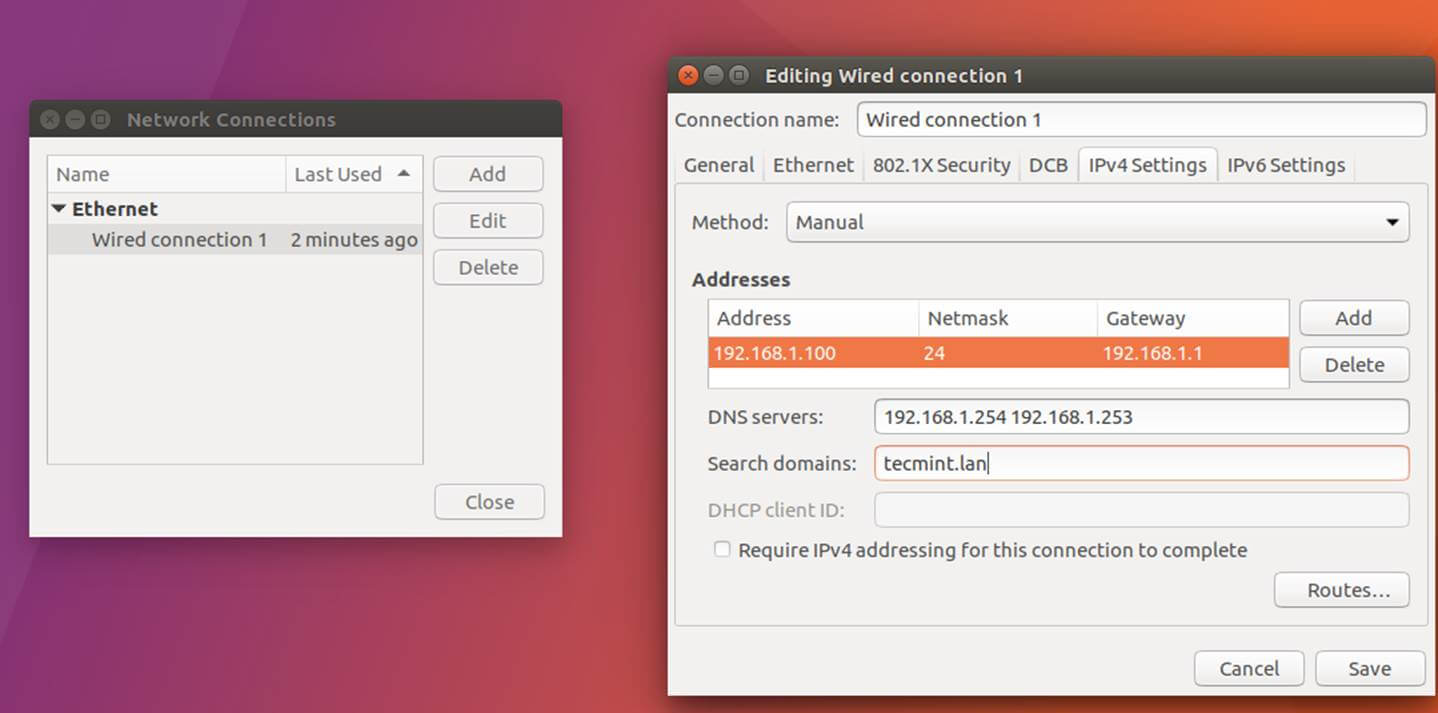][2]
|
||||
|
||||
Configure Network Interface
|
||||
|
||||
On the above screenshot, 192.168.1.254 and 192.168.1.253 represents the IP addresses of the Samba4 Domain Controllers.
|
||||
|
||||
3. Restart the network services to apply the changes using the GUI or from command line and issue a series of ping command against your domain name in order to test if DNS resolution is working as expected. Also, use host command to test DNS resolution.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking.service
|
||||
$ host your_domain.tld
|
||||
$ ping -c2 your_domain_name
|
||||
$ ping -c2 adc1
|
||||
$ ping -c2 adc2
|
||||
```
|
||||
|
||||
4. Finally, make sure that machine time is in sync with Samba4 AD. Install ntpdate package and sync time with the AD by issuing the below commands.
|
||||
|
||||
```
|
||||
$ sudo apt-get install ntpdate
|
||||
$ sudo ntpdate your_domain_name
|
||||
```
|
||||
|
||||
### Step 2: Install Required Packages
|
||||
|
||||
5. On this step install the necessary software and required dependencies in order to join Ubuntu into Samba4 AD DC: Realmd and SSSD services.
|
||||
|
||||
```
|
||||
$ sudo apt install adcli realmd krb5-user samba-common-bin samba-libs samba-dsdb-modules sssd sssd-tools libnss-sss libpam-sss packagekit policykit-1
|
||||
```
|
||||
|
||||
6. Enter the name of the default realm with uppercases and press Enter key to continue the installation.
|
||||
|
||||
[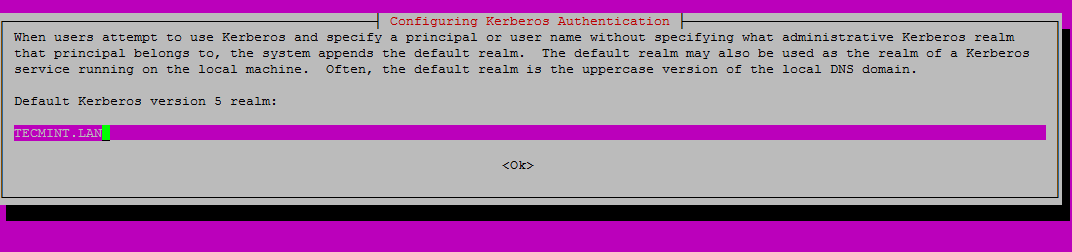][3]
|
||||
|
||||
Set Realm Name
|
||||
|
||||
7. Next, create the SSSD configuration file with the following content.
|
||||
|
||||
```
|
||||
$ sudo nano /etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
Add following lines to sssd.conf file.
|
||||
|
||||
```
|
||||
[nss]
|
||||
filter_groups = root
|
||||
filter_users = root
|
||||
reconnection_retries = 3
|
||||
[pam]
|
||||
reconnection_retries = 3
|
||||
[sssd]
|
||||
domains = tecmint.lan
|
||||
config_file_version = 2
|
||||
services = nss, pam
|
||||
default_domain_suffix = TECMINT.LAN
|
||||
[domain/tecmint.lan]
|
||||
ad_domain = tecmint.lan
|
||||
krb5_realm = TECMINT.LAN
|
||||
realmd_tags = manages-system joined-with-samba
|
||||
cache_credentials = True
|
||||
id_provider = ad
|
||||
krb5_store_password_if_offline = True
|
||||
default_shell = /bin/bash
|
||||
ldap_id_mapping = True
|
||||
use_fully_qualified_names = True
|
||||
fallback_homedir = /home/%d/%u
|
||||
access_provider = ad
|
||||
auth_provider = ad
|
||||
chpass_provider = ad
|
||||
access_provider = ad
|
||||
ldap_schema = ad
|
||||
dyndns_update = true
|
||||
dyndsn_refresh_interval = 43200
|
||||
dyndns_update_ptr = true
|
||||
dyndns_ttl = 3600
|
||||
```
|
||||
|
||||
Make sure you replace the domain name in following parameters accordingly:
|
||||
|
||||
```
|
||||
domains = tecmint.lan
|
||||
default_domain_suffix = TECMINT.LAN
|
||||
[domain/tecmint.lan]
|
||||
ad_domain = tecmint.lan
|
||||
krb5_realm = TECMINT.LAN
|
||||
```
|
||||
|
||||
8. Next, add the proper permissions for SSSD file by issuing the below command:
|
||||
|
||||
```
|
||||
$ sudo chmod 700 /etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
9. Now, open and edit Realmd configuration file and add the following lines.
|
||||
|
||||
```
|
||||
$ sudo nano /etc/realmd.conf
|
||||
```
|
||||
|
||||
Realmd.conf file excerpt:
|
||||
|
||||
```
|
||||
[active-directory]
|
||||
os-name = Linux Ubuntu
|
||||
os-version = 17.04
|
||||
[service]
|
||||
automatic-install = yes
|
||||
[users]
|
||||
default-home = /home/%d/%u
|
||||
default-shell = /bin/bash
|
||||
[tecmint.lan]
|
||||
user-principal = yes
|
||||
fully-qualified-names = no
|
||||
```
|
||||
|
||||
10. The last file you need to modify belongs to Samba daemon. Open /etc/samba/smb.conf file for editing and add the following block of code at the beginning of the file, after the [global]section as illustrated on the image below.
|
||||
|
||||
```
|
||||
workgroup = TECMINT
|
||||
client signing = yes
|
||||
client use spnego = yes
|
||||
kerberos method = secrets and keytab
|
||||
realm = TECMINT.LAN
|
||||
security = ads
|
||||
```
|
||||
[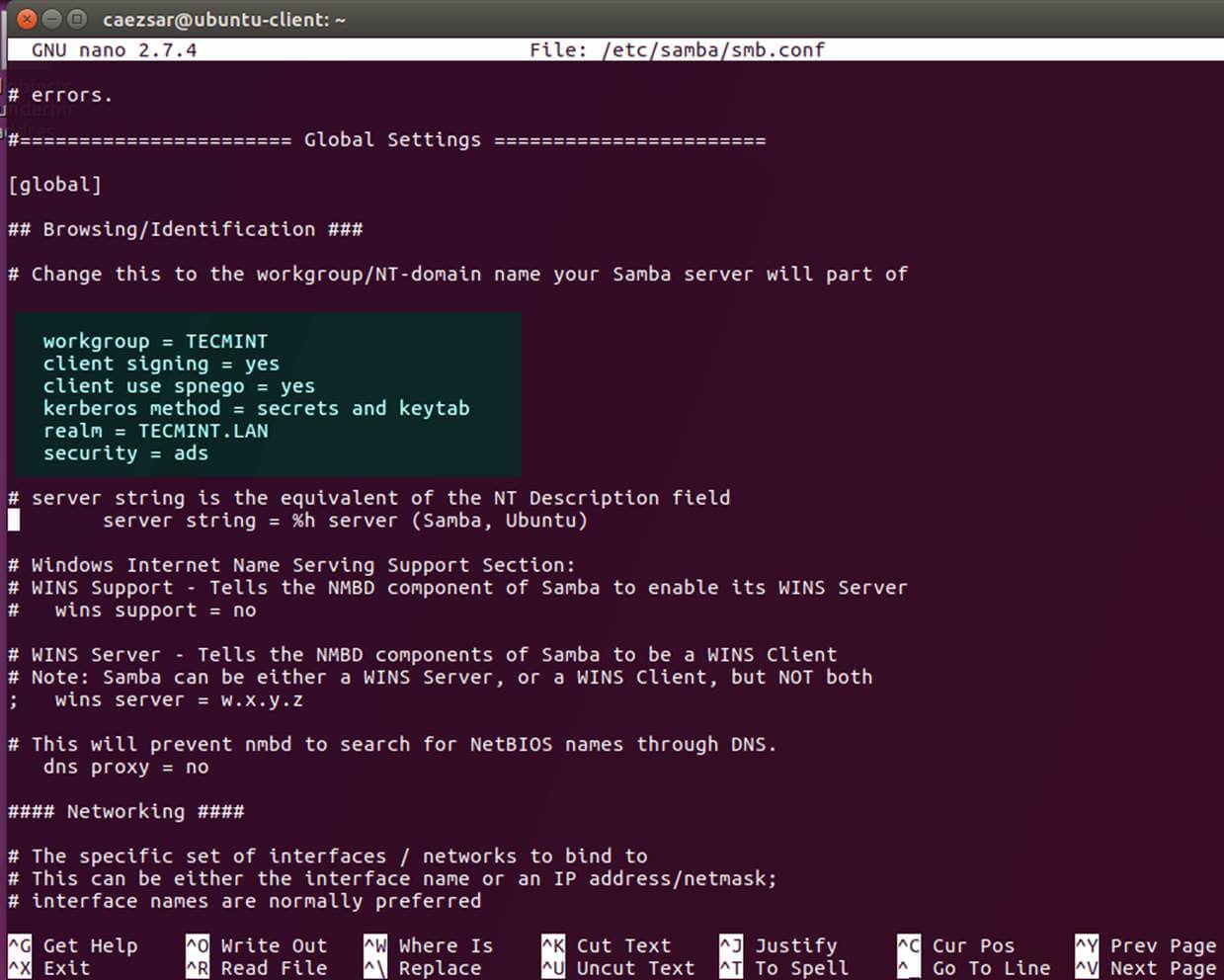][4]
|
||||
|
||||
Configure Samba Server
|
||||
|
||||
Make sure you replace the domain name value, especially the realm value to match your domain name and run testparm command in order to check if the configuration file contains no errors.
|
||||
|
||||
```
|
||||
$ sudo testparm
|
||||
```
|
||||
[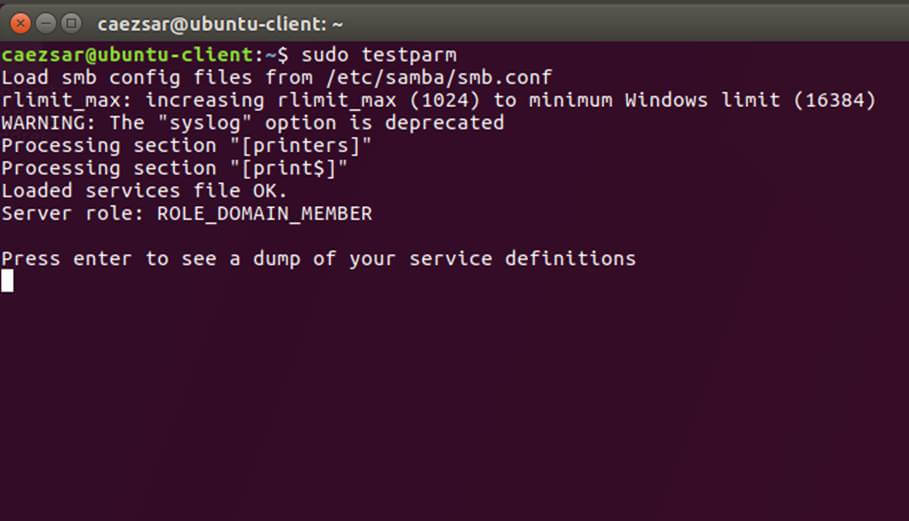][5]
|
||||
|
||||
Test Samba Configuration
|
||||
|
||||
11. After you’ve made all the required changes, test Kerberos authentication using an AD administrative account and list the ticket by issuing the below commands.
|
||||
|
||||
```
|
||||
$ sudo kinit ad_admin_user@DOMAIN.TLD
|
||||
$ sudo klist
|
||||
```
|
||||
[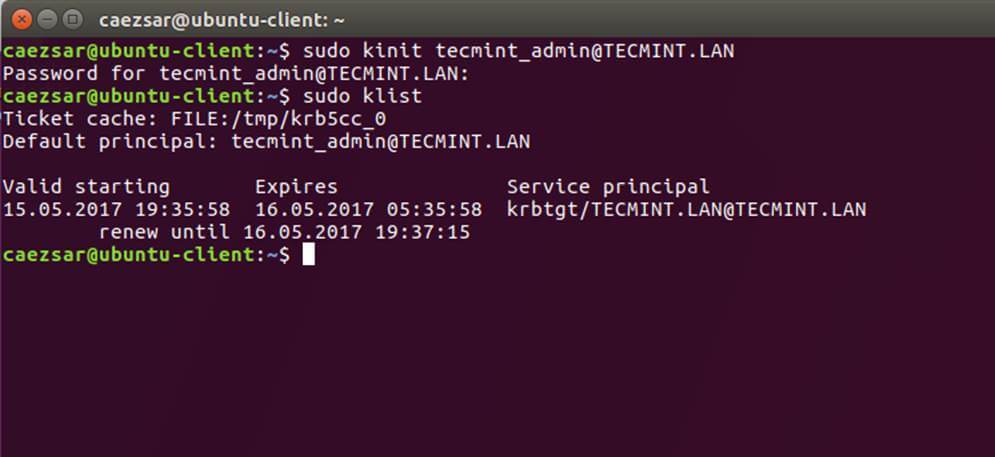][6]
|
||||
|
||||
Check Kerberos Authentication
|
||||
|
||||
### Step 3: Join Ubuntu to Samba4 Realm
|
||||
|
||||
12. To join Ubuntu machine to Samba4 Active Directory issue following series of commands as illustrated below. Use the name of an AD DC account with administrator privileges in order for the binding to realm to work as expected and replace the domain name value accordingly.
|
||||
|
||||
```
|
||||
$ sudo realm discover -v DOMAIN.TLD
|
||||
$ sudo realm list
|
||||
$ sudo realm join TECMINT.LAN -U ad_admin_user -v
|
||||
$ sudo net ads join -k
|
||||
```
|
||||
[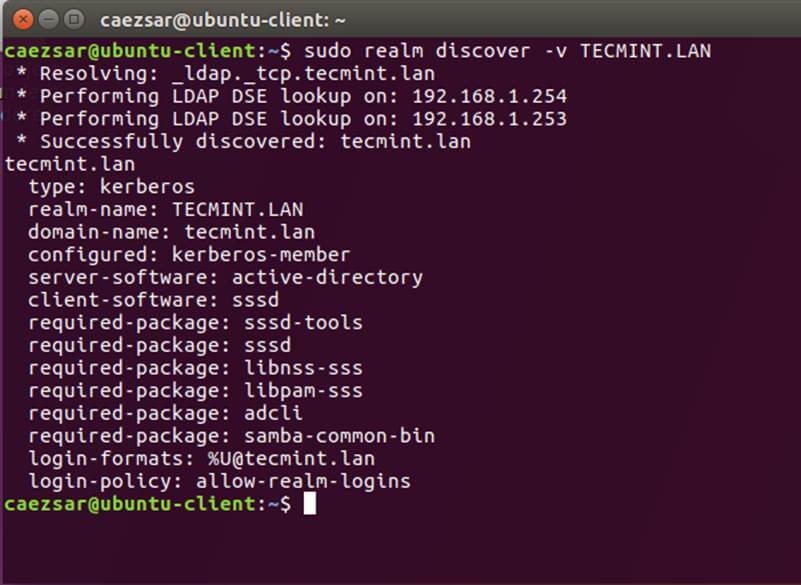][7]
|
||||
|
||||
Join Ubuntu to Samba4 Realm
|
||||
|
||||
[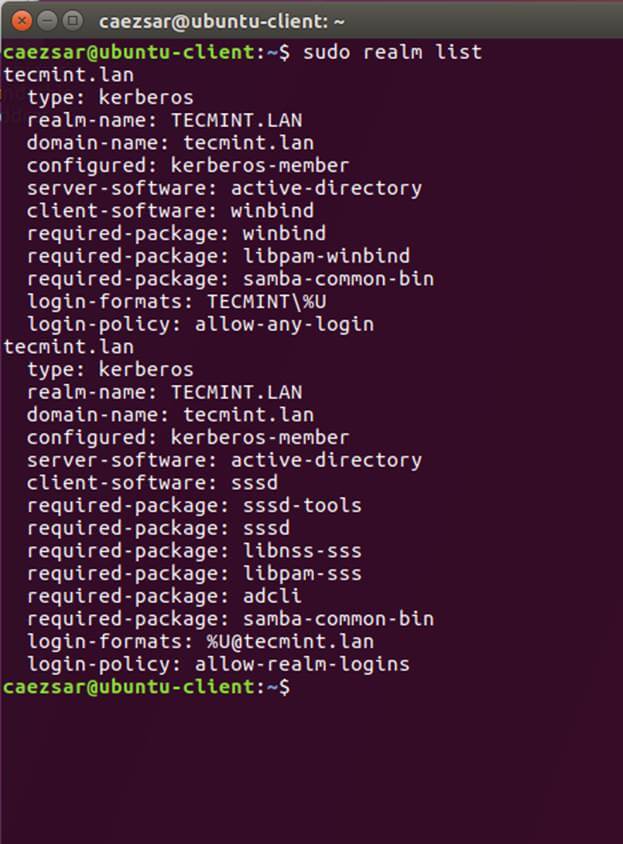][8]
|
||||
|
||||
List Realm Domain Info
|
||||
|
||||
[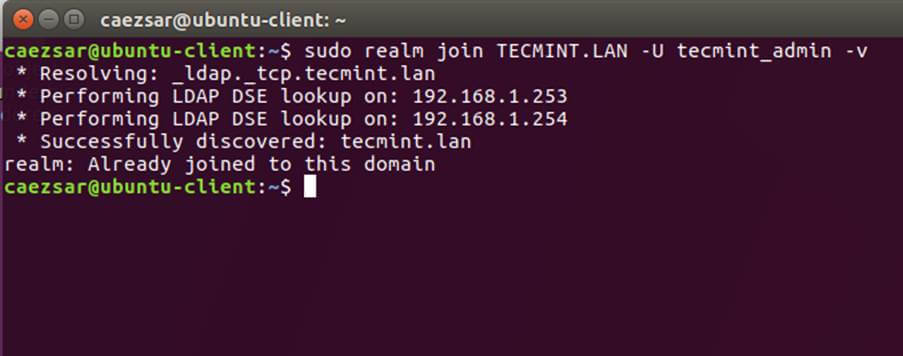][9]
|
||||
|
||||
Add User to Realm Domain
|
||||
|
||||
[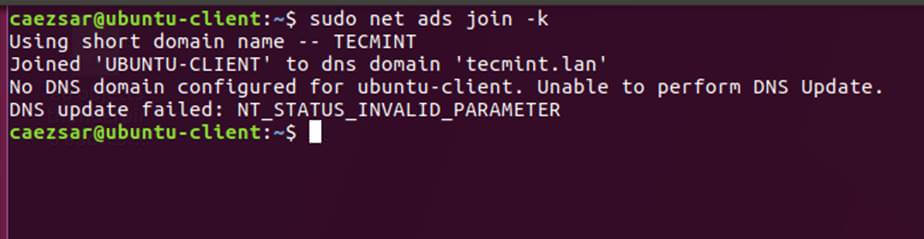][10]
|
||||
|
||||
Add Domain to Realm
|
||||
|
||||
13. After the domain binding took place, run the below command to assure that all domain accounts are permitted to authenticate on the machine.
|
||||
|
||||
```
|
||||
$ sudo realm permit -all
|
||||
```
|
||||
|
||||
Subsequently, you can allow or deny access for a domain user account or a group using realm command as presented on the below examples.
|
||||
|
||||
```
|
||||
$ sudo realm deny -a
|
||||
$ realm permit --groups ‘domain.tld\Linux Admins’
|
||||
$ realm permit user@domain.lan
|
||||
$ realm permit DOMAIN\\User2
|
||||
```
|
||||
|
||||
14. From a Windows machine with [RSAT tools installed][11] you can open AD UC and navigate to Computers container and check if an object account with the name of your machine has been created.
|
||||
|
||||
[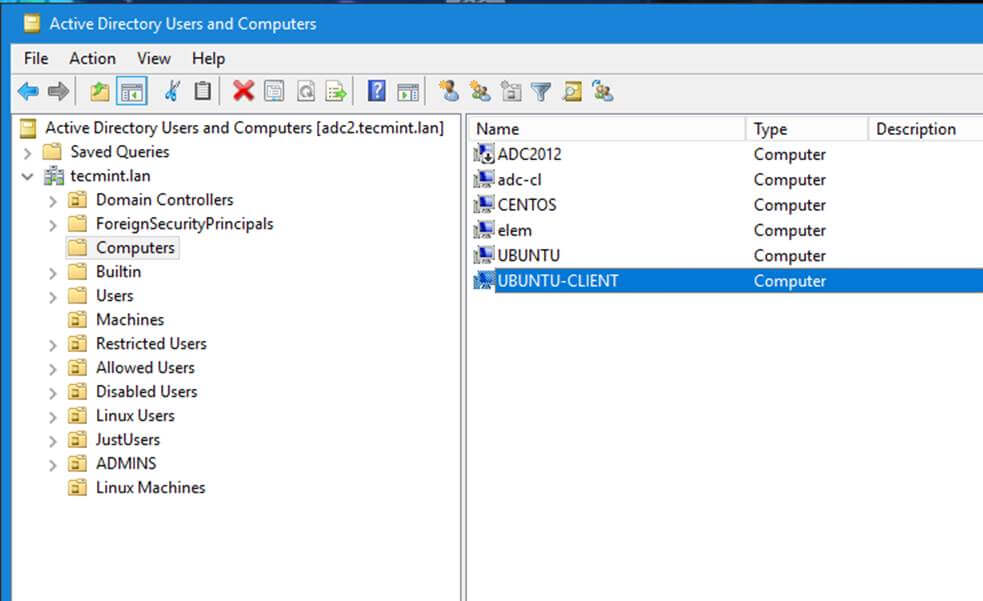][12]
|
||||
|
||||
Confirm Domain Added to AD DC
|
||||
|
||||
### Step 4: Configure AD Accounts Authentication
|
||||
|
||||
15. In order to authenticate on Ubuntu machine with domain accounts you need to run pam-auth-update command with root privileges and enable all PAM profiles including the option to automatically create home directories for each domain account at the first login.
|
||||
|
||||
Check all entries by pressing [space] key and hit ok to apply configuration.
|
||||
|
||||
```
|
||||
$ sudo pam-auth-update
|
||||
```
|
||||
[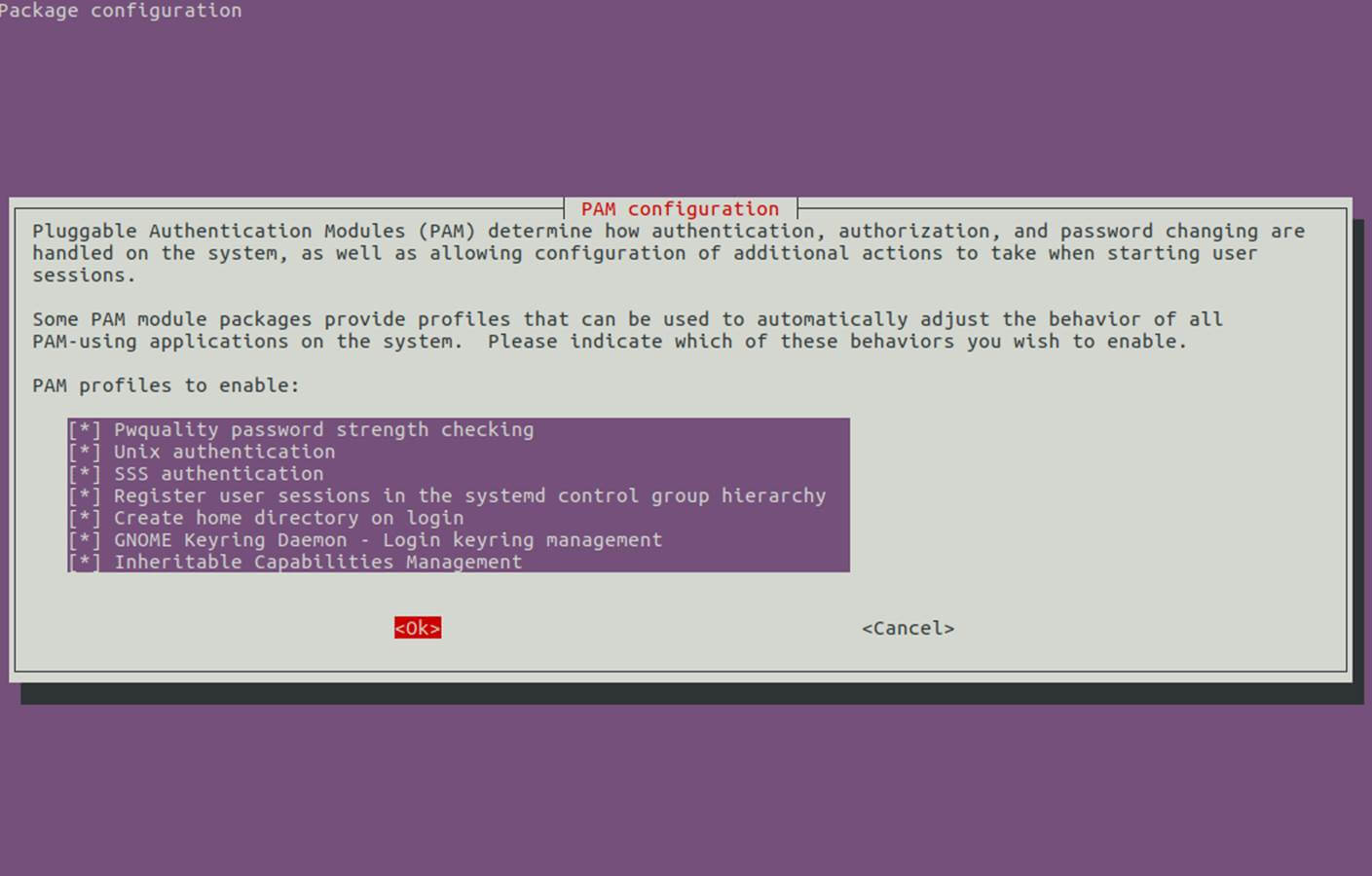][13]
|
||||
|
||||
PAM Configuration
|
||||
|
||||
16. On systems manually edit /etc/pam.d/common-account file and the following line in order to automatically create homes for authenticated domain users.
|
||||
|
||||
```
|
||||
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022
|
||||
```
|
||||
|
||||
17. If Active Directory users can’t change their password from command line in Linux, open /etc/pam.d/common-password file and remove the use_authtok statement from password line to finally look as on the below excerpt.
|
||||
|
||||
```
|
||||
password [success=1 default=ignore] pam_winbind.so try_first_pass
|
||||
```
|
||||
|
||||
18. Finally, restart and enable Realmd and SSSD service to apply changes by issuing the below commands:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart realmd sssd
|
||||
$ sudo systemctl enable realmd sssd
|
||||
```
|
||||
|
||||
19. In order to test if the Ubuntu machine was successfully integrated to realm run install winbind package and run wbinfo command to list domain accounts and groups as illustrated below.
|
||||
|
||||
```
|
||||
$ sudo apt-get install winbind
|
||||
$ wbinfo -u
|
||||
$ wbinfo -g
|
||||
```
|
||||
[][14]
|
||||
|
||||
List Domain Accounts
|
||||
|
||||
20. Also, check Winbind nsswitch module by issuing the getent command against a specific domain user or group.
|
||||
|
||||
```
|
||||
$ sudo getent passwd your_domain_user
|
||||
$ sudo getent group ‘domain admins’
|
||||
```
|
||||
[][15]
|
||||
|
||||
Check Winbind Nsswitch
|
||||
|
||||
21. You can also use Linux id command to get info about an AD account as illustrated on the below command.
|
||||
|
||||
```
|
||||
$ id tecmint_user
|
||||
```
|
||||
[][16]
|
||||
|
||||
Check AD User Info
|
||||
|
||||
22. To authenticate on Ubuntu host with a Samba4 AD account use the domain username parameter after su – command. Run id command to get extra info about the AD account.
|
||||
|
||||
```
|
||||
$ su - your_ad_user
|
||||
```
|
||||
[][17]
|
||||
|
||||
AD User Authentication
|
||||
|
||||
Use pwd command to see your domain user current working directory and passwd command if you want to change password.
|
||||
|
||||
23. To use a domain account with root privileges on your Ubuntu machine, you need to add the AD username to the sudo system group by issuing the below command:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG sudo your_domain_user@domain.tld
|
||||
```
|
||||
|
||||
Login to Ubuntu with the domain account and update your system by running apt updatecommand to check root privileges.
|
||||
|
||||
24. To add root privileges for a domain group, open end edit /etc/sudoers file using visudocommand and add the following line as illustrated.
|
||||
|
||||
```
|
||||
%domain\ admins@tecmint.lan ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
25. To use domain account authentication for Ubuntu Desktop modify LightDM display manager by editing /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf file, append the following two lines and restart lightdm service or reboot the machine apply changes.
|
||||
|
||||
```
|
||||
greeter-show-manual-login=true
|
||||
greeter-hide-users=true
|
||||
```
|
||||
|
||||
Log in to Ubuntu Desktop with a domain account using either your_domain_username or your_domain_username@your_domain.tld syntax.
|
||||
|
||||
26. To use short name format for Samba AD accounts, edit /etc/sssd/sssd.conf file, add the following line in [sssd] block as illustrated below.
|
||||
|
||||
```
|
||||
full_name_format = %1$s
|
||||
```
|
||||
|
||||
and restart SSSD daemon to apply changes.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sssd
|
||||
```
|
||||
|
||||
You will notice that the bash prompt will change to the short name of the AD user without appending the domain name counterpart.
|
||||
|
||||
27. In case you cannot login due to enumerate=true argument set in sssd.conf you must clear sssd cached database by issuing the below command:
|
||||
|
||||
```
|
||||
$ rm /var/lib/sss/db/cache_tecmint.lan.ldb
|
||||
```
|
||||
|
||||
That’s all! Although this guide is mainly focused on integration with a Samba4 Active Directory, the same steps can be applied in order to integrate Ubuntu with Realmd and SSSD services into a Microsoft Windows Server Active Directory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-ubuntu-to-samba4-ad-dc-with-sssd-and-realm/
|
||||
|
||||
作者:[ Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.jpg
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/07/Set-realm-name.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba-Server.jpg
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/Test-Samba-Configuration.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Check-Kerberos-Authentication.jpg
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Ubuntu-to-Samba4-Realm.jpg
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Realm-Domain-Info.jpg
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Add-User-to-Realm-Domain.jpg
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Add-Domain-to-Realm.jpg
|
||||
[11]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Domain-Added.jpg
|
||||
[13]:https://www.tecmint.com/wp-content/uploads/2017/07/PAM-Configuration.jpg
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Accounts.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/check-Winbind-nsswitch.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/Check-AD-User-Info.jpg
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/AD-User-Authentication.jpg
|
||||
[18]:https://www.tecmint.com/author/cezarmatei/
|
||||
[19]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[20]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
> translating by rieonke
|
||||
Containing System Services in Red Hat Enterprise Linux – Part 1
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,91 +0,0 @@
|
||||
> translating by rieon
|
||||
|
||||
DEMYSTIFYING THE OPEN CONTAINER INITIATIVE (OCI) SPECIFICATIONS
|
||||
============================================================
|
||||
|
||||
|
||||
The Open Container Initiative (OCI) announced the completion of the first versions of the container runtime and image specifications this week. The OCI is an effort under the auspices of the Linux Foundation to develop specifications and standards to support container solutions. A lot of effort has gone into the [building of these specifications][12] over the past two years. With that in mind, let’s take a look at some of the myths that have arisen over the past two years.
|
||||
|
||||

|
||||
|
||||
Myth: The OCI is a replacement for Docker
|
||||
|
||||
Standards are important, but they are far from a complete production platform. Take for example, the World Wide Web. It has evolved over the last 25 years and was built on core dependable standards like TCP/IP, HTTP and HTML. Using TCP/IP as an example, when enterprises coalesced around TCP/IP as a common protocol, it fueled the growth of routers and in particular – Cisco. However, Cisco became a leader in its market by focusing on differentiated features on its routing platform. We believe the parallel exists with the OCI specifications and Docker.
|
||||
|
||||
[Docker is a complete production platform][13] for developing, distributing, securing and orchestrating container-based solutions. The OCI specification is used by Docker, but it represents only about five percent of our code and a small part of the Docker platform concerned with the runtime behavior of a container and the layout of a container image.
|
||||
|
||||
Myth: Products and projects already are certified to the OCI specifications
|
||||
|
||||
The runtime and image specifications have just released as 1.0 this week. However, the OCI certification program is still in development so companies cannot claim compliance, conformance or compatibility until certification is formally rolled out later this year.
|
||||
|
||||
The OCI [certification working group][14] is currently defining the standard so that products and open source projects can demonstrate conformance to the specifications. Standards and specifications are important for engineers implementing solutions, but formal certification is the only way to reassure customers that the technology they are working with is truly conformant to the standard.
|
||||
|
||||
Myth: Docker doesn’t support the OCI specifications work
|
||||
|
||||
Docker has a long history with contributing to the OCI. We developed and donated a majority of the OCI code and have been instrumental in defining the OCI runtime and image specifications as maintainers of the project. When the Docker runtime and image format quickly became the de facto standards after being released as open source in 2013, we thought it would be beneficial to donate the code to a neutral governance body to avoid fragmentation and encourage innovation. The goal was to provide a dependable and standardized specification so Docker contributed runc, a simple container runtime, as the basis of the runtime specification work, and later contributed the Docker V2 image specification as the basis for the OCI image specification work.
|
||||
|
||||
Docker developers like Michael Crosby and Stephen Day have been key contributors from the beginning of this work, ensuring Docker’s experience hosting and running billions of container images carries through to the OCI. When the certification working group completes its work, Docker will bring its products through the OCI certification process to demonstrate OCI conformance.
|
||||
|
||||
Myth: The OCI specifications are about Linux containers
|
||||
|
||||
There is a misperception that the OCI is only applicable to Linux container technologies because it is under the aegis of the Linux Foundation. The reality is that although Docker technology started in the Linux world, Docker has been collaborating with Microsoft to bring our container technology, platform and tooling to the world of Windows Server. Additionally, the underlying technology that Docker has donated to the OCI is broadly applicable to multi-architecture environments including Linux, Windows and Solaris and covers x86, ARM and IBM zSeries.
|
||||
|
||||
Myth: Docker was just one of many contributors to the OCI
|
||||
|
||||
The OCI as an organization has a lot of supporting members representing the breadth of the container industry. That said, it has been a small but dedicated group of individual technologists that have contributed the time and technology to the efforts that have produced the initial specifications. Docker was a founding member of the OCI, contributing the initial code base that would form the basis of the runtime specification and later the reference implementation itself. Likewise, Docker contributed the Docker V2 Image specification to act as the basis of the OCI image specification.
|
||||
|
||||
Myth: CRI-O is an OCI project
|
||||
|
||||
CRI-O is an open source project in the Kubernetes incubator in the Cloud Native Computing Foundation (CNCF) – it is not an OCI project. It is based on an earlier version of the Docker architecture, whereas containerd is a direct CNCF project that is a larger container runtime that includes the runc reference implementation. containerd is responsible for image transfer and storage, container execution and supervision, and low-level functions to support storage and network attachments. Docker donated containerd to the CNCF with the support of the five largest cloud providers: Alibaba Cloud, AWS, Google Cloud Platform, IBM Softlayer and Microsoft Azure with a charter of being a core container runtime for multiple container platforms and orchestration systems.
|
||||
|
||||
Myth: The OCI specifications are now complete
|
||||
|
||||
While the release of the runtime and image format specifications is an important milestone, there’s still work to be done. The initial scope of the OCI was to define a narrow specification on which developers could depend for the runtime behavior of a container, preventing fragmentation in the industry, and still allowing innovation in the evolving container domain. This was later expanded to include a container image specification.
|
||||
|
||||
As the working groups complete the first stable specifications for runtime behavior and image format, new work is under consideration. Ideas for future work include distribution and signing. The next most important work for the OCI, however, is delivering on a certification process backed by a test suite now that the first specifications are stable.
|
||||
|
||||
**Learn more about OCI and Open Source at Docker:**
|
||||
|
||||
* Read the blog post about the [OCI Release of v1.0 Runtime and Image Format Specifications][1]
|
||||
|
||||
* Visit the [Open Container Initiative website][2]
|
||||
|
||||
* Visit the [Moby Project website][3]
|
||||
|
||||
* Attend [DockerCon Europe 2017][4]
|
||||
|
||||
* Attend the [Moby Summit LA][5] alongside OSS NA
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Stephen is Director, Open Source Programs at Docker. He has been a Director and Distinguished Technologist at Hewlett-Packard Enterprise. He blogs about open source software and business at “Once More Unto The Breach” (http://stephesblog.blogs.com) and opensource.com.
|
||||
|
||||
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/demystifying-open-container-initiative-oci-specifications/
|
||||
|
||||
作者:[Stephen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[1]:https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications
|
||||
[2]:https://www.opencontainers.org/join
|
||||
[3]:http://mobyproject.org/
|
||||
[4]:https://europe-2017.dockercon.com/
|
||||
[5]:https://www.eventbrite.com/e/moby-summit-los-angeles-tickets-35930560273
|
||||
[6]:https://blog.docker.com/author/stephen-walli/
|
||||
[7]:https://blog.docker.com/tag/containerd/
|
||||
[8]:https://blog.docker.com/tag/cri-o/
|
||||
[9]:https://blog.docker.com/tag/linux-containers/
|
||||
[10]:https://blog.docker.com/tag/linux-foundation/
|
||||
[11]:https://blog.docker.com/tag/oci/
|
||||
[12]:https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications
|
||||
[13]:https://www.docker.com/
|
||||
[14]:https://github.com/opencontainers/certification
|
||||
@ -1,106 +0,0 @@
|
||||
> translating by rieon
|
||||
|
||||
DOCKER LEADS OCI RELEASE OF V1.0 RUNTIME AND IMAGE FORMAT SPECIFICATIONS
|
||||
============================================================
|
||||
|
||||
|
||||
Today marks an important milestone for the Open Container Initiative (OCI) with the release of the OCI v1.0 runtime and image specifications – a journey that Docker has been central in driving and navigating over the last two years. It has been our goal to provide low-level standards as building blocks for the community, customers and the broader industry. To understand the significance of this milestone, let’s take a look at the history of Docker’s growth and progress in developing industry-standard container technologies.
|
||||
|
||||
The History of Docker Runtime and Image Donations to the OCI
|
||||
|
||||
Docker’s image format and container runtime quickly emerged as the de facto standard following its release as an open source project in 2013\. We recognized the importance of turning it over to a neutral governance body to fuel innovation and prevent fragmentation in the industry. Working together with a broad group of container technologists and industry leaders, the Open Container Project was formed to create a set of container standards and was launched under the auspices of the Linux Foundation in June 2015 at DockerCon. It became the Open Container Initiative (OCI) as the project evolved that Summer.
|
||||
|
||||
Docker contributed runc, a reference implementation for the container runtime software that had grown out of Docker employee [Michael Crosby’s][17] libcontainer project. runc is the basis for the runtime specification describing the life-cycle of a container and the behavior of a container runtime. runc is used in production across tens of millions of nodes, which is an order of magnitude more than any other code base. runc became the reference implementation for the runtime specification project itself, and continued to evolve with the project.
|
||||
|
||||
Almost a year after work began on the runtime specification, a new working group formed to specify a container image format. Docker donated the Docker V2 Image Format to the OCI as the basis for the image specification. With this donation, the OCI defines the data structures — the primitives — that make up a container image. Defining the container image format is an important step for adoption, but it takes a platform like Docker to activate its value by defining and providing tooling on how to build images, manage them and ship them around. For example, things such as the Dockerfile are not included in the OCI specifications.
|
||||
|
||||
Title: Docker’s History of Contribution to the OCI
|
||||
|
||||

|
||||
|
||||
The Journey to Open Container Standards
|
||||
|
||||
The specifications have continued to evolve for two years now. Smaller projects have been spun out of the runc reference implementation as the code has been refactored, as well as support testing tools that will become the test suite for certification.
|
||||
|
||||
See the timeline above for details about Docker’s involvement in shaping OCI, which includes: creating runc, iterating on the runtime specification with the community, creating containerd to integrate runc in Docker 1.11, donating the Docker V2 Image Format to OCI as a base for the image format specification, implementing that specification in [containerd][18] so that this core container runtime covers both the runtime and image format standards, and finally donating containerd to the Cloud Native Computing Foundation (CNCF) and iterating on it towards a 1.0 alpha release this month.
|
||||
|
||||
Maintainers [Michael Crosby][19] and [Stephen Day][20] have lead the development of these specifications and have been instrumental in bringing v1.0 to fruition, alongside contributions from Alexander Morozov, Josh Hawn, Derek McGown and Aaron Lehmann, as well as Stephen Walli participating in the certification working group.
|
||||
|
||||
Docker remains committed to driving container standards, building a strong base at the layers where everyone agrees so that the industry can innovate at the layers that are still very differentiated.
|
||||
|
||||
Open Standards are Only a Piece of the Puzzle
|
||||
|
||||
Docker is a complete platform for creating, managing, securing, and orchestrating containers and container images. The vision has always been a base of industry standard specifications that support open source components or the plumbing of a container solution. The Docker platform sits above this layer – providing users and customers with a secure container management solution from development through production.
|
||||
|
||||
The OCI runtime and image specifications become the dependable standards base that allow and encourage the greatest number of container solutions and at the same time, they do not restrict product innovation or shutout major contributors. To draw a comparison, TCP/IP, HTTP and HTML became the dependable standards base upon which the World Wide Web was built over the past 25 years. Companies continue to innovate with new tools, technologies and browsers on these standards. The OCI specifications provide the similar foundation for containers solutions going forward.
|
||||
|
||||
Open source projects also play a role in providing components for product development. The OCI runc reference implementation is used by the containerd project, a larger container runtime responsible for image transfer and storage, container execution and supervision, and low-level functions to support storage and network attachments. The containerd project was contributed by Docker to the CNCF and sits alongside other important projects to support cloud native computing solutions.
|
||||
|
||||
Docker uses containerd and more of its own core open source infrastructure elements like the LinuxKit, InfraKit and Notary projects to build and secure container solutions that become the Docker Community Edition tools. Users and organizations looking for complete container platforms that are holistic and provide container management, security, orchestration, networking and more can look to Docker Enterprise Edition.
|
||||
|
||||

|
||||
|
||||
> This diagram highlights that the OCI specifications provide a layer of standards, implemented by a container runtime: containerd and runc. To assemble a full container platform such as Docker with full container lifecycle workflow, many other components are brought together: to manage infrastructure (InfraKit), provide an operating system (LinuxKit), deliver orchestration (SwarmKit), ensure security (Notary).
|
||||
|
||||
What’s Next for the OCI
|
||||
|
||||
We should celebrate the efforts of the developers as the runtime and image specifications are published. The next critical work to be done by the Open Container Initiative is to deliver a certification program to validate claims from implementers that their products and projects do indeed conform to the runtime and image specifications. The [Certification Working Group][21] has been putting together a program that in conjunction with a developing suite of test tools for both the [runtime][22] and [image][23] specifications will show how implementations fare against the standards.
|
||||
|
||||
At the same time, the developers of the current specifications are considering the next most important areas of container technology to specify. Work is underway around a common networking interface for containers in the Cloud Native Computing Foundation, but work to support signing and distribution are areas under consideration for the OCI.
|
||||
|
||||
Alongside the OCI and its members, Docker remains committed to standardizing container technology. The OCI’s mission is to give users and companies the baseline on which they can innovate in the areas of developer tooling, image distribution, container orchestration, security, monitoring and management. Docker will continue to lead the charge in innovation – not only with tooling that increases productivity and increases efficiencies, but also by empowering users, partners and customers to innovate as well.
|
||||
|
||||
**Learn more about OCI and Open Source at Docker:**
|
||||
|
||||
* Read about the [OCI specifications Myths][1]
|
||||
|
||||
* Visit the [Open Container Initiative website][2]
|
||||
|
||||
* Visit the [Moby Project website][3]
|
||||
|
||||
* Attend [DockerCon Europe 2017][4]
|
||||
|
||||
* Attend the [Moby Summit LA][5] alongside OSS NA
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Patrick Chanezon is member of technical staff at Docker Inc. He helps to build Docker, an open platform for distributed applications for developers and sysadmins. Software developer and storyteller, he spent 10 years building platforms at Netscape & Sun, then 10 years evangelizing platforms at Google, VMware & Microsoft. His main professional interest is in building and kickstarting the network effect for these wondrous two-sided markets called Platforms. He has worked on platforms for Portals, Ads, Commerce, Social, Web, Distributed Apps, and Cloud. More information is available at linkedin.com/in/chanezon. Patrick tweets at @chanezon.
|
||||
|
||||
|
||||
|
||||
------
|
||||
|
||||
via: https://blog.docker.com/2017/07/oci-release-of-v1-0-runtime-and-image-format-specifications/
|
||||
|
||||
作者:[Patrick Chanezon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/chanezon/
|
||||
[1]:https://blog.docker.com/2017/07/demystifying-open-container-initiative-oci-specifications/
|
||||
[2]:https://www.opencontainers.org/join
|
||||
[3]:http://mobyproject.org/
|
||||
[4]:https://europe-2017.dockercon.com/
|
||||
[5]:https://www.eventbrite.com/e/moby-summit-los-angeles-tickets-35930560273
|
||||
[6]:https://blog.docker.com/author/chanezon/
|
||||
[7]:https://blog.docker.com/tag/cncf/
|
||||
[8]:https://blog.docker.com/tag/containerd/
|
||||
[9]:https://blog.docker.com/tag/containers/
|
||||
[10]:https://blog.docker.com/tag/docker/
|
||||
[11]:https://blog.docker.com/tag/docker-image-format/
|
||||
[12]:https://blog.docker.com/tag/docker-runtime/
|
||||
[13]:https://blog.docker.com/tag/infrakit/
|
||||
[14]:https://blog.docker.com/tag/linux-foundation/
|
||||
[15]:https://blog.docker.com/tag/oci/
|
||||
[16]:https://blog.docker.com/tag/open-containers/
|
||||
[17]:https://github.com/crosbymichael
|
||||
[18]:https://containerd.io/
|
||||
[19]:https://github.com/crosbymichael
|
||||
[20]:https://github.com/stevvooe
|
||||
[21]:https://github.com/opencontainers/certification
|
||||
[22]:https://github.com/opencontainers/runtime-tools
|
||||
[23]:https://github.com/opencontainers/image-tools
|
||||
@ -1,134 +0,0 @@
|
||||
translating by LHRchina
|
||||
What you need to know about hybrid cloud
|
||||
============================================================
|
||||
|
||||
### Learn the ins and outs of hybrid cloud, including what it is and how to use it.
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Jason Baker][10]. [CC BY-SA 4.0][11].
|
||||
|
||||
Of the many technologies that have emerged over the past decade, cloud computing is notable for its rapid advance from a niche technology to global domination. On its own, cloud computing has created a lot of confusion, arguments, and debates, and "hybrid" cloud, which blends several types of cloud computing, has created even more uncertainty. Read on for answers to some of the most common questions about hybrid cloud.
|
||||
|
||||
### What is a hybrid cloud?
|
||||
|
||||
Basically, a hybrid cloud is a flexible and integrated combination of on-premises infrastructure, private cloud, and public (i.e., third-party) cloud platforms. Even though public and private cloud services are bound together in a hybrid cloud, in practice they remain unique and separate entities with services that can be orchestrated together. The choice to use both public and private cloud infrastructure is based on several factors, including cost, load flexibility, and data security.
|
||||
|
||||
Advanced features, such as scale-up and scale-out, can quickly expand a cloud application's infrastructure on demand, making hybrid cloud a popular choice for services with seasonal or other variable resource demands. (Scaling up means to increase compute resources, such as CPU cores and memory, on a specific Linux instance, whereas scaling out means to provision multiple instances with similar configurations and distribute them into a cluster.)
|
||||
|
||||
Explore the open source cloud
|
||||
|
||||
* [What is the cloud?][1]
|
||||
|
||||
* [What is OpenStack?][2]
|
||||
|
||||
* [What is Kubernetes?][3]
|
||||
|
||||
* [Why the operating system matters for containers][4]
|
||||
|
||||
* [Keeping Linux containers safe and secure][5]
|
||||
|
||||
At the center of hybrid cloud solutions sits open source software, such as [OpenStack][12], that deploys and manages large networks of virtual machines. Since its initial release in October 2010, OpenStack has been thriving globally. Some of its integrated projects and tools handle core cloud computing services, such as compute, networking, storage, and identity, while dozens of other projects can be bundled together with OpenStack to create unique and deployable hybrid cloud solutions.
|
||||
|
||||
### Components of the hybrid cloud
|
||||
|
||||
As illustrated in the graphic below, a hybrid cloud consists of private cloud, public cloud, and the internal network connected and managed through orchestration, system management, and automation tools.
|
||||
|
||||
### [hybridcloud1.jpg][6]
|
||||
|
||||

|
||||
|
||||
Model of the hybrid cloud
|
||||
|
||||
### Public cloud infrastructure:
|
||||
|
||||
* **Infrastructure as a Service (IaaS) **provides compute resources, storage, networking, firewall, intrusion prevention services (IPS), etc. from a remote data center. These services can be monitored and managed using a graphical user interface (GUI) or a command line interface (CLI). Rather than purchasing and building their own infrastructure, public IaaS users consume these services as needed and pay based on usage.
|
||||
|
||||
* **Platform as a Service (PaaS)** allows users to develop, test, manage, and run applications and servers. These include the operating system, middleware, web servers, database, and so forth. Public PaaS provides users with predefined services in the form of templates that can be easily deployed and replicated, instead of manually implementing and configuring infrastructure.
|
||||
|
||||
* **Software as a Service (SaaS)** delivers software through the internet. Users can consume these services under a subscription or license model or at the account level, where they are billed as active users. SaaS software is low cost, low maintenance, painless to upgrade, and reduces the burden of buying new hardware, software, or bandwidth to support growth.
|
||||
|
||||
### Private cloud infrastructure:
|
||||
|
||||
* Private **IaaS and PaaS** are hosted in isolated data centers and integrated with public clouds that can consume the infrastructure and services available in remote data centers. This enables a private cloud owner to leverage public cloud infrastructure to expand applications and utilize their compute, storage, networking, and so forth across the globe.
|
||||
|
||||
* **SaaS** is completely monitored, managed, and controlled by public cloud providers. SaaS is generally not shared between public and private cloud infrastructure and remains a service provided through a public cloud.
|
||||
|
||||
### Cloud orchestration and automation tools:
|
||||
|
||||
A cloud orchestration tool is necessary for planning and coordinating private and public cloud instances. This tool should inherit intelligence, including the capability to streamline processes and automate repetitive tasks. Further, an integrated automation tool is responsible for automatically scaling up and scaling out when a set threshold is crossed, as well as performing self-healing if any fractional damage or downtime occurs.
|
||||
|
||||
### System and configuration management tools:
|
||||
|
||||
In a hybrid cloud, system and configuration tools, such as [Foreman][13], manage the complete lifecycles of the virtual machines provisioned in private and public cloud data centers. These tools give system administrators the power to easily control users, roles, deployments, upgrades, and instances and to apply patches, bugfixes, and enhancements in a timely manner. Including [Puppet][14] in the Foreman tool enables administrators to manage configurations and define a complete end state for all provisioned and registered hosts.
|
||||
|
||||
### Hybrid cloud features
|
||||
|
||||
The hybrid cloud makes sense for most organizations because of these key features:
|
||||
|
||||
* **Scalability:** In a hybrid cloud, integrated private and public cloud instances share a pool of compute resources for each provisioned instance. This means each instance can scale up or out anytime, as needed.
|
||||
|
||||
* **Rapid response:** Hybrid clouds' elasticity supports rapid bursting of instances in the public cloud when private cloud resources exceed their threshold. This is especially valuable when peaks in demand produce significant and variable increases in load and capacity for a running application (e.g., online retailers during the holiday shopping season).
|
||||
|
||||
* **Reliability:** Organizations can choose among public cloud providers based on the cost, efficiency, security, bandwidth, etc. that match their needs. In a hybrid cloud, organizations can also decide where to store sensitive data and whether to expand instances in a private cloud or to expand geographically through public infrastructure. Also, the hybrid model's ability to store data and configurations across multiple sites supports backup, disaster recovery, and high availability.
|
||||
|
||||
* **Management:** Managing networking, storage, instances, and/or data can be tedious in non-integrated cloud environments. Traditional orchestration tools, in comparison to hybrid tools, are extremely modest and consequently limit decision making and automation for complete end-to-end processes and tasks. With hybrid cloud and an effective management application, you can keep track of every component as their numbers grow and, by regularly optimizing those components, minimize annual expense.
|
||||
|
||||
* **Security:** Security and privacy are critical when evaluating whether to place applications and data in the cloud. The IT department must verify all compliance requirements and deployment policies. Security in the public cloud is improving and continues to mature. And, in the hybrid cloud model, organizations can store highly sensitive information in the private cloud and integrate it with less sensitive data stored in the public cloud.
|
||||
|
||||
* **Pricing:** Cloud pricing is generally based on the infrastructure and service level agreement required. In the hybrid cloud model, users can compare costs at a granular level for compute resources (CPU/memory), bandwidth, storage, networking, public IP address, etc. Prices are either fixed or variable and can be metered monthly, hourly, or even per second. Therefore, users can always shop for the best pricing among public cloud providers and deploy their instances accordingly.
|
||||
|
||||
### Where hybrid cloud is today
|
||||
|
||||
Although there is a large and growing demand for public cloud offerings and migrating systems from on-premises to the public cloud, most large organizations remain concerned. Most still keep critical applications and data in corporate data centers and legacy systems. They fear losing control, security threats, data privacy, and data authenticity in public infrastructure. Because hybrid cloud minimizes these problems and maximizes benefits, it's the best solution for most large organizations.
|
||||
|
||||
### Where we'll be five years from now
|
||||
|
||||
I expect that the hybrid cloud model will be highly accepted globally, and corporate "no-cloud" policies will be rare, within only a handful of years. Here is what else I think we will see:
|
||||
|
||||
* Since hybrid cloud acts as a shared responsibility, there will be increased coordination between corporate and public cloud providers for implementing security measures to curb cyber attacks, malware, data leakage, and other threats.
|
||||
|
||||
* Bursting of instances will be rapid, so customers can spontaneously meet load requirements or perform self-healing.
|
||||
|
||||
* Further, orchestration or automation tools (such as [Ansible][8]) will play a significant role by inheriting intelligence for solving critical situations.
|
||||
|
||||
* Metering and the concept of "pay-as-you-go" will be transparent to customers, and tools will enable users to make decisions by monitoring fluctuating prices, safely destroy existing instances, and provision new instances to get the best available pricing.
|
||||
|
||||
What predictions do you have for hybrid cloud—and cloud computing in general—over the next five years? Please share your opinions in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amit Das - Amit works as an engineer in Red Hat, and is passionate about Linux, Cloud computing, DevOps etc. He is a strong believer that new innovation and technology, in a open way which makes world more open, can positively impact the society and change many lives.
|
||||
|
||||
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/what-is-hybrid-cloud
|
||||
|
||||
作者:[Amit Das ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amit-das
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/file/364211
|
||||
[7]:https://opensource.com/article/17/7/what-is-hybrid-cloud?rate=TwB_2KyXM7iqrwDPGZpe6WultoCajdIVgp8xI4oZkTw
|
||||
[8]:https://opensource.com/life/16/8/cloud-ansible-gateway
|
||||
[9]:https://opensource.com/user/157341/feed
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://opensource.com/resources/openstack
|
||||
[13]:https://github.com/theforeman
|
||||
[14]:https://github.com/theforeman/puppet-foreman
|
||||
[15]:https://opensource.com/users/amit-das
|
||||
[16]:https://opensource.com/users/amit-das
|
||||
@ -0,0 +1,68 @@
|
||||
轻松应对 Linux 容器性能
|
||||
============================================================
|
||||
|
||||

|
||||
图片来源: CC0 Public Domain
|
||||
|
||||
应用程序的性能决定了软件能多快完成预期任务。这回答有关应用程序的几个问题,例如:
|
||||
|
||||
* 峰值负载下的响应时间
|
||||
* 与替代方案相比,它易于使用,受支持的功能和用例
|
||||
* 操作成本(CPU使用率、内存需求、数据吞吐量、带宽等)
|
||||
|
||||
该性能分析的价值超出了服务负载所需的计算资源的估计或满足峰值需求所需的应用实例数量。性能显然与成功企业的基本要素挂钩。它通知用户的总体体验,包括确定什么会拖慢客户预期的响应时间,通过设计满足带宽要求的内容交付来提高客户粘性,选择最佳设备,最终帮助企业发展业务。
|
||||
|
||||
### 问题
|
||||
|
||||
当然,这是对业务服务性能工程价值的过度简化。要了解完成我刚刚描述的挑战,让我们来做一个真正的,有点复杂的事情。
|
||||
|
||||

|
||||
|
||||
现实世界的应用程序可能托管在云端。应用程序可以利用非常大(或概念上无穷大)的计算资源。在硬件和软件方面的需求将通过云来满足。从事开发工作的开发人员将使用云提供的功能来实现更快的编码和部署。云托管不是免费的,但成本开销与应用程序的资源需求成正比。
|
||||
|
||||
搜索即服务(SaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)以及负载平衡即服务(LBaaS),它是当云端管理托管程序的流量,开发人员可能还会使用这些快速增长的云服务中的一个或多个:
|
||||
|
||||
* 安全即服务 (SECaaS),可满足软件和用户的安全需求
|
||||
* 数据即服务 (DaaS),提供用户的应用需求数据
|
||||
* 登录即服务 (LaaS),DaaS 的近亲,提供有关日志传送和使用的分析指标
|
||||
* 搜索即服务 (SaaS),用于应用程序的分析和大数据需求
|
||||
* 网络即服务 (NaaS),用于通过公共网络发送和接收数据
|
||||
|
||||
云服务也呈指数级增长,因为它们使编写复杂应用程序的开发人员更容易。除了软件复杂性之外,所有这些分布式组件的相互作用变得越来越多。用户群变得更加多元化。该软件的要求列表变得更长。对其他服务的依赖性变大。由于这些因素,这个生态系统的缺陷会引发性能问题的多米诺效应。
|
||||
|
||||
例如,假设你有一个精心编写的应用程序,它遵循安全编码实践,旨在满足不同的负载要求,并经过彻底测试。另外假设你已经将基础架构和分析工作结合起来,以支持基本的性能要求。在系统的实现、设计和架构中建立性能标准需要做些什么?软件如何跟上不断变化的市场需求和新兴技术?如何测量关键参数以调整系统以获得最佳性能?如何使系统具有弹性和自我恢复能力?你如何更快地识别任何潜在的性能问题,并尽早解决?
|
||||
|
||||
### 进入容器
|
||||
|
||||
软件[容器][2]以[微服务][3]设计或面向服务的架构(SoA)的优点为基础,提高了性能,因为包含更小,自足的代码块的系统更容易编码,对其他系统组件有更清晰、定义良好的依赖。测试更容易,包括围绕资源利用和内存过度消耗的问题比在宏架构中更容易确定。
|
||||
|
||||
当伸缩系统以增加负载时,容器应用程序复制快速而简单。安全漏洞能更好地隔离。补丁可以独立版本化并快速部署。性能监控更有针对性,测量更可靠。你还可以重写和“改版”资源密集型代码,以满足不断变化的性能要求。
|
||||
|
||||
容器启动快速,停止也快速。它比虚拟机(VM)有更高效资源利用和更好的进程隔离。容器没有空闲内存和 CPU 开销。它们允许多个应用程序共享机器,而不会丢失数据或性能。容器使应用程序可移植,因此开发人员可以构建并将应用程序发送到任何支持容器技术 Linux 的服务器上,而不必担心性能损失。容器以它们的形式存在,并遵守其集群管理器(如 Cloud Foundry 的 Diego、[Kubernetes][4]、Apache Mesos 和 Docker Swarm)所规定的配额(比如包括存储、计算和对象计数配额)。
|
||||
|
||||
虽然容器在性能方面表现出色,但即将到来的 “serverless” 计算(也称为功能即服务(FaaS))的浪潮将扩大容器的优势。在 FaaS 时代,这些临时性或短期的容器将带来超越应用程序性能的优势,直接转化为在云中托管的间接成本的节省。如果容器的工作更快,那么它的寿命就会更短,而且计算量负载纯粹是按需的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Garima 是 Red Hat 的工程经理,专注于 OpenShift 容器平台。在加入 Red Hat 之前,Garima 帮助 Akamai Technologies&MathWorks Inc. 开创了创新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/performance-container-world
|
||||
|
||||
作者:[Garima][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/garimavsharma
|
||||
[1]:https://opensource.com/article/17/2/performance-container-world?rate=RozKaIY39AZNxbayqFkUmtkkhoGdctOVuGOAJqVJII8
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers
|
||||
[3]:https://opensource.com/resources/what-are-microservices
|
||||
[4]:https://opensource.com/resources/what-is-kubernetes
|
||||
[5]:https://opensource.com/user/109286/feed
|
||||
[6]:https://opensource.com/article/17/2/performance-container-world#comments
|
||||
[7]:https://opensource.com/users/garimavsharma
|
||||
@ -0,0 +1,73 @@
|
||||
# 在 Kali Linux 的 Wireshark 中过滤数据包
|
||||
|
||||
内容
|
||||
|
||||
* * [1. 介绍][1]
|
||||
|
||||
* [2. 布尔表达式和比较运算符][2]
|
||||
|
||||
* [3. 过滤抓包][3]
|
||||
|
||||
* [4. 过滤结果][4]
|
||||
|
||||
* [5. 总结思考][5]
|
||||
|
||||
### 介绍
|
||||
|
||||
过滤可让你专注于你有兴趣查看的精确数据集。如你所见,Wireshark 默认会抓取_所有_数据包。这可能会妨碍你寻找具体的数据。 Wireshark 提供了两个功能强大的过滤工具,让你简单并且无痛苦地获得精确的数据。
|
||||
|
||||
Wireshark 可以通过两种方式过滤数据包。它可以过滤只收集某些数据包,或者在抓取数据包后进行过滤。当然,这些可以彼此结合使用,并且它们各自的用处取决于收集的数据和信息的多少。
|
||||
|
||||
### 布尔表达式和比较运算符
|
||||
|
||||
Wireshark 有很多很棒的内置过滤器。输入任何一个过滤器字段,你将看到它们会自动完成。大多数对应于用户在数据包之间会出现的更常见的区别。仅过滤 HTTP 请求将是一个很好的例子。
|
||||
|
||||
对于其他的,Wireshark 使用布尔表达式和/或比较运算符。如果你曾经做过任何编程,你应该熟悉布尔表达式。他们是使用 “and”、“or”、“not” 来验证声明或表达的真假。比较运算符要简单得多他们只是确定两件或更多件事情是否相等、大于或小于彼此。
|
||||
|
||||
### 过滤抓包
|
||||
|
||||
在深入自定义抓包过滤器之前,请先查看 Wireshark 已经内置的内容。单击顶部菜单上的 “Capture” 选项卡,然后点击 “Options”。可用接口下面是可以编写抓包过滤器的行。直接移到左边一个标有 “Capture Filter” 的按钮上。点击它,你将看到一个新的对话框,其中包含内置的抓包过滤器列表。看看里面有些什么。
|
||||
|
||||

|
||||
|
||||
|
||||
在对话框的底部,有一个小的表单来创建并保存抓包过滤器。按左边的 “New” 按钮。它将创建一个有默认数据的新的抓包过滤器。要保存新的过滤器,只需将实际需要的名称和表达式替换原来的默认值,然后单击“Ok”。过滤器将被保存并应用。使用此工具,你可以编写并保存多个不同的过滤器,并让它们将来可以再次使用。
|
||||
|
||||
抓包有自己的过滤语法。对于比较,它不使用等于号,并使用 `>` 来用于大于或小于。对于布尔值来说,它使用 “and”、“or” 和 “not”。
|
||||
|
||||
例如,如果你只想监听 80 端口的流量,你可以使用这样的表达式:`port 80`。如果你只想从特定的 IP 监听端口 80,你可以 `port 80 and host 192.168.1.20`。如你所见,抓包过滤器有特定的关键字。这些关键字用于告诉 Wireshark 如何监控数据包以及哪些数据。例如,`host` 用于查看来自 IP 的所有流量。`src`用于查看源自该 IP 的流量。与之相反,`net` 只监听目标到这个 IP 的流量。要查看一组 IP 或网络上的流量,请使用 `net`。
|
||||
|
||||
### 过滤结果
|
||||
|
||||
界面的底部菜单栏是专门用于过滤结果的菜单栏。此过滤器不会更改 Wireshark 收集的数据,它只允许你更轻松地对其进行排序。有一个文本字段用于输入新的过滤器表达式,并带有一个下拉箭头以查看以前输入的过滤器。旁边是一个标为 “Expression” 的按钮,另外还有一些用于清除和保存当前表达式的按钮。
|
||||
|
||||
点击 “Expression” 按钮。你将看到一个小窗口,其中包含多个选项。左边一栏有大量的条目,每个都有额外的折叠子列表。这些都是你可以过滤的所有不同的协议、字段和信息。你不可能看完所有,所以最好是大概看下。你应该注意到了一些熟悉的选项,如 HTTP、SSL 和 TCP。
|
||||
|
||||

|
||||
|
||||
子列表包含可以过滤的不同部分和请求方法。你可以看到通过 GET 和 POST 请求过滤 HTTP 请求。
|
||||
|
||||
你还可以在中间看到运算符列表。通过从每列中选择条目,你可以使用此窗口创建过滤器,而不用记住 Wireshark 可以过滤的每个条目。对于过滤结果,比较运算符使用一组特定的符号。 `==` 用于确定是否相等。`>`确定一件东西是否大于另一个东西,`<` 找出是否小一些。 `>=` 和 `<=` 分别用于大于等于和小于等于。它们可用于确定数据包是否包含正确的值或按大小过滤。使用 `==` 仅过滤 HTTP GET 请求的示例如下:`http.request.method == "GET"`。
|
||||
|
||||
布尔运算符基于多个条件将小的表达式串到一起。不像是抓包所使用的单词,它使用三个基本的符号来做到这一点。`&&` 代表 “and”。当使用时,`&&` 两边的两个语句都必须为 true,以便 Wireshark 来过滤这些包。`||` 表示 “或”。只要两个表达式任何一个为 true,它就会被过滤。如果你正在查找所有的 GET 和 POST 请求,你可以这样使用 `||`:`(http.request.method == "GET") || (http.request.method == "POST")`。`!`是 “not” 运算符。它会寻找除了指定的东西之外的所有东西。例如,`!http` 将展示除了 HTTP 请求之外的所有东西。
|
||||
|
||||
### 总结思考
|
||||
|
||||
过滤 Wireshark 可以让你有效监控网络流量。熟悉可以使用的选项并习惯你可以创建过滤器的强大表达式需要一些时间。然而一旦你做了,你将能够快速收集和查找你要的网络数据,而无需梳理长长的数据包或进行大量的工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
|
||||
作者:[Nick Congleton ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux
|
||||
[1]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h1-introduction
|
||||
[2]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h2-boolean-expressions-and-comparison-operators
|
||||
[3]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h3-filtering-capture
|
||||
[4]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h4-filtering-results
|
||||
[5]:https://linuxconfig.org/filtering-packets-in-wireshark-on-kali-linux#h5-closing-thoughts
|
||||
@ -0,0 +1,107 @@
|
||||
# 如何解决视频和嵌入字幕错误
|
||||
|
||||
这会是一个有点奇怪的教程。背景故事如下。最近,我创作了一堆 [Risitas y las paelleras][4] 素材中[甜蜜][1][模仿][2][片段][3],以主角 Risitas 疯狂的笑声而闻名。和往常一样,我把它们上传到了 Youtube,但是当我决定使用字幕到最终在网上可以观看,我经历了一个漫长而曲折的历程。
|
||||
|
||||
在本指南中,我想介绍几个你可能会在创作自己的媒体时会遇到的典型问题,主要是使用字幕,然后上传到媒体共享门户,特别是 Youtube 中,以及如何解决这些问题。跟我来。
|
||||
|
||||
### 背景故事
|
||||
|
||||
我选择的视频编辑软件是 Kdenlive,当我创建那愚蠢的 [Frankenstein][5] 片段时开始使用这个软件,从那以后一直是我的忠实伙伴。通常,我将文件交给具有 VP8 视频编解码器和 Vorbis 音频编解码器的 WebM 容器渲染,因为这是 Google 所喜欢的。事实上,我在过去七年里上传的大约 40 个不同的片段中都没有问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
但是,在完成了我的 Risitas&Linux 项目之后,我遇到了一个困难。视频文件和字幕文件仍然是两个独立的实体,我需要以某种方式将它们放在一起。我的原文中关于字幕提到了 Avidemux 和 Handbrake,这两个都是有效的选项。
|
||||
|
||||
但是,我对任何一个的输出都并不满意,而且由于种种原因,有些东西有所偏移。 Avidemux 不能很好处理视频编码,而 Handbrake 在最终输出中省略了几行字幕,而且字体是丑陋的。这个可以解决,但这不是今天的话题。
|
||||
|
||||
因此,我决定使用 VideoLAN(VLC) 将字幕嵌入视频。有几种方法可以做到这一点。你可以使用 “Media > Convert/Save” 选项,但这不能达到我们需要的。相反,你应该使用 “Media > Stream”,它带有一个更完整的向导,它还提供了一个我们需要的可编辑的代码转换选项 - 请参阅我的[教程][6]关于字幕的部分。
|
||||
|
||||
### 错误!
|
||||
|
||||
嵌入字幕的过程并不是微不足道的。你有可能遇到几个问题。本指南应该能帮助你解决这些问题,所以你可以专注于你的工作,而不是浪费时间调试怪异的软件错误。无论如何,在使用 VLC 中的字幕时,你将会遇到一小部分可能会遇到的问题。尝试以及出错,还有书呆子的设计。
|
||||
|
||||
### 无可播放的流
|
||||
|
||||
你可能选择了奇怪的输出设置。你要仔细检查你是否选择了正确的视频和音频编解码器。另外,请记住,一些媒体播放器可能没有所有的编解码器。此外,确保在所有要播放的系统中都测试过了。
|
||||
|
||||

|
||||
|
||||
### 字幕叠加两次
|
||||
|
||||
如果在第一步的流媒体向导中选择了 “Use a subtitle file”,则可能会发生这种情况。只需选择所需的文件,然后单击“Stream”。取消选中该框。
|
||||
|
||||

|
||||
|
||||
### 字幕没有输出
|
||||
|
||||
这可能是两个主要原因。一,你选择了错误的封装格式。在进行编辑之前,请确保在配置文件页面上正确标记了字幕。如果格式不支持字幕,它可能无法正常工作。
|
||||
|
||||

|
||||
|
||||
二,你可能已经在最终输出中启用了字幕编解码器渲染功能。你不需要这个。你只需要将字幕叠加到视频片段上。在单击 “Stream” 按钮之前,请检查生成的流输出字符串并删除 “scodec=<something>” 的选项。
|
||||
|
||||

|
||||
|
||||
### 缺少编解码器+解决方法
|
||||
|
||||
这是一个常见的 [bug][7],取决于编码器的实现的实验性,如果你选择以下配置文件,你将很有可能会看到它:“Video - H.264 + AAC (MP4)”。该文件将被渲染,如果你选择了字幕,它们也将被覆盖,但没有任何音频。但是,我们可以用技巧来解决这个问题。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
一个可能的技巧是从命令行使用 --sout-ffmpeg-strict=-2 选项(可能有用)启动 VLC。另一个更安全的解决方法是采用无音频视频,但是会有字幕重叠,并将原始项目不带字幕的作为音频源用 Kdenlive 渲染。听上去很复杂,下面是详细步骤:
|
||||
|
||||
* 将现有片段(包含音频)从视频移动到音频。删除其余的。
|
||||
|
||||
* 或者,使用渲染过的 WebM 文件作为你的音频源。
|
||||
|
||||
* 添加新的片段 - 带有字幕,并且没有音频。
|
||||
|
||||
* 将片段放置为新视频。
|
||||
|
||||
* 再次渲染为 WebM。
|
||||
|
||||

|
||||
|
||||
使用其他类型的音频编解码器将很有可能可用(例如 MP3),你将拥有一个包含视频,音频和字幕的完整项目。如果你很高兴没有遗漏,你可以现在上传到 Youtube 上。但是之后 ...
|
||||
|
||||
### Youtube 视频管理器和未知格式
|
||||
|
||||
如果你尝试上传非 WebM 片段(例如 MP4),则可能会收到未指定的错误,你的片段不符合媒体格式要求。我不知道为什么 VLC 生成一个不符合 YouTube 规定的文件。但是,修复很容易。使用 Kdenlive 重新创建视频,其中有所有正确的元字段和 Youtube 喜欢的。回到我原来的故事,我有 40 多个片段使用 Kdenlive 以这种方式创建。
|
||||
|
||||
P.S. 如果你的片段有有效的音频,则只需通过 Kdenlive 重新运行它。如果没有,重做视频/音频。根据需要将片段静音。最终, 这就像叠加一样, 除了你使用的视频来自于一个片段而音频来自于另一个片段用于最终渲染。工作完成。
|
||||
|
||||
### 更多阅读
|
||||
|
||||
|
||||
我不想用链接重复自己或垃圾邮件。在“软件与安全”部分,我有 VLC 上的片段,因此你可能需要咨询。前面提到的关于 VLC 和字幕的文章已经链接到大约六个相关教程,涵盖了其他主题,如流媒体、日志记录、视频旋转、远程文件访问等等。我相信你可以像专业人员一样使用搜索引擎。
|
||||
|
||||
### 总结
|
||||
|
||||
我希望你觉得本指南有帮助。它涵盖了很多,我试图使其线性并简单,并解决流媒体爱好者和字幕爱好者在使用 VLC 时可能遇到的许多陷阱。这都与容器和编解码器相关,而且媒体世界几乎没有标准的事实,当你从一种格式转换到另一种格式时,有时你可能会遇到边际情况。
|
||||
|
||||
如果你遇到了一些错误,这里的提示和技巧应该可以至少帮助你解决一些,包括无法播放的流、丢失或重复的字幕、缺少编解码器和 Kdenlive 解决方法、YouTube 上传错误、隐藏的 VLC 命令行选项,还有一些其他东西。是的,这些对于一段文字来说是很多的。幸运的是,这些都是好东西。保重, 互联网的孩子们。如果你有任何其他要求,我将来的 VLC 文章应该会涵盖,请随意给我发邮件。
|
||||
|
||||
干杯。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.dedoimedo.com/computers/vlc-subtitles-errors.html
|
||||
|
||||
作者:[Dedoimedo ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.dedoimedo.com/faq.html
|
||||
[1]:https://www.youtube.com/watch?v=MpDdGOKZ3dg
|
||||
[2]:https://www.youtube.com/watch?v=KHG6fXEba0A
|
||||
[3]:https://www.youtube.com/watch?v=TXw5lRi97YY
|
||||
[4]:https://www.youtube.com/watch?v=cDphUib5iG4
|
||||
[5]:http://www.dedoimedo.com/computers/frankenstein-media.html
|
||||
[6]:http://www.dedoimedo.com/computers/vlc-subtitles.html
|
||||
[7]:https://trac.videolan.org/vlc/ticket/6184
|
||||
@ -0,0 +1,309 @@
|
||||
通过开源书籍学习 RUBY 编程
|
||||
============================================================
|
||||
|
||||
### 开源的 Ruby 书籍
|
||||
|
||||
Ruby 是由 Yukihiro “Matz” Matsumoto 开发的一门通用目的、脚本化、结构化、灵活且完全面向对象的编程语言。它具有一个完全动态类型系统,这意味着它的大多数类型检查是在运行的时候进行,而非编译的时候。因此程序员不必过分担心是整数类型还是字符串类型。Ruby 会自动进行内存管理,它具有许多和 Python、Perl、Lisp、Ada、Eiffel 和 Smalltalk 相同的特性。
|
||||
|
||||
Ruby on Rails 框架对于 Ruby 的流行起到了重要作用,它是一个全栈 Web 框架,目前已被用来创建许多受欢迎的应用,包括 Basecamp、GitHub、Shopify、Airbnb、Twitch、SoundCloud、Hulu、Zendesk、Square 和 Highise 。
|
||||
|
||||
Ruby 具有很高的可移植性性,在 Linux、Windows、Mac OS X、Cygwin、FreeBSD、NetBSD、OpenBSD、BSD/OS、Solaris、Tru64 UNIX、HP-UX 以及其他许多系统上均可运行。目前,Ruby 在 TIOBE 编程社区排名 12 。
|
||||
|
||||
这篇文章有 9 本很优秀的推荐书籍,有针对包括初学者、中级程序员和高级程序员的书籍。当然,所有的书籍都是在开源许可下发布的。
|
||||
|
||||
这篇文章是[ OSSBlog 的系列文章开源编程书籍][18]的一部分。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Best Practices][1]
|
||||
|
||||
作者: Gregory Brown (328 页)
|
||||
|
||||
《Ruby Best Practices》适合那些希望像有经验的 Ruby 专家一样使用 Ruby 的程序员。本书是由 Ruby 项目 Prawn 的开发者所撰写的,它阐述了如何使用 Ruby 设计美丽的 API 和特定领域语言,以及如何利用函数式编程想法和技术,从而简化代码,提高效率。
|
||||
|
||||
《Ruby Best Practices》 更多的内容是关于如何使用 Ruby 来解决问题,它阐述的是你应该使用的最佳解决方案。这本书不是针对 Ruby 初学者的,所以对于编程新手也不会有太多帮助。这本书的假想读者应该对 Ruby 的相应技术有一定理解,并且拥有一些使用 Ruby 来开发软件的经验。
|
||||
|
||||
这本书分为两部分,前八章组成本书的核心部分,后三章附录作为补充材料。
|
||||
|
||||
这本书提供了大量的信息:
|
||||
|
||||
* 通过测试驱动代码 - 涉及了大量的测试哲学和技术。使用 mocks 和 stubs
|
||||
* 通过利用 Ruby 神秘的力量来设计漂亮的 API:灵活的参数处理和代码块
|
||||
* 利用动态工具包向开发者展示如何构建灵活的界面,实现对象行为,扩展和修改已有代码,以及程序化地构建类和模块
|
||||
* 文本处理和文件管理集中于正则表达式,文件、临时文件标准库以及文本处理策略实战
|
||||
|
||||
|
||||
* 函数式编程技术优化模块代码组织、存储、无穷目录以及更高顺序程序。
|
||||
* 理解代码如何出错以及为什么会出错,阐述如何处理日志记录
|
||||
* 通过利用 Ruby 的多语言能力削弱文化屏障
|
||||
* 熟练的项目维护
|
||||
|
||||
本书为开源书籍,在 CC NC-SA 许可证下发布。
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [I Love Ruby][2]
|
||||
|
||||
作者: Karthikeyan A K (246 页)
|
||||
|
||||
《I Love Ruby》以比传统介绍更高的深度阐述了基本概念和技术。该方法为编写有用、正确、易维护和高效的 Ruby 代码提供了一个坚实的基础。
|
||||
|
||||
章节内容涵盖:
|
||||
|
||||
* 变量
|
||||
* 字符串
|
||||
* 比较和逻辑
|
||||
* 循环
|
||||
* 数组
|
||||
* 哈希和符号
|
||||
* Ranges
|
||||
* 函数
|
||||
* 变量作用域
|
||||
* 类 & 对象
|
||||
* Rdoc
|
||||
* 模块和 Mixins
|
||||
* 日期和时间
|
||||
* 文件
|
||||
* Proc、匿名 和 块
|
||||
* 多线程
|
||||
* 异常处理
|
||||
* 正则表达式
|
||||
* Gems
|
||||
* 元编程
|
||||
|
||||
在 GNU 自由文档许可证有效期内,你可以复制、发布和修改本书,1.3 或任何更新版本由自由软件基金会发布。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Programming Ruby – The Pragmatic Programmer’s Guide][3]
|
||||
|
||||
作者: David Thomas, Andrew Hunt (HTML)
|
||||
|
||||
《Programming Ruby – The Pragmatic Programmer’s Guide》是一本 Ruby 编程语言的教程和参考书。使用 Ruby,你将能够写出更好的代码,更加有效率,并且使编程变成更加享受的体验。
|
||||
|
||||
内容涵盖以下部分:
|
||||
|
||||
* 类、对象和变量
|
||||
* 容器、块和迭代器
|
||||
* 标准类型
|
||||
* 更多方法
|
||||
* 表达式
|
||||
* 异常、捕获和抛出
|
||||
* 模块
|
||||
* 基本输入和输出
|
||||
* 线程和进程
|
||||
* 何时抓取问题
|
||||
* Ruby 和它的世界、Web、Tk 和 微软 Windows
|
||||
* 扩展 Ruby
|
||||
* 映像、对象空间和分布式 Ruby
|
||||
* 标准库
|
||||
* 面向对象设计库
|
||||
* 网络和 Web 库
|
||||
* 嵌入式文件
|
||||
* 交互式 Ruby shell
|
||||
|
||||
这本书的第一版在开放发布许可证 1.0 版或更新版的许可下发布。本书更新后的第二版涉及 Ruby 1.8 ,并且包括所有可用新库的描述,但是它不是在免费发行许可证下发布的。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Why’s (Poignant) Guide to Ruby][4]
|
||||
|
||||
作者:why the lucky stiff (176 页)
|
||||
|
||||
《Why’s (poignant) Guide to Ruby》是一本 Ruby 编程语言的介绍书籍。该书包含一些冷幽默,偶尔也会出现一些和主题无关的内容。本书包含的笑话在 Ruby 社区和卡通角色中都很出名。
|
||||
|
||||
本书的内容包括:
|
||||
|
||||
* 关于本书
|
||||
* Kon’nichi wa, Ruby
|
||||
* 一个快速(希望是无痛苦的)的 Ruby 浏览(伴随卡通角色):Ruby 核心概念的基本介绍
|
||||
* 代码浮动小叶:评估和值,哈希和列表
|
||||
* 组成规则的核心部分:case/when、while/until、变量作用域、块、方法、类定义、类属性、对象、模块、IRB 中的内省、dup、self 和 rbconfig 模块
|
||||
* 中心:元编程、正则表达式
|
||||
* 当你打算靠近胡须时:在已存在类中发送一个新方法
|
||||
* 天堂演奏
|
||||
|
||||
本书在 CC-SA 许可证许可下可用。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Hacking Guide][5]
|
||||
|
||||
作者: Minero Aoki ,翻译自 Vincent Isambart 和 Clifford Escobar Caoille (HTML)
|
||||
|
||||
通过阅读本书可以达成下面的目标:
|
||||
|
||||
* 拥有关于 Ruby 结构的知识
|
||||
* 掌握一般语言处理的知识
|
||||
* 收获阅读源代码的技能
|
||||
|
||||
本书分为四个部分:
|
||||
|
||||
* 对象
|
||||
* 动态分析
|
||||
* 评估
|
||||
* 外部评估
|
||||
|
||||
要想从本书中收获最多的东西,需要具备一定 C 语言的知识和基本的面向对象编程知识。本书在 CC-NC-SA 许可证许可下发布。
|
||||
|
||||
原书的官方支持网站为 [i.loveruby.net/ja/rhg/][10]
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Book Of Ruby][6]
|
||||
|
||||
作者: How Collingbourne (425 页)
|
||||
|
||||
《The Book Of Ruby》是一本免费的 Ruby 编程高级教程。
|
||||
|
||||
《The Book Of Ruby》以 PDF 文件格式提供,并且每一个章节的所有例子都伴有可运行的源代码。同时,也有一个介绍来阐述如何在 Steel 或其他任何你喜欢的编辑器/IDE 中运行这些 Ruby 代码。它主要集中于 Ruby 语言的 1.8.x 版本。
|
||||
|
||||
本书被分成字节大小的块。每一个章节介绍一个主题,并且分成几个不同的子话题。每一个编程主题由一个或多个小的自包含、可运行的 Ruby 程序构成。
|
||||
|
||||
* 字符串、数字、类和对象 - 获取输入和输出、字符串和外部评估、数字和条件测试:if ... then、局部变量和全局变量、类和对象、实例变量、消息、方法、多态性、构造器和检属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
* 类等级、属性和类变量 - 超类和子类,超类传参,访问器方法,’set‘ 访问器,属性读写器、超类的方法调用,以及类变量
|
||||
* 字符串和 Ranges - 用户自定义字符串定界符、引号等更多
|
||||
* 数组和哈希 - 展示如何创建一系列对象
|
||||
* 循环和迭代器 - for 循环、代码块、while 循环、while 修改器以及 until 循环
|
||||
* 条件语句 - If..Then..Else、And..Or..Not、If..Elsif、unless、if 和 unless 修改器、以及 case 语句
|
||||
* 方法 - 类方法、类变量、类方法是用来干什么的、Ruby 构造器、单例方法、单例类、重载方法以及更多
|
||||
* 传递参数和返回值 - 实例方法、类方法、单例方法、返回值、返回多重值、默认参数和多重参数、赋值和常量传递以及更多
|
||||
* 异常处理 - 涉及 rescue、ensure、else、错误数量、retry 和 raise
|
||||
* 块、Procs 和 匿名 - 阐述为什么它们对 Ruby 来说很特殊
|
||||
* 符号 - 符号和字符串、符号和变量以及为什么应该使用符号
|
||||
* 模块和 Mixins
|
||||
* 文件和 IO - 打开和关闭文件、文件和目录、复制文件、目录询问、一个关于递归的讨论以及按大小排序
|
||||
* YAML - 包括嵌套序列,保存 YAML 数据以及更多
|
||||
* Marshal - 提供一个保存和加载数据的可选择方式
|
||||
* 正则表达式 - 进行匹配、匹配群组以及更多
|
||||
* 线程 - 向你展示如何同时运行多个任务
|
||||
* 调试和测试 - 涉及交互式 Ruby shell(IRB.exe)、debugging 和 单元测试
|
||||
* Ruby on Rails - 浏览一个创建博客的实践指南
|
||||
* 动态编程 - 自修改程序、重运算魔法、特殊类型的运算、添加变量和方法以及更多
|
||||
|
||||
本书由 SapphireSteel Software 发布,SapphireSteel Software 是用于 Visual Studio 的 Ruby In Steel 集成开发环境的开发者。读者可以复制和发布本书的文本和代码(免费版)
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [The Little Book Of Ruby][7]
|
||||
|
||||
作者: Huw Collingbourne (87 页)
|
||||
|
||||
《The Little Book of Ruby》是一本一步接一步的 Ruby 编程教程。它指导读者浏览 Ruby 的基础。另外,它分享了《The Book of Ruby》一书的内容,但是它旨在作为一个简化的教程来阐述 Ruby 的主要特性。
|
||||
|
||||
章节内容涵盖:
|
||||
|
||||
* 字符串和方法 - 包括外部评估。详细描述了 Ruby 方法的语法
|
||||
* 类和对象 - 阐述如何创建一个新类型的对象
|
||||
* 类等级 - 一个特殊类型的类,其为一些其他类的简化并且继承了其他一些类的特性
|
||||
* 访问器、属性、类变量 - 访问器方法,属性读写器,属性创建变量,调用超类方法以及类变量探索
|
||||
* 数组 - 学习如何创建一系列对象:数组包括多维数组
|
||||
* 哈希 - 涉及创建哈希表,为哈希表建立索引以及哈希操作等
|
||||
* 循环和迭代器 - for 循环、块、while 循环、while 修饰器以及 until 循环
|
||||
* 条件语句 - If..Then..Else、And..Or..Not、If..Elsif、unless、if 和 unless 修饰器以及 case 语句
|
||||
* 模块和 Mixins - 包括模块方法、模块作为名字空间模块实例方法、模块或 'mixins'、来自文件的模块和预定义模块
|
||||
* 保存文件以及更多内容
|
||||
|
||||
本书可免费复制和发布,只需保留原始文本且注明版权信息。
|
||||
|
||||
|
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Kestrels, Quirky Birds, and Hopeless Egocentricity][8]
|
||||
|
||||
作者: Reg “raganwald” Braithwaite (123 页)
|
||||
|
||||
《Kestrels, Quirky Birds, and Hopeless Egocentricity》是通过收集 “Raganwald” Braithwaite 的关于组合逻辑、Method Combinators 以及 Ruby 元编程的系列文章而形成的一本方便的电子书。
|
||||
|
||||
本书提供了通过使用 Ruby 编程语言来应用组合逻辑的一个基本介绍。组合逻辑是一种数学表示方法,它足够强大,从而用于解决集合论问题以及计算中的问题。
|
||||
|
||||
在这本书中,读者会会探讨到一些标准的 Combinators,并且对于每一个 Combinators,书中都用 Ruby 编程语言写程序探讨了它的一些结果。在组合逻辑上,Combinators 之间组合并相互改变,书中的 Ruby 例子注重组合和修改 Ruby 代码。通过像 K Combinator 和 .tap 方法这样的简单例子,本书阐述了元编程的理念和递归 Combinators 。
|
||||
|
||||
本书在 MIT 许可证许可下发布。
|
||||
|
||||
|
||||
|
|
||||

|
||||
|
|
||||
|
||||
### [Ruby Programming][9]
|
||||
|
||||
作者: Wikibooks.org (261 页)
|
||||
|
||||
Ruby 是一种解释性、面向对象的编程语言。
|
||||
|
||||
本书被分为几个部分,从而方便按顺序阅读。
|
||||
|
||||
* 开始 - 向读者展示如何在其中一个操作系统环境中安装并开始使用 Ruby
|
||||
* Ruby 基础 - 阐述 Ruby 语法的主要特性。它涵盖了字符串、编码、写方法、类和对象以及异常等内容
|
||||
* Ruby 语义参考
|
||||
* 内建类
|
||||
* 可用模块,涵盖一些标准库
|
||||
* 中级 Ruby 涉及一些稍微高级的话题
|
||||
|
||||
本书在 CC-SA 3.0 本地化许可证许可下发布。
|
||||
|
||||
|
|
||||
|
||||
* * *
|
||||
|
||||
无特定顺序,我将在结束前推荐一些没有在开源许可证下发布但可以免费下载的 Ruby 编程书籍。
|
||||
|
||||
* [Mr. Neighborly 的 Humble Little Ruby Book][11] – 一个易读易学的 Ruby 完全指南。
|
||||
* [Introduction to Programming with Ruby][12] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Object Oriented Programming with Ruby][13] – 学习编程时最基本的构建块,一切从零开始。
|
||||
* [Core Ruby Tools][14] – 对 Ruby 的四个核心工具 Gems、Ruby Version Managers、Bundler 和 Rake 进行了简短的概述。
|
||||
* [Learn Ruby the Hard Way, 3rd Edition][15] – 一本适合初学者的入门书籍。
|
||||
* [Learn to Program][16] – 来自 Chris Pine。
|
||||
* [Ruby Essentials][17] – 一个准确且简单易学的 Ruby 学习指南。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ossblog.org/study-ruby-programming-with-open-source-books/
|
||||
|
||||
作者:[Steve Emms ][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ossblog.org/author/steve/
|
||||
[1]:https://github.com/practicingruby/rbp-book/tree/gh-pages/pdfs
|
||||
[2]:https://mindaslab.github.io/I-Love-Ruby/
|
||||
[3]:http://ruby-doc.com/docs/ProgrammingRuby/
|
||||
[4]:http://poignant.guide/
|
||||
[5]:http://ruby-hacking-guide.github.io/
|
||||
[6]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[7]:http://www.sapphiresteel.com/ruby-programming/The-Book-Of-Ruby.html
|
||||
[8]:https://leanpub.com/combinators
|
||||
[9]:https://en.wikibooks.org/wiki/Ruby_Programming
|
||||
[10]:http://i.loveruby.net/ja/rhg/
|
||||
[11]:http://www.humblelittlerubybook.com/
|
||||
[12]:https://launchschool.com/books/ruby
|
||||
[13]:https://launchschool.com/books/oo_ruby
|
||||
[14]:https://launchschool.com/books/core_ruby_tools
|
||||
[15]:https://learnrubythehardway.org/book/
|
||||
[16]:https://pine.fm/LearnToProgram
|
||||
[17]:http://www.techotopia.com/index.php/Ruby_Essentials
|
||||
[18]:https://www.ossblog.org/opensourcebooks/
|
||||
@ -1,91 +0,0 @@
|
||||
文件系统层次标准(FHS)简介
|
||||
============================================================
|
||||

|
||||
|
||||
当你好奇地看着系统的根目录(“/”)的时候,可能会发现自己有点不知所措。大多数三个字母的目录名称并没有告诉你他们是做什么的,如果你需要做出一些重要的修改,那就很难知道在哪里可以查看。
|
||||
|
||||
我想给大家简单地介绍下根目录。
|
||||
|
||||
### 有用的工具
|
||||
|
||||
在我们开始之前,这里有几个值得熟悉的工具,它们可以让您随时挖掘您自己找到的有趣的东西。这些程序都不会对您的文件进行任何更改。
|
||||
|
||||
最有用的工具是 “ls” -- 它列出了使用完整路径或相对路径(即从当前目录开始的路径)作为参数给出的任何目录的内容。
|
||||
|
||||
$ ls _path_
|
||||
|
||||
当您进一步深入文件系统时,重复输入长路径可能会变得很麻烦,所以如果您想简化这一操作,可以用 “cd” 替换 “ls” 来更改当前的工作目录到该目录。与 “ls” 一样,只需将目录路径作为 “cd” 的参数。
|
||||
|
||||
$ cd _path_
|
||||
|
||||
如果您不确定某个文件是什么文件类型的,可以通过运行 “file” 并且将文件名作为“file” 命令的参数。
|
||||
|
||||
$ file _filename_
|
||||
|
||||
最后,如果这个文件看起来像是人可读的,那么用 “less” 来看看(不用担心文件有改变)。与最后一个工具一样,给出一个文件名作为参数来查看它。
|
||||
|
||||
$ less _filename_
|
||||
|
||||
完成文件扫描后,点击 “q” 退出,即可返回到您的终端。
|
||||
|
||||
### 根目录之旅
|
||||
|
||||
现在就开始我们的旅程。我将按照字母顺序介绍直接在根目录下的目录。这里并没有介绍所有的目录,但到最后,我们会突出其中的亮点。
|
||||
|
||||
我们将要完成的目录的所有分类和功能都基于 Linux 文件系统层次标准(FHS)。[Linux基金会][4]维护的 Linux FHS 通过规定其工具的各个组件应该存放的位置,帮助设计师和开发人员进行发行版和程序的开发。
|
||||
|
||||
通过将所有文件,二进制文件和手册保存在程序中的一致性组织中,FHS 让学习、调试或修改更加容易。想象一下,如果不是使用 “man” 命令找到使用指南,那么你就不得不寻找每个程序的手册。
|
||||
|
||||
按照字母顺序和结构顺序,我们从 “**/bin**” 开始。该目录是包含 shell 命令的所有核心系统二进制文件(解释终端指令的程序)。没有这个目录的内容,你的系统就不能做很多事情。
|
||||
|
||||
接下来是 “**/boot**” 目录,它存储了您的计算机需要启动的所有东西。其中最重要的是引导程序和内核。引导程序是一个通过初始化一些基础工具,使引导过程继续进行的程序。在初始化结束时,引导程序会加载内核,内核允许计算机与所有其他硬件和固件进行接口。从这一点看,它可以持续地使整个操作系统工作。
|
||||
|
||||
“**/dev**” 目录是表示被系统识别为“设备”的所有文件的对象。这里包括许多显式的设备,如计算机的硬件组件:键盘,屏幕,硬盘驱动器等。
|
||||
|
||||
此外,“/dev” 还包含被系统视为“设备”的数据流的伪文件。一个例子是流入和流出您的终端的数据,可以分为三个“流”。它读取的信息被称为“标准输入”。命令或进程的输出是“标准输出”。最后,分类为调试信息的辅助输出指向“标准错误”。终端本身作为文件也可以在这里找到。
|
||||
|
||||
“**/etc**”(发音类似工艺商业网站 “Etsy”,如果你想打动 Linux 老用户的话),许多程序在这里存储他们的配置文件,用于改变他们的设置。一些程序存储这里的是默认配置的副本,这些副本将在修改之前复制到另一个位置。其他的程序在这里存储配置的唯一副本,并期望用户可以直接修改。为 root 用户保留的许多程序取决于后一种配置模式。
|
||||
|
||||
“**/home**” 目录是用户个人文件所在的位置。对于桌面用户来说,这是您花费大部分时间的地方。对于每个非特权用户,这里都有一个具有相应名称的目录。
|
||||
|
||||
“**/lib**” 是您的系统依赖运行的许多库的所在地。许多程序都会重复使用一个或多个在几十上百个程序中常见的功能或子程序。所以,如果每个程序在其二进制文件中重写它需要的每一个组件,结果会是产生出一些大而无用的程序,作为更好的替代方案,我们可以通过进行“库调用”来引用这些库中的一个或多个。
|
||||
|
||||
在 “**/media**” 目录中可以访问像 USB 闪存驱动器或摄像机这样的可移动媒体。虽然它不存在于所有系统上,但在一些专注于直观桌面的系统中还是比较普遍的,如 Ubuntu。具有存储能力的媒体在此处被“挂载”,这意味着当设备中的原始位流位于 “/dev” 目录下时,用户通常可以在这里访问那些可交互的文件对象。
|
||||
|
||||
“**/proc**” 目录是一个动态显示系统数据的虚拟文件系统。这意味着系统可以即时地创建 “/proc” 的内容,用包含运行时生成系统信息(如硬件统计信息)的文件进行填充。
|
||||
|
||||
“**/tmp**” 恰好足够的用于发送缓存数据等临时信息。这个目录不做其他更多的事情。
|
||||
|
||||
现代 Linux 系统上大多数程序的二进制文件保存在 “**/usr**” 目录中。为了统一包含二进制文件的各种目录,“/usr” 包含 “/bin”、“/sbin” 和 “/lib” 中的所有内容的副本。
|
||||
|
||||
最后,“**/var**” 里保存“可变”长度的数据。这里的可变长度数据的类型通常是会累积的数据,就像日志和缓存一样。一个例子是你的内核保留的日志。
|
||||
|
||||
为了保持硬盘远离空间用尽和崩溃的情况,“/var” 内置了“日志旋转”功能,可删除旧信息,为新信息腾出空间,维持固定的最大大小。
|
||||
|
||||
### 结尾
|
||||
|
||||
正如我所说,这里介绍的绝对不是您在根目录中可以找到的一切,但是确定系统核心功能所在地是一个很好的开始,而且可以更深入地研究这些功能是什么。
|
||||
|
||||
所以,如果你不知道要学习什么,就可能有很多的想法。如果你想得到一个更好的想法,就在这些目录中折腾自己吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
自 2017 年以来 Jonathan Terrasi 一直是 ECT 新闻网的专栏作家。他的主要兴趣是计算机安全(特别是 Linux 桌面),加密和分析政治和时事。他是全职自由作家和音乐家。他的背景包括在芝加哥委员会发表的保卫人权法案文章中提供技术评论和分析。
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: http://www.linuxinsider.com/story/84658.html
|
||||
|
||||
作者:[Jonathan Terrasi ][a]
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxinsider.com/perl/mailit/?id=84658
|
||||
[1]:http://www.linuxinsider.com/story/84658.html?rss=1#
|
||||
[2]:http://www.linuxinsider.com/perl/mailit/?id=84658
|
||||
[4]:http://www.linuxfoundation.org/
|
||||
@ -1,147 +0,0 @@
|
||||
# Ubuntu Core: 制作包含私有 snaps 的工厂镜像
|
||||
---
|
||||
这篇帖子是有关 [ROS prototype to production on Ubuntu Core][1] 系列的补充,用来回答我接收到的一个问题: “如何在不公开发布 snaps 的情况下制作一个工厂镜像?” 当然,问题和回答都不只是针对于机器人技术。在这篇帖子中,我将会通过两种方法来回答这个问题。
|
||||
|
||||
开始之前,你需要了解一些制作 Ubuntu Core 镜像的背景知识,如果你已经看过 [ROS prototype to production on Ubuntu Core][3] 系列文章(具体是第 5 部分),你就已经有了需要的背景知识,如果没有看过的话,可以查看有关 [制作你的 Ubuntu Core 镜像][5] 的教程。
|
||||
|
||||
如果你已经了解了最新的情况并且当我说 “模型定义” 或者 “模型断言” 时知道我在谈论什么,那就让我们开始通过不同的方法使用私有 sanps 来制作 Ubuntu Core 镜像吧。
|
||||
|
||||
### 方法 1: 无需上传你的 snap 到商店
|
||||
这是最简单的方法了。首先看一下这个有关模型定义的例子——**amd64-model.json**:
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-test-snap"]
|
||||
}
|
||||
```
|
||||
让我们将它转换成模型断言
|
||||
```
|
||||
$ cat amd64-model.json | snap sign -k my-key-name > amd64.model
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "my-key-name"
|
||||
4096-bit RSA key, ID 0B79B865, created 2016-01-01
|
||||
...
|
||||
```
|
||||
获得模型断言:**amd64.model** 后,如果你现在就把它交给 **ubuntu-image** 使用,你将会碰钉子:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-test-snap
|
||||
error: cannot find snap "kyrofa-test-snap": snap not found
|
||||
COMMAND FAILED: snap prepare-image --channel=stable amd64.model /tmp/tmp6p453gk9/unpack
|
||||
```
|
||||
实际上商店中并没有名为 **kyrofa-test-snap** 的 snap。这里需要重点说明的是:模型定义(以及转换后的断言)会包含一列 snap 的名字。如果你在本地有个名字相同的 snap,即使它没有存在于商店中,你也可以通过 **--extra-snaps** 选项告诉 **ubuntu-image** 在断言中增加这个名字来使用它:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable \
|
||||
--extra-snaps /path/to/kyrofa-test-snap_0.1_amd64.snap \
|
||||
amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Copying "/path/to/kyrofa-test-snap_0.1_amd64.snap" (kyrofa-test-snap)
|
||||
kyrofa-test-snap already prepared, skipping
|
||||
WARNING: "kyrofa-test-snap" were installed from local snaps
|
||||
disconnected from a store and cannot be refreshed subsequently!
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
现在,在 snap 并没有上传到商店的情况下,你已经获得一个预装了私有 snap 的 Ubuntu Core 镜像(名为 pc.img)。但是这样做有一个很大的问题,ubuntu-image 会提示一个警告:不通过连接商店预装 snap 意味着你没有办法在烧录了这些镜像的设备上更新它。你只能通过制作新的镜像并重新烧录到设备的方式来更新它。
|
||||
|
||||
### 方法 2: 使用品牌商店
|
||||
当你注册了一个商店账号并访问 [dashboard.snapcraft.io][6] 时,你其实是在标准的 Ubuntu 商店中查看你的 snaps。如果你在系统中安装 snap(原文是:If you install snapd fresh on your system,但是 snapd 并不是从 Ubuntu 商城安装的,而是通过 apt-get 命令 安装的),默认会从这个商店下载。虽然你可以在 Ubuntu 商店中发布私有的 snaps,但是你 [不能将它们预装到镜像中][7],因为只有你(以及你添加的合作者)才有权限去使用它。在这种情况下制作镜像的唯一方式就是公开发布你的 snaps,然而这并不符合这篇帖子的目的(原文是:which defeats the whole purpose of this post)。
|
||||
|
||||
对于这种用例,我们有所谓的 **[品牌商店][8]**。品牌商店仍然在 Ubuntu 商店里托管,但是它们是针对于某一特定公司或设备的一个可定制的策划(curated)版本。品牌商店可以继承或者不继承标准的 Ubuntu 商店,品牌商店也可以选择开放给所有的开发者或者将其限制在一个特定的组内(保持私有正是我们想要的)。
|
||||
|
||||
请注意,这是一个付费功能。你需要 [申请一个品牌商店][9]。请求通过后,你将可以通过访问用户名下的“stores you can access” 看到你的新商店。
|
||||
![图片.png-78.9kB][10]
|
||||
|
||||
在那里你可以看到多个有权使用的商店。最少的情况下也会有两个: 标准的 Ubuntu 商店以及你的新的品牌商店。选择品牌商店(红色矩形),进去后记录下你的商店 ID(蓝色矩形):等下你将会用到它。
|
||||
![图片.png-43.9kB][11]
|
||||
|
||||
|
||||
在品牌商店里注册名字或者上传 snaps 和标准的商店使用的方法是一样的,只是它们现在是上传到你的品牌商店而不是标准的那个。如果你没有将品牌商店列出来,那么这些 snaps 对外部用户是不可见。但是这里需要注意的是第一次上传 snap 的时候需要通过web界面来操作。在那之后,你可以继续像往常一样使用 Snapcraft 。
|
||||
|
||||
那么这些是如何改变的呢?我的 “kyrofal-store” 从 Ubuntu 商店继承了 snaps,并且还包含一个发布在稳定通道中的 “kyrofa-bran-test-snap” 。这个 snap 在 Ubuntu 商店里是使用不了的,如果你去搜索它,你是找不到的:
|
||||
```
|
||||
$ snap find kyrofa-branded
|
||||
The search "kyrofa-branded" returned 0 snaps
|
||||
```
|
||||
|
||||
但是使用我们前面记录的商店 ID,我们可以创建一个从品牌商店而不是 Ubuntu 商店下载 snaps 的模型断言。我们只需要将 “store” 键添加到 JSON 文件中,就像这样:
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-branded-test-snap"],
|
||||
"store": "ky<secret>ek"
|
||||
}
|
||||
```
|
||||
使用方法 1 中的方式对它签名,然后我们就可以像这样很简单的制作一个预装有我们品牌商店私有 snap 的 Ubuntu Core 镜像:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-branded-test-snap
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
现在,和方法 1 的最后一样,你获得了一个为工厂准备的 pc.img。并且使用这种方法制作的镜像中的所有 snaps 都从商店下载的,这意味着它们将能像平常一样自动更新。
|
||||
|
||||
### 结论
|
||||
|
||||
到目前为止,做这个只有两种方法。当我开始写这篇帖子的时候,我想过可能还有第三种(将 snap 设置为私有然后使用它制作镜像),[但最后证明是不行的][12]。
|
||||
|
||||
另外,我们也收到很多内部部署或者企业商店的请求,虽然这样的产品还没有公布,但是商店团队正在从事这项工作。一旦可用,我将会写一篇有关它的文章。
|
||||
|
||||
希望能帮助到您!
|
||||
|
||||
|
||||
---
|
||||
关于作者
|
||||
Kyle 的图片
|
||||
|
||||
![Kyle_Fazzari.jpg-12kB][13]
|
||||
|
||||
Kyle 是 Snapcraft 团队的一员,也是 Canonical 公司的常驻机器人专家,他专注于 snaps 和 snap 开发实践,以及 snaps 和 Ubuntu Core 的机器人技术实现。
|
||||
|
||||
- - -
|
||||
via: https://insights.ubuntu.com/2017/07/11/ubuntu-core-making-a-factory-image-with-private-snaps/
|
||||
|
||||
作者:[Kyle Fazzari][a]
|
||||
译者:[Snaplee](https://github.com/Snaplee)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[2]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[3]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[4]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[5]: https://tutorials.ubuntu.com/tutorial/create-your-own-core-image
|
||||
[6]: https://dashboard.snapcraft.io/dev/snaps/
|
||||
[7]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps
|
||||
[8]: https://docs.ubuntu.com/core/en/build-store/index?_ga=2.103787520.1269328701.1501772209-778441655.1499262639
|
||||
[9]: https://docs.ubuntu.com/core/en/build-store/create
|
||||
[10]: http://static.zybuluo.com/apollomoon/hzffexclyv4srqsnf52a9udc/%E5%9B%BE%E7%89%87.png
|
||||
[11]: http://static.zybuluo.com/apollomoon/9gevrgmq01s3vdtp5qfa8tp7/%E5%9B%BE%E7%89%87.png
|
||||
[12]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps/1115
|
||||
[13]: http://static.zybuluo.com/apollomoon/xaxxjof19s7cbgk00xntgmqa/Kyle_Fazzari.jpg
|
||||
[14]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
@ -0,0 +1,118 @@
|
||||
免费学习docker的最佳方法:PLAY-WITH-DOCKER(PWD)
|
||||
============================================================
|
||||
|
||||
去年在柏林的分布式系统峰会上,Docker的负责人[ Marcos Nils][15] 和[ Jonathan Leibiusky][16]宣称已经开始研究浏览器内置docker的方案,帮助人们学习Docker。 几天后,[Play-with-docker][17](PWD)就诞生了。
|
||||
|
||||
PWD像是一个Docker游乐场,用户在几秒钟内就可以运行Docker命令。 还可以在浏览器中安装免费的Alpine Linux虚拟机的,然后在虚拟机里面构建和运行Docker容器,甚至使用[ Docker 集群模式][18]创建集群。 有了Docker-in-Docker(DinD)引擎,甚至可以体验到多个虚拟机/个人电脑的效果。 除了Docker游乐场外,PWD还包括一个培训站点[training.play-with-docker.com][19],该站点提供大量的难度各异的Docker实验和测验。
|
||||
|
||||
如果你错过了峰会,Marcos和Jonathan在最后一个DockerCon Moby Cool Hack会议中提供了PWD。 观看下面的视频,深入了解基础结构和路线图。
|
||||
|
||||
在过去几个月里,Docker团队与Marcos,Jonathan,还有Docker社区的其他活跃成员展开了密切合作,为项目添加了新功能,为培训部分增加了Docker实验。
|
||||
|
||||
### PWD: 游乐场
|
||||
|
||||
以下快速的概括了游乐场的新功能:
|
||||
|
||||
##### 1\. PWD Docker机器驱动和SSH
|
||||
|
||||
随着PWD成功的成长,社区开始问他们是否可以使用PWD来运行自己的Docker研讨会和培训。 因此,对项目进行的第一次改进之一就是创建[PWD Docker机器驱动][20],从而用户可以通过自己喜爱的终端轻松创建管理PWD主机,包括使用ssh相关命令的选项。 下面是它的工作原理:
|
||||
|
||||

|
||||
|
||||
##### 2\. 支持文件上传
|
||||
|
||||
Marcos和Jonathan还带来了另一个炫酷的功能就是可以在PWD实例中通过拖放文件的方式将Dockerfile直接上传到PWD窗口。
|
||||
|
||||

|
||||
|
||||
##### 3\. 模板会话
|
||||
|
||||
除了文件上传之外,PWD还有一个功能,可以使用预定义的模板在几秒钟内启动5个节点的群集。
|
||||
|
||||
#####
|
||||

|
||||
|
||||
##### 4\. 一键使用Docker展示你的应用程序
|
||||
|
||||
PWD附带的另一个很酷的功能是它的嵌入式按钮,你可以在你的站点中使用它来设置PWD环境,还可以快速部署一个构建好的堆栈,另外还有一个[chrome 扩展][21] ,可以将“Try in PWD”按钮添加DockerHub最流行的镜像中。 以下是扩展程序的一个简短演示:
|
||||
|
||||

|
||||
|
||||
### PWD: 培训站点
|
||||
|
||||
[training.play-with-docker.com][22]站点提供了大量新的实验。有一些值得注意的两点,包括两个来源于Austind DockerCon中的可以动手实践的实验,还有两个在Docker 17.06CE版本中亮眼的新功能
|
||||
|
||||
* [可以动手实践的Docker网络实验][1]
|
||||
|
||||
* [可以动手实践的Docker编排实验][2]
|
||||
|
||||
* [多阶段构建][3]
|
||||
|
||||
* [Docker群组配置文件][4]
|
||||
|
||||
总而言之,现在有36个实验,而且一直在增加。 如果你想贡献实验,请查看[GitHub 仓库][23]然后开始。
|
||||
|
||||
### PWD: 使用情况
|
||||
|
||||
根据网站运行时我们收到的反馈,很可观的说,PWD现在有很大的牵引力。下面是一些最常见的反馈情况:
|
||||
|
||||
* 紧跟最新开发版本,尝试新功能。
|
||||
|
||||
* 快速建立集群并启动复制服务。
|
||||
|
||||
* 了解互动教程: [training.play-with-docker.com][5]。
|
||||
|
||||
* 在会议和集会上做演讲。
|
||||
|
||||
* 展开需要复杂配置的高级研讨会,例如 Jérôme’的 [先进的 Docker 编排研讨会][6]。
|
||||
|
||||
* 和社区成员写作诊断问题检测问题。
|
||||
|
||||
参与 PWD:
|
||||
|
||||
* 通过[向PWD提交PR][7]做贡献
|
||||
|
||||
* 向 [PWD 培训站点][8]贡献
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Victor是Docker, Inc. 的高级社区营销经理。他喜欢优质的葡萄酒,象棋和足球,三三项爱好部分先后顺序。 Victor 的tweet:@vcoisne推特。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/best-way-learn-docker-free-play-docker-pwd/
|
||||
|
||||
作者:[Victor ][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/victor_c/
|
||||
[1]:http://training.play-with-docker.com/docker-networking-hol/
|
||||
[2]:http://training.play-with-docker.com/orchestration-hol/
|
||||
[3]:http://training.play-with-docker.com/multi-stage/
|
||||
[4]:http://training.play-with-docker.com/swarm-config/
|
||||
[5]:http://training.play-with-docker.com/
|
||||
[6]:https://github.com/docker/labs/tree/master/Docker-Orchestration
|
||||
[7]:https://github.com/play-with-docker/
|
||||
[8]:https://github.com/play-with-docker/training
|
||||
[9]:https://blog.docker.com/author/victor_c/
|
||||
[10]:https://blog.docker.com/tag/docker-labs/
|
||||
[11]:https://blog.docker.com/tag/docker-training/
|
||||
[12]:https://blog.docker.com/tag/docker-workshops/
|
||||
[13]:https://blog.docker.com/tag/play-with-docker/
|
||||
[14]:https://blog.docker.com/tag/pwd/
|
||||
[15]:https://www.twitter.com/marcosnils
|
||||
[16]:https://www.twitter.com/xetorthio
|
||||
[17]:http://play-with-docker.com/
|
||||
[18]:https://docs.docker.com/engine/swarm/
|
||||
[19]:http://training.play-with-docker.com/
|
||||
[20]:https://github.com/play-with-docker/docker-machine-driver-pwd/releases/tag/v0.0.5
|
||||
[21]:https://chrome.google.com/webstore/detail/play-with-docker/kibbhpioncdhmamhflnnmfonadknnoan
|
||||
[22]:http://training.play-with-docker.com/
|
||||
[23]:https://github.com/play-with-docker/play-with-docker.github.io
|
||||
@ -0,0 +1,377 @@
|
||||
Samba 系列(十五):用 SSSD 和 Realm 集成 Ubuntu 到 Samba4 AD DC
|
||||
============================================================
|
||||
|
||||
|
||||
本教程将告诉你如何将 Ubuntu 桌面版机器加入到 Samba4 活动目录域中,用 SSSD 和 Realm 服务来针对活动目录认证用户。
|
||||
|
||||
#### 要求:
|
||||
|
||||
1. [在 Ubuntu 上用 Samba4 创建一个活动目录架构][1]
|
||||
|
||||
### 第 1 步: 初始配置
|
||||
|
||||
1. 在把 Ubuntu 加入活动目录前确保主机名被正确设置了。使用 hostnamectl 命令设置机器名字或者手动编辑 /etc/hostname 文件。
|
||||
|
||||
```
|
||||
$ sudo hostnamectl set-hostname your_machine_short_hostname
|
||||
$ cat /etc/hostname
|
||||
$ hostnamectl
|
||||
```
|
||||
|
||||
2. 接下来,编辑机器网络接口设置并且添加合适的 IP 设置和正确的 DNS IP 服务地址指向 Samba 活动目录域控制器如下图所示。
|
||||
|
||||
如果你已经在本地配置了 DHCP 服务来自动分配 IP 设置,给你局域网内机器合适的 AD DNS IP 地址,那么你可以跳过这一步。
|
||||
|
||||
[][2]
|
||||
|
||||
设置网络接口
|
||||
|
||||
上图中,192.168.1.254 和 192.168.1.253 代表 Samba4 域控制器的 IP 地址。
|
||||
|
||||
3. 用 GUI(图形用户界面) 或命令行重启网络服务来应用修改并且对你的域名发起一系列 ping 请求来测试 DNS 解析如期工作。 也用 host 命令来测试 DNS 解析。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart networking.service
|
||||
$ host your_domain.tld
|
||||
$ ping -c2 your_domain_name
|
||||
$ ping -c2 adc1
|
||||
$ ping -c2 adc2
|
||||
```
|
||||
|
||||
4. 最后, 确保机器时间和 Samba4 AD 同步。安装 ntpdate 包并用下列指令和 AD 同步时间。
|
||||
|
||||
```
|
||||
$ sudo apt-get install ntpdate
|
||||
$ sudo ntpdate your_domain_name
|
||||
```
|
||||
|
||||
### 第 2 步:安装需要的包
|
||||
|
||||
5. 这一步安装将 Ubuntu 加入 Samba4 活动目录域控制器所必须的软件和依赖: Realmd 和 SSSD 服务.
|
||||
|
||||
```
|
||||
$ sudo apt install adcli realmd krb5-user samba-common-bin samba-libs samba-dsdb-modules sssd sssd-tools libnss-sss libpam-sss packagekit policykit-1
|
||||
```
|
||||
|
||||
6. 输入大写的默认 realm 名称然后按下回车继续安装。
|
||||
|
||||
[][3]
|
||||
|
||||
输入 Realm 名称
|
||||
|
||||
7. 接着,创建包含以下内容的 SSSD 配置文件。
|
||||
|
||||
```
|
||||
$ sudo nano /etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
加入下面的内容到 sssd.conf 文件。
|
||||
|
||||
```
|
||||
[nss]
|
||||
filter_groups = root
|
||||
filter_users = root
|
||||
reconnection_retries = 3
|
||||
[pam]
|
||||
reconnection_retries = 3
|
||||
[sssd]
|
||||
domains = tecmint.lan
|
||||
config_file_version = 2
|
||||
services = nss, pam
|
||||
default_domain_suffix = TECMINT.LAN
|
||||
[domain/tecmint.lan]
|
||||
ad_domain = tecmint.lan
|
||||
krb5_realm = TECMINT.LAN
|
||||
realmd_tags = manages-system joined-with-samba
|
||||
cache_credentials = True
|
||||
id_provider = ad
|
||||
krb5_store_password_if_offline = True
|
||||
default_shell = /bin/bash
|
||||
ldap_id_mapping = True
|
||||
use_fully_qualified_names = True
|
||||
fallback_homedir = /home/%d/%u
|
||||
access_provider = ad
|
||||
auth_provider = ad
|
||||
chpass_provider = ad
|
||||
access_provider = ad
|
||||
ldap_schema = ad
|
||||
dyndns_update = true
|
||||
dyndsn_refresh_interval = 43200
|
||||
dyndns_update_ptr = true
|
||||
dyndns_ttl = 3600
|
||||
```
|
||||
|
||||
确保你对应地替换了域名在下面的参数:
|
||||
|
||||
```
|
||||
domains = tecmint.lan
|
||||
default_domain_suffix = TECMINT.LAN
|
||||
[domain/tecmint.lan]
|
||||
ad_domain = tecmint.lan
|
||||
krb5_realm = TECMINT.LAN
|
||||
```
|
||||
|
||||
8. 接着,用下列命令给 SSSD 文件适当的权限:
|
||||
|
||||
```
|
||||
$ sudo chmod 700 /etc/sssd/sssd.conf
|
||||
```
|
||||
|
||||
9. 现在, 打开并编辑 Realmd 配置文件输入下面这行。
|
||||
|
||||
```
|
||||
$ sudo nano /etc/realmd.conf
|
||||
```
|
||||
|
||||
Realmd.conf 文件摘录:
|
||||
|
||||
```
|
||||
[active-directory]
|
||||
os-name = Linux Ubuntu
|
||||
os-version = 17.04
|
||||
[service]
|
||||
automatic-install = yes
|
||||
[users]
|
||||
default-home = /home/%d/%u
|
||||
default-shell = /bin/bash
|
||||
[tecmint.lan]
|
||||
user-principal = yes
|
||||
fully-qualified-names = no
|
||||
```
|
||||
|
||||
10. 最后需要修改的文件属于 Samba daemon. 打开 /etc/samba/smb.conf 文件编辑然后在文件开头加入下面这块代码,在 [global]部分如下图所示之后。
|
||||
|
||||
```
|
||||
workgroup = TECMINT
|
||||
client signing = yes
|
||||
client use spnego = yes
|
||||
kerberos method = secrets and keytab
|
||||
realm = TECMINT.LAN
|
||||
security = ads
|
||||
```
|
||||
[][4]
|
||||
|
||||
配置 Samba 服务器
|
||||
|
||||
确保你替换了域名值,特别是对应域名的 realm 值并运行 testparm 命令检验设置文件是否包含错误。
|
||||
|
||||
```
|
||||
$ sudo testparm
|
||||
```
|
||||
[][5]
|
||||
|
||||
测试 Samba 配置
|
||||
|
||||
11. 在做完所有必需的修改之后,用 AD 管理员帐号验证 Kerberos 认证并用下面的命令列出票据。
|
||||
|
||||
```
|
||||
$ sudo kinit ad_admin_user@DOMAIN.TLD
|
||||
$ sudo klist
|
||||
```
|
||||
[][6]
|
||||
|
||||
检验 Kerberos 认证
|
||||
|
||||
### 第 3 步: 加入 Ubuntu 到 Samba4 Realm
|
||||
|
||||
12. 加入 Ubuntu 机器到 Samba4 活动目录键入下列命令。用有管理员权限的 AD DC 账户名字绑定 realm 以照常工作并替换对应的域名值。
|
||||
|
||||
```
|
||||
$ sudo realm discover -v DOMAIN.TLD
|
||||
$ sudo realm list
|
||||
$ sudo realm join TECMINT.LAN -U ad_admin_user -v
|
||||
$ sudo net ads join -k
|
||||
```
|
||||
[][7]
|
||||
|
||||
加入 Ubuntu 到 Samba4 Realm
|
||||
|
||||
[][8]
|
||||
|
||||
表列 Realm Domain 信息
|
||||
|
||||
[][9]
|
||||
|
||||
添加用户到 Realm Domain
|
||||
|
||||
[][10]
|
||||
|
||||
添加 Domain 到 Realm
|
||||
|
||||
13. 区域绑定好了之后,运行下面的命令确保所有域账户在这台机器上允许认证。
|
||||
|
||||
```
|
||||
$ sudo realm permit -all
|
||||
```
|
||||
|
||||
然后你可以使用下面例举的 realm 命令允许或者禁止域用户帐号或群组访问。
|
||||
|
||||
```
|
||||
$ sudo realm deny -a
|
||||
$ realm permit --groups ‘domain.tld\Linux Admins’
|
||||
$ realm permit user@domain.lan
|
||||
$ realm permit DOMAIN\\User2
|
||||
```
|
||||
|
||||
14. 从一个 [安装了 RSAT 工具的][11]Windows 机器你可以打开 AD UC 浏览电脑容器并检验是否有一个使用你机器名的对象帐号已经被创建。
|
||||
|
||||
[][12]
|
||||
|
||||
确保域被加入 AD DC
|
||||
|
||||
### 第 4 步: 配置 AD 账户认证
|
||||
|
||||
15. 为了用域账户认证 Ubuntu 机器,你需要用 root 权限运行 pam-auth-update 命令并允许所有 PAM 配置文件,包括为每个区域账户在第一次注册的时候自动创建起始目录的选项。
|
||||
|
||||
按 [空格] 键检验所有入口并敲 ok 来应用配置。
|
||||
|
||||
```
|
||||
$ sudo pam-auth-update
|
||||
```
|
||||
[][13]
|
||||
|
||||
PAM 配置
|
||||
|
||||
16. 系统上手动编辑 /etc/pam.d/common-account 文件,下面这几行是为了自动创建起始位置给认证过的区域用户。
|
||||
|
||||
```
|
||||
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022
|
||||
```
|
||||
|
||||
17. 如果活动目录用户不能用 linux 命令行修改他们的密码,打开 /etc/pam.d/common-password 文件并在 password 行移除 use_authtok 语句最后如下摘要。
|
||||
|
||||
```
|
||||
password [success=1 default=ignore] pam_winbind.so try_first_pass
|
||||
```
|
||||
|
||||
18. 最后,用下面的命令重启并应用 Realmd 和 SSSD 服务的修改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart realmd sssd
|
||||
$ sudo systemctl enable realmd sssd
|
||||
```
|
||||
|
||||
19. 为了测试 Ubuntu 机器是是否成功集成到 realm 运行安装 winbind 包并运行 wbinfo 命令列出区域账户和群组如下所示。
|
||||
|
||||
```
|
||||
$ sudo apt-get install winbind
|
||||
$ wbinfo -u
|
||||
$ wbinfo -g
|
||||
```
|
||||
[][14]
|
||||
|
||||
列出区域账户
|
||||
|
||||
20. 同样, 也可以针对特定的域用户或群组使用 getent 命令检验 Winbind nsswitch 模式。
|
||||
|
||||
```
|
||||
$ sudo getent passwd your_domain_user
|
||||
$ sudo getent group ‘domain admins’
|
||||
```
|
||||
[][15]
|
||||
|
||||
检验 Winbind Nsswitch
|
||||
|
||||
21. 你也可以用 Linux id 命令获取 AD 账户的信息,命令如下。
|
||||
|
||||
```
|
||||
$ id tecmint_user
|
||||
```
|
||||
[][16]
|
||||
|
||||
检验 AD 用户信息
|
||||
|
||||
22. 用 su – 后跟域用户名参数命令来认证 Ubuntu 主机的一个 Samba4 AD 账户。运行 id 命令获取 AD 账户的更多信息。
|
||||
|
||||
```
|
||||
$ su - your_ad_user
|
||||
```
|
||||
[][17]
|
||||
|
||||
AD 用户认证
|
||||
|
||||
用 pwd 命令查看你的域用户当前工作目录和 passwd 命令修改密码。
|
||||
|
||||
23. 在 Ubuntu 上使用有 root 权限的域账户,你需要用下面的命令添加 AD 用户名到 sudo 系统群组:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG sudo your_domain_user@domain.tld
|
||||
```
|
||||
|
||||
用域账户登录 Ubuntu 并运行 apt updatecommand 来更新你的系统以检验 root 权限。
|
||||
|
||||
24. 给一个域群组 root 权限,用 visudocommand 打开并编辑 /etc/sudoers 文件并加入如下行。
|
||||
|
||||
```
|
||||
%domain\ admins@tecmint.lan ALL=(ALL:ALL) ALL
|
||||
```
|
||||
|
||||
25. Ubuntu 桌面使用域账户认证修正 LightDM 显示管理,通过编辑 /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf 文件,增加以下两行并重启 lightdm 服务或重启机器应用修改。
|
||||
|
||||
```
|
||||
greeter-show-manual-login=true
|
||||
greeter-hide-users=true
|
||||
```
|
||||
|
||||
域账户用 your_domain_username 或 your_domain_username@your_domain.tld 语句登录 Ubuntu 桌面版。
|
||||
|
||||
26. 为使用 Samba AD 账户的简称格式,编辑 /etc/sssd/sssd.conf 文件, 在 [sssd] 块加入如下几行命令。
|
||||
|
||||
```
|
||||
full_name_format = %1$s
|
||||
```
|
||||
|
||||
并重启 SSSD 后台程序应用改变。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sssd
|
||||
```
|
||||
|
||||
你会注意到 bash 提示符会变化,对于没有增生域名副本的 AD 用户的简称。
|
||||
|
||||
27. 万一你因为 sssd.conf 里的 enumerate=true 参数设定而不能登录,你得用下面的命令清空 sssd 缓存数据:
|
||||
|
||||
```
|
||||
$ rm /var/lib/sss/db/cache_tecmint.lan.ldb
|
||||
```
|
||||
|
||||
这就是全部了!虽然这个教程主要集中于集成 Samba4 活动目录,同样的步骤也能被用于用 Realm 和 SSSD 服务的 Ubuntu 整合到微软 Windows 服务器活动目录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
我是一名网瘾少年,开源和基于 linux 系统软件的粉丝,有4年经验在 linux 发行版桌面、服务器和 bash 脚本。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-ubuntu-to-samba4-ad-dc-with-sssd-and-realm/
|
||||
|
||||
作者:[ Matei Cezar][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.jpg
|
||||
[3]:https://www.tecmint.com/wp-content/uploads/2017/07/Set-realm-name.png
|
||||
[4]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba-Server.jpg
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/Test-Samba-Configuration.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Check-Kerberos-Authentication.jpg
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Ubuntu-to-Samba4-Realm.jpg
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Realm-Domain-Info.jpg
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Add-User-to-Realm-Domain.jpg
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Add-Domain-to-Realm.jpg
|
||||
[11]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Domain-Added.jpg
|
||||
[13]:https://www.tecmint.com/wp-content/uploads/2017/07/PAM-Configuration.jpg
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Accounts.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/check-Winbind-nsswitch.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/Check-AD-User-Info.jpg
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/AD-User-Authentication.jpg
|
||||
[18]:https://www.tecmint.com/author/cezarmatei/
|
||||
[19]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[20]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,128 @@
|
||||
你需要了解的关于混合云的知识
|
||||
============================================================
|
||||
|
||||
### 了解混合云的细节,包括它是什么以及如何使用它
|
||||
|
||||

|
||||
图片提供
|
||||
|
||||
[Jason Baker][10]. [CC BY-SA 4.0][11].
|
||||
|
||||
在过去10年出现的众多技术中,云计算因其从待开发的技术向全球统治的技术的快速发展而引人注目。就其本身来说,云计算已经造成了许多困惑、争论和辩论,而混合了多种类型的云计算的"混合"云计算也带来了更多的不确定性。阅读以下有关混合云的一些最常见问题的答案
|
||||
|
||||
### 什么是混合云
|
||||
|
||||
基本上,混合云是本地基础设施、私有云和公共云(例如,第三方云服务)的灵活和集成的组合。云平台、第三方)。尽管公共云和私有云服务在混合云中是绑定在一起的,但实际上,他们是独立且分开的服务实体,尽管可以编排在一起。使用公共和私有云基础设施的选择基于以下几个因素,包括成本、负载灵活性和数据安全性。
|
||||
|
||||
高级特性,如扩展和延伸,可以快速扩展云应用程序的基础设施,使混合云成为具有季节性或其他可变资源需求的服务的流行选择。(扩展意味着在特定的Linux实例上增加计算资源,例如CPU内核和内存,而延伸则意味着提供具有相似配置的多个实例,并将它们分布到一个集群中)。
|
||||
|
||||
探索开源云
|
||||
|
||||
* [云是什么?][1]
|
||||
|
||||
* [OpenStack是什么?][2]
|
||||
|
||||
* [Kubernetes是什么?][3]
|
||||
|
||||
* [为什么操作系统对容器很重要][4]
|
||||
|
||||
* [保持Linux容器安全稳定][5]
|
||||
|
||||
在混合云解决方案的中心是开源软件,如[OpenStack ][12],它部署和管理大型虚拟机网络。自2010年10月发布以来,OpenStack一直在全球蓬勃发展。它的一些集成项目和工具处理核心的云计算服务,比如计算、网络、存储和身份识别,而其他数十个项目可以与OpenStack捆绑在一起,创建独特的、可部署的混合云解决方案。
|
||||
|
||||
### 混合云的组件
|
||||
|
||||

|
||||
|
||||
混合云模型
|
||||
|
||||
### 公共云基础设施:
|
||||
|
||||
* **基础设施即服务(IaaS) ** 从一个远程数据中心提供计算资源、存储、网络、防火墙、入侵预防服务(IPS)等。可以使用图形用户界面(GUI)或命令行接口(CLI)对这些服务进行监视和管理。公共IaaS用户不需要购买和构建自己的基础设施,而是根据需要使用这些服务,并根据使用情况付费.
|
||||
|
||||
* **平台即服务(PaaS)**允许用户开发、测试、管理和运行应用程序和服务器。这些包括操作系统、中间件、web服务器、数据库等等。公共PaaS为用户提供了可以轻松部署和复制的模板形式的预定义服务,而不是手动实现和配置基础设施。.
|
||||
|
||||
* **软件即服务(SaaS)**通过internet交付软件。用户可以根据订阅或许可模型或帐户级别使用这些服务,在这些服务中,这些服务被标榜为活跃用户。SaaS软件是低成本、低维护、不费力的升级,并且降低了购买新硬件、软件或带宽以支持增长的负担。.
|
||||
|
||||
### 私有云基础设施:
|
||||
* 私有**IaaS和PaaS** 托管在孤立的数据中心中,并与公共云集成在一起,这些云可以使用远程数据中心中可用的基础设施和服务。这使私有云所有者能够在全球范围内利用公共云基础设施来扩展应用程序,并利用其计算、存储、网络等功能.
|
||||
|
||||
* **SaaS** 是由公共云提供商完全监控、管理和控制的。SaaS一般不会在公共云和私有云基础设施之间共享,并且仍然是通过公共云提供的服务.
|
||||
|
||||
### 云编排和自动化工具:
|
||||
|
||||
对于计划和协调私有云和公共云实例,云编制工具是必要的。该工具应该继承智能,包括简化流程和自动化重复性任务的能力。此外,集成的自动化工具负责在设置阈值时自动扩展和延伸,以及在发生任何部分损坏或宕机时执行自修复。
|
||||
|
||||
### 系统和配置管理工具:
|
||||
|
||||
在混合云中,系统和配置工具,如[Foreman][13],管理在私有云和公共云数据中心提供的虚拟机的完整生命周期。这些工具使系统管理员能够轻松地控制用户、角色、部署、升级和实例,并及时地应用补丁、bug修复和增强功能。包括Foreman工具中的[Puppet][14],使管理员能够管理配置,并为所有的和注册的主机定义一个完整的结束状态
|
||||
|
||||
### 混合云的特性
|
||||
|
||||
对于大多数组织来说,混合云是有意义的,因为这些关键特性:
|
||||
|
||||
* **可扩展性:** 在混合云中,集成的私有云和公共云实例共享每个可配置的实例的计算资源池。这意味着每个实例都可以在需要时按需扩展或退出.
|
||||
|
||||
* **快速响应:** 当私有云资源超过其阈值时,混合云的弹性支持公共云中的实例快速崩溃。当需求高峰产生显著的、可变的运行应用程序的负载和容量增加时,这是特别有价值的。(例如,在线零售商在假日购物季期间).
|
||||
|
||||
* **可靠性:** 组织可以根据需要的成本、效率、安全性、带宽等来选择公共云服务提供商。在混合云中,组织还可以决定存储敏感数据的位置,以及在私有云中扩展实例,还是通过公共基础设施进行扩展。另外,混合模型在多个站点上存储数据和配置的能力支持备份、灾难恢复和高可用性
|
||||
|
||||
* **管理:** 在非集成的云环境中,管理网络、存储、实例和/或数据可能是乏味的。与混合工具相比,传统的编配工具非常有限,因此限制了对完整的端到端进程和任务的决策和自动化。使用混合云和有效的管理应用程序,您可以跟踪每个组件的数量,并通过定期优化这些组件,使年度费用最小化。
|
||||
|
||||
* **安全性:** 在评估是否在云中放置应用程序和数据时,安全性和隐私是至关重要的。IT部门必须验证所有的遵从性需求和部署策略。公共云的安全性正在改善,并将继续成熟。而且,在混合云模型中,组织可以将高度敏感的信息存储在私有云中,并将其与存储在公共云中的不敏感数据集成在一起。
|
||||
|
||||
* **定价:** 云定价通常基于所需的基础设施和服务水平协议要求。在混合云模型中,用户可以对计算资源(cpu/内存)、带宽、存储、网络、公共IP地址等的粒度进行比较,价格要么是固定的,要么是可变的,可以按月、小时、甚至每秒钟计量。因此,用户总是可以在公共云提供商中购买最好的定价,并相应地部署实例
|
||||
|
||||
### 混合云今天在哪里
|
||||
|
||||
尽管对公共云服务的需求很大且不断增长,并且从本地到公共云的迁移系统,大多数大型组织仍然关注这一问题。大多数人仍然在企业数据中心和遗留系统中保留关键的应用程序和数据。他们担心在公共基础设施中失去控制、安全威胁、数据隐私和数据真实性。因为混合云将这些问题最小化并使收益最大化,对于大多数大型组织来说,这是最好的解决方案
|
||||
|
||||
|
||||
### 五年后我们将在哪里
|
||||
|
||||
我预计混合云模型将在全球范围内被广泛接受,而公司的“无云”政策将在短短几年内非常罕见。这是我想我们会看到的
|
||||
|
||||
* 由于混合云作为一种共同的责任,企业和公共云提供商之间将加强协作,以实施安全措施来遏制网络攻击、恶意软件、数据泄漏和其他威胁
|
||||
|
||||
* 实例的爆发性将会很快,因此客户可以自发地满足负载需求或进行自我修复
|
||||
|
||||
* 此外,编排或自动化工具(如[Ansible][8])将通过继承用于解决关键问题的能力来发挥重要作用
|
||||
|
||||
* 计量和“量入为出”的概念对客户来说是透明的,并且工具将使用户能够通过监控价格波动,安全地破坏现有的实例,并提供新的实例以获得最佳的可用定价
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Amit Das是一名Red Hat的工程师,他对Linux、云计算、DevOps等充满热情,他坚信以一种开放的方式的新的创新和技术,让世界更加开放,可以对社会产生积极的影响,改变许多人的生活
|
||||
|
||||
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://opensource.com/article/17/7/what-is-hybrid-cloud
|
||||
|
||||
作者:[Amit Das ][a]
|
||||
译者:[LHRchina](https://github.com/LHRchina)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/amit-das
|
||||
[1]:https://opensource.com/resources/cloud?src=cloud_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-is-openstack?src=cloud_resource_menu2
|
||||
[3]:https://opensource.com/resources/what-is-kubernetes?src=cloud_resource_menu3
|
||||
[4]:https://opensource.com/16/12/yearbook-why-operating-system-matters?src=cloud_resource_menu4
|
||||
[5]:https://opensource.com/business/16/10/interview-andy-cathrow-anchore?src=cloud_resource_menu5
|
||||
[6]:https://opensource.com/file/364211
|
||||
[7]:https://opensource.com/article/17/7/what-is-hybrid-cloud?rate=TwB_2KyXM7iqrwDPGZpe6WultoCajdIVgp8xI4oZkTw
|
||||
[8]:https://opensource.com/life/16/8/cloud-ansible-gateway
|
||||
[9]:https://opensource.com/user/157341/feed
|
||||
[10]:https://opensource.com/users/jason-baker
|
||||
[11]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[12]:https://opensource.com/resources/openstack
|
||||
[13]:https://github.com/theforeman
|
||||
[14]:https://github.com/theforeman/puppet-foreman
|
||||
[15]:https://opensource.com/users/amit-das
|
||||
[16]:https://opensource.com/users/amit-das
|
||||
Loading…
Reference in New Issue
Block a user