mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
translated
This commit is contained in:
parent
3d8d9c47df
commit
48e1a68b4d
@ -1,108 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
Continuous Profiling of Go programs
|
||||
============================================================
|
||||
|
||||
One of the most interesting parts of Google is our fleet-wide continuous profiling service. We can see who is accountable for CPU and memory usage, we can continuously monitor our production services for contention and blocking profiles, and we can generate analysis and reports and easily can tell what are some of the highly impactful optimization projects we can work on.
|
||||
|
||||
I briefly worked on [Stackdriver Profiler][2], our new product that is filling the gap of cloud-wide profiling service for Cloud users. Note that you DON’T need to run your code on Google Cloud Platform in order to use it. Actually, I use it at development time on a daily basis now. It also supports Java and Node.js.
|
||||
|
||||
#### Profiling in production
|
||||
|
||||
pprof is safe to use in production. We target an additional 5% overhead for CPU and heap allocation profiling. The collection is happening for 10 seconds for every minute from a single instance. If you have multiple replicas of a Kubernetes pod, we make sure we do amortized collection. For example, if you have 10 replicas of a pod, the overhead will be 0.5%. This makes it possible for users to keep the profiling always on.
|
||||
|
||||
We currently support CPU, heap, mutex and thread profiles for Go programs.
|
||||
|
||||
#### Why?
|
||||
|
||||
Before explaining how you can use the profiler in production, it would be helpful to explain why you would ever want to profile in production. Some very common cases are:
|
||||
|
||||
* Debug performance problems only visible in production.
|
||||
|
||||
* Understand the CPU usage to reduce billing.
|
||||
|
||||
* Understand where the contention cumulates and optimize.
|
||||
|
||||
* Understand the impact of new releases, e.g. seeing the difference between canary and production.
|
||||
|
||||
* Enrich your distributed traces by [correlating][1] them with profiling samples to understand the root cause of latency.
|
||||
|
||||
#### Enabling
|
||||
|
||||
Stackdriver Profiler doesn’t work with the _net/http/pprof_ handlers and require you to install and configure a one-line agent in your program.
|
||||
|
||||
```
|
||||
go get cloud.google.com/go/profiler
|
||||
```
|
||||
|
||||
And in your main function, start the profiler:
|
||||
|
||||
```
|
||||
if err := profiler.Start(profiler.Config{
|
||||
Service: "indexing-service",
|
||||
ServiceVersion: "1.0",
|
||||
ProjectID: "bamboo-project-606", // optional on GCP
|
||||
}); err != nil {
|
||||
log.Fatalf("Cannot start the profiler: %v", err)
|
||||
}
|
||||
```
|
||||
|
||||
Once you start running your program, the profiler package will report the profilers for 10 seconds for every minute.
|
||||
|
||||
#### Visualization
|
||||
|
||||
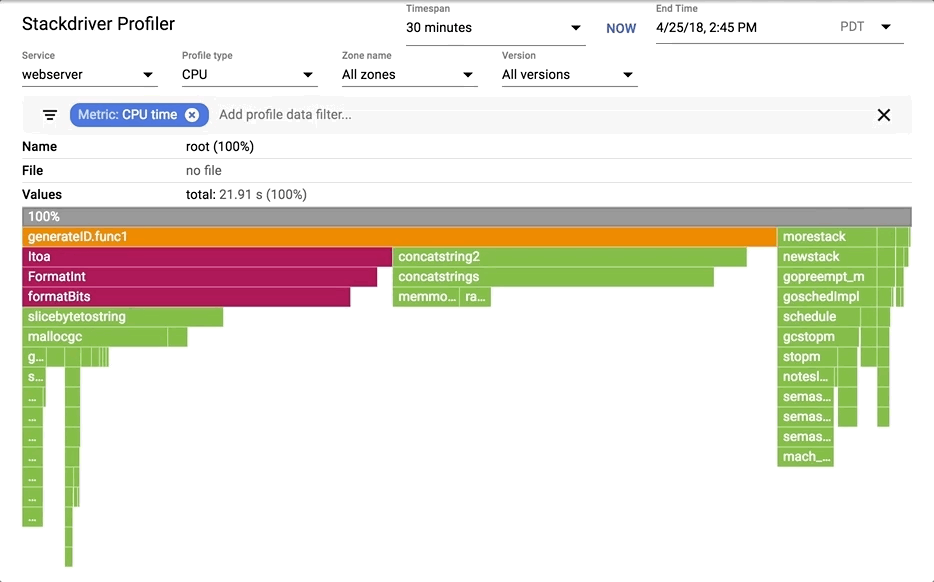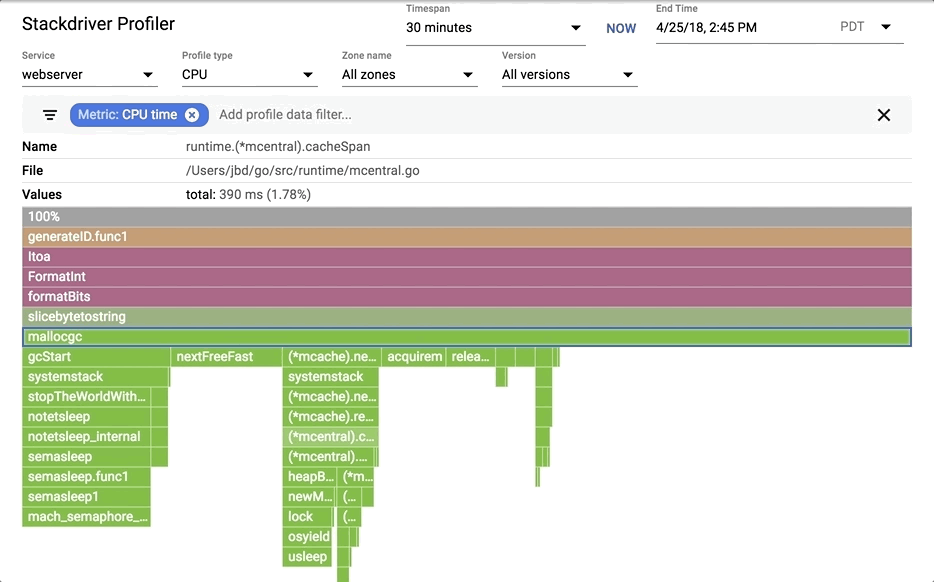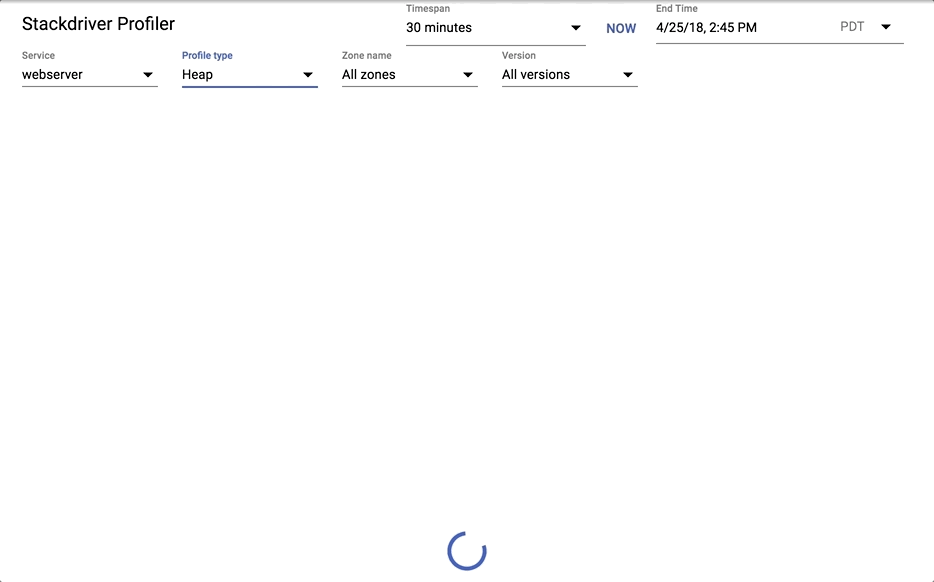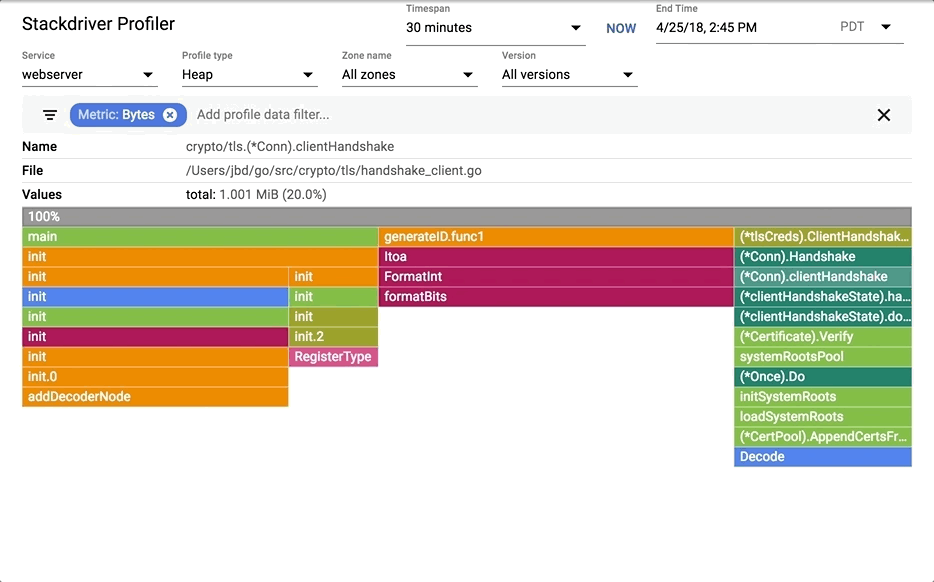
As soon as profiles are reported to the backend, you will start seeing a flamegraph at [https://console.cloud.google.com/profiler][4]. You can filter by tags and change the time span, as well as break down by service name and version. The data will be around up to 30 days.
|
||||
|
||||
|
||||
|
||||
|
||||
You can choose one of the available profiles; break down by service, zone and version. You can move in the flame and filter by tags.
|
||||
|
||||
#### Reading the flame
|
||||
|
||||
Flame graph visualization is explained by [Brendan Gregg][5] very comprehensively. Stackdriver Profiler adds a little bit of its own flavor.
|
||||
|
||||
|
||||

|
||||
|
||||
We will examine a CPU profile but all also applies to the other profiles.
|
||||
|
||||
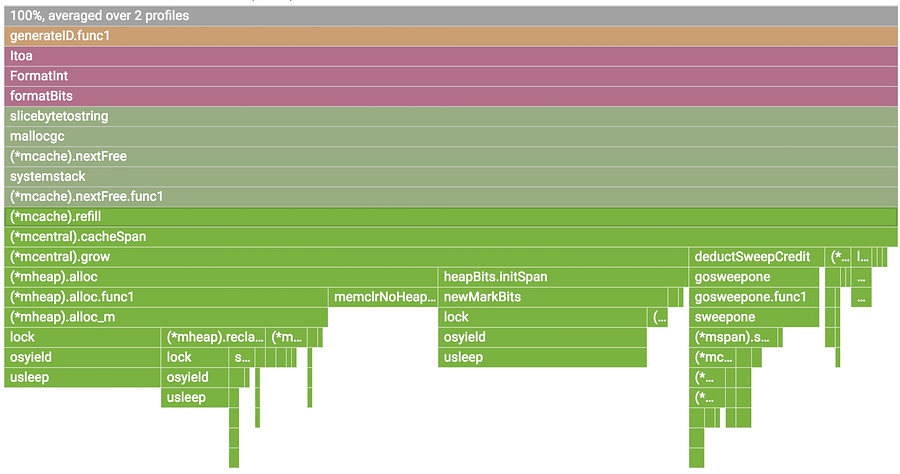
1. The top-most x-axis represents the entire program. Each box on the flame represents a frame on the call path. The width of the box is proportional to the CPU time spent to execute that function.
|
||||
|
||||
2. Boxes are sorted from left to right, left being the most expensive call path.
|
||||
|
||||
3. Frames from the same package have the same color. All runtime functions are represented with green in this case.
|
||||
|
||||
4. You can click on any box to expand the execution tree further.
|
||||
|
||||
|
||||
|
||||
|
||||
You can hover on any box to see detailed information for any frame.
|
||||
|
||||
#### Filtering
|
||||
|
||||
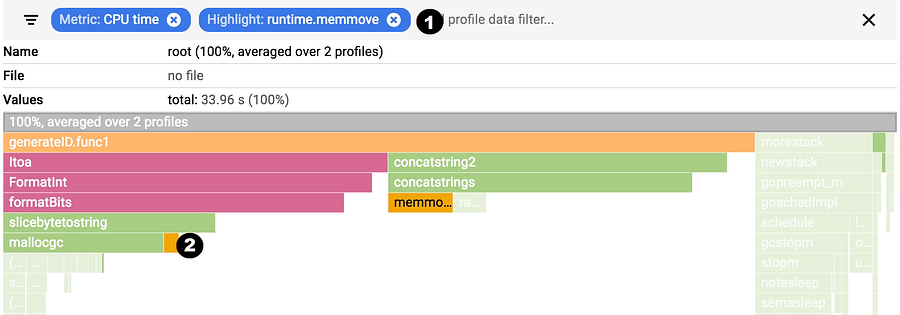
You can show, hide and and highlight by symbol name. These are extremely useful if you specifically want to understand the cost of a particular call or package.
|
||||
|
||||
|
||||
|
||||
1. Choose your filter. You can combine multiple filters. In this case, we are highlighting runtime.memmove.
|
||||
|
||||
2. The flame is going to filter the frames with the filter and visualize the filtered boxes. In this case, it is highlighting all runtime.memmove boxes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b
|
||||
|
||||
作者:[JBD ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@rakyll?source=post_header_lockup
|
||||
[1]:https://rakyll.org/profiler-labels/
|
||||
[2]:https://cloud.google.com/profiler/
|
||||
[3]:http://cloud.google.com/go/profiler
|
||||
[4]:https://console.cloud.google.com/profiler
|
||||
[5]:http://www.brendangregg.com/flamegraphs.html
|
||||
106
translated/tech/20180426 Continuous Profiling of Go programs.md
Normal file
106
translated/tech/20180426 Continuous Profiling of Go programs.md
Normal file
@ -0,0 +1,106 @@
|
||||
Go 程序的持续分析
|
||||
============================================================
|
||||
|
||||
Google 最有趣的部分之一就是我们的持续分析服务。我们可以看到谁在使用 CPU 和内存,我们可以持续地监控我们的生产服务以争用和阻止配置文件,并且我们可以生成分析和报告,并轻松地告诉我们可以进行哪些有重要影响的优化。
|
||||
|
||||
我简单研究了 [Stackdriver Profiler][2],这是我们的新产品,它填补了针对云端用户云端分析服务的空白。请注意,你无需在 Google 云平台上运行你的代码即可使用它。实际上,我现在每天都在开发时使用它。它也支持 Java 和 Node.js。
|
||||
|
||||
#### 在生产中分析
|
||||
|
||||
pprof 可安全地用于生产。我们针对 CPU 和堆分配分析的额外开销会增加 5%。一个实例中每分钟收集 10 秒。如果你有一个 Kubernetes Pod 的多个副本,我们确保进行分摊收集。例如,如果你拥有一个 pod 的 10 个副本,模式,那么开销将变为 0.5%。这使用户可以始终进行分析。
|
||||
|
||||
我们目前支持 Go 程序的 CPU、堆、互斥和线程分析。
|
||||
|
||||
#### 为什么?
|
||||
|
||||
在解释如何在生产中使用分析器之前,先解释为什么你想要在生产中进行分析将有所帮助。一些非常常见的情况是:
|
||||
|
||||
* 调试仅在生产中可见的性能问题。
|
||||
|
||||
* 了解 CPU 使用率以减少费用。
|
||||
|
||||
* 了解争用的累积和优化的地方。
|
||||
|
||||
* 了解新版本的影响,例如看到 canary 和生产之间的区别。
|
||||
|
||||
* 通过[关联][1]分析样本以了解延迟的根本原因来丰富你的分布式经验。
|
||||
|
||||
#### 启用
|
||||
|
||||
Stackdriver Profiler 不能与 _net/http/pprof_ 处理程序一起使用,并要求你在程序中安装和配置一个一行的代理。
|
||||
|
||||
```
|
||||
go get cloud.google.com/go/profiler
|
||||
```
|
||||
|
||||
在你的主函数中,启动分析器:
|
||||
|
||||
```
|
||||
if err := profiler.Start(profiler.Config{
|
||||
Service: "indexing-service",
|
||||
ServiceVersion: "1.0",
|
||||
ProjectID: "bamboo-project-606", // optional on GCP
|
||||
}); err != nil {
|
||||
log.Fatalf("Cannot start the profiler: %v", err)
|
||||
}
|
||||
```
|
||||
|
||||
当你运行你的程序后,profiler 包将每分钟报告给 profiler 10 秒钟。
|
||||
|
||||
#### 可视化
|
||||
|
||||
当分析报告给后端后,你将在 [https://console.cloud.google.com/profiler][4] 上看到火焰图。你可以按标签过滤并更改时间范围,也可以按服务名称和版本进行细分。数据将会长达 30 天。
|
||||
|
||||
|
||||

|
||||
|
||||
你可以选择其中一个分析,按服务,区域和版本分解。你可以在火焰中移动并通过标签进行过滤。
|
||||
|
||||
#### 阅读火焰图
|
||||
|
||||
火焰图可视化由 [Brendan Gregg][5] 非常全面地解释了。Stackdriver Profiler 增加了一点它自己的特点。
|
||||
|
||||
|
||||

|
||||
|
||||
我们将查看一个 CPU 分析,但这也适用于其他分析。
|
||||
|
||||
1. 最上面的 x 轴表示整个程序。火焰上的每个框表示调用路径上的一帧。框的宽度与执行该函数花费的 CPU 时间成正比。
|
||||
|
||||
2. 框从左到右排序,左边是花费最多的调用路径。
|
||||
|
||||
3. 来自同一包的帧具有相同的颜色。这里所有运行时功能均以绿色表示。
|
||||
|
||||
4. 你可以单击任何框进一步展开执行树。
|
||||
|
||||
|
||||

|
||||
|
||||
你可以将鼠标悬停在任何框上查看任何帧的详细信息。
|
||||
|
||||
#### 过滤
|
||||
|
||||
你可以显示,隐藏和高亮符号名称。如果你特别想了解某个特定调用或包的消耗,这些信息非常有用。
|
||||
|
||||

|
||||
|
||||
1. 选择你的过滤器。你可以组合多个过滤器。在这里,我们将高亮显示 runtime.memmove。
|
||||
|
||||
2. 火焰将使用过滤器过滤帧并可视化过滤后的框。在这种情况下,它高亮显示所有 runtime.memmove 框。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b
|
||||
|
||||
作者:[JBD ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@rakyll?source=post_header_lockup
|
||||
[1]:https://rakyll.org/profiler-labels/
|
||||
[2]:https://cloud.google.com/profiler/
|
||||
[3]:http://cloud.google.com/go/profiler
|
||||
[4]:https://console.cloud.google.com/profiler
|
||||
[5]:http://www.brendangregg.com/flamegraphs.html
|
||||
Loading…
Reference in New Issue
Block a user