mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
commit
4782467f13
@ -1,10 +1,11 @@
|
||||
如何配置MongoDB副本集(Replica Set)
|
||||
如何配置 MongoDB 副本集
|
||||
================================================================================
|
||||
MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档的,它的无模式设计使得它在各种各样的WEB应用当中广受欢迎。最让我喜欢的特性之一是它的副本集,副本集将同一数据的多份拷贝放在一组mongod节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
这篇教程将向你介绍如何配置一个MongoDB副本集。
|
||||
MongoDB 已经成为市面上最知名的 NoSQL 数据库。MongoDB 是面向文档的,它的无模式设计使得它在各种各样的WEB 应用当中广受欢迎。最让我喜欢的特性之一是它的副本集(Replica Set),副本集将同一数据的多份拷贝放在一组 mongod 节点上,从而实现数据的冗余以及高可用性。
|
||||
|
||||
副本集的最常见配置涉及到一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的结点从而提高了数据库客户端数据读取的吞吐量。
|
||||
这篇教程将向你介绍如何配置一个 MongoDB 副本集。
|
||||
|
||||
副本集的最常见配置需要一个主节点以及多个副节点。这之后启动的复制行为会从这个主节点到其他副节点。副本集不止可以针对意外的硬件故障和停机事件对数据库提供保护,同时也因为提供了更多的节点从而提高了数据库客户端数据读取的吞吐量。
|
||||
|
||||
### 配置环境 ###
|
||||
|
||||
@ -12,25 +13,25 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
|
||||

|
||||
|
||||
为了达到这个目的,我们使用了3个运行在VirtualBox上的虚拟机。我会在这些虚拟机上安装Ubuntu 14.04,并且安装MongoDB官方包。
|
||||
为了达到这个目的,我们使用了3个运行在 VirtualBox 上的虚拟机。我会在这些虚拟机上安装 Ubuntu 14.04,并且安装 MongoDB 官方包。
|
||||
|
||||
我会在一个虚拟机实例上配置好需要的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为master的虚拟机,执行以下安装过程。
|
||||
我会在一个虚拟机实例上配置好所需的环境,然后将它克隆到其他的虚拟机实例上。因此,选择一个名为 master 的虚拟机,执行以下安装过程。
|
||||
|
||||
首先,我们需要在apt中增加一个MongoDB密钥:
|
||||
首先,我们需要给 apt 增加一个 MongoDB 密钥:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
然后,将官方的MongoDB仓库添加到source.list中:
|
||||
然后,将官方的 MongoDB 仓库添加到 source.list 中:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
接下来更新apt仓库并且安装MongoDB。
|
||||
接下来更新 apt 仓库并且安装 MongoDB。
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
现在对/etc/mongodb.conf做一些更改
|
||||
现在对 /etc/mongodb.conf 做一些更改
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
@ -39,17 +40,17 @@ MongoDB已经成为市面上最知名的NoSQL数据库。MongoDB是面向文档
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
第一行的作用是确认我们的数据库需要验证才可以使用的。keyfile用来配置用于MongoDB结点间复制行为的密钥文件。replSet用来为副本集设置一个名称。
|
||||
第一行的作用是表明我们的数据库需要验证才可以使用。keyfile 配置用于 MongoDB 节点间复制行为的密钥文件。replSet 为副本集设置一个名称。
|
||||
|
||||
接下来我们创建一个用于所有实例的密钥文件。
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
这将会创建一个含有MD5字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在MongoDB中使用。
|
||||
这将会创建一个含有 MD5 字符串的密钥文件,但是由于其中包含了一些噪音,我们需要对他们清理后才能正式在 MongoDB 中使用。
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
grep命令的作用的是把将空格等我们不想要的内容过滤掉之后的MD5字符串打印出来。
|
||||
grep 命令的作用的是把将空格等我们不想要的内容过滤掉之后的 MD5 字符串打印出来。
|
||||
|
||||
现在我们对密钥文件进行一些操作,让它真正可用。
|
||||
|
||||
@ -57,7 +58,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
接下来,关闭此虚拟机。将其Ubuntu系统克隆到其他虚拟机上。
|
||||
接下来,关闭此虚拟机。将其 Ubuntu 系统克隆到其他虚拟机上。
|
||||
|
||||

|
||||
|
||||
@ -67,55 +68,55 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
请注意,三个虚拟机示例需要在同一个网络中以便相互通讯。因此,我们需要它们弄到“互联网"上去。
|
||||
|
||||
这里推荐给每个虚拟机设置一个静态IP地址,而不是使用DHCP。这样它们就不至于在DHCP分配IP地址给他们的时候失去连接。
|
||||
这里推荐给每个虚拟机设置一个静态 IP 地址,而不是使用 DHCP。这样它们就不至于在 DHCP 分配IP地址给他们的时候失去连接。
|
||||
|
||||
像下面这样编辑每个虚拟机的/etc/networks/interfaces文件。
|
||||
像下面这样编辑每个虚拟机的 /etc/networks/interfaces 文件。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
由于我们没有DNS服务,所以需要设置设置一下/etc/hosts这个文件,手工将主机名称放到次文件中。
|
||||
由于我们没有 DNS 服务,所以需要设置设置一下 /etc/hosts 这个文件,手工将主机名称放到此文件中。
|
||||
|
||||
在主结点上:
|
||||
在主节点上:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点1上:
|
||||
在副节点1上:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
在副结点2上:
|
||||
在副节点2上:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
使用ping命令检查各个结点之间的连接。
|
||||
使用 ping 命令检查各个节点之间的连接。
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
@ -123,9 +124,9 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
|
||||
### 配置副本集 ###
|
||||
|
||||
验证各个结点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
验证各个节点可以正常连通后,我们就可以新建一个管理员用户,用于之后的副本集操作。
|
||||
|
||||
在主节点上,打开/etc/mongodb.conf文件,将auth和replSet两项注释掉。
|
||||
在主节点上,打开 /etc/mongodb.conf 文件,将 auth 和 replSet 两项注释掉。
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
@ -133,21 +134,30 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
在一个新安装的 MongoDB 上配置任何用户或副本集之前,你需要注释掉 auth 行。默认情况下,MongoDB 并没有创建任何用户。而如果在你创建用户前启用了 auth,你就不能够做任何事情。你可以在创建一个用户后再次启用 auth。
|
||||
|
||||
重启mongod进程。
|
||||
修改 /etc/mongodb.conf 之后,重启 mongod 进程。
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接MongoDB后,新建管理员用户。
|
||||
现在连接到 MongoDB master:
|
||||
|
||||
$ mongo <master-ip-address>:27017
|
||||
|
||||
连接 MongoDB 后,新建管理员用户。
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
|
||||
重启 MongoDB:
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
连接到MongoDB,用以下命令将secondary1和secondary2节点添加到我们的副本集中。
|
||||
再次连接到 MongoDB,用以下命令将 副节点1 和副节点2节点添加到我们的副本集中。
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
@ -156,7 +166,7 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [official driver documentation][1] 来了解如何连接到副本集。如果你想要用Shell来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用附件点操作,那么以下错误信息就蹦出来招呼你了。
|
||||
现在副本集到手了,可以开始我们的项目了。参照 [官方驱动文档][1] 来了解如何连接到副本集。如果你想要用 Shell 来请求数据,那么你需要连接到主节点上来插入或者请求数据,副节点不行。如果你执意要尝试用副本集操作,那么以下错误信息就蹦出来招呼你了。
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
@ -166,6 +176,12 @@ grep命令的作用的是把将空格等我们不想要的内容过滤掉之后
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
如果你要从 shell 连接到整个副本集,你可以安装如下命令。在副本集中的失败切换是自动的。
|
||||
|
||||
$ mongo primary,secondary1,secondary2:27017/?replicaSet=myReplica
|
||||
|
||||
如果你使用其它驱动语言(例如,JavaScript、Ruby 等等),格式也许不同。
|
||||
|
||||
希望这篇教程能对你有所帮助。你可以使用Vagrant来自动完成你的本地环境配置,并且加速你的代码。
|
||||
|
||||
@ -175,7 +191,7 @@ via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,18 +1,19 @@
|
||||
Linux中通过命令行监控股票报价
|
||||
================================================================================
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将成为你日常工作中的其中一项任务。最有可能是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者阅读市场的必备,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是你的恩赐。
|
||||
如果你是那些股票投资者或者交易者中的一员,那么监控证券市场将是你的日常工作之一。最有可能的是你会使用一个在线交易平台,这个平台有着一些漂亮的实时图表和全部种类的高级股票分析和交易工具。虽然这种复杂的市场研究工具是任何严肃的证券投资者了解市场的必备工具,但是监控最新的股票报价来构建有利可图的投资组合仍然有很长一段路要走。
|
||||
|
||||
如果你是一位长久坐在终端前的全职系统管理员,而证券交易又成了你日常生活中的业余兴趣,那么一个简单地显示实时股票报价的命令行工具会是给你的恩赐。
|
||||
|
||||
在本教程中,让我来介绍一个灵巧而简洁的命令行工具,它可以让你在Linux上从命令行监控股票报价。
|
||||
|
||||
这个工具叫做[Mop][1]。它是用GO编写的一个轻量级命令行工具,可以极其方便地跟踪来自美国市场的最新股票报价。你可以很轻松地自定义要监控的证券列表,它会在一个基于ncurses的便于阅读的界面显示最新的股票报价。
|
||||
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。对于上面讲得,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
**注意**:Mop是通过雅虎金融API获取最新的股票报价的。你必须意识到,他们的的股票报价已知会有15分钟的延时。所以,如果你正在寻找0延时的“实时”股票报价,那么Mop就不是你的菜了。这种“现场”股票报价订阅通常可以通过向一些不开放的私有接口付费获取。了解这些之后,让我们来看看怎样在Linux环境下使用Mop吧。
|
||||
|
||||
### 安装 Mop 到 Linux ###
|
||||
|
||||
由于Mop部署在Go中,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
由于Mop是用Go实现的,你首先需要安装Go语言。如果你还没有安装Go,请参照[此指南][2]将Go安装到你的Linux平台中。请确保按指南中所讲的设置GOPATH环境变量。
|
||||
|
||||
安装完Go后,继续像下面这样安装Mop。
|
||||
|
||||
@ -42,7 +43,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||
### 使用Mop来通过命令行监控股票报价 ###
|
||||
|
||||
要启动Mop,只需运行名为cmd的命令。
|
||||
要启动Mop,只需运行名为cmd的命令(LCTT 译注:这名字实在是……)。
|
||||
|
||||
$ cmd
|
||||
|
||||
@ -50,7 +51,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||

|
||||
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股利以及年产量等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
报价显示了像最新价格、交易百分比、每日低/高、52周低/高、股息以及年收益率等信息。Mop从[CNN][3]获取市场总览信息,从[雅虎金融][4]获得个股报价,股票报价信息它自己会在终端内周期性更新。
|
||||
|
||||
### 自定义Mop中的股票报价 ###
|
||||
|
||||
@ -78,7 +79,7 @@ Linux中通过命令行监控股票报价
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在终端环境中花费大量时间,Mop可以很容易地适应你的工作空间,希望没有让你过多地从你的公罗流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,就让它在那干着吧。
|
||||
正如你所见,Mop是一个轻量级的,然而极其方便的证券监控工具。当然,你可以很轻松地从其它别的什么地方,从在线站点,你的智能手机等等访问到股票报价信息。然而,如果你在整天使用终端环境,Mop可以很容易地适应你的工作环境,希望没有让你过多地从你的工作流程中分心。只要让它在你其中一个终端中运行并保持市场日期持续更新,那就够了。
|
||||
|
||||
交易快乐!
|
||||
|
||||
@ -88,7 +89,7 @@ via: http://xmodulo.com/monitor-stock-quotes-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答--如何检查MatiaDB服务端版本
|
||||
Linux有问必答:如何检查MariaDB服务端版本
|
||||
================================================================================
|
||||
> **提问**: 我使用的是一台运行MariaDB的VPS。我该如何检查MariaDB服务端的版本?
|
||||
|
||||
你需要知道数据库版本的情况有:当你生你数据库或者为服务器打补丁。这里有几种方法找出MariaDB版本的方法。
|
||||
有时候你需要知道你的数据库版本,比如当你升级你数据库或对已知缺陷打补丁时。这里有几种方法找出MariaDB版本的方法。
|
||||
|
||||
### 方法一 ###
|
||||
|
||||
@ -16,7 +16,7 @@ Linux有问必答--如何检查MatiaDB服务端版本
|
||||
|
||||
### 方法二 ###
|
||||
|
||||
如果你不能访问MariaDB,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
如果你不能访问MariaDB服务器,那么你就不能用第一种方法。这种情况下你可以根据MariaDB的安装包的版本来推测。这种方法只有在MariaDB通过包管理器安装的才有用。
|
||||
|
||||
你可以用下面的方法检查MariaDB的安装包。
|
||||
|
||||
@ -42,7 +42,7 @@ via: http://ask.xmodulo.com/check-mariadb-server-version.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
如何在 Docker 容器中运行 Kali Linux 2.0
|
||||
================================================================================
|
||||
### 介绍 ###
|
||||
|
||||
Kali Linux 是一个对于安全测试人员和白帽的一个知名操作系统。它带有大量安全相关的程序,这让它很容易用于渗透测试。最近,[Kali Linux 2.0][1] 发布了,它被认为是这个操作系统最重要的一次发布。另一方面,Docker 技术由于它的可扩展性和易用性让它变得很流行。Dokcer 让你非常容易地将你的程序带给你的用户。好消息是你可以通过 Docker 运行Kali Linux 了,让我们看看该怎么做 :)
|
||||
|
||||
### 在 Docker 中运行 Kali Linux 2.0 ###
|
||||
|
||||
**相关提示**
|
||||
|
||||
> 如果你还没有在系统中安装docker,你可以运行下面的命令:
|
||||
|
||||
> **对于 Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
> sudo apt-get install docker
|
||||
|
||||
> **对于 Fedora/RHEL/CentOS:**
|
||||
|
||||
> sudo yum install docker
|
||||
|
||||
> **对于 Fedora 22:**
|
||||
|
||||
> dnf install docker
|
||||
|
||||
> 你可以运行下面的命令来启动docker:
|
||||
|
||||
> sudo docker start
|
||||
|
||||
首先运行下面的命令确保 Docker 服务运行正常:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux 的开发团队已将 Kali Linux 的 docker 镜像上传了,只需要输入下面的命令来下载镜像。
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
下载完成后,运行下面的命令来找出你下载的 docker 镜像的 ID。
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
现在运行下面的命令来从镜像文件启动 kali linux docker 容器(这里需用正确的镜像ID替换)。
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
它会立刻启动容器并且让你登录到该操作系统,你现在可以在 Kaili Linux 中工作了。
|
||||
|
||||

|
||||
|
||||
你可以在容器外面通过下面的命令来验证容器已经启动/运行中了:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
Docker 是一种最聪明的用来部署和分发包的方式。Kali Linux docker 镜像非常容易上手,也不会消耗很大的硬盘空间,这样也可以很容易地在任何安装了 docker 的操作系统上测试这个很棒的发行版了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:https://linux.cn/article-6005-1.html
|
||||
@ -1,24 +1,25 @@
|
||||
使用dd命令在Linux和Unix环境下进行硬盘I/O性能检测
|
||||
使用 dd 命令进行硬盘 I/O 性能检测
|
||||
================================================================================
|
||||
如何使用dd命令测试硬盘的性能?如何在linux操作系统下检测硬盘的读写能力?
|
||||
|
||||
如何使用dd命令测试我的硬盘性能?如何在linux操作系统下检测硬盘的读写速度?
|
||||
|
||||
你可以使用以下命令在一个Linux或类Unix操作系统上进行简单的I/O性能测试。
|
||||
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它被用来获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
- **dd命令** :它被用来在Linux和类Unix系统下对硬盘设备进行写性能的检测。
|
||||
- **hparm命令**:它用来在基于 Linux 的系统上获取或设置硬盘参数,包括测试读性能以及缓存性能等。
|
||||
|
||||
在这篇指南中,你将会学到如何使用dd命令来测试硬盘性能。
|
||||
|
||||
### 使用dd命令来监控硬盘的读写性能:###
|
||||
|
||||
- 打开shell终端(这里貌似不能翻译为终端提示符)。
|
||||
- 通过ssh登录到远程服务器。
|
||||
- 打开shell终端。
|
||||
- 或者通过ssh登录到远程服务器。
|
||||
- 使用dd命令来测量服务器的吞吐率(写速度) `dd if=/dev/zero of=/tmp/test1.img bs=1G count=1 oflag=dsync`
|
||||
- 使用dd命令测量服务器延迟 `dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync`
|
||||
|
||||
####理解dd命令的选项###
|
||||
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
在这个例子当中,我将使用搭载Ubuntu Linux 14.04 LTS系统的RAID-10(配有SAS SSD的Adaptec 5405Z)服务器阵列来运行。基本语法为:
|
||||
|
||||
dd if=/dev/input.file of=/path/to/output.file bs=block-size count=number-of-blocks oflag=dsync
|
||||
## GNU dd语法 ##
|
||||
@ -29,18 +30,19 @@
|
||||
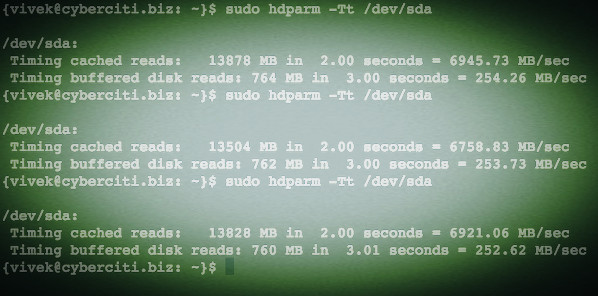
输出样例:
|
||||
|
||||

|
||||
Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
|
||||
*图01: 使用dd命令获取的服务器吞吐率*
|
||||
|
||||
请各位注意在这个实验中,我们写入一个G的数据,可以发现,服务器的吞吐率是135 MB/s,这其中
|
||||
|
||||
- `if=/dev/zero (if=/dev/input.file)` :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img (of=/path/to/output.file)` :dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G (bs=block-size)` :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1 (count=number-of-blocks)`: dd命令读取的块的个数。
|
||||
- `oflag=dsync (oflag=dsync)` :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `if=/dev/zero` (if=/dev/input.file) :用来设置dd命令读取的输入文件名。
|
||||
- `of=/tmp/test1.img` (of=/path/to/output.file):dd命令将input.file写入的输出文件的名字。
|
||||
- `bs=1G` (bs=block-size) :设置dd命令读取的块的大小。例子中为1个G。
|
||||
- `count=1` (count=number-of-blocks):dd命令读取的块的个数。
|
||||
- `oflag=dsync` (oflag=dsync) :使用同步I/O。不要省略这个选项。这个选项能够帮助你去除caching的影响,以便呈现给你精准的结果。
|
||||
- `conv=fdatasyn`: 这个选项和`oflag=dsync`含义一样。
|
||||
|
||||
在这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
在下面这个例子中,一共写了1000次,每次写入512字节来获得RAID10服务器的延迟时间:
|
||||
|
||||
dd if=/dev/zero of=/tmp/test2.img bs=512 count=1000 oflag=dsync
|
||||
|
||||
@ -50,11 +52,11 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
1000+0 records out
|
||||
512000 bytes (512 kB) copied, 0.60362 s, 848 kB/s
|
||||
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的加载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
请注意服务器的吞吐率以及延迟时间也取决于服务器/应用的负载。所以我推荐你在一个刚刚重启过并且处于峰值时间的服务器上来运行测试,以便得到更加准确的度量。现在你可以在你的所有设备上互相比较这些测试结果了。
|
||||
|
||||
####为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
###为什么服务器的吞吐率和延迟时间都这么差?###
|
||||
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是HARDWARE RAID10的控制器缓存导致的。
|
||||
低的数值并不意味着你在使用差劲的硬件。可能是硬件 RAID10的控制器缓存导致的。
|
||||
|
||||
使用hdparm命令来查看硬盘缓存的读速度。
|
||||
|
||||
@ -79,11 +81,12 @@ Fig.01: 使用dd命令获取的服务器吞吐率
|
||||
输出样例:
|
||||
|
||||
|
||||
Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
|
||||
请再一次注意由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
*图02: 检测硬盘读入以及缓存性能的Linux hdparm命令*
|
||||
|
||||
**使用dd命令来测试读入速度**
|
||||
请再次注意,由于文件文件操作的缓存属性,你将总是会看到很高的读速度。
|
||||
|
||||
###使用dd命令来测试读取速度###
|
||||
|
||||
为了获得精确的读测试数据,首先在测试前运行下列命令,来将缓存设置为无效:
|
||||
|
||||
@ -91,11 +94,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
echo 3 | sudo tee /proc/sys/vm/drop_caches
|
||||
time time dd if=/path/to/bigfile of=/dev/null bs=8k
|
||||
|
||||
**笔记本上的示例**
|
||||
####笔记本上的示例####
|
||||
|
||||
运行下列命令:
|
||||
|
||||
### Cache存在的Debian系统笔记本吞吐率###
|
||||
### 带有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
###使cache失效###
|
||||
@ -104,10 +107,11 @@ Fig.02: 检测硬盘读入以及缓存性能的Linux hdparm命令
|
||||
###没有Cache的Debian系统笔记本吞吐率###
|
||||
dd if=/dev/zero of=/tmp/laptop.bin bs=1G count=1 oflag=direct
|
||||
|
||||
**苹果OS X Unix(Macbook pro)的例子**
|
||||
####苹果OS X Unix(Macbook pro)的例子####
|
||||
|
||||
GNU dd has many more options but OS X/BSD and Unix-like dd command need to run as follows to test real disk I/O and not memory add sync option as follows:
|
||||
GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
GNU dd命令有其他许多选项,但是在 OS X/BSD 以及类Unix中, dd命令需要像下面那样执行来检测去除掉内存地址同步的硬盘真实I/O性能:
|
||||
|
||||
## 运行这个命令2-3次来获得更好地结果 ###
|
||||
time sh -c "dd if=/dev/zero of=/tmp/testfile bs=100k count=1k && sync"
|
||||
@ -124,26 +128,29 @@ GNU dd命令有其他许多选项但是在 OS X/BSD 以及类Unix中, dd命令
|
||||
|
||||
本人Macbook Pro的写速度是635346520字节(635.347MB/s)。
|
||||
|
||||
**不喜欢用命令行?^_^**
|
||||
###不喜欢用命令行?\^_^###
|
||||
|
||||
你可以在Linux或基于Unix的系统上使用disk utility(gnome-disk-utility)这款工具来得到同样的信息。下面的那个图就是在我的Fedora Linux v22 VM上截取的。
|
||||
|
||||
**图形化方法**
|
||||
####图形化方法####
|
||||
|
||||
点击“Activites”或者“Super”按键来在桌面和Activites视图间切换。输入“Disks”
|
||||
|
||||
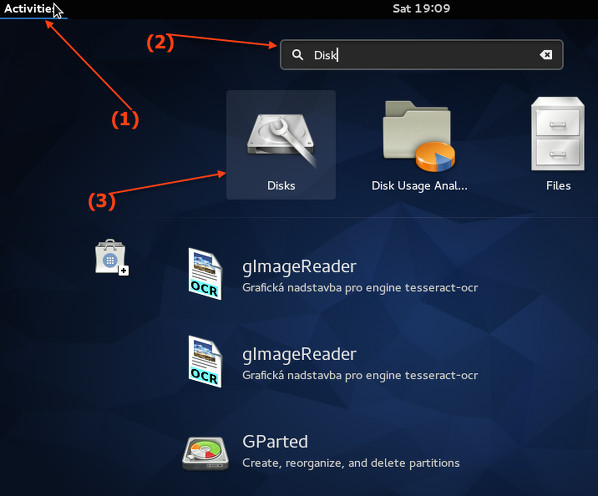
|
||||
Fig.03: 打开Gnome硬盘工具
|
||||
|
||||
*图03: 打开Gnome硬盘工具*
|
||||
|
||||
在左边的面板上选择你的硬盘,点击configure按钮,然后点击“Benchmark partition”:
|
||||
|
||||
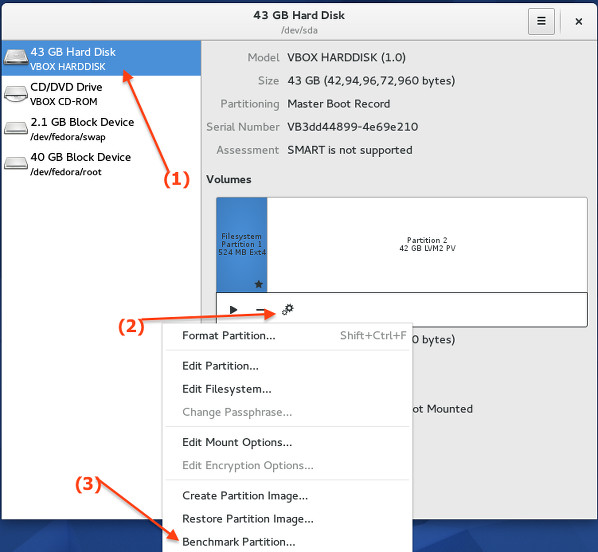
|
||||
Fig.04: 评测硬盘/分区
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能被要求输入管理员用户名和密码):
|
||||
*图04: 评测硬盘/分区*
|
||||
|
||||
最后,点击“Start Benchmark...”按钮(你可能需要输入管理员用户名和密码):
|
||||
|
||||
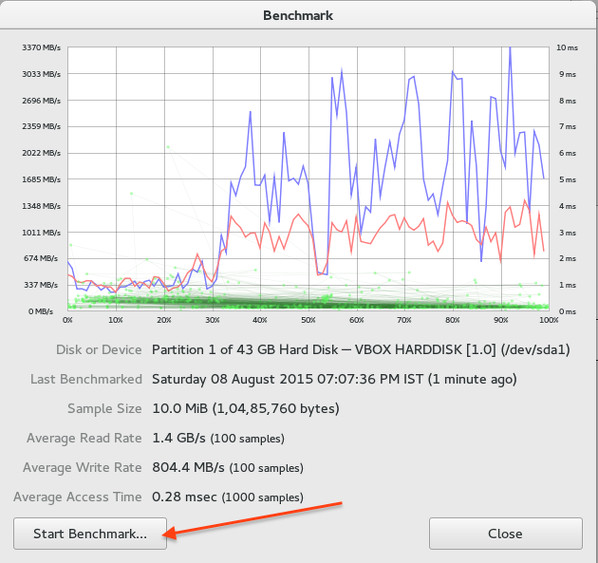
|
||||
Fig.05: 最终的评测结果
|
||||
|
||||
*图05: 最终的评测结果*
|
||||
|
||||
如果你要问,我推荐使用哪种命令和方法?
|
||||
|
||||
@ -158,7 +165,7 @@ via: http://www.cyberciti.biz/faq/howto-linux-unix-test-disk-performance-with-dd
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,89 +1,90 @@
|
||||
|
||||
在 Linux 中创建 RAID 5(条带化与分布式奇偶校验) - 第4部分
|
||||
在 Linux 下使用 RAID(四):创建 RAID 5(条带化与分布式奇偶校验)
|
||||
================================================================================
|
||||
在 RAID 5 中,条带化数据跨多个驱磁盘使用分布式奇偶校验。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带中的数据分布在多个磁盘上,它将有很好的数据冗余。
|
||||
|
||||
在 RAID 5 中,数据条带化后存储在分布式奇偶校验的多个磁盘上。分布式奇偶校验的条带化意味着它将奇偶校验信息和条带化数据分布在多个磁盘上,这样会有很好的数据冗余。
|
||||
|
||||

|
||||
|
||||
在 Linux 中配置 RAID 5
|
||||
*在 Linux 中配置 RAID 5*
|
||||
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中花费更多的成本来提供更好的数据冗余性能。
|
||||
对于此 RAID 级别它至少应该有三个或更多个磁盘。RAID 5 通常被用于大规模生产环境中,以花费更多的成本来提供更好的数据冗余性能。
|
||||
|
||||
#### 什么是奇偶校验? ####
|
||||
|
||||
奇偶校验是在数据存储中检测错误最简单的一个方法。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中一个磁盘空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
奇偶校验是在数据存储中检测错误最简单的常见方式。奇偶校验信息存储在每个磁盘中,比如说,我们有4个磁盘,其中相当于一个磁盘大小的空间被分割去存储所有磁盘的奇偶校验信息。如果任何一个磁盘出现故障,我们可以通过更换故障磁盘后,从奇偶校验信息重建得到原来的数据。
|
||||
|
||||
#### RAID 5 的优点和缺点 ####
|
||||
|
||||
- 提供更好的性能
|
||||
- 提供更好的性能。
|
||||
- 支持冗余和容错。
|
||||
- 支持热备份。
|
||||
- 将失去一个磁盘的容量存储奇偶校验信息。
|
||||
- 将用掉一个磁盘的容量存储奇偶校验信息。
|
||||
- 单个磁盘发生故障后不会丢失数据。我们可以更换故障硬盘后从奇偶校验信息中重建数据。
|
||||
- 事务处理读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作将是缓慢的。
|
||||
- 适合于面向事务处理的环境,读操作会更快。
|
||||
- 由于奇偶校验占用资源,写操作会慢一些。
|
||||
- 重建需要很长的时间。
|
||||
|
||||
#### 要求 ####
|
||||
|
||||
创建 RAID 5 最少需要3个磁盘,你也可以添加更多的磁盘,前提是你要有多端口的专用硬件 RAID 控制器。在这里,我们使用“mdadm”包来创建软件 RAID。
|
||||
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下 RAID 没有可用的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件中,例如:mdadm.conf。
|
||||
mdadm 是一个允许我们在 Linux 下配置和管理 RAID 设备的包。默认情况下没有 RAID 的配置文件,我们在创建和配置 RAID 后必须将配置文件保存在一个单独的文件 mdadm.conf 中。
|
||||
|
||||
在进一步学习之前,我建议你通过下面的文章去了解 Linux 中 RAID 的基础知识。
|
||||
|
||||
- [Basic Concepts of RAID in Linux – Part 1][1]
|
||||
- [Creating RAID 0 (Stripe) in Linux – Part 2][2]
|
||||
- [Setting up RAID 1 (Mirroring) in Linux – Part 3][3]
|
||||
- [介绍 RAID 的级别和概念][1]
|
||||
- [使用 mdadm 工具创建软件 RAID 0 (条带化)][2]
|
||||
- [用两块磁盘创建 RAID 1(镜像)][3]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.227
|
||||
Hostname : rd5.tecmintlocal.com
|
||||
Disk 1 [20GB] : /dev/sdb
|
||||
Disk 2 [20GB] : /dev/sdc
|
||||
Disk 3 [20GB] : /dev/sdd
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP 地址 : 192.168.0.227
|
||||
主机名 : rd5.tecmintlocal.com
|
||||
磁盘 1 [20GB] : /dev/sdb
|
||||
磁盘 2 [20GB] : /dev/sdc
|
||||
磁盘 3 [20GB] : /dev/sdd
|
||||
|
||||
这篇文章是 RAID 系列9教程的第4部分,在这里我们要建立一个软件 RAID 5(分布式奇偶校验)使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘在 Linux 系统或服务器中上。
|
||||
这是9篇系列教程的第4部分,在这里我们要在 Linux 系统或服务器上使用三个20GB(名为/dev/sdb, /dev/sdc 和 /dev/sdd)的磁盘建立带有分布式奇偶校验的软件 RAID 5。
|
||||
|
||||
### 第1步:安装 mdadm 并检验磁盘 ###
|
||||
|
||||
1.正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
1、 正如我们前面所说,我们使用 CentOS 6.5 Final 版本来创建 RAID 设置,但同样的做法也适用于其他 Linux 发行版。
|
||||
|
||||
# lsb_release -a
|
||||
# ifconfig | grep inet
|
||||
|
||||

|
||||
|
||||
CentOS 6.5 摘要
|
||||
*CentOS 6.5 摘要*
|
||||
|
||||
2. 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
2、 如果你按照我们的 RAID 系列去配置的,我们假设你已经安装了“mdadm”包,如果没有,根据你的 Linux 发行版使用下面的命令安装。
|
||||
|
||||
# yum install mdadm [on RedHat systems]
|
||||
# apt-get install mdadm [on Debain systems]
|
||||
# yum install mdadm [在 RedHat 系统]
|
||||
# apt-get install mdadm [在 Debain 系统]
|
||||
|
||||
3. “mdadm”包安装后,先使用‘fdisk‘命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
3、 “mdadm”包安装后,先使用`fdisk`命令列出我们在系统上增加的三个20GB的硬盘。
|
||||
|
||||
# fdisk -l | grep sd
|
||||
|
||||
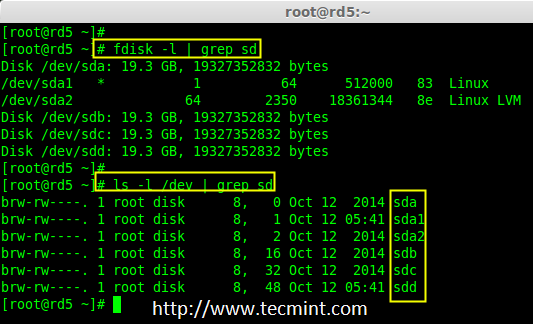
|
||||
|
||||
安装 mdadm 工具
|
||||
*安装 mdadm 工具*
|
||||
|
||||
4. 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
4、 现在该检查这三个磁盘是否存在 RAID 块,使用下面的命令来检查。
|
||||
|
||||
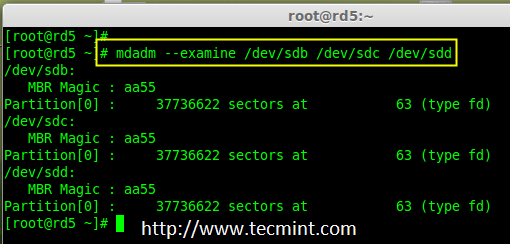
# mdadm -E /dev/sd[b-d]
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd # 或
|
||||
|
||||
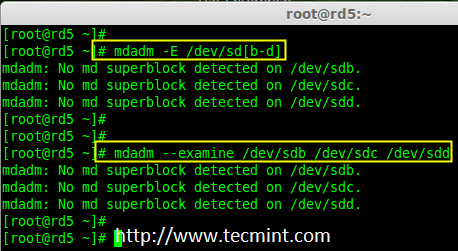
|
||||
|
||||
检查 Raid 磁盘
|
||||
*检查 Raid 磁盘*
|
||||
|
||||
**注意**: 上面的图片说明,没有检测到任何超级块。所以,这三个磁盘中没有定义 RAID。让我们现在开始创建一个吧!
|
||||
|
||||
### 第2步:为磁盘创建 RAID 分区 ###
|
||||
|
||||
5. 首先,在创建 RAID 前我们要为磁盘分区(/dev/sdb, /dev/sdc 和 /dev/sdd),在进行下一步之前,先使用‘fdisk’命令进行分区。
|
||||
5、 首先,在创建 RAID 前磁盘(/dev/sdb, /dev/sdc 和 /dev/sdd)必须有分区,因此,在进行下一步之前,先使用`fdisk`命令进行分区。
|
||||
|
||||
# fdisk /dev/sdb
|
||||
# fdisk /dev/sdc
|
||||
@ -93,20 +94,20 @@ CentOS 6.5 摘要
|
||||
|
||||
请按照下面的说明在 /dev/sdb 硬盘上创建分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1.
|
||||
- 按 `n` 创建新的分区。
|
||||
- 然后按 `P` 选择主分区。选择主分区是因为还没有定义过分区。
|
||||
- 接下来选择分区号为1。默认就是1。
|
||||
- 这里是选择柱面大小,我们没必要选择指定的大小,因为我们需要为 RAID 使用整个分区,所以只需按两次 Enter 键默认将整个容量分配给它。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 改变分区类型,按 ‘L’可以列出所有可用的类型。
|
||||
- 按 ‘t’ 修改分区类型。
|
||||
- 这里使用‘fd’设置为 RAID 的类型。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
- 然后,按 `P` 来打印创建好的分区。
|
||||
- 改变分区类型,按 `L`可以列出所有可用的类型。
|
||||
- 按 `t` 修改分区类型。
|
||||
- 这里使用`fd`设置为 RAID 的类型。
|
||||
- 然后再次使用`p`查看我们所做的更改。
|
||||
- 使用`w`保存更改。
|
||||
|
||||

|
||||
|
||||
创建 sdb 分区
|
||||
*创建 sdb 分区*
|
||||
|
||||
**注意**: 我们仍要按照上面的步骤来创建 sdc 和 sdd 的分区。
|
||||
|
||||
@ -118,7 +119,7 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdc 分区
|
||||
*创建 sdc 分区*
|
||||
|
||||
#### 创建 /dev/sdd 分区 ####
|
||||
|
||||
@ -126,93 +127,87 @@ CentOS 6.5 摘要
|
||||
|
||||

|
||||
|
||||
创建 sdd 分区
|
||||
*创建 sdd 分区*
|
||||
|
||||
6. 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
6、 创建分区后,检查三个磁盘 sdb, sdc, sdd 的变化。
|
||||
|
||||
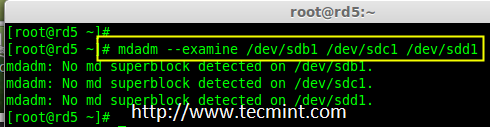
# mdadm --examine /dev/sdb /dev/sdc /dev/sdd
|
||||
|
||||
or
|
||||
|
||||
# mdadm -E /dev/sd[b-c]
|
||||
# mdadm -E /dev/sd[b-c] # 或
|
||||
|
||||
|
||||
|
||||
检查磁盘变化
|
||||
*检查磁盘变化*
|
||||
|
||||
**注意**: 在上面的图片中,磁盘的类型是 fd。
|
||||
|
||||
7.现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,创建一个新的 RAID 5 的设置在这些磁盘中。
|
||||
7、 现在在新创建的分区检查 RAID 块。如果没有检测到超级块,我们就能够继续下一步,在这些磁盘中创建一个新的 RAID 5 配置。
|
||||
|
||||
|
||||
|
||||
在分区中检查 Raid
|
||||
*在分区中检查 RAID *
|
||||
|
||||
### 第3步:创建 md 设备 md0 ###
|
||||
|
||||
8. 现在创建一个 RAID 设备“md0”(即 /dev/md0)使用所有新创建的分区(sdb1, sdc1 and sdd1) ,使用以下命令。
|
||||
8、 现在使用所有新创建的分区(sdb1, sdc1 和 sdd1)创建一个 RAID 设备“md0”(即 /dev/md0),使用以下命令。
|
||||
|
||||
# mdadm --create /dev/md0 --level=5 --raid-devices=3 /dev/sdb1 /dev/sdc1 /dev/sdd1
|
||||
|
||||
or
|
||||
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1
|
||||
# mdadm -C /dev/md0 -l=5 -n=3 /dev/sd[b-d]1 # 或
|
||||
|
||||
9. 创建 RAID 设备后,检查并确认 RAID,包括设备和从 mdstat 中输出的 RAID 级别。
|
||||
9、 创建 RAID 设备后,检查并确认 RAID,从 mdstat 中输出中可以看到包括的设备的 RAID 级别。
|
||||
|
||||
# cat /proc/mdstat
|
||||
|
||||

|
||||
|
||||
验证 Raid 设备
|
||||
*验证 Raid 设备*
|
||||
|
||||
如果你想监视当前的创建过程,你可以使用‘watch‘命令,使用 watch ‘cat /proc/mdstat‘,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
如果你想监视当前的创建过程,你可以使用`watch`命令,将 `cat /proc/mdstat` 传递给它,它会在屏幕上显示且每隔1秒刷新一次。
|
||||
|
||||
# watch -n1 cat /proc/mdstat
|
||||
|
||||
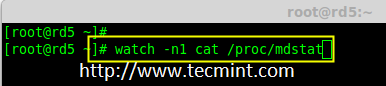
|
||||
|
||||
监控 Raid 5 过程
|
||||
*监控 RAID 5 构建过程*
|
||||
|
||||

|
||||
|
||||
Raid 5 过程概要
|
||||
*Raid 5 过程概要*
|
||||
|
||||
10. 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
10、 创建 RAID 后,使用以下命令验证 RAID 设备
|
||||
|
||||
# mdadm -E /dev/sd[b-d]1
|
||||
|
||||

|
||||
|
||||
验证 Raid 级别
|
||||
*验证 Raid 级别*
|
||||
|
||||
**注意**: 因为它显示三个磁盘的信息,上述命令的输出会有点长。
|
||||
|
||||
11. 接下来,验证 RAID 阵列的假设,这包含正在运行 RAID 的设备,并开始重新同步。
|
||||
11、 接下来,验证 RAID 阵列,假定包含 RAID 的设备正在运行并已经开始了重新同步。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
验证 Raid 阵列
|
||||
*验证 RAID 阵列*
|
||||
|
||||
### 第4步:为 md0 创建文件系统###
|
||||
|
||||
12. 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
12、 在挂载前为“md0”设备创建 ext4 文件系统。
|
||||
|
||||
# mkfs.ext4 /dev/md0
|
||||
|
||||

|
||||
|
||||
创建 md0 文件系统
|
||||
*创建 md0 文件系统*
|
||||
|
||||
13.现在,在‘/mnt‘下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下并检查下挂载点的文件,你会看到 lost+found 目录。
|
||||
13、 现在,在`/mnt`下创建目录 raid5,然后挂载文件系统到 /mnt/raid5/ 下,并检查挂载点下的文件,你会看到 lost+found 目录。
|
||||
|
||||
# mkdir /mnt/raid5
|
||||
# mount /dev/md0 /mnt/raid5/
|
||||
# ls -l /mnt/raid5/
|
||||
|
||||
14. 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
14、 在挂载点 /mnt/raid5 下创建几个文件,并在其中一个文件中添加一些内容然后去验证。
|
||||
|
||||
# touch /mnt/raid5/raid5_tecmint_{1..5}
|
||||
# ls -l /mnt/raid5/
|
||||
@ -222,9 +217,9 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
挂载 Raid 设备
|
||||
*挂载 RAID 设备*
|
||||
|
||||
15. 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。然后编辑 fstab 文件添加条目,在文件尾追加以下行,如下图所示。挂载点会根据你环境的不同而不同。
|
||||
15、 我们需要在 fstab 中添加条目,否则系统重启后将不会显示我们的挂载点。编辑 fstab 文件添加条目,在文件尾追加以下行。挂载点会根据你环境的不同而不同。
|
||||
|
||||
# vim /etc/fstab
|
||||
|
||||
@ -232,19 +227,19 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
自动挂载 Raid 5
|
||||
*自动挂载 RAID 5*
|
||||
|
||||
16. 接下来,运行‘mount -av‘命令检查 fstab 条目中是否有错误。
|
||||
16、 接下来,运行`mount -av`命令检查 fstab 条目中是否有错误。
|
||||
|
||||
# mount -av
|
||||
|
||||
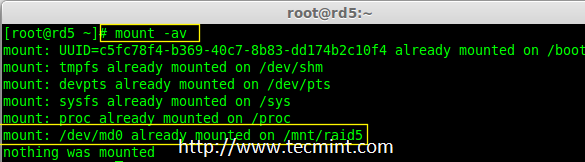
|
||||
|
||||
检查 Fstab 错误
|
||||
*检查 Fstab 错误*
|
||||
|
||||
### 第5步:保存 Raid 5 的配置 ###
|
||||
|
||||
17. 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步不跟 RAID 设备将不会存在 md0,它将会跟一些其他数子。
|
||||
17、 在前面章节已经说过,默认情况下 RAID 没有配置文件。我们必须手动保存。如果此步中没有跟随不属于 md0 的 RAID 设备,它会是一些其他随机数字。
|
||||
|
||||
所以,我们必须要在系统重新启动之前保存配置。如果配置保存它在系统重新启动时会被加载到内核中然后 RAID 也将被加载。
|
||||
|
||||
@ -252,17 +247,17 @@ Raid 5 过程概要
|
||||
|
||||

|
||||
|
||||
保存 Raid 5 配置
|
||||
*保存 RAID 5 配置*
|
||||
|
||||
注意:保存配置将保持 RAID 级别的稳定性在 md0 设备中。
|
||||
注意:保存配置将保持 md0 设备的 RAID 级别稳定不变。
|
||||
|
||||
### 第6步:添加备用磁盘 ###
|
||||
|
||||
18.备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会主动添加并重建进程,并从其他磁盘上同步数据,所以我们可以在这里看到冗余。
|
||||
18、 备用磁盘有什么用?它是非常有用的,如果我们有一个备用磁盘,当我们阵列中的任何一个磁盘发生故障后,这个备用磁盘会进入激活重建过程,并从其他磁盘上同步数据,这样就有了冗余。
|
||||
|
||||
更多关于添加备用磁盘和检查 RAID 5 容错的指令,请阅读下面文章中的第6步和第7步。
|
||||
|
||||
- [Add Spare Drive to Raid 5 Setup][4]
|
||||
- [在 RAID 5 中添加备用磁盘][4]
|
||||
|
||||
### 结论 ###
|
||||
|
||||
@ -274,12 +269,12 @@ via: http://www.tecmint.com/create-raid-5-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
[3]:http://www.tecmint.com/create-raid1-in-linux/
|
||||
[1]:https://linux.cn/article-6085-1.html
|
||||
[2]:https://linux.cn/article-6087-1.html
|
||||
[3]:https://linux.cn/article-6093-1.html
|
||||
[4]:http://www.tecmint.com/create-raid-6-in-linux/
|
||||
@ -1,87 +0,0 @@
|
||||
Plasma 5.4 Is Out And It’s Packed Full Of Features
|
||||
================================================================================
|
||||
KDE has [announced][1] a brand new feature release of Plasma 5 — and it’s a corker.
|
||||
|
||||
|
||||
|
||||
Better network details are among the changes
|
||||
|
||||
Plasma 5.4.0 builds on [April’s 5.3.0 milestone][2] in a number of ways, ranging from the inherently technical, Wayland preview session, ahoy, to lavish aesthetic touches, like **1,400 brand new icons**.
|
||||
|
||||
A handful of new components also feature in the release, including a new Plasma Widget for volume control, a monitor calibration tool and an improved user management tool.
|
||||
|
||||
The ‘Kicker’ application menu has been powered up to let you favourite all types of content, not just applications.
|
||||
|
||||
**KRunner now remembers searches** so that it can automatically offer suggestions based on your earlier queries as you type.
|
||||
|
||||
The **network applet displays a graph** to give you a better understanding of your network traffic. It also gains two new VPN plugins for SSH and SSTP connections.
|
||||
|
||||
Minor tweaks to the digital clock see it adapt better in slim panel mode, it gains ISO date support and makes it easier for you to toggle between 12 hour and 24 hour clock. Week numbers have been added to the calendar.
|
||||
|
||||
### Application Dashboard ###
|
||||
|
||||
|
||||
|
||||
The new ‘Application Dashboard’ in KDE Plasma 5.4.0
|
||||
|
||||
**A new full screen launcher, called ‘Application Dashboard’**, is also available.
|
||||
|
||||
This full-screen dash offers the same features as the traditional Application Menu but with “sophisticated scaling to screen size and full spatial keyboard navigation”.
|
||||
|
||||
Like the Unity launch, the new Plasma Application Dashboard helps you quickly find applications, sift through files and contacts based on your previous activity.
|
||||
|
||||
### Changes in KDE Plasma 5.4.0 at a glance ###
|
||||
|
||||
- Improved high DPI support
|
||||
- KRunner autocompletion
|
||||
- KRunner search history
|
||||
- Application Dashboard add on
|
||||
- 1,400 New icons
|
||||
- Wayland tech preview
|
||||
|
||||
For a full list of changes in Plasma 5.4 refer to [this changelog][3].
|
||||
|
||||
### Install Plasma 5.4 in Kubuntu 15.04 ###
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To **install Plasma 5.4 in Kubuntu 15.04** you will need to add the KDE Backports PPA to your Software Sources.
|
||||
|
||||
Adding the Kubuntu backports PPA **is not strictly advised** as it may upgrade other parts of the KDE desktop, application suite, developer frameworks or Kubuntu specific config files.
|
||||
|
||||
If you like your desktop being stable, don’t proceed.
|
||||
|
||||
The quickest way to upgrade to Plasma 5.4 once it lands in the Kubuntu Backports PPA is to use the Terminal:
|
||||
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
|
||||
sudo apt-get update && sudo apt-get dist-upgrade
|
||||
|
||||
Let the upgrade process complete. Assuming no errors emerge, reboot your computer for changes to take effect.
|
||||
|
||||
If you’re not already using Kubuntu, i.e. you’re using the Unity version of Ubuntu, you should first install the Kubuntu desktop package (you’ll find it in the Ubuntu Software Centre).
|
||||
|
||||
To undo the changes above and downgrade to the most recent version of Plasma available in the Ubuntu archives use the PPA-Purge tool:
|
||||
|
||||
sudo apt-get install ppa-purge
|
||||
|
||||
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||
|
||||
Let us know how your upgrade/testing goes in the comments below and don’t forget to mention the features you hope to see added to the Plasma 5 desktop next.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/08/plasma-5-4-new-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://dot.kde.org/2015/08/25/kde-ships-plasma-540-feature-release-august
|
||||
[2]:http://www.omgubuntu.co.uk/2015/04/kde-plasma-5-3-released-heres-how-to-upgrade-in-kubuntu-15-04
|
||||
[3]:https://www.kde.org/announcements/plasma-5.3.2-5.4.0-changelog.php
|
||||
@ -0,0 +1,68 @@
|
||||
Translating by Ping
|
||||
Xtreme Download Manager Updated With Fresh GUI
|
||||
================================================================================
|
||||

|
||||
|
||||
[Xtreme Download Manager][1], unarguably one of the [best download managers for Linux][2], has a new version named XDM 2015 which brings a fresh new look to it.
|
||||
|
||||
Xtreme Download Manager, also known as XDM or XDMAN, is a popular cross-platform download manager available for Linux, Windows and Mac OS X. It is also compatible with all major web browsers such as Chrome, Firefox, Safari enabling you to download directly from XDM when you try to download something in your web browser.
|
||||
|
||||
Applications such as XDM are particularly useful when you have slow/limited network connectivity and you need to manage your downloads. Imagine downloading a huge file from internet on a slow network. What if you could pause and resume the download at will? XDM helps you in such situations.
|
||||
|
||||
Some of the main features of XDM are:
|
||||
|
||||
- Pause and resume download
|
||||
- [Download videos from YouTube][3] and other video sites
|
||||
- Force assemble
|
||||
- Download speed acceleration
|
||||
- Schedule downloads
|
||||
- Limit download speed
|
||||
- Web browser integration
|
||||
- Support for proxy servers
|
||||
|
||||
Here you can see the difference between the old and new XDM.
|
||||
|
||||

|
||||
|
||||
Old XDM
|
||||
|
||||

|
||||
|
||||
New XDM
|
||||
|
||||
### Install Xtreme Download Manager in Ubuntu based Linux distros ###
|
||||
|
||||
Thanks to the PPA by Noobslab, you can easily install Xtreme Download Manager using the commands below. XDM requires Java but thanks to the PPA, you don’t need to bother with installing dependencies separately.
|
||||
|
||||
sudo add-apt-repository ppa:noobslab/apps
|
||||
sudo apt-get update
|
||||
sudo apt-get install xdman
|
||||
|
||||
The above PPA should be available for Ubuntu and other Ubuntu based Linux distributions such as Linux Mint, elementary OS, Linux Lite etc.
|
||||
|
||||
#### Remove XDM ####
|
||||
|
||||
To remove XDM (installed using the PPA), use the commands below:
|
||||
|
||||
sudo apt-get remove xdman
|
||||
sudo add-apt-repository --remove ppa:noobslab/apps
|
||||
|
||||
For other Linux distributions, you can download it from the link below:
|
||||
|
||||
- [Download Xtreme Download Manager][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/xtreme-download-manager-install/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://xdman.sourceforge.net/
|
||||
[2]:http://itsfoss.com/4-best-download-managers-for-linux/
|
||||
[3]:http://itsfoss.com/download-youtube-videos-ubuntu/
|
||||
[4]:http://xdman.sourceforge.net/download.html
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by H-mudcup
|
||||
|
||||
Defending the Free Linux World
|
||||
================================================================================
|
||||

|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
zpl1025
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
martin
|
||||
translating...
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
|
||||
@ -1,109 +0,0 @@
|
||||
Debian GNU/Linux Birthday : A 22 Years of Journey and Still Counting…
|
||||
================================================================================
|
||||
On 16th August 2015, the Debian project has celebrated its 22nd anniversary, making it one of the oldest popular distribution in open source world. Debian project was conceived and founded in the year 1993 by Ian Murdock. By that time Slackware had already made a remarkable presence as one of the earliest Linux Distribution.
|
||||
|
||||

|
||||
|
||||
Happy 22nd Birthday to Debian Linux
|
||||
|
||||
Ian Ashley Murdock, an American Software Engineer by profession, conceived the idea of Debian project, when he was a student of Purdue University. He named the project Debian after the name of his then-girlfriend Debra Lynn (Deb) and his name. He later married her and then got divorced in January 2008.
|
||||
|
||||

|
||||
|
||||
Debian Creator: Ian Murdock
|
||||
|
||||
Ian is currently serving as Vice President of Platform and Development Community at ExactTarget.
|
||||
|
||||
Debian (as Slackware) was the result of unavailability of up-to mark Linux Distribution, that time. Ian in an interview said – “Providing the first class Product without profit would be the sole aim of Debian Project. Even Linux was not reliable and up-to mark that time. I Remember…. Moving files between file-system and dealing with voluminous file would often result in Kernel Panic. However the project Linux was promising. The availability of Source Code freely and the potential it seemed was qualitative.”
|
||||
|
||||
I remember … like everyone else I wanted to solve problem, run something like UNIX at home, but it was not possible…neither financially nor legally, in the other sense . Then I come to know about GNU kernel Development and its non-association with any kind of legal issues, he added. He was sponsored by Free Software Foundation (FSF) in the early days when he was working on Debian, it also helped Debian to take a giant step though Ian needed to finish his degree and hence quited FSF roughly after one year of sponsorship.
|
||||
|
||||
### Debian Development History ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : Released between August 1993 – December 1993.
|
||||
- **Debian 0.91 ** – Released in January 1994 with primitive package system, No dependencies.
|
||||
- **Debian 0.93 rc5** : March 1995. It is the first modern release of Debian, dpkg was used to install and maintain packages after base system installation.
|
||||
- **Debian 0.93 rc6**: Released in November 1995. It was last a.out release, deselect made an appearance for the first time – 60 developers were maintaining packages, then at that time.
|
||||
- **Debian 1.1**: Released in June 1996. Code name – Buzz, Packages count – 474, Package Manager dpkg, Kernel 2.0, ELF.
|
||||
- **Debian 1.2**: Released in December 1996. Code name – Rex, Packages count – 848, Developers Count – 120.
|
||||
- **Debian 1.3**: Released in July 1997. Code name – Bo, package count 974, Developers count – 200.
|
||||
- **Debian 2.0**: Released in July 1998. Code name: Hamm, Support for architecture – Intel i386 and Motorola 68000 series, Number of Packages: 1500+, Number of Developers: 400+, glibc included.
|
||||
- **Debian 2.1**: Released on March 09, 1999. Code name – slink, support architecture Alpha and Sparc, apt came in picture, Number of package – 2250.
|
||||
- **Debian 2.2**: Released on August 15, 2000. Code name – Potato, Supported architecture – Intel i386, Motorola 68000 series, Alpha, SUN Sparc, PowerPC and ARM architecture. Number of packages: 3900+ (binary) and 2600+ (Source), Number of Developers – 450. There were a group of people studied and came with an article called Counting potatoes, which shows – How a free software effort could lead to a modern operating system despite all the issues around it.
|
||||
- **Debian 3.0** : Released on July 19th, 2002. Code name – woody, Architecture supported increased– HP, PA_RISC, IA-64, MIPS and IBM, First release in DVD, Package Count – 8500+, Developers Count – 900+, Cryptography.
|
||||
- **Debian 3.1**: Release on June 6th, 2005. Code name – sarge, Architecture support – same as woody + AMD64 – Unofficial Port released, Kernel – 2.4 qnd 2.6 series, Number of Packages: 15000+, Number of Developers : 1500+, packages like – OpenOffice Suite, Firefox Browser, Thunderbird, Gnome 2.8, kernel 3.3 Advanced Installation Support: RAID, XFS, LVM, Modular Installer.
|
||||
- **Debian 4.0**: Released on April 8th, 2007. Code name – etch, architecture support – same as sarge, included AMD64. Number of packages: 18,200+ Developers count : 1030+, Graphical Installer.
|
||||
- **Debian 5.0**: Released on February 14th, 2009. Code name – lenny, Architecture Support – Same as before + ARM. Number of packages: 23000+, Developers Count: 1010+.
|
||||
- **Debian 6.0** : Released on July 29th, 2009. Code name – squeeze, Package included : kernel 2.6.32, Gnome 2.3. Xorg 7.5, DKMS included, Dependency-based. Architecture : Same as pervious + kfreebsd-i386 and kfreebsd-amd64, Dependency based booting.
|
||||
- **Debian 7.0**: Released on may 4, 2013. Code name: wheezy, Support for Multiarch, Tools for private cloud, Improved Installer, Third party repo need removed, full featured multimedia-codec, Kernel 3.2, Xen Hypervisor 4.1.4 Package Count: 37400+.
|
||||
- **Debian 8.0**: Released on May 25, 2015 and Code name: Jessie, Systemd as the default init system, powered by Kernel 3.16, fast booting, cgroups for services, possibility of isolating part of the services, 43000+ packages. Sysvinit init system available in Jessie.
|
||||
|
||||
**Note**: Linux Kernel initial release was on October 05, 1991 and Debian initial release was on September 15, 1993. So, Debian is there for 22 Years running Linux Kernel which is there for 24 years.
|
||||
|
||||
### Debian Facts ###
|
||||
|
||||
Year 1994 was spent on organizing and managing Debian project so that it would be easy for others to contribute. Hence no release for users were made this year however there were certain internal release.
|
||||
|
||||
Debian 1.0 was never released. A CDROM manufacturer company by mistakenly labelled an unreleased version as Debian 1.0. Hence to avoid confusion Debian 1.0 was released as Debian 1.1 and since then only the concept of official CDROM images came into existence.
|
||||
|
||||
Each release of Debian is a character of Toy Story.
|
||||
|
||||
Debian remains available in old stable, stable, testing and experimental, all the time.
|
||||
|
||||
The Debian Project continues to work on the unstable distribution (codenamed sid, after the evil kid from the Toy Story). Sid is the permanent name for the unstable distribution and is remains ‘Still In Development’. The testing release is intended to become the next stable release and is currently codenamed jessie.
|
||||
|
||||
Debian official distribution includes only Free and OpenSource Software and nothing else. However the availability of contrib and Non-free Packages makes it possible to install those packages which are free but their dependencies are not licensed free (contrib) and Packages licensed under non-free softwares.
|
||||
|
||||
Debian is the mother of a lot of Linux distribution. Some of these Includes:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (No more active)
|
||||
- LMDE
|
||||
|
||||
Debian is the world’s largest non commercial Linux Distribution. It is written in C (32.1%) programming language and rest in 70 other languages.
|
||||
|
||||

|
||||
|
||||
Debian Contribution
|
||||
|
||||
Image Source: [Xmodulo][1]
|
||||
|
||||
Debian project contains 68.5 million actual loc (lines of code) + 4.5 million lines of comments and white spaces.
|
||||
|
||||
International Space station dropped Windows & Red Hat for adopting Debian – These astronauts are using one release back – now “squeeze” for stability and strength from community.
|
||||
|
||||
Thank God! Who would have heard the scream from space on Windows Metro Screen :P
|
||||
|
||||
#### The Black Wednesday ####
|
||||
|
||||
On November 20th, 2002 the University of Twente Network Operation Center (NOC) caught fire. The fire department gave up protecting the server area. NOC hosted satie.debian.org which included Security, non-US archive, New Maintainer, quality assurance, databases – Everything was turned to ashes. Later these services were re-built by debian.
|
||||
|
||||
#### The Future Distro ####
|
||||
|
||||
Next in the list is Debian 9, code name – Stretch, what it will have is yet to be revealed. The best is yet to come, Just Wait for it!
|
||||
|
||||
A lot of distribution made an appearance in Linux Distro genre and then disappeared. In most cases managing as it gets bigger was a concern. But certainly this is not the case with Debian. It has hundreds of thousands of developer and maintainer all across the globe. It is a one Distro which was there from the initial days of Linux.
|
||||
|
||||
The contribution of Debian in Linux ecosystem can’t be measured in words. If there had been no Debian, Linux would not have been so rich and user-friendly. Debian is among one of the disto which is considered highly reliable, secure and stable and a perfect choice for Web Servers.
|
||||
|
||||
That’s the beginning of Debian. It came a long way and still going. The Future is Here! The world is here! If you have not used Debian till now, What are you Waiting for. Just Download Your Image and get started, we will be here if you get into trouble.
|
||||
|
||||
- [Debian Homepage][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,67 @@
|
||||
The Strangest, Most Unique Linux Distros
|
||||
================================================================================
|
||||
From the most consumer focused distros like Ubuntu, Fedora, Mint or elementary OS to the more obscure, minimal and enterprise focused ones such as Slackware, Arch Linux or RHEL, I thought I've seen them all. Couldn't have been any further from the truth. Linux eco-system is very diverse. There's one for everyone. Let's discuss the weird and wacky world of niche Linux distros that represents the true diversity of open platforms.
|
||||
|
||||

|
||||
|
||||
**Puppy Linux**: An operating system which is about 1/10th the size of an average DVD quality movie rip, that's Puppy Linux for you. The OS is just 100 MB in size! And it can run from RAM making it unusually fast even in older PCs. You can even remove the boot medium after the operating system has started! Can it get any better than that? System requirements are bare minimum, most hardware are automatically detected, and it comes loaded with software catering to your basic needs. [Experience Puppy Linux][1].
|
||||
|
||||

|
||||
|
||||
**Suicide Linux**: Did the name scare you? Well it should. 'Any time - any time - you type any remotely incorrect command, the interpreter creatively resolves it into rm -rf / and wipes your hard drive'. Simple as that. I really want to know the ones who are confident enough to risk their production machines with [Suicide Linux][2]. **Warning: DO NOT try this on production machines!** The whole thing is available in a neat [DEB package][3] if you're interested.
|
||||
|
||||
|
||||
|
||||
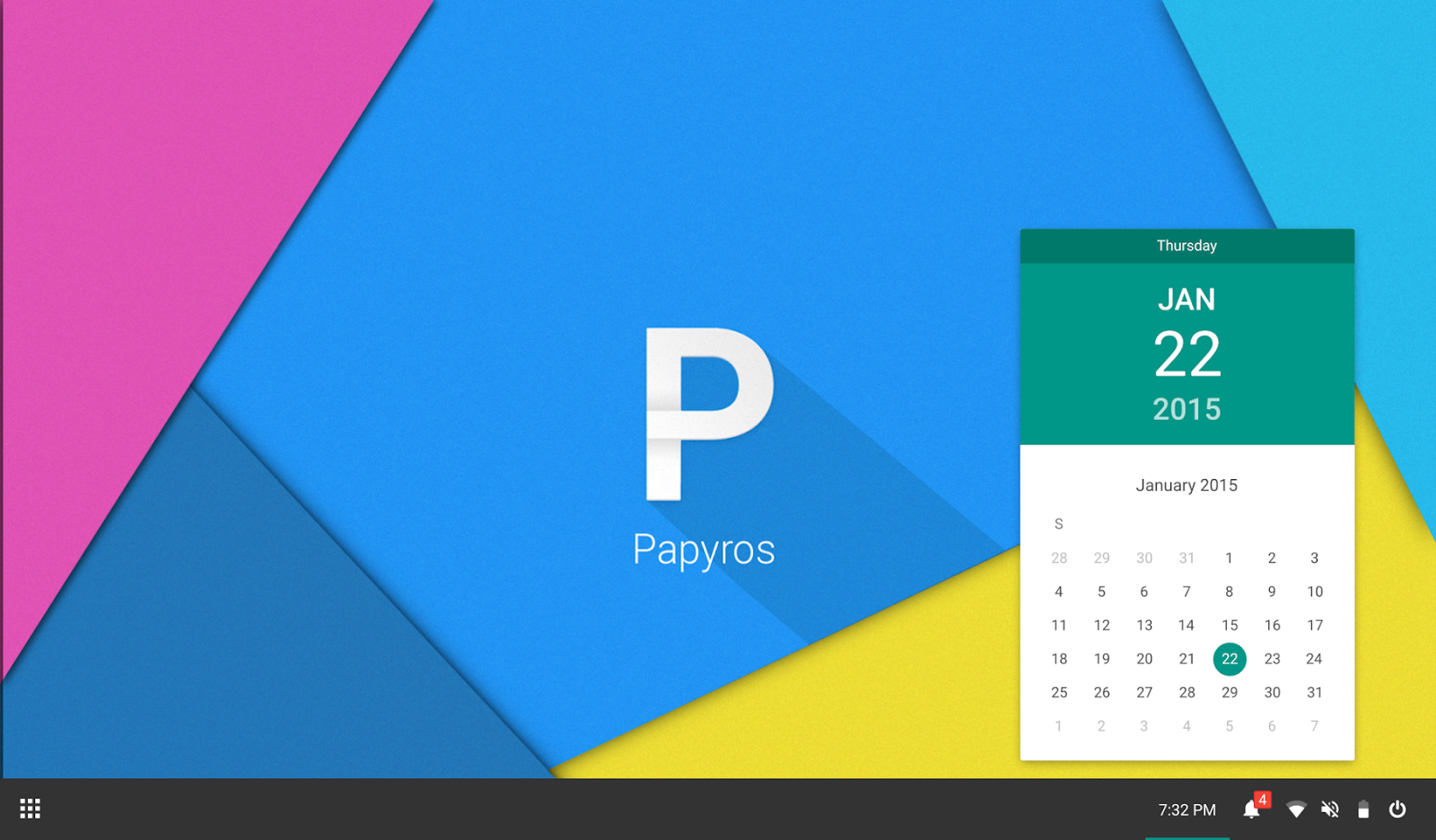
**PapyrOS**: "Strange" in a good way. PapyrOS is trying to adapt the material design language of Android into their brand new Linux distribution. Though the project is in early stages, it already looks very promising. The project page says the OS is 80% complete and one can expect the first Alpha release anytime soon. We did a small write up on [PapyrOS][4] when it was announced and by the looks of it, PapyrOS might even become a trend-setter of sorts. Follow the project on [Google+][5] and contribute via [BountySource][6] if you're interested.
|
||||
|
||||
|
||||
|
||||
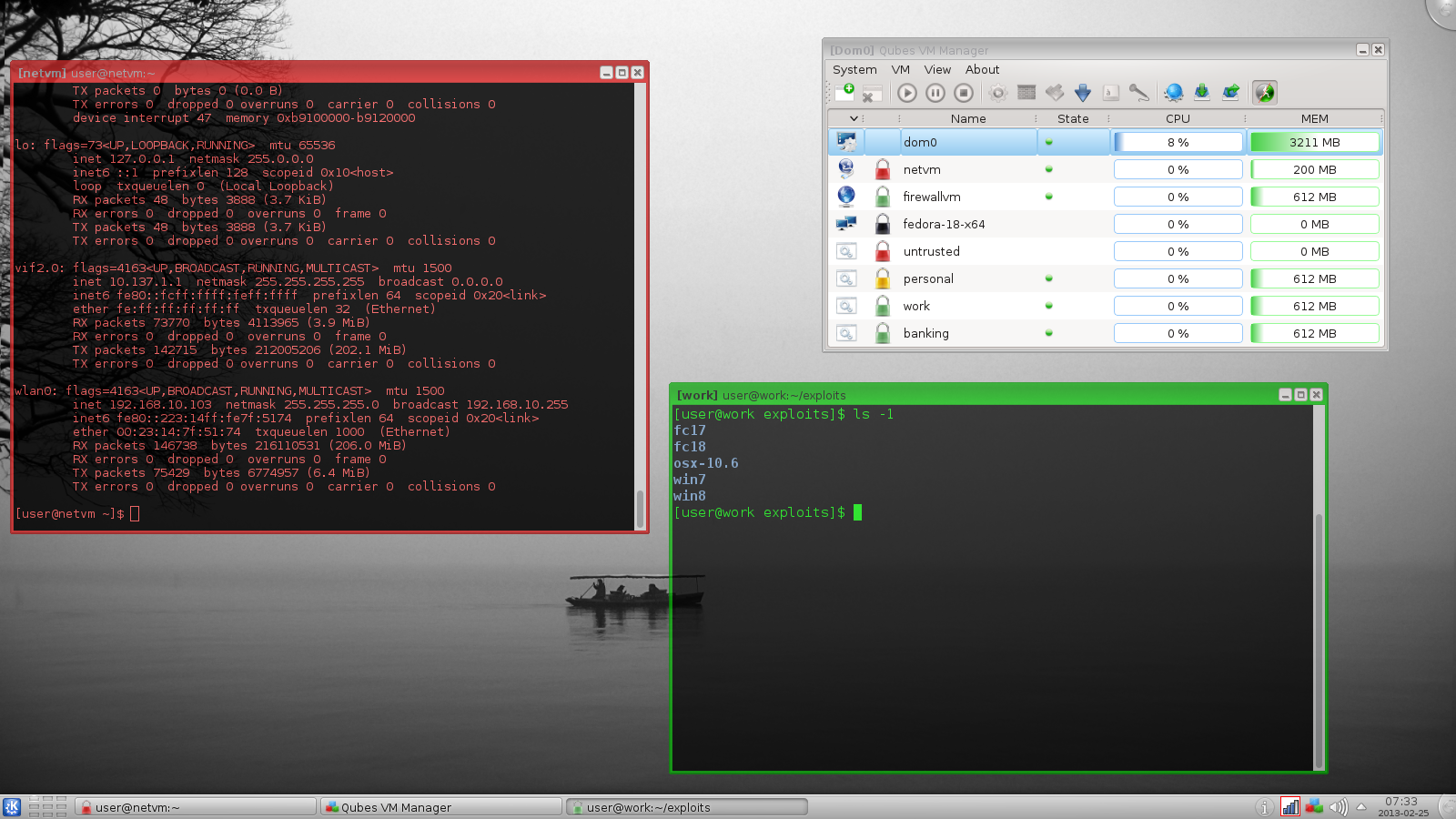
**Qubes OS**: Qubes is an open-source operating system designed to provide strong security using a Security by Compartmentalization approach. The assumption is that there can be no perfect, bug-free desktop environment. And by implementing a 'Security by Isolation' approach, [Qubes Linux][7] intends to remedy that. Qubes is based on Xen, the X Window System, and Linux, and can run most Linux applications and supports most Linux drivers. Qubes was selected as a finalist of Access Innovation Prize 2014 for Endpoint Security Solution.
|
||||
|
||||

|
||||
|
||||
**Ubuntu Satanic Edition**: Ubuntu SE is a Linux distribution based on Ubuntu. "It brings together the best of free software and free metal music" in one comprehensive package consisting of themes, wallpapers, and even some heavy-metal music sourced from talented new artists. Though the project doesn't look actively developed anymore, Ubuntu Satanic Edition is strange in every sense of that word. [Ubuntu SE (Slightly NSFW)][8].
|
||||
|
||||
|
||||
|
||||
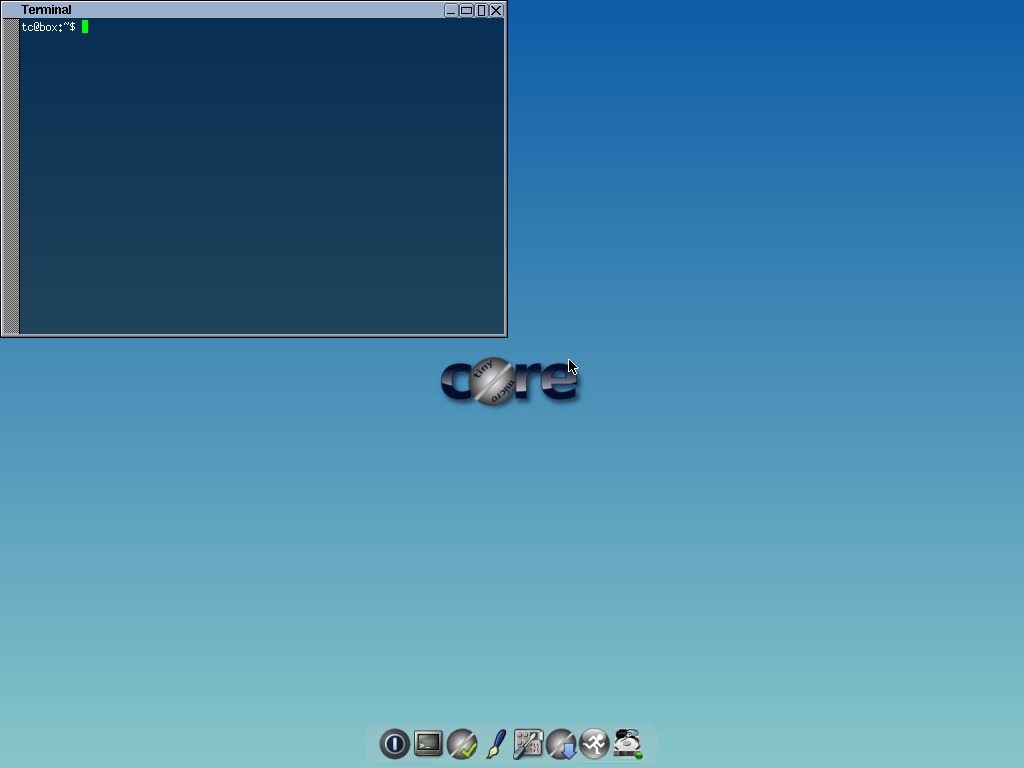
**Tiny Core Linux**: Puppy Linux not small enough? Try this. Tiny Core Linux is a 12 MB graphical Linux desktop! Yep, you read it right. One major caveat: It is not a complete desktop nor is all hardware completely supported. It represents only the core needed to boot into a very minimal X desktop typically with wired internet access. There is even a version without the GUI called Micro Core Linux which is just 9MB in size. [Tiny Core Linux][9] folks.
|
||||
|
||||
|
||||
|
||||
**NixOS**: A very experienced-user focused Linux distribution with a unique approach to package and configuration management. In other distributions, actions such as upgrades can be dangerous. Upgrading a package can cause other packages to break, upgrading an entire system is much less reliable than reinstalling from scratch. And top of all that you can't safely test what the results of a configuration change will be, there's no "Undo" so to speak. In NixOS, the entire operating system is built by the Nix package manager from a description in a purely functional build language. This means that building a new configuration cannot overwrite previous configurations. Most of the other features follow this pattern. Nix stores all packages in isolation from each other. [More about NixOS][10].
|
||||
|
||||
|
||||
|
||||
**GoboLinux**: This is another very unique Linux distro. What makes GoboLinux so different from the rest is its unique re-arrangement of the filesystem. It has its own subdirectory tree, where all of its files and programs are stored. GoboLinux does not have a package database because the filesystem is its database. In some ways, this sort of arrangement is similar to that seen in OS X. [Get GoboLinux][11].
|
||||
|
||||

|
||||
|
||||
**Hannah Montana Linux**: Here is a Linux distro based on Kubuntu with a Hannah Montana themed boot screen, KDM, icon set, ksplash, plasma, color scheme, and wallpapers (I'm so sorry). [Link][12]. Project not active anymore.
|
||||
|
||||
**RLSD Linux**: An extremely minimalistic, small, lightweight and security-hardened, text-based operating system built on Linux. "It's a unique distribution that provides a selection of console applications and home-grown security features which might appeal to hackers," developers claim. [RLSD Linux][13].
|
||||
|
||||
Did we miss anything even stranger? Let us know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techdrivein.com/2015/08/the-strangest-most-unique-linux-distros.html
|
||||
|
||||
作者:Manuel Jose
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[2]:http://qntm.org/suicide
|
||||
[3]:http://sourceforge.net/projects/suicide-linux/files/
|
||||
[4]:http://www.techdrivein.com/2015/02/papyros-material-design-linux-coming-soon.html
|
||||
[5]:https://plus.google.com/communities/109966288908859324845/stream/3262a3d3-0797-4344-bbe0-56c3adaacb69
|
||||
[6]:https://www.bountysource.com/teams/papyros
|
||||
[7]:https://www.qubes-os.org/
|
||||
[8]:http://ubuntusatanic.org/
|
||||
[9]:http://tinycorelinux.net/
|
||||
[10]:https://nixos.org/
|
||||
[11]:http://www.gobolinux.org/
|
||||
[12]:http://hannahmontana.sourceforge.net/
|
||||
[13]:http://rlsd2.dimakrasner.com/
|
||||
@ -1,114 +0,0 @@
|
||||
wyangsun translating
|
||||
Install Strongswan - A Tool to Setup IPsec Based VPN in Linux
|
||||
================================================================================
|
||||
IPsec is a standard which provides the security at network layer. It consist of authentication header (AH) and encapsulating security payload (ESP) components. AH provides the packet Integrity and confidentiality is provided by ESP component . IPsec ensures the following security features at network layer.
|
||||
|
||||
- Confidentiality
|
||||
- Integrity of packet
|
||||
- Source Non. Repudiation
|
||||
- Replay attack protection
|
||||
|
||||
[Strongswan][1] is an open source implementation of IPsec protocol and Strongswan stands for Strong Secure WAN (StrongS/WAN). It supports the both version of automatic keying exchange in IPsec VPN (Internet keying Exchange (IKE) V1 & V2).
|
||||
|
||||
Strongswan basically provides the automatic keying sharing between two nodes/gateway of the VPN and after that it uses the Linux Kernel implementation of IPsec (AH & ESP). Key shared using IKE mechanism is further used in the ESP for the encryption of data. In IKE phase, strongswan uses the encryption algorithms (AES,SHA etc) of OpenSSL and other crypto libraries. However, ESP component of IPsec uses the security algorithm which are implemented in the Linux Kernel. The main features of Strongswan are given below.
|
||||
|
||||
- 509 certificates or pre-shared keys based Authentication
|
||||
- Support of IKEv1 and IKEv2 key exchange protocols
|
||||
- Optional built-in integrity and crypto tests for plugins and libraries
|
||||
- Support of elliptic curve DH groups and ECDSA certificates
|
||||
- Storage of RSA private keys and certificates on a smartcard.
|
||||
|
||||
It can be used in the client / server (road warrior) and gateway to gateway scenarios.
|
||||
|
||||
### How to Install ###
|
||||
|
||||
Almost all Linux distro’s, supports the binary package of Strongswan. In this tutorial, we will install the strongswan from binary package and also the compilation of strongswan source code with desirable features.
|
||||
|
||||
### Using binary package ###
|
||||
|
||||
Strongswan can be installed using following command on Ubuntu 14.04 LTS .
|
||||
|
||||
$sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
The global configuration (strongswan.conf) file and ipsec configuration (ipsec.conf/ipsec.secrets) files of strongswan are under /etc/ directory.
|
||||
|
||||
### Pre-requisite for strongswan source compilation & installation ###
|
||||
|
||||
- GMP (Mathematical/Precision Library used by strongswan)
|
||||
- OpenSSL (Crypto Algorithms from this library)
|
||||
- PKCS (1,7,8,11,12)(Certificate encoding and smart card integration with Strongswan )
|
||||
|
||||
#### Procedure ####
|
||||
|
||||
**1)** Go to /usr/src/ directory using following command in the terminal.
|
||||
|
||||
$cd /usr/src
|
||||
|
||||
**2)** Download the source code from strongswan site suing following command
|
||||
|
||||
$sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz is the latest version.)
|
||||
|
||||

|
||||
|
||||
**3)** Extract the downloaded software and go inside it using following command.
|
||||
|
||||
$sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** Configure the strongswan as per desired options using configure command.
|
||||
|
||||
./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
If GMP library is not installed, then configure script will generate following error.
|
||||
|
||||

|
||||
|
||||
Therefore, first of all, install the GMP library using following command and then run the configure script.
|
||||
|
||||

|
||||
|
||||
However, if GMP is already installed and still above error exists then create soft link of libgmp.so library at /usr/lib , /lib/, /usr/lib/x86_64-linux-gnu/ paths in Ubuntu using following command.
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
After the creation of libgmp.so softlink, again run the ./configure script and it may find the gmp library. However, it may generate another error of gmp header file which is shown the following figure.
|
||||
|
||||

|
||||
|
||||
Install the libgmp-dev package using following command for the solution of above error.
|
||||
|
||||
$sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
After installation of development package of gmp library, again run the configure script and if it does not produce any error, then the following output will be displayed.
|
||||
|
||||

|
||||
|
||||
Type the following commands for the compilation and installation of strongswan.
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
After the installation of strongswan , the Global configuration (strongswan.conf) and ipsec policy/secret configuration files (ipsec.conf/ipsec.secretes) are placed in **/usr/local/etc** directory.
|
||||
|
||||
Strongswan can be used as tunnel or transport mode depends on our security need. It provides well known site-2-site and road warrior VPNs. It can be use easily with Cisco,Juniper devices.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
@ -1,440 +0,0 @@
|
||||
translating by tnuoccalanosrep
|
||||
|
||||
Linux file system hierarchy v2.0
|
||||
================================================================================
|
||||
What is a file in Linux? What is file system in Linux? Where are all the configuration files? Where do I keep my downloaded applications? Is there really a filesystem standard structure in Linux? Well, the above image explains Linux file system hierarchy in a very simple and non-complex way. It’s very useful when you’re looking for a configuration file or a binary file. I’ve added some explanation and examples below, but that’s TL;DR.
|
||||
|
||||
Another issue is when you got configuration and binary files all over the system that creates inconsistency and if you’re a large organization or even an end user, it can compromise your system (binary talking with old lib files etc.) and when you do [security audit of your Linux system][1], you find it is vulnerable to different exploits. So keeping a clean operating system (no matter Windows or Linux) is important.
|
||||
|
||||
### What is a file in Linux? ###
|
||||
|
||||
A simple description of the UNIX system, also applicable to Linux, is this:
|
||||
|
||||
> On a UNIX system, everything is a file; if something is not a file, it is a process.
|
||||
|
||||
This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
|
||||
|
||||

|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: Added title and version history.
|
||||
- – Improved: Added /srv, /media and /proc.
|
||||
- – Improved: Updated descriptions to reflect modern Linux File Systems.
|
||||
- – Fixed: Multiple typo’s.
|
||||
- – Fixed: Appearance and colour.
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: Initial diagram.
|
||||
- – Note: Discarded lowercase version.
|
||||
|
||||
### Download Links ###
|
||||
|
||||
Following are two links for download. If you need this in any other format, let me know and I will try to create that and upload it somewhere.
|
||||
|
||||
- [Large (PNG) Format – 2480×1755 px – 184KB][2]
|
||||
- [Largest (PDF) Format – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**Note**: PDF Format is best for printing and very high in quality
|
||||
|
||||
### Linux file system description ###
|
||||
|
||||
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from `MS-DOS` (Disk Operating System) for instance. The large branches contain more branches, and the branches at the end contain the tree’s leaves or normal files. For now we will use this image of the tree, but we will find out later why this is not a fully accurate image.
|
||||
|
||||
注:表格
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Directory</th>
|
||||
<th scope="col">Description</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Primary hierarchy</i> root and root directory of the entire file system hierarchy.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential command binaries that need to be available in single user mode; for all users, <i>e.g.</i>, cat, ls, cp.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/boot</code></dd>
|
||||
</dl></td>
|
||||
<td>Boot loader files, <i>e.g.</i>, kernels, initrd.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/dev</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential devices, <i>e.g.</i>, <code>/dev/null</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/etc</code></dd>
|
||||
</dl></td>
|
||||
<td>Host-specific system-wide configuration filesThere has been controversy over the meaning of the name itself. In early versions of the UNIX Implementation Document from Bell labs, /etc is referred to as the <i>etcetera directory</i>, as this directory historically held everything that did not belong elsewhere (however, the FHS restricts /etc to static configuration files and may not contain binaries). Since the publication of early documentation, the directory name has been re-designated in various ways. Recent interpretations include backronyms such as “Editable Text Configuration” or “Extended Tool Chest”.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sgml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes SGML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files for the X Window System, version 11.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/xml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Configuration files, such as catalogs, for software that processes XML.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/home</code></dd>
|
||||
</dl></td>
|
||||
<td>Users’ home directories, containing saved files, personal settings, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl></td>
|
||||
<td>Libraries essential for the binaries in <code>/bin/</code> and <code>/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl></td>
|
||||
<td>Alternate format essential libraries. Such directories are optional, but if they exist, they have some requirements.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/media</code></dd>
|
||||
</dl></td>
|
||||
<td>Mount points for removable media such as CD-ROMs (appeared in FHS-2.3).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/mnt</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporarily mounted filesystems.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl></td>
|
||||
<td>Optional application software packages.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/proc</code></dd>
|
||||
</dl></td>
|
||||
<td>Virtual filesystem providing process and kernel information as files. In Linux, corresponds to a procfs mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/root</code></dd>
|
||||
</dl></td>
|
||||
<td>Home directory for the root user.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl></td>
|
||||
<td>Essential system binaries, <i>e.g.</i>, init, ip, mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/srv</code></dd>
|
||||
</dl></td>
|
||||
<td>Site-specific data which are served by the system.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl></td>
|
||||
<td>Temporary files (see also <code>/var/tmp</code>). Often not preserved between system reboots.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/usr</code></dd>
|
||||
</dl></td>
|
||||
<td><i>Secondary hierarchy</i> for read-only user data; contains the majority of (multi-)user utilities and applications.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential command binaries (not needed in single user mode); for all users.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/include</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Standard include files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Libraries for the binaries in <code>/usr/bin/</code> and <code>/usr/sbin/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Alternate format libraries (optional).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/local</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td><i>Tertiary hierarchy</i> for local data, specific to this host. Typically has further subdirectories, <i>e.g.</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Non-essential system binaries, <i>e.g.</i>, daemons for various network-services.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/share</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Architecture-independent (shared) data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/src</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Source code, <i>e.g.</i>, the kernel source code with its header files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11R6</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window System, Version 11, Release 6.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/var</code></dd>
|
||||
</dl></td>
|
||||
<td>Variable files—files whose content is expected to continually change during normal operation of the system—such as logs, spool files, and temporary e-mail files.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/cache</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Application cache data. Such data are locally generated as a result of time-consuming I/O or calculation. The application must be able to regenerate or restore the data. The cached files can be deleted without loss of data.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>State information. Persistent data modified by programs as they run, <i>e.g.</i>, databases, packaging system metadata, etc.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lock</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Lock files. Files keeping track of resources currently in use.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/log</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Log files. Various logs.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Variable data from add-on packages that are stored in <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/run</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Information about the running system since last boot, <i>e.g.</i>, currently logged-in users and running <a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/spool</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Spool for tasks waiting to be processed, <i>e.g.</i>, print queues and outgoing mail queue.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Deprecated location for users’ mailboxes.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Temporary files to be preserved between reboots.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Types of files in Linux ###
|
||||
|
||||
Most files are just files, called `regular` files; they contain normal data, for example text files, executable files or programs, input for or output from a program and so on.
|
||||
|
||||
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
|
||||
|
||||
- `Directories`: files that are lists of other files.
|
||||
- `Special files`: the mechanism used for input and output. Most special files are in `/dev`, we will discuss them later.
|
||||
- `Links`: a system to make a file or directory visible in multiple parts of the system’s file tree. We will talk about links in detail.
|
||||
- `(Domain) sockets`: a special file type, similar to TCP/IP sockets, providing inter-process networking protected by the file system’s access control.
|
||||
- `Named pipes`: act more or less like sockets and form a way for processes to communicate with each other, without using network socket semantics.
|
||||
|
||||
### File system in reality ###
|
||||
|
||||
For most users and for most common system administration tasks, it is enough to accept that files and directories are ordered in a tree-like structure. The computer, however, doesn’t understand a thing about trees or tree-structures.
|
||||
|
||||
Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an `inode`, a kind of serial number containing information about the actual data that makes up the file: to whom this file belongs, and where is it located on the hard disk.
|
||||
|
||||
Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
|
||||
|
||||
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.At the time a new file is created, it gets a free inode. In that inode is the following information:
|
||||
|
||||
- Owner and group owner of the file.
|
||||
- File type (regular, directory, …)
|
||||
- Permissions on the file
|
||||
- Date and time of creation, last read and change.
|
||||
- Date and time this information has been changed in the inode.
|
||||
- Number of links to this file (see later in this chapter).
|
||||
- File size
|
||||
- An address defining the actual location of the file data.
|
||||
|
||||
The only information not included in an inode, is the file name and directory. These are stored in the special directory files. By comparing file names and inode numbers, the system can make up a tree-structure that the user understands. Users can display inode numbers using the -i option to ls. The inodes have their own separate space on the disk.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -1,74 +0,0 @@
|
||||
How to Run Kali Linux 2.0 In Docker Container
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
Kali Linux is a well known operating system for security testers and ethical hackers. It comes bundled with a large list of security related applications and make it easy to perform penetration testing. Recently, [Kali Linux 2.0][1] is out and it is being considered as one of the most important release for this operating system. On the other hand, Docker technology is getting massive popularity due to its scalability and ease of use. Dockers make it super easy to ship your software applications to your users. Breaking news is that you can now run Kali Linux via Dockers; let’s see how :)
|
||||
|
||||
### Running Kali Linux 2.0 In Docker ###
|
||||
|
||||
**Related Notes**
|
||||
|
||||
If you don’t have docker installed on your system, you can do it by using the following commands:
|
||||
|
||||
**For Ubuntu/Linux Mint/Debian:**
|
||||
|
||||
sudo apt-get install docker
|
||||
|
||||
**For Fedora/RHEL/CentOS:**
|
||||
|
||||
sudo yum install docker
|
||||
|
||||
**For Fedora 22:**
|
||||
|
||||
dnf install docker
|
||||
|
||||
You can start docker service by running:
|
||||
|
||||
sudo docker start
|
||||
|
||||
First of all make sure that docker service is running fine by using the following command:
|
||||
|
||||
sudo docker status
|
||||
|
||||
Kali Linux docker image has been uploaded online by Kali Linux development team, simply run following command to download this image to your system.
|
||||
|
||||
docker pull kalilinux/kali-linux-docker
|
||||
|
||||

|
||||
|
||||
Once download is complete, run following command to find out the Image ID for your downloaded Kali Linux docker image file.
|
||||
|
||||
docker images
|
||||
|
||||

|
||||
|
||||
Now run following command to start your kali Linux docker container from image file (Here replace Image ID with correct one).
|
||||
|
||||
docker run -i -t 198cd6df71ab3 /bin/bash
|
||||
|
||||
It will immediately start the container and will log you into the operating system, you can start working on Kali Linux here.
|
||||
|
||||

|
||||
|
||||
You can verify that container is started/running fine, by using the following command:
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Dockers are the smartest way to deploy and distribute your packages. Kali Linux docker image is pretty handy, does not consume any high amount of space on the disk and it is pretty easy to test this wonderful distro on any docker installed operating system now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/run-kali-linux-2-0-in-docker-container/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxpitstop.com/author/aun/
|
||||
[1]:http://linuxpitstop.com/install-kali-linux-2-0/
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun translating
|
||||
How to set up a system status page of your infrastructure
|
||||
================================================================================
|
||||
If you are a system administrator who is responsible for critical IT infrastructure or services of your organization, you will understand the importance of effective communication in your day-to-day tasks. Suppose your production storage server is on fire. You want your entire team on the same page in order to resolve the issue as fast as you can. While you are at it, you don't want half of all users contacting you asking why they cannot access their documents. When a scheduled maintenance is coming up, you want to notify interested parties of the event ahead of the schedule, so that unnecessary support tickets can be avoided.
|
||||
@ -291,4 +292,4 @@ via: http://xmodulo.com/setup-system-status-page.html
|
||||
[3]:http://ask.xmodulo.com/install-remi-repository-centos-rhel.html
|
||||
[4]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[5]:http://xmodulo.com/configure-virtual-hosts-apache-http-server.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
[6]:http://xmodulo.com/monitor-common-services-nagios.html
|
||||
|
||||
@ -0,0 +1,159 @@
|
||||
How to Convert From RPM to DEB and DEB to RPM Package Using Alien
|
||||
================================================================================
|
||||
As I’m sure you already know, there are plenty of ways to install software in Linux: using the package management system provided by your distribution ([aptitude, yum, or zypper][1], to name a few examples), compiling from source (though somewhat rare these days, it was the only method available during the early days of Linux), or utilizing a low level tool such as dpkg or rpm with .deb and .rpm standalone, precompiled packages, respectively.
|
||||
|
||||

|
||||
|
||||
Convert RPM to DEB and DEB to RPM Package Using Alien
|
||||
|
||||
In this article we will introduce you to alien, a tool that converts between different Linux package formats, with .rpm to .deb (and vice versa) being the most common usage.
|
||||
|
||||
This tool, even when its author is no longer maintaining it and states in his website that alien will always probably remain in experimental status, can come in handy if you need a certain type of package but can only find that program in another package format.
|
||||
|
||||
For example, alien saved my day once when I was looking for a .deb driver for a inkjet printer and couldn’t find any – the manufacturer only provided a .rpm package. I installed alien, converted the package, and before long I was able to use my printer without issues.
|
||||
|
||||
That said, we must clarify that this utility should not be used to replace important system files and libraries since they are set up differently across distributions. Only use alien as a last resort if the suggested installation methods at the beginning of this article are out of the question for the required program.
|
||||
|
||||
Last but not least, we must note that even though we will use CentOS and Debian in this article, alien is also known to work in Slackware and even in Solaris, besides the first two distributions and their respective families.
|
||||
|
||||
### Step 1: Installing Alien and Dependencies ###
|
||||
|
||||
To install alien in CentOS/RHEL 7, you will need to enable the EPEL and the Nux Dextop (yes, it’s Dextop – not Desktop) repositories, in that order:
|
||||
|
||||
# yum install epel-release
|
||||
# rpm --import http://li.nux.ro/download/nux/RPM-GPG-KEY-nux.ro
|
||||
|
||||
The latest version of the package that enables this repository is currently 0.5 (published on Aug. 10, 2015). You should check [http://li.nux.ro/download/nux/dextop/el7/x86_64/][2] to see whether there’s a newer version before proceeding further:
|
||||
|
||||
# rpm -Uvh http://li.nux.ro/download/nux/dextop/el7/x86_64/nux-dextop-release-0-5.el7.nux.noarch.rpm
|
||||
|
||||
then do,
|
||||
|
||||
# yum update && yum install alien
|
||||
|
||||
In Fedora, you will only need to run the last command.
|
||||
|
||||
In Debian and derivatives, simply do:
|
||||
|
||||
# aptitude install alien
|
||||
|
||||
### Step 2: Converting from .deb to .rpm Package ###
|
||||
|
||||
For this test we have chosen dateutils, which provides a set of date and time utilities to deal with large amounts of financial data. We will download the .deb package to our CentOS 7 box, convert it to .rpm and install it:
|
||||
|
||||
|
||||
|
||||
Check CentOS Version
|
||||
|
||||
# cat /etc/centos-release
|
||||
# wget http://ftp.us.debian.org/debian/pool/main/d/dateutils/dateutils_0.3.1-1.1_amd64.deb
|
||||
# alien --to-rpm --scripts dateutils_0.3.1-1.1_amd64.deb
|
||||
|
||||

|
||||
|
||||
Convert .deb to .rpm package in Linux
|
||||
|
||||
**Important**: (Please note how, by default, alien increases the version minor number of the target package. If you want to override this behavior, add the –keep-version flag).
|
||||
|
||||
If we try to install the package right away, we will run into a slight issue:
|
||||
|
||||
# rpm -Uvh dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
Install RPM Package
|
||||
|
||||
To solve this issue, we will enable the epel-testing repository and install the rpmrebuild utility to edit the settings of the package to be rebuilt:
|
||||
|
||||
# yum --enablerepo=epel-testing install rpmrebuild
|
||||
|
||||
Then run,
|
||||
|
||||
# rpmrebuild -pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||
Which will open up your default text editor. Go to the `%files` section and delete the lines that refer to the directories mentioned in the error message, then save the file and exit:
|
||||
|
||||
|
||||
|
||||
Convert .deb to Alien Version
|
||||
|
||||
When you exit the file you will be prompted to continue with the rebuild. If you choose Y, the file will be rebuilt into the specified directory (different than the current working directory):
|
||||
|
||||
# rpmrebuild –pe dateutils-0.3.1-2.1.x86_64.rpm
|
||||
|
||||

|
||||
|
||||
Build RPM Package
|
||||
|
||||
Now you can proceed to install the package and verify as usual:
|
||||
|
||||
# rpm -Uvh /root/rpmbuild/RPMS/x86_64/dateutils-0.3.1-2.1.x86_64.rpm
|
||||
# rpm -qa | grep dateutils
|
||||
|
||||

|
||||
|
||||
Install Build RPM Package
|
||||
|
||||
Finally, you can list the individual tools that were included with dateutils and alternatively check their respective man pages:
|
||||
|
||||
# ls -l /usr/bin | grep dateutils
|
||||
|
||||
|
||||
|
||||
Verify Installed RPM Package
|
||||
|
||||
### Step 3: Converting from .rpm to .deb Package ###
|
||||
|
||||
In this section we will illustrate how to convert from .rpm to .deb. In a 32-bit Debian Wheezy box, let’s download the .rpm package for the zsh shell from the CentOS 6 OS repository. Note that this shell is not available by default in Debian and derivatives.
|
||||
|
||||
# cat /etc/shells
|
||||
# lsb_release -a | tail -n 4
|
||||
|
||||
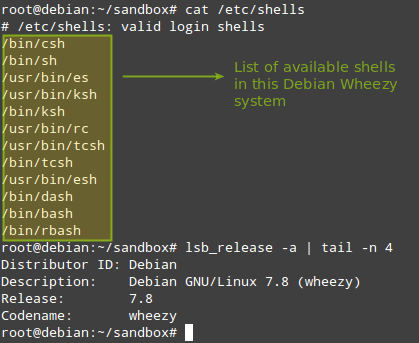
|
||||
|
||||
Check Shell and Debian OS Version
|
||||
|
||||
# wget http://mirror.centos.org/centos/6/os/i386/Packages/zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
# alien --to-deb --scripts zsh-4.3.11-4.el6.centos.i686.rpm
|
||||
|
||||
You can safely disregard the messages about a missing signature:
|
||||
|
||||

|
||||
|
||||
Convert .rpm to .deb Package
|
||||
|
||||
After a few moments, the .deb file should have been generated and be ready to install:
|
||||
|
||||
# dpkg -i zsh_4.3.11-5_i386.deb
|
||||
|
||||

|
||||
|
||||
Install RPM Converted Deb Package
|
||||
|
||||
After the installation, you can verify that zsh is added to the list of valid shells:
|
||||
|
||||
# cat /etc/shells
|
||||
|
||||
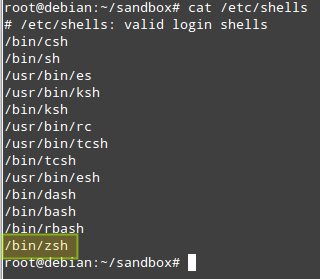
|
||||
|
||||
Confirm Installed Zsh Package
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have explained how to convert from .rpm to .deb and vice versa to install packages as a last resort when such programs are not available in the repositories or as distributable source code. You will want to bookmark this article because all of us will need alien at one time or another.
|
||||
|
||||
Feel free to share your thoughts about this article using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/convert-from-rpm-to-deb-and-deb-to-rpm-package-using-alien/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/linux-package-management/
|
||||
[2]:http://li.nux.ro/download/nux/dextop/el7/x86_64/
|
||||
@ -1,222 +0,0 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
================================================================================
|
||||
The Linux Foundation announced the LFCS (Linux Foundation Certified Sysadmin) certification, a new program that aims at helping individuals all over the world to get certified in basic to intermediate system administration tasks for Linux systems. This includes supporting running systems and services, along with first-hand troubleshooting and analysis, and smart decision-making to escalate issues to engineering teams.
|
||||
|
||||

|
||||
|
||||
Linux Foundation Certified Sysadmin – Part 1
|
||||
|
||||
Please watch the following video that demonstrates about The Linux Foundation Certification Program.
|
||||
|
||||
注:youtube 视频
|
||||
<iframe width="720" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="//www.youtube.com/embed/Y29qZ71Kicg"></iframe>
|
||||
|
||||
The series will be titled Preparation for the LFCS (Linux Foundation Certified Sysadmin) Parts 1 through 10 and cover the following topics for Ubuntu, CentOS, and openSUSE:
|
||||
|
||||
- Part 1: How to use GNU ‘sed’ Command to Create, Edit, and Manipulate files in Linux
|
||||
- Part 2: How to Install and Use vi/m as a full Text Editor
|
||||
- Part 3: Archiving Files/Directories and Finding Files on the Filesystem
|
||||
- Part 4: Partitioning Storage Devices, Formatting Filesystems and Configuring Swap Partition
|
||||
- Part 5: Mount/Unmount Local and Network (Samba & NFS) Filesystems in Linux
|
||||
- Part 6: Assembling Partitions as RAID Devices – Creating & Managing System Backups
|
||||
- Part 7: Managing System Startup Process and Services (SysVinit, Systemd and Upstart
|
||||
- Part 8: Managing Users & Groups, File Permissions & Attributes and Enabling sudo Access on Accounts
|
||||
- Part 9: Linux Package Management with Yum, RPM, Apt, Dpkg, Aptitude and Zypper
|
||||
- Part 10: Learning Basic Shell Scripting and Filesystem Troubleshooting
|
||||
|
||||
|
||||
This post is Part 1 of a 10-tutorial series, which will cover the necessary domains and competencies that are required for the LFCS certification exam. That being said, fire up your terminal, and let’s start.
|
||||
|
||||
### Processing Text Streams in Linux ###
|
||||
|
||||
Linux treats the input to and the output from programs as streams (or sequences) of characters. To begin understanding redirection and pipes, we must first understand the three most important types of I/O (Input and Output) streams, which are in fact special files (by convention in UNIX and Linux, data streams and peripherals, or device files, are also treated as ordinary files).
|
||||
|
||||
The difference between > (redirection operator) and | (pipeline operator) is that while the first connects a command with a file, the latter connects the output of a command with another command.
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
Since the redirection operator creates or overwrites files silently, we must use it with extreme caution, and never mistake it with a pipeline. One advantage of pipes on Linux and UNIX systems is that there is no intermediate file involved with a pipe – the stdout of the first command is not written to a file and then read by the second command.
|
||||
|
||||
For the following practice exercises we will use the poem “A happy child” (anonymous author).
|
||||
|
||||
|
||||
|
||||
cat command example
|
||||
|
||||
#### Using sed ####
|
||||
|
||||
The name sed is short for stream editor. For those unfamiliar with the term, a stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
|
||||
|
||||
The most basic (and popular) usage of sed is the substitution of characters. We will begin by changing every occurrence of the lowercase y to UPPERCASE Y and redirecting the output to ahappychild2.txt. The g flag indicates that sed should perform the substitution for all instances of term on every line of file. If this flag is omitted, sed will replace only the first occurrence of term on each line.
|
||||
|
||||
**Basic syntax:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**Our example:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
Should you want to search for or replace a special character (such as /, \, &) you need to escape it, in the term or replacement strings, with a backward slash.
|
||||
|
||||
For example, we will substitute the word and for an ampersand. At the same time, we will replace the word I with You when the first one is found at the beginning of a line.
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
In the above command, a ^ (caret sign) is a well-known regular expression that is used to represent the beginning of a line.
|
||||
|
||||
As you can see, we can combine two or more substitution commands (and use regular expressions inside them) by separating them with a semicolon and enclosing the set inside single quotes.
|
||||
|
||||
Another use of sed is showing (or deleting) a chosen portion of a file. In the following example, we will display the first 5 lines of /var/log/messages from Jun 8.
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
Note that by default, sed prints every line. We can override this behaviour with the -n option and then tell sed to print (indicated by p) only the part of the file (or the pipe) that matches the pattern (Jun 8 at the beginning of line in the first case and lines 1 through 5 inclusive in the second case).
|
||||
|
||||
Finally, it can be useful while inspecting scripts or configuration files to inspect the code itself and leave out comments. The following sed one-liner deletes (d) blank lines or those starting with # (the | character indicates a boolean OR between the two regular expressions).
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq Command ####
|
||||
|
||||
The uniq command allows us to report or remove duplicate lines in a file, writing to stdout by default. We must note that uniq does not detect repeated lines unless they are adjacent. Thus, uniq is commonly used along with a preceding sort (which is used to sort lines of text files). By default, sort takes the first field (separated by spaces) as key field. To specify a different key field, we need to use the -k option.
|
||||
|
||||
**Examples**
|
||||
|
||||
The du –sch /path/to/directory/* command returns the disk space usage per subdirectories and files within the specified directory in human-readable format (also shows a total per directory), and does not order the output by size, but by subdirectory and file name. We can use the following command to sort by size.
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||
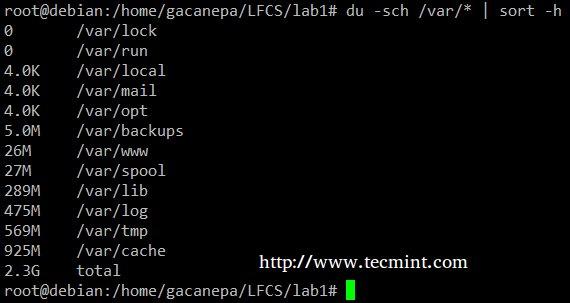
|
||||
|
||||
sort command example
|
||||
|
||||
You can count the number of events in a log by date by telling uniq to perform the comparison using the first 6 characters (-w 6) of each line (where the date is specified), and prefixing each output line by the number of occurrences (-c) with the following command.
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
Finally, you can combine sort and uniq (as they usually are). Consider the following file with a list of donors, donation date, and amount. Suppose we want to know how many unique donors there are. We will use the following command to cut the first field (fields are delimited by a colon), sort by name, and remove duplicate lines.
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- Read Also: [13 “cat” Command Examples][1]
|
||||
|
||||
#### grep Command ####
|
||||
|
||||
grep searches text files or (command output) for the occurrence of a specified regular expression and outputs any line containing a match to standard output.
|
||||
|
||||
**Examples**
|
||||
|
||||
Display the information from /etc/passwd for user gacanepa, ignoring case.
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
Show all the contents of /etc whose name begins with rc followed by any single number.
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- Read Also: [12 “grep” Command Examples][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
The tr command can be used to translate (change) or delete characters from stdin, and write the result to stdout.
|
||||
|
||||
**Examples**
|
||||
|
||||
Change all lowercase to uppercase in sortuniq.txt file.
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
Squeeze the delimiter in the output of ls –l to only one space.
|
||||
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut Command Usage ####
|
||||
|
||||
The cut command extracts portions of input lines (from stdin or files) and displays the result on standard output, based on number of bytes (-b option), characters (-c), or fields (-f). In this last case (based on fields), the default field separator is a tab, but a different delimiter can be specified by using the -d option.
|
||||
|
||||
**Examples**
|
||||
|
||||
Extract the user accounts and the default shells assigned to them from /etc/passwd (the –d option allows us to specify the field delimiter, and the –f switch indicates which field(s) will be extracted.
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
Summing up, we will create a text stream consisting of the first and third non-blank files of the output of the last command. We will use grep as a first filter to check for sessions of user gacanepa, then squeeze delimiters to only one space (tr -s ‘ ‘). Next, we’ll extract the first and third fields with cut, and finally sort by the second field (IP addresses in this case) showing unique.
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
The above command shows how multiple commands and pipes can be combined so as to obtain filtered data according to our desires. Feel free to also run it by parts, to help you see the output that is pipelined from one command to the next (this can be a great learning experience, by the way!).
|
||||
|
||||
### Summary ###
|
||||
|
||||
Although this example (along with the rest of the examples in the current tutorial) may not seem very useful at first sight, they are a nice starting point to begin experimenting with commands that are used to create, edit, and manipulate files from the Linux command line. Feel free to leave your questions and comments below – they will be much appreciated!
|
||||
|
||||
#### Reference Links ####
|
||||
|
||||
- [About the LFCS][3]
|
||||
- [Why get a Linux Foundation Certification?][4]
|
||||
- [Register for the LFCS exam][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -1,180 +0,0 @@
|
||||
struggling 翻译中
|
||||
Growing an Existing RAID Array and Removing Failed Disks in Raid – Part 7
|
||||
================================================================================
|
||||
Every newbies will get confuse of the word array. Array is just a collection of disks. In other words, we can call array as a set or group. Just like a set of eggs containing 6 numbers. Likewise RAID Array contains number of disks, it may be 2, 4, 6, 8, 12, 16 etc. Hope now you know what Array is.
|
||||
|
||||
Here we will see how to grow (extend) an existing array or raid group. For example, if we are using 2 disks in an array to form a raid 1 set, and in some situation if we need more space in that group, we can extend the size of an array using mdadm –grow command, just by adding one of the disk to the existing array. After growing (adding disk to an existing array), we will see how to remove one of the failed disk from array.
|
||||
|
||||
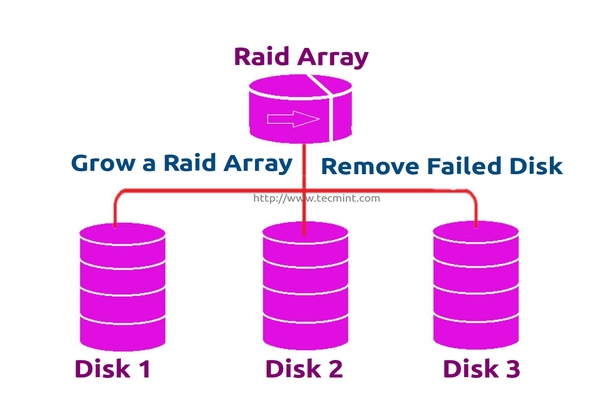
|
||||
|
||||
Growing Raid Array and Removing Failed Disks
|
||||
|
||||
Assume that one of the disk is little weak and need to remove that disk, till it fails let it under use, but we need to add one of the spare drive and grow the mirror before it fails, because we need to save our data. While the weak disk fails we can remove it from array this is the concept we are going to see in this topic.
|
||||
|
||||
#### Features of RAID Growth ####
|
||||
|
||||
- We can grow (extend) the size of any raid set.
|
||||
- We can remove the faulty disk after growing raid array with new disk.
|
||||
- We can grow raid array without any downtime.
|
||||
|
||||
Requirements
|
||||
|
||||
- To grow an RAID array, we need an existing RAID set (Array).
|
||||
- We need extra disks to grow the Array.
|
||||
- Here I’m using 1 disk to grow the existing array.
|
||||
|
||||
Before we learn about growing and recovering of Array, we have to know about the basics of RAID levels and setups. Follow the below links to know about those setups.
|
||||
|
||||
- [Understanding Basic RAID Concepts – Part 1][1]
|
||||
- [Creating a Software Raid 0 in Linux – Part 2][2]
|
||||
|
||||
#### My Server Setup ####
|
||||
|
||||
Operating System : CentOS 6.5 Final
|
||||
IP Address : 192.168.0.230
|
||||
Hostname : grow.tecmintlocal.com
|
||||
2 Existing Disks : 1 GB
|
||||
1 Additional Disk : 1 GB
|
||||
|
||||
Here, my already existing RAID has 2 number of disks with each size is 1GB and we are now adding one more disk whose size is 1GB to our existing raid array.
|
||||
|
||||
### Growing an Existing RAID Array ###
|
||||
|
||||
1. Before growing an array, first list the existing Raid array using the following command.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Check Existing Raid Array
|
||||
|
||||
**Note**: The above output shows that I’ve already has two disks in Raid array with raid1 level. Now here we are adding one more disk to an existing array,
|
||||
|
||||
2. Now let’s add the new disk “sdd” and create a partition using ‘fdisk‘ command.
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
Please use the below instructions to create a partition on /dev/sdd drive.
|
||||
|
||||
- Press ‘n‘ for creating new partition.
|
||||
- Then choose ‘P‘ for Primary partition.
|
||||
- Then choose ‘1‘ to be the first partition.
|
||||
- Next press ‘p‘ to print the created partition.
|
||||
- Here, we are selecting ‘fd‘ as my type is RAID.
|
||||
- Next press ‘p‘ to print the defined partition.
|
||||
- Then again use ‘p‘ to print the changes what we have made.
|
||||
- Use ‘w‘ to write the changes.
|
||||
|
||||

|
||||
|
||||
Create New sdd Partition
|
||||
|
||||
3. Once new sdd partition created, you can verify it using below command.
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||
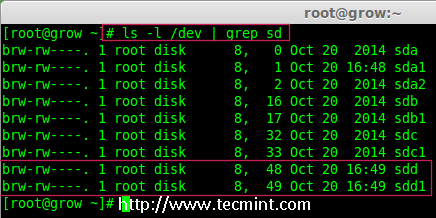
|
||||
|
||||
Confirm sdd Partition
|
||||
|
||||
4. Next, examine the newly created disk for any existing raid, before adding to the array.
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||
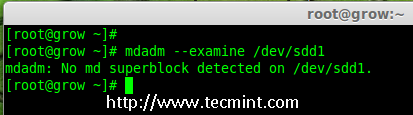
|
||||
|
||||
Check Raid on sdd Partition
|
||||
|
||||
**Note**: The above output shows that the disk has no super-blocks detected, means we can move forward to add a new disk to an existing array.
|
||||
|
||||
4. To add the new partition /dev/sdd1 in existing array md0, use the following command.
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||
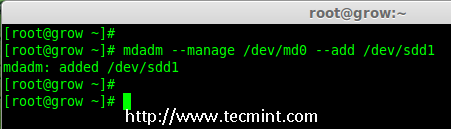
|
||||
|
||||
Add Disk To Raid-Array
|
||||
|
||||
5. Once the new disk has been added, check for the added disk in our array using.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Confirm Disk Added to Raid
|
||||
|
||||
**Note**: In the above output, you can see the drive has been added as a spare. Here, we already having 2 disks in the array, but what we are expecting is 3 devices in array for that we need to grow the array.
|
||||
|
||||
6. To grow the array we have to use the below command.
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||
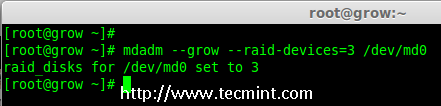
|
||||
|
||||
Grow Raid Array
|
||||
|
||||
Now we can see the third disk (sdd1) has been added to array, after adding third disk it will sync the data from other two disks.
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Confirm Raid Array
|
||||
|
||||
**Note**: For large size disk it will take hours to sync the contents. Here I have used 1GB virtual disk, so its done very quickly within seconds.
|
||||
|
||||
### Removing Disks from Array ###
|
||||
|
||||
7. After the data has been synced to new disk ‘sdd1‘ from other two disks, that means all three disks now have same contents.
|
||||
|
||||
As I told earlier let’s assume that one of the disk is weak and needs to be removed, before it fails. So, now assume disk ‘sdc1‘ is weak and needs to be removed from an existing array.
|
||||
|
||||
Before removing a disk we have to mark the disk as failed one, then only we can able to remove it.
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Disk Fail in Raid Array
|
||||
|
||||
From the above output, we clearly see that the disk was marked as faulty at the bottom. Even its faulty, we can see the raid devices are 3, failed 1 and state was degraded.
|
||||
|
||||
Now we have to remove the faulty drive from the array and grow the array with 2 devices, so that the raid devices will be set to 2 devices as before.
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||
|
||||
|
||||
Remove Disk in Raid Array
|
||||
|
||||
8. Once the faulty drive is removed, now we’ve to grow the raid array using 2 disks.
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
Grow Disks in Raid Array
|
||||
|
||||
From the about output, you can see that our array having only 2 devices. If you need to grow the array again, follow the same steps as described above. If you need to add a drive as spare, mark it as spare so that if the disk fails, it will automatically active and rebuild.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In the article, we’ve seen how to grow an existing raid set and how to remove a faulty disk from an array after re-syncing the existing contents. All these steps can be done without any downtime. During data syncing, system users, files and applications will not get affected in any case.
|
||||
|
||||
In next, article I will show you how to manage the RAID, till then stay tuned to updates and don’t forget to add your comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
@ -1,249 +0,0 @@
|
||||
[translated by xiqingongzi]
|
||||
RHCSA Series: How to Manage Users and Groups in RHEL 7 – Part 3
|
||||
================================================================================
|
||||
Managing a RHEL 7 server, as it is the case with any other Linux server, will require that you know how to add, edit, suspend, or delete user accounts, and grant users the necessary permissions to files, directories, and other system resources to perform their assigned tasks.
|
||||
|
||||

|
||||
|
||||
RHCSA: User and Group Management – Part 3
|
||||
|
||||
### Managing User Accounts ###
|
||||
|
||||
To add a new user account to a RHEL 7 server, you can run either of the following two commands as root:
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
When a new user account is added, by default the following operations are performed.
|
||||
|
||||
- His/her home directory is created (`/home/username` unless specified otherwise).
|
||||
- These `.bash_logout`, `.bash_profile` and `.bashrc` hidden files are copied inside the user’s home directory, and will be used to provide environment variables for his/her user session. You can explore each of them for further details.
|
||||
- A mail spool directory is created for the added user account.
|
||||
- A group is created with the same name as the new user account.
|
||||
|
||||
The full account summary is stored in the `/etc/passwd `file. This file holds a record per system user account and has the following format (fields are separated by a colon):
|
||||
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- These two fields `[username]` and `[Comment]` are self explanatory.
|
||||
- The second filed ‘x’ indicates that the account is secured by a shadowed password (in `/etc/shadow`), which is used to logon as `[username]`.
|
||||
- The fields `[UID]` and `[GID]` are integers that shows the User IDentification and the primary Group IDentification to which `[username]` belongs, equally.
|
||||
|
||||
Finally,
|
||||
|
||||
- The `[Home directory]` shows the absolute location of `[username]’s` home directory, and
|
||||
- `[Default shell]` is the shell that is commit to this user when he/she logins into the system.
|
||||
|
||||
Another important file that you must become familiar with is `/etc/group`, where group information is stored. As it is the case with `/etc/passwd`, there is one record per line and its fields are also delimited by a colon:
|
||||
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
where,
|
||||
|
||||
- `[Group name]` is the name of group.
|
||||
- Does this group use a group password? (An “x” means no).
|
||||
- `[GID]`: same as in `/etc/passwd`.
|
||||
- `[Group members]`: a list of users, separated by commas, that are members of each group.
|
||||
|
||||
After adding an account, at anytime, you can edit the user’s account information using usermod, whose basic syntax is:
|
||||
|
||||
# usermod [options] [username]
|
||||
|
||||
Read Also:
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### EXAMPLE 1: Setting the expiry date for an account ####
|
||||
|
||||
If you work for a company that has some kind of policy to enable account for a certain interval of time, or if you want to grant access to a limited period of time, you can use the `--expiredate` flag followed by a date in YYYY-MM-DD format. To verify that the change has been applied, you can compare the output of
|
||||
|
||||
# chage -l [username]
|
||||
|
||||
before and after updating the account expiry date, as shown in the following image.
|
||||
|
||||
|
||||
|
||||
Change User Account Information
|
||||
|
||||
#### EXAMPLE 2: Adding the user to supplementary groups ####
|
||||
|
||||
Besides the primary group that is created when a new user account is added to the system, a user can be added to supplementary groups using the combined -aG, or –append –groups options, followed by a comma separated list of groups.
|
||||
|
||||
#### EXAMPLE 3: Changing the default location of the user’s home directory and / or changing its shell ####
|
||||
|
||||
If for some reason you need to change the default location of the user’s home directory (other than /home/username), you will need to use the -d, or –home options, followed by the absolute path to the new home directory.
|
||||
|
||||
If a user wants to use another shell other than bash (for example, sh), which gets assigned by default, use usermod with the –shell flag, followed by the path to the new shell.
|
||||
|
||||
#### EXAMPLE 4: Displaying the groups an user is a member of ####
|
||||
|
||||
After adding the user to a supplementary group, you can verify that it now actually belongs to such group(s):
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
The following image depicts Examples 2 through 4:
|
||||
|
||||

|
||||
|
||||
Adding User to Supplementary Group
|
||||
|
||||
In the example above:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
To remove a user from a group, omit the `--append` switch in the command above and list the groups you want the user to belong to following the `--groups` flag.
|
||||
|
||||
#### EXAMPLE 5: Disabling account by locking password ####
|
||||
|
||||
To disable an account, you will need to use either the -l (lowercase L) or the –lock option to lock a user’s password. This will prevent the user from being able to log on.
|
||||
|
||||
#### EXAMPLE 6: Unlocking password ####
|
||||
|
||||
When you need to re-enable the user so that he can log on to the server again, use the -u or the –unlock option to unlock a user’s password that was previously blocked, as explained in Example 5 above.
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
The following image illustrates Examples 5 and 6:
|
||||
|
||||

|
||||
|
||||
Lock Unlock User Account
|
||||
|
||||
#### EXAMPLE 7: Deleting a group or an user account ####
|
||||
|
||||
To delete a group, you’ll want to use groupdel, whereas to delete a user account you will use userdel (add the –r switch if you also want to delete the contents of its home directory and mail spool):
|
||||
|
||||
# groupdel [group_name] # Delete a group
|
||||
# userdel -r [user_name] # Remove user_name from the system, along with his/her home directory and mail spool
|
||||
|
||||
If there are files owned by group_name, they will not be deleted, but the group owner will be set to the GID of the group that was deleted.
|
||||
|
||||
### Listing, Setting and Changing Standard ugo/rwx Permissions ###
|
||||
|
||||
The well-known [ls command][3] is one of the best friends of any system administrator. When used with the -l flag, this tool allows you to view a list a directory’s contents in long (or detailed) format.
|
||||
|
||||
However, this command can also be applied to a single file. Either way, the first 10 characters in the output of `ls -l` represent each file’s attributes.
|
||||
|
||||
The first char of this 10-character sequence is used to indicate the file type:
|
||||
|
||||
- – (hyphen): a regular file
|
||||
- d: a directory
|
||||
- l: a symbolic link
|
||||
- c: a character device (which treats data as a stream of bytes, i.e. a terminal)
|
||||
- b: a block device (which handles data in blocks, i.e. storage devices)
|
||||
|
||||
The next nine characters of the file attributes, divided in groups of three from left to right, are called the file mode and indicate the read (r), write(w), and execute (x) permissions granted to the file’s owner, the file’s group owner, and the rest of the users (commonly referred to as “the world”), respectively.
|
||||
|
||||
While the read permission on a file allows the same to be opened and read, the same permission on a directory allows its contents to be listed if the execute permission is also set. In addition, the execute permission in a file allows it to be handled as a program and run.
|
||||
|
||||
File permissions are changed with the chmod command, whose basic syntax is as follows:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
where new_mode is either an octal number or an expression that specifies the new permissions. Feel free to use the mode that works best for you in each case. Or perhaps you already have a preferred way to set a file’s permissions – so feel free to use the method that works best for you.
|
||||
|
||||
The octal number can be calculated based on the binary equivalent, which can in turn be obtained from the desired file permissions for the owner of the file, the owner group, and the world.The presence of a certain permission equals a power of 2 (r=22, w=21, x=20), while its absence means 0. For example:
|
||||
|
||||

|
||||
|
||||
File Permissions
|
||||
|
||||
To set the file’s permissions as indicated above in octal form, type:
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
Please take a minute to compare our previous calculation to the actual output of `ls -l` after changing the file’s permissions:
|
||||
|
||||
|
||||
|
||||
Long List Format
|
||||
|
||||
#### EXAMPLE 8: Searching for files with 777 permissions ####
|
||||
|
||||
As a security measure, you should make sure that files with 777 permissions (read, write, and execute for everyone) are avoided like the plague under normal circumstances. Although we will explain in a later tutorial how to more effectively locate all the files in your system with a certain permission set, you can -by now- combine ls with grep to obtain such information.
|
||||
|
||||
In the following example, we will look for file with 777 permissions in the /etc directory only. Note that we will use pipelining as explained in [Part 2: File and Directory Management][4] of this RHCSA series:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
Find All Files with 777 Permission
|
||||
|
||||
#### EXAMPLE 9: Assigning a specific permission to all users ####
|
||||
|
||||
Shell scripts, along with some binaries that all users should have access to (not just their corresponding owner and group), should have the execute bit set accordingly (please note that we will discuss a special case later):
|
||||
|
||||
# chmod a+x script.sh
|
||||
|
||||
**Note**: That we can also set a file’s mode using an expression that indicates the owner’s rights with the letter `u`, the group owner’s rights with the letter `g`, and the rest with `o`. All of these rights can be represented at the same time with the letter `a`. Permissions are granted (or revoked) with the `+` or `-` signs, respectively.
|
||||
|
||||

|
||||
|
||||
Set Execute Permission on File
|
||||
|
||||
A long directory listing also shows the file’s owner and its group owner in the first and second columns, respectively. This feature serves as a first-level access control method to files in a system:
|
||||
|
||||
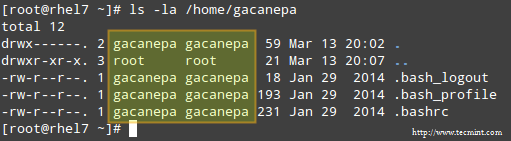
|
||||
|
||||
Check File Owner and Group
|
||||
|
||||
To change file ownership, you will use the chown command. Note that you can change the file and group ownership at the same time or separately:
|
||||
|
||||
# chown user:group file
|
||||
|
||||
**Note**: That you can change the user or group, or the two attributes at the same time, as long as you don’t forget the colon, leaving user or group blank if you want to update the other attribute, for example:
|
||||
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### EXAMPLE 10: Cloning permissions from one file to another ####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
|
||||
# chown --reference=ref_file file
|
||||
|
||||
where the owner and group of ref_file will be assigned to file as well:
|
||||
|
||||

|
||||
|
||||
Clone File Ownership
|
||||
|
||||
### Setting Up SETGID Directories for Collaboration ###
|
||||
|
||||
Should you need to grant access to all the files owned by a certain group inside a specific directory, you will most likely use the approach of setting the setgid bit for such directory. When the setgid bit is set, the effective GID of the real user becomes that of the group owner.
|
||||
|
||||
Thus, any user can access a file under the privileges granted to the group owner of such file. In addition, when the setgid bit is set on a directory, newly created files inherit the same group as the directory, and newly created subdirectories will also inherit the setgid bit of the parent directory.
|
||||
|
||||
# chmod g+s [filename]
|
||||
|
||||
To set the setgid in octal form, prepend the number 2 to the current (or desired) basic permissions.
|
||||
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
A solid knowledge of user and group management, along with standard and special Linux permissions, when coupled with practice, will allow you to quickly identify and troubleshoot issues with file permissions in your RHEL 7 server.
|
||||
|
||||
I assure you that as you follow the steps outlined in this article and use the system documentation (as explained in [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) you will master this essential competence of system administration.
|
||||
|
||||
Feel free to let us know if you have any questions or comments using the form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -1,217 +0,0 @@
|
||||
FSSlc translating
|
||||
|
||||
RHCSA Series: Securing SSH, Setting Hostname and Enabling Network Services – Part 8
|
||||
================================================================================
|
||||
As a system administrator you will often have to log on to remote systems to perform a variety of administration tasks using a terminal emulator. You will rarely sit in front of a real (physical) terminal, so you need to set up a way to log on remotely to the machines that you will be asked to manage.
|
||||
|
||||
In fact, that may be the last thing that you will have to do in front of a physical terminal. For security reasons, using Telnet for this purpose is not a good idea, as all traffic goes through the wire in unencrypted, plain text.
|
||||
|
||||
In addition, in this article we will also review how to configure network services to start automatically at boot and learn how to set up network and hostname resolution statically or dynamically.
|
||||
|
||||

|
||||
|
||||
RHCSA: Secure SSH and Enable Network Services – Part 8
|
||||
|
||||
### Installing and Securing SSH Communication ###
|
||||
|
||||
For you to be able to log on remotely to a RHEL 7 box using SSH, you will have to install the openssh, openssh-clients and openssh-servers packages. The following command not only will install the remote login program, but also the secure file transfer tool, as well as the remote file copy utility:
|
||||
|
||||
# yum update && yum install openssh openssh-clients openssh-servers
|
||||
|
||||
Note that it’s a good idea to install the server counterparts as you may want to use the same machine as both client and server at some point or another.
|
||||
|
||||
After installation, there is a couple of basic things that you need to take into account if you want to secure remote access to your SSH server. The following settings should be present in the `/etc/ssh/sshd_config` file.
|
||||
|
||||
1. Change the port where the sshd daemon will listen on from 22 (the default value) to a high port (2000 or greater), but first make sure the chosen port is not being used.
|
||||
|
||||
For example, let’s suppose you choose port 2500. Use [netstat][1] in order to check whether the chosen port is being used or not:
|
||||
|
||||
# netstat -npltu | grep 2500
|
||||
|
||||
If netstat does not return anything, you can safely use port 2500 for sshd, and you should change the Port setting in the configuration file as follows:
|
||||
|
||||
Port 2500
|
||||
|
||||
2. Only allow protocol 2:
|
||||
|
||||
Protocol 2
|
||||
|
||||
3. Configure the authentication timeout to 2 minutes, do not allow root logins, and restrict to a minimum the list of users which are allowed to login via ssh:
|
||||
|
||||
LoginGraceTime 2m
|
||||
PermitRootLogin no
|
||||
AllowUsers gacanepa
|
||||
|
||||
4. If possible, use key-based instead of password authentication:
|
||||
|
||||
PasswordAuthentication no
|
||||
RSAAuthentication yes
|
||||
PubkeyAuthentication yes
|
||||
|
||||
This assumes that you have already created a key pair with your user name on your client machine and copied it to your server as explained here.
|
||||
|
||||
- [Enable SSH Passwordless Login][2]
|
||||
|
||||
### Configuring Networking and Name Resolution ###
|
||||
|
||||
1. Every system administrator should be well acquainted with the following system-wide configuration files:
|
||||
|
||||
- /etc/hosts is used to resolve names <---> IPs in small networks.
|
||||
|
||||
Every line in the `/etc/hosts` file has the following structure:
|
||||
|
||||
IP address - Hostname - FQDN
|
||||
|
||||
For example,
|
||||
|
||||
192.168.0.10 laptop laptop.gabrielcanepa.com.ar
|
||||
|
||||
2. `/etc/resolv.conf` specifies the IP addresses of DNS servers and the search domain, which is used for completing a given query name to a fully qualified domain name when no domain suffix is supplied.
|
||||
|
||||
Under normal circumstances, you don’t need to edit this file as it is managed by the system. However, should you want to change DNS servers, be advised that you need to stick to the following structure in each line:
|
||||
|
||||
nameserver - IP address
|
||||
|
||||
For example,
|
||||
|
||||
nameserver 8.8.8.8
|
||||
|
||||
3. 3. `/etc/host.conf` specifies the methods and the order by which hostnames are resolved within a network. In other words, tells the name resolver which services to use, and in what order.
|
||||
|
||||
Although this file has several options, the most common and basic setup includes a line as follows:
|
||||
|
||||
order bind,hosts
|
||||
|
||||
Which indicates that the resolver should first look in the nameservers specified in `resolv.conf` and then to the `/etc/hosts` file for name resolution.
|
||||
|
||||
4. `/etc/sysconfig/network` contains routing and global host information for all network interfaces. The following values may be used:
|
||||
|
||||
NETWORKING=yes|no
|
||||
HOSTNAME=value
|
||||
|
||||
Where value should be the Fully Qualified Domain Name (FQDN).
|
||||
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
|
||||
Where XXX.XXX.XXX.XXX is the IP address of the network’s gateway.
|
||||
|
||||
GATEWAYDEV=value
|
||||
|
||||
In a machine with multiple NICs, value is the gateway device, such as enp0s3.
|
||||
|
||||
5. Files inside `/etc/sysconfig/network-scripts` (network adapters configuration files).
|
||||
|
||||
Inside the directory mentioned previously, you will find several plain text files named.
|
||||
|
||||
ifcfg-name
|
||||
|
||||
Where name is the name of the NIC as returned by ip link show:
|
||||
|
||||

|
||||
|
||||
Check Network Link Status
|
||||
|
||||
For example:
|
||||
|
||||
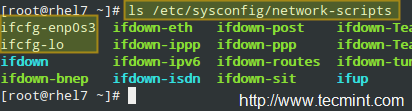
|
||||
|
||||
Network Files
|
||||
|
||||
Other than for the loopback interface, you can expect a similar configuration for your NICs. Note that some variables, if set, will override those present in `/etc/sysconfig/network` for this particular interface. Each line is commented for clarification in this article but in the actual file you should avoid comments:
|
||||
|
||||
HWADDR=08:00:27:4E:59:37 # The MAC address of the NIC
|
||||
TYPE=Ethernet # Type of connection
|
||||
BOOTPROTO=static # This indicates that this NIC has been assigned a static IP. If this variable was set to dhcp, the NIC will be assigned an IP address by a DHCP server and thus the next two lines should not be present in that case.
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no # Should be added to the Ethernet interface to prevent NetworkManager from changing the file.
|
||||
NAME=enp0s3
|
||||
UUID=14033805-98ef-4049-bc7b-d4bea76ed2eb
|
||||
ONBOOT=yes # The operating system should bring up this NIC during boot
|
||||
|
||||
### Setting Hostnames ###
|
||||
|
||||
In Red Hat Enterprise Linux 7, the hostnamectl command is used to both query and set the system’s hostname.
|
||||
|
||||
To display the current hostname, type:
|
||||
|
||||
# hostnamectl status
|
||||
|
||||
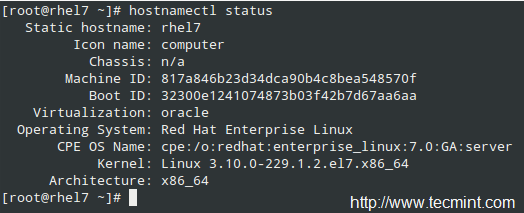
|
||||
|
||||
Check System Hostname
|
||||
|
||||
To change the hostname, use
|
||||
|
||||
# hostnamectl set-hostname [new hostname]
|
||||
|
||||
For example,
|
||||
|
||||
# hostnamectl set-hostname cinderella
|
||||
|
||||
For the changes to take effect you will need to restart the hostnamed daemon (that way you will not have to log off and on again in order to apply the change):
|
||||
|
||||
# systemctl restart systemd-hostnamed
|
||||
|
||||

|
||||
|
||||
Set System Hostname
|
||||
|
||||
In addition, RHEL 7 also includes the nmcli utility that can be used for the same purpose. To display the hostname, run:
|
||||
|
||||
# nmcli general hostname
|
||||
|
||||
and to change it:
|
||||
|
||||
# nmcli general hostname [new hostname]
|
||||
|
||||
For example,
|
||||
|
||||
# nmcli general hostname rhel7
|
||||
|
||||

|
||||
|
||||
Set Hostname Using nmcli Command
|
||||
|
||||
### Starting Network Services on Boot ###
|
||||
|
||||
To wrap up, let us see how we can ensure that network services are started automatically on boot. In simple terms, this is done by creating symlinks to certain files specified in the [Install] section of the service configuration files.
|
||||
|
||||
In the case of firewalld (/usr/lib/systemd/system/firewalld.service):
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
Alias=dbus-org.fedoraproject.FirewallD1.service
|
||||
|
||||
To enable the service:
|
||||
|
||||
# systemctl enable firewalld
|
||||
|
||||
On the other hand, disabling firewalld entitles removing the symlinks:
|
||||
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
|
||||
Enable Service at System Boot
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article we have summarized how to install and secure connections via SSH to a RHEL server, how to change its name, and finally how to ensure that network services are started on boot. If you notice that a certain service has failed to start properly, you can use systemctl status -l [service] and journalctl -xn to troubleshoot it.
|
||||
|
||||
Feel free to let us know what you think about this article using the comment form below. Questions are also welcome. We look forward to hearing from you!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
@ -1,3 +1,5 @@
|
||||
FSSlc Translating
|
||||
|
||||
RHCSA Series: Installing, Configuring and Securing a Web and FTP Server – Part 9
|
||||
================================================================================
|
||||
A web server (also known as a HTTP server) is a service that handles content (most commonly web pages, but other types of documents as well) over to a client in a network.
|
||||
@ -173,4 +175,4 @@ via: http://www.tecmint.com/rhcsa-series-install-and-secure-apache-web-server-an
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
[2]:http://www.tecmint.com/manage-and-limit-downloadupload-bandwidth-with-trickle-in-linux/
|
||||
[3]:http://www.google.com/cse?cx=partner-pub-2601749019656699:2173448976&ie=UTF-8&q=virtual+hosts&sa=Search&gws_rd=cr&ei=Dy9EVbb0IdHisASnroG4Bw#gsc.tab=0&gsc.q=apache
|
||||
[3]:http://www.google.com/cse?cx=partner-pub-2601749019656699:2173448976&ie=UTF-8&q=virtual+hosts&sa=Search&gws_rd=cr&ei=Dy9EVbb0IdHisASnroG4Bw#gsc.tab=0&gsc.q=apache
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[xiqingongzi translating]
|
||||
RHCSA Series: Yum Package Management, Automating Tasks with Cron and Monitoring System Logs – Part 10
|
||||
================================================================================
|
||||
In this article we will review how to install, update, and remove packages in Red Hat Enterprise Linux 7. We will also cover how to automate tasks using cron, and will finish this guide explaining how to locate and interpret system logs files with the focus of teaching you why all of these are essential skills for every system administrator.
|
||||
@ -194,4 +195,4 @@ via: http://www.tecmint.com/yum-package-management-cron-job-scheduling-monitorin
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/20-practical-examples-of-rpm-commands-in-linux/
|
||||
[3]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
[4]:http://www.tecmint.com/dmesg-commands/
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
Debian GNU/Linux 生日: 22年未完的美妙旅程.
|
||||
================================================================================
|
||||
在2015年8月16日, Debian项目组庆祝了 Debian 的22周年纪念日; 这也是开源世界历史最悠久, 热门的发行版之一. Debian项目于1993年由Ian Murdock创立. 彼时, Slackware 作为最早的 Linux 发行版已经名声在外.
|
||||
|
||||

|
||||
|
||||
22岁生日快乐! Debian Linux!
|
||||
|
||||
Ian Ashly Murdock, 一个美国职业软件工程师, 在他还是普渡大学的学生时构想出了 Debia n项目的计划. 他把这个项目命名为 Debian 是由于这个名字组合了他彼时女友的名字, Debra Lynn, 和他自己的名字(译者: Ian). 他之后和Lynn顺利结婚并在2008年1月离婚.
|
||||
|
||||

|
||||
|
||||
Debian 创始人:Ian Murdock
|
||||
|
||||
Ian 目前是 ExactTarget 下 Platform and Development Community 的副总裁.
|
||||
|
||||
Debian (如同Slackware一样) 都是由于当时缺乏满足作者标准的发行版才应运而生的. Ian 在一次采访中说:"免费提供一流的产品会是Debian项目的唯一使命. 尽管过去的 Linux 发行版均不尽然可靠抑或是优秀. 我印象里...比如在不同的文件系统间移动文件, 处理大型文件经常会导致内核出错. 但是 Linux 其实是很可靠的, 免费的源代码让这个项目本质上很有前途.
|
||||
|
||||
"我记得过去我也像其他人一样想解决问题, 想在家里运营一个像 UNIX 的东西. 但那是不可能的, 无论是经济上还是法律上或是别的什么角度. 然后我就听闻了GNU内核开发项目, 以及这个项目是如何没有任何法律纷争", Ian 补充到. 他早年在开发 Debian 时曾被自由软件基金会(FSF)资助, 这份资助帮助 Debian 向前迈了一大步; 尽管一年后由于学业原因 Ian 退出了 FSF 转而去完成他的学位.
|
||||
|
||||
### Debian开发历史 ###
|
||||
|
||||
- **Debian 0.01 – 0.09** : 发布于 1993 八月 – 1993 十二月.
|
||||
- **Debian 0.91 ** – 发布于 1994 一月. 有了原始的包管理系统, 没有依赖管理机制.
|
||||
- **Debian 0.93 rc5** : 发布于 1995 三月. "现代"意义的 Debian 的第一次发布, dpkg 会在系统安装后被用作安装以及管理其他软件包.
|
||||
- **Debian 0.93 rc6**: 发布于1995 十一月. 最后一次a.out发布, deselect机制第一次出现, 有60位开发者在彼时维护着软件包.
|
||||
- **Debian 1.1**: 发布于1996 六月. 项目代号 – Buzz, 软件包数量 – 474, 包管理器 dpkg, 内核版本 2.0, ELF.
|
||||
- **Debian 1.2**: 发布于1996 十二月. 项目代号 – Rex, 软件包数量 – 848, 开发者数量 – 120.
|
||||
- **Debian 1.3**: 发布于1997 七月. 项目代号 – Bo, 软件包数量 974, 开发者数量 – 200.
|
||||
- **Debian 2.0**: 发布于1998 七月. 项目代号 - Hamm, 支持构架 – Intel i386 以及 Motorola 68000 系列, 软件包数量: 1500+, 开发者数量: 400+, 内置了 glibc.
|
||||
- **Debian 2.1**: 发布于1999 三月九日. 项目代号 – slink, 支持构架 - Alpha 和 Sparc, apt 包管理器开始成型, 软件包数量 – 2250.
|
||||
- **Debian 2.2**: 发布于2000 八月十五日. 项目代号 – Potato, 支持构架 – Intel i386, Motorola 68000 系列, Alpha, SUN Sparc, PowerPC 以及 ARM 构架. 软件包数量: 3900+ (二进制) 以及 2600+ (源代码), 开发者数量 – 450. 有一群人在那时研究并发表了一篇论文, 论文展示了自由软件是如何在被各种问题包围的情况下依然逐步成长为优秀的现代操作系统的.
|
||||
- **Debian 3.0**: 发布于2002 七月十九日. 项目代号 – woody, 支持构架新增– HP, PA_RISC, IA-64, MIPS 以及 IBM, 首次以DVD的形式发布, 软件包数量 – 8500+, 开发者数量 – 900+, 支持加密.
|
||||
- **Debian 3.1**: 发布于2005 六月六日. 项目代号 – sarge, 支持构架 – 不变基础上新增 AMD64 – 非官方渠道发布, 内核 – 2.4 以及 2.6 系列, 软件包数量: 15000+, 开发者数量 : 1500+, 增加了诸如 – OpenOffice 套件, Firefox 浏览器, Thunderbird, Gnome 2.8, 内核版本 3.3 先进地支持了: RAID, XFS, LVM, Modular Installer.
|
||||
- **Debian 4.0**: 发布于2007 四月八日. 项目代号 – etch, 支持构架 – 不变基础上新增 AMD64. 软件包数量: 18,200+ 开发者数量 : 1030+, 图形化安装器.
|
||||
- **Debian 5.0**: Released on February 14th, 发布于2009. 项目代号 – lenny, 支持构架 – 保不变基础上新增 ARM. 软件包数量: 23000+, 开发者数量: 1010+.
|
||||
- **Debian 6.0**: 发布于2009 七月二十九日. 项目代号 – squeeze, 包含的软件包: 内核 2.6.32, Gnome 2.3. Xorg 7.5, 同时包含了 DKMS, 基于依赖包支持. 支持构架 : 不变基础上新增 kfreebsd-i386 以及 kfreebsd-amd64, 基于依赖管理的启动过程.
|
||||
- **Debian 7.0**: 发布于2013 五月四日. 项目代号: wheezy, 支持 Multiarch, 私人云工具, 升级了安装器, 移除了第三方软件依赖, 万能的多媒体套件-codec, 内核版本 3.2, Xen Hypervisor 4.1.4 软件包数量: 37400+.
|
||||
- **Debian 8.0**: 发布于2015 五月二十五日. 项目代号: Jessie, 将 Systemd 作为默认的启动加载器, 内核版本 3.16, 增加了快速启动(fast booting), service进程所依赖的 cgroups 使隔离部分 service 进程成为可能, 43000+ packages. Sysvinit 初始化工具首次在 Jessie 中可用.
|
||||
|
||||
**注意**: Linux的内核第一次是在1991 十月五日被发布, 而 Debian 的首次发布则在1993 九月十三日. 所以 Debian 已经在只有24岁的 Linux 内核上运行了整整22年了.
|
||||
|
||||
### 有关 Debian 的小知识 ###
|
||||
|
||||
1994年被用来管理和重整 Debian 项目以使得其他开发者能更好地加入. 所以在那一年并没有面向用户的更新被发布, 当然, 内部版本肯定是有的.
|
||||
|
||||
Debian 1.0 从来就没有被发布过. 一家 CD-ROM 的生产商错误地把某个未发布的版本标注为了 1.0, 为了避免产生混乱, 原本的 Debian 1.0 以1.1的面貌发布了. 从那以后才有了所谓的官方CD-ROM的概念.
|
||||
|
||||
每个 Debian 新版本的代号都是玩具总动员里某个角色的名字哦.
|
||||
|
||||
Debian 有四种可用版本: 旧稳定版(old stable), 稳定版, 测试版 以及 试验版(experimental). 始终如此.
|
||||
|
||||
Debian 项目组一直致力于开发写一代发行版的不稳定版本, 这个不稳定版本始终被叫做Sid(玩具总动员里那个邪恶的臭小孩). Sid是unstable版本的永久名称, 同时Sid也取自'Still In Development"(译者:还在开发中)的首字母. Sid 将会成为下一个稳定版, 此时的下一个稳定版本代号为 jessie.
|
||||
|
||||
Debian 的官方发行版只包含开源并且免费的软件, 绝无其他东西. 不过contrib 和 不免费的软件包使得安装那些本身免费但是依赖的软件包不免费的软件成为了可能. 那些依赖包本身的证书可能不属于自由/免费软件.
|
||||
|
||||
Debian 是一堆Linux 发行版的母亲. 举几个例子:
|
||||
|
||||
- Damn Small Linux
|
||||
- KNOPPIX
|
||||
- Linux Advanced
|
||||
- MEPIS
|
||||
- Ubuntu
|
||||
- 64studio (不再活跃开发)
|
||||
- LMDE
|
||||
|
||||
Debian 是世界上最大的非商业Linux 发行版.他主要是由C书写的(32.1%), 一并的还有其他70多种语言.
|
||||
|
||||

|
||||
|
||||
Debian Contribution
|
||||
|
||||
图片来源: [Xmodulo][1]
|
||||
|
||||
Debian 项目包含6,850万行代码, 以及, 450万行空格和注释.
|
||||
|
||||
国际空间站放弃了 Windows 和红帽子, 进而换成了Debian - 在上面的宇航员使用落后一个版本的稳定发行版, 目前是squeeze; 这么做是为了稳定程度以及来自 Debian 社区的雄厚帮助支持.
|
||||
|
||||
感谢上帝! 我们差点就听到来自国际空间宇航员面对 Windows Metro 界面的尖叫了 :P
|
||||
|
||||
#### 黑色星期三 ####
|
||||
|
||||
2002 十一月而是日, Twente 大学的 Network Operation Center 着火 (NOC). 当地消防部门放弃了服务器区域. NOC维护了satie.debian.org的网站服务器, 这个网站包含了安全, 非美国相关的存档, 新维护者资料, 数量报告, 数据库; 这一切都化为了灰烬. 之后这些服务被使用 Debian 重新实现了.
|
||||
|
||||
#### 未来版本 ####
|
||||
|
||||
下一个待发布版本是 Debian 9, 项目代号 – Stretch, 它会带来什么还是个未知数. 满心期待吧!
|
||||
|
||||
有很多发行版在 Linux 发行版的历史上出现过一瞬然后很快消失了. 在多数情况下, 维护一个日渐庞大的项目是开发者们面临的挑战. 但这对 Debian 来说不是问题. Debian 项目有全世界成百上千的开发者, 维护者. 它在 Linux 诞生的之初起便一直存在.
|
||||
|
||||
Debian 在 Linux 生态环境中的贡献是难以用语言描述的. 如果 Debian 没有出现过, 那么 Linux 世界将不会像现在这样丰富, 用户友好. Debian 是为数不多可以被认为安全可靠又稳定, 是作为网络服务器完美选择的发行版.
|
||||
|
||||
这仅仅是 Debian 的一个开始. 它从远古时代一路走到今天, 并将一直走下去. 未来即是现在! 世界近在眼前! 如果你到现在还从来没有使用过 Debian, 我只想问, 你还再等什么? 快去下载一份镜像试试吧, 我们会在此守候遇到任何问题的你.
|
||||
|
||||
- [Debian 主页][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/happy-birthday-to-debian-gnu-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[jerryling315](http://moelf.xyz)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://xmodulo.com/2013/08/interesting-facts-about-debian-linux.html
|
||||
[2]:https://www.debian.org/
|
||||
@ -0,0 +1,113 @@
|
||||
安装Strongswan - Linux上一个基于IPsec的vpn工具
|
||||
================================================================================
|
||||
IPsec是一个提供网络层安全的标准。它包含认证头(AH)和安全负载封装(ESP)组件。AH提供包的完整性,ESP组件提供包的保密性。IPsec确保了在网络层的安全特性。
|
||||
|
||||
- 保密性
|
||||
- 数据包完整性
|
||||
- 来源不可抵赖性
|
||||
- 重放攻击防护
|
||||
|
||||
[Strongswan][1]是一个IPsec协议实现的开源代码,Strongswan代表强壮开源广域网(StrongS/WAN)。它支持IPsec的VPN两个版本的密钥自动交换(网络密钥交换(IKE)V1和V2)。
|
||||
|
||||
Strongswan基本上提供了自动交换密钥共享VPN两个节点或网络,然后它使用Linux内核的IPsec(AH和ESP)实现。密钥共享使用了IKE机制的特性使用ESP编码数据。在IKE阶段,strongswan使用OpenSSL加密算法(AES,SHA等等)和其他加密类库。无论如何,ESP组成IPsec使用的安全算法,它是Linux内核实现的。Strongswan的主要特性是下面这些。
|
||||
|
||||
- x.509证书或基于预共享密钥认证
|
||||
- 支持IKEv1和IKEv2密钥交换协议
|
||||
- 可选内置插件和库的完整性和加密测试
|
||||
- 支持椭圆曲线DH群体和ECDSA证书
|
||||
- 在智能卡上存储RSA私钥和证书
|
||||
|
||||
它能被使用在客户端或服务器(road warrior模式)和网关到网关的情景。
|
||||
|
||||
### 如何安装 ###
|
||||
|
||||
几乎所有的Linux发行版都支持Strongswan的二进制包。在这个教程,我们将从二进制包安装strongswan也编译strongswan合适的特性的源代码。
|
||||
|
||||
### 使用二进制包 ###
|
||||
|
||||
可以使用以下命令安装Strongswan到Ubuntu 14.04 LTS
|
||||
|
||||
$sudo aptitude install strongswan
|
||||
|
||||

|
||||
|
||||
strongswan的全局配置(strongswan.conf)文件和ipsec配置(ipsec.conf/ipsec.secrets)文件都在/etc/目录下。
|
||||
|
||||
### strongswan源码编译安装的依赖包 ###
|
||||
|
||||
- GMP(strongswan使用的Mathematical/Precision 库)
|
||||
- OpenSSL(加密算法在这个库里)
|
||||
- PKCS(1,7,8,11,12)(证书编码和智能卡与Strongswan集成)
|
||||
|
||||
#### 步骤 ####
|
||||
|
||||
**1)** 在终端使用下面命令到/usr/src/目录
|
||||
|
||||
$cd /usr/src
|
||||
|
||||
**2)** 用下面命令从strongswan网站下载源代码
|
||||
|
||||
$sudo wget http://download.strongswan.org/strongswan-5.2.1.tar.gz
|
||||
|
||||
(strongswan-5.2.1.tar.gz 是最新版。)
|
||||
|
||||

|
||||
|
||||
**3)** 用下面命令提取下载软件,然后进入目录。
|
||||
|
||||
$sudo tar –xvzf strongswan-5.2.1.tar.gz; cd strongswan-5.2.1
|
||||
|
||||
**4)** 使用configure命令配置strongswan每个想要的选项。
|
||||
|
||||
./configure --prefix=/usr/local -–enable-pkcs11 -–enable-openssl
|
||||
|
||||

|
||||
|
||||
如果GMP库没有安装,然后配置脚本将会发生下面的错误。
|
||||
|
||||

|
||||
|
||||
因此,首先,使用下面命令安装GMP库然后执行配置脚本。
|
||||
|
||||

|
||||
|
||||
无论如何,如果GMP已经安装而且还一致报错,然后在Ubuntu上使用下面命令创建libgmp.so库的软连到/usr/lib,/lib/,/usr/lib/x86_64-linux-gnu/路径下。
|
||||
|
||||
$ sudo ln -s /usr/lib/x86_64-linux-gnu/libgmp.so.10.1.3 /usr/lib/x86_64-linux-gnu/libgmp.so
|
||||
|
||||

|
||||
|
||||
创建libgmp.so软连后,再执行./configure脚本也许就找到gmp库了。无论如何,gmp头文件也许发生其他错误,像下面这样。
|
||||
|
||||

|
||||
|
||||
为解决上面的错误,使用下面命令安装libgmp-dev包
|
||||
|
||||
$sudo aptitude install libgmp-dev
|
||||
|
||||

|
||||
|
||||
安装gmp的开发库后,在运行一遍配置脚本,如果没有发生错误,则将看见下面的这些输出。
|
||||
|
||||

|
||||
|
||||
使用下面的命令编译安装strongswan。
|
||||
|
||||
$ sudo make ; sudo make install
|
||||
|
||||
安装strongswan后,全局配置(strongswan.conf)和ipsec策略/密码配置文件(ipsec.conf/ipsec.secretes)被放在**/usr/local/etc**目录。
|
||||
|
||||
根据我们的安全需要Strongswan可以用作隧道或者传输模式。它提供众所周知的site-2-site模式和road warrior模式的VPN。它很容易使用在Cisco,Juniper设备上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/security/install-strongswan/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
[1]:https://www.strongswan.org/
|
||||
432
translated/tech/20150813 Linux file system hierarchy v2.0.md
Normal file
432
translated/tech/20150813 Linux file system hierarchy v2.0.md
Normal file
@ -0,0 +1,432 @@
|
||||
translating by tnuoccalanosrep
|
||||
Linux文件系统结构 v2.0
|
||||
================================================================================
|
||||
Linux中的文件是什么?它的文件系统又是什么?那些配置文件又在哪里?我下载好的程序保存在哪里了?好了,上图简明地阐释了Linux的文件系统的层次关系。当你苦于寻找配置文件或者二进制文件的时候,这便显得十分有用了。我在下方添加了一些解释以及例子,但“篇幅过长,没有阅读”。
|
||||
|
||||
有一种情况便是当你在系统中获取配置以及二进制文件时,出现了不一致性问题,如果你是一个大型组织,或者只是一个终端用户,这也有可能会破坏你的系统(比如,二进制文件运行在就旧的库文件上了)。若然你在你的Linux系统上做安全审计([security audit of your Linux system][1])的话,你将会发现它很容易遭到不同的攻击。所以,清洁操作(无论是Windows还是Linux)都显得十分重要。
|
||||
### What is a file in Linux? ###
|
||||
Linux的文件是什么?
|
||||
对于UNIX系统来说(同样适用于Linux),以下便是对文件简单的描述:
|
||||
> 在UNIX系统中,一切皆为文件;若非文件,则为进程
|
||||
|
||||
> 这种定义是比较正确的,因为有些特殊的文件不仅仅是普通文件(比如命名管道和套接字),不过为了让事情变的简单,“一切皆为文件”也是一个可以让人接受的说法。Linux系统也像UNXI系统一样,将文件和目录视如同物,因为目录只是一个包含了其他文件名的文件而已。程序,服务,文本,图片等等,都是文件。对于系统来说,输入和输出设备,基本上所有的设备,都被当做是文件。
|
||||

|
||||
|
||||
- Version 2.0 – 17-06-2015
|
||||
- – Improved: 添加标题以及版本历史
|
||||
- – Improved: 添加/srv,/meida和/proc
|
||||
- – Improved: 更新了反映当前的Linux文件系统的描述
|
||||
- – Fixed: 多处的打印错误
|
||||
- – Fixed: 外观和颜色
|
||||
- Version 1.0 – 14-02-2015
|
||||
- – Created: 基本的图表
|
||||
- – Note: 摒弃更低的版本
|
||||
|
||||
### Download Links ###
|
||||
以下是结构图的下载地址。如果你需要其他结构,请跟原作者联系,他会尝试制作并且上传到某个地方以供下载
|
||||
- [Large (PNG) Format – 2480×1755 px – 184KB][2]
|
||||
- [Largest (PDF) Format – 9919x7019 px – 1686KB][3]
|
||||
|
||||
**注意**: PDF格式文件是打印的最好选择,因为它画质很高。
|
||||
### Linux 文件系统描述 ###
|
||||
为了有序地管理那些文件,人们习惯把这些文件当做是硬盘上的有序的类树结构体,正如我们熟悉的'MS-DOS'(硬盘操作系统)。大的分枝包括更多的分枝,分枝的末梢是树的叶子或者普通的文件。现在我们将会以这树形图为例,但晚点我们会发现为什么这不是一个完全准确的一幅图。
|
||||
注:表格
|
||||
<table cellspacing="2" border="4" style="border-collapse: collapse; width: 731px; height: 2617px;">
|
||||
<thead>
|
||||
<tr>
|
||||
<th scope="col">Directory(目录)</th>
|
||||
<th scope="col">Description(描述)</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/</code></dd>
|
||||
</dl></td>
|
||||
<td><i>主层次</i> 的根,也是整个文件系统层次结构的根目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl></td>
|
||||
<td>存放在单用户模式可用的必要命令二进制文件,对于所有用户而言,则是像cat,ls,cp等等的文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/boot</code></dd>
|
||||
</dl></td>
|
||||
<td>存放引导加载程序文件,例如kernels,initrd等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/dev</code></dd>
|
||||
</dl></td>
|
||||
<td>存放必要的设备文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/etc</code></dd>
|
||||
</dl></td>
|
||||
<td>存放主机特定的系统范围内的配置文件。其实这里有个关于它名字本身意义上的的争议。在贝尔实验室的早期UNIX实施文档版本中,/etc表示是“其他目录”,因为从历史上看,这个目录是存放各种不属于其他目录的文件(然而,FSH(文件系统目录标准)限定 /ect是用于存放静态配置文件,这里不该存有二进制文件)。早期文档出版后,这个目录名又重新定义成不同的形式。近期的解释中包含着诸如“可编辑文本配置”或者“额外的工具箱”这样的重定义</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存储着新增包的配置文件 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sgml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存放配置文件,比如目录,还有那些处理SGML(译者注:标准通用标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window系统的配置文件,版本号为11</td>
|
||||
<td></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/xml</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>配置文件,比如目录,处理XML(译者注:可扩展标记语言)的软件的配置文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/home</code></dd>
|
||||
</dl></td>
|
||||
<td>用户的主目录,包括保存的文件, 个人配置, 等等.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl></td>
|
||||
<td><code>/bin/</code> and <code>/sbin/</code>中的二进制文件必不可少的库文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl></td>
|
||||
<td>备用格式的必要的库文件. 这样的目录视可选的,但如果他们存在的话, 他们还有一些要求.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/media</code></dd>
|
||||
</dl></td>
|
||||
<td>可移动的多媒体(如CD-ROMs)的挂载点.(出现于 FHS-2.3)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/mnt</code></dd>
|
||||
</dl></td>
|
||||
<td>临时挂载的文件系统</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl></td>
|
||||
<td>自定义应用程序软件包</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/proc</code></dd>
|
||||
</dl></td>
|
||||
<td>以文件形式提供进程以及内核信息的虚拟文件系统,在Linux中,对应进程文件系统的挂载点</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/root</code></dd>
|
||||
</dl></td>
|
||||
<td>根用户的主目录</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl></td>
|
||||
<td>必要系统二进制文件, <i>比如</i>, init, ip, mount.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/srv</code></dd>
|
||||
</dl></td>
|
||||
<td>系统提供的站点特定数据</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl></td>
|
||||
<td>临时文件 (另见 <code>/var/tmp</code>). 通常在系统重启后删除</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/usr</code></dd>
|
||||
</dl></td>
|
||||
<td><i>二级层级</i> 存储用户的只读数据; 包含(多)用户主要的公共文件以及应用程序</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/bin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>非必要的命令二进制文件 (在单用户模式中不需要用到的); 用于所有用户.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/include</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>标准的包含文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>库文件,用于<code>/usr/bin/</code> 和 <code>/usr/sbin/</code>.中的二进制文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib<qual></code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>备用格式库(可选的).</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/local</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td><i>三级层次</i> 用于本地数据, 具体到该主机上的.通常会有下一个子目录, <i>比如</i>, <code>bin/</code>, <code>lib/</code>, <code>share/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/sbin</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>非必要系统的二进制文件, <i>比如</i>,用于不同网络服务的守护进程</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/share</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>独立架构的 (共享) 数据.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/src</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>源代码, <i>比如</i>, 内核源文件以及与它相关的头文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/X11R6</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>X Window系统,版本号:11,发行版本:6</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd><code>/var</code></dd>
|
||||
</dl></td>
|
||||
<td>各式各样的文件,一些随着系统常规操作而持续改变的文件就放在这里,比如日志文件,脱机文件,还有临时的电子邮件文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/cache</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>应用程序缓存数据. 这些数据是根据I/O(输入/输出)的耗时结果或者是运算生成的.这些应用程序是可以重新生成或者恢复数据的.当没有数据丢失的时候,可以删除缓存文件.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lib</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>状态信息.这些信息随着程序的运行而不停地改变,比如,数据库,系统元数据的打包等等</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/lock</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>锁文件。这些文件会持续监控正在使用的资源</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/log</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>日志文件. 包含各种日志.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>内含用户邮箱的相关文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/opt</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>来自附加包的各种数据都会存储在 <code>/opt/</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/run</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>Information about the running system since last boot, <i>e.g.</i>, currently logged-in users and running <a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons</a>.</td>
|
||||
<td>存放当前系统上次启动的相关信息, <i>例如</i>, 当前登入的用户以及当前运行的<a href="http://en.wikipedia.org/wiki/Daemon_%28computing%29">daemons(守护进程)</a>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/spool</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>该spool主要用于存放将要被处理的任务, <i>比如</i>, 打印队列以及邮件传出队列</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/mail</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>过时的位置,用于放置用户邮箱文件</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><dl>
|
||||
<dd>
|
||||
<dl>
|
||||
<dd><code>/tmp</code></dd>
|
||||
</dl>
|
||||
</dd>
|
||||
</dl></td>
|
||||
<td>存放重启之前的临时接口</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Types of files in Linux ###
|
||||
### Linux的文件类型 ###
|
||||
大多数文件也仅仅是文件,他们被称为`regular`文件;他们包含普通数据,比如,文本,可执行文件,或者程序,程序输入或输出文件等等
|
||||
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
|
||||
虽然你可以认为“在Linux中,一切你看到的皆为文件”这个观点相当保险,但这里仍有着一些例外。
|
||||
|
||||
- `目录`:由其他文件组成的文件
|
||||
- `特殊文件`:用于输入和输出的途径。大多数特殊文件都储存在`/dev`中,我们将会在后面讨论这个问题。
|
||||
- `链接文件`:让文件或者目录在系统文件树结构上可见的机制。我们将详细地讨论这个链接文件。
|
||||
- `(域)套接字`:特殊的文件类型,和TCP/IP协议中的套接字有点像,提供进程网络,并受文件系统的访问控制机制保护。
|
||||
-`命名管道` : 或多或少有点像sockets(套接字),提供一个进程间的通信机制,而不用网络套接字协议。
|
||||
### File system in reality ###
|
||||
### 现实中的文件系统 ###
|
||||
对于大多数用户和常规系统管理任务而言,"文件和目录是一个有序的类树结构"是可以接受的。然而,对于电脑而言,它是不会理解什么是树,或者什么是树结构。
|
||||
|
||||
每个分区都有它自己的文件系统。想象一下,如果把那些文件系统想成一个整体,我们可以构思一个关于整个系统的树结构,不过这并没有这么简单。在文件系统中,一个文件代表着一个`inode`(索引节点),一种包含着构建文件的实际数据信息的序列号:这些数据表示文件是属于谁的,还有它在硬盘中的位置。
|
||||
|
||||
每个分区都有一套属于他们自己的inodes,在一个系统的不同分区中,可以存在有相同inodes的文件。
|
||||
|
||||
每个inode都表示着一种在硬盘上的数据结构,保存着文件的属性,包括文件数据的物理地址。当硬盘被格式化并用来存储数据时(通常发生在初始系统安装过程,或者是在一个已经存在的系统中添加额外的硬盘),每个分区都会创建关于inodes的固定值。这个值表示这个分区能够同时存储各类文件的最大数量。我们通常用一个inode去映射2-8k的数据块。当一个新的文件生成后,它就会获得一个空闲的indoe。在这个inode里面存储着以下信息:
|
||||
|
||||
- 文件属主和组属主
|
||||
- 文件类型(常规文件,目录文件......)
|
||||
- 文件权限
|
||||
- 创建、最近一次读文件和修改文件的时间
|
||||
- inode里该信息被修改的时间
|
||||
- 文件的链接数(详见下一章)
|
||||
- 文件大小
|
||||
- 文件数据的实际地址
|
||||
|
||||
唯一不在inode的信息是文件名和目录。它们存储在特殊的目录文件。通过比较文件名和inodes的数目,系统能够构造出一个便于用户理解的树结构。用户可以通过ls -i查看inode的数目。在硬盘上,inodes有他们独立的空间。
|
||||
|
||||
|
||||
|
||||
via: http://www.blackmoreops.com/2015/06/18/linux-file-system-hierarchy-v2-0/
|
||||
|
||||
译者:[译者ID](https://github.com/tnuoccalanosrep)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.blackmoreops.com/2015/02/15/in-light-of-recent-linux-exploits-linux-security-audit-is-a-must/
|
||||
[2]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-file-system-hierarchy-v2.0-2480px-blackMORE-Ops.png
|
||||
[3]:http://www.blackmoreops.com/wp-content/uploads/2015/06/Linux-File-System-Hierarchy-blackMORE-Ops.pdf
|
||||
@ -0,0 +1,166 @@
|
||||
|
||||
Linux/UNIX: Bash 下如何逐行读取一个文件
|
||||
================================================================================
|
||||
在 Linux 或类 UNIX 系统下如何使用 KSH 或 BASH shell 逐行读取一个文件?
|
||||
|
||||
在 Linux, OSX, * BSD ,或者类 Unix 系统下你可以使用while..do..done bash 的循环来逐行读取一个文件。
|
||||
|
||||
**在 Bash Unix 或者 Linux shell 中逐行读取一个文件的语法:**
|
||||
|
||||
1.对于 bash, ksh, zsh,和其他的 shells 语法如下 -
|
||||
1. while read -r line; do COMMAND; done < input.file
|
||||
1.通过 -r 选项传递给红色的命令阻止反斜杠被解释。
|
||||
1.在 read 命令之前添加 IFS= option,来防止 leading/trailing 尾随的空白字符被分割 -
|
||||
1. while IFS= read -r line; do COMMAND_on $line; done < input.file
|
||||
|
||||
这是更适合人类阅读的语法:
|
||||
|
||||
#!/bin/bash
|
||||
input="/path/to/txt/file"
|
||||
while IFS= read -r var
|
||||
do
|
||||
echo "$var"
|
||||
done < "$input"
|
||||
|
||||
**示例**
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
#!/bin/ksh
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
echo "$line"
|
||||
done <"$file"
|
||||
|
||||
在 bash shell 中相同的例子:
|
||||
|
||||
#!/bin/bash
|
||||
file="/home/vivek/data.txt"
|
||||
while IFS= read -r line
|
||||
do
|
||||
# display $line or do somthing with $line
|
||||
printf '%s\n' "$line"
|
||||
done <"$file"
|
||||
|
||||
你还可以看看这个更好的:
|
||||
|
||||
#!/bin/bash
|
||||
file="/etc/passwd"
|
||||
while IFS=: read -r f1 f2 f3 f4 f5 f6 f7
|
||||
do
|
||||
# display fields using f1, f2,..,f7
|
||||
printf 'Username: %s, Shell: %s, Home Dir: %s\n' "$f1" "$f7" "$f6"
|
||||
done <"$file"
|
||||
|
||||
示例输出:
|
||||
|
||||
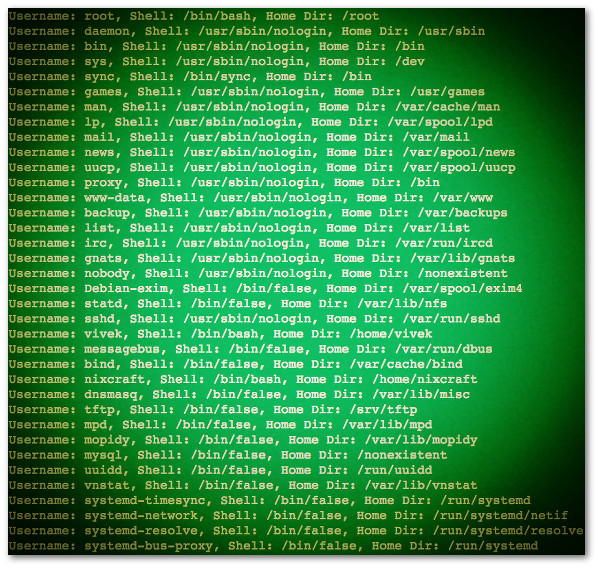
|
||||
|
||||
图01:Bash shell scripting- 读取文件并逐行输出文件
|
||||
|
||||
**Bash Scripting: 逐行读取文本文件并创建为 pdf 文件**
|
||||
|
||||
我的输入文件如下(faq.txt):
|
||||
|
||||
4|http://www.cyberciti.biz/faq/mysql-user-creation/|Mysql User Creation: Setting Up a New MySQL User Account
|
||||
4096|http://www.cyberciti.biz/faq/ksh-korn-shell/|What is UNIX / Linux Korn Shell?
|
||||
4101|http://www.cyberciti.biz/faq/what-is-posix-shell/|What Is POSIX Shell?
|
||||
17267|http://www.cyberciti.biz/faq/linux-check-battery-status/|Linux: Check Battery Status Command
|
||||
17245|http://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/|Linux Restart NTPD Service Command
|
||||
17183|http://www.cyberciti.biz/faq/ubuntu-linux-determine-your-ip-address/|Ubuntu Linux: Determine Your IP Address
|
||||
17172|http://www.cyberciti.biz/faq/determine-ip-address-of-linux-server/|HowTo: Determine an IP Address My Linux Server
|
||||
16510|http://www.cyberciti.biz/faq/unix-linux-restart-php-service-command/|Linux / Unix: Restart PHP Service Command
|
||||
8292|http://www.cyberciti.biz/faq/mounting-harddisks-in-freebsd-with-mount-command/|FreeBSD: Mount Hard Drive / Disk Command
|
||||
8190|http://www.cyberciti.biz/faq/rebooting-solaris-unix-server/|Reboot a Solaris UNIX System
|
||||
|
||||
我的 bash script:
|
||||
|
||||
#!/bin/bash
|
||||
# Usage: Create pdf files from input (wrapper script)
|
||||
# Author: Vivek Gite <Www.cyberciti.biz> under GPL v2.x+
|
||||
#---------------------------------------------------------
|
||||
|
||||
#Input file
|
||||
_db="/tmp/wordpress/faq.txt"
|
||||
|
||||
#Output location
|
||||
o="/var/www/prviate/pdf/faq"
|
||||
|
||||
_writer="~/bin/py/pdfwriter.py"
|
||||
|
||||
# If file exists
|
||||
if [[ -f "$_db" ]]
|
||||
then
|
||||
# read it
|
||||
while IFS='|' read -r pdfid pdfurl pdftitle
|
||||
do
|
||||
local pdf="$o/$pdfid.pdf"
|
||||
echo "Creating $pdf file ..."
|
||||
#Genrate pdf file
|
||||
$_writer --quiet --footer-spacing 2 \
|
||||
--footer-left "nixCraft is GIT UL++++ W+++ C++++ M+ e+++ d-" \
|
||||
--footer-right "Page [page] of [toPage]" --footer-line \
|
||||
--footer-font-size 7 --print-media-type "$pdfurl" "$pdf"
|
||||
done <"$_db"
|
||||
fi
|
||||
|
||||
**提示:从 bash 的变量开始读取**
|
||||
|
||||
让我们看看如何在 Debian 或者 Ubuntu Linux 下列出所有安装过的 php 包,请输入:
|
||||
|
||||
# 我将输出内容赋值到一个变量名为$list中 #
|
||||
|
||||
list=$(dpkg --list php\* | awk '/ii/{print $2}')
|
||||
printf '%s\n' "$list"
|
||||
|
||||
示例输出:
|
||||
|
||||
php-pear
|
||||
php5-cli
|
||||
php5-common
|
||||
php5-fpm
|
||||
php5-gd
|
||||
php5-json
|
||||
php5-memcache
|
||||
php5-mysql
|
||||
php5-readline
|
||||
php5-suhosin-extension
|
||||
|
||||
你现在可以从 $list 中看到安装的包:
|
||||
|
||||
#!/bin/bash
|
||||
# BASH can iterate over $list variable using a "here string" #
|
||||
while IFS= read -r pkg
|
||||
do
|
||||
printf 'Installing php package %s...\n' "$pkg"
|
||||
/usr/bin/apt-get -qq install $pkg
|
||||
done <<< "$list"
|
||||
printf '*** Do not forget to run php5enmod and restart the server (httpd or php5-fpm) ***\n'
|
||||
|
||||
示例输出:
|
||||
|
||||
Installing php package php-pear...
|
||||
Installing php package php5-cli...
|
||||
Installing php package php5-common...
|
||||
Installing php package php5-fpm...
|
||||
Installing php package php5-gd...
|
||||
Installing php package php5-json...
|
||||
Installing php package php5-memcache...
|
||||
Installing php package php5-mysql...
|
||||
Installing php package php5-readline...
|
||||
Installing php package php5-suhosin-extension...
|
||||
|
||||
|
||||
*** 不要忘了运行php5enmod并重新启动服务(httpd 或 php5-fpm) ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/unix-howto-read-line-by-line-from-file/
|
||||
|
||||
作者:[作者名][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,220 @@
|
||||
Translating by Xuanwo
|
||||
|
||||
Part 1 - LFCS系列第一讲:如何在Linux上使用GNU'sed'命令来创建、编辑和操作文件
|
||||
================================================================================
|
||||
Linux基金会宣布了一个全新的LFCS(Linux Foundation Certified Sysadmin,Linux基金会认证系统管理员)认证计划。这一计划旨在帮助遍布全世界的人们获得其在处理Linux系统管理任务上能力的认证。这些能力包括支持运行的系统服务,以及第一手的故障诊断和分析和为工程师团队在升级时提供智能决策。
|
||||
|
||||

|
||||
|
||||
Linux基金会认证系统管理员——第一讲
|
||||
|
||||
请观看下面关于Linux基金会认证计划的演示:
|
||||
|
||||
<embed src="http://static.video.qq.com/TPout.swf?vid=l0163eohhs9&auto=0" allowFullScreen="true" quality="high" width="480" height="400" align="middle" allowScriptAccess="always" type="application/x-shockwave-flash"></embed>
|
||||
|
||||
该系列将命名为《LFCS预备第一讲》至《LFCS预备第十讲》并覆盖关于Ubuntu,CentOS以及openSUSE的下列话题。
|
||||
|
||||
- 第一讲:如何在Linux上使用GNU'sed'命令来创建、编辑和操作文件
|
||||
- 第二讲:如何安装和使用vi/m全功能文字编辑器
|
||||
- 第三讲:归档文件/目录和在文件系统中寻找文件
|
||||
- 第四讲:为存储设备分区,格式化文件系统和配置交换分区
|
||||
- 第五讲:在Linux中挂载/卸载本地和网络(Samba & NFS)文件系统
|
||||
- 第六讲:组合分区作为RAID设备——创建&管理系统备份
|
||||
- 第七讲:管理系统启动进程和服务(使用SysVinit, Systemd 和 Upstart)
|
||||
- 第八讲:管理用户和组,文件权限和属性以及启用账户的sudo权限
|
||||
- 第九讲:Linux包管理与Yum,RPM,Apt,Dpkg,Aptitude,Zypper
|
||||
- 第十讲:学习简单的Shell脚本和文件系统故障排除
|
||||
|
||||
本文是覆盖这个参加LFCS认证考试的所必需的范围和能力的十个教程的第一讲。话虽如此,快打开你的终端,让我们开始吧!
|
||||
|
||||
### 处理Linux中的文本流 ###
|
||||
|
||||
Linux将程序中的输入和输出当成字符流或者字符序列。在开始理解重定向和管道之前,我们必须先了解三种最重要的I/O(Input and Output,输入和输出)流,事实上,它们都是特殊的文件(根据UNIX和Linux中的约定,数据流和外围设备或者设备文件也被视为普通文件)。
|
||||
|
||||
> (重定向操作符) 和 | (管道操作符)之间的区别是:前者将命令与文件相连接,而后者将命令的输出和另一个命令相连接。
|
||||
|
||||
# command > file
|
||||
# command1 | command2
|
||||
|
||||
由于重定向操作符静默创建或覆盖文件,我们必须特别小心谨慎地使用它,并且永远不要把它和管道混淆起来。在Linux和UNIX系统上管道的优势是:第一个命令的输出不会写入一个文件而是直接被第二个命令读取。
|
||||
|
||||
在下面的操作练习中,我们将会使用这首诗——《A happy child》(匿名作者)
|
||||
|
||||

|
||||
|
||||
cat command example
|
||||
|
||||
#### 使用 sed ####
|
||||
|
||||
sed是流编辑器(stream editor)的缩写。为那些不懂术语的人额外解释一下,流编辑器是用来在一个输入流(文件或者管道中的输入)执行基本的文本转换的工具。
|
||||
|
||||
sed最基本的用法是字符替换。我们将通过把每个出现的小写y改写为大写Y并且将输出重定向到ahappychild2.txt开始。g标志表示sed应该替换文件每一行中所有应当替换的实例。如果这个标志省略了,sed将会只替换每一行中第一次出现的实例。
|
||||
|
||||
**基本语法:**
|
||||
|
||||
# sed ‘s/term/replacement/flag’ file
|
||||
|
||||
**我们的样例:**
|
||||
|
||||
# sed ‘s/y/Y/g’ ahappychild.txt > ahappychild2.txt
|
||||
|
||||

|
||||
|
||||
sed command example
|
||||
|
||||
如果你要在替换文本中搜索或者替换特殊字符(如/,\,&),你需要使用反斜杠对它进行转义。
|
||||
|
||||
例如,我们将会用一个符号来替换一个文字。与此同时,我们将把一行最开始出现的第一个I替换为You。
|
||||
|
||||
# sed 's/and/\&/g;s/^I/You/g' ahappychild.txt
|
||||
|
||||

|
||||
|
||||
sed replace string
|
||||
|
||||
在上面的命令中,^(插入符号)是众所周知用来表示一行开头的正则表达式。
|
||||
|
||||
正如你所看到的,我们可以通过使用分号分隔以及用括号包裹来把两个或者更多的替换命令(并在他们中使用正则表达式)链接起来。
|
||||
|
||||
另一种sed的用法是显示或者删除文件中选中的一部分。在下面的样例中,将会显示/var/log/messages中从6月8日开始的头五行。
|
||||
|
||||
# sed -n '/^Jun 8/ p' /var/log/messages | sed -n 1,5p
|
||||
|
||||
请注意,在默认的情况下,sed会打印每一行。我们可以使用-n选项来覆盖这一行为并且告诉sed只需要打印(用p来表示)文件(或管道)中匹配的部分(第一种情况下行开头的第一个6月8日以及第二种情况下的一到五行*此处翻译欠妥,需要修正*)。
|
||||
|
||||
最后,可能有用的技巧是当检查脚本或者配置文件的时候可以保留文件本身并且删除注释。下面的单行sed命令删除(d)空行或者是开头为`#`的行(|字符返回两个正则表达式之间的布尔值)。
|
||||
|
||||
# sed '/^#\|^$/d' apache2.conf
|
||||
|
||||

|
||||
|
||||
sed match string
|
||||
|
||||
#### uniq C命令 ####
|
||||
|
||||
uniq命令允许我们返回或者删除文件中重复的行,默认写入标准输出。我们必须注意到,除非两个重复的行相邻,否则uniq命令不会删除他们。因此,uniq经常和前序排序(此处翻译欠妥)(一种用来对文本行进行排序的算法)搭配使用。默认情况下,排序使用第一个字段(用空格分隔)作为关键字段。要指定一个不同的关键字段,我们需要使用-k选项。
|
||||
|
||||
**样例**
|
||||
|
||||
du –sch /path/to/directory/* 命令将会以人类可读的格式返回在指定目录下每一个子文件夹和文件的磁盘空间使用情况(也会显示每个目录总体的情况),而且不是按照大小输出,而是按照子文件夹和文件的名称。我们可以使用下面的命令来让它通过大小排序。
|
||||
|
||||
# du -sch /var/* | sort –h
|
||||
|
||||

|
||||
|
||||
sort command example
|
||||
|
||||
你可以通过使用下面的命令告诉uniq比较每一行的前6个字符(-w 6)(指定了不同的日期)来统计日志事件的个数,而且在每一行的开头输出出现的次数(-c)。
|
||||
|
||||
|
||||
# cat /var/log/mail.log | uniq -c -w 6
|
||||
|
||||

|
||||
|
||||
Count Numbers in File
|
||||
|
||||
最后,你可以组合使用sort和uniq命令(通常如此)。考虑下面文件中捐助者,捐助日期和金额的列表。假设我们想知道有多少个捐助者。我们可以使用下面的命令来分隔第一字段(字段由冒号分隔),按名称排序并且删除重复的行。
|
||||
|
||||
# cat sortuniq.txt | cut -d: -f1 | sort | uniq
|
||||
|
||||

|
||||
|
||||
Find Unique Records in File
|
||||
|
||||
- 也可阅读: [13个“cat”命令样例][1]
|
||||
|
||||
#### grep 命令 ####
|
||||
|
||||
grep在文件(或命令输出)中搜索指定正则表达式并且在标准输出中输出匹配的行。
|
||||
|
||||
**样例**
|
||||
|
||||
显示文件/etc/passwd中用户gacanepa的信息,忽略大小写。
|
||||
|
||||
# grep -i gacanepa /etc/passwd
|
||||
|
||||

|
||||
|
||||
grep command example
|
||||
|
||||
显示/etc文件夹下所有rc开头并跟随任意数字的内容。
|
||||
|
||||
# ls -l /etc | grep rc[0-9]
|
||||
|
||||

|
||||
|
||||
List Content Using grep
|
||||
|
||||
- 也可阅读: [12个“grep”命令样例][2]
|
||||
|
||||
#### tr Command Usage ####
|
||||
|
||||
tr命令可以用来从标准输入中翻译(改变)或者删除字符并将结果写入到标准输出中。
|
||||
|
||||
**样例**
|
||||
|
||||
把sortuniq.txt文件中所有的小写改为大写。
|
||||
|
||||
# cat sortuniq.txt | tr [:lower:] [:upper:]
|
||||
|
||||

|
||||
|
||||
Sort Strings in File
|
||||
|
||||
压缩`ls –l`输出中的定界符至一个空格。
|
||||
# ls -l | tr -s ' '
|
||||
|
||||

|
||||
|
||||
Squeeze Delimiter
|
||||
|
||||
#### cut 命令使用方法 ####
|
||||
|
||||
cut命令可以基于字节数(-b选项),字符(-c)或者字段(-f)提取部分输入(从标准输入或者文件中)并且将结果输出到标准输出。在最后一种情况下(基于字段),默认的字段分隔符是一个tab,但不同的分隔符可以由-d选项来指定。
|
||||
|
||||
**样例**
|
||||
|
||||
从/etc/passwd中提取用户账户和他们被分配的默认shell(-d选项允许我们指定分界符,-f选项指定那些字段将被提取)。
|
||||
|
||||
# cat /etc/passwd | cut -d: -f1,7
|
||||
|
||||

|
||||
|
||||
Extract User Accounts
|
||||
|
||||
总结一下,我们将使用最后一个命令的输出中第一和第三个非空文件创建一个文本流。我们将使用grep作为第一过滤器来检查用户gacanepa的会话,然后将分隔符压缩至一个空格(tr -s ' ')。下一步,我们将使用cut来提取第一和第三个字段,最后使用第二个字段(本样例中,指的是IP地址)来排序之后再用uniq去重。
|
||||
|
||||
# last | grep gacanepa | tr -s ‘ ‘ | cut -d’ ‘ -f1,3 | sort -k2 | uniq
|
||||
|
||||

|
||||
|
||||
last command example
|
||||
|
||||
上面的命令显示了如何将多个命令和管道结合起来以便根据我们的愿望得到过滤后的数据。你也可以逐步地使用它以帮助你理解输出是如何从一个命令传输到下一个命令的(顺便说一句,这是一个非常好的学习经验!)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
尽管这个例子(以及在当前教程中的其他实例)第一眼看上去可能不是非常有用,但是他们是体验在Linux命令行中创建,编辑和操作文件的一个非常好的开始。请随时留下你的问题和意见——不胜感激!
|
||||
|
||||
#### 参考链接 ####
|
||||
|
||||
- [关于LFCS][3]
|
||||
- [为什么需要Linux基金会认证?][4]
|
||||
- [注册LFCS考试][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[Xuanwo](https://github.com/Xuanwo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/12-practical-examples-of-linux-grep-command/
|
||||
[3]:https://training.linuxfoundation.org/certification/LFCS
|
||||
[4]:https://training.linuxfoundation.org/certification/why-certify-with-us
|
||||
[5]:https://identity.linuxfoundation.org/user?destination=pid/1
|
||||
@ -0,0 +1,182 @@
|
||||
|
||||
在 Raid 中扩展现有的 RAID 阵列和删除故障的磁盘 - 第7部分
|
||||
================================================================================
|
||||
每个新手都会对阵列的意思产生疑惑。阵列只是磁盘的一个集合。换句话说,我们可以称阵列为一个集合或一组。就像一组鸡蛋中包含6个。同样 RAID 阵列中包含着多个磁盘,可能是2,4,6,8,12,16等,希望你现在知道了什么是阵列。
|
||||
|
||||
在这里,我们将看到如何扩展现有的阵列或 raid 组。例如,如果我们在一组 raid 中使用2个磁盘形成一个 raid 1,在某些情况,如果该组中需要更多的空间,就可以使用mdadm -grow 命令来扩展阵列大小,只是将一个磁盘加入到现有的阵列中。在扩展(添加磁盘到现有的阵列中)后,我们将看看如何从阵列中删除故障的磁盘。
|
||||
|
||||

|
||||
|
||||
扩展 RAID 阵列和删除故障的磁盘
|
||||
|
||||
假设磁盘中的一个有问题了需要删除该磁盘,但我们需要添加一个备用磁盘来扩展该镜像再删除磁盘前,因为我们需要保存数据。当磁盘发生故障时我们需要从阵列中删除它,这是这个主题中我们将要学习到的。
|
||||
|
||||
#### 扩展 RAID 的特性 ####
|
||||
|
||||
- 我们可以增加(扩大)所有 RAID 集和的大小。
|
||||
- 我们在使用新磁盘扩展 RAID 阵列后删除故障的磁盘。
|
||||
- 我们可以扩展 RAID 阵列不存在宕机时间。
|
||||
|
||||
要求
|
||||
|
||||
- 为了扩展一个RAID阵列,我们需要已有的 RAID 组(阵列)。
|
||||
- 我们需要额外的磁盘来扩展阵列。
|
||||
- 在这里,我们使用一块磁盘来扩展现有的阵列。
|
||||
|
||||
在我们了解扩展和恢复阵列前,我们必须了解有关 RAID 级别和设置的基本知识。点击下面的链接了解这些。
|
||||
|
||||
- [理解 RAID 的基础概念 – 第一部分][1]
|
||||
- [在 Linux 中创建软件 Raid 0 – 第二部分][2]
|
||||
|
||||
#### 我的服务器设置 ####
|
||||
|
||||
操作系统 : CentOS 6.5 Final
|
||||
IP地址 : 192.168.0.230
|
||||
主机名 : grow.tecmintlocal.com
|
||||
2 块现有磁盘 : 1 GB
|
||||
1 块额外磁盘 : 1 GB
|
||||
|
||||
在这里,现有的 RAID 有2块磁盘,每个大小为1GB,我们现在再增加一个磁盘到我们现有的 RAID 阵列中,其大小为1GB。
|
||||
|
||||
### 扩展现有的 RAID 阵列 ###
|
||||
|
||||
1. 在扩展阵列前,首先使用下面的命令列出现有的 RAID 阵列。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
检查现有的 RAID 阵列
|
||||
|
||||
**注意**: 以上输出显示,已经有了两个磁盘在 RAID 阵列中,级别为 RAID 1。现在我们在这里再增加一个磁盘到现有的阵列。
|
||||
|
||||
2.现在让我们添加新的磁盘“sdd”,并使用‘fdisk‘命令来创建分区。
|
||||
|
||||
# fdisk /dev/sdd
|
||||
|
||||
请使用以下步骤为 /dev/sdd 创建一个新的分区。
|
||||
|
||||
- 按 ‘n’ 创建新的分区。
|
||||
- 然后按 ‘P’ 选择主分区。
|
||||
- 接下来选择分区号为1。
|
||||
- 只需按两次回车键选择默认值即可。
|
||||
- 然后,按 ‘P’ 来打印创建好的分区。
|
||||
- 按 ‘L’,列出所有可用的类型。
|
||||
- 按 ‘t’ 去修改分区。
|
||||
- 键入 ‘fd’ 设置为 Linux 的 RAID 类型,然后按 Enter 确认。
|
||||
- 然后再次使用‘p’查看我们所做的更改。
|
||||
- 使用‘w’保存更改。
|
||||
|
||||

|
||||
|
||||
为 sdd 创建新的分区
|
||||
|
||||
3. 一旦新的 sdd 分区创建完成后,你可以使用下面的命令验证它。
|
||||
|
||||
# ls -l /dev/ | grep sd
|
||||
|
||||

|
||||
|
||||
确认 sdd 分区
|
||||
|
||||
4.接下来,在添加到阵列前先检查磁盘是否有 RAID 分区。
|
||||
|
||||
# mdadm --examine /dev/sdd1
|
||||
|
||||

|
||||
|
||||
在 sdd 分区中检查 raid
|
||||
|
||||
**注意**:以上输出显示,该盘有没有发现 super-blocks,意味着我们可以将新的磁盘添加到现有阵列。
|
||||
|
||||
4. 要添加新的分区 /dev/sdd1 到现有的阵列 md0,请使用以下命令。
|
||||
|
||||
# mdadm --manage /dev/md0 --add /dev/sdd1
|
||||
|
||||

|
||||
|
||||
添加磁盘到 Raid 阵列
|
||||
|
||||
5. 一旦新的磁盘被添加后,在我们的阵列中检查新添加的磁盘。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
确认将新磁盘添加到 Raid 中
|
||||
|
||||
**注意**: 在上面的输出,你可以看到磁盘已经被添加作为备用的。在这里,我们的阵列中已经有了2个磁盘,但我们期待阵列中有3个磁盘,因此我们需要扩展阵列。
|
||||
|
||||
6. 要扩展阵列,我们需要使用下面的命令。
|
||||
|
||||
# mdadm --grow --raid-devices=3 /dev/md0
|
||||
|
||||

|
||||
|
||||
扩展 Raid 阵列
|
||||
|
||||
现在我们可以看到第三块磁盘(sdd1)已被添加到阵列中,在第三块磁盘被添加后,它将从另外两块磁盘上同步数据。
|
||||
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
确认 Raid 阵列
|
||||
|
||||
**注意**: 对于容量磁盘会需要几个小时来同步数据。在这里,我们使用的是1GB的虚拟磁盘,所以它非常快在几秒钟内便会完成。
|
||||
|
||||
### 从阵列中删除磁盘 ###
|
||||
|
||||
7. 在数据被从其他两个磁盘同步到新磁盘‘sdd1‘后,现在三个磁盘中的数据已经相同了。
|
||||
|
||||
正如我前面所说的,假定一个磁盘出问题了需要被删除。所以,现在假设磁盘‘sdc1‘出问题了,需要从现有阵列中删除。
|
||||
|
||||
在删除磁盘前我们要将其标记为 failed,然后我们才可以将其删除。
|
||||
|
||||
# mdadm --fail /dev/md0 /dev/sdc1
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
在 Raid 阵列中模拟磁盘故障
|
||||
|
||||
从上面的输出中,我们清楚地看到,磁盘在底部被标记为 faulty。即使它是 faulty 的,我们仍然可以看到 raid 设备有3个,1个损坏了 state 是 degraded。
|
||||
|
||||
现在我们要从阵列中删除 faulty 的磁盘,raid 设备将像之前一样继续有2个设备。
|
||||
|
||||
# mdadm --remove /dev/md0 /dev/sdc1
|
||||
|
||||

|
||||
|
||||
在 Raid 阵列中删除磁盘
|
||||
|
||||
8. 一旦故障的磁盘被删除,然后我们只能使用2个磁盘来扩展 raid 阵列了。
|
||||
|
||||
# mdadm --grow --raid-devices=2 /dev/md0
|
||||
# mdadm --detail /dev/md0
|
||||
|
||||

|
||||
|
||||
在 RAID 阵列扩展磁盘
|
||||
|
||||
从上面的输出中可以看到,我们的阵列中仅有2台设备。如果你需要再次扩展阵列,按照同样的步骤,如上所述。如果你需要添加一个磁盘作为备用,将其标记为 spare,因此,如果磁盘出现故障时,它会自动顶上去并重建数据。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经看到了如何扩展现有的 RAID 集合,以及如何从一个阵列中删除故障磁盘在重新同步已有磁盘的数据后。所有这些步骤都可以不用停机来完成。在数据同步期间,系统用户,文件和应用程序不会受到任何影响。
|
||||
|
||||
在接下来的文章我将告诉你如何管理 RAID,敬请关注更新,不要忘了写评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/grow-raid-array-in-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/understanding-raid-setup-in-linux/
|
||||
[2]:http://www.tecmint.com/create-raid0-in-linux/
|
||||
@ -0,0 +1,224 @@
|
||||
RHCSA 系列: 如何管理RHEL7的用户和组 – Part 3
|
||||
================================================================================
|
||||
和管理其他Linux服务器一样,管理一个 RHEL 7 服务器 要求你能够添加,修改,暂停或删除用户帐户,并且授予他们文件,目录,其他系统资源所必要的权限。
|
||||

|
||||
|
||||
RHCSA: 用户和组管理 – Part 3
|
||||
|
||||
### 管理用户帐户##
|
||||
|
||||
如果想要给RHEL 7 服务器添加账户,你需要以root用户执行如下两条命令
|
||||
|
||||
# adduser [new_account]
|
||||
# useradd [new_account]
|
||||
|
||||
当添加新的用户帐户时,默认会执行下列操作。
|
||||
|
||||
- 他/她 的主目录就会被创建(一般是"/home/用户名",除非你特别设置)
|
||||
- 一些隐藏文件 如`.bash_logout`, `.bash_profile` 以及 `.bashrc` 会被复制到用户的主目录,并且会为用户的回话提供环境变量.你可以进一步查看他们的相关细节。
|
||||
- 会为您的账号添加一个邮件池目录
|
||||
- 会创建一个和用户名同样的组
|
||||
|
||||
用户帐户的全部信息被保存在`/etc/passwd `文件。这个文件以如下格式保存了每一个系统帐户的所有信息(以:分割)
|
||||
[username]:[x]:[UID]:[GID]:[Comment]:[Home directory]:[Default shell]
|
||||
|
||||
- `[username]` 和`[Comment]` 是用于自我解释的
|
||||
- ‘x’表示帐户的密码保护(详细在`/etc/shadow`文件),就是我们用于登录的`[username]`.
|
||||
- `[UID]` 和`[GID]`是用于显示`[username]` 的 用户认证和主用户组。
|
||||
|
||||
最后,
|
||||
|
||||
- `[Home directory]`显示`[username]`的主目录的绝对路径
|
||||
- `[Default shell]` 是当用户登录系统后使用的默认shell
|
||||
|
||||
另外一个你必须要熟悉的重要的文件是存储组信息的`/etc/group`.因为和`/etc/passwd`类似,所以也是由:分割
|
||||
[Group name]:[Group password]:[GID]:[Group members]
|
||||
|
||||
|
||||
|
||||
- `[Group name]` 是组名
|
||||
- 这个组是否使用了密码 (如果是"X"意味着没有).
|
||||
- `[GID]`: 和`/etc/passwd`中一样
|
||||
- `[Group members]`:用户列表,使用,隔开。里面包含组内的所有用户
|
||||
|
||||
添加过帐户后,任何时候你都可以通过 usermod 命令来修改用户战壕沟,基础的语法如下:
|
||||
# usermod [options] [username]
|
||||
|
||||
相关阅读
|
||||
|
||||
- [15 ‘useradd’ Command Examples][1]
|
||||
- [15 ‘usermod’ Command Examples][2]
|
||||
|
||||
#### 示例1 : 设置帐户的过期时间 ####
|
||||
|
||||
如果你的公司有一些短期使用的帐户或者你相应帐户在有限时间内使用,你可以使用 `--expiredate` 参数 ,后加YYYY-MM-DD格式的日期。为了查看是否生效,你可以使用如下命令查看
|
||||
# chage -l [username]
|
||||
|
||||
帐户更新前后的变动如下图所示
|
||||

|
||||
|
||||
修改用户信息
|
||||
|
||||
#### 示例 2: 向组内追加用户 ####
|
||||
|
||||
除了创建用户时的主用户组,一个用户还能被添加到别的组。你需要使用 -aG或 -append -group 选项,后跟逗号分隔的组名
|
||||
#### 示例 3: 修改用户主目录或默认Shell ####
|
||||
|
||||
如果因为一些原因,你需要修改默认的用户主目录(一般为 /home/用户名),你需要使用 -d 或 -home 参数,后跟绝对路径来修改主目录
|
||||
如果有用户想要使用其他的shell来取代bash(比如sh ),一般默认是bash .使用 usermod ,并使用 -shell 的参数,后加新的shell的路径
|
||||
#### 示例 4: 展示组内的用户 ####
|
||||
|
||||
当把用户添加到组中后,你可以使用如下命令验证属于哪一个组
|
||||
|
||||
# groups [username]
|
||||
# id [username]
|
||||
|
||||
下面图片的演示了示例2到示例四
|
||||
|
||||

|
||||
|
||||
添加用户到额外的组
|
||||
|
||||
在上面的示例中:
|
||||
|
||||
# usermod --append --groups gacanepa,users --home /tmp --shell /bin/sh tecmint
|
||||
|
||||
如果想要从组内删除用户,省略 `--append` 切换,并且可以使用 `--groups` 来列举组内的用户
|
||||
|
||||
#### 示例 5: 通过锁定密码来停用帐户 ####
|
||||
|
||||
如果想要关闭帐户,你可以使用 -l(小写的L)或 -lock 选项来锁定用户的密码。这将会阻止用户登录。
|
||||
|
||||
#### 示例 6: 解锁密码 ####
|
||||
|
||||
当你想要重新启用帐户让他可以继续登录时,属于 -u 或 –unlock 选项来解锁用户的密码,就像示例5 介绍的那样
|
||||
|
||||
# usermod --unlock tecmint
|
||||
|
||||
下面的图片展示了示例5和示例6
|
||||
|
||||

|
||||
|
||||
锁定上锁用户
|
||||
|
||||
#### 示例 7:删除组和用户 ####
|
||||
|
||||
如果要删除一个组,你需要使用 groupdel ,如果需要删除用户 你需要使用 userdel (添加 -r 可以删除主目录和邮件池的内容)
|
||||
# groupdel [group_name] # 删除组
|
||||
# userdel -r [user_name] # 删除用户,并删除主目录和邮件池
|
||||
|
||||
如果一些文件属于组,他们将不会被删除。但是组拥有者将会被设置为删除掉的组的GID
|
||||
### 列举,设置,并且修改 ugo/rwx 权限 ###
|
||||
|
||||
著名的 [ls 命令][3] 是管理员最好的助手. 当我们使用 -l 参数, 这个工具允许您查看一个目录中的内容(或详细格式).
|
||||
|
||||
而且,该命令还可以应用于单个文件中。无论哪种方式,在“ls”输出中的前10个字符表示每个文件的属性。
|
||||
这10个字符序列的第一个字符用于表示文件类型:
|
||||
|
||||
- – (连字符): 一个标准文件
|
||||
- d: 一个目录
|
||||
- l: 一个符号链接
|
||||
- c: 字符设备(将数据作为字节流,即一个终端)
|
||||
- b: 块设备(处理数据块,即存储设备)
|
||||
|
||||
文件属性的下一个九个字符,分为三个组,被称为文件模式,并注明读(r),写(w),并执行(x)授予文件的所有者,文件的所有组,和其他的用户(通常被称为“世界”)。
|
||||
在文件的读取权限允许打开和读取相同的权限时,允许其内容被列出,如果还设置了执行权限,还允许它作为一个程序和运行。
|
||||
文件权限是通过chmod命令改变的,它的基本语法如下:
|
||||
|
||||
# chmod [new_mode] file
|
||||
|
||||
new_mode是一个八进制数或表达式,用于指定新的权限。适合每一个随意的案例。或者您已经有了一个更好的方式来设置文件的权限,所以你觉得可以自由地使用最适合你自己的方法。
|
||||
八进制数可以基于二进制等效计算,可以从所需的文件权限的文件的所有者,所有组,和世界。一定权限的存在等于2的幂(R = 22,W = 21,x = 20),没有时意为0。例如:
|
||||

|
||||
|
||||
文件权限
|
||||
|
||||
在八进制形式下设置文件的权限,如上图所示
|
||||
|
||||
# chmod 744 myfile
|
||||
|
||||
请用一分钟来对比一下我们以前的计算,在更改文件的权限后,我们的实际输出为:
|
||||
|
||||

|
||||
|
||||
长列表格式
|
||||
|
||||
#### 示例 8: 寻找777权限的文件 ####
|
||||
|
||||
出于安全考虑,你应该确保在正常情况下,尽可能避免777权限(读、写、执行的文件)。虽然我们会在以后的教程中教你如何更有效地找到所有的文件在您的系统的权限集的说明,你现在仍可以使用LS grep获取这种信息。
|
||||
在下面的例子,我们会寻找 /etc 目录下的777权限文件. 注意,我们要使用第二章讲到的管道的知识[第二章:文件和目录管理][4]:
|
||||
|
||||
# ls -l /etc | grep rwxrwxrwx
|
||||
|
||||

|
||||
|
||||
查找所有777权限的文件
|
||||
|
||||
#### 示例 9: 为所有用户指定特定权限 ####
|
||||
|
||||
shell脚本,以及一些二进制文件,所有用户都应该有权访问(不只是其相应的所有者和组),应该有相应的执行权限(我们会讨论特殊情况下的问题):
|
||||
# chmod a+x script.sh
|
||||
|
||||
**注意**: 我们可以设置文件模式使用表示用户权限的字母如“u”,组所有者权限的字母“g”,其余的为o 。所有权限为a.权限可以通过`+` 或 `-` 来管理。
|
||||
|
||||

|
||||
|
||||
为文件设置执行权限
|
||||
|
||||
长目录列表还显示了该文件的所有者和其在第一和第二列中的组主。此功能可作为系统中文件的第一级访问控制方法:
|
||||
|
||||

|
||||
|
||||
检查文件的属主和属组
|
||||
|
||||
改变文件的所有者,您将使用chown命令。请注意,您可以在同一时间或单独的更改文件的所有权:
|
||||
# chown user:group file
|
||||
|
||||
虽然可以在同一时间更改用户或组,或在同一时间的两个属性,但是不要忘记冒号区分,如果你想要更新其他属性,让另外的选项保持空白:
|
||||
# chown :group file # Change group ownership only
|
||||
# chown user: file # Change user ownership only
|
||||
|
||||
#### 示例 10:从一个文件复制权限到另一个文件####
|
||||
|
||||
If you would like to “clone” ownership from one file to another, you can do so using the –reference flag, as follows:
|
||||
如果你想“克隆”一个文件的所有权到另一个,你可以这样做,使用–reference参数,如下:
|
||||
# chown --reference=ref_file file
|
||||
|
||||
ref_file的所有信息会复制给 file
|
||||
|
||||

|
||||
|
||||
复制文件属主信息
|
||||
|
||||
### 设置 SETGID 协作目录 ###
|
||||
|
||||
你应该授予在一个特定的目录中拥有访问所有的文件的权限给一个特点的用户组,你将有可能使用目录设置setgid的方法。当setgid后设置,真实用户的有效GID成为团队的主人。
|
||||
因此,任何用户都可以访问该文件的组所有者授予的权限的文件。此外,当setgid设置在一个目录中,新创建的文件继承同一组目录,和新创建的子目录也将继承父目录的setgid。
|
||||
# chmod g+s [filename]
|
||||
|
||||
为了设置 setgid 在八进制形式,预先准备好数字2 来给基本的权限
|
||||
# chmod 2755 [directory]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
扎实的用户和组管理知识,符合规则的,Linux权限管理,以及部分实践,可以帮你快速解决RHEL 7 服务器的文件权限。
|
||||
我向你保证,当你按照本文所概述的步骤和使用系统文档(和第一章解释的那样 [Part 1: Reviewing Essential Commands & System Documentation][5] of this series) 你将掌握基本的系统管理的能力。
|
||||
|
||||
请随时让我们知道你是否有任何问题或意见使用下面的表格。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-exam-manage-users-and-groups/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/add-users-in-linux/
|
||||
[2]:http://www.tecmint.com/usermod-command-examples/
|
||||
[3]:http://www.tecmint.com/ls-interview-questions/
|
||||
[4]:http://www.tecmint.com/file-and-directory-management-in-linux/
|
||||
[5]:http://www.tecmint.com/rhcsa-exam-reviewing-essential-commands-system-documentation/
|
||||
@ -0,0 +1,215 @@
|
||||
RHCSA 系列:安全 SSH,设定主机名及开启网络服务 – Part 8
|
||||
================================================================================
|
||||
作为一名系统管理员,你将经常使用一个终端模拟器来登陆到一个远程的系统中,执行一系列的管理任务。你将很少有机会坐在一个真实的(物理)终端前,所以你需要设定好一种方法来使得你可以登陆到你被要求去管理的那台远程主机上。
|
||||
|
||||
事实上,当你必须坐在一台物理终端前的时候,就可能是你登陆到该主机的最后一种方法。基于安全原因,使用 Telnet 来达到以上目的并不是一个好主意,因为穿行在线缆上的流量并没有被加密,它们以文本方式在传送。
|
||||
|
||||
另外,在这篇文章中,我们也将复习如何配置网络服务来使得它在开机时被自动开启,并学习如何设置网络和静态或动态地解析主机名。
|
||||
|
||||

|
||||
|
||||
RHCSA: 安全 SSH 和开启网络服务 – Part 8
|
||||
|
||||
### 安装并确保 SSH 通信安全 ###
|
||||
|
||||
对于你来说,要能够使用 SSH 远程登陆到一个 RHEL 7 机子,你必须安装 `openssh`,`openssh-clients` 和 `openssh-servers` 软件包。下面的命令不仅将安装远程登陆程序,也会安装安全的文件传输工具以及远程文件复制程序:
|
||||
|
||||
# yum update && yum install openssh openssh-clients openssh-servers
|
||||
|
||||
注意,安装上服务器所需的相应软件包是一个不错的主意,因为或许在某个时刻,你想使用同一个机子来作为客户端和服务器。
|
||||
|
||||
在安装完成后,如若你想安全地访问你的 SSH 服务器,你还需要考虑一些基本的事情。下面的设定应该在文件 `/etc/ssh/sshd_config` 中得以呈现。
|
||||
|
||||
1. 更改 sshd 守护进程的监听端口,从 22(默认的端口值)改为一个更高的端口值(2000 或更大),但首先要确保所选的端口没有被占用。
|
||||
|
||||
例如,让我们假设你选择了端口 2500 。使用 [netstat][1] 来检查所选的端口是否被占用:
|
||||
|
||||
# netstat -npltu | grep 2500
|
||||
|
||||
假如 netstat 没有返回任何信息,则你可以安全地为 sshd 使用端口 2500,并且你应该在上面的配置文件中更改端口的设定,具体如下:
|
||||
|
||||
Port 2500
|
||||
|
||||
2. 只允许协议 2:
|
||||
|
||||
Protocol 2
|
||||
|
||||
3. 配置验证超时的时间为 2 分钟,不允许以 root 身份登陆,并将允许通过 ssh 登陆的人数限制到最小:
|
||||
|
||||
LoginGraceTime 2m
|
||||
PermitRootLogin no
|
||||
AllowUsers gacanepa
|
||||
|
||||
4. 假如可能,使用基于公钥的验证方式而不是使用密码:
|
||||
|
||||
PasswordAuthentication no
|
||||
RSAAuthentication yes
|
||||
PubkeyAuthentication yes
|
||||
|
||||
这假设了你已经在你的客户端机子上创建了带有你的用户名的一个密钥对,并将公钥复制到了你的服务器上。
|
||||
|
||||
- [开启 SSH 无密码登陆][2]
|
||||
|
||||
### 配置网络和名称的解析 ###
|
||||
|
||||
1. 每个系统管理员应该对下面这个系统配置文件非常熟悉:
|
||||
|
||||
- /etc/hosts 被用来在小型网络中解析名称 <---> IP 地址。
|
||||
|
||||
文件 `/etc/hosts` 中的每一行拥有如下的结构:
|
||||
|
||||
IP address - Hostname - FQDN
|
||||
|
||||
例如,
|
||||
|
||||
192.168.0.10 laptop laptop.gabrielcanepa.com.ar
|
||||
|
||||
2. `/etc/resolv.conf` 特别指定 DNS 服务器的 IP 地址和搜索域,它被用来在没有提供域名后缀时,将一个给定的查询名称对应为一个全称域名。
|
||||
|
||||
在正常情况下,你不必编辑这个文件,因为它是由系统管理的。然而,若你非要改变 DNS 服务器的 IP 地址,建议你在该文件的每一行中,都应该遵循下面的结构:
|
||||
|
||||
nameserver - IP address
|
||||
|
||||
例如,
|
||||
|
||||
nameserver 8.8.8.8
|
||||
|
||||
3. `/etc/host.conf` 特别指定在一个网络中主机名被解析的方法和顺序。换句话说,告诉名称解析器使用哪个服务,并以什么顺序来使用。
|
||||
|
||||
尽管这个文件由几个选项,但最为常见和基本的设置包含如下的一行:
|
||||
|
||||
order bind,hosts
|
||||
|
||||
它意味着解析器应该首先查看 `resolv.conf` 中特别指定的域名服务器,然后到 `/etc/hosts` 文件中查找解析的名称。
|
||||
|
||||
4. `/etc/sysconfig/network` 包含了所有网络接口的路由和全局主机信息。下面的值可能会被使用:
|
||||
|
||||
NETWORKING=yes|no
|
||||
HOSTNAME=value
|
||||
|
||||
其中的 value 应该是全称域名(FQDN)。
|
||||
|
||||
GATEWAY=XXX.XXX.XXX.XXX
|
||||
|
||||
其中的 XXX.XXX.XXX.XXX 是网关的 IP 地址。
|
||||
|
||||
GATEWAYDEV=value
|
||||
|
||||
在一个带有多个网卡的机器中, value 为网关设备名,例如 enp0s3。
|
||||
|
||||
5. 位于 `/etc/sysconfig/network-scripts` 中的文件(网络适配器配置文件)。
|
||||
|
||||
在上面提到的目录中,你将找到几个被命名为如下格式的文本文件。
|
||||
|
||||
ifcfg-name
|
||||
|
||||
其中 name 为网卡的名称,由 `ip link show` 返回:
|
||||
|
||||

|
||||
|
||||
检查网络连接状态
|
||||
|
||||
例如:
|
||||
|
||||

|
||||
|
||||
网络文件
|
||||
|
||||
除了环回接口,你还可以为你的网卡进行一个相似的配置。注意,假如设定了某些变量,它们将为这个特别的接口,覆盖掉 `/etc/sysconfig/network` 中定义的值。在这篇文章中,为了能够解释清楚,每行都被加上了注释,但在实际的文件中,你应该避免加上注释:
|
||||
|
||||
HWADDR=08:00:27:4E:59:37 # The MAC address of the NIC
|
||||
TYPE=Ethernet # Type of connection
|
||||
BOOTPROTO=static # This indicates that this NIC has been assigned a static IP. If this variable was set to dhcp, the NIC will be assigned an IP address by a DHCP server and thus the next two lines should not be present in that case.
|
||||
IPADDR=192.168.0.18
|
||||
NETMASK=255.255.255.0
|
||||
GATEWAY=192.168.0.1
|
||||
NM_CONTROLLED=no # Should be added to the Ethernet interface to prevent NetworkManager from changing the file.
|
||||
NAME=enp0s3
|
||||
UUID=14033805-98ef-4049-bc7b-d4bea76ed2eb
|
||||
ONBOOT=yes # The operating system should bring up this NIC during boot
|
||||
|
||||
### 设定主机名 ###
|
||||
|
||||
在 RHEL 7 中, `hostnamectl` 命令被同时用来查询和设定系统的主机名。
|
||||
|
||||
要展示当前的主机名,输入:
|
||||
|
||||
# hostnamectl status
|
||||
|
||||

|
||||
|
||||
检查系统的主机名
|
||||
|
||||
要更改主机名,使用
|
||||
|
||||
# hostnamectl set-hostname [new hostname]
|
||||
|
||||
例如,
|
||||
|
||||
# hostnamectl set-hostname cinderella
|
||||
|
||||
要想使得更改生效,你需要重启 hostnamed 守护进程(这样你就不必因为要应用更改而登出系统并再登陆系统):
|
||||
|
||||
# systemctl restart systemd-hostnamed
|
||||
|
||||

|
||||
|
||||
设定系统主机名
|
||||
|
||||
另外, RHEL 7 还包含 `nmcli` 工具,它可被用来达到相同的目的。要展示主机名,运行:
|
||||
|
||||
# nmcli general hostname
|
||||
|
||||
且要改变主机名,则运行:
|
||||
|
||||
# nmcli general hostname [new hostname]
|
||||
|
||||
例如,
|
||||
|
||||
# nmcli general hostname rhel7
|
||||
|
||||

|
||||
|
||||
使用 nmcli 命令来设定主机名
|
||||
|
||||
### 在开机时开启网络服务 ###
|
||||
|
||||
作为本文的最后部分,就让我们看看如何确保网络服务在开机时被自动开启。简单来说,这个可通过创建符号链接到某些由服务的配置文件中的 [Install] 小节中指定的文件来实现。
|
||||
|
||||
以 firewalld(/usr/lib/systemd/system/firewalld.service) 为例:
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
Alias=dbus-org.fedoraproject.FirewallD1.service
|
||||
|
||||
要开启该服务,运行:
|
||||
|
||||
# systemctl enable firewalld
|
||||
|
||||
另一方面,要禁用 firewalld,则需要移除符号链接:
|
||||
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
|
||||
在开机时开启服务
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇文章中,我们总结了如何安装 SSH 及使用它安全地连接到一个 RHEL 服务器,如何改变主机名,并在最后如何确保在系统启动时开启服务。假如你注意到某个服务启动失败,你可以使用 `systemctl status -l [service]` 和 `journalctl -xn` 来进行排错。
|
||||
|
||||
请随意使用下面的评论框来让我们知晓你对本文的看法。提问也同样欢迎。我们期待着你的反馈!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/rhcsa-series-secure-ssh-set-hostname-enable-network-services-in-rhel-7/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
|
||||
[2]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
|
||||
Loading…
Reference in New Issue
Block a user