mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-18 02:00:18 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
4720607372
@ -0,0 +1,199 @@
|
||||
如何在 Linux 系统查询机器最近重启时间
|
||||
======
|
||||
|
||||
在你的 Linux 或类 UNIX 系统中,你是如何查询系统上次重新启动的日期和时间?怎样显示系统关机的日期和时间? `last` 命令不仅可以按照时间从近到远的顺序列出该会话的特定用户、终端和主机名,而且还可以列出指定日期和时间登录的用户。输出到终端的每一行都包括用户名、会话终端、主机名、会话开始和结束的时间、会话持续的时间。要查看 Linux 或类 UNIX 系统重启和关机的时间和日期,可以使用下面的命令。
|
||||
|
||||
- `last` 命令
|
||||
- `who` 命令
|
||||
|
||||
|
||||
### 使用 who 命令来查看系统重新启动的时间/日期
|
||||
|
||||
你需要在终端使用 [who][1] 命令来打印有哪些人登录了系统,`who` 命令同时也会显示上次系统启动的时间。使用 `last` 命令来查看系统重启和关机的日期和时间,运行:
|
||||
|
||||
```
|
||||
$ who -b
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
system boot 2017-06-20 17:41
|
||||
```
|
||||
|
||||
使用 `last` 命令来查询最近登录到系统的用户和系统重启的时间和日期。输入:
|
||||
|
||||
```
|
||||
$ last reboot | less
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![Fig.01: last command in action][2]][2]
|
||||
|
||||
或者,尝试输入:
|
||||
|
||||
```
|
||||
$ last reboot | head -1
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
reboot system boot 4.9.0-3-amd64 Sat Jul 15 19:19 still running
|
||||
```
|
||||
|
||||
`last` 命令通过查看文件 `/var/log/wtmp` 来显示自 wtmp 文件被创建时的所有登录(和登出)的用户。每当系统重新启动时,这个伪用户 `reboot` 就会登录。因此,`last reboot` 命令将会显示自该日志文件被创建以来的所有重启信息。
|
||||
|
||||
### 查看系统上次关机的时间和日期
|
||||
|
||||
可以使用下面的命令来显示上次关机的日期和时间:
|
||||
|
||||
```
|
||||
$ last -x|grep shutdown | head -1
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
shutdown system down 2.6.15.4 Sun Apr 30 13:31 - 15:08 (01:37)
|
||||
```
|
||||
|
||||
命令中,
|
||||
|
||||
* `-x`:显示系统关机和运行等级改变信息
|
||||
|
||||
|
||||
这里是 `last` 命令的其它的一些选项:
|
||||
|
||||
```
|
||||
$ last
|
||||
$ last -x
|
||||
$ last -x reboot
|
||||
$ last -x shutdown
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.01: How to view last Linux System Reboot Date/Time ][3]
|
||||
|
||||
### 查看系统正常的运行时间
|
||||
|
||||
评论区的读者建议的另一个命令如下:
|
||||
|
||||
```
|
||||
$ uptime -s
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
2017-06-20 17:41:51
|
||||
```
|
||||
|
||||
### OS X/Unix/FreeBSD 查看最近重启和关机时间的命令示例
|
||||
|
||||
在终端输入下面的命令:
|
||||
|
||||
```
|
||||
$ last reboot
|
||||
```
|
||||
|
||||
在 OS X 示例输出结果如下:
|
||||
|
||||
```
|
||||
reboot ~ Fri Dec 18 23:58
|
||||
reboot ~ Mon Dec 14 09:54
|
||||
reboot ~ Wed Dec 9 23:21
|
||||
reboot ~ Tue Nov 17 21:52
|
||||
reboot ~ Tue Nov 17 06:01
|
||||
reboot ~ Wed Nov 11 12:14
|
||||
reboot ~ Sat Oct 31 13:40
|
||||
reboot ~ Wed Oct 28 15:56
|
||||
reboot ~ Wed Oct 28 11:35
|
||||
reboot ~ Tue Oct 27 00:00
|
||||
reboot ~ Sun Oct 18 17:28
|
||||
reboot ~ Sun Oct 18 17:11
|
||||
reboot ~ Mon Oct 5 09:35
|
||||
reboot ~ Sat Oct 3 18:57
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
查看关机日期和时间,输入:
|
||||
|
||||
```
|
||||
$ last shutdown
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
shutdown ~ Fri Dec 18 23:57
|
||||
shutdown ~ Mon Dec 14 09:53
|
||||
shutdown ~ Wed Dec 9 23:20
|
||||
shutdown ~ Tue Nov 17 14:24
|
||||
shutdown ~ Mon Nov 16 21:15
|
||||
shutdown ~ Tue Nov 10 13:15
|
||||
shutdown ~ Sat Oct 31 13:40
|
||||
shutdown ~ Wed Oct 28 03:10
|
||||
shutdown ~ Sun Oct 18 17:27
|
||||
shutdown ~ Mon Oct 5 09:23
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
### 如何查看是谁重启和关闭机器?
|
||||
|
||||
你需要[启用 psacct 服务然后运行下面的命令][4]来查看执行过的命令(包括用户名),在终端输入 [lastcomm][5] 命令查看信息
|
||||
|
||||
```
|
||||
# lastcomm userNameHere
|
||||
# lastcomm commandNameHere
|
||||
# lastcomm | more
|
||||
# lastcomm reboot
|
||||
# lastcomm shutdown
|
||||
### 或者查看重启和关机时间
|
||||
# lastcomm | egrep 'reboot|shutdown'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
reboot S X root pts/0 0.00 secs Sun Dec 27 23:49
|
||||
shutdown S root pts/1 0.00 secs Sun Dec 27 23:45
|
||||
```
|
||||
|
||||
我们可以看到 root 用户在当地时间 12 月 27 日星期二 23:49 在 pts/0 重新启动了机器。
|
||||
|
||||
### 参见
|
||||
|
||||
* 更多信息可以查看 man 手册(`man last`)和参考文章 [如何在 Linux 服务器上使用 tuptime 命令查看历史和统计的正常的运行时间][6]。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创立者,同时也是一名经验丰富的系统管理员,也是 Linux,类 Unix 操作系统 shell 脚本的培训师。他曾与全球各行各业的客户工作过,包括 IT,教育,国防和空间研究以及非营利部门等等。你可以在 [Twitter][7]、[Facebook][8]、[Google+][9] 关注他。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-last-reboot-time-and-date-find-out.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/unix-linux-who-command-examples-syntax-usage/ "See Linux/Unix who command examples for more info"
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2006/04/last-reboot.jpg
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2006/04/check-last-time-system-was-rebooted.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/howto-log-user-activity-using-process-accounting.html
|
||||
[5]:https://www.cyberciti.biz/faq/linux-unix-lastcomm-command-examples-usage-syntax/ "See Linux/Unix lastcomm command examples for more info"
|
||||
[6]:https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,10 +1,11 @@
|
||||
我在 Twitch 平台直播编程的第一年
|
||||
我在 Twitch 平台直播编程的经验
|
||||
============================================================
|
||||
去年 7 月我进行了第一次直播。不像大多数人那样在 Twitch 上进行游戏直播,我想直播的内容是我利用个人时间进行的开源工作。我对 NodeJS 硬件库有一定的研究(其中大部分是靠我自学的)。考虑到我已经在 Twitch 上有了一个直播间,为什么不再建一个更小更专业的直播间,比如使用 <ruby>JavaScript 驱动硬件<rt>JavaScript powered hardware</rt></ruby> 来建立直播间 :) 我注册了 [我自己的频道][1] ,从那以后我就开始定期直播。
|
||||
|
||||
去年 7 月我进行了第一次直播。不像大多数人那样在 Twitch 上进行游戏直播,我想直播的内容是我利用个人时间进行的开源工作。我对 NodeJS 硬件库有一定的研究(其中大部分是靠我自学的)。考虑到我已经在 Twitch 上有了一个直播间,为什么不再建一个更小更专业的直播间,比如 <ruby>由 JavaScript 驱动的硬件<rt>JavaScript powered hardware</rt></ruby> ;) 我注册了 [我自己的频道][1] ,从那以后我就开始定期直播。
|
||||
|
||||
我当然不是第一个这么做的人。[Handmade Hero][2] 是我最早看到的几个在线直播编程的程序员之一。很快这种直播方式被 Vlambeer 发扬光大,他在 Twitch 的 [Nuclear Throne live][3] 直播间进行直播。我对 Vlambeer 尤其着迷。
|
||||
|
||||
我的朋友 [Nolan Lawson][4] 让我 _真正开始做_ 这件事,而不只是单纯地 _想要做_ 。我看了他 [在周末直播开源工作][5] ,做得棒极了。他解释了他当时做的每一件事。每一件事。回复 GitHub 上的 <ruby>问题<rt>issues</rt></ruby> ,鉴别 bug ,在 <ruby>分支<rt>branches</rt></ruby> 中调试程序,你知道的。这令我着迷,因为 Nolan 使他的开源库得到了广泛的使用。他的开源生活和我的完全不一样。
|
||||
我的朋友 [Nolan Lawson][4] 让我 _真正开始做_ 这件事,而不只是单纯地 _想要做_ 。我看了他 [在周末直播开源工作][5] ,做得棒极了。他解释了他当时做的每一件事。是的,每一件事,包括回复 GitHub 上的 <ruby>问题<rt>issues</rt></ruby> ,鉴别 bug ,在 <ruby>分支<rt>branches</rt></ruby> 中调试程序,你知道的。这令我着迷,因为 Nolan 使他的开源库得到了广泛的使用。他的开源生活和我的完全不一样。
|
||||
|
||||
你甚至可以看到我在他视频下的评论:
|
||||
|
||||
@ -14,27 +15,27 @@
|
||||
|
||||
那个星期六我极少的几个听众给了我很大的鼓舞,因此我坚持了下去。现在我有了超过一千个听众,他们中的一些人形成了一个可爱的小团体,他们会定期观看我的直播,我称呼他们为 “noopkat 家庭” 。
|
||||
|
||||
我们很开心。我想称呼这个即时编程部分为“多玩家在线组队编程”。我真的被他们每个人的热情和才能触动了。一次,一个团体成员指出我的 Arduino 开发板没有连接上软件,因为板子上的芯片丢了。这真是最有趣的时刻之一。
|
||||
我们很开心。我想称呼这个即时编程部分为“多玩家在线组队编程”。我真的被他们每个人的热情和才能触动了。一次,一个团体成员指出我的 Arduino 开发板不能随同我的软件工作,因为板子上的芯片丢了。这真是最有趣的时刻之一。
|
||||
|
||||
我经常暂停直播,检查我的收件箱,看看有没有人对我提过的,不再有时间完成的工作发起 <ruby>拉取请求<rt>pull request</rt></ruby> 。感谢我 Twitch 社区对我的帮助和鼓励。
|
||||
我经常暂停直播,检查我的收件箱,看看有没有人对我提及过但没有时间完成的工作发起 <ruby>拉取请求<rt>pull request</rt></ruby> 。感谢我 Twitch 社区对我的帮助和鼓励。
|
||||
|
||||
我很想聊聊 Twitch 直播给我带来的好处,但它的内容太多了,我应该会在我下一个博客里介绍。我在这里想要分享的,是我学习的关于如何自己实现直播编程的课程。最近几个开发者问我怎么开始自己的直播,因此我在这里想大家展示我给他们的建议!
|
||||
我很想聊聊 Twitch 直播给我带来的好处,但它的内容太多了,我应该会在我下一篇博客里介绍。我在这里想要分享的,是我学习的关于如何自己实现直播编程的课程。最近几个开发者问我怎么开始自己的直播,因此我在这里想大家展示我给他们的建议!
|
||||
|
||||
首先,我在这里贴出一个给过我很大帮助的教程 [“Streaming and Finding Success on Twitch”][7] 。它专注于 Twitch 与游戏直播,但也有很多和我们要做的东西相关的部分。我建议首先阅读这个教程,然后再考虑一些建立直播频道的细节(比如如何选择设备和软件)。
|
||||
|
||||
下面我列出我自己的配置。这些配置是从我多次的错误经验中总结出来的,其中要感谢我的直播同行的智慧与建议(对,你们知道就是你们!)。
|
||||
下面我列出我自己的配置。这些配置是从我多次的错误经验中总结出来的,其中要感谢我的直播同行的智慧与建议。(对,你们知道就是你们!)
|
||||
|
||||
### 软件
|
||||
|
||||
有很多免费的直播软件。我用的是 [Open Broadcaster Software (OBS)][8] 。它适用于大多数的平台。我觉得它十分直观且易于入门,但掌握其他的进阶功能则需要一段时间的学习。学好它你会获得很多好处!这是今天我直播时 OBS 的桌面截图(点击查看大图):
|
||||
有很多免费的直播软件。我用的是 [Open Broadcaster Software (OBS)][8] 。它适用于大多数的平台。我觉得它十分直观且易于入门,但掌握其他的进阶功能则需要一段时间的学习。学好它你会获得很多好处!这是今天我直播时 OBS 的桌面截图:
|
||||
|
||||

|
||||
|
||||
你直播时需要在不用的“场景”中进行切换。一个“场景”是多个“素材”通过堆叠和组合产生的集合。一个“素材”可以是照相机,麦克风,你的桌面,网页,动态文本,图片等等。 OBS 是一个很强大的软件。
|
||||
你直播时需要在不用的“<ruby>场景<rt>scenes</rt></ruby>”中进行切换。一个“场景”是多个“<ruby>素材<rt>sources</rt></ruby>”通过堆叠和组合产生的集合。一个“素材”可以是照相机、麦克风、你的桌面、网页、动态文本、图片等等。 OBS 是一个很强大的软件。
|
||||
|
||||
最上方的桌面场景是我编程的环境,我直播的时候主要停留在这里。我使用 iTerm 和 vim ,同时打开一个可以切换的浏览器窗口来查阅文献或在 GitHub 上分类检索资料。
|
||||
|
||||
底部的黑色长方形是我的网络摄像头,人们可以通过这种个人化的连接方式来观看我工作。
|
||||
底部的黑色长方形是我的网络摄像头,人们可以通过这种更个人化的连接方式来观看我工作。
|
||||
|
||||
我的场景中有一些“标签”,很多都与状态或者顶栏信息有关。顶栏只是添加了个性化信息,它在直播时是一个很好的连续性素材。这是我在 [GIMP][9] 里制作的图片,在你的场景里它会作为一个素材来加载。一些标签是从文本文件里添加的动态内容(例如最新粉丝)。另一个标签是一个 [custom one I made][10] ,它可以展示我直播的房间的动态温度与湿度。
|
||||
|
||||
@ -62,7 +63,7 @@
|
||||
|
||||
### 硬件
|
||||
|
||||
我从使用便宜的器材开始,当我意识到我会长期坚持直播之后,才将他们逐渐换成更好的。开始的时候尽量使用你现有的器材,即使是只用电脑内置的摄像头与麦克风。
|
||||
我从使用便宜的器材开始,当我意识到我会长期坚持直播之后,才将它们逐渐换成更好的。开始的时候尽量使用你现有的器材,即使是只用电脑内置的摄像头与麦克风。
|
||||
|
||||
现在我使用 Logitech Pro C920 网络摄像头,和一个固定有支架的 Blue Yeti 麦克风。花费是值得的。我直播的质量完全不同了。
|
||||
|
||||
@ -116,7 +117,7 @@
|
||||
|
||||
当你即将开始的时候,你会感觉很奇怪,不适应。你会在人们看着你写代码的时候感到紧张。这很正常!尽管我之前有过公共演说的经历,我一开始的时候还是感到陌生而不适应。我感觉我无处可藏,这令我害怕。我想:“大家可能都觉得我的代码很糟糕,我是一个糟糕的开发者。”这是一个困扰了我 _整个职业生涯_ 的想法,对我来说不新鲜了。我知道带着这些想法,我不能在发布到 GitHub 之前仔细地再检查一遍代码,而这样做更有利于我保持我作为开发者的声誉。
|
||||
|
||||
我从 Twitch 直播中发现了很多关于我代码风格的东西。我知道我的风格绝对是“先让它跑起来,然后再考虑可读性,然后再考虑运行速度”。我不再在前一天晚上提前排练好直播的内容(一开始的三四次直播我都是这么做的),所以我在 Twitch 上写的代码是相当粗糙的,我还得保证它们运行起来没问题。当我不看别人的聊天和讨论的时候,我可以写出我最好的代码,这样是没问题的。但我总会忘记我使用过无数遍的方法的名字,而且每次直播的时候都会犯“愚蠢的”错误。一般来说,这不是一个让你能达到你最好状态的生产环境。
|
||||
我从 Twitch 直播中发现了很多关于我代码风格的东西。我知道我的风格绝对是“先让它跑起来,然后再考虑可读性,然后再考虑运行速度”。我不再在前一天晚上提前排练好直播的内容(一开始的三、四次直播我都是这么做的),所以我在 Twitch 上写的代码是相当粗糙的,我还得保证它们运行起来没问题。当我不看别人的聊天和讨论的时候,我可以写出我最好的代码,这样是没问题的。但我总会忘记我使用过无数遍的方法的名字,而且每次直播的时候都会犯“愚蠢的”错误。一般来说,这不是一个让你能达到你最好状态的生产环境。
|
||||
|
||||
我的 Twitch 社区从来不会因为这个苛求我,反而是他们帮了我很多。他们理解我正同时做着几件事,而且真的给了很多务实的意见和建议。有时是他们帮我找到了解决方法,有时是我要向他们解释为什么他们的建议不适合解决这个问题。这真的很像一般意义的组队编程!
|
||||
|
||||
@ -128,7 +129,7 @@
|
||||
|
||||
如果你周日想要加入我的直播,你可以 [订阅我的 Twitch 频道][13] :)
|
||||
|
||||
最后我想说一下,我个人十分感谢 [Mattias Johansson][14] 在我早期开始直播的时候给我的建议和鼓励。他的 [FunFunFunction YouTube channel][15] 也是一个令人激动的定期直播频道。
|
||||
最后我想说一下,我自己十分感谢 [Mattias Johansson][14] 在我早期开始直播的时候给我的建议和鼓励。他的 [FunFunFunction YouTube channel][15] 也是一个令人激动的定期直播频道。
|
||||
|
||||
另:许多人问过我的键盘和其他工作设备是什么样的, [这是我使用的器材的完整列表][16] 。感谢关注!
|
||||
|
||||
@ -136,9 +137,9 @@
|
||||
|
||||
via: https://medium.freecodecamp.org/lessons-from-my-first-year-of-live-coding-on-twitch-41a32e2f41c1
|
||||
|
||||
作者:[ Suz Hinton][a]
|
||||
作者:[Suz Hinton][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
103
published/20180131 Why you should use named pipes on Linux.md
Normal file
103
published/20180131 Why you should use named pipes on Linux.md
Normal file
@ -0,0 +1,103 @@
|
||||
为什么应该在 Linux 上使用命名管道
|
||||
======
|
||||
|
||||
> 命名管道并不常用,但是它们为进程间通讯提供了一些有趣的特性。
|
||||
|
||||

|
||||
|
||||
估计每一位 Linux 使用者都熟悉使用 “|” 符号将数据从一个进程传输到另一个进程的操作。它使用户能简便地从一个命令输出数据到另一个命令,并筛选出想要的数据而无须写脚本进行选择、重新格式化等操作。
|
||||
|
||||
还有另一种管道, 虽然也叫“管道”这个名字却有着非常不同的性质。即您可能尚未使用甚至尚未知晓的——命名管道。
|
||||
|
||||
普通管道与命名管道的一个主要区别就是命名管道是以文件形式实实在在地存在于文件系统中的,没错,它们表现出来就是文件。但是与其它文件不同的是,命名管道文件似乎从来没有文件内容。即使用户往命名管道中写入大量数据,该文件看起来还是空的。
|
||||
|
||||
### 如何在 Linux 上创建命名管道
|
||||
|
||||
在我们研究这些空空如也的命名管道之前,先追根溯源来看看命名管道是如何被创建的。您应该使用名为 `mkfifo` 的命令来创建它们。为什么提及“FIFO”?是因为命名管道也被认为是一种 FIFO 特殊文件。术语 “FIFO” 指的是它的<ruby>先进先出<rt>first-in, first-out</rt></ruby>特性。如果你将冰淇淋盛放到碟子中,然后可以品尝它,那么你执行的就是一个LIFO(<ruby>后进先出<rt>last-in, first-out</rt></ruby>操作。如果你通过吸管喝奶昔,那你就在执行一个 FIFO 操作。好,接下来是一个创建命名管道的例子。
|
||||
|
||||
```
|
||||
$ mkfifo mypipe
|
||||
$ ls -l mypipe
|
||||
prw-r-----. 1 shs staff 0 Jan 31 13:59 mypipe
|
||||
```
|
||||
|
||||
注意一下特殊的文件类型标记 “p” 以及该文件大小为 0。您可以将重定向数据写入命名管道文件,而文件大小依然为 0。
|
||||
|
||||
```
|
||||
$ echo "Can you read this?" > mypipe
|
||||
```
|
||||
|
||||
正如上面所说,敲击回车后似乎什么都没有发生(LCTT 译注:没有返回命令行提示符)。
|
||||
|
||||
另外再开一个终端,查看该命名管道的大小,依旧是 0:
|
||||
|
||||
```
|
||||
$ ls -l mypipe
|
||||
prw-r-----. 1 shs staff 0 Jan 31 13:59 mypipe
|
||||
```
|
||||
|
||||
也许这有违直觉,用户输入的文本已经进入该命名管道,而你仍然卡在输入端。你或者其他人应该等在输出端,并准备读取放入管道的数据。现在让我们读取看看。
|
||||
|
||||
```
|
||||
$ cat mypipe
|
||||
Can you read this?
|
||||
```
|
||||
|
||||
一旦被读取之后,管道中的内容就没有了。
|
||||
|
||||
另一种研究命名管道如何工作的方式是通过将放入数据的操作置入后台来执行两个操作(将数据放入管道,而在另外一段读取它)。
|
||||
|
||||
```
|
||||
$ echo "Can you read this?" > mypipe &
|
||||
[1] 79302
|
||||
$ cat mypipe
|
||||
Can you read this?
|
||||
[1]+ Done echo "Can you read this?" > mypipe
|
||||
```
|
||||
|
||||
一旦管道被读取或“耗干”,该管道就清空了,尽管我们还能看见它并再次使用。可为什么要费此周折呢?
|
||||
|
||||
### 为何要使用命名管道?
|
||||
|
||||
命名管道很少被使用的理由似乎很充分。毕竟在 Unix 系统上,总有多种不同的方式完成同样的操作。有多种方式写文件、读文件、清空文件,尽管命名管道比它们来得更高效。
|
||||
|
||||
值得注意的是,命名管道的内容驻留在内存中而不是被写到硬盘上。数据内容只有在输入输出端都打开时才会传送。用户可以在管道的输出端打开之前向管道多次写入。通过使用命名管道,用户可以创建一个进程写入管道并且另外一个进程读取管道的流程,而不用关心协调二者时间上的同步。
|
||||
|
||||
用户可以创建一个单纯等待数据出现在管道输出端的进程,并在拿到输出数据后对其进行操作。下列命令我们采用 `tail` 来等待数据出现。
|
||||
|
||||
```
|
||||
$ tail -f mypipe
|
||||
```
|
||||
|
||||
一旦供给管道数据的进程结束了,我们就可以看到一些输出。
|
||||
|
||||
```
|
||||
$ tail -f mypipe
|
||||
Uranus replicated to WCDC7
|
||||
Saturn replicated to WCDC8
|
||||
Pluto replicated to WCDC9
|
||||
Server replication operation completed
|
||||
```
|
||||
|
||||
如果研究一下向命名管道写入的进程,用户也许会惊讶于它的资源消耗之少。在下面的 `ps` 命令输出中,唯一显著的资源消耗是虚拟内存(VSZ 那一列)。
|
||||
|
||||
```
|
||||
ps u -P 80038
|
||||
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
|
||||
shs 80038 0.0 0.0 108488 764 pts/4 S 15:25 0:00 -bash
|
||||
```
|
||||
|
||||
命名管道与 Unix/Linux 系统上更常用的管道相比足以不同到拥有另一个名号,但是“管道”确实能反映出它们如何在进程间传送数据的形象,故将称其为“命名管道”还真是恰如其分。也许您在执行操作时就能从这个聪明的 Unix/Linux 特性中获益匪浅呢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3251853/linux/why-use-named-pipes-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[YPBlib](https://github.com/YPBlib)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
|
||||
@ -1,3 +1,5 @@
|
||||
XLCYun 翻译中
|
||||
|
||||
Manjaro Gaming: Gaming on Linux Meets Manjaro’s Awesomeness
|
||||
======
|
||||
[![Meet Manjaro Gaming, a Linux distro designed for gamers with the power of Manjaro][1]][1]
|
||||
|
||||
95
sources/talk/20180201 IT automation- How to make the case.md
Normal file
95
sources/talk/20180201 IT automation- How to make the case.md
Normal file
@ -0,0 +1,95 @@
|
||||
IT automation: How to make the case
|
||||
======
|
||||
At the start of any significant project or change initiative, IT leaders face a proverbial fork in the road.
|
||||
|
||||
Path #1 might seem to offer the shortest route from A to B: Simply force-feed the project to everyone by executive mandate, essentially saying, “You’re going to do this – or else.”
|
||||
|
||||
Path #2 might appear less direct, because on this journey you take the time to explain the strategy and the reasons behind it. In fact, you’re going to be making pit stops along this route, rather than marathoning from start to finish: “Here’s what we’re doing – and why we’re doing it.”
|
||||
|
||||
Guess which path bears better results?
|
||||
|
||||
If you said #2, you’ve traveled both paths before – and experienced the results first-hand. Getting people on board with major changes beforehand is almost always the smarter choice.
|
||||
|
||||
IT leaders know as well as anyone that with significant change often comes [significant fear][1], skepticism, and other challenges. It may be especially true with IT automation. The term alone sounds scary to some people, and it is often tied to misconceptions. Helping people understand the what, why, and how of your company’s automation strategy is a necessary step to achieving your goals associated with that strategy.
|
||||
|
||||
[ **Read our related article,** [**IT automation best practices: 7 keys to long-term success**][2]. ]
|
||||
|
||||
With that in mind, we asked a variety of IT leaders for their advice on making the case for automation in your organization:
|
||||
|
||||
## 1. Show people what’s in it for them
|
||||
|
||||
Let’s face it: Self-interest and self-preservation are natural instincts. Tapping into that human tendency is a good way to get people on board: Show people how your automation strategy will benefit them and their jobs. Will automating a particular process in the software pipeline mean fewer middle-of-the-night calls for team members? Will it enable some people to dump low-skill, manual tasks in favor of more strategic, higher-order work – the sort that helps them take the next step in their career?
|
||||
|
||||
“Convey what’s in it for them, and how it will benefit clients and the whole company,” advises Vipul Nagrath, global CIO at [ADP][3]. “Compare the current state to a brighter future state, where the company enjoys greater stability, agility, efficiency, and security.”
|
||||
|
||||
The same approach holds true when making the case outside of IT; just lighten up on the jargon when explaining the benefits to non-technical stakeholders, Nagrath says.
|
||||
|
||||
Setting up a before-and-after picture is a good storytelling device for helping people see the upside.
|
||||
|
||||
“You want to paint a picture of the current state that people can relate to,” Nagrath says. “Present what’s working, but also highlight what’s causing teams to be less than agile.” Then explain how automating certain processes will improve that current state.
|
||||
|
||||
## 2. Connect automation to specific business goals
|
||||
|
||||
Part of making a strong case entails making sure people understand that you’re not just trend-chasing. If you’re automating simply for the sake of automating, people will sniff that out and become more resistant – perhaps especially within IT.
|
||||
|
||||
“The case for automation needs to be driven by a business demand signal, such as revenue or operating expense,” says David Emerson, VP and deputy CISO at [Cyxtera][4]. “No automation endeavor is self-justifying, and no technical feat, generally, should be a means unto itself, unless it’s a core competency of the company.”
|
||||
|
||||
Like Nagrath, Emerson recommends promoting the incentives associated with achieving the business goals of automation, and working toward these goals (and corresponding incentives) in an iterative, step-by-step fashion.
|
||||
|
||||
## 3. Break the automation plan into manageable pieces
|
||||
|
||||
Even if your automation strategy is literally “automate everything,” that’s a tough sell (and probably unrealistic) for most organizations. You’ll make a stronger case with a plan that approaches automation manageable piece by manageable piece, and that enables greater flexibility to adapt along the way.
|
||||
|
||||
“When making a case for automation, I recommend clearly illustrating the incentive to move to an automated process, and allowing iteration toward that goal to introduce and prove the benefits at lower risk,” Emerson says.
|
||||
|
||||
Sergey Zuev, founder at [GA Connector][5], shares an in-the-trenches account of why automating incrementally is crucial – and how it will help you build a stronger, longer-lasting argument for your strategy. Zuev should know: His company’s tool automates the import of data from CRM applications into Google Analytics. But it was actually the company’s internal experience automating its own customer onboarding process that led to a lightbulb moment.
|
||||
|
||||
“At first, we tried to build the whole onboarding funnel at once, and as a result, the project dragged [on] for months,” Zuev says. “After realizing that it [was] going nowhere, we decided to select small chunks that would have the biggest immediate effect, and start with that. As a result, we managed to implement one of the email sequences in just a week, and are already reaping the benefits of the desecrated manual effort.”
|
||||
|
||||
## 4. Sell the big-picture benefits too
|
||||
|
||||
A step-by-step approach does not preclude painting a bigger picture. Just as it’s a good idea to make the case at the individual or team level, it’s also a good idea for help people understand the company-wide benefits.
|
||||
|
||||
“If we can accelerate the time it takes for the business to get what it needs, it will silence the skeptics.”
|
||||
|
||||
Eric Kaplan, CTO at [AHEAD][6], agrees that using small wins to show automation’s value is a smart strategy for winning people over. But the value those so-called “small” wins reveal can actually help you sharpen the big picture for people. Kaplan points to the value of individual and organizational time as an area everyone can connect with easily.
|
||||
|
||||
“The best place to do this is where you can show savings in terms of time,” Kaplan says. “If we can accelerate the time it takes for the business to get what it needs, it will silence the skeptics.”
|
||||
|
||||
Time and scalability are powerful benefits business and IT colleagues, both charged with growing the business, can grasp.
|
||||
|
||||
“The result of automation is scalability – less effort per person to maintain and grow your IT environment, as [Red Hat][7] VP, Global Services John Allessio recently [noted][8]. “If adding manpower is the only way to grow your business, then scalability is a pipe dream. Automation reduces your manpower requirements and provides the flexibility required for continued IT evolution.” (See his full article, [What DevOps teams really need from a CIO][8].)
|
||||
|
||||
## 5. Promote the heck out of your results
|
||||
|
||||
At the outset of your automation strategy, you’ll likely be making the case based on goals and the anticipated benefits of achieving those goals. But as your automation strategy evolves, there’s no case quite as convincing as one grounded in real-world results.
|
||||
|
||||
“Seeing is believing,” says Nagrath, ADP’s CIO. “Nothing quiets skeptics like a track record of delivery.”
|
||||
|
||||
That means, of course, not only achieving your goals, but also doing so on time – another good reason for the iterative, step-by-step approach.
|
||||
|
||||
While quantitative results such as percentage improvements or cost savings can speak loudly, Nagrath advises his fellow IT leaders not to stop there when telling your automation story.
|
||||
|
||||
“Making a case for automation is also a qualitative discussion, where we can promote the issues prevented, overall business continuity, reductions in failures/errors, and associates taking on [greater] responsibility as they tackle more value-added tasks.”
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[2]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success?sc_cid=70160000000h0aXAAQ
|
||||
[3]:https://www.adp.com/
|
||||
[4]:https://www.cyxtera.com/
|
||||
[5]:http://gaconnector.com/
|
||||
[6]:https://www.thinkahead.com/
|
||||
[7]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
[9]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,108 @@
|
||||
Open source is 20: How it changed programming and business forever
|
||||
======
|
||||
![][1]
|
||||
|
||||
Every company in the world now uses open-source software. Microsoft, once its greatest enemy, is [now an enthusiastic open supporter][2]. Even [Windows is now built using open-source techniques][3]. And if you ever searched on Google, bought a book from Amazon, watched a movie on Netflix, or looked at your friend's vacation pictures on Facebook, you're an open-source user. Not bad for a technology approach that turns 20 on February 3.
|
||||
|
||||
Now, free software has been around since the first computers, but the philosophy of both free software and open source are both much newer. In the 1970s and 80s, companies rose up which sought to profit by making proprietary software. In the nascent PC world, no one even knew about free software. But, on the Internet, which was dominated by Unix and ITS systems, it was a different story.
|
||||
|
||||
In the late 70s, [Richard M. Stallman][6], also known as RMS, then an MIT programmer, created a free printer utility based on its source code. But then a new laser printer arrived on the campus and he found he could no longer get the source code and so he couldn't recreate the utility. The angry [RMS created the concept of "Free Software."][7]
|
||||
|
||||
RMS's goal was to create a free operating system, [Hurd][8]. To make this happen in September 1983, [he announced the creation of the GNU project][9] (GNU stands for GNU's Not Unix -- a recursive acronym). By January 1984, he was working full-time on the project. To help build it he created the grandfather of all free software/open-source compiler system [GCC][10] and other operating system utilities. Early in 1985, he published "[The GNU Manifesto][11]," which was the founding charter of the free software movement and launched the [Free Software Foundation (FSF)][12].
|
||||
|
||||
This went well for a few years, but inevitably, [RMS collided with proprietary companies][13]. The company Unipress took the code to a variation of his [EMACS][14] programming editor and turned it into a proprietary program. RMS never wanted that to happen again so he created the [GNU General Public License (GPL)][15] in 1989. This was the first copyleft license. It gave users the right to use, copy, distribute, and modify a program's source code. But if you make source code changes and distribute it to others, you must share the modified code. While there had been earlier free licenses, such as [1980's four-clause BSD license][16], the GPL was the one that sparked the free-software, open-source revolution.
|
||||
|
||||
In 1997, [Eric S. Raymond][17] published his vital essay, "[The Cathedral and the Bazaar][18]." In it, he showed the advantages of the free-software development methodologies using GCC, the Linux kernel, and his experiences with his own [Fetchmail][19] project as examples. This essay did more than show the advantages of free software. The programming principles he described led the way for both [Agile][20] development and [DevOps][21]. Twenty-first century programming owes a large debt to Raymond.
|
||||
|
||||
Like all revolutions, free software quickly divided its supporters. On one side, as John Mark Walker, open-source expert and Strategic Advisor at Glyptodon, recently wrote, "[Free software is a social movement][22], with nary a hint of business interests -- it exists in the realm of religion and philosophy. Free software is a way of life with a strong moral code."
|
||||
|
||||
On the other were numerous people who wanted to bring "free software" to business. They would become the founders of "open source." They argued that such phrases as "Free as in freedom" and "Free speech, not beer," left most people confused about what that really meant for software.
|
||||
|
||||
The [release of the Netscape web browser source code][23] sparked a meeting of free software leaders and experts at [a strategy session held on February 3rd][24], 1998 in Palo Alto, CA. There, Eric S. Raymond, Michael Tiemann, Todd Anderson, Jon "maddog" Hall, Larry Augustin, Sam Ockman, and Christine Peterson hammered out the first steps to open source.
|
||||
|
||||
Peterson created the "open-source term." She remembered:
|
||||
|
||||
> [The introduction of the term "open source software" was a deliberate effort][25] to make this field of endeavor more understandable to newcomers and to business, which was viewed as necessary to its spread to a broader community of users. The problem with the main earlier label, "free software," was not its political connotations, but that -- to newcomers -- its seeming focus on price is distracting. A term was needed that focuses on the key issue of source code and that does not immediately confuse those new to the concept. The first term that came along at the right time and fulfilled these requirements was rapidly adopted: open source.
|
||||
|
||||
To help clarify what open source was, and wasn't, Raymond and Bruce Perens founded the [Open Source Initiative (OSI)][26]. Its purpose was, and still is, to define what are real open-source software licenses and what aren't.
|
||||
|
||||
Stallman was enraged by open source. He wrote:
|
||||
|
||||
> The two terms describe almost the same method/category of software, but they stand for [views based on fundamentally different values][27]. Open source is a development methodology; free software is a social movement. For the free software movement, free software is an ethical imperative, essential respect for the users' freedom. By contrast, the philosophy of open source considers issues in terms of how to make software 'better' -- in a practical sense only. It says that non-free software is an inferior solution to the practical problem at hand. Most discussion of "open source" pays no attention to right and wrong, only to popularity and success.
|
||||
|
||||
He saw open source as kowtowing to business and taking the focus away from the personal freedom of being able to have free access to the code. Twenty years later, he's still angry about it.
|
||||
|
||||
In a recent e-mail to me, Stallman said, it is a "common error is connecting me or my work or free software in general with the term 'Open Source.' That is the slogan adopted in 1998 by people who reject the philosophy of the Free Software Movement." In another message, he continued, "I rejected 'open source' because it was meant to bury the "free software" ideas of freedom. Open source inspired the release ofu seful free programs, but what's missing is the idea that users deserve control of their computing. We libre-software activists say, 'Software you can't change and share is unjust, so let's escape to our free replacement.' Open source says only, 'If you let users change your code, they might fix bugs.' What it does says is not wrong, but weak; it avoids saying the deeper point."
|
||||
|
||||
Philosophical conflicts aside, open source has indeed become the model for practical software development. Larry Augustin, CEO of [SugarCRM][28], the open-source customer relationship management (CRM) Software-as-a-Service (SaaS), was one of the first to practice open-source in a commercial software business. Augustin showed that a successful business could be built on open-source software.
|
||||
|
||||
Other companies quickly embraced this model. Besides Linux companies such as [Canonical][29], [Red Hat][30] and [SUSE][31], technology businesses such as [IBM][32] and [Oracle][33] also adopted it. This, in turn, led to open source's commercial success. More recently companies you would never think of for a moment as open-source businesses like [Wal-Mart][34] and [Verizon][35], now rely on open-source programs and have their own open-source projects.
|
||||
|
||||
As Jim Zemlin, director of [The Linux Foundation][36], observed in 2014:
|
||||
|
||||
> A [new business model][37] has emerged in which companies are joining together across industries to share development resources and build common open-source code bases on which they can differentiate their own products and services.
|
||||
|
||||
Today, Hall looked back and said "I look at 'closed source' as a blip in time." Raymond is unsurprised at open-source's success. In an e-mail interview, Raymond said, "Oh, yeah, it *has* been 20 years -- and that's not a big deal because we won most of the fights we needed to quite a while ago, like in the first decade after 1998."
|
||||
|
||||
"Ever since," he continued, "we've been mainly dealing with the problems of success rather than those of failure. And a whole new class of issues, like IoT devices without upgrade paths -- doesn't help so much for the software to be open if you can't patch it."
|
||||
|
||||
In other words, he concludes, "The reward of victory is often another set of battles."
|
||||
|
||||
These are battles that open source is poised to win. Jim Whitehurst, Red Hat's CEO and president told me:
|
||||
|
||||
> The future of open source is bright. We are on the cusp of a new wave of innovation that will come about because information is being separated from physical objects thanks to the Internet of Things. Over the next decade, we will see entire industries based on open-source concepts, like the sharing of information and joint innovation, become mainstream. We'll see this impact every sector, from non-profits, like healthcare, education and government, to global corporations who realize sharing information leads to better outcomes. Open and participative innovation will become a key part of increasing productivity around the world.
|
||||
|
||||
Others see open source extending beyond software development methods. Nick Hopman, Red Hat's senior director of emerging technology practices, said:
|
||||
|
||||
> Open-source is much more than just a process to develop and expose technology. Open-source is a catalyst to drive change in every facet of society -- government, policy, medical diagnostics, process re-engineering, you name it -- and can leverage open principles that have been perfected through the experiences of open-source software development to create communities that drive change and innovation. Looking forward, open-source will continue to drive technology innovation, but I am even more excited to see how it changes the world in ways we have yet to even consider.
|
||||
|
||||
Indeed. Open source has turned twenty, but its influence, and not just on software and business, will continue on for decades to come.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/open-source-turns-20/
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[1]:https://zdnet1.cbsistatic.com/hub/i/r/2018/01/08/d9527281-2972-4cb7-bd87-6464d8ad50ae/thumbnail/570x322/9d4ef9007b3a3ce34de0cc39d2b15b0c/5a4faac660b22f2aba08fc3f-1280x7201jan082018150043poster.jpg
|
||||
[2]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
[3]:http://www.zdnet.com/article/microsoft-uses-open-source-software-to-create-windows/
|
||||
[4]:https://zdnet1.cbsistatic.com/hub/i/r/2016/11/18/a55b3c0c-7a8e-4143-893f-44900cb2767a/resize/220x165/6cd4e37b1904743ff1f579cb10d9e857/linux-open-source-money-penguin.jpg
|
||||
[5]:http://www.zdnet.com/article/how-do-linux-and-open-source-companies-make-money-from-free-software/
|
||||
[6]:https://stallman.org/
|
||||
[7]:https://opensource.com/article/18/2/pivotal-moments-history-open-source
|
||||
[8]:https://www.gnu.org/software/hurd/hurd.html
|
||||
[9]:https://groups.google.com/forum/#!original/net.unix-wizards/8twfRPM79u0/1xlglzrWrU0J
|
||||
[10]:https://gcc.gnu.org/
|
||||
[11]:https://www.gnu.org/gnu/manifesto.en.html
|
||||
[12]:https://www.fsf.org/
|
||||
[13]:https://www.free-soft.org/gpl_history/
|
||||
[14]:https://www.gnu.org/s/emacs/
|
||||
[15]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[16]:http://www.linfo.org/bsdlicense.html
|
||||
[17]:http://www.catb.org/esr/
|
||||
[18]:http://www.catb.org/esr/writings/cathedral-bazaar/
|
||||
[19]:http://www.fetchmail.info/
|
||||
[20]:https://www.agilealliance.org/agile101/
|
||||
[21]:https://aws.amazon.com/devops/what-is-devops/
|
||||
[22]:https://opensource.com/business/16/11/open-source-not-free-software?sc_cid=70160000001273HAAQ
|
||||
[23]:http://www.zdnet.com/article/the-beginning-of-the-peoples-web-20-years-of-netscape/
|
||||
[24]:https://opensource.org/history
|
||||
[25]:https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[26]:https://opensource.org
|
||||
[27]:https://www.gnu.org/philosophy/open-source-misses-the-point.html
|
||||
[28]:https://www.sugarcrm.com/
|
||||
[29]:https://www.canonical.com/
|
||||
[30]:https://www.redhat.com/en
|
||||
[31]:https://www.suse.com/
|
||||
[32]:https://developer.ibm.com/code/open/
|
||||
[33]:http://www.oracle.com/us/technologies/open-source/overview/index.html
|
||||
[34]:http://www.zdnet.com/article/walmart-relies-on-openstack/
|
||||
[35]:https://www.networkworld.com/article/3195490/lan-wan/verizon-taps-into-open-source-white-box-fervor-with-new-cpe-offering.html
|
||||
[36]:http://www.linuxfoundation.org/
|
||||
[37]:http://www.zdnet.com/article/it-takes-an-open-source-village-to-make-commercial-software/
|
||||
@ -1,3 +1,4 @@
|
||||
##Name1e5s Translating##
|
||||
Open source software: 20 years and counting
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,160 +0,0 @@
|
||||
Linux Find Out Last System Reboot Time and Date Command
|
||||
======
|
||||
So, how do you find out your Linux or UNIX-like system was last rebooted? How do you display the system shutdown date and time? The last utility will either list the sessions of specified users, ttys, and hosts, in reverse time order, or list the users logged in at a specified date and time. Each line of output contains the user name, the tty from which the session was conducted, any hostname, the start and stop times for the session, and the duration of the session. To view Linux or Unix system reboot and shutdown date and time stamp using the following commands:
|
||||
|
||||
* last command
|
||||
* who command
|
||||
|
||||
|
||||
|
||||
### Use who command to find last system reboot time/date
|
||||
|
||||
You need to use the [who command][1], to print who is logged on. It also displays the time of last system boot. Use the last command to display system reboot and shutdown date and time, run:
|
||||
`$ who -b`
|
||||
Sample outputs:
|
||||
```
|
||||
system boot 2017-06-20 17:41
|
||||
```
|
||||
|
||||
Use the last command to display listing of last logged in users and system last reboot time and date, enter:
|
||||
`$ last reboot | less`
|
||||
Sample outputs:
|
||||
[![Fig.01: last command in action][2]][2]
|
||||
Or, better try:
|
||||
`$ last reboot | head -1`
|
||||
Sample outputs:
|
||||
```
|
||||
reboot system boot 4.9.0-3-amd64 Sat Jul 15 19:19 still running
|
||||
```
|
||||
|
||||
The last command searches back through the file /var/log/wtmp and displays a list of all users logged in (and out) since that file was created. The pseudo user reboot logs in each time the system is rebooted. Thus last reboot command will show a log of all reboots since the log file was created.
|
||||
|
||||
### Finding systems last shutdown date and time
|
||||
|
||||
To display last shutdown date and time use the following command:
|
||||
`$ last -x|grep shutdown | head -1`
|
||||
Sample outputs:
|
||||
```
|
||||
shutdown system down 2.6.15.4 Sun Apr 30 13:31 - 15:08 (01:37)
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
* **-x** : Display the system shutdown entries and run level changes.
|
||||
|
||||
|
||||
|
||||
Here is another session from my last command:
|
||||
```
|
||||
$ last
|
||||
$ last -x
|
||||
$ last -x reboot
|
||||
$ last -x shutdown
|
||||
```
|
||||
Sample outputs:
|
||||
![Fig.01: How to view last Linux System Reboot Date/Time ][3]
|
||||
|
||||
### Find out Linux system up since…
|
||||
|
||||
Another option as suggested by readers in the comments section below is to run the following command:
|
||||
`$ uptime -s`
|
||||
Sample outputs:
|
||||
```
|
||||
2017-06-20 17:41:51
|
||||
```
|
||||
|
||||
### OS X/Unix/FreeBSD find out last reboot and shutdown time command examples
|
||||
|
||||
Type the following command:
|
||||
`$ last reboot`
|
||||
Sample outputs from OS X unix:
|
||||
```
|
||||
reboot ~ Fri Dec 18 23:58
|
||||
reboot ~ Mon Dec 14 09:54
|
||||
reboot ~ Wed Dec 9 23:21
|
||||
reboot ~ Tue Nov 17 21:52
|
||||
reboot ~ Tue Nov 17 06:01
|
||||
reboot ~ Wed Nov 11 12:14
|
||||
reboot ~ Sat Oct 31 13:40
|
||||
reboot ~ Wed Oct 28 15:56
|
||||
reboot ~ Wed Oct 28 11:35
|
||||
reboot ~ Tue Oct 27 00:00
|
||||
reboot ~ Sun Oct 18 17:28
|
||||
reboot ~ Sun Oct 18 17:11
|
||||
reboot ~ Mon Oct 5 09:35
|
||||
reboot ~ Sat Oct 3 18:57
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
To see shutdown date and time, enter:
|
||||
`$ last shutdown`
|
||||
Sample outputs:
|
||||
```
|
||||
shutdown ~ Fri Dec 18 23:57
|
||||
shutdown ~ Mon Dec 14 09:53
|
||||
shutdown ~ Wed Dec 9 23:20
|
||||
shutdown ~ Tue Nov 17 14:24
|
||||
shutdown ~ Mon Nov 16 21:15
|
||||
shutdown ~ Tue Nov 10 13:15
|
||||
shutdown ~ Sat Oct 31 13:40
|
||||
shutdown ~ Wed Oct 28 03:10
|
||||
shutdown ~ Sun Oct 18 17:27
|
||||
shutdown ~ Mon Oct 5 09:23
|
||||
|
||||
|
||||
wtmp begins Sat Oct 3 18:57
|
||||
```
|
||||
|
||||
### How do I find who rebooted/shutdown the Linux box?
|
||||
|
||||
You need [to enable psacct service and run the following command to see info][4] about executed commands including user name. Type the following [lastcomm command][5] to see
|
||||
```
|
||||
# lastcomm userNameHere
|
||||
# lastcomm commandNameHere
|
||||
# lastcomm | more
|
||||
# lastcomm reboot
|
||||
# lastcomm shutdown
|
||||
### OR see both reboot and shutdown time
|
||||
# lastcomm | egrep 'reboot|shutdown'
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
reboot S X root pts/0 0.00 secs Sun Dec 27 23:49
|
||||
shutdown S root pts/1 0.00 secs Sun Dec 27 23:45
|
||||
```
|
||||
|
||||
So root user rebooted the box from 'pts/0' on Sun, Dec, 27th at 23:49 local time.
|
||||
|
||||
### See also
|
||||
|
||||
* For more information read last(1) and [learn how to use the tuptime command on Linux server to see the historical and statistical uptime][6].
|
||||
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][7], [Facebook][8], [Google+][9].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-last-reboot-time-and-date-find-out.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/unix-linux-who-command-examples-syntax-usage/ (See Linux/Unix who command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/wp-content/uploads/2006/04/last-reboot.jpg
|
||||
[3]:https://www.cyberciti.biz/media/new/tips/2006/04/check-last-time-system-was-rebooted.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/howto-log-user-activity-using-process-accounting.html
|
||||
[5]:https://www.cyberciti.biz/faq/linux-unix-lastcomm-command-examples-usage-syntax/ (See Linux/Unix lastcomm command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/hardware/howto-see-historical-statistical-uptime-on-linux-server/
|
||||
[7]:https://twitter.com/nixcraft
|
||||
[8]:https://facebook.com/nixcraft
|
||||
[9]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,82 @@
|
||||
How to use lftp to accelerate ftp/https download speed on Linux/UNIX
|
||||
======
|
||||
lftp is a file transfer program. It allows sophisticated FTP, HTTP/HTTPS, and other connections. If the site URL is specified, then lftp will connect to that site otherwise a connection has to be established with the open command. It is an essential tool for all a Linux/Unix command line users. I have already written about [Linux ultra fast command line download accelerator][1] such as Axel and prozilla. lftp is another tool for the same job with more features. lftp can handle seven file access methods:
|
||||
|
||||
1. ftp
|
||||
2. ftps
|
||||
3. http
|
||||
4. https
|
||||
5. hftp
|
||||
6. fish
|
||||
7. sftp
|
||||
8. file
|
||||
|
||||
|
||||
|
||||
### So what is unique about lftp?
|
||||
|
||||
* Every operation in lftp is reliable, that is any not fatal error is ignored, and the operation is repeated. So if downloading breaks, it will be restarted from the point automatically. Even if FTP server does not support REST command, lftp will try to retrieve the file from the very beginning until the file is transferred completely.
|
||||
* lftp has shell-like command syntax allowing you to launch several commands in parallel in the background.
|
||||
* lftp has a builtin mirror which can download or update a whole directory tree. There is also a reverse mirror (mirror -R) which uploads or updates a directory tree on the server. The mirror can also synchronize directories between two remote servers, using FXP if available.
|
||||
|
||||
|
||||
|
||||
### How to use lftp as download accelerator
|
||||
|
||||
lftp has pget command. It allows you download files in parallel. The syntax is
|
||||
`lftp -e 'pget -n NUM -c url; exit'`
|
||||
For example, download <http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2> file using pget in 5 parts:
|
||||
```
|
||||
$ cd /tmp
|
||||
$ lftp -e 'pget -n 5 -c http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2'
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
45108964 bytes transferred in 57 seconds (775.3K/s)
|
||||
lftp :~>quit
|
||||
|
||||
```
|
||||
|
||||
Where,
|
||||
|
||||
1. pget – Download files in parallel
|
||||
2. -n 5 – Set maximum number of connections to 5
|
||||
3. -c – Continue broken transfer if lfile.lftp-pget-status exists in the current directory
|
||||
|
||||
|
||||
|
||||
### How to use lftp to accelerate ftp/https download on Linux/Unix
|
||||
|
||||
Another try with added exit command:
|
||||
`$ lftp -e 'pget -n 10 -c https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.15.tar.xz; exit'`
|
||||
|
||||
[Linux-lftp-command-demo][https://www.cyberciti.biz/tips/wp-content/uploads/2007/08/Linux-lftp-command-demo.mp4]
|
||||
|
||||
### A note about parallel downloading
|
||||
|
||||
Please note that by using download accelerator you are going to put a load on remote host. Also note that lftp may not work with sites that do not support multi-source downloads or blocks such requests at firewall level.
|
||||
|
||||
NA command offers many other features. Refer to [lftp][2] man page for more information:
|
||||
`man lftp`
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][3], [Facebook][4], [Google+][5]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][6]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-download-accelerator.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/download-accelerator-for-linux-command-line-tools.html
|
||||
[2]:https://lftp.yar.ru/
|
||||
[3]:https://twitter.com/nixcraft
|
||||
[4]:https://facebook.com/nixcraft
|
||||
[5]:https://plus.google.com/+CybercitiBiz
|
||||
[6]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,141 @@
|
||||
How to use yum-cron to automatically update RHEL/CentOS Linux
|
||||
======
|
||||
The yum command line tool is used to install and update software packages under RHEL / CentOS Linux server. I know how to apply updates using [yum update command line][1], but I would like to use cron to update packages where appropriate manually. How do I configure yum to install software patches/updates [automatically with cron][2]?
|
||||
|
||||
You need to install yum-cron package. It provides files needed to run yum updates as a cron job. Install this package if you want auto yum updates nightly via cron.
|
||||
|
||||
### How to install yum cron on a CentOS/RHEL 6.x/7.x
|
||||
|
||||
Type the following [yum command][3] on:
|
||||
`$ sudo yum install yum-cron`
|
||||

|
||||
|
||||
Turn on service using systemctl command on **CentOS/RHEL 7.x** :
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
If you are using **CentOS/RHEL 6.x** , run:
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||

|
||||
|
||||
yum-cron is an alternate interface to yum. Very convenient way to call yum from cron. It provides methods to keep repository metadata up to date, and to check for, download, and apply updates. Rather than accepting many different command line arguments, the different functions of yum-cron can be accessed through config files.
|
||||
|
||||
### How to configure yum-cron to automatically update RHEL/CentOS Linux
|
||||
|
||||
You need to edit /etc/yum/yum-cron.conf and /etc/yum/yum-cron-hourly.conf files using a text editor such as vi command:
|
||||
`$ sudo vi /etc/yum/yum-cron.conf`
|
||||
Make sure updates should be applied when they are available
|
||||
`apply_updates = yes`
|
||||
You can set the address to send email messages from. Please note that ‘localhost’ will be replaced with the value of system_name.
|
||||
`email_from = root@localhost`
|
||||
List of addresses to send messages to.
|
||||
`email_to = your-it-support@some-domain-name`
|
||||
Name of the host to connect to to send email messages.
|
||||
`email_host = localhost`
|
||||
If you [do not want to update kernel package add the following on CentOS/RHEL 7.x][4]:
|
||||
`exclude=kernel*`
|
||||
For RHEL/CentOS 6.x add [the following to exclude kernel package from updating][5]:
|
||||
`YUM_PARAMETER=kernel*`
|
||||
[Save and close the file in vi/vim][6]. You also need to update /etc/yum/yum-cron-hourly.conf file if you want to apply update hourly. Otherwise /etc/yum/yum-cron.conf will run on daily using the following cron job (us [cat command][7]:
|
||||
`$ cat /etc/cron.daily/0yum-daily.cron`
|
||||
Sample outputs:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
That is all. Now your system will update automatically everyday using yum-cron. See man page of yum-cron for more details:
|
||||
`$ man yum-cron`
|
||||
|
||||
### Method 2 – Use shell scripts
|
||||
|
||||
**Warning** : The following method is outdated. Do not use it on RHEL/CentOS 6.x/7.x. I kept it below for historical reasons only when I used it on CentOS/RHEL version 4.x/5.x.
|
||||
|
||||
Let us see how to configure CentOS/RHEL for yum automatic update retrieval and installation of security packages. You can use yum-updatesd service provided with CentOS / RHEL servers. However, this service provides a few overheads. You can create daily or weekly updates with the following shell script. Create
|
||||
|
||||
* **/etc/cron.daily/yumupdate.sh** to apply updates one a day.
|
||||
* **/etc/cron.weekly/yumupdate.sh** to apply updates once a week.
|
||||
|
||||
|
||||
|
||||
#### Sample shell script to update system
|
||||
|
||||
A shell script that instructs yum to update any packages it finds via [cron][8]:
|
||||
```
|
||||
#!/bin/bash
|
||||
YUM=/usr/bin/yum
|
||||
$YUM -y -R 120 -d 0 -e 0 update yum
|
||||
$YUM -y -R 10 -e 0 -d 0 update
|
||||
```
|
||||
|
||||
(Code listing -01: /etc/cron.daily/yumupdate.sh)
|
||||
|
||||
Where,
|
||||
|
||||
1. First command will update yum itself and next will apply system updates.
|
||||
2. **-R 120** : Sets the maximum amount of time yum will wait before performing a command
|
||||
3. **-e 0** : Sets the error level to 0 (range 0 – 10). 0 means print only critical errors about which you must be told.
|
||||
4. -d 0 : Sets the debugging level to 0 – turns up or down the amount of things that are printed. (range: 0 – 10).
|
||||
5. **-y** : Assume yes; assume that the answer to any question which would be asked is yes.
|
||||
|
||||
|
||||
|
||||
Make sure you setup executable permission:
|
||||
`# chmod +x /etc/cron.daily/yumupdate.sh`
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
Posted by:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][12]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -1,4 +1,4 @@
|
||||
How to Use the ZFS Filesystem on Ubuntu Linux
|
||||
How to Use the ZFS Filesystem on Ubuntu Linux
|
||||
======
|
||||
There are a myriad of [filesystems available for Linux][1]. So why try a new one? They all work, right? They're not all the same, and some have some very distinct advantages, like ZFS.
|
||||
|
||||
|
||||
108
sources/tech/20171101 -dev-[u]random- entropy explained.md
Normal file
108
sources/tech/20171101 -dev-[u]random- entropy explained.md
Normal file
@ -0,0 +1,108 @@
|
||||
/dev/[u]random: entropy explained
|
||||
======
|
||||
### Entropy
|
||||
|
||||
When the topic of /dev/random and /dev/urandom come up, you always hear this word: “Entropy”. Everyone seems to have their own analogy for it. So why not me? I like to think of Entropy as “Random juice”. It is juice, required for random to be more random.
|
||||
|
||||
If you have ever generated an SSL certificate, or a GPG key, you may have seen something like:
|
||||
```
|
||||
We need to generate a lot of random bytes. It is a good idea to perform
|
||||
some other action (type on the keyboard, move the mouse, utilize the
|
||||
disks) during the prime generation; this gives the random number
|
||||
generator a better chance to gain enough entropy.
|
||||
++++++++++..+++++.+++++++++++++++.++++++++++...+++++++++++++++...++++++
|
||||
+++++++++++++++++++++++++++++.+++++..+++++.+++++.+++++++++++++++++++++++++>.
|
||||
++++++++++>+++++...........................................................+++++
|
||||
Not enough random bytes available. Please do some other work to give
|
||||
the OS a chance to collect more entropy! (Need 290 more bytes)
|
||||
|
||||
```
|
||||
|
||||
|
||||
By typing on the keyboard, and moving the mouse, you help generate Entropy, or Random Juice.
|
||||
|
||||
You might be asking yourself… Why do I need Entropy? and why it is so important for random to be actually random? Well, lets say our Entropy was limited to keyboard, mouse, and disk IO. But our system is a server, so I know there is no mouse and keyboard input. This means the only factor is your IO. If it is a single disk, that was barely used, you will have low Entropy. This means your systems ability to be random is weak. In other words, I could play the probability game, and significantly decrease the amount of time it would take to crack things like your ssh keys, or decrypt what you thought was an encrypted session.
|
||||
|
||||
Okay, but that is pretty unrealistic right? No, actually it isn’t. Take a look at this [Debian OpenSSH Vulnerability][1]. This particular issue was caused by someone removing some of the code responsible for adding Entropy. Rumor has it they removed it because it was causing valgrind to throw warnings. However, in doing that, random is now MUCH less random. In fact, so much less that Brute forcing the private ssh keys generated is now a fesible attack vector.
|
||||
|
||||
Hopefully by now we understand how important Entropy is to security. Whether you realize you are using it or not.
|
||||
|
||||
### /dev/random & /dev/urandom
|
||||
|
||||
|
||||
/dev/urandom is a Psuedo Random Number Generator, and it **does not** block if you run out of Entropy.
|
||||
/dev/random is a True Random Number Generator, and it **does** block if you run out of Entropy.
|
||||
|
||||
Most often, if we are dealing with something pragmatic, and it doesn’t contain the keys to your nukes, /dev/urandom is the right choice. Otherwise if you go with /dev/random, then when the system runs out of Entropy your application is just going to behave funny. Whether it outright fails, or just hangs until it has enough depends on how you wrote your application.
|
||||
|
||||
### Checking the Entropy
|
||||
|
||||
So, how much Entropy do you have?
|
||||
```
|
||||
[root@testbox test]# cat /proc/sys/kernel/random/poolsize
|
||||
4096
|
||||
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
|
||||
2975
|
||||
[root@testbox test]#
|
||||
|
||||
```
|
||||
|
||||
/proc/sys/kernel/random/poolsize, to state the obvious is the size(in bits) of the Entropy Pool. eg: How much random-juice we should save before we stop pumping more. /proc/sys/kernel/random/entropy_avail, is the amount(in bits) of random-juice in the pool currently.
|
||||
|
||||
### How can we influence this number?
|
||||
|
||||
The number is drained as we use it. The most crude example I can come up with is catting /dev/random into /dev/null:
|
||||
```
|
||||
[root@testbox test]# cat /dev/random > /dev/null &
|
||||
[1] 19058
|
||||
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
|
||||
0
|
||||
[root@testbox test]# cat /proc/sys/kernel/random/entropy_avail
|
||||
1
|
||||
[root@testbox test]#
|
||||
|
||||
```
|
||||
|
||||
The easiest way to influence this is to run [Haveged][2]. Haveged is a daemon that uses the processor “flutter” to add Entropy to the systems Entropy Pool. Installation and basic setup is pretty straight forward
|
||||
```
|
||||
[root@b08s02ur ~]# systemctl enable haveged
|
||||
Created symlink from /etc/systemd/system/multi-user.target.wants/haveged.service to /usr/lib/systemd/system/haveged.service.
|
||||
[root@b08s02ur ~]# systemctl start haveged
|
||||
[root@b08s02ur ~]#
|
||||
|
||||
```
|
||||
|
||||
On a machine with relatively moderate traffic:
|
||||
```
|
||||
[root@testbox ~]# pv /dev/random > /dev/null
|
||||
40 B 0:00:15 [ 0 B/s] [ <=> ]
|
||||
52 B 0:00:23 [ 0 B/s] [ <=> ]
|
||||
58 B 0:00:25 [5.92 B/s] [ <=> ]
|
||||
64 B 0:00:30 [6.03 B/s] [ <=> ]
|
||||
^C
|
||||
[root@testbox ~]# systemctl start haveged
|
||||
[root@testbox ~]# pv /dev/random > /dev/null
|
||||
7.12MiB 0:00:05 [1.43MiB/s] [ <=> ]
|
||||
15.7MiB 0:00:11 [1.44MiB/s] [ <=> ]
|
||||
27.2MiB 0:00:19 [1.46MiB/s] [ <=> ]
|
||||
43MiB 0:00:30 [1.47MiB/s] [ <=> ]
|
||||
^C
|
||||
[root@testbox ~]#
|
||||
|
||||
```
|
||||
|
||||
Using pv we are able to see how much data we are passing via pipe. As you can see, before haveged, we were getting 2.1 bits per second(B/s). Whereas after starting haveged, and adding processor flutter to our Entropy pool we get ~1.5MiB/sec.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jhurani.com/linux/2017/11/01/entropy-explained.html
|
||||
|
||||
作者:[James J][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jblevins.org/log/ssh-vulnkey
|
||||
[1]:http://jhurani.com/linux/2017/11/01/%22https://jblevins.org/log/ssh-vulnkey%22
|
||||
[2]:http://www.issihosts.com/haveged/
|
||||
@ -1,3 +1,4 @@
|
||||
leemeans translating
|
||||
Getting Started with ncurses
|
||||
======
|
||||
How to use curses to draw to the terminal screen.
|
||||
|
||||
@ -1,61 +0,0 @@
|
||||
Containers, the GPL, and copyleft: No reason for concern
|
||||
============================================================
|
||||
|
||||
### Wondering how open source licensing affects Linux containers? Here's what you need to know.
|
||||
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL’s derivative work issue.
|
||||
|
||||
One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven’t yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it’s fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
|
||||
|
||||
Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
|
||||
|
||||
The FSF’s existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][4] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
|
||||
|
||||
Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][5], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][6] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][7]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
|
||||
|
||||
Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
|
||||
|
||||
It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
|
||||
|
||||
Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][8] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][9]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
|
||||
|
||||
A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
|
||||
|
||||
On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code—though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
|
||||
|
||||
Open source license compliance obligations may arise when sharing container images. But there’s nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][10] Richard Fontana - Richard is Senior Commercial Counsel on the Products and Technologies team in Red Hat's legal department. Most of his work focuses on open source-related legal issues.[More about me][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
|
||||
|
||||
作者:[Richard Fontana ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/fontana
|
||||
[1]:https://opensource.com/article/18/1/containers-gpl-and-copyleft?rate=qTlANxnuA2tf0hcGE6Po06RGUzcbB-cBxbU3dCuCt9w
|
||||
[2]:https://opensource.com/users/fontana
|
||||
[3]:https://opensource.com/user/10544/feed
|
||||
[4]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
|
||||
[5]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[6]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
|
||||
[7]:https://www.gnu.org/licenses/gpl.html#section5
|
||||
[8]:https://www.redhat.com/en/topics/microservices
|
||||
[9]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
|
||||
[10]:https://opensource.com/users/fontana
|
||||
[11]:https://opensource.com/users/fontana
|
||||
[12]:https://opensource.com/users/fontana
|
||||
[13]:https://opensource.com/tags/licensing
|
||||
[14]:https://opensource.com/tags/containers
|
||||
@ -1,140 +0,0 @@
|
||||
Being open about data privacy
|
||||
============================================================
|
||||
|
||||
### Regulations including GDPR notwithstanding, data privacy is something that's important for pretty much everybody.
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Today is [Data Privacy Day][9], ("Data Protection Day" in Europe), and you might think that those of us in the open source world should think that all data should be free, [as information supposedly wants to be][10], but life's not that simple. That's for two main reasons:
|
||||
|
||||
1. Most of us (and not just in open source) believe there's at least some data about us that we might not feel happy sharing (I compiled an example list in [a post][2] I published a while ago).
|
||||
|
||||
2. Many of us working in open source actually work for commercial companies or other organisations subject to legal requirements around what they can share.
|
||||
|
||||
So actually, data privacy is something that's important for pretty much everybody.
|
||||
|
||||
It turns out that the starting point for what data people and governments believe should be available for organisations to use is somewhat different between the U.S. and Europe, with the former generally providing more latitude for entities—particularly, the more cynical might suggest, large commercial entities—to use data they've collected about us as they will. Europe, on the other hand, has historically taken a more restrictive view, and on the 25th of May, Europe's view arguably will have triumphed.
|
||||
|
||||
### The impact of GDPR
|
||||
|
||||
That's a rather sweeping statement, but the fact remains that this is the date on which a piece of legislation called the General Data Protection Regulation (GDPR), enacted by the European Union in 2016, becomes enforceable. The GDPR basically provides a stringent set of rules about how personal data can be stored, what it can be used for, who can see it, and how long it can be kept. It also describes what personal data is—and it's a pretty broad set of items, from your name and home address to your medical records and on through to your computer's IP address.
|
||||
|
||||
What is important about the GDPR, though, is that it doesn't apply just to European companies, but to any organisation processing data about EU citizens. If you're an Argentinian, Japanese, U.S., or Russian company and you're collecting data about an EU citizen, you're subject to it.
|
||||
|
||||
"Pah!" you may say,[1][11] "I'm not based in the EU: what can they do to me?" The answer is simple: If you want to continue doing any business in the EU, you'd better comply, because if you breach GDPR rules, you could be liable for up to four percent of your _global_ revenues. Yes, that's global revenues: not just revenues in a particular country in Europe or across the EU, not just profits, but _global revenues_ . Those are the sorts of numbers that should lead you to talk to your legal team, who will direct you to your exec team, who will almost immediately direct you to your IT group to make sure you're compliant in pretty short order.
|
||||
|
||||
This may seem like it's not particularly relevant to non-EU citizens, but it is. For most companies, it's going to be simpler and more efficient to implement the same protection measures for data associated with _all_ customers, partners, and employees they deal with, rather than just targeting specific measures at EU citizens. This has got to be a good thing.[2][12]
|
||||
|
||||
However, just because GDPR will soon be applied to organisations across the globe doesn't mean that everything's fine and dandy[3][13]: it's not. We give away information about ourselves all the time—and permission for companies to use it.
|
||||
|
||||
There's a telling (though disputed) saying: "If you're not paying, you're the product." What this suggests is that if you're not paying for a service, then somebody else is paying to use your data. Do you pay to use Facebook? Twitter? Gmail? How do you think they make their money? Well, partly through advertising, and some might argue that's a service they provide to you, but actually that's them using your data to get money from the advertisers. You're not really a customer of advertising—it's only once you buy something from the advertiser that you become their customer, but until you do, the relationship is between the the owner of the advertising platform and the advertiser.
|
||||
|
||||
Some of these services allow you to pay to reduce or remove advertising (Spotify is a good example), but on the other hand, advertising may be enabled even for services that you think you do pay for (Amazon is apparently working to allow adverts via Alexa, for instance). Unless we want to start paying to use all of these "free" services, we need to be aware of what we're giving up, and making some choices about what we expose and what we don't.
|
||||
|
||||
### Who's the customer?
|
||||
|
||||
There's another issue around data that should be exercising us, and it's a direct consequence of the amounts of data that are being generated. There are many organisations out there—including "public" ones like universities, hospitals, or government departments[4][14]—who generate enormous quantities of data all the time, and who just don't have the capacity to store it. It would be a different matter if this data didn't have long-term value, but it does, as the tools for handling Big Data are developing, and organisations are realising they can be mining this now and in the future.
|
||||
|
||||
The problem they face, though, as the amount of data increases and their capacity to store it fails to keep up, is what to do with it. _Luckily_ —and I use this word with a very heavy dose of irony,[5][15] big corporations are stepping in to help them. "Give us your data," they say, "and we'll host it for free. We'll even let you use the data you collected when you want to!" Sounds like a great deal, yes? A fantastic example of big corporations[6][16] taking a philanthropic stance and helping out public organisations that have collected all of that lovely data about us.
|
||||
|
||||
Sadly, philanthropy isn't the only reason. These hosting deals come with a price: in exchange for agreeing to host the data, these corporations get to sell access to it to third parties. And do you think the public organisations, or those whose data is collected, will get a say in who these third parties are or how they will use it? I'll leave this as an exercise for the reader.[7][17]
|
||||
|
||||
### Open and positive
|
||||
|
||||
It's not all bad news, however. There's a growing "open data" movement among governments to encourage departments to make much of their data available to the public and other bodies for free. In some cases, this is being specifically legislated. Many voluntary organisations—particularly those receiving public funding—are starting to do the same. There are glimmerings of interest even from commercial organisations. What's more, there are techniques becoming available, such as those around differential privacy and multi-party computation, that are beginning to allow us to mine data across data sets without revealing too much about individuals—a computing problem that has historically been much less tractable than you might otherwise expect.
|
||||
|
||||
What does this all mean to us? Well, I've written before on Opensource.com about the [commonwealth of open source][18], and I'm increasingly convinced that we need to look beyond just software to other areas: hardware, organisations, and, relevant to this discussion, data. Let's imagine that you're a company (A) that provides a service to another company, a customer (B).[8][19] There are four different types of data in play:
|
||||
|
||||
1. Data that's fully open: visible to A, B, and the rest of the world
|
||||
|
||||
2. Data that's known, shared, and confidential: visible to A and B, but nobody else
|
||||
|
||||
3. Data that's company-confidential: visible to A, but not B
|
||||
|
||||
4. Data that's customer-confidential: visible to B, but not A
|
||||
|
||||
First of all, maybe we should be a bit more open about data and default to putting it into bucket 1\. That data—on self-driving cars, voice recognition, mineral deposits, demographic statistics—could be enormously useful if it were available to everyone.[9][20]Also, wouldn't it be great if we could find ways to make the data in buckets 2, 3, and 4—or at least some of it—available in bucket 1, whilst still keeping the details confidential? That's the hope for some of these new techniques being researched. They're a way off, though, so don't get too excited, and in the meantime, start thinking about making more of your data open by default.
|
||||
|
||||
### Some concrete steps
|
||||
|
||||
So, what can we do around data privacy and being open? Here are a few concrete steps that occurred to me: please use the comments to contribute more.
|
||||
|
||||
* Check to see whether your organisation is taking GDPR seriously. If it isn't, push for it.
|
||||
|
||||
* Default to encrypting sensitive data (or hashing where appropriate), and deleting when it's no longer required—there's really no excuse for data to be in the clear to these days except for when it's actually being processed.
|
||||
|
||||
* Consider what information you disclose when you sign up to services, particularly social media.
|
||||
|
||||
* Discuss this with your non-technical friends.
|
||||
|
||||
* Educate your children, your friends' children, and their friends. Better yet, go and talk to their teachers about it and present something in their schools.
|
||||
|
||||
* Encourage the organisations you work for, volunteer for, or interact with to make data open by default. Rather than thinking, "why should I make this public?" start with "why _shouldn't_ I make this public?"
|
||||
|
||||
* Try accessing some of the open data sources out there. Mine it, create apps that use it, perform statistical analyses, draw pretty graphs,[10][3] make interesting music, but consider doing something with it. Tell the organisations that sourced it, thank them, and encourage them to do more.
|
||||
|
||||
* * *
|
||||
|
||||
1\. Though you probably won't, I admit.
|
||||
|
||||
2\. Assuming that you believe that your personal data should be protected.
|
||||
|
||||
3\. If you're wondering what "dandy" means, you're not alone at this point.
|
||||
|
||||
4\. Exactly how public these institutions seem to you will probably depend on where you live: [YMMV][21].
|
||||
|
||||
5\. And given that I'm British, that's a really very, very heavy dose.
|
||||
|
||||
6\. And they're likely to be big corporations: nobody else can afford all of that storage and the infrastructure to keep it available.
|
||||
|
||||
7\. No. The answer's "no."
|
||||
|
||||
8\. Although the example works for people, too. Oh, look: A could be Alice, B could be Bob…
|
||||
|
||||
9\. Not that we should be exposing personal data or data that actually needs to be confidential, of course—not that type of data.
|
||||
|
||||
10\. A friend of mine decided that it always seemed to rain when she picked her children up from school, so to avoid confirmation bias, she accessed rainfall information across the school year and created graphs that she shared on social media.
|
||||
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][22] Mike Bursell - I've been in and around Open Source since around 1997, and have been running (GNU) Linux as my main desktop at home and work since then: [not always easy][4]... I'm a security bod and architect, and am currently employed as Chief Security Architect for Red Hat. I have a blog - "[Alice, Eve & Bob][5]" - where I write (sometimes rather parenthetically) about security. I live in the UK and... [more about Mike Bursell][6][More about me][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://opensource.com/article/18/1/being-open-about-data-privacy?rate=oQCDAM0DY-P97d3pEEW_yUgoCV1ZXhv8BHYTnJVeHMc
|
||||
[2]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[3]:https://opensource.com/article/18/1/being-open-about-data-privacy#10
|
||||
[4]:https://opensource.com/article/17/11/politics-linux-desktop
|
||||
[5]:https://aliceevebob.com/
|
||||
[6]:https://opensource.com/users/mikecamel
|
||||
[7]:https://opensource.com/users/mikecamel
|
||||
[8]:https://opensource.com/user/105961/feed
|
||||
[9]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[10]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[11]:https://opensource.com/article/18/1/being-open-about-data-privacy#1
|
||||
[12]:https://opensource.com/article/18/1/being-open-about-data-privacy#2
|
||||
[13]:https://opensource.com/article/18/1/being-open-about-data-privacy#3
|
||||
[14]:https://opensource.com/article/18/1/being-open-about-data-privacy#4
|
||||
[15]:https://opensource.com/article/18/1/being-open-about-data-privacy#5
|
||||
[16]:https://opensource.com/article/18/1/being-open-about-data-privacy#6
|
||||
[17]:https://opensource.com/article/18/1/being-open-about-data-privacy#7
|
||||
[18]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[19]:https://opensource.com/article/18/1/being-open-about-data-privacy#8
|
||||
[20]:https://opensource.com/article/18/1/being-open-about-data-privacy#9
|
||||
[21]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
[22]:https://opensource.com/users/mikecamel
|
||||
[23]:https://opensource.com/users/mikecamel
|
||||
[24]:https://opensource.com/users/mikecamel
|
||||
[25]:https://opensource.com/tags/open-data
|
||||
@ -1,121 +0,0 @@
|
||||
translated by cyleft
|
||||
|
||||
Linux ln Command Tutorial for Beginners (5 Examples)
|
||||
======
|
||||
|
||||
Sometimes, while working on the command line, you need to create links between files. This can be achieved using a dedicated command, dubbed **ln**. In this tutorial, we will discuss the basics of this tool using some easy to understand examples. But before we do that, it's worth mentioning that all examples here have been tested on an Ubuntu 16.04 machine.
|
||||
|
||||
### Linux ln command
|
||||
|
||||
As you'd have understood by now, the ln command lets you make links between files. Following is the syntax (or rather different syntax available) for this tool:
|
||||
|
||||
```
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
|
||||
ln [OPTION]... TARGET (2nd form)
|
||||
ln [OPTION]... TARGET... DIRECTORY (3rd form)
|
||||
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
|
||||
```
|
||||
|
||||
And here's how the tool's man page explains it:
|
||||
```
|
||||
In the 1st form, create a link to TARGET with the name LINK_NAME. In the 2nd form, create a link
|
||||
to TARGET in the current directory. In the 3rd and 4th forms, create links to each TARGET in
|
||||
DIRECTORY. Create hard links by default, symbolic links with --symbolic. By default, each
|
||||
destination (name of new link) should not already exist. When creating hard links, each TARGET
|
||||
must exist. Symbolic links can hold arbitrary text; if later resolved, a relative link is
|
||||
interpreted in relation to its parent directory.
|
||||
```
|
||||
|
||||
The following Q&A-styled examples will give you a better idea on how the ln command works. But before that, it's good you get a understanding of what's the [difference between hard links and soft links][1].
|
||||
|
||||
### Q1. How to create a hard link using ln?
|
||||
|
||||
That's pretty straightforward - all you have to do is to use the ln command in the following way:
|
||||
|
||||
```
|
||||
ln [file] [hard-link-to-file]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
ln test.txt test_hard_link.txt
|
||||
```
|
||||
|
||||
[![How to create a hard link using ln][2]][3]
|
||||
|
||||
So you can see a hard link was created with the name test_hard_link.txt.
|
||||
|
||||
### Q2. How to create soft/symbolic link using ln?
|
||||
|
||||
For this, use the -s command line option.
|
||||
|
||||
```
|
||||
ln -s [file] [soft-link-to-file]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
ln -s test.txt test_soft_link.txt
|
||||
```
|
||||
|
||||
[![How to create soft/symbolic link using ln][4]][5]
|
||||
|
||||
The test_soft_link.txt file is a soft/symbolic link, as [confirmed][6] by its sky blue text color.
|
||||
|
||||
### Q3. How to make ln remove existing destination files of same name?
|
||||
|
||||
By default, ln won't let you create a link if a file of the same name already exists in the destination directory.
|
||||
|
||||
[![ln command example][7]][8]
|
||||
|
||||
However, if you want, you can make ln override this behavior by using the **-f** command line option.
|
||||
|
||||
[![How to make ln remove existing destination files of same name][9]][10]
|
||||
|
||||
**Note** : You can use the **-i** command line option if you want to make all this deletion process interactive.
|
||||
|
||||
### Q4. How to make ln create backup of existing files with same name?
|
||||
|
||||
If you don't want ln to delete existing files of same name, you can make it create backup of these files. This can be achieved using the **-b** command line option. Backup files created this way will contain a tilde (~) towards the end of their name.
|
||||
|
||||
[![How to make ln create backup of existing files with same name][11]][12]
|
||||
|
||||
A particular destination directory (other than the current one) can be specified using the **-t** command line option. For example:
|
||||
|
||||
```
|
||||
ls test* | xargs ln -s -t /home/himanshu/Desktop/
|
||||
```
|
||||
|
||||
The aforementioned command will create links to all test* files (present in the current directory) and put them in the Desktop directory.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agreed, **ln** isn't something that you'll require on daily basis, especially if you're a newbie. But it's a helpful command to know about, as you never know when it'd save your day. We've discussed some useful command line options the tool offers. Once you're done with these, you can learn more about ln by heading to its [man page][13].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-ln-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://medium.com/meatandmachines/explaining-the-difference-between-hard-links-symbolic-links-using-bruce-lee-32828832e8d3
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/ln-hard-link.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/ln-hard-link.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/ln-soft-link.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/ln-soft-link.png
|
||||
[6]:https://askubuntu.com/questions/17299/what-do-the-different-colors-mean-in-ls
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/ln-file-exists.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/ln-file-exists.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/ln-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/ln-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/ln-b-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/ln-b-option.png
|
||||
[13]:https://linux.die.net/man/1/ln
|
||||
@ -0,0 +1,239 @@
|
||||
Python + Memcached: Efficient Caching in Distributed Applications – Real Python
|
||||
======
|
||||
|
||||
When writing Python applications, caching is important. Using a cache to avoid recomputing data or accessing a slow database can provide you with a great performance boost.
|
||||
|
||||
Python offers built-in possibilities for caching, from a simple dictionary to a more complete data structure such as [`functools.lru_cache`][2]. The latter can cache any item using a [Least-Recently Used algorithm][3] to limit the cache size.
|
||||
|
||||
Those data structures are, however, by definition local to your Python process. When several copies of your application run across a large platform, using a in-memory data structure disallows sharing the cached content. This can be a problem for large-scale and distributed applications.
|
||||
|
||||
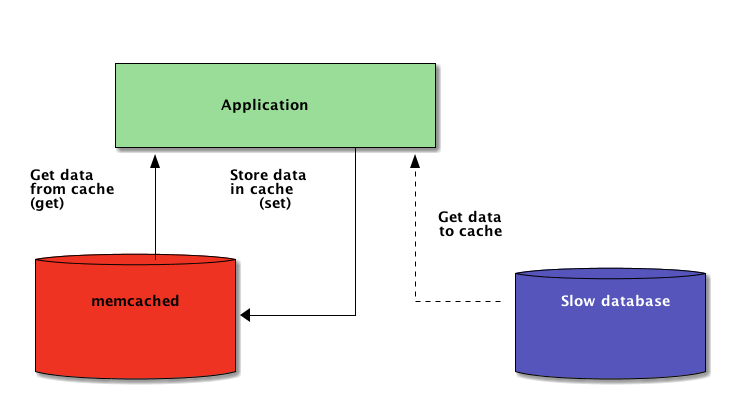
|
||||
|
||||
Therefore, when a system is distributed across a network, it also needs a cache that is distributed across a network. Nowadays, there are plenty of network servers that offer caching capability—we already covered [how to use Redis for caching with Django][4].
|
||||
|
||||
As you’re going to see in this tutorial, [memcached][5] is another great option for distributed caching. After a quick introduction to basic memcached usage, you’ll learn about advanced patterns such as “cache and set” and using fallback caches to avoid cold cache performance issues.
|
||||
|
||||
### Installing memcached
|
||||
|
||||
Memcached is [available for many platforms][6]:
|
||||
|
||||
* If you run **Linux** , you can install it using `apt-get install memcached` or `yum install memcached`. This will install memcached from a pre-built package but you can alse build memcached from source, [as explained here][6].
|
||||
* For **macOS** , using [Homebrew][7] is the simplest option. Just run `brew install memcached` after you’ve installed the Homebrew package manager.
|
||||
* On **Windows** , you would have to compile memcached yourself or find [pre-compiled binaries][8].
|
||||
|
||||
|
||||
|
||||
Once installed, memcached can simply be launched by calling the `memcached` command:
|
||||
```
|
||||
$ memcached
|
||||
|
||||
```
|
||||
|
||||
Before you can interact with memcached from Python-land you’ll need to install a memcached client library. You’ll see how to do this in the next section, along with some basic cache access operations.
|
||||
|
||||
### Storing and Retrieving Cached Values Using Python
|
||||
|
||||
If you never used memcached, it is pretty easy to understand. It basically provides a giant network-available dictionary. This dictionary has a few properties that are different from a classical Python dictionnary, mainly:
|
||||
|
||||
* Keys and values have to be bytes
|
||||
* Keys and values are automatically deleted after an expiration time
|
||||
|
||||
|
||||
|
||||
Therefore, the two basic operations for interacting with memcached are `set` and `get`. As you might have guessed, they’re used to assign a value to a key or to get a value from a key, respectively.
|
||||
|
||||
My preferred Python library for interacting with memcached is [`pymemcache`][9]—I recommend using it. You can simply [install it using pip][10]:
|
||||
```
|
||||
$ pip install pymemcache
|
||||
|
||||
```
|
||||
|
||||
The following code shows how you can connect to memcached and use it as a network-distributed cache in your Python applications:
|
||||
```
|
||||
>>> from pymemcache.client import base
|
||||
|
||||
# Don't forget to run `memcached' before running this next line:
|
||||
>>> client = base.Client(('localhost', 11211))
|
||||
|
||||
# Once the client is instantiated, you can access the cache:
|
||||
>>> client.set('some_key', 'some value')
|
||||
|
||||
# Retrieve previously set data again:
|
||||
>>> client.get('some_key')
|
||||
'some value'
|
||||
|
||||
```
|
||||
|
||||
memcached network protocol is really simple an its implementation extremely fast, which makes it useful to store data that would be otherwise slow to retrieve from the canonical source of data or to compute again:
|
||||
|
||||
While straightforward enough, this example allows storing key/value tuples across the network and accessing them through multiple, distributed, running copies of your application. This is simplistic, yet powerful. And it’s a great first step towards optimizing your application.
|
||||
|
||||
### Automatically Expiring Cached Data
|
||||
|
||||
When storing data into memcached, you can set an expiration time—a maximum number of seconds for memcached to keep the key and value around. After that delay, memcached automatically removes the key from its cache.
|
||||
|
||||
What should you set this cache time to? There is no magic number for this delay, and it will entirely depend on the type of data and application that you are working with. It could be a few seconds, or it might be a few hours.
|
||||
|
||||
Cache invalidation, which defines when to remove the cache because it is out of sync with the current data, is also something that your application will have to handle. Especially if presenting data that is too old or or stale is to be avoided.
|
||||
|
||||
Here again, there is no magical recipe; it depends on the type of application you are building. However, there are several outlying cases that should be handled—which we haven’t yet covered in the above example.
|
||||
|
||||
A caching server cannot grow infinitely—memory is a finite resource. Therefore, keys will be flushed out by the caching server as soon as it needs more space to store other things.
|
||||
|
||||
Some keys might also be expired because they reached their expiration time (also sometimes called the “time-to-live” or TTL.) In those cases the data is lost, and the canonical data source must be queried again.
|
||||
|
||||
This sounds more complicated than it really is. You can generally work with the following pattern when working with memcached in Python:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Don't forget to run `memcached' before running this code
|
||||
client = base.Client(('localhost', 11211))
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
# Whether we needed to update the cache or not,
|
||||
# at this point you can work with the data
|
||||
# stored in the `result` variable:
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
> **Note:** Handling missing keys is mandatory because of normal flush-out operations. It is also obligatory to handle the cold cache scenario, i.e. when memcached has just been started. In that case, the cache will be entirely empty and the cache needs to be fully repopulated, one request at a time.
|
||||
|
||||
This means you should view any cached data as ephemeral. And you should never expect the cache to contain a value you previously wrote to it.
|
||||
|
||||
### Warming Up a Cold Cache
|
||||
|
||||
Some of the cold cache scenarios cannot be prevented, for example a memcached crash. But some can, for example migrating to a new memcached server.
|
||||
|
||||
When it is possible to predict that a cold cache scenario will happen, it is better to avoid it. A cache that needs to be refilled means that all of the sudden, the canonical storage of the cached data will be massively hit by all cache users who lack a cache data (also known as the [thundering herd problem][11].)
|
||||
|
||||
pymemcache provides a class named `FallbackClient` that helps in implementing this scenario as demonstrated here:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
from pymemcache import fallback
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Set `ignore_exc=True` so it is possible to shut down
|
||||
# the old cache before removing its usage from
|
||||
# the program, if ever necessary.
|
||||
old_cache = base.Client(('localhost', 11211), ignore_exc=True)
|
||||
new_cache = base.Client(('localhost', 11212))
|
||||
|
||||
client = fallback.FallbackClient((new_cache, old_cache))
|
||||
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
The `FallbackClient` queries the old cache passed to its constructor, respecting the order. In this case, the new cache server will always be queried first, and in case of a cache miss, the old one will be queried—avoiding a possible return-trip to the primary source of data.
|
||||
|
||||
If any key is set, it will only be set to the new cache. After some time, the old cache can be decommissioned and the `FallbackClient` can be replaced directed with the `new_cache` client.
|
||||
|
||||
### Check And Set
|
||||
|
||||
When communicating with a remote cache, the usual concurrency problem comes back: there might be several clients trying to access the same key at the same time. memcached provides a check and set operation, shortened to CAS, which helps to solve this problem.
|
||||
|
||||
The simplest example is an application that wants to count the number of users it has. Each time a visitor connects, a counter is incremented by 1. Using memcached, a simple implementation would be:
|
||||
```
|
||||
def on_visit(client):
|
||||
result = client.get('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
client.set('visitors', result)
|
||||
|
||||
```
|
||||
|
||||
However, what happens if two instances of the application try to update this counter at the same time?
|
||||
|
||||
The first call `client.get('visitors')` will return the same number of visitors for both of them, let’s say it’s 42. Then both will add 1, compute 43, and set the number of visitors to 43. That number is wrong, and the result should be 44, i.e. 42 + 1 + 1.
|
||||
|
||||
To solve this concurrency issue, the CAS operation of memcached is handy. The following snippet implements a correct solution:
|
||||
```
|
||||
def on_visit(client):
|
||||
while True:
|
||||
result, cas = client.gets('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
if client.cas('visitors', result, cas):
|
||||
break
|
||||
|
||||
```
|
||||
|
||||
The `gets` method returns the value, just like the `get` method, but it also returns a CAS value.
|
||||
|
||||
What is in this value is not relevant, but it is used for the next method `cas` call. This method is equivalent to the `set` operation, except that it fails if the value has changed since the `gets` operation. In case of success, the loop is broken. Otherwise, the operation is restarted from the beginning.
|
||||
|
||||
In the scenario where two instances of the application try to update the counter at the same time, only one succeeds to move the counter from 42 to 43. The second instance gets a `False` value returned by the `client.cas` call, and have to retry the loop. It will retrieve 43 as value this time, will increment it to 44, and its `cas` call will succeed, thus solving our problem.
|
||||
|
||||
Incrementing a counter is interesting as an example to explain how CAS works because it is simplistic. However, memcached also provides the `incr` and `decr` methods to increment or decrement an integer in a single request, rather than doing multiple `gets`/`cas` calls. In real-world applications `gets` and `cas` are used for more complex data type or operations
|
||||
|
||||
Most remote caching server and data store provide such a mechanism to prevent concurrency issues. It is critical to be aware of those cases to make proper use of their features.
|
||||
|
||||
### Beyond Caching
|
||||
|
||||
The simple techniques illustrated in this article showed you how easy it is to leverage memcached to speed up the performances of your Python application.
|
||||
|
||||
Just by using the two basic “set” and “get” operations you can often accelerate data retrieval or avoid recomputing results over and over again. With memcached you can share the cache accross a large number of distributed nodes.
|
||||
|
||||
Other, more advanced patterns you saw in this tutorial, like the Check And Set (CAS) operation allow you to update data stored in the cache concurrently across multiple Python threads or processes while avoiding data corruption.
|
||||
|
||||
If you are interested into learning more about advanced techniques to write faster and more scalable Python applications, check out [Scaling Python][12]. It covers many advanced topics such as network distribution, queuing systems, distributed hashing, and code profiling.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/python-memcache-efficient-caching/
|
||||
|
||||
作者:[Julien Danjou][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/jdanjou/
|
||||
[1]:https://realpython.com/blog/categories/python/
|
||||
[2]:https://docs.python.org/3/library/functools.html#functools.lru_cache
|
||||
[3]:https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_Recently_Used_(LRU)
|
||||
[4]:https://realpython.com/blog/python/caching-in-django-with-redis/
|
||||
[5]:http://memcached.org
|
||||
[6]:https://github.com/memcached/memcached/wiki/Install
|
||||
[7]:https://brew.sh/
|
||||
[8]:https://commaster.net/content/installing-memcached-windows
|
||||
[9]:https://pypi.python.org/pypi/pymemcache
|
||||
[10]:https://realpython.com/learn/python-first-steps/#11-pythons-power-packagesmodules
|
||||
[11]:https://en.wikipedia.org/wiki/Thundering_herd_problem
|
||||
[12]:https://scaling-python.com
|
||||
@ -0,0 +1,262 @@
|
||||
Shallow vs Deep Copying of Python Objects – Real Python
|
||||
======
|
||||
|
||||
Assignment statements in Python do not create copies of objects, they only bind names to an object. For immutable objects, that usually doesn’t make a difference.
|
||||
|
||||
But for working with mutable objects or collections of mutable objects, you might be looking for a way to create “real copies” or “clones” of these objects.
|
||||
|
||||
Essentially, you’ll sometimes want copies that you can modify without automatically modifying the original at the same time. In this article I’m going to give you the rundown on how to copy or “clone” objects in Python 3 and some of the caveats involved.
|
||||
|
||||
> **Note:** This tutorial was written with Python 3 in mind but there is little difference between Python 2 and 3 when it comes to copying objects. When there are differences I will point them out in the text.
|
||||
|
||||
Let’s start by looking at how to copy Python’s built-in collections. Python’s built-in mutable collections like [lists, dicts, and sets][3] can be copied by calling their factory functions on an existing collection:
|
||||
```
|
||||
new_list = list(original_list)
|
||||
new_dict = dict(original_dict)
|
||||
new_set = set(original_set)
|
||||
|
||||
```
|
||||
|
||||
However, this method won’t work for custom objects and, on top of that, it only creates shallow copies. For compound objects like lists, dicts, and sets, there’s an important difference between shallow and deep copying:
|
||||
|
||||
* A **shallow copy** means constructing a new collection object and then populating it with references to the child objects found in the original. In essence, a shallow copy is only one level deep. The copying process does not recurse and therefore won’t create copies of the child objects themselves.
|
||||
|
||||
* A **deep copy** makes the copying process recursive. It means first constructing a new collection object and then recursively populating it with copies of the child objects found in the original. Copying an object this way walks the whole object tree to create a fully independent clone of the original object and all of its children.
|
||||
|
||||
|
||||
|
||||
|
||||
I know, that was a bit of a mouthful. So let’s look at some examples to drive home this difference between deep and shallow copies.
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
### Making Shallow Copies
|
||||
|
||||
In the example below, we’ll create a new nested list and then shallowly copy it with the `list()` factory function:
|
||||
```
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys = list(xs) # Make a shallow copy
|
||||
|
||||
```
|
||||
|
||||
This means `ys` will now be a new and independent object with the same contents as `xs`. You can verify this by inspecting both objects:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
To confirm `ys` really is independent from the original, let’s devise a little experiment. You could try and add a new sublist to the original (`xs`) and then check to make sure this modification didn’t affect the copy (`ys`):
|
||||
```
|
||||
>>> xs.append(['new sublist'])
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
As you can see, this had the expected effect. Modifying the copied list at a “superficial” level was no problem at all.
|
||||
|
||||
However, because we only created a shallow copy of the original list, `ys` still contains references to the original child objects stored in `xs`.
|
||||
|
||||
These children were not copied. They were merely referenced again in the copied list.
|
||||
|
||||
Therefore, when you modify one of the child objects in `xs`, this modification will be reflected in `ys` as well—that’s because both lists share the same child objects. The copy is only a shallow, one level deep copy:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
In the above example we (seemingly) only made a change to `xs`. But it turns out that both sublists at index 1 in `xs` and `ys` were modified. Again, this happened because we had only created a shallow copy of the original list.
|
||||
|
||||
Had we created a deep copy of `xs` in the first step, both objects would’ve been fully independent. This is the practical difference between shallow and deep copies of objects.
|
||||
|
||||
Now you know how to create shallow copies of some of the built-in collection classes, and you know the difference between shallow and deep copying. The questions we still want answers for are:
|
||||
|
||||
* How can you create deep copies of built-in collections?
|
||||
* How can you create copies (shallow and deep) of arbitrary objects, including custom classes?
|
||||
|
||||
|
||||
|
||||
The answer to these questions lies in the `copy` module in the Python standard library. This module provides a simple interface for creating shallow and deep copies of arbitrary Python objects.
|
||||
|
||||
### Making Deep Copies
|
||||
|
||||
Let’s repeat the previous list-copying example, but with one important difference. This time we’re going to create a deep copy using the `deepcopy()` function defined in the `copy` module instead:
|
||||
```
|
||||
>>> import copy
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs = copy.deepcopy(xs)
|
||||
|
||||
```
|
||||
|
||||
When you inspect `xs` and its clone `zs` that we created with `copy.deepcopy()`, you’ll see that they both look identical again—just like in the previous example:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
However, if you make a modification to one of the child objects in the original object (`xs`), you’ll see that this modification won’t affect the deep copy (`zs`).
|
||||
|
||||
Both objects, the original and the copy, are fully independent this time. `xs` was cloned recursively, including all of its child objects:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
You might want to take some time to sit down with the Python interpreter and play through these examples right about now. Wrapping your head around copying objects is easier when you get to experience and play with the examples firsthand.
|
||||
|
||||
By the way, you can also create shallow copies using a function in the `copy` module. The `copy.copy()` function creates shallow copies of objects.
|
||||
|
||||
This is useful if you need to clearly communicate that you’re creating a shallow copy somewhere in your code. Using `copy.copy()` lets you indicate this fact. However, for built-in collections it’s considered more Pythonic to simply use the list, dict, and set factory functions to create shallow copies.
|
||||
|
||||
### Copying Arbitrary Python Objects
|
||||
|
||||
The question we still need to answer is how do we create copies (shallow and deep) of arbitrary objects, including custom classes. Let’s take a look at that now.
|
||||
|
||||
Again the `copy` module comes to our rescue. Its `copy.copy()` and `copy.deepcopy()` functions can be used to duplicate any object.
|
||||
|
||||
Once again, the best way to understand how to use these is with a simple experiment. I’m going to base this on the previous list-copying example. Let’s start by defining a simple 2D point class:
|
||||
```
|
||||
class Point:
|
||||
def __init__(self, x, y):
|
||||
self.x = x
|
||||
self.y = y
|
||||
|
||||
def __repr__(self):
|
||||
return f'Point({self.x!r}, {self.y!r})'
|
||||
|
||||
```
|
||||
|
||||
I hope you agree that this was pretty straightforward. I added a `__repr__()` implementation so that we can easily inspect objects created from this class in the Python interpreter.
|
||||
|
||||
> **Note:** The above example uses a [Python 3.6 f-string][5] to construct the string returned by `__repr__`. On Python 2 and versions of Python 3 before 3.6 you’d use a different string formatting expression, for example:
|
||||
```
|
||||
> def __repr__(self):
|
||||
> return 'Point(%r, %r)' % (self.x, self.y)
|
||||
>
|
||||
```
|
||||
|
||||
Next up, we’ll create a `Point` instance and then (shallowly) copy it, using the `copy` module:
|
||||
```
|
||||
>>> a = Point(23, 42)
|
||||
>>> b = copy.copy(a)
|
||||
|
||||
```
|
||||
|
||||
If we inspect the contents of the original `Point` object and its (shallow) clone, we see what we’d expect:
|
||||
```
|
||||
>>> a
|
||||
Point(23, 42)
|
||||
>>> b
|
||||
Point(23, 42)
|
||||
>>> a is b
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Here’s something else to keep in mind. Because our point object uses primitive types (ints) for its coordinates, there’s no difference between a shallow and a deep copy in this case. But I’ll expand the example in a second.
|
||||
|
||||
Let’s move on to a more complex example. I’m going to define another class to represent 2D rectangles. I’ll do it in a way that allows us to create a more complex object hierarchy—my rectangles will use `Point` objects to represent their coordinates:
|
||||
```
|
||||
class Rectangle:
|
||||
def __init__(self, topleft, bottomright):
|
||||
self.topleft = topleft
|
||||
self.bottomright = bottomright
|
||||
|
||||
def __repr__(self):
|
||||
return (f'Rectangle({self.topleft!r}, '
|
||||
f'{self.bottomright!r})')
|
||||
|
||||
```
|
||||
|
||||
Again, first we’re going to attempt to create a shallow copy of a rectangle instance:
|
||||
```
|
||||
rect = Rectangle(Point(0, 1), Point(5, 6))
|
||||
srect = copy.copy(rect)
|
||||
|
||||
```
|
||||
|
||||
If you inspect the original rectangle and its copy, you’ll see how nicely the `__repr__()` override is working out, and that the shallow copy process worked as expected:
|
||||
```
|
||||
>>> rect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> rect is srect
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Remember how the previous list example illustrated the difference between deep and shallow copies? I’m going to use the same approach here. I’ll modify an object deeper in the object hierarchy, and then you’ll see this change reflected in the (shallow) copy as well:
|
||||
```
|
||||
>>> rect.topleft.x = 999
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
I hope this behaved how you expected it to. Next, I’ll create a deep copy of the original rectangle. Then I’ll apply another modification and you’ll see which objects are affected:
|
||||
```
|
||||
>>> drect = copy.deepcopy(srect)
|
||||
>>> drect.topleft.x = 222
|
||||
>>> drect
|
||||
Rectangle(Point(222, 1), Point(5, 6))
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
Voila! This time the deep copy (`drect`) is fully independent of the original (`rect`) and the shallow copy (`srect`).
|
||||
|
||||
We’ve covered a lot of ground here, and there are still some finer points to copying objects.
|
||||
|
||||
It pays to go deep (ha!) on this topic, so you may want to study up on the [`copy` module documentation][6]. For example, objects can control how they’re copied by defining the special methods `__copy__()` and `__deepcopy__()` on them.
|
||||
|
||||
### 3 Things to Remember
|
||||
|
||||
* Making a shallow copy of an object won’t clone child objects. Therefore, the copy is not fully independent of the original.
|
||||
* A deep copy of an object will recursively clone child objects. The clone is fully independent of the original, but creating a deep copy is slower.
|
||||
* You can copy arbitrary objects (including custom classes) with the `copy` module.
|
||||
|
||||
|
||||
|
||||
If you’d like to dig deeper into other intermediate-level Python programming techniques, check out this free bonus:
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/copying-python-objects/
|
||||
|
||||
作者:[Dan Bader][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/dbader/
|
||||
[1]:https://realpython.com/blog/categories/fundamentals/
|
||||
[2]:https://realpython.com/blog/categories/python/
|
||||
[3]:https://realpython.com/learn/python-first-steps/
|
||||
[4]:https://realpython.com/blog/python/copying-python-objects/
|
||||
[5]:https://dbader.org/blog/python-string-formatting
|
||||
[6]:https://docs.python.org/3/library/copy.html
|
||||
@ -1,106 +0,0 @@
|
||||
#Being translated by YPBlib
|
||||
======
|
||||
|
||||
Why you should use named pipes on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just about every Linux user is familiar with the process of piping data from one process to another using | signs. It provides an easy way to send output from one command to another and end up with only the data you want to see without having to write scripts to do all of the selecting and reformatting.
|
||||
|
||||
There is another type of pipe, however, one that warrants the name "pipe" but has a very different personality. It's one that you may have never tried or even thought about -- the named pipe.
|
||||
|
||||
**Also read:[11 pointless but awesome Linux terminal tricks][1]**
|
||||
|
||||
One of the key differences between regular pipes and named pipes is that named pipes have a presense in the file system. That is, they show up as files. But unlike most files, they never appear to have contents. Even if you write a lot of data to a named pipe, the file appears to be empty.
|
||||
|
||||
### How to set up a named pipe on Linux
|
||||
|
||||
Before we look at one of these empty named pipes, let's step back and see how a named pipe is set up. You would use a command called **mkfifo**. Why the reference to "FIFO"? Because a named pipe is also known as a FIFO special file. The term "FIFO" refers to its first-in, first-out character. If you fill a dish with ice cream and then start eating it, you'd be doing a LIFO (last-in, first-out) maneuver. If you suck a milkshake through a straw, you'd be doing a FIFO one. So, here's an example of creating a named pipe.
|
||||
```
|
||||
$ mkfifo mypipe
|
||||
$ ls -l mypipe
|
||||
prw-r-----. 1 shs staff 0 Jan 31 13:59 mypipe
|
||||
|
||||
```
|
||||
|
||||
Notice the special file type designation of "p" and the file length of zero. You can write to a named pipe by redirecting output to it and the length will still be zero.
|
||||
```
|
||||
$ echo "Can you read this?" > mypipe
|
||||
$ ls -l mypipe
|
||||
prw-r-----. 1 shs staff 0 Jan 31 13:59 mypipe
|
||||
|
||||
```
|
||||
|
||||
So far, so good, but hit return and nothing much happens.
|
||||
```
|
||||
$ echo "Can you read this?" > mypipe
|
||||
|
||||
|
||||
```
|
||||
|
||||
While it might not be obvious, your text has entered into the pipe, but you're still peeking into the _input_ end of it. You or someone else may be sitting at the _output_ end and be ready to read the data that's being poured into the pipe, now waiting for it to be read.
|
||||
```
|
||||
$ cat mypipe
|
||||
Can you read this?
|
||||
|
||||
```
|
||||
|
||||
Once read, the contents of the pipe are gone.
|
||||
|
||||
Another way to see how a named pipe works is to perform both operations (pouring the data into the pipe and retrieving it at the other end) yourself by putting the pouring part into the background.
|
||||
```
|
||||
$ echo "Can you read this?" > mypipe &
|
||||
[1] 79302
|
||||
$ cat mypipe
|
||||
Can you read this?
|
||||
[1]+ Done echo "Can you read this?" > mypipe
|
||||
|
||||
```
|
||||
|
||||
Once the pipe has been read or "drained," it's empty, though it still will be visible as an empty file ready to be used again. Of course, this brings us to the "why bother?" stage.
|
||||
|
||||
### Why use named pipes?
|
||||
|
||||
Named pipes are used infrequently for a good reason. On Unix systems, there are almost always many ways to do pretty much the same thing. There are many ways to write to a file, read from a file, and empty a file, though named pipes have a certain efficiency going for them.
|
||||
|
||||
For one thing, named pipe content resides in memory rather than being written to disk. It is passed only when both ends of the pipe have been opened. And you can write to a pipe multiple times before it is opened at the other end and read. By using named pipes, you can establish a process in which one process writes to a pipe and another reads from a pipe without much concern about trying to time or carefully orchestrate their interaction.
|
||||
|
||||
You can set up a process that simply waits for data to appear at the output end of the pipe and then works with it when it does. In the command below, we use the tail command to wait for data to appear.
|
||||
```
|
||||
$ tail -f mypipe
|
||||
|
||||
```
|
||||
|
||||
Once the process that will be feeding the pipe has finished, we will see some output.
|
||||
```
|
||||
$ tail -f mypipe
|
||||
Uranus replicated to WCDC7
|
||||
Saturn replicated to WCDC8
|
||||
Pluto replicated to WCDC9
|
||||
Server replication operation completed
|
||||
|
||||
```
|
||||
|
||||
If you look at the process writing to a named pipe, you might be surprised by how little resources it uses. In the ps output below, the only significant resource use is virtual memory (the VSZ column).
|
||||
```
|
||||
ps u -P 80038
|
||||
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
|
||||
shs 80038 0.0 0.0 108488 764 pts/4 S 15:25 0:00 -bash
|
||||
|
||||
```
|
||||
|
||||
Named pipes are different enough from the more commonly used Unix/Linux pipes to warrant a different name, but "pipe" really invokes a good image of how they move data between processes, so "named pipe" fits pretty well. Maybe you'll come across a task that will benefit significantly from this very clever Unix/Linux feature.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3251853/linux/why-use-named-pipes-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html#tk.nww-fsb
|
||||
@ -0,0 +1,131 @@
|
||||
Error establishing a database connection
|
||||
======
|
||||
![Error establishing a database connection][1]
|
||||
|
||||
Error establishing a database connection, is a very common error when you try to access your WordPress site. The database stores all the important information for your website, including your posts, comments, site configuration, user accounts, theme and plugin settings and so on. If the connection to your database cannot be established, your WordPress website will not load, and more then likely will give you the error: “Error establishing a database connection” In this tutorial we will show you, how to fix Error establishing a database connection in WordPress.
|
||||
|
||||
The most common cause for “Error establishing a database connection” issue, is one of the following:
|
||||
|
||||
Your database has been corrupted
|
||||
Incorrect login credentials in your WordPress configuration file (wp-config.php)
|
||||
Your MySQL service stopped working due to insufficient memory on the server (due to heavy traffic), or server problems
|
||||
|
||||
![Error establishing a database connection][2]
|
||||
|
||||
### 1. Requirements
|
||||
|
||||
In order to troubleshoot “Error establishing a database connection” issue, a few requirements must be met:
|
||||
|
||||
* SSH access to your server
|
||||
* The database is located on the same server
|
||||
* You need to know your database username, user password, and name of the database
|
||||
|
||||
|
||||
|
||||
Also before you try to fix “Error establishing a database connection” error, it is highly recommended that you make a backup of both your website and database.
|
||||
|
||||
### 1. Corrupted database
|
||||
|
||||
The first step to do when trying to troubleshoot “Error establishing a database connection” problem is to check whether this error is present for both the front-end and the back-end of the your site. You can access your back-end via <http://www.yourdomain.com/wp-admin> (replace “yourdomain” with your actual domain name)
|
||||
|
||||
If the error remains the same for both your front-end and back-end then you should move to the next step.
|
||||
|
||||
If you are able to access the back-end via <https://www.yourdomain.com/wp-admin, > and you see the following message:
|
||||
```
|
||||
“One or more database tables are unavailable. The database may need to be repaired”
|
||||
|
||||
```
|
||||
|
||||
it means that your database has been corrupted and you need to try to repair it.
|
||||
|
||||
To do this, you must first enable the repair option in your wp-config.php file, located inside the WordPress site root directory, by adding the following line:
|
||||
```
|
||||
define('WP_ALLOW_REPAIR', true);
|
||||
|
||||
```
|
||||
|
||||
Now you can navigate to this this page: <https://www.yourdomain.com/wp-admin/maint/repair.php> and click the “Repair and Optimize Database button.”
|
||||
|
||||
For security reasons, remember to turn off the repair option be deleting the line we added before in the wp-config.php file.
|
||||
|
||||
If this does not fix the problem or the database cannot be repaired you will probably need to restore it from a backup if you have one available.
|
||||
|
||||
### 2. Check your wp-config.php file
|
||||
|
||||
Another, probably most common reason, for failed database connection is because of incorrect database information set in your WordPress configuration file.
|
||||
|
||||
The configuration file resides in your WordPress site root directory and it is called wp-config.php .
|
||||
|
||||
Open the file and locate the following lines:
|
||||
```
|
||||
define('DB_NAME', 'database_name');
|
||||
define('DB_USER', 'database_username');
|
||||
define('DB_PASSWORD', 'database_password');
|
||||
define('DB_HOST', 'localhost');
|
||||
|
||||
```
|
||||
|
||||
Make sure the correct database name, username, and password are set. Database host should be set to “localhost”.
|
||||
|
||||
If you ever change your database username and password you should always update this file as well.
|
||||
|
||||
If everything is set up properly and you are still getting the “Error establishing a database connection” error then the problem is probably on the server side and you should move on to the next step of this tutorial.
|
||||
|
||||
### 3. Check your server
|
||||
|
||||
Depending on the resources available, during high traffic hours, your server might not be able to handle all the load and it may stop your MySQL server.
|
||||
|
||||
You can either contact your hosting provider about this or you can check it yourself if the MySQL server is properly running.
|
||||
|
||||
To check the status of MySQL, log in to your server via [SSH][3] and use the following command:
|
||||
```
|
||||
systemctl status mysql
|
||||
|
||||
```
|
||||
|
||||
Or you can check if it is up in your active processes with:
|
||||
```
|
||||
ps aux | grep mysql
|
||||
|
||||
```
|
||||
|
||||
If your MySQL is not running you can start it with the following commands:
|
||||
```
|
||||
systemctl start mysql
|
||||
|
||||
```
|
||||
|
||||
You may also need to check the memory usage on your server.
|
||||
|
||||
To check how much RAM you have available you can use the following command:
|
||||
```
|
||||
free -m
|
||||
|
||||
```
|
||||
|
||||
If your server is running low on memory you may want to consider upgrading your server.
|
||||
|
||||
### 4. Conclusion
|
||||
|
||||
Most of the time. the “Error establishing a database connection” error can be fixed by following one of the steps above.
|
||||
|
||||
![How to Fix the Error Establishing a Database Connection in WordPress][4]Of course, you don’t have to fix, Error establishing a database connection, if you use one of our [WordPress VPS Hosting Services][5], in which case you can simply ask our expert Linux admins to help you fix the Error establishing a database connection in WordPress, for you. They are available 24×7 and will take care of your request immediately.
|
||||
|
||||
**PS**. If you liked this post, on how to fix the Error establishing a database connection in WordPress, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.rosehosting.com/blog/error-establishing-a-database-connection/
|
||||
|
||||
作者:[RoseHosting][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.rosehosting.com
|
||||
[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/error-establishing-a-database-connection.jpg
|
||||
[2]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/Error-establishing-a-database-connection-e1517474875180.png
|
||||
[3]:https://www.rosehosting.com/blog/connect-to-your-linux-vps-via-ssh/
|
||||
[4]:https://www.rosehosting.com/blog/wp-content/uploads/2018/02/How-to-Fix-the-Error-Establishing-a-Database-Connection-in-WordPress.jpg
|
||||
[5]:https://www.rosehosting.com/wordpress-hosting.html
|
||||
211
sources/tech/20180202 CompositeAcceleration.md
Normal file
211
sources/tech/20180202 CompositeAcceleration.md
Normal file
@ -0,0 +1,211 @@
|
||||
CompositeAcceleration
|
||||
======
|
||||
### Composite acceleration in the X server
|
||||
|
||||
One of the persistent problems with the modern X desktop is the number of moving parts required to display application content. Consider a simple PresentPixmap call as made by the Vulkan WSI or GL using DRI3:
|
||||
|
||||
1. Application calls PresentPixmap with new contents for its window
|
||||
|
||||
2. X server receives that call and pends any operation until the target frame
|
||||
|
||||
3. At the target frame, the X server copies the new contents into the window pixmap and delivers a Damage event to the compositor
|
||||
|
||||
4. The compositor responds to the damage event by copying the window pixmap contents into the next screen pixmap
|
||||
|
||||
5. The compositor calls PresentPixmap with the new screen contents
|
||||
|
||||
6. The X server receives that call and either posts a Swap call to the kernel or delays any action until the target frame
|
||||
|
||||
|
||||
|
||||
|
||||
This sequence has a number of issues:
|
||||
|
||||
* The operation is serialized between three processes with at least three context switches involved.
|
||||
|
||||
* There is no traceable relation between when the application asked for the frame to be shown and when it is finally presented. Nor do we even have any way to tell the application what time that was.
|
||||
|
||||
* There are at least two copies of the application contents, from DRI3 buffer to window pixmap and from window pixmap to screen pixmap.
|
||||
|
||||
|
||||
|
||||
|
||||
We'd also like to be able to take advantage of the multi-plane capabilities in the display engine (where available) to directly display the application contents.
|
||||
|
||||
### Previous Attempts
|
||||
|
||||
I've tried to come up with solutions to this issue a couple of times in the past.
|
||||
|
||||
#### Composite Redirection
|
||||
|
||||
My first attempt to solve (some of) this problem was through composite redirection. The idea there was to directly pass the Present'd pixmap to the compositor and let it copy the contents directly from there in constructing the new screen pixmap image. With some additional hand waving, the idea was that we could associate that final presentation with all of the associated redirected compositing operations and at least provide applications with accurate information about when their images were presented.
|
||||
|
||||
This fell apart when I tried to figure out how to plumb the necessary events through to the compositor and back. With that, and the realization that we still weren't solving problems inherent with the three-process dance, nor providing any path to using overlays, this solution just didn't seem worth pursuing further.
|
||||
|
||||
#### Automatic Compositing
|
||||
|
||||
More recently, Eric Anholt and I have been discussing how to have the X server do all of the compositing work by natively supporting ARGB window content. By changing compositors to place all screen content in windows, the X server could then generate the screen image by itself and not require any external compositing manager assistance for each frame.
|
||||
|
||||
Given that a primitive form of automatic compositing is already supported, extending that to support ARGB windows and having the X server manage the stack seemed pretty tractable. We would extend the driver interface so that drivers could perform the compositing themselves using a mixture of GPU operations and overlays.
|
||||
|
||||
This runs up against five hard problems though.
|
||||
|
||||
1. Making transitions between Manual and Automatic compositing seamless. We've seen how well the current compositing environment works when flipping compositing on and off to allow full-screen applications to use page flipping. Lots of screen flashing and application repaints.
|
||||
|
||||
2. Dealing with RGB windows with ARGB decorations. Right now, the window frame can be an ARGB window with the client being RGB; painting the client into the frame yields an ARGB result with the A values being 1 everywhere the client window is present.
|
||||
|
||||
3. Mesa currently allocates buffers exactly the size of the target drawable and assumes that the upper left corner of the buffer is the upper left corner of the drawable. If we want to place window manager decorations in the same buffer as the client and not need to copy the client contents, we would need to allocate a buffer large enough for both client and decorations, and then offset the client within that larger buffer.
|
||||
|
||||
4. Synchronizing window configuration and content updates with the screen presentation. One of the major features of a compositing manager is that it can construct complete and consistent frames for display; partial updates to application windows need never be shown to the user, nor does the user ever need to see the window tree partially reconfigured. To make this work with automatic compositing, we'd need to both codify frame markers within the 2D rendering stream and provide some method for collecting window configuration operations together.
|
||||
|
||||
5. Existing compositing managers don't do this today. Compositing managers are currently free to paint whatever they like into the screen image; requiring that they place all screen content into windows would mean they'd have to buy in to the new mechanism completely. That could still work with older X servers, but the additional overhead of more windows containing decoration content would slow performance with those systems, making migration less attractive.
|
||||
|
||||
|
||||
|
||||
|
||||
I can think of plausible ways to solve the first three of these without requiring application changes, but the last two require significant systemic changes to compositing managers. Ick.
|
||||
|
||||
### Semi-Automatic Compositing
|
||||
|
||||
I was up visiting Pierre-Loup at Valve recently and we sat down for a few hours to consider how to help applications regularly present content at known times, and to always know precisely when content was actually presented. That names just one of the above issues, but when you consider the additional work required by pure manual compositing, solving that one issue is likely best achieved by solving all three.
|
||||
|
||||
I presented the Automatic Compositing plan and we discussed the range of issues. Pierre-Loup focused on the last problem -- getting existing Compositing Managers to adopt whatever solution we came up with. Without any easy migration path for them, it seemed like a lot to ask.
|
||||
|
||||
He suggested that we come up with a mechanism which would allow Compositing Managers to ease into the new architecture and slowly improve things for applications. Towards that, we focused on a much simpler problem
|
||||
|
||||
> How can we get a single application at the top of the window stack to reliably display frames at the desired time, and to know when that doesn't occur.
|
||||
|
||||
Coming up with a solution for this led to a good discussion and a possible path to a broader solution in the future.
|
||||
|
||||
#### Steady-state Behavior
|
||||
|
||||
Let's start by ignoring how we start and stop this new mode and look at how we want applications to work when things are stable:
|
||||
|
||||
1. Windows not moving around
|
||||
2. Other applications idle
|
||||
|
||||
|
||||
|
||||
Let's get a picture I can use to describe this:
|
||||
|
||||
[![][1]][1]
|
||||
|
||||
In this picture, the compositing manager is triple buffered (as is normal for a page flipping application) with three buffers:
|
||||
|
||||
1. Scanout. The image currently on the screen
|
||||
|
||||
2. Queued. The image queued to be displayed next
|
||||
|
||||
3. Render. The image being constructed from various window pixmaps and other elements.
|
||||
|
||||
|
||||
|
||||
|
||||
The contents of the Scanout and Queued buffers are identical with the exception of the orange window.
|
||||
|
||||
The application is double buffered:
|
||||
|
||||
1. Current. What it has displayed for the last frame
|
||||
|
||||
2. Next. What it is constructing for the next frame
|
||||
|
||||
|
||||
|
||||
|
||||
Ok, so in the steady state, here's what we want to happen:
|
||||
|
||||
1. Application calls PresentPixmap with 'Next' for its window
|
||||
|
||||
2. X server receives that call and copies Next to Queued.
|
||||
|
||||
3. X server posts a Page Flip to the kernel with the Queued buffer
|
||||
|
||||
4. Once the flip happens, the X server swaps the names of the Scanout and Queued buffers.
|
||||
|
||||
|
||||
|
||||
|
||||
If the X server supports Overlays, then the sequence can look like:
|
||||
|
||||
1. Application calls PresentPixmap
|
||||
|
||||
2. X server receives that call and posts a Page Flip for the overlay
|
||||
|
||||
3. When the page flip completes, the X server notifies the client that the previous Current buffer is now idle.
|
||||
|
||||
|
||||
|
||||
|
||||
When the Compositing Manager has content to update outside of the orange window, it will:
|
||||
|
||||
1. Compositing Manager calls PresentPixmap
|
||||
|
||||
2. X server receives that call and paints the Current client image into the Render buffer
|
||||
|
||||
3. X server swaps Render and Queued buffers
|
||||
|
||||
4. X server posts Page Flip for the Queued buffer
|
||||
|
||||
5. When the page flip occurs, the server can mark the Scanout buffer as idle and notify the Compositing Manager
|
||||
|
||||
|
||||
|
||||
|
||||
If the Orange window is in an overlay, then the X server can skip step 2.
|
||||
|
||||
#### The Auto List
|
||||
|
||||
To give the Compositing Manager control over the presentation of all windows, each call to PresentPixmap by the Compositing Manager will be associated with the list of windows, the "Auto List", for which the X server will be responsible for providing suitable content. Transitioning from manual to automatic compositing can therefore be performed on a window-by-window basis, and each frame provided by the Compositing Manager will separately control how that happens.
|
||||
|
||||
The Steady State behavior above would be represented by having the same set of windows in the Auto List for the Scanout and Queued buffers, and when the Compositing Manager presents the Render buffer, it would also provide the same Auto List for that.
|
||||
|
||||
Importantly, the Auto List need not contain only children of the screen Root window. Any descendant window at all can be included, and the contents of that drawn into the image using appropriate clipping. This allows the Compositing Manager to draw the window manager frame while the client window is drawn by the X server.
|
||||
|
||||
Any window at all can be in the Auto List. Windows with PresentPixmap contents available would be drawn from those. Other windows would be drawn from their window pixmaps.
|
||||
|
||||
#### Transitioning from Manual to Auto
|
||||
|
||||
To transition a window from Manual mode to Auto mode, the Compositing Manager would add it to the Auto List for the Render image, and associate that Auto List with the PresentPixmap request for that image. For the first frame, the X server may not have received a PresentPixmap for the client window, and so the window contents would have to come from the Window Pixmap for the client.
|
||||
|
||||
I'm not sure how we'd get the Compositing Manager to provide another matching image that the X server can use for subsequent client frames; perhaps it would just create one itself?
|
||||
|
||||
#### Transitioning from Auto to Manual
|
||||
|
||||
To transition a window from Auto mode to Manual mode, the Compositing manager would remove it from the Auto List for the Render image and then paint the window contents into the render image itself. To do that, the X server would have to paint any PresentPixmap data from the client into the window pixmap; that would be done when the Compositing Manager called GetWindowPixmap.
|
||||
|
||||
### New Messages Required
|
||||
|
||||
For this to work, we need some way for the Compositing Manager to discover windows that are suitable for Auto composting. Normally, these will be windows managed by the Window Manager, but it's possible for them to be nested further within the application hierarchy, depending on how the application is constructed.
|
||||
|
||||
I think what we want is to tag Damage events with the source window, and perhaps additional information to help Compositing Managers determine whether it should be automatically presenting those source windows or a parent of them. Perhaps it would be helpful to also know whether the Damage event was actually caused by a PresentPixmap for the whole window?
|
||||
|
||||
To notify the server about the Auto List, a new request will be needed in the Present extension to set the value for a subsequent PresentPixmap request.
|
||||
|
||||
### Actually Drawing Frames
|
||||
|
||||
The DRM module in the Linux kernel doesn't provide any mechanism to remove or replace a Page Flip request. While this may get fixed at some point, we need to deal with how it works today, if only to provide reasonable support for existing kernels.
|
||||
|
||||
I think about the best we can do is to set a timer to fire a suitable time before vblank and have the X server wake up and execute any necessary drawing and Page Flip kernel calls. We can use feedback from the kernel to know how much slack time there was between any drawing and the vblank and adjust the timer as needed.
|
||||
|
||||
Given that the goal is to provide for reliable display of the client window, it might actually be sufficient to let the client PresentPixmap request drive the display; if the Compositing Manager provides new content for a frame where the client does not, we can schedule that for display using a timer before vblank. When the Compositing Manager provides new content after the client, it would be delayed until the next frame.
|
||||
|
||||
### Changes in Compositing Managers
|
||||
|
||||
As described above, one explicit goal is to ease the burden on Compositing Managers by making them able to opt-in to this new mechanism for a limited set of windows and only for a limited set of frames. Any time they need to take control over the screen presentation, a new frame can be constructed with an empty Auto List.
|
||||
|
||||
### Implementation Plans
|
||||
|
||||
This post is the first step in developing these ideas to the point where a prototype can be built. The next step will be to take feedback and adapt the design to suit. Of course, there's always the possibility that this design will also prove unworkable in practice, but I'm hoping that this third attempt will actually succeed.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://keithp.com/blogs/CompositeAcceleration/
|
||||
|
||||
作者:[keithp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://keithp.com
|
||||
[1]:https://keithp.com/pictures/ca-steady.svg
|
||||
191
sources/tech/20180202 How do I edit files on the command line.md
Normal file
191
sources/tech/20180202 How do I edit files on the command line.md
Normal file
@ -0,0 +1,191 @@
|
||||
How do I edit files on the command line?
|
||||
======
|
||||
|
||||
In this tutorial, we will show you how to edit files on the command line. This article covers three command line editors, vi (or vim), nano, and emacs.
|
||||
|
||||
#### Editing Files with Vi or Vim Command Line Editor
|
||||
|
||||
To edit files on the command line, you can use an editor such as vi. To open the file, run
|
||||
|
||||
```
|
||||
vi /path/to/file
|
||||
```
|
||||
|
||||
Now you see the contents of the file (if there is any. Please note that the file is created if it does not exist yet.).
|
||||
|
||||
The most important commands in vi are these:
|
||||
|
||||
Press `i` to enter the `Insert` mode. Now you can type in your text.
|
||||
|
||||
To leave the Insert mode press `ESC`.
|
||||
|
||||
To delete the character that is currently under the cursor you must press `x` (and you must not be in Insert mode because if you are you will insert the character `x` instead of deleting the character under the cursor). So if you have just opened the file with vi, you can immediately use `x` to delete characters. If you are in Insert mode you have to leave it first with `ESC`.
|
||||
|
||||
If you have made changes and want to save the file, press `:x` (again you must not be in Insert mode. If you are, press `ESC` to leave it).
|
||||
|
||||
If you haven't made any changes, press `:q` to leave the file (but you must not be in Insert mode).
|
||||
|
||||
If you have made changes, but want to leave the file without saving the changes, press `:q!` (but you must not be in Insert mode).
|
||||
|
||||
Please note that during all these operations you can use your keyboard's arrow keys to navigate the cursor through the text.
|
||||
|
||||
So that was all about the vi editor. Please note that the vim editor also works more or less in the same way, although if you'd like to know vim in depth, head [here][1].
|
||||
|
||||
#### Editing Files with Nano Command Line Editor
|
||||
|
||||
Next up is the Nano editor. You can invoke it simply by running the 'nano' command:
|
||||
|
||||
```
|
||||
nano
|
||||
```
|
||||
|
||||
Here's how the nano UI looks like:
|
||||
|
||||
[![Nano command line editor][2]][3]
|
||||
|
||||
You can also launch the editor directly with a file.
|
||||
|
||||
```
|
||||
nano [filename]
|
||||
```
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
nano test.txt
|
||||
```
|
||||
|
||||
[![Open a file in nano][4]][5]
|
||||
|
||||
The UI, as you can see, is broadly divided into four parts. The line at the top shows editor version, file being edited, and the editing status. Then comes the actual edit area where you'll see the contents of the file. The highlighted line below the edit area shows important messages, and the last two lines are really helpful for beginners as they show keyboard shortcuts that you use to perform basic tasks in nano.
|
||||
|
||||
So here's a quick list of some of the shortcuts that you should know upfront.
|
||||
|
||||
Use arrow keys to navigate the text, the Backspace key to delete text, and **Ctrl+o** to save the changes you make. When you try saving the changes, nano will ask you for confirmation (see the line below the main editor area in screenshot below):
|
||||
|
||||
[![Save file in nano][6]][7]
|
||||
|
||||
Note that at this stage, you also have an option to save in different OS formats. Pressing **Altd+d** enables the DOS format, while **Atl+m** enables the Mac format.
|
||||
|
||||
[![Save file ind DOS format][8]][9]
|
||||
|
||||
Press enter and your changes will be saved.
|
||||
|
||||
[![File has been saved][10]][11]
|
||||
|
||||
Moving on, to cut and paste lines of text use **Ctrl+k** and **Ctrl+u**. These keyboard shortcuts can also be used to cut and paste individual words, but you'll have to select the words first, something you can do by pressing **Alt+A** (with the cursor under the first character of the word) and then using the arrow to key select the complete word.
|
||||
|
||||
Now comes search operations. A simple search can be initiated using **Ctrl+w** , while a search and replace operation can be done using **Ctrl+\**.
|
||||
|
||||
[![Search in files with nano][12]][13]
|
||||
|
||||
So those were some of the basic features of nano that should give you a head start if you're new to the editor. For more details, read our comprehensive coverage [here][14].
|
||||
|
||||
#### Editing Files with Emacs Command Line Editor
|
||||
|
||||
Next comes **Emacs**. If not already, you can install the editor on your system using the following command:
|
||||
|
||||
```
|
||||
sudo apt-get install emacs
|
||||
```
|
||||
|
||||
Like nano, you can directly open a file to edit in emacs in the following way:
|
||||
|
||||
```
|
||||
emacs -nw [filename]
|
||||
```
|
||||
|
||||
**Note** : The **-nw** flag makes sure emacs launches in bash itself, instead of a separate window which is the default behavior.
|
||||
|
||||
For example:
|
||||
```
|
||||
emacs -nw test.txt
|
||||
|
||||
```
|
||||
|
||||
Here's the editor's UI:
|
||||
|
||||
[![Open file in emacs][15]][16]
|
||||
|
||||
Like nano, the emacs UI is also divided into several parts. The first part is the top menu area, which is similar to the one you'd see in graphical applications. Then comes the main edit area, where the text (of the file you've opened) is displayed.
|
||||
|
||||
Below the edit area sits another highlighted bar that shows things like name of the file, editing mode ('Text' in screenshot above), and status (** for modified, - for non-modified, and %% for read only). Then comes the final area where you provide input instructions, see output as well.
|
||||
|
||||
Now coming to basic operations, after making changes, if you want to save them, use **Ctrl+x** followed by **Ctrl+s**. The last section will show you a message saying something on the lines of '**Wrote ........' . **Here's an example:
|
||||
|
||||
[![Save file in emacs][17]][18]
|
||||
|
||||
Now, if you want to discard changes and quit the editor, use **Ctrl+x** followed by **Ctrl+c**. The editor will confirm this through a prompt - see screenshot below:
|
||||
|
||||
[![Discard changes in emacs][19]][20]
|
||||
|
||||
Type 'n' followed by a 'yes' and the editor will quit without saving the changes.
|
||||
|
||||
Please note that Emacs represents 'Ctrl' as 'C' and 'Alt' as 'M'. So, for example, whenever you see something like C-x, it means Ctrl+x.
|
||||
|
||||
As for other basic editing operations, deleting is simple, as it works through the Backspace/Delete keys that most of us are already used to. However, there are shortcuts that make your deleting experience smooth. For example, use **Ctrl+k** for deleting complete line, **Alt+d** for deleting a word, and **Alt+k** for a sentence.
|
||||
|
||||
Undoing is achieved through ' **Ctrl+x** ' followed by ' **u** ', and to re-do, press **Ctrl+g** followed by **Ctrl+_**. Use **Ctrl+s** for forward search and **Ctrl+r** for reverse search.
|
||||
|
||||
[![Search in files with emacs][21]][22]
|
||||
|
||||
Moving on, to launch a replace operation, use the Alt+Shift+% keyboard shortcut. You'll be asked for the word you want to replace. Enter it. Then the editor will ask you for the replacement. For example, the following screenshot shows emacs asking user about the replacement for the word 'This'.
|
||||
|
||||
[![Replace text with emacs][23]][24]
|
||||
|
||||
Input the replacement text and press Enter. For each replacement operation emacs will carry, it'll seek your permission first:
|
||||
|
||||
[![Confirm text replacement][25]][26]
|
||||
|
||||
Press 'y' and the word will be replaced.
|
||||
|
||||
[![Press y to confirm][27]][28]
|
||||
|
||||
So that's pretty much all the basic editing operations that you should know to start using emacs. Oh, and yes, those menus at the top - we haven't discussed how to access them. Well, those can be accessed using the F10 key.
|
||||
|
||||
[![Basic editing operations][29]][30]
|
||||
|
||||
To come out of these menus, press the Esc key three times.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/faq/how-to-edit-files-on-the-command-line
|
||||
|
||||
作者:[falko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/vim-basics
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/nano-basic-ui.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/nano-basic-ui.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/nano-file-open.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/nano-file-open.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/nano-save-changes.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/big/nano-save-changes.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/nano-mac-format.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/big/nano-mac-format.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/nano-changes-saved.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/big/nano-changes-saved.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/nano-search-replace.png
|
||||
[13]:https://www.howtoforge.com/images/command-tutorial/big/nano-search-replace.png
|
||||
[14]:https://www.howtoforge.com/linux-nano-command/
|
||||
[15]:https://www.howtoforge.com/images/command-tutorial/nano-file-open1.png
|
||||
[16]:https://www.howtoforge.com/images/command-tutorial/big/nano-file-open1.png
|
||||
[17]:https://www.howtoforge.com/images/command-tutorial/emacs-save.png
|
||||
[18]:https://www.howtoforge.com/images/command-tutorial/big/emacs-save.png
|
||||
[19]:https://www.howtoforge.com/images/command-tutorial/emacs-quit-without-saving.png
|
||||
[20]:https://www.howtoforge.com/images/command-tutorial/big/emacs-quit-without-saving.png
|
||||
[21]:https://www.howtoforge.com/images/command-tutorial/emacs-search.png
|
||||
[22]:https://www.howtoforge.com/images/command-tutorial/big/emacs-search.png
|
||||
[23]:https://www.howtoforge.com/images/command-tutorial/emacs-search-replace.png
|
||||
[24]:https://www.howtoforge.com/images/command-tutorial/big/emacs-search-replace.png
|
||||
[25]:https://www.howtoforge.com/images/command-tutorial/emacs-replace-prompt.png
|
||||
[26]:https://www.howtoforge.com/images/command-tutorial/big/emacs-replace-prompt.png
|
||||
[27]:https://www.howtoforge.com/images/command-tutorial/emacs-replaced.png
|
||||
[28]:https://www.howtoforge.com/images/command-tutorial/big/emacs-replaced.png
|
||||
[29]:https://www.howtoforge.com/images/command-tutorial/emacs-accessing-menus.png
|
||||
[30]:https://www.howtoforge.com/images/command-tutorial/big/emacs-accessing-menus.png
|
||||
@ -0,0 +1,191 @@
|
||||
Shell Scripting: Dungeons, Dragons and Dice
|
||||
======
|
||||
In my [last article][1], I talked about a really simple shell script for a game called Bunco, which is a dice game played in rounds where you roll three dice and compare your values to the round number. Match all three and match the round number, and you just got a bunco for 25 points. Otherwise, any die that match the round are worth one point each. It's simple—a game designed for people who are getting tipsy at the local pub, and it also is easy to program.
|
||||
|
||||
The core function in the Bunco program was one that produced a random number between 1–6 to simulate rolling a six-sided die. It looked like this:
|
||||
|
||||
```
|
||||
|
||||
rolldie()
|
||||
{
|
||||
local result=$1
|
||||
rolled=$(( ( $RANDOM % 6 ) + 1 ))
|
||||
eval $result=$rolled
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
It's invoked with a variable name as the single argument, and it will load a random number between 1–6 into that value—for example:
|
||||
|
||||
```
|
||||
|
||||
rolldie die1
|
||||
|
||||
```
|
||||
|
||||
will assign a value 1..6 to $die1\. Make sense?
|
||||
|
||||
If you can do that, however, what's to stop you from having a second argument that specifies the number of sides of the die you want to "roll" with the function? Something like this:
|
||||
|
||||
```
|
||||
|
||||
rolldie()
|
||||
{
|
||||
local result=$1 sides=$2
|
||||
rolled=$(( ( $RANDOM % $sides ) + 1 ))
|
||||
eval $result=$rolled
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To test it, let's just write a tiny wrapper that simply asks for a 20-sided die (d20) result:
|
||||
|
||||
```
|
||||
|
||||
rolldie die 20
|
||||
echo resultant roll is $die
|
||||
|
||||
```
|
||||
|
||||
Easy enough. To make it a bit more useful, let's allow users to specify a sequence of dice rolls, using the standard D&D notation of nDm—that is, n m-sided dice. Bunco would have been done with 3d6, for example (three six-sided die). Got it?
|
||||
|
||||
Since you might well have starting flags too, let's build that into the parsing loop using the ever handy getopt:
|
||||
|
||||
```
|
||||
|
||||
while getopts "h" arg
|
||||
do
|
||||
case "$arg" in
|
||||
* ) echo "dnd-dice NdM {NdM}"
|
||||
echo "NdM = N M-sided dice"; exit 0 ;;
|
||||
esac
|
||||
done
|
||||
shift $(( $OPTIND - 1 ))
|
||||
for request in $* ; do
|
||||
echo "Rolling: $request"
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
With a well formed notation like 3d6, it's easy to break up the argument into its component parts, like so:
|
||||
|
||||
```
|
||||
|
||||
dice=$(echo $request | cut -dd -f1)
|
||||
sides=$(echo $request | cut -dd -f2)
|
||||
echo "Rolling $dice $sides-sided dice"
|
||||
|
||||
```
|
||||
|
||||
To test it, let's give it some arguments and see what the program outputs:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice 3d6 1d20 2d100 4d3 d5
|
||||
Rolling 3 6-sided dice
|
||||
Rolling 1 20-sided dice
|
||||
Rolling 2 100-sided dice
|
||||
Rolling 4 3-sided dice
|
||||
Rolling 5-sided dice
|
||||
|
||||
```
|
||||
|
||||
Ah, the last one points out a mistake in the script. If there's no number of dice specified, the default should be 1\. You theoretically could default to a six-sided die too, but that's not anywhere near so safe an assumption.
|
||||
|
||||
With that, you're close to a functional program because all you need is a loop to process more than one die in a request. It's easily done with a while loop, but let's add some additional smarts to the script:
|
||||
|
||||
```
|
||||
|
||||
for request in $* ; do
|
||||
dice=$(echo $request | cut -dd -f1)
|
||||
sides=$(echo $request | cut -dd -f2)
|
||||
echo "Rolling $dice $sides-sided dice"
|
||||
sum=0 # reset
|
||||
while [ ${dice:=1} -gt 0 ] ; do
|
||||
rolldie die $sides
|
||||
echo " dice roll = $die"
|
||||
sum=$(( $sum + $die ))
|
||||
dice=$(( $dice - 1 ))
|
||||
done
|
||||
echo " sum total = $sum"
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
This is pretty solid actually, and although the output statements need to be cleaned up a bit, the code's basically fully functional:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice 3d6 1d20 2d100 4d3 d5
|
||||
Rolling 3 6-sided dice
|
||||
dice roll = 5
|
||||
dice roll = 6
|
||||
dice roll = 5
|
||||
sum total = 16
|
||||
Rolling 1 20-sided dice
|
||||
dice roll = 16
|
||||
sum total = 16
|
||||
Rolling 2 100-sided dice
|
||||
dice roll = 76
|
||||
dice roll = 84
|
||||
sum total = 160
|
||||
Rolling 4 3-sided dice
|
||||
dice roll = 2
|
||||
dice roll = 2
|
||||
dice roll = 1
|
||||
dice roll = 3
|
||||
sum total = 8
|
||||
Rolling 5-sided dice
|
||||
dice roll = 2
|
||||
sum total = 2
|
||||
|
||||
```
|
||||
|
||||
Did you catch that I fixed the case when $dice has no value? It's tucked into the reference in the while statement. Instead of referring to it as $dice, I'm using the notation ${dice:=1}, which uses the value specified unless it's null or no value, in which case the value 1 is assigned and used. It's a handy and a perfect fix in this case.
|
||||
|
||||
In a game, you generally don't care much about individual die values; you just want to sum everything up and see what the total value is. So if you're rolling 4d20, for example, it's just a single value you calculate and share with the game master or dungeon master.
|
||||
|
||||
A bit of output statement cleanup and you can do that:
|
||||
|
||||
```
|
||||
|
||||
$ dnd-dice.sh 3d6 1d20 2d100 4d3 d5
|
||||
3d6 = 16
|
||||
1d20 = 13
|
||||
2d100 = 74
|
||||
4d3 = 8
|
||||
d5 = 2
|
||||
|
||||
```
|
||||
|
||||
Let's run it a second time just to ensure you're getting different values too:
|
||||
|
||||
```
|
||||
|
||||
3d6 = 11
|
||||
1d20 = 10
|
||||
2d100 = 162
|
||||
4d3 = 6
|
||||
d5 = 3
|
||||
|
||||
```
|
||||
|
||||
There are definitely different values, and it's a pretty useful script, all in all.
|
||||
|
||||
You could create a number of variations with this as a basis, including what some gamers enjoy called "exploding dice". The idea is simple: if you roll the best possible value, you get to roll again and add the second value too. Roll a d20 and get a 20? You can roll again, and your result is then 20 + whatever the second value is. Where this gets crazy is that you can do this for multiple cycles, so a d20 could become 30, 40 or even 50.
|
||||
|
||||
And, that's it for this article. There isn't much else you can do with dice at this point. In my next article, I'll look at...well, you'll have to wait and see! Don't forget, if there's a topic you'd like me to tackle, please send me a note!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/shell-scripting-dungeons-dragons-and-dice
|
||||
|
||||
作者:[Dave Taylor][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/dave-taylor
|
||||
[1]:http://www.linuxjournal.com/content/shell-scripting-bunco-game
|
||||
@ -0,0 +1,73 @@
|
||||
Tips for success when getting started with Ansible
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ansible is an open source automation tool used to configure servers, install software, and perform a wide variety of IT tasks from one central location. It is a one-to-many agentless mechanism where all instructions are run from a control machine that communicates with remote clients over SSH, although other protocols are also supported.
|
||||
|
||||
While targeted for system administrators with privileged access who routinely perform tasks such as installing and configuring applications, Ansible can also be used by non-privileged users. For example, a database administrator using the `mysql` login ID could use Ansible to create databases, add users, and define access-level controls.
|
||||
|
||||
Let's go over a very simple example where a system administrator provisions 100 servers each day and must run a series of Bash commands on each one before handing it off to users.
|
||||
|
||||
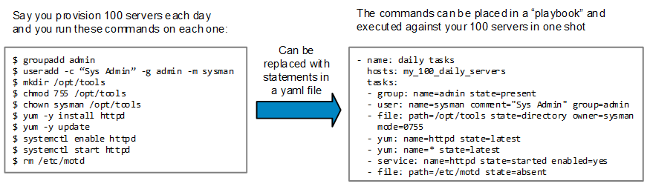
|
||||
|
||||
This is a simple example, but should illustrate how easily commands can be specified in yaml files and executed on remote servers. In a heterogeneous environment, conditional statements can be added so that certain commands are only executed in certain servers (e.g., "only execute `yum` commands in systems that are not Ubuntu or Debian").
|
||||
|
||||
One important feature in Ansible is that a playbook describes a desired state in a computer system, so a playbook can be run multiple times against a server without impacting its state. If a certain task has already been implemented (e.g., "user `sysman` already exists"), then Ansible simply ignores it and moves on.
|
||||
|
||||
### Definitions
|
||||
|
||||
* **Tasks:**``A task is the smallest unit of work. It can be an action like "Install a database," "Install a web server," "Create a firewall rule," or "Copy this configuration file to that server."
|
||||
* **Plays:**``A play is made up of tasks. For example, the play: "Prepare a database to be used by a web server" is made up of tasks: 1) Install the database package; 2) Set a password for the database administrator; 3) Create a database; and 4) Set access to the database.
|
||||
* **Playbook:**``A playbook is made up of plays. A playbook could be: "Prepare my website with a database backend," and the plays would be 1) Set up the database server; and 2) Set up the web server.
|
||||
* **Roles:**``Roles are used to save and organize playbooks and allow sharing and reuse of playbooks. Following the previous examples, if you need to fully configure a web server, you can use a role that others have written and shared to do just that. Since roles are highly configurable (if written correctly), they can be easily reused to suit any given deployment requirements.
|
||||
* **Ansible Galaxy:**``Ansible [Galaxy][1] is an online repository where roles are uploaded so they can be shared with others. It is integrated with GitHub, so roles can be organized into Git repositories and then shared via Ansible Galaxy.
|
||||
|
||||
|
||||
|
||||
These definitions and their relationships are depicted here:
|
||||
|
||||
|
||||
|
||||
Please note this is just one way to organize the tasks that need to be executed. We could have split up the installation of the database and the web server into separate playbooks and into different roles. Most roles in Ansible Galaxy install and configure individual applications. You can see examples for installing [mysql][2] and installing [httpd][3].
|
||||
|
||||
### Tips for writing playbooks
|
||||
|
||||
The best source for learning Ansible is the official [documentation][4] site. And, as usual, online search is your friend. I recommend starting with simple tasks, like installing applications or creating users. Once you are ready, follow these guidelines:
|
||||
|
||||
* When testing, use a small subset of servers so that your plays execute faster. If they are successful in one server, they will be successful in others.
|
||||
* Always do a dry run to make sure all commands are working (run with `--check-mode` flag).
|
||||
* Test as often as you need to without fear of breaking things. Tasks describe a desired state, so if a desired state is already achieved, it will simply be ignored.
|
||||
* Be sure all host names defined in `/etc/ansible/hosts` are resolvable.
|
||||
* Because communication to remote hosts is done using SSH, keys have to be accepted by the control machine, so either 1) exchange keys with remote hosts prior to starting; or 2) be ready to type in "Yes" to accept SSH key exchange requests for each remote host you want to manage.
|
||||
* Although you can combine tasks for different Linux distributions in one playbook, it's cleaner to write a separate playbook for each distro.
|
||||
|
||||
|
||||
|
||||
### In the final analysis
|
||||
|
||||
Ansible is a great choice for implementing automation in your data center:
|
||||
|
||||
* It's agentless, so it is simpler to install than other automation tools.
|
||||
* Instructions are in YAML (though JSON is also supported) so it's easier than writing shell scripts.
|
||||
* It's open source software, so contribute back to it and make it even better!
|
||||
|
||||
|
||||
|
||||
How have you used Ansible to automate your data center? Share your experience in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/tips-success-when-getting-started-ansible
|
||||
|
||||
作者:[Jose Delarosa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jdelaros1
|
||||
[1]:https://galaxy.ansible.com/
|
||||
[2]:https://galaxy.ansible.com/bennojoy/mysql/
|
||||
[3]:https://galaxy.ansible.com/xcezx/httpd/
|
||||
[4]:http://docs.ansible.com/
|
||||
@ -0,0 +1,259 @@
|
||||
API Star: Python 3 API Framework – Polyglot.Ninja()
|
||||
======
|
||||
For building quick APIs in Python, I have mostly depended on [Flask][1]. Recently I came across a new API framework for Python 3 named “API Star” which seemed really interesting to me for several reasons. Firstly the framework embraces modern Python features like type hints and asyncio. And then it goes ahead and uses these features to provide awesome development experience for us, the developers. We will get into those features soon but before we begin, I would like to thank Tom Christie for all the work he has put into Django REST Framework and now API Star.
|
||||
|
||||
Now back to API Star – I feel very productive in the framework. I can choose to write async codes based on asyncio or I can choose a traditional backend like WSGI. It comes with a command line tool – `apistar` to help us get things done faster. There’s (optional) support for both Django ORM and SQLAlchemy. There’s a brilliant type system that enables us to define constraints on our input and output and from these, API Star can auto generate api schemas (and docs), provide validation and serialization feature and a lot more. Although API Star is heavily focused on building APIs, you can also build web applications on top of it fairly easily. All these might not make proper sense until we build something all by ourselves.
|
||||
|
||||
### Getting Started
|
||||
|
||||
We will start by installing API Star. It would be a good idea to create a virtual environment for this exercise. If you don’t know how to create a virtualenv, don’t worry and go ahead.
|
||||
```
|
||||
pip install apistar
|
||||
|
||||
```
|
||||
|
||||
If you’re not using a virtual environment or the `pip` command for your Python 3 is called `pip3`, then please use `pip3 install apistar` instead.
|
||||
|
||||
Once we have the package installed, we should have access to the `apistar` command line tool. We can create a new project with it. Let’s create a new project in our current directory.
|
||||
```
|
||||
apistar new .
|
||||
|
||||
```
|
||||
|
||||
Now we should have two files created – `app.py` – which contains the main application and then `test.py` for our tests. Let’s examine our `app.py` file:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar.handlers import docs_urls, static_urls
|
||||
|
||||
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', welcome),
|
||||
Include('/docs', docs_urls),
|
||||
Include('/static', static_urls)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Before we dive into the code, let’s run the app and see if it works. If we navigate to `http://127.0.0.1:8080/` we will get this following response:
|
||||
```
|
||||
{"message": "Welcome to API Star!"}
|
||||
|
||||
```
|
||||
|
||||
And if we navigate to: `http://127.0.0.1:8080/?name=masnun`
|
||||
```
|
||||
{"message": "Welcome to API Star, masnun!"}
|
||||
|
||||
```
|
||||
|
||||
Similarly if we navigate to: `http://127.0.0.1:8080/docs/`, we will see auto generated docs for our API.
|
||||
|
||||
Now let’s look at the code. We have a `welcome` function that takes a parameter named `name` which has a default value of `None`. API Star is a smart api framework. It will try to find the `name` key in the url path or query string and pass it to our function. It also generates the API docs based on it. Pretty nice, no?
|
||||
|
||||
We then create a list of `Route` and `Include` instances and pass the list to the `App` instance. `Route` objects are used to define custom user routing. `Include` , as the name suggests, includes/embeds other routes under the path provided to it.
|
||||
|
||||
### Routing
|
||||
|
||||
Routing is simple. When constructing the `App` instance, we need to pass a list as the `routes` argument. This list should comprise of `Route` or `Include` objects as we just saw above. For `Route`s, we pass a url path, http method name and the request handler callable (function or otherwise). For the `Include` instances, we pass a url path and a list of `Routes` instance.
|
||||
|
||||
##### Path Parameters
|
||||
|
||||
We can put a name inside curly braces to declare a url path parameter. For example `/user/{user_id}` defines a path where the `user_id` is a path parameter or a variable which will be injected into the handler function (actually callable). Here’s a quick example:
|
||||
```
|
||||
from apistar import Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {'message': 'Your profile id is: {}'.format(user_id)}
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/user/{user_id}', 'GET', user_profile),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
If we visit `http://127.0.0.1:8080/user/23` we will get a response like this:
|
||||
```
|
||||
{"message": "Your profile id is: 23"}
|
||||
|
||||
```
|
||||
|
||||
But if we try to visit `http://127.0.0.1:8080/user/some_string` – it will not match. Because the `user_profile` function we defined, we added a type hint for the `user_id` parameter. If it’s not integer, the path doesn’t match. But if we go ahead and delete the type hint and just use `user_profile(user_id)`, it will match this url. This is again API Star is being smart and taking advantages of typing.
|
||||
|
||||
#### Including / Grouping Routes
|
||||
|
||||
Sometimes it might make sense to group certain urls together. Say we have a `user` module that deals with user related functionality. It might be better to group all the user related endpoints under the `/user` path. For example – `/user/new`, `/user/1`, `/user/1/update` and what not. We can easily create our handlers and routes in a separate module or package even and then include them in our own routes.
|
||||
|
||||
Let’s create a new module named `user`, the file name would be `user.py`. Let’s put these codes in this file:
|
||||
```
|
||||
from apistar import Route
|
||||
|
||||
|
||||
def user_new():
|
||||
return {"message": "Create a new user"}
|
||||
|
||||
|
||||
def user_update(user_id: int):
|
||||
return {"message": "Update user #{}".format(user_id)}
|
||||
|
||||
|
||||
def user_profile(user_id: int):
|
||||
return {"message": "User Profile for: {}".format(user_id)}
|
||||
|
||||
|
||||
user_routes = [
|
||||
Route("/new", "GET", user_new),
|
||||
Route("/{user_id}/update", "GET", user_update),
|
||||
Route("/{user_id}/profile", "GET", user_profile),
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
Now we can import our `user_routes` from within our main app file and use it like this:
|
||||
```
|
||||
from apistar import Include
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
from user import user_routes
|
||||
|
||||
routes = [
|
||||
Include("/user", user_routes)
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Now `/user/new` will delegate to `user_new` function.
|
||||
|
||||
### Accessing Query String / Query Parameters
|
||||
|
||||
Any parameters passed in the query parameters can be injected directly into handler function. Say for the url `/call?phone=1234`, the handler function can define a `phone` parameter and it will receive the value from the query string / query parameters. If the url query string doesn’t include a value for `phone`, it will get `None` instead. We can also set a default value to the parameter like this:
|
||||
```
|
||||
def welcome(name=None):
|
||||
if name is None:
|
||||
return {'message': 'Welcome to API Star!'}
|
||||
return {'message': 'Welcome to API Star, %s!' % name}
|
||||
|
||||
```
|
||||
|
||||
In the above example, we set a default value to `name` which is `None` anyway.
|
||||
|
||||
### Injecting Objects
|
||||
|
||||
By type hinting a request handler, we can have different objects injected into our views. Injecting request related objects can be helpful for accessing them directly from inside the handler. There are several built in objects in the `http` package from API Star itself. We can also use it’s type system to create our own custom objects and have them injected into our functions. API Star also does data validation based on the constraints specified.
|
||||
|
||||
Let’s define our own `User` type and have it injected in our request handler:
|
||||
```
|
||||
from apistar import Include, Route
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
from apistar import typesystem
|
||||
|
||||
|
||||
class User(typesystem.Object):
|
||||
properties = {
|
||||
'name': typesystem.string(max_length=100),
|
||||
'email': typesystem.string(max_length=100),
|
||||
'age': typesystem.integer(maximum=100, minimum=18)
|
||||
}
|
||||
|
||||
required = ["name", "age", "email"]
|
||||
|
||||
|
||||
def new_user(user: User):
|
||||
return user
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'POST', new_user),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
Now if we send this request:
|
||||
|
||||
```
|
||||
curl -X POST \
|
||||
http://127.0.0.1:8080/ \
|
||||
-H 'Cache-Control: no-cache' \
|
||||
-H 'Content-Type: application/json' \
|
||||
-d '{"name": "masnun", "email": "masnun@gmail.com", "age": 12}'
|
||||
```
|
||||
|
||||
Guess what happens? We get an error saying age must be equal to or greater than 18. The type system is allowing us intelligent data validation as well. If we enable the `docs` url, we will also get these parameters automatically documented there.
|
||||
|
||||
### Sending a Response
|
||||
|
||||
If you have noticed so far, we can just pass a dictionary and it will be JSON encoded and returned by default. However, we can set the status code and any additional headers by using the `Response` class from `apistar`. Here’s a quick example:
|
||||
```
|
||||
from apistar import Route, Response
|
||||
from apistar.frameworks.wsgi import WSGIApp as App
|
||||
|
||||
|
||||
def hello():
|
||||
return Response(
|
||||
content="Hello".encode("utf-8"),
|
||||
status=200,
|
||||
headers={"X-API-Framework": "API Star"},
|
||||
content_type="text/plain"
|
||||
)
|
||||
|
||||
|
||||
routes = [
|
||||
Route('/', 'GET', hello),
|
||||
]
|
||||
|
||||
app = App(routes=routes)
|
||||
|
||||
if __name__ == '__main__':
|
||||
app.main()
|
||||
|
||||
```
|
||||
|
||||
It should send a plain text response along with a custom header. Please note that the `content` should be bytes, not string. That’s why I encoded it.
|
||||
|
||||
### Moving On
|
||||
|
||||
I just walked through some of the features of API Star. There’s a lot more of cool stuff in API Star. I do recommend going through the [Github Readme][2] for learning more about different features offered by this excellent framework. I shall also try to cover short, focused tutorials on API Star in the coming days.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://polyglot.ninja/api-star-python-3-api-framework/
|
||||
|
||||
作者:[MASNUN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://polyglot.ninja/author/masnun/
|
||||
[1]:http://polyglot.ninja/rest-api-best-practices-python-flask-tutorial/
|
||||
[2]:https://github.com/encode/apistar
|
||||
@ -0,0 +1,84 @@
|
||||
Evolving Your Own Life: Introducing Biogenesis
|
||||
======
|
||||
|
||||
Biogenesis provides a platform where you can create entire ecosystems of lifeforms and see how they interact and how the system as a whole evolves over time.
|
||||
|
||||
You always can get the latest version from the project's main [website][1], but it also should be available in the package management systems for most distributions. For Debian-based distributions, install Biogenesis with the following command:
|
||||
|
||||
```
|
||||
|
||||
sudo apt-get install biogenesis
|
||||
|
||||
```
|
||||
|
||||
If you do download it directly from the project website, you also need to have a Java virtual machine installed in order to run it.
|
||||
|
||||
To start it, you either can find the appropriate entry in the menu of your desktop environment, or you simply can type biogenesis in a terminal window. When it first starts, you will get an empty window within which to create your world.
|
||||
|
||||

|
||||
|
||||
Figure 1\. When you first start Biogenesis, you get a blank canvas so you can start creating your world.
|
||||
|
||||
The first step is to create a world. If you have a previous instance that you want to continue with, click the Game→Open menu item and select the appropriate file. If you want to start fresh, click Game→New to get a new world with a random selection of organisms.
|
||||
|
||||

|
||||
|
||||
Figure 2\. When you launch a new world, you get a random selection of organisms to start your ecosystem.
|
||||
|
||||
The world starts right away, with organisms moving and potentially interacting immediately. However, you can pause the world by clicking on the icon that is second from the right in the toolbar. Alternatively, you also can just press the p key to pause and resume the evolution of the world.
|
||||
|
||||
At the bottom of the window, you'll find details about the world as it currently exists. There is a display of the frames per second, along with the current time within the world. Next, there is a count of the current population of organisms. And finally, there is a display of the current levels of oxygen and carbon dioxide. You can adjust the amount of carbon dioxide within the world either by clicking the relevant icon in the toolbar or selecting the World menu item and then clicking either Increase CO2 or Decrease CO2.
|
||||
|
||||
There also are several parameters that govern how the world works and how your organisms will fare. If you select World→Parameters, you'll see a new window where you can play with those values.
|
||||
|
||||

|
||||
|
||||
Figure 3\. The parameter configuration window allows you to set parameters on the physical characteristics of the world, along with parameters that control the evolution of your organisms.
|
||||
|
||||
The General tab sets the amount of time per frame and whether hardware acceleration is used for display purposes. The World tab lets you set the physical characteristics of the world, such as the size and the initial oxygen and carbon dioxide levels. The Organisms tab allows you to set the initial number of organisms and their initial energy levels. You also can set their life span and mutation rate, among other items. The Metabolism tab lets you set the parameters around photosynthetic metabolism. And, the Genes tab allows you to set the probabilities and costs for the various genes that can be used to define your organisms.
|
||||
|
||||
What about the organisms within your world though? If you click on one of the organisms, it will be highlighted and the display will change.
|
||||
|
||||

|
||||
|
||||
Figure 4\. You can select individual organisms to find information about them, as well as apply different types of actions.
|
||||
|
||||
The icon toolbar at the top of the window will change to provide actions that apply to organisms. At the bottom of the window is an information bar describing the selected organism. It shows physical characteristics of the organism, such as age, energy and mass. It also describes its relationships to other organisms. It does this by displaying the number of its children and the number of its victims, as well as which generation it is.
|
||||
|
||||
If you want even more detail about an organism, click the Examine genes button in the bottom bar. This pops up a new window called the Genetic Laboratory that allows you to look at and alter the genes making up this organism. You can add or delete genes, as well as change the parameters of existing genes.
|
||||
|
||||

|
||||
|
||||
Figure 5\. The Genetic Laboratory allows you to play with the individual genes that make up an organism.
|
||||
|
||||
Right-clicking on a particular organism displays a drop-down menu that provides even more tools to work with. The first one allows you to track the selected organism as the world evolves. The next two entries allow you either to feed your organism extra food or weaken it. Normally, organisms need a certain amount of energy before they can reproduce. Selecting the fourth entry forces the selected organism to reproduce immediately, regardless of the energy level. You also can choose either to rejuvenate or outright kill the selected organism. If you want to increase the population of a particular organism quickly, simply copy and paste a number of a given organism.
|
||||
|
||||
Once you have a particularly interesting organism, you likely will want to be able to save it so you can work with it further. When you right-click an organism, one of the options is to export the organism to a file. This pops up a standard save dialog box where you can select the location and filename. The standard file ending for Biogenesis genetic code files is .bgg. Once you start to have a collection of organisms you want to work with, you can use them within a given world by right-clicking a blank location on the canvas and selecting the import option. This allows you to pull those saved organisms back into a world that you are working with.
|
||||
|
||||
Once you have allowed your world to evolve for a while, you probably will want to see how things are going. Clicking World→Statistics will pop up a new window where you can see what's happening within your world.
|
||||
|
||||

|
||||
|
||||
Figure 6\. The statistics window gives you a breakdown of what's happening within the world you have created.
|
||||
|
||||
The top of the window gives you the current statistics, including the time, the number of organisms, how many are dead, and the oxygen and carbon dioxide levels. It also provides a bar with the relative proportions of the genes.
|
||||
|
||||
Below this pane is a list of some remarkable organisms within your world. These are organisms that have had the most children, the most victims or those that are the most infected. This way, you can focus on organisms that are good at the traits you're interested in.
|
||||
|
||||
On the right-hand side of the window is a display of the world history to date. The top portion displays the history of the population, and the bottom portion displays the history of the atmosphere. As your world continues evolving, click the update button to get the latest statistics.
|
||||
|
||||
This software package could be a great teaching tool for learning about genetics, the environment and how the two interact. If you find a particularly interesting organism, be sure to share it with the community at the project website. It might be worth a look there for starting organisms too, allowing you to jump-start your explorations.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/evolving-your-own-life-introducing-biogenesis
|
||||
|
||||
作者:[Joey Bernard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/joey-bernard
|
||||
[1]:http://biogenesis.sourceforge.net
|
||||
@ -0,0 +1,122 @@
|
||||
How to print filename with awk on Linux / Unix
|
||||
======
|
||||
|
||||
I would like to print filename with awk on Linux / Unix-like system. How do I print filename in BEGIN section of awk? Can I print the name of the current input file using gawk/awk?
|
||||
|
||||
The name of the current input file set in FILENAME variable. You can use FILENAME to display or print current input file name If no files are specified on the command line, the value of FILENAME is “-” (stdin). However, FILENAME is undefined inside the BEGIN rule unless set by getline.
|
||||
|
||||
### How to print filename with awk
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
awk '{ print FILENAME }' fileNameHere
|
||||
awk '{ print FILENAME }' /etc/hosts
|
||||
```
|
||||
You might see file name multiple times as awk read file line-by-line. To avoid this problem update your awk/gawk syntax as follows:
|
||||
```
|
||||
awk 'FNR == 1{ print FILENAME } ' /etc/passwd
|
||||
awk 'FNR == 1{ print FILENAME } ' /etc/hosts
|
||||
```
|
||||

|
||||
|
||||
### How to print filename in BEGIN section of awk
|
||||
|
||||
Use the following syntax:
|
||||
```
|
||||
awk 'BEGIN{print ARGV[1]}' fileNameHere
|
||||
awk 'BEGIN{print ARGV[1]}{ print "someting or do something on data" }END{}' fileNameHere
|
||||
awk 'BEGIN{print ARGV[1]}' /etc/hosts
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
/etc/hosts
|
||||
|
||||
```
|
||||
|
||||
However, ARGV[1] might not always work. For example:
|
||||
`ls -l /etc/hosts | awk 'BEGIN{print ARGV[1]} { print }'`
|
||||
So you need to modify it as follows (assuming that ls -l only produced a single line of output):
|
||||
`ls -l /etc/hosts | awk '{ print "File: " $9 ", Owner:" $3 ", Group: " $4 }'`
|
||||
Sample outputs:
|
||||
```
|
||||
File: /etc/hosts, Owner:root, Group: roo
|
||||
|
||||
```
|
||||
|
||||
### How to deal with multiple filenames specified by a wild card
|
||||
|
||||
Use the following simple syntax:
|
||||
```
|
||||
awk '{ print FILENAME; nextfile } ' *.c
|
||||
awk 'BEGIN{ print "Starting..."} { print FILENAME; nextfile }END{ print "....DONE"} ' *.conf
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
Starting...
|
||||
blkid.conf
|
||||
cryptconfig.conf
|
||||
dhclient6.conf
|
||||
dhclient.conf
|
||||
dracut.conf
|
||||
gai.conf
|
||||
gnome_defaults.conf
|
||||
host.conf
|
||||
idmapd.conf
|
||||
idnalias.conf
|
||||
idn.conf
|
||||
insserv.conf
|
||||
iscsid.conf
|
||||
krb5.conf
|
||||
ld.so.conf
|
||||
logrotate.conf
|
||||
mke2fs.conf
|
||||
mtools.conf
|
||||
netscsid.conf
|
||||
nfsmount.conf
|
||||
nscd.conf
|
||||
nsswitch.conf
|
||||
openct.conf
|
||||
opensc.conf
|
||||
request-key.conf
|
||||
resolv.conf
|
||||
rsyncd.conf
|
||||
sensors3.conf
|
||||
slp.conf
|
||||
smartd.conf
|
||||
sysctl.conf
|
||||
vconsole.conf
|
||||
warnquota.conf
|
||||
wodim.conf
|
||||
xattr.conf
|
||||
xinetd.conf
|
||||
yp.conf
|
||||
....DONE
|
||||
|
||||
```
|
||||
|
||||
nextfile tells awk to stop processing the current input file. The next input record read comes from the next input file. For more information see awk/[gawk][1] command man page:
|
||||
```
|
||||
man awk
|
||||
man gawk
|
||||
```
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][5]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-print-filename-with-awk-on-linux-unix/
|
||||
|
||||
作者:Vivek GIte[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.gnu.org/software/gawk/manual/
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
[5]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,131 @@
|
||||
Python Hello World and String Manipulation
|
||||
======
|
||||
|
||||
|
||||
|
||||
Before starting, I should mention that the [code][1] used in this blog post and in the [video][2] below is available on my github.
|
||||
|
||||
With that, let’s get started! If you get lost, I recommend opening the [video][3] below in a separate tab.
|
||||
|
||||
[Hello World and String Manipulation Video using Python][2]
|
||||
|
||||
#### ** Get Started (Prerequisites)
|
||||
|
||||
Install Anaconda (Python) on your operating system. You can either download anaconda from the [official site][4] and install on your own or you can follow these anaconda installation tutorials below.
|
||||
|
||||
Install Anaconda on Windows: [Link][5]
|
||||
|
||||
Install Anaconda on Mac: [Link][6]
|
||||
|
||||
Install Anaconda on Ubuntu (Linux): [Link][7]
|
||||
|
||||
#### Open a Jupyter Notebook
|
||||
|
||||
Open your terminal (Mac) or command line and type the following ([see 1:16 in the video to follow along][8]) to open a Jupyter Notebook:
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### Print Statements/Hello World
|
||||
|
||||
Type the following into a cell in Jupyter and type **shift + enter** to execute code.
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing ‘Hello World!’
|
||||
|
||||
#### Strings and String Manipulation
|
||||
|
||||
Strings are a special type of a python class. As objects, in a class, you can call methods on string objects using the .methodName() notation. The string class is available by default in python, so you do not need an import statement to use the object interface to strings.
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of printing the variable firstVariable
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using .lower(), .upper() , and title() methods
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Output of using the split method (in this case, split on space)
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
string concatenation
|
||||
|
||||
#### Look up what Methods Do
|
||||
|
||||
For new programmers, they often ask how you know what each method does. Python provides two ways to do this.
|
||||
|
||||
1. (works in and out of Jupyter Notebook) Use **help** to lookup what each method does.
|
||||
|
||||
|
||||
|
||||
![][9]
|
||||
Look up what each method does
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
Look up what each method does in Jupyter
|
||||
|
||||
#### Closing Remarks
|
||||
|
||||
Please let me know if you have any questions either here or in the comments section of the [youtube video][2]. The code in the post is also available on my [github][1]. Part 2 of the tutorial series is [Simple Math][10].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulation-gdgwd8ymp
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/mgalarny
|
||||
[1]:https://github.com/mGalarnyk/Python_Tutorials/blob/master/Python_Basics/Intro/Python3Basics_Part1.ipynb
|
||||
[2]:https://www.youtube.com/watch?v=JqGjkNzzU4s
|
||||
[3]:https://www.youtube.com/watch?v=kApPBm1YsqU
|
||||
[4]:https://www.continuum.io/downloads
|
||||
[5]:https://medium.com/@GalarnykMichael/install-python-on-windows-anaconda-c63c7c3d1444
|
||||
[6]:https://medium.com/@GalarnykMichael/install-python-on-mac-anaconda-ccd9f2014072
|
||||
[7]:https://medium.com/@GalarnykMichael/install-python-on-ubuntu-anaconda-65623042cb5a
|
||||
[8]:https://youtu.be/JqGjkNzzU4s?t=1m16s
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
|
||||
[10]:https://medium.com/@GalarnykMichael/python-basics-2-simple-math-4ac7cc928738
|
||||
@ -1,14 +1,14 @@
|
||||
八种在 Linux 上生成随机密码的方法
|
||||
======
|
||||
学习使用 8 种 Linux 原生命令或第三方组件来生成随机密码。
|
||||
学习使用 8 种 Linux 原生命令或第三方实用程序来生成随机密码。
|
||||
|
||||
![][1]
|
||||
|
||||
在这篇文章中,我们将引导你通过几种不同的方式在 Linux 中生成随机密码。其中几种利用原生 Linux 命令,另外几种则利用极易在 Linux 机器上安装的第三方工具或组件实现。在这里我们利用像 `openssl`, [dd][2], `md5sum`, `tr`, `urandom` 这样的原生命令和 mkpasswd,randpw,pwgen,spw,gpg,xkcdpass,diceware,revelation,keepaasx,passwordmaker 这样的第三方工具。
|
||||
在这篇文章中,我们将引导你通过几种不同的方式在 Linux 终端中生成随机密码。其中几种利用原生 Linux 命令,另外几种则利用极易在 Linux 机器上安装的第三方工具或实用程序实现。在这里我们利用像 `openssl`, [dd][2], `md5sum`, `tr`, `urandom` 这样的原生命令和 mkpasswd,randpw,pwgen,spw,gpg,xkcdpass,diceware,revelation,keepaasx,passwordmaker 这样的第三方工具。
|
||||
|
||||
其实这些方法就是生成一些能被用作密码的随机字母字符串。随机密码可以用于新用户的密码,不管用户基数有多大,这些密码都是独一无二的。话不多说,让我们来看看 8 种不同的在 Linux 上生成随机密码的方法吧。
|
||||
|
||||
##### 使用 mkpasswd 组件生成密码
|
||||
##### 使用 mkpasswd 实用程序生成密码
|
||||
|
||||
`mkpasswd` 在基于 RHEL 的系统上随 `expect` 软件包一起安装。在基于 Debian 的系统上 `mkpasswd` 则在软件包 `whois` 中。直接安装 `mkpasswd` 软件包将会导致错误 -
|
||||
|
||||
@ -28,7 +28,7 @@ root@kerneltalks# mkpasswd teststring << on Ubuntu
|
||||
XnlrKxYOJ3vik
|
||||
```
|
||||
|
||||
这个命令在不同的系统上表现得不一样,所以要对应工作。你也可以通过参数来控制长度等选项。你可以查阅 man 手册来探索。
|
||||
这个命令在不同的系统上表现得不一样,所以要对应工作。你也可以通过参数来控制长度等选项,可以查阅 man 手册来探索。
|
||||
|
||||
##### 使用 openssl 生成密码
|
||||
|
||||
@ -43,7 +43,7 @@ nU9LlHO5nsuUvw==
|
||||
|
||||
##### 使用 urandom 生成密码
|
||||
|
||||
设备文件 `/dev/urandom` 是另一个获得随机字符串的方法。我们使用 `tr` 功能裁剪输出来获得随机字符串,并把它作为密码。
|
||||
设备文件 `/dev/urandom` 是另一个获得随机字符串的方法。我们使用 `tr` 功能并裁剪输出来获得随机字符串,并把它作为密码。
|
||||
|
||||
```bash
|
||||
root@kerneltalks # strings /dev/urandom |tr -dc A-Za-z0-9 | head -c20; echo
|
||||
@ -71,7 +71,7 @@ F8c3a4joS+a3BdPN9C++
|
||||
|
||||
##### 使用 md5sum 生成密码
|
||||
|
||||
另一种获取可用作密码的随机字符串的方法是计算 MD5 校验值!校验值看起来确实像是随机字符串组合在一起,我们可以用作为密码。确保你的计算源是个变量,这样的话每次运行命令时生成的校验值都不一样。比如 `date`![date 命令][3] 总会生成不同的输出。
|
||||
另一种获取可用作密码的随机字符串的方法是计算 MD5 校验值!校验值看起来确实像是随机字符串组合在一起,我们可以用作密码。确保你的计算源是个变量,这样的话每次运行命令时生成的校验值都不一样。比如 `date`![date 命令][3] 总会生成不同的输出。
|
||||
|
||||
```bash
|
||||
root@kerneltalks # date |md5sum
|
||||
@ -82,7 +82,7 @@ root@kerneltalks # date |md5sum
|
||||
|
||||
##### 使用 pwgen 生成密码
|
||||
|
||||
`pwgen` 软件包在[类 EPEL 仓库][5](译者注:企业版 Linux 附加软件包)中。`pwgen` 更专注于生成可发音的密码,但它们不在英语词典中,也不是纯英文的。标准发行版仓库中可能并不包含这个工具。安装这个软件包然后运行 `pwgen` 命令行。Boom !
|
||||
`pwgen` 软件包在类似 [EPEL 软件仓库][5](译者注:企业版 Linux 附加软件包)中。`pwgen` 更专注于生成可发音的密码,但它们不在英语词典中,也不是纯英文的。标准发行版仓库中可能并不包含这个工具。安装这个软件包然后运行 `pwgen` 命令行。Boom !
|
||||
|
||||
```bash
|
||||
root@kerneltalks # pwgen
|
||||
@ -255,7 +255,7 @@ via: https://kerneltalks.com/tips-tricks/8-ways-to-generate-random-password-in-l
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Locez](https://github.com/locez)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,115 @@
|
||||
为初学者准备的 Linux ln 命令教程(5 个示例)
|
||||
======
|
||||
|
||||
当我们在命令行上工作时,您可能需要创建文件链接。这时,您可以可以借助一个专用命令,**ln**。本教程中,我们将基于此命令通过一些简明的例子展开讨论。在此之前,有必要明确,本教程所有测试都是基于 Ubuntu 16.04 设备开展的。
|
||||
|
||||
### Linux ln 命令
|
||||
|
||||
正如现在你所了解的,ln 命令能够让您链接文件。下面就是 ln 工具的语法(或者使用其他一些可行的语法)。
|
||||
|
||||
```
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
|
||||
ln [OPTION]... TARGET (2nd form)
|
||||
ln [OPTION]... TARGET... DIRECTORY (3rd form)
|
||||
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
|
||||
```
|
||||
|
||||
下面是 ln 工具 man 文档描述的内容:
|
||||
```
|
||||
在第一种形式下,创建名为 LINK_NAME 的链接目标。
|
||||
第二种形式为创建链接在当前目录。
|
||||
第三和第四中形式中,在 DIRECTORY 目录下创建链接目标。默认创建硬链接,字符链接需要 --symbolic 选项。默认创建硬链接,目标文件必须存在。字符链接可以保存任何文件。
|
||||
```
|
||||
|
||||
同故宫下面问答风格的例子,可能会给你更好的理解。但是在此之前,建议您先了解 [软连接和硬链接的区别][1].
|
||||
|
||||
### Q1. 如何通过 ln 命令创建硬链接?
|
||||
|
||||
这很简单,你只需要使用下面的 ln 命令:
|
||||
|
||||
```
|
||||
ln [file] [hard-link-to-file]
|
||||
```
|
||||
|
||||
这里有一个示例:
|
||||
|
||||
```
|
||||
ln test.txt test_hard_link.txt
|
||||
```
|
||||
|
||||
[![如何通过 ln 命令创建硬链接][2]][3]
|
||||
|
||||
如此,您便可以看见一个已经创建好了的硬链接,名为 test_hard_link.txt。
|
||||
|
||||
### Q2. 如何通过 ln 命令创建软/字符链接?
|
||||
|
||||
使用 -s 命令行选项
|
||||
|
||||
```
|
||||
ln -s [file] [soft-link-to-file]
|
||||
```
|
||||
|
||||
这里有一个示例:
|
||||
|
||||
```
|
||||
ln -s test.txt test_soft_link.txt
|
||||
```
|
||||
|
||||
[![如何通过 ln 命令创建软/字符链接][4]][5]
|
||||
|
||||
test_soft_link.txt 文件就是一个软/字符链接,被天蓝色文本 [标识][6]。
|
||||
|
||||
### Q3. 如何通过 ln 命令删除既存的同名目标文件?
|
||||
|
||||
默认情况下,ln 不允许您在目标文件目录下创建同名链接。
|
||||
|
||||
[![ln 命令示例][7]][8]
|
||||
|
||||
然而,如果一定要这么做,您可以使用 **-f** 命令行选项忽视此行为。
|
||||
|
||||
[![如何通过 ln 命令创建软/字符链接][9]][10]
|
||||
|
||||
**贴士** : 如果您想忽略删除过程中所有的命令行交互,您可以使用 **-i** 选项。
|
||||
|
||||
### Q4. 如何通过 ln 命令创建既存文件的同名备份?
|
||||
|
||||
如果您不想通过 ln 删除同名的既存文件,您可以让它为此文件创建备份。使用 **-b** 即可实现此效果。被创建的备份文件,会在其文件名结尾处包含一个(~) 字符标识。
|
||||
|
||||
[![如何通过 ln 命令创建既存文件的同名备份][11]][12]
|
||||
|
||||
使用 **-t** 选项指定一个文件目录(除了当前目录)。比如:
|
||||
|
||||
```
|
||||
ls test* | xargs ln -s -t /home/himanshu/Desktop/
|
||||
```
|
||||
|
||||
上述命令会为所有 test* 文件(当前目录下的 test* 文件)创建链接到桌面。
|
||||
|
||||
### 总结
|
||||
|
||||
当然,**ln** 并不是日常必备命令,尤其对于新手。但是了解此命令益处良多,有备无患,万一它哪一天刚好可以拯救你。对于这个命令,我们已经讨论了一些实用的选项,更多详情请查询 [man 文档][13]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-ln-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://medium.com/meatandmachines/explaining-the-difference-between-hard-links-symbolic-links-using-bruce-lee-32828832e8d3
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/ln-hard-link.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/big/ln-hard-link.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/ln-soft-link.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/big/ln-soft-link.png
|
||||
[6]:https://askubuntu.com/questions/17299/what-do-the-different-colors-mean-in-ls
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/ln-file-exists.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/ln-file-exists.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/ln-f-option.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/ln-f-option.png
|
||||
[11]:https://www.howtoforge.com/images/command-tutorial/ln-b-option.png
|
||||
[12]:https://www.howtoforge.com/images/command-tutorial/big/ln-b-option.png
|
||||
[13]:https://linux.die.net/man/1/ln
|
||||
Loading…
Reference in New Issue
Block a user