mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge remote-tracking branch 'lcct/master'
This commit is contained in:
commit
46d1ff9da1
@ -0,0 +1,111 @@
|
||||
在 Linux 上如何用命令行获取 Freely RSS 源
|
||||
================================================================================
|
||||
|
||||
也许你并不知道 Feedly,它是世界上最流行的在线新闻聚合服务之一;它提供了平滑而一致的新闻阅读体验,你可以使用电脑的浏览器扩展,Android 和 iOS 设备上的移动应用程序等来体验Feedly。Feedly 在2013年Google Reader 停用后,迅速的获得了一大批Google Reader的用户。我就是他们之中的一位。从这以后,Feedly就一直是我的默认RSS(简易信息聚合)阅读器。
|
||||
|
||||
除了使用我非常喜欢的Feedly浏览器扩展和手机上的Feedly程序,这里还有一种途径来获取Feedly:Linux命令行。没错,你可以用命令行来获取Feedly上的新闻概要。听起来非常傻?但是对于那些在服务器上工作的系统管理员来说,这是非常有用的。
|
||||
|
||||
点击进入[Feednix][2],这个用c++编写的开源软件是Feedly的非官方命令行客户端。它允许你在一个基于ncurses的终端界面(例如:bash)下浏览Feedly的新闻。默认模式下,Feednix 关联了一个叫做 w3m 的基于控制台的浏览器,允许你在命令行终端的环境下阅读文章。当然你也可以选择使用你喜欢的网页浏览器。
|
||||
|
||||
在这个教程中,我准备示范一下怎样在命令行下安装和配置Feednix 来获取Feedly。
|
||||
|
||||
### 在Linux下安装Feednix ###
|
||||
|
||||
你可以通过以下的步骤从源代码中构建Feednix。同时,在其官方的github仓库的Ubuntu-stable(Ubuntu稳定版本)的分支上有最新的Feednix源代码。现在让我们开始吧:
|
||||
|
||||
作为必要组件,你需要安装一组开发包,和w3m浏览器(文字式页面浏览器)。
|
||||
|
||||
#### 在Debian、Ubuntu 和Linux Mint 操作 ####
|
||||
|
||||
$ sudo apt-get install git automake g++ make libncursesw5-dev libjsoncpp-dev libcurl4-gnutls-dev w3m
|
||||
$ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
|
||||
$ cd Feednix
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
|
||||
#### 在Fedora 下操作 ####
|
||||
|
||||
$ sudo yum groupinstall "C Development Tools and Libraries"
|
||||
$ sudo yum install gcc-c++ git automake make ncurses-devel jsoncpp-devel libcurl-devel w3m
|
||||
$ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
|
||||
$ cd Feednix
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Arch Linux ####
|
||||
|
||||
在Arch Linux发行版下,你可以非常容易的从 [AUR][3]安装Feednix。
|
||||
|
||||
### 配置Feednix ###
|
||||
|
||||
在安装完软件后,用下面的命令启动Feednix
|
||||
|
||||
$ feednix
|
||||
|
||||
如果你是第一次运行Feddnix,它会弹出一个网页浏览器窗口,在这个窗口里,你需要登录来创建一个Feedly的账户ID和相应的开发人员密钥。
|
||||
|
||||
如果你是在无桌面环境下运行Feednix,先在另外一台电脑上打开一个网页,进入到网站:https://feedly.com/v3/auth/dev 。
|
||||
|
||||

|
||||
|
||||
当你登录后,你对应的Feedly账户ID就生成了。
|
||||
|
||||

|
||||
|
||||
为了得到一个访问密钥,你需要在浏览器上访问发送你的邮箱中的密钥链接。之后就会在浏览器窗口显示你的用户ID,密钥,和密钥的有效期。请注意密钥的长度是非常长的(超过200个字符),所以密钥显示在一个带有垂直滚动条的文本框内,请确保把整个密钥复制下来。
|
||||
|
||||
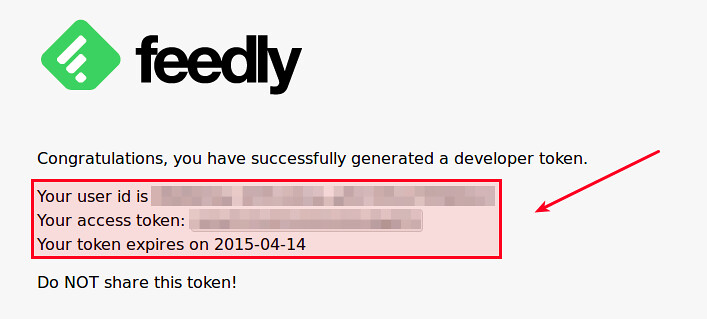
|
||||
|
||||
像下面这样,把你的用户ID和密钥输入到Feddnix的命令行提示下:
|
||||
|
||||
[Enter User ID] >> XXXXXX
|
||||
[Enter token] >> YYYYY
|
||||
|
||||
成功授权后,你会在屏幕上见到一个初始化为两个窗格的Feednix界面。左边的标题为“Categories”窗格,显示了一个新闻分类栏;右边“Posts”窗格显示了当前类别的新闻文章。
|
||||
|
||||
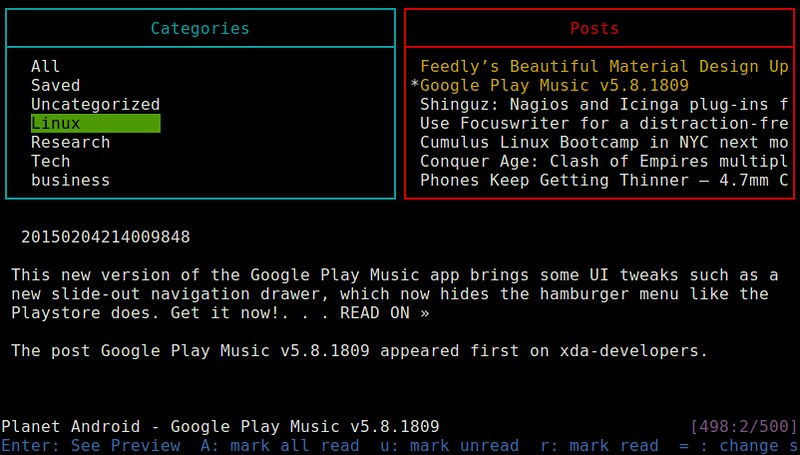
|
||||
|
||||
### 用Feednix读文章 ###
|
||||
|
||||
这里我想简要描叙一下怎样通过Feednix来访问Feedly。
|
||||
|
||||
#### 在Feednix中导航 ####
|
||||
|
||||
像我之前提过的,Feednix窗口包含了两个窗格。想在两个窗口之间进行切换的话,可以使用"TAB"健。想在一个窗格内的列表中上下移动,可以使用"j"和"k"。这些快捷健明显是受到了Vim编辑器的启发。
|
||||
|
||||
#### 阅读文章 ####
|
||||
|
||||
想阅读一篇特定的文章,可以在当前的文章上使用"o"健。它会调用w3m浏览器,并且在浏览器里面加载文章。当你读完之后,可以使用"q"健来退出浏览器,并返回到Feednix。如果你的电脑环境允许打开网页浏览器,你可以按"0"健来在你默认的网页浏览器里面加载文章,比如使用Firefox。
|
||||
|
||||
|
||||
|
||||
#### 订阅新闻源 ####
|
||||
|
||||
你可以在Feednix界面中来为你的Feedly账户增加任何一种RSS新闻源。要这么做,仅仅只需要按下"a"键,它会在屏幕底部显示一个"[ENTER FEED]:"的提示。在输入完RSS新闻源后,继续输入新闻源的名字和及其首选分类。
|
||||
|
||||
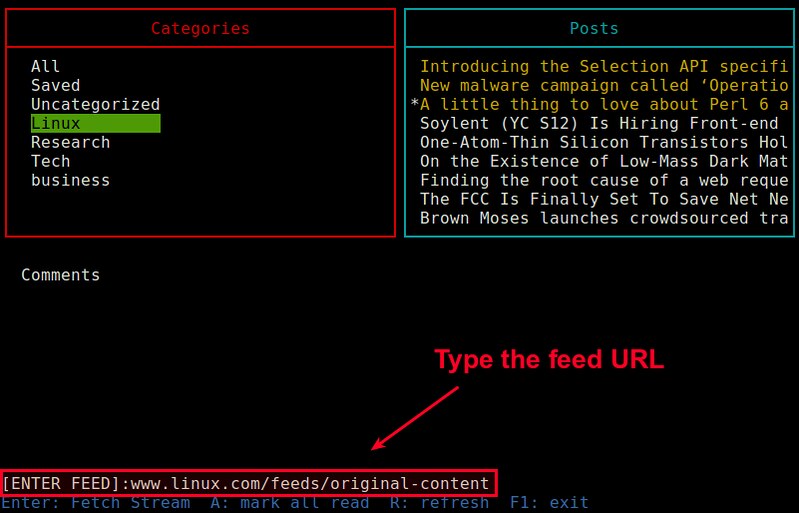
|
||||
|
||||
#### 总结 ####
|
||||
|
||||
如你所见, Feednix 是一个非常方便易用的命令行RSS阅读器。如果你是重度依赖命令行的用户,同时也是一个Feedly用户的话,Feednix 是肯定值得去尝试的。我和Feednix的开发者Jarkore交流解决了一些问题。我想说,对于[bug的报告][4]和修复他非常的积极。鼓励大家来试用Feednix,并且给他(Jarkore)一些回馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/feedly-rss-feed-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[chenzhijun](https://github.com/chenzhijun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://feedly.com/
|
||||
[2]:https://github.com/Jarkore/Feednix
|
||||
[3]:https://aur.archlinux.org/packages/feednix/
|
||||
[4]:https://github.com/Jarkore/Feednix/issues
|
||||
@ -1,14 +1,15 @@
|
||||
在Apache中使用Mod_Security和Mod_evasive来抵御暴力破解和DDos攻击
|
||||
在Apache中使用mod\_security和mod\_evasive来抵御暴力破解和DDos攻击
|
||||
================================================================================
|
||||
对于那些托管主机或者需要将您的主机暴露在因特网中的人来说,保证您的系统在面对攻击时安全是一个重要的事情。
|
||||
|
||||
mod_security(一个开源的可以无缝接入Web服务器的用于Web应用入侵检测和防护的引擎)和mod_evasive是两个在服务器端对抗暴力破解和(D)Dos攻击的非常重要的工具。
|
||||
对于那些需要在因特网上提供服务或托管主机的人来说,保证您的系统在面对攻击时的安全是一个重要的事情。
|
||||
|
||||
mod_evasive,如它的名字一样,在受攻击时提供避实就虚的功能,它像一个雨伞一样保护Web服务器免受那些威胁。
|
||||
mod\_security(一个开源的用于Web应用入侵检测及防护的引擎,可以无缝地集成到Web服务器)和mod\_evasive是两个在服务器端对抗暴力破解和(D)Dos攻击的非常重要的工具。
|
||||
|
||||
mod\_evasive,如它的名字一样,在受攻击时提供避实就虚的功能,它像一个雨伞一样保护Web服务器免受那些威胁。
|
||||
|
||||

|
||||
|
||||
安装Mod_Security和Mod_Evasive来保护Apache
|
||||
*安装mod\_security和mod\_evasive来保护Apache*
|
||||
|
||||
在这篇文章中我们将讨论如何安装、配置以及在RHEL/CentOS6、7和Fedora 21-15上将它们整合到Apache。另外,我们会模拟攻击以便验证服务器做出了正确的反应。
|
||||
|
||||
@ -16,91 +17,77 @@ mod_evasive,如它的名字一样,在受攻击时提供避实就虚的功能
|
||||
|
||||
- [在RHEL/CentOS 7中安装LAMP][1]
|
||||
|
||||
如果您在运行RHEL/CentOS 7或Fedora 21,您还需要安装iptables作为默认[防火墙][2]前端以取代firewalld。这样做是为了在RHEL/CentOS 7或Fedora 21中使用同样的工具。
|
||||
(LCTT 译注:本文有修改。原文为了在RHEL/CentOS 7或Fedora 21中使用同样的工具,而删除了自带的 firewalld,使用了旧式的iptables。译者以为这样并不恰当,因此,译文中做了相应删节,并增加了firewalld的相应脚本。)
|
||||
|
||||
### 步骤 1: 在RHEL/CentOS 7和Fedora 21上安装Iptables防火墙 ###
|
||||
|
||||
用下面的命令停止和禁用firewalld:
|
||||
|
||||
# systemctl stop firewalld
|
||||
# systemctl disable firewalld
|
||||
|
||||

|
||||
禁用firewalld服务
|
||||
|
||||
接下来在使能iptables之前安装iptables-services包:
|
||||
|
||||
# yum update && yum install iptables-services
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
# systemctl status iptables
|
||||
|
||||

|
||||
安装Iptables防火墙
|
||||
|
||||
### 步骤 2: 安装Mod_Security和Mod_evasive ###
|
||||
### 步骤 1: 安装mod\_security和mod\_evasive ###
|
||||
|
||||
另外,在安装LAMP后,您还需要在RHEL/CentOS 7/6中[开启EPEL仓库][3]来安装这两个包。Fedora用户不需要开启这个仓库,因为epel已经是Fedora项目的一部分了。
|
||||
|
||||
# yum update && yum install mod_security mod_evasive
|
||||
|
||||
当安装结束后,您会在/etc/httpd/conf.d下找到两个工具的配置文件。
|
||||
当安装结束后,您会在/etc/httpd/conf.d下找到这两个工具的配置文件。
|
||||
|
||||
# ls -l /etc/httpd/conf.d
|
||||
|
||||

|
||||
mod_security + mod_evasive 配置文件
|
||||
|
||||
现在,为了整合这两个模块到Apache,并在启动时加载它们。请确保下面几行出现在mod_evasive.conf和mod_security.conf的顶层部分,它们分别为:
|
||||
*mod\_security + mod\_evasive 配置文件*
|
||||
|
||||
现在,为了整合这两个模块到Apache,并在启动时加载它们。请确保下面几行出现在mod\_evasive.conf和mod\_security.conf的顶层部分,它们分别为:
|
||||
|
||||
LoadModule evasive20_module modules/mod_evasive24.so
|
||||
LoadModule security2_module modules/mod_security2.so
|
||||
|
||||
请注意modules/mod_security2.so和modules/mod_evasive24.so都是从/etc/httpd到模块源文件的相对路径。您可以通过列出/etc/httpd/modules的内容来验证(如果需要的话,修改它):
|
||||
请注意modules/mod\_security2.so和modules/mod\_evasive24.so都是从/etc/httpd到模块源文件的相对路径。您可以通过列出/etc/httpd/modules的内容来验证(如果需要的话,修改它):
|
||||
|
||||
# cd /etc/httpd/modules
|
||||
# pwd
|
||||
# ls -l | grep -Ei '(evasive|security)'
|
||||
|
||||
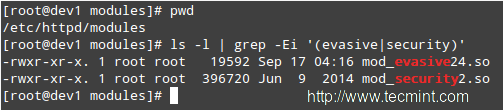
|
||||
验证mod_security + mod_evasive模块
|
||||
|
||||
接下来重启Apache并且核实它已加载了mod_evasive和mod_security:
|
||||
*验证mod\_security + mod\_evasive模块*
|
||||
|
||||
接下来重启Apache并且核实它已加载了mod\_evasive和mod\_security:
|
||||
|
||||
# service httpd restart [在RHEL/CentOS 6和Fedora 20-18上]
|
||||
# systemctl restart httpd [在RHEL/CentOS 7和Fedora 21上]
|
||||
|
||||
----------
|
||||
|
||||
[输出已加载的静态模块和动态模块列表]
|
||||
|
||||
# httpd -M | grep -Ei '(evasive|security)'
|
||||
# httpd -M | grep -Ei '(evasive|security)' [输出已加载的静态模块和动态模块列表]
|
||||
|
||||
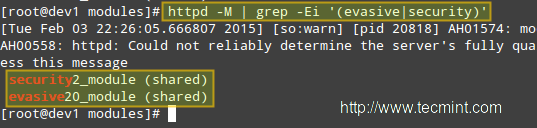
|
||||
检查mod_security + mod_evasive模块已加载
|
||||
|
||||
### 步骤 3: 安装一个核心规则集并且配置Mod_Security ###
|
||||
*检查mod\_security + mod\_evasive模块已加载*
|
||||
|
||||
简单来说,一个核心规则集(即CRS)为web服务器提供特定状况下如何反应的指令。mod_security的开发者们提供了一个免费的CRS,叫做OWASP([开放Web应用安全项目])ModSecurity CRS,可以从下面的地址下载和安装。
|
||||
### 步骤 2: 安装一个核心规则集并且配置mod\_security ###
|
||||
|
||||
1. 下载OWASP CRS到为之创建的目录
|
||||
简单来说,一个核心规则集(即CRS)为web服务器提供特定状况下如何反应的指令。mod\_security的开发者们提供了一个免费的CRS,叫做OWASP([开放Web应用安全项目])ModSecurity CRS,可以从下面的地址下载和安装。
|
||||
|
||||
# mkdir /etc/httpd/crs-tecmint
|
||||
# cd /etc/httpd/crs-tecmint
|
||||
####下载OWASP CRS到为之创建的目录####
|
||||
|
||||
# mkdir /etc/httpd/crs-tecmint
|
||||
# cd /etc/httpd/crs-tecmint
|
||||
# wget https://github.com/SpiderLabs/owasp-modsecurity-crs/tarball/master
|
||||
|
||||

|
||||
下载mod_security核心规则
|
||||
|
||||
2. 解压CRS文件并修改文件夹名称
|
||||
*下载mod\_security核心规则*
|
||||
|
||||
#### 解压CRS文件并修改文件夹名称####
|
||||
|
||||
# tar xzf master
|
||||
# mv SpiderLabs-owasp-modsecurity-crs-ebe8790 owasp-modsecurity-crs
|
||||
|
||||

|
||||
解压mod_security核心规则
|
||||
|
||||
3. 现在,是时候配置mod_security了。将同样的规则文件(owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example)拷贝至另一个没有.example扩展的文件。
|
||||

|
||||
|
||||
*解压mod\_security核心规则*
|
||||
|
||||
####现在,是时候配置mod\_security了####
|
||||
|
||||
将示例的规则文件(owasp-modsecurity-crs/modsecurity_crs_10_setup.conf.example)拷贝为同名的配置文件。
|
||||
|
||||
# cp modsecurity_crs_10_setup.conf.example modsecurity_crs_10_setup.conf
|
||||
|
||||
@ -111,7 +98,7 @@ mod_security + mod_evasive 配置文件
|
||||
Include crs-tecmint/owasp-modsecurity-crs/base_rules/*.conf
|
||||
</IfModule>
|
||||
|
||||
最后,建议您在/etc/httpd/modsecurity.d目录下创建自己的配置文件,在那里我们可以用我们自定义的文件夹(接下来的示例中,我们会将其命名为tecmint.conf)而无需修改CRS文件的目录。这样做能够在CRSs发布新版本时更加容易的升级。
|
||||
最后,建议您在/etc/httpd/modsecurity.d目录下创建自己的配置文件,在那里我们可以用我们自定义的文件夹(接下来的示例中,我们会将其命名为tecmint.conf)而无需修改CRS文件的目录。这样做能够在CRS发布新版本时更加容易的升级。
|
||||
|
||||
<IfModule mod_security2.c>
|
||||
SecRuleEngine On
|
||||
@ -121,13 +108,13 @@ mod_security + mod_evasive 配置文件
|
||||
SecDataDir /tmp
|
||||
</IfModule>
|
||||
|
||||
您可以在[SpiderLabs的ModSecurity GitHub][5]仓库中参考关于mod_security目录的更完整的解释。
|
||||
您可以在[SpiderLabs的ModSecurity GitHub][5]仓库中参考关于mod\_security目录的更完整的解释。
|
||||
|
||||
### 步骤 4: 配置Mod_Evasive ###
|
||||
### 步骤 3: 配置mod\_evasive ###
|
||||
|
||||
mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。与mod_security不同,由于在包升级时没有规则来更新,因此我们不需要独立的文件来添加自定义指令。
|
||||
mod\_evasive被配置为使用/etc/httpd/conf.d/mod\_evasive.conf中的指令。与mod\_security不同,由于在包升级时没有规则来更新,因此我们不需要独立的文件来添加自定义指令。
|
||||
|
||||
默认的mod_evasive.conf开启了下列的目录(注意这个文件被详细的注释了,因此我们剔掉了注释以重点显示配置指令):
|
||||
默认的mod\_evasive.conf开启了下列的目录(注意这个文件被详细的注释了,因此我们剔掉了注释以重点显示配置指令):
|
||||
|
||||
<IfModule mod_evasive24.c>
|
||||
DOSHashTableSize 3097
|
||||
@ -140,8 +127,8 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
这些指令的解释:
|
||||
|
||||
- DOSHashTableSize: 这个指令指明了哈希表的大小,它用来追踪基于IP地址的活动。增加这个数字将使查询站点访问历史变得更快,但如果被设置的太高则会影响整体性能。
|
||||
- DOSPageCount: 在DOSPageInterval间隔内可由一个用户发起的面向特定的URI(例如,一个Apache托管的文件)的同一个请求的数量。
|
||||
- DOSHashTableSize: 这个指令指明了哈希表的大小,它用来追踪基于IP地址的活动。增加这个数字将使得站点访问历史的查询变得更快,但如果被设置的太大则会影响整体性能。
|
||||
- DOSPageCount: 在DOSPageInterval间隔内可由一个用户发起的针对特定的URI(例如,一个Apache 提供服务的文件)的同一个请求的数量。
|
||||
- DOSSiteCount: 类似DOSPageCount,但涉及到整个站点总共有多少的请求可以在DOSSiteInterval间隔内被发起。
|
||||
- DOSBlockingPeriod: 如果一个用户超过了DOSSPageCount的限制或者DOSSiteCount,他的源IP地址将会在DOSBlockingPeriod期间内被加入黑名单。在DOSBlockingPeriod期间,任何从这个IP地址发起的请求将会遭遇一个403禁止错误。
|
||||
|
||||
@ -149,7 +136,7 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
**一个小警告**: 如果这些值设置的不合适,则您会蒙受阻挡合法用户的风险。
|
||||
|
||||
您也许想考虑下其他有用的指令:
|
||||
您也许还会用到以下其它有用的指令:
|
||||
|
||||
#### DOSEmailNotify ####
|
||||
|
||||
@ -157,11 +144,11 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
# setsebool -P httpd_can_sendmail 1
|
||||
|
||||
接下来,将这个指令和其他指令一起加入到mod_evasive.conf文件。
|
||||
接下来,将这个指令和其他指令一起加入到mod\_evasive.conf文件。
|
||||
|
||||
DOSEmailNotify you@yourdomain.com
|
||||
|
||||
如果这个值被合适的设置并且您的邮件服务器在正常的运行,则当一个IP地址被加入黑名单时,会有一封邮件被发送到相应的地址。
|
||||
如果这个指令设置了合适的值,并且您的邮件服务器在正常的运行,则当一个IP地址被加入黑名单时,会有一封邮件被发送到相应的地址。
|
||||
|
||||
#### DOSSystemCommand ####
|
||||
|
||||
@ -169,31 +156,47 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
DOSSystemCommand </command>
|
||||
|
||||
这个指令指定当一个IP地址被加入黑名单时执行的命令。它通常结合shell脚本来使用,在脚本中添加一条防火墙规则来阻挡某个IP进一步的连接。
|
||||
这个指令指定当一个IP地址被加入黑名单时执行的命令。它通常结合shell脚本来使用,比如在脚本中添加一条防火墙规则来阻挡某个IP进一步的连接。
|
||||
|
||||
**写一个shell脚本在防火墙阶段处理IP黑名单**
|
||||
#####写一个shell脚本在防火墙阶段处理IP黑名单#####
|
||||
|
||||
当一个IP地址被加入黑名单,我们需要阻挡它进一步的连接。我们需要下面的shell脚本来执行这个任务。在/usr/local/bin下创建一个叫做scripts-tecmint的文件夹(或其他的名字),以及一个叫做ban_ip.sh的文件。
|
||||
|
||||
**用于iptables防火墙**
|
||||
|
||||
#!/bin/sh
|
||||
# 由mod_evasive检测出,将被阻挡的IP地址
|
||||
IP=$1
|
||||
# iptables的完整路径
|
||||
IPTABLES="/sbin/iptables"
|
||||
# mod_evasive锁文件夹
|
||||
MOD_EVASIVE_LOGDIR=/var/log/mod_evasive
|
||||
mod_evasive_LOGDIR=/var/log/mod_evasive
|
||||
# 添加下面的防火墙规则 (阻止所有从$IP流入的流量)
|
||||
$IPTABLES -I INPUT -s $IP -j DROP
|
||||
# 为了未来的检测,移除锁文件
|
||||
rm -f "$MOD_EVASIVE_LOGDIR"/dos-"$IP"
|
||||
rm -f "$mod_evasive_LOGDIR"/dos-"$IP"
|
||||
|
||||
**用于firewalld防火墙**
|
||||
|
||||
#!/bin/sh
|
||||
# 由mod_evasive检测出,将被阻挡的IP地址
|
||||
IP=$1
|
||||
# firewalld-cmd的完整路径
|
||||
FIREWALL_CMD="/usr/bin/firewall-cmd"
|
||||
# mod_evasive锁文件夹
|
||||
mod_evasive_LOGDIR=/var/log/mod_evasive
|
||||
# 添加下面的防火墙规则 (阻止所有从$IP流入的流量)
|
||||
$FIREWALL_CMD --zone=drop --add-source $IP
|
||||
# 为了未来的检测,移除锁文件
|
||||
rm -f "$mod_evasive_LOGDIR"/dos-"$IP"
|
||||
|
||||
我们的DOSSystemCommand指令应该是这样的:
|
||||
|
||||
DOSSystemCommand "sudo /usr/local/bin/scripts-tecmint/ban_ip.sh %s"
|
||||
|
||||
上面一行的%s代表了由mod_evasive检测到的攻击IP地址。
|
||||
上面一行的%s代表了由mod\_evasive检测到的攻击IP地址。
|
||||
|
||||
**将apache用户添加到sudoers文件**
|
||||
#####将apache用户添加到sudoers文件#####
|
||||
|
||||
请注意,如果您不给予apache用户以无需终端和密码的方式运行我们脚本(关键就是这个脚本)的权限,则这一切都不起作用。通常,您只需要以root权限键入visudo来存取/etc/sudoers文件,接下来添加下面的两行即可:
|
||||
|
||||
@ -201,14 +204,16 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
Defaults:apache !requiretty
|
||||
|
||||

|
||||
添加Apache用户到Sudoers
|
||||
|
||||
**重要**: 作为默认的安全策略,您只能在终端中运行sudo。由于这个时候我们需要在没有tty的时候运行sudo,我们像下面图片中那样必须注释掉下面这一行:
|
||||
*添加Apache用户到Sudoers*
|
||||
|
||||
**重要**: 在默认的安全策略下您只能在终端中运行sudo。由于这个时候我们需要在没有tty的时候运行sudo,我们必须像下图中那样注释掉下面这一行:
|
||||
|
||||
#Defaults requiretty
|
||||
|
||||
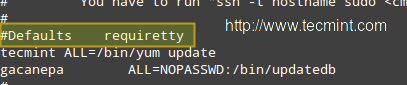
|
||||
为Sudo禁用tty
|
||||
|
||||
*为Sudo禁用tty*
|
||||
|
||||
最后,重启web服务器:
|
||||
|
||||
@ -219,7 +224,7 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
有许多工具可以在您的服务器上模拟外部的攻击。您可以google下“tools for simulating ddos attacks”来找一找相关的工具。
|
||||
|
||||
注意,您(也只有您)将负责您模拟所造成的结果。请不要考虑向不在您网络中的服务器发起模拟攻击。
|
||||
注意,您(也只有您)将负责您模拟所造成的结果。请不要考虑向不在您自己网络中的服务器发起模拟攻击。
|
||||
|
||||
假如您想对一个由别人托管的VPS做这些事情,您需要向您的托管商发送适当的警告或就那样的流量通过他们的网络获得允许。Tecmint.com不会为您的行为负责!
|
||||
|
||||
@ -228,21 +233,20 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
我们的测试环境由一个CentOS 7服务器[IP 192.168.0.17]和一个Windows组成,在Windows[IP 192.168.0.103]上我们发起攻击:
|
||||
|
||||

|
||||
确认主机IP地址
|
||||
|
||||
请播放下面的视频,并跟从列出的步骤来模拟一个Dos攻击:
|
||||
*确认主机IP地址*
|
||||
|
||||
注:youtube视频,发布的时候不行做个链接吧
|
||||
<iframe width="640" height="405" frameborder="0" allowfullscreen="allowfullscreen" src="https://www.youtube.com/embed/-U_mdet06Jk"></iframe>
|
||||
请播放下面的视频(YT 视频,请自备梯子: https://www.youtube.com/-U_mdet06Jk ),并跟从列出的步骤来模拟一个Dos攻击:
|
||||
|
||||
然后攻击者的IP将被iptables阻挡:
|
||||
然后攻击者的IP将被防火墙阻挡:
|
||||
|
||||

|
||||
阻挡攻击者的IP地址
|
||||
|
||||
*阻挡攻击者的IP地址*
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在开启mod_security和mod_evasive的情况下,模拟攻击会导致CPU和RAM用量在源IP地址被加入黑名单之前出现短暂几秒的使用峰值。如果没有这些模块,模拟攻击绝对会很快将服务器击溃,并使服务器在攻击期间无法提供服务。
|
||||
在开启mod\_security和mod\_evasive的情况下,模拟攻击会导致CPU和RAM用量在源IP地址被加入黑名单之前出现短暂几秒的使用峰值。如果没有这些模块,模拟攻击绝对会很快将服务器击溃,并使服务器在攻击期间无法提供服务。
|
||||
|
||||
我们很高兴听见您打算使用(或已经使用过)这些工具。我们期望得到您的反馈,所以,请在留言处留下您的评价和问题,谢谢!
|
||||
|
||||
@ -253,18 +257,18 @@ mod_evasive被配置为使用/etc/httpd/conf.d/mod_evasive.conf中的指令。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/protect-apache-using-mod_security-and-mod_evasive-on-rhel-centos-fedora/
|
||||
via: http://www.tecmint.com/protect-apache-using-mod\_security-and-mod\_evasive-on-rhel-centos-fedora/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
[2]:http://www.tecmint.com/configure-firewalld-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-4425-1.html
|
||||
[3]:https://linux.cn/article-2324-1.html
|
||||
[4]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
|
||||
[5]:https://github.com/SpiderLabs/ModSecurity/wiki/Reference-Manual#Configuration_Directives
|
||||
[6]:https://www.modsecurity.org/
|
||||
@ -0,0 +1,80 @@
|
||||
为LUKS加密的磁盘/分区做增量备份
|
||||
================================================================================
|
||||
我们中有些人出于安全原因,在家里或者[VPS][1]上通过[Linux统一密钥配置(LUKS)][2]为硬盘驱动器加密,而这些驱动器的容量很快会增长到数十或数百GB。因此,虽然我们享受着LUKS设备带来的安全感,但是我们也该开始考虑一个可能的远程备份方案了。对于安全的非现场备份,我们将需要能在LUKS加密的设备上以块级别操作的东西。因此,最后我们发现这么个状况,我们每次都需要传输想要做备份的整个LUKS设备(比如说200GB大)。很明显,这是不可行的。我们该怎么来处理这个问题呢?
|
||||
|
||||
### 一个解决方案: Bdsync ###
|
||||
|
||||
这时,一个卓越的开源工具来拯救我们了,它叫[Bdsync][3](多亏了Rolf Fokkens)。顾名思义,Bdsync可以通过网络同步“块设备”。对于快速同步,Bdsync会生成并对比本地/远程块设备的块的MD5校验和,只同步差异部分。rsync在文件系统级别可以做的,Bdsync可以在块设备级别完成。很自然,对于LUKS加密的设备它也能工作得很好。相当地灵巧!
|
||||
|
||||
使用Bdsync,首次备份将拷贝整个LUKS块设备到远程主机,因而会花费大量时间来完成。然而,在初始备份后,如果我们在LUKS设备新建一些文件,再次备份就会很快完成,因为我们只需拷贝修改过的块。经典的增量备份在起作用了!
|
||||
|
||||
### 安装Bdsync到Linux ###
|
||||
|
||||
Bdsync并不包含在Linux发行版的标准仓库中,因而你需要从源代码来构建它。使用以下针对特定版本的指令来安装Bdsync及其手册页到你的系统中。
|
||||
|
||||
#### Debian,Ubuntu或Linux Mint ####
|
||||
|
||||
$ sudo apt-get install git gcc libssl-dev
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
#### Fedora或CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc openssl-devel
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
### 对LUKS加密的设备实施非现场增量备份 ###
|
||||
|
||||
我假定你已经准备好了一个LUKS加密的块设备作为备份源(如,/dev/LOCDEV)。同时,我假定你也有一台远程主机,用以作为源设备的备份点(如,/dev/REMDEV)。
|
||||
|
||||
你需要在两台系统上具有root帐号访问权限,并且设置从本地访问远程的[无密码SSH访问][5]。最后,你需要安装Bdsync到两台主机上。
|
||||
|
||||
要在本地主机上初始化一个远程备份进程,我们需要以root执行以下命令:
|
||||
|
||||
# bdsync "ssh root@remote_host bdsync --server" /dev/LOCDEV /dev/REMDEV | gzip > /some_local_path/DEV.bdsync.gz
|
||||
|
||||
这里需要进行一些说明。Bdsync客户端将以root打开一个到远程主机的SSH连接,并执行带有--server选项的Bdsync客户端。明确说明一下,/dev/LOCDEV是我们的本地主机上的源LUKS块设备,而/dev/REMDEV是远程主机上的目标块设备。它们可以是/dev/sda(作为整个磁盘),或者/dev/sda2(作为单个分区)。本地Bdsync客户端的输出结果随后被管道输送到gzip,用来在本地主机中创建DEV.bdsync.gz(所谓的二进制补丁文件)。
|
||||
|
||||
你第一次运行上面的命令的时候,它会花费很长一段时间,这取决于你的互联网/局域网速度,以及/dev/LOCDEV的大小。记住,你必须有两个大小相同的块设备(/dev/LOCDEV和/dev/REMDEV)。
|
||||
|
||||
下一步是要将补丁文件从本地主机拷贝到远程主机。一种方式是使用scp:
|
||||
|
||||
# scp /some_local_path/DEV.bdsync.gz root@remote_host:/remote_path
|
||||
|
||||
最后一步,是要在远程主机上执行以下命令,它们会将补丁文件应用到/dev/REMDEV:
|
||||
|
||||
# gzip -d < /remote_path/DEV.bdsync.gz | bdsync --patch=/dev/DSTDEV
|
||||
|
||||
我推荐在使用真实数据部署Bdsync前,使用一些(没有任何重要数据)小分区来做这些测试。在你完全弄懂整个设置是如何工作之后,你可以开始备份真实数据。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
小结之,我们演示了如何使用Bdsync来为LUKS设备实施增量备份。和rsync一样,每次备份只有一小部分数据,而不是整个LUKS设备,需要被推送到非现场备份点,这样会节省带宽和备份时间。剩下来,需要通过SSH或SCP来保证所有数据传输的安全,事实上设备自身是由LUKS加密的。也可以通过使用可以运行bdsync的专用用户(而非root)来改进该配置。我们也可以将bdsync用于任何块设备,如LVM卷或RAID磁盘,也可以很轻易地设置Bdsync备份本地磁盘到USB驱动器上。如你所见,它有着无限可能性!
|
||||
|
||||
随时分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/remote-incremental-backup-luks-encrypted-disk-partition.html
|
||||
|
||||
作者:[Iulian Murgulet][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/iulian
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-create-encrypted-disk-partition-on-linux.html
|
||||
[3]:http://bdsync.rolf-fokkens.nl/
|
||||
[4]:http://xmodulo.com/recommend/linuxbook
|
||||
[5]:https://linux.cn/article-5444-1.html
|
||||
@ -0,0 +1,143 @@
|
||||
用命令行工具Speedtest-CLI来测试你的上下行网速
|
||||
================================================================================
|
||||
|
||||
我们经常需要到检查家里与办公室之间的网络是否连通,那么我们要怎么做呢?打开网站Speedtest.net然后开始测试。网站是通过加载浏览器中的JavaScript脚本然后选择最佳的服务器测速然后用Flash产生图形化的结果。
|
||||
|
||||
那么远程服务器呢?要知道大多数远程服务器是没有浏览器可以打开web页面的。用浏览器打开网页测速的瓶颈就在此,你不能按计划的对服务器进行定期的常规测试。这时需要到一个名为Speedtest-cli的软件来打破这个瓶颈,它能让你通过命令行来测试互联网连接的速度。
|
||||
|
||||
#### Speedtest-cli是什么 ####
|
||||
|
||||
此程序是基于Python开发的脚本程序,利用了speedtest.net的服务来测量出上下行的宽带。Speedtest-cli能根据机房离测速服务器的物理距离来列出测速服务器,或者针对某一服务器进行测速,同时还能为你生成一个URL以便你分享你的测速结果。
|
||||
|
||||
要在Linux上安装最新版本的speedtest-cli,你必须安装2.4-3.4或者更高版本的Python。
|
||||
|
||||
### 在Linux上安装speedtest-cli ###
|
||||
|
||||
有两种方法可以安装speedtest-cli。第一种方法需要用到`python-pip`包管理器,第二种方法需要安装Python脚本,生成安装文件然后运行,这里我们分别介绍两种方法:
|
||||
|
||||
#### 使用pythin-pip安装speedtest-cli####
|
||||
|
||||
首先你需要安装`python-pip`包管理器,之后你就可以用pip命令来安装speedtest-cli
|
||||
|
||||
$ sudo apt-get install python-pip
|
||||
$ sudo pip install speedtest-cli
|
||||
|
||||
如果要把speedtest-cli升级至最新版本,你需要输入以下命令
|
||||
|
||||
$ sudo pip install speedtest-cli --upgrade
|
||||
|
||||
#### 通过Pyhton脚本来安装speedtest-cli ####
|
||||
|
||||
首先要用wget命令从github上下来Python脚本,然后解压提取下载的文件(master.zip)
|
||||
|
||||
$ wget https://github.com/sivel/speedtest-cli/archive/master.zip
|
||||
$ unzip master.zip
|
||||
|
||||
提取出文件后,进入提取出的目录`speedtest-cli-master`然后使脚本可以执行。
|
||||
|
||||
$ cd speedtest-cli-master/
|
||||
$ chmod 755 speedtest_cli.py
|
||||
|
||||
下一步,把可执行的脚本移动到`/usr/bin`文件夹,这样你就不用每次都输入完整的脚本路径了。
|
||||
|
||||
$ sudo mv speedtest_cli.py /usr/bin/
|
||||
|
||||
### 用speedtest-cli测试互联网连通速度###
|
||||
|
||||
**1. 要测试你的下载与上传速度,只需要运行`speedtest-cli`命令,不需要带参数。**
|
||||
|
||||
$ speedtest_cli.py
|
||||
|
||||
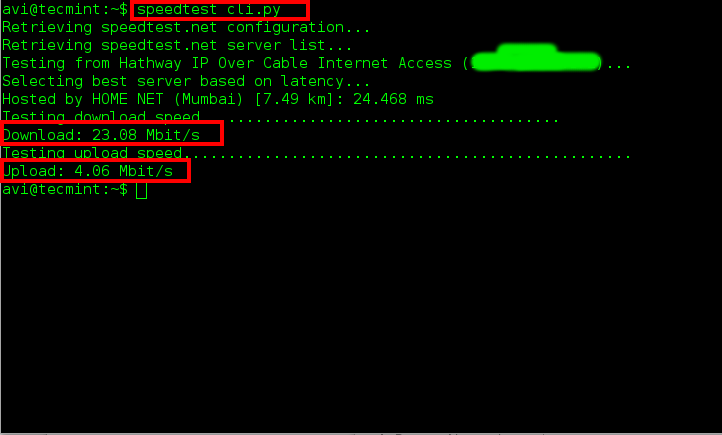
|
||||
|
||||
*在Linux下测试上传下载速度*
|
||||
|
||||
**2. 测试上传下载的速度(以字节计算)**
|
||||
|
||||
$ speedtest_cli.py --bytes
|
||||
|
||||
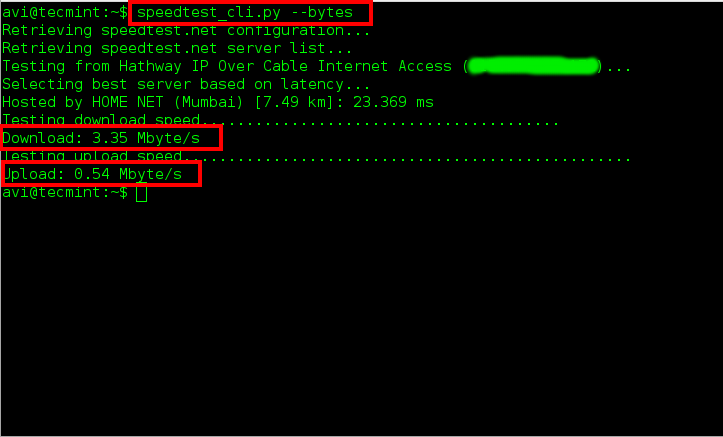
|
||||
|
||||
*测试bytes的速度*
|
||||
|
||||
**3. 工具提供一个链接来下载由你的宽带测试结果生成的图片,你可以分享给你的家人朋友。**
|
||||
|
||||

|
||||
|
||||
*分享测速结果*
|
||||
|
||||
下面的图片就是你通过以上的命令行测速而生成的图片
|
||||
|
||||

|
||||
|
||||
*测速结果*
|
||||
|
||||
**4.如果你仅仅需要Ping,上传,下载的结果,就运行以下命令:**
|
||||
|
||||
$ speedtest_cli.py --simple
|
||||
|
||||
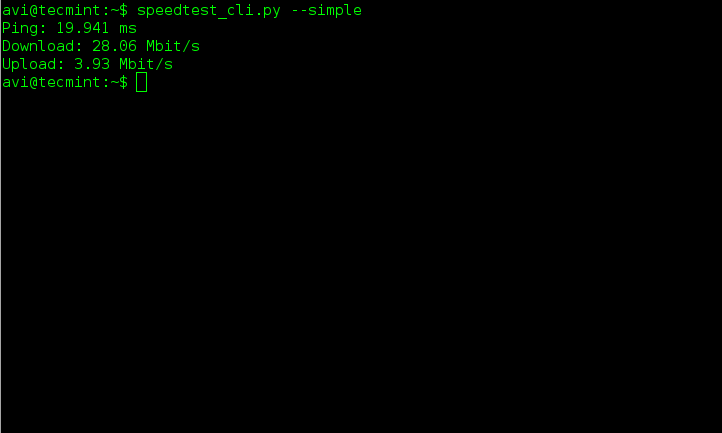
|
||||
|
||||
*测试Ping,上传,下载的速度*
|
||||
|
||||
**5. 列出`speedtest.net`所有的服务器距离你的物理距离,单位是千米(km)**
|
||||
|
||||
$ speedtest_cli.py --list
|
||||
|
||||

|
||||
|
||||
*列出Speedtest.net的服务器*
|
||||
|
||||
**6. 当获得一个非常长的服务器列表之后,怎么列出我想要的某个服务器?如果我要在speedtest.net服务器列表中找出位于Mumbai(印度)的服务器呢?**
|
||||
|
||||
$ speedtest_cli.py --list | grep -i Mumbai
|
||||
|
||||

|
||||
|
||||
*列出最近的服务器*
|
||||
|
||||
**7. 对指定的服务器进行测速。我们使用上面例子5和例子6中获取的服务器ID:**
|
||||
|
||||
$ speedtest_cli.py --server [server ID]
|
||||
$ speedtest_cli.py --server [5060] ## 这里使用服务器ID为5060作为例子
|
||||
|
||||

|
||||
|
||||
*对指定的服务器进行测速*
|
||||
|
||||
**8. 输出`speedtest-cli`的版本信息和帮助文档**
|
||||
|
||||
$ speedtest_cli.py --version
|
||||
|
||||

|
||||
|
||||
*输出版本号*
|
||||
|
||||
$ speedtest_cli.py --help
|
||||
|
||||

|
||||
|
||||
*输出帮助文档*
|
||||
|
||||
**提醒:**报告中的延迟并不是确切的结果,不应该过于依赖它;这个数值可以当作相对延迟,这对你选择某一测试服务器来说是可靠的。同时,CPU和内存的容量会影响结果的准确度。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
系统管理员和开发者应该必备这个简单的脚本工具,这个轻量级的工具功能齐全,真是太赞了。我不喜欢Speedtest.net的原因是它使用来flash,相反speedtest-cli刚好戳中了我的痛点。
|
||||
|
||||
speedtest_cli是一个第三方工具,也不能自动地记录下宽带速度。Speedtest.net拥有上百万的用户,你可以自己[配制一个小型的测速服务器][1]。
|
||||
|
||||
上面就是所有内容,更多内容敬请关注我们。如果你有任何反馈记得在文章下方评论,如果你喜欢别忘了给我们点个赞,分享我们的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-internet-speed-from-command-line-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[NearTan](https://github.com/NearTan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/speedtest-mini-server-to-test-bandwidth-speed/
|
||||
@ -1,8 +1,8 @@
|
||||
Linux中7个用来浏览网页和下载文件的命令
|
||||
Linux中7个用来浏览网页和下载文件的命令
|
||||
================================================================================
|
||||
上一篇文章中,我们提到了`rTorrent`、`wget`、`cURL`、`w3m`、`Elinks`等几个有用的工具,很多人回信说还有其它几个类似的工具也值得讨论,所以就有了这篇文章。如果错过了第一部分的讨论,可以通过下面的链接来回顾。
|
||||
|
||||
- [5个下载文件和浏览网页的命令行工具][1]
|
||||
- [5 个基于Linux命令行的文件下载和网站浏览工具][1]
|
||||
|
||||
这篇文章介绍了Linux下用于浏览网页和下载文件的其它几个命令行工具。
|
||||
|
||||
@ -23,7 +23,7 @@ Links是用C语言写的一个开源web浏览器,支持包括Linux、Windows
|
||||
|
||||

|
||||
|
||||
如何你想安装links的图形界面版本,可能需要从[http://links.twibright.com/download/][2]下载最新的版本tarball(version 2.9)的源代码。
|
||||
如何你想安装links的图形界面版本,可能需要从[http://links.twibright.com/download/][2]下载最新的版本(version 2.9)的源代码压缩包。
|
||||
|
||||
同样,也可以像下面那样使用wget下载安装。
|
||||
|
||||
@ -34,7 +34,7 @@ Links是用C语言写的一个开源web浏览器,支持包括Linux、Windows
|
||||
# make
|
||||
# make install
|
||||
|
||||
**注意**:links源代码的编译需要安装libpng, libjpeg, TIFF library, SVGAlib, XFree86, C Compiler and make这几个包。
|
||||
**注意**:links源代码的编译需要安装libpng, libjpeg, TIFF library, SVGAlib, XFree86, C Compiler 和 make这几个包。
|
||||
|
||||
### 2. links2 ###
|
||||
|
||||
@ -49,7 +49,7 @@ Links是Twibright实验室编写的web浏览器,而Links2是基于它的一个
|
||||
|
||||
lynx是一个基于文本的web浏览器,使用GNU GPLv2协议发布,用ISO C编写。lynx是一个可高度配置的web浏览器,是许多系统管理员的救世主,有最悠久的web浏览器之称,并且至今仍然处在积极开发中。
|
||||
|
||||
通过下面的命令安装lyns。
|
||||
通过下面的命令安装lynx。
|
||||
|
||||
# apt-get install lynx
|
||||
# yum install lynx
|
||||
@ -125,7 +125,7 @@ aria2安装完成后,可以像下图那样运行这个命令下载任意文件
|
||||
|
||||
|
||||
|
||||
Aria2: Linux命令行下载工具
|
||||
*Aria2: Linux命令行下载工具*
|
||||
|
||||
目前就这么多了。稍后咱们讨论另一个有意思的话题。请保持联系,常来Tecmint逛逛。别忘了在评论中给我们提供您的宝贵反馈,您的喜爱和分享帮助我们不断前行。
|
||||
|
||||
@ -135,12 +135,12 @@ via: http://www.tecmint.com/command-line-web-browser-download-file-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/linux-command-line-tools-for-downloading-files/
|
||||
[1]:https://linux.cn/article-5546-1.html
|
||||
[2]:http://links.twibright.com/download/
|
||||
[3]:http://www.tecmint.com/command-line-web-browsers/
|
||||
[4]:http://www.tecmint.com/install-youtube-dl-command-line-video-download-tool/
|
||||
@ -1,44 +1,48 @@
|
||||
RHEL/CentOS 7中安装并配置‘PowerDNS’(与MariaDB搭配)和‘PowerAdmin’
|
||||
RHEL/CentOS 7中安装并配置 PowerDNS 和 PowerAdmin
|
||||
================================================================================
|
||||
PowerDNS是一个运行在许多Linux/Unix衍生版上的DNS服务器,它可以使用不同的后端进行配置,包括BIND类型的区域文件、相关的数据库,或者负载均衡/失效转移算法。它也可以被配置成一台DNS递归器,作为服务器上的一个独立进程运行。
|
||||
PowerDNS是一个运行在许多Linux/Unix衍生版上的DNS服务器,它可以使用不同的后端进行配置,包括BIND类型的区域文件、关系型数据库,或者负载均衡/失效转移算法。它也可以被配置成一台DNS递归器,作为服务器上的一个独立进程运行。
|
||||
|
||||
PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以获得的版本是3.4.3。我推荐安装EPEL仓库中提供的那一个,因为该版本已经在CentOS和Fedora中测试过。那样,你也可以在今后很容易地更新PowerDNS。
|
||||
|
||||
本文倾向于向你演示如何安装并配置以MariaDB作为后端的PowerDNS和
|
||||
本文用于向你演示如何安装并配置以MariaDB作为后端的PowerDNS,以及它的界面友好的 Web 管理工具 PowerAdmin。
|
||||
|
||||
出于本文的写作目的,我将使用以下服务器:
|
||||
|
||||
主机名: centos7.localhost
|
||||
IP地址: 192.168.0.102
|
||||
|
||||
### 步骤 1: 安装带有MariaDB后端的PowerDNS ###
|
||||
### 第一部分: 安装带有MariaDB后端的PowerDNS ###
|
||||
|
||||
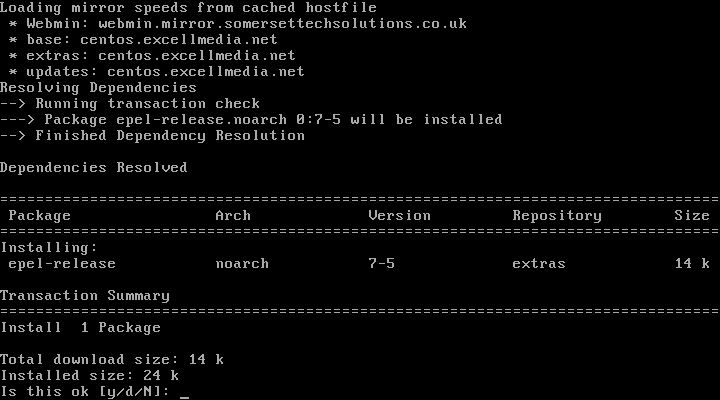
#### 1. 首先,你需要为你的系统启用EPEL仓库,只需使用: ####
|
||||
1、 首先,你需要为你的系统启用EPEL仓库,只需使用:
|
||||
|
||||
# yum install epel-release.noarch
|
||||
|
||||
|
||||
启用Epel仓库
|
||||
|
||||
#### 2. 下一步是安装MariaDB服务器。运行以下命令即可达成: ####
|
||||
*启用Epel仓库*
|
||||
|
||||
2、 下一步是安装MariaDB服务器。运行以下命令即可达成:
|
||||
|
||||
# yum -y install mariadb-server mariadb
|
||||
|
||||

|
||||
安装MariaDB服务器
|
||||
|
||||
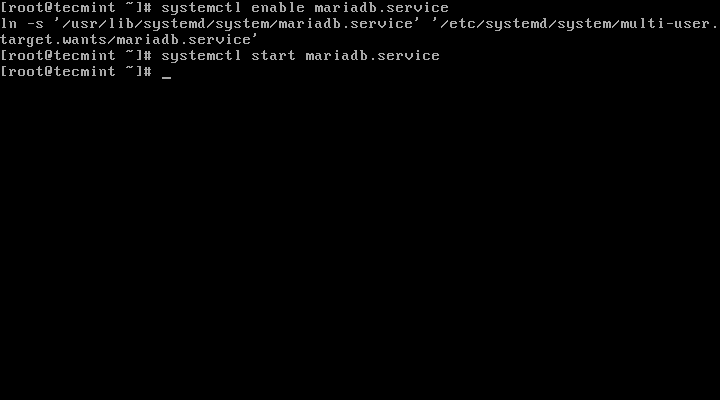
#### 3. 接下来,我们将配置并启用MySQL,并设置开机启动: ####
|
||||
*安装MariaDB服务器*
|
||||
|
||||
3、 接下来,我们将配置并启用MariaDB,并设置开机启动:
|
||||
|
||||
# systemctl enable mariadb.service
|
||||
# systemctl start mariadb.service
|
||||
|
||||
|
||||
启用MariaDB开机启动
|
||||
|
||||
#### 4. 由于MySQL服务正在运行,我们将为MariaDB设置密码进行安全加固,运行以下命令: ####
|
||||
*启用MariaDB开机启动*
|
||||
|
||||
4、 现在MariaDB服务运行起来了,我们将为MariaDB设置密码进行安全加固,运行以下命令:
|
||||
|
||||
# mysql_secure_installation
|
||||
|
||||
#### 按照指示做 ####
|
||||
**按照指示做**
|
||||
|
||||
/bin/mysql_secure_installation: line 379: find_mysql_client: command not found
|
||||
|
||||
@ -102,33 +106,36 @@ PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以
|
||||
|
||||
Thanks for using MariaDB!
|
||||
|
||||
#### 5. MariaDB配置成功后,我们可以继续去安装PowerDNS。运行以下命令即可轻易完成: ####
|
||||
5、 MariaDB配置成功后,我们可以继续去安装PowerDNS。运行以下命令即可轻易完成:
|
||||
|
||||
# yum -y install pdns pdns-backend-mysql
|
||||
|
||||

|
||||
安装带有MariaDB后端的PowerDNS
|
||||
|
||||
#### 6. PowerDNS的配置文件位于`/etc/pdns/pdns`,在编辑之前,我们将为PowerDNS服务配置一个MySQL数据库。首先,我们将连接到MySQL服务器并创建一个名为powerdns的数据库: ####
|
||||
*安装带有MariaDB后端的PowerDNS*
|
||||
|
||||
6、 PowerDNS的配置文件位于`/etc/pdns/pdns`,在编辑之前,我们将为PowerDNS服务配置一个MariaDB数据库。首先,我们将连接到MariaDB服务器并创建一个名为powerdns的数据库:
|
||||
|
||||
# mysql -u root -p
|
||||
MariaDB [(none)]> CREATE DATABASE powerdns;
|
||||
|
||||

|
||||
创建PowerDNS数据库
|
||||
|
||||
#### 7. 接下来,我们将创建一个名为powerdns的数据库用户: ####
|
||||
*创建PowerDNS数据库*
|
||||
|
||||
7、 接下来,我们将创建一个名为powerdns的数据库用户:
|
||||
|
||||
MariaDB [(none)]> GRANT ALL ON powerdns.* TO 'powerdns'@'localhost' IDENTIFIED BY ‘tecmint123’;
|
||||
MariaDB [(none)]> GRANT ALL ON powerdns.* TO 'powerdns'@'centos7.localdomain' IDENTIFIED BY 'tecmint123';
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
|
||||
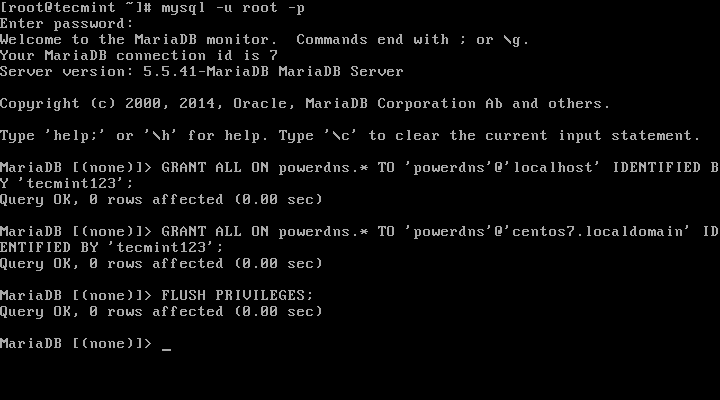
|
||||
创建PowerDNS用户
|
||||
|
||||
*创建PowerDNS用户*
|
||||
|
||||
**注意**: 请将“tecmint123”替换为你想要设置的实际密码。
|
||||
|
||||
#### 8. 我们继续创建PowerDNS要使用的数据库表。像堆积木一样执行以下这些: ####
|
||||
8、 我们继续创建PowerDNS要使用的数据库表。像堆积木一样执行以下这些:
|
||||
|
||||
MariaDB [(none)]> USE powerdns;
|
||||
MariaDB [(none)]> CREATE TABLE domains (
|
||||
@ -143,7 +150,8 @@ PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以
|
||||
);
|
||||
|
||||

|
||||
创建用于PowerDNS的表域
|
||||
|
||||
*创建用于PowerDNS的表domains*
|
||||
|
||||
MariaDB [(none)]> CREATE UNIQUE INDEX name_index ON domains(name);
|
||||
MariaDB [(none)]> CREATE TABLE records (
|
||||
@ -158,15 +166,17 @@ PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以
|
||||
primary key(id)
|
||||
);
|
||||
|
||||

|
||||
创建用于PowerDNS的索引域
|
||||

|
||||
|
||||
*创建用于PowerDNS的表 records*
|
||||
|
||||
MariaDB [(none)]> CREATE INDEX rec_name_index ON records(name);
|
||||
MariaDB [(none)]> CREATE INDEX nametype_index ON records(name,type);
|
||||
MariaDB [(none)]> CREATE INDEX domain_id ON records(domain_id);
|
||||
|
||||

|
||||
创建索引记录
|
||||

|
||||
|
||||
*创建表索引*
|
||||
|
||||
MariaDB [(none)]> CREATE TABLE supermasters (
|
||||
ip VARCHAR(25) NOT NULL,
|
||||
@ -175,13 +185,14 @@ PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以
|
||||
);
|
||||
|
||||

|
||||
创建表的超主
|
||||
|
||||
你现在可以输入以下命令退出MySQL控制台:
|
||||
*创建表supermasters*
|
||||
|
||||
你现在可以输入以下命令退出MariaDB控制台:
|
||||
|
||||
MariaDB [(none)]> quit;
|
||||
|
||||
#### 9. 最后,我们可以继续以MySQL作为后台的方式配置PowerDNS。请打开PowerDNS的配置文件: ####
|
||||
9、 最后,我们可以继续配置PowerDNS了,以MariaDB作为后台。请打开PowerDNS的配置文件:
|
||||
|
||||
# vim /etc/pdns/pdns.conf
|
||||
|
||||
@ -203,35 +214,39 @@ PowerDNS授权服务器的最新版本是3.4.4,但是当前EPEL仓库中可以
|
||||
修改“user-pass”为你先前设置的实际密码,配置如下:
|
||||
|
||||

|
||||
配置PowerDNS
|
||||
|
||||
*配置PowerDNS*
|
||||
|
||||
保存修改并退出。
|
||||
|
||||
#### 10. 现在,我们将启动并添加PowerDNS到系统开机启动列表: ####
|
||||
10、 现在,我们将启动并添加PowerDNS到系统开机启动列表:
|
||||
|
||||
# systemctl enable pdns.service
|
||||
# systemctl start pdns.service
|
||||
|
||||

|
||||
启用并启动PowerDNS
|
||||
|
||||
*启用并启动PowerDNS*
|
||||
|
||||
到这一步,你的PowerDNS服务器已经起来并运行了。要获取更多关于PowerDNS的信息,你可以参考手册[http://downloads.powerdns.com/documentation/html/index.html][1]
|
||||
|
||||
### 步骤 2: 安装PowerAdmin来管理PowerDNS ###
|
||||
### 第二部分: 安装PowerAdmin来管理PowerDNS ###
|
||||
|
||||
#### 11. 现在,我们将安装PowerAdmin——一个友好的网页接口PowerDNS服务器管理器。由于它是用PHP写的,我们将需要安装PHP和一台网络服务器(Apache): ####
|
||||
11、 现在,我们将安装PowerAdmin——一个界面友好的PowerDNS服务器的 Web 管理器。由于它是用PHP写的,我们将需要安装PHP和一台网络服务器(Apache):
|
||||
|
||||
# yum install httpd php php-devel php-gd php-imap php-ldap php-mysql php-odbc php-pear php-xml php-xmlrpc php-mbstring php-mcrypt php-mhash gettext
|
||||
|
||||

|
||||
安装Apache PHP
|
||||
|
||||
*安装Apache 和 PHP*
|
||||
|
||||
PowerAdmin也需要两个PEAR包:
|
||||
|
||||
# yum -y install php-pear-DB php-pear-MDB2-Driver-mysql
|
||||
|
||||

|
||||
安装Pear
|
||||
|
||||
*安装Pear*
|
||||
|
||||
你也可以参考一下文章了解CentOS 7中安装LAMP堆栈的完整指南:
|
||||
|
||||
@ -243,58 +258,66 @@ PowerAdmin也需要两个PEAR包:
|
||||
# systemctl start httpd.service
|
||||
|
||||

|
||||
启用Apache开机启动
|
||||
|
||||
#### 12. 由于已经满足PowerAdmin的所有系统要求,我们可以继续下载软件包。因为Apache默认的网页目录位于/var/www/html/,我们将下载软件包到这里。 ####
|
||||
*启用Apache开机启动*
|
||||
|
||||
12、 由于已经满足PowerAdmin的所有系统要求,我们可以继续下载软件包。因为Apache默认的网页目录位于/var/www/html/,我们将下载软件包到这里。
|
||||
|
||||
# cd /var/www/html/
|
||||
# wget http://downloads.sourceforge.net/project/poweradmin/poweradmin-2.1.7.tgz
|
||||
# tar xfv poweradmin-2.1.7.tgz
|
||||
|
||||

|
||||
下载PowerAdmin
|
||||
|
||||
#### 13. 现在,我们可以启动PowerAdmin的网页安装器了,只需打开: ####
|
||||
*下载PowerAdmin*
|
||||
|
||||
13、 现在,我们可以启动PowerAdmin的网页安装器了,只需打开:
|
||||
|
||||
http://192.168.0.102/poweradmin-2.1.7/install/
|
||||
|
||||
这会进入安装过程的第一步:
|
||||
|
||||

|
||||
选择安装语言
|
||||
|
||||
*选择安装语言*
|
||||
|
||||
上面的页面会要求你为PowerAdmin选择语言,请选择你想要使用的那一个,然后点击“进入步骤 2”按钮。
|
||||
|
||||
#### 14. 安装器需要PowerDNS数据库: ####
|
||||
14、 安装器需要PowerDNS数据库:
|
||||
|
||||

|
||||
PowerDNS数据库
|
||||
|
||||
#### 15. 因为我们已经创建了一个,所以我们可以继续进入下一步。你会被要求提供先前配置的数据库详情,你也需要为Poweradmin设置管理员密码: ####
|
||||
*PowerDNS数据库*
|
||||
|
||||
15、 因为我们已经创建了一个数据库,所以我们可以继续进入下一步。你会被要求提供先前配置的数据库详情,你也需要为Poweradmin设置管理员密码:
|
||||
|
||||

|
||||
输入PowerDNS数据库配置
|
||||
|
||||
#### 16. 输入这些信息后,进入步骤 4。你将创建为Poweradmin创建一个受限用户。这里你需要输入的字段是: ####
|
||||
*输入PowerDNS数据库配置*
|
||||
|
||||
- 用户名 - PowerAdmin用户名。
|
||||
- 密码 – 上述用户的密码。
|
||||
- 注册人 - 当创建SOA记录而你没有制定注册人时,该值会被使用。
|
||||
- 辅助域名服务器 – 该值在创建新的DNS区域时会被用于作为主域名服务器。
|
||||
16、 输入这些信息后,进入步骤 4。你将创建为Poweradmin创建一个受限用户。这里你需要输入的字段是:
|
||||
|
||||
- 用户名(Username) - PowerAdmin用户名。
|
||||
- 密码(Password) – 上述用户的密码。
|
||||
- 主机管理员(Hostmaster) - 当创建SOA记录而你没有指定主机管理员时,该值会被用作默认值。
|
||||
- 主域名服务器 - 该值在创建新的DNS区域时会被用于作为主域名服务器。
|
||||
- 辅域名服务器 – 该值在创建新的DNS区域时会被用于作为辅域名服务器。
|
||||
|
||||

|
||||
PowerDNS配置设置
|
||||
|
||||
#### 17. 在下一步中,Poweradmin会要求你在数据库表中创建新的受限数据库用户,它会提供你需要在MySQL控制台输入的代码: ####
|
||||
*PowerDNS配置设置*
|
||||
|
||||
17、 在下一步中,Poweradmin会要求你在数据库表中创建一个新的受限数据库用户,它会提供你需要在MariaDB控制台输入的代码:
|
||||
|
||||

|
||||
创建新的数据库用户
|
||||
|
||||
#### 18. 现在打开终端并运行: ####
|
||||
*创建新的数据库用户*
|
||||
|
||||
18、 现在打开终端并运行:
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
提供你的密码并执行由Poweradmin提供的代码:
|
||||
提供你的密码并执行由PowerAdmin提供的代码:
|
||||
|
||||
MariaDB [(none)]> GRANT SELECT, INSERT, UPDATE, DELETE
|
||||
ON powerdns.*
|
||||
@ -302,27 +325,30 @@ PowerDNS配置设置
|
||||
IDENTIFIED BY '123qweasd';
|
||||
|
||||

|
||||
为用户授予Mysql权限
|
||||
|
||||
#### 19. 现在,回到浏览器中并继续下一步。安装器将尝试创建配置文件到/var/www/html/poweradmin-2.1.7/inc。 ####
|
||||
*为用户授予Mysql权限*
|
||||
|
||||
19、 现在,回到浏览器中并继续下一步。安装器将尝试创建配置文件到/var/www/html/poweradmin-2.1.7/inc。
|
||||
|
||||
文件名是config.inc.php。为防止该脚本没有写权限,你可以手动复制这些内容到上述文件中:
|
||||
|
||||

|
||||
配置PowerDNS设置
|
||||
|
||||
#### 20. 现在,进入最后页面,该页面会告知你安装已经完成以及如何访问安装好的Poweradmin: ####
|
||||
*配置PowerDNS设置*
|
||||
|
||||
20、 现在,进入最后页面,该页面会告知你安装已经完成以及如何访问安装好的PowerAdmin:
|
||||
|
||||

|
||||
PowerDNS安装完成
|
||||
|
||||
你可以通过运行以下命令来启用其他动态DNS提供商的URL:
|
||||
*PowerDNS安装完成*
|
||||
|
||||
你可以通过运行以下命令来启用用于其他动态DNS提供商的URL:
|
||||
|
||||
# cp install/htaccess.dist .htaccess
|
||||
|
||||
出于该目的,你将需要在Apache的配置中启用mod_rewrite。
|
||||
|
||||
#### 21. 现在,需要移除从Poweradmin的根目录中移除“install”文件夹,这一点很重要。使用以下命令: ####
|
||||
21、 现在,需要移除从PowerAdmin的根目录中移除“install”文件夹,这一点很重要。使用以下命令:
|
||||
|
||||
# rm -fr /var/www/html/poweradmin/install/
|
||||
|
||||
@ -331,78 +357,86 @@ PowerDNS安装完成
|
||||
http://192.168.0.102/poweradmin-2.1.7/
|
||||
|
||||

|
||||
PowerDNS登录
|
||||
|
||||
在登录后,你应该会看到Poweradmin的主页:
|
||||
*PowerDNS登录*
|
||||
|
||||
在登录后,你应该会看到PowerAdmin的主页:
|
||||
|
||||

|
||||
PowerDNS仪表盘
|
||||
|
||||
*PowerDNS仪表盘*
|
||||
|
||||
到这里,安装已经完成了,你也可以开始管理你的DNS区域了。
|
||||
|
||||
### 步骤 3: PowerDNS中添加、编辑和删除DNS区域 ###
|
||||
### 第三部分: PowerDNS中添加、编辑和删除DNS区域 ###
|
||||
|
||||
#### 22. 要添加新的主区域,只需点击“添加主区域”: ####
|
||||
22、 要添加新的主区域,只需点击“添加主区域”:
|
||||
|
||||

|
||||
添加主区域
|
||||
|
||||
*添加主区域*
|
||||
|
||||
在下一页中,你需要填写一些东西:
|
||||
|
||||
- 域 – 你要添加区域的域。
|
||||
- 所有者 – 设置DNS区域的所有者。
|
||||
- 模板 – DNS模板 – 留空。
|
||||
- DNSSEC – Donany名称系统安全扩展(可选——检查你是否需要)。
|
||||
- 域(Domain) – 你要添加区域的域。
|
||||
- 所有者(Owner) – 设置DNS区域的所有者。
|
||||
- 模板(Template)– DNS模板 – 留空。
|
||||
- DNSSEC – 域名系统安全扩展(可选——看看你是否需要)。
|
||||
|
||||
点击“添加区域”按钮来添加DNS区域。
|
||||
|
||||

|
||||
主DNS区域
|
||||
|
||||
现在,你可以点击“首页”链接回到Poweradmin的首页。要查看所有现存的DNS区域,只需转到“列出区域”:
|
||||
*主DNS区域*
|
||||
|
||||
现在,你可以点击“首页”链接回到PowerAdmin的首页。要查看所有现存的DNS区域,只需转到“列出区域(List Zones)”:
|
||||
|
||||

|
||||
检查区域列表
|
||||
|
||||
*查看区域列表*
|
||||
|
||||
你现在应该看到一个可用DNS区域列表:
|
||||
|
||||

|
||||
检查DNS区域列表
|
||||
|
||||
#### 23. 要编辑现存DNS区域或者添加新的记录,点击编辑图标: ####
|
||||
*检查DNS区域列表*
|
||||
|
||||
23、 要编辑现存DNS区域或者添加新的记录,点击编辑图标:
|
||||
|
||||

|
||||
编辑DNS区域
|
||||
|
||||
*编辑DNS区域*
|
||||
|
||||
在接下来的页面,你会看到你选择的DNS区域的条目:
|
||||
|
||||

|
||||
主DNS区域条目
|
||||
|
||||
#### 24. 在此处添加新的DNS区域,你需要设置以下信息: ####
|
||||
*域名的DNS区域条目*
|
||||
|
||||
- 名称 – 条目名称。只需添加域/子域的第一部分,Poweradmin会添加剩下的。
|
||||
- 类型 – 选择记录类型。
|
||||
- 优先级 – 记录优先级。
|
||||
24、 在此处添加新的DNS条目,你需要设置以下信息:
|
||||
|
||||
- 名称(Name) – 条目名称。只需添加域/子域的第一部分,PowerAdmin会添加剩下的。
|
||||
- 类型(Type) – 选择记录类型。
|
||||
- 优先级(Priority) – 记录优先级。
|
||||
- TTL – 存活时间,以秒计算。
|
||||
|
||||
出于本文目的,我将为子域new.example.com添加一个A记录用于解析IP地址192.168.0.102,设置存活时间为14400秒:
|
||||
|
||||

|
||||
添加新DNS记录
|
||||
|
||||
*添加新DNS记录*
|
||||
|
||||
最后,点击“添加记录”按钮。
|
||||
|
||||
#### 25. 如果你想要删除DNS区域,你可以回到“列出区域”页面,然后点击你想要删除的DNS区域旁边“垃圾桶”图标: ####
|
||||
25、 如果你想要删除DNS区域,你可以回到“列出区域”页面,然后点击你想要删除的DNS区域旁边“垃圾桶”图标:
|
||||
|
||||

|
||||
删除DNS区域
|
||||
|
||||
*删除DNS区域*
|
||||
|
||||
Poweradmin将问你是否确定想要删除DNS区域。只需点击“是”来完成删除。
|
||||
|
||||
如要获取更多关于怎样创建、编辑和删除区域的说明,你可以参与Poweradmin的文档:
|
||||
|
||||
[https://github.com/poweradmin/poweradmin/wiki/Documentation][3]
|
||||
如要获取更多关于怎样创建、编辑和删除区域的说明,你可以参与Poweradmin的文档:[https://github.com/poweradmin/poweradmin/wiki/Documentation][3]
|
||||
|
||||
我希望你已经发现本文很有趣,也很有用。一如既往,如果你有问题或要发表评论,请别犹豫,在下面评论区提交你的评论吧。
|
||||
|
||||
@ -412,7 +446,7 @@ via: http://www.tecmint.com/install-powerdns-poweradmin-mariadb-in-centos-rhel/
|
||||
|
||||
作者:[Marin Todorov][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,33 +2,35 @@ Linux中,创建聊天服务器、移除冗余软件包的实用命令
|
||||
=============================================================================
|
||||
这里,我们来看Linux命令行实用技巧的下一个部分。如果你错过了Linux Tracks之前的文章,可以从这里找到。
|
||||
|
||||
- [5 Linux Command Line Tracks][1]
|
||||
- [5个有趣的Linux命令行技巧][1]
|
||||
|
||||
本篇中,我们将会介绍6个命令行小技巧,包括使用Netcat命令创建Linux命令行聊天,从某个命令的输出中对某一列做加法,移除Debian和CentOS上多余的包,从命令行中获取本地与远程的IP地址,在终端获得彩色的输出与解码各样的颜色,最后是Linux命令行里井号标签的使用。让我们来一个一个地看一下。
|
||||
|
||||

|
||||
6个实用的命令行技巧
|
||||
|
||||
*6个实用的命令行技巧*
|
||||
|
||||
### 1. 创建Linux命令行聊天服务 ###
|
||||
我们大家使用聊天服务都有很长一段时间了。对于Google Chat,Hangout,Facebook Chat,Whatsapp,Hike和其他一些应用与集成的聊天服务,我们都很熟悉了。那你知道Linux的nc命令可以使你的Linux盒子变成一个聊天服务器,而仅仅只需要一行命令吗。什么是nc命令,它又是怎么工作的呢?
|
||||
|
||||
nc是Linux netcat命令的旧版。nc就像瑞士军刀一样,内建呢大量的功能。nc可用做调式工具,调查工具,使用TCP/UDP读写网络连接,DNS正向/反向检查。
|
||||
我们大家使用聊天服务都有很长一段时间了。对于Google Chat,Hangout,Facebook Chat,Whatsapp,Hike和其他一些应用与集成的聊天服务,我们都很熟悉了。那你知道Linux的nc命令可以使你的Linux机器变成一个聊天服务器,而仅仅只需要一行命令吗。什么是nc命令,它又是怎么工作的呢?
|
||||
|
||||
nc即Linux netcat命令。nc就像瑞士军刀一样,内建了大量的功能。nc可用做调式工具,调查工具,使用TCP/UDP读写网络连接,DNS正向/反向查询等等。
|
||||
|
||||
nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使用任何闲置的端口和任何本地网络源地址。
|
||||
|
||||
使用nc命令(在192.168.0.7的服务器上)创建一个命令行即时信息传输服务器。
|
||||
|
||||
$ nc -l -vv 11119
|
||||
$ nc -l -vv -p 11119
|
||||
|
||||
对上述命令的解释。
|
||||
|
||||
- -v : 表示 Verbose
|
||||
- -vv : 更多的 Verbose
|
||||
- -v : 显示冗余信息
|
||||
- -vv : 显示更多的冗余信息
|
||||
- -p : 本地端口号
|
||||
|
||||
你可以用任何其他的本地端口号替换11119。
|
||||
|
||||
接下来在客户端机器(IP地址:192.168.0.15),运行下面的命令初始化聊天会话(信息传输服务正在运行)。
|
||||
接下来在客户端机器(IP地址:192.168.0.15),运行下面的命令初始化聊天会话(这里需要上面提到的信息服务器正在运行)。
|
||||
|
||||
$ nc 192.168.0.7:11119
|
||||
|
||||
@ -38,7 +40,7 @@ nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使
|
||||
|
||||
### 2. Linux中如何统计某一列的总值 ###
|
||||
|
||||
如何统计在终端里,某个命令的输出中,其中一列的数值总和,
|
||||
如何在终端里统计某个命令的输出中其中一列的数值总和,
|
||||
|
||||
‘ls -l’命令的输出。
|
||||
|
||||
@ -64,7 +66,7 @@ nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使
|
||||
|
||||
废弃包是指那些作为其他包的依赖而被安装,但是当源包被移除之后就不再需要的包。
|
||||
|
||||
假设我们安装了gtprogram,依赖是gtdependency。除非我们安装了gtdependency,否则安装不了gtprogram。
|
||||
假设我们安装了一个叫gtprogram的软件包,其依赖是gtdependency。除非我们安装了gtdependency,否则安装不了gtprogram。
|
||||
|
||||
当我们移除gtprogram的时候,默认并不会移除gtdependency。并且如果我们不移除gtdependency的话,它就会遗留下来成为废弃包,与其他任何包再无联系。
|
||||
|
||||
@ -116,13 +118,13 @@ nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使
|
||||
|
||||
### 5.如何在Linux终端彩色输出 ###
|
||||
|
||||
你可能在终端看见过彩色的输出。同时你也可能知道在终端里允许/禁用彩色输出。如果都不知道的话,里可以参考下面的步骤。
|
||||
你可能在终端看见过彩色的输出。同时你也可能知道在终端里允许/禁用彩色输出。如果都不知道的话,你可以参考下面的步骤。
|
||||
|
||||
在Linux中,每个用户都有`'.bashrc'`文件,被用来管理你的终端输出。打开并且编辑该文件,用你喜欢的编辑器。注意一下,这个文件是隐藏的(文件开头为点的代表隐藏文件)。
|
||||
|
||||
$ vi /home/$USER/.bashrc
|
||||
|
||||
确保以下的行没有被注释掉。ie.,行开头没有#。
|
||||
确保以下的行没有被注释掉。即,行开头没有#。
|
||||
|
||||
if [ -x /usr/bin/dircolors ]; then
|
||||
test -r ~/.dircolors && eval "$(dircolors -b ~/.dircolors)" || eval "$(dirc$
|
||||
@ -139,27 +141,27 @@ nc主要用在端口扫描,文件传输,后台和端口监听。nc可以使
|
||||
|
||||
完成后!保存并退出。为了让改动生效,需要注销账户后再次登录。
|
||||
|
||||
现在,你会看见列出的文件和文件夹名字有着不同的颜色,根据文件类型来决定。为了解码颜色,可以运行下面的命令。
|
||||
现在,你会看见列出的文件和文件夹名字有着不同的颜色,根据文件类型来决定。要了解所用的颜色代码,可以运行下面的命令。
|
||||
|
||||
$ dircolors -p | less
|
||||
|
||||

|
||||
|
||||
### 6.如何用井号标记和Linux命令和脚本 ###
|
||||
### 6.如何用#号标记Linux命令和脚本 ###
|
||||
|
||||
我们一直在Twitter,Facebook和Google Plus(可能是其他我们没有提到的地方)上使用井号标签。那些井号标签使得其他人搜索一个标签更加容易。可是很少人知道,我们可以在Linux命令行使用井号标签。
|
||||
我们一直在Twitter,Facebook和Google Plus(可能是其他我们没有提到的地方)上使用#号标签。那些#号标签使得其他人搜索一个标签更加容易。可是很少人知道,我们可以在Linux命令行使用#号标签。
|
||||
|
||||
我们已经知道配置文件里的`#`,在大多数的编程语言中,这个符号被用作注释行,即不被执行。
|
||||
|
||||
运行一个命令,然后为这个命令创建一个井号标签,这样之后我们就可以找到它。假设我们有一个很长的脚本,就上面第四点被执行的命令。现在为它创建一个井号标签。我们知道ifconfig可以被sudo或者root执行,因此用root来执行。
|
||||
运行一个命令,然后为这个命令创建一个#号标签,这样之后我们就可以找到它。假设我们有一个很长的脚本,就上面第四点被执行的命令。现在为它创建一个#号标签。我们知道ifconfig可以被sudo或者root执行,因此用root来执行。
|
||||
|
||||
# ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d: #myip
|
||||
|
||||
上述脚本被’mytag‘给标记了。现在在reverse-i-search(按下ctrl+r)搜索一下这个标签,在终端里,并输入’mytag‘。你可以从这里开始执行。
|
||||
上述脚本被’myip‘给标记了。现在在reverse-i-search(按下ctrl+r)搜索一下这个标签,在终端里,并输入’myip‘。你可以从这里开始执行。
|
||||
|
||||

|
||||
|
||||
你可以创建很多的井号标签,为每个命令,之后使用reverse-i-search找到它。
|
||||
你可以为每个命令创建#号标签,之后使用reverse-i-search找到它。
|
||||
|
||||
目前就这么多了。我们一直在辛苦的工作,创造有趣的,有知识性的内容给你。你觉得我们是如何工作的呢?欢迎咨询任何问题。你可以在下面评论。保持联络!Kudox。
|
||||
|
||||
@ -169,9 +171,9 @@ via: http://www.tecmint.com/linux-commandline-chat-server-and-remove-unwanted-pa
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/5-linux-command-line-tricks/
|
||||
[1]:https://linux.cn/article-5485-1.html
|
||||
@ -1,14 +1,14 @@
|
||||
45 个用于 ‘Suse‘ Linux 包管理的 Zypper 命令
|
||||
用于 ‘Suse‘ Linux 包管理的 Zypper 命令大全
|
||||
======================================================================
|
||||
SUSE( Software and System Entwicklung,即软件和系统开发。其中‘entwicklung‘是德语,意为开发)Linux是 Novell 公司在 Linux 内核基础上发布的操作系统。SUSE Linux 有两个发行分支。其中之一名为 OpenSUSE,这是一款自由而且免费的操作系统。该系统由开源社区开发维护,支持一些最新版本的应用软件,其最新的稳定版本为 13.2。
|
||||
SUSE( Software and System Entwicklung,即软件和系统开发。其中‘entwicklung‘是德语,意为开发)Linux 是由 Novell 公司在 Linux 内核基础上建立的操作系统。SUSE Linux 有两个发行分支。其中之一名为 openSUSE,这是一款自由而且免费的操作系统 (free as in speech as well as free as in wine)。该系统由开源社区开发维护,支持一些最新版本的应用软件,其最新的稳定版本为 13.2。
|
||||
|
||||
另外一个分支是SUSE Linux 企业版。该分支是一个为企业及商业化产品设计的 Linux 发行版,包含了大量的企业应用以及适用于商业产品生产环境的特性。其最新的稳定版本为 12。
|
||||
另外一个分支是 SUSE Linux 企业版。该分支是一个为企业及商业化产品设计的 Linux 发行版,包含了大量的企业应用以及适用于商业产品生产环境的特性。其最新的稳定版本为 12。
|
||||
|
||||
以下的链接包含了安装企业版 SUSE Linux 服务器的详细信息。
|
||||
|
||||
- [如何安装企业版 SUSE Linux 12][1]
|
||||
|
||||
Zypper 和 Yast 是 SUSE Linux 平台上的软件包管理工具,他们的底层使用了 RPM(译者注:RPM 最初指 Redhat Pacakge Manager ,现普遍解释为递归短语 RPM Package Manager 的缩写)。
|
||||
Zypper 和 Yast 是 SUSE Linux 平台上的软件包管理工具,他们的底层使用了 RPM(LCTT 译者注:RPM 最初指 Redhat Pacakge Manager ,现普遍解释为递归短语 RPM Package Manager 的缩写)。
|
||||
|
||||
Yast(Yet another Setup Tool )是 OpenSUSE 以及企业版 SUSE 上用于系统管理、设置和配置的工具。
|
||||
|
||||
@ -16,21 +16,21 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
本文将介绍实际应用中常见的一些Zypper命令。这些命令用来进行安装、更新、删除等任何软件包管理器所能够胜任的工作。
|
||||
|
||||
**重要** : 切记所有的这些指令都将在系统全局范围内产生影响,所以必须以 root 身份执行,否则命令将失败。
|
||||
**重要** : 切记所有的这些命令都将在系统全局范围内产生影响,所以必须以 root 身份执行,否则命令将失败。
|
||||
|
||||
### 获取基本的 Zypper 帮助信息 ###
|
||||
|
||||
1. 不带任何选项的执行 zypper, 将输出该命令的全局选项以及子命令列表(译者注:全局选项,global option,控制台命令的输入分为可选参数和位置参数两大类。按照习惯,一般可选参数称为选项'option',而位置参数称为参数 'argument')。
|
||||
1. 不带任何选项的执行 zypper, 将输出该命令的全局选项以及子命令列表(LCTT 译者注:全局选项,global option,控制台命令的输入分为可选参数和位置参数两大类。按照习惯,一般可选参数称为选项'option',而位置参数称为参数 'argument')。
|
||||
|
||||
<pre><code>%> zypper
|
||||
<pre><code># zypper
|
||||
Usage:
|
||||
zypper [--global-options]</code></pre>
|
||||
|
||||
2. 获取一个具体的子命令的帮助信息,比如 'in' (install),可以执行下面的命令
|
||||
|
||||
<pre><code>%> zypper help in</code></pre>
|
||||
<pre><code># zypper help in</code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper help install
|
||||
<pre><code># zypper help install
|
||||
install (in) [options] {capability | rpm_file_uri}
|
||||
|
||||
Install packages with specified capabilities or RPM files with specified
|
||||
@ -96,7 +96,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
4. 获取一个模式包的信息(以 lamp_server 为例)。
|
||||
|
||||
<pre><code>%> zypper info -t pattern lamp_server
|
||||
<pre><code># zypper info -t pattern lamp_server
|
||||
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
@ -136,9 +136,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
5. 开启一个Zypper Shell 的会话。
|
||||
|
||||
<pre><code> %>zypper shell </code></pre>
|
||||
<pre><code># zypper shell </code></pre>
|
||||
或者
|
||||
<pre><code> %>zypper sh </code></pre>
|
||||
<pre><code># zypper sh </code></pre>
|
||||
|
||||
<pre><code>zypper> help
|
||||
Usage:
|
||||
@ -151,9 +151,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
6. 使用 'zypper repos' 或者 'zypper lr' 来列举所有已定以的软件库。
|
||||
|
||||
<pre><code>%> zypper repos</code></pre>
|
||||
<pre><code># zypper repos</code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper lr
|
||||
<pre><code># zypper lr
|
||||
| Alias | Name | Enabled | Refresh
|
||||
--+---------------------------+------------------------------------+---------+--------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No
|
||||
@ -183,7 +183,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
8. 根据优先级列举软件库。
|
||||
|
||||
<pre><code>%> zypper lr -P
|
||||
<pre><code># zypper lr -P
|
||||
| Alias | Name | Enabled | Refresh | Priority
|
||||
--+---------------------------+------------------------------------+---------+---------+---------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No | 99
|
||||
@ -200,9 +200,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
9. 使用 'zypper refresh' or 'zypper ref' 来刷新 zypper 软件库。
|
||||
|
||||
<pre><code>%> zypper refresh </code></pre>
|
||||
<pre><code># zypper refresh </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper ref
|
||||
<pre><code># zypper ref
|
||||
Repository 'openSUSE-13.2-0' is up to date.
|
||||
Repository 'openSUSE-13.2-Debug' is up to date.
|
||||
Repository 'openSUSE-13.2-Non-Oss' is up to date.
|
||||
@ -213,13 +213,13 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
10. 刷新一个指定的软件库(以 'repo-non-oss' 为例 )。
|
||||
|
||||
<pre><code>%> zypper refresh repo-non-oss
|
||||
<pre><code># zypper refresh repo-non-oss
|
||||
Repository 'openSUSE-13.2-Non-Oss' is up to date.
|
||||
Specified repositories have been refreshed. </code></pre>
|
||||
|
||||
11. 强制更新一个软件库(以 'repo-non-oss' 为例 )。
|
||||
|
||||
<pre><code>%> zypper ref -f repo-non-oss
|
||||
<pre><code># zypper ref -f repo-non-oss
|
||||
Forcing raw metadata refresh
|
||||
Retrieving repository 'openSUSE-13.2-Non-Oss' metadata ............................................................[done]
|
||||
Forcing building of repository cache
|
||||
@ -230,9 +230,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
本文中我们使用‘zypper modifyrepo‘ 或者 ‘zypper mr‘ 来关闭或者开启 zypper 软件库。
|
||||
|
||||
12. 在关闭一个软件库之前,我们需要知道在 zypper中,每一个软件库有一个唯一的标示数字与之关联,该数字用于打开或者关闭与之相联系的软件库。假设我们需要关闭 'repo-oss' 软件库,那么我们可以通过以下的法来获得该软件库的标志数字。
|
||||
12. 在关闭一个软件库之前,我们需要知道在 zypper 中,每一个软件库有一个唯一的标示数字与之关联,该数字用于打开或者关闭与之相联系的软件库。假设我们需要关闭 'repo-oss' 软件库,那么我们可以通过以下的法来获得该软件库的标志数字。
|
||||
|
||||
<pre><code>%> zypper lr
|
||||
<pre><code># zypper lr
|
||||
| Alias | Name | Enabled | Refresh
|
||||
--+---------------------------+------------------------------------+---------+--------
|
||||
1 | openSUSE-13.2-0 | openSUSE-13.2-0 | Yes | No
|
||||
@ -246,23 +246,23 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
9 | repo-update-non-oss | openSUSE-13.2-Update-Non-Oss | Yes | Yes</code></pre>
|
||||
从以上输出的列表中我们可以看到 'repo-oss' 库的标示数字是 6,因此通过以下的命令来关闭该库。
|
||||
|
||||
<pre><code>%> zypper mr -d 6
|
||||
<pre><code># zypper mr -d 6
|
||||
Repository 'repo-oss' has been successfully disabled.</code></pre>
|
||||
|
||||
13. 如果需要再次开启软件库 ‘repo-oss‘, 接上例,与之相关联的标示数字为 6。
|
||||
|
||||
<pre><code>%> zypper mr -e 6
|
||||
<pre><code># zypper mr -e 6
|
||||
Repository 'repo-oss' has been successfully enabled.</code></pre>
|
||||
|
||||
14. 针对某一个软件库(以 'repo-non-oss' 为例 )开启自动刷新( auto-refresh )和 rpm 缓存,并设置该软件库的优先级,比如85。
|
||||
|
||||
<pre><code>%> zypper mr -rk -p 85 repo-non-oss
|
||||
<pre><code># zypper mr -rk -p 85 repo-non-oss
|
||||
Repository 'repo-non-oss' priority has been left unchanged (85)
|
||||
Nothing to change for repository 'repo-non-oss'.</code></pre>
|
||||
|
||||
15. 对所有的软件库关闭 rpm 文件缓存。
|
||||
|
||||
<pre><code>%> zypper mr -Ka
|
||||
<pre><code># zypper mr -Ka
|
||||
RPM files caching has been disabled for repository 'openSUSE-13.2-0'.
|
||||
RPM files caching has been disabled for repository 'repo-debug'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update'.
|
||||
@ -274,7 +274,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been disabled for repository 'repo-update-non-oss'.</pre></code>
|
||||
|
||||
16. 对所有的软件库开启 rpm 文件缓存。
|
||||
<pre><code> zypper mr -ka
|
||||
<pre><code># zypper mr -ka
|
||||
RPM files caching has been enabled for repository 'openSUSE-13.2-0'.
|
||||
RPM files caching has been enabled for repository 'repo-debug'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update'.
|
||||
@ -285,8 +285,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been enabled for repository 'repo-update'.
|
||||
RPM files caching has been enabled for repository 'repo-update-non-oss'.</code></pre>
|
||||
|
||||
17. 关闭远程库的rpm 文件缓存
|
||||
<pre><code>%> zypper mr -Kt
|
||||
17. 关闭远程库的 rpm 文件缓存
|
||||
<pre><code># zypper mr -Kt
|
||||
RPM files caching has been disabled for repository 'repo-debug'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update'.
|
||||
RPM files caching has been disabled for repository 'repo-debug-update-non-oss'.
|
||||
@ -297,7 +297,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
RPM files caching has been disabled for repository 'repo-update-non-oss'.</code></pre>
|
||||
|
||||
18. 开启远程软件库的 rpm 文件缓存。
|
||||
<pre><code>%> zypper mr -kt
|
||||
<pre><code># zypper mr -kt
|
||||
RPM files caching has been enabled for repository 'repo-debug'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update'.
|
||||
RPM files caching has been enabled for repository 'repo-debug-update-non-oss'.
|
||||
@ -313,7 +313,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
19. 增加一个新的软件库( 以 “http://download.opensuse.org/update/12.3/” 为例 )。
|
||||
|
||||
<pre><code>%> zypper ar http://download.opensuse.org/update/11.1/ update
|
||||
<pre><code># zypper ar http://download.opensuse.org/update/11.1/ update
|
||||
Adding repository 'update' .............................................................................................................................................................[done]
|
||||
Repository 'update' successfully added
|
||||
Enabled : Yes
|
||||
@ -323,14 +323,14 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
20. 更改一个软件库的名字,这将仅仅改变软件库的别名。 命令 'zypper namerepo' 或者 'zypperr nr' 可以胜任此工作。例如更改标示数字为10的软件库的名字为 'upd8',或者说将标示数字为10的软件库的别名改为 'upd8',可以使用下面的命令。
|
||||
|
||||
<pre><code>%> zypper nr 10 upd8
|
||||
<pre><code># zypper nr 10 upd8
|
||||
Repository 'update' renamed to 'upd8'.</code></pre>
|
||||
|
||||
#### 删除软件库 ####
|
||||
|
||||
21. 删除一个软件库。要从系统删除一个软件库可以使 'zypper removerepo' 或者 'zypper rr'。例如以下的命令可以删除软件库 'upd8'
|
||||
|
||||
<pre><code>%> zypper rr upd8
|
||||
<pre><code># zypper rr upd8
|
||||
# Removing repository 'upd8' .........................................................................................[done]
|
||||
Repository 'upd8' has been removed.</code></pre>
|
||||
|
||||
@ -339,7 +339,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
#### 用 zypper 安装一个软件包 ####
|
||||
|
||||
22. 在 zypper 中,我们可以通过软件包的功能名称来安装一个软件包。以 Firefox 为例,以下的命令可以用来安装该软件包。
|
||||
<pre><code>%> zypper in MozillaFirefox
|
||||
|
||||
<pre><code># zypper in MozillaFirefox
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -370,8 +371,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Retrieving: hicolor-icon-theme-0.13-2.1.2.noarch.rpm ...................................................................................................................................[done]
|
||||
Retrieving package sound-theme-freedesktop-0.8-7.1.2.noarch (3/128), 372.6 KiB (460.3 KiB unpacked) </code></pre>
|
||||
|
||||
23. 安装指定版本号的软件包,(以 gcc 5.1 为例)。
|
||||
<pre><code> %>zypper in 'gcc<5.1'
|
||||
23. 安装指定版本号的软件包,(以 gcc 5.1 为例)。
|
||||
|
||||
<pre><code># zypper in 'gcc<5.1'
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -385,7 +387,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
24. 为特定的CPU架构安装软件包(以兼容 i586 的 gcc 为例)。
|
||||
|
||||
<pre><code>%> zypper in gcc.i586
|
||||
<pre><code># zypper in gcc.i586
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -403,7 +405,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
25. 为特定的CPU架构安装指定版本号的软件包(以兼容 i586 且版本低于5.1的 gcc 为例)
|
||||
|
||||
<pre><code>%> zypper in 'gcc.i586<5.1'
|
||||
<pre><code># zypper in 'gcc.i586<5.1'
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -418,8 +420,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
In cache libatomic1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (2/13), 14.3 KiB ( 26.1 KiB unpacked)
|
||||
In cache libgomp1-gcc49-4.9.0+r211729-2.1.7.x86_64.rpm (3/13), 41.1 KiB ( 90.7 KiB unpacked) </code></pre>
|
||||
|
||||
26. 从指定的软件库里面安装一个软件包,例如从 amarok 中安装 libxine。
|
||||
<pre><code>%> zypper in amarok upd:libxine1
|
||||
26. 从指定的软件库里面安装一个软件包,例如从 amarok 中安装 libxine。
|
||||
|
||||
<pre><code># zypper in amarok upd:libxine1
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -431,7 +434,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
27. 通过指定软件包的名字安装软件包。
|
||||
|
||||
<pre><code>%> zypper in -n git
|
||||
<pre><code># zypper in -n git
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -451,8 +454,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 15.6 MiB. Already cached: 0 B After the operation, additional 56.7 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): y </code></pre>
|
||||
|
||||
28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
|
||||
<pre><code>%> zypper in php5*
|
||||
28. 通过通配符来安装软件包,例如,安装所有 php5 的软件包。
|
||||
|
||||
<pre><code># zypper in php5*
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -484,9 +488,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
do not install php5-pear-Horde_Pdf-2.0.1-6.1.3.noarch
|
||||
....</code></pre>
|
||||
|
||||
29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包
|
||||
29. 使用模式名称(模式名称是一类软件包的名字)来批量安装软件包。
|
||||
|
||||
<pre><code>%> zypper in -t pattern lamp_server
|
||||
<pre><code># zypper in -t pattern lamp_server
|
||||
ading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -506,7 +510,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 7.2 MiB. Already cached: 1.2 MiB After the operation, additional 34.7 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): </code></pre>
|
||||
|
||||
30. 使用一行命令安转一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
|
||||
30. 使用一行命令安装一个软件包同时卸载另一个软件包,例如在安装 nano 的同时卸载 vi
|
||||
|
||||
<pre><code># zypper in nano -vi
|
||||
Loading repository data...
|
||||
@ -530,7 +534,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
31. 使用 zypper 安装 rpm 软件包。
|
||||
|
||||
<pre><code>%> zypper in teamviewer*.rpm
|
||||
<pre><code># zypper in teamviewer*.rpm
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -552,9 +556,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
32. 命令 ‘zypper remove‘ 和 ‘zypper rm‘ 用于卸载软件包。例如卸载 apache2:
|
||||
|
||||
<pre><code>%> zypper remove apache2 </code></pre>
|
||||
<pre><code># zypper remove apache2 </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper rm apache2
|
||||
<pre><code># zypper rm apache2
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -572,9 +576,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
33. 更新所有的软件包,可以使用 ‘zypper update‘ 或者 ‘zypper up‘。
|
||||
|
||||
<pre><code>%> zypper up </code></pre>
|
||||
<pre><code># zypper up </code></pre>
|
||||
或者
|
||||
<pre><code>%> zypper update
|
||||
<pre><code># zypper update
|
||||
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
@ -591,9 +595,9 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
Nothing to do.</code></pre>
|
||||
|
||||
35. 安装一个软件库,例如 ariadb,如果该库存在则更新之。
|
||||
35. 安装一个软件库,例如 mariadb,如果该库存在则更新之。
|
||||
|
||||
<pre><code>%> zypper in mariadb
|
||||
<pre><code># zypper in mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -608,7 +612,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
36. 安装某一个软件包的源文件及其依赖关系,例如 mariadb。
|
||||
|
||||
<pre><code>%> zypper si mariadb
|
||||
<pre><code># zypper si mariadb
|
||||
Reading installed packages...
|
||||
Loading repository data...
|
||||
Resolving package dependencies...
|
||||
@ -626,7 +630,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
37. 仅为某一个软件包安装源文件,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper in -D mariadb
|
||||
<pre><code># zypper in -D mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -637,7 +641,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
38. 仅为某一个软件包安装依赖关系,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper si -d mariadb
|
||||
<pre><code># zypper si -d mariadb
|
||||
Reading installed packages...
|
||||
Loading repository data...
|
||||
Resolving package dependencies...
|
||||
@ -653,11 +657,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Overall download size: 33.7 MiB. Already cached: 129.5 KiB After the operation, additional 144.3 MiB will be used.
|
||||
Continue? [y/n/? shows all options] (y): y</code></pre>
|
||||
|
||||
#### Zypper in Scripts and Applications ####
|
||||
#### 在脚本和应用中调用 Zypper (非交互式) ####
|
||||
|
||||
39. 安装一个软件包,并且在安装过程中跳过与用户的交互, 例如 mariadb。
|
||||
|
||||
<pre><code>%> zypper --non-interactive in mariadb
|
||||
<pre><code># zypper --non-interactive in mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
'mariadb' is already installed.
|
||||
@ -668,7 +672,7 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
40. 卸载一个软件包,并且在卸载过程中跳过与用户的交互,例如 mariadb
|
||||
|
||||
<pre><code>%> zypper --non-interactive rm mariadb
|
||||
<pre><code># zypper --non-interactive rm mariadb
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -681,18 +685,18 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
Continue? [y/n/? shows all options] (y): y
|
||||
(1/1) Removing mariadb-10.0.13-2.6.1 .............................................................................[done] </code></pre>
|
||||
|
||||
41. 将 zypper 输出用 XML 格式打印。
|
||||
41. 以 XML 格式显示 zypper 的输出。
|
||||
|
||||
<pre><code>%> zypper --xmlout
|
||||
<pre><code># zypper --xmlout
|
||||
Usage:
|
||||
zypper [--global-options] <command> [--command-options] [arguments]
|
||||
|
||||
Global Options
|
||||
....</code></pre>
|
||||
|
||||
42. 禁止详细信息输出到屏幕。
|
||||
42. 在安装过程中禁止详细信息输出到屏幕。
|
||||
|
||||
<pre><code>%> zypper --quiet in mariadb
|
||||
<pre><code># zypper --quiet in mariadb
|
||||
The following NEW package is going to be installed:
|
||||
mariadb
|
||||
|
||||
@ -703,10 +707,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
43. 在卸载过程中禁止详细信息输出到屏幕
|
||||
|
||||
<pre><code>%> zypper --quiet rm mariadb </code></pre>
|
||||
<pre><code># zypper --quiet rm mariadb </code></pre>
|
||||
|
||||
44. 自动地同意版权或者协议。
|
||||
<pre><code>%> zypper patch --auto-agree-with-licenses
|
||||
44. 自动地同意版权或者协议。
|
||||
|
||||
<pre><code># zypper patch --auto-agree-with-licenses
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
@ -717,15 +722,15 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
45. 以下指令可以用来清理Zypper缓存。
|
||||
|
||||
<pre><code>%> zypper clean
|
||||
<pre><code># zypper clean
|
||||
All repositories have been cleaned up.</code></pre>
|
||||
|
||||
如果需要一次性地清理元数据以及软件包缓存,可以通过 -all/-a 选项来达到目的
|
||||
如果需要一次性地清理元数据以及软件包缓存,可以通过 -all 或 -a 选项来达到目的
|
||||
|
||||
<pre><code>%> zypper clean -a
|
||||
<pre><code># zypper clean -a
|
||||
All repositories have been cleaned up.</code></pre>
|
||||
|
||||
46. 查看 Zypper 的历史信息。籍由 Zypper 所有的软件包管理动作,包括安装、更新以及卸载都会在 /var/log/zypp/history中保留历史信息。可以通过 cat 来查看此文件,或者通过过滤器来筛选希望看到的信息。
|
||||
46. 查看 Zypper 的历史信息。任何通过 Zypper 进行的软件包管理动作,包括安装、更新以及卸载都会在 /var/log/zypp/history中保留历史信息。可以通过 cat 来查看此文件,或者通过过滤器来筛选希望看到的信息。
|
||||
|
||||
<pre><code> cat /var/log/zypp/history
|
||||
2015-05-07 15:43:03|install|boost-license1_54_0|1.54.0-10.1.3|noarch||openSUSE-13.2-0|0523b909d2aae5239f9841316dafaf3a37b4f096|
|
||||
@ -742,7 +747,8 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
#### 使用 Zypper 进行SUSE系统升级 ####
|
||||
|
||||
47. 可以使用 Zypper 命令的 'dist-upgrade' 选项来将当前的SUSE Linux升级至最新版本。
|
||||
47. 可以使用 Zypper 命令的 'dist-upgrade' 选项来将当前的 SUSE Linux 升级至最新版本。
|
||||
|
||||
<pre><code># zypper dist-upgrade
|
||||
You are about to do a distribution upgrade with all enabled repositories. Make sure these repositories are compatible before you continue. See 'man zypper' for more information about this command.
|
||||
Building repository 'openSUSE-13.2-0' cache .....................................................................[done]
|
||||
@ -755,11 +761,11 @@ Zypper 是软件包管理器ZYpp的命令行接口,可用于安装、删除SUS
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
原文地址: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
via: http://www.tecmint.com/zypper-commands-to-manage-suse-linux-package-management/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[张博约](https://github.com/zhangboyue)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,214 @@
|
||||
在Linux命令行下令人惊叹的惊叹号(!)
|
||||
================================================================================
|
||||
`'!'`符号在Linux中不但可以用作否定符号,还可以用来从历史命令记录中取出命令或不加修改的执行之前运行的命令。下面的所有命令都已经在Bash Shell中经过确切地检验。尽管我没有试过,但大多都不能在别的Shell中运行。这里我们介绍下Linux命令行中符号`'!'`那惊人和奇妙的用法。
|
||||
|
||||
### 1. 使用数字从历史命令列表中找一条命令来执行 ###
|
||||
|
||||
您也许没有意识到您可以从历史命令列表(之前已经执行的命令集)中找出一条来运行。首先,通过"history"命令查找之前命令的序号。
|
||||
|
||||
$ history
|
||||
|
||||

|
||||
|
||||
*使用history命令找到最后执行的命令*
|
||||
|
||||
现在,只需要使用历史命令输出中显示在该命令前面的数字便可以运行这个命令。例如,运行一个在`history`输出中编号是1551的命令。
|
||||
|
||||
$ !1551
|
||||
|
||||

|
||||
|
||||
*使用命令ID来执行最后运行的命令*
|
||||
|
||||
这样,编号为1551的命令(上面的例子是[top命令][1])便运行了。这种通过ID号来执行之前的命令的方式很有用,尤其是在这些命令都很长的情况下。您只需要使用**![history命令输出的序号]**便可以调用它。
|
||||
|
||||
### 2. 运行之前的倒数第二个、第七个命令等 ###
|
||||
|
||||
您可以以另一种方式来运行之前执行的命令,通过使用-1代表最后的命令,-2代表倒数第二个命令,-7代表倒数第七个命令等。
|
||||
|
||||
首先使用history命令来获得执行过的命令的列表。**history命令的执行很有必要**,因为您可以通过它来确保没有`rm command > file`或其他会导致危险的命令。接下来执行倒数第六个、第八个、第十个命令。
|
||||
|
||||
$ history
|
||||
$ !-6
|
||||
$ !-8
|
||||
$ !-10
|
||||
|
||||

|
||||
|
||||
*通过负数序号运行之前执行的命令*
|
||||
|
||||
### 3. 传递最后执行的命令的参数,以方便的运行新的命令 ###
|
||||
|
||||
我需要显示`/home/$USER/Binary/firefox`文件夹的内容,因此我执行:
|
||||
|
||||
$ ls /home/$USER/Binary/firefox
|
||||
|
||||
接下来,我意识到我应该执行'ls -l'来查看哪个文件是可执行文件。因此我应该重新输入整个命令么?不,我不需要。我仅需要在新的命令中带上最后的参数,类似:
|
||||
|
||||
$ ls -l !$
|
||||
|
||||
这里`!$`将把最后执行的命令的参数传递到这个新的命令中。
|
||||
|
||||

|
||||
|
||||
*将上一个命令的参数传递给新命令*
|
||||
|
||||
### 4. 如何使用!来处理两个或更多的参数 ###
|
||||
|
||||
比如说我在桌面创建了一个文本文件file1.txt。
|
||||
|
||||
$ touch /home/avi/Desktop/1.txt
|
||||
|
||||
然后在cp命令中使用绝对路径将它拷贝到`/home/avi/Downloads`。
|
||||
|
||||
$ cp /home/avi/Desktop/1.txt /home/avi/downloads
|
||||
|
||||
这里,我们给cp命令传递了两个参数。第一个是`/home/avi/Desktop/1.txt`,第二个是`/home/avi/Downloads`。让我们分别处理他们,使用`echo [参数]`来打印两个不同的参数。
|
||||
|
||||
$ echo "1st Argument is : !^"
|
||||
$ echo "2nd Argument is : !cp:2"
|
||||
|
||||
注意第一个参数可以使用`"!^"`进行打印,其余的命令可以通过`"![命令名]:[参数编号]"`打印。
|
||||
|
||||
在上面的例子中,第一个命令是`cp`,第二个参数也需要被打印。因此是`"!cp:2"`,如果任何命令比如xyz运行时有5个参数,而您需要获得第四个参数,您可以使用`"!xyz:4"`。所有的参数都可以通过`"!*"`来获得。
|
||||
|
||||

|
||||
|
||||
*处理两个或更多的参数*
|
||||
|
||||
### 5. 以关键字为基础执行上个的命令 ###
|
||||
|
||||
我们可以以关键字为基础执行上次执行的命令。可以从下面的例子中理解:
|
||||
|
||||
$ ls /home > /dev/null [命令1]
|
||||
$ ls -l /home/avi/Desktop > /dev/null [命令2]
|
||||
$ ls -la /home/avi/Downloads > /dev/null [命令3]
|
||||
$ ls -lA /usr/bin > /dev/null [命令4]
|
||||
|
||||
上面我们使用了同样的命令(ls),但有不同的开关和不同的操作文件夹。而且,我们还将输出传递到`/dev/null`,我们并未显示输出,因而终端依旧很干净。
|
||||
|
||||
现在以关键字为基础执行上个的命令。
|
||||
|
||||
$ ! ls [命令1]
|
||||
$ ! ls -l [命令2]
|
||||
$ ! ls -la [命令3]
|
||||
$ ! ls -lA [命令4]
|
||||
|
||||
检查输出,您将惊奇发现您仅仅使用关键字`ls`便执行了您已经执行过的命令。
|
||||
|
||||

|
||||
|
||||
*以关键字为基础执行命令*
|
||||
|
||||
(LCTT 译注:澄清一下,这种用法会按照命令名来找到最后匹配的命令,不会匹配参数。所以上述执行的四个命令都是执行了 `ls -lA /usr/bin > /dev/null`,并增加了新的参数而已。)
|
||||
|
||||
### 6. !!操作符的威力 ###
|
||||
|
||||
您可以使用`(!!)`运行/修改您上个运行的命令。它将附带一些修改/调整并调用上个命令。让我给您展示一些实际情境。
|
||||
|
||||
昨天我运行了一行脚本来获得我的私有IP,因此我执行了:
|
||||
|
||||
$ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/
|
||||
|
||||
接着,我突然发现我需要将上面脚本的输出重定向到一个ip.txt的文件,因此,我该怎么办呢?我该重新输入整个命令并重定向到一个文件么?一个简单的解决方案是使用向上光标键并添加`'> ip.txt'`来将输出重定向到文件。
|
||||
|
||||
$ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/ > ip.txt
|
||||
|
||||
在这里要感谢救世主"向上光标键"。现在,考虑下面的情况,这次我运行了下面这一行脚本。
|
||||
|
||||
$ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||
一旦我运行了这个脚本,Bash提示符便返回了错误消息`"bash: ifconfig: command not found"`。原因并不难猜,我运行了本应以root权限的运行的命令。
|
||||
|
||||
所以,怎么解决呢?以root用户登录并且再次键入整个命令就太麻烦了!而且向上导航键也不管用了(LCTT 译注:当你以新的用户身份登录了,是不能用向上光标键找到之前的另外一个用户的命令历史的)。因此,我们需要调用`"!!"`(去掉引号),它将为那个用户调用上个命令。
|
||||
|
||||
$ su -c !! root
|
||||
|
||||
这里su是用来切换到root用户的,`-c`用来以某用户运行特定的命令,最重要的部分是`!!`,它将被替换为上次运行的命令。当然!您需要提供root密码。
|
||||
|
||||

|
||||
|
||||
*!!操作符的威力*
|
||||
|
||||
我通常在下面的情景中使用`!!`。
|
||||
|
||||
当我用普通用户来运行apt-get,我通常收到提示说我没有权限来执行。
|
||||
|
||||
$ apt-get upgrade && apt-get dist-upgrade
|
||||
|
||||
好吧,有错误。但别担心,使用下面的命令来成功的执行...
|
||||
|
||||
$ su -c !!
|
||||
|
||||
同样的适用于:
|
||||
|
||||
$ service apache2 start
|
||||
|
||||
或
|
||||
|
||||
$ /etc/init.d/apache2 start
|
||||
|
||||
或
|
||||
|
||||
$ systemctl start apache2
|
||||
|
||||
普通用户不被授权执行那些任务,这样相当于我运行:
|
||||
|
||||
$ su -c 'service apache2 start'
|
||||
|
||||
或
|
||||
|
||||
$ su -c '/etc/init.d/apache2 start'
|
||||
|
||||
或
|
||||
|
||||
$ su -c 'systemctl start apache2'
|
||||
|
||||
(LCTT 译注:使用`!!`之前,一定要确认你执行的是什么命令!另外,在 root 身份下,千万不要养成使用它的习惯,因为你总是会在不合适的目录执行不合适的命令!)
|
||||
|
||||
### 7.运行一个影响所有除了![FILE_NAME]的文件命令 ###
|
||||
|
||||
`!`(逻辑非)能用来对除了`'!'`后的文件的所有的文件/扩展名执行命令。
|
||||
|
||||
A.从文件夹移除所有文件,2.txt除外。
|
||||
|
||||
$ rm !(2.txt)
|
||||
|
||||
B.从文件夹移除所有的文件类型,pdf类型除外。
|
||||
|
||||
$ rm !(*.pdf)
|
||||
|
||||
### 8.检查某个文件夹(比如/home/avi/Tecmint)是否存在?并打印 ###
|
||||
|
||||
这里,我们使用`'! -d'`来验证文件夹是否存在,当文件夹不存在时,将使用其后跟随AND操作符`(&&)`进行打印,当文件夹存在时,将使用OR操作符`(||)`进行打印。
|
||||
|
||||
逻辑上,当`[ ! -d /home/avi/Tecmint ]`的输出为0时,它将执行AND逻辑符后面的内容,否则,它将执行OR逻辑符`(||)`后面的内容。
|
||||
|
||||
$ [ ! -d /home/avi/Tecmint ] && printf '\nno such /home/avi/Tecmint directory exist\n' || printf '\n/home/avi/Tecmint directory exist\n'
|
||||
|
||||
### 9.检查某文件夹是否存在?如果不存在则退出该命令 ###
|
||||
|
||||
类似于上面的情况,但这里当期望的文件夹不存在时,该命令会退出。
|
||||
|
||||
$ [ ! -d /home/avi/Tecmint ] && exit
|
||||
|
||||
### 10.如果您的home文件夹内不存在一个文件夹(比方说test),则创建它 ###
|
||||
|
||||
这是脚本语言中的一个常用的实现,当期望的文件夹不存在时,创建一个。
|
||||
|
||||
[ ! -d /home/avi/Tecmint ] && mkdir /home/avi/Tecmint
|
||||
|
||||
这便是全部了。如果您知道或偶尔遇到其他值得了解的`'!'`使用方法,请您在反馈的地方给我们提建议。保持联系!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysterious-uses-of-symbol-or-operator-in-linux-commands/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
@ -1,14 +1,14 @@
|
||||
70 个可能的 Shell 脚本面试问题及解答
|
||||
Shell 脚本面试问题大全
|
||||
================================================================================
|
||||
我们为你的面试准备选择了 70 个可能的 shell 脚面问题及解答。了解脚本或至少知道基础知识对系统管理员来说至关重要,它也有助于你在工作环境中自动完成很多任务。在过去的几年里,我们注意到所有的 linux 工作职位都要求脚本技能。
|
||||
我们为你的面试准备选择了 70 个你可能遇到的 shell 脚面问题及解答。了解脚本或至少知道基础知识对系统管理员来说至关重要,它也有助于你在工作环境中自动完成很多任务。在过去的几年里,我们注意到所有的 linux 工作职位都要求脚本技能。
|
||||
|
||||
### 1) 如何向脚本传递参数 ? ###
|
||||
|
||||
./script argument
|
||||
./script argument
|
||||
|
||||
**例子** : 显示文件名称脚本
|
||||
|
||||
./show.sh file1.txt
|
||||
./show.sh file1.txt
|
||||
|
||||
cat show.sh
|
||||
#!/bin/bash
|
||||
@ -16,12 +16,11 @@
|
||||
|
||||
### 2) 如何在脚本中使用参数 ? ###
|
||||
|
||||
第一个参数: $1,
|
||||
第二个参数 : $2
|
||||
第一个参数 : $1,第二个参数 : $2
|
||||
|
||||
例子 : 脚本会复制文件(arg1) 到目标地址(arg2)
|
||||
|
||||
./copy.sh file1.txt /tmp/
|
||||
./copy.sh file1.txt /tmp/
|
||||
|
||||
cat copy.sh
|
||||
#!/bin/bash
|
||||
@ -29,127 +28,129 @@
|
||||
|
||||
### 3) 如何计算传递进来的参数 ? ###
|
||||
|
||||
$#
|
||||
$#
|
||||
|
||||
### 4) 如何在脚本中获取脚本名称 ? ###
|
||||
|
||||
$0
|
||||
$0
|
||||
|
||||
### 5) 如何检查之前的命令是否运行成功 ? ###
|
||||
|
||||
$?
|
||||
$?
|
||||
|
||||
### 6) 如何获取文件的最后一行 ? ###
|
||||
|
||||
tail -1
|
||||
tail -1
|
||||
|
||||
### 7) 如何获取文件的第一行 ? ###
|
||||
|
||||
head -1
|
||||
head -1
|
||||
|
||||
### 8) 如何获取一个文件每一行的第三个元素 ? ###
|
||||
|
||||
awk '{print $3}'
|
||||
awk '{print $3}'
|
||||
|
||||
### 9) 假如第一个等于 FIND,如何获取文件中每行的第二个元素 ###
|
||||
### 9) 假如文件中每行第一个元素是 FIND,如何获取第二个元素 ###
|
||||
|
||||
awk '{ if ($1 == "FIND") print $2}'
|
||||
awk '{ if ($1 == "FIND") print $2}'
|
||||
|
||||
### 10) 如何调试 bash 脚本 ###
|
||||
|
||||
Add -xv to #!/bin/bash
|
||||
|
||||
例子
|
||||
将 -xv 参数加到 #!/bin/bash 后
|
||||
|
||||
#!/bin/bash –xv
|
||||
例子:
|
||||
|
||||
#!/bin/bash –xv
|
||||
|
||||
### 11) 举例如何写一个函数 ? ###
|
||||
|
||||
function example {
|
||||
echo "Hello world!"
|
||||
}
|
||||
function example {
|
||||
echo "Hello world!"
|
||||
}
|
||||
|
||||
### 12) 如何向 string 添加 string ? ###
|
||||
### 12) 如何向连接两个字符串 ? ###
|
||||
|
||||
V1="Hello"
|
||||
V2="World"
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
V1="Hello"
|
||||
V2="World"
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
|
||||
Output
|
||||
输出
|
||||
|
||||
Hello+World
|
||||
Hello+World
|
||||
|
||||
### 13) 如何进行两个整数相加 ? ###
|
||||
|
||||
V1=1
|
||||
V2=2
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
V1=1
|
||||
V2=2
|
||||
V3=$V1+$V2
|
||||
echo $V3
|
||||
|
||||
Output
|
||||
3
|
||||
输出
|
||||
|
||||
3
|
||||
|
||||
### 14) 如何检查文件系统中是否存在某个文件 ? ###
|
||||
|
||||
if [ -f /var/log/messages ]
|
||||
then
|
||||
echo "File exists"
|
||||
fi
|
||||
if [ -f /var/log/messages ]
|
||||
then
|
||||
echo "File exists"
|
||||
fi
|
||||
|
||||
### 15) 写出 shell 脚本中所有循环语法 ? ###
|
||||
|
||||
#### for loop : ####
|
||||
#### for 循环 : ####
|
||||
|
||||
for i in $( ls ); do
|
||||
echo item: $i
|
||||
done
|
||||
for i in $( ls ); do
|
||||
echo item: $i
|
||||
done
|
||||
|
||||
#### while loop : ####
|
||||
#### while 循环 : ####
|
||||
|
||||
#!/bin/bash
|
||||
COUNTER=0
|
||||
while [ $COUNTER -lt 10 ]; do
|
||||
echo The counter is $COUNTER
|
||||
let COUNTER=COUNTER+1
|
||||
done
|
||||
#!/bin/bash
|
||||
COUNTER=0
|
||||
while [ $COUNTER -lt 10 ]; do
|
||||
echo The counter is $COUNTER
|
||||
let COUNTER=COUNTER+1
|
||||
done
|
||||
|
||||
#### untill oop : ####
|
||||
#### until 循环 : ####
|
||||
|
||||
#!/bin/bash
|
||||
COUNTER=20
|
||||
until [ $COUNTER -lt 10 ]; do
|
||||
echo COUNTER $COUNTER
|
||||
let COUNTER-=1
|
||||
done
|
||||
#!/bin/bash
|
||||
COUNTER=20
|
||||
until [ $COUNTER -lt 10 ]; do
|
||||
echo COUNTER $COUNTER
|
||||
let COUNTER-=1
|
||||
done
|
||||
|
||||
### 16) 每个脚本开始的 #!/bin/sh 或 #!/bin/bash 表示什么意思 ? ###
|
||||
|
||||
这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python
|
||||
这一行说明要使用的 shell。#!/bin/bash 表示脚本使用 /bin/bash。对于 python 脚本,就是 #!/usr/bin/python。(LCTT译注:这一行称之为[释伴行](https://linux.cn/article-3664-1.html)。)
|
||||
|
||||
### 17) 如何获取文本文件的第 10 行 ? ###
|
||||
|
||||
head -10 file|tail -1
|
||||
head -10 file|tail -1
|
||||
|
||||
### 18) bash 脚本文件的第一个符号是什么 ###
|
||||
|
||||
#
|
||||
#
|
||||
|
||||
### 19) 命令:[ -z "" ] && echo 0 || echo 1 的输出是什么 ###
|
||||
|
||||
0
|
||||
0
|
||||
|
||||
### 20) 命令 “export” 有什么用 ? ###
|
||||
|
||||
使变量在子 shell 中公有
|
||||
使变量在子 shell 中可用。
|
||||
|
||||
### 21) 如何在后台运行脚本 ? ###
|
||||
|
||||
在脚本后面添加 “&”
|
||||
在脚本后面添加 “&”。
|
||||
|
||||
### 22) "chmod 500 script" 做什么 ? ###
|
||||
|
||||
使脚本所有者拥有可执行权限
|
||||
使脚本所有者拥有可执行权限。
|
||||
|
||||
### 23) ">" 做什么 ? ###
|
||||
|
||||
@ -157,8 +158,8 @@ head -10 file|tail -1
|
||||
|
||||
### 24) & 和 && 有什么区别 ###
|
||||
|
||||
& - 希望脚本在后台运行的时候使用它
|
||||
&& - 当第一个脚本成功完成才执行命令/脚本的时候使用它
|
||||
- & - 希望脚本在后台运行的时候使用它
|
||||
- && - 当前一个脚本成功完成才执行后面的命令/脚本的时候使用它
|
||||
|
||||
### 25) 什么时候要在 [ condition ] 之前使用 “if” ? ###
|
||||
|
||||
@ -166,81 +167,87 @@ head -10 file|tail -1
|
||||
|
||||
### 26) 命令: name=John && echo 'My name is $name' 的输出是什么 ###
|
||||
|
||||
My name is $name
|
||||
My name is $name
|
||||
|
||||
### 27) bash shell 脚本中哪个符号用于注释 ? ###
|
||||
|
||||
#
|
||||
#
|
||||
|
||||
### 28) 命令: echo ${new:-variable} 的输出是什么 ###
|
||||
|
||||
variable
|
||||
variable
|
||||
|
||||
### 29) ' 和 " 引号有什么区别 ? ###
|
||||
|
||||
' - 当我们不希望把变量转换为值的时候使用它。
|
||||
" - 会计算所有变量的值并用值代替。
|
||||
- ' - 当我们不希望把变量转换为值的时候使用它。
|
||||
- " - 会计算所有变量的值并用值代替。
|
||||
|
||||
### 30) 如何在脚本文件中重定向标准输入输出流到 log.txt 文件 ? ###
|
||||
### 30) 如何在脚本文件中重定向标准输出和标准错误流到 log.txt 文件 ? ###
|
||||
|
||||
在脚本文件中添加 "exec >log.txt 2>&1" 命令
|
||||
在脚本文件中添加 "exec >log.txt 2>&1" 命令。
|
||||
|
||||
### 31) 如何只用 echo 命令获取 string 变量的一部分 ? ###
|
||||
### 31) 如何只用 echo 命令获取字符串变量的一部分 ? ###
|
||||
|
||||
echo ${variable:x:y}
|
||||
x - 起始位置
|
||||
y - 长度
|
||||
|
||||
echo ${variable:x:y}
|
||||
x - 起始位置
|
||||
y - 长度
|
||||
例子:
|
||||
variable="My name is Petras, and I am developer."
|
||||
echo ${variable:11:6} # 会显示 Petras
|
||||
|
||||
### 32) 如果给定字符串 variable="User:123:321:/home/dir" 如何只用 echo 命令获取 home_dir ? ###
|
||||
variable="My name is Petras, and I am developer."
|
||||
echo ${variable:11:6} # 会显示 Petras
|
||||
|
||||
### 32) 如果给定字符串 variable="User:123:321:/home/dir",如何只用 echo 命令获取 home_dir ? ###
|
||||
|
||||
echo ${variable#*:*:*:}
|
||||
|
||||
echo ${variable#*:*:*:}
|
||||
或
|
||||
echo ${variable##*:}
|
||||
|
||||
echo ${variable##*:}
|
||||
|
||||
### 33) 如何从上面的字符串中获取 “User” ? ###
|
||||
|
||||
echo ${variable%:*:*:*}
|
||||
echo ${variable%:*:*:*}
|
||||
|
||||
或
|
||||
echo ${variable%%:*}
|
||||
|
||||
echo ${variable%%:*}
|
||||
|
||||
### 34) 如何使用 awk 列出 UID 小于 100 的用户 ? ###
|
||||
|
||||
awk -F: '$3<100' /etc/passwd
|
||||
awk -F: '$3<100' /etc/passwd
|
||||
|
||||
### 35) 写程序为用户计算主组数目并显示次数和组名 ###
|
||||
|
||||
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
|
||||
do
|
||||
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
|
||||
done
|
||||
cat /etc/passwd|cut -d: -f4|sort|uniq -c|while read c g
|
||||
do
|
||||
{ echo $c; grep :$g: /etc/group|cut -d: -f1;}|xargs -n 2
|
||||
done
|
||||
|
||||
### 36) 如何在 bash shell 中更改标注域分隔符为 ":" ? ###
|
||||
### 36) 如何在 bash shell 中更改标准的域分隔符为 ":" ? ###
|
||||
|
||||
IFS=":"
|
||||
IFS=":"
|
||||
|
||||
### 37) 如何获取变量长度 ? ###
|
||||
|
||||
${#variable}
|
||||
${#variable}
|
||||
|
||||
### 38) 如何打印变量的最后 5 个字符 ? ###
|
||||
|
||||
echo ${variable: -5}
|
||||
echo ${variable: -5}
|
||||
|
||||
### 39) ${variable:-10} 和 ${variable: -10} 有什么区别? ###
|
||||
|
||||
${variable:-10} - 如果之前没有给 variable 赋值则输出 10
|
||||
${variable: -10} - 输出 variable 的最后 10 个字符
|
||||
- ${variable:-10} - 如果之前没有给 variable 赋值则输出 10
|
||||
- ${variable: -10} - 输出 variable 的最后 10 个字符
|
||||
|
||||
### 40) 如何只用 echo 命令替换字符串的一部分 ? ###
|
||||
|
||||
echo ${variable//pattern/replacement}
|
||||
echo ${variable//pattern/replacement}
|
||||
|
||||
### 41) 哪个命令将命令替换为大写 ? ###
|
||||
|
||||
tr '[:lower:]' '[:upper:]'
|
||||
tr '[:lower:]' '[:upper:]'
|
||||
|
||||
### 42) 如何计算本地用户数目 ? ###
|
||||
|
||||
@ -250,141 +257,151 @@ cat /etc/passwd|wc -l
|
||||
|
||||
### 43) 不用 wc 命令如何计算字符串中的单词数目 ? ###
|
||||
|
||||
set ${string}
|
||||
echo $#
|
||||
set ${string}
|
||||
echo $#
|
||||
|
||||
### 44) "export $variable" 或 "export variable" 哪个正确 ? ###
|
||||
|
||||
export variable
|
||||
export variable
|
||||
|
||||
### 45) 如何列出第二个字母是 a 或 b 的文件 ? ###
|
||||
|
||||
ls -d ?[ab]*
|
||||
ls -d ?[ab]*
|
||||
|
||||
### 46) 如何将整数 a 加到 b 并赋值给 c ? ###
|
||||
|
||||
c=$((a+b))
|
||||
c=$((a+b))
|
||||
|
||||
或
|
||||
c=`expr $a + $b`
|
||||
|
||||
c=`expr $a + $b`
|
||||
|
||||
或
|
||||
c=`echo "$a+$b"|bc`
|
||||
|
||||
c=`echo "$a+$b"|bc`
|
||||
|
||||
### 47) 如何去除字符串中的所有空格 ? ###
|
||||
|
||||
echo $string|tr -d " "
|
||||
echo $string|tr -d " "
|
||||
|
||||
### 48) 重写命令输出变量转换为复数的句子: item="car"; echo "I like $item" ? ###
|
||||
### 48) 重写这个命令,将输出变量转换为复数: item="car"; echo "I like $item" ? ###
|
||||
|
||||
item="car"; echo "I like ${item}s"
|
||||
item="car"; echo "I like ${item}s"
|
||||
|
||||
### 49) 写出输出数字 0 到 100 中 3 的倍数(0 3 6 9 …)的命令 ? ###
|
||||
|
||||
for i in {0..100..3}; do echo $i; done
|
||||
for i in {0..100..3}; do echo $i; done
|
||||
|
||||
或
|
||||
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
|
||||
|
||||
for (( i=0; i<=100; i=i+3 )); do echo "Welcome $i times"; done
|
||||
|
||||
### 50) 如何打印传递给脚本的所有参数 ? ###
|
||||
|
||||
echo $*
|
||||
echo $*
|
||||
|
||||
或
|
||||
echo $@
|
||||
|
||||
echo $@
|
||||
|
||||
### 51) [ $a == $b ] 和 [ $a -eq $b ] 有什么区别 ###
|
||||
|
||||
[ $a == $b ] - 用于字符串比较
|
||||
[ $a -eq $b ] - 用于数字比较
|
||||
- [ $a == $b ] - 用于字符串比较
|
||||
- [ $a -eq $b ] - 用于数字比较
|
||||
|
||||
### 52) = 和 == 有什么区别 ###
|
||||
|
||||
= - 用于为变量复制
|
||||
== - 用于字符串比较
|
||||
- = - 用于为变量复制
|
||||
- == - 用于字符串比较
|
||||
|
||||
### 53) 写出测试 $a 是否大于 12 的命令 ? ###
|
||||
|
||||
[ $a -gt 12 ]
|
||||
[ $a -gt 12 ]
|
||||
|
||||
### 54) 写出测试 $b 是否小于等于 12 的命令 ? ###
|
||||
|
||||
[ $b -le 12 ]
|
||||
[ $b -le 12 ]
|
||||
|
||||
### 55) 如何检查字符串是否以字母 "abc" 开头 ? ###
|
||||
|
||||
[[ $string == abc* ]]
|
||||
[[ $string == abc* ]]
|
||||
|
||||
### 56) [[ $string == abc* ]] 和 [[ $string == "abc*" ]] 有什么区别 ###
|
||||
|
||||
[[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
|
||||
[[ $string == "abc* " ]] - 检查字符串是否完全等于 abc*
|
||||
- [[ $string == abc* ]] - 检查字符串是否以字母 abc 开头
|
||||
- [[ $string == "abc*" ]] - 检查字符串是否完全等于 abc*
|
||||
|
||||
### 57) 如何列出以 ab 或 xy 开头的用户名 ? ###
|
||||
|
||||
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
|
||||
egrep "^ab|^xy" /etc/passwd|cut -d: -f1
|
||||
|
||||
### 58) bash 中 $! 表示什么意思 ? ###
|
||||
|
||||
后台最近命令的 PID
|
||||
后台最近执行命令的 PID.
|
||||
|
||||
### 59) $? 表示什么意思 ? ###
|
||||
|
||||
前台最近命令的结束状态
|
||||
前台最近命令的结束状态。
|
||||
|
||||
### 60) 如何输出当前 shell 的 PID ? ###
|
||||
|
||||
echo $$
|
||||
echo $$
|
||||
|
||||
### 61) 如何获取传递给脚本的参数数目 ? ###
|
||||
|
||||
echo $#
|
||||
echo $#
|
||||
|
||||
(LCTT 译注:和第3题重复了。)
|
||||
|
||||
### 62) $* 和 $@ 有什么区别 ###
|
||||
|
||||
$* - 以一个字符串形式输出所有传递到脚本的参数
|
||||
$@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
|
||||
- $* - 以一个字符串形式输出所有传递到脚本的参数
|
||||
- $@ - 以 $IFS 为分隔符列出所有传递到脚本中的参数
|
||||
|
||||
### 63) 如何在 bash 中定义数组 ? ###
|
||||
|
||||
array=("Hi" "my" "name" "is")
|
||||
array=("Hi" "my" "name" "is")
|
||||
|
||||
### 64) 如何打印数组的第一个元素 ? ###
|
||||
|
||||
echo ${array[0]}
|
||||
echo ${array[0]}
|
||||
|
||||
### 65) 如何打印数组的所有元素 ? ###
|
||||
|
||||
echo ${array[@]}
|
||||
echo ${array[@]}
|
||||
|
||||
### 66) 如何输出所有数组索引 ? ###
|
||||
|
||||
echo ${!array[@]}
|
||||
echo ${!array[@]}
|
||||
|
||||
### 67) 如何移除数组中索引为 2 的元素 ? ###
|
||||
|
||||
unset array[2]
|
||||
unset array[2]
|
||||
|
||||
### 68) 如何在数组中添加 id 为 333 的元素 ? ###
|
||||
|
||||
array[333]="New_element"
|
||||
array[333]="New_element"
|
||||
|
||||
### 69) shell 脚本如何获取输入的值 ? ###
|
||||
|
||||
a) 通过参数
|
||||
|
||||
./script param1 param2
|
||||
./script param1 param2
|
||||
|
||||
b) 通过 read 命令
|
||||
|
||||
read -p "Destination backup Server : " desthost
|
||||
read -p "Destination backup Server : " desthost
|
||||
|
||||
### 70) 在脚本中如何使用 "expect" ? ###
|
||||
|
||||
/usr/bin/expect << EOD
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
expect "*?assword:*"
|
||||
send "${password}\r"
|
||||
expect eof
|
||||
EOD
|
||||
/usr/bin/expect << EOD
|
||||
spawn rsync -ar ${line} ${desthost}:${destpath}
|
||||
expect "*?assword:*"
|
||||
send "${password}\r"
|
||||
expect eof
|
||||
EOD
|
||||
|
||||
好运 !! 如果你有任何疑问或者问题需要解答都可以在下面的评论框中写下来。让我们知道这对你的面试有所帮助:-)
|
||||
祝你好运 !! 如果你有任何疑问或者问题需要解答都可以在下面的评论框中写下来。让我们知道这对你的面试有所帮助:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -392,7 +409,7 @@ via: http://linoxide.com/linux-shell-script/shell-scripting-interview-questions-
|
||||
|
||||
作者:[Petras Liumparas][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
Linux 有问必答--如何修复 Raspbian 上的 “Encountered a section with no Package: header” 错误
|
||||
Linux 有问必答:如何修复 Rasbian 上的 “Encountered a section with no Package: header” 错误
|
||||
================================================================================
|
||||
> **问题**: 我在 Raspberry Pi 上安装新版的 Rasbian。但当我使用 sudo apt-get update 命令更新 APT 软件包索引的时候,它抛出下面的错误:
|
||||
> **问题**: 我在树莓派上安装新版的 Rasbian。但当我使用 sudo apt-get update 命令更新 APT 软件包索引的时候,它抛出下面的错误:
|
||||
|
||||
E: Encountered a section with no Package: header
|
||||
E: Problem with MergeList /var/lib/dpkg/status
|
||||
@ -10,7 +10,7 @@ Linux 有问必答--如何修复 Raspbian 上的 “Encountered a section with n
|
||||
|
||||
|
||||
|
||||
错误说 "Problem with MergeList /var/lib/dpkg/status" 表示由于某些原因状态文件损坏了,因此无法解释。这个状态文件包括了已经安装的 deb 软件包的信息,因此需要小心备份。
|
||||
这个错误说 "Problem with MergeList /var/lib/dpkg/status" 表示由于某些原因状态文件损坏了,因此无法解析。这个状态文件包括了已经安装的 deb 软件包的信息,因此需要小心备份。
|
||||
|
||||
在这种情况下,由于这是新安装的 Raspbian,你可以安全地删除状态文件,然后用下面的命令重新生成。
|
||||
|
||||
@ -24,7 +24,7 @@ via: http://ask.xmodulo.com/encountered-section-with-no-package-header-error.htm
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,16 @@
|
||||
Linux有问必答——Linux上如何查看某个进程的线程
|
||||
Linux有问必答:Linux上如何查看某个进程的线程
|
||||
================================================================================
|
||||
> **问题**: 我的程序创建并在它里头执行了多个线程,我怎样才能在该程序创建线程后监控其中单个线程?我想要看到带有它们名称的单个线程详细情况(如,CPU/内存使用率)。
|
||||
> **问题**: 我的程序在其内部创建并执行了多个线程,我怎样才能在该程序创建线程后监控其中单个线程?我想要看到带有它们名称的单个线程详细情况(如,CPU/内存使用率)。
|
||||
|
||||
线程是现代操作系统上进行并行执行的一个流行的编程方面的抽象概念。当一个程序内有多个线程被叉分出用以执行多个流时,这些线程就会在它们之间共享特定的资源(如,内存地址空间、打开的文件),以使叉分开销最小化,并避免大量花销IPC(进程间通信)频道。这些功能让线程在并发执行时成为一个高效的机制。
|
||||
线程是现代操作系统上进行并行执行的一个流行的编程方面的抽象概念。当一个程序内有多个线程被叉分出用以执行多个流时,这些线程就会在它们之间共享特定的资源(如,内存地址空间、打开的文件),以使叉分开销最小化,并避免大量高成本的IPC(进程间通信)通道。这些功能让线程在并发执行时成为一个高效的机制。
|
||||
|
||||
在Linux中,程序中创建的线程(也称为轻量级进程,LWP)会具有和程序的PID相同的“线程组ID”。然后,各个线程会获得其自身的线程ID(TID)。对于Linux内核调度器而言,线程不过是恰好共享特定资源的标准的进程。经典的命令行工具,如ps或top,都可以用来显示线程级别的信息,默认情况下它们会显示进程级别的信息。
|
||||
在Linux中,程序中创建的线程(也称为轻量级进程,LWP)会具有和程序的PID相同的“线程组ID”。然后,各个线程会获得其自身的线程ID(TID)。对于Linux内核调度器而言,线程不过是恰好共享特定资源的标准的进程而已。经典的命令行工具,如ps或top,都可以用来显示线程级别的信息,只是默认情况下它们显示进程级别的信息。
|
||||
|
||||
这里提供了**在Linux上显示某个进程的线程**的几种方式。
|
||||
|
||||
### 方法一:PS ###
|
||||
|
||||
在ps命令中,“-T”选项可以开启线程查看。下面的命令列出了由进程号为<pid>的进程创建的所有线程。
|
||||
在ps命令中,“-T”选项可以开启线程查看。下面的命令列出了由进程号为\<pid>的进程创建的所有线程。
|
||||
|
||||
$ ps -T -p <pid>
|
||||
|
||||
@ -26,7 +26,7 @@ top命令可以实时显示各个线程情况。要在top输出中开启线程
|
||||
|
||||
|
||||
|
||||
要让top输出某个特定进程<pid>并检查该进程内运行的线程状况:
|
||||
要让top输出某个特定进程\<pid>并检查该进程内运行的线程状况:
|
||||
|
||||
$ top -H -p <pid>
|
||||
|
||||
@ -36,7 +36,7 @@ top命令可以实时显示各个线程情况。要在top输出中开启线程
|
||||
|
||||
一个对用户更加友好的方式是,通过htop查看单个进程的线程,它是一个基于ncurses的交互进程查看器。该程序允许你在树状视图中监控单个独立线程。
|
||||
|
||||
要在htop中启用线程查看,请开启htop,然后按<F2>来进入htop的设置菜单。选择“设置”栏下面的“显示选项”,然后开启“树状视图”和“显示自定义线程名”选项。按<F10>退出设置。
|
||||
要在htop中启用线程查看,请开启htop,然后按\<F2>来进入htop的设置菜单。选择“设置”栏下面的“显示选项”,然后开启“树状视图”和“显示自定义线程名”选项。按\<F10>退出设置。
|
||||
|
||||
|
||||
|
||||
@ -50,7 +50,7 @@ via: http://ask.xmodulo.com/view-threads-process-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
64
published/20150520 How to Use tmpfs on RHEL or CentOS 7.0.md
Normal file
64
published/20150520 How to Use tmpfs on RHEL or CentOS 7.0.md
Normal file
@ -0,0 +1,64 @@
|
||||
如何在RHEL/CentOS 7.0中使用tmpfs
|
||||
================================================================================
|
||||
今天我们来谈谈 Centos 7 中的一个文件系统tmpfs,这是一个将所有文件和文件夹写到虚拟内存中而不是实际写到磁盘中的虚拟文件系统。这意味中tmpfs中所有的内容都是临时的,在tmpfs卸载、系统重启或者电源切断后内容都将会丢失。技术的角度上来说,tmpfs将所有的内容放在内核内部缓存中并且会调整大小来容纳文件,并可从交换空间中交换出不需要的页。
|
||||
|
||||
CentOS默认使用tmpfs做的几种用途可用df -h命令的输出来看:
|
||||
|
||||
# df –h
|
||||
|
||||

|
||||
|
||||
- /dev - 含有针对所有设备的设备文件的目录
|
||||
- /dev/shm - 包含共享内存分配
|
||||
- /run - 用于系统日志
|
||||
- /sys/fs/cgroup - 用于cgrpups, 一个针对特定进程限制、管制和审计资源利用的内核特性
|
||||
|
||||
显然,它也可以用作/tmp目录, 你可以用下面的两种方法来做到:
|
||||
|
||||
### 使用systemctl来在/tmp中启用tmpfs ###
|
||||
|
||||
你可以使用systemctl命令在tmp目录启用tmpfs, 首先用下面的命令来检查这个特性是否可用:
|
||||
|
||||
# systemctl is-enabled tmp.mount
|
||||
|
||||
这会显示当先的状态,(如果未启用,)你可以使用下面的命令来启用它:
|
||||
|
||||
# systemctl enable tmp.mount
|
||||
|
||||

|
||||
|
||||
这会让系统控制/tmp目录并在该目录下挂载一个tmpfs文件系统。
|
||||
|
||||
### 手动挂载/tmp文件系统 ###
|
||||
|
||||
你可以在/etc/fstab中添加下面这行,来手工在/tmp下挂载 tmpfs。
|
||||
|
||||
tmpfs /tmp tmpfs size=512m 0 0
|
||||
|
||||
接着运行这条命令
|
||||
|
||||
# mount –a
|
||||
|
||||

|
||||
|
||||
这应该就会在df -h中显示tmpfs了,同样也会在你下次重启时自动挂载。
|
||||
|
||||
### 立即创建tmpfs ###
|
||||
|
||||
如果由于一些原因,你需要在一个文件夹下立即创建tmpfs,你可以使用下面的命令:
|
||||
|
||||
# mount -t tmpfs -o size=1G tmpfs /mnt/mytmpfs
|
||||
|
||||
当然你可以在size选项中指定你希望的大小和希望的挂载点,只要记住是有效的目录就行了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/use-tmpfs-rhel-centos-7-0/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
@ -1,4 +1,4 @@
|
||||
Linux 有问必答--如何在桌面版 Ubuntu 中安装 Unity Tweak Tool
|
||||
Linux 有问必答:如何在桌面版 Ubuntu 中安装 Unity Tweak Tool
|
||||
================================================================================
|
||||
> **问题**: 我试着给刚安装的桌面版 Ubuntu 自定制桌面。我想使用 Unity Tweak Tool。我怎样才能在 Ubuntu 上安装 Unity Tweak Tool 呢?
|
||||
|
||||
@ -6,7 +6,7 @@ Linux 有问必答--如何在桌面版 Ubuntu 中安装 Unity Tweak Tool
|
||||
|
||||
|
||||
|
||||
尽管 Unity Tweak Tool 是桌面版 Ubuntu 的重要工具,并没有在桌面版 Ubuntu 中预安装。为了能自定制 Unity 桌面,下面介绍一下如何在桌面版 Ubuntu 中安装 Unity Tweak Tool。
|
||||
尽管 Unity Tweak Tool 是桌面版 Ubuntu 的重要工具,但并没有在桌面版 Ubuntu 中预安装。为了能自定制 Unity 桌面,下面介绍一下如何在桌面版 Ubuntu 中安装 Unity Tweak Tool。
|
||||
|
||||
### 在 Ubuntu 13.04 或更高版本中安装 Unity Tweak Tool ###
|
||||
|
||||
@ -34,7 +34,7 @@ via: http://ask.xmodulo.com/install-unity-tweak-tool-ubuntu-desktop.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
每个Linux用户都应该知道的3个有用技巧
|
||||
Linux 用户的 3 个命令行小技巧
|
||||
================================================================================
|
||||
Linux世界充满了乐趣,我们越深入进去,就会发现越多有趣的事物。我们会努力给你提供一些小技巧,让你和其他人有所不同,下面就是我们准备的3个小技巧。
|
||||
|
||||
### 1. 如何在不使用Cron的情况调度Linux下的作业 ###
|
||||
在Linux下,调度一个作业/命令可以缩写为Cron。当我们需要调度一个作业时,我们会使用Cron,但你知道我们在不使用Cron的情况也可以调度一个在将来时间运行的作业吗?你可以按照如下建议操作……
|
||||
### 1. 如何在不使用Cron的情况调度Linux下的任务 ###
|
||||
|
||||
在Linux下,调度一个任务/命令称之为Cron。当我们需要调度一个任务时,我们会使用Cron,但你知道我们在不使用Cron的情况也可以调度一个在将来时间运行的任务吗?你可以按照如下建议操作……
|
||||
|
||||
每5秒钟运行一个命令(date)然后将结果写入到一个文件(data.txt)。为了实现这一点,我们可以直接在命令提示符运行如下单行脚本。
|
||||
|
||||
@ -21,13 +22,13 @@ Linux世界充满了乐趣,我们越深入进去,就会发现越多有趣的
|
||||
|
||||
类似地,我们可以这样运行任何脚本。下边的例子是每100秒运行一个名为`script_name.sh`的脚本。
|
||||
|
||||
另外值得一提的是上边的脚本文件必须处于当前目录中,否则需要使用完整路径(`/home/$USER/…/script_name.sh`)。实现如上功能的单行脚本如下:
|
||||
另外值得一提的是上面提到的脚本文件必须处于当前目录中,否则需要使用完整路径(`/home/$USER/…/script_name.sh`)。实现如上功能的单行脚本如下:
|
||||
|
||||
$ while true; do /bin/sh script_name.sh ; sleep 100 ; done &
|
||||
|
||||
**总结**:上述的单行脚本并不是Cron的替代品,因为Cron工具支持众多选项,更加灵活,可定制性也更高。然而如果我们想运行某些测试,比如I/O评测,上述的单行脚本也管用。
|
||||
|
||||
还可以参考:[11 Linux Cron Job Scheduling Examples][1]
|
||||
还可以参考:[Linux 下 11 个定时调度任务例子][1]
|
||||
|
||||
### 2. 如何不使用clear命令清空终端的内容 ###
|
||||
|
||||
@ -37,23 +38,23 @@ Linux世界充满了乐趣,我们越深入进去,就会发现越多有趣的
|
||||
|
||||
**总结**:因为`ctrl + l`是一个快捷键,我们不可以在脚本中使用。所以如果我们需要在脚本中清空屏幕内容,还是需要使用`clear`命令。但我能想到的所有其他情况,`ctrl + l`都更加有效。
|
||||
|
||||
### 3. 运行一个命令,然后自动回到当前的工作目录 ###
|
||||
### 3. 在其它目录运行一个命令,然后自动返回当前工作目录 ###
|
||||
|
||||
这是一个很多人可能不知道的令人吃惊的技巧。你可能想运行任何一个命令,然后再回到当前目录。你只需要将命令放在一个圆括号里。
|
||||
这是一个很多人可能不知道的令人吃惊的技巧。你可能想在其它目录运行任何一个命令,然后再回到当前目录。要实现这样的目的,你只需要将命令放在一个圆括号里。
|
||||
|
||||
我们来看一个例子:
|
||||
|
||||
avi@deb:~$ (cd /home/avi/Downloads/)
|
||||
|
||||
#### 示例输出 ####
|
||||
|
||||
avi@deb:~
|
||||
示例输出:
|
||||
|
||||
avi@deb:~
|
||||
|
||||
它首先会cd到Downloads目录,然后又回到了之前的家目录。也许你认为里边的命令根本没有执行,或者是出了某种错误,因为从命令提示符看不出任何变化。让我们简单修改一下这个命令:
|
||||
|
||||
avi@deb:~$ (cd /home/avi/Downloads/ && ls -l)
|
||||
|
||||
#### 示例输出 ####
|
||||
|
||||
示例输出:
|
||||
|
||||
-rw-r----- 1 avi avi 54272 May 3 18:37 text1.txt
|
||||
-rw-r----- 1 avi avi 54272 May 3 18:37 text2.txt
|
||||
@ -70,7 +71,7 @@ via: http://www.tecmint.com/useful-linux-hacks-commands/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,226 @@
|
||||
如何在linux中用“OpenCart”创建自己的在线商店
|
||||
================================================================================
|
||||
在网络世界我们可以用电脑做所有事情,电子商务(e-commerce)即是其中之一。电子商务并不是什么新鲜事,它起源于早期的阿帕网,当时就出现了麻省理工学院和斯坦福大学人工智能实验室的学生之间的交易。
|
||||
|
||||
近些年出现了上百家电子商务网站,如 Flipcart, eBay, Alibaba, Zappos, IndiaMART, Amazon, 等等。你想做一个自己的亚马逊和Flipcart这样的基于web的应用程序服务器吗?如果是!这个文章正适合你。
|
||||
|
||||
Opencart是一个免费开源的使用PHP语言编写的电子商务程序,它可以用来架设一个类似于亚马逊和Flipcart的购物车系统。如果你想在线卖你的产品或想在关门时为你的客户提供服务,Opencart就是给你准备的。你可以使用可靠和专业Opencart应用程序建立一个成功的网上商店(网上商家)。
|
||||
|
||||
### OpenCart 网页面板演示 ###
|
||||
|
||||
- 商店前端 – [http://demo.opencart.com/][1]
|
||||
- 管理登录 – [http://demo.opencart.com/admin/][2]
|
||||
|
||||
--
|
||||
------------------ 管理登录 ------------------
|
||||
|
||||
用户名: demo
|
||||
密码: demo
|
||||
|
||||
#### Opencart的特点 ####
|
||||
|
||||
Opencart是一个符合所有在线商家需求的应用程序。它具备您用来制作自己的电子商务网站的所有特性(见下文)。
|
||||
|
||||
- 它是一个免费(如啤酒般免费)而开源(如言论般自由)的应用,在GNU GPL许可下发布。
|
||||
- 每个东西都有完善的文档,你不需要到谷歌喊救命。
|
||||
- 任意时间的支持和更新。
|
||||
- 支持无限数量的类别、产品和制造商。
|
||||
- 一切都是基于模板的。
|
||||
- 支持多语言和多币种。它确保你的产品遍及全球。
|
||||
- 内置产品评论和评级功能。
|
||||
- 支持可下载的产品(即电子书)。
|
||||
- 支持自动缩放图像。
|
||||
- 类似多税率(许多国家都是这样)、查看相关产品、资料页、装船重量计算,使用折扣优惠券,等等功能默认都有了。
|
||||
- 内置的备份和恢复工具。
|
||||
- 搜索引擎优化做的很好。
|
||||
- 发票打印、错误日志和销售报告等都做的很好。
|
||||
|
||||
#### 系统需求 ####
|
||||
|
||||
- Web 服务器 (首选 Apache HTTP服务器)
|
||||
- PHP (5.2 或以上)
|
||||
- 数据库 (首选MySQL,但是我这里用的是MariaDB)
|
||||
|
||||
#### PHP需要的库和模块 ####
|
||||
|
||||
这些扩展必须在您的系统上安装并启用,才能确保Opencart正确安装在web服务器上
|
||||
|
||||
- Curl
|
||||
- Zip
|
||||
- Zlib
|
||||
- GD Library
|
||||
- Mcrypt
|
||||
- Mbstrings
|
||||
|
||||
### 第一步: 安装 Apache、 PHP 和 MariaDB ###
|
||||
|
||||
1. 像我说的,OpenCart需要一定的技术要求,比如在系统上安装Apache,PHP扩展和数据库(MySQL或MariaDB),才能正常运行Opencart。
|
||||
|
||||
让我们使用命令行安装Apache,PHP和MariaDB。
|
||||
|
||||
**安装 Apache**
|
||||
|
||||
# apt-get install apache2 (在基于Debian系统上)
|
||||
# yum install httpd (在基于RedHat系统上)
|
||||
|
||||
**安装 PHP and Extensions**
|
||||
|
||||
# apt-get install php5 libapache2-mod-php5 php5-curl php5-mcrypt (在基于Debian系统上)
|
||||
# yum install php php-mysql php5-curl php5-mcrypt (在基于RedHat系统上)
|
||||
|
||||
**安装 MariaDB**
|
||||
|
||||
# apt-get install mariadb-server mariadb-client (在基于Debian系统上)
|
||||
# yum install mariadb-server mariadb (在基于RedHat系统上)
|
||||
|
||||
2. 在安装所有需要上面的东西后,你可以使用如下命令启动 Apache 和 MariaDB 服务。
|
||||
|
||||
------------------- 在基于Debian系统上 -------------------
|
||||
# systemctl restart apache2.service
|
||||
# systemctl restart mariadb.service
|
||||
|
||||
--
|
||||
------------------- 在基于RedHat系统上 -------------------
|
||||
# systemctl restart httpd.service
|
||||
# systemctl restart mariadb.service
|
||||
|
||||
### 第二步:下载和设置 OpenCart ###
|
||||
|
||||
3. 最新版本的OpenCart(2.0.2.0)可以从[OpenCart 网站][3]下载,或直接从github获得。
|
||||
|
||||
作为一种选择,你可以使用wget命令直接从github库下载最新版本的OpenCart,如下所示。
|
||||
|
||||
# wget https://github.com/opencart/opencart/archive/master.zip
|
||||
|
||||
4. 下载压缩文件后,拷贝到Apache工作目录下(例如/var/www/html)然后解压缩master.zip文件。
|
||||
|
||||
# cp master.zip /var/www/html/
|
||||
# cd /var/www/html
|
||||
# unzip master.zip
|
||||
|
||||
5. 提取‘master.zip’文件后,切换到提取目录下,然后移动upload目录到应用程序的根文件夹(opencart-master)
|
||||
|
||||
# cd opencart-master
|
||||
# mv -v upload/* ../opencart-master/
|
||||
|
||||
6. 现在需要重命名或复制OpenCart配置文件,如下所示。
|
||||
|
||||
# cp /var/www/html/opencart-master/admin/config-dist.php /var/www/html/opencart-master/admin/config.php
|
||||
# cp /var/www/html/opencart-master/config-dist.php /var/www/html/opencart-master/config.php
|
||||
|
||||
7. 下一步,设置/var/www/html/opencart-master的文件和文件夹正确的权限。您需要提供RWX权限给文件和文件夹,用递归方式。
|
||||
|
||||
# chmod 777 -R /var/www/html/opencart-master
|
||||
|
||||
**重要**: 设置权限777可能是危险的,所以一旦你完成所有设置,递归恢复755权限到上层的文件夹。
|
||||
|
||||
### 第三步: 创建 OpenCart 数据库 ###
|
||||
|
||||
8. 下一步是给你的电子商务网站创建一个数据库(比如叫做 opencartdb)来存储数据。连接到数据库服务器并创建一个数据库和用户,并授予用户正确的权限以完全控制该数据库。
|
||||
|
||||
# mysql -u root -p
|
||||
CREATE DATABASE opencartdb;
|
||||
CREATE USER 'opencartuser'@'localhost' IDENTIFIED BY 'mypassword';
|
||||
GRANT ALL PRIVILEDGES ON opencartdb.* TO 'opencartuser'@'localhost' IDENTIFIED by 'mypassword';
|
||||
|
||||
### 第四步: OpenCart 网站安装 ###
|
||||
|
||||
9. 一旦所有设置正确,到web浏览器地址栏输入`http://<web服务器IP地址>`访问OpenCart web安装。
|
||||
|
||||
点击“继续”,同意许可证协议。
|
||||
|
||||

|
||||
|
||||
*同意OpenCart许可证*
|
||||
|
||||
10. 下一个屏幕是安装前服务器设置检查,查看服务器所需的所有模块是否安装正确并且有OpenCart文件的权限。
|
||||
|
||||
如果在第1和2区域有红色标志突出显示,这意味着你需要在服务器上正确安装这些组件满足web服务器的要求。
|
||||
|
||||
如果在第3和4区域有红色标志突出显示,这意味着你的文件有问题。如果一切正确配置您应该看到所有都是绿色标志(见下面),你可以按“继续”。
|
||||
|
||||

|
||||
|
||||
*服务器需求检查*
|
||||
|
||||
11. 在下一个屏幕上输入数据库凭证信息,如数据库驱动类型、主机名、用户名、密码、数据库。你不应该改动数据库端口和前缀,除非你知道你在做什么。
|
||||
|
||||
另外输入管理员账号的用户名、密码和邮箱地址。注意这些凭证将用于管理员登录到Opencart管理面板,所以保证它的安全。完成后单击继续!
|
||||
|
||||
|
||||
|
||||
*OpenCart数据库详情*
|
||||
|
||||
12. 下一个屏幕显示的信息如“Installation Complete”和“Ready to Start Selling”。这里还警告说,要记得删除安装目录,所有需要这个目录安装的设置已经完成。
|
||||
|
||||

|
||||
|
||||
*OpenCart安装完成*
|
||||
|
||||
删除安装目录,你可以执行下面的命令。
|
||||
|
||||
# rm -rf /var/www/html/opencart-master/install
|
||||
|
||||
### 第四步: 进入OpenCart 及其管理界面 ###
|
||||
|
||||
13. 现在打开浏览器到`http://<web server IP address>/opencart-master/`然后你会看到类似下面的截屏。
|
||||
|
||||

|
||||
|
||||
*OpenCart产品示例*
|
||||
|
||||
14. 要登录到Opencart管理面板,你需要浏览`http://<web server IP address>/opencart-master/admin`然后填写之前设置的凭证。
|
||||
|
||||

|
||||
|
||||
*OpenCart管理登录*
|
||||
|
||||
15. 如果全部OK你应该可以看到Opencart的控制台。
|
||||
|
||||

|
||||
|
||||
*OpenCart控制台*
|
||||
|
||||
在管理控制台可以设置很多选项,如类别、产品、选择、制造商、下载、评论、信息、扩展安装、运输、付款选项、订单总数、礼品券、贝宝、优惠券、子公司、营销、邮件、设计风格和设置、错误日志、内置分析等等。
|
||||
|
||||
#### 测试了这个工具之后呢? ####
|
||||
|
||||
如果您已经测试了这个应用程序,就会发现它可定制、灵活、稳定、易于维护和使用,您可能需要一个好的主机托管提供商托管你的OpenCart应用,以便保持24 x7的在线支持。尽管有很多选择,我们建议Hostgator主机提供商。(广告硬植-.-!,以下硬广和 LCTT 无关~)
|
||||
|
||||
Hostgator是以服务和功能出名的域名注册和虚拟机托管提供商。它为你提供无限的磁盘空间、无限带宽、易于安装(一键安装脚本)、99.9%的正常运行时间、荣获24x7x365技术支持和45天退款保证,这意味着如果你不喜欢这个产品和服务就可以在45天内拿回你的采购费,注意这45天是一个长的测试时间。
|
||||
|
||||
所以如果你有什么想卖的你可以免费地去做了(我的意思是免费,想想你会花在实体存储上的费用,然后比较其与建设虚拟商店的成本。你就会感受到它的免费了)。
|
||||
|
||||
**注**: 当你从Hostgator购买虚拟主机(和/或域名)你将获得一个**25%折扣**。这只提供给Tecmint网站的读者。
|
||||
|
||||
你所要做的就是在购买虚拟机支付时输入优惠码“**TecMint025**”。付款预览截屏优惠码以供参考用。
|
||||
|
||||
|
||||
|
||||
*[注册 Hostgator][4] (折扣码: TecMint025)*
|
||||
|
||||
**注**: 还值得一提的,每个你从Hostgator购买的托管OpenCart的虚拟机,我们将得到少量的佣金,只是为了保持Tecmint存活 (通过支付带宽和托管服务器)。
|
||||
|
||||
所以如果你使用上面的代码买它,你得到折扣,我们会得到少量收入。还要注意,你不会支付任何额外的费用,事实上你支付的账单总额将减少25%。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
OpenCart是一个开箱可用的应用。它易于安装,您可以选择选择最适合的模板,添加你的产品然后你就成为了一个在线店主。
|
||||
|
||||
很多社区开发的扩展(有免费和付费的)使它变得丰富。这是一个给那些想要建立一个保持24X7小时用户可访问的虚拟商店的美妙应用。让我们知道你对这个应用程序的体验吧。欢迎任何建议和反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-e-commerce-online-shopping-store-using-opencart-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://demo.opencart.com/
|
||||
[2]:http://demo.opencart.com/admin/
|
||||
[3]:http://www.opencart.com/index.php?route=download/download/
|
||||
[4]:http://secure.hostgator.com/%7Eaffiliat/cgi-bin/affiliates/clickthru.cgi?id=tecmint
|
||||
237
published/20150528 Things To Do After Installing Fedora 22.md
Normal file
237
published/20150528 Things To Do After Installing Fedora 22.md
Normal file
@ -0,0 +1,237 @@
|
||||
安装 Fedora 22 后要做的事情
|
||||
================================================================================
|
||||
|
||||
Red Hat操作系统的社区开发版的最新成员Fedora 22,已经于2015年5月26日发布了。对这个经典的Fedora发行版的发布充斥着各种猜测和预期,而最终Fedora 22推出了许多重大变化。
|
||||
|
||||
就初始化进程而言,Systemd还是个新生儿,但它已经准备好替换古老的sysvinit这个一直是Linux生态系统一部分的模块。另外一个用户会碰到的重大改变存在于基本仓库的python版本中,这里提供了两种不同口味的python版本,2.x和3.x分支,各个都有其不同的偏好和优点。所以,那些偏好2.x口味的用户可能想要安装他们喜爱的python版本。自从Fedora 18开始 dandified YUM安装器(即 DNF)就准备替换过时陈旧的YUM安装器了,Fedora最后决定,现在就用DNF来替换YUM。
|
||||
|
||||
### 1) 配置RPMFusion仓库 ###
|
||||
|
||||
正如我已经提到过的,Fedora的意识形态很是严谨,它不会自带任何非自由组件。官方仓库不会提供一些包含有非自由组件的基本软件,比如像多媒体编码。因此,安装一些第三方仓库很有必要,这些仓库会为我们提供一些基本的软件。幸运的是,RPMFusion仓库前来拯救我们了。
|
||||
|
||||
$ sudo dnf install --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-22.noarch.rpm
|
||||
|
||||
### 2) 安装VLC媒体播放器 ###
|
||||
|
||||
Fedora 22默认自带了媒体播放器,即 gnome视频播放器(以前叫做totem)。如果你觉得还好,那么我们可以跳过这一步继续往前走。但是,如果你像我一样,偏好使用最广泛的VLC,那么就去从RPMFusion仓库安装吧。安装方法如下:
|
||||
|
||||
sudo dnf install vlc -y
|
||||
|
||||
### 3) 安装多媒体编码 ###
|
||||
|
||||
刚刚我们说过,一些多媒体编码和插件不会随Fedora一起发送。现在,有谁想仅仅是因为专有编码而错过他们最爱的节目和电影?试试这个吧:
|
||||
|
||||
$ sudo dnf install gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-ugly gstreamer-ffmpeg gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer-plugins-base-tools gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-good gstreamer1-plugins-base gstreamer1
|
||||
|
||||
### 4) 更新系统 ###
|
||||
|
||||
Fedora是一个前锐的发行版,因此它会不断发布更新用以修复系统中出现的错误和漏洞。因而,保持系统更新到最新,是个不错的做法。
|
||||
|
||||
$ sudo dnf update -y
|
||||
|
||||
### 5) 卸载你不需要的软件 ###
|
||||
|
||||
Fedora预装了一些大多数用户都有用的软件包,但是对于更高级的用户,你可能知道到你并不需要它。要移除你不需要的包相当容易,只需使用以下命令——我选择卸载rhythmbox,因为我知道我不会用到它:
|
||||
|
||||
$ sudo dnf remove rhythmbox
|
||||
|
||||
### 6) 安装Adobe Flash ###
|
||||
|
||||
我们都希望Adobe Flash不要再存在了,因为它并不被认为是最安全的,或者存在资源问题,但是暂时先让它待着吧。Fedora 22安装Adobe Flash的唯一途径是从Adobe安装官方RPM,就像下面这样。
|
||||
|
||||
你可以从[这里][1]下载RPM。下载完后,你可以直接右击并像下面这样打开:
|
||||
|
||||

|
||||
|
||||
右击并选择“用软件安装打开”
|
||||
|
||||
然后,只需在弹出窗口中点击安装:
|
||||
|
||||

|
||||
|
||||
*点击“安装”来完成安装Adobe定制RPM的过程*
|
||||
|
||||
该过程完成后,“安装”按钮会变成“移除”,而此时安装也完成了。如果在此过程中你的浏览器开着,会提示你先把它关掉或在安装完成后重启以使修改生效。
|
||||
|
||||
### 7) 用Gnome Boxes加速虚拟机 ###
|
||||
|
||||
你刚刚安装了Fedora,你也很是喜欢,但是出于某些私人原因,你也许仍然需要Windows,或者你只是想玩玩另外一个Linux发行版。不管哪种情况,你都可以使用Gnome Boxes来简单地创建一个虚拟机或使用一个live发行版,Fedora 22提供了该软件。遵循以下步骤,使用你所选的ISO来开始吧!谁知道呢,也许你可以检验一下某个[Fedora Spin][2]。
|
||||
|
||||
首先,打开Gnome Boxes,然后在顶部左边选择“新建”:
|
||||
|
||||

|
||||
|
||||
点击“新建”来开始添加一个新虚拟机的进程吧。
|
||||
|
||||
接下来,点击打开文件并选择一个ISO:
|
||||
|
||||

|
||||
|
||||
*在点击了“选择文件或ISO”后,选择你的ISO。这里,我已经安装了一个Debian ISO。*
|
||||
|
||||
最后,自定义VM设置或使用默认配置,然后点击“创建”。VM默认会启动,可用的VM会在Gnome Boxes以小缩略图的方式显示。
|
||||
|
||||

|
||||
|
||||
*自定义你自己的设置,或者也可以保持默认。完成后,点击“创建”,VM就一切就绪了。*
|
||||
|
||||
### 8) 添加社交媒体和其它在线帐号 ###
|
||||
|
||||
Gnome自带有不错的内建功能用于容纳帐号相关的东西,像Facebook,Google以及其它在线帐号。你可以通过Gnome设置应用访问在线帐号设置,可以在桌面上右键点击或在应用程序中找到该应用。然后,只需点击在线帐号,并添加你所选择的帐号。如果你要添加一个帐号,比如像Google,你可以用它来作为默认帐号,用来完成诸如发送邮件、日历提醒、相片和文档交互,以及诸如此类的更多事情。
|
||||
|
||||
### 9) 安装KDE或另一个桌面环境 ###
|
||||
|
||||
我们中的某些人不喜欢Gnome,那也没问题。在终端中运行以下命令来安装KDE所需的一切来替换它。这些指令也可以用以安装xfce、lxde或其它桌面环境。
|
||||
|
||||
$ sudo dnf install @kde-desktop
|
||||
|
||||
安装完成后,登出。当你点击你的用户名时,注意那个表示设置的小齿轮。点击它,然后选择“Plasma”。当你再次登录时,一个全新的KDE桌面就会欢迎你。
|
||||
|
||||

|
||||
|
||||
*刚刚安装到Fedora 22上的Plasma环境*
|
||||
|
||||
####在 Fedora 22中安装 Cinnamon桌面:####
|
||||
|
||||
打开SSH终端,输入或粘帖如下命令并回车:
|
||||
|
||||
sudo dnf install @cinnamon-desktop
|
||||
|
||||
####在 Fedora 22中安装 MATE桌面:####
|
||||
|
||||
打开SSH终端,输入或粘帖如下命令并回车:
|
||||
|
||||
sudo dnf install @mate-desktop
|
||||
|
||||
####在 Fedora 22中安装 XFCE桌面:####
|
||||
|
||||
打开SSH终端,输入或粘帖如下命令并回车:
|
||||
|
||||
sudo dnf install @xfce-desktop
|
||||
|
||||
####在 Fedora 22中安装 LXDE桌面:####
|
||||
|
||||
打开SSH终端,输入或粘帖如下命令并回车:
|
||||
|
||||
sudo dnf install @lxde-desktop
|
||||
|
||||
### 10) 定制桌面并优化设置 ###
|
||||
|
||||
默认的 Gnome 带有一张黑色背景和一个新的锁屏,幸运的是,很容易通过下面的方式来改变:
|
||||
|
||||

|
||||
|
||||
*右键点击桌面,然后点修改背景*
|
||||
|
||||

|
||||
|
||||
*你会看到这个窗口,这里你选择新的桌面背景或锁屏图片*
|
||||
|
||||
进一步,如果你点击“设置”,你会看到一个菜单展示你所以可以修改的设置。举个例子,在笔记本电脑上,你可以修改电源设置来控制合上笔记本电脑时的动作。
|
||||
|
||||
|
||||
### 11) 安装 Fedy 4.0###
|
||||
|
||||
Fedy 可以帮助用户和系统管理员来监控系统的运作,并让他们可以控制系统如其所预期的工作。这里有一行脚本可以安装最新版本的 Fedy。打开终端,输入或粘帖如下行并按下回车。
|
||||
|
||||
su -c "curl https://satya164.github.io/fedy/fedy-installer -o fedy-installer && chmod +x fedy-installer && ./fedy-installer"
|
||||
|
||||
### 12) 安装 Java###
|
||||
|
||||
使用如下命令可以很容易的安装 Java。
|
||||
|
||||
sudo dnf install java -y
|
||||
|
||||
它会根据你的系统架构自动安装32位或64位的 Java 发行版。
|
||||
|
||||
### 13) 在 Fedora 22 上安装浏览器 ###
|
||||
|
||||
Fedora 22的默认浏览器是 Firefox,不过其它的浏览器也各有优缺点。最终用户选择浏览器会有种种原因。这里我们提供一些在 Fedora 22上安装其它浏览器的方法。
|
||||
|
||||
#### 安装 Google Chrome####
|
||||
|
||||
使用你惯用的编辑器,在 yum 库目录中打开或创建 google-chrome.repo 文件。
|
||||
|
||||
sudo gedit /etc/yum.repos.d/google-chrome.repo
|
||||
|
||||
加入以下内容并保存。
|
||||
|
||||
[google-chrome]
|
||||
name=google-chrome
|
||||
baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch
|
||||
enabled=1
|
||||
gpgcheck=1
|
||||
gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub
|
||||
|
||||
现在 yum 就配置好可以找到稳定版本的 Chrome 了,使用如下命令安装它。
|
||||
|
||||
sudo dnf install google-chrome-stable
|
||||
|
||||
#### 安装 Tor 浏览器 ####
|
||||
|
||||
在 Fedora 22 中安装 Tor 有一点棘手,在 /etc/yum.repos.d 目录中打开或创建 torproject.repo 文件。
|
||||
|
||||
sudo gedit /etc/yum.repos.d/torproject.repo
|
||||
|
||||
插入以下内容。
|
||||
|
||||
[tor]
|
||||
name=Tor repo
|
||||
enabled=1
|
||||
baseurl=https://deb.torproject.org/torproject.org/rpm/fc/22/$basearch/
|
||||
gpgcheck=1
|
||||
gpgkey=https://deb.torproject.org/torproject.org/rpm/RPM-GPG-KEY-torproject.org.asc
|
||||
|
||||
[tor-source]
|
||||
name=Tor source repo
|
||||
enabled=1
|
||||
autorefresh=0
|
||||
baseurl=https://deb.torproject.org/torproject.org/rpm/fc/22/SRPMS
|
||||
gpgcheck=1
|
||||
gpgkey=https://deb.torproject.org/torproject.org/rpm/RPM-GPG-KEY-torproject.org.asc
|
||||
|
||||
也许会问到 GPG 键的指纹,它应该如下。
|
||||
|
||||
3B9E EEB9 7B1E 827B CF0A 0D96 8AF5 653C 5AC0 01F1
|
||||
|
||||
不幸的是,在 EPEL 和 Fedora 仓库中有一个相同名字的软件包,你需要明确排除这个来避免安装/删除/修改它。所以,在/etc/yum.repos.d/epel.repo 中加入 `Exclude=tor` 一行。
|
||||
|
||||
最后,使用如下命令来安装 Tor。
|
||||
|
||||
sudo dnf install tor
|
||||
|
||||
安装完成,启动服务。
|
||||
|
||||
sudo service tor start
|
||||
|
||||
#### 安装 Vivaldi####
|
||||
|
||||
根据你的系统架构下载32位或64位的 Vivaldi 浏览器。
|
||||
|
||||
sudo wget https://vivaldi.com/download/Vivaldi_TP3.1.0.162.9-1.i386.rpm
|
||||
sudo wget https://vivaldi.com/download/Vivaldi_TP3.1.0.162.9-1.x86_64.rpm
|
||||
|
||||
使用下列命令安装下载的 RPM。
|
||||
|
||||
sudo rpm -ivh Vivaldi_TP3.1.0.162.9-1.i386.rpm
|
||||
sudo rpm -ivh Vivaldi_TP3.1.0.162.9-1.x86_64.rpm
|
||||
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
就是这样了,一切就绪。使用新系统吧,试试新东西。如果你找不到与你喜好的东西,linux赋予你自由修改它的权利。Fedora自带有最新的Gnome Shell作为其桌面环境,如果你觉得太臃肿而不喜欢,那么试试KDE或一些轻量级的DE,像Cinnamon、xfce之类。愿你的Fedora之旅十分开心并且没有困扰!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/things-do-after-installing-fedora-22/
|
||||
|
||||
作者:[Jonathan DeMasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/jonathande/
|
||||
[1]:https://get.adobe.com/flashplayer/
|
||||
[2]:http://spins.fedoraproject.org/
|
||||
[3]:https://www.google.com/intl/en/chrome/browser/desktop/index.html
|
||||
@ -0,0 +1,57 @@
|
||||
一款很棒的GTK桌面主题:Arc
|
||||
================================================================================
|
||||
|
||||
|
||||
距离本站上次推荐的GTK主题已经过了很久了。但是看到上图中的Arc主题后,就值得打破冷场了。我们不能不推荐它!
|
||||
|
||||
### Arc GTK主题 ###
|
||||
|
||||

|
||||
|
||||
*透明,并不符合每个人的口味*
|
||||
|
||||
Arc是一个扁平化主题并有微妙的配色方案,窗口的选中区域是透明的,如GTK的顶栏和Nautilus的侧边栏。
|
||||
|
||||
它的效果不像我们之前介绍的主题那样将程序渲染的像那么混乱。有点像 OSX Yosemite,效果用的不多但是很好。
|
||||
|
||||
与之伴随的图标集(称为Vertex)同样工作的很好。
|
||||
|
||||
**是的它支持Unity**
|
||||
|
||||
Arc主题支持基于GTK3和GTK2桌面环境,包含Gnome Shell(当然了)和标准的Ubuntu Unity。
|
||||
|
||||
它可以很好地游刃于轻量级的Budgie和elementary的Pantheon桌面之间,并且与Cinnamon配合也不错。
|
||||
|
||||

|
||||
|
||||
*Arc中的开关、滑块和小挂件*
|
||||
|
||||
它并不容易下载与安装- *understatement klaxon* - 因为它还在密集开发中。
|
||||
|
||||
安装包需要GTK 3.14及以上,这意味着Ubuntu 14.04 LTS和14.10的用户无法使用了。
|
||||
|
||||
那些使用Ubuntu 15.04的用户可以使用这个主题。你可以添加ppa或者双击.deb包来安装。
|
||||
|
||||
如果你喜欢它,你需要卷起你的袖子并查看github上的编译指导。
|
||||
|
||||
- [Github中Arc安装指导][1]
|
||||
|
||||
更新6/7:现在可以使用软件库来安装它(由 openSUSE 用户 Horst1380 创建,也可用于 Ubuntu 用户),也可以下载预打包的 .deb 文件。
|
||||
|
||||
- [Horst31890 的 Arc 主题库][2]
|
||||
- [下载 Arc 主题 .deb][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/arc-gtk-theme
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/horst3180/Arc-theme
|
||||
[2]:http://software.opensuse.org/download.html?project=home%3AHorst3180&package=arc-theme
|
||||
[3]:http://download.opensuse.org/repositories/home:/Horst3180/xUbuntu_15.04/all/arc-theme_1433786431.697b2c3_all.deb
|
||||
@ -0,0 +1,106 @@
|
||||
在Linux上如何清除内存的 Cache、Buffer 和交换空间
|
||||
============================================
|
||||
|
||||
像任何其他的操作系统一样,GNU/Linux 已经实现的内存管理不仅有效,而且更好。但是,如果有任何进程正在蚕食你的内存,而你想要清除它的话,Linux 提供了一个刷新或清除RAM缓存方法。
|
||||
|
||||

|
||||
|
||||
### 如何在 Linux 中清除缓存(Cache)?###
|
||||
|
||||
每个 Linux 系统有三种选项来清除缓存而不需要中断任何进程或服务。
|
||||
|
||||
(LCTT 译注:Cache,译作“缓存”,指 CPU 和内存之间高速缓存。Buffer,译作“缓冲区”,指在写入磁盘前的存储再内存中的内容。在本文中,Buffer 和 Cache 有时候会通指。)
|
||||
|
||||
1. 仅清除页面缓存(PageCache)
|
||||
|
||||
# sync; echo 1 > /proc/sys/vm/drop_caches
|
||||
|
||||
2. 清除目录项和inode
|
||||
|
||||
# sync; echo 2 > /proc/sys/vm/drop_caches
|
||||
|
||||
3. 清除页面缓存,目录项和inode
|
||||
|
||||
# sync; echo 3 > /proc/sys/vm/drop_caches
|
||||
|
||||
|
||||
上述命令的说明:
|
||||
|
||||
sync 将刷新文件系统缓冲区(buffer),命令通过“;”分隔,顺序执行,shell在执行序列中的下一个命令之前会等待命令的终止。正如内核文档中提到的,写入到drop_cache将清空缓存而不会杀死任何应用程序/服务,[echo命令][1]做写入文件的工作。
|
||||
|
||||
如果你必须清除磁盘高速缓存,第一个命令在企业和生产环境中是最安全,`"...echo 1> ..."`只会清除页面缓存。
|
||||
在生产环境中不建议使用上面的第三个选项`"...echo 3 > ..."` ,除非你明确自己在做什么,因为它会清除缓存页,目录项和inodes。
|
||||
|
||||
**在Linux上释放也许被内核所使用的缓冲区(Buffer)和缓存(Cache)是否是个好主意?**
|
||||
|
||||
当你设置许多设定想要检查效果时,如果它实际上是专门针对 I/O 范围的基准测试,那么你可能需要清除缓冲区和缓存。你可以如上所示删除缓存,无需重新启动系统(即无需停机)。
|
||||
|
||||
Linux被设计成它在寻找磁盘之前到磁盘缓存寻找的方式。如果它发现该资源在缓存中,则该请求不会发送到磁盘。如果我们清理缓存,磁盘缓存就起不到作用了,系统会到磁盘上寻找资源。
|
||||
|
||||
此外,当清除缓存后它也将减慢系统运行速度,系统会将每一个被请求的资源再次加载到磁盘缓存中。
|
||||
|
||||
|
||||
现在,我们将创建一个 shell 脚本,通过一个 cron 调度任务在每天下午2点自动清除RAM缓存。如下创建一个 shell 脚本 clearcache.sh 并在其中添加以下行:
|
||||
|
||||
#!/bin/bash
|
||||
# 注意,我们这里使用了 "echo 3",但是不推荐使用在产品环境中,应该使用 "echo 1"
|
||||
echo "echo 3 > /proc/sys/vm/drop_caches"
|
||||
|
||||
给clearcache.sh文件设置执行权限
|
||||
|
||||
# chmod 755 clearcache.sh
|
||||
|
||||
现在,当你需要清除内存缓存时只需要调用脚本。
|
||||
|
||||
现在设置一个每天下午2点的定时任务来清除RAM缓存,打开crontab进行编辑。
|
||||
|
||||
# crontab -e
|
||||
|
||||
添加以下行,保存并退出。
|
||||
|
||||
0 3 * * * /path/to/clearcache.sh
|
||||
|
||||
有关如何创建一个定时任务,更多细节你可以查看我们的文章 [11 个定时调度任务的例子][2]。
|
||||
|
||||
**在生产环境的服务器上自动清除RAM是否是一个好主意?**
|
||||
|
||||
不!它不是。想想一个情况,当你已经预定脚本在每天下午2点来清除内存缓存。那么其时该脚本会执行并刷新你的内存缓存。在某一天由于某些原因,可能您的网站的在线用户会超过预期地从你的服务器请求资源。
|
||||
|
||||
|
||||
而在这时,按计划调度的脚本运行了,并清除了缓存中的一切。当所有的用户都从磁盘读取数据时,这将导致服务器崩溃并损坏数据库。因此,清除缓存仅在必要时并且在你的预料之中,否则你就是个呆瓜系统管理员。
|
||||
|
||||
###如何清除Linux的交换空间?###
|
||||
|
||||
如果你想清除掉的空间,你可以运行下面的命令:
|
||||
|
||||
# swapoff -a && swapon -a
|
||||
|
||||
此外,了解有关风险后,您可以将上面的命令添加到cron中。
|
||||
|
||||
现在,我们将上面两种命令结合成一个命令,写成正确的脚本来同时清除RAM缓存和交换空间。
|
||||
|
||||
# echo 3 > /proc/sys/vm/drop_caches && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
或
|
||||
|
||||
su -c 'echo 3 > /proc/sys/vm/drop_caches' && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
在测试上面的命令之前,我们在执行脚本前后运行“free -m” 来检查缓存。
|
||||
|
||||
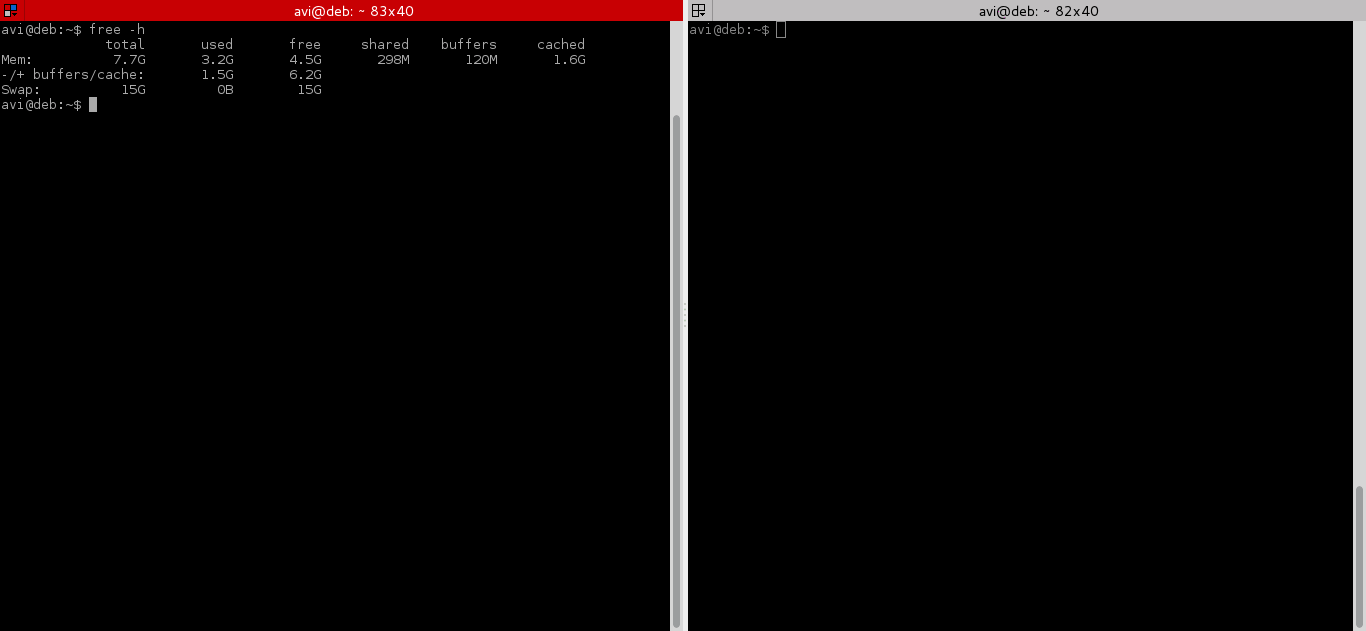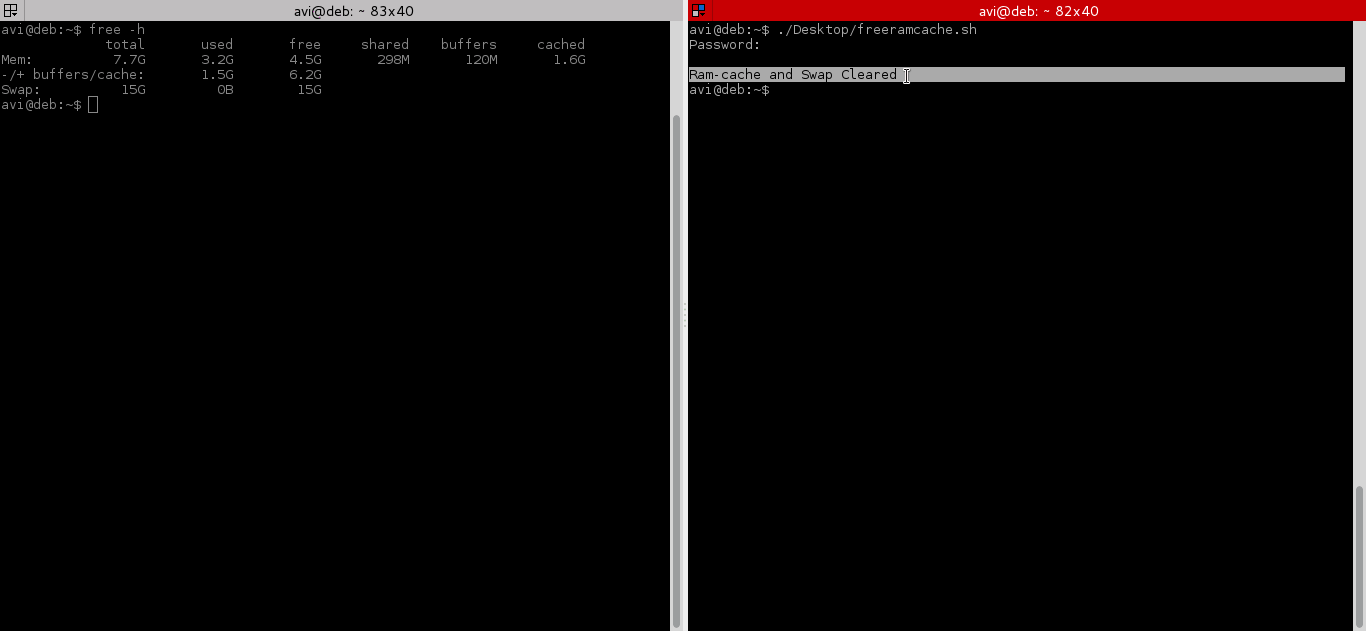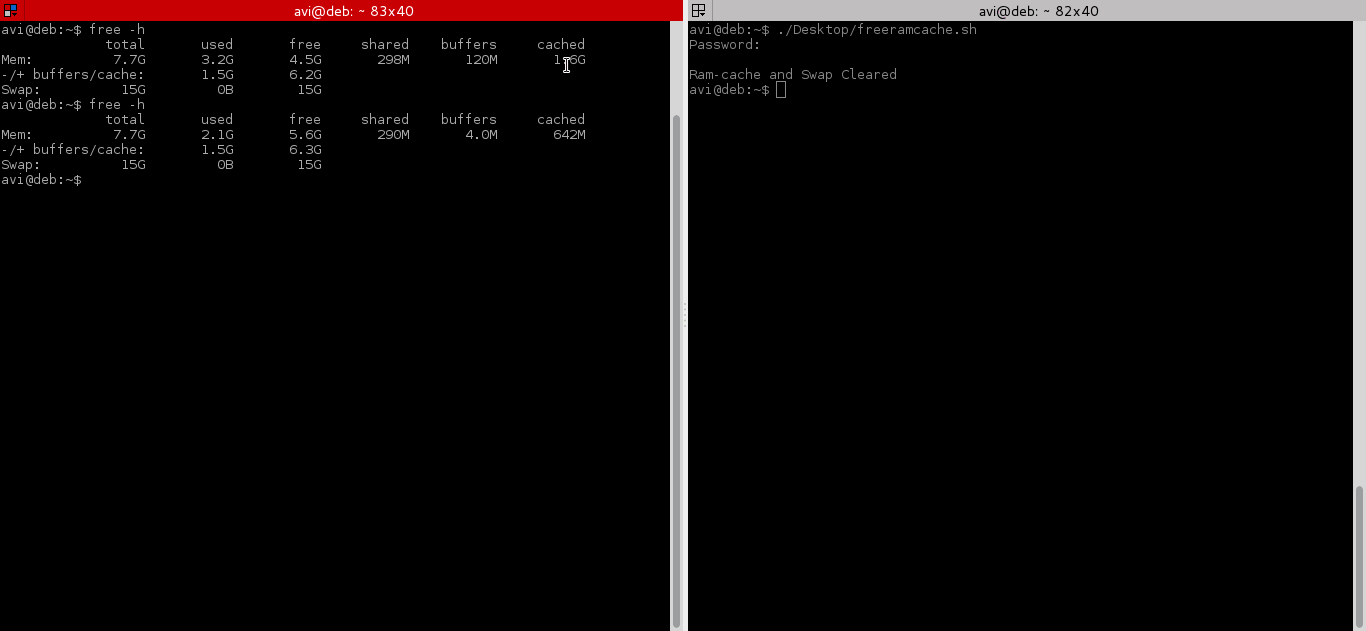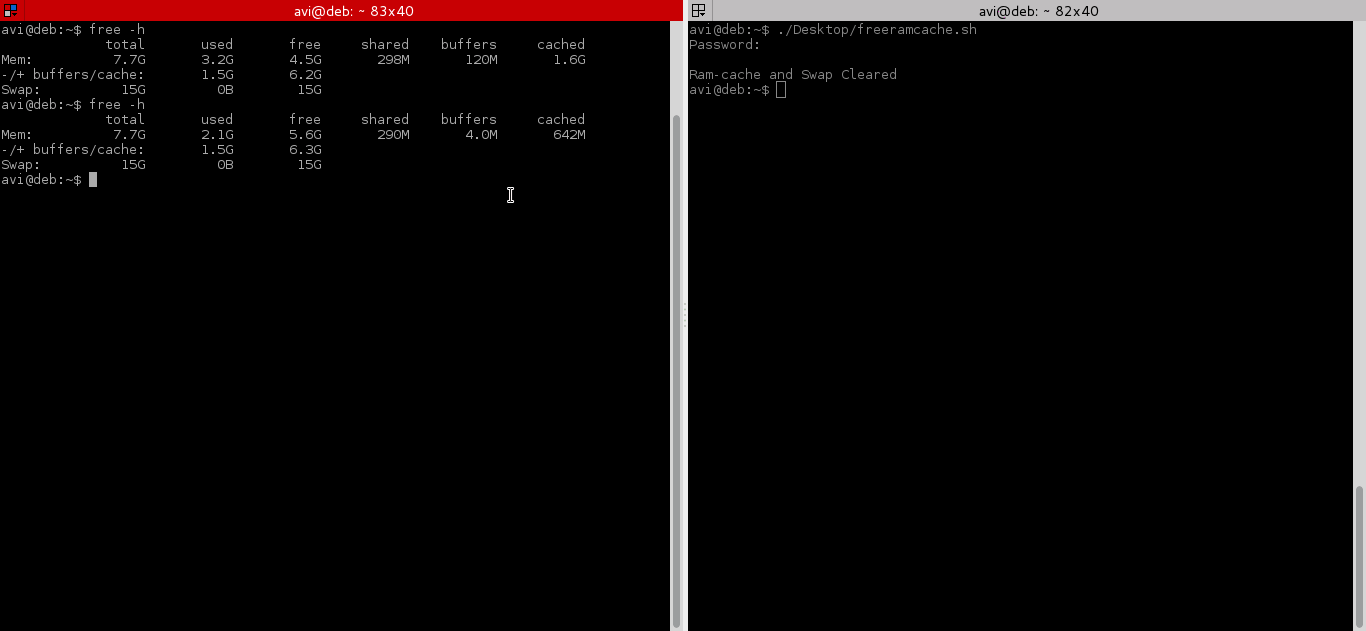
|
||||
|
||||
就是这样,如果你喜欢这篇文章,不要忘记向我们提供您宝贵的意见,让我们知道,您认为在企业和生产环境中清除内存缓存和缓冲区是否是一个好主意?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/clear-ram-memory-cache-buffer-and-swap-space-on-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://linux.cn/article-3592-1.html
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -1,99 +0,0 @@
|
||||
3 Open Source Python Shells
|
||||
================================================================================
|
||||
Python is a high-level, general-purpose, structured, powerful, open source programming language that is used for a wide variety of programming tasks. It features a fully dynamic type system and automatic memory management, similar to that of Scheme, Ruby, Perl, and Tcl, avoiding many of the complexities and overheads of compiled languages. The language was created by Guido van Rossum in 1991, and continues to grow in popularity.
|
||||
|
||||
Python is a very useful and popular computer language. One of the benefits of using an interpreted language such as Python is exploratory programming with its interactive shell. You can try out code without having to write a script. But there are limitations with the Python shell. Fortunately, there are some excellent alternative Python shells that extend on the basic shell. They each offer an excellent interactive Python experience.
|
||||
|
||||
----------
|
||||
|
||||
### bpython ###
|
||||
|
||||

|
||||
|
||||
bpython is a fancy interface to the Python interpreter for Linux, BSD, OS X and Windows.
|
||||
|
||||
The idea is to provide the user with all the features in-line, much like modern IDEs, but in a simple, lightweight package that can be run in a terminal window.
|
||||
|
||||
bpython doesn't seek to create anything new or groundbreaking. Instead, it brings together a few neat ideas and focuses on practicality and usefulness.
|
||||
|
||||
Features include:
|
||||
|
||||
- In-line syntax highlighting - uses Pygments for lexing the code as you type, and colours appropriately
|
||||
- Readline-like autocomplete with suggestions displayed as you type
|
||||
- Expected parameter list for any Python function - seeks to display a list of parameters for any function you call
|
||||
- "Rewind" function to pop the last line of code from memory and re-evaluate
|
||||
- Send the code you've entered off to a pastebin
|
||||
- Save the code you've entered to a file
|
||||
- Auto-indentation
|
||||
- Python 3 support
|
||||
|
||||
- Website: [www.bpython-interpreter.org][1]
|
||||
- Developer: Bob Farrell and contributors
|
||||
- License: MIT License
|
||||
- Version Number: 0.14.1
|
||||
|
||||
----------
|
||||
|
||||
### IPython ###
|
||||
|
||||

|
||||
|
||||
IPython is an enhanced interactive Python shell. It provides a rich toolkit to help you make the most out of using Python interactively.
|
||||
|
||||
IPython can be used as a replacement for the standard Python shell, or it can be used as a complete working environment for scientific computing (like Matlab or Mathematica) when paired with the standard Python scientific and numerical tools. It supports dynamic object introspections, numbered input/output prompts, a macro system, session logging, session restoring, complete system shell access, verbose and colored traceback reports, auto-parentheses, auto-quoting, and is embeddable in other Python programs.
|
||||
|
||||
Features include:
|
||||
|
||||
- Powerful interactive shells (terminal and Qt-based)
|
||||
- A browser-based notebook with support for code, rich text, mathematical expressions, inline plots and other rich media
|
||||
- Support for interactive data visualization and use of GUI toolkits
|
||||
- Flexible, embeddable interpreters to load into your own projects
|
||||
- Easy to use, high performance tools for parallel computing
|
||||
|
||||
- Website: [ipython.org][2]
|
||||
- Developer: The IPython Development Team
|
||||
- License: BSD
|
||||
- Version Number: 3.1
|
||||
|
||||
----------
|
||||
|
||||
### DreamPie ###
|
||||
|
||||

|
||||
|
||||
DreamPie is a Python shell which is designed to be reliable and fun.
|
||||
|
||||
DreamPie can use just about any Python interpreter (Jython, IronPython, PyPy).
|
||||
|
||||
Features include:
|
||||
|
||||
- New concept for an interactive shell: the window is divided into the history box, which lets you view previous commands and their output, and the code box, where you write your code. This allows you to edit any amount of code, just like in your favorite editor, and execute it when it's ready. You can also copy code from anywhere, edit it and run it instantly
|
||||
- The Copy code only command will copy the code you want to keep, so you can save it in a file. The code is already formatted nicely with a four-space indentation
|
||||
- Automatic completion of attributes and file names
|
||||
- Automatically displays function arguments and documentation
|
||||
- Keeps your recent results in the result history, for later use
|
||||
- Can automatically fold long outputs, so you can concentrate on what's important
|
||||
- Save the history of the session as an HTML file, for future reference. You can then load the history file into DreamPie, and quickly redo previous commands
|
||||
- Automatically adds parentheses and optionally quotes when you press space after functions and methods. For example, type execfile fn and get execfile("fn")
|
||||
- Supports interactive plotting with matplotlib
|
||||
- Xupport for Python 2.5, Python 2.6, Python 3.1, Jython 2.5, IronPython 2.6, and PyPy
|
||||
- Extremely fast and responsive.
|
||||
|
||||
- Website: [www.dreampie.org][3]
|
||||
- Developer: Noam Yorav-Raphael
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 1.2.1
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150523032756576/PythonShells.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.bpython-interpreter.org/
|
||||
[2]:http://ipython.org/
|
||||
[3]:http://www.dreampie.org/
|
||||
@ -1,173 +0,0 @@
|
||||
translating wi-cuckoo
|
||||
12 Globally Recognized Linux Certifications
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn about some of the very precious globally recognized Linux Certifications. Linux Certifications are the certification programme hosted by different Linux Professional Institutes across the globe. Linux Certifications allows Linux Professionals to get easily enrolled with the Linux related jobs in servers, companies, etc. Linux Certifications enables how much a person is expertise in that respective field of Linux. There are pretty many Linux Professional Institutes providing different Linux Certifications. But there are some few well recognized Linux Certification Programmes running across the globe which are at high priority while getting a job in companies where we need to manage servers, virtualizations, installations, configurations, application support and other stuffs with Linux Operating System. With the increment of servers running Linux Operating System throughout the globe, the demand of Linux Professional are increasing. For better authenticated and authorized Linux Professional, better and renowned Certifications are always at higher priority by the companies across the globe.
|
||||
|
||||
Here are some globally recognized Linux Certifications that we'll discuss about.
|
||||
|
||||
### 1. CompTIA Linux+ ###
|
||||
|
||||
CompTIA Linux+ is a Linux Certification programme hosted by LPI "Linux Professional Institute" providing knowledge all over the world. It provides knowledge on Linux which enables to produce a bunch of Linux related Professional jobs like Linux Administrators, Junior Network Administrators, Systems Administrators, Linux Database Administrators and Web Administrators. If anyone is aware of installing and maintaining Linux Operating System, this course will help to meet the certification requirements and prepare for the exam by providing with a broad awareness of Linux operating systems. The main objective of CompTIA Linux+ Certification by LPI is to provide the certificate holders enough knowledge on a critical knowledge of installation, operation, administration and troubleshooting devices. We can earn three industry-recognized certifications for the cost, time, and effort of one, by completing the CompTIA Linux+ powered by LPI certification, we can automatically receive the **LPI LPIC-1** and the **SUSE Certified Linux Administrator (CLA)** certifications.
|
||||
|
||||
- **Certification Codes** : LX0-103 and LX0-104 (launches March 30, 2015) OR LX0-101 and LX0-102
|
||||
- Number of questions: 60 questions per exam
|
||||
- Type of Questions: Multiple choice
|
||||
- Length of test period: 90 minutes
|
||||
- Prerequisites: A+, Network+ and at least 12 months of Linux administration experience
|
||||
- Passing score: 500 (on a scale of 200-800)
|
||||
- Languages: English. Coming soon on German, Portuguese (Brazilian), Traditional Chinese, Spanish.
|
||||
- Validity: Valid till 3 Years after certified.
|
||||
|
||||
**Note**: Exams from different series cannot be combined. If you start with LX0-101, you MUST take LX0-102 to complete your certification. The same applies for the LX0-103 and LX0-104 series. The LX0-103 and LX0-104 series is an update to the LX0-101 and LX0-102 series.
|
||||
|
||||
### 2. LPIC ###
|
||||
|
||||
LPIC stands for Linux Professional Institute Certification which is a Linux certification programme by Linux Professional Institute. It is a multi level certification program which requires passing of a number (usually two) certification exams for each level. There are three levels of certification which includes Junior Level Certification **LPIC-1**, Advanced Level Certification **LPIC-2** and Senior Level Certification **LPIC-3**. The first two certification aims on **Linux System Administration** whereas the final certification aims on several specialties including Virtualization and Security. To become **LPIC-3** certified, a candidate with an active **LPIC-1** and **LPIC-2** certification must pass at least one of 300 Mixed Environment, 303 Security and 304 Virtualization and High Availability. LPIC-1 certification is designed in such a way that the certification holder will be able to install, maintain, configure tasks running Linux with command line interface with basic networking where as LPIC-2 certification validates candidate to administer small to medium–sized mixed networks. LPIC-3 certification is designed for enterprise-level Linux professional and represents the highest level of professional, distribution-neutral Linux certification within the industry.
|
||||
|
||||
- **Certification Codes** : LPIC-1 (101 and 102), LPIC-2 (201 and 202) and LPIC-3 (300, 303 or 304)
|
||||
- Type of Questions: 60 Multiple choice questions
|
||||
- Length of Test Period: 90 minutes
|
||||
- Prerequisites: None, Linux Essentials is recommended
|
||||
- Passing Score: 500 (on a scale of 200-800)
|
||||
- Languages: LPIC-1: English, German, Italian, Portuguese (Brazilian), Spanish (Modern), Chinese (Simplified), Chinese (Traditional), Japanese
|
||||
- LPIC-2: English, German, Portuguese (Brazilian), Japanese
|
||||
- LPIC-3: English, Japanese
|
||||
- Validity: Valid till 5 years of Retirement.
|
||||
|
||||
### 3. Oracle Linux OCA ###
|
||||
|
||||
Oracle Certified Associate (OCA) is designed for the individuals who are interested for a strong foundation of knowledge to implement and administer the Oracle Linux Operating System. This certification expertise individuals on the Oracle Linux distribution that's fully optimized for Oracle products and for running on Oracle's engineered systems including Oracle Exadata Database Machine, Oracle Exalytics In-Memory Machine, Oracle Exalogic Elastic Cloud, and Oracle Database Appliance. Oracle Linux's Unbreakable Enterprise Kernel delivers extreme performance, advanced scalability and reliability for enterprise applications. The OCA certification covers objectives such as managing local disk devices, managing file systems, installing and removing Solaris packages and patches, performing system boot procedures and system processes. It is initial step in achievement of flagship of OCP credential. This certification was formerly known as Sun Certified Solaris Associate (SCSAS).
|
||||
|
||||
- **Certification Codes** : OCA
|
||||
- Type of Questions: 75 Multiple choice questions
|
||||
- Length of Test Period: 120 minutes
|
||||
- Prerequisites: None
|
||||
- Passing Score: 64%
|
||||
- Validity: Never Expires
|
||||
|
||||
### 4. Oracle Linux OCP ###
|
||||
|
||||
Oracle Certified Professional (OCP) is the certification provided by Oracle Corporation for Oracle Linux which covers more advanced knowledge and skills of an Oracle Linux Administrator. It covers knowledge such as configuring network interfaces, managing swap configurations, crash dumps, managing applications, databases and core files. OCP certification is benchmark of technical expertise and professional skill needed for developing, implementing, and managing applications, middleware and databases widely in enterprise. Job opportunities for Oracle Linux OCP are increased depending on job market and economy. It is designed such a way that the certificate holder has the ability to perform security administration, prepare Oracle Linux system for Oracle database, troubleshoot problems and perform corrective action, install software packages, installing and configuring kernel modules, maintain swap space, perform User and Group administration, creating file systems, configuring logical volume manager (LVM), file sharing services and more.
|
||||
|
||||
- **Certification Codes** : OCP
|
||||
- Type of Questions: 60 to 80 Multiple choice questions
|
||||
- Length of Test Period: 120 minutes
|
||||
- Prerequisites: Oracle Linux OCA
|
||||
- Passing Score: 64%
|
||||
- Validity: Never Expires
|
||||
|
||||
### 5. RHCSA ###
|
||||
|
||||
RHCSA is a certification programme by Red Hat Incorporation as Red Hat Certified System Administrator. RHCSAs are the person who has the skill, and ability to perform core system administrations in the renowned Red Hat Linux environments. It is an initial entry-level certification programme that focuses on actual competencies at system administration, including installation and configuration of a Red Hat Linux system and attaching it to a live network running network services. A Red Hat Certified System Administrator (RHCSA) is able to understand and use essential tools for handling files, directories, command-line environments, and documentation, operate running systems, including booting into different run levels, identifying processes, starting and stopping virtual machines, and controlling services, configure local storage using partitions and logical volumes, create and configure file systems and file system attributes, such as permissions, encryption, access control lists, and network file systemsm, deploy, configure, and maintain systems, including software installation, update, and core services, manage users and groups, including use of a centralized directory for authentication, security, including basic firewall and SELinux configuration. One should be RHCSA certified to gain RHCE and other certifications.
|
||||
|
||||
- **Certification Codes** : RHCSA
|
||||
- Course Codes: RH124, RH134 and RH199
|
||||
- Exam Codes: EX200
|
||||
- Length of Test Period: 21-22 hours depending on the elective course choosen.
|
||||
- Prerequisites: None. Better if has some fundamental knowledge of Linux.
|
||||
- Passing Score: 210 out of 300 points (70%)
|
||||
- Validity: 3 years
|
||||
|
||||
### 6. RHCE ###
|
||||
|
||||
RHCE, also known as Red Hat Certified Engineer is a mid to advanced level certification programme for Red Hat Certified System Administrator (RHCSA) who wants to acquire additional skills and knowledge required of a senior system administrator responsible for Red Hat Enterprise Linux. RHCE has the ability, knowledge and skills of configuring static routes, packet filtering, and network address translation, setting kernel runtime parameters, configuring an Internet Small Computer System Interface (iSCSI) initiator, producing and delivering reports on system utilization, using shell scripting to automate system maintenance tasks, configuring system logging, including remote logging, system to provide networking services including HTTP/HTTPS, File Transfer Protocol (FTP), network file system (NFS), server message block (SMB), Simple Mail Transfer Protocol (SMTP), secure shell (SSH) and Network Time Protocol (NTP) and more. RHCSAs who wish to earn a more senior-level credential and who have completed System Administration I, II, and II, or who have completed the RHCE Rapid Track Course is recommended to go for RHCE certification.
|
||||
|
||||
- **Certification Codes** : RHCE
|
||||
- Course Codes: RH124, RH134, RH254 and RH199
|
||||
- Exam Codes: EX200 and EX300
|
||||
- Length of Test Period: 21-22 hours depending on the elective course choosen.
|
||||
- Prerequisites: A RHCSA credential
|
||||
- Passing Score: 210 out of 300 (70%)
|
||||
- Validity: 3 years
|
||||
|
||||
### 7. RHCA ###
|
||||
|
||||
RHCA stands for Red Hat Certified Architect which is a certification programme by Red Hat Incorporation. It focuses on actual competencies at system administration, including installation and configuration of a Red Hat Linux system and attaching it to a live network running network services. RHCA is the highest level of certification of all the Red Hat Certifications. Candidates are required to choose the concentration they wish to focus on or can choose any combination of eligible Red Hat certifications to create a custom concentration of their own. There are three main concentration Datacenter, Cloud and Application Platform. RHCA with the concentration of Datacenter has the skills and ability to work, manage a datacenter whereas with the concentration of Cloud has the ability create, configure and manage private, hybrid clouds, cloud application platforms, flexible storage solutions using Red Hat Enterprise Linux Platform. RHCA with the concentration of Application Platform includes skills like installing, configuring and managing Red Hat JBoss Enterprise Application Platform and applications, cloud application platforms and hybrid cloud environments with OpenShift Enterprise by Red Hat and federating data from multiple sources using Red Hat JBoss Data Virtualization.
|
||||
|
||||
- **Certification Codes** : RHCA
|
||||
- Course Codes: CL210,CL220,CL280, RH236, RH318,RH401,RH413, RH436,RH442,JB248 and JB450
|
||||
- Exam Codes: EX333, EX401, EX423 or EX318, EX436 and EX442
|
||||
- Length of Test Period: 21-22 hours depending on the elective course choosen.
|
||||
- Prerequisites: Active RHCE credential
|
||||
- Passing Score: 210 out of 300 (70%)
|
||||
- Validity: 3 years
|
||||
|
||||
### 8. SUSE CLA ###
|
||||
|
||||
SUSE Certified Linux Administrator (SUSE CLA) is a initialcertification by SUSE which focuses on daily administration tasks in SUSE Linux Enterprise Server environments. To gain SUSE CLA certification, it is not necessary to perform the course work, one has to pass the examination to get certified. SUSE CLA are capable and has skills to use Linux Desktop, locate and use help resources, manage Linux File System, work with the Linux Shell and Command Line, install SLE 11 SP22, manage system installation, hardware, backup and recovery, administer Linux with YaST, linux processes and services, storage, configure network, remote access, monitor SLE 11 SP2, automate tasks and manage user access and security. We can gain dual certificates of SUSE CLA and LPIC-1 and CompTIA Linux powered by LPI as SUSE, Linux Professional Institute and CompTIA have teamed up to offer you the chance to earn three Linux certifications.
|
||||
|
||||
- **Certification Codes** : SUSE CLA
|
||||
- Course Codes: 3115, 3116
|
||||
- Exam Codes: 050-720, 050-710
|
||||
- Type of Questions: multiple choice exams
|
||||
- Length of Test Period: 90 minutes
|
||||
- Prerequisites: None
|
||||
- Passing Score: 512
|
||||
|
||||
### 9. SUSE CLP ###
|
||||
|
||||
SUSE Certified Linux Professional (CLP) is a certification programme for the one who is interested to gain more seniority and professionalism in SUSE Linux Enterprise Servers. SUSE CLP is the next step after receiving the SUSE CLA certificate. One should pass the examination and should have certification of CLA to gain the certification of CLP thought the candidate has passed the examination of CLP. SUSE CLP certified person has the skills and ability of installing and configuring SUSE Linux Enterprise Server 11 systems, maintaining the file system, managing softwarepackages, processes, printing, configuring fundamental network services, samba, web servers, using IPv6 and creating and running bash shell scripts.
|
||||
|
||||
- **Certification Codes** : SUSE CLP
|
||||
- Course Codes: 3115, 3116 and 3117
|
||||
- Exam Codes: 050-721, 050-697
|
||||
- Type of Test: hands on
|
||||
- Length of Test Period: 180 minute practicum
|
||||
- Prerequisites: SUSE CLA Certified
|
||||
|
||||
### 10. SUSE CLE ###
|
||||
|
||||
SUSE Certified Linux Engineer (CLE) is an engineer level advanced certification for those candidates who have passed the examination of CLE. To acquire a CLE certificate, one should gain the certificates of SUSE CLA and SUSE CLP. The candidate gaining the CLE certification has the skills of architecting complex SUSE Linux Enterprise Server environments. CLE certified person has the skill to configure fundamental networking services, manage printing, configure and use Open LDAP, samba, web servers, IPv6, perform Health Check and Performance Tuning, create and execute Shell Scripts, deploy SUSE Linux Enterprise, virtualization with Xen and more.
|
||||
|
||||
- **Certification Codes** : SUSE CLE
|
||||
- Course Codes: 3107
|
||||
- Exam Codes: 050-723
|
||||
- Type of Test: hands on
|
||||
- Length of Test Period: 120 minute practicum
|
||||
- Prerequisites: SUSE CLP 10 or 11 Certified
|
||||
|
||||
### 11. LFCS ###
|
||||
|
||||
Linux Foundation Certified System Admin (LFCS) certified candidates possesses knowledge on the use of Linux and using Linux with the terminal environment. LFCS is a certification programme by Linux Foundation for system administrators and engineers working with the Linux operating system. The Linux Foundation collaborated with industry experts and the Linux kernel community to identify the core domains and the critical skills, knowledge and abilities applicable for the certification. LFCS certified candidates has the skills, knowledge and ability of editing and manipulating text files on the command line, managing and troubleshooting File Systems and Storage, assembling partitions as LVM devices, configuring SWAP partitions, managing networked filesystems, managing user accounts, permissions and ownerships, maintaining security, creating and executing bash shell scripts, installing, upgrading, removing software packages and more.
|
||||
|
||||
- **Certification Codes** : LFCS
|
||||
- Course Codes: LFS201, LFS220 (Optional)
|
||||
- Exam Codes: LFCS exam
|
||||
- Length of Test Period: 2 hours
|
||||
- Prerequisites: None.
|
||||
- Passing Score: 74%
|
||||
- Languages: English
|
||||
- Validity: 2 years
|
||||
|
||||
### 12. LFCE ###
|
||||
|
||||
Linux Foundation Certified Engineer (LFCE), a certification for Linux Engineers by Linux Foundation. LFCE certified candidates possesses a wider range of skills on Linux than LFCS. It is a engineer-level advanced certification programme. The LFCE certified candidates possesses skills and abilities of Network Administraton like configuring network services, configuring packet filtering, monitor network performance, IP traffics, configuring filesystems and file services, network filesystems, install, update packages from the repositories, managing network security, configuring iptables, http services, proxy servers, email servers and many more. It is believed that LFCE is pretty difficult to pass and study than LFCS as its advanced engineering level certification programme.
|
||||
|
||||
- **Certification Codes** : LFCE
|
||||
- Course Codes: LFS230
|
||||
- Exam Codes: LFCE exam
|
||||
- Length of Test Period: 2 hours
|
||||
- Prerequisites: LFCS certified.
|
||||
- Passing Score: 72%
|
||||
- Languages: English
|
||||
- Validity: 2 years
|
||||
|
||||
### Facts we found (This is only our views) ###
|
||||
|
||||
Recent surveys conducted on different top recruitment agency, says 80% of linux job profile preferred Redhat certification. If you are a student / newbie and want to learn linux then we prefer Linux Foundation Certifications as its getting much popular or CompTIA Linux would be also a choice. If you already know oracle or suse or working on their products then would prefer oracle / suse linux or if you working in an company these certification might enhance your career growth :-)
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There are thousands of big companies in this world running servers and mainframes running Linux Operating System, to handle, configure and work on those servers there is always a need of highly qualified and certified Linux Technical/Professional. These globally recognized Linux certificates has a big role of someones career in Linux. The companies around the world running Linux and wanting Linux Engineers, System Administrators and ethusiasts chooses one who has gained certificates and has good score in the related field of Linux. Globally recognized certifications are highly essential for excellence in the profession and career in Linux, so preparing best for the examination and getting the certification is a good choice for building career in Linux. If you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/12-globally-recognized-linux-certifications/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,34 +0,0 @@
|
||||
sevenot translating
|
||||
Read about The Document Foundation achievements in 2014: download the Annual Report!
|
||||
================================================================================
|
||||

|
||||
|
||||
TDF ReportThe Document Foundation (TDF) is proud to announce its 2014 Annual Report, which can be downloaded from the following link: [http://tdf.io/report2014][1] (3.2 MB PDF). The version with HD images can be downloaded from [http://tdf.io/report2014hq][2] (15.9 MB PDF).
|
||||
|
||||
TDF Annual Report starts with a Review of 2014, with highlights about TDF and LibreOffice, and a summary of financials and budget.
|
||||
|
||||
Community, Projects & Events covers the LibreOffice Conference 2014 in Bern, Certification, Website and QA, Hackfests in Brussels, Gran Canaria, Paris, Boston and Tolouse, Native-Language Projects, Infrastructure, Documentation, Marketing and Design.
|
||||
|
||||
Software, Development & Code reports about the activities of the Engineering Steering Committee, LibreOffice Development, the Document Liberation Project and LibreOffice on Android.
|
||||
|
||||
The last section focuses on People, starting with Top Contributors, followed by TDF Staff, the Board of Directors and the Membership Committee, the Board of Trustees, or the body of TDF Members, and the Advisory Board.
|
||||
|
||||
TDF 2014 Annual Report has been edited by Sophie Gautier, Alexander Werner, Christian Lohmaier, Florian Effenberger, Italo Vignoli and Robinson Tryon, and designed by Barak Paz, with the help of the fantastic LibreOffice community.
|
||||
|
||||
To allow the widest distribution of the document, this is released with a CC BY 3.0 DE License, unless otherwise noted, to TDF Members and free software advocates worldwide.
|
||||
|
||||
[The German version of TDF Annual Report is available from [http://tdf.io/bericht2014][3]].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.documentfoundation.org/2015/06/03/read-about-the-document-foundation-achievements-in-2014-download-the-annual-report/
|
||||
|
||||
作者:italovignoli
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.documentfoundation.org/File:TDF2014AnnualReport.pdf
|
||||
[2]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportHQ.pdf
|
||||
[3]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportDE.pdf
|
||||
127
sources/share/20150616 Linux Humor on the Command-line.md
Normal file
127
sources/share/20150616 Linux Humor on the Command-line.md
Normal file
@ -0,0 +1,127 @@
|
||||
Linux Humor on the Command-line
|
||||
================================================================================
|
||||
The desktop is full of eye candy. It enhances the visual experience and, in some cases, can also increase functionality of software. But it also makes software fun. Working on the command-line does not have to be always serious. If you want some fun on the command-line, there are lots of commands to raise a smile.
|
||||
|
||||
Linux is a fun operating system. Linux offers a vast collection of small open source utilities that perform functions ranging from the obvious to the bizarre. It is the quality and selection of these tools that help Linux stand out. Check out these 7 small utilities.
|
||||
|
||||
### lolcat ###
|
||||
|
||||

|
||||
|
||||
lolcat is a program that concatenates files, or standard input, to standard output (like the generic cat), and adds rainbow coloring to it.
|
||||
|
||||
lolcat is often combined with other tools such as toilet or figlet to generate text. This software should not be confused with a lolcat; an image macro of one or more cats.
|
||||
|
||||
lolcat was written by Moe.
|
||||
|
||||
Website: [github.com][1]
|
||||
|
||||
### cowsay ###
|
||||
|
||||

|
||||
|
||||
cowsay is a configurable open source program which generates ASCII pictures of a cow with a message in a speech bubble. cowsay is written in Perl.
|
||||
|
||||
cowsay is not limited to generating pictures of cows. It can generate pre-made images of other animals including a duck, elephant, koala, moose, pony, sheep, stegosaurus, and turkey, as well as cheese, snowman, and a skeleton.
|
||||
|
||||
There is a related program called cowthink, which generates cows with thought bubbles, as opposed to speech bubbles.
|
||||
|
||||
Features include:
|
||||
|
||||
- Make scripts more interesting
|
||||
- Borg mode
|
||||
- Ways to alter the way the cow looks, for example making the cow look greedy, paranoid, stoned, tired, wired, youthful and more
|
||||
- xcowsay variant available
|
||||
|
||||
Website: [nog.net][2]
|
||||
|
||||
### doge ###
|
||||
|
||||

|
||||
|
||||
doge is a simple motd script based on the slightly stupid but very funny doge meme. It prints random grammatically incorrect statements that are sometimes based on things from your computer.
|
||||
|
||||
Doge is an Internet meme that became popular in 2013. The meme typically consists of a picture of a Shiba Inu accompanied by multicolored text in Comic Sans font in the foreground. The text, representing a kind of internal monologue, is deliberately written in a form of broken English.
|
||||
|
||||
- Randomly placed and colored random strings, complete with broken english
|
||||
- Awesome Shibe in the terminal
|
||||
- Fetching of system data, such as hostname, running processes, current user and $EDITOR
|
||||
- If you have lolcat, you can do this gem: while true; do doge | lolcat -a -d 100 -s 100 -p 1; done
|
||||
- stdin support: ls /usr/bin | doge will doge-print some of the executables found in /usr/bin. wow. There are also multiple command line switches that control filtering and statistical frequency of words
|
||||
|
||||
Website: [github.com/thiderman/doge][3]
|
||||
|
||||
### ASCIIQuarium ###
|
||||
|
||||

|
||||
|
||||
ASCIIQuarium is an aquarium/sea animation in ASCII art. Enjoy the fascinating creatures that live in the water from your computer.
|
||||
|
||||
To run ASCIIQuarium you need to have installed Perl's curses package, and the Term::Animation module. To install the former, type sudo apt-get install libcurses-perl. To install the latter, type sudo cpan Term::Animation, both at the command line.
|
||||
|
||||
Features include:
|
||||
|
||||
- Multicolored fish
|
||||
- Amusing animations, including a fish hook
|
||||
- There are swans, ducks, dolphins, and ships too
|
||||
|
||||
Website: [www.robobunny.com][4]
|
||||
|
||||
### sl - Steam Locomotive ###
|
||||
|
||||

|
||||
|
||||
sl is an amusing command line tool that displays animations to correct users who accidentally type sl instead of ls.
|
||||
|
||||
I'm rather sloppy at typing, preferring speed to accuracy. But typos can be a tad dangerous on the command line. So sl can serve as a practical reminder of curing a bad habit of mistyping. It always raises a chuckle too.
|
||||
|
||||
Features include:
|
||||
|
||||
- With -F, train flies
|
||||
- With -l, it shows a small train
|
||||
- With -a, an accident seems to happen
|
||||
|
||||
Website: [github.com/mtoyoda/sl][5]
|
||||
|
||||
### aafire ###
|
||||
|
||||

|
||||
|
||||
aafire displays burning ASCII art flames in the terminal. It demonstrates the the capabilities of the aalib library, an ascii art library.
|
||||
|
||||
Website: [aa-project.sourceforge.net/aalib][6]
|
||||
|
||||
### CMatrix ###
|
||||
|
||||

|
||||
|
||||
CMatrix is an ncurses program that simulates the display from "The Matrix". If you have been living in a cave for the past 15 years, you might not know The Matrix is a 1999 American science fiction acting film starring Keanu Reeves, Laurence Fishburne, Carrie-Anne Moss, Hugo Weaving, and Joe Pantoliano.
|
||||
|
||||
It works with terminal settings up to 132x300 and can scroll lines all at the same rate or asynchronously and at a user-defined speed.
|
||||
|
||||
Features include:
|
||||
|
||||
- Change the text colour
|
||||
- Turn on bold characters
|
||||
- Asynchronous scroll
|
||||
- Use old-style scrolling
|
||||
- "Screensaver" mode
|
||||
|
||||
Website: [www.asty.org/cmatrix][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150614112018846/Humor.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://github.com/busyloop/lolcat
|
||||
[2]:https://web.archive.org/web/20120225123719/http://www.nog.net/%7Etony/warez/cowsay.shtml
|
||||
[3]:https://github.com/thiderman/doge
|
||||
[4]:http://www.robobunny.com/projects/asciiquarium/html/
|
||||
[5]:https://github.com/mtoyoda/sl
|
||||
[6]:http://aa-project.sourceforge.net/aalib/
|
||||
[7]:http://www.asty.org/cmatrix/
|
||||
@ -1,153 +0,0 @@
|
||||
The top 10 rookie open source projects
|
||||
================================================================================
|
||||
Black Duck presents its Open Source Rookies of the Year -- the 10 most exciting, active new projects germinated by the global open source community
|
||||
|
||||

|
||||
|
||||
### Open Source Rookies of the Year ###
|
||||
|
||||
Each year sees the start of thousands of new open source projects. Only a handful gets real traction. Some projects gain momentum by building on existing, well-known technologies; others truly break new ground. Many projects are created to solve a simple development problem, while others begin with loftier intentions shared by like-minded developers around the world.
|
||||
|
||||
Since 2009, the open source software logistics company Black Duck has identified the [Open Source Rookies of the Year][1], based on activity tracked by its [Open Hub][2] (formerly Ohloh) site. This year, we're delighted to present 10 winners and two honorable mentions for 2015, selected from thousands of open source projects. Using a weighted scoring system, points were awarded based on project activity, the pace of commits, and several other factors.
|
||||
|
||||
Open source has become the industry's engine of innovation. This year, for example, growth in projects related to Docker containerization trumped every other rookie area -- and not coincidentally reflected the most exciting area of enterprise technology overall. At the very least, the projects described here provide a window on what the global open source developer community is thinking, which is fast becoming a good indicator of where we're headed.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3] is a collection of [Ansible][4] playbooks and roles, scalable from one container to an entire data center. Founder Maciej Delmanowski open-sourced DebOps to ensure his work outlived his current work environment and could grow in strength and depth from outside contributors.
|
||||
|
||||
DebOps began at a small university in Poland that ran its own data center, where everything was configured by hand. Crashes sometimes led to days of downtime -- and Delmanowski realized that a configuration management system was needed. Starting with a Debian base, DebOps is a group of Ansible playbooks that configure an entire data infrastructure. The project has been implemented in many different working environments, and the founders plan to continue supporting and improving it as time goes on.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Code Combat ###
|
||||
|
||||

|
||||
|
||||
The traditional pen-and-paper way of learning falls short for technical subjects. Games, however, are all about engagement -- which is why the founders of [CodeCombat][5] went about creating a multiplayer programming game to teach people how to code.
|
||||
|
||||
At its inception, CodeCombat was an idea for a startup, but the founders decided to create an open source project instead. The idea blossomed within the community, and the project gained contributors at a steady rate. A mere two months after its launch, the game was accepted into Google’s Summer of Code. The game reaches a broad audience and is available in 45 languages. CodeCombat hopes to become the standard for people who want to learn to code and have fun at the same time.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6] is a peer-to-peer cloud storage network that implements end-to-end encryption, enabling users to transfer and share data without reliance on a third party. Based on bitcoin blockchain technology and peer-to-peer protocols, Storj provides secure, private, and encrypted cloud storage.
|
||||
|
||||
Opponents of cloud-based data storage worry about cost efficiencies and vulnerability to attack. Intended to address both concerns, Storj is a private cloud storage marketplace where space is purchased and traded via Storjcoin X (SJCX). Files uploaded to Storj are shredded, encrypted, and stored across the community. File owners are the sole individuals who possess keys to the encrypted information.
|
||||
|
||||
The proof of concept for this decentralized cloud storage marketplace was first presented at the Texas Bitcoin Conference Hackathon in 2014. After winning first place in the hackathon, the project founders and leaders used open forums, Reddit, bitcoin forums, and social media to grow an active community, now an essential part of the Storj decision-making process.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Neovim ###
|
||||
|
||||

|
||||
|
||||
Since its inception in 1991, Vim has been a beloved text editor adopted by millions of software developers. [Neovim][6] is the next generation.
|
||||
|
||||
The software development ecosystem has experienced exponential growth and innovation over the past 23 years. Neovim founder Thiago de Arruda knew that Vim was lacking in modern-day features and development speed. Although determined to preserve the signature features of Vim, the community behind Neovim seeks to improve and evolve the technology of its favorite text editor. Crowdfunding initially enabled de Arruda to focus six uninterrupted months on launching this endeavor. He credits the Neovim community for supporting the project and for inspiring him to continue contributing.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
Former Googlers are bringing a big-company data solution to open source in the form of [CockroachDB][8], a scalable, geo-replicated, transactional data store.
|
||||
|
||||
To maintain the terabytes of data transacted over its global online properties, Google developed Spanner. This powerful tool provides Google with scalability, survivability, and transactionality -- qualities that the team behind CockroachDB is serving up to the open source community. Like an actual cockroach, CockroachDB can survive without its head, tolerating the failure of any node. This open source project has a devoted community of experienced contributors, actively cultivated by the founders via social media, GitHub, networking, conferences, and meet-ups.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
In introducing containerized software development to the open source community, [Docker][9] has become the backbone of a strong, innovative set of tools and technologies. [Kubernetes][10], which Google introduced last June, is an open source container management tool used to accelerate development and simplify operations.
|
||||
|
||||
Google has been using containers for years in its internal operations. At the summer 2014 DockerCon, the Internet giant open-sourced Kubernetes, which was developed to meet the needs of the exponentially growing Docker ecosystem. Through collaborations with other organizations and projects, such as Red Hat and CoreOS, Kubernetes project managers have grown their project to be the No. 1 downloaded tool on the Docker Hub. The Kubernetes team hopes to expand the project and grow the community, so software developers can spend less time managing infrastructure and more time building the apps they want.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
[OpenBazaar][11] is a decentralized marketplace for trading with anyone using bitcoin. The proof of concept for OpenBazaar was born at a hackathon, where its founders combined BitTorent, bitcoin, and traditional financial server methodologies to create a censorship-resistant trading platform. The OpenBazaar team sought new members, and before long they were able to expand the OpenBazaar community immensely. The table stakes of OpenBazaar -- transparency and a common goal to revolutionize trade and commerce -- are helping founders and contributors work toward a real-world, uncontrolled, and decentralized marketplace.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: IPFS ###
|
||||
|
||||

|
||||
|
||||
[IPFS (InterPlanetary File System)][12] is a global, versioned, peer-to-peer file system.It synthesizes many of the ideas behind Git, BitTorrent, and HTTP to bring a new data and data structure transport protocol to the open Web.
|
||||
|
||||
Open source is known for developing simple solutions to complex problems that result in many innovations, but these powerful projects represent only one slice of the open source community. IFPS belong to a more radical group whose proof of concept seems daring, outrageous, and even unattainable -- in this case, a peer-to-peer distributed file system that seeks to connect all computing devices. This possible HTTP replacement maintains a community through multiple mediums, including the Git community and an IRC channel that has more than 100 current contributors. This “crazy” idea will be available for alpha testing in 2015.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] is a daemon that collects, aggregates, processes, and exports information about running containers, providing container users with an understanding of resource usage and performance characteristics. For each container, cAdvisor keeps resource isolation parameters, historical resource usage, histograms of complete historical resource usage, and network statistics. This data is exported by container and across machines.
|
||||
|
||||
cAdvisor can run on most Linux distros and supports many container types, including Docker. It has become the de facto monitoring agent for containers, has been integrated into many systems, and is one of the most downloaded images on the Docker Hub. The team hopes to grow cAdvisor to understand application performance more deeply and to integrate this information into clusterwide systems.
|
||||
|
||||
### 2015 Open Source Rookie of the Year: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14] provides a common configuration to launch infrastructure, from physical and virtual servers to email and DNS providers. The idea is to encompass everything from custom in-house solutions to services offered by public cloud platforms. Once launched, Terraform enables ops to change infrastructure safely and efficiently as the configuration evolves.
|
||||
|
||||
Working at a devops company, Terraform.io's founders identified a pain point in codifying the knowledge required to build a complete data center, from plugged-in servers to a fully networked and functional data center. Infrastructure is described using a high-level configuration syntax, which allows a blueprint of your data center to be versioned and treated as you would any other code. Sponsorship from the well-respected open source company HashiCorp helped launch the project.
|
||||
|
||||
### Honorable mention: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] provides fast, isolated development environments using [Docker][16]. It moves the configuration required to orchestrate Docker into a simple fig.yml file. It handles all the work of building and running containers and forwarding their ports, as well as sharing volumes and linking them.
|
||||
|
||||
Orchard formed Fig last year to create a new system of tools to make Docker work. It was developed as a way of setting up development environments with Docker, enabling users to define the exact environment for their apps, while also running databases and caches inside Docker. Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
|
||||
### Honorable mention: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18] is a Continuous Integration platform built on Docker and [written in Go][19]. The Drone project grew out of frustration with existing available technologies and processes for setting up development environments.
|
||||
|
||||
Drone provides a simple approach to automated testing and continuous delivery: Simply pick a Docker image tailored to your needs, connect GitHub, and commit. Drone uses Docker containers to provision isolated testing environments, giving every project complete control over its stack without the burden of traditional server administration. The community behind Drone is 100 contributors strong and hopes to bring this project to the enterprise and to mobile app development.
|
||||
|
||||
### Open source rookies ###
|
||||
|
||||

|
||||
|
||||
- [Open Source Rookies of the 2014 Year][20]
|
||||
- [InfoWorld's 2015 Technology of the Year Award winners][21]
|
||||
- [Bossies: The Best of Open Source Software Awards][22]
|
||||
- [15 essential open source tools for Windows admins][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -1,58 +0,0 @@
|
||||
No reboot patching comes to Linux 4.0
|
||||
================================================================================
|
||||
> **Summary**:With the new Linux 4.0 kernel, you'll need to reboot Linux less often than ever.
|
||||
|
||||
With [Linux 4.0][1], you may never need to reboot your operating system again.
|
||||
|
||||

|
||||
Using Linux means never having to reboot. -- SUSE
|
||||
|
||||
One reason to love Linux on your servers or in your data-center is that you so seldom needed to reboot it. True, critical patches require a reboot, but you could go months without rebooting. Now, with the latest changes to the Linux kernel you may be able to go years between reboots.
|
||||
|
||||
This is actually a feature that was available in Linux in 2009 thanks to a program called [Ksplice][2]. This program compares the original and patched kernels and then uses a customized kernel module to patch the new code into the running kernel. Each Ksplice-enabled kernel comes with a special set of flags for each function that will be patched. The [Ksplice process][3] then watches for a moment when the code for the function being patched isn't in use, and ta-da, the patch is made and your server runs on.
|
||||
|
||||
[Oracle acquired Ksplice][4] in 2011, and kept it just for its own [Oracle Linux][5], a [Red Hat Enterprise Linux (RHEL)][6] clone, and as a RHEL subscription service. That left all the other enterprise and server Linux back where they started.
|
||||
|
||||
Then [KernelCare released a service that could provide bootless patches][7] for most enterprise Linux distros. This program use proprietary software and is only available as a service with a monthly fee. That was a long way from satisfying many Linux system administrators.
|
||||
|
||||
So, [Red Hat][8] and [SUSE][9] both started working on their own purely open-source means of giving Linux the ability to keep running even while critical patches were being installed. Red Hat's program was named [kpatch][10], while SUSE' is named [kGraft][11].
|
||||
|
||||
The two companies took different approaches. Kpatch issues a stop_machine() command. After that it looks at the stack of existing processes using [ftrace][12] and, if the patch can be made safely, it redirects the running code to the patched functions and then removes the now outdated code.
|
||||
|
||||
Kgraft also uses ftrace, but it works on the thread level. When an old function is called it makes sure the thread reaches a point that it can switch to the new function.
|
||||
|
||||
While the end result is the same, the operating system keeps running while patches are made, there are significant differences in performance. Kpatch takes from one to forty milliseconds, while kGraft might take several minutes but there's never even a millisecond of down time.
|
||||
|
||||
At the Linux Plumbers Conference in October 2014, the two groups got together and started work on a way to [patch Linux without rebooting that combines the best of both programs][13]. Essentially, what they ended up doing was putting both kpatch and kGraft in the 4.0 Linux kernel.
|
||||
|
||||
Jiri Kosina, a SUSE software engineer and Linux kernel developer, explained, that live-patching in the Linux kernel will "provides a basic infrastructure for function "live patching" (i.e. code redirection), including API [application programming interface] for kernel modules containing the actual patches, and API/ABI [application binary interface] for userspace to be able to operate on the patches. This is "relatively simple and minimalistic, as it's making use of existing kernel infrastructure (namely ftrace) as much as possible. It's also self-contained, in a sense that it doesn't hook itself in any other kernel subsystem (it doesn't even touch any other code)."
|
||||
|
||||
The release candidate for Linux 4.0 is now out. Kosina stated that "It's now implemented for x86 only as a reference architecture, but support for powerpc, s390 and arm is already in the works." And, indeed, the source code for these architectures is already in the [Live Patching Git code][14].
|
||||
|
||||
Simply having the code in there is just the start. Your Linux distribution will have to support it with patches that can make use of it. With both Red Hat and SUSE behind it, live patching will soon be the default in all serious business Linux distributions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.zdnet.com/article/no-reboot-patching-comes-to-linux-4-0/#ftag=RSSbaffb68
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.zdnet.com/meet-the-team/us/sjvn/
|
||||
[1]:http://www.zdnet.com/article/linux-kernel-turns-over-release-odometer-to-4-0/
|
||||
[2]:http://www.computerworld.com/article/2466389/open-source-tools/never-reboot-again-with-linux-and-ksplice.html
|
||||
[3]:http://www.ksplice.com/
|
||||
[4]:http://www.zdnet.com/article/oracle-acquires-zero-downtime-linux-upgrade-software/
|
||||
[5]:http://www.oracle.com/us/technologies/linux/overview/index.html
|
||||
[6]:http://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[7]:http://www.zdnet.com/article/kernelcare-new-no-reboot-linux-patching-system/
|
||||
[8]:http://www.redhat.com/
|
||||
[9]:http://www.suse.com/
|
||||
[10]:http://rhelblog.redhat.com/2014/02/26/kpatch/
|
||||
[11]:http://www.zdnet.com/article/suse-gets-live-patching/
|
||||
[12]:http://elinux.org/Ftrace
|
||||
[13]:http://linuxplumbersconf.org/2014/wp-content/uploads/2014/10/LPC2014_LivePatching.txt
|
||||
[14]:https://kernel.googlesource.com/pub/scm/linux/kernel/git/jikos/livepatching/+/9ec0de0ee0c9f0ffe4f72da9158194121cc22807
|
||||
@ -0,0 +1,83 @@
|
||||
translating wi-cuckoo
|
||||
PHP at 20: From pet project to powerhouse
|
||||
================================================================================
|
||||

|
||||
|
||||
Credit: [Steve Jurvetson via Flickr][1]
|
||||
|
||||
> The one-time ‘silly little project’ has transformed into a Web powerhouse, thanks to flexibility, pragmatism, and a vibrant community of Web devs
|
||||
|
||||
When Rasmus Lerdorf released “[a set of small tight CGI binaries written in C][2],” he had no idea how much his creation would impact Web development. Delivering the opening keynote at this year’s SunshinePHP conference in Miami, Lerdorf quipped, “In 1995, I thought I had unleashed a C API upon the Web. Obviously, that’s not what happened, or we’d all be C programmers.”
|
||||
|
||||
In fact, when Lerdorf released version 1.0 of Personal Home Page Tools -- as PHP was then known -- the Web was very young. HTML 2.0 would not be published until November of that year, and HTTP/1.0 not until May the following year. NCSA HTTPd was the most widely deployed Web server, and Netscape Navigator was the most popular Web browser, with Internet Explorer 1.0 to arrive in August. In other words, PHP’s beginnings coincided with the eve of the browser wars.
|
||||
|
||||
Those early days speak volumes about PHP’s impact on Web development. Back then, our options were limited when it came to server-side processing for Web apps. PHP stepped in to fill our need for a tool that would enable us to do dynamic things on the Web. That practical flexibility captured our imaginations, and PHP has since grown up with the Web. Now powering [more than 80 percent of the Web][3], PHP has matured into a scripting language that is especially suited to solve the Web problem. Its unique pedigree tells a story of pragmatism over theory and problem solving over purity.
|
||||
|
||||
### The Web glue we got hooked on ###
|
||||
|
||||
PHP didn’t start out as a language, and this is clear from its design -- or lack thereof, as detractors point out. It began as an API to help Web developers access lower-level C libraries. The first version was a small CGI binary that provided form-processing functionality with access to request parameters and the mSQL database. And its facility with a Web app’s database would prove key in sparking our interest in PHP and PHP’s subsequent ascendancy.
|
||||
|
||||
By version 2 -- aka PHP/FI -- database support had expanded to include PostgreSQL, MySQL, Oracle, Sybase, and more. It supported these databases by wrapping their C libraries, making them a part of the PHP binary. PHP/FI could also wrap the GD library to create and manipulate GIF images. It could be run as an Apache module or compiled with FastCGI support, and it introduced the PHP script language with support for variables, arrays, language constructs, and functions. For many of us working on the Web at that time, PHP was the kind of glue we'd been looking for.
|
||||
|
||||
As PHP folded in more and more programming language features, morphing into version 3 and onward, it never lost this gluelike aspect. Through repositories like PECL (PHP Extension Community Library), PHP could tie together libraries and expose their functionality to the PHP layer. This capacity to bring together components became a significant facet of the beauty of PHP, though it was not limited to its source code.
|
||||
|
||||
### The Web as a community of coders ###
|
||||
|
||||
PHP’s lasting impact on Web development isn’t limited to what can be done with the language itself. How PHP work is done and who participates -- these too are important parts of PHP’s legacy.
|
||||
|
||||
As early as 1997, PHP user groups began forming. One of the earliest was the Midwest PHP User’s Group (later known as Chicago PHP), which held its [first meeting in February 1997][4]. This was the beginning of what would become a vibrant, energetic community of developers assembled over an affinity for a little tool that helped them solve problems on the Web. The ubiquity of PHP made it a natural choice for Web development. It became especially popular in the shared hosting world, and its low barrier to entry was attractive to many early Web developers.
|
||||
|
||||
With a growing community came an assortment of tools and resources for PHP developers. The year 2000 -- a watershed moment for PHP -- witnessed the first PHP Developers’ Meeting, a gathering of the core developers of the programming language, who met in Tel Aviv to discuss the forthcoming 4.0 release. PHP Extension and Application Repository (PEAR) also launched in 2000 to provide high-quality userland code packages following standards and best practices. The first PHP conference, PHP Kongress, was held in Germany soon after. [PHPDeveloper.org][5] came online, and to this day, it is the most authoritative news source in the PHP community.
|
||||
|
||||
This communal momentum proved vital to PHP’s growth in subsequent years, and as the Web development industry erupted, so did PHP. PHP began powering more and larger websites. More user groups formed around the world. Mailing lists; online forums; IRC; conferences; trade journals such as php[architect], the German PHP Magazin, and International PHP Magazine -- the vibrancy of the PHP community had a significant impact on the way Web work would be done: collectively and openly, with an emphasis on code sharing.
|
||||
|
||||
Then, 10 years ago, shortly after the release of PHP 5, an interesting thing happened in Web development that created a general shift in how the PHP community built libraries and applications: Ruby on Rails was released.
|
||||
|
||||
### The rise of frameworks ###
|
||||
|
||||
The Ruby on Rails framework for the Ruby programming language created an increased focus and attention on the MVC (model-view-controller) architectural pattern. The Mojavi PHP framework a few years prior had used this pattern, but the hype around Ruby on Rails is what firmly cemented MVC in the PHP frameworks that followed. Frameworks exploded in the PHP community, and frameworks have changed the way developers build PHP applications.
|
||||
|
||||
Many important projects and developments have arisen, thanks to the proliferation of frameworks in the PHP community. The PHP [Framework Interoperability Group][6] formed in 2009 to aid in establishing coding standards, naming conventions, and best practices among frameworks. Codifying these standards and practices helped provide more interoperable software for developers using member projects’ code. This interoperability meant that each framework could be split into components and stand-alone libraries could be used together with monolithic frameworks. With interoperability came another important milestone: The Composer project was born in 2011.
|
||||
|
||||
Inspired by Node.js’s NPM and Ruby’s Bundler, Composer has ushered in a new era of PHP application development, creating a PHP renaissance of sorts. It has encouraged interoperability between packages, standard naming conventions, adoption of coding standards, and increased test coverage. It is an essential tool in any modern PHP application.
|
||||
|
||||
### The need for speed and innovation ###
|
||||
|
||||
Today, the PHP community has a thriving ecosystem of applications and libraries. Some of the most widely installed PHP applications include WordPress, Drupal, Joomla, and MediaWiki. These applications power the Web presence of businesses of all sizes, from small mom-and-pop shops to sites like whitehouse.gov and Wikipedia. Six of the Alexa top 10 sites use PHP to serve billions of pages a day. As a result, PHP applications have been optimized for speed -- and much innovation has gone into PHP core to improve performance.
|
||||
|
||||
In 2010, Facebook unveiled its HipHop for PHP source-to-source compiler, which translates PHP code into C++ code and compiles it into a single executable binary application. Facebook’s size and growth necessitated the move away from standard interpreted PHP code to a faster, optimized executable. However, Facebook wanted to continue using PHP for its ease of use and rapid development cycles. HipHop for PHP evolved into HHVM, a JIT (just-in-time) compilation-based execution engine for PHP, which included a new language based on PHP: [Hack][7].
|
||||
|
||||
Facebook’s innovations, as well as other VM projects, created competition at the engine level, leading to discussions about the future of the Zend Engine that still powers PHP’s core, as well as the question of a language specification. In 2014, a language specification project was created “to provide a complete and concise definition of the syntax and semantics of the PHP language,” making it possible for compiler projects to create interoperable PHP implementations.
|
||||
|
||||
The next major version of PHP became a topic of intense debate, and a project known as phpng (next generation) was offered as an option to clean up, refactor, optimize, and improve the PHP code base, which also showed substantial improvements to the performance of real-world applications. After deciding to name the next major version “PHP 7,” due to a previous, unreleased PHP 6.0 version, the phpng branch was merged in, and plans were made to proceed with PHP 7, working in many of the language features offered by Hack, such as scalar and return type hinting.
|
||||
|
||||
With the [first PHP 7 alpha release due out today][8] and benchmarks showing [performance as good as or better than that of HHVM][9] in many cases, PHP is keeping up with the pace of modern Web development needs. Likewise, the PHP-FIG continues to innovate and push frameworks and libraries to collaborate and cooperate -- most recently with the adoption of [PSR-7][10], which will change the way PHP projects handle HTTP. User groups, conferences, publications, and initiatives like [PHPMentoring.org][11] continue to advocate best practices, coding standards, and testing to the PHP developer community.
|
||||
|
||||
PHP has seen the Web mature through various stages, and PHP has matured. Once a simple API wrapper around lower-level C libraries, PHP has become a full-fledged programming language in its own right. Its developer community is vibrant and helpful, priding themselves in pragmatism and welcoming newcomers. PHP has stood the test of time for 20 years, and current activity in the language and community is ensuring it will be a relevant and useful language for years to come.
|
||||
|
||||
During his SunshinePHP keynote, Rasmus Lerdorf reflected, “Did I think I’d be here 20 years later talking about this silly little project I did? No, I didn’t.”
|
||||
|
||||
Here’s to Lerdorf and the rest of the PHP community for transforming this “silly little project” into a lasting, powerful component of the Web today.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2933858/php/php-at-20-from-pet-project-to-powerhouse.html
|
||||
|
||||
作者:[Ben Ramsey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Ben-Ramsey/
|
||||
[1]:https://www.flickr.com/photos/jurvetson/13049862325
|
||||
[2]:https://groups.google.com/d/msg/comp.infosystems.www.authoring.cgi/PyJ25gZ6z7A/M9FkTUVDfcwJ
|
||||
[3]:http://w3techs.com/technologies/overview/programming_language/all
|
||||
[4]:http://web.archive.org/web/20061215165756/http://chiphpug.php.net/mpug.htm
|
||||
[5]:http://www.phpdeveloper.org/
|
||||
[6]:http://www.php-fig.org/
|
||||
[7]:http://www.infoworld.com/article/2610885/facebook-q-a--hack-brings-static-typing-to-php-world.html
|
||||
[8]:https://wiki.php.net/todo/php70#timetable
|
||||
[9]:http://talks.php.net/velocity15
|
||||
[10]:http://www.php-fig.org/psr/psr-7/
|
||||
[11]:http://phpmentoring.org/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by wwy-hust
|
||||
|
||||
What is good audio editing software on Linux
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -1,108 +0,0 @@
|
||||
translating by chenzhijun
|
||||
|
||||
How to access Feedly RSS feed from the command line on Linux
|
||||
================================================================================
|
||||
In case you didn't know, [Feedly][1] is one of the most popular online news aggregation services. It offers seamlessly unified news reading experience across desktops, Android and iOS devices via browser extensions and mobile apps. Feedly took on the demise of Google Reader in 2013, quickly gaining a lot of then Google Reader users. I was one of them, and Feedly has remained my default RSS reader since then.
|
||||
|
||||
While I appreciate the sleek interface of Feedly's browser extensions and mobile apps, there is yet another way to access Feedly: Linux command-line. That's right. You can access Feedly's news feed from the command line. Sounds geeky? Well, at least for system admins who live on headless servers, this can be pretty useful.
|
||||
|
||||
Enter [Feednix][2]. This open-source software is a Feedly's unofficial command-line client written in C++. It allows you to browse Feedly's news feed in ncurses-based terminal interface. By default, Feednix is linked with a console-based browser called w3m to allow you to read articles within a terminal environment. You can choose to read from your favorite web browser though.
|
||||
|
||||
In this tutorial, I am going to demonstrate how to install and configure Feednix to access Feedly from the command line.
|
||||
|
||||
### Install Feednix on Linux ###
|
||||
|
||||
You can build Feednix from the source using the following instructions. At the moment, the "Ubuntu-stable" branch of the official Github repository has the most up-to-date code. So let's use this branch to build it.
|
||||
|
||||
As prerequisites, you will need to install a couple of development libraries, as well as w3m browser.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install git automake g++ make libncursesw5-dev libjsoncpp-dev libcurl4-gnutls-dev w3m
|
||||
$ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
|
||||
$ cd Feednix
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
#### Fedora ####
|
||||
|
||||
$ sudo yum groupinstall "C Development Tools and Libraries"
|
||||
$ sudo yum install gcc-c++ git automake make ncurses-devel jsoncpp-devel libcurl-devel w3m
|
||||
$ git clone -b Ubuntu-stable https://github.com/Jarkore/Feednix.git
|
||||
$ cd Feednix
|
||||
$ ./autogen.sh
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
Arch Linux
|
||||
|
||||
On Arch Linux, you can easily install Feednix from [AUR][3].
|
||||
|
||||
### Configure Feednix for the First Time ###
|
||||
|
||||
After installing it, launch Feednix as follows.
|
||||
|
||||
$ feednix
|
||||
|
||||
The first time you run Feednix, it will pop up a web browser window, where you need to sign up to create a Feedly's user ID and its corresponding developer access token. If you are running Feednix in a desktop-less environment, open a web browser on another computer, and go to https://feedly.com/v3/auth/dev.
|
||||
|
||||

|
||||
|
||||
Once you sign in, you will see your Feedly user ID generated.
|
||||
|
||||

|
||||
|
||||
To retrieve an access token, you need to follow the token link sent to your email address in your browser. Only then will you see the window showing your user ID, access token, and its expiration date. Be aware that access token is quite long (more than 200 characters). The token appears in a horizontally scrollable text box, so make sure to copy the whole access token string.
|
||||
|
||||

|
||||
|
||||
Paste your user ID and access token into the Feednix' command-line prompt.
|
||||
|
||||
[Enter User ID] >> XXXXXX
|
||||
[Enter token] >> YYYYY
|
||||
|
||||
After successful authentication, you will see an initial Feednix screen with two panes. The left-side "Categories" pane shows a list of news categories, while the right-side "Posts" pane displays a list of news articles in the current category.
|
||||
|
||||

|
||||
|
||||
### Read News in Feednix ###
|
||||
|
||||
Here I am going to briefly describe how to access Feedly via Feednix.
|
||||
|
||||
#### Navigate Feednix ####
|
||||
|
||||
As I mentioned, the top screen of Feednix consists of two panes. To switch focus between the two panes, use TAB key. To move up and down the list within a pane, use 'j' and 'k' keys, respectively. These keyboard shorcuts are obviously inspired by Vim text editor.
|
||||
|
||||
#### Read an Article ####
|
||||
|
||||
To read a particular article, press 'o' key at the current article. It will invoke w2m browser, and load the article inside the browser. Once you are done reading, press 'q' to quit the browser, and come back to Feednix. If your environment can open a web browser, you can press 'O' to load an article on your default web browser such as Firefox.
|
||||
|
||||

|
||||
|
||||
#### Subscribe to a News Feed ####
|
||||
|
||||
You can add any arbitrary RSS news feed to your Feedly account from Feednix interface. To do so, simply press 'a' key. This will show "[ENTER FEED]:" prompt at the bottom of the screen. After typing the RSS feed, go ahead and fill in the name of the feed and its preferred category.
|
||||
|
||||

|
||||
|
||||
#### Summary ####
|
||||
|
||||
As you can see, Feednix is a quite convenient and easy-to-use command-line RSS reader. If you are a command-line junkie as well as a regular Feedly user, Feednix is definitely worth trying. I have been communicating with the creator of Feednix, Jarkore, to troubleshoot some issue. As far as I can tell, he is very active in responding to bug reports and fixing bugs. I encourage you to try out Feednix and let him know your feedback.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/feedly-rss-feed-command-line-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://feedly.com/
|
||||
[2]:https://github.com/Jarkore/Feednix
|
||||
[3]:https://aur.archlinux.org/packages/feednix/
|
||||
@ -1,80 +0,0 @@
|
||||
How to make remote incremental backup of LUKS-encrypted disk/partition
|
||||
================================================================================
|
||||
Some of us have our hard drives at home or on a [VPS][1] encrypted by [Linux Unified Key Setup (LUKS)][2] for security reasons, and these drives can quickly grow to tens or hundreds of GBs in size. So while we enjoy the security of our LUKS device, we may start to think about a possible remote backup solution. For secure off-site backup, we will need something that operates at the block level of the encrypted LUKS device, and not at the un-encrypted file system level. So in the end we find ourselves in a situation where we will need to transfer the entire LUKS device (let's say 200GB for example) each time we want to make a backup. Clearly not feasible. How can we deal with this problem?
|
||||
|
||||
### A Solution: Bdsync ###
|
||||
|
||||
This is when a brilliant open-source tool called [Bdsync][3] (thanks to Rolf Fokkens) comes to our rescue. As the name implies, Bdsync can synchronize "block devices" over network. For fast synchronization, Bdsync generates and compares MD5 checksums of blocks in the local/remote block devices, and sync only the differences. What rsync can do at the file system level, Bdsync can do it at the block device level. Naturally, it works with encrypted LUKS devices as well. Pretty neat!
|
||||
|
||||
Using Bdsync, the first-time backup will copy the entire LUKS block device to a remote host, so it will take a lot of time to finish. However, after that initial backup, if we make some new files on the LUKS device, the second backup will be finished quickly because we will need to copy only that blocks which have been changed. Classic incremental backup at play!
|
||||
|
||||
### Install Bdsync on Linux ###
|
||||
|
||||
Bdsync is not included in the standard repositories of [Linux][4] distributions. Thus you need to build it from the source. Use the following distro-specific instructions to install Bdsync and its man page on your system.
|
||||
|
||||
#### Debian, Ubuntu or Linux Mint ####
|
||||
|
||||
$ sudo apt-get install git gcc libssl-dev
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
#### Fedora or CentOS/RHEL ####
|
||||
|
||||
$ sudo yum install git gcc openssl-devel
|
||||
$ git clone https://github.com/TargetHolding/bdsync.git
|
||||
$ cd bdsync
|
||||
$ make
|
||||
$ sudo cp bdsync /usr/local/sbin
|
||||
$ sudo mkdir -p /usr/local/man/man1
|
||||
$ sudo sh -c 'gzip -c bdsync.1 > /usr/local/man/man1/bdsync.1.gz'
|
||||
|
||||
### Perform Off-site Incremental Backup of LUKS-Encrypted Device ###
|
||||
|
||||
I assume that you have already provisioned a LUKS-encrypted block device as a backup source (e.g., /dev/LOCDEV). I also assume that you have a remote host where the source device will be backed up (e.g., as /dev/REMDEV).
|
||||
|
||||
You need to access the root account on both systems, and set up [password-less SSH access][5] from the local host to a remote host. Finally, you need to install Bdsync on both hosts.
|
||||
|
||||
To initiate a remote backup process on the local host, we execute the following command as the root:
|
||||
|
||||
# bdsync "ssh root@remote_host bdsync --server" /dev/LOCDEV /dev/REMDEV | gzip > /some_local_path/DEV.bdsync.gz
|
||||
|
||||
Some explanations are needed here. Bdsync client will open an SSH connection to the remote host as the root, and execute Bdsync client with --server option. As clarified, /dev/LOCDEV is our source LUKS block device on the local host, and /dev/REMDEV is the target block device on the remote host. They could be /dev/sda (for an entire disk) or /dev/sda2 (for a single partition). The output of the local Bdsync client is then piped to gzip, which creates DEV.bdsync.gz (so-called binary patch file) in the local host.
|
||||
|
||||
The first time you run the above command, it will take very long time, depending on your Internet/LAN speed and the size of /dev/LOCDEV. Remember that you must have two block devices (/dev/LOCDEV and /dev/REMDEV) with the same size.
|
||||
|
||||
The next step is to copy the generated patch file from the local host to the remote host. Using scp is one possibility:
|
||||
|
||||
# scp /some_local_path/DEV.bdsync.gz root@remote_host:/remote_path
|
||||
|
||||
The final step is to execute the following command on the remote host, which will apply the patch file to /dev/REMDEV:
|
||||
|
||||
# gzip -d < /remote_path/DEV.bdsync.gz | bdsync --patch=/dev/DSTDEV
|
||||
|
||||
I recommend doing some tests with small partitions (without any important data) before deploying Bdsync with real data. After you fully understand how the entire setup works, you can start backing up real data.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In conclusion, we showed how to use Bdsync to perform incremental backups for LUKS devices. Like rsync, only a fraction of data, not the entire LUKS device, is needed to be pushed to an off-site backup site at each backup, which saves bandwidth and backup time. Rest assured that all the data transfer is secured by SSH or SCP, on top of the fact that the device itself is encrypted by LUKS. It is also possible to improve this setup by using a dedicated user (instead of the root) who can run bdsync. We can also use bdsync for ANY block device, such as LVM volumes or RAID disks, and can easily set up Bdsync to back up local disks on to USB drives as well. As you can see, its possibility is limitless!
|
||||
|
||||
Feel free to share your thought.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/remote-incremental-backup-luks-encrypted-disk-partition.html
|
||||
|
||||
作者:[Iulian Murgulet][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/iulian
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-create-encrypted-disk-partition-on-linux.html
|
||||
[3]:http://bdsync.rolf-fokkens.nl/
|
||||
[4]:http://xmodulo.com/recommend/linuxbook
|
||||
[5]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
@ -1,132 +0,0 @@
|
||||
How to Test Your Internet Speed Bidirectionally from Command Line Using ‘Speedtest-CLI’ Tool
|
||||
================================================================================
|
||||
We always need to check the speed of the Internet connection at home and office. What we do for this? Go to websites like Speedtest.net and begin test. It loads JavaScript in the web browser and then select best server based upon ping and output the result. It also uses a Flash player to produce graphical results.
|
||||
|
||||
What about headless server, where isn’t any web based browser and the main point is, most of the servers are headless. The another bottleneck of such web browser based speed testing is that, you can’t schedule the speed testing at regular interval. Here comes an application “Speedtest-cli” that removes such bottlenecks and let you test the speed of Internet connection from command line.
|
||||
|
||||
#### What is Speedtest-cli ####
|
||||
|
||||
The application is basically a script developed in Python programming Language. It measures Internet Bandwidth speed bidirectionally. It used speedtest.net infrastructure to measure the speed. Speedtest-cli is able to list server based upon physical distance, test against specific server, and gives you URL to share the result of your internet speed test.
|
||||
|
||||
To install latest speedtest-cli tool in Linux systems, you must have Python 2.4-3.4 or higher version installed on the system.
|
||||
|
||||
### Install speedtest-cli in Linux ###
|
||||
|
||||
There are two ways to install speedtest-cli tool. The first method involves the use of `python-pip` package while the second method is to download the Python script, make it executable and run, here I will cover both ways….
|
||||
|
||||
#### Install speedtest-cli Using pythin-pip ####
|
||||
|
||||
First you need to install `python-pip` package, then afterwards you can install the speedtest-cli tool using pip command as shown below.
|
||||
|
||||
$ sudo apt-get install python-pip
|
||||
$ sudo pip install speedtest-cli
|
||||
|
||||
To upgrade speedtest-cli, at later stage, use.
|
||||
|
||||
$ sudo pip install speedtest-cli --upgrade
|
||||
|
||||
#### Install speedtest-cli Using Python Script ####
|
||||
|
||||
First download the python script from github using wget command, unpack the downloaded file (master.zip) and extract it..
|
||||
|
||||
$ wget https://github.com/sivel/speedtest-cli/archive/master.zip
|
||||
$ unzip master.zip
|
||||
|
||||
After extracting the file, go to the extracted directory `speedtest-cli-master` and make the script file executable.
|
||||
|
||||
$ cd speedtest-cli-master/
|
||||
$ chmod 755 speedtest_cli.py
|
||||
|
||||
Next, move the executable to `/usr/bin` folder, so that you don’t need to type the full path everytime.
|
||||
|
||||
$ sudo mv speedtest_cli.py /usr/bin/
|
||||
|
||||
### Testing Internet Connection Speed with speedtest-cli ###
|
||||
|
||||
**1. To test Download and Upload speed of your internet connection, run the `speedtest-cli` command without any argument as shown below.**
|
||||
|
||||
$ speedtest_cli.py
|
||||
|
||||

|
||||
Test Download Upload Speed in Linux
|
||||
|
||||
**2. To check the speed result in bytes in place of bits.**
|
||||
|
||||
$ speedtest_cli.py --bytes
|
||||
|
||||

|
||||
Test Internet Speed in Bytes
|
||||
|
||||
**3. Share your bandwidth speed with your friends or family. You are provided with a link that can be used to download an image.**
|
||||
|
||||

|
||||
Share Internet Speed Results
|
||||
|
||||
The following picture is a sample speed test result generated using above command.
|
||||
|
||||

|
||||
Speed Test Results
|
||||
|
||||
**4. Don’t need any additional information other than Ping, Download and upload?**
|
||||
|
||||
$ speedtest_cli.py --simple
|
||||
|
||||

|
||||
Test Ping Download Upload Speed
|
||||
|
||||
**5. List the `speedtest.net` server based upon physical distance. The distance in km is mentioned.**
|
||||
|
||||
$ speedtest_cli.py --list
|
||||
|
||||

|
||||
Check Speedtest.net Servers
|
||||
|
||||
**6. The last stage generated a huge list of servers sorted on the basis of distance. How to get desired output? Say I only want to see the speedtest.net server located in Mumbai (India).**
|
||||
|
||||
$ speedtest_cli.py --list | grep -i Mumbai
|
||||
|
||||

|
||||
Check Nearest Server
|
||||
|
||||
**7. Test connection speed against a specific server. Use Server Id generated in example 5 and example 6 in above.**
|
||||
|
||||
$ speedtest_cli.py --server [server ID]
|
||||
$ speedtest_cli.py --server [5060] ## Here server ID 5060 is used in the example.
|
||||
|
||||

|
||||
Test Connection Against Server
|
||||
|
||||
**8. To check the version number and help of `speedtest-cli` tool.**
|
||||
|
||||
$ speedtest_cli.py --version
|
||||
|
||||

|
||||
Check SpeedCli Version
|
||||
|
||||
$ speedtest_cli.py --help
|
||||
|
||||

|
||||
SpeedCli Help
|
||||
|
||||
**Note:** Latency reported by tool is not its goal and one should not rely on it. The relative latency values output is responsible for server selected to be tested against. CPU and Memory capacity will influence the result to certain extent.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The tool is must for system administrators and developers. A simple script which runs without any issue. I must say that the application is wonderful, lightweight and do what it promises. I disliked Speedtest.net for the reason it was using flash, but speedtest-cli gave me a reason to love them.
|
||||
|
||||
speedtest_cli is a third party application and should not be used to automatically record the bandwidth speed. Speedtest.net is used by millions of users and it is a good idea to [Set Your Own Speedtest Mini Server][1].
|
||||
|
||||
That’s all for now, till then stay tuned and connected to Tecmint. Don’t forget to give your valuable feedback in the comments below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/check-internet-speed-from-command-line-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/speedtest-mini-server-to-test-bandwidth-speed/
|
||||
@ -1,188 +0,0 @@
|
||||
How to Install Percona Server on CentOS 7
|
||||
================================================================================
|
||||
In this article we are going to learn about percona server, an opensource drop-in replacement for MySQL and also for MariaDB. The InnoDB database engine make it very attractive and a good alternative if you need performance, reliability and a cost efficient solution
|
||||
|
||||
In the following sections I am going to cover the installation of the percona server on the CentOS 7, I will also cover the steps needed to make backup of your current data, configuration and how to restore your backup.
|
||||
|
||||
### Table of contents ###
|
||||
|
||||
1. What is and why use percona
|
||||
1. Backup your databases
|
||||
1. Remove previous SQL server
|
||||
1. Installing Percona binaries
|
||||
1. Configuring Percona
|
||||
1. Securing your environment
|
||||
1. Restore your backup
|
||||
|
||||
### 1. What is and why use Percona ###
|
||||
|
||||
Percona is an opensource alternative to the MySQL and MariaDB databases, it's a fork of the MySQL with many improvements and unique features that makes it more reliable, powerful and faster than MySQL, and yet is fully compatible with it, you can even use replication between Oracle's MySQL and Percona.
|
||||
|
||||
#### Features exclusive to Percona ####
|
||||
|
||||
- Partitioned Adaptive Hash Search
|
||||
- Fast Checksum Algorithm
|
||||
- Buffer Pool Pre-Load
|
||||
- Support for FlashCache
|
||||
|
||||
#### MySQL Enterprise and Percona specific features ####
|
||||
|
||||
- Import Tables From Different Servers
|
||||
- PAM authentication
|
||||
- Audit Log
|
||||
- Threadpool
|
||||
|
||||
Now that you are pretty excited to see all these good things together, we are going show you how to install and do basic configuration of Percona Server.
|
||||
|
||||
### 2. Backup your databases ###
|
||||
|
||||
The following, command creates a mydatabases.sql file with the SQL commands to recreate/restore salesdb and employeedb databases, replace the databases names to reflect your setup, skip if this is a brand new setup
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
Copy the current configuration file, you can also skip this in fresh setups
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3. Remove your previous SQL Server ###
|
||||
|
||||
Stop the MySQL/MariaDB if it's running.
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
Uninstall MariaDB and MySQL
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
Move / Rename the MariaDB files in **/var/lib/mysql**, it's a safer and faster than just removing, it's like a 2nd level instant backup. :)
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4. Installing Percona binaries ###
|
||||
|
||||
You can choose from a number of options on how to install Percona, in a CentOS system it's generally a better idea to use yum or RPM, so these are the way that are covered by this article, compiling and install from sources are not covered by this article.
|
||||
|
||||
Installing from Yum repository:
|
||||
|
||||
First you need to set the Percona's Yum repository with this:
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
And then install Percona with:
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
The above command installs Percona server and clients, shared libraries, possibly Perl and perl modules such as DBI::MySQL, if that are not already installed, and also other dependencies as needed.
|
||||
|
||||
Installing from RPM package:
|
||||
|
||||
We can download all rpm packages with the help of wget:
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
And with rpm utility, you install all the packages once:
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
Note the backslash '\' on the end of the sentences on the above commands, if you install individual packages, remember that to met dependencies, the shared package must be installed before client and client before server.
|
||||
|
||||
### 5. Configuring Percona Server ###
|
||||
|
||||
#### Restoring previous configuration ####
|
||||
|
||||
As we are moving from MariaDB, you can just restore the backup of my.cnf file that you made in earlier steps.
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### Creating a new my.cnf ####
|
||||
|
||||
If you need a new configuration file that fit your needs or if you don't have made a copy of my.cnf, you can use this wizard, it will generate for you, through simple steps.
|
||||
|
||||
Here is a sample my.cnf file that comes with Percona-Server package
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
#
|
||||
# Remove leading # and set to the amount of RAM for the most important data
|
||||
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
|
||||
# innodb_buffer_pool_size = 128M
|
||||
#
|
||||
# Remove leading # to turn on a very important data integrity option: logging
|
||||
# changes to the binary log between backups.
|
||||
# log_bin
|
||||
#
|
||||
# Remove leading # to set options mainly useful for reporting servers.
|
||||
# The server defaults are faster for transactions and fast SELECTs.
|
||||
# Adjust sizes as needed, experiment to find the optimal values.
|
||||
# join_buffer_size = 128M
|
||||
# sort_buffer_size = 2M
|
||||
# read_rnd_buffer_size = 2M
|
||||
datadir=/var/lib/mysql
|
||||
socket=/var/lib/mysql/mysql.sock
|
||||
|
||||
# Disabling symbolic-links is recommended to prevent assorted security risks
|
||||
symbolic-links=0
|
||||
|
||||
[mysqld_safe]
|
||||
log-error=/var/log/mysqld.log
|
||||
pid-file=/var/run/mysqld/mysqld.pid
|
||||
|
||||
After making your my.cnf file fit your needs, it's time to start the service:
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
If everything goes fine, your server is now up and ready to ready to receive SQL commands, you can try the following command to check:
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
If you can't start the service, you can look for a reason in **/var/log/mysql/mysqld.log** this file is set by the **log-error** option in my.cnf's **[mysqld_safe]** session.
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
You can also take a look in a file inside **/var/lib/mysql/** with name in the form of **[hostname].err** as the following example:
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
If this also fail in show what is wrong, you can also try strace:
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
|
||||
The above command is extremely verbous and it's output is quite low level but can show you the reason you can't start service in most times.
|
||||
|
||||
### 6. Securing your environment ###
|
||||
|
||||
Ok, you now have your RDBMS ready to receive SQL queries, but it's not a good idea to put your precious data on a server without minimum security, it's better to make it safer with mysql_secure_instalation, this utility helps in removing unused default features, also set the root main password and make access restrictions for using this user.
|
||||
Just invoke it by the shell and follow instructions on the screen.
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
### 7. Restore your backup ###
|
||||
|
||||
If you are coming from a previous setup, now you can restore your databases, just use mysqldump once again.
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
|
||||
Congratulations, you just installed Percona on your CentOS Linux, your server is now fully ready for use; You can now use your service as it was MySQL, and your services are fully compatible with it.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There is a lot of things to configure in order to achieve better performance, but here is some straightforward options to improve your setup. When using innodb engine it's also a good idea to set the **innodb_file_per_table** option **on**, it gonna distribute table indexes in a file per table basis, it means that each table have it's own index file, it makes the overall system, more robust and easier to repair.
|
||||
|
||||
Other option to have in mind is the **innodb_buffer_pool_size** option, InnoDB should have large enough to your datasets, and some value **between 70% and 80%** of the total available memory should be reasonable.
|
||||
|
||||
By setting the **innodb-flush-method** to **O_DIRECT** you disable write cache, if you have **RAID**, this should be set to improved performance as this cache is already done in a lower level.
|
||||
|
||||
If your data is not that critical and you don't need fully **ACID** compliant transactions, you can adjust to 2 the option **innodb_flush_log_at_trx_commit**, this will also lead to improved performance.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
@ -0,0 +1,191 @@
|
||||
Install Plex Media Server On Ubuntu / CentOS 7.1 / Fedora 22
|
||||
================================================================================
|
||||
In this article we will show you how easily you can setup Plex Home Media Server on major Linux distributions with their latest releases. After its successful installation of Plex you will be able to use your centralized home media playback system that streams its media to many Plex player Apps and the Plex Home will allows you to setup your environment by adding your devices and to setup a group of users that all can use Plex Together. So let’s start its installation first on Ubuntu 15.04.
|
||||
|
||||
### Basic System Resources ###
|
||||
|
||||
System resources mainly depend on the type and number of devices that you are planning to connect with the server. So according to our requirements we will be using as following system resources and software for a standalone server.
|
||||
|
||||
注:表格
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Home Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Base Operating System</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM and CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Hard Disk</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Plex Media Server 0.9.12.3 on Ubuntu 15.04 ###
|
||||
|
||||
We are now ready to start the installations process of Plex Media Server on Ubuntu so let’s start with the following steps to get it ready.
|
||||
|
||||
#### Step 1: System Update ####
|
||||
|
||||
Login to your server with root privileges Make your that your system is upto date if not then do by using below command.
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### Step 2: Download the Latest Plex Media Server Package ####
|
||||
|
||||
Create a new directory and download .deb plex Media Package in it from the official website of Plex for Ubuntu using wget command.
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### Step 3: Install the Debian Package of Plex Media Server ####
|
||||
|
||||
Now within the same directory run following command to start installation of debian package and then check the status of plekmediaserver.
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Ubuntu 15.04 ###
|
||||
|
||||
Let's open your web browser within your localhost network and open the Web Interface with your localhost IP and port 32400 and do following steps to configure it:
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### Step 1:Sign UP before Login ####
|
||||
|
||||
After you have access to the web interface of Plesk Media Server make sure to Sign Up and set your username email ID and Password to login as.
|
||||
|
||||

|
||||
|
||||
#### Step 2: Enter Your Pin to Secure Your Plex Media Home User ####
|
||||
|
||||

|
||||
|
||||
Now you have successfully configured your user under Plex Home Media.
|
||||
|
||||

|
||||
|
||||
### Opening Plex Web App on Devices Other than Localhost Server ###
|
||||
|
||||
As we have seen in our Plex media home page that it indicates that "You do not have permissions to access this server". Its because of we are on a different network than the Server computer.
|
||||
|
||||

|
||||
|
||||
Now we need to resolve this permissions issue so that we can have access to server on the devices other than the hosted server by doing following setup.
|
||||
|
||||
### Setup SSH Tunnel for Windows System to access Linux Server ###
|
||||
|
||||
First we need to set up a SSH tunnel so that we can access things as if they were local. This is only necessary for the initial setup.
|
||||
|
||||
If you are using Windows as your local system and server on Linux then we can setup SSH-Tunneling using Putty as shown.
|
||||
|
||||

|
||||
|
||||
**Once you have the SSH tunnel set up:**
|
||||
|
||||
Open your Web browser window and type following URL in the address bar.
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
The browser will connect to the server and load the Plex Web App with same functionality as on local.
|
||||
Agree to the terms of Services and start
|
||||
|
||||

|
||||
|
||||
Now a fully functional Plex Home Media Server is ready to add new media libraries, channels, playlists etc.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on CentOS 7.1 ###
|
||||
|
||||
We will follow the same steps on CentOS-7.1 that we did for the installation of Plex Home Media Server on Ubuntu 15.04.
|
||||
|
||||
So lets start with Plex Media Servers Package Installation.
|
||||
|
||||
#### Step 1: Plex Media Server Installation ####
|
||||
|
||||
To install Plex Media Server on centOS 7.1 we need to download the .rpm package from the official website of Plex. So we will use wget command to download .rpm package for this purpose in a new directory.
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 2: Install .RPM Package ####
|
||||
|
||||
After completion of complete download package we will install this package using rpm command within the same direcory where we installed the .rpm package.
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 3: Start Plexmediaservice ####
|
||||
|
||||
We have successfully installed Plex Media Server Now we just need to restart its service and then enable it permanently.
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### Plex Home Media Web App Setup on CentOS-7.1 ###
|
||||
|
||||
Now we just need to repeat all steps that we performed during the Web app setup of Ubuntu.
|
||||
So let's Open a new window in your web browser and access the Plex Media Server Web app using localhost or IP or your Plex server.
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
Then to get full permissions on the server you need to repeat the steps to create the SSH-Tunnel.
|
||||
After signing up with new user account we will be able to access its all features and can add new users, add new libraries and setup it per our needs.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on Fedora 22 Work Station ###
|
||||
|
||||
The Basic steps to download and install Plex Media Server are the same as its we did for in CentOS 7.1.
|
||||
We just need to download its .rpm package and then install it with rpm command.
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Fedora 22 Work Station ###
|
||||
|
||||
We had setup Plex Media Server on the same host so we don't need to setup SSH-Tunnel in this time scenario. Just open the web browser in your Fedora 22 Workstation with default port 32400 of Plex Home Media Server and accept the Plex Terms of Services Agreement.
|
||||
|
||||

|
||||
|
||||
**Welcome to Plex Home Media Server on Fedora 22 Workstation**
|
||||
|
||||
Lets login with your plex account and start with adding your libraries for your favorite movie channels , create your playlists, add your photos and enjoy with many other features of Plex Home Media Server.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We had successfully installed and configured Plex Media Server on Major Linux Distributions. So, Plex Home Media Server has always been a best choice for media management. Its so simple to setup on cross platform as we did for Ubuntu, CentOS and Fedora. It has simplifies the tasks of organizing your media content and streaming to other computers and devices then to share it with your friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -0,0 +1,176 @@
|
||||
Lolcat – A Command Line Tool to Output Rainbow Of Colors in Linux Terminal
|
||||
================================================================================
|
||||
For those who believe that Linux Command Line is boring and there isn’t any fun, then you’re wrong here are the articles on Linux, that shows how funny and naughty is Linux..
|
||||
|
||||
- [20 Funny Commands of Linux or Linux is Fun in Terminal][1]
|
||||
- [6 Interesting Funny Commands of Linux (Fun in Terminal)][2]
|
||||
- [Fun in Linux Terminal – Play with Word and Character Counts][3]
|
||||
|
||||
Here in this article, I will be discussing about a small utility called “lolcat” – Which produce rainbow of colors in terminal.
|
||||
|
||||

|
||||
|
||||
Lolcat Command to Output Rainbow of Colors for Terminal
|
||||
|
||||
#### What is lolcat? ####
|
||||
|
||||
Lolcat is an utility for Linux, BSD and OSX which concatenates like similar to [cat command][4] and adds rainbow coloring to it. Lolcat is primarily used for rainbow coloring of text in Linux Terminal.
|
||||
|
||||
### Installation of Lolcat in Linux ###
|
||||
|
||||
**1. Lolcat utility is available in the repository of lots of Linux distributions, but the available version bit older. Alternatively you can download and install latest version of lolcat from git repository.**
|
||||
|
||||
Lolcat is a ruby gem hence it is essential to have latest version of RUBY installed on your system.
|
||||
|
||||
# apt-get install ruby [On APT based Systems]
|
||||
# yum install ruby [On Yum based Systems]
|
||||
# dnf install ruby [On DNF based Systems]
|
||||
|
||||
Once ruby package has been installed, make sure to verify the version of ruby installed.
|
||||
|
||||
# ruby --version
|
||||
|
||||
ruby 2.1.5p273 (2014-11-13) [x86_64-linux-gnu]
|
||||
|
||||
**2. Next download and install the most recent version of lolcat from the git repository using following commands.**
|
||||
|
||||
# wget https://github.com/busyloop/lolcat/archive/master.zip
|
||||
# unzip master.zip
|
||||
# cd lolcat-master/bin
|
||||
# gem install lolcat
|
||||
|
||||
Once lolcat is installed, you can check the version.
|
||||
|
||||
# lolcat --version
|
||||
|
||||
lolcat 42.0.99 (c)2011 moe@busyloop.net
|
||||
|
||||
### Usage of Lolcat ###
|
||||
|
||||
**3. Before starting usage of lolcat, make sure to know the available options and help using following command.**
|
||||
|
||||
# lolcat -h
|
||||
|
||||

|
||||
|
||||
Lolcat Help
|
||||
|
||||
**4. Next, pipeline lolcat with commads say ps, date and cal as:**
|
||||
|
||||
# ps | lolcat
|
||||
# date | lolcat
|
||||
# cal | lolcat
|
||||
|
||||
|
||||
|
||||
ps Command Output
|
||||
|
||||

|
||||
|
||||
Date Output
|
||||
|
||||

|
||||
|
||||
Calendar Output
|
||||
|
||||
**5. 3. Use lolcat to display codes of a script file as:**
|
||||
|
||||
# lolcat test.sh
|
||||
|
||||

|
||||
|
||||
Display Codes with Lolcat
|
||||
|
||||
**6. Pipeline lolcat with figlet command. Figlet is a utility which displays large characters made up of ordinary screen characters. We can pipeline the output of figlet with lolcat to make the output colorful as:**
|
||||
|
||||
# echo I ❤ Tecmint | lolcat
|
||||
# figlet I Love Tecmint | lolcat
|
||||
|
||||

|
||||
|
||||
Colorful Texts
|
||||
|
||||
**Note**: Not to mention that ❤ is an unicode character and to install figlet you have to yum and apt to get the required packages as:
|
||||
|
||||
# apt-get figlet
|
||||
# yum install figlet
|
||||
# dnf install figlet
|
||||
|
||||
**7. Animate a text in rainbow of colours, as:**
|
||||
|
||||
$ echo I ❤ Tecmit | lolcat -a -d 500
|
||||
|
||||

|
||||
|
||||
Animated Text
|
||||
|
||||
Here the option -a is for Animation and -d is for duration. In the above example duration count is 500.
|
||||
|
||||
**8. Read a man page (say man ls) in rainbow of colors as:**
|
||||
|
||||
# man ls | lolcat
|
||||
|
||||

|
||||
|
||||
List Files Colorfully
|
||||
|
||||
**9. Pipeline lolcat with cowsay. cowsay is a configurable thinking and/or speaking cow, which supports a lot of other animals as well.**
|
||||
|
||||
Install cowsay as:
|
||||
|
||||
# apt-get cowsay
|
||||
# yum install cowsay
|
||||
# dnf install cowsay
|
||||
|
||||
After install, print the list of all the animals in cowsay as:
|
||||
|
||||
# cowsay -l
|
||||
|
||||
**Sample Output**
|
||||
|
||||
Cow files in /usr/share/cowsay/cows:
|
||||
apt beavis.zen bong bud-frogs bunny calvin cheese cock cower daemon default
|
||||
dragon dragon-and-cow duck elephant elephant-in-snake eyes flaming-sheep
|
||||
ghostbusters gnu head-in hellokitty kiss kitty koala kosh luke-koala
|
||||
mech-and-cow meow milk moofasa moose mutilated pony pony-smaller ren sheep
|
||||
skeleton snowman sodomized-sheep stegosaurus stimpy suse three-eyes turkey
|
||||
turtle tux unipony unipony-smaller vader vader-koala www
|
||||
|
||||
Output of cowsay pipelined with lolcat and ‘gnu‘ cowfile is used.
|
||||
|
||||
# cowsay -f gnu ☛ Tecmint ☚ is the best Linux Resource Available online | lolcat
|
||||
|
||||
|
||||
|
||||
Cowsay with Lolcat
|
||||
|
||||
**Note**: You can use lolcat with any other command in pipeline and get colored output in terminal.
|
||||
|
||||
**10. You may create alias for the most frequently used commands to get command output in rainbow of colors. You can alias ‘ls -l‘ command which is used for long list the contents of directory as below.**
|
||||
|
||||
# alias lolls="ls -l | lolcat"
|
||||
# lolls
|
||||
|
||||

|
||||
|
||||
Alias Commands with Colorful
|
||||
|
||||
You may create alias for any command as suggested above. To create permanent alias, you have to add the relevant code (above code for ls -l alias) to ~/.bashrc file and also make sure to logout and login back for the changes to be taken into effect.
|
||||
|
||||
That’s all for now. I would like to know if you were aware of lolcat previously? Did you like the post? And suggestion and feedback is welcome in the comment section below. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/lolcat-command-to-output-rainbow-of-colors-in-linux-terminal/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-funny-commands-of-linux-or-linux-is-fun-in-terminal/
|
||||
[2]:http://www.tecmint.com/linux-funny-commands/
|
||||
[3]:http://www.tecmint.com/play-with-word-and-character-counts-in-linux/
|
||||
[4]:http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||
@ -1,226 +0,0 @@
|
||||
wyangsun翻译中
|
||||
How to Create Own Online Shopping Store Using “OpenCart” in Linux
|
||||
================================================================================
|
||||
In the Internet world we are doing everything using a computer. Electronic Commerce aka e-commerce is one one of them. E-Commerce is nothing new and it started in the early days of ARPANET, where ARPANET used to arrange sale between students of Massachusetts Institute of Technology and Stanford Artificial Intelligence Laboratory.
|
||||
|
||||
These days there are some 100’s of E-Commerce site viz., Flipcart, eBay, Alibaba, Zappos, IndiaMART, Amazon, etc. Have you thought of making your own Amazon and Flipcart like web-based Application Server? If yes! This article is for you.
|
||||
|
||||
Opencart is a free and open source E-Commerce Application written in PHP, which can be used to develop a shopping cart system similar to Amazon and Flipcart. If you want to sell your products online or want to serve your customers even when you are closed Opencart is for you. You can build a successful online store (for online merchants) using reliable and professional Opencart Application.
|
||||
|
||||
### OpenCart Web Panel Demo ###
|
||||
|
||||
- Store Front – [http://demo.opencart.com/][1]
|
||||
- Admin Login – [http://demo.opencart.com/admin/][2]
|
||||
|
||||
------------------ Admin Login ------------------
|
||||
Username: demo
|
||||
Password: demo
|
||||
|
||||
#### Features of Opencart ####
|
||||
|
||||
Opencart is an application that meets all the requirements of an online merchant. It has all the features (see below) using which you can make your own E-Commerce Website.
|
||||
|
||||
- It is a Free (as in beer) and Open Source (as in speech) Application released under GNU GPL License.
|
||||
- Everything is well documented, means you don’t need to Google and shout for help.
|
||||
- Free Life time support and updates.
|
||||
- Unlimited number of categories, Products and manufacturer supported.
|
||||
- Everything is Template based.
|
||||
- Multi-Language and Multi-Currency Supported. It ensures your product gets a global reach.
|
||||
- Built-in Product Review and Rating Features.
|
||||
- Downloadable Products (viz., ebook) supported.
|
||||
- Automatic Image Resizing supported.
|
||||
- Features like Multi tax Rates (as in various country), Viewing Related Products, Information Page, Shipping Weight Calculation, Availing Discount Coupons, etc are well implemented by default.
|
||||
- Built-in Backup and Restore tools.
|
||||
- Well implemented SEO.
|
||||
- Invoice Printing, Error Log and sales report are supported as well.
|
||||
|
||||
#### System Requirements ####
|
||||
|
||||
- Web Server (Apache HTTP Server Preferred)
|
||||
- PHP (5.2 and above).
|
||||
- Database (MySQLi Preferred but I am using MariaDB).
|
||||
|
||||
#### Required PHP Libraries and Modules ####
|
||||
|
||||
These extensions must be installed and enabled on your system to install Opencart properly on the web server.
|
||||
|
||||
- Curl
|
||||
- Zip
|
||||
- Zlib
|
||||
- GD Library
|
||||
- Mcrypt
|
||||
- Mbstrings
|
||||
|
||||
### Step 1: Installing Apache, PHP and MariaDB ###
|
||||
|
||||
1. As I said, OpenCart requires certain technical requirements such as Apache, PHP with extensions and Database (MySQL or MariaDB) to be installed on the system, in order to run Opencart properly.
|
||||
|
||||
Let’s install Apache, PHP and MariaDB using following Command.
|
||||
|
||||
**Install Apache**
|
||||
|
||||
# apt-get install apache2 (On Debian based Systems)
|
||||
# yum install httpd (On RedHat based Systems)
|
||||
|
||||
**Install PHP and Extensions**
|
||||
|
||||
# apt-get install php5 libapache2-mod-php5 php5-curl php5-mcrypt (On Debian based Systems)
|
||||
# yum install php php-mysql php5-curl php5-mcrypt (On RedHat based Systems)
|
||||
|
||||
**Install MariaDB**
|
||||
|
||||
# apt-get install mariadb-server mariadb-client (On Debian based Systems)
|
||||
# yum install mariadb-server mariadb (On RedHat based Systems)
|
||||
|
||||
2. After installing all the above required things, you can start the Apache and MariaDB services using following commands.
|
||||
|
||||
------------------- On Debian based Systems -------------------
|
||||
# systemctl restart apache2.service
|
||||
# systemctl restart mariadb.service
|
||||
|
||||
----------
|
||||
|
||||
------------------- On RedHat based Systems -------------------
|
||||
# systemctl restart httpd.service
|
||||
# systemctl restart mariadb.service
|
||||
|
||||
### Step 2: Downloading and Setting OpenCart ###
|
||||
|
||||
3. The most recent version of OpenCart (2.0.2.0) can be obtained from [OpenCart website][3] or directly from github.
|
||||
|
||||
Alternatively, you may use following wget command to download the latest version of OpenCart directly from github repository as shown below.
|
||||
|
||||
# wget https://github.com/opencart/opencart/archive/master.zip
|
||||
|
||||
4. After downloading zip file, copy to Apache Working directory (i.e. /var/www/html) and unzip the master.zip file.
|
||||
|
||||
# cp master.zip /var/www/html/
|
||||
# cd /var/www/html
|
||||
# unzip master.zip
|
||||
|
||||
5. After extracting ‘master.zip‘ file, cd to extracted directory and move the content of upload directory to the root of the application folder (opencart-master).
|
||||
|
||||
# cd opencart-master
|
||||
# mv -v upload/* ../opencart-master/
|
||||
|
||||
6. Now you need to rename or copy OpenCart configuration files as shown below.
|
||||
|
||||
# cp /var/www/html/opencart-master/admin/config-dist.php /var/www/html/opencart-master/admin/config.php
|
||||
# cp /var/www/html/opencart-master/config-dist.php /var/www/html/opencart-master/config.php
|
||||
|
||||
7. Next, set correct Permissions to the files and folders of /var/www/html/opencart-master. You need to provide RWX permission to all the files and folders there, recursively.
|
||||
|
||||
# chmod 777 -R /var/www/html/opencart-master
|
||||
|
||||
**Important**: Setting permission 777 may be dangerous, so as soon as you finish setting up everything, revert back to permission 755 recursively on the above folder.
|
||||
|
||||
### Step 3: Creating OpenCart Database ###
|
||||
|
||||
8. Next step is to create a database (say opencartdb) for the E-Commerce site to store data on the database. Connect to databaser server and create a database, user and grant correct privileges on the user to have full control over the database.
|
||||
|
||||
# mysql -u root -p
|
||||
CREATE DATABASE opencartdb;
|
||||
CREATE USER 'opencartuser'@'localhost' IDENTIFIED BY 'mypassword';
|
||||
GRANT ALL PRIVILEDGES ON opencartdb.* TO 'opencartuser'@'localhost' IDENTIFIED by 'mypassword';
|
||||
|
||||
### Step 4: OpenCart Web Installation ###
|
||||
|
||||
9. Once everything set correctly, navigate to the web browser and type `http://<web server IP address>` to access the OpenCart web installation.
|
||||
|
||||
Click ‘CONTINUE‘ to Agree the License Agreement.
|
||||
|
||||

|
||||
|
||||
Accept OpenCart License
|
||||
|
||||
10. The next screen is Pre-installation Server Setup Check, to see that the server has all the required modules are installed properly and have correct permission on the OpenCart files.
|
||||
|
||||
If any red marks are highlighted on #1 or #2, that means you need to install those components properly on the server to meet web server requirements.
|
||||
|
||||
If there are any red marks on #3 or #4, that means there is issue with your files. If everything is correctly configured you should see all green marks are visible (as seen below), you may press “Continue“.
|
||||
|
||||

|
||||
|
||||
Server Requirement Check
|
||||
|
||||
11. On the next screen enter your Database Credentials like Database Driver, Hostname, User-name, Password, database. You should not touch db_port and Prefix, until and unless you know what you are doing.
|
||||
|
||||
Also Enter User_name, Password and Email Address for Administrative account. Note these credentials will be used for logging in to Opencart Admin Panel as root, so keep it safe. Click continue when done!
|
||||
|
||||

|
||||
|
||||
OpenCart Database Details
|
||||
|
||||
12. The next screen shows message like “Installation Complete” with the Tag Line Ready to Start Selling. Also it warns to delete the installation directory, as everything required to setup using this directory has been accomplished.
|
||||
|
||||

|
||||
|
||||
OpenCart Installation Completes
|
||||
|
||||
To Remove install directory, you may like to run the below command.
|
||||
|
||||
# rm -rf /var/www/html/opencart-master/install
|
||||
|
||||
### Step 4: Access OpenCart Web and Admin ###
|
||||
|
||||
13. Now point your browser to `http://<web server IP address>/opencart-master/` and you would see something like the below screenshot.
|
||||
|
||||

|
||||
|
||||
OpenCart Product Showcase
|
||||
|
||||
14. In order to login to Opencart Admin Panel, point your browser to http://<web server IP address>/opencart-master/admin and fill the Admin Credentials you input, while setting it up.
|
||||
|
||||

|
||||
|
||||
OpenCart Admin Login
|
||||
|
||||
15. If everything ok! You should be able to see the Admin Dashboard of Opencart.
|
||||
|
||||

|
||||
|
||||
OpenCart Dashboard
|
||||
|
||||
Here in Admin Dashboard you may set up a lots of options like categories, product, options, Manufacturers, Downloads, Review, Information, Extension Installer, Shipping, Payment options, order totals, gift voucher, Paypal, Coupons, Affiliates, marketing, mails, Design and Settings, Error logs, in-built analytics and what not.
|
||||
|
||||
#### What after testing the tools? ####
|
||||
|
||||
If you have already tested the Application and finds it customizable, flexible, Rock Solid, Easy to maintain and use, you may need a good hosting provider to host OpenCart application, that remains live 24X7 support. Though there are a lot of options for hosting providers we recommend Hostgator.
|
||||
|
||||
Hostgator is a Domain Registrant and Hosting Provider that is very well known for the service and feature it provides. It Provides you with UNLIMITED Disk Space, UNLIMITED Bandwidth, Easy to install (1-click install script), 99.9% Uptime, Award winning 24x7x365 Technical Support and 45 days money back guarantee, which means if you didn’t like the product and service you get your money back within 45 days of purchasing and mind it 45 days is a long time to Test.
|
||||
|
||||
So if you have something to sell you can do it for free (by free I mean, Think of the cost you would spend on getting a physical store and then compare it with virtual store setting-up cost. You will feel its free).
|
||||
|
||||
**Note**: When you buy hosting (and/or Domain) from Hostgator you will get a **Flat 25% OFF**. This offer is valid only for the readers of Tecmint Site.
|
||||
|
||||
All you have to do is to Enter Promocode “**TecMint025**” during the payment of hosting. For reference see the preview of payment screen with promo code.
|
||||
|
||||

|
||||
|
||||
[Sign up for Hostgator][4] (Coupon code: TecMint025)
|
||||
|
||||
**Note**: Also worth mentioning, that for each hosting you buy from Hostgator to host OpenCart, we will get a small amount of commission, just to keep Tecmint Live (by Paying Bandwidth and hosting charges of server).
|
||||
|
||||
So If you buy it using the above code, you get discount and we will get a small amount. Also note that you won’t pay anything extra, infact you will be paying 25% less on total bill.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
OpenCart is an application that performs out-of-the box. It is easy to install and you have the option to choose best suited templates, add your products and you become an online merchant.
|
||||
|
||||
A lots of community made extensions(free and paid) makes it rich. It is a wonderful application for those who want to setup a virtual store and remain accessible to their customer 24X7. Let me know yours experience with the application. Any suggestion and feedback is welcome as well.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-e-commerce-online-shopping-store-using-opencart-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://demo.opencart.com/
|
||||
[2]:http://demo.opencart.com/admin/
|
||||
[3]:http://www.opencart.com/index.php?route=download/download/
|
||||
[4]:http://secure.hostgator.com/%7Eaffiliat/cgi-bin/affiliates/clickthru.cgi?id=tecmint
|
||||
@ -1,108 +0,0 @@
|
||||
Translating by goreliu ...
|
||||
|
||||
11 pointless but awesome Linux terminal tricks
|
||||
================================================================================
|
||||
Here are some great Linux terminal tips and tricks, each one as pointless as it is awesome.
|
||||
|
||||

|
||||
|
||||
### All work and no play... ###
|
||||
|
||||
Linux is one of the most astoundingly functional and utilitarian Operating Systems around when it comes to working from the command line. Need to perform a particular task? Odds are there is an application or script you can use to get it done. Right from the terminal. But, as they say in the good book, "All work and no play make Jack really bored or something." So here is a collection of my favorite pointless, stupid, annoying or amusing things that you can do right in your Linux Terminal.
|
||||
|
||||
|
||||
|
||||
### Give the terminal an attitude ###
|
||||
|
||||
Step 1) Type "sudo visudo".
|
||||
|
||||
Step 2) At the bottom of the "Defaults" (near the top of the file) add, on a new line, "Defaults insults".
|
||||
|
||||
Step 3) Save the file.
|
||||
|
||||
"What did I just do to my computer?" you may be asking yourself. Something wonderful. Now, whenever you issue a sudo command and misstype your password, your computer will call you names. My favorite: "Listen, burrito brains, I don't have time to listen to this trash."
|
||||
|
||||
|
||||
|
||||
### apt-get moo ###
|
||||
|
||||
That screenshot you see? That's what typing "apt-get moo" (on a Debian-based system) does. That's it. Don't go looking for this to do something fancy. It won't. That, I kid you not, is it. But it's one of the most commonly known little Easter eggs on Linux. So I include it here, right near the beginning, so I won't get 5,000 emails telling me I missed it in this list.
|
||||
|
||||
|
||||
|
||||
### aptitude moo ###
|
||||
|
||||
A bit more entertaining is aptitude's take on "moo." Type "aptitude moo" (on Ubuntu and the like) and you'll be corrected about thinking "moo" would do anything. But you know better. Try the same command again, this time with an optional "-v" attribute. Don't stop there. Add v's, one at a time, until aptitude gives you what you want.
|
||||
|
||||
|
||||
|
||||
### Arch: Put Pac-Man in pacman ###
|
||||
|
||||
This is one just for the Arch-lovers out there. The de facto package manager, pacman, is pretty fantastic already. Let's make it even better.
|
||||
|
||||
Step 1) Open "/etc/pacman.conf".
|
||||
|
||||
Step 2) In the "# Misc options", remove the "#" from in front of "Color".
|
||||
|
||||
Step 3) Add "ILoveCandy".
|
||||
|
||||
Now the progress for installing new packages, in pacman, will include a little tiny Pac-Man. Which should really just be the default anyway.
|
||||
|
||||
|
||||
|
||||
### Cowsay! ###
|
||||
|
||||
Making aptitude moo is neat, I guess, but you really can't use it for much. Enter "cowsay." It does what you think. You make a cow say things. Anything you like. And it's not even limited to cows. Calvin, Beavis, and the Ghostbusters logo are all available in full ASCII art glory – type "cowsay -l" for a full list of what's available in this, Linux's most powerful tool. Remember that, like most great terminal applications, you can pipe the output from other applications straight into cowsay (ala "fortune | cowsay").
|
||||
|
||||
|
||||
|
||||
### Become an 3l33t h@x0r ###
|
||||
|
||||
Typing "nmap" isn't something one typically needs to do on a day-to-day basis. But when one does need to "whip out the nmap," one wants to look as l33t as humanly possible. Add a "-oS" to any nmap command (such as "nmap -oS - google.com"). Bam. You're now in what is officially known as "[Script Kiddie Mode][1]." Angelina Jolie and Keanu Reeves would be proud.
|
||||
|
||||
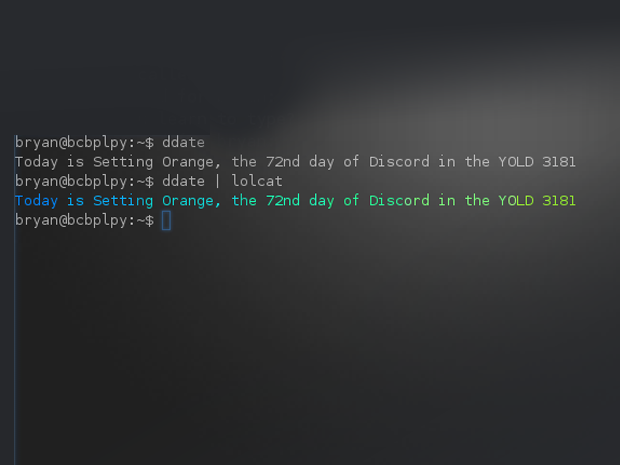
|
||||
|
||||
### Getting all Discordian ddate ###
|
||||
|
||||
If you've ever been sitting around thinking, "Hey! I want today's date to be written in an essentially useless, but whimsical, way"…try typing "ddate". Results like "Today is Setting Orange, the 72nd day of Discord in the YOLD 3181," can really spice up your server logs.
|
||||
|
||||
Note: Technically, this is a real thing called the [Discordian Calendar][2], used (in theory) by the followers of [Discordianism][3]. Which means I probably offended somebody. Or maybe not. I'm not really sure. Either way, ddate is a handy tool in any office.
|
||||
|
||||
|
||||
|
||||
### I See Colors Everywhere! ###
|
||||
|
||||
Tired of boring old text? Looking to spruce things up and show the world your true style? lolcat. Install it. Use it. Everywhere. It takes any text input and turns it into a rainbow of wonder and enchantment. Piping text into lolcat (ala "fortune | lolcat") is sure to liven up any party.
|
||||
|
||||
|
||||
|
||||
### The Steam Locomotive ###
|
||||
|
||||
Animated ASCII art steam locomotive in your terminal. You want this. You need this. Install and run "sl". Use "sl -l" for a tiny version. Or, if you want to really spend some time on this, "sl-h". This is the full train, including passenger cars.
|
||||
|
||||
|
||||
|
||||
### Reverse any text ###
|
||||
|
||||
Pipe the output of any text into "rev" and it will reverse the text. "fortune | rev" gives you a fortune. In reverse. Which is, as odd as it may seem, not a misfortune.
|
||||
|
||||
|
||||
|
||||
### The Matrix is still cool, right? ###
|
||||
|
||||
Want your terminal to do that scrolling text, l33t, Matrix-y thing? "cmatrix" is your friend. You can even have it output different colors, which is snazzy. Learn how by typing "man cmatrix". Or, better yet, "man cmatrix | lolcat". Which, really, is the most pointless (but wonderful) thing you can do in the Linux Terminal. So that's where I leave you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:http://nmap.org/book/output-formats-script-kiddie.html
|
||||
[2]:http://en.wikipedia.org/wiki/Discordian_calendar
|
||||
[3]:http://en.wikipedia.org/wiki/Discordianism
|
||||
@ -1,99 +0,0 @@
|
||||
How to Clear RAM Memory Cache, Buffer and Swap Space on Linux
|
||||
================================================================================
|
||||
Like any other operating system, GNU/Linux has implemented a memory management efficiently and even more than that. But if any process is eating away your memory and you want to clear it, Linux provides a way to flush or clear ram cache.
|
||||
|
||||

|
||||
|
||||
### How to Clear Cache in Linux? ###
|
||||
|
||||
Every Linux System has three options to clear cache without interrupting any processes or services.
|
||||
|
||||
1. Clear PageCache only.
|
||||
|
||||
# sync; echo 1 > /proc/sys/vm/drop_caches
|
||||
|
||||
2. Clear dentries and inodes.
|
||||
|
||||
# sync; echo 2 > /proc/sys/vm/drop_caches
|
||||
|
||||
3. Clear PageCache, dentries and inodes.
|
||||
|
||||
# sync; echo 3 > /proc/sys/vm/drop_caches
|
||||
|
||||
Explanation of above command.
|
||||
|
||||
sync will flush the file system buffer. Command Separated by `“;”` run sequentially. The shell wait for each command to terminate before executing the next command in the sequence. As mentioned in kernel documentation, writing to drop_cache will clean cache without killing any application/service, [command echo][1] is doing the job of writing to file.
|
||||
|
||||
If you have to clear the disk cache, the first command is safest in enterprise and production as `“...echo 1 > ….”` will clear the PageCache only. It is not recommended to use third option above `“...echo 3 >”` in production until you know what you are doing, as it will clear PageCache, dentries and inodes.
|
||||
|
||||
**Is it a good idea to free Buffer and Cache in Linux that might be used by Linux Kernel?**
|
||||
|
||||
When you are applying various settings and want to check, if it is actually implemented specially on I/O-extensive benchmark, then you may need to clear buffer cache. You can drop cache as explained above without rebooting the System i.e., no downtime required.
|
||||
|
||||
Linux is designed in such a way that it looks into disk cache before looking onto the disk. If it finds the resource in the cache, then the request doesn’t reach the disk. If we clean the cache, the disk cache will be less useful as the OS will look for the resource on the disk.
|
||||
|
||||
Moreover it will also slow the system for a few seconds while the cache is cleaned and every resource required by OS is loaded again in the disk-cache.
|
||||
|
||||
Now we will be creating a shell script to auto clear RAM cache daily at 2PM via a cron scheduler task. Create a shell script clearcache.sh and add the following lines.
|
||||
|
||||
#!/bin/bash
|
||||
# Note, we are using "echo 3", but it is not recommended in production instead use "echo 1"
|
||||
echo "echo 3 > /proc/sys/vm/drop_caches"
|
||||
|
||||
Set execute permission on the clearcache.sh file.
|
||||
|
||||
# chmod 755 clearcache.sh
|
||||
|
||||
Now you may call the script whenever you required to clear ram cache.
|
||||
|
||||
Now set a cron to clear RAM cache everyday at 2PM. Open crontab for editing.
|
||||
|
||||
# crontab -e
|
||||
|
||||
Append the below line, save and exit to run it at 2PM daily.
|
||||
|
||||
0 3 * * * /path/to/clearcache.sh
|
||||
|
||||
For more details on how to cron a job you may like to check our article on [11 Cron Scheduling Jobs][2].
|
||||
|
||||
**Is it good idea to auto clear RAM cache on production server?**
|
||||
|
||||
No! it is not. Think of a situation when you have scheduled the script to clear ram cache everyday at 2PM. Everyday at 2PM the script is executed and it flushes your RAM cache. One day for whatsoever reason, may be more than expected users are online on your website and seeking resource from your server.
|
||||
|
||||
At the same time scheduled script run and clears everything in cache. Now all the user are fetching data from disk. It will result in server crash and corrupt the database. So clear ram-cache only when required,and known your foot steps, else you are a Cargo Cult System Administrator.
|
||||
|
||||
#### How to Clear Swap Space in Linux? ####
|
||||
|
||||
If you want to clear Swap space, you may like to run the below command.
|
||||
|
||||
# swapoff -a && swapon -a
|
||||
|
||||
Also you may add above command to a cron script above, after understanding all the associated risk.
|
||||
|
||||
Now we will be combining both above commands into one single command to make a proper script to clear RAM Cache and Swap Space.
|
||||
|
||||
# echo 3 > /proc/sys/vm/drop_caches && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
OR
|
||||
|
||||
su -c 'echo 3 >/proc/sys/vm/drop_caches' && swapoff -a && swapon -a && printf '\n%s\n' 'Ram-cache and Swap Cleared'
|
||||
|
||||
After testing both above command, we will run command “free -h” before and after running the script and will check cache.
|
||||
|
||||

|
||||
|
||||
That’s all for now, if you liked the article, don’t forget to provide us with your valuable feedback in the comments to let us know, what you think is it a good idea to clear ram cache and buffer in production and Enterprise?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/clear-ram-memory-cache-buffer-and-swap-space-on-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
|
||||
@ -1,129 +0,0 @@
|
||||
How to Install nginx and google pagespeed on Ubuntu 15.04 (Vivid Vervet)
|
||||
================================================================================
|
||||
Nginx (engine-x) is a open source and high performance HTTP server, reverse proxy and IMAP/POP3 proxy server. The outstanding features of Nginx are: stability, rich feature set, simple configuration and low resource consumption. Nginx is being used by some of the largest websites on the internet and is gaining more and more popularity in the webmaster community. This tutorials shows how to build a nginx .deb package for Ubuntu 15.04 from source that has Google pagespeed module compiled in.
|
||||
|
||||
|
||||
Pagespeed is a web server module developed by Google to speed up a website response times, optimize html and reduce the page load time. ngx_pagespeed features include :
|
||||
|
||||
- Image optimization: stripping meta-data, dynamic resizing, recompression.
|
||||
- CSS & JavaScript minification, concatenation, inlining, and outlining.
|
||||
- Small resource inlining.
|
||||
- Deferring image and JavaScript loading.
|
||||
- HTML rewriting.
|
||||
- Cache lifetime extension.
|
||||
|
||||
see more [https://developers.google.com/speed/pagespeed/module/][1].
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
Ubuntu Server 15.04 64 bit
|
||||
root privileges
|
||||
|
||||
What we will do in this tutorial :
|
||||
|
||||
- Install the prerequisite packages.
|
||||
- Installing nginx with ngx_pagespeed.
|
||||
- Testing.
|
||||
|
||||
#### Install the prerequisite packages ####
|
||||
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||
#### Installing nginx with ngx_pagespeed ####
|
||||
|
||||
**Step 1 - Adding nginx repository**
|
||||
|
||||
vim /etc/apt/sources.list.d/nginx.list
|
||||
|
||||
add the line:
|
||||
|
||||
deb http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
deb-src http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
|
||||
Update your repository:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
note : if you get the messege : GPG error [...] NO_PUBKEY [...] bla bla
|
||||
|
||||
please add the the key:
|
||||
|
||||
sudo sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys KEYNUMBER
|
||||
sudo apt-get update
|
||||
|
||||
**Step 2 - Download nginx 1.8 from ubuntu repository**
|
||||
|
||||
sudo su
|
||||
cd ~
|
||||
mkdir -p ~/new/nginx_source/
|
||||
cd ~/new/nginx_source/
|
||||
apt-get source nginx
|
||||
apt-get build-dep nginx
|
||||
|
||||
**Step 3 - Download Pagespeed**
|
||||
|
||||
cd ~
|
||||
mkdir -p ~/new/ngx_pagespeed/
|
||||
cd ~/new/ngx_pagespeed/
|
||||
ngx_version=1.9.32.3
|
||||
wget https://github.com/pagespeed/ngx_pagespeed/archive/release-${ngx_version}-beta.zip
|
||||
unzip release-${ngx_version}-beta.zip
|
||||
|
||||
cd ngx_pagespeed-release-1.9.32.3-beta/
|
||||
wget https://dl.google.com/dl/page-speed/psol/${ngx_version}.tar.gz
|
||||
tar -xzf 1.9.32.3.tar.gz
|
||||
|
||||
**Step 4 - Configure nginx to build with Pagespeed**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/debin/
|
||||
vim rules
|
||||
|
||||
add the module under CFLAGS `.configure` :
|
||||
|
||||
--add-module=../../ngx_pagespeed/ngx_pagespeed-release-1.9.32.3-beta \
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**Step 5 - Build nginx package and Install**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/
|
||||
dpkg-buildpackage -b
|
||||
|
||||
The dpkg-buildpackage command will build the nginx.deb under ~/new/ngix_source/ Once package building is complete, please look in the directory:
|
||||
|
||||
cd ~/new/ngix_source/
|
||||
ls
|
||||
|
||||
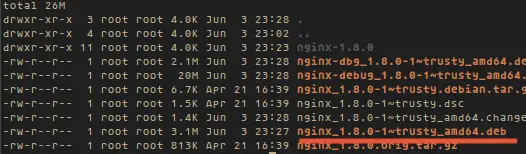
|
||||
|
||||
And then install nginx.
|
||||
|
||||
dpkg -i nginx_1.8.0-1~trusty_amd64.deb
|
||||
|
||||
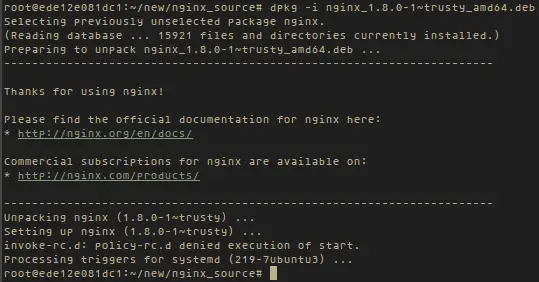
|
||||
|
||||
#### Testing ####
|
||||
|
||||
Run nginx -V to see the ngx_pagespeed was builted with nginx.
|
||||
|
||||
nginx -V
|
||||
|
||||
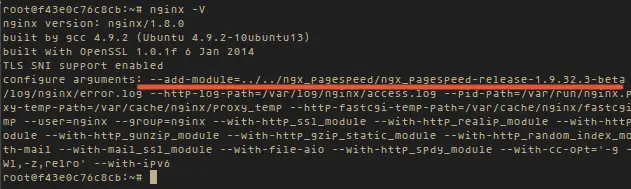
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The nginx web server there is a stable and fast open source http server that supports a variety of modules for optimization. One of these modules is the 'PageSpeed module' which is developed by google. Unlike apache, nginx modules are not dynamically loadable, so you have to select the desired modules before you build the nginx package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/#step-build-nginx-package-and-install
|
||||
|
||||
作者:Muhammad Arul
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://developers.google.com/speed/pagespeed/module/
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
How to Manipulate Filenames Having Spaces and Special Characters in Linux
|
||||
================================================================================
|
||||
We come across files and folders name very regularly. In most of the cases file/folder name are related to the content of the file/folder and starts with number and characters. Alpha-Numeric file name are pretty common and very widely used, but this is not the case when we have to deal with file/folder name that has special characters in them.
|
||||
@ -432,4 +433,4 @@ via: http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/15-basic-ls-command-examples-in-linux/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
[2]:http://www.tecmint.com/8-pratical-examples-of-linux-touch-command/
|
||||
|
||||
@ -1,233 +0,0 @@
|
||||
How to secure your Linux server
|
||||
================================================================================
|
||||
> A server is made up of so many different components that makes it hard to offer one solution for everyone's needs. This articles tries to cover some useful tips and tricks to help you keep your server and users protected.
|
||||
|
||||
No doubt improving server security is one of the most important things system administrators should always look for. This of course has been a topic of many different articles, blogs and forum threads.
|
||||
|
||||
A server is made up of so many different components that makes it hard to offer one solution for everyone’s needs. This articles tries to cover some useful tips and tricks to help you keep your server and users protected.
|
||||
|
||||
There are a few things that every system administrator should know and there is no way to talk about security without mentioning:
|
||||
|
||||
- Keep your system **up to date**
|
||||
- Change passwords frequently – use numeric, alphabetical and non-alphabetical symbols
|
||||
- Give users the **minimum** permissions they need to do their job.
|
||||
- Install only packages that you really need
|
||||
|
||||
Here comes the more interesting part:
|
||||
|
||||
### Change default SSH port ###
|
||||
|
||||
The first thing that I would like to change when setting up a new server is the default SSH port. This simple change can save your server from thousands of brute force attempts.
|
||||
|
||||
To change the default SSH port, open your sshd_config:
|
||||
|
||||
sudo vim /etc/ssh/sshd_config
|
||||
|
||||
Find the following line:
|
||||
|
||||
#Port 22
|
||||
|
||||
The “#” symbol means that this line is a comment. Remove the # symbol then change the port to a number of your choice. The port number should not be larger than 65535. Make sure not to use any port already used by your system or other services. You can see a list of commonly used ports in [Wikipedia][1]. For the purpose of this article I will use:
|
||||
|
||||
Port 16543
|
||||
|
||||
Now save the file and close it for a moment.
|
||||
|
||||
Next important step is to:
|
||||
|
||||
### Use SSH Keys ###
|
||||
|
||||
It is extremely important to use SSH keys when accessing the server over SSH. This adds additional protection and ensure that only people who have the key can access the server.
|
||||
|
||||
To generate SSH key on your local computer run:
|
||||
|
||||
ssh-keygen -t rsa
|
||||
|
||||
You will receive an output asking you to setup the file name where the key should be written as well as setup a password:
|
||||
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa): my_key
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in my_key.
|
||||
Your public key has been saved in my_key.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:MqD/pzzTRsCjZb6mpfjyrr5v1pJLBcgprR5tjNoI20A
|
||||
|
||||
When compete, you will have two files:
|
||||
|
||||
my_key
|
||||
|
||||
my_key.pub
|
||||
|
||||
Now copy the my_key.pub to ~/.ssh/authorized_keys
|
||||
|
||||
cp my_key.pub ~/.ssh/authorized_keys
|
||||
|
||||
Now upload your key on the server by using:
|
||||
|
||||
scp -P16543 authorized_keys user@yourserver-ip:/home/user/.ssh/
|
||||
|
||||
Now you can access the server from the same local machine without having to enter any password.
|
||||
|
||||
### Disable password authentication for SSH ###
|
||||
|
||||
Now that we have SSH keys, it is safe to disable the password authentication for SSH. Open again the sshd_config file and set the following changes:
|
||||
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
|
||||
### Disable Root login ###
|
||||
|
||||
The next important step is to disable direct access with root user. Instead you should use sudo or su to perform administrative jobs. To do this you will need to add a new user that has root privileges. To do this you will need to edit the sudoers file located in:
|
||||
|
||||
/etc/sudoers/
|
||||
|
||||
You may edit that file with command such as **visudo**. I would recommend you using this command as it will check the file for any syntax errors prior closing the file. This is useful if you have wrongly edited the file.
|
||||
|
||||
Now to give root privileges to a user. For the purpose of this tutorial I will use user **sysadmin**. Make sure you are using an existing user on your system when you edit your own file. Now find the following line:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
Copy that line and paste it below. In the new line change “root” with “sysadmin”. You should now have these two lines:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
sysadmin ALL=(ALL) ALL
|
||||
|
||||
I would like to explain what each of the options in the above line represents:
|
||||
|
||||
(1) root (2)ALL=(3)(ALL) (4)ALL
|
||||
|
||||
(1) User
|
||||
|
||||
(2) Terminal from which user can use sudo
|
||||
|
||||
(3) Which users User may act as
|
||||
|
||||
(4) Which commands he may use
|
||||
|
||||
|
||||
You can use this settings to give access to users to some of the system tools.
|
||||
|
||||
At this point it is safe to save your file.
|
||||
|
||||
To disable direct root access over SSH open again the **sshd_config** file and find the following line:
|
||||
|
||||
#PermitRootLogin yes
|
||||
|
||||
and change it to:
|
||||
|
||||
PermitRootLogin no
|
||||
|
||||
Now save the file and restart the sshd daemon so the changes can take effect. Simply run the following command:
|
||||
|
||||
sudo /etc/init.d/sshd restart
|
||||
|
||||
### Setup firewall ###
|
||||
|
||||
A firewall can help you block incoming and outgoing ports as well as block brute force login attempts. I like using SCF (Config Server Firewall) as it a powerful solution that uses iptables, it’s easy to manage and has a web interface for people who don’t like typing too many commands.
|
||||
|
||||
To install CSF access your server and navigate to:
|
||||
|
||||
cd /usr/local/src/
|
||||
|
||||
Then execute the following commands as root:
|
||||
|
||||
wget https://download.configserver.com/csf.tgz
|
||||
tar -xzf csf.tgz
|
||||
csf
|
||||
sh install.sh
|
||||
|
||||
You will need to wait for the installer to finish its job. We will edit CSF configuration by editing:
|
||||
|
||||
/etc/csf/csf.conf
|
||||
|
||||
By default CSF will be started in testing mode. You will need to set it to product by changing the “TESTING” value to 0
|
||||
|
||||
TESTING = "0"
|
||||
|
||||
Next thing you can edit are the allowed ports on your server. For that purpose find the following section of the csf.conf file and modify the ports per your needs:
|
||||
|
||||
# Allow incoming TCP ports
|
||||
TCP_IN = "20,21,25,53,80,110,143,443,465,587,993,995,16543"
|
||||
# Allow outgoing TCP ports
|
||||
TCP_OUT = "20,21,22,25,53,80,110,113,443,587,993,995,16543"
|
||||
# Allow incoming UDP ports
|
||||
UDP_IN = "20,21,53"
|
||||
# Allow outgoing UDP ports
|
||||
# To allow outgoing traceroute add 33434:33523 to this list
|
||||
UDP_OUT = "20,21,53,113,123"
|
||||
|
||||
Setup these per your requirements. I would recommend you using only the ports you need and avoiding allowing huge ranges of ports. Additionally you can avoid using the unsecured services unsecured ports. For example instead of allowing the default SMTP port 25 you can only allow ports 465 and 587 for outgoing emails.
|
||||
|
||||
**IMPORTANT**: Do not forget to allow your customized SSH port.
|
||||
|
||||
It is important to allow your IP address so it will never get blocked. Such IP addresses can be defined in:
|
||||
|
||||
/etc/csf/csf.ignore
|
||||
|
||||
The blocked IP address will appear in:
|
||||
|
||||
/etc/csf/csf.deny
|
||||
|
||||
When you have finished making changes – restart csf with:
|
||||
|
||||
sudo /etc/init.d/csf restart
|
||||
|
||||
Just to show you how useful CSF is I will show you part of csf.deny on one of my servers:
|
||||
|
||||
211.216.48.205 # lfd: (sshd) Failed SSH login from 211.216.48.205 (KR/Korea, Republic of/-): 5 in the last 3600 secs - Fri Mar 6 00:30:35 2015
|
||||
103.41.124.53 # lfd: (sshd) Failed SSH login from 103.41.124.53 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:06:46 2015
|
||||
103.41.124.42 # lfd: (sshd) Failed SSH login from 103.41.124.42 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:59:04 2015
|
||||
103.41.124.26 # lfd: (sshd) Failed SSH login from 103.41.124.26 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 02:48:26 2015
|
||||
109.169.74.58 # lfd: (sshd) Failed SSH login from 109.169.74.58 (GB/United Kingdom/mail2.algeos.com): 5 in the last 3600 secs - Fri Mar 6 03:49:03 2015
|
||||
|
||||
The IP addresses that performed the brute force login attempt got blocked and they will not bother me again.
|
||||
|
||||
#### Lock accounts ####
|
||||
|
||||
In case an account is not going to be used for a long period of time you can lock it in order to prevent access to it. You can do this with:
|
||||
|
||||
passwd -l accountName
|
||||
|
||||
Account can still be used by the root user.
|
||||
|
||||
### Know your services ###
|
||||
|
||||
The whole idea of a server is to provide access to different services. Limit those to only the ones you need and disable the unused ones. This will not only free some resources, but will make your server a little bit more secured. For example if you are running a headless server you will definitely not need X display or a desktop environment. If there are no Windows network shares, you can safely disable Samba.
|
||||
|
||||
You can use the commands below to see which services are started upon system boot:
|
||||
|
||||
chkconfig --list | grep "3:on"
|
||||
|
||||
If your system runs with **systemd**:
|
||||
|
||||
systemctl list-unit-files --type=service | grep enabled
|
||||
|
||||
To disable a service you can use commands such as:
|
||||
|
||||
chkconfig service off
|
||||
systemctl disable service
|
||||
|
||||
In the above example change “service” with the name of the actual service you wish to stop. Here is an example:
|
||||
|
||||
chkconfig httpd off
|
||||
systemctl disable httpd
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This article was meant to cover some of the general security steps you can take to start securing your server. You can always take additional actions to increase the server protection. Remember that it is your responsibility to keep your server secured and make the wise decision while doing it. Unfortunately there is no easy way to do this and the “perfect” setup requires lots of time and tests until you achieve the desired result.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/06/03/secure-linux-server/
|
||||
|
||||
作者:[Marin Todorow][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/marin_todorov/
|
||||
[1]:http://en.wikipedia.org/wiki/Port_%28computer_networking%29#Common_port_numbers
|
||||
@ -1,212 +0,0 @@
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
**1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used?**
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
**2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line?**
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
**3. What are the basic differences between between iptables and firewalld?**
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
**4. Would you replace iptables with firewalld on all your servers, if given a chance?**
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
**5. You seems confident with iptables and the plus point is even we are using iptables on our server.**
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> - Nat Table
|
||||
> - Mangle Table
|
||||
> - Filter Table
|
||||
> - Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
**6. What are the target values (that can be specified in target) in iptables and what they do, be brief!**
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> - ACCEPT : Accept Packets
|
||||
> - QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> - DROP : Drop Packets
|
||||
> - RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
**7. Lets move to the technical aspects of iptables, by technical I means practical.**
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
**8. How to Check and ensure if iptables service is running?**
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
**9. How will you review the current Rules defined in iptables?**
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**10. How will you flush all iptables rules or a particular chain?**
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
**11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7)**
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
**12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables.**
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:
|
||||
>
|
||||
> To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
**13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do?**
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 21,22,23,80 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com or you may submit your interview experience using following form.
|
||||
|
||||
- [Share Your Interview Experience][2]
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
[2]:https://docs.google.com/a/tecmint.com/forms/d/1jfu1Kg8_qToqvyi6pOT1HQb0dAFvRE-Yc_aOkj0RoSg/viewform
|
||||
@ -1,133 +0,0 @@
|
||||
watch - Repeat Linux / Unix Commands Regular Intervals
|
||||
================================================================================
|
||||
A server administrator needs to maintain the system and keep it updated and safe. A number of intrusion attempts may happen every day. There are some other activities that maintain their log. These logs are updated regularly. In order to check these updates, the commands are executed repeatedly. For example, for simply reading a file, commands like head, tail, cat etc are used. These commands need to be executed repeatedly. The watch command can be used to repeat a command at regular intervals.
|
||||
|
||||
### Watch Command ###
|
||||
|
||||
Watch is a simple command, with a few options. The basic syntax of watch command is:
|
||||
|
||||
watch [-dhvt] [-n <seconds>] [--differences[=cumulative]] [--help] [--interval=<seconds>] [--no-title] [--version] <command>
|
||||
|
||||
Watch command runs the command specified to it after every 2 seconds by default. This time is counted between the completion of command and beginning of next execution. As a simple example, watch command can be used to watch the log updates, The updates are appended at the end of the file, so tail command can be used with watch to see the updates to the file. This command continues to run until you hit CTRL + C to return to the prompt.
|
||||
|
||||
### Examples ###
|
||||
|
||||
> Keep an eye on errors/notices/warning being generated at run time every couple of seconds.
|
||||
|
||||
watch tail /var/log/messages
|
||||
|
||||

|
||||
|
||||
> Keep an eye on disk usage after specified time interval.
|
||||
|
||||
watch df -h
|
||||
|
||||

|
||||
|
||||
> It is very important for administrators to keep an eye on high I/O wait causing disk operations especially the Mysql transactions.
|
||||
|
||||
watch mysqladmin processlist
|
||||
|
||||

|
||||
|
||||
> Keep an eye on server load and uptime at runtime.
|
||||
|
||||
watch uptime
|
||||
|
||||

|
||||
|
||||
> Keep an eye on queue size for Exim at the time a cron is run to send notices to subscribers.
|
||||
|
||||
watch exim -bpc
|
||||
|
||||

|
||||
|
||||
### 1) Iteration delay ###
|
||||
|
||||
watch [-n <seconds>] <command>
|
||||
|
||||
The default interval between the commands can be changed with -n switch. The following command will run the tail command after 5 seconds:
|
||||
|
||||
watch -n 5 date
|
||||
|
||||

|
||||
|
||||
### 2) Successive output comparison ###
|
||||
|
||||
If you use -d option with watch command, it will highlight the differences between the first command output to every next command output cumulatively.
|
||||
|
||||
watch [-d or --differences[=cumulative]] <command>
|
||||
|
||||
#### Example1 ####
|
||||
|
||||
Let’s see the successive time outputs extracted using following watch command and observe how the difference is highlighted.
|
||||
|
||||
watch -n 15 -d date
|
||||
|
||||
First time date is capture when command is executed, the next iteration will be repeated after 15 seconds.
|
||||
|
||||

|
||||
|
||||
Upon the execution of next iteration, it can be seen that all output is exactly same except the seconds have increased from 14 to 29 which is highlighted.
|
||||
|
||||

|
||||
|
||||
#### Example 2 ####
|
||||
|
||||
Let’s experience in difference between two successive outputs of “uptime” command repeated by watch.
|
||||
|
||||
watch -n 20 -d uptime
|
||||
|
||||

|
||||
|
||||
Now the difference between the time is highlighted as well as the three load snapshots as well.
|
||||
|
||||

|
||||
|
||||
### 3) Output without title ###
|
||||
|
||||
If you don’t want to display extra details about the iteration delay and actual command run by watch then –t switch can be used.
|
||||
|
||||
watch [-t or --no-title] <command>
|
||||
|
||||
Let’s see the output of following command as an example.
|
||||
|
||||
watch -t date
|
||||
|
||||

|
||||
|
||||
### Watch help ###
|
||||
|
||||
Brief details of the watch command can be found by typing the following command in SSH.
|
||||
|
||||
watch -h [or --help]
|
||||
|
||||

|
||||
|
||||
### Watch version ###
|
||||
|
||||
Run the following command in SSH terminal to check the version of watch.
|
||||
|
||||
watch -v [--version]
|
||||
|
||||

|
||||
|
||||
**BUGS**
|
||||
|
||||
Unfortunately, upon terminal resize, the screen will not be correctly repainted until the next scheduled update. All --differences highlight-ing is lost on that update as well.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Watch is a very powerful utility for system administrators because it can be used to monitor, logs, operations, performance and throughput of the system at run time. One can easily format and delay the output of watch utility. Any Linux command / utility or script and be supplied to watch for desired and continuous output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/linux-watch-command/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
@ -0,0 +1,95 @@
|
||||
How to Configure Swarm Native Clustering for Docker
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn about Swarm and how we can create native clusters using Docker with Swarm. [Docker Swarm][1] is a native clustering program for Docker which turns a pool of Docker hosts into a single virtual host. Swarm serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Swarm follows the "batteries included but removable" principle as other Docker Projects. It ships with a simple scheduling backend out of the box, and as initial development settles, an API will develop to enable pluggable backends. The goal is to provide a smooth out-of-box experience for simple use cases, and allow swapping in more powerful backends, like Mesos, for large scale production deployments. Swarm is extremely easy to setup and get started.
|
||||
|
||||
So, here are some features of Swarm 0.2 out of the box.
|
||||
|
||||
1. Swarm 0.2.0 is about 85% compatible with the Docker Engine.
|
||||
2. It supports Resource Management.
|
||||
3. It has Advanced Scheduling feature with constraints and affinities.
|
||||
4. It supports multiple Discovery Backends (hubs, consul, etcd, zookeeper)
|
||||
5. It uses TLS encryption method for security and authentication.
|
||||
|
||||
So, here are some very simple and easy steps on how we can use Swarm.
|
||||
|
||||
### 1. Pre-requisites to run Swarm ###
|
||||
|
||||
We must install Docker 1.4.0 or later on all nodes. While each node's IP need not be public, the Swarm manager must be able to access each node across the network.
|
||||
|
||||
Note: Swarm is currently in beta, so things are likely to change. We don't recommend you use it in production yet.
|
||||
|
||||
### 2. Creating Swarm Cluster ###
|
||||
|
||||
Now, we'll create swarm cluster by running the below command. Each node will run a swarm node agent. The agent registers the referenced Docker daemon, monitors it, and updates the discovery backend with the node's status. The below command returns a token which is a unique cluster id, it will be used when starting the Swarm Agent on nodes.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. Starting the Docker Daemon in each nodes ###
|
||||
|
||||
We'll need to login into each node that we'll use to create clusters and start the Docker Daemon into it using flag -H . It ensures that the docker remote API on the node is available over TCP for the Swarm Manager. To do start the docker daemon, we'll need to run the following command inside the nodes.
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. Adding the Nodes ###
|
||||
|
||||
After enabling Docker Daemon, we'll need to add the Swarm Nodes to the discovery service. We must ensure that node's IP must be accessible from the Swarm Manager. To do so, we'll need to run the following command.
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**Note**: Here, we'll need to replace <node_ip> and <cluster_id> with the IP address of the Node and the cluster ID we got from step 2.
|
||||
|
||||
### 5. Starting the Swarm Manager ###
|
||||
|
||||
Now, as we have got the nodes connected to the cluster. Now, we'll start the swarm manager, we'll need to run the following command in the node.
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. Checking the Configuration ###
|
||||
|
||||
Once the manager is running, we can check the configuration by running the following command.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**Note**: We'll need to replace <manager_ip:manager_port> with the ip address and port of the host running the swarm manager.
|
||||
|
||||
### 7. Using the docker CLI to access nodes ###
|
||||
|
||||
After everything is done perfectly as explained above, this part is the most important part of the Docker Swarm. We can use Docker CLI to access the nodes and run containers on them.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. Listing nodes in the cluster ###
|
||||
|
||||
We can get a list of all of the running nodes using the swarm list command.
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Swarm is really an awesome feature of docker that can be used for creating and managing clusters. It is pretty easy to setup and use. It is more beautiful when we use constraints and affinities on top of it. Advanced Scheduling is an awesome feature of it which applies filters to exclude nodes with ports, labels, health and it uses strategies to pick the best node. So, if you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
@ -0,0 +1,175 @@
|
||||
wyangsun 申领
|
||||
Inside NGINX: How We Designed for Performance & Scale
|
||||
================================================================================
|
||||
NGINX leads the pack in web performance, and it’s all due to the way the software is designed. Whereas many web servers and application servers use a simple threaded or process-based architecture, NGINX stands out with a sophisticated event-driven architecture that enables it to scale to hundreds of thousands of concurrent connections on modern hardware.
|
||||
|
||||
The [Inside NGINX][1] infographic drills down from the high-level process architecture to illustrate how NGINX handles multiple connections within a single process. This blog explains how it all works in further detail.
|
||||
|
||||
### Setting the Scene – the NGINX Process Model ###
|
||||
|
||||
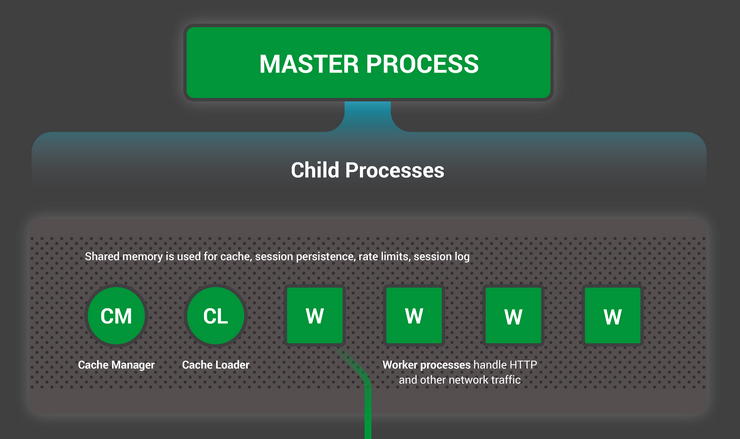
|
||||
|
||||
To better understand this design, you need to understand how NGINX runs. NGINX has a master process (which performs the privileged operations such as reading configuration and binding to ports) and a number of worker and helper processes.
|
||||
|
||||
# service nginx restart
|
||||
* Restarting nginx
|
||||
# ps -ef --forest | grep nginx
|
||||
root 32475 1 0 13:36 ? 00:00:00 nginx: master process /usr/sbin/nginx \
|
||||
-c /etc/nginx/nginx.conf
|
||||
nginx 32476 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32477 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32479 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32480 32475 0 13:36 ? 00:00:00 \_ nginx: worker process
|
||||
nginx 32481 32475 0 13:36 ? 00:00:00 \_ nginx: cache manager process
|
||||
nginx 32482 32475 0 13:36 ? 00:00:00 \_ nginx: cache loader process
|
||||
|
||||
On this 4-core server, the NGINX master process creates 4 worker processes and a couple of cache helper processes which manage the on-disk content cache.
|
||||
|
||||
### Why Is Architecture Important? ###
|
||||
|
||||
The fundamental basis of any Unix application is the thread or process. (From the Linux OS perspective, threads and processes are mostly identical; the major difference is the degree to which they share memory.) A thread or process is a self-contained set of instructions that the operating system can schedule to run on a CPU core. Most complex applications run multiple threads or processes in parallel for two reasons:
|
||||
|
||||
- They can use more compute cores at the same time.
|
||||
- Threads and processes make it very easy to do operations in parallel (for example, to handle multiple connections at the same time).
|
||||
|
||||
Processes and threads consume resources. They each use memory and other OS resources, and they need to be swapped on and off the cores (an operation called a context switch). Most modern servers can handle hundreds of small, active threads or processes simultaneously, but performance degrades seriously once memory is exhausted or when high I/O load causes a large volume of context switches.
|
||||
|
||||
The common way to design network applications is to assign a thread or process to each connection. This architecture is simple and easy to implement, but it does not scale when the application needs to handle thousands of simultaneous connections.
|
||||
|
||||
### How Does NGINX Work? ###
|
||||
|
||||
NGINX uses a predictable process model that is tuned to the available hardware resources:
|
||||
|
||||
- The master process performs the privileged operations such as reading configuration and binding to ports, and then creates a small number of child processes (the next three types).
|
||||
- The cache loader process runs at startup to load the disk-based cache into memory, and then exits. It is scheduled conservatively, so its resource demands are low.
|
||||
- The cache manager process runs periodically and prunes entries from the disk caches to keep them within the configured sizes.
|
||||
- The worker processes do all of the work! They handle network connections, read and write content to disk, and communicate with upstream servers.
|
||||
|
||||
The NGINX configuration recommended in most cases – running one worker process per CPU core – makes the most efficient use of hardware resources. You configure it by including the [worker_processes auto][2] directive in the configuration:
|
||||
|
||||
worker_processes auto;
|
||||
|
||||
When an NGINX server is active, only the worker processes are busy. Each worker process handles multiple connections in a non-blocking fashion, reducing the number of context switches.
|
||||
|
||||
Each worker process is single-threaded and runs independently, grabbing new connections and processing them. The processes can communicate using shared memory for shared cache data, session persistence data, and other shared resources.
|
||||
|
||||
### Inside the NGINX Worker Process ###
|
||||
|
||||
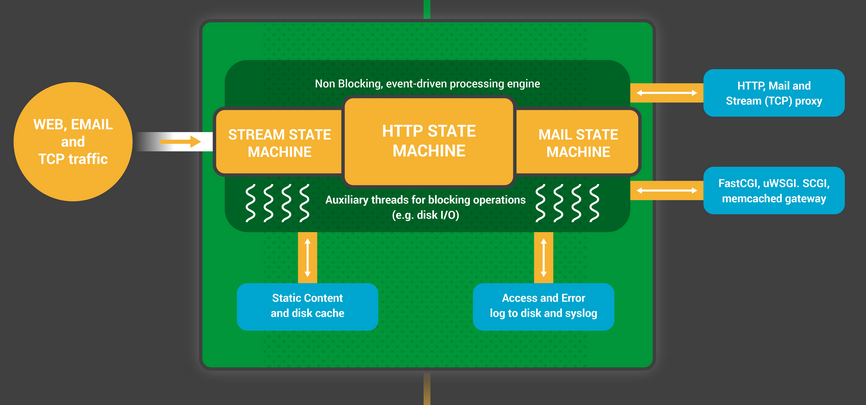
|
||||
|
||||
Each NGINX worker process is initialized with the NGINX configuration and is provided with a set of listen sockets by the master process.
|
||||
|
||||
The NGINX worker processes begin by waiting for events on the listen sockets ([accept_mutex][3] and [kernel socket sharding][4]). Events are initiated by new incoming connections. These connections are assigned to a state machine – the HTTP state machine is the most commonly used, but NGINX also implements state machines for stream (raw TCP) traffic and for a number of mail protocols (SMTP, IMAP, and POP3).
|
||||
|
||||
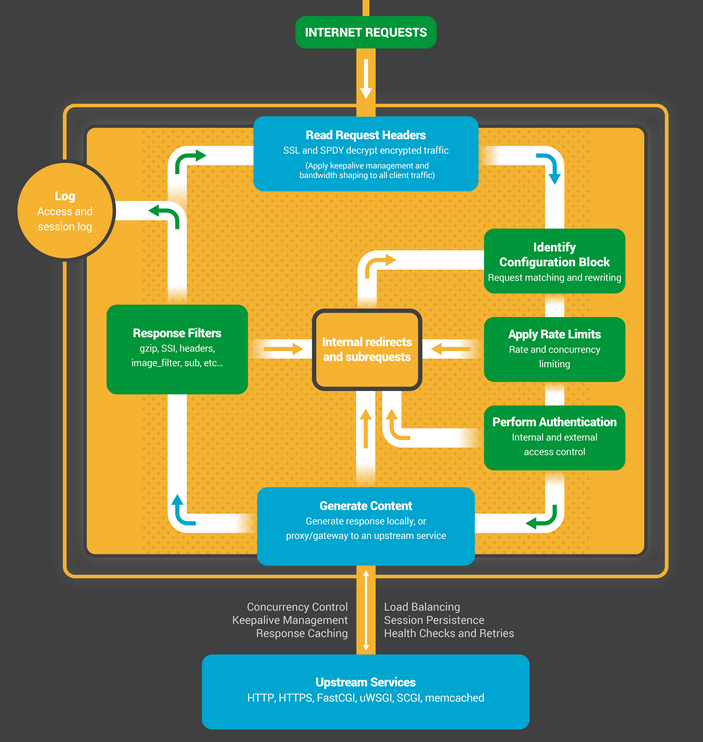
|
||||
|
||||
The state machine is essentially the set of instructions that tell NGINX how to process a request. Most web servers that perform the same functions as NGINX use a similar state machine – the difference lies in the implementation.
|
||||
|
||||
### Scheduling the State Machine ###
|
||||
|
||||
Think of the state machine like the rules for chess. Each HTTP transaction is a chess game. On one side of the chessboard is the web server – a grandmaster who can make decisions very quickly. On the other side is the remote client – the web browser that is accessing the site or application over a relatively slow network.
|
||||
|
||||
However, the rules of the game can be very complicated. For example, the web server might need to communicate with other parties (proxying to an upstream application) or talk to an authentication server. Third-party modules in the web server can even extend the rules of the game.
|
||||
|
||||
#### A Blocking State Machine ####
|
||||
|
||||
Recall our description of a process or thread as a self-contained set of instructions that the operating system can schedule to run on a CPU core. Most web servers and web applications use a process-per-connection or thread-per-connection model to play the chess game. Each process or thread contains the instructions to play one game through to the end. During the time the process is run by the server, it spends most of its time ‘blocked’ – waiting for the client to complete its next move.
|
||||
|
||||

|
||||
|
||||
1. The web server process listens for new connections (new games initiated by clients) on the listen sockets.
|
||||
1. When it gets a new game, it plays that game, blocking after each move to wait for the client’s response.
|
||||
1. Once the game completes, the web server process might wait to see if the client wants to start a new game (this corresponds to a keepalive connection). If the connection is closed (the client goes away or a timeout occurs), the web server process returns to listening for new games.
|
||||
|
||||
The important point to remember is that every active HTTP connection (every chess game) requires a dedicated process or thread (a grandmaster). This architecture is simple and easy to extend with third-party modules (‘new rules’). However, there’s a huge imbalance: the rather lightweight HTTP connection, represented by a file descriptor and a small amount of memory, maps to a separate thread or process, a very heavyweight operating system object. It’s a programming convenience, but it’s massively wasteful.
|
||||
|
||||
#### NGINX is a True Grandmaster ####
|
||||
|
||||
Perhaps you’ve heard of [simultaneous exhibition][5] games, where one chess grandmaster plays dozens of opponents at the same time?
|
||||
|
||||

|
||||
|
||||
[Kiril Georgiev played 360 people simultaneously in Sofia, Bulgaria][6]. His final score was 284 wins, 70 draws and 6 losses.
|
||||
|
||||
That’s how an NGINX worker process plays “chess.” Each worker (remember – there’s usually one worker for each CPU core) is a grandmaster that can play hundreds (in fact, hundreds of thousands) of games simultaneously.
|
||||
|
||||
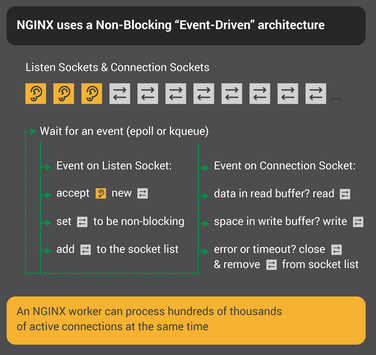
|
||||
|
||||
1. The worker waits for events on the listen and connection sockets.
|
||||
1. Events occur on the sockets and the worker handles them:
|
||||
|
||||
- An event on the listen socket means that a client has started a new chess game. The worker creates a new connection socket.
|
||||
- An event on a connection socket means that the client has made a new move. The worker responds promptly.
|
||||
|
||||
A worker never blocks on network traffic, waiting for its “opponent” (the client) to respond. When it has made its move, the worker immediately proceeds to other games where moves are waiting to be processed, or welcomes new players in the door.
|
||||
|
||||
### Why Is This Faster than a Blocking, Multi-Process Architecture? ###
|
||||
|
||||
NGINX scales very well to support hundreds of thousands of connections per worker process. Each new connection creates another file descriptor and consumes a small amount of additional memory in the worker process. There is very little additional overhead per connection. NGINX processes can remain pinned to CPUs. Context switches are relatively infrequent and occur when there is no work to be done.
|
||||
|
||||
In the blocking, connection-per-process approach, each connection requires a large amount of additional resources and overhead, and context switches (swapping from one process to another) are very frequent.
|
||||
|
||||
For a more detailed explanation, check out this [article][7] about NGINX architecture, by Andrew Alexeev, VP of Corporate Development and Co-Founder at NGINX, Inc.
|
||||
|
||||
With appropriate [system tuning][8], NGINX can scale to handle hundreds of thousands of concurrent HTTP connections per worker process, and can absorb traffic spikes (an influx of new games) without missing a beat.
|
||||
|
||||
### Updating Configuration and Upgrading NGINX ###
|
||||
|
||||
NGINX’s process architecture, with a small number of worker processes, makes for very efficient updating of the configuration and even the NGINX binary itself.
|
||||
|
||||
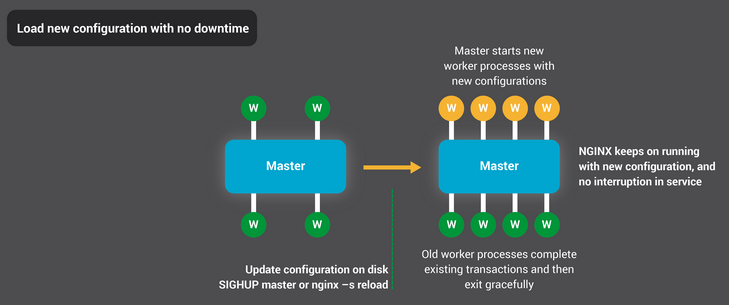
|
||||
|
||||
Updating NGINX configuration is a very simple, lightweight, and reliable operation. It typically just means running the `nginx –s reload` command, which checks the configuration on disk and sends the master process a SIGHUP signal.
|
||||
|
||||
When the master process receives a SIGHUP, it does two things:
|
||||
|
||||
- Reloads the configuration and forks a new set of worker processes. These new worker processes immediately begin accepting connections and processing traffic (using the new configuration settings).
|
||||
- Signals the old worker processes to gracefully exit. The worker processes stop accepting new connections. As soon as each current HTTP request completes, the worker process cleanly shuts down the connection (that is, there are no lingering keepalives). Once all connections are closed, the worker processes exit.
|
||||
|
||||
This reload process can cause a small spike in CPU and memory usage, but it’s generally imperceptible compared to the resource load from active connections. You can reload the configuration multiple times per second (and many NGINX users do exactly that). Very rarely, issues arise when there are many generations of NGINX worker processes waiting for connections to close, but even those are quickly resolved.
|
||||
|
||||
NGINX’s binary upgrade process achieves the holy grail of high-availability – you can upgrade the software on the fly, without any dropped connections, downtime, or interruption in service.
|
||||
|
||||
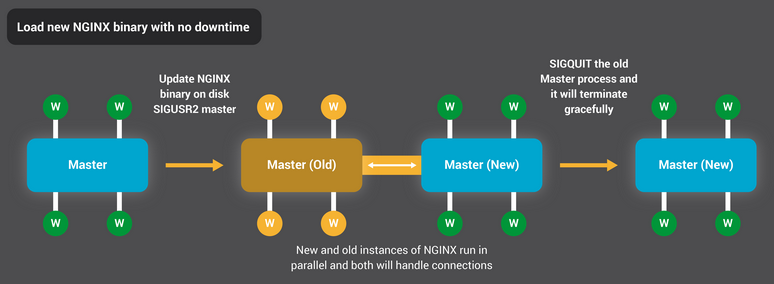
|
||||
|
||||
The binary upgrade process is similar in approach to the graceful reload of configuration. A new NGINX master process runs in parallel with the original master process, and they share the listening sockets. Both processes are active, and their respective worker processes handle traffic. You can then signal the old master and its workers to gracefully exit.
|
||||
|
||||
The entire process is described in more detail in [Controlling NGINX][9].
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The [Inside NGINX infographic][10] provides a high-level overview of how NGINX functions, but behind this simple explanation is over ten years of innovation and optimization that enable NGINX to deliver the best possible performance on a wide range of hardware while maintaining the security and reliability that modern web applications require.
|
||||
|
||||
If you’d like to read more about the optimizations in NGINX, check out these great resources:
|
||||
|
||||
- [Installing and Tuning NGINX for Performance][11] (webinar; [slides][12] at Speaker Deck)
|
||||
- [Tuning NGINX for Performance][13]
|
||||
- [The Architecture of Open Source Applications – NGINX][14]
|
||||
- [Socket Sharding in NGINX Release 1.9.1][15] (using the SO_REUSEPORT socket option)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nginx.com/blog/inside-nginx-how-we-designed-for-performance-scale/
|
||||
|
||||
作者:[Owen Garrett][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://nginx.com/author/owen/
|
||||
[1]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[2]:http://nginx.org/en/docs/ngx_core_module.html#worker_processes
|
||||
[3]:http://nginx.org/en/docs/ngx_core_module.html#accept_mutex
|
||||
[4]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
[5]:http://en.wikipedia.org/wiki/Simultaneous_exhibition
|
||||
[6]:http://gambit.blogs.nytimes.com/2009/03/03/in-chess-records-were-made-to-be-broken/
|
||||
[7]:http://www.aosabook.org/en/nginx.html
|
||||
[8]:http://nginx.com/blog/tuning-nginx/
|
||||
[9]:http://nginx.org/en/docs/control.html
|
||||
[10]:http://nginx.com/resources/library/infographic-inside-nginx/
|
||||
[11]:http://nginx.com/resources/webinars/installing-tuning-nginx/
|
||||
[12]:https://speakerdeck.com/nginx/nginx-installation-and-tuning
|
||||
[13]:http://nginx.com/blog/tuning-nginx/
|
||||
[14]:http://www.aosabook.org/en/nginx.html
|
||||
[15]:http://nginx.com/blog/socket-sharding-nginx-release-1-9-1/
|
||||
@ -0,0 +1,183 @@
|
||||
Linux_Logo – A Command Line Tool to Print Color ANSI Logos of Linux Distributions
|
||||
================================================================================
|
||||
linuxlogo or linux_logo is a Linux command line utility that generates a color ANSI picture of Distribution logo with a few system information.
|
||||
|
||||

|
||||
|
||||
Linux_Logo – Prints Color ANSI Logs of Linux Distro
|
||||
|
||||
This utility obtains System Information from /proc Filesystem. linuxlogo is capable of showing color ANSI image of various logos other than the host distribution logo.
|
||||
|
||||
The System information associated with logo includes – Linux Kernel Version, Time when Kernel was last Compiled, Number/core of processor, Speed, Manufacturer and processor Generation. It also show information about total physical RAM.
|
||||
|
||||
It is worth mentioning here that screenfetch is another tool of similar kind, which shows distribution logo and a more detailed and formatted system inform http://www.tecmint.com/screenfetch-system-information-generator-for-linux/ation. We have already covered screenfetch long ago, which you may refer at:
|
||||
|
||||
- [ScreenFetch – Generates Linux System Information][15]
|
||||
|
||||
linux_logo and Screenfetch should not be compared to each other. While the output of screenfetch is more formatted and detailed, where linux_logo produce maximum number of color ANSI diagram, and option to format the output.
|
||||
|
||||
linux_logo is written primarily in C programming Language, which displays linux logo in an X Window System and hence User Interface X11 aka X Window System should be installed. The software is released under GNU General Public License Version 2.0.
|
||||
|
||||
For the purpose of this article, we’re using following testing environment to test the linux_logo utility.
|
||||
|
||||
Operating System : Debian Jessie
|
||||
Processor : i3 / x86_64
|
||||
|
||||
### Installing Linux Logo Utility in Linux ###
|
||||
|
||||
**1. The linuxlogo package (stable version 5.11) is available to install from default package repository under all Linux distributions using apt, yum or dnf package manager as shown below.**
|
||||
|
||||
# apt-get install linux_logo [On APT based Systems]
|
||||
# yum install linux_logo [On Yum based Systems]
|
||||
# dnf install linux_logo [On DNF based Systems]
|
||||
OR
|
||||
# dnf install linux_logo.x86_64 [For 64-bit architecture]
|
||||
|
||||
**2. Once linuxlogo package has been installed, you can run the command `linuxlogo` to get the default logo for the distribution you are using..**
|
||||
|
||||
# linux_logo
|
||||
OR
|
||||
# linuxlogo
|
||||
|
||||

|
||||
|
||||
Get Default OS Logo
|
||||
|
||||
**3. Use the option `[-a]`, not to print any fancy color. Useful if viewing linux_logo over black and white terminal.**
|
||||
|
||||
# linux_logo -a
|
||||
|
||||

|
||||
|
||||
Black and White Linux Logo
|
||||
|
||||
**4. Use option `[-l]` to print LOGO only and exclude all other System Information.**
|
||||
|
||||
# linux_logo -l
|
||||
|
||||

|
||||
|
||||
Print Distribution Logo
|
||||
|
||||
**5. The `[-u]` switch will display system uptime.**
|
||||
|
||||
# linux_logo -u
|
||||
|
||||

|
||||
|
||||
Print System Uptime
|
||||
|
||||
**6. If you are interested in Load Average, use option `[-y]`. You may use more than one option at a time.**
|
||||
|
||||
# linux_logo -y
|
||||
|
||||

|
||||
|
||||
Print System Load Average
|
||||
|
||||
For more options and help on them, you may like to run.
|
||||
|
||||
# linux_logo -h
|
||||
|
||||

|
||||
|
||||
Linuxlogo Options and Help
|
||||
|
||||
**7. There are a lots of built-in Logos for various Linux distributions. You may see all those logos using option `-L list` switch.**
|
||||
|
||||
# linux_logo -L list
|
||||
|
||||

|
||||
|
||||
List of Linux Logos
|
||||
|
||||
Now you want to print any of the logo from the list, you may use `-L NUM` or `-L NAME` to display selected logo.
|
||||
|
||||
- -L NUM – will print logo with number NUM (deprecated).
|
||||
- -L NAME – will print the logo with name NAME.
|
||||
|
||||
For example, to display AIX Logo, you may use command as:
|
||||
|
||||
# linux_logo -L 1
|
||||
OR
|
||||
# linux_logo -L aix
|
||||
|
||||

|
||||
|
||||
Print AIX Logo
|
||||
|
||||
**Notice**: The `-L 1` in the command where 1 is the number at which AIX logo appears in the list, where `-L aix` is the name at which AIX logo appears in the list.
|
||||
|
||||
Similarly, you may print any logo using these options, few examples to see..
|
||||
|
||||
# linux_logo -L 27
|
||||
# linux_logo -L 21
|
||||
|
||||

|
||||
|
||||
Various Linux Logos
|
||||
|
||||
This way, you can use any of the logos just by using the number or name, that is against it.
|
||||
|
||||
### Some Useful Tricks of Linux_logo ###
|
||||
|
||||
**8. You may like to print your Linux distribution logo at login. To print default logo at login you may add the below line at the end of `~/.bashrc` file.**
|
||||
|
||||
if [ -f /usr/bin/linux_logo ]; then linux_logo; fi
|
||||
|
||||
**Notice**: If there isn’t any` ~/.bashrc` file, you may need to create one under user home directory.
|
||||
|
||||
**9. After adding above line, just logout and re-login again to see the default logo of your Linux distribution.**
|
||||
|
||||

|
||||
|
||||
Print Logo on User Login
|
||||
|
||||
Also note, that you may print any logo, after login, simply by adding the below line.
|
||||
|
||||
if [ -f /usr/bin/linux_logo ]; then linux_logo -L num; fi
|
||||
|
||||
**Important**: Don’t forget to replace num with the number that is against the logo, you want to use.
|
||||
|
||||
**10. You can also print your own logo by simply specifying the location of the logo as shown below.**
|
||||
|
||||
# linux_logo -D /path/to/ASCII/logo
|
||||
|
||||
**11. Print logo on Network Login.**
|
||||
|
||||
# /usr/local/bin/linux_logo > /etc/issue.net
|
||||
|
||||
You may like to use ASCII logo if there is no support for color filled ANSI Logo as:
|
||||
|
||||
# /usr/local/bin/linux_logo -a > /etc/issue.net
|
||||
|
||||
**12. Create a Penguin port – A set of port to answer connection. To create Penguin port Add the below line to file /etc/services file.**
|
||||
|
||||
penguin 4444/tcp penguin
|
||||
|
||||
Here ‘4444‘ is the port number which is currently free and not used by any resource. You may use a different port.
|
||||
|
||||
Also add the below line to file /etc/inetd.conf file.
|
||||
|
||||
penguin stream tcp nowait root /usr/local/bin/linux_logo
|
||||
|
||||
Restart the service inetd as:
|
||||
|
||||
# killall -HUP inetd
|
||||
|
||||
Moreover linux_logo can be used in bootup script to fool the attacker as well as you can play a prank with your friend. This is a nice tool and I might use it in some of my scripts to get output as per distribution basis.
|
||||
|
||||
Try it once and you won’t regret. Let us know what you think of this utility and how it can be useful for you. Keep Connected! Keep Commenting. Like and share us and help us get spread.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux_logo-tool-to-print-color-ansi-logos-of-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/screenfetch-system-information-generator-for-linux/
|
||||
91
sources/tech/20150615 How to combine two graphs on Cacti.md
Normal file
91
sources/tech/20150615 How to combine two graphs on Cacti.md
Normal file
@ -0,0 +1,91 @@
|
||||
How to combine two graphs on Cacti
|
||||
================================================================================
|
||||
[Cacti][1] a fantastic open source network monitoring system that is widely used to graph network elements like bandwidth, storage, processor and memory utilization. Using its web based interface, you can create and organize graphs easily. However, some advanced features like merging graphs, creating aggregate graphs using multiple sources, migration of Cacti to another server are not provided by default. You might need some experience with Cacti to pull these off. In this tutorial, we will see how we can merge two Cacti graphs into one.
|
||||
|
||||
Consider this example. Client-A has been connected to port 5 of switch-A for the last six months. Port 5 becomes faulty, and so the client is migrated to Port 6. As Cacti uses different graphs for each interface/element, the bandwidth history of the client would be split into port 5 and port 6. So we end up with two graphs for one client - one with six months' worth of old data, and the other that contains ongoing data.
|
||||
|
||||
In such cases, we can actually combine the two graphs so the old data is appended to the new graph, and we get to keep a single graph containing historic and new data for one customer. This tutorial will explain exactly how we can achieve that.
|
||||
|
||||
Cacti stores the data of each graph in its own RRD (round robin database) file. When a graph is requested, the values stored in a corresponding RRD file are used to generate the graph. RRD files are stored in `/var/lib/cacti/rra` in Ubuntu/Debian systems and in `/var/www/cacti/rra` in CentOS/RHEL systems.
|
||||
|
||||
The idea behind merging graphs is to alter these RRD files so the values from the old RRD file are appended to the new RRD file.
|
||||
|
||||
### Scenario ###
|
||||
|
||||
The services for a client is running on eth0 for over a year. Because of hardware failure, the client has been migrated to eth1 interface of another server. We want to graph the bandwidth of the new interface, while retaining the historic data for over a year. The client would see only one graph.
|
||||
|
||||
### Identifying the RRD for the Graph ###
|
||||
|
||||
The first step during graph merging is to identify the RRD file associated with a graph. We can check the file by opening the graph in debug mode. To do this, go to Cacti's menu: Console > Graph Management > Select Graph > Turn On Graph Debug Mode.
|
||||
|
||||
#### Old graph: ####
|
||||
|
||||
|
||||
|
||||
#### New graph: ####
|
||||
|
||||
|
||||
|
||||
From the example output (which is based on a Debian system), we can identify the RRD files for two graphs:
|
||||
|
||||
- **Old graph**: /var/lib/cacti/rra/old_graph_traffic_in_8.rrd
|
||||
- **New graph**: /var/lib/cacti/rra/new_graph_traffic_in_10.rrd
|
||||
|
||||
### Preparing a Script ###
|
||||
|
||||
We will merge two RRD files using a [RRD splice script][2]. Download this PHP script, and install it as /var/lib/cacti/rra/rrdsplice.php (for Debian/Ubuntu) or /var/www/cacti/rra/rrdsplice.php (for CentOS/RHEL).
|
||||
|
||||
Next, make sure that the file is owned by Apache user.
|
||||
|
||||
On Debian or Ubuntu, run the following command:
|
||||
|
||||
# chown www-data:www-data rrdsplice.php
|
||||
|
||||
and update rrdsplice.php accordingly. Look for the following line:
|
||||
|
||||
chown($finrrd, "apache");
|
||||
|
||||
and replace it with:
|
||||
|
||||
chown($finrrd, "www-data");
|
||||
|
||||
On CentOS or RHEL, run the following command:
|
||||
|
||||
# chown apache:apache rrdsplice.php
|
||||
|
||||
### Merging Two Graphs ###
|
||||
|
||||
The syntax usage of the script can easily be found by running it without any parameters.
|
||||
|
||||
# cd /path/to/rrdsplice.php
|
||||
# php rrdsplice.php
|
||||
|
||||
----------
|
||||
|
||||
USAGE: rrdsplice.php --oldrrd=file --newrrd=file --finrrd=file
|
||||
|
||||
Now we are ready to merge two RRD files. Simply supply the names of an old RRD file and a new RRD file. We will overwrite the merged result back to the new RRD file.
|
||||
|
||||
# php rrdsplice.php --oldrrd=old_graph_traffic_in_8.rrd --newrrd=new_graph_traffic_in_10.rrd --finrrd=new_graph_traffic_in_10.rrd
|
||||
|
||||
Now the data from the old RRD file should be appended to the new RRD. Any new data will continue to be written by Cacti to the new RRD file. If we click on the graph, we should be able to verify that the weekly, monthly and yearly records have also been added from the old graph. The second graph in the following diagram shows weekly records from the old graph.
|
||||
|
||||
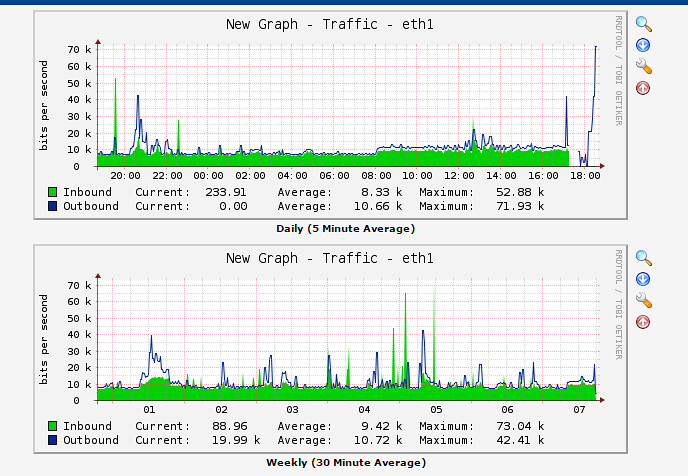
|
||||
|
||||
To sum up, this tutorial showed how we can easily merge two Cacti graphs into one. This trick is useful when a service is migrated to another device/interface and we want to deal with only one graph instead of two. The script is very handy as it can join graphs regardless of the source device e.g., Cisco 1800 router and Cisco 2960 switch.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/combine-two-graphs-cacti.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/install-configure-cacti-linux.html
|
||||
[2]:http://svn.cacti.net/viewvc/developers/thewitness/rrdsplice/rrdsplice.php
|
||||
@ -0,0 +1,238 @@
|
||||
Installing LAMP (Linux, Apache, MariaDB, PHP/PhpMyAdmin) in RHEL/CentOS 7.0
|
||||
================================================================================
|
||||
Skipping the LAMP introduction, as I’m sure that most of you know what is all about. This tutorial will concentrate on how to install and configure famous LAMP stack – Linux Apache, MariaDB, PHP, PhpMyAdmin – on the last release of Red Hat Enterprise Linux 7.0 and CentOS 7.0, with the mention that both distributions have upgraded httpd daemon to Apache HTTP 2.4.
|
||||
|
||||

|
||||
|
||||
Install LAMP in RHEL/CentOS 7.0
|
||||
|
||||
#### Requirements ####
|
||||
|
||||
Depending on the used distribution, RHEL or CentOS 7.0, use the following links to perform a minimal system installation, using a static IP Address for network configuration.
|
||||
|
||||
**For RHEL 7.0**
|
||||
|
||||
- [RHEL 7.0 Installation Procedure][1]
|
||||
- [Register and Enable Subscriptions/Repositories on RHEL 7.0][2]
|
||||
|
||||
**For CentOS 7.0**
|
||||
|
||||
- [CentOS 7.0 Installation Procedure][3]
|
||||
|
||||
### Step 1: Install Apache Server with Basic Configurations ###
|
||||
|
||||
**1. After performing a minimal system installation and configure your server network interface with a [Static IP Address on RHEL/CentOS 7.0][4], go ahead and install Apache 2.4 httpd service binary package provided form official repositories using the following command.**
|
||||
|
||||
# yum install httpd
|
||||
|
||||
|
||||
|
||||
Install Apache Web Server
|
||||
|
||||
**2. After yum manager finish installation, use the following commands to manage Apache daemon, since RHEL and CentOS 7.0 both migrated their init scripts from SysV to systemd – you can also use SysV and Apache scripts the same time to manage the service.**
|
||||
|
||||
# systemctl status|start|stop|restart|reload httpd
|
||||
|
||||
OR
|
||||
|
||||
# service httpd status|start|stop|restart|reload
|
||||
|
||||
OR
|
||||
|
||||
# apachectl configtest| graceful
|
||||
|
||||

|
||||
|
||||
Start Apache Web Server
|
||||
|
||||
**3. On the next step start Apache service using systemd init script and open RHEL/CentOS 7.0 Firewall rules using firewall-cmd, which is the default command to manage iptables through firewalld daemon.**
|
||||
|
||||
# firewall-cmd --add-service=http
|
||||
|
||||
**NOTE**: Make notice that using this rule will lose its effect after a system reboot or firewalld service restart, because it opens on-fly rules, which are not applied permanently. To apply consistency iptables rules on firewall use –permanent option and restart firewalld service to take effect.
|
||||
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
# systemctl restart firewalld
|
||||
|
||||

|
||||
|
||||
Enable Firewall in CentOS 7
|
||||
|
||||
Other important Firewalld options are presented below:
|
||||
|
||||
# firewall-cmd --state
|
||||
# firewall-cmd --list-all
|
||||
# firewall-cmd --list-interfaces
|
||||
# firewall-cmd --get-service
|
||||
# firewall-cmd --query-service service_name
|
||||
# firewall-cmd --add-port=8080/tcp
|
||||
|
||||
**4. To verify Apache functionality open a remote browser and type your server IP Address using HTTP protocol on URL (http://server_IP), and a default page should appear like in the screenshot below.**
|
||||
|
||||

|
||||
|
||||
Apache Default Page
|
||||
|
||||
**5. For now, Apache DocumentRoot path it’s set to /var/www/html system path, which by default doesn’t provide any index file. If you want to see a directory list of your DocumentRoot path open Apache welcome configuration file and set Indexes statement from – to + on <LocationMach> directive, using the below screenshot as an example.**
|
||||
|
||||
# nano /etc/httpd/conf.d/welcome.conf
|
||||
|
||||

|
||||
|
||||
Apache Directory Listing
|
||||
|
||||
**6. Close the file, restart Apache service to reflect changes and reload your browser page to see the final result.**
|
||||
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Apache Index File
|
||||
|
||||
### Step 2: Install PHP5 Support for Apache ###
|
||||
|
||||
**7. Before installing PHP5 dynamic language support for Apache, get a full list of available PHP modules and extensions using the following command.**
|
||||
|
||||
# yum search php
|
||||
|
||||

|
||||
|
||||
Install PHP in CentOS 7
|
||||
|
||||
**8. Depending on what type of applications you want to use, install the required PHP modules from the above list, but for a basic MariaDB support in PHP and PhpMyAdmin you need to install the following modules.**
|
||||
|
||||
# yum install php php-mysql php-pdo php-gd php-mbstring
|
||||
|
||||

|
||||
|
||||
Install PHP Modules
|
||||
|
||||

|
||||
|
||||
Install PHP mbstring Module
|
||||
|
||||
**9. To get a full information list on PHP from your browser, create a info.php file on Apache Document Root using the following command from root account, restart httpd service and direct your browser to the http://server_IP/info.php address.**
|
||||
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Check PHP Info in CentOS 7
|
||||
|
||||
**10. If you get an error on PHP Date and Timezone, open php.ini configuration file, search and uncomment date.timezone statement, append your physical location and restart Apache daemon.**
|
||||
|
||||
# nano /etc/php.ini
|
||||
|
||||
Locate and change date.timezone line to look like this, using [PHP Supported Timezones list][5].
|
||||
|
||||
date.timezone = Continent/City
|
||||
|
||||

|
||||
|
||||
Set Timezone in PHP
|
||||
|
||||
### Step 3: Install and Configure MariaDB Database ###
|
||||
|
||||
**11. Red Hat Enterprise Linux/CentOS 7.0 switched from MySQL to MariaDB for its default database management system. To install MariaDB database use the following command.**
|
||||
|
||||
# yum install mariadb-server mariadb
|
||||
|
||||

|
||||
|
||||
Install MariaDB in CentOS 7
|
||||
|
||||
**12. After MariaDB package is installed, start database daemon and use mysql_secure_installation script to secure database (set root password, disable remotely logon from root, remove test database and remove anonymous users).**
|
||||
|
||||
# systemctl start mariadb
|
||||
# mysql_secure_installation
|
||||
|
||||

|
||||
|
||||
Start MariaDB Database
|
||||
|
||||

|
||||
|
||||
Secure MySQL Installation
|
||||
|
||||
**13. To test database functionality login to MariaDB using its root account and exit using quit statement.**
|
||||
|
||||
mysql -u root -p
|
||||
MariaDB > SHOW VARIABLES;
|
||||
MariaDB > quit
|
||||
|
||||

|
||||
|
||||
Connect MySQL Database
|
||||
|
||||
### Step 4: Install PhpMyAdmin ###
|
||||
|
||||
**14. By default official RHEL 7.0 or CentOS 7.0 repositories doesn’t provide any binary package for PhpMyAdmin Web Interface. If you are uncomfortable using MySQL command line to manage your database you can install PhpMyAdmin package by enabling CentOS 7.0 rpmforge repositories using the following command.**
|
||||
|
||||
# yum install http://pkgs.repoforge.org/rpmforge-release/rpmforge-release-0.5.3-1.el7.rf.x86_64.rpm
|
||||
|
||||
After enabling rpmforge repository, next install PhpMyAdmin.
|
||||
|
||||
# yum install phpmyadmin
|
||||
|
||||

|
||||
|
||||
Enable RPMForge Repository
|
||||
|
||||
**15. Next configure PhpMyAdmin to allow connections from remote hosts by editing phpmyadmin.conf file, located on Apache conf.d directory, commenting the following lines.**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
|
||||
Use a # and comment this lines.
|
||||
|
||||
# Order Deny,Allow
|
||||
# Deny from all
|
||||
# Allow from 127.0.0.1
|
||||
|
||||

|
||||
|
||||
Allow Remote PhpMyAdmin Access
|
||||
|
||||
**16. To be able to login to PhpMyAdmin Web interface using cookie authentication method add a blowfish string to phpmyadmin config.inc.php file like in the screenshot below using the [generate a secret string][6], restart Apache Web service and direct your browser to the URL address http://server_IP/phpmyadmin/.**
|
||||
|
||||
# nano /etc/httpd/conf.d/phpmyadmin.conf
|
||||
# systemctl restart httpd
|
||||
|
||||

|
||||
|
||||
Add Blowfish in PhpMyAdmin
|
||||
|
||||

|
||||
|
||||
PhpMyAdmin Dashboard
|
||||
|
||||
### Step 5: Enable LAMP System-wide ###
|
||||
|
||||
**17. If you need MariaDB and Apache services to be automatically started after reboot issue the following commands to enable them system-wide.**
|
||||
|
||||
# systemctl enable mariadb
|
||||
# systemctl enable httpd
|
||||
|
||||

|
||||
|
||||
Enable Services System Wide
|
||||
|
||||
That’s all it takes for a basic LAMP installation on Red Hat Enterprise 7.0 or CentOS 7.0. The next series of articles related to LAMP stack on CentOS/RHEL 7.0 will discuss how to create Virtual Hosts, generate SSL Certificates and Keys and add SSL transaction support for Apache HTTP Server.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-lamp-in-centos-7/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
[1]:http://www.tecmint.com/redhat-enterprise-linux-7-installation/
|
||||
[2]:http://www.tecmint.com/enable-redhat-subscription-reposiories-and-updates-for-rhel-7/
|
||||
[3]:http://www.tecmint.com/centos-7-installation/
|
||||
[4]:http://www.tecmint.com/configure-network-interface-in-rhel-centos-7-0/
|
||||
[5]:http://php.net/manual/en/timezones.php
|
||||
[6]:http://www.question-defense.com/tools/phpmyadmin-blowfish-secret-generator
|
||||
177
sources/tech/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
sources/tech/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
||||
LINUX 101: POWER UP YOUR SHELL
|
||||
================================================================================
|
||||
> Get a more versatile,featureful and colourful command line interface with our guide to shell basics.
|
||||
|
||||
**WHY DO THIS?**
|
||||
|
||||
- Make life at the shell prompt easier and faster.
|
||||
- Resume sessions after losing a connection.
|
||||
- Stop pushing around that fiddly rodent!
|
||||
|
||||
|
||||
|
||||
Here’s our souped-up prompt on steroids. It’s a bit long for this small terminal window, but you can tweak it to your liking.
|
||||
|
||||
As a Linux user, you’re probably familiar with the shell (aka command line). You may pop up the occasional terminal now and then for some essential jobs that you can’t do at the GUI, or perhaps you live in a tiling window manager environment and the shell is your main way of interacting with your Linux box.
|
||||
|
||||
In either case, you’re probably using the stock Bash configuration that came with your distro – and while it’s powerful enough for most jobs, it could still be a lot better. In this tutorial we’ll show you how to pimp up your shell to make it more informative, useful and pleasant to work in. We’ll customise the prompt to make it provide better feedback than the defaults, and we’ll show you how to manage sessions and run multiple programs together with the incredibly cool tmux tool. And for a bit of eye candy, we’ll look at colour schemes as well. So, onwards!
|
||||
|
||||
### Make your prompt sing ###
|
||||
|
||||
Most distributions ship with very plain prompts – they show a bit of information, and generally get you by, but the prompt can do so much more. Take the default prompt on a Debian 7 installation, for instance:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
This shows the user, hostname, current directory and account type symbol (if you switch to root, the **$** changes to #). But where is this information stored? The answer is in the **PS1** environment variable. If you enter **echo $PS1** you’ll see this at the end of the text string that appears:
|
||||
|
||||
u@h:w$
|
||||
|
||||
This looks a bit ugly, and at first glance you might start screaming, assuming it to be a dreaded regular expression, but we’re not going to fry our brains with the complexity of those. No, the slashes here are escape sequences, telling the prompt to do special things. The **u** part, for instance, tells the prompt to show the username, while w means the working directory.
|
||||
|
||||
Here’s a list of things you can use in the prompt:
|
||||
|
||||
- d The current date.
|
||||
- h The hostname.
|
||||
- n A newline character.
|
||||
- A The current time (HH:MM).
|
||||
- u The current user.
|
||||
- w (lowercase) The whole working directory.
|
||||
- W (uppercase) The basename of the working directory.
|
||||
- $ A prompt symbol that changes to # for root.
|
||||
- ! The shell history number of this command.
|
||||
|
||||
To clarify the difference in the **w** and **W** options: with the former, you’ll see the whole path for the directory in which you’re working (eg **/usr/local/bin**), whereas for the latter it will just show the **bin** part.
|
||||
|
||||
Now, how do you go about changing the prompt? You need to modify the contents of the **PS1** environment variable. Try this:
|
||||
|
||||
export PS1=”I am u and it is A $”
|
||||
|
||||
Now your prompt will look something like:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
From here you can experiment with the other escape sequences shown above to create the prompt of your dreams. But wait a second – when you log out, all of your hard work will be lost, because the value of the **PS1** environment variable is reset each time you start a terminal. The simplest way to fix this is to open the **.bashrc** configuration file (in your home directory) and add the complete export command to the bottom. This **.bashrc** file will be read by Bash every time you start a new shell session, so your beefed-up prompt will always appear. You can also spruce up your prompt with extra colour. This is a bit tricky at first, as you have to use some rather odd-looking escape sequences, but the results can be great. Add this to a point in your **PS1** string and it will change the text to red:
|
||||
|
||||
[e[31m]
|
||||
|
||||
You can change 31 here to other numbers for different colours:
|
||||
|
||||
- 30 Black
|
||||
- 32 Green
|
||||
- 33 Yellow
|
||||
- 34 Blue
|
||||
- 35 Magenta
|
||||
- 36 Cyan
|
||||
- 37 White
|
||||
|
||||
So, let’s finish off this section by creating the mother of all prompts, using the escape sequences and colours we’ve already looked at. Take a deep breath, flex your fingers, and then type this beast:
|
||||
|
||||
export PS1=”(!) [e[31m][A] [e[32m]u@h [e[34m]w [e[30m]$ “
|
||||
|
||||
This provides a Bash command history number, current time, and colours for the user/hostname combination and working directory. If you’re feeling especially ambitious, you can change the background colours as well as the foreground ones, for really striking combinations. The ever useful Arch wiki has a full list of colour codes: [http://tinyurl.com/3gvz4ec][1].
|
||||
|
||||
> ### Shell essentials ###
|
||||
>
|
||||
> If you’re totally new to Linux and have just picked up this magazine for the first time, you might find the tutorial a bit heavy going. So here are the basics to get you familiar with the shell. It’s usually found as Terminal, XTerm or Konsole in your menus, and when you start it the most useful commands are:
|
||||
>
|
||||
> **ls** (list files); **cp one.txt two.txt** (copy file); **rm file.txt** (remove file); **mv old.txt new.txt** (move or rename);
|
||||
>
|
||||
> **cd /some/directory** (change directory); **cd ..** (change to directory above); **./program** (run program in current directory); **ls > list.txt** (redirect output to a file).
|
||||
>
|
||||
> Almost every command has a manual page explaining options (eg **man ls** – press Q to quit the viewer). There you can learn about command options, so you can see that **ls -la** shows a detailed list including hidden files. Use the up and down cursor keys to cycle through previous commands, and use Tab after entering part of a file or directory name to auto-complete it.
|
||||
|
||||
### Tmux: A window manager for your shell ###
|
||||
|
||||
A window manager inside a text mode environment – it sounds crazy, right? Well, do you remember when web browsers first implemented tabbed browsing? It was a major step forward in usability at the time, and reduced clutter in desktop taskbars and window lists enormously. Instead of having taskbar or pager icons for every single site you had open, you just had the one button for your browser, and then the ability to switch sites inside the browser itself. It made an awful lot of sense.
|
||||
|
||||
If you end up running several terminals at the same time, a similar situation occurs; you might find it annoying to keep jumping between them, and finding the right one in your taskbar or window list each time. With a text-mode window manager you can not only run multiple shell sessions simultaneously inside the same terminal window, but you can even arrange them side-by-side.
|
||||
|
||||
And there’s another benefit too: detaching and reattaching. The best way to see how this works is to try it yourself. In a terminal window, enter **screen** (it’s installed by default on most distros, or will be available in your package repositories). Some welcome text appears – just hit Enter to dismiss it. Now run an interactive text mode program, such as **nano**, and close the terminal window.
|
||||
|
||||
In a normal shell session, the act of closing the window would terminate every process running inside it – so your Nano editing session would be a goner. But not with screen. Open a new terminal and enter:
|
||||
|
||||
screen -r
|
||||
|
||||
And voilà: the Nano session you started before is back!
|
||||
|
||||
When you originally ran **screen**, it created a new shell session that was independent and not tied to a specific terminal window, so it could be detached and reattached (hence the **-r** option) later.
|
||||
|
||||
This is especially useful if you’re using SSH to connect to another machine, doing some work, and don’t want a flaky connection to ruin all your progress. If you do your work inside a **screen** session and your connection goes down (or your laptop battery dies, or your computer explodes), you can simply reconnect/recharge/buy a new computer, then SSH back in to the remote box, run **screen -r** to reattach and carry on from where you left off.
|
||||
|
||||
Now, we’ve been talking about GNU **screen** here, but the title of this section mentions tmux. Essentially, **tmux** (terminal multiplexer) is like a beefed up version of **screen** with lots of useful extra features, so we’re going to focus on it here. Some distros include **tmux** by default; in others it’s usually just an **apt-get, yum install** or **pacman -S** command away.
|
||||
|
||||
Once you have it installed, enter **tmux** to start it. You’ll notice right away that there’s a green line of information along the bottom. This is very much like a taskbar from a traditional window manager: there’s a list of running programs, the hostname of the machine, a clock and the date. Now run a program, eg Nano again, and hit Ctrl+B followed by C. This creates a new window inside the tmux session, and you can see this in the taskbar at the bottom:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
Each window has a number, and the currently displayed program is marked with an asterisk symbol. Ctrl+B is the standard way of interacting with tmux, so if you hit that key combo followed by a window number, you’ll switch to that window. You can also use Ctrl+B followed by N and P to switch to the next and previous windows respectively – or use Ctrl+B followed by L to switch between the two most recently used windows (a bit like the classic Alt+Tab behaviour on the desktop). To get a window list, use Ctrl+B followed by W.
|
||||
|
||||
So far, so good: you can now have multiple programs running inside a single terminal window, reducing clutter (especially if you often have multiple SSH logins active on the same remote machine). But what about seeing two programs at the same time?
|
||||
|
||||
For this, tmux uses “panes”. Hit Ctrl+B followed by % and the current window will be split into two sections, one on the left and one on the right. You can switch between them Using Ctrl+B followed by O. This is especially useful if you want to see two things at the same time – eg a manual page in one pane, and an editor with a configuration file in another.
|
||||
|
||||
Sometimes you’ll want to resize the individual panes, and this is a bit trickier. First you have to hit Ctrl+B followed by : (colon), which turns the tmux bar along the bottom into a dark orange colour. You’re now in command mode, where you can type in commands to operate tmux. Enter **resize-pane -R** to resize the current pane one character to the right, or use **-L** to resize in a leftward direction. These may seem like long commands for a relatively simple operation, but note that the tmux command mode (started with the aforementioned colon) has tab completion. So you don’t have to type the whole command – just enter “**resi**” and hit Tab to complete. Also note that the **tmux** command mode also has a history, so if you want to repeat the resize operation, hit Ctrl+B followed by colon and then use the up cursor key to retrieve the command that you entered previously.
|
||||
|
||||
Finally, let’s look at detaching and reattaching – the awesome feature of screen we demonstrated earlier. Inside tmux, hit Ctrl+B followed by D to detach the current tmux session from the terminal window, which leaves everything running in the background. To reattach to the session use **tmux a**. But what happens if you have multiple tmux sessions running? Use this command to list them:
|
||||
|
||||
tmux ls
|
||||
|
||||
This shows a number for each session; if you want to reattach to session 1, use tmux a -t 1. tmux is hugely configurable, with the ability to add custom keybindings and change colour schemes, so once you’re comfortable with the main features, delve into the manual page to learn more.
|
||||
|
||||
tmux: a window manager for your shell
|
||||
|
||||
|
||||
|
||||
Here’s tmux with two panes open: the left has Vim editing a configuration file, while the right shows a manual page
|
||||
|
||||
> ### Zsh: an alternative shell ###
|
||||
>
|
||||
> Choice is good, but standardisation is also important as well. So it makes sense that almost every mainstream Linux distribution uses the Bash shell by default – although there are others. Bash provides pretty much everything you need from a shell, including command history, filename completion and lots of scripting ability. It’s mature, reliable and well documented – but it’s not the only shell in town.
|
||||
>
|
||||
> Many advanced users swear by Zsh, the Z Shell. This is a replacement for Bash that offers almost all of the same functionality, with some extra features on top. For instance, in Zsh you can enter **ls** - and hit Tab to get quick descriptions of the various options available for **ls**. No need to open the manual page!
|
||||
>
|
||||
> Zsh sports other great auto-completion features: type **cd /u/lo/bi** and hit Tab, for instance, and the full path of **/usr/local/bin** will appear (providing there aren’t other paths containing **u**, **lo** and **bi**). Or try **cd** on its own followed by Tab, and you’ll see nicely coloured directory listings – much better than the plain ones used by Bash.
|
||||
>
|
||||
> Zsh is available in the package repositories of all major distros; install it and enter **zsh** to start it. To change your default shell from Bash to Zsh, use the **chsh** command. And for more information visit [www.zsh.org][2].
|
||||
|
||||
### The terminals of the Future ###
|
||||
|
||||
You might be wondering why the application that contains your command prompt is called a terminal. Back in the early days of Unix, people tended to work on multi-user machines, with a giant mainframe computer occupying a room somewhere in a building, and people connected to it using screen and keyboard combinations at the end of some wires. These terminal machines were often called “dumb”, because they didn’t do any important processing themselves – they just displayed whatever was sent down the wire from the mainframe, and sent keyboard presses back to it.
|
||||
|
||||
Today, almost all of us do the actual processing on our own machines, so our computers are not terminals in a traditional sense. This is why programs like **XTerm**, Gnome Terminal, Konsole etc. are called “terminal emulators” – they provide the same facilities as the physical terminals of yesteryear. And indeed, in many respects they haven’t moved on much. Sure, we have anti-aliased fonts now, better colours and the ability to click on URLs, but by and large they’ve been working in the same way for decades.
|
||||
|
||||
Some programmers are trying to change this though. **Terminology** ([http://tinyurl.com/osopjv9][3]), from the team behind the ultra-snazzy Enlightenment window manager, aims to bring terminals into the 21st century with features such as inline media display. You can enter **ls** in a directory full of images and see thumbnails, or even play videos from directly inside your terminal. This makes the terminal work a bit more like a file manager, and means that you can quickly check the contents of media files without having to open them in a separate application.
|
||||
|
||||
Then there’s Xiki ([www.xiki.org][4]), which describes itself as “the command revolution”. It’s like a cross between a traditional shell, a GUI and a wiki; you can type commands anywhere, store their output as notes for reference later, and create very powerful custom commands. It’s hard to describe it in mere words, so the authors have made a video (see the Screencasts section of the **Xiki** site) which shows how much potential it has.
|
||||
|
||||
And Xiki is definitely not a flash in the pan project that will die of bitrot in a few months. The authors ran a successful Kickstarter campaign to fund its development, netting over $84,000 at the end of July. Yes, you read that correctly – $84K for a terminal emulator. It might be the most unusual crowdfunding campaign since some crazy guys decided to start their own Linux magazine…
|
||||
|
||||
### Next-gen terminals ###
|
||||
|
||||
Many command line and text-based programs match their GUI equivalents for feature parity, and are often much faster and more efficient to use. Our recommendations: **Irssi** (IRC client); **Mutt** (mail client); **rTorrent** (BitTorrent); **Ranger** (file manager); **htop** (process monitor). ELinks does a decent job for web browsing, given the limitations of the terminal, and it’s useful for reading text-heavy websites such as Wikipedia.
|
||||
|
||||
> ### Fine-tune your colour scheme ###
|
||||
>
|
||||
> We’re not obsessed with eye-candy at Linux Voice, but we do recognise the importance of aesthetics when you’re staring at something for several hours every day. Many of us love to tweak our desktops and window managers to perfection, crafting pixel-perfect drop shadows and fiddling with colour schemes until we’re 100% happy. (And then fiddling some more out of habit.)
|
||||
>
|
||||
> But then we tend to ignore the terminal window. Well, that deserves some love too, and at [http://ciembor.github.io/4bit][5] you’ll find a highly awesome colour scheme designer that can export settings for all of the popular terminal emulators (**XTerm, Gnome Terminal, Konsole and Xfce4 Terminal are among the apps supported.**) Move the sliders until you attain colour scheme nirvana, then click on the Get Scheme button at the top-right of the page.
|
||||
>
|
||||
> Similarly, if you spend a lot of time in a text editor such as Vim or Emacs, it’s worth using a well-crafted palette there as well. **Solarized at** [http://ethanschoonover.com/solarized][6] is an excellent scheme that’s not just pretty, but designed for maximum usability, with plenty of research and testing behind it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
264
sources/tech/20150616 XBMC--build a remote control.md
Normal file
264
sources/tech/20150616 XBMC--build a remote control.md
Normal file
@ -0,0 +1,264 @@
|
||||
XBMC: build a remote control
|
||||
================================================================================
|
||||
**Take control of your home media player with a custom remote control running on your Android phone.**
|
||||
|
||||
**XBMC** is a great piece of software, and can turn almost can computer into a media centre. It can play music and videos, display pictures, and even fetch a weather forecast. To make it easy to use in a home theatre setup, you can control it via mobile phone apps that access a server running on the XBMC machine via Wi-Fi. There are loads of these available for almost all smartphone systems.
|
||||
|
||||
> ### Kodi ###
|
||||
>
|
||||
> By the time you read this, **XBMC** may be no more. The project team have decided to rename it **Kodi** for legal reasons (and because **XBMC**, or X**-Box Media Centre**, refers to older hardware that is no longer supported). Other than the name, though, nothing has changed. Or at least nothing other than the usual raft of improvements you’d expect from a new release. This shouldn’t affect the remote software though, and it should work on both existing **XBMC** systems, and newer Kodi systems.
|
||||
|
||||
We’ve recently set up an **XBMC** system for playing music, and none of the XBMC remotes we found really excel at this task, especially when the TV attached to the media centre is turned off. They were all a bit too complex, as they packed too much functionality into small screens. We wanted a system designed from the ground up to just access a music library and a radio addon, so we decided to build one ourselves. It didn’t need to be able to access the full capabilities of XBMC, because for tasks other than music, we’d simply switch back to a general-purpose XBMC remote control. Our test system was a Raspberry Pi running the RaspBMC distribution, but nothing here is specific to either the Pi or that distro, and it should work on any Linux-based XBMC system provided the appropriate packages are available.
|
||||
|
||||
The first thing a remote control needs is a user interface. Many XBMC remote controls are written as standalone apps. However, this is just for our music, and we want to be accessible to guests without them having to install anything. The obvious solution is to make a web interface. XBMC does have a built-in web server, but to give us more control, we decided to use a separate web framework. There’s no problem running more than one web server on a computer at a time, but they can’t run on the same port.
|
||||
|
||||
There are quite a few web frameworks available. We’ve used Bottle because it’s a simple, fast framework, and we don’t need any complex functions. Bottle is a Python module, so that’s the language in which we’ll write the server.
|
||||
|
||||
You’ll probably find Bottle in your package manager. In Debian-based systems (including Raspbmc), you can grab it with:
|
||||
|
||||
sudo apt-get install python-bottle
|
||||
|
||||
A remote control is really just a layer that connects the user to a system. Bottle provides what we need to interact with the user, and we’ll interact with **XBMC** using its JSON API. This enables us to control the media player by sending JSON-encoded information.
|
||||
|
||||
We’re going to use a simple wrapper around the XBMC JSON API called xbmcjson. It’s just enough to allow you send requests without having to worry about the actual JSON formatting or any of the banalities of communicating with a server. It’s not included in the PIP package manager, so you need to install it straight from **GitHub**:
|
||||
|
||||
git clone https://github.com/jcsaaddupuy/python-xbmc.git
|
||||
cd python-xbmc
|
||||
sudo python setup.py install
|
||||
|
||||
This is everything you need, so let’s get coding.
|
||||
|
||||
#### Get started with Bottle ####
|
||||
|
||||
The basic structure of our program is:
|
||||
|
||||
from xbmcjson import XBMC
|
||||
from bottle import route, run, template, redirect, static_file, request
|
||||
import os
|
||||
xbmc = XBMC(“http://192.168.0.5/jsonrpc”, “xbmc”, “xbmc”)
|
||||
@route(‘/hello/<name>’)
|
||||
def index(name):
|
||||
return template(‘<h1>Hello {{name}}!</h1>’, name=name)
|
||||
run(host=”0.0.0.0”, port=8000)
|
||||
|
||||
This connects to **XBMC** (though doesn’t actually use it); then Bottle starts serving up the website. In this case, it listens on host 0.0.0.0 (which is every hostname), and port 8000. It only has one site, which is /hello/XXXX where XXXX can be anything. Whatever XXXX is gets passed to index() as the parameter name. This then passes it to the template, which substitutes it into the HTML.
|
||||
|
||||
You can try this out by entering the above into a file (we’ve called it remote.py), and starting it with:
|
||||
|
||||
python remote.py
|
||||
|
||||
You can then point your browser to localhost:8000/hello/world to see the template in action.
|
||||
|
||||
@route() sets up a path in the web server, and the function index() returns the data for that path. Usually, this means returning HTML that’s generated via a template, but it doesn’t have to be (as we’ll see later).
|
||||
|
||||
As we go on, we’ll add more routes to the application to make it a fully-featured XBMC remote control, but it will still be structured in the same way.
|
||||
|
||||
The XBMC JSON API can be accessed by any computer on the same network as the XBMC machine. This means that you can develop it on your desktop, then deploy it to your media centre rather than fiddle round uploading every change to your home theatre PC.
|
||||
|
||||
Templates – like the simple one in the previous example – are a way of combining Python and HTML to control the output. In principal, they can do quite a bit of processing, but they can get messy. We’ll use them just to format the data correctly. Before we can do that, though, we have to have some data.
|
||||
|
||||
> ### Paste ###
|
||||
>
|
||||
> Bottle includes its own web server, which is what we’ve been using for testing the remote control. However, we found that it didn’t always perform well. When we put the remote into action, we wanted something that could deliver pages a bit quicker. Bottle can work with quite a few different web servers, and we found Paste worked quite well. In order to use this, just install it (in the package python-paste on Debian), and change the run call to:
|
||||
>
|
||||
> run(host=hostname, port=hostport, server=”paste”)
|
||||
>
|
||||
> You can see details of how to use other servers at [http://bottlepy.org/docs/dev/deployment.html][1].
|
||||
|
||||
#### Getting data from XBMC ####
|
||||
|
||||
The XBMC JSON API is split up into 14 namespaces: JSONRPC, Player, Playlist, Files, AudioLibrary, VideoLibrary, Input, Application, System, Favourites, Profiles, Settings, Textures and XBMC. Each of these is available from an XBMC object in Python (apart from Favourites, in an apparent oversight). In each of these namespaces there are methods that you can use to control the application. For example, Playlist.GetItems() can be used to get the items on a particular playlist. The server returns data to us in JSON, but the xbmcjson module converts it to a Python dictionary for us.
|
||||
|
||||
There are two items in XBMC that we need to use to control playback: players and playlists. Players hold a playlist and move through it item by item as each song finishes. In order to see what’s currently playing, we need to get the ID of the active player, and through that find out the ID of the current playlist. We’ve done this with the following function:
|
||||
|
||||
def get_playlistid():
|
||||
player = xbmc.Player.GetActivePlayers()
|
||||
if len(player[‘result’]) > 0:
|
||||
playlist_data = xbmc.Player.GetProperties({“playerid”:0, “properties”:[“playlistid”]})
|
||||
if len(playlist_data[‘result’]) > 0 and “playlistid” in playlist_data[‘result’].keys():
|
||||
return playlist_data[‘result’][‘playlistid’]
|
||||
return -1
|
||||
|
||||
If there isn’t a currently active player (that is, if the length of the results section in the returned data is 0), or if the current player has no playlist, this will return -1. Otherwise, it will return the numeric ID of the current playlist.
|
||||
|
||||
Once we’ve got the ID of the current playlist, we can get the details of it. For our purposes, two things are important: the list of items in the playlist, and the position we are in the playlist (items aren’t removed from the playlist after they’ve been played; the current position just marches on).
|
||||
|
||||
def get_playlist():
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
data = xbmc.Playlist.GetItems({“playlistid”:playlistid, “properties”: [“title”, “album”, “artist”, “file”]})
|
||||
position_data = xbmc.Player.GetProperties({“playerid”:0, ‘properties’:[“position”]})
|
||||
position = int(position_data[‘result’][‘position’])
|
||||
return data[‘result’][‘items’][position:], position
|
||||
return [], -1
|
||||
|
||||
This returns the current playlist starting with the item that’s currently playing (since we don’t care about stuff that’s finished), and it also includes the position as this is needed for removing items from the playlist.
|
||||
|
||||
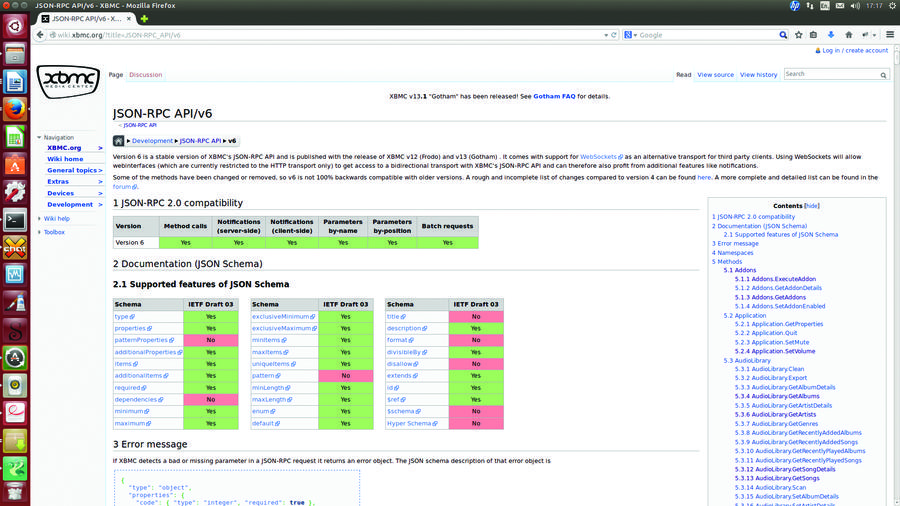
|
||||
|
||||
The API is documented at [http://wiki.xbmc.org/?title=JSON-RPC_API/v6][2]. It lists all the available functions, but it a little short on details of how to use them.
|
||||
|
||||
> ### JSON ###
|
||||
>
|
||||
> JSON stands for JavaScript Object Notation, and was originally designed as a way of serialising JavaScript Objects. It still is used for that, but it’s also a useful way of encoding all sorts of data.
|
||||
>
|
||||
> JSON objects always have the form:
|
||||
>
|
||||
> {property1:value1, property2:value2, property3:value3}
|
||||
>
|
||||
> For an arbitrary number of property/value pairs. To Python programmers, this all looks suspiciously similar to dictionaries, and the two are very similar.
|
||||
>
|
||||
> As with dictionaries, the value can itself be another JSON object, or a list, so the following is perfectly valid:
|
||||
>
|
||||
> {“name”:“Ben”, “jobs”:[“cook”, “bottle-washer”], “appearance”: {“height”:195, “skin”:“fair”}}
|
||||
>
|
||||
> JSON is often used in web services to send data back and fourth, and it’s well supported by most programming languages, so if Python’s not your thing, you should easily be able to use the same functions to control XBMC from software written in the language of your choice.
|
||||
|
||||
#### Bringing them together ####
|
||||
|
||||
The code to link the previous functions to a HTML page is simply:
|
||||
|
||||
@route(‘/juke’)
|
||||
def index():
|
||||
current_playlist, position = get_playlist()
|
||||
return template(‘list’, playlist=current_playlist, offset = position)
|
||||
|
||||
This only has to grab the playlist (using the function we defined above), and pass it to a template that handles the display.
|
||||
|
||||
The main part of the template that handles the display of this data is:
|
||||
|
||||
<h2>Currently Playing:</h2>
|
||||
% if playlist is not None:
|
||||
% position = offset
|
||||
% for song in playlist:
|
||||
<strong> {{song[‘title’]}} </strong>
|
||||
% if song[‘type’] == ‘unknown’:
|
||||
Radio
|
||||
% else:
|
||||
{{song[‘artist’][0]}}
|
||||
% end
|
||||
% if position != offset:
|
||||
<a href=”/remove/{{position}}”>remove</a>
|
||||
% else:
|
||||
<a href=”/skip/{{position}}”>skip</a>
|
||||
% end
|
||||
<br>
|
||||
% position += 1
|
||||
% end
|
||||
|
||||
As you can see, templates are mostly written in HTML, but with a few extra bits to control output. Variables enclosed by double parenthesise are output in place (as we saw in the first ‘hello world’ example). You can also include Python code on lines starting with a percentage sign. Since indents aren’t used, you need a % end to close any code block (such as a loop or if statement).
|
||||
|
||||
This template first checks that the playlist isn’t empty, then loops through every item on the playlist. Each item is displayed as the song title in bold, then the name of the artist, then a link to either skip it (if it’s the currently playing song), or remove it from the playlist. All songs have a type of ‘song’, so if the type is ‘unknown’, then it isn’t a song, but a radio station.
|
||||
|
||||
The /remove/ and /skip/ routes are simple wrappers around XBMC controls that reload /juke after the change has taken effect:
|
||||
|
||||
@route(‘/skip/<position>’)
|
||||
def index(position):
|
||||
print xbmc.Player.GoTo({‘playerid’:0, ‘to’:’next’})
|
||||
redirect(“/juke”)
|
||||
@route(‘/remove/<position>’)
|
||||
def index(position):
|
||||
playlistid = get_playlistid()
|
||||
if playlistid >= 0:
|
||||
xbmc.Playlist.Remove({‘playlistid’:int(playlistid), ‘position’:int(position)})
|
||||
redirect(“/juke”)
|
||||
|
||||
Of course, it’s no good being able to manage your playlist if you can’t add music to it.
|
||||
|
||||
This is complicated slightly by the fact that once a playlist finishes, it disappears, so you need to create a new one. Rather confusingly, playlists are created by calling the Playlist.Clear() method. This can also be used to kill a playlist that is currently playing a radio station (where the type is unknown). The other complication is that radio streams sit in the playlist and never leave, so if there’s currently a radio station playing, we need to clear the playlist as well.
|
||||
|
||||
These pages include a link to play the songs, which points to /play/<songid>. This page is handled by:
|
||||
|
||||
@route(‘/play/<id>’)
|
||||
def index(id):
|
||||
playlistid = get_playlistid()
|
||||
playlist, not_needed= get_playlist()
|
||||
if playlistid < 0 or playlist[0][‘type’] == ‘unknown’:
|
||||
xbmc.Playlist.Clear({“playlistid”:0})
|
||||
xbmc.Playlist.Add({“playlistid”:0, “item”:{“songid”:int(id)}})
|
||||
xbmc.Player.open({“item”:{“playlistid”:0}})
|
||||
playlistid = 0
|
||||
else:
|
||||
xbmc.Playlist.Add({“playlistid”:playlistid, “item”:{“songid”:int(id)}})
|
||||
remove_duplicates(playlistid)
|
||||
redirect(“/juke”)
|
||||
|
||||
The final thing here is a call to remove_duplicates. This isn’t essential – and some people may not like it – but it makes sure that no song appears in the playlist more than once.
|
||||
|
||||
We also have pages that list all the artists in the collection, and list the songs and albums by particular artists. These are quite straightforward, and work in the same basic way as /juke.
|
||||
|
||||
|
||||
|
||||
The UI still needs a bit of attention, but it’s working.
|
||||
|
||||
> ### Logging ###
|
||||
>
|
||||
> It’s not always clear how to do something using the XBMC JSON API, and the documentation is sometimes a little opaque. One way of finding out how to do something is seeing how other remote controls do it. If you turn on logging, you can see what API calls are being performed as you use another remote control, then incorporate these into your code.
|
||||
>
|
||||
> To turn on logging, hook your XBMC media centre up to a display and go to Settings > System > Debugging, and turn on Enable Debug Logging. With logging turned on, you need to access the XBMC machine (eg via SSH), then you can view the log. Its location should be displayed in the top-left corner of the XBMC display. In RaspBMC, it’s at /home/pi/.xbmc/temp/xbmc.log. You can then keep an eye on what API calls are being performed in real time using:
|
||||
>
|
||||
> cd /home/pi/.xbmc/temp
|
||||
> tail -f xbmc.log | grep “JSON”
|
||||
|
||||
#### Adding functionality ####
|
||||
|
||||
The above code all works with songs in the XBMC library, but we also wanted to be able to play radio stations. Addons each have their own plugin URL that can be used to pull information out of them using the usual XBMC JSON commands. For example, to get the selected stations from the radio plugin, we use:
|
||||
|
||||
@route(‘/radio/’)
|
||||
def index():
|
||||
my_stations = xbmc.Files.GetDirectory({“directory”:”plugin://plugin.audio.radio_de/stations/my/”, “properties”:
|
||||
[“title”,”thumbnail”,”playcount”,”artist”,”album”,”episode”,”season”,”showtitle”]})
|
||||
if ‘result’ in my_stations.keys():
|
||||
return template(‘radio’, stations=my_stations[‘result’][‘files’])
|
||||
else:
|
||||
return template(‘error’, error=’radio’)
|
||||
|
||||
This includes a file that can be added to a playlist just as any song can be. However, these files never finish playing, so (as we saw before) you need to recreate the playlist before adding any songs to it.
|
||||
|
||||
#### Sharing songs ####
|
||||
|
||||
As well as serving up templates, Bottle can serve static files. These are useful whenever you need things that don’t change based on the user input. That could be a CSS file, an image or an MP3. In our simple controller there’s not (yet) any CSS or images to make things look pretty, but we have added a way to download the songs. This lets the media centre act as a sort of NAS box for songs. If you’re transferring large amounts of data, it’s probably best to use something like Samba, but serving static files is a good way of grabbing a couple of tunes on your phone.
|
||||
|
||||
The Bottle code to download a song by its ID is :
|
||||
|
||||
@route(‘/download/<id>’)
|
||||
def index(id):
|
||||
data = xbmc.AudioLibrary.GetSongDetails({“songid”:int(id), “properties”:[“file”]})
|
||||
full_filename = data[‘result’][‘songdetails’][‘file’]
|
||||
path, filename = os.path.split(full_filename)
|
||||
return static_file(filename, root=path, download=True)
|
||||
|
||||
To use this, we just put a link to the appropriate ID in the /songsby/ page.
|
||||
|
||||
We’ve gone through all the mechanics of the code, but there are a few more bits that just tie it all together. You can see for yourself at the GitHub page:[https://github.com/ben-ev/xbmc-remote][3].
|
||||
|
||||
> ### Setting up ###
|
||||
>
|
||||
> Once you’ve developed your remote control, you’ll need a way of ensuring that it starts every time you turn on your media centre. There are a few ways of doing this, but the easiest is just to add a command launching it to /etc/rc.local. We installed our file to /opt/xbmc-remote/remote.py with all the other files alongside it. We then added the following line to /etc/rc.local before the final exit 0 line.
|
||||
>
|
||||
> cd /opt/xbmc-remote && python remote.py &
|
||||
|
||||
> ### GitHub ###
|
||||
>
|
||||
> This project is quite bare-bones at the moment, but – the business of running a magazine means we don’t have as much time as we’d like to program. However, we’ve set up a GitHub project where we hope to keep working on it, and if you think you’d benefit from the project as well, we’d love your input.
|
||||
>
|
||||
> To see what’s going on, head over to [https://github.com/ben-ev/xbmc-remote][4] and take a look at what state it’s in. You can get a copy of the latest code from that web page, or clone it from the command line.
|
||||
>
|
||||
> If you want to improve it, you can fork the project to develop in your own branch, and then send a pull request when your features are working. For more information on working with GitHub, head to [https://github.com/features][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/xbmc-build-a-remote-control/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://bottlepy.org/docs/dev/deployment.html
|
||||
[2]:http://wiki.xbmc.org/?title=JSON-RPC_API/v6
|
||||
[3]:https://github.com/ben-ev/xbmc-remote
|
||||
[4]:https://github.com/ben-ev/xbmc-remote
|
||||
[5]:https://github.com/features
|
||||
436
sources/tech/20150617 The Art of Command Line.md
Normal file
436
sources/tech/20150617 The Art of Command Line.md
Normal file
@ -0,0 +1,436 @@
|
||||
Translating by GOLinux!
|
||||
The Art of Command Line
|
||||
================================================================================
|
||||
- [Basics](#basics)
|
||||
- [Everyday use](#everyday-use)
|
||||
- [Processing files and data](#processing-files-and-data)
|
||||
- [System debugging](#system-debugging)
|
||||
- [One-liners](#one-liners)
|
||||
- [Obscure but useful](#obscure-but-useful)
|
||||
- [More resources](#more-resources)
|
||||
- [Disclaimer](#disclaimer)
|
||||
|
||||
|
||||

|
||||
|
||||
Fluency on the command line is a skill often neglected or considered arcane, but it improves your flexibility and productivity as an engineer in both obvious and subtle ways. This is a selection of notes and tips on using the command-line that I've found useful when working on Linux. Some tips are elementary, and some are fairly specific, sophisticated, or obscure. This page is not long, but if you can use and recall all the items here, you know a lot.
|
||||
|
||||
Much of this
|
||||
[originally](http://www.quora.com/What-are-some-lesser-known-but-useful-Unix-commands)
|
||||
[appeared](http://www.quora.com/What-are-the-most-useful-Swiss-army-knife-one-liners-on-Unix)
|
||||
on [Quora](http://www.quora.com/What-are-some-time-saving-tips-that-every-Linux-user-should-know),
|
||||
but given the interest there, it seems it's worth using Github, where people more talented than I can readily suggest improvements. If you see an error or something that could be better, please submit an issue or PR!
|
||||
|
||||
Scope:
|
||||
|
||||
- The goals are breadth and brevity. Every tip is essential in some situation or significantly saves time over alternatives.
|
||||
- This is written for Linux. Many but not all items apply equally to MacOS (or even Cygwin).
|
||||
- The focus is on interactive Bash, though many tips apply to other shells and to general Bash scripting.
|
||||
- Descriptions are intentionally minimal, with the expectation you'll use `man`, `apt-get`/`yum`/`dnf` to install, and Google for more background.
|
||||
|
||||
|
||||
## Basics
|
||||
|
||||
- Learn basic Bash. Actually, type `man bash` and at least skim the whole thing; it's pretty easy to follow and not that long. Alternate shells can be nice, but Bash is powerful and always available (learning *only* zsh, fish, etc., while tempting on your own laptop, restricts you in many situations, such as using existing servers).
|
||||
|
||||
- Learn at least one text-based editor well. Ideally Vim (`vi`), as there's really no competition for random editing in a terminal (even if you use Emacs, a big IDE, or a modern hipster editor most of the time).
|
||||
|
||||
- Learn about redirection of output and input using `>` and `<` and pipes using `|`. Learn about stdout and stderr.
|
||||
|
||||
- Learn about file glob expansion with `*` (and perhaps `?` and `{`...`}`) and quoting and the difference between double `"` and single `'` quotes. (See more on variable expansion below.)
|
||||
|
||||
- Be familiar with Bash job management: `&`, **ctrl-z**, **ctrl-c**, `jobs`, `fg`, `bg`, `kill`, etc.
|
||||
|
||||
- Know `ssh`, and the basics of passwordless authentication, via `ssh-agent`, `ssh-add`, etc.
|
||||
|
||||
- Basic file management: `ls` and `ls -l` (in particular, learn what every column in `ls -l` means), `less`, `head`, `tail` and `tail -f` (or even better, `less +F`), `ln` and `ln -s` (learn the differences and advantages of hard versus soft links), `chown`, `chmod`, `du` (for a quick summary of disk usage: `du -sk *`), `df`, `mount`.
|
||||
|
||||
- Basic network management: `ip` or `ifconfig`, `dig`.
|
||||
|
||||
- Know regular expressions well, and the various flags to `grep`/`egrep`. The `-i`, `-o`, `-A`, and `-B` options are worth knowing.
|
||||
|
||||
- Learn to use `apt-get`, `yum`, or `dnf` (depending on distro) to find and install packages. And make sure you have `pip` to install Python-based command-line tools (a few below are easiest to install via `pip`).
|
||||
|
||||
|
||||
## Everyday use
|
||||
|
||||
- In Bash, use **ctrl-r** to search through command history.
|
||||
|
||||
- In Bash, use **ctrl-w** to delete the last word, and **ctrl-u** to delete the whole line. Use **alt-b** and **alt-f** to move by word, and **ctrl-k** to kill to the end of the line. See `man readline` for all the default keybindings in Bash. There are a lot. For example **alt-.** cycles through previous arguments, and **alt-*** expands a glob.
|
||||
|
||||
- To go back to the previous working directory: `cd -`
|
||||
|
||||
- If you are halfway through typing a command but change your mind, hit **alt-#** to add a `#` at the beginning and enter it as a comment (or use **ctrl-a**, **#**, **enter**). You can then return to it later via command history.
|
||||
|
||||
- Use `xargs` (or `parallel`). It's very powerful. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use `xargs echo` first. Also, `-I{}` is handy. Examples:
|
||||
```bash
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- `pstree -p` is a helpful display of the process tree.
|
||||
|
||||
- Use `pgrep` and `pkill` to find or signal processes by name (`-f` is helpful).
|
||||
|
||||
- Know the various signals you can send processes. For example, to suspend a process, use `kill -STOP [pid]`. For the full list, see `man 7 signal`
|
||||
|
||||
- Use `nohup` or `disown` if you want a background process to keep running forever.
|
||||
|
||||
- Check what processes are listening via `netstat -lntp`.
|
||||
|
||||
- See also `lsof` for open sockets and files.
|
||||
|
||||
- In Bash scripts, use `set -x` for debugging output. Use strict modes whenever possible. Use `set -e` to abort on errors. Use `set -o pipefail` as well, to be strict about errors (though this topic is a bit subtle). For more involved scripts, also use `trap`.
|
||||
|
||||
- In Bash scripts, subshells (written with parentheses) are convenient ways to group commands. A common example is to temporarily move to a different working directory, e.g.
|
||||
```bash
|
||||
# do something in current dir
|
||||
(cd /some/other/dir; other-command)
|
||||
# continue in original dir
|
||||
```
|
||||
|
||||
- In Bash, note there are lots of kinds of variable expansion. Checking a variable exists: `${name:?error message}`. For example, if a Bash script requires a single argument, just write `input_file=${1:?usage: $0 input_file}`. Arithmetic expansion: `i=$(( (i + 1) % 5 ))`. Sequences: `{1..10}`. Trimming of strings: `${var%suffix}` and `${var#prefix}`. For example if `var=foo.pdf`, then `echo ${var%.pdf}.txt` prints `foo.txt`.
|
||||
|
||||
- The output of a command can be treated like a file via `<(some command)`. For example, compare local `/etc/hosts` with a remote one:
|
||||
```sh
|
||||
diff /etc/hosts <(ssh somehost cat /etc/hosts)
|
||||
```
|
||||
|
||||
- Know about "here documents" in Bash, as in `cat <<EOF ...`.
|
||||
|
||||
- In Bash, redirect both standard output and standard error via: `some-command >logfile 2>&1`. Often, to ensure a command does not leave an open file handle to standard input, tying it to the terminal you are in, it is also good practice to add `</dev/null`.
|
||||
|
||||
- Use `man ascii` for a good ASCII table, with hex and decimal values. For general encoding info, `man unicode`, `man utf-8`, and `man latin1` are helpful.
|
||||
|
||||
- Use `screen` or `tmux` to multiplex the screen, especially useful on remote ssh sessions and to detach and re-attach to a session. A more minimal alternative for session persistence only is `dtach`.
|
||||
|
||||
- In ssh, knowing how to port tunnel with `-L` or `-D` (and occasionally `-R`) is useful, e.g. to access web sites from a remote server.
|
||||
|
||||
- It can be useful to make a few optimizations to your ssh configuration; for example, this `~/.ssh/config` contains settings to avoid dropped connections in certain network environments, use compression (which is helpful with scp over low-bandwidth connections), and multiplex channels to the same server with a local control file:
|
||||
```
|
||||
TCPKeepAlive=yes
|
||||
ServerAliveInterval=15
|
||||
ServerAliveCountMax=6
|
||||
Compression=yes
|
||||
ControlMaster auto
|
||||
ControlPath /tmp/%r@%h:%p
|
||||
ControlPersist yes
|
||||
```
|
||||
|
||||
- A few other options relevant to ssh are security sensitive and should be enabled with care, e.g. per subnet or host or in trusted networks: `StrictHostKeyChecking=no`, `ForwardAgent=yes`
|
||||
|
||||
- To get the permissions on a file in octal form, which is useful for system configuration but not available in `ls` and easy to bungle, use something like
|
||||
```sh
|
||||
stat -c '%A %a %n' /etc/timezone
|
||||
```
|
||||
|
||||
- For interactive selection of values from the output of another command, use [`percol`](https://github.com/mooz/percol).
|
||||
|
||||
- For interaction with files based on the output of another command (like `git`), use `fpp` ([PathPicker](https://github.com/facebook/PathPicker)).
|
||||
|
||||
- For a simple web server for all files in the current directory (and subdirs), available to anyone on your network, use:
|
||||
`python -m SimpleHTTPServer 7777` (for port 7777 and Python 2).
|
||||
|
||||
|
||||
## Processing files and data
|
||||
|
||||
- To locate a file by name in the current directory, `find . -iname '*something*'` (or similar). To find a file anywhere by name, use `locate something` (but bear in mind `updatedb` may not have indexed recently created files).
|
||||
|
||||
- For general searching through source or data files (more advanced than `grep -r`), use [`ag`](https://github.com/ggreer/the_silver_searcher).
|
||||
|
||||
- To convert HTML to text: `lynx -dump -stdin`
|
||||
|
||||
- For Markdown, HTML, and all kinds of document conversion, try [`pandoc`](http://pandoc.org/).
|
||||
|
||||
- If you must handle XML, `xmlstarlet` is old but good.
|
||||
|
||||
- For JSON, use `jq`.
|
||||
|
||||
- For Excel or CSV files, [csvkit](https://github.com/onyxfish/csvkit) provides `in2csv`, `csvcut`, `csvjoin`, `csvgrep`, etc.
|
||||
|
||||
- For Amazon S3, [`s3cmd`](https://github.com/s3tools/s3cmd) is convenient and [`s4cmd`](https://github.com/bloomreach/s4cmd) is faster. Amazon's [`aws`](https://github.com/aws/aws-cli) is essential for other AWS-related tasks.
|
||||
|
||||
- Know about `sort` and `uniq`, including uniq's `-u` and `-d` options -- see one-liners below.
|
||||
|
||||
- Know about `cut`, `paste`, and `join` to manipulate text files. Many people use `cut` but forget about `join`.
|
||||
|
||||
- Know that locale affects a lot of command line tools in subtle ways, including sorting order (collation) and performance. Most Linux installations will set `LANG` or other locale variables to a local setting like US English. But be aware sorting will change if you change locale. And know i18n routines can make sort or other commands run *many times* slower. In some situations (such as the set operations or uniqueness operations below) you can safely ignore slow i18n routines entirely and use traditional byte-based sort order, using `export LC_ALL=C`.
|
||||
|
||||
- Know basic `awk` and `sed` for simple data munging. For example, summing all numbers in the third column of a text file: `awk '{ x += $3 } END { print x }'`. This is probably 3X faster and 3X shorter than equivalent Python.
|
||||
|
||||
- To replace all occurrences of a string in place, in one or more files:
|
||||
```sh
|
||||
perl -pi.bak -e 's/old-string/new-string/g' my-files-*.txt
|
||||
```
|
||||
|
||||
- To rename many files at once according to a pattern, use `rename`. For complex renames, [`repren`](https://github.com/jlevy/repren) may help.
|
||||
```sh
|
||||
# Recover backup files foo.bak -> foo:
|
||||
rename 's/\.bak$//' *.bak
|
||||
# Full rename of filenames, directories, and contents foo -> bar:
|
||||
repren --full --preserve-case --from foo --to bar .
|
||||
```
|
||||
|
||||
- Use `shuf` to shuffle or select random lines from a file.
|
||||
|
||||
- Know `sort`'s options. Know how keys work (`-t` and `-k`). In particular, watch out that you need to write `-k1,1` to sort by only the first field; `-k1` means sort according to the whole line.
|
||||
|
||||
- Stable sort (`sort -s`) can be useful. For example, to sort first by field 2, then secondarily by field 1, you can use `sort -k1,1 | sort -s -k2,2`
|
||||
|
||||
- If you ever need to write a tab literal in a command line in Bash (e.g. for the -t argument to sort), press **ctrl-v** **[Tab]** or write `$'\t'` (the latter is better as you can copy/paste it).
|
||||
|
||||
- For binary files, use `hd` for simple hex dumps and `bvi` for binary editing.
|
||||
|
||||
- Also for binary files, `strings` (plus `grep`, etc.) lets you find bits of text.
|
||||
|
||||
- To convert text encodings, try `iconv`. Or `uconv` for more advanced use; it supports some advanced Unicode things. For example, this command lowercases and removes all accents (by expanding and dropping them):
|
||||
```sh
|
||||
uconv -f utf-8 -t utf-8 -x '::Any-Lower; ::Any-NFD; [:Nonspacing Mark:] >; ::Any-NFC; ' < input.txt > output.txt
|
||||
```
|
||||
|
||||
- To split files into pieces, see `split` (to split by size) and `csplit` (to split by a pattern).
|
||||
|
||||
- Use `zless`, `zmore`, `zcat`, and `zgrep` to operate on compressed files.
|
||||
|
||||
|
||||
## System debugging
|
||||
|
||||
- For web debugging, `curl` and `curl -I` are handy, or their `wget` equivalents, or the more modern [`httpie`](https://github.com/jakubroztocil/httpie).
|
||||
|
||||
- To know disk/cpu/network status, use `iostat`, `netstat`, `top` (or the better `htop`), and (especially) `dstat`. Good for getting a quick idea of what's happening on a system.
|
||||
|
||||
- For a more in-depth system overview, use [`glances`](https://github.com/nicolargo/glances). It presents you with several system level statistics in one terminal window. Very helpful for quickly checking on various subsystems.
|
||||
|
||||
- To know memory status, run and understand the output of `free` and `vmstat`. In particular, be aware the "cached" value is memory held by the Linux kernel as file cache, so effectively counts toward the "free" value.
|
||||
|
||||
- Java system debugging is a different kettle of fish, but a simple trick on Oracle's and some other JVMs is that you can run `kill -3 <pid>` and a full stack trace and heap summary (including generational garbage collection details, which can be highly informative) will be dumped to stderr/logs.
|
||||
|
||||
- Use `mtr` as a better traceroute, to identify network issues.
|
||||
|
||||
- For looking at why a disk is full, `ncdu` saves time over the usual commands like `du -sh *`.
|
||||
|
||||
- To find which socket or process is using bandwidth, try `iftop` or `nethogs`.
|
||||
|
||||
- The `ab` tool (comes with Apache) is helpful for quick-and-dirty checking of web server performance. For more complex load testing, try `siege`.
|
||||
|
||||
- For more serious network debugging, `wireshark`, `tshark`, or `ngrep`.
|
||||
|
||||
- Know about `strace` and `ltrace`. These can be helpful if a program is failing, hanging, or crashing, and you don't know why, or if you want to get a general idea of performance. Note the profiling option (`-c`), and the ability to attach to a running process (`-p`).
|
||||
|
||||
- Know about `ldd` to check shared libraries etc.
|
||||
|
||||
- Know how to connect to a running process with `gdb` and get its stack traces.
|
||||
|
||||
- Use `/proc`. It's amazingly helpful sometimes when debugging live problems. Examples: `/proc/cpuinfo`, `/proc/xxx/cwd`, `/proc/xxx/exe`, `/proc/xxx/fd/`, `/proc/xxx/smaps`.
|
||||
|
||||
- When debugging why something went wrong in the past, `sar` can be very helpful. It shows historic statistics on CPU, memory, network, etc.
|
||||
|
||||
- For deeper systems and performance analyses, look at `stap` ([SystemTap](https://sourceware.org/systemtap/wiki)), [`perf`](http://en.wikipedia.org/wiki/Perf_(Linux)), and [`sysdig`](https://github.com/draios/sysdig).
|
||||
|
||||
- Confirm what Linux distribution you're using (works on most distros): `lsb_release -a`
|
||||
|
||||
- Use `dmesg` whenever something's acting really funny (it could be hardware or driver issues).
|
||||
|
||||
|
||||
## One-liners
|
||||
|
||||
A few examples of piecing together commands:
|
||||
|
||||
- It is remarkably helpful sometimes that you can do set intersection, union, and difference of text files via `sort`/`uniq`. Suppose `a` and `b` are text files that are already uniqued. This is fast, and works on files of arbitrary size, up to many gigabytes. (Sort is not limited by memory, though you may need to use the `-T` option if `/tmp` is on a small root partition.) See also the note about `LC_ALL` above.
|
||||
```sh
|
||||
cat a b | sort | uniq > c # c is a union b
|
||||
cat a b | sort | uniq -d > c # c is a intersect b
|
||||
cat a b b | sort | uniq -u > c # c is set difference a - b
|
||||
```
|
||||
|
||||
- Summing all numbers in the third column of a text file (this is probably 3X faster and 3X less code than equivalent Python):
|
||||
```sh
|
||||
awk '{ x += $3 } END { print x }' myfile
|
||||
```
|
||||
|
||||
- If want to see sizes/dates on a tree of files, this is like a recursive `ls -l` but is easier to read than `ls -lR`:
|
||||
```sh
|
||||
find . -type f -ls
|
||||
```
|
||||
|
||||
- Use `xargs` or `parallel` whenever you can. Note you can control how many items execute per line (`-L`) as well as parallelism (`-P`). If you're not sure if it'll do the right thing, use xargs echo first. Also, `-I{}` is handy. Examples:
|
||||
```sh
|
||||
find . -name '*.py' | xargs grep some_function
|
||||
cat hosts | xargs -I{} ssh root@{} hostname
|
||||
```
|
||||
|
||||
- Say you have a text file, like a web server log, and a certain value that appears on some lines, such as an `acct_id` parameter that is present in the URL. If you want a tally of how many requests for each `acct_id`:
|
||||
```sh
|
||||
cat access.log | egrep -o 'acct_id=[0-9]+' | cut -d= -f2 | sort | uniq -c | sort -rn
|
||||
```
|
||||
|
||||
- Run this function to get a random tip from this document (parses Markdown and extracts an item):
|
||||
```sh
|
||||
function taocl() {
|
||||
curl -s https://raw.githubusercontent.com/jlevy/the-art-of-command-line/master/README.md |
|
||||
pandoc -f markdown -t html |
|
||||
xmlstarlet fo --html --dropdtd |
|
||||
xmlstarlet sel -t -v "(html/body/ul/li[count(p)>0])[$RANDOM mod last()+1]" |
|
||||
xmlstarlet unesc | fmt -80
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## Obscure but useful
|
||||
|
||||
- `expr`: perform arithmetic or boolean operations or evaluate regular expressions
|
||||
|
||||
- `m4`: simple macro processor
|
||||
|
||||
- `screen`: powerful terminal multiplexing and session persistence
|
||||
|
||||
- `yes`: print a string a lot
|
||||
|
||||
- `cal`: nice calendar
|
||||
|
||||
- `env`: run a command (useful in scripts)
|
||||
|
||||
- `look`: find English words (or lines in a file) beginning with a string
|
||||
|
||||
- `cut `and `paste` and `join`: data manipulation
|
||||
|
||||
- `fmt`: format text paragraphs
|
||||
|
||||
- `pr`: format text into pages/columns
|
||||
|
||||
- `fold`: wrap lines of text
|
||||
|
||||
- `column`: format text into columns or tables
|
||||
|
||||
- `expand` and `unexpand`: convert between tabs and spaces
|
||||
|
||||
- `nl`: add line numbers
|
||||
|
||||
- `seq`: print numbers
|
||||
|
||||
- `bc`: calculator
|
||||
|
||||
- `factor`: factor integers
|
||||
|
||||
- `gpg`: encrypt and sign files
|
||||
|
||||
- `toe`: table of terminfo entries
|
||||
|
||||
- `nc`: network debugging and data transfer
|
||||
|
||||
- `ngrep`: grep for the network layer
|
||||
|
||||
- `dd`: moving data between files or devices
|
||||
|
||||
- `file`: identify type of a file
|
||||
|
||||
- `stat`: file info
|
||||
|
||||
- `tac`: print files in reverse
|
||||
|
||||
- `shuf`: random selection of lines from a file
|
||||
|
||||
- `comm`: compare sorted files line by line
|
||||
|
||||
- `hd` and `bvi`: dump or edit binary files
|
||||
|
||||
- `strings`: extract text from binary files
|
||||
|
||||
- `tr`: character translation or manipulation
|
||||
|
||||
- `iconv `or uconv: conversion for text encodings
|
||||
|
||||
- `split `and `csplit`: splitting files
|
||||
|
||||
- `7z`: high-ratio file compression
|
||||
|
||||
- `ldd`: dynamic library info
|
||||
|
||||
- `nm`: symbols from object files
|
||||
|
||||
- `ab`: benchmarking web servers
|
||||
|
||||
- `strace`: system call debugging
|
||||
|
||||
- `mtr`: better traceroute for network debugging
|
||||
|
||||
- `cssh`: visual concurrent shell
|
||||
|
||||
- `wireshark` and `tshark`: packet capture and network debugging
|
||||
|
||||
- `host` and `dig`: DNS lookups
|
||||
|
||||
- `lsof`: process file descriptor and socket info
|
||||
|
||||
- `dstat`: useful system stats
|
||||
|
||||
- [`glances`](https://github.com/nicolargo/glances): high level, multi-subsystem overview
|
||||
|
||||
- `iostat`: CPU and disk usage stats
|
||||
|
||||
- `htop`: improved version of top
|
||||
|
||||
- `last`: login history
|
||||
|
||||
- `w`: who's logged on
|
||||
|
||||
- `id`: user/group identity info
|
||||
|
||||
- `sar`: historic system stats
|
||||
|
||||
- `iftop` or `nethogs`: network utilization by socket or process
|
||||
|
||||
- `ss`: socket statistics
|
||||
|
||||
- `dmesg`: boot and system error messages
|
||||
|
||||
- `hdparm`: SATA/ATA disk manipulation/performance
|
||||
|
||||
- `lsb_release`: Linux distribution info
|
||||
|
||||
- `lshw`: hardware information
|
||||
|
||||
- `fortune`, `ddate`, and `sl`: um, well, it depends on whether you consider steam locomotives and Zippy quotations "useful"
|
||||
|
||||
|
||||
## More resources
|
||||
|
||||
- [awesome-shell](https://github.com/alebcay/awesome-shell): A curated list of shell tools and resources.
|
||||
- [Strict mode](http://redsymbol.net/articles/unofficial-bash-strict-mode/) for writing better shell scripts.
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
With the exception of very small tasks, code is written so others can read it. With power comes responsibility. The fact you *can* do something in Bash doesn't necessarily mean you should! ;)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/jlevy/the-art-of-command-line
|
||||
|
||||
作者:[jlevy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/jlevy
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,206 @@
|
||||
Tor Browser: An Ultimate Web Browser for Anonymous Web Browsing in Linux
|
||||
================================================================================
|
||||
Most of us give a considerable time of ours to Internet. The primary Application we require to perform our internet activity is a browser, a web browser to be more perfect. Over Internet most of our’s activity is logged to Server/Client machine which includes IP address, Geographical Location, search/activity trends and a whole lots of Information which can potentially be very harmful, if used intentionally the other way.
|
||||
|
||||

|
||||
|
||||
Tor Browser: Anonymous Browsing
|
||||
|
||||
Moreover the National Security Agency (NSA) aka International Spying Agency keeps tracks of ours digital footprints. Not to mention a restricted proxy server which again can be used as data ripping server is not the answer. And most of the corporates and companies wont allow you to access a proxy server.
|
||||
|
||||
So, what we need here is an application, preferably small in size and let it be standalone, portable and which servers the purpose. Here comes an application – the Tor Browser, which has all the above discussed features and even beyond that.
|
||||
|
||||
In this article we will be discussing Tor browser, its features, its usages and Area of Application, Installation and other important aspects of The Tor Browser Application.
|
||||
|
||||
#### What is Tor Browser? ####
|
||||
|
||||
Tor is a Freely distributed Application Software, released under BSD style Licensing which allows to surf Internet anonymously, through its safe and reliable onion like structure. Tor previously was called as ‘The Onion Router‘ because of its structure and functioning mechanism. This Application is written in C programming Language.
|
||||
|
||||
#### Features of Tor Browser ####
|
||||
|
||||
- Cross Platform Availability. i.e., this application is available for Linux, Windows as well as Mac.
|
||||
- Complex Data encryption before it it sent over Internet.
|
||||
- Automatic data decryption at client side.
|
||||
- It is a combination of Firefox Browser + Tor Project.
|
||||
- Provides anonymity to servers and websites.
|
||||
- Makes it possible to visit locked websites.
|
||||
- Performs task without revealing IP of Source.
|
||||
- Capable of routing data to/from hidden services and application behind firewall.
|
||||
- Portable – Run a preconfigured web browser directly from the USB storage Device. No need to install it locally.
|
||||
- Available for architectures x86 and x86_64.
|
||||
- Easy to set FTP with Tor using configuration as “socks4a” proxy on “localhost” port “9050”
|
||||
- Tor is capable of handling thousands of relay and millions of users.
|
||||
|
||||
#### How Tor Browser Works? ####
|
||||
|
||||
Tor works on the concept of Onion routing. Onion routing resemble to onion in structure. In onion routing the layers are nested one over the other similar to the layers of onion. This nested layer is responsible for encrypting data several times and sends it through virtual circuits. On the client side each layer decrypt the data before passing it to the next level. The last layer decrypts the innermost layer of encrypted data before passing the original data to the destination.
|
||||
|
||||
In this process of decryption all the layers function so intelligently that there is no need to reveal IP and Geographical location of User thus limiting any chance of anybody watching your internet connection or the sites you are visiting.
|
||||
|
||||
All these working seems a bit complex, but the end user execution and working of Tor browser is nothing to worry about. In-fact Tor browser resembles any other browser (Especially Mozilla Firefox) in functioning.
|
||||
|
||||
### Installation of Tor Browser in Linux ###
|
||||
|
||||
As discussed above, Tor browser is available for Linux, Windows and Mac. The user need to download the latest version (i.e. Tor Browser 4.0.4) application from the link below as per their system and architecture.
|
||||
|
||||
- [https://www.torproject.org/download/download-easy.html.en][1]
|
||||
|
||||
After downloading the Tor browser, we need to install it. But the good thing with ‘Tor’ is that we don’t need to install it. It can run directly from a Pen Drive and the browser can be preconfigured. That means plug and Run Feature in perfect sense of Portability.
|
||||
|
||||
After downloading the Tar-ball (*.tar.xz) we need to Extract it.
|
||||
|
||||
**On 32-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
$ tar xpvf tor-browser-linux32-4.0.4_en-US.tar.xz
|
||||
|
||||
**On 64-Bit System**
|
||||
|
||||
$ wget https://www.torproject.org/dist/torbrowser/4.0.4/tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
$ tar -xpvf tor-browser-linux64-4.0.4_en-US.tar.xz
|
||||
|
||||
**Note** : In the above command we used ‘$‘ which means that the package is extracted as user and not root. It is strictly suggested to extract and run tor browser not as root.
|
||||
|
||||
After successful extraction, we can move the extracted browser to anywhere/USB Mass Storage device. And run the application from the extracted folder and run ‘start-tor-browser’ strictly not as root.
|
||||
|
||||
$ cd tor-browser_en-US
|
||||
$ ./start-tor-browser
|
||||
|
||||
|
||||
|
||||
Starting Tor Browser
|
||||
|
||||
**1. Trying to connect to the Tor Network. Click “Connect” and Tor will do rest of the settings for you.**
|
||||
|
||||

|
||||
|
||||
Connecting to Tor Network
|
||||
|
||||
**2. The welcome Window/Tab.**
|
||||
|
||||
|
||||
|
||||
Tor Welcome Screen
|
||||
|
||||
**3. Tor Browser Running a Video from Youtube.**
|
||||
|
||||

|
||||
|
||||
Watching Video on Youtube
|
||||
|
||||
**4. Opening a banking site for online Purchasing/Transaction.**
|
||||
|
||||

|
||||
|
||||
Browsing a Banking Site
|
||||
|
||||
**5. The browser showing my current proxy IP. Note that the text that reads “Proxy Server detected”.**
|
||||
|
||||
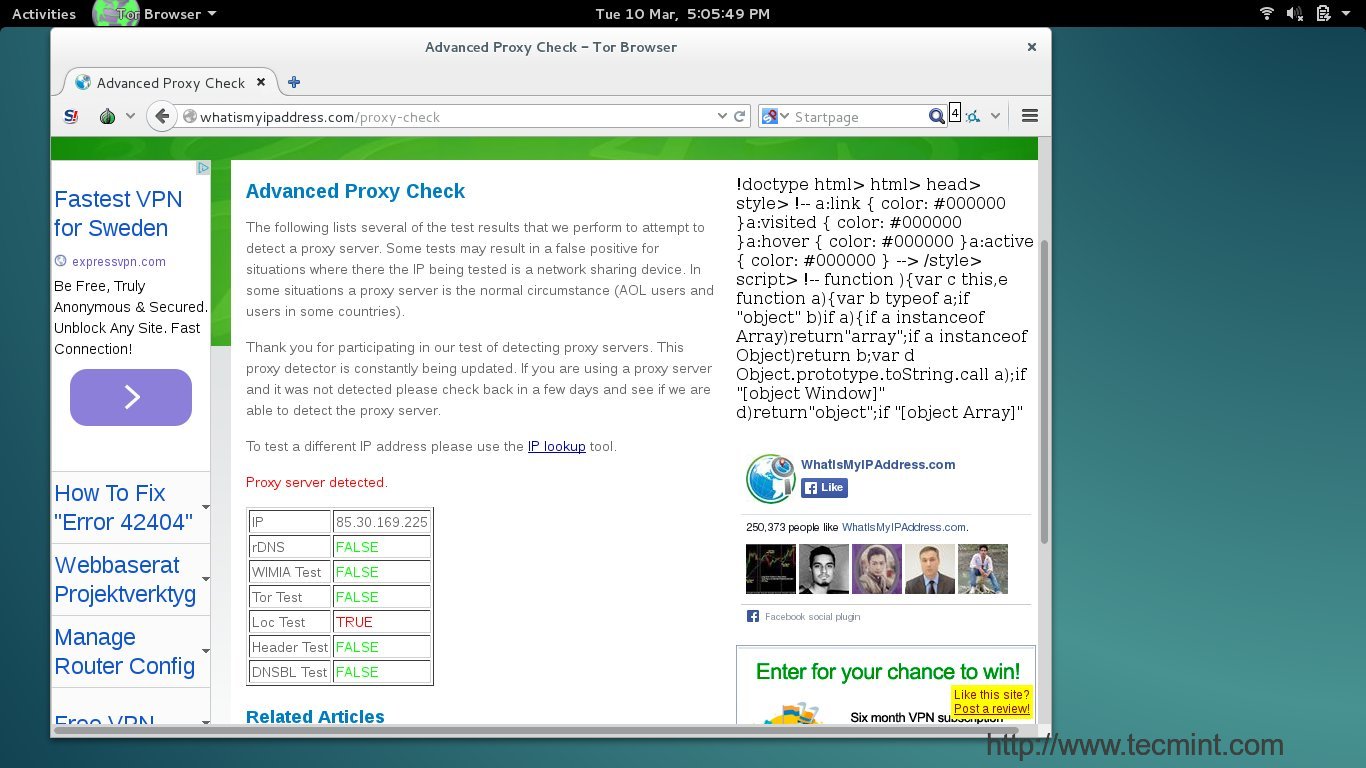
|
||||
|
||||
Checking IP Address
|
||||
|
||||
**Note**: That you need to point to the Tor startup script using text session, everytime you want to run Tor. Moreover a terminal will be busy all the time till you are running tor. How to overcome this and create a desktop/dock-bar Icon?
|
||||
|
||||
6. We need to create `tor.desktop` file inside the directory where extracted files resides.
|
||||
|
||||
$ touch tor.desktop
|
||||
|
||||
Now edit the file using your favourite editor with the text below. Save and exit. I used nano.
|
||||
|
||||
$ nano tor.desktop
|
||||
|
||||
----------
|
||||
|
||||
#!/usr/bin/env xdg-open
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Tor
|
||||
Comment=Anonymous Browse
|
||||
Type=Application
|
||||
Terminal=false
|
||||
Exec=/home/avi/Downloads/tor-browser_en-US/start-tor-browser
|
||||
Icon=/home/avi/Downloads/tor-browser_en-US/Browser/browser/icons/mozicon128.png
|
||||
StartupNotify=true
|
||||
Categories=Network;WebBrowser;
|
||||
|
||||
**Note**: Make sure to replace the path with the location of your tor browser in the above.
|
||||
|
||||
**7. Once done! Double click the file `tor.desktop` to fire Tor browser. You may need to trust it for the first time.**
|
||||
|
||||

|
||||
|
||||
Tor Application Launcher
|
||||
|
||||
**8. Once you trust you might note that the icon of `tor.desktop` changed.**
|
||||
|
||||

|
||||
|
||||
Tor icon Changed
|
||||
|
||||
9. You may drag and drop the `tor.desktop` icon to create shortcut on Desktop and Dock Bar.
|
||||
|
||||

|
||||
|
||||
Add Tor Shortcut on Desktop
|
||||
|
||||
**10. About Tor Browser.**
|
||||
|
||||

|
||||
|
||||
About Tor Browser
|
||||
|
||||
**Note**: If you are using older version of Tor, you may update it from the above window.
|
||||
|
||||
#### Usability/Area of Application ####
|
||||
|
||||
- Anonymous communication over web.
|
||||
- Surf to Blocked web Pages.
|
||||
- Link other Application Viz (FTP) to this secure Internet Browsing Application.
|
||||
|
||||
#### Controversies of Tor-browser ####
|
||||
|
||||
- No security at the boundary of Tor Application i.e., Data Entry and Exit Points.
|
||||
- A study in 2011 reveals that a specific way of attacking Tor will reveal IP address of BitTorrent Users.
|
||||
- Some protocols shows the tendency of leaking IP address, revealed in a study.
|
||||
- Earlier version of Tor bundled with older versions of Firefox browser were found to be JavaScript Attack Vulnerable.
|
||||
- Tor Browser Seems to Work slow.
|
||||
|
||||
#### Real world Implementation of Tor-browser ####
|
||||
|
||||
- Vuze BitTorrent Client
|
||||
- Anonymous Os
|
||||
- Os’es from Scratch
|
||||
- whonix, etc.
|
||||
|
||||
#### Future of Tor Browser ####
|
||||
|
||||
Tor browser is promising. Perhaps the first application of its kind is implemented very brilliantly. Tor browser must invest for Support, Scalability and research for securing the data from latest attacks. This application is need of the future.
|
||||
|
||||
#### Download Free eBook ####
|
||||
|
||||
Unofficial Guide to Tor Private Browsing
|
||||
|
||||
[][2]
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Tor bowser is a must tool in the present time where the organization you are working for don’t allow you to access certain websites or if you don’t want others to look into your private business or you don’t want to provide your digital footprints to NSA.
|
||||
|
||||
**Note**: Tor Browser don’t provide any safety from Viruses, Trojans or other threats of this kind. Moreover by writing an article of this we never mean to indulge into illegal activity by hiding our identity over Internet. This Post is totally for educational Purpose and for any illegal use of it neither the author of the post nor Tecmint will be responsible. It is the sole responsibility of user.
|
||||
|
||||
Tor-browser is a wonderful application and you must give it a try. That’s all for now. I’ll be here again with another interesting article you people will love to read. Till then stay tuned and connected to Tecmint. Don’t forget to provide us with your value-able feedback in our comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/tor-browser-for-anonymous-web-browsing/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:https://www.torproject.org/download/download-easy.html.en
|
||||
[2]:http://tecmint.tradepub.com/free/w_make129/prgm.cgi
|
||||
@ -0,0 +1,275 @@
|
||||
RHCSA Series: Setting Up LDAP-based Authentication in RHEL 7 – Part 14
|
||||
================================================================================
|
||||
We will begin this article by outlining some LDAP basics (what it is, where it is used and why) and show how to set up a LDAP server and configure a client to authenticate against it using Red Hat Enterprise Linux 7 systems.
|
||||
|
||||

|
||||
|
||||
RHCSA Series: Setup LDAP Server and Client Authentication – Part 14
|
||||
|
||||
As we will see, there are several other possible application scenarios, but in this guide we will focus entirely on LDAP-based authentication. In addition, please keep in mind that due to the vastness of the subject, we will only cover its basics here, but you can refer to the documentation outlined in the summary for more in-depth details.
|
||||
|
||||
For the same reason, you will note that I have decided to leave out several references to man pages of LDAP tools for the sake of brevity, but the corresponding explanations are at a fingertip’s distance (man ldapadd, for example).
|
||||
|
||||
That said, let’s get started.
|
||||
|
||||
**Our Testing Environment**
|
||||
|
||||
Our test environment consists of two RHEL 7 boxes:
|
||||
|
||||
Server: 192.168.0.18. FQDN: rhel7.mydomain.com
|
||||
Client: 192.168.0.20. FQDN: ldapclient.mydomain.com
|
||||
|
||||
If you want, you can use the machine installed in [Part 12: Automate RHEL 7 installations][1] using Kickstart as client.
|
||||
|
||||
#### What is LDAP? ####
|
||||
|
||||
LDAP stands for Lightweight Directory Access Protocol and consists in a set of protocols that allows a client to access, over a network, centrally stored information (such as a directory of login shells, absolute paths to home directories, and other typical system user information, for example) that should be accessible from different places or available to a large number of end users (another example would be a directory of home addresses and phone numbers of all employees in a company).
|
||||
|
||||
Keeping such (and more) information centrally means it can be more easily maintained and accessed by everyone who has been granted permissions to use it.
|
||||
|
||||
The following diagram offers a simplified diagram of LDAP, and is described below in greater detail:
|
||||
|
||||
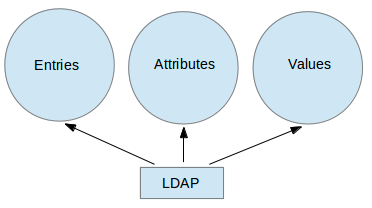
|
||||
|
||||
LDAP Diagram
|
||||
|
||||
Explanation of above diagram in detail.
|
||||
|
||||
- An entry in a LDAP directory represents a single unit or information and is uniquely identified by what is called a Distinguished Name.
|
||||
- An attribute is a piece of information associated with an entry (for example, addresses, available contact phone numbers, and email addresses).
|
||||
- Each attribute is assigned one or more values consisting in a space-separated list. A value that is unique per entry is called a Relative Distinguished Name.
|
||||
|
||||
That being said, let’s proceed with the server and client installations.
|
||||
|
||||
### Installing and Configuring a LDAP Server and Client ###
|
||||
|
||||
In RHEL 7, LDAP is implemented by OpenLDAP. To install the server and client, use the following commands, respectively:
|
||||
|
||||
# yum update && yum install openldap openldap-clients openldap-servers
|
||||
# yum update && yum install openldap openldap-clients nss-pam-ldapd
|
||||
|
||||
Once the installation is complete, there are some things we look at. The following steps should be performed on the server alone, unless explicitly noted:
|
||||
|
||||
**1. Make sure SELinux does not get in the way by enabling the following booleans persistently, both on the server and the client:**
|
||||
|
||||
# setsebool -P allow_ypbind=0 authlogin_nsswitch_use_ldap=0
|
||||
|
||||
Where allow_ypbind is required for LDAP-based authentication, and authlogin_nsswitch_use_ldap may be needed by some applications.
|
||||
|
||||
**2. Enable and start the service:**
|
||||
|
||||
# systemctl enable slapd.service
|
||||
# systemctl start slapd.service
|
||||
|
||||
Keep in mind that you can also disable, restart, or stop the service with [systemctl][2] as well:
|
||||
|
||||
# systemctl disable slapd.service
|
||||
# systemctl restart slapd.service
|
||||
# systemctl stop slapd.service
|
||||
|
||||
**3. Since the slapd service runs as the ldap user (which you can verify with ps -e -o pid,uname,comm | grep slapd), such user should own the /var/lib/ldap directory in order for the server to be able to modify entries created by administrative tools that can only be run as root (more on this in a minute).**
|
||||
|
||||
Before changing the ownership of this directory recursively, copy the sample database configuration file for slapd into it:
|
||||
|
||||
# cp /usr/share/openldap-servers/DB_CONFIG.example /var/lib/ldap/DB_CONFIG
|
||||
# chown -R ldap:ldap /var/lib/ldap
|
||||
|
||||
**4. Set up an OpenLDAP administrative user and assign a password:**
|
||||
|
||||
# slappasswd
|
||||
|
||||
as shown in the next image:
|
||||
|
||||

|
||||
|
||||
Set LDAP Admin Password
|
||||
|
||||
and create an LDIF file (ldaprootpasswd.ldif) with the following contents:
|
||||
|
||||
dn: olcDatabase={0}config,cn=config
|
||||
changetype: modify
|
||||
add: olcRootPW
|
||||
olcRootPW: {SSHA}PASSWORD
|
||||
|
||||
where:
|
||||
|
||||
- PASSWORD is the hashed string obtained earlier.
|
||||
- cn=config indicates global config options.
|
||||
- olcDatabase indicates a specific database instance name and can be typically found inside /etc/openldap/slapd.d/cn=config.
|
||||
|
||||
Referring to the theoretical background provided earlier, the `ldaprootpasswd.ldif` file will add an entry to the LDAP directory. In that entry, each line represents an attribute: value pair (where dn, changetype, add, and olcRootPW are the attributes and the strings to the right of each colon are their corresponding values).
|
||||
|
||||
You may want to keep this in mind as we proceed further, and please note that we are using the same Common Names `(cn=)` throughout the rest of this article, where each step depends on the previous one.
|
||||
|
||||
**5. Now, add the corresponding LDAP entry by specifying the URI referring to the ldap server, where only the protocol/host/port fields are allowed.**
|
||||
|
||||
# ldapadd -H ldapi:/// -f ldaprootpasswd.ldif
|
||||
|
||||
The output should be similar to:
|
||||
|
||||

|
||||
|
||||
LDAP Configuration
|
||||
|
||||
and import some basic LDAP definitions from the `/etc/openldap/schema` directory:
|
||||
|
||||
# for def in cosine.ldif nis.ldif inetorgperson.ldif; do ldapadd -H ldapi:/// -f /etc/openldap/schema/$def; done
|
||||
|
||||

|
||||
|
||||
LDAP Definitions
|
||||
|
||||
**6. Have LDAP use your domain in its database.**
|
||||
|
||||
Create another LDIF file, which we will call `ldapdomain.ldif`, with the following contents, replacing your domain (in the Domain Component dc=) and password as appropriate:
|
||||
|
||||
dn: olcDatabase={1}monitor,cn=config
|
||||
changetype: modify
|
||||
replace: olcAccess
|
||||
olcAccess: {0}to * by dn.base="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth"
|
||||
read by dn.base="cn=Manager,dc=mydomain,dc=com" read by * none
|
||||
|
||||
dn: olcDatabase={2}hdb,cn=config
|
||||
changetype: modify
|
||||
replace: olcSuffix
|
||||
olcSuffix: dc=mydomain,dc=com
|
||||
|
||||
dn: olcDatabase={2}hdb,cn=config
|
||||
changetype: modify
|
||||
replace: olcRootDN
|
||||
olcRootDN: cn=Manager,dc=mydomain,dc=com
|
||||
|
||||
dn: olcDatabase={2}hdb,cn=config
|
||||
changetype: modify
|
||||
add: olcRootPW
|
||||
olcRootPW: {SSHA}PASSWORD
|
||||
|
||||
dn: olcDatabase={2}hdb,cn=config
|
||||
changetype: modify
|
||||
add: olcAccess
|
||||
olcAccess: {0}to attrs=userPassword,shadowLastChange by
|
||||
dn="cn=Manager,dc=mydomain,dc=com" write by anonymous auth by self write by * none
|
||||
olcAccess: {1}to dn.base="" by * read
|
||||
olcAccess: {2}to * by dn="cn=Manager,dc=mydomain,dc=com" write by * read
|
||||
|
||||
Then load it as follows:
|
||||
|
||||
# ldapmodify -H ldapi:/// -f ldapdomain.ldif
|
||||
|
||||
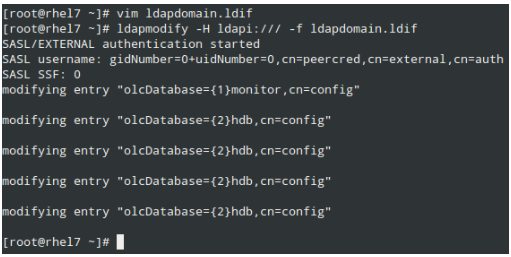
|
||||
|
||||
LDAP Domain Configuration
|
||||
|
||||
**7. Now it’s time to add some entries to our LDAP directory. Attributes and values are separated by a colon `(:)` in the following file, which we’ll name `baseldapdomain.ldif`:**
|
||||
|
||||
dn: dc=mydomain,dc=com
|
||||
objectClass: top
|
||||
objectClass: dcObject
|
||||
objectclass: organization
|
||||
o: mydomain com
|
||||
dc: mydomain
|
||||
|
||||
dn: cn=Manager,dc=mydomain,dc=com
|
||||
objectClass: organizationalRole
|
||||
cn: Manager
|
||||
description: Directory Manager
|
||||
|
||||
dn: ou=People,dc=mydomain,dc=com
|
||||
objectClass: organizationalUnit
|
||||
ou: People
|
||||
|
||||
dn: ou=Group,dc=mydomain,dc=com
|
||||
objectClass: organizationalUnit
|
||||
ou: Group
|
||||
|
||||
Add the entries to the LDAP directory:
|
||||
|
||||
# ldapadd -x -D cn=Manager,dc=mydomain,dc=com -W -f baseldapdomain.ldif
|
||||
|
||||
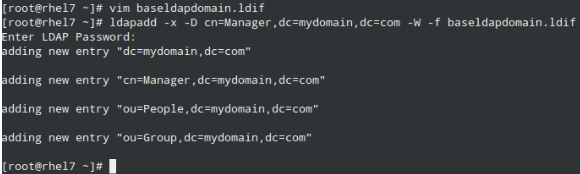
|
||||
|
||||
Add LDAP Domain Attributes and Values
|
||||
|
||||
**8. Create a LDAP user called ldapuser (adduser ldapuser), then create the definitions for a LDAP group in `ldapgroup.ldif`.**
|
||||
|
||||
# adduser ldapuser
|
||||
# vi ldapgroup.ldif
|
||||
|
||||
Add following content.
|
||||
|
||||
dn: cn=Manager,ou=Group,dc=mydomain,dc=com
|
||||
objectClass: top
|
||||
objectClass: posixGroup
|
||||
gidNumber: 1004
|
||||
|
||||
where gidNumber is the GID in /etc/group for ldapuser) and load it:
|
||||
|
||||
# ldapadd -x -W -D "cn=Manager,dc=mydomain,dc=com" -f ldapgroup.ldif
|
||||
|
||||
**9. Add a LDIF file with the definitions for user ldapuser (`ldapuser.ldif`):**
|
||||
|
||||
dn: uid=ldapuser,ou=People,dc=mydomain,dc=com
|
||||
objectClass: top
|
||||
objectClass: account
|
||||
objectClass: posixAccount
|
||||
objectClass: shadowAccount
|
||||
cn: ldapuser
|
||||
uid: ldapuser
|
||||
uidNumber: 1004
|
||||
gidNumber: 1004
|
||||
homeDirectory: /home/ldapuser
|
||||
userPassword: {SSHA}fiN0YqzbDuDI0Fpqq9UudWmjZQY28S3M
|
||||
loginShell: /bin/bash
|
||||
gecos: ldapuser
|
||||
shadowLastChange: 0
|
||||
shadowMax: 0
|
||||
shadowWarning: 0
|
||||
|
||||
and load it:
|
||||
|
||||
# ldapadd -x -D cn=Manager,dc=mydomain,dc=com -W -f ldapuser.ldif
|
||||
|
||||

|
||||
|
||||
LDAP User Configuration
|
||||
|
||||
Likewise, you can delete the user entry you just created:
|
||||
|
||||
# ldapdelete -x -W -D cn=Manager,dc=mydomain,dc=com "uid=ldapuser,ou=People,dc=mydomain,dc=com"
|
||||
|
||||
**10. Allow communication through the firewall:**
|
||||
|
||||
# firewall-cmd --add-service=ldap
|
||||
|
||||
**11. Last, but not least, enable the client to authenticate using LDAP.**
|
||||
|
||||
To help us in this final step, we will use the authconfig utility (an interface for configuring system authentication resources).
|
||||
|
||||
Using the following command, the home directory for the requested user is created if it doesn’t exist after the authentication against the LDAP server succeeds:
|
||||
|
||||
# authconfig --enableldap --enableldapauth --ldapserver=rhel7.mydomain.com --ldapbasedn="dc=mydomain,dc=com" --enablemkhomedir --update
|
||||
|
||||

|
||||
|
||||
LDAP Client Configuration
|
||||
|
||||
### Summary ###
|
||||
|
||||
In this article we have explained how to set up basic authentication against a LDAP server. To further configure the setup described in the present guide, please refer to [Chapter 13 – LDAP Configuration][3] in the RHEL 7 System administrator’s guide, paying special attention to the security settings using TLS.
|
||||
|
||||
Feel free to leave any questions you may have using the comment form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/setup-ldap-server-and-configure-client-authentication/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
[1]:http://www.tecmint.com/automatic-rhel-installations-using-kickstart/
|
||||
[2]:http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux/
|
||||
[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/ch-Directory_Servers.html
|
||||
100
translated/share/20150527 3 Open Source Python Shells.md
Normal file
100
translated/share/20150527 3 Open Source Python Shells.md
Normal file
@ -0,0 +1,100 @@
|
||||
3个开源的Python Shell
|
||||
=========================================================================
|
||||
Python是一个高级,通用,结构化且强大的开源编程语言,用于广泛的编程工作。它拥有一个完全的动态类型系统和自动内存管理,与Scheme,Ruby,Perl和Tcl的十分相似,避免编译型语言的许多复杂地方和难以理解。Python于1991年由Guido van Rossum创造,然后逐渐成长,流行。
|
||||
|
||||
Python是一个非常实用,而且流行的计算机编程语言。使用一个如Python这样的解释型语言的好处之一就是,可以借助其交互的shell考察式地编程。你可以试用代码,而不必写一个脚本。但是Python shell也有一些局限性。基本来说,有许多很nice的Python shell可选择,都是在基础shell上扩展的。他们每一个都提供了一个极好的交互性的Python 体验。
|
||||
|
||||
--------------
|
||||
|
||||
### bpython ###
|
||||
|
||||

|
||||
|
||||
对于Linux,BSD,OS X和Windows来说,bpython是Python解释器一个受欢迎的接口。
|
||||
|
||||
想法是提供给用户所有的内置功能,很像现在的IDEs(集成开发环境),但是是在一个简单,轻量级的包里,可以在终端窗口里面运行。
|
||||
|
||||
bpython并不追求创造任何新的或者开创性的东西。相反,她聚集了一些简洁的理念,关注于实用性和操作性。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 内置的语法高亮 - 使用Pygments排版你敲出的代码,并合理地上色
|
||||
- 根据你的行为,显示自动补全的建议。
|
||||
- 为任何Python函数列出期望的参数 - 力求显示一列参数,为你调用的任何函数
|
||||
- “Rewind”功能,弹出内存里的最后一行代码并重新评定
|
||||
- 发送你已经解除占用的代码到粘贴缓存
|
||||
- 保存你已经输入到一个文件里的代码
|
||||
- 自动缩进
|
||||
- 支持Python 3
|
||||
|
||||
- 网址: [www.bpython-interpreter.org][1]
|
||||
- 开发者: Bob Farrell and contributors
|
||||
- 证书: MIT License
|
||||
- 版本号: 0.14.1
|
||||
|
||||
----------
|
||||
|
||||
### IPython ###
|
||||
|
||||

|
||||
|
||||
IPython是Python shell的一个交互加强版。她提供了一个丰富的工具集合,帮助你交互式地充分利用Python。
|
||||
|
||||
IPython可以用来取代标准的Python shell,或者当与标准Python 科学和数值处理工具配合,用做一个科学计算(如Matlab或者Mathematical)的完整工作环境。她支持动态对象内省,有限的输入/输出提示,一个宏观系统,会话登录,会话恢复,完整的系统接入,详尽且彩色的追踪报告,自动圆括号,自动应用和可嵌入其他Python程序。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 强大的交互Shell(终端或者基于Qt)
|
||||
- 一个基于浏览器的记事本,支持代码,多样文本,数学表达式,内置飞行图表和其他丰富媒介。
|
||||
- 支持交互式的数据虚拟化和GUI工具箱使用
|
||||
- 灵活,嵌入式的解释器可以加载进你自己的项目里
|
||||
- 易于使用,高效的并行运算工具
|
||||
|
||||
- 网址: [ipython.org][2]
|
||||
- 开发者: The IPython Development Team
|
||||
- 证书: BSD
|
||||
- 版本号: 3.1
|
||||
|
||||
----------
|
||||
|
||||
### DreamPie ###
|
||||
|
||||

|
||||
|
||||
DreamPie是一个为可靠性和兴趣设计的Python shell。
|
||||
|
||||
DreamPie可以用于任何Python解释器(Jython,IronPython,PyPy)。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 一个交互shell的新概念:窗口被分成历史区域和代码区域,历史区域可以让你看到之前的命令及其输出,代码区域是里敲代码的地方。这样,你可以编辑任意数量的代码,就好像在你最喜欢的编辑器里一样,并且适当时候可以执行它。你也可以从其他地方复制你想保存的代码,所以你可以把它存入一个文件。代码可以很好地格式化为四级缩进。
|
||||
- 自动补全属性和文件名字
|
||||
- 自动显示函数参数和文档
|
||||
- 在结果历史中保存你最近的结果,备以后用
|
||||
- 可以自动展开很长的输出,所以你可以专注于重要的地方
|
||||
- 保存会话的历史记录为一个HTML文件,备以后查询。你可以加载历史文件到DreamPie里,并且快速回退到之前的命令。
|
||||
- 自动添加圆括号与可选的引用,当你在函数与方法后按下空格键。例如,键入execfile fn并且获得execfile("fn")
|
||||
- 支持交互的matplotlib绘图
|
||||
- 支持Python 2.5,Python 2.6,Python 3.1,Jython 2.5,IronPython 2.6和PyPy
|
||||
- 难以置信的快速反应
|
||||
|
||||
- 网址: [www.dreampie.org][3]
|
||||
- 开发者: Noam Yorav-Raphael
|
||||
- 证书: GNU GPL v3
|
||||
- 版本号: 1.2.1
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150523032756576/PythonShells.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.bpython-interpreter.org/
|
||||
[2]:http://ipython.org/
|
||||
[3]:http://www.dreampie.org/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -1,55 +0,0 @@
|
||||
Arc是一个很棒的Linux桌面的GTK主题
|
||||
================================================================================
|
||||

|
||||
|
||||
距离本站上次推荐的GTK主题已经过了很久了。
|
||||
|
||||
但是看到上面的Arc后,需要纠正这点了。
|
||||
|
||||
我们不能不提到它。
|
||||
|
||||
### Arc GTK主题 ###
|
||||
|
||||

|
||||
|
||||
Transparency. Not to everyones’ taste.
|
||||
透明并不符合每个人的口味
|
||||
|
||||
Arc是一个扁平化主题并有微妙的配色并部分选中的窗口透明,就像GTK的顶拦和Nautilus的侧边栏。
|
||||
|
||||
|
||||
它的效果不像我们之前的主题那样将程序渲染的像躲猫猫那样混乱。像OSX Yosemite,效果用的不变多但是很好。
|
||||
|
||||
随之的图标集(称为Vertex)同样可用。
|
||||
|
||||
**是的它支持Unity**
|
||||
|
||||
Arc主题支持基于GTK3和GTK2桌面环境,包含Gnome Shell(当然)和标准的Ubuntu Unity。
|
||||
|
||||
它也可以很好地与轻量级的Budgie和elementary的Pantheon桌面以及也可以工作在Cinnamon上。
|
||||
|
||||

|
||||
|
||||
Arc中的开关、滑块和小挂件。
|
||||
|
||||
它并不容易下载与安装- *understatement klaxon* - 因为它还在密集开发中。
|
||||
|
||||
|
||||
安装包需要GTK 3.14或者更新,这意味着Ubuntu 14.04 LTS和14.10的用户无法使用了。
|
||||
|
||||
那些使用Ubuntu 15.04的用户可以使用这个主题。你还不能添加ppa或者双击.deb包。如果你喜欢你看见的你需要卷起你的袖子并查看github上的编译指导。
|
||||
|
||||
- [Github中Arc安装指导][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/06/arc-gtk-theme
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/horst3180/Arc-theme
|
||||
@ -1,18 +1,18 @@
|
||||
如何在Linux中安装漂亮的扁平化Arc GTK+主题
|
||||
================================================================================
|
||||
> 易于看懂的每步都有的教程
|
||||
> 易于理解的分步教程
|
||||
|
||||
**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版见荣发。[这个主题叫Arc][1]。**
|
||||
**今天我们将向你介绍最新发布的GTK+主题,它拥有透明和扁平元素,并且与多个桌面环境和Linux发行版兼容。[这个主题叫Arc][1]。**
|
||||
|
||||
开始讲细节之前,我建议你快速地看一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该意识到它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
|
||||
开始讲细节之前,我建议你快速浏览一下下面的图,这样你有会对这个主题就会有一个基本的概念了。同样你应该知道它目前可以工作在GTK+ 2.x、GTK+ 3.x、GNOME-Shell、 Budgie、 Unity和Pantheon用户界面,它们都使用了GNOME栈。
|
||||
|
||||
同样、Arc主题的开发者提醒我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
|
||||
同样、Arc主题的开发者告诉我们它已经成功地在Ubuntu 15.04(Vivid Vervet)、 Arch Linux、 elementary OS 0.3 Freya、 Fedora 21、 Fedora 22、 Debian GNU/Linux 8.0 (Jessie)、 Debian Testing、 Debian Unstable、 openSUSE 13.2、 openSUSE Tumbleweed和Gentoo测试过了。
|
||||
|
||||
### 要求和安装指导 ###
|
||||
|
||||
要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对Fedora的pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对Fedora的gtk-murrine-engine)。
|
||||
要构建Arc主题,你需要先安装一些包,比如autoconf、 automake、 pkg-config (对于Fedora则是pkgconfig)、基于Debian/Ubuntu-based发行版的libgtk-3-dev或者基于RPM的gtk3-devel、 git、 gtk2-engines-pixbuf和gtk-engine-murrine (对于Fedora则是gtk-murrine-engine)。
|
||||
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续一步。
|
||||
Arc主题还没有二进制包,因此你需要从git仓库中取下最新的源码并编译。这样,打开终端并运行下面的命令,一行行地,并在每行的末尾按下回车键并等待上一步完成来继续下一步。
|
||||
|
||||
git clone https://github.com/horst3180/arc-theme --depth 1 && cd arc-theme
|
||||
git fetch --tags
|
||||
@ -20,7 +20,7 @@ Arc主题还没有二进制包,因此你需要从git仓库中取下最新的
|
||||
./autogen.sh --prefix=/usr
|
||||
sudo make install
|
||||
|
||||
就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具或者如果你使用Unity可以使用Unity Tweak工具来激活主题。玩得开心也不要忘了在下面的评论栏里留下你的截图。
|
||||
就是这样!此时你已经在你的GNU/Linux发行版中安装了Arc主题,如果你使用GNOME可以使用GONME Tweak工具,如果你使用Ubuntu的Unity可以使用Unity Tweak工具来激活主题。玩得开心但不要忘了在下面的评论栏里留下你的截图。
|
||||
|
||||
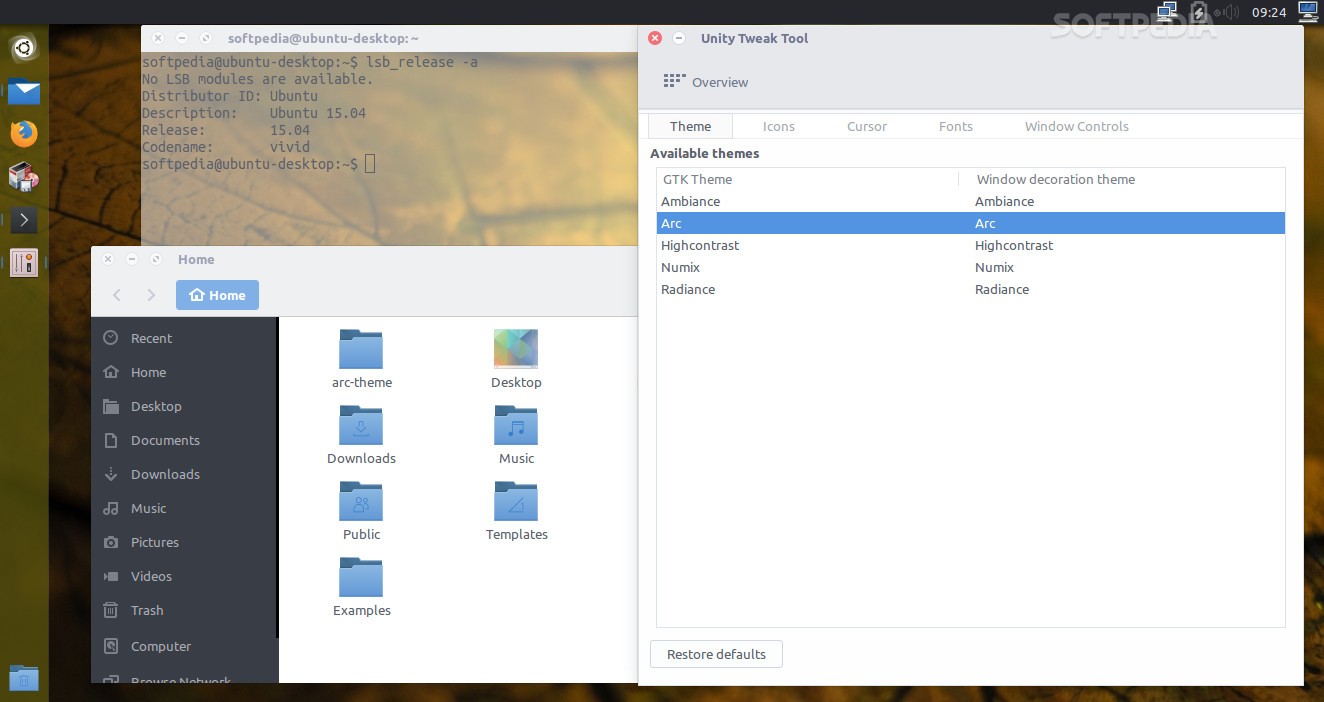
|
||||
|
||||
@ -34,28 +34,9 @@ via: http://news.softpedia.com/news/Here-s-How-to-Install-the-Beautiful-Arc-GTK-
|
||||
|
||||
作者:[Marius Nestor][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/marius-nestor
|
||||
[1]:https://github.com/horst3180/Arc-theme
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
|
||||
@ -0,0 +1,172 @@
|
||||
12个全球认可的Linux认证
|
||||
================================================================================
|
||||
大家好,今天我们将会认识一些非常有价值的全球认可的Linux认证。Linux认证是不同Linux专业机构在全球范围内进行的认证程序。Linux认证可以让Linux专业人才很容易获得Linux相关的工作,在服务器或者公司等等这些地方。Linux认证评估一个人在Linux的各个领域里的专业程度。有很多不错的Linux专业机构提供不同的Linux认证。但是全球仅有少数被十分认可的Linux认证,在公司谋取一份工作时含金量很高,这些工作包括管理服务器,虚拟化,安装系统与软件,配置程序,应用支持和其他Linux操作系统相关的东西。随着全球使用Linux操作系统的服务器的增长,拉动了对于Linux专业人才的需求。为了更好的证明Linux专业技术,公司进行的著名的认证一直有着更高的优先级,在全球看来。
|
||||
|
||||
这里是一些全球认可的Linux认证,我们接下来将会一一讨论。
|
||||
|
||||
### 1. CompTIA Linxu+ ###
|
||||
|
||||
CompTIA Linux+ 是LPI“Linux Professional Institute”主办的一个Linux认证,在全世界范围内提供培训。其提供的Linux相关知识,使得产生了一大批Linux相关专业的工作,如Linux管理员,高级网络管理员,系统管理员,Linux数据库管理员和网页管理员。如果任何人想从事安装和维护Linux操作系统,该课程会帮助达到认证要求,并且通过提供对Linux系统更宽阔的认识,能够为考试做好准备。LPI的CompTIA Linux+认证的主要目的就是,提供给证书持有者足够扎实的知识,关于安装软件,操作,管理和设备排障的。我们可以用一定的费用,时间和努力,,完成CompTIA Linux+,赢得三个业内认可的证书,我们可以自动收到**LPI LPIC-1**和**SUSE Certified Linux Administrator (CLA)**证书。
|
||||
|
||||
- ** 认证代码** : LX0-103和LX0-104 (2015年三月30日启动)或者LX0-101和LX0-102
|
||||
- 题目数量:一次考试60道题
|
||||
- 题目类型:多选
|
||||
- 考试时长:90分钟
|
||||
- 要求:A+,Network+,并且有至少12个月的Linux管理经历
|
||||
- 分数线:500 (对于200-800的范围来说)
|
||||
- 语言:英语,将来会有德语,葡萄牙语,汉语,西班牙。
|
||||
- 有效期:认证后三年有效
|
||||
|
||||
**注意**:不同系列的考试不能交叉。如果你考的是LX0-101,那么你必须考LX0-102完成认证。同样的,你必须考完LX0-103和LX0-104。LX0-103和LX0-104是LX0-101和LX0-102的升级版。
|
||||
|
||||
### 2. LPIC ###
|
||||
|
||||
LPIC,全称Linux专业委员会认证,是Linux专业委员会的一个Linux认证程序。这是一个多层次的认证程序,要求在每个级别通过一系列(通常是两个)的认证考试。该认证有三个层次,包括初级水平认证 **LPIC-1** ,高级水平认证 **LPIC-2**和最高水平认证 **LPIC-3**。前两个认证侧重于 **Linux系统管理**,而最后一个认证侧重一些专业技能,包括虚拟化和安全。为了得到 **LPIC-3** 认证,一个持有 **LPIC-1** 与**LPIC-2** 的考生必须通过300复杂环境测试,303安全测试,304虚拟化测试和高可用性的其中一个。**LPIC-1**认证按照证书持有者可以通过运行Linux,使用命令行界面和基本的网络知识安装,维护,配置任务而设计,LPIC-2验证考生很少的管理知识,主要是中型混合网络方面。LPIC-3认证按照企业级别的Linux专业技能设计,代表了最高的专业水平(==最后这句不知道如何翻译==)
|
||||
|
||||
- **认证代码**:LPIC-1(101和102),LPIC-2(201和202)和LPIC-3(300,303或者304)
|
||||
- 题目类型:60个多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:Linux基础
|
||||
- 分数线:500(在200-800的范围内)
|
||||
- 语言:LPIC-1:英语,德语,意大利语,葡萄牙语,西班牙语(现代),汉语(简体),汉语(繁体),日语
|
||||
- LPIC-2:英语,德语,葡萄牙语,日语
|
||||
- LPIC-3:英语,日语
|
||||
- 有效期:退休之后五年内仍然有效
|
||||
|
||||
### 3.Oracle Linux OCA ###
|
||||
|
||||
Oracle联合认证(OCA)为个人而定制,那些对部署和管理Oracle Linux操作系统且想证明知识牢固感兴趣的人。该认证专业知识仅仅是在Oracle Linux发行版上,这个系统完全是为Oracle产品特别剪裁的,为了运行在Oracle设计的系统上面,包括Oracle Exadata数据库机器,Oracle Exalytics 内存中机器,Oracle Exalogic 均衡云,和Oracle数据库应用。Oracle Linux稳定的企业级内核对于企业应用表现突出,高扩展性和稳定性。OCA认证覆盖如管理本地磁盘设备,文件系统,安装和移除Solaris包与补丁,协调系统启动过程和系统进程方面。这是达到OCP证书佼佼者的第一步。OCA认证以其前身为Sun Certified Solaris Associate(SCSAS)而为人所知。
|
||||
|
||||
- **认证代码**:OCA
|
||||
- 题目类型:75道多项选择
|
||||
- 考试时长:120分钟
|
||||
- 要求:无
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 4. Oracle Linux OCP ###
|
||||
|
||||
Oracle Certified Professional(OCP),时Oracle公司为Oracle Linux提供的一个认证,覆盖更多的进阶知识和技能,对于一个Oracle Linux管理员来说。它囊括的知识有配置网络接口,映射交换配置,清理垃圾,管理软件、数据库和核心文件。OCP认证是技术性专业知识和专业技能的基准测试,这些知识与技能需要在公司里广泛用于开发,部署和管理应用,中间设备和数据库。Oracle Linux OCP的工作机会在增长,得益于工作市场和经济。根据考试纲领,证书持有者有能力胜任安全管理,为Oracle 数据库准备Oracle Linux系统,排除故障,安装软件包,安装和配置内核模块,维护交换空间,完成用户和组管理,创建文件系统,配置逻辑卷管理(LVM)、文件分享服务等等。
|
||||
|
||||
- **认证代码**:OCP
|
||||
- 题目类型:60至80道多项选择题
|
||||
- 考试时长:120分钟
|
||||
- 要求:Oracle Linux OCA
|
||||
- 分数线:64%
|
||||
- 有效期:永远有效
|
||||
|
||||
### 5. RHCSA ###
|
||||
|
||||
RHCSA是红帽公司作为红帽认证系统工程师推出的一个认证程序。RHCSAs指一些拥有技能和能力在著名的红帽Linux环境下完成核心系统管理的人。这是一个入门级的认证程序,关注在系统管理上的实际胜任能力,包括安装、配置一个红帽Linux系统,接入一个可用的网络运行网络服务。一个红帽认证的系统管理员可以理解和使用基本的工具,用以处理文件,目录,命令行环境和文档,操作运行中的系统,包括以不同的启动级别启动,标记进程,开启和停止虚拟机和控制服务,使用分区和逻辑卷配置本地存储,部署配置和维护系统,包括软件安装、更新和核心服务,管理用户和组,包括使用一个中心的目录用于验证,安全性工作,包括基本的基本防火墙和SELinux配置。要获得RHCE和其他认证,首先得认证过RHCSA。
|
||||
|
||||
- **认证代码**:RHCSA
|
||||
- 课程代码:RH124,RH134和RH199
|
||||
- 考试代码:EX200
|
||||
- 考试时长:21-22小时,取决于选择的课程
|
||||
- 要求:无。有一些Linux基础知识更好
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 6. RHCE ###
|
||||
|
||||
RHCE,也叫做红帽认证工程师,是一个中到高级水平的认证程序,为一些红帽认证系统管理员(RHCSA),想学习一个负责红帽企业Linux的高级系统管理员要求的额外技能和知识而开设的,RHCE有能力,知识和技能配置静态的路由,包过滤,网络地址转换(NAT),设定内核运行参数,配置一个互联网小型计算机系统接口(ISCSI)初始化程序,产生并推送系统使用的报告,使用shell脚本自动完成系统维护任务,配置系统登入,包括远程登录,提供网络服务如HTTP/HTTPS,文件传输协议(FTP),网络文件系统(NFS),服务信息块(SMB),简单邮件传输协议(SMTP),安全shell(SSH)和网络时间协议(NTP)等等。RHCSAs希望获得更多高级水平的认证,并且已经完成系统管理员I,II和III,或者RHCE认证建议的RHCE快速跟进课程。
|
||||
|
||||
- **认证代码**:RHCE
|
||||
- 课程代码:RH124,RH134,RH254和RH199
|
||||
- 考试代码:EX200和EX300
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:一个RHCSA证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 7. RHCA ###
|
||||
|
||||
RHCA就是红帽认证架构师,是红帽公司的一个认证程序。它的关注点在系统管理的实际能力,包括安装和配置一个红帽Linux系统,并加入到一个可用网络中运行网络服务。RHCA是所有红帽认证中最高水平的认证。考生需要选择他们希望关注的集合,或者选择合格的红帽认证的任意组合,以此来创建一个他们自己的集合。这里有三个主要的集合,数据中心,云和应用平台。精通数据中心集合的RHCA能够运行,管理数据中心,而熟悉云的可以创建,配置和管理私有的,混合的云,云应用平台以及使用红帽企业Linux平台的灵活存储方案。精通应用平台集合的RHCA拥有技能如安装,配置和管理红帽JBoss企业应用平台和应用,云应用平台和混合云环境,借助红帽的OpenShift企业版,使用红帽JBoss数据虚拟化技术从多个资源里组合数据。
|
||||
|
||||
- **认证代码**:RHCA
|
||||
- 课程代码:CL210,CL220.CL280,RH236,RH318,RH413,RH436,RH442,JB248和JB450
|
||||
- 考试代码:EX333,EX401,EX423或者EX318,EX436和EX442
|
||||
- 考试时长:21-22个小时,取决于所选课程
|
||||
- 要求:未过期的RHCE证书
|
||||
- 分数线:300总分,210过(70%)
|
||||
- 有效期:3年
|
||||
|
||||
### 8. SUSE CLA ###
|
||||
|
||||
SUSE认证Linux管理员(SUSE CLA)是SUSE推出的一个初级认证,关注点在SUSE Linux企业服务器环境下的日常任务管理。为了获得SUSE CLA认证,完成课程任务不是必须的,你不得不通过考试获得认证。SUSE CLA有能力,也有技术去使用Linux桌面,定位并利用帮助资源,管理Linux文件系统,用Linux Shell和命令行工作,安装SLE 11 SP22,管理系统安装,硬件,备份和恢复,用YaST管理Linux,Linux进程和服务,存储,配置网络,远程接入,SLE 11 SP2模拟器,任务自动化和管理用户访问和安全工作。我们可以同时获得LPI的SUSE CLA,LPIC-1和CompTIA Linux,因为SUSE,Linux Professional Institute和CompATI合作提供给你这个机会,去获得三个Linux认证。
|
||||
|
||||
- **认证代码**:SUSE CLA
|
||||
- 课程代码:3115,3116
|
||||
- 考试代码:050-720,050-710
|
||||
- 问题类型:多项选择
|
||||
- 考试时长:90分钟
|
||||
- 要求:无
|
||||
- 分数线:512
|
||||
|
||||
### 9. SUSE CLP ###
|
||||
|
||||
SUSE认证Linux专业人员(CLP)是一个认证程序,为那些希望获得关于SUSE Linux企业服务器更多高级且专业的知识的人而服务。SUSE CLP是通过SUSE CLA认证后的下一步。一个人应该通过CLA的考试并拥有证书,然后才能获得CLP的认证,通过完成CLP的考试。通过SUSE CLP认证的人员有能力完成安装和配置SUSE Linux企业服务器11系统,维护文件系统,管理软件包,进程,打印,使用IPv6配置基础网络服务,samba,网页服务器,创建和运行bash shell脚本。
|
||||
|
||||
- **认证代码**:SUSE CLP
|
||||
- 课程代码:3115,3116和3117
|
||||
- 考试代码:050-721,050-697
|
||||
- 考试类型:手写
|
||||
- 考试时长:180分钟
|
||||
- 要求:SUSE CLA 认证
|
||||
|
||||
### 10. SUSE CLE ###
|
||||
|
||||
SUSE认证Linux工程师(CLE)是一个工程师级别的高级认证,为那些已经通过CLE考试的人准备。为了获得CLE认证,人们需要获得SUSE CLA和CLP的认证。获得CLE认证的人员拥有架设复杂SUSE Linux企业服务器环境的技能。CLE认证过的人可以配置基本的网络服务,管理打印,配置和使用Open LDAP,samba,IPv6,完成健康检测和(这里不知道),创建和执行shell脚本,部署SUSE Linux企业板,通过Xen实现虚拟化等等。
|
||||
|
||||
- **认证代码**:SUSE CLE
|
||||
- 课程代码:3107
|
||||
- 考试代码:050-723
|
||||
- 考试类型:手写
|
||||
- 考试时长:120分钟
|
||||
- 要求:SUSE CLP 10或者11证书
|
||||
|
||||
### 11. LFCS ###
|
||||
|
||||
Linux基金会认证系统管理员(LFCS)认证考生Linux使用中拥有的知识和通过终端环境使用Linux。LFCS是Linux基金会的一个认证程序,为使用Linux操作系统工作的系统管理员和工程师准备。Linux基金会联合工业级专家,Linux内核社区,测试考生扎实的技能,知识和应用能力。通过LFCS认证的人员拥有一些技能,知识和能力,包括在命令行下编辑和操作文件,管理和处理文件系统与存储的错误,聚合分区作为LVM设备,配置SWAP分区,管理网络文件系统,管理用户帐号,权限和属组,创建并执行bash shell脚本,安装,升级,移除软件包等等。
|
||||
|
||||
- **认证代码**:LFCS
|
||||
- 课程代码:LFCS201,LFCS220(可选)
|
||||
- 考试代码:LFCS 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:无
|
||||
- 分数线:74%
|
||||
- 语言:英语
|
||||
- 有效期:两年
|
||||
|
||||
### 12. LFCE ###
|
||||
|
||||
Linux基金会认证工程师(LFCE),是Linux基金会为Linux工程师推出的认证。通过LFCE认证的人员拥有一个对于Linux较宽范围的技能,相比于LFCS。这是一个工程师级别的高级认证程序。LFCE认证的人具备一些网络管理方面的技能和能力,如配置网络服务,包过滤,网络运行模拟器,IP连通,配置文件系统和文件服务,网络文件系统,从仓库安装,升级软件包,管理网络安全,配置iptables,http服务,代理服务,邮件服务等等。由于其为高级工程级别的认证程序,所以普遍认为相比LFCS,学习和通过的难度更大些。
|
||||
|
||||
- **认证代码**:LFCE
|
||||
- 课程代码:LFS230
|
||||
- 考试代码:LFCE 考试
|
||||
- 考试时长:2小时
|
||||
- 要求:认证过LFCS
|
||||
- 分数线:72%
|
||||
- 语言:英语
|
||||
- 有效期:2年
|
||||
|
||||
### 我们发现的情况(这仅仅是我们的观点)###
|
||||
|
||||
最近的调查表明,在不同的高端招聘代理中,称80%的Linux工作描述更倾向于红帽的认证。如果你是一个学生/新手,并且想学习Linux,那么我们建议选择越来越流行的Linux基金会认证,或者CompTIA Linux也可以是一个选择。如果你已经知道了oracle或suse,或者在他们的产品上工作,那oracle/suse的认证会更好些,如果你在一个公司工作了,这些认证会对你的职业生涯成长有帮助:-)
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这个世界上,成千上万的大公司正在运行跑着Linux操作系统的服务器和主框架,为了在这些服务器上管理,配置和工作,总是存在对Linux技术/专业知识高度认证的需求。这些国际上承认的认证对某些人在Linux的职业生涯扮演很重要的角色。全世界范围内的这些公司运行着Linux,需要Linux工程师,系统管理员和已经获得认证且在Linux相关领域干得不错的有热情的人员。全球认可的Linux认证,对于专业知识和职业生涯的辉煌都是很基础的,所以好好准备考试并获得认证,对于在Linux建立职业生涯是一个很好的选择。如果你有任何问题,想法,反馈,请写在下方的评论框里,让我们好知道哪些东西需要添加或者改进。谢谢!:-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/12-globally-recognized-linux-certifications/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,35 @@
|
||||
sevenot translated
|
||||
下载年度报告,了解The Document Foundation2014年的成果
|
||||
================================================================================
|
||||

|
||||
|
||||
|
||||
TDF ReportThe Document Foundation (TDF)郑重地发布了2014年度报告,你可以点击这里下载: [http://tdf.io/report2014][1] (3.2 MB PDF)。高清质量的可以点击这里下载 [http://tdf.io/report2014hq][2] (15.9 MB PDF)。
|
||||
|
||||
TDF年度报告中,以回顾2014年开始了这篇报告,其中包括了TDF和LibreOffice的精彩集锦,并且总结了财务情况和预算。
|
||||
|
||||
该报告涉及到项目和活动的会议包括:2014年在伯尔尼的LibreOffice大会,在布鲁塞尔、大加那利岛、巴黎、波士顿和土鲁斯的认证项目,网站与质量保证,Hackfests项目,本土语言项目,基础设施,文档项目,市场设计与营销。
|
||||
|
||||
该报告涉及到的软件开发活动和代码包括:工程指导委员会的活动,LibreOffice的开发,文档解放项目,LibreOffice的安卓移植。
|
||||
|
||||
报告的最后一部分则把焦点对准了那些做出了极大贡献的人们,他们是TDF的工作人员,董事会成员,委员会成员,委托组织成员,TDF的核心成员和咨询委员会成员。
|
||||
|
||||
TDF 2014年度报告的编辑工作由Sophie Gautier, Alexander Werner, Christian Lohmaier, Florian Effenberger, Italo Vignoli 和 Robinson Tryon完成,由Barak Paz设计样式,Libreoffice社区协助完成。
|
||||
|
||||
|
||||
为了使该文档分布达到最大程度的分布,采用了CC3 认证发布,除非特殊标注,TDF成员和自由软件基金会拥有其所有权。
|
||||
[德语版年度报告下载请点击[http://tdf.io/bericht2014][3]].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.documentfoundation.org/2015/06/03/read-about-the-document-foundation-achievements-in-2014-download-the-annual-report/
|
||||
|
||||
作者:italovignoli
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://wiki.documentfoundation.org/File:TDF2014AnnualReport.pdf
|
||||
[2]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportHQ.pdf
|
||||
[3]:https://wiki.documentfoundation.org/File:TDF2014AnnualReportDE.pdf
|
||||
@ -0,0 +1,153 @@
|
||||
sevenot translated
|
||||
排名前十的年度开源项目新秀
|
||||
================================================================================
|
||||
黑鸭(Black Duck)软件公布了一份名叫“年度开源项目新秀”的报告,介绍了由全球开源协会发起的10个最有趣、最活跃的新项目。
|
||||
|
||||

|
||||
|
||||
### 年度开源项目新秀 ###
|
||||
|
||||
每年都有上千新的开源项目问世,但只有少数能够真正的吸引我们的关注。一些项目因为利用了当前比较流行的技术而发展壮大,有一些则真正地开启了一个新的邻域。很多开源项目建立的初衷是为了解决一些生产上的问题,还有一些项目则是世界各地志同道合的开发者们共同发起的一个宏伟项目。
|
||||
|
||||
从2009年起,开源软件公司黑鸭便发起了[年度开源项目新秀][1]这一活动,它的评选根据[Open Hub][2] 网站(即以前的Ohloh)。今年,我们很荣幸能够报道2015年10大开源项目新秀的得主和2名荣誉奖得主,它们是从上千个开源项目中脱颖而出的。评选采用了加权评分系统,得分标准基于项目的活跃度,交付速度,和几个其它因数。
|
||||
|
||||
开源俨然成为了产业创新的引擎,就拿今年来说,和Docker容器相关的开源项目在全球各地新起,这也不恰巧反映了企业最感兴趣的技术邻域吗?最后,我们接下来介绍的项目,将会让你了解到全球开源项目的开发者们的在思考什么,这很快将会成为一个指引我们发展的领头羊。
|
||||
|
||||
### 2015年度开源项目新秀: DebOps ###
|
||||
|
||||

|
||||
|
||||
[DebOps][3]收集打包了一套[Ansible][4] (Ansible是一种自动化运维工具)方案和规则,可以从1个容器扩展到一个完整的数据中心。它的创始人Maciej Delmanowski将DebOps开源来保证项目长久进行,从而更好的利用外部贡献者来发展下去
|
||||
|
||||
DebOps始创于波兰的一个不起眼大学校园里,在自己的数据中心上运行,一切都是手工配置的。有时系统崩溃而导致几天的宕机,这时Delmanowski意识到一个配置管理系统是很有必要的。从Debian的基础做起,DebOps是一组配置一整个数据基础设施Ansible方案。此项目已经在许多不同的工作环境下实现,而创始者们则打算继续支持和开发这个项目。
|
||||
|
||||
###2015年度开源项目新秀: Code Combat ###
|
||||
|
||||

|
||||
|
||||
传统的纸笔学习方法已近不能满足技术学科了。然而游戏都是关于参与者,这也就是为什么[CodeCombat][5] 的创始人会去开发一款多人协同编程游戏来教人们如何编码。
|
||||
|
||||
刚开始CodeCombat是一个创业想法,但其创始人决定创建一个开源项目将其取代。此想法在社区传播开来,很快不少贡献者加入到项目中来。项目发起仅仅两个月后,这款游戏就被收入Google’s Summer of Code。这款游戏吸引了大量玩家,并被翻译成45种语言。CodeCombat希望成为那些想要一边学习代码同时获得乐趣的同学的风向标。
|
||||
|
||||
### 2015年度开源项目新秀: Storj ###
|
||||
|
||||

|
||||
|
||||
[Storj][6]是一个点对点的云存储网络,可实现端到端加密,保证用户不用依赖第三方即可传输、共享数据。基于比特币block chain技术和点对点协议,Storj提供安全、私密、加密的云存储。
|
||||
|
||||
云数据存储的反对者担心成本开销和漏洞攻击。为了做到没有死角,Storj是一个私有云存储市场,用户可以通过Storjcoin X(SJCX) 购买交易存储空间。上传到Storj的文件会被粉碎、加密和存储到整个社区。只有文件所有者拥有密钥加密的信息
|
||||
|
||||
在2014年举办的Texas Bitcoin Conference Hackathon会议上,云存储市场概念首次被提出并证明可行。在第一次赢得黑客马拉松活动后,项目创始人们和领导团队利用开源论坛Reddit、比特币论坛和社交媒体推广此项目。如今,它们已成为Storj决策过程的一个重要组成部分。
|
||||
|
||||
### 2015年度开源项目新秀: Neovim ###
|
||||
|
||||

|
||||
|
||||
自1991年提出概念以来,Vim已经成为数以百万计软件开发人员所钟爱的文本编辑器。 [Neovim][6] 是它的下一个版本。
|
||||
|
||||
在过去的23年里,软件开发生态系统经历了无数增长和创新。Neovim创始人Thiago de Arruda知道Vim缺少当代元素,跟不上时代的发展。在保留Vim的签名功能的前提下,Neovim团队同样在寻求最受欢迎的文本编辑器改善和发展技术。集资初期,Thiago de Arruda连续6个月时间关注推出此项目。他相信他的团队和支持他激励他继续发展Neovim。
|
||||
|
||||
### 2015年度开源项目新秀: CockroachDB ###
|
||||
|
||||

|
||||
|
||||
前谷歌员工开发了一个开源的企业数据存储项目[CockroachDB][8],它是一个可扩展的、跨地域复制且支持事务的数据存储的解决方案。
|
||||
|
||||
为了保证在线百万兆字节流量业务的质量,Google公开了他们的Spanner系统,这是一个可扩展的,稳定的,支持事务的系统。许多参与开发CockroachDB的团队现在都服务与开源社区。就像真正的蟑螂一样,CockroachDB可以在没有数据头、没有任何节点的情况下正常运行。这个开源项目有很多富有经验的贡献者,创始人们通过社会媒体、Github、网络、会议和聚会结识他们并鼓励他们参与其中。
|
||||
|
||||
### 2015年度开源项目新秀: Kubernetes ###
|
||||
|
||||

|
||||
|
||||
在介绍集装箱化的软件对开源社区的发展时,[Docker][9]是一匹黑马,它在技术和工具的设置上做了创新。去年6月谷歌推出了[Kubernetes][10],这是一款开源的容器管理工具,用来加快开发和简化操作。
|
||||
|
||||
谷歌在它的网络系统上使用容器技术多年了。在2014年夏天的DockerCon上大会上,谷歌这个互联网巨头开源了Kubernetes,Kubernetes的开发是为了满足迅速增长的Docker生态系统的需要。通过和其它的组织、项目合作,比如 Red Hat和CoreOS,Kubernetes的管理者们促使它登上了Docker Hub的工具下载榜榜首。Kubernetes的开发团队希望扩大这个项目,发展它的社区,这样的话软件开发者就能花更少的时间在管理基础设施上,而更多的去开发他们自己的APP。
|
||||
|
||||
### 2015年度开源项目新秀: Open Bazaar ###
|
||||
|
||||

|
||||
|
||||
OpenBazaar是一个使用比特币和其他人交易的市场。OpenBazaar这一概念最早在编程马拉松(hackathon)活动中被提出,它的创始人结合了BitTorent,比特币和传统的金融服务方式,创造了一个不受审查的交易平台。OpenBazaar的开发团队在寻求新的成员,而且不久以后他们将无限扩大Open Bazaar的社区。Open Bazaar旨在透明度和同一个目标去在商务交易中掀起一场革命,这会帮助创始人和贡献者向着一个真实的世界奋斗,一个没有控制,分散的市场。
|
||||
|
||||
### 2015年度开源项目新秀: IPFS ###
|
||||
|
||||

|
||||
|
||||
IPFS 是一个全球的点对点式的分布式版本文件系统。它综合了Git,BitTorrent,HTTP的思想,开启了一个新的数据和数据结构传输协议。
|
||||
|
||||
开源被人们所知晓的原因,是它本意用简单的方法解决复杂的问题,这样产生许多新颖的想法,但是着些强大的项目仅仅是开源社区的冰山一角。IFPS有一个积极的团队,这个概念的提出是大胆的,令人惊讶的,有点甚至高不可攀。这样来看,一个点对点的分布是文件系统是在寻找所有连在一起的计算设备。也许HTTP的更换可以靠着通过多种手段继续保持一个社区,包括Git社区和超过100名贡献者的IRC。这个疯狂的想法将在2015年进行软件内部测试。
|
||||
|
||||
### 2015年度开源项目新秀: cAdvisor ###
|
||||
|
||||

|
||||
|
||||
[cAdvisor (Container Advisor)][13] 是一个针对在运行中的容器进行收集,合计,处理和输出信息的工具,它可以给容器的使用者提供资源的使用情况和工作特性。对于每一个容器,cAdvisor记录着资源的分离参数,资源使用历史,资源使用历史对比框图,网络状态。这些从容器输出的数据在机器中传递。
|
||||
|
||||
cAdvisor可以在绝大多数的Linux上运行,并且支持包括Docker在内的多种容器类型。事实上它成为了一种容器的代理,并被集成在了很多系统中。cAdvisor在DockerHub下载量也是位居前茅。cAdvisor的开发团队希望把cAdvisor发展到能够更深入地理解应用并且集成到集群系统。
|
||||
|
||||
### 2015年度开源项目新秀: Terraform ###
|
||||
|
||||

|
||||
|
||||
[Terraform][14]提供了一些列的设置来创建一个基础设施,从物理机到虚拟机再到email服务器、DNS服务器。这个概念包括从家庭个人机解决方案到公共云平台提供的服务。一旦建立好了以后,Terraform便进行一系列的操作来改变你的基础设施,安全又高效,就如同配置一样。
|
||||
|
||||
如果你在Devops模式下的公司里工作,Terraform.io的创始者找到了一个窍门把建立一个完整的数据中心所需的知识结合在一起,从插入服务器到整个网络和功能齐备的数据中心。基础设施的描述采用高级的配置语法,允许你把数据中心的蓝图做成多版本并且可以使用多种代码。著名开源公司HashiCorp赞助开发这个项目。
|
||||
|
||||
### 荣誉奖: Docker Fig ###
|
||||
|
||||

|
||||
|
||||
[Fig][15] 为[Docker][16]的使用提供了一个快速的,分离的开发环境。Docker的移植只需要将配置信息放到一个简单的 fig.yml文件里。它会处理所有工作,包括建立、运行,端口转发,分享磁盘和容器链接。
|
||||
Fig solved a major pain point for developers. Docker fully supports this open source project and [recently purchased Orchard][17] to expand the reach of Fig.
|
||||
Orchard去年发起了Fig,来创造一个使Docker工作的系统工具。它的开发像是为Docker设置开发环境,为了确保用户能够为他们的APP准确定义环境,在Docker中会运行数据库和缓存。Fig解决了开发者的一个难题。Docker全面支持这个开源项目,最近将买下Orchard来扩张这个项目。
|
||||
|
||||
### 荣誉奖: Drone ###
|
||||
|
||||

|
||||
|
||||
[Drone][18]是一个基于Docker的持续集成平台,而且它是用Go语言写的。Drone项目不满于现存的技术和流程,它旨在开发环境。
|
||||
|
||||
Drone提供了一个简单的自动测试和持续交付的方法:简单选择一个Docker形象来满足你的需求,连接并提交至GitHub即可。Drone使用Docker容器来提供隔离的测试环境,让每个项目完全自主控制堆栈,没有传统的服务器管理的负担。Drone背后的100位社区贡献者强烈希望把这个项目带到企业和移动应用程序开发中
|
||||
### 开源新秀 ###
|
||||
|
||||

|
||||
|
||||
- [2014年度开源项目新秀][20]
|
||||
- [InfoWorld2015年年度技术奖][21]
|
||||
- [Bossies: 开源软件最高荣誉][22]
|
||||
- [ Windows管理员15个必不可少的开源工具][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2875439/open-source-software/the-top-10-rookie-open-source-projects.html
|
||||
|
||||
作者:[Black Duck Software][a]
|
||||
译者:[sevenot](https://github.com/sevenot)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Black-Duck-Software/
|
||||
[1]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[2]:https://www.openhub.net/
|
||||
[3]:https://github.com/debops/debops
|
||||
[4]:http://www.infoworld.com/article/2612397/data-center/review--ansible-orchestration-is-a-veteran-unix-admin-s-dream.html
|
||||
[5]:https://codecombat.com/
|
||||
[6]:http://storj.io/
|
||||
[7]:http://neovim.org/
|
||||
[8]:https://github.com/cockroachdb/cockroach
|
||||
[9]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[10]:http://kubernetes.io/
|
||||
[11]:https://openbazaar.org/
|
||||
[12]:http://ipfs.io/
|
||||
[13]:https://github.com/google/cadvisor
|
||||
[14]:https://www.terraform.io/
|
||||
[15]:http://www.fig.sh/
|
||||
[16]:http://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker
|
||||
[17]:http://www.infoworld.com/article/2608546/application-virtualization/docker-acquires-orchard-in-a-sign-of-rising-ambitions.html
|
||||
[18]:https://drone.io/
|
||||
[19]:http://www.infoworld.com/article/2683845/google-go/164121-Fast-guide-to-Go-programming.html
|
||||
[20]:https://www.blackducksoftware.com/open-source-rookies
|
||||
[21]:http://www.infoworld.com/article/2871935/application-development/infoworlds-2015-technology-of-the-year-award-winners.html
|
||||
[22]:http://www.infoworld.com/article/2688104/open-source-software/article.html
|
||||
[23]:http://www.infoworld.com/article/2854954/microsoft-windows/15-essential-open-source-tools-for-windows-admins.html
|
||||
@ -0,0 +1,77 @@
|
||||
translated by strugglingyouth
|
||||
在linux上使用交换文件扩展交换空间
|
||||
================================================================================
|
||||
想像一种情景,当我们的Linux系统用尽交换空间时,在这种情况下,
|
||||
我们想要使用swap分区扩展交换空间,但在某些情况下磁盘上的空闲分区是不可用的,
|
||||
致使我们不能把它扩大。
|
||||
|
||||
因此,在这种情况下,我们可以使用交换文件增加swap空间。
|
||||
|
||||
### 以下是使用交换文件在Linux上扩展swap空间的方法 ###
|
||||
|
||||
让我们首先检查现有的交换空间/分区的大小,使用命令 ‘**free -m‘** 或者 ‘**swapon -s**‘
|
||||
|
||||

|
||||
free-output-with-swap
|
||||
|
||||
我的交换分区大小是2 GB,我们将把交换空间扩展1GB。
|
||||
|
||||
#### 第一步:使用下面的dd命令创建大小为1GB交换文件d ####
|
||||
|
||||
[root@linuxtechi ~]# dd if=/dev/zero of=/swap_file bs=1G count=1
|
||||
1+0 records in
|
||||
1+0 records out
|
||||
1073741824 bytes (1.1 GB) copied, 414.898 s, 2.6 MB/s
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
根据你的需要替换 ‘**bs**‘ 和 ‘**count**‘ 的大小.
|
||||
|
||||
####第二步:设置交换文件权限为644. ####
|
||||
|
||||
[root@linuxtechi ~]# chmod 600 /swap_file
|
||||
|
||||
#### 第三步:用文件开启交换区(swap_file)####
|
||||
|
||||
用mkswap命令开启交换区
|
||||
|
||||
[root@linuxtechi ~]# mkswap /swap_file
|
||||
Setting up swapspace version 1, size = 1048572 KiB
|
||||
no label, UUID=f7b3ae59-c09a-4dc2-ba4d-c02abb7db33b
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
#### 第四步:在fstab文件中添加交换文件条目 ####
|
||||
|
||||
在fstab文件中添加以下条目,以便交换文件每次重启后互能继续使用.
|
||||
|
||||
/swap_file swap swap defaults 0 0
|
||||
|
||||
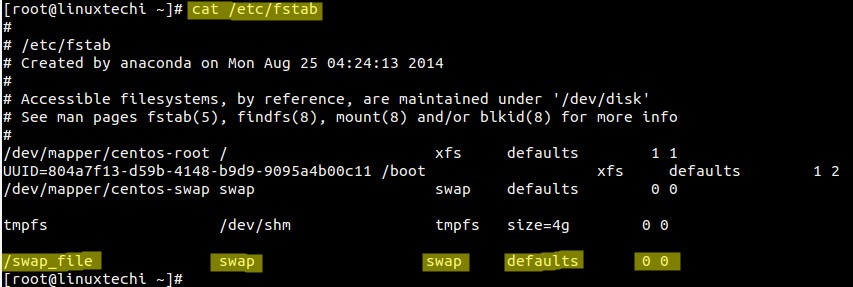
|
||||
|
||||
#### 第五步:用命令 ‘mkswap on’ 启用交换文件. ####
|
||||
|
||||
[root@linuxtechi ~]# swapon /swap_file
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
#### 第六步:现在查看交换空间 ####
|
||||
|
||||
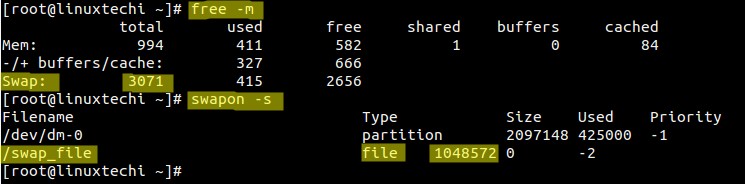
|
||||
|
||||
**Note**: 为了避免出现意外的情况,如下所示使用swapoff命令关闭它,
|
||||
仅在需要使用时,使用步骤5所示的swapon命令,重新启用交换文件。.
|
||||
|
||||
[root@linuxtechi ~]# swapoff /swap_file
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
请分享您的宝贵意见或者评论此文章.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/extend-swap-space-using-swap-file-in-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,220 @@
|
||||
|
||||
如何在CentOS 7上安装Percona Server
|
||||
|
||||
================================================================================
|
||||
在这篇文章中我们将了解关于Percona Server,一个开源简易的MySQL,MariaDB的替代。InnoDB的数据库引擎使得Percona Server非常有吸引力,如果你需要的高性能,高可靠性和高性价比的解决方案,它将是一个很好的选择。
|
||||
|
||||
在下文中将介绍在CentOS 7上Percona的服务器的安装,以及备份当前数据,配置的步骤和如何恢复备份。
|
||||
|
||||
|
||||
###目录###
|
||||
|
||||
|
||||
1.什么是Percona,为什么使用它
|
||||
2.备份你的数据库
|
||||
3.删除之前的SQL服务器
|
||||
4.使用二进制包安装Percona
|
||||
5.配置Percona
|
||||
6.保护你的数据
|
||||
7.恢复你的备份
|
||||
|
||||
|
||||
### 1.什么是Percona,为什么使用它 ###
|
||||
|
||||
|
||||
Percona是一个开源简易的MySQL,MariaDB数据库的替代,它是MYSQL的一个分支,相当多的改进和独特的功能使得它比MYSQL更可靠,性能更强,速度更快,它与MYSQL完全兼容,你甚至可以在Oracle的MYSQL与Percona之间使用复制命令。
|
||||
|
||||
#### 在Percona中独具特色的功能 ####
|
||||
|
||||
|
||||
-分段自适应哈希搜索
|
||||
-快速校验算法
|
||||
-缓冲池预加载
|
||||
-支持FlashCache
|
||||
|
||||
#### MySQL企业版和Percona的特定功能 ####
|
||||
|
||||
-从不同的服务器导入表
|
||||
-PAM认证
|
||||
-审计日志
|
||||
-线程池
|
||||
|
||||
|
||||
现在,你肯定很兴奋地看到这些好的东西整理在一起,我们将告诉你如何安装和做些的Percona Server的基本配置。
|
||||
|
||||
### 2. 备份你的数据库 ###
|
||||
|
||||
|
||||
接下来,在命令行下使用SQL命令创建一个mydatabases.sql文件来重建/恢复salesdb和employeedb数据库,重命名数据库以便反映你的设置,如果没有安装MYSQL跳过此步
|
||||
|
||||
mysqldump -u root -p --databases employeedb salesdb > mydatabases.sql
|
||||
|
||||
复制当前的配置文件,如果你没有安装MYSQL也可跳过
|
||||
|
||||
|
||||
cp my.cnf my.cnf.bkp
|
||||
|
||||
### 3.删除之前的SQL服务器 ###
|
||||
|
||||
|
||||
停止MYSQL/MariaDB如果它们还在运行
|
||||
|
||||
|
||||
systemctl stop mysql.service
|
||||
|
||||
卸载MariaDB和MYSQL
|
||||
|
||||
|
||||
yum remove MariaDB-server MariaDB-client MariaDB-shared mysql mysql-server
|
||||
|
||||
移动重命名在/var/lib/mysql当中的MariaDB文件,这比仅仅只是移除更为安全快速,这就像2级即时备份。:)
|
||||
|
||||
|
||||
mv /var/lib/mysql /var/lib/mysql_mariadb
|
||||
|
||||
### 4.使用二进制包安装Percona ###
|
||||
|
||||
|
||||
你可以在众多Percona安装方法中选择,在CentOS中使用Yum或者RPM包安装通常是更好的主意,所以这些是本文介绍的方式,下载源文件编译后安装在本文中并没有介绍。
|
||||
|
||||
|
||||
从Yum仓库中安装:
|
||||
|
||||
|
||||
首先,你需要设置的Percona的Yum库:
|
||||
|
||||
|
||||
yum install http://www.percona.com/downloads/percona-release/redhat/0.1-3/percona-release-0.1-3.noarch.rpm
|
||||
|
||||
接下来安装Percona:
|
||||
|
||||
|
||||
yum install Percona-Server-client-56 Percona-Server-server-56
|
||||
|
||||
上面的命令安装Percona的服务器和客户端,共享库,可能需要Perl和Perl模块,以及其他依赖的需要。如DBI::MySQL的,如果这些尚未安装,
|
||||
|
||||
使用RPM包安装:
|
||||
|
||||
|
||||
我们可以使用wget命令下载所有的rpm包:
|
||||
|
||||
|
||||
wget -r -l 1 -nd -A rpm -R "*devel*,*debuginfo*" \ http://www.percona.com/downloads/Percona-Server-5.5/Percona-Server-5.5.42-37.1/binary/redhat/7/x86_64/
|
||||
|
||||
使用rpm工具,一次性安装所有的rpm包:
|
||||
|
||||
|
||||
rpm -ivh Percona-Server-server-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-client-55-5.5.42-rel37.1.el7.x86_64.rpm \ Percona-Server-shared-55-5.5.42-rel37.1.el7.x86_64.rpm
|
||||
|
||||
注意在上面命令语句中最后的反斜杠'\',如果您安装单独的软件包,记住要解决依赖关系,在安装客户端之前要先安装共享包,在安装服务器之前请先安装客户端。
|
||||
|
||||
### 5.配置Percona服务器 ###
|
||||
|
||||
|
||||
|
||||
#### 恢复之前的配置 ####
|
||||
|
||||
|
||||
当我们从MariaDB迁移过来时,你可以将之前的my.cnf的备份文件恢复回来。
|
||||
|
||||
|
||||
cp /etc/my.cnf.bkp /etc/my.cnf
|
||||
|
||||
#### 创建一个新的my.cnf文件 ####
|
||||
|
||||
|
||||
如果你需要一个适合你需求的新的配置文件或者你并没有备份配置文件,你可以使用以下方法,通过简单的几步生成新的配置文件。
|
||||
|
||||
下面是Percona-server软件包自带的my.cnf文件
|
||||
|
||||
|
||||
# Percona Server template configuration
|
||||
|
||||
[mysqld]
|
||||
#
|
||||
# Remove leading # and set to the amount of RAM for the most important data
|
||||
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
|
||||
# innodb_buffer_pool_size = 128M
|
||||
#
|
||||
# Remove leading # to turn on a very important data integrity option: logging
|
||||
# changes to the binary log between backups.
|
||||
# log_bin
|
||||
#
|
||||
# Remove leading # to set options mainly useful for reporting servers.
|
||||
# The server defaults are faster for transactions and fast SELECTs.
|
||||
# Adjust sizes as needed, experiment to find the optimal values.
|
||||
# join_buffer_size = 128M
|
||||
# sort_buffer_size = 2M
|
||||
# read_rnd_buffer_size = 2M
|
||||
datadir=/var/lib/mysql
|
||||
socket=/var/lib/mysql/mysql.sock
|
||||
|
||||
# Disabling symbolic-links is recommended to prevent assorted security risks
|
||||
symbolic-links=0
|
||||
|
||||
[mysqld_safe]
|
||||
log-error=/var/log/mysqld.log
|
||||
pid-file=/var/run/mysqld/mysqld.pid
|
||||
|
||||
根据你的需要配置好my.cnf后,就可以启动该服务了:
|
||||
|
||||
|
||||
systemctl restart mysql.service
|
||||
|
||||
如果一切顺利的话,它已经准备好执行SQL命令了,你可以用以下命令检查它是否已经正常启动:
|
||||
|
||||
|
||||
mysql -u root -p -e 'SHOW VARIABLES LIKE "version_comment"'
|
||||
|
||||
如果你不能够正常启动它,你可以在**/var/log/mysql/mysqld.log**中查找原因,该文件可在my.cnf的[mysql_safe]的log-error中设置。
|
||||
|
||||
tail /var/log/mysql/mysqld.log
|
||||
|
||||
你也可以在/var/lib/mysql/文件夹下查找格式为[hostname].err的文件,就像下面这个例子样:
|
||||
|
||||
|
||||
tail /var/lib/mysql/centos7.err
|
||||
|
||||
如果还是没找出原因,你可以试试strace:
|
||||
|
||||
|
||||
yum install strace && systemctl stop mysql.service && strace -f -f mysqld_safe
|
||||
上面的命令挺长的,输出的结果也相对简单,但绝大多数时候你都能找到无法启动的原因。
|
||||
|
||||
### 6.保护你的数据 ###
|
||||
|
||||
好了,你的关系数据库管理系统已经准备好接收SQL查询,但是把你宝贵的数据放在没有最起码安全保护的服务器上并不可取,为了更为安全最好使用mysql_secure_instalation,这个工具可以帮助删除未使用的默认功能,还设置root的密码,并限制使用此用户进行访问。
|
||||
只需要在shell中执行,并参照屏幕上的说明。
|
||||
|
||||
mysql_secure_install
|
||||
|
||||
### 7.还原备份 ###
|
||||
|
||||
如果您参照之前的设置,现在你可以恢复数据库,只需再用mysqldump一次。
|
||||
|
||||
|
||||
mysqldump -u root -p < mydatabases.sql
|
||||
恭喜你,你刚刚已经在你的CentOS上成功安装了Percona,你的服务器已经可以正式投入使用;你可以像使用MYSQL一样使用它,你的服务器与他完全兼容。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
为了获得更强的性能你需要对配置文件做大量的修改,但这里也有一些简单的选项来提高机器的性能。当使用InnoDB引擎时,将innodb_file_per_table设置为on,它将在一个文件中为每个表创建索引表,这意味着每个表都有它自己的索引文件,它使系统更强大和更容易维修。
|
||||
|
||||
可以修改innodb_buffer_pool_size选项,InnoDB应该有足够的缓存池来应对你的数据集,大小应该为当前可用内存的70%到80%。
|
||||
|
||||
过将innodb-flush-method设置为O_DIRECT,关闭写入高速缓存,如果你使用了RAID,这可以提升性能因为在底层已经完成了缓存操作。
|
||||
|
||||
如果你的数据并不是十分关键并且并不需要对数据库事务正确执行的四个基本要素完全兼容,可以将innodb_flush_log_at_trx_commit设置为2,这也能提升系统的性能。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/percona-server-centos-7/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[FatJoe123](https://github.com/FatJoe123)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
@ -1,193 +0,0 @@
|
||||
10个(!)符号在Linux命令行下惊人和奇妙的用法
|
||||
================================================================================
|
||||
`'!'`符号在Linux中不但可以用作否定符号,还可以用来从历史命令记录中取出命令或不加修改的执行之前运行的命令。下面的所有命令都已经在Bash Shell中经过确切地检查。尽管我没有试过,但大多都不能在别的Shell中运行。这里我们介绍下Linux命令行中符号`'!'`那惊人和奇妙的用法。
|
||||
|
||||
### 1. 使用数字从历史命令列表中找一条命令来执行 ###
|
||||
|
||||
您也许没有意识到您可以从历史命令列表(之前已经执行的命令集)中找出一条来运行。首先,通过"history"命令查找之前命令的序号。
|
||||
|
||||
$ history
|
||||
|
||||

|
||||
|
||||
现在,只需要使用历史命令输出中显示在该命令前面的数字便可以运行这个命令。例如,运行一个在`history`输出中编号是1551的命令。
|
||||
|
||||
$ !1551
|
||||
|
||||

|
||||
|
||||
这样,编号为1551的命令(上面的例子是[top命令][1])便运行了。这种通过ID号来执行之前的命令的方式很有用,尤其是在这些命令都很长的情况下。您只需要使用**![history命令输出的序号]**便可以调用它。
|
||||
|
||||
### 2. 运行之前的倒数第二个、第七个命令等 ###
|
||||
|
||||
您可以以另一种方式来运行之前执行的命令,通过使用-1代表最后的命令,-2代表倒数第二个命令,-7代表倒数第七个命令等。
|
||||
|
||||
首先使用history命令来获得执行过的命令的列表。history命令的执行很有必要,因为您可以通过它来确保没有`rm command > file`或其他会导致危险的命令。接下来执行倒数第六个、第八个、第十个命令。
|
||||
|
||||
$ history
|
||||
$ !-6
|
||||
$ !-8
|
||||
$ !-10
|
||||
|
||||

|
||||
通过负数序号运行之前执行的命令
|
||||
|
||||
### 3. 向最后的命令传递参数,以方便的运行新的命令 ###
|
||||
|
||||
我需要显示`/home/$USER/Binary/firefox`文件夹的内容,因此我执行:
|
||||
|
||||
$ ls /home/$USER/Binary/firefox
|
||||
|
||||
接下来,我意识到我应该执行'ls -l'来查看哪个文件是可执行文件。因此我应该重新输入整个命令么?不,我不需要。我仅需要在新的命令中带上最后的参数,类似:
|
||||
|
||||
$ ls -l !$
|
||||
|
||||
这里`!$`将把最后执行的命令的参数传递到这个新的命令中。
|
||||
|
||||

|
||||
将上一个命令的参数传递给新命令
|
||||
|
||||
### 4. 如何使用!来处理两个或更多的参数 ###
|
||||
|
||||
比如说我在桌面创建了一个文本文件file1.txt。
|
||||
|
||||
$ touch /home/avi/Desktop/1.txt
|
||||
|
||||
然后在cp命令中使用绝对路径将它拷贝到`/home/avi/Downloads`。
|
||||
|
||||
$ cp /home/avi/Desktop/1.txt /home/avi/downloads
|
||||
|
||||
现在,我们给cp命令传递了两个参数。第一个是`/home/avi/Desktop/1.txt`,第二个是`/home/avi/Downloads`。让我们分别处理他们,使用`echo [arguments]`来打印两个不同的参数。
|
||||
|
||||
$ echo "1st Argument is : !^"
|
||||
$ echo "2nd Argument is : !cp:2"
|
||||
|
||||
注意第一个参数可以使用`"!^"`进行打印,其余的命令可以通过`"![命令名]:[参数编号]"`打印。
|
||||
|
||||
在上面的例子中,第一个命令是`cp`,第二个参数也需要被打印。因此是`"!cp:2"`,如果任何命令比如xyz运行时有5个参数,而您需要获得第四个参数,您可以使用`"!xyz:4"`。所有的参数都可以通过`"!*"`来获得。
|
||||
|
||||

|
||||
处理两个或更多的参数
|
||||
|
||||
### 5. 以关键字为基础执行上个的命令 ###
|
||||
|
||||
我们可以以关键字为基础执行上次执行的命令。可以从下面的例子中理解:
|
||||
|
||||
$ ls /home > /dev/null [命令1]
|
||||
$ ls -l /home/avi/Desktop > /dev/null [命令2]
|
||||
$ ls -la /home/avi/Downloads > /dev/null [命令3]
|
||||
$ ls -lA /usr/bin > /dev/null [命令4]
|
||||
|
||||
上面我们使用了同样的命令(ls),但有不同的开关和不同的操作文件夹。而且,我们还将输出传递到`/dev/null`,我们并未处理输出,因而终端依旧很干净。
|
||||
|
||||
现在以关键字为基础执行上个的命令。
|
||||
|
||||
$ ! ls [命令1]
|
||||
$ ! ls -l [命令2]
|
||||
$ ! ls -la [命令3]
|
||||
$ ! ls -lA [命令4]
|
||||
|
||||
检查输出,您将惊奇发现您仅仅使用关键字`ls`便执行了您已经执行过的命令。
|
||||
|
||||

|
||||
以关键字为基础执行命令
|
||||
|
||||
### 6. !!操作符的威力 ###
|
||||
|
||||
您可以使用`(!!)`运行/修改您上个运行的命令。它将附带一些修改/调整并调用上个命令。让我给您展示一些实际情境。
|
||||
|
||||
昨天我运行了一行脚本来获得我的私密IP,因此我执行了:
|
||||
|
||||
$ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/
|
||||
|
||||
接着,我突然发现我需要将上面脚本的输出重定向到一个ip.txt的文件,因此,我改怎么办呢?我改重新输入整个命令并重定向到一个文件么?一个简单的解决方案是使用向上导航键并添加`'> ip.txt'`来将输出重定向到文件。
|
||||
|
||||
$ ip addr show | grep inet | grep -v 'inet6'| grep -v '127.0.0.1' | awk '{print $2}' | cut -f1 -d/ > ip.txt
|
||||
|
||||
在这里感谢救世主"向上导航键"。现在,考虑下面的情况,这次我运行了下面这一行脚本。
|
||||
|
||||
$ ifconfig | grep "inet addr:" | awk '{print $2}' | grep -v '127.0.0.1' | cut -f2 -d:
|
||||
|
||||
一旦我运行了这个脚本,Bash提示符便返回了错误消息`"bash: ifconfig: command not found"`。原因并不难猜,我运行了本应以root权限的运行的命令。
|
||||
|
||||
所以,怎么解决呢?我们很难以root用户登录并且再次键入整个命令!而且向上导航键也不管用了。因此,我们需要调用`"!!"`(去掉引号),它将为那个用户调用上个命令。
|
||||
|
||||
$ su -c "!!" root
|
||||
|
||||
这里su是用来切换到root用户的,`-c`用来以某用户运行特定的命令,最重要的部分是`!!`,它将被替换为上次运行的命令。对的!您需要提供root密码。
|
||||
|
||||

|
||||
!!操作符的威力
|
||||
|
||||
我通常在下面的情景中使用`!!`。
|
||||
|
||||
1.当我用普通用户来运行apt-get,我通常收到提示说我没有权限来执行。
|
||||
|
||||
$ apt-get upgrade && apt-get dist-upgrade
|
||||
|
||||
好吧,有错误。但别担心,使用下面的命令来成功的执行...
|
||||
|
||||
$ su -c !!
|
||||
|
||||
同样的适用于:
|
||||
|
||||
$ service apache2 start
|
||||
或
|
||||
$ /etc/init.d/apache2 start
|
||||
或
|
||||
$ systemctl start apache2
|
||||
|
||||
普通用户不被授权执行那些任务,所以我运行:
|
||||
|
||||
$ su -c 'service apache2 start'
|
||||
或
|
||||
$ su -c '/etc/init.d/apache2 start'
|
||||
或
|
||||
$ su -c 'systemctl start apache2'
|
||||
|
||||
### 7.运行一个影响所有除了![FILE_NAME]的文件命令 ###
|
||||
|
||||
`!`(逻辑非)能用来对除了`'!'`后的文件的所有的文件/扩展执行命令。
|
||||
|
||||
A.从文件夹移除所有文件,2.txt除外。
|
||||
|
||||
$ rm !(2.txt)
|
||||
|
||||
B.从文件夹移除所有的文件类型,pdf类型除外。
|
||||
|
||||
$ rm !(*.pdf)
|
||||
|
||||
### 8.检查某个文件夹(比如/home/avi/Tecmint)是否存在?并打印 ###
|
||||
|
||||
这里,我们使用`'! -d'`来验证文件夹是否存在,当文件夹不存在时,将使用其后跟随AND操作符`(&&)`进行打印,当文件夹存在时,将使用OR操作符`(||)`进行打印。
|
||||
|
||||
逻辑上,当`[ ! -d /home/avi/Tecmint ]`的输出为0时,它将执行AND逻辑符后面的内容,否则,它将执行OR逻辑符`(||)`后面的内容。
|
||||
|
||||
$ [ ! -d /home/avi/Tecmint ] && printf '\nno such /home/avi/Tecmint directory exist\n' || printf '\n/home/avi/Tecmint directory exist\n'
|
||||
|
||||
### 9.检查某文件夹是否存在?如果不存在则退出该命令 ###
|
||||
|
||||
类似于上面的情况,但这里当期望的文件夹不存在时,该命令会退出。
|
||||
|
||||
$ [ ! -d /home/avi/Tecmint ] && exit
|
||||
|
||||
### 10.如果您的home文件夹内不存在一个文件夹(比方说test),则创建它 ###
|
||||
|
||||
这是脚本语言中的一个常用的实现,当期望的文件夹不存在时,创建一个。
|
||||
|
||||
[ ! -d /home/avi/Tecmint ] && mkdir /home/avi/Tecmint
|
||||
|
||||
这便是全部了。如果您知道或偶尔遇到其他值得了解的`'!'`使用方法,请您在反馈的地方给我们提建议。保持联系!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/mysterious-uses-of-symbol-or-operator-in-linux-commands/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/12-top-command-examples-in-linux/
|
||||
@ -1,64 +0,0 @@
|
||||
如何在RHEL/CentOS 7.0中使用tmpfs
|
||||
================================================================================
|
||||
7中的tmpfs,这是一个将所有文件和文件夹写到虚拟内存中而不是实际写到磁盘中的虚拟文件系统。这意味中tmpfs中所有的内容都是临时的,在取消挂载、系统重启或者电源切断后内容都将会丢失。技术的角度上来说,tmpfs将搜有的内容放在内核内部缓存中并且会增大或者缩小来容纳文件并可从交换空间中交换处不需要的页。
|
||||
|
||||
CentOS默认使用tmpfs做的事可用df -h命令的输出来看:
|
||||
|
||||
# df –h
|
||||
|
||||

|
||||
|
||||
/dev - 含有针对所有设备的设备文件的目录
|
||||
/dev/shm – 包含共享内存分配
|
||||
/run - 用于系统日志
|
||||
/sys/fs/cgroup - 用于cgrpups, 一个针对特定进程限制、管制和审计资源利用的内核特性
|
||||
|
||||
/tmp目录, 你可以用下面的两种方法来做到:
|
||||
|
||||
### 使用systemctl来在/tmp中启用tmpfs ###
|
||||
|
||||
你可以使用systemctl命令在tmp目录启用tmpfs, 首先用下面的命令来检查这个特性是否可用:
|
||||
|
||||
# systemctl is-enabled tmp.mount
|
||||
|
||||
这会显示当先的状态,你可以使用下面的命令来启用它:
|
||||
|
||||
# systemctl enable tmp.mount
|
||||
|
||||

|
||||
|
||||
这会控制/tmp目录并挂载tmpfs。
|
||||
|
||||
### 手动挂载/tmp/文件系统 ###
|
||||
|
||||
你可以在/etc/fstab中添加下面这行在/tmp挂载tmpfs。
|
||||
|
||||
tmpfs /tmp tmpfs size=512m 0 0
|
||||
|
||||
接着运行这条命令
|
||||
|
||||
# mount –a
|
||||
|
||||

|
||||
|
||||
这应该就会在df -h中显示tmpfs了,同样也会在你下次重启是会自动挂载。
|
||||
|
||||
### 立即创建tmpfs ###
|
||||
|
||||
如果由于一些原因,你写昂立即创建tmpfs,你可以使用下面的命令:
|
||||
|
||||
# mount -t tmpfs -o size=1G tmpfs /mnt/mytmpfs
|
||||
|
||||
当然你可以在size选项中指定你希望的大小和希望的挂载点,只要记住是有效的目录就行了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/use-tmpfs-rhel-centos-7-0/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
@ -0,0 +1,104 @@
|
||||
11个让人惊叹的Linux终端彩蛋
|
||||
================================================================================
|
||||
这里有一些很酷的Linux终端彩蛋,其中的每一个看上去并没有实际用途,但很精彩。
|
||||
|
||||

|
||||
|
||||
### 只工作不玩耍…… ###
|
||||
|
||||
当我们使用命令行工作时,Linux是功能和实用性最好的操作系统之一。想要执行一个特殊任务?可能一个程序或者脚本就可以帮你搞定。但就像一本书中说到的,只工作不玩耍聪明的孩子也会变傻。下边是我最喜欢的可以在终端做的没有实际用途的、傻傻的、恼人的、可笑的事情。
|
||||
|
||||
### 给终端一个态度 ###
|
||||
|
||||
* 第一步)敲入`sudo visudo`
|
||||
* 第二步)在“Defaults”末尾(文件的前半部分)添加一行“Defaults insults”。
|
||||
* 第三步)保存文件。
|
||||
|
||||
“我刚才对电脑做了什么?”你可能这样问自己。一定是美妙的事情吧。现在,在sudo命令提示提示下输出错误的口令,你的电脑就会呼唤你的名字。我最喜欢的一句:“听好了,煎饼一样的脑子,我没有时间听你胡说八道了。”
|
||||
|
||||

|
||||
|
||||
### apt-get moo ###
|
||||
|
||||
你看过这张截图?那就是运行`apt-get moo`(在基于Debian的系统)的结果。对,就是它了。不要对它抱太多幻想,你会失望的,我不骗你。但是这是Linux世界最被人熟知的彩蛋之一。所以我把它包含进来,并且放在前排,然后我也就不会收到5千封邮件,指责我把它遗漏了。
|
||||
|
||||

|
||||
|
||||
### aptitude moo ###
|
||||
|
||||
更有趣的是将moo应用到aptitude上。敲入`aptitude moo`(在Ubuntu及其衍生版),你对`moo`可以做什么事情的看法会有所变化。你还还会知道更多事情,尝试重新输入这条命令,但这次添加一个`-v`参数。这还没有结束,试着添加更多`v`,一次添加一个,直到aptitude给了你想要的东西。
|
||||
|
||||

|
||||
|
||||
### Arch: 将吃豆人放入pacman ###
|
||||
|
||||
这里有一个只为Arch爱好者准备的彩蛋。Pacman包管理工具已经很棒了,但我们可以让它变得更棒。
|
||||
|
||||
* 第一步)打开“/etc/pacman.conf”文件。
|
||||
* 第二步)在“# Misc options”部分,去掉“Color”前的“#”。
|
||||
* 第三步)添加“ILoveCandy”。
|
||||
|
||||
现在我们使用pacman安装新软件包时,进度条里会出现一个小吃豆人。真应该默认就是这样的。
|
||||
|
||||

|
||||
|
||||
### Cowsay! ###
|
||||
|
||||
`aptitude moo`的输出格式很漂亮,但我想你苦于不能自由自在地使用。输入`cowsay`,它会做到你想做的事情。你可以让牛说任何你喜欢的东西。而且不只可以用牛,还可以用Calvin、Beavis和Ghostbusters的ASCII logo——输入`cowsay -l`可以得到所有可用的logo。它是Linux世界的强大工具。像很多其他命令一样,你可以使用管道把其他程序的输出输送给它,比如`fortune | cowsay`。
|
||||
|
||||

|
||||
|
||||
### 变成3l33t h@x0r ###
|
||||
|
||||
`nmap`并不是我们平时经常使用的基本命令。但如果你想蹂躏`nmap`的话,可能想在它的输出中看到l33t。在任何`nmap`命令(比如`nmap -oS - google.com`)后添加`-oS`。现在你的`nmap`已经处于官方名称是“[Script Kiddie Mode][1]”的模式了。Angelina Jolie和Keanu Reeves会为此骄傲的。
|
||||
|
||||

|
||||
|
||||
### 获得所有的Discordian日期 ###
|
||||
|
||||
如果你们曾经坐在一起思考,“嗨!我想使用无用但异想天开的方式来书写今天的日期……”试试运行`ddate`。结果类似于“Today is Setting Orange, the 72nd day of Discord in the YOLD 3181”,这会让你的服务树日志平添不少香料。
|
||||
|
||||
注意:在技术层面,确实有一个[Discordian Calendar][2],理论上被[Discordianism][3]追随者所使用。这意味着我可能得罪某些人。或者不会,我不确定。不管怎样,`ddate`是一个方便的工具。
|
||||
|
||||

|
||||
|
||||
### 我可以在任何地方看到颜色!###
|
||||
|
||||
厌倦了老旧的文本?想向世界展示出自己的个性?使用`lolcat`。安装它,然后在任何地方使用。它可以接收任何文本,然后将其转换成美轮美奂的彩虹效果。可以使用`fortune | lolcat`体验。
|
||||
|
||||

|
||||
|
||||
### 蒸汽机车 ###
|
||||
|
||||
在你的终端显示蒸汽机车的ASCII图形。如果你需要它,安装并运行`sl`命令。`sl -l`可以看到一个袖珍版本的。或者,如果你真想在上边花费更多时间,运行`sl -h`。这会显示一个完整的或者,还包括乘客车厢。
|
||||
|
||||

|
||||
|
||||
### 将任何文本逆序输出 ###
|
||||
|
||||
将任何文本使用管道输送给`rev`命令,它就会将文本内容逆序输出。`fortune | rev`会给你好运。当然,这不意味着rev会将幸运转换成不幸。
|
||||
|
||||

|
||||
|
||||
### Matrix依然很酷,不是吗? ###
|
||||
|
||||
想让你的终端显示滚动的文字、l33t和Matrix电影中的坠落数码?`cmatrix`是你的朋友。你甚至可以用它输出不同的颜色,非常华丽。使用`man cmatrix`学习使用方法。或者使用更好的方法,“man cmatrix | lolcat”。这确实是你在Linux终端可以做的最没实际用途却又精彩的事情了。
|
||||
|
||||

|
||||
|
||||
以上就是全部内容了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2926630/linux/11-pointless-but-awesome-linux-terminal-tricks.html
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[goreliu](https://github.com/goreliu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Bryan-Lunduke/
|
||||
[1]:http://nmap.org/book/output-formats-script-kiddie.html
|
||||
[2]:http://en.wikipedia.org/wiki/Discordian_calendar
|
||||
[3]:http://en.wikipedia.org/wiki/Discordianism
|
||||
@ -1,113 +0,0 @@
|
||||
安装Fedora 22后要做的事
|
||||
================================================================================
|
||||
Fedora 22,Red Hat操作系统的社区开发版的最新成员,已经于2015年5月26日发布了。这个令人神圣的Fedora发行版充斥着各种炒作和预期,Fedora 22推出了大量的重大变化。
|
||||
|
||||
就初始化进程而言,Systemd还是个新生儿,但它已经准备好替换脆弱的sysvinit这个一直是Linux生态系统一部分的模块。另外一个用户会碰到的重大改变存在于基本仓库的python版本中,这里提供了两种不同口味的python版本2.x和3.x分线,各个都有其不同的癖好和优点。所以,那些偏好2.x口味的用户可能想要安装他们喜爱的python版本。自从Fedora 18开始被打扮得更加时髦的Yum安装器也被设置来替换过时陈旧的YUM安装器后。Fedora也已最后决定,现在是时候用DNF来替换YUM了。
|
||||
### 1) 安装VLC媒体播放器 ###
|
||||
|
||||
Fedora 22默认自带了媒体播放器viz gnome视频播放器(前身是totem)。如果你对此不感冒,那么我们可以跳过这一步继续往前走。但是,如果你像我一样,偏好使用最广泛的VLC,那么就去从RPMFusion仓库安装吧。安装方法如下:
|
||||
|
||||
sudo dnf install vlc -y
|
||||
|
||||
### 2) 配置RPMFusion仓库 ###
|
||||
|
||||
正如我已经提到过的,Fedora的意识形态很是严谨,它不会自带任何非自由组件。官方仓库不会提供一些包含有非自由组件的基本软件,比如像多媒体编码。因此,安装一些第三方仓库很有必要,这些仓库会为我们提供一些基本的软件。幸运的是,RPMFusion仓库前来拯救我们了。
|
||||
|
||||
$ sudo dnf install --nogpgcheck http://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-22.noarch.rpm
|
||||
|
||||
### 3) 安装多媒体编码 ###
|
||||
|
||||
刚刚我们说过,一些多媒体编码和插件不会随Fedora一起发送。现在,有谁想仅仅是因为专有编码而错过他们最爱的节目和电影?试试这个吧:
|
||||
|
||||
$ sudo dnf install gstreamer-plugins-bad gstreamer-plugins-bad-free-extras gstreamer-plugins-ugly gstreamer-ffmpeg gstreamer1-libav gstreamer1-plugins-bad-free-extras gstreamer1-plugins-bad-freeworld gstreamer-plugins-base-tools gstreamer1-plugins-good-extras gstreamer1-plugins-ugly gstreamer1-plugins-bad-free gstreamer1-plugins-good gstreamer1-plugins-base gstreamer1
|
||||
|
||||
### 4) 更新系统 ###
|
||||
|
||||
Fedora是一个尖端的发行版,因此它会持续发布更新用以修复系统中出现的错误和漏洞。因而,保持系统更新到最新,是个不错的做法。
|
||||
|
||||
$ sudo dnf update -y
|
||||
|
||||
### 5) 卸载你不需要的软件 ###
|
||||
|
||||
Fedora预装了一些大多数用户可以利用的包,但是对于更高级的用户,你可能意识到你并不需要它。要移除你不需要的包相当容易,只需使用以下命令——我选择卸载rhythmbox,因为我知道我不会用到它:
|
||||
|
||||
$ sudo dnf remove rhythmbox
|
||||
|
||||
### 6) 安装Adobe Flash ###
|
||||
|
||||
我们都希望Adobe Flash不要再存在了,因为它并不被认为是最安全的,或者资源利用最好的,但是暂时先让它待着吧。Fedora 22安装Adobe Flash的唯一途径是从Adobe安装官方RPM,就像下面这样。
|
||||
|
||||
你可以从[这里][1]下载RPM。下载完后,你可以直接右击并像下面这样打开:
|
||||
|
||||

|
||||
|
||||
右击并选择“用软件安装打开”
|
||||
|
||||
然后,只需在弹出窗口中点击安装:
|
||||
|
||||

|
||||
|
||||
点击“安装”来完成从Adobe安装自定义RPM的过程
|
||||
|
||||
该过程完成后,“安装”按钮会变成“移除”,而此时安装也完成了。如果在此过程中你的浏览器开着,会提示你先把它关掉或在安装完成后重启以使修改生效。
|
||||
|
||||
### 7) 用Gnome Boxes加速虚拟机 ###
|
||||
|
||||
你刚刚安装了Fedora,你也很是喜欢,但是出于某些私人原因,你也许仍然需要Windows,或者你只是想玩玩另外一个Linux发行版。不管哪种情况,你都可以使用Gnome Boxes来简单地创建一个虚拟机或使用一个live发行版,Fedora 22提供了该软件。遵循以下步骤,使用你所选的ISO来开始吧!谁知道呢,也许你可以检验一下某个[Fedora Spin][2]。
|
||||
|
||||
首先,打开Gnome Boxes,然后在顶部左边选择“新建”:
|
||||
|
||||

|
||||
|
||||
点击“新建”来开始添加一个新虚拟机的进程吧。
|
||||
|
||||
接下来,点击打开文件并选择一个ISO:
|
||||
|
||||

|
||||
|
||||
在选择选择了选择文件或ISO后,选择你的ISO。这里,我已经安装了一个Debian ISO。
|
||||
|
||||
最后,自定义VM设置或使用默认,然后点击“创建”。VM会以默认方式启动,可用的VM会在Gnome Boxes以小缩略图的方式显示。
|
||||
|
||||

|
||||
|
||||
自定义设置为你所选择的,或者也可以保持默认。完成后,点击“创建”,VM就一切就绪了。
|
||||
|
||||
### 8) 安装Google Chrome ###
|
||||
|
||||
Firefox被包含在Fedora 22中,但是就跟大多数软件一样,每个人都有他们自己的选择。如果你所喜爱的浏览器恰好是Google Chrome,你可以使用和上面安装Adobe Flash Player类似的指令。然而,很明显,你得使用来自Google的任何你所下载的版本的RPM。最新的版本通常可以在[这里][3]找到。
|
||||
|
||||
### 9) 添加社交媒体和其它在线帐号 ###
|
||||
|
||||
Gnome自带有不错的内建功能用于容纳帐号相关的东西,像Facebook,Google以及其它在线帐号。你可以通过主Gnome设置应用访问在线帐号设置。然后,只需点击在线帐号,并添加你所选择的帐号。如果你要添加一个帐号,比如像Google,你可以用它来作为默认帐号,用来完成诸如发送邮件、日历提醒、相片和文档交互,以及诸如此类的更多事情。
|
||||
|
||||
### 10) 安装KDE或另一个桌面环境 ###
|
||||
|
||||
我们中的某些人不喜欢Gnome,那也没问题。在终端中运行以下命令来安装KDE所需的一切来替换它。这些指令也可以用以安装xfce、lxde或其它桌面环境。
|
||||
|
||||
$ sudo dnf install @kde-desktop
|
||||
|
||||
安装完成后,登出。当你点击你的用户名时,注意那个表示设置的小齿轮。点击它,然后选择“Plasma”。当你再次登录时,一个全新的KDE桌面就会欢迎你。
|
||||
|
||||

|
||||
|
||||
刚刚安装到Fedora 22上的Plasma环境
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
就是这样了,一切就绪。使用新系统吧,试试新东西。如果你找不到与你喜好相关的东西,linux赋予你自由修改它的权利。Fedora自带有最新的Gnome Shell作为其桌面环境,如果你觉得太臃肿而不喜欢,那么试试KDE或一些轻量级的DE,像Cinnamon、xfce之类。愿你的Fedora之旅十分开心并且没有困扰。!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/things-do-after-installing-fedora-22/
|
||||
|
||||
作者:[Jonathan DeMasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/jonathande/
|
||||
[1]:https://get.adobe.com/flashplayer/
|
||||
[2]:http://spins.fedoraproject.org/
|
||||
[3]:https://www.google.com/intl/en/chrome/browser/desktop/index.html
|
||||
@ -0,0 +1,205 @@
|
||||
Nishita Agarwal分享它关于Linux防火墙'iptables'的面试经验
|
||||
================================================================================
|
||||
Nishita Agarwal是Tecmint的用户,她将分享关于她刚刚经历的一家公司(私人公司Pune,印度)的面试经验。在面试中她被问及许多不同的问题,但她是iptables方面的专家,因此她想分享这些关于iptables的问题和相应的答案给那些以后可能会进行相关面试的人。
|
||||
|
||||

|
||||
|
||||
所有的问题和相应的答案都基于Nishita Agarwal的记忆并经过了重写。
|
||||
|
||||
> “嗨,朋友!我叫**Nishita Agarwal**。我已经取得了理学学士学位,我的专业集中在UNIX和它的变种(BSD,Linux)。它们一直深深的吸引着我。我在存储方面有1年多的经验。我正在寻求职业上的变化,并将供职于印度的Pune公司。”
|
||||
|
||||
下面是我在面试中被问到的问题的集合。我已经把我记忆中有关iptables的问题和它们的答案记录了下来。希望这会对您未来的面试有所帮助。
|
||||
|
||||
### 1. 你听说过Linux下面的iptables和Firewalld么?知不知道它们是什么,是用来干什么的? ###
|
||||
|
||||
> **答案** : iptables和Firewalld我都知道,并且我已经使用iptables好一段时间了。iptables主要由C语言写成,并且以GNU GPL许可证发布。它是从系统管理员的角度写的,最新的稳定版是iptables 1.4.21。iptables通常被认为是类UNIX系统中的防火墙,更准确的说,可以称为iptables/netfilter。管理员通过终端/GUI工具与iptables打交道,来添加和定义防火墙规则到预定义的表中。Netfilter是内核中的一个模块,它执行过滤的任务。
|
||||
>
|
||||
> Firewalld是RHEL/CentOS 7(也许还有其他发行版,但我不太清楚)中最新的过滤规则的实现。它已经取代了iptables接口,并与netfilter相连接。
|
||||
|
||||
### 2. 你用过一些iptables的GUI或命令行工具么? ###
|
||||
|
||||
> **答案** : 虽然我既用过GUI工具,比如与[Webmin][1]结合的Shorewall;以及直接通过终端访问iptables。但我必须承认通过Linux终端直接访问iptables能给予用户更高级的灵活性、以及对其背后工作更好的理解的能力。GUI适合初级管理员而终端适合有经验的管理员。
|
||||
|
||||
### 3. 那么iptables和firewalld的基本区别是什么呢? ###
|
||||
|
||||
> **答案** : iptables和firewalld都有着同样的目的(包过滤),但它们使用不同的方式。iptables与firewalld不同,在每次发生更改时都刷新整个规则集。通常iptables配置文件位于‘/etc/sysconfig/iptables‘,而firewalld的配置文件位于‘/etc/firewalld/‘。firewalld的配置文件是一组XML文件。以XML为基础进行配置的firewalld比iptables的配置更加容易,但是两者都可以完成同样的任务。例如,firewalld可以在自己的命令行界面以及基于XML的配置文件下使用iptables。
|
||||
|
||||
### 4. 如果有机会的话,你会在你所有的服务器上用firewalld替换iptables么? ###
|
||||
|
||||
> **答案** : 我对iptables很熟悉,它也工作的很好。如果没有任何需求需要firewalld的动态特性,那么没有理由把所有的配置都从iptables移动到firewalld。通常情况下,目前为止,我还没有看到iptables造成什么麻烦。IT技术的通用准则也说道“为什么要修一件没有坏的东西呢?”。上面是我自己的想法,但如果组织愿意用firewalld替换iptables的话,我不介意。
|
||||
|
||||
### 5. 你看上去对iptables很有信心,巧的是,我们的服务器也在使用iptables。 ###
|
||||
|
||||
iptables使用的表有哪些?请简要的描述iptables使用的表以及它们所支持的链。
|
||||
|
||||
> **答案** : 谢谢您的赞赏。至于您问的问题,iptables使用的表有四个,它们是:
|
||||
>
|
||||
> Nat 表
|
||||
> Mangle 表
|
||||
> Filter 表
|
||||
> Raw 表
|
||||
>
|
||||
> Nat表 : Nat表主要用于网络地址转换。根据表中的每一条规则修改网络包的IP地址。流中的包仅遍历一遍Nat表。例如,如果一个通过某个接口的包被修饰(修改了IP地址),该流中其余的包将不再遍历这个表。通常不建议在这个表中进行过滤,由NAT表支持的链称为PREROUTING Chain,POSTROUTING Chain和OUTPUT Chain。
|
||||
>
|
||||
> Mangle表 : 正如它的名字一样,这个表用于校正网络包。它用来对特殊的包进行修改。它能够修改不同包的头部和内容。Mangle表不能用于地址伪装。支持的链包括PREROUTING Chain,OUTPUT Chain,Forward Chain,InputChain和POSTROUTING Chain。
|
||||
>
|
||||
> Filter表 : Filter表是iptables中使用的默认表,它用来过滤网络包。如果没有定义任何规则,Filter表则被当作默认的表,并且基于它来过滤。支持的链有INPUT Chain,OUTPUT Chain,FORWARD Chain。
|
||||
>
|
||||
> Raw表 : Raw表在我们想要配置之前被豁免的包时被使用。它支持PREROUTING Chain 和OUTPUT Chain。
|
||||
|
||||
### 6. 简要谈谈什么是iptables中的目标值(能被指定为目标),他们有什么用 ###
|
||||
|
||||
> **答案** : 下面是在iptables中可以指定为目标的值:
|
||||
>
|
||||
> ACCEPT : 接受包
|
||||
> QUEUE : 将包传递到用户空间 (应用程序和驱动所在的地方)
|
||||
> DROP : 丢弃包
|
||||
> RETURN : 将控制权交回调用的链并且为当前链中的包停止执行下一调规则
|
||||
|
||||
### 7. 让我们来谈谈iptables技术方面的东西,我的意思是说实际使用方面 ###
|
||||
|
||||
你怎么检测在CentOS中安装iptables时需要的iptables的rpm?
|
||||
|
||||
> **答案** : iptables已经被默认安装在CentOS中,我们不需要单独安装它。但可以这样检测rpm:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> 如果您需要安装它,您可以用yum来安装。
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
### 8. 怎样检测并且确保iptables服务正在运行? ###
|
||||
|
||||
> **答案** : 您可以在终端中运行下面的命令来检测iptables的状态。
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> 如果iptables没有在运行,可以使用下面的语句
|
||||
>
|
||||
> ---------------- 在CentOS 6/5下 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- 在CentOS 7下 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> 我们还可以检测iptables的模块是否被加载:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
### 9. 你怎么检查iptables中当前定义的规则呢? ###
|
||||
|
||||
> **答案** : 当前的规则可以简单的用下面的命令查看:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> 示例输出
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
### 10. 你怎样刷新所有的iptables规则或者特定的链呢? ###
|
||||
|
||||
> **答案** : 您可以使用下面的命令来刷新一个特定的链。
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> 要刷新所有的规则,可以用:
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
### 11. 请在iptables中添加一条规则,接受所有从一个信任的IP地址(例如,192.168.0.7)过来的包。 ###
|
||||
|
||||
> **答案** : 上面的场景可以通过运行下面的命令来完成。
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> 我们还可以在源IP中使用标准的斜线和子网掩码:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. 怎样在iptables中添加规则以ACCEPT,REJECT,DENY和DROP ssh的服务? ###
|
||||
|
||||
> **答案** : 但愿ssh运行在22端口,那也是ssh的默认端口,我们可以在iptables中添加规则来ACCEPT ssh的tcp包(在22号端口上)。
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
>
|
||||
> REJECT ssh服务(22号端口)的tcp包。
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
>
|
||||
> DENY ssh服务(22号端口)的tcp包。
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
>
|
||||
> DROP ssh服务(22号端口)的tcp包。
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
### 13. 让我给你另一个场景,假如有一台电脑的本地IP地址是192.168.0.6。你需要封锁在21、22、23和80号端口上的连接,你会怎么做? ###
|
||||
|
||||
> **答案** : 这时,我所需要的就是在iptables中使用‘multiport‘选项,并将要封锁的端口号跟在它后面。上面的场景可以用下面的一条语句搞定:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
>
|
||||
> 可以用下面的语句查看写入的规则。
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**面试官** : 好了,我问的就是这些。你是一个很有价值的雇员,我们不会错过你的。我将会向HR推荐你的名字。如果你有什么问题,请问我。
|
||||
|
||||
作为一个候选人我不愿不断的问将来要做的项目的事以及公司里其他的事,这样会打断愉快的对话。更不用说HR轮会不会比较难,总之,我获得了机会。
|
||||
|
||||
同时我要感谢Avishek和Ravi(我的朋友)花时间帮我整理我的面试。
|
||||
|
||||
朋友!如果您有过类似的面试,并且愿意与数百万Tecmint读者一起分享您的面试经历,请将您的问题和答案发送到admin@tecmint.com。
|
||||
|
||||
谢谢!保持联系。如果我能更好的回答我上面的问题的话,请记得告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,129 @@
|
||||
如何在Ubuntu 15.04(Vivid Vervet)中安装nginx和google pagespeed
|
||||
================================================================================
|
||||
Nginx (engine-x)是一个开源高性能http、反向代理和IMAP/POP3代理服务器。nginx杰出的功能有:稳定、丰富的功能集、简单的配置和低资源消耗。nginx被用于一些高性能网站并在站长之间变得越来越流行。本教程会从源码构建一个带有google paespeed模块用于Ubuntu 15.04中的.deb包。
|
||||
|
||||
|
||||
pagespeed是一个由google开发的web服务器模块来加速网站响应时间、优化html和减少页面加载时间。ngx_pagespeed的功能如下:
|
||||
|
||||
- 图像优化:去除meta数据、动态剪裁、重压缩。
|
||||
- CSS与JavaScript 放大、串联、内联、外联。
|
||||
- 小资源内联
|
||||
- 延迟图像与JavaScript加载
|
||||
- HTML重写。
|
||||
- 缓存生命期插件
|
||||
|
||||
更多请见 [https://developers.google.com/speed/pagespeed/module/][1].
|
||||
|
||||
### 预备要求 ###
|
||||
|
||||
Ubuntu Server 15.04 64位
|
||||
root 权限
|
||||
|
||||
本篇我们将要:
|
||||
|
||||
- 安装必备包
|
||||
- 安装带ngx_pagespeed的nginx
|
||||
- 测试
|
||||
|
||||
#### 安装必备包 ####
|
||||
|
||||
sudo apt-get install dpkg-dev build-essential zlib1g-dev libpcre3 libpcre3-dev
|
||||
|
||||
#### 安装带ngx_pagespeed的nginx ####
|
||||
|
||||
**第一步 - 添加nginx仓库**
|
||||
|
||||
vim /etc/apt/sources.list.d/nginx.list
|
||||
|
||||
加入下面的行:
|
||||
|
||||
deb http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
deb-src http://nginx.org/packages/ubuntu/ trusty nginx
|
||||
|
||||
更新仓库:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
注意:如果你看到信息:GPG error [...] NO_PUBKEY [...] 等等
|
||||
|
||||
请添加key:
|
||||
|
||||
sudo sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys KEYNUMBER
|
||||
sudo apt-get update
|
||||
|
||||
**第二步 - 从仓库下载nginx 1.8**
|
||||
|
||||
sudo su
|
||||
cd ~
|
||||
mkdir -p ~/new/nginx_source/
|
||||
cd ~/new/nginx_source/
|
||||
apt-get source nginx
|
||||
apt-get build-dep nginx
|
||||
|
||||
**第三步 - 下载Pagespeed**
|
||||
|
||||
cd ~
|
||||
mkdir -p ~/new/ngx_pagespeed/
|
||||
cd ~/new/ngx_pagespeed/
|
||||
ngx_version=1.9.32.3
|
||||
wget https://github.com/pagespeed/ngx_pagespeed/archive/release-${ngx_version}-beta.zip
|
||||
unzip release-${ngx_version}-beta.zip
|
||||
|
||||
cd ngx_pagespeed-release-1.9.32.3-beta/
|
||||
wget https://dl.google.com/dl/page-speed/psol/${ngx_version}.tar.gz
|
||||
tar -xzf 1.9.32.3.tar.gz
|
||||
|
||||
**第三步 - 配置nginx来编译Pagespeed**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/debin/
|
||||
vim rules
|
||||
|
||||
在CFLAGS `.configure`下添加模块:
|
||||
|
||||
--add-module=../../ngx_pagespeed/ngx_pagespeed-release-1.9.32.3-beta \
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**第五步 - 打包nginx包并安装**
|
||||
|
||||
cd ~/new/nginx_source/nginx-1.8.0/
|
||||
dpkg-buildpackage -b
|
||||
|
||||
dpkg-buildpackage会编译 ~/new/ngix_source/成nginx.deb。打包完成后,看一下目录:
|
||||
|
||||
cd ~/new/ngix_source/
|
||||
ls
|
||||
|
||||

|
||||
|
||||
接着安装nginx。
|
||||
|
||||
dpkg -i nginx_1.8.0-1~trusty_amd64.deb
|
||||
|
||||

|
||||
|
||||
#### 测试 ####
|
||||
|
||||
运行nginx -V测试nginx是否已经自带ngx_pagespeed。
|
||||
|
||||
nginx -V
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
稳定、快速、开源的nginx支持许多不同的优化模块。这其中之一是google开发的‘pagespeed’。不像apache,nginx模块不是动态加载的,因此你必须在编译之前就选择完需要的模块。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-nginx-and-google-pagespeed-on-ubuntu-15-04/#step-build-nginx-package-and-install
|
||||
|
||||
作者:Muhammad Arul
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://developers.google.com/speed/pagespeed/module/
|
||||
236
translated/tech/20150610 How to secure your Linux server.md
Normal file
236
translated/tech/20150610 How to secure your Linux server.md
Normal file
@ -0,0 +1,236 @@
|
||||
Linux服务器安全攻略
|
||||
================================================================================
|
||||
> 一台服务器由大量功能各异的部件组成,这一点使得很难根据每个人的需求去提供定制的解决方案。这篇文章尽可能涵盖一些有所裨益的小技巧来帮助管理员保证服务器和用户安全。
|
||||
|
||||
毋庸置疑,对于系统管理员,提高服务器的安全性是最重要的事情之一。因此,也就有了许多针对这个话题而生的文章、博客和论坛帖子。
|
||||
|
||||
一台服务器由大量功能各异的部件组成,这一点使得很难根据每个人的需求去提供定制的解决方案。这篇文章尽可能涵盖一些有所裨益的小技巧来帮助管理员保证服务器和用户安全。
|
||||
|
||||
有一些常识是每个系统管理员都应该烂熟于心的,所以下面的几点在后文将不会提及:
|
||||
|
||||
- 务必保证系统是**最新的**
|
||||
- 经常更换密码 - 使用数字、阿拉伯字母和非阿拉伯字母的符号组合
|
||||
- 给予用户**最小**的权限,满足他们日常使用所需即可
|
||||
- 只安装那些真正需要的软件包
|
||||
|
||||
下面是一些更有意思的内容:
|
||||
|
||||
### 更改SSH默认端口 ###
|
||||
|
||||
在搭建好一台全新的服务器后要做的第一件事情就是更改SSH的默认端口。这个小小单的改动能够使你的服务器避免受到成千上万的暴力攻击(译者注:不更改默认端口相当于黑客们知道你家的门牌号,这样他们只需要一把一把的试钥匙就可能打开你家的锁)。
|
||||
|
||||
要更改默认的SSH端口,先打开sshd_config文件:
|
||||
|
||||
sudo vim /etc/ssh/sshd_config
|
||||
|
||||
找到下面这行:
|
||||
|
||||
#Port 22
|
||||
|
||||
“#”号表示这行是注释。首先删除#号,然后把端口号改成目的端口。端口号不能超过65535,确保要指定的端口号没有被系统或其它服务占用。建议在[维基百科]上查看常用端口号列表。在本文中,使用这个端口号:
|
||||
|
||||
Port 16543
|
||||
|
||||
然后保存并关闭文件,等待更改生效。
|
||||
|
||||
接下来的一步是:
|
||||
|
||||
### 使用SSH密钥 ###、
|
||||
|
||||
在通过SSH访问服务器时,使用SSH密钥进行认证是尤其重要的。这样做为服务器增加了额外的保护,确保只有那些拥有密钥的人才能访问服务器。
|
||||
|
||||
在本地机器上运行下面命令以生成SSH密钥:
|
||||
|
||||
ssh-keygen -t rsa
|
||||
|
||||
你会看到下面的输出,询问要将密钥写到哪一个文件,并且设置一个密码:
|
||||
|
||||
Generating public/private rsa key pair.
|
||||
Enter file in which to save the key (/root/.ssh/id_rsa): my_key
|
||||
Enter passphrase (empty for no passphrase):
|
||||
Enter same passphrase again:
|
||||
Your identification has been saved in my_key.
|
||||
Your public key has been saved in my_key.pub.
|
||||
The key fingerprint is:
|
||||
SHA256:MqD/pzzTRsCjZb6mpfjyrr5v1pJLBcgprR5tjNoI20A
|
||||
|
||||
完成之后,就得到两个文件:
|
||||
|
||||
my_key
|
||||
|
||||
my_key.pub
|
||||
|
||||
接下来把my_key.pub拷贝到~/.ssh/authorized_key中
|
||||
|
||||
cp my_key.pub ~/.ssh/authorized_keys
|
||||
|
||||
然后使用下面命令将密钥上传到服务器:
|
||||
|
||||
scp -P16543 authorized_keys user@yourserver-ip:/home/user/.ssh/
|
||||
|
||||
至此,你就可以从这台本地机器上无密码地访问服务器了。
|
||||
|
||||
### 关闭SSH的密码认证 ###
|
||||
|
||||
既然已经有了SSH密钥,那么关闭SSH的密码认证就很安全了。再次打开并编辑sshd_config,按如下设置:
|
||||
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
|
||||
### 关闭Root登录 ###
|
||||
|
||||
下面关键的一步是关闭root用户的直接访问,而使用sudo或su来执行管理员任务。首先需要添加一个有root权限的新用户,所以编辑这个路径下的sudoers文件:
|
||||
|
||||
/etc/sudoers/
|
||||
|
||||
可以使用如**visudo**这样的命令编辑文件,推荐使用这个命令,因为它会在关闭文件之前检查任何可能出现的语法错误。当你在编辑文件时出错了,这就很有用了。
|
||||
|
||||
接下来赋予某个用户root权限。在本文中,使用用户**sysadmin**。确保在编辑后这个文件时使用的用户是系统已有的用户。找到下面这行:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
|
||||
拷贝这行,然后粘贴在下一行,然后把root更改为“sysadmin”,如下所示:
|
||||
|
||||
root ALL=(ALL) ALL
|
||||
sysadmin ALL=(ALL) ALL
|
||||
|
||||
现在解释一下这行的每一个选项的含义:
|
||||
|
||||
(1) root (2)ALL=(3)(ALL) (4)ALL
|
||||
|
||||
(1) 指定用户
|
||||
|
||||
(2) 指定用户使用sudo的终端
|
||||
|
||||
(3) 指定用户可以担任的用户角色
|
||||
|
||||
(4) 这个用户可以使用的命令
|
||||
|
||||
使用这个配置可以给用户访问一些系统工具的权限。
|
||||
|
||||
这时,可以放心保存文件了。
|
||||
|
||||
为了关闭通过SSH直接访问root,需要再次打开**sshd_config**,找到下面这行:
|
||||
|
||||
#PermitRootLogin yes
|
||||
|
||||
更改为:
|
||||
|
||||
PermitRootLogin no
|
||||
|
||||
然后保存文件,重启sshd守护进程使改动生效。执行下面命令即可:
|
||||
|
||||
sudo /etc/init.d/sshd restart
|
||||
|
||||
### 设置防火墙 ###
|
||||
|
||||
防火墙有助于过滤出入端口和阻止使用暴力法的登录尝试。我倾向于使用SCF(Config Server Firewall)这个强力防火墙。它使用了iptables,易于管理,而且对于不擅于输入命令的用户提供了web界面。
|
||||
|
||||
要安装CSF,先登录到服务器,切换到这个目录下:
|
||||
|
||||
cd /usr/local/src/
|
||||
|
||||
然后以root权限执行下面命令:
|
||||
|
||||
wget https://download.configserver.com/csf.tgz
|
||||
tar -xzf csf.tgz
|
||||
csf
|
||||
sh install.sh
|
||||
|
||||
只需等待安装程序完成,然后编辑CSF的配置文件:
|
||||
|
||||
/etc/csf/csf.conf
|
||||
|
||||
默认情况下CSF是以测试模式运行。通过将“TESTING”的值设置成0,切换到product模式。
|
||||
|
||||
TESTING = "0"
|
||||
|
||||
下面要设置的就是服务器上允许通过的端口。在csf.conf中定位到下面的部分,根据需要修改端口:
|
||||
|
||||
# Allow incoming TCP ports
|
||||
TCP_IN = "20,21,25,53,80,110,143,443,465,587,993,995,16543"
|
||||
# Allow outgoing TCP ports
|
||||
TCP_OUT = "20,21,22,25,53,80,110,113,443,587,993,995,16543"
|
||||
# Allow incoming UDP ports
|
||||
UDP_IN = "20,21,53"
|
||||
# Allow outgoing UDP ports
|
||||
# To allow outgoing traceroute add 33434:33523 to this list
|
||||
UDP_OUT = "20,21,53,113,123"
|
||||
|
||||
请根据需要逐一设置,推荐只使用那些需要的端口,避免设置对端口进行大范围设置。此外,也要避免使用不安全服务的不安全端口。比如只允许端口465和587来发送电子邮件,取代默认的SMTP端口25.
|
||||
|
||||
**重要**:千万不要忘记允许自定义SHH端口。
|
||||
|
||||
允许防火墙通过你的IP地址使其不被屏蔽,这一点很重要。IP地址定义在下面的文件中:
|
||||
|
||||
/etc/csf/csf.ignore
|
||||
|
||||
被屏蔽的IP地址会出现在这个文件中:
|
||||
|
||||
/etc/csf/csf.deny
|
||||
|
||||
一旦完成更改,使用这个命令重启csf:
|
||||
|
||||
sudo /etc/init.d/csf restart
|
||||
|
||||
下面是在某台服务器上的csf.deny文件的部分内容,来说明CSF是很有用的:
|
||||
|
||||
211.216.48.205 # lfd: (sshd) Failed SSH login from 211.216.48.205 (KR/Korea, Republic of/-): 5 in the last 3600 secs - Fri Mar 6 00:30:35 2015
|
||||
103.41.124.53 # lfd: (sshd) Failed SSH login from 103.41.124.53 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:06:46 2015
|
||||
103.41.124.42 # lfd: (sshd) Failed SSH login from 103.41.124.42 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 01:59:04 2015
|
||||
103.41.124.26 # lfd: (sshd) Failed SSH login from 103.41.124.26 (HK/Hong Kong/-): 5 in the last 3600 secs - Fri Mar 6 02:48:26 2015
|
||||
109.169.74.58 # lfd: (sshd) Failed SSH login from 109.169.74.58 (GB/United Kingdom/mail2.algeos.com): 5 in the last 3600 secs - Fri Mar 6 03:49:03 2015
|
||||
|
||||
可以看到,尝试通过暴力法登录的IP地址都被屏蔽了,真是眼不见心不烦啊!
|
||||
|
||||
#### 锁住账户 ####
|
||||
|
||||
如果某个账户在很长一段时间内都不会被使用了,那么可以将其锁住以防止其它人访问。使用如下命令:
|
||||
|
||||
passwd -l accountName
|
||||
|
||||
当然,这个账户依然可以被root用户使用。
|
||||
|
||||
### 了解服务器上的服务 ###
|
||||
|
||||
服务器的本质是为各种服务提供访问功能。使服务器只运行所需的服务,关闭没有使用的服务。这样做不仅会释放一些系统资源,而且也会使服务器变得更加安全。比如,如果只是运行一个简单的服务器,显然不需要X显示或者桌面环境。如果不需要Windows网络共享功能,则可以放心关闭Samba。
|
||||
|
||||
使用下面的命令能查看伴随系统启动而启动的服务:
|
||||
|
||||
chkconfig --list | grep "3:on"
|
||||
|
||||
如果系统运行了**systemd**,执行这条命令:
|
||||
|
||||
systemctl list-unit-files --type=service | grep enabled
|
||||
|
||||
然后使用下面的命令关闭服务:
|
||||
|
||||
chkconfig service off
|
||||
systemctl disable service
|
||||
|
||||
在上面的例子中,把“service”替换成真正想要停止的服务名称。实例如下:
|
||||
|
||||
chkconfig httpd off
|
||||
systemctl disable httpd
|
||||
|
||||
### 小结 ###
|
||||
|
||||
这篇文章的目的是涵盖一些通用的安全步骤以便帮助你保护服务器。你可以采取额外的方式去增强对服务器的保护。请记住保证服务器安全是你的责任,在维护服务器安全时尽量做出明智的选择,尽管并没有什么容易的方式去完成这件事情,而建立“完善的”安全需要花费大量的时间和测试直到达到想要的结果。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxveda.com/2015/06/03/secure-linux-server/
|
||||
|
||||
作者:[Marin Todorow][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxveda.com/author/marin_todorov/
|
||||
[1]:http://en.wikipedia.org/wiki/Port_%28computer_networking%29#Common_port_numbers
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,133 @@
|
||||
watch - 定期重复Linux / Unix命令
|
||||
================================================================================
|
||||
服务器管理员需要维护系统并保持更新和安全。每天需要尝试大量的指令。一些其他的活动存储在日志中。这些日志定期地更新。为了检车这些更新,需要重复地执行命令。比如,为了读取一个文件需要使用head、tail、cat等命令。这些命令需要重读地执行。watch命令可以用于定期地执行一个命令。
|
||||
|
||||
### Watch 命令 ###
|
||||
|
||||
watch是一个简单的命令,只有几个选项。watch命令的基本语法是:
|
||||
|
||||
watch [-dhvt] [-n <seconds>] [--differences[=cumulative]] [--help] [--interval=<seconds>] [--no-title] [--version] <command>
|
||||
|
||||
watch命令默认每隔2秒执行后面的命令。这个时间根据的是命令执行结束到上次执行的间隔来算的。比如,watch命令可以用于监测日志更新,更新时在文件的后面追加新行,因此tail命令可以用来检测文件的更新。这个命令会持续地运行直到你按下 CTRL + C回到提示符。
|
||||
|
||||
### 例子 ###
|
||||
|
||||
> 每两秒监测 errors/notices/warning 生成的情况。
|
||||
|
||||
watch tail /var/log/messages
|
||||
|
||||

|
||||
|
||||
> 用指定的时间监测磁盘的使用率。
|
||||
|
||||
watch df -h
|
||||
|
||||

|
||||
|
||||
> 对磁盘管理员而言关注高I/O等待导致的磁盘操作尤其是mysql事务是很重要的。
|
||||
|
||||
watch mysqladmin processlist
|
||||
|
||||

|
||||
|
||||
> 监测服务器负载和运行时间。
|
||||
|
||||
watch uptime
|
||||
|
||||

|
||||
|
||||
> 检测exim排队给用户发送通知队列的大小。
|
||||
|
||||
watch exim -bpc
|
||||
|
||||

|
||||
|
||||
### 1) 掩饰循环 ###
|
||||
|
||||
watch [-n <seconds>] <command>
|
||||
|
||||
命令默认运行的间隔用-n改变,下面的命令会在5秒后运行后面的命令:
|
||||
|
||||
watch -n 5 date
|
||||
|
||||

|
||||
|
||||
### 2) 连续输出比较###
|
||||
|
||||
如果你使用-d选项,它会累次地高亮第一次和下一次命令之间输出的差别。
|
||||
|
||||
watch [-d or --differences[=cumulative]] <command>
|
||||
|
||||
#### 例子 1 ####
|
||||
|
||||
用下面的命令连续地输出时间病观察高亮出来的不同部分。
|
||||
|
||||
watch -n 15 -d date
|
||||
|
||||
第一次执行date的输出会被捕捉,15后会会重复运行命令。
|
||||
|
||||

|
||||
|
||||
在下一次执行时,可以看到输出除了被高亮的秒数从14到29之外其他的都一样。
|
||||
|
||||

|
||||
|
||||
#### 例子 2 ####
|
||||
|
||||
让我们来体验一下两个连续的“uptime”命令输出的不同。
|
||||
|
||||
watch -n 20 -d uptime
|
||||
|
||||

|
||||
|
||||
现在列出了时间和3个负载快照之间的不同。
|
||||
|
||||

|
||||
|
||||
### 3) 不带标题输出 ###
|
||||
|
||||
如果你不希望显示更多关于延迟和实际命令的信息可以使用-t选项。
|
||||
|
||||
watch [-t or --no-title] <command>
|
||||
|
||||
让我们看下下面例子命令的输出:
|
||||
|
||||
watch -t date
|
||||
|
||||

|
||||
|
||||
### Watch 帮助 ###
|
||||
|
||||
可以在ssh中输入下面的命令来得到watch的简要帮助。
|
||||
|
||||
watch -h [or --help]
|
||||
|
||||

|
||||
|
||||
### Watch 版本 ###
|
||||
|
||||
在ssh终端中运行下面的命令来检查watch的版本。
|
||||
|
||||
watch -v [--version]
|
||||
|
||||

|
||||
|
||||
**问题**
|
||||
|
||||
不幸的是,在终端大小调整时,屏幕不能在下次运行前重画。所有用--difference高亮的内容也会在更新时丢失。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
watch对系统管理员而言是一个非常强大的工具因为它可以用于监控、日志、运维、性能和系统运行时的吞吐量。人们可以非常简单地格式化和推延watch的输出。任何Linux命令/程序或脚本可以按照所需监测和连续输出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/linux-watch-command/
|
||||
|
||||
作者:[Aun Raza][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunrz/
|
||||
@ -0,0 +1,279 @@
|
||||
如何在Fedora 22上面配置Apache的Docker容器
|
||||
=============================================================================
|
||||
在这篇文章中,我们将会学习关于Docker的一些知识,如何使用Docker部署Apache httpd服务,并且共享到Docker Hub上面去。首先,我们学习怎样拉取和使用Docker Hub里面的镜像,然后交互式地安装Apache到一个Fedora 22的镜像里去,之后我们将会学习如何用一个Dockerfile文件来制作一个镜像,以一种更快,更优雅的方式。最后,我们会在Docker Hub上公开我们创建地镜像,这样以后任何人都可以下载并使用它。
|
||||
|
||||
### 安装Docker,运行hello world ###
|
||||
|
||||
**要求**
|
||||
|
||||
运行Docker,里至少需要满足这些:
|
||||
|
||||
- 你需要一个64位的内核,版本3.10或者更高
|
||||
- Iptables 1.4 - Docker会用来做网络配置,如网络地址转换(NAT)
|
||||
- Git 1.7 - Docker会使用Git来与仓库交流,如Docker Hub
|
||||
- ps - 在大多数环境中这个工具都存在,在procps包里有提供
|
||||
- root - 防止一般用户可以通过TCP或者其他方式运行Docker,为了简化,我们会假定你就是root
|
||||
|
||||
### 使用dnf安装docker ###
|
||||
|
||||
以下的命令会安装Docker
|
||||
|
||||
dnf update && dnf install docker
|
||||
|
||||
**注意**:在Fedora 22里,你仍然可以使用Yum命令,但是被DNF取代了,而且在纯净安装时不可用了。
|
||||
|
||||
### 检查安装 ###
|
||||
|
||||
我们将要使用的第一个命令是docker info,这会输出很多信息给你:
|
||||
|
||||
docker info
|
||||
|
||||
也可以试着用**docker version**:
|
||||
|
||||
docker version
|
||||
|
||||
### 启动Dcoker为守护进程 ###
|
||||
|
||||
你应该启动一个docker实例,然后她会处理我们的请求。
|
||||
|
||||
docker -d
|
||||
|
||||
让我们用Busybox来打印hello world:
|
||||
|
||||
dockr run -t busybox /bin/echo "hello world"
|
||||
|
||||
这个命令里,我们告诉Docker执行 /bin/echo "hello world",在Busybox镜像的一个实例/容器里。Busybox是一个小型的POSIX环境,将许多小工具都结合到了一个单独的可执行程序里。
|
||||
|
||||
如果Docker不能在你的系统里找到本地的Busybox镜像,她就会自动从Docker Hub里拉取镜像,正如你可以看下如下的快照:
|
||||
|
||||

|
||||
|
||||
Hello world with Busybox
|
||||
|
||||
再次尝试相同的命令,这次由于Docker已经有了本地的Busybox镜像,所有你将会看到的就是echo的输出:
|
||||
|
||||
docker run -t busybox /bin/echo "hello world"
|
||||
|
||||
也可以尝试以下的命令进入到容器环境里去:
|
||||
|
||||
docker run -it busybox /bin/sh
|
||||
|
||||
使用**exit**命令可以离开容器并停止它
|
||||
|
||||
### 交互式地Docker化Apache ###
|
||||
|
||||
拉取/下载 Fedora 镜像:
|
||||
|
||||
docker pull fedora:22
|
||||
|
||||
起一个容器在后台运行:
|
||||
|
||||
docker run -d -t fedora:22 /bin/bash
|
||||
|
||||
列出正在运行地容器,并用名字标识,如下
|
||||
|
||||
docker ps
|
||||
|
||||

|
||||
|
||||
使用docker ps列出,并使用docker attach进入一个容器里
|
||||
|
||||
angry_noble是docker分配给我们容器的名字,所以我们来附上去:
|
||||
|
||||
docker attach angry_noble
|
||||
|
||||
注意:每次你起一个容器,就会被给与一个新的名字,如果你的容器需要一个固定的名字,你应该在 docker run 命令里使用 -name 参数。
|
||||
|
||||
### 安装Apache ###
|
||||
|
||||
下面的命令会更新DNF的数据库,下载安装Apache(httpd包)并清理dnf缓存使镜像尽量小
|
||||
|
||||
dnf -y update && dnf -y install httpd && dnf -y clean all
|
||||
|
||||
配置Apache
|
||||
|
||||
我们需要修改httpd.conf的唯一地方就是ServerName,这会使Apache停止抱怨
|
||||
|
||||
sed -i.orig 's/#ServerName/ServerName/' /etc/httpd/conf/httpd.conf
|
||||
|
||||
**设定环境**
|
||||
|
||||
为了使Apache运行为单机模式,你必须以环境变量的格式提供一些信息,并且你也需要在这些变量里的目录设定,所以我们将会用一个小的shell脚本干这个工作,当然也会启动Apache
|
||||
|
||||
vi /etc/httpd/run_apache_foreground
|
||||
|
||||
----------
|
||||
|
||||
#!/bin/bash
|
||||
|
||||
#set variables
|
||||
APACHE_LOG_DI=R"/var/log/httpd"
|
||||
APACHE_LOCK_DIR="/var/lock/httpd"
|
||||
APACHE_RUN_USER="apache"
|
||||
APACHE_RUN_GROUP="apache"
|
||||
APACHE_PID_FILE="/var/run/httpd/httpd.pid"
|
||||
APACHE_RUN_DIR="/var/run/httpd"
|
||||
|
||||
#create directories if necessary
|
||||
if ! [ -d /var/run/httpd ]; then mkdir /var/run/httpd;fi
|
||||
if ! [ -d /var/log/httpd ]; then mkdir /var/log/httpd;fi
|
||||
if ! [ -d /var/lock/httpd ]; then mkdir /var/lock/httpd;fi
|
||||
|
||||
#run Apache
|
||||
httpd -D FOREGROUND
|
||||
|
||||
**另外地**,你可以粘贴这个片段代码到容器shell里并运行:
|
||||
|
||||
dnf -y install git && git clone https://github.com/gaiada/run-apache-foreground.git && cd run-apach* && ./install && dnf erase git
|
||||
|
||||
上面的内嵌脚本会安装Git,克隆[这个仓库][1],到文件里去运行脚本,并询问你是否卸载Git。
|
||||
|
||||
**保存你的容器状态**
|
||||
|
||||
你的容器现在可以运行Apache,是时候保存容器当前的状态为一个镜像,以备你需要的时候使用。
|
||||
|
||||
为了离开容器环境,你必须顺序按下 **Ctrl+q** 和 **Ctrl+p**,如果你仅仅在shell执行exit,你同时也会停止容器,失去目前为止你做过的所有工作。
|
||||
|
||||
回到Docker主机,使用 **docker commit** 加容器和你期望的仓库名字/标签:
|
||||
|
||||
docker commit angry_noble gaiada/apache
|
||||
|
||||
现在,你保存了容器的状态到一个镜像里,可以使用 **docker stop** 停止容器了:
|
||||
|
||||
docker stop angry_noble
|
||||
|
||||
**运行并测试你的镜像**
|
||||
|
||||
最后,从你的新镜像起一个容器,并且重定向80端口到容器:
|
||||
|
||||
docker run -p 80:80 -d -t gaiada/apache /etc/httpd/run_apache_foreground
|
||||
|
||||
|
||||
|
||||
到目前,你正在你的容器里运行Apache,打开你的浏览器访问该服务,在[http://localhost][2],你将会看到如下Apache默认的页面
|
||||
|
||||

|
||||
|
||||
在容器里运行的Apache默认页面
|
||||
|
||||
### 使用Dockerfile Docker化Apache ###
|
||||
|
||||
现在,我们将要去创建一个新的Apache镜像,这次所有步骤会写在一个Dockerfile文件里,文件将会被用于生成该镜像。
|
||||
|
||||
首先,新建一个目录,在里面放Dockerfile文件,并进入该目录:
|
||||
|
||||
mkdir apachedf; cd apachedf
|
||||
|
||||
然后创建一个名为Dockerfile的文件,添加以下内容:
|
||||
|
||||
FROM fedora:22
|
||||
|
||||
MAINTAINER Carlos Alberto
|
||||
LABEL version="0.1"
|
||||
|
||||
RUN dnf -y update && dnf -y install httpd && dnf -y clean all
|
||||
|
||||
RUN [ -d /var/log/httpd ] || mkdir /var/log/httpd
|
||||
RUN [ -d /var/run/httpd ] || mkdir /var/run/httpd
|
||||
RUN [ -d /var/lock/httpd ] || mkdir /var/lock/httpd
|
||||
|
||||
RUN sed -i.orig 's/#ServerName/ServerName/' /etc/httpd/conf/httpd.conf
|
||||
|
||||
ENV APACHE_RUN_USER apache
|
||||
ENV APACHE_RUN_GROUP apache
|
||||
ENV APACHE_LOG_DIR /var/log/httpd
|
||||
ENV APACHE_LOCK_DIR /var/lock/httpd
|
||||
ENV APACHE_RUN_DIR /var/run/httpd
|
||||
ENV APACHE_PID_FILE /var/run/httpd/httpd.pid
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
CMD ["/usr/sbin/httpd", "-D", "FOREGROUND"]
|
||||
|
||||
|
||||
|
||||
我们一起来看看Dockerfile里面有什么:
|
||||
|
||||
**FROM** - 这告诉docker,我们将要使用Fedora 22作为基础镜像
|
||||
|
||||
**MAINTAINER** 和 **LABLE** - 这些命令对镜像没有直接作用,属于标记信息
|
||||
|
||||
**RUN** - 自动完成我们之前交互式做的工作,安装Apache,新建目录并编辑httpd.conf
|
||||
|
||||
**ENV** - 设置环境变量,现在我们再不需要run_apache_foreground脚本
|
||||
|
||||
**EXPOSE** - 暴露80端口给外网
|
||||
|
||||
**CMD** - 设置默认的命令启动httpd服务,这样我们就不需要每次起一个新的容器都重复这个工作
|
||||
|
||||
**建立该镜像**
|
||||
|
||||
现在,我们将要建立这个镜像,并为其添加tag gaiada/apachedf
|
||||
|
||||
docker build -t gaiada/apachedf:0.1 .
|
||||
|
||||

|
||||
|
||||
docker完成创建
|
||||
|
||||
使用 **docker images** 列出本地镜像,查看是否存在你新建的镜像:
|
||||
|
||||
docker images
|
||||
|
||||
然后运行新的镜像:
|
||||
|
||||
docker run -t -p 80:80 gaiada/apachedf
|
||||
|
||||
这就是Dockerfile的工作,使用这项功能会使得事情更加容易,快速并且可重复生成。
|
||||
|
||||
### 公开你的镜像 ###
|
||||
|
||||
直到现在,你仅仅是从Docker Hub拉取了镜像,但是你也可以推送你的镜像,以后需要也可以再次拉取他们。实际上,其他人也可以下载你的镜像,在他们的系统中使用它而不需要改变任何东西。现在我们将要学习如何使我们的镜像对世界上的其他人可用。
|
||||
|
||||
**创建帐号**
|
||||
|
||||
为了能够在Docker Hub上推送你的镜像,你需要创建一个帐号。访问 [https://hub.docker.com/account/signup/][3],填写下面的表格:
|
||||
|
||||

|
||||
|
||||
Docker Hub 注册页面
|
||||
|
||||
**登录**
|
||||
|
||||
输入下面的命令,接着输入你注册时提供的用户名,密码和邮箱
|
||||
|
||||
docker login
|
||||
|
||||
第一次登录过后,你的帐号信息会被记录在 **~/.dockercfg**
|
||||
|
||||
**推送**
|
||||
|
||||
推送镜像,使用 **docker push [registry/]your_login/repository_name[:tag]**
|
||||
|
||||
docker push docker.io/gaiada/apachedf
|
||||
|
||||
你可能会看见像这样的输出,在你的控制台上:
|
||||
|
||||

|
||||
|
||||
Docker推送Apache镜像完成
|
||||
|
||||
### 结论 ###
|
||||
|
||||
现在,你知道如何Docker化Apache,试一试包含其他一些组块,Perl,PHP,proxy,HTTPS,或者任何你需要的东西。我希望你们这些家伙喜欢她,并推送你们自己的镜像到Docker Hub。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-apache-containers-docker-fedora-22/
|
||||
|
||||
作者:[Carlos Alberto][a]
|
||||
译者:[wi-cuckoo](https://github.com/wi-cuckoo)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/carlosal/
|
||||
[1]:https://github.com/gaiada/run-apache-foreground
|
||||
[2]:http://localhost/
|
||||
[3]:https://hub.docker.com/account/signup/
|
||||
|
||||
1646
translated/tech/Tmux_doc_cn.md
Normal file
1646
translated/tech/Tmux_doc_cn.md
Normal file
File diff suppressed because it is too large
Load Diff
Loading…
Reference in New Issue
Block a user