mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
46aa7dccbb
@ -0,0 +1,72 @@
|
||||
Apple Watch之后,下一个智能手表会是Ubuntu吗?
|
||||
===
|
||||
|
||||
**苹果借助‘Apple Watch’的发布,证实了其进军穿戴式电子设备市场的长期传言**
|
||||
|
||||

|
||||
|
||||
Ubuntu智能手表 - 好主意?
|
||||
|
||||
拥有一系列稳定功能、硬件解决方案和应用合作伙伴关系的支持,手腕穿戴设备被许多公司预示为“人与技术关系的新篇章”。
|
||||
|
||||
它的到来,以及用户兴趣的提升,有可能意味着Ubuntu需要跟进一个为智能手表定制的Ubuntu版本。
|
||||
|
||||
### 大的方面还是成功的 ###
|
||||
|
||||
苹果在正确的时间加入了快速发展的智能手表行列。手腕穿戴设备功能的界限并不是一成不变。失败的设计、简陋的用户界面以及主流用户使用穿戴技术功能的弱定制化,这些都见证了硬件类产品仍然很脆弱 - 这一因素使得Cupertino把时间花费在Apple Watch上。
|
||||
|
||||
> ‘分析师说:超过2200万的智能手表将在今年销售’
|
||||
|
||||
去年全球范围内可穿戴设备的销售数量(包括健身追踪器)仅仅1000万。今年,分析师希望设备的销量可以超过2200万 - 不包括苹果手表,因为其直到2015年初才开始零售。
|
||||
|
||||
其实,我们很容易就可以看出增长的来源。今年九月初柏林举办的IFA 2014展览会,展示了一系列来自主要制造商们的可穿戴设备,包括索尼和华硕。大多数搭载着Google最新发布的安卓穿戴平台。
|
||||
|
||||
更成熟的一个表现是:安卓穿戴设备打破了与形式因素保持一致的新奇争论,进而呈现出一致且令人信服的用户方案。和新的苹果手表一样,它紧密地连接在一个现存的智能手机生态系统上。
|
||||
|
||||
但Ubuntu手腕穿戴系统是否能与之匹配,成为一个实用案例,目前还不清楚。
|
||||
|
||||
#### 目前还没有Ubuntu智能手表的计划 ####
|
||||
|
||||
Ubuntu操作系统的通用性将多种设备的严格标准与统一的未来目标联合在一起,Canonical已经将目标指向了智能电视,平板电脑和智能手机。公司自家的显示服务Mir,甚至被用来为所有尺寸的屏幕提供驱动接口(虽然不是公认1.5"的)。
|
||||
|
||||
今年年初,Canonical社区负责人Jono Bacon被问到是否有制作Ubuntu智能手表的打算。Bacon提供了他对这个问题的看法:“为[Ubuntu触摸设备]路线增加额外的形式因素只会减缓现有的进度”。
|
||||
|
||||
在Ubuntu手机发布两周年之际,我们还是挺赞同他的想法的。
|
||||
|
||||
###除了A面还有B面!###
|
||||
|
||||
但是并不是没有希望的。在[几个月之后的一次电话采访][1]中,Ubuntu创始人Mark Shuttleworth提到,可穿戴技术和智能电视、平板电脑、智能手机一样,都在公司计划当中。
|
||||
|
||||
> “Ubuntu因其在电话中的完美设计变得独一无二,但同时它的设计也能够满足其他生态系统,从穿戴设备到PC机。”
|
||||
|
||||
然而这还没得到具体的证实,它更像一个指针,在某个方向给我们提供一个乐观的指引。
|
||||
|
||||
#### 不大可能 — 但这就是原因所在 ####
|
||||
|
||||
Canonical并不反对利用牢固的专利进军市场。事实上,它恰恰是公司DNA基因的一部分 — 犹如服务器端的RHEL,桌面端的Windows,智能手机上的安卓...
|
||||
|
||||
设备上的Ubuntu系统被制作成可以在更小的屏幕上扩展和适配运行,甚至在小如手表一样的屏幕上。当普通的代码基础已经在手机、平板电脑、桌面和TV上准备就绪,在同样的方向上,如果看不到社区的努力是十分令人吃惊的。
|
||||
|
||||
但是我之所以不认为它会从Canonical发生,至少目前还没有,是基于今年早些时候Jono Bacon的个人思想得出的结论:时间和努力。
|
||||
|
||||
Tim Cook在他的主题演讲中说道:“*我们并没有追随iPhone,也没有缩水用户界面,将其强硬捆绑在你的手腕上。*”这是一个很明显的陈述。为如此小的屏幕设计UI和UX模型、通过交互原则工作、对硬件和输入模式的推崇,这些都不是容易的事。
|
||||
|
||||
可穿戴技术仍然是一个新兴的市场。在这个阶段,Canonical可能会在探寻的过程中浪费一些发展、设计和商业上的机会。如果在一些更为紧迫的领域落后了,造成的后果远比眼前利益的损失更严重。
|
||||
|
||||
打一场持久战,耐心等待,看哪些努力成功哪些会失败,这是一条更难的路线,但是却更适合Ubuntu,就如同今天它做的一样。在新产品出现之前,Canonical把力量用在现存的产品上是更好的选择(这是一些已经来迟的理论)
|
||||
|
||||
想更进一步了解什么是Ubuntu智能手表,点击下面的[视频][2],里面展示了一个交互的Unity主题皮肤Tizen(它已经支持Samsung Galaxy Gear智能手表)。
|
||||
|
||||
---
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/09/ubuntu-smartwatch-apple-iwatch
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/03/ubuntu-tablets-coming-year
|
||||
[2]:https://www.youtube.com/embed/8Zf5dktXzEs?feature=oembed
|
||||
@ -1,8 +1,7 @@
|
||||
IPv6:IPv4犯的罪,为什么要我来弥补
|
||||
IPv6:IPv4犯的错,为什么要我来弥补
|
||||
================================================================================
|
||||
(LCTT:标题党了一把,哈哈哈好过瘾,求不拍砖)
|
||||
|
||||
在过去的十年间,IPv6 本来应该得到很大的发展,但事实上这种好事并没有降临。由此导致了一个结果,那就是大部分人都不了解 IPv6 的一些知识:它是什么,怎么使用,以及,为什么它会存在?(LCTT:这是要回答蒙田的“我是谁”哲学思考题吗?)
|
||||
在过去的十年间,IPv6 本来应该得到很大的发展,但事实上这种好事并没有降临。由此导致了一个结果,那就是大部分人都不了解 IPv6 的一些知识:它是什么,怎么使用,以及,为什么它会存在?
|
||||
|
||||

|
||||
|
||||
@ -12,15 +11,15 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
自从1981年发布了 RFC 791 标准以来我们就一直在使用 **IPv4**。在那个时候,电脑又大又贵还不多见,而 IPv4 号称能提供**40亿条 IP 地址**,在当时看来,这个数字好大好大。不幸的是,这么多的 IP 地址并没有被充分利用起来,地址与地址之间存在间隙。举个例子,一家公司可能有**254(2^8-2)**条地址,但只使用其中的25条,剩下的229条被空占着,以备将来之需。于是这些空闲着的地址不能服务于真正需要它们的用户,原因就是网络路由规则的限制。最终的结果是在1981年看起来那个好大好大的数字,在2014年看起来变得好小好小。
|
||||
|
||||
互联网工程任务组(**IETF**)在90年代指出了这个问题,并提供了两套解决方案:无类型域间选路(**CIDR**)以及私有地址。在 CIDR 出现之前,你只能选择三种网络地址长度:**24 位** (共可用16,777,214个地址), **20位** (共可用1,048,574个地址)以及**16位** (共可用65,534个地址)。CIDR 出现之后,你可以将一个网络再划分成多个子网。
|
||||
互联网工程任务组(**IETF**)在90年代初指出了这个问题,并提供了两套解决方案:无类型域间选路(**CIDR**)以及私有IP地址。在 CIDR 出现之前,你只能选择三种网络地址长度:**24 位** (共16,777,214个可用地址), **20位** (共1,048,574个可用地址)以及**16位** (共65,534个可用地址)。CIDR 出现之后,你可以将一个网络再划分成多个子网。
|
||||
|
||||
举个例子,如果你需要**5个 IP 地址**,你的 ISP 会为你提供一个子网,里面的主机地址长度为3位,也就是说你最多能得到**6个地址**(LCTT:抛开子网的网络号,3位主机地址长度可以表示0~7共8个地址,但第0个和第7个有特殊用途,不能被用户使用,所以你最多能得到6个地址)。这种方法让 ISP 能尽最大效率分配 IP 地址。“私有地址”这套解决方案的效果是,你可以自己创建一个网络,里面的主机可以访问外网的主机,但外网的主机很难访问到你创建的那个网络上的主机,因为你的网络是私有的、别人不可见的。你可以创建一个非常大的网络,因为你可以使用16,777,214个主机地址,并且你可以将这个网络分割成更小的子网,方便自己管理。
|
||||
|
||||
也许你现在正在使用私有地址。看看你自己的 IP 地址,如果这个地址在这些范围内:**10.0.0.0 – 10.255.255.255**、**172.16.0.0 – 172.31.255.255**或**192.168.0.0 – 192.168.255.255**,就说明你在使用私有地址。这两套方案有效地将“IP 地址用尽”这个灾难延迟了好长时间,但这毕竟只是权宜之计,现在我们正面临最终的审判。
|
||||
|
||||
**IPv4** 还有另外一个问题,那就是这个协议的消息头长度可变。如果数据通过软件来路由,这个问题还好说。但现在路由器功能都是由硬件提供的,处理变长消息头对硬件来说是一件困难的事情。一个大的路由器需要处理来自世界各地的大量数据包,这个时候路由器的负载是非常大的。所以很明显,我们需要固定消息头的长度。
|
||||
**IPv4** 还有另外一个问题,那就是这个协议的消息头长度可变。如果数据的路由通过软件来实现,这个问题还好说。但现在路由器功能都是由硬件提供的,处理变长消息头对硬件来说是一件困难的事情。一个大的路由器需要处理来自世界各地的大量数据包,这个时候路由器的负载是非常大的。所以很明显,我们需要固定消息头的长度。
|
||||
|
||||
还有一个问题,在分配 IP 地址的时候,美国人发了因特网(LCTT:这个万恶的资本主义国家占用了大量 IP 地址)。其他国家只得到了 IP 地址的碎片。我们需要重新定制一个架构,让连续的 IP 地址能在地理位置上集中分布,这样一来路由表可以做的更小(LCTT:想想吧,网速肯定更快)。
|
||||
在分配 IP 地址的同时,还有一个问题,因特网是美国人发明的(LCTT:这个万恶的资本主义国家占用了大量 IP 地址)。其他国家只得到了 IP 地址的碎片。我们需要重新定制一个架构,让连续的 IP 地址能在地理位置上集中分布,这样一来路由表可以做的更小(LCTT:想想吧,网速肯定更快)。
|
||||
|
||||
还有一个问题,这个问题你听起来可能还不大相信,就是 IPv4 配置起来比较困难,而且还不好改变。你可能不会碰到这个问题,因为你的路由器为你做了这些事情,不用你去操心。但是你的 ISP 对此一直是很头疼的。
|
||||
|
||||
@ -28,10 +27,10 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
### IPv6 和它的优点 ###
|
||||
|
||||
**IETF** 在1995年12月公布了下一代 IP 地址标准,名字叫 IPv6,为什么不是 IPv5?因为某个错误原因,“版本5”这个编号被其他项目用去了。IPv6 的优点如下:
|
||||
**IETF** 在1995年12月公布了下一代 IP 地址标准,名字叫 IPv6,为什么不是 IPv5?→_→ 因为某个错误原因,“版本5”这个编号被其他项目用去了。IPv6 的优点如下:
|
||||
|
||||
- 128位地址长度(共有3.402823669×10³⁸个地址)
|
||||
- 这个架构下的地址在逻辑上聚合
|
||||
- 其架构下的地址在逻辑上聚合
|
||||
- 消息头长度固定
|
||||
- 支持自动配置和修改你的网络。
|
||||
|
||||
@ -43,7 +42,7 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
#### 聚合 ####
|
||||
|
||||
有这么多的地址,这个地址可以被稀稀拉拉地分配给主机,从而更高效地路由数据包。算一笔帐啊,你的 ISP 拿到一个**80位**地址长度的网络空间,其中16位是 ISP 的子网地址,剩下64位分给你作为主机地址。这样一来,你的 ISP 可以分配65,534个子网。
|
||||
有这么多的地址,这些地址可以被稀稀拉拉地分配给主机,从而更高效地路由数据包。算一笔帐啊,你的 ISP 拿到一个**80位**地址长度的网络空间,其中16位是 ISP 的子网地址,剩下64位分给你作为主机地址。这样一来,你的 ISP 可以分配65,534个子网。
|
||||
|
||||
然而,这些地址分配不是一成不变地,如果 ISP 想拥有更多的小子网,完全可以做到(当然,土豪 ISP 可能会要求再来一个80位网络空间)。最高的48位地址是相互独立地,也就是说 ISP 与 ISP 之间虽然可能分到相同地80位网络空间,但是这两个空间是相互隔离的,好处就是一个网络空间里面的地址会聚合在一起。
|
||||
|
||||
@ -51,25 +50,25 @@ IPv4 和 IPv6 的区别
|
||||
|
||||
**IPv4** 消息头长度可变,但 **IPv6** 消息头长度被固定为40字节。IPv4 会由于额外的参数导致消息头变长,IPv6 中,如果有额外参数,这些信息会被放到一个紧挨着消息头的地方,不会被路由器处理,当消息到达目的地时,这些额外参数会被软件提取出来。
|
||||
|
||||
IPv6 消息头有一个部分叫“flow”,是一个20位伪随机数,用于简化路由器对数据包地路由过程。如果一个数据包存在“flow”,路由器就可以根据这个值作为索引查找路由表,不必慢吞吞地遍历整张路由表来查询路由路径。这个优点使 **IPv6** 更容易被路由。
|
||||
IPv6 消息头有一个部分叫“flow”,是一个20位伪随机数,用于简化路由器对数据包的路由过程。如果一个数据包存在“flow”,路由器就可以根据这个值作为索引查找路由表,不必慢吞吞地遍历整张路由表来查询路由路径。这个优点使 **IPv6** 更容易被路由。
|
||||
|
||||
#### 自动配置 ####
|
||||
|
||||
**IPv6** 中,当主机开机时,会检查本地网络,看看有没有其他主机使用了自己的 IP 地址。如果地址没有被使用,就接着查询本地的 IPv6 路由器,找到后就向它请求一个 IPv6 地址。然后这台主机就可以连上互联网了 —— 它有自己的 IP 地址,和自己的默认路由器。
|
||||
|
||||
如果这台默认路由器当机,主机就会接着找其他路由器,作为备用路由器。这个功能在 IPv4 协议里实现起来非常困难。同样地,假如路由器想改变自己的地址,自己改掉就好了。主机会自动搜索路由器,并自动更新路由器地址。路由器会同时保存新老地址,直到所有主机都把自己地路由器地址更新成新地址。
|
||||
如果这台默认路由器宕机,主机就会接着找其他路由器,作为备用路由器。这个功能在 IPv4 协议里实现起来非常困难。同样地,假如路由器想改变自己的地址,自己改掉就好了。主机会自动搜索路由器,并自动更新路由器地址。路由器会同时保存新老地址,直到所有主机都把自己地路由器地址更新成新地址。
|
||||
|
||||
IPv6 自动配置还不是一个完整地解决方案。想要有效地使用互联网,一台主机还需要另外的东西:域名服务器、时间同步服务器、或者还需要一台文件服务器。于是 **dhcp6** 出现了,提供与 dhcp 一样的服务,唯一的区别是 dhcp6 的机器可以在可路由的状态下启动,一个 dhcp 进程可以为大量网络提供服务。
|
||||
|
||||
#### 唯一的大问题 ####
|
||||
|
||||
如果 IPv6 真的比 IPv4 好那么多,为什么它还没有被广泛使用起来(Google 在**2014年5月份**估计 IPv6 的市场占有率为**4%**)?一个最基本的原因是“先有鸡还是先有蛋”问题,用户需要让自己的服务器能为尽可能多的客户提供服务,这就意味着他们必须部署一个 **IPv4** 地址。
|
||||
如果 IPv6 真的比 IPv4 好那么多,为什么它还没有被广泛使用起来(Google 在**2014年5月份**估计 IPv6 的市场占有率为**4%**)?一个最基本的原因是“先有鸡还是先有蛋”。服务商想让自己的服务器为尽可能多的客户提供服务,这就意味着他们必须部署一个 **IPv4** 地址。
|
||||
|
||||
当然,他们可以同时使用 IPv4 和 IPv6 两套地址,但很少有客户会用到 IPv6,并且你还需要对你的软件做一些小修改来适应 IPv6。另外比较头疼的一点是,很多家庭的路由器压根不支持 IPv6。还有就是 ISP 也不愿意支持 IPv6,我问过我的 ISP 这个问题,得到的回答是:只有客户明确指出要部署这个时,他们才会用 IPv6。然后我问了现在有多少人有这个需求,答案是:包括我在内,共有1个。
|
||||
|
||||
与这种现实状况呈明显对比的是,所有主流操作系统:Windows、OS X、Linux 都默认支持 IPv6 好多年了。这些操作系统甚至提供软件让 IPv6 的数据包披上 IPv4 的皮来骗过那些会丢弃 IPv6 数据包的主机,从而达到传输数据的目的(LCTT:呃,这是高科技偷渡?)。
|
||||
与这种现实状况呈明显对比的是,所有主流操作系统:Windows、OS X、Linux 都默认支持 IPv6 好多年了。这些操作系统甚至提供软件让 IPv6 的数据包披上 IPv4 的皮来骗过那些会丢弃 IPv6 数据包的主机,从而达到传输数据的目的。
|
||||
|
||||
#### 总结 ####
|
||||
### 总结 ###
|
||||
|
||||
IPv4 已经为我们服务了好长时间。但是它的缺陷会在不远的将来遭遇不可克服的困难。IPv6 通过改变地址分配规则、简化数据包路由过程、简化首次加入网络时的配置过程等策略,可以完美解决这个问题。
|
||||
|
||||
@ -81,7 +80,7 @@ via: http://www.tecmint.com/ipv4-and-ipv6-comparison/
|
||||
|
||||
作者:[Jeff Silverman][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,两个桌面环境都有强有弱,这两者到底怎样呢?
|
||||
|
||||
只要稍加留意,任何人都会相信,Google 在桌面领域绝不是“玩玩而已”。在近几年,我们见到的 [ChromeOS][1] 制造的 [Google Chromebook][2] 相当的轰动。和同期人气火爆的 Amazon 一样,ChromeOS 似乎势不可挡。
|
||||
|
||||
在本文中,我们要了解的是 ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,整个 ChromeOS 对于Linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大问题,以及为什么没人针对这些问题做点什么。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说 ChromeOS 是否是 Linux 的一个发行版时,我都会这样回答:ChromeOS 之于 Linux 就如同 OS X 之于 BSD。换句话说,我认为,ChromeOS 是 Linux 的一个派生操作系统,运行于 Linux 内核的引擎之下。而这个操作系统的大部分由 Google 的专利代码及软件组成。
|
||||
|
||||
尽管 ChromeOS 是利用了 Linux 的内核引擎,但是和现在流行的 Linux 分支版本相比,它仍然有很大的不同。
|
||||
|
||||
其实,ChromeOS 的差异化越来越明显的原因,是在于它给终端用户提供的包括 Web 应用在内的 app。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于 Linux 用户来说,可能会有很多不一样的感受,但是,对于没有 Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
比方说,每一个以“依赖 Google 产品”为生活方式的人来说,在 ChromeOS 上的感觉将会非常良好,就好像是回家一样,特别是这个人已经接受了 Chrome 浏览器、Google Drive 云存储和Gmail 的话。久而久之,他们使用ChromeOS 也就是很自然的事情了,因为他们很容易接受使用早已习惯的 Chrome 浏览器。
|
||||
|
||||
然而,对于 Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择是被限制、被禁锢的,再加上要想玩游戏和 VoIP 是完全不可能的。对不起,因为 [GooglePlus Hangouts][3] 是代替不了VoIP 软件的。甚至这种情况将持续很长一段时间。
|
||||
|
||||
### ChromeOS 还是 Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对 Linux 产生影响,只有在 Linux 停下来浮出水面喘气的时候,或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面 Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,就如同我们在 Windows 和 OS X 阵营看到的一样。但是,令人失望的是,在美国, Linux 恰恰在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现 Linux 桌面系统最适合那些能够提供在线技术支持的环境中。比如说:可以在家里操作和处理更新的高级用户、政府和学校的 IT 部门等等。这些环境中,Linux 桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于 ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为 Google 的 ChromeOS 伴随着其硬件一起提供,大部分情况下都无需担心错误的驱动、适配什么的问题。对于某些人来说,这太好了。
|
||||
|
||||
然而有些人则认为这是一个很严重的问题,不过滑稽的是,对 ChomeOS 来说,这些人压根就不在它的目标市场里。简言之,这只是一些狂热的 Linux 爱好者在对 ChomeOS 鸡蛋里挑骨头罢了。要我说,还是停止这些没必要的批评吧。
|
||||
|
||||
问题的关键在于:ChromeOS 的市场份额和 Linux 桌面系统在很长的一段时间内是不同的。这个局面可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对 ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对 ChromeOS 的电脑。命名为 [Dell Chromebox][5],这款 ChromeOS 设备将会是对传统设备的又一次冲击。它没有软件光驱,没有反病毒软件,能够提供无缝的幕后自动更新。对于一般的用户,Chromebox 和 Chromebook 正逐渐成为那些工作在 Web 浏览器上的人们的一个可靠选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘大小和严重依赖于云存储,ChromeOS 对于那些需要使用基本的浏览器功能之外的人们来说还不够用。
|
||||
|
||||
### ChromeOS 和 Linux 的异同点 ###
|
||||
|
||||
以前,我注意到 ChromeOS 和 Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于 Linux 社区在线下的桌面支持上一直都有着极其糟糕的表现。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux特点”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,以让他们得到 Linux 方面更多的帮助。
|
||||
|
||||
事实上,线下问题的出现可能是这样的:
|
||||
|
||||
- 有些用户偶然的在当地的 Linux 活动中发现了 Linux。
|
||||
- 他们带回了 DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功完成了安装过程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人只能寄希望于在网上论坛里搜索帮助。他们很难通过主流的计算机网络经验或视频教程解决这些问题。
|
||||
-于是这些人受够了。后来有很多失望的用户拿着他们的电脑到 Windows 商店来“维修”。除了重装一个 Windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边的真事,而且是经常发生。醒醒吧,Linux 社区的人们,我们的推广模式早已过期无力了。
|
||||
|
||||
### 伟大的平台,糟糕的营销和最终结论 ###
|
||||
|
||||
如果非要找一个 ChromeOS 和 Linux 桌面系统的共同点,除了它们都使用了 Linux 内核,那就是它们都是伟大的产品却拥有极其差劲的市场营销。对此,Google 认为自己的优势是,它能投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的问题不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 最严重的失误之一。而当地的 Linux 零售商则坚信,对于不怎么上网的人,自然不必担心他们会受到 Google巨大的在线存储的诱惑。
|
||||
|
||||
我的建议是:Linux 可以通过线下的努力,提供桌面系统,渗透 ChromeOS 市场。这就意味着 Linux 社区需要在节假日筹集资金来出席博览会、商场展览,并且在社区中进行免费的教学课程。这会立即使 Linux 桌面系统走入人们的视线,否则,最终将会是一个 ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有像我说的这样,别担心。Linux 桌面系统的市场仍然会像 ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -0,0 +1,64 @@
|
||||
Linux上几款好用的字幕编辑器
|
||||
================================================================================
|
||||
如果你经常看国外的大片,你应该会喜欢带字幕版本而不是有国语配音的版本。我在法国长大,童年的记忆里充满了迪斯尼电影。但是这些电影因为有了法语的配音而听起来很怪。如果现在有机会能看原始的版本,我想,对于大多数的人来说,字幕还是必须的。我很高兴能为家人制作字幕。给我带来希望的是,Linux 也不乏有很多花哨、开源的字幕编辑器。总之一句话,文中Linux上字幕编辑器的列表并不详尽,你可以告诉我哪一款是你认为最好的字幕编辑器。
|
||||
|
||||
### 1. Gnome Subtitles ###
|
||||
|
||||
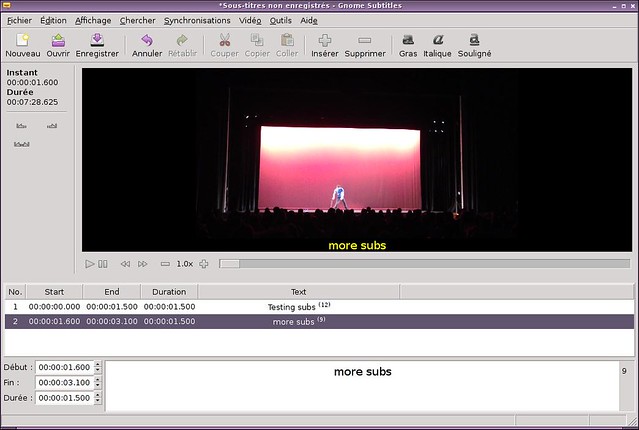
|
||||
|
||||
当有现有字幕需要快速编辑时,[Gnome Subtitles][1] 是我的一个选择。你可以载入视频,载入字幕文本,然后就可以即刻开始了。我很欣赏其对于易用性和高级特性之间的平衡。它带有一个同步工具以及一个拼写检查工具。最后但同样重要的的一点,这么好用最主要的是因为它的快捷键:当你编辑很多的台词的时候,你最好把你的手放在键盘上,使用其内置的快捷键来移动。
|
||||
|
||||
### 2. Aegisub ###
|
||||
|
||||
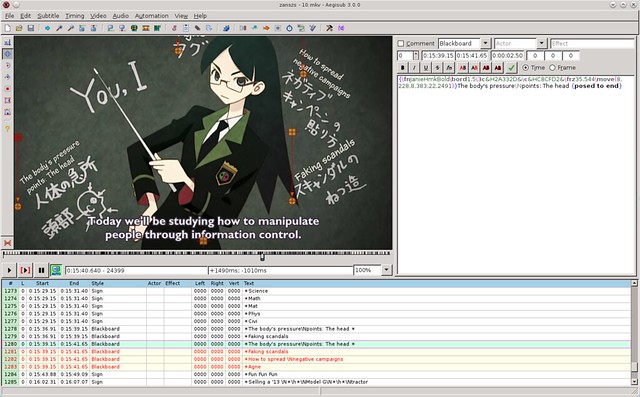
|
||||
|
||||
[Aegisub][2] 已经是一款高级别的复杂字幕编辑器。仅仅是界面就反映出了一定的学习曲线。但是,除了它吓人的样子以外,Aegisub 是一个非常完整的软件,提供的工具远远超出你能想象的。和Gnome Subtitles 一样,Aegisub也采用了所见即所得(WYSIWYG:what you see is what you get)的处理方式。但是是一个全新的高度:可以再屏幕上任意拖动字幕,也可以在另一边查看音频的频谱,并且可以利用快捷键做任何的事情。除此以外,它还带有一个汉字工具,有一个kalaok模式,并且你可以导入lua 脚本让它自动完成一些任务。我希望你在用之前,先去阅读下它的[指南][3]。
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
另一个操作复杂的软件是[Gaupol][4],不像Aegisub ,Gaupol 很容易上手而且采用了一个和Gnome Subtitles 很像的界面。但是在这些相对简单背后,它拥有很多很必要的工具:快捷键、第三方扩展、拼写检查,甚至是语音识别(由[CMU Sphinx][5]提供)。这里也提一个缺点,我注意到有时候在测试的时候也,软件会有消极怠工的表现,不是很严重,但是也足以让我更有理由喜欢Gnome Subtitles了。
|
||||
|
||||
### 4. Subtitle Editor ###
|
||||
|
||||
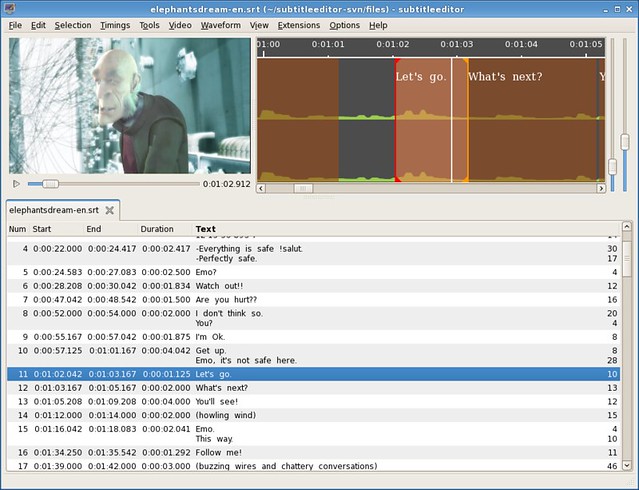
|
||||
|
||||
[Subtitle Editor][6]和 Gaupol 很像,但是它的界面有点不太直观,特性也只是稍微的高级一点点。我很欣赏的一点是,它可以定义“关键帧”,而且提供所有的同步选项。然而,多一点的图标,或者是少一点的文字都能提供界面的特性。作为一个值得称赞的字幕编辑器,Subtitle Editor 可以模仿“作家”打字的效果,虽然我不确定它是否特别有用。最后但同样重要的一点,重定义快捷键的功能很实用。
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
[Jubler][7]是一个用Java编写并有多平台支持的字幕编辑器。我对它的界面印象特别深刻。在上面我确实看出了Java特点的东西,但是,它仍然是经过精心的构造和构思的。像Aegisub 一样,你可以再屏幕上任意的拖动字幕,让你有愉快的体验而不单单是打字。它也可以为字幕自定义一个风格,在另外的一个轨道播放音频,翻译字幕,或者是是做拼写检查。不过,要注意的是,你需要事先安装好媒体播放器并且正确的配置,如果你想完整的使用Jubler。我把这些归功于在[官方页面][8]下载了脚本以后其简便的安装方式。
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
[Subtitle Composer][9]被视为“KDE里的字幕作曲家”,它能够唤起对很多传统功能的回忆。伴随着KDE界面,我们充满了期待。我们自然会说到快捷键,我特别喜欢这个功能。除此之外,Subtitle Composer 与上面提到的编辑器最大的不同地方就在于,它可以执行用JavaScript,Python,甚至是Ruby写成的脚本。软件带有几个例子,肯定能够帮助你很好的学习使用这些特性的语法。
|
||||
|
||||
最后,不管你是否喜欢,都来为你的家庭编辑几个字幕吧,重新同步整个轨道,或者是一切从头开始,那么Linux 有很好的工具给你。对我来说,快捷键和易用性使得各个工具有差异,想要更高级别的使用体验,脚本和语音识别就成了很便利的一个功能。
|
||||
|
||||
你会使用哪个字幕编辑器,为什么?你认为还有没有更好用的字幕编辑器这里没有提到的?在评论里告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -1,22 +1,22 @@
|
||||
Linux用户应该了解一下开源硬件
|
||||
Linux用户,你们真的了解开源硬件吗?
|
||||
================================================================================
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们将会很失望。
|
||||
> Linux用户不了解一点开源硬件制造相关的事情,他们就会经常陷入失望的情绪中。
|
||||
|
||||
商业软件和免费软件已经互相纠缠很多年了,但是这俩经常误解对方。这并不奇怪 -- 对一方来说是生意,而另一方只是一种生活方式。但是,这种误解会给人带来痛苦,这也是为什么值得花精力去揭露这里面的内幕。
|
||||
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他几个。不管是评论员或终端用户,一般的免费软件用户会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,最终放弃整个产品。
|
||||
一个逐渐普遍的现象:对开源硬件的不断尝试,不管是Canonical,Jolla,MakePlayLive,或者其他公司。无论是评论员或是终端用户,通常免费软件用户都会为新的硬件平台发布表现出过分的狂热,然后因为不断延期有所醒悟,直到最终放弃整个产品。
|
||||
|
||||
这是一个没有人获益的怪圈,而且滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
这是一个没有人获益的怪圈,而且常常滋生出不信任 - 都是因为一般的Linux用户根本不知道这些新闻背后发生的事情。
|
||||
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还不知道谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新加入的厂商。
|
||||
我个人对于把产品推向市场的经验很有限。但是,我还没听说谁能有所突破。推出一个开源硬件或其他产品到市场仍然不仅仅是个残酷的生意,而且严重不利于新进厂商。
|
||||
|
||||
### 寻找合作伙伴 ###
|
||||
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生成商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
不管是数码产品的生产还是分销都被相对较少的一些公司控制着,有时需要数月的预订。利润率也会很低,所以就像那些购买古老情景喜剧的电影工作室一样,生产商一般也希望复制当前热销产品的成功。像Aaron Seigo在谈到他花精力开发Vivaldi平板时告诉我的,生产商更希望能由其他人去承担开发新产品的风险。
|
||||
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来可复制生意的人合作。
|
||||
不仅如此,他们更希望和那些有现成销售记录的有可能带来长期客户生意的人合作。
|
||||
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星合作,因为它们的订单很可能是几百K。
|
||||
而且,一般新加入的厂商所关心的产品只有几千的量。芯片制造商更愿意和苹果或三星这样的公司合作,因为它们的订单很可能是几十上百万的量。
|
||||
|
||||
面对这种情形,开源硬件制造者们可能会发现他们在工厂的列表中被淹没了,除非能找到二线或三线厂愿意尝试一下小批量生产新产品。
|
||||
|
||||
@ -28,9 +28,9 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
这样必然会引起潜在用户的批评,但是开源硬件制造者没得选,只能折中他们的愿景。寻找其他生产商也不能解决问题,有一个原因是这样做意味着更多延迟,但是更多的是因为完全免授权费的硬件是不存在的。像三星这样的业内巨头对免费硬件没有任何兴趣,而作为新人,开源硬件制造者也没有影响力去要求什么。
|
||||
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一样的仗。
|
||||
更何况,就算有免费硬件,生产商也不能保证会用在下一批生产中。制造者们会轻易地发现他们每次需要生产的时候都要重打一次一模一样的仗。
|
||||
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。机会来了,产业标准已经变更,他们也许为了升级产品规格又要从头来过。
|
||||
这些都还不够,这个时候开源硬件制造者们也许已经花了6-12个月时间来讨价还价。等机会终于来了,产业标准却已经变更,于是他们可能为了升级产品规格又要从头来过。
|
||||
|
||||
### 短暂而且残忍的货架期 ###
|
||||
|
||||
@ -42,15 +42,15 @@ Linux用户应该了解一下开源硬件
|
||||
|
||||
### 衡量整件怪事 ###
|
||||
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认出我形容成标准的东西。而更糟糕的是,开源硬件制造者们通常在这个过程中才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
在这里我只是粗略地概括了一下,但是任何涉足过制造的人会认同我形容为行业标准的东西。而更糟糕的是,开源硬件制造者们通常只有在亲身经历过后才会有所觉悟。不可避免,他们也会犯错,从而带来更多的延迟。
|
||||
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的消息的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远不会真正发布。
|
||||
但重点是,一旦你对整个过程有所了解,你对另一个开源硬件进行尝试的新闻的反应就会改变。这个过程意味着,除非哪家公司处于严格的保密模式,对于产品将于六个月内发布的声明会很快会被证实是过期的推测。很可能是12-18个月,而且面对之前提过的那些困难很可能意味着这个产品永远都不会真正发布。
|
||||
|
||||
举个例子,就像我写的,人们等待第一代Steam Machines面世,它是一台基于Linux的游戏主机。他们相信Steam Machines能彻底改变Linux和游戏。
|
||||
|
||||
作为一个市场分类,Steam Machines也许比其他新产品更有优势,因为参与开发的人员至少有开发软件产品的经验。然而,整整一年过去了Steam Machines的开发成果都还只有原型机,而且直到2015年中都不一定能买到。面对硬件生产的实际情况,就算有一半能见到阳光都是很幸运了。而实际上,能发布2-4台也许更实际。
|
||||
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些即使是短暂的成功的产品。
|
||||
我做出这个预测并没有考虑个体努力。但是,对硬件生产的理解,比起那些Linux和游戏的黄金年代之类的预言,我估计这个更靠谱。如果我错了也会很开心,但是事实不会改变:让人吃惊的不是如此多的Linux相关硬件产品失败了,而是那些虽然短暂但却成功的产品。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -58,7 +58,7 @@ via: http://www.datamation.com/open-source/what-linux-users-should-know-about-op
|
||||
|
||||
作者:[Bruce Byfield][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -95,7 +95,7 @@ via: http://xmodulo.com/configure-peer-to-peer-vpn-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,324 @@
|
||||
使用 Quagga 将你的 CentOS 系统变成一个 BGP 路由器
|
||||
================================================================================
|
||||
|
||||
在[之前的教程中][1],我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些介绍。Quagga是一个开源路由软件套件。在这个教程中,我将会重点讲讲**如何把一个Linux系统变成一个BGP路由器,还是使用Quagga**,演示如何建立BGP与其它BGP路由器对等。
|
||||
|
||||
在我们进入细节之前,一些BGP的背景知识还是必要的。边界网关协议(即BGP)是互联网的域间路由协议的实际标准。在BGP术语中,全球互联网是由成千上万相关联的自治系统(AS)组成,其中每一个AS代表每一个特定运营商提供的一个网络管理域([据说][2],美国前总统乔治.布什都有自己的 AS 编号)。
|
||||
|
||||
为了使其网络在全球范围内路由可达,每一个AS需要知道如何在英特网中到达其它的AS。这时候就需要BGP出来扮演这个角色了。BGP是一个AS去与相邻的AS交换路由信息的语言。这些路由信息通常被称为BGP线路或者BGP前缀。包括AS号(ASN;全球唯一号码)以及相关的IP地址块。一旦所有的BGP线路被当地的BGP路由表学习和记录,每一个AS将会知道如何到达互联网的任何公网IP。
|
||||
|
||||
在不同域(AS)之间路由的能力是BGP被称为外部网关协议(EGP)或者域间协议的主要原因。就如一些路由协议,例如OSPF、IS-IS、RIP和EIGRP都是内部网关协议(IGPs)或者域内路由协议,用于处理一个域内的路由.
|
||||
|
||||
### 测试方案 ###
|
||||
|
||||
在这个教程中,让我们来使用以下拓扑。
|
||||
|
||||

|
||||
|
||||
我们假设运营商A想要建立一个BGP来与运营商B对等交换路由。它们的AS号和IP地址空间的细节如下所示:
|
||||
|
||||
- **运营商 A**: ASN (100), IP地址空间 (100.100.0.0/22), 分配给BGP路由器eth1网卡的IP地址(100.100.1.1)
|
||||
|
||||
- **运营商 B**: ASN (200), IP地址空间 (200.200.0.0/22), 分配给BGP路由器eth1网卡的IP地址(200.200.1.1)
|
||||
|
||||
路由器A和路由器B使用100.100.0.0/30子网来连接到对方。从理论上来说,任何子网从运营商那里都是可达的、可互连的。在真实场景中,建议使用掩码为30位的公网IP地址空间来实现运营商A和运营商B之间的连通。
|
||||
|
||||
### 在 CentOS中安装Quagga ###
|
||||
|
||||
如果Quagga还没安装好,我们可以使用yum来安装Quagga。
|
||||
|
||||
# yum install quagga
|
||||
|
||||
如果你正在使用的是CentOS7系统,你需要应用一下策略来设置SELinux。否则,SElinux将会阻止Zebra守护进程写入它的配置目录。如果你正在使用的是CentOS6,你可以跳过这一步。
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
Quagga软件套件包含几个守护进程,这些进程可以协同工作。关于BGP路由,我们将把重点放在建立以下2个守护进程。
|
||||
|
||||
- **Zebra**:一个核心守护进程用于内核接口和静态路由.
|
||||
- **BGPd**:一个BGP守护进程.
|
||||
|
||||
### 配置日志记录 ###
|
||||
|
||||
在Quagga被安装后,下一步就是配置Zebra来管理BGP路由器的网络接口。我们通过创建一个Zebra配置文件和启用日志记录来开始第一步。
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
在CentOS7系统中:
|
||||
|
||||
# systemctl start zebra
|
||||
# systemctl enable zebra
|
||||
|
||||
Quagga提供了一个叫做vtysh特有的命令行工具,你可以输入与路由器厂商(例如Cisco和Juniper)兼容和支持的命令。我们将使用vtysh shell来配置BGP路由在教程的其余部分。
|
||||
|
||||
启动vtysh shell 命令,输入:
|
||||
|
||||
# vtysh
|
||||
|
||||
提示将被改成该主机名,这表明你是在vtysh shell中。
|
||||
|
||||
Router-A#
|
||||
|
||||
现在我们将使用以下命令来为Zebra配置日志文件:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# log file /var/log/quagga/quagga.log
|
||||
Router-A(config)# exit
|
||||
|
||||
永久保存Zebra配置:
|
||||
|
||||
Router-A# write
|
||||
|
||||
在路由器B操作同样的步骤。
|
||||
|
||||
### 配置对等的IP地址 ###
|
||||
|
||||
下一步,我们将在可用的接口上配置对等的IP地址。
|
||||
|
||||
Router-A# show interface #显示接口信息
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
配置eth0接口的参数:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 100.100.0.1/30
|
||||
site-A-RTR(config-if)# description "to Router-B"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
|
||||
继续配置eth1接口的参数:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 100.100.1.1/24
|
||||
site-A-RTR(config-if)# description "test ip from provider A network"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
现在确认配置:
|
||||
|
||||
Router-A# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
Description: "to Router-B"
|
||||
inet 100.100.0.1/30 broadcast 100.100.0.3
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
Description: "test ip from provider A network"
|
||||
inet 100.100.1.1/24 broadcast 100.100.1.255
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show interface description #显示接口描述
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown "to Router-B"
|
||||
eth1 up unknown "test ip from provider A network"
|
||||
|
||||
|
||||
如果一切看起来正常,别忘记保存配置。
|
||||
|
||||
Router-A# write
|
||||
|
||||
同样地,在路由器B重复一次配置。
|
||||
|
||||
在我们继续下一步之前,确认下彼此的IP是可以ping通的。
|
||||
|
||||
Router-A# ping 100.100.0.2
|
||||
|
||||
----------
|
||||
|
||||
PING 100.100.0.2 (100.100.0.2) 56(84) bytes of data.
|
||||
64 bytes from 100.100.0.2: icmp_seq=1 ttl=64 time=0.616 ms
|
||||
|
||||
下一步,我们将继续配置BGP对等和前缀设置。
|
||||
|
||||
### 配置BGP对等 ###
|
||||
|
||||
Quagga守护进程负责BGP的服务叫bgpd。首先我们来准备它的配置文件。
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service bgpd start
|
||||
# chkconfig bgpd on
|
||||
|
||||
在CentOS7中:
|
||||
|
||||
# systemctl start bgpd
|
||||
# systemctl enable bgpd
|
||||
|
||||
现在,让我们来进入Quagga 的shell。
|
||||
|
||||
# vtysh
|
||||
|
||||
第一步,我们要确认当前没有已经配置的BGP会话。在一些版本,我们可能会发现一个AS号为7675的BGP会话。由于我们不需要这个会话,所以把它移除。
|
||||
|
||||
Router-A# show running-config
|
||||
|
||||
----------
|
||||
|
||||
... ... ...
|
||||
router bgp 7675
|
||||
bgp router-id 200.200.1.1
|
||||
... ... ...
|
||||
|
||||
我们将移除一些预先配置好的BGP会话,并建立我们所需的会话取而代之。
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# no router bgp 7675
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# no auto-summary
|
||||
Router-A(config)# no synchronizaiton
|
||||
Router-A(config-router)# neighbor 100.100.0.2 remote-as 200
|
||||
Router-A(config-router)# neighbor 100.100.0.2 description "provider B"
|
||||
Router-A(config-router)# exit
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
路由器B将用同样的方式来进行配置,以下配置提供作为参考。
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# no router bgp 7675
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# no auto-summary
|
||||
Router-B(config)# no synchronizaiton
|
||||
Router-B(config-router)# neighbor 100.100.0.1 remote-as 100
|
||||
Router-B(config-router)# neighbor 100.100.0.1 description "provider A"
|
||||
Router-B(config-router)# exit
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
当相关的路由器都被配置好,两台路由器之间的对等将被建立。现在让我们通过运行下面的命令来确认:
|
||||
|
||||
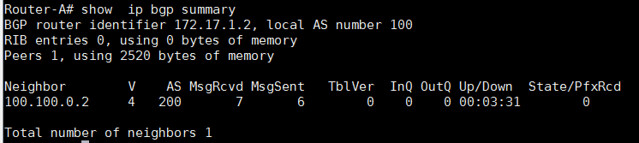
Router-A# show ip bgp summary
|
||||
|
||||
|
||||
|
||||
|
||||
从输出中,我们可以看到"State/PfxRcd"部分。如果对等关闭,输出将会显示"Idle"或者"Active'。请记住,单词'Active'这个词在路由器中总是不好的意思。它意味着路由器正在积极地寻找邻居、前缀或者路由。当对等是up状态,"State/PfxRcd"下的输出状态将会从特殊邻居接收到前缀号。
|
||||
|
||||
在这个例子的输出中,BGP对等只是在AS100和AS200之间呈up状态。因此没有前缀被更改,所以最右边列的数值是0。
|
||||
|
||||
### 配置前缀通告 ###
|
||||
|
||||
正如一开始提到,AS 100将以100.100.0.0/22作为通告,在我们的例子中AS 200将同样以200.200.0.0/22作为通告。这些前缀需要被添加到BGP配置如下。
|
||||
|
||||
在路由器-A中:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# network 100.100.0.0/22
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
在路由器-B中:
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# network 200.200.0.0/22
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
在这一点上,两个路由器会根据需要开始通告前缀。
|
||||
|
||||
### 测试前缀通告 ###
|
||||
|
||||
首先,让我们来确认前缀的数量是否被改变了。
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||
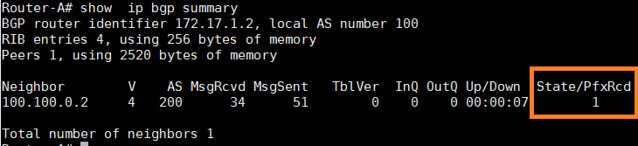
|
||||
|
||||
为了查看所接收的更多前缀细节,我们可以使用以下命令,这个命令用于显示邻居100.100.0.2所接收到的前缀总数。
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 advertised-routes
|
||||
|
||||
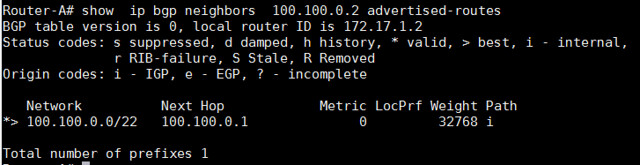
|
||||
|
||||
查看哪一个前缀是我们从邻居接收到的:
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 routes
|
||||
|
||||
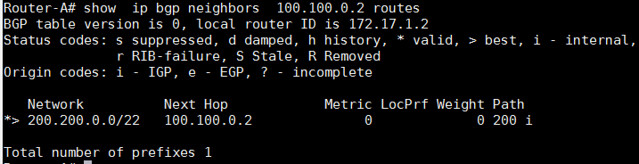
|
||||
|
||||
我们也可以查看所有的BGP路由器:
|
||||
|
||||
Router-A# show ip bgp
|
||||
|
||||
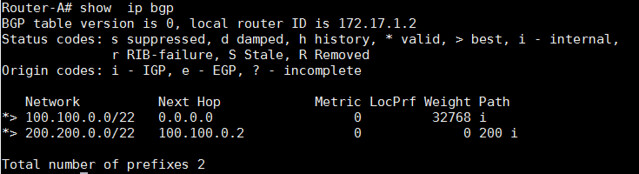
|
||||
|
||||
|
||||
以上的命令都可以被用于检查哪个路由器通过BGP在路由器表中被学习到。
|
||||
|
||||
Router-A# show ip route
|
||||
|
||||
----------
|
||||
|
||||
代码: K - 内核路由, C - 已链接 , S - 静态 , R - 路由信息协议 , O - 开放式最短路径优先协议,
|
||||
|
||||
I - 中间系统到中间系统的路由选择协议, B - 边界网关协议, > - 选择路由, * - FIB 路由
|
||||
|
||||
C>* 100.100.0.0/30 is directly connected, eth0
|
||||
C>* 100.100.1.0/24 is directly connected, eth1
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:06:45
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show ip route bgp
|
||||
|
||||
----------
|
||||
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:08:13
|
||||
|
||||
|
||||
BGP学习到的路由也将会在Linux路由表中出现。
|
||||
|
||||
[root@Router-A~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
100.100.0.0/30 dev eth0 proto kernel scope link src 100.100.0.1
|
||||
100.100.1.0/24 dev eth1 proto kernel scope link src 100.100.1.1
|
||||
200.200.0.0/22 via 100.100.0.2 dev eth0 proto zebra
|
||||
|
||||
|
||||
最后,我们将使用ping命令来测试连通。结果将成功ping通。
|
||||
|
||||
[root@Router-A~]# ping 200.200.1.1 -c 2
|
||||
|
||||
|
||||
总而言之,本教程将重点放在如何在CentOS系统中运行一个基本的BGP路由器。这个教程让你开始学习BGP的配置,一些更高级的设置例如设置过滤器、BGP属性调整、本地优先级和预先路径准备等,我将会在后续的教程中覆盖这些主题。
|
||||
|
||||
希望这篇教程能给大家一些帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://linux.cn/article-4232-1.html
|
||||
[2]:http://weibo.com/3181671860/BngyXxEUF
|
||||
297
published/20141027 ntpq -p output.md
Normal file
297
published/20141027 ntpq -p output.md
Normal file
@ -0,0 +1,297 @@
|
||||
网络时间的那些事情及 ntpq 详解
|
||||
================================================================================
|
||||
[Gentoo][1](也许其他发行版也是?)中 ["ntpq -p" 的 man page][2] 只有简短的描述:“*打印出该服务器已知的节点列表和它们的状态概要信息。*”
|
||||
|
||||
我还没见到关于这个命令的说明文档,因此这里对此作一个总结,可以补充进 "[man ntpq][3]" man page 中。更多的细节见这里 “[ntpq – 标准 NTP 请求程序][4]”(原作者),和 [其他关于 man ntpq 的例子][5].
|
||||
|
||||
[NTP][6] 是一个设计用于通过 [udp][9] 网络 ([WAN][7] 或者 [LAN][8]) 来同步计算机时钟的协议。引用 [Wikipedia – NTP][10]:
|
||||
|
||||
> 网络时间协议(英语:Network Time Protocol,NTP)一种协议和软件实现,用于通过使用有网络延迟的报文交换网络同步计算机系统间的时钟。最初由美国特拉华大学的 David L. Mills 设计,现在仍然由他和志愿者小组维护,它于 1985 年之前开始使用,是因特网中最老的协议之一。
|
||||
|
||||
想了解更多有关时间和 NTP 协议的知识,可以参考 “[The NTP FAQ, Time, what Time?][11]”和 [RFCs for NTP][12]。早期的“Network Time Protocol (Version 3) RFC” ([txt][13], or [pdf][14], Appendix E, The NTP Timescale and its Chronometry, p70) 包含了对过去 5000 年我们的计时系统的变化和关系的有趣解释。维基百科的文章 [Time][15] 和 [Calendar][16] 提供了更宏观的视角。
|
||||
|
||||
命令 "ntpq -q" 输出下面这样的一个表:
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
LOCAL(0) .LOCL. 10 l 96h 64 0 0.000 0.000 0.000
|
||||
*ns2.example.com 10.193.2.20 2 u 936 1024 377 31.234 3.353 3.096
|
||||
|
||||
### 更多细节 ###
|
||||
|
||||
#### 表头 ####
|
||||
|
||||
|
||||
- **remote** – 用于同步的远程节点或服务器。“LOCAL”表示本机 (当没有远程服务器可用时会出现)
|
||||
- **refid** – 远程的服务器进行同步的更高一级服务器
|
||||
- **st** – 远程节点或服务器的 [Stratum][17](级别,NTP 时间同步是分层的)
|
||||
- **t** – 类型 (u: [unicast(单播)][18] 或 [manycast(选播)][19] 客户端, b: [broadcast(广播)][20] 或 [multicast(多播)][21] 客户端, l: 本地时钟, s: 对称节点(用于备份), A: 选播服务器, B: 广播服务器, M: 多播服务器, 参见“[Automatic Server Discovery][22]“)
|
||||
- **when** – 最后一次同步到现在的时间 (默认单位为秒, “h”表示小时,“d”表示天)
|
||||
- **poll** – 同步的频率:[rfc5905][23]建议在 NTPv4 中这个值的范围在 4 (16秒) 至 17 (36小时) 之间(即2的指数次秒),然而观察发现这个值的实际大小在一个小的多的范围内 :64 (2^6 )秒 至 1024 (2^10 )秒
|
||||
- **reach** – 一个8位的左移移位寄存器值,用来测试能否和服务器连接,每成功连接一次它的值就会增加,以 [8 进制][24]显示
|
||||
- **delay** – 从本地到远程节点或服务器通信的往返时间(毫秒)
|
||||
- **offset** – 主机与远程节点或服务器时间源的时间偏移量,offset 越接近于0,主机和 NTP 服务器的时间越接近(以[方均根][25]表示,单位为毫秒)
|
||||
- **jitter** – 与远程节点同步的时间源的平均偏差(多个时间样本中的 offset 的偏差,单位是毫秒),这个数值的绝对值越小,主机的时间就越精确
|
||||
|
||||
#### 字段的统计代码 ####
|
||||
|
||||
表中第一个字符(统计代码)是状态标识(参见 [Peer Status Word][26]),包含 " ","x","-","#","+","*","o":
|
||||
|
||||
- " " – 无状态,表示:
|
||||
- 没有远程通信的主机
|
||||
- "LOCAL" 即本机
|
||||
- (未被使用的)高层级服务器
|
||||
- 远程主机使用的这台机器作为同步服务器
|
||||
- “**x**” – 已不再使用
|
||||
- “**-**” – 已不再使用
|
||||
- “**#**” – 良好的远程节点或服务器但是未被使用 (不在按同步距离排序的前六个节点中,作为备用节点使用)
|
||||
- “**+**” – 良好的且优先使用的远程节点或服务器(包含在组合算法中)
|
||||
- “*” – 当前作为优先主同步对象的远程节点或服务器
|
||||
- “**o**” – PPS 节点 (当优先节点是有效时)。实际的系统同步是源于秒脉冲信号(pulse-per-second,PPS),可能通过PPS 时钟驱动或者通过内核接口。
|
||||
|
||||
参考 [Clock Select Algorithm][27].
|
||||
|
||||
#### refid ####
|
||||
|
||||
**refid** 有下面这些状态值
|
||||
|
||||
- 一个IP地址 – 远程节点或服务器的 [IP 地址][28]
|
||||
- **.LOCL.** – 本机 (当没有远程节点或服务器可用时)
|
||||
- **.PPS.** – 时间标准中的“[Pulse Per Second][29]”(秒脉冲)
|
||||
- **.IRIG.** – [Inter-Range Instrumentation Group][30] 时间码
|
||||
- **.ACTS.** – 美国 [NIST 标准时间][31] 电话调制器
|
||||
- **.NIST.** –美国 NIST 标准时间电话调制器
|
||||
- **.PTB.** – 德国 [PTB][32] 时间标准电话调制器
|
||||
- **.USNO.** – 美国 [USNO 标准时间][33] 电话调制器
|
||||
- **.CHU.** – [CHU][34] ([HF][35], Ottawa, ON, Canada) 标准时间无线电接收器
|
||||
- **.DCFa.** – [DCF77][36] ([LF][37], Mainflingen, Germany) 标准时间无线电接收器
|
||||
- **.HBG.** – [HBG][38] (LF Prangins, Switzerland) 标准时间无线电接收器
|
||||
- **.JJY.** – [JJY][39] (LF Fukushima, Japan) 标准时间无线电接收器
|
||||
- **.LORC.** – [LORAN][40]-C station ([MF][41]) 标准时间无线电接收器,注: [不再可用][42] (被 [eLORAN][43] 废弃)
|
||||
- **.MSF.** – [MSF][44] (LF, Anthorn, Great Britain) 标准时间无线电接收器
|
||||
- **.TDF.** – [TDF][45] (MF, Allouis, France)标准时间无线电接收器
|
||||
- **.WWV.** – [WWV][46] (HF, Ft. Collins, CO, America) 标准时间无线电接收器
|
||||
- **.WWVB.** – [WWVB][47] (LF, Ft. Collins, CO, America) 标准时间无线电接收器
|
||||
- **.WWVH.** – [WWVH][48] (HF, Kauai, HI, America) 标准时间无线电接收器
|
||||
- **.GOES.** – 美国[静止环境观测卫星][49];
|
||||
- **.GPS.** – 美国 [GPS][50];
|
||||
- **.GAL.** – [伽利略定位系统][51]欧洲 [GNSS][52];
|
||||
- **.ACST.** – 选播服务器
|
||||
- **.AUTH.** – 认证错误
|
||||
- **.AUTO.** – Autokey (NTP 的一种认证机制)顺序错误
|
||||
- **.BCST.** – 广播服务器
|
||||
- **.CRYPT.** – Autokey 协议错误
|
||||
- **.DENY.** – 服务器拒绝访问;
|
||||
- **.INIT.** – 关联初始化
|
||||
- **.MCST.** – 多播服务器
|
||||
- **.RATE.** – (轮询) 速率超出限定
|
||||
- **.TIME.** – 关联超时
|
||||
- **.STEP.** – 间隔时长改变,偏移量比危险阈值小(1000ms) 比间隔时间 (125ms)大
|
||||
|
||||
#### 操作要点 ####
|
||||
|
||||
一个时间服务器只会报告时间信息而不会从客户端更新时间(单向更新),而一个节点可以更新其他同级节点的时间,结合出一个彼此同意的时间(双向更新)。
|
||||
|
||||
[初次启动][53]时:
|
||||
|
||||
> 除非使用 iburst 选项,客户端通常需要花几分钟来和服务器同步。如果客户端在启动时时间与 NTP 服务器的时间差大于 1000 秒,守护进程会退出并在系统日志中记录,让操作者手动设置时间差小于 1000 秒后再重新启动。如果时间差小于 1000 秒,但是大于 128 秒,会自动矫正间隔,并自动重启守护进程。
|
||||
|
||||
> 当第一次启动时,时间频率文件(通常是 ntp.drift 文件,记录时间偏移)不存在,守护进程进入一个特殊模式来矫正频率。当时钟不符合[规范][54]时这会需要 900 秒。当校正完成后,守护进程创建时间频率文件进入普通模式,并分步校正剩余的偏差。
|
||||
|
||||
NTP 0 层(Stratum 0 )的设备如原子钟(铯,铷),GPS 时钟或者其他标准时间的无线电时钟为 1 层(Stratum 1)的时间服务器提供时间信号。NTP 只报告[UTC][55] 时间(统一协调时,Coordinated Universal Time)。客户端程序使用[时区][56]从 UTC 导出本地时间。
|
||||
|
||||
NTP 协议是高精度的,使用的精度小于纳秒(2的 -32 次方)。主机的时间精度和其他参数(受硬件和操作系统限制)使用命令 “ntpq -c rl” 查看(参见 [rfc1305][57] 通用变量和 [rfc5905][58])。
|
||||
|
||||
#### “ntpq -c rl”输出参数 ####
|
||||
|
||||
- **precision** 为四舍五入值,且为 2 的幂数。因此精度为 2^precision (秒)
|
||||
- **rootdelay** – 与同步网络中主同步服务器的总往返延时。注意这个值可以是正数或者负数,取决于时钟的精度。
|
||||
- **rootdisp** – 相对于同步网络中主同步服务器的偏差(秒)
|
||||
- **tc** – NTP 算法 [PLL][59] (phase locked loop,锁相环路) 或 [FLL][60] (frequency locked loop,锁频回路) 时间常量
|
||||
- **mintc** – NTP 算法 PLL/FLL 最小时间常亮或“最快响应
|
||||
- **offset** – 由结合算法得出的系统时钟偏移量(毫秒)
|
||||
- **frequency** – 系统时钟频率
|
||||
- **sys_jitter** – 由结合算法得出的系统时钟平均偏差(毫秒)
|
||||
- **clk_jitter** – 硬件时钟平均偏差(毫秒)
|
||||
- **clk_wander** – 硬件时钟偏移([PPM][61] – 百分之一)
|
||||
|
||||
Jitter (也叫 timing jitter) 表示短期变化大于10HZ 的频率, wander 表示长期变化大于10HZ 的频率 (Stability 表示系统的频率随时间的变化,和 aging, drift, trends 等是同义词)
|
||||
|
||||
#### 操作要点(续) ####
|
||||
|
||||
NTP 软件维护一系列连续更新的频率变化的校正值。对于设置正确的稳定系统,在非拥塞的网络中,现代硬件的 NTP 时钟同步通常与 UTC 标准时间相差在毫秒内。(在千兆 LAN 网络中可以达到何种精度?)
|
||||
|
||||
对于 UTC 时间,[闰秒 leap second ][62] 可以每两年插入一次用于同步地球自传的变化。注意本地时间为[夏令时][63]时时间会有一小时的变化。在重同步之前客户端设备会使用独立的 UTC 时间,除非客户端使用了偏移校准。
|
||||
|
||||
#### [闰秒发生时会怎样][64] ####
|
||||
|
||||
> 闰秒发生时,会对当天时间增加或减少一秒。闰秒的调整在 UTC 时间当天的最后一秒。如果增加一秒,UTC 时间会出现 23:59:60。即 23:59:59 到 0:00:00 之间实际上需要 2 秒钟。如果减少一秒,时间会从 23:59:58 跳至 0:00:00 。另见 [The Kernel Discipline][65].
|
||||
|
||||
那么… 间隔阈值(step threshold)的真实值是多少: 125ms 还是 128ms? PLL/FLL tc 的单位是什么 (log2 s? ms?)?在非拥塞的千兆 LAN 中时间节点间的精度能达到多少?
|
||||
|
||||
感谢 Camilo M 和 Chris B的评论。 欢迎校正错误和更多细节的探讨。
|
||||
|
||||
谢谢
|
||||
Martin
|
||||
|
||||
### 附录 ###
|
||||
|
||||
- [NTP 的纪元][66] 从 1900 开始而 UNIX 的从 1970开始.
|
||||
- [时间校正][67] 是逐渐进行的,因此时间的完全同步可能会画上几个小时。
|
||||
- [节点状态][68] 可以被记录到 [summarise/plot time offsets and errors][69]
|
||||
- [RMS][70] – 均方根
|
||||
- [PLL][71] – 锁相环路
|
||||
- [FLL][72] – 锁频回路
|
||||
- [PPM][73] – 百万分之一,用于描述频率的变化
|
||||
- [man ntpq (Gentoo 简明版本)][74]
|
||||
- [man ntpq (长期维护版本)][75]
|
||||
- [man ntpq (Gentoo 长期维护版本)][76]
|
||||
|
||||
### 另见 ###
|
||||
|
||||
- [ntpq – 标准 NTP 查询程序][77]
|
||||
- [The Network Time Protocol (NTP) 分布][78]
|
||||
- NTP 的简明[历史][79]
|
||||
- 一个更多细节的简明历史 “Mills, D.L., A brief history of NTP time: confessions of an Internet timekeeper. Submitted for publication; please do not cite or redistribute” ([pdf][80])
|
||||
- [NTP RFC][81] 标准文档
|
||||
- Network Time Protocol (Version 3) RFC – [txt][82], or [pdf][83]. Appendix E, The NTP Timescale and its Chronometry, p70, 包含了对过去 5000 年我们的计时系统的变化和关系的有趣解释。
|
||||
- 维基百科: [Time][84] 和 [Calendar][85]
|
||||
- [John Harrison and the Longitude problem][86]
|
||||
- [Clock of the Long Now][87] – The 10,000 Year Clock
|
||||
- John C Taylor – [Chronophage][88]
|
||||
- [Orders of magnitude of time][89]
|
||||
- [Greenwich Time Signal][90]
|
||||
|
||||
### 其他 ###
|
||||
|
||||
SNTP (Simple Network Time Protocol, [RFC 4330][91],简单网络协议)基本上也是NTP,但是少了一些基于 [RFC 1305][92] 实现的 NTP 的一些不再需要的内部算法。
|
||||
|
||||
Win32 时间 [Windows Time Service][93] 是 SNTP 的非标准实现,没有精度的保证,并假设精度几乎有 1-2 秒的范围。(因为没有系统时间变化校正)
|
||||
|
||||
还有一个[PTP (IEEE 1588)][95] Precision Time Protocol(精准时间协议)。见维基百科:[Precision Time Protocol][96]。软件程序为 [PTPd][97]。虫咬的功能是这是一个 [LAN][98] 高精度主从同步系统,精度在毫秒级,使用 [International Atomic Time][99] (TAI, [monotonic][100],无闰秒)。数据报时间戳需要在网卡中启用。支持 PTP 的网络会对数据报记录时间戳以减少交换机路由器的影响。也可以在不记录时间戳的网络中使用 PTP 但可能应为时间偏差太大而无法同步。因此使用这个需要对网络进行设置。
|
||||
|
||||
### 更老的时间同步协议 ###
|
||||
|
||||
- DTSS – DEC公司的数字时间同步服务, 被 NTP 所取代。例子: [DTSS VMS C code c2000][101]。 (哪里有关于 DTSS 的文章或文档吗?)
|
||||
- [DAYTIME protocol][102],使用 [TCP][103] 或 [UDP][104] 13 端口同步
|
||||
- [ICMP Timestamp][105] 和 [ICMP Timestamp Reply][106],使用 [ICMP][107] 协议同步
|
||||
- [Time Protocol][108],使用 TCP 或 UDP 37 号端口同步
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831
|
||||
|
||||
作者:Martin L
|
||||
译者:[Liao](https://github.com/liaosishere)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.gentoo.org/
|
||||
[2]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[3]:http://www.thelinuxblog.com/linux-man-pages/1/ntpq
|
||||
[4]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[5]:http://linux.die.net/man/8/ntpq
|
||||
[6]:http://www.ntp.org/
|
||||
[7]:http://en.wikipedia.org/wiki/Wide_area_network
|
||||
[8]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[9]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[10]:http://en.wikipedia.org/wiki/Network_Time_Protocol
|
||||
[11]:http://www.ntp.org/ntpfaq/NTP-s-time.htm
|
||||
[12]:http://www.ntp.org/rfc.html
|
||||
[13]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[14]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[15]:http://en.wikipedia.org/wiki/Time
|
||||
[16]:http://en.wikipedia.org/wiki/Calendar
|
||||
[17]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Clock_strata
|
||||
[18]:http://en.wikipedia.org/wiki/Unicast
|
||||
[19]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html#mcst
|
||||
[20]:http://en.wikipedia.org/wiki/Broadcasting_%28computing%29
|
||||
[21]:http://en.wikipedia.org/wiki/Multicast
|
||||
[22]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html
|
||||
[23]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[24]:http://en.wikipedia.org/wiki/Octal#In_computers
|
||||
[25]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[26]:http://www.eecis.udel.edu/~mills/ntp/html/decode.html#peer
|
||||
[27]:http://www.eecis.udel.edu/~mills/ntp/html/select.html
|
||||
[28]:http://en.wikipedia.org/wiki/Ip_address
|
||||
[29]:http://en.wikipedia.org/wiki/Pulse_per_second
|
||||
[30]:http://en.wikipedia.org/wiki/Inter-Range_Instrumentation_Group
|
||||
[31]:http://en.wikipedia.org/wiki/Standard_time_and_frequency_signal_service
|
||||
[32]:http://www.ptb.de/index_en.html
|
||||
[33]:http://en.wikipedia.org/wiki/United_States_Naval_Observatory#Time_service
|
||||
[34]:http://en.wikipedia.org/wiki/CHU_%28radio_station%29
|
||||
[35]:http://en.wikipedia.org/wiki/High_frequency
|
||||
[36]:http://en.wikipedia.org/wiki/DCF77
|
||||
[37]:http://en.wikipedia.org/wiki/Low_frequency
|
||||
[38]:http://en.wikipedia.org/wiki/HBG_%28time_signal%29
|
||||
[39]:http://en.wikipedia.org/wiki/JJY#Time_standards
|
||||
[40]:http://en.wikipedia.org/wiki/LORAN#Timing_and_synchronization
|
||||
[41]:http://en.wikipedia.org/wiki/Medium_frequency
|
||||
[42]:http://en.wikipedia.org/wiki/LORAN#The_future_of_LORAN
|
||||
[43]:http://en.wikipedia.org/wiki/LORAN#eLORAN
|
||||
[44]:http://en.wikipedia.org/wiki/Time_from_NPL#The_.27MSF_signal.27_and_the_.27Rugby_clock.27
|
||||
[45]:http://en.wikipedia.org/wiki/T%C3%A9l%C3%A9_Distribution_Fran%C3%A7aise
|
||||
[46]:http://en.wikipedia.org/wiki/WWV_%28radio_station%29#Time_signals
|
||||
[47]:http://en.wikipedia.org/wiki/WWVB
|
||||
[48]:http://en.wikipedia.org/wiki/WWVH
|
||||
[49]:http://en.wikipedia.org/wiki/GOES#Further_reading
|
||||
[50]:http://en.wikipedia.org/wiki/Gps#Timekeeping
|
||||
[51]:http://en.wikipedia.org/wiki/Galileo_%28satellite_navigation%29#The_concept
|
||||
[52]:http://en.wikipedia.org/wiki/Gnss
|
||||
[53]:http://www.eecis.udel.edu/~mills/ntp/html/debug.html
|
||||
[54]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[55]:http://en.wikipedia.org/wiki/Coordinated_Universal_Time
|
||||
[56]:http://en.wikipedia.org/wiki/Time_zone
|
||||
[57]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[58]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[59]:http://en.wikipedia.org/wiki/PLL
|
||||
[60]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[61]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[62]:http://en.wikipedia.org/wiki/Leap_second
|
||||
[63]:http://en.wikipedia.org/wiki/Daylight_saving_time
|
||||
[64]:http://www.ntp.org/ntpfaq/NTP-s-time.htm#Q-TIME-LEAP-SECOND
|
||||
[65]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[66]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#AEN1895
|
||||
[67]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#Q-ACCURATE-CLOCK
|
||||
[68]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#Q-TRB-MON-STATFIL
|
||||
[69]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#AEN5086
|
||||
[70]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[71]:http://en.wikipedia.org/wiki/PLL
|
||||
[72]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[73]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[74]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[75]:http://nlug.ml1.co.uk/2012/01/man-ntpq-long-version/855
|
||||
[76]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-long-version/856
|
||||
[77]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[78]:http://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[79]:http://www.ntp.org/ntpfaq/NTP-s-def-hist.htm
|
||||
[80]:http://www.eecis.udel.edu/~mills/database/papers/history.pdf
|
||||
[81]:http://www.ntp.org/rfc.html
|
||||
[82]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[83]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[84]:http://en.wikipedia.org/wiki/Time
|
||||
[85]:http://en.wikipedia.org/wiki/Calendar
|
||||
[86]:http://www.rmg.co.uk/harrison
|
||||
[87]:http://longnow.org/clock/
|
||||
[88]:http://johnctaylor.com/
|
||||
[89]:http://en.wikipedia.org/wiki/Orders_of_magnitude_%28time%29
|
||||
[90]:http://en.wikipedia.org/wiki/Greenwich_Time_Signal
|
||||
[91]:http://tools.ietf.org/html/rfc4330
|
||||
[92]:http://tools.ietf.org/html/rfc1305
|
||||
[93]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Microsoft_Windows
|
||||
[94]:http://en.wikipedia.org/wiki/Personal_computer
|
||||
[95]:http://www.nist.gov/el/isd/ieee/ieee1588.cfm
|
||||
[96]:http://en.wikipedia.org/wiki/IEEE_1588
|
||||
[97]:http://ptpd.sourceforge.net/
|
||||
[98]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[99]:http://en.wikipedia.org/wiki/International_Atomic_Time
|
||||
[100]:http://en.wikipedia.org/wiki/Monotonic_function
|
||||
[101]:http://antinode.info/ftp/dtss_ntp/
|
||||
[102]:http://en.wikipedia.org/wiki/DAYTIME
|
||||
[103]:http://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
||||
[104]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[105]:http://en.wikipedia.org/wiki/ICMP_Timestamp
|
||||
[106]:http://en.wikipedia.org/wiki/ICMP_Timestamp_Reply
|
||||
[107]:http://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[108]:http://en.wikipedia.org/wiki/Time_Protocol
|
||||
@ -1,6 +1,6 @@
|
||||
Linux 和类Unix 系统上5个极品的开源软件备份工具
|
||||
Linux 和类 Unix 系统上5个最佳开源备份工具
|
||||
================================================================================
|
||||
一个好的备份最基本的就是为了能够从一些错误中恢复
|
||||
一个好的备份最基本的目的就是为了能够从一些错误中恢复:
|
||||
|
||||
- 人为的失误
|
||||
- 磁盘阵列或是硬盘故障
|
||||
@ -13,7 +13,7 @@ Linux 和类Unix 系统上5个极品的开源软件备份工具
|
||||
|
||||
确定你正在部署的软件具有下面的特性
|
||||
|
||||
1. **开源软件** - 你务必要选择那些源码可以免费获得,并且可以修改的软件。确信可以恢复你的数据,即使是软件的供应商或者/或是项目停止继续维护这个软件或者是拒绝继续为这个软件提供补丁。
|
||||
1. **开源软件** - 你务必要选择那些源码可以免费获得,并且可以修改的软件。确信可以恢复你的数据,即使是软件供应商/项目停止继续维护这个软件,或者是拒绝继续为这个软件提供补丁。
|
||||
|
||||
2. **跨平台支持** - 确定备份软件可以很好的运行各种需要部署的桌面操作系统和服务器系统。
|
||||
|
||||
@ -21,21 +21,21 @@ Linux 和类Unix 系统上5个极品的开源软件备份工具
|
||||
|
||||
4. **自动转换** - 自动转换本来是没什么,除了对于各种备份设备,包括图书馆,近线存储和自动加载,自动转换可以自动完成一些任务,包括加载,挂载和标签备份像磁带这些媒体设备。
|
||||
|
||||
5. **备份介质** - 确定你可以备份到磁带,硬盘,DVD 和云存储像AWS。
|
||||
5. **备份介质** - 确定你可以备份到磁带,硬盘,DVD 和像 AWS 这样的云存储。
|
||||
|
||||
6. **加密数据流** - 确定所有客户端到服务器的传输都被加密,保证在LAN/WAN/Internet 中传输的安全性。
|
||||
6. **加密数据流** - 确定所有客户端到服务器的传输都被加密,保证在 LAN/WAN/Internet 中传输的安全性。
|
||||
|
||||
7. **数据库支持** - 确定备份软件可以备份到数据库,像MySQL 或是 Oracle。
|
||||
|
||||
8. **备份可以跨越多个卷** - 备份软件(转存文件)可以把每个备份文件分成几个部分,允许将每个部分存在于不同的卷。这样可以保证一些数据量很大的备份(像100TB的文件)可以被存储在一些比单个部分大的设备中,比如说像硬盘和磁盘卷。
|
||||
8. **备份可以跨越多个卷** - 备份软件(转储文件时)可以把每个备份文件分成几个部分,允许将每个部分存在于不同的卷。这样可以保证一些数据量很大的备份(像100TB的文件)可以被存储在一些单个容量较小的设备中,比如说像硬盘和磁盘卷。
|
||||
|
||||
9. **VSS (卷影复制)** - 这是[微软的卷影复制服务(VSS)][1],通过创建数据的快照来备份。确定备份软件支持VSS的MS-Windows 客户端/服务器。
|
||||
|
||||
10. **重复数据删除** - 这是一种数据压缩技术,用来消除重复数据的副本(比如,图片)。
|
||||
|
||||
11. **许可证和成本** - 确定你[理解和使用的开源许可证][3]下的软件源码你可以得到。
|
||||
11. **许可证和成本** - 确定你对备份软件所用的[许可证了解和明白其使用方式][3]。
|
||||
|
||||
12. **商业支持** - 开源软件可以提供社区支持(像邮件列表和论坛)和专业的支持(像发行版提供额外的付费支持)。你可以使用付费的专业支持以培训和咨询为目的。
|
||||
12. **商业支持** - 开源软件可以提供社区支持(像邮件列表和论坛)和专业的支持(如发行版提供额外的付费支持)。你可以使用付费的专业支持为你提供培训和咨询。
|
||||
|
||||
13. **报告和警告** - 最后,你必须能够看到备份的报告,当前的工作状态,也能够在备份出错的时候提供警告。
|
||||
|
||||
@ -59,7 +59,7 @@ Linux 和类Unix 系统上5个极品的开源软件备份工具
|
||||
|
||||
### Amanda - 又一个客户端服务器备份工具 ###
|
||||
|
||||
AMANDA 是 Advanced Maryland Automatic Network Disk Archiver 的缩写。它允许系统管理员创建一个单独的服务器来备份网络上的其他主机到磁带驱动器或硬盘或者是自动转换器。
|
||||
AMANDA 是 Advanced Maryland Automatic Network Disk Archiver 的缩写。它允许系统管理员创建一个单独的备份服务器来将网络上的其他主机的数据备份到磁带驱动器、硬盘或者是自动换盘器。
|
||||
|
||||
- 操作系统:支持跨平台运行。
|
||||
- 备份级别:完全,差异,增量,合并。
|
||||
@ -75,7 +75,7 @@ AMANDA 是 Advanced Maryland Automatic Network Disk Archiver 的缩写。它允
|
||||
|
||||
### Backupninja - 轻量级备份系统 ###
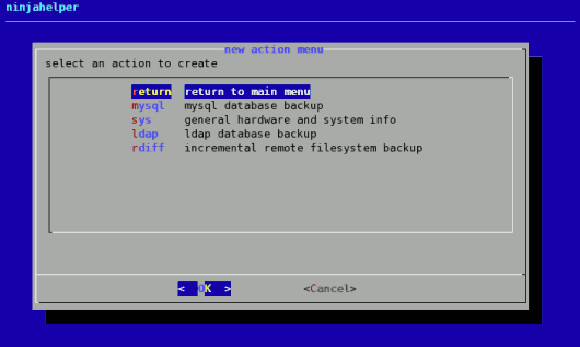
|
||||
|
||||
Backupninja 是一个简单易用的备份系统。你可以简单的拖放配置文件到 /etc/backup.d/ 目录来备份多个主机。
|
||||
Backupninja 是一个简单易用的备份系统。你可以简单的拖放一个配置文件到 /etc/backup.d/ 目录来备份到多个主机。
|
||||
|
||||
|
||||
|
||||
@ -93,7 +93,7 @@ Backupninja 是一个简单易用的备份系统。你可以简单的拖放配
|
||||
|
||||
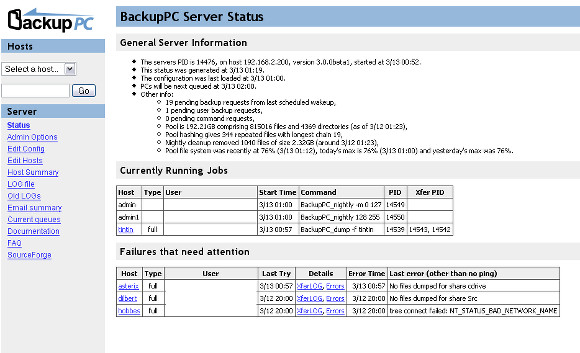
### Backuppc - 高效的客户端服务器备份工具###
|
||||
|
||||
Backuppc 可以用来备份基于LInux 和Windows 系统的主服务器硬盘。它配备了一个巧妙的池计划来最大限度的减少磁盘储存,磁盘I/O 和网络I/O。
|
||||
Backuppc 可以用来备份基于Linux 和Windows 系统的主服务器硬盘。它配备了一个巧妙的池计划来最大限度的减少磁盘储存、磁盘 I/O 和网络I/O。
|
||||
|
||||
|
||||
|
||||
@ -111,7 +111,7 @@ Backuppc 可以用来备份基于LInux 和Windows 系统的主服务器硬盘。
|
||||
|
||||
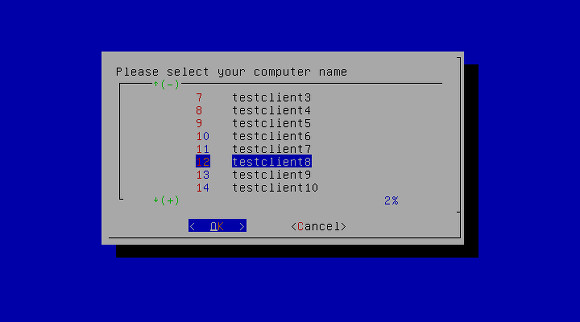
### UrBackup - 最容易配置的客户端服务器系统 ###
|
||||
|
||||
UrBackup 是一个非常容易配置的开源客户端服务器备份系统,通过图像和文件备份的组合完成了数据安全性和快速的恢复。你的文件可以通过Web界面或者是在Windows资源管理器中恢复,而驱动卷的备份用引导CD或者是USB 棒来恢复(逻辑恢复)。一个Web 界面使得配置你自己的备份服务变得非常简单。
|
||||
UrBackup 是一个非常容易配置的开源客户端服务器备份系统,通过镜像 方式和文件备份的组合完成了数据安全性和快速的恢复。磁盘卷备份可以使用可引导 CD 或U盘,通过Web界面或Windows资源管理器来恢复你的文件(硬恢复)。一个 Web 界面使得配置你自己的备份服务变得非常简单。
|
||||
|
||||
|
||||
|
||||
@ -129,19 +129,19 @@ UrBackup 是一个非常容易配置的开源客户端服务器备份系统,
|
||||
|
||||
### 其他供你考虑的一些极好用的开源备份软件 ###
|
||||
|
||||
Amanda,Bacula 和上面所提到的软件都是功能丰富,但是配置比较复杂对于一些小的网络或者是单独的服务器。我建议你学习和使用一下的备份软件:
|
||||
Amanda,Bacula 和上面所提到的这些软件功能都很丰富,但是对于一些小的网络或者是单独的服务器来说配置比较复杂。我建议你学习和使用一下的下面这些备份软件:
|
||||
|
||||
1. [Rsnapshot][10] - 我建议用这个作为对本地和远程的文件系统快照工具。查看[怎么设置和使用这个工具在Debian 和Ubuntu linux][11]和[基于CentOS,RHEL 的操作系统][12]。
|
||||
1. [Rsnapshot][10] - 我建议用这个作为对本地和远程的文件系统快照工具。看看[在Debian 和Ubuntu linux][11]和[基于CentOS,RHEL 的操作系统][12]怎么设置和使用这个工具。
|
||||
2. [rdiff-backup][13] - 另一个好用的类Unix 远程增量备份工具。
|
||||
3. [Burp][14] - Burp 是一个网络备份和恢复程序。它使用了librsync来节省网络流量和节省每个备份占用的空间。它也使用了VSS(卷影复制服务),在备份Windows计算机时进行快照。
|
||||
4. [Duplicity][15] - 伟大的加密和高效的备份类Unix操作系统。查看如何[安装Duplicity来加密云备份][16]来获取更多的信息。
|
||||
5. [SafeKeep][17] - SafeKeep是一个集中和易于使用的备份应用程序,结合了镜像和增量备份最佳功能的备份应用程序。
|
||||
5. [SafeKeep][17] - SafeKeep是一个中心化的、易于使用的备份应用程序,结合了镜像和增量备份最佳功能的备份应用程序。
|
||||
6. [DREBS][18] - DREBS 是EBS定期快照的工具。它被设计成在EBS快照所连接的EC2主机上运行。
|
||||
7. 古老的unix 程序,像rsync, tar, cpio, mt 和dump。
|
||||
|
||||
###结论###
|
||||
|
||||
我希望你会发现这篇有用的文章来备份你的数据。不要忘了验证你的备份和创建多个数据备份。然而,对于磁盘阵列并不是一个备份解决方案。使用任何一个上面提到的程序来备份你的服务器,桌面和笔记本电脑和私人的移动设备。如果你知道其他任何开源的备份软件我没有提到的,请分享在评论里。
|
||||
我希望你会发现这篇有用的文章来备份你的数据。不要忘了验证你的备份和创建多个数据备份。注意,磁盘阵列并不是一个备份解决方案!使用任何一个上面提到的程序来备份你的服务器、桌面和笔记本电脑和私人的移动设备。如果你知道其他任何开源的备份软件我没有提到的,请分享在评论里。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -149,7 +149,7 @@ via: http://www.cyberciti.biz/open-source/awesome-backup-software-for-linux-unix
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
66
published/20141108 When hackers grow old.md
Normal file
66
published/20141108 When hackers grow old.md
Normal file
@ -0,0 +1,66 @@
|
||||
ESR:黑客年暮
|
||||
================================================================================
|
||||
近来我一直在与某资深开源开发团队中的多个成员缠斗,尽管密切关注我的人们会在读完本文后猜到是哪个组织,但我不会在这里说出这个组织的名字。
|
||||
|
||||
怎么让某些人进入 21 世纪就这么难呢?真是的...
|
||||
|
||||
我快 56 岁了,也就是大部分年轻人会以为的我将时不时朝他们发出诸如“滚出我的草坪”之类歇斯底里咆哮的年龄。但事实并非如此 —— 我发现,尤其是在技术背景之下,我变得与我的年龄非常不相称。
|
||||
|
||||
在我这个年龄的大部分人确实变成了爱发牢骚、墨守成规的老顽固。并且,尴尬的是,偶尔我会成为那个打断谈话的人,我会指出他们某个在 1995 年(或者在某些特殊情况下,1985 年)时很适合的方法... 几十年后的今天就不再是好方法了。
|
||||
|
||||
为什么是我?因为年轻人在我的同龄人中很难有什么说服力。如果有人想让那帮老头改变主意,首先他得是自己同龄人中具有较高思想觉悟的佼佼者。即便如此,在与习惯做斗争的过程中,我也比看起来花费了更多的时间。
|
||||
|
||||
年轻人犯下无知的错误是可以被原谅的。他们还年轻。年轻意味着缺乏经验,缺乏经验通常会导致片面的判断。我很难原谅那些经历了足够多本该有经验的人,却被*长期的固化思维*蒙蔽,无法发觉近在咫尺的东西。
|
||||
|
||||
(补充一下:我真的不是保守党拥护者。那些和我争论政治的,无论保守党还是非保守党都没有注意到这点,我觉得这颇有点嘲讽的意味。)
|
||||
|
||||
那么,现在我们来讨论下 GNU 更新日志文件(ChangeLog)这件事。在 1985 年的时候,这是一个不错的主意,甚至可以说是必须的。当时的想法是用单独的更新日志条目来记录多个相关文件的变更情况。用这种方式来对那些存在版本缺失或者非常原始的版本进行版本控制确实不错。当时我也*在场*,所以我知道这些。
|
||||
|
||||
不过即使到了 1995 年,甚至 21 世纪早期,许多版本控制系统仍然没有太大改进。也就是说,这些版本控制系统并非对批量文件的变化进行分组再保存到一条记录上,而是对每个变化的文件分别进行记录并保存到不同的地方。CVS,当时被广泛使用的版本控制系统,仅仅是模拟日志变更 —— 并且在这方面表现得很糟糕,导致大多数人不再依赖这个功能。即便如此,更新日志文件的出现依然是必要的。
|
||||
|
||||
但随后,版本控制系统 Subversion 于 2003 年发布 beta 版,并于 2004 年发布 1.0 正式版,Subversion 真正实现了更新日志记录功能,得到了人们的广泛认可。它与一年后兴起的分布式版本控制系统(Distributed Version Control System,DVCS)共同引发了主流世界的激烈争论。因为如果你在项目上同时使用了分布式版本控制与更新日志文件记录的功能,它们将会因为争夺相同元数据的控制权而产生不可预料的冲突。
|
||||
|
||||
有几种不同的方法可以折衷解决这个问题。一种是继续将更新日志作为代码变更的授权记录。这样一来,你基本上只能得到简陋的、形式上的提交评论数据。
|
||||
|
||||
另一种方法是对提交的评论日志进行授权。如果你这样做了,不久后你就会开始思忖为什么自己仍然对所有的日志更新条目进行记录。提交元数据与变化的代码具有更好的相容性,毕竟这才是当初设计它的目的。
|
||||
|
||||
(现在,试想有这样一个项目,同样本着把项目做得最好的想法,但两拨人却做出了完全不同的选择。因此你必须同时阅读更新日志和评论日志以了解到底发生了什么。最好在矛盾激化前把问题解决....)
|
||||
|
||||
第三种办法是尝试同时使用以上两种方法 —— 在更新日志条目中,以稍微变化后的的格式复制一份评论数据,将其作为评论提交的一部分。这会导致各种你意想不到的问题,最具代表性的就是它不符合“真理的单点性(single point of truth)”原理;只要其中有拷贝文件损坏,或者日志文件条目被修改,这就不再是同步时数据匹配的问题,它将导致在其后参与进来的人试图搞清人们是怎么想的时候变得非常困惑。(LCTT 译注:《[程序员修炼之道][1]》(The Pragmatic Programmer):任何一个知识点在系统内都应当有一个唯一、明确、权威的表述。根据Brian Kernighan的建议,把这个原则称为“真理的单点性(Single Point of Truth)”或者SPOT原则。)
|
||||
|
||||
或者,正如这个*我就不说出具体名字的特定项目*所做的,它的高层开发人员在电子邮件中最近声明说,提交可以包含多个更新日志条目,并且提交的元数据与更新日志是无关的。这导致我们直到现在还得不断进行记录。
|
||||
|
||||
当时我读到邮件的时候都要吐了。什么样的傻瓜才会意识不到这是自找麻烦 —— 事实上,在 DVCS 中针对可靠的提交日志有很好的浏览工具,围绕更新日志文件的整个定制措施只会成为负担和拖累。
|
||||
|
||||
唉,这是比较特殊的笨蛋:变老的并且思维僵化了的黑客。所有的合理化改革他都会极力反对。他所遵循的行事方法在几十年前是有效的,但现在只能适得其反。如果你试图向他解释这些不仅仅和 git 的摘要信息有关,同时还为了正确适应当前的工具集,以便实现更新日志的去条目化... 呵呵,那你就准备好迎接无法忍受、无法想象的疯狂对话吧。
|
||||
|
||||
的确,它成功激怒了我。这样那样的胡言乱语使这个项目变成了很难完成的工作。而且,同样的糟糕还体现在他们吸引年轻开发者的过程中,我认为这是真正的问题。相关 Google+ 社区的人员数量已经达到了 4 位数,他们大部分都是孩子,还没有成长起来。显然外界已经接受了这样的信息:这个项目的开发者都是部落中地位根深蒂固的崇高首领,最好的崇拜方式就是远远的景仰着他们。
|
||||
|
||||
这件事给我的最大触动就是每当我要和这些部落首领较量时,我都会想:有一天我也会这样吗?或者更糟的是,我看到的只是如同镜子一般对我自己的真实写照,而我自己却浑然不觉?我的意思是,我所得到的印象来自于他的网站,这个特殊的笨蛋要比我年轻。年轻至少 15 岁呢。
|
||||
|
||||
我总是认为自己的思路很清晰。当我和那些比我聪明的人打交道时我不会受挫,我只会因为那些思路跟不上我、看不清事实的人而沮丧。但这种自信也许只是邓宁·克鲁格效应(Dunning-Krueger effect)在我身上的消极影响,我并不确定这意味着什么。很少有什么事情会让我感到害怕;而这件事在让我害怕的事情名单上是名列前茅的。
|
||||
|
||||
另一件让人不安的事是当我逐渐变老的时候,这样的矛盾发生得越来越频繁。不知怎的,我希望我的黑客同行们能以更加优雅的姿态老去,即使身体老去也应该保持一颗年轻的心灵。有些人确实是这样;但可惜绝大多数人都不是。真令人悲哀。
|
||||
|
||||
我不确定我的职业生涯会不会完美收场。假如我最后成功避免了思维僵化(注意我说的是假如),我想我一定知道其中的部分原因,但我不确定这种模式是否可以被复制 —— 为了达成目的也许得在你的头脑中发生一些复杂的化学反应。尽管如此,无论对错,请听听我给年轻黑客以及其他有志青年的建议。
|
||||
|
||||
你们——对的,也包括你——一定无法在你中年老年的时候保持不错的心灵,除非你能很好的控制这点。你必须不断地去磨练你的内心、在你还年轻的时候完成自己的种种心愿,你必须把这些行为养成一种习惯直到你老去。
|
||||
|
||||
有种说法是中年人锻炼身体的最佳时机是 30 岁以前。我以为同样的方法,坚持我以上所说的习惯能让你在 56 岁,甚至 65 岁的时候仍然保持灵活的头脑。挑战你的极限,使不断地挑战自己成为一种习惯。立刻离开安乐窝,由此当你以后真正需要它的时候你可以建立起自己的安乐窝。
|
||||
|
||||
你必须要清楚的了解这点;还有一个可选择的挑战是你选择一个可以实现的目标并且为了这个目标不断努力。这个月我要学习 Go 语言。不是指游戏,我早就玩儿过了(虽然玩儿的不是太好)。并不是因为工作需要,而是因为我觉得是时候来扩展下我自己了。
|
||||
|
||||
保持这个习惯。永远不要放弃。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=6485
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://book.51cto.com/art/200809/88490.htm
|
||||
@ -2,7 +2,7 @@
|
||||
================================================================================
|
||||
你能快速定位CPU性能回退的问题么? 如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。
|
||||
|
||||
辛亏有了[CPU火焰图][1](flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。
|
||||
幸亏有了[CPU火焰图][1](flame graphs),CPU使用率的问题一般都比较好定位。但要处理性能回退问题,就要在修改前后的火焰图之间,不断切换对比,来找出问题所在,这感觉就是像在太阳系中搜寻冥王星。虽然,这种方法可以解决问题,但我觉得应该会有更好的办法。
|
||||
|
||||
所以,下面就隆重介绍**红/蓝差分火焰图(red/blue differential flame graphs)**:
|
||||
|
||||
@ -14,7 +14,7 @@
|
||||
|
||||
这张火焰图中各火焰的形状和大小都是和第二次抓取的profile文件对应的CPU火焰图是相同的。(其中,y轴表示栈的深度,x轴表示样本的总数,栈帧的宽度表示了profile文件中该函数出现的比例,最顶层表示正在运行的函数,再往下就是调用它的栈)
|
||||
|
||||
在下面这个案例展示了,在系统升级后,一个工作负载的CPU使用率上升了。 下面是对应的CPU火焰图([SVG格式][4])
|
||||
在下面这个案例展示了,在系统升级后,一个工作载荷的CPU使用率上升了。 下面是对应的CPU火焰图([SVG格式][4])
|
||||
|
||||
<p><object data="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" type="image/svg+xml" width=720 height=296>
|
||||
<img src="http://www.brendangregg.com/blog/images/2014/zfs-flamegraph-after.svg" width=720 />
|
||||
@ -22,7 +22,7 @@
|
||||
|
||||
通常,在标准的火焰图中栈帧和栈塔的颜色是随机选择的。 而在红/蓝差分火焰图中,使用不同的颜色来表示两个profile文件中的差异部分。
|
||||
|
||||
在第二个profile中deflate_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被使能了,而在系统升级前这项功能是关闭的。
|
||||
在第二个profile中deflate_slow()函数以及它后续调用的函数运行的次数要比前一次更多,所以在上图中这个栈帧被标为了红色。可以看出问题的原因是ZFS的压缩功能被启用了,而在系统升级前这项功能是关闭的。
|
||||
|
||||
这个例子过于简单,我甚至可以不用差分火焰图也能分析出来。但想象一下,如果是在分析一个微小的性能下降,比如说小于5%,而且代码也更加复杂的时候,问题就为那么好处理了。
|
||||
|
||||
@ -69,7 +69,9 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
在上面的例子中"func_a()->func_b()->func_c()" 代表调用栈,这个调用栈在profile1文件中共出现了31次,在profile2文件中共出现了33次。然后,使用flamegraph.pl脚本处理这3列数据,会自动生成一张红/蓝差分火焰图。
|
||||
|
||||
### 其他选项 ###
|
||||
|
||||
再介绍一些有用的选项:
|
||||
|
||||
**difffolded.pl -n**:这个选项会把两个profile文件中的数据规范化,使其能相互匹配上。如果你不这样做,抓取到所有栈的统计值肯定会不相同,因为抓取的时间和CPU负载都不同。这样的话,看上去要么就是一片红(负载增加),要么就是一片蓝(负载下降)。-n选项对第一个profile文件进行了平衡,这样你就可以得到完整红/蓝图谱。
|
||||
|
||||
**difffolded.pl -x**: 这个选项会把16进制的地址删掉。 profiler时常会无法将地址转换为符号,这样的话栈里就会有16进制地址。如果这个地址在两个profile文件中不同,这两个栈就会认为是不同的栈,而实际上它们是相同的。遇到这样的问题就用-x选项搞定。
|
||||
@ -77,6 +79,7 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
**flamegraph.pl --negate**: 用于颠倒红/蓝配色。 在下面的章节中,会用到这个功能。
|
||||
|
||||
### 不足之处 ###
|
||||
|
||||
虽然我的红/蓝差分火焰图很有用,但实际上还是有一个问题:如果一个代码执行路径完全消失了,那么在火焰图中就找不到地方来标注蓝色。你只能看到当前的CPU使用情况,而不知道为什么会变成这样。
|
||||
|
||||
一个办法是,将对比顺序颠倒,画一个相反的差分火焰图。例如:
|
||||
@ -95,12 +98,13 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
|
||||
这样,把前面生成diff2.svg一并使用,我们就能得到:
|
||||
|
||||
- **diff1.svg**: 宽度是以修改前profile文件为基准, 颜色表明将要发生的情况
|
||||
- **diff2.svg**: 宽度以修改后的profile文件为基准,颜色表明已经发生的情况
|
||||
- **diff1.svg**: 宽度是以修改前profile文件为基准,颜色表明将要发生的情况
|
||||
- **diff2.svg**: 宽度是以修改后profile文件为基准,颜色表明已经发生的情况
|
||||
|
||||
如果是在做功能验证测试,我会同时生成这两张图。
|
||||
|
||||
### CPI 火焰图 ###
|
||||
|
||||
这些脚本开始是被使用在[CPI火焰图][8]的分析上。与比较修改前后的profile文件不同,在分析CPI火焰图时,可以分析CPU工作周期与停顿周期的差异变化,这样可以凸显出CPU的工作状态来。
|
||||
|
||||
### 其他的差分火焰图 ###
|
||||
@ -110,6 +114,7 @@ difffolded.p只能对“折叠”过的堆栈profile文件进行操作,折叠
|
||||
也有其他人做过类似的工作。[Robert Mustacchi][10]在不久前也做了一些尝试,他使用的方法类似于代码检视时的标色风格:只显示了差异的部分,红色表示新增(上升)的代码路径,蓝色表示删除(下降)的代码路径。一个关键的差别是栈帧的宽度只体现了差异的样本数。右边是一个例子。这个是个很好的主意,但在实际使用中会感觉有点奇怪,因为缺失了完整profile文件的上下文作为背景,这张图显得有些难以理解。
|
||||
|
||||
[][12]
|
||||
|
||||
Cor-Paul Bezemer也制作了一种差分显示方法[flamegraphdiff][13],他同时将3张火焰图放在同一张图中,修改前后的标准火焰图各一张,下面再补充了一张差分火焰图,但栈帧宽度也是差异的样本数。 上图是一个[例子][14]。在差分图中将鼠标移到栈帧上,3张图中同一栈帧都会被高亮显示。这种方法中补充了两张标准的火焰图,因此解决了上下文的问题。
|
||||
|
||||
我们3人的差分火焰图,都各有所长。三者可以结合起来使用:Cor-Paul方法中上方的两张图,可以用我的diff1.svg 和 diff2.svg。下方的火焰图可以用Robert的方式。为保持一致性,下方的火焰图可以用我的着色方式:蓝->白->红。
|
||||
@ -128,7 +133,7 @@ via: http://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -24,11 +24,11 @@
|
||||
|
||||
|
||||
|
||||
然后 4 会被插入到文件中。
|
||||
然后计算结果“4 ”会被插入到文件中。
|
||||
|
||||
### 查找重复的连续的单词 ###
|
||||
|
||||
当你很快地打字时,很有可能会连续输入同一个单词两次,就像 this this。这种错误可能骗过任何一个人,即使是你自己重新阅读一边也不可避免。幸运的是,有一个简单的正则表达式可以用来预防这个错误。使用搜索命令(默认时 `/`)然后输入:
|
||||
当你很快地打字时,很有可能会连续输入同一个单词两次,就像 this this。这种错误可能骗过任何一个人,即使是你自己重新阅读一遍也不可避免。幸运的是,有一个简单的正则表达式可以用来预防这个错误。使用搜索命令(默认时 `/`)然后输入:
|
||||
|
||||
\(\<\w\+\>\)\_s*\1
|
||||
|
||||
@ -72,7 +72,7 @@
|
||||
|
||||
`gg` 把光标移动到 Vim 缓冲区的第一行,`V` 进入可视模式,`G` 把光标移动到缓冲区的最后一行。因此,`ggVG` 使可视模式覆盖这个当前缓冲区。最后 `g?` 使用 ROT13 对整个区域进行编码。
|
||||
|
||||
注意它应该被映射到一个最长使用的键。它对字母符号也可以很好地工作。要对它进行撤销,最好的方法就是使用撤销命令:`u`。
|
||||
注意它可以被映射到一个最常使用的键。它对字母符号也可以很好地工作。要对它进行撤销,最好的方法就是使用撤销命令:`u`。
|
||||
|
||||
###自动补全 ###
|
||||
|
||||
@ -110,7 +110,7 @@
|
||||
|
||||
### 按时间回退文件 ###
|
||||
|
||||
Vim 会记录文件的更改,你很容易可以回退到之前某个时间。该命令时相当直观的。比如:
|
||||
Vim 会记录文件的更改,你很容易可以回退到之前某个时间。该命令是相当直观的。比如:
|
||||
|
||||
:earlier 1m
|
||||
|
||||
@ -122,7 +122,7 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
### 删除标记内部的文字 ###
|
||||
|
||||
当我开始使用 Vim 时一件我总是想很方便做的事情是如何轻松的删除方括号或圆括号里的内容。转到开始的标记,然后使用下面的语法:
|
||||
当我开始使用 Vim 时,一件我总是想很方便做的事情是如何轻松的删除方括号或圆括号里的内容。转到开始的标记,然后使用下面的语法:
|
||||
|
||||
di[标记]
|
||||
|
||||
@ -164,11 +164,11 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
### 把光标下的文字置于屏幕中央 ###
|
||||
|
||||
所有要做的事情都包含在标题中。如果你想强制滚动屏幕来把光标下的文字置于屏幕的中央,在可视模式中使用命令(译者注:在普通模式中也可以):
|
||||
我们所要做的事情如标题所示。如果你想强制滚动屏幕来把光标下的文字置于屏幕的中央,在可视模式中使用命令(译者注:在普通模式中也可以):
|
||||
|
||||
zz
|
||||
|
||||
### 跳到上一个/下一个 位置 ###
|
||||
### 跳到上一个/下一个位置 ###
|
||||
|
||||
当你编辑一个很大的文件时,经常要做的事是在某处进行修改,然后跳到另外一处。如果你想跳回之前修改的地方,使用命令:
|
||||
|
||||
@ -196,7 +196,7 @@ Vim 会记录文件的更改,你很容易可以回退到之前某个时间。
|
||||
|
||||
总的来说,这一系列命令是在我读了许多论坛主题和 [Vim Tips wiki][3](如果你想学习更多关于编辑器的知识,我非常推荐这篇文章) 之后收集起来的。
|
||||
|
||||
如果你还知道哪些非常有用但你认为大多数人并不知道的命令,可以随意在评论中分享出来。就像引言中所说的,一个“鲜为人知但很有用的”命令是很主观的,但分享出来总是好的。
|
||||
如果你还知道哪些非常有用但你认为大多数人并不知道的命令,可以随意在评论中分享出来。就像引言中所说的,一个“鲜为人知但很有用的”命令也许只是你自己的看法,但分享出来总是好的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -204,7 +204,7 @@ via: http://xmodulo.com/useful-vim-commands.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[wangjiezhe](https://github.com/wangjiezhe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,37 +1,40 @@
|
||||
四招搞定Linux内核热补丁
|
||||
不重启不当机!Linux内核热补丁的四种技术
|
||||
================================================================================
|
||||

|
||||
Credit: Shutterstock
|
||||
|
||||
多种技术在竞争成为实现inux内核热补丁的最优方案。
|
||||
供图: Shutterstock
|
||||
|
||||
有多种技术在竞争成为实现Linux内核热补丁的最优方案。
|
||||
|
||||
没人喜欢重启机器,尤其是涉及到一个内核问题的最新补丁程序。
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供对内核进行运行时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
为达到不重启的目的,目前有3个项目在朝这方面努力,将为大家提供内核升级时打热补丁的机制,这样就可以做到完全不重启机器。
|
||||
|
||||
### Ksplice项目 ###
|
||||
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,将内核的修改点列全即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
首先要介绍的项目是Ksplice,它是热补丁技术的创始者,并于2008年建立了与项目同名的公司。Ksplice在替换新内核时,不需要预先修改;只需要一个diff文件,列出内核即将接受的修改即可。Ksplice公司免费提供软件,但技术支持是需要收费的,目前能够支持大部分常用的Linux发行版本。
|
||||
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle的Linux发行版本中,且只对Oralcle的版本提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
但在2011年[Oracle收购了这家公司][1]后,情况发生了变化。 这项功能被合入到Oracle自己的Linux发行版本中,只对Oralcle自己提供技术更新。 这就导致,其他内核hacker们开始寻找替代Ksplice的方法,以避免缴纳Oracle税。
|
||||
|
||||
### Kgraft项目 ###
|
||||
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有的实现。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
2014年2月,Suse提供了一个很好的解决方案:[Kgraft][2],该内核更新技术以GPLv2/GPLv3混合许可证发布,且Suse不会将其作为一个专有发明封闭起来。Kgraft被[提交][3]到Linux内核主线,很有可能被内核主线采用。目前Suse已经把此技术集成到[Suse Linux Enterprise Server 12][4]。
|
||||
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本中对应的部分,当补丁打完后就可以切换新的版本。
|
||||
Kgraft和Ksplice在工作原理上很相似,都是使用一组diff文件来计算内核中需要修改的部分。但与Ksplice不同的是,Kgraft在做替换时,不需要完全停止内核。 在打补丁时,正在运行的函数可以先使用老版本或新内核中对应的部分,当补丁打完后就可以完全切换新的版本。
|
||||
|
||||
### Kpatch项目 ###
|
||||
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在今年年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
Red Hat也提出了他们的内核热补丁技术。同样是在2014年初 -- 与Suse在这方面的工作差不多 -- [Kpatch][5]的工作原理也和Kgraft相似。
|
||||
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch不能将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
主要的区别点在于,正如Red Hat的Josh Poimboeuf[总结][6]的那样,Kpatch并不将内核调用重定向到老版本。相反,它会等待所有函数调用都停止时,再切换到新内核。Red Hat的工程师认为这种方法更为安全,且更容易维护,缺点就是在打补丁的过程中会带来更大的延迟。
|
||||
|
||||
和Kgraft一样,Kpatch不仅仅能在Red Hat的发行版本上可以使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
和Kgraft一样,Kpatch不仅仅可以在Red Hat的发行版本上使用,同时也被提交到了内核主线,作为一个可能的候选。 坏消息是Red Hat还未将此技术集成到产品中。 它只是被合入到了Red Hat Enterprise Linux 7的技术预览版中。
|
||||
|
||||
### ...也许 Kgraft + Kpatch更合适? ###
|
||||
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了热补丁的注册机制”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的进行。
|
||||
Red Hat的工程师Seth Jennings在2014年11月初,提出了[第四种解决方案][7]。将Kgraft和Kpatch结合起来, 补丁包用这两种方式都可以。在新的方法中,Jennings提出,“热补丁核心为其他内核模块提供了一个热补丁的注册接口”, 通过这种方法,打补丁的过程 -- 更准确的说,如何处理运行时内核调用 --可以被更加有序的组织起来。
|
||||
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Linux官方近期的动态。
|
||||
这项新建议也意味着两个方案都还需要更长的时间,才能被linux内核正式采纳。尽管Suse步子迈得更快,并把Kgraft应用到了最新的enterprise版本中。让我们也关注一下Red Hat和Canonical近期是否会跟进。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -40,7 +43,7 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[tinyeyeser](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -51,4 +54,4 @@ via: http://www.infoworld.com/article/2851028/linux/four-ways-linux-is-headed-fo
|
||||
[4]:http://www.infoworld.com/article/2838421/linux/suse-linux-enterprise-12-goes-light-on-docker-heavy-on-reliability.html
|
||||
[5]:https://github.com/dynup/kpatch
|
||||
[6]:https://lwn.net/Articles/597123/
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
[7]:http://lkml.iu.edu/hypermail/linux/kernel/1411.0/04020.html
|
||||
@ -1,20 +1,19 @@
|
||||
Linux FAQs with Answers--How to disable Apport internal error reporting on Ubuntu
|
||||
有问必答--如何禁止Ubuntu的Apport内部错误报告程序
|
||||
Linux有问必答:如何禁止Ubuntu的Apport内部错误报告程序
|
||||
================================================================================
|
||||
> **问题**:在桌面版Ubuntu中,我经常遇到一些弹窗窗口,警告我Ubuntu发生了内部错误,问我要不要发送错误报告。每次软件崩溃都要烦扰我,我如何才能关掉这个错误报告功能呢?
|
||||
|
||||
Ubuntu桌面版预安装了Apport,它是一个错误收集系统,会收集软件崩溃、未处理异常和其他,包括程序bug,并为调试目的生成崩溃报告。当一个应用程序崩溃或者出现Bug时候,Apport就会通过弹窗警告用户并且询问用户是否提交崩溃报告。你也许也看到过下面的消息。
|
||||
Ubuntu桌面版预装了Apport,它是一个错误收集系统,会收集软件崩溃、未处理异常和其他,包括程序bug,并为调试目的生成崩溃报告。当一个应用程序崩溃或者出现Bug时候,Apport就会通过弹窗警告用户并且询问用户是否提交崩溃报告。你也许也看到过下面的消息。
|
||||
|
||||
- "Sorry, the application XXXX has closed unexpectedly."
|
||||
- "对不起,应用程序XXXX意外关闭了"
|
||||
- "对不起,应用程序XXXX意外关闭了。"
|
||||
- "Sorry, Ubuntu XX.XX has experienced an internal error."
|
||||
- "对不起,Ubuntu XX.XX 经历了一个内部错误"
|
||||
- "对不起,Ubuntu XX.XX 发生了一个内部错误。"
|
||||
- "System program problem detected."
|
||||
- "系统程序问题发现"
|
||||
- "检测到系统程序问题。"
|
||||
|
||||
|
||||
|
||||
也许因为应用一直崩溃,频繁的错误报告会使人心烦。也许你担心Apport会收集和上传你的Ubuntu系统的敏感信息。无论什么原因,你需要关掉Apport的错误报告功能。
|
||||
也许因为应用一直崩溃,频繁的错误报告会使人心烦。也许你担心Apport会收集和上传你的Ubuntu系统的敏感信息。无论什么原因,你想关掉Apport的错误报告功能。
|
||||
|
||||
### 临时关闭Apport错误报告 ###
|
||||
|
||||
@ -41,6 +40,6 @@ Ubuntu桌面版预安装了Apport,它是一个错误收集系统,会收集
|
||||
via: http://ask.xmodulo.com/disable-apport-internal-error-reporting-ubuntu.html
|
||||
|
||||
译者:[VicYu/Vic020](http://www.vicyu.net/)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,6 +1,4 @@
|
||||
Traslated by H-mudcup
|
||||
|
||||
美国海军陆战队想把雷达操作系统从Windows XP换成Linux
|
||||
美国海军陆战队要把雷达操作系统从Windows XP换成Linux
|
||||
================================================================================
|
||||
**一个新的雷达系统已经被送回去升级了**
|
||||
|
||||
@ -18,13 +16,13 @@ Traslated by H-mudcup
|
||||
|
||||
>一谈到稳定性和性能,没什么能真的比得过Linux。这就是为什么美国海军陆战队的领导们已经决定让Northrop Grumman Corp. Electronic Systems把新送到的地面/空中任务导向雷达(G/ATOR)的操作系统从Windows XP换成Linux。
|
||||
|
||||
地面/空中任务导向雷达(G/ATOR)系统已经研制了很多年。很可能在这项工程启动的时候Windows XP被认为是合理的选择。在研制的这段时间,事情发生了变化。微软已经撤销了对Windows XP的支持而且只有极少的几个组织会使用它。操作系统要么升级要么被换掉。在这种情况下,Linux成了合理的选择。特别是当替换的费用很可能远远少于更新的费用。
|
||||
地面/空中任务导向雷达(G/ATOR)系统已经研制了很多年。很可能在这项工程启动的时候Windows XP被认为是合理的选择。但在研制的这段时间,事情发生了变化。微软已经撤销了对Windows XP的支持而且只有极少的几个组织会使用它。操作系统要么升级要么被换掉。在这种情况下,Linux成了合理的选择。特别是当替换的费用很可能远远少于更新的费用。
|
||||
|
||||
有个很有趣的地方值得注意一下。地面/空中任务导向雷达(G/ATOR)才刚刚送到美国海军陆战队,但是制造它的公司却还是选择了保留这个过时的操作系统。一定有人注意到的这样一个事实。这是一个糟糕的决定,并且指挥系统已经被告知了可能出现的问题了。
|
||||
|
||||
### G/ATOR雷达的软件将是基于Linux的 ###
|
||||
|
||||
Unix类系统,比如基于BSD或者基于Linux的操作系统,通常会出现在条件苛刻的领域,或者任何情况下都不能失败的的技术中。例如,这就是为什么大多数的服务器都运行着Linux。一个雷达系统配上一个几乎不可能崩溃的操作系统看起来非常相配。
|
||||
Unix类系统,比如基于BSD或者基于Linux的操作系统,通常会出现在条件苛刻的领域,或者任何情况下都不允许失败的的技术中。例如,这就是为什么大多数的服务器都运行着Linux。一个雷达系统配上一个几乎不可能崩溃的操作系统看起来非常相配。
|
||||
|
||||
“弗吉尼亚州Quantico海军基地海军陆战队系统司令部的官员,在周三宣布了一项与Northrop Grumman Corp. Electronic Systems在林西科姆高地的部分的总经理签订的价值1020万美元的修正合同。这个合同的修改将包括这样一项,把G/ATOR的控制电脑从微软的Windows XP操作系统换成与国防信息局(DISA)兼容的Linux操作系统。”
|
||||
|
||||
@ -40,7 +38,7 @@ via: http://news.softpedia.com/news/U-S-Marine-Corps-Want-to-Change-OS-for-Radar
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
NetHack
|
||||
也许是有史以来最好的游戏:NetHack
|
||||
================================================================================
|
||||
## 一直以来最好的游戏? ##
|
||||
|
||||
**这款游戏非常容易让你上瘾。你可能需要花费一生的时间来掌握它。许多人玩了几十年也没有通关。欢迎来到 NetHack 的世界...**
|
||||
|
||||
不管你信不信,在 NetHack 里你见到字母 D 的时候你会被吓着。但是当你看见一个 % 的时候,你将会欣喜若狂。(忘了说 ^,你看见它将会更激动)在你寻思我们的脑子是不是烧坏了并准备关闭浏览器标签之前,请给我们一点时间解释:这些符号分别代表龙、食物以及陷阱。欢迎来到 NetHack 的世界,在这里你的想象力需要发挥巨大的作用。
|
||||
不管你信不信,在 NetHack 里你见到字母 **D** 的时候你会被吓着。但是当你看见一个 **%** 的时候,你将会欣喜若狂。(忘了说 **\^**,你看见它将会更激动)在你寻思我们的脑子是不是烧坏了并准备关闭浏览器标签之前,请给我们一点时间解释:这些符号分别代表龙、食物以及陷阱。欢迎来到 NetHack 的世界,在这里你的想象力需要发挥巨大的作用。
|
||||
|
||||
如你所见,NetHack 是一款文字模式的游戏:它仅仅使用标准终端字符集来刻画玩家、敌人、物品还有环境。游戏的图形版是存在的,不过 NetHack 的骨灰级玩家们都倾向于不去使用它们,问题在于假如你使用图形界面,当你通过 SSH 登录到你的古董级的运行着 NetBSD 的 Amiga 3000 上时,你还能进行游戏吗?在某些方面,NetHack 和 Vi 非常相似 - 几乎被移植到了现存的所有的操作系统上,并且依赖都非常少。
|
||||
|
||||
@ -16,68 +15,68 @@ NetHack
|
||||
|
||||
|
||||
|
||||
NetHack 界面
|
||||
*NetHack 界面*
|
||||
|
||||
### 也许是最古老的仍在开发的游戏里 ###
|
||||
|
||||
名非其实,NetHack 并不是一款网络游戏。它只不过是基于一款出现较早的名为 Hack 的地牢探险类游戏开发出来的,而这款 Hack 游戏是 1980 年的游戏 Rogue 的后代。NetHack 在 1987 年发布了第一个版本,并于 2003 年发布了 3.4.3 版本,尽管在这期间一直没有加入新的功能,但各种补丁、插件,以及衍生作品还是在网络上疯狂流传。这使得它可以说是最古老的、拥有众多对游戏乐此不疲的粉丝的游戏。当你访问 [www.reddit.com/r/nethack][1] 之后,你就会了解我们的意思了 - 骨灰级的 NetHack 的玩家们仍然聚集在一起讨论新的策略、发现和技巧。偶尔你也可以发现 NetHack 的元老级玩家在历经千辛万苦终于通关之后发出的欢呼。
|
||||
|
||||
|
||||
但怎样才能通关呢?首先,NetHack 被设定在既大又深的地牢中。游戏开始时你在最顶层 - 第 1 层 - 你的目标是不断往下深入直到你找到一个非常宝贵的物品,护身符 Yendor。通常来说 Yendor 在 第 20 层或者更深的地方,但它是可以变化的。随着你在地牢的不断深入,你会遇到各种各样的怪物、陷阱以及 NPC;有些会试图杀掉你,有些会挡在你前进的路上,还有些... 总而言之,在你靠近 TA 们之前你永远不知道 TA 们会怎样。
|
||||
|
||||
> 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。
|
||||
|
||||
是 NetHack 如此引人入胜的原因是游戏中所加入的大量物品。武器、盔甲、附魔书、戒指、宝石 - 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。怪物在死亡后经常会掉落一些有用的物品,以及某些物品如果你不正确使用的话会产生及其不良的作用。你可以在地牢找到商店,里面有许多看似平凡实则非常有用的物品,,不过别指望店主能给你详细的描述。你只能靠自己的经验来了解各个物品的用途。有些物品确实没有太大用处,NetHack 中有很多的恶搞元素 - 比如你可以把一块奶油砸到自己的脸上。
|
||||
使 NetHack 如此引人入胜的原因是游戏中所加入的大量物品。武器、盔甲、附魔书、戒指、宝石 - 要学习的有太多太多,绝大多数物品只有在和其他物品同时使用的情况下才会发挥最好的效果。怪物在死亡后经常会掉落一些有用的物品,以及某些物品如果你不正确使用的话会产生及其不良的作用。你可以在地牢找到商店,里面有许多看似平凡实则非常有用的物品,不过别指望店主能给你详细的描述。你只能靠自己的经验来了解各个物品的用途。有些物品确实没有太大用处,NetHack 中有很多的恶搞元素 - 比如你可以把一块奶油砸到自己的脸上。
|
||||
|
||||
不过在你踏入地牢之前,NetHack 会询问你要选择哪种角色进行游戏。你可以为你接下来的地牢之行选择骑士、修道士、巫师,或者卑微的旅者,还有许多其他的角色类型。每种角色都有其独特的优势与弱点,NetHack 的重度玩家喜欢选择那些相对较弱的角色来挑战游戏。你懂的,这样可以向其他玩家炫耀自己的实力。
|
||||
|
||||
> ## 情报不会降低游戏的乐趣 ##
|
||||
> **情报不会降低游戏的乐趣**
|
||||
|
||||
> 用 NetHack 的说法来讲,“情报员”给指其他玩家提供关于怪物、物品、武器和盔甲信息的玩家。理论上来说,完全可以不借助任何外来信息而通关,但几乎没有几个玩家能做到,游戏实在是太难了。因此使用情报并不会被视为一件糟糕的事情 - 但是一开始由你自己来探索游戏和解决难题,这样才会获得更多的乐趣,只有当你遇到瓶颈的时候再去使用那些情报。
|
||||
|
||||
> 在这里给出一个比较有名的情报站点 [www.statslab.cam.ac.uk/~eva/nethack/spoilerlist.html][2],其中的情报被分为了不同的类别。游戏中随机发生的事,比如在喷泉旁饮水可能导致的不同结果,从这里你可以得知已确定的不同结果的发生概率。
|
||||
>
|
||||
> ### 你的首次地牢之行 ###
|
||||
|
||||
NetHack 几乎可以在所有的主流操作系统以及 Linux 发行版上运行,因此你可以通过 "apt-get install nethack" 或者 "yum install nethack" 等适合你用的发行版的命令来安装游戏。安装完毕后,在一个命令行窗口中键入 "nethack" 就可以开始游戏了。游戏开始时系统会询问是否为你随机挑选一位角色 - 但作为一个新手,你最好自己从里面挑选一位比较强的角色。所以,你应该点 "n",然后点 "v" 以选取女武神(Valkyrie),最后点 "d" 选择成为侏儒(dwarf)。
|
||||
### 你的首次地牢之行 ###
|
||||
|
||||
NetHack 几乎可以在所有的主流操作系统以及 Linux 发行版上运行,因此你可以通过 "apt-get install nethack" 或者 "yum install nethack" 等适合你用的发行版的命令来安装游戏。安装完毕后,在一个命令行窗口中键入 "nethack" 就可以开始游戏了。游戏开始时系统会询问是否为你随机挑选一位角色 - 但作为一个新手,你最好自己从里面挑选一位比较强的角色。所以,你应该点 "n",然后点 "v" 以选取女武神(Valkyrie),而点 "d" 会选择成为侏儒(dwarf)。
|
||||
|
||||
接着 NetHack 上会显示出剧情,说你的神正在寻找护身符 Yendor,你的目标就是找到它并将它带给神。阅读完毕后点击空格键(其他任何时候当你见到屏幕上的 "-More-" 时都可以这样)。接着就让我们出发 - 开始地牢之行吧!
|
||||
|
||||
先前已经介绍过了,你的角色用 @ 来表示。你可以看见角色所出房间周围的墙壁,房间里显示点的那些地方是你可以移动的空间。首先,你得明白怎样移动角色:h、j、k 以及 l。(是的,和 Vim 中移动光标的操作相同)这些操作分别会使角色向向左、向下、向上以及向右移动。你也可以通过 y、u、b 和 n 来使角色斜向移动。在你熟悉如何控制角色移动前你最好在房间里来回移动你的角色。
|
||||
先前已经介绍过了,你的角色用 @ 来表示。你可以看见角色所出房间周围的墙壁,房间里显示“点”的那些地方是你可以移动的空间。首先,你得明白怎样移动角色:h、j、k 以及 l。(是的,和 Vim 中移动光标的操作相同)这些操作分别会使角色向向左、向下、向上以及向右移动。你也可以通过 y、u、b 和 n 来使角色斜向移动。在你熟悉如何控制角色移动前你最好在房间里来回移动你的角色。
|
||||
|
||||
NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然在进行。这是你可以提前计划你的行动。你可以看见一个 "d" 字符或者 "f" 字符在房间里来回移动:这是你的宠物狗/猫,(通常情况下)它们 不会伤害你而是帮助你击杀怪物。但是宠物也会被惹怒 - 它们偶尔也会抢在你接近食物或者怪物尸体之前吃掉它们。
|
||||
NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然在进行。这是你可以提前计划你的行动。你可以看见一个 "d" 字符或者 "f" 字符在房间里来回移动:这是你的宠物狗/猫,(通常情况下)它们不会伤害你而是帮助你击杀怪物。但是宠物也会被惹怒 - 它们偶尔也会抢在你接近食物或者怪物尸体之前吃掉它们。
|
||||
|
||||
|
||||
|
||||
点击 “i” 列出你当前携带的物品清单
|
||||
*点击 “i” 列出你当前携带的物品清单*
|
||||
|
||||
### 门后有什么? ###
|
||||
|
||||
接下来,让我们离开房间。房间四周的墙壁某处会有缝隙,可能是 "+" 号。"+" 号表示一扇关闭的门,这时你应该靠近它然后点击 "o" 来开门。接着系统会询问你开门的方向,假如门在你的左方,就点击 "h"。(如果门被卡住了,就多试几次)然后你就可以看见门后的走廊了,它们由 "#" 号表示,沿着走廊前进直到你找到另一个房间。
|
||||
|
||||
地牢之行中你会见到各种各样的物品。某些物品,比如金币(由 "$" 号表示)会被自动捡起来;至于另一些物品,你只能站在上面按下逗号键手动拾起。如果同一位置有多个物品,系统会给你显示一个列表,你只要通过合适的案件选择列表中你想要的物品最后按下 "Enter" 键即可。任何时间你都可以点击 "i" 键在屏幕上列出你当前携带的物品清单。
|
||||
地牢之行中你会见到各种各样的物品。某些物品,比如金币(由 "$" 号表示)会被自动捡起来;至于另一些物品,你只能站在上面按下逗号键手动拾起。如果同一位置有多个物品,系统会给你显示一个列表,你只要通过合适的按键选择列表中你想要的物品最后按下 "Enter" 键即可。任何时间你都可以点击 "i" 键在屏幕上列出你当前携带的物品清单。
|
||||
|
||||
如果看见了怪物该怎么办?在游戏早期,你可能会遇到的怪物会用符号 "d"、"x" 和 ":" 表示。想要攻击的话,只要简单地朝怪物的方向移动即可。系统会在屏幕顶部通过信息显示来告诉你你的攻击是否成功 - 以及怪物做出了何种反应。早期的怪物很容易击杀,所以你可以毫不费力地打败他们,但请留意底部状态栏里显示的角色的 HP 值。
|
||||
如果看见了怪物该怎么办?在游戏早期,你可能会遇到的怪物会用符号 "d"、"x" 和 ":" 表示。想要攻击的话,只要简单地朝怪物的方向移动即可。系统会在屏幕顶部通过信息显示来告诉你攻击是否成功 - 以及怪物做出了何种反应。早期的怪物很容易击杀,所以你可以毫不费力地打败他们,但请留意底部状态栏里显示的角色的 HP 值。
|
||||
|
||||
> 早期的怪物很容易击杀,但请留意角色的 HP 值。
|
||||
|
||||
如果怪物死后掉落了一具尸体("%"),你可以点击逗号进行拾取,并点击 "e" 来食用。(在任何时候系统提示你选择一件物品,你都可以从物品列表中点击相应的按键,或者点击 "?" 来查询迷你菜单。)主意!有些尸体是有毒的,这些知识你将在日后的冒险中逐渐学会掌握。
|
||||
如果怪物死后掉落了一具尸体("%"),你可以点击逗号进行拾取,并点击 "e" 来食用。(在任何时候系统提示你选择一件物品,你都可以从物品列表中点击相应的按键,或者点击 "?" 来查询迷你菜单。)注意!有些尸体是有毒的,这些知识你将在日后的冒险中逐渐学会掌握。
|
||||
|
||||
如果你在走廊里行进时遇到了死胡同,你可以点击 "s" 进行搜寻直到找到一扇门。这会花费时间,但是你由此加速了游戏进程:输入 "10" 并点击 "s" 你将一下搜索 10 次。这将花费游戏中进行 10 次动作的时间,不过如果你正在饥饿状态,你将有可能会被饿死。
|
||||
如果你在走廊里行进时遇到了死胡同,你可以点击 "s" 进行搜寻直到找到一扇门。这会花费时间,但是你可以这样加速游戏进程:输入 "10" 并点击 "s" 你将一下搜索 10 次。这将花费游戏中进行 10 次动作的时间,不过如果你正在饥饿状态,你将有可能会被饿死!
|
||||
|
||||
通常你可以在地牢顶部找到 "{"(喷泉)以及 "!"(药水)。当你找到喷泉的时候,你可以站在上面并点击 "q" 键开始 “畅饮(quaff)” - 引用后会得到积极的到致命的多种效果。当你找到药水的时候,将其拾起并点击 "q" 来引用。如果你找到一个商店,你可以拾取其中的物品并在离开前点击 "p" 键进行支付。当你负重过大时,你可以点击 "d" 键丢掉一些东西。
|
||||
通常你可以在地牢顶部找到 "{"(喷泉)以及 "!"(药水)。当你找到喷泉的时候,你可以站在上面并点击 "q" 键开始 “畅饮(quaff)” - 引用后会得到从振奋的到致命的多种效果。当你找到药水的时候,将其拾起并点击 "q" 来饮用。如果你找到一个商店,你可以拾取其中的物品并在离开前点击 "p" 键进行支付。当你负重过大时,你可以点击 "d" 键丢掉一些东西。
|
||||
|
||||
|
||||
|
||||
现在已经有带音效的 3D 版 Nethack 了,如:Falcon’s Eye
|
||||
*现在已经有带音效的 3D 版 Nethack 了,如:Falcon’s Eye*
|
||||
|
||||
> ## 愚蠢的死法 ##
|
||||
> **愚蠢的死法**
|
||||
|
||||
> 在 NetHack 玩家中流行着一个缩写词 "YASD" - 又一种愚蠢的死法(Yet Another Stupid Death)。这个缩写词表示了玩家由于自身的的愚蠢或者粗心大意导致了角色的死亡。我们搜集了很多这类死法,但我们最喜欢的是下面描述的:
|
||||
> 在 NetHack 玩家中流行着一个缩写词 "YASD" - 又一种愚蠢的死法(Yet Another Stupid Death)。这个缩写词表示了玩家由于自身的的愚蠢或者粗心大意导致了角色的死亡。我们搜集了很多这类死法,但我们最喜欢的是下面这种死法:
|
||||
|
||||
> 我们正在商店浏览商品,这时一条蛇突然从药剂后面跳了出来。在杀死蛇之后,系统弹出一条信息提醒我们角色饥饿值过低了,因此我们顺手食用了蛇的尸体。坏事了!这使得我们的角色失明,导致我们的角色再也不能看见商店里的其他角色及地上的商品了。我们试图离开商店,但在慌乱中却撞在了店主身上并攻击了他。这种做法激怒了店主:他立即向我们的角色使用了火球术。我们试图逃到商店外的走廊上,但却在逃亡的过程中被烧死。
|
||||
|
||||
> 如果你有类似的死法,一定要来我们的论坛告诉我们。不要担心 - 没有人会嘲笑你。经历这样的死法也是你在 NetHack 的世界里不断成长的一部分。
|
||||
> 如果你有类似的死法,一定要来我们的论坛告诉我们。不要担心 - 没有人会嘲笑你。经历这样的死法也是你在 NetHack 的世界里不断成长的一部分。哈哈。
|
||||
|
||||
### 武装自己 ###
|
||||
|
||||
@ -85,7 +84,7 @@ NetHack 采用了回合制,因此即使你不进行任何动作,游戏仍然
|
||||
|
||||
在靠近掉在地下的装备之前最好检查一下身上的东西。点击 ";"(分号)后,"Pick an object"(选择一样物品)选项将出现在屏幕顶部。选择该选项,使用移动键直到选中你想要检查的物品,然后点击 ":"(冒号)。接着屏幕顶部将出现这件物品的描述。
|
||||
|
||||
因为你的目标是不断深入地牢直到找到护身符 Yendor,所以请随时留意周围的 "<" 和 ">" 符号。这两个符号分别表示向上和向下的楼梯,你可以用与之对应的按键来上楼或下楼。注意!如果你想让宠物跟随你进入下/上一层地牢,下/上楼前请确保你的宠物在你邻近的方格内。若果你想退出,点击 "S"(大写的 s)来保存进度,输入 #quit 退出游戏。当你再次运行 NetHack 时,系统将会自动读取你上次退出时的游戏进度。
|
||||
因为你的目标是不断深入地牢直到找到护身符 Yendor,所以请随时留意周围的 "<" 和 ">" 符号。这两个符号分别表示向上和向下的楼梯,你可以用与之对应的按键来上楼或下楼。注意!如果你想让宠物跟随你进入下/上一层地牢,下/上楼前请确保你的宠物在你邻近的方格内。若果你想退出,点击 "S"(大写的)来保存进度,输入 #quit 退出游戏。当你再次运行 NetHack 时,系统将会自动读取你上次退出时的游戏进度。
|
||||
|
||||
我们就不继续剧透了,地牢深处还有更多的神秘细节、陌生的 NPC 以及不为人知的秘密等着你去发掘。那么,我们再给你点建议:当你遇到了让你困惑不已的物品时,你可以尝试去 NetHack 维基 [http://nethack.wikia.com][3] 进行搜索。你也可以在 [www.nethack.org/v343/Guidebook.html][4] 找到一本非常不错(尽管很长)的指导手册。最后,祝游戏愉快!
|
||||
|
||||
@ -95,7 +94,7 @@ via: http://www.linuxvoice.com/nethack/
|
||||
|
||||
作者:[Mike Saunders][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,76 @@
|
||||
没错,Linux是感染了木马!但,这并非企鹅的末日。
|
||||
================================================================================
|
||||

|
||||
|
||||
译注:原文标题中Tuxpocalypse是作者造的词,由Tux和apocalypse组合而来。Tux是Linux的LOGO中那只企鹅的名字,apocalypse意为末世、大灾变,这里翻译成企鹅的末日。
|
||||
|
||||
你被监视了吗?
|
||||
|
||||
带上一箱罐头,挖一个深坑碉堡,准备进入一个完全不同的新世界吧:[一个强大的木马已经在Linux中被发现][1]。
|
||||
|
||||
没错,迄今为止最牢不可破的计算机世外桃源已经被攻破了,安全专家们都已成惊弓之鸟。
|
||||
|
||||
关掉电脑,拔掉键盘,然后再买只猫(忘掉YouTube吧)。企鹅末日已经降临,我们的日子不多了。
|
||||
|
||||
我去?这是真的吗?依我看,不一定吧~
|
||||
|
||||
### 一次可怕的异常事件! ###
|
||||
|
||||
先声明,**我并没有刻意轻视此次威胁(人们给这个木马起名为‘Turla’)的严重性**,为了避免质疑,我要强调的是,作为Linux用户,我们不应该为此次事件过分担心。
|
||||
|
||||
此次发现的木马能够在人们毫无察觉的情况下感染Linux系统,这是非常可怕的。事实上,它的主要工作是搜寻并向外发送各种类型的敏感信息,这一点同样令人感到恐惧。据了解,它已经存在至少4年时间,而且无需root权限就能完成这些工作。呃,这是要把人吓尿的节奏吗?
|
||||
|
||||
But - 但是 - 新闻稿里常常这个时候该出现‘but’了 - 要说恐慌正在横扫桌面Linux的粉丝,那就有点断章取义、甚至不着边际了。
|
||||
|
||||
对我们中的有些人来说,计算机安全隐患的确是一种新鲜事物,然而我们应该对其审慎对待:对桌面用户来说,Linux仍然是一个天生安全的操作系统。一次瑕疵不应该否定它的一切,我们没有必要慌忙地割断网线。
|
||||
|
||||
### 国家资助,目标政府 ###
|
||||
|
||||

|
||||
|
||||
企鹅和蛇的组合该叫‘企蛇’还是‘蛇鹅’?
|
||||
|
||||
‘Turla’木马是一个复杂、高级的持续威胁,四年多来,它以政府、大使馆以及制药公司的系统为目标,其使用的攻击方式所基于的代码[至少在14年前][2]就已存在了。
|
||||
|
||||
在Windows系统中,安全研究领域来自赛门铁克和卡巴斯基实验室的超级英雄们首先发现了这条黏黏的蛇,他们发现Turla及其组件已经**感染了45个国家的数百台个人电脑**,其中许多都是通过未打补丁的0day漏洞感染的。
|
||||
|
||||
*微软,干得漂亮。*
|
||||
|
||||
经过卡巴斯基实验室的进一步努力,他们发现,同样的木马出现在了Linux上。
|
||||
|
||||
这款木马无需高权限就可以“拦截传入的数据包,在系统中执行传入的命令”,但是它的触角到底有多深,有多少Linux系统被感染,它的完整功能都有哪些,这些目前都暂时还不明朗。
|
||||
|
||||
根据它选定的目标,我们推断“Turla”(及其变种)是由某些民族的国家资助的。美国和英国的读者不要想当然以为这些国家就是“那些国家”。不要忘了我们自己的政府也很乐于趟这摊浑水。
|
||||
|
||||
#### 观点 与 责任 ####
|
||||
|
||||
这次的发现从情感上、技术上、伦理上,都是一次严重的失利,但它远没有达到说我们已经进入一个病毒和恶意软件针对桌面自由肆虐的时代。
|
||||
|
||||
**Turla 并不是那种用户关注的“我想要你的信用卡”病毒**,那些病毒往往绑定在一个伪造的软件下载链接中。Turla是一种复杂的、经过巧妙处理的、具有高度适应性的威胁,它时刻都具有着特定的目标(因此它绝不仅仅满足于搜集一些卖萌少女的网站账户密码,sorry 绿茶婊们!)。
|
||||
|
||||
卡巴斯基实验室是这样介绍的:
|
||||
|
||||
> “Linux上的Turla模块是一个链接多个静态库的C/C++可执行文件,这大大增加了它的文件体积。但它并没有着重减小自身的文件体积,而是剥离了自身的符号信息,这样就增加了对它逆向分析的难度。它的功能主要包括隐藏网络通信、远程执行任意命令以及远程管理等等。它的大部分代码都基于公开源码。”
|
||||
|
||||
不管它的影响和感染率如何,它的技术优势都将不断给那些号称聪明的专家们留下一个又一个问题,就让他们花费大把时间去追踪、分析、解决这些问题吧。
|
||||
|
||||
我不是一个计算机安全专家,但我是一个理智的网络脑残粉,要我说,这次事件应该被看做是一个通(jing)报(gao),而并非有些网站所标榜的洪(shi)水(jie)猛(mo)兽(ri)。
|
||||
|
||||
在更多细节披露之前,我们都不必恐慌。只需继续计算机领域的安全实践,避免从不信任的网站或PPA源下载运行脚本、app或二进制文件,更不要冒险进入web网络的黑暗领域。
|
||||
|
||||
如果你仍然十分担心,你可以前往[卡巴斯基的博客][1]查看更多细节,以确定自己是否感染。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/government-spying-turla-linux-trojan-found
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[Mr小眼儿](http://blog.csdn.net/tinyeyeser)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://twitter.com/joernchen/status/542060412188262400
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
@ -1,10 +1,10 @@
|
||||
Linux有问必答-- 如何在Linux上安装内核头文件
|
||||
Linux有问必答:如何在Linux上安装内核头文件
|
||||
================================================================================
|
||||
> **提问**:我在安装一个设备驱动前先要安装内核头文件。怎样安装合适的内核头文件?
|
||||
|
||||
当你在编译一个设备驱动模块时,你需要在系统中安装内核头文件。内核头文件同样在你编译与内核直接链接的用户空间程序时需要。当你在这些情况下安装内核头文件时,你必须确保内核头文件精确地与你当前内核版本匹配(比如:3.13.0-24-generic)。
|
||||
|
||||
如果你的内核发行版自带的内核版本,或者使用默认的包管理器的基础仓库升级的(比如:apt-ger、aptitude或者yum),你也可以使用包管理器来安装内核头文件。另一方面,如果下载的是[kernel源码][1]并且手动编译的,你可以使用[make命令][2]来安装匹配的内核头文件。
|
||||
如果你的内核是发行版自带的内核版本,或者使用默认的包管理器的基础仓库升级的(比如:apt-ger、aptitude或者yum),你也可以使用包管理器来安装内核头文件。另一方面,如果下载的是[kernel源码][1]并且手动编译的,你可以使用[make命令][2]来安装匹配的内核头文件。
|
||||
|
||||
现在我们假设你的内核是发行版自带的,让我们看下该如何安装匹配的头文件。
|
||||
|
||||
@ -41,7 +41,7 @@ Debian、Ubuntu、Linux Mint默认头文件在**/usr/src**下。
|
||||
|
||||
假设你没有手动编译内核,你可以使用yum命令来安装匹配的内核头文件。
|
||||
|
||||
首先,用下面的命令检查系统是否已经按炸ung了头文件。如果下面的命令没有任何输出,这就意味着还没有头文件。
|
||||
首先,用下面的命令检查系统是否已经安装了头文件。如果下面的命令没有任何输出,这就意味着还没有头文件。
|
||||
|
||||
$ rpm -qa | grep kernel-headers-$(uname -r)
|
||||
|
||||
@ -66,7 +66,7 @@ Fedora、CentOS 或者 RHEL上默认内核头文件的位置是**/usr/include/li
|
||||
via: http://ask.xmodulo.com/install-kernel-headers-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,8 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
2014年Linux界发生的好事,坏事和丑事
|
||||
================================================================================
|
||||

|
||||
|
||||
2014年已经接近尾声,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
2014年已经过去,现在正是盘点**2014年Linux大事件**的时候。整整一年,我们关注了有关Linux和开源的一些好事,坏事和丑事。让我们来快速回顾一下2014对于Linux是怎样的一年。
|
||||
|
||||
### 好事 ###
|
||||
|
||||
@ -14,7 +12,7 @@ Translated by H-mudcup
|
||||
|
||||

|
||||
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
从使用Wine到[使用Chrome的测试功能][1],为了能让Netflix能在Linux上工作,Linux用户曾尝试了各种方法。好消息是Netflix终于在2014年带来了Linux的本地支持。这让所有能使用Netflix的地区的Linux用户的脸上浮现出了微笑。不过,想在[美国以外的地区使用Netflix][2](或其他官方授权使用Netflix的国家之外)的人还是得靠其他的方法。
|
||||
|
||||
#### 欧洲国家采用开源/Linux ####
|
||||
|
||||
@ -30,19 +28,19 @@ Translated by H-mudcup
|
||||
|
||||
### 坏事 ###
|
||||
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开源的形象。
|
||||
Linux在2014年并不是一帆风顺。某些事件的发生败坏了Linux/开源的形象。
|
||||
|
||||
#### Heartbleed心血 ####
|
||||
#### Heartbleed 心血漏洞 ####
|
||||
|
||||

|
||||
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血][10]。不必说,这个漏洞在OpenSSL的更新中被修复了。
|
||||
在今年的四月份,检测到[OpenSSL][8]有一个缺陷。这个漏洞被命名为[Heartbleed心血漏洞][9]。他影响了包括Facebook和Google在内的50多万个“安全”网站。这项漏洞可以真正的允许任何人读取系统的内存,并能因此给予用于加密数据流的密匙的访问权限。[xkcd上的漫画以更简单的方式解释了心血漏洞][10]。自然,这个漏洞在OpenSSL的更新中被修复了。
|
||||
|
||||
#### Shellshock ####
|
||||
#### Shellshock 破壳漏洞 ####
|
||||
|
||||

|
||||
|
||||
好像有个心血还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
好像有个心血漏洞还不够似的,在Bash里的一个缺陷更严重的震撼了Linux世界。这个漏洞被命名为[Shellshock 破壳漏洞][11]。这个漏洞把Linux往远程攻击的危险深渊又推了一把。这项漏洞是通过黑客的DDoS攻击暴露出来的。升级一下Bash版本应该能修复这个问题。
|
||||
|
||||
#### Ubuntu Phone和Steam控制台 ####
|
||||
|
||||
@ -52,13 +50,13 @@ Linux在2014年并不是一帆风顺。某些事件的发生损坏了Linux/开
|
||||
|
||||
### 丑事 ###
|
||||
|
||||
systemd的归属战变得不知廉耻。
|
||||
是否采用 systemd 的争论变得让人羞耻。
|
||||
|
||||
### systemd大论战 ###
|
||||
|
||||

|
||||
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux and Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
用init还是systemd的争吵已经进行了一段时间了。但是在2014年当systemd准备在包括Debian, Ubuntu, OpenSUSE, Arch Linux 和 Fedora几个主流Linux分布中替代init时,事情变得不知廉耻了起来。它是如此的一发不可收拾,以至于它已经不限于boycottsystemd.org这类网站了。Lennart Poettering(systemd的首席开发人员及作者)在一条Google Plus状态上声明,说那些反对systemd的人在“收集比特币来雇杀手杀他”。Lennart还声称开源社区“是个恶心得不能待的地方”。人们吵得越来越离谱以至于把Debian分裂成了一个新的操作系统,称为[Devuan][15]。
|
||||
|
||||
### 还有诡异的事 ###
|
||||
|
||||
@ -81,10 +79,10 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
|
||||
[1]:http://linux.cn/article-3024-1.html
|
||||
[2]:http://itsfoss.com/easiest-watch-netflix-hulu-usa/
|
||||
[3]:http://itsfoss.com/french-city-toulouse-saved-1-million-euro-libreoffice/
|
||||
[4]:http://itsfoss.com/italian-city-turin-open-source/
|
||||
[3]:http://linux.cn/article-3575-1.html
|
||||
[4]:http://linux.cn/article-3602-1.html
|
||||
[5]:http://itsfoss.com/170-primary-public-schools-geneva-switch-ubuntu/
|
||||
[6]:http://itsfoss.com/german-town-gummersbach-completes-switch-open-source/
|
||||
[7]:http://itsfoss.com/windows-10-inspired-linux/
|
||||
@ -95,8 +93,8 @@ via: http://itsfoss.com/biggest-linux-stories-2014/
|
||||
[12]:http://itsfoss.com/ubuntu-phone-specification-release-date-pricing/
|
||||
[13]:http://www.tecmint.com/systemd-replaces-init-in-linux/
|
||||
[14]:https://plus.google.com/+LennartPoetteringTheOneAndOnly/posts/J2TZrTvu7vd
|
||||
[15]:http://debianfork.org/
|
||||
[16]:http://thenewstack.io/microsoft-professes-love-for-linux-adds-support-for-coreos-cloudera-and-host-of-new-features/
|
||||
[15]:http://linux.cn/article-4512-1.html
|
||||
[16]:http://linux.cn/article-4056-1.html
|
||||
[17]:http://www.theregister.co.uk/2001/06/02/ballmer_linux_is_a_cancer/
|
||||
[18]:http://azure.microsoft.com/en-us/
|
||||
[19]:http://www.zdnet.com/article/top-five-linux-contributor-microsoft/
|
||||
@ -4,7 +4,9 @@ Windows和Ubuntu双系统,修复UEFI引导的两种办法
|
||||
|
||||
这里有两种修复EFI启动引导的方法,使Ubuntu可以正常启动
|
||||
|
||||
 "将GRUB2设置为启动引导"
|
||||

|
||||
|
||||
*将GRUB2设置为启动引导*
|
||||
|
||||
### 1. 启用GRUB引导 ###
|
||||
|
||||
@ -18,22 +20,22 @@ Windows和Ubuntu双系统,修复UEFI引导的两种办法
|
||||
|
||||
可以按照以下几个步骤将GRUB2设置为默认的引导程序:
|
||||
|
||||
1.登录Windows 8
|
||||
2.转到桌面
|
||||
3.右击开始按钮,选择管理员命令行
|
||||
4.输入 mountvol g: (将你的EFI目录结构映射到G盘)
|
||||
5.输入 cd g:\EFI
|
||||
6.当你输入 dir 列出文件夹内容时,你可以看到一个Ubuntu的文件夹
|
||||
7.这里的参数可以是grubx64.efi或者shimx64.efi
|
||||
8.运行下列命令将grub64.efi设置为启动引导程序:
|
||||
1. 登录Windows 8
|
||||
2. 转到桌面
|
||||
3. 右击开始按钮,选择管理员命令行
|
||||
4. 输入 mountvol g: /s (这将你的EFI目录结构映射到G盘)
|
||||
5. 输入 cd g:\EFI
|
||||
6. 当你输入 dir 列出文件夹内容时,你可以看到一个Ubuntu的文件夹
|
||||
7. 这里的参数可以是grubx64.efi或者shimx64.efi
|
||||
8. 运行下列命令将grub64.efi设置为启动引导程序:
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\grubx64.efi
|
||||
9.重启你的电脑
|
||||
10.你将会看到一个包含Ubuntu和Windows选项的GRUB菜单
|
||||
11.如果你的电脑仍然直接启动到Windows,重复步骤1到7,但是这次输入:
|
||||
9. 重启你的电脑
|
||||
10. 你将会看到一个包含Ubuntu和Windows选项的GRUB菜单
|
||||
11. 如果你的电脑仍然直接启动到Windows,重复步骤1到7,但是这次输入:
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
12.重启你的电脑
|
||||
12. 重启你的电脑
|
||||
|
||||
这里你做的事情是登录Windows管理员命令行,将EFI引导区映射到磁盘上,来查看Ubuntu的引导程序是否安装成功,然后选择grubx64.efi或者shimx64.efi作为引导程序。
|
||||
这里你做的事情就是登录Windows管理员命令行,将EFI引导区映射到磁盘上,来查看Ubuntu的引导程序是否安装成功,然后选择grubx64.efi或者shimx64.efi作为引导程序。
|
||||
|
||||
那么[grubx64.efi和shimx64.efi有什么区别呢][4]?在安全启动(serureboot)关闭的情况下,你可以使用grubx64.efi。如果安全启动打开则需要选择shimx64.efi。
|
||||
|
||||
@ -41,28 +43,30 @@ bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
|
||||
### 2.使用rEFInd引导Ubuntu和Windows双系统 ###
|
||||
|
||||

|
||||
|
||||
[rEFInd引导程序][5]会以图标的方式列出你所有的操作系统。因此,你可以通过点击相应的图标来启动Windows、Ubuntu或者优盘中的操作系统。
|
||||
|
||||
[点击这里][6]下载rEFInd for Windows 8。
|
||||
|
||||
下载和解压以后,按照以下的步骤安装rEFInd。
|
||||
|
||||
1.返回桌面
|
||||
2.右击开始按钮,选择管理员命令行
|
||||
3.输入 mountvol g: (将你的EFI目录结构映射到G盘)
|
||||
4.进入解压的rEFInd目录。例如:
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4
|
||||
1. 返回桌面
|
||||
2. 右击开始按钮,选择管理员命令行
|
||||
3. 输入 mountvol g: /s (这将你的EFI目录结构映射到G盘)
|
||||
4. 进入解压的rEFInd目录。例如:
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4 。
|
||||
当你输入 dir 命令,你可以看到一个refind目录
|
||||
5.输入如下命令将refind拷贝到EFI引导区
|
||||
5. 输入如下命令将refind拷贝到EFI引导区
|
||||
xcopy /E refind g:\EFI\refind\
|
||||
6.输入如下命令进入refind文件夹
|
||||
6. 输入如下命令进入refind文件夹
|
||||
cd g:\EFI\refind
|
||||
7.重命名示例配置文件
|
||||
7. 重命名示例配置文件
|
||||
rename refind.conf-sample refind.conf
|
||||
8.运行如下命令将rEFind设置为引导程序
|
||||
8. 运行如下命令将rEFind设置为引导程序
|
||||
bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
9.重启你的电脑
|
||||
10.你将会看到一个包含Ubuntu和Windows的图形菜单
|
||||
9. 重启你的电脑
|
||||
10. 你将会看到一个包含Ubuntu和Windows的图形菜单
|
||||
|
||||
这个过程和选择GRUB引导程序十分相似。
|
||||
|
||||
@ -72,17 +76,20 @@ bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
|
||||
希望这篇文章可以解决有些人在安装Ubuntu和Windows 8.1双系统时出现的问题。如果你仍然有问题,可以通过上面的电邮和我进行交流。
|
||||
|
||||
---
|
||||
via: http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[zhouj-sh](https://github.com/zhouj-sh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
via:http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/The-Ultimate-Windows-81-And-Ubuntu-
|
||||
[2]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows_3.htm#step-heading
|
||||
[3]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
[1]:http://linux.cn/article-3178-1.html
|
||||
[2]:http://linux.cn/article-3178-1.html#4_3289
|
||||
[3]:http://linux.cn/article-3178-1.html#4_1717
|
||||
[4]:https://wiki.ubuntu.com/SecurityTeam/SecureBoot
|
||||
[5]:http://www.rodsbooks.com/refind/installing.html#windows
|
||||
[6]:http://sourceforge.net/projects/refind/files/0.8.4/refind-bin-0.8.4.zip/download
|
||||
@ -1,74 +0,0 @@
|
||||
Yes, This Trojan Infects Linux. No, It’s Not The Tuxpocalypse
|
||||
================================================================================
|
||||

|
||||
|
||||
Is something watching you?
|
||||
|
||||
Grab a crate of canned food, start digging a deep underground bunker and prepare to settle into a world that will never be the same again: [a powerful trojan has been uncovered on Linux][1].
|
||||
|
||||
Yes, the hitherto impregnable fortress of computing nirvana has been compromised in a way that has left security experts a touch perturbed.
|
||||
|
||||
Unplug your PC, disinfect your keyboard and buy a cat (no more YouTube ). The Tuxpocalypse is upon us. We’ve reached the end of days.
|
||||
|
||||
Right? RIGHT? Nah, not quite.
|
||||
|
||||
### A Terrifying Anomalous Thing! ###
|
||||
|
||||
Let me set off by saying that **I am not underplaying the severity of this threat (known by the nickname ‘Turla’)** nor, for the avoidance of doubt, am I suggesting that we as Linux users shouldn’t be concerned by the implications.
|
||||
|
||||
The discovery of a silent trojan infecting Linux systems is terrifying. The fact it was tasked with sucking up and sending off all sorts of sensitive information is horrific. And to learn it’s been doing this for at least four years and doesn’t require root privileges? My seat is wet. I’m sorry.
|
||||
|
||||
But — and along with hyphens and typos, there’s always a ‘but’ on this site — the panic currently sweeping desktop Linux fans, Mexican wave style, is a little out of context.
|
||||
|
||||
Vulnerability may be a new feeling for some of us, yet let’s keep it in check: Linux remains an inherently secure operating system for desktop users. One clever workaround does not negate that and shouldn’t send you scurrying offline.
|
||||
|
||||
### State Sponsored, Targeting Governments ###
|
||||
|
||||

|
||||
|
||||
Is a penguin snake a ‘Penguake’ or a ‘Snaguin’?
|
||||
|
||||
‘Turla’ is a complex APT (Advanced Persistent Threat) that has (thus far) targeted government, embassy and pharmaceutical companies’ systems for around four years using a method based on [14 year old code, no less][2].
|
||||
|
||||
On Windows, where the superhero security researchers at Symantec and Kaspersky Lab first sighted the slimy snake, Turla and components of it were found to have **infected hundreds (100s) of PCs across 45 countries**, many through unpatched zero-day exploits.
|
||||
|
||||
*Nice one Microsoft.*
|
||||
|
||||
Further diligence by Kaspersky Lab has now uncovered that parts of the same trojan have also been active on Linux for some time.
|
||||
|
||||
The Trojan doesn’t require elevated privileges and can “intercept incoming packets and run incoming commands on the system”, but it’s not yet clear how deep its tentacles reach or how many Linux systems are infected, nor is the full extent of its capabilities known.
|
||||
|
||||
“Turla” (and its children) are presumed to be nation-state sponsored due to its choice of targets. US and UK readers shouldn’t assume it’s “*them*“, either. Our own governments are just as happy to play in the mud, too.
|
||||
|
||||
#### Perspective and Responsibility ####
|
||||
|
||||
As terrible a breach as this discovery is emotionally, technically and ethically it remains far, far, far away from being an indication that we’re entering a new “free for all” era of viruses and malware aimed at the desktop.
|
||||
|
||||
**Turla is not a user-focused “i wantZ ur CredIt carD” virus** bundled inside a faux software download. It’s a complex, finessed and adaptable threat with specific targets in mind (ergo grander ambitions than collecting a bunch of fruity tube dot com passwords, sorry ego!).
|
||||
|
||||
Kaspersky Lab explains:
|
||||
|
||||
> “The Linux Turla module is a C/C++ executable statically linked against multiple libraries, greatly increasing its file size. It was stripped of symbol information, more likely intended to increase analysis effort than to decrease file size. Its functionality includes hidden network communications, arbitrary remote command execution, and remote management. Much of its code is based on public sources.”
|
||||
|
||||
Regardless of impact or infection rate its precedes will still raise big, big questions that clever, clever people will now spend time addressing, analysing and (importantly) solving.
|
||||
|
||||
IANACSE (I am not a computer security expert) but IAFOA (I am a fan of acronyms), and AFAICT (as far as I can tell) this news should be viewed as as a cautionary PSA or FYI than the kind of OMGGTFO that some sites are painting it as.
|
||||
|
||||
Until more details are known none of us should panic. Let’s continue to practice safe computing. Avoid downloading/running scripts, apps, or binaries from untrusted sites or PPAs, and don’t venture into dodgy dark parts of the web.
|
||||
|
||||
If you remain super concerned you can check out the [Kaspersky blog][1] for details on how to check that you’re not infected.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/12/government-spying-turla-linux-trojan-found
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://twitter.com/joernchen/status/542060412188262400
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
@ -1,25 +0,0 @@
|
||||
Git 2.2.1 Released To Fix Critical Security Issue
|
||||
================================================================================
|
||||
|
||||
|
||||
Git 2.2.1 was released this afternoon to fix a critical security vulnerability in Git clients. Fortunately, the vulnerability doesn't plague Unix/Linux users but rather OS X and Windows.
|
||||
|
||||
Today's Git vulnerability affects those using the Git client on case-insensitive file-systems. On case-insensitive platforms like Windows and OS X, committing to .Git/config could overwrite the user's .git/config and could lead to arbitrary code execution. Fortunately with most Phoronix readers out there running Linux, this isn't an issue thanks to case-sensitive file-systems.
|
||||
|
||||
Besides the attack vector from case insensitive file-systems, Windows and OS X's HFS+ would map some strings back to .git too if certain characters are present, which could lead to overwriting the Git config file. Git 2.2.1 addresses these issues.
|
||||
|
||||
More details via the [Git 2.2.1 release announcement][1] and [GitHub has additional details][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.phoronix.com/scan.php?page=news_item&px=MTg2ODA
|
||||
|
||||
作者:[Michael Larabel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.michaellarabel.com/
|
||||
[1]:http://article.gmane.org/gmane.linux.kernel/1853266
|
||||
[2]:https://github.com/blog/1938-git-client-vulnerability-announced
|
||||
@ -1,166 +0,0 @@
|
||||
Easy File Comparisons With These Great Free Diff Tools
|
||||
================================================================================
|
||||
by Frazer Kline
|
||||
|
||||
File comparison compares the contents of computer files, finding their common contents and their differences. The result of the comparison is often known as a diff.
|
||||
|
||||
diff is also the name of a famous console based file comparison utility that outputs the differences between two files. The diff utility was developed in the early 1970s on the Unix operating system. diff will output the parts of the files where they are different.
|
||||
|
||||
Linux has many good GUI tools that enable you to clearly see the difference between two files or two versions of the same file. This roundup selects 5 of my favourite GUI diff tools, with all but one released under an open source license.
|
||||
|
||||
These utilities are an essential software development tool, as they visualize the differences between files or directories, merge files with differences, resolve conflicts and save output to a new file or patch, and assist file changes reviewing and comment production (e.g. approving source code changes before they get merged into a source tree). They help developers work on a file, passing it back and forth between each other. The diff tools are not only useful for showing differences in source code files; they can be used on many text-based file types as well. The visualisations make it easier to compare files.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Meld is an open source graphical diff viewer and merge application for the Gnome desktop. It supports 2 and 3-file diffs, recursive directory diffs, diffing of directories under version control (Bazaar, Codeville, CVS, Darcs, Fossil SCM, Git, Mercurial, Monotone, Subversion), as well as the ability to manually and automatically merge file differences.
|
||||
|
||||
Meld's focus is on helping developers compare and merge source files, and get a visual overview of changes in their favourite version control system.
|
||||
|
||||
Features include
|
||||
|
||||
- Edit files in-place, and your comparison updates on-the-fly
|
||||
- Perform twoand three-way diffs and merges
|
||||
- Easily navigate between differences and conflicts
|
||||
- Visualise global and local differences with insertions, changes and conflicts marked
|
||||
- Built-in regex text filtering to ignore uninteresting differences
|
||||
- Syntax highlighting (with optional gtksourceview)
|
||||
- Compare two or three directories file-by-file, showing new, missing, and altered files
|
||||
- Directly open file comparisons of any conflicting or differing files
|
||||
- Filter out files or directories to avoid seeing spurious differences
|
||||
- Auto-merge mode and actions on change blocks help make merges easier
|
||||
- Simple file management is also available
|
||||
- Supports many version control systems, including Git, Mercurial, Bazaar and SVN
|
||||
- Launch file comparisons to check what changes were made, before you commit
|
||||
- View file versioning statuses
|
||||
- Simple version control actions are also available (i.e., commit/update/add/remove/delete files)
|
||||
- Automatically merge two files using a common ancestor
|
||||
- Mark and display the base version of all conflicting changes in the middle pane
|
||||
- Visualise and merge independent modifications of the same file
|
||||
- Lock down read-only merge bases to avoid mistakes
|
||||
- Command line interface for easy integration with existing tools, including git mergetool
|
||||
- Internationalization support
|
||||
- Visualisations make it easier to compare your files
|
||||
|
||||
- Website: [meldmerge.org][1]
|
||||
- Developer: Kai Willadsen
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 1.8.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
注:上面这个图访问不到,图的地址是原文地址的小图的链接地址,发布的时候在验证一下,如果还访问不到,不行先采用小图或者网上搜一下看有没有大图
|
||||
|
||||
DiffMerge is an application to visually compare and merge files on Linux, Windows, and OS X.
|
||||
|
||||
Features include:
|
||||
|
||||
- Graphically shows the changes between two files. Includes intra-line highlighting and full support for editing
|
||||
- Graphically shows the changes between 3 files. Allows automatic merging (when safe to do so) and full control over editing the resulting file
|
||||
- Performs a side-by-side comparison of 2 folders, showing which files are only present in one file or the other, as well as file pairs which are identical, equivalent or different
|
||||
- Rulesets and options provide for customized appearance and behavior
|
||||
- Unicode-based application and can import files in a wide range of character encodings
|
||||
- Cross-platform tool
|
||||
|
||||
- Website: [sourcegear.com/diffmerge][2]
|
||||
- Developer: SourceGear LLC
|
||||
- License: Licensed for use free of charge (not open source)
|
||||
- Version Number: 4.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
xxdiff is an open source graphical file and directories comparator and merge tool.
|
||||
|
||||
xxdiff can be used for viewing the differences between two or three files, or two directories, and can be used to produce a merged version. The texts of the two or three files are presented side by side with their differences highlighted with colors for easy identification.
|
||||
|
||||
This program is an essential software development tool that can be used to visualize the differences between files or directories, merge files with differences, resolving conflicts and saving output to a new file or patch, and assist file changes reviewing and comment production (e.g. approving source code changes before they get merged into a source tree).
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare two files, three files, or two directories (shallow and recursive)
|
||||
- Horizontal diffs highlighting
|
||||
- Files can be merged interactively and resulting output visualized and saved
|
||||
- Features to assist in performing merge reviews/policing
|
||||
- Unmerge CVS conflicts in automatically merged file and display them as two files, to help resolve conflicts
|
||||
- Uses external diff program to compute differences: works with GNU diff, SGI diff and ClearCase's cleardiff, and any other diff whose output is similar to those
|
||||
- Fully customizable with a resource file
|
||||
- Look-and-feel similar to Rudy Wortel's/SGI xdiff, it is desktop agnostic
|
||||
- Features and output that ease integration with scripts
|
||||
|
||||
- Website: [furius.ca/xxdiff][3]
|
||||
- Developer: Martin Blais
|
||||
- License: GNU GPL
|
||||
- Version Number: 4.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Diffuse is an open source graphical tool for merging and comparing text files. Diffuse is able to compare an arbitrary number of files side-by-side and offers the ability to manually adjust line-matching and directly edit files. Diffuse can also retrieve revisions of files from bazaar, CVS, darcs, git, mercurial, monotone, Subversion and GNU Revision Control System (RCS) repositories for comparison and merging.
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare and merge an arbitrary number of files side-by-side (n-way merges)
|
||||
- Line matching can be manually corrected by the user
|
||||
- Directly edit files
|
||||
- Syntax highlighting
|
||||
- Bazaar, CVS, Darcs, Git, Mercurial, Monotone, RCS, Subversion, and SVK support
|
||||
- Unicode support
|
||||
- Unlimited undo
|
||||
- Easy keyboard navigation
|
||||
|
||||
- Website: [diffuse.sourceforge.net][]
|
||||
- Developer: Derrick Moser
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 0.4.7
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Kompare is an open source GUI front-end program that enables differences between source files to be viewed and merged. Kompare can be used to compare differences on files or the contents of folders. Kompare supports a variety of diff formats and provide many options to customize the information level displayed.
|
||||
|
||||
Whether you are a developer comparing source code, or you just want to see the difference between that research paper draft and the final document, Kompare is a useful tool.
|
||||
|
||||
Kompare is part of the KDE desktop environment.
|
||||
|
||||
Features include:
|
||||
|
||||
- Compare two text files
|
||||
- Recursively compare directories
|
||||
- View patches generated by diff
|
||||
- Merge a patch into an existing directory
|
||||
- Entertain you during that boring compile
|
||||
|
||||
- Website: [www.caffeinated.me.uk/kompare/][5]
|
||||
- Developer: The Kompare Team
|
||||
- License: GNU GPL
|
||||
- Version Number: Part of KDE
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2014062814400262/FileComparisons.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://meldmerge.org/
|
||||
[2]:https://sourcegear.com/diffmerge/
|
||||
[3]:http://furius.ca/xxdiff/
|
||||
[4]:http://diffuse.sourceforge.net/
|
||||
[5]:http://www.caffeinated.me.uk/kompare/
|
||||
@ -1,55 +0,0 @@
|
||||
Flow ‘N Play Movie Player Has a Stylish Interface [Ubuntu Installation]
|
||||
================================================================================
|
||||
**Flow ‘N Play** is a new video player written in Qt which features a pretty slick and simple interface which provides only the basic features for playing movies.
|
||||
|
||||
|
||||
|
||||
[Flow ‘N Play][1] is relatively new video player (the first release was made earlier this year in March) with a beautiful interface and a pretty simple approach, with one of the features being the possibility to slide over the list of movies by dragging the mouse. The player comes with basic functionality, a search function, support for colored themes.
|
||||
|
||||
Opening a new video – you can also choose a custom cover in the same dialog:
|
||||
|
||||
|
||||
|
||||
The Settings dialog – customize some basic options here:
|
||||
|
||||
|
||||
|
||||
Flow ‘N Play is still in early development though, and as such it has a few downsides over more advanced players. There are few options to customize it, no support for subtitles or video and audio filters. Currently there seems to be either a bug or strange behavior upon opening a new movie, which doesn’t always start automatically.
|
||||
|
||||
I believe a few more features could be added before it gets to being usable as a decent alternative to other players, but given the time, Flow ‘N Play looks really promising.
|
||||
|
||||
### Install Flow ‘N Play 0.922 in Ubuntu 14.04 ###
|
||||
|
||||
There are several different ways to install Flow N’ Play in Ubuntu. There are DEB packages, RUN Bash installers, and standalone binaries available on the [Qt-Apps page][2].
|
||||
|
||||
To install Flow ‘N Play first get the dependencies:
|
||||
|
||||
sudo apt-get install libqt5multimediaquick-p5 qtdeclarative5-controls-plugin qtdeclarative5 qtmultimedia-plugin qtdeclarative5-qtquick2-plugin qtdeclarative5-quicklayouts-plugin
|
||||
|
||||
Then download the DEB package and either double click it or change the working directory to the one where you saved it and type the following in a terminal (for 64-bit, replace the DEB file for 32-bit):
|
||||
|
||||
sudo dpkg -i flow-n-play_v0.926_qt-5.3.2_x64.deb
|
||||
|
||||
Then type **flow-n-play** in a terminal to run it. Notice that in case you get dependency errors when trying to install the DEB file, you can run **sudo apt-get -f install**, which will fetch the missing dependencies automatically and will install Flow ‘N Play as well.
|
||||
|
||||
To install Flow ‘N Play using the RUN script, install the dependencies mentioned above and then run the script:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
sudo ./flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
|
||||
The third method is to install it manually to a location of your choice (just download the binary provided after installing the dependencies) e.g. for 32-bit:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/Flow-N-Play_v0.926_Qt-5.3.2_x86
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tuxarena.com/2014/11/flow-n-play-movie-player-has-a-stylish-interface-ubuntu-installation/
|
||||
|
||||
作者:Craciun Dan
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.prest1ge-c0ding.24.eu/programme-php/app-flow_n_play.php?lang=en
|
||||
[2]:http://qt-apps.org/content/show.php/Flow+%27N+Play?content=167736
|
||||
@ -1,62 +0,0 @@
|
||||
Tomahawk Music Player Returns With New Look, Features
|
||||
================================================================================
|
||||
**After a quiet year Tomahawk, the Swiss Army knife of music players, is back with a brand new release to sing about. **
|
||||
|
||||

|
||||
|
||||
Version 0.8 of the open-source and cross-platform app adds **support for more online services**, refreshes its appearance, and doubles down on making sure its innovative social features work flawlessly.
|
||||
|
||||
### Tomahawk — The Best of Both Worlds ###
|
||||
|
||||
Tomahawk marries a traditional app structure with the modernity of our “on demand” culture. It can browse and play music from local libraries as well as online services like Spotify, Grooveshark, and SoundCloud. In its latest release it adds Google Play Music and Beats Music to its roster.
|
||||
|
||||
That may sound cumbersome or confusing on paper but in practice it all works fantastically.
|
||||
|
||||
When you want to play a song, and don’t care where it’s played back from, you just tell Tomahawk the track title and artist and it automatically finds a high-quality version from enabled sources — you don’t need to do anything.
|
||||
|
||||

|
||||
|
||||
The app also sports some additional features, like EchoNest profiling, Last.fm suggestions, and Jabber support so you can ‘play’ friends’ music. There’s also a built-in messaging service so you can quickly share playlists and tracks with others.
|
||||
|
||||
> “This fundamentally different approach to music enables a range of new music consumption and sharing experiences previously not possible,” the project says on its website. And with little else like it, it’s not wrong.
|
||||
|
||||
|
||||
|
||||
Tomahawk supports the Sound Menu
|
||||
|
||||
### Tomahawk 0.8 Release Highlights ###
|
||||
|
||||
- New UI
|
||||
- Support for Beats Music support
|
||||
- Support for Google Play Music (stored and Play All Access)
|
||||
- Support for drag and drop iTunes, Spotify, etc. web links
|
||||
- Now Playing notifications
|
||||
- Android app (beta)
|
||||
- Inbox improvements
|
||||
|
||||
### Install Tomahawk 0.8 in Ubuntu ###
|
||||
|
||||
As a big music streaming user I’ll be using the app over the next few days to get a fuller appreciation of the changes on offer. In the mean time, to go hands on for yourself, you can.
|
||||
|
||||
Tomahawk 0.8 is available for Ubuntu 14.04 LTS and Ubuntu 14.10 via an official PPA.
|
||||
|
||||
sudo add-apt-repository ppa:tomahawk/ppa
|
||||
|
||||
sudo apt-get update && sudo apt-get install tomahawk
|
||||
|
||||
Standalone installers, and more information, can be found on the official project website.
|
||||
|
||||
- [Visit the Official Tomahawk Website][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/tomahawk-media-player-returns-new-look-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://gettomahawk.com/
|
||||
@ -1,48 +0,0 @@
|
||||
[Translating by Stevarzh]
|
||||
How to Download Music from Grooveshark with a Linux OS
|
||||
================================================================================
|
||||
> The solution is actually much simpler than you think
|
||||
|
||||

|
||||
|
||||
**Grooveshark is a great online platform for people who want to listen to music, and there are a number of ways to download music from there. Groovesquid is just one of the applications that let users get music from Grooveshark, and it's multiplatform.**
|
||||
|
||||
If there is a service that streams something online, then there is a way to download the stuff that you are just watching or listening. As it turns out, it's not that difficult and there are a ton of solutions, no matter the platform. For example, there are dozens of YouTube downloaders and it stands to reason that it's not all that difficult to get stuff from Grooveshark either.
|
||||
|
||||
Now, there is the problem of legality. Like many other applications out there, Groovesquid is not actually illegal. It's the user's fault if they do something illegal with an application. The same reasoning can be applied to apps like utorrent or Bittorrent. As long as you don't touch copyrighted material, there are no problems in using Groovesquid.
|
||||
|
||||
### Groovesquid is fast and efficient ###
|
||||
|
||||
The only problem that you could find with Groovesquid is the fact that it's based on Java and that's never a good sign. This is a good way to ensure that an application runs on all the platforms, but it's an issue when it comes to the interface. It's not great, but it doesn't really matter all that much for users, especially since the app is doing a great job.
|
||||
|
||||
There is one caveat though. Groovesquid is a free application, but in order to remain free, it has to display an ad on the right side of the menu. This shouldn't be a problem for most people, but it's a good idea to mention that right from the start.
|
||||
|
||||
From a usability point of view, the application is pretty straightforward. Users can download a single song by entering the link in the top field, but the purpose of that field can be changed by accessing the small drop-down menu to its left. From there, it's possible to change to Song, Popular, Albums, Playlist, and Artist. Some of the options provide access to things like the most popular song on Grooveshark and other options allow you to download an entire playlist, for example.
|
||||
|
||||
You can download Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] File size: 3.8 MB
|
||||
- [tar.gz][2] File size: 549 KB
|
||||
|
||||
You will get a Jar file and all you have to do is to make it executable and let Java do the rest.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -0,0 +1,59 @@
|
||||
This App Can Write a Single ISO to 20 USB Drives Simultaneously
|
||||
================================================================================
|
||||
**If I were to ask you to burn a single Linux ISO to 17 USB thumb drives how would you go about doing it?**
|
||||
|
||||
Code savvy folks would write a little bash script to automate the process, and a large number would use a GUI tool like the USB Startup Disk Creator to burn the ISO to each drive in turn, one by one. But the rest of us would fast conclude that neither method is ideal.
|
||||
|
||||
### Problem > Solution ###
|
||||
|
||||
|
||||
|
||||
GNOME MultiWriter in action
|
||||
|
||||
Richard Hughes, a GNOME developer, faced a similar dilemma. He wanted to create a number of USB drives pre-loaded with an OS, but wanted a tool simple enough for someone like his dad to use.
|
||||
|
||||
His response was to create a **brand new app** that combines both approaches into one easy to use tool.
|
||||
|
||||
It’s called “[GNOME MultiWriter][1]” and lets you write a single ISO or IMG to multiple USB drives at the same time.
|
||||
|
||||
It nixes the need to customize or create a command line script and relinquishes the need to waste an afternoon performing an identical set of actions on repeat.
|
||||
|
||||
All you need is this app, an ISO, some thumb-drives and lots of empty USB ports.
|
||||
|
||||
### Use Cases and Installing ###
|
||||
|
||||

|
||||
|
||||
The app can be installed on Ubuntu
|
||||
|
||||
The app has a pretty defined usage scenario, that being situations where USB sticks pre-loaded with an OS or live image are being distributed.
|
||||
|
||||
That being said, it should work just as well for anyone wanting to create a solitary bootable USB stick, too — and since I’ve never once successfully created a bootable image from Ubuntu’s built-in disk creator utility, working alternatives are welcome news to me!
|
||||
|
||||
Hughes, the developer, says it **supports up to 20 USB drives**, each being between 1GB and 32GB in size.
|
||||
|
||||
The drawback (for now) is that GNOME MultiWriter is not a finished, stable product. It works, but at this early blush there are no pre-built binaries to install or a PPA to add to your overstocked software sources.
|
||||
|
||||
If you know your way around the usual configure/make process you can get it up and running in no time. On Ubuntu 14.10 you may also need to install the following packages first:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
If you get it up and running, give it a whirl and let us know what you think!
|
||||
|
||||
Bugs and pull requests can be longed on the GitHub page for the project, which is where you’ll also found tarball downloads for manual installation.
|
||||
|
||||
- [GNOME MultiWriter on Github][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -0,0 +1,111 @@
|
||||
Best GNOME Shell Themes For Ubuntu 14.04
|
||||
================================================================================
|
||||

|
||||
|
||||
Themes are the best way to customize your Linux desktop. If you [install GNOME on Ubuntu 14.04][1] or 14.10, you might want to change the default theme and give it a different look. To help you in this task, I have compiled here a **list of best GNOME shell themes for Ubuntu** or any other Linux OS that has GNOME shell installed on it. But before we see the list, let’s first see how to change install new themes in GNOME Shell.
|
||||
|
||||
### Install themes in GNOME Shell ###
|
||||
|
||||
To install new themes in GNOME with Ubuntu, you can use Gnome Tweak Tool which is available in software repository in Ubuntu. Open a terminal and use the following command:
|
||||
|
||||
sudo apt-get install gnome-tweak-tool
|
||||
|
||||
Alternatively, you can use themes by putting them in ~/.themes directory. I have written a detailed tutorial on [how to install and use themes in GNOME Shell][2], in case you need it.
|
||||
|
||||
### Best GNOME Shell themes ###
|
||||
|
||||
The themes listed here are tested on GNOME Shell 3.10.4 but it should work for all version of GNOME 3 and higher. For the sake of mentioning, the themes are not in any kind of priority order. Let’s have a look at the best GNOME themes:
|
||||
|
||||
#### Numix ####
|
||||
|
||||

|
||||
|
||||
No list can be completed without the mention of [Numix themes][3]. These themes got so popular that it encouraged [Numix team to work on a new Linux OS, Ozon][4]. Considering their design work with Numix theme, it won’t be exaggeration to call it one of the [most beautiful Linux OS][5] releasing in near future.
|
||||
|
||||
To install Numix theme in Ubuntu based distributions, use the following commands:
|
||||
|
||||
sudo apt-add-repository ppa:numix/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install numix-icon-theme-circle
|
||||
|
||||
#### Elegance Colors ####
|
||||
|
||||

|
||||
|
||||
Another beautiful theme from Satyajit Sahoo, who is also a member of Numix team. [Elegance Colors][6] has its own PPA so that you can easily install it:
|
||||
|
||||
sudo add-apt-repository ppa:satyajit-happy/themes
|
||||
sudo apt-get update
|
||||
sudo apt-get install gnome-shell-theme-elegance-colors
|
||||
|
||||
#### Moka ####
|
||||
|
||||

|
||||
|
||||
[Moka][7] is another mesmerizing theme that is always included in the list of beautiful themes. Designed by the same developer who gave us Unity Tweak Tool, Moka is a must try:
|
||||
|
||||
sudo add-apt-repository ppa:moka/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install moka-gnome-shell-theme
|
||||
|
||||
#### Viva ####
|
||||
|
||||

|
||||
|
||||
Based on Gnome’s default Adwaita theme, Viva is a nice theme with shades of black and oranges. You can download Viva from the link below.
|
||||
|
||||
- [Download Viva GNOME Shell Theme][8]
|
||||
|
||||
#### Ciliora-Prima ####
|
||||
|
||||

|
||||
|
||||
Previously known as Zukitwo Dark, Ciliora-Prima has square icons theme. Theme is available in three versions that are slightly different from each other. You can download it from the link below.
|
||||
|
||||
- [Download Ciliora-Prima GNOME Shell Theme][9]
|
||||
|
||||
#### Faience ####
|
||||
|
||||

|
||||
|
||||
Faience has been a popular theme for quite some time and rightly so. You can install Faience using the PPA below for GNOME 3.10 and higher.
|
||||
|
||||
sudo add-apt-repository ppa:tiheum/equinox
|
||||
sudo apt-get update
|
||||
sudo apt-get install faience-theme
|
||||
|
||||
#### Paper [Incomplete] ####
|
||||
|
||||

|
||||
|
||||
Ever since Google talked about Material Design, people have been going gaga over it. Paper GTK theme, by Sam Hewitt (of Moka Project), is inspired by Google Material design and currently under development. Which means you will not have the best experience with Paper at the moment. But if your a bit experimental, like me, you can definitely give it a try.
|
||||
|
||||
sudo add-apt-repository ppa:snwh/pulp
|
||||
sudo apt-get update
|
||||
sudo apt-get install paper-gtk-theme
|
||||
|
||||
That concludes my list. If you are trying to give a different look to your Ubuntu, you should also try the list of [best icon themes for Ubuntu 14.04][10].
|
||||
|
||||
How do you find this list of **best GNOME Shell themes**? Which one is your favorite among the one listed here? And if it’s not listed here, do let us know which theme you think is the best GNOME Shell theme.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/gnome-shell-themes-ubuntu-1404/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/how-to-install-gnome-in-ubuntu-14-04/
|
||||
[2]:http://itsfoss.com/install-switch-themes-gnome-shell/
|
||||
[3]:https://numixproject.org/
|
||||
[4]:http://itsfoss.com/numix-linux-distribution/
|
||||
[5]:http://itsfoss.com/new-beautiful-linux-2015/
|
||||
[6]:http://satya164.deviantart.com/art/Gnome-Shell-Elegance-Colors-305966388
|
||||
[7]:http://mokaproject.com/
|
||||
[8]:https://github.com/vivaeltopo/gnome-shell-theme-viva
|
||||
[9]:http://zagortenay333.deviantart.com/art/Ciliora-Prima-Shell-451947568
|
||||
[10]:http://itsfoss.com/best-icon-themes-ubuntu-1404/
|
||||
@ -0,0 +1,83 @@
|
||||
What is a good IDE for C/C++ on Linux
|
||||
================================================================================
|
||||
"A real coder doesn't use an IDE, a real coder uses [insert a text editor name here] with such and such plugins." We all heard that somewhere. Yet, as much as one can agree with that statement, an IDE remains quite useful. An IDE is easy to set up and use out of the box. Hence there is no better way to start coding a project from scratch. So for this post, let me present you with my list of good IDEs for C/C++ on Linux. Why is C/C++ specifically? Because C is my favorite language, and we need to start somewhere. Also note that there are in general a lot of ways to code in C, so in order to trim down the list, I only selected "real out-of-the-box IDE", not text editors like Gedit or Vim pumped with [plugins][1]. Not that this alternative is bad in any way, just that the list will go on forever if I include text editors.
|
||||
|
||||
### 1. Code::Blocks ###
|
||||
|
||||
|
||||
|
||||
Starting all out with my personal favorite, [Code::Blocks][2] is a simple and fast IDE for C/C++ exclusively. Like any respectable IDE, it integrates syntax highlighting, bookmarking, word completion, project management, and a debugger. Where it shines is via its simple plugin system which adds indispensable tools like Valgrind and CppCheck, and less indispensable like a Tetris mini-game. But my reason for liking it particularly is for its coherent set of handy shortcuts, and the large number of options that never feel too overwhelming.
|
||||
|
||||
### 2. Eclipse ###
|
||||
|
||||
|
||||
|
||||
I know that I said only "real out-of-the-box IDE" and not a text editor pumped with plugins, but [Eclipse][3] is a "real out-of-the-box IDE." It's just that Eclipse needs a little [plugin][4] (or a variant) to code in C. So I technically did not contradict myself. And it would have been impossible to make an IDE list without mentioning the behemoth that is Eclipse. Like it or not, Eclipse remains a great tool to code in Java. And thanks to the [CDT Project][5], it is possible to program in C/C++ too. You will benefit from all the power of Eclipse and its traditional features like word completion, code outline, code generator, and advanced refactoring. What it lacks in my opinion is the lightness of Code::Blocks. It is still very heavy and takes time to load. But if your machine can take it, or if you are a hardcore Eclipse fan, it is a very safe option.
|
||||
|
||||
### 3. Geany ###
|
||||
|
||||
|
||||
|
||||
With a lot less features but a lot more flexibility, [Geany][6] is at the opposite of Eclipse. But what it lacks (like a debugger for example), Geany makes it up with nice little features: a space for note taking, creation from template, code outline, customizable shortcuts, and plugins management. Geany is still closer to an extensive text editor than an IDE here. However I keep it in the list for its lightness and its well designed interface.
|
||||
|
||||
### 4. MonoDevelop ###
|
||||
|
||||
|
||||
|
||||
Another monster to add to the list, [MonoDevelop][7] has a very unique feel derived from its look and interface. I personally love its project management and its integrated version control system. The plugin system is also pretty amazing. But for some reason, all the options and the support for all kind of programming languages make it feel a bit overwhelming to me. It remains a great tool that I used many times in the past, but just not my number one when dealing with "simplistic" C.
|
||||
|
||||
### 5. Anjuta ###
|
||||
|
||||
|
||||
|
||||
With a very strong "GNOME feeling" attached to it, [Anjuta][8]'s appearance is a hit or miss. I tend to see it as an advanced version of Geany with a debugger included, but the interface is actually a lot more elaborate. I do enjoy the tab system to switch between the project, folders, and code outline view. I would have liked maybe a bit more shortcuts to move around in a file. However, it is a good tool, and offers outstanding compilation and build options, which can support the most specific needs.
|
||||
|
||||
### 6. Komodo Edit ###
|
||||
|
||||
|
||||
|
||||
I was not very familiar with [Komodo Edit][9], but after trying it a few days, it surprised me with many many good things. First, the tab-based navigation is always appreciable. Then the fancy looking code outline reminds me a lot of Sublime Text. Furthermore, the macro system and the file comparator make Komodo Edit very practical. Its plugin library makes it almost perfect. "Almost" because I do not find the shortcuts as nice as in other IDEs. Also, I would enjoy more specific C/C++ tools, and this is typically the flaw of general IDEs. Yet, very enjoyable software.
|
||||
|
||||
### 7. NetBeans ###
|
||||
|
||||
|
||||
|
||||
Just like Eclipse, impossible to avoid this beast. With navigation via tabs, project management, code outline, change history tracking, and a plethora of tools, [NetBeans][10] might be the most complete IDE out there. I could list for half a page all of its amazing features. But that will tip you off too easily about its main disadvantage, it might be too big. As great as it is, I prefer plugin based software because I doubt that anyone will need both Git and Mercurial integration for the same project. Call me crazy. But if you have the patience to master all of its options, you will be pretty much become the master of IDEs everywhere.
|
||||
|
||||
### 8. KDevelop ###
|
||||
|
||||
|
||||
|
||||
For all KDE fans out there, [KDevelop][11] might be the answer to your prayers. With a lot of configuration options, KDevelop is yours if you manage to seize it. Call me superficial but I never really got past the interface. But it's too bad for me as the editor itself packs quite a punch with a lot of navigation options and customizable shortcuts. The debugger is also very advanced and will take a bit of practice to master. However, this patience will be rewarded with this very flexible IDE's full power. And it gets special credits for its amazing embedded documentation.
|
||||
|
||||
### 9. CodeLite ###
|
||||
|
||||
|
||||
|
||||
Finally, last for not least, [CodeLite][12] shows that you can take a traditional formula and still get something with its own feeling attached to it. If the interface really reminded me of Code::Blocks and Anjuta at first, I was just blown away by the extensive plugin library. Whether you want to diff a file, insert a copyright block, define an abbreviation, or push your work on Git, there is a plugin for you. If I had to nitpick, I would say that it lacks a few navigation shortcuts for my taste, but that's really it.
|
||||
|
||||
To conclude, I hope that this list had you discover new IDEs for coding in your favorite language. While Code::Blocks remains my favorite, it has some serious challengers. Also we are far from covering all the ways to code in C/C++ using an IDE on Linux. So if you have another one to propose, let us know in the comments. Also if you would like me to cover IDEs for a different language next, also let us know in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-ide-for-c-cpp-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/turn-vim-full-fledged-ide.html
|
||||
[2]:http://www.codeblocks.org/
|
||||
[3]:https://eclipse.org/
|
||||
[4]:http://xmodulo.com/how-to-set-up-c-cpp-development-environment-in-eclipse.html
|
||||
[5]:https://eclipse.org/cdt/
|
||||
[6]:http://www.geany.org/
|
||||
[7]:http://www.monodevelop.com/
|
||||
[8]:http://anjuta.org/
|
||||
[9]:http://komodoide.com/komodo-edit/
|
||||
[10]:https://netbeans.org/
|
||||
[11]:https://www.kdevelop.org/
|
||||
[12]:http://codelite.org/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by barney-ro
|
||||
|
||||
2015 will be the year Linux takes over the enterprise (and other predictions)
|
||||
================================================================================
|
||||
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
|
||||
@ -62,7 +64,7 @@ What are your predictions for Linux and open source in 2015? Share your thoughts
|
||||
via: http://www.techrepublic.com/article/2015-will-be-the-year-linux-takes-over-the-enterprise-and-other-predictions/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
[translating by KayGuoWhu]
|
||||
A brief history of Linux malware
|
||||
================================================================================
|
||||
A look at some of the worms and viruses and Trojans that have plagued Linux throughout the years.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by ZTinoZ
|
||||
20 Linux Commands Interview Questions & Answers
|
||||
================================================================================
|
||||
**Q:1 How to check current run level of a linux server ?**
|
||||
@ -140,4 +141,4 @@ via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
[20]:
|
||||
|
||||
@ -0,0 +1,48 @@
|
||||
(translating by runningwater)
|
||||
2015: Open Source Has Won, But It Isn't Finished
|
||||
================================================================================
|
||||
> After the wins of 2014, what's next?
|
||||
|
||||
At the beginning of a new year, it's traditional to look back over the last 12 months. But as far as this column is concerned, it's easy to summarise what happened then: open source has won. Let's take it from the top:
|
||||
|
||||
**Supercomputers**. Linux is so dominant on the Top 500 Supercomputers lists it is almost embarrassing. The [November 2014 figures][1] show that 485 of the top 500 systems were running some form of Linux; Windows runs on just one. Things are even more impressive if you look at the numbers of cores involved. Here, Linux is to be found on 22,851,693 of them, while Windows is on just 30,720; what that means is that not only does Linux dominate, it is particularly strong on the bigger systems.
|
||||
|
||||
**Cloud computing**. The Linux Foundation produced an interesting [report][2] last year, which looked at the use of Linux in the cloud by large companies. It found that 75% of them use Linux as their primary platform there, against just 23% that use Windows. It's hard to translate that into market share, since the mix between cloud and non-cloud needs to be factored in; however, given the current popularity of cloud computing, it's safe to say that the use of Linux is high and increasing. Indeed, the same survey found Linux deployments in the cloud have increased from 65% to 79%, while those for Windows have fallen from 45% to 36%. Of course, some may not regard the Linux Foundation as totaly disinterested here, but even allowing for that, and for statistical uncertainties, it's pretty clear which direction things are moving in.
|
||||
|
||||
**Web servers**. Open source has dominated this sector for nearly 20 years - an astonishing record. However, more recently there's been some interesting movement in market share: at one point, Microsoft's IIS managed to overtake Apache in terms of the total number of Web servers. But as Netcraft explains in its most recent [analysis][3], there's more than meets the eye here:
|
||||
|
||||
> This is the second month in a row where there has been a large drop in the total number of websites, giving this month the lowest count since January. As was the case in November, the loss has been concentrated at just a small number of hosting companies, with the ten largest drops accounting for over 52 million hostnames. The active sites and web facing computers metrics were not affected by the loss, with the sites involved being mostly advertising linkfarms, having very little unique content. The majority of these sites were running on Microsoft IIS, causing it to overtake Apache in the July 2014 survey. However the recent losses have resulted in its market share dropping to 29.8%, leaving it now over 10 percentage points behind Apache.
|
||||
|
||||
As that indicates, Microsoft's "surge" was more apparent than real, and largely based on linkfarms with little useful content. Indeed, Netcraft's figures for active sites paints a very different picture: Apache has 50.57% market share, with nginx second on 14.73%; Microsoft IIS limps in with a rather feeble 11.72%. This means that open source has around 65% of the active Web server market - not quite at the supercomputer level, but pretty good.
|
||||
|
||||
**Mobile systems**. Here, the march of open source as the foundation of Android continues. Latest figures show that Android accounted for [83.6%][4] of smartphone shipments in the third quarter of 2014, up from 81.4% in the same quarter the previous year. Apple achieved 12.3%, down from 13.4%. As far as tablets are concerned, Android is following a similar trajectory: for the second quarter of 2014, Android notched up around [75% of global tablet sales][5], while Apple was on 25%.
|
||||
|
||||
**Embedded systems**. Although it's much harder to quantify the market share of Linux in the important embedded system market, but figures from one 2013 study indicated that around [half of planned embedded systems][6] would use it.
|
||||
|
||||
**Internet of Things**. In many ways this is simply another incarnation of embedded systems, with the difference that they are designed to be online, all the time. It's too early to talk of market share, but as I've [discussed][7] recently, AllSeen's open source framework is coming on apace. What's striking by their absence are any credible closed-source rivals; it therefore seems highly likely that the Internet of Things will see supercomputer-like levels of open source adoption.
|
||||
|
||||
Of course, this level of success always begs the question: where do we go from here? Given that open source is approaching saturation levels of success in many sectors, surely the only way is down? In answer to that question, I recommend a thought-provoking essay from 2013 written by Christopher Kelty for the Journal of Peer Production, with the intriguing title of "[There is no free software.][8]" Here's how it begins:
|
||||
|
||||
> Free software does not exist. This is sad for me, since I wrote a whole book about it. But it was also a point I tried to make in my book. Free software—and its doppelganger open source—is constantly becoming. Its existence is not one of stability, permanence, or persistence through time, and this is part of its power.
|
||||
|
||||
In other words, whatever amazing free software 2014 has already brought us, we can be sure that 2015 will be full of yet more of it, as it continues its never-ending evolution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -0,0 +1,29 @@
|
||||
Linus Tells Wired Leap Second Irrelevant
|
||||
================================================================================
|
||||

|
||||
|
||||
Two larger publications today featured Linux and the effect of the upcoming leap second. The Register today said that the leap second effects of the past are no longer an issue. Coincidentally, Wired talked to Linus Torvalds about the same issue today as well.
|
||||
|
||||
**Linus Torvalds** spoke with Wired's Robert McMillan about the approaching leap second due to be added in June. The Register said the last leap second in 2012 took out Mozilla, StumbleUpon, Yelp, FourSquare, Reddit and LinkedIn as well as several major airlines and travel reservation services that ran Linux. Torvalds told Wired today that the kernel is patched and he doesn't expect too many issues this time around. [He said][1], "Just take the leap second as an excuse to have a small nonsensical party for your closest friends. Wear silly hats, get a banner printed, and get silly drunk. That’s exactly how relevant it should be to most people."
|
||||
|
||||
**However**, The Register said not everyone agrees with Torvalds' sentiments. They quote Daily Mail saying, "The year 2015 will have an extra second — which could wreak havoc on the infrastructure powering the Internet," then remind us of the Y2K scare that ended up being a non-event. The Register's Gavin [Clarke concluded][2]:
|
||||
|
||||
> No reason the Penguins were caught sans pants.
|
||||
|
||||
> Now they've gone belt and braces.
|
||||
|
||||
The take-away is: move along, nothing to see here.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/linus-tells-wired-leap-second-irrelevant
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:http://www.wired.com/2015/01/torvalds_leapsecond/
|
||||
[2]:http://www.theregister.co.uk/2015/01/09/leap_second_bug_linux_hysteria/
|
||||
@ -0,0 +1,36 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
||||
|
||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
||||
|
||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
||||
|
||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
||||
|
||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
||||
|
||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
||||
|
||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
||||
|
||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
||||
|
||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
||||
|
||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
||||
|
||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
||||
|
||||
作者:[Zack Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
||||
81
sources/talk/20150114 Why Mac users don't switch to Linux.md
Normal file
81
sources/talk/20150114 Why Mac users don't switch to Linux.md
Normal file
@ -0,0 +1,81 @@
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
[Datamation took a look at these questions][1] and tried to answer them. Datamation’s conclusion was that it’s really about the applications and workflow, not the operating system:
|
||||
|
||||
> …there are some instances where replacing existing applications with new options isn’t terribly practical – both in workflow and in overall functionality. This is an area where, sadly, Apple has excelled in. So while it’s hardly “impossible” to get around these issues, they are definitely a large enough challenge that it will give the typical Mac enthusiast pause.
|
||||
>
|
||||
> But outside of Web developers, honestly, I don’t see Mac users “en masse,” seeking to disrupt their workflows for the mere idea of avoiding the upgrade to OS X Yosemite. Granted, having seen Yosemite up close – Mac users who are considered power users will absolutely find this change-up to be hideous. However, despite poor OS X UI changes, the core workflow for existing Mac users will remain largely unchanged and unchallenged.
|
||||
>
|
||||
> No, I believe Linux adoption will continue to be sporadic and random. Ever-growing, but not something that is easily measured or accurately calculated.
|
||||
|
||||
I agree to a certain extent with Datamation’s take on the importance of applications and workflows, both things are important and matter in the choice of a desktop operating system. But I think there’s something more going on with Mac users than just that. I believe that there’s a different mentality that exists between Linux and Mac users, and I think that’s the real reason why many Mac users don’t switch to Linux.
|
||||
|
||||

|
||||
|
||||
### It’s all about control for Linux users ###
|
||||
|
||||
Linux users tend to want control over their computing experience, they want to be able to change things to make them the way that they want them. One simply cannot do that in the same way with OS X or any other Apple products. With Apple you get what they give you for the most part.
|
||||
|
||||
For Mac (and iOS) users this is fine, they seem mostly content to stay within Apple’s walled garden and live according to whatever standards and options Apple gives them. But this is totally unacceptable to most Linux users. People who move to Linux usually come from Windows, and it’s there that they develop their loathing for someone else trying to define or control their computing experiences.
|
||||
|
||||
And once someone like that has tasted the freedom that Linux offers, it’s almost impossible for them to want to go back to living under the thumb of Apple, Microsoft or anyone else. You’d have to pry Linux from their cold, dead fingers before they’d accept the computing experience created for them Apple or Microsoft.
|
||||
|
||||
But you won’t find that same determination to have control among most Mac users. For them it’s mostly about getting the most out of whatever Apple has done with OS X in its latest update. They tend to adjust fairly quickly to new versions of OS X and even when unhappy with Apple’s changes they seem content to continue living within Apple’s walled garden.
|
||||
|
||||
So the need for control is a huge difference between Mac and Linux users. I don’t see it as a problem though since it just reflects the reality of two very different attitudes toward using computers.
|
||||
|
||||
### Mac users need Apple’s support mechanisms ###
|
||||
|
||||
Linux users are also different in the sense that they don’t mind getting their hands dirty by getting “under the hood” of their computers. Along with control comes the personal responsibility of making sure that their Linux systems work well and efficiently, and digging into the operating system is something that many Linux users have no problem doing.
|
||||
|
||||
When a Linux user needs to fix something, chances are they will attempt to do so immediately themselves. If that doesn’t work then they’ll seek additional information online from other Linux users and work through the problem until it has been resolved.
|
||||
|
||||
But Mac users are most likely not going to do that to the same extent. That is probably one of the reasons why Apple stores are so popular and why so many Mac users opt to buy Apple Care when they get a new Mac. A Mac user can simply take his or her computer to the Apple store and ask someone to fix it for them. There they can belly up to the Genius Bar and have their computer looked at by someone Apple has paid to fix it.
|
||||
|
||||
Most Linux users would blanche at the thought of doing such a thing. Who wants some guy you don’t even know to lay hands on your computer and start trying to fix it for you? Some Linux users would shudder at the very idea of such a thing happening.
|
||||
|
||||
So it would be hard for a Mac user to switch to Linux and suddenly be bereft of the support from Apple that he or she was used to getting in the past. Some Mac users might feel very vulnerable and uncertain if they were cut off from the Apple mothership in terms of support.
|
||||
|
||||
### Mac users love Apple’s hardware ###
|
||||
|
||||
The Datamation article focused on software, but I believe that hardware also matters to Mac users. Most Apple customers tend to love Apple’s hardware. When they buy a Mac, they aren’t just buying it for OS X. They are also buying Apple’s industrial design expertise and that can be an important differentiator for Mac users. Mac users are willing to pay more because they perceive that the overall value they are getting from Apple for a Mac is worth it.
|
||||
|
||||
Linux users, on the other hand, seem less concerned by such things. I think they tend to focus more on cost and less on the looks or design of their computer hardware. For them it’s probably about getting the most value from the hardware at the lowest cost. They aren’t in love with the way their computer hardware looks in the same way that some Mac users probably are, and so they don’t make buying decisions based on it.
|
||||
|
||||
I think both points of view on hardware are equally valid. It ultimately gets down to the needs of the individual user and what matters to them when they choose to buy or, in the case of some Linux users, build their computer. Value is the key for both groups, and each has its own perceptions of what constitutes real value in a computer.
|
||||
|
||||
Of course it is [possible to run Linux on a Mac][2], directly or indirectly via virtual machine. So a user that really liked Apple’s hardware does have the option of keeping their Mac but installing Linux on it.
|
||||
|
||||
### Too many Linux distros to choose from? ###
|
||||
|
||||
Another reason that might make it hard for a Mac user to move to Linux is the sheer number of distributions to choose from in the world of Linux. While most Linux users probably welcome the huge diversity of distros available, it could also be very confusing for a Mac user who hasn’t learned to navigate those choices.
|
||||
|
||||
Over time I think a Mac user would learn and adjust by figuring out which distribution worked best for him or her. But in the short term it might be a very daunting hurdle to overcome after being used to OS X for a long period of time. I don’t think it’s insurmountable, but it’s definitely something that is worth mentioning here.
|
||||
|
||||
Of course we do have helpful resources like [DistroWatch][3] and even my own [Desktop Linux Reviews][4] blog that can help people find the right Linux distribution. Plus there are many articles available about “the best Linux distro” and that sort of thing that Mac users can use as resources when trying to figure out the distribution they want to use.
|
||||
|
||||
But one of the reasons why Apple customers buy Macs is the simplicity and all-in-one solution that they offer in terms of the hardware and software being unified by Apple. So I am not sure how many Mac users would really want to spend the time trying to find the right Linux distribution. It might be something that puts them off really considering the switch to Linux.
|
||||
|
||||
### Mac users are apples and Linux users are oranges ###
|
||||
|
||||
I see nothing wrong with Mac and Linux users going their separate ways. I think we’re just talking about two very different groups of people, and it’s a good thing that both groups can find and use the operating system and software that they prefer. Let Mac users enjoy OS X and let Linux users enjoy Linux, and hopefully both groups will be happy and content with their computers.
|
||||
|
||||
Every once in a while a Mac user might stray over to Linux or vice versa, but for the most part I think the two groups live in different worlds and mostly prefer to stay separate and apart from one another. I generally don’t compare the two because when you get right down to it, it’s really just a case of apples and oranges.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jimlynch.com/linux-articles/why-mac-users-dont-switch-to-linux/
|
||||
|
||||
作者:[Jim Lynch][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://jimlynch.com/author/Jim/
|
||||
[1]:http://www.datamation.com/open-source/why-linux-isnt-winning-over-mac-users-1.html
|
||||
[2]:http://www.howtogeek.com/187410/how-to-install-and-dual-boot-linux-on-a-mac/
|
||||
[3]:http://distrowatch.com/
|
||||
[4]:http://desktoplinuxreviews.com/
|
||||
@ -1,273 +0,0 @@
|
||||
How to configure HTTP load balancer with HAProxy on Linux
|
||||
================================================================================
|
||||
Increased demand on web based applications and services are putting more and more weight on the shoulders of IT administrators. When faced with unexpected traffic spikes, organic traffic growth, or internal challenges such as hardware failures and urgent maintenance, your web application must remain available, no matter what. Even modern devops and continuous delivery practices can threaten the reliability and consistent performance of your web service.
|
||||
|
||||
Unpredictability or inconsistent performance is not something you can afford. But how can we eliminate these downsides? In most cases a proper load balancing solution will do the job. And today I will show you how to set up HTTP load balancer using [HAProxy][1].
|
||||
|
||||
### What is HTTP load balancing? ###
|
||||
|
||||
HTTP load balancing is a networking solution responsible for distributing incoming HTTP or HTTPS traffic among servers hosting the same application content. By balancing application requests across multiple available servers, a load balancer prevents any application server from becoming a single point of failure, thus improving overall application availability and responsiveness. It also allows you to easily scale in/out an application deployment by adding or removing extra application servers with changing workloads.
|
||||
|
||||
### Where and when to use load balancing? ###
|
||||
|
||||
As load balancers improve server utilization and maximize availability, you should use it whenever your servers start to be under high loads. Or if you are just planning your architecture for a bigger project, it's a good habit to plan usage of load balancer upfront. It will prove itself useful in the future when you need to scale your environment.
|
||||
|
||||
### What is HAProxy? ###
|
||||
|
||||
HAProxy is a popular open-source load balancer and proxy for TCP/HTTP servers on GNU/Linux platforms. Designed in a single-threaded event-driven architecture, HAproxy is capable of handling [10G NIC line rate][2] easily, and is being extensively used in many production environments. Its features include automatic health checks, customizable load balancing algorithms, HTTPS/SSL support, session rate limiting, etc.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
In this tutorial, we will go through the process of configuring a HAProxy-based load balancer for HTTP web servers.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
### Install HAProxy on Linux ###
|
||||
|
||||
For most distributions, we can install HAProxy using your distribution's package manager.
|
||||
|
||||
#### Install HAProxy on Debian ####
|
||||
|
||||
In Debian we need to add backports for Wheezy. To do that, please create a new file called "backports.list" in /etc/apt/sources.list.d, with the following content:
|
||||
|
||||
deb http://cdn.debian.net/debian wheezybackports main
|
||||
|
||||
Refresh your repository data and install HAProxy.
|
||||
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on Ubuntu ####
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on CentOS and RHEL ####
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### Configure HAProxy ###
|
||||
|
||||
In this tutorial, we assume that there are two HTTP web servers up and running with IP addresses 192.168.100.2 and 192.168.100.3. We also assume that the load balancer will be configured at a server with IP address 192.168.100.4.
|
||||
|
||||
To make HAProxy functional, you need to change a number of items in /etc/haproxy/haproxy.cfg. These changes are described in this section. In case some configuration differs for different GNU/Linux distributions, it will be noted in the paragraph.
|
||||
|
||||
#### 1. Configure Logging ####
|
||||
|
||||
One of the first things you should do is to set up proper logging for your HAProxy, which will be useful for future debugging. Log configuration can be found in the global section of /etc/haproxy/haproxy.cfg. The following are distro-specific instructions for configuring logging for HAProxy.
|
||||
|
||||
**CentOS or RHEL:**
|
||||
|
||||
To enable logging on CentOS/RHEL, replace:
|
||||
|
||||
log 127.0.0.1 local2
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
The next step is to set up separate log files for HAProxy in /var/log. For that, we need to modify our current rsyslog configuration. To make the configuration simple and clear, we will create a new file called haproxy.conf in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian or Ubuntu:**
|
||||
|
||||
To enable logging for HAProxy on Debian or Ubuntu, replace:
|
||||
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
Next, to configure separate log files for HAProxy, edit a file called haproxy.conf (or 49-haproxy.conf in Debian) in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. Setting Defaults ####
|
||||
|
||||
The next step is to set default variables for HAProxy. Find the defaults section in /etc/haproxy/haproxy.cfg, and replace it with the following configuration.
|
||||
|
||||
defaults
|
||||
log global
|
||||
mode http
|
||||
option httplog
|
||||
option dontlognull
|
||||
retries 3
|
||||
option redispatch
|
||||
maxconn 20000
|
||||
contimeout 5000
|
||||
clitimeout 50000
|
||||
srvtimeout 50000
|
||||
|
||||
The configuration stated above is recommended for HTTP load balancer use, but it may not be the optimal solution for your environment. In that case, feel free to explore HAProxy man pages to tweak it.
|
||||
|
||||
#### 3. Webfarm Configuration ####
|
||||
|
||||
Webfarm configuration defines the pool of available HTTP servers. Most of the settings for our load balancer will be placed here. Now we will create some basic configuration, where our nodes will be defined. Replace all of the configuration from frontend section until the end of file with the following code:
|
||||
|
||||
listen webfarm *:80
|
||||
mode http
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
balance roundrobin
|
||||
cookie LBN insert indirect nocache
|
||||
option httpclose
|
||||
option forwardfor
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The line "listen webfarm *:80" defines on which interfaces our load balancer will listen. For the sake of the tutorial, I've set that to "*" which makes the load balancer listen on all our interfaces. In a real world scenario, this might be undesirable and should be replaced with an interface that is accessible from the internet.
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
The above settings declare that our load balancer statistics can be accessed on http://<load-balancer-IP>/haproxy?stats. The access is secured with a simple HTTP authentication with login name "haproxy" and password "stats". These settings should be replaced with your own credentials. If you don't need to have these statistics available, then completely disable them.
|
||||
|
||||
Here is an example of HAProxy statistics.
|
||||
|
||||
|
||||
|
||||
The line "balance roundrobin" defines the type of load balancing we will use. In this tutorial we will use simple round robin algorithm, which is fully sufficient for HTTP load balancing. HAProxy also offers other types of load balancing:
|
||||
|
||||
- **leastconn**: gives connections to the server with the lowest number of connections.
|
||||
- **source**: hashes the source IP address, and divides it by the total weight of the running servers to decide which server will receive the request.
|
||||
- **uri**: the left part of the URI (before the question mark) is hashed and divided by the total weight of the running servers. The result determines which server will receive the request.
|
||||
- **url_param**: the URL parameter specified in the argument will be looked up in the query string of each HTTP GET request. You can basically lock the request using crafted URL to specific load balancer node.
|
||||
- **hdr(name**): the HTTP header <name> will be looked up in each HTTP request and directed to specific node.
|
||||
|
||||
The line "cookie LBN insert indirect nocache" makes our load balancer store persistent cookies, which allows us to pinpoint which node from the pool is used for a particular session. These node cookies will be stored with a defined name. In our case, I used "LBN", but you can specify any name you like. The node will store its string as a value for this cookie.
|
||||
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The above part is the definition of our pool of web server nodes. Each server is represented with its internal name (e.g., web01, web02). IP address, and unique cookie string. The cookie string can be defined as anything you want. I am using simple node1, node2 ... node(n).
|
||||
|
||||
### Start HAProxy ###
|
||||
|
||||
When you are done with the configuration, it's time to start HAProxy and verify that everything is working as intended.
|
||||
|
||||
#### Start HAProxy on Centos/RHEL ####
|
||||
|
||||
Enable HAProxy to be started after boot and turn it on using:
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
And of course don't forget to enable port 80 in the firewall as follows.
|
||||
|
||||
**Firewall on CentOS/RHEL 7:**
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**Firewall on CentOS/RHEL 6:**
|
||||
|
||||
Add following line into section ":OUTPUT ACCEPT" of /etc/sysconfig/iptables:
|
||||
|
||||
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
|
||||
|
||||
and restart **iptables**:
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### Start HAProxy on Debian ####
|
||||
|
||||
#### Start HAProxy with: ####
|
||||
|
||||
# service haproxy start
|
||||
|
||||
Don't forget to enable port 80 in the firewall by adding the following line into /etc/iptables.up.rules:
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### Start HAProxy on Ubuntu ####
|
||||
|
||||
Enable HAProxy to be started after boot by setting "ENABLED" option to "1" in /etc/default/haproxy:
|
||||
|
||||
ENABLED=1
|
||||
|
||||
Start HAProxy:
|
||||
|
||||
# service haproxy start
|
||||
|
||||
and enable port 80 in the firewall:
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### Test HAProxy ###
|
||||
|
||||
To check whether HAproxy is working properly, we can do the following.
|
||||
|
||||
First, prepare test.php file with the following content:
|
||||
|
||||
<?php
|
||||
header('Content-Type: text/plain');
|
||||
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
|
||||
echo "\nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
|
||||
?>
|
||||
|
||||
This PHP file will tell us which server (i.e., load balancer) forwarded the request, and what backend web server actually handled the request.
|
||||
|
||||
Place this PHP file in the root directory of both backend web servers. Now use curl command to fetch this PHP file from the load balancer (192.168.100.4).
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
When we run this command multiple times, we should see the following two outputs alternate (due to the round robin algorithm).
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
----------
|
||||
|
||||
Server IP: 192.168.100.3
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
If we stop one of the two backend web servers, the curl command should still work, directing requests to the other available web server.
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now you should have a fully operational load balancer that supplies your web nodes with requests in round robin mode. As always, feel free to experiment with the configuration to make it more suitable for your infrastructure. I hope this tutorial helped you to make your web projects more resistant and available.
|
||||
|
||||
As most of you already noticed, this tutorial contains settings for only one load balancer. Which means that we have just replaced one single point of failure with another. In real life scenarios you should deploy at least two or three load balancers to cover for any failures that might happen, but that is out of the scope of this tutorial right now.
|
||||
|
||||
If you have any questions or suggestions feel free to post them in the comments and I will do my best to answer or advice.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
@ -1,86 +0,0 @@
|
||||
How to convert image, audio and video formats on Ubuntu
|
||||
================================================================================
|
||||
If you need to work with a variety of image, audio and video files encoded in all sorts of different formats, you are probably using more than one tools to convert among all those heterogeneous media formats. If there is a versatile all-in-one media conversion tool that is capable of dealing with all different image/audio/video formats, that will be awesome.
|
||||
|
||||
[Format Junkie][1] is one such all-in-one media conversion tool with an extremely user-friendly GUI. Better yet, it is free software! With Format Junkie, you can convert image, audio, video and archive files of pretty much all the popular formats simply with a few mouse clicks.
|
||||
|
||||
### Install Format Junkie on Ubuntu 12.04, 12.10 and 13.04 ###
|
||||
|
||||
Format Junkie is available for installation via Ubuntu PPA format-junkie-team. This PPA supports Ubuntu 12.04, 12.10 and 13.04. To install Format Junkie on one of those Ubuntu releases, simply run the following.
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 13.10 ###
|
||||
|
||||
If you are running Ubuntu 13.10 (Saucy Salamander), you can download and install .deb package for Ubuntu 13.04 as follows. Since the .deb package for Format Junkie requires quite a few dependent packages, install it using [gdebi deb installer][2].
|
||||
|
||||
On 32-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
On 64-bit Ubuntu 13.10:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### Install Format Junkie on Ubuntu 14.04 or Later ###
|
||||
|
||||
The currently available official Format Junkie .deb file requires libavcodec-extra-53 which has become obsolete starting from Ubuntu 14.04. Thus if you want to install Format Junkie on Ubuntu 14.04 or later, you can use the following third-party PPA repositories instead.
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
|
||||
### How to Use Format Junkie ###
|
||||
|
||||
To start Format Junkie after installation, simply run:
|
||||
|
||||
$ formatjunkie
|
||||
|
||||
#### Convert audio, video, image and archive formats with Format Junkie ####
|
||||
|
||||
The user interface of Format Junkie is pretty simple and intuitive, as shown below. To choose among audio, video, image and iso media, click on one of four tabs at the top. You can add as many files as you want for batch conversion. After you add files, and select output format, simply click on "Start Converting" button to convert.
|
||||
|
||||

|
||||
|
||||
Format Junkie supports conversion among the following media formats:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
- **Image**: jpg, png, ico, bmp, svg, tif, pcx, pdf, tga, pnm.
|
||||
- **Archive**: iso, cso.
|
||||
|
||||
#### Subtitle encoding with Format Junkie ####
|
||||
|
||||
Besides media conversion, Format Junkie also provides GUI for subtitle encoding. Actual subtitle encoding is done by MEncoder. In order to do subtitle encoding via Format Junkie interface, first you need to install MEencoder.
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
Then click on "Advanced" tab on Format Junkie. Choose AVI/subtitle files to use for encoding, as shown below.
|
||||
|
||||

|
||||
|
||||
Overall, Format Junkie is an extremely easy-to-use and versatile media conversion tool. One drawback, though, is that it does not allow any sort of customization during conversion (e.g., bitrate, fps, sampling frequency, image quality, size). So this tool is recommended for newbies who are looking for an easy-to-use simple media conversion tool.
|
||||
|
||||
Enjoyed this post? I will appreciate your like/share buttons on Facebook, Twitter and Google+.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -1,301 +0,0 @@
|
||||
“ntpq -p” output
|
||||
================================================================================
|
||||
The [Gentoo][1] (and others?) [incomplete man pages for “ntpq -p”][2] merely give the description: “*Print a list of the peers known to the server as well as a summary of their state.*”
|
||||
|
||||
I had not seen this documented, hence here is a summary that can be used in addition to the brief version of the man page “[man ntpq][3]“. More complete details are given on: “[ntpq – standard NTP query program][4]” (source author), and [other examples of the man ntpq pages][5].
|
||||
|
||||
[NTP][6] is a protocol designed to synchronize the clocks of computers over a ([WAN][7] or [LAN][8]) [udp][9] network. From [Wikipedia – NTP][10]:
|
||||
|
||||
> The Network Time Protocol (NTP) is a protocol and software implementation for synchronizing the clocks of computer systems over packet-switched, variable-latency data networks. Originally designed by David L. Mills of the University of Delaware and still maintained by him and a team of volunteers, it was first used before 1985 and is one of the oldest Internet protocols.
|
||||
|
||||
For an awful lot more than you might ever want to know about time and NTP, see “[The NTP FAQ, Time, what Time?][11]” and the current [RFCs for NTP][12]. The earlier “Network Time Protocol (Version 3) RFC” ([txt][13], or [pdf][14], Appendix E, The NTP Timescale and its Chronometry, p70) includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so. Wikipedia gives a broader view in the articles [Time][15] and [Calendar][16].
|
||||
|
||||
The command “ntpq -p” outputs a table such as for example:
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
LOCAL(0) .LOCL. 10 l 96h 64 0 0.000 0.000 0.000
|
||||
*ns2.example.com 10.193.2.20 2 u 936 1024 377 31.234 3.353 3.096
|
||||
|
||||
### Further detail: ###
|
||||
|
||||
#### Table headings: ####
|
||||
|
||||
|
||||
- **remote** – The remote peer or server being synced to. “LOCAL” is this local host (included in case there are no remote peers or servers available);
|
||||
- **refid** – Where or what the remote peer or server is itself synchronised to;
|
||||
- **st** – The remote peer or server [Stratum][17]
|
||||
- **t** – Type (u: [unicast][18] or [manycast][19] client, b: [broadcast][20] or [multicast][21] client, l: local reference clock, s: symmetric peer, A: manycast server, B: broadcast server, M: multicast server, see “[Automatic Server Discovery][22]“);
|
||||
- **when** – When last polled (seconds ago, “h” hours ago, or “d” days ago);
|
||||
- **poll** – Polling frequency: [rfc5905][23] suggests this ranges in NTPv4 from 4 (16s) to 17 (36h) (log2 seconds), however observation suggests the actual displayed value is seconds for a much smaller range of 64 (26) to 1024 (210) seconds;
|
||||
- **reach** – An 8-bit left-shift shift register value recording polls (bit set = successful, bit reset = fail) displayed in [octal][24];
|
||||
- **delay** – Round trip communication delay to the remote peer or server (milliseconds);
|
||||
- **offset** – Mean offset (phase) in the times reported between this local host and the remote peer or server ([RMS][25], milliseconds);
|
||||
- **jitter** – Mean deviation (jitter) in the time reported for that remote peer or server (RMS of difference of multiple time samples, milliseconds);
|
||||
|
||||
#### Select Field tally code: ####
|
||||
|
||||
The first character displayed in the table (Select Field tally code) is a state flag (see [Peer Status Word][26]) that follows the sequence ” “, “x”, “-“, “#”, “+”, “*”, “o”:
|
||||
|
||||
|
||||
- ”** **” – No state indicated for:
|
||||
- non-communicating remote machines,
|
||||
- “LOCAL” for this local host,
|
||||
- (unutilised) high stratum servers,
|
||||
- remote machines that are themselves using this host as their synchronisation reference;
|
||||
- “**x**” – Out of tolerance, do not use (discarded by intersection algorithm);
|
||||
- “**-**” – Out of tolerance, do not use (discarded by the cluster algorithm);
|
||||
- “**#**” – Good remote peer or server but not utilised (not among the first six peers sorted by synchronization distance, ready as a backup source);
|
||||
- “**+**” – Good and a preferred remote peer or server (included by the combine algorithm);
|
||||
- “*****” – The remote peer or server presently used as the primary reference;
|
||||
- “**o**” – PPS peer (when the prefer peer is valid). The actual system synchronization is derived from a pulse-per-second (PPS) signal, either indirectly via the PPS reference clock driver or directly via kernel interface.
|
||||
|
||||
See the [Clock Select Algorithm][27].
|
||||
|
||||
#### “refid”: ####
|
||||
|
||||
The **refid** can have the status values:
|
||||
|
||||
|
||||
- An IP address – The [IP address][28] of a remote peer or server;
|
||||
- **.LOCL.** – This local host (a place marker at the lowest stratum included in case there are no remote peers or servers available);
|
||||
- **.PPS.** – “[Pulse Per Second][29]” from a time standard;
|
||||
- **.IRIG.** – [Inter-Range Instrumentation Group][30] time code;
|
||||
- **.ACTS.** – American [NIST time standard][31] telephone modem;
|
||||
- **.NIST.** – American NIST time standard telephone modem;
|
||||
- **.PTB.** – German [PTB][32] time standard telephone modem;
|
||||
- **.USNO.** – American [USNO time standard][33] telephone modem;
|
||||
- **.CHU.** – [CHU][34] ([HF][35], Ottawa, ON, Canada) time standard radio receiver;
|
||||
- **.DCFa.** – [DCF77][36] ([LF][37], Mainflingen, Germany) time standard radio receiver;
|
||||
- **.HBG.** – [HBG][38] (LF Prangins, Switzerland) time standard radio receiver;
|
||||
- **.JJY.** – [JJY][39] (LF Fukushima, Japan) time standard radio receiver;
|
||||
- **.LORC.** – [LORAN][40]-C station ([MF][41]) time standard radio receiver. Note, [no longer operational][42] (superseded by [eLORAN][43]);
|
||||
- **.MSF.** – [MSF][44] (LF, Anthorn, Great Britain) time standard radio receiver;
|
||||
- **.TDF.** – [TDF][45] (MF, Allouis, France) time standard radio receiver;
|
||||
- **.WWV.** – [WWV][46] (HF, Ft. Collins, CO, America) time standard radio receiver;
|
||||
- **.WWVB.** – [WWVB][47] (LF, Ft. Collins, CO, America) time standard radio receiver;
|
||||
- **.WWVH.** – [WWVH][48] (HF, Kauai, HI, America) time standard radio receiver;
|
||||
- **.GOES.** – American [Geosynchronous Orbit Environment Satellite][49];
|
||||
- **.GPS.** – American [GPS][50];
|
||||
- **.GAL.** – [Galileo][51] European [GNSS][52];
|
||||
- **.ACST.** – manycast server;
|
||||
- **.AUTH.** – authentication error;
|
||||
- **.AUTO.** – Autokey sequence error;
|
||||
- **.BCST.** – broadcast server;
|
||||
- **.CRYPT.** – Autokey protocol error;
|
||||
- **.DENY.** – access denied by server;
|
||||
- **.INIT.** – association initialized;
|
||||
- **.MCST.** – multicast server;
|
||||
- **.RATE.** – (polling) rate exceeded;
|
||||
- **.TIME.** – association timeout;
|
||||
- **.STEP.** – step time change, the offset is less than the panic threshold (1000ms) but greater than the step threshold (125ms).
|
||||
|
||||
#### Operation notes ####
|
||||
|
||||
A time server will report time information with no time updates from clients (unidirectional updates), whereas a peer can update fellow participating peers to converge upon a mutually agreed time (bidirectional updates).
|
||||
|
||||
During [initial startup][53]:
|
||||
|
||||
> Unless using the iburst option, the client normally takes a few minutes to synchronize to a server. If the client time at startup happens to be more than 1000s distant from NTP time, the daemon exits with a message to the system log directing the operator to manually set the time within 1000s and restart. If the time is less than 1000s but more than 128s distant, a step correction occurs and the daemon restarts automatically.
|
||||
|
||||
> When started for the first time and a frequency file is not present, the daemon enters a special mode in order to calibrate the frequency. This takes 900s during which the time is not [disciplined][54]. When calibration is complete, the daemon creates the frequency file and enters normal mode to amortize whatever residual offset remains.
|
||||
|
||||
Stratum 0 devices are such as atomic (caesium, rubidium) clocks, GPS clocks, or other time standard radio clocks providing a time signal to the Stratum 1 time servers. NTP reports [UTC][55] (Coordinated Universal Time) only. Client programs/utilities then use [time zone][56] data to report local time from the synchronised UTC.
|
||||
|
||||
The protocol is highly accurate, using a resolution of less than a nanosecond (about 2-32 seconds). The time resolution achieved and other parameters for a host (host hardware and operating system limited) is reported by the command “ntpq -c rl” (see [rfc1305][57] Common Variables and [rfc5905][58]).
|
||||
|
||||
#### “ntpq -c rl” output parameters: ####
|
||||
|
||||
- **precision** is rounded to give the next larger integer power of two. The achieved resolution is thus 2precision (seconds)
|
||||
- **rootdelay** – total roundtrip delay to the primary reference source at the root of the synchronization subnet. Note that this variable can take on both positive and negative values, depending on clock precision and skew (seconds)
|
||||
- **rootdisp** – maximum error relative to the primary reference source at the root of the synchronization subnet (seconds)
|
||||
- **tc** – NTP algorithm [PLL][59] (phase locked loop) or [FLL][60] (frequency locked loop) time constant (log2)
|
||||
- **mintc** – NTP algorithm PLL/FLL minimum time constant or ‘fastest response’ (log2)
|
||||
- **offset** – best and final offset determined by the combine algorithm used to discipline the system clock (ms)
|
||||
- **frequency** – system clock period (log2 seconds)
|
||||
- **sys_jitter** – best and final jitter determined by the combine algorithm used to discipline the system clock (ms)
|
||||
- **clk_jitter** – host hardware(?) system clock jitter (ms)
|
||||
- **clk_wander** – host hardware(?) system clock wander ([PPM][61] – parts per million)
|
||||
|
||||
Jitter (also called timing jitter) refers to short-term variations in frequency with components greater than 10Hz, while wander refers to long-term variations in frequency with components less than 10Hz. (Stability refers to the systematic variation of frequency with time and is synonymous with aging, drift, trends, etc.)
|
||||
|
||||
#### Operation notes (continued) ####
|
||||
|
||||
The NTP software maintains a continuously updated drift correction. For a correctly configured and stable system, a reasonable expectation for modern hardware synchronising over an uncongested internet connection is for network client devices to be synchronised to within a few milliseconds of UTC at the time of synchronising to the NTP service. (What accuracy can be expected between peers on an uncongested Gigabit LAN?)
|
||||
|
||||
Note that for UTC, a [leap second][62] can be inserted into the reported time up to twice a year to allow for variations in the Earth’s rotation. Also beware of the one hour time shifts for when local times are reported for “[daylight savings][63]” times. Also, the clock for a client device will run independently of UTC until resynchronised oncemore, unless that device is calibrated or a drift correction is applied.
|
||||
|
||||
#### [What happens during a Leap Second?][64] ####
|
||||
|
||||
> During a leap second, either one second is removed from the current day, or a second is added. In both cases this happens at the end of the UTC day. If a leap second is inserted, the time in UTC is specified as 23:59:60. In other words, it takes two seconds from 23:59:59 to 0:00:00 instead of one. If a leap second is deleted, time will jump from 23:59:58 to 0:00:00 in one second instead of two. See also [The Kernel Discipline][65].
|
||||
|
||||
So… What actually is the value for the step threshold: 125ms or 128ms? And what are the PLL/FLL tc units (log2 s? ms?)? And what accuracy can be expected between peers on an uncongested Gigabit LAN?
|
||||
|
||||
|
||||
|
||||
Thanks for comments from Camilo M and Chris B. Corrections and further details welcomed.
|
||||
|
||||
Cheers,
|
||||
Martin
|
||||
|
||||
### Apocrypha: ###
|
||||
|
||||
- The [epoch for NTP][66] starts in year 1900 while the epoch in UNIX starts in 1970.
|
||||
- [Time corrections][67] are applied gradually, so it may take up to three hours until the frequency error is compensated.
|
||||
- [Peerstats and loopstats][68] can be logged to [summarise/plot time offsets and errors][69]
|
||||
- [RMS][70] – Root Mean Square
|
||||
- [PLL][71] – Phase locked loop
|
||||
- [FLL][72] – Frequency locked loop
|
||||
- [PPM][73] – Parts per million, used here to describe rate of time drift
|
||||
- [man ntpq (Gentoo brief version)][74]
|
||||
- [man ntpq (long version)][75]
|
||||
- [man ntpq (Gentoo long version)][76]
|
||||
|
||||
### See: ###
|
||||
|
||||
- [ntpq – standard NTP query program][77]
|
||||
- [The Network Time Protocol (NTP) Distribution][78]
|
||||
- A very brief [history][79] of NTP
|
||||
- A more detailed brief history: “Mills, D.L., A brief history of NTP time: confessions of an Internet timekeeper. Submitted for publication; please do not cite or redistribute” ([pdf][80])
|
||||
- [NTP RFC][81] standards documents
|
||||
- Network Time Protocol (Version 3) RFC – [txt][82], or [pdf][83]. Appendix E, The NTP Timescale and its Chronometry, p70, includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so
|
||||
- Wikipedia: [Time][84] and [Calendar][85]
|
||||
- [John Harrison and the Longitude problem][86]
|
||||
- [Clock of the Long Now][87] – The 10,000 Year Clock
|
||||
- John C Taylor – [Chronophage][88]
|
||||
- [Orders of magnitude of time][89]
|
||||
- The [Greenwich Time Signal][90]
|
||||
|
||||
### Others: ###
|
||||
|
||||
SNTP (Simple Network Time Protocol, [RFC 4330][91]) is basically also NTP, but lacks some internal algorithms for servers where the ultimate performance of a full NTP implementation based on [RFC 1305][92] is neither needed nor justified.
|
||||
|
||||
The W32Time [Windows Time Service][93] is a non-standard implementation of SNTP, with no accuracy guarantees, and an assumed accuracy of no better than about a 1 to 2 second range. (Is that due to there being no system clock drift correction and a time update applied only once every 24 hours assumed for a [PC][94] with typical clock drift?)
|
||||
|
||||
There is also the [PTP (IEEE 1588)][95] Precision Time Protocol. See Wikipedia: [Precision Time Protocol][96]. A software demon is [PTPd][97]. The significant features are that it is intended as a [LAN][98] high precision master-slave synchronisation system synchronising at the microsecond scale to a master clock for [International Atomic Time][99] (TAI, [monotonic][100], no leap seconds). Data packet timestamping can be appended by hardware at the physical layer by a network interface card or switch for example. Network kit supporting PTP can timestamp data packets in and out in a way that removes the delay effect of processing within the switch/router. You can run PTP without hardware timestamping but it might not synchronise if the time errors introduced are too great. Also it will struggle to work through a router (large delays) for the same reason.
|
||||
|
||||
### Older time synchronization protocols: ###
|
||||
|
||||
- DTSS – Digital Time Synchronisation Service by Digital Equipment Corporation, superseded by NTP. See an example of [DTSS VMS C code c2000][101]. (Any DTSS articles/documentation anywhere?)
|
||||
- [DAYTIME protocol][102], synchronization protocol using [TCP][103] or [UDP][104] port 13
|
||||
- [ICMP Timestamp][105] and [ICMP Timestamp Reply][106], synchronization protocol using [ICMP][107]
|
||||
- [Time Protocol][108], synchronization protocol using TCP or UDP port 37
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831
|
||||
|
||||
作者:Martin L
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.gentoo.org/
|
||||
[2]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[3]:http://www.thelinuxblog.com/linux-man-pages/1/ntpq
|
||||
[4]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[5]:http://linux.die.net/man/8/ntpq
|
||||
[6]:http://www.ntp.org/
|
||||
[7]:http://en.wikipedia.org/wiki/Wide_area_network
|
||||
[8]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[9]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[10]:http://en.wikipedia.org/wiki/Network_Time_Protocol
|
||||
[11]:http://www.ntp.org/ntpfaq/NTP-s-time.htm
|
||||
[12]:http://www.ntp.org/rfc.html
|
||||
[13]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[14]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[15]:http://en.wikipedia.org/wiki/Time
|
||||
[16]:http://en.wikipedia.org/wiki/Calendar
|
||||
[17]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Clock_strata
|
||||
[18]:http://en.wikipedia.org/wiki/Unicast
|
||||
[19]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html#mcst
|
||||
[20]:http://en.wikipedia.org/wiki/Broadcasting_%28computing%29
|
||||
[21]:http://en.wikipedia.org/wiki/Multicast
|
||||
[22]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html
|
||||
[23]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[24]:http://en.wikipedia.org/wiki/Octal#In_computers
|
||||
[25]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[26]:http://www.eecis.udel.edu/~mills/ntp/html/decode.html#peer
|
||||
[27]:http://www.eecis.udel.edu/~mills/ntp/html/select.html
|
||||
[28]:http://en.wikipedia.org/wiki/Ip_address
|
||||
[29]:http://en.wikipedia.org/wiki/Pulse_per_second
|
||||
[30]:http://en.wikipedia.org/wiki/Inter-Range_Instrumentation_Group
|
||||
[31]:http://en.wikipedia.org/wiki/Standard_time_and_frequency_signal_service
|
||||
[32]:http://www.ptb.de/index_en.html
|
||||
[33]:http://en.wikipedia.org/wiki/United_States_Naval_Observatory#Time_service
|
||||
[34]:http://en.wikipedia.org/wiki/CHU_%28radio_station%29
|
||||
[35]:http://en.wikipedia.org/wiki/High_frequency
|
||||
[36]:http://en.wikipedia.org/wiki/DCF77
|
||||
[37]:http://en.wikipedia.org/wiki/Low_frequency
|
||||
[38]:http://en.wikipedia.org/wiki/HBG_%28time_signal%29
|
||||
[39]:http://en.wikipedia.org/wiki/JJY#Time_standards
|
||||
[40]:http://en.wikipedia.org/wiki/LORAN#Timing_and_synchronization
|
||||
[41]:http://en.wikipedia.org/wiki/Medium_frequency
|
||||
[42]:http://en.wikipedia.org/wiki/LORAN#The_future_of_LORAN
|
||||
[43]:http://en.wikipedia.org/wiki/LORAN#eLORAN
|
||||
[44]:http://en.wikipedia.org/wiki/Time_from_NPL#The_.27MSF_signal.27_and_the_.27Rugby_clock.27
|
||||
[45]:http://en.wikipedia.org/wiki/T%C3%A9l%C3%A9_Distribution_Fran%C3%A7aise
|
||||
[46]:http://en.wikipedia.org/wiki/WWV_%28radio_station%29#Time_signals
|
||||
[47]:http://en.wikipedia.org/wiki/WWVB
|
||||
[48]:http://en.wikipedia.org/wiki/WWVH
|
||||
[49]:http://en.wikipedia.org/wiki/GOES#Further_reading
|
||||
[50]:http://en.wikipedia.org/wiki/Gps#Timekeeping
|
||||
[51]:http://en.wikipedia.org/wiki/Galileo_%28satellite_navigation%29#The_concept
|
||||
[52]:http://en.wikipedia.org/wiki/Gnss
|
||||
[53]:http://www.eecis.udel.edu/~mills/ntp/html/debug.html
|
||||
[54]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[55]:http://en.wikipedia.org/wiki/Coordinated_Universal_Time
|
||||
[56]:http://en.wikipedia.org/wiki/Time_zone
|
||||
[57]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[58]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[59]:http://en.wikipedia.org/wiki/PLL
|
||||
[60]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[61]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[62]:http://en.wikipedia.org/wiki/Leap_second
|
||||
[63]:http://en.wikipedia.org/wiki/Daylight_saving_time
|
||||
[64]:http://www.ntp.org/ntpfaq/NTP-s-time.htm#Q-TIME-LEAP-SECOND
|
||||
[65]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[66]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#AEN1895
|
||||
[67]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#Q-ACCURATE-CLOCK
|
||||
[68]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#Q-TRB-MON-STATFIL
|
||||
[69]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#AEN5086
|
||||
[70]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[71]:http://en.wikipedia.org/wiki/PLL
|
||||
[72]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[73]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[74]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[75]:http://nlug.ml1.co.uk/2012/01/man-ntpq-long-version/855
|
||||
[76]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-long-version/856
|
||||
[77]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[78]:http://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[79]:http://www.ntp.org/ntpfaq/NTP-s-def-hist.htm
|
||||
[80]:http://www.eecis.udel.edu/~mills/database/papers/history.pdf
|
||||
[81]:http://www.ntp.org/rfc.html
|
||||
[82]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[83]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[84]:http://en.wikipedia.org/wiki/Time
|
||||
[85]:http://en.wikipedia.org/wiki/Calendar
|
||||
[86]:http://www.rmg.co.uk/harrison
|
||||
[87]:http://longnow.org/clock/
|
||||
[88]:http://johnctaylor.com/
|
||||
[89]:http://en.wikipedia.org/wiki/Orders_of_magnitude_%28time%29
|
||||
[90]:http://en.wikipedia.org/wiki/Greenwich_Time_Signal
|
||||
[91]:http://tools.ietf.org/html/rfc4330
|
||||
[92]:http://tools.ietf.org/html/rfc1305
|
||||
[93]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Microsoft_Windows
|
||||
[94]:http://en.wikipedia.org/wiki/Personal_computer
|
||||
[95]:http://www.nist.gov/el/isd/ieee/ieee1588.cfm
|
||||
[96]:http://en.wikipedia.org/wiki/IEEE_1588
|
||||
[97]:http://ptpd.sourceforge.net/
|
||||
[98]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[99]:http://en.wikipedia.org/wiki/International_Atomic_Time
|
||||
[100]:http://en.wikipedia.org/wiki/Monotonic_function
|
||||
[101]:http://antinode.info/ftp/dtss_ntp/
|
||||
[102]:http://en.wikipedia.org/wiki/DAYTIME
|
||||
[103]:http://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
||||
[104]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[105]:http://en.wikipedia.org/wiki/ICMP_Timestamp
|
||||
[106]:http://en.wikipedia.org/wiki/ICMP_Timestamp_Reply
|
||||
[107]:http://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[108]:http://en.wikipedia.org/wiki/Time_Protocol
|
||||
@ -1,77 +0,0 @@
|
||||
SPccman...................
|
||||
Quick systemd-nspawn guide
|
||||
================================================================================
|
||||
I switched to using systemd-nspawn in place of chroot and wanted to give a quick guide to using it. The short version is that I’d strongly recommend that anybody running systemd that uses chroot switch over - there really are no downsides as long as your kernel is properly configured.
|
||||
|
||||
Chroot should be no stranger to anybody who works on distros, and I suspect that the majority of Gentoo users have need for it from time to time.
|
||||
|
||||
### The Challenges of chroot ###
|
||||
|
||||
For most interactive uses it isn’t sufficient to just run chroot. Usually you need to mount /proc, /sys, and bind mount /dev so that you don’t have issues like missing ptys, etc. If you use tmpfs you might also want to mount the new tmp, var/tmp as tmpfs. Then you might want to make other bind mounts into the chroot. None of this is particularly difficult, but you usually end up writing a small script to manage it.
|
||||
|
||||
Now, I routinely do full backups, and usually that involves excluding stuff like tmp dirs, and anything resembling a bind mount. When I set up a new chroot that means updating my backup config, which I usually forget to do since most of the time the chroot mounts aren’t running anyway. Then when I do leave it mounted overnight I end up with backups consuming lots of extra space (bind mounts of large trees).
|
||||
|
||||
Finally, systemd now by default handles bind mounts a little differently when they contain other mount points (such as when using -rbind). Apparently unmounting something in the bind mount will cause systemd to unmount the corresponding directory on the other side of the bind. Imagine my surprise when I unmounted my chroot bind to /dev and discovered /dev/pts and /dev/shm no longer mounted on the host. It looks like there are ways to change that, but this isn’t the point of my post (it just spurred me to find another way).
|
||||
|
||||
### Systemd-nspawn’s Advantages ###
|
||||
|
||||
Systemd-nspawn is a tool that launches a container, and it can operate just like chroot in its simplest form. By default it automatically sets up most of the overhead like /dev, /tmp, etc. With a few options it can also set up other bind mounts as well. When the container exits all the mounts are cleaned up.
|
||||
|
||||
From the outside of the container nothing appears different when the container is running. In fact, you could spawn 5 different systemd-nspawn container instances from the same chroot and they wouldn’t have any interaction except via the filesystem (and that excludes /dev, /tmp, and so on - only changes in /usr, /etc will propagate across). Your backup won’t see the bind mounts, or tmpfs, or anything else mounted within the container.
|
||||
|
||||
The container also has all those other nifty container benefits like containment - a killall inside the container won’t touch anything outside, and so on. The security isn’t airtight - the intent is to prevent accidental mistakes.
|
||||
|
||||
Then, if you use a compatible sysvinit (which includes systemd, and I think recent versions of openrc), you can actually boot the container, which drops you to a getty inside. That means you can use fstab to do additional mounts inside the container, run daemons, and so on. You get almost all the benefits of virtualization for the cost of a chroot (no need to build a kernel, and so on). It is a bit odd to be running systemctl poweroff inside what looks just like a chroot, but it works.
|
||||
|
||||
Note that unless you do a bit more setup you will share the same network interface with the host, so no running sshd on the container if you have it on the host, etc. I won’t get into this but it shouldn’t be hard to run a separate network namespace and bind the interfaces so that the new instance can run dhcp.
|
||||
|
||||
### How to do it ###
|
||||
|
||||
So, getting it actually working will likely be the shortest bit in this post.
|
||||
|
||||
You need support for namespaces and multiple devpts instances in your kernel:
|
||||
|
||||
CONFIG_UTS_NS=y
|
||||
CONFIG_IPC_NS=y
|
||||
CONFIG_USER_NS=y
|
||||
CONFIG_PID_NS=y
|
||||
CONFIG_NET_NS=y
|
||||
CONFIG_DEVPTS_MULTIPLE_INSTANCES=y
|
||||
|
||||
From there launching a namespace just like a chroot is really simple:
|
||||
|
||||
systemd-nspawn -D .
|
||||
|
||||
That’s it - you can exit from it just like a chroot. From inside you can run mount and see that it has taken care of /dev and /tmp for you. The “.” is the path to the chroot, which I assume is the current directory. With nothing further it runs bash inside.
|
||||
|
||||
If you want to add some bind mounts it is easy:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage
|
||||
|
||||
Now your /usr/portage is bound to your host, so no need to sync/etc. If you want to bind to a different destination add a “:dest” after the source, relative to the root of the chroot (so --bind foo is the same as --bind foo:foo).
|
||||
|
||||
If the container has a functional init that can handle being run inside, you can add a -b to boot it:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -b
|
||||
|
||||
Watch the init do its job. Shut down the container to exit.
|
||||
|
||||
Now, if that container is running systemd you can direct its journal to the host journal with -h:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -j -b
|
||||
|
||||
Now, nspawn registers the container so that it shows up in machinectl. That makes it easy to launch a new getty on it, or ssh to it (if it is running ssh - see my note above about network namespaces), or power it off from the host.
|
||||
|
||||
That’s it. If you’re running systemd I’d suggest ditching chroot almost entirely in favor of nspawn.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://rich0gentoo.wordpress.com/2014/07/14/quick-systemd-nspawn-guide/
|
||||
|
||||
作者:[rich0][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rich0gentoo.wordpress.com/
|
||||
@ -1,75 +0,0 @@
|
||||
(translating by runningwater)
|
||||
Linux FAQs with Answers--How to install 7zip on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to extract files from an ISO image, and for that I want to use 7zip program. How can I install 7zip on [insert your Linux distro]?
|
||||
|
||||
7zip is an open-source archive program originally developed for Windows, which can pack or unpack a variety of archive formats including its native format 7z as well as XZ, GZIP, TAR, ZIP and BZIP2. 7zip is also popularly used to extract RAR, DEB, RPM and ISO files. Besides simple archiving, 7zip can support AES-256 encryption as well as self-extracting and multi-volume archiving. For POSIX systems (Linux, Unix, BSD), the original 7zip program has been ported as p7zip (short for "POSIX 7zip").
|
||||
|
||||
Here is how to install 7zip (or p7zip) on Linux.
|
||||
|
||||
### Install 7zip on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
Debian-based distributions come with three packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7zr (a minimal 7zip archive tool) which can handle its native 7z format only.
|
||||
- **p7zip-full**: contains 7z which can support 7z, LZMA2, XZ, ZIP, CAB, GZIP, BZIP2, ARJ, TAR, CPIO, RPM, ISO and DEB.
|
||||
- **p7zip-rar**: contains a plugin for extracting RAR files.
|
||||
|
||||
It is recommended to install p7zip-full package (not p7zip) since this is the most complete 7zip package which supports many archive formats. In addition, if you want to extract RAR files, you also need to install p7zip-rar package as well. The reason for having a separate plugin package is because RAR is a proprietary format.
|
||||
|
||||
$ sudo apt-get install p7zip-full p7zip-rar
|
||||
|
||||
### Install 7zip on Fedora or CentOS/RHEL ###
|
||||
|
||||
Red Hat-based distributions offer two packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7za command which can support 7z, ZIP, GZIP, CAB, ARJ, BZIP2, TAR, CPIO, RPM and DEB.
|
||||
- **p7zip-plugins**: contains 7z command and additional plugins to extend 7za command (e.g., ISO extraction).
|
||||
|
||||
On CentOS/RHEL, you need to enable [EPEL repository][1] before running yum command below. On Fedora, there is not need to set up additional repository.
|
||||
|
||||
$ sudo yum install p7zip p7zip-plugins
|
||||
|
||||
Note that unlike Debian based distributions, Red Hat based distributions do not offer a RAR plugin. Therefore you will not be able to extract RAR files using 7z command.
|
||||
|
||||
### Create or Extract an Archive with 7z ###
|
||||
|
||||
Once you installed 7zip, you can use 7z command to pack or unpack various types of archives. The 7z command uses other plugins to handle the archives.
|
||||
|
||||
|
||||
|
||||
To create an archive, use "a" option. Supported archive types for creation are 7z, XZ, GZIP, TAR, ZIP and BZIP2. If the specified archive file already exists, it will "add" the files to the existing archive, instead of overwriting it.
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
To extract an archive, use "e" option. It will extract the archive in the current directory. Supported archive types for extraction are a lot more than those for creation. The list includes 7z, XZ, GZIP, TAR, ZIP, BZIP2, LZMA2, CAB, ARJ, CPIO, RPM, ISO and DEB.
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
Another way to unpack an archive is to use "x" option. Unlike "e" option, it will extract the content with full paths.
|
||||
|
||||
$ 7z x <archive-filename>
|
||||
|
||||
To see a list of files in an archive, use "l" option.
|
||||
|
||||
$ 7z l <archive-filename>
|
||||
|
||||
You can update or remove file(s) in an archive with "u" and "d" options, respectively.
|
||||
|
||||
$ 7z u <archive-filename> <list-of-files-to-update>
|
||||
$ 7z d <archive-filename> <list-of-files-to-delete>
|
||||
|
||||
To test the integrity of an archive:
|
||||
|
||||
$ 7z t <archive-filename>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -1,203 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
How to Install Bugzilla 4.4 on Ubuntu / CentOS 6.x
|
||||
================================================================================
|
||||
Here, we are gonna show you how we can install Bugzilla in an Ubuntu 14.04 or CentOS 6.5/7. Bugzilla is a Free and Open Source Software(FOSS) which is web based bug tracking tool used to log and track defect database, its Bug-tracking systems allow individual or groups of developers effectively to keep track of outstanding problems with their product. Despite being "free", Bugzilla has many features its expensive counterparts lack. Consequently, Bugzilla has quickly become a favorite of thousands of organizations across the globe.
|
||||
|
||||
Bugzilla is very adaptable to various situations. They are used now a days in different IT support queues, Systems Administration deployment management, chip design and development problem tracking (both pre-and-post fabrication), and software and hardware bug tracking for luminaries such as Redhat, NASA, Linux-Mandrake, and VA Systems.
|
||||
|
||||
### 1. Installing dependencies ###
|
||||
|
||||
Setting up Bugzilla is fairly **easy**. This blog is specific to Ubuntu 14.04 and CentOS 6.5 ( though it might work with older versions too )
|
||||
|
||||
In order to get Bugzilla up and running in Ubuntu or CentOS, we are going to install Apache webserver ( SSL enabled ) , MySQL database server and also some tools that are required to install and configure Bugzilla.
|
||||
|
||||
To install Bugzilla in your server, you'll need to have the following components installed:
|
||||
|
||||
- Per l(5.8.1 or above)
|
||||
- MySQL
|
||||
- Apache2
|
||||
- Bugzilla
|
||||
- Perl modules
|
||||
- Bugzilla using apache
|
||||
|
||||
As we have mentioned that this article explains installation of both Ubuntu 14.04 and CentOS 6.5/7, we will have 2 different sections for them.
|
||||
|
||||
Here are the steps you need to follow to setup Bugzilla in your Ubuntu 14.04 LTS and CentOS 7:
|
||||
|
||||
**Preparing the required dependency packages:**
|
||||
|
||||
You need to install the essential packages by running the following command:
|
||||
|
||||
**For Ubuntu:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**For CentOS:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**Note: Please run all the commands in a shell or terminal and make sure you have root access (sudo) on the machine.**
|
||||
|
||||
### 2. Running Apache server ###
|
||||
|
||||
As you have already installed the apache server from the above step, we need to now configure apache server and run it. We'll need to go for sudo or root mode to get all the commands working so, we'll gonna switch to root access.
|
||||
|
||||
$ sudo -s
|
||||
|
||||
Now, we need to open port 80 in the firewall and need to save the changes.
|
||||
|
||||
# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
|
||||
# service iptables save
|
||||
|
||||
Now, we need to run the service:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd start
|
||||
|
||||
Lets make sure that Apache will restart every time you restart the machine:
|
||||
|
||||
# /sbin/chkconfig httpd on
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 start
|
||||
|
||||
Now, as we have started our apache http server, we will be able to open apache server at IP address of 127.0.0.1 by default.
|
||||
|
||||
### 3. Configuring MySQL Server ###
|
||||
|
||||
Now, we need to start our MySQL server:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# chkconfig mysqld on
|
||||
# service start mysqld
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service mysql-server start
|
||||
|
||||

|
||||
|
||||
Login with root access to MySQL and create a DB for Bugzilla. Change “mypassword” to anything you want for your mysql password. You will need it later when configuring Bugzilla too.
|
||||
|
||||
For Both CentOS 6.5 and Ubuntu 14.04 Trusty
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
# password: (You'll need to enter your password)
|
||||
|
||||
# mysql > create database bugs;
|
||||
|
||||
# mysql > grant all on bugs.* to root@localhost identified by "mypassword";
|
||||
|
||||
#mysql > quit
|
||||
|
||||
**Note: Please remember the DB name, passwords for mysql , we'll need it later.**
|
||||
|
||||
### 4. Installing and configuring Bugzilla ###
|
||||
|
||||
Now, as we have all the required packages set and running, we'll want to configure our Bugzilla.
|
||||
|
||||
So, first we'll want to download the latest Bugzilla package, here I am downloading version 4.5.2 .
|
||||
|
||||
To download using wget in a shell or terminal:
|
||||
|
||||
wget http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-4.5.2.tar.gz
|
||||
|
||||
You can also download from their official site ie. [http://www.bugzilla.org/download/][1]
|
||||
|
||||
**Extracting and renaming the downloaded bugzilla tarball:**
|
||||
|
||||
# tar zxvf bugzilla-4.5.2.tar.gz -C /var/www/html/
|
||||
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**Note**: Here, **/var/www/html/bugzilla/** is the directory where we're gonna **host Bugzilla**.
|
||||
|
||||
Now, we'll configure buzilla:
|
||||
|
||||
# cd /var/www/html/bugzilla/
|
||||
|
||||
# ./checksetup.pl --check-modules
|
||||
|
||||

|
||||
|
||||
After the check is done, we will see some missing modules that needs to be installed And that can be installed by the command below:
|
||||
|
||||
# cd /var/www/html/bugzilla
|
||||
# perl install-module.pl --all
|
||||
|
||||
This will take a bit time to download and install all dependencies. Run the **checksetup.pl –check-modules** command again to verify there are nothing left to install.
|
||||
|
||||
Now we'll need to run the below command which will automatically generate a file called “localconfig” in the /var/www/html/bugzilla directory.
|
||||
|
||||
# ./checksetup.pl
|
||||
|
||||
Make sure you input the correct database name, user, and password we created earlier in the localconfig file
|
||||
|
||||
# nano ./localconfig
|
||||
|
||||
# checksetup.pl
|
||||
|
||||

|
||||
|
||||
If all is well, checksetup.pl should now successfully configure Bugzilla.
|
||||
|
||||
Now we need to add Bugzilla to our Apache config file. so, we'll need to open /etc/httpd/conf/httpd.conf (For CentOS) or etc/apache2/apache2.conf (For Ubuntu) with a text editor:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# nano /etc/httpd/conf/httpd.conf
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# nano etc/apache2/apache2.conf
|
||||
|
||||
Now, we'll need to configure Apache server we'll need to add the below configuration in the config file:
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /var/www/html/bugzilla/
|
||||
</VirtualHost>
|
||||
|
||||
<Directory /var/www/html/bugzilla>
|
||||
AddHandler cgi-script .cgi
|
||||
Options +Indexes +ExecCGI
|
||||
DirectoryIndex index.cgi
|
||||
AllowOverride Limit FileInfo Indexes
|
||||
</Directory>
|
||||
|
||||
Lastly, we need to edit .htaccess file and comment out “Options -Indexes” line at the top by adding “#”
|
||||
|
||||
Lets restart our apache server and test our installation.
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd restart
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||

|
||||
|
||||
Finally, our Bugzilla is ready to get bug reports now in our Ubuntu 14.04 LTS and CentOS 6.5 and you can browse to bugzilla by going to the localhost page ie 127.0.0.1 or to your IP address in your web browser .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.bugzilla.org/download/
|
||||
@ -0,0 +1,203 @@
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
|
||||
Security is one of the main factor that we need to consider. We must maintain it because we don't want someone steal our data. Security includes many things. Audit, is one of it.
|
||||
|
||||
On Linux system, we know that we have a tool named **auditd**. This tool is by default exist in most of Linux operating system. What is auditd tool and how to use it? We will cover it below.
|
||||
|
||||
### What is auditd? ###
|
||||
|
||||
Auditd or audit daemon, is a userspace component to the Linux Auditing System. It’s responsible for writing audit records to the disk.
|
||||
|
||||

|
||||
|
||||
### Installing auditd ###
|
||||
|
||||
On Ubuntu based system , we can use [wajig][1] tool or **apt-get tool** to install auditd.
|
||||
|
||||

|
||||
|
||||
Just follow the instruction to get it done. Once it finish it will install some tools related to auditd tool. Here are the tools :
|
||||
|
||||
- **auditctl ;** is a tool to control the behaviour of the daemon on the fly, adding rules, etc
|
||||
- **/etc/audit/audit.rules ;** is the file that contains audit rules
|
||||
- **aureport ;** is tool to generate and view the audit report
|
||||
- **ausearch ;** is a tool to search various events
|
||||
- **auditspd ;** is a tool which can be used to relay event notifications to other applications instead of writing them to disk in the audit log
|
||||
- **autrace ;** is a command that can be used to trace a process
|
||||
- **/etc/audit/auditd.conf ;** is the configuration file of auditd tool
|
||||
- When the first time we install **auditd**, there will be no rules available yet.
|
||||
|
||||
We can check it using this command :
|
||||
|
||||
$ sudo auditctl -l
|
||||
|
||||

|
||||
|
||||
To add rules on auditd, let’s continue to the section below.
|
||||
|
||||
### How to use it ###
|
||||
|
||||
#### Audit files and directories access ####
|
||||
|
||||
One of the basic need for us to use an audit tool are, how can we know if someone change a file(s) or directories? Using auditd tool, we can do with those commands (please remember, we will need root privileges to configure auditd tool):
|
||||
|
||||
**Audit files**
|
||||
|
||||
$ sudo auditctl -w /etc/passwd -p rwxa
|
||||
|
||||

|
||||
|
||||
**With :**
|
||||
|
||||
- **-w path ;** this parameter will insert a watch for the file system object at path. On the example above, auditd will wacth /etc/passwd file
|
||||
- **-p ; **this parameter describes the permission access type that a file system watch will trigger on
|
||||
- **rwxa ;** are the attributes which bind to -p parameter above. r is read, w is write, x is execute and a is attribute
|
||||
|
||||
#### Audit directories ####
|
||||
|
||||
To audit directories, we will use a similar command. Let’s take a look at the command below :
|
||||
|
||||
$ sudo auditctl -w /production/
|
||||
|
||||

|
||||
|
||||
The above command will watch any access to the **/production folder**.
|
||||
|
||||
Now, if we run **auditctl -l** command again, we will see that new rules are added.
|
||||
|
||||

|
||||
|
||||
Now let’s see the audit log says.
|
||||
|
||||
### Viewing the audit log ###
|
||||
|
||||
After rules are added, now we can see how auditd in action. To view audit log, we can use **ausearch** tool.
|
||||
|
||||
We already add rule to watch /etc/passwd file. Now we will try to use **ausearch** tool to view the audit log.
|
||||
|
||||
$ sudo ausearch -f /etc/passwd
|
||||
|
||||
- **-f** parameter told ausearch to investigate /etc/passwd file
|
||||
- The result is shown below :
|
||||
> **time**->Mon Dec 22 09:39:16 2014
|
||||
> type=PATH msg=audit(1419215956.471:194): item=0 **name="/etc/passwd"** inode=142512 dev=08:01 mode=0100644 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419215956.471:194): **cwd="/home/pungki"**
|
||||
> type=SYSCALL msg=audit(1419215956.471:194): arch=40000003 **syscall=5** success=yes exit=3 a0=b779694b a1=80000 a2=1b6 a3=b8776aa8 items=1 ppid=2090 pid=2231 **auid=4294967295 uid=1000 gid=1000** euid=0 suid=0 fsuid=0 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=4294967295 **comm="sudo" exe="/usr/bin/sudo"** key=(null)
|
||||
|
||||
Now let’s we understand the result.
|
||||
|
||||
- **time ;** is when the audit is done
|
||||
- **name ;** is the object name to be audited
|
||||
- **cwd ;** is the current directory
|
||||
- **syscall ;** is related syscall
|
||||
- **auid ;** is the audit user ID
|
||||
- **uid and gid ;** are User ID and Group ID of the user who access the file
|
||||
- **comm ;** is the command that the user is used to access the file
|
||||
- **exe ;** is the location of the command of comm parameter above
|
||||
- The above audit log is the original file.
|
||||
|
||||
Next, we are going to add a new user, to see how the auditd record the activity to /etc/passwd file.
|
||||
|
||||
> **time->**Mon Dec 22 11:25:23 2014
|
||||
> type=PATH msg=audit(1419222323.628:510): item=1 **name="/etc/passwd.lock"** inode=143992 dev=08:01 mode=0100600 ouid=0 ogid=0 rdev=00:00 nametype=DELETE
|
||||
> type=PATH msg=audit(1419222323.628:510): item=0 **name="/etc/"** inode=131073 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=PARENT
|
||||
> type=CWD msg=audit(1419222323.628:510): **cwd="/root"**
|
||||
> type=SYSCALL msg=audit(1419222323.628:510): arch=40000003 **syscall=10** success=yes exit=0 a0=bfc0ceec a1=0 a2=bfc0ceec a3=897764c items=2 ppid=2978 pid=2994 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="chfn" exe="/usr/bin/chfn"** key=(null)
|
||||
|
||||
As we can see above, that on that particular time, **/etc/passwd was accessed** by user root (uid = 0 and gid = 0) **from** directory /root (cwd = /root). The /etc/passwd file was accessed using **chfn** command which located in **/usr/bin/chfn**
|
||||
|
||||
If we type **man chfn** on the console, we will see more detail about what is chfn.
|
||||
|
||||

|
||||
|
||||
Now we take a look at another example.
|
||||
|
||||
We already told auditd to watch directory /production/ . That is a new directory. So when we try to use ausearch tool at the first time, it found nothing.
|
||||
|
||||

|
||||
|
||||
Next, root account try to list the /production directory using ls command. The second time we use ausearch tool, it will show us some information.
|
||||
|
||||

|
||||
|
||||
> **time->**Mon Dec 22 14:18:28 2014
|
||||
> type=PATH msg=audit(1419232708.344:527): item=0 **name="/production/"** inode=797104 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419232708.344:527): cwd="/root"
|
||||
> type=SYSCALL msg=audit(1419232708.344:527): arch=40000003 syscall=295 success=yes exit=3 a0=ffffff9c a1=95761e8 a2=98800 a3=0 items=1 ppid=3033 pid=3444 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="ls" exe="/bin/ls"** key=(null)
|
||||
|
||||
Similar with the previous one, we can determine that **/production folder was looked** by root account (uid=0 gid=0) **using ls command** (comm = ls) and the ls command is **located in /bin/ls folder**.
|
||||
|
||||
### Viewing the audit reports ###
|
||||
|
||||
Once we put the audit rules, it will run automatically. And after a period of time, we want to see how auditd can help us to track them.
|
||||
|
||||
Auditd comes with another tool called **aureport**. As we can guess from its name, **aureport** is a tool that produces summary reports of the audit system log.
|
||||
|
||||
We already told auditd to track /etc/passwd before. And a moment after the auditd parameter is developed, the audit.log file is created.
|
||||
|
||||
To generate the report of audit, we can use aureport tool. Without any parameters, aureport will generate a summary report of audit activity.
|
||||
|
||||
$ sudo aureport
|
||||
|
||||

|
||||
|
||||
As we can see, there are some information available which cover most important area.
|
||||
|
||||
On the picture above we see there are **3 times failed authentication**. Using aureport, we can drill down to that information.
|
||||
|
||||
We can use this command to look deeper on failed authentication :
|
||||
|
||||
$ sudo aureport -au
|
||||
|
||||

|
||||
|
||||
As we can see on the picture above, there are two users which at the particular time are failed to authenticated
|
||||
|
||||
If we want to see all events related to account modification, we can use -m parameter.
|
||||
|
||||
$ sudo aureport -m
|
||||
|
||||

|
||||
|
||||
### Auditd configuration file ###
|
||||
|
||||
Previously we already added :
|
||||
|
||||
- $ sudo auditctl -w /etc/passwd -p rwxa
|
||||
- $ sudo auditctl -w /production/
|
||||
- Now, if we sure the rules are OK, we can add it into
|
||||
|
||||
**/etc/audit/audit.rules** to make them permanently.Here’s how to put them into the /etc/audit/audit.rules fileSample of audit rule file
|
||||
|
||||

|
||||
|
||||
**Then don’t forget to restart auditd daemon.**
|
||||
|
||||
# /etc/init.d/auditd restart
|
||||
|
||||
OR
|
||||
|
||||
# service auditd restart
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Auditd is one of the audit tool that available on Linux system. You can explore more detail about auditd and its related tools by reading its manual page. For example, just type **man auditd** to see more detail about auditd. Or type **man ausearch** to see more detail about ausearch tool.
|
||||
|
||||
**Please be careful before creating rules**. It will increase your log file size significantly if too much information to record.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
@ -1,132 +0,0 @@
|
||||
Docker Image Insecurity
|
||||
================================================================================
|
||||
Recently while downloading an “official” container image with Docker I saw this line:
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified
|
||||
|
||||
I assumed this referenced Docker’s [heavily promoted][1] image signing system and didn’t investigate further at the time. Later, while researching the cryptographic digest system that Docker tries to secure images with, I had the opportunity to explore further. What I found was a total systemic failure of all logic related to image security.
|
||||
|
||||
Docker’s report that a downloaded image is “verified” is based solely on the presence of a signed manifest, and Docker never verifies the image checksum from the manifest. An attacker could provide any image alongside a signed manifest. This opens the door to a number of serious vulnerabilities.
|
||||
|
||||
Images are downloaded from an HTTPS server and go through an insecure streaming processing pipeline in the Docker daemon:
|
||||
|
||||
[decompress] -> [tarsum] -> [unpack]
|
||||
|
||||
This pipeline is performant but completely insecure. Untrusted input should not be processed before verifying its signature. Unfortunately Docker processes images three times before checksum verification is supposed to occur.
|
||||
|
||||
However, despite [Docker’s claims][2], image checksums are never actually checked. This is the only section[0][3] of Docker’s code related to verifying image checksums, and I was unable to trigger the warning even when presenting images with mismatched checksums.
|
||||
|
||||
if img.Checksum != "" && img.Checksum != checksum {
|
||||
log.Warnf("image layer checksum mismatch: computed %q,
|
||||
expected %q", checksum, img.Checksum)
|
||||
}
|
||||
|
||||
### Insecure processing pipeline ###
|
||||
|
||||
**Decompress**
|
||||
|
||||
Docker supports three compression algorithms: gzip, bzip2, and xz. The first two use the Go standard library implementations, which are [memory-safe][4], so the exploit types I’d expect to see here are denial of service attacks like crashes and excessive CPU and memory usage.
|
||||
|
||||
The third compression algorithm, xz, is more interesting. Since there is no native Go implementation, Docker [execs][5] the `xz` binary to do the decompression.
|
||||
|
||||
The xz binary comes from the [XZ Utils][6] project, and is built from approximately[1][7] twenty thousand lines of C code. C is not a memory-safe language. This means malicious input to a C program, in this case the Docker image XZ Utils is unpacking, could potentially execute arbitrary code.
|
||||
|
||||
Docker exacerbates this situation by *running* `xz` as root. This means that if there is a single vulnerability in `xz`, a call to `docker pull` could result in the complete compromise of your entire system.
|
||||
|
||||
**Tarsum**
|
||||
|
||||
The use of tarsum is well-meaning but completely flawed. In order to get a deterministic checksum of the contents of an arbitrarily encoded tar file, Docker decodes the tar and then hashes specific portions, while excluding others, in a [deterministic order][8].
|
||||
|
||||
Since this processing is done in order to generate the checksum, it is decoding untrusted data which could be designed to exploit the tarsum code[2][9]. Potential exploits here are denial of service as well as logic flaws that could cause files to be injected, skipped, processed differently, modified, appended to, etc. without the checksum changing.
|
||||
|
||||
**Unpacking**
|
||||
|
||||
Unpacking consists of decoding the tar and placing files on the disk. This is extraordinarily dangerous as there have been three other vulnerabilities reported[3][10] in the unpack stage at the time of writing.
|
||||
|
||||
There is no situation where data that has not been verified should be unpacked onto disk.
|
||||
|
||||
### libtrust ###
|
||||
|
||||
[libtrust][11] is a Docker package that claims to provide “authorization and access control through a distributed trust graph.” Unfortunately no specification appears to exist, however it looks like it implements some parts of the [Javascript Object Signing and Encryption][12] specifications along with other unspecified algorithms.
|
||||
|
||||
Downloading an image with a manifest signed and verified using libtrust is what triggers this inaccurate message (only the manifest is checked, not the actual image contents):
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified
|
||||
|
||||
Currently only “official” image manifests published by Docker, Inc are signed using this system, but from discussions I participated in at the last Docker Governance Advisory Board meeting[4][13], my understanding is that Docker, Inc is planning on deploying this more widely in the future. The intended goal is centralization with Docker, Inc controlling a Certificate Authority that then signs images and/or client certificates.
|
||||
|
||||
I looked for the signing key in Docker’s code but was unable to find it. As it turns out the key is not embedded in the binary as one would expect. Instead the Docker daemon fetches it [over HTTPS from a CDN][14] before each image download. This is a terrible approach as a variety of attacks could lead to trusted keys being replaced with malicious ones. These attacks include but are not limited to: compromise of the CDN vendor, compromise of the CDN origin serving the key, and man in the middle attacks on clients downloading the keys.
|
||||
|
||||
### Remediation ###
|
||||
|
||||
I [reported][15] some of the issues I found with the tarsum system before I finished this research, but so far nothing I have reported has been fixed.
|
||||
|
||||
Some steps I believe should be taken to improve the security of the Docker image download system:
|
||||
Drop tarsum and actually verify image digests
|
||||
|
||||
Tarsum should not be used for security. Instead, images must be fully downloaded and their cryptographic signatures verified before any processing takes place.
|
||||
|
||||
**Add privilege isolation**
|
||||
|
||||
Image processing steps that involve decompression or unpacking should be run in isolated processes (containers?) that have only the bare minimum required privileges to operate. There is no scenario where a decompression tool like `xz` should be run as root.
|
||||
|
||||
**Replace libtrust**
|
||||
|
||||
Libtrust should be replaced with [The Update Framework][16] which is explicitly designed to solve the real problems around signing software binaries. The threat model is very comprehensive and addresses many things that have not been considered in libtrust. There is a complete specification as well as a reference implementation written in Python, and I have begun work on a [Go implementation][17] and welcome contributions.
|
||||
|
||||
As part of adding TUF to Docker, a local keystore should be added that maps root keys to registry URLs so that users can have their own signing keys that are not managed by Docker, Inc.
|
||||
|
||||
I would like to note that using non-Docker, Inc hosted registries is a very poor user experience in general. Docker, Inc seems content with relegating third party registries to second class status when there is no technical reason to do so. This is a problem both for the ecosystem in general and the security of end users. A comprehensive, decentralized security model for third party registries is both necessary and desirable. I encourage Docker, Inc to take this into consideration when redesigning their security model and image verification system.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Docker users should be aware that the code responsible for downloading images is shockingly insecure. Users should only download images whose provenance is without question. At present, this does *not* include “trusted” images hosted by Docker, Inc including the official Ubuntu and other base images.
|
||||
|
||||
The best option is to block `index.docker.io` locally, and download and verify images manually before importing them into Docker using `docker load`. Red Hat’s security blog has [a good post about this][18].
|
||||
|
||||
Thanks to Lewis Marshall for pointing out the tarsums are never verified.
|
||||
|
||||
- [Checksum code context][19].
|
||||
- [cloc][20] says 18,141 non-blank, non-comment lines of C and 5,900 lines of headers in v5.2.0.
|
||||
- Very similar bugs been [found in Android][21], which allowed arbitrary files to be injected into signed packages, and [the Windows Authenticode][22] signature system, which allowed binary modification.
|
||||
- Specifically: [CVE-2014-6407][23], [CVE-2014-9356][24], and [CVE-2014-9357][25]. There were two Docker [security releases][26] in response.
|
||||
- See page 8 of the [notes from the 2014-10-28 DGAB meeting][27].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://titanous.com/posts/docker-insecurity
|
||||
|
||||
作者:[titanous][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/titanous
|
||||
[1]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[2]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[3]:https://titanous.com/posts/docker-insecurity#fn:0
|
||||
[4]:https://en.wikipedia.org/wiki/Memory_safety
|
||||
[5]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/archive/archive.go#L91-L95
|
||||
[6]:http://tukaani.org/xz/
|
||||
[7]:https://titanous.com/posts/docker-insecurity#fn:1
|
||||
[8]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/tarsum/tarsum_spec.md
|
||||
[9]:https://titanous.com/posts/docker-insecurity#fn:2
|
||||
[10]:https://titanous.com/posts/docker-insecurity#fn:3
|
||||
[11]:https://github.com/docker/libtrust
|
||||
[12]:https://tools.ietf.org/html/draft-ietf-jose-json-web-signature-11
|
||||
[13]:https://titanous.com/posts/docker-insecurity#fn:4
|
||||
[14]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/trust/trusts.go#L38
|
||||
[15]:https://github.com/docker/docker/issues/9719
|
||||
[16]:http://theupdateframework.com/
|
||||
[17]:https://github.com/flynn/go-tuf
|
||||
[18]:https://securityblog.redhat.com/2014/12/18/before-you-initiate-a-docker-pull/
|
||||
[19]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/image/image.go#L114-L116
|
||||
[20]:http://cloc.sourceforge.net/
|
||||
[21]:http://www.saurik.com/id/17
|
||||
[22]:http://blogs.technet.com/b/srd/archive/2013/12/10/ms13-098-update-to-enhance-the-security-of-authenticode.aspx
|
||||
[23]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-6407
|
||||
[24]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9356
|
||||
[25]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9357
|
||||
[26]:https://groups.google.com/d/topic/docker-user/nFAz-B-n4Bw/discussion
|
||||
[27]:https://docs.google.com/document/d/1JfWNzfwptsMgSx82QyWH_Aj0DRKyZKxYQ1aursxNorg/edit?pli=1
|
||||
@ -0,0 +1,111 @@
|
||||
hi ! 让我来翻译
|
||||
|
||||
How to debug a C/C++ program with Nemiver debugger
|
||||
================================================================================
|
||||
If you read [my post on GDB][1], you know how important and useful a debugger I think can be for a C/C++ program. However, if a command line debugger like GDB sounds more like a problem than a solution to you, you might be more interested in Nemiver. [Nemiver][2] is a GTK+-based standalone graphical debugger for C/C++ programs, using GDB as its back-end. Admirable for its speed and stability, Nemiver is a very reliable debugger filled with goodies.
|
||||
|
||||
### Installation of Nemiver ###
|
||||
|
||||
For Debian based distributions, it should be pretty straightforward:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
For Arch Linux:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
For Fedora:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
If you prefer compiling yourself, the latest sources are available from [GNOME website][3].
|
||||
|
||||
As a bonus, it integrates very well with the GNOME environment.
|
||||
|
||||
### Basic Usage of Nemiver ###
|
||||
|
||||
Start Nemiver with the command:
|
||||
|
||||
$ nemiver
|
||||
|
||||
You can also summon it with an executable with:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
Note that Nemiver will be much more helpful if the executable is compiled in debug mode (the -g flag with GCC).
|
||||
|
||||
A good thing is that Nemiver is really fast to load, so you should instantly see the main screen in the default layout.
|
||||
|
||||
|
||||
|
||||
By default, a breakpoint has been placed in the first line of the main function. This gives you the time to recognize the basic debugger functions:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
|
||||
But maybe my personal favorite is the option "Run to cursor" which makes the program run until a precise line under your cursor, and is by default mapped to F11.
|
||||
|
||||
Next, the breakpoints are also easy to use. The quick way to lay a breakpoint at a line is using F8. But Nemiver also has a more complex menu under "Debug" which allows you to set up a breakpoint at a particular function, line number, location of binary file, or even at an event like an exception, a fork, or an exec.
|
||||
|
||||
|
||||
|
||||
You can also watch a variable by tracking it. In "Debug" you can inspect an expression by giving its name and examining it. It is then possible to add it to the list of controlled variable for easy access. This is probably one of the most useful aspects as I have never been a huge fan of hovering over a variable to get its value. Note that hovering does work though. And to make it even better, Nemiver is capable of watching a struct, and giving you the values of all the member variables.
|
||||
|
||||
|
||||
|
||||
Talking about easy access to information, I also really appreciate the layout of the program. By default, the code is in the upper half and the tabs in the lower part. This grants you access to a terminal for output, a context tracker, a breakpoints list, register addresses, memory map, and variable control. But note that under "Edit" "Preferences" "Layout" you can select different layouts, including a dynamic one for you to modify.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
And naturally, once you set up all your breakpoints, watch-points, and layout, you can save your session under “File” for easy retrieval in case you close Nemiver.
|
||||
|
||||
### Advanced Usage of Nemiver ###
|
||||
|
||||
So far, we talked about the basic features of Nemiver, i.e., what you need to get started and debug simple programs immediately. If you have more advanced needs, and especially more complex programs, you might be more interested in some of these features mentioned here.
|
||||
|
||||
#### Debugging a running process ####
|
||||
|
||||
Nemiver allows you to attach to a running process for debugging. Under the "File" menu, you can filter the list of running processes, and connect to a process.
|
||||
|
||||

|
||||
|
||||
#### Debugging a program remotely over a TCP connection ####
|
||||
|
||||
Nemiver supports remote-debugging, where you set up a lightweight debug server on a remote machine, and launch Nemiver from another machine to debug a remote target hosted by the debug server. Remote debugging can be useful if you cannot run full-fledged Nemiver or GDB on the remote machine for some reason. Under the "File" menu, specify the binary, shared library location, and the address and port.
|
||||
|
||||
|
||||
|
||||
#### Using your own GDB binary to debug ####
|
||||
|
||||
In case you compiled Nemiver yourself, you can specify a new location for GDB under "Edit" "Preferences" "Debug". This option can be useful if you want to use a custom version of GDB in Nemiver for some reason.
|
||||
|
||||
#### Follow a child or parent process ####
|
||||
|
||||
Nemiver is capable of following a child or parent process in case your program forks. To enable this feature, go to "Preferences" under "Debugger" tab.
|
||||
|
||||
|
||||
|
||||
To conclude, Nemiver is probably my favorite program for debugging without an IDE. It even beats GDB in my opinion, and [command line][4] programs generally have a good grip on me. So if you have never used it, I really recommend it. I can only congratulate the team behind it for giving us such a reliable and stable program.
|
||||
|
||||
What do you think of Nemiver? Would you consider it for standalone debugging? Or do you still stick to an IDE? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -0,0 +1,134 @@
|
||||
How to set up a cross-platform backup server on Linux with BackupPC
|
||||
================================================================================
|
||||
Just in case you haven't been able to tell from my earlier posts on [backupninja][1] and [backup-manager][2], I am a big backup fan. When it comes to backup, I'd rather have too much than not enough, because if the need arises, you will be grateful that you took the time and effort to generate extra copies of your important data.
|
||||
|
||||
In this post, I will introduce you to [BackupPC][3], a cross-platform backup server software which can perform pull backup of Linux, Windows and MacOS client hosts over network. BackupPC adds a number of features that make managing backups an almost fun thing to do.
|
||||
|
||||
### Features of BackupPC ###
|
||||
|
||||
BackupPC comes with a robust web interface that allows you to collect and manage backups of other remote client hosts in a centralized fashion. Using the web interface, you can examine logs and configuration files, start/cancel/schedule backups of other remote hosts, and visualize current status of backup tasks. You can also browse through archived files and restore individual files or entire jobs from backup archives very easily. To restore individual single files, you can download them from any previous backup directly from the web interface. As if this weren't enough, no special client-side software is needed for client hosts. On Windows clients, the native SMB protocol is used, whereas on *nix clients, you will use `rsync` or tar over SSH, RSH or NFS.
|
||||
|
||||
### Installing BackupPC ###
|
||||
|
||||
On Debian, Ubuntu and their derivatives, run the following command.
|
||||
|
||||
# aptitude install backuppc
|
||||
|
||||
On Fedora, use `yum` command. Note the case sensitive package name.
|
||||
|
||||
On CentOS/RHEL 6, first enable [EPEL repository][4]. On CentOS/RHEL 7, enable [Nux Dextop][5] repository instead. Then go ahead with `yum` command:
|
||||
|
||||
# yum install BackupPC
|
||||
|
||||
As usual, both package management systems will take care of dependency resolution automatically. In addition, as part of the installation process, you may be asked to configure, or reconfigure the web server that will be used for the graphical user interface. The following screenshot is from a Debian system:
|
||||
|
||||

|
||||
|
||||
Select your choice by pressing the space bar, and then move to Ok with the tab key and hit ENTER.
|
||||
|
||||
You will then be presented with the following screen informing you that an administrative user account 'backuppc', along with its corresponding password (which can be changed later if desired), has been created to manage BackupPC. Note that both a HTTP user account and a regular Linux account of the same name 'backuppc' will be created with an identical password. The former is needed to access BackupPC's protected web interface, while the latter is needed to perform backup using rsync over SSH.
|
||||
|
||||
|
||||
|
||||
You can change the default password for the HTTP user 'backuppc' with the following command:
|
||||
|
||||
# htpasswd /path/to/hash/file backuppc
|
||||
|
||||
As for a regular 'backuppc' [Linux][6] user account, use passwd command to change its default password.
|
||||
|
||||
# passwd backuppc
|
||||
|
||||
Note that the installation process creates the web and the program's configuration files automatically.
|
||||
|
||||
### Launching BackupPC and Configuring Backups ###
|
||||
|
||||
To start, open a browser window and point to http://<server's FQDN or IP address>/backuppc/. When prompted, enter the default HTTP user credentials that were supplied to you earlier. If the authentication succeeds, you will be taken to the main page of the web interface.
|
||||
|
||||
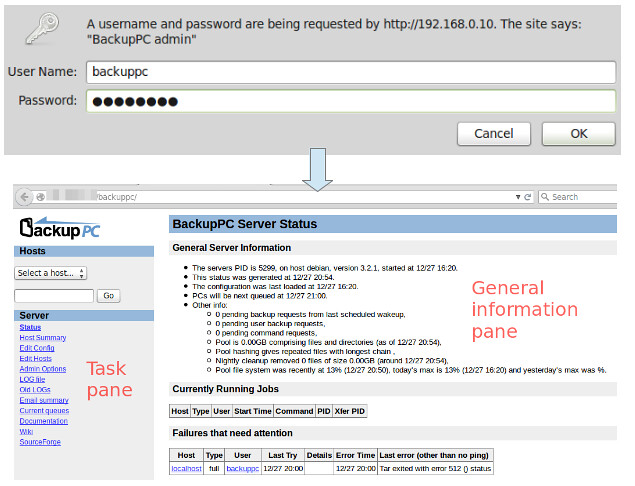
|
||||
|
||||
Most likely the first thing that you will want to do is add a new client host to back up. Go to "Edit Hosts" in the Task pane. We will add two client hosts:
|
||||
|
||||
- Host #1: CentOS 7 [IP 192.168.0.17]
|
||||
- Host #2: Windows 7 [IP 192.168.0.103]
|
||||
|
||||
We will back up the CentOS host using rsync over SSH and the Windows host using SMB. Prior to performing the backup, we need to set up [key-based authentication][7] to our CentOS host and a shared folder in our Windows machine.
|
||||
|
||||
Here are the instructions for setting up key-based authentication for a remote CentOS host. We create the 'backuppc' user's RSA key pair, and transfer its public key to the root account of the CentOS host.
|
||||
|
||||
# usermod -s /bin/bash backuppc
|
||||
# su - backuppc
|
||||
# ssh-keygen -t rsa
|
||||
# ssh-copy-id root@192.168.0.17
|
||||
|
||||
When prompted, type yes and enter root's password for 192.168.0.17.
|
||||
|
||||
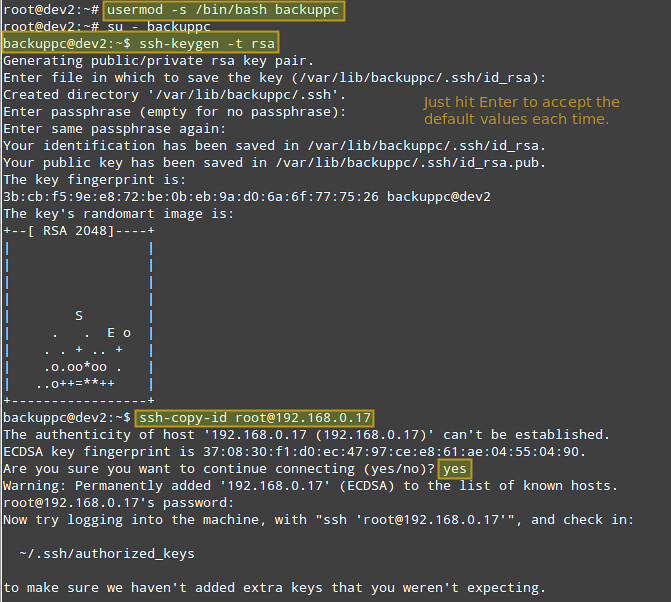
|
||||
|
||||
You will need root access for a remote CentOS host to grant write access to all its file system in case of restoring a backup of files or directories owned by root.
|
||||
|
||||
Once the CentOS and Windows hosts are ready, add them to BackupPC using the web interface:
|
||||
|
||||
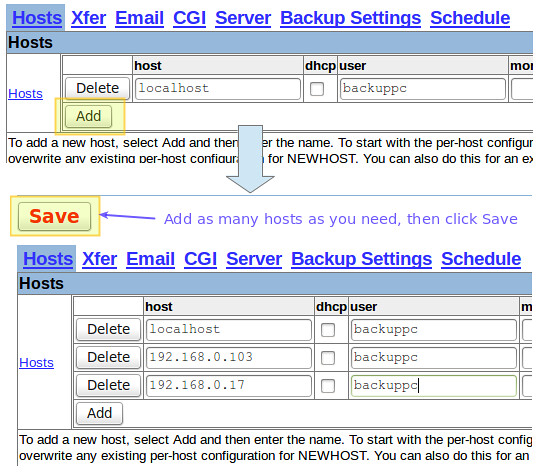
|
||||
|
||||
The next step consists of modifying each host's backup settings:
|
||||
|
||||
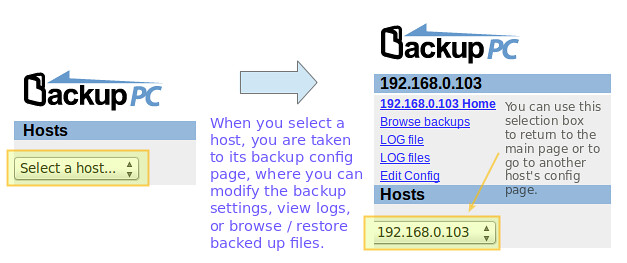
|
||||
|
||||
The following image shows the configuration for the backup of the Windows machine:
|
||||
|
||||
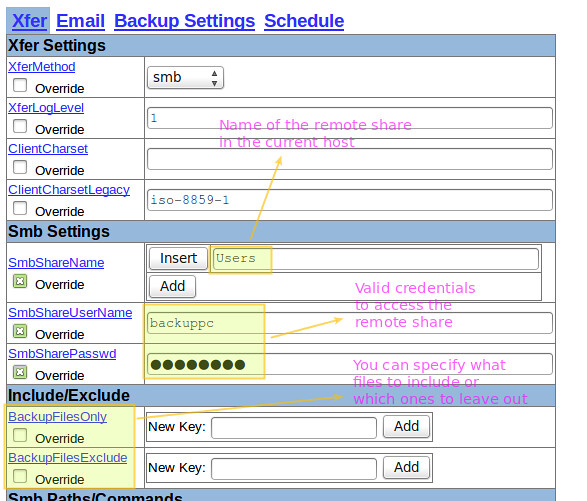
|
||||
|
||||
And the following screenshot shows the settings for the backup of the CentOS box:
|
||||
|
||||
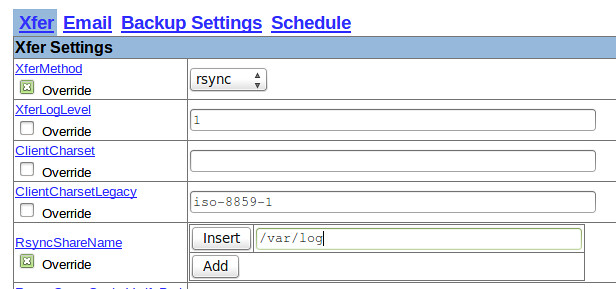
|
||||
|
||||
### Starting a Backup ###
|
||||
|
||||
To start each backup, go to each host's settings, and then click "Start Full Backup":
|
||||
|
||||
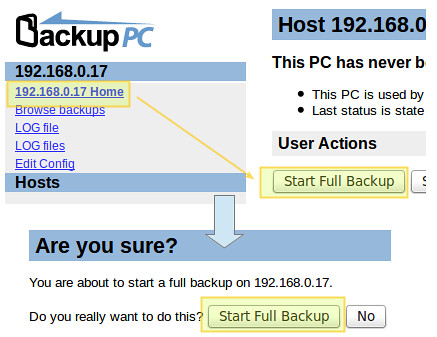
|
||||
|
||||
At any time, you can view the status of the process by clicking on the host's home as shown in the image above. If it fails for some reason, a link to a page with the error message(s) will appear in the host menu as well. When a backup completes successfully, a directory with the host's name or IP address is created under /var/lib/backuppc/pc in the server:
|
||||
|
||||

|
||||
|
||||
Feel free to browse those directories for the files from the command line, but there is an easier way to look for those files and restore them.
|
||||
|
||||
### Restoring Backup ###
|
||||
|
||||
To view the files that have been saved, go to "Browse backups" under each host's main menu. You can visualize the directories and files at a glance, and select those that you want to restore. Alternatively, you can click on files to open them with the default program, or right click and choose Save link as to download it to the machine where you're working at the time:
|
||||
|
||||
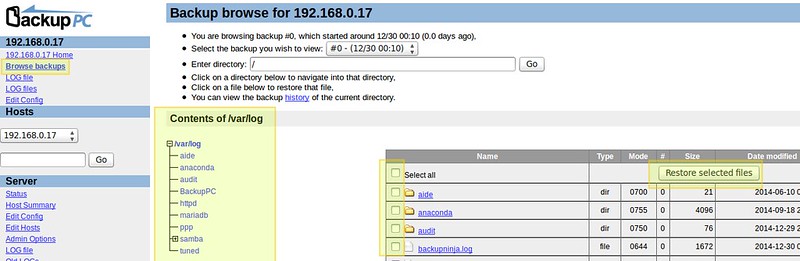
|
||||
|
||||
If you want, you can download a zip or tar file containing the backup's contents:
|
||||
|
||||
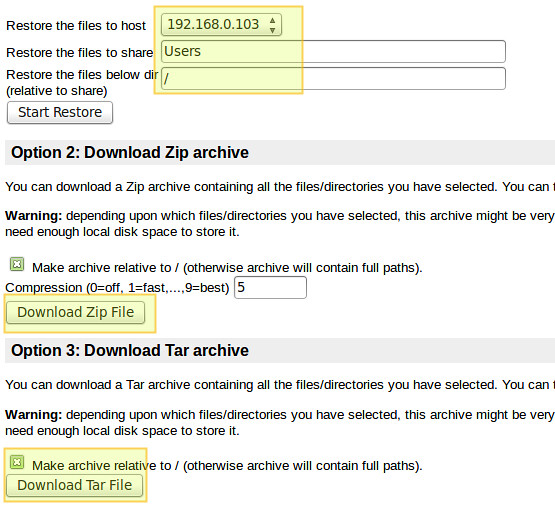
|
||||
|
||||
or just restore the file(s):
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
There is a saying that goes, "the simpler, the better", and that is just what BackupPC has to offer. In BackupPC, you will not only find a backup tool but also a very versatile interface to manage your backups of several operating systems without needing any client-side application. I believe that's more than reason enough for you to give it at least a try.
|
||||
|
||||
Feel free to leave your comments and questions, if you have any, using the form below. I am always happy to hear what readers have to say!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/backuppc-cross-platform-backup-server-linux.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/gabriel
|
||||
[1]:http://xmodulo.com/backup-debian-system-backupninja.html
|
||||
[2]:http://xmodulo.com/linux-backup-manager.html
|
||||
[3]:http://backuppc.sourceforge.net/
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[5]:http://ask.xmodulo.com/enable-nux-dextop-repository-centos-rhel.html
|
||||
[6]:http://xmodulo.com/recommend/linuxguide
|
||||
[7]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
@ -0,0 +1,136 @@
|
||||
Interface (NICs) Bonding in Linux using nmcli
|
||||
================================================================================
|
||||
Today, we'll learn how to perform Interface (NICs) bonding in our CentOS 7.x using nmcli (Network Manager Command Line Interface).
|
||||
|
||||
NICs (Interfaces) bonding is a method for linking **NICs** together logically to allow fail-over or higher throughput. One of the ways to increase the network availability of a server is by using multiple network interfaces. The Linux bonding driver provides a method for aggregating multiple network interfaces into a single logical bonded interface. It is a new implementation that does not affect the older bonding driver in linux kernel; it offers an alternate implementation.
|
||||
|
||||
**NIC bonding is done to provide two main benefits for us:**
|
||||
|
||||
1. **High bandwidth**
|
||||
1. **Redundancy/resilience**
|
||||
|
||||
Now lets configure NICs bonding in CentOS 7. We'll need to decide which interfaces that we would like to configure a Team interface.
|
||||
|
||||
run **ip link** command to check the available interface in the system.
|
||||
|
||||
$ ip link
|
||||
|
||||

|
||||
|
||||
Here we are using **eno16777736** and **eno33554960** NICs to create a team interface in **activebackup** mode.
|
||||
|
||||
Use **nmcli** command to create a connection for the network team interface,with the following syntax.
|
||||
|
||||
# nmcli con add type team con-name CNAME ifname INAME [config JSON]
|
||||
|
||||
Where **CNAME** will be the name used to refer the connection ,**INAME** will be the interface name and **JSON** (JavaScript Object Notation) specifies the runner to be used.**JSON** has the following syntax:
|
||||
|
||||
'{"runner":{"name":"METHOD"}}'
|
||||
|
||||
where **METHOD** is one of the following: **broadcast, activebackup, roundrobin, loadbalance** or **lacp**.
|
||||
|
||||
### 1. Creating Team Interface ###
|
||||
|
||||
Now let us create the team interface. here is the command we used to create the team interface.
|
||||
|
||||
# nmcli con add type team con-name team0 ifname team0 config '{"runner":{"name":"activebackup"}}'
|
||||
|
||||

|
||||
|
||||
run **# nmcli con show** command to verify the team configuration.
|
||||
|
||||
# nmcli con show
|
||||
|
||||

|
||||
|
||||
### 2. Adding Slave Devices ###
|
||||
|
||||
Now lets add the slave devices to the master team0. here is the syntax for adding the slave devices.
|
||||
|
||||
# nmcli con add type team-slave con-name CNAME ifname INAME master TEAM
|
||||
|
||||
Here we are adding **eno16777736** and **eno33554960** as slave devices for **team0** interface.
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port1 ifname eno16777736 master team0
|
||||
|
||||
# nmcli con add type team-slave con-name team0-port2 ifname eno33554960 master team0
|
||||
|
||||

|
||||
|
||||
Verify the connection configuration using **#nmcli con show** again. now we could see the slave configuration.
|
||||
|
||||
#nmcli con show
|
||||
|
||||

|
||||
|
||||
### 3. Assigning IP Address ###
|
||||
|
||||
All the above command will create the required configuration files under **/etc/sysconfig/network-scripts/**.
|
||||
|
||||
Lets assign an IP address to this team0 interface and enable the connection now. Here is the command to perform the IP assignment.
|
||||
|
||||
# nmcli con mod team0 ipv4.addresses "192.168.1.24/24 192.168.1.1"
|
||||
# nmcli con mod team0 ipv4.method manual
|
||||
# nmcli con up team0
|
||||
|
||||

|
||||
|
||||
### 4. Verifying the Bonding ###
|
||||
|
||||
Verify the IP address information in **#ip add show team0** command.
|
||||
|
||||
#ip add show team0
|
||||
|
||||

|
||||
|
||||
Now lets check the **activebackup** configuration functionality using the **teamdctl** command.
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
Now lets disconnect the active port and check the state again. to confirm whether the active backup configuration is working as expected.
|
||||
|
||||
# nmcli dev dis eno33554960
|
||||
|
||||

|
||||
|
||||
disconnected the active port and now check the state again using **#teamdctl team0 state**.
|
||||
|
||||
# teamdctl team0 state
|
||||
|
||||

|
||||
|
||||
Yes its working cool !! we will connect the disconnected connection back to team0 using the following command.
|
||||
|
||||
#nmcli dev con eno33554960
|
||||
|
||||

|
||||
|
||||
We have one more command called **teamnl** let us show some options with **teamnl** command.
|
||||
|
||||
to check the ports in team0 run the following command.
|
||||
|
||||
# teamnl team0 ports
|
||||
|
||||

|
||||
|
||||
Display currently active port of **team0**.
|
||||
|
||||
# teamnl team0 getoption activeport
|
||||
|
||||

|
||||
|
||||
Hurray, we have successfully configured NICs bonding :-) Please share feedback if any.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/interface-nics-bonding-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,135 @@
|
||||
What are useful command-line network monitors on Linux
|
||||
================================================================================
|
||||
Network monitoring is a critical IT function for businesses of all sizes. The goal of network monitoring can vary. For example, the monitoring activity can be part of long-term network provisioning, security protection, performance troubleshooting, network usage accounting, and so on. Depending on its goal, network monitoring is done in many different ways, such as performing packet-level sniffing, collecting flow-level statistics, actively injecting probes into the network, parsing server logs, etc.
|
||||
|
||||
While there are many dedicated network monitoring systems capable of 24/7/365 monitoring, you can also leverage command-line network monitors in certain situations, where a dedicated monitor is an overkill. If you are a system admin, you are expected to have hands-on experience with some of well known CLI network monitors. Here is a list of **popular and useful command-line network monitors on Linux**.
|
||||
|
||||
### Packet-Level Sniffing ###
|
||||
|
||||
In this category, monitoring tools capture individual packets on the wire, dissect their content, and display decoded packet content or packet-level statistics. These tools conduct network monitoring from the lowest level, and as such, can possibly do the most fine-grained monitoring at the cost of network I/O and analysis efforts.
|
||||
|
||||
1. **dhcpdump**: a comman-line DHCP traffic sniffer capturing DHCP request/response traffic, and displays dissected DHCP protocol messages in a human-friendly format. It is useful when you are troubleshooting DHCP related issues.
|
||||
|
||||
2. **[dsniff][1]**: a collection of command-line based sniffing, spoofing and hijacking tools designed for network auditing and penetration testing. They can sniff various information such as passwords, NSF traffic, email messages, website URLs, and so on.
|
||||
|
||||
3. **[httpry][2]**: an HTTP packet sniffer which captures and decode HTTP requests and response packets, and display them in a human-readable format.
|
||||
|
||||
4. **IPTraf**: a console-based network statistics viewer. It displays packet-level, connection-level, interface-level, protocol-level packet/byte counters in real-time. Packet capturing can be controlled by protocol filters, and its operation is full menu-driven.
|
||||
|
||||
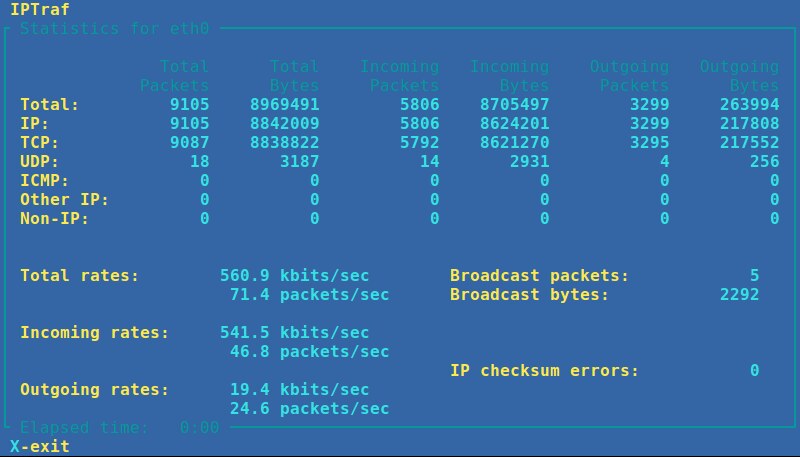
|
||||
|
||||
5. **[mysql-sniffer][3]**: a packet sniffer which captures and decodes packets associated with MySQL queries. It displays the most frequent or all queries in a human-readable format.
|
||||
|
||||
6. **[ngrep][4]**: grep over network packets. It can capture live packets, and match (filtered) packets against regular expressions or hexadecimal expressions. It is useful for detecting and storing any anomalous traffic, or for sniffing particular patterns of information from live traffic.
|
||||
|
||||
7. **[p0f][5]**: a passive fingerprinting tool which, based on packet sniffing, reliably identifies operating systems, NAT or proxy settings, network link types and various other properites associated with an active TCP connection.
|
||||
|
||||
8. **pktstat**: a command-line tool which analyzes live packets to display connection-level bandwidth usages as well as descriptive information of protocols involved (e.g., HTTP GET/POST, FTP, X11).
|
||||
|
||||
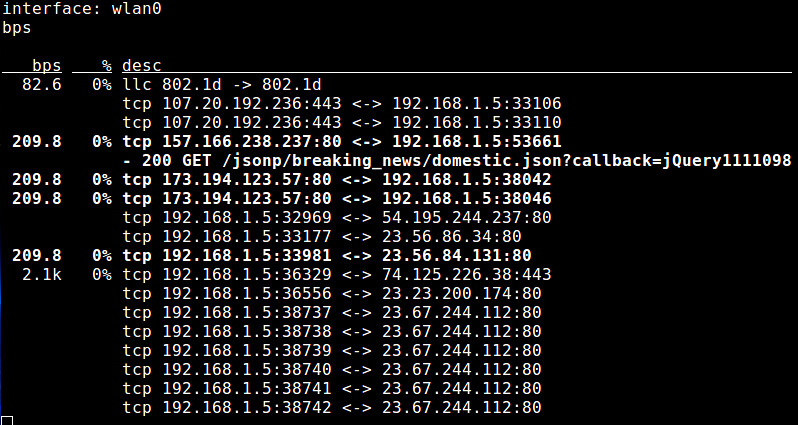
|
||||
|
||||
9. **Snort**: an intrusion detection and prevention tool which can detect/prevent a variety of backdoor, botnets, phishing, spyware attacks from live traffic based on rule-driven protocol analysis and content matching.
|
||||
|
||||
10. **tcpdump**: a command-line packet sniffer which is capable of capturing nework packets on the wire based on filter expressions, dissect the packets, and dump the packet content for packet-level analysis. It is widely used for any kinds of networking related troubleshooting, network application debugging, or [security][6] monitoring.
|
||||
|
||||
11. **tshark**: a command-line packet sniffing tool that comes with Wireshark GUI program. It can capture and decode live packets on the wire, and show decoded packet content in a human-friendly fashion.
|
||||
|
||||
### Flow-/Process-/Interface-Level Monitoring ###
|
||||
|
||||
In this category, network monitoring is done by classifying network traffic into flows, associated processes or interfaces, and collecting per-flow, per-process or per-interface statistics. Source of information can be libpcap packet capture library or sysfs kernel virtual filesystem. Monitoring overhead of these tools is low, but packet-level inspection capabilities are missing.
|
||||
|
||||
12. **bmon**: a console-based bandwidth monitoring tool which shows various per-interface information, including not-only aggregate/average RX/TX statistics, but also a historical view of bandwidth usage.
|
||||
|
||||
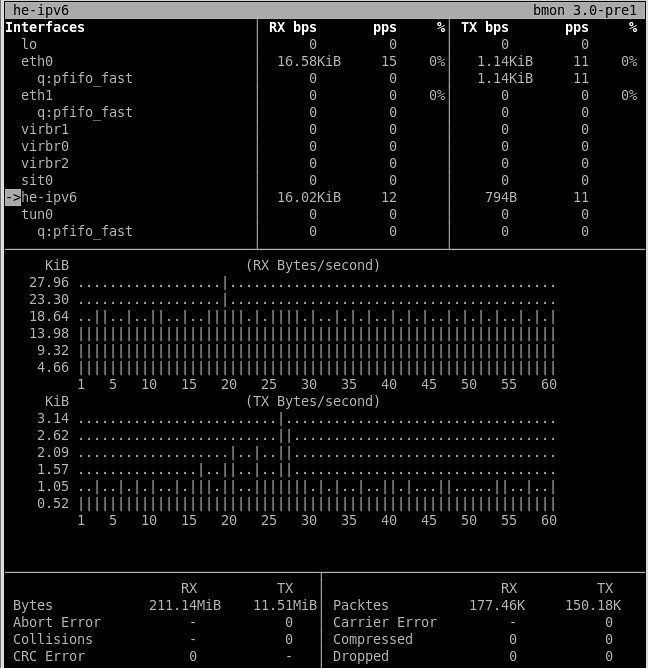
|
||||
|
||||
13. **[iftop][7]**: a bandwidth usage monitoring tool that can shows bandwidth usage for individual network connections in real time. It comes with ncurses-based interface to visualize bandwidth usage of all connections in a sorted order. It is useful for monitoring which connections are consuming the most bandwidth.
|
||||
|
||||
14. **nethogs**: a process monitoring tool which offers a real-time view of upload/download bandwidth usage of individual processes or programs in an ncurses-based interface. This is useful for detecting bandwidth hogging processes.
|
||||
|
||||
15. **netstat**: a command-line tool that shows various statistics and properties of the networking stack, such as open TCP/UDP connections, network interface RX/TX statistics, routing tables, protocol/socket statistics. It is useful when you diagnose performance and resource usage related problems of the networking stack.
|
||||
|
||||
16. **[speedometer][8]**: a console-based traffic monitor which visualizes the historical trend of an interface's RX/TX bandwidth usage with ncurses-drawn bar charts.
|
||||
|
||||
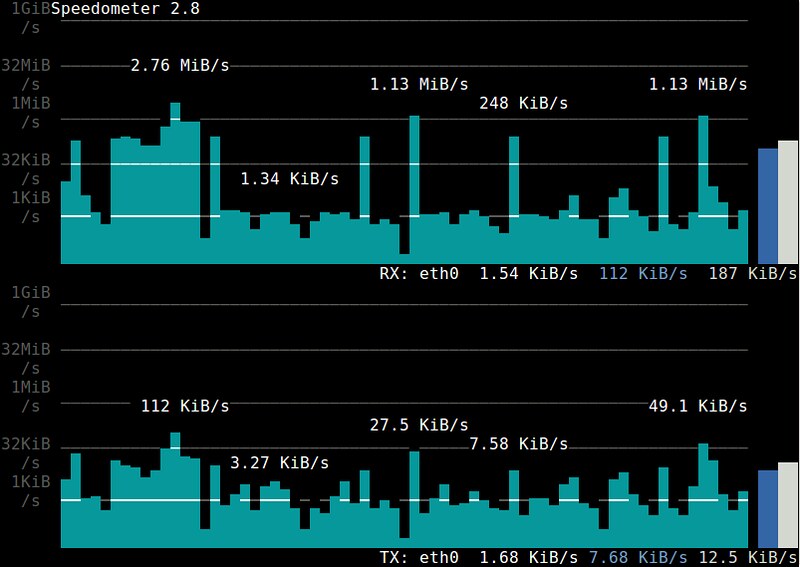
|
||||
|
||||
17. **[sysdig][9]**: a comprehensive system-level debugging tool with a unified interface for investigating different Linux subsystems. Its network monitoring module is capable of monitoring, either online or offline, various per-process/per-host networking statistics such as bandwidth usage, number of connections/requests, etc.
|
||||
|
||||
18. **tcptrack**: a TCP connection monitoring tool which displays information of active TCP connections, including source/destination IP addresses/ports, TCP state, and bandwidth usage.
|
||||
|
||||
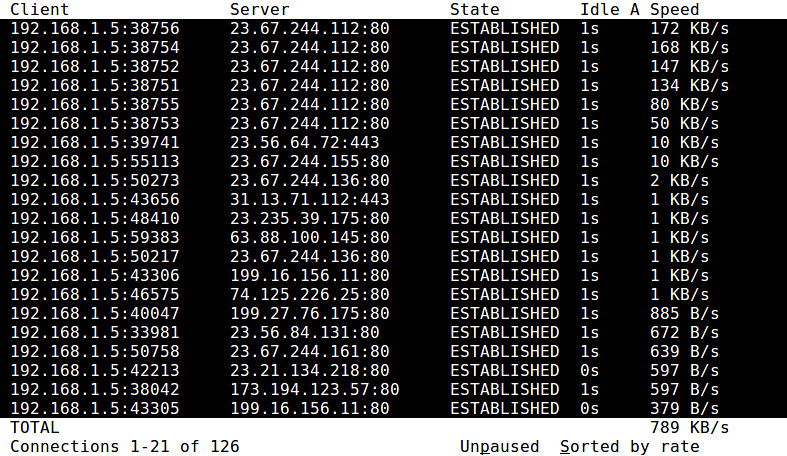
|
||||
|
||||
19. **vnStat**: a command-line traffic monitor which maintains a historical view of RX/TX bandwidh usage (e.g., current, daily, monthly) on a per-interface basis. Running as a background daemon, it collects and stores interface statistics on bandwidth rate and total bytes transferred.
|
||||
|
||||
### Active Network Monitoring ###
|
||||
|
||||
Unlike passive monitoring tools presented so far, tools in this category perform network monitoring by actively "injecting" probes into the network and collecting corresponding responses. Monitoring targets include routing path, available bandwidth, loss rates, delay, jitter, system settings or vulnerabilities, and so on.
|
||||
|
||||
20. **[dnsyo][10]**: a DNS monitoring tool which can conduct DNS lookup from open resolvers scattered across more than 1,500 different networks. It is useful when you check DNS propagation or troubleshoot DNS configuration.
|
||||
|
||||
21. **[iperf][11]**: a TCP/UDP bandwidth measurement utility which can measure maximum available bandwidth between two end points. It measures available bandwidth by having two hosts pump out TCP/UDP probe traffic between them either unidirectionally or bi-directionally. It is useful when you test the network capacity, or tune the parameters of network stack. A variant called [netperf][12] exists with more features and better statistics.
|
||||
|
||||
22. **[netcat][13]/socat**: versatile network debugging tools capable of reading from, writing to, or listen on TCP/UDP sockets. They are often used alongside with other programs or scripts for backend network transfer or port listening.
|
||||
|
||||
23. **nmap**: a command-line port scanning and network discovery utility. It relies on a number of TCP/UDP based scanning techniques to detect open ports, live hosts, or existing operating systems on the local network. It is useful when you audit local hosts for vulnerabilities or build a host map for maintenance purpose. [zmap][14] is an alernative scanning tool with Internet-wide scanning capability.
|
||||
|
||||
24. ping: a network testing tool which works by exchaning ICMP echo and reply packets with a remote host. It is useful when you measure round-trip-time (RTT) delay and loss rate of a routing path, as well as test the status or firewall rules of a remote system. Variations of ping exist with fancier interface (e.g., [noping][15]), multi-protocol support (e.g., [hping][16]) or parallel probing capability (e.g., [fping][17]).
|
||||
|
||||
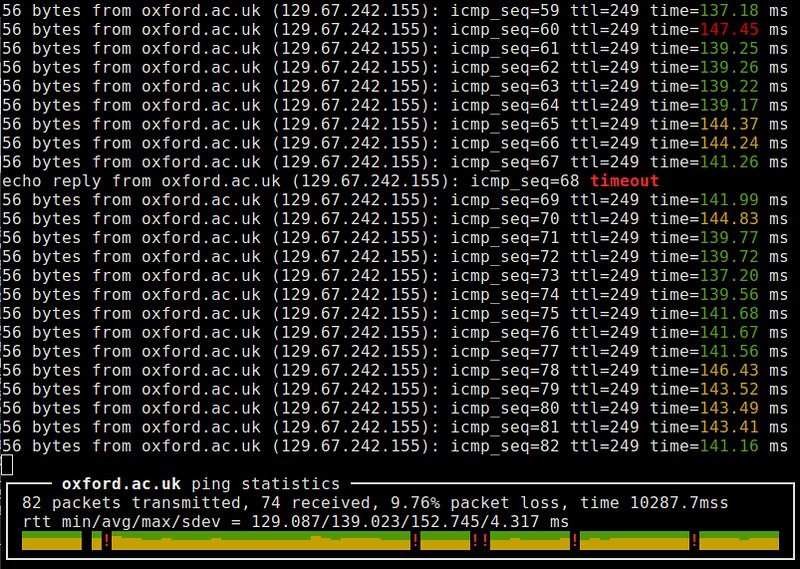
|
||||
|
||||
25. **[sprobe][18]**: a command-line tool that heuristically infers the bottleneck bandwidth between a local host and any arbitrary remote IP address. It uses TCP three-way handshake tricks to estimate the bottleneck bandwidth. It is useful when troubleshooting wide-area network performance and routing related problems.
|
||||
|
||||
26. **traceroute**: a network discovery tool which reveals a layer-3 routing/forwarding path from a local host to a remote host. It works by sending TTL-limited probe packets and collecting ICMP responses from intermediate routers. It is useful when troubleshooting slow network connections or routing related problems. Variations of traceroute exist with better RTT statistics (e.g., [mtr][19]).
|
||||
|
||||
### Application Log Parsing ###
|
||||
|
||||
In this category, network monitoring is targeted at a specific server application (e.g., web server or database server). Network traffic generated or consumed by a server application is monitored by analyzing its log file. Unlike network-level monitors presented in earlier categories, tools in this category can analyze and monitor network traffic from application-level.
|
||||
|
||||
27. **[GoAccess][20]**: a console-based interactive viewer for Apache and Nginx web server traffic. Based on access log analysis, it presents a real-time statistics of a number of metrics including daily visits, top requests, client operating systems, client locations, client browsers, in a scrollable view.
|
||||
|
||||
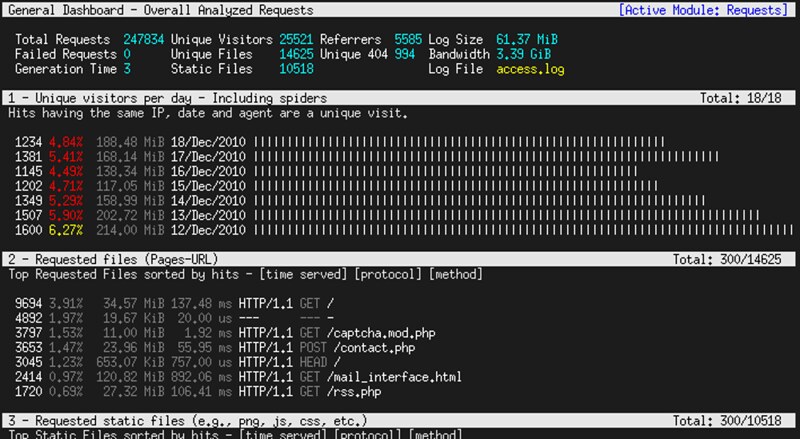
|
||||
|
||||
28. **[mtop][21]**: a command-line MySQL/MariaDB server moniter which visualizes the most expensive queries and current database server load. It is useful when you optimize MySQL server performance and tune server configurations.
|
||||
|
||||
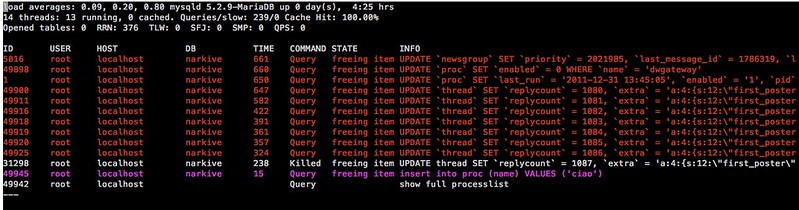
|
||||
|
||||
29. **[ngxtop][22]**: a traffic monitoring tool for Nginx and Apache web server, which visualizes web server traffic in a top-like interface. It works by parsing a web server's access log file and collecting traffic statistics for individual destinations or requests.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this article, I presented a wide variety of command-line network monitoring tools, ranging from the lowest packet-level monitors to the highest application-level network monitors. Knowing which tool does what is one thing, and choosing which tool to use is another, as any single tool cannot be a universal solution for your every need. A good system admin should be able to decide which tool is right for the circumstance at hand. Hopefully the list helps with that.
|
||||
|
||||
You are always welcome to improve the list with your comment!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/useful-command-line-network-monitors-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://www.monkey.org/~dugsong/dsniff/
|
||||
[2]:http://xmodulo.com/monitor-http-traffic-command-line-linux.html
|
||||
[3]:https://github.com/zorkian/mysql-sniffer
|
||||
[4]:http://ngrep.sourceforge.net/
|
||||
[5]:http://lcamtuf.coredump.cx/p0f3/
|
||||
[6]:http://xmodulo.com/recommend/firewallbook
|
||||
[7]:http://xmodulo.com/how-to-install-iftop-on-linux.html
|
||||
[8]:https://excess.org/speedometer/
|
||||
[9]:http://xmodulo.com/monitor-troubleshoot-linux-server-sysdig.html
|
||||
[10]:http://xmodulo.com/check-dns-propagation-linux.html
|
||||
[11]:https://iperf.fr/
|
||||
[12]:http://www.netperf.org/netperf/
|
||||
[13]:http://xmodulo.com/useful-netcat-examples-linux.html
|
||||
[14]:https://zmap.io/
|
||||
[15]:http://noping.cc/
|
||||
[16]:http://www.hping.org/
|
||||
[17]:http://fping.org/
|
||||
[18]:http://sprobe.cs.washington.edu/
|
||||
[19]:http://xmodulo.com/better-alternatives-basic-command-line-utilities.html#mtr_link
|
||||
[20]:http://goaccess.io/
|
||||
[21]:http://mtop.sourceforge.net/
|
||||
[22]:http://xmodulo.com/monitor-nginx-web-server-command-line-real-time.html
|
||||
@ -0,0 +1,180 @@
|
||||
How To Recover Windows 7 And Delete Ubuntu In 3 Easy Steps
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
This is a strange article for me to write as I am normally in a position where I would advocate installing Ubuntu and getting rid of Windows.
|
||||
|
||||
What makes writing this article today doubly strange is that I am choosing to write it on the day that Windows 7 mainstream support comes to an end.
|
||||
|
||||
So why am I writing this now?
|
||||
|
||||
I have been asked on so many occasions now how to remove Ubuntu from a dual booting Windows 7 or a dual booting Windows 8 system and it just makes sense to write the article.
|
||||
|
||||
I spent the Christmas period looking through the comments that people have left on articles and it is time to write the posts that are missing and update some of those that have become old and need attention.
|
||||
|
||||
I am going to spend the rest of January doing just that. This is the first step. If you have Windows 7 dual booting with Ubuntu and you want Windows 7 back without restoring to factory settings follow this guide. (Note there is a separate guide required for Windows 8)
|
||||
|
||||
### The Steps Required To Remove Ubuntu ###
|
||||
|
||||
1. Remove Grub By Fixing The Windows Boot Record
|
||||
1. Delete The Ubuntu Partitions
|
||||
1. Expand The Windows Partition
|
||||
|
||||
### Back Up Your System ###
|
||||
|
||||
Before you begin I recommend taking a backup of your system.
|
||||
|
||||
I also recommend not leaving this to chance nor Microsoft's own tools.
|
||||
|
||||
[Click here for a guide showing how to backup your drive using Macrium Reflect.][1]
|
||||
|
||||
If you have any data you wish to save within Ubuntu log into it now and back up the data to external hard drives, USB drives or DVDs.
|
||||
|
||||
### Step 1 - Remove The Grub Boot Menu ###
|
||||
|
||||
|
||||
|
||||
When you boot your system you will see a menu similar to the one in the image.
|
||||
|
||||
To remove this menu and boot straight into Windows you have to fix the master boot record.
|
||||
|
||||
To do this I am going to show you how to create a system recovery disk, how to boot to the recovery disk and how to fix the master boot record.
|
||||
|
||||

|
||||
|
||||
Press the "Start" button and search for "backup and restore". Click the icon that appears.
|
||||
|
||||
A window should open as shown in the image above.
|
||||
|
||||
Click on "Create a system repair disc".
|
||||
|
||||
You will need a [blank DVD][2].
|
||||
|
||||

|
||||
|
||||
Insert the blank DVD in the drive and select your DVD drive from the dropdown list.
|
||||
|
||||
Click "Create Disc".
|
||||
|
||||
Restart your computer leaving the disk in and when the message appears to boot from CD press "Enter" on the keyboard.
|
||||
|
||||
|
||||
|
||||
A set of "Systems Recovery Options" screens will appear.
|
||||
|
||||
You will be asked to choose your keyboard layout.
|
||||
|
||||
Choose the appropriate options from the lists provided and click "Next".
|
||||
|
||||
|
||||
|
||||
The next screen lets you choose an operating system to attempt to fix.
|
||||
|
||||
Alternatively you can restore your computer using a system image saved earlier.
|
||||
|
||||
Leave the top option checked and click "Next".
|
||||
|
||||
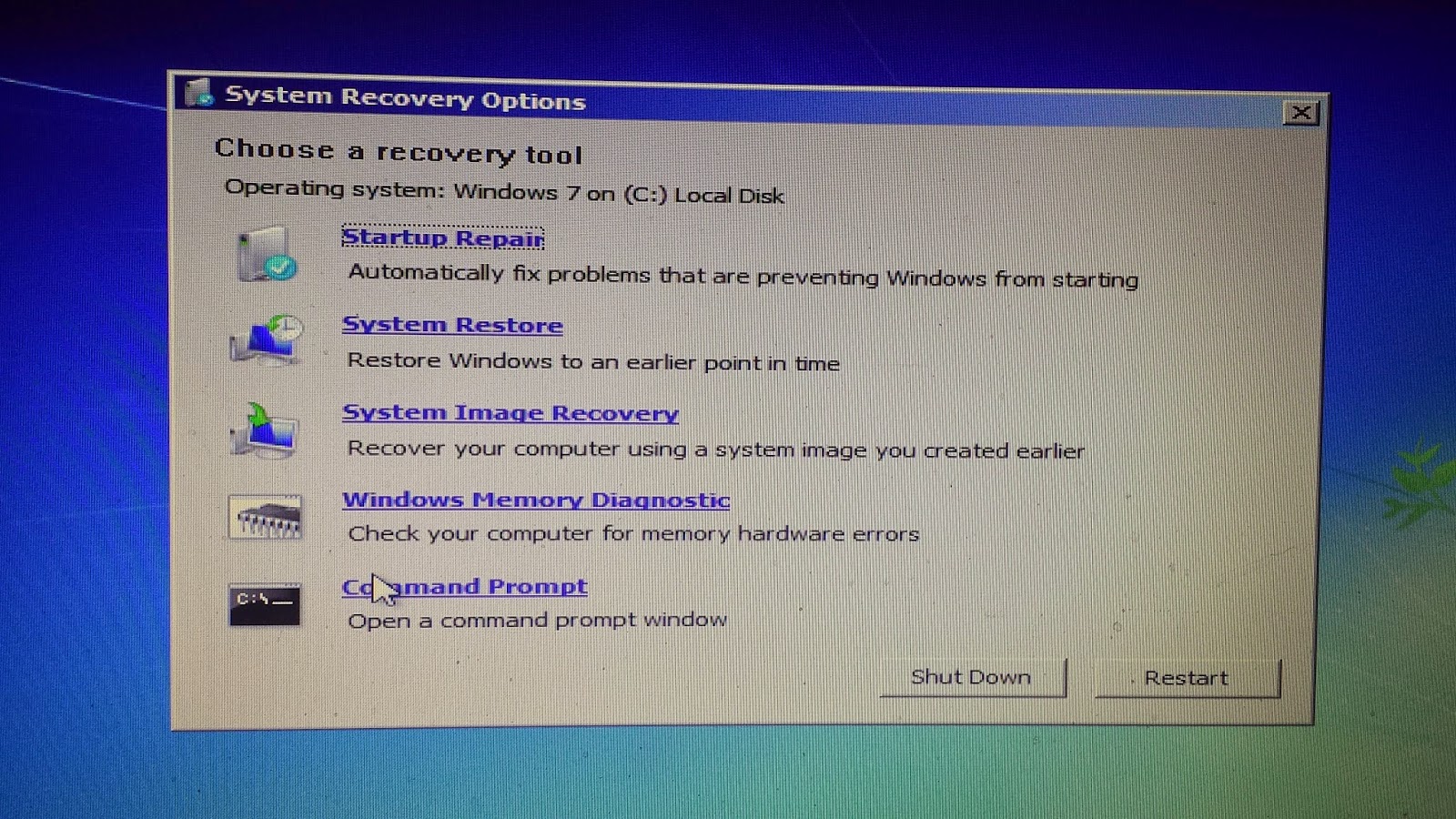
|
||||
|
||||
You will now see a screen with options to repair your disk and restore your system etc.
|
||||
|
||||
All you need to do is fix the master boot record and this can be done from the command prompt.
|
||||
|
||||
Click "Command Prompt".
|
||||
|
||||
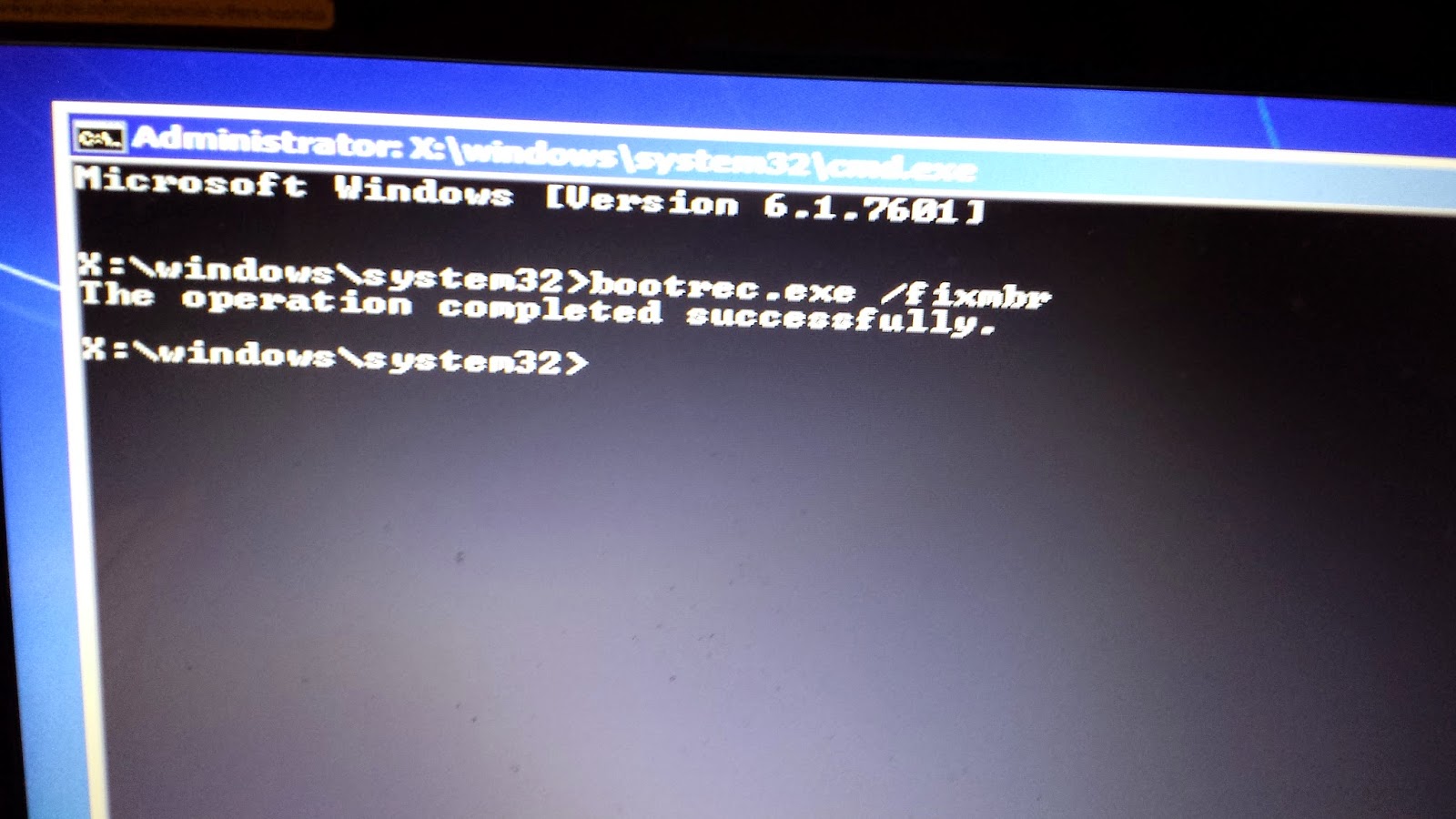
|
||||
|
||||
Now simply type the following command into the command prompt:
|
||||
|
||||
bootrec.exe /fixmbr
|
||||
|
||||
A message will appear stating that the operation has completed successfully.
|
||||
|
||||
You can now close the command prompt window.
|
||||
|
||||
Click the "Restart" button and remove the DVD.
|
||||
|
||||
Your computer should boot straight into Windows 7.
|
||||
|
||||
### Step 2 - Delete The Ubuntu Partitions ###
|
||||
|
||||

|
||||
|
||||
To delete Ubuntu you need to use the "Disk Management" tool from within Windows.
|
||||
|
||||
Press "Start" and type "Create and format hard disk partitions" into the search box. A window will appear similar to the image above.
|
||||
|
||||
Now my screen above isn't going to be quite the same as yours but it won't be much different. If you look at disk 0 there is 101 MB of unallocated space and then 4 partitions.
|
||||
|
||||
The 101 MB of space is a mistake I made when installing Windows 7 in the first place. The C: drive is Windows 7, the next partition (46.57 GB) is Ubuntu's root partition. The 287 GB partition is the /HOME partition and the 8 GB partition is the SWAP space.
|
||||
|
||||
The only one we really need for Windows is the C: drive so the rest can be deleted.
|
||||
|
||||
**Note: Be careful. You may have recovery partitions on the disk. Do not delete the recovery partitions. They should be labelled and will have file systems set to NTFS or FAT32**
|
||||
|
||||
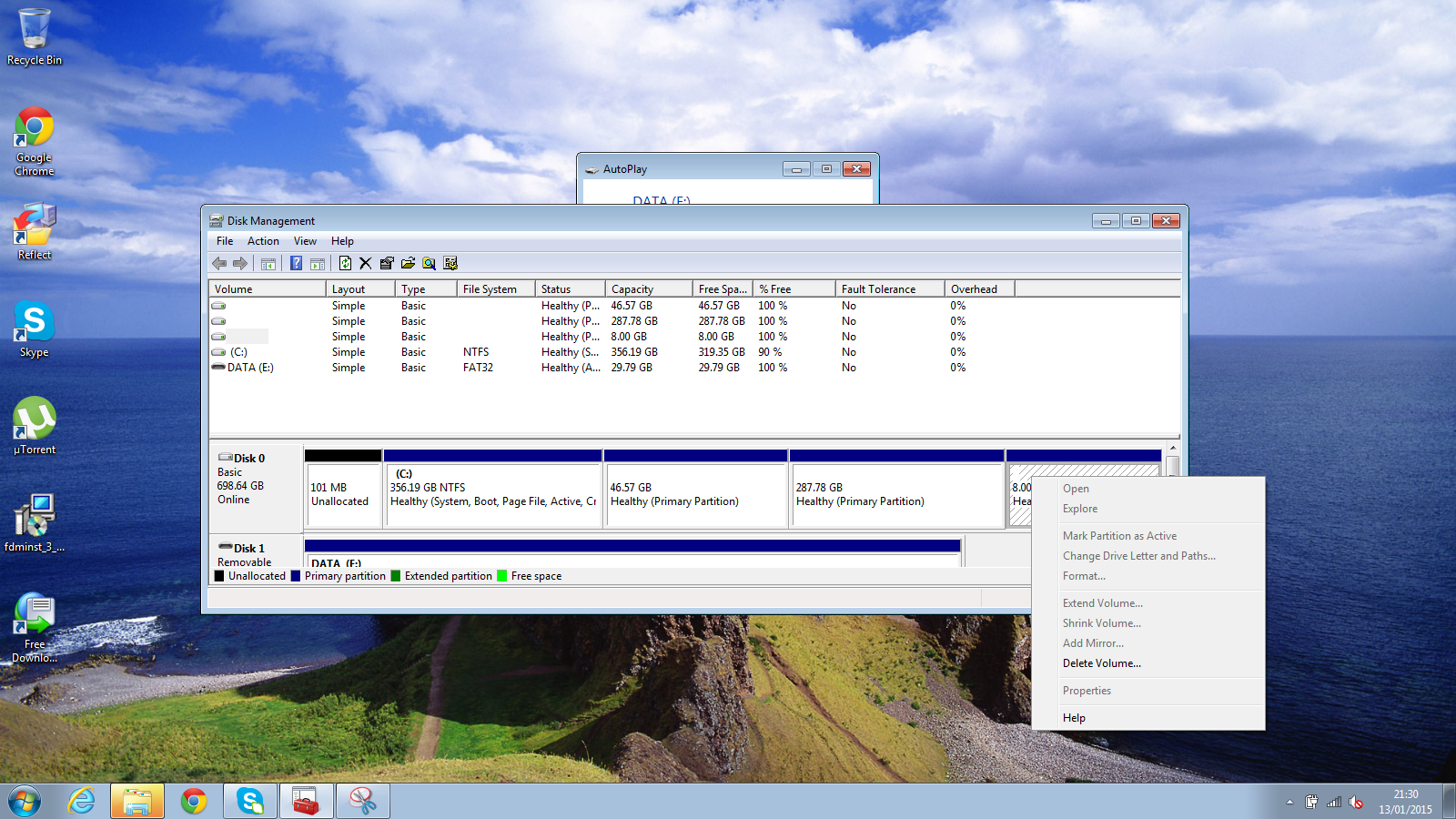
|
||||
|
||||
Right click on one of the partitions you wish to delete (i.e. the root, home and swap partitions) and from the menu click "Delete Volume".
|
||||
|
||||
**(Do not delete any partitions that have a file system of NTFS or FAT32)**
|
||||
|
||||
Repeat this process for the other two partitions.
|
||||
|
||||

|
||||
|
||||
After the partitions have been deleted you will have a large area of free space. Right click the free space and choose delete.
|
||||
|
||||

|
||||
|
||||
Your disk will now contain your C drive and a large amount of unallocated space.
|
||||
|
||||
### Step 3 - Expand The Windows Partition ###
|
||||
|
||||
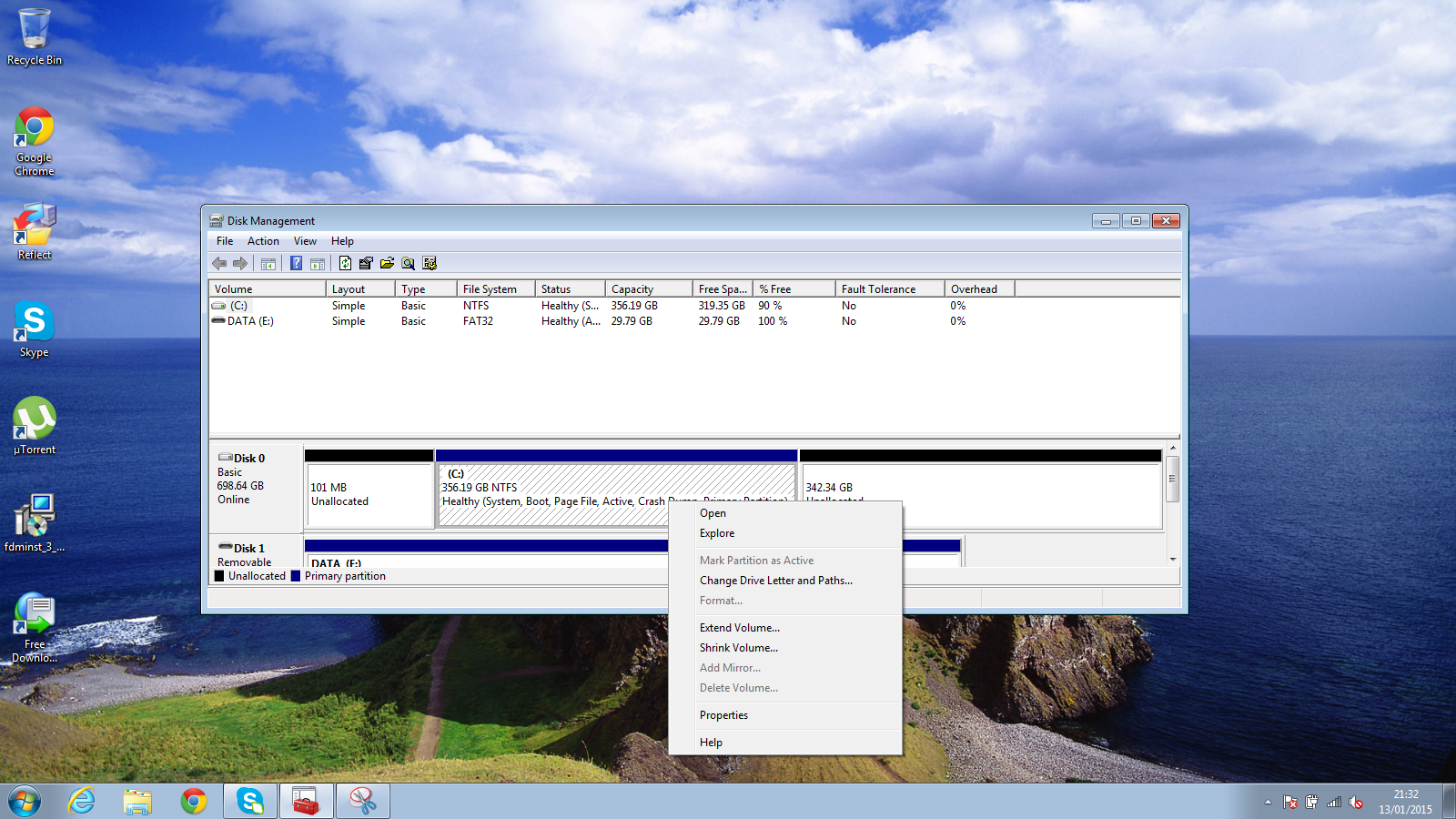
|
||||
|
||||
The final step is to expand Windows so that it is one large partition again.
|
||||
|
||||
To do this right click on the Windows partition (C: drive) and choose "Extend Volume".
|
||||
|
||||
|
||||
|
||||
When the Window to the left appears click "Next",
|
||||
|
||||

|
||||
|
||||
The next screen shows a wizard whereby you can select the disks to expand to and change the size to expand to.
|
||||
|
||||
By default the wizard shows the maximum amount of disk space it can claim from unallocated space.
|
||||
|
||||
Accept the defaults and click "Next".
|
||||
|
||||
|
||||
|
||||
The final screen shows the settings that you chose from the previous screen.
|
||||
|
||||
Click "Finish" to expand the disk.
|
||||
|
||||

|
||||
|
||||
As you can see from the image above my Windows partition now takes up the entire disk (except for the 101 MB that I accidentally created before installing Windows in the first place).
|
||||
|
||||
### Summary ###
|
||||
|
||||

|
||||
|
||||
That is all folks. A site dedicated to Linux has just shown you how to remove Linux and replace it with Windows 7.
|
||||
|
||||
Any questions? Use the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.everydaylinuxuser.com/2015/01/how-to-recover-windows-7-and-delete.html
|
||||
|
||||
作者:Gary Newell
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/Create-A-Recovery-Drive-For-All-Versions-Of-Windows.htm
|
||||
[2]:http://www.amazon.co.uk/gp/product/B0006L2HTK/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1634&creative=6738&creativeASIN=B0006L2HTK&linkCode=as2&tag=evelinuse-21&linkId=3R363EA63XB4Z3IL
|
||||
@ -0,0 +1,146 @@
|
||||
How to Configure Chroot Environment in Ubuntu 14.04
|
||||
================================================================================
|
||||
There are many instances when you may wish to isolate certain applications, user, or environments within a Linux system. Different operating systems have different methods of achieving isolation, and in Linux, a classic way is through a `chroot` environment.
|
||||
|
||||
In this guide, we'll show you step wise on how to setup an isolated environment using chroot in order to create a barrier between your regular operating system and a contained environment. This is mainly useful for testing purposes. We will teach you the steps on an **Ubuntu 14.04** VPS instance.
|
||||
|
||||
Most system administrators will benefit from knowing how to accomplish a quick and easy chroot environment and it is a valuable skill to have.
|
||||
|
||||
### The chroot environment ###
|
||||
|
||||
A chroot environment is an operating system call that will change the root location temporarily to a new folder. Typically, the operating system's conception of the root directory is the actual root located at "/". However, with `chroot`, you can specify another directory to serve as the top-level directory for the duration of a chroot.
|
||||
|
||||
Any applications that are run from within the `chroot` will be unable to see the rest of the operating system in principle.
|
||||
|
||||
#### Advantages of Chroot Environment ####
|
||||
|
||||
> - Test applications without the risk of compromising the entire host system.
|
||||
>
|
||||
> - From the security point of view, whatever happens in the chroot environment won't affect the host system (not even under root user).
|
||||
>
|
||||
> - A different operating system running in the same hardware.
|
||||
|
||||
For instance, it allows you to build, install, and test software in an environment that is separated from your normal operating system. It could also be used as a method of **running 32-bit applications in a 64-bit environment**.
|
||||
|
||||
But while chroot environments will certainly make additional work for an unprivileged user, they should be considered a hardening feature instead of a security feature, meaning that they attempt to reduce the number of attack vectors instead of creating a full solution. If you need full isolation, consider a more complete solution, such as Linux containers, Docker, vservers, etc.
|
||||
|
||||
### Debootstrap and Schroot ###
|
||||
|
||||
The necessary packages to setup the chroot environment are **debootstrap** and **schroot**, which are available in the ubuntu repository. The schroot command is used to setup the chroot environment.
|
||||
|
||||
**Debootstrap** allows you to install a new fresh copy of any Debian (or debian-based) system from a repository in a directory with all the basic commands and binaries needed to run a basic instance of the operating system.
|
||||
|
||||
The **schroot** allows access to chroots for normal users using the same mechanism, but with permissions checking and allowing additional automated setup of the chroot environment, such as mounting additional filesystems and other configuration tasks.
|
||||
|
||||
These are the steps to implement this functionality in Ubuntu 14.04 LTS:
|
||||
|
||||
### 1. Installing the Packages ###
|
||||
|
||||
Firstly, We're gonna install debootstrap and schroot in our host Ubuntu 14.04 LTS.
|
||||
|
||||
$ sudo apt-get install debootstrap
|
||||
$ sudo apt-get install schroot
|
||||
|
||||
### 2. Configuring Schroot ###
|
||||
|
||||
Now that we have the appropriate tools, we just need to specify a directory that we want to use as our chroot environment. We will create a directory called linoxide in our root directory to setup chroot there:
|
||||
|
||||
sudo mkdir /linoxide
|
||||
|
||||
We have to configure schroot to suit our needs in the configuration file .we will modify the schroot configuration file with the information we require to get configured.
|
||||
|
||||
sudo nano /etc/schroot/schroot.conf
|
||||
|
||||
We are on an Ubuntu 14.04 LTS (Trusty Tahr) system currently, but let's say that we want to test out some packages available on Ubuntu 13.10, code named "Saucy Salamander". We can do that by creating an entry that looks like this:
|
||||
|
||||
[saucy]
|
||||
description=Ubuntu Saucy
|
||||
location=/linoxide
|
||||
priority=3
|
||||
users=arun
|
||||
root-groups=root
|
||||
|
||||

|
||||
|
||||
Modify the values of the configuration parameters in the above example to fit your system:
|
||||
|
||||
### 3. Installing 32 bit Ubuntu with debootstrap ###
|
||||
|
||||
Debootstrap downloads and installs a minimal operating system inside your **chroot environment**. You can install any debian-based distro of your choice, as long as you have a repository available.
|
||||
|
||||
Above, we placed the chroot environment under the directory **/linoxide** and this is the root directory of the chroot environment. So we'll need to run debootstrap inside that directory which we have already created:
|
||||
|
||||
cd /linoxide
|
||||
sudo debootstrap --variant=buildd --arch amd64 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
sudo chroot /linoxide /debootstrap/debootstrap --second-stage
|
||||
|
||||
You can replace amd64 in --arch as i386 or other bit OS you wanna setup available in the repository. You can replace the mirror http://archive.ubuntu.com/ubuntu/ above as the one closest, you can get the closest one from the official [Ubuntu Mirror Page][1].
|
||||
|
||||
**Note: You will need to add --foreign above 3rd line command if you choose to setup i386 bit OS choot in your 64 bit Host Ubuntu as:**
|
||||
|
||||
sudo debootstrap --variant=buildd --foreign --arch i386 saucy /linoxide/ http://archive.ubuntu.com/ubuntu/
|
||||
|
||||
It takes some time (depending on your bandwidth) to download, install and configure the complete system. It takes about 500 MBs for a minimal installation.
|
||||
|
||||
### 4. Finallizing the chroot environment ###
|
||||
|
||||
After the system is installed, we'll need to do some final configurations to make sure the system functions correctly. First, we'll want to make sure our host `fstab` is aware of some pseudo-systems in our guest.
|
||||
|
||||
sudo nano /etc/fstab
|
||||
|
||||
Add the below lines like these to the bottom of your fstab:
|
||||
|
||||
proc /linoxide/proc proc defaults 0 0
|
||||
sysfs /linoxide/sys sysfs defaults 0 0
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Now, we're going to need to mount these filesystems within our guest:
|
||||
|
||||
$ sudo mount proc /linoxide/proc -t proc
|
||||
$sudo mount sysfs /linoxide/sys -t sysfs
|
||||
|
||||
We'll also want to copy our /etc/hosts file so that we will have access to the correct network information:
|
||||
|
||||
$ sudo cp /etc/hosts /linoxide/etc/hosts
|
||||
|
||||
Finally, You can list the available chroot environments using the schroot command.
|
||||
|
||||
$ schroot -l
|
||||
|
||||
We can enter the chroot environment through a command like this:
|
||||
|
||||
$ sudo chroot /linoxide/ /bin/bash
|
||||
|
||||
You can test the chroot environment by checking the version of distributions installed.
|
||||
|
||||
# lsb_release -a
|
||||
# uname -a
|
||||
|
||||
To finish this tutorial, in order to run a graphic application from the chroot, you have to export the DISPLAY environment variable.
|
||||
|
||||
$ DISPLAY=:0.0 ./apps
|
||||
|
||||
Here, we have successfully installed Chrooted Ubuntu 13.10(Saucy Salamander) in your host Ubuntu 14.04 LTS (Trusty Tahr).
|
||||
|
||||
You can exit chroot environment successfully by running the commands below:
|
||||
|
||||
# exit
|
||||
|
||||
Afterwards, we need to unmount our proc and sys filesystems:
|
||||
|
||||
$ sudo umount /test/proc
|
||||
$ sudo umount /test/sys
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/configure-chroot-environment-ubuntu-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
@ -0,0 +1,93 @@
|
||||
How to Manage Network using nmcli Tool in RedHat / CentOS 7.x
|
||||
================================================================================
|
||||
A new feature of [**Red Hat Enterprise Linux 7**][1] and **CentOS 7** is that the default networking service is provided by **NetworkManager**, a dynamic network control and configuration daemon that attempts to keep network devices and connections up and active when they are available while still supporting the traditional ifcfg type configuration files. NetworkManager can be used with the following types of connections: Ethernet, VLANs, Bridges, Bonds, Teams, Wi-Fi, mobile broadband (such as cellular 3G), and IP-over-InfiniBand. For these connection types, NetworkManager can configure network aliases, IP addresses, static routes, DNS information, and VPN connections, as well as many connection-specific parameters.
|
||||
|
||||
The NetworkManager can be controlled with the command-line tool, **nmcli**.
|
||||
|
||||
### General nmcli usage ###
|
||||
|
||||
The general syntax for nmcli is:
|
||||
|
||||
# nmcli [ OPTIONS ] OBJECT { COMMAND | help }
|
||||
|
||||
One cool thing is that you can use the TAB key to complete actions when you write the command so if at any time you forget the syntax you can just press TAB to see a list of available options.
|
||||
|
||||

|
||||
|
||||
Some examples of general nmcli usage:
|
||||
|
||||
# nmcli general status
|
||||
|
||||
Will display the overall status of NetworkManager.
|
||||
|
||||
# nmcli connection show
|
||||
|
||||
Will display all connections.
|
||||
|
||||
# nmcli connection show -a
|
||||
|
||||
Will display only the active connections.
|
||||
|
||||
# nmcli device status
|
||||
|
||||
Will display a list of devices recognized by NetworkManager and their current state.
|
||||
|
||||

|
||||
|
||||
### Starting / stopping network interfaces ###
|
||||
|
||||
You can use the nmcli tool to start or stop network interfaces from the command line, this is the equivalent of up/down in ifconfig.
|
||||
|
||||
To stop an interface use the following syntax:
|
||||
|
||||
# nmcli device disconnect eno16777736
|
||||
|
||||
To start it you can use this syntax:
|
||||
|
||||
# nmcli device connect eno16777736
|
||||
|
||||
### Adding an ethernet connection with static IP ###
|
||||
|
||||
To add a new ethernet connection with a static IP address you can use the following command:
|
||||
|
||||
# nmcli connection add type ethernet con-name NAME_OF_CONNECTION ifname interface-name ip4 IP_ADDRESS gw4 GW_ADDRESS
|
||||
|
||||
replacing the NAME_OF_CONNECTION with the name you wish to apply to the new connection, the IP_ADDRESS with the IP address you wish to use and the GW_ADDRESS with the gateway address you use (if you don't use a gateway you can omit this last part).
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW ifname eno16777736 ip4 192.168.1.141 gw4 192.168.1.1
|
||||
|
||||
To set the DNS servers for this connection you can use the following command:
|
||||
|
||||
# nmcli connection modify NEW ipv4.dns "8.8.8.8 8.8.4.4"
|
||||
|
||||
To bring up the new Ethernet connection, issue a command as follows:
|
||||
|
||||
# nmcli connection up NEW ifname eno16777736
|
||||
|
||||
To view detailed information about the newly configured connection, issue a command as follows:
|
||||
|
||||
# nmcli -p connection show NEW
|
||||
|
||||

|
||||
|
||||
### Adding a connection that will use DHCP ###
|
||||
|
||||
If you wish to add a new connection that will use DHCP to configure the interface IP address, gateway address and dns servers, all you have to do is omit the ip/gw address part of the command and Network Manager will use DHCP to get the configuration details.
|
||||
|
||||
For example, to create a DHCP configured connection profile named NEW_DHCP, on device
|
||||
eno16777736 you can use the following command:
|
||||
|
||||
# nmcli connection add type ethernet con-name NEW_DHCP ifname eno16777736
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/nmcli-tool-red-hat-centos-7/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/7.0_Release_Notes/
|
||||
@ -0,0 +1,168 @@
|
||||
Translated By H-mudcup
|
||||
|
||||
文件轻松比对,伟大而自由的比较软件们
|
||||
================================================================================
|
||||
作者 Frazer Kline
|
||||
|
||||
文件比较工具用于比较电脑文件的内容,找到他们之间相同与不同之处。比较的结果通常被称为diff。
|
||||
|
||||
diff同时也是一个著名的,基于控制台的,能输出两个文件之间不同之处的,文件比较程序的名字。diff是二十世纪70年代早期,在Unix操作系统上被开发出来的。diff将会把两个文件之间不同之处的部分进行输出。
|
||||
|
||||
Linux拥有很多不错的,能使你能清楚的看到两个文件或同一文件不同版本之间的不同之处的,很棒的GUI工具。这次我从自己最喜欢的GUI比较工具中选出了五个推荐给大家。除了其中的一个,其他的都有开源许可证。
|
||||
|
||||
这些应用程序可以让文件或目录的差别变得可见,能合并有差异的文件,可以解决冲突并将其输出成一个新的文件或补丁,还能帮助回顾文件被改动过的地方并评论最终产品(比如,在源代码合并到源文件树之前,要先批准源代码的改变)。因此它们是非常重要的软件开发工具。它们不停的把文件传来传,帮助开发人员们在同一个文件上工作。这些比较工具不仅仅能用于显示源代码文件中的不同之处;他们还适用于很多种文本类文件。可视化的特性使文件比较变得容易、简单。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Meld是一个适用于Gnome桌面的,开源的,图形化的文件差异查看和合并的应用程序。它支持2到3个文件的同时比较,递归式的目录比较,版本控制(Bazaar, Codeville, CVS, Darcs, Fossil SCM, Git, Mercurial, Monotone, Subversion)之下的目录比较。还能够手动或自动合并文件差异。
|
||||
|
||||
eld的重点在于帮助开发人员比较和合并多个源文件,并在他们最喜欢的版本控制系统下能直观的浏览改动过的地方。
|
||||
|
||||
功能包括
|
||||
|
||||
- 原地编辑文件,即时更新
|
||||
- 进行两到三个文件的比较及合并
|
||||
- 差异和冲突之间的导航
|
||||
- 可视化本地和总体间的插入、改变和冲突这几种不同之处。
|
||||
- 内置正则表达式文本过滤器,可以忽略不重要的差异
|
||||
- 语法高亮度显示(可选择gtksourceview)
|
||||
- 将两到三个目录一个文件一个文件的进行比较,显示新建,缺失和替换过的文件。
|
||||
- 可直接开启任何有冲突或差异的文件的比较
|
||||
- 可以过滤文件或目录以避免出现假差异
|
||||
- 被改动区域的自动合并模式使合并更容易
|
||||
- 简单的文件管理
|
||||
- 支持多种版本控制系统,包括Git, Mercurial, Bazaar and SVN
|
||||
- 在提交前开启文件比较来检查改动的地方和内容
|
||||
- 查看文件版本状态
|
||||
- 还能进行简单的版本控制操作(例如,提交、更新、添加、移动或删除文件)
|
||||
- 继承自同一文件的两个文件进行自动合并
|
||||
- 标注并在中间的窗格显示所有有冲突的变更的基础版本
|
||||
- 显示并合并同一文件的各自独立的修改
|
||||
- 锁定只读性质的基础文件以避免出错
|
||||
- 可以整合到已有的命令行界面中,包括gitmergetool
|
||||
- 国际化支持
|
||||
- 可视化使文件比较更简单
|
||||
|
||||
- 网址: [meldmerge.org][1]
|
||||
- 开发人员: Kai Willadsen
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 1.8.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
注:上面这个图访问不到,图的地址是原文地址的小图的链接地址,发布的时候在验证一下,如果还访问不到,不行先采用小图或者网上搜一下看有没有大图
|
||||
|
||||
DiffMerge是一个可以在Linux、Windows和OS X上运行的,可以可视化文件的比较和合并的应用软件。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 图形化的显示两个文件之间的差别。包括插入行,高亮标注以及对编辑的全面支持。
|
||||
- 图形化的显示三个文件之间的差别。(安全的前提下)允许自动合并还完全拥有最终文件的编辑权。
|
||||
- 并排显示两个文件夹的比较,显示哪一个文件只存在于其中一个文件夹而不存在于与之相比较的那个文件夹,还能一对一的将完全相同的、等价的或不同的文件配对。
|
||||
- 规则设置和选项让你可以个性化它的外观和行为
|
||||
- 基于Unicode,可以导入多种编码的字符
|
||||
- 跨平台工具
|
||||
|
||||
- 网址: [sourcegear.com/diffmerge][2]
|
||||
- 开发人员: SourceGear LLC
|
||||
- 证书: Licensed for use free of charge (not open source)
|
||||
- 版本号: 4.2
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
xxdiff是个开源的图形化的,可进行文件、目录比较及合并的工具。
|
||||
|
||||
xxdiff可以用于显示两到三个文件或两个目录的差别,还能产生一个合并后的版本。被比较的两到三个文件会并排显示,并将有区别的文字内容用不同颜色高亮显示以便于识别。
|
||||
|
||||
这个程序是个非常重要的软件开发工具。他可以图形化的显示两个文件或目录之间的差别,合并有差异的文件,解决冲突并评论结果(例如在源代码合并到一个源文件树里之前必须先允许其改变)
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两到三个文件,或是两个目录(浅层或递归)
|
||||
- 水平差别高亮显示
|
||||
- 文件可以被交互式的合并,可视化的输出和保存
|
||||
- 可以可视化合并的评论/监管
|
||||
- 保留自动合并文件中的冲突,并以两个文件显示以便于解决冲突
|
||||
- 用额外的比较程序估算差异:适用于GNU diff、SGI diff和ClearCase的cleardiff,以及所有与这些程序输出相似的文件比较程序。
|
||||
- 可以在源文件上实现完全的个性化设置
|
||||
- 用起来感觉和Rudy Wortel或SGI的xdiff差不多, it is desktop agnostic
|
||||
- 功能和输出可以和脚本轻松集成
|
||||
|
||||
- 网址: [furius.ca/xxdiff][3]
|
||||
- 开发人员: Martin Blais
|
||||
- 证书: GNU GPL
|
||||
- 版本号: 4.0
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Diffuse是个开源的图形化工具,可用于合并和比较文本文件。Diffuse能够比较任意数量的文件,并排显示,并提供手动行匹配调整,能直接编辑文件。Diffuse还能从bazaar、CVS、darcs, git, mercurial, monotone, Subversion和GNU矫正控制系统(GNU Revision Control System ,RCS)这些关于比较及合并的资源中对文件进行恢复和矫正。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较任意数量的文件,并排显示(多方合并)
|
||||
- 行匹配可以被用户人工矫正
|
||||
- 直接编辑文件
|
||||
- 语法高亮
|
||||
- 支持Bazaar, CVS, Darcs, Git, Mercurial, Monotone, RCS, Subversion和SVK
|
||||
- 支持Unicode
|
||||
- 可无限撤销
|
||||
- 简易键盘导航
|
||||
|
||||
- 网址: [diffuse.sourceforge.net][]
|
||||
- 开发人员: Derrick Moser
|
||||
- 证书: GNU GPL v2
|
||||
- 版本号: 0.4.7
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Kompare是个开源的GUI前端程序,可以开启不同源文件之间差异的可视化和合并。Kompare可以比较文件或文件夹内容的差异。Kompare支持很多种diff格式,并提供各种选项来设置显示的信息级别。
|
||||
|
||||
不论你是个想比较源代码的开发人员,还是只想比较一下研究论文手稿与最终文档的差异,Kompare都是个有用的工具。
|
||||
|
||||
Kompare是KDE桌面环境的一部分。
|
||||
|
||||
功能包括:
|
||||
|
||||
- 比较两个文本文件
|
||||
- 递归式比较目录
|
||||
- 显示diff产生的补丁
|
||||
- 将补丁合并到一个已存在的目录
|
||||
- 在无聊的编译时刻,逗你玩
|
||||
|
||||
- 网址: [www.caffeinated.me.uk/kompare/][5]
|
||||
- 开发者: The Kompare Team
|
||||
- 证书: GNU GPL
|
||||
- 版本号: Part of KDE
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/2014062814400262/FileComparisons.html
|
||||
|
||||
译者:[H-mudcup](https://github.com/H-mudcup) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://meldmerge.org/
|
||||
[2]:https://sourcegear.com/diffmerge/
|
||||
[3]:http://furius.ca/xxdiff/
|
||||
[4]:http://diffuse.sourceforge.net/
|
||||
[5]:http://www.caffeinated.me.uk/kompare/
|
||||
@ -0,0 +1,57 @@
|
||||
Translated by H-mudcup
|
||||
|
||||
Flow 'N Play视频播放器有着独具风格的界面【Ubuntu上的安装】
|
||||
================================================================================
|
||||
**Flow ‘N Play**是个用Qt编写的新视频播放器。它有着漂亮又简洁的只提供基本播放功能的界面。
|
||||
|
||||

|
||||
|
||||
[Flow ‘N Play][1]是个比较新的有着漂亮的界面和简单操作的视频播放器(今年三月份第一次发行)。其中一个功能就是能通过拖动鼠标滑动视频列表。播放器带有基本功能,一个搜索功能,支持彩色主题。
|
||||
|
||||
打开一个新的视频——你还可以在同一个对话框下自定义一个封面:
|
||||
|
||||

|
||||
|
||||
设置对话框——在这里设置基本的选项:
|
||||
|
||||

|
||||
|
||||
Flow ‘N Play仍然处在早起开发中,因此相对于更高级的播放器它有一些瑕疵。可以设置的选项少,不支持加载字幕或视频和声音的过滤器。目前,在打开一个新的视频时偶尔会出错或是表现异常。
|
||||
|
||||
我相信在它变得能替代其他播放器之前,会先添加几个功能。但从长远来看,Flow ‘N Play很有前途。
|
||||
|
||||
### 在Ubuntu 14.04上安装Flow ‘N Play 0.922 ###
|
||||
|
||||
在Ubuntu上有几种不同的方法安装Flow ‘N Play,可以用DEB包,或用Bash命令编写的RUN安装文件,或在[Qt-Apps页面][2]上获得单独的二进制安装文件。
|
||||
|
||||
要安装Flow ‘N Play得先获取依赖项:
|
||||
|
||||
sudo apt-get install libqt5multimediaquick-p5 qtdeclarative5-controls-plugin qtdeclarative5 qtmultimedia-plugin qtdeclarative5-qtquick2-plugin qtdeclarative5-quicklayouts-plugin
|
||||
|
||||
Then download the DEB package and either double click it or change the working directory to the one where you saved it and type the following in a terminal (for 64-bit, replace the DEB file for 32-bit)然后下载DEB安装包,可以双击或在终端里把正操作的目录换到你保存安装包的目录下并输入以下命令(这个是64位的命令,对于32位的系统请将DEB文件换成32位的):
|
||||
|
||||
sudo dpkg -i flow-n-play_v0.926_qt-5.3.2_x64.deb
|
||||
|
||||
然后在终端里输入**flow-n-play**来运行它。注意:为防止产生依赖项错误,当你试图安装DEB问件事你可以运行**sudo apt-get -f install**,这样可以自动获取丢失的依赖项并安装Flow ‘N Play。
|
||||
|
||||
若用RUN脚本安装,先安装上边提到的依赖项,然后运行这个脚本:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
sudo ./flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
|
||||
第三种方法是手动安装到你选择的地方(在安装完依赖项后下载提供的二进制文件)以32位版本为例:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/Flow-N-Play_v0.926_Qt-5.3.2_x86
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tuxarena.com/2014/11/flow-n-play-movie-player-has-a-stylish-interface-ubuntu-installation/
|
||||
|
||||
作者:Craciun Dan
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.prest1ge-c0ding.24.eu/programme-php/app-flow_n_play.php?lang=en
|
||||
[2]:http://qt-apps.org/content/show.php/Flow+%27N+Play?content=167736
|
||||
@ -0,0 +1,63 @@
|
||||
|
||||
Tomahawk音乐播放器带着新形象、新功能回来了
|
||||
================================================================================
|
||||
**在悄无声息得过了一年之后,Tomahawk——音乐播放器中的瑞士军刀——带着值得歌颂的全新发行版回归了。 **
|
||||
|
||||

|
||||
|
||||
这个0.8版的开源跨平台应用增添了**更多在线服务的支持**,更新了它的外观,又一次确保了它创新的社交功能完美运行。
|
||||
|
||||
### Tomahawk——两个世界的极品 ###
|
||||
|
||||
Tomahawk嫁给了一个带有我们的“即时”现代文化的传统应用结构。它可以浏览和播放本地的音乐和Spotify、Grooveshark以及SoundCloud这类的线上音乐。在最新的发行版中,它把Google Play Music和Beats Music列入了它的名册。
|
||||
|
||||
这可能听着很繁复或令人困惑,但实际上它表现得出奇的好。
|
||||
|
||||
若你想要播放一首歌,而且不介意它是从哪里来的,你只需告诉Tomahawk音乐的标题和作者,它就会自动从可获取的源里找出高品质版本的音乐——你不需要做任何事。
|
||||
|
||||

|
||||
|
||||
这个应用还弄了一些附加的功能,比如EchoNest剖析,Last.fm建议,还有对Jabber的支持,这样你就能‘播放’朋友的音乐。它还有一个内置的信息服务,以便于你能和其他人快速的分享播放列表和音乐。
|
||||
|
||||
>“这种从根本上就与众不同的听音乐的方式,开启了前所未有的音乐的消费和分享体验”,项目的网站上这样写道。而且即便它如此独特,这也没有错。
|
||||
|
||||

|
||||
|
||||
支持声音菜单
|
||||
|
||||
### Tomahawk0.8发行版的亮点 ###
|
||||
|
||||
- 新的交互界面
|
||||
- 对Beats Music的支持
|
||||
- 对Google Play Music的支持(保存的和播放全部链接)
|
||||
- 对拖拽iTunes,Spotify这类网站的链接的支持
|
||||
- 正在播放的提示
|
||||
- Android应用(测试版)
|
||||
- 收件箱的改进
|
||||
|
||||
### 在Ubuntu上安装Tomahawk0.8 ###
|
||||
|
||||
作为一个流媒体音乐的大用户,我会在接下来的几天里体验一下这个应用软件,然后提供一个关于他的改变的更全面的赏析。与此同时,你也可以尝尝鲜。
|
||||
|
||||
在Ubuntu 14.04 LTS和Ubuntu 14.10上可以通过官方PPA获得Tomahawk。
|
||||
|
||||
sudo add-apt-repository ppa:tomahawk/ppa
|
||||
|
||||
sudo apt-get update && sudo apt-get install tomahawk
|
||||
|
||||
在官方项目网站上可以找的独立安装程序和更详细的信息。
|
||||
|
||||
- [Visit the Official Tomahawk Website][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/11/tomahawk-media-player-returns-new-look-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://gettomahawk.com/
|
||||
@ -1,22 +0,0 @@
|
||||
开始使用Ubuntu 14.04(PDF指南)
|
||||
================================================================================
|
||||
开始熟悉每天的任务,像上网冲浪,听听音乐,还有扫描文档之类。
|
||||
|
||||
好好享受这份全面而综合的Ubuntu操作系统初学者指南吧。本教程适用于任何经验等级的人,跟着傻瓜式的指令一步一步操作吧。好好探索Ubuntu系统的潜力吧,你不会因为技术细节而陷入困境。
|
||||
|
||||
- [**开始使用Ubuntu 14.04 (PDF指南)**][1]
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/getting-started-with-ubuntu-14-04-pdf-guide.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://ubuntugeek.tradepub.com/free/w_ubun06/
|
||||
@ -0,0 +1,47 @@
|
||||
如何使用 Linux 从 Grooveshark 下载音乐
|
||||
================================================================================
|
||||
> 解决办法通常没有那么难
|
||||
|
||||

|
||||
|
||||
**Grooveshark 对于喜欢音乐的人来说是一个不错的在线平台,同时有多种从上面下载音乐的方法。Groovesquid 是众多允许用户从 Grooveshark 上下载音乐的应用之一,并且是支持多平台的。**
|
||||
|
||||
只要有在线流媒体服务,就一定有方法从获取你之前看过或听过的视频及音乐。即使下载接口关闭了,也不是什么大不了的事,因为还有很多种解决方法,无论你用的什么操作系统。比如,网络上就有许多种 YouTube 下载器,同样的道理,从 Grooveshark 上下载音乐也并非难事。
|
||||
|
||||
现在,得考虑合法性的问题。与许多其他应用一样,Groovesquid 并非是完全不合法的。如果有用户使用应用去做一些非法的事情,那责任应归咎于用户。同样的道理也适用于 utorrent 或者 Bittorrent。只要你不触及版权问题,那你就可以无所顾忌的使用 Groovesquid 了。
|
||||
|
||||
### 快捷高效的 Groovesquid ###
|
||||
|
||||
你能够找到的 Groovesquid 的唯一缺点是,它是基于 Java 而编写的,这从来都不是一个好的兆头。虽然为了确保应用的可移植性这样做确实是一个好方法,但这样做的结果导致了其糟糕的界面。确实是非常糟糕的的界面,不过这一点并不会影响到用户的使用体验,特别是这款应用所完成的工作时如此的有用。
|
||||
|
||||
有一点需要注意的地方。Groovesquid 是一款免费的应用,但为了将免费保持下去,它会在菜单栏的右侧显示一则广告。这对大多数人来说都应该不是问题,不过最好在打开应用后注意下菜单栏右侧。
|
||||
|
||||
从易用性的角度来看,这款应用非常简洁。用户可以通过在顶部地址栏里输入链接直接下载单曲,地址栏的位置可以通过其左侧的下拉菜单进行修改。在下拉菜单中,也可以修改为歌曲名称、流行度、专辑名称、播放列表以及艺术家。有些选项向你提供了诸如查看 Grooveshark 上最流行的音乐,或者下载整个播放列表等。
|
||||
|
||||
你可以下载 Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] 文件大小:3.8 MB
|
||||
- [tar.gz][2] 文件大小:549 KB
|
||||
|
||||
下载完 Jar 文件后,你所需要做的是将其权限修改为可执行,然后让 Java 来完成剩下的工作。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -1,72 +0,0 @@
|
||||
伴随苹果手表的揭幕,Ubuntu智能手表会成为下一个吗?
|
||||
===
|
||||
|
||||
**今天,苹果借助‘苹果手表’的发布,证实了其进军穿戴式计算设备市场的长期传言**
|
||||
|
||||

|
||||
|
||||
Ubuntu智能手表 - 好的主意?
|
||||
|
||||
拥有一系列稳定功能,硬件解决方案和应用合作伙伴关系的支持,手腕穿戴设备被许多公司预示为“人与技术关系的新篇章”。
|
||||
|
||||
它的到来,以及用户兴趣的提升,有可能意味着Ubuntu需要遵循一个为智能手表定制的Ubuntu版本。
|
||||
|
||||
### 大的方面还是成功的 ###
|
||||
|
||||
苹果在正确时间加入了快速发展的智能手表部门。约束手腕穿戴电脑功能的界限并不是一成不变。失败的设计,不良的用户界面以及主流用户使用穿戴技术功能的弱参数化,这些都见证了硬件种类保持着高效的影响力 - 一个准许Cupertino把时间花费在苹果手表上的因素。
|
||||
|
||||
> ‘分析师说:超过2200万的智能手表将在今年销售’
|
||||
|
||||
去年全球范围内可穿戴设备的销售数量(包括健身追踪器)仅仅1000万。今年,分析师希望设备数量的改变可以超过2200万 - 不包括苹果手表,因为其直到2015年初才开始零售。
|
||||
|
||||
很容易就可以看出增长的来源。今年九月初柏林举办的IFA 2014展览会,展示了一系列来自主要制造商们的可穿戴设备,包括索尼和华硕。大多数搭载着Google最新发布的安卓穿戴系统。
|
||||
|
||||
一个更加成熟的表现:安卓穿戴设备打破了与形式因素保持一致的新奇争论,进而呈现出一致并令人折服的用户方案。和新的苹果手表一样,它紧密地连接在一个现存的智能手机生态系统上。
|
||||
|
||||
可能它只是一个使用案例,Ubuntu手腕穿戴系统是否能匹配它还不清楚。
|
||||
|
||||
#### 目前还没有Ubuntu智能手表的计划 ####
|
||||
|
||||
Ubuntu操作系统的通用性,结合以为多装置设备和趋势性未来定制的严格版本,已经产生了典型目标智能电视,平板电脑和智能手机。Mir,公司的本土显示服务器,被用来运转所有尺寸屏幕上的接口(虽然不是公认1.5"的)
|
||||
|
||||
今年年初,Canonical社区负责人Jono Bacon被询问是否有制作Ubuntu智能手表的打算。Bacon提供了他对这个问题的看法:“增加另一个形式因素到[Ubuntu触摸设备]路线只会减缓其余的东西”。
|
||||
|
||||
在Ubuntu电话发布两周年之际,我们还是挺赞同他的想法的。
|
||||
|
||||
滴答,滴答,对冲你的赌注点(实在不懂什么意思...)
|
||||
|
||||
但是并不是没有希望的。在一个[几个月之后的电话采访][1]中,Ubuntu创始人Mark Shuttleworth提及到可穿戴技术和智能电视,平板电脑,智能手机一样,都在公司计划当中。
|
||||
|
||||
> “Ubuntu因其在电话中的完美设计变得独一无二,但是它同时也被设计成满足其余生态系统的样子,比如从穿戴设备到PC机。”
|
||||
|
||||
然而这还没得到具体的证实,它更像一个指针,在这个方向是给我们提供一个乐观的指引。
|
||||
|
||||
### 不可能 — 这就是原因所在 ###
|
||||
|
||||
Canonical并不反对利用牢固的专利进军市场。事实上,它的重要性犹如公司的DHA — 犹如服务器上的RHEL,桌面上的Windows,智能手机上的安卓...
|
||||
|
||||
设备上的Ubuntu系统被制作成可以在更小的屏幕上扩展和适应性运行。甚至很有可能在和手表一样小的屏幕上运行。当普通的代码基础已经在手机,平板电脑,桌面和TV上准备就绪,我想如果我们没有看到来自社区这一方向上的努力,我会感到奇怪。
|
||||
|
||||
但是我之所以不认为它会从规范社区发生,至少目前还没有,是今年早些时候Jono Bacon个人思想的共鸣:时间和努力。
|
||||
|
||||
Tim Cook在他的主题演讲中说道:“*我们并没有追随iPhone,也没有缩水用户界面,将其强硬捆绑在你的手腕上。*”这是一个很明显的陈述。为如此小的屏幕设计UI和UX模型;通过交互原则工作;对硬件和输入模式的恭维,都不是一件容易的事。
|
||||
|
||||
可穿戴技术仍然是一个新兴的市场。在这个阶段,Canonical将会浪费发展,设计以及进行中的业务。在一些更为紧迫的地区,任何利益的重要性将要超过损失。
|
||||
|
||||
玩一局更久的游戏,等待直到看出那些努力在何地成功和失败,这是一条更难的路线。但是更适合Ubuntu的就是今天。在新产品出现之前,让Canonical把力量用在现存的产品上是更好的选择(这是一些已经来迟的理论)
|
||||
|
||||
想更进一步了解什么是Ubuntu智能手表,点击下面的[视频][2]。它展示了一个互动的主体性皮肤Tizen(它已经支持Samsung Galaxy Gear智能手表)。
|
||||
|
||||
---
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/09/ubuntu-smartwatch-apple-iwatch
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:http://www.omgubuntu.co.uk/2014/03/ubuntu-tablets-coming-year
|
||||
[2]:https://www.youtube.com/embed/8Zf5dktXzEs?feature=oembed
|
||||
@ -1,82 +0,0 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
任何不关注Google 的人都不会相信Google在桌面用户当中扮演着一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon 一样,似乎ChromeOS 势不可挡。
|
||||
|
||||
在本文中,我们要了解的是ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,和整个 ChromeOS 对于linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个版本时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是linux 的一个派生操作系统,运行于Linux 内核的引擎之下。而很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux 分支版本。
|
||||
|
||||
尽管ChromeOS 的差异化越来越明显,是在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
就是说,每一个以Google-centric 为生活方式的人来说,在ChromeOS上的感觉将会非常良好,就好像是回家一样。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友使用ChromeOs 也就是很自然的事情了,就好像是他们很容易接受Chrome 浏览器,因为他们觉得早已经用过。
|
||||
|
||||
然而,对于Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择被限制,有范围的,在加上要想玩游戏和VoIP 是完全不可能的。那么对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS 还是Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对Linux 产生影响,只有在Linux 停下来浮出水面栖息的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现Linux 桌面系统最适合做网上技术支持来管理。比如说:家里的高级用户可以操作和处理更新政府和学校的IT 部门。Linux 还可以应用于这样的环境,Linux桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为Google 的ChromeOS 附带一个硬件脉冲,它允许“犯错误”。对于某些人来说,这是一个很奇妙的地方。
|
||||
|
||||
滑稽的是,有些人却宣称,ChomeOs 的远期的市场存在很多问题。简言之,这只是一些Linux 激情的爱好者在找对于ChomeOS 的抱怨罢了。在我看来,停止造谣这些子虚乌有的事情才是关键。
|
||||
|
||||
问题是:ChromeOS 的市场份额和Linux 桌面系统在很长的一段时间内是不同的。这个存在可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对ChromeOS 的电脑。命名为[Dell Chromebox][5],这款ChromeOS 设备将会是另一些传统设备的终结者。它没有软件光驱,没有反病毒软件,offers 能够无缝的在屏幕后面自动更新。对于一般的用户,Chromebox 和Chromebook 正逐渐成为那些工作在web 浏览器上的人的一个选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘的大小和严重依赖于云存储,并且ChromeOS 不会为了任何使用它们电脑的人消减基本的web 浏览器的功能。
|
||||
|
||||
### ChromeOS 和Linux 的异同点 ###
|
||||
|
||||
以前,我注意到ChromeOS 和Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于,Linux 社区的致力于提升Linux 桌面系统的脱机性能。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux 的问题”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,确保他们得到Linux 最多的帮助。
|
||||
|
||||
事实上,脱机故障可能是这样发现的:
|
||||
|
||||
- 有些用户偶然的在Linux 本地事件发现了Linux 的问题。
|
||||
- 他们带回了DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功的安装成功了这个进程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人希望在网上论坛里搜索帮助。很难做一个主计算机,没有网络和视频的问题。
|
||||
- 我真的是受够了,后来有很多失望的用户拿着他们的电脑到windows 商店来“维修”。除了重装一个windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边真实的事的,而且是经常发生。醒醒吧,Linux 社区的人们,我们的这种模式已经过时了。
|
||||
|
||||
### 伟大的平台,强大的营销和结论 ###
|
||||
|
||||
如果非要说ChromeOS 和Linux 桌面系统相同的地方,除了它们都使用了Linux 内核,就是它们都伟大的产品却拥有极其差劲的市场营销。而Google 的好处就是,他们投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的影响不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 历史上最大的一个失误之一。相信,如果你没有接触到他们在线的努力,你不值得困扰,仅仅就当是他们在是在选择网上存储空间上做出反击。
|
||||
|
||||
我的建议是:通过Google 的线下影响,提供Linux 桌面系统给ChromeOS 的市场。这就意味着Linux 社区的人需要筹集资金来出席县博览会、商场展览,在节日季节,和在社区中进行免费的教学课程。这会立即使Linux 桌面系统走入人们的视线,否则,最终将会是一个ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有想我说的这样,别担心。Linux 桌面系统的市场仍然会像ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -1,64 +0,0 @@
|
||||
Linux 上好用的几款字幕编辑器介绍
|
||||
================================================================================
|
||||
如果你经常看国外的大片,你应该会喜欢带字幕版本而不是有国语配音的版本。在法国长大,我的童年记忆里充满了迪斯尼电影。但是这些电影因为有了法语的配音而听起来很怪。如果现在有机会能看原始的版本,我知道,对于大多数的人来说,字幕还是必须的。我很高兴能为家人制作字幕。最让我感到希望的是,Linux 也不无花哨,而且有很多开源的字幕编辑器。总之一句话,这篇文章并不是一个详尽的Linux上字幕编辑器的列表。你可以告诉我那一款是你认为最好的字幕编辑器。
|
||||
|
||||
### 1. Gnome Subtitles ###
|
||||
|
||||

|
||||
|
||||
[Gnome Subtitles][1] 我的一个选择,当有字幕需要快速编辑时。你可以载入视频,载入字幕文本,然后就可以即刻开始了。我很欣赏其对于易用性和高级特性之间的平衡性。它带有一个同步工具以及一个拼写检查工具。最后,虽然最后,但并不是不重要,这么好用最主要的是因为它的快捷键:当你编辑很多的台词的时候,你最好把你的手放在键盘上,使用其内置的快捷键来移动。
|
||||
|
||||
### 2. Aegisub ###
|
||||
|
||||

|
||||
|
||||
[Aegisub][2] 有更高级别的复杂性。接口仅仅反映了学习曲线。但是,除了它吓人的样子以外,Aegisub 是一个非常完整的软件,提供的工具远远超出你能想象的。和Gnome Subtitles 一样,Aegisub也采用了所见即所得(WYSIWYG:what you see is what you get)的处理方式。但是是一个全新的高度:可以再屏幕上任意拖动字幕,也可以在另一边查看音频的频谱,并且可以利用快捷键做任何的事情。除此以外,它还带有一个汉字工具,有一个kalaok模式,并且你可以导入lua 脚本让它自动完成一些任务。我希望你在用之前,先去阅读下它的[指南][3]。
|
||||
|
||||
### 3. Gaupol ###
|
||||
|
||||

|
||||
|
||||
另一个操作复杂的软件是[Gaupol][4],不像Aegisub ,Gaupol 很容易上手而且采用了一个和Gnome Subtitles 很像的界面。但是在这些相对简单背后,它拥有很多很必要的工具:快捷键、第三方扩展、拼写检查,甚至是语音识别(由[CMU Sphinx][5]提供)。这里也提一个缺点,我注意到有时候在测试的时候也,软件会有消极怠工的表现,不是很严重,但是也足以让我更有理由喜欢Gnome Subtitles了。
|
||||
|
||||
### 4. Subtitle Editor ###
|
||||
|
||||

|
||||
|
||||
[Subtitle Editor][6]和Gaupol 很像。但是,它的界面有点不太直观,特性也只是稍微的高级一点点。我很欣赏的一点是,它可以定义“关键帧”,而且提供所有的同步选项。然而,多一点的图标,或者是少一点的文字都能提供界面的特性。作为一个好人,我认为,Subtitle Editor 可以模仿“作家”打字的效果,虽然我不知道它是否有用。最后但并非不重要。重定义快捷键的功能很实用。
|
||||
|
||||
### 5. Jubler ###
|
||||
|
||||

|
||||
|
||||
用Java 写的,[Jubler][7]是一个多平台支持的字幕编辑器。我对它的界面印象特别深刻。在上面我确实看出了Java-ish 方面的东西,但是,它仍然是经过精心的构造和构思的。像Aegisub 一样,你可以再屏幕上任意的拖动字幕,让你有愉快的体验而不单单是打字。它也可以为字幕自定义一个风格,在另外的一个轨道播放音频,翻译字幕,或者是是做拼写检查,然而,你必须要注意的是,你必须事先安装好媒体播放器并且正确的配置,如果你想完整的使用Jubler。我把这些归功于在[官方页面][8]下载了脚本以后其简便的安装方式。
|
||||
|
||||
### 6. Subtitle Composer ###
|
||||
|
||||

|
||||
|
||||
被视为“KDE里的字幕作曲家”,[Subtitle Composer][9]能够唤起对很多传统功能的回忆。伴随着KDE界面,我们很期望。很自然的我们就会说到快捷键,我特别喜欢这个功能。除此之外,Subtitle Composer 与上面提到的编辑器最大的不同地方就在于,它可以执行用JavaScript,Python,甚至是Ruby写成的脚本。软件带有几个例子,肯定能够帮助你很好的学习使用这些特性的语法。
|
||||
|
||||
最后,不管你喜不喜欢我,都要为你的家庭编辑几个字幕,重新同步整个轨道,或者是一切从头开始,那么Linux 有很好的工具给你。对我来说,快捷键和易用性使得各个工具有差异,想要更高级别的使用体验,脚本和语音识别就成了很便利的一个功能。
|
||||
|
||||
你会使用哪个字幕编辑器,为什么?你认为还有没有更好用的字幕编辑器这里没有提到的?在评论里告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/good-subtitle-editor-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://gnomesubtitles.org/
|
||||
[2]:http://www.aegisub.org/
|
||||
[3]:http://docs.aegisub.org/3.2/Main_Page/
|
||||
[4]:http://home.gna.org/gaupol/
|
||||
[5]:http://cmusphinx.sourceforge.net/
|
||||
[6]:http://home.gna.org/subtitleeditor/
|
||||
[7]:http://www.jubler.org/
|
||||
[8]:http://www.jubler.org/download.html
|
||||
[9]:http://sourceforge.net/projects/subcomposer/
|
||||
@ -1,65 +0,0 @@
|
||||
黑客年暮
|
||||
================================================================================
|
||||
近来我一直在与某资深开源组织的各成员进行争斗,尽管密切关注我的人们会在读完本文后猜到是哪个组织,但我不会在这里说出这个组织的名字。
|
||||
|
||||
怎么让某些人进入 21 世纪就这么难呢?真是的...
|
||||
|
||||
我快56 岁了,也就是大部分年轻人会以为的我将时不时朝他们发出诸如“滚出我的草坪”之类歇斯底里咆哮的年龄。但事实并非如此 —— 我发现,尤其是在技术背景之下,我变得与我的年龄非常不相称。
|
||||
|
||||
在我这个年龄的大部分人确实变成了爱发牢骚、墨守成规的老顽固。并且,尴尬的是,偶尔我会成为那个打断谈话的人,然后提出在 1995 年(或者在某些特殊情况下,1985 年)时很适合的方法... 但十年后就不是个好方法了。
|
||||
|
||||
为什么是我?因为我的同龄人里大部分人在孩童时期都没有什么名气。任何想要改变自己的人,就必须成为他们中具有较高思想觉悟的佼佼者。即便如此,在与习惯做斗争的过程中,我也比实际上花费了更多的时间。
|
||||
|
||||
年轻人犯下无知的错误是可以被原谅的。他们还年轻。年轻意味着缺乏经验,缺乏经验通常会导致片面的判断。我很难原谅那些经历了足够多本该有经验的人,却被<em>长期的固化思维</em>蒙蔽,无法发觉近在咫尺的东西。
|
||||
|
||||
(补充一下:我真的不是老顽固。那些和我争论政治的,无论保守派还是非保守派都没有注意到这点,我觉得这颇有点嘲讽的意味。)
|
||||
|
||||
那么,现在我们来讨论下 GNU 更新日志文件这件事。在 1985 年的时候,这是一个不错的主意,甚至可以说是必须的。当时的想法是用单独的更新日志文件来记录相关文件的变更情况。用这种方式来对那些存在版本缺失或者非常原始的版本进行版本控制确实不错。当时我也在场,所以我知道这些。
|
||||
|
||||
不过即使到了 1995 年,甚至 21 世纪早期,许多版本控制系统仍然没有太大改进。也就是说,这些版本控制系统并非对批量文件的变化进行分组再保存到一条记录上,而是对每个变化的文件分别进行记录并保存到不同的地方。CVS,当时被广泛使用的版本控制系统,仅仅是模拟日志变更 —— 并且在这方面表现得很糟糕,导致大多数人不再依赖这个功能。即便如此,更新日志文件的出现依然是必要的。
|
||||
|
||||
但随后,版本控制系统 Subversion 于 2003 年发布 beta 版,并于 2004 年发布 1.0 正式版,Subversion 真正实现了更新日志记录功能,得到了人们的广泛认可。它与一年后兴起的分散式版本控制系统(Distributed Version Control System,DVCS)共同引发了主流世界的激烈争论。因为如果你在项目上同时使用了分散式版本控制与更新日志文件记录的功能,它们将会因为争夺相同元数据的控制权而产生不可预料的冲突。
|
||||
|
||||
另一种方法是对提交的评论日志进行授权。如果你这样做了,不久后你就会开始思忖为什么自己仍然对所有的日志更新条目进行记录。提交的元数据与变化的代码具有更好的相容性,毕竟这就是它当初设计的目的。
|
||||
|
||||
(现在,试想有这样一个项目,同样本着把项目做得最好的想法,但两拨人却做出了完全不同的选择。因此你必须同时阅读更新日志和评论日志以了解到底发生了什么。最好在矛盾激化前把问题解决....)
|
||||
|
||||
第三种办法是尝试同时使用两种方法 —— 以另一种格式再次提交评论数据,作为更新日志提交的一部分。这解决了所有你期待的有代表性的问题,并且没有任何缺陷遗留下来;只要其中有拷贝文件损坏,日志文件就会修改,因此这不再是同步时数据匹配的问题,而且导致在其后参与进来的人试图搞清人们是怎么想的时候将会变得非常困惑。
|
||||
|
||||
或者,如某个<em>我就不说出具体名字的特定项目</em>的高层开发只是通过电子邮件来完成这些,声明提交可以包含多个更新日志,以及提交的元数据与更新日志是无关的。这导致我们直到现在还得不断进行记录。
|
||||
|
||||
当我读到那条的时候我的眼光停在了那个地方。什么样的傻瓜才会没有意识到这是在自找麻烦 —— 事实上,针对更新日志文件采取的定制措施完全是不必要的,尤其是在分散式版本控制系统中
|
||||
有很好的浏览工具来阅读可靠的提交日志的时候。
|
||||
|
||||
唉,这是比较特殊的笨蛋:变老的并且思维僵化了的黑客。所有的合理化改革他都会极力反对。他所遵循的行事方法在十年前是有效的,但现在只能使得其反了。如果你试图解释不只是git的总摘要,还得正确掌握当前的各种工具才能完全弃用更新日志... 呵呵,准备好迎接无法忍受、无法想象的疯狂对话吧。
|
||||
|
||||
幸运的是这激怒了我。因为这点还有其他相关的胡言乱语使这个项目变成了很难完成的工作。而且,这类糟糕的事时常发生在年轻的开发者身上,这才是问题所在。相关 G+ 社群的数量已经达到了 4 位数,他们大部分都是孩子,他们也没有紧张起来。显然消息已经传到了外面;这个项目的开发者都是被莫名关注者的老牌黑客,同时还有很多对他们崇拜的人。
|
||||
|
||||
这件事给我的最大触动就是每当我要和这些老牌黑客较量时,我都会想:有一天我也会这样吗?或者更糟的是,我看到的只是如同镜子一般对我自己的真实写照,而我自己却浑然不觉吗?我的意思是,我的印象来自于他的网站,这个特殊的样本要比我年轻。通过十五年的仔细观察得出的结论。
|
||||
|
||||
我觉得思路很清晰。当我和那些比我聪明的人打交道时我不会受挫,我只会因为那些不能跟上我的人而
|
||||
沮丧,这些人也不能看见事实。但这种自信也许只是邓宁·克鲁格效应的消极影响,至少我明白这点。很少有什么事情会让我感到害怕;而这件事在让我害怕的事情名单上是名列前茅的。
|
||||
|
||||
另一件让人不安的事是当我逐渐变老的时候,这样的矛盾发生得越来越频繁。不知怎的,我希望我的黑客同行们能以更加优雅的姿态老去,即使身体老去也应该保持一颗年轻的心灵。有些人确实是这样;但可是绝大多数人都不是。真令人悲哀。
|
||||
|
||||
我不确定我的职业生涯会不会完美收场。假如我最后成功避免了思维僵化(注意我说的是假如),我想我一定知道其中的部分原因,但我不确定这种模式是否可以被复制 —— 为了达成目的也许得在你的头脑中发生一些复杂的化学反应。尽管如此,无论对错,请听听我给年轻黑客以及其他有志青年的建议。
|
||||
|
||||
你们 —— 对的,也包括你 —— 一定无法在你中年老年的时候保持不错的心灵,除非你能很好的控制这点。你必须不断地去磨练你的内心、在你还年轻的时候完成自己的种种心愿,你必须把这些行为养成一种习惯直到你老去。
|
||||
|
||||
有种说法是中年人锻炼身体的最佳时机是他进入中年的 30 年前。我以为同样的方法,坚持我以上所说的习惯能让你在 56 岁,甚至 65 岁的时候仍然保持灵活的头脑。挑战你的极限,使不断地挑战自己成为一种习惯。立刻离开安乐窝,由此当你以后真正需要它的时候你可以建立起自己的安乐窝。
|
||||
|
||||
你必须要清楚的了解这点;还有一个可选择的挑战是你选择一个可以实现的目标并且为了这个目标不断努力。这个月我要学习 Go 语言。不是指游戏,我早就玩儿过了(虽然玩儿的不是太好)。并不是因为工作需要,而是因为我觉得是时候来扩展下我自己了。
|
||||
|
||||
保持这个习惯。永远不要放弃。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=6485
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[Stevearzh](https://github.com/Stevearzh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
@ -0,0 +1,155 @@
|
||||
如何使用Aptik来备份和恢复Ubuntu中的Apps和PPAs
|
||||
================================================================================
|
||||

|
||||
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,寻到一个便捷的方法去重新安装之前的应用并且重置其设置是很有用的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
|
||||
Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用及其主题和设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
|
||||
注意:当我们在此文章中说到输入某些东西的时候,如果被输入的内容被引号包裹,请不要将引号一起输入进去,除非我们有特殊说明。
|
||||
|
||||
想要安装Aptik,需要先添加其PPA。使用Ctrl + Alt + T快捷键打开一个新的终端窗口。输入以下文字,并按回车执行。
|
||||
|
||||
sudo apt-add-repository –y ppa:teejee2008/ppa
|
||||
|
||||
当提示输入密码的时候,输入你的密码然后按回车。
|
||||
|
||||

|
||||
|
||||
输入下边的命令到提示符旁边,来确保资源库已经是最新版本。
|
||||
|
||||
sudo apt-get update
|
||||
|
||||

|
||||
|
||||
更新完毕后,你就完成了安装Aptik的准备工作。接下来输入以下命令并按回车:
|
||||
|
||||
sudo apt-get install aptik
|
||||
|
||||
注意:你可能会看到一些有关于获取不到包更新的错误提示。不过别担心,如果这些提示看起来跟下边图片中类似的话,你的Aptik的安装就没有任何问题。
|
||||
|
||||

|
||||
|
||||
安装过程会被显示出来。其中一个被显示出来的消息会提到此次安装会使用掉多少磁盘空间,然后提示你是否要继续,按下“y”再按回车,继续安装。
|
||||
|
||||

|
||||
|
||||
当安装完成后,输入“Exit”并按回车或者按下左上角的“X”按钮,关闭终端窗口。
|
||||
|
||||

|
||||
|
||||
在正式运行Aptik前,你需要设置好备份目录到一个U盘、网络驱动器或者类似于Dropbox和Google Drive的云帐号上。这儿的例子中,我们使用的是Dropbox。
|
||||
|
||||

|
||||
|
||||
一旦设置好备份目录,点击启动栏上方的“Search”按钮。
|
||||
|
||||

|
||||
|
||||
在搜索框中键入 “aptik”。结果会随着你的输入显示出来。当Aptik图标显示出来的时候,点击它打开应用。
|
||||
|
||||

|
||||
|
||||
此时一个对话框会显示出来要求你输入密码。输入你的密码并按“OK”按钮。
|
||||
|
||||

|
||||
|
||||
Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选择“Other…”。这个操作允许你选择你已经建立好的备份目录。
|
||||
|
||||
注意:在下拉列表的右侧的 “Open” 按钮会在一个文件管理窗口中打开选择目录功能。
|
||||
|
||||

|
||||
|
||||
在 “Backup Directory” 对话窗口中,定位到你的备份目录,然后按“Open”。
|
||||
|
||||
注意:如果此时你尚未建立备份目录或者想在备份目录中新建个子目录,你可以点“Create Folder”来新建目录。
|
||||
|
||||

|
||||
|
||||
点击“Software Sources (PPAs).”右侧的 “Backup”来备份已安装的PPAs。
|
||||
|
||||

|
||||
|
||||
然后“Backup Software Sources”对话窗口显示出来。已安装的包和对应的源(PPA)同时也显示出来了。选择你需要备份的源(PPAs),或者点“Select All”按钮选择所有源。
|
||||
|
||||

|
||||
|
||||
点击 “Backup” 开始备份。
|
||||
|
||||

|
||||
|
||||
备份完成后,一个提示你备份完成的对话窗口会蹦出来。点击 “OK” 关掉。
|
||||
|
||||
一个名为“ppa.list”的文件出现在了备份目录中。
|
||||
|
||||

|
||||
|
||||
接下来,“Downloaded Packages (APT Cache)”的项目只对重装同样版本的Ubuntu有用处。它会备份下你系统缓存(/var/cache/apt/archives)中的包。如果你是升级系统的话,可以跳过这个条目,因为针对新系统的包会比现有系统缓存中的包更加新一些。
|
||||
|
||||
备份和回复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
|
||||
如果你是重装相同版本的Ubuntu系统的话,点击 “Downloaded Packages (APT Cache)” 右侧的 “Backup” 按钮来备份系统缓存中的包。
|
||||
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
|
||||

|
||||
|
||||
有一些包是你的Ubuntu发行版的一部分。因为安装Ubuntu系统的时候会自动安装它们,所以它们是不会被备份下来的。例如,火狐浏览器在Ubuntu和其他类似Linux发行版上都是默认被安装的,所以默认情况下,它不会被选择备份。
|
||||
|
||||
像[package for the Chrome web browser][1]这种系统安装完后才安装的包或者包含 Aptik 的包会默认被选择上。这可以方便你备份这些后安装的包。
|
||||
|
||||
按照需要选择想要备份的包。点击 “Software Selections” 右侧的 “Backup” 按钮备份顶层包。
|
||||
|
||||
注意:依赖包不会出现在这个备份中。
|
||||
|
||||

|
||||
|
||||
名为 “packages.list” and “packages-installed.list” 的两个文件出现在了备份目录中,并且一个用来通知你备份完成的对话框出现。点击 ”OK“关闭它。
|
||||
|
||||
注意:“packages-installed.list”文件包含了所有的包,而 “packages.list” 在包含了所有包的前提下还指出了那些包被选择上了。
|
||||
|
||||

|
||||
|
||||
要备份已安装软件的设置的话,点击 Aptik 主界面 “Application Settings” 右侧的 “Backup” 按钮,选择你要备份的设置,点击“Backup”。
|
||||
|
||||
注意:如果你要选择所有设置,点击“Select All”按钮。
|
||||
|
||||

|
||||
|
||||
被选择的配置文件统一被打包到一个名叫 “app-settings.tar.gz” 的文件中。
|
||||
|
||||

|
||||
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击”OK“,关掉。
|
||||
|
||||

|
||||
|
||||
来自 “/usr/share/themes” 目录的主题和来自 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要取消到一些然后点击 “Backup” 进行备份。
|
||||
|
||||

|
||||
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击”OK“关闭它。
|
||||
|
||||

|
||||
|
||||
一旦你完成了需要的备份,点击主界面左上角的”X“关闭 Aptik 。
|
||||
|
||||

|
||||
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时取阅。
|
||||
|
||||

|
||||
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中让其可被使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppas-in-ubuntu-using-aptik/
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/203768
|
||||
@ -0,0 +1,275 @@
|
||||
如何在 Linux 上使用 HAProxy 配置 HTTP 负载均衡器
|
||||
================================================================================
|
||||
随着基于 Web 的应用和服务的增多,IT 系统管理员肩上的责任也越来越重。当遇到不可预期的事件如流量达到高峰,流量增大或者内部的挑战比如硬件的损坏或紧急维修,无论如何,你的 Web 应用都必须要保持可用性。甚至现在流行的 devops 和持续交付也可能威胁到你的 Web 服务的可靠性和性能的一致性。
|
||||
|
||||
不可预测,不一直的性能表现是你无法接受的。但是我们怎样消除这些缺点呢?大多数情况下一个合适的负载均衡解决方案可以解决这个问题。今天我会给你们介绍如何使用 [HAProxy][1] 配置 HTTP 负载均衡器。
|
||||
|
||||
###什么是 HTTP 负载均衡? ###
|
||||
|
||||
HTTP 负载均衡是一个网络解决方案,它将发入的 HTTP 或 HTTPs 请求分配至一组提供相同的 Web 应用内容的服务器用于响应。通过将请求在这样的多个服务器间进行均衡,负载均衡器可以防止服务器出现单点故障,可以提升整体的可用性和响应速度。它还可以让你能够简单的通过添加或者移除服务器来进行横向扩展或收缩,对工作负载进行调整。
|
||||
|
||||
### 什么时候,什么情况下需要使用负载均衡? ###
|
||||
|
||||
负载均衡可以提升服务器的使用性能和最大可用性,当你的服务器开始出现高负载时就可以使用负载均衡。或者你在为一个大型项目设计架构时,在前端使用负载均衡是一个很好的习惯。当你的环境需要扩展的时候它会很有用。
|
||||
|
||||
|
||||
### 什么是 HAProxy? ###
|
||||
|
||||
HAProxy 是一个流行的开源的 GNU/Linux 平台下的 TCP/HTTP 服务器的负载均衡和代理软件。HAProxy 是单线程,事件驱动架构,可以轻松的处理 [10 Gbps 速率][2] 的流量,在生产环境中被广泛的使用。它的功能包括自动健康状态检查,自定义负载均衡算法,HTTPS/SSL 支持,会话速率限制等等。
|
||||
|
||||
### 这个教程要实现怎样的负载均衡 ###
|
||||
|
||||
在这个教程中,我们会为 HTTP Web 服务器配置一个基于 HAProxy 的负载均衡。
|
||||
|
||||
### 准备条件 ###
|
||||
|
||||
你至少要有一台,或者最好是两台 Web 服务器来验证你的负载均衡的功能。我们假设后端的 HTTP Web 服务器已经配置好并[可以运行][3]。
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
### 在 Linux 中安装 HAProxy ###
|
||||
|
||||
对于大多数的发行版,我们可以使用发行版的包管理器来安装 HAProxy。
|
||||
|
||||
#### 在 Debian 中安装 HAProxy ####
|
||||
|
||||
在 Debian Wheezy 中我们需要添加源,在 /etc/apt/sources.list.d 下创建一个文件 "backports.list" ,写入下面的内容
|
||||
|
||||
deb http://cdn.debian.net/debian wheezybackports main
|
||||
|
||||
刷新仓库的数据,并安装 HAProxy
|
||||
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 Ubuntu 中安装 HAProxy ####
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### 在 CentOS 和 RHEL 中安装 HAProxy ####
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### 配置 HAProxy ###
|
||||
|
||||
本教程假设有两台运行的 HTTP Web 服务器,它们的 IP 地址是 192.168.100.2 和 192.168.100.3。我们将负载均衡配置在 192.168.100.4 的这台服务器上。
|
||||
|
||||
为了让 HAProxy 工作正常,你需要修改 /etc/haproxy/haproxy.cfg 中的一些选项。我们会在这一节中解释这些修改。一些配置可能因 GNU/Linux 发行版的不同而变化,这些会被标注出来。
|
||||
|
||||
#### 1. 配置日志功能 ####
|
||||
|
||||
你要做的第一件事是为 HAProxy 配置日志功能,在排错时日志将很有用。日志配置可以在 /etc/haproxy/haproxy.cfg 的 global 段中找到他们。下面是针对不同的 Linux 发型版的 HAProxy 日志配置。
|
||||
|
||||
**CentOS 或 RHEL:**
|
||||
|
||||
在 CentOS/RHEL中启用日志,将下面的:
|
||||
|
||||
log 127.0.0.1 local2
|
||||
|
||||
替换为:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
然后配置 HAProxy 在 /var/log 中的日志分割,我们需要修改当前的 rsyslog 配置。为了简洁和明了,我们在 /etc/rsyslog.d 下创建一个叫 haproxy.conf 的文件,添加下面的内容:
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
这个配置会基于 $template 在 /var/log 中分割 HAProxy 日志。现在重启 rsyslog 应用这些更改。
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian 或 Ubuntu:**
|
||||
|
||||
在 Debian 或 Ubuntu 中启用日志,将下面的内容
|
||||
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
|
||||
替换为:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
然后为 HAProxy 配置日志分割,编辑 /etc/rsyslog.d/ 下的 haproxy.conf (在 Debian 中可能叫 49-haproxy.conf),写入下面你的内容
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
这个配置会基于 $template 在 /var/log 中分割 HAProxy 日志。现在重启 rsyslog 应用这些更改。
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. 设置默认选项 ####
|
||||
|
||||
下一步是设置 HAProxy 的默认选项。在 /etc/haproxy/haproxy.cfg 的 default 段中,替换为下面的配置:
|
||||
|
||||
defaults
|
||||
log global
|
||||
mode http
|
||||
option httplog
|
||||
option dontlognull
|
||||
retries 3
|
||||
option redispatch
|
||||
maxconn 20000
|
||||
contimeout 5000
|
||||
clitimeout 50000
|
||||
srvtimeout 50000
|
||||
|
||||
上面的配置是当 HAProxy 为 HTTP 负载均衡时建议使用的,但是并不一定是你的环境的最优方案。你可以自己研究 HAProxy 的手册并配置它。
|
||||
|
||||
#### 3. Web 集群配置 ####
|
||||
|
||||
Web 集群配置定义了一组可用的 HTTP 服务器。我们的负载均衡中的大多数设置都在这里。现在我们会创建一些基本配置,定义我们的节点。将配置文件中从 frontend 段开始的内容全部替换为下面的:
|
||||
|
||||
listen webfarm *:80
|
||||
mode http
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
balance roundrobin
|
||||
cookie LBN insert indirect nocache
|
||||
option httpclose
|
||||
option forwardfor
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
"listen webfarm *:80" 定义了负载均衡器监听的地址和端口。为了教程的需要,我设置为 "\*" 表示监听在所有接口上。在真实的场景汇总,这样设置可能不太合适,应该替换为可以从 internet 访问的那个网卡接口。
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
上面的设置定义了,负载均衡器的状态统计信息可以通过 http://<load-balancer-IP>/haproxy?stats 访问。访问需要简单的 HTTP 认证,用户名为 "haproxy" 密码为 "stats"。这些设置可以替换为你自己的认证方式。如果你不需要状态统计信息,可以完全禁用掉。
|
||||
|
||||
下面是一个 HAProxy 统计信息的例子
|
||||
|
||||

|
||||
|
||||
"balance roundrobin" 这一行表明我们使用的负载均衡类型。这个教程中,我们使用简单的轮询算法,可以完全满足 HTTP 负载均衡的需要。HAProxy 还提供其他的负载均衡类型:
|
||||
|
||||
- **leastconn**:将请求调度至连接数最少的服务器
|
||||
- **source**:对请求的客户端 IP 地址进行哈希计算,根据哈希值和服务器的权重将请求调度至后端服务器。
|
||||
- **uri**:对 URI 的左半部分(问号之前的部分)进行哈希,根据哈希结果和服务器的权重对请求进行调度
|
||||
- **url_param**:根据每个 HTTP GET 请求的 URL 查询参数进行调度,使用固定的请求参数将会被调度至指定的服务器上
|
||||
- **hdr(name**):根据 HTTP 首部中的 <name> 字段来进行调度
|
||||
|
||||
"cookie LBN insert indirect nocache" 这一行表示我们的负载均衡器会存储 cookie 信息,可以将后端服务器池中的节点与某个特定会话绑定。节点的 cookie 存储为一个自定义的名字。这里,我们使用的是 "LBN",你可以指定其他的名称。后端节点会保存这个 cookie 的会话。
|
||||
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
上面是我们的 Web 服务器节点的定义。服务器有由内部名称(如web01,web02),IP 地址和唯一的 cookie 字符串表示。cookie 字符串可以自定义,我这里使用的是简单的 node1,node2 ... node(n)
|
||||
|
||||
### 启动 HAProxy ###
|
||||
|
||||
如果你完成了配置,现在启动 HAProxy 并验证是否运行正常。
|
||||
|
||||
#### 在 Centos/RHEL 中启动 HAProxy ####
|
||||
|
||||
让 HAProxy 开机自启,使用下面的命令
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
当然,防火墙需要开放 80 端口,想下面这样
|
||||
|
||||
**CentOS/RHEL 7 的防火墙**
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**CentOS/RHEL 6 的防火墙**
|
||||
|
||||
把下面内容加至 /etc/sysconfig/iptables 中的 ":OUTPUT ACCEPT" 段中
|
||||
|
||||
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
|
||||
|
||||
重启**iptables**:
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### 在 Debian 中启动 HAProxy ####
|
||||
|
||||
#### 启动 HAProxy ####
|
||||
|
||||
# service haproxy start
|
||||
|
||||
不要忘了防火墙开放 80 端口,在 /etc/iptables.up.rules 中加入:
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### 在 Ubuntu 中启动HAProxy ####
|
||||
|
||||
让 HAProxy 开机自动启动在 /etc/default/haproxy 中配置
|
||||
|
||||
ENABLED=1
|
||||
|
||||
启动 HAProxy:
|
||||
|
||||
# service haproxy start
|
||||
|
||||
防火墙开放 80 端口:
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### 测试 HAProxy ###
|
||||
|
||||
检查 HAProxy 是否工作正常,我们可以这样做
|
||||
|
||||
首先准备一个 test.php 文件,文件内容如下
|
||||
|
||||
<?php
|
||||
header('Content-Type: text/plain');
|
||||
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
|
||||
echo "\nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
|
||||
?>
|
||||
|
||||
这个 PHP 文件会告诉我们哪台服务器(如负载均衡)转发了请求,哪台后端 Web 服务器实际处理了请求。
|
||||
|
||||
将这个 PHP 文件放到两个后端 Web 服务器的 Web 根目录中。然后用 curl 命令通过负载均衡器(192.168.100.4)访问这个文件
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
我们多次使用这个命令此时,会发现交替的输出下面的内容(因为使用了轮询算法):
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
----------
|
||||
|
||||
Server IP: 192.168.100.3
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
如果我们停掉一台后端 Web 服务,curl 命令仍然正常工作,请求被分发至另一台可用的 Web 服务器。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
现在你有了一个完全可用的负载均衡器,以轮询的模式对你的 Web 节点进行负载均衡。还可以去实验其他的配置选项以适应你的环境。希望这个教程可以帮会组你们的 Web 项目有更好的可用性。
|
||||
|
||||
你可能已经发现了,这个教程只包含单台负载均衡的设置。这意味着我们仍然有单点故障的问题。在真实场景中,你应该至少部署 2 台或者 3 台负载均衡以防止意外发生,但这不是本教程的范围。
|
||||
|
||||
如果 你有任何问题或建议,请在评论中提出,我会尽我的努力回答。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[Liao](https://github.com/liaoishere)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
@ -0,0 +1,87 @@
|
||||
如何在Ubuntu上转换图片音频和视频格式
|
||||
================================================================================
|
||||
|
||||
如果你的工作中需要接触到各种不同编码格式的图片、音频和视频,那么你或许正在使用多个工具来转换这些不同的媒介格式。如果存在一个能够处理所有文件/音频/视频格式的多和一的转换工具,那就太好了。
|
||||
|
||||
[Format Junkie][1] 就是这样一个有着极其友好的用户界面的多和一的媒介转换工具。更棒的是它是一个免费软件。你可以使用 Format Junkie 来转换几乎所有的流行格式的图像、音频、视频和归档文件(或称压缩文件),所有这些只需要简单地点击几下鼠标而已。
|
||||
|
||||
### 在Ubuntu 12.04, 12.10 和 13.04 上安装 Format Junkie ###
|
||||
|
||||
Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PPA支持Ubuntu 12.04, 12.10 和 13.04。在以上任意一种Ubuntu版本中安装Format Junkie的话,简单的执行一下命令即可:
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 13.10 ###
|
||||
|
||||
如果你正在运行Ubuntu 13.10 (Saucy Salamander),你可以按照以下步骤下载 .deb 安装包来进行安装。由于Format Junkie 的 .deb 安装包只有很少的依赖包,所以使用 [gdebi deb installer][2] 来按安装它。
|
||||
|
||||
在32位版Ubuntu 13.10上:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_i386.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
在32位版Ubuntu 13.10上:
|
||||
|
||||
$ wget https://launchpad.net/~format-junkie-team/+archive/release/+files/formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 14.04 或 之后版本 ###
|
||||
|
||||
现有的可供使用的官方 Format Junkie .deb 文件 需要 libavcodec-extra-53,这个东西从Ubuntu 14.04开始就已经过时了。所以如果你想在Ubuntu 14.04或之后版本上安装Format Junkie的话,可以使用以下的第三方PPA来代替。
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install formatjunkie
|
||||
|
||||
### 如何使用 Format Junkie ###
|
||||
|
||||
安装完成后,只需运行以下命令即可启动 Format Junkie:
|
||||
|
||||
$ formatjunkie
|
||||
|
||||
#### 使用 Format Junkie 来转换音频、视频、图像和归档格式 ####
|
||||
|
||||
就像下方展示的一样,Format Junkie 的用户界面简单而且直观。在音频、视频、图像和iso媒介之间进行选择,在顶部四个标签当中点击你需要的那个。你可以根据需要添加无限量的文件用于批量转换。添加文件后,选择输出格式,直接点击 "Start Converting" 按钮进行转换。
|
||||
|
||||

|
||||
|
||||
Format Junkie支持以下媒介媒介媒介格式间的转换:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
- **Image**: jpg, png, ico, bmp, svg, tif, pcx, pdf, tga, pnm.
|
||||
- **Archive**: iso, cso.
|
||||
|
||||
#### 用 Format Junkie 进行字幕编码 ####
|
||||
|
||||
除了媒介转换,Format Junkie 可提供了字幕编码的图形界面。实际的字幕编码是由MEncoder来完成的。为了使用Format Junkie的字幕编码接口,首先你需要安装MEencoder。
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
然后点击Format Junkie 中的 "Advanced"标签。选择 AVI/subtitle 文件来进行编码,如下所示:
|
||||
|
||||

|
||||
|
||||
总而言之,Format Junkie 是一个非常易于使用和多才多艺的媒介转换工具。但也有一个缺陷,它不允许对转换进行任何定制化(例如:比特率,帧率,采样频率,图像质量,尺寸)。所以这个工具推荐正在寻找一个简单易用的媒介转换工具的新手使用。
|
||||
|
||||
喜欢这篇文章吗?在facebook、twitter和google+上给我点赞吧。多谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:https://launchpad.net/format-junkie
|
||||
[2]:http://xmodulo.com/how-to-install-deb-file-with-dependencies.html
|
||||
@ -1,365 +0,0 @@
|
||||
How to turn your CentOS box into a BGP router using Quagga
|
||||
如何使用Quagga把你的CentOS系统变成一个BGP路由器?
|
||||
================================================================================
|
||||
|
||||
|
||||
在[之前的教程中][1](注:此文原文做过,文件名:“20140928 How to turn your CentOS box into an OSPF router using Quagga.md”,如果前面翻译发布了,可以修改此链接),我对如何简单地使用Quagga把CentOS系统变成一个不折不扣地OSPF路由器做了一些描述,Quagga是一个开源路由软件套件.在这个教程中,我将会着重**把一个Linux系统变成一个BGP路由器,又是使用Quagga**,演示如何建立BGP与其它BGP路由器对等.
|
||||
|
||||
|
||||
在我们进入细节之前,一些BGP的背景知识还是必要的.边界网关协议(或者BGP)是互联网的域间路由协议的实际标准。在BGP术语中,全球互联网是由成千上万相关联的自治系统(ASE)组成,其中每一个AS代表每一个特定运营商提供的一个网络管理域.
|
||||
|
||||
|
||||
|
||||
为了使其网络在全球范围内路由可达,每一个AS需要知道如何在英特网中到达其它的AS.这时候BGP出来取代这个角色了.BGP作为一种语言用于一个AS去与相邻的AS交换路由信息的一种工具.这些路由信息通常被称为BGP线路或者BGP前缀,包括AS号(ASN;全球唯一号码)以及相关的IP地址块.一旦所有的BGP线路被当地的BGP路由表学习和填充,每一个AS将会知道如何到达互联网的任何公网IP.
|
||||
|
||||
|
||||
路由在不同域(ASes)的能力是BGP被称为外部网关协议(EGP)或者域间协议的主要原因.就如一些路由协议例如OSPF,IS-IS,RIP和EIGRP都是内部网关协议(IGPs)或者域内路由协议.
|
||||
|
||||
|
||||
### 测试方案 ###
|
||||
|
||||
|
||||
在这个教程中,让我们来关注以下拓扑.
|
||||
|
||||

|
||||
|
||||
|
||||
我们假设运营商A想要建立一个BGP来与运营商B对等交换路由.它们的AS号和IP地址空间登细节如下所示.
|
||||
|
||||
- **运营商 A**: ASN (100), IP地址空间 (100.100.0.0/22), 分配给BGP路由器eth1网卡的IP地址(100.100.1.1)
|
||||
|
||||
|
||||
- **运营商 B**: ASN (200), IP地址空间 (200.200.0.0/22), 分配给BGP路由器eth1网卡的IP地址(200.200.1.1)
|
||||
|
||||
|
||||
路由器A和路由器B使用100.100.0.0/30子网来连接到对方.从理论上来说,任何子网从运营商那里都是可达的,可互连的.在真实场景中,建议使用掩码为30位的公网IP地址空间来实现运营商A和运营商B之间的连通.
|
||||
|
||||
|
||||
### 在 CentOS中安装Quagga ###
|
||||
|
||||
如果Quagga还没被安装,我们可以使用yum来安装Quagga.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
|
||||
如果你正在使用的是CentOS7系统,你需要应用一下策略来设置SELinux.否则,SElinux将会阻止Zebra守护进程写入它的配置目录.如果你正在使用的是CentOS6,你可以跳过这一步.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
|
||||
|
||||
Quagga软件套件包含几个守护进程,这些进程可以一起工作.关于BGP路由,我们将把重点放在建立一下2个守护进程.
|
||||
|
||||
|
||||
- **Zebra**:一个核心守护进程用于内核接口和静态路由.
|
||||
- **BGPd**:一个BGP守护进程.
|
||||
|
||||
|
||||
### 配置日志记录 ###
|
||||
|
||||
在Quagga被安装后,下一步就是配置Zebra来管理BGP路由器的网络接口.我们通过创建一个Zebra配置文件和启用日志记录来开始第一步.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
|
||||
在CentOS7系统中:
|
||||
# systemctl start zebra
|
||||
# systemctl enable zebra
|
||||
|
||||
|
||||
Quagga提供了一个叫做vtysh特有的命令行工具,你可以输入路由器厂商(例如Cisco和Juniper)兼容和支持的命令.我们将使用vtysh shell来配置BGP路由在教程的其余部分.
|
||||
|
||||
启动vtysh shell 命令,输入:
|
||||
|
||||
# vtysh
|
||||
|
||||
|
||||
提示将被改成主机名,这表明你是在vtysh shell中.
|
||||
|
||||
|
||||
Router-A#
|
||||
|
||||
现在我们将使用以下命令来为Zebra配置日志文件:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# log file /var/log/quagga/quagga.log
|
||||
Router-A(config)# exit
|
||||
|
||||
永久保存Zebra配置:
|
||||
|
||||
Router-A# write
|
||||
|
||||
在路由器B操作同样的步骤.
|
||||
|
||||
|
||||
### 配置对等的IP地址 ###
|
||||
|
||||
|
||||
下一步,我们将在可用的接口上配置对等的IP地址.
|
||||
|
||||
Router-A# show interface #显示接口信息
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
配置eth0接口的参数:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 100.100.0.1/30
|
||||
site-A-RTR(config-if)# description "to Router-B"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
|
||||
继续配置eth1接口的参数:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 100.100.1.1/24
|
||||
site-A-RTR(config-if)# description "test ip from provider A network"
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
site-A-RTR(config-if)# exit
|
||||
|
||||
现在确认配置:
|
||||
|
||||
Router-A# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
Description: "to Router-B"
|
||||
inet 100.100.0.1/30 broadcast 100.100.0.3
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
Description: "test ip from provider A network"
|
||||
inet 100.100.1.1/24 broadcast 100.100.1.255
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show interface description #现实接口描述
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown "to Router-B"
|
||||
eth1 up unknown "test ip from provider A network"
|
||||
|
||||
|
||||
如果一切看起来正常,别忘记保存配置.
|
||||
|
||||
Router-A# write
|
||||
|
||||
同样地,在路由器B重复一次配置.
|
||||
|
||||
|
||||
在我们继续下一步之前,确认下彼此的IP是可以ping通的.
|
||||
|
||||
Router-A# ping 100.100.0.2
|
||||
|
||||
----------
|
||||
|
||||
PING 100.100.0.2 (100.100.0.2) 56(84) bytes of data.
|
||||
64 bytes from 100.100.0.2: icmp_seq=1 ttl=64 time=0.616 ms
|
||||
|
||||
下一步,我们将继续配置BGP对等和前缀设置.
|
||||
|
||||
|
||||
### 配置BGP对等 ###
|
||||
|
||||
|
||||
|
||||
Quagga守护进程负责BGP的服务叫bgpd.首先我们来准备它的配置文件.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
|
||||
在CentOS6系统中:
|
||||
|
||||
# service bgpd start
|
||||
# chkconfig bgpd on
|
||||
|
||||
|
||||
在CentOS7中
|
||||
|
||||
# systemctl start bgpd
|
||||
# systemctl enable bgpd
|
||||
|
||||
现在,让我们来进入Quagga 的shell.
|
||||
|
||||
# vtysh
|
||||
|
||||
|
||||
第一步,我们要确认当前没有已经配置的BGP会话.在一些版本,我们可能会发现一个AS号为7675的BGP会话.由于我们不需要这个会话,所以把它移除.
|
||||
|
||||
Router-A# show running-config
|
||||
|
||||
----------
|
||||
|
||||
... ... ...
|
||||
router bgp 7675
|
||||
bgp router-id 200.200.1.1
|
||||
... ... ...
|
||||
|
||||
|
||||
我们将移除一些预先配置好的BGP会话,并建立我们所需的会话取而代之.
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# no router bgp 7675
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# no auto-summary
|
||||
Router-A(config)# no synchronizaiton
|
||||
Router-A(config-router)# neighbor 100.100.0.2 remote-as 200
|
||||
Router-A(config-router)# neighbor 100.100.0.2 description "provider B"
|
||||
Router-A(config-router)# exit
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
|
||||
|
||||
路由器B将用同样的方式来进行配置,以下配置提供作为参考.
|
||||
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# no router bgp 7675
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# no auto-summary
|
||||
Router-B(config)# no synchronizaiton
|
||||
Router-B(config-router)# neighbor 100.100.0.1 remote-as 100
|
||||
Router-B(config-router)# neighbor 100.100.0.1 description "provider A"
|
||||
Router-B(config-router)# exit
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
当相关的路由器都被配置好,两台路由器之间的对等将被建立.现在让我们通过运行下面的命令来确认:
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||

|
||||
|
||||
|
||||
从输出中,我们可以看到"State/PfxRcd"部分.如果对等关闭,输出将会现实"空闲"或者"活动'.请记住,单词'Active'这个词在路由器中总是不好的意思.它意味着路由器正在积极地寻找邻居,前缀或者路由.当对等是up状态,"State/PfxRcd"下的输出状态将会从特殊邻居接收到前缀号.
|
||||
|
||||
在这个例子的输出中,BGP对等知识在AS100和AS200之间呈up状态.因此,没有前缀被更改,所以最右边列的数值是0.
|
||||
|
||||
|
||||
### 配置前缀通告 ###
|
||||
|
||||
正如一开始提到,AS 100将以100.100.0.0/22作为通告,在我们的例子中AS 200将同样以200.200.0.0/22作为通告.这些前缀需要被添加到BGP配置如下.
|
||||
|
||||
在路由器-A中:
|
||||
|
||||
Router-A# configure terminal
|
||||
Router-A(config)# router bgp 100
|
||||
Router-A(config)# network 100.100.0.0/22
|
||||
Router-A(config)# exit
|
||||
Router-A# write
|
||||
|
||||
|
||||
在路由器-B中:
|
||||
Router-B# configure terminal
|
||||
Router-B(config)# router bgp 200
|
||||
Router-B(config)# network 200.200.0.0/22
|
||||
Router-B(config)# exit
|
||||
Router-B# write
|
||||
|
||||
|
||||
在这一点上,两个路由器会根据需要开始通告前缀.
|
||||
|
||||
|
||||
### 测试前缀通告 ###
|
||||
|
||||
首先,让我们来确认前缀的数量是否被改变了.
|
||||
|
||||
Router-A# show ip bgp summary
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
为了查看所接收的更多前缀细节,我们可以使用一下命令,这个命令用于显示邻居100.100.0.2所接收到的前缀总数.
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 advertised-routes
|
||||
|
||||

|
||||
|
||||
|
||||
查看哪一个前缀是我们从邻居接收到的:
|
||||
|
||||
Router-A# show ip bgp neighbors 100.100.0.2 routes
|
||||
|
||||

|
||||
|
||||
|
||||
我们也可以查看所有的BGP路由器:
|
||||
|
||||
Router-A# show ip bgp
|
||||
|
||||

|
||||
|
||||
|
||||
以上的命令都可以被用于检查哪个路由器通过BGP在路由器表中被学习到.
|
||||
|
||||
Router-A# show ip route
|
||||
|
||||
----------
|
||||
|
||||
|
||||
代码: K - 内核路由, C - 已链接 , S - 静态 , R - 路由信息协议 , O - 开放式最短路径优先协议,
|
||||
|
||||
|
||||
I - 中间系统到中间系统的路由选择协议, B - 边界网关协议, > - 选择路由, * - FIB 路由
|
||||
|
||||
C>* 100.100.0.0/30 is directly connected, eth0
|
||||
C>* 100.100.1.0/24 is directly connected, eth1
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:06:45
|
||||
|
||||
----------
|
||||
|
||||
Router-A# show ip route bgp
|
||||
|
||||
----------
|
||||
|
||||
B>* 200.200.0.0/22 [20/0] via 100.100.0.2, eth0, 00:08:13
|
||||
|
||||
|
||||
BGP学习到的路由也将会在Linux路由表中出现.
|
||||
|
||||
[root@Router-A~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
100.100.0.0/30 dev eth0 proto kernel scope link src 100.100.0.1
|
||||
100.100.1.0/24 dev eth1 proto kernel scope link src 100.100.1.1
|
||||
200.200.0.0/22 via 100.100.0.2 dev eth0 proto zebra
|
||||
|
||||
|
||||
最后,我们将使用ping命令来测试连通.结果将成功ping通.
|
||||
|
||||
[root@Router-A~]# ping 200.200.1.1 -c 2
|
||||
|
||||
|
||||
总而言之,该教程将重点放在如何运行一个基本的BGP在CentOS系统中.当这个教程让你开始BGP的配置,那么一些更高级的设置例如设置过滤器,BGP属性调整,本地优先级和预先路径准备等.我将会在后续的教程中覆盖这些主题.
|
||||
|
||||
希望这篇教程能给大家一些帮助.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[disylee](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
@ -6,7 +6,7 @@
|
||||
|
||||
虽然对于本教程,我只会演示怎样来添加**64位**网络安装镜像,但对于Ubuntu或者Debian的**32位**系统,或者其它架构的镜像,操作步骤也基本相同。同时,就我而言,我会解释添加Ubuntu 32位源的方法,但不会演示配置。
|
||||
|
||||
从PXE服务器安装 **Ubuntu**或者**Debian**要求你的客户机必须激活网络连接,最好是使用**DHCP**通过**NAT**来进行动态分配地址。以便安装器拉取需求包并完成安装进程。
|
||||
从PXE服务器安装 **Ubuntu**或者**Debian**要求你的客户机必须激活网络连接,最好是使用**DHCP**通过**NAT**来进行动态分配地址。以便安装器拉取所需的包并完成安装过程。
|
||||
|
||||
#### 需求 ####
|
||||
|
||||
@ -14,11 +14,11 @@
|
||||
|
||||
## 步骤 1: 添加Ubuntu 14.10和Ubuntu 14.04服务器到PXE菜单 ##
|
||||
|
||||
**1.** 为**Ubuntu 14.10**何**Ubuntu 14.04**添加网络安装源到PXE菜单可以通过两种方式实现:其一是通过下载Ubuntu CD ISO镜像并挂载到PXE服务器机器上以便可以读取Ubuntu网络启动文件,其二是通过直接下载Ubuntu网络启动归档包并将其解压缩到系统中。下面,我将进一步讨论这两种方法:
|
||||
**1.** 为**Ubuntu 14.10**和**Ubuntu 14.04**添加网络安装源到PXE菜单可以通过两种方式实现:其一是通过下载Ubuntu CD ISO镜像并挂载到PXE服务器机器上以便可以读取Ubuntu网络启动文件,其二是通过直接下载Ubuntu网络启动归档包并将其解压缩到系统中。下面,我将进一步讨论这两种方法:
|
||||
|
||||
### 使用Ubuntu 14.10和Ubuntu 14.04 CD ISO镜像 ###
|
||||
|
||||
为了能使用此方法,你的PXE服务器需要有一台可工作的CD/DVD驱动器。在一台专有计算机上,转到[Ubuntu 14.10下载][2]和[Ubuntu 14.04 下载][3]页,抓取64位**服务器安装镜像**,将它烧录到CD,并将CD镜像放到PXE服务器DVD/CD驱动器,然后使用以下命令挂载到系统。
|
||||
为了能使用此方法,你的PXE服务器需要有一台可工作的CD/DVD驱动器。在一台专有计算机上,转到[Ubuntu 14.10下载][2]和[Ubuntu 14.04 下载][3]页,获取64位**服务器安装镜像**,将它烧录到CD,并将CD镜像放到PXE服务器DVD/CD驱动器,然后使用以下命令挂载到系统。
|
||||
|
||||
# mount /dev/cdrom /mnt
|
||||
|
||||
@ -26,28 +26,28 @@
|
||||
|
||||
#### 在Ubuntu 14.10上 ####
|
||||
|
||||
------------------ 32位上 ------------------
|
||||
------------------ 32位 ------------------
|
||||
|
||||
# wget http://releases.ubuntu.com/14.10/ubuntu-14.10-server-i386.iso
|
||||
# mount -o loop /path/to/ubuntu-14.10-server-i386.iso /mnt
|
||||
|
||||
----------
|
||||
|
||||
------------------ 64位上 ------------------
|
||||
------------------ 64位 ------------------
|
||||
|
||||
# wget http://releases.ubuntu.com/14.10/ubuntu-14.10-server-amd64.iso
|
||||
# mount -o loop /path/to/ubuntu-14.10-server-amd64.iso /mnt
|
||||
|
||||
#### 在Ubuntu 14.04上 ####
|
||||
|
||||
------------------ 32位上 ------------------
|
||||
------------------ 32位 ------------------
|
||||
|
||||
# wget http://releases.ubuntu.com/14.04/ubuntu-14.04.1-server-i386.iso
|
||||
# mount -o loop /path/to/ubuntu-14.04.1-server-i386.iso /mnt
|
||||
|
||||
----------
|
||||
|
||||
------------------ 64位上 ------------------
|
||||
------------------ 64位 ------------------
|
||||
|
||||
# wget http://releases.ubuntu.com/14.04/ubuntu-14.04.1-server-amd64.iso
|
||||
# mount -o loop /path/to/ubuntu-14.04.1-server-amd64.iso /mnt
|
||||
@ -58,33 +58,33 @@
|
||||
|
||||
#### 在Ubuntu 14.04上 ####
|
||||
|
||||
------------------ 32位上 ------------------
|
||||
------------------ 32位 ------------------
|
||||
|
||||
# cd
|
||||
# wget http://archive.ubuntu.com/ubuntu/dists/utopic/main/installer-i386/current/images/netboot/netboot.tar.gz
|
||||
|
||||
----------
|
||||
|
||||
------------------ 64位上 ------------------
|
||||
------------------ 64位 ------------------
|
||||
|
||||
# cd
|
||||
# http://archive.ubuntu.com/ubuntu/dists/utopic/main/installer-amd64/current/images/netboot/netboot.tar.gz
|
||||
|
||||
#### 在Ubuntu 14.04上 ####
|
||||
|
||||
------------------ 32位上 ------------------
|
||||
------------------ 32位 ------------------
|
||||
|
||||
# cd
|
||||
# wget http://archive.ubuntu.com/ubuntu/dists/trusty-updates/main/installer-i386/current/images/netboot/netboot.tar.gz
|
||||
|
||||
----------
|
||||
|
||||
------------------ 64位上 ------------------
|
||||
------------------ 64位 ------------------
|
||||
|
||||
# cd
|
||||
# wget http://archive.ubuntu.com/ubuntu/dists/trusty-updates/main/installer-amd64/current/images/netboot/netboot.tar.gz
|
||||
|
||||
对于其它处理器架构,请访问下面的Ubuntu 14.10和Ubuntu 14.04网络启动官方页面,选择你的架构类型并下载需求文件。
|
||||
对于其它处理器架构,请访问下面的Ubuntu 14.10和Ubuntu 14.04网络启动官方页面,选择你的架构类型并下载所需文件。
|
||||
|
||||
- [http://cdimage.ubuntu.com/netboot/14.10/][4]
|
||||
- [http://cdimage.ubuntu.com/netboot/14.04/][5]
|
||||
@ -101,7 +101,7 @@
|
||||
# tar xfz netboot.tar.gz
|
||||
# cp -rf ubuntu-installer/ /var/lib/tftpboot/
|
||||
|
||||
如果你想要在PXE服务器上同时使用两种Ubuntu服务器架构,先请下载,然后根据不同的情况挂载并解压缩32位并拷贝**ubuntu-installer**目录到**/var/lib/tftpboot**,然后卸载CD或删除网络启动归档以及解压缩的文件和文件夹。对于64位架构,请重复上述步骤,以便让最终的**tftp**路径形成以下结构。
|
||||
如果你想要在PXE服务器上同时使用两种Ubuntu服务器架构,先请下载,然后根据不同的情况挂载或解压缩32位架构,然后拷贝**ubuntu-installer**目录到**/var/lib/tftpboot**,然后卸载CD或删除网络启动归档以及解压缩的文件和文件夹。对于64位架构,请重复上述步骤,以便让最终的**tftp**路径形成以下结构。
|
||||
|
||||
/var/lib/tftpboot/ubuntu-installer/amd64
|
||||
/var/lib/tftpboot/ubuntu-installer/i386
|
||||
@ -238,7 +238,7 @@ via: http://www.tecmint.com/add-ubuntu-to-pxe-network-boot/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Mr小眼儿](https://github.com/tinyeyeser)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
Linux 有问必答--Linux 中如何安装 7zip
|
||||
================================================================================
|
||||
> **问题**: 我需要要从 ISO 映像中获取某些文件,为此我想要使用 7zip 程序。那么我应该如何安装 7zip 软件呢,[在 Linux 发布版本上完全安装]?
|
||||
|
||||
7zip 是一款开源的归档应用程序,开始是为 Windows 系统而开发的。它能对多种格式的档案文件进行打包或解包处理,除了支持原生的 7z 格式的文档外,还支持包括 XZ、GZIP、TAR、ZIP 和 BZIP2 等这些格式。 一般地,7zip 也常用来解压 RAR、DEB、RPM 和 ISO 等格式的文件。除了简单的归档功能,7zip 还具有支持 AES-256 算法加密以及自解压和建立多卷存档功能。在以 POSIX 协议为标准的系统上(Linux、Unix、BSD),原生的 7zip 程序被移植过来并被命名为 p7zip(“POSIX 7zip” 的简称)。
|
||||
|
||||
下面介绍如何在 Linux 中安装 7zip (或 p7zip)。
|
||||
|
||||
### 在 Debian、Ubuntu 或 Linux Mint 系统中安装 7zip ###
|
||||
|
||||
在基于的 Debian 的发布系统中存在有三种 7zip 的软件包。
|
||||
|
||||
- **p7zip**: 包含 7zr(最小的 7zip 归档工具),仅仅只能处理原生的 7z 格式。
|
||||
- **p7zip-full**: 包含 7z ,支持 7z、LZMA2、XZ、ZIP、CAB、GZIP、BZIP2、ARJ、TAR、CPIO、RPM、ISO 和 DEB 格式。
|
||||
- **p7zip-rar**: 包含一个能解压 RAR 文件的插件。
|
||||
|
||||
建议安装 p7zip-full 包(不是 p7zip),因为这是最完全的 7zip 程序包,它支持很多归档格式。此外,如果您想处理 RAR 文件话,还需要安装 p7zip-rar 包,做成一个独立的插件包的原因是因为 RAR 是一种专有格式。
|
||||
|
||||
$ sudo apt-get install p7zip-full p7zip-rar
|
||||
|
||||
### 在 Fedora 或 CentOS/RHEL 系统中安装 7zip ###
|
||||
|
||||
基于红帽的发布系统上提供了两个 7zip 的软件包。
|
||||
|
||||
- **p7zip**: 包含 7za 命令,支持 7z、ZIP、GZIP、CAB、ARJ、BZIP2、TAR、CPIO、RPM 和 DEB 格式。
|
||||
- **p7zip-plugins**: 包含 7z 命令,额外的插件,它扩展了 7za 命令(例如 支持 ISO 格式的抽取)。
|
||||
|
||||
在 CentOS/RHEL 系统中,在运行下面命令前您需要确保 [EPEL 资源库][1] 可用,但在 Fedora 系统中就不需要额外的资源库了。
|
||||
|
||||
$ sudo yum install p7zip p7zip-plugins
|
||||
|
||||
注意,跟基于 Debian 的发布系统不同的是,基于红帽的发布系统没有提供 RAR 插件,所以您不能使用 7z 命令来抽取解压 RAR 文件。
|
||||
|
||||
### 使用 7z 创建或提取归档文件 ###
|
||||
|
||||
一旦安装好 7zip 软件后,就可以使用 7z 命令来打包解包各式各样的归档文件了。7z 命令会使用不同的插件来辅助处理对应格式的归档文件。
|
||||
|
||||

|
||||
|
||||
使用 “a” 选项就可以创建一个归档文件,它可以创建 7z、XZ、GZIP、TAR、 ZIP 和 BZIP2 这几种格式的文件。如果指定的归档文件已经存在的话,它会把文件“添加”到存在的归档中,而不是覆盖原有归档文件。
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
使用 “e” 选项可以抽取出一个归档文件,抽取出的文件会放在当前目录。抽取支持的格式比创建时支持的格式要多的多,包括 7z、XZ、GZIP、TAR、ZIP、BZIP2、LZMA2、CAB、ARJ、CPIO、RPM、ISO 和 DEB 这些格式。
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
解包的另外一种方式是使用 “x” 选项。和 “e” 选项不同的是,它使用的是全路径来抽取归档的内容。
|
||||
|
||||
$ 7z x <archive-filename>
|
||||
|
||||
要查看归档的文件列表,使用 “l” 选项。
|
||||
|
||||
$ 7z l <archive-filename>
|
||||
|
||||
要更新或删除归档文件,分别使用 “u” 和 “d” 选项。
|
||||
|
||||
$ 7z u <archive-filename> <list-of-files-to-update>
|
||||
$ 7z d <archive-filename> <list-of-files-to-delete>
|
||||
|
||||
要测试归档的完整性,使用:
|
||||
|
||||
$ 7z t <archive-filename>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,202 @@
|
||||
如何在Ubuntu / CentOS 6.x上安装Bugzilla 4.4
|
||||
================================================================================
|
||||
这里,我们将展示如何在一台Ubuntu 14.04或CentOS 6.5/7上安装Bugzilla。Bugzilla是一款基于web,用来记录跟踪缺陷数据库的bug跟踪软件,它同时是一款免费及开源软件(FOSS),它的bug跟踪系统允许个人和开发团体有效地记录下他们产品的一些突出问题。尽管是"免费"的,Bugzilla依然有很多其它同类产品所没有的“珍贵”特性。因此,Bugzilla很快就变成了全球范围内数以千计的组织最喜欢的bug管理工具。
|
||||
|
||||
Bugzilla对于不同状况的适应能力非常强。如今它们应用在各个不同的IT领域,系统管理员部署管理、芯片设计和部署问题跟踪(制作前后),还有为那些诸如Redhat,NASA,Linux-Mandrake和VA Systems这些名家提供软硬件bug跟踪。
|
||||
|
||||
### 1. 安装依赖程序 ###
|
||||
|
||||
安装Bugzilla相当**简单**。这篇文章特别针对Ubuntu 14.04和CentOS 6.5两个版本(不过也适用于更老的版本)。
|
||||
|
||||
为了获取并能在Ubuntu或CentOS系统中运行Bugzilla,我们要安装Apache网络服务器(允许SSL),MySQL数据库服务器和一些需要来安装并配置Bugzilla的工具。
|
||||
|
||||
要在你的服务器上安装使用Bugzilla,你需要安装好以下程序:
|
||||
|
||||
- Perl(5.8.1 或以上)
|
||||
- MySQL
|
||||
- Apache2
|
||||
- Bugzilla
|
||||
- Perl模块
|
||||
- 使用apache的Bugzilla
|
||||
|
||||
正如我们所提到的本文会阐述Ubuntu 14.04和CentOS 6.5/7两种发行版的安装过程,为此我们会分成两部分来表示。
|
||||
|
||||
以下就是在你的Ubuntu 14.04 LTS和CentOS 7机器安装Bugzilla的步骤:
|
||||
|
||||
**准备所需的依赖包:**
|
||||
|
||||
你需要运行以下命令来安装些必要的包:
|
||||
|
||||
**Ubuntu版本:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**CentOS版本:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**注意:请在shell或者终端下运行所有的命令并且确保你用root用户(sudo)连接机器。**
|
||||
|
||||
### 2. 启动Apache服务 ###
|
||||
|
||||
你已经按照以上步骤安装好了apache服务,那么我们现在需要配置apache服务并运行它。我们需要用sodo或root来敲命令去完成它,我们先切换到root连接。
|
||||
|
||||
$ sudo -s
|
||||
|
||||
我们需要在防火墙中打开80端口并保存改动。
|
||||
|
||||
# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
|
||||
# service iptables save
|
||||
|
||||
现在,我们需要启动服务:
|
||||
|
||||
CentOS版本:
|
||||
|
||||
# service httpd start
|
||||
|
||||
我们来确保Apache会在每次你重启机器的时候一并启动起来:
|
||||
|
||||
# /sbin/chkconfig httpd on
|
||||
|
||||
Ubuntu版本:
|
||||
|
||||
# service apache2 start
|
||||
|
||||
现在,由于我们已经启动了我们apache的http服务,我们就能在默认的127.0.0.1地址下打开apache服务了。
|
||||
|
||||
### 3. 配置MySQL服务器 ###
|
||||
|
||||
现在我们需要启动我们的MySQL服务:
|
||||
|
||||
CentOS版本:
|
||||
|
||||
# chkconfig mysqld on
|
||||
# service start mysqld
|
||||
|
||||
Ubuntu版本:
|
||||
|
||||
# service mysql-server start
|
||||
|
||||

|
||||
|
||||
用root用户登录连接MySQL并给Bugzilla创建一个数据库,把你的mysql密码更改成你想要的,稍后配置Bugzilla的时候会用到它。
|
||||
|
||||
CentOS 6.5和Ubuntu 14.04 Trusty两个版本:
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
# password: (You'll need to enter your password)
|
||||
|
||||
# mysql > create database bugs;
|
||||
|
||||
# mysql > grant all on bugs.* to root@localhost identified by "mypassword";
|
||||
|
||||
#mysql > quit
|
||||
|
||||
**注意:请记住数据库名和mysql的密码,我们稍后会用到它们。**
|
||||
|
||||
### 4. 安装并配置Bugzilla ###
|
||||
|
||||
现在,我们所有需要的包已经设置完毕并运行起来了,我们就要配置我们的Bugzilla。
|
||||
|
||||
那么,首先我们要下载最新版的Bugzilla包,这里我下载的是4.5.2版本。
|
||||
|
||||
使用wget工具在shell或终端上下载:
|
||||
|
||||
wget http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-4.5.2.tar.gz
|
||||
|
||||
你也可以从官方网站进行下载。[http://www.bugzilla.org/download/][1]
|
||||
|
||||
**从下载下来的bugzilla压缩包中提取文件并重命名:**
|
||||
|
||||
# tar zxvf bugzilla-4.5.2.tar.gz -C /var/www/html/
|
||||
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**注意**:这里,**/var/www/html/bugzilla/**就是**Bugzilla主目录**.
|
||||
|
||||
现在,我们来配置buzilla:
|
||||
|
||||
# cd /var/www/html/bugzilla/
|
||||
|
||||
# ./checksetup.pl --check-modules
|
||||
|
||||

|
||||
|
||||
检查完成之后,我们会发现缺少了一些组件,我们需要安装它们,用以下命令即可实现:
|
||||
|
||||
# cd /var/www/html/bugzilla
|
||||
# perl install-module.pl --all
|
||||
|
||||
这一步会花掉一点时间去下载安装所有依赖程序,然后再次运行**checksetup.pl --check-modules**命令来验证有没有漏装什么。
|
||||
|
||||
现在我们需要运行以下这条命令,它会在/var/www/html/bugzilla路径下自动生成一个名为localconfig的文件。
|
||||
|
||||
# ./checksetup.pl
|
||||
|
||||
确认一下你刚才在localconfig文件中所输入的数据库名、用户和密码是否正确。
|
||||
|
||||
# nano ./localconfig
|
||||
|
||||
# checksetup.pl
|
||||
|
||||

|
||||
|
||||
如果一切正常,checksetup.pl现在应该就成功地配置Bugzilla了。
|
||||
|
||||
现在我们需要添加Bugzilla至我们的Apache配置文件中。那么,我们需要用文本编辑器打开 /etc/httpd/conf/httpd.conf 文件(CentOS版本)或者 /etc/apache2/apache2.conf 文件(Ubuntu版本):
|
||||
|
||||
CentOS版本:
|
||||
|
||||
# nano /etc/httpd/conf/httpd.conf
|
||||
|
||||
Ubuntu版本:
|
||||
|
||||
# nano etc/apache2/apache2.conf
|
||||
|
||||
现在,我们需要配置Apache服务器,我们要把以下配置添加到配置文件里:
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /var/www/html/bugzilla/
|
||||
</VirtualHost>
|
||||
|
||||
<Directory /var/www/html/bugzilla>
|
||||
AddHandler cgi-script .cgi
|
||||
Options +Indexes +ExecCGI
|
||||
DirectoryIndex index.cgi
|
||||
AllowOverride Limit FileInfo Indexes
|
||||
</Directory>
|
||||
|
||||
接着,我们需要编辑 .htaccess 文件并用“#”注释掉顶部“Options -Indexes”这一行。
|
||||
|
||||
让我们重启我们的apache服务并测试下我们的安装情况。
|
||||
|
||||
CentOS版本:
|
||||
|
||||
# service httpd restart
|
||||
|
||||
Ubuntu版本:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||

|
||||
|
||||
这样,我们的Bugzilla就准备好在我们的Ubuntu 14.04 LTS和CentOS 6.5上获取bug报告了,你就可以通过本地回环地址或你网页浏览器上的IP地址来浏览bugzilla了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.bugzilla.org/download/
|
||||
135
translated/tech/20150104 Docker Image Insecurity.md
Normal file
135
translated/tech/20150104 Docker Image Insecurity.md
Normal file
@ -0,0 +1,135 @@
|
||||
Docker的镜像并不安全!
|
||||
================================================================================
|
||||
最近使用Docker下载“官方”容器镜像的时候,我发现这样一句话:
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified (您所拉取的镜像已经经过验证)
|
||||
|
||||
起初我以为这条信息引自Docker[大力推广][1]的镜像签名系统,因此也就没有继续跟进。后来,研究加密摘要系统的时候——Docker用这套系统来对镜像进行安全加固——我才有机会更深入的发现,逻辑上整个与镜像安全相关的部分具有一系列系统性问题。
|
||||
|
||||
Docker所报告的,一个已下载的镜像经过“验证”,它基于的仅仅是一个标记清单(signed manifest),而Docker却从未根据清单对镜像的校验和进行验证。一名攻击者以此可以提供任意所谓具有标记清单的镜像。一系列严重漏洞的大门就此敞开。
|
||||
|
||||
镜像经由HTTPS服务器下载后,通过一个未加密的管道流进入Docker守护进程:
|
||||
|
||||
[decompress] -> [tarsum] -> [unpack]
|
||||
|
||||
这条管道的性能没有问题,但是却完全没有经过加密。不可信的输入在签名验证之前是不应当进入管道的。不幸的是,Docker在上面处理镜像的三个步骤中,都没有对校验和进行验证。
|
||||
|
||||
然而,不论Docker如何[声明][2],实际上镜像的校验和从未经过校验。下面是Docker与镜像校验和的验证相关的代码[片段][3],即使我提交了校验和不匹配的镜像,都无法触发警告信息。
|
||||
|
||||
if img.Checksum != "" && img.Checksum != checksum {
|
||||
log.Warnf("image layer checksum mismatch: computed %q,
|
||||
expected %q", checksum, img.Checksum)
|
||||
}
|
||||
|
||||
### 不安全的处理管道 ###
|
||||
|
||||
**解压缩**
|
||||
|
||||
Docker支持三种压缩算法:gzip、bzip2和xz。前两种使用Go的标准库实现,是[内存安全(memory-safe)][4]的,因此这里我预计的攻击类型应该是拒绝服务类的攻击,包括CPU和内存使用上的当机或过载等等。
|
||||
|
||||
第三种压缩算法,xz,比较有意思。因为没有现成的Go实现,Docker 通过[执行(exec)][5]`xz`二进制命令来实现解压缩。
|
||||
|
||||
xz二进制程序来自于[XZ Utils][6]项目,由[大概][7]2万行C代码生成而来。而C语言不是一门内存安全的语言。这意味着C程序的恶意输入,在这里也就是Docker镜像的XZ Utils解包程序,潜在地可能会执行任意代码。
|
||||
|
||||
Docker以root权限*运行* `xz` 命令,更加恶化了这一潜在威胁。这意味着如果在`xz`中出现了一个漏洞,对`docker pull`命令的调用就会导致用户整个系统的完全沦陷。
|
||||
|
||||
**Tarsum**
|
||||
|
||||
对tarsum的使用,其出发点是好的,但却是最大的败笔。为了得到任意一个加密tar文件的准确校验和,Docker先对tar文件进行解密,然后求出特定部分的哈希值,同时排除剩余的部分,而这些步骤的[顺序都是固定的][8]。
|
||||
|
||||
由于其生成校验和的步骤固定,它解码不可信数据的过程就有可能被设计成[攻破tarsum的代码][9]。这里潜在的攻击既包括拒绝服务攻击,还有逻辑上的漏洞攻击,可能导致文件被感染、忽略、进程被篡改、植入等等,这一切攻击的同时,校验和可能都是不变的。
|
||||
|
||||
|
||||
**解包**
|
||||
|
||||
解包的过程包括tar解码和生成硬盘上的文件。这一过程尤其危险,因为在解包写入硬盘的过程中有另外三个[已报告的漏洞][10]。
|
||||
|
||||
任何情形下未经验证的数据都不应当解包后直接写入硬盘。
|
||||
|
||||
### libtrust ###
|
||||
|
||||
Docker的工具包[libtrust][11],号称“通过一个分布式的信任图表进行认证和访问控制”。很不幸,对此官方没有任何具体的说明,看起来它好像是实现了一些[javascript对象标记和加密][12]规格以及其他一些未说明的算法。
|
||||
|
||||
使用libtrust下载一个清单经过签名和认证的镜像,就可以触发下面这条不准确的信息(说不准确,是因为事实上它验证的只是清单,并非真正的镜像):
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified(您所拉取的镜像已经经过验证)
|
||||
|
||||
目前只有Docker公司“官方”发布的镜像清单使用了这套签名系统,但是上次我参加Docker[管理咨询委员会][13]的会议讨论时,我所理解的是,Docker公司正计划在未来扩大部署这套系统。他们的目标是以Docker公司为中心,控制一个认证授权机构,对镜像进行签名和(或)客户认证。
|
||||
|
||||
我试图从Docker的代码中找到签名秘钥,但是没找到。好像它并不像我们所期望的把密钥嵌在二进制代码中,而是在每次镜像下载前,由Docker守护进程[通过HTTPS从CDN][14]远程获取。这是一个多么糟糕的方案,有无数种攻击手段可能会将可信密钥替换成恶意密钥。这些攻击包括但不限于:CDN供应商出问题、CDN初始密钥出现问题、客户端下载时的中间人攻击等等。
|
||||
|
||||
### 补救 ###
|
||||
|
||||
研究结束前,我[报告][15]了一些在tarsum系统中发现的问题,但是截至目前我报告的这些问题仍然
|
||||
没有修复。
|
||||
|
||||
要改进Docker镜像下载系统的安全问题,我认为应当有以下措施:
|
||||
|
||||
**摒弃tarsum并且真正对镜像本身进行验证**
|
||||
|
||||
出于安全原因tarsum应当被摒弃,同时,镜像在完整下载后、其他步骤开始前,就对镜像的加密签名进行验证。
|
||||
|
||||
**添加权限隔离**
|
||||
|
||||
镜像的处理过程中涉及到解压缩或解包的步骤必须在隔离的进程(容器?)中进行,即只给予其操作所需的最小权限。任何场景下都不应当使用root运行`xz`这样的解压缩工具。
|
||||
|
||||
**替换 libtrust**
|
||||
|
||||
应当用[更新框架(The Update Framework)][16]替换掉libtrust,这是专门设计用来解决软件二进制签名此类实际问题的。其威胁模型非常全方位,能够解决libtrust中未曾考虑到的诸多问题,目前已经有了完整的说明文档。除了已有的Python实现,我已经开始着手用[Go语言实现][17]的工作,也欢迎大家的贡献。
|
||||
|
||||
作为将更新框架加入Docker的一部分,还应当加入一个本地密钥存储池,将root密钥与registry的地址进行映射,这样用户就可以拥有他们自己的签名密钥,而不必使用Docker公司的了。
|
||||
|
||||
我注意到使用Docker公司非官方的宿主仓库往往会是一种非常糟糕的用户体验。当没有技术上的原因时,Docker也会将第三方的仓库内容降为二等地位来看待。这个问题不仅仅是生态问题,还是一个终端用户的安全问题。针对第三方仓库的全方位、去中心化的安全模型即必须又迫切。我希望Docker公司在重新设计他们的安全模型和镜像认证系统时能采纳这一点。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
Docker用户应当意识到负责下载镜像的代码是非常不安全的。用户们应当只下载那些出处没有问题的镜像。目前,这里的“没有问题”并不包括Docker公司的“可信(trusted)”镜像,例如官方的Ubuntu和其他基础镜像。
|
||||
|
||||
最好的选择就是在本地屏蔽 `index.docker.io`,然后使用`docker load`命令在导入Docker之前手动下载镜像并对其进行验证。Red Hat的安全博客有一篇[很好的文章][18],大家可以看看。
|
||||
|
||||
感谢Lewis Marshall指出tarsum从未真正验证。
|
||||
|
||||
- [校验和的代码][19]
|
||||
- [cloc][20]介绍了18141行没有空格没有注释的C代码,以及5900行的header代码,版本号为v5.2.0。
|
||||
- [Android中也发现了][21]类似的bug,能够感染已签名包中的任意文件。同样出现问题的还有[Windows的Authenticode][22]认证系统,二进制文件会被篡改。
|
||||
- 特别的:[CVE-2014-6407][23]、 [CVE-2014-9356][24]以及 [CVE-2014-9357][25]。目前已有两个Docker[安全发布][26]有了回应。
|
||||
- 参见[2014-10-28 DGAB会议记录][27]的第8页。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://titanous.com/posts/docker-insecurity
|
||||
|
||||
作者:[titanous][a]
|
||||
译者:[Mr小眼儿](http://blog.csdn.net/tinyeyeser)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/titanous
|
||||
[1]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[2]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[3]:https://titanous.com/posts/docker-insecurity#fn:0
|
||||
[4]:https://en.wikipedia.org/wiki/Memory_safety
|
||||
[5]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/archive/archive.go#L91-L95
|
||||
[6]:http://tukaani.org/xz/
|
||||
[7]:https://titanous.com/posts/docker-insecurity#fn:1
|
||||
[8]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/tarsum/tarsum_spec.md
|
||||
[9]:https://titanous.com/posts/docker-insecurity#fn:2
|
||||
[10]:https://titanous.com/posts/docker-insecurity#fn:3
|
||||
[11]:https://github.com/docker/libtrust
|
||||
[12]:https://tools.ietf.org/html/draft-ietf-jose-json-web-signature-11
|
||||
[13]:https://titanous.com/posts/docker-insecurity#fn:4
|
||||
[14]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/trust/trusts.go#L38
|
||||
[15]:https://github.com/docker/docker/issues/9719
|
||||
[16]:http://theupdateframework.com/
|
||||
[17]:https://github.com/flynn/go-tuf
|
||||
[18]:https://securityblog.redhat.com/2014/12/18/before-you-initiate-a-docker-pull/
|
||||
[19]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/image/image.go#L114-L116
|
||||
[20]:http://cloc.sourceforge.net/
|
||||
[21]:http://www.saurik.com/id/17
|
||||
[22]:http://blogs.technet.com/b/srd/archive/2013/12/10/ms13-098-update-to-enhance-the-security-of-authenticode.aspx
|
||||
[23]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-6407
|
||||
[24]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9356
|
||||
[25]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9357
|
||||
[26]:https://groups.google.com/d/topic/docker-user/nFAz-B-n4Bw/discussion
|
||||
[27]:https://docs.google.com/document/d/1JfWNzfwptsMgSx82QyWH_Aj0DRKyZKxYQ1aursxNorg/edit?pli=1
|
||||
123
translated/tech/20150104 How To Install Websvn In CentOS 7.md
Normal file
123
translated/tech/20150104 How To Install Websvn In CentOS 7.md
Normal file
@ -0,0 +1,123 @@
|
||||
CentOS 7中安装Websvn
|
||||
================================================================================
|
||||
**WebSVN**为你的Subversion提供了一个试图,它设计用来反映Subversion的一整套方法。你可以检查任何文件或目录的日志,以及查看任何指定修改库中修改、添加或删除过的文件列表。你也可以检查同一文件两个版本的不同之处,以便确切地查看某个特性修订版中的修改。
|
||||
|
||||
### 特性 ###
|
||||
|
||||
WebSVN提供了以下这些特性:
|
||||
|
||||
- 易于使用的界面;
|
||||
- 可自定义的模板系统;
|
||||
- 文件列表的着色;
|
||||
- 过错视图;
|
||||
- 日志信息搜索;
|
||||
- 支持RSS订阅;
|
||||
|
||||
### 安装 ###
|
||||
|
||||
我使用以下链接来将Subversion安装到CentOS 7。
|
||||
|
||||
- [CentOS 7上如何安装Subversion][1]
|
||||
|
||||
**1 – 下载websvn到/var/www/html。**
|
||||
|
||||
cd /var/www/html
|
||||
|
||||
----------
|
||||
|
||||
wget http://websvn.tigris.org/files/documents/1380/49057/websvn-2.3.3.zip
|
||||
|
||||
**2 – 解压zip包。**
|
||||
|
||||
unzip websvn-2.3.3.zip
|
||||
|
||||
----------
|
||||
|
||||
mv websvn-2.3.3 websvn
|
||||
|
||||
**3 – 安装php到你的系统。**
|
||||
|
||||
yum install php
|
||||
|
||||
**4 – 编辑web svn配置。**
|
||||
|
||||
cd /var/www/html/websvn/include
|
||||
|
||||
----------
|
||||
|
||||
cp distconfig.php config.php
|
||||
|
||||
----------
|
||||
|
||||
vi config.php
|
||||
|
||||
----------
|
||||
|
||||
// Configure these lines if your commands aren't on your path.
|
||||
//
|
||||
$config->setSVNCommandPath('/usr/bin'); // e.g. c:\\program files\\subversion\\bin
|
||||
$config->setDiffPath('/usr/bin');
|
||||
----------
|
||||
// For syntax colouring, if option enabled...
|
||||
$config->setEnscriptPath('/usr/bin');
|
||||
$config->setSedPath('/bin');
|
||||
----------
|
||||
// For delivered tarballs, if option enabled...
|
||||
$config->setTarPath('/bin');
|
||||
----------
|
||||
// For delivered GZIP'd files and tarballs, if option enabled...
|
||||
$config->setGZipPath('/bin');
|
||||
----------
|
||||
//
|
||||
$config->parentPath('/svn/');
|
||||
----------
|
||||
$extEnscript[".pl"] = "perl";
|
||||
$extEnscript[".py"] = "python";
|
||||
$extEnscript[".sql"] = "sql";
|
||||
$extEnscript[".java"] = "java";
|
||||
$extEnscript[".html"] = "html";
|
||||
$extEnscript[".xml"] = "html";
|
||||
$extEnscript[".thtml"] = "html";
|
||||
$extEnscript[".tpl"] = "html";
|
||||
$extEnscript[".sh"] = "bash";
|
||||
~
|
||||
|
||||
保存并退出。
|
||||
|
||||
**6 – 重新加载apache并启动websvn链接http://ip/websvn。**
|
||||
|
||||

|
||||
|
||||
一切搞定。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-websvn-centos-7/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://www.unixmen.com/install-subversion-centos-7/
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -0,0 +1,207 @@
|
||||
如何配置fail2ban来保护Apache服务器
|
||||
================================================================================
|
||||
生产环境中的Apache服务器可能会受到不同的攻击。攻击者或许试图通过暴力攻击或者执行恶意脚本来获取未经授权或者禁止访问的目录。一些恶意爬虫或许会扫描你网站下的任意安全漏洞,或者手机email地址或者web表格来发送垃圾邮件。
|
||||
|
||||
Apache服务器具有综合的日志功能来捕捉不同表明是攻击的异常事件。然而,它还不能系统地解析具体的apache日志并迅速地反应到潜在的攻击(比如,禁止/解禁IP地址)。这时候`fail2ban`可以解救这一切,解放了系统管理员的工作。
|
||||
|
||||
`fail2ban`是一款入侵防御工具,可以基于系统日志检测不同的工具并且可以自动采取保护措施比如:通过`iptables`禁止ip、阻止/etc/hosts.deny中的连接、或者通过邮件通知事件。fail2ban具有一系列预定义的“监狱”,它使用特定程序日志过滤器来检测通常的攻击。你也可以编写自定义的规则来检测来自任意程序的攻击。
|
||||
|
||||
在本教程中,我会演示如何配置fail2ban来保护你的apache服务器。我假设你已经安装了apache和fail2ban。对于安装,请参考[另外一篇教程][1]。
|
||||
|
||||
### 什么是 Fail2ban 监狱 ###
|
||||
|
||||
让我们更深入地了解fail2ban监狱。监狱定义了具体的应用策略,它会为指定的程序触发一个保护措施。fail2ban在/etc/fail2ban/jail.conf 下为一些流行程序如Apache、Dovecot、Lighttpd、MySQL、Postfix、[SSH][2]等预定义了一些监狱。每个依赖于特定的程序日志过滤器(在/etc/fail2ban/fileter.d 下面)来检测通常的攻击。让我看一个例子监狱:SSH监狱。
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
SSH监狱的配置定义了这些参数:
|
||||
|
||||
- **[ssh]**: 方括号内是监狱的名字。
|
||||
- **enabled**:是否启用监狱
|
||||
- **port**: 端口的数字 (或者数字对应的名称).
|
||||
- **filter**: 检测攻击的检测规则
|
||||
- **logpath**: 检测的日志文件
|
||||
- **maxretry**: 禁止前失败的最大数字
|
||||
- **banaction**: 禁止操作
|
||||
|
||||
定义配置文件中的任意参数都会覆盖相应的默认配置`fail2ban-wide` 中的参数。相反,任意缺少的参数都会使用定义在[DEFAULT]字段的值。
|
||||
|
||||
预定义日志过滤器都必须在/etc/fail2ban/filter.d,可以采取的操作在/etc/fail2ban/action.d。
|
||||
|
||||
|
||||
|
||||
如果你想要覆盖`fail2ban`的默认操作或者定义任何自定义监狱,你可以创建*/etc/fail2ban/jail.local**文件。本篇教程中,我会使用/etc/fail2ban/jail.local。
|
||||
|
||||
### 启用预定义的apache监狱 ###
|
||||
|
||||
`fail2ban`的默认安装为Apache服务提供了一些预定义监狱以及过滤器。我要启用这些内建的Apache监狱。由于Debian和红买配置的稍微不同,我会分别它们的配置文件。
|
||||
|
||||
#### 在Debian 或者 Ubuntu启用Apache监狱 ####
|
||||
|
||||
要在基于Debian的系统上启用预定义的apache监狱,如下创建/etc/fail2ban/jail.local。
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
由于上面的监狱没有指定措施,这些监狱都将会触发默认的措施。要查看默认的措施,在/etc/fail2ban/jail.conf中的[DEFAULT]下找到“banaction”。
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
本例中,默认的操作是iptables-multiport(定义在/etc/fail2ban/action.d/iptables-multiport.conf)。这个措施使用iptable的多端口模块禁止一个IP地址。
|
||||
|
||||
在启用监狱后,你必须重启fail2ban来加载监狱。
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### 在CentOS/RHEL 或者 Fedora中启用Apache监狱 ####
|
||||
|
||||
要在基于红帽的系统中启用预定义的监狱,如下创建/etc/fail2ban/jail.local。
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
注意这些监狱文件默认的操作是iptables-multiport(定义在/etc/fail2ban/jail.conf中[DEFAULT]字段下的“banaction”中)。这个措施使用iptable的多端口模块禁止一个IP地址。
|
||||
|
||||
启用监狱后,你必须重启fail2ban来加载监狱。
|
||||
|
||||
在 Fedora 或者 CentOS/RHEL 7中:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
在 CentOS/RHEL 6中:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### 检查和管理fail2ban禁止状态 ###
|
||||
|
||||
监狱一旦激活后,你可以用fail2ban的客户端命令行工具来监测当前的禁止状态。
|
||||
|
||||
查看激活的监狱列表:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
查看特定监狱的状态(包含禁止的IP列表):
|
||||
|
||||
$ sudo fail2ban-client status [监狱名]
|
||||
|
||||
|
||||
|
||||
你也可以手动禁止或者解禁IP地址
|
||||
|
||||
要用制定监狱禁止IP:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
要解禁指定监狱屏蔽的IP:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇教程解释了fail2ban监狱如何工作以及如何使用内置的监狱来保护Apache服务器。依赖于你的环境以及要保护的web服务器类型,你或许要适配已存在的监狱或者编写自定义监狱和日志过滤器。查看outfail2ban的[官方Github页面][3]来获取最新的监狱和过滤器示例。
|
||||
|
||||
你有在生产环境中使用fail2ban么?分享一下你的经验吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
@ -0,0 +1,51 @@
|
||||
Ubuntu14.04或Mint17如何安装Kodi14(XBMC)
|
||||
================================================================================
|
||||

|
||||
|
||||
[Kodi][1],原名就是大名鼎鼎的XBMC,发布[最新版本14][2],命名为Helix。感谢官方XMBC提供的PPA,现在可以很简单地在Ubuntu14.04中安装了。
|
||||
|
||||
Kodi是一个优秀的自由和开源的(GPL)媒体中心软件,支持所有平台,如Windows, Linux, Mac, Android等。此软件拥有全屏幕的媒体中心,可以管理所有音乐和视频,不单支持本地文件还支持网络播放,如Tube,[Netflix][3], Hulu, Amazon Prime和其他串流服务商。
|
||||
|
||||
### Ubuntu 14.04, 14.10 和 Linux Mint 17 中安装XBMC 14 Kodi Helix ###
|
||||
|
||||
再次感谢官方的PPA,让我们可以轻松安装Kodi 14。
|
||||
支持Ubuntu 14.04, Ubuntu 12.04, Linux Mint 17, Pinguy OS 14.04, Deepin 2014, LXLE 14.04, Linux Lite 2.0, Elementary OS and 其他基于Ubuntu的Linux 发行版。
|
||||
打开终端(Ctrl+Alt+T)然后使用下列命令。
|
||||
|
||||
sudo add-apt-repository ppa:team-xbmc/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install kodi
|
||||
|
||||
需要下载大约100MB,在我的观点这不是很大。若需安装解码插件,使用下列命令:
|
||||
|
||||
sudo apt-get install kodi-audioencoder-* kodi-pvr-*
|
||||
|
||||
#### 从Ubuntu中移除Kodi 14 ####
|
||||
|
||||
从系统中移除Kodi 14 ,使用下列命令:
|
||||
|
||||
sudo apt-get remove kodi
|
||||
|
||||
同样也应该移除PPA软件源:
|
||||
|
||||
sudo add-apt-repository --remove ppa:team-xbmc/ppa
|
||||
|
||||
我希望这个简单的文章可以帮助到你,在Ubuntu, Linux Mint 和其他 Linux版本中轻松安装Kodi 14。
|
||||
你怎么发现Kodi 14 Helix?
|
||||
你有没有使用其他的什么媒体中心?
|
||||
可以在下面的评论区分享你的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-kodi-14-xbmc-in-ubuntu-14-04-linux-mint-17/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[Vic020/VicYu](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://kodi.tv/
|
||||
[2]:http://kodi.tv/kodi-14-0-helix-unwinds/
|
||||
[3]:http://itsfoss.com/watch-netflix-in-ubuntu-14-04/
|
||||
@ -0,0 +1,47 @@
|
||||
如何在Ubuntu 14.04 中安装Winusb
|
||||
================================================================================
|
||||

|
||||
|
||||
[WinUSB][1]是一款简单的且有用的工具,可以让你从Windows ISO镜像或者DVD中创建USB安装盘。它结合了GUI和命令行,你可以根据你的喜好决定使用哪种。
|
||||
|
||||
在本篇中我们会展示**如何在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
|
||||
|
||||
### 在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB ###
|
||||
|
||||
直到Ubuntu 13.10, WinUSBu一直都在积极开发,且在官方PPA中可以找到。这个PPA还没有为Ubuntu 14.04 和14.10更新,但是二进制文件仍旧可在更新版本的Ubuntu和Linux Mint中运行。基于[基于你使用的系统是32位还是64位的][2],使用下面的命令来下载二进制文件:
|
||||
|
||||
打开终端,并在32位的系统下使用下面的命令:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_i386.deb
|
||||
|
||||
对于64位的系统,使用下面的命令:
|
||||
|
||||
wget https://launchpad.net/~colingille/+archive/freshlight/+files/winusb_1.0.11+saucy1_amd64.deb
|
||||
|
||||
一旦你下载了正确的二进制包,你可以用下面的命令安装WinUSB:
|
||||
|
||||
sudo dpkg -i winusb*
|
||||
|
||||
不要担心在你安装WinUSB时看见错误。使用这条命令修复依赖:
|
||||
|
||||
sudo apt-get -f install
|
||||
|
||||
之后,你就可以在Unity Dash中查找WinUSB并且用它在Ubuntu 14.04 中创建Windows的live USB了。
|
||||
|
||||

|
||||
|
||||
我希望这篇文章能够帮到你**在Ubuntu 14.04、14.10 和 Linux Mint 17 中安装WinUSB**。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-winusb-in-ubuntu-14-04/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.congelli.eu/prog_info_winusb.html
|
||||
[2]:http://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
@ -0,0 +1,189 @@
|
||||
实例展示Ubuntu中apt-get和apt-cache命令的使用
|
||||
================================================================================
|
||||
apt-get和apt-cache是**Ubuntu Linux**中的命令行下的**包管理**工具。 apt-get的GUI版本是Synaptic包管理器,本篇中我们会讨论apt-get和apt-cache命令的不同。
|
||||
|
||||
### 示例:1 列出所有可用包 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache pkgnames
|
||||
account-plugin-yahoojp
|
||||
ceph-fuse
|
||||
dvd+rw-tools
|
||||
e3
|
||||
gnome-commander-data
|
||||
grub-gfxpayload-lists
|
||||
gweled
|
||||
.......................................
|
||||
|
||||
### 示例:2 用关键字搜索包 ###
|
||||
|
||||
这个命令在你不确定包名时很有用,只要在apt-cache(这里原文是apt-get,应为笔误)后面输入与包相关的关键字即可/
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache search "web server"
|
||||
apache2 - Apache HTTP Server
|
||||
apache2-bin - Apache HTTP Server (binary files and modules)
|
||||
apache2-data - Apache HTTP Server (common files)
|
||||
apache2-dbg - Apache debugging symbols
|
||||
apache2-dev - Apache HTTP Server (development headers)
|
||||
apache2-doc - Apache HTTP Server (on-site documentation)
|
||||
apache2-utils - Apache HTTP Server (utility programs for web servers)
|
||||
......................................................................
|
||||
|
||||
**注意**: 如果你安装了“**apt-file**”包,我们就可以像下面那样用配置文件搜索包。
|
||||
|
||||
linuxtechi@localhost:~$ apt-file search nagios.cfg
|
||||
ganglia-nagios-bridge: /usr/share/doc/ganglia-nagios-bridge/nagios.cfg
|
||||
nagios3-common: /etc/nagios3/nagios.cfg
|
||||
nagios3-common: /usr/share/doc/nagios3-common/examples/nagios.cfg.gz
|
||||
pnp4nagios-bin: /etc/pnp4nagios/nagios.cfg
|
||||
pnp4nagios-bin: /usr/share/doc/pnp4nagios/examples/nagios.cfg
|
||||
|
||||
### 示例:3 显示特定包的基本信息 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache show postfix
|
||||
Package: postfix
|
||||
Priority: optional
|
||||
Section: mail
|
||||
Installed-Size: 3524
|
||||
Maintainer: LaMont Jones <lamont@debian.org>
|
||||
Architecture: amd64
|
||||
Version: 2.11.1-1
|
||||
Replaces: mail-transport-agent
|
||||
Provides: default-mta, mail-transport-agent
|
||||
.....................................................
|
||||
|
||||
### 示例:4 列出包的依赖 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache depends postfix
|
||||
postfix
|
||||
Depends: libc6
|
||||
Depends: libdb5.3
|
||||
Depends: libsasl2-2
|
||||
Depends: libsqlite3-0
|
||||
Depends: libssl1.0.0
|
||||
|Depends: debconf
|
||||
Depends: <debconf-2.0>
|
||||
cdebconf
|
||||
debconf
|
||||
Depends: netbase
|
||||
Depends: adduser
|
||||
Depends: dpkg
|
||||
............................................
|
||||
|
||||
### 示例:5 使用apt-cache显示缓存统计 ###
|
||||
|
||||
linuxtechi@localhost:~$ apt-cache stats
|
||||
Total package names: 60877 (1,218 k)
|
||||
Total package structures: 102824 (5,758 k)
|
||||
Normal packages: 71285
|
||||
Pure virtual packages: 1102
|
||||
Single virtual packages: 9151
|
||||
Mixed virtual packages: 1827
|
||||
Missing: 19459
|
||||
Total distinct versions: 74913 (5,394 k)
|
||||
Total distinct descriptions: 93792 (2,251 k)
|
||||
Total dependencies: 573443 (16.1 M)
|
||||
Total ver/file relations: 78007 (1,872 k)
|
||||
Total Desc/File relations: 93792 (2,251 k)
|
||||
Total Provides mappings: 16583 (332 k)
|
||||
Total globbed strings: 171 (2,263 )
|
||||
Total dependency version space: 2,665 k
|
||||
Total slack space: 37.3 k
|
||||
Total space accounted for: 29.5 M
|
||||
|
||||
### 示例:6 使用 “apt-get update” 更新仓库 ###
|
||||
|
||||
使用命令“apt-get update”, 我们可以重新从源仓库中同步文件索引。包的索引从“/etc/apt/sources.list”中检索
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get update
|
||||
Ign http://extras.ubuntu.com utopic InRelease
|
||||
Hit http://extras.ubuntu.com utopic Release.gpg
|
||||
Hit http://extras.ubuntu.com utopic Release
|
||||
Hit http://extras.ubuntu.com utopic/main Sources
|
||||
Hit http://extras.ubuntu.com utopic/main amd64 Packages
|
||||
Hit http://extras.ubuntu.com utopic/main i386 Packages
|
||||
Ign http://in.archive.ubuntu.com utopic InRelease
|
||||
Ign http://in.archive.ubuntu.com utopic-updates InRelease
|
||||
Ign http://in.archive.ubuntu.com utopic-backports InRelease
|
||||
................................................................
|
||||
|
||||
### 示例:7 使用apt-get安装包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get install icinga
|
||||
|
||||
上面的命令会安装叫“icinga”的包。
|
||||
|
||||
### 示例:8 升级所有已安装的包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get upgrade
|
||||
|
||||
### 示例:9 更新特定的包 ###
|
||||
|
||||
在apt-get命令中的“install”选项后面接上“-only-upgrade”用来更新一个特定的包,如下所示:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get install filezilla --only-upgrade
|
||||
|
||||
### 示例:10 使用apt-get卸载包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get remove skype
|
||||
|
||||
上面的命令只会删除skype包,如果你想要删除它的配置文件,在apt-get命令中使用“purge”选项。如下所示:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get purge skype
|
||||
|
||||
我们可以结合使用上面的两个命令:
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get remove --purge skype
|
||||
|
||||
### 示例:11 在当前的目录中下载包 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get download icinga
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu/ utopic/universe icinga amd64 1.11.6-1build1 [1,474 B]
|
||||
Fetched 1,474 B in 1s (1,363 B/s)
|
||||
|
||||
上面的目录会从你当前的目录下载icinga包。
|
||||
|
||||
### 示例:12 清理本地包占用的磁盘空间 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get clean
|
||||
|
||||
上面的命令会清零apt-get在下载包时占用的磁盘空间。
|
||||
|
||||
我们也可以使用“**autoclean**”选项来代替“**clean**“,两者之间主要的区别是autoclean清理不再使用且没用的下载。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get autoclean
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
|
||||
### 示例:13 使用“autoremove”删除包 ###
|
||||
|
||||
当在apt-get命令中使用“autoremove”时,它会删除为了满足依赖而安装且现在没用的包。
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get autoremove icinga
|
||||
|
||||
### 示例:14 显示包的更新日志 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get changelog apache2
|
||||
Get:1 Changelog for apache2 (http://changelogs.ubuntu.com/changelogs/pool/main/a/apache2/apache2_2.4.10-1ubuntu1/changelog) [195 kB]
|
||||
Fetched 195 kB in 3s (60.9 kB/s)
|
||||
|
||||
上面的命令会下载apache2的更新日志,并在你屏幕上显示。
|
||||
|
||||
### 示例15 使用 “check” 选项显示损坏的依赖 ###
|
||||
|
||||
linuxtechi@localhost:~$ sudo apt-get check
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/ubuntu-apt-get-apt-cache-commands-examples/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
@ -0,0 +1,64 @@
|
||||
如何在Ubuntu 14.04 和14.10 上安装新的字体
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu默认自带了很多字体。但你或许对这些字体还不满意。因此,你可以做的是在**Ubuntu 14.04、 14.10或者像Linux Mint其他的系统中安装额外的字体**。
|
||||
|
||||
### 第一步: 获取字体 ###
|
||||
|
||||
第一步也是最重要的,下载你选择的字体。现在你或许在考虑从哪里下载字体。不要担心,Google搜索可以给你提供几个免费的字体网站。你可以先去看看[ Lost Type 的字体][1]。[Squirrel的字体][2]同样也是一个下载字体的好地方。
|
||||
|
||||
### 第二步:在Ubuntu中安装新字体 ###
|
||||
|
||||
Font Viewer. In here, you can see the option to install the font in top right corner:
|
||||
下载的字体文件可能是一个压缩包。先解压它。大多数字体文件的格式是[TTF][3] (TrueType Fonts) 或者[OTF][4] (OpenType Fonts)。无论是哪种,只要双击字体文件。它会自动用字体查看器打开。这里你可以在右上角看到安装安装选项。
|
||||
|
||||

|
||||
|
||||
在安装字体时不会看到其他信息。几秒钟后,你会看到状态变成已安装。不用猜,这就是已安装的字体。
|
||||
|
||||

|
||||
|
||||
安装完毕后,你就可以在GIMP、Pina等应用中看到你新安装的字体了。
|
||||
|
||||
### 第二步:在Linux上一次安装几个字体 ###
|
||||
|
||||
我没有打错。这仍旧是第二步但是只是是一个备选方案。我上面看到的在Ubuntu中安装字体的方法是不错的。但是这有一个小问题。当你有20个新字体要安装时。一个个单独双击即繁琐又麻烦。你不这么认为么?
|
||||
|
||||
要在Ubuntu中一次安装几个字体,你要做的是创建一个.fonts文件夹,如果在你的家目录下还不存在这个目录的话。并把解压后的TTF和OTF文件复制到这个文件夹内。
|
||||
|
||||
在文件管理器中进入家目录。按下Ctrl+H [显示Ubuntu中的隐藏文件][5]。 右键创建一个文件夹并命名为.fonts。 这里的点很重要。在Linux中,在文件的前面加上点意味在普通的视图中都会隐藏。
|
||||
|
||||
#### 备选方案: ####
|
||||
|
||||
另外你可以安装字体管理程序来以GUI的形式管理字体。要在Ubuntu中安装字体管理程序,打开终端并输入下面的命令:
|
||||
|
||||
sudo apt-get install font-manager
|
||||
|
||||
Open the Font Manager from Unity Dash. You can see installed fonts and option to install new fonts, remove existing fonts etc here.
|
||||
从Unity Dash中打开字体管理器。你可以看到已安装的字体和安装新字体、删除字体等选项。
|
||||
|
||||

|
||||
|
||||
要卸载字体管理器,使用下面的命令:
|
||||
|
||||
sudo apt-get remove font-manager
|
||||
|
||||
我希望这篇文章可以帮助你在Ubuntu或其他Linux系统上安装字体。如果你有任何问题或建议请让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://www.losttype.com/browse/
|
||||
[2]:http://www.fontsquirrel.com/
|
||||
[3]:http://en.wikipedia.org/wiki/TrueType
|
||||
[4]:http://en.wikipedia.org/wiki/OpenType
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
@ -0,0 +1,76 @@
|
||||
如何在Linux上使用dupeGuru删除重复文件
|
||||
================================================================================
|
||||
最近,我被要求清理我父亲的文件和文件夹。有一个难题是,里面存在很多不正确的名字的重复文件。有移动硬盘的备份,同时还为同一个文件编辑了多个版本,甚至改变的目录结构,同一个文件被复制了好几次,改变名字,改变位置等,这些挤满了磁盘空间。追踪每一个文件成了一个最大的问题。万幸的是,有一个小巧的软件可以帮助你省下很多时间来找到删除你系统中重复的文件:[dupeGuru][1]。它用Python写成,这个去重软件几个小时钱前切换到了GPLv3许可证。因此是时候用它来清理你的文件了!
|
||||
|
||||
### dupeGuru的安装 ###
|
||||
|
||||
在Ubuntu上, 你可以加入Hardcoded的软件PPA:
|
||||
|
||||
$ sudo apt-add-repository ppa:hsoft/ppa
|
||||
$ sudo apt-get update
|
||||
|
||||
接着用下面的命令安装:
|
||||
|
||||
$ sudo apt-get install dupeguru-se
|
||||
|
||||
在ArchLinux中,这个包在[AUR][2]中。
|
||||
|
||||
如果你想自己编译,源码在[GitHub][3]上。
|
||||
|
||||
### dupeGuru的基本使用 ###
|
||||
|
||||
DupeGuru的构想是既快又安全。这意味着程序不会在你的系统上疯狂地运行。它很少会删除你不想要删除的文件。然而,既然在讨论文件删除,保持谨慎和小心总是好的:备份总是需要的。
|
||||
|
||||
你看完注意事项后,你可以用下面的命令运行duprGuru了:
|
||||
|
||||
$ dupeguru_se
|
||||
|
||||
你应该看到要你选择文件夹的欢迎界面,在这里加入你你想要扫描的重复文件夹。
|
||||
|
||||

|
||||
|
||||
一旦你选择完文件夹并启动扫描后,dupeFuru会以列表的形式显示重复文件的组:
|
||||
|
||||

|
||||
|
||||
注意的是默认上dupeGuru基于文件的内容匹配,而不是他们的名字。为了防止意外地删除了重要的文件,匹配那列列出了使用的匹配算法。在这里,你可以选择你想要删除的匹配文件,并按下“Action” 按钮来看到可用的操作。
|
||||
|
||||

|
||||
|
||||
可用的选项是相当广泛的。简而言之,你可以删除重复、移动到另外的位置、忽略它们、打开它们、重命名它们甚至用自定义命令运行它们。如果你选择删除重复文件,你可能会像我一样非常意外竟然还有删除选项。
|
||||
|
||||

|
||||
|
||||
你不及可以将删除文件移到垃圾箱或者永久删除,还可以选择留下指向原文件的链接(软链接或者硬链接)。也就是说,重复文件按将会删除但是会保留下指向原文件的链接。这将会省下大量的磁盘空间。如果你将这些文件导入到工作空间或者它们有一些依赖时很有用。
|
||||
|
||||
还有一个奇特的选项:你可以用HTML或者CSV文件导出结果。不确定你会不会这么做,但是我假设你想追踪重复文件而不是想让dupeGuru处理它们时会有用。
|
||||
|
||||
最后但并不是最不重要的是,偏好菜单可以让你对去重的想法成真。
|
||||
|
||||

|
||||
|
||||
这里你可以选择扫描的标准,基于内容还是基于文字,并且有一个阈值来控制结果的数量。这里同样可以定义自定义在执行中可以选择的命令。在无数其他小的选项中,要注意的是dupeGuru默认忽略小于10KB的文件。
|
||||
|
||||
要了解更多的信息,我建议你到[official website][4]官方网站看下,这里有很多文档、论坛支持和其他好东西。
|
||||
|
||||
总结一下,dupeGuru是我无论何时准备备份或者释放空间时想到的软件。我发现这对高级用户而言也足够强大了,对新人而言也很直观。锦上添花的是:dupeGuru是跨平台的额,这意味着你可以在Mac或者在Windows PC上都可以使用。如果你有特定的需求,想要清理音乐或者图片。这里有两个变种:[dupeguru-me][5]和 [dupeguru-pe][6], 相应地可以清理音频和图片文件。与常规版本的不同是它不仅比较文件格式还比较特定的媒体数据像质量和码率。
|
||||
|
||||
你dupeGuru怎么样?你会考虑使用它么?或者你有任何可以替代的软件的建议么?让我在评论区知道你们的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/dupeguru-deduplicate-files-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.hardcoded.net/dupeguru/
|
||||
[2]:https://aur.archlinux.org/packages/dupeguru-se/
|
||||
[3]:https://github.com/hsoft/dupeguru
|
||||
[4]:http://www.hardcoded.net/dupeguru/
|
||||
[5]:http://www.hardcoded.net/dupeguru_me/
|
||||
[6]:http://www.hardcoded.net/dupeguru_pe/
|
||||
@ -0,0 +1,340 @@
|
||||
SaltStack:Linux服务器配置管理神器
|
||||
================================================================================
|
||||

|
||||
|
||||
我在搜索[Puppet][1]的替代品时,偶然间碰到了Salt。我喜欢puppet,但是我又爱上Salt了:)。我发现Salt在配置和使用上都要比Puppet简单,当然这只是一家之言,你大可不必介怀。另外一个爱上Salt的理由是,它可以让你从命令行管理服务器配置,比如:
|
||||
|
||||
要通过Salt来更新所有服务器,你只需运行以下命令
|
||||
|
||||
salt ‘*’ pkg.upgrade
|
||||
|
||||
**安装SaltStack到Linux上。**
|
||||
|
||||
如果你是在CentOS 6/7上安装的话,那么Salt可以通过EPEL仓库获取到。而对于Pi和Ubuntu Linux用户,你可以从[这里][2]添加Salt仓库。Salt是基于python的,所以你也可以使用‘pip’来安装,但是你得用yum-utils或是其它包管理器来自己处理它的依赖关系哦。
|
||||
|
||||
Salt遵循服务器-客户端模式,服务器端称为领主,而客户端则称为下属。
|
||||
|
||||
**安装并配置Salt领主**
|
||||
|
||||
[root@salt-master~]# yum install salt-master
|
||||
|
||||
Salt配置文件位于/etc/salt和/srv/salt。Salt虽然可以开箱即用,但我还是建议你将日志配置得更详细点,以方便日后排除故障。
|
||||
|
||||
[root@salt-master ~]# vim /etc/salt/master
|
||||
# 默认是warning,修改如下
|
||||
log_level: debug
|
||||
log_level_logfile: debug
|
||||
|
||||
[root@salt-master ~]# systemctl start salt-master
|
||||
|
||||
**安装并配置Salt下属**
|
||||
|
||||
[root@salt-minion~]#yum install salt-minion
|
||||
|
||||
# 添加你的Salt领主的主机名
|
||||
[root@salt-minion~]#vim /etc/salt/minion
|
||||
master: salt-master.com
|
||||
# 启动下属
|
||||
[root@salt-minion~] systemctl start salt-minion
|
||||
|
||||
在启动时,下属客户机会生成一个密钥和一个id。然后,它会连接到Salt领主服务器并验证自己的身份。Salt领主服务器在允许下属客户机下载配置之前,必须接受下属的密钥。
|
||||
|
||||
**在Salt领主服务器上列出并接受密钥**
|
||||
|
||||
# 列出所有密钥
|
||||
[root@salt-master~] salt-key -L
|
||||
Accepted Keys:
|
||||
Unaccepted Keys:
|
||||
minion.com
|
||||
Rejected Keys:
|
||||
|
||||
# 使用id 'minion.com'命令接受密钥
|
||||
[root@salt-master~]salt-key -a minion.com
|
||||
|
||||
[root@salt-master~] salt-key -L
|
||||
Accepted Keys:
|
||||
minion.com
|
||||
Unaccepted Keys:
|
||||
Rejected Keys:
|
||||
|
||||
在接受下属客户机的密钥后,你可以使用‘salt’命令来立即获取信息。
|
||||
|
||||
**Salt命令行实例**
|
||||
|
||||
# 检查下属是否启动并运行
|
||||
[root@salt-master~] salt 'minion.com' test.ping
|
||||
minion.com:
|
||||
True
|
||||
# 在下属客户机上运行shell命令
|
||||
[root@salt-master~]# salt 'minion.com' cmd.run 'ls -l'
|
||||
minion.com:
|
||||
total 2988
|
||||
-rw-r--r--. 1 root root 1024 Jul 31 08:24 1g.img
|
||||
-rw-------. 1 root root 940 Jul 14 15:04 anaconda-ks.cfg
|
||||
-rw-r--r--. 1 root root 1024 Aug 14 17:21 test
|
||||
# 安装/更新所有服务器上的软件
|
||||
[root@salt-master ~]# salt '*' pkg.install git
|
||||
|
||||
salt命令需要一些组件来发送信息,其中之一是mimion id,而另一个是下属客户机上要调用的函数。
|
||||
|
||||
在第一个实例中,我使用‘test’模块的‘ping’函数来检查系统是否启动。该函数并不是真的实施一次ping,它仅仅是在下属客户机作出回应时返回‘真’。
|
||||
|
||||
‘cmd.run’用于执行远程命令,而‘pkg’模块包含了包管理的函数。本文结尾提供了全部内建模块的列表。
|
||||
|
||||
**颗粒实例**
|
||||
|
||||
Salt使用一个名为**颗粒**的界面来获取系统信息。你可以使用颗粒在指定属性的系统上运行命令。
|
||||
|
||||
[root@vps4544 ~]# salt -G 'os:Centos' test.ping
|
||||
minion:
|
||||
True
|
||||
|
||||
更多颗粒实例,请访问http://docs.saltstack.com/en/latest/topics/targeting/grains.html
|
||||
|
||||
**通过状态文件系统进行包管理。**
|
||||
|
||||
为了是软件配置自动化,你需要使用状态系统,并创建状态文件。这些文件使用YAML格式和python字典、列表、字符串以及编号来构成数据结构。将这些文件从头到尾研读一遍,这将有助于你更好地理解它的配置。
|
||||
|
||||
**VIM状态文件实例**
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/vim.sls
|
||||
vim-enhanced:
|
||||
pkg.installed
|
||||
/etc/vimrc:
|
||||
file.managed:
|
||||
- source: salt://vimrc
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 644
|
||||
|
||||
该文件的第一和第三行成为状态id,它们必须包含有需要管理的包或文件的确切名称或路径。在状态id之后是状态和函数声明,‘pkg’和‘file’是状态声明,而‘installed’和‘managed’是函数声明。函数接受参数,用户、组、模式和源都是函数‘managed’的参数。
|
||||
|
||||
要将该配置应用到下属客户端,请移动你的‘vimrc’文件到‘/src/salt’,然后运行以下命令。
|
||||
|
||||
[root@salt-master~]# salt 'minion.com' state.sls vim
|
||||
minion.com:
|
||||
----------
|
||||
ID: vim-enhanced
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: The following packages were installed/updated: vim-enhanced.
|
||||
Started: 09:36:23.438571
|
||||
Duration: 94045.954 ms
|
||||
Changes:
|
||||
----------
|
||||
vim-enhanced:
|
||||
----------
|
||||
new:
|
||||
7.4.160-1.el7
|
||||
old:
|
||||
|
||||
|
||||
Summary
|
||||
------------
|
||||
Succeeded: 1 (changed=1)
|
||||
Failed: 0
|
||||
------------
|
||||
Total states run: 1
|
||||
|
||||
你也可以添加依赖关系到你的配置中。
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/ssh.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://ssh/sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- require:
|
||||
- pkg: openssh-server
|
||||
|
||||
这里的‘require’声明是必须的,它在‘service’和‘pkg’状态之间创建依赖关系。该声明将首先检查包是否安装,然后运行服务。
|
||||
|
||||
但是,我更偏向于使用‘watch’声明,因为它也可以检查文件是否修改和重启服务。
|
||||
|
||||
[root@salt-master~]# vim /srv/salt/ssh.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- watch:
|
||||
- pkg: openssh-server
|
||||
- file: /etc/ssh/sshd_config
|
||||
|
||||
[root@vps4544 ssh]# salt 'minion.com' state.sls ssh
|
||||
seven.leog.in:
|
||||
Changes:
|
||||
----------
|
||||
ID: openssh-server
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package openssh-server is already installed.
|
||||
Started: 13:01:55.824367
|
||||
Duration: 1.156 ms
|
||||
Changes:
|
||||
----------
|
||||
ID: /etc/ssh/sshd_config
|
||||
Function: file.managed
|
||||
Result: True
|
||||
Comment: File /etc/ssh/sshd_config updated
|
||||
Started: 13:01:55.825731
|
||||
Duration: 334.539 ms
|
||||
Changes:
|
||||
----------
|
||||
diff:
|
||||
---
|
||||
+++
|
||||
@@ -14,7 +14,7 @@
|
||||
# SELinux about this change.
|
||||
# semanage port -a -t ssh_port_t -p tcp #PORTNUMBER
|
||||
#
|
||||
-Port 22
|
||||
+Port 422
|
||||
#AddressFamily any
|
||||
#ListenAddress 0.0.0.0
|
||||
#ListenAddress ::
|
||||
|
||||
----------
|
||||
ID: sshd
|
||||
Function: service.running
|
||||
Result: True
|
||||
Comment: Service restarted
|
||||
Started: 13:01:56.473121
|
||||
Duration: 407.214 ms
|
||||
Changes:
|
||||
----------
|
||||
sshd:
|
||||
True
|
||||
|
||||
Summary
|
||||
------------
|
||||
Succeeded: 4 (changed=2)
|
||||
Failed: 0
|
||||
------------
|
||||
Total states run: 4
|
||||
|
||||
在单一目录中维护所有的配置文件是一项复杂的大工程,因此,你可以创建子目录并在其中添加配置文件init.sls文件。
|
||||
|
||||
[root@salt-master~]# mkdir /srv/salt/ssh
|
||||
[root@salt-master~]# vim /srv/salt/ssh/init.sls
|
||||
openssh-server:
|
||||
pkg.installed
|
||||
|
||||
|
||||
/etc/ssh/sshd_config:
|
||||
file.managed:
|
||||
- user: root
|
||||
- group: root
|
||||
- mode: 600
|
||||
- source: salt://ssh/sshd_config
|
||||
|
||||
sshd:
|
||||
service.running:
|
||||
- watch:
|
||||
- pkg: openssh-server
|
||||
- file: /etc/ssh/sshd_config
|
||||
|
||||
[root@vps4544 ssh]# cp /etc/ssh/sshd_config /srv/salt/ssh/
|
||||
[root@vps4544 ssh]# salt 'minion.com' state.sls ssh
|
||||
|
||||
**Top文件和环境。**
|
||||
|
||||
top文件(top.sls)是用来定义你的环境的文件,它允许你映射下属客户机到包,默认环境是‘base’。你需要定义在基本环境下,哪个包会被安装到哪台服务器。
|
||||
|
||||
如果对于一台特定的下属客户机而言,有多个环境,并且有多于一个的定义,那么默认情况下,基本环境将取代其它环境。
|
||||
|
||||
要定义环境,你需要将它添加到领主配置文件的‘file_roots’指针。
|
||||
|
||||
[root@salt-master ~]# vim /etc/salt/master
|
||||
file_roots:
|
||||
base:
|
||||
- /srv/salt
|
||||
dev:
|
||||
- /srv/salt/dev
|
||||
|
||||
现在,添加一个top.sls文件到/src/salt
|
||||
|
||||
[root@salt-master ~]# vim /srv/salt/top.sls
|
||||
base:
|
||||
'*':
|
||||
- vim
|
||||
'minion.com':
|
||||
- ssh
|
||||
|
||||
应用top文件配置
|
||||
|
||||
[root@salt-master~]# salt '*' state.highstate
|
||||
minion.com:
|
||||
----------
|
||||
ID: vim-enhanced
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package vim-enhanced is already installed.
|
||||
Started: 13:10:55
|
||||
Duration: 1678.779 ms
|
||||
Changes:
|
||||
----------
|
||||
ID: openssh-server
|
||||
Function: pkg.installed
|
||||
Result: True
|
||||
Comment: Package openssh-server is already installed.
|
||||
Started: 13:10:55.
|
||||
Duration: 2.156 ms
|
||||
|
||||
下属客户机将下载top文件并搜索用于它的配置,领主服务器也会将配置应用到所有下属客户机。
|
||||
|
||||
这仅仅是一个Salt的简明教程,如果你想要深入学习并理解,你可以访问以下链接。如果你已经在使用Salt,那么请告诉我你的建议和意见吧。
|
||||
|
||||
更新: [Foreman][3] 已经通过[插件][4]支持salt。
|
||||
|
||||
阅读链接
|
||||
|
||||
- http://docs.saltstack.com/en/latest/ref/states/top.html#how-top-files-are-compiled
|
||||
- http://docs.saltstack.com/en/latest/topics/tutorials/states_pt1.html
|
||||
- http://docs.saltstack.com/en/latest/ref/states/highstate.html#state-declaration
|
||||
|
||||
颗粒
|
||||
|
||||
- http://docs.saltstack.com/en/latest/topics/targeting/grains.html
|
||||
|
||||
Salt模块列表
|
||||
|
||||
Salt和Puppet的充分比较
|
||||
|
||||
- https://mywushublog.com/2013/03/configuration-management-with-salt-stack/
|
||||
|
||||
内建执行模块的完全列表
|
||||
|
||||
- http://docs.saltstack.com/en/latest/ref/modules/all/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://techarena51.com/index.php/getting-started-with-saltstack/
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techarena51.com/
|
||||
[1]:http://techarena51.com/index.php/a-simple-way-to-install-and-configure-a-puppet-server-on-linux/
|
||||
[2]:http://docs.saltstack.com/en/latest/topics/installation/index.html
|
||||
[3]:http://techarena51.com/index.php/using-foreman-opensource-frontend-puppet/
|
||||
[4]:https://github.com/theforeman/foreman_salt/wiki
|
||||
@ -0,0 +1,73 @@
|
||||
如何在Ubuntu 14.04 上为Apache 2.4 安装SSL
|
||||
================================================================================
|
||||
今天我会站如如何为你的个人网站或者博客安装**SSL 证书**,来保护你的访问者和网站之间通信的安全。
|
||||
|
||||
安全套接字层或称SSL,是一种加密网站和浏览器之间连接的标准安全技术。这确保服务器和浏览器之间传输的数据保持隐私和安全。这被成千上万的人使用来保护他们与客户的通信。要启用SSL链接,web服务器需要安装SSL证书。
|
||||
|
||||
你可以创建你自己的SSL证书,但是这默认不会被浏览器信任,要修复这个问题,你需要从受信任的证书机构(CA)处购买证书,我们会向你展示如何
|
||||
或者证书并在apache中安装。
|
||||
|
||||
### 生成一个证书签名请求 ###
|
||||
|
||||
证书机构(CA)会要求你在你的服务器上生成一个证书签名请求(CSR)。这是一个很简单的过程,只需要一会就行,你需要运行下面的命令并输入需要的信息:
|
||||
|
||||
# openssl req -new -newkey rsa:2048 -nodes -keyout yourdomainname.key -out yourdomainname.csr
|
||||
|
||||
输出看上去会像这样:
|
||||
|
||||

|
||||
|
||||
这一步会生成两个文件按:一个用于解密SSL证书的私钥文件,一个证书签名请求(CSR)文件(用于申请你的SSL证书)。
|
||||
|
||||
根据你申请的机构,你会需要上传csr文件或者在网站表格中粘帖他的内容。
|
||||
|
||||
### 在Apache中安装实际的证书 ###
|
||||
|
||||
生成步骤完成之后,你会收到新的数字证书,本篇教程中我们使用[Comodo SSL][1]并在一个zip文件中收到了证书。要在apache中使用它,你首先需要用下面的命令为收到的证书创建一个组合的证书:
|
||||
|
||||
# cat COMODORSADomainValidationSecureServerCA.crt COMODORSAAddTrustCA.crt AddTrustExternalCARoot.crt > bundle.crt
|
||||
|
||||

|
||||
|
||||
用下面的命令确保ssl模块已经加载进apache了:
|
||||
|
||||
# a2enmod ssl
|
||||
|
||||
如果你看到了“Module ssl already enabled”这样的信息就说明你成功了,如果你看到了“Enabling module ssl”,那么你还需要用下面的命令重启apache:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||
最后像下面这样修改你的虚拟主机文件(通常在/etc/apache2/sites-enabled 下):
|
||||
|
||||
DocumentRoot /var/www/html/
|
||||
ServerName linoxide.com
|
||||
SSLEngine on
|
||||
SSLCertificateFile /usr/local/ssl/crt/yourdomainname.crt
|
||||
SSLCertificateKeyFile /usr/local/ssl/yourdomainname.key
|
||||
SSLCACertificateFile /usr/local/ssl/bundle.crt
|
||||
|
||||
你现在应该可以用https://YOURDOMAIN/(注意使用‘https’而不是‘http’)来访问你的网站了,并可以看到SSL的进度条了(通常在你浏览器中用一把锁来表示)。
|
||||
|
||||
**NOTE:** All the links must now point to https, if some of the content on the website (like images or css files) still point to http links you will get a warning in the browser, to fix this you have to make sure that every link points to https.
|
||||
**注意:** 现在所有的链接都必须指向https,如果网站上的一些内容(像图片或者css文件等)仍旧指向http链接的话,你会在浏览器中得到一个警告,要修复这个问题,请确保每个链接都指向了https。
|
||||
|
||||
### 在你的网站上重定向HTTP请求到HTTPS中 ###
|
||||
|
||||
如果你希望重定向常规的HTTP请求到HTTPS,添加下面的文本到你希望的虚拟主机或者如果希望给服务器上所有网站都添加的话就加入到apache.conf中:
|
||||
|
||||
RewriteEngine On
|
||||
RewriteCond %{HTTPS} off
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-ssl-apache-2-4-in-ubuntu/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:https://ssl.comodo.com/
|
||||
@ -0,0 +1,130 @@
|
||||
如何在Ubuntu 14.04 LTS安装网络爬虫工具
|
||||
================================================================================
|
||||
这是一款提取网站数据的开源工具。Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展。我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS。
|
||||
|
||||
### 安装 Scrapy ###
|
||||
|
||||
Scrapy依赖于Python、开发库和pip。Python最新的版本已经在Ubuntu上预装了。因此我们在安装Scrapy之前只需安装pip和python开发库就可以了。
|
||||
|
||||
pip是作为python包索引器easy_install的替代品。用于安装和管理Python包。pip包的安装可见图 1。
|
||||
|
||||
sudo apt-get install python-pip
|
||||
|
||||

|
||||
|
||||
图:1 pip安装
|
||||
|
||||
我们必须要用下面的命令安装python开发库。如果包没有安装那么就会在安装scrapy框架的时候报关于python.h头文件的错误。
|
||||
|
||||
sudo apt-get install python-dev
|
||||
|
||||

|
||||
|
||||
图:2 Python 开发库
|
||||
|
||||
scrapy框架即可从deb包安装也可以从源码安装。然而在图3中我们已经用pip(Python 包管理器)安装了deb包了。
|
||||
|
||||
sudo pip install scrapy
|
||||
|
||||

|
||||
|
||||
图:3 Scrapy 安装
|
||||
|
||||
图4中scrapy的成功安装需要一些时间。
|
||||
|
||||

|
||||
|
||||
图:4 成功安装Scrapy框架
|
||||
|
||||
### 使用scrapy框架提取数据 ###
|
||||
|
||||
**(基础教程)**
|
||||
|
||||
我们将用scrapy从fatwallet.com上提取店名(提供卡的店)。首先,我们使用下面的命令新建一个scrapy项目“store name”, 见图5。
|
||||
|
||||
$sudo scrapy startproject store_name
|
||||
|
||||

|
||||
|
||||
图:5 Scrapy框架新建项目
|
||||
|
||||
Above command creates a directory with title “store_name” at current path. This main directory of the project contains files/folders which are shown in the following Figure 6.
|
||||
上面的命令在当前路径创建了一个“store_name”的目录。项目主目录下包含的文件/文件夹见图6。
|
||||
|
||||
$sudo ls –lR store_name
|
||||
|
||||

|
||||
|
||||
图:6 store_name项目的内容
|
||||
|
||||
每个文件/文件夹的概要如下:
|
||||
|
||||
- scrapy.cfg 是项目配置文件
|
||||
- store_name/ 主目录下的另一个文件夹。 这个目录包含了项目的python代码
|
||||
- store_name/items.py 包含了将由蜘蛛爬取的项目
|
||||
- store_name/pipelines.py 是管道文件
|
||||
- store_name/settings.py 是项目的配置文件
|
||||
- store_name/spiders/, 包含了用于爬取的蜘蛛
|
||||
|
||||
由于我们要从fatwallet.com上如提取店名,因此我们如下修改文件。
|
||||
|
||||
import scrapy
|
||||
|
||||
class StoreNameItem(scrapy.Item):
|
||||
|
||||
name = scrapy.Field() # extract the names of Cards store
|
||||
|
||||
之后我们要在项目的store_name/spiders/文件夹下写一个新的蜘蛛。蜘蛛是一个python类,它包含了下面几个必须的属性:
|
||||
|
||||
1. 蜘蛛名 (name )
|
||||
2. 爬取起点url (start_urls)
|
||||
3. 包含了从响应中提取需要内容相应的正则表达式的解析方法。解析方法对爬虫而言很重要。
|
||||
|
||||
我们在store_name/spiders/目录下创建了“store_name.py”爬虫,并添加如下的代码来从fatwallet.com上提取点名。爬虫的输出到文件(**StoreName.txt**)中,见图7。
|
||||
|
||||
from scrapy.selector import Selector
|
||||
from scrapy.spider import BaseSpider
|
||||
from scrapy.http import Request
|
||||
from scrapy.http import FormRequest
|
||||
import re
|
||||
class StoreNameItem(BaseSpider):
|
||||
name = "storename"
|
||||
allowed_domains = ["fatwallet.com"]
|
||||
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
|
||||
|
||||
def parse(self,response):
|
||||
output = open('StoreName.txt','w')
|
||||
resp = Selector(response)
|
||||
|
||||
tags = resp.xpath('//tr[@class="storeListRow"]|\
|
||||
//tr[@class="storeListRow even"]|\
|
||||
//tr[@class="storeListRow even last"]|\
|
||||
//tr[@class="storeListRow last"]').extract()
|
||||
for i in tags:
|
||||
i = i.encode('utf-8', 'ignore').strip()
|
||||
store_name = ''
|
||||
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
|
||||
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
|
||||
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
|
||||
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
|
||||
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
|
||||
#print store_name
|
||||
output.write(store_name+""+"\n")
|
||||
|
||||

|
||||
|
||||
图:7 爬虫的输出
|
||||
|
||||
*注意: 本教程的目的仅用于理解scrapy框架*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/scrapy-install-ubuntu/
|
||||
|
||||
作者:[nido][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/naveeda/
|
||||
@ -0,0 +1,93 @@
|
||||
如何在Linux上找出并删除重复的文件
|
||||
================================================================================
|
||||
大家好,今天我们会学习如何在Linux PC或者服务器上找出和删除重复文件。这里有一款工具你可以工具自己的需要使用。
|
||||
|
||||
无论你是否正在使用Linux桌面或者服务器,有一些很好的工具能一帮你扫描系统中的重复文件并删除它们来释放空间。图形界面和命令行界面的都有。重复文件是磁盘空间不必要的浪费。毕竟,如果你的确需要在不同的位置享有同一个文件,你可以使用软链接或者硬链接,这样就可以这样就可以在磁盘的一处地方存储数据了。
|
||||
|
||||
### FSlint ###
|
||||
|
||||
[FSlint][1] 在不同的Linux发行办二进制仓库中都有,包括Ubuntu、Debian、Fedora和Red Hat。只需你运行你的包管理器并安装“fslint”包就行。这个工具默认提供了一个简单的图形化界面,同样也有包含各种功能的命令行版本。
|
||||
|
||||
不要让它让你害怕使用FSlint的图形化界面。默认情况下,它会自动选中Duplicate窗格,并以你的家目录作为搜索路径。
|
||||
|
||||
要安装fslint,若像我这样运行的是Ubuntu,这里是默认的命令:
|
||||
|
||||
$ sudo apt-get install fslint
|
||||
|
||||
这里还有针对其他发行版的安装命令:
|
||||
|
||||
Debian:
|
||||
|
||||
svn checkout http://fslint.googlecode.com/svn/trunk/ fslint-2.45
|
||||
cd fslint-2.45
|
||||
dpkg-buildpackage -I.svn -rfakeroot -tc
|
||||
sudo dpkg -i ../fslint_2.45-1_all.deb
|
||||
|
||||
Fedora:
|
||||
|
||||
sudo yum install fslint
|
||||
|
||||
For OpenSuse:
|
||||
|
||||
[ -f /etc/mandrake-release ] && pkg=rpm
|
||||
[ -f /etc/SuSE-release ] && pkg=packages
|
||||
wget http://www.pixelbeat.org/fslint/fslint-2.42.tar.gz
|
||||
sudo rpmbuild -ta fslint-2.42.tar.gz
|
||||
sudo rpm -Uvh /usr/src/$pkg/RPMS/noarch/fslint-2.42-1.*.noarch.rpm
|
||||
|
||||
对于其他发行版:
|
||||
|
||||
wget http://www.pixelbeat.org/fslint/fslint-2.44.tar.gz
|
||||
tar -xzf fslint-2.44.tar.gz
|
||||
cd fslint-2.44
|
||||
(cd po && make)
|
||||
./fslint-gui
|
||||
|
||||
要在Ubuntu中运行fslint的GUI版本fslint-gui, 使用Alt+F2运行命令或者在终端输入:
|
||||
|
||||
$ fslint-gui
|
||||
|
||||
默认情况下,它会自动选中Duplicate窗格,并以你的家目录作为搜索路径。你要做的就是点击Find按钮,FSlint会自动在你的家目录下找出重复文件列表。
|
||||
|
||||

|
||||
|
||||
使用按钮来删除任何你要删除的文件,并且可以双击预览。
|
||||
|
||||
完成这一切后,我们就成功地删除你系统中的重复文件了。
|
||||
|
||||
**注意** 的是命令行工具默认不在环境的路径中,你不能像典型的命令那样运行它。在Ubuntu中,你可以在/usr/share/fslint/fslint下找到它。因此,如果你要在一个单独的目录运行fslint完整扫描,下面是Ubuntu中的运行命令:
|
||||
|
||||
cd /usr/share/fslint/fslint
|
||||
|
||||
./fslint /path/to/directory
|
||||
|
||||
**这个命令实际上并不会删除任何文件。它只会打印出重复文件的列表-你需要自己做接下来的事。**
|
||||
|
||||
$ /usr/share/fslint/fslint/findup --help
|
||||
find dUPlicate files.
|
||||
Usage: findup [[[-t [-m|-d]] | [--summary]] [-r] [-f] paths(s) ...]
|
||||
|
||||
If no path(s) specified then the current directory is assumed.
|
||||
|
||||
When -m is specified any found duplicates will be merged (using hardlinks).
|
||||
When -d is specified any found duplicates will be deleted (leaving just 1).
|
||||
When -t is specfied, only report what -m or -d would do.
|
||||
When --summary is specified change output format to include file sizes.
|
||||
You can also pipe this summary format to /usr/share/fslint/fslint/fstool/dupwaste
|
||||
to get a total of the wastage due to duplicates.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/file-system/find-remove-duplicate-files-linux/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.pixelbeat.org/fslint/
|
||||
[2]:http://www.pixelbeat.org/fslint/fslint-2.42.tar.gz
|
||||
@ -0,0 +1,74 @@
|
||||
如何在Ubuntu Server 14.04 LTS(Trusty) 上安装Ghost
|
||||
================================================================================
|
||||
今天我们将会在Ubuntu Server 14.04 LTS (Trusty)上安装一个博客平台Ghost。
|
||||
|
||||
Ghost是一款设计优美的发布平台,很容易使用且对任何人都免费。它是免费的开源软件(FOSS),它的源码在Github上。截至2014年1月,它的界面很简单还有分析面板。编辑使用的是分屏显示。
|
||||
|
||||
因此有了这篇步骤明确的在Ubuntu Server上安装Ghost的教程:
|
||||
|
||||
### 1. 升级Ubuntu ###
|
||||
|
||||
第一步是运行Ubuntu软件升级并安装一系列需要的额外包。
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade -y
|
||||
sudo aptitude install -y build-essential zip vim wget
|
||||
|
||||
### 2. 下载并安装 Node.js 源码 ###
|
||||
|
||||
wget http://nodejs.org/dist/node-latest.tar.gz
|
||||
tar -xzf node-latest.tar.gz
|
||||
cd node-v*
|
||||
|
||||
现在,我们使用下面的命令安装Node.js:
|
||||
|
||||
./configure
|
||||
make
|
||||
sudo make install
|
||||
|
||||
### 3. 下载并安装Ghost ###
|
||||
|
||||
sudo mkdir -p /var/www/
|
||||
cd /var/www/
|
||||
sudo wget https://ghost.org/zip/ghost-latest.zip
|
||||
sudo unzip -d ghost ghost-latest.zip
|
||||
cd ghost/
|
||||
sudo npm install --production
|
||||
|
||||
### 4. 配置Ghost ###
|
||||
|
||||
sudo nano config.example.js
|
||||
|
||||
在“Production”字段,将:
|
||||
|
||||
host: '127.0.0.1',
|
||||
|
||||
修改成
|
||||
|
||||
host: '0.0.0.0',
|
||||
|
||||
### 创建Ghost用户 ###
|
||||
|
||||
sudo adduser --shell /bin/bash --gecos 'Ghost application' ghost
|
||||
sudo chown -R ghost:ghost /var/www/ghost/
|
||||
|
||||
现在启动Ghost,你需要以“ghsot”用户登录。
|
||||
|
||||
su - ghost
|
||||
cd /var/www/ghost/
|
||||
|
||||
现在,你已经以“ghsot”用户登录,并可启动Ghost:
|
||||
|
||||
npm start --production
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/install-ghost-ubuntu-server-14-04/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -0,0 +1,149 @@
|
||||
在Ubuntu/Fedora/CentOS中安装Gitblit
|
||||
================================================================================
|
||||
**Git**是一款注重速度、数据完整性、分布式支持和非线性工作流的分布式版本控制工具。Git最初由Linus Torvalds在2005年为Linux内核开发而设计,如今已经成为被广泛接受的版本控制系统。
|
||||
|
||||
和其他大多数分布式版本控制系统比起来,不像大多数客户端-服务端的系统,每个Git工作目录是一个完整的仓库,带有完整的历史记录和完整的版本跟踪能力,不需要依赖网络或者中心服务器。像Linux内核一样,Git意识在GPLv2许可证下的免费软件。
|
||||
|
||||
本篇教程我会演示如何安装gitlit服务器。gitlit的最新稳定版是1.6.2。[Gitblit][1]是一款开源、纯Java开发的用于管理浏览和服务的[Git][2]仓库。它被设计成一款为希望托管中心仓库的小工作组服务的工具。
|
||||
|
||||
mkdir -p /opt/gitblit; cd /opt/gitblit; wget http://dl.bintray.com/gitblit/releases/gitblit-1.6.2.tar.gz
|
||||
|
||||
### 列出目录: ###
|
||||
|
||||
root@vps124229 [/opt/gitblit]# ls
|
||||
./ docs/ gitblit-stop.sh* LICENSE service-ubuntu.sh*
|
||||
../ ext/ install-service-centos.sh* migrate-tickets.sh*
|
||||
add-indexed-branch.sh* gitblit-1.6.2.tar.gz install-service-fedora.sh* NOTICE
|
||||
authority.sh* gitblit.jar install-service-ubuntu.sh* reindex-tickets.sh*
|
||||
data/ gitblit.sh* java-proxy-config.sh* service-centos.sh*
|
||||
|
||||
默认配置文件在data/gitblit.properties,你可以根据需要自己修改。
|
||||
|
||||
### 启动gitlit服务: ###
|
||||
|
||||
### 通过service命令: ###
|
||||
|
||||
root@vps124229 [/opt/gitblit]# cp service-centos.sh /etc/init.d/gitblit
|
||||
root@vps124229 [/opt/gitblit]# chkconfig --add gitblit
|
||||
root@vps124229 [/opt/gitblit]# service gitblit start
|
||||
Starting gitblit server
|
||||
.
|
||||
|
||||
### 手动启动: ###
|
||||
|
||||
root@vps124229 [/opt/gitblit]# java -jar gitblit.jar --baseFolder data
|
||||
2015-01-10 09:16:53 [INFO ] *****************************************************************
|
||||
2015-01-10 09:16:53 [INFO ] _____ _ _ _ _ _ _
|
||||
2015-01-10 09:16:53 [INFO ] | __ \(_)| | | | | |(_)| |
|
||||
2015-01-10 09:16:53 [INFO ] | | \/ _ | |_ | |__ | | _ | |_
|
||||
2015-01-10 09:16:53 [INFO ] | | __ | || __|| '_ \ | || || __|
|
||||
2015-01-10 09:16:53 [INFO ] | |_\ \| || |_ | |_) || || || |_
|
||||
2015-01-10 09:16:53 [INFO ] \____/|_| \__||_.__/ |_||_| \__|
|
||||
2015-01-10 09:16:53 [INFO ] Gitblit v1.6.2
|
||||
2015-01-10 09:16:53 [INFO ]
|
||||
2015-01-10 09:16:53 [INFO ] *****************************************************************
|
||||
2015-01-10 09:16:53 [INFO ] Running on Linux (3.8.13-xxxx-grs-ipv6-64-vps)
|
||||
2015-01-10 09:16:53 [INFO ] Logging initialized @842ms
|
||||
2015-01-10 09:16:54 [INFO ] Using JCE Unlimited Strength Jurisdiction Policy files
|
||||
2015-01-10 09:16:54 [INFO ] Setting up HTTPS transport on port 8443
|
||||
2015-01-10 09:16:54 [INFO ] certificate alias = localhost
|
||||
2015-01-10 09:16:54 [INFO ] keyStorePath = /opt/gitblit/data/serverKeyStore.jks
|
||||
2015-01-10 09:16:54 [INFO ] trustStorePath = /opt/gitblit/data/serverTrustStore.jks
|
||||
2015-01-10 09:16:54 [INFO ] crlPath = /opt/gitblit/data/certs/caRevocationList.crl
|
||||
2015-01-10 09:16:54 [INFO ] Shutdown Monitor listening on port 8081
|
||||
2015-01-10 09:16:54 [INFO ] jetty-9.2.3.v20140905
|
||||
2015-01-10 09:16:55 [INFO ] NO JSP Support for /, did not find org.apache.jasper.servlet.JspServlet
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IRuntimeManager]----
|
||||
2015-01-10 09:16:55 [INFO ] Basefolder : /opt/gitblit/data
|
||||
2015-01-10 09:16:55 [INFO ] Settings : /opt/gitblit/data/gitblit.properties
|
||||
2015-01-10 09:16:55 [INFO ] JVM timezone: America/Montreal (EST -0500)
|
||||
2015-01-10 09:16:55 [INFO ] App timezone: America/Montreal (EST -0500)
|
||||
2015-01-10 09:16:55 [INFO ] JVM locale : en_US
|
||||
2015-01-10 09:16:55 [INFO ] App locale : <client>
|
||||
2015-01-10 09:16:55 [INFO ] PF4J runtime mode is 'deployment'
|
||||
2015-01-10 09:16:55 [INFO ] Enabled plugins: []
|
||||
2015-01-10 09:16:55 [INFO ] Disabled plugins: []
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.INotificationManager]----
|
||||
2015-01-10 09:16:55 [WARN ] Mail service disabled.
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IUserManager]----
|
||||
2015-01-10 09:16:55 [INFO ] ConfigUserService(/opt/gitblit/data/users.conf)
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IAuthenticationManager]----
|
||||
2015-01-10 09:16:55 [INFO ] External authentication disabled.
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ---- [com.gitblit.transport.ssh.IPublicKeyManager]----
|
||||
2015-01-10 09:16:55 [INFO ] FileKeyManager (/opt/gitblit/data/ssh)
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IRepositoryManager]----
|
||||
2015-01-10 09:16:55 [INFO ] Repositories folder : /opt/gitblit/data/git
|
||||
2015-01-10 09:16:55 [INFO ] Identifying repositories...
|
||||
2015-01-10 09:16:55 [INFO ] 0 repositories identified with calculated folder sizes in 11 msecs
|
||||
2015-01-10 09:16:55 [INFO ] Lucene will process indexed branches every 2 minutes.
|
||||
2015-01-10 09:16:55 [INFO ] Garbage Collector (GC) is disabled.
|
||||
2015-01-10 09:16:55 [INFO ] Mirror service is disabled.
|
||||
2015-01-10 09:16:55 [INFO ] Alias UTF-9 & UTF-18 encodings as UTF-8 in JGit
|
||||
2015-01-10 09:16:55 [INFO ] Preparing 14 day commit cache. please wait...
|
||||
2015-01-10 09:16:55 [INFO ] 0 repositories identified with calculated folder sizes in 0 msecs
|
||||
2015-01-10 09:16:55 [INFO ] built 14 day commit cache of 0 commits across 0 repositories in 2 msecs
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IProjectManager]----
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IFederationManager]----
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IGitblit]----
|
||||
2015-01-10 09:16:55 [INFO ] Starting services manager...
|
||||
2015-01-10 09:16:55 [INFO ] Federation passphrase is blank! This server can not be PULLED from.
|
||||
2015-01-10 09:16:55 [INFO ] Fanout PubSub service is disabled.
|
||||
2015-01-10 09:16:55 [INFO ] Git Daemon is listening on 0.0.0.0:9418
|
||||
2015-01-10 09:16:55 [INFO ] SSH Daemon (NIO2) is listening on 0.0.0.0:29418
|
||||
2015-01-10 09:16:55 [WARN ] No ticket service configured.
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] ----[com.gitblit.manager.IPluginManager]----
|
||||
2015-01-10 09:16:55 [INFO ] No plugins
|
||||
2015-01-10 09:16:55 [INFO ]
|
||||
2015-01-10 09:16:55 [INFO ] All managers started.
|
||||
|
||||
打开浏览器,依据你的配置进入**http://localhost:8080** 或者 **https://localhost:8443**。 输入默认的管理员授权:**admin / admin** 并点击**Login** 按钮
|
||||
|
||||

|
||||
|
||||
### 添加用户: ###
|
||||
|
||||

|
||||
|
||||
添加仓库:
|
||||
|
||||

|
||||
|
||||
### 用命令行创建新的仓库: ###
|
||||
|
||||
touch README.md
|
||||
git init
|
||||
git add README.md
|
||||
git commit -m "first commit"
|
||||
git remote add origin ssh://admin@142.4.202.70:29418/Programming.git
|
||||
git push -u origin master
|
||||
|
||||
### 从命令行推送已有的仓库: ###
|
||||
|
||||
git remote add origin ssh://admin@142.4.202.70:29418/Programming.git
|
||||
git push -u origin master
|
||||
|
||||
完成!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-gitblit-ubuntu-fedora-centos/
|
||||
|
||||
作者:[M.el Khamlichi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/pirat9/
|
||||
[1]:http://gitblit.com/
|
||||
[2]:http://git-scm.com/
|
||||
@ -0,0 +1,159 @@
|
||||
在CentOS/RHEL/Scientific Linux 6 & 7 上安装Telnet
|
||||
================================================================================
|
||||
|
||||
#### 声明: ####
|
||||
|
||||
在安装和使用Telnet之前,需要记住以下几点。
|
||||
|
||||
- 在公网(WAN)中使用Telnet是非常不好的想法。它会以明文的格式传输登入数据。每个人都可以看到明文。
|
||||
- 如果你还是需要Telnet,强烈建议你只在局域网内部使用。
|
||||
- 你可以使用**SSH**作为替代方法。但是确保不要用root用户登录。
|
||||
|
||||
### Telnet是什么? ###
|
||||
|
||||
[Telnet][1] 是用于通过TCP/IP网络远程登录计算机的协议。一旦与远程计算机建立了连接,它就会成为一个虚拟终端且允许你与远程计算机通信。
|
||||
|
||||
在本篇教程中,我们会展示如何安装Telnet并且如何通过Telnet访问远程系统。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
打开终端并输入下面的命令来安装telnet:
|
||||
|
||||
yum install telnet telnet-server -y
|
||||
|
||||
现在telnet已经安装在你的服务器上了。接下来编辑文件**/etc/xinetd.d/telnet**:
|
||||
|
||||
vi /etc/xinetd.d/telnet
|
||||
|
||||
设置 **disable = no**:
|
||||
|
||||
# default: on
|
||||
# description: The telnet server serves telnet sessions; it uses \
|
||||
# unencrypted username/password pairs for authentication.
|
||||
service telnet
|
||||
{
|
||||
flags = REUSE
|
||||
socket_type = stream
|
||||
wait = no
|
||||
user = root
|
||||
server = /usr/sbin/in.telnetd
|
||||
log_on_failure += USERID
|
||||
disable = no
|
||||
}
|
||||
|
||||
保存并退出文件。记住我们不必在CentOS 7做这步。
|
||||
|
||||
接下来使用下面的命令重启telnet服务:
|
||||
|
||||
在CentOS 6.x 系统中:
|
||||
|
||||
service xinetd start
|
||||
|
||||
让这个服务在每次重启时都会启动:
|
||||
|
||||
在CentOS 6上:
|
||||
|
||||
chkconfig telnet on
|
||||
chkconfig xinetd on
|
||||
|
||||
在CentOS 7上:
|
||||
|
||||
systemctl start telnet.socket
|
||||
systemctl enable telnet.socket
|
||||
|
||||
让telnet的默认端口**23**可以通过防火墙和路由器。要让telnet端口可以通过防火墙,在CentOS 6.x系统中编辑下面的文件:
|
||||
|
||||
vi /etc/sysconfig/iptables
|
||||
|
||||
加入红色显示的行:
|
||||
|
||||
# Firewall configuration written by system-config-firewall
|
||||
# Manual customization of this file is not recommended.
|
||||
*filter
|
||||
:INPUT ACCEPT [0:0]
|
||||
:FORWARD ACCEPT [0:0]
|
||||
:OUTPUT ACCEPT [0:0]
|
||||
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A INPUT -p tcp -m state --state NEW --dport 23 -j ACCEPT
|
||||
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
|
||||
COMMIT
|
||||
|
||||
保存并退出文件。重启iptables服务:
|
||||
|
||||
service iptables restart
|
||||
|
||||
在CentOS 7中,运行下面的命令让telnet服务可以通过防火墙。
|
||||
|
||||
firewall-cmd --permanent --add-port=23/tcp
|
||||
firewall-cmd --reload
|
||||
|
||||
就是这样。现在telnet服务就可以使用了。
|
||||
|
||||
#### 创建用户 ####
|
||||
|
||||
创建一个测试用户,比如用户名是“**sk**”,密码是“**centos**“:
|
||||
|
||||
useradd sk
|
||||
passwd sk
|
||||
|
||||
#### 客户端配置 ####
|
||||
|
||||
安装telnet包:
|
||||
|
||||
yum install telnet
|
||||
|
||||
在基于DEB的系统中:
|
||||
|
||||
sudo apt-get install telnet
|
||||
|
||||
现在,打开终端,尝试访问你的服务器(远程主机)。
|
||||
|
||||
如果你的客户端是Linux系统,打开终端并输入下面的命令来连接到telnet服务器上。
|
||||
|
||||
telnet 192.168.1.150
|
||||
|
||||
输入服务器上已经创建的用户名和密码:
|
||||
|
||||
示例输出:
|
||||
|
||||
Trying 192.168.1.150...
|
||||
Connected to 192.168.1.150.
|
||||
Escape character is '^]'.
|
||||
|
||||
Kernel 3.10.0-123.13.2.el7.x86_64 on an x86_64
|
||||
server1 login: sk
|
||||
Password:
|
||||
[sk@server1 ~]$
|
||||
|
||||
如你所见,已经成功从本地访问远程主机了。
|
||||
|
||||
如果你的系统是windows,进入**开始 -> 运行 -> 命令提示符**。
|
||||
|
||||
在命令提示符中,输入命令:
|
||||
|
||||
telnet 192.168.1.150
|
||||
|
||||
**192.168.1.150**是远程主机IP地址。
|
||||
|
||||
现在你就可以连接到你的服务器上了。
|
||||
|
||||
就是这样。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/installing-telnet-centosrhelscientific-linux-6-7/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://en.wikipedia.org/wiki/Telnet
|
||||
77
translated/tech/Quick systemd-nspawn guide.md
Normal file
77
translated/tech/Quick systemd-nspawn guide.md
Normal file
@ -0,0 +1,77 @@
|
||||
systemd-nspawn 指南
|
||||
===========================
|
||||
我目前已从 chroot(译者注:chroot可以构建类似沙盒的环境,建议各位同学先了解chroot) 迁移到 systemd-nspawn,同时我写了一篇快速指南。简单的说,我强烈建议正在使用 systemd 的用户从 chroot 转为 systemd-nspawn,因为只要你的内核配置正确的话,它几乎没有什么缺点。
|
||||
|
||||
想必在各大发行版中的用户对 chroot 都不陌生,而且我猜想 Gentoo 用户要时不时的使用它。
|
||||
|
||||
###chroot 面临的挑战
|
||||
|
||||
大多数交互环境下,仅运行chroot还不够。通常还要挂载 /proc, /sys,另外为了确保不会出现类似“丢失 ptys”之类的错误,我们还得 bind(译者注:bind 是 mount 的一个选项) 挂载 /dev。如果你使用 tmpfs,你可能想要以 tmpfs 类型挂载新的 tmp, var/tmp。接下来你可能还想将其他的挂载点 bind 到 chroot 中。这些都不是特别难,但是一般情况下要写一个脚本来管理它。
|
||||
|
||||
现在我按照日常计划执行备份操作,当然有一些不必备份的数据如 tmp 目录,或任何 bind 挂载的内容。当我配置了一个新的 chroot 意味着我要更新我的备份配置了,但我经常忘记这点,因为大多数时间里 chroot 挂载点并没有运行。当这些挂载点任然存在的情况下执行备份的话,那么备份中会多出很多不需要的内容。
|
||||
|
||||
当 bind 挂载点包含其他挂载点时(比如挂载时使用 -rbind 选项),这种情况下 systemd 的默认处理方式略有不同。在 bind 挂载中卸载一些东西时,systemd 会将处于 bind 另一边的目录也卸载掉。想像一下,如果我卸载了 chroot 中以bind 挂载 /dev 的某个目录后发现主机上的 /dev/pts 与 /dev/shm 也不见了,我肯定会很吃惊。不过好像有其他方法可以避免,但是这不是我们此次讨论的重点。
|
||||
|
||||
### Systemd-nspawn 优点
|
||||
|
||||
Systemd-nspawn 用于启动一个容器,并且它的最简模式就可以像 chroot 那样运行。默认情况下,它自动配置容器所需的开销如 /dev, /tmp 等等。通过配合一些选项它也可配置其他的 bind 挂载点。当容器退出后,所有的挂载点都会被清除。
|
||||
|
||||
容器运行时,从外部看上去没什么变化。事实上,可以从同一个 chroot 产生5个不同的 systemd-nspawn 容器实例,并且除了文件系统(不包括 /dev, /tmp等,只有 /usr,/etc 的改变会传递)外它们之间没有任何联系。你的备份将会忽略 bind 挂载点、tmpfs 及任何挂载在容器中的内容。
|
||||
|
||||
它同时具有其它优秀容器的优点,比如 containment - 可以杀死容器内的所有活动但不影响外部,等等。它的安全性并不是无懈可击的-它的作用仅仅是防止意外的错误。
|
||||
|
||||
如果你使用的是兼容的 sysvinit(它包含了 systemd,openrc),你可以启动容器。这意味着,你可以在容器中使用 fstab 添加挂载点,运行守护进程等。只需要一个 chroot 的开销,几乎就可以获得虚拟化的所有好处(不需要构建内核等)。在一个看起来像 chroot 的容器中运行systemctl poweroff 看起来很奇怪,但这条命令能够起作用。
|
||||
|
||||
注意,如果不做额外配置的话那么容器就会共享主机的网络,所以主机上的容器不要运行 sshd。运行一个分离的网络 namespace 不是太难,为了新的实例可以使用DHCP,分离之后记得绑定接口。
|
||||
|
||||
###操作步骤
|
||||
|
||||
让它工作起来是此次讨论中最简短的部分了。
|
||||
|
||||
首先系统内核要支持 namespaces 与 devpts:
|
||||
|
||||
CONFIG_UTS_NS=y
|
||||
CONFIG_IPC_NS=y
|
||||
CONFIG_USER_NS=y
|
||||
CONFIG_PID_NS=y
|
||||
CONFIG_NET_NS=y
|
||||
CONFIG_DEVPTS_MULTIPLE_INSTANCES=y
|
||||
|
||||
像 chroot 那样启动 namespace 是非常简单的:
|
||||
|
||||
systemd-nspawn -D .
|
||||
|
||||
也可以像 chroot 那样退出。在内部可以运行 mount 并且可以看到默认它已将 /dev 与 /tmp 准备好了。 ”.“就是 chroot 的路径,也就是当前路径。在它内部运行的是 bash。
|
||||
|
||||
如果要添加一些 bind 挂载点也非常简便:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage
|
||||
|
||||
现在,容器中的 /usr/portage 就与主机的对应目录绑定起来了,我们无需 sync /etc。如果想要绑定到指定的路径,只要在原路径后添加 ”:dest“,相当于 chroot 的 root(--bind foo 与 --bind foo:foo是一样的)。
|
||||
|
||||
如果容器具有 init 功能并且可以在内部运行,可以通过添加 -b 选项启动它:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -b
|
||||
|
||||
可以观察到 init 的运作。关闭容器会自动退出。
|
||||
|
||||
如果容器内运行了 systemd ,你可以使用 -h 选项将它的日志重定向到主机的systemd日志:
|
||||
|
||||
systemd-nspawn -D . --bind /usr/portage -j -b
|
||||
|
||||
使用 nspawn 注册容器以便它能够在 machinectl 中显示。如此可以方便的在主机上对它进行操作,如启动新的 getty, ssh 连接,关机等。
|
||||
|
||||
如果你正在使用 systemd 那么甩开 chroot 拥抱 nspawn 吧。
|
||||
|
||||
---------------------
|
||||
|
||||
via: http://rich0gentoo.wordpress.com/2014/07/14/quick-systemd-nspawn-guide/
|
||||
|
||||
作者:[rich0][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rich0gentoo.wordpress.com/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user