mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
4626949d4c
@ -1,36 +1,35 @@
|
||||
你需要知道的最佳 Linux Adobe 替代品
|
||||
Adobe 软件的最佳 Linux 替代品
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
你是一名正在寻找 Adobe 的替代品的 Linux 用户吗?那你不是一个人。如果你是一个狂热的平面设计师,那么你可能很擅长避开昂贵的 Adobe 产品。不过,对于 Adobe 来说,Linux 用户通常是其支持最不利的。因此,Adobe 的替代品是必须的 —— 但是最好的选择是什么?
|
||||
|
||||
这最终要看具体的 Adobe 程序和你希望完成的事情。幸运的是,由于需求是所有发明之母,有人响应了这些号召。其结果是出现了一系列高效的 Adobe 替代品。
|
||||
|
||||
作为一名 Linux 用户正在寻找 Adobe 的替代品?你不是一个人。如果你是一个狂热的平面设计师,那么你可能很擅长避开昂贵的 Adobe 产品。不过,对于 Adobe 来说,Linux 用户通常是不利的一面。因此,Adobe 的替代品是必须的 - 但是最好的选择是什么?
|
||||
|
||||
它最终归结到具体的 Adobe 程序和你希望完成的事情。幸运的是,由于需求是所有发明之母,有人响应了号召。其结果是出现了一系列高效的 Adobe 插件。
|
||||
|
||||
### Evince (Adobe Acrobat)
|
||||
### Evince (Adobe Acrobat Reader)
|
||||
|
||||

|
||||
|
||||
就像 Adobe Acrobat Reader 一样,[Evince][6] 是一个“支持多种文档格式的文档查看器”。例如,用户可以使用 Evince 作为 PDF 查看器。它还支持各种漫画书格式(cbr、cbz、cb7 和 cbt)。你可以在 Evince 网站上找到[支持格式的完整列表][7]。
|
||||
|
||||
Evince 没有高看或低看 Linux 用户,因为它是标准的。你可以在需要时前往官方网站进行更新。
|
||||
对于 Evince ,Linux 用户不用高估,也不用贬低,它就是个标准的查看器。你可以在需要时前往官方网站进行更新。
|
||||
|
||||
### Pixlr (Adobe Photoshop)
|
||||
|
||||

|
||||
|
||||
关于 [Pixlr][8] 的很棒的一点在于 Adobe 的各种替代工具可以在线获得。如果你有一个互联网连接,那么你就有一个强大的图像编辑工作区。
|
||||
关于 [Pixlr][8] 的很棒的一点是这个 Adobe 替代品的各种工具可以在线获得。如果你有一个互联网连接,那么你就有一个强大的图像编辑工作区。
|
||||
|
||||
[Pixlr Editor][9] 是 Photoshop 的一个功能强大的插件,因为你可以使用图层和相关效果。它还有一些漂亮的绘图和颜色编辑工具。[Pixlr Express][10] 没有这么多功能,因为它主要用于图像增强。调整颜色和清晰度,并增加一些 Instagram 友好的效果!
|
||||
[Pixlr Editor][9] 是 Photoshop 的一个功能强大的替代品,你可以使用图层和相关效果。它还有一些漂亮的绘图和颜色编辑工具。[Pixlr Express][10] 没有这么多功能,因为它主要用于图像增强、调整颜色和清晰度,并增加一些 Instagram 适用的效果!
|
||||
|
||||
你可以通过 Pixlr 完成任务,这是完全免费的。
|
||||
你可以通过 Pixlr 完成的任务简直不可置信,而且完全免费的。
|
||||
|
||||
### Inkscape (Adobe Illustrator)
|
||||
|
||||

|
||||
|
||||
[Inkscape][11]是另一个值得推荐的免费 Adobe 替代品。它主要作为一个“专业的矢量图形编辑器”。除了 Illustrator,Inkscape 也受到了 Corel Draw、Freehand 和 Xara X 的限制。
|
||||
[Inkscape][11]是另一个值得推荐的免费 Adobe 替代品。它主要作为一个“专业的矢量图形编辑器”。除了 Illustrator,Inkscape 也与 Corel Draw、Freehand 和 Xara X 的功能差不多。
|
||||
|
||||
它的矢量设计工具可用于制作 logo 和“高可伸缩性”艺术品。Inkscape 包含绘图、形状和文本工具。图层工具允许你锁定、分组或隐藏单个图层。
|
||||
|
||||
@ -38,9 +37,9 @@ Evince 没有高看或低看 Linux 用户,因为它是标准的。你可以在
|
||||
|
||||

|
||||
|
||||
[Pinegrow Web Editor][12] 是 Linux 上 Dreamweaver 的绝佳替代品。该程序可让你在桌面上直接制作 HTML 网站。
|
||||
[Pinegrow Web Editor][12] 是 Dreamweaver 在 Linux 上的绝佳替代品。该程序可让你在桌面上直接制作 HTML 网站。
|
||||
|
||||
不仅是使用代码创建(而且需要稍后预览),Pinegrow 可以提供详细的视觉编辑体验。你可以直接查看和测试你的 HTML 项目,实时了解链接是否正常工作,或者图片是否在它该在的地方。Pinegrow 还附带了 WordPress 主题构建器。
|
||||
不仅是使用代码创建(而且需要稍后预览),Pinegrow 可以提供详细的可视化编辑体验。你可以直接查看和测试你的 HTML 项目,实时了解链接是否正常工作,或者图片是否在它该在的地方。Pinegrow 还附带了 WordPress 主题构建器。
|
||||
|
||||
免费试用 30 天。如果你喜欢,你可以一次性支付 $49 购买。
|
||||
|
||||
@ -50,55 +49,55 @@ Evince 没有高看或低看 Linux 用户,因为它是标准的。你可以在
|
||||
|
||||
[Scribus][13] 可能是最接近 Adobe InDesign 的替代品。根据开发者的说法,你应该[认真考虑使用][14] Scribus,因为它是可靠和免费的。
|
||||
|
||||
实际上,Scribus 不仅仅是一个出色的桌面出版工具,也是一个很好的_自我_出版工具。当你可以自己做高质量的杂志和书籍时,为什么要依靠昂贵的商业软件来创建?Scribus 目前允许设计师使用一个 200 色的调色板,下一个稳定版中[承诺将会加倍颜色][15]。
|
||||
实际上,Scribus 不仅仅是一个出色的桌面出版工具,也是一个很好的自出版工具。当你可以自己做高质量的杂志和书籍时,为什么要依靠昂贵的商业软件来创建?Scribus 目前允许设计师使用一个 200 色的调色板,下一个稳定版中[承诺将会加倍颜色数][15]。
|
||||
|
||||
### digiKam (Adobe Lightroom)
|
||||
|
||||

|
||||
|
||||
[digiKam][16] 也许是目前 Linux 用户最好的 Lightroom 选择。功能包括导入照片、整理图片集、图像增强、创建幻灯片等功能。
|
||||
[digiKam][16] 也许是目前 Linux 用户最好的 Lightroom 替代品。功能包括导入照片、整理图片集、图像增强、创建幻灯片等功能。
|
||||
|
||||
它的时尚设计和先进的功能是真正的爱的劳动。实际上,digiKam 背后的人是摄影师。不仅如此,他们希望在 Linux 中完成在 Lightroom 能做的任何工作。
|
||||
它的时尚设计和先进的功能是真正用心之作。实际上,digiKam 背后的人是摄影师们。不仅如此,他们希望在 Linux 中完成在 Lightroom 能做的任何工作。
|
||||
|
||||
### Webflow (Adobe Muse)
|
||||
|
||||

|
||||
|
||||
[Webflow][17] 是另一个可以证明你无需下载软件而可以完成很多事的网站。一个非常方便的 Adobe Muse 替代品,Webflow 是创建高响应式网站设计的理想选择。
|
||||
[Webflow][17] 是另一个可以证明你无需下载软件而可以完成很多事的网站。这是一个非常方便的 Adobe Muse 替代品,Webflow 是创建高响应式网站设计的理想选择。
|
||||
|
||||
Webflow 的最好的一方面是你不需要自己编写代码。你只需拖放图像并写入文本。Webflow 为你做了所有杂事。你可以从头开始构建网站,也可以使用各种模板。虽然是免费的,但是高级选项还有额外的功能,如能够轻松地导出 HTML 和 CSS 以在其他地方使用。
|
||||
Webflow 的最好的一方面是你不需要自己编写代码。你只需拖放图像并写入文本。Webflow 为你做了所有杂事。你可以从头开始构建网站,也可以使用各种模板。虽然是免费的,但是其高级版本还提供了额外的功能,如能够轻松地导出 HTML 和 CSS 以在其他地方使用。
|
||||
|
||||
### Tupi (Adobe Animate)
|
||||
|
||||

|
||||
|
||||
[Tupi][18] 是 Adobe Animate 的替代品,或者那些[不太热衷于 Flash 的人][19]。当然,Tupi 的作者说这并不是与 Flash 竞争。然而,能够使用 HTML5 并不能阻止它成为理想的替代品。
|
||||
[Tupi][18] 是 Adobe Animate 的替代品,或者也可以用于那些[不太热衷于 Flash 的人][19]。当然,Tupi 的作者说这并不是与 Flash 竞争。然而,其使用 HTML5 的能力使其成为了理想的替代品。
|
||||
|
||||
在 PC 或平板电脑上绘制 2D 动画。不确定如何开始?使用网站的[ YouTube 教程][20]了解如何制作剪贴画动画以及更多。
|
||||
在 PC 或平板电脑上绘制 2D 动画。不确定如何开始?使用网站的 [YouTube 教程][20]了解如何制作剪贴画动画以及更多。
|
||||
|
||||
### Black Magic Fusion (Adobe After Effects)
|
||||
|
||||

|
||||
|
||||
[Black Magic Fusion][21]注定是 Adobe After Effects 的替代者。这个视觉效果软件有大约 25 年的开发!Fusion 通常用于在好莱坞电影和电视节目中制造令人印象深刻的效果 - 将其详细和时尚的功能带到家庭。
|
||||
[Black Magic Fusion][21] 注定是 Adobe After Effects 的替代者。这个视觉效果软件历经了大约 25 年的开发!Fusion 通常用于在好莱坞电影和电视节目中制造令人印象深刻的效果 —— 这靠的是其丰富而时尚的功能。
|
||||
|
||||
Fusion 通过使用节点,那些“代表效果、过滤器和其他处理的小图标”工作。将这些节点连接在一起,创建一系列复杂的视觉效果。该程序包括许多功能,如图片修饰、对象跟踪和令人兴奋的 3D 效果。
|
||||
Fusion 通过使用节点,即那些“代表效果、过滤器和其他处理的小图标”工作。将这些节点连接在一起,创建一系列复杂的视觉效果。该程序包括许多功能,如图片修饰、对象跟踪和令人兴奋的 3D 效果。
|
||||
|
||||
你可以选择免费版或者 $995 的 Fusion Studio。为了帮助你决定,[你可以比较][22]免费和高级版的 Fusion 功能。
|
||||
|
||||
### 总结
|
||||
|
||||
如你所见,其他的远远超过你的 Adobe 替代品。由于开源独创性,显著提升的替代品的持续发布。我们很快就会看到一个仅为 Linux 用户创建的完整套件。在此之前,你可以随意选择这些替代品。
|
||||
如你所见,这些远不止于是 Adobe 替代品。由于开源的缘故,显著提升的替代品的不断地发布。我们很快就会看到一个仅为 Linux 用户创建的完整套件。在此之前,你可以随意选择这些替代品。
|
||||
|
||||
知道这里没有提到的任何有用的 Adobe 替代品?在下面的评论区分享软件建议。
|
||||
知道这里没有提到的其它有用的 Adobe 替代品吗?在下面的评论区分享软件建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/adobe-alternatives-for-linux/
|
||||
|
||||
作者:[ Toni Matthews-El][a]
|
||||
作者:[Toni Matthews-El][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,6 @@
|
||||
详解 Ubuntu snap 包的制作过程
|
||||
============================================================
|
||||
|
||||
|
||||
> 如果你看过译者以前翻译的 snappy 文章,不知有没有感觉相关主题都是浅尝辄止,讲得不够透彻,看得也不太过瘾?如果有的话,相信这篇详细讲解如何从零开始制作一个 snap 包的文章应该不会让你失望。
|
||||
|
||||
在这篇文章中,我们将看到如何为名为 [timg][1] 的实用程序制作对应的 snap 包。如果这是你第一次听说 snap 安装包,你可以先看看 [如何创建你的第一个 snap 包][2]。
|
||||
@ -9,10 +8,8 @@
|
||||
今天我们将学习以下有关使用 snapcraft 制作 snap 包的内容:
|
||||
|
||||
* [timg][3] 源码中的 Makefile 文件是手工编写,我们需要修改一些 [make 插件参数][4]。
|
||||
|
||||
* 这个程序是用 C++ 语言写的,依赖几个额外的库文件。我们需要把相关的代码添加到 snap 包中。
|
||||
|
||||
* 严格限制还是传统限制?我们将会讨论如何在它们之间进行选择。
|
||||
* [严格限制还是传统限制][38]?我们将会讨论如何在它们之间进行选择。
|
||||
|
||||
首先,我们了解下 [timg][5] 有什么用?
|
||||
|
||||
@ -22,15 +19,15 @@ Linux 终端模拟器已经变得非常炫酷,并且还能显示颜色!
|
||||
|
||||
![1.png-19.9kB][6]
|
||||
|
||||
除了标准的颜色,大多数终端模拟器都支持真彩色(1600 万种颜色)。
|
||||
除了标准的颜色,大多数终端模拟器(如上图显示的 GNOME 终端)都支持真彩色(1600 万种颜色)。
|
||||
|
||||
![图片.png-61.9kB][7]
|
||||
|
||||
是的!终端模拟器已经支持真彩色了!从这个页面 [多个终端和终端应用程序已经支持真彩色(1600 万种颜色)][8] 可以获取 AWK 代码进行测试。你可以看到在代码中使用了一些 [转义序列][9] 来指定 RGB 的值(256 * 256 * 256 ~= 1600 万种颜色)。
|
||||
是的!终端模拟器已经支持真彩色了!从这个页面“ [多个终端和终端应用程序已经支持真彩色(1600 万种颜色)][8]” 可以获取 AWK 代码自己进行测试。你可以看到在代码中使用了一些 [转义序列][9] 来指定 RGB 的值(256 * 256 * 256 ~= 1600 万种颜色)。
|
||||
|
||||
### timg 是什么?
|
||||
|
||||
好了,言归正传,[timg][10] 有什么用?它能将输入的图片重新调整为终端窗口字符能显示范围的大小(比如:80 x 25),然后在终端窗口的任何分辨率用彩色字符显示图像。
|
||||
好了,言归正传,[timg][10] 有什么用?它能将输入的图片重新调整为终端窗口字符所能显示范围的大小(比如:80 x 25),然后在任何分辨率的终端窗口用彩色字符显示图像。
|
||||
|
||||
![图片.png-37.3kB][11]
|
||||
|
||||
@ -40,28 +37,26 @@ Linux 终端模拟器已经变得非常炫酷,并且还能显示颜色!
|
||||
|
||||
这是 [@Doug8888 拍摄的花][14]。
|
||||
|
||||
如果你通过远程连接服务器来管理自己的业务,并希望查看图像文件,那么 [timg][15] 将会特别有用。
|
||||
如果你通过远程连接服务器来管理自己的业务,并想要查看图像文件,那么 [timg][15] 将会特别有用。
|
||||
|
||||
除了静态图片,[timg][16] 同样也可以显示 gif 动图。让我们开始 snap 之旅吧!
|
||||
除了静态图片,[timg][16] 同样也可以显示 gif 动图。
|
||||
|
||||
那么让我们开始 snap 之旅吧!
|
||||
|
||||
### 熟悉 timg 的源码
|
||||
|
||||
[timg][17] 的源码可以在 [这里][18] 找到。让我们试着手动编译它,以了解它有什么需求。
|
||||
[timg][17] 的源码可以在 [https://github.com/hzeller/timg][18] 找到。让我们试着手动编译它,以了解它有什么需求。
|
||||
|
||||
![图片.png-128.4kB][19]
|
||||
|
||||
`Makefile` 在 `src/` 子文件夹中而不是项目的根文件夹中。在 github 页面上,他们说需要安装这两个开发包(GraphicsMagic++ 和 WebP),然后使用 `make` 就能生成可执行文件。在截图中可以看到我已经将它们安装好了(在我读完相关的 Readme.md 文件后)。
|
||||
`Makefile` 在 `src/` 子文件夹中而不是项目的根文件夹中。在 github 页面上,他们说需要安装两个开发包(GraphicsMagic++ 和 WebP),然后使用 `make` 就能生成可执行文件。在截图中可以看到我已经将它们安装好了(在我读完相关的 Readme.md 文件后)。
|
||||
|
||||
因此,在编写 `snapcraft.yaml` 文件时已经有了四条腹稿:
|
||||
|
||||
因此,在编写 snapcraft.yaml 文件时已经有了四条腹稿:
|
||||
|
||||
1. Makefile 在 src/ 子文件夹中而不是项目的根文件夹中。
|
||||
|
||||
1. `Makefile` 在 `src/` 子文件夹中而不是项目的根文件夹中。
|
||||
2. 这个程序编译时需要两个开发库。
|
||||
|
||||
3. 为了让 timg 以 snap 包形式运行,我们需要将这两个库捆绑在 snap 包中(或者静态链接它们)。
|
||||
|
||||
4. [timg][20] 是用 C++ 编写的,所以需要安装 g++。在编译之前,让我们通过 snapcraft.yaml 文件来检查 `build-essential` 元包是否已经安装。
|
||||
4. [timg][20] 是用 C++ 编写的,所以需要安装 g++。在编译之前,让我们通过 `snapcraft.yaml` 文件来检查 `build-essential` 元包是否已经安装。
|
||||
|
||||
### 从 snapcraft 开始
|
||||
|
||||
@ -91,19 +86,14 @@ parts:
|
||||
|
||||
### 填充元数据
|
||||
|
||||
snapcraft.yaml 配置文件的上半部分是元数据。我们需要一个一个把它们填满,这算是比较容易的部分。元数据由以下字段组成:
|
||||
`snapcraft.yaml` 配置文件的上半部分是元数据。我们需要一个一个把它们填满,这算是比较容易的部分。元数据由以下字段组成:
|
||||
|
||||
1. `名字` —— snap 包的名字,它将公开在 Ubuntu 商店中。
|
||||
|
||||
2. `版本` —— snap 包的版本号。可以是源代码存储库中一个适当的分支或者标记,如果没有分支或标记的话,也可以是当前日期。
|
||||
|
||||
3. `摘要` —— 不超过 80 个字符的简短描述。
|
||||
|
||||
4. `描述` —— 长一点的描述, 100 个字以下.
|
||||
|
||||
5. `等级` —— 稳定或者开发。因为我们想要在 Ubuntu 商店的稳定通道中发布这个 snap 包,所以在 snap 包能正常工作后,就把它设置成稳定。
|
||||
|
||||
6. `限制` —— 我们首先设置为开发模式,这样系统将不会以任何方式限制 snap 包。一旦它在开发模式 下能正常工作,我们再考虑选择严格还是传统限制。
|
||||
1. `name` (名字)—— snap 包的名字,它将公开在 Ubuntu 商店中。
|
||||
2. `version` (版本)—— snap 包的版本号。可以是源代码存储库中一个适当的分支或者标记,如果没有分支或标记的话,也可以是当前日期。
|
||||
3. `summary` (摘要)—— 不超过 80 个字符的简短描述。
|
||||
4. `description` (描述)—— 长一点的描述, 100 个字以下。
|
||||
5. `grade` (等级)—— `stable` (稳定)或者 `devel` (开发)。因为我们想要在 Ubuntu 商店的稳定通道中发布这个 snap 包,所以在 snap 包能正常工作后,就把它设置成 `stable`。
|
||||
6. `confinement` (限制)—— 我们首先设置为 `devmode` (开发模式),这样系统将不会以任何方式限制 snap 包。一旦它在 `devmode`下能正常工作,我们再考虑选择 `strict` (严格)还是 `classic` (传统)限制。
|
||||
|
||||
我们将使用 `timg` 这个名字:
|
||||
|
||||
@ -125,11 +115,11 @@ You already own the name 'timg'.
|
||||
|
||||
然而主分支(`master`)中有两个看起来很重要的提交。因此我们使用主分支而不用 `v0.9.5` 标签的那个。我们使用今天的日期—— `20170226` 做为版本号。
|
||||
|
||||
我们从仓库中搜集了摘要和描述。其中摘要的内容为 `一个终端图像查看器`,描述的内容为 `一个能用 24 位颜色和 unicode 字符块来在终端中显示图像的查看器`。
|
||||
我们从仓库中搜集了摘要和描述。其中摘要的内容为 `A terminal image viewer`,描述的内容为 `A viewer that uses 24-Bit color capabilities and unicode character blocks to display images in the terminal`。
|
||||
|
||||
最后,将等级设置为稳定,将限制设置为开发模式(一直到 snap 包真正起作用)。
|
||||
最后,将 `grade` (等级)设置为 `stable` (稳定),将 `confinement` 限制设置为 `devmode` (开发模式)(一直到 snap 包真正起作用)。
|
||||
|
||||
这是更新后的 snapcraft.yaml,带有所有的元数据:
|
||||
这是更新后的 `snapcraft.yaml`,带有所有的元数据:
|
||||
|
||||
```
|
||||
ubuntu@snaps:~/timg-snap$ cat snap/snapcraft.yaml
|
||||
@ -148,22 +138,19 @@ parts:
|
||||
plugin: nil
|
||||
```
|
||||
|
||||
### 弄清楚 "parts:" 是什么
|
||||
### 弄清楚 `parts:` 是什么
|
||||
|
||||
现在我们需要将上面已经存在的 `parts:` 部分替换成真实的 `parts:`。
|
||||
|
||||
![timg-git-url.png-8kB][23]
|
||||
|
||||
<dd> Git 仓库的 URL。 </dd>
|
||||
*Git 仓库的 URL。*
|
||||
|
||||
![图片.png-28.7kB][24]
|
||||
|
||||
<dd> 存在 Makefile,因此我们需要 make 插件。</dd>
|
||||
*存在 Makefile,因此我们需要 make 插件。*
|
||||
|
||||
(这两张图在原文中是并排显示的,在 markdown 中不知道怎么设置。。)
|
||||
|
||||
|
||||
我们已经知道 git 仓库的 URL 链接,并且 timg 源码中存在 Makefile 文件。至于 [snapcraft make 插件][25] 的 Makefile 命令,正如文档所言,这个插件总是会运行 `make` 后再运行 `make install`。为了确认 `make` 插件的用法,我查看了 [snapcraft 可用插件列表][26]。
|
||||
我们已经知道 git 仓库的 URL 链接,并且 timg 源码中已有了 `Makefile` 文件。至于 [snapcraft make 插件][25] 的 Makefile 命令,正如文档所言,这个插件总是会运行 `make` 后再运行 `make install`。为了确认 `make` 插件的用法,我查看了 [snapcraft 可用插件列表][26]。
|
||||
|
||||
因此,我们将最初的配置:
|
||||
|
||||
@ -183,7 +170,7 @@ parts:
|
||||
plugin: make
|
||||
```
|
||||
|
||||
这是当前 snapcraft.yaml 文件的内容:
|
||||
这是当前 `snapcraft.yaml` 文件的内容:
|
||||
|
||||
```
|
||||
name: timg
|
||||
@ -222,13 +209,13 @@ Command '['/bin/sh', '/tmp/tmpem97fh9d', 'make', '-j4']' returned non-zero exit
|
||||
ubuntu@snaps:~/timg-snap$
|
||||
```
|
||||
|
||||
我们可以看到 `snapcraft` 无法在源代码中找到 `Makefile` 文件,正如我们之前所暗示的,`Makefile` 只位于 `src/` 子文件夹中。那么,我们可以让 `snapcraft` 使用 `src/` 文件夹中的 `Makefile` 文件吗?
|
||||
我们可以看到 `snapcraft` 无法在源代码中找到 `Makefile` 文件,正如我们之前所暗示的,`Makefile` 位于 `src/` 子文件夹中。那么,我们可以让 `snapcraft` 使用 `src/` 文件夹中的 `Makefile` 文件吗?
|
||||
|
||||
每个 snapcraft 插件都有自己的选项,并且有一些通用选项是所有插件共享的。在本例中,我们希望研究那些[与源代码相关的 snapcraft 选项][27]。我们开始吧:
|
||||
|
||||
* source-subdir:path
|
||||
**source-subdir:path**
|
||||
|
||||
snapcraft 会检出(checkout) `source` 关键字所引用的仓库或者解压归档文件到 `parts/<part-name>/src/` 中,但是它只会将特定的子目录复制到 `parts/<part-name>/build/` 中。
|
||||
snapcraft 会<ruby>检出<rt>checkout</rt></ruby> `source` 关键字所引用的仓库或者解压归档文件到 `parts/<part-name>/src/` 中,但是它只会将特定的子目录复制到 `parts/<part-name>/build/` 中。
|
||||
|
||||
我们已经有了适当的选项,下面更新下 `parts`:
|
||||
|
||||
@ -240,7 +227,7 @@ parts:
|
||||
plugin: make
|
||||
```
|
||||
|
||||
然后再次运行 snapcraft prime:
|
||||
然后再次运行 `snapcraft prime`:
|
||||
|
||||
```
|
||||
ubuntu@snaps:~/timg-snap$ snapcraft prime
|
||||
@ -270,11 +257,11 @@ Command '['/bin/sh', '/tmp/tmpeeyxj5kw', 'make', '-j4']' returned non-zero exit
|
||||
ubuntu@snaps:~/timg-snap$
|
||||
```
|
||||
|
||||
从错误信息我们可以得知 snapcraft 找不到 GraphicsMagick++ 这个开发库文件。根据 [snapcraft 常见关键字][29] 可知,我们需要在 snapcraft.yaml 中指定这个库文件,这样 snapcraft 才能安装它。
|
||||
从错误信息我们可以得知 snapcraft 找不到 GraphicsMagick++ 这个开发库文件。根据 [snapcraft 常见关键字][29] 可知,我们需要在 `snapcraft.yaml` 中指定这个库文件,这样 snapcraft 才能安装它。
|
||||
|
||||
* `build-packages`:[deb, deb, deb…]
|
||||
**build-packages:[deb, deb, deb…]**
|
||||
|
||||
构建 part 前需要在主机中安装的 Ubuntu 包列表。这些包通常不会进入最终的 snap 包中,除非它们含有 snap 包中二进制文件直接依赖的库文件(在这种情况下,可以通过 `ldd` 发现他们),或者在 `stage-package` 中显式地指定了它们。
|
||||
列出构建 part 前需要在主机中安装的 Ubuntu 包。这些包通常不会进入最终的 snap 包中,除非它们含有 snap 包中二进制文件直接依赖的库文件(在这种情况下,可以通过 `ldd` 发现它们),或者在 `stage-package` 中显式地指定了它们。
|
||||
|
||||
让我们寻找下这个开发包的名字:
|
||||
|
||||
@ -346,7 +333,7 @@ parts:
|
||||
- libwebp-dev
|
||||
```
|
||||
|
||||
下面是更新后 snapcraft.yaml 文件的内容:
|
||||
下面是更新后的 `snapcraft.yaml` 文件的内容:
|
||||
|
||||
```
|
||||
name: timg
|
||||
@ -408,9 +395,9 @@ terminal-canvas.cc terminal-canvas.o timg.cc
|
||||
ubuntu@snaps:~/timg-snap/parts/timg$
|
||||
```
|
||||
|
||||
在 `build/` 子目录中,我们可以找到 `make` 的输出结果。由于我们设置了 `source-subdir:` 为 `src`,所以 `artifacts:` 的基目录为 `build/src`。在这里我们可以找到可执行文件 `timg`,我们需要将它设置为 `artifacts:` 的一个参数:。通过 `artifacts:`,我们可以把 `make` 输出的某些文件复制到 snap 包的安装目录(在 `prime/` 中)。
|
||||
在 `build/` 子目录中,我们可以找到 `make` 的输出结果。由于我们设置了 `source-subdir:` 为 `src`,所以 `artifacts:` 的基目录为 `build/src`。在这里我们可以找到可执行文件 `timg`,我们需要将它设置为 `artifacts:` 的一个参数。通过 `artifacts:`,我们可以把 `make` 输出的某些文件复制到 snap 包的安装目录(在 `prime/` 中)。
|
||||
|
||||
下面是更新后 snapcraft.yaml 文件 parts: 部分的内容:
|
||||
下面是更新后 `snapcraft.yaml` 文件 `parts:` 部分的内容:
|
||||
|
||||
```
|
||||
parts:
|
||||
@ -423,7 +410,9 @@ parts:
|
||||
- libwebp-dev
|
||||
artifacts: [timg]
|
||||
```
|
||||
|
||||
让我们运行 `snapcraft prime`:
|
||||
|
||||
```
|
||||
ubuntu@snaps:~/timg-snap$ snapcraft prime
|
||||
Preparing to pull timg
|
||||
@ -459,7 +448,7 @@ meta/ snap/ timg* usr/
|
||||
ubuntu@snaps:~/timg-snap$
|
||||
```
|
||||
|
||||
它在 `prime/` 子文件夹的根目录中。现在,我们已经准备好要在 snapcaft.yaml 中增加 `apps:` 的内容:
|
||||
它在 `prime/` 子文件夹的根目录中。现在,我们已经准备好要在 `snapcaft.yaml` 中增加 `apps:` 的内容:
|
||||
|
||||
```
|
||||
ubuntu@snaps:~/timg-snap$ cat snap/snapcraft.yaml
|
||||
@ -503,9 +492,9 @@ ubuntu@snaps:~/timg-snap$
|
||||
|
||||
![图片.png-42.3kB][32]
|
||||
|
||||
图片来源: https://www.flickr.com/photos/mustangjoe/6091603784/
|
||||
*图片来源: https://www.flickr.com/photos/mustangjoe/6091603784/*
|
||||
|
||||
我们可以通过 `snap try --devmode prime/ ` 使能 snap 包然后测试 timg 命令。这是一种高效的测试方法,可以避免生成 .snap 文件,并且无需安装和卸载它们,因为 `snap try prime/` 直接使用了 `prime/` 文件夹中的内容。
|
||||
我们可以通过 `snap try --devmode prime/ ` 启用该 snap 包然后测试 `timg` 命令。这是一种高效的测试方法,可以避免生成 .snap 文件,并且无需安装和卸载它们,因为 `snap try prime/` 直接使用了 `prime/` 文件夹中的内容。
|
||||
|
||||
### 限制 snap
|
||||
|
||||
@ -527,9 +516,9 @@ Trouble loading pexels-photo-149813.jpeg (Magick: Unable to open file (pexels-ph
|
||||
ubuntu@snaps:~/timg-snap$
|
||||
```
|
||||
|
||||
通过这种方式,我们可以无需修改 snapcraft.yaml 文件就从开发模式切换到限制模式(confinement: strict)。正如预期的那样,timg 无法读取图像,因为我们没有开放访问文件系统的权限。
|
||||
通过这种方式,我们可以无需修改 `snapcraft.yaml` 文件就从开发模式(`devmode`)切换到限制模式(`jailmode`)(`confinement: strict`)。正如预期的那样,`timg` 无法读取图像,因为我们没有开放访问文件系统的权限。
|
||||
|
||||
现在,我们需要作出决定。使用限制模式,我们可以很容易授予某个命令访问用户 `$HOME` 目录中文件的权限,但是只能访问那里。如果图像文件位于其它地方,我们总是需要复制到 `$HOME` 目录并在 `$HOME` 的副本上运行 timg。如果我们对此感到满意,那我们可以设置 snapcraf.yaml 为:
|
||||
现在,我们需要作出决定。使用限制模式,我们可以很容易授予某个命令访问用户 `$HOME` 目录中文件的权限,但是只能访问那里。如果图像文件位于其它地方,我们总是需要复制到 `$HOME` 目录并在 `$HOME` 的副本上运行 timg。如果我们觉得可行,那我们可以设置 `snapcraf.yaml` 为:
|
||||
|
||||
```
|
||||
name: timg
|
||||
@ -558,7 +547,7 @@ parts:
|
||||
artifacts: [timg]
|
||||
```
|
||||
|
||||
另一方面,如果希望 timg snap 包能访问整个文件系统,我们可以设置 传统限制来实现。对应的 snapcraft.yaml 内容如下:
|
||||
另一方面,如果希望 timg snap 包能访问整个文件系统,我们可以设置传统限制来实现。对应的 `snapcraft.yaml` 内容如下:
|
||||
|
||||
```
|
||||
name: timg
|
||||
@ -586,7 +575,7 @@ parts:
|
||||
artifacts: [timg]
|
||||
```
|
||||
|
||||
接下来我们将选择严格约束选项。因此,图像应该只能放在 $HOME 中。
|
||||
接下来我们将选择严格(`strict`)约束选项。因此,图像应该只能放在 $HOME 中。
|
||||
|
||||
### 打包和测试
|
||||
|
||||
@ -663,9 +652,9 @@ latest amd64 16 stable 20170226 6
|
||||
The 'stable' channel is now open.
|
||||
```
|
||||
|
||||
我们把 .snap 包推送到 Ubuntu 商店后,得到了一个 `修订版本号 6`。然后,我们将 timg `修订版本 6` 发布到了 Ubuntu 商店的稳定通道。
|
||||
我们把 .snap 包推送到 Ubuntu 商店后,得到了一个 `Revision 6`。然后,我们将 timg `Revision 6` 发布到了 Ubuntu 商店的稳定通道。
|
||||
|
||||
在候选通道中没有已发布的 snap 包,他继承的是稳定通道的包,所以显示 `^` 字符。
|
||||
在候选通道中没有已发布的 snap 包,它继承的是稳定通道的包,所以显示 `^` 字符。
|
||||
|
||||
在之前的测试中,我将一些较老版本的 snap 包上传到了测试和边缘通道。这些旧版本使用了 timg 标签为 `0.9.5` 的源代码。
|
||||
|
||||
@ -688,7 +677,7 @@ latest amd64 16 stable 20170226 6
|
||||
|
||||
### 使用 timg
|
||||
|
||||
让我们不带参数运行 timg:
|
||||
让我们不带参数运行 `timg`:
|
||||
|
||||
```
|
||||
ubuntu@snaptesting:~$ timg
|
||||
@ -709,7 +698,7 @@ If both -w and -t are given for some animation/scroll, -t takes precedence
|
||||
ubuntu@snaptesting:~$
|
||||
```
|
||||
|
||||
这里说,当前我们终端模拟器的缩放级别,即分辨率为:80 × 48。
|
||||
这里提到当前我们终端模拟器的缩放级别,即分辨率为:80 × 48。
|
||||
|
||||
让我们缩小一点,并最大化 GNOME 终端窗口。
|
||||
|
||||
@ -723,13 +712,13 @@ ubuntu@snaptesting:~$
|
||||
|
||||
你所看到的是调整后的图像(1080p)。虽然它是用彩色文本字符显示的,但看起来依旧很棒。
|
||||
|
||||
接下来呢?timg 其实也可以播放 gif 动画哦!
|
||||
接下来呢?`timg` 其实也可以播放 gif 动画哦!
|
||||
|
||||
```
|
||||
$ wget https://m.popkey.co/9b7141/QbAV_f-maxage-0.gif -O JonahHillAmazed.gif$ timg JonahHillAmazed.gif
|
||||
```
|
||||
|
||||
你可以试着安装 timg 来体验 gif 动画。要是不想自己动手,可以在 [asciinema][36] 上查看相关记录 (如果视频看上去起伏不定的,请重新运行它)。
|
||||
你可以试着安装 `timg` 来体验 gif 动画。要是不想自己动手,可以在 [asciinema][36] 上查看相关记录 (如果视频看上去起伏不定的,请重新运行它)。
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
@ -743,13 +732,13 @@ via:https://blog.simos.info/how-to-create-a-snap-for-timg-with-snapcraft-on-ub
|
||||
|
||||
作者:[Mi blog lah!][37]
|
||||
译者:[Snapcrafter](https://github.com/Snapcrafter)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]: https://github.com/hzeller/timg
|
||||
[2]:https://tutorials.ubuntu.com/tutorial/create-first-snap
|
||||
[2]: https://tutorials.ubuntu.com/tutorial/create-your-first-snap
|
||||
[3]: https://github.com/hzeller/timg
|
||||
[4]: https://snapcraft.io/docs/reference/plugins/make
|
||||
[5]:https://github.com/hzeller/timg
|
||||
@ -785,3 +774,4 @@ via:https://blog.simos.info/how-to-create-a-snap-for-timg-with-snapcraft-on-ub
|
||||
[35]: http://static.zybuluo.com/apollomoon/clnv44g3bwhaqog7o1jpvpcd/%E5%9B%BE%E7%89%87.png
|
||||
[36]: https://asciinema.org/a/dezbe2gpye84e0pjndp8t0pvh
|
||||
[37]: https://blog.simos.info/
|
||||
[38]:https://snapcraft.io/docs/reference/confinement
|
||||
@ -1,48 +1,50 @@
|
||||
OpenGL 与 Go 教程 第一节: Hello, OpenGL
|
||||
OpenGL 与 Go 教程(一)Hello, OpenGL
|
||||
============================================================
|
||||
|
||||
_[第一节: Hello, OpenGL][6]_ | _[第二节: 绘制游戏面板][7]_ | _[第三节: 实现游戏功能][8]_
|
||||
- [第一节: Hello, OpenGL][6]
|
||||
- [第二节: 绘制游戏面板][7]
|
||||
- [第三节: 实现游戏功能][8]
|
||||
|
||||
_这篇教程的所有源代码都可以在 [GitHub][9] 上找到。_
|
||||
这篇教程的所有源代码都可以在 [GitHub][9] 上找到。
|
||||
|
||||
### 介绍
|
||||
|
||||
[OpenGL][19] 是一门相当好的技术,适用于多种类型的绘图工作,从桌面的 GUI 到游戏,到移动应用甚至 web 应用。我敢保证,你今天看到的图形有些就是用 OpenGL 渲染的。可是,不管 OpenGL 多受欢迎、有多好用,与学习其它高层次的绘图库相比,学习 OpenGL 是要相当足够的决心的。
|
||||
[OpenGL][19] 是一门相当好的技术,适用于从桌面的 GUI 到游戏,到移动应用甚至 web 应用的多种类型的绘图工作。我敢保证,你今天看到的图形有些就是用 OpenGL 渲染的。可是,不管 OpenGL 多受欢迎、有多好用,与学习其它高级绘图库相比,学习 OpenGL 是要相当足够的决心的。
|
||||
|
||||
这个教程的目的是给你一个切入点,让你对 OpenGL 有个基本的了解,然后教你怎么用 [Go][20] 操作它。几乎每种编程语言都有绑定 OpenGL 的库,Go 也不例外,它有 [go-gl][21] 这个包。这是一个完整的套件,可以绑定 OpenGL ,适用于多种版本的 OpenGL。
|
||||
|
||||
这篇教程会按照下面列出的几个阶段进行介绍,我们最终的目标是用 OpenGL 在桌面窗口绘制游戏面板,进而实现 [Conway's Game of Life][22]。完整的源代码可以在 GitHub [github.com/KyleBanks/conways-gol][23] 上获得,当你有疑惑的时候可以随时查看源代码,或者你要按照自己的方式学习也可以参考这个代码。
|
||||
这篇教程会按照下面列出的几个阶段进行介绍,我们最终的目标是用 OpenGL 在桌面窗口绘制游戏面板,进而实现[康威生命游戏][22]。完整的源代码可以在 GitHub [github.com/KyleBanks/conways-gol][23] 上获得,当你有疑惑的时候可以随时查看源代码,或者你要按照自己的方式学习也可以参考这个代码。
|
||||
|
||||
在我们开始之前,我们要先弄明白 _Conway's Game of Life_ 到底是什么。这里是 [Wikipedia][24] 上面的总结:
|
||||
在我们开始之前,我们要先弄明白<ruby>康威生命游戏<rt>Conway's Game of Life</rt></ruby> 到底是什么。这里是 [Wikipedia][24] 上面的总结:
|
||||
|
||||
> 《Game of Life》,也可以简称为 Life,是一个细胞自动变化的过程,由英国数学家 John Horton Conway 于 1970 年提出。
|
||||
> 《生命游戏》,也可以简称为 Life,是一个细胞自动变化的过程,由英国数学家 John Horton Conway 于 1970 年提出。
|
||||
>
|
||||
> 这个“游戏”没有玩家,也就是说它的发展依靠的是它的初始状态,不需要输入。用户通过创建初始配置文件、观察它如何演变,或者对于高级“玩家”可以创建特殊属性的模式,进而与《Game of Life》进行交互。
|
||||
> 这个“游戏”没有玩家,也就是说它的发展依靠的是它的初始状态,不需要输入。用户通过创建初始配置文件、观察它如何演变,或者对于高级“玩家”可以创建特殊属性的模式,进而与《生命游戏》进行交互。
|
||||
>
|
||||
> 规则
|
||||
> `规则`
|
||||
>
|
||||
> 《Game of Life》的世界是一个无穷多的二维正交的正方形细胞的格子,每一个格子都有两种可能的状态,“存活”或者“死亡”,也可以说是“填充态”或“未填充态”(区别可能很小,除非把它看作一个模拟人类/哺乳动物行为的早期模型,或者在一个人如何看待方格里的空白时)。每一个细胞与它周围的八个细胞相关联,这八个细胞分别是水平、垂直、斜对角相接的。在游戏中的每一步,下列事情中的一件将会发生:
|
||||
> 《生命游戏》的世界是一个无穷多的二维正交的正方形细胞的格子世界,每一个格子都有两种可能的状态,“存活”或者“死亡”,也可以说是“填充态”或“未填充态”(区别可能很小,可以把它看作一个模拟人类/哺乳动物行为的早期模型,这要看一个人是如何看待方格里的空白)。每一个细胞与它周围的八个细胞相关联,这八个细胞分别是水平、垂直、斜对角相接的。在游戏中的每一步,下列事情中的一件将会发生:
|
||||
>
|
||||
> 1. 任何存活着的细胞当任何一个存活的 cell 的附近少于 2 个存活的 cell 时,该 cell 将会消亡,就像人口过少所导致的结果一样
|
||||
> 2. 当任何一个存活的 cell 的附近有 2 至 3 个存活的 cell 时,该 cell 在下一代中仍然存活。
|
||||
> 3. 当任何一个存活的 cell 的附近多于 3 个存活的 cell 时,该 cell 将会消亡,就像人口过多所导致的结果一样
|
||||
> 4. 任何一个消亡的 cell 附近刚好有 3 个存活的 cell,该 cell 会变为存活的状态,就像重生一样。
|
||||
> 1. 当任何一个存活的细胞的附近少于 2 个存活的细胞时,该细胞将会消亡,就像人口过少所导致的结果一样
|
||||
> 2. 当任何一个存活的细胞的附近有 2 至 3 个存活的细胞时,该细胞在下一代中仍然存活。
|
||||
> 3. 当任何一个存活的细胞的附近多于 3 个存活的细胞时,该细胞将会消亡,就像人口过多所导致的结果一样
|
||||
> 4. 任何一个消亡的细胞附近刚好有 3 个存活的细胞,该细胞会变为存活的状态,就像重生一样。
|
||||
|
||||
不需要其他工具,这里由一个我们将会制作的演示程序:
|
||||
不需要其他工具,这里有一个我们将会制作的演示程序:
|
||||
|
||||

|
||||

|
||||
|
||||
在我们的运行过程中,白色的细胞表示它是存活着的,黑色的细胞表示它已经死亡。
|
||||
|
||||
### 概述
|
||||
|
||||
本教程将会涉及到很多基础内容,从最基本的开始,但是你还是要对 Go 由一些最基本的了解 - 至少你应该知道变量,切片,函数和结构体,并且装了一个 Go 的运行环境。我写这篇教程用的 Go 版本是 1.8,但它应该与之前的版本兼容。这里用 Go 语言实现没有什么特别新奇的东西,因此只要你有过类似的编程经历就行。
|
||||
本教程将会涉及到很多基础内容,从最基本的开始,但是你还是要对 Go 由一些最基本的了解 —— 至少你应该知道变量、切片、函数和结构体,并且装了一个 Go 的运行环境。我写这篇教程用的 Go 版本是 1.8,但它应该与之前的版本兼容。这里用 Go 语言实现没有什么特别新奇的东西,因此只要你有过类似的编程经历就行。
|
||||
|
||||
这里是我们在这个教程里将会讲到的东西:
|
||||
|
||||
* [第一节: Hello, OpenGL][10]: 安装 OpenGL 和 [GLFW][11],在窗口上绘制一个三角形。
|
||||
* [第二节: 绘制游戏面板][12]: 用三角形拼成方形,在窗口上用方形绘成格子。
|
||||
* [第三节: 实现游戏功能][13]: 实现 Conway 游戏
|
||||
* [第一节: Hello, OpenGL][10]: 安装 OpenGL 和 [GLFW][11],在窗口上绘制一个三角形。
|
||||
* [第二节: 绘制游戏面板][12]: 用三角形拼成方形,在窗口上用方形绘成格子。
|
||||
* [第三节: 实现游戏功能][13]: 实现 Conway 游戏
|
||||
|
||||
最后的源代码可以在 [GitHub][25] 上获得,每一节的末尾有个_回顾_,包含该节相关的代码。如果有什么不清楚的地方或者是你感到疑惑的,看看每一节末尾的完整代码。
|
||||
|
||||
@ -50,9 +52,9 @@ OpenGL 与 Go 教程 第一节: Hello, OpenGL
|
||||
|
||||
### 安装 OpenGL 和 GLFW
|
||||
|
||||
我们介绍过 OpenGL,但是为了使用它,我们要有个窗口可以绘制东西。 [GLFW][26] 是一款对于 OpenGL 跨平台的 API,允许我们创建窗口并使用,而且它是 [go-gl][27] 套件中提供的。
|
||||
我们介绍过 OpenGL,但是为了使用它,我们要有个窗口可以绘制东西。 [GLFW][26] 是一款用于 OpenGL 的跨平台 API,允许我们创建并使用窗口,而且它也是 [go-gl][27] 套件中提供的。
|
||||
|
||||
我们要做的第一件事就是确定 OpenGL 的版本。为了方便本教程,我们将会使用 **OpenGL v4.1**,但你也可以用 **v2.1** 要是你的操作系统不支持最新的 OpenGL。要安装 OpenGL,我们需要做这些事:
|
||||
我们要做的第一件事就是确定 OpenGL 的版本。为了方便本教程,我们将会使用 `OpenGL v4.1`,但要是你的操作系统不支持最新的 OpenGL,你也可以用 `v2.1`。要安装 OpenGL,我们需要做这些事:
|
||||
|
||||
```
|
||||
# 对于 OpenGL 4.1
|
||||
@ -68,7 +70,7 @@ $ go get github.com/go-gl/gl/v2.1/gl
|
||||
$ go get github.com/go-gl/glfw/v3.2/glfw
|
||||
```
|
||||
|
||||
安装好这两个包之后,我们就可以开始了!先创建 **main.go** 文件,导入相应的包(我们待会儿会用到的其他东西)。
|
||||
安装好这两个包之后,我们就可以开始了!先创建 `main.go` 文件,导入相应的包(我们待会儿会用到的其它东西)。
|
||||
|
||||
```
|
||||
package main
|
||||
@ -82,8 +84,7 @@ import (
|
||||
)
|
||||
```
|
||||
|
||||
Next lets define the **main** function, the purpose of which is to initialize OpenGL and GLFW and display the window:
|
||||
接下来定义一个叫做 **main** 的函数,这是用来初始化 OpenGL 以及 GLFW,显示窗口的:
|
||||
接下来定义一个叫做 `main` 的函数,这是用来初始化 OpenGL 以及 GLFW,并显示窗口的:
|
||||
|
||||
```
|
||||
const (
|
||||
@ -124,11 +125,11 @@ func initGlfw() *glfw.Window {
|
||||
}
|
||||
```
|
||||
|
||||
好了,让我们花一分钟来运行一下这个程序,看看会发生什么。首先定义了一些常量, **width** 和 **height** - 它们决定窗口的像素大小。
|
||||
好了,让我们花一分钟来运行一下这个程序,看看会发生什么。首先定义了一些常量, `width` 和 `height` —— 它们决定窗口的像素大小。
|
||||
|
||||
然后就是 **main** 函数。这里我们使用了 **runtime** 包的 **LockOSThread()**,这能确保我们总是在操作系统的一个线程中运行代码,这对 GLFW 来说很重要,GLFW 被初始化之后需要在同一个进程里被调用多次。讲完这个,接下来我们调用 **initGlfw** 来获得一个窗口的引用,并且 defer glfw 的 terminating 方法。窗口的引用会被用在一个 for 循环中,只要窗口是打开的状态,就执行某些事情。我们待会儿会讲要做的事情是什么。
|
||||
然后就是 `main` 函数。这里我们使用了 `runtime` 包的 `LockOSThread()`,这能确保我们总是在操作系统的同一个线程中运行代码,这对 GLFW 来说很重要,GLFW 需要在其被初始化之后的线程里被调用。讲完这个,接下来我们调用 `initGlfw` 来获得一个窗口的引用,并且推迟(`defer`)其终止。窗口的引用会被用在一个 `for` 循环中,只要窗口处于打开的状态,就执行某些事情。我们待会儿会讲要做的事情是什么。
|
||||
|
||||
**initGlfw** 是另一个函数,这里我们调用 **glfw.Init()** 来初始化 GLFW 包。然后我们定义了 GLFW 的一些全局属性,包括禁用调整窗口大小和改变 OpenGL 的属性。然后创建了 **glfw.Window**,这会在稍后的绘图中用到。我们仅仅告诉它我们想要的宽度和高度,以及标题,然后调用 **window.MakeContextCurrent**,将窗口绑定到当前的进程中。最后就是返回窗口的引用了。
|
||||
`initGlfw` 是另一个函数,这里我们调用 `glfw.Init()` 来初始化 GLFW 包。然后我们定义了 GLFW 的一些全局属性,包括禁用调整窗口大小和改变 OpenGL 的属性。然后创建了 `glfw.Window`,这会在稍后的绘图中用到。我们仅仅告诉它我们想要的宽度和高度,以及标题,然后调用 `window.MakeContextCurrent`,将窗口绑定到当前的线程中。最后就是返回窗口的引用了。
|
||||
|
||||
如果你现在就构建、运行这个程序,你看不到任何东西。很合理,因为我们还没有用这个窗口做什么实质性的事。
|
||||
|
||||
@ -149,9 +150,9 @@ func initOpenGL() uint32 {
|
||||
}
|
||||
```
|
||||
|
||||
**initOpenGL** 就像之前的 **initGlfw** 函数一样,初始化 OpenGL 库,创建一个_程序_。这个程序是一个包含了着色器的引用,稍后会用于绘图。待会儿会讲这一点,现在只用知道 OpenGL 已经初始化完成了,我们有一个 **program** 的引用。我们还打印了 OpenGL 的版本,这对于 debug 很有帮助。
|
||||
`initOpenGL` 就像之前的 `initGlfw` 函数一样,初始化 OpenGL 库,创建一个<ruby>程序<rt>program</rt></ruby>。“程序”是一个包含了<ruby>着色器<rt>shader</rt></ruby>的引用,稍后会用<ruby>着色器<rt>shader</rt></ruby>绘图。待会儿会讲这一点,现在只用知道 OpenGL 已经初始化完成了,我们有一个程序的引用。我们还打印了 OpenGL 的版本,可以用于之后的调试。
|
||||
|
||||
回到 **main** 函数里,调用这个新函数:
|
||||
回到 `main` 函数里,调用这个新函数:
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -168,7 +169,7 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
你应该注意到了现在我们有 **program** 的引用,在我们的窗口循环中,调用新的 **draw** 函数。最终这个函数会绘制出所有细胞,让游戏状态变得可视化,但是现在它做的仅仅是情况窗口,所以我们只能看到一个全黑的屏幕:
|
||||
你应该注意到了现在我们有 `program` 的引用,在我们的窗口循环中,调用新的 `draw` 函数。最终这个函数会绘制出所有细胞,让游戏状态变得可视化,但是现在它做的仅仅是清除窗口,所以我们只能看到一个全黑的屏幕:
|
||||
|
||||
```
|
||||
func draw(window *glfw.Window, program uint32) {
|
||||
@ -180,19 +181,19 @@ func draw(window *glfw.Window, program uint32) {
|
||||
}
|
||||
```
|
||||
|
||||
我们首先做的是调用 **gl.clear** 函数来清除上一帧在窗口中绘制的东西,给我们一个干净的面板。然后我们告诉 OpenGL 去使用程序引用,这个引用还没有做什么事。最终我们告诉 GLFW 用 **PollEvents** 去检查是否有鼠标或者键盘事件(这一节里还不会对这些事件进行处理),告诉窗口 **SwapBuffers**。 [Buffer swapping][28](交换缓冲区) 很重要,因为 GLFW(像其他图形库一样)使用双缓冲,也就是说你绘制的所有东西实际上是绘制到一个不可见的画布上,当你准备好进行展示的时候就把绘制的这些东西放到可见的画布中 - 这种情况下,就需要调用 **SwapBuffers** 函数。
|
||||
我们首先做的是调用 `gl.clear` 函数来清除上一帧在窗口中绘制的东西,给我们一个干净的面板。然后我们告诉 OpenGL 去使用我们的程序引用,这个引用还没有做什么事。最终我们告诉 GLFW 用 `PollEvents` 去检查是否有鼠标或者键盘事件(这一节里还不会对这些事件进行处理),告诉窗口去交换缓冲区 `SwapBuffers`。 [交换缓冲区][28] 很重要,因为 GLFW(像其他图形库一样)使用双缓冲,也就是说你绘制的所有东西实际上是绘制到一个不可见的画布上,当你准备好进行展示的时候就把绘制的这些东西放到可见的画布中 —— 这种情况下,就需要调用 `SwapBuffers` 函数。
|
||||
|
||||
好了,到这里我们已经讲了很多东西,花一点时间看看我们的实验成果。运行这个程序,你应该可以看到你所绘制的第一个东西:
|
||||
|
||||
|
||||

|
||||
|
||||
完美!
|
||||
|
||||
### 在窗口里绘制三角形
|
||||
|
||||
我们已经完成了一些复杂的步骤,即使看上去和图片不像,但我们仍然需要绘制一些东西。我们会以三角形绘制开始,可能这第一眼看上去要比我们最终要绘制的方形更难,但你会知道这样的想法是错的。你可能不知道的是三角形或许是绘制的图形中最简单的,实际上我们最终会用某种方式把三角形拼成方形。
|
||||
我们已经完成了一些复杂的步骤,即使看起来不多,但我们仍然需要绘制一些东西。我们会以三角形绘制开始,可能这第一眼看上去要比我们最终要绘制的方形更难,但你会知道这样的想法是错的。你可能不知道的是三角形或许是绘制的图形中最简单的,实际上我们最终会用某种方式把三角形拼成方形。
|
||||
|
||||
好吧,那么我们想要绘制一个三角形,怎么做呢?我们通过定义图形的顶点来绘制图形,把它们交给 OpenGL 来进行绘制。先在 **main.go** 的顶部里定义我们的三角形:
|
||||
好吧,那么我们想要绘制一个三角形,怎么做呢?我们通过定义图形的顶点来绘制图形,把它们交给 OpenGL 来进行绘制。先在 `main.go` 的顶部里定义我们的三角形:
|
||||
|
||||
```
|
||||
var (
|
||||
@ -204,9 +205,9 @@ var (
|
||||
)
|
||||
```
|
||||
|
||||
这看上去很奇怪,让我们分开来看。首先我们用了一个 **float32** 切片(slice),这是一种我们总会在向 OpenGL 传递顶点时用到的数据类型。这个切片包含 9 个值,每三个值构成三角形的一个点。第一行, **0, 0.5, 0** 表示的是 X、Y、Z 坐标,是最上方的顶点,第二行是左边的顶点,第三行是右边的顶点。每一组的三个点都表示相对于窗口中心点的 X、Y、Z 坐标,在 **-1 和 1** 之间。因此最上面的顶点 X 坐标是 0,因为它在 X 方向上位于窗口中央,Y 坐标是 _0.5_ 意味着它会相对窗口中央上移 1/4 个单位(因为窗口的范围是 -1 到 1),Z 坐标是 0.因为我们只需要在二维空间中绘图,所以 Z 值永远是 0。现在看一看左右两边的顶点,看看你能不能理解为什么它们是这样定义的 —— 如果不能立刻就弄清楚也没关系,我们将会在屏幕上去观察它,因此我们需要一个完美的图形来进行观察。
|
||||
这看上去很奇怪,让我们分开来看。首先我们用了一个 `float32` <ruby>切片<rt>slice</rt></ruby>,这是一种我们总会在向 OpenGL 传递顶点时用到的数据类型。这个切片包含 9 个值,每三个值构成三角形的一个点。第一行, `0, 0.5, 0` 表示的是 X、Y、Z 坐标,是最上方的顶点,第二行是左边的顶点,第三行是右边的顶点。每一组的三个点都表示相对于窗口中心点的 X、Y、Z 坐标,大小在 `-1` 和 `1` 之间。因此最上面的顶点 X 坐标是 `0`,因为它在 X 方向上位于窗口中央,Y 坐标是 `0.5` 意味着它会相对窗口中央上移 1/4 个单位(因为窗口的范围是 `-1` 到 `1`),Z 坐标是 0。因为我们只需要在二维空间中绘图,所以 Z 值永远是 `0`。现在看一看左右两边的顶点,看看你能不能理解为什么它们是这样定义的 —— 如果不能立刻就弄清楚也没关系,我们将会在屏幕上去观察它,因此我们需要一个完美的图形来进行观察。
|
||||
|
||||
好了,我们定义了一个三角形,但是现在我们得把它画出来。要画出这个三角形,我们需要一个叫做 **Vertex Array Object** 或者叫 **vao** 的东西,这是由一系列的点(也就是我们定义的三角形)创造的,这个东西可以提供给 OpenGL 来进行绘制。创建一个叫做 **makeVao** 的函数,然后我们可以提供一组切片的点,让它返回一个指向 OpenGL vertex array object 的指针:
|
||||
好了,我们定义了一个三角形,但是现在我们得把它画出来。要画出这个三角形,我们需要一个叫做<ruby>顶点数组对象<rt>Vertex Array Object</rt></ruby>或者叫 vao 的东西,这是由一系列的点(也就是我们定义的三角形)创造的,这个东西可以提供给 OpenGL 来进行绘制。创建一个叫做 `makeVao` 的函数,然后我们可以提供一个点的切片,让它返回一个指向 OpenGL 顶点数组对象的指针:
|
||||
|
||||
```
|
||||
// makeVao 执行初始化并从提供的点里面返回一个顶点数组
|
||||
@ -227,11 +228,11 @@ func makeVao(points []float32) uint32 {
|
||||
}
|
||||
```
|
||||
|
||||
首先我们创造了 **Vertex Buffer Object** 或者说 **vbo** 绑定到我们的 **vao** 上,**vbo** 是通过所占空间(也就是**4 x len(points)**大小的空间)和一个指向顶点的指针(**gl.Ptr(points)**)来创建的。你也许会好奇为什么它是 **4 x len(points)** - 而不是 6 或者 3 或者 1078 呢?原因在于我们用的是 **float32** 切片,32 个 bit 的 float 浮点型变量是 4 个字节,因此我们说这个缓冲区以字节为单位的大小是点个数的 4 倍。
|
||||
首先我们创造了<ruby>顶点缓冲区对象<rt>Vertex Buffer Object</rt></ruby> 或者说 vbo 绑定到我们的 `vao` 上,`vbo` 是通过所占空间(也就是 4 倍 `len(points)` 大小的空间)和一个指向顶点的指针(`gl.Ptr(points)`)来创建的。你也许会好奇为什么它是 4 倍 —— 而不是 6 或者 3 或者 1078 呢?原因在于我们用的是 `float32` 切片,32 个位的浮点型变量是 4 个字节,因此我们说这个缓冲区以字节为单位的大小是点个数的 4 倍。
|
||||
|
||||
现在我们有缓冲区了,可以创建 **vao** 并用 **gl.BindBuffer** 把它绑定到缓冲区上,最后返回 **vao**。这个 **vao** 将会被用于绘制三角形!
|
||||
现在我们有缓冲区了,可以创建 `vao` 并用 `gl.BindBuffer` 把它绑定到缓冲区上,最后返回 `vao`。这个 `vao` 将会被用于绘制三角形!
|
||||
|
||||
回到 **main** 函数:
|
||||
回到 `main` 函数:
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -243,7 +244,7 @@ func main() {
|
||||
}
|
||||
}
|
||||
|
||||
这里我们调用了 **makeVao** ,从我们之前定义的 **triangle** 顶点中获得 **vao** 引用,将它作为一个新的参数传递给 **draw** 函数:
|
||||
这里我们调用了 `makeVao` ,从我们之前定义的 `triangle` 顶点中获得 `vao` 引用,将它作为一个新的参数传递给 `draw` 函数:
|
||||
|
||||
func draw(vao uint32, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
@ -257,13 +258,13 @@ func draw(vao uint32, window *glfw.Window, program uint32) {
|
||||
}
|
||||
```
|
||||
|
||||
然后我们把 OpenGL 绑定到 **vao** 上,这样当我们告诉 OpenGL 三角形切片的顶点数(除以 3,是因为每一个点有 X、Y、Z 坐标),让它去 **DrawArrays** ,它就知道要画多少个顶点了。
|
||||
然后我们把 OpenGL 绑定到 `vao` 上,这样当我们告诉 OpenGL 三角形切片的顶点数(除以 3,是因为每一个点有 X、Y、Z 坐标),让它去 `DrawArrays` ,它就知道要画多少个顶点了。
|
||||
|
||||
如果你这时候运行程序,你可能希望在窗口中央看到一个美丽的三角形,但是不幸的是你还看不到。还有一件事情没做,我们告诉 OpenGL 我们要画一个三角形,但是我们还要告诉它_怎么_画出来。
|
||||
|
||||
要让它画出来,我们需要叫做片元着色器和顶点着色器的东西,这些已经超出本教程的范围了(老实说,也超出了我对 OpenGL 的了解),但 [Harold Serrano On Quora][29] 关于它们是什么给出了完美的介绍。我们只需要理解,对于这个应用来说,着色器是它内部的小程序(用 [OpenGL Shader Language or GLSL][30] 编写的),操作顶点进行绘制,也可用于确定图形的颜色。
|
||||
要让它画出来,我们需要叫做<ruby>片元着色器<rt>fragment shader</rt></ruby>和<ruby>顶点着色器<rt>vertex shader</rt></ruby>的东西,这些已经超出本教程的范围了(老实说,也超出了我对 OpenGL 的了解),但 [Harold Serrano 在 Quora][29] 上对对它们是什么给出了完美的介绍。我们只需要理解,对于这个应用来说,着色器是它内部的小程序(用 [OpenGL Shader Language 或 GLSL][30] 编写的),它操作顶点进行绘制,也可用于确定图形的颜色。
|
||||
|
||||
添加两个 imports 和一个叫做 **compileShader** 的函数:
|
||||
添加两个 `import` 和一个叫做 `compileShader` 的函数:
|
||||
|
||||
```
|
||||
import (
|
||||
@ -297,7 +298,7 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
|
||||
这个函数的目的是以字符串的形式接受着色器源代码和它的类型,然后返回一个指向这个编译好的着色器的指针。如果编译失败,我们就会获得出错的详细信息。
|
||||
|
||||
现在定义着色器,在 **makeProgram** 里编译。回到我们的 **const** 块中,我们在这里定义了 **width** 和 **hegiht**。
|
||||
现在定义着色器,在 `makeProgram` 里编译。回到我们的 `const` 块中,我们在这里定义了 `width` 和 `hegiht`。
|
||||
|
||||
```
|
||||
vertexShaderSource = `
|
||||
@ -317,11 +318,11 @@ fragmentShaderSource = `
|
||||
` + "\x00"
|
||||
```
|
||||
|
||||
你能看到这是两个着色器程序,包含了 GLSL 源代码的字符串,一个是_顶点着色器_,另一个是_片元着色器_。唯一比较特殊的地方是它们都要在末尾加上一个空终止字符,**\x00** —— OpenGL 需要它才能编译着色器。注意 **fragmentShaderSource**,这是我们用 RGBA 形式的值通过 **vec4** 来定义我们图形的颜色。你可以修改这里的值来改变这个三角形的颜色,现在的值是 **RGBA(1, 1, 1, 1)** 或者说是 _white_。
|
||||
如你所见,这是两个包含了 GLSL 源代码字符串的着色器,一个是<ruby>顶点着色器<rt>vertex shader</rt></ruby>,另一个是<ruby>片元着色器<rt>fragment shader</rt></ruby>。唯一比较特殊的地方是它们都要在末尾加上一个空终止字符,`\x00` —— OpenGL 需要它才能编译着色器。注意 `fragmentShaderSource`,这是我们用 RGBA 形式的值通过 `vec4` 来定义我们图形的颜色。你可以修改这里的值来改变这个三角形的颜色,现在的值是 `RGBA(1, 1, 1, 1)` 或者说是白色。
|
||||
|
||||
同样需要注意的是这两个程序都是运行在 **#version 410** 版本下,如果你用的是 OpenGL 2.1,那你也可以改成 **#version 120**。**120** 不是打错的,如果你用的是 OpenGL 2.1,要用 **120** 而不是 **210**!
|
||||
同样需要注意的是这两个程序都是运行在 `#version 410` 版本下,如果你用的是 OpenGL 2.1,那你也可以改成 `#version 120`。这里 `120` 不是打错的,如果你用的是 OpenGL 2.1,要用 `120` 而不是 `210`!
|
||||
|
||||
接下来在 **initOpenGL** 中我们会编译着色器,把它们附加到我们的 **program** 中。
|
||||
接下来在 `initOpenGL` 中我们会编译着色器,把它们附加到我们的 `program` 中。
|
||||
|
||||
```
|
||||
func initOpenGL() uint32 {
|
||||
@ -348,27 +349,24 @@ func initOpenGL() uint32 {
|
||||
}
|
||||
```
|
||||
|
||||
这里我们用 _顶点着色器_ 调用了 **compileShader** 函数,指定它的类型是 **gl.VERTEX_SHADER**,对 _片元着色器_ 做了同样的事情,但是指定的类型是 **gl.FRAGMENT_SHADER**。编译完成后,我们把它们附加到程序中,调用 **gl.AttachShader**,传递程序以及编译好的着色器。
|
||||
这里我们用顶点着色器(`vertexShader`)调用了 `compileShader` 函数,指定它的类型是 `gl.VERTEX_SHADER`,对片元着色器(`fragmentShader`)做了同样的事情,但是指定的类型是 `gl.FRAGMENT_SHADER`。编译完成后,我们把它们附加到程序中,调用 `gl.AttachShader`,传递程序(`prog`)以及编译好的着色器作为参数。
|
||||
|
||||
现在我们终于可以看到我们漂亮的三角形了!运行程序,如果一切顺利的话你会看到这些:
|
||||
|
||||

|
||||

|
||||
|
||||
### 总结
|
||||
|
||||
是不是很惊喜!这些代码画出了一个三角形,但我保证我们已经完成了大部分的 OpenGL 代码,在接下来的章节中我们还会用到这些代码。我十分推荐你花几分钟修改一下代码,看看你能不能移动三角形,改变三角形的大小和颜色。OpenGL 可以令人心生畏惧,有时想要理解发生了什么很困难,但是要记住,这不是魔术 - 它就是它看上去的东西。
|
||||
是不是很惊喜!这些代码画出了一个三角形,但我保证我们已经完成了大部分的 OpenGL 代码,在接下来的章节中我们还会用到这些代码。我十分推荐你花几分钟修改一下代码,看看你能不能移动三角形,改变三角形的大小和颜色。OpenGL 可以令人心生畏惧,有时想要理解发生了什么很困难,但是要记住,这不是魔法 - 它只不过看上去像魔法。
|
||||
|
||||
下一节里我们讲会用两个锐角三角形拼出一个方形 - 看看你能不能试着修改这一节的代码,再进入下一节。不能也没有关系,因为我们在 [第二节][31] 还会编写代码, 按照创建一个有许多方形的格子,我们把它当做游戏面板。
|
||||
下一节里我们讲会用两个锐角三角形拼出一个方形 - 看看你能不能在进入下一节前试着修改这一节的代码。不能也没有关系,因为我们在 [第二节][31] 还会编写代码, 接着创建一个有许多方形的格子,我们把它当做游戏面板。
|
||||
|
||||
最后,在[第三节][32] 里我们会用格子来实现 _Conway’s Game of Life_!
|
||||
|
||||
_[第一节: Hello, OpenGL][14]_ | _[第二节: 绘制游戏面板][15]_ | _[第三节:实现游戏功能][16]_
|
||||
|
||||
_本教程的完整源代码可在 [GitHub][17] 上获得。_
|
||||
|
||||
### 回顾
|
||||
|
||||
本教程 **main.go** 文件的内容如下:
|
||||
本教程 `main.go` 文件的内容如下:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -528,9 +526,9 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[kylewbanks][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
OpenGL 与 Go 教程第二节:绘制游戏面板
|
||||
OpenGL 与 Go 教程(二)绘制游戏面板
|
||||
============================================================
|
||||
|
||||
_[第一节: Hello, OpenGL][6]_ | _[第二节: 绘制游戏面板][7]_ | _[第三节:实现游戏功能][8]_
|
||||
- [第一节: Hello, OpenGL][6]
|
||||
- [第二节: 绘制游戏面板][7]
|
||||
- [第三节:实现游戏功能][8]
|
||||
|
||||
_这篇教程的所有源代码都可以在 [GitHub][9] 上找到._
|
||||
这篇教程的所有源代码都可以在 [GitHub][9] 上找到。
|
||||
|
||||
欢迎回到《OpenGL 与 Go 教程》。如果你还没有看过[第一节][15],那就要回过头去看看那一节。
|
||||
|
||||
@ -13,7 +15,7 @@ OpenGL 与 Go 教程第二节:绘制游戏面板
|
||||
|
||||
### 利用三角形绘制方形
|
||||
|
||||
在我们绘制方形之前,先把三角形变成直角三角形。打开 **main.go** 文件,把 **triangle** 的定义改成像这个样子:
|
||||
在我们绘制方形之前,先把三角形变成直角三角形。打开 `main.go` 文件,把 `triangle` 的定义改成像这个样子:
|
||||
|
||||
```
|
||||
triangle = []float32{
|
||||
@ -23,11 +25,11 @@ triangle = []float32{
|
||||
}
|
||||
```
|
||||
|
||||
我们做的事情是,把最上面的顶点 X 坐标移动到左边(也就是变为**-0.5**),这就变成了像这样的三角形:
|
||||
我们做的事情是,把最上面的顶点 X 坐标移动到左边(也就是变为 `-0.5`),这就变成了像这样的三角形:
|
||||
|
||||

|
||||

|
||||
|
||||
很简单,对吧?现在让我们用两个这样的三角形顶点做成正方形。把 **triangle** 重命名为 **square**,然后添加第二个三角形的顶点数据,把直角三角形变成这样的:
|
||||
很简单,对吧?现在让我们用两个这样的三角形顶点做成正方形。把 `triangle` 重命名为 `square`,然后添加第二个倒置的三角形的顶点数据,把直角三角形变成这样的:
|
||||
|
||||
```
|
||||
square = []float32{
|
||||
@ -41,17 +43,17 @@ square = []float32{
|
||||
}
|
||||
```
|
||||
|
||||
注意:你也要把在 **main** 和 **draw** 里面命名的 **triangle** 改为 **square**。
|
||||
注意:你也要把在 `main` 和 `draw` 里面命名的 `triangle` 改为 `square`。
|
||||
|
||||
我们通过添加三个顶点,把顶点数增加了一倍,这三个顶点就是右上角的三角形,用来拼成方形。运行它看看效果:
|
||||
|
||||

|
||||

|
||||
|
||||
很好,现在我们能够绘制正方形了!OpenGL 一点都不难,对吧?
|
||||
|
||||
### 在窗口中绘制方形格子
|
||||
|
||||
现在我们能画一个方形,怎么画 100 个吗?我们来创建一个 **cell** 结构体,用来表示格子的每一个单元,因此我们能够很灵活的选择绘制的数量:
|
||||
现在我们能画一个方形,怎么画 100 个吗?我们来创建一个 `cell` 结构体,用来表示格子的每一个单元,因此我们能够很灵活的选择绘制的数量:
|
||||
|
||||
```
|
||||
type cell struct {
|
||||
@ -62,7 +64,7 @@ type cell struct {
|
||||
}
|
||||
```
|
||||
|
||||
**cell** 结构体包含一个 **drawable** 属性,这是一个 **Vertex Array Object(顶点数组对象)**,就像我们在之前创建的一样,这个结构体还包含 X 和 Y 坐标,用来表示这个格子的位置。
|
||||
`cell` 结构体包含一个 `drawable` 属性,这是一个顶点数组对象,就像我们在之前创建的一样,这个结构体还包含 X 和 Y 坐标,用来表示这个格子的位置。
|
||||
|
||||
我们还需要两个常量,用来设定格子的大小和形状:
|
||||
|
||||
@ -91,9 +93,9 @@ func makeCells() [][]*cell {
|
||||
}
|
||||
```
|
||||
|
||||
这里我们创建多维的 slice(注:这是 Go 语言中的一种动态数组),代表我们的游戏面板,用 **newCell** 新函数创建的 **cell** 来填充矩阵的每个元素,我们待会就来实现 **newCell** 这个函数。
|
||||
这里我们创建多维的<ruby>切片<rt>slice</rt></ruby>,代表我们的游戏面板,用名为 `newCell` 的新函数创建的 `cell` 来填充矩阵的每个元素,我们待会就来实现 `newCell` 这个函数。
|
||||
|
||||
在接着往下阅读前,我们先花一点时间来看看 **makeCells** 函数做了些什么。我们创造了一个 slice(切片),这个 slice 的长度和格子的行数相等,每一个 slice 里面都有一个用 slice 包含的一系列格子,这些格子的数量与列数相等。如果我们把 **rows** 和 **columns** 都设定成 2,那么就会创建如下的矩阵:
|
||||
在接着往下阅读前,我们先花一点时间来看看 `makeCells` 函数做了些什么。我们创造了一个切片,这个切片的长度和格子的行数相等,每一个切片里面都有一个<ruby>细胞<rt>cell</rt></ruby>的切片,这些细胞的数量与列数相等。如果我们把 `rows` 和 `columns` 都设定成 2,那么就会创建如下的矩阵:
|
||||
|
||||
```
|
||||
[
|
||||
@ -102,7 +104,7 @@ func makeCells() [][]*cell {
|
||||
]
|
||||
```
|
||||
|
||||
还可以创建一个更大的矩阵,包含 **10x10** 个格子:
|
||||
还可以创建一个更大的矩阵,包含 `10x10` 个细胞:
|
||||
|
||||
```
|
||||
[
|
||||
@ -119,7 +121,7 @@ func makeCells() [][]*cell {
|
||||
]
|
||||
```
|
||||
|
||||
现在应该理解了我们创造的矩阵的形状和表示方法。让我们看看 **newCell** 函数到底是怎么填充矩阵的:
|
||||
现在应该理解了我们创造的矩阵的形状和表示方法。让我们看看 `newCell` 函数到底是怎么填充矩阵的:
|
||||
|
||||
```
|
||||
func newCell(x, y int) *cell {
|
||||
@ -156,15 +158,15 @@ func newCell(x, y int) *cell {
|
||||
}
|
||||
```
|
||||
|
||||
这个函数里有很多内容,我们把它分成几个部分。我们做的第一件事是复制了 **square** 的定义。这让我们能够修改该定义,定制当前的格子位置,而不会影响其它使用 **square** 定义的格子。然后我们基于当前索引迭代复制后的 **points**。我们用求余数的方法来判断我们是在操作 X 坐标(**i % 3 == 0**),还是在操作 Y 坐标(**i % 3 == 1**)(跳过 Z 坐标是因为我们仅在二维层面上进行操作),跟着确定格子的大小(也就是占据整个游戏面板的比例),当然它的位置是基于格子在 **相对游戏面板的** X 和 Y 坐标。
|
||||
这个函数里有很多内容,我们把它分成几个部分。我们做的第一件事是复制了 `square` 的定义。这让我们能够修改该定义,定制当前的细胞位置,而不会影响其它使用 `square` 切片定义的细胞。然后我们基于当前索引迭代 `points` 副本。我们用求余数的方法来判断我们是在操作 X 坐标(`i % 3 == 0`),还是在操作 Y 坐标(`i % 3 == 1`)(跳过 Z 坐标是因为我们仅在二维层面上进行操作),跟着确定细胞的大小(也就是占据整个游戏面板的比例),当然它的位置是基于细胞在 `相对游戏面板的` X 和 Y 坐标。
|
||||
|
||||
接着,我们改变那些包含在 **square** slice 中定义的 **0.5**,**0**, **-0.5** 这样的点。如果点小于 0,我们就把它设置成原来的 2 倍(因为 OpenGL 坐标的范围在 **-1** 到 **1** 之间,范围大小是 2),减 1 是为了归一化 OpenGL 坐标。如果点大于等于 0,我们的做法还是一样的,不过要加上我们计算出的尺寸。
|
||||
接着,我们改变那些包含在 `square` 切片中定义的 `0.5`,`0`, `-0.5` 这样的点。如果点小于 0,我们就把它设置成原来的 2 倍(因为 OpenGL 坐标的范围在 `-1` 到 `1` 之间,范围大小是 2),减 1 是为了归一化 OpenGL 坐标。如果点大于等于 0,我们的做法还是一样的,不过要加上我们计算出的尺寸。
|
||||
|
||||
这样做是为了设置每个格子的大小,这样它就能只填充它在面板中的部分。因为我们有 10 行 10 列,每一个格子能分到游戏面板的 10% 宽度和高度。
|
||||
这样做是为了设置每个细胞的大小,这样它就能只填充它在面板中的部分。因为我们有 10 行 10 列,每一个格子能分到游戏面板的 10% 宽度和高度。
|
||||
|
||||
最后,确定了所有点的位置和大小,我们用提供的 X 和 Y 坐标创建一个格子,设置 **drawable** 字段和我们刚刚操作 **points** 得到的 **Vertex Array Object** 对象一致。
|
||||
最后,确定了所有点的位置和大小,我们用提供的 X 和 Y 坐标创建一个 `cell`,并设置 `drawable` 字段与我们刚刚操作 `points` 得到的顶点数组对象(vao)一致。
|
||||
|
||||
好了,现在我们在 **main** 函数里可以移去对 **makeVao** 的调用了,用 **makeCells** 代替。我们还修改了 **draw**,让它绘制一系列的格子而不是一个 **vao**。
|
||||
好了,现在我们在 `main` 函数里可以移去对 `makeVao` 的调用了,用 `makeCells` 代替。我们还修改了 `draw`,让它绘制一系列的细胞而不是一个 `vao`。
|
||||
|
||||
```
|
||||
func main() {
|
||||
@ -189,7 +191,7 @@ func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
}
|
||||
```
|
||||
|
||||
现在我们要让每个格子知道怎么绘制出自己。在 **cell** 里面添加一个 **draw** 函数:
|
||||
现在我们要让每个细胞知道怎么绘制出自己。在 `cell` 里面添加一个 `draw` 函数:
|
||||
|
||||
```
|
||||
func (c *cell) draw() {
|
||||
@ -198,9 +200,9 @@ func (c *cell) draw() {
|
||||
}
|
||||
```
|
||||
|
||||
这看上去很熟悉,它很像我们之前在 **vao** 里写的 **draw**,唯一的区别是我们的 **BindVertexArray** 函数用的是 **c.drawable**,这是我们在 **newCell** 中创造的格子的 **vao**。
|
||||
这看上去很熟悉,它很像我们之前在 `vao` 里写的 `draw`,唯一的区别是我们的 `BindVertexArray` 函数用的是 `c.drawable`,这是我们在 `newCell` 中创造的细胞的 `vao`。
|
||||
|
||||
回到 main 中的 **draw** 函数上,我们可以循环每个格子,让它们自己绘制自己:
|
||||
回到 main 中的 `draw` 函数上,我们可以循环每个细胞,让它们自己绘制自己:
|
||||
|
||||
```
|
||||
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
@ -218,13 +220,13 @@ func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
}
|
||||
```
|
||||
|
||||
你看到了我们循环每一个格子,调用它的 **draw** 函数。如果运行这段代码,你能看到像下面这样的东西:
|
||||
如你所见,我们循环每一个细胞,调用它的 `draw` 函数。如果运行这段代码,你能看到像下面这样的东西:
|
||||
|
||||

|
||||

|
||||
|
||||
这是你想看到的吗?我们做的是在格子里为每一行每一列创建了一个方块,然后给它上色,这就填满了整个面板!
|
||||
|
||||
注释掉 for 循环,我们就可以看到分隔的格子,像这样:
|
||||
注释掉 for 循环,我们就可以看到一个明显独立的细胞,像这样:
|
||||
|
||||
```
|
||||
// for x := range cells {
|
||||
@ -236,26 +238,21 @@ func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
cells[2][3].draw()
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
这只绘制坐标在 **(X=2, Y=3)** 的格子。你可以看到,每一个独立的格子占据着面板的一小块部分,并且会绘制自己那部分空间。我们也能看到游戏面板有自己的原点,也就是坐标为 **(X=0, Y=0)** 的点,在窗口的左下方。这仅仅是我们的 **newCell** 函数计算位置的方式,也可以用右上角,右下角,左上角,中央,或者其它任何位置当作原点。
|
||||
这只绘制坐标在 `(X=2, Y=3)` 的格子。你可以看到,每一个独立的细胞占据着面板的一小块部分,并且负责绘制自己那部分空间。我们也能看到游戏面板有自己的原点,也就是坐标为 `(X=0, Y=0)` 的点,在窗口的左下方。这仅仅是我们的 `newCell` 函数计算位置的方式,也可以用右上角,右下角,左上角,中央,或者其它任何位置当作原点。
|
||||
|
||||
接着往下做,移除 **cells[2][3].draw()** 这一行,取消 for 循环的那部分注释,变成之前那样全部绘制的样子。
|
||||
接着往下做,移除 `cells[2][3].draw()` 这一行,取消 for 循环的那部分注释,变成之前那样全部绘制的样子。
|
||||
|
||||
### 总结
|
||||
|
||||
好了,我们现在能用两个三角形画出一个正方形了,我们还有一个游戏的面板了!我们该为此自豪,目前为止我们已经接触到了很多零碎的内容,老实说,最难的部分还在前面等着我们!
|
||||
|
||||
在接下来的 [第三节],我们会实现游戏核心逻辑,看到很酷的东西!
|
||||
|
||||
_[第 1 节: Hello, OpenGL][10]_ | _[第二节: 绘制游戏面板][11]_ | _[第三节:实现游戏功能][12]_
|
||||
|
||||
_该教程的完整源代码可以在 [GitHub][13] 上获得。_
|
||||
|
||||
在接下来的第三节,我们会实现游戏核心逻辑,看到很酷的东西!
|
||||
|
||||
### 回顾
|
||||
|
||||
这是这一部分教程中 **main.go** 文件的内容:
|
||||
这是这一部分教程中 `main.go` 文件的内容:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -390,7 +387,7 @@ func (c *cell) draw() {
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use. 初始化 glfw,返回一个可用的 Window
|
||||
// 初始化 glfw,返回一个可用的 Window
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
@ -410,7 +407,7 @@ func initGlfw() *glfw.Window {
|
||||
return window
|
||||
}
|
||||
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program. 初始化 OpenGL 并返回一个可用的着色器程序
|
||||
// 初始化 OpenGL 并返回一个可用的着色器程序
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
@ -435,7 +432,7 @@ func initOpenGL() uint32 {
|
||||
return prog
|
||||
}
|
||||
|
||||
// makeVao initializes and returns a vertex array from the points provided. 初始化并返回由 points 提供的顶点数组
|
||||
// 初始化并返回由 points 提供的顶点数组
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
@ -483,9 +480,9 @@ func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
作者:[kylewbanks][a]
|
||||
译者:[GitFtuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -495,16 +492,16 @@ via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-
|
||||
[3]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board%20by%20%40kylewbanks
|
||||
[4]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[5]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[6]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[6]:https://linux.cn/article-8933-1.html
|
||||
[7]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[9]:https://github.com/KyleBanks/conways-gol
|
||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[10]:https://linux.cn/article-8933-1.html
|
||||
[11]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[13]:https://github.com/KyleBanks/conways-gol
|
||||
[14]:https://twitter.com/kylewbanks
|
||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[15]:https://linux.cn/article-8933-1.html
|
||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[17]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board%20by%20%40kylewbanks
|
||||
[18]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
115
published/20170516 What's the point of DevOps.md
Normal file
115
published/20170516 What's the point of DevOps.md
Normal file
@ -0,0 +1,115 @@
|
||||
DevOps 的意义
|
||||
========================================
|
||||
|
||||
> 真正的组织文化变革有助于弥合你原以为无法跨过的鸿沟
|
||||
|
||||
|
||||
|
||||
回想一下你最近一次尝试改掉一个个人习惯的事情,你可能遇到过这样的情形,你需要改变你思考的方式并且改掉之前的习惯。这很艰难,你只能试着改变_你自己的_思维方式。
|
||||
|
||||
所以你可能会试着让自己置身于新的环境。新的环境实际上可帮助我们养成_新的_习惯,它反过来又会促成新的思维方式。
|
||||
|
||||
那就是能否成功改变的所在:思考的越多,得到的越多。你需要知道你在改变的原因以及你的目的所在(而不仅仅你要怎么做),因为改变本身往往是短暂和短视的。
|
||||
|
||||
现在想想你的 IT 组织需要做出的改变。也许你正在考虑采用像 DevOps 这样的东西。这个我们称之为 “DevOps” 的东西有三个组件:人、流程和工具。人和流程是_任何_团体组织的基础。因此,采用 DevOps 需要对大多数组织的核心进行根本性的改变,而不仅仅是学习新的工具。
|
||||
|
||||
如同其它的改变一样,它也是短视的。如果您将注意力集中在将改变作为单点解决方案 —— 例如,“获得更好的报警工具” —— 你可能只是管中窥豹。这种思维方式或许可以提供一套拥有更多铃声、口哨以及可以更好地处理呼叫轮询的工具,但是它不能解决这样的实际问题:警报不能送达到正确的团队,或者故障得不到解决,因为实际上没有人知道如何修复服务。
|
||||
|
||||
新的工具(或者至少一个新工具的想法)创造了一个讨论潜在问题的机会,可以让你的团队讨论对监控的看法。新工具让你能够做出更大的改变 —— 信仰和做法的改变 —— 它们作为你组织的基础而显得更加重要。
|
||||
|
||||
创造更深层次的变革需要一种可以全新地改变观念的方法。要找到这种方法,我们首先需要更好的理解变革的驱动力。
|
||||
|
||||
### 清除栅栏
|
||||
|
||||
> 就改革而言,它不同于推翻。这是一条直白且简单的原则,这个原则或许被视作悖论。在这种情况下,存在某种制度或法律;这么说吧,为了简单起见,在一条路上架设了一个栅栏或门。当今的改革者们来到这儿,并说:“我看不到它的用处,让我们把它清除掉。”更聪明的改革者会很好地回答:“如果你看不到它的用处,我肯定不会让你清除它,回去想想,然后你可以回来告诉我你知道了它的用处,我也许会允许你摧毁它。” — G.K Chesterton, 1929
|
||||
|
||||
为了了解对 DevOps 的需求 —— 它试图将传统意义上分开的开发部门和运维部门进行重新组合 —— 我们首先必须明白这个分开是如何产生的。一旦我们"知道了它的用处",然后我们就会知道将它们分开是为了什么,并且在必要的时候可以取消分开。
|
||||
|
||||
今天我们没有一个单一的管理理论,但是大多数现代管理理论的起源可以追溯到<ruby>弗雷德里克·温斯洛·泰勒<rt>Frederick Winslow Taylor</rt></ruby>。泰勒是一名机械工程师,他创建了一个衡量钢厂工人效率的系统。泰勒认为,他可以对工厂的劳动者运用科学分析的方法,不仅可以改进个人任务,也证明发现了有一个可以用来执行_任何_任务最佳方法。
|
||||
|
||||
我们可以很容易地画一个以泰勒为起源的历史树。从泰勒早在 18 世纪 80 年代后期的研究出现的时间运动研究和其他质量改进计划,跨越 20 世纪 20 年代一直到今天,我们可以从中看到六西格玛、精益,等等类似方法。自上而下、指导式管理,再加上研究过程的系统方法,主宰了今天主流商业文化。它主要侧重于把效率作为工人成功的测量标准。
|
||||
|
||||
如果泰勒是我们这颗历史树的根,那么我们主干上的下一个主叉将是 20 世纪 20 年代通用汽车公司的<ruby>阿尔弗雷德·斯隆<rt>Alfred P. Sloan</rt></ruby>。通用汽车公司创造的斯隆结构不仅持续强劲到 21 世纪初,而且在未来五十年的大部分时间里,都将成为该公司的主要模式。
|
||||
|
||||
1920 年,通用公司正经历一场管理危机,或者说是缺乏管理的危机。斯隆向董事会写了一份为通用汽车的多个部门提出了一个新的结构《组织研究》。这一新结构的核心概念是“集中管理下放业务”。与雪佛兰,凯迪拉克和别克等品牌相关的各个部门将独立运作,同时为中央管理层提供推动战略和控制财务的手段。
|
||||
|
||||
在斯隆的建议下(以及后来就任 CEO 的指导下),通用汽车在美国汽车工业中占据了主导地位。斯隆的计划把一个处于灾难边缘公司创造成了一个非常成功的公司。从中间来看,自治单位是黑盒子,激励和目标被设置在顶层,而团队在底层推动。
|
||||
|
||||
泰勒思想的“最佳实践” —— 标准、可互换和可重复的行为 —— 仍然在今天的管理理念中占有一席之地,与斯隆公司结构的层次模式相结合,主导了僵化部门的分裂和孤岛化以实现最大的控制。
|
||||
|
||||
我们可以指出几份管理研究来证明这一点,但商业文化不是通过阅读书籍而创造和传播的。组织文化是 *真实的* 人在 *实际的* 情形下执行推动文化规范的 *具体的* 行为的产物。这就是为何类似泰勒和斯隆这样的理论变得固化而不可动摇的原因。
|
||||
|
||||
技术部门投资就是一个例子。以下是这个周期是如何循环的:投资者只投资于他们认为可以实现 *他们的* 特定成功观点的公司。这个成功的模式并不一定源于公司本身(和它的特定的目标);它来自董事会对一家成功的公司 *应该* 如何看待的想法。许多投资者来自从经营企业的尝试和苦难中幸存下来的公司,因此他们对什么会使一个公司成功有 *不同的* 理念。他们为那些能够被教导模仿他们的成功模式的公司提供资金,希望获得资金的公司学会模仿。这样,初创公司孵化器就是一种重现理想的结构和文化的*直接的*方式。
|
||||
|
||||
“开发”和“运维”的分开不是因为人的原因,也不是因为不同的技能,或者放在新员工头上的一顶魔法分院帽;它是泰勒和斯隆的理论的副产品。责任与人员之间的清晰而不可渗透的界线是一个管理功能,同时也注重员工的工作效率。管理上的分开可以很容易的落在产品或者项目界线上,而不是技能上,但是通过今天的业务管理理论的历史告诉我们,基于技能的分组是“最好”的高效方式。
|
||||
|
||||
不幸的是,那些界线造成了紧张局势,这些紧张局势是由不同的管理链出于不同的目标设定的相反目标的直接结果。例如:
|
||||
|
||||
* 敏捷 ⟷ 稳定
|
||||
* 吸引新用户 ⟷ 现有用户的体验
|
||||
* 让应用程序增加新功能 ⟷ 让应用程序保持可用
|
||||
* 打败竞争对手 ⟷ 维持收入
|
||||
* 修复出现的问题 ⟷ 在问题出现之前就进行预防
|
||||
|
||||
今天,我们可以看到组织的高层领导人越来越认识到,现有的商业文化(并扩大了它所产生的紧张局势)是一个严重的问题。在 2016 年的 Gartner 报告中,57% 的受访者表示,文化变革是 2020 年之前企业面临的主要挑战之一。像作为一种影响组织变革的手段的敏捷和 DevOps 这样的新方法的兴起反映了这一认识。“[影子 IT][7]” 的出现更是事物的另一个方面;最近的估计有将近 30% 的 IT 支出在 IT 组织的控制之外。
|
||||
|
||||
这些只是企业正在面临的一些“文化担忧”。改变的必要性是明确的,但前进的道路仍然受到昨天的决定的约束。
|
||||
|
||||
### 抵抗并不是没用的
|
||||
|
||||
> Bert Lance 认为如果他能让政府采纳一条简单的格言“如果东西还没损坏,那就别去修理它”,他就可以为国家节省三十亿。他解释说:“这是政府的问题:‘修复没有损坏的东西,而不是修复已经损坏了的东西。’” — Nation's Business, 1977.5
|
||||
|
||||
通常,改革是组织针对所出现的错误所做的应对。在这个意义上说,如果紧张局势(即使逆境)是变革的正常催化剂,那么对变化的 *抵抗* 就是成功的指标。但是过分强调成功的道路会使组织变得僵硬、衰竭和独断。重视有效结果的政策导向是这种不断增长的僵局的症状。
|
||||
|
||||
传统 IT 部门的成功加剧了 IT 孤岛的壁垒。其他部门现在变成了“顾客”,而不是伙伴。试图将 IT 从成本中心转移出来创建一个新的操作模式,它可以将 IT 与其他业务目标断开。这反过来又会对敏捷性造成限制,增加摩擦,降低反应能力。合作被搁置转而偏向“专家方向”。结果是一个孤立主义的观点,IT 只能带来更多的伤害而不是好处。
|
||||
|
||||
正如“软件吃掉世界”,IT 越来越成为组织整体成功的核心。具有前瞻性的 IT 组织认识到这一点,并且已经对其战略规划进行了有意义的改变,而不是将改变视为恐惧。
|
||||
|
||||
例如,Facebook 与人类学家<ruby>罗宾·邓巴<rt>Robin Dunbar</rt></ruby>就社会团体的方法进行了磋商,而且意识到这一点对公司成长的内部团体(不仅仅是该网站的外部用户)的影响。<ruby>扎波斯<rt>Zappos</rt></ruby>的文化得到了很多的赞誉,该组织创立了一个部门,专注于培养他人对于核心价值观和企业文化的看法。当然,这本书是 《开放式组织》的姊妹篇,那是一本描述被应用于管理的开放原则 —— 透明度、参与度和社区 —— 可以如何为我们快节奏的互联时代重塑组织。
|
||||
|
||||
### 决心改变
|
||||
|
||||
> “如果外界的变化率超过了内部的变化率,那末日就不远了。” — Jack Welch, 2004
|
||||
|
||||
一位同事曾经告诉我他可以只用 “[信息技术基础设施库(ITIL)][9]” 框架里面的词汇向一位项目经理解释 DevOps。
|
||||
|
||||
虽然这些框架 *似乎* 是反面的,但实际上它们都集中在风险和变革管理上。它们简单地介绍了这种管理的不同流程和工具。在 IT 圈子外面谈论 DevOps 时,这一点需要注意。不要强调流程问题和故障,而是显示更小的变化引起的风险 *更小* 等等。这是强调改变团队文化的有益方式:专注于 *新的* 功能而不是老问题,是改变的有效中介,特别是当您采用别人的框架进行参考时。
|
||||
|
||||
改革不仅仅只是 *重构* 组织;它也是跨越历史上不可跨越的鸿沟的新途径 —— 通过拒绝把像“敏捷”和“稳定”这样的东西作为互相排斥的力量来解决我之前提到的那些紧张局势。建立注重 *结果* 胜过 *功能* 的跨部门团队是一个有效的策略。把不同的团队 —— 其中每个人的工作依赖于其他人 —— 聚集起来围绕一个项目或目标是最常见的方法之一。消除这些团队之间的摩擦和改善沟通能够产生巨大的改进 —— 即使在坚持铁仓管理结构时(如果可以掌握,则不需要拆除孤岛)。在这些情况下,对改革的 *抵抗* 不是成功的一个指标;而对改革的拥抱才是。
|
||||
|
||||
这些也不是“最佳实例”,它们只是一种检查你自己的栅栏的方式。每个组织都会有独特的、由他们内部人员创造的栅栏。一旦你“知道了它的用途”,你就可以决定它是需要拆解还是掌握。
|
||||
|
||||
** 本文是 Opensource.com 即将推出的关于开放组织和 IT 文化指南的一部分。[你可以在这注册以便当它发布时收到通知][5]**
|
||||
|
||||
(题图 : opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Matt Micene 是 Red Hat 公司的 Linux 和容器传播者。从架构和系统设计到数据中心设计,他在信息技术方面拥有超过 15 年的经验。他对关键技术(如容器,云计算和虚拟化)有深入的了解。他目前的重点是宣传红帽企业版 Linux,以及操作系统如何与计算环境的新时代相关。
|
||||
|
||||
------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps
|
||||
|
||||
作者:[Matt Micene][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[apemost](https://github.com/apemost),[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/matt-micene
|
||||
[1]:https://opensource.com/open-organization/resources/leaders-manual?src=too_resource_menu
|
||||
[2]:https://opensource.com/open-organization/resources/field-guide?src=too_resource_menu
|
||||
[3]:https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu
|
||||
[4]:https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu
|
||||
[5]:https://opensource.com/open-organization/resources/book-series
|
||||
[6]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps?rate=gOQvGqsEbNk_RSnoU0wP3PJ71E_XDYiYo7KS2HKFfP0
|
||||
[7]:https://thenewstack.io/parity-check-dont-afraid-shadow-yet/
|
||||
[8]:http://www.npr.org/2017/01/13/509358157/is-there-a-limit-to-how-many-friends-we-can-have
|
||||
[9]:https://en.wikipedia.org/wiki/ITIL
|
||||
[10]:https://opensource.com/user/18066/feed
|
||||
[11]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps#comments
|
||||
[12]:https://opensource.com/users/matt-micene
|
||||
187
published/20170529 LFCS sed Command.md
Normal file
187
published/20170529 LFCS sed Command.md
Normal file
@ -0,0 +1,187 @@
|
||||
LFCS 基础:sed 命令
|
||||
=====================
|
||||
|
||||
Linux 基金会认证系统管理员(LFCS)的另一个有用的命令是 “sed”,最初表示“流式编辑器” (Streaming EDitor)。
|
||||
|
||||
“sed” 命令是一个可以将文件作为流进行编辑的编辑器。流式传输文件的方法是从另一个命令使用管道(`>` 或 `|`)传递,或将其直接加载到 “sed” 中。
|
||||
|
||||
该命令的工作方式与其他编辑器相同,只是文件不显示,也不允许可视化编辑。命令被传递给 “sed” 来操纵流。
|
||||
|
||||
用 “sed” 可以做五件基本的事。当然,“sed” 如此强大,还有其他高级的功能,但你只需要集中精力在五件基本的事上。五种功能类型如下:
|
||||
|
||||
1. 搜索
|
||||
2. 替换
|
||||
3. 删除
|
||||
4. 添加
|
||||
5. 改变/变换
|
||||
|
||||
在深入命令参数之前,我们需要看看基本的语法。
|
||||
|
||||
### 语法
|
||||
|
||||
“sed” 命令的语法是:
|
||||
|
||||
```
|
||||
sed [选项] 命令 [要编辑的文件]
|
||||
```
|
||||
|
||||
本文将在适当的部分中介绍这些“选项”。“命令”可以是正则表达式的搜索和替换模式。请继续阅读了解 “sed” 如何工作的并学习基本命令。正如我之前提到的,“sed” 是一个非常强大的工具,有更多的选项可用,我将在本文中介绍。
|
||||
|
||||
### 示例文件
|
||||
|
||||
如果你打开一个终端,那你可以创建一个用于 “sed” 示例的文件。执行以下命令:
|
||||
|
||||
```
|
||||
cd ~
|
||||
grep --help >grephelp.txt
|
||||
```
|
||||
|
||||
你现在应该在 HOME 文件夹中有一个名为 `grephelp.txt` 的文件。该文件的内容是 `grep` 命令的帮助说明。
|
||||
|
||||
### 搜索
|
||||
|
||||
搜索特定字符串是编辑器的常见功能,在 “sed” 中执行搜索也不例外。
|
||||
|
||||
执行搜索以在文件中查找字符串。我们来看一下基本的搜索。
|
||||
|
||||
如果我们想在示例文件搜索 `PATTERN` 这个词,我们将使用如下命令:
|
||||
|
||||
```
|
||||
sed -n 's/PATTERN/PATTERN/p' grephelp.txt
|
||||
```
|
||||
|
||||
**注意:** 如果剪切粘贴命令,请确保将单引号替换为键盘上的标准单引号。
|
||||
|
||||
参数 `-n` 用于抑制每行的自动打印(除了用 `p` 命令指定的行)。默认情况下,流入 “sed” 的每一行将被打印到标准输出(stdout)。如果你不使用 “-n” 选项运行上述命令,你将看到原始文件的每一行以及匹配的行。
|
||||
|
||||
要搜索的文件名是我们在“示例文件”部分中创建的 “grephelp.txt”。
|
||||
|
||||
剩下的部分是 `'s/PATTERN/PATTERN/p'` 。这一段基本分为四个部分。第一部分的 `s` 指定执行替换,或搜索并替换。
|
||||
|
||||
剩下的第二部分和第三部分是模式。第一个是要搜索的模式,最后一个是替换流中匹配字符串的模式。此例中,我们找到字符串 `PATTERN`,并用 `PATTERN` 替换。通过查找和替换相同的字符串,我们完全不会更改文件,甚至在屏幕上也一样。
|
||||
|
||||
最后一个命令是 `p`。 它指定在替换后打印新行。当然,因为替换的是相同的字符串,所以没有改变。由于我们使用 `-n` 参数抑制打印行,所以更改的行将使用 `p` 命令打印。
|
||||
|
||||
这个完整的命令允许我们执行搜索并查看匹配的结果。
|
||||
|
||||
### 替换
|
||||
|
||||
当搜索特定字符串时,你可能希望用匹配的字符串替换新字符串。用另一个字符串替换是很常见的操作。
|
||||
|
||||
我们可以使用以下命令执行相同的搜索:
|
||||
|
||||
```
|
||||
sed -n 's/PATTERN/Pattern/p' grephelp.txt
|
||||
```
|
||||
|
||||
在这时,字符串 “PATTERN” 变为 “Pattern” 并显示。如果你使用命令 `cat grephelp.txt` 查看文件,你会看到该文件没有更改。该更改仅对屏幕上的输出进行。你可以使用以下命令将输出通过管道传输到另一个文件:
|
||||
|
||||
```
|
||||
sed 's/PATTERN/Pattern/' grephelp.txt > grephelp1.txt
|
||||
```
|
||||
|
||||
现在将存在一个名为 `grephelp1.txt` 的新文件,其中保存了更改的文件。如果 `p` 作为第四个选项留下,那么有个问题是被替换的字符串的每一行将在文件中重复两次。我们也可以删除 “-n” 参数以允许所有的行打印。
|
||||
|
||||
使用相同字符串替换字符串的另一种方法是使用 `&` 符号来表示搜索字符串。例如,命令 `s/PATTERN/&/p` 效果是一样的。我们可以添加字符串,例如添加 `S`,可以使用命令 `s/PATTERN/&S/p`。
|
||||
|
||||
如果我们希望在每一行中只替换某种模式呢?可以指定要替换的匹配项的特定出现。当然,每一行的替换都是一个特定的编号。例如,示例文件上有很多破折号。一些行至少有两条破折号,所以我们可以用另一个字符代替每一行的第二个破折号。每行用星号 `*` 替换第二个破折号 `-` 的命令将是:
|
||||
|
||||
```
|
||||
sed 's/-/*/2' grephelp.txt
|
||||
```
|
||||
|
||||
在这里,我们用最初的 `s` 来执行替换。字符 `-` 被替换为 `*`。`2` 表示我们想要替换每行上的第二个 `-`(如果存在)。如果我们忽略了命令 `2`,则替换第一次出现的破折号。只有第一个破折号而不是每行的破折号都被替换。
|
||||
|
||||
如果要搜索并替换带有星号的行上的所有破折号,请使用 `g` 命令:
|
||||
|
||||
```
|
||||
sed 's/-/*/g' grephelp.txt
|
||||
```
|
||||
|
||||
命令也可以组合。假设你想要替换从第二次开始出现的破折号,命令将是:
|
||||
|
||||
```
|
||||
sed 's/-/*/2g' grephelp.txt
|
||||
```
|
||||
|
||||
现在从第二个开始出现的破折号将被星号取代。
|
||||
|
||||
### 删除
|
||||
|
||||
搜索过程中有很多时候你可能想要完全删除搜索字符串。
|
||||
|
||||
例如,如果要从文件中删除所有破折号,你可以使用以下命令:
|
||||
|
||||
```
|
||||
sed 's/-//g' grephelp.txt
|
||||
```
|
||||
|
||||
替换字符串为空白,因此匹配的字符串将被删除。
|
||||
|
||||
### 添加
|
||||
|
||||
当找到匹配时,你可以添加一行特定的文本,来使这行在浏览或打印中突出。
|
||||
|
||||
如果要在匹配后插入新行,那么使用 `a` 命令,后面跟上新行的字符串。还包括要匹配的字符串。例如,我们可以找到一个 `--`,并在匹配的行之后添加一行。新行的字符串将是 `double dash before this line`。
|
||||
|
||||
```
|
||||
sed '/--/ a "double dash before this line"' grephelp.txt
|
||||
```
|
||||
|
||||
如果要在包含匹配字符串的行之前加上这行,请使用 `i` 命令,如下所示:
|
||||
|
||||
```
|
||||
sed '/--/ i "double dash after this line"' grephelp.txt
|
||||
```
|
||||
|
||||
### 改变/变换
|
||||
|
||||
如果需要改变/变换一行,则可以使用命令 `c`。
|
||||
|
||||
假设我们有个有一些私人信息的文档,我们需要更改包含特定字符串的行。`c` 命令将改变整行,而不仅仅是搜索字符串。
|
||||
|
||||
假设我们想要阻止示例文件中包含单词 `PATTERN` 的每一行。更改的行将显示为 `This line is Top Secret`。命令是:
|
||||
|
||||
```
|
||||
sed '/PATTERN/ c This line is Top Secret' grephelp.txt
|
||||
```
|
||||
|
||||
可以进行更改特定字母的大小写的转换。例如,我们可以使用命令 `y` 将所有小写 `a` 更改为大写 `A`,如下所示:
|
||||
|
||||
```
|
||||
sed 'y/a/A/' grephelp.txt
|
||||
```
|
||||
|
||||
可以指定多个字母,如 `abdg`,如下命令所示:
|
||||
|
||||
```
|
||||
sed 'y/abdg/ABDG/' grephelp.txt
|
||||
```
|
||||
|
||||
确保第二组字母与第一组字母的顺序相同,否则会被替换和转换。例如,字符串 `y/a/D/` 将用大写 `D` 替换所有小写的 `a`。
|
||||
|
||||
### 就地更改
|
||||
|
||||
如果你确实要更改所使用的文件,请使用 `-i` 选项。
|
||||
|
||||
例如,要将 `PATTERN` 改为 `Pattern`,并对文件进行更改,则命令为:
|
||||
|
||||
```
|
||||
sed -i 's/PATTERN/Pattern/' grephelp.txt
|
||||
```
|
||||
|
||||
现在文件 `grephelp.txt` 将被更改。`-i` 选项可以与上述任何命令一起使用来更改原始文件的内容。
|
||||
|
||||
练习这些命令,并确保你理解它们。“sed” 命令非常强大。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.org/threads/lfcs-sed-command.4561/
|
||||
|
||||
作者:[Jarret B][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.org/threads/lfcs-sed-command.4561/
|
||||
@ -1,61 +1,65 @@
|
||||
# [开源社交机器人套件运行在 Raspberry Pi 和 Arduino 上][22]
|
||||
|
||||
|
||||
运行在树莓派和 Arduino 上的开源社交机器人套件
|
||||
============
|
||||
|
||||

|
||||
Thecorpora 的发布的 “Q.bo One” 机器人基于 RPi 3 和 Arduino,并提供立体相机、麦克风、扬声器,以及视觉和语言识别。
|
||||
|
||||
2010 年,机器人开发商 Francisco Paz 及其巴塞罗那的 Thecorpora 公司推出了首款 [Qbo][6] “Cue-be-oh” 机器人作为一个开源概念验证和用于探索 AI 在多传感器、交互式机器人的能力的研究项目。目前,在 2 月移动世界大会上的预览之后,Thecorpora 把它放到了 Indiegogo 上,与 Arrow 合作推出了第一个批量生产的社交机器人版本。
|
||||
*Thecorpora 的发布的 “Q.bo One” 机器人基于 RPi 3 和 Arduino,并提供立体相机、麦克风、扬声器,以及视觉和语言识别。*
|
||||
|
||||
[][7] [][8]
|
||||
**Q.bo One 的左侧和顶部**
|
||||
2010 年,作为一个开源概念验证和用于探索 AI 在多传感器、交互式机器人的能力的研究项目,机器人开发商 Francisco Paz 及它在巴塞罗那的 Thecorpora 公司推出了首款 [Qbo][6] “Cue-be-oh” 机器人。在今年 2 月移动世界大会上的预览之后,Thecorpora 把它放到了 Indiegogo 上,与 Arrow 合作推出了第一个批量生产的社交机器人版本。
|
||||
|
||||
[][7]
|
||||
|
||||
像原来一样,新的 Q.bo One 有一个带眼睛的球形头(双立体相机)、耳朵(3 个麦克风)和嘴(扬声器),并由 WiFi 和蓝牙控制。 Q.bo One 也同样有开源 Linux 软件和开放规格硬件。然而,它不是使用基于 Intel Atom 的 Mini-ITX 板,而是在与 Arduino 兼容的主板相连的 Raspberry Pi 3 上运行 Raspbian。
|
||||
*Q.bo One 的左侧*
|
||||
|
||||
[][8]
|
||||
|
||||
[][9]
|
||||
**Q.bo One side views**
|
||||
*Q.bo One 的顶部*
|
||||
|
||||
像原来一样,新的 Q.bo One 有一个带眼睛的球形头(双立体相机)、耳朵(3 个麦克风)和嘴(扬声器),并由 WiFi 和蓝牙控制。 Q.bo One 也同样采用开源 Linux 软件和开放规格硬件。然而,它不是使用基于 Intel Atom 的 Mini-ITX 板,而是在与 Arduino 兼容的主板相连的 Raspberry Pi 3 上运行 Raspbian。
|
||||
|
||||
Q.bo One 于 7 月中旬在 Indiegogo 上架,起价为 369 美元(早期买家)或 399 美元,有包括内置的 Raspberry Pi 3 和基于 Arduino 的 “Qboard” 控制器板。它还有售价 $499 的完整套装。目前,Indiegogo 上的弹性目标是 $100,000,现在大概达成了 15%,并且它 12 月出货。
|
||||
[][9]
|
||||
|
||||
更专业的机器人工程师和嵌入式开发人员可能会想要使用只有 RPI 和 Qboard PCB 和软件的价值 $99 的版本,或者提供没有电路板的机器人套件的 $249 版本。使用此版本,你可以用自己的 Arduino 控制器替换 Qboard,并将 RPi 3 替换为另一个 Linux SBC。该公司列出了 Banana Pi、BeagleBone、Tinker Board 以及[即将退市的 Intel Edison][10],作为兼容替代品的示例。
|
||||
*Q.bo One 侧视图**
|
||||
|
||||
<center>
|
||||
[][11]
|
||||
**Q.bo One kit**
|
||||
(click image to enlarge)
|
||||
</center>
|
||||
Q.bo One 于 7 月中旬在 Indiegogo 上架,起价为 369 美元(早期买家)或 399 美元,有包括内置的树莓派 3 和基于 Arduino 的 “Qboard” 控制器板。它还有售价 $499 的完整套装。目前,Indiegogo 上的众筹目标是 $100,000,现在大概达成了 15%,并且它 12 月出货。
|
||||
|
||||
与 2010 年的 Qbo 不同,Q.bo One 除了球面头部之外无法移动,它在双重伺服系统的帮助下在底座上旋转,以便跟踪声音和动作。Robotis Dynamixel 舵机,也在开源中找到,Raspberry Pi 基于 [TurtleBot 3][23] 机器人工具包,除了左右之外,还可以上下移动。
|
||||
更专业的机器人工程师和嵌入式开发人员可能会想要使用价值 $99 的只有树莓派和 Qboard PCB 和软件的版本,或者提供没有电路板的机器人套件的 $249 版本。使用此版本,你可以用自己的 Arduino 控制器替换 Qboard,并将树莓派 3 替换为另一个 Linux SBC。该公司列出了 Banana Pi、BeagleBone、Tinker Board 以及[即将退市的 Intel Edison][10],作为兼容替代品的示例。
|
||||
|
||||
<center>
|
||||
[][12] [][13]
|
||||
**Q.bo One detail view (left) and Qboard detail**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
[][11]
|
||||
|
||||
Q.bo One 也可类似地与基于 Linux 的 [Jibo][24] “社交机器人”相比,它于 2014 年在 Indiegogo 推出,最后达到 360 万美元。然而,Jibo 还没有出货,[最近的推迟][25]迫使它在今年的某个时候发布一个版本。
|
||||
*Q.bo One 套件*
|
||||
|
||||
与 2010 年的 Qbo 不同,Q.bo One 除了球面头部之外无法移动,它可以在双重伺服系统的帮助下在底座上旋转,以便跟踪声音和动作。Robotis Dynamixel 舵机同样开源,树莓派基于 [TurtleBot 3][23] 机器人工具包,除了左右之外,还可以上下移动。
|
||||
|
||||
[][12]
|
||||
|
||||
*Q.bo One 细节*
|
||||
|
||||
[][13]
|
||||
|
||||
*Qboard 细节*
|
||||
|
||||
Q.bo One 类似于基于 Linux 的 [Jibo][24] “社交机器人”,它于 2014 年在 Indiegogo 众筹,最后达到 360 万美元。然而,Jibo 还没有出货,[最近的推迟][25]迫使它在今年的某个时候发布一个版本。
|
||||
|
||||
|
|
||||

|
||||
|
||||
**Q.bo One** |
|
||||
*Q.bo One*
|
||||
|
||||
我们大胆预测 Q.bo One 将会在 2017 年接近 12 月出货。核心技术和 AI 软件已被证明,而 Raspberry Pi 和 Arduino 技术也是如此。Qboard 主板已经由 Arrow 制造和认证。
|
||||
我们大胆预测 Q.bo One 将会在 2017 年接近 12 月出货。核心技术和 AI 软件已被证明,而树莓派和 Arduino 技术也是如此。Qboard 主板已经由 Arrow 制造和认证。
|
||||
|
||||
开源设计表明, 即使是移动版本也不会有问题。这使它更像是滚动的人形生物 [Pepper][14],一个来自 Softbank 和 Aldeberan 类似的人工智能对话机器人。
|
||||
开源设计表明,即使是移动版本也不会有问题。这使它更像是滚动的人形生物 [Pepper][14],这是一个来自 Softbank 和 Aldeberan 类似的人工智能对话机器人。
|
||||
|
||||
Q.bo One 自原版以来添加了一些技巧,例如由 20 个 LED 组成的“嘴巴”, 它以不同的、可编程的方式在语音中模仿嘴唇移动。如果你想点击机器人获得关注,那么它的头上还有三个触摸传感器。但是,你真正需要做的就是说话,而 Q.bo One 会像一个可卡犬一样转身并凝视着你。
|
||||
Q.bo One 自原始版以来添加了一些技巧,例如由 20 个 LED 组成的“嘴巴”, 它以不同的、可编程的方式在语音中模仿嘴唇开合。如果你想点击机器人获得关注,那么它的头上还有三个触摸传感器。但是,你其实只需要说话就行,而 Q.bo One 会像一个可卡犬一样转身并凝视着你。
|
||||
|
||||
接口和你在 Raspberry Pi 3 上的一样,它在我们的[2017 黑客电路板调查][15]中消灭了其他对手。为 RPi 3 的 WiFi 和蓝牙安装了天线。
|
||||
接口和你在树莓派 3 上的一样,它在我们的 [2017 黑客电路板调查][15]中消灭了其他对手。为树莓派 3 的 WiFi 和蓝牙安装了天线。
|
||||
|
||||
<center>
|
||||
[][16] [][17]
|
||||
**Q.bo One software architecture (left) and Q.bo One with Scratch screen**
|
||||
(click images to enlarge)
|
||||
</center>
|
||||
[][16]
|
||||
|
||||
*Q.bo One 软件架构*
|
||||
|
||||
[][17]
|
||||
|
||||
*Q.bo One 及 Scratch 编程*
|
||||
|
||||
Qboard(也称为 Q.board)在 Atmel ATSAMD21 MCU 上运行 Arduino 代码,并有三个麦克风、扬声器、触摸传感器、Dynamixel 控制器和用于嘴巴的 LED 矩阵。其他功能包括 GPIO、I2C接口和可连接到台式机的 micro-USB 口。
|
||||
|
||||
@ -66,19 +70,17 @@ Q.bo One 可以识别脸部和追踪移动,机器人甚至可以在镜子中
|
||||
基于 Raspbian 的软件使用 OpenCV 进行视觉处理,并可以使用各种语言(包括 C++)进行编程。该软件还提供了 IBM Bluemix、NodeRED 和 ROS 的钩子。大概你也可以整合 [Alexa][18] 或 [Google Assistant][19]语音代理,虽然 Thecorpora 没有提及这一点。
|
||||
|
||||
|
||||
|
||||
**更多信息**
|
||||
|
||||
Q.bo One 在 7 月中旬在 Indiegogo 上架,起价为 $369 的完整套件和 $499 的所有组合
|
||||
。出货量预计在 2017 年 12 月。更多信息请参见[ Q.bo One 的 Indiegogo 页面][20] 和[ Thecorpora 网站][21]。
|
||||
Q.bo One 在 7 月中旬在 Indiegogo 上架,起价为完整套件 $369 和完整组合 $499 。出货预计在 2017 年 12 月。更多信息请参见 [Q.bo One 的 Indiegogo 页面][20] 和[Thecorpora 网站][21]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/open-source-social-robot-kit-runs-on-raspberry-pi-and-arduino/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
作者:[Eric Brown][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,36 +1,22 @@
|
||||
编写 Linux 调试器第 8 部分:堆栈展开
|
||||
开发一个 Linux 调试器(八):堆栈展开
|
||||
============================================================
|
||||
|
||||
有时你需要知道的最重要的信息是什么,你当前的程序状态是如何到达那里的。这有一个 `backtrace` 命令,它给你提供了程序当前的函数调用链。这篇文章将向你展示如何在 x86_64 上实现堆栈展开以生成这样的回溯。
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### 系列索引
|
||||
|
||||
这些链接将会随着其他帖子的发布而上线。
|
||||
|
||||
1. [设置][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [ELF 和 DWARF][4]
|
||||
|
||||
5. [源和信号][5]
|
||||
|
||||
6. [源码级单步调试][6]
|
||||
|
||||
5. [源码和信号][5]
|
||||
6. [源码级逐步执行][6]
|
||||
7. [源码级断点][7]
|
||||
|
||||
8. [堆栈展开][8]
|
||||
|
||||
9. 读取变量
|
||||
|
||||
10. 下一步
|
||||
|
||||
* * *
|
||||
10. 之后步骤
|
||||
|
||||
用下面的程序作为例子:
|
||||
|
||||
@ -53,7 +39,7 @@ int main() {
|
||||
}
|
||||
```
|
||||
|
||||
如果调试器停在 `//stopped here' 这行,那么有两种方法可以达到:`main->b->a` 或 `main->c->a`。如果我们用 LLDB 设置一个断点,继续并请求一个回溯,那么我们将得到以下内容:
|
||||
如果调试器停在 `//stopped here' 这行,那么有两种方法可以达到:`main->b->a` 或 `main->c->a`。如果我们用 LLDB 设置一个断点,继续执行并请求一个回溯,那么我们将得到以下内容:
|
||||
|
||||
```
|
||||
* frame #0: 0x00000000004004da a.out`a() + 4 at bt.cpp:3
|
||||
@ -61,12 +47,11 @@ int main() {
|
||||
frame #2: 0x00000000004004fe a.out`main + 9 at bt.cpp:14
|
||||
frame #3: 0x00007ffff7a2e830 libc.so.6`__libc_start_main + 240 at libc-start.c:291
|
||||
frame #4: 0x0000000000400409 a.out`_start + 41
|
||||
|
||||
```
|
||||
|
||||
这说明我们目前在函数 `a` 中,`a` 从函数 `b` 中跳转,`b` 从 `main` 中跳转等等。最后两个帧是编译器如何引导 `main` 函数。
|
||||
这说明我们目前在函数 `a` 中,`a` 从函数 `b` 中跳转,`b` 从 `main` 中跳转等等。最后两个帧是编译器如何引导 `main` 函数的。
|
||||
|
||||
现在的问题是我们如何在 x86_64 上实现。最稳定的方法是解析 ELF 文件的 `.eh_frame` 部分,并解决如何从那里展开堆栈,但这会很痛苦。你可以使用 `libunwind` 或类似的来做,但这很无聊。相反,我们假设编译器以某种方式设置了堆栈,我们将手动进行。为了做到这一点,我们首先需要了解堆栈的布局。
|
||||
现在的问题是我们如何在 x86_64 上实现。最稳健的方法是解析 ELF 文件的 `.eh_frame` 部分,并解决如何从那里展开堆栈,但这会很痛苦。你可以使用 `libunwind` 或类似的来做,但这很无聊。相反,我们假设编译器以某种方式设置了堆栈,我们将手动遍历它。为了做到这一点,我们首先需要了解堆栈的布局。
|
||||
|
||||
```
|
||||
High
|
||||
@ -89,7 +74,7 @@ ESP+--> | Var 2 |
|
||||
|
||||
```
|
||||
|
||||
你可以看到,最后一个堆栈帧的帧指针存储在当前堆栈帧的开始处,创建一个链接的指针列表。按照这个链表解开堆栈。我们可以通过查找 DWARF 信息中的返回地址来找出列表中下一帧的函数。一些编译器将忽略跟踪 `EBP` 的帧基址,因为这可以表示为 `ESP` 的偏移量,并可以释放一个额外的寄存器。即使启用了优化,传递 `-fno-omit-frame-pointer` 到 GCC 或 Clang 会强制它遵循我们依赖的约定。
|
||||
如你所见,最后一个堆栈帧的帧指针存储在当前堆栈帧的开始处,创建一个链接的指针列表。堆栈依据这个链表解开。我们可以通过查找 DWARF 信息中的返回地址来找出列表中下一帧的函数。一些编译器将忽略跟踪 `EBP` 的帧基址,因为这可以表示为 `ESP` 的偏移量,并可以释放一个额外的寄存器。即使启用了优化,传递 `-fno-omit-frame-pointer` 到 GCC 或 Clang 会强制它遵循我们依赖的约定。
|
||||
|
||||
我们将在 `print_backtrace` 函数中完成所有的工作:
|
||||
|
||||
@ -113,14 +98,14 @@ void debugger::print_backtrace() {
|
||||
output_frame(current_func);
|
||||
```
|
||||
|
||||
接下来我们需要获取当前函数的帧指针和返回地址。帧指针存储在 `rbp` 寄存器中,返回地址从帧指针堆栈起的 8 字节。
|
||||
接下来我们需要获取当前函数的帧指针和返回地址。帧指针存储在 `rbp` 寄存器中,返回地址是从帧指针堆栈起的 8 字节。
|
||||
|
||||
```
|
||||
auto frame_pointer = get_register_value(m_pid, reg::rbp);
|
||||
auto return_address = read_memory(frame_pointer+8);
|
||||
```
|
||||
|
||||
现在我们拥有了展开堆栈所需的所有信息。我只需要继续展开,直到调试器命中 `main`,但是当帧指针为 `0x0`时,你也可以选择停止,这些是你在调用 `main` 函数之前调用的函数。我们将从每帧抓取帧指针和返回地址,并打印出信息。
|
||||
现在我们拥有了展开堆栈所需的所有信息。我只需要继续展开,直到调试器命中 `main`,但是当帧指针为 `0x0` 时,你也可以选择停止,这些是你在调用 `main` 函数之前调用的函数。我们将从每帧抓取帧指针和返回地址,并打印出信息。
|
||||
|
||||
```
|
||||
while (dwarf::at_name(current_func) != "main") {
|
||||
@ -168,9 +153,7 @@ void debugger::print_backtrace() {
|
||||
|
||||
### 测试
|
||||
|
||||
测试此功能的一个方法是通过编写一个测试程序与一堆互相调用的小函数。设置几个断点,跳在代码附近,并确保你的回溯是准确的。
|
||||
|
||||
* * *
|
||||
测试此功能的一个方法是通过编写一个测试程序与一堆互相调用的小函数。设置几个断点,跳到代码附近,并确保你的回溯是准确的。
|
||||
|
||||
我们已经从一个只能产生并附加到其他程序的程序走了很长的路。本系列的倒数第二篇文章将通过支持读写变量来完成调试器的实现。在此之前,你可以在[这里][9]找到这个帖子的代码。
|
||||
|
||||
@ -180,17 +163,17 @@ via: https://blog.tartanllama.xyz/c++/2017/06/24/writing-a-linux-debugger-unwind
|
||||
|
||||
作者:[Simon Brand][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/c++/2017/03/31/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/c++/2017/04/05/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/c++/2017/04/24/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/c++/2017/05/06/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://blog.tartanllama.xyz/c++/2017/06/19/writing-a-linux-debugger-source-break/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8663-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://linux.cn/article-8812-1.html
|
||||
[6]:https://linux.cn/article-8813-1.html
|
||||
[7]:https://linux.cn/article-8890-1.html
|
||||
[8]:https://blog.tartanllama.xyz/c++/2017/06/24/writing-a-linux-debugger-unwinding/
|
||||
[9]:https://github.com/TartanLlama/minidbg/tree/tut_unwind
|
||||
@ -0,0 +1,159 @@
|
||||
用 Linux、Python 和树莓派酿制啤酒
|
||||
============================================================
|
||||
|
||||
> 怎样在家用 Python 和树莓派搭建一个家用便携的自制酿啤酒装置
|
||||
|
||||

|
||||
|
||||
大约十年前我开始酿制自制啤酒,和许多自己酿酒的人一样,我开始在厨房制造提纯啤酒。这需要一些设备并且做出来后确实是好的啤酒,最终,我用一个放入了所有大麦的大贮藏罐作为我的麦芽浆桶。几年之后我一次酿制过 5 加仑啤酒,但是酿制 10 加仑时也会花费同样的时间和效用(只是容器比之前大些),之前我就是这么做的。容量提升到 10 加仑之后,我偶然看到了 [StrangeBrew Elsinore][38] ,我意识到我真正需要的是将整个酿酒过程转换成全电子化的,用树莓派来运行它。
|
||||
|
||||
建造自己的家用电动化酿酒系统需要大量这方面的技术信息,许多学习酿酒的人是在 [TheElectricBrewery.com][28] 这个网站起步的,只不过将那些控制版搭建在一起是十分复杂的,尽管最简单的办法在这个网站上总结的很好。当然你也能用[一个小成本的方法][26]并且依旧可以得到相同的结果 —— 用一个热水壶和热酒容器通过一个 PID 控制器来加热你的酿酒原料。但是我认为这有点太无聊(这也意味着你不能体验到完整的酿酒过程)。
|
||||
|
||||
### 需要用到的硬件
|
||||
|
||||
在我开始我的这个项目之前, 我决定开始买零件,我最基础的设计是一个可以将液体加热到 5500 瓦的热酒容器(HLT)和开水壶,加一个活底的麦芽浆桶,我通过一个 50 英尺的不锈钢线圈在热酒容器里让泵来再循环麦芽浆(["热量交换再循环麦芽浆系统, 也叫 HERMS][27])。同时我需要另一个泵来在热酒容器里循环水,并且把水传输到麦芽浆桶里,整个电子部件全部是用树莓派来控制的。
|
||||
|
||||
建立我的电子酿酒系统并且尽可能的自动化意味着我需要以下的组件:
|
||||
|
||||
* 一个 5500 瓦的电子加热酒精容器(HLT)
|
||||
* 能够放入加热酒精容器里的 50 英尺(0.5 英寸)的不锈钢线圈(热量交换再循环麦芽浆系统)
|
||||
* 一个 5500 瓦的电子加热水壶
|
||||
* 多个固态继电器加热开关
|
||||
* 2 个高温食品级泵
|
||||
* 泵的开关用继电器
|
||||
* 可拆除装置和一个硅管
|
||||
* 不锈钢球阀
|
||||
* 一个测量温度的探针
|
||||
* 很多线
|
||||
* 一个来容纳这些配件的电路盒子
|
||||
|
||||

|
||||
|
||||
*酿酒系统 (photo by Christopher Aedo. [CC BY-SA 4.0)][5]*
|
||||
|
||||
建立酿酒系统的电气化方面的细节 [The Electric Brewery][28] 这个网站概括的很好,这里我不再重复,当你计划用树莓派代替这个 PID 控制器的话,你可以读以下的建议。
|
||||
|
||||
一个重要的事情需要注意,固态继电器(SSR)信号电压,许多教程建议使用一个 12 伏的固态继电器来关闭电路,树莓派的 GPIO 针插口只支持 3 伏输出电压,然而,必须购买继电器将电压变为 3 伏。
|
||||
|
||||

|
||||
|
||||
*Inkbird SSR (photo by Christopher Aedo. [CC BY-SA 4.0)][6]*
|
||||
|
||||
要运行酿酒系统,你的树莓派必须做两个关键事情:测量来自几个不同位置的温度,用继电器开关来控制加热元件,树莓派很容易来处理这些任务。
|
||||
|
||||
这里有一些不同的方法来将温度传感器连到树莓派上,但是我找到了最方便的方法用[单总线][29]。这就可以让多个传感器分享相同的线路(实际上是三根线),这三根线可以使酿酒系统的多个设备更方便的工作,如果你要从网上找一个防水的 DS18B20 温度传感器,你可以会找到很多选择。我用的是[日立 DS18B20 防水温度传感器][30]。
|
||||
|
||||
要控制加热元件,树莓派包括了几个用来软件寻址的总线扩展器(GPIO),它会通过在某个文件写入 0 或者 1 让你发送3.3v 的电压到一个继电器,在我第一次了解树莓派是怎样工作的时候,这个[用 GPIO 驱动继电器的树莓派教程][46]对我来说是最有帮助的,总线扩展器控制着多个固态继电器,通过酿酒软件来直接控制加热元件的开关。
|
||||
|
||||
我首先将所有部件放到这个电路盒子,因为这将成为一个滚动的小车,我要让它便于移动,而不是固定不动的,如果我有一个店(比如说在车库、工具房、或者地下室),我需要要用一个装在墙上的更大的电路盒,而现在我找到一个大小正好的[防水工程盒子][31],能放进每件东西,最后它成为小巧紧凑工具盒,并且能够工作。在左下角是和树莓派连接的为总线扩展器到单总线温度探针和[固态继电器][32]的扩展板。
|
||||
|
||||
要保持 240v 的固态继电器温度不高,我在盒子上切了个洞,在盒子的外面用 CPU 降温凝胶把[铜片散热片][33]安装到盒子外面的热槽之间。它工作的很好,盒子里没有温度上的问题了,在盒子盖上我放了两个开关为 120v 的插座,加两个240v 的 led 来显示加热元件是否通电。我用干燥器的插座和插头,所以可以很容易的断开电热水壶的连接。首次尝试每件事情都工作正常。(第一次绘制电路图必有回报)
|
||||
|
||||
这个照片来自“概念”版,最终生产系统应该有两个以上的固态继电器,以便 240v 的电路两个针脚能够切换,另外我将通过软件来切换泵的开关。现在通过盒子前面的物理开关控制它们,但是也很容易用继电器控制它们。
|
||||
|
||||

|
||||
|
||||
*控制盒子 (photo by Christopher Aedo. [CC BY-SA 4.0)][7]*
|
||||
|
||||
唯一剩下有点棘手的事情是温度探针的压合接头,这个探针安装在加热酒精容器和麦芽浆桶球形的最底部阀门前的 T 字型接头上。当液体流过温度传感器,温度可以准确显示。我考虑加一个套管到热水壶里,但是对于我的酿造工艺没有什么用。最后,我买到了[四分之一英寸的压合接头][34],它们工作完美。
|
||||
|
||||
### 软件
|
||||
|
||||
一旦硬件整理好,我就有时间来处理软件了,我在树莓派上跑了最新的 [Raspbian 发行版][35],操作系统方面没有什么特别的。
|
||||
|
||||
我开始使用 [Strangebrew Elsinore][36] 酿酒软件,当我的朋友问我是否我听说过 [Hosehead][37](一个基于树莓派的酿酒控制器),我找到了 [Strangebrew Elsinore][36] 。我认为 [Hosehead][37] 很棒,但我并不是要买一个酿酒控制器,而是要挑战自己,搭建一个自己的。
|
||||
|
||||
设置 [Strangebrew Elsinore][36] 很简单,其[文档][38]直白,没有遇到任何的问题。尽管 Strangebrew Elsinore 工作的很好,但在我的一代树莓派上运行 java 有时是费力的,不止崩溃一次。我看到这个软件开发停顿也很伤心,似乎他们也没有更多贡献者的大型社区(尽管有很多人还在用它)。
|
||||
|
||||
#### CraftBeerPi
|
||||
|
||||
之后我偶然遇到了一个用 Python 写的 [CraftbeerPI][39],它有活跃的贡献者支持的开发社区。原作者(也是当前维护者) Manuel Fritsch 在贡献和反馈问题处理方面做的很好。克隆[这个仓库][40]然后开始只用了我一点时间。其 README 文档也是一个连接 DS1820 温度传感器的好例子,同时也有关于硬件接口到树莓派或者[芯片电脑][41] 的注意事项。
|
||||
|
||||
在启动的时候,CraftbeerPI 引导用户通过一个设置过程来发现温度探针是否可用,并且让你指定哪个 GPIO 总线扩展器指针来管理树莓派上哪个配件。
|
||||
|
||||

|
||||
|
||||
*CraftBeerPi (photo by Christopher Aedo. [CC BY-SA 4.0)][8]*
|
||||
|
||||
用这个系统进行自制酿酒是容易的,我能够依靠它掌握可靠的温度,我能输入多个温度段来控制麦芽浆温度,用CraftbeerPi 酿酒的日子有一点点累,但是我很高兴用传统的手工管理丙烷燃烧器的“兴奋”来换取这个系统的有效性和持续性。
|
||||
|
||||
CraftBeerPI 的用户友好性鼓舞我设置了另一个控制器来运行“发酵室”。就我来说,那是一个二手冰箱,我用了 50 美元加上放在里面的 25 美元的加热器。CraftBeerPI 很容易控制电器元件的冷热,你也能够设置多个温度阶段。举个例子,这个图表显示我最近做的 IPA 进程的发酵温度。发酵室发酵麦芽汁在 67F° 的温度下需要 4 天,然后每 12 小时上升一度直到温度到达 72F°。剩下两天温度保持不变是为了双乙酰生成。之后 5 天温度降到 65F°,这段时间是让啤酒变“干”,最后啤酒发酵温度直接降到 38F°。CraftBeerPI 可以加入各个阶段,让软件管理发酵更加容易。
|
||||
|
||||

|
||||
|
||||
*SIPA 发酵设置 (photo by Christopher Aedo. [CC BY-SA 4.0)][9]*
|
||||
|
||||
我也试验过用[液体比重计][42]来对酵啤酒的比重进行监测,通过蓝牙连接的浮动传感器可以达到。有一个整合的计划能让 CraftbeerPi 很好工作,现在它记录这些比重数据到谷歌的电子表格里。一旦这个液体比重计能连接到发酵控制器,设置的自动发酵设置会基于酵母的活动性直接运行且更加容易,而不是在 4 天内完成主要发酵,可以在比重稳定 24 小时后设定温度。
|
||||
|
||||
像这样的一些项目,构想并计划改进和增加组件是很容易,不过,我很高兴今天经历过的事情。我用这种装置酿造了很多啤酒,每次都能达到预期的麦芽汁比率,而且啤酒一直都很美味。我的最重要的消费者 —— 就是我!很高兴我可以随时饮用。
|
||||
|
||||

|
||||
|
||||
*随时饮用 (photo by Christopher Aedo. [CC BY-SA 4.0)][10]*
|
||||
|
||||
这篇文章基于 Christopher 的开放的西部的讲话《用Linux、Python 和树莓派酿制啤酒》。
|
||||
|
||||
(题图:[Quinn Dombrowski][21]. Modified by Opensource.com. [CC BY-SA 4.0][22])
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Christopher Aedo 从他的学生时代就从事并且贡献于开源软件事业。最近他在 IBM 领导一个极棒的上游开发者团队,同时他也是开发者拥护者。当他不再工作或者实在会议室演讲的时候,他可能在波特兰市俄勒冈州用树莓派酿制和发酵一杯美味的啤酒。
|
||||
|
||||
----
|
||||
via: https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi
|
||||
|
||||
作者:[Christopher Aedo][a]
|
||||
译者:[hwlife](https://github.com/hwlife)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu2
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu3
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu4
|
||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[8]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/file/358661
|
||||
[12]:https://opensource.com/file/358666
|
||||
[13]:https://opensource.com/file/358676
|
||||
[14]:https://opensource.com/file/359061
|
||||
[15]:https://opensource.com/file/358681
|
||||
[16]:https://opensource.com/file/359071
|
||||
[17]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi?rate=fbKzT1V9gqGsmNCTuQIashC1xaHT5P_2LUaeTn6Kz1Y
|
||||
[18]:https://www.openwest.org/custom/description.php?id=139
|
||||
[19]:https://www.openwest.org/
|
||||
[20]:https://opensource.com/user/145976/feed
|
||||
[21]:https://www.flickr.com/photos/quinndombrowski/
|
||||
[22]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[23]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||
[24]:https://opensource.com/tags/raspberry-pi
|
||||
[25]:http://www.theelectricbrewery.com/
|
||||
[26]:http://www.instructables.com/id/Electric-Brewery-Control-Panel-on-the-Cheap/
|
||||
[27]:https://byo.com/hops/item/1325-rims-and-herms-brewing-advanced-homebrewing
|
||||
[28]:http://theelectricbrewery.com/
|
||||
[29]:https://en.wikipedia.org/wiki/1-Wire
|
||||
[30]:https://smile.amazon.com/gp/product/B018KFX5X0/
|
||||
[31]:http://amzn.to/2hupFCr
|
||||
[32]:http://amzn.to/2hL8JDS
|
||||
[33]:http://amzn.to/2i4DYwy
|
||||
[34]:https://www.brewershardware.com/CF1412.html
|
||||
[35]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[36]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||
[37]:https://brewtronix.com/
|
||||
[38]:http://dougedey.github.io/SB_Elsinore_Server/
|
||||
[39]:http://www.craftbeerpi.com/
|
||||
[40]:https://github.com/manuel83/craftbeerpi
|
||||
[41]:https://www.nextthing.co/pages/chip
|
||||
[42]:https://tilthydrometer.com/
|
||||
[43]:https://opensource.com/users/docaedo
|
||||
[44]:https://opensource.com/users/docaedo
|
||||
[45]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi#comments
|
||||
[46]:http://www.susa.net/wordpress/2012/06/raspberry-pi-relay-using-gpio/
|
||||
@ -0,0 +1,339 @@
|
||||
GitHub 的 MySQL 基础架构自动化测试
|
||||
============================================================
|
||||
|
||||
我们 MySQL 数据库基础架构是 Github 关键组件。 MySQL 提供 Github.com、 GitHub 的 API 和验证等等的服务。每一次的 `git` 请求都以某种方式触及 MySQL。我们的任务是保持数据的可用性,并保持其完整性。即使我们 MySQL 集群是按流量分配的,但是我们还是需要执行深度清理、即时更新、在线<ruby>模式<rt>schema</rt></ruby>迁移、集群拓扑重构、<ruby>连接池化<rt>pooling</rt></ruby>和负载平衡等任务。 我们建有基础架构来自动化测试这些操作,在这篇文章中,我们将分享几个例子,来说明我们是如何通过持续测试打造我们的基础架构的。这是让我们一梦到天亮的根本保障。
|
||||
|
||||
### 备份
|
||||
|
||||
没有比备份数据更重要的了,如果您没有备份数据库,在它出事前这可能并不是什么问题。Percona 的 [Xtrabackup][37] 是我们一直用来完整备份 MySQL 数据库的工具。如果有专门需要备份的数据,我们就会备份到另一个专门备份数据的服务器上。
|
||||
|
||||
除了完整的二进制备份外,我们每天还会多次运行逻辑备份。这些备份数据可以让我们的工程师获取到最新的数据副本。有时候,他们希望从表中获取一整套数据,以便他们可以在一个生产级规模的表上测试索引的修改,或查看特定时间以来的数据。Hubot 可以让我们恢复备份的表,并且当表准备好使用时会通知我们。
|
||||
|
||||
**tomkrouper**
|
||||
|
||||
```
|
||||
.mysql backup-list locations
|
||||
```
|
||||
|
||||
**Hubot**
|
||||
|
||||
```
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
||||
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
||||
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
||||
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
||||
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
||||
| ...
|
||||
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
||||
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
```
|
||||
|
||||
**tomkrouper**
|
||||
|
||||
```
|
||||
.mysql restore 1699133
|
||||
```
|
||||
|
||||
**Hubot**
|
||||
|
||||
```
|
||||
A restore job has been created for the backup job 1699133. You will be notified in #database-ops when the restore is complete.
|
||||
```
|
||||
|
||||
**Hubot**
|
||||
|
||||
```
|
||||
@tomkrouper: the locations table has been restored as locations_2017_07_01_16_11 in the restores database on db-mysql-0482
|
||||
```
|
||||
|
||||
数据被加载到非生产环境的数据库,该数据库可供请求该次恢复的工程师访问。
|
||||
|
||||
我们保留数据的“备份”的最后一个方法是使用<ruby>[延迟副本][38]<rt>delayed replica</rt></ruby>。这与其说是备份,不如说是保护。对于每个生产集群,我们有一个延迟 4 个小时复制的主机。如果运行了一个不该运行的请求,我们可以在 chatops 中运行 `mysql panic` 。这将导致我们所有的延迟副本立即停止复制。这也将给值班 DBA 发送消息。从而我们可以使用延迟副本来验证是否有问题,并快速前进到二进制日志的错误发生之前的位置。然后,我们可以将此数据恢复到主服务器,从而恢复数据到该时间点。
|
||||
|
||||
备份固然好,但如果发生了一些未知或未捕获的错误破坏它们,它们就没有价值了。让脚本恢复备份的好处是它允许我们通过 cron 自动执行备份验证。我们为每个集群设置了一个专用的主机,用于运行最新备份的恢复。这样可以确保备份运行正常,并且我们能够从备份中检索数据。
|
||||
|
||||
根据数据集大小,我们每天运行几次恢复。恢复的服务器被加入到复制工作流,并通过复制保持数据更新。这测试不仅让我们得到了可恢复的备份,而且也让我们得以正确地确定备份的时间点,并且可以从该时间点进一步应用更改。如果恢复过程中出现问题,我们会收到通知。
|
||||
|
||||
我们还追踪恢复所需的时间,所以我们知道在紧急情况下建立新的副本或还原需要多长时间。
|
||||
|
||||
以下是由 Hubot 在我们的机器人聊天室中输出的自动恢复过程。
|
||||
|
||||
**Hubot**
|
||||
|
||||
```
|
||||
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
||||
gh-mysql-backup-restore: db-mysql-0752: Determining backup to restore for cluster 'prodcluster'.
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Removing MySQL files
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-restore
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore file: xtrabackup-notify-2017-07-02_0000.xbstream
|
||||
gh-mysql-backup-restore: db-mysql-0752: Running gh-xtrabackup-prepare
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Update file ownership
|
||||
gh-mysql-backup-restore: db-mysql-0752: Upgrade MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Stopping MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: Backup Host: db-mysql-0034
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting up replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Starting replication
|
||||
gh-mysql-backup-restore: db-mysql-0752: Replication catch-up
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore complete (replication running)
|
||||
gh-mysql-backup-restore: db-mysql-0752: Enabling Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: Disabling maintenance mode
|
||||
gh-mysql-backup-restore: db-mysql-0752: Setting orchestrator downtime
|
||||
gh-mysql-backup-restore: db-mysql-0752: Restore process complete.
|
||||
```
|
||||
|
||||
还有一件我们可以使用备份做的事情是向一组现有的 MySQL 服务器添加一个新的副本。我们初始化一个新的服务器,一旦我们得知它准备就绪,我们就可以开始恢复该特定集群的最新备份。我们有一个脚本,可以运行所有需要手动执行的恢复命令。我们的自动恢复系统基本上使用的是相同的脚本。这简化了系统构建过程,并允许我们在一个启动运行的主机上使用几个对话命令(chatops)来替代一堆手动执行命令。下面显示的是在该对话(chatops)中手动执行的恢复:
|
||||
|
||||
**jessbreckenridge**
|
||||
```
|
||||
.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
||||
```
|
||||
**Hubot**
|
||||
```
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Determining backup to restore for cluster 'mycluster'.
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling maintenance mode
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting orchestrator downtime
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling Puppet
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Removing MySQL files
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-restore
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore file: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Running gh-xtrabackup-prepare
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Update file ownership
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Upgrade MySQL
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Stopping MySQL
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting MySQL
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Setting up replication
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Starting replication
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Backup Host: db-mysql-0201
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication catch-up
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Replication behind by 4589 seconds, waiting 1800 seconds before next check.
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Restore complete (replication running)
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Enabling puppet
|
||||
@jessbreckenridge gh-mysql-backup-restore: db-mysql-0007: Disabling maintenance mode
|
||||
```
|
||||
|
||||
### 故障转移
|
||||
|
||||
[我们使用协调器][40] 来为<ruby>主服务器<rt>master</rt></ruby>和<ruby>中间服务器<rt>intermediate master</rt></ruby>执行自动化故障切换。我们期望<ruby>协调器<rt>orchestrator</rt></ruby>能够正确检测主服务器故障,指定一个副本进行晋升,在所指定的副本下修复拓扑,完成晋升。我们预期 VIP(虚拟 IP)、连接池可以相应地进行变化、客户端进行重连、puppet 在晋升后的主服务器上运行基本组件等等。故障转移是一项复杂的任务,涉及到我们基础架构的许多方面。
|
||||
|
||||
为了建立对我们的故障转移的信赖,我们建立了一个_类生产环境_的测试集群,并且我们不断地崩溃它来观察故障转移情况。
|
||||
|
||||
这个_类生产环境_的测试集群是一套复制环境,与我们的生产集群的各个方面都相同:硬件类型、操作系统、MySQL 版本、网络环境、VIP、puppet 配置、[haproxy 设置][41] 等。与生产集群唯一不同的是它不发送/接收生产流量。
|
||||
|
||||
我们在测试集群上模拟写入负载,同时避免复制滞后。写入负载不会太大,但是有一些有意地写入相同数据集的竞争请求。这在正常情况下并不是很有用,但是事实证明这在故障转移中是有用的,我们将会稍后简要描述它。
|
||||
|
||||
我们的测试集群有来自三个数据中心的典型的服务器。我们希望故障转移能够从同一个数据中心内晋升替代副本。我们希望在这样的限制下尽可能多地恢复副本。我们要求尽可能地实现这两者。协调器对拓扑结构没有<ruby>先验假定<rt>prior assumption</rt></ruby>;它必须依据崩溃时的状态作出反应。
|
||||
|
||||
然而,我们有兴趣创建各种复杂而多变的故障恢复场景。我们的故障转移测试脚本为故障转移提供了基础:
|
||||
|
||||
* 它能够识别现有的主服务器
|
||||
* 它能够重构拓扑结构,来代表主服务器下的所有的三个数据中心。不同的数据中心具有不同的网络延迟,并且预期会在不同的时间对主机崩溃做出反应。
|
||||
* 能够选择崩溃方式。可以选择干掉主服务器(`kill -9`)或网络隔离(比较好的方式: `iptables -j REJECT` 或无响应的方式: `iptables -j DROP`)方式。
|
||||
|
||||
脚本通过选择的方法使主机崩溃,并等待协调器可靠地检测到崩溃然后执行故障转移。虽然我们期望检测和晋升在 30 秒钟内完成,但脚本会稍微放宽这一期望,并在查找故障转移结果之前休眠一段指定的时间。然后它将检查:
|
||||
|
||||
* 一个新的(不同的)主服务器是否到位
|
||||
* 集群中有足够的副本
|
||||
* 主服务器是可写的
|
||||
* 对主服务器的写入在副本上可见
|
||||
* 内部服务发现项已更新(如预期般识别到新的主服务器;移除旧的主服务器)
|
||||
* 其他内部检查
|
||||
|
||||
这些测试可以证实故障转移是成功的,不仅是 MySQL 级别的,而是在更大的基础设施范围内成功的。VIP 被赋予;特定的服务已经启动;信息到达了应该去的地方。
|
||||
|
||||
该脚本进一步继续恢复那个失败的服务器:
|
||||
|
||||
* 从备份恢复它,从而隐含地测试了我们的备份/恢复过程
|
||||
* 验证服务器配置是否符合预期(该服务器不再认为其是主服务器)
|
||||
* 将其加入到复制集群,期望找到在主服务器上写入的数据
|
||||
|
||||
看一下以下可视化的计划的故障转移测试:从运行良好的群集,到在某些副本上发现问题,诊断主服务器(`7136`)是否死机,选择一个服务器(`a79d`)来晋升,重构该服务器下的拓扑,晋升它(故障切换成功),恢复失败的(原)主服务器并将其放回群集。
|
||||
|
||||
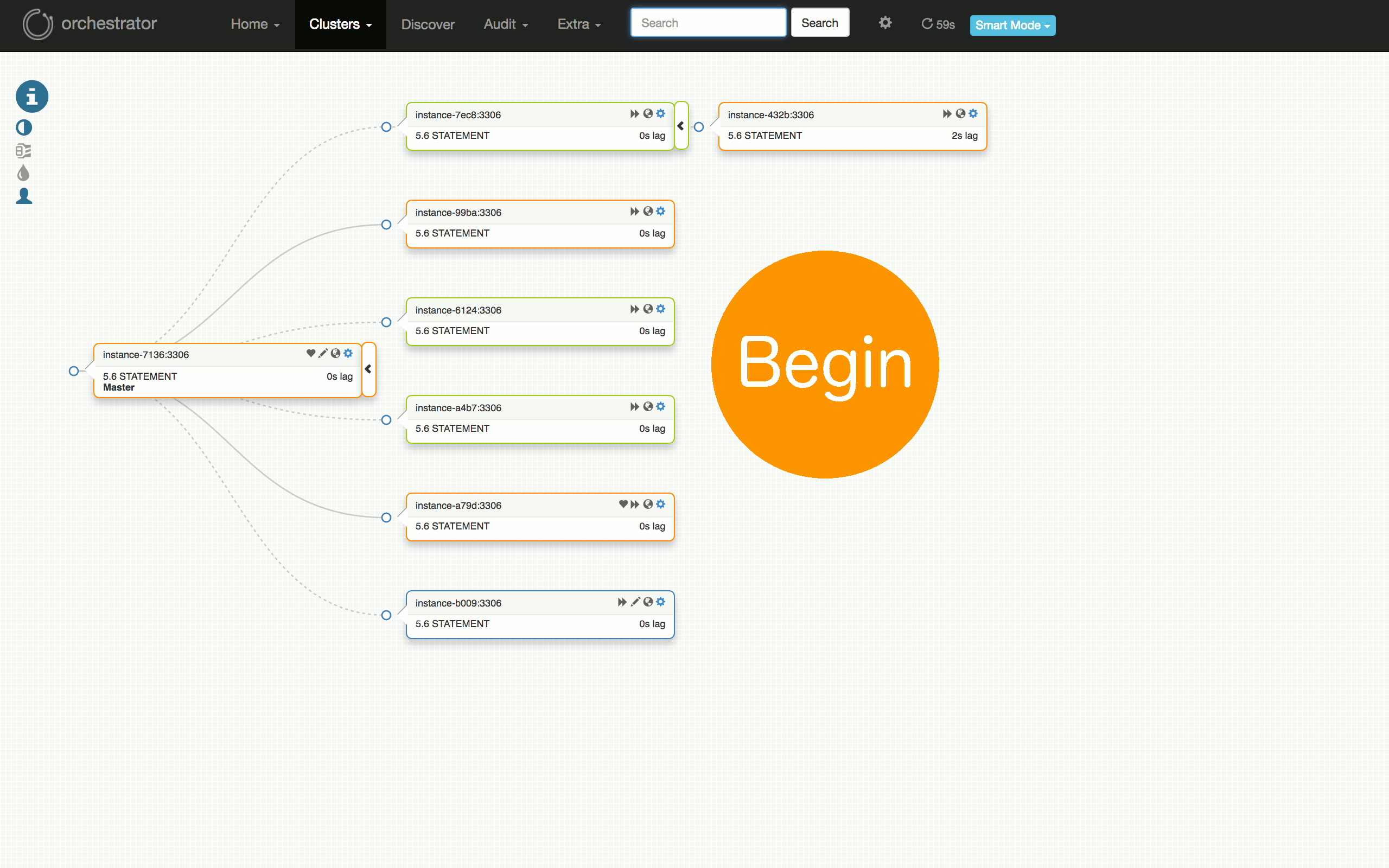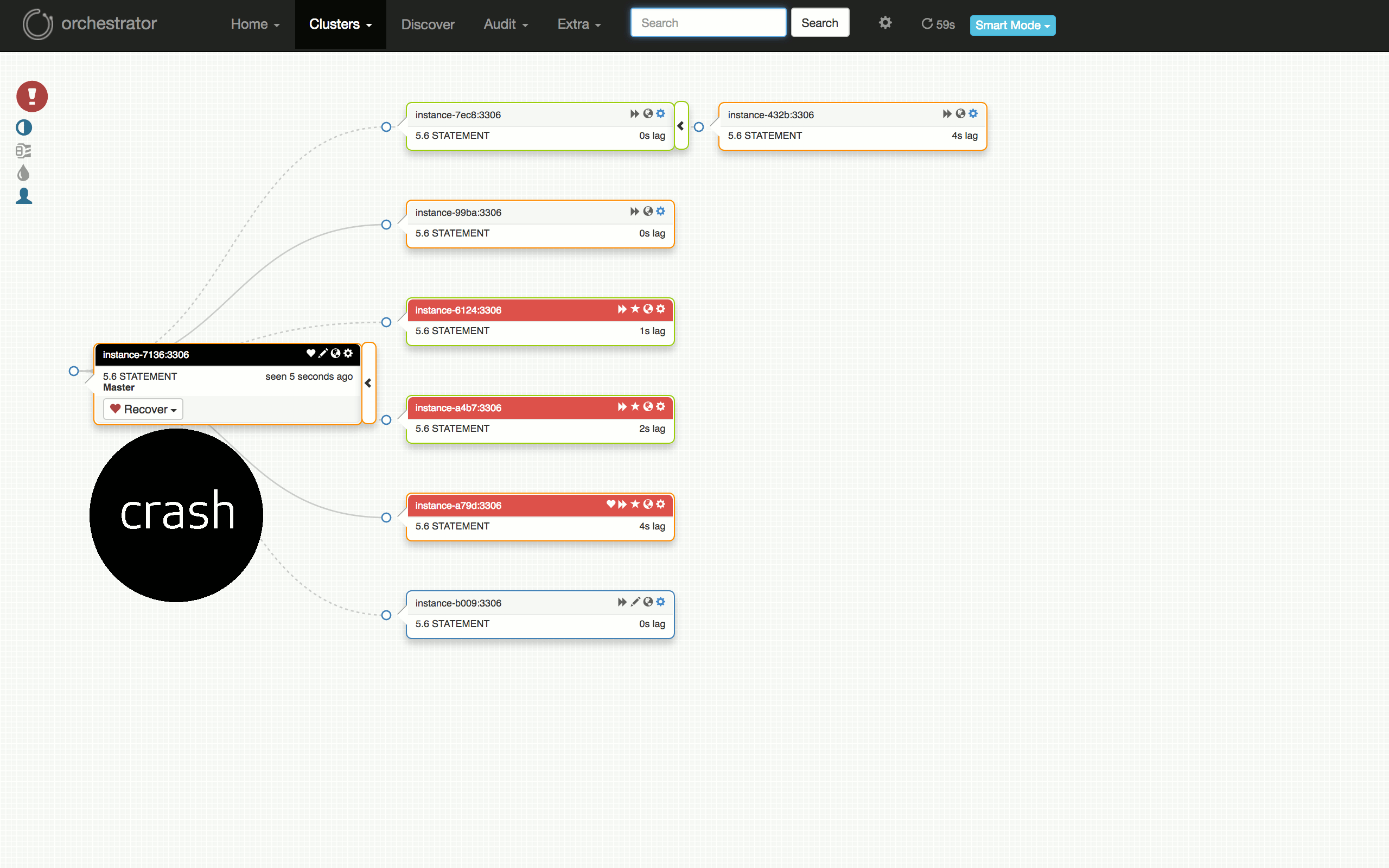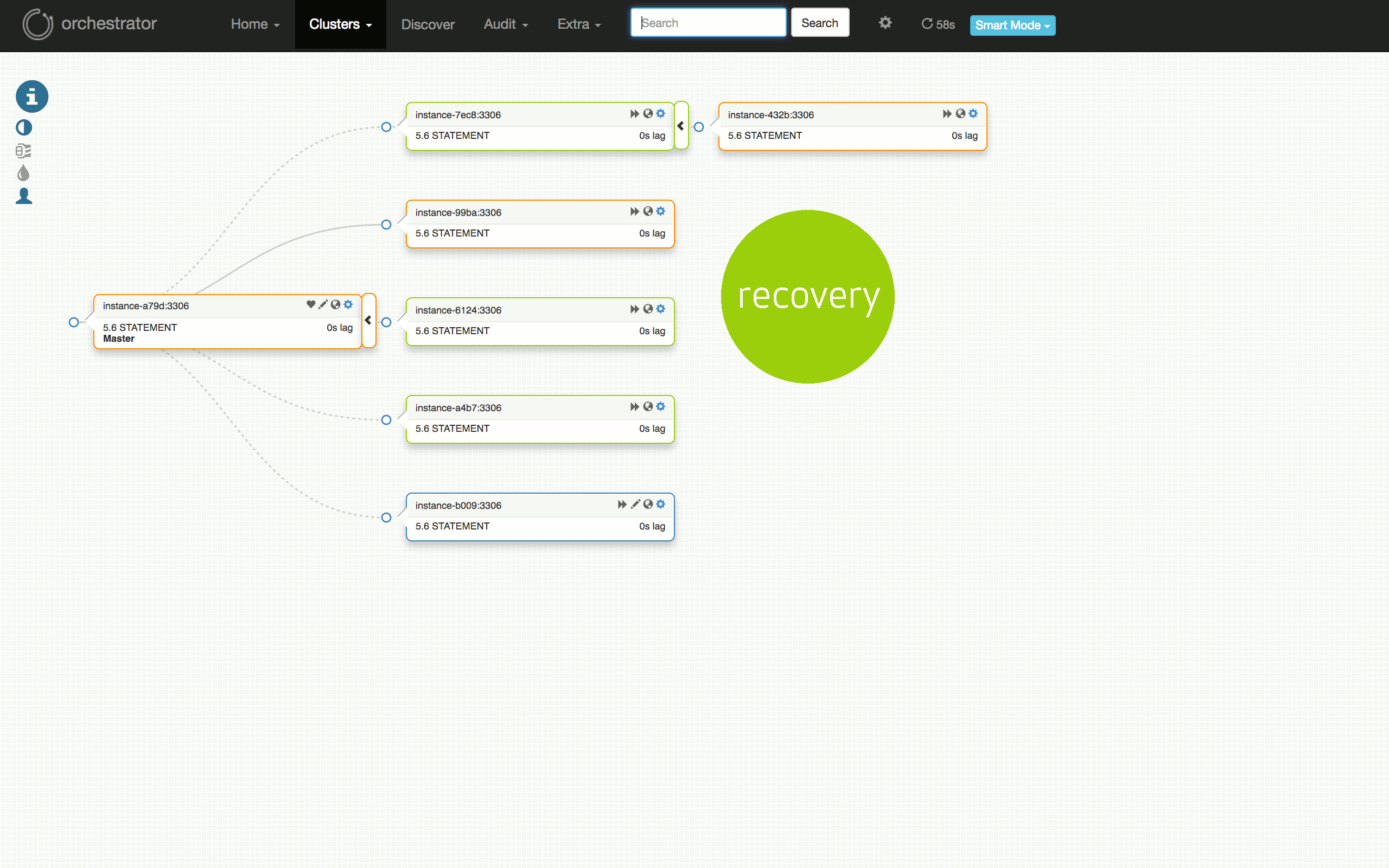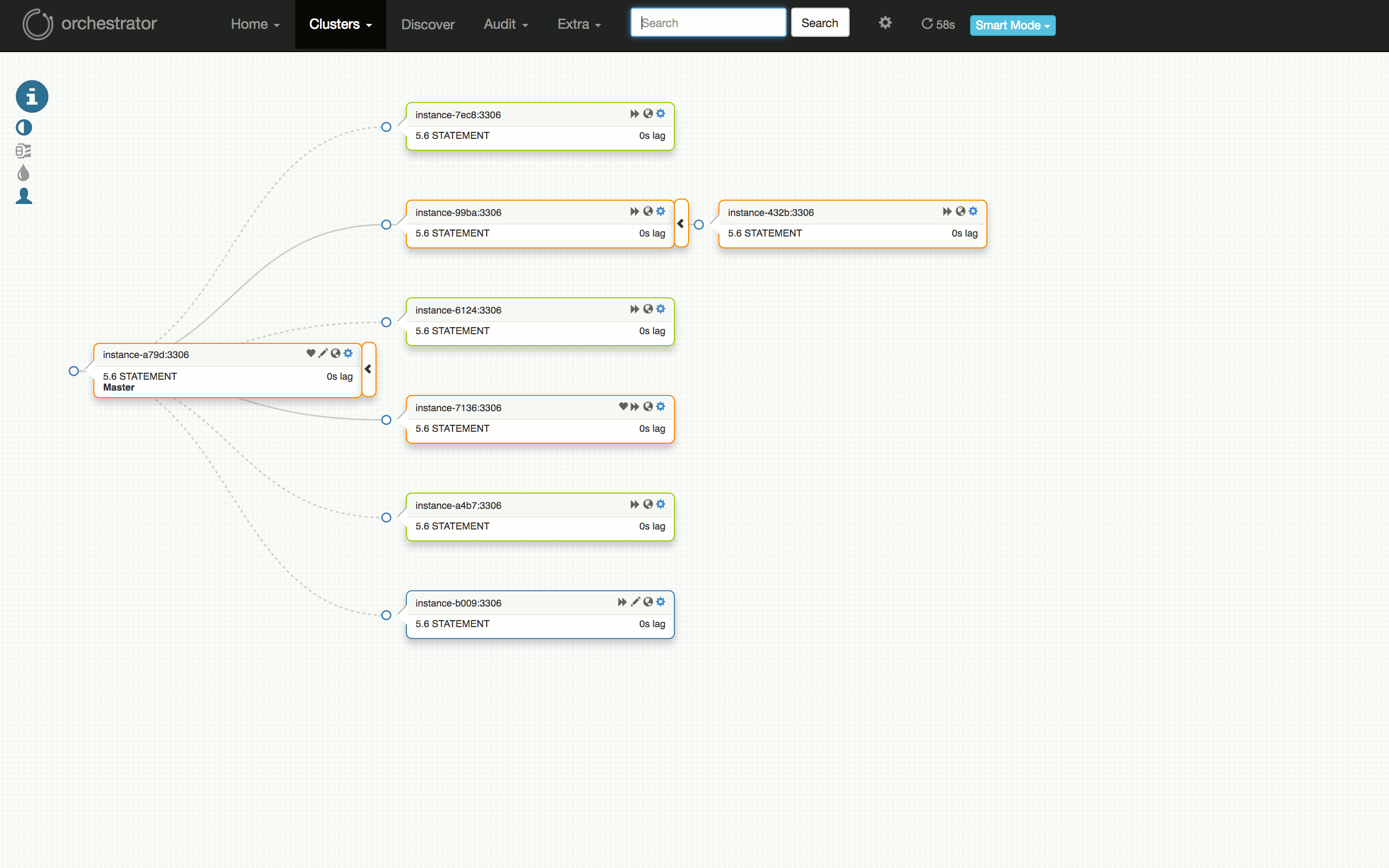
|
||||
|
||||
#### 测试失败怎么样?
|
||||
|
||||
我们的测试脚本使用了一种“停止世界”的方法。任何故障切换组件中的单个故障都将导致整个测试失败,因此在有人解决该问题之前,无法进行任何进一步的自动化测试。我们会得到警报,并检查状态和日志进行处理。
|
||||
|
||||
脚本将各种情况下失败,如不可接受的检测或故障转移时间;备份/还原出现问题;失去太多服务器;在故障切换后的意外配置等等。
|
||||
|
||||
我们需要确保协调器正确地连接服务器。这是竞争性写入负载有用的地方:如果设置不正确,复制很容易中断。我们会得到 `DUPLICATE KEY` 或其他错误提示出错。
|
||||
|
||||
这是特别重要的,因此我们改进协调器并引入新的行为,以允许我们在安全的环境中测试这些变化。
|
||||
|
||||
#### 出现:混乱测试
|
||||
|
||||
上面所示的测试程序将捕获(并已经捕获)我们基础设施许多部分的问题。这些够了吗?
|
||||
|
||||
在生产环境中总是有其他的东西。有些特定测试方法不适用于我们的生产集群。它们不具有相同的流量和流量方式,也不具有完全相同的服务器集。故障类型可能有所不同。
|
||||
|
||||
我们正在为我们的生产集群设计混乱测试。 混乱测试将会在我们的生产中,但是按照预期的时间表和充分控制的方式来逐个破坏我们的部分生产环境。 混乱测试在恢复机制中引入更高层次的信赖,并影响(因此测试)我们的基础设施和应用程序的更大部分。
|
||||
|
||||
这是微妙的工作:当我们承认需要混乱测试时,我们也希望可以避免对我们的服务造成不必要的影响。不同的测试将在风险级别和影响方面有所不同,我们将努力确保我们的服务的可用性。
|
||||
|
||||
### 模式迁移
|
||||
|
||||
[我们使用 gh-ost][43]来运行实时<ruby>模式迁移<rt>schema migration</rt></ruby>。gh-ost 是稳定的,但也处于活跃开发中,重大新功能正在不断开发和计划中。
|
||||
|
||||
gh-ost 通过将数据复制到 ghost 表来迁移,将由二进制日志拦截的进一步更改应用到 ghost 表中,就如其正在写入原始表。然后它将 ghost 表交换代替原始表。迁移完成时,GitHub 继续使用由 gh-ost 生成和填充的表。
|
||||
|
||||
在这个时候,几乎所有的 GitHub 的 MySQL 数据都被 gh-ost 重新创建,其中大部分重新创建多次。我们必须高度信赖 gh-ost,让它一遍遍地操弄我们的数据,即使它还处于活跃开发中。下面是我们如何获得这种信赖的。
|
||||
|
||||
gh-ost 提供生产环境测试能力。它支持在副本上运行迁移,其方式与在主服务器上运行的方式大致相同: gh-ost 将连接到副本,并将其视为主服务器。它将采用与实际主机迁移相同的方式解析其二进制日志。但是,它将复制行并将二进制日志事件应用于副本,并避免对主服务器进行写入。
|
||||
|
||||
我们在生产环境中给 gh-ost 提供专用的副本。这些副本并不为生产环境提供服务。每个这样的副本将检索生产表的当前列表,并以随机顺序对其进行迭代。一个接一个地选择一个表并在该表上执行复制迁移。迁移实际上并不修改表结构,而是运行一个微不足道的 `ENGINE=InnoDB` 更改。该测试运行迁移时,如果表正在生产环境中使用,会复制实际的生产数据,并接受二进制日志之外的真实的生产环境流量。
|
||||
|
||||
这些迁移可以被审计。以下是我们如何从对话中(chatops)检查运行中的测试状态:
|
||||
|
||||
**ggunson**
|
||||
|
||||
```
|
||||
.migration test-status
|
||||
```
|
||||
|
||||
**Hubot**
|
||||
|
||||
```
|
||||
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
||||
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
||||
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
||||
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
||||
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
||||
# panic-flag-file: /tmp/ghost-test-panic.flag
|
||||
# Serving on unix socket: /tmp/gh-ost.test.sock
|
||||
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
||||
```
|
||||
|
||||
当测试迁移完成表数据的复制时,它将停止复制并执行切换,使用 ghost 表替换原始表,然后交换回来。我们对实际替换数据并不感兴趣。相反,我们将留下原始的表和 ghost 表,它们应该是相同的。我们通过校验两个表的整个表数据来验证。
|
||||
|
||||
测试能以下列方式完成:
|
||||
|
||||
* _成功_ :一切顺利,校验和相同。我们期待看到这一结果。
|
||||
* _失败_ :执行问题。这可能偶尔发生,因为迁移进程被杀死、复制问题等,并且通常与 gh-ost 自身无关。
|
||||
* _校验失败_ :表数据不一致。对于被测试的分支,这个需要修复。对于正在进行的 master 分支测试,这意味着立即阻止生产迁移。我们不会遇到后者。
|
||||
|
||||
测试结果经过审核,发送到机器人聊天室,作为事件发送到我们的度量系统。下图中的每条垂直线代表成功的迁移测试:
|
||||
|
||||
|
||||
|
||||
这些测试不断运行。如果发生故障,我们会收到通知。当然,我们可以随时访问机器人聊天室(chatops),了解发生了什么。
|
||||
|
||||
#### 测试新版本
|
||||
|
||||
我们不断改进 gh-ost。我们的开发流程基于 git 分支,然后我们通过[拉取请求(PR)][44]来提供合并。
|
||||
|
||||
提交的 gh-ost 拉取请求(PR)通过持续集成(CI)进行基本的编译和单元测试。一旦通过,该 PR 在技术上就有资格合并,但更好的是它[有资格通过 Heaven 进行部署][45]。作为我们基础架构中的敏感组件,在其进入 master 分支前,我们会小心部署分支进行密集测试。
|
||||
|
||||
**shlomi-noach**
|
||||
|
||||
```
|
||||
.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
||||
```
|
||||
|
||||
**Hubot**
|
||||
```
|
||||
@shlomi-noach is deploying gh-ost/fix-reappearing-throttled-reasons (baee4f6) to production (ghost-db-mysql-0007).
|
||||
@shlomi-noach's production deployment of gh-ost/fix-reappearing-throttled-reasons (baee4f6) is done! (2s)
|
||||
@shlomi-noach, make sure you watch for exceptions in haystack
|
||||
```
|
||||
**jonahberquist**
|
||||
```
|
||||
.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
||||
```
|
||||
**Hubot**
|
||||
```
|
||||
@jonahberquist is deploying gh-ost/interactive-command-question (be1ab17) to production (ghost-db-mysql-0012).
|
||||
@jonahberquist's production deployment of gh-ost/interactive-command-question (be1ab17) is done! (2s)
|
||||
@jonahberquist, make sure you watch for exceptions in haystack
|
||||
```
|
||||
**shlomi-noach**
|
||||
```
|
||||
.wcid gh-ost
|
||||
```
|
||||
**Hubot**
|
||||
```
|
||||
shlomi-noach testing fix-reappearing-throttled-reasons 41 seconds ago: ghost-db-mysql-0007
|
||||
jonahberquist testing interactive-command-question 7 seconds ago: ghost-db-mysql-0012
|
||||
|
||||
Nobody is in the queue.
|
||||
```
|
||||
|
||||
一些 PR 很小,不影响数据本身。对状态消息,交互式命令等的更改对 gh-ost 应用程序的影响较小。而其他的 PR 对迁移逻辑和操作会造成重大变化,我们将严格测试这些,通过我们的生产表车队运行这些,直到其满足了这些改变不会造成数据损坏威胁的程度。
|
||||
|
||||
### 总结
|
||||
|
||||
在整个测试过程中,我们建立对我们的系统的信赖。通过自动化这些测试,在生产环境中,我们得到了一切都按预期工作的反复确认。随着我们继续发展我们的基础设施,我们还通过调整测试来覆盖最新的变化。
|
||||
|
||||
产品总会有令你意想不到的未被测试覆盖的场景。我们对生产环境的测试越多,我们对应用程序的期望越多,基础设施的能力就越强。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
|
||||
作者:[tomkrouper][a], [Shlomi Noach][b]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/tomkrouper
|
||||
[b]:https://github.com/shlomi-noach
|
||||
[1]:https://github.com/tomkrouper
|
||||
[2]:https://github.com/jessbreckenridge
|
||||
[3]:https://github.com/jessbreckenridge
|
||||
[4]:https://github.com/jessbreckenridge
|
||||
[5]:https://github.com/jessbreckenridge
|
||||
[6]:https://github.com/jessbreckenridge
|
||||
[7]:https://github.com/jessbreckenridge
|
||||
[8]:https://github.com/jessbreckenridge
|
||||
[9]:https://github.com/jessbreckenridge
|
||||
[10]:https://github.com/jessbreckenridge
|
||||
[11]:https://github.com/jessbreckenridge
|
||||
[12]:https://github.com/jessbreckenridge
|
||||
[13]:https://github.com/jessbreckenridge
|
||||
[14]:https://github.com/jessbreckenridge
|
||||
[15]:https://github.com/jessbreckenridge
|
||||
[16]:https://github.com/jessbreckenridge
|
||||
[17]:https://github.com/jessbreckenridge
|
||||
[18]:https://github.com/jessbreckenridge
|
||||
[19]:https://github.com/jessbreckenridge
|
||||
[20]:https://github.com/jessbreckenridge
|
||||
[21]:https://github.com/jessbreckenridge
|
||||
[22]:https://github.com/jessbreckenridge
|
||||
[23]:https://github.com/jessbreckenridge
|
||||
[24]:https://github.com/jessbreckenridge
|
||||
[25]:https://github.com/shlomi-noach
|
||||
[26]:https://github.com/shlomi-noach
|
||||
[27]:https://github.com/shlomi-noach
|
||||
[28]:https://github.com/jonahberquist
|
||||
[29]:https://github.com/jonahberquist
|
||||
[30]:https://github.com/jonahberquist
|
||||
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
[32]:https://github.com/tomkrouper
|
||||
[33]:https://github.com/tomkrouper
|
||||
[34]:https://github.com/shlomi-noach
|
||||
[35]:https://github.com/shlomi-noach
|
||||
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
||||
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
||||
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
||||
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
||||
[40]:http://githubengineering.com/orchestrator-github/
|
||||
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
||||
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
||||
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
||||
[44]:https://github.com/github/gh-ost/pulls
|
||||
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
||||
@ -1,118 +1,79 @@
|
||||
开发一个 Linux 调试器(九):处理变量
|
||||
============================================================
|
||||
|
||||
变量是偷偷摸摸的。有时,它们会很高兴地呆在寄存器中,但是一转头就会跑到堆栈中。为了优化,编译器可能会完全将它们从窗口中抛出。无论变量在内存中的移动频率如何,我们都需要一些方法在调试器中跟踪和操作它们。这篇文章将会教你如何处理调试器中的变量,并使用 `libelfin` 演示一个简单的实现。
|
||||
|
||||
* * *
|
||||
变量是偷偷摸摸的。有时,它们会很高兴地呆在寄存器中,但是一转头就会跑到堆栈中。为了优化,编译器可能会完全将它们从窗口中抛出。无论变量在内存中的如何移动,我们都需要一些方法在调试器中跟踪和操作它们。这篇文章将会教你如何处理调试器中的变量,并使用 `libelfin` 演示一个简单的实现。
|
||||
|
||||
### 系列文章索引
|
||||
|
||||
1. [设置][1]
|
||||
|
||||
1. [准备环境][1]
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [ELF 和 DWARF][4]
|
||||
|
||||
5. [源和信号][5]
|
||||
|
||||
6. [源码级单步调试][6]
|
||||
|
||||
5. [源码和信号][5]
|
||||
6. [源码级逐步执行][6]
|
||||
7. [源码级断点][7]
|
||||
|
||||
8. [堆栈展开][8]
|
||||
|
||||
9. [处理变量][9]
|
||||
|
||||
10. [高级话题][10]
|
||||
|
||||
* * *
|
||||
在开始之前,请确保你使用的 `libelfin` 版本是[我分支上的 `fbreg`][11]。这包含了一些 hack 来支持获取当前堆栈帧的基址并评估位置列表,这些都不是由原生的 `libelfin` 提供的。你可能需要给 GCC 传递 `-gdwarf-2` 参数使其生成兼容的 DWARF 信息。但是在实现之前,我将详细说明 DWARF 5 最新规范中的位置编码方式。如果你想要了解更多信息,那么你可以从[这里][12]获取该标准。
|
||||
|
||||
在开始之前,请确保你使用的 `libelfin` 版本是[我分支上的 `fbreg`][11]。这包含了一些 hack 来支持获取当前堆栈帧的基址并评估位置列表,这些都不是由原生的 `libelfin` 提供的。你可能需要给 GCC 传递 `-gdwarf-2` 参数使其生成兼容的 DWARF 信息。但是在实现之前,我将详细说明 DWARF 5 最新规范中的位置编码方式。如果你想要了解更多信息,那么你可以从[这里][12]获取标准。
|
||||
### DWARF 位置
|
||||
|
||||
### DWARF 未知
|
||||
某一给定时刻的内存中变量的位置使用 `DW_AT_location` 属性编码在 DWARF 信息中。位置描述可以是单个位置描述、复合位置描述或位置列表。
|
||||
|
||||
使用 `DW_AT_location` 属性在 DWARF 信息中编码给定时刻内存中变量的位置。位置描述可以是单个位置描述,复合位置描述或位置列表。
|
||||
* 简单位置描述:描述了对象的一个连续的部分(通常是所有部分)的位置。简单位置描述可以描述可寻址存储器或寄存器中的位置,或缺少位置(具有或不具有已知值)。比如,`DW_OP_fbreg -32`: 一个整个存储的变量 - 从堆栈帧基址开始的32个字节。
|
||||
* 复合位置描述:根据片段描述对象,每个对象可以包含在寄存器的一部分中或存储在与其他片段无关的存储器位置中。比如, `DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2`:前四个字节位于寄存器 3 中,后两个字节位于寄存器 10 中的一个变量。
|
||||
* 位置列表:描述了具有有限生存期或在生存期内更改位置的对象。比如:
|
||||
* `<loclist with 3 entries follows>`
|
||||
* `[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0`
|
||||
* `[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3`
|
||||
* `[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2`
|
||||
* 根据程序计数器的当前值,位置在寄存器之间移动的变量。
|
||||
|
||||
* 简单的位置描述描述对象的一个连续的部分(通常是所有)的位置。简单位置描述可以描述可寻址存储器或寄存器中的位置,或缺少位置(具有或不具有已知值)。
|
||||
* 比如:
|
||||
* `DW_OP_fbreg -32`
|
||||
|
||||
* 一个完全存储的变量 - 从堆栈帧基址开始的32个字节
|
||||
|
||||
* 复合位置描述根据片段描述对象,每个对象可以包含在寄存器的一部分中或存储在与其他片段无关的存储器位置中。
|
||||
* 比如:
|
||||
* `DW_OP_reg3 DW_OP_piece 4 DW_OP_reg10 DW_OP_piece 2`
|
||||
|
||||
* 前四个字节位于寄存器 3 中,后两个字节位于寄存器 10 中的一个变量。
|
||||
|
||||
* 位置列表描述了具有有限周期或在周期内更改位置的对象。
|
||||
* 比如:
|
||||
* `<loclist with 3 entries follows>`
|
||||
* `[ 0]<lowpc=0x2e00><highpc=0x2e19>DW_OP_reg0`
|
||||
|
||||
* `[ 1]<lowpc=0x2e19><highpc=0x2e3f>DW_OP_reg3`
|
||||
|
||||
* `[ 2]<lowpc=0x2ec4><highpc=0x2ec7>DW_OP_reg2`
|
||||
|
||||
* 根据程序计数器的当前值,位置在寄存器之间移动的变量
|
||||
|
||||
根据位置描述的种类,`DW_AT_location` 以三种不同的方式进行编码。`exprloc` 编码简单和复合的位置描述。它们由一个字节长度组成,后跟一个 DWARF 表达式或位置描述。`loclist` 和 `loclistptr` 的编码位置列表。它们在 `.debug_loclists` 部分中提供索引或偏移量,该部分描述了实际的位置列表。
|
||||
根据位置描述的种类,`DW_AT_location` 以三种不同的方式进行编码。`exprloc` 编码简单和复合的位置描述。它们由一个字节长度组成,后跟一个 DWARF 表达式或位置描述。`loclist` 和 `loclistptr` 的编码位置列表,它们在 `.debug_loclists` 部分中提供索引或偏移量,该部分描述了实际的位置列表。
|
||||
|
||||
### DWARF 表达式
|
||||
|
||||
使用 DWARF 表达式计算变量的实际位置。这包括操作堆栈值的一系列操作。有很多 DWARF 操作可用,所以我不会详细解释它们。相反,我会从每一个表达式中给出一些例子,给你一个可用的东西。另外,不要害怕这些; `libelfin` 将为我们处理所有这些复杂性。
|
||||
使用 DWARF 表达式计算变量的实际位置。这包括操作堆栈值的一系列操作。有很多 DWARF 操作可用,所以我不会详细解释它们。相反,我会从每一个表达式中给出一些例子,给你一个可用的东西。另外,不要害怕这些;`libelfin` 将为我们处理所有这些复杂性。
|
||||
|
||||
* 字面编码
|
||||
* `DW_OP_lit0`、`DW_OP_lit1`。。。`DW_OP_lit31`
|
||||
* 将字面值压入堆栈
|
||||
|
||||
* `DW_OP_lit0`、`DW_OP_lit1`……`DW_OP_lit31`
|
||||
* 将字面量压入堆栈
|
||||
* `DW_OP_addr <addr>`
|
||||
* 将地址操作数压入堆栈
|
||||
|
||||
* `DW_OP_constu <unsigned>`
|
||||
* 将无符号值压入堆栈
|
||||
|
||||
* 寄存器值
|
||||
* `DW_OP_fbreg <offset>`
|
||||
* 压入在堆栈帧基址找到的值,偏移给定值
|
||||
|
||||
* `DW_OP_breg0`、`DW_OP_breg1`。。。 `DW_OP_breg31 <offset>`
|
||||
* `DW_OP_breg0`、`DW_OP_breg1`…… `DW_OP_breg31 <offset>`
|
||||
* 将给定寄存器的内容加上给定的偏移量压入堆栈
|
||||
|
||||
* 堆栈操作
|
||||
* `DW_OP_dup`
|
||||
* 复制堆栈顶部的值
|
||||
|
||||
* `DW_OP_deref`
|
||||
* 将堆栈顶部视为内存地址,并将其替换为该地址的内容
|
||||
|
||||
* 算术和逻辑运算
|
||||
* `DW_OP_and`
|
||||
* 弹出堆栈顶部的两个值,并压回它们的逻辑 `AND`
|
||||
|
||||
* `DW_OP_plus`
|
||||
* 与 `DW_OP_and` 相同,但是会添加值
|
||||
|
||||
* 控制流操作
|
||||
* `DW_OP_le`、`DW_OP_eq`、`DW_OP_gt` 等
|
||||
* 弹出前两个值,比较它们,并且如果条件为真,则压入 `1`,否则为 `0`
|
||||
|
||||
* `DW_OP_bra <offset>`
|
||||
* 条件分支:如果堆栈的顶部不是 `0`,则通过 `offset` 在表达式中向后或向后跳过
|
||||
|
||||
* 输入转化
|
||||
* `DW_OP_convert <DIE offset>`
|
||||
* 将堆栈顶部的值转换为不同的类型,它由给定偏移量的 DWARF 信息条目描述
|
||||
|
||||
* 特殊操作
|
||||
* `DW_OP_nop`
|
||||
* 什么都能不做!
|
||||
* 什么都不做!
|
||||
|
||||
### DWARF 类型
|
||||
|
||||
DWARF 的类型表示需要足够强大来为调试器用户提供有用的变量表示。用户经常希望能够在应用程序级别进行调试,而不是在机器级别进行调试,并且他们需要了解他们的变量正在做什么。
|
||||
DWARF 类型的表示需要足够强大来为调试器用户提供有用的变量表示。用户经常希望能够在应用程序级别进行调试,而不是在机器级别进行调试,并且他们需要了解他们的变量正在做什么。
|
||||
|
||||
DWARF 类型与大多数其他调试信息一起编码在 DIE 中。它们可以具有指示其名称、编码、大小、字节等的属性。无数的类型标签可用于表示指针、数组、结构体、typedef 以及 C 或 C++ 程序中可以看到的任何其他内容。
|
||||
|
||||
@ -168,7 +129,7 @@ struct test{
|
||||
|
||||
```
|
||||
|
||||
每个成员都有一个名称,一个类型(它是一个 DIE 偏移量),一个声明文件和行,以及一个字节偏移到该成员所在的结构体中。类型指向下一个。
|
||||
每个成员都有一个名称、一个类型(它是一个 DIE 偏移量)、一个声明文件和行,以及一个指向其成员所在的结构体的字节偏移。其类型指向如下。
|
||||
|
||||
```
|
||||
< 1><0x00000063> DW_TAG_base_type
|
||||
@ -195,11 +156,9 @@ struct test{
|
||||
|
||||
如你所见,我笔记本电脑上的 `int` 是一个 4 字节的有符号整数类型,`float`是一个 4 字节的浮点数。整数数组类型通过指向 `int` 类型作为其元素类型,`sizetype`(可以认为是 `size_t`)作为索引类型,它具有 `2a` 个元素。 `test *` 类型是 `DW_TAG_pointer_type`,它引用 `test` DIE。
|
||||
|
||||
* * *
|
||||
|
||||
### 实现简单的变量读取器
|
||||
|
||||
如上所述,`libelfin` 将处理我们大部分的复杂性。但是,它并没有实现用于表示可变位置的所有不同方法,并且在我们的代码中处理这些将变得非常复杂。因此,我现在选择只支持 `exprloc`。请随意添加对更多类型表达式的支持。如果你真的有勇气,请提交补丁到 `libelfin` 中来帮助完成必要的支持!
|
||||
如上所述,`libelfin` 将为我们处理大部分复杂性。但是,它并没有实现用于表示可变位置的所有方法,并且在我们的代码中处理这些将变得非常复杂。因此,我现在选择只支持 `exprloc`。请根据需要添加对更多类型表达式的支持。如果你真的有勇气,请提交补丁到 `libelfin` 中来帮助完成必要的支持!
|
||||
|
||||
处理变量主要是将不同部分定位在存储器或寄存器中,读取或写入与之前一样。为了简单起见,我只会告诉你如何实现读取。
|
||||
|
||||
@ -305,29 +264,27 @@ void debugger::read_variables() {
|
||||
|
||||
编写一些具有一些变量的小功能,不用优化并带有调试信息编译它,然后查看是否可以读取变量的值。尝试写入存储变量的内存地址,并查看程序改变的行为。
|
||||
|
||||
* * *
|
||||
|
||||
已经有九篇文章了,还剩最后一篇!下一次我会讨论一些你可能会感兴趣的更高级的概念。现在你可以在[这里][13]找到这个帖子的代码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
|
||||
作者:[ Simon Brand][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-break/
|
||||
[8]:https://blog.tartanllama.xyz/writing-a-linux-debugger-unwinding/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8663-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://linux.cn/article-8812-1.html
|
||||
[6]:https://linux.cn/article-8813-1.html
|
||||
[7]:https://linux.cn/article-8890-1.html
|
||||
[8]:https://linux.cn/article-8930-1.html
|
||||
[9]:https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
[11]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
@ -1,95 +1,68 @@
|
||||
开发一个 Linux 调试器(十):高级主题
|
||||
============================================================
|
||||
|
||||
我们终于来到这个系列的最后一篇文章!这一次,我将对调试中的一些更高级的概念进行高层的概述:远程调试、共享库支持、表达式计算和多线程支持。这些想法实现起来比较复杂,所以我不会详细说明如何做,但是如果有的话,我很乐意回答有关这些概念的问题。
|
||||
|
||||
* * *
|
||||
我们终于来到这个系列的最后一篇文章!这一次,我将对调试中的一些更高级的概念进行高层的概述:远程调试、共享库支持、表达式计算和多线程支持。这些想法实现起来比较复杂,所以我不会详细说明如何做,但是如果你有问题的话,我很乐意回答有关这些概念的问题。
|
||||
|
||||
### 系列索引
|
||||
|
||||
1. [准备环境][1]
|
||||
|
||||
2. [断点][2]
|
||||
|
||||
3. [寄存器和内存][3]
|
||||
|
||||
4. [Elves 和 dwarves][4]
|
||||
|
||||
5. [源码和信号][5]
|
||||
|
||||
6. [源码层逐步执行][6]
|
||||
|
||||
7. [源码层断点][7]
|
||||
|
||||
8. [调用栈][8]
|
||||
|
||||
9. [处理变量][9]
|
||||
|
||||
10. [高级主题][10]
|
||||
|
||||
* * *
|
||||
|
||||
### 远程调试
|
||||
|
||||
远程调试对于嵌入式系统或不同环境的调试非常有用。它还在高级调试器操作和与操作系统和硬件的交互之间设置了一个很好的分界线。事实上,像 GDB 和 LLDB 这样的调试器即使在调试本地程序时也可以作为远程调试器运行。一般架构是这样的:
|
||||
远程调试对于嵌入式系统或对不同环境进行调试非常有用。它还在高级调试器操作和与操作系统和硬件的交互之间设置了一个很好的分界线。事实上,像 GDB 和 LLDB 这样的调试器即使在调试本地程序时也可以作为远程调试器运行。一般架构是这样的:
|
||||
|
||||

|
||||
|
||||
调试器是我们通过命令行交互的组件。也许如果你使用的是 IDE,那么顶层中另一个层可以通过_机器接口_与调试器进行通信。在目标机器上(可能与本机一样)有一个 _debug stub_ ,它理论上是一个非常小的操作系统调试库的包装程序,它执行所有的低级调试任务,如在地址上设置断点。我说“在理论上”,因为如今 stub 变得越来越大。例如,我机器上的 LLDB debug stub 大小是 7.6MB。debug stub 通过一些使用特定于操作系统的功能(在我们的例子中是 “ptrace”)和被调试进程以及通过远程协议的调试器通信。
|
||||
调试器是我们通过命令行交互的组件。也许如果你使用的是 IDE,那么在其上有另一个层可以通过_机器接口_与调试器进行通信。在目标机器上(可能与本机一样)有一个<ruby>调试存根<rt>debug stub</rt></ruby> ,理论上它是一个非常小的操作系统调试库的包装程序,它执行所有的低级调试任务,如在地址上设置断点。我说“在理论上”,因为如今调试存根变得越来越大。例如,我机器上的 LLDB 调试存根大小是 7.6MB。调试存根通过使用一些特定于操作系统的功能(在我们的例子中是 `ptrace`)和被调试进程以及通过远程协议的调试器通信。
|
||||
|
||||
最常见的远程调试协议是 GDB 远程协议。这是一种基于文本的数据包格式,用于在调试器和 debug
|
||||
stub 之间传递命令和信息。我不会详细介绍它,但你可以在[这里][11]阅读你想知道的。如果你启动 LLDB 并执行命令 `log enable gdb-remote packets`,那么你将获得通过远程协议发送的所有数据包的跟踪。在 GDB 上,你可以用 `set remotelogfile <file>` 做同样的事情。
|
||||
最常见的远程调试协议是 GDB 远程协议。这是一种基于文本的数据包格式,用于在调试器和调试存根之间传递命令和信息。我不会详细介绍它,但你可以在[这里][11]进一步阅读。如果你启动 LLDB 并执行命令 `log enable gdb-remote packets`,那么你将获得通过远程协议发送的所有数据包的跟踪信息。在 GDB 上,你可以用 `set remotelogfile <file>` 做同样的事情。
|
||||
|
||||
作为一个简单的例子,这是数据包设置断点:
|
||||
作为一个简单的例子,这是设置断点的数据包:
|
||||
|
||||
```
|
||||
$Z0,400570,1#43
|
||||
|
||||
```
|
||||
|
||||
`$` 标记数据包的开始。`Z0` 是插入内存断点的命令。`400570` 和 `1` 是参数,其中前者是设置断点的地址,后者是特定目标的断点类型说明符。最后,`#43` 是校验值,以确保数据没有损坏。
|
||||
|
||||
GDB 远程协议非常易于扩展自定义数据包,这对于实现平台或语言特定的功能非常有用。
|
||||
|
||||
* * *
|
||||
|
||||
### 共享库和动态加载支持
|
||||
|
||||
调试器需要知道调试程序加载了哪些共享库,以便它可以设置断点,获取源代码级别的信息和符号等。除查找被动态链接的库之外,调试器还必须跟踪在运行时通过 `dlopen` 加载的库。为了打到这个目的,动态链接器维护一个 _交会结构体_。该结构体维护共享描述符的链表以及指向每当更新链表时调用的函数的指针。这个结构存储在 ELF 文件的 `.dynamic` 段中,在程序执行之前被初始化。
|
||||
调试器需要知道被调试程序加载了哪些共享库,以便它可以设置断点、获取源代码级别的信息和符号等。除查找被动态链接的库之外,调试器还必须跟踪在运行时通过 `dlopen` 加载的库。为了达到这个目的,动态链接器维护一个 _交汇结构体_。该结构体维护共享库描述符的链表,以及一个指向每当更新链表时调用的函数的指针。这个结构存储在 ELF 文件的 `.dynamic` 段中,在程序执行之前被初始化。
|
||||
|
||||
一个简单的跟踪算法:
|
||||
|
||||
* 追踪程序在 ELF 头中查找程序的入口(或者可以使用存储在 `/proc/<pid>/aux` 中的辅助向量)
|
||||
|
||||
* 追踪程序在 ELF 头中查找程序的入口(或者可以使用存储在 `/proc/<pid>/aux` 中的辅助向量)。
|
||||
* 追踪程序在程序的入口处设置一个断点,并开始执行。
|
||||
|
||||
* 当到达断点时,通过在 ELF 文件中查找 `.dynamic` 的加载地址找到交汇结构体的地址。
|
||||
|
||||
* 检查交汇结构体以获取当前加载的库的列表。
|
||||
|
||||
* 链接器更新函数上设置断点
|
||||
|
||||
* 每当到达断点时,列表都会更新
|
||||
|
||||
* 链接器更新函数上设置断点。
|
||||
* 每当到达断点时,列表都会更新。
|
||||
* 追踪程序无限循环,继续执行程序并等待信号,直到追踪程序信号退出。
|
||||
|
||||
我给这些概念写了一个小例子,你可以在[这里][12]找到。如果有人有兴趣,我可以将来写得更详细一点。
|
||||
|
||||
* * *
|
||||
|
||||
### 表达式计算
|
||||
|
||||
表达式计算是程序的一项功能,允许用户在调试程序时对原始源语言中的表达式进行计算。例如,在 LLDB 或 GDB 中,可以执行 `print foo()` 来调用 `foo` 函数并打印结果。
|
||||
|
||||
根据表达的复杂程度,有几种不同的计算方法。如果表达式只是一个简单的标识符,那么调试器可以查看调试信息,找到变量并打印出该值,就像我们在本系列最后一部分中所做的那样。如果表达式有点复杂,则可能将代码编译成中间表达式 (IR) 并解释来获得结果。例如,对于某些表达式,LLDB 将使用 Clang 将表达式编译为 LLVM IR 并将其解释。如果表达式更复杂,或者需要调用某些函数,那么代码可能需要 JIT 到目标并在被调试者的地址空间中执行。这涉及到调用 `mmap` 来分配一些可执行内存,然后将编译的代码复制到该块并执行。LLDB 通过使用 LLVM 的 JIT 功能来实现。
|
||||
根据表达式的复杂程度,有几种不同的计算方法。如果表达式只是一个简单的标识符,那么调试器可以查看调试信息,找到该变量并打印出该值,就像我们在本系列最后一部分中所做的那样。如果表达式有点复杂,则可能将代码编译成中间表达式 (IR) 并解释来获得结果。例如,对于某些表达式,LLDB 将使用 Clang 将表达式编译为 LLVM IR 并将其解释。如果表达式更复杂,或者需要调用某些函数,那么代码可能需要 JIT 到目标并在被调试者的地址空间中执行。这涉及到调用 `mmap` 来分配一些可执行内存,然后将编译的代码复制到该块并执行。LLDB 通过使用 LLVM 的 JIT 功能来实现。
|
||||
|
||||
如果你想更多地了解 JIT 编译,我强烈推荐[ Eli Bendersky 关于这个主题的文章][13]。
|
||||
|
||||
* * *
|
||||
如果你想更多地了解 JIT 编译,我强烈推荐 [Eli Bendersky 关于这个主题的文章][13]。
|
||||
|
||||
### 多线程调试支持
|
||||
|
||||
本系列展示的调试器仅支持单线程应用程序,但是为了调试大多数真实程序,多线程支持是非常需要的。支持这一点的最简单的方法是跟踪线程创建并解析 procfs 以获取所需的信息。
|
||||
本系列展示的调试器仅支持单线程应用程序,但是为了调试大多数真实程序,多线程支持是非常需要的。支持这一点的最简单的方法是跟踪线程的创建,并解析 procfs 以获取所需的信息。
|
||||
|
||||
Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用 `clone` 系统调用来创建一个新的线程,我们可以用 `ptrace` 跟踪这个系统调用(假设你的内核早于 2.5.46)。为此,你需要在连接到调试器之后设置一些 `ptrace` 选项:
|
||||
|
||||
@ -97,7 +70,7 @@ Linux 线程库称为 `pthreads`。当调用 `pthread_create` 时,库会使用
|
||||
ptrace(PTRACE_SETOPTIONS, m_pid, nullptr, PTRACE_O_TRACECLONE);
|
||||
```
|
||||
|
||||
现在当 `clone` 被调用时,该进程将收到我们的老朋友 `SIGTRAP` 发出信号。对于本系列中的调试器,你可以将一个例子添加到 `handle_sigtrap` 来处理新线程的创建:
|
||||
现在当 `clone` 被调用时,该进程将收到我们的老朋友 `SIGTRAP` 信号。对于本系列中的调试器,你可以将一个例子添加到 `handle_sigtrap` 来处理新线程的创建:
|
||||
|
||||
```
|
||||
case (SIGTRAP | (PTRACE_EVENT_CLONE << 8)):
|
||||
@ -115,32 +88,30 @@ GDB 使用 `libthread_db`,它提供了一堆帮助函数,这样你就不需
|
||||
|
||||
多线程支持中最复杂的部分是调试器中线程状态的建模,特别是如果你希望支持[不间断模式][15]或当你计算中涉及不止一个 CPU 的某种异构调试。
|
||||
|
||||
* * *
|
||||
|
||||
### 最后!
|
||||
|
||||
呼!这个系列花了很长时间才写完,但是我在这个过程中学到了很多东西,我希望它是有帮助的。如果你聊有关调试或本系列中的任何问题,请在 Twitter [@TartanLlama][16]或评论区联系我。如果你有想看到的其他任何调试主题,让我知道我或许会再发其他的文章。
|
||||
呼!这个系列花了很长时间才写完,但是我在这个过程中学到了很多东西,我希望它是有帮助的。如果你有关于调试或本系列中的任何问题,请在 Twitter [@TartanLlama][16]或评论区联系我。如果你有想看到的其他任何调试主题,让我知道我或许会再发其他的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
作者:[Simon Brand][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.twitter.com/TartanLlama
|
||||
[1]:https://blog.tartanllama.xyz/writing-a-linux-debugger-setup/
|
||||
[2]:https://blog.tartanllama.xyz/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://blog.tartanllama.xyz/writing-a-linux-debugger-registers/
|
||||
[4]:https://blog.tartanllama.xyz/writing-a-linux-debugger-elf-dwarf/
|
||||
[5]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-signal/
|
||||
[6]:https://blog.tartanllama.xyz/writing-a-linux-debugger-dwarf-step/
|
||||
[7]:https://blog.tartanllama.xyz/writing-a-linux-debugger-source-break/
|
||||
[8]:https://blog.tartanllama.xyz/writing-a-linux-debugger-unwinding/
|
||||
[9]:https://blog.tartanllama.xyz/writing-a-linux-debugger-variables/
|
||||
[1]:https://linux.cn/article-8626-1.html
|
||||
[2]:https://linux.cn/article-8645-1.html
|
||||
[3]:https://linux.cn/article-8663-1.html
|
||||
[4]:https://linux.cn/article-8719-1.html
|
||||
[5]:https://linux.cn/article-8812-1.html
|
||||
[6]:https://linux.cn/article-8813-1.html
|
||||
[7]:https://linux.cn/article-8890-1.html
|
||||
[8]:https://linux.cn/article-8930-1.html
|
||||
[9]:https://linux.cn/article-8936-1.html
|
||||
[10]:https://blog.tartanllama.xyz/writing-a-linux-debugger-advanced-topics/
|
||||
[11]:https://sourceware.org/gdb/onlinedocs/gdb/Remote-Protocol.html
|
||||
[12]:https://github.com/TartanLlama/dltrace
|
||||
@ -1,4 +1,4 @@
|
||||
论 HTTP 性能,Go 与 .NET Core 谁争雌雄
|
||||
论 HTTP 性能,Go 与 .NET Core 一争雌雄
|
||||
============================================================
|
||||
|
||||

|
||||
@ -9,25 +9,25 @@
|
||||
|
||||
因为是新出的,我不想立马就比较两个不同的东西,所以我耐心等待,想等发布更稳定的版本后再进行。
|
||||
|
||||
本周一,微软[发布 .NET Core 2.0 版本][7],因此,我准备开始。您们认为呢?
|
||||
本周一(8 月 14 日),微软[发布 .NET Core 2.0 版本][7],因此,我准备开始。您们认为呢?
|
||||
|
||||
如前面所提的,我们会比较他们相同的东西,比如应用程序、预期响应及运行时的稳定性,所以我们不会把像对 `JSON` 或者 `XML` 的编码、解码这些烦多的事情加入比较游戏中来,仅仅只会使用简单的文本消息。为了公平起见,我们会分别使用 Go 和 .NET Core 的[ MVC 架构模式][8]。
|
||||
如前面所提的,我们会比较它们相同的东西,比如应用程序、预期响应及运行时的稳定性,所以我们不会把像对 JSON 或者 XML 的编码、解码这些烦多的事情加入比较游戏中来,仅仅只会使用简单的文本消息。为了公平起见,我们会分别使用 Go 和 .NET Core 的 [MVC 架构模式][8]。
|
||||
|
||||
### 先决条件
|
||||
### 参赛选手
|
||||
|
||||
[Go][9] (或者 Golang): 是一种[快速增长][10]的开源编程语言,旨在构建出简单、快捷和稳定可靠的应用软件。
|
||||
[Go][9] (或称 Golang): 是一种[快速增长][10]的开源编程语言,旨在构建出简单、快捷和稳定可靠的应用软件。
|
||||
|
||||
用于支持 Go 语言的 MVC web 框架并不多,还好我们找到了 Iris ,可胜任此工作。
|
||||
|
||||
[Iris][11]: 支持 Go 语言的快速、简单和高效的微型 Web 框架。它为您的下一代网站、API 或分布式应用程序奠定了精美的表现方式和易于使用的基础。
|
||||
[Iris][11]: 支持 Go 语言的快速、简单和高效的微型 Web 框架。它为您的下一代网站、API 或分布式应用程序奠定了精美的表现方式和易于使用的基础。
|
||||
|
||||
[C#][12]: 是一种通用的,面向对象的编程语言。其开发团队由 [Anders Hejlsberg][13] 领导。
|
||||
[C#][12]: 是一种通用的、面向对象的编程语言。其开发团队由 [Anders Hejlsberg][13] 领导。
|
||||
|
||||
[.NET Core][14]: 跨平台,可以在极少时间内开发出高性能的应用程序。
|
||||
[.NET Core][14]: 跨平台,可以在极少时间内开发出高性能的应用程序。
|
||||
|
||||
从 [https://golang.org/dl][15] 下载 Go ,从 [https://www.microsoft.com/net/core][16] 下载 .NET Core。
|
||||
可从 [https://golang.org/dl][15] 下载 Go ,从 [https://www.microsoft.com/net/core][16] 下载 .NET Core。
|
||||
|
||||
在下载和安装好这些软件后,还需要在 Go 端安装 Iris。安装很简单,仅仅只需要打开终端,然后执行如下语句:
|
||||
在下载和安装好这些软件后,还需要为 Go 安装 Iris。安装很简单,仅仅只需要打开终端,然后执行如下语句:
|
||||
|
||||
```
|
||||
go get -u github.com/kataras/iris
|
||||
@ -37,31 +37,27 @@ go get -u github.com/kataras/iris
|
||||
|
||||
#### 硬件
|
||||
|
||||
* 处理器: Intel(R) Core(TM) i7–4710HQ CPU @ 2.50GHz 2.50GHz
|
||||
|
||||
* 内存: 8.00 GB
|
||||
* 处理器: Intel(R) Core(TM) i7–4710HQ CPU @ 2.50GHz 2.50GHz
|
||||
* 内存: 8.00 GB
|
||||
|
||||
#### 软件
|
||||
|
||||
* 操作系统: 微软 Windows [10.0.15063 版本], 电源计划设置为“高性能”
|
||||
|
||||
* HTTP 基准工具: [https://github.com/codesenberg/bombardier][1], 使用最新的 1.1 版本。
|
||||
|
||||
* .NET Core: [https://www.microsoft.com/net/core][2], 使用最新的 2.0 版本。
|
||||
|
||||
* Iris: [https://github.com/kataras/iris][3], 使用基于 [Go 1.8.3][4] 构建的新新 8.3 版本。
|
||||
* 操作系统: 微软 Windows [10.0.15063 版本], 电源计划设置为“高性能”
|
||||
* HTTP 基准工具: [https://github.com/codesenberg/bombardier][1], 使用最新的 1.1 版本。
|
||||
* .NET Core: [https://www.microsoft.com/net/core][2], 使用最新的 2.0 版本。
|
||||
* Iris: [https://github.com/kataras/iris][3], 使用基于 [Go 1.8.3][4] 构建的最新 8.3 版本。
|
||||
|
||||
两个应用程序都通过请求路径 “api/values/{id}” 返回文本“值”。
|
||||
|
||||
.NET Core MVC
|
||||
|
||||
##### .NET Core MVC
|
||||
|
||||

|
||||
|
||||
Logo 由 [Pablo Iglesias][5] 设计。
|
||||
|
||||
可以使用 `dotnet new webapi` 命令创建项目,其 `webapi` 模板会为您生成代码,代码包含 `GET` 请求方法的 `返回“值”`。
|
||||
|
||||
_源代码_
|
||||
源代码:
|
||||
|
||||
```
|
||||
using System;
|
||||
@ -165,8 +161,7 @@ namespace netcore_mvc.Controllers
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
_运行 .NET Core web 服务项目_
|
||||
运行 .NET Core web 服务项目:
|
||||
|
||||
```
|
||||
$ cd netcore-mvc
|
||||
@ -177,7 +172,7 @@ Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_运行和定位 HTTP 基准工具_
|
||||
运行和定位 HTTP 基准工具:
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
@ -193,13 +188,13 @@ Statistics Avg Stdev Max
|
||||
Throughput: 8.91MB/s
|
||||
```
|
||||
|
||||
Iris MVC
|
||||
|
||||
##### Iris MVC
|
||||
|
||||

|
||||
|
||||
Logo 由 [Santosh Anand][6] 设计。
|
||||
|
||||
_源代码_
|
||||
源代码:
|
||||
|
||||
```
|
||||
package main
|
||||
@ -217,7 +212,6 @@ func main() {
|
||||
view raw
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
package controllers
|
||||
|
||||
@ -242,8 +236,7 @@ func (vc *ValuesController) Put() {}
|
||||
func (vc *ValuesController) Delete() {}
|
||||
```
|
||||
|
||||
|
||||
_运行 Go web 服务项目_
|
||||
运行 Go web 服务项目:
|
||||
|
||||
```
|
||||
$ cd iris-mvc
|
||||
@ -252,7 +245,7 @@ Now listening on: http://localhost:5000
|
||||
Application started. Press CTRL+C to shut down.
|
||||
```
|
||||
|
||||
_运行和定位 HTTP 基准工具_
|
||||
运行和定位 HTTP 基准工具:
|
||||
|
||||
```
|
||||
$ bombardier -c 125 -n 5000000 http://localhost:5000/api/values/5
|
||||
@ -275,55 +268,44 @@ Statistics Avg Stdev Max
|
||||
#### 总结
|
||||
|
||||
* 完成 `5000000 个请求`的时间 - 越短越好。
|
||||
|
||||
* 请求次数/每秒 - 越大越好。
|
||||
|
||||
* 等待时间 — 越短越好。
|
||||
|
||||
* 吞吐量 — 越大越好。
|
||||
|
||||
* 内存使用 — 越小越好。
|
||||
|
||||
* LOC (代码行数) — 越少越好。
|
||||
|
||||
.NET Core MVC 应用程序,使用 86 行代码,运行 2 分钟 8 秒,每秒接纳 39311.56 个请求,平均每秒有 3.19ms 等待,最大时到 229.73ms,内存使用大约为 126MB(不包括 dotnet 框架)。
|
||||
.NET Core MVC 应用程序,使用 86 行代码,运行 2 分钟 8 秒,每秒接纳 39311.56 个请求,平均 3.19ms 等待,最大时到 229.73ms,内存使用大约为 126MB(不包括 dotnet 框架)。
|
||||
|
||||
Iris MVC 应用程序,使用 27 行代码,运行 47 秒,每秒接纳 105643.71 个请求,平均每秒有 1.18ms 等待,最大时到 22.01ms,内存使用大约为 12MB。
|
||||
Iris MVC 应用程序,使用 27 行代码,运行 47 秒,每秒接纳 105643.71 个请求,平均 1.18ms 等待,最大时到 22.01ms,内存使用大约为 12MB。
|
||||
|
||||
> 还有另外一个模板的基准,滚动到底部。
|
||||
|
||||
2017 年 8 月 20 号更新
|
||||
**2017 年 8 月 20 号更新**
|
||||
|
||||
[Josh Clark] [24] 和 [Scott Hanselman] [25]在此 [tweet 评论] [26]上指出,.NET Core `Startup.cs` 文件中 `services.AddMvc();` 这行可以替换为 `services.AddMvcCore();`。我听从他们的意见,修改代码,重新运行基准,该文章的 .NET Core 应用程序的基准输出已经修改。
|
||||
|
||||
@topdawgevh @shanselman 他们也在使用 `AddMvc()` 而不是 `AddMvcCore()` ...,难道都不包含中间件?
|
||||
|
||||
@topdawgevh @shanselman 他们也在使用 AddMvc() 而不是 AddMvcCore() ...,难道都不包含中间件?
|
||||
|
||||
— @clarkis117
|
||||
— @clarkis117
|
||||
|
||||
@clarkis117 @topdawgevh Cool @MakisMaropoulos @ben_a_adams @davidfowl 我们来看看。认真学习下怎么使用更简单的性能默认值。
|
||||
|
||||
— @shanselman
|
||||
— @shanselman
|
||||
|
||||
@shanselman @clarkis117 @topdawgevh @ben_a_adams @davidfowl @shanselman @ben_a_adams @davidfowl 谢谢您们的反馈意见。我已经修改,更新了结果,没什么不同。对其它的建议,我非常欢迎。
|
||||
|
||||
— @MakisMaropoulos
|
||||
|
||||
>它有点稍微的不同但相差不大(从 8.61MB/s 到 8.91MB/s)
|
||||
|
||||
— @MakisMaropoulos
|
||||
|
||||
> 它有点稍微的不同但相差不大(从 8.61MB/s 到 8.91MB/s)
|
||||
|
||||
想要了解跟 `services.AddMvc()` 标准比较结果的,可以点击[这儿][27]。
|
||||
|
||||
* * *
|
||||
|
||||
### 想再多了解点儿吗?
|
||||
|
||||
我们再制定一个基准,产生 `1000000 次请求`,这次会通过视图引擎由模板生成 `HTML` 页面。
|
||||
|
||||
#### .NET Core MVC 使用的模板
|
||||
|
||||
|
||||
```
|
||||
using System;
|
||||
|
||||
@ -477,8 +459,7 @@ https://github.com/kataras/iris/tree/master/_benchmarks/netcore-mvc-templates
|
||||
```
|
||||
|
||||
|
||||
_运行 .NET Core 服务项目_
|
||||
|
||||
运行 .NET Core 服务项目:
|
||||
|
||||
```
|
||||
$ cd netcore-mvc-templates
|
||||
@ -489,7 +470,7 @@ Now listening on: http://localhost:5000
|
||||
Application started. Press Ctrl+C to shut down.
|
||||
```
|
||||
|
||||
_运行和定位 HTTP 基准工具_
|
||||
运行 HTTP 基准工具:
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
@ -620,10 +601,7 @@ https://github.com/kataras/iris/tree/master/_benchmarks/iris-mvc-templates
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
_运行 Go 服务项目_
|
||||
|
||||
运行 Go 服务项目:
|
||||
|
||||
```
|
||||
$ cd iris-mvc-templates
|
||||
@ -633,7 +611,7 @@ Application started. Press CTRL+C to shut down.
|
||||
|
||||
```
|
||||
|
||||
_运行和定位 HTTP 基准工具_
|
||||
运行 HTTP 基准工具:
|
||||
|
||||
```
|
||||
Bombarding http://localhost:5000 with 1000000 requests using 125 connections
|
||||
@ -648,22 +626,17 @@ Statistics Avg Stdev Max
|
||||
Throughput: 192.51MB/s
|
||||
```
|
||||
|
||||
总结
|
||||
#### 总结
|
||||
|
||||
* 完成 `1000000 个请求`的时间 - 越短越好。
|
||||
|
||||
* 请求次数/每秒 - 越大越好。
|
||||
|
||||
* 等待时间 — 越短越好。
|
||||
|
||||
* 内存使用 — 越小越好。
|
||||
|
||||
* 吞吐量 — 越大越好。
|
||||
|
||||
.NET Core MVC 模板应用程序,运行 1 分钟 20 秒,每秒接纳 11738.60 个请求,同时每秒生成 89.03M 页面,平均 10.10ms 等待,最大时到 1.97s,内存使用大约为 193MB(不包括 dotnet 框架)。
|
||||
|
||||
.NET Core MVC 模板应用程序,运行 1 分钟 20 秒,每秒接纳 11738.60 个请求,同时每秒生成 89.03M 页面,平均每秒有 10.10ms 等待,最大时到 1.97s,内存使用大约为 193MB(不包括 dotnet 框架)。
|
||||
|
||||
Iris MVC 模板应用程序,运行 37 秒,每秒接纳 26656.76 个请求,同时每秒生成 192.51M 页面,平均每秒有 1.18ms 等待,最大时到 22.52ms,内存使用大约为 17MB。
|
||||
Iris MVC 模板应用程序,运行 37 秒,每秒接纳 26656.76 个请求,同时每秒生成 192.51M 页面,平均 1.18ms 等待,最大时到 22.52ms,内存使用大约为 17MB。
|
||||
|
||||
### 接下来呢?
|
||||
|
||||
@ -673,10 +646,6 @@ Iris MVC 模板应用程序,运行 37 秒,每秒接纳 26656.76 个请求,
|
||||
|
||||
我也需要亲自感谢下 [dev.to][34] 团队,感谢把我的这篇文章分享到他们的 Twitter 账户。
|
||||
|
||||
论 HTTP 性能,Go 与 .NET Core 谁争雌雄 {作者:@MakisMaropoulos} https://t.co/IXL5LSpnjX
|
||||
|
||||
— @ThePracticalDev
|
||||
|
||||
|
||||
感谢大家真心反馈,玩得开心!
|
||||
|
||||
@ -684,15 +653,15 @@ Iris MVC 模板应用程序,运行 37 秒,每秒接纳 26656.76 个请求,
|
||||
|
||||
很多人联系我,希望看到一个基于 .NET Core 的较低级别 Kestrel 的基准测试文章。
|
||||
|
||||
因此我完成了,请点击下面的链接来了解 Kestrel 和 Iris 之间的性能差异,它还包含一个会话存储管理基准!
|
||||
因此我完成了,请点击下面的[链接][35]来了解 Kestrel 和 Iris 之间的性能差异,它还包含一个会话存储管理基准!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b67b8
|
||||
|
||||
作者:[ Gerasimos Maropoulos][a]
|
||||
作者:[Gerasimos Maropoulos][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -731,3 +700,4 @@ via: https://hackernoon.com/go-vs-net-core-in-terms-of-http-performance-7535a61b
|
||||
[32]:https://github.com/kataras/iris/tree/master/_benchmarks
|
||||
[33]:https://github.com/kataras/iris
|
||||
[34]:https://dev.to/kataras/go-vsnet-core-in-terms-of-http-performance
|
||||
[35]:https://medium.com/@kataras/iris-go-vs-net-core-kestrel-in-terms-of-http-performance-806195dc93d5
|
||||
@ -0,0 +1,75 @@
|
||||
编排工具充分发挥了 Linux 容器技术优势
|
||||
============================================================
|
||||
|
||||
> 一旦公司越过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器
|
||||
|
||||

|
||||
|
||||
需要快速、高效地交付程序的公司 —— 而今天,哪些公司不需要这样做?—— 是那些正在转向 Linux 容器的公司。他们还发现,一旦公司越过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器。
|
||||
|
||||
Linux 容器技术不是新技术,但它随着最初由 Docker 发明的创新性打包格式(现在的 [OCI][3] 格式)以及新应用对持续开发和部署的需求开始变得流行。在 Red Hat 的 2016 年 5 月的 Forrester 研究中,有 48% 的受访者表示已经在开发中使用容器,今年的数字预计将达到 53%。只有五分之一的受访者表示,他们在 2017 年不会在开发过程中利用容器。
|
||||
|
||||
像乐高积木一样,容器镜像可以轻松地重用代码和服务。每个容器镜像就像一个单独的、旨在做好一部分工作的乐高积木。它可能是数据库、数据存储、甚至预订服务或分析服务。通过单独包装每个组件,从而可以在不同的应用中使用。但是,如果没有某种程序定义(即<ruby>指令手册<rt>instruction booklet</rt></ruby>),则难以在不同环境中创建完整应用程序的副本。那就是容器编排的来由。
|
||||
|
||||
|
||||
|
||||
容器编排提供了像乐高系统这样的基础设施 —— 开发人员可以提供如何构建应用程序的简单说明。编排引擎将知道如何运行它。这使得可以轻松创建同一应用程序的多个副本,跨越开发人员电脑、CI/CD 系统,甚至生产数据中心和云提供商环境。
|
||||
|
||||
Linux 容器镜像允许公司在整个运行时环境(操作系统部件)中打包和隔离应用程序的构建块。在此基础上,通过容器编排,可以很容易地定义并运行所有的块,并一起构成完整的应用程序。一旦定义了完整的应用程序,它们就可以在不同的环境(开发、测试、生产等)之间移动,而不会破坏它们,且不改变它们的行为。
|
||||
|
||||
### 仔细调查容器
|
||||
|
||||
很明显,容器是有意义的,越来越多的公司像“对轮胎踹两脚”一样去研究容器。一开始,可能是一个开发人员使用一个容器工作,或是一组开发人员在使用多个容器。在后一种情况下,开发人员可能会随手编写一些代码来处理在容器部署超出单个实例之后快速出现的复杂性。
|
||||
|
||||
这一切都很好,毕竟他们是开发人员 —— 他们已经做到了。但即使在开发人员世界也会变得混乱,而且随手代码模式也没法跟着容器进入 QA 和生产环境下。
|
||||
|
||||
编排工具基本上做了两件事。首先,它们帮助开发人员定义他们的应用程序的表现 —— 一组用来构建应用程序实例的服务 —— 数据库、数据存储、Web 服务等。编排器帮助标准化应用程序的所有部分,在一起运行并彼此通信,我将这称之为标准化程序定义。其次,它们管理一个计算资源集群中启动、停止、升级和运行多个容器的过程,这在运行任何给定应用程序的多个副本时特别有用,例如持续集成 (CI) 和连续交付 (CD)。
|
||||
|
||||
想像一个公寓楼。居住在那里的每个人都有相同的街道地址,但每个人都有一个数字或字母或两者的组合,专门用来识别他或她。这是必要的,就像将正确的邮件和包裹交付给合适的租户一样。
|
||||
|
||||
同样,在容器中,只要你有两个容器或两个要运行这些容器的主机,你必须跟踪开发人员测试数据库连接或用户连接到正在运行的服务的位置。容器编排工具实质上有助于管理跨多个主机的容器的后勤。它们将生命周期管理功能扩展到由多个容器组成的完整应用程序,部署在一组机器上,从而允许用户将整个集群视为单个部署目标。
|
||||
|
||||
这真的很简单,又很复杂。编排工具提供了许多功能,从配置容器到识别和重新调度故障容器,将容器暴露给集群外的系统和服务,根据需要添加和删除容器等等。
|
||||
|
||||
虽然容器技术已经存在了一段时间,但容器编排工具只出现了几年。编排工具是 Google 从内部的高性能计算(HPC)和应用程序管理中吸取的经验教训开发的。在本质上,其要解决的就是在一堆服务器上运行一堆东西(批处理作业、服务等)。从那时起,编排工具已经进化到可以使公司能够战略性地利用容器。
|
||||
|
||||
一旦你的公司确定需要容器编排,下一步就是确定哪个平台对于业务是最有意义的。在评估容器编排时,请仔细查看(尤其):
|
||||
|
||||
* 应用程序定义语言
|
||||
* 现有能力集
|
||||
* 添加新功能的速度
|
||||
* 开源还是专有
|
||||
* 社区健康度(成员的积极性/高效,成员提交的质量/数量,贡献者的个人和公司的多样性)
|
||||
* 强化努力
|
||||
* 参考架构
|
||||
* 认证
|
||||
* 产品化过程
|
||||
|
||||
有三个主要的容器编排平台,它们似乎领先于其他,每个都有自己的历史。
|
||||
|
||||
1. **Docker Swarm:** Swarm 是容器典范 Docker 的附件。Swarm 允许用户建立并管理 Docker 节点的集群为单个虚拟系统。Swarm 似乎正在成为一个单一供应商的项目。
|
||||
2. **Mesos:** Mesos 是从 Apache 和高性能计算中成长起来的,因此是一个优秀的调度员。Mesos 的技术也非常先进,虽然与其他相比似乎没有发展速度或投资优势。
|
||||
3. **Kubernetes:** 由 Google 开发,由其内部编排工具 Borg 经验而来,Kubernetes 被广泛使用,并拥有强大的社区。其实这是 GitHub 上排名第一的项目。Mesos 目前可能比 Kubernetes 略有技术优势,但是 Kubernetes 是一个快速发展的项目,这也是为了长期技术上的收益而进行的架构投资。在不久的将来,在技术能力上应该能赶超 Mesos。
|
||||
|
||||
### 编排的未来
|
||||
|
||||
展望未来,企业们可以期待看到编排工具在应用程序和服务为中心的方向上发展。因为在现实中,如今快速应用程序开发实际上是在快速地利用服务、代码和数据的组合。无论这些服务是开源的,还是由内部团队部署的抑或从云提供商处购买的,未来将会是两者的混合。由于今天的编排器也在处理应用程序定义方面的挑战,所以期望看到它们越来越多地应对外部服务的整合。
|
||||
|
||||
此时此刻,想要充分利用容器的公司必须利用容器编排。
|
||||
|
||||
(题图:Thinkstock)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3205304/containers/orchestration-tools-enable-companies-to-fully-exploit-linux-container-technology.html
|
||||
|
||||
作者:[Scott McCarty][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Scott-McCarty/
|
||||
[1]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||
[2]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||
[3]:https://github.com/opencontainers/image-spec
|
||||
@ -1,120 +1,112 @@
|
||||
从 Node 到 Go:深层比较
|
||||
从 Node 到 Go:一个粗略的比较
|
||||
============================================================
|
||||
|
||||
在 XO 公司,我们最初使用 Node 和 Ruby 构建互联服务系统。我们享受 Node 带来的明显性能优势,以及可以访问已有的大型软件包仓库。我们也可以轻松地在公司内部发布并复用已有的插件和模块。极大地提高了开发效率,使得我们可以快速编写可拓展和可靠的应用。庞大的 Node 社区使我们的工程师向开源软件贡献更加容易。(比如 [BunnyBus][9] 和 [Felicity][10])
|
||||
在 XO 公司,我们最初使用 Node 和 Ruby 构建相互连接的服务系统。我们享受 Node 带来的明显性能优势,以及可以访问已有的大型软件包仓库。我们也可以轻松地在公司内部发布并复用已有的插件和模块。极大地提高了开发效率,使得我们可以快速编写出可拓展的和可靠的应用。而且,庞大的 Node 社区使我们的工程师向开源软件贡献更加容易(比如 [BunnyBus][9] 和 [Felicity][10])。
|
||||
|
||||
虽然我在大学时期和刚刚工作的一些时间在使用更严格的编译语言,比如 C++ 和 C#,后来我开始使用 JavaScript。我很喜欢它的自由和灵活,但是我最近开始怀念静态和结构化的语言。因为当时有一个同事让我对 Go 语言产生了兴趣。
|
||||
虽然我在大学时期和刚刚工作的一些时间在使用更严谨的编译语言,比如 C++ 和 C#,而后来我开始使用 JavaScript。我很喜欢它的自由和灵活,但是我最近开始怀念静态和结构化的语言,因为当时有一个同事让我对 Go 语言产生了兴趣。
|
||||
|
||||
我从写 JavaScript 到写 Go,我发现两种语言有很多相似之处。两者速度都很快并且易于上手,都具有充满表现力的语法,并且在开发者社区中都有很多工作机会。没有完美的编程语言,所以你应该总是选择一个适合手头项目的语言。我将要在这篇文章中说明这两种语言深层次上的关键区别,希望能鼓励没有用过 Go 语言的用户使用 Go 。
|
||||
|
||||
* * *
|
||||
我从写 JavaScript 到写 Go,我发现两种语言有很多相似之处。两者学习起来都很快并且易于上手,都具有充满表现力的语法,并且在开发者社区中都有很多工作机会。没有完美的编程语言,所以你应该总是选择一个适合手头项目的语言。在这篇文章中,我将要说明这两种语言深层次上的关键区别,希望能鼓励没有用过 Go 语言的用户~~可以~~有机会使用 Go 。
|
||||
|
||||
### 大体上的差异
|
||||
|
||||
在深入细节之前,我们应该先了解一下两种语言之间的重要区别。
|
||||
|
||||
Go,或称 Golang,是 Google 在 2007 年创建的免费开源编程语言。它被设计成快速和简单的。Go 被直接编译成机器码,这就是它速度的来源。使用编译语言调试是相当容易的,因为你可以在早期捕获大量错误。Go 也是一种强类型的语言,它有助于数据完整,并可以在编译时查找类型错误。
|
||||
Go,或称 Golang,是 Google 在 2007 年创建的自由开源编程语言。它以快速和简单为设计目标。Go 被直接编译成机器码,这就是它速度的来源。使用编译语言调试是相当容易的,因为你可以在早期捕获大量错误。Go 也是一种强类型的语言,它有助于数据完整,并可以在编译时查找类型错误。
|
||||
|
||||
另一方面,JavaScript 是一种弱类型语言。忽略验证数据的类型和真值判断陷阱带来的额外负担外,使用弱类型语言也有自己的好处。比起使用接口和范型,柯里化和可变的形参个数让函数变得更加灵活。JavaScript 在运行时被解释,这可能导致错误处理和调试的问题。Node 是一款基于 Google V8 虚拟机的 JavaScript 运行库,这使它成为一个轻量和快速的 Web 开发平台。
|
||||
|
||||
* * *
|
||||
另一方面,JavaScript 是一种弱类型语言。除了忽略验证数据的类型和真值判断陷阱所带来的额外负担之外,使用弱类型语言也有自己的好处。比起使用<ruby>接口<rt>interfaces</rt></ruby>和<ruby>范型<rt>generics</rt></ruby>,<ruby>柯里化<rt>currying</rt></ruby>和<ruby>可变的形参个数<rt>flexible arity</rt></ruby>让函数变得更加灵活。JavaScript 在运行时进行解释,这可能导致错误处理和调试的问题。Node 是一款基于 Google V8 虚拟机的 JavaScript 运行库,这使它成为一个轻量和快速的 Web 开发平台。
|
||||
|
||||
### 语法
|
||||
|
||||
作为原来的 JavaScript 开发者,Go 简单和直观的语法很吸引我。由于两种语言的语法都是从 C 语言演变的,所以它们的语法有很多相同之处。Go 被普遍认为是一种容易学习的语言。那时因为它的对开发者友好的工具,精简的语法和自以为是的约定(存疑)。
|
||||
作为原来的 JavaScript 开发者,Go 简单和直观的语法很吸引我。由于两种语言的语法可以说都是从 C 语言演变而来的,所以它们的语法有很多相同之处。Go 被普遍认为是一种“容易学习的语言”。那是因为它的对开发者友好的工具、精简的语法和固守惯例(LCTT 译注:惯例优先)。
|
||||
|
||||
Go 包含大量的自带特性有助于简化开发。你可以用标准 Go 构建工具把你的程序用 go build 命令编译成二进制可执行文件。使用内置的测试套件运行测试只需要运行 go test。 诸如原生支持的并发等特性甚至在语言层面上提供。
|
||||
Go 包含大量有助于简化开发的内置特性。你可以用标准 Go 构建工具把你的程序用 `go build` 命令编译成二进制可执行文件。使用内置的测试套件进行测试只需要运行 `go test` 即可。 诸如原生支持的并发等特性甚至在语言层面上提供。
|
||||
|
||||
[Google 的 Go 开发者][11]认为,现在的编程太复杂了,“太多的记账一样,重复劳动和文书工作”。这就是为什么 Go 的语法被设计得简单和干净,以减少混乱,提高效率和增强可读性。它还鼓励开发人员编写明确,易于理解的代码。Go 只有 [25 个唯一关键字][12]和唯一一种循环(for 循环),而不像 JavaScript 有 [ ~84 个关键字][13](包括保留字,对象,属性和方法)。
|
||||
[Google 的 Go 开发者][11]认为,现在的编程太复杂了,太多的“记账一样,重复劳动和文书工作”。这就是为什么 Go 的语法被设计得如此简单和干净,以减少混乱、提高效率和增强可读性。它还鼓励开发人员编写明确的、易于理解的代码。Go 只有 [25 个保留关键字][12]和一种循环(`for` 循环),而不像 JavaScript 有 [ 大约 84 个关键字][13](包括保留关键字字、对象、属性和方法)。
|
||||
|
||||
为了说明语法的一些差异和相似之处,我们来看几个例子:
|
||||
|
||||
* 标点符号: Go 去除了所有多余的符号以提高效率和可读性。尽管 JavaScript 中需要符号的地方也不多(见: [Lisp][1]),而且经常是可选的,但我更加喜欢 Go 的简单。
|
||||
* 标点符号: Go 去除了所有多余的符号以提高效率和可读性。尽管 JavaScript 中需要符号的地方也不多(参见: [Lisp][1]),而且经常是可选的,但我更加喜欢 Go 的简单。
|
||||
|
||||
```
|
||||
```
|
||||
// JavaScript 的逗号和分号
|
||||
for (var i = 0; i < 10; i++) {
|
||||
console.log(i);
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript 中的标点
|
||||
*JavaScript 中的标点*
|
||||
|
||||
```
|
||||
// Go uses minimal punctuation 使用最少数量标点的 Go
|
||||
```
|
||||
// Go 使用最少数量标点
|
||||
for i := 0; i < 10; i++ {
|
||||
fmt.Println(i)
|
||||
}
|
||||
```
|
||||
Go 中的标点
|
||||
*Go 中的标点*
|
||||
|
||||
* 赋值:由于 Go 是强类型语言,所以你在初始化变量时可以使用 := 操作符来进行类型推断,以避免[重复声明][2],而 JavaScript 则在运行时声明类型。
|
||||
* 赋值:由于 Go 是强类型语言,所以你在初始化变量时可以使用 `:=` 操作符来进行类型推断,以避免[重复声明][2],而 JavaScript 则在运行时声明类型。
|
||||
|
||||
|
||||
```
|
||||
// Javascript assignment JavaScript 赋值
|
||||
```
|
||||
// JavaScript 赋值
|
||||
var foo = "bar";
|
||||
```
|
||||
|
||||
JavaScript 中的赋值
|
||||
*JavaScript 中的赋值*
|
||||
|
||||
```
|
||||
```
|
||||
// Go 的赋值
|
||||
var foo string //不使用类型推导
|
||||
foo = "bar"
|
||||
|
||||
foo := "bar" //使用类型推导
|
||||
```
|
||||
|
||||
Go 的赋值
|
||||
*Go 的赋值*
|
||||
|
||||
* 导出:在 JavaScript 中,你必须从某个模块中显式地导出。 在 Go 中,任何大写的函数将被默认导出。
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
const Bar = () => {};
|
||||
|
||||
module.exports = {
|
||||
Bar
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript 中的导出
|
||||
*JavaScript 中的导出*
|
||||
|
||||
```
|
||||
```
|
||||
// Go 中的导出
|
||||
package foo //define package name 定义包名
|
||||
package foo // 定义包名
|
||||
func Bar (s string) string {
|
||||
//Bar will be exported Bar 将被导出为 Bar
|
||||
// Bar 将被导出
|
||||
}
|
||||
```
|
||||
|
||||
Go 中的导出
|
||||
*Go 中的导出*
|
||||
|
||||
* 导入:在 JavaScript 中被导入的依赖项和模块所依赖的库是必需的,而 Go 则利用原生的 import 关键字通过包的路径导入模块。另一个区别是,与Node的中央NPM存储库不同,Go使用URL作为路径来导入非标准库的包,这是为了从包的源码仓库直接克隆依赖。
|
||||
```
|
||||
* 导入:在 JavaScript 中 `required` 库是导入依赖项和模块所必需的,而 Go 则利用原生的 `import` 关键字通过包的路径导入模块。另一个区别是,与 Node 的中央 NPM 存储库不同,Go 使用 URL 作为路径来导入非标准库的包,这是为了从包的源码仓库直接克隆依赖。
|
||||
|
||||
```
|
||||
// Javascript 的导入
|
||||
var foo = require('foo');
|
||||
foo.bar();
|
||||
```
|
||||
|
||||
JavaScript 的导入
|
||||
*JavaScript 的导入*
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
// Go 的导入
|
||||
import (
|
||||
"fmt" // part of Go’s standard library Go 的标准库部分
|
||||
"github.com/foo/foo" // imported directly from repository 直接从仓库导入
|
||||
"fmt" // Go 的标准库部分
|
||||
"github.com/foo/foo" // 直接从仓库导入
|
||||
)
|
||||
foo.Bar()
|
||||
```
|
||||
|
||||
Go 的导入
|
||||
*Go 的导入*
|
||||
|
||||
* 返回多值:通过 Go 的多值返回特性可以优雅地传递和处理返回值和错误,并且通过传递引用代替不正确的值传递。在 JavaScript 中需要通过一个对象或者数组来返回多个值。
|
||||
* 返回值:通过 Go 的多值返回特性可以优雅地传递和处理返回值和错误,并且通过传递引用减少了不正确的值传递。在 JavaScript 中需要通过一个对象或者数组来返回多个值。
|
||||
|
||||
```
|
||||
```
|
||||
// Javascript - 返回多值
|
||||
function foo() {
|
||||
return {a: 1, b: 2};
|
||||
@ -122,9 +114,9 @@ function foo() {
|
||||
const { a, b } = foo();
|
||||
```
|
||||
|
||||
JavaScript 的返回
|
||||
*JavaScript 的返回*
|
||||
|
||||
```
|
||||
```
|
||||
// Go - 返回多值
|
||||
func foo() (int, int) {
|
||||
return 1, 2
|
||||
@ -132,89 +124,81 @@ func foo() (int, int) {
|
||||
a, b := foo()
|
||||
```
|
||||
|
||||
Go 的返回
|
||||
|
||||
*Go 的返回*
|
||||
|
||||
* 错误处理:Go 推荐在错误出现的地方捕获它们,而不是像 Node 一样在回调中让错误冒泡。
|
||||
|
||||
```
|
||||
```
|
||||
// Node 的错误处理
|
||||
foo('bar', function(err, data) {
|
||||
//handle error
|
||||
// 处理错误
|
||||
}
|
||||
```
|
||||
|
||||
JavaScript 的错误处理
|
||||
*JavaScript 的错误处理*
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
//Go 的错误处理
|
||||
foo, err := bar()
|
||||
if err != nil {
|
||||
// handle error with defer, panic, recover, or log.fatal, etc...
|
||||
// 用 defer、 panic、 recover 或 log.fatal 等等处理错误.
|
||||
}
|
||||
```
|
||||
|
||||
Go 的错误处理
|
||||
*Go 的错误处理*
|
||||
|
||||
* 可变参数函数:Go 和 JavaScript 的函数都支持传入不定数量的参数。
|
||||
|
||||
```
|
||||
```
|
||||
function foo (...args) {
|
||||
console.log(args.length);
|
||||
}
|
||||
|
||||
foo(); // 0
|
||||
foo(1, 2, 3); // 3
|
||||
```
|
||||
|
||||
JavaScript 中的可变参数函数
|
||||
*JavaScript 中的可变参数函数*
|
||||
|
||||
```
|
||||
```
|
||||
func foo (args ...int) {
|
||||
fmt.Println(len(args))
|
||||
}
|
||||
|
||||
func main() {
|
||||
foo() // 0
|
||||
foo(1,2,3) // 3
|
||||
}
|
||||
```
|
||||
|
||||
Go 中的可变参数函数
|
||||
*Go 中的可变参数函数*
|
||||
|
||||
* * *
|
||||
|
||||
### 社区
|
||||
|
||||
当比较 Go 和 Node 提供的编程范式哪种更方便时,两边都有不同的拥护者。Node 在软件包数量和社区的大小上完全胜过了 Go。Node 包管理器(NPM),世界上最大的软件仓库,拥有[超过 410,000 个软件包,每天以 555 个新软件包的惊人速度增长][14]。这个数字可能看起来令人吃惊(确实是),但是需要注意的是,这些包许多是重复的和/或质量不足以在生产环境。 相比之下,Go 大约有 13 万个包。
|
||||
当比较 Go 和 Node 提供的编程范式哪种更方便时,两边都有不同的拥护者。Node 在软件包数量和社区的大小上完全胜过了 Go。Node 包管理器(NPM),是世界上最大的软件仓库,拥有[超过 410,000 个软件包,每天以 555 个新软件包的惊人速度增长][14]。这个数字可能看起来令人吃惊(确实是),但是需要注意的是,这些包许多是重复的,且质量不足以用在生产环境。 相比之下,Go 大约有 13 万个包。
|
||||
|
||||
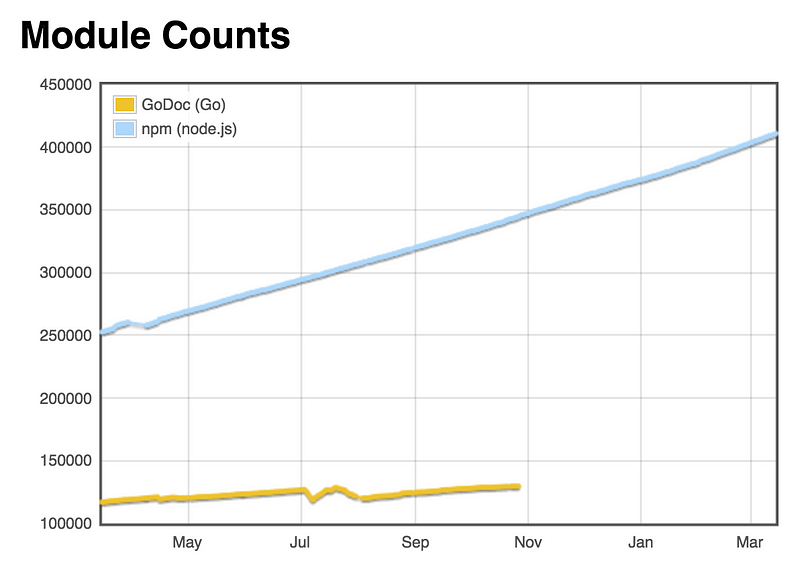
|
||||
|
||||
Node 和 Go 包的数量
|
||||
*Node 和 Go 包的数量*
|
||||
|
||||
尽管 Node 和 Go 岁数相仿,JavaScript 使用更加广泛,并拥有巨大的开发者和开源社区。因为 Node 是为所有人开发的并在开始的时候就带有一个强壮的包管理器而 Go 是特地为 Google 开发的。下面的[排行榜][15]显示了当前流行的的顶尖 Web 开发语言。
|
||||
尽管 Node 和 Go 岁数相仿,但 JavaScript 使用更加广泛,并拥有巨大的开发者和开源社区。因为 Node 是为所有人开发的,并在开始的时候就带有一个强壮的包管理器,而 Go 是特地为 Google 开发的。下面的[Spectrum 排行榜][15]显示了当前流行的的顶尖 Web 开发语言。
|
||||
|
||||
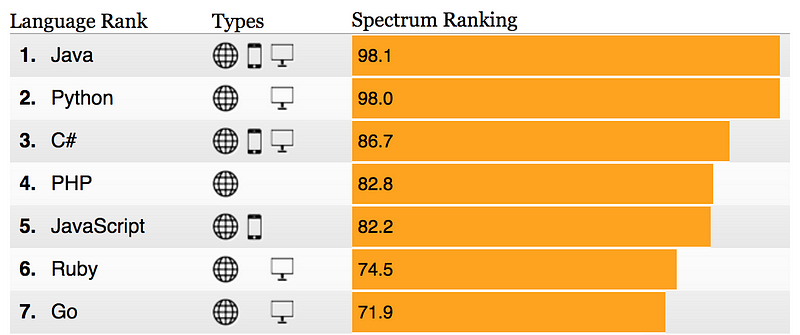
|
||||

|
||||
|
||||
Web 开发语言排行榜前 7 名
|
||||
*Web 开发语言排行榜前 7 名*
|
||||
|
||||
JavaScript 的受欢迎程度近年来似乎保持相对稳定,而 [Go 一直在保持上升趋势][16]。
|
||||
|
||||
|
||||

|
||||
|
||||
Programming language trends 编程语言趋势
|
||||
|
||||
* * *
|
||||
*编程语言趋势*
|
||||
|
||||
### 性能
|
||||
|
||||
如果你的主要关注点是速度呢?当今似乎人们比以前更重视性能的优化。用户不喜欢等待信息。 事实上,如果网页的加载时间超过 3 秒,[40% 的用户会放弃访问您的网站][17]。
|
||||
|
||||
Node 经常被认为是高性能的语言,因为它的非阻塞异步 I/O。另外,正如我之前提到的,Node 运行在针对动态语言进行了优化的 Google V8 引擎上。而 Go 的设计也考虑到速度。[Google 的开发者][18]也达成了这一目标,通过建立了一个“充满表现力而轻量级的类型系统,并发和垃圾回收机制,强制地指定依赖版本等等”。
|
||||
因为它的非阻塞异步 I/O,Node 经常被认为是高性能的语言。另外,正如我之前提到的,Node 运行在针对动态语言进行了优化的 Google V8 引擎上。而 Go 的设计也考虑到速度。[Google 的开发者们][18]通过建立了一个“充满表现力而轻量级的类型系统;并发和垃圾回收机制;强制地指定依赖版本等等”,达成了这一目标。
|
||||
|
||||
我运行了一些测试来比较 Node 和 Go 之间的性能。这些测试注重于语言提供的初级能力。如果我准备测试例如 HTTP 请求 或者 CPU 密集型运算,我会使用 Go 语言级别的并发工具(goroutines/channels)。但是我更注重于各个语言提供的基本特性(看 [三种并发方法][19] 了解关于 goroutines 和 channels 的更多知识)。
|
||||
我运行了一些测试来比较 Node 和 Go 之间的性能。这些测试注重于语言提供的初级能力。如果我准备测试例如 HTTP 请求或者 CPU 密集型运算,我会使用 Go 语言级别的并发工具(goroutines/channels)。但是我更注重于各个语言提供的基本特性(参见 [三种并发方法][19] 了解关于 goroutines 和 channels 的更多知识)。
|
||||
|
||||
我在基准测试中也加入了 Python,所以无论如何我们对 Node 和 Go 的结果都很满意。
|
||||
|
||||
@ -229,7 +213,7 @@ for (var c = 0; c < 1000000000; c++) {
|
||||
}
|
||||
```
|
||||
|
||||
Node
|
||||
*Node*
|
||||
|
||||
```
|
||||
package main
|
||||
@ -241,28 +225,27 @@ func main() {
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
*Go*
|
||||
|
||||
|
||||
```
|
||||
sum(xrange(1000000000))
|
||||
```
|
||||
|
||||
Python
|
||||
*Python*
|
||||
|
||||
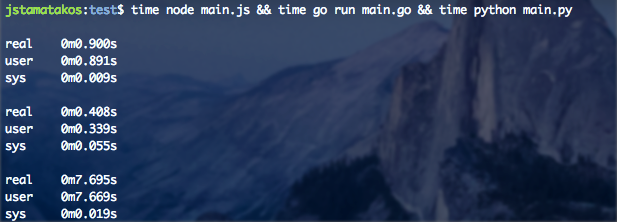
|
||||
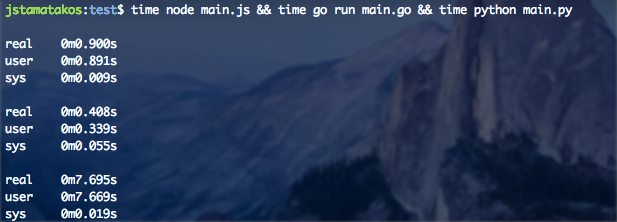
|
||||
|
||||
结果
|
||||
*结果*
|
||||
|
||||
这里的输家无疑是 Python,花了超过 7 秒的 cpu 时间。而 Node 和 Go 都相当高效,分别用了 900 ms 和 408 ms。
|
||||
这里的输家无疑是 Python,花了超过 7 秒的 CPU 时间。而 Node 和 Go 都相当高效,分别用了 900 ms 和 408 ms。
|
||||
|
||||
修正:由于一些评论表明 Python 的性能还可以提高。我更新了结果来反映这些变化。同时,使用 PyPy 大大地提高了性能。当使用 Python 3.6.1 和 PyPy 3.5.7 运行时,性能提升到 1.234 秒,但仍然不及 Go 和 Node 。_
|
||||
_修正:由于一些评论表明 Python 的性能还可以提高。我更新了结果来反映这些变化。同时,使用 PyPy 大大地提高了性能。当使用 Python 3.6.1 和 PyPy 3.5.7 运行时,性能提升到 1.234 秒,但仍然不及 Go 和 Node 。_
|
||||
|
||||
#### I/O
|
||||
|
||||
遍历一百万个数字并将其写入一个文件。
|
||||
|
||||
|
||||
```
|
||||
var fs = require('fs');
|
||||
var wstream = fs.createWriteStream('node');
|
||||
@ -273,28 +256,29 @@ for (var c = 0; c < 1000000; ++c) {
|
||||
wstream.end();
|
||||
```
|
||||
|
||||
Node
|
||||
*Node*
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"io"
|
||||
"os"
|
||||
"strconv"
|
||||
"bufio"
|
||||
"os"
|
||||
"strconv"
|
||||
)
|
||||
|
||||
func main() {
|
||||
file, _ := os.Create("go")
|
||||
for c := 0; c < 1000000; c++ {
|
||||
num := strconv.Itoa(c)
|
||||
io.WriteString(file, num)
|
||||
}
|
||||
file.Close()
|
||||
file, _ := os.Create("go")
|
||||
b := bufio.NewWriter(file)
|
||||
for c := 0; c < 1000000; c++ {
|
||||
num := strconv.Itoa(c)
|
||||
b.WriteString(num)
|
||||
}
|
||||
file.Close()
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
*Go*
|
||||
|
||||
```
|
||||
with open("python", "a") as text_file:
|
||||
@ -302,21 +286,21 @@ with open("python", "a") as text_file:
|
||||
text_file.write(str(i))
|
||||
```
|
||||
|
||||
Python
|
||||
*Python*
|
||||
|
||||
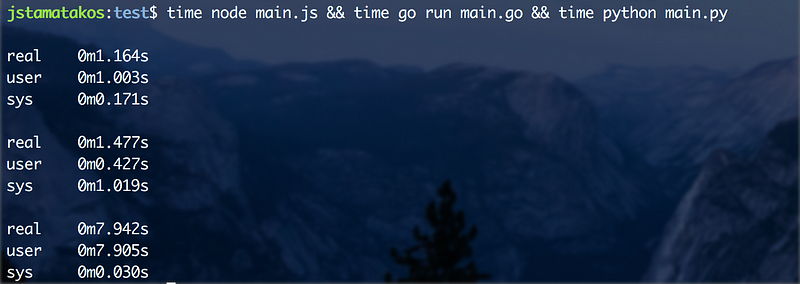
|
||||
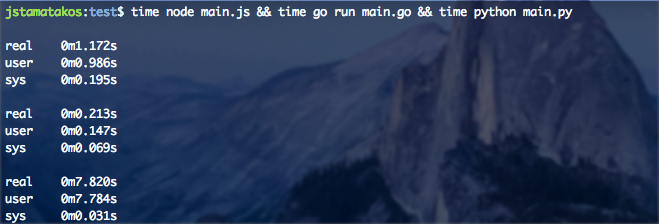
|
||||
|
||||
结果
|
||||
*结果*
|
||||
|
||||
Python 以 7.94 秒再次排名第三。 这次测试中,Node 和 Go 之间的差距很小,Node 花费大约 1.164 秒,Go 花费了1.477秒(尽管这包括了编译 Go 的代码所花费的时间—使用编译好的文件将缩短 ~200 ms 的整体时间)。
|
||||
Python 以 7.82 秒再次排名第三。 这次测试中,Node 和 Go 之间的差距很大,Node 花费大约 1.172 秒,Go 花费了 213 毫秒。真正令人印象深刻的是,Go 大部分的处理时间花费在编译上。如果我们将代码编译,以二进制运行,这个 I/O 测试仅花费 78 毫秒——要比 Node 快 15 倍。
|
||||
|
||||
*修正:修改了 Go 代码以实现缓存 I/O。*
|
||||
|
||||
#### 冒泡排序
|
||||
|
||||
将含有十个元素的数组排序一千万次
|
||||
将含有十个元素的数组排序一千万次。
|
||||
|
||||
```
|
||||
const toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0];
|
||||
|
||||
function bubbleSort(input) {
|
||||
var n = input.length;
|
||||
var swapped = true;
|
||||
@ -331,12 +315,13 @@ function bubbleSort(input) {
|
||||
}
|
||||
}
|
||||
|
||||
for (var c = 0; c < 10000000; c++) {
|
||||
for (var c = 0; c < 1000000; c++) {
|
||||
const toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0];
|
||||
bubbleSort(toBeSorted);
|
||||
}
|
||||
```
|
||||
|
||||
Node
|
||||
*Node*
|
||||
|
||||
```
|
||||
package main
|
||||
@ -358,18 +343,15 @@ func bubbleSort(input [10]int) {
|
||||
}
|
||||
|
||||
func main() {
|
||||
for c := 0; c < 10000000; c++ {
|
||||
for c := 0; c < 1000000; c++ {
|
||||
bubbleSort(toBeSorted)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
|
||||
*Go*
|
||||
|
||||
```
|
||||
toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0]
|
||||
|
||||
def bubbleSort(input):
|
||||
length = len(input)
|
||||
swapped = True
|
||||
@ -381,17 +363,18 @@ def bubbleSort(input):
|
||||
input[i], input[i - 1] = input[i - 1], input[i]
|
||||
swapped = True
|
||||
|
||||
for i in range(10000000):
|
||||
for i in range(1000000):
|
||||
toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0]
|
||||
bubbleSort(toBeSorted)
|
||||
```
|
||||
Python
|
||||
|
||||
*Python*
|
||||
|
||||

|
||||
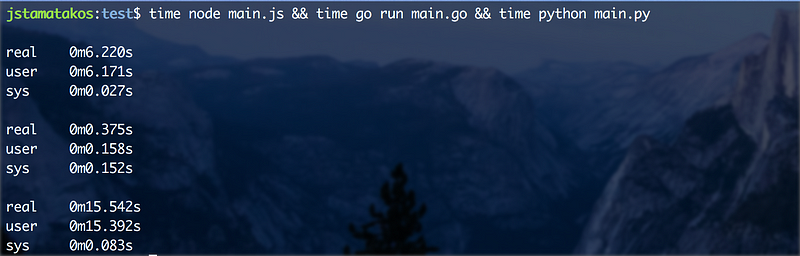
|
||||
|
||||
<figcaption class="imageCaption" style="position: relative; left: 0px; width: 700px; top: 0px; margin-top: 10px; color: rgba(0, 0, 0, 0.6); outline: 0px; text-align: center; z-index: 300; --baseline-multiplier:0.157; font-family: medium-content-sans-serif-font, "Lucida Grande", "Lucida Sans Unicode", "Lucida Sans", Geneva, Arial, sans-serif; font-feature-settings: 'liga' 1, 'lnum' 1; font-size: 14px; line-height: 1.4; letter-spacing: 0px;">Results</figcaption>
|
||||
*结果*
|
||||
|
||||
像刚才一样,Python 的表现是最差的,大约花费 13 秒完成了任务。 Go 完成任务的速度是 Node 的两倍多。
|
||||
像刚才一样,Python 的表现是最差的,大约花费 15 秒完成了任务。 Go 完成任务的速度是 Node 的 16 倍。
|
||||
|
||||
#### 判决
|
||||
|
||||
@ -401,17 +384,12 @@ Go 无疑是这三个测试中的赢家,而 Node 大部分表现都很出色
|
||||
* [Multiple Language Performance Test][4]
|
||||
* [Benchmarks Game][5]
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### 结论
|
||||
|
||||
这个帖子不是为了证明一种语言比另一种语言更好。由于各种原因,每种编程语言都在软件开发社区中占有一席之地。 我的意图是强调 Go 和 Node 之间的差异,并且促进展示一种新的 Web 开发语言。 在为一个项目选择语言时,有各种因素需要考虑,比如开发人员的熟悉程度,花费和实用性。 我鼓励在决定哪种语言适合您时进行一次彻底的底层分析。
|
||||
这个帖子不是为了证明一种语言比另一种语言更好。由于各种原因,每种编程语言都在软件开发社区中占有一席之地。 我的意图是强调 Go 和 Node 之间的差异,并且促进展示一种新的 Web 开发语言。 在为一个项目选择语言时,有各种因素需要考虑,比如开发人员的熟悉程度、花费和实用性。 我鼓励在决定哪种语言适合您时进行一次彻底的底层分析。
|
||||
|
||||
正如我们所看到的,Go 有如下的优点:接近底层语言的性能,简单的语法和相对简单的学习曲线使它成为构建可拓展和安全的 Web 应用的理想选择。随着 Go 的使用率和社区活动的快速增长,它将会成为现代网络开发中的重要角色。话虽如此,我相信如果 Node 被正确地实现,它正在向正确的方向努力,仍然是一种强大而有用的语言。它具有大量的追随者和活跃的社区,使其成为一个简单的平台,可以让 Web 应用在任何时候启动和运行。
|
||||
|
||||
* * *
|
||||
|
||||
### 资料
|
||||
|
||||
如果你对学习 Go 语言感兴趣,可以参阅下面的资源:
|
||||
@ -427,7 +405,7 @@ via: https://medium.com/xo-tech/from-node-to-go-a-high-level-comparison-56c8b717
|
||||
|
||||
作者:[John Stamatakos][a]
|
||||
译者:[trnhoe](https://github.com/trnhoe)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,104 @@
|
||||
关于 Linux 你可能不是非常了解的七件事
|
||||
===
|
||||
|
||||

|
||||
|
||||
使用 Linux 最酷的事情之一就是随着时间的推移,你可以不断获得新的知识。每天,你都可能会遇到一个新的实用工具,或者只是一个不太熟悉的奇技淫巧,但是却非常有用。这些零碎的东西并不总是能够改变生活,但是却是专业知识的基础。
|
||||
|
||||
即使是专家,也不可能事事皆知。无论你有多少经验,可能总会有更多的东西需要你去学习。所以,在这儿我列出了七件关于 Linux 你可能不知道的事情。
|
||||
|
||||
### 一个查找命令历史的交互模式
|
||||
|
||||
你可能对 `history` 命令非常熟悉,它会读取 bash 历史,然后以编号列表的方式输出到标准输出(`stdout`)。然而,如果你在 `curl` 命令的海洋里寻找一个特定的链接(URL),那么这个列表并不总是那么容易阅读的。
|
||||
|
||||
你还可以有另一个选择,Linux 有一个交互式的反向搜索可以帮助你解决这个问题。你可以通过快捷键 `ctrl+r`启动交互模式,然后进入一个交互提示中,它将会根据你提供的字符串来向后搜索 bash 历史,你可以通过再次按下 `ctrl+r` 向后搜索更老的命令,或者按下 `ctrl+s` 向前搜索。
|
||||
|
||||
注意,`ctrl+s` 有时会与 XON/XOFF 流控制冲突,即 XON/XOFF 流控制也会使用该快捷键。你可以通过运行 `stty -ixon` 命令来禁用该快捷键。在你的个人电脑上,这通常是有用的,但是在禁用前,确保你不需要 XON/XOFF 。
|
||||
|
||||
### Cron 不是安排任务的唯一方式
|
||||
|
||||
Cron 任务对于任何水平的系统管理员,无论是毫无经验的初学者,还是经验丰富的专家来说,都是非常有用的。但是,如果你需要安排一个一次性的任务,那么 `at` 命令为你提供了一个快捷的方式来创建任务,从而你不需要接触 crontab 。
|
||||
|
||||
`at` 命令的运行方式是在后面紧跟着你想要运行任务的运行时间。时间是灵活的,因为它支持许多时间格式。包括下面这些例子:
|
||||
|
||||
```
|
||||
at 12:00 PM September 30 2017
|
||||
at now + 1 hour
|
||||
at 9:00 AM tomorrow
|
||||
```
|
||||
|
||||
当你以带参数的方式输入 `at` 命令以后,将会提示你该命令将在你的 Linux 系统上运行。这可能是一个备份脚本,一套维护任务,或者甚至是一个普通的 bash 命令。如果要结束任务,可以按 `ctrl+d` 。
|
||||
|
||||
另外,你可以使用 `atq` 命令查看当前用户的所有任务,或者使用 `sudo atq` 查看所有用户的任务。它将会展示出所有排定好的任务,并且每个任务都伴有一个 ID 。如果你想取消一个排定好的任务,可以使用 `atrm` 命令,并且以任务 ID 作为参数。
|
||||
|
||||
### 你可以按照功能搜索命令,而不仅仅是通过名字
|
||||
|
||||
记住命令的名字非常困难,特别是对于初学者来说。幸运的是,Linux 附带了一个通过名字和描述来搜索 man 页面的工具。
|
||||
|
||||
下次,如果你没有记住你想要使用的工具的名称,你可以尝试使用 `apropos` 命令加上你想要干的事情的描述。比如,`apropos build filesystem` 将会返回一系列名字和描述包括了 “build” 和 “filesystem” 单词的工具。
|
||||
|
||||
`apropos` 命令接受一个或多个字符串作为参数,但同时它也有其他参数,比如你可以使用 `-r` 参数,从而通过正则表达式来搜索。
|
||||
|
||||
### 一个允许你来管理系统版本的替代系统
|
||||
|
||||
如果你曾进行过软件开发,你就会明白跨项目管理不同版本的语言的支持的重要性。许多 Linux 发行版都有工具可以来处理不同的内建版本。
|
||||
|
||||
可执行文件比如 `java` 往往符号链接到目录 `/etc/alternatives` 下。反过来,该目录会将符号链接存储为二进制文件并提供一个管理这些链接的接口。Java 可能是替代系统最常管理的语言,但是,经过一些配置,它也可以作为其他应用程序替代品,比如 NVM 和 RVM (NVM 和 RVM 分别是 NodeJS 和 Ruby 的版本管理器)。
|
||||
|
||||
在基于 Debian 的系统中,你可以使用 `update-alternatives` 命令创建和管理这些链接。在 CentOS 中,这个工具就叫做 `alternatives` 。通过更改你的 alternatives 文件中的链接,你便可以安装一个语言的多个版本,并且在不同的情况下使用不同的二进制。这个替代系统也提供了对任何你可能在命令行运行的程序的支持。
|
||||
|
||||
### `shred` 命令是更加安全的删除文件方式
|
||||
|
||||
我们大多数时候总是使用 `rm` 命令来删除文件。但是文件去哪儿了呢?真相是 `rm` 命令所做的事情并不是像你所想像的那样,它仅仅删除了文件系统和硬盘上的数据的硬链接。硬盘上的数据依旧存在,直到被另一个应用重写覆盖。对于非常敏感的数据来说,这会带来一个很大的安全隐患。
|
||||
|
||||
`shred` 命令是 `rm` 命令的升级版。当你使用 `shred` 命令删除一个文件之后,文件中的数据会被多次随机覆写。甚至有一个选项可以在随机覆写之后对所有的数据进行清零。
|
||||
|
||||
如果你想安全的删除一个文件并且以零覆盖,那么可以使用下面的命令:
|
||||
|
||||
`shred -u -z [file name]`
|
||||
|
||||
同时,你也可以使用 `-n` 选项和一个数字作为参数,从而指定在随机覆盖数据的时候迭代多少次。
|
||||
|
||||
### 通过自动更正来避免输入很长的无效文件路径
|
||||
|
||||
有多少次,你输入一个文件的绝对路径,然而却看到“没有该文件或目录”的消息。任何人都会明白输入一个很长的字符串的痛苦。幸运的是,有一个很简单的解决办法。
|
||||
|
||||
内建的 `shopt` 命令允许你设置不同的选项来改变 shell 的行为。设置 `cdspell` 选项是避免输入文件路径时一个字母出错的头痛的一个简单方式。你可以通过运行 `shopt -s cdspell` 命令来启用该选项。启用该选项后,当你想要切换目录时,会自动更正为最匹配的目录。
|
||||
|
||||
Shell 选项是节省时间的一个好方法(更不用说减少麻烦),此外还有许许多多的其他选项。如果想查看你的系统中所有选项的完整列表,可以运行不带参数的 `shopt` 命令。需要注意的是,这是 bash 的特性,如果你运行 zsh 或者其他可供选择的 shell,可能无法使用。
|
||||
|
||||
### 通过子 shell 返回到当前目录
|
||||
|
||||
如果你曾经配置过一个比较复杂的系统,那么你可能会发现你需要频繁的更换目录,从而很难跟踪你所在的位置。如果在运行完一个命令后自动返回到当前位置,不是很好吗?
|
||||
|
||||
Linux 系统实际上提供了一个解决该问题的方法,并且非常简单。如果你想通过 `cd` 命令进入另一个目录完成一些任务,然后再返回当前工作目录,那么你可以将命令置于括号中。你可以在你的 Linux 系统上尝试下面这个命令。记住你当前的工作目录,然后运行:
|
||||
|
||||
```
|
||||
(cd /etc && ls -a)
|
||||
```
|
||||
|
||||
该命令会输出 `/etc` 目录的内容。现在,检查你的当前工作目录。它和执行该命令前的目录一样,而不是 `/etc` 目录。
|
||||
|
||||
它是如何工作的呢?运行一个括号中的命令会创建一个子 shell 或一个当前 shell 进程的复刻副本。该子 shell 可以访问所有的父变量,反之则不行。所以请记住,你是在运行一个非常复杂的单行命令。
|
||||
|
||||
在并行处理中经常使用子 shell ,但是在命令行中,它也能为你带来同样的力量,从而使你在浏览文件系统时更加容易。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Phil Zona 是 Linux Academy 的技术作家。他编写了 AWS、Microsoft Azure 和 Linux 系统管理的指南和教程。他同时也管理着 Cloud Assessments 博客,该博客旨在帮助个人通过技术实现他们的事业目标。
|
||||
|
||||
-----------------
|
||||
|
||||
via: http://opensourceforu.com/2017/09/top-7-things-linux-may-not-known-far/
|
||||
|
||||
作者:[PHIL ZONA][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensourceforu.com/author/phil-zona/
|
||||
[1]:http://opensourceforu.com/2017/09/top-7-things-linux-may-not-known-far/#disqus_thread
|
||||
[2]:http://opensourceforu.com/author/phil-zona/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by @explosic4
|
||||
|
||||
Education of a Programmer
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
translating by penghuster
|
||||
|
||||
How To Code Like The Top Programmers At NASA — 10 Critical Rules
|
||||
============================================================
|
||||
|
||||
_**[][1] Short Bytes:** Do you know how top programmers write mission-critical code at NASA? To make such code clearer, safer, and easier to understand, NASA’s Jet Propulsion Laboratory has laid 10 rules for developing software._
|
||||
|
||||
The developers at NASA have one of the most challenging jobs in the programming world. They write code and develop mission-critical applications with safety as their primary concerns.
|
||||
|
||||
In such situations, it’s important to follow some serious coding guidelines. These rules cover different aspects of software development like how a software should be written, which language features should be used etc.
|
||||
|
||||
Even though it’s difficult to establish a consensus over a good coding standard, NASA’s Jet Propulsion Laboratory (JPL) follows a set of [guidelines of code][2] named “The Power of Ten–Rules for Developing Safety Critical Code”.
|
||||
|
||||
This guide focuses mainly on code written in C programming languages due to JPL’s long association with the language. But, these guidelines could be easily applied on other programming languages as well.
|
||||
|
||||
Laid by JPL lead scientist Gerard J. Holzmann, these strict coding rules focus on security.
|
||||
|
||||
[][3]
|
||||
|
||||
NASA’s 10 rules for writing mission-critical code:
|
||||
|
||||
1. _Restrict all code to very simple control flow constructs – do not use goto statements, setjmp or longjmp _ constructs _, and direct or indirect recursion._
|
||||
|
||||
2. _All loops must have a fixed_ _upper-bound. It must be trivially possible for a checking tool to prove statically that a preset upper-bound on the number of iterations of a loop cannot be exceeded. If the loop-bound cannot be proven statically, the rule is considered violated._
|
||||
|
||||
3. _Do not use dynamic memory allocation after initialization._
|
||||
|
||||
4. _No function should be longer than what can be printed on a single sheet of paper in a standard reference format with one line per statement and one line per declaration. Typically, this means no more than about 60 lines of code per function._
|
||||
|
||||
5. _The assertion density of the code should average to a minimum of two assertions per function. Assertions are used to check for anomalous conditions that should never happen in real-life executions. Assertions must always be side-effect free and should be defined as Boolean tests. When an assertion fails, an explicit recovery action must be taken, e.g., by returning an error condition to the caller of the function that executes the failing assertion. Any assertion for which a static checking tool can prove that it can never fail or never hold violates this rule (I.e., it is not possible to satisfy the rule by adding unhelpful “assert(true)” statements)._
|
||||
|
||||
6. _Data objects must be declared at the smallest possible level of scope._
|
||||
|
||||
7. _The return value of non-void functions must be checked by each calling function, and the validity of parameters must be checked inside each function._
|
||||
|
||||
8. _The use of the preprocessor must be limited to the inclusion of header files and simple macro definitions. Token pasting, variable argument lists (ellipses), and recursive macro calls are not allowed. All macros must expand into complete syntactic units. The use of conditional compilation directives is often also dubious, but cannot always be avoided. This means that there should rarely be justification for more than one or two conditional compilation directives even in large software development efforts, beyond the standard boilerplate that avoids multiple inclusion of the same header file. Each such use should be flagged by a tool-based checker and justified in the code._
|
||||
|
||||
9. _The use of pointers should be restricted. Specifically, no more than one level of dereferencing is allowed. Pointer dereference operations may not be hidden in macro definitions or inside typedef declarations. Function pointers are not permitted._
|
||||
|
||||
10. _All code must be compiled, from the first day of development, with all compiler warnings enabled at the compiler’s most pedantic setting. All code must compile with these setting without any warnings. All code must be checked daily with at least one, but preferably more than one, state-of-the-art static source code analyzer and should pass the analyses with zero warnings._
|
||||
|
||||
About these rules, here’s what NASA has to say:
|
||||
|
||||
The rules act like the seatbelt in your car: initially they are perhaps a little uncomfortable, but after a while their use becomes second-nature and not using them becomes unimaginable.
|
||||
|
||||
[Source][4]
|
||||
|
||||
Did you find this article helpful? Don’t forget to drop your feedback in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Adarsh Verma
|
||||
Fossbytes co-founder and an aspiring entrepreneur who keeps a close eye on open source, tech giants, and security. Get in touch with him by sending an email — adarsh.verma@fossbytes.com
|
||||
|
||||
------------------
|
||||
|
||||
via: https://fossbytes.com/nasa-coding-programming-rules-critical/
|
||||
|
||||
作者:[Adarsh Verma ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fossbytes.com/author/adarsh/
|
||||
[1]:http://fossbytes.com/wp-content/uploads/2016/06/rules-of-coding-nasa.jpg
|
||||
[2]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
[3]:https://fossbytes.com/wp-content/uploads/2016/12/learn-to-code-banner-ad-content-1.png
|
||||
[4]:http://pixelscommander.com/wp-content/uploads/2014/12/P10.pdf
|
||||
@ -0,0 +1,287 @@
|
||||
Server-side I/O Performance: Node vs. PHP vs. Java vs. Go
|
||||
============
|
||||
|
||||
Understanding the Input/Output (I/O) model of your application can mean the difference between an application that deals with the load it is subjected to, and one that crumples in the face of real-world use cases. Perhaps while your application is small and does not serve high loads, it may matter far less. But as your application’s traffic load increases, working with the wrong I/O model can get you into a world of hurt.
|
||||
|
||||
And like most any situation where multiple approaches are possible, it’s not just a matter of which one is better, it’s a matter of understanding the tradeoffs. Let’s take a walk across the I/O landscape and see what we can spy.
|
||||
|
||||

|
||||
|
||||
In this article, we’ll be comparing Node, Java, Go, and PHP with Apache, discussing how the different languages model their I/O, the advantages and disadvantages of each model, and conclude with some rudimentary benchmarks. If you’re concerned about the I/O performance of your next web application, this article is for you.
|
||||
|
||||
### I/O Basics: A Quick Refresher
|
||||
|
||||
To understand the factors involved with I/O, we must first review the concepts down at the operating system level. While it is unlikely that will have to deal with many of these concepts directly, you deal with them indirectly through your application’s runtime environment all the time. And the details matter.
|
||||
|
||||
### System Calls
|
||||
|
||||
Firstly, we have system calls, which can be described as follows:
|
||||
|
||||
* Your program (in “user land,” as they say) must ask the operating system kernel to perform an I/O operation on its behalf.
|
||||
|
||||
* A “syscall” is the means by which your program asks the kernel do something. The specifics of how this is implemented vary between OSes but the basic concept is the same. There is going to be some specific instruction that transfers control from your program over to the kernel (like a function call but with some special sauce specifically for dealing with this situation). Generally speaking, syscalls are blocking, meaning your program waits for the kernel to return back to your code.
|
||||
|
||||
* The kernel performs the underlying I/O operation on the physical device in question (disk, network card, etc.) and replies to the syscall. In the real world, the kernel might have to do a number of things to fulfill your request including waiting for the device to be ready, updating its internal state, etc., but as an application developer, you don’t care about that. That’s the kernel’s job.
|
||||
|
||||
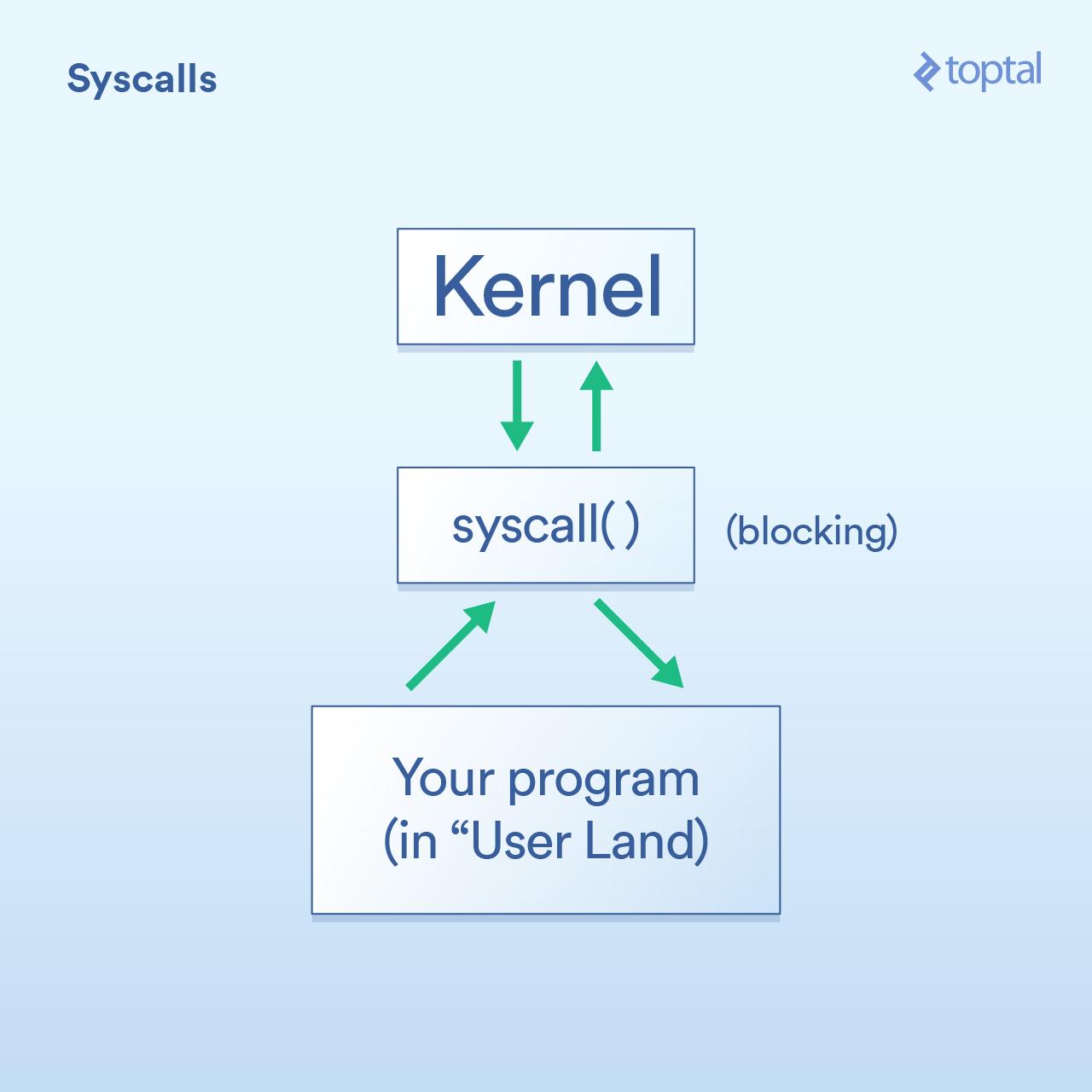
|
||||
|
||||
### Blocking vs. Non-blocking Calls
|
||||
|
||||
Now, I just said above that syscalls are blocking, and that is true in a general sense. However, some calls are categorized as “non-blocking,” which means that the kernel takes your request, puts it in queue or buffer somewhere, and then immediately returns without waiting for the actual I/O to occur. So it “blocks” for only a very brief time period, just long enough to enqueue your request.
|
||||
|
||||
Some examples (of Linux syscalls) might help clarify: - `read()` is a blocking call - you pass it a handle saying which file and a buffer of where to deliver the data it reads, and the call returns when the data is there. Note that this has the advantage of being nice and simple. - `epoll_create()`, `epoll_ctl()` and `epoll_wait()` are calls that, respectively, let you create a group of handles to listen on, add/remove handlers from that group and then block until there is any activity. This allows you to efficiently control a large number of I/O operations with a single thread, but I’m getting ahead of myself. This is great if you need the functionality, but as you can see it’s certainly more complex to use.
|
||||
|
||||
It’s important to understand the order of magnitude of difference in timing here. If a CPU core is running at 3GHz, without getting into optimizations the CPU can do, it’s performing 3 billion cycles per second (or 3 cycles per nanosecond). A non-blocking system call might take on the order of 10s of cycles to complete - or “a relatively few nanoseconds”. A call that blocks for information being received over the network might take a much longer time - let’s say for example 200 milliseconds (1/5 of a second). And let’s say, for example, the non-blocking call took 20 nanoseconds, and the blocking call took 200,000,000 nanoseconds. Your process just waited 10 million times longer for the blocking call.
|
||||
|
||||

|
||||
The kernel provides the means to do both blocking I/O (“read from this network connection and give me the data”) and non-blocking I/O (“tell me when any of these network connections have new data”). And which mechanism is used will block the calling process for dramatically different lengths of time.
|
||||
|
||||
### Scheduling
|
||||
|
||||
The third thing that’s critical to follow is what happens when you have a lot of threads or processes that start blocking.
|
||||
|
||||
For our purposes, there is not a huge difference between a thread and process. In real life, the most noticeable performance-related difference is that since threads share the same memory, and processes each have their own memory space, making separate processes tends to take up a lot more memory. But when we’re talking about scheduling, what it really boils down to is a list of things (threads and processes alike) that each need to get a slice of execution time on the available CPU cores. If you have 300 threads running and 8 cores to run them on, you have to divide the time up so each one gets its share, with each core running for a short period of time and then moving onto the next thread. This is done through a “context switch,” making the CPU switch from running one thread/process to the next.
|
||||
|
||||
These context switches have a cost associated with them - they take some time. In some fast cases, it may be less than 100 nanoseconds, but it is not uncommon for it to take 1000 nanoseconds or longer depending on the implementation details, processor speed/architecture, CPU cache, etc.
|
||||
|
||||
And the more threads (or processes), the more context switching. When we’re talking about thousands of threads, and hundreds of nanoseconds for each, things can get very slow.
|
||||
|
||||
However, non-blocking calls in essence tell the kernel “only call me when you have some new data or event on one of any of these connections.” These non-blocking calls are designed to efficiently handle large I/O loads and reduce context switching.
|
||||
|
||||
With me so far? Because now comes the fun part: Let’s look at what some popular languages do with these tools and draw some conclusions about the tradeoffs between ease of use and performance… and other interesting tidbits.
|
||||
|
||||
As a note, while the examples shown in this article are trivial (and partial, with only the relevant bits shown); database access, external caching systems (memcache, et. all) and anything that requires I/O is going to end up performing some sort of I/O call under the hood which will have the same effect as the simple examples shown. Also, for the scenarios where the I/O is described as “blocking” (PHP, Java), the HTTP request and response reads and writes are themselves blocking calls: Again, more I/O hidden in the system with its attendant performance issues to take into account.
|
||||
|
||||
There are a lot of factors that go into choosing a programming language for a project. There are even a lot factors when you only consider performance. But, if you are concerned that your program will be constrained primarily by I/O, if I/O performance is make or break for your project, these are things you need to know. ## The “Keep It Simple” Approach: PHP
|
||||
|
||||
Back in the 90’s, a lot of people were wearing [Converse][1] shoes and writing CGI scripts in Perl. Then PHP came along and, as much as some people like to rag on it, it made making dynamic web pages much easier.
|
||||
|
||||
The model PHP uses is fairly simple. There are some variations to it but your average PHP server looks like:
|
||||
|
||||
An HTTP request comes in from a user’s browser and hits your Apache web server. Apache creates a separate process for each request, with some optimizations to re-use them in order to minimize how many it has to do (creating processes is, relatively speaking, slow). Apache calls PHP and tells it to run the appropriate `.php` file on the disk. PHP code executes and does blocking I/O calls. You call `file_get_contents()` in PHP and under the hood it makes `read()` syscalls and waits for the results.
|
||||
|
||||
And of course the actual code is simply embedded right into your page, and operations are blocking:
|
||||
|
||||
```
|
||||
<?php
|
||||
|
||||
// blocking file I/O
|
||||
$file_data = file_get_contents(‘/path/to/file.dat’);
|
||||
|
||||
// blocking network I/O
|
||||
$curl = curl_init('http://example.com/example-microservice');
|
||||
$result = curl_exec($curl);
|
||||
|
||||
// some more blocking network I/O
|
||||
$result = $db->query('SELECT id, data FROM examples ORDER BY id DESC limit 100');
|
||||
|
||||
?>
|
||||
|
||||
```
|
||||
|
||||
In terms of how this integrates with system, it’s like this:
|
||||
|
||||
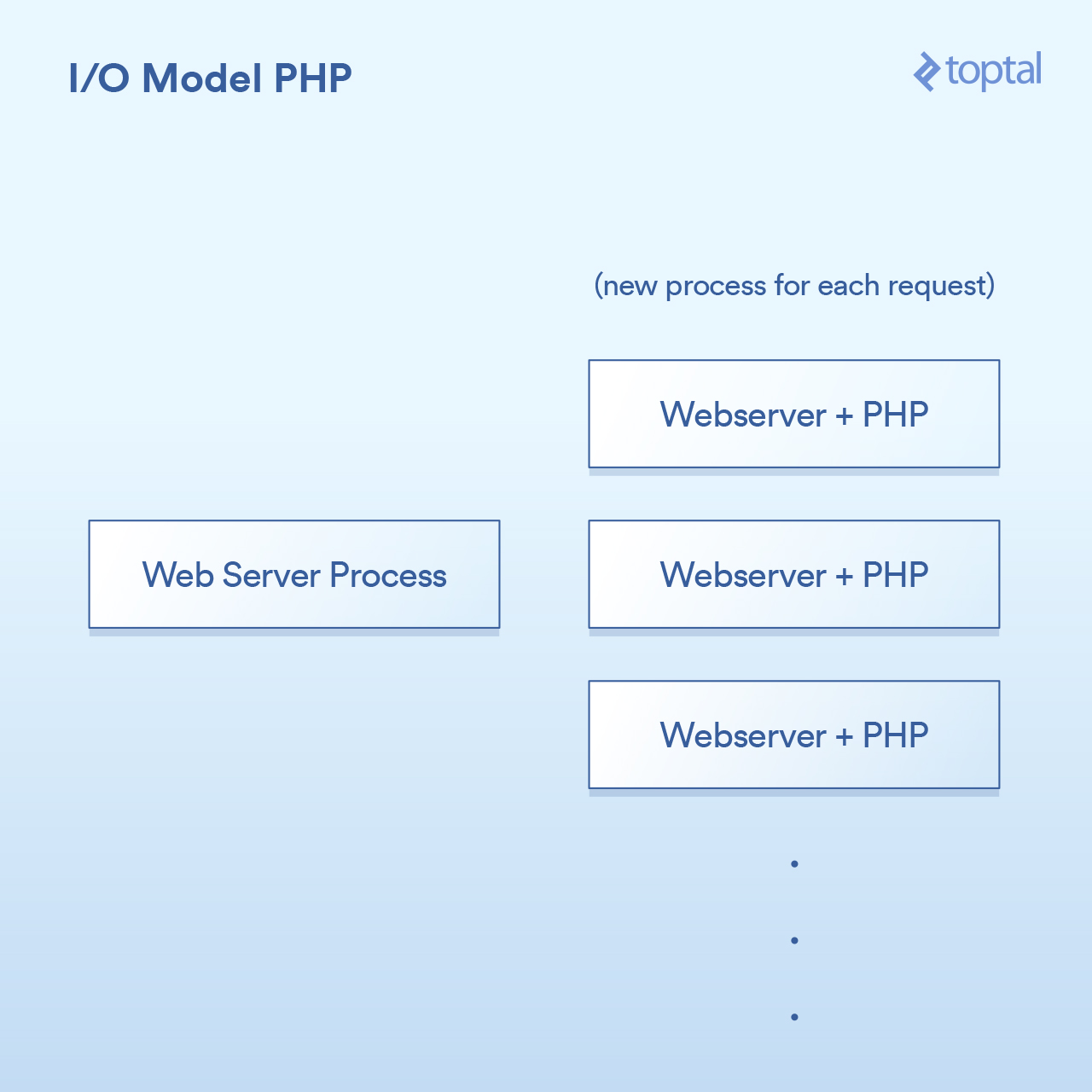
|
||||
|
||||
Pretty simple: one process per request. I/O calls just block. Advantage? It’s simple and it works. Disadvantage? Hit it with 20,000 clients concurrently and your server will burst into flames. This approach does not scale well because the tools provided by the kernel for dealing with high volume I/O (epoll, etc.) are not being used. And to add insult to injury, running a separate process for each request tends to use a lot of system resources, especially memory, which is often the first thing you run out of in a scenario like this.
|
||||
|
||||
_Note: The approach used for Ruby is very similar to that of PHP, and in a broad, general, hand-wavy way they can be considered the same for our purposes._
|
||||
|
||||
### The Multithreaded Approach: Java
|
||||
|
||||
So Java comes along, right about the time you bought your first domain name and it was cool to just randomly say “dot com” after a sentence. And Java has multithreading built into the language, which (especially for when it was created) is pretty awesome.
|
||||
|
||||
Most Java web servers work by starting a new thread of execution for each request that comes in and then in this thread eventually calling the function that you, as the application developer, wrote.
|
||||
|
||||
Doing I/O in a Java Servlet tends to look something like:
|
||||
|
||||
```
|
||||
public void doGet(HttpServletRequest request,
|
||||
HttpServletResponse response) throws ServletException, IOException
|
||||
{
|
||||
|
||||
// blocking file I/O
|
||||
InputStream fileIs = new FileInputStream("/path/to/file");
|
||||
|
||||
// blocking network I/O
|
||||
URLConnection urlConnection = (new URL("http://example.com/example-microservice")).openConnection();
|
||||
InputStream netIs = urlConnection.getInputStream();
|
||||
|
||||
// some more blocking network I/O
|
||||
out.println("...");
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Since our `doGet` method above corresponds to one request and is run in its own thread, instead of a separate process for each request which requires its own memory, we have a separate thread. This has some nice perks, like being able to share state, cached data, etc. between threads because they can access each other’s memory, but the impact on how it interacts with the schedule it still almost identical to what is being done in the PHP example previously. Each request gets a new thread and the various I/O operations block inside that thread until the request is fully handled. Threads are pooled to minimize the cost of creating and destroying them, but still, thousands of connections means thousands of threads which is bad for the scheduler.
|
||||
|
||||
An important milestone is that in version 1.4 Java (and a significant upgrade again in 1.7) gained the ability to do non-blocking I/O calls. Most applications, web and otherwise, don’t use it, but at least it’s available. Some Java web servers try to take advantage of this in various ways; however, the vast majority of deployed Java applications still work as described above.
|
||||
|
||||
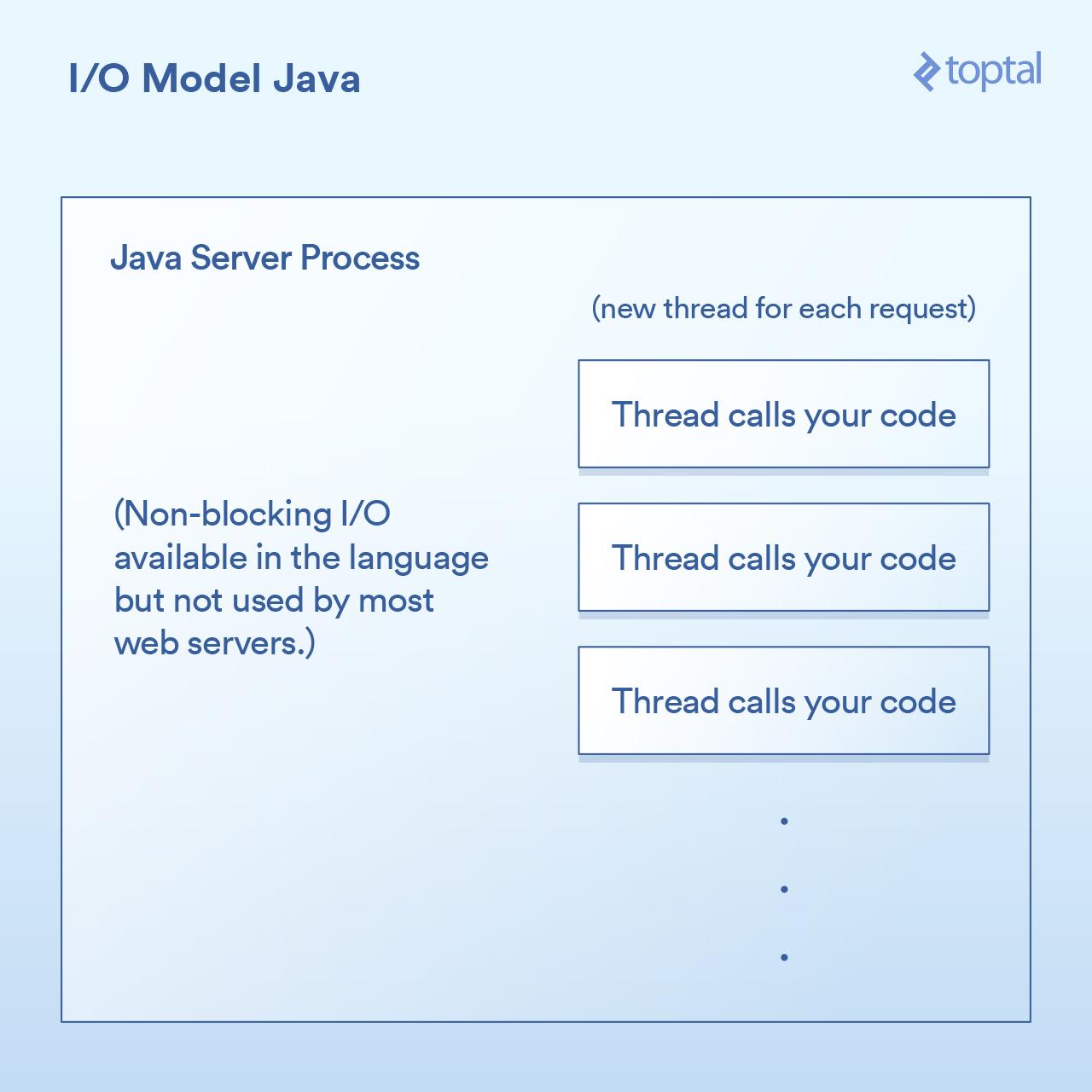
|
||||
|
||||
Java gets us closer and certainly has some good out-of-the-box functionality for I/O, but it still doesn’t really solve the problem of what happens when you have a heavily I/O bound application that is getting pounded into the ground with many thousands of blocking threads.
|
||||
|
||||
<form action="https://www.toptal.com/blog/subscription" class="embeddable_form" data-entity="blog_subscription" data-remote="" data-view="form#form" method="post" style="border: 0px; vertical-align: baseline; min-height: 0px; min-width: 0px;">Like what you're reading?Get the latest updates first.<input autocomplete="off" class="input is-medium" data-role="email" name="blog_subscription[email]" placeholder="Enter your email address..." type="text" style="-webkit-appearance: none; background: rgb(250, 250, 250); border-radius: 4px; border-width: 1px; border-style: solid; border-color: rgb(238, 238, 238); color: rgb(60, 60, 60); font-family: proxima-nova, Arial, sans-serif; font-size: 14px; padding: 15px 12px; transition: all 0.2s; width: 799.36px;"><input class="button is-green_candy is-default is-full_width" data-loader-text="Subscribing..." data-role="submit" type="submit" value="Get Exclusive Updates" style="-webkit-appearance: none; font-weight: 600; border-radius: 4px; transition: background 150ms; background: linear-gradient(rgb(67, 198, 146), rgb(57, 184, 133)); border-width: 1px; border-style: solid; border-color: rgb(31, 124, 87); box-shadow: rgb(79, 211, 170) 0px 1px inset; color: rgb(255, 255, 255); position: relative; text-shadow: rgb(28, 143, 61) 0px 1px 0px; font-size: 14px; padding: 15px 20px; width: 549.32px;">No spam. Just great engineering posts.</form>
|
||||
|
||||
### Non-blocking I/O as a First Class Citizen: Node
|
||||
|
||||
The popular kid on the block when it comes to better I/O is Node.js. Anyone who has had even the briefest introduction to Node has been told that it’s “non-blocking” and that it handles I/O efficiently. And this is true in a general sense. But the devil is in the details and the means by which this witchcraft was achieved matter when it comes to performance.
|
||||
|
||||
Essentially the paradigm shift that Node implements is that instead of essentially saying “write your code here to handle the request”, they instead say “write code here to start handling the request.” Each time you need to do something that involves I/O, you make the request and give a callback function which Node will call when it’s done.
|
||||
|
||||
Typical Node code for doing an I/O operation in a request goes like this:
|
||||
|
||||
```
|
||||
http.createServer(function(request, response) {
|
||||
fs.readFile('/path/to/file', 'utf8', function(err, data) {
|
||||
response.end(data);
|
||||
});
|
||||
});
|
||||
|
||||
```
|
||||
|
||||
As you can see, there are two callback functions here. The first gets called when a request starts, and the second gets called when the file data is available.
|
||||
|
||||
What this does is basically give Node an opportunity to efficiently handle the I/O in between these callbacks. A scenario where it would be even more relevant is where you are doing a database call in Node, but I won’t bother with the example because it’s the exact same principle: You start the database call, and give Node a callback function, it performs the I/O operations separately using non-blocking calls and then invokes your callback function when the data you asked for is available. This mechanism of queuing up I/O calls and letting Node handle it and then getting a callback is called the “Event Loop.” And it works pretty well.
|
||||
|
||||
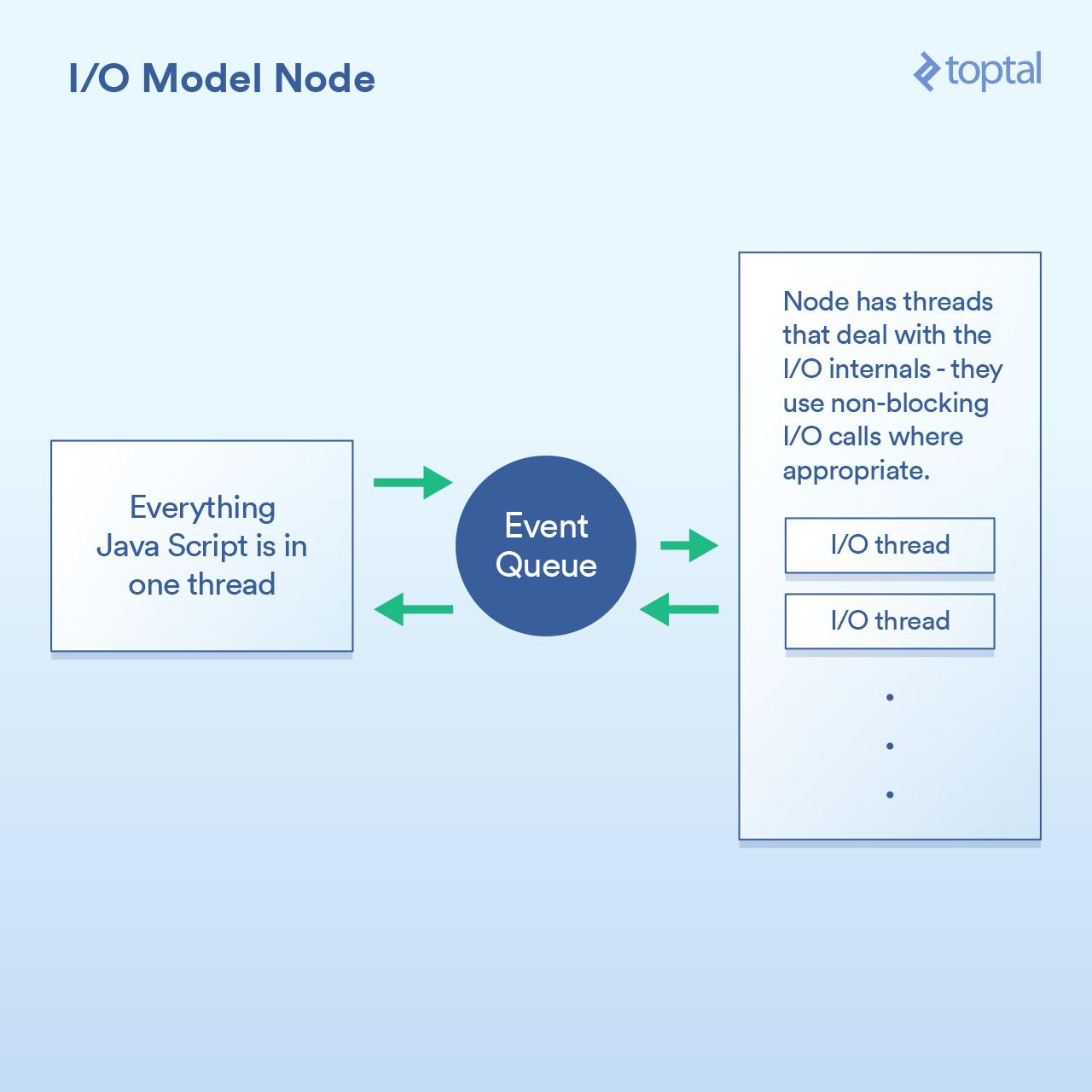
|
||||
|
||||
There is however a catch to this model. Under the hood, the reason for it has a lot more to do with how the V8 JavaScript engine (Chrome’s JS engine that is used by Node) is implemented [<sup style="border: 0px; vertical-align: super; min-height: 0px; min-width: 0px;">1</sup>][2] than anything else. The JS code that you write all runs in a single thread. Think about that for a moment. It means that while I/O is performed using efficient non-blocking techniques, your JS can that is doing CPU-bound operations runs in a single thread, each chunk of code blocking the next. A common example of where this might come up is looping over database records to process them in some way before outputting them to the client. Here’s an example that shows how that works:
|
||||
|
||||
```
|
||||
var handler = function(request, response) {
|
||||
|
||||
connection.query('SELECT ...', function (err, rows) {
|
||||
|
||||
if (err) { throw err };
|
||||
|
||||
for (var i = 0; i < rows.length; i++) {
|
||||
// do processing on each row
|
||||
}
|
||||
|
||||
response.end(...); // write out the results
|
||||
|
||||
})
|
||||
|
||||
};
|
||||
|
||||
```
|
||||
|
||||
While Node does handle the I/O efficiently, that `for` loop in the example above is using CPU cycles inside your one and only main thread. This means that if you have 10,000 connections, that loop could bring your entire application to a crawl, depending on how long it takes. Each request must share a slice of time, one at a time, in your main thread.
|
||||
|
||||
The premise this whole concept is based on is that the I/O operations are the slowest part, thus it is most important to handle those efficiently, even if it means doing other processing serially. This is true in some cases, but not in all.
|
||||
|
||||
The other point is that, and while this is only an opinion, it can be quite tiresome writing a bunch of nested callbacks and some argue that it makes the code significantly harder to follow. It’s not uncommon to see callbacks nested four, five, or even more levels deep inside Node code.
|
||||
|
||||
We’re back again to the trade-offs. The Node model works well if your main performance problem is I/O. However, its achilles heel is that you can go into a function that is handling an HTTP request and put in CPU-intensive code and bring every connection to a crawl if you’re not careful.
|
||||
|
||||
### Naturally Non-blocking: Go
|
||||
|
||||
Before I get into the section for Go, it’s appropriate for me to disclose that I am a Go fanboy. I’ve used it for many projects and I’m openly a proponent of its productivity advantages, and I see them in my work when I use it.
|
||||
|
||||
That said, let’s look at how it deals with I/O. One key feature of the Go language is that it contains its own scheduler. Instead of each thread of execution corresponding to a single OS thread, it works with the concept of “goroutines.” And the Go runtime can assign a goroutine to an OS thread and have it execute, or suspend it and have it not be associated with an OS thread, based on what that goroutine is doing. Each request that comes in from Go’s HTTP server is handled in a separate Goroutine.
|
||||
|
||||
The diagram of how the scheduler works looks like this:
|
||||
|
||||
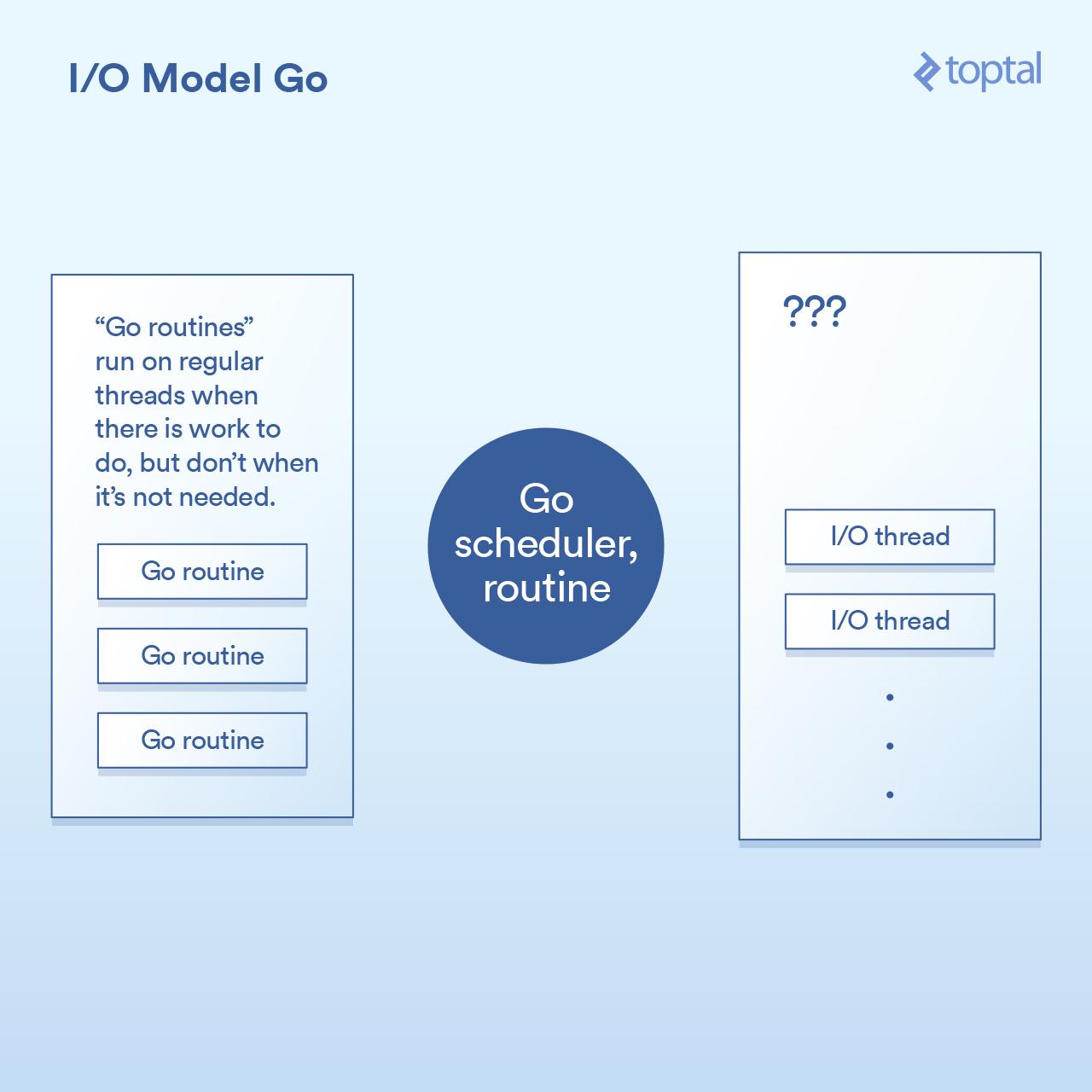
|
||||
|
||||
Under the hood, this is implemented by various points in the Go runtime that implement the I/O call by making the request to write/read/connect/etc., put the current goroutine to sleep, with the information to wake the goroutine back up when further action can be taken.
|
||||
|
||||
In effect, the Go runtime is doing something not terribly dissimilar to what Node is doing, except that the callback mechanism is built into the implementation of the I/O call and interacts with the scheduler automatically. It also does not suffer from the restriction of having to have all of your handler code run in the same thread, Go will automatically map your Goroutines to as many OS threads it deems appropriate based on the logic in its scheduler. The result is code like this:
|
||||
|
||||
```
|
||||
func ServeHTTP(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
// the underlying network call here is non-blocking
|
||||
rows, err := db.Query("SELECT ...")
|
||||
|
||||
for _, row := range rows {
|
||||
// do something with the rows,
|
||||
// each request in its own goroutine
|
||||
}
|
||||
|
||||
w.Write(...) // write the response, also non-blocking
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
As you can see above, the basic code structure of what we are doing resembles that of the more simplistic approaches, and yet achieves non-blocking I/O under the hood.
|
||||
|
||||
In most cases, this ends up being “the best of both worlds.” Non-blocking I/O is used for all of the important things, but your code looks like it is blocking and thus tends to be simpler to understand and maintain. The interaction between the Go scheduler and the OS scheduler handles the rest. It’s not complete magic, and if you build a large system, it’s worth putting in the time to understand more detail about how it works; but at the same time, the environment you get “out-of-the-box” works and scales quite well.
|
||||
|
||||
Go may have its faults, but generally speaking, the way it handles I/O is not among them.
|
||||
|
||||
### Lies, Damned Lies and Benchmarks
|
||||
|
||||
It is difficult to give exact timings on the context switching involved with these various models. I could also argue that it’s less useful to you. So instead, I’ll give you some basic benchmarks that compare overall HTTP server performance of these server environments. Bear in mind that a lot of factors are involved in the performance of the entire end-to-end HTTP request/response path, and the numbers presented here are just some samples I put together to give a basic comparison.
|
||||
|
||||
For each of these environments, I wrote the appropriate code to read in a 64k file with random bytes, ran a SHA-256 hash on it N number of times (N being specified in the URL’s query string, e.g., `.../test.php?n=100`) and print the resulting hash in hex. I chose this because it’s a very simple way to run the same benchmarks with some consistent I/O and a controlled way to increase CPU usage.
|
||||
|
||||
See [these benchmark notes][3] for a bit more detail on the environments used.
|
||||
|
||||
First, let’s look at some low concurrency examples. Running 2000 iterations with 300 concurrent requests and only one hash per request (N=1) gives us this:
|
||||
|
||||
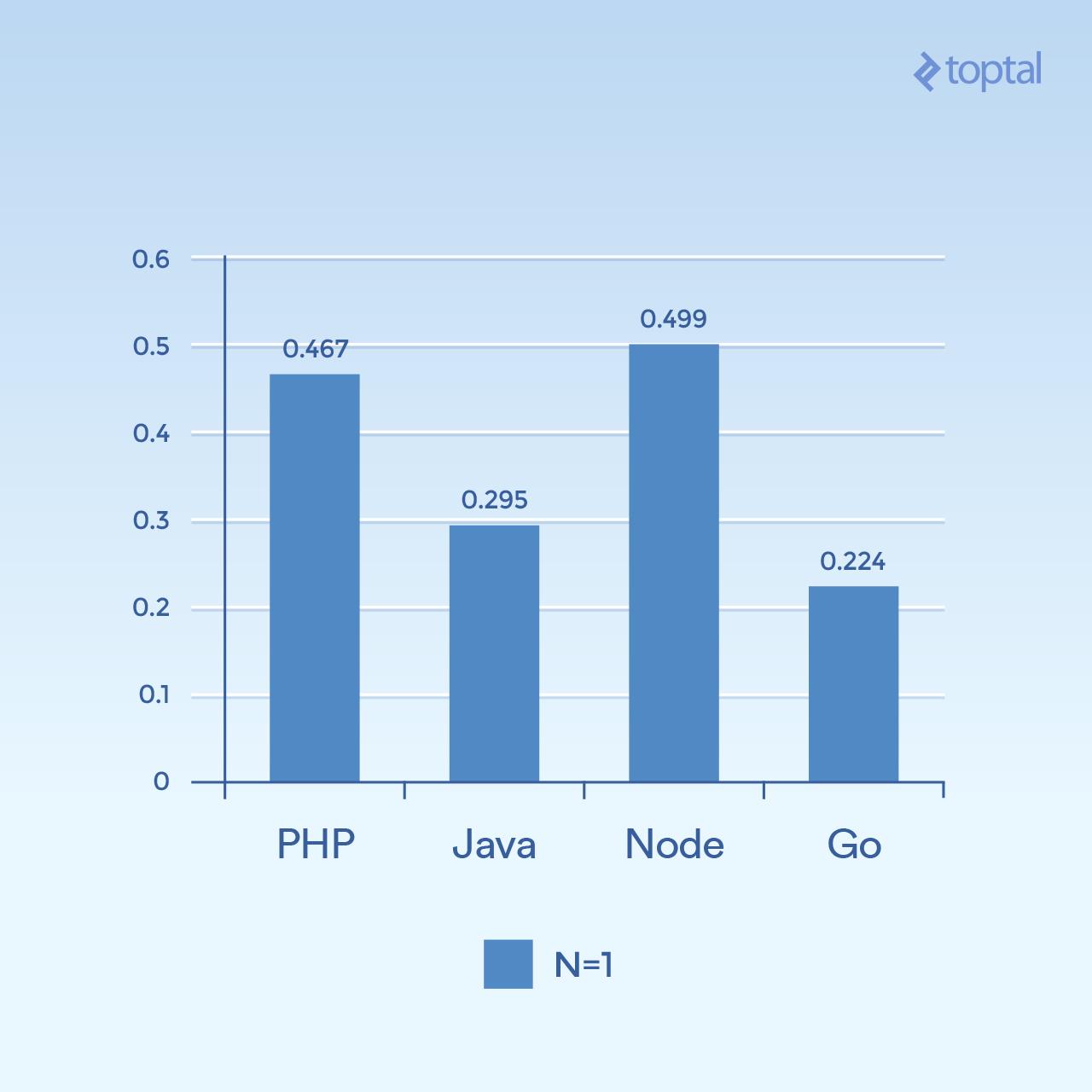
|
||||
|
||||
Times are the mean number of milliseconds to complete a request across all concurrent requests. Lower is better.
|
||||
|
||||
It’s hard to draw a conclusion from just this one graph, but this to me seems that, at this volume of connection and computation, we’re seeing times that more to do with the general execution of the languages themselves, much more so that the I/O. Note that the languages which are considered “scripting languages” (loose typing, dynamic interpretation) perform the slowest.
|
||||
|
||||
But what happens if we increase N to 1000, still with 300 concurrent requests - the same load but 100x more hash iterations (significantly more CPU load):
|
||||
|
||||
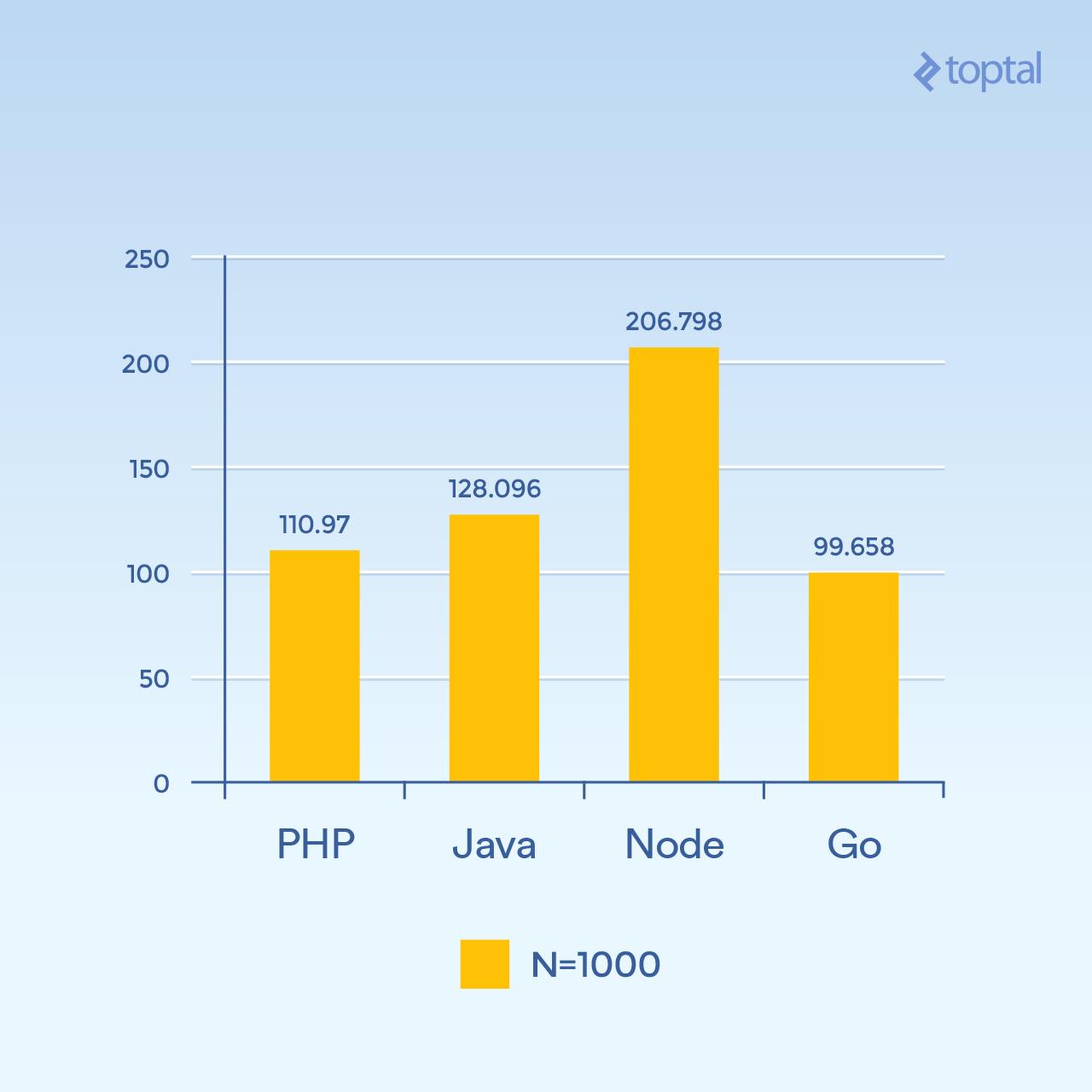
|
||||
|
||||
Times are the mean number of milliseconds to complete a request across all concurrent requests. Lower is better.
|
||||
|
||||
All of a sudden, Node performance drops significantly, because the CPU-intensive operations in each request are blocking each other. And interestingly enough, PHP’s performance gets much better (relative to the others) and beats Java in this test. (It’s worth noting that in PHP the SHA-256 implementation is written in C and the execution path is spending a lot more time in that loop, since we’re doing 1000 hash iterations now).
|
||||
|
||||
Now let’s try 5000 concurrent connections (with N=1) - or as close to that as I could come. Unfortunately, for most of these environments, the failure rate was not insignificant. For this chart, we’ll look at the total number of requests per second. _The higher the better_ :
|
||||
|
||||
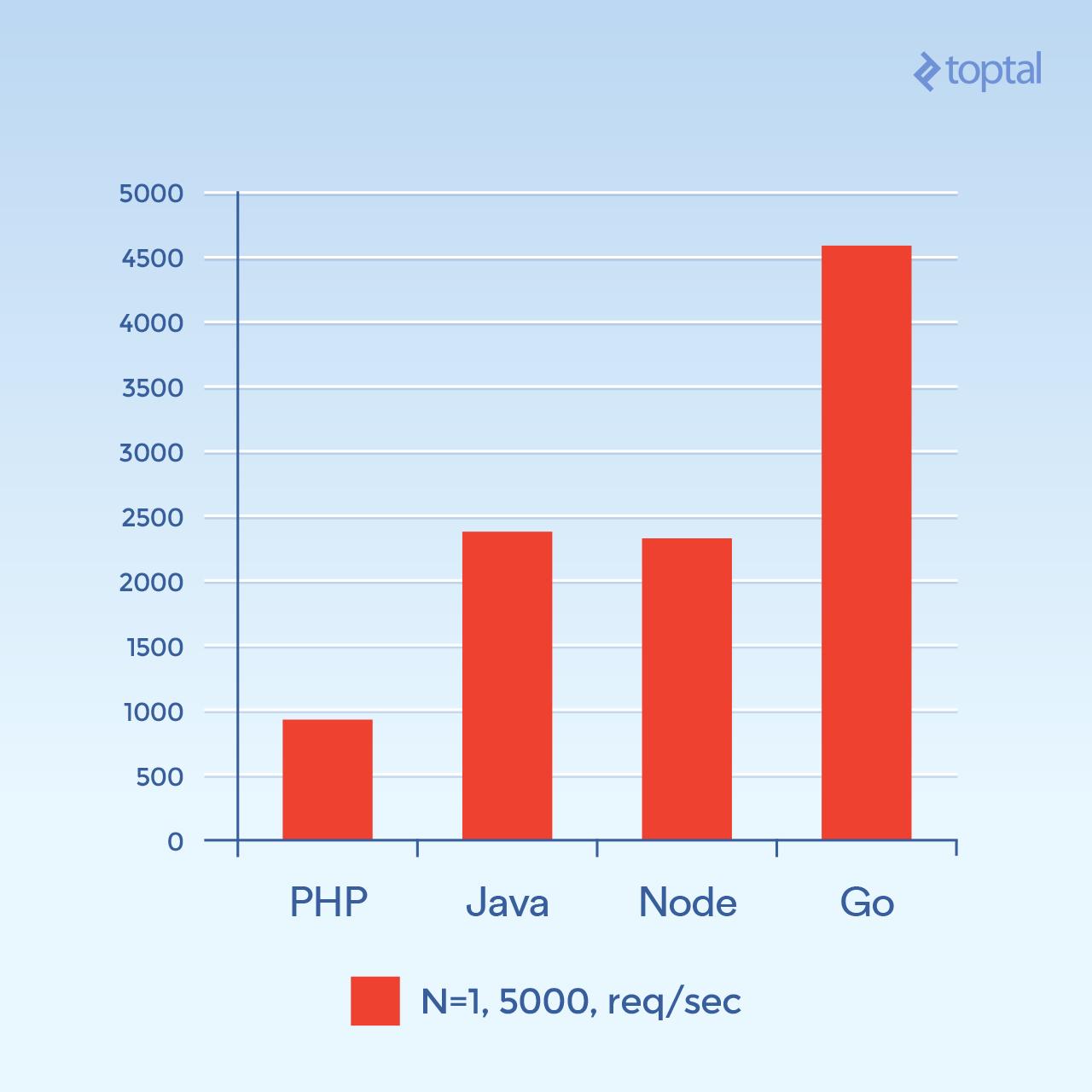
|
||||
|
||||
Total number of requests per second. Higher is better.
|
||||
|
||||
And the picture looks quite different. It’s a guess, but it looks like at high connection volume the per-connection overhead involved with spawning new processes and the additional memory associated with it in PHP+Apache seems to become a dominant factor and tanks PHP’s performance. Clearly, Go is the winner here, followed by Java, Node and finally PHP.
|
||||
|
||||
While the factors involved with your overall throughput are many and also vary widely from application to application, the more you understand about the guts of what is going on under the hood and the tradeoffs involved, the better off you’ll be.
|
||||
|
||||
### In Summary
|
||||
|
||||
With all of the above, it’s pretty clear that as languages have evolved, the solutions to dealing with large-scale applications that do lots of I/O have evolved with it.
|
||||
|
||||
To be fair, both PHP and Java, despite the descriptions in this article, do have [implementations][4] of [non-blocking I/O][5] [available for use][6] in [web applications][7]. But these are not as common as the approaches described above, and the attendant operational overhead of maintaining servers using such approaches would need to be taken into account. Not to mention that your code must be structured in a way that works with such environments; your “normal” PHP or Java web application usually will not run without significant modifications in such an environment.
|
||||
|
||||
As a comparison, if we consider a few significant factors that affect performance as well as ease of use, we get this:
|
||||
|
||||
| Language | Threads vs. Processes | Non-blocking I/O | Ease of Use |
|
||||
| --- | --- | --- | --- |
|
||||
| PHP | Processes | No | |
|
||||
| Java | Threads | Available | Requires Callbacks |
|
||||
| Node.js | Threads | Yes | Requires Callbacks |
|
||||
| Go | Threads (Goroutines) | Yes | No Callbacks Needed |
|
||||
|
||||
Threads are generally going to be much more memory efficient than processes, since they share the same memory space whereas processes don’t. Combining that with the factors related to non-blocking I/O, we can see that at least with the factors considered above, as we move down the list the general setup as it related to I/O improves. So if I had to pick a winner in the above contest, it would certainly be Go.
|
||||
|
||||
Even so, in practice, choosing an environment in which to build your application is closely connected to the familiarity your team has with said environment, and the overall productivity you can achieve with it. So it may not make sense for every team to just dive in and start developing web applications and services in Node or Go. Indeed, finding developers or the familiarity of your in-house team is often cited as the main reason to not use a different language and/or environment. That said, times have changed over the past fifteen years or so, a lot.
|
||||
|
||||
Hopefully the above helps paint a clearer picture of what is happening under the hood and gives you some ideas of how to deal with real-world scalability for your application. Happy inputting and outputting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.toptal.com/back-end/server-side-io-performance-node-php-java-go
|
||||
|
||||
作者:[ BRAD PEABODY][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.toptal.com/resume/brad-peabody
|
||||
[1]:https://www.pinterest.com/pin/414401603185852181/
|
||||
[2]:http://www.journaldev.com/7462/node-js-architecture-single-threaded-event-loop
|
||||
[3]:https://peabody.io/post/server-env-benchmarks/
|
||||
[4]:http://reactphp.org/
|
||||
[5]:http://amphp.org/
|
||||
[6]:http://undertow.io/
|
||||
[7]:https://netty.io/
|
||||
@ -1,192 +0,0 @@
|
||||
Brewing beer with Linux, Python, and Raspberry Pi
|
||||
============================================================
|
||||
|
||||
### A handy how-to for building a homemade homebrew setup with Python and the Raspberry Pi.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
[Quinn Dombrowski][21]. Modified by Opensource.com. [CC BY-SA 4.0][22].
|
||||
|
||||
I started brewing my own beer more than 10 years ago. Like most homebrewers, I started in my kitchen making extract-based brews. This required the least equipment and still resulted in really tasty beer. Eventually I stepped up to all-grain brewing using a big cooler for my mash tun. For several years I was brewing 5 gallons at a time, but brewing 10 gallons takes the same amount of time and effort (and only requires slightly larger equipment), so a few years ago I stepped it up. After moving up to 10 gallons, I stumbled across [StrangeBrew Elsinore][23] and realized what I _really_ needed to do was convert my whole system to be all-electric, and run it with a [Raspberry Pi][24].
|
||||
|
||||
There is a ton of great information available for building your own all-electric homebrew system, and most brewers start out at [TheElectricBrewery.com][25]. Just putting together the control panel can get pretty complicated, although the simplest approach is outlined well there. Of course you can also take [a less expensive approach][26] and still end up with the same result—a boil kettle and hot liquor tank powered by heating elements and managed by a PID controller. I think that's a little too boring though (and it also means you don't get neat graphs of your brew process).
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
|
||||
* [What is Raspberry Pi?][2]
|
||||
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
### Hardware supplies
|
||||
|
||||
Before I talked myself out of the project, I decided to start buying parts. My basic design was a Hot Liquor Tank (HLT) and boil kettle with 5500w heating elements in them, plus a mash tun with a false bottom. I would use a pump to recirculate the mash through a 50' stainless coil in the HLT (a ["heat exchanger recirculating mash system", known as HERMS][27]). I would need a second pump to circulate the water in the HLT, and to help with transferring water to the mash tun. All of the electrical components would be controlled with a Raspberry Pi.
|
||||
|
||||
Building my electric brew system and automating as much of it as possible meant I was going to need the following:
|
||||
|
||||
* HLT with a 5500w electric heating element
|
||||
|
||||
* HERMS coil (50' 1/2" stainless steel) in the HLT
|
||||
|
||||
* boil kettle with a 5500w electric heating element
|
||||
|
||||
* multiple solid-state relays to switch the heaters on and off
|
||||
|
||||
* 2 high-temp food-grade pumps
|
||||
|
||||
* relays for switching the pumps on and off
|
||||
|
||||
* fittings and high-temp silicon tubing
|
||||
|
||||
* stainless ball valves
|
||||
|
||||
* 1-wire temperature probes
|
||||
|
||||
* lots of wire
|
||||
|
||||
* electrical box to hold everything
|
||||
|
||||
### [aedo-f1.png][11]
|
||||
|
||||

|
||||
|
||||
Brew system (photo by Christopher Aedo. [CC BY-SA 4.0)][5]
|
||||
|
||||
The details of building out the electrical side of the system are really well covered by [The Electric Brewery][28], so I won't repeat their detailed information. You can read through and follow their suggestions while planning to replace the PID controllers with a Raspberry Pi.
|
||||
|
||||
One important thing to note is the solid-state relay (SSR) signal voltage. Many tutorials suggest using SSRs that need a 12-volt signal to close the circuit. The Raspberry Pi GPIO pins will only output 3v, however. Be sure to purchase relays that will trigger on 3 volts.
|
||||
|
||||
### [aedo-f2.png][12]
|
||||
|
||||

|
||||
|
||||
Inkbird SSR (photo by Christopher Aedo. [CC BY-SA 4.0)][6]
|
||||
|
||||
To run your brew system, your Pi must do two key things: sense temperature from a few different places, and turn relays on and off to control the heating elements. The Raspberry Pi easily is able to handle these tasks.
|
||||
|
||||
There are a few different ways to connect temp sensors to a Pi, but I've found the most convenient approach is to use the [1-Wire bus][29]. This allows for multiple sensors to share the same wire (actually three wires), which makes it a convenient way to instrument multiple components in your brew system. If you look for waterproof DS18B20 temperature sensors online, you'll find lots of options available. I used [Hilitchi DS18B20 Waterproof Temperature Sensors][30] for my project.
|
||||
|
||||
To control the heating elements, the Raspberry Pi includes several General Purpose IO (GPIO) pins that are software addressable. This allows you to send 3.3v to a relay by simply putting a **1** or a **0** in a file. The _Raspberry Pi—Driving a Relay using GPIO_ tutorial was the most helpful for me when I was first learning how all this worked. The GPIO controls multiple solid-state relays, turning on and off the heating elements as directed by the brewing software.
|
||||
|
||||
I first started working on the box to hold all the components. Because this would all be on a rolling cart, I wanted it to be relatively portable rather than permanently mounted. If I had a spot (for example, inside a garage, utility room, or basement), I would have used a larger electrical box mounted on the wall. Instead I found a decent-size [waterproof project box][31] that I expected I could shoehorn everything into. In the end, it turned out to be a little bit of a tight fit, but it worked out. In the bottom left corner is the Pi with a breakout board for connecting the GPIO to the 1-Wire temperature probes and the [solid state relays][32].
|
||||
|
||||
To keep the 240v SSRs cool, I cut holes in the case and stacked [copper shims][33] with CPU cooling grease between them and heat sinks mounted on the outside of the box. It worked out well and there haven't been any cooling issues inside the box. On the cover I put two switches for 120v outlets, plus two 240v LEDs to show which heating element was energized. I used dryer plugs and outlets for all connections so disconnecting a kettle from everything is easy. Everything worked right on the first try, too. (Sketching a wiring diagram first definitely pays off.)
|
||||
|
||||
The pictures are from the "proof-of-concept" version—the final production system should have two more SSRs so that both legs of the 240v circuit would be switched. The other thing I would like to switch via software is the pumps. Right now they're controlled via physical switches on the front of the box, but they could easily be controlled with relays.
|
||||
|
||||
### [aedo-f3.png][13]
|
||||
|
||||

|
||||
|
||||
Control box (photo by Christopher Aedo. [CC BY-SA 4.0)][7]
|
||||
|
||||
The only other thing I needed that was a little tricky to find was a compression fitting for the temperature probes. The probes were mounted in T fittings before the valve on the lowest bulkhead in both the HLT and the mash tun. As long as the liquid is flowing past the temp sensor, it's going to be accurate. I thought about adding a thermowell into the kettles as well, but realized that's not going to be useful for me based on my brewing process. Anyway, I purchased [1/4" compression fittings][34] and they worked out perfectly.
|
||||
|
||||
### Software
|
||||
|
||||
Once the hardware was sorted out, I had time to play with the software. I ran the latest [Raspbian distribution][35] on the Pi; nothing special was required on the operating-system side.
|
||||
|
||||
I started with [Strangebrew Elsinore][36] brewing software, which I had discovered when a friend asked whether I had heard of [Hosehead][37], a Raspberry Pi-based brewing controller. I thought Hosehead looked great, but rather than buying a brewing controller, I wanted the challenge of building my own.
|
||||
|
||||
Setting up Strangebrew Elsinore was straightforward—the [documentation][38] was thorough and I did not encounter any problems. Even though Strangebrew Elsinore was working fine, Java seemed to be taxing my first-generation Pi sometimes, and it crashed on me more than once. I also was sad to see development stall and there did not seem to be a big community of additional contributors (although there were—and still are—plenty of people using it).
|
||||
|
||||
### CraftBeerPi
|
||||
|
||||
Then I stumbled across [CraftBeerPI][39], which is written in Python and supported by a development community of active contributors. The original author (and current maintainer) Manuel Fritsch is great about handling contributions and giving feedback on issues that folks open. Cloning [the repo][40] and getting started only took me a few minutes. The README also has a good example of connecting DS1820 temp sensors, along with notes on interfacing hardware to a Pi or a [C.H.I.P. computer][41].
|
||||
|
||||
On startup, CraftBeerPi walks users through a configuration process that discovers the temperature probes available and lets you specify which GPIO pins are managing which pieces of equipment.
|
||||
|
||||
### [aedo-f4.png][14]
|
||||
|
||||

|
||||
|
||||
CraftBeerPi (photo by Christopher Aedo. [CC BY-SA 4.0)][8]
|
||||
|
||||
Running a brew with this system is easy. I can count on it holding temperatures reliably, and I can input steps for a multi-temp step mash. Using CraftBeerPi has made my brew days a little bit boring, but I'm happy to trade off the "excitement" of traditional manually managed propane burners for the efficiency and consistency of this system.
|
||||
|
||||
CraftBeerPI's user-friendliness inspired me to set up another controller to run a "fermentation chamber." In my case, that was a second-hand refrigerator I found for US$ 50 plus a $25 heater) on the inside. CraftBeerPI easily can control the cooling and heating elements, and you can set up multiple temperature steps. For instance, this graph shows the fermentation temperatures for a session IPA I made recently. The fermentation chamber held the fermenting wort at 67F for four days, then ramped up one degree every 12 hours until it was at 72F. That temp was held for a two-day diacetyl rest. After that it was set to drop down to 65F for five days, during which time I "dry hopped" the beer. Finally, the beer was cold-crashed down to 38F. CraftBeerPI made adding each step and letting the software manage the fermentation easy.
|
||||
|
||||
### [aedo-f5.png][15]
|
||||
|
||||

|
||||
|
||||
SIPA fermentation profile (photo by Christopher Aedo. [CC BY-SA 4.0)][9]
|
||||
|
||||
I have also been experimenting with the [TILT hydrometer][42] to monitor the gravity of the fermenting beer via a Bluetooth-connected floating sensor. There are integration plans for this to get it working with CraftBeerPI, but for now it logs the gravity to a Google spreadsheet. Once this hydrometer can talk to the fermentation controller, setting automated fermentation profiles that take action directly based on the yeast activity would be easy—rather than banking on primary fermentation completing in four days, you can set the temperature ramp to kick off after the gravity is stable for 24 hours.
|
||||
|
||||
As with any project like this, imaging and planning improvements and additional components is easy. Still, I'm happy with where things stand today. I've brewed a lot of beer with this setup and am hitting the expected mash efficiency every time, and the beer has been consistently tasty. My most important customer—me!—is pleased with what I've been putting on tap in my kitchen.
|
||||
|
||||
### [aedo-f6.png][16]
|
||||
|
||||

|
||||
|
||||
Homebrew on tap (photo by Christopher Aedo. [CC BY-SA 4.0)][10]
|
||||
|
||||
_This article is based on Christopher's OpenWest talk, [Brewing Beer with Linux, Python and a RaspberryPi][18]. [OpenWest][19] will be held July 12-15, 2017 in Salt Lake City, Utah._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Christopher Aedo - Christopher Aedo has been working with and contributing to open source software since his college days. Most recently he can be found leading an amazing team of upstream developers at IBM who are also developer advocates. When he’s not at work or speaking at a conference, he’s probably using a RaspberryPi to brew and ferment a tasty homebrew in Portland OR.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi
|
||||
|
||||
作者:[ Christopher Aedo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu1
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu2
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu3
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu4
|
||||
[5]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[8]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[9]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[10]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[11]:https://opensource.com/file/358661
|
||||
[12]:https://opensource.com/file/358666
|
||||
[13]:https://opensource.com/file/358676
|
||||
[14]:https://opensource.com/file/359061
|
||||
[15]:https://opensource.com/file/358681
|
||||
[16]:https://opensource.com/file/359071
|
||||
[17]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi?rate=fbKzT1V9gqGsmNCTuQIashC1xaHT5P_2LUaeTn6Kz1Y
|
||||
[18]:https://www.openwest.org/custom/description.php?id=139
|
||||
[19]:https://www.openwest.org/
|
||||
[20]:https://opensource.com/user/145976/feed
|
||||
[21]:https://www.flickr.com/photos/quinndombrowski/
|
||||
[22]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[23]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||
[24]:https://opensource.com/tags/raspberry-pi
|
||||
[25]:http://www.theelectricbrewery.com/
|
||||
[26]:http://www.instructables.com/id/Electric-Brewery-Control-Panel-on-the-Cheap/
|
||||
[27]:https://byo.com/hops/item/1325-rims-and-herms-brewing-advanced-homebrewing
|
||||
[28]:http://theelectricbrewery.com/
|
||||
[29]:https://en.wikipedia.org/wiki/1-Wire
|
||||
[30]:https://smile.amazon.com/gp/product/B018KFX5X0/
|
||||
[31]:http://amzn.to/2hupFCr
|
||||
[32]:http://amzn.to/2hL8JDS
|
||||
[33]:http://amzn.to/2i4DYwy
|
||||
[34]:https://www.brewershardware.com/CF1412.html
|
||||
[35]:https://www.raspberrypi.org/downloads/raspbian/
|
||||
[36]:https://github.com/DougEdey/SB_Elsinore_Server
|
||||
[37]:https://brewtronix.com/
|
||||
[38]:http://dougedey.github.io/SB_Elsinore_Server/
|
||||
[39]:http://www.craftbeerpi.com/
|
||||
[40]:https://github.com/manuel83/craftbeerpi
|
||||
[41]:https://www.nextthing.co/pages/chip
|
||||
[42]:https://tilthydrometer.com/
|
||||
[43]:https://opensource.com/users/docaedo
|
||||
[44]:https://opensource.com/users/docaedo
|
||||
[45]:https://opensource.com/article/17/7/brewing-beer-python-and-raspberry-pi#comments
|
||||
@ -0,0 +1,436 @@
|
||||
【toutoudnf@gmail.com】翻译中
|
||||
Creating TCP / IP (port forwarding) tunnels with SSH: The 8 possible scenarios using OpenSSH
|
||||
============================================================
|
||||
|
||||
The typical function of the [Secure Shell (SSH)][21] network protocol is to access a remote system in terminal mode and execute commands there safely, because the data is encrypted. In addition, through this secure data connection, it is possible to create tunnels ( _port forwarding_ ) between the connected ends so that the TCP / IP connections are channeled through the SSH connection so that we can get away with any Firewall or port blocking whenever we have the possibility to connect with SSH.
|
||||
|
||||
As this topic is very much addressed by the entire network:
|
||||
|
||||
* [Wikipedia: SSH Tunneling][12]
|
||||
|
||||
* [O’Reilly: Using SSH Tunneling][13]
|
||||
|
||||
* [Ssh.com: Tunneling Explained][14]
|
||||
|
||||
* [Ssh.com: Port Forwarding][15]
|
||||
|
||||
* [SecurityFocus: SSH Port Forwarding][16]
|
||||
|
||||
* [Red Hat Magazine: SSH Port Forwarding][17]
|
||||
|
||||
In this entry we will not go into the details of port forwarding, but pretend to be a _cheat sheet_ , a quick reference ( _cheat sheet_ ) on how to forward TCP ports with [OpenSSH][22] in the 8 different scenarios that can be given. Other SSH clients such as [PuTTY][23] also allow port forwarding, but the configuration will be done with a graphical interface. We will focus on OpenSSH.
|
||||
|
||||
In the following examples and situations we will assume that we have an external network and an internal network and between both networks, the only possible connection is an SSH connection between the node of the external external _network1_ and the node of the internal internal _network1_ . The _external node2_ is on the external network and has full connectivity with _external1_ . The node _interno2_ is on the internal network and has full connectivity with _interno1_ .
|
||||
|
||||

|
||||
|
||||
Table of Contents [[hide][1]]
|
||||
|
||||
* [1 Scenario 1: Use on external1 a TCP service offered by internal1 (Local port forwarding / bind_address = localhost / host = localhost)][2]
|
||||
|
||||
* [2 Scenario 2: Use on external2 a TCP service offered by internal1 (Local port forwarding / bind_address = 0.0.0.0 / host = localhost)][3]
|
||||
|
||||
* [3 Scenario 3: Use in internal1 a TCP service offered by external1 (Remote port forwarding / bind_address = localhost / host = localhost)][4]
|
||||
|
||||
* [4 Scenario 4: Use in internal2 a TCP service offered by external1 (Remote port forwarding / bind_address = 0.0.0.0 / host = localhost)][5]
|
||||
|
||||
* [5 Scenario 5: Use in external1 a TCP service offered by internal2 (Local port forwarding / bind_address = localhost / host = internal2)][6]
|
||||
|
||||
* [6 Scenario 6: Use in internal1 a TCP service offered by external2 (Remote port forwarding / bind_address = localhost / host = external2)][7]
|
||||
|
||||
* [7 Scenario 7: Use in external2 a TCP service offered by internal2 (Local port forwarding / bind_address = 0.0.0.0 / host = internal2)][8]
|
||||
|
||||
* [8 Scenario 8: Use in internal2 a TCP service offered by external2 (Remote port forwarding / bind_address = 0.0.0.0 / host = external2)][9]
|
||||
|
||||
#### Scenario 1: Use on _external1_ a TCP service offered by _internal1_ (Local port forwarding / bind_address = localhost / host = localhost)
|
||||
|
||||
The system _externo1_ can be connected to the system _interno1 _ through OpenSSH and also wants to connect to the system server VNC (port 5900) _interno1_ :
|
||||
|
||||

|
||||
|
||||
We will achieve this with this command:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 7900: localhost: 5900 user @ internal1
|
||||
```
|
||||
|
||||
Now in the _external system1_ we can verify that port 7900 is waiting for connections:
|
||||
|
||||
```
|
||||
External1 $ netstat -ltn
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
...
|
||||
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
|
||||
...
|
||||
```
|
||||
|
||||
We only need to execute now on _external1_ :
|
||||
|
||||
```
|
||||
External1 $ vncviewer localhost :: 7900
|
||||
```
|
||||
|
||||
To connect to the _internal_ VNC _server1_ .
|
||||
|
||||
Note: This way to change the port is not documented in the
|
||||
|
||||
```
|
||||
<a href="http://www.realvnc.com/products/free/4.1/man/vncviewer.html">man vncviewer</a>
|
||||
```
|
||||
|
||||
. Appears in: [About VNCViewer configuration of the output TCP port][18]. This is also how [the TightVNC vncviewer][19] does.
|
||||
|
||||
#### Scenario 2: Use on _external2_ a TCP service offered by _internal1_ (Local port forwarding / bind_address = 0.0.0.0 / host = localhost)
|
||||
|
||||
This time we start from a situation similar to the previous one but now we want it to be _external2_ who connects to the _internal_ VNC _server1_ :
|
||||
|
||||

|
||||
|
||||
The appropriate command would be this:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 0.0.0.0:7900:localhost:5900 user @ internal1
|
||||
```
|
||||
|
||||
It is similar to the first scenario; But in that, if we look at the output of
|
||||
|
||||
```
|
||||
netstat
|
||||
```
|
||||
|
||||
the port, 7900 had been associated with the address of localhost, at 127.0.0.1, so only local processes could connect to it. This time we specify that the port is associated with 0.0.0.0, so that the system accepts connections to any local IP of the machine:
|
||||
|
||||
```
|
||||
External1 $ netstat -ltn
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
...
|
||||
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
|
||||
...
|
||||
```
|
||||
|
||||
So now, from _external2_ , we can execute:
|
||||
|
||||
```
|
||||
External2 $ vncviewer external1 :: 7900
|
||||
```
|
||||
|
||||
To connect to the _internal_ VNC _server1_ .
|
||||
|
||||
Instead of specifying the IP
|
||||
|
||||
```
|
||||
0.0.0.0
|
||||
```
|
||||
|
||||
, we could also use the option
|
||||
|
||||
```
|
||||
-g
|
||||
```
|
||||
|
||||
( _Allows remote hosts to connect to local forwarded ports_ ) like this:
|
||||
|
||||
```
|
||||
External1 $ ssh -g -L 7900: localhost: 5900 user @ internal1
|
||||
```
|
||||
|
||||
With exactly the same result as the previous command:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 0.0.0.0:7900:localhost:5900 user @ internal1
|
||||
```
|
||||
|
||||
On the other hand, if we had wanted to restrict the connection to only one of the local IPs of the system, we could have been more specific:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 192.168.24.80:7900:localhost:5900 user @ internal1
|
||||
|
||||
External1 $ netstat -ltn
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
...
|
||||
Tcp 0 0 192.168.24.80:7900 0.0.0.0:* LISTEN
|
||||
...
|
||||
```
|
||||
|
||||
#### Scenario 3: Use in _internal1_ a TCP service offered by _external1_ (Remote port forwarding / bind_address = localhost / host = localhost)
|
||||
|
||||
In the first scenario, it was the system itself with the SSH server that offered another service. Now the system with the SSH client is the one that offers the service that the system with the SSH server wants to use:
|
||||
|
||||

|
||||
|
||||
The command we will use is the same as in the first scenario by changing the parameter
|
||||
|
||||
```
|
||||
-L
|
||||
```
|
||||
|
||||
to
|
||||
|
||||
```
|
||||
-R
|
||||
```
|
||||
|
||||
:
|
||||
|
||||
```
|
||||
External1 $ ssh -R 7900: localhost: 5900 user @ internal1
|
||||
```
|
||||
|
||||
|
||||
And now where we will see that we have port 7900 listening is in _interno1_ :
|
||||
|
||||
```
|
||||
Internal1 $ netstat -lnt
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
...
|
||||
Tcp 0 0 127.0.0.1:7900 0.0.0.0:* LISTEN
|
||||
...
|
||||
```
|
||||
|
||||
So now from _internal1_ we can use the VNC server from _external1_ like this:
|
||||
|
||||
```
|
||||
Internal1 $ vncviewer localhost :: 7900
|
||||
```
|
||||
|
||||
|
||||
#### Scenario 4: Use in _internal2_ a TCP service offered by _external1_ (Remote port forwarding / bind_address = 0.0.0.0 / host = localhost)
|
||||
|
||||
Similar to the third scenario but now, as we did in the second scenario, we will associate the forwarded port with the IP
|
||||
|
||||
```
|
||||
0.0.0.0
|
||||
```
|
||||
|
||||
so that other nodes can use the service:
|
||||
|
||||

|
||||
|
||||
The appropriate command is:
|
||||
|
||||
```
|
||||
External1 $ ssh -R 0.0.0.0:7900:localhost:5900 user @ internal1
|
||||
```
|
||||
|
||||
|
||||
However, it is important to understand that, for security reasons, this will not work if in the configuration of the SSH server we do not modify the value of the parameter
|
||||
|
||||
```
|
||||
GatewayPorts
|
||||
```
|
||||
|
||||
|
||||
that by default is
|
||||
|
||||
```
|
||||
no
|
||||
```
|
||||
|
||||
:
|
||||
|
||||
```
|
||||
GatewayPorts
|
||||
```
|
||||
|
||||
> Specifies whether remote hosts are allowed to connect to ports forwarded for the client. By default, sshd(8) binds remote port forwardings to the loopback address. This prevents other remote hosts from connecting to forwarded ports. GatewayPorts can be used to specify that sshd should allow remote port forwardings to bind to non-loopback addresses, thus allowing other hosts to connect. The argument may be “no” to force remote port forwardings to be available to the local host only, “yes” to force remote port forwardings to bind to the wildcard address, or “clientspecified” to allow the client to select the address to which the forwarding is bound. The default is “no”.
|
||||
|
||||
|
||||
|
||||
If we do not have the possibility to modify the configuration of the server, we will not be able to use this type of port forwarding. At least not simply because, if there are no other impediments, a user can open a port (> 1024) to listen to external connections and forward that request to
|
||||
|
||||
```
|
||||
localhost:7900
|
||||
```
|
||||
|
||||
|
||||
. This could be done, for example, with [netcat][24] ( [Debian # 310431: sshd_config should warn about the GatewayPorts workaround.][25] )
|
||||
|
||||
So we
|
||||
|
||||
```
|
||||
/etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
will add:
|
||||
|
||||
```
|
||||
GatewayPorts clientspecified
|
||||
```
|
||||
|
||||
|
||||
After which we will have to reread the configuration with ”
|
||||
|
||||
```
|
||||
sudo /etc/init.d/ssh reload
|
||||
```
|
||||
|
||||
|
||||
” (Debian and Ubuntu).
|
||||
|
||||
We verify that _internal1_ is listening for requests from all IPs:
|
||||
|
||||
```
|
||||
Internal1 $ netstat -ltn
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State
|
||||
...
|
||||
Tcp 0 0 0.0.0.0:7900 0.0.0.0:* LISTEN
|
||||
...
|
||||
```
|
||||
|
||||
And we can already use the VNC service from _internal2_ :
|
||||
|
||||
```
|
||||
Internal2 $ internal vncviewer1 :: 7900
|
||||
```
|
||||
|
||||
|
||||
#### Scenario 5: Use in _external1_ a TCP service offered by _internal2_ (Local port forwarding / bind_address = localhost / host = internal2)
|
||||
|
||||

|
||||
|
||||
In this scenario we will use the following command:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 7900: internal2: 5900 user @ internal1
|
||||
```
|
||||
|
||||
And we will access the service by running the command in _external1_ :
|
||||
|
||||
```
|
||||
External1 $ vncviewer localhost :: 7900
|
||||
```
|
||||
|
||||
#### Scenario 6: Use in _internal1_ a TCP service offered by _external2_ (Remote port forwarding / bind_address = localhost / host = external2)
|
||||
|
||||

|
||||
|
||||
In this scenario we will use the following command:
|
||||
|
||||
```
|
||||
External1 $ ssh -R 7900: external2: 5900 user @ internal1
|
||||
```
|
||||
|
||||
And we will access the service by running the command in _internal1_ :
|
||||
|
||||
```
|
||||
Internal1 $ vncviewer localhost :: 7900
|
||||
```
|
||||
|
||||
#### Scenario 7: Use in _external2_ a TCP service offered by _internal2_ (Local port forwarding / bind_address = 0.0.0.0 / host = internal2)
|
||||
|
||||

|
||||
|
||||
In this scenario we will use the following command:
|
||||
|
||||
```
|
||||
External1 $ ssh -L 0.0.0.0:7900:internal2:5900 user @ internal1
|
||||
```
|
||||
|
||||
|
||||
Or alternatively:
|
||||
|
||||
```
|
||||
External1 $ ssh -g -L 7900: internal2: 5900 user @ internal1
|
||||
```
|
||||
|
||||
|
||||
And we will access the service by running the command in _external2_ :
|
||||
|
||||
```
|
||||
External2 $ vncviewer external1 :: 7900
|
||||
```
|
||||
|
||||
#### Scenario 8: Use in _internal2_ a TCP service offered by _external2_ (Remote port forwarding / bind_address = 0.0.0.0 / host = external2)
|
||||
|
||||

|
||||
|
||||
In this scenario we will use the following command:
|
||||
|
||||
```
|
||||
External1 $ ssh -R 0.0.0.0:7900:external2:5900 user @ internal1
|
||||
```
|
||||
|
||||
The SSH server must be configured with ”
|
||||
|
||||
```
|
||||
GatewayPorts clientspecified
|
||||
```
|
||||
|
||||
”, as we have seen in scenario 4.
|
||||
|
||||
And we will access the service by running the command in _internal2_ :
|
||||
|
||||
```
|
||||
Internal2 $ internal vncviewer1 :: 7900
|
||||
```
|
||||
|
||||
If we want to create many tunnels at once, it may be convenient to use a configuration file instead of composing a very long command. Let’s imagine that our only entry point to a network is through SSH and we need to create tunnels to access the different servers in the network via SSH, VNC or [Remote Desktop][26]. We could compose a file like the following with all the redirects that we will need (in relation to the mentioned SOCKS server.
|
||||
|
||||
```
|
||||
# SOCKS server
|
||||
DynamicForward 1080
|
||||
|
||||
# SSH redirects
|
||||
LocalForward 2221 serverlinux1: 22
|
||||
LocalForward 2222 serverlinux2: 22
|
||||
LocalForward 2223 172.16.23.45:22
|
||||
LocalForward 2224 172.16.23.48:22
|
||||
|
||||
# RDP redirects for Windows systems
|
||||
LocalForward 3391 serverwindows1: 3389
|
||||
LocalForward 3392 serverwindows2: 3389
|
||||
|
||||
# VNC redirects for systems with "vncserver"
|
||||
LocalForward 5902 serverlinux1: 5901
|
||||
LocalForward 5903 172.16.23.45:5901
|
||||
```
|
||||
|
||||
|
||||
And we only need to execute this to create all the redirects:
|
||||
|
||||
```
|
||||
External1 $ ssh -F $ HOME / redirects user @ internal1
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/
|
||||
|
||||
作者:[ Ahmad][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://wesharethis.com/author/ahmad/
|
||||
[1]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#
|
||||
[2]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_1_Use_onexternal1a_TCP_service_offered_byinternal1Local_port_forwarding_bind_address_localhost_host_localhost
|
||||
[3]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_2_Use_onexternal2a_TCP_service_offered_byinternal1Local_port_forwarding_bind_address_0000_host_localhost
|
||||
[4]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_3_Use_ininternal1a_TCP_service_offered_byexternal1Remote_port_forwarding_bind_address_localhost_host_localhost
|
||||
[5]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_4_Use_ininternal2a_TCP_service_offered_byexternal1Remote_port_forwarding_bind_address_0000_host_localhost
|
||||
[6]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_5_Use_inexternal1a_TCP_service_offered_byinternal2Local_port_forwarding_bind_address_localhost_host_internal2
|
||||
[7]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_6_Use_ininternal1a_TCP_service_offered_byexternal2Remote_port_forwarding_bind_address_localhost_host_external2
|
||||
[8]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_7_Use_inexternal2a_TCP_service_offered_byinternal2Local_port_forwarding_bind_address_0000_host_internal2
|
||||
[9]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#Scenario_8_Use_ininternal2a_TCP_service_offered_byexternal2Remote_port_forwarding_bind_address_0000_host_external2
|
||||
[10]:https://wesharethis.com/author/ahmad/
|
||||
[11]:https://wesharethis.com/2017/07/creating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh/#comments
|
||||
[12]:http://en.wikipedia.org/wiki/Tunneling_protocol#SSH_tunneling
|
||||
[13]:http://www.oreillynet.com/pub/a/wireless/2001/02/23/wep.html
|
||||
[14]:http://www.ssh.com/support/documentation/online/ssh/winhelp/32/Tunneling_Explained.html
|
||||
[15]:http://www.ssh.com/support/documentation/online/ssh/adminguide/32/Port_Forwarding.html
|
||||
[16]:http://www.securityfocus.com/infocus/1816
|
||||
[17]:http://magazine.redhat.com/2007/11/06/ssh-port-forwarding/
|
||||
[18]:http://www.realvnc.com/pipermail/vnc-list/2006-April/054551.html
|
||||
[19]:http://www.tightvnc.com/vncviewer.1.html
|
||||
[20]:https://bufferapp.com/add?url=https%3A%2F%2Fwesharethis.com%2F2017%2F07%2Fcreating-tcp-ip-port-forwarding-tunnels-ssh-8-possible-scenarios-using-openssh%2F&text=Creating%20TCP%20/%20IP%20(port%20forwarding)%20tunnels%20with%20SSH:%20The%208%20possible%20scenarios%20using%20OpenSSH
|
||||
[21]:http://en.wikipedia.org/wiki/Secure_Shell
|
||||
[22]:http://www.openssh.com/
|
||||
[23]:http://www.chiark.greenend.org.uk/~sgtatham/putty/
|
||||
[24]:http://en.wikipedia.org/wiki/Netcat
|
||||
[25]:http://bugs.debian.org/cgi-bin/bugreport.cgi?bug=310431
|
||||
[26]:http://en.wikipedia.org/wiki/Remote_Desktop_Services
|
||||
@ -1,3 +1,4 @@
|
||||
translate by hwlife
|
||||
[Betting on the Web][27]
|
||||
============================================================
|
||||
|
||||
|
||||
358
sources/tech/20170909 12 cool things you can do with GitHub.md
Normal file
358
sources/tech/20170909 12 cool things you can do with GitHub.md
Normal file
@ -0,0 +1,358 @@
|
||||
12 cool things you can do with GitHub
|
||||
============================================================
|
||||
translating by softpaopao
|
||||
|
||||
I can’t for the life of me think of an intro, so…
|
||||
|
||||
### #1 Edit code on GitHub.com
|
||||
|
||||
I’m going to start with one that I _think_ most people know (even though I didn’t know until a week ago).
|
||||
|
||||
When you’re in GitHub, looking at a file (any text file, any repository), there’s a little pencil up in the top right. If you click it, you can edit the file. When you’re done, hit Propose file change and GitHub will fork the repo for you and create a pull request.
|
||||
|
||||
Isn’t that wild? It creates the fork for you!
|
||||
|
||||
No need to fork and pull and change locally and push and create a PR.
|
||||
|
||||
|
||||
|
||||
|
||||
Not a real PR
|
||||
|
||||
This is great for fixing typos and a somewhat terrible idea for editing code.
|
||||
|
||||
### #2 Pasting images
|
||||
|
||||
You’re not just limited to text in comments and issue descriptions. Did you know you can paste an image straight from the clipboard? When you paste, you’ll see it gets uploaded (to the ‘cloud’, no doubt) and becomes the markdown for showing an image.
|
||||
|
||||
Neat.
|
||||
|
||||
### #3 Formatting code
|
||||
|
||||
If you want to write a code block, you can start with three backticks — just like you learned when you read the [Mastering Markdown][3] page — and GitHub will make an attempt to guess what language you’re writing.
|
||||
|
||||
But if you’re posting a snippet of something like Vue, Typescript or JSX, you can specify that explicitly to get the right highlighting.
|
||||
|
||||
Note the ````jsx` on the first line here:
|
||||
|
||||
|
||||
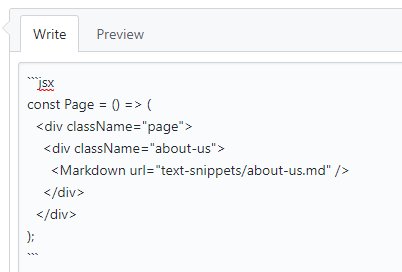
|
||||
|
||||
…which means the snippet is rendered correctly:
|
||||
|
||||
|
||||
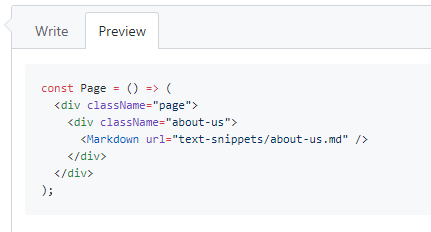
|
||||
|
||||
(This extends to gists, by the way. If you give a gist the extension of `.jsx`you’ll get JSX syntax highlighting.)
|
||||
|
||||
Here’s a list of [all the supported syntaxes][4].
|
||||
|
||||
### #4 Closing issues with magic words in PRs
|
||||
|
||||
Let’s say you’re creating a pull request that fixes issue #234\. You can put the text “fixes #234” in the description of your PR (or indeed anywhere in any comment on the PR).
|
||||
|
||||
Then, merging the PR automagically closes that issue. Isn’t that cool?
|
||||
|
||||
There’s [more to learn in the help][5].
|
||||
|
||||
### #5 Linking to comments
|
||||
|
||||
Have you even wanted to link to a particular comment but couldn’t work out how? That’s because you don’t know how to do it. But those days are behind you my friend, because I am here to tell you that clicking on the date/time next to the name is how you link to a comment.
|
||||
|
||||
|
||||
|
||||
|
||||
Hey, gaearon got a picture!
|
||||
|
||||
### #6 Linking to code
|
||||
|
||||
So you want to link to a specific line of code. I get that.
|
||||
|
||||
Try this: while looking at the file, click the line number next to said code.
|
||||
|
||||
Whoa, did you see that? The URL was updated with the line number! If you hold down shift and click another line number, SHAZAAM, the URL is updated again and now you’ve highlighted a range of lines.
|
||||
|
||||
Sharing that URL will link to this file and those lines. But hold on, that’s pointing to the current branch. What if the file changes? Perhaps a permalink to the file in its current state is what you’re after.
|
||||
|
||||
I’m lazy so I’ve done all of the above in one screenshot:
|
||||
|
||||
|
||||
|
||||
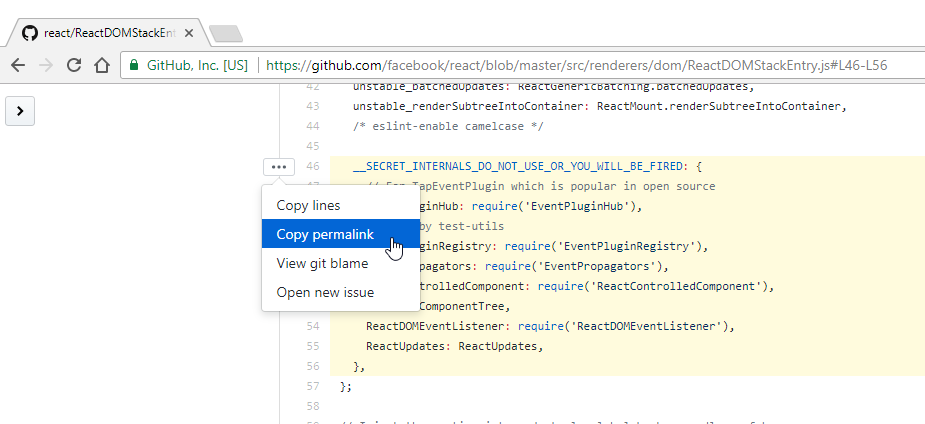
|
||||
|
||||
Speaking of URLs…
|
||||
|
||||
### #7 Using the GitHub URL like the command line
|
||||
|
||||
Navigating around GitHub using the UI is all well and fine. But sometimes the fastest way to get where you want to be is just to type it in the URL. For example, if I want to jump to a branch that I’m working on and see the diff with master, I can type `/compare/branch-name` after my repo name.
|
||||
|
||||
That will land me on the diff page for that branch:
|
||||
|
||||
|
||||
|
||||
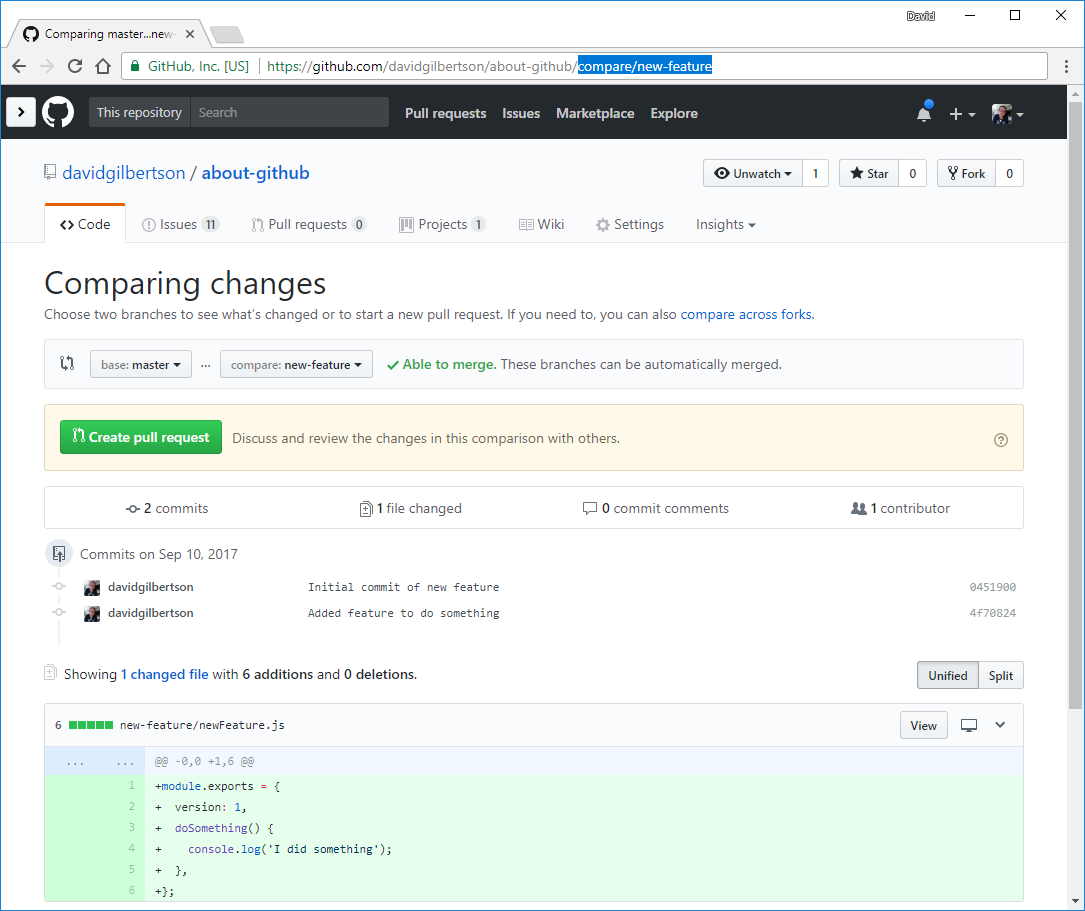
|
||||
|
||||
That’s a diff with master though, if I was working off an integration branch, I’d type `/compare/integration-branch...my-branch`
|
||||
|
||||
|
||||
|
||||
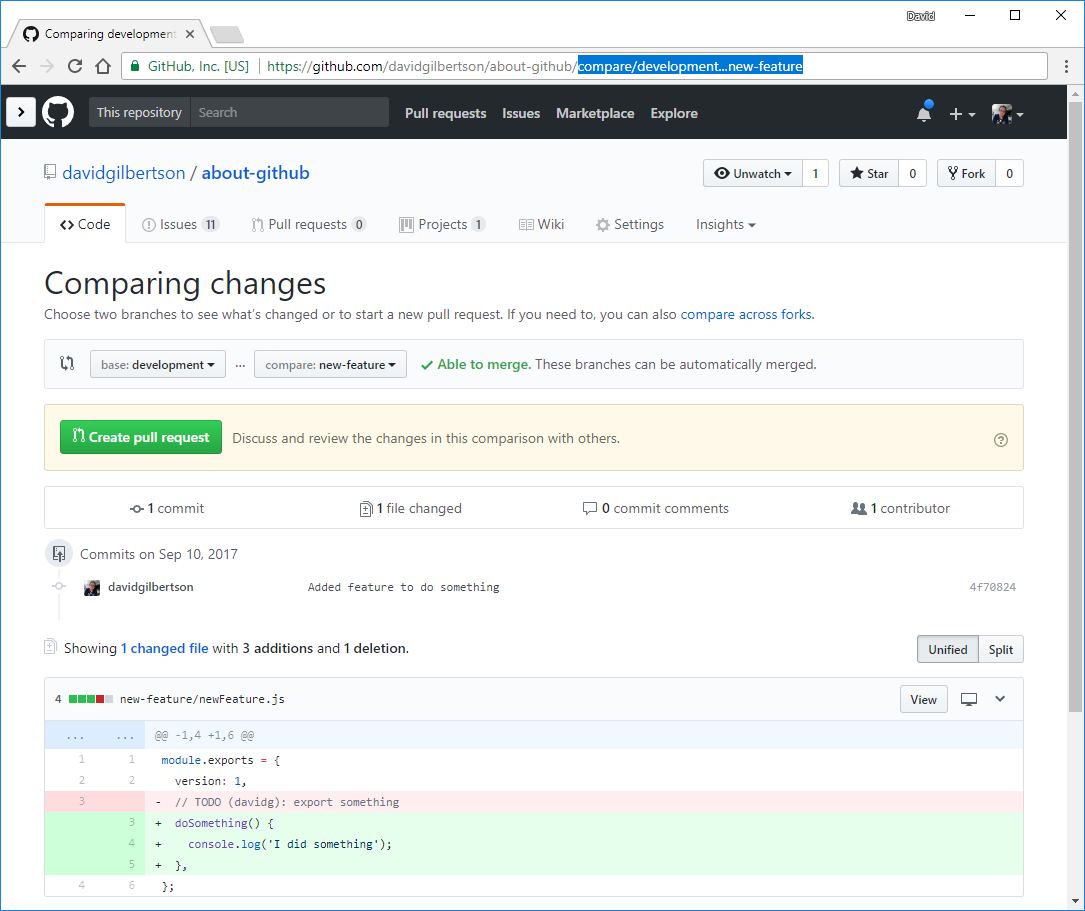
|
||||
|
||||
For you keyboard short-cutters out there, `ctrl`+`L` or `cmd`+`L` will jump the cursor up into the URL (in Chrome at least). This — coupled with the fact that your browser is going to do auto-complete — can make it a handy way to jump around between branches.
|
||||
|
||||
Pro-tip: use the arrow keys to move through Chrome’s auto-complete suggestions and hit `shift`+`delete` to remove an item from history (e.g. once a branch is merged).
|
||||
|
||||
(I really wonder if those shortcuts would be easier to read if I did them like `shift + delete`. But technically the ‘+’ isn’t part of it, so I don’t feel comfortable with that. This is what keeps _me_ up at night, Rhonda.)
|
||||
|
||||
### #8 Create lists, in issues
|
||||
|
||||
Do you want to see a list of check boxes in your issue?
|
||||
|
||||
|
||||
|
||||
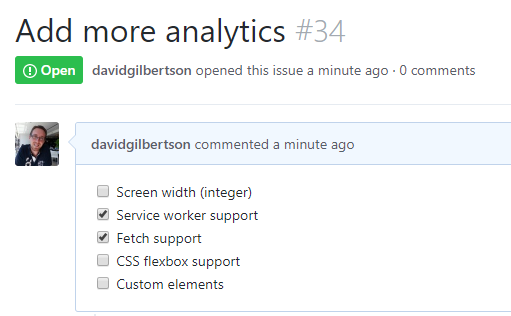
|
||||
|
||||
And would you like that to show up as a nifty “2 of 5” bar when looking at the issue in a list?
|
||||
|
||||
|
||||
|
||||
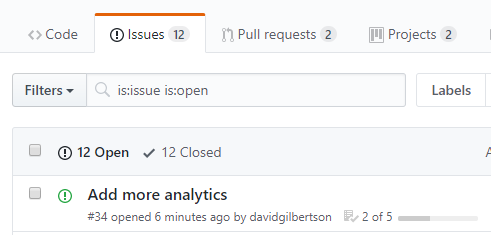
|
||||
|
||||
That’s great! You can create interactive check boxes with this syntax:
|
||||
|
||||
```
|
||||
- [ ] Screen width (integer)
|
||||
- [x] Service worker support
|
||||
- [x] Fetch support
|
||||
- [ ] CSS flexbox support
|
||||
- [ ] Custom elements
|
||||
```
|
||||
|
||||
That’s a space and a dash and a space and a left bracket and a space (or an x) and a close bracket and a space and then some words.
|
||||
|
||||
Then you can actually check/uncheck those boxes! For some reason this seems like technical wizardry to me. You can _check_ the boxes! And it updates the underlying text!
|
||||
|
||||
What will they think of next.
|
||||
|
||||
Oh and if you have this issue on a project board, it will show the progress there too:
|
||||
|
||||
|
||||
|
||||
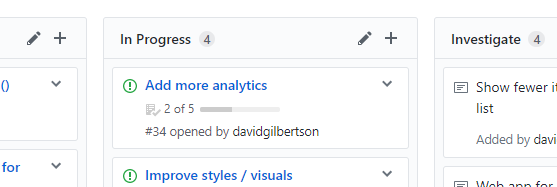
|
||||
|
||||
If you don’t know what I’m talking about when I say “on a project board” then you’re in for a treat further down the page.
|
||||
|
||||
Like, 2cm further down the page.
|
||||
|
||||
### #9 Project boards in GitHub
|
||||
|
||||
I’ve always used Jira for big projects. And for solo projects I’ve always used Trello. I quite like both of them.
|
||||
|
||||
When I learned a few weeks back that GitHub has its own offering, right there on the Projects tab of my repo, I thought I’d replicate a set of tasks that I already had on the boil in Trello.
|
||||
|
||||
|
||||
|
||||
|
||||
None of them are funny
|
||||
|
||||
And here’s the same in a GitHub project:
|
||||
|
||||
|
||||
|
||||
|
||||
Your eyes adjust to the lack of contrast eventually
|
||||
|
||||
For the sake of speed I added all of the above as ‘notes’ — which means they’re not actual GitHub issues.
|
||||
|
||||
But the power of managing your tasks in GitHub is that it’s integrated with the rest of the repository — so you’ll probably want to add existing issues from the repo to the board.
|
||||
|
||||
You can click Add Cards up in the top right and find the things you want to add. Here the special [search syntax][6] comes in handy, for example, type `is:pr is:open` and now you can drag any open PRs onto the board, or `label:bug` if you want to smash some bugs.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Or you can convert existing notes to issues.
|
||||
|
||||
|
||||
|
||||
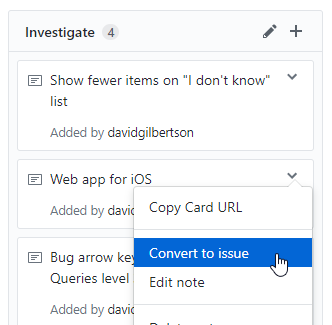
|
||||
|
||||
Or lastly, from an existing issue’s screen, add it to a project in the right pane.
|
||||
|
||||
|
||||
|
||||
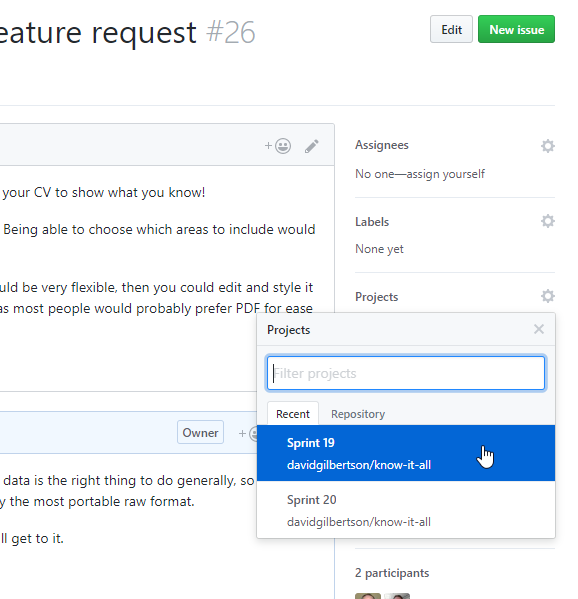
|
||||
It will go into a triage list on that project board so you can decide which column to put it in.
|
||||
|
||||
There’s a huge (huuuuge) benefit in having your ‘task’ definition in the same repo as the code that implements that task. It means that years from now you can do a git blame on a line of code and find your way back to the original rationale behind the task that resulted in that code, without needing to go and track it down in Jira/Trello/elsewhere.
|
||||
|
||||
#### The downsides
|
||||
|
||||
I’ve been trialling doing all tasks in GitHub instead of Jira for the last three weeks (on a smaller project that is kinda-sorta Kanban style) and I’m liking it so far.
|
||||
|
||||
But I can’t imagine using it on scrum project where I want to do proper estimating and calculate velocity and all that good stuff.
|
||||
|
||||
The good news is, there are so few ‘features’ of GitHub Projects that it won’t take you long to assess if it’s something you could switch to. So give it a crack, see what you think.
|
||||
|
||||
FWIW, I have _heard_ of [ZenHub][7] and opened it up 10 minutes ago for the first time ever. It effectively extends GitHub so you can estimate your issues and create epics and dependencies. There’s velocity and burndown charts too; it looks like it _might just be_ the greatest thing on earth.
|
||||
|
||||
Further reading: [GitHub help on Projects][8].
|
||||
|
||||
### #10 GitHub wiki
|
||||
|
||||
For an unstructured collection of pages — just like Wikipedia — the GitHub Wiki offering (which I will henceforth refer to as Gwiki) is great.
|
||||
|
||||
For a structured collection of pages — for example, your documentation — not so much. There is no way to say “this page is a child of that page”, or have nice things like ‘Next section’ and ‘Previous section’ buttons. And Hansel and Gretel would be screwed, because there’s no breadcrumbs.
|
||||
|
||||
(Side note, have you _read_ that story? It’s brutal. The two jerk kids murder the poor hungry old woman by burning her to death in her _own oven_ . No doubt leaving her to clean up the mess. I think this is why youths these days are so darn sensitive — bedtime stories nowadays don’t contain enough violence.)
|
||||
|
||||
Moving on — to take Gwiki for a spin, I entered a few pages from the NodeJS docs as wiki pages, then created a custom sidebar so that I could emulate having some actual structure. The sidebar is there at all times, although it doesn’t highlight the page you are currently on.
|
||||
|
||||
Links have to be manually maintained, but over all, I think it would work just fine. [Take a look][9] if you feel the need.
|
||||
|
||||
|
||||
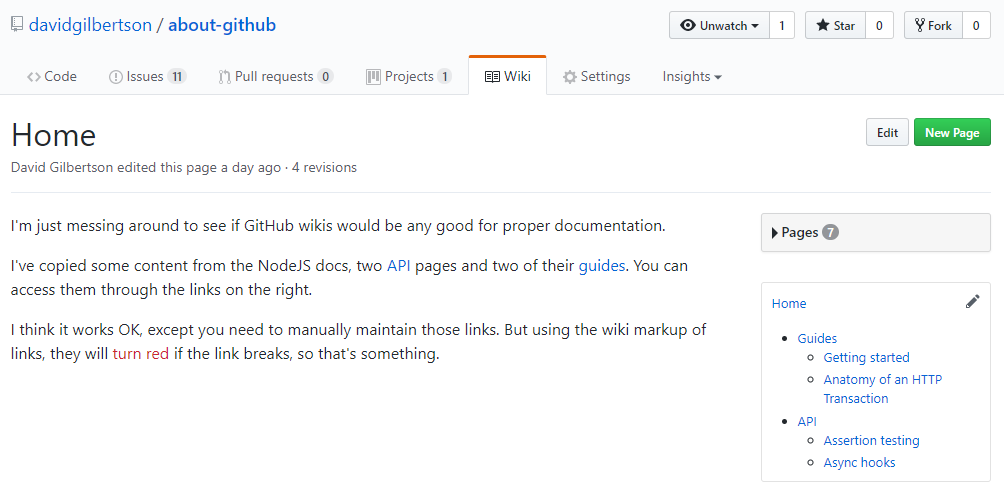
|
||||
|
||||
It’s not going to compete with something like GitBook (that’s what the [Redux docs][10] use) or a bespoke website. But it’s a solid 80% and it’s all right there in your repo.
|
||||
|
||||
I’m a fan.
|
||||
|
||||
My suggestion: if you’ve outgrown a single `README.md` file and want a few different pages for user guides or more detailed documentation, then your next stop should be a Gwiki.
|
||||
|
||||
If you start to feel the lack of structure/navigation is holding you back, move on to something else.
|
||||
|
||||
### #11 GitHub Pages (with Jekyll)
|
||||
|
||||
You may already know that you can use GitHub Pages to host a static site. And if you didn’t now you do. However this section is specifically about using _Jekyll_ to build out a site.
|
||||
|
||||
At its very simplest, GitHub Pages + Jekyll will render your `README.md` in a pretty theme. For example, take a look at my readme page from [about-github][11]:
|
||||
|
||||
|
||||
|
||||
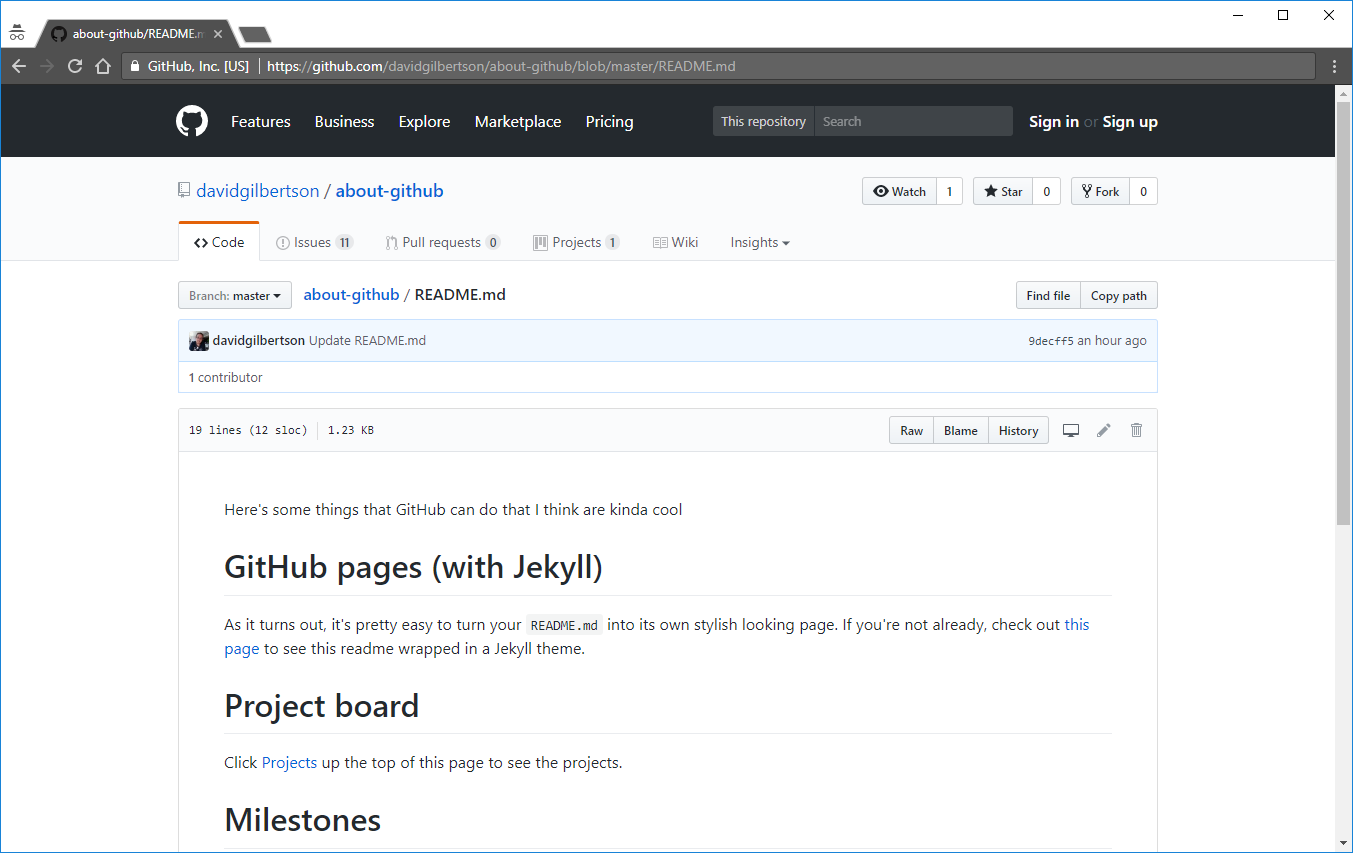
|
||||
|
||||
If I click the ‘settings’ tab for my site in GitHub, turn on GitHub Pages, and pick a Jekyll theme…
|
||||
|
||||
|
||||
|
||||
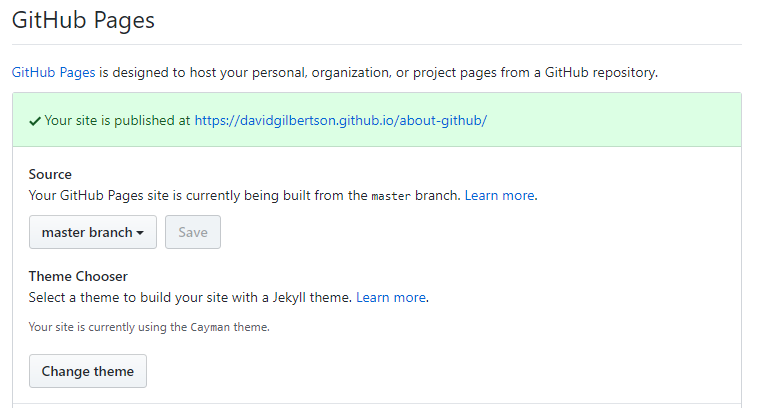
|
||||
|
||||
I will get a [Jekyll-themed page][12]:
|
||||
|
||||
|
||||
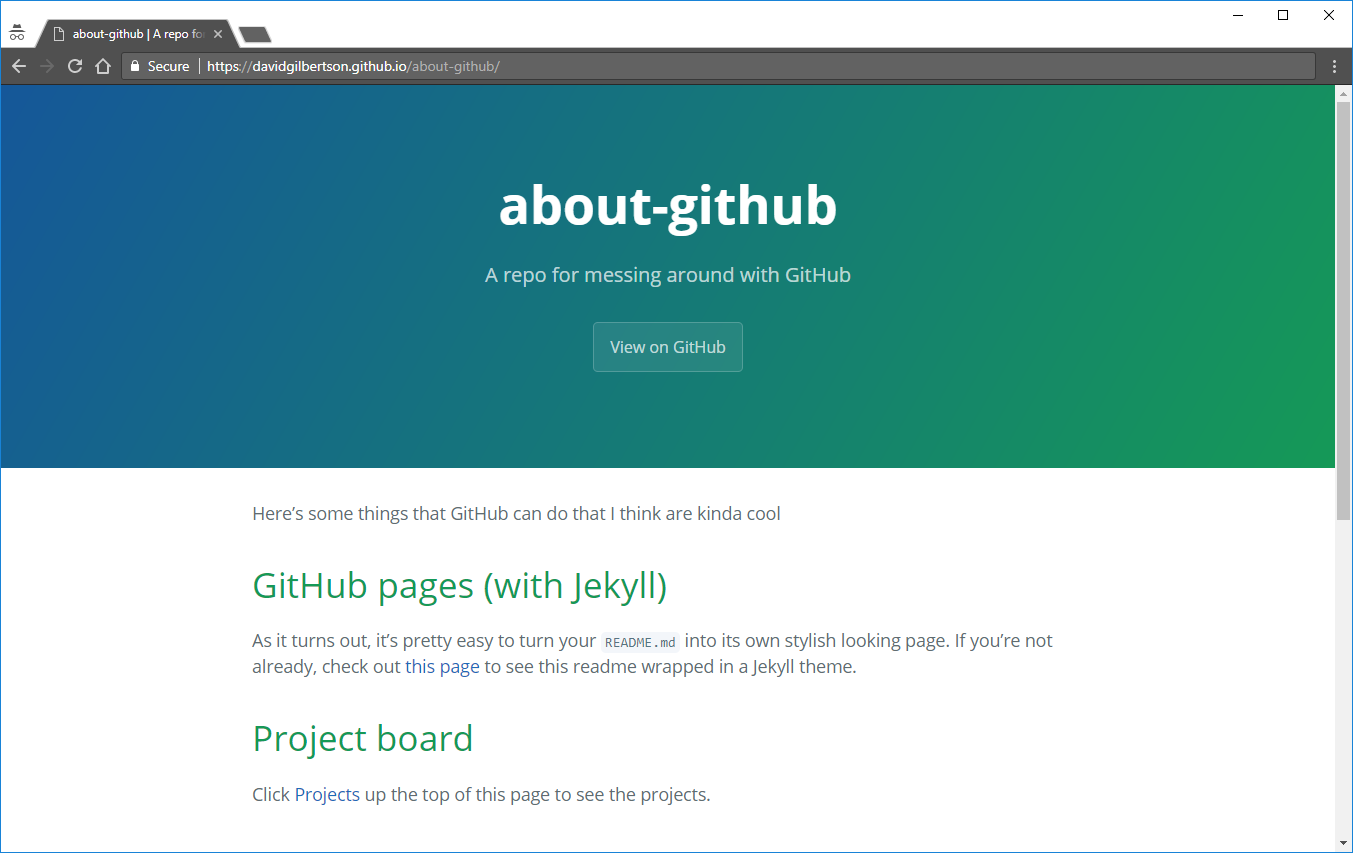
|
||||
|
||||
From this point on I can build out a whole static site based mostly around markdown files that are easily editable, essentially turning GitHub into a CMS.
|
||||
|
||||
I haven’t actually used it, but this is how the React and Bootstrap sites are made, so it can’t be terrible.
|
||||
|
||||
Note, it requires Ruby to run locally (Windows users will exchange knowing glances and walk in the other direction. macOS users will be like “What’s the problem, where are you going? Ruby is a universal platform! GEMS!”)
|
||||
|
||||
(It’s also worth adding here that “Violent or threatening content or activity” is not allowed on GitHub Pages, so you can’t go hosting your Hansel and Gretel reboot.)
|
||||
|
||||
#### My opinion
|
||||
|
||||
The more I looked into GitHub Pages + Jekyll (for this post), the more it seemed like there was something a bit strange about the whole thing.
|
||||
|
||||
The idea of ‘taking all the complexity out of having your own web site’ is great. But you still need a build setup to work on it locally. And there’s an awful lot of CLI commands for something so ‘simple’.
|
||||
|
||||
I just skimmed over the seven pages in the [Getting Started section][13], and I feel like _I’m_ the only simple thing around here. And I haven’t even learnt the simple “Front Matter” syntax or the ins and outs of the simple “Liquid templating engine” yet.
|
||||
|
||||
I’d rather just write a website.
|
||||
|
||||
To be honest I’m a bit surprised Facebook use this for the React docs when they could probably build their help docs with React and [pre-render to static HTML files][14] in under a day.
|
||||
|
||||
All they would need is some way to consume their existing markdown files as though they were coming from a CMS.
|
||||
|
||||
I wonder if…
|
||||
|
||||
### #12 Using GitHub as a CMS
|
||||
|
||||
Let’s say you have a website with some text in it, but you don’t want to store that text in the actual HTML markup.
|
||||
|
||||
Instead, you want to store chunks of text somewhere so they can easily be edited by non-developers. Perhaps with some form of version control. Maybe even a review process.
|
||||
|
||||
Here’s my suggestion: use markdown files stored in your repository to hold the text. Then have a component in your front end that fetches those chunks of text and renders them on the page.
|
||||
|
||||
I’m a React guy, so here’s an example of a `<Markdown>` component that, given the path to some markdown, will fetch, parse and render it as HTML.
|
||||
|
||||
|
||||
(I’m using the [marked][1] npm package to parse the markdown into HTML.)
|
||||
|
||||
That’s pointing to my example repo that has some markdown files in `[/text-snippets][2]`.
|
||||
|
||||
(You could also use the GiHub API to [get the contents][15] — but I’m not sure why you would.)
|
||||
|
||||
You would use such a component like so:
|
||||
|
||||
So now GitHub is your CMS, sort of, for whatever chunks of text you want it to house.
|
||||
|
||||
The above example only fetches the markdown after the component has mounted in the browser. If you want a static site then you’ll want to server-render this.
|
||||
|
||||
Good news! There’s nothing stopping you from fetching all the markdown files on the server (coupled with whatever caching strategy works for you). If you go down that road you might want to look at the GitHub API to get a list of all the markdown files in a directory.
|
||||
|
||||
### Bonus round — GitHub tools!
|
||||
|
||||
I’ve used the [Octotree Chrome extension][16] for a while now and I recommend it. Not wholeheartedly, but I recommend it nonetheless.
|
||||
|
||||
It gives you a panel over on the left with a tree view of whatever repo you’re looking at.
|
||||
|
||||
|
||||
|
||||
|
||||
From [this video][17] I learned about [octobox][18], which so far seems pretty good. It’s an inbox for your GitHub issues. That’s all I have to say about that.
|
||||
|
||||
Speaking of colors, I’ve taken all my screenshots above in the light theme so as not to startle you. But really, everything else I look at is dark themed, why must I endure a pallid GitHub?
|
||||
|
||||
|
||||
|
||||
|
||||
That’s a combo of the [Stylish][19] Chrome extension (which can apply themes to any website) and the [GitHub Dark][20] style. And to complete the look, the dark theme of Chrome DevTools (which is built in, turn it on in settings) and the [Atom One Dark Theme][21] for Chrome.
|
||||
|
||||
### Bitbucket
|
||||
|
||||
This doesn’t strictly fit anywhere in this post, but it wouldn’t be right if I didn’t give a shout-out to Bitbucket.
|
||||
|
||||
Two years ago I was starting a project and spent half a day assessing which git host was best, and Bitbucket won by a considerable margin. Their code review flow was just so far ahead (this was long before GitHub even had the concept of assigning a reviewer).
|
||||
|
||||
GitHub has since caught up in the review game, which is great. But sadly I haven’t had the chance to use Bitbucket in the last year — perhaps they’ve bounded ahead in some other way. So, I would urge anyone in the position of choosing a git host to check out Bitbucket too.
|
||||
|
||||
### Outro
|
||||
|
||||
So that’s it! I hope there were at least three things in here that you didn’t know already, and also I hope that you have a nice day.
|
||||
|
||||
Edit: there’s more tips in the comments; feel free to leave your own favourite. And seriously, I really do hope you have a nice day.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/12-cool-things-you-can-do-with-github-f3e0424cf2f0
|
||||
|
||||
作者:[David Gilbertson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@david.gilbertson
|
||||
[1]:https://www.npmjs.com/package/marked
|
||||
[2]:https://github.com/davidgilbertson/about-github/tree/master/text-snippets
|
||||
[3]:https://guides.github.com/features/mastering-markdown/
|
||||
[4]:https://github.com/github/linguist/blob/fc1404985abb95d5bc33a0eba518724f1c3c252e/vendor/README.md
|
||||
[5]:https://help.github.com/articles/closing-issues-using-keywords/
|
||||
[6]:https://help.github.com/articles/searching-issues-and-pull-requests/
|
||||
[7]:https://www.zenhub.com/
|
||||
[8]:https://help.github.com/articles/tracking-the-progress-of-your-work-with-project-boards/
|
||||
[9]:https://github.com/davidgilbertson/about-github/wiki
|
||||
[10]:http://redux.js.org/
|
||||
[11]:https://github.com/davidgilbertson/about-github
|
||||
[12]:https://davidgilbertson.github.io/about-github/
|
||||
[13]:https://jekyllrb.com/docs/home/
|
||||
[14]:https://github.com/facebookincubator/create-react-app/blob/master/packages/react-scripts/template/README.md#pre-rendering-into-static-html-files
|
||||
[15]:https://developer.github.com/v3/repos/contents/#get-contents
|
||||
[16]:https://chrome.google.com/webstore/detail/octotree/bkhaagjahfmjljalopjnoealnfndnagc?hl=en-US
|
||||
[17]:https://www.youtube.com/watch?v=NhlzMcSyQek&index=2&list=PLNYkxOF6rcIB3ci6nwNyLYNU6RDOU3YyL
|
||||
[18]:https://octobox.io/
|
||||
[19]:https://chrome.google.com/webstore/detail/stylish-custom-themes-for/fjnbnpbmkenffdnngjfgmeleoegfcffe/related?hl=en
|
||||
[20]:https://userstyles.org/styles/37035/github-dark
|
||||
[21]:https://chrome.google.com/webstore/detail/atom-one-dark-theme/obfjhhknlilnfgfakanjeimidgocmkim?hl=en
|
||||
@ -0,0 +1,47 @@
|
||||
polebug is translating
|
||||
|
||||
PostgreSQL's Hash Indexes Are Now Cool
|
||||
=======
|
||||
Since I just committed the last pending patch to improve hash indexes to PostgreSQL 11, and since most of the improvements to hash indexes were committed to PostgreSQL 10 which is expected to be released next week, it seems like a good time for a brief review of all the work that has been done over the last 18 months or so. Prior to version 10, hash indexes didn't perform well under concurrency, lacked write-ahead logging and thus were not safe in the face either of crashes or of replication, and were in various other ways second-class citizens. In PostgreSQL 10, this is largely fixed.
|
||||
|
||||
While I was involved in some of the design, credit for the hash index improvements goes first and foremost to my colleague Amit Kapila, whose [blog entry on this topic is worth reading][1]. The problem with hash indexes wasn't simply that nobody had bothered to write the code for write-ahead logging, but that the code was not structured in a way that made it possible to add write-ahead logging that would actually work correctly. To split a bucket, the system would lock the existing bucket (using a fairly inefficient locking mechanism), move half the tuples to the new bucket, compact the existing bucket, and release the lock. Even if the individual changes had been logged, a crash at the wrong time could have left the index in a corrupted state. So, Amit's first step was to redesign the locking mechanism. The [new mechanism][2] allows scans and splits to proceed in parallel to some degree, and allows a split interrupted by an error or crash to be completed at a later time. Once that was done a bunch of resulting bugs fixed, and some refactoring work completed, another patch from Amit added [write-ahead logging support for hash indexes][3].
|
||||
|
||||
In the meantime, it was discovered that hash indexes had missed out on many fairly obvious performance improvements which had been applied to btree over the years. Because hash indexes had no support for write-ahead logging, and because the old locking mechanism was so ponderous, there wasn't much motivation to make other performance improvements either. However, this meant that if hash indexes were to become a really useful technology, there was more to do than just add write-ahead logging. PostgreSQL's index access method abstraction layer allows indexes to retain a backend-private cache of information about the index so that the index itself need not be repeatedly consulted to obtain relevant metadata. btree and spgist indexes were using this mechanism, but hash indexes were not, so my colleague Mithun Cy wrote a patch to [cache the hash index's metapage using this mechanism][4]. Similarly, btree indexes have an optimization called "single page vacuum" which opportunistically removes dead index pointers from index pages, preventing a huge amount of index bloat which would otherwise occur. My colleague Ashutosh Sharma wrote a patch to [port this logic over to hash indexes][5], dramatically reducing index bloat there as well. Finally, btree indexes have since 2006 had a feature to avoid locking and unlocking the same index page repeatedly -- instead, all tuples are slurped from the page in one shot and then returned one at a time. Ashutosh Sharma also [ported this logic to hash indexes][6], but that optimization didn't make it into v10 for lack of time. Of everything mentioned in this blog entry, this is the only improvement that won't show up until v11.
|
||||
|
||||
One of the more interesting aspects of the hash index work was the difficulty of determining whether the behavior was in fact correct. Changes to locking behavior may fail only under heavy concurrency, while a bug in write-ahead logging will probably only manifest in the case of crash recovery. Furthermore, in each case, the problems may be subtle. It's not enough that things run without crashing; they must also produce the right answer in all cases, and this can be difficult to verify. To assist in that task, my colleague Kuntal Ghosh followed up on work initially begun by Heikki Linnakangas and Michael Paquier and produced a WAL consistency checker that could be used not only as a private patch for developer testing but actually [committed to PostgreSQL][7]. The write-ahead logging code for hash indexes was extensively tested using this tool prior to commit, and it was very successful at finding bugs. The tool is not limited to hash indexes, though: it can be used to validate the write-ahead logging code for other modules as well, including the heap, all index AMs we have today, and other things that are developed in the future. In fact, it already succeeded in [finding a bug in BRIN][8].
|
||||
|
||||
While wal_consistency_checking is primarily a developer tool -- though it is suitable for use by users as well if a bug is suspected -- upgrades were also made to several tools intended for DBAs. Jesper Pedersen wrote a patch to [upgrade the pageinspect contrib module with support for hash indexes][9], on which Ashutosh Sharma did further work and to which Peter Eisentraut contributed test cases (which was a really good idea, since those test cases promptly failed, provoking several rounds of bug-fixing). The pgstattuple contrib module also [got support for hash indexes][10], due to work by Ashutosh Sharma.
|
||||
|
||||
Along the way, there were a few other performance improvements as well. One thing that I had not realized at the outset is that when a hash index begins a new round of bucket splits, the size on disk tended to abruptly double, which is not really a problem for a 1MB index but is a bit unfortunate if you happen to have a 64GB index. Mithun Cy addressed this problem to a degree by writing a patch to allow the doubling to be [divided into four stages][11], meaning that we'll go from 64GB to 80GB to 96GB to 112GB to 128GB instead of going from 64GB to 128GB in one shot. This could be improved further, but it would require deeper restructuring of the on-disk format and some careful thinking about the effects on lookup performance.
|
||||
|
||||
A report from [a tester who goes by "AP"][12] in July tipped us off to the need for a few further tweaks. AP found that trying to insert 2 billion rows into a newly-created hash index was causing an error. To address that problem, Amit modified the bucket split code to [attempt a cleanup of the old bucket just after each split][13], which greatly reduced the accumulation of overflow pages. Just to be sure, Amit and I also [increased the maximum number of bitmap pages][14], which are used to track overflow page allocations, by a factor of four.
|
||||
|
||||
While there's [always more that can be done][15], I feel that my colleagues and I -- with help from others in the PostgreSQL community -- have accomplished our goal of making hash indexes into a first-class feature rather than a badly neglected half-feature. One may well ask, however, what the use case for that feature may be. The blog entry from Amit to which I referred (and linked) at the beginning of this post shows that even for a pgbench workload, it's possible for a hash index to outperform btree at both low and high levels of concurrency. However, in some sense, that's really a worst case. One of the selling points of hash indexes is that the index stores the hash value, not the actual indexed value - so I expect that the improvements will be larger for wide keys, such as UUIDs or long strings. They will likely to do better on read-heavy workloads, as we have not optimized writes to the same degree as reads, but I would encourage anyone who is interested in this technology to try it out and post results to the mailing list (or send private email), because the real key for a feature like this is not what some developer thinks will happen in the lab but what actually does happen in the field.
|
||||
|
||||
In closing, I'd like to thank Jeff Janes and Jesper Pedersen for their invaluable testing work, both related to this project and in general. Getting a project of this magnitude correct is not simple, and having persistent testers who are determined to break whatever can be broken is a great help. Others not already mentioned who deserve credit for testing, review, and general help of various sorts include Andreas Seltenreich, Dilip Kumar, Tushar Ahuja, Álvaro Herrera, Michael Paquier, Mark Kirkwood, Tom Lane, and Kyotaro Horiguchi. Thank you, and thanks as well to anyone whose work should have been mentioned here but which I have inadvertently omitted.
|
||||
|
||||
---
|
||||
via:https://rhaas.blogspot.jp/2017/09/postgresqls-hash-indexes-are-now-cool.html?showComment=1507079869582#c6521238465677174123
|
||||
|
||||
作者:[作者名][a]
|
||||
译者:[译者ID](https://github.com/id)
|
||||
校对:[校对者ID](https://github.com/id)
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/)荣誉推出
|
||||
|
||||
|
||||
[a]:http://rhaas.blogspot.jp
|
||||
[1]:http://amitkapila16.blogspot.jp/2017/03/hash-indexes-are-faster-than-btree.html
|
||||
[2]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6d46f4783efe457f74816a75173eb23ed8930020
|
||||
[3]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=c11453ce0aeaa377cbbcc9a3fc418acb94629330
|
||||
[4]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=293e24e507838733aba4748b514536af2d39d7f2
|
||||
[5]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=6977b8b7f4dfb40896ff5e2175cad7fdbda862eb
|
||||
[6]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7c75ef571579a3ad7a1d3ee909f11dba5e0b9440
|
||||
[7]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=a507b86900f695aacc8d52b7d2cfcb65f58862a2
|
||||
[8]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=7403561c0f6a8c62b79b6ddf0364ae6c01719068
|
||||
[9]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=08bf6e529587e1e9075d013d859af2649c32a511
|
||||
[10]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=e759854a09d49725a9519c48a0d71a32bab05a01
|
||||
[11]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ea69a0dead5128c421140dc53fac165ba4af8520
|
||||
[12]:https://www.postgresql.org/message-id/20170704105728.mwb72jebfmok2nm2@zip.com.au
|
||||
[13]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af
|
||||
[14]:https://git.postgresql.org/gitweb/?p=postgresql.git;a=commitdiff;h=ff98a5e1e49de061600feb6b4de5ce0a22d386af
|
||||
[15]:https://www.postgresql.org/message-id/CA%2BTgmoax6DhnKsuE_gzY5qkvmPEok77JAP1h8wOTbf%2Bdg2Ycrw%40mail.gmail.com
|
||||
@ -1,119 +0,0 @@
|
||||
DevOps 的意义
|
||||
========================================
|
||||
|
||||
> 真正的组织文化变革有助于你弥合你原先认为无法跨过的鸿沟
|
||||
|
||||

|
||||
|
||||
|
||||
回想你最近一次尝试改掉一个个人习惯的事情,你可能遇到过这样的情形,你需要改变你思考的方式并且改掉之前的习惯。这很艰难,你只是试着改变 _你自己的_ 思维方式而已。
|
||||
|
||||
所以你可能会努力让自己处于新的环境。新的环境实际上可帮助我们养成 _新的_ 习惯,它反过来又会促成新的思维方式。
|
||||
|
||||
那就是能否成功改变的所在:看起来是那么回事,实际上它就是那么回事 。你需要知道 _为什么_ 你正在改变以及你的目的 _所在_ (而不是仅仅你要怎么做),因为改变本身往往是短暂和短视的。
|
||||
|
||||
现在想想你的 IT 组织需要做出的改变。也许你正在考虑采用像 DevOps 这样的东西。这个我们称之为 “DevOps” 的东西有三个组件:人、流程和工具。人和流程是 _任何_ 团体组织的基础。因此,采用 DevOps 需要对大多数组织的核心进行根本性的改变,而不仅仅是学习新的工具。
|
||||
|
||||
和其他改变一样,它也是短视的。如果您将注意力集中在改变作为单点解决方案——例如,“获得更好的工具进行报警”——你可能想出一个狭隘的问题。这种思维方式或许可以提供一套拥有更多铃声和口哨并且可以有一种可以更好地处理随叫随到的方式的工具,但是它不能解决这样的实际问题:警报不能到达正确的团队,或者故障得不到解决,因为实际上没有人知道如何修复服务。
|
||||
|
||||
新的工具(或者至少一个新工具的想法)创造了一个时刻来谈论困扰你的团队对监控的评价的潜在问题。新工具让你能够做出更大的改变——信仰和做法的改变——它们作为你组织的基础而显得更加重要。
|
||||
|
||||
创造更深层次的变革需要一种可以全新地改变观念的方法。要找到这种方法,我们首先需要更好的理解变革的驱动力。
|
||||
|
||||
### 清除栅栏
|
||||
|
||||
> 就改革而言,它不同于腐化。有一条明显且简单的原则,这个原则可能被称为悖论。在这种情况下,存在某种制度或法律;让我们说,为了简单起见,在一条路上架设了一个栅栏或门。现代化的改革者们来到这儿,并说:“我看不到它的用处,让我们把它清除掉。”聪明的改革者会很好地回答:“如果你看不到它的用处,我肯定不会让你清除它,回去想想,然后你可以回来告诉我你看到它的用处,我会允许你摧毁它。” — G.K Chesterton, 1929
|
||||
|
||||
为了了解对 DevOps 的需求——它试图将传统意义上分开的开发部门和运维部门进行重新组合——我们首先必须明白这个分开是如何产生的。一旦我们"知道了它的用处",然后我们就会知道将它们分开是为了什么,并且在必要的时候可以取消分开。
|
||||
|
||||
今天我们没有一个单一的管理理论,但是我们可以将大多数现代管理理论的起源追溯到弗雷德里克·温斯洛·泰勒。泰勒是一名机械工程师,他创建了一个衡量钢厂工人效率的系统。泰勒认为,他可以对工厂的劳动者应用科学分析,不仅为了改进个人任务,还为了证明有一个可以发现的用来执行 _任何_ 任务最佳方法。
|
||||
|
||||
我们可以很容易地画一个以 Taylor 为起源的历史树。基于泰勒早在 18 世纪 80 年代后期的研究而出现的时间运动研究和其他质量改进计划跨越 20 世纪 20 年代一直到今天,我们可以从中看到六西格玛、精益,等等一些。自上而下、指导式管理,再加上研究过程的有条理的方法,今天主宰主流商业文化。它主要侧重于把效率作为工人成功的测量标准。
|
||||
|
||||
> “开发”和“运维”的分开不是因为人的原因,不同的技能,或者放在新员工头上的一顶魔术帽,它是 Taylor 和 Sloan 的理论的副产品。
|
||||
|
||||
如果 Taylor 是我们的历史树的根,那么我们主干上的下一个主叉将是 20 世纪 20 年代通用汽车公司的 Alfred P. Sloan。通用汽车公司创造的斯隆结构不仅持续强劲到 21 世纪初,而且在未来五十年的大部分时间里,都将成为该公司的主要模式。
|
||||
|
||||
1920 年,通用公司正经历一场管理危机,或者说是缺乏管理的危机。Sloan 向董事会写了一份为通用汽车的多个部门提出了一个新的结构《组织研究》。这一新结构的核心概念是“集中管理下放业务”。与雪佛兰,凯迪拉克和别克等品牌相关的各个部门将独立运作,同时为中央管理层提供推动战略和控制财务的手段。
|
||||
|
||||
在 Sloan 的建议下(以及后来就任 CEO 的指导),通用汽车在美国汽车工业中占据了主导地位。Sloan 的计划把一个处于灾难边缘公司创造成了一个非常成功的公司。从中间来看,自治单位是黑盒子,激励和目标被设置在顶层,而团队在底层推动。
|
||||
|
||||
泰勒思想的“最佳实践”——标准、可互换和可重复的行为——仍然在今天的管理理念中占有一席之地,与斯隆公司结构的层次模式相结合,主导了僵化的部门分裂和孤岛以实现最大的控制。
|
||||
|
||||
我们可以指出几份管理研究来证明这一点,但商业文化不是通过阅读书籍而创造和传播的。组织文化是 *真实的* 人在 *实际的* 情形下执行推动文化规范的 *具体的* 行为的产物。这就是为何类似 Taylor 和 Sloan 的主张这样的事情变得固化而不可动摇的原因。
|
||||
|
||||
技术部门投资就是一个例子。以下是这个周期是如何循环的:投资者只投资于他们认为可以实现 *他们的* 特定成功观点的公司。这个成功的模式并不一定源于公司本身(和它的特定的目标);它来自董事会对一家成功的公司 *应该* 如何看待的想法。许多投资者来自在经营企业的尝试和苦难中幸存下来的公司,因此他们对什么会使一个公司成功有 *不同的* 蓝图。他们为那些能够被教导模仿他们的成功模式的公司提供资金,所以希望获得资金的公司学会模仿。这样,初创公司孵化器就是一种重现理想的结构和文化的直接的方式。
|
||||
|
||||
开发和运维的分开是不是因为人的原因,不同的技能,或者放在新员工头上的一顶魔术帽;它是 Taylor 和 Sloan 的理论的副产品。责任与人员之间的透明和不可渗透的界线是一个管理功能,同时也注重员工的工作效率。管理上的分开可以很容易的落在产品或者项目界线上,而不是技能上,但是通过今天的业务管理理论的历史告诉我们,基于技能的分组是“最好”的高效方式。
|
||||
|
||||
不幸的是,那些界线造成了紧张局势,这些紧张局势是由不同的管理链出于不同的目标设定的相反目标的直接结果。例如:
|
||||
|
||||
* 敏捷 ⟷ 稳定
|
||||
* 吸引新用户 ⟷ 现有用户的体验
|
||||
* 让应用程序增加新功能 ⟷ 让应用程序可以使用
|
||||
* 打败竞争对手 ⟷ 保护收入
|
||||
* 修复出现的问题 ⟷ 在问题出现之前就进行预防
|
||||
|
||||
今天,我们可以看到组织的高层领导人越来越认识到,现有的商业文化(并扩大了它所产生的紧张局势)是一个严重的问题。在 2016 年的 Gartner 报告中,57% 的受访者表示,文化变革是 2020 年之前企业面临的主要挑战之一。像作为一种影响组织变革的手段的敏捷和DevOps这样的新方法的兴起反映了这一认识。"[shadow IT][7]" 的出现是硬币的反面;最近的估计有将近 30% 的 IT 支出在 IT 组织的控制之外。
|
||||
|
||||
这些只是企业正在面临的一些“文化担忧”。改变的必要性是明确的,但前进的道路仍然受到昨天的决定的约束。
|
||||
|
||||
### 抵抗并不是没用的
|
||||
|
||||
> Bert Lance 认为如果他能让政府采纳一条简单的格言“如果东西还没损坏,那就别去修理它”,他就可以为山姆拯救三十亿。他解释说:“这是政府的麻烦:‘修复没有损坏的东西,而不是修复已经损坏了的东西。’” — Nation's Business, 1977.5
|
||||
|
||||
通常,改革是组织针对所出现的错误所做的应对。在这个意义上说,如果紧张局势(即使逆境)是变革的正常催化剂,那么 *抵抗* 变化就是成功的指标。但是过分强调成功的道路会使组织变得僵硬、衰竭和独断。重视有效结果的政策导航是这种不断增长的僵局的症状。
|
||||
|
||||
传统 IT 部门的成功加剧了 IT 仓库的墙壁。其他部门现在变成了“顾客”,而不是同事。试图将 IT 从成本中心转移出来创建一个新的操作模式,它可以将 IT 与其他业务目标断开。这反过来又会对敏捷性造成限制,增加摩擦,降低反应能力。合作被搁置而支持“专家方向”。结果是一个孤立主义的观点,IT 只能带来更多的伤害而不是好处。
|
||||
|
||||
正如“软件吃掉世界”,IT 越来越成为组织整体成功的核心。具有前瞻性的 IT 组织认识到这一点,并且已经对其战略规划进行了有意义的改变,而不是将改变视为恐惧。
|
||||
|
||||
> 改革不仅仅只是重构组织,它也是关于跨越历史上不可跨越的鸿沟的新途径。
|
||||
|
||||
例如,Facebook 与人类学家罗宾·邓巴(Robin Dunbar)就社会团体的方法进行了磋商,而且意识到这一点对公司成长的内部团体(不仅仅是网站的外部用户)的影响。扎波斯的文化得到了很多的赞誉,该组织创立了一个部门,专注于培养他人对于核心价值观和企业文化的看法。当然,这本书是 _The Open Organization_ 的姊妹篇, 一本描述被应用于管理的开放原则——透明度、参与度和社区——可以如何为我们快节奏的有联系的时代重塑组织。
|
||||
|
||||
### 决心改变
|
||||
|
||||
> “如果外界的变化率超过了内部的变化率,那末日就不远了。” — Jack Welch, 2004
|
||||
|
||||
一位同事曾经告诉我他可以只用 [Information Technology Infrastructure Library][9] 框架里面的词汇向一位项目经理解释 DevOps。
|
||||
|
||||
虽然这些框架 *似乎* 是反对的,但实际上它们都集中在风险和变革管理上。他们简单地介绍了这种管理的不同流程和工具。在 IT 圈子外面谈论 DevOps 时,这一点需要注意。不要强调流程故障和故障,而是显示更小的变化引起的风险 *更小* 等等。这是强调改变团队文化的有益方式:专注于 *新的* 功能而不是老问题是改变的有效代理,特别是当您采用别人的参考框架时。
|
||||
|
||||
改革不仅仅只是 *重构* 组织;它也是关于跨越历史上不可跨越的鸿沟的新途径——通过拒绝把像“敏捷”和“稳定”这样的东西作为互相排斥的力量来解决我之前提到的那些紧张局势。建立注重 *结果* 胜过 *功能* 的跨部门团队是一个有效的策略。把不同的团队——其中每个人的工作依赖于其他人——聚集起来围绕一个项目或目标是最常见的方法之一。消除这些团队之间的摩擦和改善沟通能够产生巨大的改进——即使在坚持铁仓管理结构时(如果可以掌握,则不需要拆除筒仓)。在这些情况下,*抵抗* 改革不是成功的一个指标;而拥抱改革是一个指标。
|
||||
|
||||
这些也不是“最佳实例”,它们只是一种检查你自己的栅栏的方式。每个组织都会有独特的由他们内部人员创造的栅栏。一旦你“知道了它的用途”,你就可以决定它是需要拆解还是掌握。
|
||||
|
||||
** 本文是 Opensource.com 即将推出的关于开放组织和 IT 文化指南的一部分。[你可以在这注册以便当它发布时收到通知][5]
|
||||
|
||||
(题图 : opensource.com)
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Matt Micene——Matt Micene 是 Red Hat 公司的 Linux 和容器传播者。他在信息技术方面拥有超过 15 年的经验,从架构和系统设计到数据中心设计。他对关键技术(如容器,云计算和虚拟化)有深入的了解。他目前的重点是宣传红帽企业版 Linux,以及操作系统如何与计算环境的新时代相关。
|
||||
|
||||
------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps
|
||||
|
||||
作者:[Matt Micene ][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[apemost](https://github.com/apemost)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/matt-micene
|
||||
[1]:https://opensource.com/open-organization/resources/leaders-manual?src=too_resource_menu
|
||||
[2]:https://opensource.com/open-organization/resources/field-guide?src=too_resource_menu
|
||||
[3]:https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu
|
||||
[4]:https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu
|
||||
[5]:https://opensource.com/open-organization/resources/book-series
|
||||
[6]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps?rate=gOQvGqsEbNk_RSnoU0wP3PJ71E_XDYiYo7KS2HKFfP0
|
||||
[7]:https://thenewstack.io/parity-check-dont-afraid-shadow-yet/
|
||||
[8]:http://www.npr.org/2017/01/13/509358157/is-there-a-limit-to-how-many-friends-we-can-have
|
||||
[9]:https://en.wikipedia.org/wiki/ITIL
|
||||
[10]:https://opensource.com/user/18066/feed
|
||||
[11]:https://opensource.com/open-organization/17/5/what-is-the-point-of-DevOps#comments
|
||||
[12]:https://opensource.com/users/matt-micene
|
||||
@ -1,173 +0,0 @@
|
||||
LFCS sed 命令
|
||||
=====================
|
||||
|
||||
Linux 基金会认证系统管理员(LFCS)的另一个有用的命令是 “sed”,最初表示“流式编辑器” (Streaming EDitor)。
|
||||
|
||||
“sed” 命令是一个可以将文件作为流进行编辑的编辑器。流式传输文件的方法是从另一个命令使用管道(> 或 |)传递,或将其直接加载到 “sed” 中。
|
||||
|
||||
该命令的工作方式与其他编辑器相同,只是文件不显示,也不允许可视化编辑。命令被传递给 “sed” 来操纵流。
|
||||
|
||||
用 “sed” 可以做五件基本的事。当然,“sed” 如此强大,还有其他高级的功能,但你只需要集中精力在五件基本的事上。五种功能类型如下:
|
||||
|
||||
1. 搜索
|
||||
|
||||
2. 替换
|
||||
|
||||
3. 删除
|
||||
|
||||
4. 添加
|
||||
|
||||
5. 改变/变换
|
||||
|
||||
在深入命令参数之前,我们需要看看基本的语法。
|
||||
|
||||
**语法**
|
||||
|
||||
“sed” 命令的语法是:
|
||||
|
||||
_sed [选项] 命令 [要编辑的文件]_
|
||||
|
||||
本文将在适当的部分中介绍这些选项。命令是可以是正则表达式的搜索和替换模式。继续阅读了解 “sed” 如何工作并学习基本命令。正如我之前提到的,“sed” 是一个非常强大的工具,有更多的选项可用,我将在本文中介绍。
|
||||
|
||||
**示例文件**
|
||||
|
||||
如果你打开一个终端,那你可以创建一个用于 “sed” 示例的文件。执行以下命令:
|
||||
|
||||
_cd ~
|
||||
grep --help >grephelp.txt_
|
||||
|
||||
你现在应该在 HOME 文件夹中有一个名为 “grephelp.txt” 的文件。该文件的内容是命令 “grep” 的帮助说明。
|
||||
|
||||
**搜索**
|
||||
|
||||
搜索特定字符串是编辑器的常见功能,在 “sed” 中执行搜索也不例外。
|
||||
|
||||
执行搜索以在文件中查找字符串。我们来看一下基本的搜索。
|
||||
|
||||
如果我们想在示例文件搜索 “PATTERN” 这个词,我们将使用这个命令,在图 1 中查看结果:
|
||||
|
||||
_sed -n 's/PATTERN/PATTERN/p' grephelp.txt_
|
||||
|
||||
**注意:** 如果剪切粘贴命令,请确保将单引号替换为键盘上的标准单引号。
|
||||
|
||||
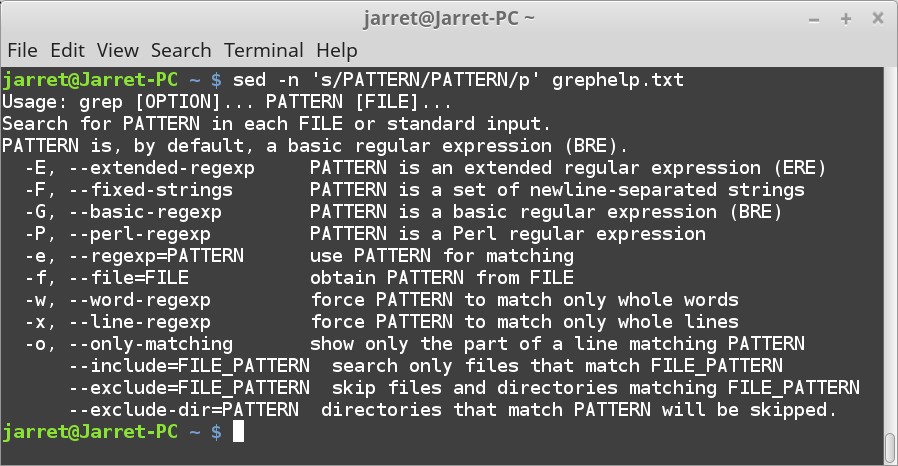
|
||||
|
||||
**图 1**
|
||||
|
||||
参数 “-n” 用于自动抑制每行的打印。这些行包括不包含搜索模式的行。通过使用 “-n”,将显示有匹配结果的行。流入 “sed” 的每一行将被打印到标准输出(stdout)。如果你不使用 “-n” 选项运行上述命令,你将看到原始文件的每一行,以及每个匹配的重复行。
|
||||
|
||||
要搜索的文件名是我们在“示例文件”部分中创建的 “grephelp.txt”。
|
||||
|
||||
剩下的部分是 _'s/PATTERN/PATTERN/p'_ 。这一段基本分为四个部分。第一部分的 “s” 指定执行替换,或搜索和替换。
|
||||
|
||||
剩下的第二部分和第三部分是模式。第一个是要搜索的模式,最后一个是替换流中匹配字符串的模式。此例中,我们找到字符串 “PATTERN”,并用 “PATTERN” 替换。通过查找和替换相同的字符串,我们完全不会更改文件,甚至在屏幕上也一样。
|
||||
|
||||
最后一个命令是 “p”。 “p” 指定在替换后打印新行。当然,因为替换的是相同的字符串,所以没有改变。由于我们使用 “-n” 参数抑制打印行,所以更改的行将使用 “p” 命令打印。
|
||||
|
||||
完整的命令允许我们执行搜索并查看匹配的结果。
|
||||
|
||||
**替换**
|
||||
|
||||
当搜索特定字符串时,你可能希望用匹配的字符串替换新字符串。用另一个字符串替换是很常见的。
|
||||
|
||||
我们可以使用以下命令执行相同的搜索,结果如图 2 所示:
|
||||
|
||||
_sed -n 's/PATTERN/Pattern/p' grephelp.txt_
|
||||
|
||||
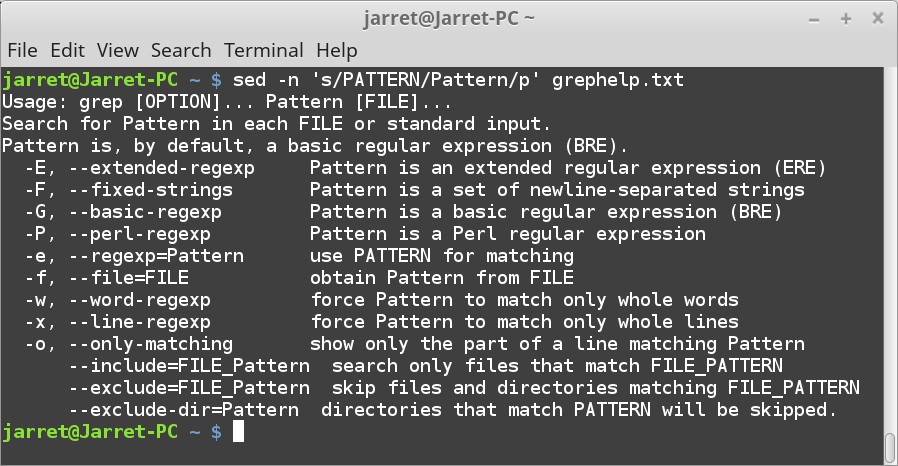
|
||||
|
||||
**图 2**
|
||||
|
||||
在这时,字符串 “PATTERN” 变为 “Pattern” 并显示。如果你使用命令 “cat grephelp.txt” 查看文件,你会看到该文件没有更改。该更改仅对屏幕上的输出进行。你可以使用以下命令将输出通过管道传输到另一个文件:
|
||||
|
||||
_sed 's/PATTERN/Pattern/' grephelp.txt > grephelp1.txt_
|
||||
|
||||
现在将存在一个名为 “grephelp1.txt” 的新文件,其中保存了更改的文件。如果 “p” 作为第四个选项留下,那么有个问题是每一行被替换的字符串将在文件中重复两次。我们也删除 “-n” 参数以允许所有的行打印。
|
||||
|
||||
使用相同字符串替换字符串的另一种方法是使用 “&” 符号来表示搜索字符串。例如,命令 “s/PATTERN/&/p” 效果是一样的。我们可以添加字符串,例如添加 “S” , 可以使用命令 “s/PATTERN/&S/p”。
|
||||
|
||||
如果我们希望在每一行中只替换某种模式呢?可以指定要替换的匹配项的特定出现。当然,每一行的替换都是一个特定的编号。例如,示例文件上有很多破折号。一些行至少有两条破折号,所以我们可以用另一个字符代替每一行的第二个破折号。每行用星号(*)替换第二个破折号( - )的命令将是:
|
||||
|
||||
sed 's/-/*/2' grephelp.txt
|
||||
|
||||
在这里,我们用最初的 “s” 来执行替换。字符 “-” 被替换为 “*”。“2” 表示我们想要替换每行上的第二个 “-”(如果存在)。示例结果如图 3 所示。如果我们忽略了命令 “2”,则替换第一次出现的破折号。只有第一个破折号而不是每行的破折号都被替换。
|
||||
|
||||
|
||||
|
||||
**图 3**
|
||||
|
||||
如果要搜索并替换带有星号的行上的所有破折号,请使用 “g” 命令:
|
||||
|
||||
_sed 's/-/*/g' grephelp.txt_
|
||||
|
||||
命令也可以组合。假设你想要替换从第二次开始出现的破折号,命令将是:
|
||||
|
||||
_sed 's/-/*/2g' grephelp.txt_
|
||||
|
||||
现在从第二个开始出现的破折号将被星号取代。
|
||||
|
||||
**删除**
|
||||
|
||||
搜索过程中有很多时候你可能想要完全删除搜索字符串。
|
||||
|
||||
例如,如果要从文件中删除所有破折号,你可以使用以下命令:
|
||||
|
||||
_sed ‘s/-//g’ grephelp.txt_
|
||||
|
||||
替换字符串为空白,因此匹配的字符串将被删除。
|
||||
|
||||
**添加**
|
||||
|
||||
当找到匹配时,你可以添加一行特定的文本,来使这行在浏览或打印中突出。
|
||||
|
||||
如果要在匹配后插入新行,那么使用 “a” 命令,后面跟上新行的字符串。还包括要匹配的字符串。例如,我们可以找到一个 “--”,并在匹配的行之后添加一行。新行的字符串将是 “double dash before this line”。
|
||||
|
||||
_sed '/--/ a "double dash before this line"' grephelp.txt_
|
||||
|
||||
如果要在包含匹配字符串的行之前加上这行,请使用 “i” 命令,如下所示:
|
||||
|
||||
_sed '/--/ i "double dash after this line"' grephelp.txt_
|
||||
|
||||
**改变/变换**
|
||||
|
||||
如果需要改变/变换一行,则可以使用命令 “c”。
|
||||
|
||||
假设我们有个有一些私人信息的文档,我们需要更改包含特定字符串的行。“c” 命令将改变整行,而不仅仅是搜索字符串。
|
||||
|
||||
假设我们想要阻止示例文件中包含单词 “PATTERN” 的每一行。更改的行将显示为 “This line is Top Secret”。命令是:
|
||||
|
||||
_sed ‘/PATTERN/ c This line is Top Secret’ grephelp.txt_
|
||||
|
||||
可以进行更改特定字母的大小写的转换。例如,我们可以使用命令 “y” 将所有小写 “a” 更改为大写 “A”,如下所示:
|
||||
|
||||
_sed ‘y/a/A/’ grephelp.txt_
|
||||
|
||||
可以指定多个字母,如 “abdg”,如下命令所示:
|
||||
|
||||
_sed ‘y/abdg/ABDG/’ grephelp.txt_
|
||||
|
||||
确保第二组字母与第一组字母的顺序相同,否则会被替换和转换。例如,字符串 ‘y/a/D/’ 将用大写 “D” 替换所有小写的 “a”。
|
||||
|
||||
**就地更改**
|
||||
|
||||
如果你确实要更改所使用的文件,请使用 “-i” 选项。
|
||||
|
||||
例如,要将 “PATTERN” 改为 “Pattern”,并对文件进行更改,则命令为:
|
||||
|
||||
sed -i 's/PATTERN/Pattern/' grephelp.txt
|
||||
|
||||
现在文件 “grephelp.txt” 将被更改。“-i” 选项可以与上述任何命令一起使用来更改原始文件的内容。
|
||||
|
||||
练习这些命令,并确保你理解它们。“sed” 命令非常强大。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.org/threads/lfcs-sed-command.4561/
|
||||
|
||||
作者:[Jarret B ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.org/threads/lfcs-sed-command.4561/
|
||||
@ -1,315 +0,0 @@
|
||||
[GitHub 的 MySql 基础架构自动化测试][31]
|
||||
============================================================
|
||||
|
||||
我们 MySQL 数据库基础架构是 Github 关键组件。 MySQL 提供 Github.com, GitHub 的 API 和验证等等的服务。每一次的 `git` 请求都以某种方式触及 MySQL。即使我们 MySQL 集群是按流量的,但是我们还是需要执行重型清理,即时更新,在线模式迁移,集群拓扑重构,池化和负载平衡等任务。 我们建有基础架构自动化测试这种方式,在这篇文章中,我们分享几个例子,说明我们如何通过连续不间断的来测试建立基础架构的。这样的方式是为了让我们晚上有一个好梦到早晨。
|
||||
|
||||
### 备份[][36]
|
||||
|
||||
备份数据是非常重要的,如果您没有备份数据库,虽然当时没有说明问题,在之后可能就是一个大问题。Percona [Xtrabackup][37] 是我们一直使用的 MySQL 数据库备份工具。如果有需要备份数据库我们就会备份到另一个专门备份数据的服务器上。
|
||||
|
||||
In addition to the full binary backups, we run logical backups several times a day. These backups allow our engineers to get a copy of recent data. There are times that they would like a complete set of data from a table so they can test an index change on a production sized table or see data from a certain point of time. Hubot allows us to restore a backed up table and will ping us when the table is ready to use.
|
||||
|
||||
除了完整的二进制备份外,我们每天还会多次运行逻辑备份。这些备份数据允许我们的工程师获取最新的副本。有时候,他们希望从表中获取一整套数据,以便他们可以测试表上的索引,更改或从特定时间点查看数据。Hubot 允许我们恢复备份的表,并且当表准备使用时会自动检测连接( ping )我们。
|
||||
|
||||

|
||||
**tomkrouper**.mysql 备份列表的位置
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| Backup ID | Table Name | Donor Host | Backup Start | Backup End | File Name |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
| 1699494 | locations | db-mysql-0903 | 2017-07-01 22:09:17 | 2017-07-01 22:09:17 | backup-mycluster-locations-1498593122.sql.gz |
|
||||
| 1699133 | locations | db-mysql-0903 | 2017-07-01 16:11:37 | 2017-07-01 16:11:39 | backup-mycluster-locations-1498571521.sql.gz |
|
||||
| 1698772 | locations | db-mysql-0903 | 2017-07-01 10:09:21 | 2017-07-01 10:09:22 | backup-mycluster-locations-1498549921.sql.gz |
|
||||
| 1698411 | locations | db-mysql-0903 | 2017-07-01 04:12:32 | 2017-07-01 04:12:32 | backup-mycluster-locations-1498528321.sql.gz |
|
||||
| 1698050 | locations | db-mysql-0903 | 2017-06-30 22:18:23 | 2017-06-30 22:18:23 | backup-mycluster-locations-1498506721.sql.gz |
|
||||
| ...
|
||||
| 1262253 | locations | db-mysql-0088 | 2016-08-01 01:58:51 | 2016-08-01 01:58:54 | backup-mycluster-locations-1470034801.sql.gz |
|
||||
| 1064984 | locations | db-mysql-0088 | 2016-04-04 13:07:40 | 2016-04-04 13:07:43 | backup-mycluster-locations-1459494001.sql.gz |
|
||||
+-----------+------------+---------------+---------------------+---------------------+----------------------------------------------+
|
||||
|
||||
```
|
||||
|
||||

|
||||
**tomkrouper**.mysql 恢复 1699133
|
||||

|
||||
**Hubot**已为备份作业 1699133 创建还原作业,还原完成后,将在 #database-ops 中收到通知。
|
||||

|
||||
**Hubot**[@tomkrouper][1]: 恢复 db-mysql-0482 上数据库中的 locations 表已恢复为 locations_2017_07_01_16_11
|
||||
|
||||
数据被加载到非生产环境的数据库,该数据库可供请求恢复的工程师访问。
|
||||
|
||||
我们保留数据的“备份”的最后一个方法是使用 [延迟的副本delayed replicas][38]。这不是一个备份,而是更多层次的保护。对于每个生产集群中,我们有一个主机延迟4个小时。如果运行一个不应该有的查询,我们可以在 chatops 中运行 `mysql panic` 。这将导致我们所有的延迟副本立即停止复制。这也将页面呼叫DBA。从那里我们可以使用延迟复制来验证是否有问题,然后将二进制日志快速转发到错误之前的位置。然后,我们可以将此数据恢复到主服务器,从而恢复数据到该点。
|
||||
|
||||
备份是很棒的,但如果一些未知或未捕获的错误发生破坏它们,它们就显得没有价值了。让脚本恢复备份的好处是它允许我们通过 cron 自动执行备份验证。我们为每个集群设置了一个专用的主机,用于运行最新备份的恢复。这样可以确保备份运行正常,并且我们能够从备份中检索数据。
|
||||
|
||||
根据数据集大小,我们每天运行多个恢复。预期恢复的服务器将加入复制流并能够赶上复制。这不仅测试了我们采取可恢复的备份,而且我们正确地确定采取的时间点,并且可以从该时间点进一步应用更改。如果恢复过程中出现问题,我们会收到通知。
|
||||
|
||||
我们还追踪恢复所需的时间,所以我们知道在紧急情况下建立新的副本或还原需要多长时间。
|
||||
|
||||
以下是由 Hubot 在我们的机器人聊天室中编写的自动恢复过程的输出。
|
||||
|
||||

|
||||
**Hubot**
|
||||
gh-mysql-backup-restore: db-mysql-0752: restore_log.id = 4447
|
||||
gh-mysql-backup-restore: db-mysql-0752: 确定要为集群 “prodcluster” 还原备份。
|
||||
gh-mysql-backup-restore: db-mysql-0752: 启用维护模式
|
||||
gh-mysql-backup-restore: db-mysql-0752: 设置协调器停机时间
|
||||
gh-mysql-backup-restore: db-mysql-0752: 禁用 Puppet
|
||||
gh-mysql-backup-restore: db-mysql-0752: 停止 MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: 删除 MySQL 文件
|
||||
gh-mysql-backup-restore: db-mysql-0752: 运行中 gh-xtrabackup-restore
|
||||
gh-mysql-backup-restore: db-mysql-0752: 恢复文件: xtrabackup-notify-2017-07-02_0000.xbstream
|
||||
gh-mysql-backup-restore: db-mysql-0752: 运行 gh-xtrabackup-prepare
|
||||
gh-mysql-backup-restore: db-mysql-0752: 启动 MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: 更新文件权限
|
||||
gh-mysql-backup-restore: db-mysql-0752: 升级 MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: 停止 MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: 启动 MySQL
|
||||
gh-mysql-backup-restore: db-mysql-0752: 备份 Host: db-mysql-0034
|
||||
gh-mysql-backup-restore: db-mysql-0752: 设置开启复制
|
||||
gh-mysql-backup-restore: db-mysql-0752: 启动复制
|
||||
gh-mysql-backup-restore: db-mysql-0752: 响应缓存
|
||||
gh-mysql-backup-restore: db-mysql-0752: 还原完成 (响应运行中)
|
||||
gh-mysql-backup-restore: db-mysql-0752: 开启操作
|
||||
gh-mysql-backup-restore: db-mysql-0752: 关闭维护模式
|
||||
gh-mysql-backup-restore: db-mysql-0752: 设置协调器停机时间
|
||||
gh-mysql-backup-restore: db-mysql-0752: 恢复过程完成
|
||||
|
||||
我们使用备份的一件事是向现有的一组 MySQL 服务器添加一个新的副本。我们将启动一个新的服务器的构建,一旦我们通知它已经准备就绪,我们可以开始恢复该特定集群的最新备份。我们有一个脚本,运行我们手动执行的所有恢复命令。我们的自动恢复系统基本上使用相同的脚本。这简化了系统构建过程,并允许我们使用少数几个手动进程的聊天命令来启动和运行主机。下面显示的是在聊天中手动恢复:
|
||||
|
||||

|
||||
**jessbreckenridge**.mysql backup-restore -H db-mysql-0007 -o -r magic_word=daily_rotating_word
|
||||

|
||||
**Hubot**
|
||||
[@jessbreckenridge][2] gh-mysql-backup-restore: db-mysql-0007: 确定要还原群集'mycluster'的备份
|
||||
[@jessbreckenridge][3] gh-mysql-backup-restore: db-mysql-0007: restore_log.id = 4449
|
||||
[@jessbreckenridge][4] gh-mysql-backup-restore: db-mysql-0007: 启用维护模式
|
||||
[@jessbreckenridge][5] gh-mysql-backup-restore: db-mysql-0007: 设置协调器停机时间
|
||||
[@jessbreckenridge][6] gh-mysql-backup-restore: db-mysql-0007: 禁用操作
|
||||
[@jessbreckenridge][7] gh-mysql-backup-restore: db-mysql-0007: 停止 MySQL
|
||||
[@jessbreckenridge][8] gh-mysql-backup-restore: db-mysql-0007: 删除 MySQL 文件
|
||||
[@jessbreckenridge][9] gh-mysql-backup-restore: db-mysql-0007: 运行 gh-xtrabackup-restore
|
||||
[@jessbreckenridge][10] gh-mysql-backup-restore: db-mysql-0007: 恢复文件: xtrabackup-mycluster-2017-07-02_0015.xbstream
|
||||
[@jessbreckenridge][11] gh-mysql-backup-restore: db-mysql-0007: 运行 gh-xtrabackup-prepare
|
||||
[@jessbreckenridge][12] gh-mysql-backup-restore: db-mysql-0007: 更新文件权限
|
||||
[@jessbreckenridge][13] gh-mysql-backup-restore: db-mysql-0007: 启用 MySQL
|
||||
[@jessbreckenridge][14] gh-mysql-backup-restore: db-mysql-0007: 升级 MySQL
|
||||
[@jessbreckenridge][15] gh-mysql-backup-restore: db-mysql-0007: 停止 MySQL
|
||||
[@jessbreckenridge][16] gh-mysql-backup-restore: db-mysql-0007: 开启 MySQL
|
||||
[@jessbreckenridge][17] gh-mysql-backup-restore: db-mysql-0007: 设置开启复制
|
||||
[@jessbreckenridge][18] gh-mysql-backup-restore: db-mysql-0007: 启动复制
|
||||
[@jessbreckenridge][19] gh-mysql-backup-restore: db-mysql-0007: 备份 Host: db-mysql-0201
|
||||
[@jessbreckenridge][20] gh-mysql-backup-restore: db-mysql-0007: 复制缓存
|
||||
[@jessbreckenridge][21] gh-mysql-backup-restore: db-mysql-0007: 复制后 4589 秒,下次检查之前等待 1800 秒
|
||||
[@jessbreckenridge][22] gh-mysql-backup-restore: db-mysql-0007: 还原完成 (响应运行中)
|
||||
[@jessbreckenridge][23] gh-mysql-backup-restore: db-mysql-0007: 禁用操作
|
||||
[@jessbreckenridge][24] gh-mysql-backup-restore: db-mysql-0007: 禁用维护模式
|
||||
|
||||
### 故障转移[][39]
|
||||
|
||||
[我们使用协调器][40] 在主和从中执行自动化故障切换。我们期望 orchestrator 正确检测主故障,指定副本进行升级,在所指定的副本下修复拓扑,进行升级。我们期待 VIP 变化,池变化,客户端重连,`puppet` 运行的基本组件等等。故障转移是一项复杂的任务,涉及到我们基础架构的许多方面。
|
||||
|
||||
为了建立对我们的故障转移的信任,我们建立了一个 _类似生产的测试集群_ ,并且我们不断地崩溃它来观察故障转移。
|
||||
|
||||
_类似生产的测试集群_ 是一个复制设置,在所有方面与我们的生产集群相同:硬件类型,操作系统,MySQL版本,网络环境,VIP,`puppet` 配置,[haproxy 设置][41] 等。与此集群不同的是它不发送/接收生产流量。
|
||||
|
||||
我们在测试集群上模拟写入负载,同时避免复制滞后。写入负载不会太大,但是有一些有意争取写入相同数据集的查询。这在正常的时间并不是太有意思,但是证明在故障转移中是有用的,正如我们将会简要描述的那样。
|
||||
|
||||
我们的测试集群有三个数据中心的代表服务器。 我们希望故障转移能够在同一个数据中心内推广替代副本。 我们希望在这样的限制下尽可能多地复制副本。 我们要求尽可能适用。 协调者对拓扑结构没有先前的假设; 它必须对崩溃时的状态作出反应。
|
||||
|
||||
然而,我们有兴趣为故障切换创建复杂而多变的场景。我们的故障转移测试脚本为故障转移准备了理由:
|
||||
|
||||
* 它识别现有的主人
|
||||
|
||||
* 重构拓扑结构,使所有三个数据中心的代表成为主控。不同的 DC 具有不同的网络延迟,并且预期会在不同的时间对主机崩溃做出反应。
|
||||
|
||||
* 它选择一个崩溃方法。我们选择 master(`kill -9`)或网络划分它: `iptables -j REJECT` (nice-ish) 或 `iptables -j DROP`(unresponsive无响应)。
|
||||
|
||||
脚本继续通过选择的方法使主机崩溃,并等待 `orchestrator` 可靠地检测到崩溃并执行故障转移。虽然我们期望检测和升级在 `30` 几秒钟内 完成,但脚本会打破这一期望,并在查找故障转移结果之前睡觉一段指定的时间。然后:
|
||||
|
||||
* 检查一个新的(不同的)master 是否到位
|
||||
|
||||
* 集群中有很多副本
|
||||
|
||||
* master 是可写的
|
||||
|
||||
* 对 master 的写入在副本上可见
|
||||
|
||||
* 更新内部服务发现条目(新 master 的身份如预期;旧 master 已删除)
|
||||
|
||||
* 其他内部检查
|
||||
|
||||
这些测试证实故障转移是成功的,不仅是 MySQL 明智的,而且在更大的基础设施范围。VIP 被拒绝; 特别服务已经开始; 信息到达应该去的地方。
|
||||
|
||||
该脚本进一步继续恢复失败的服务器:
|
||||
|
||||
* 从备份恢复,从而隐含地测试我们的备份/恢复过程
|
||||
|
||||
* 验证服务器配置是否符合预期(服务器不再相信是主服务器)
|
||||
|
||||
* 返回到复制集群,期望找到在主机上写入的数据
|
||||
|
||||
考虑以下可视化的计划故障转移测试:从运行良好的群集到某些副本上的问题,诊断主机 (`7136`) 是否死机,选择一个服务器来促进 (`a79d`) ,重构该服务器下面的拓扑,推动它(故障切换成功),恢复死主机并将其放回群集。
|
||||
|
||||

|
||||
|
||||
#### 测试失败怎么样?
|
||||
|
||||
我们的测试脚本使用了一种停止世界的方法。任何故障切换组件中的单个故障都将失败,因此在人类解决问题之前,无法进行任何未来的自动化测试。我们得到警报,并继续检查状态和日志。
|
||||
|
||||
脚本将在不可接受的检测或故障转移时间失败; 备份/还原问题; 失去太多服务器; 在故障切换后的意外配置; 等等
|
||||
|
||||
我们需要确保 `orchestrator` 正确连接服务器。这是竞争性写入负载有用的地方:如果设置不正确,复制很容易中断。我们会得到 `DUPLICATE KEY` 或其他错误提示出错。
|
||||
|
||||
这是特别重要的,因为我们改进 `orchestrator` 并引入新的行为,允许我们在安全的环境中测试这些变化。
|
||||
|
||||
#### 来了:chaos 测试
|
||||
|
||||
上面所示的测试程序将捕获(并已经捕获)我们基础设施许多部分的问题。这些够了吗?
|
||||
|
||||
在生产环境中总是有其他的东西。关于不适用于我们的生产集群的特定测试方法。它们不具有相同的流量和流量操纵,也不具有完全相同的服务器集。故障类型可能有所不同。
|
||||
|
||||
我们正在为我们的生产集群设计 chaos 测试。 chaos 测试将会在我们的生产中,但是按照预期的时间表和充分控制的方式来破坏碎片。 chaos 测试在恢复机制中引入更高层次的信任,并影响(因此测试)我们的基础设施和应用程序的较大部分。
|
||||
|
||||
这是微妙的工作:当我们承认 chaos 测试的需要时,我们也希望避免对我们的服务造成不必要的影响。不同的测试将在风险级别和影响方面有所不同,我们将努力确保我们的服务的可用性。
|
||||
|
||||
### 模式迁移[][42]
|
||||
|
||||
[我们使用 gh-ost ][43]来运行实时模式迁移。 `gh-ost` 它是稳定的,但也在迅速的发展,增加或计划的主要新功能。
|
||||
|
||||
`gh-ost` 通过将数据复制到 _gh-ost_ 表来迁移,将进行的二进制日志拦截的更改应用到 _gh-ost_表,即使正在写入原始表。然后它将 _gh-ost_ 表交换代替原始表。迁移完成时,GitHub 继续使用生成和填充的 `gh-ost` 表。
|
||||
|
||||
在这个时候,几乎所有的 GitHub 的 MySQL 数据都被重新创建 `gh-ost`,其中大部分都是重新创建的。我们必须高度信任 `gh-ost`,即使面对快速的发展,也可以一再修改数据。这是我们如何获得这种信任。
|
||||
|
||||
`gh-ost` 提供生产测试能力。它支持在副本上运行迁移,其方式与在主服务器上运行的方式大致相同: `gh-ost` 将连接到副本,并将其视为主服务器。它将解析其二进制日志的方式与实际主机迁移相同。但是,它将复制行并将二进制日志事件应用于副本,并避免对主机进行写入。
|
||||
|
||||
我们经营的 `gh-ost` 复制品在生产中。这些副本不能提供生产流量。每个这样的副本将检索生产表的当前列表,并以随机顺序对其进行迭代。一个接一个地,它选择一个表并在该表上执行复制迁移。迁移实际上并不修改表结构,而是运行一个微不足道的 `ENGINE=InnoDB`。测试运行迁移,即使在生产中使用表,从而复制实际的生产数据,并将真正的生产流量从二进制日志中应用。
|
||||
|
||||
这些迁移可以被审计。以下是我们如何从聊天中检查运行测试的状态:
|
||||
|
||||

|
||||
**ggunson**.migration test-status
|
||||

|
||||
**Hubot**
|
||||
```
|
||||
# Migrating `prod`.`pull_requests`; Ghost table is `prod`.`_pull_requests_gho`
|
||||
# Migrating ghost-db-mysql-0007:3306; inspecting ghost-db-mysql-0007:3306; executing on ghost-db-mysql-0007
|
||||
# Migration started at Mon Jan 30 02:13:39 -0800 2017
|
||||
# chunk-size: 2500; max-lag-millis: 1500ms; max-load: Threads_running=30; critical-load: Threads_running=1000; nice-ratio: 0.000000
|
||||
# throttle-additional-flag-file: /tmp/gh-ost.throttle
|
||||
# panic-flag-file: /tmp/ghost-test-panic.flag
|
||||
# Serving on unix socket: /tmp/gh-ost.test.sock
|
||||
Copy: 57992500/86684838 66.9%; Applied: 57708; Backlog: 1/100; Time: 3h28m38s(total), 3h28m36s(copy); streamer: mysql-bin.000576:142993938; State: migrating; ETA: 1h43m12s
|
||||
```
|
||||
|
||||
当测试迁移完成表数据的复制时,它将停止复制并执行切换,使用 _gh-ost_ 表替换原始表,然后交换回来。我们对实际更换数据并不感兴趣。相反,我们将留下原始的表和 _gh-ost_ 表,它们都应该是相同的。我们通过校验两个表的整个表数据来验证。
|
||||
|
||||
测试可以完成:
|
||||
|
||||
* _成功_ : 一切顺利,校验和相同。我们期待看到这一点。
|
||||
|
||||
* _失败_ : 执行问题。这可能偶尔发生,因为迁移过程被杀死,复制问题等,并且通常与 `gh-ost` 自身无关。
|
||||
|
||||
* _校验失败_ : 表数据不一致。对于被测试的分支,这个调用修复。对于正在进行的 `master` 分支测试,这意味着立即阻止生产迁移。我们不会得到后者。
|
||||
|
||||
测试结果经过审核,发送到机器人聊天室,作为事件发送到我们的度量系统。下图中的每条垂直线代表成功的迁移测试:
|
||||
|
||||

|
||||
|
||||
这些测试不断运行。如果发生故障,我们会收到通知。当然,我们可以随时访问机器人聊天室,了解发生了什么。
|
||||
|
||||
#### 测试新版本
|
||||
|
||||
我们不断提高 `gh-ost`。我们的开发流程基于 `git` 分支机构,然后我们提供通过[拉请求][44]进行合并。
|
||||
|
||||
提交的 `gh-ost` 拉请求通过持续集成(CI)进行基本的编译和单元测试。一旦过去,公关在技术上有资格合并,但更有趣的是它有 [eligible for deployment via Heaven][45] 。作为我们基础架构中的敏感组件,我们 `gh-ost` 在合并之前,要小心部署 master 分支机构,进行密集测试。
|
||||
|
||||

|
||||
**shlomi-noach**.deploy gh-ost/fix-reappearing-throttled-reasons to prod/ghost-db-mysql-0007
|
||||

|
||||
**Hubot**[@shlomi-noach][25] 正在部署 gh-ost/fix-reappearing-throttled-reasons (baee4f6) 到生产中 (ghost-db-mysql-0007).
|
||||
[@shlomi-noach][26] gh-ost/fix-reappearing-throttled-reasons (baee4f6) 的生产部署已经完成了! (2s)
|
||||
[@shlomi-noach][27] 确保你在 haystack 中看到异常
|
||||

|
||||
**jonahberquist**.deploy gh-ost/interactive-command-question to prod/ghost-db-mysql-0012
|
||||

|
||||
**Hubot**[@jonahberquist][28] 正在部署 gh-ost/interactive-command-question (be1ab17) 到生产 (ghost-db-mysql-0012).
|
||||
[@jonahberquist][29] gh-ost/interactive-command-question (be1ab17) 的生产部署已经完成了!(2s)
|
||||
[@jonahberquist][30] 确保你在 haystack 中看到异常
|
||||

|
||||
**shlomi-noach**.wcid gh-ost
|
||||

|
||||
**Hubot**shlomi-noach 测试 fix-reappearing-throttled-reasons 41 秒前: ghost-db-mysql-0007
|
||||
jonahberquist 测试 interactive-command-question 7 秒前: ghost-db-mysql-0012
|
||||
|
||||
没人在排队。
|
||||
|
||||
一些 PR 很小,不影响数据本身。对状态消息,交互式命令等的更改对 `gh-ost` 应用程序的影响较小 。其他对迁移逻辑和操作造成重大变化。我们将严格测试这些,通过我们的生产表车队,直到满足这些变化不会造成数据损坏的威胁。
|
||||
|
||||
### 总结[][46]
|
||||
|
||||
在整个测试过程中,我们建立对系统的信任。通过自动化这些测试,在生产中,我们得到重复的确认,一切都按预期工作。随着我们继续发展我们的基础设施,我们还通过调整测试来覆盖最新的变化。
|
||||
|
||||
生产总是令人惊奇的,不包括测试的场景。我们对生产环境的测试越多,我们对应用程序的期望越多,基础设施的能力就越强。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
|
||||
作者:[tomkrouper ][a], [Shlomi Noach][b]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/tomkrouper
|
||||
[b]:https://github.com/shlomi-noach
|
||||
[1]:https://github.com/tomkrouper
|
||||
[2]:https://github.com/jessbreckenridge
|
||||
[3]:https://github.com/jessbreckenridge
|
||||
[4]:https://github.com/jessbreckenridge
|
||||
[5]:https://github.com/jessbreckenridge
|
||||
[6]:https://github.com/jessbreckenridge
|
||||
[7]:https://github.com/jessbreckenridge
|
||||
[8]:https://github.com/jessbreckenridge
|
||||
[9]:https://github.com/jessbreckenridge
|
||||
[10]:https://github.com/jessbreckenridge
|
||||
[11]:https://github.com/jessbreckenridge
|
||||
[12]:https://github.com/jessbreckenridge
|
||||
[13]:https://github.com/jessbreckenridge
|
||||
[14]:https://github.com/jessbreckenridge
|
||||
[15]:https://github.com/jessbreckenridge
|
||||
[16]:https://github.com/jessbreckenridge
|
||||
[17]:https://github.com/jessbreckenridge
|
||||
[18]:https://github.com/jessbreckenridge
|
||||
[19]:https://github.com/jessbreckenridge
|
||||
[20]:https://github.com/jessbreckenridge
|
||||
[21]:https://github.com/jessbreckenridge
|
||||
[22]:https://github.com/jessbreckenridge
|
||||
[23]:https://github.com/jessbreckenridge
|
||||
[24]:https://github.com/jessbreckenridge
|
||||
[25]:https://github.com/shlomi-noach
|
||||
[26]:https://github.com/shlomi-noach
|
||||
[27]:https://github.com/shlomi-noach
|
||||
[28]:https://github.com/jonahberquist
|
||||
[29]:https://github.com/jonahberquist
|
||||
[30]:https://github.com/jonahberquist
|
||||
[31]:https://githubengineering.com/mysql-testing-automation-at-github/
|
||||
[32]:https://github.com/tomkrouper
|
||||
[33]:https://github.com/tomkrouper
|
||||
[34]:https://github.com/shlomi-noach
|
||||
[35]:https://github.com/shlomi-noach
|
||||
[36]:https://githubengineering.com/mysql-testing-automation-at-github/#backups
|
||||
[37]:https://www.percona.com/software/mysql-database/percona-xtrabackup
|
||||
[38]:https://dev.mysql.com/doc/refman/5.6/en/replication-delayed.html
|
||||
[39]:https://githubengineering.com/mysql-testing-automation-at-github/#failovers
|
||||
[40]:http://githubengineering.com/orchestrator-github/
|
||||
[41]:https://githubengineering.com/context-aware-mysql-pools-via-haproxy/
|
||||
[42]:https://githubengineering.com/mysql-testing-automation-at-github/#schema-migrations
|
||||
[43]:http://githubengineering.com/gh-ost-github-s-online-migration-tool-for-mysql/
|
||||
[44]:https://github.com/github/gh-ost/pulls
|
||||
[45]:https://githubengineering.com/deploying-branches-to-github-com/
|
||||
[46]:https://githubengineering.com/mysql-testing-automation-at-github/#summary
|
||||
@ -1,86 +0,0 @@
|
||||
编排工具充分利用 Linux 容器技术
|
||||
============================================================
|
||||
|
||||
### 一旦公司过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器
|
||||
|
||||

|
||||
>Thinkstock
|
||||
|
||||
需要快速、高效地交付程序的公司 - 而今天,哪些公司不需要这样做?- 是那些正在转向 Linux 容器的公司。他们还发现,一旦公司过了“让我们看看这些容器如何工作”的阶段,他们最终会在许多不同的地方运行容器。
|
||||
|
||||
Linux 容器技术不是新技术,但它随着最初由 Docker 发明的创新性包装格式(现在的[OCI][3]f格式)以及新程序对持续开发和部署的需求开始变得流行。在 Red Hat 的 2016 年 5 月的 Forrester 研究中,有 48% 的受访者表示已经在开发中使用容器,今年的数字预计将达到 53%。只有五分之一的受访者表示,他们在 2017 年不会在开发过程中利用容器。
|
||||
|
||||
像乐高积木一样,容器镜像可以轻松重用代码和服务。每个容器镜像就像一个单独的旨在做好一部分工作的乐高积木。它可能是数据库、数据存储、甚至预订服务或分析服务。通过单独包装每个组件,从而可以在不同的应用中使用。但是,如果没有某种程序定义(指令手册),则难以在不同环境中创建完整应用程序的副本。那就是容器编排的来由。
|
||||
|
||||

|
||||
Scott McCarty
|
||||
|
||||
容器编排提供了像乐高系统这样的基础设施 - 开发人员可以提供如何构建应用程序的简单说明。编排引擎将知道如何运行它。这使得可以轻松创建同一应用程序的多个副本、跨越开发人员电脑、CI/CD 系统,甚至生产数据中心和云提供商环境。
|
||||
|
||||
Linux 容器镜像允许公司在整个运行时环境(操作系统部件)中打包和隔离应用程序的构建块。在此基础上,通过容器编排,可以很容易地将所有块定义并运行为一个完整的应用程序。一旦定义了完整的应用程序,它们就可以在不同的环境(开发、测试、生产等)之间移动,而不会破坏它们,且不改变它们的行为。
|
||||
|
||||
### 仔细调查容器
|
||||
|
||||
很明显,容器是有意义的,越来越多的公司在调查容器。一开始,可能是一个开发人员使用一个容器工作,或是一组使用多个容器的开发人员。在后一种情况下,开发人员可能会编写本地代码来处理容器部署超出单个实例之后快速出现的复杂性。
|
||||
|
||||
这一切都很好,毕竟他们是开发人员 - 他们已经有了。但即使在开发人员世界也会变得混乱,而且本地代码模式在容器进入 QA 和生产环境下无法工作。
|
||||
|
||||
编排工具基本上做了两件事。首先,它们帮助开发人员定义他们的应用程序的外观 - 一组用来构建应用程序实例的服务 - 数据库、数据存储、Web 服务等。编排器帮助标准化应用程序的所有部分,在一起运行并彼此通信,我将这称之为标准化程序定义。第二,它们管理一个计算资源集群中启动、停止、升级和运行多个容器的过程,这在运行任何给定应用程序的多个副本时特别有用,例如持续集成 (CI) 和连续交付 (CD)。
|
||||
|
||||
|
||||
想像一个公寓楼。居住在那里的每个人都有相同的街道地址,但每个人都有一个数字或字母或两者的组合,专门用来识别他或她。这是必要的,例如,将正确的邮件和包裹交付给合适的租户。
|
||||
|
||||
同样,在容器中,只要你有两个容器或两个要运行这些容器的主机,你必须跟踪开发人员测试数据库连接或用户连接到正在运行的服务的位置。容器编排工具实质上有助于管理跨多个主机的容器的后勤。它们将生命周期管理功能扩展到由多个容器组成的完整应用程序,部署在一组机器上,从而允许用户将整个集群视为单个部署目标。
|
||||
|
||||
这真的很简单,又很复杂。编排工具提供了许多功能,从配置容器到识别和重新安排故障容器,将容器暴露给集群外的系统和服务,根据需要添加和删除容器。
|
||||
|
||||
虽然容器技术已经存在了一段时间,但容器编排工具只出现了几年。编排工具是 Google 从内部高性能计算(HPC)和应用程序管理中吸取的经验教训开发的。在本质上,要处理怪物就是在一堆服务器上运行一堆东西(批处理作业、服务等)。从那时起,编排工具已经进化成使公司能够战略性地利用容器。
|
||||
|
||||
一旦你的公司确定需要容器编排,下一步就是确定哪个平台对于业务是最有意义的。在评估容器编排时,请仔细查看(尤其):
|
||||
|
||||
* 应用程序定义语言
|
||||
|
||||
* 现有能力集
|
||||
|
||||
* 添加新功能的速度
|
||||
|
||||
* 开源还是专有
|
||||
|
||||
* 社区健康(成员的积极性/高效,成员提交的质量/数量,贡献者的个人和公司的多样性)
|
||||
|
||||
* 强化努力
|
||||
|
||||
* 参考架构
|
||||
|
||||
* 认证
|
||||
|
||||
* 产品化过程
|
||||
|
||||
有三个主要的容器编排平台,它们似乎领先于其他,每个都有自己的历史。
|
||||
|
||||
1. **Docker Swarm:** Swarm 是 Docker 的附件,可以说是容器后面的孩子。Swarm 允许用户将 Docker 节点集群建立并管理为单个虚拟系统。Swarm 的挑战似乎是成为单一供应商的项目。
|
||||
|
||||
2. **Mesos:** Mesos 是从 Apache 和高性能计算中成长起来的,因此是一个优秀的调度员。Mesos 的技术也非常先进,虽然与其他相比似乎没有速度或投资。
|
||||
|
||||
3. **Kubernetes:** 由 Google 开发,由内部编排工具 Borg 受到的教训而来,Kubernetes 被广泛使用,并拥有强大的社区。其实这是 GitHub 上第一的项目。Mesos 目前可能比 Kubernetes 具有轻微的技术优势,但是 Kubernetes 是一个快速发展的项目,这也是为了长期技术上的收益而进行的架构投资。在不久的将来,在技术能力上应该能赶超 Mesos。
|
||||
|
||||
### 编排的未来
|
||||
|
||||
展望未来,企业可以期待看到编排工具在应用程序和服务为中心方向上发展。因为在现实中,如今快速应用程序开发实际上是在快速利用服务、代码和数据的组合。无论这些服务是开源,还是由内部团队部署,还是从云提供商处购买,未来将会是两者的混合。由于今天的编排器也在处理应用程序定义方面的挑战,所以期望看到它们越来越多地应对外部服务的整合。
|
||||
|
||||
此时此刻,想要充分利用容器的公司必须利用容器编排。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3205304/containers/orchestration-tools-enable-companies-to-fully-exploit-linux-container-technology.html
|
||||
|
||||
作者:[ Scott McCarty][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.infoworld.com/author/Scott-McCarty/
|
||||
[1]:https://www.infoworld.com/article/3204171/what-is-docker-linux-containers-explained.html#tk.ifw-infsb
|
||||
[2]:https://www.infoworld.com/resources/16373/application-virtualization/the-beginners-guide-to-docker.html#tk.ifw-infsb
|
||||
[3]:https://github.com/opencontainers/image-spec
|
||||
Loading…
Reference in New Issue
Block a user