mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
TSL&PRF
@wxy
This commit is contained in:
parent
29aa09cfe8
commit
45ed386f3e
@ -1,166 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Prometheus)
|
||||
[#]: via: (https://opensource.com/article/18/12/introduction-prometheus)
|
||||
[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
|
||||
|
||||
Getting started with Prometheus
|
||||
======
|
||||
Learn to install and write queries for the Prometheus monitoring and alerting system.
|
||||

|
||||
|
||||
[Prometheus][1] is an open source monitoring and alerting system that directly scrapes metrics from agents running on the target hosts and stores the collected samples centrally on its server. Metrics can also be pushed using plugins like **collectd_exporter** —although this is not Promethius' default behavior, it may be useful in some environments where hosts are behind a firewall or prohibited from opening ports by security policy.
|
||||
|
||||
Prometheus, a project of the [Cloud Native Computing Foundation][2], scales up using a federation model, which enables one Prometheus server to scrape another Prometheus server. This allows creation of a hierarchical topology, where a central system or higher-level Prometheus server can scrape aggregated data already collected from subordinate instances.
|
||||
|
||||
Besides the Prometheus server, its most common components are its [Alertmanager][3] and its exporters.
|
||||
|
||||
Alerting rules can be created within Prometheus and configured to send custom alerts to Alertmanager. Alertmanager then processes and handles these alerts, including sending notifications through different mechanisms like email or third-party services like [PagerDuty][4].
|
||||
|
||||
Prometheus' exporters can be libraries, processes, devices, or anything else that exposes the metrics that will be scraped by Prometheus. The metrics are available at the endpoint **/metrics** , which allows Prometheus to scrape them directly without needing an agent. The tutorial in this article uses **node_exporter** to expose the target hosts' hardware and operating system metrics. Exporters' outputs are plaintext and highly readable, which is one of Prometheus' strengths.
|
||||
|
||||
In addition, you can configure [Grafana][5] to use Prometheus as a backend to provide data visualization and dashboarding functions.
|
||||
|
||||
### Making sense of Prometheus' configuration file
|
||||
|
||||
The number of seconds between when **/metrics** is scraped controls the granularity of the time-series database. This is defined in the configuration file as the **scrape_interval** parameter, which by default is set to 60 seconds.
|
||||
|
||||
Targets are set for each scrape job in the **scrape_configs** section. Each job has its own name and a set of labels that can help filter, categorize, and make it easier to identify the target. One job can have many targets.
|
||||
|
||||
### Installing Prometheus
|
||||
|
||||
In this tutorial, for simplicity, we will install a Prometheus server and **node_exporter** with docker. Docker should already be installed and configured properly on your system. For a more in-depth, automated method, I recommend Steve Ovens' article [How to use Ansible to set up system monitoring with Prometheus][6].
|
||||
|
||||
Before starting, create the Prometheus configuration file **prometheus.yml** in your work directory as follows:
|
||||
|
||||
```
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 15s
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
|
||||
static_configs:
|
||||
- targets: ['localhost:9090']
|
||||
|
||||
- job_name: 'webservers'
|
||||
|
||||
static_configs:
|
||||
- targets: ['<node exporter node IP>:9100']
|
||||
```
|
||||
|
||||
Start Prometheus with Docker by running the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -p 9090:9090 -v
|
||||
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
|
||||
prom/prometheus
|
||||
```
|
||||
|
||||
By default, the Prometheus server will use port 9090. If this port is already in use, you can change it by adding the parameter **\--web.listen-address=" <IP of machine>:<port>"** at the end of the previous command.
|
||||
|
||||
In the machine you want to monitor, download and run the **node_exporter** container by using the following command:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
|
||||
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
|
||||
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
|
||||
mount-points "^/(sys|proc|dev|host|etc)($|/)"
|
||||
```
|
||||
|
||||
For the purposes of this learning exercise, you can install **node_exporter** and Prometheus on the same machine. Please note that it's not wise to run **node_exporter** under Docker in production—this is for testing purposes only.
|
||||
|
||||
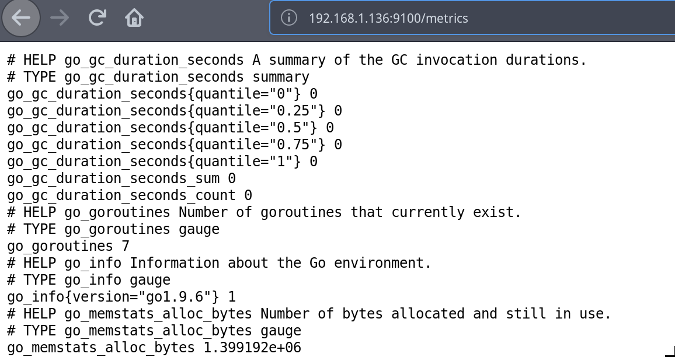
To verify that **node_exporter** is running, open your browser and navigate to **http:// <IP of Node exporter host>:9100/metrics**. All the metrics collected will be displayed; these are the same metrics Prometheus will scrape.
|
||||
|
||||
|
||||
|
||||
To verify the Prometheus server installation, open your browser and navigate to <http://localhost:9090>.
|
||||
|
||||
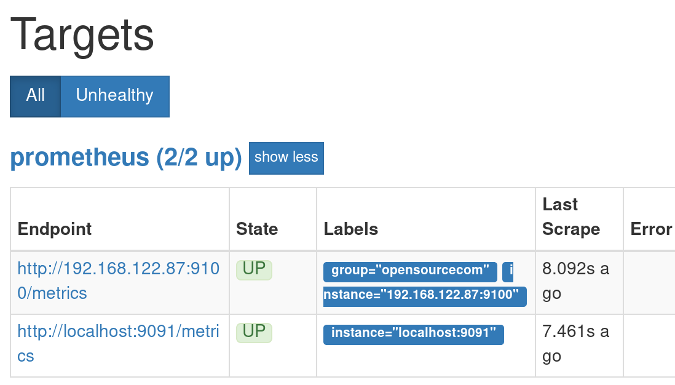
You should see the Prometheus interface. Click on **Status** and then **Targets**. Under State, you should see your machines listed as **UP**.
|
||||
|
||||
|
||||
|
||||
### Using Prometheus queries
|
||||
|
||||
It's time to get familiar with [PromQL][7], Prometheus' query syntax, and its graphing web interface. Go to **<http://localhost:9090/graph>** on your Prometheus server. You will see a query editor and two tabs: Graph and Console.
|
||||
|
||||
Prometheus stores all data as time series, identifying each one with a metric name. For example, the metric **node_filesystem_avail_bytes** shows the available filesystem space. The metric's name can be used in the expression box to select all of the time series with this name and produce an instant vector. If desired, these time series can be filtered using selectors and labels—a set of key-value pairs—for example:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype="ext4"}
|
||||
```
|
||||
|
||||
When filtering, you can match "exactly equal" ( **=** ), "not equal" ( **!=** ), "regex-match" ( **=~** ), and "do not regex-match" ( **!~** ). The following examples illustrate this:
|
||||
|
||||
To filter **node_filesystem_avail_bytes** to show both ext4 and XFS filesystems:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
|
||||
```
|
||||
|
||||
To exclude a match:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype!="xfs"}
|
||||
```
|
||||
|
||||
You can also get a range of samples back from the current time by using square brackets. You can use **s** to represent seconds, **m** for minutes, **h** for hours, **d** for days, **w** for weeks, and **y** for years. When using time ranges, the vector returned will be a range vector.
|
||||
|
||||
For example, the following command produces the samples from five minutes to the present:
|
||||
|
||||
```
|
||||
node_memory_MemAvailable_bytes[5m]
|
||||
```
|
||||
|
||||
Prometheus also includes functions to allow advanced queries, such as this:
|
||||
|
||||
```
|
||||
100 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))
|
||||
```
|
||||
|
||||
Notice how the labels are used to filter the job and the mode. The metric **node_cpu_seconds_total** returns a counter, and the **irate()** function calculates the per-second rate of change based on the last two data points of the range interval (meaning the range can be smaller than five minutes). To calculate the overall CPU usage, you can use the idle mode of the **node_cpu_seconds_total** metric. The idle percent of a processor is the opposite of a busy processor, so the **irate** value is subtracted from 1. To make it a percentage, multiply it by 100.
|
||||
|
||||
|
||||
|
||||
### Learn more
|
||||
|
||||
Prometheus is a powerful, scalable, lightweight, and easy to use and deploy monitoring tool that is indispensable for every system administrator and developer. For these and other reasons, many companies are implementing Prometheus as part of their infrastructure.
|
||||
|
||||
To learn more about Prometheus and its functions, I recommend the following resources:
|
||||
|
||||
+ About [PromQL][8]
|
||||
+ What [node_exporters collects][9]
|
||||
+ [Prometheus functions][10]
|
||||
+ [4 open source monitoring tools][11]
|
||||
+ [Now available: The open source guide to DevOps monitoring tools][12]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/introduction-prometheus
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://prometheus.io/
|
||||
[2]: https://www.cncf.io/
|
||||
[3]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[4]: https://en.wikipedia.org/wiki/PagerDuty
|
||||
[5]: https://grafana.com/
|
||||
[6]: https://opensource.com/article/18/3/how-use-ansible-set-system-monitoring-prometheus
|
||||
[7]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[8]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[9]: https://github.com/prometheus/node_exporter#collectors
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/functions/
|
||||
[11]: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
[12]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
|
||||
167
translated/tech/20181220 Getting started with Prometheus.md
Normal file
167
translated/tech/20181220 Getting started with Prometheus.md
Normal file
@ -0,0 +1,167 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Prometheus)
|
||||
[#]: via: (https://opensource.com/article/18/12/introduction-prometheus)
|
||||
[#]: author: (Michael Zamot https://opensource.com/users/mzamot)
|
||||
|
||||
Prometheus 入门
|
||||
======
|
||||
|
||||
> 学习安装 Prometheus 监控和警报系统并编写它的查询。
|
||||
|
||||

|
||||
|
||||
[Prometheus][1] 是一个开源的监控和警报系统,它直接从目标主机上运行的代理程序中抓取指标,并将收集的样本集中存储在其服务器上。也可以使用像 `collectd_exporter` 这样的插件推送指标,尽管这不是 Promethius 的默认行为,但在主机位于防火墙后面或位于安全策略禁止打开端口的某些环境中它可能很有用。
|
||||
|
||||
Prometheus 是[云原生计算基金会(CNCF)][2]的一个项目。它使用<ruby>联合模型<rt>federation model</rt></ruby>进行扩展,该模型使得一个 Prometheus 服务器能够抓取另一个 Prometheus 服务器的数据。这允许创建分层拓扑,其中中央系统或更高级别的 Prometheus 服务器可以抓取已从下级实例收集的聚合数据。
|
||||
|
||||
除 Prometheus 服务器外,其最常见的组件是[警报管理器][3]及其输出器。
|
||||
|
||||
警报规则可以在 Prometheus 中创建,并配置为向警报管理器发送自定义警报。然后,警报管理器处理和管理这些警报,包括通过电子邮件或第三方服务(如 [PagerDuty][4])等不同机制发送通知。
|
||||
|
||||
Prometheus 的输出器可以是库、进程、设备或任何其他能将 Prometheus 抓取的指标公开出去的东西。 这些指标可在端点 `/metrics` 中获得,它允许 Prometheus 无需代理直接抓取它们。本文中的教程使用 `node_exporter` 来公开目标主机的硬件和操作系统指标。输出器的输出是明文的、高度可读的,这是 Prometheus 的优势之一。
|
||||
|
||||
此外,你可以将 Prometheus 作为后端,配置 [Grafana][5] 来提供数据可视化和仪表板功能。
|
||||
|
||||
### 理解 Prometheus 的配置文件
|
||||
|
||||
抓取 `/metrics` 的间隔秒数控制了时间序列数据库的粒度。这在配置文件中定义为 `scrape_interval` 参数,默认情况下设置为 60 秒。
|
||||
|
||||
在 `scrape_configs` 部分中为每个抓取作业设置了目标。每个作业都有自己的名称和一组标签,可以帮助你过滤、分类并更轻松地识别目标。一项作业可以有很多目标。
|
||||
|
||||
### 安装 Prometheus
|
||||
|
||||
在本教程中,为简单起见,我们将使用 Docker 安装 Prometheus 服务器和 `node_exporter`。Docker 应该已经在你的系统上正确安装和配置。对于更深入、自动化的方法,我推荐 Steve Ovens 的文章《[如何使用 Ansible 与 Prometheus 建立系统监控][6]》。
|
||||
|
||||
在开始之前,在工作目录中创建 Prometheus 配置文件 `prometheus.yml`,如下所示:
|
||||
|
||||
```
|
||||
global:
|
||||
scrape_interval: 15s
|
||||
evaluation_interval: 15s
|
||||
|
||||
scrape_configs:
|
||||
- job_name: 'prometheus'
|
||||
|
||||
static_configs:
|
||||
- targets: ['localhost:9090']
|
||||
|
||||
- job_name: 'webservers'
|
||||
|
||||
static_configs:
|
||||
- targets: ['<node exporter node IP>:9100']
|
||||
```
|
||||
|
||||
通过运行以下命令用 Docker 启动 Prometheus:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -p 9090:9090 -v
|
||||
/path/to/prometheus.yml:/etc/prometheus/prometheus.yml
|
||||
prom/prometheus
|
||||
```
|
||||
|
||||
默认情况下,Prometheus 服务器将使用端口 9090。如果此端口已在使用,你可以通过在上一个命令的后面添加参数 `--web.listen-address="<IP of machine>:<port>"` 来更改它。
|
||||
|
||||
在要监视的计算机中,使用以下命令下载并运行 `node_exporter` 容器:
|
||||
|
||||
```
|
||||
$ sudo docker run -d -v "/proc:/host/proc" -v "/sys:/host/sys" -v
|
||||
"/:/rootfs" --net="host" prom/node-exporter --path.procfs
|
||||
/host/proc --path.sysfs /host/sys --collector.filesystem.ignored-
|
||||
mount-points "^/(sys|proc|dev|host|etc)($|/)"
|
||||
```
|
||||
|
||||
出于本文练习的目的,你可以在同一台机器上安装 `node_exporter` 和 Prometheus。请注意,生产环境中在 Docker 下运行 `node_exporter` 是不明智的 —— 这仅用于测试目的。
|
||||
|
||||
要验证 `node_exporter` 是否正在运行,请打开浏览器并导航到 `http://<IP of Node exporter host>:9100/metrics`,这将显示收集到的所有指标;也即是 Prometheus 将要抓取的相同指标。
|
||||
|
||||

|
||||
|
||||
要确认 Prometheus 服务器安装成功,打开浏览器并导航至:<http://localhost:9090>。
|
||||
|
||||
你应该看到了 Prometheus 的界面。单击“Status”,然后单击“Targets”。在 “Status” 下,你应该看到你的机器被列为 “UP”。
|
||||
|
||||

|
||||
|
||||
### 使用 Prometheus 查询
|
||||
|
||||
现在是时候熟悉一下 [PromQL][7](Prometheus 的查询语法)及其图形化 Web 界面了。转到 Prometheus 服务器上的 `http://localhost:9090/graph`。你将看到一个查询编辑器和两个选项卡:“Graph” 和 “Console”。
|
||||
|
||||
Prometheus 将所有数据存储为时间序列,使用指标名称标识每个数据。例如,指标 `node_filesystem_avail_bytes` 显示可用的文件系统空间。指标的名称可以在表达式框中使用,以选择具有此名称的所有时间序列并生成即时向量。如果需要,可以使用选择器和标签(一组键值对)过滤这些时间序列,例如:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype="ext4"}
|
||||
```
|
||||
|
||||
过滤时,你可以匹配“完全相等”(`=`)、“不等于”(`!=`),“正则匹配”(`=~`)和“正则排除匹配”(`!~`)。以下示例说明了这一点:
|
||||
|
||||
要过滤 `node_filesystem_avail_bytes` 以显示 ext4 和 XFS 文件系统:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype=~"ext4|xfs"}
|
||||
```
|
||||
|
||||
要排除匹配:
|
||||
|
||||
```
|
||||
node_filesystem_avail_bytes{fstype!="xfs"}
|
||||
```
|
||||
|
||||
你还可以使用方括号得到从当前时间往回的一系列样本。你可以使用 `s` 表示秒,`m` 表示分钟,`h` 表示小时,`d` 表示天,`w` 表示周,而 `y` 表示年。使用时间范围时,返回的向量将是范围向量。
|
||||
|
||||
例如,以下命令生成从五分钟前到现在的样本:
|
||||
|
||||
```
|
||||
node_memory_MemAvailable_bytes[5m]
|
||||
```
|
||||
|
||||
Prometheus 还包括了高级查询的功能,例如:
|
||||
|
||||
```
|
||||
100 * (1 - avg by(instance)(irate(node_cpu_seconds_total{job='webservers',mode='idle'}[5m])))
|
||||
```
|
||||
|
||||
请注意标签如何用于过滤作业和模式。指标 `node_cpu_seconds_total` 返回一个计数器,`irate()`函数根据范围间隔的最后两个数据点计算每秒的变化率(意味着该范围可以小于五分钟)。要计算 CPU 总体使用率,可以使用 `node_cpu_seconds_total` 指标的空闲(`idle`)模式。处理器的空闲比例与繁忙比例相反,因此从 1 中减去 `irate` 值。要使其为百分比,请将其乘以 100。
|
||||
|
||||

|
||||
|
||||
### 了解更多
|
||||
|
||||
Prometheus 是一个功能强大、可扩展、轻量级、易于使用和部署的监视工具,对于每个系统管理员和开发人员来说都是必不可少的。出于这些原因和其他原因,许多公司正在将 Prometheus 作为其基础设施的一部分。
|
||||
|
||||
要了解有关 Prometheus 及其功能的更多信息,我建议使用以下资源:
|
||||
|
||||
+ 关于 [PromQL][8]
|
||||
+ 什么是 [node_exporters 集合][9]
|
||||
+ [Prometheus 函数][10]
|
||||
+ [4 个开源监控工具] [11]
|
||||
+ [现已推出:DevOps 监控工具的开源指南] [12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/introduction-prometheus
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mzamot
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://prometheus.io/
|
||||
[2]: https://www.cncf.io/
|
||||
[3]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[4]: https://en.wikipedia.org/wiki/PagerDuty
|
||||
[5]: https://grafana.com/
|
||||
[6]: https://opensource.com/article/18/3/how-use-ansible-set-system-monitoring-prometheus
|
||||
[7]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[8]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[9]: https://github.com/prometheus/node_exporter#collectors
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/functions/
|
||||
[11]: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
[12]: https://opensource.com/article/18/8/now-available-open-source-guide-devops-monitoring-tools
|
||||
Loading…
Reference in New Issue
Block a user