mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
4561908be4
2
.gitignore
vendored
2
.gitignore
vendored
@ -3,3 +3,5 @@ members.md
|
||||
*.html
|
||||
*.bak
|
||||
.DS_Store
|
||||
sources/*/.*
|
||||
translated/*/.*
|
||||
95
published/20180128 Being open about data privacy.md
Normal file
95
published/20180128 Being open about data privacy.md
Normal file
@ -0,0 +1,95 @@
|
||||
对数据隐私持开放的态度
|
||||
======
|
||||
|
||||
> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
|
||||
|
||||

|
||||
|
||||
今天(LCTT 译注:本文发表于 2018/1/28)是<ruby>[数据隐私日][1]<rt>Data Privacy Day</rt></ruby>,(在欧洲叫“<ruby>数据保护日<rt>Data Protection Day</rt></ruby>”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
|
||||
|
||||
1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3])
|
||||
2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
|
||||
|
||||
所以实际上,数据隐私对于每个人来说是很重要的。
|
||||
|
||||
事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
|
||||
|
||||
### 通用数据保护条例(GDPR)的影响
|
||||
|
||||
那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为<ruby>通用数据保护条例<rt>General Data Protection Regulation</rt></ruby>(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
|
||||
|
||||
通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
|
||||
|
||||
“哼!” 你可能会这样说^注1 ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
|
||||
|
||||
看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。^注2
|
||||
|
||||
然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好^注3 :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
|
||||
|
||||
有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
|
||||
|
||||
有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
|
||||
|
||||
### 谁是顾客?
|
||||
|
||||
关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门^注4 ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
|
||||
|
||||
然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词^注5 ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司^注6 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
|
||||
|
||||
不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。^注7
|
||||
|
||||
### 开放和积极
|
||||
|
||||
然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
|
||||
|
||||
这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B^注8 提供一项服务 。在此有四种不同类型的数据:
|
||||
|
||||
1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
|
||||
2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
|
||||
3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
|
||||
4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
|
||||
|
||||
首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。^注9 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
|
||||
然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
|
||||
|
||||
### 一些具体的措施
|
||||
|
||||
我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
|
||||
|
||||
* 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
|
||||
* 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
|
||||
* 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
|
||||
* 和你的非技术朋友讨论这个话题。
|
||||
* 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
|
||||
* 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
|
||||
* 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,^注10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
|
||||
|
||||
**注:**
|
||||
|
||||
1. 我承认你可能尽管不会。
|
||||
2. 假设你坚信你的个人数据应该被保护。
|
||||
3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
|
||||
4. 事实上这些机构能够有多开放取决于你所居住的地方。
|
||||
5. 假设我是英国人,那是非常非常大的剂量。
|
||||
6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
|
||||
7. 不,答案是“不”。
|
||||
8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
|
||||
9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
|
||||
10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[4]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
@ -0,0 +1,40 @@
|
||||
在 Arch 用户仓库(AUR)中发现恶意软件
|
||||
======
|
||||
|
||||
7 月 7 日,有一个 AUR 软件包被改入了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般的 Linux 用户)在安装之前应该尽可能检查所有由用户生成的软件包。
|
||||
|
||||
[AUR][3](即 Arch(Linux)用户仓库)包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全的,并且用户应尽可能在使用之前检查其内容。毕竟,AUR 在网页中以粗体显示 “**AUR 包是用户制作的内容。任何使用该提供的文件的风险由你自行承担。**”
|
||||
|
||||
这次[发现][4]包含恶意代码的 AUR 包证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了一个 systemd 单元以定期运行该脚本。
|
||||
|
||||
**看来有[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(它们注册在更新软件包的同一天)。**
|
||||
|
||||
这些恶意代码没有做任何真正有害的事情 —— 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单元信息)的输出到 pastebin.com。我说“试图”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
|
||||
|
||||
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们真的不明白他们在做什么。(LCTT 译注:意即这是一个菜鸟“黑客”,还不懂得如何有经验地隐藏自己。)
|
||||
|
||||
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
|
||||
|
||||
**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
|
||||
|
||||
**另一个更新:**你究竟应该在那些用户生成的软件包检查什么(如 AUR 中发现的)?情况各有不同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学做法”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须懂得 Debian 如何打包,并且这些源代码是可以直接更改的,因为它托管在 PPA 中并由用户上传的。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我觉得你应该只安装你信任的用户/打包器生成的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -2,19 +2,20 @@
|
||||
======
|
||||
|
||||

|
||||
Thunderbird 是由 [Mozilla][1] 开发的流行免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
|
||||
|
||||
Thunderbird 是由 [Mozilla][1] 开发的流行的免费电子邮件客户端。与 Firefox 类似,Thunderbird 提供了大量加载项来用于额外功能和自定义。本文重点介绍四个加载项,以改善你的隐私。
|
||||
|
||||
### Enigmail
|
||||
|
||||
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在 Magazine 上的入门介绍][2]。
|
||||
使用 GPG(GNU Privacy Guard)加密电子邮件是保持其内容私密性的最佳方式。如果你不熟悉 GPG,请[查看我们在这里的入门介绍][2]。
|
||||
|
||||
[Enigmail][3] 是使用 OpenPGP 和 Thunderbird 的首选加载项。实际上,Enigmail 与 Thunderbird 集成良好,可让你加密、解密、数字签名和验证电子邮件。
|
||||
|
||||
### Paranoia
|
||||
|
||||
[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
|
||||
[Paranoia][4] 可让你查看有关收到的电子邮件的重要信息。用一个表情符号显示电子邮件在到达收件箱之前经过的服务器之间的加密状态。
|
||||
|
||||
黄色,快乐的表情告诉你所有连接都已加密。蓝色,悲伤的表情意味着一个连接未加密。最后,红色的,害怕的表情表示在多个连接上该消息未加密。
|
||||
黄色、快乐的表情告诉你所有连接都已加密。蓝色、悲伤的表情意味着有一个连接未加密。最后,红色的、害怕的表情表示在多个连接上该消息未加密。
|
||||
|
||||
还有更多有关这些连接的详细信息,你可以用来检查哪台服务器用于投递邮件。
|
||||
|
||||
@ -30,9 +31,9 @@ Thunderbird 是由 [Mozilla][1] 开发的流行免费电子邮件客户端。与
|
||||
|
||||
如果你真的担心自己的隐私,[TorBirdy][6] 就是给你设计的加载项。它将 Thunderbird 配置为使用 [Tor][7] 网络。
|
||||
|
||||
据其[文档][8]所述,TorBirdy 在以前没有使用 Tor 的电子邮件帐户上提供较少的隐私。
|
||||
据其[文档][8]所述,TorBirdy 为以前没有使用 Tor 的电子邮件帐户提供了少量隐私保护。
|
||||
|
||||
>请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 - 你经常旅行并且不想通过发送电子邮件来披露你的所有位置--TorBirdy 非常有效!
|
||||
> 请记住,跟之前使用 Tor 访问的电子邮件帐户相比,之前没有使用 Tor 访问的电子邮件帐户提供**更少**的隐私/匿名/更弱的假名。但是,TorBirdy 仍然对现有帐户或实名电子邮件地址有用。例如,如果你正在寻求隐匿位置 —— 你经常旅行并且不想通过发送电子邮件来披露你的所有位置 —— TorBirdy 非常有效!
|
||||
|
||||
请注意,要使用此加载项,必须在系统上安装 Tor。
|
||||
|
||||
@ -46,7 +47,7 @@ via: https://fedoramagazine.org/4-addons-privacy-thunderbird/
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1 +0,0 @@
|
||||
lujun9972@T520.854:1532408217
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
# Understanding metrics and monitoring with Python
|
||||
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Asynchronous Processing with Go using Kafka and MongoDB
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,58 +0,0 @@
|
||||
Everything old is new again: Microservices – DXC Blogs
|
||||
======
|
||||

|
||||
|
||||
If I told you about a software architecture in which components of an application provided services to other components via a communications protocol over a network you would say it was…
|
||||
|
||||
Well, it depends. If you got your start programming in the 90s, you’d say I just defined a [Service-Oriented Architecture (SOA)][1]. But, if you’re younger and cut your developer teeth on the cloud, you’d say: “Oh, you’re talking about [microservices][2].”
|
||||
|
||||
You’d both be right. To really understand the differences, you need to dive deeper into these architectures.
|
||||
|
||||
In SOA, a service is a function, which is well-defined, self-contained, and doesn’t depend on the context or state of other services. There are two kinds of services. A service consumer, which requests a service from the other type, a service provider. An SOA service can play both roles.
|
||||
|
||||
SOA services can trade data with each other. Two or more services can also coordinate with each other. These services carry out basic jobs such as creating a user account, providing login functionality, or validating a payment.
|
||||
|
||||
SOA isn’t so much about modularizing an application as it is about composing an application by integrating distributed, separately-maintained and deployed components. These components run on servers.
|
||||
|
||||
Early versions of SOA used object-oriented protocols to communicate with each other. For example, Microsoft’s [Distributed Component Object Model (DCOM)][3] and [Object Request Brokers (ORBs)][4] use the [Common Object Request Broker Architecture (CORBA)][5] specification.
|
||||
|
||||
Later versions used messaging services such as [Java Message Service (JMS)][6] or [Advanced Message Queuing Protocol (AMQP)][7]. These service connections are called Enterprise Service Buses (ESB). Over these buses, data, almost always in eXtensible Markup Language (XML) format, is transmitted and received.
|
||||
|
||||
[Microservices][2] is an architectural style where applications are made up from loosely coupled services or modules. It lends itself to the Continuous Integration/Continuous Deployment (CI/CD) model of developing large, complex applications. An application is the sum of its modules.
|
||||
|
||||
Each microservice provides an application programming interface (API) endpoint. These are connected by lightweight protocols such as [REpresentational State Transfer (REST)][8], or [gRPC][9]. Data tends to be represented by [JavaScript Object Notation (JSON)][10] or [Protobuf][11].
|
||||
|
||||
Both architectures stand as an alternative to the older, monolithic style of architecture where applications are built as single, autonomous units. For example, in a client-server model, a typical Linux, Apache, MySQL, PHP/Python/Perl (LAMP) server-side application would deal with HTTP requests, run sub-programs and retrieves/updates from the underlying MySQL database. These are all tied closely together. When you change anything, you must build and deploy a new version.
|
||||
|
||||
With SOA, you may need to change several components, but never the entire application. With microservices, though, you can make changes one service at a time. With microservices, you’re working with a true decoupled architecture.
|
||||
|
||||
Microservices are also lighter than SOA. While SOA services are deployed to servers and virtual machines (VMs), microservices are deployed in containers. The protocols are also lighter. This makes microservices more flexible than SOA. Hence, it works better with Agile shops.
|
||||
|
||||
So what does this mean? The long and short of it is that microservices are an SOA variation for container and cloud computing.
|
||||
|
||||
Old style SOA isn’t going away, but as we continue to move applications to containers, the microservice architecture will only grow more popular.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
|
||||
|
||||
作者:[Cloudy Weather][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
|
||||
[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
|
||||
[2]:http://microservices.io/
|
||||
[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
|
||||
[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
|
||||
[5]:http://www.corba.org/
|
||||
[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
|
||||
[7]:https://www.amqp.org/
|
||||
[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
|
||||
[9]:https://grpc.io/
|
||||
[10]:https://www.json.org/
|
||||
[11]:https://github.com/google/protobuf/
|
||||
@ -1,127 +0,0 @@
|
||||
How To Check Ubuntu Version and Other System Information Easily
|
||||
======
|
||||
**Brief: Wondering which Ubuntu version are you using? Here’s how to check Ubuntu version, desktop environment and other relevant system information.**
|
||||
|
||||
You can easily find the Ubuntu version you are using in the command line or via the graphical interface. Knowing the exact Ubuntu version, desktop environment and other system information helps a lot when you are trying to follow a tutorial from the web or seeking help in various forums.
|
||||
|
||||
In this quick tip, I’ll show you various ways to check [Ubuntu][1] version and other common system information.
|
||||
|
||||
### How to check Ubuntu version in terminal
|
||||
|
||||
This is the best way to find Ubuntu version. I could have mentioned the graphical way first but then I chose this method because this one doesn’t depend on the [desktop environment][2] you are using. You can use it on any Ubuntu variant.
|
||||
|
||||
Open a terminal (Ctrl+Alt+T) and type the following command:
|
||||
```
|
||||
lsb_release -a
|
||||
|
||||
```
|
||||
|
||||
The output of the above command should be like this:
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
As you can see, the current Ubuntu installed in my system is Ubuntu 16.04 and its code name is Xenial.
|
||||
|
||||
Wait! Why does it say Ubuntu 16.04.4 in Description and 16.04 in the Release? Which one is it, 16.04 or 16.04.4? What’s the difference between the two?
|
||||
|
||||
The short answer is that you are using Ubuntu 16.04. That’s the base image. 16.04.4 signifies the fourth point release of 16.04. A point release can be thought of as a service pack in Windows era. Both 16.04 and 16.04.4 will be the correct answer here.
|
||||
|
||||
What’s Xenial in the output? That’s the codename of the Ubuntu 16.04 release. You can read this [article to know about Ubuntu naming convention][4].
|
||||
|
||||
#### Some alternate ways to find Ubuntu version
|
||||
|
||||
Alternatively, you can use either of the following commands to find Ubuntu version:
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
|
||||
```
|
||||
|
||||
The output of the above command would look like this:
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
You can also use this command to know Ubuntu version
|
||||
```
|
||||
cat /etc/issue
|
||||
|
||||
```
|
||||
|
||||
The output of this command will be like this:
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
|
||||
```
|
||||
|
||||
Forget the \n \l. The Ubuntu version is 16.04.4 in this case or simply Ubuntu 16.04.
|
||||
|
||||
### How to check Ubuntu version graphically
|
||||
|
||||
Checking Ubuntu version graphically is no big deal either. I am going to use screenshots from Ubuntu 18.04 GNOME here. Things may look different if you are using Unity or some other desktop environment. This is why I recommend the command line version discussed in the previous sections because that doesn’t depend on the desktop environment.
|
||||
|
||||
I’ll show you how to find the desktop environment in the next section.
|
||||
|
||||
For now, go to System Settings and look under the Details segment.
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
You should see the Ubuntu version here along with the information about the desktop environment you are using, [GNOME][7] being the case here.
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
### How to know the desktop environment and other system information in Ubuntu
|
||||
|
||||
So you just learned how to find Ubuntu version. What about the desktop environment in use? Which Linux kernel version is being used?
|
||||
|
||||
Of course, there are various commands you can use to get all those information but I’ll recommend a command line utility called [Neofetch][9]. This will show you essential system information in the terminal beautifully with the logo of Ubuntu or any other Linux distribution you are using.
|
||||
|
||||
Install Neofetch using the command below:
|
||||
```
|
||||
sudo apt install neofetch
|
||||
|
||||
```
|
||||
|
||||
Once installed, simply run the command `neofetch` in the terminal and see a beautiful display of system information.
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
As you can see, Neofetch shows you the Linux kernel version, Ubuntu version, desktop environment in use along with its version, themes and icons in use etc.
|
||||
|
||||
I hope it helps you to find Ubuntu version and other system information. If you have suggestions to improve this article, feel free to drop it in the comment section. Ciao :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Splicing the Cloud Native Stack, One Floor at a Time
|
||||
======
|
||||
At Packet, our value (automated infrastructure) is super fundamental. As such, we spend an enormous amount of time looking up at the players and trends in all the ecosystems above us - as well as the very few below!
|
||||
|
||||
@ -1,94 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Give Your Linux Desktop a Stunning Makeover With Xenlism Themes
|
||||
============================================================
|
||||
|
||||
|
||||
_Brief: Xenlism theme pack provides an aesthetically pleasing GTK theme, colorful icons, and minimalist wallpapers to transform your Linux desktop into an eye-catching setup._
|
||||
|
||||
It’s not every day that I dedicate an entire article to a theme unless I find something really awesome. I used to cover themes and icons regularly. But lately, I preferred having lists of [best GTK themes][6] and icon themes. This is more convenient for me and for you as well as you get to see many beautiful themes in one place.
|
||||
|
||||
After [Pop OS theme][7] suit, Xenlism is another theme that has left me awestruck by its look.
|
||||
|
||||

|
||||
|
||||
Xenlism GTK theme is based on the Arc theme, an inspiration behind so many themes these days. The GTK theme provides Windows buttons similar to macOS which I neither like nor dislike. The GTK theme has a flat, minimalist layout and I like that.
|
||||
|
||||
There are two icon themes in the Xenlism suite. Xenlism Wildfire is an old one and had already made to our list of [best icon themes][8].
|
||||
|
||||

|
||||
Xenlism Wildfire Icons
|
||||
|
||||
Xenlsim Storm is the relatively new icon theme but is equally beautiful.
|
||||
|
||||

|
||||
Xenlism Storm Icons
|
||||
|
||||
Xenlism themes are open source under GPL license.
|
||||
|
||||
### How to install Xenlism theme pack on Ubuntu 18.04
|
||||
|
||||
Xenlism dev provides an easier way of installing the theme pack through a PPA. Though the PPA is available for Ubuntu 16.04, I found the GTK theme wasn’t working with Unity. It works fine with the GNOME desktop in Ubuntu 18.04.
|
||||
|
||||
Open a terminal (Ctrl+Alt+T) and use the following commands one by one:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:xenatt/xenlism
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
This PPA offers four packages:
|
||||
|
||||
* xenlism-finewalls: for a set of wallpapers that will be available directly in the wallpaper section of Ubuntu. One of the wallpapers has been used in the screenshot.
|
||||
|
||||
* xenlism-minimalism-theme: GTK theme
|
||||
|
||||
* xenlism-storm: an icon theme (see previous screenshots)
|
||||
|
||||
* xenlism-wildfire-icon-theme: another icon theme with several color variants (folder colors get changed in the variants)
|
||||
|
||||
You can decide on your own what theme component you want to install. Personally, I don’t see any harm in installing all the components.
|
||||
|
||||
```
|
||||
sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
|
||||
```
|
||||
|
||||
You can use GNOME Tweaks for changing the theme and icons. If you are not familiar with the procedure already, I suggest reading this tutorial to learn [how to install themes in Ubuntu 18.04 GNOME][9].
|
||||
|
||||
### Getting Xenlism themes in other Linux distributions
|
||||
|
||||
You can install Xenlism themes on other Linux distributions as well. Installation instructions for various Linux distributions can be found on its website:
|
||||
|
||||
[Install Xenlism Themes][10]
|
||||
|
||||
### What do you think?
|
||||
|
||||
I know not everyone would agree with me but I loved this theme. I think you are going to see the glimpse of Xenlism theme in the screenshots in future tutorials on It’s FOSS.
|
||||
|
||||
Did you like Xenlism theme? If not, what theme do you like the most? Share your opinion in the comment section below.
|
||||
|
||||
#### 关于作者
|
||||
|
||||
I am a professional software developer, and founder of It's FOSS. I am an avid Linux lover and Open Source enthusiast. I use Ubuntu and believe in sharing knowledge. Apart from Linux, I love classic detective mysteries. I'm a huge fan of Agatha Christie's work.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/xenlism-theme/
|
||||
|
||||
作者:[Abhishek Prakash ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/xenlism-theme/#comments
|
||||
[3]:https://itsfoss.com/category/desktop/
|
||||
[4]:https://itsfoss.com/tag/themes/
|
||||
[5]:https://itsfoss.com/tag/xenlism/
|
||||
[6]:https://itsfoss.com/best-gtk-themes/
|
||||
[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
|
||||
[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[9]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[10]:http://xenlism.github.io/minimalism/#install
|
||||
@ -1,3 +1,5 @@
|
||||
pinewall translating
|
||||
|
||||
How Graphics Cards Work
|
||||
======
|
||||
![AMD-Polaris][1]
|
||||
|
||||
@ -1,311 +0,0 @@
|
||||
pinewall translating
|
||||
|
||||
Using MQTT to send and receive data for your next project
|
||||
======
|
||||
|
||||

|
||||
|
||||
Last November we bought an electric car, and it raised an interesting question: When should we charge it? I was concerned about having the lowest emissions for the electricity used to charge the car, so this is a specific question: What is the rate of CO2 emissions per kWh at any given time, and when during the day is it at its lowest?
|
||||
|
||||
### Finding the data
|
||||
|
||||
I live in New York State. About 80% of our electricity comes from in-state generation, mostly through natural gas, hydro dams (much of it from Niagara Falls), nuclear, and a bit of wind, solar, and other fossil fuels. The entire system is managed by the [New York Independent System Operator][1] (NYISO), a not-for-profit entity that was set up to balance the needs of power generators, consumers, and regulatory bodies to keep the lights on in New York.
|
||||
|
||||
Although there is no official public API, as part of its mission, NYISO makes [a lot of open data][2] available for public consumption. This includes reporting on what fuels are being consumed to generate power, at five-minute intervals, throughout the state. These are published as CSV files on a public archive and updated throughout the day. If you know the number of megawatts coming from different kinds of fuels, you can make a reasonable approximation of how much CO2 is being emitted at any given time.
|
||||
|
||||
We should always be kind when building tools to collect and process open data to avoid overloading those systems. Instead of sending everyone to their archive service to download the files all the time, we can do better. We can create a low-overhead event stream that people can subscribe to and get updates as they happen. We can do that with [MQTT][3]. The target for my project ([ny-power.org][4]) was inclusion in the [Home Assistant][5] project, an open source home automation platform that has hundreds of thousands of users. If all of these users were hitting this CSV server all the time, NYISO might need to restrict access to it.
|
||||
|
||||
### What is MQTT?
|
||||
|
||||
MQTT is a publish/subscribe (pubsub) wire protocol designed with small devices in mind. Pubsub systems work like a message bus. You send a message to a topic, and any software with a subscription for that topic gets a copy of your message. As a sender, you never really know who is listening; you just provide your information to a set of topics and listen for any other topics you might care about. It's like walking into a party and listening for interesting conversations to join.
|
||||
|
||||
This can make for extremely efficient applications. Clients subscribe to a narrow selection of topics and only receive the information they are looking for. This saves both processing time and network bandwidth.
|
||||
|
||||
As an open standard, MQTT has many open source implementations of both clients and servers. There are client libraries for every language you could imagine, even a library you can embed in Arduino for making sensor networks. There are many servers to choose from. My go-to is the [Mosquitto][6] server from Eclipse, as it's small, written in C, and can handle tens of thousands of subscribers without breaking a sweat.
|
||||
|
||||
### Why I like MQTT
|
||||
|
||||
Over the past two decades, we've come up with tried and true models for software applications to ask questions of services. Do I have more email? What is the current weather? Should I buy this thing now? This pattern of "ask/receive" works well much of the time; however, in a world awash with data, there are other patterns we need. The MQTT pubsub model is powerful where lots of data is published inbound to the system. Clients can subscribe to narrow slices of data and receive updates instantly when that data comes in.
|
||||
|
||||
MQTT also has additional interesting features, such as "last-will-and-testament" messages, which make it possible to distinguish between silence because there is no relevant data and silence because your data collectors have crashed. MQTT also has retained messages, which provide the last message on a topic to clients when they first connect. This is extremely useful for topics that update slowly.
|
||||
|
||||
In my work with the Home Assistant project, I've found this message bus model works extremely well for heterogeneous systems. If you dive into the Internet of Things space, you'll quickly run into MQTT everywhere.
|
||||
|
||||
### Our first MQTT stream
|
||||
|
||||
One of NYSO's CSV files is the real-time fuel mix. Every five minutes, it's updated with the fuel sources and power generated (in megawatts) during that time period.
|
||||
|
||||
The CSV file looks something like this:
|
||||
|
||||
| Time Stamp | Time Zone | Fuel Category | Gen MW |
|
||||
| 05/09/2018 00:05:00 | EDT | Dual Fuel | 1400 |
|
||||
| 05/09/2018 00:05:00 | EDT | Natural Gas | 2144 |
|
||||
| 05/09/2018 00:05:00 | EDT | Nuclear | 4114 |
|
||||
| 05/09/2018 00:05:00 | EDT | Other Fossil Fuels | 4 |
|
||||
| 05/09/2018 00:05:00 | EDT | Other Renewables | 226 |
|
||||
| 05/09/2018 00:05:00 | EDT | Wind | 1 |
|
||||
| 05/09/2018 00:05:00 | EDT | Hydro | 3229 |
|
||||
| 05/09/2018 00:10:00 | EDT | Dual Fuel | 1307 |
|
||||
| 05/09/2018 00:10:00 | EDT | Natural Gas | 2092 |
|
||||
| 05/09/2018 00:10:00 | EDT | Nuclear | 4115 |
|
||||
| 05/09/2018 00:10:00 | EDT | Other Fossil Fuels | 4 |
|
||||
| 05/09/2018 00:10:00 | EDT | Other Renewables | 224 |
|
||||
| 05/09/2018 00:10:00 | EDT | Wind | 40 |
|
||||
| 05/09/2018 00:10:00 | EDT | Hydro | 3166 |
|
||||
|
||||
The only odd thing in the table is the dual-fuel category. Most natural gas plants in New York can also burn other fossil fuel to generate power. During cold snaps in the winter, the natural gas supply gets constrained, and its use for home heating is prioritized over power generation. This happens at a low enough frequency that we can consider dual fuel to be natural gas (for our calculations).
|
||||
|
||||
The file is updated throughout the day. I created a simple data pump that polls for the file every minute and looks for updates. It publishes any new entries out to the MQTT server into a set of topics that largely mirror this CSV file. The payload is turned into a JSON object that is easy to parse from nearly any programming language.
|
||||
```
|
||||
ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
```
|
||||
|
||||
This direct reflection is a good first step in turning open data into open events. We'll be converting this into a CO2 intensity, but other applications might want these raw feeds to do other calculations with them.
|
||||
|
||||
### MQTT topics
|
||||
|
||||
Topics and topic structures are one of MQTT's major design points. Unlike more "enterprisey" message buses, in MQTT topics are not preregistered. A sender can create topics on the fly, the only limit being that they are less than 220 characters. The `/` character is special; it's used to create topic hierarchies. As we'll soon see, you can subscribe to slices of data in these hierarchies.
|
||||
|
||||
Out of the box with Mosquitto, every client can publish to any topic. While it's great for prototyping, before going to production you'll want to add an access control list (ACL) to restrict writing to authorized applications. For example, my app's tree is accessible to everyone in read-only format, but only clients with specific credentials can publish to it.
|
||||
|
||||
There is no automatic schema around topics nor a way to discover all the possible topics that clients will publish to. You'll have to encode that understanding directly into any application that consumes the MQTT bus.
|
||||
|
||||
So how should you design your topics? The best practice is to start with an application-specific root name, in our case, `ny-power`. After that, build a hierarchy as deep as you need for efficient subscription. The `upstream` tree will contain data that comes directly from an upstream source without any processing. Our `fuel-mix` category is a specific type of data. We may add others later.
|
||||
|
||||
### Subscribing to topics
|
||||
|
||||
Subscriptions in MQTT are simple string matches. For processing efficiency, only two wildcards are allowed:
|
||||
|
||||
* `#` matches everything recursively to the end
|
||||
* `+` matches only until the next `/` character
|
||||
|
||||
|
||||
|
||||
It's easiest to explain this with some examples:
|
||||
```
|
||||
ny-power/# - match everything published by the ny-power app
|
||||
|
||||
ny-power/upstream/# - match all raw data
|
||||
|
||||
ny-power/upstream/fuel-mix/+ - match all fuel types
|
||||
|
||||
ny-power/+/+/Hydro - match everything about Hydro power that's
|
||||
|
||||
nested 2 deep (even if it's not in the upstream tree)
|
||||
|
||||
```
|
||||
|
||||
A wide subscription like `ny-power/#` is common for low-volume applications. Just get everything over the network and handle it in your own application. This works poorly for high-volume applications, as most of the network bandwidth will be wasted as you drop most of the messages on the floor.
|
||||
|
||||
To stay performant at higher volumes, applications will do some clever topic slides like `ny-power/+/+/Hydro` to get exactly the cross-section of data they need.
|
||||
|
||||
### Adding our next layer of data
|
||||
|
||||
From this point forward, everything in the application will work off existing MQTT streams. The first additional layer of data is computing the power's CO2 intensity.
|
||||
|
||||
Using the 2016 [U.S. Energy Information Administration][7] numbers for total emissions and total power by fuel type in New York, we can come up with an [average emissions rate][8] per megawatt hour of power.
|
||||
|
||||
This is encapsulated in a dedicated microservice. This has a subscription on `ny-power/upstream/fuel-mix/+`, which matches all upstream fuel-mix entries from the data pump. It then performs the calculation and publishes out to a new topic tree:
|
||||
```
|
||||
ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
```
|
||||
|
||||
In turn, there is another process that subscribes to this topic tree and archives that data into an [InfluxDB][9] instance. It then publishes a 24-hour time series to `ny-power/archive/co2/24h`, which makes it easy to graph the recent changes.
|
||||
|
||||
This layer model works well, as the logic for each of these programs can be distinct from each other. In a more complicated system, they may not even be in the same programming language. We don't care, because the interchange format is MQTT messages, with well-known topics and JSON payloads.
|
||||
|
||||
### Consuming from the command line
|
||||
|
||||
To get a feel for MQTT in action, it's useful to just attach it to a bus and see the messages flow. The `mosquitto_sub` program included in the `mosquitto-clients` package is a simple way to do that.
|
||||
|
||||
After you've installed it, you need to provide a server hostname and the topic you'd like to listen to. The `-v` flag is important if you want to see the topics being posted to. Without that, you'll see only the payloads.
|
||||
```
|
||||
mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
|
||||
|
||||
```
|
||||
|
||||
Whenever I'm writing or debugging an MQTT application, I always have a terminal with `mosquitto_sub` running.
|
||||
|
||||
### Accessing MQTT directly from the web
|
||||
|
||||
We now have an application providing an open event stream. We can connect to it with our microservices and, with some command-line tooling, it's on the internet for all to see. But the web is still king, so it's important to get it directly into a user's browser.
|
||||
|
||||
The MQTT folks thought about this one. The protocol specification is designed to work over three transport protocols: [TCP][10], [UDP][11], and [WebSockets][12]. WebSockets are supported by all major browsers as a way to retain persistent connections for real-time applications.
|
||||
|
||||
The Eclipse project has a JavaScript implementation of MQTT called [Paho][13], which can be included in your application. The pattern is to connect to the host, set up some subscriptions, and then react to messages as they are received.
|
||||
```
|
||||
// ny-power web console application
|
||||
|
||||
var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
|
||||
|
||||
|
||||
|
||||
// set callback handlers
|
||||
|
||||
client.onMessageArrived = onMessageArrived;
|
||||
|
||||
|
||||
|
||||
// connect the client
|
||||
|
||||
client.reconnect = true;
|
||||
|
||||
client.connect({onSuccess: onConnect});
|
||||
|
||||
|
||||
|
||||
// called when the client connects
|
||||
|
||||
function onConnect() {
|
||||
|
||||
// Once a connection has been made, make a subscription and send a message.
|
||||
|
||||
console.log("onConnect");
|
||||
|
||||
client.subscribe("ny-power/computed/co2");
|
||||
|
||||
client.subscribe("ny-power/archive/co2/24h");
|
||||
|
||||
client.subscribe("ny-power/upstream/fuel-mix/#");
|
||||
|
||||
}
|
||||
|
||||
|
||||
|
||||
// called when a message arrives
|
||||
|
||||
function onMessageArrived(message) {
|
||||
|
||||
console.log("onMessageArrived:"+message.destinationName + message.payloadString);
|
||||
|
||||
if (message.destinationName == "ny-power/computed/co2") {
|
||||
|
||||
var data = JSON.parse(message.payloadString);
|
||||
|
||||
$("#co2-per-kwh").html(Math.round(data.value));
|
||||
|
||||
$("#co2-units").html(data.units);
|
||||
|
||||
$("#co2-updated").html(data.ts);
|
||||
|
||||
}
|
||||
|
||||
if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
|
||||
|
||||
fuel_mix_graph(message);
|
||||
|
||||
}
|
||||
|
||||
if (message.destinationName == "ny-power/archive/co2/24h") {
|
||||
|
||||
var data = JSON.parse(message.payloadString);
|
||||
|
||||
var plot = [
|
||||
|
||||
{
|
||||
|
||||
x: data.ts,
|
||||
|
||||
y: data.values,
|
||||
|
||||
type: 'scatter'
|
||||
|
||||
}
|
||||
|
||||
];
|
||||
|
||||
var layout = {
|
||||
|
||||
yaxis: {
|
||||
|
||||
title: "g CO2 / kWh",
|
||||
|
||||
}
|
||||
|
||||
};
|
||||
|
||||
Plotly.newPlot('co2_graph', plot, layout);
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This application subscribes to a number of topics because we're going to display a few different kinds of data. The `ny-power/computed/co2` topic provides us a topline number of current intensity. Whenever we receive that topic, we replace the related contents on the site.
|
||||
|
||||
|
||||
![NY ISO Grid CO2 Intensity][15]
|
||||
|
||||
NY ISO Grid CO2 Intensity graph from [ny-power.org][4].
|
||||
|
||||
The `ny-power/archive/co2/24h` topic provides a time series that can be loaded into a [Plotly][16] line graph. And `ny-power/upstream/fuel-mix` provides the data needed to provide a nice bar graph of the current fuel mix.
|
||||
|
||||
|
||||
![Fuel mix on NYISO grid][18]
|
||||
|
||||
Fuel mix on NYISO grid, [ny-power.org][4].
|
||||
|
||||
This is a dynamic website that is not polling the server. It is attached to the MQTT bus and listening on its open WebSocket. The webpage is a pub/sub client just like the data pump and the archiver. This one just happens to be executing in your browser instead of a microservice in the cloud.
|
||||
|
||||
You can see the page in action at <http://ny-power.org>. That includes both the graphics and a real-time MQTT console to see the messages as they come in.
|
||||
|
||||
### Diving deeper
|
||||
|
||||
The entire ny-power.org application is [available as open source on GitHub][19]. You can also check out [this architecture overview][20] to see how it was built as a set of Kubernetes microservices deployed with [Helm][21]. You can see another interesting MQTT application example with [this code pattern][22] using MQTT and OpenWhisk to translate text messages in real time.
|
||||
|
||||
MQTT is used extensively in the Internet of Things space, and many more examples of MQTT use can be found at the [Home Assistant][23] project.
|
||||
|
||||
And if you want to dive deep into the protocol, [mqtt.org][3] has all the details for this open standard.
|
||||
|
||||
To learn more, attend Sean Dague's talk, [Adding MQTT to your toolkit][24], at [OSCON][25], which will be held July 16-19 in Portland, Oregon.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/mqtt
|
||||
|
||||
作者:[Sean Dague][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sdague
|
||||
[1]:http://www.nyiso.com/public/index.jsp
|
||||
[2]:http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp
|
||||
[3]:http://mqtt.org/
|
||||
[4]:http://ny-power.org/#
|
||||
[5]:https://www.home-assistant.io
|
||||
[6]:https://mosquitto.org/
|
||||
[7]:https://www.eia.gov/
|
||||
[8]:https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60
|
||||
[9]:https://www.influxdata.com/
|
||||
[10]:https://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
||||
[11]:https://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[12]:https://en.wikipedia.org/wiki/WebSocket
|
||||
[13]:https://www.eclipse.org/paho/
|
||||
[14]:/file/400041
|
||||
[15]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso-co2intensity.png (NY ISO Grid CO2 Intensity)
|
||||
[16]:https://plot.ly/
|
||||
[17]:/file/400046
|
||||
[18]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso_fuel-mix.png (Fuel mix on NYISO grid)
|
||||
[19]:https://github.com/IBM/ny-power
|
||||
[20]:https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/
|
||||
[21]:https://helm.sh/
|
||||
[22]:https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/
|
||||
[23]:https://www.home-assistant.io/
|
||||
[24]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/77317
|
||||
[25]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to reset, revert, and return to previous states in Git
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Bitcoin is a Cult — Adam Caudill
|
||||
======
|
||||
The Bitcoin community has changed greatly over the years; from technophiles that could explain a [Merkle tree][1] in their sleep, to speculators driven by the desire for a quick profit & blockchain startups seeking billion dollar valuations led by people who don’t even know what a Merkle tree is. As the years have gone on, a zealotry has been building around Bitcoin and other cryptocurrencies driven by people who see them as something far grander than they actually are; people who believe that normal (or fiat) currencies are becoming a thing of the past, and the cryptocurrencies will fundamentally change the world’s economy.
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to Run Windows Apps on Android with Wine
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
A sysadmin's guide to network management
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
15 open source applications for MacOS
|
||||
======
|
||||
|
||||
|
||||
@ -1,92 +0,0 @@
|
||||
6 open source cryptocurrency wallets
|
||||
======
|
||||
|
||||

|
||||
|
||||
Without crypto wallets, cryptocurrencies like Bitcoin and Ethereum would just be another pie-in-the-sky idea. These wallets are essential for keeping, sending, and receiving cryptocurrencies.
|
||||
|
||||
The revolutionary growth of [cryptocurrencies][1] is attributed to the idea of decentralization, where a central authority is absent from the network and everyone has a level playing field. Open source technology is at the heart of cryptocurrencies and [blockchain][2] networks. It has enabled the vibrant, nascent industry to reap the benefits of decentralization—such as immutability, transparency, and security.
|
||||
|
||||
If you're looking for a free and open source cryptocurrency wallet, read on to start exploring whether any of the following options meet your needs.
|
||||
|
||||
### 1\. Copay
|
||||
|
||||
[Copay][3] is an open source Bitcoin crypto wallet that promises convenient storage. The software is released under the [MIT License][4].
|
||||
|
||||
The Copay server is also open source. Therefore, developers and Bitcoin enthusiasts can assume complete control of their activities by deploying their own applications on the server.
|
||||
|
||||
The Copay wallet empowers you to take the security of your Bitcoin in your own hands, instead of trusting unreliable third parties. It allows you to use multiple signatories for approving transactions and supports the storage of multiple, separate wallets within the same app.
|
||||
|
||||
Copay is available for a range of platforms, such as Android, Windows, MacOS, Linux, and iOS.
|
||||
|
||||
### 2\. MyEtherWallet
|
||||
|
||||
As the name implies, [MyEtherWallet][5] (abbreviated MEW) is a wallet for Ethereum transactions. It is open source (under the [MIT License][6]) and is completely online, accessible through a web browser.
|
||||
|
||||
The wallet has a simple client-side interface, which allows you to participate in the Ethereum blockchain confidently and securely.
|
||||
|
||||
### 3\. mSIGNA
|
||||
|
||||
[mSIGNA][7] is a powerful desktop application for completing transactions on the Bitcoin network. It is released under the [MIT License][8] and is available for MacOS, Windows, and Linux.
|
||||
|
||||
The blockchain wallet provides you with complete control over your Bitcoin stash. Some of its features include user-friendliness, versatility, decentralized offline key generation capabilities, encrypted data backups, and multi-device synchronization.
|
||||
|
||||
### 4\. Armory
|
||||
|
||||
[Armory][9] is an open source wallet (released under the [GNU AGPLv3][10]) for producing and keeping Bitcoin private keys on your computer. It enhances security by providing users with cold storage and multi-signature support capabilities.
|
||||
|
||||
With Armory, you can set up a wallet on a computer that is completely offline; you'll use the watch-only feature for observing your Bitcoin details on the internet, which improves security. The wallet also allows you to create multiple addresses and use them to complete different transactions.
|
||||
|
||||
Armory is available for MacOS, Windows, and several flavors of Linux (including Raspberry Pi).
|
||||
|
||||
### 5\. Electrum
|
||||
|
||||
[Electrum][11] is a Bitcoin wallet that navigates the thin line between beginner user-friendliness and expert functionality. The open source wallet is released under the [MIT License][12].
|
||||
|
||||
Electrum encrypts your private keys locally, supports cold storage, and provides multi-signature capabilities with minimal resource usage on your machine.
|
||||
|
||||
It is available for a wide range of operating systems and devices, including Windows, MacOS, Android, iOS, and Linux, and hardware wallets such as [Trezor][13].
|
||||
|
||||
### 6\. Etherwall
|
||||
|
||||
[Etherwall][14] is the first wallet for storing and sending Ethereum on the desktop. The open source wallet is released under the [GPLv3 License][15].
|
||||
|
||||
Etherwall is intuitive and fast. What's more, to enhance the security of your private keys, you can operate it on a full node or a thin node. Running it as a full-node client will enable you to download the whole Ethereum blockchain on your local machine.
|
||||
|
||||
Etherwall is available for MacOS, Linux, and Windows, and it also supports the Trezor hardware wallet.
|
||||
|
||||
### Words to the wise
|
||||
|
||||
Open source and free crypto wallets are playing a vital role in making cryptocurrencies easily available to more people.
|
||||
|
||||
Before using any digital currency software wallet, make sure to do your due diligence to protect your security, and always remember to comply with best practices for safeguarding your finances.
|
||||
|
||||
If your favorite open source cryptocurrency wallet is not on this list, please share what you know in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/crypto-wallets
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://www.liveedu.tv/guides/cryptocurrency/
|
||||
[2]:https://opensource.com/tags/blockchain
|
||||
[3]:https://copay.io/
|
||||
[4]:https://github.com/bitpay/copay/blob/master/LICENSE
|
||||
[5]:https://www.myetherwallet.com/
|
||||
[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
|
||||
[7]:https://ciphrex.com/
|
||||
[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
|
||||
[9]:https://www.bitcoinarmory.com/
|
||||
[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
|
||||
[11]:https://electrum.org/#home
|
||||
[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
|
||||
[13]:https://trezor.io/
|
||||
[14]:https://www.etherwall.com/
|
||||
[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
A sysadmin's guide to SELinux: 42 answers to the big questions
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Convert video using Handbrake
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,284 @@
|
||||
Building a network attached storage device with a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this three-part series, I'll explain how to set up a simple, useful NAS (network attached storage) system. I use this kind of setup to store my files on a central system, creating incremental backups automatically every night. To mount the disk on devices that are located in the same network, NFS is installed. To access files offline and share them with friends, I use [Nextcloud][1].
|
||||
|
||||
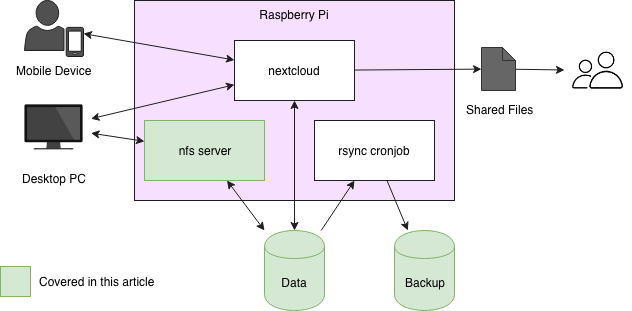
This article will cover the basic setup of software and hardware to mount the data disk on a remote device. In the second article, I will discuss a backup strategy and set up a cron job to create daily backups. In the third and last article, we will install Nextcloud, a tool for easy file access to devices synced offline as well as online using a web interface. It supports multiple users and public file-sharing so you can share pictures with friends, for example, by sending a password-protected link.
|
||||
|
||||
The target architecture of our system looks like this:
|
||||
|
||||
|
||||
### Hardware
|
||||
|
||||
Let's get started with the hardware you need. You might come up with a different shopping list, so consider this one an example.
|
||||
|
||||
The computing power is delivered by a [Raspberry Pi 3][2], which comes with a quad-core CPU, a gigabyte of RAM, and (somewhat) fast ethernet. Data will be stored on two USB hard drives (I use 1-TB disks); one is used for the everyday traffic, the other is used to store backups. Be sure to use either active USB hard drives or a USB hub with an additional power supply, as the Raspberry Pi will not be able to power two USB drives.
|
||||
|
||||
### Software
|
||||
|
||||
The operating system with the highest visibility in the community is [Raspbian][3] , which is excellent for custom projects. There are plenty of [guides][4] that explain how to install Raspbian on a Raspberry Pi, so I won't go into details here. The latest official supported version at the time of this writing is [Raspbian Stretch][5] , which worked fine for me.
|
||||
|
||||
At this point, I will assume you have configured your basic Raspbian and are able to connect to the Raspberry Pi by `ssh`.
|
||||
|
||||
### Prepare the USB drives
|
||||
|
||||
To achieve good performance reading from and writing to the USB hard drives, I recommend formatting them with ext4. To do so, you must first find out which disks are attached to the Raspberry Pi. You can find the disk devices in `/dev/sd/<x>`. Using the command `fdisk -l`, you can find out which two USB drives you just attached. Please note that all data on the USB drives will be lost as soon as you follow these steps.
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk -l
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0xe8900690
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x6aa4f598
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
|
||||
|
||||
```
|
||||
|
||||
As those devices are the only 1TB disks attached to the Raspberry Pi, we can easily see that `/dev/sda` and `/dev/sdb` are the two USB drives. The partition table at the end of each disk shows how it should look after the following steps, which create the partition table and format the disks. To do this, repeat the following steps for each of the two devices by replacing `sda` with `sdb` the second time (assuming your devices are also listed as `/dev/sda` and `/dev/sdb` in `fdisk`).
|
||||
|
||||
First, delete the partition table of the disk and create a new one containing only one partition. In `fdisk`, you can use interactive one-letter commands to tell the program what to do. Simply insert them after the prompt `Command (m for help):` as follows (you can also use the `m` command anytime to get more information):
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk /dev/sda
|
||||
|
||||
|
||||
|
||||
Welcome to fdisk (util-linux 2.29.2).
|
||||
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Command (m for help): o
|
||||
|
||||
Created a new DOS disklabel with disk identifier 0x9c310964.
|
||||
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
|
||||
Partition type
|
||||
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
|
||||
e extended (container for logical partitions)
|
||||
|
||||
Select (default p): p
|
||||
|
||||
Partition number (1-4, default 1):
|
||||
|
||||
First sector (2048-1953525167, default 2048):
|
||||
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
|
||||
|
||||
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
|
||||
|
||||
|
||||
|
||||
Command (m for help): p
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x9c310964
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
Command (m for help): w
|
||||
|
||||
The partition table has been altered.
|
||||
|
||||
Syncing disks.
|
||||
|
||||
```
|
||||
|
||||
Now we will format the newly created partition `/dev/sda1` using the ext4 filesystem:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
|
||||
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
|
||||
Discarding device blocks: done
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Allocating group tables: done
|
||||
|
||||
Writing inode tables: done
|
||||
|
||||
Creating journal (1024 blocks): done
|
||||
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
After repeating the above steps, let's label the new partitions according to their usage in your system:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
|
||||
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
|
||||
|
||||
```
|
||||
|
||||
Now let's get those disks mounted to store some data. My experience, based on running this setup for over a year now, is that USB drives are not always available to get mounted when the Raspberry Pi boots up (for example, after a power outage), so I recommend using autofs to mount them when needed.
|
||||
|
||||
First install autofs and create the mount point for the storage:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install autofs
|
||||
|
||||
pi@raspberrypi:~ $ sudo mkdir /nas
|
||||
|
||||
```
|
||||
|
||||
Then mount the devices by adding the following line to `/etc/auto.master`:
|
||||
```
|
||||
/nas /etc/auto.usb
|
||||
|
||||
```
|
||||
|
||||
Create the file `/etc/auto.usb` if not existing with the following content, and restart the autofs service:
|
||||
```
|
||||
data -fstype=ext4,rw :/dev/disk/by-label/data
|
||||
|
||||
backup -fstype=ext4,rw :/dev/disk/by-label/backup
|
||||
|
||||
pi@raspberrypi3:~ $ sudo service autofs restart
|
||||
|
||||
```
|
||||
|
||||
Now you should be able to access the disks at `/nas/data` and `/nas/backup`, respectively. Clearly, the content will not be too thrilling, as you just erased all the data from the disks. Nevertheless, you should be able to verify the devices are mounted by executing the following commands:
|
||||
```
|
||||
pi@raspberrypi3:~ $ cd /nas/data
|
||||
|
||||
pi@raspberrypi3:/nas/data $ cd /nas/backup
|
||||
|
||||
pi@raspberrypi3:/nas/backup $ mount
|
||||
|
||||
<...>
|
||||
|
||||
/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
|
||||
|
||||
<...>
|
||||
|
||||
/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
```
|
||||
|
||||
First move into the directories to make sure autofs mounts the devices. Autofs tracks access to the filesystems and mounts the needed devices on the go. Then the `mount` command shows that the two devices are actually mounted where we wanted them.
|
||||
|
||||
Setting up autofs is a bit fault-prone, so do not get frustrated if mounting doesn't work on the first try. Give it another chance, search for more detailed resources (there is plenty of documentation online), or leave a comment.
|
||||
|
||||
### Mount network storage
|
||||
|
||||
Now that you have set up the basic network storage, we want it to be mounted on a remote Linux machine. We will use the network file system (NFS) for this. First, install the NFS server on the Raspberry Pi:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
|
||||
|
||||
```
|
||||
|
||||
Next we need to tell the NFS server to expose the `/nas/data` directory, which will be the only device accessible from outside the Raspberry Pi (the other one will be used for backups only). To export the directory, edit the file `/etc/exports` and add the following line to allow all devices with access to the NAS to mount your storage:
|
||||
```
|
||||
/nas/data *(rw,sync,no_subtree_check)
|
||||
|
||||
```
|
||||
|
||||
For more information about restricting the mount to single devices and so on, refer to `man exports`. In the configuration above, anyone will be able to mount your data as long as they have access to the ports needed by NFS: `111` and `2049`. I use the configuration above and allow access to my home network only for ports 22 and 443 using the routers firewall. That way, only devices in the home network can reach the NFS server.
|
||||
|
||||
To mount the storage on a Linux computer, run the commands:
|
||||
```
|
||||
you@desktop:~ $ sudo mkdir /nas/data
|
||||
|
||||
you@desktop:~ $ sudo mount -t nfs <raspberry-pi-hostname-or-ip>:/nas/data /nas/data
|
||||
|
||||
```
|
||||
|
||||
Again, I recommend using autofs to mount this network device. For extra help, check out [How to use autofs to mount NFS shares][6].
|
||||
|
||||
Now you are able to access files stored on your own RaspberryPi-powered NAS from remote devices using the NFS mount. In the next part of this series, I will cover how to automatically back up your data to the second hard drive using `rsync`. To save space on the device while still doing daily backups, you will learn how to create incremental backups with `rsync`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[3]:https://www.raspbian.org/
|
||||
[4]:https://www.raspberrypi.org/documentation/installation/installing-images/
|
||||
[5]:https://www.raspberrypi.org/blog/raspbian-stretch/
|
||||
[6]:https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
@ -0,0 +1,140 @@
|
||||
Learn how to build your own Twitter bot with Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
Twitter allows one to [share][1] blog posts and articles with the world. Using Python and the tweepy library makes it easy to create a Twitter bot that takes care of all the tweeting for you. This article shows you how to build such a bot. Hopefully you can take the concepts here and apply them to other projects that use online services.
|
||||
|
||||
### Getting started
|
||||
|
||||
To create a Twitter bot the [tweepy][2] library comes handy. It manages the Twitter API calls and provides a simple interface.
|
||||
|
||||
The following commands use Pipenv to install tweepy into a virtual environment. If you don’t have Pipenv installed, check out our previous article, [How to install Pipenv on Fedora][3].
|
||||
```
|
||||
$ mkdir twitterbot
|
||||
$ cd twitterbot
|
||||
$ pipenv --three
|
||||
$ pipenv install tweepy
|
||||
$ pipenv shell
|
||||
|
||||
```
|
||||
|
||||
### Tweepy – Getting started
|
||||
|
||||
To use the Twitter API the bot needs to authenticate against Twitter. For that, tweepy uses the OAuth authentication standard. You can get credentials by creating a new application at <https://apps.twitter.com/>.
|
||||
|
||||
#### Create a new Twitter application
|
||||
|
||||
After you fill in the following form and click on the Create your Twitter application button, you have access to the application credentials. Tweepy requires the Consumer Key (API Key) and the Consumer Secret (API Secret), both available from the Keys and Access Tokens.
|
||||
|
||||
![][4]
|
||||
|
||||
After scrolling down the page, generate an Access Token and an Access Token Secret using the Create my access token button.
|
||||
|
||||
#### Using Tweepy – print your timeline
|
||||
|
||||
Now that you have all the credentials needed, open a new file and write the following Python code.
|
||||
```
|
||||
import tweepy
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret")
|
||||
|
||||
api = tweepy.API(auth)
|
||||
|
||||
public_tweets = api.home_timeline()
|
||||
|
||||
for tweet in public_tweets:
|
||||
print(tweet.text)
|
||||
|
||||
```
|
||||
|
||||
After making sure that you are using the Pipenv virtual environment, run your program.
|
||||
```
|
||||
$ python tweet.py
|
||||
|
||||
```
|
||||
|
||||
The above program calls the home_timeline API method to retrieve the 20 most recent tweets from your timeline. Now that the bot is able to use tweepy to get data from Twitter, try changing the code to send a tweet.
|
||||
|
||||
#### Using Tweepy – send a tweet
|
||||
|
||||
To send a tweet, the API method update_status comes in handy. The usage is simple:
|
||||
```
|
||||
api.update_status("The awesome text you would like to tweet")
|
||||
|
||||
```
|
||||
|
||||
The tweepy library has many other methods that can be useful for a Twitter bot. For the full details of the API, check the [documentation][5].
|
||||
|
||||
### A magazine bot
|
||||
|
||||
Let’s create a bot that searches for Fedora Magazine tweets and automatically retweets them.
|
||||
|
||||
To avoid retweeting the same tweet multiple times, the bot stores the tweet ID of the last retweet. Two helper functions, store_last_id and get_last_id, will be used to save and retrieve this ID.
|
||||
|
||||
Then the bot uses the tweepy search API to find the Fedora Magazine tweets that are more recent than the stored ID.
|
||||
```
|
||||
import tweepy
|
||||
|
||||
|
||||
def store_last_id(tweet_id):
|
||||
""" Store a tweet id in a file """
|
||||
with open("lastid", "w") as fp:
|
||||
fp.write(str(tweet_id))
|
||||
|
||||
|
||||
def get_last_id():
|
||||
""" Read the last retweeted id from a file """
|
||||
with open("lastid", "r") as fp:
|
||||
return fp.read()
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
|
||||
auth = tweepy.OAuthHandler("your_consumer_key", "your_consumer_key_secret")
|
||||
|
||||
auth.set_access_token("your_access_token", "your_access_token_secret") api = tweepy.API(auth)
|
||||
|
||||
try:
|
||||
last_id = get_last_id()
|
||||
except FileNotFoundError:
|
||||
print("No retweet yet")
|
||||
last_id = None
|
||||
|
||||
for tweet in tweepy.Cursor(api.search, q="fedoramagazine.org", since_id=last_id).items():
|
||||
if tweet.user.name == 'Fedora Project':
|
||||
store_last_id(tweet.id)
|
||||
tweet.retweet()
|
||||
print(f'"{tweet.text}" was retweeted'
|
||||
|
||||
```
|
||||
|
||||
In order to retweet only tweets from the Fedora Magazine, the bot searches for tweets that contain fedoramagazine.org and are published by the “Fedora Project” Twitter account.
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this article you saw how to create a Twitter application using the tweepy Python library to automate reading, sending and searching tweets. You can now use your creativity to create a Twitter bot of your own.
|
||||
|
||||
The source code of the example in this article is available on [Github][6].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-build-twitter-bot-python/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://twitter.com
|
||||
[2]:https://tweepy.readthedocs.io/en/v3.5.0/
|
||||
[3]:https://fedoramagazine.org/install-pipenv-fedora/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Screenshot-from-2018-07-19-20-17-17.png
|
||||
[5]:http://docs.tweepy.org/en/v3.5.0/api.html#id1
|
||||
[6]:https://github.com/cverna/magabot
|
||||
@ -1,95 +0,0 @@
|
||||
对数据隐私持开放的态度
|
||||
======
|
||||

|
||||
|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
今天是[数据隐私日][1],(在欧洲叫"数据保护日"),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该免费,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
|
||||
1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些列子[3])
|
||||
2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
|
||||
|
||||
所以实际上,数据隐私对于每个人来说是很重要的。
|
||||
|
||||
事实证明,在美国和欧洲之间,人们和政府认为让组织使用的数据的起点是有些不同的。前者通常为实体提供更多的自由度,更愤世嫉俗的是--大型的商业体利用他们收集到的关于我们的数据。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在5月25日,欧洲的观点可以说取得了胜利。
|
||||
|
||||
## 通用数据保护条例的影响
|
||||
|
||||
那是一个相当全面的声明,其实事实上就是欧盟在2016年通过的一项关于通用数据保护的立法,使它变得可实施。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据--而且涉及的条目范围非常广泛,从你的姓名家庭住址到你的医疗记录以及接通你电脑的IP地址。
|
||||
|
||||
通用数据保护条例的重要之处是他并不仅仅适用于欧洲的公司,如果你是阿根廷人,日本人,美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
|
||||
|
||||
“哼!” 你可能会这样说,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简答:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你全球总收入百分之四的惩罚。是的,你没听错,是全球总收入不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的IT团队,确保你的行为相当短的时间内是符合要求的。
|
||||
|
||||
看上去这和欧盟之外的城市没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是只是在欧盟的城市实施,这将会是一件很有利的事情。2
|
||||
|
||||
然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好:事实并非如此,我们一直在丢弃关于我们自己的信息--而且允许公司去使用它。
|
||||
|
||||
有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。
|
||||
你有付费使用Facebook、推特?谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客-只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
|
||||
|
||||
有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(列如,亚马逊正在允许通过Alexa广告)除非我们想要开始为这些所有的免费服务付费,我们需要清除我们所放弃的,而且在我们想要揭发和不想的里面做一些选择。
|
||||
|
||||
### 谁是顾客?
|
||||
|
||||
关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门4--
|
||||
而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去开采这些数据。
|
||||
|
||||
然而他们面临的是,随着数据的增长和存储量的不足他们是如何处理的。幸运--而且我是带有讽刺意味的使用了这个词,5大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司的一个极具代表性的列子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
|
||||
|
||||
不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售非第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方在他们如何使用上面能有发言权吗?我将把这个问题当做一个练习留给读者去思考。7
|
||||
|
||||
### 开放和积极
|
||||
|
||||
然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励部门能够将免费开放他们的数据给公众或者其他组织。这项行动目前正在被实施立法。许多
|
||||
支援组织--尤其是那些收到公共基金的--正在开始推动同样的活动。即使商业组织也有些许的兴趣。而且,在技术上已经可行了,例如围绕不同的隐私和多方计算上,正在允许我们根据数据设置和不揭露太多关于个人的前提下开采数据--一个历史性的计算问题比你想象的要容易处理的多。
|
||||
|
||||
这些对我们来说意味着什么呢?我之前在网站Opensource.com上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件,组织,和这次讨论有关的,数据。让我们假设一下你是A公司要提向另一家公司提供一项服务,客户B。在游戏中有四种不同类型的数据:
|
||||
1. 数据完全开放:对A和B都是可得到的,世界上任何人都可以得到
|
||||
2. 数据是已知的,共享的,和机密的:A和B可得到,但其他人不能得到。
|
||||
3. 数据是公司级别上保密的:A公司可以得到,但B顾客不能
|
||||
4. 数据是顾客级别保密的:B顾客可以得到,但A公司不能
|
||||
|
||||
首先,也许我们对数据应该更开放些,将数据默认放到选项一中。如果那些数据对所有人开放--在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的,9
|
||||
如果我们能够找到方法将数据放到选项2,3和4中,不是很好嘛--或者至少它们中的一些--在选项一中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
|
||||
然而又很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
|
||||
|
||||
### 一些具体的措施
|
||||
|
||||
我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
|
||||
* 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
|
||||
* 要默认去加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉--除非数据正在被处理使用否则没有任何借口让数据清晰可见。
|
||||
* 当你注册一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
|
||||
* 和你的非技术朋友讨论这个话题。
|
||||
* 教育你的孩子,你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师交谈在他们的学校中展示。
|
||||
* 鼓励你工作志愿服务的组织,或者和他们互动推动数据的默认开放。不是去思考为什么我要使数据开放而是以我为什么不让数据开放开始。
|
||||
* 尝试去访问一些开源数据。开采使用它。开发应用来使用它,进行数据分析,画漂亮的图,10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
|
||||
|
||||
|
||||
|
||||
1. 我承认你可能尽管不会
|
||||
2. 假设你坚信你的个人数据应该被保护。
|
||||
3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
|
||||
4. 事实上这些机构能够有多开放取决于你所居住的地方。
|
||||
5. 假设我是英国人,那是非常非常大的剂量。
|
||||
6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
|
||||
7. 不,答案是“不”。
|
||||
8. 尽管这个列子也同样适用于个人。看看:A可能是Alice,B 可能是BOb...
|
||||
9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然--不是那类的数据。
|
||||
10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/being-open-about-data-privacy
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者FelixYFZ](https://github.com/FelixYFZ)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
|
||||
[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
|
||||
[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
|
||||
[4]:https://opensource.com/article/17/11/commonwealth-open-source
|
||||
[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
|
||||
@ -1,78 +1,78 @@
|
||||
谁是 Python 的目标受众?
|
||||
盘点 Python 的目标受众
|
||||
============================================================
|
||||
|
||||
Python 是为谁设计的?
|
||||
|
||||
* [Python 使用情况的参考][8]
|
||||
* [Python 的参考解析器使用情况][8]
|
||||
* [CPython 主要服务于哪些受众?][9]
|
||||
* [这些相关问题的原因是什么?][10]
|
||||
* [适合进入 PyPI 规划的方面有哪些?][11]
|
||||
* [当增加它到标准库中时,为什么一些 API 会被改变?][12]
|
||||
* [为什么一些 API 是以<ruby>临时<rt>provisional</rt></ruby>的形式被增加的?][13]
|
||||
* [当添加它们到标准库中时,为什么一些 API 会被改变?][12]
|
||||
* [为什么一些 API 是以<ruby>临时<rt>provisional</rt></ruby>的形式被添加的?][13]
|
||||
* [为什么只有一些标准库 API 被升级?][14]
|
||||
* [标准库任何部分都有独立的版本吗?][15]
|
||||
* [这些注意事项为什么很重要?][16]
|
||||
|
||||
几年前, 我在 python-dev 邮件列表里面、活跃的 CPython 核心开发人员、以及决定参与该过程的人员中[强调][38]说,“CPython 的动作太快了也太慢了”,作为这种冲突的一个主要原因是,他们不能有效地使用他们的个人时间和精力。
|
||||
几年前,我在 python-dev 邮件列表中,以及在活跃的 CPython 核心开发人员和认为参与这一过程不是有效利用他们个人时间和精力的人中[强调][38]说,“CPython 的发展太快了也太慢了”是很多冲突的原因之一。
|
||||
|
||||
我一直在考虑这种情况,在参与的这几年,我也花费了一些时间去思考这一点,在我写那篇文章的时候,我还在<ruby>波音防务澳大利亚公司<rt>Boeing Defence Australia</rt></ruby>工作。下个月,我将离开波音进入<ruby>红帽亚太<rt>Red Hat Asia-Pacific</rt></ruby>,并且开始在大企业的[开源供应链管理][39]上形成<ruby>再分发者<rt>redistributor</rt></ruby>层面的观点。
|
||||
我一直认为事实确实如此,但这也是一个要点,在这几年中我也花费了一些时间去反思它。在我写那篇文章的时候,我还在<ruby>波音防务澳大利亚公司<rt>Boeing Defence Australia</rt></ruby>工作。下个月,我将离开波音进入<ruby>红帽亚太<rt>Red Hat Asia-Pacific</rt></ruby>,并且开始在大企业的[开源供应链管理][39]上获得<ruby>再分发者<rt>redistributor</rt></ruby>层面的视角。
|
||||
|
||||
### Python 使用情况的参考
|
||||
### Python 的参考解析器使用情况
|
||||
|
||||
我尝试将 CPython 的使用情况分解如下,它虽然有些过于简化(注意,这些分类并不是很清晰,他们仅关注影响新软件特性和版本的部署不同因素):
|
||||
我尝试将 CPython 的使用情况分解如下,它虽然有些过于简化(注意,这些分类的界线并不是很清晰,他们仅关注于思考新软件特性和版本发布后不同因素的影响):
|
||||
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不会去_ 写或维护软件产品。例如:
|
||||
* 教育类:教育工作者的主要兴趣在于建模方法的教学和计算操作方面,_不会去_ 写或维护生产级别的软件。例如:
|
||||
* 澳大利亚的 [数字课程][1]
|
||||
* Lorena A. Barba 的 [AeroPython][2]
|
||||
* 个人的自动化爱好者的项目:主要的是软件,经常是只有软件,而且用户通常是写它的人。例如:
|
||||
* my Digital Blasphemy [image download notebook][3]
|
||||
* 个人级的自动化和爱好者的项目:主要的是软件,而且经常是只有软件,用户通常是写它的人。例如:
|
||||
* my Digital Blasphemy [图片下载器][3]
|
||||
* Paul Fenwick 的 (Inter)National [Rick Astley Hotline][4]
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程的自动化:主要是软件,经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核心开发工作流工具][5]
|
||||
* Linux 发行版的开发、构建 & 发行工具
|
||||
* <ruby>组织<rt>organisational</rt></ruby>过程自动化:主要是软件,而且经常是只有软件,用户是为了利益而编写它的组织。例如:
|
||||
* CPython 的 [核心工作流工具][5]
|
||||
* Linux 发行版的开发、构建 & 发行管理工具
|
||||
* “<ruby>一劳永逸<rt>Set-and-forget</rt></ruby>” 的基础设施中:这里是软件,(这种说法有时候有些争议),在生命周期中该软件几乎不会升级,但是,在底层平台可能会升级。例如:
|
||||
* 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这是让人非常不安的)
|
||||
* 大多数的自我管理的企业或机构的基础设施(在那些资金充足的可持续工程计划中,这种情况是让人非常不安的)
|
||||
* 拨款资助的软件(当最初的拨款耗尽时,维护通常会终止)
|
||||
* 有严格认证要求的软件(如果没有绝对必要的话,从经济性考虑,重新认证比常规更新来说要昂贵很多)
|
||||
* 没有自动升级功能的嵌入式软件系统
|
||||
* 持续升级的基础设施:具有健壮的持续工程化模型的软件,对于依赖和平台升级被认为是例行的,而不去关心其它的代码改变。例如:
|
||||
* 持续升级的基础设施:具有健壮支撑的工程学模型的软件,对于依赖和平台升级通常是例行的,而不去关心其它的代码改变。例如:
|
||||
* Facebook 的 Python 服务基础设施
|
||||
* 滚动发布的 Linux 分发版
|
||||
* 大多数的公共 PaaS 无服务器环境(Heroku、OpenShift、AWS Lambda、Google Cloud Functions、Azure Cloud Functions等等)
|
||||
* 间歇性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* 间隔性升级的标准的操作环境:对其核心组件进行常规升级,但这些升级以年为单位进行,而不是周或月。例如:
|
||||
* [VFX 平台][6]
|
||||
* 长周期支持的 Linux 分发版
|
||||
* CPython 和 Python 标准库
|
||||
* 基础设施管理 & 业务流程工具(比如 OpenStack、 Ansible)
|
||||
* 基础设施管理 & 编排工具(比如 OpenStack、 Ansible)
|
||||
* 硬件控制系统
|
||||
* 短生命周期的软件:软件仅被使用一次,然后就丢弃或忽略,而不是随后接着升级。例如:
|
||||
* <ruby>临时<rt>Ad hoc</rt></ruby>自动脚本
|
||||
* 被确定为 “终止” 的单用户游戏(你玩它们一次后,甚至都忘了去卸载它,或许在一个新的设备上都不打算再去安装它)
|
||||
* 短暂的或非持久状态的单用户游戏(如果你卸载并重安装它们,你的游戏体验也不会有什么大的变化)
|
||||
* 特定事件的应用程序(这些应用程序与特定的物理事件捆绑,一旦事件结束,这些应用程序就不再有用了)
|
||||
* 定期使用的应用程序:部署后定期升级的软件。例如:
|
||||
* 频繁使用的应用程序:部署后定期升级的软件。例如:
|
||||
* 业务管理软件
|
||||
* 个人 & 专业的生产力应用程序(比如,Blender)
|
||||
* 开发工具 & 服务(比如,Mercurial、 Buildbot、 Roundup)
|
||||
* 多用户游戏,和其它明显的处于持续状态的还没有被定义为 “终止” 的游戏
|
||||
* 有自动升级功能的嵌入式软件系统
|
||||
* 共享的抽象层:软件组件的设计使它能够在特定的问题域有效地工作,即使你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 共享的抽象层:在一个特定的问题领域中,设计用于让工作更高效的软件组件。即便是你没有亲自掌握该领域的所有错综复杂的东西。例如:
|
||||
* 大多数的运行时库和归入这一类的框架(比如,Django、Flask、Pyramid、SQL Alchemy、NumPy、SciPy、requests)
|
||||
* 也适合归入这里的许多测试和类型引用工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
* 适合归入这一类的许多测试和类型推断工具(比如,pytest、Hypothesis、vcrpy、behave、mypy)
|
||||
* 其它应用程序的插件(比如,Blender plugins、OpenStack hardware adapters)
|
||||
* 本身就代表了 “Python 世界” 的基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
|
||||
* 本身就代表了 “Python 世界” 基准的标准库(那是一个 [难以置信的复杂][7] 的世界观)
|
||||
|
||||
### CPython 主要服务于哪些受众?
|
||||
|
||||
最终,CPython 和标准库的主要受众是哪些,不论什么原因,比较有限的标准库和从 PyPI 安装的显式声明的第三方库的组合,所提供的服务是不够的。
|
||||
从根本上说,CPython 和标准库的主要受众是哪些呢,是那些不管出于什么原因,将有限的标准库和从 PyPI 显式声明安装的第三方库组合起来所提供的服务,还不能够满足需求的那些人。
|
||||
|
||||
为了更进一步简化上面回顾的不同用法和部署模式,尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些环境中将 Python 作为一种_脚本语言_使用的;另外一种是将它用作一个_应用程序开发语言_,最终发布的是一种产品而不是他们的脚本。
|
||||
为了更进一步简化上面回顾的不同用法和部署模型,尽可能的总结,将最大的 Python 用户群体分开来看,一种是,在一些感兴趣的环境中将 Python 作为一种_脚本语言_使用的那些人;另外一种是将它用作一个_应用程序开发语言_的那些人,他们最终发布的是一种产品而不是他们的脚本。
|
||||
|
||||
当把 Python 作为一种脚本语言来使用时,它们典型的开发者特性包括:
|
||||
把 Python 作为一种脚本语言来使用的开发者的典型特性包括:
|
||||
|
||||
* 主要的处理单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 目录和元数据文件
|
||||
* 没有任何形式的单独的构建步骤 —— 是_作为_一个脚本分发的,类似于分发一个单独的 shell 脚本的方法
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境
|
||||
* 主要的工作单元是由一个 Python 文件组成的(或 Jupyter notebook !),而不是一个 Python 和元数据文件的目录
|
||||
* 没有任何形式的单独的构建步骤 —— 是_作为_一个脚本分发的,类似于分发一个独立的 shell 脚本的方式
|
||||
* 没有单独的安装步骤(除了下载这个文件到一个合适的位置),除了在目标系统上要求预配置运行时环境外
|
||||
* 没有显式的规定依赖关系,除了最低的 Python 版本,或一个预期的运行环境声明。如果需要一个标准库以外的依赖项,他们会通过一个环境脚本去提供(无论是操作系统、数据分析平台、还是嵌入 Python 运行时的应用程序)
|
||||
* 没有单独的测试套件,使用“通过你给定的输入,这个脚本是否给出了你期望的结果?” 这种方式来进行测试
|
||||
* 如果在执行前需要测试,它将以 “试运行” 和 “预览” 模式来向用户展示软件_将_怎样运行
|
||||
@ -80,79 +80,79 @@ Python 是为谁设计的?
|
||||
|
||||
相比之下,使用 Python 作为一个应用程序开发语言的开发者特征包括:
|
||||
|
||||
* 主要的工作单元是由 Python 的目录和元数据文件组成的,而不是单个 Python 文件
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,即使是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档
|
||||
* 主要的工作单元是由 Python 和元数据文件组成的目录,而不是单个 Python 文件
|
||||
* 在发布之前有一个单独的构建步骤去预处理应用程序,哪怕是把它的这些文件一起打包进一个 Python sdist、wheel 或 zipapp 文档中
|
||||
* 是否有独立的安装步骤去预处理将要使用的应用程序,取决于应用程序是如何打包的,和支持的目标环境
|
||||
* 外部的依赖直接在项目目录中的一个元数据文件中表示(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),或作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
|
||||
* 存在一个独立的测试套件,或者作为一个 Python API 的一个测试单元、功能接口的集成测试、或者是两者的一个结合
|
||||
* 静态分析工具的使用是在项目级配置的,作为测试管理的一部分,而不是依赖
|
||||
* 外部的依赖明确表示为项目目录中的一个元数据文件中,要么是直接在项目的目录中(比如,`pyproject.toml`、`requirements.txt`、`Pipfile`),要么是作为生成的发行包的一部分(比如,`setup.py`、`flit.ini`)
|
||||
* 存在一个独立的测试套件,或者作为一个 Python API 的一个单元测试,或者作为功能接口的集成测试,或者是两者的一个结合
|
||||
* 静态分析工具的使用是在项目级配置的,并作为测试管理的一部分,而不是取决于环境
|
||||
|
||||
作为以上分类的一个结果,CPython 和标准库最终提供的主要用途是,在合适的 CPython 特性发布后 3 - 5 年,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境呈现的功能,定义重新分发的独立基准。
|
||||
作为以上分类的一个结果,CPython 和标准库的主要用途是,在相应的 CPython 特性发布后,为教育和<ruby>临时<rt>ad hoc</rt></ruby>的 Python 脚本环境,最终提供的是定义重分发者假定功能的独立基准 3- 5 年。
|
||||
|
||||
对于<ruby>临时<rt>ad hoc</rt></ruby>脚本使用的情况,这个 3 - 5 年的延迟是由于新版本重分发给用户的延迟造成的,以及那些再分发版的用户花在修改他们的标准操作环境上的时间。
|
||||
对于<ruby>临时<rt>ad hoc</rt></ruby>脚本使用的情况,这个 3 - 5 年的延迟是由于重分发者给用户制作新版本的延迟造成的,以及那些重分发版本的用户们花在修改他们的标准操作环境上的时间。
|
||||
|
||||
在教育环境中的情况,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
|
||||
在教育环境中的情况是,教育工作者需要一些时间去评估新特性,和决定是否将它们包含进提供给他们的学生的课程中。
|
||||
|
||||
### 这些相关问题的原因是什么?
|
||||
|
||||
这篇文章很大程序上是受 Twitter 上对 [我的这个评论][20] 的讨论鼓舞的,它援引了定义在 [PEP 411][21] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
这篇文章很大程度上是受 Twitter 上对 [我的这个评论][20] 的讨论鼓舞的,它援引了定义在 [PEP 411][21] 中<ruby>临时<rt>Provisional</rt></ruby> API 的情形,作为一个开源项目的例子,对用户发出事实上的邀请,请其作为共同开发者去积极参与设计和开发过程,而不是仅被动使用已准备好的最终设计。
|
||||
|
||||
这些回复包括一些在更高级别的库中支持的临时 API 的困难程度的一些沮丧表述,这些库没有临时状态的传递,以及因此而被限制为只有临时 API 的最新版本支持这些相关特性,而没有任何的早期迭代版本。
|
||||
这些回复包括一些在更高级别的库中支持临时 API 的困难程度的一些沮丧性表述、没有这些库做临时状态的传递、以及因此而被限制为只有临时 API 的最新版本才支持这些相关特性,而不是任何早期版本的迭代。
|
||||
|
||||
我的 [主要反应][22] 是去建议,开源提供者应该努力加强他们需要的有限支持,以加强他们的维护工作的可持续性。这意味着,如果支持老版本的临时 API 是非常痛苦的,然后,只有项目开发人员自己需要时,或者,有人为此支付费用时,他们才会去提供支持。这类似于我的观点,志愿者提供的项目是否应该免费支持老的商业的长周期支持的 Python 版本,这对他们来说是非常麻烦的事,我[不认他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的、习以为常的惯性,而不是真正的需求(真正的需求,它应该去支付费用来解决问题)
|
||||
我的 [主要回应][22] 是,建议开源提供者应该强制实施有限支持,通过这种强制的有限支持可以让个人的维护努力变得可持续。这意味着,如果对临时 API 的老版本提供迭代支持是非常痛苦的,到那时,只有在项目开发人员自己需要、或有人为此支付费用时,他们才会去提供支持。这与我的这个观点是类似的,那就是,志愿者提供的项目是否应该免费支持老的、商业性质的、长周期的 Python 版本,这对他们来说是非常麻烦的事,我[不认为他们应该去做][23],正如我所期望的那样,大多数这样的需求都来自于管理差劲的、习以为常的惯性,而不是真正的需求(真正的需求,应该去支付费用来解决问题)。
|
||||
|
||||
然而,我的[第二个反应][24]是,去认识到这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中 2011 的一篇年的文章中,以及在 Python 3 问答的回答中 [在这里][25]、[这里][26]、和[这里][27],和在去年的 [Python 包生态系统][28]上的一篇文章中的一小部分),我从来没有真实尝试直接去解释过它对标准库设计过程中的影响。
|
||||
而我的[第二个回应][24]是去实现这一点,尽管多年来一直在讨论这个问题(比如,在上面链接中最早在 2011 年的一篇的文章中,以及在 Python 3 问答的回复中的 [这里][25]、[这里][26]、和[这里][27],以及去年的这篇文章 [Python 包生态系统][28] 中也提到了一些),但我从来没有真实地尝试直接去解释它在标准库设计过程中的影响。
|
||||
|
||||
如果没有这些背景,设计过程中的一些方面,如临时 API 的介绍,或者是<ruby>受到不同的启发<rt>inspired-by-not-the-same-as</rt></ruby>的介绍,看起来似乎是很荒谬的,因为它们似乎是在试图标准化 API,而实际上并没有对 API 进行标准化。
|
||||
如果没有这些背景,设计过程中的一部分,比如临时 API 的引入,或者是<ruby>受启发而不同于它<rt>inspired-by-not-the-same-as</rt></ruby>的引入,看起来似乎是完全没有意义的,因为他们看起来似乎是在尝试对 API 进行标准化,而实际上并没有。
|
||||
|
||||
### 适合进入 PyPI 规划的方面有哪些?
|
||||
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议的第一个门槛就是,清楚地回答这个问题,“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,但有几个常见的方面可以考虑:
|
||||
提交给 python-ideas 或 python-dev 的_任何_建议所面临的第一个门槛就是清楚地回答这个问题:“为什么 PyPI 上的一个模块不够好?”。绝大多数的建议都在这一步失败了,为了通过这一步,这里有几个常见的话题:
|
||||
|
||||
* 大多数新手可能经常是从互联网上去 “复制粘贴” 错误的指导,而不是去下载一个合适的第三方库。(比如,这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,因为安全敏感的原因,这是用于游戏和统计模拟的)
|
||||
* 这个模块是用于提供一个实现的参考,并去允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
|
||||
* 这个模块是用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
|
||||
* 与其去下载一个合适的第三方库,新手一般可能更倾向于从互联网上 “复制粘贴” 错误的指导。(比如,这就是为什么存在 `secrets` 库的原因:它使得人们很少去使用 `random` 模块,由于安全敏感的原因,它预期用于游戏和统计模拟的)
|
||||
* 这个模块是打算去提供一个实现的参考,并允许与其它的相互竞争的实现之间提供互操作性,而不是对所有人的所有事物都是必要的。(比如,`asyncio`、`wsgiref`、`unittest`、和 `logging` 全部都是这种情况)
|
||||
* 这个模块是预期用于标准库的其它部分(比如,`enum` 就是这种情况,像`unittest`一样)
|
||||
* 这个模块是被设计去支持语言之外的一些语法(比如,`contextlib`、`asyncio` 和 `typing` 模块,就是这种情况)
|
||||
* 这个模块只是普通的临时的脚本用途(比如,`pathlib` 和 `ipaddress` 就是这种情况)
|
||||
* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你不会用它来做全部的统计分析)
|
||||
* 这个模块被用于一个教育环境(比如,`statistics` 模块允许进行交互式地探索统计的概念,尽管你可能根本就不会用它来做全部的统计分析)
|
||||
|
||||
通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足够转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的 Python 开发人员的经验有所改提升?”
|
||||
通过前面的 “PyPI 是不是明显不够好” 的检查,一个模块还不足以确保被接收到标准库中,但它已经足以转变问题为 “在接下来的几年中,你所推荐的要包含的库能否对一般的入门级 Python 开发人员的经验有所提升?”
|
||||
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的介绍也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
标准库中的 `ensurepip` 和 `venv` 模块的引入也明确地告诉再分发者,我们期望的 Python 级别的打包和安装工具在任何平台的特定分发机制中都予以支持。
|
||||
|
||||
### 当增加它到标准库中时,为什么一些 API 会被改变?
|
||||
### 当添加它们到标准库中时,为什么一些 API 会被改变?
|
||||
|
||||
现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上增加进行的是重新设计和重新实现的 API,只是它参照了现有 API 的用户体验,但是,根据另外的设计参考,删除或修改了一些细节,和附属于语言参考实现部分的权限。
|
||||
现在已经存在的第三方模块有时候会被批量地采用到标准库中,在其它情况下,实际上添加的是吸收了用户对现有 API 体验之后,进行重新设计和重新实现的 API,但是,会根据另外的设计考虑和已经成为其中一部分的语言实现参考来进行一些删除或细节修改。
|
||||
|
||||
例如,不像第三方库的广受欢迎的前身 `path.py`,`pathlib` 并_没有_定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许与文件系统路径一起使用的接口,去使用更大范围的对象。
|
||||
例如,不像广受欢迎的第三方库的前身 `path.py`,`pathlib` 并_没有_定义字符串子类,而是以独立的类型替代。作为解决文件互操作性问题的结果,定义了文件系统路径协议,它允许使用文件系统路径的接口去使用更多的对象。
|
||||
|
||||
为 `ipaddress` 模块设计的 API 将地址和网络的定义,调整为显式的单独主机接口定义(IP 地址关联到特定的 IP 网络),是为教学 IP 地址概念而提供的一个最佳的教学工具,而最原始的 `ipaddr` 模块中,使用网络术语的方式不那么严格。
|
||||
为了在“IP 地址” 这个概念的教学上提供一个更好的工具,为 `ipaddress` 模块设计的 API,将地址和网络的定义调整为显式的、独立定义的主机接口(IP 地址被关联到特定的 IP 网络),而最原始的 `ipaddr` 模块中,在网络术语的使用方式上不那么严格。
|
||||
|
||||
在其它情况下,标准库被构建为多种现有方法的一个综合,而且,还有可能依赖于定义现有库的 API 时所不存在的特性。对于 `asyncio` 和 `typing` 模块就有这些考虑因素,虽然后来对 `dataclasses` API 的考虑因素被放到了 PEP 557 (它可以被总结为 “像属性一样,但是使用变量注释作为字段声明”)。
|
||||
另外的情况是,标准库将综合多种现有的方法的来构建,以及为早已存在的库定义 API 时,还有可能依靠不存在的语法特性。比如,`asyncio` 和 `typing` 模块就全部考虑了这些因素,虽然在 PEP 557 中正在考虑将后者所考虑的因素应用到 `dataclasses` API 上。(它可以被总结为 “像属性一样,但是使用可变注释作为字段声明”)。
|
||||
|
||||
这类改变的工作原理是,这类库不会消失,而且,它们的维护者经常并不关心与标准库相关的限制(特别是,相对缓慢的发行节奏)。在这种情况下,对于标准库版本的文档来说,使用 “See Also” 链接指向原始模块是很常见的,特别是,如果第三方版本提供了标准库模块中忽略的其他特性和灵活性时。
|
||||
这类改变的原理是,这类库不会消失,并且它们的维护者对标准库维护相关的那些限制通常并不感兴趣(特别是,相对缓慢的发行节奏)。在这种情况下,在标准库文档的更新版本中,很常见的做法是使用 “See Also” 链接指向原始模块,尤其是在第三方版本提供了额外的特性以及标准库模块中忽略的那些特性时。
|
||||
|
||||
### 为什么一些 API 是以临时的形式被增加的?
|
||||
### 为什么一些 API 是以临时的形式被添加的?
|
||||
|
||||
虽然 CPython 确实设置了 API 的弃用策略,但我们通常不希望在没有令人信服的理由的情况下去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
虽然 CPython 维护了 API 的弃用策略,但在没有正当理由的情况下,我们通常不会去使用该策略(在其他项目试图与 Python 2.7 保持兼容性时,尤其如此)。
|
||||
|
||||
然而,当增加一个受已有的第三方启发去设计的而不是去拷贝的新 API 时,在设计实践中,有些设计实践可能会出现问题,这比平常的风险要高。
|
||||
然而在实践中,当添加这种受已有的第三方启发而不是直接精确拷贝第三方设计的新 API 时,所承担的风险要高于一些正常设计决定可能出现问题的风险。
|
||||
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时(`provisional`),表示保守的终端用户要避免完全依赖它们,并且,共享抽象层的开发者可能希望考虑,对他们准备支持的临时 API 的版本实施比平时更严格的限制。
|
||||
当我们考虑这种改变的风险比平常要高,我们将相关的 API 标记为临时,表示保守的终端用户要避免完全依赖它们,而共享抽象层的开发者可能希望,对他们准备去支持的那个临时 API 的版本,考虑实施比平时更严格的限制。
|
||||
|
||||
### 为什么只有一些标准库 API 被升级?
|
||||
|
||||
这里简短的回答得到升级的主要 API 有哪些?:
|
||||
|
||||
* 不适合外部因素驱动的补充更新
|
||||
* 无论是临时脚本使用情况,还是为促进将来的多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 不太可能有大量的外部因素干扰的附加更新
|
||||
* 无论是对临时脚本使用案例还是对促进将来多个第三方解决方案之间的互操作性,都有明显好处的
|
||||
* 对这方面感兴趣的人提交了一个可接受的建议
|
||||
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制,比如,`datetime`,如果重分发版通过替代一个现成的第三方模块有所改善,比如,`requests`,或者,如果标准库的发布节奏与所需要的包之间真的存在冲突,比如,`certifi`,那么,计划对标准库版本进行改变的因素将显著减少。
|
||||
如果一个用于应用程序开发的模块存在一个非常明显的限制,比如,`datetime`,如果重分发者通过可供替代的第三方选择很容易地实现了改善,比如,`requests`,或者,如果标准库的发布节奏与所需要的包之间真的存在冲突,比如,`certifi`,那么,建议对标准库版本进行改变的因素将显著减少。
|
||||
|
||||
从本质上说,这和关于 PyPI 上面的问题是相反的:因为,PyPI 分发机制对增强应用程序开发人员的体验来说,通常_是_足够好的,这样的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为缺省提供的一部分。
|
||||
从本质上说,这和上面的关于 PyPI 问题正好相反:因为,从应用程序开发人员体验改善的角度来说,PyPI 分发机制通常_是_足够好的,这种分发方式的改进是有意义的,允许重分发者和平台提供者自行决定将哪些内容作为他们缺省提供的一部分。
|
||||
|
||||
当改变后的能力假设在 3-5 年内缺省出现时被认为是有价值的,才会将这些改变进入到 CPython 和标准库中。
|
||||
假设在 3-5 年时间内,缺省出现了被认为是改变带来的可感知的价值时,才会将这些改变纳入到 CPython 和标准库中。
|
||||
|
||||
### 标准库任何部分都有独立的版本吗?
|
||||
|
||||
@ -160,19 +160,19 @@ Python 是为谁设计的?
|
||||
|
||||
最有可能的第一个候选者是 `distutils` 构建系统,因为切换到这种模式将允许构建系统在多个发行版本之间保持一致。
|
||||
|
||||
这种处理方式的其它可能的候选者是 Tcl/Tk 图形捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成可选安装项。
|
||||
这种处理方式的其它的可能候选者是 Tcl/Tk 图形捆绑和 IDLE 编辑器,它们已经被拆分,并且通过一些重分发程序转换成可选安装项。
|
||||
|
||||
### 这些注意事项为什么很重要?
|
||||
|
||||
从最本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
从本质上说,那些积极参与开源开发的人就是那些致力于开源应用程序和共享抽象层的人。
|
||||
|
||||
写一些临时脚本和为学生设计一些教学习题的人,通常不会认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师等等。
|
||||
那些写一些临时脚本或为学生设计一些教学习题的人,通常不认为他们是软件开发人员 —— 他们是教师、系统管理员、数据分析人员、金融工程师、流行病学家、物理学家、生物学家、商业分析师、动画师、架构设计师等等。
|
||||
|
||||
当我们所有的担心是,语言是开发人员的经验时,那么,我们可以简单假设人们知道一些什么,他们使用的工具,所遵循的开发流程,以及构建和部署他们软件的方法。
|
||||
对于一种语言,当我们全部的担心都是开发人员的经验时,那么我们就可以根据人们所知道的内容、他们使用的工具种类、他们所遵循的开发流程种类、构建和部署他们软件的方法等假定,来做大量的简化。
|
||||
|
||||
当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在一个项目中去平衡两种需求,就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
|
||||
当一个应用程序运行时(runtime),_也_作为一个脚本引擎广为流行时,事情将变的更加复杂。在同一个项目中去平衡两种受众的需求,将就会导致双方的不理解和怀疑,做任何一件事都将变得很困难。
|
||||
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是指出添加到 Python 标准库中的看上去很荒谬的特性的最合理的反应,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此,它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
这篇文章不是为了说,我们在开发 CPython 过程中从来没有做出过不正确的决定 —— 它只是去合理地回应那些对添加到 Python 标准库中的看上去很荒谬的特性的质疑,它将是 “我不是那个特性的预期目标受众的一部分”,而不是 “我对它没有兴趣,因此它对所有人都是毫无用处和没有价值的,添加它纯属骚扰我”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
@ -0,0 +1,57 @@
|
||||
老树发新芽:微服务 – DXC Blogs
|
||||
======
|
||||

|
||||
|
||||
如果我告诉你有这样一种软件架构,一个应用程序的组件通过基于网络的通讯协议为其它组件提供服务,我估计你可能会说它是 …
|
||||
|
||||
是的,确实是。如果你从上世纪九十年代就开始了你的编程生涯,那么你肯定会说它是 [面向服务的架构 (SOA)][1]。但是,如果你是个年青人,并且在云上获得初步的经验,那么,你将会说:“哦,你说的是 [微服务][2]。”
|
||||
|
||||
你们都没错。如果想真正地了解它们的差别,你需要深入地研究这两种架构。
|
||||
|
||||
在 SOA 中,一个服务是一个功能,它是定义好的、自包含的、并且是不依赖上下文和其它服务的状态的功能。总共有两种服务。一种是消费者服务,它从另外类型的服务 —— 提供者服务 —— 中请求一个服务。一个 SOA 服务可以同时扮演这两种角色。
|
||||
|
||||
SOA 服务可以与其它服务交换数据。两个或多个服务也可以彼此之间相互协调。这些服务执行基本的任务,比如创建一个用户帐户、提供登陆功能、或验证支付。
|
||||
|
||||
与其说 SOA 是模块化一个应用程序,还不如说它是把分布式的、独立维护和部署的组件,组合成一个应用程序。然后在服务器上运行这些组件。
|
||||
|
||||
早期版本的 SOA 使用面向对象的协议进行组件间通讯。例如,微软的 [分布式组件对象模型 (DCOM)][3] 和使用 [通用对象请求代理架构 (CORBA)][5] 规范的 [对象请求代理 (ORBs)][4]。
|
||||
|
||||
用于消息服务的最新版本,比如 [Java 消息服务 (JMS)][6] 或者 [高级消息队列协议 (AMQP)][7]。这些服务通过企业服务总线 (ESB) 进行连接。基于这些总线,来传递和接收可扩展标记语言(XML)格式的数据。
|
||||
|
||||
[微服务][2] 是一个架构样式,其中的应用程序以松散耦合的服务或模块组成。它适用于开发大型的、复杂的应用程序的持续集成/持续部署(CI/CD)模型。一个应用程序就是一堆模块的汇总。
|
||||
|
||||
每个微服务提供一个应用程序编程接口(API)端点。它们通过轻量级协议连接,比如,[表述性状态转移 (REST)][8],或 [gRPC][9]。数据倾向于使用 [JavaScript 对象标记 (JSON)][10] 或 [Protobuf][11] 来表示。
|
||||
|
||||
这两种架构都可以用于去替代以前老的整体式架构,整体式架构的应用程序被构建为单个自治的单元。例如,在一个客户机 - 服务器模式中,一个典型的 Linux、Apache、MySQL、PHP/Python/Perl (LAMP) 服务器端应用程序将去处理 HTTP 请求、运行子程序、以及从底层的 MySQL 数据库中检索/更新数据。所有这些应用程序”绑“在一起提供服务。当你改变了任何一个东西,你都必须去构建和部署一个新版本。
|
||||
|
||||
使用 SOA,你可以只改变需要的几个组件,而不是整个应用程序。使用微服务,你可以做到一次只改变一个服务。使用微服务,你才能真正做到一个解耦架构。
|
||||
|
||||
微服务也比 SOA 更轻量级。不过 SOA 服务是部署到服务器和虚拟机上,而微服务是部署在容器中。协议也更轻量级。这使得微服务比 SOA 更灵活。因此,它更适合于要求敏捷性的电商网站。
|
||||
|
||||
说了这么多,到底意味着什么呢?微服务就是 SOA 在容器和云计算上的变种。
|
||||
|
||||
老式的 SOA 并没有离我们远去,但是,因为我们持续将应用程序搬迁到容器中,所以微服务架构将越来越流行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blogs.dxc.technology/2018/05/08/everything-old-is-new-again-microservices/
|
||||
|
||||
作者:[Cloudy Weather][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blogs.dxc.technology/author/steven-vaughan-nichols/
|
||||
[1]:https://www.service-architecture.com/articles/web-services/service-oriented_architecture_soa_definition.html
|
||||
[2]:http://microservices.io/
|
||||
[3]:https://technet.microsoft.com/en-us/library/cc958799.aspx
|
||||
[4]:https://searchmicroservices.techtarget.com/definition/Object-Request-Broker-ORB
|
||||
[5]:http://www.corba.org/
|
||||
[6]:https://docs.oracle.com/javaee/6/tutorial/doc/bncdq.html
|
||||
[7]:https://www.amqp.org/
|
||||
[8]:https://www.service-architecture.com/articles/web-services/representational_state_transfer_rest.html
|
||||
[9]:https://grpc.io/
|
||||
[10]:https://www.json.org/
|
||||
[11]:https://github.com/google/protobuf/
|
||||
@ -0,0 +1,175 @@
|
||||
|
||||
如何方便的检查Ubuntu版本以及其他系统信息
|
||||
======
|
||||
|
||||
|
||||
**简要:想知道你正在使用的Ubuntu具体是什么版本吗?这篇文档将告诉你如何检查你的Ubuntu版本,桌面环境以及其他相关的系统信息**
|
||||
|
||||
|
||||
|
||||
通常,你能非常容易的通过命令行或者图形界面获取你正在使用的Ubutnu的版本。当你正在尝试学习一篇互联网上的入门教材或者正在从各种各样的论坛里获取帮助的时候,知道当前正在使用的Ubuntu确切的版本号,桌面环境以及其他的系统信息将是尤为重要的。
|
||||
|
||||
|
||||
|
||||
在这篇简短的文章中,作者将展示各种检查[Ubuntu][1] 版本以及其他常用的系统信息的方法。
|
||||
|
||||
|
||||
### 如何在命令行检查Ubuntu版本
|
||||
|
||||
|
||||
这个是获得Ubuntu版本的最好的办法。 我本想先展示如何用图形界面做到这一点但是我决定还是先从命令行方法说起,因为这种方法不依赖于你使用的任何桌面环境[desktop environment][2]。 你可以在任何Ubuntu的变种系统上使用这种方法。
|
||||
|
||||
|
||||
打开你的命令行终端 (Ctrl+Alt+T), 键入下面的命令:
|
||||
|
||||
```
|
||||
lsb_release -a
|
||||
|
||||
```
|
||||
|
||||
|
||||
上面命令的输出应该如下:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.4 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][3]
|
||||
|
||||
|
||||
正像你所看到的,当前我的系统安装的Ubuntu版本是 Ubuntu 16.04, 版本代号: Xenial
|
||||
|
||||
|
||||
且慢!为什么版本描述中显示的是Ubuntu 16.04.4而发行号是16.04?到底哪个才是正确的版本?16.04还是16.04.4? 这两者之间有什么区别?
|
||||
|
||||
|
||||
如果言简意赅的回答这个问题的话,那么答案应该是你正在使用Ubuntu 16.04. 这个是基准版本, 而16.04.4进一步指明这是16.04的第四个补丁版本。你可以将补丁版本理解为Windows世界里的服务包。在这里,16.04和16.04.4都是正确的版本号。
|
||||
|
||||
|
||||
那么输出的Xenial又是什么?那正是Ubuntu 16.04版本代号。你可以阅读下面这篇文章获取更多信息[article to know about Ubuntu naming convention][4].
|
||||
|
||||
|
||||
|
||||
#### 其他一些获取Ubuntu版本的方法
|
||||
|
||||
|
||||
|
||||
你也可以使用下面任意的命令得到Ubuntu的版本:
|
||||
|
||||
```
|
||||
cat /etc/lsb-release
|
||||
|
||||
```
|
||||
|
||||
|
||||
输出如下信息:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.4 LTS"
|
||||
|
||||
```
|
||||
|
||||
![How to check Ubuntu version in command line][5]
|
||||
|
||||
|
||||
你还可以使用下面的命令来获得Ubuntu版本
|
||||
|
||||
```
|
||||
cat /etc/issue
|
||||
|
||||
```
|
||||
|
||||
|
||||
命令行的输出将会如下:
|
||||
|
||||
```
|
||||
Ubuntu 16.04.4 LTS \n \l
|
||||
|
||||
```
|
||||
|
||||
|
||||
不要介意输出末尾的\n \l. 这里Ubuntu版本就是16.04.4或者更加简单:16.04.
|
||||
|
||||
|
||||
### 如何在图形界面下得到Ubuntu版本
|
||||
|
||||
|
||||
在图形界面下获取Ubuntu版本更是小事一桩。这里我使用了Ubuntu 18.04的图形界面系统GNOME的屏幕截图来展示如何做到这一点。如果你在使用Unity或者别的桌面环境的话,显示可能会有所不同。这也是为什么我推荐使用命令行方式来获得版本的原因:你不用依赖形形色色的图形界面。
|
||||
|
||||
|
||||
|
||||
下面我来展示如何在桌面环境获取Ubuntu版本。
|
||||
|
||||
|
||||
|
||||
进入‘系统设置’并点击下面的‘详细信息’栏。
|
||||
|
||||
![Finding Ubuntu version graphically][6]
|
||||
|
||||
|
||||
|
||||
你将会看到系统的Ubuntu版本和其他和桌面系统有关的系统信息 这里的截图来自[GNOME][7] 。
|
||||
|
||||
![Finding Ubuntu version graphically][8]
|
||||
|
||||
|
||||
|
||||
### 如何知道桌面环境以及其他的系统信息
|
||||
|
||||
|
||||
|
||||
你刚才学习的是如何得到Ubuntu的版本信息,那么如何知道桌面环境呢? 更进一步, 如果你还想知道当前使用的Linux内核版本呢?
|
||||
|
||||
|
||||
有各种各样的命令你可以用来得到这些信息,不过今天我想推荐一个命令行工具, 叫做[Neofetch][9]。 这个工具能在命令行完美展示系统信息,包括Ubuntu或者其他Linux发行版的系统图标。
|
||||
|
||||
|
||||
用下面的命令安装Neofetch:
|
||||
|
||||
```
|
||||
sudo apt install neofetch
|
||||
|
||||
```
|
||||
|
||||
|
||||
安装成功后,运行'neofetch'将会优雅的展示系统的信息如下。
|
||||
|
||||
![System information in Linux terminal][10]
|
||||
|
||||
|
||||
如你所见,neofetch 完全展示了Linux内核版本,Ubuntu的版本,桌面系统版本以及环境,主题和图标等等信息。
|
||||
|
||||
|
||||
希望我如上展示方法能帮到你更快的找到你正在使用的Ubuntu版本和其他系统信息。如果你对这篇文章有其他的建议,欢迎在评论栏里留言。
|
||||
再见。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://en.wikipedia.org/wiki/Desktop_environment
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-1-800x216.jpeg
|
||||
[4]:https://itsfoss.com/linux-code-names/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/check-ubuntu-version-command-line-2-800x185.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-version-system-settings.jpeg
|
||||
[7]:https://www.gnome.org/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/checking-ubuntu-version-gui.jpeg
|
||||
[9]:https://itsfoss.com/display-linux-logo-in-ascii/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2013/03/ubuntu-system-information-terminal-800x400.jpeg
|
||||
@ -0,0 +1,92 @@
|
||||
使用 Xenlism 主题为你的 Linux 桌面带来令人惊叹的改造
|
||||
============================================================
|
||||
|
||||
|
||||
_简介:Xenlism 主题包提供了一个美观的 GTK 主题、彩色图标和简约壁纸,将你的 Linux 桌面转变为引人注目的设置._
|
||||
|
||||
除非我找到一些非常棒的东西,否则我不会每天都把整篇文章献给一个主题。我曾经经常发布主题和图标。但最近,我更喜欢列出[最佳 GTK 主题][6]和图标主题。这对我和你来说都更方便,你可以在一个地方看到许多美丽的主题。
|
||||
|
||||
在[ Pop OS 主题][7]套件之后,Xenlism 是另一个让我对它的外观感到震惊的主题。
|
||||
|
||||

|
||||
|
||||
Xenlism GTK 主题基于 Arc 主题,这后面有许多主题的灵感。GTK 主题提供类似于 macOS 的 Windows 按钮,我既没有喜欢,也没有不喜欢。GTK 主题采用扁平、简约的布局,我喜欢这样。
|
||||
|
||||
Xenlism 套件中有两个图标主题。Xenlism Wildfire是以前的,已经进入我们的[最佳图标主题][8]列表。
|
||||
|
||||

|
||||
Xenlism Wildfire 图标
|
||||
|
||||
Xenlsim Storm 是一个相对较新的图标主题,但同样美观。
|
||||
|
||||

|
||||
Xenlism Storm 图标
|
||||
|
||||
Xenlism 主题在 GPL 许可下的开源。
|
||||
|
||||
### 如何在 Ubuntu 18.04 上安装 Xenlism 主题包
|
||||
|
||||
Xenlism 开发提供了一种通过 PPA 安装主题包的更简单方法。尽管 PPA 可用于 Ubuntu 16.04,但我发现 GTK 主题不适用于 Unity。它适用于 Ubuntu 18.04 中的 GNOME 桌面。
|
||||
|
||||
打开终端(Ctrl+Alt+T)并逐个使用以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:xenatt/xenlism
|
||||
sudo apt update
|
||||
```
|
||||
|
||||
该 PPA 提供四个包:
|
||||
|
||||
* xenlism-finewalls:一组壁纸,可直接在 Ubuntu 的壁纸中使用。截图中使用了其中一个壁纸。
|
||||
|
||||
* xenlism-minimalism-theme:GTK主题
|
||||
|
||||
* xenlism-storm:一个图标主题(见前面的截图)
|
||||
|
||||
* xenlism-wildfire-icon-theme:具有多种颜色变化的另一个图标主题(文件夹颜色在变体中更改)
|
||||
|
||||
你可以自己决定要安装的主题组件。就个人而言,我认为安装所有组件没有任何损害。
|
||||
|
||||
```
|
||||
sudo apt install xenlism-minimalism-theme xenlism-storm-icon-theme xenlism-wildfire-icon-theme xenlism-finewalls
|
||||
```
|
||||
|
||||
你可以使用 GNOME Tweaks 来更改主题和图标。如果你不熟悉该过程,我建议你阅读本教程以学习[如何在 Ubuntu 18.04 GNOME 中安装主题][9]。
|
||||
|
||||
### 在其他 Linux 发行版中获取 Xenlism 主题
|
||||
|
||||
你也可以在其他 Linux 发行版上安装 Xenlism 主题。各种 Linux 发行版的安装说明可在其网站上找到:
|
||||
|
||||
[安装 Xenlism 主题][10]
|
||||
|
||||
### 你怎么看?
|
||||
|
||||
我知道不是每个人都会同意我,但我喜欢这个主题。我想你将来会在 It's FOSS 的教程中会看到 Xenlism 主题的截图。
|
||||
|
||||
你喜欢 Xenlism 主题吗?如果不喜欢,你最喜欢什么主题?在下面的评论部分分享你的意见。
|
||||
|
||||
#### 关于作者
|
||||
|
||||
我是一名专业软件开发人员,也是 It's FOSS 的创始人。我是一名狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信分享知识。除了Linux,我喜欢经典侦探之谜。我是 Agatha Christie 作品的忠实粉丝。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/xenlism-theme/
|
||||
|
||||
作者:[Abhishek Prakash ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/xenlism-theme/#comments
|
||||
[3]:https://itsfoss.com/category/desktop/
|
||||
[4]:https://itsfoss.com/tag/themes/
|
||||
[5]:https://itsfoss.com/tag/xenlism/
|
||||
[6]:https://itsfoss.com/best-gtk-themes/
|
||||
[7]:https://itsfoss.com/pop-icon-gtk-theme-ubuntu/
|
||||
[8]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[9]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[10]:http://xenlism.github.io/minimalism/#install
|
||||
@ -0,0 +1,256 @@
|
||||
使用 MQTT 实现项目数据收发
|
||||
======
|
||||
|
||||

|
||||
|
||||
去年 11 月我们购买了一辆电动汽车,同时也引发了有趣的思考:我们应该什么时候为电动汽车充电?对于电动汽车充电所用的电,我希望能够对应最小的二氧化碳排放,归结为一个特定的问题:对于任意给定时刻,每千瓦时对应的二氧化碳排放量是多少,一天中什么时间这个值最低?
|
||||
|
||||
|
||||
### 寻找数据
|
||||
|
||||
我住在纽约州,大约 80% 的电力消耗可以自给自足,主要来自天然气、水坝(大部分来自于<ruby>尼亚加拉<rt>Niagara</rt></ruby>大瀑布)、核能发电,少部分来自风力、太阳能和其它化石燃料发电。非盈利性组织 [<ruby>纽约独立电网运营商<rt>New York Independent System Operator</rt></ruby>][1] (NYISO) 负责整个系统的运作,实现发电机组发电与用电之间的平衡,同时也是纽约路灯系统的监管部门。
|
||||
|
||||
尽管没有为公众提供公开 API,NYISO 还是尽责提供了[不少公开数据][2]供公众使用。每隔 5 分钟汇报全州各个发电机组消耗的燃料数据。数据以 CSV 文件的形式发布于公开的档案库中,全天更新。如果你了解不同燃料对发电瓦数的贡献比例,你可以比较准确的估计任意时刻的二氧化碳排放情况。
|
||||
|
||||
在构建收集处理公开数据的工具时,我们应该时刻避免过度使用这些资源。相比将这些数据打包并发送给所有人,我们有更好的方案。我们可以创建一个低开销的<ruby>事件流<rt>event stream</rt></ruby>,人们可以订阅并第一时间得到消息。我们可以使用 [MQTT][3] 实现该方案。我的 ([ny-power.org][4]) 项目目标是收录到 [Home Assistant][5] 项目中;后者是一个开源的<ruby>家庭自动化<rt>home automation</rt></ruby>平台,拥有数十万用户。如果所有用户同时访问 CSV 文件服务器,估计 NYISO 不得不增加访问限制。
|
||||
|
||||
### MQTT 是什么?
|
||||
|
||||
MQTT 是一个<ruby>发布订阅线协议<rt>publish/subscription wire protocol</rt></ruby>,为小规模设备设计。发布订阅系统工作原理类似于消息总线。你将一条消息发布到一个<ruby>主题<rt>topic</rt></ruby>上,那么所有订阅了该主题的客户端都可以获得该消息的一份拷贝。对于消息发送者而言,无需知道哪些人在订阅消息;你只需将消息发布到一系列主题,同时订阅一些你感兴趣的主题。就像参加了一场聚会,你选取并加入感兴趣的对话。
|
||||
|
||||
MQTT 可应用构建极为高效的应用。客户端订阅有限的几个主题,也只收到他们感兴趣的内容。不仅节省了处理时间,还降低了网络带宽使用。
|
||||
|
||||
作为一个开放标准,MQTT 有很多开源的客户端和服务端实现。对于你能想到的每种编程语言,都有对应的客户端库;甚至有嵌入到 Arduino 的库,可以构建传感器网络。服务端可供选择的也很多,我的选择是 Eclipse 项目提供的 [Mosquitto][6] 服务端,这是因为它体积小、用 C 编写,可以承载数以万计的订阅者。
|
||||
|
||||
### 为何我喜爱 MQTT
|
||||
|
||||
在过去二十年间,我们为软件应用设计了可靠且准确的模型,用于解决服务遇到的问题。我还有其它邮件吗?当前的天气情况如何?我应该此刻购买这种产品吗?在绝大多数情况下,这种<ruby>问答式<rt>ask/receive</rt></ruby>的模型工作良好;但对于一个数据爆炸的世界,我们需要其它的模型。MQTT 的发布订阅模型十分强大,可以将大量数据发送到系统中。客户可以订阅数据中的一小部分并在订阅数据发布的第一时间收到更新。
|
||||
|
||||
MQTT 还有一些有趣的特性,其中之一是<ruby>遗嘱<rt>last-will-and-testament</rt></ruby>消息,可以用于区分两种不同的静默,一种是没有主题相关数据推送,另一种是你的数据接收器出现故障。MQTT 还包括<ruby>保留消息<rt>retained message</rt></ruby>,当客户端初次连接时会提供相关主题的最后一条消息。这对那些更新缓慢的主题来说很有必要。
|
||||
|
||||
我在 Home Assistant 项目开发过程中,发现这种消息总线模型对<ruby>异构系统<rt>heterogeneous systems</rt></ruby>尤为适合。如果你深入<ruby>物联网<rt>Internet of Things</rt></ruby>领域,你会发现 MQTT 无处不在。
|
||||
|
||||
### 我们的第一个 MQTT 流
|
||||
|
||||
NYSO 公布的 CSV 文件中有一个是实时的燃料混合使用情况。每 5 分钟,NYSO 发布这 5 分钟内发电使用的燃料类型和相应的发电量(以兆瓦为单位)。
|
||||
|
||||
The CSV file looks something like this:
|
||||
|
||||
| 时间戳 | 时区 | 燃料类型 | 兆瓦为单位的发电量 |
|
||||
| --- | --- | --- | --- |
|
||||
| 05/09/2018 00:05:00 | EDT | 混合燃料 | 1400 |
|
||||
| 05/09/2018 00:05:00 | EDT | 天然气 | 2144 |
|
||||
| 05/09/2018 00:05:00 | EDT | 核能 | 4114 |
|
||||
| 05/09/2018 00:05:00 | EDT | 其它化石燃料 | 4 |
|
||||
| 05/09/2018 00:05:00 | EDT | 其它可再生资源 | 226 |
|
||||
| 05/09/2018 00:05:00 | EDT | 风力 | 1 |
|
||||
| 05/09/2018 00:05:00 | EDT | 水力 | 3229 |
|
||||
| 05/09/2018 00:10:00 | EDT | 混合燃料 | 1307 |
|
||||
| 05/09/2018 00:10:00 | EDT | 天然气 | 2092 |
|
||||
| 05/09/2018 00:10:00 | EDT | 核能 | 4115 |
|
||||
| 05/09/2018 00:10:00 | EDT | 其它化石燃料 | 4 |
|
||||
| 05/09/2018 00:10:00 | EDT | 其它可再生资源 | 224 |
|
||||
| 05/09/2018 00:10:00 | EDT | 风力 | 40 |
|
||||
| 05/09/2018 00:10:00 | EDT | 水力 | 3166 |
|
||||
|
||||
表中唯一令人不解就是燃料类别中的混合燃料。纽约的大多数天然气工厂也通过燃烧其它类型的化石燃料发电。在冬季寒潮到来之际,家庭供暖的优先级高于发电;但这种情况出现的次数不多,(在我们计算中)可以将混合燃料类型看作天然气类型。
|
||||
|
||||
CSV 文件全天更新。我编写了一个简单的数据泵,每隔 1 分钟检查是否有数据更新,并将新条目发布到 MQTT 服务器的一系列主题上,主题名称基本与 CSV 文件有一定的对应关系。数据内容被转换为 JSON 对象,方便各种编程语言处理。
|
||||
|
||||
```
|
||||
ny-power/upstream/fuel-mix/Hydro {"units": "MW", "value": 3229, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Dual Fuel {"units": "MW", "value": 1400, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Natural Gas {"units": "MW", "value": 2144, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Other Fossil Fuels {"units": "MW", "value": 4, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Wind {"units": "MW", "value": 41, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Other Renewables {"units": "MW", "value": 226, "ts": "05/09/2018 00:05:00"}
|
||||
ny-power/upstream/fuel-mix/Nuclear {"units": "MW", "value": 4114, "ts": "05/09/2018 00:05:00"}
|
||||
|
||||
```
|
||||
|
||||
这种直接的转换是种不错的尝试,可将公开数据转换为公开事件。我们后续会继续将数据转换为二氧化碳排放强度,但这些原始数据还可被其它应用使用,用于其它计算用途。
|
||||
|
||||
### MQTT 主题
|
||||
|
||||
主题和<ruby>主题结构<rt>topic structure</rt></ruby>是 MQTT 的一个主要特色。与其它标准的企业级消息总线不同,MQTT 的主题无需事先注册。发送者可以凭空创建主题,唯一的限制是主题的长度,不超过 220 字符。其中 `/` 字符有特殊含义,用于创建主题的层次结构。我们即将看到,你可以订阅这些层次中的一些分片。
|
||||
|
||||
基于开箱即用的 Mosquitto,任何一个客户端都可以向任何主题发布消息。在原型设计过程中,这种方式十分便利;但一旦部署到生产环境,你需要增加<ruby>访问控制列表<rt>access control list, ACL</rt></ruby>只允许授权的应用发布消息。例如,任何人都能以只读的方式访问我的应用的主题层级,但只有那些具有特定<ruby>凭证<rt>credentials</rt></ruby>的客户端可以发布内容。
|
||||
|
||||
主题中不包含<ruby>自动样式<rt>automatic schema</rt></ruby>,也没有方法查找客户端可以发布的全部主题。因此,对于那些从 MQTT 总线消费数据的应用,你需要让其直接使用已知的主题和消息格式样式。
|
||||
|
||||
那么应该如何设计主题呢?最佳实践包括使用应用相关的根名称,例如在我的应用中使用 `ny-power`。接着,为提高订阅效率,构建足够深的层次结构。`upstream` 层次结构包含了直接从数据源获取的、不经处理的原始数据,而 `fuel-mix` 层次结构包含特定类型的数据;我们后续还可以增加其它的层次结构。
|
||||
|
||||
### 订阅主题
|
||||
|
||||
在 MQTT 中,订阅仅仅是简单的字符串匹配。为提高处理效率,只允许如下两种通配符:
|
||||
|
||||
* `#` 以递归方式匹配,直到字符串结束
|
||||
* `+` 匹配下一个 `/` 之前的内容
|
||||
|
||||
|
||||
为便于理解,下面给出几个例子:
|
||||
```
|
||||
ny-power/# - 匹配 ny-power 应用发布的全部主题
|
||||
ny-power/upstream/# - 匹配全部原始数据的主题
|
||||
ny-power/upstream/fuel-mix/+ - 匹配全部燃料类型的主题
|
||||
ny-power/+/+/Hydro - 匹配全部两次层级之后为 Hydro 类型的主题(即使不位于 upstream 层次结构下)
|
||||
```
|
||||
|
||||
类似 `ny-power/#` 的大范围订阅适用于<ruby>低数据量<rt>low-volume</rt></ruby>的应用,应用从网络获取全部数据并处理。但对<ruby>高数据量<rt>high-volume</rt></ruby>应用而言则是一个灾难,由于绝大多数消息并不会被使用,大部分的网络带宽被白白浪费了。
|
||||
|
||||
在大数据量情况下,为确保性能,应用需要使用恰当的主题筛选(如 `ny-power/+/+/Hydro`)尽量准确获取业务所需的数据。
|
||||
|
||||
### 增加我们自己的数据层次
|
||||
|
||||
接下来,应用中的一切都依赖于已有的 MQTT 流并构建新流。第一个额外的数据层用于计算发电对应的二氧化碳排放。
|
||||
|
||||
利用[<ruby>美国能源情报署<rt>U.S. Energy Information Administration</rt></ruby>][7] 给出的 2016 年纽约各类燃料发电及排放情况,我们可以给出各类燃料的[平均排放率][8],单位为克/兆瓦时。
|
||||
|
||||
上述结果被封装到一个专用的微服务中。该微服务订阅 `ny-power/upstream/fuel-mix/+`,即数据泵中燃料组成情况的原始数据,接着完成计算并将结果(单位为克/千瓦时)发布到新的主题层次结构上:
|
||||
```
|
||||
ny-power/computed/co2 {"units": "g / kWh", "value": 152.9486, "ts": "05/09/2018 00:05:00"}
|
||||
```
|
||||
|
||||
接着,另一个服务会订阅该主题层次结构并将数据打包到 [InfluxDB][9] 进程中;同时,发布 24 小时内的时间序列数据到 `ny-power/archive/co2/24h` 主题,这样可以大大简化当前变化数据的绘制。
|
||||
|
||||
这种层次结构的主题模型效果不错,可以将上述程序之间的逻辑解耦合。在复杂系统中,各个组件可能使用不同的编程语言,但这并不重要,因为交换格式都是 MQTT 消息,即主题和 JSON 格式的消息内容。
|
||||
|
||||
### 从终端消费数据
|
||||
|
||||
为了更好的了解 MQTT 完成了什么工作,将其绑定到一个消息总线并查看消息流是个不错的方法。`mosquitto-clients` 包中的 `mosquitto_sub` 可以让我们轻松实现该目标。
|
||||
|
||||
安装程序后,你需要提供服务器名称以及你要订阅的主题。如果有需要,使用参数 `-v` 可以让你看到有新消息发布的那些主题;否则,你只能看到主题内的消息数据。
|
||||
|
||||
```
|
||||
mosquitto_sub -h mqtt.ny-power.org -t ny-power/# -v
|
||||
|
||||
```
|
||||
|
||||
只要我编写或调试 MQTT 应用,我总会在一个终端中运行 `mosquitto_sub`。
|
||||
|
||||
### 从网页直接访问 MQTT
|
||||
|
||||
到目前为止,我们已经有提供公开事件流的应用,可以用微服务或命令行工具访问该应用。但考虑到互联网仍占据主导地位,因此让用户可以从浏览器直接获取事件流是很重要。
|
||||
|
||||
MQTT 的设计者已经考虑到了这一点。协议标准支持三种不同的传输协议:[TCP][10],[UDP][11] 和 [WebSockets][12]。主流浏览器都支持 WebSockets,可以维持持久连接,用于实时应用。
|
||||
|
||||
Eclipse 项目提供了 MQTT 的一个 JavaScript 实现,叫做 [Paho][13],可包含在你的应用中。工作模式为与服务器建立连接、建立一些订阅,然后根据接收到的消息进行响应。
|
||||
|
||||
```
|
||||
// ny-power web console application
|
||||
|
||||
var client = new Paho.MQTT.Client(mqttHost, Number("80"), "client-" + Math.random());
|
||||
|
||||
// set callback handlers
|
||||
client.onMessageArrived = onMessageArrived;
|
||||
|
||||
// connect the client
|
||||
client.reconnect = true;
|
||||
client.connect({onSuccess: onConnect});
|
||||
|
||||
// called when the client connects
|
||||
function onConnect() {
|
||||
// Once a connection has been made, make a subscription and send a message.
|
||||
console.log("onConnect");
|
||||
client.subscribe("ny-power/computed/co2");
|
||||
client.subscribe("ny-power/archive/co2/24h");
|
||||
client.subscribe("ny-power/upstream/fuel-mix/#");
|
||||
}
|
||||
|
||||
// called when a message arrives
|
||||
function onMessageArrived(message) {
|
||||
console.log("onMessageArrived:"+message.destinationName + message.payloadString);
|
||||
if (message.destinationName == "ny-power/computed/co2") {
|
||||
var data = JSON.parse(message.payloadString);
|
||||
$("#co2-per-kwh").html(Math.round(data.value));
|
||||
$("#co2-units").html(data.units);
|
||||
$("#co2-updated").html(data.ts);
|
||||
}
|
||||
|
||||
if (message.destinationName.startsWith("ny-power/upstream/fuel-mix")) {
|
||||
fuel_mix_graph(message);
|
||||
}
|
||||
|
||||
if (message.destinationName == "ny-power/archive/co2/24h") {
|
||||
var data = JSON.parse(message.payloadString);
|
||||
var plot = [
|
||||
{
|
||||
x: data.ts,
|
||||
y: data.values,
|
||||
type: 'scatter'
|
||||
}
|
||||
];
|
||||
var layout = {
|
||||
yaxis: {
|
||||
title: "g CO2 / kWh",
|
||||
}
|
||||
};
|
||||
Plotly.newPlot('co2_graph', plot, layout);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
上述应用订阅了不少主题,因为我们将要呈现若干种不同类型的数据;其中 `ny-power/computed/co2` 主题为我们提供当前二氧化碳排放的参考值。一旦收到该主题的新消息,网站上的相应内容会被相应替换。
|
||||
|
||||
|
||||
![NYISO 二氧化碳排放图][15]
|
||||
|
||||
[ny-power.org][4] 网站提供的 NYISO 二氧化碳排放图。
|
||||
|
||||
`ny-power/archive/co2/24h` 主题提供了时间序列数据,用于为 [Plotly][16] 线表提供数据。`ny-power/upstream/fuel-mix` 主题提供当前燃料组成情况,为漂亮的柱状图提供数据。
|
||||
|
||||
![NYISO 燃料组成情况][18]
|
||||
|
||||
[ny-power.org][4] 网站提供的燃料组成情况。
|
||||
|
||||
这是一个动态网站,数据不从服务器拉取,而是结合 MQTT 消息总线,监听对外开放的 WebSocket。就像数据泵和打包器程序那样,网站页面也是一个发布订阅客户端,只不过是在你的浏览器中执行,而不是在公有云的微服务上。
|
||||
|
||||
你可以在 <http://ny-power.org> 站点点看到动态变更,包括图像和可以看到消息到达的实时 MQTT 终端。
|
||||
|
||||
### 继续深入
|
||||
|
||||
ny-power.org 应用的完整内容开源在 [GitHub][19] 中。你也可以查阅 [架构简介][20],学习如何使用 [Helm][21] 部署一系列 Kubernetes 微服务构建应用。另一个有趣的 MQTT 示例使用 MQTT 和 OpenWhisk 进行实时文本消息翻译,<ruby>代码模式<rt>code pattern</rt></ruby>参考[链接][22]。
|
||||
|
||||
MQTT 被广泛应用于物联网领域,更多关于 MQTT 用途的例子可以在 [Home Assistant][23] 项目中找到。
|
||||
|
||||
如果你希望深入了解协议内容,可以从 [mqtt.org][3] 获得该公开标准的全部细节。
|
||||
|
||||
想了解更多,可以参加 Sean Dague 在 [OSCON][25] 上的演讲,主题为 [将 MQTT 加入到你的工具箱][24],会议将于 7 月 16-19 日在奥尔良州波特兰举办。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/mqtt
|
||||
|
||||
作者:[Sean Dague][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sdague
|
||||
[1]:http://www.nyiso.com/public/index.jsp
|
||||
[2]:http://www.nyiso.com/public/markets_operations/market_data/reports_info/index.jsp
|
||||
[3]:http://mqtt.org/
|
||||
[4]:http://ny-power.org/#
|
||||
[5]:https://www.home-assistant.io
|
||||
[6]:https://mosquitto.org/
|
||||
[7]:https://www.eia.gov/
|
||||
[8]:https://github.com/IBM/ny-power/blob/master/src/nypower/calc.py#L1-L60
|
||||
[9]:https://www.influxdata.com/
|
||||
[10]:https://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
||||
[11]:https://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[12]:https://en.wikipedia.org/wiki/WebSocket
|
||||
[13]:https://www.eclipse.org/paho/
|
||||
[14]:/file/400041
|
||||
[15]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso-co2intensity.png (NY ISO Grid CO2 Intensity)
|
||||
[16]:https://plot.ly/
|
||||
[17]:/file/400046
|
||||
[18]:https://opensource.com/sites/default/files/uploads/mqtt_nyiso_fuel-mix.png (Fuel mix on NYISO grid)
|
||||
[19]:https://github.com/IBM/ny-power
|
||||
[20]:https://developer.ibm.com/code/patterns/use-mqtt-stream-real-time-data/
|
||||
[21]:https://helm.sh/
|
||||
[22]:https://developer.ibm.com/code/patterns/deploy-serverless-multilingual-conference-room/
|
||||
[23]:https://www.home-assistant.io/
|
||||
[24]:https://conferences.oreilly.com/oscon/oscon-or/public/schedule/speaker/77317
|
||||
[25]:https://conferences.oreilly.com/oscon/oscon-or
|
||||
@ -1,44 +0,0 @@
|
||||
在 Arch 用户仓库(AUR)中发现恶意软件
|
||||
======
|
||||
|
||||
7 月 7 日,AUR 软件包被修改了一些恶意代码,提醒 [Arch Linux][1] 用户(以及一般 Linux 用户)在安装之前应该检查所有用户生成的软件包(如果可能)。
|
||||
|
||||
[AUR][3] 或者称 Arch(Linux)用户仓库包含包描述,也称为 PKGBUILD,它使得从源代码编译包变得更容易。虽然这些包非常有用,但它们永远不应被视为安全,并且用户应尽可能在使用之前检查其内容。毕竟,AUR在网页中以粗体显示 “AUR 包是用户制作的内容。任何使用提供的文件的风险由你自行承担。”
|
||||
|
||||
|
||||
包含恶意代码的 AUR 包的[发现][4]证明了这一点。[acroread][5] 于 7 月 7 日(看起来它以前是“孤儿”,意思是它没有维护者)被一位名为 “xeactor” 的用户修改,它包含了一行从 pastebin 使用 `curl` 下载脚本的命令。然后,该脚本下载了另一个脚本并安装了systemd 单元以定期运行该脚本。
|
||||
|
||||
**看来[另外两个][2] AUR 包以同样的方式被修改。所有违规软件包都已删除,并暂停了用于上传它们的用户帐户(在更新软件包同一天注册了那些帐户)。**
|
||||
|
||||
恶意代码没有做任何真正有害的事情 - 它只是试图上传一些系统信息,比如机器 ID、`uname -a` 的输出(包括内核版本、架构等)、CPU 信息、pacman 信息,以及 `systemctl list-units`(列出 systemd 单位信息)的输出到 pastebin.com。我说“尝试”是因为第二个脚本中存在错误而没有实际上传系统信息(上传函数为 “upload”,但脚本试图使用其他名称 “uploader” 调用它)。
|
||||
|
||||
此外,将这些恶意脚本添加到 AUR 的人将脚本中的个人 Pastebin API 密钥以明文形式留下,再次证明他们不确切地知道他们在做什么。
|
||||
|
||||
尝试将此信息上传到 Pastebin 的目的尚不清楚,特别是原本可以上传更加敏感信息的情况下,如 GPG / SSH 密钥。
|
||||
|
||||
**更新:** Reddit用户 u/xanaxdroid_ [提及][6]同一个名为 “xeactor” 的用户也发布了一些加密货币挖矿软件包,因此他推测 “xeactor” 可能正计划添加一些隐藏的加密货币挖矿软件到 AUR([两个月][7]前的一些 Ubuntu Snap 软件包也是如此)[7]。这就是 “xeactor” 可能试图获取各种系统信息的原因。此 AUR 用户上传的所有包都已删除,因此我无法检查。
|
||||
|
||||
**另一个更新:**
|
||||
|
||||
你究竟应该在那些用户生成的软件包 (如 AUR 中找到的) 检查什么?情况各有相同,我无法准确地告诉你,但你可以从寻找任何尝试使用 `curl`、`wget`和其他类似工具下载内容的东西开始,看看他们究竟想要下载什么。还要检查从中下载软件包源的服务器,并确保它是官方来源。不幸的是,这不是一个确切的“科学”。例如,对于 Launchpad PPA,事情变得更加复杂,因为你必须知道 Debian 打包,并且可以直接更改源,因为它在 PPA 中托管并由用户上传。使用 Snap 软件包会变得更加复杂,因为在安装之前你无法检查这些软件包(据我所知)。在后面这些情况下,作为通用解决方案,我猜你应该只安装你信任的用户/打包器生成的软件包。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/07/malware-found-on-arch-user-repository.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://www.archlinux.org/
|
||||
[2]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034153.html
|
||||
[3]:https://aur.archlinux.org/
|
||||
[4]:https://lists.archlinux.org/pipermail/aur-general/2018-July/034152.html
|
||||
[5]:https://aur.archlinux.org/cgit/aur.git/commit/?h=acroread&id=b3fec9f2f16703c2dae9e793f75ad6e0d98509bc
|
||||
[6]:https://www.reddit.com/r/archlinux/comments/8x0p5z/reminder_to_always_read_your_pkgbuilds/e21iugg/
|
||||
[7]:https://www.linuxuprising.com/2018/05/malware-found-in-ubuntu-snap-store.html
|
||||
@ -0,0 +1,92 @@
|
||||
6 个开源的数字货币钱包
|
||||
======
|
||||
|
||||

|
||||
|
||||
没有加密钱包,像比特币和以太坊这样的数字货币将成为另一个天方夜谭。这些钱包对于保存、发送、以及接收数字货币来说是必需的东西。
|
||||
|
||||
迅速成长的 [数字货币][1] 之所以是革命性的,都归功于它的去中心化,网络中没有中央权威,每个人都享有平等的权力。开源技术是数字货币和 [区块链][2] 网络的核心所在。它使得这个充满活力的新兴行业能够从去中心化中获益 —— 比如,不可改变、透明、和安全。
|
||||
|
||||
如果你正在寻找一个自由开源的数字货币钱包,请继续阅读,并开始去探索以下的选择能否满足你的需求。
|
||||
|
||||
### 1\. Copay
|
||||
|
||||
[Copay][3] 是一个能够很方便地存储比特币的开源数字货币钱包。这个软件以 [MIT 许可证][4] 发布。
|
||||
|
||||
Copay 服务器也是开源的。因此,开发者和比特币热衷者可以在服务器上部署他们自己的应用程序来完全控制他们的活动。
|
||||
|
||||
Copay 钱包能让你手中的比特币更加安全,而不是去信任不可靠的第三方。它允许你对事务批准使用多重签名,并且支持多处存储,在同一个 app 内钱包是独立的。
|
||||
|
||||
Copay 可以在多种平台上使用,比如 Android、Windows、MacOS、Linux、和 iOS。
|
||||
|
||||
### 2\. MyEtherWallet
|
||||
|
||||
正如它的名字所示,[MyEtherWallet][5] (缩写为 MEW) 是一个以太坊钱包。它是开源的(遵循 [MIT 许可证][6])并且是完全在线的,可以通过 web 浏览器来访问它。
|
||||
|
||||
这个钱包的客户端界面非常简洁,它可以让你自信而安全地参与到以太坊区块链中。
|
||||
|
||||
### 3\. mSIGNA
|
||||
|
||||
[mSIGNA][7] 是一个在比特币网络上执行全部事务的强大的桌面版应用程序。它遵循 [MIT 许可证][8] 并且在 MacOS、Windows、和 Linux 上可用。
|
||||
|
||||
这个区块链钱包可以让你完全控制你存储的比特币。其中一些特性包括用户友好性、灵活性、去中心化的密钥生成能力、加密的数据备份、以及多设备同步功能。
|
||||
|
||||
### 4\. Armory
|
||||
|
||||
[Armory][9] 是一个在你的计算机上产生和保管比特币私钥的开源钱包(遵循 [GNU AGPLv3][10])。它通过使用冷存储和支持多签名的能力增强了安全性。
|
||||
|
||||
使用 Armory,你可以在计算机上将钱包设置成完全离线状态;你将通过<ruby>仅查看<rt>watch-only</rt></ruby>功能在因特网上查看你的比特币具体信息,这样有助于改善安全性。这个钱包也允许你去创建多个地址,并使用它们去完成不同的事务。
|
||||
|
||||
Armory 可用于 MacOS、Windows、和几个比较有特色的 Linux 平台上(包括树莓派)。
|
||||
|
||||
### 5\. Electrum
|
||||
|
||||
[Electrum][11] 是一个既对新手友好又具备专家功能的比特币钱包。它遵循 [MIT 许可证][12] 来发行。
|
||||
|
||||
Electrum 可以在你的本地机器上使用较少的资源来实现本地加密你的私钥,支持冷存储,并且提供多签名能力。
|
||||
|
||||
它在各种操作系统和设备上都可以使用,包括 Windows、MacOS、Android、iOS、和 Linux,并且也可以在像 [Trezor][13] 这样的硬件钱包中使用。
|
||||
|
||||
### 6\. Etherwall
|
||||
|
||||
[Etherwall][14] 是第一款在桌面版上存储和发送以太坊的钱包。它是一个遵循 [GPLv3 许可证][15] 的开源钱包。
|
||||
|
||||
Etherwall 非常直观而且速度很快。更重要的是,它增加了你的私钥安全性,你可以在一个完全节点或瘦节点上来运行它。它作为完全节点客户端运行时,可以允许你在本地机器上下载整个以太坊区块链。
|
||||
|
||||
Etherwall 可以在 MacOS、Linux、和 Windows 平台上运行,并且它也支持 Trezor 硬件钱包。
|
||||
|
||||
### 智者之言
|
||||
|
||||
自由开源的数字钱包在让更多的人快速上手数字货币方面扮演至关重要的角色。
|
||||
|
||||
在你使用任何数字货币软件钱包之前,你一定要确保你的安全,而且总是要记住并完全遵循确保你的资金安全的最佳实践。
|
||||
|
||||
如果你喜欢的开源数字货币钱包不在以上的清单中,请在下面的评论区共享出你所知道的开源钱包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/crypto-wallets
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drmjg
|
||||
[1]:https://www.liveedu.tv/guides/cryptocurrency/
|
||||
[2]:https://opensource.com/tags/blockchain
|
||||
[3]:https://copay.io/
|
||||
[4]:https://github.com/bitpay/copay/blob/master/LICENSE
|
||||
[5]:https://www.myetherwallet.com/
|
||||
[6]:https://github.com/kvhnuke/etherwallet/blob/mercury/LICENSE.md
|
||||
[7]:https://ciphrex.com/
|
||||
[8]:https://github.com/ciphrex/mSIGNA/blob/master/LICENSE
|
||||
[9]:https://www.bitcoinarmory.com/
|
||||
[10]:https://github.com/etotheipi/BitcoinArmory/blob/master/LICENSE
|
||||
[11]:https://electrum.org/#home
|
||||
[12]:https://github.com/spesmilo/electrum/blob/master/LICENCE
|
||||
[13]:https://trezor.io/
|
||||
[14]:https://www.etherwall.com/
|
||||
[15]:https://github.com/almindor/etherwall/blob/master/LICENSE
|
||||
Loading…
Reference in New Issue
Block a user