mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
44e0d8db1f
published
20171002 Concurrent Servers Part 1 - Introduction.md20171017 How to deploy multi-cloud serverless and Cloud Foundry APIs at scale.md20171020 Why and how you should switch to Linux.md
sources/tech
20161216 Kprobes Event Tracing on ARMv8.md20170215 How to take screenshots on Linux using Scrot.md20170820 Your Serverless Raspberry Pi cluster with Docker.md20170929 12 Practices every Android Development Beginner should know — Part 1.md20171004 Concurrent Servers Part 2 - Threads.md20171020 Why and how you should switch to Linux.md
translated/tech
@ -1,4 +1,4 @@
|
||||
[并发服务器: 第一节 —— 简介][18]
|
||||
并发服务器(一):简介
|
||||
============================================================
|
||||
|
||||
这是关于并发网络服务器编程的第一篇教程。我计划测试几个主流的、可以同时处理多个客户端请求的服务器并发模型,基于可扩展性和易实现性对这些模型进行评判。所有的服务器都会监听套接字连接,并且实现一些简单的协议用于与客户端进行通讯。
|
||||
@ -6,34 +6,32 @@
|
||||
该系列的所有文章:
|
||||
|
||||
* [第一节 - 简介][7]
|
||||
|
||||
* [第二节 - 线程][8]
|
||||
|
||||
* [第三节 - 事件驱动][9]
|
||||
|
||||
### 协议
|
||||
|
||||
该系列教程所用的协议都非常简单,但足以展示并发服务器设计的许多有趣层面。而且这个协议是 _有状态的_ —— 服务器根据客户端发送的数据改变内部状态,然后根据内部状态产生相应的行为。并非所有的协议都是有状态的 —— 实际上,基于 HTTP 的许多协议是无状态的,但是有状态的协议对于保证重要会议的可靠很常见。
|
||||
该系列教程所用的协议都非常简单,但足以展示并发服务器设计的许多有趣层面。而且这个协议是 _有状态的_ —— 服务器根据客户端发送的数据改变内部状态,然后根据内部状态产生相应的行为。并非所有的协议都是有状态的 —— 实际上,基于 HTTP 的许多协议是无状态的,但是有状态的协议也是很常见,值得认真讨论。
|
||||
|
||||
在服务器端看来,这个协议的视图是这样的:
|
||||
|
||||
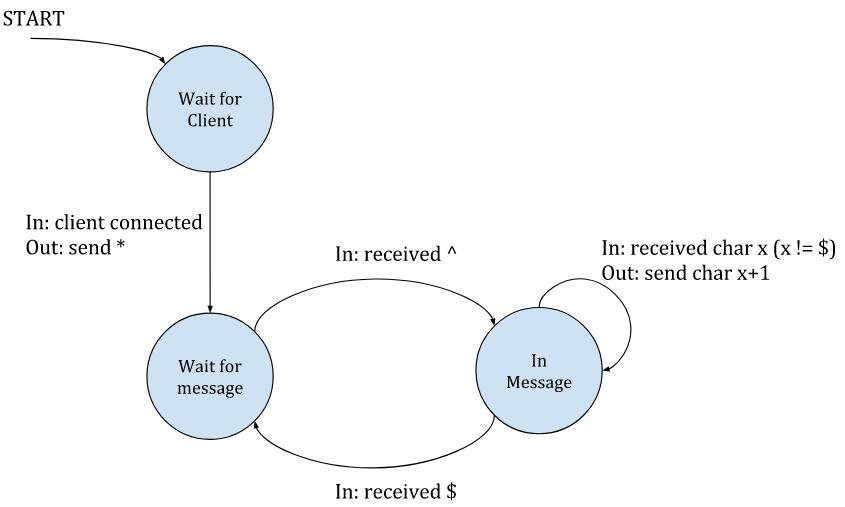
|
||||
|
||||
总之:服务器等待新客户端的连接;当一个客户端连接的时候,服务器会向该客户端发送一个 `*` 字符,进入“等待消息”的状态。在该状态下,服务器会忽略客户端发送的所有字符,除非它看到了一个 `^` 字符,这表示一个新消息的开始。这个时候服务器就会转变为“正在通信”的状态,这时它会向客户端回送数据,把收到的所有字符的每个字节加 1 回送给客户端 [ [1][10] ]。当客户端发送了 `$`字符,服务器就会退回到等待新消息的状态。`^` 和 `$` 字符仅仅用于分隔消息 —— 它们不会被服务器回送。
|
||||
总之:服务器等待新客户端的连接;当一个客户端连接的时候,服务器会向该客户端发送一个 `*` 字符,进入“等待消息”的状态。在该状态下,服务器会忽略客户端发送的所有字符,除非它看到了一个 `^` 字符,这表示一个新消息的开始。这个时候服务器就会转变为“正在通信”的状态,这时它会向客户端回送数据,把收到的所有字符的每个字节加 1 回送给客户端^注1 。当客户端发送了 `$` 字符,服务器就会退回到等待新消息的状态。`^` 和 `$` 字符仅仅用于分隔消息 —— 它们不会被服务器回送。
|
||||
|
||||
每个状态之后都有个隐藏的箭头指向 “等待客户端” 状态,用来防止客户端断开连接。因此,客户端要表示“我已经结束”的方法很简单,关掉它那一端的连接就好。
|
||||
每个状态之后都有个隐藏的箭头指向 “等待客户端” 状态,用来客户端断开连接。因此,客户端要表示“我已经结束”的方法很简单,关掉它那一端的连接就好。
|
||||
|
||||
显然,这个协议是真实协议的简化版,真实使用的协议一般包含复杂的报文头,转义字符序列(例如让消息体中可以出现 `$` 符号),额外的状态变化。但是我们这个协议足以完成期望。
|
||||
显然,这个协议是真实协议的简化版,真实使用的协议一般包含复杂的报文头、转义字符序列(例如让消息体中可以出现 `$` 符号),额外的状态变化。但是我们这个协议足以完成期望。
|
||||
|
||||
另一点:这个系列是引导性的,并假设客户端都工作的很好(虽然可能运行很慢);因此没有设置超时,也没有设置特殊的规则来确保服务器不会因为客户端的恶意行为(或是故障)而出现阻塞,导致不能正常结束。
|
||||
另一点:这个系列是介绍性的,并假设客户端都工作的很好(虽然可能运行很慢);因此没有设置超时,也没有设置特殊的规则来确保服务器不会因为客户端的恶意行为(或是故障)而出现阻塞,导致不能正常结束。
|
||||
|
||||
### 有序服务器
|
||||
### 顺序服务器
|
||||
|
||||
这个系列中我们的第一个服务端程序是一个简单的“有序”服务器,用 C 进行编写,除了标准的 POSIX 中用于套接字的内容以外没有使用其它库。服务器程序是有序的,因为它一次只能处理一个客户端的请求;当有客户端连接时,像之前所说的那样,服务器会进入到状态机中,并且不再监听套接字接受新的客户端连接,直到当前的客户端结束连接。显然这不是并发的,而且即便在很少的负载下也不能服务多个客户端,但它对于我们的讨论很有用,因为我们需要的是一个易于理解的基础。
|
||||
这个系列中我们的第一个服务端程序是一个简单的“顺序”服务器,用 C 进行编写,除了标准的 POSIX 中用于套接字的内容以外没有使用其它库。服务器程序是顺序,因为它一次只能处理一个客户端的请求;当有客户端连接时,像之前所说的那样,服务器会进入到状态机中,并且不再监听套接字接受新的客户端连接,直到当前的客户端结束连接。显然这不是并发的,而且即便在很少的负载下也不能服务多个客户端,但它对于我们的讨论很有用,因为我们需要的是一个易于理解的基础。
|
||||
|
||||
这个服务器的完整代码在 [这里][11];接下来,我会着重于高亮的部分。`main` 函数里面的外层循环用于监听套接字,以便接受新客户端的连接。一旦有客户端进行连接,就会调用 `serve_connection`,这个函数中的代码会一直运行,直到客户端断开连接。
|
||||
这个服务器的完整代码在[这里][11];接下来,我会着重于一些重点的部分。`main` 函数里面的外层循环用于监听套接字,以便接受新客户端的连接。一旦有客户端进行连接,就会调用 `serve_connection`,这个函数中的代码会一直运行,直到客户端断开连接。
|
||||
|
||||
有序服务器在循环里调用 `accept` 用来监听套接字,并接受新连接:
|
||||
顺序服务器在循环里调用 `accept` 用来监听套接字,并接受新连接:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
@ -105,25 +103,23 @@ void serve_connection(int sockfd) {
|
||||
|
||||
它完全是按照状态机协议进行编写的。每次循环的时候,服务器尝试接收客户端的数据。收到 0 字节意味着客户端断开连接,然后循环就会退出。否则,会逐字节检查接收缓存,每一个字节都可能会触发一个状态。
|
||||
|
||||
`recv` 函数返回接收到的字节数与客户端发送消息的数量完全无关(`^...$` 闭合序列的字节)。因此,在保持状态的循环中,遍历整个缓冲区很重要。而且,每一个接收到的缓冲中可能包含多条信息,但也有可能开始了一个新消息,却没有显式的结束字符;而这个结束字符可能在下一个缓冲中才能收到,这就是处理状态在循环迭代中进行维护的原因。
|
||||
`recv` 函数返回接收到的字节数与客户端发送消息的数量完全无关(`^...$` 闭合序列的字节)。因此,在保持状态的循环中遍历整个缓冲区很重要。而且,每一个接收到的缓冲中可能包含多条信息,但也有可能开始了一个新消息,却没有显式的结束字符;而这个结束字符可能在下一个缓冲中才能收到,这就是处理状态在循环迭代中进行维护的原因。
|
||||
|
||||
例如,试想主循环中的 `recv` 函数在某次连接中返回了三个非空的缓冲:
|
||||
|
||||
1. `^abc$de^abte$f`
|
||||
|
||||
2. `xyz^123`
|
||||
|
||||
3. `25$^ab$abab`
|
||||
|
||||
服务端返回的是哪些数据?追踪代码对于理解状态转变很有用。(答案见 [ [2][12] ])
|
||||
服务端返回的是哪些数据?追踪代码对于理解状态转变很有用。(答案见^注[2] )
|
||||
|
||||
### 多个并发客户端
|
||||
|
||||
如果多个客户端在同一时刻向有序服务器发起连接会发生什么事情?
|
||||
如果多个客户端在同一时刻向顺序服务器发起连接会发生什么事情?
|
||||
|
||||
服务器端的代码(以及它的名字 `有序的服务器`)已经说的很清楚了,一次只能处理 _一个_ 客户端的请求。只要服务器在 `serve_connection` 函数中忙于处理客户端的请求,就不会接受别的客户端的连接。只有当前的客户端断开了连接,`serve_connection` 才会返回,然后最外层的循环才能继续执行接受其他客户端的连接。
|
||||
服务器端的代码(以及它的名字 “顺序服务器”)已经说的很清楚了,一次只能处理 _一个_ 客户端的请求。只要服务器在 `serve_connection` 函数中忙于处理客户端的请求,就不会接受别的客户端的连接。只有当前的客户端断开了连接,`serve_connection` 才会返回,然后最外层的循环才能继续执行接受其他客户端的连接。
|
||||
|
||||
为了演示这个行为,[该系列教程的示例代码][13] 包含了一个 Python 脚本,用于模拟几个想要同时连接服务器的客户端。每一个客户端发送类似之前那样的三个数据缓冲 [ [3][14] ],不过每次发送数据之间会有一定延迟。
|
||||
为了演示这个行为,[该系列教程的示例代码][13] 包含了一个 Python 脚本,用于模拟几个想要同时连接服务器的客户端。每一个客户端发送类似之前那样的三个数据缓冲 ^注3 ,不过每次发送数据之间会有一定延迟。
|
||||
|
||||
客户端脚本在不同的线程中并发地模拟客户端行为。这是我们的序列化服务器与客户端交互的信息记录:
|
||||
|
||||
@ -158,30 +154,26 @@ INFO:2017-09-16 14:14:24,176:conn0 received b'36bc1111'
|
||||
INFO:2017-09-16 14:14:24,376:conn0 disconnecting
|
||||
```
|
||||
|
||||
这里要注意连接名:`conn1` 是第一个连接到服务器的,先跟服务器交互了一段时间。接下来的连接 `conn2` —— 在第一个断开连接后,连接到了服务器,然后第三个连接也是一样。就像日志显示的那样,每一个连接让服务器变得繁忙,保持大约 2.2 秒的时间(这实际上是人为地在客户端代码中加入的延迟),在这段时间里别的客户端都不能连接。
|
||||
这里要注意连接名:`conn1` 是第一个连接到服务器的,先跟服务器交互了一段时间。接下来的连接 `conn2` —— 在第一个断开连接后,连接到了服务器,然后第三个连接也是一样。就像日志显示的那样,每一个连接让服务器变得繁忙,持续了大约 2.2 秒的时间(这实际上是人为地在客户端代码中加入的延迟),在这段时间里别的客户端都不能连接。
|
||||
|
||||
显然,这不是一个可扩展的策略。这个例子中,客户端中加入了延迟,让服务器不能处理别的交互动作。一个智能服务器应该能处理一堆客户端的请求,而这个原始的服务器在结束连接之前一直繁忙(我们将会在之后的章节中看到如何实现智能的服务器)。尽管服务端有延迟,但这不会过度占用CPU;例如,从数据库中查找信息(时间基本上是花在连接到数据库服务器上,或者是花在硬盘中的本地数据库)。
|
||||
显然,这不是一个可扩展的策略。这个例子中,客户端中加入了延迟,让服务器不能处理别的交互动作。一个智能服务器应该能处理一堆客户端的请求,而这个原始的服务器在结束连接之前一直繁忙(我们将会在之后的章节中看到如何实现智能的服务器)。尽管服务端有延迟,但这不会过度占用 CPU;例如,从数据库中查找信息(时间基本上是花在连接到数据库服务器上,或者是花在硬盘中的本地数据库)。
|
||||
|
||||
### 总结及期望
|
||||
|
||||
这个示例服务器达成了两个预期目标:
|
||||
|
||||
1. 首先是介绍了问题范畴和贯彻该系列文章的套接字编程基础。
|
||||
2. 对于并发服务器编程的抛砖引玉 —— 就像之前的部分所说,顺序服务器还不能在非常轻微的负载下进行扩展,而且没有高效的利用资源。
|
||||
|
||||
2. 对于并发服务器编程的抛砖引玉 —— 就像之前的部分所说,有序服务器还不能在几个轻微的负载下进行扩展,而且没有高效的利用资源。
|
||||
|
||||
在看下一篇文章前,确保你已经理解了这里所讲的服务器/客户端协议,还有有序服务器的代码。我之前介绍过了这个简单的协议;例如 [串行通信分帧][15] 和 [协同运行,作为状态机的替代][16]。要学习套接字网络编程的基础,[Beej's 教程][17] 用来入门很不错,但是要深入理解我推荐你还是看本书。
|
||||
在看下一篇文章前,确保你已经理解了这里所讲的服务器/客户端协议,还有顺序服务器的代码。我之前介绍过了这个简单的协议;例如 [串行通信分帧][15] 和 [用协程来替代状态机][16]。要学习套接字网络编程的基础,[Beej 的教程][17] 用来入门很不错,但是要深入理解我推荐你还是看本书。
|
||||
|
||||
如果有什么不清楚的,请在评论区下进行评论或者向我发送邮件。深入理解并发服务器!
|
||||
|
||||
***
|
||||
|
||||
|
||||
[ [1][1] ] 状态转变中的 In/Out 记号是指 [Mealy machine][2]。
|
||||
|
||||
[ [2][3] ] 回应的是 `bcdbcuf23436bc`。
|
||||
|
||||
[ [3][4] ] 这里在结尾处有一点小区别,加了字符串 `0000` —— 服务器回应这个序列,告诉客户端让其断开连接;这是一个简单的握手协议,确保客户端有足够的时间接收到服务器发送的所有回复。
|
||||
- 注1:状态转变中的 In/Out 记号是指 [Mealy machine][2]。
|
||||
- 注2:回应的是 `bcdbcuf23436bc`。
|
||||
- 注3:这里在结尾处有一点小区别,加了字符串 `0000` —— 服务器回应这个序列,告诉客户端让其断开连接;这是一个简单的握手协议,确保客户端有足够的时间接收到服务器发送的所有回复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -189,7 +181,7 @@ via: https://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
如何成规模地部署多云的无服务器程序和 Cloud Foundry API
|
||||
============================================================
|
||||
|
||||
> IBM 的 Ken Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考。”
|
||||
|
||||
领导 IBM 的 API 网关和 Big Blue 开源项目的的 Ken Parmelee 对以开源方式 “进攻” API 以及如何创建微服务和使其伸缩有一些思考。
|
||||
|
||||
Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考这些问题。当你开始这么做,人们依赖它作为它们业务的一部分。这是你在这个领域所做的关键方面。”
|
||||
|
||||

|
||||
|
||||
他在最近的[北欧 APIs 2017 平台峰会][3]登上讲台,并挑战了一些流行的观念。
|
||||
|
||||
“快速失败不是一个很好的概念。你想在第一场比赛中获得一些非常棒的东西。这并不意味着你需要花费大量的时间,而是应该让它变得非常棒,然后不断的发展和改进。如果一开始真的很糟糕,人们就不会想要用你。”
|
||||
|
||||
他谈及包括 [OpenWhisk][4] 在内的 IBM 现代无服务器架构,这是一个 IBM 和 Apache 之间的开源伙伴关系。 云优先的基于分布式事件的编程服务是这两年多来重点关注这个领域的成果;IBM 是该领域领先的贡献者,它是 IBM 云服务的基础。它提供基础设施即服务(IaaS)、自动缩放、为多种语言提供支持、用户只需支付实际使用费用即可。这次旅程充满了挑战,因为他们发现服务器操作需要安全、并且需要轻松 —— 匿名访问、缺少使用路径、固定的 URL 格式等。
|
||||
|
||||
任何人都可以在 30 秒内在 [https://console.bluemix.net/openwhisk/][5] 上尝试这些无服务器 API。“这听起来很有噱头,但这是很容易做到的。我们正在结合 [Cloud Foundry 中完成的工作][6],并在 OpenWhisk 下的 Bluemix 中发布了它们,以提供安全性和可扩展性。”
|
||||
|
||||
他说:“灵活性对于微服务也是非常重要的。 当你使用 API 在现实世界中工作时,你开始需要跨云进行扩展。”这意味着从你的内部云走向公共云,并且“对你要怎么做有一个实在的概念很重要”。
|
||||
|
||||

|
||||
|
||||
在思考“任何云概念”的时候,他警告说,不是“将其放入一个 Docker 容器,并到处运行。这很棒,但需要在这些环境中有效运行。Docker 和 Kubernetes 有提供了很多帮助,但是你想要你的操作方式付诸实施。” 提前考虑 API 的使用,无论是在内部运行还是扩展到公有云并可以公开调用 - 你需要有这样的“架构观”,他补充道。
|
||||
|
||||
Parmelee 说:“我们都希望我们所创造的有价值,并被广泛使用。” API 越成功,将其提升到更高水平的挑战就越大。
|
||||
|
||||

|
||||
|
||||
*API 是微服务或“服务间”的组成部分。*
|
||||
|
||||
他说,API 的未来是原生云的 - 无论你从哪里开始。关键因素是可扩展性,简化后端管理,降低成本,避免厂商锁定。
|
||||
|
||||
你可以在下面或在 [YouTube][7] 观看他整整 23 分钟的演讲。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||
|
||||
作者:[Superuser][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://superuser.openstack.org/articles/author/superuser/
|
||||
[1]:http://superuser.openstack.org/articles/author/superuser/
|
||||
[2]:http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||
[3]:https://nordicapis.com/events/the-2017-api-platform-summit/
|
||||
[4]:https://developer.ibm.com/openwhisk/
|
||||
[5]:https://console.bluemix.net/openwhisk/
|
||||
[6]:https://cloudfoundry.org/the-foundry/ibm-cloud/
|
||||
[7]:https://www.youtube.com/jA25Kmxr6fU
|
||||
75
published/20171020 Why and how you should switch to Linux.md
Normal file
75
published/20171020 Why and how you should switch to Linux.md
Normal file
@ -0,0 +1,75 @@
|
||||
为什么要切换到 Linux 系统?我该怎么做?
|
||||
============================================================
|
||||
|
||||
> 是时候做出改变了。
|
||||
|
||||

|
||||
|
||||
*让 Ubuntu,一个简单易用的 Linux 版本,来掌管你的电脑。*
|
||||
|
||||
当你在选购电脑的时候,你可能会在 [Windows][1] 和 [macOS][2] 之间犹豫,但是可能基本不会想到 Linux。尽管如此,这个名气没那么大的操作系统仍然拥有庞大而忠诚的粉丝。因为它相对于它的竞争者,有很大的优势。
|
||||
|
||||
不管你是完全不了解 Linux,或是已经尝试过一两次,我们希望你考虑一下在你的下一台笔记本或台式机上运行 Linux,或者可以和现存系统做个双启动。请继续阅读下去,看是不是时候该切换了。
|
||||
|
||||
### 什么是 Linux?
|
||||
|
||||
如果你已经非常熟悉 Linux,可以跳过这个部分。对于不熟悉的其他人,Linux 是一个免费的开源操作系统,所有人都可以去探索它的代码。技术上来说,术语“Linux”说的只是内核,或者核心代码。不过,人们一般用这个名字统称整个操作系统,包括界面和集成的应用。
|
||||
|
||||
因为所有人都可以修改它,Linux 有非常自由的可定制性,这鼓舞了很多程序员制作并发布了自己的系统——常称为<ruby>发行版<rt>distro</rt></ruby>。这些不同口味的系统,每一个都有自己特色的软件和界面。一些比较有名的发行版,模仿了熟悉的 Windows 或 macOS 操作系统,比如 [Ubuntu][3]、 [Linux Mint][4] 和 [Zorin OS][5]。当你准备选择一个发行版时,可以去它们官网看一下,试试看是不是适合自己。
|
||||
|
||||
为了制作和维护这些 Linux 发行版,大量的开发者无偿地贡献了自己的时间。有时候,利润主导的公司为了拓展自己的软件销售领域,也会主导开发带有独特特性的 Linux 版本。比如 Android(它虽然不能当作一个完整的 Linux 操作系统)就是以基于 Linux 内核的,这也是为什么它有很多[不同变种][6]的原因。另外,很多服务器和数据中心也运行了 Linux,所以很有可能这个操作系统托管着你正在看的网页。
|
||||
|
||||
### 有什么好处?
|
||||
|
||||
首先,Linux 是免费而且开源的,意味着你可以将它安装到你现有的电脑或笔记本上,或者你自己组装的机器,而不用支付任何费用。系统会自带一些常用软件,包括网页浏览器、媒体播放器、[图像编辑器][7]和[办公软件][8],所以你也不用为了查看图片或处理文档再支付其他额外费用。而且,以后还可以免费升级。
|
||||
|
||||
Linux 比其他系统能更好的防御恶意软件,强大到你都不需要运行杀毒软件。开发者们在最早构建时就考虑了安全性,比如说,操作系统只运行可信的软件。而且,很少有恶意软件针对这个系统,对于黑客来说,这样做没有价值。Linux 也并不是完全没有任何漏洞,只不过对于一般只运行已验证软件的家庭用户来说,并不用太担心安全性。
|
||||
|
||||
这个操作系统对硬件资源的要求比起数据臃肿的 Windows 或 macOS 来说也更少。一些发行版不像它们名气更大的表兄弟,默认集成了更少的组件,开发者特别开发了一些,比如 [Puppy Linux][9] 和 [Linux Lite][10],让系统尽可能地轻量。这让 Linux 非常适合那些家里有很老的电脑的人。如果你的远古笔记本正在原装操作系统的重压下喘息,试试装一个 Linux,应该会快很多。如果不愿意的话,你也不用抛弃旧系统,我们会在后面的部分里解释怎么做。
|
||||
|
||||
尽管你可能会需要一点时间来适应新系统,不过不用太久,你就会发现 Linux 界面很容易使用。任何年龄和任何技术水平的人都可以掌握这个软件。而且在线的 Linux 社区提供了大量的帮助和支持。说到社区,下载 Linux 也是对开源软件运动的支持:这些开发者一起工作,并不收取任何费用,为全球用户开发更优秀的软件。
|
||||
|
||||
### 我该从哪儿开始?
|
||||
|
||||
Linux 据说只有专家才能安装。不过比起前几年,现在安装并运行操作系统已经非常简单了。
|
||||
|
||||
首先,打开你喜欢的发行版的网站,按照上面的安装指南操作。一般会需要烧录一张 DVD 或者制作一个带有必要程序的 U 盘,然后重启你的电脑,执行这段程序。实际上,这个操作系统的一个好处是,你可以将它直接安装在可插拔的 U 盘上,我们有一个[如何把电脑装在 U 盘里][11]的完整指南。
|
||||
|
||||
如果你想在不影响原来旧系统的情况下运行 Linux,你可以选择从 DVD 或 U 盘或者电脑硬盘的某个分区(分成不同的区来独立运行不同的操作系统)单独启动。有些 Linux 发行版在安装过程中会帮你自动处理磁盘分区。或者你可以用[磁盘管理器][12] (Windows)或者[磁盘工具][13] (macOS)自己调整分区。
|
||||
|
||||
这些安装说明可能看上去很模糊,但是不要担心:每个发行版都会提供详细的安装指引,虽然大多数情况下过程都差不多。比如,如果你想安装 Ubuntu(最流行的家用 Linux 发行版中的一个),可以[参考这里的指引][14]。(在安装之前,你也可以[尝试运行一下][15])你需要下载最新的版本,烧录到 DVD 或是 U 盘里,然后再用光盘或 U 盘引导开机,然后跟随安装向导里的指引操作。安装完成时提示安装额外软件时,Ubuntu 会引导你打开合适的工具。
|
||||
|
||||
如果你要在一台全新的电脑上安装 Linux,那没什么需要特别留意的。不过如果你要保留旧系统的情况下安装新系统,我们建议你首先[备份自己的数据][16]。在安装过程中,也要注意选择双启动选项,避免擦除现有的系统和文件。你选好的发行版的介绍里会有更详细的说明:你可以在[这里][17]查看 Zorin OS 的完整介绍,[这里][18]有 Linux Mint的,其他发行版的介绍在他们各自的网站上也都会有。
|
||||
|
||||
就这些了!那么,你准备好试试 Linux 了吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.popsci.com/switch-to-linux-operating-system
|
||||
|
||||
作者:[David Nield][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.popsci.com/authors/david-nield
|
||||
[1]:https://www.popsci.com/windows-tweaks-improve-performance
|
||||
[2]:https://www.popsci.com/macos-tweaks-improve-performance
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://linuxmint.com/
|
||||
[5]:https://zorinos.com/
|
||||
[6]:https://lineageos.org/
|
||||
[7]:https://www.gimp.org/
|
||||
[8]:https://www.libreoffice.org/
|
||||
[9]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[10]:https://www.linuxliteos.com/
|
||||
[11]:https://www.popsci.com/portable-computer-usb-stick
|
||||
[12]:https://www.disk-partition.com/windows-10/windows-10-disk-management-0528.html
|
||||
[13]:https://support.apple.com/kb/PH22240?locale=en_US
|
||||
[14]:https://tutorials.ubuntu.com/tutorial/tutorial-install-ubuntu-desktop?backURL=%2F#0
|
||||
[15]:https://tutorials.ubuntu.com/tutorial/try-ubuntu-before-you-install?backURL=%2F#0
|
||||
[16]:https://www.popsci.com/back-up-and-protect-your-data
|
||||
[17]:https://zorinos.com/help/install-zorin-os/
|
||||
[18]:https://linuxmint.com/documentation.php
|
||||
[19]:https://www.popsci.com/authors/david-nield
|
||||
@ -1,7 +1,6 @@
|
||||
# Kprobes Event Tracing on ARMv8
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
### Introduction
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
翻译中 by zionfuo
|
||||
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,420 +0,0 @@
|
||||
【翻译中 @haoqixu】Your Serverless Raspberry Pi cluster with Docker
|
||||
============================================================
|
||||
|
||||
|
||||
This blog post will show you how to create your own Serverless Raspberry Pi cluster with Docker and the [OpenFaaS][33] framework. People often ask me what they should do with their cluster and this application is perfect for the credit-card sized device - want more compute power? Scale by adding more RPis.
|
||||
|
||||
> "Serverless" is a design pattern for event-driven architectures just like "bridge", "facade", "factory" and "cloud" are also abstract concepts - [so is "serverless"][21].
|
||||
|
||||
Here's my cluster for the blog post - with brass stand-offs used to separate each device.
|
||||
|
||||
|
||||
|
||||
### What is Serverless and why does it matter to you?
|
||||
|
||||
> As an industry we have some explaining to do regarding what the term "serverless" means. For the sake of this blog post let us assume that it is a new architectural pattern for event-driven architectures and that it lets you write tiny, reusable functions in whatever language you like. [Read more on Serverless here][22].
|
||||
|
||||
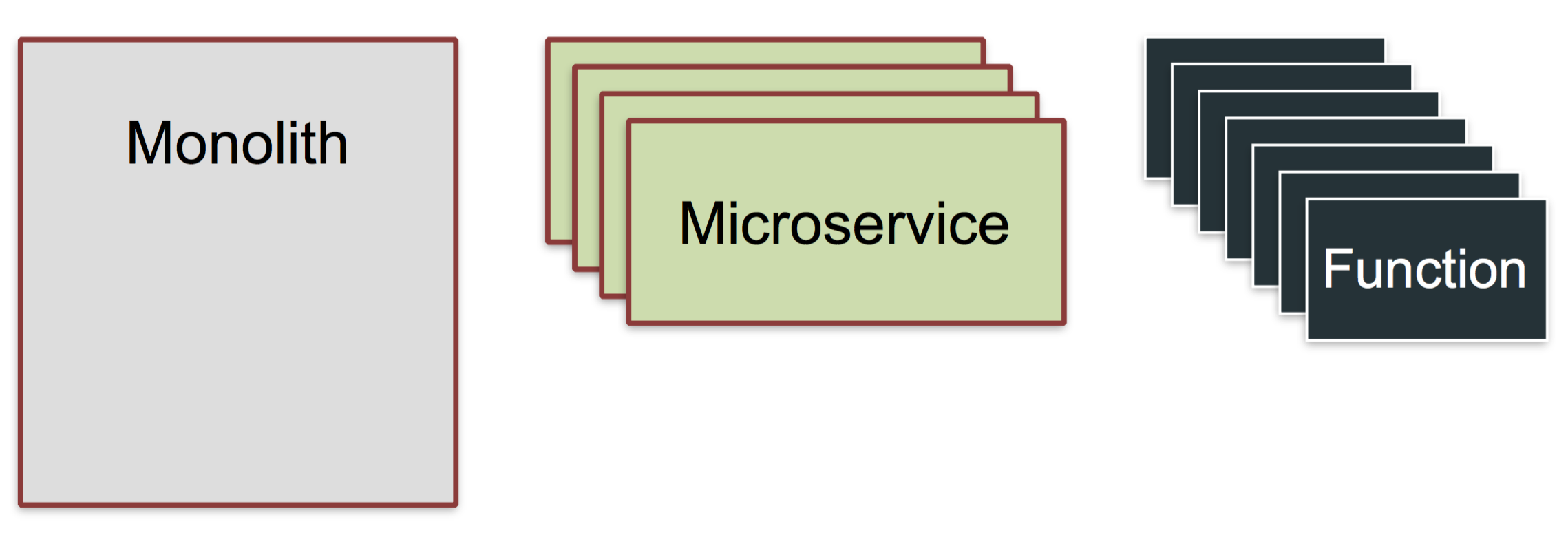
|
||||
_Serverless is an architectural pattern resulting in: Functions as a Service, or FaaS_
|
||||
|
||||
Serverless functions can do anything, but usually work on a given input - such as an event from GitHub, Twitter, PayPal, Slack, your Jenkins CI pipeline - or in the case of a Raspberry Pi - maybe a real-world sensor input such as a PIR motion sensor, laser tripwire or even a temperature gauge.
|
||||
|
||||

|
||||
|
||||
Let's also assume that serverless functions tend to make use of third-party back-end services to become greater than the sum of their parts.
|
||||
|
||||
For more background information checkout my latest blog post - [Introducing Functions as a Service (FaaS)][34]
|
||||
|
||||
### Overview
|
||||
|
||||
We'll be using [OpenFaaS][35] which lets you turn any single host or cluster into a back-end to run serverless functions. Any binary, script or programming language that can be deployed with Docker will work on [OpenFaaS][36] and you can chose on a scale between speed and flexibility. The good news is a UI and metrics are also built-in.
|
||||
|
||||
Here's what we'll do:
|
||||
|
||||
* Set up Docker on one or more hosts (Raspberry Pi 2/3)
|
||||
|
||||
* Join them together in a Docker Swarm
|
||||
|
||||
* Deploy [OpenFaaS][23]
|
||||
|
||||
* Write our first function in Python
|
||||
|
||||
### Docker Swarm
|
||||
|
||||
Docker is a technology for packaging and deploying applications, it also has clustering built-in which is secure by default and only takes one line to set up. OpenFaaS uses Docker and Swarm to spread your serverless functions across all your available RPis.
|
||||
|
||||

|
||||
_Pictured: 3x Raspberry Pi Zero_
|
||||
|
||||
I recommend using Raspberry Pi 2 or 3 for this project along with an Ethernet switch and a [powerful USB multi-adapter][37].
|
||||
|
||||
### Prepare Raspbian
|
||||
|
||||
Flash [Raspbian Jessie Lite][38] to an SD card, 8GB will do but 16GB is recommended.
|
||||
|
||||
_Note: do not download Raspbian Stretch_
|
||||
|
||||
> The community is helping the Docker team to ready support for Raspbian Stretch, but it's not yet seamless. Please download Jessie Lite from the [RPi foundation's archive here][24]
|
||||
|
||||
I recommend using [Etcher.io][39] to flash the image.
|
||||
|
||||
> Before booting the RPi you'll need to create a file in the boot partition called "ssh". Just keep the file blank. This enables remote logins.
|
||||
|
||||
* Power up and change the hostname
|
||||
|
||||
Now power up the RPi and connect with `ssh`
|
||||
|
||||
```
|
||||
$ ssh pi@raspberrypi.local
|
||||
|
||||
```
|
||||
|
||||
> The password is `raspberry`.
|
||||
|
||||
Use the `raspi-config` utility to change the hostname to `swarm-1` or similar and then reboot.
|
||||
|
||||
While you're here you can also change the memory split between the GPU (graphics) and the system to 16mb.
|
||||
|
||||
* Now install Docker
|
||||
|
||||
We can use a utility script for this:
|
||||
|
||||
```
|
||||
$ curl -sSL https://get.docker.com | sh
|
||||
|
||||
```
|
||||
|
||||
> This installation method may change in the future. As noted above you need to be running Jessie so we have a known configuration.
|
||||
|
||||
You may see a warning like this, but you can ignore it and you should end up with Docker CE 17.05:
|
||||
|
||||
```
|
||||
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||
Installing the legacy docker-engine package...
|
||||
|
||||
```
|
||||
|
||||
After, make sure your user account can access the Docker client with this command:
|
||||
|
||||
```
|
||||
$ usermod pi -aG docker
|
||||
|
||||
```
|
||||
|
||||
> If your username isn't `pi` then replace `pi` with `alex` for instance.
|
||||
|
||||
* Change the default password
|
||||
|
||||
Type in `$sudo passwd pi` and enter a new password, please don't skip this step!
|
||||
|
||||
* Repeat
|
||||
|
||||
Now repeat the above for each of the RPis.
|
||||
|
||||
### Create your Swarm cluster
|
||||
|
||||
Log into the first RPi and type in the following:
|
||||
|
||||
```
|
||||
$ docker swarm init
|
||||
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
|
||||
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
|
||||
192.168.0.79:2377
|
||||
|
||||
```
|
||||
|
||||
You'll see the output with your join token and the command to type into the other RPis. So log into each one with `ssh` and paste in the command.
|
||||
|
||||
Give this a few seconds to connect then on the first RPi check all your nodes are listed:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
|
||||
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
|
||||
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||
```
|
||||
|
||||
Congratulations! You have a Raspberry Pi cluster!
|
||||
|
||||
_*More on clusters_
|
||||
|
||||
You can see my three hosts up and running. Only one is a manager at this point. If our manager were to go _down_ then we'd be in an unrecoverable situation. The way around this is to add redundancy by promoting more of the nodes to managers - they will still run workloads, unless you specifically set up your services to only be placed on workers.
|
||||
|
||||
To upgrade a worker to a manager, just type in `docker node promote <node_name>`from one of your managers.
|
||||
|
||||
> Note: Swarm commands such as `docker service ls` or `docker node ls` can only be done on the manager.
|
||||
|
||||
For a deeper dive into how managers and workers keep "quorum" head over to the [Docker Swarm admin guide][40].
|
||||
|
||||
### OpenFaaS
|
||||
|
||||
Now let's move on to deploying a real application to enable Serverless functions to run on our cluster. [OpenFaaS][41] is a framework for Docker that lets any process or container become a serverless function - at scale and on any hardware or cloud. Thanks to Docker and Golang's portability it also runs very well on a Raspberry Pi.
|
||||
|
||||

|
||||
|
||||
> Please show your support and **star** the [OpenFaaS][25] repository on GitHub.
|
||||
|
||||
Log into the first RPi (where we ran `docker swarm init`) and clone/deploy the project:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas/
|
||||
$ cd faas
|
||||
$ ./deploy_stack.armhf.sh
|
||||
Creating network func_functions
|
||||
Creating service func_gateway
|
||||
Creating service func_prometheus
|
||||
Creating service func_alertmanager
|
||||
Creating service func_nodeinfo
|
||||
Creating service func_markdown
|
||||
Creating service func_wordcount
|
||||
Creating service func_echoit
|
||||
|
||||
```
|
||||
|
||||
Your other RPis will now be instructed by Docker Swarm to start pulling the Docker images from the internet and extracting them to the SD card. The work will be spread across all the RPis so that none of them are overworked.
|
||||
|
||||
This could take a couple of minutes, so you can check when it's done by typing in:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
ID NAME MODE REPLICAS IMAGE PORTS
|
||||
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
|
||||
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
|
||||
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
|
||||
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
|
||||
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
|
||||
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
|
||||
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
|
||||
|
||||
```
|
||||
|
||||
We want to see 1/1 listed on all of our services.
|
||||
|
||||
Given any service name you can type in the following to see which RPi it was scheduled to:
|
||||
|
||||
```
|
||||
$ docker service ps func_markdown
|
||||
ID IMAGE NODE STATE
|
||||
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
|
||||
The state should be `Running` - if it says `Pending` then the image could still be on its way down from the internet.
|
||||
|
||||
At that point, find the IP address of your RPi and open that in a web-browser on port 8080:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
For example if your IP was: 192.168.0.100 - then go to [http://192.168.0.100:8080][42]
|
||||
|
||||
At this point you should see the FaaS UI also called the API Gateway. This is where you can define, test and invoke your functions.
|
||||
|
||||
Click on the Markdown conversion function called func_markdown and type in some Markdown (this is what Wikipedia uses to write its content).
|
||||
|
||||
Then hit invoke. You'll see the invocation count go up and the bottom half of the screen shows the result of your function:
|
||||
|
||||
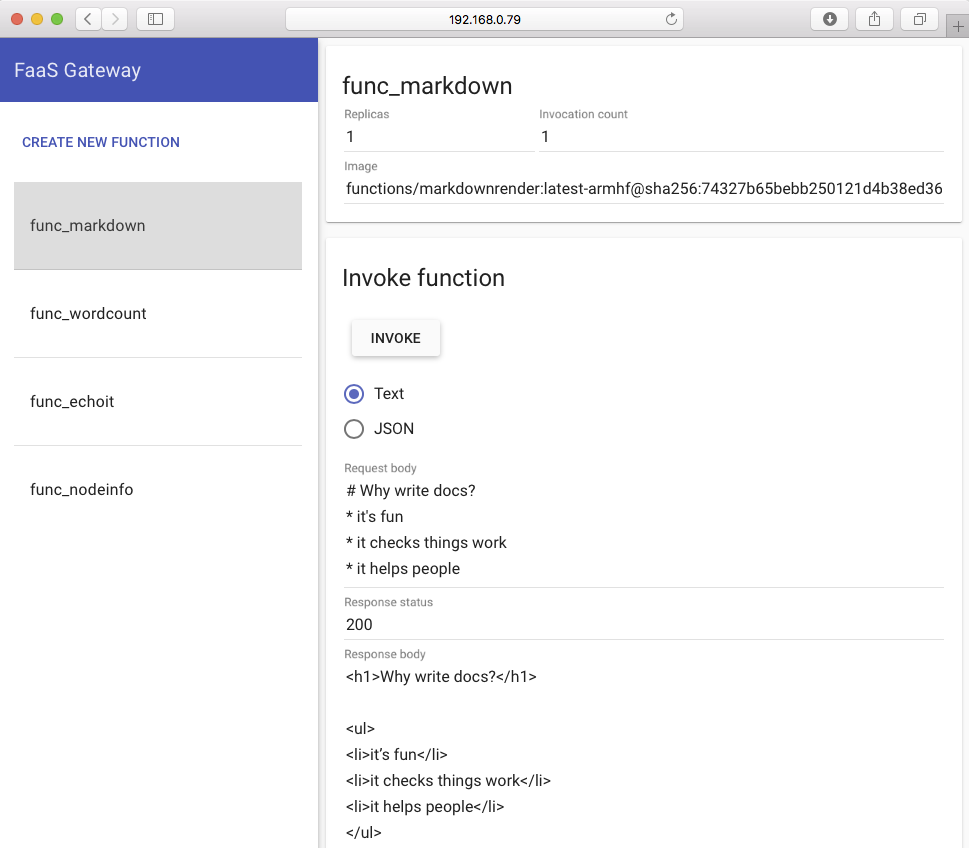
|
||||
|
||||
### Deploy your first serverless function:
|
||||
|
||||
There is already a tutorial written for this section, but we'll need to get the RPi set up with a couple of custom steps first.
|
||||
|
||||
* Get the FaaS-CLI
|
||||
|
||||
```
|
||||
$ curl -sSL cli.openfaas.com | sudo sh
|
||||
armv7l
|
||||
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||
|
||||
```
|
||||
|
||||
* Clone the samples:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas-cli
|
||||
$ cd faas-cli
|
||||
|
||||
```
|
||||
|
||||
* Patch the samples for Raspberry Pi
|
||||
|
||||
We'll temporarily update our templates so they work with the Raspberry Pi:
|
||||
|
||||
```
|
||||
$ cp template/node-armhf/Dockerfile template/node/
|
||||
$ cp template/python-armhf/Dockerfile template/python/
|
||||
|
||||
```
|
||||
|
||||
The reason for doing this is that the Raspberry Pi has a different processor to most computers we interact with on a daily basis.
|
||||
|
||||
> Get up to speed on Docker on the Raspberry Pi - read: [5 Things you need to know][26]
|
||||
|
||||
Now you can follow the same tutorial written for PC, Laptop and Cloud available below, but we are going to run a couple of commands first for the Raspberry Pi.
|
||||
|
||||
* [Your first serverless Python function with OpenFaaS][27]
|
||||
|
||||
Pick it up at step 3:
|
||||
|
||||
* Instead of placing your functions in `~/functions/hello-python` - place them inside the `faas-cli` folder we just cloned from GitHub.
|
||||
|
||||
* Also replace "localhost" for the IP address of your first RPi in the `stack.yml`file.
|
||||
|
||||
Note that the Raspberry Pi may take a few minutes to download your serverless function to the relevant RPi. You can check on your services to make sure you have 1/1 replicas showing up with this command:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||
|
||||
```
|
||||
|
||||
**Continue the tutorial:** [Your first serverless Python function with OpenFaaS][43]
|
||||
|
||||
For more information on working with Node.js or other languages head over to the main [FaaS repo][44]
|
||||
|
||||
### Check your function metrics
|
||||
|
||||
With a Serverless experience, you don't want to spend all your time managing your functions. Fortunately [Prometheus][45] metrics are built into OpenFaaS meaning you can keep track of how long each functions takes to run and how often it's being called.
|
||||
|
||||
_Metrics drive auto-scaling_
|
||||
|
||||
If you generate enough load on any of of the functions then OpenFaaS will auto-scale your function and when the demand eases off you'll get back to a single replica again.
|
||||
|
||||
Here is a sample query you can paste into Safari, Chrome etc:
|
||||
|
||||
Just change the IP address to your own.
|
||||
|
||||
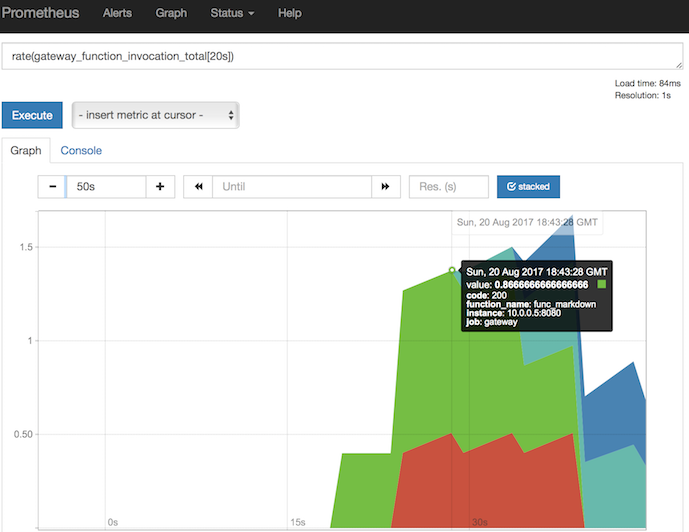
|
||||
|
||||
```
|
||||
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||
|
||||
```
|
||||
|
||||
The queries are written in PromQL - Prometheus query language. The first one shows us how often the function is being called:
|
||||
|
||||
```
|
||||
rate(gateway_function_invocation_total[20s])
|
||||
|
||||
```
|
||||
|
||||
The second query shows us how many replicas we have of each function, there should be only one of each at the start:
|
||||
|
||||
```
|
||||
gateway_service_count
|
||||
|
||||
```
|
||||
|
||||
If you want to trigger auto-scaling you could try the following on the RPi:
|
||||
|
||||
```
|
||||
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||
|
||||
```
|
||||
|
||||
Check the Prometheus "alerts" page, and see if you are generating enough load for the auto-scaling to trigger, if you're not then run the command in a few additional Terminal windows too.
|
||||
|
||||
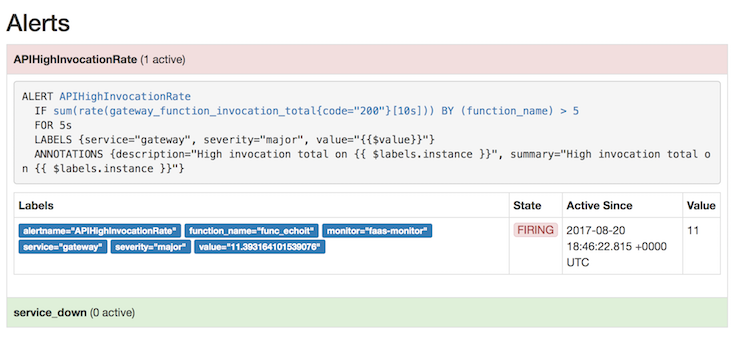
|
||||
|
||||
After you reduce the load, the replica count shown in your second graph and the `gateway_service_count` metric will go back to 1 again.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
We've now set up Docker, Swarm and run OpenFaaS - which let us treat our Raspberry Pi like one giant computer - ready to crunch through code.
|
||||
|
||||
> Please show support for the project and **Star** the [FaaS GitHub repository][28]
|
||||
|
||||
How did you find setting up your Docker Swarm first cluster and running OpenFaaS? Please share a picture or a Tweet on Twitter [@alexellisuk][46]
|
||||
|
||||
**Watch my Dockercon video of OpenFaaS**
|
||||
|
||||
I presented OpenFaaS (then called FaaS) [at Dockercon in Austin][47] - watch this video for a high-level introduction and some really interactive demos Alexa and GitHub.
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
Got questions? Ask in the comments below - or send your email over to me for an invite to my Raspberry Pi, Docker and Serverless Slack channel where you can chat with like-minded people about what you're working on.
|
||||
|
||||
**Want to learn more about Docker on the Raspberry Pi?**
|
||||
|
||||
I'd suggest starting with [5 Things you need to know][48] which covers things like security and and the subtle differences between RPi and a regular PC.
|
||||
|
||||
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||
|
||||
* [Control GPIO with Docker Swarm][19]
|
||||
|
||||
* [Is that a Docker Engine in your pocket??][20]
|
||||
|
||||
_Share on Twitter_
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/alexellisuk
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=898978596773138436
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=898978596773138436
|
||||
[4]:https://twitter.com/intent/like?tweet_id=898978596773138436
|
||||
[5]:https://twitter.com/alexellisuk
|
||||
[6]:https://twitter.com/alexellisuk
|
||||
[7]:https://twitter.com/Docker
|
||||
[8]:https://twitter.com/Raspberry_Pi
|
||||
[9]:https://twitter.com/alexellisuk/status/898978596773138436
|
||||
[10]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[11]:https://twitter.com/alexellisuk
|
||||
[12]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[13]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[14]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[15]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[16]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[17]:https://support.twitter.com/articles/20175256
|
||||
[18]:https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/
|
||||
[19]:https://blog.alexellis.io/gpio-on-swarm/
|
||||
[20]:https://blog.alexellis.io/docker-engine-in-your-pocket/
|
||||
[21]:https://news.ycombinator.com/item?id=15052192
|
||||
[22]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[23]:https://github.com/alexellis/faas
|
||||
[24]:http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/
|
||||
[25]:https://github.com/alexellis/faas
|
||||
[26]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
[27]:https://blog.alexellis.io/first-faas-python-function
|
||||
[28]:https://github.com/alexellis/faas
|
||||
[29]:https://blog.alexellis.io/tag/docker/
|
||||
[30]:https://blog.alexellis.io/tag/raspberry-pi/
|
||||
[31]:https://blog.alexellis.io/tag/openfaas/
|
||||
[32]:https://blog.alexellis.io/tag/faas/
|
||||
[33]:https://github.com/alexellis/faas
|
||||
[34]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[35]:https://github.com/alexellis/faas
|
||||
[36]:https://github.com/alexellis/faas
|
||||
[37]:https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY
|
||||
[38]:http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/
|
||||
[39]:https://etcher.io/
|
||||
[40]:https://docs.docker.com/engine/swarm/admin_guide/
|
||||
[41]:https://github.com/alexellis/faas
|
||||
[42]:http://192.168.0.100:8080/
|
||||
[43]:https://blog.alexellis.io/first-faas-python-function
|
||||
[44]:https://github.com/alexellis/faas
|
||||
[45]:https://prometheus.io/
|
||||
[46]:https://twitter.com/alexellisuk
|
||||
[47]:https://blog.alexellis.io/dockercon-2017-captains-log/
|
||||
[48]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025 translating
|
||||
12 Practices every Android Development Beginner should know — Part 1
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,300 +0,0 @@
|
||||
[Concurrent Servers: Part 2 - Threads][19]
|
||||
============================================================
|
||||
|
||||
GitFuture is Translating
|
||||
|
||||
This is part 2 of a series on writing concurrent network servers. [Part 1][20] presented the protocol implemented by the server, as well as the code for a simple sequential server, as a baseline for the series.
|
||||
|
||||
In this part, we're going to look at multi-threading as one approach to concurrency, with a bare-bones threaded server implementation in C, as well as a thread pool based implementation in Python.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][8]
|
||||
|
||||
* [Part 2 - Threads][9]
|
||||
|
||||
* [Part 3 - Event-driven][10]
|
||||
|
||||
### The multi-threaded approach to concurrent server design
|
||||
|
||||
When discussing the performance of the sequential server in part 1, it was immediately obvious that a lot of compute resources are wasted while the server processes a client connection. Even assuming a client that sends messages immediately and doesn't do any waiting, network communication is still involved; networks tend to be millions (or more) times slower than a modern CPU, so the CPU running the sequential server will spend the vast majority of time in gloriuos boredom waiting for new socket traffic to arrive.
|
||||
|
||||
Here's a chart showing how sequential client processing happens over time:
|
||||
|
||||
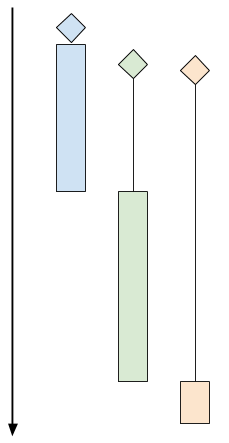
|
||||
|
||||
The diagrams shows 3 clients. The diamond shapes denote the client's "arrival time" (the time at which the client attempted to connect to the server). The black lines denote "wait time" (the time clients spent waiting for the server to actually accept their connection), and the colored bars denote actual "processing time" (the time server and client are interacting using the protocol). At the end of the colored bar, the client disconnects.
|
||||
|
||||
In the diagram above, even though the green and orange clients arrived shortly after the blue one, they have to wait for a while until the server is done with the blue client. At this point the green client is accepted, while the orange one has to wait even longer.
|
||||
|
||||
A multi-threaded server would launch multiple control threads, letting the OS manage concurrency on the CPU (and across multiple CPU cores). When a client connects, a thread is created to serve it, while the server is ready to accept more clients in the main thread. The time chart for this mode looks like the following:
|
||||
|
||||
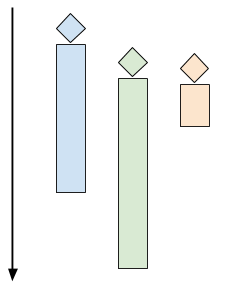
|
||||
|
||||
### One thread per client, in C using pthreads
|
||||
|
||||
Our [first code sample][11] in this post is a simple "one thread per client" server, written in C using the foundational [pthreads API][12] for multi-threading. Here's the main loop:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd =
|
||||
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
pthread_t the_thread;
|
||||
|
||||
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
|
||||
if (!config) {
|
||||
die("OOM");
|
||||
}
|
||||
config->sockfd = newsockfd;
|
||||
pthread_create(&the_thread, NULL, server_thread, config);
|
||||
|
||||
// Detach the thread - when it's done, its resources will be cleaned up.
|
||||
// Since the main thread lives forever, it will outlive the serving threads.
|
||||
pthread_detach(the_thread);
|
||||
}
|
||||
```
|
||||
|
||||
And this is the `server_thread` function:
|
||||
|
||||
```
|
||||
void* server_thread(void* arg) {
|
||||
thread_config_t* config = (thread_config_t*)arg;
|
||||
int sockfd = config->sockfd;
|
||||
free(config);
|
||||
|
||||
// This cast will work for Linux, but in general casting pthread_id to an
|
||||
// integral type isn't portable.
|
||||
unsigned long id = (unsigned long)pthread_self();
|
||||
printf("Thread %lu created to handle connection with socket %d\n", id,
|
||||
sockfd);
|
||||
serve_connection(sockfd);
|
||||
printf("Thread %lu done\n", id);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
The thread "configuration" is passed as a `thread_config_t` structure:
|
||||
|
||||
```
|
||||
typedef struct { int sockfd; } thread_config_t;
|
||||
```
|
||||
|
||||
The `pthread_create` call in the main loop launches a new thread that runs the `server_thread` function. This thread terminates when `server_thread` returns. In turn, `server_thread` returns when `serve_connection` returns.`serve_connection` is exactly the same function from part 1.
|
||||
|
||||
In part 1 we used a script to launch multiple clients concurrently and observe how the server handles them. Let's do the same with the multithreaded server:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-20 06:31:56,632:conn1 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn2 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn0 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
|
||||
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
|
||||
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
|
||||
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
|
||||
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
|
||||
```
|
||||
|
||||
Indeed, all clients connected at the same time, and their communication with the server occurs concurrently.
|
||||
|
||||
### Challenges with one thread per client
|
||||
|
||||
Even though threads are fairly efficient in terms of resource usage on modern OSes, the approach outlined in the previous section can still present challenges with some workloads.
|
||||
|
||||
Imagine a scenario where many clients are connecting simultaneously, and some of the sessions are long-lived. This means that many threads may be active at the same time in the server. Too many threads can consume a large amount of memory and CPU time just for the context switching [[1]][13]. An alternative way to look at it is as a security problem: this design makes it the server an easy target for a [DoS attack][14] - connect a few 100,000s of clients at the same time and let them all sit idle - this will likely kill the server due to excessive resource usage.
|
||||
|
||||
A larger problem occurs when there's a non-trivial amount of CPU-bound computation the server has to do for each client. In this case, swamping the server is considerably easier - just a few dozen clients can bring a server to its knees.
|
||||
|
||||
For these reasons, it's prudent the do some _rate-limiting_ on the number of concurrent clients handled by a multi-threaded server. There's a number of ways to do this. The simplest that comes to mind is simply count the number of clients currently connected and restrict that number to some quantity (that was determined by careful benchmarking, hopefully). A variation on this approach that's very popular in concurrent application design is using a _thread pool_ .
|
||||
|
||||
### Thread pools
|
||||
|
||||
The idea of a [thread pool][15] is simple, yet powerful. The server creates a number of working threads that all expect to get tasks from some queue. This is the "pool". Then, each client connection is dispatched as a task to the pool. As long as there's an idle thread in the pool, it's handed the task. If all the threads in the pool are currently busy, the server blocks until the pool accepts the task (which happens after one of the busy threads finished processing its current task and went back to an idle state).
|
||||
|
||||
Here's a diagram showing a pool of 4 threads, each processing a task. Tasks (client connections in our case) are waiting until one of the threads in the pool is ready to accept new tasks.
|
||||
|
||||
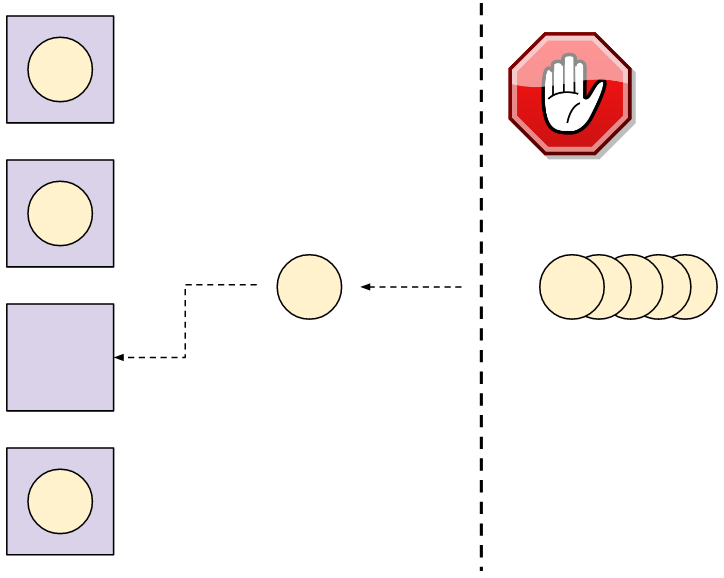
|
||||
|
||||
It should be fairly obvious that the thread pool approach provides a rate-limiting mechanism in its very definition. We can decide ahead of time how many threads we want our server to have. Then, this is the maximal number of clients processed concurrently - the rest are waiting until one of the threads becomes free. If we have 8 threads in the pool, 8 is the maximal number of concurrent clients the server handles - even if thousands are attempting to connect simultaneously.
|
||||
|
||||
How do we decide how many threads should be in the pool? By a careful analysis of the problem domain, benchmarking, experimentation and also by the HW we have. If we have a single-core cloud instance that's one answer, if we have a 100-core dual socket server available, the answer is different. Picking the thread pool size can also be done dynamically at runtime based on load - I'll touch upon this topic in future posts in this series.
|
||||
|
||||
Servers that use thread pools manifest _graceful degradation_ in the face of high load - clients are accepted at some steady rate, potentially slower than their rate of arrival for some periods of time; that said, no matter how many clients are trying to connect simultaneously, the server will remain responsive and will just churn through the backlog of clients to its best ability. Contrast this with the one-thread-per-client server which can merrily accept a large number of clients until it gets overloaded, at which point it's likely to either crash or start working very slowly for _all_ processed clients due to resource exhaustion (such as virtual memory thrashing).
|
||||
|
||||
### Using a thread pool for our network server
|
||||
|
||||
For [this variation of the server][16] I've switched to Python, which comes with a robust implementation of a thread pool in the standard library (`ThreadPoolExecutor` from the `concurrent.futures` module) [[2]][17].
|
||||
|
||||
This server creates a thread pool, then loops to accept new clients on the main listening socket. Each connected client is dispatched into the pool with `submit`:
|
||||
|
||||
```
|
||||
pool = ThreadPoolExecutor(args.n)
|
||||
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
sockobj.bind(('localhost', args.port))
|
||||
sockobj.listen(15)
|
||||
|
||||
try:
|
||||
while True:
|
||||
client_socket, client_address = sockobj.accept()
|
||||
pool.submit(serve_connection, client_socket, client_address)
|
||||
except KeyboardInterrupt as e:
|
||||
print(e)
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
The `serve_connection` function is very similar to its C counterpart, serving a single client until the client disconnects, while following our protocol:
|
||||
|
||||
```
|
||||
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
|
||||
|
||||
def serve_connection(sockobj, client_address):
|
||||
print('{0} connected'.format(client_address))
|
||||
sockobj.sendall(b'*')
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
|
||||
while True:
|
||||
try:
|
||||
buf = sockobj.recv(1024)
|
||||
if not buf:
|
||||
break
|
||||
except IOError as e:
|
||||
break
|
||||
for b in buf:
|
||||
if state == ProcessingState.WAIT_FOR_MSG:
|
||||
if b == ord(b'^'):
|
||||
state = ProcessingState.IN_MSG
|
||||
elif state == ProcessingState.IN_MSG:
|
||||
if b == ord(b'$'):
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
else:
|
||||
sockobj.send(bytes([b + 1]))
|
||||
else:
|
||||
assert False
|
||||
|
||||
print('{0} done'.format(client_address))
|
||||
sys.stdout.flush()
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
Let's see how the thread pool size affects the blocking behavior for multiple concurrent clients. For demonstration purposes, I'll run the threadpool server with a pool size of 2 (only two threads are created to service clients):
|
||||
|
||||
```
|
||||
$ python3.6 threadpool-server.py -n 2
|
||||
```
|
||||
|
||||
And in a separate terminal, let's run the client simulator again, with 3 concurrent clients:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-22 05:58:52,815:conn1 connected...
|
||||
INFO:2017-09-22 05:58:52,827:conn0 connected...
|
||||
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
|
||||
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
|
||||
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
|
||||
INFO:2017-09-22 05:58:55,032:conn2 connected...
|
||||
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
|
||||
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
|
||||
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
|
||||
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
|
||||
```
|
||||
|
||||
Recall the behavior of previously discussed servers:
|
||||
|
||||
1. In the sequential server, all connections were serialized. One finished, and only then the next started.
|
||||
|
||||
2. In the thread-per-client server earlier in this post, all connections wer accepted and serviced concurrently.
|
||||
|
||||
Here we see another possibility: two connections are serviced concurrently, and only when one of them is done the third is admitted. This is a direct result of the thread pool size set to 2\. For a more realistic use case we'd set the thread pool size to much higher, depending on the machine and the exact protocol. This buffering behavior of thread pools is well understood - I've written about it more in detail [just a few months ago][18] in the context of Clojure's `core.async` module.
|
||||
|
||||
### Summary and next steps
|
||||
|
||||
This post discusses multi-threading as a means of concurrency in network servers. The one-thread-per-client approach is presented for an initial discussion, but this method is not common in practice since it's a security hazard.
|
||||
|
||||
Thread pools are much more common, and most popular programming languages have solid implementations (for some, like Python, it's in the standard library). The thread pool server presented here doesn't suffer from the problems of one-thread-per-client.
|
||||
|
||||
However, threads are not the only way to handle multiple clients concurrently. In the next post we're going to look at some solutions using _asynchronous_ , or _event-driven_ programming.
|
||||
|
||||
* * *
|
||||
|
||||
[[1]][1] To be fair, modern Linux kernels can tolerate a significant number of concurrent threads - as long as these threads are mostly blocked on I/O, of course. [Here's a sample program][2] that launches a configurable number of threads that sleep in a loop, waking up every 50 ms. On my 4-core Linux machine I can easily launch 10000 threads; even though these threads sleep almost all the time, they still consume between one and two cores for the context switching. Also, they occupy 80 GB of virtual memory (8 MB is the default per-thread stack size for Linux). More realistic threads that actually use memory and not just sleep in a loop can therefore exhaust the physical memory of a machine fairly quickly.
|
||||
|
||||
[[2]][3] Implementing a thread pool from scratch is a fun exercise, but I'll leave it for another day. I've written about hand-rolled [thread pools for specific tasks][4] in the past. That's in Python; doing it in C would be more challenging, but shouldn't take more than a few of hours for an experienced programmer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id1
|
||||
[2]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadspammer.c
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/12/27/python-threads-communication-and-stopping
|
||||
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||
[7]:https://eli.thegreenplace.net/tag/python
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threaded-server.c
|
||||
[12]:http://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id3
|
||||
[14]:https://en.wikipedia.org/wiki/Denial-of-service_attack
|
||||
[15]:https://en.wikipedia.org/wiki/Thread_pool
|
||||
[16]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadpool-server.py
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id4
|
||||
[18]:http://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[20]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
@ -1,78 +0,0 @@
|
||||
Why and how you should switch to Linux
|
||||
============================================================
|
||||
|
||||
It's time for a change.
|
||||
|
||||
|
||||

|
||||
|
||||
Let Ubuntu, an easy-to-use version of Linux, run your computer.
|
||||
|
||||
Ubuntu
|
||||
|
||||
When you start comparing computers, you probably pit [Windows][1] against [macOS][2]—but Linux rarely gets a mention. Still, this lesser-known operating system has a strong and loyal following. That's because it offers a number of advantages over its competitors.
|
||||
|
||||
Whether you're completely new to Linux or have dabbled with it once or twice already, we want you to consider running it on your next laptop or desktop—or alongside your existing operating system. Read on to decide if it's time to make the switch.
|
||||
|
||||
### What is Linux?
|
||||
|
||||
If you're already familiar with Linux, you can skip this section. For everyone else, Linux is a free open-source operating system, which means the code is available for anyone to explore. Technically speaking, the term "Linux" refers to just the kernel, or the core, of the code. However, people often use the name to talk about the whole operating system, including the interface and bundled apps.
|
||||
|
||||
Because anyone can tinker with it, Linux is incredibly customizable, encouraging programmers to make their own distributions—better known as distros—of the system. Each one of these different flavors of the OS comes with its own programs and interfaces. Some of the most well-known distros, which work much like the familiar Windows or macOS operating systems, include [Ubuntu][3], [Linux Mint][4], and [Zorin OS][5]. When you're ready to choose a distro, check out those websites—and see if free trials are available—in order to determine which is right for you.
|
||||
|
||||
To code and maintain these Linux distros, a huge number of developers volunteer their time. In other cases, for-profit companies develop their own versions of Linux with specific features in order to sell the software to other businesses. For example, Android—although it doesn't count as a full Linux OS—is based on the Linux kernel, which is why it comes in [different variations][6]. Many computer servers and data centers also run on Linux, so there's a good chance the OS hosts the webpage you're reading.
|
||||
|
||||
### What are the benefits?
|
||||
|
||||
For a start, Linux is free and open source, which means you can add it to a computer or laptop you already own—or a machine you've built yourself—without paying anything. The system also comes with similarly-available software, including a web browser, media player, [image editor][7] and [office suite][8], so you won't need to fork out extra cash just to work on photos or documents. And of course, you get all future updates for free too.
|
||||
|
||||
Linux also offers stronger malware protection than its competitors, strong enough that you won't need to run an antivirus program. Developers built it, from the ground up, with security in mind: For example, the OS only works with trusted software. Plus, very few malware programs target the system—for hackers, it's just not worth the effort. Linux isn't invulnerable, but the average home user sticking to approved apps doesn't need to worry about security.
|
||||
|
||||
This operating system also requires fewer hardware resources than the more data-heavy Windows or macOS. Distros have fewer components than their more famous cousins, and developers have specifically written some, such [Puppy Linux][9] and [Linux Lite][10], to be as lightweight as possible. That makes Linux a particularly good choice for those who own older computers. If your ancient laptop is wheezing under the strain of a corporate operating system, try installing Linux on top, and the machine should speed up. You don't have to ditch your old OS if you don't want to though, as we'll explain in the next section.
|
||||
|
||||
Although you may take a little time to adjust to your new operating system, before long, you should find the Linux interface easy to use. So people of all ages and levels of technical know-how can come to grips with the software. And the online Linux community offers plenty of help and support. Speaking of the community, downloading Linux also supports the open-source software movement: developers who work together to make better programs, without chasing a profit, for users across the globe.
|
||||
|
||||
### How do I get started?
|
||||
|
||||
Linux has a reputation as software that only specialists might install. But getting the operating system up and running is much more simple than it was only a few years ago.
|
||||
|
||||
To get started, head to the website of the distro you prefer, and follow the installation instructions. You'll usually have to burn a DVD or set up a USB drive with the necessary code, then reboot your machine to run that code. In fact, one of the operating system's advantages is that you can store it on a portable USB stick—read more in our full [guide to putting a computer on a USB drive][11].
|
||||
|
||||
If you want to run Linux without completely ditching your old operating system, you can either run Linux from that DVD or USB drive or partition your computer's hard drive (split it into chunks to run two operating systems alongside each other). Several Linux distros will take care of the partitioning for you during the installation process. Or you can partition it yourself using [Disk Management][12] (for Windows) or [Disk Utility][13](for macOS).
|
||||
|
||||
These instructions may sound vague, but don't panic: Individual distros provide much more detailed instructions, although the procedure is pretty similar in most cases. For example, if you want to install Ubuntu—one of the most popular Linux distros for home users—[follow the guide here][14]. (Before you install it, you can also [give it a trial run][15].) You'll need to download the latest version to a computer, put it on a DVD or USB stick, then use that disc or drive to boot up your computer, following the instructions in the setup wizard. Where you need extra software to complete the steps, the Ubuntu tutorial will guide you to the right tools.
|
||||
|
||||
If you're installing Linux on a completely new machine, you don't have much to worry about. But if you're installing a new system alongside an existing one, we'd recommend that you first [back up all your stuff][16]. During the setup process, also take care to choose the dual-boot option to avoid wiping out your existing OS and files. The tutorials for your distro of choice will explain this in more detail: You can find full tutorials for Zorin OS [here][17], for Linux Mint [here][18], and for other distros on their own websites.
|
||||
|
||||
And that's it! So, are you ready to give Linux a try?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.popsci.com/switch-to-linux-operating-system
|
||||
|
||||
作者:[David Nield][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.popsci.com/authors/david-nield
|
||||
[1]:https://www.popsci.com/windows-tweaks-improve-performance
|
||||
[2]:https://www.popsci.com/macos-tweaks-improve-performance
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://linuxmint.com/
|
||||
[5]:https://zorinos.com/
|
||||
[6]:https://lineageos.org/
|
||||
[7]:https://www.gimp.org/
|
||||
[8]:https://www.libreoffice.org/
|
||||
[9]:http://puppylinux.org/main/Overview%20and%20Getting%20Started.htm
|
||||
[10]:https://www.linuxliteos.com/
|
||||
[11]:https://www.popsci.com/portable-computer-usb-stick
|
||||
[12]:https://www.disk-partition.com/windows-10/windows-10-disk-management-0528.html
|
||||
[13]:https://support.apple.com/kb/PH22240?locale=en_US
|
||||
[14]:https://tutorials.ubuntu.com/tutorial/tutorial-install-ubuntu-desktop?backURL=%2F#0
|
||||
[15]:https://tutorials.ubuntu.com/tutorial/try-ubuntu-before-you-install?backURL=%2F#0
|
||||
[16]:https://www.popsci.com/back-up-and-protect-your-data
|
||||
[17]:https://zorinos.com/help/install-zorin-os/
|
||||
[18]:https://linuxmint.com/documentation.php
|
||||
[19]:https://www.popsci.com/authors/david-nield
|
||||
@ -0,0 +1,421 @@
|
||||
使用 Docker 构建你的 Serverless 树莓派集群
|
||||
============================================================
|
||||
|
||||
|
||||
这篇博文将向你展示如何使用 Docker 和 [OpenFaaS][33] 框架构建你自己的 Serverless 树莓派集群。大家常常问我他们能用他们的集群来做些什么?这个应用完美匹配卡片尺寸的设备——只需添加更多的树莓派就能获取更强的计算能力。
|
||||
|
||||
> “Serverless” 是事件驱动架构的一种设计模式,与“桥接模式”、“外观模式”、“工厂模式”和“云”这些名词一样,都是一种抽象概念。
|
||||
|
||||
这是我在本文中描述的集群,用黄铜支架分隔每个设备。
|
||||
|
||||
|
||||
|
||||
### Serverless 是什么?它为何重要?
|
||||
|
||||
行业对于“serverless”这个术语的含义有几种解释。在这篇博文中,我们就把它理解为一种事件驱动的架构模式,它能让你用自己喜欢的任何语言编写轻量可复用的功能。[更多关于 Serverless 的资料][22]。
|
||||
|
||||

|
||||
_Serverless 架构也引出了“功能即服务服务”模式,简称 FaaS_
|
||||
|
||||
Serverless 的“功能”可以做任何事,但通常用于处理给定的输入——例如来自 GitHub、Twitter、PayPal、Slack、Jenkins CI pipeline 的事件;或者以树莓派为例,处理像红外运动传感器、激光绊网、温度计等真实世界的传感器的输入。
|
||||
|
||||

|
||||
|
||||
Serverless 功能能够更好地结合第三方的后端服务,使系统整体的能力大于各部分之和。
|
||||
|
||||
|
||||
了解更多背景信息,可以阅读我最近一偏博文:[Introducing Functions as a Service (FaaS)][34]。
|
||||
|
||||
### 概述
|
||||
|
||||
我们将使用 [OpenFaaS][35], 它能够让主机或者集群作为支撑 Serverless 功能运行的后端。任何能够使用 Docker 部署的可执行二进制文件、脚本或者编程语言都能在 [OpenFaaS][36] 上运作,你可以根据速度和伸缩性选择部署的规模。另一个优点是,它还内建了用户界面和监控系统。
|
||||
|
||||
这是我们要执行的步骤:
|
||||
|
||||
* 在一个或多个主机上配置 Docker (树莓派 2 或者 3);
|
||||
|
||||
* 利用 Docker Swarm 将它们连接;
|
||||
|
||||
* 部署 [OpenFaaS][23];
|
||||
|
||||
* 使用 Python 编写我们的第一个功能。
|
||||
|
||||
### Docker Swarm
|
||||
|
||||
Docker 是一项打包和部署应用的技术,支持集群上运行,有着安全的默认设置,而且在搭建集群时只需要一条命令。OpenFaaS 使用 Docker 和 Swarm 在你的可用树莓派上传递你的 Serverless 功能。
|
||||
|
||||

|
||||
_图片:3 个 Raspberry Pi Zero_
|
||||
|
||||
我推荐你在这个项目中使用带树莓派 2 或者 3,以太网交换机和[强大的 USB 多端口电源适配器][37]。
|
||||
|
||||
### 准备 Raspbian
|
||||
|
||||
把 [Raspbian Jessie Lite][38] 写入 SD 卡(8GB 容量就正常工作了,但还是推荐使用 16GB 的 SD 卡)。
|
||||
|
||||
_注意:不要下载成 Raspbian Stretch 了_
|
||||
|
||||
> 社区在努力让 Docker 支持 Raspbian Stretch,但是还未能做到完美运行。请从[树莓派基金会网站][24]下载 Jessie Lite 镜像。
|
||||
|
||||
我推荐使用 [Etcher.io][39] 烧写镜像。
|
||||
|
||||
> 在引导树莓派之前,你需要在引导分区创建名为“ssh”的空白文件。这样才能允许远程登录。
|
||||
|
||||
* 接通电源,然后修改主机名
|
||||
|
||||
现在启动树莓派的电源并且使用`ssh`连接:
|
||||
|
||||
```
|
||||
$ ssh pi@raspberrypi.local
|
||||
|
||||
```
|
||||
|
||||
> 默认密码是`raspberry`
|
||||
|
||||
使用 `raspi-config` 工具把主机名改为 `swarm-1` 或者类似的名字,然后重启。
|
||||
|
||||
当你到了这一步,你还可以把划分给 GPU (显卡)的内存设置为 16MB。
|
||||
|
||||
* 现在安装 Docker
|
||||
|
||||
我们可以使用通用脚本来安装:
|
||||
|
||||
```
|
||||
$ curl -sSL https://get.docker.com | sh
|
||||
|
||||
```
|
||||
|
||||
> 这个安装方式在将来可能会发生变化。如上文所说,你的系统需要是 Jessie,这样才能得到一个确定的配置。
|
||||
|
||||
你可能会看到类似下面的警告,不过你可以安全地忽略它并且成功安装上 Docker CE 17.05:
|
||||
|
||||
```
|
||||
WARNING: raspbian is no longer updated @ https://get.docker.com/
|
||||
Installing the legacy docker-engine package...
|
||||
|
||||
```
|
||||
|
||||
之后,用下面这个命令确保你的用户帐号可以访问 Docker 客户端:
|
||||
|
||||
```
|
||||
$ usermod pi -aG docker
|
||||
|
||||
```
|
||||
|
||||
> 如果你的用户名不是 `pi`,那就把它替换成你的用户名。
|
||||
|
||||
* 修改默认密码
|
||||
|
||||
输入 `$sudo passwd pi`,然后设置一个新密码,请不要跳过这一步!
|
||||
|
||||
* 重复以上步骤
|
||||
|
||||
现在为其它的树莓派重复上述步骤。
|
||||
|
||||
### 创建你的 Swarm 集群
|
||||
|
||||
登录你的第一个树莓派,然后输入下面的命令:
|
||||
|
||||
```
|
||||
$ docker swarm init
|
||||
Swarm initialized: current node (3ra7i5ldijsffjnmubmsfh767) is now a manager.
|
||||
|
||||
To add a worker to this swarm, run the following command:
|
||||
|
||||
docker swarm join \
|
||||
--token SWMTKN-1-496mv9itb7584pzcddzj4zvzzfltgud8k75rvujopw15n3ehzu-af445b08359golnzhncbdj9o3 \
|
||||
192.168.0.79:2377
|
||||
|
||||
```
|
||||
|
||||
你会看到它显示了一个口令,以及其它结点加入集群的命令。接下来使用 `ssh` 登录每个树莓派,运行这个加入集群的命令。
|
||||
|
||||
等待连接完成后,在第一个树莓派上查看集群的结点:
|
||||
|
||||
```
|
||||
$ docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
3ra7i5ldijsffjnmubmsfh767 * swarm1 Ready Active Leader
|
||||
k9mom28s2kqxocfq1fo6ywu63 swarm3 Ready Active
|
||||
y2p089bs174vmrlx30gc77h4o swarm4 Ready Active
|
||||
|
||||
```
|
||||
|
||||
恭喜你!你现在拥有一个树莓派集群了!
|
||||
|
||||
* _更多关于集群的内容_
|
||||
|
||||
你可以看到三个结点启动运行。这时只有一个结点是集群管理者。如果我们的管理结点_死机_了,集群就进入了不可修复的状态。我们可以通过添加冗余的管理结点解决这个问题。而且它们依然会运行工作负载,除非你明确设置了让你的服务只运作在工作结点上。
|
||||
|
||||
要把一个工作结点升级为管理结点,只需要在其中一个管理结点上运行 `docker node promote <node_name>` 命令。
|
||||
|
||||
> 注意: Swarm 命令,例如 `docker service ls` 或者 `docker node ls` 只能在管理结点上运行。
|
||||
|
||||
想深入了解管理结点与工作结点如何保持一致性,可以查阅 [Docker Swarm 管理指南][40]。
|
||||
|
||||
### OpenFaaS
|
||||
|
||||
现在我们继续部署程序,让我们的集群能够运行 Serverless 功能。[OpenFaaS][41] 是一个利用 Docker 在任何硬件或者云上让任何进程或者容器成为一个 Serverless 功能的框架。因为 Docker 和 Golang 的可移植性,它也能很好地运行在树莓派上。
|
||||
|
||||

|
||||
|
||||
> 如果你支持 [OpenFaaS][41],希望你能 **start** [OpenFaaS][25] 的 GitHub 仓库。
|
||||
|
||||
登录你的第一个树莓派(你运行 `docker swarm init` 的结点),然后部署这个项目:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas/
|
||||
$ cd faas
|
||||
$ ./deploy_stack.armhf.sh
|
||||
Creating network func_functions
|
||||
Creating service func_gateway
|
||||
Creating service func_prometheus
|
||||
Creating service func_alertmanager
|
||||
Creating service func_nodeinfo
|
||||
Creating service func_markdown
|
||||
Creating service func_wordcount
|
||||
Creating service func_echoit
|
||||
|
||||
```
|
||||
|
||||
你的其它树莓派会收到 Docer Swarm 的指令,开始从网上拉取这个 Docker 镜像,并且解压到 SD 卡上。这些工作会分布到各个结点上,所以没有哪个结点产生过高的负载。
|
||||
|
||||
这个过程会持续几分钟,你可以用下面指令查看它的完成状况:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
ID NAME MODE REPLICAS IMAGE PORTS
|
||||
57ine9c10xhp func_wordcount replicated 1/1 functions/alpine:latest-armhf
|
||||
d979zipx1gld func_prometheus replicated 1/1 alexellis2/prometheus-armhf:1.5.2 *:9090->9090/tcp
|
||||
f9yvm0dddn47 func_echoit replicated 1/1 functions/alpine:latest-armhf
|
||||
lhbk1fc2lobq func_markdown replicated 1/1 functions/markdownrender:latest-armhf
|
||||
pj814yluzyyo func_alertmanager replicated 1/1 alexellis2/alertmanager-armhf:0.5.1 *:9093->9093/tcp
|
||||
q4bet4xs10pk func_gateway replicated 1/1 functions/gateway-armhf:0.6.0 *:8080->8080/tcp
|
||||
v9vsvx73pszz func_nodeinfo replicated 1/1 functions/nodeinfo:latest-armhf
|
||||
|
||||
```
|
||||
|
||||
我们希望看到每个服务都显示“1/1”。
|
||||
|
||||
你可以根据服务名查看该服务被调度到哪个树莓派上:
|
||||
|
||||
```
|
||||
$ docker service ps func_markdown
|
||||
ID IMAGE NODE STATE
|
||||
func_markdown.1 functions/markdownrender:latest-armhf swarm4 Running
|
||||
|
||||
```
|
||||
|
||||
状态一项应该显示 `Running`,如果它是 `Pending`,那么镜像可能还在下载中。
|
||||
|
||||
在这时,查看树莓派的 IP 地址,然后在浏览器中访问它的 8080 端口:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
|
||||
```
|
||||
|
||||
例如,如果你的 IP 地址是 192.168.0.100,那就访问 [http://192.168.0.100:8080][42]。
|
||||
|
||||
这是你会看到 FaaS UI(也叫 API 网关)。这是你定义、测试、调用功能的地方。
|
||||
|
||||
点击名称为 func_markdown 的 Markdown 转换功能,输入一些 Markdown(这是 Wikipedia 用来组织内容的语言)文本。
|
||||
|
||||
然后点击 `invoke`。你会看到调用计数增加,屏幕下方显示功能调用的结果。
|
||||
|
||||

|
||||
|
||||
### 部署你的第一个 Serverless 功能:
|
||||
|
||||
这一节的内容已经有相关的教程,但是我们需要几个步骤来配置树莓派。
|
||||
|
||||
* 获取 FaaS-CLI:
|
||||
|
||||
```
|
||||
$ curl -sSL cli.openfaas.com | sudo sh
|
||||
armv7l
|
||||
Getting package https://github.com/alexellis/faas-cli/releases/download/0.4.5-b/faas-cli-armhf
|
||||
|
||||
```
|
||||
|
||||
* 下载样例:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/alexellis/faas-cli
|
||||
$ cd faas-cli
|
||||
|
||||
```
|
||||
|
||||
* 为树莓派修补样例:
|
||||
|
||||
我们临时修改我们的模版,让它们能在树莓派上工作:
|
||||
|
||||
```
|
||||
$ cp template/node-armhf/Dockerfile template/node/
|
||||
$ cp template/python-armhf/Dockerfile template/python/
|
||||
|
||||
```
|
||||
|
||||
这么做是因为树莓派和我们平时关注的大多数计算机使用不一样的处理器架构。
|
||||
|
||||
> 了解 Docker 在树莓派上的最新状况,请查阅: [5 Things you need to know][26]
|
||||
|
||||
现在你可以跟着下面为 PC,笔记本和云端所写的教程操作,但我们在树莓派上要先运行一些命令。
|
||||
|
||||
* [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][27]
|
||||
|
||||
注意第 3 步:
|
||||
|
||||
* 把你的功能放到先前从 GitHub 下载的 `faas-cli` 文件夹中,而不是 `~/functinos/hello-python` 里。
|
||||
|
||||
* 同时,在 `stack.yml` 文件中把 `localhost` 替换成第一个树莓派的 IP 地址。
|
||||
|
||||
集群可能会花费几分钟把 Serverless 功能下载到相关的树莓派上。你可以用下面的命令查看你的服务,确保副本一项显示“1/1”:
|
||||
|
||||
```
|
||||
$ watch 'docker service ls'
|
||||
pv27thj5lftz hello-python replicated 1/1 alexellis2/faas-hello-python-armhf:latest
|
||||
|
||||
```
|
||||
|
||||
**继续阅读教程:** [使用 OpenFaaS 运行你的第一个 Serverless Python 功能][43]
|
||||
|
||||
关于 Node.js 或者其它语言的更多信息,可以进一步访问 [FaaS 仓库][44]。
|
||||
|
||||
### 检查功能的指标
|
||||
|
||||
既然使用 Serverless,你也不想花时间监控你的功能。幸运的是,OpenFaaS 内建了 [Prometheus][45] 指标检测,这意味着你可以追踪每个功能的运行时长和调用频率。
|
||||
|
||||
_指标驱动自动伸缩_
|
||||
|
||||
如果你给一个功能生成足够的负载,OpenFaaS 将自动扩展你的功能;当需求消失时,你又会回到单一副本的状态。
|
||||
|
||||
这个请求样例你可以复制到浏览器中:
|
||||
|
||||
只要把 IP 地址改成你的即可。
|
||||
|
||||

|
||||
|
||||
```
|
||||
http://192.168.0.25:9090/graph?g0.range_input=15m&g0.stacked=1&g0.expr=rate(gateway_function_invocation_total%5B20s%5D)&g0.tab=0&g1.range_input=1h&g1.expr=gateway_service_count&g1.tab=0
|
||||
|
||||
```
|
||||
|
||||
这些请求使用 PromQL(Prometheus 请求语言)编写。第一个请求返回功能调用的频率:
|
||||
|
||||
```
|
||||
rate(gateway_function_invocation_total[20s])
|
||||
|
||||
```
|
||||
|
||||
第二个请求显示每个功能的副本数量,最开始应该是每个功能只有一个副本。
|
||||
|
||||
```
|
||||
gateway_service_count
|
||||
|
||||
```
|
||||
|
||||
如果你想触发自动扩展,你可以在树莓派上尝试下面指令:
|
||||
|
||||
```
|
||||
$ while [ true ]; do curl -4 localhost:8080/function/func_echoit --data "hello world" ; done
|
||||
|
||||
```
|
||||
|
||||
查看 Prometheus 的“alerts”页面,可以知道你是否产生足够的负载来触发自动扩展。如果没有,你可以尝试在多个终端同时运行上面的指令。
|
||||
|
||||

|
||||
|
||||
当你降低负载,副本数量显示在你的第二个图表中,并且 `gateway_service_count` 指标再次降回 1。
|
||||
|
||||
### 结束演讲
|
||||
|
||||
我们现在配置好了 Docker、Swarm, 并且让 OpenFaaS 运行代码,把树莓派像大型计算机一样使用。
|
||||
|
||||
> 希望大家支持这个项目,**Star** [FaaS 的 GitHub 仓库][28]。
|
||||
|
||||
你是如何搭建好了自己的 Docker Swarm 集群并且运行 OpenFaaS 的呢?在 Twitter [@alexellisuk][46] 上分享你的照片或推文吧。
|
||||
|
||||
**观看我在 Dockercon 上关于 OpenFaaS 的视频**
|
||||
|
||||
我在 [Austin 的 Dockercon][47] 上展示了 OpenFaaS。——观看介绍和互动例子的视频:
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
|
||||
有问题?在下面的评论中提出,或者给我发邮件,邀请我进入你和志同道合者讨论树莓派、Docker、Serverless 的 Slack channel。
|
||||
|
||||
**想要学习更多关于树莓派上运行 Docker 的内容?**
|
||||
|
||||
我建议从 [5 Things you need to know][48] 开始,它包含了安全性、树莓派和普通 PC 间微妙差别等话题。
|
||||
|
||||
* [Dockercon tips: Docker & Raspberry Pi][18]
|
||||
|
||||
* [Control GPIO with Docker Swarm][19]
|
||||
|
||||
* [Is that a Docker Engine in your pocket??][20]
|
||||
|
||||
_在 Twitter 上分享_
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-serverless-raspberry-pi-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
译者:[haoqixu](https://github.com/haoqixu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/alexellisuk
|
||||
[1]:https://twitter.com/alexellisuk
|
||||
[2]:https://twitter.com/intent/tweet?in_reply_to=898978596773138436
|
||||
[3]:https://twitter.com/intent/retweet?tweet_id=898978596773138436
|
||||
[4]:https://twitter.com/intent/like?tweet_id=898978596773138436
|
||||
[5]:https://twitter.com/alexellisuk
|
||||
[6]:https://twitter.com/alexellisuk
|
||||
[7]:https://twitter.com/Docker
|
||||
[8]:https://twitter.com/Raspberry_Pi
|
||||
[9]:https://twitter.com/alexellisuk/status/898978596773138436
|
||||
[10]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[11]:https://twitter.com/alexellisuk
|
||||
[12]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[13]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[14]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[15]:https://twitter.com/alexellisuk/status/898978596773138436/photo/1
|
||||
[16]:https://twitter.com/alexellisuk/status/899545370916728832/photo/1
|
||||
[17]:https://support.twitter.com/articles/20175256
|
||||
[18]:https://blog.alexellis.io/dockercon-tips-docker-raspberry-pi/
|
||||
[19]:https://blog.alexellis.io/gpio-on-swarm/
|
||||
[20]:https://blog.alexellis.io/docker-engine-in-your-pocket/
|
||||
[21]:https://news.ycombinator.com/item?id=15052192
|
||||
[22]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[23]:https://github.com/alexellis/faas
|
||||
[24]:http://downloads.raspberrypi.org/raspbian_lite/images/raspbian_lite-2017-07-05/
|
||||
[25]:https://github.com/alexellis/faas
|
||||
[26]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
[27]:https://blog.alexellis.io/first-faas-python-function
|
||||
[28]:https://github.com/alexellis/faas
|
||||
[29]:https://blog.alexellis.io/tag/docker/
|
||||
[30]:https://blog.alexellis.io/tag/raspberry-pi/
|
||||
[31]:https://blog.alexellis.io/tag/openfaas/
|
||||
[32]:https://blog.alexellis.io/tag/faas/
|
||||
[33]:https://github.com/alexellis/faas
|
||||
[34]:https://blog.alexellis.io/introducing-functions-as-a-service/
|
||||
[35]:https://github.com/alexellis/faas
|
||||
[36]:https://github.com/alexellis/faas
|
||||
[37]:https://www.amazon.co.uk/Anker-PowerPort-Family-Sized-Technology-Smartphones/dp/B00PK1IIJY
|
||||
[38]:http://downloads.raspberrypi.org/raspbian/images/raspbian-2017-07-05/
|
||||
[39]:https://etcher.io/
|
||||
[40]:https://docs.docker.com/engine/swarm/admin_guide/
|
||||
[41]:https://github.com/alexellis/faas
|
||||
[42]:http://192.168.0.100:8080/
|
||||
[43]:https://blog.alexellis.io/first-faas-python-function
|
||||
[44]:https://github.com/alexellis/faas
|
||||
[45]:https://prometheus.io/
|
||||
[46]:https://twitter.com/alexellisuk
|
||||
[47]:https://blog.alexellis.io/dockercon-2017-captains-log/
|
||||
[48]:https://blog.alexellis.io/5-things-docker-rpi/
|
||||
298
translated/tech/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
298
translated/tech/20171004 Concurrent Servers Part 2 - Threads.md
Normal file
@ -0,0 +1,298 @@
|
||||
[并发服务器:第二节 - 线程][19]
|
||||
============================================================
|
||||
|
||||
这是并发网络服务器系列的第二节。[第一节][20] 提出了服务端实现的协议,还有简单的有序服务器的代码,是这整个系列的基础。
|
||||
|
||||
这一节里,我们来看看怎么用多线程来实现并发,用 C 实现一个最简单的多线程服务器,和用 Python 实现的线程池。
|
||||
|
||||
该系列的所有文章:
|
||||
|
||||
* [第一节 - 简介][8]
|
||||
|
||||
* [第二节 - 线程][9]
|
||||
|
||||
* [第三节 - 事件驱动][10]
|
||||
|
||||
### 多线程的方法设计并发服务器
|
||||
|
||||
说起第一节里的有序服务器的性能,最显而易见的,是在服务器处理客户端连接时,计算机的很多资源都被浪费掉了。尽管假定客户端快速发送完消息,不做任何等待,仍然需要考虑网络通信的开销;网络要比现在的 CPU 慢上百万倍还不止,因此 CPU 运行服务器时会等待接收套接字的流量,而大量的时间都花在完全不必要的等待中,。
|
||||
|
||||
这里是一份示意图,表明有序时客户端的运行过程:
|
||||
|
||||
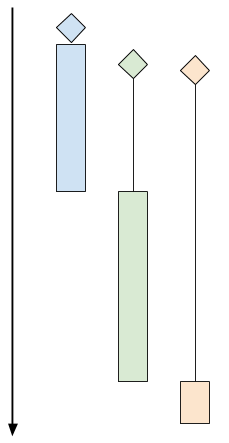
|
||||
|
||||
这个图片上有 3 个客户端程序。棱形表示客户端的“到达时间”(即客户端尝试连接服务器的时间)。黑色线条表示“等待时间”(客户端等待服务器真正接受连接所用的时间),有色矩形表示“处理时间”(服务器和客户端使用协议进行交互所用的时间)。有色矩形的末端表示客户端断开连接。
|
||||
|
||||
上图中,绿色和橘色的客户端尽管紧跟在蓝色客户端之后到达服务器,也要等到服务器处理完蓝色客户端的请求。这时绿色客户端得到响应,橘色的还要等待一段时间。
|
||||
|
||||
多线程服务器会开启多个控制线程,让操作系统管理 CPU 的并发(使用多个 CPU 核心)。当客户端连接的时候,创建一个线程与之交互,而在主线程中,服务器能够接受其他的客户端连接。下图是该模式的时间轴:
|
||||
|
||||

|
||||
|
||||
### 每个客户端一个线程,在 C 语言里要用 pthread
|
||||
|
||||
这篇文章的 [第一个示例代码][11] 是一个简单的 “每个客户端一个线程” 的服务器,用 C 语言编写,使用了 [phtreads API][12] 用于实现多线程。这里是主循环代码:
|
||||
|
||||
```
|
||||
while (1) {
|
||||
struct sockaddr_in peer_addr;
|
||||
socklen_t peer_addr_len = sizeof(peer_addr);
|
||||
|
||||
int newsockfd =
|
||||
accept(sockfd, (struct sockaddr*)&peer_addr, &peer_addr_len);
|
||||
|
||||
if (newsockfd < 0) {
|
||||
perror_die("ERROR on accept");
|
||||
}
|
||||
|
||||
report_peer_connected(&peer_addr, peer_addr_len);
|
||||
pthread_t the_thread;
|
||||
|
||||
thread_config_t* config = (thread_config_t*)malloc(sizeof(*config));
|
||||
if (!config) {
|
||||
die("OOM");
|
||||
}
|
||||
config->sockfd = newsockfd;
|
||||
pthread_create(&the_thread, NULL, server_thread, config);
|
||||
|
||||
// 回收线程 —— 在线程结束的时候,它占用的资源会被回收
|
||||
// 因为主线程在一直运行,所以它比服务线程存活更久。
|
||||
pthread_detach(the_thread);
|
||||
}
|
||||
```
|
||||
|
||||
这是 `server_thread` 函数:
|
||||
|
||||
```
|
||||
void* server_thread(void* arg) {
|
||||
thread_config_t* config = (thread_config_t*)arg;
|
||||
int sockfd = config->sockfd;
|
||||
free(config);
|
||||
|
||||
// This cast will work for Linux, but in general casting pthread_id to an 这个类型转换在 Linux 中可以正常运行,但是一般来说将 pthread_id 类型转换成整形不便于移植代码
|
||||
// integral type isn't portable.
|
||||
unsigned long id = (unsigned long)pthread_self();
|
||||
printf("Thread %lu created to handle connection with socket %d\n", id,
|
||||
sockfd);
|
||||
serve_connection(sockfd);
|
||||
printf("Thread %lu done\n", id);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
线程 “configuration” 是作为 `thread_config_t` 结构体进行传递的:
|
||||
|
||||
```
|
||||
typedef struct { int sockfd; } thread_config_t;
|
||||
```
|
||||
|
||||
主循环中调用的 `pthread_create` 产生一个新线程,然后运行 `server_thread` 函数。这个线程会在 `server_thread` 返回的时候结束。而在 `serve_connection` 返回的时候 `server_thread` 才会返回。`serve_connection` 和第一节完全一样。
|
||||
|
||||
第一节中我们用脚本生成了多个并发访问的客户端,观察服务器是怎么处理的。现在来看看多线程服务器的处理结果:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-20 06:31:56,632:conn1 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn2 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn0 connected...
|
||||
INFO:2017-09-20 06:31:56,632:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,632:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-20 06:31:56,633:conn1 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn2 received b'b'
|
||||
INFO:2017-09-20 06:31:56,633:conn0 received b'b'
|
||||
INFO:2017-09-20 06:31:56,670:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:56,671:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn1 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-20 06:31:57,634:conn2 received b'234'
|
||||
INFO:2017-09-20 06:31:57,634:conn0 received b'234'
|
||||
INFO:2017-09-20 06:31:58,635:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,635:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,636:conn1 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,636:conn2 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-20 06:31:58,637:conn0 received b'36bc1111'
|
||||
INFO:2017-09-20 06:31:58,836:conn2 disconnecting
|
||||
INFO:2017-09-20 06:31:58,836:conn1 disconnecting
|
||||
INFO:2017-09-20 06:31:58,837:conn0 disconnecting
|
||||
```
|
||||
|
||||
实际上,所有客户端同时连接,它们与服务器的通信是同时发生的。
|
||||
|
||||
### 每个客户端一个线程的难点
|
||||
|
||||
尽管在现代操作系统中就资源利用率方面来看,线程相当的高效,但前一节中讲到的方法在高负载时却会出现纰漏。
|
||||
|
||||
想象一下这样的情景:很多客户端同时进行连接,某些回话持续的时间长。这意味着某个时刻服务器上有很多活跃的线程。太多的线程会消耗掉大量的内存和 CPU 资源,仅仅是用于上下文切换 [ [1][13] ]。一个可行的方法是将其视为安全问题:因为这样的设计容易让服务器成为 [Dos 攻击][14] 的目标 —— 上百万个客户端同时连接,并且客户端都处于闲置状态,这样耗尽了所有资源就就可能让服务器宕机。
|
||||
|
||||
当服务器要与每个客户端通信,CPU 进行大量计算时,就会出现更严重的问题。这种情况下,容易想到的方法是减少服务器的响应能力 —— 只有其中一些客户端能得到服务器的响应。
|
||||
|
||||
因此,对多线程服务器所能够处理的并发客户端数做一些 _速率限制_ 就是个明智的选择。有很多方法可以实现。最容易想到的是计数当前已经连接上的客户端,把连接数限制在某个范围内(需要通过仔细的测试后决定)。另一种流行的多线程应用设计是使用 _线程池_。
|
||||
|
||||
### 线程池
|
||||
|
||||
[线程池][15] 很简单,也很有用。服务器创建几个任务线程,这些线程从某些队列中获取任务。这就是“池”。然后每一个客户端的连接被当成任务分发到池中。只要池中有空闲的线程,它就会去处理任务。如果当前池中所有线程都是繁忙状态,那么服务器就会阻塞,直到线程池可以接受任务(某个繁忙状态的线程处理完当前任务后,变回空闲的状态)。
|
||||
|
||||
这里有个 4 线程的线程池处理任务的图。任务(这里就是客户端的连接)要等到线程池中的某个线程可以接受新任务。
|
||||
|
||||

|
||||
|
||||
非常明显,线程池的定义就是一种按比例限制的机制。我们可以提前设定服务器所能拥有的线程数。那么这就是并发连接的最多的客户端数 —— 其它的客户端就要等到线程空闲。如果我们的池中有 8 个线程,那么 8 就是服务器可以处理的最多的客户端并发连接数,哪怕上千个客户端想要同时连接。
|
||||
|
||||
那么怎么确定池中需要有多少个线程呢?通过对问题范畴进行细致的分析,评估,实验以及根据我们拥有的硬件配置。如果是单核的云服务器,答案只有一个;如果是 100 核心的多套接字的服务器,那么答案就有很多种。也可以在运行时根据负载动态选择池的大小 —— 我会在这个系列之后的文章中谈到这个东西。
|
||||
|
||||
使用线程池的服务器在高负载情况下表现出 _性能退化_ —— 客户端能够以稳定的速率进行连接,可能会比其它时刻得到响应的用时稍微久一点;也就是说,无论多少个客户端同时进行连接,服务器总能保持响应,尽最大能力响应等待的客户端。与之相反,每个客户端一个线程的服务器,会接收多个客户端的连接直到过载,这时它更容易崩溃或者因为要处理_所有_客户端而变得缓慢,因为资源都被耗尽了(比如虚拟内存的占用)。
|
||||
|
||||
### 在服务器上使用线程池
|
||||
|
||||
为了 [改变服务器的实现][16],我用了 Python,在 Python 的标准库中带有一个已经实现好的稳定的线程池。(`concurrent.futures` 模块里的 `ThreadPoolExecutor`) [ [2][17] ]。
|
||||
|
||||
服务器创建一个线程池,然后进入循环,监听套接字接收客户端的连接。用 `submit` 把每一个连接的客户端分配到池中:
|
||||
|
||||
```
|
||||
pool = ThreadPoolExecutor(args.n)
|
||||
sockobj = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
|
||||
sockobj.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
sockobj.bind(('localhost', args.port))
|
||||
sockobj.listen(15)
|
||||
|
||||
try:
|
||||
while True:
|
||||
client_socket, client_address = sockobj.accept()
|
||||
pool.submit(serve_connection, client_socket, client_address)
|
||||
except KeyboardInterrupt as e:
|
||||
print(e)
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
`serve_connection` 函数和 C 的那部分很像,与一个客户端交互,直到其断开连接,并且遵循我们的协议:
|
||||
|
||||
```
|
||||
ProcessingState = Enum('ProcessingState', 'WAIT_FOR_MSG IN_MSG')
|
||||
|
||||
def serve_connection(sockobj, client_address):
|
||||
print('{0} connected'.format(client_address))
|
||||
sockobj.sendall(b'*')
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
|
||||
while True:
|
||||
try:
|
||||
buf = sockobj.recv(1024)
|
||||
if not buf:
|
||||
break
|
||||
except IOError as e:
|
||||
break
|
||||
for b in buf:
|
||||
if state == ProcessingState.WAIT_FOR_MSG:
|
||||
if b == ord(b'^'):
|
||||
state = ProcessingState.IN_MSG
|
||||
elif state == ProcessingState.IN_MSG:
|
||||
if b == ord(b'$'):
|
||||
state = ProcessingState.WAIT_FOR_MSG
|
||||
else:
|
||||
sockobj.send(bytes([b + 1]))
|
||||
else:
|
||||
assert False
|
||||
|
||||
print('{0} done'.format(client_address))
|
||||
sys.stdout.flush()
|
||||
sockobj.close()
|
||||
```
|
||||
|
||||
来看看线程池的大小对并行访问的客户端的阻塞行为有什么样的影响。为了演示,我会运行一个池大小为 2 的线程池服务器(只生成两个线程用于响应客户端)。
|
||||
|
||||
```
|
||||
$ python3.6 threadpool-server.py -n 2
|
||||
```
|
||||
|
||||
在另外一个终端里,运行客户端模拟器,产生 3 个并发访问的客户端:
|
||||
|
||||
```
|
||||
$ python3.6 simple-client.py -n 3 localhost 9090
|
||||
INFO:2017-09-22 05:58:52,815:conn1 connected...
|
||||
INFO:2017-09-22 05:58:52,827:conn0 connected...
|
||||
INFO:2017-09-22 05:58:52,828:conn1 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:52,828:conn1 received b'b'
|
||||
INFO:2017-09-22 05:58:52,828:conn0 received b'b'
|
||||
INFO:2017-09-22 05:58:52,867:conn1 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:52,867:conn0 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:53,829:conn1 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,829:conn0 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:53,830:conn1 received b'234'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'2'
|
||||
INFO:2017-09-22 05:58:53,831:conn0 received b'34'
|
||||
INFO:2017-09-22 05:58:54,831:conn1 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,832:conn1 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:54,832:conn0 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:54,833:conn0 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:55,032:conn1 disconnecting
|
||||
INFO:2017-09-22 05:58:55,032:conn2 connected...
|
||||
INFO:2017-09-22 05:58:55,033:conn2 sending b'^abc$de^abte$f'
|
||||
INFO:2017-09-22 05:58:55,033:conn0 disconnecting
|
||||
INFO:2017-09-22 05:58:55,034:conn2 received b'b'
|
||||
INFO:2017-09-22 05:58:55,071:conn2 received b'cdbcuf'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 sending b'xyz^123'
|
||||
INFO:2017-09-22 05:58:56,036:conn2 received b'234'
|
||||
INFO:2017-09-22 05:58:57,037:conn2 sending b'25$^ab0000$abab'
|
||||
INFO:2017-09-22 05:58:57,038:conn2 received b'36bc1111'
|
||||
INFO:2017-09-22 05:58:57,238:conn2 disconnecting
|
||||
```
|
||||
|
||||
回顾之前讨论的服务器行为:
|
||||
|
||||
1. 在有序服务器中,所有的连接都是串行的。一个连接结束后,下一个连接才能开始。
|
||||
|
||||
2. 前面讲到的每个客户端一个线程的服务器中,所有连接都被同时接受并得到服务。
|
||||
|
||||
这里可以看到一种可能的情况:两个连接同时得到服务,只有其中一个结束连接后第三个才能连接上。这就是把线程池大小设置成 2 的结果。真实用例我们会把线程池设置的更大些,取决于机器和实际的协议。线程池的缓冲机制就能很好理解了 —— 我 [几个月前][18] 更详细的介绍过这种机制,关于 Clojure 的 `core.async` 模块。
|
||||
|
||||
### Summary and next steps总结与展望
|
||||
|
||||
这篇文章讨论了在服务器中,用多线程作并发的方法。每个客户端一个线程的方法最早提出来,但是实际上却不常用,因为它并不安全。
|
||||
|
||||
线程池就常见多了,最受欢迎的几个编程语言有良好的实现(某些编程语言,像 Python,就是标准库中的实现)。这里说的使用线程池的服务器,不会受到每个客户端一个线程的弊端。
|
||||
|
||||
然而,线程不是处理多个客户端并行访问的唯一方法。下一节中我们会看看其它的解决方案,可以使用_异步处理_,或者_事件驱动_的编程。
|
||||
|
||||
* * *
|
||||
|
||||
[ [1][1] ] 老实说,现代 Linux 内核可以承受足够多的并发线程 —— 只要这些线程主要在 I/O 上被阻塞。[这里有个示例程序][2],它产生可配置数量的线程,线程在循环体中是休眠的,每 50 ms 唤醒一次。我在 4 核的 Linux 机器上可以轻松的产生 10000 个线程;哪怕这些线程大多数时间都在睡眠,它们仍然消耗一到两个核心,以便实现上下文切换。而且,它们占用了 80 GB 的虚拟内存(Linux 上每个线程的栈大小默认是 8MB)。实际使用中,线程会使用内存并且不会在循环体中休眠,因此它可以非常快的占用完一个机器的内存。
|
||||
|
||||
[ [2][3] ] 自己动手实现一个线程池是个有意思的练习,但我现在还不想做。我曾写过用来练手的 [针对特殊任务的线程池][4]。是用 Python 写的;用 C 重写的话有些难度,但对于经验丰富的程序员,几个小时就够了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[GitFuture](https://github.com/GitFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id1
|
||||
[2]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadspammer.c
|
||||
[3]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/12/27/python-threads-communication-and-stopping
|
||||
[5]:https://eli.thegreenplace.net/tag/concurrency
|
||||
[6]:https://eli.thegreenplace.net/tag/c-c
|
||||
[7]:https://eli.thegreenplace.net/tag/python
|
||||
[8]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[9]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[10]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[11]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threaded-server.c
|
||||
[12]:http://eli.thegreenplace.net/2010/04/05/pthreads-as-a-case-study-of-good-api-design
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id3
|
||||
[14]:https://en.wikipedia.org/wiki/Denial-of-service_attack
|
||||
[15]:https://en.wikipedia.org/wiki/Thread_pool
|
||||
[16]:https://github.com/eliben/code-for-blog/blob/master/2017/async-socket-server/threadpool-server.py
|
||||
[17]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/#id4
|
||||
[18]:http://eli.thegreenplace.net/2017/clojure-concurrency-and-blocking-with-coreasync/
|
||||
[19]:https://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[20]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
@ -1,53 +0,0 @@
|
||||
[如何成规模地部署多个云无服务器程序和 Cloud Foundry API][2]
|
||||
============================================================
|
||||
|
||||
IBM 的 Ken Parmelee 说:“微服务和 API 是产品,我们需要以这种方式思考。”
|
||||
|
||||

|
||||
|
||||
领导 IBM API 网关和 Big Blue 开源项目的的 Ken Parmelee 对开源“攻击” API 方法以及如何创建微服务并伸缩有一些想法。
|
||||
|
||||
Parmelee说:“微服务和 API 是产品,我们需要以这种方式思考这些问题。当你开始这么做,人们依赖它作为它们业务的一部分。这是你在这个领域你做的关键方面”
|
||||
|
||||

|
||||
|
||||
他在最近的[北欧 API 2017 平台峰会][3]站上讲台,并挑战了一些流行的观念。
|
||||
|
||||
“快速失败不是一个很好的概念。你想在第一场比赛中获得一些非常棒的东西。这并不意味着你需要花费大量的时间,而是让它变得非常棒,然后不断的发展和改进。如果一开始真的很糟糕,人们就不会想要用你。”
|
||||
|
||||
他通过 IBM 的现代无服务器架构运行,包括 [OpenWhisk][4],一个 IBM 和 Apache 之间的开源伙伴关系。 云优先分布式事件编程服务是两年多的重点关注这个领域的结果。IBM 是领先的贡献者,它是 IBM 云功能的基础。它提供基础设施即服务,自动缩放、为多种语言提供支持、用户只需支付实际使用费用。挑战也是这次旅程的一部分,因为他们发现服务器操作需要安全、并且需要轻松-匿名访问、缺少使用路径、固定的 URL 格式等。
|
||||
|
||||
任何人都可以在 [https://console.bluemix.net/openwhisk/][5] 上在 30 秒内尝试这些无服务器 API。“这听起来很有噱头, 但这是很容易做到的。我们正在结合[ Cloud Foundry 中完成的工作][6],并在 OpenWhisk 下的 Bluemix 中发布了它们,以提供安全性和可扩展性。”
|
||||
|
||||
他说:“灵活性对于微服务也是非常重要的。 当你使用 API 在现实世界中工作时,你开始需要跨云进行扩展。”这意味着从你的内部云到公共云,并且对你要怎么做有一个诚实的概念很重要。
|
||||
|
||||

|
||||
|
||||
他警告说,在思考“任何云概念”的时候,不是“将其放入一个 Docker 容器,并到处运行。这很棒,但需要在这些环境中有效运行。Docker 和 Kubernetes 有提供了很多帮助,但是你想要你的操作方式付诸实施。” 提前考虑 API 的消耗,无论是在内部运行还是扩展到公有云并且可以公开消费 - 你需要有这样的“架构观”,他补充道。
|
||||
|
||||
Parmelee说:“我们都希望我们所创造的有价值,并被广泛使用。” API 越成功,将其提升到更高水平的挑战就越大。
|
||||

|
||||
API 是微服务或“服务间”的组成部分。
|
||||
|
||||
他说,API 的未来是原生云的 - 无论你从哪里开始。关键因素是可扩展性,简化后端管理,降低成本,避免锁定厂商。
|
||||
|
||||
你可以在下面或在 [YouTube][7] 观看他整整 23 分钟的演讲。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||
|
||||
作者:[Superuser ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://superuser.openstack.org/articles/author/superuser/
|
||||
[1]:http://superuser.openstack.org/articles/author/superuser/
|
||||
[2]:http://superuser.openstack.org/articles/deploy-multi-cloud-serverless-cloud-foundry-apis-scale/
|
||||
[3]:https://nordicapis.com/events/the-2017-api-platform-summit/
|
||||
[4]:https://developer.ibm.com/openwhisk/
|
||||
[5]:https://console.bluemix.net/openwhisk/
|
||||
[6]:https://cloudfoundry.org/the-foundry/ibm-cloud/
|
||||
[7]:https://www.youtube.com/jA25Kmxr6fU
|
||||
Loading…
Reference in New Issue
Block a user