diff --git a/published/20150708 Choosing a Linux Tracer (2015).md b/published/20150708 Choosing a Linux Tracer (2015).md
new file mode 100644
index 0000000000..2d04d8594f
--- /dev/null
+++ b/published/20150708 Choosing a Linux Tracer (2015).md
@@ -0,0 +1,189 @@
+Linux 跟踪器之选
+======
+
+[![][1]][2]
+
+> Linux 跟踪很神奇!
+
+跟踪器是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
+
+有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
+
+你喜欢使用哪一个呢?
+
+我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
+
+### 对于大多数人
+
+大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
+
+#### 1. 使用 perf_events 进行 CPU 剖析
+
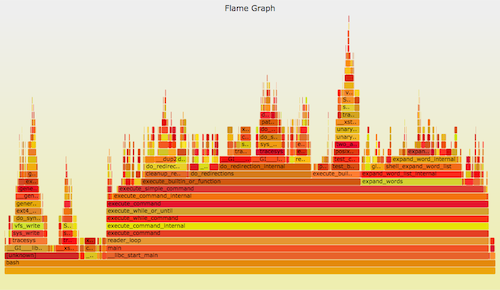
+可以使用 perf_events 进行 CPU 剖析。它可以用一个 [火焰图][3] 来形象地表示。比如:
+
+```
+git clone --depth 1 https://github.com/brendangregg/FlameGraph
+perf record -F 99 -a -g -- sleep 30
+perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
+```
+
+
+
+Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
+
+`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是采样。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
+
+#### 2. 知道它能干什么
+
+正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
+
+简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
+
+#### 3. 需要一个前端工具
+
+如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
+
+我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
+
+```
+# ./execsnoop
+Tracing exec()s. Ctrl-C to end.
+ PID PPID ARGS
+ 22898 22004 man ls
+ 22905 22898 preconv -e UTF-8
+ 22908 22898 pager -s
+ 22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
+[...]
+```
+
+在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
+
+### 对于性能或者内核工程师
+
+一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
+
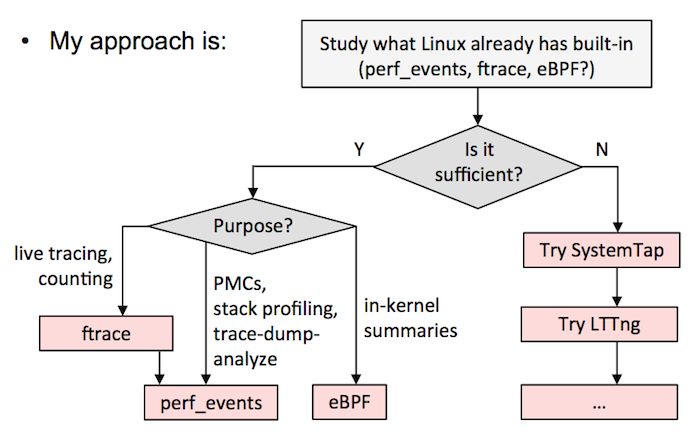
+在这里我建议选择如下,要么:
+
+A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
+
+B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
+
+
+
+以下是我对各个跟踪器的评价:
+
+#### 1. ftrace
+
+我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;函数流步进。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易调校,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是可编程的,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
+
+#### 2. perf_events
+
+[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用调试信息进行行级跟踪。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
+
+#### 3. eBPF
+
+扩展的伯克利包过滤器(eBPF)是一个内核内的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供内核内编程,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的延迟热力图。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
+
+#### 4. SystemTap
+
+[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
+
+#### 5. LTTng
+
+[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
+
+#### 6. ktap
+
+[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
+
+#### 7. dtrace4linux
+
+[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些供应器可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
+
+#### 8. OL DTrace
+
+[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
+
+#### 9. sysdig
+
+[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理系统调用事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
+
+### 深入阅读
+
+我自己的工作中使用到的跟踪器包括:
+
+- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
+- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
+- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
+- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
+- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
+- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
+- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
+- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
+- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
+- **其它** : 关于 [strace][46],我写了一些告诫文章。
+
+不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
+
+感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
+
+--------------------------------------------------------------------------------
+
+via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
+
+作者:[Brendan Gregg][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.brendangregg.com
+[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
+[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
+[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
+[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
+[5]:http://lwn.net/Articles/608497/
+[6]:http://www.brendangregg.com/perf.html
+[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
+[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
+[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
+[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
+[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
+[12]:http://lwn.net/Articles/370423/
+[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
+[14]:https://perf.wiki.kernel.org/index.php/Main_Page
+[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
+[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
+[17]:https://sourceware.org/systemtap/wiki
+[18]:http://lttng.org/
+[19]:http://ktap.org/
+[20]:https://github.com/dtrace4linux/linux
+[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
+[22]:http://www.sysdig.org/
+[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
+[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
+[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
+[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
+[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
+[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
+[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
+[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
+[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
+[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
+[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
+[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
+[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
+[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
+[37]:https://github.com/brendangregg/BPF-tools
+[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
+[39]:https://github.com/brendangregg/systemtap-lwtools
+[40]:http://www.brendangregg.com/ktap.html
+[41]:http://www.brendangregg.com/sysperfbook.html
+[42]:https://github.com/dtrace4linux/linux/issues/55
+[43]:http://www.brendangregg.com
+[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
+[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
+[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
+[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
+[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
+[49]:http://www.beginningwithi.com/
diff --git a/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md b/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md
new file mode 100644
index 0000000000..bf2e2d972a
--- /dev/null
+++ b/published/20170310 9 Lightweight Linux Applications to Speed Up Your System.md
@@ -0,0 +1,210 @@
+9 个提高系统运行速度的轻量级 Linux 应用
+======
+
+**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
+
+![在 ubunt 使用轻量级应用程序替代方案][4]
+
+### 9 个常用 Linux 应用程序的轻量级替代方案
+
+你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
+
+所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
+
+由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
+
+### 1. Midori: Web 浏览器
+
+[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
+
+![Midori Browser][6]
+
+Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
+
+
+#### 在基于 Ubuntu 的发行版上安装 Midori
+
+在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
+
+```
+sudo apt install midori
+```
+
+### 2. Trojita:电子邮件客户端
+
+[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
+
+![Trojitá][10]
+
+Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
+
+#### 在基于 Ubuntu 的发行版上安装 Trojita
+
+Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
+
+```
+sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
+wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
+sudo apt-key add - < Release.key
+sudo apt update
+sudo apt install trojita
+```
+
+### 3. GDebi:包安装程序
+
+有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
+
+Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
+
+![GDebi][12]
+
+GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
+
+#### 在基于 Ubuntu 的发行版上安装 GDebi
+
+只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
+
+```
+sudo apt install gdebi
+```
+
+### 4. App Grid:软件中心
+
+如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
+
+![App Grid][14]
+
+App Grid 支持应用程序的评分、评论和屏幕截图。
+
+#### 在基于 Ubuntu 的发行版上安装 App Grid
+
+App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
+
+```
+sudo add-apt-repository ppa:appgrid/stable
+sudo apt update
+sudo apt install appgrid
+```
+
+### 5. Yarock:音乐播放器
+
+[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
+
+![Yarock][16]
+
+Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
+
+### 在基于 Ubuntu 的发行版上安装 Yarock
+
+您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
+
+```
+sudo add-apt-repository ppa:nilarimogard/webupd8
+sudo apt update
+sudo apt install yarock
+```
+
+### 6. VLC:视频播放器
+
+谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
+
+![VLC][18]
+
+VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
+
+#### 在基于 Ubuntu 的发行版上安装 VLC
+
+VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
+
+```
+sudo apt install vlc
+```
+
+### 7. PCManFM:文件管理器
+
+PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
+
+![PCManFM][20]
+
+尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
+
+#### 在基于 Ubuntu 的发行版上安装 PCManFM
+
+在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
+
+```
+sudo apt install pcmanfm
+```
+
+### 8. Mousepad:文本编辑器
+
+在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
+
+![Mousepad][21]
+
+Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
+
+#### 在基于 Ubuntu 的发行版上安装 Mousepad
+
+想要安装 Mousepad ,可以使用以下指令:
+
+```
+sudo apt install mousepad
+```
+
+### 9. GNOME Office:办公软件
+
+许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
+
+**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
+
+![AbiWord][22]
+
+**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
+
+![Gnumeric][23]
+
+在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
+
+#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
+
+要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
+
+```
+sudo apt install abiword gnumeric
+```
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
+
+作者:[Munif Tanjim][a]
+译者:[imquanquan](https://github.com/imquanquan)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/munif/
+[1]:https://itsfoss.com/speed-up-ubuntu-1310/
+[2]:https://itsfoss.com/essential-linux-applications/
+[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
+[5]:https://itsfoss.com/lightweight-linux-beginners/
+[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
+[7]:http://midori-browser.org/faqs/
+[8]:http://midori-browser.org/
+[9]:https://itsfoss.com/best-email-clients-linux/
+[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
+[11]:http://trojita.flaska.net/
+[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
+[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
+[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
+[15]:http://www.appgrid.org/
+[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
+[17]:https://seb-apps.github.io/yarock/
+[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
+[19]:http://www.videolan.org/index.html
+[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
+[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
+[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
+[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
+[24]:https://gnome.org/gnome-office/
diff --git a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
similarity index 51%
rename from translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
rename to published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
index d486a777de..cfeade8a8b 100644
--- a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
+++ b/published/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
@@ -1,18 +1,20 @@
-使用一个命令重置 Linux 桌面到默认设置
+使用一个命令重置 Linux 桌面为默认设置
======
+

-前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
+前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
### 将 Linux 桌面重置为默认设置
-这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
+这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
-**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
+**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
-好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
+好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
+
```
dconf reset -f /
```
@@ -29,12 +31,13 @@ dconf reset -f /
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
-有关 “dconf” 命令的更多详细信息,请参阅手册页。
+有关 `dconf` 命令的更多详细信息,请参阅手册页。
+
```
man dconf
```
-在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
+在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
@@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
作者:[Edwin Arteaga][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://www.ostechnix.com
-[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
+[1]:https://linux.cn/article-9217-1.html
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
-[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
diff --git a/published/20171009 10 layers of Linux container security - Opensource.com.md b/published/20171009 10 layers of Linux container security - Opensource.com.md
new file mode 100644
index 0000000000..26188dd1ec
--- /dev/null
+++ b/published/20171009 10 layers of Linux container security - Opensource.com.md
@@ -0,0 +1,129 @@
+Linux 容器安全的 10 个层面
+======
+
+> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
+
+
+
+容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
+
+
+
+企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
+
+对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
+
+请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
+
+### 1. 容器宿主机操作系统和多租户环境
+
+由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
+
+容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
+
+### 2. 容器内容(使用可信来源)
+
+在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
+
+### 3. 容器注册(安全访问容器镜像)
+
+你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
+
+### 4. 安全性与构建过程
+
+在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
+
+不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
+
+ * 运营团队管理基础镜像
+ * 架构师管理中间件、运行时、数据库,以及其它解决方案
+ * 开发者专注于应用程序层面,并且只写代码
+
+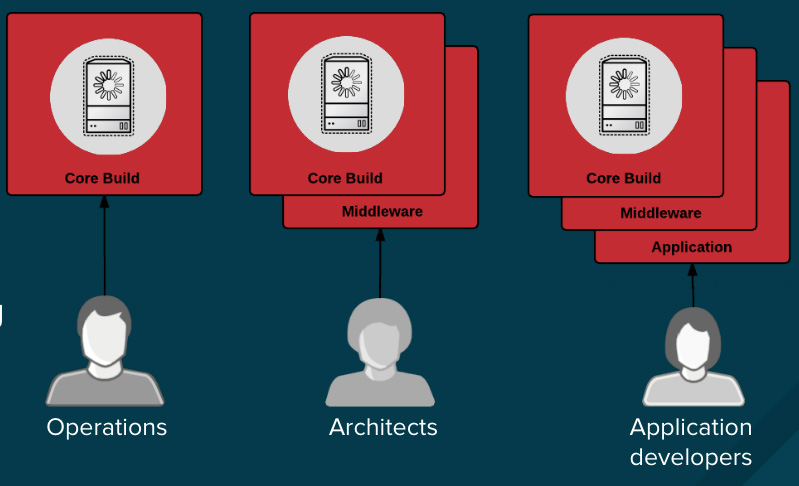
+
+最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
+
+### 5. 控制好在同一个集群内部署应用
+
+如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
+
+我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
+
+一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
+
+### 6. 容器编配:保护容器平台安全
+
+当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
+
+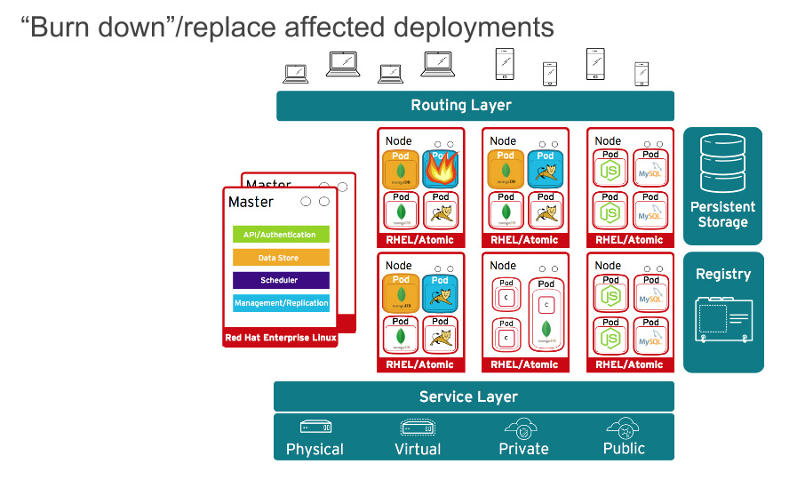
+
+在大规模的容器部署时,你应该考虑:
+
+ * 哪个容器应该被部署在哪个宿主机上?
+ * 那个宿主机应该有什么样的性能?
+ * 哪个容器需要访问其它容器?它们之间如何发现彼此?
+ * 你如何控制和管理对共享资源的访问,像网络和存储?
+ * 如何监视容器健康状况?
+ * 如何去自动扩展性能以满足应用程序的需要?
+ * 如何在满足安全需求的同时启用开发者的自助服务?
+
+考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
+
+### 7. 网络隔离
+
+在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
+
+使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
+
+### 8. 存储
+
+容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
+
+一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
+
+### 9. API 管理、终端安全、以及单点登录(SSO)
+
+保护你的应用安全,包括管理应用、以及 API 的认证和授权。
+
+Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
+
+API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
+
+这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
+
+### 10. 在一个联合集群中的角色和访问管理
+
+在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
+
+当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
+
+### 选择一个容器平台
+
+当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
+
+想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
+
+### 关于作者
+
+Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/10/10-layers-container-security
+
+作者:[Daniel Oh][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/daniel-oh
+[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
+[2]:https://en.wikipedia.org/wiki/Cgroups
+[3]:https://en.wikipedia.org/wiki/Seccomp
+[4]:https://en.wikipedia.org/wiki/Software-defined_networking
+[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
+[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
+[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
diff --git a/translated/tech/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md b/published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
similarity index 55%
rename from translated/tech/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
rename to published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
index 6d01bec236..3d4478ece2 100644
--- a/translated/tech/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
+++ b/published/20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md
@@ -1,45 +1,44 @@
-# 让 “rm” 命令将文件移动到“垃圾桶”,而不是完全删除它们
+给 “rm” 命令添加个“垃圾桶”
+============
-人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf * `。当你使用 rm 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 `垃圾箱`。
+人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
-有时我们会将不应该删除的文件删除掉,所以当错误的删除文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
+有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
-将文件移动到“垃圾桶”是一个好主意,当你无意中运行 rm 命令时,可以节省你的时间,但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
+将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
-这适用于服务器和桌面两种环境。 如果脚本检测到 **GNOME 、KDE、Unity 或 LXDE** 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 **\$HOME/.local/share/Trash/files**,否则会在您的主目录中创建垃圾箱文件夹 **$HOME/Trash**。
+这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
+
+`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
-saferm.sh 脚本托管在 Github 中,可以从 repository 中克隆,也可以创建一个名为 saferm.sh 的文件并复制其上的代码。
```
$ git clone https://github.com/lagerspetz/linux-stuff
$ sudo mv linux-stuff/scripts/saferm.sh /bin
$ rm -Rf linux-stuff
-
```
-在 `bashrc` 文件中设置别名,
+在 `.bashrc` 文件中设置别名,
```
alias rm=saferm.sh
-
```
执行下面的命令使其生效,
```
$ source ~/.bashrc
-
```
-一切就绪,现在你可以执行 rm 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
+一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
+
+测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
-测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行显式的说明了 `Moving magi.txt to $HOME/.local/share/Trash/file`
```
$ rm -rf magi.txt
Moving magi.txt to /home/magi/.local/share/Trash/files
-
```
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
@@ -47,47 +46,16 @@ Moving magi.txt to /home/magi/.local/share/Trash/files
```
$ ls -lh /home/magi/.local/share/Trash/files
Permissions Size User Date Modified Name
-.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
-
+.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
```
或者我们可以通过文件管理器界面中查看相同的内容。
![![][3]][4]
-创建一个定时任务,每天清理一次“垃圾桶”,( LCTT 注:原文为每周一次,但根据下面的代码,应该是每天一次)
+(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
-```
-$ 1 1 * * * trash-empty
-
-```
-
-`注意` 对于服务器环境,我们需要使用 rm 命令手动删除。
-
-```
-$ rm -rf /root/Trash/
-/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
-Deleting /root/Trash/magi1.txt
-
-```
-
-对于桌面环境,trash-put 命令也可以做到这一点。
-
-在 `bashrc` 文件中创建别名,
-
-```
-alias rm=trash-put
-
-```
-
-执行下面的命令使其生效。
-
-```
-$ source ~/.bashrc
-
-```
-
-要了解 saferm.sh 的其他选项,请查看帮助。
+要了解 `saferm.sh` 的其他选项,请查看帮助。
```
$ saferm.sh -h
@@ -112,7 +80,7 @@ via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
作者:[2DAYGEEK][a]
译者:[amwps290](https://github.com/amwps290)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md b/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md
new file mode 100644
index 0000000000..c221094e63
--- /dev/null
+++ b/published/20171017 What Are the Hidden Files in my Linux Home Directory For.md
@@ -0,0 +1,59 @@
+我的 Linux 主目录中的隐藏文件是干什么用的?
+======
+
+
+
+在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
+
+### 在主目录中隐藏的文件是干什么用的?
+
+![hidden-files-liunux-2][1]
+
+通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
+
+通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
+
+依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
+
+### 主目录中某些隐藏文件的特定用途是什么?
+
+![hidden-files-linux-3][2]
+
+每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
+
+#### 系统设置
+
+系统设置包括桌面环境和 shell 的配置。
+
+* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
+* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名][3]。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
+* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
+
+#### 应用配置文件
+
+你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
+
+* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
+* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
+* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存][4]),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
+* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
+
+### 结论
+
+在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
+
+作者:[Alexander Fox][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/alexfox/
+[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
+[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
+[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
+[4]:https://www.maketecheasier.com/clear-spotify-cache/
diff --git a/published/20171102 What is huge pages in Linux.md b/published/20171102 What is huge pages in Linux.md
new file mode 100644
index 0000000000..1f1d0b50a0
--- /dev/null
+++ b/published/20171102 What is huge pages in Linux.md
@@ -0,0 +1,140 @@
+Linux 中的“大内存页”(hugepage)是个什么?
+======
+
+> 学习 Linux 中的大内存页。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
+
+![Huge Pages in Linux][1]
+
+本文中我们会详细介绍大内存页,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
+
+首先让我们从“大内存页”的基础知识开始讲起。
+
+### Linux 中的“大内存页”是个什么玩意?
+
+“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
+
+在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
+
+### 为什么使用“大内存页”?
+
+在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
+
+使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
+
+简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
+
+### 如何配置“大内存页”?
+
+运行下面命令来查看当前“大内存页”的详细内容。
+
+```
+root@kerneltalks # grep Huge /proc/meminfo
+AnonHugePages: 0 kB
+HugePages_Total: 0
+HugePages_Free: 0
+HugePages_Rsvd: 0
+HugePages_Surp: 0
+Hugepagesize: 2048 kB
+```
+
+从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
+
+运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
+
+```
+#!/bin/bash
+#
+# hugepages_settings.sh
+#
+# Linux bash script to compute values for the
+# recommended HugePages/HugeTLB configuration
+#
+# Note: This script does calculation for all shared memory
+# segments available when the script is run, no matter it
+# is an Oracle RDBMS shared memory segment or not.
+# Check for the kernel version
+KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
+# Find out the HugePage size
+HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
+# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
+NUM_PG=1
+# Cumulative number of pages required to handle the running shared memory segments
+for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
+do
+ MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
+ if [ $MIN_PG -gt 0 ]; then
+ NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
+ fi
+done
+# Finish with results
+case $KERN in
+ '2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
+ echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
+ '2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
+ *) echo "Unrecognized kernel version $KERN. Exiting." ;;
+esac
+# End
+```
+
+将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
+
+```
+root@kerneltalks # sh /tmp/hugepages_settings.sh
+Recommended setting: vm.nr_hugepages = 124
+```
+
+你的输出类似如上结果,只是数字会有一些出入。
+
+这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
+
+### 配置内核中的“大内存页”
+
+本文最后一部分内容是配置上面提到的 [内核参数 ][2] ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
+
+```
+vm.nr_hugepages=126
+```
+
+注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
+
+现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
+
+你需要编辑 `/etc/security/limits.conf` 中的如下配置:
+
+```
+soft memlock 258048
+hard memlock 258048
+```
+
+某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
+
+这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
+
+### 如何禁用“大内存页”?
+
+“大内存页”默认是开启的。使用下面命令来查看“大内存页”的当前状态。
+
+```
+root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
+[always] madvise never
+```
+
+输出中的 `[always]` 标志说明系统启用了“大内存页”。
+
+若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
+
+若想禁用“大内存页”,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
+
+作者:[Shrikant Lavhate][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
+[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
diff --git a/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md b/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md
new file mode 100644
index 0000000000..bd0959ea64
--- /dev/null
+++ b/published/20171110 How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora).md
@@ -0,0 +1,94 @@
+如何在 Linux 中配置 ssh 登录导语
+======
+
+> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
+
+![Login banners in Linux][1]
+
+无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是登录导语。
+
+![Login welcome messages in Linux][2]
+
+在本文中,我们将引导你配置它们。
+
+你可以配置两种类型的导语。
+
+1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
+2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
+
+### 如何在用户登录前连接系统时显示消息
+
+当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
+
+你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
+
+```
+# cat /etc/login.warn
+ !!!! Welcome to KernelTalks test server !!!!
+This server is meant for testing Linux commands and tools. If you are
+not associated with kerneltalks.com and not authorized please dis-connect
+immediately.
+```
+
+现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
+
+这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
+
+保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
+
+```
+root@kerneltalks # ps -ef | grep -i sshd
+root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
+root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
+root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
+
+root@kerneltalks # kill -HUP 14255
+```
+
+就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
+
+![Login banner in Linux][3]
+
+你可以在用户输入密码登录系统之前看到此消息。
+
+### 如何在用户登录后显示消息
+
+消息用户在成功登录系统后看到的当天消息(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
+
+```
+root@kerneltalks # cat /etc/motd
+ W E L C O M E
+Welcome to the testing environment of kerneltalks.
+Feel free to use this system for testing your Linux
+skills. In case of any issues reach out to admin at
+info@kerneltalks.com. Thank you.
+
+```
+
+你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
+
+![motd in linux][4]
+
+你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
+
+你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
+
+作者:[kerneltalks][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
+[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
+[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
+[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
+[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
+[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
+[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
+[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
diff --git a/published/20171115 How to create better documentation with a kanban board.md b/published/20171115 How to create better documentation with a kanban board.md
new file mode 100644
index 0000000000..fa92553ea2
--- /dev/null
+++ b/published/20171115 How to create better documentation with a kanban board.md
@@ -0,0 +1,46 @@
+如何使用看板(kanban)创建更好的文档
+======
+> 通过卡片分类和看板来给用户提供他们想要的信息。
+
+
+
+如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
+
+卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
+
+我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
+
+我发现[看板][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
+
+我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
+
+### 怎么运行的
+
+我最成功的看板体验是在写 [Gluster][3] 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
+
+首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
+
+处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
+
+### 使用数据
+
+在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
+
+将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
+
+我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/11/kanban-boards-card-sorting
+
+作者:[Heidi Waterhouse][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/hwaterhouse
+[1]:https://en.wikipedia.org/wiki/Kanban
+[2]:https://opensource.com/alternatives/trello
+[3]:https://www.gluster.org/
diff --git a/published/20171116 Record and Share Terminal Session with Showterm.md b/published/20171116 Record and Share Terminal Session with Showterm.md
new file mode 100644
index 0000000000..a82efb3744
--- /dev/null
+++ b/published/20171116 Record and Share Terminal Session with Showterm.md
@@ -0,0 +1,78 @@
+使用 Showterm 录制和分享终端会话
+======
+
+
+
+你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
+
+Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
+
+**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
+
+### 在 Linux 中安装 Showterm
+
+Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
+
+```
+gem install showterm
+```
+
+如果你没有在 Linux 上安装 Ruby,可以这样:
+
+```
+sudo curl showterm.io/showterm > ~/bin/showterm
+sudo chmod +x ~/bin/showterm
+```
+
+如果你只是想运行程序而不是安装:
+
+```
+bash <(curl record.showterm.io)
+```
+
+你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
+
+**相关**:[如何在 Ubuntu 中录制终端会话][3]
+
+### 录制终端会话
+
+![showterm terminal][4]
+
+录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
+
+Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete ` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry
-
-
-
-
-