mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
commit
42c718d87d
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,189 @@
|
||||
Linux 跟踪器之选
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
> Linux 跟踪很神奇!
|
||||
|
||||
<ruby>跟踪器<rt>tracer</rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
|
||||
|
||||
### 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
|
||||
|
||||
#### 1. 使用 perf_events 进行 CPU 剖析
|
||||
|
||||
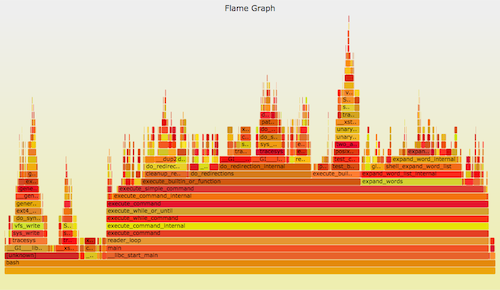
可以使用 perf_events 进行 CPU <ruby>剖析<rt>profiling</rt></ruby>。它可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
```
|
||||
|
||||
|
||||
|
||||
Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby>采样<rt>sampling</rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
|
||||
|
||||
#### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
|
||||
|
||||
#### 3. 需要一个前端工具
|
||||
|
||||
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
```
|
||||
|
||||
在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
|
||||
|
||||
### 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
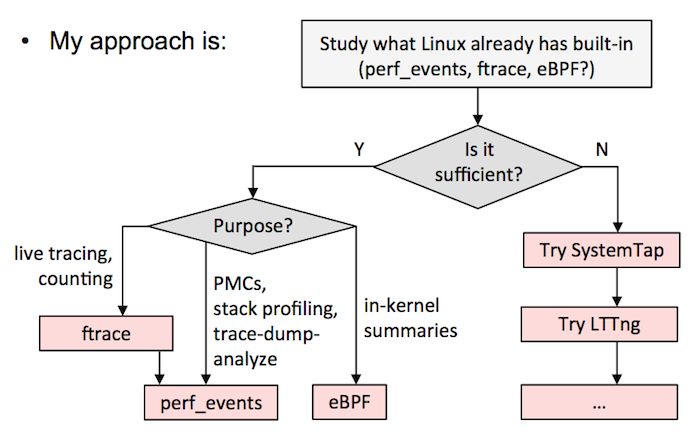
在这里我建议选择如下,要么:
|
||||
|
||||
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
#### 1. ftrace
|
||||
|
||||
我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby>函数流步进<rt>function-flow walking</rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby>调校<rt>hackable</rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby>可编程的<rt>programmable</rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
|
||||
|
||||
#### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby>调试信息<rt>debuginfo</rt></ruby>进行<ruby>行级跟踪<rt>line tracing</rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
|
||||
|
||||
#### 3. eBPF
|
||||
|
||||
<ruby>扩展的伯克利包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>(eBPF)是一个<ruby>内核内<rt>in-kernel</rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供<ruby>内核内编程<rt>in-kernel programming</rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby>延迟热力图<rt>latency heat map</rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
#### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
#### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
|
||||
|
||||
#### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
#### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby>供应器<rt>provider</rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
#### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
#### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby>系统调用<rt>syscall</rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
### 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
|
||||
- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
|
||||
- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
|
||||
- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
|
||||
- **其它** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,210 @@
|
||||
9 个提高系统运行速度的轻量级 Linux 应用
|
||||
======
|
||||
|
||||
**简介:** [加速 Ubuntu 系统][1]有很多方法,办法之一是使用轻量级应用来替代一些常用应用程序。我们之前之前发布过一篇 [Linux 必备的应用程序][2],如今将分享这些应用程序在 Ubuntu 或其他 Linux 发行版的轻量级替代方案。
|
||||
|
||||
![在 ubunt 使用轻量级应用程序替代方案][4]
|
||||
|
||||
### 9 个常用 Linux 应用程序的轻量级替代方案
|
||||
|
||||
你的 Linux 系统很慢吗?应用程序是不是很久才能打开?你最好的选择是使用[轻量级的 Linux 系统][5]。但是重装系统并非总是可行,不是吗?
|
||||
|
||||
所以如果你想坚持使用你现在用的 Linux 发行版,但是想要提高性能,你应该使用更轻量级应用来替代你一些常用的应用。这篇文章会列出各种 Linux 应用程序的轻量级替代方案。
|
||||
|
||||
由于我使用的是 Ubuntu,因此我只提供了基于 Ubuntu 的 Linux 发行版的安装说明。但是这些应用程序可以用于几乎所有其他 Linux 发行版。你只需去找这些轻量级应用在你的 Linux 发行版中的安装方法就可以了。
|
||||
|
||||
### 1. Midori: Web 浏览器
|
||||
|
||||
[Midori][8] 是与现代互联网环境具有良好兼容性的最轻量级网页浏览器之一。它是开源的,使用与 Google Chrome 最初所基于的相同的渲染引擎 —— WebKit。并且超快速,最小化但高度可定制。
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
Midori 浏览器有很多可以定制的扩展和选项。如果你有最高权限,使用这个浏览器也是一个不错的选择。如果在浏览网页的时候遇到了某些问题,请查看其网站上[常见问题][7]部分 -- 这包含了你可能遇到的常见问题及其解决方案。
|
||||
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Midori
|
||||
|
||||
在 Ubuntu 上,可通过官方源找到 Midori 。运行以下指令即可安装它:
|
||||
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita:电子邮件客户端
|
||||
|
||||
[Trojita][11] 是一款开源强大的 IMAP 电子邮件客户端。它速度快,资源利用率高。我可以肯定地称它是 [Linux 最好的电子邮件客户端之一][9]。如果你只需电子邮件客户端提供 IMAP 支持,那么也许你不用再进一步考虑了。
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita 使用各种技术 —— 按需电子邮件加载、离线缓存、带宽节省模式等 —— 以实现其令人印象深刻的性能。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Trojita
|
||||
|
||||
Trojita 目前没有针对 Ubuntu 的官方 PPA 。但这应该不成问题。您可以使用以下命令轻松安装它:
|
||||
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi:包安装程序
|
||||
|
||||
有时您需要快速安装 DEB 软件包。Ubuntu 软件中心是一个消耗资源严重的应用程序,仅用于安装 .deb 文件并不明智。
|
||||
|
||||
Gdebi 无疑是一款可以完成同样目的的漂亮工具,而它只有个极简的图形界面。
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi 是完全轻量级的,完美无缺地完成了它的工作。你甚至应该[让 Gdebi 成为 DEB 文件的默认安装程序][13]。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 GDebi
|
||||
|
||||
只需一行指令,你便可以在 Ubuntu 上安装 GDebi:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid:软件中心
|
||||
|
||||
如果您经常在 Ubuntu 上使用软件中心搜索、安装和管理应用程序,则 [App Grid][15] 是必备的应用程序。它是默认的 Ubuntu 软件中心最具视觉吸引力且速度最快的替代方案。
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid 支持应用程序的评分、评论和屏幕截图。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 App Grid
|
||||
|
||||
App Grid 拥有 Ubuntu 的官方 PPA。使用以下指令安装 App Grid:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock:音乐播放器
|
||||
|
||||
[Yarock][17] 是一个优雅的音乐播放器,拥有现代而最轻量级的用户界面。尽管在设计上是轻量级的,但 Yarock 有一个全面的高级功能列表。
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
Yarock 的主要功能包括多种音乐收藏、评级、智能播放列表、多种后端选项、桌面通知、音乐剪辑、上下文获取等。
|
||||
|
||||
### 在基于 Ubuntu 的发行版上安装 Yarock
|
||||
|
||||
您得通过 PPA 使用以下指令在 Ubuntu 上安装 Yarock:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC:视频播放器
|
||||
|
||||
谁不需要视频播放器?谁还从未听说过 [VLC][19]?我想并不需要对它做任何介绍。
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC 能满足你在 Ubuntu 上播放各种媒体文件的全部需求,而且它非常轻便。它甚至可以在非常旧的 PC 上完美运行。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 VLC
|
||||
|
||||
VLC 为 Ubuntu 提供官方 PPA。可以输入以下命令来安装它:
|
||||
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM:文件管理器
|
||||
|
||||
PCManFM 是 LXDE 的标准文件管理器。与 LXDE 的其他应用程序一样,它也是轻量级的。如果您正在为文件管理器寻找更轻量级的替代品,可以尝试使用这个应用。
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
尽管来自 LXDE,PCManFM 也同样适用于其他桌面环境。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 PCManFM
|
||||
|
||||
在 Ubuntu 上安装 PCManFM 只需要一条简单的指令:
|
||||
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad:文本编辑器
|
||||
|
||||
在轻量级方面,没有什么可以击败像 nano、vim 等命令行文本编辑器。但是,如果你想要一个图形界面,你可以尝试一下 Mousepad -- 一个最轻量级的文本编辑器。它非常轻巧,速度非常快。带有简单的可定制的用户界面和多个主题。
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad 支持语法高亮显示。所以,你也可以使用它作为基础的代码编辑器。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 Mousepad
|
||||
|
||||
想要安装 Mousepad ,可以使用以下指令:
|
||||
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office:办公软件
|
||||
|
||||
许多人需要经常使用办公应用程序。通常,大多数办公应用程序体积庞大且很耗资源。Gnome Office 在这方面非常轻便。Gnome Office 在技术上不是一个完整的办公套件。它由不同的独立应用程序组成,在这之中 AbiWord&Gnumeric 脱颖而出。
|
||||
|
||||
**AbiWord** 是文字处理器。它比其他替代品轻巧并且快得多。但是这样做是有代价的 —— 你可能会失去宏、语法检查等一些功能。AdiWord 并不完美,但它可以满足你基本的需求。
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** 是电子表格编辑器。就像 AbiWord 一样,Gnumeric 也非常快速,提供了精确的计算功能。如果你正在寻找一个简单轻便的电子表格编辑器,Gnumeric 已经能满足你的需求了。
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
在 [Gnome Office][24] 下面还有一些其它应用程序。你可以在官方页面找到它们。
|
||||
|
||||
#### 在基于 Ubuntu 的发行版上安装 AbiWord&Gnumeric
|
||||
|
||||
要安装 AbiWord&Gnumeric,只需在终端中输入以下指令:
|
||||
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[imquanquan](https://github.com/imquanquan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:http://trojita.flaska.net/img/2016-03-22-trojita-home.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,18 +1,20 @@
|
||||
使用一个命令重置 Linux 桌面到默认设置
|
||||
使用一个命令重置 Linux 桌面为默认设置
|
||||
======
|
||||
|
||||

|
||||
|
||||
前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
前段时间,我们分享了一篇关于 [Resetter][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
|
||||
|
||||
### 将 Linux 桌面重置为默认设置
|
||||
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 Arch Linux MATE 和 Ubuntu 16.04 Unity 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
|
||||
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中固定的应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
|
||||
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
|
||||
好的是它只会重置桌面设置。它不会影响其他不使用 `dconf` 的程序。此外,它不会删除你的个人资料。
|
||||
|
||||
现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
|
||||
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
@ -29,12 +31,13 @@ dconf reset -f /
|
||||
|
||||
看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
|
||||
|
||||
有关 “dconf” 命令的更多详细信息,请参阅手册页。
|
||||
有关 `dconf` 命令的更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
在重置桌面上我个人更喜欢 “Resetter” 而不是 `dconf` 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 `dconf` 命令在几分钟内将你的 Linux 系统重置为默认设置。
|
||||
|
||||
就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
|
||||
|
||||
@ -48,12 +51,12 @@ via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-comma
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[1]:https://linux.cn/article-9217-1.html
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png
|
||||
@ -0,0 +1,129 @@
|
||||
Linux 容器安全的 10 个层面
|
||||
======
|
||||
|
||||
> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
|
||||
|
||||

|
||||
|
||||
容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
|
||||
|
||||

|
||||
|
||||
企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
|
||||
|
||||
对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
|
||||
|
||||
请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
|
||||
|
||||
### 1. 容器宿主机操作系统和多租户环境
|
||||
|
||||
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
|
||||
|
||||
容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
|
||||
|
||||
### 2. 容器内容(使用可信来源)
|
||||
|
||||
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
|
||||
|
||||
### 3. 容器注册(安全访问容器镜像)
|
||||
|
||||
你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
|
||||
|
||||
### 4. 安全性与构建过程
|
||||
|
||||
在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
|
||||
|
||||
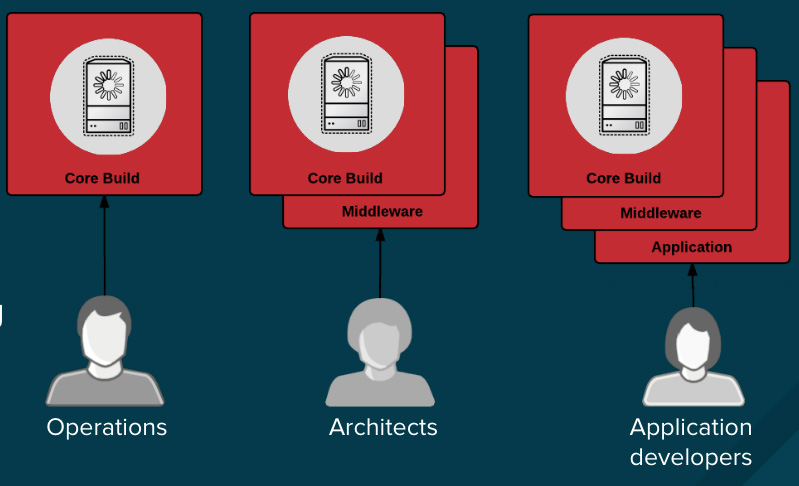
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
|
||||
|
||||
* 运营团队管理基础镜像
|
||||
* 架构师管理中间件、运行时、数据库,以及其它解决方案
|
||||
* 开发者专注于应用程序层面,并且只写代码
|
||||
|
||||
|
||||
|
||||
最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
|
||||
|
||||
### 5. 控制好在同一个集群内部署应用
|
||||
|
||||
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
|
||||
|
||||
一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
|
||||
|
||||
### 6. 容器编配:保护容器平台安全
|
||||
|
||||
当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
|
||||
|
||||
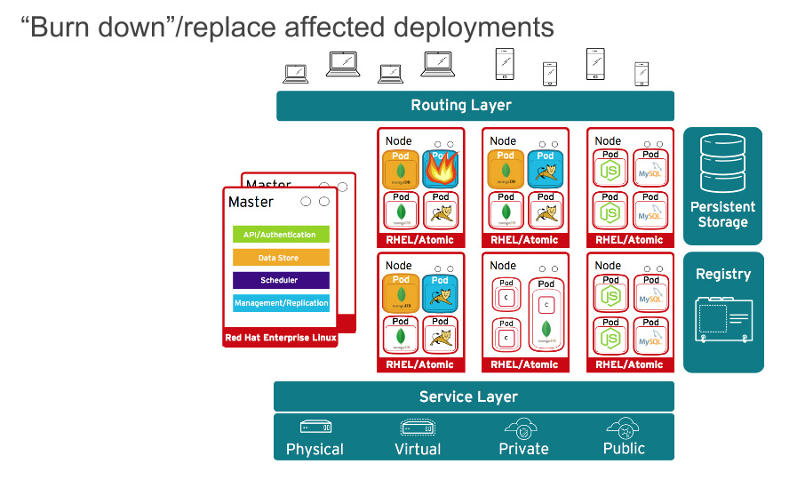
|
||||
|
||||
在大规模的容器部署时,你应该考虑:
|
||||
|
||||
* 哪个容器应该被部署在哪个宿主机上?
|
||||
* 那个宿主机应该有什么样的性能?
|
||||
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
|
||||
* 你如何控制和管理对共享资源的访问,像网络和存储?
|
||||
* 如何监视容器健康状况?
|
||||
* 如何去自动扩展性能以满足应用程序的需要?
|
||||
* 如何在满足安全需求的同时启用开发者的自助服务?
|
||||
|
||||
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
|
||||
|
||||
### 7. 网络隔离
|
||||
|
||||
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
|
||||
|
||||
使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
|
||||
|
||||
### 8. 存储
|
||||
|
||||
容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
|
||||
|
||||
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
|
||||
|
||||
### 9. API 管理、终端安全、以及单点登录(SSO)
|
||||
|
||||
保护你的应用安全,包括管理应用、以及 API 的认证和授权。
|
||||
|
||||
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
|
||||
|
||||
API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
|
||||
|
||||
这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
|
||||
|
||||
### 10. 在一个联合集群中的角色和访问管理
|
||||
|
||||
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
|
||||
|
||||
当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
|
||||
|
||||
### 选择一个容器平台
|
||||
|
||||
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
|
||||
|
||||
想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -1,45 +1,44 @@
|
||||
# 让 “rm” 命令将文件移动到“垃圾桶”,而不是完全删除它们
|
||||
给 “rm” 命令添加个“垃圾桶”
|
||||
============
|
||||
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf * `。当你使用 rm 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 `垃圾箱`。
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
|
||||
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误的删除文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
|
||||
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
|
||||
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 rm 命令时,可以节省你的时间,但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 **GNOME 、KDE、Unity 或 LXDE** 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 **\$HOME/.local/share/Trash/files**,否则会在您的主目录中创建垃圾箱文件夹 **$HOME/Trash**。
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
|
||||
|
||||
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
|
||||
|
||||
saferm.sh 脚本托管在 Github 中,可以从 repository 中克隆,也可以创建一个名为 saferm.sh 的文件并复制其上的代码。
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
|
||||
```
|
||||
|
||||
在 `bashrc` 文件中设置别名,
|
||||
在 `.bashrc` 文件中设置别名,
|
||||
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效,
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
一切就绪,现在你可以执行 rm 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行显式的说明了 `Moving magi.txt to $HOME/.local/share/Trash/file`
|
||||
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
|
||||
```
|
||||
|
||||
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
|
||||
@ -47,47 +46,16 @@ Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
```
|
||||
|
||||
或者我们可以通过文件管理器界面中查看相同的内容。
|
||||
|
||||
![![][3]][4]
|
||||
|
||||
创建一个定时任务,每天清理一次“垃圾桶”,( LCTT 注:原文为每周一次,但根据下面的代码,应该是每天一次)
|
||||
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
|
||||
|
||||
```
|
||||
$ 1 1 * * * trash-empty
|
||||
|
||||
```
|
||||
|
||||
`注意` 对于服务器环境,我们需要使用 rm 命令手动删除。
|
||||
|
||||
```
|
||||
$ rm -rf /root/Trash/
|
||||
/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
|
||||
Deleting /root/Trash/magi1.txt
|
||||
|
||||
```
|
||||
|
||||
对于桌面环境,trash-put 命令也可以做到这一点。
|
||||
|
||||
在 `bashrc` 文件中创建别名,
|
||||
|
||||
```
|
||||
alias rm=trash-put
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
要了解 saferm.sh 的其他选项,请查看帮助。
|
||||
要了解 `saferm.sh` 的其他选项,请查看帮助。
|
||||
|
||||
```
|
||||
$ saferm.sh -h
|
||||
@ -112,7 +80,7 @@ via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
我的 Linux 主目录中的隐藏文件是干什么用的?
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 系统中,你可能会在主目录中存储了大量文件和文件夹。但在这些文件之外,你知道你的主目录还附带了很多隐藏的文件和文件夹吗?如果你在主目录中运行 `ls -a`,你会发现一堆带有点前缀的隐藏文件和目录。这些隐藏的文件到底做了什么?
|
||||
|
||||
### 在主目录中隐藏的文件是干什么用的?
|
||||
|
||||
![hidden-files-liunux-2][1]
|
||||
|
||||
通常,主目录中的隐藏文件和目录包含该用户程序访问的设置或数据。它们不打算让用户编辑,只需要应用程序进行编辑。这就是为什么它们被隐藏在用户的正常视图之外。
|
||||
|
||||
通常,删除和修改自己主目录中的文件不会损坏操作系统。然而,依赖这些隐藏文件的应用程序可能不那么灵活。从主目录中删除隐藏文件时,通常会丢失与其关联的应用程序的设置。
|
||||
|
||||
依赖该隐藏文件的程序通常会重新创建它。 但是,你将从“开箱即用”设置开始,如全新用户一般。如果你在使用应用程序时遇到问题,那实际上可能是一个巨大的帮助。它可以让你删除可能造成麻烦的自定义设置。但如果你不这样做,这意味着你需要把所有的东西都设置成原来的样子。
|
||||
|
||||
### 主目录中某些隐藏文件的特定用途是什么?
|
||||
|
||||
![hidden-files-linux-3][2]
|
||||
|
||||
每个人在他们的主目录中都会有不同的隐藏文件。每个人都有一些。但是,无论应用程序如何,这些文件都有类似的用途。
|
||||
|
||||
#### 系统设置
|
||||
|
||||
系统设置包括桌面环境和 shell 的配置。
|
||||
|
||||
* shell 和命令行程序的**配置文件**:根据你使用的特定 shell 和类似命令的应用程序,特定的文件名称会变化。你会看到 `.bashrc`、`.vimrc` 和 `.zshrc`。这些文件包含你已经更改的有关 shell 的操作环境的任何设置,或者对 `vim` 等命令行实用工具的设置进行的调整。删除这些文件将使关联的应用程序返回到其默认状态。考虑到许多 Linux 用户多年来建立了一系列微妙的调整和设置,删除这个文件可能是一个非常头疼的问题。
|
||||
* **用户配置文件**:像上面的配置文件一样,这些文件(通常是 `.profile` 或 `.bash_profile`)保存 shell 的用户设置。该文件通常包含你的 `PATH` 环境变量。它还包含你设置的[别名][3]。用户也可以在 `.bashrc` 或其他位置放置别名。`PATH` 环境变量控制着 shell 寻找可执行命令的位置。通过添加或修改 `PATH`,可以更改 shell 的命令查找位置。别名更改了原有命令的名称。例如:一个别名可能将 `ls -l` 设置为 `ll`。这为经常使用的命令提供基于文本的快捷方式。如果删除 `.profile` 文件,通常可以在 `/etc/skel` 目录中找到默认版本。
|
||||
* **桌面环境设置**:这里保存你的桌面环境的任何定制。其中包括桌面背景、屏幕保护程序、快捷键、菜单栏和任务栏图标以及用户针对其桌面环境设置的其他任何内容。当你删除这个文件时,用户的环境会在下一次登录时恢复到新的用户环境。
|
||||
|
||||
#### 应用配置文件
|
||||
|
||||
你会在 Ubuntu 的 `.config` 文件夹中找到它们。 这些是针对特定应用程序的设置。 它们将包含喜好列表和设置等内容。
|
||||
|
||||
* **应用程序的配置文件**:这包括应用程序首选项菜单中的设置、工作区配置等。 你在这里找到的具体取决于应用程序。
|
||||
* **Web 浏览器数据**:这可能包括书签和浏览历史记录等内容。这些文件大部分是缓存。这是 Web 浏览器临时存储下载文件(如图片)的地方。删除这些内容可能会降低你首次访问某些媒体网站的速度。
|
||||
* **缓存**:如果用户应用程序缓存仅与该用户相关的数据(如 [Spotify 应用程序存储播放列表的缓存][4]),则主目录是存储该目录的默认地点。 这些缓存可能包含大量数据或仅包含几行代码:这取决于应用程序需要什么。 如果你删除这些文件,则应用程序会根据需要重新创建它们。
|
||||
* **日志**:一些用户应用程序也可能在这里存储日志。根据开发人员设置应用程序的方式,你可能会发现存储在你的主目录中的日志文件。然而,这不是一个常见的选择。
|
||||
|
||||
### 结论
|
||||
|
||||
在大多数情况下,你的 Linux 主目录中的隐藏文件用于存储用户设置。 这包括命令行程序以及基于 GUI 的应用程序的设置。删除它们将删除用户设置。 通常情况下,它不会导致程序被破坏。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/hidden-files-linux-home-directory/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-liunux-2.png (hidden-files-liunux-2)
|
||||
[2]:https://www.maketecheasier.com/assets/uploads/2017/06/hidden-files-linux-3.png (hidden-files-linux-3)
|
||||
[3]:https://www.maketecheasier.com/making-the-linux-command-line-a-little-friendlier/#aliases
|
||||
[4]:https://www.maketecheasier.com/clear-spotify-cache/
|
||||
140
published/20171102 What is huge pages in Linux.md
Normal file
140
published/20171102 What is huge pages in Linux.md
Normal file
@ -0,0 +1,140 @@
|
||||
Linux 中的“大内存页”(hugepage)是个什么?
|
||||
======
|
||||
|
||||
> 学习 Linux 中的<ruby>大内存页<rt>hugepage</rt></ruby>。理解什么是“大内存页”,如何进行配置,如何查看当前状态以及如何禁用它。
|
||||
|
||||
![Huge Pages in Linux][1]
|
||||
|
||||
本文中我们会详细介绍<ruby>大内存页<rt>huge page</rt></ruby>,让你能够回答:Linux 中的“大内存页”是什么?在 RHEL6、RHEL7、Ubuntu 等 Linux 中,如何启用/禁用“大内存页”?如何查看“大内存页”的当前值?
|
||||
|
||||
首先让我们从“大内存页”的基础知识开始讲起。
|
||||
|
||||
### Linux 中的“大内存页”是个什么玩意?
|
||||
|
||||
“大内存页”有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,它们还能帮助管理内存中的巨大的页面。使用“大内存页”,你最大可以定义 1GB 的页面大小。
|
||||
|
||||
在系统启动期间,你能用“大内存页”为应用程序预留一部分内存。这部分内存,即被“大内存页”占用的这些存储器永远不会被交换出内存。它会一直保留其中,除非你修改了配置。这会极大地提高像 Oracle 数据库这样的需要海量内存的应用程序的性能。
|
||||
|
||||
### 为什么使用“大内存页”?
|
||||
|
||||
在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射。如果你的内存页很小,那么你需要加载的页就会很多,导致内核会加载更多的映射表。而这会降低性能。
|
||||
|
||||
使用“大内存页”,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
|
||||
|
||||
简而言之,通过启用“大内存页”,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
|
||||
|
||||
### 如何配置“大内存页”?
|
||||
|
||||
运行下面命令来查看当前“大内存页”的详细内容。
|
||||
|
||||
```
|
||||
root@kerneltalks # grep Huge /proc/meminfo
|
||||
AnonHugePages: 0 kB
|
||||
HugePages_Total: 0
|
||||
HugePages_Free: 0
|
||||
HugePages_Rsvd: 0
|
||||
HugePages_Surp: 0
|
||||
Hugepagesize: 2048 kB
|
||||
```
|
||||
|
||||
从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`),并且系统中目前有 `0` 个“大内存页”(`HugePages_Total`)。这里“大内存页”的大小可以从 `2MB` 增加到 `1GB`。
|
||||
|
||||
运行下面的脚本可以知道系统当前需要多少个巨大页。该脚本取之于 Oracle。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#
|
||||
# hugepages_settings.sh
|
||||
#
|
||||
# Linux bash script to compute values for the
|
||||
# recommended HugePages/HugeTLB configuration
|
||||
#
|
||||
# Note: This script does calculation for all shared memory
|
||||
# segments available when the script is run, no matter it
|
||||
# is an Oracle RDBMS shared memory segment or not.
|
||||
# Check for the kernel version
|
||||
KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
|
||||
# Find out the HugePage size
|
||||
HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
|
||||
# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
|
||||
NUM_PG=1
|
||||
# Cumulative number of pages required to handle the running shared memory segments
|
||||
for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
|
||||
do
|
||||
MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
|
||||
if [ $MIN_PG -gt 0 ]; then
|
||||
NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
|
||||
fi
|
||||
done
|
||||
# Finish with results
|
||||
case $KERN in
|
||||
'2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
|
||||
echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
|
||||
'2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
|
||||
*) echo "Unrecognized kernel version $KERN. Exiting." ;;
|
||||
esac
|
||||
# End
|
||||
```
|
||||
|
||||
将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
|
||||
|
||||
```
|
||||
root@kerneltalks # sh /tmp/hugepages_settings.sh
|
||||
Recommended setting: vm.nr_hugepages = 124
|
||||
```
|
||||
|
||||
你的输出类似如上结果,只是数字会有一些出入。
|
||||
|
||||
这意味着,你系统需要 124 个每个 2MB 的“大内存页”!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
|
||||
|
||||
### 配置内核中的“大内存页”
|
||||
|
||||
本文最后一部分内容是配置上面提到的 [内核参数 ][2] ,然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
|
||||
|
||||
```
|
||||
vm.nr_hugepages=126
|
||||
```
|
||||
|
||||
注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量之外多一些额外的空闲页。
|
||||
|
||||
现在,内核已经配置好了,但是要让应用能够使用这些“大内存页”还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
|
||||
|
||||
你需要编辑 `/etc/security/limits.conf` 中的如下配置:
|
||||
|
||||
```
|
||||
soft memlock 258048
|
||||
hard memlock 258048
|
||||
```
|
||||
|
||||
某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
|
||||
|
||||
这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
|
||||
|
||||
### 如何禁用“大内存页”?
|
||||
|
||||
“大内存页”默认是开启的。使用下面命令来查看“大内存页”的当前状态。
|
||||
|
||||
```
|
||||
root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
|
||||
[always] madvise never
|
||||
```
|
||||
|
||||
输出中的 `[always]` 标志说明系统启用了“大内存页”。
|
||||
|
||||
若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
|
||||
|
||||
若想禁用“大内存页”,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
|
||||
[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
|
||||
@ -0,0 +1,94 @@
|
||||
如何在 Linux 中配置 ssh 登录导语
|
||||
======
|
||||
|
||||
> 了解如何在 Linux 中创建登录导语,来向要登录或登录后的用户显示不同的警告或消息。
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
无论何时登录公司的某些生产系统,你都会看到一些登录消息、警告或关于你将登录或已登录的服务器的信息,如下所示。这些是<ruby>登录导语<rt>login banner</rt></ruby>。
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
在本文中,我们将引导你配置它们。
|
||||
|
||||
你可以配置两种类型的导语。
|
||||
|
||||
1. 用户登录前显示的导语信息(在你选择的文件中配置,例如 `/etc/login.warn`)
|
||||
2. 用户成功登录后显示的导语信息(在 `/etc/motd` 中配置)
|
||||
|
||||
### 如何在用户登录前连接系统时显示消息
|
||||
|
||||
当用户连接到服务器并且在登录之前,这个消息将被显示给他。意味着当他输入用户名时,该消息将在密码提示之前显示。
|
||||
|
||||
你可以使用任何文件名并在其中输入信息。在这里我们使用 `/etc/login.warn` 并且把我们的消息放在里面。
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
现在,需要将此文件和路径告诉 `sshd` 守护进程,以便它可以为每个用户登录请求获取此标语。对于此,打开 `/etc/sshd/sshd_config` 文件并搜索 `#Banner none`。
|
||||
|
||||
这里你需要编辑该配置文件,并写下你的文件名并删除注释标记(`#`)。它应该看起来像:`Banner /etc/login.warn`。
|
||||
|
||||
保存文件并重启 `sshd` 守护进程。为避免断开现有的连接用户,请使用 HUP 信号重启 sshd。
|
||||
|
||||
```
|
||||
root@kerneltalks # ps -ef | grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
就是这样了!打开新的会话并尝试登录。你将看待你在上述步骤中配置的消息。
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
你可以在用户输入密码登录系统之前看到此消息。
|
||||
|
||||
### 如何在用户登录后显示消息
|
||||
|
||||
消息用户在成功登录系统后看到的<ruby>当天消息<rt>Message Of The Day</rt></ruby>(MOTD)由 `/etc/motd` 控制。编辑这个文件并输入当成功登录后欢迎用户的消息。
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
你不需要重启 `sshd` 守护进程来使更改生效。只要保存该文件,`sshd` 守护进程就会下一次登录请求时读取和显示。
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
你可以在上面的截图中看到:黄色框是由 `/etc/motd` 控制的 MOTD,绿色框就是我们之前看到的登录导语。
|
||||
|
||||
你可以使用 [cowsay][5]、[banner][6]、[figlet][7]、[lolcat][8] 等工具创建出色的引人注目的登录消息。此方法适用于几乎所有 Linux 发行版,如 RedHat、CentOs、Ubuntu、Fedora 等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://a1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://a3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -0,0 +1,46 @@
|
||||
如何使用看板(kanban)创建更好的文档
|
||||
======
|
||||
> 通过卡片分类和看板来给用户提供他们想要的信息。
|
||||
|
||||

|
||||
|
||||
如果你正在处理文档、网站或其他面向用户的内容,那么了解用户希望找到的内容(包括他们想要的信息以及信息的组织和结构)很有帮助。毕竟,如果人们无法找到他们想要的东西,那么再出色的内容也没有用。
|
||||
|
||||
卡片分类是一种简单而有效的方式,可以从用户那里收集有关菜单界面和页面的内容。最简单的实现方式是在计划在网站或文档中的部分分类标注一些索引卡,并要求用户按照查找信息的方式对卡片进行分类。一个变体是让人们编写自己的菜单标题或内容元素。
|
||||
|
||||
我们的目标是了解用户的期望以及他们希望在哪里找到它,而不是自己弄清楚菜单和布局。当与用户处于相同的物理位置时,这是相对简单的,但当尝试从多个位置的人员获得反馈时,这会更具挑战性。
|
||||
|
||||
我发现[<ruby>看板<rt>kanban</rt></ruby>][1]对于这些情况是一个很好的工具。它允许人们轻松拖动虚拟卡片进行分类和排名,而且与专门卡片分类软件不同,它们是多用途的。
|
||||
|
||||
我经常使用 Trello 进行卡片分类,但有几种你可能想尝试的[开源替代品][2]。
|
||||
|
||||
### 怎么运行的
|
||||
|
||||
我最成功的看板体验是在写 [Gluster][3] 文档的时候 —— 这是一个自由开源的可扩展的网络存储文件系统。我需要携带大量随着时间而增长的文档,并将其分成若干类别以创建导航系统。由于我没有必要的技术知识来分类,我向 Gluster 团队和开发人员社区寻求指导。
|
||||
|
||||
首先,我创建了一个共享看板。我列出了一些通用名称,这些名称可以为我计划在文档中涵盖的所有主题排序和创建卡片。我标记了一些不同颜色的卡片,以表明某个主题缺失并需要创建,或者它存在并需要删除。然后,我把所有卡片放入“未排序”一列,并要求人们将它们拖到他们认为这些卡片应该组织到的地方,然后给我一个他们认为是理想状态的截图。
|
||||
|
||||
处理所有截图是最棘手的部分。我希望有一个合并或共识功能可以帮助我汇总每个人的数据,而不必检查一堆截图。幸运的是,在第一个人对卡片进行分类之后,人们或多或少地对该结构达成一致,而只做了很小的修改。当对某个主题的位置有不同意见时,我发起一个快速会议,让人们可以解释他们的想法,并且可以排除分歧。
|
||||
|
||||
### 使用数据
|
||||
|
||||
在这里,很容易将捕捉到的信息转换为菜单并对其进行优化。如果用户认为项目应该成为子菜单,他们通常会在评论中或在电话聊天时告诉我。对菜单组织的看法因人们的工作任务而异,所以从来没有完全达成一致意见,但用户进行测试意味着你不会对人们使用什么以及在哪里查找有很多盲点。
|
||||
|
||||
将卡片分类与分析功能配对,可以让你更深入地了解人们在寻找什么。有一次,当我对一些我正在写的培训文档进行分析时,我惊讶地发现搜索量最大的页面是关于资本的。所以我在顶层菜单层面上显示了该页面,即使我的“逻辑”设置将它放在了子菜单中。
|
||||
|
||||
我发现看板卡片分类是一种很好的方式,可以帮助我创建用户想要查看的内容,并将其放在希望被找到的位置。你是否发现了另一种对用户友好的组织内容的方法?或者看板的另一种有趣用途是什么?如果有的话,请在评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -0,0 +1,78 @@
|
||||
使用 Showterm 录制和分享终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
|
||||
|
||||
Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
|
||||
|
||||
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
|
||||
|
||||
### 在 Linux 中安装 Showterm
|
||||
|
||||
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
|
||||
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
如果你没有在 Linux 上安装 Ruby,可以这样:
|
||||
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
如果你只是想运行程序而不是安装:
|
||||
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
|
||||
|
||||
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
|
||||
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
|
||||
|
||||
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
|
||||
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面][1]获得。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/brunoedoh/
|
||||
[1]:https://github.com/ConradIrwin/showterm
|
||||
[2]:https://www.maketecheasier.com/record-terminal-session-as-video/ (2 Simple Applications That Record Your Terminal Session as Video [Linux])
|
||||
[3]:https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ (How to Record Terminal Session in Ubuntu)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-interface.png (showterm terminal)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-site.png (showtermio)
|
||||
@ -1,32 +1,31 @@
|
||||
在你下一次技术面试的时候要提的 3 个基本问题
|
||||
下一次技术面试时要问的 3 个重要问题
|
||||
======
|
||||
|
||||

|
||||
|
||||
面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Linux 基金会
|
||||
> 面试可能会有压力,但 58% 的公司告诉 Dice 和 Linux 基金会,他们需要在未来几个月内聘请开源人才。学习如何提出正确的问题。
|
||||
|
||||
Dice 和 Linux 基金会的年度[开源工作报告][1]揭示了开源专业人士的前景以及未来一年的招聘活动。在今年的报告中,86% 的科技专业人士表示,了解开源推动了他们的职业生涯。然而,当在他们自己的组织内推进或在别处申请新职位的时候,有这些经历会发生什么呢?
|
||||
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你对我有什么问题吗?”时适当的回答更增添了压力。
|
||||
面试新工作绝非易事。除了在准备新职位时还要应付复杂的工作,当面试官问“你有什么问题要问吗?”时,适当的回答更增添了压力。
|
||||
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
在 Dice,我们从事职业、建议,并将技术专家与雇主连接起来。但是我们也在公司里雇佣技术人才来开发开源项目。实际上,Dice 平台基于许多 Linux 发行版,我们利用开源数据库作为我们搜索功能的基础。总之,如果没有开源软件,我们就无法运行 Dice,因此聘请了解和热爱开源软件的专业人士至关重要。
|
||||
|
||||
多年来,我在面试中了解到提出好问题的重要性。这是一个了解你的潜在新雇主的机会,以及更好地了解他们是否与你的技能相匹配。
|
||||
|
||||
这里有三个重要的问题需要以及其重要的原因:
|
||||
这里有三个要问的重要问题,以及其重要的原因:
|
||||
|
||||
**1\. 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?**
|
||||
### 1、 公司对员工在空闲时间致力于开源项目或编写代码的立场是什么?
|
||||
|
||||
这个问题的答案会告诉正在面试的公司的很多信息。一般来说,只要它与你在该公司所从事的工作没有冲突,公司会希望技术专家为网站或项目做出贡献。在公司之外允许这种情况,也会在技术组织中培养出一种创业精神,并教授技术技能,否则在正常的日常工作中你可能无法获得这些技能。
|
||||
|
||||
**2\. 项目在这如何分优先级?**
|
||||
### 2、 项目如何区分优先级?
|
||||
|
||||
由于所有的公司都成为了科技公司,所以在创新的客户面对技术项目与改进平台本身之间往往存在着分歧。你会努力保持现有的平台最新么?或者致力于公众开发新产品?根据你的兴趣,答案可以决定公司是否适合你。
|
||||
|
||||
**3\. 谁主要决定新产品,开发者在决策过程中有多少投入?**
|
||||
### 3、 谁主要决定新产品,开发者在决策过程中有多少投入?
|
||||
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来没有困难,但有时会错过这步,意味着在新产品发布之前是协作环境或者混乱的过程。
|
||||
这个问题是了解谁负责公司创新(以及与他/她有多少联系),还有一个是了解你在公司的职业道路。在开发新产品之前,一个好的公司会和开发人员和开源人才交流。这看起来不用多想,但有时会错过这步,意味着在新产品发布之前协作环境的不同或者混乱的过程。
|
||||
|
||||
面试可能会有压力,但是 58% 的公司告诉 Dice 和 Linux 基金会他们需要在未来几个月内聘用开源人才,所以记住高需求会让像你这样的专业人士成为雇员。以你想要的方向引导你的事业。
|
||||
|
||||
@ -38,7 +37,7 @@ via: https://www.linux.com/blog/os-jobs/2017/12/3-essential-questions-ask-your-n
|
||||
|
||||
作者:[Brian Hostetter][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
并发服务器(五):Redis 案例研究
|
||||
======
|
||||
|
||||
这是我写的并发网络服务器系列文章的第五部分。在前四部分中我们讨论了并发服务器的结构,这篇文章我们将去研究一个在生产系统中大量使用的服务器的案例—— [Redis][10]。
|
||||
|
||||

|
||||
|
||||
Redis 是一个非常有魅力的项目,我关注它很久了。它最让我着迷的一点就是它的 C 源代码非常清晰。它也是一个高性能、大并发的内存数据库服务器的非常好的例子,它是研究网络并发服务器的一个非常好的案例,因此,我们不能错过这个好机会。
|
||||
|
||||
我们来看看前四部分讨论的概念在真实世界中的应用程序。
|
||||
|
||||
本系列的所有文章有:
|
||||
|
||||
* [第一节 - 简介][3]
|
||||
* [第二节 - 线程][4]
|
||||
* [第三节 - 事件驱动][5]
|
||||
* [第四节 - libuv][6]
|
||||
* [第五节 - Redis 案例研究][7]
|
||||
|
||||
### 事件处理库
|
||||
|
||||
Redis 最初发布于 2009 年,它最牛逼的一件事情大概就是它的速度 —— 它能够处理大量的并发客户端连接。需要特别指出的是,它是用*一个单线程*来完成的,而且还不对保存在内存中的数据使用任何复杂的锁或者同步机制。
|
||||
|
||||
Redis 之所以如此牛逼是因为,它在给定的系统上使用了其可用的最快的事件循环,并将它们封装成由它实现的事件循环库(在 Linux 上是 epoll,在 BSD 上是 kqueue,等等)。这个库的名字叫做 [ae][11]。ae 使得编写一个快速服务器变得很容易,只要在它内部没有阻塞即可,而 Redis 则保证 ^注1 了这一点。
|
||||
|
||||
在这里,我们的兴趣点主要是它对*文件事件*的支持 —— 当文件描述符(如网络套接字)有一些有趣的未决事情时将调用注册的回调函数。与 libuv 类似,ae 支持多路事件循环(参阅本系列的[第三节][5]和[第四节][6])和不应该感到意外的 `aeCreateFileEvent` 信号:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
它在 `fd` 上使用一个给定的事件循环,为新的文件事件注册一个回调(`proc`)函数。当使用的是 epoll 时,它将调用 `epoll_ctl` 在文件描述符上添加一个事件(可能是 `EPOLLIN`、`EPOLLOUT`、也或许两者都有,取决于 `mask` 参数)。ae 的 `aeProcessEvents` 功能是 “运行事件循环和发送回调函数”,它在底层调用了 `epoll_wait`。
|
||||
|
||||
### 处理客户端请求
|
||||
|
||||
我们通过跟踪 Redis 服务器代码来看一下,ae 如何为客户端事件注册回调函数的。`initServer` 启动时,通过注册一个回调函数来读取正在监听的套接字上的事件,通过使用回调函数 `acceptTcpHandler` 来调用 `aeCreateFileEvent`。当新的连接可用时,这个回调函数被调用。它调用 `accept` ^注2 ,接下来是 `acceptCommonHandler`,它转而去调用 `createClient` 以初始化新客户端连接所需要的数据结构。
|
||||
|
||||
`createClient` 的工作是去监听来自客户端的入站数据。它将套接字设置为非阻塞模式(一个异步事件循环中的关键因素)并使用 `aeCreateFileEvent` 去注册另外一个文件事件回调函数以读取事件 —— `readQueryFromClient`。每当客户端发送数据,这个函数将被事件循环调用。
|
||||
|
||||
`readQueryFromClient` 就让我们期望的那样 —— 解析客户端命令和动作,并通过查询和/或操作数据来回复。因为客户端套接字是非阻塞的,所以这个函数必须能够处理 `EAGAIN`,以及部分数据;从客户端中读取的数据是累积在客户端专用的缓冲区中,而完整的查询可能被分割在回调函数的多个调用当中。
|
||||
|
||||
### 将数据发送回客户端
|
||||
|
||||
在前面的内容中,我说到了 `readQueryFromClient` 结束了发送给客户端的回复。这在逻辑上是正确的,因为 `readQueryFromClient` *准备*要发送回复,但它不真正去做实质的发送 —— 因为这里并不能保证客户端套接字已经准备好写入/发送数据。我们必须为此使用事件循环机制。
|
||||
|
||||
Redis 是这样做的,它注册一个 `beforeSleep` 函数,每次事件循环即将进入休眠时,调用它去等待套接字变得可以读取/写入。`beforeSleep` 做的其中一件事情就是调用 `handleClientsWithPendingWrites`。它的作用是通过调用 `writeToClient` 去尝试立即发送所有可用的回复;如果一些套接字不可用时,那么*当*套接字可用时,它将注册一个事件循环去调用 `sendReplyToClient`。这可以被看作为一种优化 —— 如果套接字可用于立即发送数据(一般是 TCP 套接字),这时并不需要注册事件 ——直接发送数据。因为套接字是非阻塞的,它从不会去阻塞循环。
|
||||
|
||||
### 为什么 Redis 要实现它自己的事件库?
|
||||
|
||||
在 [第四节][14] 中我们讨论了使用 libuv 来构建一个异步并发服务器。需要注意的是,Redis 并没有使用 libuv,或者任何类似的事件库,而是它去实现自己的事件库 —— ae,用 ae 来封装 epoll、kqueue 和 select。事实上,Antirez(Redis 的创建者)恰好在 [2011 年的一篇文章][15] 中回答了这个问题。他的回答的要点是:ae 只有大约 770 行他理解的非常透彻的代码;而 libuv 代码量非常巨大,也没有提供 Redis 所需的额外功能。
|
||||
|
||||
现在,ae 的代码大约增长到 1300 多行,比起 libuv 的 26000 行(这是在没有 Windows、测试、示例、文档的情况下的数据)来说那是小巫见大巫了。libuv 是一个非常综合的库,这使它更复杂,并且很难去适应其它项目的特殊需求;另一方面,ae 是专门为 Redis 设计的,与 Redis 共同演进,只包含 Redis 所需要的东西。
|
||||
|
||||
这是我 [前些年在一篇文章中][16] 提到的软件项目依赖关系的另一个很好的示例:
|
||||
|
||||
> 依赖的优势与在软件项目上花费的工作量成反比。
|
||||
|
||||
在某种程度上,Antirez 在他的文章中也提到了这一点。他提到,提供大量附加价值(在我的文章中的“基础” 依赖)的依赖比像 libuv 这样的依赖更有意义(它的例子是 jemalloc 和 Lua),对于 Redis 特定需求,其功能的实现相当容易。
|
||||
|
||||
### Redis 中的多线程
|
||||
|
||||
[在 Redis 的绝大多数历史中][17],它都是一个不折不扣的单线程的东西。一些人觉得这太不可思议了,有这种想法完全可以理解。Redis 本质上是受网络束缚的 —— 只要数据库大小合理,对于任何给定的客户端请求,其大部分延时都是浪费在网络等待上,而不是在 Redis 的数据结构上。
|
||||
|
||||
然而,现在事情已经不再那么简单了。Redis 现在有几个新功能都用到了线程:
|
||||
|
||||
1. “惰性” [内存释放][8]。
|
||||
2. 在后台线程中使用 fsync 调用写一个 [持久化日志][9]。
|
||||
3. 运行需要执行一个长周期运行的操作的用户定义模块。
|
||||
|
||||
对于前两个特性,Redis 使用它自己的一个简单的 bio(它是 “Background I/O" 的首字母缩写)库。这个库是根据 Redis 的需要进行了硬编码,它不能用到其它的地方 —— 它运行预设数量的线程,每个 Redis 后台作业类型需要一个线程。
|
||||
|
||||
而对于第三个特性,[Redis 模块][18] 可以定义新的 Redis 命令,并且遵循与普通 Redis 命令相同的标准,包括不阻塞主线程。如果在模块中自定义的一个 Redis 命令,希望去执行一个长周期运行的操作,这将创建一个线程在后台去运行它。在 Redis 源码树中的 `src/modules/helloblock.c` 提供了这样的一个示例。
|
||||
|
||||
有了这些特性,Redis 使用线程将一个事件循环结合起来,在一般的案例中,Redis 具有了更快的速度和弹性,这有点类似于在本系统文章中 [第四节][19] 讨论的工作队列。
|
||||
|
||||
- 注1: Redis 的一个核心部分是:它是一个 _内存中_ 数据库;因此,查询从不会运行太长的时间。当然了,这将会带来各种各样的其它问题。在使用分区的情况下,服务器可能最终路由一个请求到另一个实例上;在这种情况下,将使用异步 I/O 来避免阻塞其它客户端。
|
||||
- 注2: 使用 `anetAccept`;`anet` 是 Redis 对 TCP 套接字代码的封装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:https://linux.cn/article-8993-1.html
|
||||
[4]:https://linux.cn/article-9002-1.html
|
||||
[5]:https://linux.cn/article-9117-1.html
|
||||
[6]:https://linux.cn/article-9397-1.html
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:https://linux.cn/article-9397-1.html
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:https://linux.cn/article-9397-1.html
|
||||
@ -0,0 +1,198 @@
|
||||
使用 pelican 和 Github pages 来搭建博客
|
||||
===============================
|
||||
|
||||
今天我将谈一下[我这个博客][a]是如何搭建的。在我们开始之前,我希望你熟悉使用 Github 并且可以搭建一个 Python 虚拟环境来进行开发。如果你不能做到这些,我推荐你去学习一下 [Django Girls 教程][2],它包含以上和更多的内容。
|
||||
|
||||
这是一篇帮助你发布由 Github 托管的个人博客的教程。为此,你需要一个正常的 Github 用户账户 (而不是一个工程账户)。
|
||||
|
||||
你要做的第一件事是创建一个放置代码的 Github 仓库。如果你想要你的博客仅仅指向你的用户名 (比如 rsip22.github.io) 而不是一个子文件夹 (比如 rsip22.github.io/blog),你必须创建一个带有全名的仓库。
|
||||
|
||||
![][3]
|
||||
|
||||
*Github 截图,打开了创建新仓库的菜单,正在以 'rsip22.github.io' 名字创建一个新的仓库*
|
||||
|
||||
我推荐你使用 `README`、用于 Python 的 `.gitignore` 和 [一个自由软件许可证][4] 初始化你的仓库。如果你使用自由软件许可证,你仍然拥有这些代码,但是你使得其他人能从中受益,允许他们学习和复用它,并且更重要的是允许他们享有这些代码。
|
||||
|
||||
既然仓库已经创建好了,那我们就克隆到本机中将用来保存代码的文件夹下:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/YOUR_USERNAME/YOUR_USERNAME.github.io.git
|
||||
```
|
||||
|
||||
并且切换到新的目录:
|
||||
|
||||
```
|
||||
$ cd YOUR_USERNAME.github.io
|
||||
```
|
||||
|
||||
因为 Github Pages 偏好运行的方式是从 master 分支提供文件,你必须将你的源代码放到新的分支,防止 Pelican 产生的静态文件输出到 master 分支。为此,你必须创建一个名为 source 的分支。
|
||||
|
||||
```
|
||||
$ git checkout -b source
|
||||
```
|
||||
|
||||
用你的系统所安装的 Pyhton 3 创建该虚拟环境(virtualenv)。
|
||||
|
||||
在 GNU/Linux 系统中,命令可能如下:
|
||||
|
||||
```
|
||||
$ python3 -m venv venv
|
||||
```
|
||||
|
||||
或者像这样:
|
||||
|
||||
```
|
||||
$ virtualenv --python=python3.5 venv
|
||||
```
|
||||
|
||||
并且激活它:
|
||||
|
||||
```
|
||||
$ source venv/bin/activate
|
||||
```
|
||||
|
||||
在虚拟环境里,你需要安装 pelican 和它的依赖包。你也应该安装 ghp-import (来帮助我们发布到 Github 上)和 Markdown (为了使用 markdown 语法来写文章)。运行如下命令:
|
||||
|
||||
```
|
||||
(venv)$ pip install pelican markdown ghp-import
|
||||
```
|
||||
|
||||
一旦完成,你就可以使用 `pelican-quickstart` 开始创建你的博客了:
|
||||
|
||||
```
|
||||
(venv)$ pelican-quickstart
|
||||
```
|
||||
|
||||
这将会提示我们一系列的问题。在回答它们之前,请看一下如下我的答案:
|
||||
|
||||
```
|
||||
> Where do you want to create your new web site? [.] ./
|
||||
> What will be the title of this web site? Renata's blog
|
||||
> Who will be the author of this web site? Renata
|
||||
> What will be the default language of this web site? [pt] en
|
||||
> Do you want to specify a URL prefix? e.g., http://example.com (Y/n) n
|
||||
> Do you want to enable article pagination? (Y/n) y
|
||||
> How many articles per page do you want? [10] 10
|
||||
> What is your time zone? [Europe/Paris] America/Sao_Paulo
|
||||
> Do you want to generate a Fabfile/Makefile to automate generation and publishing? (Y/n) Y **# PAY ATTENTION TO THIS!**
|
||||
> Do you want an auto-reload & simpleHTTP script to assist with theme and site development? (Y/n) n
|
||||
> Do you want to upload your website using FTP? (y/N) n
|
||||
> Do you want to upload your website using SSH? (y/N) n
|
||||
> Do you want to upload your website using Dropbox? (y/N) n
|
||||
> Do you want to upload your website using S3? (y/N) n
|
||||
> Do you want to upload your website using Rackspace Cloud Files? (y/N) n
|
||||
> Do you want to upload your website using GitHub Pages? (y/N) y
|
||||
> Is this your personal page (username.github.io)? (y/N) y
|
||||
Done. Your new project is available at /home/username/YOUR_USERNAME.github.io
|
||||
```
|
||||
|
||||
关于时区,应该指定为 TZ 时区(这里是全部列表: [tz 数据库时区列表][5])。
|
||||
|
||||
现在,继续往下走并开始创建你的第一篇博文!你可能想在你喜爱的代码编辑器里打开工程目录并且找到里面的 `content` 文件夹。然后创建一个新文件,它可以被命名为 `my-first-post.md` (别担心,这只是为了测试,以后你可以改变它)。在文章内容之前,应该以元数据开始,这些元数据标识标题、日期、目录及更多,像下面这样:
|
||||
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
Title: My first post
|
||||
Date: 2017-11-26 10:01
|
||||
Modified: 2017-11-27 12:30
|
||||
Category: misc
|
||||
Tags: first, misc
|
||||
Slug: My-first-post
|
||||
Authors: Your name
|
||||
Summary: What does your post talk about? Write here.
|
||||
|
||||
This is the *first post* from my Pelican blog. **YAY!**
|
||||
```
|
||||
|
||||
让我们看看它长什么样?
|
||||
|
||||
进入终端,产生静态文件并且启动服务器。要这么做,使用下面命令:
|
||||
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
当这条命令正在运行,你应该可以在你喜爱的 web 浏览器地址栏中键入 `localhost:8000` 来访问它。
|
||||
|
||||
![][6]
|
||||
|
||||
*博客主页的截图。它有一个带有 Renata's blog 标题的头部,第一篇博文在左边,文章的信息在右边,链接和社交在底部*
|
||||
|
||||
相当简洁,对吧?
|
||||
|
||||
现在,如果你想在文章中放一张图片,该怎么做呢?好,首先你在放置文章的内容目录里创建一个目录。为了引用简单,我们将这个目录命名为 `image`。现在你必须让 Pelican 使用它。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且添加一个包含你的图片目录的变量:
|
||||
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
STATIC_PATHS = ['images']
|
||||
```
|
||||
|
||||
保存它。打开文章并且以如下方式添加图片:
|
||||
|
||||
```
|
||||
.lang="markdown" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||

|
||||
```
|
||||
|
||||
你可以在终端中随时按下 `CTRL+C` 来中断服务器。但是你应该再次启动它并检查图片是否正确。你能记住怎么样做吗?
|
||||
|
||||
```
|
||||
(venv)$ make html && make serve
|
||||
```
|
||||
|
||||
在你代码完工之前的最后一步:你应该确保任何人都可以使用 ATOM 或 RSS 流来读你的文章。找到 `pelicanconf.py` 文件,这个文件是你配置系统的地方,并且编辑关于 RSS 流产生的部分:
|
||||
|
||||
```
|
||||
.lang="python" # DON'T COPY this line, it exists just for highlighting purposes
|
||||
|
||||
FEED_ALL_ATOM = 'feeds/all.atom.xml'
|
||||
FEED_ALL_RSS = 'feeds/all.rss.xml'
|
||||
AUTHOR_FEED_RSS = 'feeds/%s.rss.xml'
|
||||
RSS_FEED_SUMMARY_ONLY = False
|
||||
```
|
||||
|
||||
保存所有,这样你才可以将代码上传到 Github 上。你可以通过添加所有文件,使用一个信息(“first commit”)来提交它,并且使用 `git push`。你将会被问起你的 Github 登录名和密码。
|
||||
|
||||
```
|
||||
$ git add -A && git commit -a -m 'first commit' && git push --all
|
||||
```
|
||||
|
||||
还有...记住在最开始的时候,我给你说的怎样防止 Pelican 产生的静态文件输出 master 分支吗。现在对你来说是时候产生它们了:
|
||||
|
||||
```
|
||||
$ make github
|
||||
```
|
||||
|
||||
你将会被再次问及 Github 登录名和密码。好了!你的新博客应该创建在 `https://YOUR_USERNAME.github.io`。
|
||||
|
||||
如果你在过程中任何一步遇到一个错误,请重新读一下这篇手册,尝试并看看你是否能发现错误发生的部分,因为这是调试的第一步。有时甚至一些简单的东西比如一个错字或者 Python 中错误的缩进都可以给我们带来麻烦。说出来并向网上或你的社区求助。
|
||||
|
||||
对于如何使用 Markdown 来写文章,你可以读一下 [Daring Fireball Markdown 指南][7]。
|
||||
|
||||
为了获取其它主题,我建议你访问 [Pelican 主题][8]。
|
||||
|
||||
这篇文章改编自 [Adrien Leger 的使用一个 Bottstrap3 主题来搭建由 Github 托管的 Pelican 博客][9]。
|
||||
|
||||
-----------------------------------------------------------
|
||||
|
||||
via: https://rsip22.github.io/blog/create-a-blog-with-pelican-and-github-pages.html
|
||||
|
||||
作者:[rsip22][a]
|
||||
译者:[liuxinyu123](https://github.com/liuxinyu123)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://rsip22.github.io
|
||||
[1]:https://rsip22.github.io/blog/category/blog.html
|
||||
[2]:https://tutorial.djangogirls.org
|
||||
[3]:https://rsip22.github.io/blog/img/create_github_repository.png
|
||||
[4]:https://www.gnu.org/licenses/license-list.html
|
||||
[5]:https://en.wikipedia.org/wiki/List_of_tz_database_time_zones
|
||||
[6]:https://rsip22.github.io/blog/img/blog_screenshot.png
|
||||
[7]:https://daringfireball.net/projects/markdown/syntax
|
||||
[8]:http://www.pelicanthemes.com/
|
||||
[9]:https://a-slide.github.io/blog/github-pelican
|
||||
@ -1,35 +1,37 @@
|
||||
6 个开源的家庭自动化工具
|
||||
======
|
||||
|
||||
> 用这些开源软件解决方案构建一个更智能的家庭。
|
||||
|
||||

|
||||
|
||||
[物联网][13] 不仅是一个时髦词,在现实中,自 2016 年我们发布了一篇关于家庭自动化工具的评论文章以来,它也在迅速占领着我们的生活。在 2017,[26.5% 的美国家庭][14] 已经使用了一些智能家居技术;预计五年内,这一数字还将翻倍。
|
||||
|
||||
使用数量持续增加的各种设备,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
随着这些数量持续增加的各种设备的使用,可以帮助你实现对家庭的自动化管理、安保、和监视,在家庭自动化方面,从来没有像现在这样容易和更加吸引人过。不论你是要远程控制你的 HVAC 系统,集成一个家庭影院,保护你的家免受盗窃、火灾、或是其它威胁,还是节省能源或只是控制几盏灯,现在都有无数的设备可以帮到你。
|
||||
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人能够访问它呢?
|
||||
但同时,还有许多用户担心安装在他们家庭中的新设备带来的安全和隐私问题 —— 这是一个很现实也很 [严肃的问题][15]。他们想要去控制有谁可以接触到这个重要的系统,这个系统管理着他们的应用程序,记录了他们生活中的点点滴滴。这种想法是可以理解的:毕竟在一个连你的冰箱都是智能设备的今天,你不想要一个基本的保证吗?甚至是如果你授权了设备可以与外界通讯,它是否是仅被授权的人访问它呢?
|
||||
|
||||
[对安全的担心][16] 是为什么开源对我们将来使用的互联设备至关重要的众多理由之一。由于源代码运行在他们自己的设备上,完全可以去搞明白控制你的家庭的程序,也就是说你可以查看它的代码,如果必要的话甚至可以去修改它。
|
||||
|
||||
虽然联网设备通常都包含他们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口—— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
虽然联网设备通常都包含它们专有的组件,但是将开源引入家庭自动化的第一步是确保你的设备和这些设备可以共同工作 —— 它们为你提供一个接口 —— 并且是开源的。幸运的是,现在有许多解决方案可供选择,从 PC 到树莓派,你可以在它们上做任何事情。
|
||||
|
||||
这里有几个我比较喜欢的。
|
||||
|
||||
### Calaos
|
||||
|
||||
[Calaos][17] 是一个设计为全栈家庭自动化的平台,包含一个服务器应用程序、触摸屏接口、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
[Calaos][17] 是一个设计为全栈的家庭自动化平台,包含一个服务器应用程序、触摸屏界面、Web 应用程序、支持 iOS 和 Android 的原生移动应用、以及一个运行在底层的预配置好的 Linux 操作系统。Calaos 项目出自一个法国公司,因此它的支持论坛以法语为主,不过大量的介绍资料和文档都已经翻译为英语了。
|
||||
|
||||
Calaos 使用的是 [GPL][18] v3 的许可证,你可以在 [GitHub][19] 上查看它的源代码。
|
||||
|
||||
### Domoticz
|
||||
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
[Domoticz][20] 是一个有大量设备库支持的家庭自动化系统,在它的项目网站上有大量的文档,从气象站到远程控制的烟雾探测器,以及大量的第三方 [集成软件][21] 。它使用一个 HTML5 前端,可以从桌面浏览器或者大多数现代的智能手机上访问它,它是一个轻量级的应用,可以运行在像树莓派这样的低功耗设备上。
|
||||
|
||||
Domoticz 是用 C++ 写的,使用 [GPLv3][22] 许可证。它的 [源代码][23] 在 GitHub 上。
|
||||
|
||||
### Home Assistant
|
||||
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络附加存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源的和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
[Home Assistant][24] 是一个开源的家庭自动化平台,它可以轻松部署在任何能运行 Python 3 的机器上,从树莓派到网络存储(NAS),甚至可以使用 Docker 容器轻松地部署到其它系统上。它集成了大量的开源和商业的产品,允许你去连接它们,比如,IFTTT、天气信息、或者你的 Amazon Echo 设备,去控制从锁到灯的各种硬件。
|
||||
|
||||
Home Assistant 以 [MIT 许可证][25] 发布,它的源代码可以从 [GitHub][26] 上下载。
|
||||
|
||||
@ -41,26 +43,26 @@ MisterHouse 使用 [GPLv2][28] 许可证,你可以在 [GitHub][29] 上查看
|
||||
|
||||
### OpenHAB
|
||||
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中大家熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
[OpenHAB][30](开放家庭自动化总线的简称)是在开源爱好者中所熟知的家庭自动化工具,它拥有大量用户的社区以及支持和集成了大量的设备。它是用 Java 写的,OpenHAB 非常轻便,可以跨大多数主流操作系统使用,它甚至在树莓派上也运行的很好。支持成百上千的设备,OpenHAB 被设计为与设备无关的,这使开发者在系统中添加他们的设备或者插件很容易。OpenHAB 也支持通过 iOS 和 Android 应用来控制设备以及设计工具,因此,你可以为你的家庭系统创建你自己的 UI。
|
||||
|
||||
你可以在 GitHub 上找到 OpenHAB 的 [源代码][31],它使用 [Eclipse 公共许可证][32]。
|
||||
|
||||
### OpenMotics
|
||||
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便的改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
[OpenMotics][33] 是一个开源的硬件和软件家庭自动化系统。它的设计目标是为控制设备提供一个综合的系统,而不是从不同的供应商处将各种设备拼接在一起。不像其它的系统主要是为了方便改装而设计的,OpenMotics 专注于硬件解决方案。更多资料请查阅来自 OpenMotics 的后端开发者 Frederick Ryckbosch的 [完整文章][34] 。
|
||||
|
||||
OpenMotics 使用 [GPLv2][35] 许可证,它的源代码可以从 [GitHub][36] 上下载。
|
||||
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是它们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
当然了,我们的选择不仅有这些。许多家庭自动化爱好者使用不同的解决方案,甚至是他们自己动手做。其它用户选择使用单独的智能家庭设备而无需集成它们到一个单一的综合系统中。
|
||||
|
||||
如果上面的解决方案并不能满足你的需求,下面还有一些潜在的替代者可以去考虑:
|
||||
|
||||
* [EventGhost][1] 是一个开源的([GPL v2][2])家庭影院自动化工具,它只能运行在 Microsoft Windows PC 上。它允许用户去控制多媒体电脑和连接的硬件,它通过触发宏指令的插件或者定制的 Python 脚本来使用。
|
||||
* [ioBroker][3] 是一个基于 JavaScript 的物联网平台,它能够控制灯、锁、空调、多媒体、网络摄像头等等。它可以运行在任何可以运行 Node.js 的硬件上,包括 Windows、Linux、以及 macOS,它使用 [MIT 许可证][4]。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hubs,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [Jeedom][5] 是一个由开源软件([GPL v2][6])构成的家庭自动化平台,它可以控制灯、锁、多媒体等等。它包含一个移动应用程序(Android 和 iOS),并且可以运行在 Linux PC 上;该公司也销售 hub,它为配置家庭自动化提供一个现成的解决方案。
|
||||
* [LinuxMCE][7] 标称它是你的多媒体与电子设备之间的“数字粘合剂”。它运行在 Linux(包括树莓派)上,它基于 Pluto 开源 [许可证][8] 发布,它可以用于家庭安全、电话(VoIP 和语音信箱)、A/V 设备、家庭自动化、以及玩视频游戏。
|
||||
* [OpenNetHome][9],和这一类中的其它解决方案一样,是一个控制灯、报警、应用程序等等的一个开源软件。它基于 Java 和 Apache Maven,可以运行在 Windows、macOS、以及 Linux —— 包括树莓派,它以 [GPLv3][10] 许可证发布。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户接口。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
* [Smarthomatic][11] 是一个专注于硬件设备和软件的开源家庭自动化框架,而不仅是用户界面。它基于 [GPLv3][12] 许可证,它可用于控制灯、电器、以及空调、检测温度、提醒给植物浇水。
|
||||
|
||||
现在该轮到你了:你已经准备好家庭自动化系统了吗?或者正在研究去设计一个。你对家庭自动化的新手有什么建议,你会推荐什么样的系统?
|
||||
|
||||
@ -70,7 +72,7 @@ via: https://opensource.com/life/17/12/home-automation-tools
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
110
published/20171214 IPv6 Auto-Configuration in Linux.md
Normal file
@ -0,0 +1,110 @@
|
||||
在 Linux 中自动配置 IPv6 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 [KVM 中测试 IPv6 网络:第 1 部分][1] 一文中,我们学习了关于<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)的相关内容。在本文中,我们将学习如何为 ULA 自动配置 IP 地址。
|
||||
|
||||
### 何时使用唯一本地地址
|
||||
|
||||
<ruby>唯一本地地址<rt>unique local addresses</rt></ruby>(ULA)使用 `fd00::/8` 地址块,它类似于我们常用的 IPv4 的私有地址:`10.0.0.0/8`、`172.16.0.0/12`、以及 `192.168.0.0/16`。但它们并不能直接替换。IPv4 的私有地址分类和网络地址转换(NAT)功能是为了缓解 IPv4 地址短缺的问题,这是个明智的解决方案,它延缓了本该被替换的 IPv4 的生命周期。IPv6 也支持 NAT,但是我想不出使用它的理由。IPv6 的地址数量远远大于 IPv4;它是不一样的,因此需要做不一样的事情。
|
||||
|
||||
那么,ULA 存在的意义是什么呢?尤其是在我们已经有了<ruby>本地链路地址<rt>link-local addresses</rt></ruby>(`fe80::/10`)时,到底需不需要我们去配置它们呢?它们之间(LCTT 译注:指的是唯一本地地址和本地链路地址)有两个重要的区别。一是,本地链路地址是不可路由的,因此,你不能跨子网使用它。二是,ULA 是你自己管理的;你可以自己选择它用于子网的地址范围,并且它们是可路由的。
|
||||
|
||||
使用 ULA 的另一个好处是,如果你只是在局域网中“混日子”的话,你不需要为它们分配全局单播 IPv6 地址。当然了,如果你的 ISP 已经为你分配了 IPv6 的<ruby>全局单播地址<rt>global unicast addresses</rt></ruby>,就不需要使用 ULA 了。你也可以在同一个网络中混合使用全局单播地址和 ULA,但是,我想不出这样使用的一个好理由,并且要一定确保你不使用网络地址转换(NAT)以使 ULA 可公共访问。在我看来,这是很愚蠢的行为。
|
||||
|
||||
ULA 是仅为私有网络使用的,并且应该阻止其流出你的网络,不允许进入因特网。这很简单,在你的边界设备上只要阻止整个 `fd00::/8` 范围的 IPv6 地址即可实现。
|
||||
|
||||
### 地址自动配置
|
||||
|
||||
ULA 不像本地链路地址那样自动配置的,但是使用 radvd 设置自动配置是非常容易的,radva 是路由器公告守护程序。在你开始之前,运行 `ifconfig` 或者 `ip addr show` 去查看你现有的 IP 地址。
|
||||
|
||||
在生产系统上使用时,你应该将 radvd 安装在一台单独的路由器上,如果只是测试使用,你可以将它安装在你的网络中的任意 Linux PC 上。在我的小型 KVM 测试实验室中,我使用 `apt-get install radvd` 命令把它安装在 Ubuntu 上。安装完成之后,我先不启动它,因为它还没有配置文件:
|
||||
|
||||
```
|
||||
$ sudo systemctl status radvd
|
||||
● radvd.service - LSB: Router Advertising Daemon
|
||||
Loaded: loaded (/etc/init.d/radvd; bad; vendor preset: enabled)
|
||||
Active: active (exited) since Mon 2017-12-11 20:08:25 PST; 4min 59s ago
|
||||
Docs: man:systemd-sysv-generator(8)
|
||||
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Starting LSB: Router Advertising Daemon...
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: Starting radvd:
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * /etc/radvd.conf does not exist or is empty.
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * See /usr/share/doc/radvd/README.Debian
|
||||
Dec 11 20:08:25 ubunut1 radvd[3541]: * radvd will *not* be started.
|
||||
Dec 11 20:08:25 ubunut1 systemd[1]: Started LSB: Router Advertising Daemon.
|
||||
```
|
||||
|
||||
这些所有的消息有点让人困惑,实际上 radvd 并没有运行,你可以使用经典命令 `ps | grep radvd` 来验证这一点。因此,我们现在需要去创建 `/etc/radvd.conf` 文件。拷贝这个示例,将第一行的网络接口名替换成你自己的接口名字:
|
||||
|
||||
```
|
||||
interface ens7 {
|
||||
AdvSendAdvert on;
|
||||
MinRtrAdvInterval 3;
|
||||
MaxRtrAdvInterval 10;
|
||||
prefix fd7d:844d:3e17:f3ae::/64
|
||||
{
|
||||
AdvOnLink on;
|
||||
AdvAutonomous on;
|
||||
};
|
||||
|
||||
};
|
||||
```
|
||||
|
||||
前缀(`prefix`)定义了你的网络地址,它是地址的前 64 位。前两个字符必须是 `fd`,前缀接下来的剩余部分你自己定义它,最后的 64 位留空,因为 radvd 将去分配最后的 64 位。前缀后面的 16 位用来定义子网,剩余的地址定义为主机地址。你的子网必须总是 `/64`。RFC 4193 要求地址必须随机生成;查看 [在 KVM 中测试 IPv6 Networking:第 1 部分][1] 学习创建和管理 ULAs 的更多知识。
|
||||
|
||||
### IPv6 转发
|
||||
|
||||
IPv6 转发必须要启用。下面的命令去启用它,重启后生效:
|
||||
|
||||
```
|
||||
$ sudo sysctl -w net.ipv6.conf.all.forwarding=1
|
||||
```
|
||||
|
||||
取消注释或者添加如下的行到 `/etc/sysctl.conf` 文件中,以使它永久生效:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.forwarding = 1
|
||||
```
|
||||
|
||||
启动 radvd 守护程序:
|
||||
|
||||
```
|
||||
$ sudo systemctl stop radvd
|
||||
$ sudo systemctl start radvd
|
||||
```
|
||||
|
||||
这个示例在我的 Ubuntu 测试系统中遇到了一个怪事;radvd 总是停止,我查看它的状态却没有任何问题,做任何改变之后都需要重新启动 radvd。
|
||||
|
||||
启动成功后没有任何输出,并且失败也是如此,因此,需要运行 `sudo systemctl status radvd` 去查看它的运行状态。如果有错误,`systemctl` 会告诉你。一般常见的错误都是 `/etc/radvd.conf` 中的语法错误。
|
||||
|
||||
在 Twitter 上抱怨了上述问题之后,我学到了一件很酷的技巧:当你运行 ` journalctl -xe --no-pager` 去调试 `systemctl` 错误时,你的输出会被换行,然后,你就可以看到错误信息。
|
||||
|
||||
现在检查你的主机,查看它们自动分配的新地址:
|
||||
|
||||
```
|
||||
$ ifconfig
|
||||
ens7 Link encap:Ethernet HWaddr 52:54:00:57:71:50
|
||||
[...]
|
||||
inet6 addr: fd7d:844d:3e17:f3ae:9808:98d5:bea9:14d9/64 Scope:Global
|
||||
[...]
|
||||
```
|
||||
|
||||
本文到此为止,下周继续学习如何为 ULA 管理 DNS,这样你就可以使用一个合适的主机名来代替这些长长的 IPv6 地址。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的 [“Linux 入门”][2] 免费课程学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/ipv6-auto-configuration-linux
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-kvm-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,83 +1,85 @@
|
||||
如何使用 syslog-ng 从远程 Linux 机器上收集日志
|
||||
======
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
Image: Jack Wallen
|
||||
![linuxhero.jpg][1]
|
||||
|
||||
如果你的数据中心全是 Linux 服务器,而你就是系统管理员。那么你的其中一项工作内容就是查看服务器的日志文件。但是,如果你在大量的机器上去查看日志文件,那么意味着你需要挨个去登入到机器中来阅读日志文件。如果你管理的机器很多,仅这项工作就可以花费你一天的时间。
|
||||
|
||||
另外的选择是,你可以配置一台单独的 Linux 机器去收集这些日志。这将使你的每日工作更加高效。要实现这个目的,有很多的不同系统可供你选择,而 syslog-ng 就是其中之一。
|
||||
|
||||
使用 syslog-ng 的问题是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
syslog-ng 的不足是文档并不容易梳理。但是,我已经解决了这个问题,我可以通过这种方法马上进行安装和配置 syslog-ng。下面我将在 Ubuntu Server 16.04 上示范这两种方法:
|
||||
|
||||
* UBUNTUSERVERVM 的 IP 地址是 192.168.1.118 ,将配置为日志收集器
|
||||
* UBUNTUSERVERVM2 将配置为一个客户端,发送日志文件到收集器
|
||||
|
||||
现在我们来开始安装和配置。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
安装很简单。为了尽可能容易,我将从标准仓库安装。打开一个终端窗口,运行如下命令:
|
||||
|
||||
```
|
||||
sudo apt install syslog-ng
|
||||
```
|
||||
|
||||
在作为收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
你必须在收集器和客户端的机器上都要运行上面的命令。安装完成之后,你将开始配置。
|
||||
|
||||
## 配置收集器
|
||||
### 配置收集器
|
||||
|
||||
现在,我们开始日志收集器的配置。它的配置文件是 `/etc/syslog-ng/syslog-ng.conf`。syslog-ng 安装完成时就已经包含了一个配置文件。我们不使用这个默认的配置文件,可以使用 `mv /etc/syslog-ng/syslog-ng.conf /etc/syslog-ng/syslog-ng.conf.BAK` 将这个自带的默认配置文件重命名。现在使用 `sudo nano /etc/syslog/syslog-ng.conf` 命令创建一个新的配置文件。在这个文件中添加如下的行:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
options {
|
||||
time-reap(30);
|
||||
mark-freq(10);
|
||||
keep-hostname(yes);
|
||||
};
|
||||
source s_local { system(); internal(); };
|
||||
source s_network {
|
||||
syslog(transport(tcp) port(514));
|
||||
};
|
||||
destination d_local {
|
||||
file("/var/log/syslog-ng/messages_${HOST}"); };
|
||||
destination d_logs {
|
||||
file(
|
||||
"/var/log/syslog-ng/logs.txt"
|
||||
owner("root")
|
||||
group("root")
|
||||
perm(0777)
|
||||
); };
|
||||
log { source(s_local); source(s_network); destination(d_logs); };
|
||||
```
|
||||
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保你的网络上它可以被访问。
|
||||
需要注意的是,syslog-ng 使用 514 端口,你需要确保在你的网络上它可以被访问。
|
||||
|
||||
保存并关闭这个文件。上面的配置将转存期望的日志文件(由 `system()` 和 `internal()` 指出)到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
|
||||
保存和关闭这个文件。上面的配置将转存期望的日志文件(使用 system() and internal())到 `/var/log/syslog-ng/logs.txt` 中。因此,你需要使用如下的命令去创建所需的目录和文件:
|
||||
```
|
||||
sudo mkdir /var/log/syslog-ng
|
||||
sudo touch /var/log/syslog-ng/logs.txt
|
||||
```
|
||||
|
||||
使用如下的命令启动和启用 syslog-ng:
|
||||
|
||||
```
|
||||
sudo systemctl start syslog-ng
|
||||
sudo systemctl enable syslog-ng
|
||||
```
|
||||
|
||||
## 配置为客户端
|
||||
### 配置客户端
|
||||
|
||||
我们将在客户端上做同样的事情(移动默认配置文件并创建新配置文件)。拷贝下列文本到新的客户端配置文件中:
|
||||
|
||||
```
|
||||
@version: 3.5
|
||||
@include "scl.conf"
|
||||
@include "`scl-root`/system/tty10.conf"
|
||||
source s_local { system(); internal(); };
|
||||
destination d_syslog_tcp {
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
syslog("192.168.1.118" transport("tcp") port(514)); };
|
||||
log { source(s_local);destination(d_syslog_tcp); };
|
||||
```
|
||||
|
||||
@ -87,11 +89,9 @@ log { source(s_local);destination(d_syslog_tcp); };
|
||||
|
||||
## 查看日志文件
|
||||
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出 ( **Figure A** )。
|
||||
回到你的配置为收集器的服务器上,运行这个命令 `sudo tail -f /var/log/syslog-ng/logs.txt`。你将看到包含了收集器和客户端的日志条目的输出(图 A)。
|
||||
|
||||
**Figure A**
|
||||
|
||||
![Figure A][3]
|
||||
![图 A][3]
|
||||
|
||||
恭喜你!syslog-ng 已经正常工作了。你现在可以登入到你的收集器上查看本地机器和远程客户端的日志了。如果你的数据中心有很多 Linux 服务器,在每台服务器上都安装上 syslog-ng 并配置它们作为客户端发送日志到收集器,这样你就不需要登入到每个机器去查看它们的日志了。
|
||||
|
||||
@ -101,7 +101,7 @@ via: https://www.techrepublic.com/article/how-to-use-syslog-ng-to-collect-logs-f
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
Linux 下最好的图片截取和视频截录工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 Stack Overflow 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送截图。在 GNOME 中有一些这种类型的程序和 shell 拓展工具。这里介绍的是 Linux 最好的屏幕截图工具,可以供你截取图片或截录视频。
|
||||
|
||||
### 1. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。它也有一个扩展菜单,展示在 GNOME 顶部面板,使得用户进入软件变得更人性化,非常方便使用。
|
||||
|
||||
你可以截取选区、窗口、桌面、当前光标下的窗口、区域、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务商。它同样允许用户在保存截图之前编辑器图片;同时提供了一些可自由添加或移除的插件。
|
||||
|
||||
终端内键入下列命令安装此工具:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
[Vokoscreen][5] 是一款允许你记录和叙述屏幕活动的一款软件。它易于使用,有一个简洁的界面和顶部面板的菜单,方便用户录制视频。
|
||||
|
||||
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个选区。自定义记录可以让你轻松得到所需的保存类型,你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,用于你写作教程吸引学习者。记录完成后,你还可以在该应用程序中回放视频记录,这样就不必到处去找你记录的内容。
|
||||
|
||||
[][6]
|
||||
|
||||
你可以从你的发行版仓库安装 Vocoscreen,或者你也可以在 [pkgs.org][7] 选择下载你需要的版本。
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的流媒体。它允许你看到自己所录制的内容或你叙述的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件进行视频编辑。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
如果 FFmpeg 安装完成,在终端中键入如下安装 OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] 是一款界面简单的程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是屏幕上的选区,以便于只在自己的记录中保留需要的内容;你还可以自定义最终保存的视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束后的命令运行选项,这样,就可以在视频录制结束后立即运行。
|
||||
|
||||
在终端中键入如下命令来安装 green recorder:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制,也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口安排的非常好,和其它软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
|
||||
|
||||
终端中键入如下命令来安装 Kazam:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
如果没有找到该 PPA,你需要使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. GNOME 扩展截屏工具
|
||||
|
||||
[][1]
|
||||
|
||||
GNOME 的一个扩展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它的话。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在调整工具中禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索 “_Screenshot Tool_”,在你的 GNOME 中安装它。
|
||||
|
||||
你需要安装 gnome 扩展的 chrome 扩展组件和 GNOME 调整工具才能使用这个工具。
|
||||
|
||||
[][14]
|
||||
|
||||
当你碰到一个问题,不知道怎么处理,想要在 [Linux 社区][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
@ -1,56 +1,56 @@
|
||||
如何在 Linux 上安装/更新 Intel 微码固件
|
||||
======
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行方式去安装或者更新 Intel/AMD CPU 的微码固件呢?
|
||||
|
||||
如果你是一个 Linux 系统管理方面的新手,如何在 Linux 上使用命令行选项去安装或者更新 Intel/AMD CPU 的微码固件?
|
||||
|
||||
|
||||
微码只是由 Intel/AMD 提供的 CPU 固件而已。Linux 的内核可以在系统引导时不需要升级 BIOS 的情况下更新 CPU 的固件。处理器微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的升级微码可以去修复 bug 或者使用补丁来防范 bugs。这篇文章演示了如何使用包管理器去安装 AMD 或者 Intel 微码更新,或者由 lntel 提供的 Linux 上的处理器微码更新。
|
||||
|
||||
## 如何查看当前的微码状态
|
||||
<ruby>微码<rt>microcode</rt></ruby>就是由 Intel/AMD 提供的 CPU 固件。Linux 的内核可以在引导时更新 CPU 固件,而无需 BIOS 更新。处理器的微码保存在内存中,在每次启动系统时,内核可以更新这个微码。这些来自 Intel/AMD 的微码的更新可以去修复 bug 或者使用补丁来防范 bug。这篇文章演示了如何使用包管理器或由 lntel 提供的 Linux 处理器微码更新来安装 AMD 或 Intel 的微码更新。
|
||||
|
||||
### 如何查看当前的微码状态
|
||||
|
||||
以 root 用户运行下列命令:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
[![Verify microcode update on a CentOS RHEL Fedora Ubuntu Debian Linux][1]][1]
|
||||
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下图这样的:
|
||||
请注意,你的 CPU 在这里完全有可能出现没有可用的微码更新的情况。如果是这种情况,它的输出可能是如下这样的:
|
||||
|
||||
```
|
||||
[ 0.952699] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 0.952773] microcode: Microcode Update Driver: v2.2.
|
||||
|
||||
```
|
||||
|
||||
## 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 Linux 系统的 x86/amd64 架构的 CPU 上,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:**sudo apt install intel-microcode**
|
||||
3. CentOS/RHEL Linux 用户输入:**sudo yum install microcode_ctl**
|
||||
### 如何在 Linux 上使用包管理器去安装微码固件更新
|
||||
|
||||
对于运行在 x86/amd64 架构的 CPU 上的 Linux 系统,Linux 自带了工具去更改或者部署微码固件。在 Linux 上安装 AMD 或者 Intel 的微码固件的过程如下:
|
||||
|
||||
1. 打开终端应用程序
|
||||
2. Debian/Ubuntu Linux 用户推输入:`sudo apt install intel-microcode`
|
||||
3. CentOS/RHEL Linux 用户输入:`sudo yum install microcode_ctl`
|
||||
|
||||
对于流行的 Linux 发行版,这个包的名字一般如下 :
|
||||
|
||||
* microcode_ctl 和 linux-firmware —— CentOS/RHEL 微码更新包
|
||||
* intel-microcode —— Debian/Ubuntu 和 clones 发行版适用于 Intel CPU 的微码更新包
|
||||
* amd64-microcode —— Debian/Ubuntu 和 clones 发行版适用于 AMD CPU 的微码固件
|
||||
* linux-firmware —— 适用于 AMD CPU 的 Arch Linux 发行版微码固件(你不用做任何操作,它是默认安装的)
|
||||
* intel-ucode —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* microcode_ctl 和 ucode-intel —— Suse/OpenSUSE Linux 微码更新包
|
||||
* `microcode_ctl` 和 `linux-firmware` —— CentOS/RHEL 微码更新包
|
||||
* `intel-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 Intel CPU 的微码更新包
|
||||
* `amd64-microcode` —— Debian/Ubuntu 和衍生发行版的适用于 AMD CPU 的微码固件
|
||||
* `linux-firmware` —— 适用于 AMD CPU 的 Arch Linux 发行版的微码固件(你不用做任何操作,它是默认安装的)
|
||||
* `intel-ucode` —— 适用于 Intel CPU 的 Arch Linux 发行版微码固件
|
||||
* `microcode_ctl` 、`linux-firmware` 和 `ucode-intel` —— Suse/OpenSUSE Linux 微码更新包
|
||||
|
||||
**警告 :在某些情况下,微码更新可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
|
||||
**警告 :在某些情况下,更新微码可能会导致引导问题,比如,服务器在引导时被挂起或者自动重置。以下的步骤是在我的机器上运行过的,并且我是一个经验丰富的系统管理员。对于由此引发的任何硬件故障,我不承担任何责任。在做固件更新之前,请充分评估操作风险!**
|
||||
|
||||
### 示例
|
||||
#### 示例
|
||||
|
||||
在使用 Intel CPU 的 Debian/Ubuntu Linux 系统上,输入如下的 [apt 命令][2]/[apt-get 命令][3]:
|
||||
|
||||
`$ sudo apt-get install intel-microcode`
|
||||
```
|
||||
$ sudo apt-get install intel-microcode
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -58,11 +58,15 @@
|
||||
|
||||
你 [必须重启服务器以激活微码][5] 更新:
|
||||
|
||||
`$ sudo reboot`
|
||||
```
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后检查微码状态:
|
||||
|
||||
`# dmesg | grep 'microcode'`
|
||||
```
|
||||
# dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
@ -70,7 +74,6 @@
|
||||
[ 0.000000] microcode: microcode updated early to revision 0x1c, date = 2015-02-26
|
||||
[ 1.604672] microcode: sig=0x306a9, pf=0x10, revision=0x1c
|
||||
[ 1.604976] microcode: Microcode Update Driver: v2.01 <tigran@aivazian.fsnet.co.uk>, Peter Oruba
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 RHEL/CentOS 系统,使用 [yum 命令][6] 尝试去安装或者更新以下两个包:
|
||||
@ -81,13 +84,14 @@ $ sudo reboot
|
||||
$ sudo dmesg | grep 'microcode'
|
||||
```
|
||||
|
||||
## 如何去更新/安装从 Intel 网站上下载的微码
|
||||
### 如何更新/安装从 Intel 网站上下载的微码
|
||||
|
||||
仅当你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
只有在你的 CPU 制造商建议这么做的时候,才可以使用下列的方法去更新/安装微码,除此之外,都应该使用上面的方法去更新。大多数 Linux 发行版都可以通过包管理器来维护、更新微码。使用包管理器的方法是经过测试的,对大多数用户来说是最安全的方式。
|
||||
|
||||
### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
#### 如何为 Linux 安装 Intel 处理器微码块(20180108 发布)
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 `~/Downloads/microcode-20180108.tgz` 的文件(不要忘了去验证它的检验和),它的用途是去防范 `meltdown/Spectre` bug。先使用 `tar` 命令去提取它:
|
||||
|
||||
首先通过 AMD 或 [Intel 网站][7] 去获取最新的微码固件。在本示例中,我有一个名称为 ~/Downloads/microcode-20180108.tgz(不要忘了去验证它的检验和),它的用途是去防范 meltdown/Spectre bugs。先使用 tar 命令去提取它:
|
||||
```
|
||||
$ mkdir firmware
|
||||
$ cd firmware
|
||||
@ -101,33 +105,44 @@ $ ls -l
|
||||
drwxr-xr-x 2 vivek vivek 4096 Jan 8 12:41 intel-ucode
|
||||
-rw-r--r-- 1 vivek vivek 4847056 Jan 8 12:39 microcode.dat
|
||||
-rw-r--r-- 1 vivek vivek 1907 Jan 9 07:03 releasenote
|
||||
|
||||
```
|
||||
|
||||
检查一下,确保存在 /sys/devices/system/cpu/microcode/reload 目录:
|
||||
> 我只在 CentOS 7.x/RHEL、 7.x/Debian 9.x 和 Ubuntu 17.10 上测试了如下操作。如果你没有找到 `/sys/devices/system/cpu/microcode/reload` 文件的话,更老的发行版所带的更老的内核也许不能使用此方法。参见下面的讨论。请注意,在应用了固件更新之后,有一些客户遇到了系统重启现象。特别是对于[那些运行 Intel Broadwell 和 Haswell CPU][12] 的用于客户机和数据中心服务器上的系统。不要在 Intel Broadwell 和 Haswell CPU 上应用 20180108 版本。尽可能使用软件包管理器方式。
|
||||
|
||||
`$ ls -l /sys/devices/system/cpu/microcode/reload`
|
||||
检查一下,确保存在 `/sys/devices/system/cpu/microcode/reload`:
|
||||
|
||||
你必须使用 [cp 命令][8] 拷贝 intel-ucode 目录下的所有文件到 /lib/firmware/intel-ucode/ 下面:
|
||||
```
|
||||
$ ls -l /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
`$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/`
|
||||
你必须使用 [cp 命令][8] 拷贝 `intel-ucode` 目录下的所有文件到 `/lib/firmware/intel-ucode/` 下面:
|
||||
|
||||
你只需要将 intel-ucode 这个目录整个拷贝到 /lib/firmware/ 目录下即可。然后在重新加载接口中写入 1 去重新加载微码文件:
|
||||
```
|
||||
$ sudo cp -v intel-ucode/* /lib/firmware/intel-ucode/
|
||||
```
|
||||
|
||||
`# echo 1 > /sys/devices/system/cpu/microcode/reload`
|
||||
你只需要将 `intel-ucode` 这个目录整个拷贝到 `/lib/firmware/` 目录下即可。然后在重新加载接口中写入 `1` 去重新加载微码文件:
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时通过内核来加载:
|
||||
```
|
||||
# echo 1 > /sys/devices/system/cpu/microcode/reload
|
||||
```
|
||||
|
||||
更新现有的 initramfs,以便于下次启动时它能通过内核来加载:
|
||||
|
||||
```
|
||||
$ sudo update-initramfs -u
|
||||
$ sudo reboot
|
||||
```
|
||||
|
||||
重启后通过以下的命令验证微码是否已经更新:
|
||||
`# dmesg | grep microcode`
|
||||
|
||||
```
|
||||
# dmesg | grep microcode
|
||||
```
|
||||
|
||||
到此为止,就是更新处理器微码的全部步骤。如果一切顺利的话,你的 Intel CPU 的固件将已经是最新的版本了。
|
||||
|
||||
## 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人、一位经验丰富的系统管理员、Linux/Unix 操作系统 shell 脚本培训师。他与全球的包括 IT、教育、国防和空间研究、以及非盈利组织等各行业的客户一起工作。可以在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。
|
||||
|
||||
@ -137,7 +152,7 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -153,3 +168,4 @@ via: https://www.cyberciti.biz/faq/install-update-intel-microcode-firmware-linux
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://newsroom.intel.com/news/intel-security-issue-update-addressing-reboot-issues/
|
||||
@ -1,21 +1,21 @@
|
||||
Partclone - 多功能的分区和克隆免费软件
|
||||
Partclone:多功能的分区和克隆的自由软件
|
||||
======
|
||||
|
||||
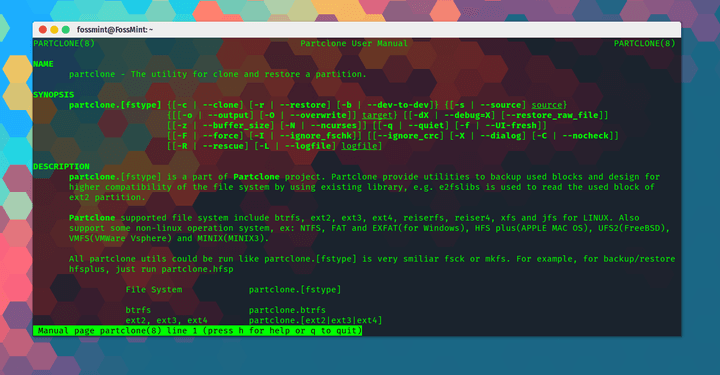
|
||||
|
||||
**[Partclone][1]** 是由 **Clonezilla** 开发者开发的免费开源的用于创建和克隆分区镜像的软件。实际上,**Partclone** 是基于 **Clonezilla** 的工具之一。
|
||||
[Partclone][1] 是由 Clonezilla 的开发者们开发的用于创建和克隆分区镜像的自由开源软件。实际上,Partclone 是 Clonezilla 所基于的工具之一。
|
||||
|
||||
它为用户提供了备份与恢复占用的分区块工具,并与多个文件系统的高度兼容,这要归功于它能够使用像 **e2fslibs** 这样的现有库来读取和写入分区,例如 **ext2**。
|
||||
它为用户提供了备份与恢复已用分区的工具,并与多个文件系统高度兼容,这要归功于它能够使用像 e2fslibs 这样的现有库来读取和写入分区,例如 ext2。
|
||||
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs +、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs+、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
|
||||
它还有许多的程序,包括 **partclone.ext2**ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
它还有许多的程序,包括 partclone.ext2(ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
|
||||
### Partclone中的功能
|
||||
|
||||
* **免费软件:** **Partclone**免费供所有人下载和使用。
|
||||
* **开源:** **Partclone**是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* **跨平台**:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 免费软件: Partclone 免费供所有人下载和使用。
|
||||
* 开源: Partclone 是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* 跨平台:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 一个在线的[文档页面][3],你可以从中查看帮助文档并跟踪其 GitHub 问题。
|
||||
* 为初学者和专业人士提供的在线[用户手册][4]。
|
||||
* 支持救援。
|
||||
@ -25,55 +25,53 @@ Partclone - 多功能的分区和克隆免费软件
|
||||
* 支持 raw 克隆。
|
||||
* 显示传输速率和持续时间。
|
||||
* 支持管道。
|
||||
* 支持 crc32。
|
||||
* 支持 crc32 校验。
|
||||
* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
|
||||
|
||||
Partclone 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
|
||||
**Partclone** 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
[下载 Linux 中的 Partclone][6]
|
||||
- [下载 Linux 中的 Partclone][6]
|
||||
|
||||
### 如何安装和使用 Partclone
|
||||
|
||||
在 Linux 上安装 Partclone。
|
||||
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
```
|
||||
|
||||
克隆分区为镜像。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
|
||||
```
|
||||
|
||||
将镜像恢复到分区。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
分区到分区克隆。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
|
||||
```
|
||||
|
||||
显示镜像信息。
|
||||
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
检查镜像。
|
||||
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
你是 **Partclone** 的用户吗?我最近在 [**Deepin Clone**][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
你是 Partclone 的用户吗?我最近在 [Deepin Clone][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
|
||||
请在下面的评论区与我们分享你的想法和建议。
|
||||
|
||||
@ -81,13 +79,13 @@ $ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
|
||||
作者:[Martins D. Okoi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
224
published/20180116 Analyzing the Linux boot process.md
Normal file
224
published/20180116 Analyzing the Linux boot process.md
Normal file
@ -0,0 +1,224 @@
|
||||
Linux 启动过程分析
|
||||
======
|
||||
|
||||
> 理解运转良好的系统对于处理不可避免的故障是最好的准备。
|
||||
|
||||

|
||||
|
||||
*图片由企鹅和靴子“赞助”,由 Opensource.com 修改。CC BY-SA 4.0。*
|
||||
|
||||
关于开源软件最古老的笑话是:“代码是<ruby>自具文档化的<rt>self-documenting</rt></ruby>”。经验表明,阅读源代码就像听天气预报一样:明智的人依然出门会看看室外的天气。本文讲述了如何运用调试工具来观察和分析 Linux 系统的启动。分析一个功能正常的系统启动过程,有助于用户和开发人员应对不可避免的故障。
|
||||
|
||||
从某些方面看,启动过程非常简单。内核在单核上以单线程和同步状态启动,似乎可以理解。但内核本身是如何启动的呢?[initrd(initial ramdisk)][1] 和<ruby>引导程序<rt>bootloader</rt></ruby>具有哪些功能?还有,为什么以太网端口上的 LED 灯是常亮的呢?
|
||||
|
||||
请继续阅读寻找答案。在 GitHub 上也提供了 [介绍演示和练习的代码][2]。
|
||||
|
||||
### 启动的开始:OFF 状态
|
||||
|
||||
#### <ruby>局域网唤醒<rt>Wake-on-LAN</rt></ruby>
|
||||
|
||||
OFF 状态表示系统没有上电,没错吧?表面简单,其实不然。例如,如果系统启用了局域网唤醒机制(WOL),以太网指示灯将亮起。通过以下命令来检查是否是这种情况:
|
||||
|
||||
```
|
||||
# sudo ethtool <interface name>
|
||||
```
|
||||
|
||||
其中 `<interface name>` 是网络接口的名字,比如 `eth0`。(`ethtool` 可以在同名的 Linux 软件包中找到。)如果输出中的 `Wake-on` 显示 `g`,则远程主机可以通过发送 [<ruby>魔法数据包<rt>MagicPacket</rt></ruby>][3] 来启动系统。如果您无意远程唤醒系统,也不希望其他人这样做,请在系统 BIOS 菜单中将 WOL 关闭,或者用以下方式:
|
||||
|
||||
```
|
||||
# sudo ethtool -s <interface name> wol d
|
||||
```
|
||||
|
||||
响应魔法数据包的处理器可能是网络接口的一部分,也可能是 [<ruby>底板管理控制器<rt>Baseboard Management Controller</rt></ruby>][4](BMC)。
|
||||
|
||||
#### 英特尔管理引擎、平台控制器单元和 Minix
|
||||
|
||||
BMC 不是唯一的在系统关闭时仍在监听的微控制器(MCU)。x86_64 系统还包含了用于远程管理系统的英特尔管理引擎(IME)软件套件。从服务器到笔记本电脑,各种各样的设备都包含了这项技术,它开启了如 KVM 远程控制和英特尔功能许可服务等 [功能][5]。根据 [Intel 自己的检测工具][7],[IME 存在尚未修补的漏洞][6]。坏消息是,要禁用 IME 很难。Trammell Hudson 发起了一个 [me_cleaner 项目][8],它可以清除一些相对恶劣的 IME 组件,比如嵌入式 Web 服务器,但也可能会影响运行它的系统。
|
||||
|
||||
IME 固件和<ruby>系统管理模式<rt>System Management Mode</rt></ruby>(SMM)软件是 [基于 Minix 操作系统][9] 的,并运行在单独的<ruby>平台控制器单元<rt>Platform Controller Hub</rt></ruby>上(LCTT 译注:即南桥芯片),而不是主 CPU 上。然后,SMM 启动位于主处理器上的<ruby>通用可扩展固件接口<rt>Universal Extensible Firmware Interface</rt></ruby>(UEFI)软件,相关内容 [已被提及多次][10]。Google 的 Coreboot 小组已经启动了一个雄心勃勃的 [<ruby>非扩展性缩减版固件<rt>Non-Extensible Reduced Firmware</rt></ruby>][11](NERF)项目,其目的不仅是要取代 UEFI,还要取代早期的 Linux 用户空间组件,如 systemd。在我们等待这些新成果的同时,Linux 用户现在就可以从 Purism、System76 或 Dell 等处购买 [禁用了 IME][12] 的笔记本电脑,另外 [带有 ARM 64 位处理器笔记本电脑][13] 还是值得期待的。
|
||||
|
||||
#### 引导程序
|
||||
|
||||
除了启动那些问题不断的间谍软件外,早期引导固件还有什么功能呢?引导程序的作用是为新上电的处理器提供通用操作系统(如 Linux)所需的资源。在开机时,不但没有虚拟内存,在控制器启动之前连 DRAM 也没有。然后,引导程序打开电源,并扫描总线和接口,以定位内核镜像和根文件系统的位置。U-Boot 和 GRUB 等常见的引导程序支持 USB、PCI 和 NFS 等接口,以及更多的嵌入式专用设备,如 NOR 闪存和 NAND 闪存。引导程序还与 [<ruby>可信平台模块<rt>Trusted Platform Module</rt></ruby>][14](TPM)等硬件安全设备进行交互,在启动最开始建立信任链。
|
||||
|
||||
![Running the U-boot bootloader][16]
|
||||
|
||||
*在构建主机上的沙盒中运行 U-boot 引导程序。*
|
||||
|
||||
包括树莓派、任天堂设备、汽车主板和 Chromebook 在内的系统都支持广泛使用的开源引导程序 [U-Boot][17]。它没有系统日志,当发生问题时,甚至没有任何控制台输出。为了便于调试,U-Boot 团队提供了一个沙盒,可以在构建主机甚至是夜间的持续集成(CI)系统上测试补丁程序。如果系统上安装了 Git 和 GNU Compiler Collection(GCC)等通用的开发工具,使用 U-Boot 沙盒会相对简单:
|
||||
|
||||
```
|
||||
# git clone git://git.denx.de/u-boot; cd u-boot
|
||||
# make ARCH=sandbox defconfig
|
||||
# make; ./u-boot
|
||||
=> printenv
|
||||
=> help
|
||||
```
|
||||
|
||||
在 x86_64 上运行 U-Boot,可以测试一些棘手的功能,如 [模拟存储设备][2] 的重新分区、基于 TPM 的密钥操作以及 USB 设备热插拔等。U-Boot 沙盒甚至可以在 GDB 调试器下单步执行。使用沙盒进行开发的速度比将引导程序刷新到电路板上的测试快 10 倍,并且可以使用 `Ctrl + C` 恢复一个“变砖”的沙盒。
|
||||
|
||||
### 启动内核
|
||||
|
||||
#### 配置引导内核
|
||||
|
||||
引导程序完成任务后将跳转到已加载到主内存中的内核代码,并开始执行,传递用户指定的任何命令行选项。内核是什么样的程序呢?用命令 `file /boot/vmlinuz` 可以看到它是一个 “bzImage”,意思是一个大的压缩的镜像。Linux 源代码树包含了一个可以解压缩这个文件的工具—— [extract-vmlinux][18]:
|
||||
|
||||
```
|
||||
# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
|
||||
# file vmlinux
|
||||
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
|
||||
linked, stripped
|
||||
```
|
||||
|
||||
内核是一个 [<ruby>可执行与可链接格式<rt> Executable and Linking Format</rt></ruby>][19](ELF)的二进制文件,就像 Linux 的用户空间程序一样。这意味着我们可以使用 `binutils` 包中的命令,如 `readelf` 来检查它。比较一下输出,例如:
|
||||
|
||||
```
|
||||
# readelf -S /bin/date
|
||||
# readelf -S vmlinux
|
||||
```
|
||||
|
||||
这两个二进制文件中的段内容大致相同。
|
||||
|
||||
所以内核必须像其他的 Linux ELF 文件一样启动,但用户空间程序是如何启动的呢?在 `main()` 函数中?并不确切。
|
||||
|
||||
在 `main()` 函数运行之前,程序需要一个执行上下文,包括堆栈内存以及 `stdio`、`stdout` 和 `stderr` 的文件描述符。用户空间程序从标准库(多数 Linux 系统在用 “glibc”)中获取这些资源。参照以下输出:
|
||||
|
||||
```
|
||||
# file /bin/date
|
||||
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
|
||||
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
|
||||
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
|
||||
stripped
|
||||
```
|
||||
|
||||
ELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但是解释器不需要像脚本那样用 `#!` 指定,因为 ELF 是 Linux 的原生格式。ELF 解释器通过调用 `_start()` 函数来用所需资源 [配置一个二进制文件][20],这个函数可以从 glibc 源代码包中找到,可以 [用 GDB 查看][21]。内核显然没有解释器,必须自我配置,这是怎么做到的呢?
|
||||
|
||||
用 GDB 检查内核的启动给出了答案。首先安装内核的调试软件包,内核中包含一个<ruby>未剥离的<rt>unstripped</rt></ruby> vmlinux,例如 `apt-get install linux-image-amd64-dbg`,或者从源代码编译和安装你自己的内核,可以参照 [Debian Kernel Handbook][22] 中的指令。`gdb vmlinux` 后加 `info files` 可显示 ELF 段 `init.text`。在 `init.text` 中用 `l *(address)` 列出程序执行的开头,其中 `address` 是 `init.text` 的十六进制开头。用 GDB 可以看到 x86_64 内核从内核文件 [arch/x86/kernel/head_64.S][23] 开始启动,在这个文件中我们找到了汇编函数 `start_cpu0()`,以及一段明确的代码显示在调用 `x86_64 start_kernel()` 函数之前创建了堆栈并解压了 zImage。ARM 32 位内核也有类似的文件 [arch/arm/kernel/head.S][24]。`start_kernel()` 不针对特定的体系结构,所以这个函数驻留在内核的 [init/main.c][25] 中。`start_kernel()` 可以说是 Linux 真正的 `main()` 函数。
|
||||
|
||||
### 从 start_kernel() 到 PID 1
|
||||
|
||||
#### 内核的硬件清单:设备树和 ACPI 表
|
||||
|
||||
在引导时,内核需要硬件信息,不仅仅是已编译过的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。有两种主要的数据存储方法:[<ruby>设备树<rt>device-tree</rt></ruby>][26] 和 [高级配置和电源接口(ACPI)表][27]。内核通过读取这些文件了解每次启动时需要运行的硬件。
|
||||
|
||||
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个与内核源代码同时编译的文件,通常与 `vmlinux` 一样位于 `/boot` 目录中。要查看 ARM 设备上的设备树的内容,只需对名称与 `/boot/*.dtb` 匹配的文件执行 `binutils` 包中的 `strings` 命令即可,这里 `dtb` 是指<ruby>设备树二进制文件<rt>device-tree binary</rt></ruby>。显然,只需编辑构成它的类 JSON 的文件并重新运行随内核源代码提供的特殊 `dtc` 编译器即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由命令行引导程序传递给内核,但近年来增加了一个 [设备树覆盖][28] 的功能,内核在启动后可以动态加载热插拔的附加设备。
|
||||
|
||||
x86 系列和许多企业级的 ARM64 设备使用 [ACPI][27] 机制。与设备树不同的是,ACPI 信息存储在内核在启动时通过访问板载 ROM 而创建的 `/sys/firmware/acpi/tables` 虚拟文件系统中。读取 ACPI 表的简单方法是使用 `acpica-tools` 包中的 `acpidump` 命令。例如:
|
||||
|
||||
![ACPI tables on Lenovo laptops][30]
|
||||
|
||||
*联想笔记本电脑的 ACPI 表都是为 Windows 2001 设置的。*
|
||||
|
||||
是的,你的 Linux 系统已经准备好用于 Windows 2001 了,你要考虑安装吗?与设备树不同,ACPI 具有方法和数据,而设备树更多地是一种硬件描述语言。ACPI 方法在启动后仍处于活动状态。例如,运行 `acpi_listen` 命令(在 `apcid` 包中),然后打开和关闭笔记本机盖会发现 ACPI 功能一直在运行。暂时地和动态地 [覆盖 ACPI 表][31] 是可能的,而永久地改变它需要在引导时与 BIOS 菜单交互或刷新 ROM。如果你遇到那么多麻烦,也许你应该 [安装 coreboot][32],这是开源固件的替代品。
|
||||
|
||||
#### 从 start_kernel() 到用户空间
|
||||
|
||||
[init/main.c][25] 中的代码竟然是可读的,而且有趣的是,它仍然在使用 1991 - 1992 年的 Linus Torvalds 的原始版权。在一个刚启动的系统上运行 `dmesg | head`,其输出主要来源于此文件。第一个 CPU 注册到系统中,全局数据结构被初始化,并且调度程序、中断处理程序(IRQ)、定时器和控制台按照严格的顺序逐一启动。在 `timekeeping_init()` 函数运行之前,所有的时间戳都是零。内核初始化的这部分是同步的,也就是说执行只发生在一个线程中,在最后一个完成并返回之前,没有任何函数会被执行。因此,即使在两个系统之间,`dmesg` 的输出也是完全可重复的,只要它们具有相同的设备树或 ACPI 表。Linux 的行为就像在 MCU 上运行的 RTOS(实时操作系统)一样,如 QNX 或 VxWorks。这种情况持续存在于函数 `rest_init()` 中,该函数在终止时由 `start_kernel()` 调用。
|
||||
|
||||
![Summary of early kernel boot process.][34]
|
||||
|
||||
*早期的内核启动流程。*
|
||||
|
||||
函数 `rest_init()` 产生了一个新进程以运行 `kernel_init()`,并调用了 `do_initcalls()`。用户可以通过将 `initcall_debug` 附加到内核命令行来监控 `initcalls`,这样每运行一次 `initcall` 函数就会产生 一个 `dmesg` 条目。`initcalls` 会历经七个连续的级别:early、core、postcore、arch、subsys、fs、device 和 late。`initcalls` 最为用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储和显示器等等,同时加载其内核模块。`rest_init()` 也会在引导处理器上产生第二个线程,它首先运行 `cpu_idle()`,然后等待调度器分配工作。
|
||||
|
||||
`kernel_init()` 也可以 [设置对称多处理(SMP)结构][35]。在较新的内核中,如果 `dmesg` 的输出中出现 “Bringing up secondary CPUs...” 等字样,系统便使用了 SMP。SMP 通过“热插拔” CPU 来进行,这意味着它用状态机来管理其生命周期,这种状态机在概念上类似于热插拔的 U 盘一样。内核的电源管理系统经常会使某个<ruby>核<rt>core</rt></ruby>离线,然后根据需要将其唤醒,以便在不忙的机器上反复调用同一段的 CPU 热插拔代码。观察电源管理系统调用 CPU 热插拔代码的 [BCC 工具][36] 称为 `offcputime.py`。
|
||||
|
||||
请注意,`init/main.c` 中的代码在 `smp_init()` 运行时几乎已执行完毕:引导处理器已经完成了大部分一次性初始化操作,其它核无需重复。尽管如此,跨 CPU 的线程仍然要在每个核上生成,以管理每个核的中断(IRQ)、工作队列、定时器和电源事件。例如,通过 `ps -o psr` 命令可以查看服务每个 CPU 上的线程的 softirqs 和 workqueues。
|
||||
|
||||
```
|
||||
# ps -o pid,psr,comm $(pgrep ksoftirqd)
|
||||
PID PSR COMMAND
|
||||
7 0 ksoftirqd/0
|
||||
16 1 ksoftirqd/1
|
||||
22 2 ksoftirqd/2
|
||||
28 3 ksoftirqd/3
|
||||
|
||||
# ps -o pid,psr,comm $(pgrep kworker)
|
||||
PID PSR COMMAND
|
||||
4 0 kworker/0:0H
|
||||
18 1 kworker/1:0H
|
||||
24 2 kworker/2:0H
|
||||
30 3 kworker/3:0H
|
||||
[ . . . ]
|
||||
```
|
||||
|
||||
其中,PSR 字段代表“<ruby>处理器<rt>processor</rt></ruby>”。每个核还必须拥有自己的定时器和 `cpuhp` 热插拔处理程序。
|
||||
|
||||
那么用户空间是如何启动的呢?在最后,`kernel_init()` 寻找可以代表它执行 `init` 进程的 `initrd`。如果没有找到,内核直接执行 `init` 本身。那么为什么需要 `initrd` 呢?
|
||||
|
||||
#### 早期的用户空间:谁规定要用 initrd?
|
||||
|
||||
除了设备树之外,在启动时可以提供给内核的另一个文件路径是 `initrd` 的路径。`initrd` 通常位于 `/boot` 目录中,与 x86 系统中的 bzImage 文件 vmlinuz 一样,或是与 ARM 系统中的 uImage 和设备树相同。用 `initramfs-tools-core` 软件包中的 `lsinitramfs` 工具可以列出 `initrd` 的内容。发行版的 `initrd` 方案包含了最小化的 `/bin`、`/sbin` 和 `/etc` 目录以及内核模块,还有 `/scripts` 中的一些文件。所有这些看起来都很熟悉,因为 `initrd` 大致上是一个简单的最小化 Linux 根文件系统。看似相似,其实不然,因为位于虚拟内存盘中的 `/bin` 和 `/sbin` 目录下的所有可执行文件几乎都是指向 [BusyBox 二进制文件][38] 的符号链接,由此导致 `/bin` 和 `/sbin` 目录比 glibc 的小 10 倍。
|
||||
|
||||
如果要做的只是加载一些模块,然后在普通的根文件系统上启动 `init`,为什么还要创建一个 `initrd` 呢?想想一个加密的根文件系统,解密可能依赖于加载一个位于根文件系统 `/lib/modules` 的内核模块,当然还有 `initrd` 中的。加密模块可能被静态地编译到内核中,而不是从文件加载,但有多种原因不希望这样做。例如,用模块静态编译内核可能会使其太大而不能适应存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人类输入设备(HID)驱动程序也可能存在于 `initrd` 中。`initrd` 基本上包含了任何挂载根文件系统所必需的非内核代码。`initrd` 也是用户存放 [自定义ACPI][38] 表代码的地方。
|
||||
|
||||
![Rescue shell and a custom <code>initrd</code>.][40]
|
||||
|
||||
*救援模式的 shell 和自定义的 `initrd` 还是很有意思的。*
|
||||
|
||||
`initrd` 对测试文件系统和数据存储设备也很有用。将这些测试工具存放在 `initrd` 中,并从内存中运行测试,而不是从被测对象中运行。
|
||||
|
||||
最后,当 `init` 开始运行时,系统就启动啦!由于第二个处理器现在在运行,机器已经成为我们所熟知和喜爱的异步、可抢占、不可预测和高性能的生物。的确,`ps -o pid,psr,comm -p 1` 很容易显示用户空间的 `init` 进程已不在引导处理器上运行了。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 引导过程听起来或许令人生畏,即使是简单嵌入式设备上的软件数量也是如此。但换个角度来看,启动过程相当简单,因为启动中没有抢占、RCU 和竞争条件等扑朔迷离的复杂功能。只关注内核和 PID 1 会忽略了引导程序和辅助处理器为运行内核执行的大量准备工作。虽然内核在 Linux 程序中是独一无二的,但通过一些检查 ELF 文件的工具也可以了解其结构。学习一个正常的启动过程,可以帮助运维人员处理启动的故障。
|
||||
|
||||
要了解更多信息,请参阅 Alison Chaiken 的演讲——[Linux: The first second][41],已于 1 月 22 日至 26 日在悉尼举行。参见 [linux.conf.au][42]。
|
||||
|
||||
感谢 [Akkana Peck][43] 的提议和指正。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/analyzing-linux-boot-process
|
||||
|
||||
作者:[Alison Chaiken][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
|
||||
[2]:https://github.com/chaiken/LCA2018-Demo-Code
|
||||
[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
|
||||
[4]:https://lwn.net/Articles/630778/
|
||||
[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&amp;amp;amp;amp;amp;index=65&amp;amp;amp;amp;amp;list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
|
||||
[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&amp;amp;amp;amp;amp;languageid=en-fr
|
||||
[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
|
||||
[8]:https://github.com/corna/me_cleaner
|
||||
[9]:https://lwn.net/Articles/738649/
|
||||
[10]:https://lwn.net/Articles/699551/
|
||||
[11]:https://trmm.net/NERF
|
||||
[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
|
||||
[13]:https://lwn.net/Articles/733837/
|
||||
[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
|
||||
[15]:/file/383501
|
||||
[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png "Running the U-boot bootloader"
|
||||
[17]:http://www.denx.de/wiki/DULG/Manual
|
||||
[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
|
||||
[19]:http://man7.org/linux/man-pages/man5/elf.5.html
|
||||
[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
|
||||
[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
|
||||
[22]:http://kernel-handbook.alioth.debian.org/
|
||||
[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
|
||||
[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
|
||||
[25]:https://github.com/torvalds/linux/blob/master/init/main.c
|
||||
[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
|
||||
[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
|
||||
[28]:http://lwn.net/Articles/616859/
|
||||
[29]:/file/383506
|
||||
[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png "ACPI tables on Lenovo laptops"
|
||||
[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
|
||||
[32]:https://www.coreboot.org/Supported_Motherboards
|
||||
[33]:/file/383511
|
||||
[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png "Summary of early kernel boot process."
|
||||
[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
|
||||
[36]:http://www.brendangregg.com/ebpf.html
|
||||
[37]:https://www.busybox.net/
|
||||
[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
|
||||
[39]:/file/383516
|
||||
[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png "Rescue shell and a custom <code>initrd</code>."
|
||||
[41]:https://rego.linux.conf.au/schedule/presentation/16/
|
||||
[42]:https://linux.conf.au/index.html
|
||||
[43]:http://shallowsky.com/
|
||||
@ -1,4 +1,4 @@
|
||||
SPARTA —— 用于网络渗透测试的 GUI 工具套件
|
||||
SPARTA:用于网络渗透测试的 GUI 工具套件
|
||||
======
|
||||
|
||||

|
||||
@ -7,12 +7,11 @@ SPARTA 是使用 Python 开发的 GUI 应用程序,它是 Kali Linux 内置的
|
||||
|
||||
SPARTA GUI 工具套件最擅长的事情是扫描和发现目标端口和运行的服务。
|
||||
|
||||
因此,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
此外,作为枚举阶段的一部分功能,它提供对开放端口和服务的暴力攻击。
|
||||
|
||||
延伸阅读:[网络渗透检查清单][1]
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
请从 GitHub 上克隆最新版本的 SPARTA:
|
||||
|
||||
@ -21,64 +20,58 @@ git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
|
||||
或者,从 [这里][2] 下载最新版本的 Zip 文件。
|
||||
|
||||
```
|
||||
cd /usr/share/
|
||||
git clone https://github.com/secforce/sparta.git
|
||||
```
|
||||
将 "sparta" 文件放到 /usr/bin/ 目录下并赋于可运行权限。
|
||||
|
||||
将 `sparta` 文件放到 `/usr/bin/` 目录下并赋于可运行权限。
|
||||
|
||||
在任意终端中输入 'sparta' 来启动应用程序。
|
||||
|
||||
### 网络渗透测试的范围
|
||||
|
||||
## 网络渗透测试的范围:
|
||||
|
||||
* 添加一个目标主机或者目标主机的列表到范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
* 选择菜单条 - File > Add host(s) to scope
|
||||
|
||||
添加一个目标主机或者目标主机的列表到测试范围中,来发现一个组织的网络基础设备在安全方面的薄弱环节。
|
||||
|
||||
选择菜单条 - “File” -> “Add host(s) to scope”
|
||||
|
||||
[![Network Penetration Testing][3]][4]
|
||||
|
||||
[![Network Penetration Testing][5]][6]
|
||||
|
||||
* 上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
* 扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
|
||||
|
||||
## 打开 Ports & Services:
|
||||
|
||||
* Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
上图展示了在扫描范围中添加 IP 地址。根据你网络的具体情况,你可以添加一个 IP 地址的范围去扫描。
|
||||
扫描范围添加之后,Nmap 将开始扫描,并很快得到结果,扫描阶段结束。
|
||||
|
||||
### 打开的端口及服务
|
||||
|
||||
Nmap 扫描结果提供了目标上开放的端口和服务。
|
||||
|
||||
[![Network Penetration Testing][7]][8]
|
||||
|
||||
* 上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
|
||||
|
||||
## 在开放端口上实施暴力攻击:
|
||||
|
||||
* 我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
上图展示了扫描发现的目标操作系统、开发的端口和服务。
|
||||
|
||||
### 在开放端口上实施暴力攻击
|
||||
|
||||
我们来通过 445 端口的服务器消息块(SMB)协议来暴力获取用户列表和它们的有效密码。
|
||||
|
||||
[![Network Penetration Testing][9]][10]
|
||||
|
||||
* 右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
* 浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
右键并选择 “Send to Brute” 选项。也可以选择发现的目标上的开放端口和服务。
|
||||
|
||||
浏览和在用户名密码框中添加字典文件。
|
||||
|
||||
[![Network Penetration Testing][11]][12]
|
||||
|
||||
* 点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
* 在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
* 密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
* 强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登陆尝试之后将锁定帐户)
|
||||
* 将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
点击 “Run” 去启动对目标的暴力攻击。上图展示了对目标 IP 地址进行的暴力攻击取得成功,找到了有效的密码。
|
||||
|
||||
在 Windows 中失败的登陆尝试总是被记录到事件日志中。
|
||||
|
||||
密码每 15 到 30 天改变一次的策略是非常好的一个实践经验。
|
||||
|
||||
强烈建议使用强密码策略。密码锁定策略是阻止这种暴力攻击的最佳方法之一( 5 次失败的登录尝试之后将锁定帐户)。
|
||||
|
||||
将关键业务资产整合到 SIEM( 安全冲突 & 事件管理)中将尽可能快地检测到这类攻击行为。
|
||||
|
||||
SPARTA 对渗透测试的扫描和枚举阶段来说是一个非常省时的 GUI 工具套件。SPARTA 可以扫描和暴力破解各种协议。它有许多的功能!祝你测试顺利!
|
||||
|
||||
@ -88,7 +81,7 @@ via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
|
||||
|
||||
作者:[Balaganesh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,35 +1,38 @@
|
||||
如何在 Linux 上使用 Vundle 管理 Vim 插件
|
||||
======
|
||||
|
||||
|
||||
|
||||
毋庸置疑,**Vim** 是一款强大的文本文件处理的通用工具,能够管理系统配置文件,编写代码。通过插件,vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 **~/.vim** 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
毋庸置疑,Vim 是一款强大的文本文件处理的通用工具,能够管理系统配置文件和编写代码。通过插件,Vim 可以被拓展出不同层次的功能。通常,所有的插件和附属的配置文件都会存放在 `~/.vim` 目录中。由于所有的插件文件都被存储在同一个目录下,所以当你安装更多插件时,不同的插件文件之间相互混淆。因而,跟踪和管理它们将是一个恐怖的任务。然而,这正是 Vundle 所能处理的。Vundle,分别是 **V** im 和 B **undle** 的缩写,它是一款能够管理 Vim 插件的极其实用的工具。
|
||||
|
||||
Vundle 为每一个你安装和存储的拓展配置文件创建各自独立的目录树。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已存在的插件、更新插件配置、搜索安装插件和清理不使用的插件。所有的操作都可以在单一按键的交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
Vundle 为每一个你安装的插件创建一个独立的目录树,并在相应的插件目录中存储附加的配置文件。因此,相互之间没有混淆的文件。简言之,Vundle 允许你安装新的插件、配置已有的插件、更新插件配置、搜索安装的插件和清理不使用的插件。所有的操作都可以在一键交互模式下完成。在这个简易的教程中,让我告诉你如何安装 Vundle,如何在 GNU/Linux 中使用它来管理 Vim 插件。
|
||||
|
||||
### Vundle 安装
|
||||
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 **vim**。如果没有,安装 vim,尽情 **git**(下载 vundle)去吧。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
如果你需要 Vundle,那我就当作你的系统中,已将安装好了 Vim。如果没有,请安装 Vim 和 git(以下载 Vundle)。在大部分 GNU/Linux 发行版中的官方仓库中都可以获取到这两个包。比如,在 Debian 系列系统中,你可以使用下面的命令安装这两个包。
|
||||
|
||||
```
|
||||
sudo apt-get install vim git
|
||||
```
|
||||
|
||||
**下载 Vundle**
|
||||
#### 下载 Vundle
|
||||
|
||||
复制 Vundle 的 GitHub 仓库地址:
|
||||
|
||||
```
|
||||
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
|
||||
```
|
||||
|
||||
**配置 Vundle**
|
||||
#### 配置 Vundle
|
||||
|
||||
创建 **~/.vimrc** 文件,通知 vim 使用新的插件管理器。这个文件获得有安装、更新、配置和移除插件的权限。
|
||||
创建 `~/.vimrc` 文件,以通知 Vim 使用新的插件管理器。安装、更新、配置和移除插件需要这个文件。
|
||||
|
||||
```
|
||||
vim ~/.vimrc
|
||||
```
|
||||
|
||||
在此文件顶部,加入如下若干行内容:
|
||||
|
||||
```
|
||||
set nocompatible " be iMproved, required
|
||||
filetype off " required
|
||||
@ -76,35 +79,39 @@ filetype plugin indent on " required
|
||||
" Put your non-Plugin stuff after this line
|
||||
```
|
||||
|
||||
被标记的行中,是 Vundle 的请求项。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。一旦你安装过,键入 **:wq** 保存退出。
|
||||
被标记为 “required” 的行是 Vundle 的所需配置。其余行仅是一些例子。如果你不想安装那些特定的插件,可以移除它们。完成后,键入 `:wq` 保存退出。
|
||||
|
||||
最后,打开 Vim:
|
||||
|
||||
最后,打开 vim
|
||||
```
|
||||
vim
|
||||
```
|
||||
|
||||
然后键入下列命令安装插件。
|
||||
然后键入下列命令安装插件:
|
||||
|
||||
```
|
||||
:PluginInstall
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
将会弹出一个新的分窗口,.vimrc 中陈列的项目都会自动安装。
|
||||
将会弹出一个新的分窗口,我们加在 `.vimrc` 文件中的所有插件都会自动安装。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口:
|
||||
|
||||
安装完毕之后,键入下列命令,可以删除高速缓存区缓存并关闭窗口。
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
在终端上使用下面命令,规避使用 vim 安装插件
|
||||
你也可以在终端上使用下面命令安装插件,而不用打开 Vim:
|
||||
|
||||
```
|
||||
vim +PluginInstall +qall
|
||||
```
|
||||
|
||||
使用 [**fish shell**][4] 的朋友,添加下面这行到你的 **.vimrc** 文件中。
|
||||
使用 [fish shell][4] 的朋友,添加下面这行到你的 `.vimrc` 文件中。
|
||||
|
||||
```
|
||||
set shell=/bin/bash
|
||||
@ -112,123 +119,138 @@ set shell=/bin/bash
|
||||
|
||||
### 使用 Vundle 管理 Vim 插件
|
||||
|
||||
**添加新的插件**
|
||||
#### 添加新的插件
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件:
|
||||
|
||||
首先,使用下面的命令搜索可以使用的插件。
|
||||
```
|
||||
:PluginSearch
|
||||
```
|
||||
|
||||
命令之后添加 **"! "**,刷新 vimscripts 网站内容到本地。
|
||||
要从 vimscripts 网站刷新本地的列表,请在命令之后添加 `!`。
|
||||
|
||||
```
|
||||
:PluginSearch!
|
||||
```
|
||||
|
||||
一个陈列可用插件列表的新分窗口将会被弹出。
|
||||
会弹出一个列出可用插件列表的新分窗口:
|
||||
|
||||
[![][1]][5]
|
||||
![][5]
|
||||
|
||||
你还可以通过直接指定插件名的方式,缩小搜索范围。
|
||||
|
||||
```
|
||||
:PluginSearch vim
|
||||
```
|
||||
|
||||
这样将会列出包含关键词“vim”的插件。
|
||||
这样将会列出包含关键词 “vim” 的插件。
|
||||
|
||||
当然你也可以指定确切的插件名,比如:
|
||||
|
||||
```
|
||||
:PluginSearch vim-dasm
|
||||
```
|
||||
|
||||
移动焦点到正确的一行上,点击 **" i"** 来安装插件。现在,被选择的插件将会被安装。
|
||||
移动焦点到正确的一行上,按下 `i` 键来安装插件。现在,被选择的插件将会被安装。
|
||||
|
||||
[![][1]][6]
|
||||
![][6]
|
||||
|
||||
类似的,在你的系统中安装所有想要的插件。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
|
||||
在你的系统中,所有想要的的插件都以类似的方式安装。一旦安装成功,使用下列命令删除 Vundle 缓存:
|
||||
```
|
||||
:bdelete
|
||||
```
|
||||
|
||||
现在,插件已经安装完成。在 .vimrc 文件中添加安装好的插件名,让插件正确加载。
|
||||
现在,插件已经安装完成。为了让插件正确的自动加载,我们需要在 `.vimrc` 文件中添加安装好的插件名。
|
||||
|
||||
这样做:
|
||||
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
添加这一行:
|
||||
|
||||
```
|
||||
[...]
|
||||
Plugin 'vim-dasm'
|
||||
[...]
|
||||
```
|
||||
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 ESC,键入 **:wq** 保存退出。
|
||||
用自己的插件名替换 vim-dasm。然后,敲击 `ESC`,键入 `:wq` 保存退出。
|
||||
|
||||
请注意,所有插件都必须在 `.vimrc` 文件中追加如下内容。
|
||||
|
||||
请注意,所有插件都必须在 .vimrc 文件中追加如下内容。
|
||||
```
|
||||
[...]
|
||||
filetype plugin indent on
|
||||
```
|
||||
|
||||
**列出已安装的插件**
|
||||
#### 列出已安装的插件
|
||||
|
||||
键入下面命令列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
[![][1]][7]
|
||||
![][7]
|
||||
|
||||
**更新插件**
|
||||
#### 更新插件
|
||||
|
||||
键入下列命令更新插件:
|
||||
|
||||
```
|
||||
:PluginUpdate
|
||||
```
|
||||
|
||||
键入下列命令重新安装所有插件
|
||||
键入下列命令重新安装所有插件:
|
||||
|
||||
```
|
||||
:PluginInstall!
|
||||
```
|
||||
|
||||
**卸载插件**
|
||||
#### 卸载插件
|
||||
|
||||
首先,列出所有已安装的插件:
|
||||
|
||||
```
|
||||
:PluginList
|
||||
```
|
||||
|
||||
之后将焦点置于正确的一行上,敲 **" SHITF+d"** 组合键。
|
||||
之后将焦点置于正确的一行上,按下 `SHITF+d` 组合键。
|
||||
|
||||
[![][1]][8]
|
||||
![][8]
|
||||
|
||||
然后编辑你的 `.vimrc` 文件:
|
||||
|
||||
然后编辑你的 .vimrc 文件:
|
||||
```
|
||||
:e ~/.vimrc
|
||||
```
|
||||
|
||||
再然后删除插件入口。最后,键入 **:wq** 保存退出。
|
||||
删除插件入口。最后,键入 `:wq` 保存退出。
|
||||
|
||||
或者,你可以通过移除插件所在 `.vimrc` 文件行,并且执行下列命令,卸载插件:
|
||||
|
||||
或者,你可以通过移除插件所在 .vimrc 文件行,并且执行下列命令,卸载插件:
|
||||
```
|
||||
:PluginClean
|
||||
```
|
||||
|
||||
这个命令将会移除所有不在你的 .vimrc 文件中但是存在于 bundle 目录中的插件。
|
||||
这个命令将会移除所有不在你的 `.vimrc` 文件中但是存在于 bundle 目录中的插件。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 Vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
|
||||
你应该已经掌握了 Vundle 管理插件的基本方法了。在 vim 中使用下列命令,查询帮助文档,获取更多细节。
|
||||
```
|
||||
:h vundle
|
||||
```
|
||||
|
||||
**捎带看看:**
|
||||
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注 OSTechNix!
|
||||
现在我已经把所有内容都告诉你了。很快,我就会出下一篇教程。保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
**来源:**
|
||||
### 资源
|
||||
|
||||
[Vundle GitHub 仓库][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -236,16 +258,17 @@ via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png
|
||||
[9]:https://github.com/VundleVim/Vundle.vim
|
||||
@ -1,28 +1,28 @@
|
||||
为初学者介绍的 Linux tee 命令(6 个例子)
|
||||
======
|
||||
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 **tee** 的命令可以帮助你。
|
||||
有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 `tee` 的命令可以帮助你。
|
||||
|
||||
本教程中,我们将基于 tee 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
本教程中,我们将基于 `tee` 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
|
||||
|
||||
### Linux tee 命令
|
||||
|
||||
tee 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
`tee` 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
|
||||
|
||||
```
|
||||
tee [OPTION]... [FILE]...
|
||||
```
|
||||
|
||||
这里是帮助文档的说明:
|
||||
```
|
||||
从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
```
|
||||
|
||||
> 从标准输入中复制到每一个文件,并输出到标准输出。
|
||||
|
||||
|
||||
让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
|
||||
|
||||
### Q1. 如何在 Linux 上使用这个命令?
|
||||
### Q1、 如何在 Linux 上使用这个命令?
|
||||
|
||||
假设因为某些原因,你正在使用 ping 命令。
|
||||
假设因为某些原因,你正在使用 `ping` 命令。
|
||||
|
||||
```
|
||||
ping google.com
|
||||
@ -30,29 +30,29 @@ ping google.com
|
||||
|
||||
[![如何在 Linux 上使用 tee 命令][1]][2]
|
||||
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,tee 命令就有其用武之地了。
|
||||
然后同时,你想要输出的信息也同时能写入文件。这个时候,`tee` 命令就有其用武之地了。
|
||||
|
||||
```
|
||||
ping google.com | tee output.txt
|
||||
```
|
||||
|
||||
下面的截图展示了这个输出内容不仅被写入 ‘output.txt’ 文件,也被显示在标准输出中。
|
||||
下面的截图展示了这个输出内容不仅被写入 `output.txt` 文件,也被显示在标准输出中。
|
||||
|
||||
[![tee command 输出][3]][4]
|
||||
|
||||
如此应当明确了 tee 的基础用法。
|
||||
如此应当明白了 `tee` 的基础用法。
|
||||
|
||||
### Q2. 如何确保 tee 命令追加信息到文件中?
|
||||
### Q2、 如何确保 tee 命令追加信息到文件中?
|
||||
|
||||
默认情况下,在同一个文件下再次使用 tee 命令会覆盖之前的信息。如果你想的话,可以通过 -a 命令选项改变默认设置。
|
||||
默认情况下,在同一个文件下再次使用 `tee` 命令会覆盖之前的信息。如果你想的话,可以通过 `-a` 命令选项改变默认设置。
|
||||
|
||||
```
|
||||
[command] | tee -a [file]
|
||||
```
|
||||
|
||||
基本上,-a 选项强制 tee 命令追加信息到文件。
|
||||
基本上,`-a` 选项强制 `tee` 命令追加信息到文件。
|
||||
|
||||
### Q3. 如何让 tee 写入多个文件?
|
||||
### Q3、 如何让 tee 写入多个文件?
|
||||
|
||||
这非常之简单。你仅仅只需要写明文件名即可。
|
||||
|
||||
@ -70,7 +70,7 @@ ping google.com | tee output1.txt output2.txt output3.txt
|
||||
|
||||
### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
|
||||
|
||||
使用 tee 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入‘output.txt’文件中,还会通过 wc 命令让你知道输入到 output.txt 中的文件数目。
|
||||
使用 `tee` 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入 `output.txt` 文件中,还会通过 `wc` 命令让你知道输入到 `output.txt` 中的文件数目。
|
||||
|
||||
```
|
||||
ls file* | tee output.txt | wc -l
|
||||
@ -80,11 +80,11 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q5. 如何使用 tee 命令提升文件写入权限?
|
||||
|
||||
假如你使用 [Vim editor][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 sudo 权限保存修改。
|
||||
假如你使用 [Vim 编辑器][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 `sudo` 权限保存修改。
|
||||
|
||||
[![如何使用 tee 命令提升文件写入权限][10]][11]
|
||||
|
||||
如此情况下,你可以使用 tee 命令来提高权限。
|
||||
如此情况下,你可以(在 Vim 内)使用 `tee` 命令来提高权限。
|
||||
|
||||
```
|
||||
:w !sudo tee %
|
||||
@ -94,17 +94,17 @@ ls file* | tee output.txt | wc -l
|
||||
|
||||
### Q6. 如何让 tee 命令忽视中断?
|
||||
|
||||
-i 命令行选项使 tee 命令忽视通常由 crl+c 组合键发起的中断信号(`SIGINT`)。
|
||||
`-i` 命令行选项使 `tee` 命令忽视通常由 `ctrl+c` 组合键发起的中断信号(`SIGINT`)。
|
||||
|
||||
```
|
||||
[command] | tee -i [file]
|
||||
```
|
||||
|
||||
当你想要使用 crl+c 中断命令的同时,让 tee 命令优雅的退出,这个选项尤为实用。
|
||||
当你想要使用 `ctrl+c` 中断该命令,同时让 `tee` 命令优雅的退出,这个选项尤为实用。
|
||||
|
||||
### 总结
|
||||
|
||||
现在你可能已经认同 tee 是一个非常实用的命令。基于 tee 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
现在你可能已经认同 `tee` 是一个非常实用的命令。基于 `tee` 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -113,7 +113,7 @@ via: https://www.howtoforge.com/linux-tee-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
5 个在视觉上最轻松的黑暗主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
人们在电脑上选择黑暗主题有几个原因。有些人觉得对于眼睛轻松,而另一些人因为他们的医学条件选择黑色。特别地,程序员喜欢黑暗的主题,因为可以减少眼睛的眩光。
|
||||
|
||||
如果你是一位 Linux 用户和黑暗主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow][2] 是 OSX-Arc 主题集合的一部分。该集合还包括其他几个主题(黑暗和明亮)。你可以下载整个系列并使用黑色主题。
|
||||
|
||||
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面][3]中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此 [AUR 链接][4]。最后,要手动安装主题,请将 zip 解压到 `~/.themes` ,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
该主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
|
||||
|
||||
前往 [gnome-looks][6],在“文件”菜单下下载主题。安装过程很简单:将主题解压到 `~/.themes` 中,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux 是另一个基于 Materia 主题的简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
|
||||
|
||||
[下载压缩文件][8]并将其解压缩到你的 `~/.themes` 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面][9]了解最新的增加内容。
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark 是一个完全黑暗的主题。对于那些喜欢更黑暗的人来说,这个主题绝对是值得考虑的。此外,它还可以减少电脑屏幕的眩光量。另外,它支持 Unity。[在这里下载 Deepin Dark][11]。
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 是一个简单的黑暗主题,它使得重要细节突出。它有助于专注,不花哨。它与 Deepin Dark 非常相似。特别是对于 Ubuntu 用户,它与 Ubuntu 17.04 兼容。你可以从[这里][13]下载并尝试。
|
||||
|
||||
### 总结
|
||||
|
||||
如果你长时间使用电脑,黑暗主题是减轻眼睛疲劳的好方法。即使你不这样做,黑暗主题也可以在其他方面帮助你,例如提高专注。让我们知道你最喜欢哪一个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
@ -1,9 +1,9 @@
|
||||
如何在 Linux 上安装 Spotify
|
||||
如何在 Linux 上使用 snap 安装 Spotify(声破天)
|
||||
======
|
||||
|
||||
如何在 Ubuntu Linux 桌面上安装 Spotify 来在线听音乐?
|
||||
如何在 Ubuntu Linux 桌面上安装 spotify 来在线听音乐?
|
||||
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅。可以创建播放列表。订阅用户可以免广告收听音乐。你会得到更好的音质。本教程**展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版**上的 snap 包管理器安装 Spotify。
|
||||
Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以免费收听或者购买订阅,可以创建播放列表。订阅用户可以免广告收听音乐,你会得到更好的音质。本教程展示如何使用在 Ubuntu、Mint、Debian、Fedora、Arch 和其他更多发行版上的 snap 包管理器安装 Spotify。
|
||||
|
||||
### 在 Linux 上安装 spotify
|
||||
|
||||
@ -11,33 +11,28 @@ Spotify 是一个可让你访问大量歌曲的数字音乐流服务。你可以
|
||||
|
||||
1. 安装 snapd
|
||||
2. 打开 snapd
|
||||
3. 找到 Spotify snap:
|
||||
```
|
||||
snap find spotify
|
||||
```
|
||||
4. 安装 spotify:
|
||||
```
|
||||
do snap install spotify
|
||||
```
|
||||
5. 运行:
|
||||
```
|
||||
spotify &
|
||||
```
|
||||
3. 找到 Spotify snap:`snap find spotify`
|
||||
4. 安装 spotify:`sudo snap install spotify`
|
||||
5. 运行:`spotify &`
|
||||
|
||||
让我们详细看看所有的步骤和例子。
|
||||
|
||||
### 步骤 1 - 安装 Snapd
|
||||
### 步骤 1 - 安装 snapd
|
||||
|
||||
你需要安装 snapd 包。它是一个守护进程(服务),并能在 Linux 系统上启用 snap 包管理。
|
||||
|
||||
#### Debian/Ubuntu/Mint Linux 上的 Snapd
|
||||
#### Debian/Ubuntu/Mint Linux 上的 snapd
|
||||
|
||||
输入以下[ apt 命令][1]/ [apt-get 命令][2]:
|
||||
`$ sudo apt install snapd`
|
||||
输入以下 [apt 命令][1]/ [apt-get 命令][2]:
|
||||
|
||||
```
|
||||
$ sudo apt install snapd
|
||||
```
|
||||
|
||||
#### 在 Arch Linux 上安装 snapd
|
||||
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 yaourt 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
snapd 只包含在 Arch User Repository(AUR)中。运行 `yaourt` 命令(参见[如何在 Archlinux 上安装 yaourt][3]):
|
||||
|
||||
```
|
||||
$ sudo yaourt -S snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
@ -45,7 +40,8 @@ $ sudo systemctl enable --now snapd.socket
|
||||
|
||||
#### 在 Fedora 上获取 snapd
|
||||
|
||||
运行 snapd 命令
|
||||
运行 snapd 命令:
|
||||
|
||||
```
|
||||
sudo dnf install snapd
|
||||
sudo ln -s /var/lib/snapd/snap /snap
|
||||
@ -53,26 +49,67 @@ sudo ln -s /var/lib/snapd/snap /snap
|
||||
|
||||
#### OpenSUSE 安装 snapd
|
||||
|
||||
执行如下的 `zypper` 命令:
|
||||
|
||||
```
|
||||
### Tumbleweed verson ###
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Tumbleweed/ snappy
|
||||
### Leap version ##
|
||||
$ sudo zypper addrepo http://download.opensuse.org/repositories/system:/snappy/openSUSE_Leap_42.3/ snappy
|
||||
```
|
||||
|
||||
安装:
|
||||
|
||||
```
|
||||
$ sudo zypper install snapd
|
||||
$ sudo systemctl enable --now snapd.socket
|
||||
```
|
||||
|
||||
### 步骤 2 - 在 Linux 上使用 snap 安装 spofity
|
||||
|
||||
执行 snap 命令:
|
||||
`$ snap find spotify`
|
||||
|
||||
```
|
||||
$ snap find spotify
|
||||
```
|
||||
|
||||
[![snap search for spotify app command][4]][4]
|
||||
|
||||
安装它:
|
||||
`$ sudo snap install spotify`
|
||||
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
```
|
||||
|
||||
[![How to install Spotify application on Linux using snap command][5]][5]
|
||||
|
||||
### 步骤 3 - 运行 spotify 并享受它(译注:原博客中就是这么直接跳到 step3 的)
|
||||
### 步骤 3 - 运行 spotify 并享受它
|
||||
|
||||
从 GUI 运行它,或者只需输入:
|
||||
`$ spotify`
|
||||
|
||||
```
|
||||
$ spotify
|
||||
```
|
||||
|
||||
在启动时自动登录你的帐户:
|
||||
|
||||
```
|
||||
$ spotify --username vivek@nixcraft.com
|
||||
$ spotify --username vivek@nixcraft.com --password 'myPasswordHere'
|
||||
```
|
||||
|
||||
在初始化时使用给定的 URI 启动 Spotify 客户端:
|
||||
`$ spotify--uri=<uri>`
|
||||
|
||||
```
|
||||
$ spotify --uri=<uri>
|
||||
```
|
||||
|
||||
以指定的网址启动:
|
||||
`$ spotify--url=<url>`
|
||||
|
||||
```
|
||||
$ spotify --url=<url>
|
||||
```
|
||||
|
||||
[![Spotify client app running on my Ubuntu Linux desktop][6]][6]
|
||||
|
||||
### 关于作者
|
||||
@ -85,7 +122,7 @@ via: https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
搭建私有云:OwnCloud
|
||||
======
|
||||
|
||||
所有人都在讨论云。尽管市面上有很多为我们提供云存储和其他云服务的主要服务商,但是我们还是可以为自己搭建一个私有云。
|
||||
|
||||
在本教程中,我们将讨论如何利用 OwnCloud 搭建私有云。OwnCloud 是一个可以安装在我们 Linux 设备上的 web 应用程序,能够存储和用我们的数据提供服务。OwnCloud 可以分享日历、联系人和书签,共享音/视频流等等。
|
||||
|
||||
本教程中,我们使用的是 CentOS 7 系统,但是本教程同样适用于其他 Linux 发行版中安装 OwnCloud。让我们开始安装 OwnCloud 并且做一些准备工作,
|
||||
|
||||
- 推荐阅读:[如何在 CentOS & RHEL 上使用 Apache 作为反向代理服务器][1]
|
||||
- 同时推荐:[实时 Linux 服务器监测和 GLANCES 监测工具][2]
|
||||
|
||||
### 预备
|
||||
|
||||
* 我们需要在机器上配置 LAMP。参照阅读我们的文章《[在 CentOS/RHEL 上配置 LAMP 服务器最简单的教程][3]》 & 《[在 Ubuntu 搭建 LAMP][4]》。
|
||||
* 我们需要在自己的设备里安装这些包,`php-mysql`、 `php-json`、 `php-xml`、 `php-mbstring`、 `php-zip`、 `php-gd`、 `curl、 `php-curl` 、`php-pdo`。使用包管理器安装它们。
|
||||
|
||||
```
|
||||
$ sudo yum install php-mysql php-json php-xml php-mbstring php-zip php-gd curl php-curl php-pdo
|
||||
```
|
||||
|
||||
### 安装
|
||||
|
||||
安装 OwnCloud,我们现在需要在服务器上下载 OwnCloud 安装包。使用下面的命令从官方网站下载最新的安装包(10.0.4-1):
|
||||
|
||||
```
|
||||
$ wget https://download.owncloud.org/community/owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
使用下面的命令解压:
|
||||
|
||||
```
|
||||
$ tar -xvf owncloud-10.0.4.tar.bz2
|
||||
```
|
||||
|
||||
现在,将所有解压后的文件移动至 `/var/www/html`:
|
||||
|
||||
```
|
||||
$ mv owncloud/* /var/www/html
|
||||
```
|
||||
|
||||
下一步,我们需要在 Apache 的配置文件 `httpd.conf` 上做些修改:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
更改下面的选项:
|
||||
|
||||
```
|
||||
AllowOverride All
|
||||
```
|
||||
|
||||
保存该文件,并修改 OwnCloud 文件夹的文件权限:
|
||||
|
||||
```
|
||||
$ sudo chown -R apache:apache /var/www/html/
|
||||
$ sudo chmod 777 /var/www/html/config/
|
||||
```
|
||||
|
||||
然后重启 Apache 服务器执行修改:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart httpd
|
||||
```
|
||||
|
||||
现在,我们需要在 MariaDB 上创建一个数据库,保存来自 OwnCloud 的数据。使用下面的命令创建数据库和数据库用户:
|
||||
|
||||
```
|
||||
$ mysql -u root -p
|
||||
MariaDB [(none)] > create database owncloud;
|
||||
MariaDB [(none)] > GRANT ALL ON owncloud.* TO ocuser@localhost IDENTIFIED BY 'owncloud';
|
||||
MariaDB [(none)] > flush privileges;
|
||||
MariaDB [(none)] > exit
|
||||
```
|
||||
|
||||
服务器配置部分完成后,现在我们可以在网页浏览器上访问 OwnCloud。打开浏览器,输入您的服务器 IP 地址,我这边的服务器是 10.20.30.100:
|
||||
|
||||
![安装 owncloud][7]
|
||||
|
||||
一旦 URL 加载完毕,我们将呈现上述页面。这里,我们将创建管理员用户同时提供数据库信息。当所有信息提供完毕,点击“Finish setup”。
|
||||
|
||||
我们将被重定向到登录页面,在这里,我们需要输入先前创建的凭据:
|
||||
|
||||
![安装 owncloud][9]
|
||||
|
||||
认证成功之后,我们将进入 OwnCloud 面板:
|
||||
|
||||
![安装 owncloud][11]
|
||||
|
||||
我们可以使用手机应用程序,同样也可以使用网页界面更新我们的数据。现在,我们已经有自己的私有云了,同时,关于如何安装 OwnCloud 创建私有云的教程也进入尾声。请在评论区留下自己的问题或建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-personal-cloud-install-owncloud/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/apache-as-reverse-proxy-centos-rhel/
|
||||
[2]:http://linuxtechlab.com/linux-server-glances-monitoring-tool/
|
||||
[3]:http://linuxtechlab.com/easiest-guide-creating-lamp-server/
|
||||
[4]:http://linuxtechlab.com/install-lamp-stack-on-ubuntu/
|
||||
[6]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=400%2C647
|
||||
[7]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud1-compressor.jpg?resize=400%2C647
|
||||
[8]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=876%2C541
|
||||
[9]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud2-compressor1.jpg?resize=876%2C541
|
||||
[10]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=981%2C474
|
||||
[11]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2018/01/owncloud3-compressor1.jpg?resize=981%2C474
|
||||
@ -3,10 +3,9 @@
|
||||
|
||||
[][8]
|
||||
|
||||
|
||||
HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程序员询问了他们何时开始编码。
|
||||
|
||||
39,441 名专业和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。
|
||||
39,441 名专业人员和学生开发者于 2016 年 10 月 16 日至 11 月 1 日完成了在线调查,超过 25% 的被调查的开发者在 16 岁前编写了他们的第一段代码。(LCTT 译注:日期恐有误)
|
||||
|
||||
### 程序员是如何学习的
|
||||
|
||||
@ -16,7 +15,7 @@ HackerRank 最近公布了 2018 年开发者技能报告的结果,其中向程
|
||||
|
||||
开发者平均了解四种语言,但他们想学习更多语言。
|
||||
|
||||
对学习的渴望因人而异 - 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
对学习的渴望因人而异 —— 18 至 24 岁的开发者计划学习 6 种语言,而 35 岁以上的开发者只计划学习 3 种语言。
|
||||
|
||||
[][5]
|
||||
|
||||
@ -46,9 +45,9 @@ HackerRank 说:“在某些方面,我们发现了一个小矛盾。开发人
|
||||
|
||||
via: https://mybroadband.co.za/news/smartphones/246583-how-programmers-learn-to-code.html
|
||||
|
||||
作者:[Staff Writer ][a]
|
||||
作者:[Staff Writer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
50
published/20180131 An old DOS BBS in a Docker container.md
Normal file
50
published/20180131 An old DOS BBS in a Docker container.md
Normal file
@ -0,0 +1,50 @@
|
||||
Docker 容器中的老式 DOS BBS
|
||||
======
|
||||
|
||||
不久前,我写了一篇[我的 Debian Docker 基本映像][1]。我决定进一步扩展这个概念:在 Docker 中运行 DOS 程序。
|
||||
|
||||
但首先,来看一张截图:
|
||||
|
||||
![][2]
|
||||
|
||||
事实证明这是可能的,但很难。我使用了所有三种主要的 DOS 模拟器(dosbox、qemu 和 dosemu)。我让它们都能在 Docker 容器中运行,但有很多有趣的问题需要解决。
|
||||
|
||||
都要做的事是在 DOS 环境下提供一个伪造的调制解调器。它需要作为 TCP 端口暴露在容器外部。有很多方法可以做到 —— 我使用的是 tcpser。dosbox 有一个 TCP 调制解调器接口,但事实证明,这样做太问题太多了。
|
||||
|
||||
挑战来自你希望能够一次接受多个传入 telnet(或 TCP)连接。DOS 不是一个多任务操作系统,所以当时有很多黑客式的方法。一种是有多台物理机,每个有一根传入电话线。或者它们可能会在 [DESQview][3]、OS/2 甚至 Windows 3.1 等多任务层下运行多个伪 DOS 实例。
|
||||
|
||||
(注意:我刚刚了解到 [DESQview/X][4],它将 DESQview 与 X11R5 集成在一起,并[取代了 Windows 3 驱动程序][5]来把 Windows 作为 X 应用程序运行。)
|
||||
|
||||
出于各种原因,我不想尝试在 Docker 中运行其中任何一个系统。这让我模拟了原来的多物理节点设置。从理论上讲,非常简单 —— 运行一组 DOS 实例,每个实例最多使用 1MB 的模拟 RAM,这就行了。但是这里面临挑战。
|
||||
|
||||
在多物理节点设置中,你需要某种文件共享,因为你的节点需要访问共享的消息和文件存储。在老式的 DOS 时代,有很多笨重的方法可以做到这一点 —— [Netware][6]、[LAN manager][7],甚至一些 PC NFS 客户端。我没有访问 Netware。我尝试了 DOS 中的 Microsoft LM 客户端,与在 Docker 容器内运行的 Samba 服务器交互。这样可以使用,但 LM 客户端即使有各种高内存技巧还是占用了很多内存,BBS 软件也无法运行。我无法在多个 dosbox 实例中挂载底层文件系统,因为 dosbox 缓存不兼容。
|
||||
|
||||
这就是为什么我使用 dosemu 的原因。除了有比 dosbox 更完整的模拟器之外,它还有一种共享主机文件系统的方式。
|
||||
|
||||
所以,所有这一切都在此:[jgoerzen/docker-bbs-renegade][8]。
|
||||
|
||||
我还为其他想做类似事情的人准备了构建块:[docker-dos-bbs][9] 和底层 [docker-dosemu][10]。
|
||||
|
||||
意外的收获是,我也试图了在 Joyent 的 Triton(基于 Solaris 的 SmartOS)下运行它。让我感到高兴的印象是,几乎可以在这下面工作。是的,在 Solaris 机器上的一个基于 Linux 的 DOS 模拟器的容器中运行 Renegade DOS BBS。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
@ -0,0 +1,119 @@
|
||||
如何在使用 Vim 时访问/查看 Python 帮助
|
||||
======
|
||||
|
||||
我是一名新的 Vim 编辑器用户。我用它编写 Python 代码。有没有办法在 vim 中查看 Python 文档而无需访问互联网?假设我的光标在 Python 的 `print` 关键字下,然后按下 F1,我想查看关键字 `print` 的帮助。如何在 vim 中显示 python `help()` ?如何在不离开 vim 的情况下调用 `pydoc3`/`pydoc` 寻求帮助?
|
||||
|
||||
`pydoc` 或 `pydoc3` 命令可以根据 Python 关键字、主题、函数、模块或包的名称显示文本文档,或在模块内或包中的模块对类或函数的引用。你可以从 Vim 中调用 `pydoc`。让我们看看如何在 Vim 编辑器中使用 `pydoc` 访问 Python 文档。
|
||||
|
||||
### 使用 pydoc 访问 python 帮助
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
pydoc keyword
|
||||
pydoc3 keyword
|
||||
pydoc len
|
||||
pydoc print
|
||||
```
|
||||
|
||||
编辑你的 `~/.vimrc`:
|
||||
|
||||
```
|
||||
$ vim ~/.vimrc
|
||||
```
|
||||
|
||||
为 `pydoc3` 添加以下配置(python v3.x 文档)。在正常模式下创建 `H` 键的映射:
|
||||
|
||||
```
|
||||
nnoremap <buffer> H :<C-u>execute "!pydoc3 " . expand("<cword>")<CR>
|
||||
```
|
||||
|
||||
保存并关闭文件。打开 Vim 编辑器:
|
||||
|
||||
```
|
||||
$ vim file.py
|
||||
```
|
||||
|
||||
写一些代码:
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
x=5
|
||||
y=10
|
||||
z=x+y
|
||||
print(z)
|
||||
print("Hello world")
|
||||
```
|
||||
|
||||
将光标置于 Python 关键字 `print` 的下方,然后按下 `Shift`,然后按 `H`。你将看到下面的输出:
|
||||
|
||||
[![Access Python Help Within Vim][1]][1]
|
||||
|
||||
*按 H 查看 Python 关键字 print 的帮助*
|
||||
|
||||
### 如何在使用 Vim 时查看 python 帮助
|
||||
|
||||
[jedi-vim][2] 是一个绑定自动补全库 Jed 的 Vim 插件。它可以做很多事情,包括当你按下 `Shift` 后跟 `K` (即按大写 `K`) 就显示关键字的帮助。
|
||||
|
||||
#### 如何在 Linux 或类 Unix 系统上安装 jedi-vim
|
||||
|
||||
使用 [pathogen][3]、[vim-plug][4] 或 [Vundle][5] 安装 jedi-vim。我使用的是 vim-plug。在 `~/.vimrc` 中添加以下行:
|
||||
|
||||
```
|
||||
Plug 'davidhalter/jedi-vim'
|
||||
```
|
||||
|
||||
保存并关闭文件。启动 Vim 并输入:
|
||||
|
||||
```
|
||||
PlugInstall
|
||||
```
|
||||
|
||||
在 Arch Linux 上,你还可以使用 `pacman` 命令从官方仓库中的 vim-jedi 安装 jedi-vim:
|
||||
|
||||
```
|
||||
$ sudo pacman -S vim-jedi
|
||||
```
|
||||
|
||||
它也可以在 Debian(比如 8)和 Ubuntu( 比如 14.04)上使用 [apt-get command][6]/[apt-get command][7] 安装 vim-python-jedi:
|
||||
|
||||
```
|
||||
$ sudo apt install vim-python-jedi
|
||||
```
|
||||
|
||||
在 Fedora Linux 上,它可以用 `dnf` 安装 vim-jedi:
|
||||
|
||||
```
|
||||
$ sudo dnf install vim-jedi
|
||||
```
|
||||
|
||||
Jedi 默认是自动初始化的。所以你不需要进一步的配置。要查看 Documentation/Pydoc,请按 `K`。它将弹出帮助窗口:
|
||||
|
||||
[![How to view python help when using vim][8]][8]
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,也是经验丰富的系统管理员和 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Access-Python-Help-Within-Vim.gif
|
||||
[2]:https://github.com/davidhalter/jedi-vim
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://www.cyberciti.biz/programming/vim-plug-a-beautiful-and-minimalist-vim-plugin-manager-for-unix-and-linux-users/
|
||||
[5]:https://github.com/gmarik/vundle
|
||||
[6]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-view-Python-Documentation-using-pydoc-within-vim-on-Linux-Unix.jpg
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,114 +1,94 @@
|
||||
如何使用 Seahorse 管理 PGP 和 SSH 密钥
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。[Creative Commons Zero][6]
|
||||
|
||||
安全无异于内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是当你可以采用几种方法和技术去确保你的桌面或者服务器系统的安全时,你为什么还要停止使用差不多已经接受的平台呢?
|
||||
> 学习使用 Seahorse GUI 工具去管理 PGP 和 SSH 密钥。
|
||||
|
||||
其中一项技术涉及到密钥 —在 PGP 和 SSH 中,PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
|
||||
安全即内心的平静。毕竟,安全是许多用户迁移到 Linux 的最大理由。但是为什么要止步于仅仅采用该平台,你还可以采用多种方法和技术去确保你的桌面或者服务器系统的安全。
|
||||
|
||||
当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于摆脱命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平因此,使用 GUI!
|
||||
其中一项技术涉及到密钥 —— 用在 PGP 和 SSH 中。PGP 密钥允许你去加密和解密电子邮件和文件,而 SSH 密钥允许你使用一个额外的安全层去登入服务器。
|
||||
|
||||
当然,你可以通过命令行接口(CLI)来管理这些密钥,但是,如果你使用一个华丽的 GUI 桌面环境呢?经验丰富的 Linux 用户可能对于脱离命令行来工作感到很不适应,但是,并不是所有用户都具备与他们相同的技术和水平,因此,使用 GUI 吧!
|
||||
|
||||
在本文中,我将带你探索如何使用 [Seahorse][14] GUI 工具来管理 PGP 和 SSH 密钥。Seahorse 有非常强大的功能,它可以:
|
||||
|
||||
* 加密/解密/签名文件和文本。
|
||||
|
||||
* 管理你的密钥和密钥对。
|
||||
|
||||
* 同步你的密钥和密钥对到远程密钥服务器。
|
||||
|
||||
* 签名和发布密钥。
|
||||
|
||||
* 缓存你的密码。
|
||||
|
||||
* 备份密钥和密钥对。
|
||||
|
||||
* 在任何一个 GDK 支持的格式中添加一个图像作为一个 OpenPGP photo ID。
|
||||
|
||||
* 创建、配置、和缓存 SSH 密钥。
|
||||
|
||||
对于那些不了解 Seahorse 的人来说,它是一个在 GNOME 密钥对中管理加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面上。并且由于 Seahorse 是在标准仓库中创建的,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。因此,你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
|
||||
对于那些不了解 Seahorse 的人来说,它是一个管理 GNOME 钥匙环中的加密密钥和密码的 GNOME 应用程序。不用担心,Seahorse 可以安装在许多的桌面环境上。并且由于 Seahorse 可以在标准的仓库中找到,你可以打开你的桌面应用商店(比如,Ubuntu Software 或者 Elementary OS AppCenter)去安装它。你可以在你的发行版的应用商店中点击去安装它。安装完成后,你就可以去使用这个很方便的工具了。
|
||||
|
||||
我们开始去使用它吧。
|
||||
|
||||
### PGP 密钥
|
||||
|
||||
我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(使用一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。一个 PGP 密钥也可以用于加密文件。任何人使用你的公钥都可以解密你的电子邮件和文件。没有 PGP 密钥是做不到的。
|
||||
我们需要做的第一件事情就是生成一个新的 PGP 密钥。正如前面所述,PGP 密钥可以用于加密电子邮件(通过一些工具,像 [Thunderbird][15] 的 [Enigmail][16] 或者使用 [Evolution][17] 内置的加密功能)。PGP 密钥也可以用于加密文件。任何人都可以使用你的公钥加密电子邮件和文件发给你(LCTT 译注:原文此处“加密”误作“解密”)。没有 PGP 密钥是做不到的。
|
||||
|
||||
使用 Seahorse 创建一个新的 PGP 密钥对是非常简单的。以下是操作步骤:
|
||||
|
||||
1. 打开 Seahorse 应用程序
|
||||
|
||||
2. 在主面板的左上角点击 + 按钮
|
||||
|
||||
3. 选择 PGP Key(如图 1 )
|
||||
|
||||
4. 点击 Continue
|
||||
|
||||
2. 在主面板的左上角点击 “+” 按钮
|
||||
3. 选择 “<ruby>PGP 密钥<rt>PGP Key</rt></ruby>”(如图 1 )
|
||||
4. 点击 “<ruby>继续<rt>Continue</rt></ruby>”
|
||||
5. 当提示时,输入完整的名字和电子邮件地址
|
||||
|
||||
6. 点击 Create
|
||||
|
||||
6. 点击 “<ruby>创建<rt>Create</rt></ruby>”
|
||||
|
||||

|
||||
图 1:使用 Seahorse 创建一个 PGP 密钥。[Used with permission][1]
|
||||
|
||||
在创建你的 PGP 密钥期间,你可以点击 Advanced key options 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。
|
||||
*图 1:使用 Seahorse 创建一个 PGP 密钥。*
|
||||
|
||||
在创建你的 PGP 密钥期间,你可以点击 “<ruby>高级密钥选项<rt>Advanced key options</rt></ruby>” 展开选项部分,在那里你可以为密钥添加注释信息、加密类型、密钥长度、以及过期时间(如图 2)。
|
||||
|
||||

|
||||
图 2:PGP 密钥高级选项[Used with permission][2]
|
||||
|
||||
*图 2:PGP 密钥高级选项*
|
||||
|
||||
增加注释部分可以很方便帮你记住密钥的用途(或者其它的信息)。
|
||||
要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 Names 和 Signatures 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 Sign 按钮然后(在结果窗口中)标识 how carefully you’ve checked this key 和 how others will see the signature(如图 3)。
|
||||
|
||||
要使用你创建的 PGP,可在密钥列表中双击它。在结果窗口中,点击 “<ruby>名字<rt>Names</rt></ruby>” 和 “<ruby>签名<rt>Signatures</rt></ruby>” 选项卡。在这个窗口中,你可以签名你的密钥(表示你信任这个密钥)。点击 “<ruby>签名<rt>Sign</rt></ruby>” 按钮然后(在结果窗口中)指出 “<ruby>你是如何仔细的检查这个密钥的?<rt>how carefully you’ve checked this key?</rt></ruby>” 和 “<ruby>其他人将如何看到该签名<rt>how others will see the signature</rt></ruby>”(如图 3)。
|
||||
|
||||

|
||||
图 3:签名一个密钥表示信任级别。[Used with permission][3]
|
||||
|
||||
当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项工作并且完全信任这个重要的密钥。
|
||||
*图 3:签名一个密钥表示信任级别。*
|
||||
|
||||
谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 .asc 为后缀)。你的系统上有其他人的公钥,意味着你可以解密从他们那里发送给你的电子邮件和文件。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 olivia.asc,你想去导入到 Seahorse 中使用它,你将只能运行命令 gpg2 --import olivia.asc。那个密钥将出现在 GnuPG 密钥列表中。你可以打开密钥,点击 I trust signatures 按钮,然后在问题 how carefully you’ve checked the key 中,点击 Sign this key 按钮去标示。
|
||||
当你处理其它人的密钥时,密钥签名是非常重要的,因为一个签名的密钥将确保你的系统(和你)做了这项签名工作并且完全信任这个重要的密钥。
|
||||
|
||||
谈到导入的密钥,Seahorse 可以允许你很容易地去导入其他人的公钥文件(这个文件以 `.asc` 为后缀)。你的系统上有其他人的公钥,意味着你可以加密发送给他们的电子邮件和文件(LCTT 译注:原文将“加密”误作“解密”)。然而,Seahorse 在很长的一段时间内都存在一个 [已知的 bug][18]。这个问题是,Seahorse 导入使用 GPG 版本 1,但是显示的是 GPG 版本 2。这意味着,在这个存在了很长时间的 bug 被修复之前,导入公钥总是失败的。如果你想导入一个公钥文件到 Seahorse 中,你只能去使用命令行。因此,如果有人发送给你一个文件 `olivia.asc`,你想去导入到 Seahorse 中使用它,你将只能运行命令 `gpg2 --import olivia.asc`。那个密钥将出现在 GnuPG 密钥列表中。你可以打开该密钥,点击 “<ruby>我信任签名<rt>I trust signatures</rt></ruby>” 按钮,然后在问题 “<ruby>你是如何仔细地检查该密钥的?<rt>how carefully you’ve checked the key</rt></ruby>” 中,点击 “<ruby>签名这个密钥<rt>Sign this key</rt></ruby>” 按钮去签名。
|
||||
|
||||
### SSH 密钥
|
||||
|
||||
现在我们来谈谈我认为 Seahorse 中最重要的一个方面 — SSH 密钥。Seahorse 不仅可以很容易地生成一个 SSH 密钥,而且它也可以很容易地将生成的密钥发送到服务器上,因此,你可以享受到 SSH 密钥验证的好处。下面是如何生成一个新的密钥以及如何导出它到一个远程服务器上。
|
||||
|
||||
1. 打开 Seahorse 应用程序
|
||||
|
||||
2. 点击 + 按钮
|
||||
|
||||
3. 选择 Secure Shell Key
|
||||
|
||||
4. 点击 Continue
|
||||
|
||||
2. 点击 “+” 按钮
|
||||
3. 选择 “Secure Shell Key”
|
||||
4. 点击 “Continue”
|
||||
5. 提供一个密钥描述信息
|
||||
|
||||
6. 点击 Set Up 去创建密钥
|
||||
|
||||
6. 点击 “Set Up” 去创建密钥
|
||||
7. 输入密钥的验证密钥
|
||||
|
||||
8. 点击 OK
|
||||
|
||||
9. 输入远程服务器地址和服务器上的登陆名(如图 4)
|
||||
|
||||
9. 输入远程服务器地址和服务器上的登录名(如图 4)
|
||||
10. 输入远程用户的密码
|
||||
|
||||
11. 点击 OK
|
||||
|
||||
|
||||

|
||||
图 4:上传一个 SSH 密钥到远程服务器。[Used with permission][4]
|
||||
|
||||
新密钥将上传到远程服务器上以准备好使用它。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
|
||||
*图 4:上传一个 SSH 密钥到远程服务器。*
|
||||
|
||||
需要注意的是,在创建一个 SSH 密钥期间,你可以点击 Advanced key options 去展开它,配置加密类型和密钥长度(如图 5)。
|
||||
新密钥将上传到远程服务器上以备使用。如果你的服务器已经设置为使用 SSH 密钥验证,那就一切就绪了。
|
||||
|
||||
需要注意的是,在创建一个 SSH 密钥期间,你可以点击 “<ruby>高级密钥选项<rt>Advanced key options</rt></ruby>”去展开它,配置加密类型和密钥长度(如图 5)。
|
||||
|
||||

|
||||
图 5:高级 SSH 密钥选项。[Used with permission][5]
|
||||
|
||||
*图 5:高级 SSH 密钥选项。*
|
||||
|
||||
### Linux 新手必备
|
||||
|
||||
@ -120,9 +100,9 @@
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-manage-pgp-and-ssh-keys-seahorse
|
||||
|
||||
作者:[JACK WALLEN ][a]
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxt](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,22 +1,21 @@
|
||||
如何检查你的计算机使用的是 UEFI 还是 BIOS
|
||||
======
|
||||
**简介:一个快速的教程,来告诉你的系统使用的是现代 UEFI 或者传统 BIOS。同时提供 Windows 和 Linux 的说明。**
|
||||
|
||||
当你尝试[双启动 Linux 和 Windows ][1]时,你需要知道系统上是否有 UEFI 或 BIOS 启动模式。它可以帮助你决定安装 Linux 的分区。
|
||||
**简介:这是一个快速的教程,来告诉你的系统使用的是现代 UEFI 或者传统 BIOS。同时提供 Windows 和 Linux 的说明。**
|
||||
|
||||
当你尝试[双启动 Linux 和 Windows][1] 时,你需要知道系统上是否有 UEFI 或 BIOS 启动模式。它可以帮助你决定安装 Linux 的分区。
|
||||
|
||||
我不打算在这里讨论[什么是 BIOS][2]。不过,我想通过 BIOS 告诉你一些 [UEFI][3] 的优点。
|
||||
|
||||
UEFI 或者说统一可扩展固件接口旨在克服 BIO S的某些限制。它增加了使用大于 2TB 磁盘的能力,并具有独立于 CPU 的体系结构和驱动程序。采用模块化设计,即使没有安装操作系统,也可以支持远程诊断和修复,以及灵活的无操作系统环境(包括网络功能)。
|
||||
UEFI 即(<ruby>统一可扩展固件接口<rt>Unified Extensible Firmware Interface</rt></ruby>)旨在克服 BIOS 的某些限制。它增加了使用大于 2TB 磁盘的能力,并具有独立于 CPU 的体系结构和驱动程序。采用模块化设计,即使没有安装操作系统,也可以支持远程诊断和修复,以及灵活的无操作系统环境(包括网络功能)。
|
||||
|
||||
### UEFI 优于 BIOS 的点
|
||||
### UEFI 优于 BIOS 的地方
|
||||
|
||||
* UEFI在初始化硬件时速度更快。
|
||||
* UEFI 在初始化硬件时速度更快。
|
||||
* 提供安全启动,这意味着你在加载操作系统之前加载的所有内容都必须签名。这为你的系统提供了额外的保护层。
|
||||
* BIOS 不支持超过 2TB 的分区。
|
||||
* 最重要的是,如果你是双引导,那么建议始终在相同的引导模式下安装两个操作系统。
|
||||
|
||||
|
||||
|
||||
![How to check if system has UEFI or BIOS][4]
|
||||
|
||||
如果试图查看你的系统运行的是 UEFI 还是 BIOS,这并不难。首先让我从 Windows 开始,然后看看如何在 Linux 系统上查看用的是 UEFI 还是 BIOS。
|
||||
@ -27,39 +26,39 @@ UEFI 或者说统一可扩展固件接口旨在克服 BIO S的某些限制。它
|
||||
|
||||
![][5]
|
||||
|
||||
**另一个方法**:如果你使用 Windows 10,可以打开文件资源管理器并进入到 C:\Windows\Panther 来查看你使用的是 UEFI 还是 BIOS。打开文件 setupact.log 并搜索下面的字符串。
|
||||
**另一个方法**:如果你使用 Windows 10,可以打开文件资源管理器并进入到 `C:\Windows\Panther` 来查看你使用的是 UEFI 还是 BIOS。打开文件 setupact.log 并搜索下面的字符串。
|
||||
|
||||
```
|
||||
Detected boot environment
|
||||
|
||||
```
|
||||
|
||||
我建议在 notepad++ 中打开这个文件,因为这是一个很大的文件和记事本可能挂起(至少它对我来说是 6GB )。
|
||||
我建议在 notepad++ 中打开这个文件,因为这是一个很大的文件,记事本很可能挂起(至少它对我来说是 6GB !)。
|
||||
|
||||
你会看到几行有用的信息。
|
||||
|
||||
```
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect:FirmwareType 1.
|
||||
2017-11-27 09:11:31, Info IBS Callback_BootEnvironmentDetect: Detected boot environment: BIOS
|
||||
|
||||
```
|
||||
|
||||
### 在 Linux 中检查使用的是 UEFI 还是 BIOS
|
||||
|
||||
最简单地找出使用的是 UEFI 还是 BIOS 的方法是查找 /sys/firmware/efi 文件夹。如果使用的 BIOS 那么文件夹不存在。
|
||||
最简单地找出使用的是 UEFI 还是 BIOS 的方法是查找 `/sys/firmware/efi` 文件夹。如果使用的 BIOS 那么该文件夹不存在。
|
||||
|
||||
![Find if system uses UEFI or BIOS on Ubuntu Linux][6]
|
||||
|
||||
**另一种方法**:安装名为 efibootmgr 的软件包。
|
||||
|
||||
在基于 Debian 和 Ubuntu 的发行版中,你可以使用以下命令安装 efibootmgr 包:
|
||||
|
||||
```
|
||||
sudo apt install efibootmgr
|
||||
|
||||
```
|
||||
|
||||
完成后,输入以下命令:
|
||||
|
||||
```
|
||||
sudo efibootmgr
|
||||
|
||||
```
|
||||
|
||||
如果你的系统支持 UEFI,它会输出不同的变量。如果没有,你将看到一条消息指出 EFI 变量不支持。
|
||||
@ -76,7 +75,7 @@ via: https://itsfoss.com/check-uefi-or-bios/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,23 +8,23 @@
|
||||
### 在 Linux 中纠正拼写错误的 Bash 命令
|
||||
|
||||
你有没有运行过类似于下面的错误输入命令?
|
||||
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
你注意到了吗?上面的命令中有一个错误。我在 “uname” 命令缺少了字母 “a”。
|
||||
你注意到了吗?上面的命令中有一个错误。我在 `uname` 命令缺少了字母 `a`。
|
||||
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令,并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
|
||||
要轻松更正上述拼写错误的命令,只需运行:
|
||||
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
这会将 “uname” 命令中将 “nm” 替换为 “nam”。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
这会将 `uname` 命令中将 `nm` 替换为 `nam`。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
@ -32,49 +32,49 @@ $ ^nm^nam^
|
||||
|
||||
**额外提示:**
|
||||
|
||||
你有没有想过在使用 “cd” 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
你有没有想过在使用 `cd` 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
|
||||
这个技巧只能纠正使用 “cd” 命令时的拼写错误。
|
||||
这个技巧只能纠正使用 `cd` 命令时的拼写错误。
|
||||
|
||||
比如说,你想使用命令切换到 `Downloads` 目录:
|
||||
|
||||
比如说,你想使用命令切换到 “Downloads” 目录:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
哎呀!没有名称为 “Donloads” 的文件或目录。是的,正确的名称是 “Downloads”。上面的命令中缺少 “w”。
|
||||
哎呀!没有名称为 `Donloads` 的文件或目录。是的,正确的名称是 `Downloads`。上面的命令中缺少 `w`。
|
||||
|
||||
要解决此问题并在使用 `cd` 命令时自动更正错误,请编辑你的 `.bashrc` 文件:
|
||||
|
||||
要解决此问题并在使用 cd 命令时自动更正错误,请编辑你的 **.bashrc** 文件:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
最后添加以下行。
|
||||
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
输入 **:wq** 保存并退出文件。
|
||||
输入 `:wq` 保存并退出文件。
|
||||
|
||||
最后,运行以下命令更新更改。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
现在,如果在使用 cd 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
现在,如果在使用 `cd` 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的命令中看到的那样,我故意输错(“Donloads” 而不是 “Downloads”),但 Bash 自动检测到正确的目录名并 cd 进入它。
|
||||
正如你在上面的命令中看到的那样,我故意输错(`Donloads` 而不是 `Downloads`),但 Bash 自动检测到正确的目录名并 `cd` 进入它。
|
||||
|
||||
[**Fish**][4] 和**Zsh** shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
[Fish][4] 和 Zsh shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 “cd donloads” 而不是 “cd Donloads”,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 `cd donloads` 而不是 `cd Donloads`,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -83,7 +83,7 @@ via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,11 +3,12 @@ Dnsmasq 进阶技巧
|
||||
|
||||

|
||||
|
||||
许多人熟知和热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
|
||||
许多人熟知并热爱 Dnsmasq,并在他们的本地域名服务上使用它。今天我们将介绍进阶配置文件管理、如何测试你的配置、一些基础的安全知识、DNS 泛域名、快速 DNS 配置,以及其他一些技巧与窍门。下个星期我们将继续详细讲解如何配置 DNS 和 DHCP。
|
||||
|
||||
### 测试配置
|
||||
|
||||
当你测试新的配置的时候,你应该从命令行运行 Dnsmasq,而不是使用守护进程。下面的例子演示了如何不用守护进程运行它,同时显示指令的输出并保留运行日志:
|
||||
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries
|
||||
dnsmasq: started, version 2.75 cachesize 150
|
||||
@ -17,112 +18,111 @@ dnsmasq: compile time options: IPv6 GNU-getopt
|
||||
dnsmasq: reading /etc/resolv.conf
|
||||
dnsmasq: using nameserver 192.168.0.1#53
|
||||
dnsmasq: read /etc/hosts - 9 addresses
|
||||
|
||||
```
|
||||
|
||||
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统域名服务文件、以及它的监听地址。可以使用 Ctrl+C 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`、在每个匹配的文件名之后显示匹配的行数,并忽略 `/var/log/dist-upgrade` 里的内容:
|
||||
在这个小例子中你能看到许多有用的信息,包括版本、编译参数、系统名字服务文件,以及它的监听地址。可以使用 `Ctrl+C` 停止进程。在默认情况下,Dnsmasq 没有自己的日志文件,所以日志会被记录到 `/var/log` 目录下的多个地方。你可以使用经典的 `grep` 来找到 Dnsmasq 的日志文件。下面这条指令会递归式地搜索 `/var/log`,在每个匹配的文件名之后显示匹配的行号,并忽略 `/var/log/dist-upgrade` 里的内容:
|
||||
|
||||
```
|
||||
# grep -ir --exclude-dir=dist-upgrade dnsmasq /var/log/
|
||||
|
||||
```
|
||||
|
||||
使用 `grep --exclude-dir=` 时有一个有趣的小陷阱需要注意:不要使用完整路径,而应该只写目录名称。
|
||||
|
||||
你可以使用如下的命令行参数来让 Dnsmasq 使用你指定的文件作为它专属的日志文件:
|
||||
|
||||
```
|
||||
# dnsmasq --no-daemon --log-queries --log-facility=/var/log/dnsmasq.log
|
||||
|
||||
```
|
||||
|
||||
或者在你的 Dnsmasq 配置文件中加上 `log-facility=/var/log/dnsmasq.log`。
|
||||
|
||||
### 配置文件
|
||||
|
||||
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 Linux 七嘴八舌秘密议会的旨意)。你有很多自由来随意安置你的配置文件。
|
||||
Dnsmasq 的配置文件位于 `/etc/dnsmasq.conf`。你的 Linux 发行版也可能会使用 `/etc/default/dnsmasq`、`/etc/dnsmasq.d/`,或者 `/etc/dnsmasq.d-available/`(不,我们不能统一标准,因为这违反了 <ruby>Linux 七嘴八舌秘密议会<rt>Linux Cat Herd Ruling Cabal</rt></ruby>的旨意)。你有很多自由来随意安置你的配置文件。
|
||||
|
||||
`/etc/dnsmasq.conf` 是德高望重的老大。Dnsmasq 在启动时会最先读取它。`/etc/dnsmasq.conf` 可以使用 `conf-file=` 选项来调用其他的配置文件,例如 `conf-file=/etc/dnsmasqextrastuff.conf`,或使用 `conf-dir=` 选项来调用目录下的所有文件,例如 `conf-dir=/etc/dnsmasq.d`。
|
||||
|
||||
每当你对配置文件进行了修改,你都必须重启 Dnsmasq。
|
||||
|
||||
你可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示忽略:
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/,*.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d,.old, .bak, .tmp
|
||||
你也可以根据扩展名来包含或忽略配置文件。星号表示包含,不加星号表示排除:
|
||||
|
||||
```
|
||||
conf-dir=/etc/dnsmasq.d/, *.conf, *.foo
|
||||
conf-dir=/etc/dnsmasq.d, .old, .bak, .tmp
|
||||
```
|
||||
|
||||
你可以用 `--addn-hosts=` 选项来把你的主机配置分布在多个文件中。
|
||||
|
||||
Dnsmasq 包含了一个语法检查器:
|
||||
|
||||
```
|
||||
$ dnsmasq --test
|
||||
dnsmasq: syntax check OK.
|
||||
|
||||
```
|
||||
|
||||
### 实用配置
|
||||
|
||||
永远加入这几行:
|
||||
|
||||
```
|
||||
domain-needed
|
||||
bogus-priv
|
||||
|
||||
```
|
||||
|
||||
它们可以避免含有格式出错的域名或私人 IP 地址的数据包离开你的网络。
|
||||
它们可以避免含有格式出错的域名或私有 IP 地址的数据包离开你的网络。
|
||||
|
||||
让你的名字服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的名字服务文件:
|
||||
|
||||
让你的域名服务只使用 Dnsmasq,而不去使用 `/etc/resolv.conf` 或任何其他的域名服务文件:
|
||||
```
|
||||
no-resolv
|
||||
|
||||
```
|
||||
|
||||
使用其他的域名服务器。第一个例子是只对于某一个域名使用不同的域名服务器。第二个和第三个例子是 OpenDNS 公用服务器:
|
||||
|
||||
```
|
||||
server=/fooxample.com/192.168.0.1
|
||||
server=208.67.222.222
|
||||
server=208.67.220.220
|
||||
|
||||
```
|
||||
|
||||
你也可以将某些域名限制为只能本地解析,但不影响其他域名。这些被限制的域名只能从 `/etc/hosts` 或 DHCP 解析:
|
||||
|
||||
```
|
||||
local=/mehxample.com/
|
||||
local=/fooxample.com/
|
||||
|
||||
```
|
||||
|
||||
限制 Dnsmasq 监听的网络接口:
|
||||
|
||||
```
|
||||
interface=eth0
|
||||
interface=wlan1
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 在默认设置下会读取并使用 `/etc/hosts`。这是一个又快又好的配置大量域名的方法,并且 `/etc/hosts` 只需要和 Dnsmasq 在同一台电脑上。你还可以让这个过程再快一些,可以在 `/etc/hosts` 文件中只写主机名,然后用 Dnsmasq 来添加域名。`/etc/hosts` 看上去是这样的:
|
||||
|
||||
```
|
||||
127.0.0.1 localhost
|
||||
192.168.0.1 host2
|
||||
192.168.0.2 host3
|
||||
192.168.0.3 host4
|
||||
|
||||
```
|
||||
|
||||
然后把这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
|
||||
然后把下面这几行写入 `dnsmasq.conf`(当然,要换成你自己的域名):
|
||||
|
||||
```
|
||||
expand-hosts
|
||||
domain=mehxample.com
|
||||
|
||||
```
|
||||
|
||||
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 host2 会变为 host2.mehxample.com。
|
||||
Dnsmasq 会自动把这些主机名扩展为完整的域名,比如 `host2` 会变为 `host2.mehxample.com`。
|
||||
|
||||
### DNS 泛域名
|
||||
|
||||
一般来说,使用 DNS 泛域名不是一个好习惯,因为它们太容易被误用了。但它们有时会很有用,比如在你的局域网的严密保护之下的时候。一个例子是使用 DNS 泛域名会让 Kubernetes 集群变得容易管理许多,除非你喜欢给你成百上千的应用写 DNS 记录。假设你的 Kubernetes 域名是 mehxample.com,那么下面这行配置可以让 Dnsmasq 解析所有对 mehxample.com 的请求:
|
||||
|
||||
```
|
||||
address=/mehxample.com/192.168.0.5
|
||||
|
||||
```
|
||||
|
||||
这里使用的地址是你的集群的公网 IP 地址。这会响应对 mehxample.com 的所有主机名和子域名的请求,除非请求的目标地址已经在 DHCP 或者 `/etc/hosts` 中配置过。
|
||||
@ -131,21 +131,18 @@ address=/mehxample.com/192.168.0.5
|
||||
|
||||
### 更多参考
|
||||
|
||||
* [使用 Dnsmasq 进行 DNS 欺骗][1]
|
||||
|
||||
* [使用 Dnsmasq 进行 DNS 伪装][1]
|
||||
* [使用 Dnsmasq 配置简单的局域网域名服务][2]
|
||||
|
||||
* [Dnsmasq][3]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/advanced-dnsmasq-tips-and-tricks
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[yixunx](https://github.com/yixunx)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,42 @@
|
||||
没有 chrome-gnome-shell 的 Gnome
|
||||
去掉了 chrome-gnome-shell 的 Gnome
|
||||
======
|
||||
|
||||
新的笔记本有触摸屏,它可以折叠成平板电脑,我听说 gnome-shell 将是桌面环境的一个很好的选择,我设法调整它足以按照现有的习惯重用。
|
||||
新的笔记本有触摸屏,它可以折叠成平板电脑,我听说 gnome-shell 将是桌面环境的一个很好的选择,我设法调整它以按照现有的习惯使用。
|
||||
|
||||
然而,我有一个很大的问题,它怎么会鼓励人们从互联网上下载随机扩展,并将它们作为整个桌面环境的一部分运行。 一个更大的问题是,[gnome-core][1] 对 [chrome-gnome-shell] [2] 有强制依赖,插件不用 root 用户编辑 `/etc` 下的文件则无法禁用,这会给网站暴露我的桌面环境。
|
||||
然而,我发现一个很大的问题,它怎么会鼓励人们从互联网上下载随机扩展,并将它们作为整个桌面环境的一部分运行呢? 一个更大的问题是,[gnome-core][1] 对 [chrome-gnome-shell] [2] 有强制依赖,这个插件如果不用 root 用户编辑 `/etc` 下的文件则无法禁用,这会给将我的桌面环境暴露给网站。
|
||||
|
||||
访问[这个网站][3],它会知道你已经安装了哪些扩展,并且能够安装更多。我不信任它,我不需要那样,我不想那样。我为此感到震惊。
|
||||
|
||||
[我想出了一个临时解决方法][4]。
|
||||
[我想出了一个临时解决方法][4]。(LCTT 译注:作者做了一个空的依赖包来满足依赖,而不会做任何可能危害你的隐私和安全的操作。)
|
||||
|
||||
人们会在 firefox 中如何做呢?
|
||||
|
||||
### 描述
|
||||
|
||||
chrome-gnome-shell 是 gnome-core 的一个强制依赖项,它安装了一个可能不需要的浏览器插件,并强制它使用系统范围的 chrome 策略。
|
||||
chrome-gnome-shell 是 gnome-core 的一个强制依赖项,它安装了一个你可能不需要的浏览器插件,并强制它使用系统级的 chrome 策略。
|
||||
|
||||
我认为使用 chrome-gnome-shell 会不必要地增加系统的攻击面,我作为主要用户,它会获取下载和执行随机未经审查代码的可疑特权。
|
||||
|
||||
这个包满足了 chrome-gnome-shell 的依赖,但不会安装任何东西。
|
||||
(我做的)这个包满足了 chrome-gnome-shell 的依赖,但不会安装任何东西。
|
||||
|
||||
请注意,在安装此包之后,如果先前安装了 chrome-gnome-shell,则需要清除 chrome-gnome-shell,以使其在 /etc/chromium 中删除 chromium 策略文件
|
||||
请注意,在安装此包之后,如果先前安装了 chrome-gnome-shell,则需要清除 chrome-gnome-shell,以使其在 `/etc/chromium` 中删除 chromium 策略文件。
|
||||
|
||||
### 说明
|
||||
|
||||
```
|
||||
apt install equivs
|
||||
equivs-build contain-gnome-shell
|
||||
sudo dpkg -i contain-gnome-shell_1.0_all.deb
|
||||
sudo dpkg --purge chrome-gnome-shell
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.enricozini.org/blog/2018/debian/gnome-without-chrome-gnome-shell/
|
||||
|
||||
作者:[Enrico Zini][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
简单介绍 ldd 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 `ldd` ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,`ldd` 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
```
|
||||
ldd [option]... file...
|
||||
```
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
> ldd 会输出命令行指定的每个程序或共享对象所需的共享对象(共享库)。
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一、 如何使用 ldd 命令?
|
||||
|
||||
`ldd` 的基本用法非常简单,只需运行 `ldd` 命令以及可执行文件或共享对象的文件名称作为输入。
|
||||
|
||||
```
|
||||
ldd [object-name]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
ldd test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2、 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 `ldd` 生成详细信息,包括符号版本控制数据,则可以使用 `-v` 命令行选项。例如,该命令
|
||||
|
||||
```
|
||||
ldd -v test
|
||||
```
|
||||
|
||||
当使用 `-v` 命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[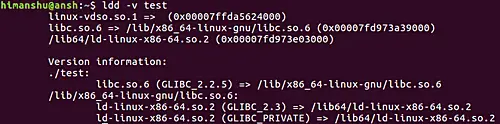](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3、 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 `-u` 命令行选项。这是一个例子:
|
||||
|
||||
```
|
||||
ldd -u test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4、 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:`-d` 和 `-r`。 前者告诉 `ldd` 执行数据重定位,后者则使 `ldd` 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
```
|
||||
ldd -d
|
||||
ldd -r
|
||||
```
|
||||
|
||||
### Q5、 如何获得关于ldd的帮助?
|
||||
|
||||
`--help` 命令行选项使 `ldd` 为该工具生成有用的用法相关信息。
|
||||
|
||||
```
|
||||
ldd --help
|
||||
```
|
||||
|
||||
[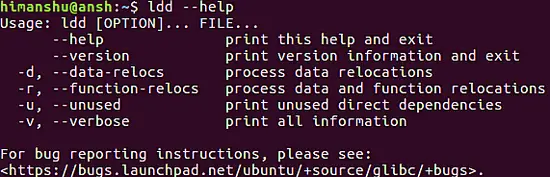](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
`ldd` 不像 `cd`、`rm` 和 `mkdir` 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 `ldd` 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
---------
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/)
|
||||
选题: [lujun9972](https://github.com/lujun9972)
|
||||
译者: [MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
@ -0,0 +1,149 @@
|
||||
有用的 Bash 快捷键清单
|
||||
======
|
||||

|
||||
|
||||
现如今,我在终端上花的时间更多,尝试在命令行完成比在图形界面更多的工作。随着时间推移,我学了许多 BASH 的技巧。这是一份每个 Linux 用户都应该知道的 BASH 快捷键,这样在终端做事就会快很多。我不会说这是一份完全的 BASH 快捷键清单,但是这足够让你的 BASH shell 操作比以前更快了。学习更快地使用 BASH 不仅节省了更多时间,也让你因为学到了有用的知识而感到自豪。那么,让我们开始吧。
|
||||
|
||||
### ALT 快捷键
|
||||
|
||||
1. `ALT+A` – 光标移动到行首。
|
||||
2. `ALT+B` – 光标移动到所在单词词首。
|
||||
3. `ALT+C` – 终止正在运行的命令/进程。与 `CTRL+C` 相同。
|
||||
4. `ALT+D` – 关闭空的终端(也就是它会关闭没有输入的终端)。也删除光标后的全部字符。
|
||||
5. `ALT+F` – 移动到光标所在单词词末。
|
||||
6. `ALT+T` – 交换最后两个单词。
|
||||
7. `ALT+U` – 将单词内光标后的字母转为大写。
|
||||
8. `ALT+L` – 将单词内光标后的字母转为小写。
|
||||
9. `ALT+R` – 撤销对从历史记录中带来的命令的修改。
|
||||
|
||||
正如你在上面输出所见,我使用反向搜索拉取了一个指令,并更改了那个指令的最后一个字母,并使用 `ALT+R` 撤销了更改。
|
||||
10. `ALT+.` (注意末尾的点号) – 使用上一条命令的最后一个单词。
|
||||
|
||||
如果你想要对多个命令进行相同的操作的话,你可以使用这个快捷键来获取前几个指令的最后一个单词。例如,我需要使用 `ls -r` 命令输出以文件名逆序排列的目录内容。同时,我也想使用 `uname -r` 命令来查看我的内核版本。在这两个命令中,相同的单词是 `-r` 。这就是需要 `ALT+.` 的地方。快捷键很顺手。首先运行 `ls -r` 来按文件名逆序输出,然后在其他命令,比如 `uname` 中使用最后一个单词 `-r` 。
|
||||
|
||||
### CTRL 快捷键
|
||||
|
||||
1. `CTRL+A` – 快速移动到行首。
|
||||
|
||||
我们假设你输入了像下面这样的命令。当你在第 N 行时,你发现在行首字符有一个输入错误
|
||||
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
```
|
||||
|
||||
注意到了吗?上面的命令中我输入了 `gind` 而不是 `find` 。你可以通过一直按着左箭头键定位到第一个字母然后用 `g` 替换 `f` 。或者,仅通过 `CTRL+A` 或 `HOME` 键来立刻定位到行首,并替换拼错的单词。这将节省你几秒钟的时间。
|
||||
|
||||
2. `CTRL+B` – 光标向前移动一个字符。
|
||||
|
||||
这个快捷键可以使光标向前移动一个字符,即光标前的一个字符。或者,你可以使用左箭头键来向前移动一个字符。
|
||||
|
||||
3. `CTRL+C` – 停止当前运行的命令。
|
||||
|
||||
如果一个命令运行时间过久,或者你误运行了,你可以通过使用 `CTRL+C` 来强制停止或退出。
|
||||
|
||||
4. `CTRL+D` – 删除光标后的一个字符。
|
||||
|
||||
如果你的系统退格键无法工作的话,你可以使用 `CTRL+D` 来删除光标后的一个字符。这个快捷键也可以让你退出当前会话,和 exit 类似。
|
||||
|
||||
5. `CTRL+E` – 移动到行末。
|
||||
|
||||
当你修正了行首拼写错误的单词,按下 `CTRL+E` 来快速移动到行末。或者,你也可以使用你键盘上的 `END` 键。
|
||||
|
||||
6. `CTRL+F` – 光标向后移动一个字符。
|
||||
|
||||
如果你想将光标向后移动一个字符的话,按 `CTRL+F` 来替代右箭头键。
|
||||
|
||||
7. `CTRL+G` – 退出历史搜索模式,不运行命令。
|
||||
|
||||
正如你在上面的截图看到的,我进行了反向搜索,但是我执行命令,并退出了历史搜索模式。
|
||||
|
||||
8. `CTRL+H` – 删除光标签的一个字符,和退格键相同。
|
||||
|
||||
9. `CTRL+J` – 和 ENTER/RETURN 键相同。
|
||||
|
||||
回车键不工作?没问题! `CTRL+J` 或 `CTRL+M` 可以用来替换回车键。
|
||||
|
||||
10. `CTRL+K` – 删除光标后的所有字符。
|
||||
|
||||
你不必一直按着删除键来删除光标后的字符。只要按 `CTRL+K` 就能删除光标后的所有字符。
|
||||
|
||||
11. `CTRL+L` – 清空屏幕并重新显示当前行。
|
||||
|
||||
别输入 `clear` 来清空屏幕了。只需按 `CTRL+M` 即可清空并重新显示当前行。
|
||||
|
||||
12. `CTRL+M` – 和 `CTRL+J` 或 RETURN键相同。
|
||||
|
||||
13. `CTRL+N` – 在命令历史中显示下一行。
|
||||
|
||||
你也可以使用下箭头键。
|
||||
|
||||
14. `CTRL+O` – 运行你使用反向搜索时发现的命令,即 CTRL+R。
|
||||
|
||||
15. `CTRL+P` – 显示命令历史的上一条命令。
|
||||
|
||||
你也可以使用上箭头键。
|
||||
|
||||
16. `CTRL+R` – 向后搜索历史记录(反向搜索)。
|
||||
|
||||
17. `CTRL+S` – 向前搜索历史记录。
|
||||
|
||||
18. `CTRL+T` – 交换最后两个字符。
|
||||
|
||||
这是我最喜欢的一个快捷键。假设你输入了 `sl` 而不是 `ls` 。没问题!这个快捷键会像下面这张截图一样交换字符。
|
||||
|
||||
![][2]
|
||||
|
||||
19. `CTRL+U` – 删除光标前的所有字符(从光标后的点删除到行首)。
|
||||
|
||||
这个快捷键立刻删除前面的所有字符。
|
||||
|
||||
20. `CTRL+V` – 逐字显示输入的下一个字符。
|
||||
|
||||
21. `CTRL+W` – 删除光标前的一个单词。
|
||||
|
||||
不要和 CTRL+U 弄混了。CTRL+W 不会删除光标前的所有东西,而是只删除一个单词。
|
||||
|
||||
![][3]
|
||||
|
||||
22. `CTRL+X` – 列出当前单词可能的文件名补全。
|
||||
|
||||
23. `CTRL+XX` – 移动到行首位置(再移动回来)。
|
||||
|
||||
24. `CTRL+Y` – 恢复你上一个删除或剪切的条目。
|
||||
|
||||
记得吗,我们在第 21 个命令用 `CTRL+W` 删除了单词“-al”。你可以使用 `CTRL+Y` 立刻恢复。
|
||||
|
||||
![][4]
|
||||
|
||||
看见了吧?我没有输入“-al”。取而代之,我按了 `CTRL+Y` 来恢复它。
|
||||
|
||||
25. `CTRL+Z` – 停止当前的命令。
|
||||
|
||||
你也许很了解这个快捷键。它终止了当前运行的命令。你可以在前台使用 `fg` 或在后台使用 `bg` 来恢复它。
|
||||
|
||||
26. `CTRL+[` – 和 `ESC` 键等同。
|
||||
|
||||
### 杂项
|
||||
|
||||
1. `!!` – 重复上一个命令。
|
||||
|
||||
2. `ESC+t` – 交换最后两个单词。
|
||||
|
||||
这就是我所能想到的了。将来我遇到 Bash 快捷键时我会持续添加的。如果你觉得文章有错的话,请在下方的评论区留言。我会尽快更新。
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
69
published/20180219 How Linux became my job.md
Normal file
69
published/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
Linux 如何成为我的工作
|
||||
======
|
||||
|
||||
> IBM 工程师 Phil Estes 分享了他的 Linux 爱好如何使他成为了一位开源领袖、贡献者和维护者。
|
||||
|
||||

|
||||
|
||||
从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有火狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,甚至几乎没有互联网。事实上,那个时候最热门的是最新的 Linux 2.0 内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 [a.out][2] 格式被 [ELF 格式][1]代替,导致升级一些 [Linux][3] 的安装可能有些棘手。
|
||||
|
||||
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
|
||||
|
||||
### Linux 为乐趣为生,而非利益
|
||||
|
||||
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,它们会连接到这个叫做互联网的新东西上。我知道这难以置信!(那时,)“Web”(就是所知道的那个)大多是手写的 HTML,`cgi-bin` 目录是启用动态 Web 交互的一个新平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本、[Perl][4]、HTML,以及所有我们在父母的 Windows 3.1 PC 上从没有见过的简短的 UNIX 命令。
|
||||
|
||||
毕业后,我加入 IBM,工作在一个不能访问 UNIX 系统的 PC 操作系统上,不久,我的大学切断了我通往工程实验室的远程通道。我该如何继续通过 [Pine][6] 使用 `vi` 和 `ls` 读我的电子邮件的呢?我一直听说开源 Linux,但我还没有时间去研究它。
|
||||
|
||||
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 体验!
|
||||
|
||||
所以我拿了一个旧电脑,找到了一个 Linux 发行版本 Slackware 3.0,在我的 IBM 办公室下载了一张又一张的软盘。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于 Makefile 和 `make` 系统、构建软件、补丁还有源码控制的知识。虽然我开始使用 Linux 只是为了兴趣和个人知识,但它最终改变了我的职业生涯。
|
||||
|
||||
虽然我是一个愉快的 Linux 用户,但我认为开源开发仍然是其他人的工作;我觉得在线邮件列表都是神秘的 [UNIX][7] 极客的。我很感激像 Linux HOWTO 这样的项目,它们在我尝试添加软件包、升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序撞得鼻青脸肿时帮助了我。但是要处理源代码并进行修改或提交到上游……那是别人的事,不是我。
|
||||
|
||||
### Linux 如何成为我的工作
|
||||
|
||||
1999 年,我终于有理由把我对 Linux 的个人兴趣与我在 IBM 的日常工作结合起来了。我接了一个研究项目,将 IBM 的 Java 虚拟机(JVM)移植到 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个塑封的盒装的 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,为了编写我们的 JVM 即时编译器(JIT),参考了 AIX JVM 源代码和 Windows 及 OS/2 的 JVM 源代码,我们在几周内就有了一个可以工作在 Linux 上的 JVM,击败了 SUN 公司官方宣告花了几个月才把 Java 移植到 Linux。既然我在 Linux 平台上做得了开发,我就更喜欢它了。
|
||||
|
||||
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 [Dan Frye][8] 的远见和坚持,IBM 在 Linux 上下了“[一亿美元的赌注][9]”,在 1999 年创建了 Linux 技术中心(LTC)。在 LTC 里面有内核开发者、开源贡献者、IBM 硬件设备的驱动程序编写者,以及各种各样的针对 Linux 的开源工作。比起留在与 LTC 联系不大的部门,我更想要成为这个令人兴奋的 IBM 新天地的一份子。
|
||||
|
||||
从 2003 年到 2013 年我深度参与了 IBM 的 Linux 战略和 Linux 发行版(在 IBM 内部)的使用,最终组成了一个团队成为大约 60 个产品的信息交换所,Linux 的使用涉及了 IBM 每个部门。我参与了收购,期望每个设备、管理系统和虚拟机或者基于物理设备的中间件都能运行 Linux。我开始熟悉 Linux 发行版的构建,包括打包、选择上游来源、开发发行版维护的补丁集、做定制,并通过我们的发行版合作伙伴提供支持。
|
||||
|
||||
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 [Ulrich Drepper][10] (将一个小补丁提交到 glibc)和改变[时区数据库][11]的工作贡献了自己的力量(Arthur David Olson 在 NIH 的 FTP 站点维护它的时候接受了这个改变)。但我仍然没有把开源项目的正式贡献者的工作来当做我的工作的一部分。是该改变这种情况的时候了。
|
||||
|
||||
在 2013 年末,我加入了 IBM 在开源社区的云组织,并正在寻找一个上游社区参与进来。我会在 Cloud Foundry 工作,还是会加入 IBM 为 OpenStack 贡献的大组中呢?都不是,因为在 2014 年 Docker 席卷了全球,IBM 要我们几个参与到这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 `git clone` [学习了关于 Git 的更多知识][12],做过 Pull Request 的审查,用 Go 语言写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维护者,为 Dockr 创造下一版的镜像规范(支持多个架构),并在一个关于容器技术的会议上出席和讲话。
|
||||
|
||||
### 如今的我
|
||||
|
||||
一晃几年过去,我已经成为了包括 CNCF 的 [containerd][13] 项目在内的开源项目的维护者。我还创建了项目(如 [manifest-tool][14] 和 [bucketbench][15])。我也通过 OCI 参与了开源治理,我现在是技术监督委员会的成员;而在Moby 项目,我是技术指导委员会的成员。我乐于在世界各地的会议、沙龙、IBM 内部发表关于开源的演讲。
|
||||
|
||||
开源现在是我在 IBM 职业生涯的一部分。我与工程师、开发人员和行业领袖的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
|
||||
|
||||
这个旅程 —— 从我第一次使用 Linux 到今天成为一个领袖、贡献者,和现在云原生开源世界的维护者 —— 我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[ranchong](https://github.com/ranchong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://linux.cn/article-9319-1.html
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -1,3 +1,5 @@
|
||||
lontow Translating
|
||||
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
@ -1,51 +0,0 @@
|
||||
An old DOS BBS in a Docker container
|
||||
======
|
||||
Awhile back, I wrote about [my Debian Docker base images][1]. I decided to extend this concept a bit further: to running DOS applications in Docker.
|
||||
|
||||
But first, a screenshot:
|
||||
|
||||
![][2]
|
||||
|
||||
It turns out this is possible, but difficult. I went through all three major DOS emulators available (dosbox, qemu, and dosemu). I got them all running inside the Docker container, but had a number of, er, fun issues to resolve.
|
||||
|
||||
The general thing one has to do here is present a fake modem to the DOS environment. This needs to be exposed outside the container as a TCP port. That much is possible in various ways -- I wound up using tcpser. dosbox had a TCP modem interface, but it turned out to be too buggy for this purpose.
|
||||
|
||||
The challenge comes in where you want to be able to accept more than one incoming telnet (or TCP) connection at a time. DOS was not a multitasking operating system, so there were any number of hackish solutions back then. One might have had multiple physical computers, one for each incoming phone line. Or they might have run multiple pseudo-DOS instances under a multitasking layer like [DESQview][3], OS/2, or even Windows 3.1.
|
||||
|
||||
(Side note: I just learned of [DESQview/X][4], which integrated DESQview with X11R5 and [replaced the Windows 3 drivers][5] to allow running Windows as an X application).
|
||||
|
||||
For various reasons, I didn't want to try running one of those systems inside Docker. That left me with emulating the original multiple physical node setup. In theory, pretty easy -- spin up a bunch of DOS boxes, each using at most 1MB of emulated RAM, and go to town. But here came the challenge.
|
||||
|
||||
In a multiple-physical-node setup, you need some sort of file sharing, because your nodes have to access the shared message and file store. There were a myriad of clunky ways to do this in the old DOS days - [Netware][6], [LAN manager][7], even some PC NFS clients. I didn't have access to Netware. I tried the Microsoft LM client in DOS, talking to a Samba server running inside the Docker container. This I got working, but the LM client used so much RAM that, even with various high memory tricks, BBS software wasn't going to run. I couldn't just mount an underlying filesystem in multiple dosbox instances either, because dosbox did caching that wasn't going to be compatible.
|
||||
|
||||
This is why I wound up using dosemu. Besides being a more complete emulator than dosbox, it had a way of sharing the host's filesystems that was going to work.
|
||||
|
||||
So, all of this wound up with this: [jgoerzen/docker-bbs-renegade][8].
|
||||
|
||||
I also prepared building blocks for others that want to do something similar: [docker-dos-bbs][9] and the lower-level [docker-dosemu][10].
|
||||
|
||||
As a side bonus, I also attempted running this under Joyent's Triton (SmartOS, Solaris-based). I was pleasantly impressed that I got it all almost working there. So yes, a Renegade DOS BBS running under a Linux-based DOS emulator in a container on a Solaris machine.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://changelog.complete.org/archives/9836-an-old-dos-bbs-in-a-docker-container
|
||||
|
||||
作者:[John Goerzen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://changelog.complete.org/archives/author/jgoerzen
|
||||
[1]:https://changelog.complete.org/archives/9794-fixing-the-problems-with-docker-images
|
||||
[2]:https://raw.githubusercontent.com/jgoerzen/docker-bbs-renegade/master/renegade-login.png
|
||||
[3]:https://en.wikipedia.org/wiki/DESQview
|
||||
[4]:http://toastytech.com/guis/dvx.html
|
||||
[5]:http://toastytech.com/guis/dvx3.html
|
||||
[6]:https://en.wikipedia.org/wiki/NetWare
|
||||
[7]:https://en.wikipedia.org/wiki/LAN_Manager
|
||||
[8]:https://github.com/jgoerzen/docker-bbs-renegade
|
||||
[9]:https://github.com/jgoerzen/docker-dos-bbs
|
||||
[10]:https://github.com/jgoerzen/docker-dosemu
|
||||
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
98
sources/talk/20180214 11 awesome vi tips and tricks.md
Normal file
@ -0,0 +1,98 @@
|
||||
11 awesome vi tips and tricks
|
||||
======
|
||||
|
||||

|
||||
|
||||
The [vi editor][1] is one of the most popular text editors on Unix and Unix-like systems, such as Linux. Whether you're new to vi or just looking for a refresher, these 11 tips will enhance how you use it.
|
||||
|
||||
### Editing
|
||||
|
||||
Editing a long script can be tedious, especially when you need to edit a line so far down that it would take hours to scroll to it. Here's a faster way.
|
||||
|
||||
1. The command `:set number` numbers each line down the left side.
|
||||
|
||||

|
||||
|
||||
You can directly reach line number 26 by opening the file and entering this command on the CLI: `vi +26 sample.txt`. To edit line 26 (for example), the command `:26` will take you directly to it.
|
||||
|
||||

|
||||
|
||||
### Fast navigation
|
||||
|
||||
2. `i` changes your mode from "command" to "insert" and starts inserting text at the current cursor position.
|
||||
3. `a` does the same, except it starts just after the current cursor position.
|
||||
4. `o` starts the cursor position from the line below the current cursor position.
|
||||
|
||||
|
||||
|
||||
### Delete
|
||||
|
||||
If you notice an error or typo, being able to make a quick fix is important. Good thing vi has it all figured out.
|
||||
|
||||
Understanding vi's delete function so you don't accidentally press a key and permanently remove a line, paragraph, or more, is critical.
|
||||
|
||||
5. `x` deletes the character under the cursor.
|
||||
6. `dd` deletes the current line. (Yes, the whole line!)
|
||||
|
||||
|
||||
|
||||
Here's the scary part: `30dd` would delete 30 lines starting with the current line! Proceed with caution when using this command.
|
||||
|
||||
### Search
|
||||
|
||||
You can search for keywords from the "command" mode rather than manually navigating and looking for a specific word in a plethora of text.
|
||||
|
||||
7. `:/<keyword>` searches for the word mentioned in the `< >` space and takes your cursor to the first match.
|
||||
8. To navigate to the next instance of that word, type `n`, and keep pressing it until you get to the match you're looking for.
|
||||
|
||||
|
||||
|
||||
For example, in the image below I searched for `ssh`, and vi highlighted the beginning of the first result.
|
||||
|
||||

|
||||
|
||||
After I pressed `n`, vi highlighted the next instance.
|
||||
|
||||

|
||||
|
||||
### Save and exit
|
||||
|
||||
Developers (and others) will probably find this next command useful.
|
||||
|
||||
9. `:x` saves your work and exits vi.
|
||||
|
||||

|
||||
|
||||
10. If you think every nanosecond is worth saving, here's a faster way to shift to terminal mode in vi. Instead of pressing `Shift+:` on the keyboard, you can press `Shift+q` (or Q, in caps) to access [Ex mode][2], but this doesn't really make any difference if you just want to save and quit by typing `x` (as shown above).
|
||||
|
||||
|
||||
|
||||
### Substitution
|
||||
|
||||
Here is a neat trick if you want to substitute every occurrence of one word with another. For example, if you want to substitute "desktop" with "laptop" in a large file, it would be monotonous and waste time to search for each occurrence of "desktop," delete it, and type "laptop."
|
||||
|
||||
11. The command `:%s/desktop/laptop/g` would replace each occurrence of "desktop" with "laptop" throughout the file; it works just like the Linux `sed` command.
|
||||
|
||||
|
||||
|
||||
In this example, I replaced "root" with "user":
|
||||
|
||||
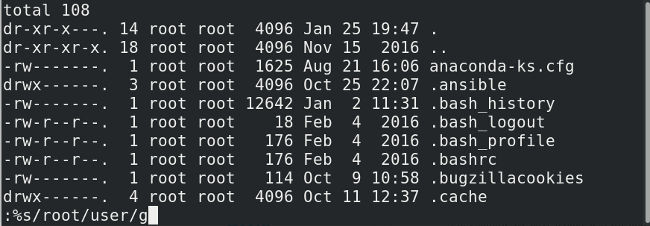
|
||||
|
||||
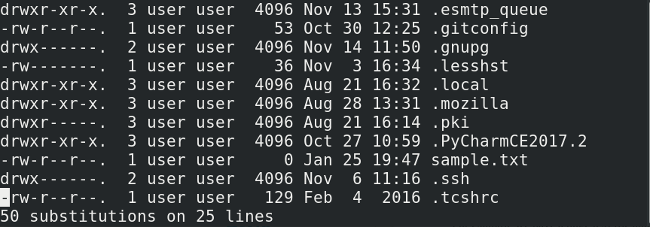
|
||||
|
||||
These tricks should help anyone get started using vi. Are there other neat tips I missed? Share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/top-11-vi-tips-and-tricks
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:http://ex-vi.sourceforge.net/
|
||||
[2]:https://en.wikibooks.org/wiki/Learning_the_vi_Editor/Vim/Modes#Ex-mode
|
||||
@ -1,69 +0,0 @@
|
||||
How Linux became my job
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been using open source since what seems like prehistoric times. Back then, there was nothing called social media. There was no Firefox, no Google Chrome (not even a Google), no Amazon, barely an internet. In fact, the hot topic of the day was the new Linux 2.0 kernel. The big technical challenges in those days? Well, the [ELF format][1] was replacing the old [a.out][2] format in binary [Linux][3] distributions, and the upgrade could be tricky on some installs of Linux.
|
||||
|
||||
How I transformed a personal interest in this fledgling young operating system to a [career][4] in open source is an interesting story.
|
||||
|
||||
### Linux for fun, not profit
|
||||
|
||||
I graduated from college in 1994 when computer labs were small networks of UNIX systems; if you were lucky they connected to this new thing called the internet. Hard to believe, I know! The "web" (as we knew it) was mostly handwritten HTML, and the `cgi-bin` directory was a new playground for enabling dynamic web interactions. Many of us were excited about these new technologies, and we taught ourselves shell scripting, [Perl][5], HTML, and all the terse UNIX commands that we had never seen on our parents' Windows 3.1 PCs.
|
||||
|
||||
`vi` and `ls` and reading my email via
|
||||
|
||||
After graduation, I joined IBM, working on a PC operating system with no access to UNIX systems, and soon my university cut off my remote access to the engineering lab. How was I going to keep usingandand reading my email via [Pine][6] ? I kept hearing about open source Linux, but I hadn't had time to look into it.
|
||||
|
||||
In 1996, I was about to begin a master's degree program at the University of Texas at Austin. I knew it would involve programming and writing papers, and who knows what else, and I didn't want to use proprietary editors or compilers or word processors. I wanted my UNIX experience!
|
||||
|
||||
So I took an old PC, found a Linux distribution—Slackware 3.0—and downloaded it, diskette after diskette, in my IBM office. Let's just say I've never looked back after that first install of Linux. In those early days, I learned a lot about makefiles and the `make` system, about building software, and about patches and source code control. Even though I started working with Linux for fun and personal knowledge, it ended up transforming my career.
|
||||
|
||||
While I was a happy Linux user, I thought open source development was still other people's work; I imagined an online mailing list of mystical [UNIX][7] geeks. I appreciated things like the Linux HOWTO project for helping with the bumps and bruises I acquired trying to add packages, upgrade my Linux distribution, or install device drivers for new hardware or a new PC. But working with source code and making modifications or submitting them upstream … that was for other people, not me.
|
||||
|
||||
### How Linux became my job
|
||||
|
||||
In 1999, I finally had a reason to combine my personal interest in Linux with my day job at IBM. I took on a skunkworks project to port the IBM Java Virtual Machine (JVM) to Linux. To ensure we were legally safe, IBM purchased a shrink-wrapped, boxed copy of Red Hat Linux 6.1 to do this work. Working with the IBM Tokyo Research lab, which wrote our JVM just-in-time (JIT) compiler, and both the AIX JVM source code and the Windows & OS/2 JVM source code reference, we had a working JVM on Linux within a few weeks, beating the announcement of Sun's official Java on Linux port by several months. Now that I had done development on the Linux platform, I was sold on it.
|
||||
|
||||
By 2000, IBM's use of Linux was growing rapidly. Due to the vision and persistence of [Dan Frye][8], IBM made a "[billion dollar bet][9]" on Linux, creating the Linux Technology Center (LTC) in 1999. Inside the LTC were kernel developers, open source contributors, device driver authors for IBM hardware, and all manner of Linux-focused open source work. Instead of remaining tangentially connected to the LTC, I wanted to be part of this exciting new area at IBM.
|
||||
|
||||
From 2003 to 2013 I was deeply involved in IBM's Linux strategy and use of Linux distributions, culminating with having a team that became the clearinghouse for about 60 different product uses of Linux across every division of IBM. I was involved in acquisitions where it was an expectation that every appliance, management system, and virtual or physical appliance-based middleware ran Linux. I became well-versed in the construction of Linux distributions, including packaging, selecting upstream sources, developing distro-maintained patch sets, doing customizations, and offering support through our distro partners.
|
||||
|
||||
Due to our downstream providers, I rarely got to submit patches upstream, but I got to contribute by interacting with [Ulrich Drepper][10] (including getting a small patch into glibc) and working on changes to the [timezone database][11], which Arthur David Olson accepted while he was maintaining it on the NIH FTP site. But I still hadn't worked as a regular contributor on an open source project as part of my work. It was time for that to change.
|
||||
|
||||
In late 2013, I joined IBM's cloud organization in the open source group and was looking for an upstream community in which to get involved. Would it be our work on Cloud Foundry, or would I join IBM's large group of contributors to OpenStack? It was neither, because in 2014 Docker took the world by storm, and IBM asked a few of us to get involved with this hot new technology. I experienced many firsts in the next few months: using GitHub, [learning a lot more about Git][12] than just `git clone`, having pull requests reviewed, writing in Go, and more. Over the next year, I became a maintainer in the Docker engine project, working with Docker on creating the next version of the image specification (to support multiple architectures), and attending and speaking at conferences about container technology.
|
||||
|
||||
### Where I am today
|
||||
|
||||
Fast forward a few years, and I've become a maintainer of open source projects, including the Cloud Native Computing Foundation (CNCF) [containerd][13] project. I've also created projects (such as [manifest-tool][14] and [bucketbench][15]). I've gotten involved in open source governance via the Open Containers Initiative (OCI), where I'm now a member of the Technical Oversight Board, and the Moby Project, where I'm a member of the Technical Steering Committee. And I've had the pleasure of speaking about open source at conferences around the world, to meetup groups, and internally at IBM.
|
||||
|
||||
Open source is now part of the fiber of my career at IBM. The connections I've made to engineers, developers, and leaders across the industry may rival the number of people I know and work with inside IBM. While open source has many of the same challenges as proprietary development teams and vendor partnerships have, in my experience the relationships and connections with people around the globe in open source far outweigh the difficulties. The sharpening that occurs with differing opinions, perspectives, and experiences can generate a culture of learning and improvement for both the software and the people involved.
|
||||
|
||||
This journey—from my first use of Linux to becoming a leader, contributor, and maintainer in today's cloud-native open source world—has been extremely rewarding. I'm looking forward to many more years of open source collaboration and interactions with people around the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
42
sources/talk/20180221 3 warning flags of DevOps metrics.md
Normal file
42
sources/talk/20180221 3 warning flags of DevOps metrics.md
Normal file
@ -0,0 +1,42 @@
|
||||
3 warning flags of DevOps metrics
|
||||
======
|
||||

|
||||
|
||||
Metrics. Measurements. Data. Monitoring. Alerting. These are all big topics for DevOps and for cloud-native infrastructure and application development more broadly. In fact, acm Queue, a magazine published by the Association of Computing Machinery, recently devoted an [entire issue][1] to the topic.
|
||||
|
||||
I've argued before that we conflate a lot of things under the "metrics" term, from key performance indicators to critical failure alerts to data that may be vaguely useful someday for something or other. But that's a topic for another day. What I want to discuss here is how metrics affect behavior.
|
||||
|
||||
In 2008, Daniel Ariely published [Predictably Irrational][2] , one of a number of books written around that time that introduced behavioral psychology and behavioral economics to the general public. One memorable quote from that book is the following: "Human beings adjust behavior based on the metrics they're held against. Anything you measure will impel a person to optimize his score on that metric. What you measure is what you'll get. Period."
|
||||
|
||||
This shouldn't be surprising. It's a finding that's been repeatedly confirmed by research. It should also be familiar to just about anyone with business experience. It's certainly not news to anyone in sales management, for example. Base sales reps' (or their managers'!) bonuses solely on revenue, and they'll discount whatever it takes to maximize revenue even if it puts margin in the toilet. Conversely, want the sales force to push a new product line—which will probably take extra effort—but skip the [spiffs][3]? Probably not happening.
|
||||
|
||||
And lest you think I'm unfairly picking on sales, this behavior is pervasive, all the way up to the CEO, as Ariely describes in [a 2010 Harvard Business Review article][4]. "CEOs care about stock value because that's how we measure them. If we want to change what they care about, we should change what we measure," writes Ariely.
|
||||
|
||||
Think developers and operations folks are immune from such behaviors? Think again. Let's consider some problematic measurements. They're not all bad or wrong but, if you rely too much on them, warning flags should go up.
|
||||
|
||||
### Three warning signs for DevOps metrics
|
||||
|
||||
First, there are the quantity metrics. Lines of code or bugs fixed are perhaps self-evidently absurd. But there are also the deployments per week or per month that are so widely quoted to illustrate DevOps velocity relative to more traditional development and deployment practices. Speed is good. It's one of the reasons you're probably doing DevOps—but don't reward people on it excessively relative to quality and other measures.
|
||||
|
||||
Second, it's obvious that you want to reward individuals who do their work quickly and well. Yes. But. Whether it's your local pro sports team or some project team you've been on, you can probably name someone who was really a talent, but was just so toxic and such a distraction for everyone else that they were a net negative for the team. Moral: Don't provide incentives that solely encourage individual behaviors. You may also want to put in place programs, such as peer rewards, that explicitly value collaboration. [As Red Hat's Jen Krieger told me][5] in a podcast last year: "Having those automated pots of awards, or some sort of system that's tracked for that, can only help teams feel a little more cooperative with one another as in, 'Hey, we're all working together to get something done.'"
|
||||
|
||||
The third red flag area is incentives that don't actually incent because neither the individual nor the team has a meaningful ability to influence the outcome. It's often a good thing when DevOps metrics connect to business goals and outcomes. For example, customer ticket volume relates to perceived shortcomings in applications and infrastructure. And it's also a reasonable proxy for overall customer satisfaction, which certainly should be of interest to the executive suite. The best reward systems to drive DevOps behaviors should be tied to specific individual and team actions as opposed to just company success generally.
|
||||
|
||||
You've probably noticed a common theme. That theme is balance. Velocity is good but so is quality. Individual achievement is good but not when it damages the effectiveness of the team. The overall success of the business is certainly important, but the best reward systems also tie back to actions and behaviors within development and operations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/three-warning-flags-devops-metrics
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://queue.acm.org/issuedetail.cfm?issue=3178368
|
||||
[2]:https://en.wikipedia.org/wiki/Predictably_Irrational
|
||||
[3]:https://en.wikipedia.org/wiki/Spiff
|
||||
[4]:https://hbr.org/2010/06/column-you-are-what-you-measure
|
||||
[5]:http://bitmason.blogspot.com/2015/09/podcast-making-devops-succeed-with-red.html
|
||||
48
sources/talk/20180301 How to hire the right DevOps talent.md
Normal file
48
sources/talk/20180301 How to hire the right DevOps talent.md
Normal file
@ -0,0 +1,48 @@
|
||||
How to hire the right DevOps talent
|
||||
======
|
||||
|
||||

|
||||
|
||||
DevOps culture is quickly gaining ground, and demand for top-notch DevOps talent is greater than ever at companies all over the world. With the [annual base salary for a junior DevOps engineer][1] now topping $100,000, IT professionals are hurrying to [make the transition into DevOps.][2]
|
||||
|
||||
But how do you choose the right candidate to fill your DevOps role?
|
||||
|
||||
### Overview
|
||||
|
||||
Most teams are looking for candidates with a background in operations and infrastructure, software engineering, or development. This is in conjunction with skills that relate to configuration management, continuous integration, and deployment (CI/CD), as well as cloud infrastructure. Knowledge of container orchestration is also in high demand.
|
||||
|
||||
In a perfect world, the two backgrounds would meet somewhere in the middle to form Dev and Ops, but in most cases, candidates lean toward one side or the other. Yet they must possess the skills necessary to understand the needs of their counterparts to work effectively as a team to achieve continuous delivery and deployment. Since every company is different, there is no single right or wrong since so much depends on a company’s tech stack and infrastructure, as well as the goals and the skills of other team members. So how do you focus your search?
|
||||
|
||||
### Decide on the background
|
||||
|
||||
Begin by assessing the strength of your current team. Do you have rock-star software engineers but lack infrastructure knowledge? Focus on closing the skill gaps. Just because you have the budget to hire a DevOps engineer doesn’t mean you should spend weeks, or even months, trying to find the best software engineer who also happens to use Kubernetes and Docker because they are currently the trend. Instead, look for someone who will provide the most value in your environment, and see how things go from there.
|
||||
|
||||
### There is no “Ctrl + F” solution
|
||||
|
||||
Instead of concentrating on specific tools, concentrate on a candidate's understanding of DevOps and CI/CD-related processes. You'll be better off with someone who understands methodologies over tools. It is more important to ensure that candidates comprehend the concept of CI/CD than to ask if they prefer Jenkins, Bamboo, or TeamCity. Don’t get too caught up in the exact toolchain—rather, focus on problem-solving skills and the ability to increase efficiency, save time, and automate manual processes. You don't want to miss out on the right candidate just because the word “Puppet” was not on their resume.
|
||||
|
||||
### Check your ego
|
||||
|
||||
As mentioned above, DevOps is a rapidly growing field, and DevOps engineers are in hot demand. That means candidates have great buying power. You may have an amazing company or product, but hiring top talent is no longer as simple as putting up a “Help Wanted” sign and waiting for top-quality applicants to rush in. I'm not suggesting that maintaining a reputation a great place to work is unimportant, but in today's environment, you need to make an effort to sell your position. Flaws or glitches in the hiring process, such as abruptly canceling interviews or not offering feedback after interviews, can lead to negative reviews spreading across the industry. Remember, it takes just a couple of minutes to leave a negative review on Glassdoor.
|
||||
|
||||
### Contractor or permanent employee?
|
||||
|
||||
Most recruiters and hiring managers immediately start searching for a full-time employee, even though they may have other options. If you’re looking to design, build, and implement a new DevOps environment, why not hire a senior person who has done this in the past? Consider hiring a senior contractor, along with a junior full-time hire. That way, you can tap the knowledge and experience of the contractor by having them work with the junior employee. Contractors can be expensive, but they bring invaluable knowledge—especially if the work can be done within a short timeframe.
|
||||
|
||||
### Cultivate from within
|
||||
|
||||
With so many companies competing for talent, it is difficult to find the right DevOps engineer. Not only will you need to pay top dollar to hire this person, but you must also consider that the search can take several months. However, since few companies are lucky enough to find the ideal DevOps engineer, consider searching for a candidate internally. You might be surprised at the talent you can cultivate from within your own organization.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-hire-right-des-talentvop
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://www.glassdoor.com/Salaries/junior-devops-engineer-salary-SRCH_KO0,22.htm
|
||||
[2]:https://squadex.com/insights/system-administrator-making-leap-devops/
|
||||
@ -0,0 +1,53 @@
|
||||
Beyond metrics: How to operate as team on today's open source project
|
||||
======
|
||||
|
||||

|
||||
|
||||
How do we traditionally think about community health and vibrancy?
|
||||
|
||||
We might quickly zero in on metrics related primarily to code contributions: How many companies are contributing? How many individuals? How many lines of code? Collectively, these speak to both the level of development activity and the breadth of the contributor base. The former speaks to whether the project continues to be enhanced and expanded; the latter to whether it has attracted a diverse group of developers or is controlled primarily by a single organization.
|
||||
|
||||
The [Linux Kernel Development Report][1] tracks these kinds of statistics and, unsurprisingly, it appears extremely healthy on all counts.
|
||||
|
||||
However, while development cadence and code contributions are still clearly important, other aspects of the open source communities are also coming to the forefront. This is in part because, increasingly, open source is about more than a development model. It’s also about making it easier for users and other interested parties to interact in ways that go beyond being passive recipients of code. Of course, there have long been user groups. But open source streamlines the involvement of users, just as it does software development.
|
||||
|
||||
This was the topic of my discussion with Diane Mueller, the director of community development for OpenShift.
|
||||
|
||||
When OpenShift became a container platform based in part on Kubernetes in version 3, Mueller saw a need to broaden the community beyond the core code contributors. In part, this was because OpenShift was increasingly touching a broad range of open source projects and organizations such those associated with the [Open Container Initiative (OCI)][2] and the [Cloud Native Computing Foundation (CNCF)][3]. In addition to users, cloud service providers who were offering managed services also wanted ways to get involved in the project.
|
||||
|
||||
“What we tried to do was open up our minds about what the community constituted,” Mueller explained, adding, “We called it the [Commons][4] because Red Hat's near Boston, and I'm from that area. Boston Common is a shared resource, the grass where you bring your cows to graze, and you have your farmer's hipster market or whatever it is today that they do on Boston Common.”
|
||||
|
||||
This new model, she said, was really “a new ecosystem that incorporated all of those different parties and different perspectives. We used a lot of virtual tools, a lot of new tools like Slack. We stepped up beyond the mailing list. We do weekly briefings. We went very virtual because, one, I don't scale. The Evangelist and Dev Advocate team didn't scale. We need to be able to get all that word out there, all this new information out there, so we went very virtual. We worked with a lot of people to create online learning stuff, a lot of really good tooling, and we had a lot of community help and support in doing that.”
|
||||
|
||||
![diane mueller open shift][6]
|
||||
|
||||
Diane Mueller, director of community development at Open Shift, discusses the role of strong user communities in open source software development. (Credit: Gordon Haff, CC BY-SA 4.0)
|
||||
|
||||
However, one interesting aspect of the Commons model is that it isn’t just virtual. We see the same pattern elsewhere in many successful open source communities, such as the Linux kernel. Lots of day-to-day activities happen on mailings lists, IRC, and other collaboration tools. But this doesn’t eliminate the benefits of face-to-face time that allows for both richer and informal discussions and exchanges.
|
||||
|
||||
This interview with Mueller took place in London the day after the [OpenShift Commons Gathering][7]. Gatherings are full-day events, held a number of times a year, which are typically attended by a few hundred people. Much of the focus is on users and user stories. In fact, Mueller notes, “Here in London, one of the Commons members, Secnix, was really the major reason we actually hosted the gathering here. Justin Cook did an amazing job organizing the venue and helping us pull this whole thing together in less than 50 days. A lot of the community gatherings and things are driven by the Commons members.”
|
||||
|
||||
Mueller wants to focus on users more and more. “The OpenShift Commons gathering at [Red Hat] Summit will be almost entirely case studies,” she noted. “Users talking about what's in their stack. What lessons did they learn? What are the best practices? Sharing those ideas that they've done just like we did here in London.”
|
||||
|
||||
Although the Commons model grew out of some specific OpenShift needs at the time it was created, Mueller believes it’s an approach that can be applied more broadly. “I think if you abstract what we've done, you can apply it to any existing open source community,” she said. “The foundations still, in some ways, play a nice role in giving you some structure around governance, and helping incubate stuff, and helping create standards. I really love what OCI is doing to create standards around containers. There's still a role for that in some ways. I think the lesson that we can learn from the experience and we can apply to other projects is to open up the community so that it includes feedback mechanisms and gives the podium away.”
|
||||
|
||||
The evolution of the community model though approaches like the OpenShift Commons mirror the healthy evolution of open source more broadly. Certainly, some users have been involved in the development of open source software for a long time. What’s striking today is how widespread and pervasive direct user participation has become. Sure, open source remains central to much of modern software development. But it’s also becoming increasingly central to how users learn from each other and work together with their partners and developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-communities-are-evolving
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://www.linuxfoundation.org/2017-linux-kernel-report-landing-page/
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://commons.openshift.org/
|
||||
[5]:/file/388586
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/39369010275_7df2c3c260_z.jpg?itok=gIhnBl6F (diane mueller open shift)
|
||||
[7]:https://www.meetup.com/London-OpenShift-User-Group/events/246498196/
|
||||
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
75
sources/talk/20180303 4 meetup ideas- Make your data open.md
Normal file
@ -0,0 +1,75 @@
|
||||
4 meetup ideas: Make your data open
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Open Data Day][1] (ODD) is an annual, worldwide celebration of open data and an opportunity to show the importance of open data in improving our communities.
|
||||
|
||||
Not many individuals and organizations know about the meaningfulness of open data or why they might want to liberate their data from the restrictions of copyright, patents, and more. They also don't know how to make their data open—that is, publicly available for anyone to use, share, or republish with modifications.
|
||||
|
||||
This year ODD falls on Saturday, March 3, and there are [events planned][2] in every continent except Antarctica. While it might be too late to organize an event for this year, it's never too early to plan for next year. Also, since open data is important every day of the year, there's no reason to wait until ODD 2019 to host an event in your community.
|
||||
|
||||
There are many ways to build local awareness of open data. Here are four ideas to help plan an excellent open data event any time of year.
|
||||
|
||||
### 1. Organize an entry-level event
|
||||
|
||||
You can host an educational event at a local library, college, or another public venue about how open data can be used and why it matters for all of us. If possible, invite a [local speaker][3] or have someone present remotely. You could also have a roundtable discussion with several knowledgeable people in your community.
|
||||
|
||||
Consider offering resources such as the [Open Data Handbook][4], which not only provides a guide to the philosophy and rationale behind adopting open data, but also offers case studies, use cases, how-to guides, and other material to support making data open.
|
||||
|
||||
### 2. Organize an advanced-level event
|
||||
|
||||
For a deeper experience, organize a hands-on training event for open data newbies. Ideas for good topics include [training teachers on open science][5], [creating audiovisual expressions from open data][6], and using [open government data][7] in meaningful ways.
|
||||
|
||||
The options are endless. To choose a topic, think about what is locally relevant, identify issues that open data might be able to address, and find people who can do the training.
|
||||
|
||||
### 3. Organize a hackathon
|
||||
|
||||
Open data hackathons can be a great way to bring open data advocates, developers, and enthusiasts together under one roof. Hackathons are more than just training sessions, though; the idea is to build prototypes or solve real-life challenges that are tied to open data. In a hackathon, people in various groups can contribute to the entire assembly line in multiple ways, such as identifying issues by working collaboratively through [Etherpad][8] or creating focus groups.
|
||||
|
||||
Once the hackathon is over, make sure to upload all the useful data that is produced to the internet with an open license.
|
||||
|
||||
### 4. Release or relicense data as open
|
||||
|
||||
Open data is about making meaningful data publicly available under open licenses while protecting any data that might put people's private information at risk. (Learn [how to protect private data][9].) Try to find existing, interesting, and useful data that is privately owned by individuals or organizations and negotiate with them to relicense or release the data online under any of the [recommended open data licenses][10]. The widely popular [Creative Commons licenses][11] (particularly the CC0 license and the 4.0 licenses) are quite compatible with relicensing public data. (See this FAQ from Creative Commons for more information on [openly licensing data][12].)
|
||||
|
||||
Open data can be published on multiple platforms—your website, [GitHub][13], [GitLab][14], [DataHub.io][15], or anywhere else that supports open standards.
|
||||
|
||||
### Tips for event success
|
||||
|
||||
No matter what type of event you decide to do, here are some general planning tips to improve your chances of success.
|
||||
|
||||
* Find a venue that's accessible to the people you want to reach, such as a library, a school, or a community center.
|
||||
* Create a curriculum that will engage the participants.
|
||||
* Invite your target audience—make sure to distribute information through social media, community events calendars, Meetup, and the like.
|
||||
|
||||
|
||||
|
||||
Have you attended or hosted a successful open data event? If so, please share your ideas in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/celebrate-open-data-day
|
||||
|
||||
作者:[Subhashish Panigraphi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psubhashish
|
||||
[1]:http://www.opendataday.org/
|
||||
[2]:http://opendataday.org/#map
|
||||
[3]:https://openspeakers.org/
|
||||
[4]:http://opendatahandbook.org/
|
||||
[5]:https://docs.google.com/forms/d/1BRsyzlbn8KEMP8OkvjyttGgIKuTSgETZW9NHRtCbT1s/viewform?edit_requested=true
|
||||
[6]:http://dattack.lv/en/
|
||||
[7]:https://www.eventbrite.co.nz/e/open-data-open-potential-event-friday-2-march-2018-tickets-42733708673
|
||||
[8]:http://etherpad.org/
|
||||
[9]:https://ssd.eff.org/en/module/keeping-your-data-safe
|
||||
[10]:https://opendatacommons.org/licenses/
|
||||
[11]:https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[12]:https://wiki.creativecommons.org/wiki/Data#Frequently_asked_questions_about_data_and_CC_licenses
|
||||
[13]:https://github.com/MartinBriza/MediaWriter
|
||||
[14]:https://about.gitlab.com/
|
||||
[15]:https://datahub.io/
|
||||
@ -0,0 +1,130 @@
|
||||
What’s next in IT automation: 6 trends to watch
|
||||
======
|
||||
|
||||

|
||||
|
||||
We’ve recently covered the [factors fueling IT automation][1], the [current trends][2] to watch as adoption grows, and [helpful tips][3] for those organizations just beginning to automate certain processes.
|
||||
|
||||
Oh, and we also shared expert advice on [how to make the case for automation][4] in your company, as well as [keys for long-term success][5].
|
||||
|
||||
Now, there’s just one question: What’s next? We asked a range of experts to share a peek into the not-so-distant future of [automation][6]. Here are six trends they advise IT leaders to monitor closely.
|
||||
|
||||
### 1. Machine learning matures
|
||||
|
||||
For all of the buzz around [machine learning][7] (and the overlapping phrase “self-learning systems”), it’s still very early days for most organizations in terms of actual implementations. Expect that to change, and for machine learning to play a significant role in the next waves of IT automation.
|
||||
|
||||
Mehul Amin, director of engineering for [Advanced Systems Concepts, Inc.][8], points to machine learning as one of the next key growth areas for IT automation.
|
||||
|
||||
“With the data that is developed, automation software can make decisions that otherwise might be the responsibility of the developer,” Amin says. “For example, the developer builds what needs to be executed, but identifying the best system to execute the processes might be [done] by software using analytics from within the system.”
|
||||
|
||||
That extends elsewhere in this same hypothetical system; Amin notes that machine learning can enable automated systems to provision additional resources when necessary to meet timelines or SLAs, as well as retire those resources when they’re no longer needed, and other possibilities.
|
||||
|
||||
Amin is certainly not alone.
|
||||
|
||||
“IT automation is moving towards self-learning,” says Kiran Chitturi, CTO architect at [Sungard Availability Services][9]. “Systems will be able to test and monitor themselves, enhancing business processes and software delivery.”
|
||||
|
||||
Chitturi points to automated testing as an example; test scripts are already in widespread adoption, but soon those automated testing processes may be more likely to learn as they go, developing, for example, wider recognition of how new code or code changes will impact production environments.
|
||||
|
||||
### 2. Artificial intelligence spawns automation opportunities
|
||||
|
||||
The same principles above hold true for the related (but separate) field of [artificial intelligence][10]. Depending on your definition of AI, it seems likely that machine learning will have the more significant IT impact in the near term (and we’re likely to see a lot of overlapping definitions and understandings of the two fields). Assume that emerging AI technologies will spawn new automation opportunities, too.
|
||||
|
||||
“The integration of artificial intelligence (AI) and machine learning capabilities is widely perceived as critical for business success in the coming years,” says Patrick Hubbard, head geek at [SolarWinds][11].
|
||||
|
||||
### 3. That doesn’t mean people are obsolete
|
||||
|
||||
Let’s try to calm those among us who are now hyperventilating into a paper bag: The first two trends don’t necessarily mean we’re all going to be out of a job.
|
||||
|
||||
It is likely to mean changes to various roles – and the creation of [new roles][12] altogether.
|
||||
|
||||
But in the foreseeable future, at least, you don’t need to practice bowing to your robot overlords.
|
||||
|
||||
“A machine can only consider the environment variables that it is given – it can’t choose to include new variables, only a human can do this today,” Hubbard explains. “However, for IT professionals this will necessitate the cultivation of AI- and automation-era skills such as programming, coding, a basic understanding of the algorithms that govern AI and machine learning functionality, and a strong security posture in the face of more sophisticated cyberattacks.”
|
||||
|
||||
Hubbard shares the example of new tools or capabilities such as AI-enabled security software or machine-learning applications that remotely spot maintenance needs in an oil pipeline. Both might improve efficiency and effectiveness; neither automatically replaces the people necessary for information security or pipeline maintenance.
|
||||
|
||||
“Many new functionalities still require human oversight,” Hubbard says. “In order for a machine to determine if something ‘predictive’ could become ‘prescriptive,’ for example, human management is needed.”
|
||||
|
||||
The same principle holds true even if you set machine learning and AI aside for a moment and look at IT automation more generally, especially in the software development lifecycle.
|
||||
|
||||
Matthew Oswalt, lead architect for automation at [Juniper Networks][13], points out that the fundamental reason IT automation is growing is that it is creating immediate value by reducing the amount of manual effort required to operate infrastructure.
|
||||
|
||||
Rather than responding to an infrastructure issue at 3 a.m. themselves, operations engineers can use event-driven automation to define their workflows ahead of time, as code.
|
||||
|
||||
“It also sets the stage for treating their operations workflows as code rather than easily outdated documentation or tribal knowledge,” Oswalt explains. “Operations staff are still required to play an active role in how [automation] tooling responds to events. The next phase of adopting automation is to put in place a system that is able to recognize interesting events that take place across the IT spectrum and respond in an autonomous fashion. Rather than responding to an infrastructure issue at 3 a.m. themselves, operations engineers can use event-driven automation to define their workflows ahead of time, as code. They can rely on this system to respond in the same way they would, at any time.”
|
||||
|
||||
### 4. Automation anxiety will decrease
|
||||
|
||||
Hubbard of SolarWinds notes that the term “automation” itself tends to spawn a lot of uncertainty and concern, not just in IT but across professional disciplines, and he says that concern is legitimate. But some of the attendant fears may be overblown, and even perpetuated by the tech industry itself. Reality might actually be the calming force on this front: When the actual implementation and practice of automation helps people realize #3 on this list, then we’ll see #4 occur.
|
||||
|
||||
“This year we’ll likely see a decrease in automation anxiety and more organizations begin to embrace AI and machine learning as a way to augment their existing human resources,” Hubbard says. “Automation has historically created room for more jobs by lowering the cost and time required to accomplish smaller tasks and refocusing the workforce on things that cannot be automated and require human labor. The same will be true of AI and machine learning.”
|
||||
|
||||
Automation will also decrease some anxiety around the topic most likely to increase an IT leader’s blood pressure: Security. As Matt Smith, chief architect, [Red Hat][14], recently [noted][15], automation will increasingly help IT groups reduce the security risks associated with maintenance tasks.
|
||||
|
||||
His advice: “Start by documenting and automating the interactions between IT assets during maintenance activities. By relying on automation, not only will you eliminate tasks that historically required much manual effort and surgical skill, you will also be reducing the risks of human error and demonstrating what’s possible when your IT organization embraces change and new methods of work. Ultimately, this will reduce resistance to promptly applying security patches. And it could also help keep your business out of the headlines during the next major security event.”
|
||||
|
||||
**[ Read the full article: [12 bad enterprise security habits to break][16]. ] **
|
||||
|
||||
### 5. Continued evolution of scripting and automation tools
|
||||
|
||||
Many organizations see the first steps toward increasing automation – usually in the form of scripting or automation tools (sometimes referred to as configuration management tools) – as "early days" work.
|
||||
|
||||
But views of those tools are evolving as the use of various automation technologies grows.
|
||||
|
||||
“There are many processes in the data center environment that are repetitive and subject to human error, and technologies such as [Ansible][17] help to ameliorate those issues,” says Mark Abolafia, chief operating officer at [DataVision][18]. “With Ansible, one can write a specific playbook for a set of actions and input different variables such as addresses, etc., to automate long chains of process that were previously subject to human touch and longer lead times.”
|
||||
|
||||
**[ Want to learn more about this aspect of Ansible? Read the related article:[Tips for success when getting started with Ansible][19]. ]**
|
||||
|
||||
Another factor: The tools themselves will continue to become more advanced.
|
||||
|
||||
“With advanced IT automation tools, developers will be able to build and automate workflows in less time, reducing error-prone coding,” says Amin of ASCI. “These tools include pre-built, pre-tested drag-and-drop integrations, API jobs, the rich use of variables, reference functionality, and object revision history.”
|
||||
|
||||
### 6. Automation opens new metrics opportunities
|
||||
|
||||
As we’ve said previously in this space, automation isn’t IT snake oil. It won’t fix busted processes or otherwise serve as some catch-all elixir for what ails your organization. That’s true on an ongoing basis, too: Automation doesn’t eliminate the need to measure performance.
|
||||
|
||||
**[ See our related article[DevOps metrics: Are you measuring what matters?][20] ]**
|
||||
|
||||
In fact, automation should open up new opportunities here.
|
||||
|
||||
“As more and more development activities – source control, DevOps pipelines, work item tracking – move to the API-driven platforms – the opportunity and temptation to stitch these pieces of raw data together to paint the picture of your organization's efficiency increases,” says Josh Collins, VP of architecture at [Janeiro Digital][21].
|
||||
|
||||
Collins thinks of this as a possible new “development organization metrics-in-a-box.” But don’t mistake that to mean machines and algorithms can suddenly measure everything IT does.
|
||||
|
||||
“Whether measuring individual resources or the team in aggregate, these metrics can be powerful – but should be balanced with a heavy dose of context,” Collins says. “Use this data for high-level trends and to affirm qualitative observations – not to clinically grade your team.”
|
||||
|
||||
**Want more wisdom like this, IT leaders?[Sign up for our weekly email newsletter][22].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
|
||||
[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
|
||||
[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
|
||||
[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
|
||||
[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
|
||||
[6]:https://enterprisersproject.com/tags/automation
|
||||
[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
|
||||
[8]:https://www.advsyscon.com/en-us/
|
||||
[9]:https://www.sungardas.com/en/
|
||||
[10]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[11]:https://www.solarwinds.com/
|
||||
[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
|
||||
[13]:https://www.juniper.net/
|
||||
[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
|
||||
[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
|
||||
[17]:https://opensource.com/tags/ansible
|
||||
[18]:https://datavision.com/
|
||||
[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
|
||||
[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
|
||||
[21]:https://www.janeirodigital.com/
|
||||
[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -0,0 +1,59 @@
|
||||
Try, learn, modify: The new IT leader's code
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just about every day, new technological developments threaten to destabilize even the most intricate and best-laid business plans. Organizations often find themselves scrambling to adapt to new conditions, and that's created a shift in how they plan for the future.
|
||||
|
||||
According to a 2017 [study][1] by CompTIA, only 34% of companies are currently developing IT architecture plans that extend beyond 12 months. One reason for that shift away from a longer-term plan is that business contexts are changing so quickly that planning any further into the future is nearly impossible. "If your company is trying to set a plan that will last five to 10 years down the road," [CIO.com writes][1], "forget it."
|
||||
|
||||
I've heard similar statements from countless customers and partners around the world. Technological innovations are occurring at an unprecedented pace.
|
||||
|
||||
The result is that long-term planning is dead. We need to be thinking differently about the way we run our organizations if we're going to succeed in this new world.
|
||||
|
||||
### How planning died
|
||||
|
||||
As I wrote in The Open Organization, traditionally-run organizations are optimized for industrial economies. They embrace hierarchical structures and rigidly prescribed processes as they work to achieve positional competitive advantage. To be successful, they have to define the strategic positions they want to achieve. Then they have to formulate and dictate plans for getting there, and execute on those plans in the most efficient ways possible—by coordinating activities and driving compliance.
|
||||
|
||||
Management's role is to optimize this process: plan, prescribe, execute. It consists of saying: Let's think of a competitively advantaged position; let's configure our organization to ultimately get there; and then let's drive execution by making sure all aspects of the organization comply. It's what I'll call "mechanical management," and it's a brilliant solution for a different time.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating. Classic, long-term, strategic planning and execution isn't as effective as it used to be.
|
||||
|
||||
If long-term planning has become so difficult, then prescribing necessary behaviors is even more challenging. And measuring compliance against a plan is next to impossible.
|
||||
|
||||
All this dramatically affects the way people work. Unlike workers in the traditionally-run organizations of the past—who prided themselves on being able to act repetitively, with little variation and comfortable certainty—today's workers operate in contexts of abundant ambiguity. Their work requires greater creativity, intuition, and critical judgment—there is a greater demand to deviate from yesterday's "normal" and adjust to today's new conditions.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating.
|
||||
|
||||
Working in this new way has become more critical to value creation. Our management systems must focus on building structures, systems, and processes that help create engaged, motivated workers—people who are enabled to innovate and act with speed and agility.
|
||||
|
||||
We need to come up with a different solution for optimizing organizations for a very different economic era, one that works from the bottom up rather than the top down. We need to replace that old three-step formula for success—plan, prescribe, execute—with one much better suited to today's tumultuous climate: try, learn, modify.
|
||||
|
||||
### Try, learn, modify
|
||||
|
||||
Because conditions can change so rapidly and with so little warning—and because the steps we need to take next are no longer planned in advance—we need to cultivate environments that encourage creative trial and error, not unyielding allegiance to a five-year schedule. Here are just a few implications of beginning to work this way:
|
||||
|
||||
* **Shorter planning cycles (try).** Rather than agonize over long-term strategic directions, managers need to be thinking of short-term experiments they can try quickly. They should be seeking ways to help their teams take calculated risks and leverage the data at their disposal to make best guesses about the most beneficial paths forward. They can do this by lowering overhead and giving teams the freedom to try new approaches quickly.
|
||||
* **Higher tolerance for failure (learn).** Greater frequency of experimentation means greater opportunity for failure. Creative and resilient organizations have a[significantly higher tolerance for failure][2] than traditional organizations do. Managers should treat failures as learning opportunities—moments to gather feedback on the tests their teams are running.
|
||||
* **More adaptable structures (modify).** An ability to easily modify organizational structures and strategic directions—and the willingness to do it when conditions necessitate—is the key to ensuring that organizations can evolve in line with rapidly changing environmental conditions. Managers can't be wedded to any idea any longer than that idea proves itself to be useful for accomplishing a short-term goal.
|
||||
|
||||
|
||||
|
||||
If long-term planning is dead, then long live shorter-term experimentation. Try, learn, and modify—that's the best path forward during uncertain times.
|
||||
|
||||
[Subscribe to our weekly newsletter][3] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/try-learn-modify
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.cio.com/article/3246027/enterprise-architecture/the-death-of-long-term-it-planning.html?upd=1515780110970
|
||||
[2]:https://opensource.com/open-organization/16/12/building-culture-innovation-your-organization
|
||||
[3]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,134 @@
|
||||
20 questions DevOps job candidates should be prepared to answer
|
||||
======
|
||||
|
||||

|
||||
Hiring the wrong person is [expensive][1]. Recruiting, hiring, and onboarding a new employee can cost a company as much as $240,000, according to Jörgen Sundberg, CEO of Link Humans. When you make the wrong hire:
|
||||
|
||||
* You lose what they know.
|
||||
* You lose who they know.
|
||||
* Your team could go into the [storming][2] phase of group development.
|
||||
* Your company risks disorganization.
|
||||
|
||||
|
||||
|
||||
When you lose an employee, you lose a piece of the fabric of the company. It's also worth mentioning the pain on the other end. The person hired into the wrong job may experience stress, feelings of overall dissatisfaction, and even health issues.
|
||||
|
||||
On the other hand, when you get it right, your new hire will:
|
||||
|
||||
* Enhance the existing culture, making your organization an even a better place to work. Studies show that a positive work culture helps [drive long-term financial performance][3] and that if you work in a happy environment, you’re more likely to do better in life.
|
||||
* Love working with your organization. When people love what they do, they tend to do it well.
|
||||
|
||||
|
||||
|
||||
Hiring to fit or enhance your existing culture is essential in DevOps and agile teams. That means hiring someone who can encourage effective collaboration so that individual contributors from varying backgrounds, and teams with different goals and working styles, can work together productively. Your new hire should help teams collaborate to maximize their value while also increasing employee satisfaction and balancing conflicting organizational goals. He or she should be able to choose tools and workflows wisely to complement your organization. Culture is everything.
|
||||
|
||||
As a follow-up to our November 2017 post, [20 questions DevOps hiring managers should be prepared to answer][4], this article will focus on how to hire for the best mutual fit.
|
||||
|
||||
### Why hiring goes wrong
|
||||
|
||||
The typical hiring strategy many companies use today is based on a talent surplus:
|
||||
|
||||
* Post on job boards.
|
||||
* Focus on candidates with the skills they need.
|
||||
* Find as many candidates as possible.
|
||||
* Interview to weed out the weak.
|
||||
* Conduct formal interviews to do more weeding.
|
||||
* Assess, vote, and select.
|
||||
* Close on compensation.
|
||||
|
||||

|
||||
|
||||
Job boards were invented during the Great Depression when millions of people were out of work and there was a talent surplus. There is no talent surplus in today's job market, yet we’re still using a hiring strategy that's based on one.
|
||||
|
||||

|
||||
|
||||
### Hire for mutual fit: Use culture and emotions
|
||||
|
||||
The idea behind the talent surplus hiring strategy is to design jobs and then slot people into them.
|
||||
|
||||
Instead, do the opposite: Find talented people who will positively add to your business culture, then find the best fit for them in a job they’ll love. To do this, you must be open to creating jobs around their passions.
|
||||
|
||||
**Who is looking for a job?** According to a 2016 survey of more than 50,000 U.S. developers, [85.7% of respondents][5] were either not interested in new opportunities or were not actively looking for them. And of those who were looking, a whopping [28.3% of job discoveries][5] came from referrals by friends. If you’re searching only for people who are looking for jobs, you’re missing out on top talent.
|
||||
|
||||
**Use your team to find and vet potential recruits**. For example, if Diane is a developer on your team, chances are she has [been coding for years][6] and has met fellow developers along the way who also love what they do. Wouldn’t you think her chances of vetting potential recruits for skills, knowledge, and intelligence would be higher than having someone from HR find and vet potential recruits? And before asking Diane to share her knowledge of fellow recruits, inform her of the upcoming mission, explain your desire to hire a diverse team of passionate explorers, and describe some of the areas where help will be needed in the future.
|
||||
|
||||
**What do employees want?** A comprehensive study comparing the wants and needs of Millennials, GenX’ers, and Baby Boomers shows that within two percentage points, we all [want the same things][7]:
|
||||
|
||||
1. To make a positive impact on the organization
|
||||
2. To help solve social and/or environmental challenges
|
||||
3. To work with a diverse group of people
|
||||
|
||||
|
||||
|
||||
### The interview challenge
|
||||
|
||||
The interview should be a two-way conversation for finding a mutual fit between the person hiring and the person interviewing. Focus your interview on CQ ([Cultural Quotient][7]) and EQ ([Emotional Quotient][8]): Will this person reinforce and add to your culture and love working with you? Can you help make them successful at their job?
|
||||
|
||||
**For the hiring manager:** Every interview is an opportunity to learn how your organization could become more irresistible to prospective team members, and every positive interview can be your best opportunity to finding talent, even if you don’t hire that person. Everyone remembers being interviewed if it is a positive experience. Even if they don’t get hired, they will talk about the experience with their friends, and you may get a referral as a result. There is a big upside to this: If you’re not attracting this talent, you have the opportunity to learn the reason and fix it.
|
||||
|
||||
**For the interviewee** : Each interview experience is an opportunity to unlock your passions.
|
||||
|
||||
### 20 questions to help you unlock the passions of potential hires
|
||||
|
||||
1. What are you passionate about?
|
||||
|
||||
2. What makes you think, "I can't wait to get to work this morning!”
|
||||
|
||||
3. What is the most fun you’ve ever had?
|
||||
|
||||
4. What is your favorite example of a problem you’ve solved, and how did you solve it?
|
||||
|
||||
5. How do you feel about paired learning?
|
||||
|
||||
6. What’s at the top of your mind when you arrive at, and leave, the office?
|
||||
|
||||
7. If you could have changed one thing in your previous/current job, what would it be?
|
||||
|
||||
8. What are you excited to learn while working here?
|
||||
|
||||
9. What do you aspire to in life, and how are you pursuing it?
|
||||
|
||||
10. What do you want, or feel you need, to learn to achieve these aspirations?
|
||||
|
||||
11. What values do you hold?
|
||||
|
||||
12. How do you live those values?
|
||||
|
||||
13. What does balance mean in your life?
|
||||
|
||||
14. What work interactions are you are most proud of? Why?
|
||||
|
||||
15. What type of environment do you like to create?
|
||||
|
||||
16. How do you like to be treated?
|
||||
|
||||
17. What do you trust vs. verify?
|
||||
|
||||
18. Tell me about a recent learning you had when working on a project.
|
||||
|
||||
19. What else should we know about you?
|
||||
|
||||
20. If you were hiring me, what questions would you ask me?
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/questions-devops-employees-should-answer
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:https://www.shrm.org/resourcesandtools/hr-topics/employee-relations/pages/cost-of-bad-hires.aspx
|
||||
[2]:https://en.wikipedia.org/wiki/Tuckman%27s_stages_of_group_development
|
||||
[3]:http://www.forbes.com/sites/johnkotter/2011/02/10/does-corporate-culture-drive-financial-performance/
|
||||
[4]:https://opensource.com/article/17/11/inclusive-workforce-takes-work
|
||||
[5]:https://insights.stackoverflow.com/survey/2016#work-job-discovery
|
||||
[6]:https://research.hackerrank.com/developer-skills/2018/
|
||||
[7]:http://www-935.ibm.com/services/us/gbs/thoughtleadership/millennialworkplace/
|
||||
[8]:https://en.wikipedia.org/wiki/Emotional_intelligence
|
||||
95
sources/talk/20180308 What is open source programming.md
Normal file
95
sources/talk/20180308 What is open source programming.md
Normal file
@ -0,0 +1,95 @@
|
||||
What is open source programming?
|
||||
======
|
||||
|
||||

|
||||
|
||||
At the simplest level, open source programming is merely writing code that other people can freely use and modify. But you've heard the old chestnut about playing Go, right? "So simple it only takes a minute to learn the rules, but so complex it requires a lifetime to master." Writing open source code is a pretty similar experience. It's easy to chuck a few lines of code up on GitHub, Bitbucket, SourceForge, or your own blog or site. But doing it right requires some personal investment, effort, and forethought.
|
||||
|
||||

|
||||
|
||||
### What open source programming isn't
|
||||
|
||||
Let's be clear up front about something: Just being on GitHub in a public repo does not make your code open source. Copyright in nearly all countries attaches automatically when a work is fixed in a medium, without need for any action by the author. For any code that has not been licensed by the author, it is only the author who can exercise the rights associated with copyright ownership. Unlicensed code—no matter how publicly accessible—is a ticking time bomb for anyone who is unwise enough to use it.
|
||||
|
||||
A well-meaning author may think, "well, it's obvious this is free to use," and have no plans ever to sue anyone, but that doesn't mean the code is safe to use. No matter what you think someone will do, that author has the right to sue anyone who uses, modifies, or embeds that code anywhere else without an expressly granted license.
|
||||
|
||||
Clearly, you shouldn't put your own code out in public without a license and expect others to use or contribute to it. I would also recommend you avoid using (or even looking at) such code yourself. If you create a highly similar function or routine to a piece of unlicensed work you inspected at some point in the past, you could open yourself or your employer to infringement lawsuits.
|
||||
|
||||
Let's say that Jill Schmill writes AwesomeLib and puts it on GitHub without a license. Even if Jill never sues anybody, she might eventually sell all the rights to AwesomeLib to EvilCorp, who will. (Think of it as a lurking vulnerability, just waiting to be exploited.)
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
### Choosing the right license
|
||||
|
||||
OK, you've decided you want to write a new program, and you want people to have open source rights to use it. The next step is figuring out which [license][1] best fits your needs. You can get started with the GitHub-curated [choosealicense.com][2], which is just what it says on the tin. The site is laid out a bit like a simple quiz, and most people should be one or two clicks at most from finding the right license for their project.
|
||||
|
||||
Unlicensed code is unsafe code, period.
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the
|
||||
|
||||
A word of caution: Don't get overly fancy or self-important. If you choose a commonly used and well-known license like the [Apache License][3] or the [GPLv3][4] , it's easy for people to understand what their rights are and what your rights are without needing a team of lawyers to look for pitfalls and problems. The further you stray from the beaten path, though, the more problems you open yourself and others up to.
|
||||
|
||||
Most importantly, do not write your own license! Making up your own license is an unnecessary source of confusion for everyone. Don't do it. If you absolutely must have your own special terms that you can't find in any existing license, write them as an addendum to an otherwise well-understood license... and keep the main license and your addendum clearly separated so everyone involved knows which parts they've got to be extra careful about.
|
||||
|
||||
I know some people stubborn up and say, "I don't care about licenses and don't want to think about them; it's public domain." The problem with that is that "public domain" isn't a universally understood term in a legal sense. It means different things from one country to the next, with different rights and terms attached. In some countries, you can't even place your own works in the public domain, because the government reserves control over that. Luckily, the [Unlicense][5] has you covered. The Unlicense uses as few words as possible to clearly describe what "just make it public domain!" means in a clear and universally enforceable way.
|
||||
|
||||
### How to apply the license
|
||||
|
||||
Once you've chosen a license, you need to clearly and unambiguously apply it. If you're publishing somewhere like GitHub or GitLab or BitBucket, you'll have what amounts to a folder structure for your project's files. In the root folder of your project, you should have a plaintext file called LICENSE.txt that contains the text of the license you selected.
|
||||
|
||||
Putting LICENSE.txt in the root folder of your project isn't quite the last step—you also need a comment block declaring the license at the header of each significant file in your project. This is one of those times where it comes in handy to be using a well-established license. A comment that says: `# this work (c)2018 myname, licensed GPLv3—see https://www.gnu.org/licenses/gpl-3.0.en.html` is much, much stronger and more useful than a comment block that merely makes a cryptic reference to a completely custom license.
|
||||
|
||||
If you're self-publishing your code on your own site, you'll want to follow basically the same process. Have a LICENSE.txt, put the full copy of your license in it, and link to your license in an abbreviated comment block at the head of each significant file.
|
||||
|
||||
### Open source code is different
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen. As a 40-something sysadmin, I've written a lot of code. Most of it has been effectively proprietary—I started out writing code for myself to make my own jobs easier and scratch my own and/or my company's itches. The goal of such code is simple: All it has to do is work, in the exact way and under the exact circumstance its creator planned. As long as the thing you expected to happen when you invoked the program happens more frequently than not, it's a success.
|
||||
|
||||
A big difference between proprietary and open source code is that open source code is meant to be seen.
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Open source code is very different. When you write open source code, you know that it not only has to work, it has to work in situations you never dreamed of and may not have planned for. Maybe you only had one very narrow use case for your code and invoked it in exactly the same way every time. The people you share it with, though... they'll expose use cases, mixtures of arguments, and just plain strange thought processes you never considered. Your code doesn't necessarily have to satisfy all of them—but it at least needs to handle their requests gracefully, and fail in predictable and logical ways when it can't service them. (For example: "Division by zero on line 583" is not an acceptable response to a failure to supply a command-line argument.)
|
||||
|
||||
Your open source code also has to avoid unduly embarrassing you. That means that after you struggle and struggle to get a balky function or sub to finally produce the output you expected, you don't just sigh and move on to the next thing—you clean it up, because you don't want the rest of the world seeing your obvious house of cards. It means that you stop littering your code with variables like `$variable` and `$lol` and replace them with meaningful names like `$iterationcounter` or `$modelname`. And it means commenting things professionally (even if they're obvious to you in the heat of the moment) since you expect other people to be able to follow your code later.
|
||||
|
||||
This can be a little painful and frustrating at first—it's work you're not accustomed to doing. It makes you a better programmer, though, and it makes your code better as well. Just as important: Even if you're the only contributor your project ever has, it saves you work in the long run. Trust me, a year from now when you have to revisit your app, you're going to be very glad that `$modelname`, which gets parsed by several stunningly opaque regular expressions before getting socked into some other array somewhere, isn't named `$lol` anymore.
|
||||
|
||||
### You're not writing just for yourself
|
||||
|
||||
The true heart of open source isn't the code at all: it's the community. Projects with a strong community survive longer and are adopted much more heavily than those that don't. With that in mind, it's a good idea not only to embrace but actively plan for the community you hope to build around your project.
|
||||
|
||||
Batman might spend hundreds of hours in seclusion furiously building a project in secrecy, but you don't have to. Take to Twitter, Reddit, or mailing lists relevant to your project's scope, and announce that you're thinking of creating a new project. Talk about your design goals and how you plan to achieve them. Request input, listen to similar (but maybe not identical) use cases, and build that information into your process as you write code. You don't have to accept every suggestion or request—but if you know about them ahead of time, you can avoid pitfalls that require arduous major overhauls later.
|
||||
|
||||
This process doesn't end with the initial announcement. If you want your project to be adopted and used by other people, you need to develop it that way too. This isn't a barrier to entry; it's just a pattern to use. So don't just hunker down privately on your own machine with a text editor—start a real, publicly accessible project at one of the big foundries, and treat it as though the community was already there and watching.
|
||||
|
||||
### Ways to build a real public project
|
||||
|
||||
You can open accounts for open source projects at GitHub, GitLab, or BitBucket for free. Once you've opened your account and created a repository for your project, use it—create a README, assign a LICENSE, and push code incrementally as you develop it. This will build the habits you'll need to work with a real team later as you get accustomed to writing your code in measurable, documented commits with clear goals. The further you go, the more likely you'll start generating interest—usually in the form of end users first.
|
||||
|
||||
The users will start opening tickets, which will both delight and annoy you. You should take those tickets seriously and treat their owners courteously. Some of them will be based on tremendous misunderstandings of what your project is and what is or isn't within its scope—treat those courteously and professionally, also. In some cases, you'll guide those users into the fold of what you're doing. In others, however haltingly, they'll guide you into realizing the larger—or slightly differently centered—scope you probably should have planned for in the first place.
|
||||
|
||||
If you do a good job with the users, eventually fellow developers will show up and take an interest. This will also both delight and annoy you. At first, you'll probably just get trivial bugfixes. Eventually, you'll start to get pull requests that would either hardcode really, really niche special use-cases into your project (which would be a nightmare to maintain) or significantly alter the scope or even the focus of your project. You'll need to learn how to recognize which contributions are which and decide which ones you want to embrace and which you should politely reject.
|
||||
|
||||
### Why bother with all of this?
|
||||
|
||||
If all of this sounds like a lot of work, there's a good reason: it is. But it's rewarding work that you can cash in on in plenty of ways. Open source work sharpens your skills in ways you never realized were dull—from writing cleaner, more maintainable code to learning how to communicate well and work as a team. It's also the best possible resume builder for a working or aspiring professional developer; potential employers can hit your repository and see what you're capable of, and developers you've worked with on community projects may want to bring you in on paying gigs.
|
||||
|
||||
Ultimately, working on open source projects—yours or others'—means personal growth, because you're working on something larger than yourself.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-salter
|
||||
[1]:https://opensource.com/tags/licensing
|
||||
[2]:https://choosealicense.com/
|
||||
[3]:https://choosealicense.com/licenses/apache-2.0/
|
||||
[4]:https://choosealicense.com/licenses/gpl-3.0/
|
||||
[5]:https://choosealicense.com/licenses/unlicense/
|
||||
@ -1,143 +0,0 @@
|
||||
translating by shipsw
|
||||
|
||||
How to use yum-cron to automatically update RHEL/CentOS Linux
|
||||
======
|
||||
The yum command line tool is used to install and update software packages under RHEL / CentOS Linux server. I know how to apply updates using [yum update command line][1], but I would like to use cron to update packages where appropriate manually. How do I configure yum to install software patches/updates [automatically with cron][2]?
|
||||
|
||||
You need to install yum-cron package. It provides files needed to run yum updates as a cron job. Install this package if you want auto yum updates nightly via cron.
|
||||
|
||||
### How to install yum cron on a CentOS/RHEL 6.x/7.x
|
||||
|
||||
Type the following [yum command][3] on:
|
||||
`$ sudo yum install yum-cron`
|
||||

|
||||
|
||||
Turn on service using systemctl command on **CentOS/RHEL 7.x** :
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
If you are using **CentOS/RHEL 6.x** , run:
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||

|
||||
|
||||
yum-cron is an alternate interface to yum. Very convenient way to call yum from cron. It provides methods to keep repository metadata up to date, and to check for, download, and apply updates. Rather than accepting many different command line arguments, the different functions of yum-cron can be accessed through config files.
|
||||
|
||||
### How to configure yum-cron to automatically update RHEL/CentOS Linux
|
||||
|
||||
You need to edit /etc/yum/yum-cron.conf and /etc/yum/yum-cron-hourly.conf files using a text editor such as vi command:
|
||||
`$ sudo vi /etc/yum/yum-cron.conf`
|
||||
Make sure updates should be applied when they are available
|
||||
`apply_updates = yes`
|
||||
You can set the address to send email messages from. Please note that ‘localhost’ will be replaced with the value of system_name.
|
||||
`email_from = root@localhost`
|
||||
List of addresses to send messages to.
|
||||
`email_to = your-it-support@some-domain-name`
|
||||
Name of the host to connect to to send email messages.
|
||||
`email_host = localhost`
|
||||
If you [do not want to update kernel package add the following on CentOS/RHEL 7.x][4]:
|
||||
`exclude=kernel*`
|
||||
For RHEL/CentOS 6.x add [the following to exclude kernel package from updating][5]:
|
||||
`YUM_PARAMETER=kernel*`
|
||||
[Save and close the file in vi/vim][6]. You also need to update /etc/yum/yum-cron-hourly.conf file if you want to apply update hourly. Otherwise /etc/yum/yum-cron.conf will run on daily using the following cron job (us [cat command][7]:
|
||||
`$ cat /etc/cron.daily/0yum-daily.cron`
|
||||
Sample outputs:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
That is all. Now your system will update automatically everyday using yum-cron. See man page of yum-cron for more details:
|
||||
`$ man yum-cron`
|
||||
|
||||
### Method 2 – Use shell scripts
|
||||
|
||||
**Warning** : The following method is outdated. Do not use it on RHEL/CentOS 6.x/7.x. I kept it below for historical reasons only when I used it on CentOS/RHEL version 4.x/5.x.
|
||||
|
||||
Let us see how to configure CentOS/RHEL for yum automatic update retrieval and installation of security packages. You can use yum-updatesd service provided with CentOS / RHEL servers. However, this service provides a few overheads. You can create daily or weekly updates with the following shell script. Create
|
||||
|
||||
* **/etc/cron.daily/yumupdate.sh** to apply updates one a day.
|
||||
* **/etc/cron.weekly/yumupdate.sh** to apply updates once a week.
|
||||
|
||||
|
||||
|
||||
#### Sample shell script to update system
|
||||
|
||||
A shell script that instructs yum to update any packages it finds via [cron][8]:
|
||||
```
|
||||
#!/bin/bash
|
||||
YUM=/usr/bin/yum
|
||||
$YUM -y -R 120 -d 0 -e 0 update yum
|
||||
$YUM -y -R 10 -e 0 -d 0 update
|
||||
```
|
||||
|
||||
(Code listing -01: /etc/cron.daily/yumupdate.sh)
|
||||
|
||||
Where,
|
||||
|
||||
1. First command will update yum itself and next will apply system updates.
|
||||
2. **-R 120** : Sets the maximum amount of time yum will wait before performing a command
|
||||
3. **-e 0** : Sets the error level to 0 (range 0 – 10). 0 means print only critical errors about which you must be told.
|
||||
4. -d 0 : Sets the debugging level to 0 – turns up or down the amount of things that are printed. (range: 0 – 10).
|
||||
5. **-y** : Assume yes; assume that the answer to any question which would be asked is yes.
|
||||
|
||||
|
||||
|
||||
Make sure you setup executable permission:
|
||||
`# chmod +x /etc/cron.daily/yumupdate.sh`
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
Posted by:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11]. Get the **latest tutorials on SysAdmin, Linux/Unix and open source topics via[my RSS/XML feed][12]**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -1,3 +1,5 @@
|
||||
translating by yizhuoyan
|
||||
|
||||
How To Set Readonly File Permissions On Linux / Unix Web Server DocumentRoot
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by kimii
|
||||
How To Safely Generate A Random Number — Quarrelsome
|
||||
======
|
||||
### Use urandom
|
||||
|
||||
@ -1,220 +0,0 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
Hello! Today I was working a bit on my [ruby stacktrace project][1] and I realized that now I know a couple of things about how gdb works internally.
|
||||
|
||||
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`:
|
||||
|
||||
### getting a global variable
|
||||
|
||||
Here’s how to get the address of the global `ruby_current_thread`:
|
||||
|
||||
```
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb` came up with `0x5598a9a8f7f0`.
|
||||
|
||||
We can find the approximate region this variable lives in by looking at a cool file in `/proc` called `/proc/$pid/maps`.
|
||||
|
||||
```
|
||||
$ sudo cat /proc/2983/maps | grep bin/ruby
|
||||
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
So! There’s this starting address `5598a9605000` That’s _like_ `0x5598a9a8f7f0`, but different. How different? Well, here’s what I get when I subtract them:
|
||||
|
||||
```
|
||||
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
|
||||
$4 = 0x48a7f0
|
||||
|
||||
```
|
||||
|
||||
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table**for our program with `nm`.
|
||||
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
What’s that we see? Could it be `0x48a7f0`? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`, and we’re done!
|
||||
|
||||
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
|
||||
|
||||
### dereferencing pointers
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
The next thing we’re going to do is **dereference** that `ruby_current_thread`pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
You remember this address `0x5598a9a8f7f0`? gdb is asking “hey, what’s in that address exactly”? `2983` is the PID of the process we’re running gdb on. It’s using the `ptrace` system call which is how gdb does everything.
|
||||
|
||||
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable` and `x/40b variable` which will display 40 words / bytes at a given address, respectively.
|
||||
|
||||
### describing structs
|
||||
|
||||
The memory at an address looks like this. A bunch of bytes!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
|
||||
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
|
||||
|
||||
```
|
||||
(gdb) p *(ruby_current_thread)
|
||||
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
|
||||
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump` on my Ruby binary, I get some output like this:
|
||||
|
||||
(I’ve redacted it heavily to make it easier to understand)
|
||||
|
||||
```
|
||||
DW_AT_name "rb_thread_struct"
|
||||
DW_AT_byte_size 0x000003e8
|
||||
DW_TAG_member
|
||||
DW_AT_name "self"
|
||||
DW_AT_type <0x00000579>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 0
|
||||
DW_TAG_member
|
||||
DW_AT_name "vm"
|
||||
DW_AT_type <0x0000270c>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 8
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack"
|
||||
DW_AT_type <0x000006b3>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 16
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack_size"
|
||||
DW_AT_type <0x00000031>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 24
|
||||
DW_TAG_member
|
||||
DW_AT_name "cfp"
|
||||
DW_AT_type <0x00002712>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 32
|
||||
DW_TAG_member
|
||||
DW_AT_name "safe_level"
|
||||
DW_AT_type <0x00000066>
|
||||
|
||||
```
|
||||
|
||||
So. The name of the type of `ruby_current_thread` is `rb_thread_struct`. It has size `0x3e8` (or 1000 bytes), and it has a bunch of member items. `stack_size` is one of them, at an offset of 24, and it has type 31\. What’s 31? No worries! We can look that up in the DWARF info too!
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
DW_AT_name "size_t"
|
||||
DW_AT_type <0x0000003c>
|
||||
< 1><0x0000003c> DW_TAG_base_type
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
DW_AT_name "long unsigned int"
|
||||
|
||||
```
|
||||
|
||||
So! `stack_size` has type `size_t`, which means `long unsigned int`, and is 8 bytes. That means that we can read the stack size!
|
||||
|
||||
How that would break down, once we have the DWARF debugging data, is:
|
||||
|
||||
1. Read the region of memory that `ruby_current_thread` is pointing to
|
||||
|
||||
2. Add 24 bytes to get to `stack_size`
|
||||
|
||||
3. Read 8 bytes (in little-endian format, since we’re on x86)
|
||||
|
||||
4. Get the answer!
|
||||
|
||||
Which in this case is 131072 or 128 kb.
|
||||
|
||||
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0` meant.
|
||||
|
||||
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
|
||||
|
||||
### DWARF is confusing
|
||||
|
||||
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
|
||||
|
||||
Also, I casually remarked that you can look at `DW_AT_data_member_location` to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer][2]. Basically you start with a check like:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
and then it keeps GOING. Why are there 8 million different `DW_FORM_data` things I need to check for? What is happening? I have no idea.
|
||||
|
||||
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
|
||||
|
||||
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
|
||||
|
||||
### unwinding stacktraces
|
||||
|
||||
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
|
||||
|
||||
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
|
||||
|
||||
### other things gdb does
|
||||
|
||||
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday][3], we see that gdb also knows how to
|
||||
|
||||
* disassemble assembly
|
||||
|
||||
* show you the contents of your registers
|
||||
|
||||
and in terms of manipulating your program, it can
|
||||
|
||||
* set breakpoints and step through a program
|
||||
|
||||
* modify memory (!! danger !!)
|
||||
|
||||
Knowing more about how gdb works makes me feel a lot more confident when using it! I used to get really confused because gdb kind of acts like a C REPL sometimes – you type `ruby_current_thread->cfp->iseq`, and it feels like writing C code! But you’re not really writing C at all, and it was easy for me to run into limitations in gdb and not understand why.
|
||||
|
||||
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
|
||||
[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
|
||||
[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
|
||||
@ -1,215 +0,0 @@
|
||||
translating by imquanquan
|
||||
|
||||
9 Lightweight Linux Applications to Speed Up Your System
|
||||
======
|
||||
**Brief:** One of the many ways to [speed up Ubuntu][1] system is to use lightweight alternatives of the popular applications. We have already seen [must have Linux application][2] earlier. we'll see the lightweight alternative applications for Ubuntu and other Linux distributions.
|
||||
|
||||
![Use these Lightweight alternative applications in Ubuntu Linux][4]
|
||||
|
||||
## 9 Lightweight alternatives of popular Linux applications
|
||||
|
||||
Is your Linux system slow? Are the applications taking a long time to open? The best option you have is to use a [light Linux distro][5]. But it's not always possible to reinstall an operating system, is it?
|
||||
|
||||
So if you want to stick to your present Linux distribution, but want improved performance, you should use lightweight alternatives of the applications you are using. Here, I'm going to put together a small list of lightweight alternatives to various Linux applications.
|
||||
|
||||
Since I am using Ubuntu, I have provided installation instructions for Ubuntu-based Linux distributions. But these applications will work on almost all other Linux distribution. You just have to find a way to install these lightweight Linux software in your distro.
|
||||
|
||||
### 1. Midori: Web Browser
|
||||
|
||||
Midori is one of the most lightweight web browsers that have reasonable compatibility with the modern web. It is open source and uses the same rendering engine that Google Chrome was initially built on -- WebKit. It is super fast and minimal yet highly customizable.
|
||||
|
||||
![Midori Browser][6]
|
||||
|
||||
It has plenty of extensions and options to tinker with. So if you are a power user, it's a great choice for you too. If you face any problems browsing round the web, check the [Frequently Asked Question][7] section of their website -- it contains the common problems you might face along with their solution.
|
||||
|
||||
[Midori][8]
|
||||
|
||||
#### Installing Midori on Ubuntu based distributions
|
||||
|
||||
Midori is available on Ubuntu via the official repository. Just run the following commands for installing it:
|
||||
```
|
||||
sudo apt install midori
|
||||
```
|
||||
|
||||
### 2. Trojita: email client
|
||||
|
||||
Trojita is an open source robust IMAP e-mail client. It is fast and resource efficient. I can certainly call it one of the [best email clients for Linux][9]. If you can live with only IMAP support on your e-mail client, you might not want to look any further.
|
||||
|
||||
![Trojitá][10]
|
||||
|
||||
Trojita uses various techniques -- on-demand e-mail loading, offline caching, bandwidth-saving mode etc. -- for achieving its impressive performance.
|
||||
|
||||
[Trojita][11]
|
||||
|
||||
#### Installing Trojita on Ubuntu based distributions
|
||||
|
||||
Trojita currently doesn't have an official PPA for Ubuntu. But that shouldn't be a problem. You can install it quite easily using the following commands:
|
||||
```
|
||||
sudo sh -c "echo 'deb http://download.opensuse.org/repositories/home:/jkt-gentoo:/trojita/xUbuntu_16.04/ /' > /etc/apt/sources.list.d/trojita.list"
|
||||
wget http://download.opensuse.org/repositories/home:jkt-gentoo:trojita/xUbuntu_16.04/Release.key
|
||||
sudo apt-key add - < Release.key
|
||||
sudo apt update
|
||||
sudo apt install trojita
|
||||
```
|
||||
|
||||
### 3. GDebi: Package Installer
|
||||
|
||||
Sometimes you need to quickly install DEB packages. Ubuntu Software Center is a resource-heavy application and using it just for installing .deb files is not wise.
|
||||
|
||||
Gdebi is certainly a nifty tool for the same purpose, just with a minimal graphical interface.
|
||||
|
||||
![GDebi][12]
|
||||
|
||||
GDebi is totally lightweight and does its job flawlessly. You should even [make Gdebi the default installer for DEB files][13].
|
||||
|
||||
#### Installing GDebi on Ubuntu based distributions
|
||||
|
||||
You can install GDebi on Ubuntu with this simple one-liner:
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
### 4. App Grid: Software Center
|
||||
|
||||
If you use software center frequently for searching, installing and managing applications on Ubuntu, App Grid is a must have application. It is the most visually appealing and yet fast alternative to the default Ubuntu Software Center.
|
||||
|
||||
![App Grid][14]
|
||||
|
||||
App Grid supports ratings, reviews and screenshots for applications.
|
||||
|
||||
[App Grid][15]
|
||||
|
||||
#### Installing App Grid on Ubuntu based distributions
|
||||
|
||||
App Grid has its official PPA for Ubuntu. Use the following commands for installing App Grid:
|
||||
```
|
||||
sudo add-apt-repository ppa:appgrid/stable
|
||||
sudo apt update
|
||||
sudo apt install appgrid
|
||||
```
|
||||
|
||||
### 5. Yarock: Music Player
|
||||
|
||||
Yarock is an elegant music player with a modern and minimal user interface. It is lightweight in design and yet it has a comprehensive list of advanced features.
|
||||
|
||||
![Yarock][16]
|
||||
|
||||
The main features of Yarock include multiple music collections, rating, smart playlist, multiple back-end option, desktop notification, scrobbling, context fetching etc.
|
||||
|
||||
[Yarock][17]
|
||||
|
||||
#### Installing Yarock on Ubuntu based distributions
|
||||
|
||||
You will have to install Yarock on Ubuntu via PPA using the following commands:
|
||||
```
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
sudo apt update
|
||||
sudo apt install yarock
|
||||
```
|
||||
|
||||
### 6. VLC: Video Player
|
||||
|
||||
Who doesn't need a video player? And who has never heard about VLC? It doesn't really need any introduction.
|
||||
|
||||
![VLC][18]
|
||||
|
||||
VLC is all you need to play various media files on Ubuntu and it is quite lightweight too. It works flawlessly on even on very old PCs.
|
||||
|
||||
[VLC][19]
|
||||
|
||||
#### Installing VLC on Ubuntu based distributions
|
||||
|
||||
VLC has official PPA for Ubuntu. Enter the following commands for installing it:
|
||||
```
|
||||
sudo apt install vlc
|
||||
```
|
||||
|
||||
### 7. PCManFM: File Manager
|
||||
|
||||
PCManFM is the standard file manager from LXDE. As with the other applications from LXDE, this one too is lightweight. If you are looking for a lighter alternative for your file manager, try this one.
|
||||
|
||||
![PCManFM][20]
|
||||
|
||||
Although coming from LXDE, PCManFM works with other desktop environments just as well.
|
||||
|
||||
#### Installing PCManFM on Ubuntu based distributions
|
||||
|
||||
Installing PCManFM on Ubuntu will just take one simple command:
|
||||
```
|
||||
sudo apt install pcmanfm
|
||||
```
|
||||
|
||||
### 8. Mousepad: Text Editor
|
||||
|
||||
Nothing can beat command-line text editors like - nano, vim etc. in terms of being lightweight. But if you want a graphical interface, here you go -- Mousepad is a minimal text editor. It's extremely lightweight and blazing fast. It comes with a simple customizable user interface with multiple themes.
|
||||
|
||||
![Mousepad][21]
|
||||
|
||||
Mousepad supports syntax highlighting. So, you can also use it as a basic code editor.
|
||||
|
||||
#### Installing Mousepad on Ubuntu based distributions
|
||||
|
||||
For installing Mousepad use the following command:
|
||||
```
|
||||
sudo apt install mousepad
|
||||
```
|
||||
|
||||
### 9. GNOME Office: Office Suite
|
||||
|
||||
Many of us need to use office applications quite often. Generally, most of the office applications are bulky in size and resource hungry. Gnome Office is quite lightweight in that respect. Gnome Office is technically not a complete office suite. It's composed of different standalone applications and among them, **AbiWord** & **Gnumeric** stands out.
|
||||
|
||||
**AbiWord** is the word processor. It is lightweight and a lot faster than other alternatives. But that came to be at a cost -- you might miss some features like macros, grammar checking etc. It's not perfect but it works.
|
||||
|
||||
![AbiWord][22]
|
||||
|
||||
**Gnumeric** is the spreadsheet editor. Just like AbiWord, Gnumeric is also very fast and it provides accurate calculations. If you are looking for a simple and lightweight spreadsheet editor, Gnumeric has got you covered.
|
||||
|
||||
![Gnumeric][23]
|
||||
|
||||
There are some other applications listed under Gnome Office. You can find them in the official page.
|
||||
|
||||
[Gnome Office][24]
|
||||
|
||||
#### Installing AbiWord & Gnumeric on Ubuntu based distributions
|
||||
|
||||
For installing AbiWord & Gnumeric, simply enter the following command in your terminal:
|
||||
```
|
||||
sudo apt install abiword gnumeric
|
||||
```
|
||||
|
||||
That's all for today. Would you like to add some other **lightweight Linux applications** to this list? Do let us know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lightweight-alternative-applications-ubuntu/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
[2]:https://itsfoss.com/essential-linux-applications/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Lightweight-alternative-applications-for-Linux-800x450.jpg
|
||||
[5]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Midori-800x497.png
|
||||
[7]:http://midori-browser.org/faqs/
|
||||
[8]:http://midori-browser.org/
|
||||
[9]:https://itsfoss.com/best-email-clients-linux/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Trojit%C3%A1-800x608.png
|
||||
[11]:http://trojita.flaska.net/
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/GDebi.png
|
||||
[13]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AppGrid-800x553.png
|
||||
[15]:http://www.appgrid.org/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Yarock-800x529.png
|
||||
[17]:https://seb-apps.github.io/yarock/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/VLC-800x526.png
|
||||
[19]:http://www.videolan.org/index.html
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/PCManFM.png
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Mousepad.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/AbiWord-800x626.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/03/Gnumeric-800x470.png
|
||||
[24]:https://gnome.org/gnome-office/
|
||||
@ -1,142 +0,0 @@
|
||||
How to use GNU Stow to manage programs installed from source and dotfiles
|
||||
======
|
||||
|
||||
### Objective
|
||||
|
||||
Easily manage programs installed from source and dotfiles using GNU stow
|
||||
|
||||
### Requirements
|
||||
|
||||
* Root permissions
|
||||
|
||||
|
||||
|
||||
### Difficulty
|
||||
|
||||
EASY
|
||||
|
||||
### Conventions
|
||||
|
||||
* **#** \- requires given command to be executed with root privileges either directly as a root user or by use of `sudo` command
|
||||
* **$** \- given command to be executed as a regular non-privileged user
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
Sometimes we have to install programs from source: maybe they are not available through standard channels, or maybe we want a specific version of a software. GNU stow is a very nice `symlinks factory` program which helps us a lot by keeping files organized in a very clean and easy to maintain way.
|
||||
|
||||
### Obtaining stow
|
||||
|
||||
Your distribution repositories is very likely to contain `stow`, for example in Fedora, all you have to do to install it is:
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
or on Ubuntu/Debian you can install stow by executing:
|
||||
```
|
||||
|
||||
# apt install stow
|
||||
|
||||
```
|
||||
|
||||
In some distributions, stow it's not available in standard repositories, but it can be easily obtained by adding some extra software sources (for example epel in the case of Rhel and CentOS7) or, as a last resort, by compiling it from source: it requires very little dependencies.
|
||||
|
||||
### Compiling stow from source
|
||||
|
||||
The latest available stow version is the `2.2.2`: the tarball is available for download here: `https://ftp.gnu.org/gnu/stow/`.
|
||||
|
||||
Once you have downloaded the sources, you must extract the tarball. Navigate to the directory where you downloaded the package and simply run:
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
After the sources have been extracted, navigate inside the stow-2.2.2 directory, and to compile the program simply run:
|
||||
```
|
||||
|
||||
$ ./configure
|
||||
$ make
|
||||
|
||||
```
|
||||
|
||||
Finally, to install the package:
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
By default the package will be installed in the `/usr/local/` directory, but we can change this, specifying the directory via the `--prefix` option of the configure script, or by adding `prefix="/your/dir"` when running the `make install` command.
|
||||
|
||||
At this point, if all worked as expected we should have `stow` installed on our system
|
||||
|
||||
### How does stow work?
|
||||
|
||||
The main concept behind stow it's very well explained in the program manual:
|
||||
```
|
||||
|
||||
The approach used by Stow is to install each package into its own tree,
|
||||
then use symbolic links to make it appear as though the files are
|
||||
installed in the common tree.
|
||||
|
||||
```
|
||||
|
||||
To better understand the working of the package, let's analyze its key concepts:
|
||||
|
||||
#### The stow directory
|
||||
|
||||
The stow directory is the root directory which contains all the `stow packages`, each with their own private subtree. The typical stow directory is `/usr/local/stow`: inside it, each subdirectory represents a `package`
|
||||
|
||||
#### Stow packages
|
||||
|
||||
As said above, the stow directory contains "packages", each in its own separate subdirectory, usually named after the program itself. A package is nothing more than a list of files and directories related to a specific software, managed as an entity.
|
||||
|
||||
#### The stow target directory
|
||||
|
||||
The stow target directory is very a simple concept to explain. It is the directory in which the package files must appear to be installed. By default the stow target directory is considered to be the one above the directory in which stow is invoked from. This behaviour can be easily changed by using the `-t` option (short for --target), which allows us to specify an alternative directory.
|
||||
|
||||
### A practical example
|
||||
|
||||
I believe a well done example is worth 1000 words, so let's show how stow works. Suppose we want to compile and install `libx264`. Lets clone the git repository containing its sources:
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
Few seconds after running the command, the "x264" directory will be created, and it will contain the sources, ready to be compiled. We now navigate inside it and run the `configure` script, specifying the /usr/local/stow/libx264 directory as `--prefix`:
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
Then we build the program and install it:
|
||||
```
|
||||
|
||||
$ make
|
||||
# make install
|
||||
|
||||
```
|
||||
|
||||
The directory x264 should have been created inside of the stow directory: it contains all the stuff that would have been normally installed in the system directly. Now, all we have to do, is to invoke stow. We must run the command either from inside the stow directory, by using the `-d` option to specify manually the path to the stow directory (default is the current directory), or by specifying the target with `-t` as said before. We should also provide the name of the package to be stowed as an argument. In this case we run the program from the stow directory, so all we need to type is:
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
All the files and directories contained in the libx264 package have now been symlinked in the parent directory (/usr/local) of the one from which stow has been invoked, so that, for example, libx264 binaries contained in `/usr/local/stow/x264/bin` are now symlinked in `/usr/local/bin`, files contained in `/usr/local/stow/x264/etc` are now symlinked in `/usr/local/etc` and so on. This way it will appear to the system that the files were installed normally, and we can easily keep track of each program we compile and install. To revert the action, we just use the `-D` option:
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
It is done! The symlinks don't exist anymore: we just "uninstalled" a stow package, keeping our system in a clean and consistent state. At this point it should be clear why stow it's also used to manage dotfiles. A common practice is to have all user-specific configuration files inside a git repository, to manage them easily and have them available everywhere, and then using stow to place them where appropriate, in the user home directory.
|
||||
|
||||
Stow will also prevent you from overriding files by mistake: it will refuse to create symbolic links if the destination file already exists and doesn't point to a package into the stow directory. This situation is called a conflict in stow terminology.
|
||||
|
||||
That's it! For a complete list of options, please consult the stow manpage and don't forget to tell us your opinions about it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -1,200 +0,0 @@
|
||||
How to Use GNOME Shell Extensions [Complete Guide]
|
||||
======
|
||||
**Brief: This is a detailed guide showing you how to install GNOME Shell Extensions manually or easily via a browser. **
|
||||
|
||||
While discussing [how to install themes in Ubuntu 17.10][1], I briefly mentioned GNOME Shell Extension. It was used to enable user themes. Today, we'll have a detailed look at GNOME Shell Extensions in Ubuntu 17.10.
|
||||
|
||||
I may use the term GNOME Extensions instead of GNOME Shell Extensions but both have the same meaning here.
|
||||
|
||||
What are GNOME Shell Extensions? How to install GNOME Shell Extensions? And how to manage and remove GNOME Shell Extensions? I'll explain all these questions, one by one.
|
||||
|
||||
Before that, if you prefer video, I have demonstrated all these on [It's FOSS YouTube channel][2]. I highly recommend that you subscribe to it for more Linux videos.
|
||||
|
||||
## What is a GNOME Shell Extension?
|
||||
|
||||
A [GNOME Shell Extension][3] is basically a tiny piece of code that enhances the capability of GNOME desktop.
|
||||
|
||||
Think of it as an add-on in your browser. For example, you can install an add-on in your browser to disable ads. This add-on is developed by a third-party developer. Though your web browser doesn't provide it by default, installing this add-on enhances the capability of your web browser.
|
||||
|
||||
Similarly, GNOME Shell Extensions are like those third-party add-ons and plugins that you can install on top of GNOME. These extensions are created to perform specific tasks such as display weather condition, internet speed etc. Mostly, you can access them in the top panel.
|
||||
|
||||
![GNOME Shell Extension in action][5]
|
||||
|
||||
There are also GNOME Extensions that are not visible on the top panel. But they still tweak GNOME's behavior. For example, middle mouse button can be used to close an application with one such extension.
|
||||
|
||||
## Installing GNOME Shell Extensions
|
||||
|
||||
Now that you know what are GNOME Shell Extensions, let's see how to install them. There are three ways you can use GNOME Extensions:
|
||||
|
||||
* Use a minimal set of extensions from Ubuntu (or your Linux distribution)
|
||||
* Find and install extensions in your web browser
|
||||
* Download and manually install extensions
|
||||
|
||||
|
||||
|
||||
Before you learn how to use GNOME Shell Extensions, you should install GNOME Tweak Tool. You can find it in the Software Center. Alternatively, you can use this command:
|
||||
```
|
||||
sudo apt install gnome-tweak-tool
|
||||
```
|
||||
|
||||
At times, you would also need to know the version of GNOME Shell you are using. This helps in determining whether an extension is compatible with your system or not. You can use the command below to find it:
|
||||
```
|
||||
gnome-shell --version
|
||||
```
|
||||
|
||||
### 1\. Use gnome-shell-extensions package [easiest and safest way]
|
||||
|
||||
Ubuntu (and several other Linux distributions such as Fedora) provide a package with a minimal set of GNOME extensions. You don't have to worry about the compatibility here as it is tested by your Linux distribution.
|
||||
|
||||
If you want a no-brainer, just get this package and you'll have 8-10 GNOME extensions installed.
|
||||
```
|
||||
sudo apt install gnome-shell-extensions
|
||||
```
|
||||
|
||||
You'll have to reboot your system (or maybe just restart GNOME Shell, I don't remember it at this point). After that, start GNOME Tweaks and you'll find a few extensions installed. You can just toggle the button to start using an installed extension.
|
||||
|
||||
![Change GNOME Shell theme in Ubuntu 17.1][6]
|
||||
|
||||
### 2. Install GNOME Shell extensions from a web browser
|
||||
|
||||
GNOME project has an entire website dedicated to extensions. That's not it. You can find, install, and manage your extensions on this website itself. No need even for GNOME Tweaks tool.
|
||||
|
||||
[GNOME Shell Extensions Website][3]
|
||||
|
||||
But in order to install extensions a web browser, you need two things: a browser add-on and a native host connector in your system.
|
||||
|
||||
#### Step 1: Install browser add-on
|
||||
|
||||
When you visit the GNOME Shell Extensions website, you'll see a message like this:
|
||||
|
||||
> "To control GNOME Shell extensions using this site you must install GNOME Shell integration that consists of two parts: browser extension and native host messaging application."
|
||||
|
||||
![Installing GNOME Shell Extensions][7]
|
||||
|
||||
You can simply click on the suggested add-on link by your web browser. You can install them from the link below as well:
|
||||
|
||||
#### Step 2: Install native connector
|
||||
|
||||
Just installing browser add-on won't help you. You'll still see an error like:
|
||||
|
||||
> "Although GNOME Shell integration extension is running, native host connector is not detected. Refer documentation for instructions about installing connector"
|
||||
|
||||
![How to install GNOME Shell Extensions][8]
|
||||
|
||||
This is because you haven't installed the host connector yet. To do that, use this command:
|
||||
```
|
||||
sudo apt install chrome-gnome-shell
|
||||
```
|
||||
|
||||
Don't worry about the 'chrome' prefix in the package name. It has nothing to do with Chrome. You don't have to install a separate package for Firefox or Opera here.
|
||||
|
||||
#### Step 3: Installing GNOME Shell Extensions in web browser
|
||||
|
||||
Once you have completed these two requirements, you are all set to roll. Now when you go to GNOME Shell Extension, you won't see any error message.
|
||||
|
||||
![GNOME Shell Extension][9]
|
||||
|
||||
A good thing to do would be to sort the extensions by your GNOME Shell version. It is not mandatory though. What happens here is that a developer creates an extension for the present GNOME version. In one year, there will be two more GNOME releases. But the developer didn't have time to test or update his/her extension.
|
||||
|
||||
As a result, you wouldn't know if that extension is compatible with your system or not. It's possible that the extension works fine even in the newer GNOME Shell version despite that the extension is years old. It is also possible that the extension doesn't work in the newer GNOME Shell.
|
||||
|
||||
You can search for an extension as well. Let's say you want to install a weather extension. Just search for it and go for one of the search results.
|
||||
|
||||
When you visit the extension page, you'll see a toggle button.
|
||||
|
||||
![Installing GNOME Shell Extension ][10]
|
||||
|
||||
Click on it and you'll be prompted if you want to install this extension:
|
||||
|
||||
![Install GNOME Shell Extensions via web browser][11]
|
||||
|
||||
Obviously, go for Install here. Once it's installed, you'll see that the toggle button is now on and there is a setting option available next to it. You can configure the extension using the setting option. You can also disable the extension from here.
|
||||
|
||||
![Configuring installed GNOME Shell Extensions][12]
|
||||
|
||||
You can also configure the settings of an extension that you installed via the web browser in GNOME Tweaks tool:
|
||||
|
||||
![GNOME Tweaks to handle GNOME Shell Extensions][13]
|
||||
|
||||
You can see all your installed extensions on the website under [installed extensions section][14]. You can also delete the extensions that you installed via web browser here
|
||||
|
||||
![Manage your installed GNOME Shell Extensions][15]
|
||||
|
||||
One major advantage of using the GNOME Extensions website is that you can see if there is an update available for an extension. You won't get it in GNOME Tweaks or system update.
|
||||
|
||||
### 3. Install GNOME Shell Extensions manually
|
||||
|
||||
It's not that you have to be always online to install GNOME Shell extensions. You can download the files and install it later, without needing internet.
|
||||
|
||||
Go to GNOME Extensions website and download the extension with the latest version.
|
||||
|
||||
![Download GNOME Shell Extension][16]
|
||||
|
||||
Extract the downloaded file. Copy the folder to **~/.local/share/gnome-shell/extensions** directory. Go to your Home directory and press Crl+H to show hidden folders. Locate .local folder here and from there, you can find your path till extensions directory.
|
||||
|
||||
Once you have the files copied in the correct directory, go inside it and open metadata.json file. Look for the value of uuid.
|
||||
|
||||
Make sure that the name of the extension's folder is same as the value of uuid in the metadata.json file. If not, rename the directory to the value of this uuid.
|
||||
|
||||
![Manually install GNOME Shell extension][17]
|
||||
|
||||
Almost there! Now restart GNOME Shell. Press Alt+F2 and enter r to restart GNOME Shell.
|
||||
|
||||
![Restart GNOME Shell][18]
|
||||
|
||||
Restart GNOME Tweaks tool as well. You should see the manually installed GNOME extension in the Tweak tool now. You can configure or enable the newly installed extension here.
|
||||
|
||||
And that's all you need to know about installing GNOME Shell Extensions.
|
||||
|
||||
## Remove GNOME Shell Extensions
|
||||
|
||||
It is totally understandable that you might want to remove an installed GNOME Shell Extension.
|
||||
|
||||
If you installed it via a web browser, you can go to the [installed extensions section on GNOME website][14] and remove it from there (as shown in an earlier picture).
|
||||
|
||||
If you installed it manually, you can remove it by deleting the extension files from ~/.local/share/gnome-shell/extensions directory.
|
||||
|
||||
## Bonus Tip: Get notified of GNOME Shell Extensions updates
|
||||
|
||||
By now you have realized that there is no way to know if an update is available for a GNOME Shell extension except for visiting the GNOME extension website.
|
||||
|
||||
Luckily for you, there is a GNOME Shell Extension that notifies you if there is an update available for an installed extension. You can get it from the link below:
|
||||
|
||||
[Extension Update Notifier][19]
|
||||
|
||||
### How do you manage GNOME Shell Extensions?
|
||||
|
||||
I find it rather weird that you cannot update the extensions via the system updates. It's as if GNOME Shell extensions are not even part of the system.
|
||||
|
||||
If you are looking for some recommendation, read this article about [best GNOME extensions][20]. At the same time, share your experience with GNOME Shell extensions. Do you often use them? If yes, which ones are your favorite?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gnome-shell-extensions/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[2]:https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[3]:https://extensions.gnome.org/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-weather.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/enableuser-themes-extension-gnome.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-1.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-2.jpeg
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-3.jpeg
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-4.jpeg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-5.jpeg
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-6.jpeg
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-7-800x572.jpeg
|
||||
[14]:https://extensions.gnome.org/local/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-8.jpeg
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-9-800x456.jpeg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/gnome-shell-extension-installation-10-800x450.jpg
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/restart-gnome-shell-800x299.jpeg
|
||||
[19]:https://extensions.gnome.org/extension/1166/extension-update-notifier/
|
||||
[20]:https://itsfoss.com/best-gnome-extensions/
|
||||
@ -1,97 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to configure login banners in Linux (RedHat, Ubuntu, CentOS, Fedora)
|
||||
======
|
||||
Learn how to create login banners in Linux to display different warning or information messages to user who is about to log in or after he logs in.
|
||||
|
||||
![Login banners in Linux][1]
|
||||
|
||||
Whenever you login to some production systems of firm, you get to see some login messages, warnings or info about server you are about to login or already logged in like below. Those are the login banners.
|
||||
|
||||
![Login welcome messages in Linux][2]
|
||||
|
||||
In this article we will walk you through how to configure them.
|
||||
|
||||
There are two types of banners you can configure.
|
||||
|
||||
1. Banner message to display before user log in (configure in file of your choice eg. `/etc/login.warn`)
|
||||
2. Banner message to display after user successfully logged in (configure in `/etc/motd`)
|
||||
|
||||
|
||||
|
||||
### How to display message when user connects to system before login
|
||||
|
||||
This message will be displayed to user when he connects to server and before he logged in. Means when he enter the username, this message will be displayed before password prompt.
|
||||
|
||||
You can use any filename and enter your message within. Here we used `/etc/login.warn` file and put our messages inside.
|
||||
|
||||
```
|
||||
# cat /etc/login.warn
|
||||
!!!! Welcome to KernelTalks test server !!!!
|
||||
This server is meant for testing Linux commands and tools. If you are
|
||||
not associated with kerneltalks.com and not authorized please dis-connect
|
||||
immediately.
|
||||
```
|
||||
|
||||
Now, you need to supply this file and path to `sshd` daemon so that it can fetch this banner for each user login request. For that open `/etc/sshd/sshd_config` file and search for line `#Banner none`
|
||||
|
||||
Here you have to edit file and write your filename and remove hash mark. It should look like : `Banner /etc/login.warn`
|
||||
|
||||
Save file and restart `sshd` daemon. To avoid disconnecting existing connected users, use HUP signal to restart sshd.
|
||||
|
||||
```
|
||||
oot@kerneltalks # ps -ef |grep -i sshd
|
||||
root 14255 1 0 18:42 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 19074 14255 0 18:46 ? 00:00:00 sshd: ec2-user [priv]
|
||||
root 19177 19127 0 18:54 pts/0 00:00:00 grep -i sshd
|
||||
|
||||
root@kerneltalks # kill -HUP 14255
|
||||
```
|
||||
|
||||
Thats it! Open new session and try login. You will be greeted with the message you configured in above steps .
|
||||
|
||||
![Login banner in Linux][3]
|
||||
|
||||
You can see message is displayed before user enter his password and log in to system.
|
||||
|
||||
### How to display message after user logs in
|
||||
|
||||
Message user sees after he logs into system successfully is **M** essage **O** f **T** he **D** ay & is controlled by `/etc/motd` file. Edit this file and enter message you want to greet user with once he successfully logged in.
|
||||
|
||||
```
|
||||
root@kerneltalks # cat /etc/motd
|
||||
W E L C O M E
|
||||
Welcome to the testing environment of kerneltalks.
|
||||
Feel free to use this system for testing your Linux
|
||||
skills. In case of any issues reach out to admin at
|
||||
info@kerneltalks.com. Thank you.
|
||||
|
||||
```
|
||||
|
||||
You dont need to restart `sshd` daemon to take this change effect. As soon as you save the file, its content will be read and displayed by sshd daemon from very next login request it serves.
|
||||
|
||||
![motd in linux][4]
|
||||
|
||||
You can see in above screenshot : Yellow box is MOTD controlled by `/etc/motd` and green box is what we saw earlier login banner.
|
||||
|
||||
You can use tools like [cowsay][5], [banner][6], [figlet][7], [lolcat ][8]to create fancy, eye-catching messages to display at login. This method works on almost all Linux distros like RedHat, CentOs, Ubuntu, Fedora etc.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-configure-login-banners-in-linux/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/login-banner-message-in-linux.png
|
||||
[2]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/Login-message-in-linux.png
|
||||
[3]:https://c1.kerneltalks.com/wp-content/uploads/2017/11/login-banner.png
|
||||
[4]:https://c3.kerneltalks.com/wp-content/uploads/2017/11/motd-message-in-linux.png
|
||||
[5]:https://kerneltalks.com/tips-tricks/cowsay-fun-in-linux-terminal/
|
||||
[6]:https://kerneltalks.com/howto/create-nice-text-banner-hpux/
|
||||
[7]:https://kerneltalks.com/tips-tricks/create-beautiful-ascii-text-banners-linux/
|
||||
[8]:https://kerneltalks.com/linux/lolcat-tool-to-rainbow-color-linux-terminal/
|
||||
@ -1,129 +0,0 @@
|
||||
My Adventure Migrating Back To Windows
|
||||
======
|
||||
I have had linux as my primary OS for about a decade now, and primarily use Ubuntu. But with the latest release I have decided to migrate back to an OS I generally dislike, Windows 10.
|
||||
|
||||
![Ubuntu On Windows][1]
|
||||
I have always been a fan of Linux, with my two favorite distributions being debian and ubuntu. Now as a server OS, linus is perfect and unquestionable, but there has always been problems of varing degree on the desktop.
|
||||
|
||||
The most recent set of problems I had made me realise that I dont need to use linux as my desktop os to still be a fan so based on my experience fresh installing Ubutnu 17.10 I have decided to move back to windows.
|
||||
|
||||
### What Caused Me to Switch Back?
|
||||
|
||||
The problem was, when 17.10 came out I did a fresh install like usual but faced some really strange an new issues.
|
||||
|
||||
* Dell D3100 Dock no longer worked (Including the Work Arounds)
|
||||
* Ubuntu kept Freezing (Randomly)
|
||||
* Double Clicking Icons on the desktop did nothing
|
||||
* Using the HUD to search for programs such as "tweaks" would try installing MATE versions.
|
||||
* The GUI felt worse than standard GNOME
|
||||
|
||||
|
||||
|
||||
Now I did considor going back to using 16.04 or to another distro. But I feel Unity 7 was the most polished desktop environment, and the only other which is as polished and stable is windows 10.
|
||||
|
||||
In addition to the above, there were also the inherent set backs from using Linux over Windows. Such as;
|
||||
|
||||
* Most Propriatry Commerical Software is unavailable, E.G Maya, PhotoShop, Microsoft Office (In most cases the alternatives are not on par)
|
||||
* Most Games are not ported to Linux, including games from major studios like EA, Rockstar Ect.
|
||||
* Drivers for most hardware is a second thought for the manufacturers when it comes to linux.
|
||||
|
||||
|
||||
|
||||
Before deciding upon windows I did look at other distributions and operatong systems.
|
||||
|
||||
While doing so I looked more at the "Microsoft Loves Linux" compaign and came across WSL. Their new developer focused angle was interesting to me, so I gave it a try.
|
||||
|
||||
### What I am Looking For in Windows
|
||||
|
||||
I use computers mainly for programming, and I use virtual machines, git , ssh and rely heavily on bash for most of what I do. I also occasionally game, watch netflix and some light office work.
|
||||
|
||||
In short I am looking to keep my current workflow in Ubuntu and transplant it onto Windows. I also want to take advantage of Windows strong points.
|
||||
|
||||
* All PC Games Written For Windows
|
||||
* Native Support for Most Programs
|
||||
* Microsoft Office
|
||||
|
||||
|
||||
|
||||
Now there are caveats with using windows, but I intend to maintain it correctly so I am not worried about the usual windows nasties such as viruses and malware.
|
||||
|
||||
### Windows Subsystem For Linux (Bash on Ubuntu on Windows)
|
||||
|
||||
Microsoft has worked closely with Canonical to bring Ubuntu to Windows. After quickly setting up and launching the program, you have a very familiar bash interface.
|
||||
|
||||
Now I have been looking into the limitations of this, but the only real limitation I hit at the time of writing this article is that it is abstracted away from the hardware. For instance lsblk won't show what partitions you have, because Ubuntu is not being given that information.
|
||||
|
||||
But besides accessing low level tools, I found the experience to be quite familiar and nice.
|
||||
|
||||
I utilised this within my workflow for the following.
|
||||
|
||||
* Generating SSH Keypair
|
||||
* Using Git with Github to manage my repositories
|
||||
* SSH into several servers, including passwordless
|
||||
* Running MySQL for Local Databases
|
||||
* Monitoring System Resources
|
||||
* Using VIM for Config Files
|
||||
* Running Bash Scripts
|
||||
* Running Local Web Server
|
||||
* Running PHP, NodeJS
|
||||
|
||||
|
||||
|
||||
It has proven so far to be quite the formidable tool, and besides being in the Window 10 UI, my workflow feels almost identical to when I was on Ubuntu itself. Although most of my workload can be handled in WSL, i still intend on having virtual machines on had for mote indepth work which may be beyond the scope of wsl.
|
||||
|
||||
### No WINE for me
|
||||
|
||||
Another major upside I am experiencing is compatibility.Now I rarely used WINE to enable me to use windows software. But on occasion it was needed, and usually was not very good.
|
||||
|
||||
#### HeidiSQL
|
||||
|
||||
One of the first Programs I installed was HeidiSQL, one of my favourite DB Clients. It does work under wine, but it felt horrid so I ditched it for MySQL Workbench. Having it back in pride of place in windows is like having a trusty old friend back.
|
||||
|
||||
#### Gaming / Steam
|
||||
|
||||
What is a Windows PC without a little gaming. I installed steam from its website and was greated with all my linux catalogue, plus my windows catalogue which was 5 times bigger and including AAA titles like GTA V. Something I could only dream about in Ubuntu.
|
||||
|
||||
Now I had so much hope for SteamOS and still do, but I don't think it will ever make a dent in the gaming market anywhere in the near future. So if you want to game on a pc, you really do need windows.
|
||||
|
||||
Something else noted, the driver support was better for ny nvidia graphics card which made some linux native games like TF2 run slightly better.
|
||||
|
||||
**Windows will always be superior in gaming, so this was not much of a surprise**
|
||||
|
||||
### Running From a USB HDD and WHY
|
||||
|
||||
I run linux on my main sss drives, but have in the past run from usb keys and usb hard drives. I got used to this durability of linux which allowed me to try out multiple versiobs long term without loosing my main os. Now the last time i tried installing windows to a usb connected hdd it just did not work and was impossoble, so when I did a clone of my Windows HDD as a backup, I was surprised when I could boot from it over USB.
|
||||
|
||||
This has become a handy option for me as I plan to migrate my work laptop back to windows, but did not want to be risky and just throw it on there.
|
||||
|
||||
So for the past few days I have ran it from the USB, and apart from a few buggy messages, I have had no real downside from running it over USB.
|
||||
|
||||
The notable issues doing this is:
|
||||
|
||||
* Slower Boot Speed
|
||||
* Annoying Don't Unplug Your USB message
|
||||
* Not been able to get it to Activate
|
||||
|
||||
|
||||
|
||||
**I might do an article just on Windows on a USB Drive so we can go into more detail.**
|
||||
|
||||
### So what is the verdict?
|
||||
|
||||
I have been using windows 10 for about two weeks now, and have not noticed any negative effect to my work flow. All the tools I need are on hand and the OS is generally behaving, although there have been some minor hiccups along the way.
|
||||
|
||||
## Will I stay with windows
|
||||
|
||||
Although it's early days, I think I will be sticking with windows the the forseable future.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:https://winaero.com/blog/wp-content/uploads/2016/07/Ubutntu-on-Windows-10-logo-banner.jpg
|
||||
@ -1,43 +0,0 @@
|
||||
How to create better documentation with a kanban board
|
||||
======
|
||||

|
||||
If you're working on documentation, a website, or other user-facing content, it's helpful to know what users expect to find--both the information they want and how the information is organized and structured. After all, great content isn't very useful if people can't find what they're looking for.
|
||||
|
||||
Card sorting is a simple and effective way to gather input from users about what they expect from menu interfaces and pages. The simplest implementation is to label a stack of index cards with the sections you plan to include in your website or documentation and ask users to sort the cards in the way they would look for the information. Variations include letting people write their own menu headers or content elements.
|
||||
|
||||
The goal is to learn what your users expect and where they expect to find it, rather than having to figure out your menu and layout on your own. This is relatively straightforward when you have users in the same physical location, but it's more challenging when you are trying to get feedback from people in many locations.
|
||||
|
||||
I've found [kanban][1] boards are a great tool for these situations. They allow people to easily drag virtual cards around to categorize and rank them, and they are multi-purpose, unlike dedicated card-sorting software.
|
||||
|
||||
I often use Trello for card sorting, but there are several [open source alternatives][2] that you might want to try.
|
||||
|
||||
### How it works
|
||||
|
||||
My most successful kanban experiment was when I was working on documentation for [Gluster][3], a free and open source scalable network-attached storage filesystem. I needed to take a large pile of documentation that had grown over time and break it into categories to create a navigation system. BEcause I didn't have the technical knowledge necessary to sort it, I turned to the Gluster team and developer community for guidance.
|
||||
|
||||
First, I created a shared Kanban board. I gave the columns general names that would enable sorting and created cards for all the topics I planned to cover in the documentation. I flagged some cards with different colors to indicate either a topic was missing and needed to be created, or it was present and needed to be removed. Then I put all the cards into an "unsorted" column and asked people to drag them where they thought the cards should be organized and send me a screen capture of what they thought was the ideal state.
|
||||
|
||||
Dealing with all the screen captures was the trickiest part. I wish there was a merge or consensus feature that would've helped me aggregate everyone's data, rather than having to examine a bunch of screen captures. Fortunately, after the first person sorted the cards, people more or less agreed on the structure and made only minor modifications. When opinions differed on a topic's placement, I set up flash meetings where people could explain their thinking and we could hash out the disagreements.
|
||||
|
||||
### Using the data
|
||||
|
||||
From here, it was easy to convert the information I captured into menus and refine it. If users thought items should become submenus, they usually told me in comments or when we talked on the phone. Perceptions of menu organization vary depending upon people's job tasks, so you never have complete agreement, but testing with users means you won't have as many blind spots about what people use and where they will look for it.
|
||||
|
||||
Pairing card sorting with analytics gives you even more insight on what people are looking for. Once, when I ran analytics on some training documentation I was working on, I was surprised that to learn that the most searched page was about title capitalization. So I surfaced that page at the top-menu level, even though my "logical" setting put it far down in a sub-menu.
|
||||
|
||||
I've found kanban card-sorting a great way to help me create content that users want to see and put it where they expect to find it. Have you found another great way to organize your content for users' benefit? Or another interesting use for kanban boards? If so, please share your thoughts in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/kanban-boards-card-sorting
|
||||
|
||||
作者:[Heidi Waterhouse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hwaterhouse
|
||||
[1]:https://en.wikipedia.org/wiki/Kanban
|
||||
[2]:https://opensource.com/alternatives/trello
|
||||
[3]:https://www.gluster.org/
|
||||
@ -1,76 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Record and Share Terminal Session with Showterm
|
||||
======
|
||||
|
||||

|
||||
|
||||
You can easily record your terminal sessions with virtually all screen recording programs. However, you are very likely to end up with an oversized video file. There are several terminal recorders available in Linux, each with its own strengths and weakness. Showterm is a tool that makes it pretty easy to record terminal sessions, upload them, share, and embed them in any web page. On the plus side, you don't end up with any huge file to deal with.
|
||||
|
||||
Showterm is open source, and the project can be found on this [GitHub page][1].
|
||||
|
||||
**Related** : [2 Simple Applications That Record Your Terminal Session as Video [Linux]][2]
|
||||
|
||||
### Installing Showterm for Linux
|
||||
|
||||
Showterm requires that you have Ruby installed on your computer. Here's how to go about installing the program.
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
If you don't have Ruby installed on your Linux system:
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
If you just want to run the application without installation:
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
You can type `showterm --help` for the help screen. If a help page doesn't appear, showterm is probably not installed. Now that you have Showterm installed (or are running the standalone version), let us dive into using the tool to record.
|
||||
|
||||
**Related** : [How to Record Terminal Session in Ubuntu][3]
|
||||
|
||||
### Recording Terminal Session
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
Recording a terminal session is pretty simple. From the command line run `showterm`. This should start the terminal recording in the background. All commands entered in the command line from hereon are recorded by Showterm. Once you are done recording, press Ctrl + D or type `exit` in the command line to stop your recording.
|
||||
|
||||
Showterm should upload your video and output a link to the video that looks like http://showterm.io/<long alpha-numeric characters>. It is rather unfortunate that terminal sessions are uploaded right away without any prompting. Don't panic! You can delete any uploaded recording by entering `showterm --delete <recording URL>`. Before uploading your recordings, you'll have the chance to change the timing by adding the `-e` option to the showterm command. If by any chance a recording fails to upload, you can use `showterm --retry <script> <times>` to force a retry.
|
||||
|
||||
When viewing your recordings, the timing of the video can also be controlled by appending "#slow," "#fast," or "#stop" to the URL. Slow makes the video run at normal speed; fast doubles the speed; and stop, as the name suggests, stops the video.
|
||||
|
||||
Showterm terminal recordings can easily be embedded in web pages via iframes. This can be achieved by adding the iframe source to the showterm video URL as shown below.
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
As an open source tool, Showterm allows for further customization. For instance, to run your own Showterm server, you need to run the command:
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
|
||||
so your client can communicate with it. Additional features can be added with little programming knowledge. The Showterm server project is available from this [GitHub page][1].
|
||||
|
||||
### Conclusion
|
||||
|
||||
In case you are thinking of sharing some command line tutorials with a colleague, be sure to remember Showterm. Showterm is text-based; hence, it will yield a relatively small-sized video compared to other screen recorders. The tool itself is pretty small in size - only a few kilobytes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/brunoedoh/
|
||||
[1]:https://github.com/ConradIrwin/showterm
|
||||
[2]:https://www.maketecheasier.com/record-terminal-session-as-video/ (2 Simple Applications That Record Your Terminal Session as Video [Linux])
|
||||
[3]:https://www.maketecheasier.com/record-terminal-session-in-ubuntu/ (How to Record Terminal Session in Ubuntu)
|
||||
[4]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-interface.png (showterm terminal)
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/11/showterm-site.png (showtermio)
|
||||
@ -1,83 +0,0 @@
|
||||
translating by yizhuoyan
|
||||
|
||||
5 Tips to Improve Technical Writing for an International Audience
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Writing in English for an international audience takes work; here are some handy tips to remember.[Creative Commons Zero][2]
|
||||
|
||||
Writing in English for an international audience does not necessarily put native English speakers in a better position. On the contrary, they tend to forget that the document's language might not be the first language of the audience. Let's have a look at the following simple sentence as an example: “Encrypt the password using the 'foo bar' command.”
|
||||
|
||||
Grammatically, the sentence is correct. Given that "-ing" forms (gerunds) are frequently used in the English language, most native speakers would probably not hesitate to phrase a sentence like this. However, on closer inspection, the sentence is ambiguous: The word “using” may refer either to the object (“the password”) or to the verb (“encrypt”). Thus, the sentence can be interpreted in two different ways:
|
||||
|
||||
* Encrypt the password that uses the 'foo bar' command.
|
||||
|
||||
* Encrypt the password by using the 'foo bar' command.
|
||||
|
||||
As long as you have previous knowledge about the topic (password encryption or the 'foo bar' command), you can resolve this ambiguity and correctly decide that the second reading is the intended meaning of this sentence. But what if you lack in-depth knowledge of the topic? What if you are not an expert but a translator with only general knowledge of the subject? Or, what if you are a non-native speaker of English who is unfamiliar with advanced grammatical forms?
|
||||
|
||||
### Know Your Audience
|
||||
|
||||
Even native English speakers may need some training to write clear and straightforward technical documentation. Raising awareness of usability and potential problems is the first step. This article, based on my talk at[ Open Source Summit EU][5], offers several useful techniques. Most of them are useful not only for technical documentation but also for everyday written communication, such as writing email or reports.
|
||||
|
||||
**1. Change perspective. **Step into your audience's shoes. Step one is to know your intended audience. If you are a developer writing for end users, view the product from their perspective. The [persona technique][6] can help to focus on the target audience and to provide the right level of detail for your readers.
|
||||
|
||||
**2\. Follow the KISS principle. **Keep it short and simple. The principle can be applied to several levels, like grammar, sentences, or words. Here are some examples:
|
||||
|
||||
_Words: _ Uncommon and long words slow down reading and might be obstacles for non-native speakers. Use simpler alternatives:
|
||||
|
||||
“utilize” → “use”
|
||||
|
||||
“indicate” → “show”, “tell”, “say”
|
||||
|
||||
“prerequisite” → “requirement”
|
||||
|
||||
_Grammar: _ Use the simplest tense that is appropriate. For example, use present tense when mentioning the result of an action: "Click _OK_ . The _Printer Options_ dialog appears.”
|
||||
|
||||
_Sentences: _ As a rule of thumb, present one idea in one sentence. However, restricting sentence length to a certain amount of words is not useful in my opinion. Short sentences are not automatically easy to understand (especially if they are a cluster of nouns). Sometimes, trimming down sentences to a certain word count can introduce ambiquities, which can, in turn, make sentences even more difficult to understand.
|
||||
|
||||
**3\. Beware of ambiguities. **As authors, we often do not notice ambiguity in a sentence. Having your texts reviewed by others can help identify such problems. If that's not an option, try to look at each sentence from different perspectives: Does the sentence also work for readers without in-depth knowledge of the topic? Does it work for readers with limited language skills? Is the grammatical relationship between all sentence parts clear? If the sentence does not meet these requirements, rephrase it to resolve the ambiguity.
|
||||
|
||||
**4\. Be consistent. **This applies to choice of words, spelling, and punctuation as well as phrases and structure. For lists, use parallel grammatical construction. For example:
|
||||
|
||||
Why white space is important:
|
||||
|
||||
* It focuses attention.
|
||||
|
||||
* It visually separates sections.
|
||||
|
||||
* It splits content into chunks.
|
||||
|
||||
**5\. Remove redundant content.** Keep only information that is relevant for your target audience. On a sentence level, avoid fillers (basically, easily) and unnecessary modifications:
|
||||
|
||||
"already existing" → "existing"
|
||||
|
||||
"completely new" → "new"
|
||||
|
||||
As you might have guessed by now, writing is rewriting. Good writing requires effort and practice. But even if you write only occasionally, you can significantly improve your texts by focusing on the target audience and by using basic writing techniques. The better the readability of a text, the easier it is to process, even for an audience with varying language skills. When it comes to localization especially, good quality of the source text is important: Garbage in, garbage out. If the original text has deficiencies, it will take longer to translate the text, resulting in higher costs. In the worst case, the flaws will be multiplied during translation and need to be corrected in various languages.
|
||||
|
||||
|
||||

|
||||
|
||||
Tanja Roth, Technical Documentation Specialist at SUSE Linux GmbH[Used with permission][1]
|
||||
|
||||
_Driven by an interest in both language and technology, Tanja has been working as a technical writer in mechanical engineering, medical technology, and IT for many years. She joined SUSE in 2005 and contributes to a wide range of product and project documentation, including High Availability and Cloud topics._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/event/open-source-summit-eu/2017/12/technical-writing-international-audience?sf175396579=1
|
||||
|
||||
作者:[TANJA ROTH ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/tanja-roth
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/tanja-rothjpg
|
||||
[4]:https://www.linux.com/files/images/typewriter-8019211920jpg
|
||||
[5]:https://osseu17.sched.com/event/ByIW
|
||||
[6]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
What DevOps teams really need from a CIO
|
||||
======
|
||||
IT leaders can learn from plenty of material exploring [DevOps][1] and the challenging cultural shift required for [making the DevOps transition][2]. But are you in tune with the short and long term challenges that a DevOps team faces - and what they really need from a CIO?
|
||||
|
||||
@ -1,120 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Concurrent Servers: Part 5 - Redis case study
|
||||
======
|
||||
This is part 5 in a series of posts on writing concurrent network servers. After discussing techniques for constructing concurrent servers in parts 1-4, this time we're going to do a case study of an existing production-quality server - [Redis][10].
|
||||
|
||||

|
||||
|
||||
Redis is a fascinating project and I've been following it with interest for a while now. One of the things I admire most about Redis is the clarity of its C source code. It also happens to be a great example of a high-performance concurrent in-memory database server, so the opportunity to use it as a case study for this series was too good to ignore.
|
||||
|
||||
Let's see how the ideas discussed in parts 1-4 apply to a real-world application.
|
||||
|
||||
All posts in the series:
|
||||
|
||||
* [Part 1 - Introduction][3]
|
||||
|
||||
* [Part 2 - Threads][4]
|
||||
|
||||
* [Part 3 - Event-driven][5]
|
||||
|
||||
* [Part 4 - libuv][6]
|
||||
|
||||
* [Part 5 - Redis case study][7]
|
||||
|
||||
### Event-handling library
|
||||
|
||||
One of Redis's main claims to fame around the time of its original release in 2009 was its speed - the sheer number of concurrent client connections the server could handle. It was especially notable that Redis did this all in a single thread, without any complex locking and synchronization schemes on the data stored in memory.
|
||||
|
||||
This feat was achieved by Redis's own implementation of an event-driven library which is wrapping the fastest event loop available on a system (epoll for Linux, kqueue for BSD and so on). This library is called [ae][11]. ae makes it possible to write a fast server as long as none of the internals are blocking, which Redis goes to great lengths to guarantee [[1]][12].
|
||||
|
||||
What mainly interests us here is ae's support of file events - registering callbacks to be invoked when file descriptors (like network sockets) have something interesting pending. Like libuv, ae supports multiple event loops and - having read parts 3 and 4 in this series - the signature of aeCreateFileEvent shouldn't be surprising:
|
||||
|
||||
```
|
||||
int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask,
|
||||
aeFileProc *proc, void *clientData);
|
||||
```
|
||||
|
||||
It registers a callback (proc) for new file events on fd, with the given event loop. When using epoll, it will call epoll_ctl to add an event on the file descriptor (either EPOLLIN, EPOLLOUT or both, depending on the mask parameter). ae's aeProcessEvents is the "run the event loop and dispatch callbacks" function, and it calls epoll_wait under the hood.
|
||||
|
||||
### Handling client requests
|
||||
|
||||
Let's trace through the Redis server code to see how ae is used to register callbacks for client events. initServer starts it by registering a callback for read events on the socket(s) being listened to, by calling aeCreateFileEvent with the callback acceptTcpHandler. This callback is invoked when new client connections are available. It calls accept [[2]][13] and then acceptCommonHandler, which in turn calls createClient to initialize the data structures required to track a new client connection.
|
||||
|
||||
createClient's job is to start listening for data coming in from the client. It sets the socket to non-blocking mode (a key ingredient in an asynchronous event loop) and registers another file event callback with aeCreateFileEvent - for read events - readQueryFromClient. This function will be invoked by the event loop every time the client sends some data.
|
||||
|
||||
readQueryFromClient does just what we'd expect - parses the client's command and acts on it by querying and/or manipulating data and sending a reply back. Since the client socket is non-blocking, this function has to be able to handle EAGAIN, as well as partial data; data read from the client is accumulated in a client-specific buffer, and the full query may be split across multiple invocations of the callback.
|
||||
|
||||
### Sending data back to clients
|
||||
|
||||
In the previous paragraph I said that readQueryFromClient ends up sending replies back to clients. This is logically true, because readQueryFromClient prepares the reply to be sent, but it doesn't actually do the physical sending - since there's no guarantee the client socket is ready for writing/sending data. We have to use the event loop machinery for that.
|
||||
|
||||
The way Redis does this is by registering a beforeSleep function to be called every time the event loop is about to go sleeping waiting for sockets to become available for reading/writing. One of the things beforeSleep does is call handleClientsWithPendingWrites. This function tries to send all available replies immediately by calling writeToClient; if some of the sockets are unavailable, it registers an event-loop callback to invoke sendReplyToClient when the socket is ready. This can be seen as a kind of optimization - if the socket is immediately ready for sending (which often is the case for TCP sockets), there's no need to register the event - just send the data. Since sockets are non-blocking, this never actually blocks the loop.
|
||||
|
||||
### Why does Redis roll its own event library?
|
||||
|
||||
In [part 4][14] we've discussed building asynchronous concurrent servers using libuv. It's interesting to ponder the fact that Redis doesn't use libuv, or any similar event library, and instead implements its own - ae, including wrappers for epoll, kqueue and select. In fact, antirez (Redis's creator) answered precisely this question [in a blog post in 2011][15]. The gist of his answer: ae is ~770 lines of code he intimately understands; libuv is huge, without providing additional functionality Redis needs.
|
||||
|
||||
Today, ae has grown to ~1300 lines, which is still trivial compared to libuv's 26K (this is without Windows, test, samples, docs). libuv is a far more general library, which makes it more complex and more difficult to adapt to the particular needs of another project; ae, on the other hand, was designed for Redis, co-evolved with Redis and contains only what Redis needs.
|
||||
|
||||
This is another great example of the dependencies in software projects formula I mentioned [in a post earlier this year][16]:
|
||||
|
||||
> The benefit of dependencies is inversely proportional to the amount of effort spent on a software project.
|
||||
|
||||
antirez referred to this, to some extent, in his post. He mentioned that dependencies that provide a lot of added value ("foundational" dependencies in my post) make more sense (jemalloc and Lua are his examples) than dependencies like libuv, whose functionality is fairly easy to implement for the particular needs of Redis.
|
||||
|
||||
### Multi-threading in Redis
|
||||
|
||||
[For the vast majority of its history][17], Redis has been a purely single-threaded affair. Some people find this surprising, but it makes total sense with a bit of thought. Redis is inherently network-bound - as long as the database size is reasonable, for any given client request, much more time is spent waiting on the network than inside Redis's data structures.
|
||||
|
||||
These days, however, things are not quite that simple. There are several new capabilities in Redis that use threads:
|
||||
|
||||
1. "Lazy" [freeing of memory][8].
|
||||
|
||||
2. Writing a [persistence journal][9] with fsync calls in a background thread.
|
||||
|
||||
3. Running user-defined modules that need to perform a long-running operation.
|
||||
|
||||
For the first two features, Redis uses its own simple bio library (the acronym stands for "Background I/O"). The library is hard-coded for Redis's needs and can't be used outside it - it runs a pre-set number of threads, one per background job type Redis needs.
|
||||
|
||||
For the third feature, [Redis modules][18] could define new Redis commands, and thus are held to the same standards as regular Redis commands, including not blocking the main thread. If a custom Redis command defined in a module wants to perform a long-running operation, it has to spin up a thread to run it in the background. src/modules/helloblock.c in the Redis tree provides an example.
|
||||
|
||||
With these features, Redis combines an event loop with threading to get both speed in the common case and flexibility in the general case, similarly to the work queue discussion in [part 4][19] of this series.
|
||||
|
||||
|
||||
| [[1]][1] | A core aspect of Redis is its being an _in-memory_ database; therefore, queries should never take too long to execute. There are all kinds of complications, however. In case of partitioning, a server may end up routing the request to another instance; in this case async I/O is used to avoid blocking other clients. |
|
||||
|
||||
|
||||
| [[2]][2] | Through anetAccept; anet is Redis's wrapper for TCP socket code. |
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://eli.thegreenplace.net/pages/about
|
||||
[1]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id1
|
||||
[2]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id2
|
||||
[3]:http://eli.thegreenplace.net/2017/concurrent-servers-part-1-introduction/
|
||||
[4]:http://eli.thegreenplace.net/2017/concurrent-servers-part-2-threads/
|
||||
[5]:http://eli.thegreenplace.net/2017/concurrent-servers-part-3-event-driven/
|
||||
[6]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[7]:http://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/
|
||||
[8]:http://antirez.com/news/93
|
||||
[9]:https://redis.io/topics/persistence
|
||||
[10]:https://redis.io/
|
||||
[11]:https://redis.io/topics/internals-rediseventlib
|
||||
[12]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id4
|
||||
[13]:https://eli.thegreenplace.net/2017/concurrent-servers-part-5-redis-case-study/#id5
|
||||
[14]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
[15]:http://oldblog.antirez.com/post/redis-win32-msft-patch.html
|
||||
[16]:http://eli.thegreenplace.net/2017/benefits-of-dependencies-in-software-projects-as-a-function-of-effort/
|
||||
[17]:http://antirez.com/news/93
|
||||
[18]:https://redis.io/topics/modules-intro
|
||||
[19]:http://eli.thegreenplace.net/2017/concurrent-servers-part-4-libuv/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Will DevOps steal my job?
|
||||
======
|
||||
|
||||
|
||||
@ -1,254 +0,0 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb call functions?
|
||||
============================================================
|
||||
|
||||
(previous gdb posts: [how does gdb work? (2016)][4] and [three things you can do with gdb (2014)][5])
|
||||
|
||||
I discovered this week that you can call C functions from gdb! I thought this was cool because I’d previously thought of gdb as mostly a read-only debugging tool.
|
||||
|
||||
I was really surprised by that (how does that WORK??). As I often do, I asked [on Twitter][6] how that even works, and I got a lot of really useful answers! My favorite answer was [Evan Klitzke’s example C code][7] showing a way to do it. Code that _works_ is very exciting!
|
||||
|
||||
I believe (through some stracing & experiments) that that example C code is different from how gdb actually calls functions, so I’ll talk about what I’ve figured out about what gdb does in this post and how I’ve figured it out.
|
||||
|
||||
There is a lot I still don’t know about how gdb calls functions, and very likely some things in here are wrong.
|
||||
|
||||
### What does it mean to call a C function from gdb?
|
||||
|
||||
Before I get into how this works, let’s talk quickly about why I found it surprising / nonobvious.
|
||||
|
||||
So, you have a running C program (the “target program”). You want to run a function from it. To do that, you need to basically:
|
||||
|
||||
* pause the program (because it is already running code!)
|
||||
|
||||
* find the address of the function you want to call (using the symbol table)
|
||||
|
||||
* convince the program (the “target program”) to jump to that address
|
||||
|
||||
* when the function returns, restore the instruction pointer and registers to what they were before
|
||||
|
||||
Using the symbol table to figure out the address of the function you want to call is pretty straightforward – here’s some sketchy (but working!) Rust code that I’ve been using on Linux to do that. This code uses the [elf crate][8]. If I wanted to find the address of the `foo` function in PID 2345, I’d run `elf_symbol_value("/proc/2345/exe", "foo")`.
|
||||
|
||||
```
|
||||
fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::error::Error>> {
|
||||
// open the ELF file
|
||||
let file = elf::File::open_path(file_name).ok().ok_or("parse error")?;
|
||||
// loop over all the sections & symbols until you find the right one!
|
||||
let sections = &file.sections;
|
||||
for s in sections {
|
||||
for sym in file.get_symbols(&s).ok().ok_or("parse error")? {
|
||||
if sym.name == symbol_name {
|
||||
return Ok(sym.value);
|
||||
}
|
||||
}
|
||||
}
|
||||
None.ok_or("No symbol found")?
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This won’t totally work on its own, you also need to look at the memory maps of the file and add the symbol offset to the start of the place that file is mapped. But finding the memory maps isn’t so hard, they’re in `/proc/PID/maps`.
|
||||
|
||||
Anyway, this is all to say that finding the address of the function to call seemed straightforward to me but that the rest of it (change the instruction pointer? restore the registers? what else?) didn’t seem so obvious!
|
||||
|
||||
### You can’t just jump
|
||||
|
||||
I kind of said this already but – you can’t just find the address of the function you want to run and then jump to that address. I tried that in gdb (`jump foo`) and the program segfaulted. Makes sense!
|
||||
|
||||
### How you can call C functions from gdb
|
||||
|
||||
First, let’s see that this is possible. I wrote a tiny C program that sleeps for 1000 seconds and called it `test.c`:
|
||||
|
||||
```
|
||||
#include <unistd.h>
|
||||
|
||||
int foo() {
|
||||
return 3;
|
||||
}
|
||||
int main() {
|
||||
sleep(1000);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Next, compile and run it:
|
||||
|
||||
```
|
||||
$ gcc -o test test.c
|
||||
$ ./test
|
||||
|
||||
```
|
||||
|
||||
Finally, let’s attach to the `test` program with gdb:
|
||||
|
||||
```
|
||||
$ sudo gdb -p $(pgrep -f test)
|
||||
(gdb) p foo()
|
||||
$1 = 3
|
||||
(gdb) quit
|
||||
|
||||
```
|
||||
|
||||
So I ran `p foo()` and it ran the function! That’s fun.
|
||||
|
||||
### Why is this useful?
|
||||
|
||||
a few possible uses for this:
|
||||
|
||||
* it lets you treat gdb a little bit like a C REPL, which is fun and I imagine could be useful for development
|
||||
|
||||
* utility functions to display / navigate complex data structures quickly while debugging in gdb (thanks [@invalidop][1])
|
||||
|
||||
* [set an arbitrary process’s namespace while it’s running][2] (featuring a not-so-surprising appearance from my colleague [nelhage][3]!)
|
||||
|
||||
* probably more that I don’t know about
|
||||
|
||||
### How it works
|
||||
|
||||
I got a variety of useful answers on Twitter when I asked how calling functions from gdb works! A lot of them were like “well you get the address of the function from the symbol table” but that is not the whole story!!
|
||||
|
||||
One person pointed me to this nice 2 part series on how gdb works that they’d written: [Debugging with the natives, part 1][9] and [Debugging with the natives, part 2][10]. Part 1 explains approximately how calling functions works (or could work – figuring out what gdb **actually** does isn’t trivial, but I’ll try my best!).
|
||||
|
||||
The steps outlined there are:
|
||||
|
||||
1. Stop the process
|
||||
|
||||
2. Create a new stack frame (far away from the actual stack)
|
||||
|
||||
3. Save all the registers
|
||||
|
||||
4. Set the registers to the arguments you want to call your function with
|
||||
|
||||
5. Set the stack pointer to the new stack frame
|
||||
|
||||
6. Put a trap instruction somewhere in memory
|
||||
|
||||
7. Set the return address to that trap instruction
|
||||
|
||||
8. Set the instruction pointer register to the address of the function you want to call
|
||||
|
||||
9. Start the process again!
|
||||
|
||||
I’m not going to go through how gdb does all of these (I don’t know!) but here are a few things I’ve learned about the various pieces this evening.
|
||||
|
||||
**Create a stack frame**
|
||||
|
||||
If you’re going to run a C function, most likely it needs a stack to store variables on! You definitely don’t want it to clobber your current stack. Concretely – before gdb calls your function (by setting the instruction pointer to it and letting it go), it needs to set the **stack pointer** to… something.
|
||||
|
||||
There was some speculation on Twitter about how this works:
|
||||
|
||||
> i think it constructs a new stack frame for the call right on top of the stack where you’re sitting!
|
||||
|
||||
and:
|
||||
|
||||
> Are you certain it does that? It could allocate a pseudo stack, then temporarily change sp value to that location. You could try, put a breakpoint there and look at the sp register address, see if it’s contiguous to your current program register?
|
||||
|
||||
I did an experiment where (inside gdb) I ran:`
|
||||
|
||||
```
|
||||
(gdb) p $rsp
|
||||
$7 = (void *) 0x7ffea3d0bca8
|
||||
(gdb) break foo
|
||||
Breakpoint 1 at 0x40052a
|
||||
(gdb) p foo()
|
||||
Breakpoint 1, 0x000000000040052a in foo ()
|
||||
(gdb) p $rsp
|
||||
$8 = (void *) 0x7ffea3d0bc00
|
||||
|
||||
```
|
||||
|
||||
This seems in line with the “gdb constructs a new stack frame for the call right on top of the stack where you’re sitting” theory, since the stack pointer (`$rsp`) goes from being `...bca8` to `..bc00` – stack pointers grow downward, so a `bc00`stack pointer is **after** a `bca8` pointer. Interesting!
|
||||
|
||||
So it seems like gdb just creates the new stack frames right where you are. That’s a bit surprising to me!
|
||||
|
||||
**change the instruction pointer**
|
||||
|
||||
Let’s see whether gdb changes the instruction pointer!
|
||||
|
||||
```
|
||||
(gdb) p $rip
|
||||
$1 = (void (*)()) 0x7fae7d29a2f0 <__nanosleep_nocancel+7>
|
||||
(gdb) b foo
|
||||
Breakpoint 1 at 0x40052a
|
||||
(gdb) p foo()
|
||||
Breakpoint 1, 0x000000000040052a in foo ()
|
||||
(gdb) p $rip
|
||||
$3 = (void (*)()) 0x40052a <foo+4>
|
||||
|
||||
```
|
||||
|
||||
It does! The instruction pointer changes from `0x7fae7d29a2f0` to `0x40052a` (the address of the `foo` function).
|
||||
|
||||
I stared at the strace output and I still don’t understand **how** it changes, but that’s okay.
|
||||
|
||||
**aside: how breakpoints are set!!**
|
||||
|
||||
Above I wrote `break foo`. I straced gdb while running all of this and understood almost nothing but I found ONE THING that makes sense to me!!
|
||||
|
||||
Here are some of the system calls that gdb uses to set a breakpoint. It’s really simple! It replaces one instruction with `cc` (which [https://defuse.ca/online-x86-assembler.htm][11] tells me means `int3` which means `send SIGTRAP`), and then once the program is interrupted, it puts the instruction back the way it was.
|
||||
|
||||
I was putting a breakpoint on a function `foo` with the address `0x400528`.
|
||||
|
||||
This `PTRACE_POKEDATA` is how gdb changes the code of running programs.
|
||||
|
||||
```
|
||||
// change the 0x400528 instructions
|
||||
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003b8e589]) = 0
|
||||
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003cce589) = 0
|
||||
// start the program running
|
||||
25622 ptrace(PTRACE_CONT, 25618, 0x1, SIG_0) = 0
|
||||
// get a signal when it hits the breakpoint
|
||||
25622 ptrace(PTRACE_GETSIGINFO, 25618, NULL, {si_signo=SIGTRAP, si_code=SI_KERNEL, si_value={int=-1447215360, ptr=0x7ffda9bd3f00}}) = 0
|
||||
// change the 0x400528 instructions back to what they were before
|
||||
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003cce589]) = 0
|
||||
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003b8e589) = 0
|
||||
|
||||
```
|
||||
|
||||
**put a trap instruction somewhere**
|
||||
|
||||
When gdb runs a function, it **also** puts trap instructions in a bunch of places! Here’s one of them (per strace). It’s basically replacing one instruction with `cc` (`int3`).
|
||||
|
||||
```
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_POKEDATA, 5810, 0x7f6fa7c0b260, 0x48f389fd894853cc) = 0
|
||||
|
||||
```
|
||||
|
||||
What’s `0x7f6fa7c0b260`? Well, I looked in the process’s memory maps, and it turns it’s somewhere in `/lib/x86_64-linux-gnu/libc-2.23.so`. That’s weird! Why is gdb putting trap instructions in libc?
|
||||
|
||||
Well, let’s see what function that’s in. It turns out it’s `__libc_siglongjmp`. The other functions gdb is putting traps in are `__longjmp`, `____longjmp_chk`, `dl_main`, and `_dl_close_worker`.
|
||||
|
||||
Why? I don’t know! Maybe for some reason when our function `foo()` returns, it’s calling `longjmp`, and that is how gdb gets control back? I’m not sure.
|
||||
|
||||
### how gdb calls functions is complicated!
|
||||
|
||||
I’m going to stop there (it’s 1am!), but now I know a little more!
|
||||
|
||||
It seems like the answer to “how does gdb call a function?” is definitely not that simple. I found it interesting to try to figure a little bit of it out and hopefully you have too!
|
||||
|
||||
I still have a lot of unanswered questions about how exactly gdb does all of these things, but that’s okay. I don’t really need to know the details of how this works and I’m happy to have a slightly improved understanding.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:https://twitter.com/invalidop/status/949161146526781440
|
||||
[2]:https://github.com/baloo/setns/blob/master/setns.c
|
||||
[3]:https://github.com/nelhage
|
||||
[4]:https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
[5]:https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
[6]:https://twitter.com/b0rk/status/948060808243765248
|
||||
[7]:https://github.com/eklitzke/ptrace-call-userspace/blob/master/call_fprintf.c
|
||||
[8]:https://cole14.github.io/rust-elf
|
||||
[9]:https://www.cl.cam.ac.uk/~srk31/blog/2016/02/25/#native-debugging-part-1
|
||||
[10]:https://www.cl.cam.ac.uk/~srk31/blog/2017/01/30/#native-debugging-part-2
|
||||
[11]:https://defuse.ca/online-x86-assembler.htm
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Tlog - A Tool to Record / Play Terminal IO and Sessions
|
||||
======
|
||||
Tlog is a terminal I/O recording and playback package for Linux Distros. It's suitable for implementing centralized user session recording. It logs everything that passes through as JSON messages. The primary purpose of logging in JSON format is to eventually deliver the recorded data to a storage service such as Elasticsearch, where it can be searched and queried, and from where it can be played back. At the same time, they retain all the passed data and timing.
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
translatng---geekpi
|
||||
|
||||
5 of the Best Linux Dark Themes that Are Easy on the Eyes
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are several reasons people opt for dark themes on their computers. Some find them easy on the eye while others prefer them because of their medical condition. Programmers, especially, like dark themes because they reduce glare on the eyes.
|
||||
|
||||
If you are a Linux user and a dark theme lover, you are in luck. Here are five of the best dark themes for Linux. Check them out!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
As its name implies, this theme is inspired by OS X. It is a flat theme based on Arc. The theme supports GTK 3 and GTK 2 desktop environments, so Gnome, Cinnamon, Unity, Manjaro, Mate, and XFCE users can install and use the theme. [OSX-Arc-Shadow][2] is part of the OSX-Arc theme collection. The collection has several other themes (dark and light) included. You can download the whole collection and just use the dark variants.
|
||||
|
||||
Debian- and Ubuntu-based distro users have the option of installing the stable release using the .deb files found on this [page][3]. The compressed source files are also on the same page. Arch Linux users, check out this [AUR link][4]. Finally, to install the theme manually, extract the zip content to the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
The theme is only a few days old. It has a darker look compared to OSX-Arc-Shadow and red selection outlines. It is especially appealing to those who want more contrast and less glare from the computer screen. Hence, It reduces distraction when used at night or in places with low lights. It supports GTK 3 and GTK2.
|
||||
|
||||
Head to [gnome-looks][6] to download the theme under the "Files" menu. The installation procedure is simple: extract the theme into the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux is another simple dark theme based on Materia Theme. It has a neutral dark color tone and is not overly fancy. The contrast between the selection outlines is also minimal and not as sharp as the red color in Kiss-Kool-Red. The theme is truly made with reduction of eye strain in mind.
|
||||
|
||||
[Download the compressed file][8] and unzip it into your "~/.themes" folder. Then, you can set it as your theme. You can check [its GitHub page][9] for the latest additions.
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark is a completely dark theme. For those who like a little more darkness, this theme is definitely one to consider. Moreover, it also reduces the amount of glare from the computer screen. Additionally, it supports Unity. [Download Deepin Dark here][11].
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 is a simple dark theme, so it makes the important details stand out. It helps with focus as is not unnecessarily fancy. It is very similar to Deepin Dark. Especially relevant to Ubuntu users, it is compatible with Ubuntu 17.04. You can download and try it from [here][13].
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you use a computer for a very long time, dark themes are a great way to reduce the strain on your eyes. Even if you don't, dark themes can help you in many other ways like improving your focus. Let us know which is your favorite.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
195
sources/tech/20180122 How to Create a Docker Image.md
Normal file
195
sources/tech/20180122 How to Create a Docker Image.md
Normal file
@ -0,0 +1,195 @@
|
||||
How to Create a Docker Image
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn the basic steps for creating Docker images in this tutorial.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
In the previous [article][4], we learned about how to get started with Docker on Linux, macOS, and Windows. In this article, we will get a basic understanding of creating Docker images. There are prebuilt images available on DockerHub that you can use for your own project, and you can publish your own image there.
|
||||
|
||||
We are going to use prebuilt images to get the base Linux subsystem, as it’s a lot of work to build one from scratch. You can get Alpine (the official distro used by Docker Editions), Ubuntu, BusyBox, or scratch. In this example, I will use Ubuntu.
|
||||
|
||||
Before we start building our images, let’s “containerize” them! By this I just mean creating directories for all of your Docker images so that you can maintain different projects and stages isolated from each other.
|
||||
|
||||
```
|
||||
$ mkdir dockerprojects
|
||||
|
||||
cd dockerprojects
|
||||
```
|
||||
|
||||
Now create a _Dockerfile_ inside the _dockerprojects_ directory using your favorite text editor; I prefer nano, which is also easy for new users.
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And add this line:
|
||||
|
||||
```
|
||||
FROM Ubuntu
|
||||
```
|
||||
|
||||

|
||||
|
||||
Save it with Ctrl+Exit then Y.
|
||||
|
||||
Now create your new image and provide it with a name (run these commands within the same directory):
|
||||
|
||||
```
|
||||
$ docker build -t dockp .
|
||||
```
|
||||
|
||||
(Note the dot at the end of the command.) This should build successfully, so you'll see:
|
||||
|
||||
```
|
||||
Sending build context to Docker daemon 2.048kB
|
||||
|
||||
Step 1/1 : FROM ubuntu
|
||||
|
||||
---> 2a4cca5ac898
|
||||
|
||||
Successfully built 2a4cca5ac898
|
||||
|
||||
Successfully tagged dockp:latest
|
||||
```
|
||||
|
||||
It’s time to run and test your image:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
```
|
||||
|
||||
You should see root prompt:
|
||||
|
||||
```
|
||||
root@c06fcd6af0e8:/#
|
||||
```
|
||||
|
||||
This means you are literally running bare minimal Ubuntu inside Linux, Windows, or macOS. You can run all native Ubuntu commands and CLI utilities.
|
||||
|
||||

|
||||
|
||||
Let’s check all the Docker images you have in your directory:
|
||||
|
||||
```
|
||||
$docker images
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
dockp latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
hello-world latest f2a91732366c 8 weeks ago 1.85kB
|
||||
```
|
||||
|
||||
You can see all three images: _dockp, Ubuntu_ _,_ and _hello-world_ , which I created a few weeks ago when working on the previous articles of this series. Building a whole LAMP stack can be challenging, so we are going create a simple Apache server image with Dockerfile.
|
||||
|
||||
Dockerfile is basically a set of instructions to install all the needed packages, configure, and copy files. In this case, it’s Apache and Nginx.
|
||||
|
||||
You may also want to create an account on DockerHub and log into your account before building images, in case you are pulling something from DockerHub. To log into DockerHub from the command line, just run:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
```
|
||||
|
||||
Enter your username and password and you are logged in.
|
||||
|
||||
Next, create a directory for Apache inside the dockerproject:
|
||||
|
||||
```
|
||||
$ mkdir apache
|
||||
```
|
||||
|
||||
Create a Dockerfile inside Apache folder:
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
```
|
||||
|
||||
And paste these lines:
|
||||
|
||||
```
|
||||
FROM ubuntu
|
||||
|
||||
MAINTAINER Kimbro Staken version: 0.1
|
||||
|
||||
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
ENV APACHE_RUN_USER www-data
|
||||
|
||||
ENV APACHE_RUN_GROUP www-data
|
||||
|
||||
ENV APACHE_LOG_DIR /var/log/apache2
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
|
||||
```
|
||||
|
||||
Then, build the image:
|
||||
|
||||
```
|
||||
docker build -t apache .
|
||||
```
|
||||
|
||||
(Note the dot after a space at the end.)
|
||||
|
||||
It will take some time, then you should see successful build like this:
|
||||
|
||||
```
|
||||
Successfully built e7083fd898c7
|
||||
|
||||
Successfully tagged ng:latest
|
||||
|
||||
Swapnil:apache swapnil$
|
||||
```
|
||||
|
||||
Now let’s run the server:
|
||||
|
||||
```
|
||||
$ docker run –d apache
|
||||
|
||||
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
|
||||
```
|
||||
|
||||
Eureka. Your container image is running. Check all the running containers:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
|
||||
```
|
||||
|
||||
You can kill the container with the _docker kill_ command:
|
||||
|
||||
```
|
||||
$docker kill a189a4db0f7
|
||||
```
|
||||
|
||||
So, you see the “image” itself is persistent that stays in your directory, but the container runs and goes away. Now you can create as many images as you want and spin and nuke as many containers as you need from those images.
|
||||
|
||||
That’s how to create an image and run containers.
|
||||
|
||||
To learn more, you can open your web browser and check out the documentation about how to build more complicated Docker images like the whole LAMP stack. Here is a[ Dockerfile][5] file for you to play with. In the next article, I’ll show how to push images to DockerHub.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/container-imagejpg-0
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[5]:https://github.com/fauria/docker-lamp/blob/master/Dockerfile
|
||||
@ -1,195 +0,0 @@
|
||||
translated by cyleft
|
||||
|
||||
Migrating to Linux: The Command Line
|
||||
======
|
||||
|
||||

|
||||
|
||||
This is the fourth article in our series on migrating to Linux. If you missed the previous installments, we've covered [Linux for new users][1], [files and filesystems][2], and [graphical environments][3]. Linux is everywhere. It's used to run most Internet services like web servers, email servers, and others. It's also used in your cell phone, your car console, and a whole lot more. So, you might be curious to try out Linux and learn more about how it works.
|
||||
|
||||
Under Linux, the command line is very useful. On desktop Linux systems, although the command line is optional, you will often see people have a command line window open alongside other application windows. On Internet servers, and when Linux is running in a device, the command line is often the only way to interact directly with the system. So, it's good to know at least some command line basics.
|
||||
|
||||
In the command line (often called a shell in Linux), everything is done by entering commands. You can list files, move files, display the contents of files, edit files, and more, even display web pages, all from the command line.
|
||||
|
||||
If you are already familiar with using the command line in Windows (either CMD.EXE or PowerShell), you may want to jump down to the section titled Familiar with Windows Command Line? and read that first.
|
||||
|
||||
### Navigating
|
||||
|
||||
In the command line, there is the concept of the current working directory (Note: A folder and a directory are synonymous, and in Linux they're usually called directories). Many commands will look in this directory by default if no other directory path is specified. For example, typing ls to list files, will list files in this working directory. For example:
|
||||
```
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
```
|
||||
|
||||
The command, ls Documents, will instead list files in the Documents directory:
|
||||
```
|
||||
$ ls Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
You can display the current working directory by typing pwd. For example:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
```
|
||||
|
||||
You can change the current directory by typing cd and then the directory you want to change to. For example:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
```
|
||||
|
||||
A directory path is a list of directories separated by a / (slash) character. The directories in a path have an implied hierarchy, for example, where the path /home/student expects there to be a directory named home in the top directory, and a directory named student to be in that directory home.
|
||||
|
||||
Directory paths are either absolute or relative. Absolute directory paths start with the / character.
|
||||
|
||||
Relative paths start with either . (dot) or .. (dot dot). In a path, a . (dot) means the current directory, and .. (dot dot) means one directory up from the current one. For example, ls ../Documents means look in the directory up one from the current one and show the contents of the directory named Documents in there:
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
$ ls ../Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
When you first open a command line window on a Linux system, your current working directory is set to your home directory, usually: /home/<your login name here>. Your home directory is dedicated to your login where you can store your own files.
|
||||
|
||||
The environment variable $HOME expands to the directory path to your home directory. For example:
|
||||
```
|
||||
$ echo $HOME
|
||||
/home/student
|
||||
```
|
||||
|
||||
The following table shows a summary of some of the common commands used to navigate directories and manage simple text files.
|
||||
|
||||
### Searching
|
||||
|
||||
Sometimes I forget where a file resides, or I forget the name of the file I am looking for. There are a couple of commands in the Linux command line that you can use to help you find files and search the contents of files.
|
||||
|
||||
The first command is find. You can use find to search for files and directories by name or other attribute. For example, if I forgot where I kept my todo.txt file, I can run the following:
|
||||
```
|
||||
$ find $HOME -name todo.txt
|
||||
/home/student/Documents/todo.txt
|
||||
```
|
||||
|
||||
The find program has a lot of features and options. A simple form of the command is:
|
||||
find <directory to search> -name <filename>
|
||||
|
||||
If there is more than one file named todo.txt from the example above, it will show me all the places where it found a file by that name. The find command has many options to search by type (file, directory, or other), by date, newer than date, by size, and more. You can type:
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
to get help on how to use the find command.
|
||||
|
||||
You can also use a command called grep to search inside files for specific contents. For example:
|
||||
```
|
||||
grep "01/02/2018" todo.txt
|
||||
```
|
||||
|
||||
will show me all the lines that have the January 2, 2018 date in them.
|
||||
|
||||
### Getting Help
|
||||
|
||||
There are a lot of commands in Linux, and it would be too much to describe all of them here. So the next best step to show how to get help on commands.
|
||||
|
||||
The command apropos helps you find commands that do certain things. Maybe you want to find out all the commands that operate on directories or get a list of open files, but you don't know what command to run. So, you can try:
|
||||
```
|
||||
apropos directory
|
||||
```
|
||||
|
||||
which will give a list of commands and have the word "directory" in their help text. Or, you can do:
|
||||
```
|
||||
apropos "list open files"
|
||||
```
|
||||
|
||||
which will show one command, lsof, that you can use to list open files.
|
||||
|
||||
If you know the command you need to use but aren't sure which options to use to get it to behave the way you want, you can use the command called man, which is short for manual. You would use man <command>, for example:
|
||||
```
|
||||
man ls
|
||||
```
|
||||
|
||||
You can try man ls on your own. It will give several pages of information.
|
||||
|
||||
The man command explains all the options and parameters you can give to a command, and often will even give an example.
|
||||
|
||||
Many commands often also have a help option (e.g., ls --help), which will give information on how to use a command. The man pages are usually more detailed, while the --help option is useful for a quick lookup.
|
||||
|
||||
### Scripts
|
||||
|
||||
One of the best things about the Linux command line is that the commands that are typed in can be scripted, and run over and over again. Commands can be placed as separate lines in a file. You can put #!/bin/sh as the first line in the file, followed by the commands. Then, once the file is marked as executable, you can run the script as if it were its own command. For example,
|
||||
```
|
||||
--- contents of get_todays_todos.sh ---
|
||||
#!/bin/sh
|
||||
todays_date=`date +"%m/%d/%y"`
|
||||
grep $todays_date $HOME/todos.txt
|
||||
```
|
||||
|
||||
Scripts help automate certain tasks in a set of repeatable steps. Scripts can also get very sophisticated if needed, with loops, conditional statements, routines, and more. There's not space here to go into detail, but you can find more information about Linux bash scripting online.
|
||||
|
||||
Familiar with Windows Command Line?
|
||||
|
||||
If you are familiar with the Windows CMD or PowerShell program, typing commands at a command prompt should feel familiar. However, several things work differently in Linux and if you don't understand those differences, it may be confusing.
|
||||
|
||||
First, under Linux, the PATH environment variable works different than it does under Windows. In Windows, the current directory is assumed to be the first directory on the path, even though it's not listed in the list of directories in PATH. Under Linux, the current directory is not assumed to be on the path, and it is not explicitly put on the path either. Putting . in the PATH environment variable is considered to be a security risk under Linux. In Linux, to run a program in the current directory, you need to prefix it with ./ (which is the file's relative path from the current directory). This trips up a lot of CMD users. For example:
|
||||
```
|
||||
./my_program
|
||||
```
|
||||
|
||||
rather than
|
||||
```
|
||||
my_program
|
||||
```
|
||||
|
||||
In addition, in Windows paths are separated by a ; (semicolon) character in the PATH environment variable. On Linux, in PATH, directories are separated by a : (colon) character. Also in Linux, directories in a single path are separated by a / (slash) character while under Windows directories in a single path are separated by a \ (backslash) character. So a typical PATH environment variable in Windows might look like:
|
||||
```
|
||||
PATH="C:\Program Files;C:\Program Files\Firefox;"
|
||||
while on Linux it might look like:
|
||||
PATH="/usr/bin:/opt/mozilla/firefox"
|
||||
```
|
||||
|
||||
Also note that environment variables are expanded with a $ on Linux, so $PATH expands to the contents of the PATH environment variable whereas in Windows you need to enclose the variable in percent symbols (e.g., %PATH%).
|
||||
|
||||
In Linux, options are commonly passed to programs using a - (dash) character in front of the option, while under Windows options are passed by preceding options with a / (slash) character. So, under Linux, you would do:
|
||||
```
|
||||
a_prog -h
|
||||
```
|
||||
|
||||
rather than
|
||||
```
|
||||
a_prog /h
|
||||
```
|
||||
|
||||
Under Linux, file extensions generally don't signify anything. For example, renaming myscript to myscript.bat doesn't make it executable. Instead to make a file executable, the file's executable permission flag needs to be set. File permissions are covered in more detail next time.
|
||||
|
||||
Under Linux when file and directory names start with a . (dot) character they are hidden. So, for example, if you're told to edit the file, .bashrc, and you don't see it in your home directory, it probably really is there. It's just hidden. In the command line, you can use option -a on the command ls to see hidden files. For example:
|
||||
```
|
||||
ls -a
|
||||
```
|
||||
|
||||
Under Linux, common commands are also different from those in the Windows command line. The following table that shows a mapping from common items used under CMD and the alternative used under Linux.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Keep Accurate Time on Linux with NTP
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
@qhh0205 翻译中
|
||||
Running a Python application on Kubernetes
|
||||
============================================================
|
||||
|
||||
@ -277,4 +278,4 @@ via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
[14]:https://opensource.com/users/nanjekyejoannah
|
||||
[15]:https://opensource.com/users/nanjekyejoannah
|
||||
[16]:https://opensource.com/tags/python
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Your instant Kubernetes cluster
|
||||
============================================================
|
||||
|
||||
@ -168,4 +169,4 @@ via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
|
||||
[12]:https://weave.works/
|
||||
[13]:https://kubernetes.io/docs/tasks/access-application-cluster/web-ui-dashboard/
|
||||
[14]:https://blog.alexellis.io/docker-for-mac-with-kubernetes/
|
||||
[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
|
||||
[15]:https://blog.alexellis.io/your-instant-kubernetes-cluster/#
|
||||
|
||||
@ -1,214 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : Jason Baker for Opensource.com.
|
||||
|
||||
As a long-time member of the documentation team at Scribus, I keep up-to-date with the latest updates of the source so I can help make updates and additions to the documentation. When I recently did a "checkout" using Subversion on a computer I had just upgraded to Fedora 27, I was amazed at how long it took to download the documentation, which consists of HTML pages and associated images. I became concerned that the project's documentation seemed much larger than it should be and suspected that some of the content was "zombie" documentation--HTML files that aren't used anymore and images that have lost all references in the currently used HTML.
|
||||
|
||||
I decided to create a project for myself to figure this out. One way to do this is to search for existing image files that aren't used. If I could scan through all the HTML files for image references, then compare that list to the actual image files, chances are I would see a mismatch.
|
||||
|
||||
Here is a typical image tag:
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I'm interested in the part between the first set of quotation marks, after `src=`. After some searching for a solution, I found a Python module called [BeautifulSoup][1]. The tasty part of the script I wrote looks like this:
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
We can use this `findAll` method to pluck out the image tags. Here is a tiny piece of the output:
|
||||
```
|
||||
|
||||
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
So far, so good. I thought that the next step might be to just carve this down, but when I tried some string methods in the script, it returned errors about this being tags and not strings. I saved the output to a file and went through the process of editing in [KWrite][2]. One nice thing about KWrite is that you can do a "find & replace" using regular expressions (regex), so I could replace `<img` with `\n<img`, which made it easier to see how to carve this down from there. Another nice thing with KWrite is that, if you make an injudicious choice with regex, you can undo it.
|
||||
|
||||
But I thought, surely there is something better than this, so I turned to regex, or more specifically the `re` module for Python. The relevant part of this new script looks like this:
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
And a tiny piece of its output looks like this:
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
At first glance, it looks similar to the output above, and has the nice feature of trimming out parts of the image tag, but there are puzzling inclusions of table tags and other content. I think this relates to this regex expression `src="(.*)/>`, which is termed greedy, meaning it doesn't necessarily stop at the first instance of `/>` it encounters. I should add that I also tried `src="(.*)"` which was really no better. Not being a regexpert (just made this up), my searching around for various ideas to improve this didn't help.
|
||||
|
||||
After a series of other things, even trying out `HTML::Parser` with Perl, I finally tried to compare this to the situation of some scripts that I wrote for Scribus that analyze the contents of a text frame, character by character, then take some action. For my purposes, what I finally came up with improves on all these methods and requires no regex or HTML parser at all. Let's go back to that example `img` tag I showed.
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
I decided to home in on the `src=` piece. One way would be to wait for an occurrence of `s`, then see if the next character is `r`, the next `c`, and the next `=`. If so, bingo! Then what follows between two sets of double quotation marks is what I need. The problem with this is the structure it takes to hang onto these. One way of looking at a string of characters representing a line of HTML text would be:
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
But the logic was just too messy to hang onto the previous `c`, and the one before that, the one before that, and the one before that.
|
||||
|
||||
In the end, I decided to focus on the `=` and to use an indexing method whereby I could easily reference any prior or future character in the string. Here is the searching part:
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
I start the search with the fourth character (indexing starts at 0), so I don't get an indexing error down below, and realistically, there will not be an equal sign before the fourth character of a line. The first test is to see if we find `=` as we're marching through the string, and if not, we march on. If we do see one, then we ask if the three previous characters were `s`, `r`, and `c`, in that order. If that happens, we call the function `imagefound`:
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
We're sending the function the current index, which represents the `=`. We know the next character will be `"`, so we jump two characters and begin adding characters to a holding string named `newimage`, until we reach the following `"`, at which point we're done. We add the string plus a `newline` character to our list `imagelist` and `return`, keeping in mind there may be more image tags in this remaining string of HTML, so we're right back in the middle of our searching loop.
|
||||
|
||||
Here's what our output looks like now:
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
Ahhh, much cleaner, and this only took a few seconds to run. I could have jumped seven more index spots to cut out the `images/` part, but I like having it there to make sure I haven't chopped off the first letter of the image filename, and this is so easy to edit out with KWrite--you don't even need regex. After doing that and saving the file, the next step was to run another script I wrote called `sortlist.py`:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
This pulls in the file contents as a list, sorts it, then saves it as another file. After that I could just do the following:
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
Then I need to run `sortlist.py` on that file too, since the method `ls` uses to sort is different from Python. I could have run a comparison script on these files, but I preferred to do this visually. In the end, I ended up with 42 images that had no HTML reference from the documentation.
|
||||
|
||||
Here is my parsing script in its entirety:
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
Its name, `parseimg4.py`, doesn't really reflect the number of scripts I wrote along the way, with both minor and major rewrites, plus discards and starting over. Notice that I've hardcoded these directory and filenames, but it would be easy enough to generalize, asking for user input for these pieces of information. Also as they were working scripts, I sent the output to `/tmp`, so they disappear once I reboot my system.
|
||||
|
||||
This wasn't the end of the story, since the next question was: What about zombie HTML files? Any of these files that are not used might reference images not picked up by the previous method. We have a `menu.xml` file that serves as the table of contents for the online manual, but I also needed to consider that some files listed in the TOC might reference files not in the TOC, and yes, I did find some.
|
||||
|
||||
I'll conclude by saying that this was a simpler task than this image search, and it was greatly helped by the processes I had already developed.
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[][7] Greg Pittman - Greg is a retired neurologist in Louisville, Kentucky, with a long-standing interest in computers and programming, beginning with Fortran IV in the 1960s. When Linux and open source software came along, it kindled a commitment to learning more, and eventually contributing. He is a member of the Scribus Team.[More about me][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
@ -1,95 +0,0 @@
|
||||
Install AWFFull web server log analysis application on ubuntu 17.10
|
||||
======
|
||||
|
||||
|
||||
AWFFull is a web server log analysis program based on "The Webalizer".AWFFull produces usage statistics in HTML format for viewing with a browser. The results are presented in both columnar and graphical format, which facilitates interpretation. Yearly, monthly, daily and hourly usage statistics are presented, along with the ability to display usage by site, URL, referrer, user agent (browser), user name,search strings, entry/exit pages, and country (some information may not be available if not present in the log file being processed).
|
||||
|
||||
|
||||
|
||||
AWFFull supports CLF (common log format) log files, as well as Combined log formats as defined by NCSA and others, and variations of these which it attempts to handle intelligently. In addition, AWFFull also supports wu-ftpd xferlog formatted log files, allowing analysis of ftp servers, and squid proxy logs. Logs may also be compressed, via gzip.
|
||||
|
||||
AWFFull is a web server log analysis program based on "The Webalizer".AWFFull produces usage statistics in HTML format for viewing with a browser. The results are presented in both columnar and graphical format, which facilitates interpretation. Yearly, monthly, daily and hourly usage statistics are presented, along with the ability to display usage by site, URL, referrer, user agent (browser), user name,search strings, entry/exit pages, and country (some information may not be available if not present in the log file being processed).AWFFull supports CLF (common log format) log files, as well as Combined log formats as defined by NCSA and others, and variations of these which it attempts to handle intelligently. In addition, AWFFull also supports wu-ftpd xferlog formatted log files, allowing analysis of ftp servers, and squid proxy logs. Logs may also be compressed, via gzip.
|
||||
|
||||
If a compressed log file is detected, it will be automatically uncompressed while it is read. Compressed logs must have the standard gzip extension of .gz.
|
||||
|
||||
### Changes from Webalizer
|
||||
|
||||
AWFFull is based on the Webalizer code and has a number of large and small changes. These include:
|
||||
|
||||
o Beyond the raw statistics: Making use of published formulae to provide additional insights into site usage.
|
||||
|
||||
o GeoIP IP Address look-ups for more accurate country detection.
|
||||
|
||||
o Resizable graphs.
|
||||
|
||||
o Integration with GNU gettext allowing for ease of translations.Currently 32 languages are supported.
|
||||
|
||||
o Display more than 12 months of the site history on the front page.
|
||||
|
||||
o Additional page count tracking and sort by same.
|
||||
|
||||
o Some minor visual tweaks, including Geolizer's use of Kb, Mb etc for Volumes.
|
||||
|
||||
o Additional Pie Charts for URL counts, Entry and Exit Pages, and Sites.
|
||||
|
||||
o Horizontal lines on graphs that are more sensible and easier to read.
|
||||
|
||||
o User Agent and Referral tracking is now calculated via PAGES not HITS.
|
||||
|
||||
o GNU style long command line options are now supported (eg --help).
|
||||
|
||||
o Can choose what is a page by excluding "what isn't" vs the original "what is" method.
|
||||
|
||||
o Requests to the site being analysed are displayed with the matching referring URL.
|
||||
|
||||
o A Table of 404 Errors, and the referring URL can be generated.
|
||||
|
||||
o An external CSS file can be used with the generated html.
|
||||
|
||||
o Manual performance optimisation of the config file is now easier with a post analysis summary output.
|
||||
|
||||
o Specified IP's & Addresses can be assigned to a given country.
|
||||
|
||||
o Additional Dump options for detailed analysis with other tools.
|
||||
|
||||
o Lotus Domino v6 logs are now detected and processed.
|
||||
|
||||
**Install awffull on ubuntu 17.10**
|
||||
|
||||
> sudo apt-get install awffull
|
||||
|
||||
### Configuring AWFFULL
|
||||
|
||||
You have to edit awffull config file at /etc/awffull/awffull.conf. If you have multiple virtual websites running in the same machine, you can make several copies of the default config file.
|
||||
|
||||
> sudo vi /etc/awffull/awffull.conf
|
||||
|
||||
Make sure the following lines are there
|
||||
|
||||
> LogFile /var/log/apache2/access.log.1
|
||||
> OutputDir /var/www/html/awffull
|
||||
|
||||
Save and exit the file
|
||||
|
||||
You can run the awffull config using the following command
|
||||
|
||||
> awffull -c [your config file name]
|
||||
|
||||
This will create all the required files under /var/www/html/awffull directory so you can access your webserver stats using http://serverip/awffull/
|
||||
|
||||
You should see similar to the following screen
|
||||
|
||||
If you have more site and you can automate the process using shell script and cron job.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -1,88 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to access/view Python help when using vim
|
||||
======
|
||||
|
||||
I am a new Vim text editor user. I am writing Python code. Is there is a way to see Python documentation within vim and without visiting the Internet? Say my cursor is under the print Python keyword, and I press F1. I want to look at the help for the print keyword. How do I show python help() inside vim? How do I call pydoc3/pydoc to seek help without leaving vim?
|
||||
|
||||
The pydoc or pydoc3 command show text documentation on the name of a Python keyword, topic, function, module, or package, or a dotted reference to a class or function within a module or module in a package. You can call pydoc from vim itself. Let us see how to access Python documentation using pydoc within vim text editor.
|
||||
|
||||
### Access python help using pydoc
|
||||
|
||||
The syntax is:
|
||||
```
|
||||
pydoc keyword
|
||||
pydoc3 keyword
|
||||
pydoc len
|
||||
pydoc print
|
||||
```
|
||||
Edit your ~/.vimrc:
|
||||
`$ vim ~/.vimrc`
|
||||
Append the following configuration for pydoc3 (python v3.x docs). Create a mapping for H key that works in normal mode:
|
||||
```
|
||||
nnoremap <buffer> H :<C-u>execute "!pydoc3 " . expand("<cword>")<CR>
|
||||
```
|
||||
|
||||
|
||||
Save and close the file. Open vim text editor:
|
||||
`$ vim file.py`
|
||||
Write some code:
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
x=5
|
||||
y=10
|
||||
z=x+y
|
||||
print(z)
|
||||
print("Hello world")
|
||||
```
|
||||
|
||||
Position cursor under the print Python keyword and press Shift followed by H. You will see output as follows:
|
||||
|
||||
[![Access Python Help Within Vim][1]][1]
|
||||
Gif.01: Press H to view help for the print Python keyword
|
||||
|
||||
### How to view python help when using vim
|
||||
|
||||
[jedi-vim][2] is a VIM binding to the autocompletion library Jed. It can do many things including display help for keyword when you press Shift followed by K i.e. press capital K.
|
||||
|
||||
#### How to install jedi-vim on Linux or Unix-like system
|
||||
|
||||
Use [pathogen][3], [vim-plug][4] or [Vundle][5] to install jedi-vim. I am using Vim-Plug. Add the following line in ~/vimrc:
|
||||
`Plug 'davidhalter/jedi-vim'`
|
||||
Save and close the file. Start vim and type:
|
||||
`PlugInstall`
|
||||
On Arch Linux, you can also install jedi-vim from official repositories as vim-jedi using pacman command:
|
||||
`$ sudo pacman -S vim-jedi`
|
||||
It is also available on Debian (?8) and Ubuntu (?14.04) as vim-python-jedi using [apt command][6]/[apt-get command][7]:
|
||||
`$ sudo apt install vim-python-jedi`
|
||||
On Fedora Linux, it is available as vim-jedi using dnf command:
|
||||
`$ sudo dnf install vim-jedi`
|
||||
Jedi is by default automatically initialized. So no further configuration needed on your part. To see Documentation/Pydoc press K. It shows a popup with assignments:
|
||||
[![How to view python help when using vim][8]][8]
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][9], [Facebook][10], [Google+][11].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-access-view-python-help-when-using-vim/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2018/01/Access-Python-Help-Within-Vim.gif
|
||||
[2]:https://github.com/davidhalter/jedi-vim
|
||||
[3]:https://github.com/tpope/vim-pathogen
|
||||
[4]:https://www.cyberciti.biz/programming/vim-plug-a-beautiful-and-minimalist-vim-plugin-manager-for-unix-and-linux-users/
|
||||
[5]:https://github.com/gmarik/vundle
|
||||
[6]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[8]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-view-Python-Documentation-using-pydoc-within-vim-on-Linux-Unix.jpg
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Microservices vs. monolith: How to choose
|
||||
============================================================
|
||||
|
||||
@ -173,4 +174,4 @@ via: https://opensource.com/article/18/1/how-choose-between-monolith-microservic
|
||||
[19]:https://opensource.com/users/jakelumetta
|
||||
[20]:https://opensource.com/users/jakelumetta
|
||||
[21]:https://opensource.com/tags/microservices
|
||||
[22]:https://opensource.com/tags/devops
|
||||
[22]:https://opensource.com/tags/devops
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
How to Run Your Own Public Time Server on Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,98 +0,0 @@
|
||||
A File Transfer Utility To Download Only The New Parts Of A File
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just because Internet plans are getting cheaper every day, you shouldn’t waste your data by repeatedly downloading the same stuff over and over. The one fine example is downloading development version of Ubuntu or any Linux images. As you may know, Ubuntu developers releases daily builds, alpha, beta ISO images every few months for testing. In the past, I used to download those images whenever they are available to test and review each edition. Not anymore! Thanks to **Zsync** file transfer program. Now it is possible to download only the new parts of the ISO image. This will save you a lot of time and Internet bandwidth. Not just time and bandwidth, it will save you the resources on server side and client side.
|
||||
|
||||
Zsync uses the same algorithm as **Rsync** , but it only download the new parts of a file that you have a copy of an older version of the file on your computer already. Rsync is mainly for synchronizing data between computers, whereas Zsync is for distributing data. To put this simply, the one file on a central location can be distributed to thousands of downloaders using Zsync. It is completely free and open source released under the Artistic License V2.
|
||||
|
||||
### Installing Zsync
|
||||
|
||||
Zsync is available in the default repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives, install it using command:
|
||||
```
|
||||
$ sudo pacman -S zsync
|
||||
|
||||
```
|
||||
|
||||
On **Fedora** :
|
||||
|
||||
Enable Zsync repository:
|
||||
```
|
||||
$ sudo dnf copr enable ngompa/zsync
|
||||
|
||||
```
|
||||
|
||||
And install it using command:
|
||||
```
|
||||
$ sudo dnf install zsync
|
||||
|
||||
```
|
||||
|
||||
On **Debian, Ubuntu, Linux Mint** :
|
||||
```
|
||||
$ sudo apt-get install zsync
|
||||
|
||||
```
|
||||
|
||||
For other distributions, you can download the binary from the [**Zsync download page**][1] and manually compile and install it as shown below.
|
||||
```
|
||||
$ wget http://zsync.moria.org.uk/download/zsync-0.6.2.tar.bz2
|
||||
$ tar xjf zsync-0.6.2.tar.bz2
|
||||
$ cd zsync-0.6.2/
|
||||
$ configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Please be mindful that **zsync is only useful if people offer zsync downloads**. Currently, Debian, Ubuntu (all flavours) ISO images are available as .zsync downloads. For example, visit the following link.
|
||||
|
||||
As you may noticed, Ubuntu 18.04 LTS daily build is available as direct ISO and .zsync file. If you download .ISO file, you have to download the full ISO whenever the ISO gets new updates. But, if you download .zsync file, the Zsync will download only the new changes in future. You don’t need to download the whole ISO image each time.
|
||||
|
||||
A .zsync file contains a meta-data needed by zsync program. This file contains the pre-calculated checksums for the rsync algorithm; it is generated on the server, once, and is then used by any number of downloaders. To download a .zsync file using Zsync client program, all you have to do:
|
||||
```
|
||||
$ zsync <.zsync-file-URL>
|
||||
|
||||
```
|
||||
|
||||
Example:
|
||||
```
|
||||
$ zsync http://cdimage.ubuntu.com/ubuntu/daily-live/current/bionic-desktop-amd64.iso.zsync
|
||||
|
||||
```
|
||||
|
||||
If you already have the old image file on your system, Zsync will calculate the difference between the old and new file in the remote server and download only the new parts. You will see the calculation process as a series of dots or stars on your Terminal.
|
||||
|
||||
If there is an old version of the file you’re just downloading is available in the current working directory, Zsync will download only the new parts. Once the download is finished, you will get two images, the one you just downloaded and the old image with **.iso.zs-old** extension on its filename.
|
||||
|
||||
If there is no relevent local data found, Zsync will download the whole file.
|
||||
|
||||
|
||||
|
||||
You can cancel the download process at any time by pressing **CTRL-C**.
|
||||
|
||||
Just imagine if you use the direct .ISO file or torrent, you will lose around 1.4GB bandwidth whenever you download new image. So, instead of downloading entire alpha, beta and daily build images, Zsync just downloads the new parts of the ISO file that you already have a copy of an older version of it on your system.
|
||||
|
||||
And, that’s all for today. Hope this helps. I will be soon here with another useful guide. Until then stay tuned with OSTechNix!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-file/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://zsync.moria.org.uk/downloads
|
||||
@ -1,535 +0,0 @@
|
||||
Manage printers and printing
|
||||
======
|
||||
|
||||
|
||||
### Printing in Linux
|
||||
|
||||
Although much of our communication today is electronic and paperless, we still have considerable need to print material from our computers. Bank statements, utility bills, financial and other reports, and benefits statements are just some of the items that we still print. This tutorial introduces you to printing in Linux using CUPS.
|
||||
|
||||
CUPS, formerly an acronym for Common UNIX Printing System, is the printer and print job manager for Linux. Early computer printers typically printed lines of text in a particular character set and font size. Today's graphical printers are capable of printing both graphics and text in a variety of sizes and fonts. Nevertheless, some of the commands you use today have their history in the older line printer daemon (LPD) technology.
|
||||
|
||||
This tutorial helps you prepare for Objective 108.4 in Topic 108 of the Linux Server Professional (LPIC-1) exam 102. The objective has a weight of 2.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX® commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Fedora 27 for examples.
|
||||
|
||||
### Some printing history
|
||||
|
||||
This small history is not part of the LPI objectives but may help you with context for this objective.
|
||||
|
||||
Early computers mostly used line printers. These were impact printers that printed a line of text at a time using fixed-pitch characters and a single font. To speed up overall system performance, early mainframe computers interleaved work for slow peripherals such as card readers, card punches, and line printers with other work. Thus was born Simultaneous Peripheral Operation On Line or spooling, a term that is still commonly used when talking about computer printing.
|
||||
|
||||
In UNIX and Linux systems, printing initially used the Berkeley Software Distribution (BSD) printing subsystem, consisting of a line printer daemon (lpd) running as a server, and client commands such as `lpr` to submit jobs for printing. This protocol was later standardized by the IETF as RFC 1179, **Line Printer Daemon Protocol**.
|
||||
|
||||
System also had a printing daemon. It was functionally similar to the Berkeley LPD, but had a different command set. You will frequently see two commands with different options that accomplish the same task. For example, `lpr` from the Berkeley implementation and `lp` from the System V implementation each print files.
|
||||
|
||||
Advances in printer technology made it possible to mix different fonts on a page and to print images as well as words. Variable pitch fonts, and more advanced printing techniques such as kerning and ligatures, are now standard. Several improvements to the basic lpd/lpr approach to printing were devised, such as LPRng, the next generation LPR, and CUPS.
|
||||
|
||||
Many printers capable of graphical printing initially used the Adobe PostScript language. A PostScript printer has an engine that interprets the commands in a print job and produces finished pages from these commands. PostScript is often used as an intermediate form between an original file, such as a text or an image file, and a final form suitable for a particular printer that does not have PostScript capability. Conversion of a print job, such as an ASCII text file or a JPEG image to PostScript, and conversion from PostScript to the final raster form required for a non-PostScript printer is done using filters.
|
||||
|
||||
Today, Portable Document Format (PDF), which is based on PostScript, has largely replaced raw PostScript. PDF is designed to be independent of hardware and software and to encapsulate a full description of the pages to be printed. You can view PDF files as well as print them.
|
||||
|
||||
### Manage print queues
|
||||
|
||||
Users direct print jobs to a logical entity called a print queue. In single-user systems, a print queue and a printer are usually equivalent. However, CUPS allows a system without an attached printer to queue print jobs for eventual printing on a remote system, and, through the use of classes to allow a print job directed to a class to be printed on the first available printer of that class.
|
||||
|
||||
You can inspect and manipulate print queues. Some of the commands to do so are new for CUPS. Others are compatibility commands that have their roots in LPD commands, although the current options are usually a limited subset of the original LPD printing system options.
|
||||
|
||||
You can check the queues known to the system using the CUPS `lpstat` command. Some common options are shown in Table 1.
|
||||
|
||||
###### Table 1. Options for lpstat
|
||||
| Option | Purpose |
|
||||
| -a | Display accepting status of printers. |
|
||||
| -c | Display print classes. |
|
||||
| -p | Display print status: enabled or disabled. |
|
||||
| -s | Display default printer, printers, and classes. Equivalent to -d -c -v. Note that multiple options must be separated as values can be specified for many. |
|
||||
| -s | Display printers and their devices. |
|
||||
|
||||
|
||||
You may also use the LPD `lpc` command, found in /usr/sbin, with the `status` option. If you do not specify a printer name, all queues are listed. Listing 1 shows some examples of both commands.
|
||||
|
||||
###### Listing 1. Displaying available print queues
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
This example shows two printers, HL-2280DW and XP-610, and a class, `anyprint`, which allows print jobs to be directed to the first available of these two printers.
|
||||
|
||||
In this example, queuing of print jobs to HL-2280DW is currently disabled, although printing is enabled, as might be done in order to drain the queue before taking the printer offline for maintenance. Whether queuing is enabled or disabled is controlled by the `cupsaccept` and `cupsreject` commands. Formerly, these were `accept` and `reject`, but you will probably find these commands in /usr/sbin are now just links to the newer commands. Similarly, whether printing is enabled or disabled is controlled by the `cupsenable` and `cupsdisable` commands. In earlier versions of CUPS, these were called `enable` and `disable`, which allowed confusion with the builtin bash shell `enable`. Listing 2 shows how to enable queuing on printer HL-2280DW while disabling printing. Several of the CUPS commands support a `-r` option to give a reason for the action. This reason is displayed when you use `lpstat`, but not if you use `lpc`.
|
||||
|
||||
###### Listing 2. Enabling queuing and disabling printing
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
Note that an authorized user must perform these tasks. This may be root or another authorized user. See the SystemGroup entry in /etc/cups/cups-files.conf and the man page for cups-files.conf for more information on authorizing user groups.
|
||||
|
||||
### Manage user print jobs
|
||||
|
||||
Now that you have seen a little of how to check on print queues and classes, I will show you how to manage jobs on printer queues. The first thing you might want to do is find out whether any jobs are queued for a particular printer or for all printers. You do this with the `lpq` command. If no option is specified, `lpq` displays the queue for the default printer. Use the `-P` option with a printer name to specify a particular printer or the `-a` option to specify all printers, as shown in Listing 3.
|
||||
|
||||
###### Listing 3. Checking print queues with lpq
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
In this example, five jobs, 4, 6, 7, 8, and 9, are queued for the printer named HL-2280DW and none for XP-610. Using the `-P` option in this case simply shows that the printer is ready but has no queued hobs. Note that CUPS printer names are not case-sensitive. Note also that user ian submitted a job twice, a common user action when a job does not print the first time.
|
||||
|
||||
In general, you can view or manipulate your own print jobs, but root or another authorized user is usually required to manipulate the jobs of others. Most CUPS commands also encrypted communication between the CUPS client command and CUPS server using a `-E` option
|
||||
|
||||
Use the `lprm` command to remove one of the .bashrc jobs from the queue. With no options, the current job is removed. With the `-` option, all jobs are removed. Otherwise, specify a list of jobs to be removed as shown in Listing 4.
|
||||
|
||||
###### Listing 4. Deleting print jobs with lprm
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
Note that user pat was not able to remove the first job on the queue, because it was for user ian. However, ian was able to remove his own job number 8.
|
||||
|
||||
Another command that will help you manipulate jobs on print queues is the `lp` command. Use it to alter attributes of jobs, such as priority or number of copies. Let us assume user ian wants his job 9 to print before those of user pat, and he really did want two copies of it. The job priority ranges from a lowest priority of 1 to a highest priority of 100 with a default of 50. User ian could use the `-i`, `-n`, and `-q` options to specify a job to alter and a new number of copies and priority as shown in Listing 5. Note the use of the `-l` option of the `lpq` command, which provides more verbose output.
|
||||
|
||||
###### Listing 5. Changing the number of copies and priority with lp
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
Finally, the `lpmove` command allows jobs to be moved from one queue to another. For example, we might want to do this because printer HL-2280DW is not currently printing. You can specify just a hob number, such as 9, or you can qualify it with the queue name and a hyphen, such as HL-2280DW-0. The `lpmove` command requires an authorized user. Listing 6 shows how to move these jobs to another queue, specifying first by printer and job ID, then all jobs for a given printer. By the time we check the queues again, one of the jobs is already printing.
|
||||
|
||||
###### Listing 6. Moving jobs to another print queue with lpmove
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
If you happen to use a print server that is not CUPS, such as LPD or LPRng, many of the queue administration functions are handled as subcommands of the `lpc` command. For example, you might use `lpc topq` to move a job to the top of a queue. Other `lpc` subcommands include `disable`, `down`, `enable`, `hold`, `move`, `redirect`, `release`, and `start`. These subcommands are not implemented in the CUPS `lpc` compatibility command.
|
||||
|
||||
#### Printing files
|
||||
|
||||
How are print jobs erected? Many graphical programs provide a method of printing, usually under the **File** menu option. These programs provide graphical tools for choosing a printer, margin sizes, color or black-and-white printing, number of copies, selecting 2-up printing (which is 2 pages per sheet, often used for handouts), and so on. Here I show you the command-line tools for controlling such features, and then a graphical implementation for comparison.
|
||||
|
||||
The simplest way to print any file is to use the `lpr` command and provide the file name. This prints the file on the default printer. The `lp` command can print files as well as modify print jobs. Listing 7 shows a simple example using both commands. Note that `lpr` quietly spools the job, but `lp` displays the job number of the spooled job.
|
||||
|
||||
###### Listing 7. Printing with lpr and lp
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
Table 2 shows some options that you may use with `lpr`. Note that `lp` has similar options to `lpr`, but names may differ; for example, `-#` on `lpr` is equivalent to `-n` on `lp`. Check the man pages for more information.
|
||||
|
||||
###### Table 2. Options for lpr
|
||||
|
||||
| Option | Purpose |
|
||||
| -C, -J, or -T | Set a job name. |
|
||||
| -P | Select a particular printer. |
|
||||
| -# | Specify number of copies. Note this is different from the -n option you saw with the lp command. |
|
||||
| -m | Send email upon job completion. |
|
||||
| -l | Indicate that the print file is already formatted for printing. Equivalent to -o raw. |
|
||||
| -o | Set a job option. |
|
||||
| -p | Format a text file with a shaded header. Equivalent to -o prettyprint. |
|
||||
| -q | Hold (or queue) the job for later printing. |
|
||||
| -r | Remove the file after it has been spooled for printing. |
|
||||
|
||||
Listing 8 shows some of these options in action. I request an email confirmation after printing, that the job be held and that the file be deleted after printing.
|
||||
|
||||
###### Listing 8. Printing with lpr
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
I now have a held job in the HL-2280DW print queue. What to do? The `lp` command has options to hold and release jobs, using various values with the `-H` option. Listing 9 shows how to release the held job. Check the `lp` man page for information on other options.
|
||||
|
||||
###### Listing 9. Resuming printing of a held print job
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
Not all of the vast array of available printers support the same set of options. Use the `lpoptions` command to see the general options that are set for a printer. Add the `-l` option to display printer-specific options. Listing 10 shows two examples. Many common options relate to portrait/landscape printing, page dimensions, and placement of the output on the pages. See the man pages for details.
|
||||
|
||||
###### Listing 10. Checking printer options
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
Most GUI applications have a print dialog, often using the **File >Print** menu choice. Figure 1 shows an example in GIMP, an image manipulation program.
|
||||
|
||||
###### Figure 1. Printing from the GIMP
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
So far, all our commands have been implicitly directed to the local CUPS print server. You can also direct most commands to the server on another system, by specifying the `-h` option along with a port number if it is not the CUPS default of 631.
|
||||
|
||||
### CUPS and the CUPS server
|
||||
|
||||
At the heart of the CUPS printing system is the `cupsd` print server which runs as a daemon process. The CUPS configuration file is normally located in /etc/cups/cupsd.conf. The /etc/cups directory also contains other configuration files related to CUPS. CUPS is usually started during system initialization, but may be controlled by the CUPS script located in /etc/rc.d/init.d or /etc/init.d, according to your distribution. For newer systems using systemd initialization, the CUPS service script is likely in /usr/lib/systemd/system/cups.service. As with most such scripts, you can stop, start, or restart the daemon. See our tutorial [Learn Linux, 101: Runlevels, boot targets, shutdown, and reboot][4] for more information on using initialization scripts.
|
||||
|
||||
The configuration file, /etc/cups/cupsd.conf, contains parameters that control things such as access to the printing system, whether remote printing is allowed, the location of spool files, and so on. On some systems, a second part describes individual print queues and is usually generated automatically by configuration tools. Listing 11 shows some entries for a default cupsd.conf file. Note that comments start with a # character. Defaults are usually shown as comments and entries that are changed from the default have the leading # character removed.
|
||||
|
||||
###### Listing 11. Parts of a default /etc/cups/cupsd.conf file
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
File, directory, and user configuration directives that used to be allowed in cupsd.conf are now stored in cups-files.conf instead. This is to prevent certain types of privilege escalation attacks. Listing 12 shows some entries from cups-files.conf. Note that spool files are stored by default in the /var/spool file system as you would expect from the Filesystem Hierarchy Standard (FHS). See the man pages for cupsd.conf and cups-files.conf for more details on these configuration files.
|
||||
|
||||
###### Listing 12. Parts of a default /etc/cups/cups-files.conf
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
Listing 12 refers to the /etc/printcap file. This was the name of the configuration file for LPD print servers, and some applications still use it to determine available printers and their properties. It is usually generated automatically in a CUPS system, so you will probably not modify it yourself. However, you may need to check it if you are diagnosing user printing problems. Listing 13 shows an example.
|
||||
|
||||
###### Listing 13. Automatically generated /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
Each line here has a printer name and printer description as well as the name of the remote machine (rm) and remote printer (rp) on that machine. Older /etc/printcap file also described the printer capabilities.
|
||||
|
||||
#### File conversion filters
|
||||
|
||||
You can print many types of files using CUPS, including plain text, PDF, PostScript, and a variety of image formats without needing to tell the `lpr` or `lp` command anything more than the file name. This magic feat is accomplished through the use of filters. Indeed, a popular filter for many years was named magicfilter.
|
||||
|
||||
CUPS uses Multipurpose Internet Mail Extensions (MIME) types to determine the appropriate conversion filter when printing a file. Other printing packages might use the magic number mechanism as used by the `file` command. See the man pages for `file` or `magic` for more details.
|
||||
|
||||
Input files are converted to an intermediate raster or PostScript format using filters. Job information such as number of copies is added. The data is finally sent through a beckend to the destination printer. There are some filters (such as `a2ps` or `dvips`) that you can use to manually filter input. You might do this to obtain special formatting results, or to handle a file format that CUPS does not support natively.
|
||||
|
||||
#### Adding printers
|
||||
|
||||
CUPS supports a variety of printers, including:
|
||||
|
||||
* Locally attached parallel and USB printers
|
||||
* Internet Printing Protocol (IPP) printers
|
||||
* Remote LPD printers
|
||||
* Microsoft® Windows® printers using SAMBA
|
||||
* Novell printers using NCP
|
||||
* HP Jetdirect attached printers
|
||||
|
||||
|
||||
|
||||
Most systems today attempt to autodetect and autoconfigure local hardware when the system starts or when the device is attached. Similarly, many network printers can be autodetected. Use the CUPS web administration tool ((<http://localhost:631> or <http://127.0.0.1:631>) to search for or add printers. Many distributions include their own configuration tools, for example YaST on SUSE systems. Figure 2 shows the CUPS interface using localhost:631 and Figure 3 shows the GNOME printer settings dialog on Fedora 27.
|
||||
|
||||
###### Figure 2. Using the CUPS web interface
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### Figure 3. Using printer settings on Fedora 27
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
You can also configure printers from a command line. Before you configure a printer, you need some basic information about the printer and about how it is connected. If a remote system needs a user ID or password, you will also need that information.
|
||||
|
||||
You need to know what driver to use for your printer. Not all printers are fully supported on Linux and some may not work at all, or only with limitations. Check at OpenPrinting.org (see Related topics) to see if there is a driver for your particular printer. The `lpinfo` command can also help you identify the available device types and drivers. Use the `-v` option to list supported devices and the `-m` option to list drivers, as shown in Listing 14.
|
||||
|
||||
###### Listing 14. Available printer drivers
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
The Epson-XP-610_Series-epson-escpr-en.ppd.gz driver is located in the /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ directory on my system.
|
||||
|
||||
Is you don't find a driver, check the printer manufacturer's website in case a proprietary driver is available. For example, at the time of writing Brother has a driver for my HL-2280DW printer, but this driver is not listed at OpenPrinting.org.
|
||||
|
||||
Once you have the basic information, you can configure a printer using the `lpadmin` command as shown in Listing 15. For this purpose, I will create another instance of my HL-2280DW printer for duplex printing.
|
||||
|
||||
###### Listing 15. Configuring a printer
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
Rather than creating a copy of the printer for duplex printing, you can just create a new class for duplex printing using `lpadmin` with the `-c` option .
|
||||
|
||||
If you need to remove a printer, use `lpadmin` with the `-x` option.
|
||||
|
||||
Listing 16 shows how to remove the printer and create a class instead.
|
||||
|
||||
###### Listing 16. Removing a printer and creating a class
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
You can also set various printer options using the `lpadmin` or `lpoptions` commands. See the man pages for more details.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If you are having trouble printing, try these tips:
|
||||
|
||||
* Ensure that the CUPS server is running. You can use the `lpstat` command, which will report an error if it is unable to connect to the cupsd daemon. Alternatively, you might use the `ps -ef` command and check for cupsd in the output.
|
||||
* If you try to queue a job for printing and get an error message indicating that the printer is not accepting jobs results, use `lpstat -a` or `lpc status` to check that the printer is accepting jobs.
|
||||
* If a queued job does not print, use `lpstat -p` or `lpc status` to check that the printer is accepting jobs. You may need to move the job to another printer as discussed earlier.
|
||||
* If the printer is remote, check that it still exists on the remote system and that it is operational.
|
||||
* Check the configuration file to ensure that a particular user or remote system is allowed to print on the printer.
|
||||
* Ensure that your firewall allows remote printing requests, either from another system to your system, or from your system to another, as appropriate.
|
||||
* Verify that you have the right driver.
|
||||
|
||||
|
||||
|
||||
As you can see, printing involves the correct functioning of several components of your system and possibly network. In a tutorial of this length, we can only give you starting points for diagnosis. Most CUPS systems also have a graphical interface to the command-line functions that we discuss here. Generally, this interface is accessible from the local host using a browser pointed to port 631 (<http://localhost:631> or <http://127.0.0.1:631>), as shown earlier in Figure 2.
|
||||
|
||||
You can debug CUPS by running it in the foreground rather than as a daemon process. You can also test alternate configuration files if necessary. Run `cupsd -h` for more information, or see the man pages.
|
||||
|
||||
CUPS also maintains an access log and an error log. You can change the level of logging using the LogLevel statement in cupsd.conf. By default, logs are stored in the /var/log/cups directory. They may be viewed from the **Administration** tab on the browser interface (<http://localhost:631>). Use the `cupsctl` command without any options to display logging options. Either edit cupsd.conf, or use `cupsctl` to adjust various logging parameters. See the `cupsctl` man page for more details.
|
||||
|
||||
The Ubuntu Wiki also has a good page on [Debugging Printing Problems][7].
|
||||
|
||||
This concludes your introduction to printing and CUPS.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
@ -0,0 +1,203 @@
|
||||
How to clone, modify, add, and delete files in Git
|
||||
======
|
||||

|
||||
|
||||
In the [first article in this series][1] on getting started with Git, we created a simple Git repo and added a file to it by connecting it with our computer. In this article, we will learn a handful of other things about Git, namely how to clone (download), modify, add, and delete files in a Git repo.
|
||||
|
||||
### Let's make some clones
|
||||
|
||||
Say you already have a Git repo on GitHub and you want to get your files from it—maybe you lost the local copy on your computer or you're working on a different computer and want access to the files in your repository. What should you do? Download your files from GitHub? Exactly! We call this "cloning" in Git terminology. (You could also download the repo as a ZIP file, but we'll explore the clone method in this article.)
|
||||
|
||||
Let's clone the repo, called Demo, we created in the last article. (If you have not yet created a Demo repo, jump back to that article and do those steps before you proceed here.) To clone your file, just open your browser and navigate to `https://github.com/<your_username>/Demo` (where `<your_username>` is the name of your own repo. For example, my repo is `https://github.com/kedark3/Demo`). Once you navigate to that URL, click the "Clone or download" button, and your browser should look something like this:
|
||||
|
||||
|
||||
|
||||
As you can see above, the "Clone with HTTPS" option is open. Copy your repo's URL from that dropdown box (`https://github.com/<your_username>/Demo.git`). Open the terminal and type the following command to clone your GitHub repo to your computer:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
Then, to see the list of files in the `Demo` directory, enter the command:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
Your terminal should look like this:
|
||||
|
||||

|
||||
|
||||
### Modify files
|
||||
|
||||
Now that we have cloned the repo, let's modify the files and update them on GitHub. To begin, enter the commands below, one by one, to change the directory to `Demo/`, check the contents of `README.md`, echo new (additional) content to `README.md`, and check the status with `git status`:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
This is how it will look in the terminal if you run these commands one by one:
|
||||
|
||||

|
||||
|
||||
Let's look at the output of `git status` and walk through what it means. Don't worry about the part that says:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
|
||||
because we haven't learned it yet. The next line says: `Changes not staged for commit`; this is telling you that the files listed below it aren't marked ready ("staged") to be committed. If you run `git add`, Git takes those files and marks them as `Ready for commit`; in other (Git) words, `Changes staged for commit`. Before we do that, let's check what we are adding to Git with the `git diff` command, then run `git add`.
|
||||
|
||||
Here is your terminal output:
|
||||
|
||||

|
||||
|
||||
Let's break this down:
|
||||
|
||||
* `diff --git a/README.md b/README.md` is what Git is comparing (i.e., `README.md` in this example).
|
||||
* `--- a/README.md` would show anything removed from the file.
|
||||
* `+++ b/README.md` would show anything added to your file.
|
||||
* Anything added to the file is printed in green text with a + at the beginning of the line.
|
||||
* If we had removed anything, it would be printed in red text with a - sign at the beginning.
|
||||
* Git status now says `Changes to be committed:` and lists the filename (i.e., `README.md`) and what happened to that file (i.e., it has been `modified` and is ready to be committed).
|
||||
|
||||
|
||||
|
||||
Tip: If you have already run `git add`, and now you want to see what's different, the usual `git diff` won't yield anything because you already added the file. Instead, you must use `git diff --cached`. It will show you the difference between the current version and previous version of files that Git was told to add. Your terminal output would look like this:
|
||||
|
||||
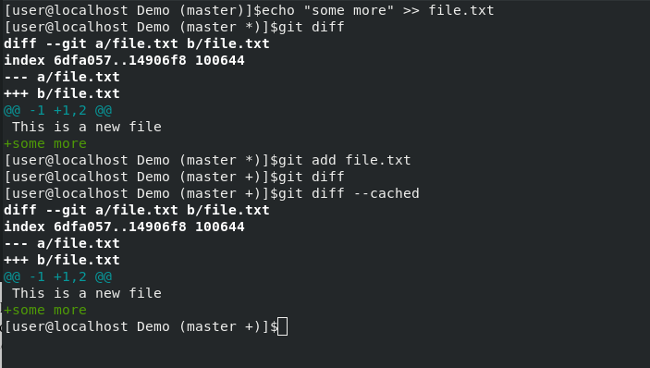
|
||||
|
||||
### Upload a file to your repo
|
||||
|
||||
We have modified the `README.md` file with some new content and it's time to upload it to GitHub.
|
||||
|
||||
Let's commit the changes and push those to GitHub. Run:
|
||||
```
|
||||
git commit -m "Updated Readme file"
|
||||
|
||||
```
|
||||
|
||||
This tells Git that you are "committing" to changes that you have "added" to it. You may recall from the first part of this series that it's important to add a message to explain what you did in your commit so you know its purpose when you look back at your Git log later. (We will look more at this topic in the next article.) `Updated Readme file` is the message for this commit—if you don't think this is the most logical way to explain what you did, feel free to write your commit message differently.
|
||||
|
||||
Run `git push -u origin master`. This will prompt you for your username and password, then upload the file to your GitHub repo. Refresh your GitHub page, and you should see the changes you just made to `README.md`.
|
||||
|
||||
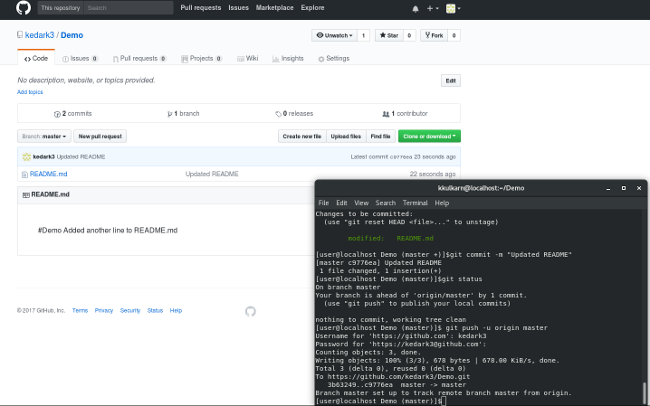
|
||||
|
||||
The bottom-right corner of the terminal shows that I committed the changes, checked the Git status, and pushed the changes to GitHub. Git status says:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
The first line indicates there is one commit in the local repo but not present in origin/master (i.e., on GitHub). The next line directs us to push those changes to origin/master, and that is what we did. (To refresh your memory on what "origin" means in this case, refer to the first article in this series. I will explain what "master" means in the next article, when we discuss branching.)
|
||||
|
||||
### Add a new file to Git
|
||||
|
||||
Now that we have modified a file and updated it on GitHub, let's create a new file, add it to Git, and upload it to GitHub. Run:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a new file named `file.txt`.
|
||||
|
||||
If you `cat` it out:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
|
||||
You should see the contents of the file. Now run:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Git reports that you have an untracked file (named `file.txt`) in your repository. This is Git's way of telling you that there is a new file in the repo directory on your computer that you haven't told Git about, and Git is not tracking that file for any changes you make.
|
||||
|
||||
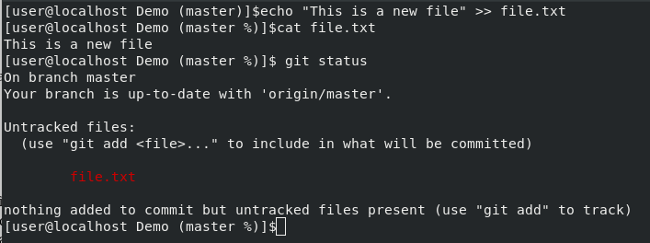
|
||||
|
||||
We need to tell Git to track this file so we can commit it and upload it to our repo. Here's the command to do that:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Your terminal output is:
|
||||
|
||||

|
||||
|
||||
Git status is telling you there are changes to `file.txt` to be committed, and that it is a `new file` to Git, which it was not aware of before this. Now that we have added `file.txt` to Git, we can commit the changes and push it to origin/master.
|
||||
|
||||

|
||||
|
||||
Git has now uploaded this new file to GitHub; if you refresh your GitHub page, you should see the new file, `file.txt`, in your Git repo on GitHub.
|
||||
|
||||
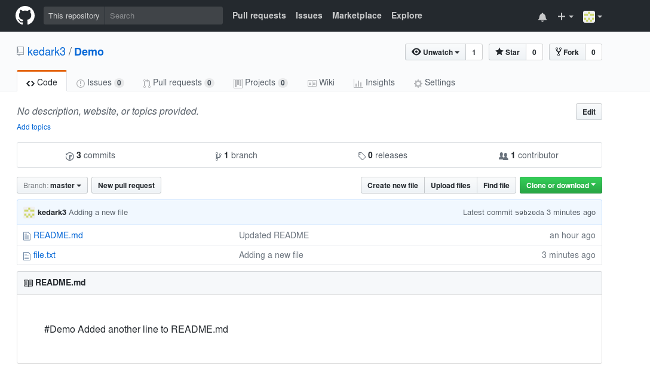
|
||||
|
||||
With these steps, you can create as many files as you like, add them to Git, and commit and push them up to GitHub.
|
||||
|
||||
### Delete a file from Git
|
||||
|
||||
What if we discovered we made an error and need to delete `file.txt` from our repo. One way is to remove the file from our local copy of the repo with this command:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
If you do `git status` now, Git says there is a file that is `not staged for commit` and it has been `deleted` from the local copy of the repo. If we now run:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
I know we are deleting the file, but we still run `git add` ** because we need to tell Git about the **change** we are making. `git add` ** can be used when we are adding a new file to Git, modifying contents of an existing file and adding it to Git, or deleting a file from a Git repo. Effectively, `git add` takes all the changes into account and stages those changes for commit. If in doubt, carefully look at output of each command in the terminal screenshot below.
|
||||
|
||||
Git will tell us the deleted file is staged for commit. As soon as you commit this change and push it to GitHub, the file will be removed from the repo on GitHub as well. Do this by running:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
Now your terminal looks like this:
|
||||
|
||||
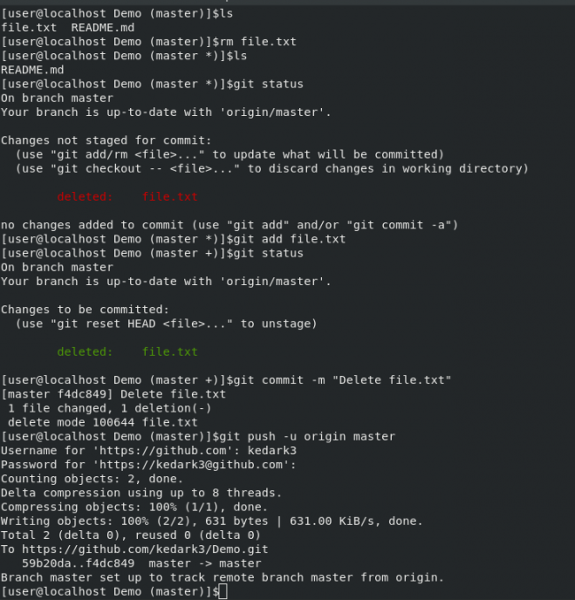
|
||||
|
||||
And your GitHub looks like this:
|
||||
|
||||
|
||||
|
||||
Now you know how to clone, add, modify, and delete Git files from your repo. The next article in this series will examine Git branching.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
@ -0,0 +1,256 @@
|
||||
Build a bikesharing app with Redis and Python
|
||||
======
|
||||
|
||||

|
||||
|
||||
I travel a lot on business. I'm not much of a car guy, so when I have some free time, I prefer to walk or bike around a city. Many of the cities I've visited on business have bikeshare systems, which let you rent a bike for a few hours. Most of these systems have an app to help users locate and rent their bikes, but it would be more helpful for users like me to have a single place to get information on all the bikes in a city that are available to rent.
|
||||
|
||||
To solve this problem and demonstrate the power of open source to add location-aware features to a web application, I combined publicly available bikeshare data, the [Python][1] programming language, and the open source [Redis][2] in-memory data structure server to index and query geospatial data.
|
||||
|
||||
The resulting bikeshare application incorporates data from many different sharing systems, including the [Citi Bike][3] bikeshare in New York City. It takes advantage of the General Bikeshare Feed provided by the Citi Bike system and uses its data to demonstrate some of the features that can be built using Redis to index geospatial data. The Citi Bike data is provided under the [Citi Bike data license agreement][4].
|
||||
|
||||
### General Bikeshare Feed Specification
|
||||
|
||||
The General Bikeshare Feed Specification (GBFS) is an [open data specification][5] developed by the [North American Bikeshare Association][6] to make it easier for map and transportation applications to add bikeshare systems into their platforms. The specification is currently in use by over 60 different sharing systems in the world.
|
||||
|
||||
The feed consists of several simple [JSON][7] data files containing information about the state of the system. The feed starts with a top-level JSON file referencing the URLs of the sub-feed data:
|
||||
```
|
||||
{
|
||||
|
||||
"data": {
|
||||
|
||||
"en": {
|
||||
|
||||
"feeds": [
|
||||
|
||||
{
|
||||
|
||||
"name": "system_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/system_information.json"
|
||||
|
||||
},
|
||||
|
||||
{
|
||||
|
||||
"name": "station_information",
|
||||
|
||||
"url": "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
|
||||
|
||||
},
|
||||
|
||||
. . .
|
||||
|
||||
]
|
||||
|
||||
}
|
||||
|
||||
},
|
||||
|
||||
"last_updated": 1506370010,
|
||||
|
||||
"ttl": 10
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The first step is loading information about the bikesharing stations into Redis using data from the `system_information` and `station_information` feeds.
|
||||
|
||||
The `system_information` feed provides the system ID, which is a short code that can be used to create namespaces for Redis keys. The GBFS spec doesn't specify the format of the system ID, but does guarantee it is globally unique. Many of the bikeshare feeds use short names like coast_bike_share, boise_greenbike, or topeka_metro_bikes for system IDs. Others use familiar geographic abbreviations such as NYC or BA, and one uses a universally unique identifier (UUID). The bikesharing application uses the identifier as a prefix to construct unique keys for the given system.
|
||||
|
||||
The `station_information` feed provides static information about the sharing stations that comprise the system. Stations are represented by JSON objects with several fields. There are several mandatory fields in the station object that provide the ID, name, and location of the physical bike stations. There are also several optional fields that provide helpful information such as the nearest cross street or accepted payment methods. This is the primary source of information for this part of the bikesharing application.
|
||||
|
||||
### Building the database
|
||||
|
||||
I've written a sample application, [load_station_data.py][8], that mimics what would happen in a backend process for loading data from external sources.
|
||||
|
||||
### Finding the bikeshare stations
|
||||
|
||||
Loading the bikeshare data starts with the [systems.csv][9] file from the [GBFS repository on GitHub][5].
|
||||
|
||||
The repository's [systems.csv][9] file provides the discovery URL for registered bikeshare systems with an available GBFS feed. The discovery URL is the starting point for processing bikeshare information.
|
||||
|
||||
The `load_station_data` application takes each discovery URL found in the systems file and uses it to find the URL for two sub-feeds: system information and station information. The system information feed provides a key piece of information: the unique ID of the system. (Note: the system ID is also provided in the systems.csv file, but some of the identifiers in that file do not match the identifiers in the feeds, so I always fetch the identifier from the feed.) Details on the system, like bikeshare URLs, phone numbers, and emails, could be added in future versions of the application, so the data is stored in a Redis hash using the key `${system_id}:system_info`.
|
||||
|
||||
### Loading the station data
|
||||
|
||||
The station information provides data about every station in the system, including the system's location. The `load_station_data` application iterates over every station in the station feed and stores the data about each into a Redis hash using a key of the form `${system_id}:station:${station_id}`. The location of each station is added to a geospatial index for the bikeshare using the `GEOADD` command.
|
||||
|
||||
### Updating data
|
||||
|
||||
On subsequent runs, I don't want the code to remove all the feed data from Redis and reload it into an empty Redis database, so I carefully considered how to handle in-place updates of the data.
|
||||
|
||||
The code starts by loading the dataset with information on all the bikesharing stations for the system being processed into memory. When information is loaded for a station, the station (by key) is removed from the in-memory set of stations. Once all station data is loaded, we're left with a set containing all the station data that must be removed for that system.
|
||||
|
||||
The application iterates over this set of stations and creates a transaction to delete the station information, remove the station key from the geospatial indexes, and remove the station from the list of stations for the system.
|
||||
|
||||
### Notes on the code
|
||||
|
||||
There are a few interesting things to note in [the sample code][8]. First, items are added to the geospatial indexes using the `GEOADD` command but removed with the `ZREM` command. As the underlying implementation of the geospatial type uses sorted sets, items are removed using `ZREM`. A word of caution: For simplicity, the sample code demonstrates working with a single Redis node; the transaction blocks would need to be restructured to run in a cluster environment.
|
||||
|
||||
If you are using Redis 4.0 (or later), you have some alternatives to the `DELETE` and `HMSET` commands in the code. Redis 4.0 provides the [`UNLINK`][10] command as an asynchronous alternative to the `DELETE` command. `UNLINK` will remove the key from the keyspace, but it reclaims the memory in a separate thread. The [`HMSET`][11] command is [deprecated in Redis 4.0 and the `HSET` command is now variadic][12] (that is, it accepts an indefinite number of arguments).
|
||||
|
||||
### Notifying clients
|
||||
|
||||
At the end of the process, a notification is sent to the clients relying on our data. Using the Redis pub/sub mechanism, the notification goes out over the `geobike:station_changed` channel with the ID of the system.
|
||||
|
||||
### Data model
|
||||
|
||||
When structuring data in Redis, the most important thing to think about is how you will query the information. The two main queries the bikeshare application needs to support are:
|
||||
|
||||
* Find stations near us
|
||||
* Display information about stations
|
||||
|
||||
|
||||
|
||||
Redis provides two main data types that will be useful for storing our data: hashes and sorted sets. The [hash type][13] maps well to the JSON objects that represent stations; since Redis hashes don't enforce a schema, they can be used to store the variable station information.
|
||||
|
||||
Of course, finding stations geographically requires a geospatial index to search for stations relative to some coordinates. Redis provides [several commands][14] to build up a geospatial index using the [sorted set][15] data structure.
|
||||
|
||||
We construct keys using the format `${system_id}:station:${station_id}` for the hashes containing information about the stations and keys using the format `${system_id}:stations:location` for the geospatial index used to find stations.
|
||||
|
||||
### Getting the user's location
|
||||
|
||||
The next step in building out the application is to determine the user's current location. Most applications accomplish this through built-in services provided by the operating system. The OS can provide applications with a location based on GPS hardware built into the device or approximated from the device's available WiFi networks.
|
||||
|
||||
|
||||
|
||||
### Finding stations
|
||||
|
||||
After the user's location is found, the next step is locating nearby bikesharing stations. Redis' geospatial functions can return information on stations within a given distance of the user's current coordinates. Here's an example of this using the Redis command-line interface.
|
||||
|
||||
Imagine I'm at the Apple Store on Fifth Avenue in New York City, and I want to head downtown to Mood on West 37th to catch up with my buddy [Swatch][16]. I could take a taxi or the subway, but I'd rather bike. Are there any nearby sharing stations where I could get a bike for my trip?
|
||||
|
||||
The Apple store is located at 40.76384, -73.97297. According to the map, two bikeshare stations—Grand Army Plaza & Central Park South and East 58th St. & Madison—fall within a 500-foot radius (in blue on the map above) of the store.
|
||||
|
||||
I can use Redis' `GEORADIUS` command to query the NYC system index for stations within a 500-foot radius:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft
|
||||
|
||||
1) "NYC:station:3457"
|
||||
|
||||
2) "NYC:station:281"
|
||||
|
||||
```
|
||||
|
||||
Redis returns the two bikeshare locations found within that radius, using the elements in our geospatial index as the keys for the metadata about a particular station. The next step is looking up the names for the two stations:
|
||||
```
|
||||
127.0.0.1:6379> hget NYC:station:281 name
|
||||
|
||||
"Grand Army Plaza & Central Park S"
|
||||
|
||||
|
||||
|
||||
127.0.0.1:6379> hget NYC:station:3457 name
|
||||
|
||||
"E 58 St & Madison Ave"
|
||||
|
||||
```
|
||||
|
||||
Those keys correspond to the stations identified on the map above. If I want, I can add more flags to the `GEORADIUS` command to get a list of elements, their coordinates, and their distance from our current point:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUS NYC:stations:location -73.97297 40.76384 500 ft WITHDIST WITHCOORD ASC
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "289.1995"
|
||||
|
||||
3) 1) "-73.97371262311935425"
|
||||
|
||||
2) "40.76439830559216659"
|
||||
|
||||
2) 1) "NYC:station:3457"
|
||||
|
||||
2) "383.1782"
|
||||
|
||||
3) 1) "-73.97209256887435913"
|
||||
|
||||
2) "40.76302702144496237"
|
||||
|
||||
```
|
||||
|
||||
Looking up the names associated with those keys generates an ordered list of stations I can choose from. Redis doesn't provide directions or routing capability, so I use the routing features of my device's OS to plot a course from my current location to the selected bike station.
|
||||
|
||||
The `GEORADIUS` function can be easily implemented inside an API in your favorite development framework to add location functionality to an app.
|
||||
|
||||
### Other query commands
|
||||
|
||||
In addition to the `GEORADIUS` command, Redis provides three other commands for querying data from the index: `GEOPOS`, `GEODIST`, and `GEORADIUSBYMEMBER`.
|
||||
|
||||
The `GEOPOS` command can provide the coordinates for a given element from the geohash. For example, if I know there is a bikesharing station at West 38th and 8th and its ID is 523, then the element name for that station is NYC🚉523. Using Redis, I can find the station's longitude and latitude:
|
||||
```
|
||||
127.0.0.1:6379> geopos NYC:stations:location NYC:station:523
|
||||
|
||||
1) 1) "-73.99138301610946655"
|
||||
|
||||
2) "40.75466497634030105"
|
||||
|
||||
```
|
||||
|
||||
The `GEODIST` command provides the distance between two elements of the index. If I wanted to find the distance between the station at Grand Army Plaza & Central Park South and the station at East 58th St. & Madison, I would issue the following command:
|
||||
```
|
||||
127.0.0.1:6379> GEODIST NYC:stations:location NYC:station:281 NYC:station:3457 ft
|
||||
|
||||
"671.4900"
|
||||
|
||||
```
|
||||
|
||||
Finally, the `GEORADIUSBYMEMBER` command is similar to the `GEORADIUS` command, but instead of taking a set of coordinates, the command takes the name of another member of the index and returns all the members within a given radius centered on that member. To find all the stations within 1,000 feet of the Grand Army Plaza & Central Park South, enter the following:
|
||||
```
|
||||
127.0.0.1:6379> GEORADIUSBYMEMBER NYC:stations:location NYC:station:281 1000 ft WITHDIST
|
||||
|
||||
1) 1) "NYC:station:281"
|
||||
|
||||
2) "0.0000"
|
||||
|
||||
2) 1) "NYC:station:3132"
|
||||
|
||||
2) "793.4223"
|
||||
|
||||
3) 1) "NYC:station:2006"
|
||||
|
||||
2) "911.9752"
|
||||
|
||||
4) 1) "NYC:station:3136"
|
||||
|
||||
2) "940.3399"
|
||||
|
||||
5) 1) "NYC:station:3457"
|
||||
|
||||
2) "671.4900"
|
||||
|
||||
```
|
||||
|
||||
While this example focused on using Python and Redis to parse data and build an index of bikesharing system locations, it can easily be generalized to locate restaurants, public transit, or any other type of place developers want to help users find.
|
||||
|
||||
This article is based on [my presentation][17] at Open Source 101 in Raleigh this year.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/building-bikesharing-application-open-source-tools
|
||||
|
||||
作者:[Tague Griffith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tague
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://redis.io/
|
||||
[3]:https://www.citibikenyc.com/
|
||||
[4]:https://www.citibikenyc.com/data-sharing-policy
|
||||
[5]:https://github.com/NABSA/gbfs
|
||||
[6]:http://nabsa.net/
|
||||
[7]:https://www.json.org/
|
||||
[8]:https://gist.github.com/tague/5a82d96bcb09ce2a79943ad4c87f6e15
|
||||
[9]:https://github.com/NABSA/gbfs/blob/master/systems.csv
|
||||
[10]:https://redis.io/commands/unlink
|
||||
[11]:https://redis.io/commands/hmset
|
||||
[12]:https://raw.githubusercontent.com/antirez/redis/4.0/00-RELEASENOTES
|
||||
[13]:https://redis.io/topics/data-types#Hashes
|
||||
[14]:https://redis.io/commands#geo
|
||||
[15]:https://redis.io/topics/data-types-intro#redis-sorted-sets
|
||||
[16]:https://twitter.com/swatchthedog
|
||||
[17]:http://opensource101.com/raleigh/talks/building-location-aware-apps-open-source-tools/
|
||||
@ -0,0 +1,264 @@
|
||||
Check Linux Distribution Name and Version
|
||||
======
|
||||
You have joined new company and want to install some software’s which is requested by DevApp team, also want to restart few of the service after installation. What to do?
|
||||
|
||||
In this situation at least you should know what Distribution & Version is running on it. It will help you perform the activity without any issue.
|
||||
|
||||
Administrator should gather some of the information about the system before doing any activity, which is first task for him.
|
||||
|
||||
There are many ways to find the Linux distribution name and version. You might ask, why i want to know this basic things?
|
||||
|
||||
We have four major distributions such as RHEL, Debian, openSUSE & Arch Linux. Each distribution comes with their own package manager which help us to install packages on the system.
|
||||
|
||||
If you don’t know the distribution name then you wont be able to perform the package installation.
|
||||
|
||||
Also you won’t able to run the proper command for service bounces because most of the distributions implemented systemd command instead of SysVinit script.
|
||||
|
||||
It’s good to have the basic commands which will helps you in many ways.
|
||||
|
||||
Use the following Methods to Check Your Linux Distribution Name and Version.
|
||||
|
||||
### List of methods
|
||||
|
||||
* lsb_release command
|
||||
* /etc/*-release file
|
||||
* uname command
|
||||
* /proc/version file
|
||||
* dmesg Command
|
||||
* YUM or DNF Command
|
||||
* RPM command
|
||||
* APT-GET command
|
||||
|
||||
|
||||
|
||||
### Method-1: lsb_release Command
|
||||
|
||||
LSB stands for Linux Standard Base that prints distribution-specific information such as Distribution name, Release version and codename.
|
||||
```
|
||||
# lsb_release -a
|
||||
No LSB modules are available.
|
||||
Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.3 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
### Method-2: /etc/arch-release /etc/os-release File
|
||||
|
||||
release file typically known as Operating system identification. The `/etc` directory contains many files that contains various information about the distribution. Each distribution has their own set of files, which display this information.
|
||||
|
||||
The below set of files are present on Ubuntu/Debian system.
|
||||
```
|
||||
# cat /etc/issue
|
||||
Ubuntu 16.04.3 LTS \n \l
|
||||
|
||||
# cat /etc/issue.net
|
||||
Ubuntu 16.04.3 LTS
|
||||
|
||||
# cat /etc/lsb-release
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=16.04
|
||||
DISTRIB_CODENAME=xenial
|
||||
DISTRIB_DESCRIPTION="Ubuntu 16.04.3 LTS"
|
||||
|
||||
# cat /etc/os-release
|
||||
NAME="Ubuntu"
|
||||
VERSION="16.04.3 LTS (Xenial Xerus)"
|
||||
ID=ubuntu
|
||||
ID_LIKE=debian
|
||||
PRETTY_NAME="Ubuntu 16.04.3 LTS"
|
||||
VERSION_ID="16.04"
|
||||
HOME_URL="http://www.ubuntu.com/"
|
||||
SUPPORT_URL="http://help.ubuntu.com/"
|
||||
BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/"
|
||||
VERSION_CODENAME=xenial
|
||||
UBUNTU_CODENAME=xenial
|
||||
|
||||
# cat /etc/debian_version
|
||||
9.3
|
||||
|
||||
```
|
||||
|
||||
The below set of files are present on RHEL/CentOS/Fedora system. The `/etc/redhat-release` & `/etc/system-release` files symlinks with `/etc/[distro]-release` file.
|
||||
```
|
||||
# cat /etc/centos-release
|
||||
CentOS release 6.9 (Final)
|
||||
|
||||
# cat /etc/fedora-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
# cat /etc/os-release
|
||||
NAME=Fedora
|
||||
VERSION="27 (Twenty Seven)"
|
||||
ID=fedora
|
||||
VERSION_ID=27
|
||||
PRETTY_NAME="Fedora 27 (Twenty Seven)"
|
||||
ANSI_COLOR="0;34"
|
||||
CPE_NAME="cpe:/o:fedoraproject:fedora:27"
|
||||
HOME_URL="https://fedoraproject.org/"
|
||||
SUPPORT_URL="https://fedoraproject.org/wiki/Communicating_and_getting_help"
|
||||
BUG_REPORT_URL="https://bugzilla.redhat.com/"
|
||||
REDHAT_BUGZILLA_PRODUCT="Fedora"
|
||||
REDHAT_BUGZILLA_PRODUCT_VERSION=27
|
||||
REDHAT_SUPPORT_PRODUCT="Fedora"
|
||||
REDHAT_SUPPORT_PRODUCT_VERSION=27
|
||||
PRIVACY_POLICY_URL="https://fedoraproject.org/wiki/Legal:PrivacyPolicy"
|
||||
|
||||
# cat /etc/redhat-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
# cat /etc/system-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
```
|
||||
|
||||
### Method-3: uname Command
|
||||
|
||||
uname (stands for unix name) is an utility that prints the system information like kernel name, version and other details about the system and the operating system running on it.
|
||||
|
||||
**Suggested Read :** [6 Methods To Check The Running Linux Kernel Version On System][1]
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.12.14-300.fc26.x86_64 #1 SMP Wed Sep 20 16:28:07 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
The above colored words describe the version of operating system as Fedora Core 26.
|
||||
|
||||
### Method-4: /proc/version File
|
||||
|
||||
This file specifies the version of the Linux kernel, the version of gcc used to compile the kernel, and the time of kernel compilation. It also contains the kernel compiler’s user name (in parentheses).
|
||||
```
|
||||
# cat /proc/version
|
||||
Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
|
||||
```
|
||||
|
||||
### Method-5: dmesg Command
|
||||
|
||||
dmesg (stands for display message or driver message) is a command on most Unix-like operating systems that prints the message buffer of the kernel.
|
||||
```
|
||||
# dmesg | grep "Linux"
|
||||
[ 0.000000] Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
[ 0.001000] SELinux: Initializing.
|
||||
[ 0.001000] SELinux: Starting in permissive mode
|
||||
[ 0.470288] SELinux: Registering netfilter hooks
|
||||
[ 0.616351] Linux agpgart interface v0.103
|
||||
[ 0.630063] usb usb1: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ehci_hcd
|
||||
[ 0.688949] usb usb2: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ohci_hcd
|
||||
[ 2.564554] SELinux: Disabled at runtime.
|
||||
[ 2.564584] SELinux: Unregistering netfilter hooks
|
||||
|
||||
```
|
||||
|
||||
### Method-6: Yum/Dnf Command
|
||||
|
||||
Yum (Yellowdog Updater Modified) is one of the package manager utility in Linux operating system. Yum command is used to install, update, search & remove packages on some Linux distributions based on RedHat.
|
||||
|
||||
**Suggested Read :** [YUM Command To Manage Packages on RHEL/CentOS Systems][2]
|
||||
```
|
||||
# yum info nano
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.zswap.net
|
||||
* extras: mirror2.evolution-host.com
|
||||
* updates: centos.zswap.net
|
||||
Available Packages
|
||||
Name : nano
|
||||
Arch : x86_64
|
||||
Version : 2.3.1
|
||||
Release : 10.el7
|
||||
Size : 440 k
|
||||
Repo : base/7/x86_64
|
||||
Summary : A small text editor
|
||||
URL : http://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
The below yum repolist command shows that Base, Extras, and Updates repositories are coming from CentOS 7 repository.
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.zswap.net
|
||||
* extras: mirror2.evolution-host.com
|
||||
* updates: centos.zswap.net
|
||||
repo id repo name status
|
||||
base/7/x86_64 CentOS-7 - Base 9591
|
||||
extras/7/x86_64 CentOS-7 - Extras 388
|
||||
updates/7/x86_64 CentOS-7 - Updates 1929
|
||||
repolist: 11908
|
||||
|
||||
```
|
||||
|
||||
We can also use Dnf command to check distribution name and version.
|
||||
|
||||
**Suggested Read :** [DNF (Fork of YUM) Command To Manage Packages on Fedora System][3]
|
||||
```
|
||||
# dnf info nano
|
||||
Last metadata expiration check: 0:01:25 ago on Thu Feb 15 01:59:31 2018.
|
||||
Installed Packages
|
||||
Name : nano
|
||||
Version : 2.8.7
|
||||
Release : 1.fc27
|
||||
Arch : x86_64
|
||||
Size : 2.1 M
|
||||
Source : nano-2.8.7-1.fc27.src.rpm
|
||||
Repo : @System
|
||||
From repo : fedora
|
||||
Summary : A small text editor
|
||||
URL : https://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
### Method-7: RPM Command
|
||||
|
||||
RPM stands for RedHat Package Manager is a powerful, command line Package Management utility for Red Hat based system such as CentOS, Oracle Linux & Fedora. This help us to identify the running system version.
|
||||
|
||||
**Suggested Read :** [RPM commands to manage packages on RHEL based systems][4]
|
||||
```
|
||||
# rpm -q nano
|
||||
nano-2.8.7-1.fc27.x86_64
|
||||
|
||||
```
|
||||
|
||||
### Method-8: APT-GET Command
|
||||
|
||||
Apt-Get stands for Advanced Packaging Tool (APT). apg-get is a powerful command-line tool which is used to automatically download and install new software packages, upgrade existing software packages, update the package list index, and to upgrade the entire Debian based systems.
|
||||
|
||||
**Suggested Read :** [Apt-Get & Apt-Cache commands to manage packages on Debian Based Systems][5]
|
||||
```
|
||||
# apt-cache policy nano
|
||||
nano:
|
||||
Installed: 2.5.3-2ubuntu2
|
||||
Candidate: 2.5.3-2ubuntu2
|
||||
Version table:
|
||||
* 2.5.3-2ubuntu2 500
|
||||
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial-updates/main amd64 Packages
|
||||
100 /var/lib/dpkg/status
|
||||
2.5.3-2 500
|
||||
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/main amd64 Packages
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/check-find-linux-distribution-name-and-version/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/check-find-determine-running-installed-linux-kernel-version/
|
||||
[2]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[3]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[4]:https://www.2daygeek.com/rpm-command-examples/
|
||||
[5]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
70
sources/tech/20180215 What is a Linux -oops.md
Normal file
70
sources/tech/20180215 What is a Linux -oops.md
Normal file
@ -0,0 +1,70 @@
|
||||
translating----geekpi
|
||||
|
||||
What is a Linux 'oops'?
|
||||
======
|
||||
If you check the processes running on your Linux systems, you might be curious about one called "kerneloops." And that’s “kernel oops,” not “kerne loops” just in case you didn’t parse that correctly.
|
||||
|
||||
Put very bluntly, an “oops” is a deviation from correct behavior on the part of the Linux kernel. Did you do something wrong? Probably not. But something did. And the process that did something wrong has probably at least just been summarily knocked off the CPU. At worst, the kernel may have panicked and abruptly shut the system down.
|
||||
|
||||
For the record, “oops” is NOT an acronym. It doesn’t stand for something like “object-oriented programming and systems” or “out of procedural specs”; it actually means “oops” like you just dropped your glass of wine or stepped on your cat. Oops! The plural of "oops" is "oopses."
|
||||
|
||||
An oops means that something running on the system has violated the kernel’s rules about proper behavior. Maybe the code tried to take a code path that was not allowed or use an invalid pointer. Whatever it was, the kernel — always on the lookout for process misbehavior — most likely will have stopped the particular process in its tracks and written some messages about what it did to the console, to /var/log/dmesg or the /var/log/kern.log file.
|
||||
|
||||
An oops can be caused by the kernel itself or by some process that tries to get the kernel to violate its rules about how things are allowed to run on the system and what they're allowed to do.
|
||||
|
||||
An oops will generate a crash signature that can help kernel developers figure out what went wrong and improve the quality of their code.
|
||||
|
||||
The kerneloops process running on your system will probably look like this:
|
||||
```
|
||||
kernoops 881 1 0 Feb11 ? 00:00:01 /usr/sbin/kerneloops
|
||||
|
||||
```
|
||||
|
||||
You might notice that the process isn't run by root, but by a user named "kernoops" and that it's accumulated extremely little run time. In fact, the only task assigned to this particular user is running kerneloops.
|
||||
```
|
||||
$ sudo grep kernoops /etc/passwd
|
||||
kernoops:x:113:65534:Kernel Oops Tracking Daemon,,,:/:/bin/false
|
||||
|
||||
```
|
||||
|
||||
If your Linux system isn't one that ships with kerneloops (like Debian), you might consider adding it. Check out this [Debian page][1] for more information.
|
||||
|
||||
### When should you be concerned about an oops?
|
||||
|
||||
An oops is not a big deal, except when it is. It depends in part on the role that the particular process was playing. It also depends on the class of oops.
|
||||
|
||||
Some oopses are so severe that they result in system panics. Technically speaking, a panic is a subset of the oops (i.e., the more serious of the oopses). A panic occurs when a problem detected by the kernel is bad enough that the kernel decides that it (the kernel) must stop running immediately to prevent data loss or other damage to the system. So, the system then needs to be halted and rebooted to keep any inconsistencies from making it unusable or unreliable. So a system that panics is actually trying to protect itself from irrevocable damage.
|
||||
|
||||
In short, all panics are oops, but not all oops are panics.
|
||||
|
||||
The /var/log/kern.log and related rotated logs (/var/log/kern.log.1, /var/log/kern.log.2 etc.) contain the logs produced by the kernel and handled by syslog.
|
||||
|
||||
The kerneloops program collects and by default submits information on the problems it runs into <http://oops.kernel.org/> where it can be analyzed and presented to kernel developers. Configuration details for this process are specified in the /etc/kerneloops.conf file. You can look at the settings easily with the command shown below:
|
||||
```
|
||||
$ sudo cat /etc/kerneloops.conf | grep -v ^# | grep -v ^$
|
||||
[sudo] password for shs:
|
||||
allow-submit = ask
|
||||
allow-pass-on = yes
|
||||
submit-url = http://oops.kernel.org/submitoops.php
|
||||
log-file = /var/log/kern.log
|
||||
submit-pipe = /usr/share/apport/kernel_oops
|
||||
|
||||
```
|
||||
|
||||
In the above (default) settings, information on kernel problems can be submitted, but the user is asked for permission. If set to allow-submit = always, the user will not be asked.
|
||||
|
||||
Debugging kernel problems is one of the finer arts of working with Linux systems. Fortunately, most Linux users seldom or never experience oops or panics. Still, it's nice to know what processes like kerneloops are doing on your system and to understand what might be reported and where when your system runs into a serious kernel violation.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3254778/linux/what-is-a-linux-oops.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://packages.debian.org/stretch/kerneloops
|
||||
140
sources/tech/20180216 Q4OS Makes Linux Easy for Everyone.md
Normal file
140
sources/tech/20180216 Q4OS Makes Linux Easy for Everyone.md
Normal file
@ -0,0 +1,140 @@
|
||||
Q4OS Makes Linux Easy for Everyone
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern Linux distributions tend to target a variety of users. Some claim to offer a flavor of the open source platform that anyone can use. And, I’ve seen some such claims succeed with aplomb, while others fall flat. [Q4OS][1] is one of those odd distributions that doesn’t bother to make such a claim but pulls off the feat anyway.
|
||||
|
||||
So, who is the primary market for Q4OS? According to its website, the distribution is a:
|
||||
|
||||
“fast and powerful operating system based on the latest technologies while offering highly productive desktop environment. We focus on security, reliability, long-term stability and conservative integration of verified new features. System is distinguished by speed and very low hardware requirements, runs great on brand new machines as well as legacy computers. It is also very applicable for virtualization and cloud computing.”
|
||||
|
||||
What’s very interesting here is that the Q4OS developers offer commercial support for the desktop. Said support can cover the likes of system customization (including core level API programming) as well as user interface modifications.
|
||||
|
||||
Once you understand this (and have installed Q4OS), the target audience becomes quite obvious: Business users looking for a Windows XP/7 replacement. But that should not prevent home users from giving Q4OS at try. It’s a Linux distribution that has a few unique tools that come together to make a solid desktop distribution.
|
||||
|
||||
Let’s take a look at Q4OS and see if it’s a version of Linux that might work for you.
|
||||
|
||||
### What Q4OS all about
|
||||
|
||||
Q4OS that does an admirable job of being the open source equivalent of Windows XP/7. Out of the box, it pulls this off with the help of the [Trinity Desktop][2] (a fork of KDE). With a few tricks up its sleeve, Q4OS turns the Trinity Desktop into a remarkably similar desktop (Figure 1).
|
||||
|
||||
![default desktop][4]
|
||||
|
||||
Figure 1: The Q4OS default desktop.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
When you fire up the desktop, you will be greeted by a Welcome screen that makes it very easy for new users to start setting up their desktop with just a few clicks. From this window, you can:
|
||||
|
||||
* Run the Desktop Profiler (which allows you to select which desktop environment to use as well as between a full-featured desktop, a basic desktop, or a minimal desktop—Figure 2).
|
||||
|
||||
* Install applications (which opens the Synaptic Package Manager).
|
||||
|
||||
* Install proprietary codecs (which installs all the necessary media codecs for playing audio and video).
|
||||
|
||||
* Turn on Desktop effects (if you want more eye candy, turn this on).
|
||||
|
||||
* Switch to Kickoff start menu (switches from the default start menu to the newer kickoff menu).
|
||||
|
||||
* Set Autologin (allows you to set login such that it won’t require your password upon boot).
|
||||
|
||||
|
||||
|
||||
|
||||
![Desktop Profiler][7]
|
||||
|
||||
Figure 2: The Desktop Profiler allows you to further customize your desktop experience.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
If you want to install a different desktop environment, open up the Desktop Profiler and then click the Desktop environments drop-down, in the upper left corner of the window. A new window will appear, where you can select your desktop of choice from the drop-down (Figure 3). Once back at the main Profiler Window, select which type of desktop profile you want, and then click Install.
|
||||
|
||||
![Desktop Profiler][9]
|
||||
|
||||
Figure 3: Installing a different desktop is quite simple from within the Desktop Profiler.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Note that installing a different desktop will not wipe the default desktop. Instead, it will allow you to select between the two desktops (at the login screen).
|
||||
|
||||
### Installed software
|
||||
|
||||
After selecting full-featured desktop, from the Desktop Profiler, I found the following user applications ready to go:
|
||||
|
||||
* LibreOffice 5.2.7.2
|
||||
|
||||
* VLC 2.2.7
|
||||
|
||||
* Google Chrome 64.0.3282
|
||||
|
||||
* Thunderbird 52.6.0 (Includes Lightning addon)
|
||||
|
||||
* Synaptic 0.84.2
|
||||
|
||||
* Konqueror 14.0.5
|
||||
|
||||
* Firefox 52.6.0
|
||||
|
||||
* Shotwell 0.24.5
|
||||
|
||||
|
||||
|
||||
|
||||
Obviously some of those applications are well out of date. Since this distribution is based on Debian, we can run and update/upgrade with the commands:
|
||||
```
|
||||
sudo apt update
|
||||
|
||||
sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
However, after running both commands, it seems everything is up to date. This particular release (2.4) is an LTS release (supported until 2022). Because of this, expect software to be a bit behind. If you want to test out the bleeding edge version (based on Debian “Buster”), you can download the testing image [here][10].
|
||||
|
||||
### Security oddity
|
||||
|
||||
There is one rather disturbing “feature” found in Q4OS. In the developer’s quest to make the distribution closely resemble Windows, they’ve made it such that installing software (from the command line) doesn’t require a password! You read that correctly. If you open the Synaptic package manager, you’re asked for a password. However (and this is a big however), open up a terminal window and issue a command like sudo apt-get install gimp. At this point, the software will install… without requiring the user to type a sudo password.
|
||||
|
||||
Did you cringe at that? You should.
|
||||
|
||||
I get it, the developers want to ease away the burden of Linux and make a platform the masses could easily adapt to. They’ve done a splendid job of doing just that. However, in the process of doing so, they’ve bypassed a crucial means of security. Is having as near an XP/7 clone as you can find on Linux worth that lack of security? I would say that if it enables more people to use Linux, then yes. But the fact that they’ve required a password for Synaptic (the GUI tool most Windows users would default to for software installation) and not for the command-line tool makes no sense. On top of that, bypassing passwords for the apt and dpkg commands could make for a significant security issue.
|
||||
|
||||
Fear not, there is a fix. For those that prefer to require passwords for the command line installation of software, you can open up the file /etc/sudoers.d/30_q4os_apt and comment out the following three lines:
|
||||
```
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-get *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-key *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/dpkg *
|
||||
|
||||
```
|
||||
|
||||
Once commented out, save and close the file, and reboot the system. At this point, users will now be prompted for a password, should they run the apt-get, apt-key, or dpkg commands.
|
||||
|
||||
### A worthy contender
|
||||
|
||||
Setting aside the security curiosity, Q4OS is one of the best attempts at recreating Windows XP/7 I’ve come across in a while. If you have users who fear change, and you want to migrate them away from Windows, this distribution might be exactly what you need. I would, however, highly recommend you re-enable passwords for the apt-get, apt-key, and dpkg commands… just to be on the safe side.
|
||||
|
||||
In any case, the addition of the Desktop Profiler, and the ability to easily install alternative desktops, makes Q4OS a distribution that just about anyone could use.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/q4os-makes-linux-easy-everyone
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://q4os.org
|
||||
[2]:https://www.trinitydesktop.org/
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_1.jpg?itok=dalJk9Xf (default desktop)
|
||||
[5]:/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_2.jpg?itok=GlouIm73 (Desktop Profiler)
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_3.jpg?itok=riSTP_1z (Desktop Profiler)
|
||||
[10]:https://q4os.org/downloads2.html
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
59
sources/tech/20180217 Louis-Philippe Véronneau .md
Normal file
59
sources/tech/20180217 Louis-Philippe Véronneau .md
Normal file
@ -0,0 +1,59 @@
|
||||
Louis-Philippe Véronneau -
|
||||
======
|
||||
I've been watching [Critical Role][1]1 for a while now and since I've started my master's degree I haven't had much time to sit down and watch the show on YouTube as I used to do.
|
||||
|
||||
I thus started listening to the podcasts instead; that way, I can listen to the show while I'm doing other productive tasks. Pretty quickly, I grew tired of manually downloading every episode each time I finished the last one. To make things worst, the podcast is hosted on PodBean and they won't let you download episodes on a mobile device without their app. Grrr.
|
||||
|
||||
After the 10th time opening the terminal on my phone to download the podcast using some `wget` magic I decided enough was enough: I was going to write a dumb script to download them all in one batch.
|
||||
|
||||
I'm a little ashamed to say it took me more time than I had intended... The PodBean website uses semi-randomized URLs, so I could not figure out a way to guess the paths to the hosted audio files. I considered using `youtube-dl` to get the DASH version of the show on YouTube, but Google has been heavily throttling DASH streams recently. Not cool Google.
|
||||
|
||||
I then had the idea to use iTune's RSS feed to get the audio files. Surely they would somehow be included there? Of course Apple doesn't give you a simple RSS feed link on the iTunes podcast page, so I had to rummage around and eventually found out this is the link you have to use:
|
||||
```
|
||||
https://itunes.apple.com/lookup?id=1243705452&entity=podcast
|
||||
|
||||
```
|
||||
|
||||
Surprise surprise, from the json file this links points to, I found out the main Critical Role podcast page [has a proper RSS feed][2]. To my defense, the RSS button on the main podcast page brings you to some PodBean crap page.
|
||||
|
||||
Anyway, once you have the RSS feed, it's only a matter of using `grep` and `sed` until you get what you want.
|
||||
|
||||
Around 20 minutes later, I had downloaded all the episodes, for a total of 22Gb! Victory dance!
|
||||
|
||||
Video clip loop of the Critical Role doing a victory dance.
|
||||
|
||||
### Script
|
||||
|
||||
Here's the bash script I wrote. You will need `recode` to run it, as the RSS feed includes some HTML entities.
|
||||
```
|
||||
# Get the whole RSS feed
|
||||
wget -qO /tmp/criticalrole.rss http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
|
||||
# Extract the URLS and the episode titles
|
||||
mp3s=( $(grep -o "http.\+mp3" /tmp/criticalrole.rss) )
|
||||
titles=( $(tail -n +45 /tmp/criticalrole.rss | grep -o "<title>.\+</title>" \
|
||||
| sed -r 's@</?title>@@g; s@ @\\@g' | recode html..utf8) )
|
||||
|
||||
# Download all the episodes under their titles
|
||||
for i in ${!titles[*]}
|
||||
do
|
||||
wget -qO "$(sed -e "s@\\\@\\ @g" <<< "${titles[$i]}").mp3" ${mp3s[$i]}
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
1 - For those of you not familiar with Critical Role, it's web series where a group of voice actresses and actors from LA play Dungeons & Dragons. It's so good even people like me who never played D&D can enjoy it..
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/downloading-all-the-critical-role-podcasts-in-one-batch.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://en.wikipedia.org/wiki/Critical_Role
|
||||
[2]:http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
@ -1,163 +0,0 @@
|
||||
The List Of Useful Bash Keyboard Shortcuts
|
||||
======
|
||||
translating by heart4lor
|
||||
|
||||

|
||||
|
||||
Nowadays, I spend more time in Terminal, trying to accomplish more in CLI than GUI. I learned many BASH tricks over time. And, here is the list of useful of BASH shortcuts that every Linux users should know to get things done faster in their BASH shell. I won’t claim that this list is a complete list of BASH shortcuts, but just enough to move around your BASH shell faster than before. Learning how to navigate faster in BASH Shell not only saves some time, but also makes you proud of yourself for learning something worth. Well, let’s get started.
|
||||
|
||||
### List Of Useful Bash Keyboard Shortcuts
|
||||
|
||||
#### ALT key shortcuts
|
||||
|
||||
1\. **ALT+A** – Go to the beginning of a line.
|
||||
|
||||
2\. **ALT+B** – Move one character before the cursor.
|
||||
|
||||
3\. **ALT+C** – Suspends the running command/process. Same as CTRL+C
|
||||
|
||||
4\. **ALT+D** – Closes the empty Terminal (I.e it closes the Terminal when there is nothing typed). Also deletes all chracters after the cursor.
|
||||
|
||||
5\. **ALT+F** – Move forward one character.
|
||||
|
||||
6\. **ALT+T** – Swaps the last two words.
|
||||
|
||||
7\. **ALT+U** – Capitalize all characters in a word after the cursor.
|
||||
|
||||
8\. **ALT+L** – Uncaptalize all characters in a word after the cursor.
|
||||
|
||||
9\. **ALT+R** – Undo any changes to a command that you have brought from the history if you’ve edited it.
|
||||
|
||||
As you see in the above output, I have pulled a command using reverse search and changed the last characters in that command and revert the changes using **ALT+R**.
|
||||
|
||||
10\. **ALT+.** (note the dot at the end) – Use the last word of the previous command.
|
||||
|
||||
If you want to use the same options for multiple commands, you can use this shortcut to bring back the last word of previous command. For instance, I need to short the contents of a directory using “ls -r” command. Also, I want to view my Kernel version using “uname -r”. In both commands, the common word is “-r”. This is where ALT+. shortcut comes in handy. First run, ls -r command to do reverse shorting and use the last word “-r” in the nex command i.e uname.
|
||||
|
||||
#### CTRL key shortcuts
|
||||
|
||||
1\. **CTRL+A** – Quickly move to the beginning of line.
|
||||
|
||||
Let us say you’re typing a command something like below. While you’re at the N’th line, you noticed there is a typo in the first character
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
|
||||
```
|
||||
|
||||
Did you notice? I typed “gind” instead of “find” in the above command. You can correct this error by pressing the left arrow all the way to the first letter and replace “g” with “f”. Alternatively, just hit the **CTRL+A** or **Home** key to instantly go to the beginning of the line and replace the misspelled character. This will save you a few seconds.
|
||||
|
||||
2\. **CTRL+B** – To move backward one character.
|
||||
|
||||
This shortcut key can move the cursor backward one character i.e one character before the cursor. Alternatively, you can use LEFT arrow to move backward one character.
|
||||
|
||||
3\. **CTRL+C** – Stop the currently running command
|
||||
|
||||
If a command takes too long to complete or if you mistakenly run it, you can forcibly stop or quit the command by using **CTRL+C**.
|
||||
|
||||
4\. **CTRL+D** – Delete one character backward.
|
||||
|
||||
If you have a system where the BACKSPACE key isn’t working, you can use **CTRL+D** to delete one character backward. This shortcut also lets you logs out of the current session, similar to exit.
|
||||
|
||||
5\. **CTRL+E** – Move to the end of line
|
||||
|
||||
After you corrected any misspelled word in the start of a command or line, just hit **CTRL+E** to quickly move to the end of the line. Alternatively, you can use END key in your keyboard.
|
||||
|
||||
6\. **CTRL+F** – Move forward one character
|
||||
|
||||
If you want to move the cursor forward one character after another, just press **CTRL+F** instead of RIGHT arrow key.
|
||||
|
||||
7\. **CTRL+G** – Leave the history searching mode without running the command.
|
||||
|
||||
As you see in the above screenshot, I did the reverse search, but didn’t execute the command and left the history searching mode.
|
||||
|
||||
8\. **CTRL+H** – Delete the characters before the cursor, same as BASKSPACE.
|
||||
|
||||
9\. **CTRL+J** – Same as ENTER/RETURN key.
|
||||
|
||||
ENTER key is not working? No problem! **CTRL+J** or **CTRL+M** can be used as an alternative to ENTER key.
|
||||
|
||||
10\. **CTRL+K** – Delete all characters after the cursor.
|
||||
|
||||
You don’t have to keep hitting the DELETE key to delete the characters after the cursor. Just press **CTRL+K** to delete all characters after the cursor.
|
||||
|
||||
11\. **CTRL+L** – Clears the screen and redisplay the line.
|
||||
|
||||
Don’t type “clear” to clear the screen. Just press CTRL+L to clear and redisplay the currently typed line.
|
||||
|
||||
12\. **CTRL+M** – Same as CTRL+J or RETURN.
|
||||
|
||||
13\. **CTRL+N** – Display next line in command history.
|
||||
|
||||
You can also use DOWN arrow.
|
||||
|
||||
14\. **CTRL+O** – Run the command that you found using reverse search i.e CTRL+R.
|
||||
|
||||
15\. **CTRL+P** – Displays the previous line in command history.
|
||||
|
||||
You can also use UP arrow.
|
||||
|
||||
16\. **CTRL+R** – Searches the history backward (Reverse search).
|
||||
|
||||
17\. **CTRL+S** – Searches the history forward.
|
||||
|
||||
18\. **CTRL+T** – Swaps the last two characters.
|
||||
|
||||
This is one of my favorite shortcut. Let us say you typed “sl” instead of “ls”. No problem! This shortcut will transposes the characters as in the below screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
19\. **CTRL+U** – Delete all characters before the cursor (Kills backward from point to the beginning of line).
|
||||
|
||||
This shortcut will delete all typed characters backward at once.
|
||||
|
||||
20\. **CTRL+V** – Makes the next character typed verbatim
|
||||
|
||||
21\. **CTRL+W** – Delete the words before the cursor.
|
||||
|
||||
Don’t confuse it with CTRL+U. CTRL+W won’t delete everything behind a cursor, but a single word.
|
||||
|
||||
![][3]
|
||||
|
||||
22\. **CTRL+X** – Lists the possible filename completions of the current word.
|
||||
|
||||
23\. **CTRL+XX** – Move between start of command line and current cursor position (and back again).
|
||||
|
||||
24\. **CTRL+Y** – Retrieves last item that you deleted or cut.
|
||||
|
||||
Remember, we deleted a word “-al” using CTRL+W in the 21st command. You can retrieve that word instantly using CTRL+Y.
|
||||
|
||||
![][4]
|
||||
|
||||
See? I didn’t type “-al”. Instead, I pressed CTRL+Y to retrieve it.
|
||||
|
||||
25\. **CTRL+Z** – Stops the current command.
|
||||
|
||||
You may very well know this shortcut. It kills the currently running command. You can resume it with **fg** in the foreground or **bg** in the background.
|
||||
|
||||
26\. **CTRL+[** – Equivalent to ESC key.
|
||||
|
||||
#### Miscellaneous
|
||||
|
||||
1\. **!!** – Repeats the last command.
|
||||
|
||||
2\. **ESC+t** – Swaps the last tow words.
|
||||
|
||||
That’s all I have in mind now. I will keep adding more if I came across any Bash shortcut keys in future. If you think there is a mistake in this article, please do notify me in the comments section below. I will update it asap.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
@ -0,0 +1,119 @@
|
||||
Learn to code with Thonny — a Python IDE for beginners
|
||||
======
|
||||
|
||||

|
||||
Learning to program is hard. Even when you finally get your colons and parentheses right, there is still a big chance that the program doesn’t do what you intended. Commonly, this means you overlooked something or misunderstood a language construct, and you need to locate the place in the code where your expectations and reality diverge.
|
||||
|
||||
Programmers usually tackle this situation with a tool called a debugger, which allows running their program step-by-step. Unfortunately, most debuggers are optimized for professional usage and assume the user already knows the semantics of language constructs (e.g. function call) very well.
|
||||
|
||||
Thonny is a beginner-friendly Python IDE, developed in [University of Tartu][1], Estonia, which takes a different approach as its debugger is designed specifically for learning and teaching programming.
|
||||
|
||||
Although Thonny is suitable for even total beginners, this post is meant for readers who have at least some experience with Python or another imperative language.
|
||||
|
||||
### Getting started
|
||||
|
||||
Thonny is included in Fedora repositories since version 27. Install it with sudo dnf install thonny or with a graphical tool of your choice (such as Software).
|
||||
|
||||
When first launching Thonny, it does some preparations and then presents an empty editor and the Python shell. Copy following program text into the editor and save it into a file (Ctrl+S).
|
||||
```
|
||||
n = 1
|
||||
while n < 5:
|
||||
print(n * "*")
|
||||
n = n + 1
|
||||
|
||||
```
|
||||
|
||||
Let’s first run the program in one go. For this press F5 on the keyboard. You should see a triangle made of periods appear in the shell pane.
|
||||
|
||||
![A simple program in Thonny][2]
|
||||
|
||||
Did Python just analyze your code and understand that you wanted to print a triangle? Let’s find out!
|
||||
|
||||
Start by selecting “Variables” from the “View” menu. This opens a table which will show us how Python manages program’s variables. Now run the program in debug mode by pressing Ctrl+F5 (or Ctrl+Shift+F5 in XFCE). In this mode Thonny makes Python pause before each step it takes. You should see the first line of the program getting surrounded with a box. We’ll call this the focus and it indicates the part of the code Python is going to execute next.
|
||||
|
||||
![Thonny debugger focus][3]
|
||||
|
||||
The piece of code you see in the focus box is called assignment statement. For this kind of statement, Python is supposed to evaluate the expression on the right and store the value under the name shown on the left. Press F7 to take the next step. You will see that Python focused on the right part of the statement. In this case the expression is really simple, but for generality Thonny presents the expression evaluation box, which allows turning expressions into values. Press F7 again to turn the literal 1 into value 1. Now Python is ready to do the actual assignment — press F7 again and you should see the variable n with value 1 appear in the variables table.
|
||||
|
||||
![Thonny with variables table][4]
|
||||
|
||||
Continue pressing F7 and observe how Python moves forward with really small steps. Does it look like something which understands the purpose of your code or more like a dumb machine following simple rules?
|
||||
|
||||
### Function calls
|
||||
|
||||
Function call is a programming concept which often causes great deal of confusion to beginners. On the surface there is nothing complicated — you give name to a code and refer to it (call it) somewhere else in the code. Traditional debuggers show us that when you step into the call, the focus jumps into the function definition (and later magically back to the original location). Is it the whole story? Do we need to care?
|
||||
|
||||
Turns out the “jump model” is sufficient only with the simplest functions. Understanding parameter passing, local variables, returning and recursion all benefit from the notion of stack frame. Luckily, Thonny can explain this concept intuitively without sweeping important details under the carpet.
|
||||
|
||||
Copy following recursive program into Thonny and run it in debug mode (Ctrl+F5 or Ctrl+Shift+F5).
|
||||
```
|
||||
def factorial(n):
|
||||
if n == 0:
|
||||
return 1
|
||||
else:
|
||||
return factorial(n-1) * n
|
||||
|
||||
print(factorial(4))
|
||||
|
||||
```
|
||||
|
||||
Press F7 repeatedly until you see the expression factorial(4) in the focus box. When you take the next step, you see that Thonny opens a new window containing function code, another variables table and another focus box (move the window to see that the old focus box is still there).
|
||||
|
||||
![Thonny stepping through a recursive function][5]
|
||||
|
||||
This window represents a stack frame, the working area for resolving a function call. Several such windows on top of each other is called the call stack. Notice the relationship between argument 4 on the call site and entry n in the local variables table. Continue stepping with F7 and observe how new windows get created on each call and destroyed when the function code completes and how the call site gets replaced by the return value.
|
||||
|
||||
### Values vs. references
|
||||
|
||||
Now let’s make an experiment inside the Python shell. Start by typing in the statements shown in the screenshot below:
|
||||
|
||||
![Thonny shell showing list mutation][6]
|
||||
|
||||
As you see, we appended to list b, but list a also got updated. You may know why this happened, but what’s the best way to explain it to a beginner?
|
||||
|
||||
When teaching lists to my students I tell them that I have been lying about Python memory model. It is actually not as simple as the variables table suggests. I tell them to restart the interpreter (the red button on the toolbar), select “Heap” from the “View” menu and make the same experiment again. If you do this, then you see that variables table doesn’t contain the values anymore — they actually live in another table called “Heap”. The role of the variables table is actually to map the variable names to addresses (or ID-s) which refer to the rows in the heap table. As assignment changes only the variables table, the statement b = a only copied the reference to the list, not the list itself. This explained why we see the change via both variables.
|
||||
|
||||
![Thonny in heap mode][7]
|
||||
|
||||
(Why do I postpone telling the truth about the memory model until the topic of lists? Does Python store lists differently compared to floats or strings? Go ahead and use Thonny’s heap mode to find this out! Tell me in the comments what do you think!)
|
||||
|
||||
If you want to understand the references system deeper, copy following program to Thonny and small-step (F7) through it with the heap table open.
|
||||
```
|
||||
def do_something(lst, x):
|
||||
lst.append(x)
|
||||
|
||||
a = [1,2,3]
|
||||
n = 4
|
||||
do_something(a, n)
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
Even if the “heap mode” shows us authentic picture, it is rather inconvenient to use. For this reason, I recommend you now switch back to normal mode (unselect “Heap” in the View menu) but remember that the real model includes variables, references and values.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The features I touched in this post were the main reason for creating Thonny. It’s easy to form misconceptions about both function calls and references but traditional debuggers don’t really help in reducing the confusion.
|
||||
|
||||
Besides these distinguishing features, Thonny offers several other beginner friendly tools. Please look around at [Thonny’s homepage][8] to learn more!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/learn-code-thonny-python-ide-beginners/
|
||||
|
||||
作者:[Aivar Annamaa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/
|
||||
[1]:https://www.ut.ee/en
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2017/12/scr1.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr2.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr3.png
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr4.png
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr5.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2017/12/thonny-scr6.png
|
||||
[8]:http://thonny.org
|
||||
@ -1,177 +0,0 @@
|
||||
translating by kimii
|
||||
Protecting Code Integrity with PGP — Part 2: Generating Your Master Key
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this article series, we're taking an in-depth look at using PGP and provide practical guidelines for developers working on free software projects. In the previous article, we provided an introduction to [basic tools and concepts][1]. In this installment, we show how to generate and protect your master PGP key.
|
||||
|
||||
### Checklist
|
||||
|
||||
1. Generate a 4096-bit RSA master key (ESSENTIAL)
|
||||
|
||||
2. Back up the master key using paperkey (ESSENTIAL)
|
||||
|
||||
3. Add all relevant identities (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Understanding the "Master" (Certify) key
|
||||
|
||||
In this and next section we'll talk about the "master key" and "subkeys." It is important to understand the following:
|
||||
|
||||
1. There are no technical differences between the "master key" and "subkeys."
|
||||
|
||||
2. At creation time, we assign functional limitations to each key by giving it specific capabilities.
|
||||
|
||||
3. A PGP key can have four capabilities.
|
||||
|
||||
* [S] key can be used for signing
|
||||
|
||||
* [E] key can be used for encryption
|
||||
|
||||
* [A] key can be used for authentication
|
||||
|
||||
* [C] key can be used for certifying other keys
|
||||
|
||||
4. A single key may have multiple capabilities.
|
||||
|
||||
|
||||
|
||||
|
||||
The key carrying the [C] (certify) capability is considered the "master" key because it is the only key that can be used to indicate relationship with other keys. Only the [C] key can be used to:
|
||||
|
||||
* Add or revoke other keys (subkeys) with S/E/A capabilities
|
||||
|
||||
* Add, change or revoke identities (uids) associated with the key
|
||||
|
||||
* Add or change the expiration date on itself or any subkey
|
||||
|
||||
* Sign other people's keys for the web of trust purposes
|
||||
|
||||
|
||||
|
||||
|
||||
In the Free Software world, the [C] key is your digital identity. Once you create that key, you should take extra care to protect it and prevent it from falling into malicious hands.
|
||||
|
||||
#### Before you create the master key
|
||||
|
||||
Before you create your master key you need to pick your primary identity and your master passphrase.
|
||||
|
||||
##### Primary identity
|
||||
|
||||
Identities are strings using the same format as the "From" field in emails:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.org>
|
||||
|
||||
```
|
||||
|
||||
You can create new identities, revoke old ones, and change which identity is your "primary" one at any time. Since the primary identity is shown in all GnuPG operations, you should pick a name and address that are both professional and the most likely ones to be used for PGP-protected communication, such as your work address or the address you use for signing off on project commits.
|
||||
|
||||
##### Passphrase
|
||||
|
||||
The passphrase is used exclusively for encrypting the private key with a symmetric algorithm while it is stored on disk. If the contents of your .gnupg directory ever get leaked, a good passphrase is the last line of defense between the thief and them being able to impersonate you online, which is why it is important to set up a good passphrase.
|
||||
|
||||
A good guideline for a strong passphrase is 3-4 words from a rich or mixed dictionary that are not quotes from popular sources (songs, books, slogans). You'll be using this passphrase fairly frequently, so it should be both easy to type and easy to remember.
|
||||
|
||||
##### Algorithm and key strength
|
||||
|
||||
Even though GnuPG has had support for Elliptic Curve crypto for a while now, we'll be sticking to RSA keys, at least for a little while longer. While it is possible to start using ED25519 keys right now, it is likely that you will come across tools and hardware devices that will not be able to handle them correctly.
|
||||
|
||||
You may also wonder why the master key is 4096-bit, if later in the guide we state that 2048-bit keys should be good enough for the lifetime of RSA public key cryptography. The reasons are mostly social and not technical: master keys happen to be the most visible ones on the keychain, and some of the developers you interact with will inevitably judge you negatively if your master key has fewer bits than theirs.
|
||||
|
||||
#### Generate the master key
|
||||
|
||||
To generate your new master key, issue the following command, putting in the right values instead of "Alice Engineer:"
|
||||
```
|
||||
$ gpg --quick-generate-key 'Alice Engineer <alice@example.org>' rsa4096 cert
|
||||
|
||||
```
|
||||
|
||||
A dialog will pop up asking to enter the passphrase. Then, you may need to move your mouse around or type on some keys to generate enough entropy until the command completes.
|
||||
|
||||
Review the output of the command, it will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid Alice Engineer <alice@example.org>
|
||||
|
||||
```
|
||||
|
||||
Note the long string on the second line -- that is the full fingerprint of your newly generated key. Key IDs can be represented in three different forms:
|
||||
|
||||
* Fingerprint, a full 40-character key identifier
|
||||
|
||||
* Long, last 16-characters of the fingerprint (AAAABBBBCCCCDDDD)
|
||||
|
||||
* Short, last 8 characters of the fingerprint (CCCCDDDD)
|
||||
|
||||
|
||||
|
||||
|
||||
You should avoid using 8-character "short key IDs" as they are not sufficiently unique.
|
||||
|
||||
At this point, I suggest you open a text editor, copy the fingerprint of your new key and paste it there. You'll need to use it for the next few steps, so having it close by will be handy.
|
||||
|
||||
#### Back up your master key
|
||||
|
||||
For disaster recovery purposes -- and especially if you intend to use the Web of Trust and collect key signatures from other project developers -- you should create a hardcopy backup of your private key. This is supposed to be the "last resort" measure in case all other backup mechanisms have failed.
|
||||
|
||||
The best way to create a printable hardcopy of your private key is using the paperkey software written for this very purpose. Paperkey is available on all Linux distros, as well as installable via brew install paperkey on Macs.
|
||||
|
||||
Run the following command, replacing [fpr] with the full fingerprint of your key:
|
||||
```
|
||||
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
```
|
||||
|
||||
The output will be in a format that is easy to OCR or input by hand, should you ever need to recover it. Print out that file, then take a pen and write the key passphrase on the margin of the paper. This is a required step because the key printout is still encrypted with the passphrase, and if you ever change the passphrase on your key, you will not remember what it used to be when you had first created it -- guaranteed.
|
||||
|
||||
Put the resulting printout and the hand-written passphrase into an envelope and store in a secure and well-protected place, preferably away from your home, such as your bank vault.
|
||||
|
||||
**Note on printers:** Long gone are days when printers were dumb devices connected to your computer's parallel port. These days they have full operating systems, hard drives, and cloud integration. Since the key content we send to the printer will be encrypted with the passphrase, this is a fairly safe operation, but use your best paranoid judgement.
|
||||
|
||||
#### Add relevant identities
|
||||
|
||||
If you have multiple relevant email addresses (personal, work, open-source project, etc), you should add them to your master key. You don't need to do this for any addresses that you don't expect to use with PGP (e.g., probably not your school alumni address).
|
||||
|
||||
The command is (put the full key fingerprint instead of [fpr]):
|
||||
```
|
||||
$ gpg --quick-add-uid [fpr] 'Alice Engineer <allie@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can review the UIDs you've already added using:
|
||||
```
|
||||
$ gpg --list-key [fpr] | grep ^uid
|
||||
|
||||
```
|
||||
|
||||
##### Pick the primary UID
|
||||
|
||||
GnuPG will make the latest UID you add as your primary UID, so if that is different from what you want, you should fix it back:
|
||||
```
|
||||
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <alice@example.org>'
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at generating PGP subkeys, which are the keys you'll actually be using for day-to-day work.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,4 @@
|
||||
leemeans translating
|
||||
How to block local spoofed addresses using the Linux firewall
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,215 @@
|
||||
10 Quick Tips About sudo command for Linux systems
|
||||
======
|
||||
|
||||
![Linux-sudo-command-tips][1]
|
||||
|
||||
### Overview
|
||||
|
||||
**sudo** stands for **superuser do**. It allows authorized users to execute command as an another user. Another user can be regular user or superuser. However, most of the time we use it to execute command with elevated privileges.
|
||||
|
||||
sudo command works in conjunction with security policies, default security policy is sudoers and it is configurable via **/etc/sudoers** file. Its security policies are highly extendable. One can develop and distribute their own policies as plugins.
|
||||
|
||||
#### How it’s different than su
|
||||
|
||||
In GNU/Linux there are two ways to run command with elevated privileges:
|
||||
|
||||
* Using **su** command
|
||||
* Using **sudo** command
|
||||
|
||||
|
||||
|
||||
**su** stands for **switch user**. Using su, we can switch to root user and execute command. But there are few drawbacks with this approach.
|
||||
|
||||
* We need to share root password with another user.
|
||||
* We cannot give controlled access as root user is superuser
|
||||
* We cannot audit what user is doing.
|
||||
|
||||
|
||||
|
||||
sudo addresses these problems in unique way.
|
||||
|
||||
1. First of all, we don’t need to compromise root user password. Regular user uses its own password to execute command with elevated privileges.
|
||||
2. We can control access of sudo user meaning we can restrict user to execute only certain commands.
|
||||
3. In addition to this all activities of sudo user are logged hence we can always audit what actions were done. On Debian based GNU/Linux all activities are logged in **/var/log/auth.log** file.
|
||||
|
||||
|
||||
|
||||
Later sections of this tutorial sheds light on these points.
|
||||
|
||||
#### Hands on with sudo
|
||||
|
||||
Now, we have fair understanding about sudo. Let us get our hands dirty with practical. For demonstration, I am using Ubuntu. However, behavior with another distribution should be identical.
|
||||
|
||||
#### Allow sudo access
|
||||
|
||||
Let us add regular user as a sudo user. In my case user’s name is linuxtechi
|
||||
|
||||
1) Edit /etc/sudoers file as follows:
|
||||
```
|
||||
$ sudo visudo
|
||||
|
||||
```
|
||||
|
||||
2) Add below line to allow sudo access to user linuxtechi:
|
||||
```
|
||||
linuxtechi ALL=(ALL) ALL
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* linuxtechi indicates user name
|
||||
* First ALL instructs to permit sudo access from any terminal/machine
|
||||
* Second (ALL) instructs sudo command to be allowed to execute as any user
|
||||
* Third ALL indicates all command can be executed as root
|
||||
|
||||
|
||||
|
||||
#### Execute command with elevated privileges
|
||||
|
||||
To execute command with elevated privileges, just prepend sudo word to command as follows:
|
||||
```
|
||||
$ sudo cat /etc/passwd
|
||||
|
||||
```
|
||||
|
||||
When you execute this command, it will ask linuxtechi’s password and not root user password.
|
||||
|
||||
#### Execute command as an another user
|
||||
|
||||
In addition to this we can use sudo to execute command as another user. For instance, in below command, user linuxtechi executes command as a devesh user:
|
||||
```
|
||||
$ sudo -u devesh whoami
|
||||
[sudo] password for linuxtechi:
|
||||
devesh
|
||||
|
||||
```
|
||||
|
||||
#### Built in command behavior
|
||||
|
||||
One of the limitation of sudo is – Shell’s built in command doesn’t work with it. For instance, history is built in command, if you try to execute this command with sudo then command not found error will be reported as follows:
|
||||
```
|
||||
$ sudo history
|
||||
[sudo] password for linuxtechi:
|
||||
sudo: history: command not found
|
||||
|
||||
```
|
||||
|
||||
**Access root shell**
|
||||
|
||||
To overcome above problem, we can get access to root shell and execute any command from there including Shell’s built in.
|
||||
|
||||
To access root shell, execute below command:
|
||||
```
|
||||
$ sudo bash
|
||||
|
||||
```
|
||||
|
||||
After executing this command – you will observe that prompt sign changes to pound (#) character.
|
||||
|
||||
### Recipes
|
||||
|
||||
In this section we’ll discuss some useful recipes which will help you to improve productivity. Most of the commands can be used to complete day-to-day task.
|
||||
|
||||
#### Execute previous command as a sudo user
|
||||
|
||||
Let us suppose you want to execute previous command with elevated privileges, then below trick will be useful:
|
||||
```
|
||||
$ sudo !4
|
||||
|
||||
```
|
||||
|
||||
Above command will execute 4th command from history with elevated privileges.
|
||||
|
||||
#### sudo command with Vim
|
||||
|
||||
Many times we edit system’s configuration files and while saving we realize that we need root access to do this. Because this we may lose our changes. There is no need to get panic, we can use below command in Vim to rescue from this situation:
|
||||
```
|
||||
:w !sudo tee %
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* Colon (:) indicates we are in Vim’s ex mode
|
||||
* Exclamation (!) mark indicates that we are running shell command
|
||||
* sudo and tee are the shell commands
|
||||
* Percentage (%) sign indicates all lines from current line
|
||||
|
||||
|
||||
|
||||
#### Execute multiple commands using sudo
|
||||
|
||||
So far we have executed only single command with sudo but we can execute multiple commands with it. Just separate commands using semicolon (;) as follows:
|
||||
```
|
||||
$ sudo -- bash -c 'pwd; hostname; whoami'
|
||||
|
||||
```
|
||||
|
||||
In above command:
|
||||
|
||||
* Double hyphen (–) stops processing of command line switches
|
||||
* bash indicates shell name to be used for execution
|
||||
* Commands to be executed are followed by –c option
|
||||
|
||||
|
||||
|
||||
#### Run sudo command without password
|
||||
|
||||
When sudo command is executed first time then it will prompt for password and by default password will be cached for next 15 minutes. However, we can override this behavior and disable password authentication using NOPASSWD keyword as follows:
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: ALL
|
||||
|
||||
```
|
||||
|
||||
#### Restrict user to execute certain commands
|
||||
|
||||
To provide controlled access we can restrict sudo user to execute only certain commands. For instance, below line allows execution of echo and ls commands only
|
||||
```
|
||||
linuxtechi ALL=(ALL) NOPASSWD: /bin/echo /bin/ls
|
||||
|
||||
```
|
||||
|
||||
#### Insights about sudo
|
||||
|
||||
Let us dig more about sudo command to get insights about it.
|
||||
```
|
||||
$ ls -l /usr/bin/sudo
|
||||
-rwsr-xr-x 1 root root 145040 Jun 13 2017 /usr/bin/sudo
|
||||
|
||||
```
|
||||
|
||||
If you observe file permissions carefully, **setuid** bit is enabled on sudo. When any user runs this binary it will run with the privileges of the user that owns the file. In this case it is root user.
|
||||
|
||||
To demonstrate this, we can use id command with it as follows:
|
||||
```
|
||||
$ id
|
||||
uid=1002(linuxtechi) gid=1002(linuxtechi) groups=1002(linuxtechi)
|
||||
|
||||
```
|
||||
|
||||
When we execute id command without sudo then id of user linuxtechi will be displayed.
|
||||
```
|
||||
$ sudo id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
|
||||
```
|
||||
|
||||
But if we execute id command with sudo then id of root user will be displayed.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Takeaway from this article is – sudo provides more controlled access to regular users. Using these techniques multiple users can interact with GNU/Linux in secure manner.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/quick-tips-sudo-command-linux-systems/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/03/Linux-sudo-command-tips.jpg
|
||||
@ -0,0 +1,81 @@
|
||||
5 open source software tools for supply chain management
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was originally posted on January 14, 2016, and last updated March 2, 2018.
|
||||
|
||||
If you manage a business that deals with physical goods, [supply chain management][1] is an important part of your business process. Whether you're running a tiny Etsy store with just a few customers, or a Fortune 500 manufacturer or retailer with thousands of products and millions of customers worldwide, it's important to have a close understanding of your inventory and the parts and raw materials you need to make your products.
|
||||
|
||||
Keeping track of physical items, suppliers, customers, and all the many moving parts associated with each can greatly benefit from, and in some cases be totally dependent on, specialized software to help manage these workflows. In this article, we'll take a look at some free and open source software options for supply chain management and some of the features of each.
|
||||
|
||||
Supply chain management goes a little further than just inventory management. It can help you keep track of the flow of goods to reduce costs and plan for scenarios in which the supply chain could change. It can help you keep track of compliance issues, whether these fall under the umbrella of legal requirements, quality minimums, or social and environmental responsibility. It can help you plan the minimum supply to keep on hand and enable you to make smart decisions about order quantities and delivery times.
|
||||
|
||||
Because of its nature, a lot of supply chain management software is bundled with similar software, such as [customer relationship management][2] (CRM) and [enterprise resource planning][3] (ERP) tools. So, when making a decision about which tool is best for your organization, you may wish to consider integration with other tools as a part of your decision-making criteria.
|
||||
|
||||
### Apache OFBiz
|
||||
|
||||
[Apache OFBiz][4] is a suite of related tools for helping you manage a variety of business processes. While it can manage a variety of related issues like catalogs, e-commerce sites, accounting, and point of sale, its primary supply chain functions focus on warehouse management, fulfillment, order, and manufacturing management. It is very customizable, but the flip side of that is that it requires a good deal of careful planning to set up and integrate with your existing processes. That's one reason it is probably the best fit for a midsize to large operation. The project's functionality is built across three layers: presentation, business, and data, making it a scalable solution, but again, a complex one.
|
||||
|
||||
The source code of Apache OFBiz can be found in the [project's repository][5]. Apache OFBiz is written in Java and is licensed under an [Apache 2.0 license][6].
|
||||
|
||||
If this looks interesting, you might also want to check out [opentaps][7], which is built on top of OFBiz. Opentaps enhances OFBiz's user interface and adds core ERP and CRM features, including warehouse management, purchasing, and planning. It's licensed under [AGPL 3.0][8], with a commercial license available for organizations that don't want to be bound by the open source license.
|
||||
|
||||
### OpenBoxes
|
||||
|
||||
[OpenBoxes][9] is a supply chain management and inventory control project, primarily and originally designed for keeping track of pharmaceuticals in a healthcare environment, but it can be modified to track any type of stock and the flows associated with it. It has tools for demand forecasting based on historical order quantities, tracking stock, supporting multiple facilities, expiration date tracking, kiosk support, and many other features that make it ideal for healthcare situations, but could also be useful for other industries.
|
||||
|
||||
Available under an [Eclipse Public License][10], OpenBoxes is written primarily in Groovy and its source code can be browsed on [GitHub][11].
|
||||
|
||||
### OpenLMIS
|
||||
|
||||
Like OpenBoxes, [OpenLMIS][12] is a supply chain management tool for the healthcare sector, but it was specifically designed for use in low-resource areas in Africa to ensure medications and medical supplies get to patients in need. Its API-driven approach enables users to customize and extend OpenLMIS while maintaining a connection to the common codebase. It was developed with funding from the Rockefeller Foundation, and other contributors include the UN, USAID, and the Bill & Melinda Gates Foundation.
|
||||
|
||||
OpenLMIS is written in Java and JavaScript with AngularJS. It is available under an [AGPL 3.0 license][13], and its source code is accessible on [GitHub][13].
|
||||
|
||||
### Odoo
|
||||
|
||||
You might recognize [Odoo][14] from our previous top [ERP projects][3] article. In fact, a full ERP may be a good fit for you, depending on your needs. Odoo's supply chain management tools mostly revolve around inventory and purchase management, as well as connectivity with e-commerce and point of sale, but it can also connect to other tools like [frePPLe][15] for open source production planning.
|
||||
|
||||
Odoo is available both as a software-as-a-service solution and an open source community edition. The open source edition is released under [LGPL][16] version 3, and the source is available on [GitHub][17]. Odoo is primarily written in Python.
|
||||
|
||||
### xTuple
|
||||
|
||||
Billing itself as "supply chain management software for growing businesses," [xTuple][18] focuses on businesses that have outgrown their conventional small business ERP and CRM solutions. Its open source version, called Postbooks, adds some inventory, distribution, purchasing, and vendor reporting features to its core accounting, CRM, and ERP capabilities, and a commercial version expands the [features][19] for manufacturers and distributors.
|
||||
|
||||
xTuple is available under the Common Public Attribution License ([CPAL][20]), and the project welcomes developers to fork it to create other business software for inventory-based manufacturers. Its web app core is written in JavaScript, and its source code can be found on [GitHub][21].
|
||||
|
||||
There are, of course, other open source tools that can help with supply chain management. Know of a good one that we left off? Let us know in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/tools/supply-chain-management
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
|
||||
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
|
||||
[3]:https://opensource.com/resources/top-4-open-source-erp-systems
|
||||
[4]:http://ofbiz.apache.org/
|
||||
[5]:http://ofbiz.apache.org/source-repositories.html
|
||||
[6]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[7]:http://www.opentaps.org/
|
||||
[8]:http://www.fsf.org/licensing/licenses/agpl-3.0.html
|
||||
[9]:http://openboxes.com/
|
||||
[10]:http://opensource.org/licenses/eclipse-1.0.php
|
||||
[11]:https://github.com/openboxes/openboxes
|
||||
[12]:http://openlmis.org/
|
||||
[13]:https://github.com/OpenLMIS/openlmis-ref-distro/blob/master/LICENSE
|
||||
[14]:https://www.odoo.com/
|
||||
[15]:https://frepple.com/
|
||||
[16]:https://github.com/odoo/odoo/blob/9.0/LICENSE
|
||||
[17]:https://github.com/odoo/odoo
|
||||
[18]:https://xtuple.com/
|
||||
[19]:https://xtuple.com/comparison-chart
|
||||
[20]:https://xtuple.com/products/license-options#cpal
|
||||
[21]:http://xtuple.github.io/
|
||||
@ -0,0 +1,170 @@
|
||||
How to manage your workstation configuration with Ansible
|
||||
======
|
||||
|
||||

|
||||
|
||||
Configuration management is a very important aspect of both server administration and DevOps. The "infrastructure as code" methodology makes it easy to deploy servers in various configurations and dynamically scale an organization's resources to keep up with user demands. But less attention is paid to individual administrators who want to automate the setup of their own laptops and desktops (workstations).
|
||||
|
||||
In this series, I'll show you how to automate your workstation setup via [Ansible][1] , which will allow you to easily restore your entire configuration if you want or need to reload your machine. In addition, if you have multiple workstations, you can use this same approach to make the configuration identical on each. In this first article, we'll set up basic configuration management for our personal or work computers and set the foundation for the rest of the series. By the end of this article, you'll have a working setup to benefit from right away. Each article will automate more things and grow in complexity.
|
||||
|
||||
### Why Ansible?
|
||||
|
||||
Many configuration management solutions are available, including Salt Stack, Chef, and Puppet. I prefer Ansible because it's lighter in terms of resource utilization, its syntax is easier to read, and when harnessed properly it can revolutionize your configuration management. Ansible's lightweight nature is especially relevant to the topic at hand, because we may not want to run an entire server just to automate the setup of our laptops and desktops. Ideally, we want something fast; something we can use to get up and running quickly should we need to restore our workstations or synchronize our configuration between multiple machines. My specific method for Ansible (which I'll demonstrate in this article) is perfect for this—there's no server to maintain. You just download your configuration and run it.
|
||||
|
||||
### My approach
|
||||
|
||||
Typically, Ansible is run from a central server. It utilizes an inventory file, which is a text file that contains a list of all the hosts and their IP addresses or domain names we want Ansible to manage. This is great for static environments, but it is not ideal for workstations. The reason being we really don't know what the status of our workstations will be at any one moment. Perhaps I powered down my desktop or my laptop may be suspended and stowed in my bag. In either case, the Ansible server would complain, as it can't reach my machines if they are offline. We need something that's more of an on-demand approach, and the way we'll accomplish that is by utilizing `ansible-pull`. The `ansible-pull` command, which is part of Ansible, allows you to download your configuration from a Git repository and apply it immediately. You won't need to maintain a server or an inventory list; you simply run the `ansible-pull` command, feed it a Git repository URL, and it will do the rest for you.
|
||||
|
||||
### Getting started
|
||||
|
||||
First, install Ansible on the computer you want it to manage. One problem is that a lot of distributions ship with an older version. I can tell you from experience you'll definitely want the latest version available. New features are introduced into Ansible quite frequently, and if you're running an older version, example syntax you find online may not be functional because it's using features that aren't implemented in the version you have installed. Even point releases have quite a few new features. One example of this is the `dconf` module, which is new to Ansible as of 2.4. If you try to utilize syntax that makes use of this module, unless you have 2.4 or newer it will fail. In Ubuntu and its derivatives, we can easily install the latest version of Ansible with the official personal package archive ([PPA][2]). The following commands will do the trick:
|
||||
```
|
||||
sudo apt-get install software-properties-common
|
||||
|
||||
sudo apt-add-repository ppa:ansible/ansible
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install ansible
|
||||
|
||||
```
|
||||
|
||||
If you're not using Ubuntu, [consult Ansible's documentation][3] on how to obtain it for your platform.
|
||||
|
||||
Next, we'll need a Git repository to hold our configuration. The easiest way to satisfy this requirement is to create an empty repository on GitHub, or you can utilize your own Git server if you have one. To keep things simple, I'll assume you're using GitHub, so adjust the commands if you're using something else. Create a repository in GitHub; you'll end up with a repository URL that will be similar to this:
|
||||
```
|
||||
git@github.com:<your_user_name>/ansible.git
|
||||
|
||||
```
|
||||
|
||||
Clone that repository to your local working directory (ignore any message that complains that the repository is empty):
|
||||
```
|
||||
git clone git@github.com:<your_user_name>/ansible.git
|
||||
|
||||
```
|
||||
|
||||
Now we have an empty repository we can work with. Change your working directory to be inside the repository (`cd ./ansible` for example) and create a file named `local.yml` in your favorite text editor. Place the following configuration in that file:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
tasks:
|
||||
|
||||
- name: Install htop
|
||||
|
||||
apt: name=htop
|
||||
|
||||
```
|
||||
|
||||
The file you just created is known as a **playbook** , and the instruction to install `htop` (a package I arbitrarily picked to serve as an example) is known as a **play**. The playbook itself is a file in the YAML format, which is a simple to read markup language. A full walkthrough of YAML is beyond the scope of this article, but you don't need to have an expert understanding of it to be proficient with Ansible. The configuration is easy to read; by simply looking at this file, you can easily glean that we're installing the `htop` package. Pay special attention to the `apt` module on the last line, which will only work on Debian-based systems. You can change this to `yum` instead of `apt` if you're using a Red Hat platform or change it to `dnf` if you're using Fedora. The `name` line simply gives information regarding our task and will be shown in the output. Therefore, you'll want to make sure the name is descriptive so it's easy to find if you need to troubleshoot multiple plays.
|
||||
|
||||
Next, let's commit our new file to our repository:
|
||||
```
|
||||
git add local.yml
|
||||
|
||||
git commit -m "initial commit"
|
||||
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
Now our new playbook should be present in our repository on GitHub. We can apply the playbook we created with the following command:
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git
|
||||
|
||||
```
|
||||
|
||||
If executed properly, the `htop` package should be installed on your system. You might've seen some warnings near the beginning that complain about the lack of an inventory file. This is fine, as we're not using an inventory file (nor do we need to for this use). At the end of the output, it will give you an overview of what it did. If `htop` was installed properly, you should see `changed=1` on the last line of the output.
|
||||
|
||||
How did this work? The `ansible-pull` command uses the `-U` option, which expects a repository URL. I gave it the `https` version of the repository URL for security purposes because I don't want any hosts to have write access back to the repository (`https` is read-only by default). The `local.yml` playbook name is assumed, so we didn't need to provide a filename for the playbook—it will automatically run a playbook named `local.yml` if it finds it in the repository's root. Next, we used `sudo` in front of the command since we are modifying the system.
|
||||
|
||||
Let's go ahead and add additional packages to our playbook. I'll add two additional packages so that it looks like this:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
tasks:
|
||||
|
||||
- name: Install htop
|
||||
|
||||
apt: name=htop
|
||||
|
||||
|
||||
|
||||
- name: Install mc
|
||||
|
||||
apt: name=mc
|
||||
|
||||
|
||||
|
||||
- name: Install tmux
|
||||
|
||||
apt: name=tmux
|
||||
|
||||
```
|
||||
|
||||
I added additional plays (tasks) for installing two other packages, `mc` and `tmux`. It doesn't matter what packages you choose to have this playbook install; I just picked these arbitrarily. You should install whichever packages you want all your systems to have. The only caveat is that you have to know that the packages exist in the repository for your distribution ahead of time.
|
||||
|
||||
Before we commit and apply this updated playbook, we should clean it up. It will work fine as it is, but (to be honest) it looks kind of messy. Let's try installing all three packages in just one play. Replace the contents of your `local.yml` with this:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
become: true
|
||||
|
||||
tasks:
|
||||
|
||||
- name: Install packages
|
||||
|
||||
apt: name={{item}}
|
||||
|
||||
with_items:
|
||||
|
||||
- htop
|
||||
|
||||
- mc
|
||||
|
||||
- tmux
|
||||
|
||||
```
|
||||
|
||||
Now that looks cleaner and more efficient. We used `with_items` to consolidate our package list into one play. If we want to add additional packages, we simply add another line with a hyphen and a package name. Consider `with_items` to be similar to a `for` loop. Every package we list will be installed.
|
||||
|
||||
Commit our new changes back to the repository:
|
||||
```
|
||||
git add local.yml
|
||||
|
||||
git commit -m "added additional packages, cleaned up formatting"
|
||||
|
||||
git push origin master
|
||||
|
||||
```
|
||||
|
||||
Now we can run our playbook to benefit from the new configuration:
|
||||
```
|
||||
sudo ansible-pull -U https://github.com/<your_user_name>/ansible.git
|
||||
|
||||
```
|
||||
|
||||
Admittedly, this example doesn't do much yet; all it does is install a few packages. You could've installed these packages much faster just using your package manager. However, as this series continues, these examples will become more complex and we'll automate more things. By the end, the Ansible configuration you'll create will automate more and more tasks. For example, the one I use automates the installation of hundreds of packages, sets up `cron` jobs, handles desktop configuration, and more.
|
||||
|
||||
From what we've accomplished so far, you can probably already see the big picture. All we had to do was create a repository, put a playbook in that repository, then utilize the `ansible-pull` command to pull down that repository and apply it to our machine. We didn't need to set up a server. In the future, if we want to change our config, we can pull down the repo, update it, then push it back to our repository and apply it. If we're setting up a new machine, we only need to install Ansible and apply the configuration.
|
||||
|
||||
In the next article, we'll automate this even further via `cron` and some additional items. In the meantime, I've copied the code for this article into [my GitHub repository][4] so you can check your syntax against mine. I'll update the code as we go along.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/manage-workstation-ansible
|
||||
|
||||
作者:[Jay LaCroix][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jlacroix
|
||||
[1]:https://www.ansible.com/
|
||||
[2]:https://launchpad.net/ubuntu/+ppas
|
||||
[3]:http://docs.ansible.com/ansible/latest/intro_installation.html
|
||||
[4]:https://github.com/jlacroix82/ansible_article
|
||||
@ -0,0 +1,135 @@
|
||||
Getting started with Python for data science
|
||||
======
|
||||
|
||||

|
||||
|
||||
Whether you're a budding data science enthusiast with a math or computer science background or an expert in an unrelated field, the possibilities data science offers are within your reach. And you don't need expensive, highly specialized enterprise software—the open source tools discussed in this article are all you need to get started.
|
||||
|
||||
[Python][1], its machine-learning and data science libraries ([pandas][2], [Keras][3], [TensorFlow][4], [scikit-learn][5], [SciPy][6], [NumPy][7], etc.), and its extensive list of visualization libraries ([Matplotlib][8], [pyplot][9], [Plotly][10], etc.) are excellent FOSS tools for beginners and experts alike. Easy to learn, popular enough to offer community support, and armed with the latest emerging techniques and algorithms developed for data science, these comprise one of the best toolsets you can acquire when starting out.
|
||||
|
||||
Many of these Python libraries are built on top of each other (known as dependencies), and the basis is the [NumPy][7] library. Designed specifically for data science, NumPy is often used to store relevant portions of datasets in its ndarray datatype, which is a convenient datatype for storing records from relational tables as `cvs` files or in any other format, and vice-versa. It is particularly convenient when scikit functions are applied to multidimensional arrays. SQL is great for querying databases, but to perform complex and resource-intensive data science operations, storing data in ndarray boosts efficiency and speed (but make sure you have ample RAM when dealing with large datasets). When you get to using pandas for knowledge extraction and analysis, the almost seamless conversion between DataFrame datatype in pandas and ndarray in NumPy creates a powerful combination for extraction and compute-intensive operations, respectively.
|
||||
|
||||
For a quick demonstration, let’s fire up the Python shell and load an open dataset on crime statistics from the city of Baltimore in a pandas DataFrame variable, and view a portion of the loaded frame:
|
||||
```
|
||||
>>> import pandas as pd
|
||||
|
||||
>>> crime_stats = pd.read_csv('BPD_Arrests.csv')
|
||||
|
||||
>>> crime_stats.head()
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
We can now perform most of the queries on this pandas DataFrame that we can with SQL in databases. For instance, to get all the unique values of the "Description" attribute, the SQL query is:
|
||||
```
|
||||
$ SELECT unique(“Description”) from crime_stats;
|
||||
|
||||
```
|
||||
|
||||
This same query written for a pandas DataFrame looks like this:
|
||||
```
|
||||
>>> crime_stats['Description'].unique()
|
||||
|
||||
['COMMON ASSAULT' 'LARCENY' 'ROBBERY - STREET' 'AGG. ASSAULT'
|
||||
|
||||
'LARCENY FROM AUTO' 'HOMICIDE' 'BURGLARY' 'AUTO THEFT'
|
||||
|
||||
'ROBBERY - RESIDENCE' 'ROBBERY - COMMERCIAL' 'ROBBERY - CARJACKING'
|
||||
|
||||
'ASSAULT BY THREAT' 'SHOOTING' 'RAPE' 'ARSON']
|
||||
|
||||
```
|
||||
|
||||
which returns a NumPy array (ndarray):
|
||||
```
|
||||
>>> type(crime_stats['Description'].unique())
|
||||
|
||||
<class 'numpy.ndarray'>
|
||||
|
||||
```
|
||||
|
||||
Next let’s feed this data into a neural network to see how accurately it can predict the type of weapon used, given data such as the time the crime was committed, the type of crime, and the neighborhood in which it happened:
|
||||
```
|
||||
>>> from sklearn.neural_network import MLPClassifier
|
||||
|
||||
>>> import numpy as np
|
||||
|
||||
>>>
|
||||
|
||||
>>> prediction = crime_stats[[‘Weapon’]]
|
||||
|
||||
>>> predictors = crime_stats['CrimeTime', ‘CrimeCode’, ‘Neighborhood’]
|
||||
|
||||
>>>
|
||||
|
||||
>>> nn_model = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5,
|
||||
|
||||
2), random_state=1)
|
||||
|
||||
>>>
|
||||
|
||||
>>>predict_weapon = nn_model.fit(prediction, predictors)
|
||||
|
||||
```
|
||||
|
||||
Now that the learning model is ready, we can perform several tests to determine its quality and reliability. For starters, let’s feed a training set data (the portion of the original dataset used to train the model and not included in creating the model):
|
||||
```
|
||||
>>> predict_weapon.predict(training_set_weapons)
|
||||
|
||||
array([4, 4, 4, ..., 0, 4, 4])
|
||||
|
||||
```
|
||||
|
||||
As you can see, it returns a list, with each number predicting the weapon for each of the records in the training set. We see numbers rather than weapon names, as most classification algorithms are optimized with numerical data. For categorical data, there are techniques that can reliably convert attributes into numerical representations. In this case, the technique used is Label Encoding, using the LabelEncoder function in the sklearn preprocessing library: `preprocessing.LabelEncoder()`. It has a function to transform and inverse transform data and their numerical representations. In this example, we can use the `inverse_transform` function of LabelEncoder() to see what Weapons 0 and 4 are:
|
||||
```
|
||||
>>> preprocessing.LabelEncoder().inverse_transform(encoded_weapons)
|
||||
|
||||
array(['HANDS', 'FIREARM', 'HANDS', ..., 'FIREARM', 'FIREARM', 'FIREARM']
|
||||
|
||||
```
|
||||
|
||||
This is fun to see, but to get an idea of how accurate this model is, let's calculate several scores as percentages:
|
||||
```
|
||||
>>> nn_model.score(X, y)
|
||||
|
||||
0.81999999999999995
|
||||
|
||||
```
|
||||
|
||||
This shows that our neural network model is ~82% accurate. That result seems impressive, but it is important to check its effectiveness when used on a different crime dataset. There are other tests, like correlations, confusion, matrices, etc., to do this. Although our model has high accuracy, it is not very useful for general crime datasets as this particular dataset has a disproportionate number of rows that list ‘FIREARM’ as the weapon used. Unless it is re-trained, our classifier is most likely to predict ‘FIREARM’, even if the input dataset has a different distribution.
|
||||
|
||||
It is important to clean the data and remove outliers and aberrations before we classify it. The better the preprocessing, the better the accuracy of our insights. Also, feeding the model/classifier with too much data to get higher accuracy (generally over ~90%) is a bad idea because it looks accurate but is not useful due to [overfitting][11].
|
||||
|
||||
[Jupyter notebooks][12] are a great interactive alternative to the command line. While the CLI is fine for most things, Jupyter shines when you want to run snippets on the go to generate visualizations. It also formats data better than the terminal.
|
||||
|
||||
[This article][13] has a list of some of the best free resources for machine learning, but plenty of additional guidance and tutorials are available. You will also find many open datasets available to use, based on your interests and inclinations. As a starting point, the datasets maintained by [Kaggle][14], and those available at state government websites are excellent resources.
|
||||
|
||||
Payal Singh will be presenting at SCaLE16x this year, March 8-11 in Pasadena, California. To attend and get 50% of your ticket, [register][15] using promo code **OSDC**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/getting-started-data-science
|
||||
|
||||
作者:[Payal Singh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/payalsingh
|
||||
[1]:https://www.python.org/
|
||||
[2]:https://pandas.pydata.org/
|
||||
[3]:https://keras.io/
|
||||
[4]:https://www.tensorflow.org/
|
||||
[5]:http://scikit-learn.org/stable/
|
||||
[6]:https://www.scipy.org/
|
||||
[7]:http://www.numpy.org/
|
||||
[8]:https://matplotlib.org/
|
||||
[9]:https://matplotlib.org/api/pyplot_api.html
|
||||
[10]:https://plot.ly/
|
||||
[11]:https://www.kdnuggets.com/2014/06/cardinal-sin-data-mining-data-science.html
|
||||
[12]:http://jupyter.org/
|
||||
[13]:https://machinelearningmastery.com/best-machine-learning-resources-for-getting-started/
|
||||
[14]:https://www.kaggle.com/
|
||||
[15]:https://register.socallinuxexpo.org/reg6/
|
||||
70
sources/tech/20180306 Exploring free and open web fonts.md
Normal file
70
sources/tech/20180306 Exploring free and open web fonts.md
Normal file
@ -0,0 +1,70 @@
|
||||
Exploring free and open web fonts
|
||||
======
|
||||
|
||||

|
||||
|
||||
There is no question that the face of the web has been transformed in recent years by open source fonts. Prior to 2010, the only typefaces you were likely to see in a web browser were the generic "web safe" [core fonts][1] from Microsoft. But that year saw the start of several revolutions: the introduction of the Web Open Font Format ([WOFF][2]), which offered an open standard for efficiently delivering font files over HTTP, and the launch of web-font services like [Google Fonts][3] and the [Open Font Library][4]—both of which offered web publishers access to a large collection of fonts, for free, available under open licenses.
|
||||
|
||||
It is hard to overstate the positive impact of these events on web typography. But it can be all too easy to equate the successes of open web fonts with open source typography as a whole and conclude that the challenges are behind us, the puzzles solved. That is not the case, so if you care about type, the good news is there are a lot of opportunities to get involved in improvement.
|
||||
|
||||
For starters, it's critical to understand that Google Fonts and Open Font Library offer a specialized service—delivering fonts in web pages—and they don't implement solutions for other use cases. That is not a shortcoming on the services' side; it simply means that we have to develop other solutions.
|
||||
|
||||
There are a number of problems to solve. Probably the most obvious example is the awkwardness of installing fonts on a desktop Linux machine for use in other applications. You can download any of the web fonts offered by either service, but all you will get is a generic ZIP file with some TTF or OTF binaries inside and a plaintext license file. What happens next is up to you to guess.
|
||||
|
||||
Most users learn quickly that the "right" step is to manually copy those font binaries into any one of a handful of special directories on their hard drive. But that just makes the files visible to the operating system; it doesn't offer much in the way of a user experience. Again, this is not a flaw with the web-font service; rather it's evidence of the point where the service stops and more work needs to be done on the other side.
|
||||
|
||||
A big improvement from the user's perspective would be for the OS or the desktop environment to be smarter at this "just downloaded" stage. Not only would it install the font files to the right location but, more importantly, it could add important metadata that the user will want to access when selecting a font to use in a project.
|
||||
|
||||
What this additional information consists of and how it is presented to the user is tied to another challenge: Managing a font collection on Linux is noticeably less pleasant than on other operating systems. Periodically, font manager applications appear (see [GTK+ Font Manager][5] for one of the most recent examples), but they rarely catch on. I've been thinking a lot about where I think they come up short; one core factor is they have limited themselves to displaying only the information embedded in the font binary: basic character-set coverage, weight/width/slope settings, embedded license and copyright statements, etc.
|
||||
|
||||
But a lot of decisions go into the process of selecting a font for a job besides what's in this embedded data. Serious font users—like information designers, journal article authors, or book designers—make their font-selection decisions in the context of each document's requirements and needs. That includes license information, naturally, but it includes much more, like information about the designer and the foundry, stylistic trends, or details about how the font works in use.
|
||||
|
||||
For example, if your document includes both English and Arabic text, you probably want a font where the Latin and Arabic glyphs were designed together by someone experienced with the two scripts. Otherwise, you'll waste a ton of time making tiny adjustments to the font sizes and line spacing trying to get the two languages to mix well. You may have learned from experience that certain designers or vendors are better at multi-script design than others. Or it might be relevant to your project that today's fashion magazines almost exclusively use "[Didone][6]"-style typefaces, a name that refers to super-high-contrast styles pioneered by [Firmin Didot][7] and [Giambattista Bodoni][8] around 200 years ago. It just happens to be the trend.
|
||||
|
||||
But none of those terms (Didone, Didot, or Bodoni) are likely to show up in the binary's embedded data, nor is easy to tell whether the Latin and Arabic fit together or anything else about the typeface's back history. That information might appear in supplementary material like a type specimen or font documentation—if any exists.
|
||||
|
||||
A specimen is a designed document (often a PDF) that shows the font in use and includes background information; it frequently serves a dual role as a marketing piece and a sample to look at when choosing a font. The considered design of a specimen showcases how the font functions in practice and in a manner that an automatically generated character table simply cannot. Documentation may include some other vital information, like how to activate the font's OpenType features, what mathematical or archaic forms it provides, or how it varies stylistically across supported languages. Making this sort of material available to the user in the font-management application would go a long way towards helping users find the fonts that fit their projects' needs.
|
||||
|
||||
Of course, if we're going to consider a font manager that can handle documentation and specimens, we also have to take a hard look at what comes with the font packages provided by distributions. Linux users start with a few fonts automatically installed, and repository-provided packages are the only font source most users have besides downloading the generic ZIP archive. Those packages tend to be pretty bare-bones. Commercial fonts generally include specimens, documentation, and other support items, whereas open source fonts usually do not.
|
||||
|
||||
There are some excellent examples of open fonts that do provide quality specimens and documentation (see [SIL Gentium][9] and [Bungee][10] for two distinctly different but valid approaches), but they rarely (if ever) make their way into the downstream packaging chain. We plainly can do better.
|
||||
|
||||
There are some technical obstacles to offering a richer user experience for interacting with the fonts on your system. For one thing, the [AppStream][11] metadata standard defines a few [parameters][12] specific to font files, but so far includes nothing that would cover specimens, designer and foundry information, and other relevant details. For another, the [SPDX][13] (Software Package Data Exchange) format does not cover many of the software licenses (and license variants) used to distribute fonts.
|
||||
|
||||
Finally, as any audiophile will tell you, a music player that does not let you edit and augment the ID3 tags in your MP3 collection is going to get frustrating quickly. You want to fix errors in the tags, you want to add things like notes and album art—essentially, you want to polish your library. You would want to do the same to keep your local font library in a pleasant-to-use state.
|
||||
|
||||
But editing the embedded data in a font file has been taboo because fonts tend to get embedded and attached to other documents. If you monkey with the fields in a font binary, then redistribute it with your presentation slides, anyone who downloads those slides can end up with bad metadata through no fault of their own. So anyone making improvements to the font-management experience will have to figure out how to strategically wrangle repeated changes to the embedded and external font metadata.
|
||||
|
||||
In addition to the technical angle, enriching the font-management experience is also a design challenge. As I said above, good specimens and well-written documentation exist for several open fonts. But there are many more packages missing both, and there are a lot of older font packages that are no longer being maintained. That probably means the only way that most open font packages are going to get specimens or documentation is for the community to create them.
|
||||
|
||||
Perhaps that's a tall order. But the open source design community is bigger than it has ever been, and it is a highly motivated segment of the overall free and open source software movement. So who knows; maybe this time next year finding, downloading, and using fonts on a desktop Linux system will be an entirely different experience.
|
||||
|
||||
One train of thought on the typography challenges of modern Linux users includes packaging, document design, and maybe even a few new software components for desktop environments. There are other trains to consider, too. The commonality is that where the web-font service ends, matters get more difficult.
|
||||
|
||||
The best news, from my perspective, is that there are more people interested in this topic than ever before. For that, I think we have the higher profile that open fonts have received from big web-font services like Google Fonts and Open Font Library to thank.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/webfonts
|
||||
|
||||
作者:[Nathan Willis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/n8willis
|
||||
[1]:https://en.wikipedia.org/wiki/Core_fonts_for_the_Web
|
||||
[2]:https://en.wikipedia.org/wiki/Web_Open_Font_Format
|
||||
[3]:https://fonts.google.com/
|
||||
[4]:https://fontlibrary.org/
|
||||
[5]:https://fontmanager.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Didone_(typography)
|
||||
[7]:https://en.wikipedia.org/wiki/Firmin_Didot
|
||||
[8]:https://en.wikipedia.org/wiki/Giambattista_Bodoni
|
||||
[9]:https://software.sil.org/gentium/
|
||||
[10]:https://djr.com/bungee/
|
||||
[11]:https://www.freedesktop.org/wiki/Distributions/AppStream/
|
||||
[12]:https://www.freedesktop.org/software/appstream/docs/sect-Metadata-Fonts.html
|
||||
[13]:https://spdx.org/
|
||||
@ -0,0 +1,518 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How To Check All Running Services In Linux
|
||||
======
|
||||
|
||||
There are many ways and tools to check and list all running services in Linux. Usually most of the administrator use `service service-name status` or `/etc/init.d/service-name status` for sysVinit system and `systemctl status service-name` for systemd systems.
|
||||
|
||||
The above command clearly shows that the mentioned service is running on server or not. It is very simple and basic command that should known by every Linux administrator.
|
||||
|
||||
If you are new to your environment and you don’t know what services are running on the system. How do you check?
|
||||
|
||||
Yes, we can check this. This will will help us to understand what are the services are running on the system and whether it’s necessary or need to disable.
|
||||
|
||||
### What Is SysVinit
|
||||
|
||||
init (short for initialization) is the first process started during booting of the computer system. Init is a daemon process that continues running until the system is shut down.
|
||||
|
||||
SysVinit is an old and traditional init system and system manager for old systems. Most of the latest distributions were adapted to systemd system due to some of the long pending issues on sysVinit system.
|
||||
|
||||
### What Is systemd
|
||||
|
||||
systemd is a new init system and system manager which is become very popular and widely adapted new standard init system by most of Linux distributions. Systemctl is a systemd utility which is help us to manage systemd system.
|
||||
|
||||
### Method-1: How To Check Running Services In sysVinit System
|
||||
|
||||
The below command helps us to check and list all running services in sysVinit system.
|
||||
|
||||
If you have many number of services, i would advise you to use file view commands such as less, more, etc commands for clear view.
|
||||
```
|
||||
# service --status-all
|
||||
or
|
||||
# service --status-all | more
|
||||
or
|
||||
# service --status-all | less
|
||||
|
||||
abrt-ccpp hook is installed
|
||||
abrtd (pid 2131) is running...
|
||||
abrt-dump-oops is stopped
|
||||
acpid (pid 1958) is running...
|
||||
atd (pid 2164) is running...
|
||||
auditd (pid 1731) is running...
|
||||
Frequency scaling enabled using ondemand governor
|
||||
crond (pid 2153) is running...
|
||||
hald (pid 1967) is running...
|
||||
htcacheclean is stopped
|
||||
httpd is stopped
|
||||
Table: filter
|
||||
Chain INPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 ACCEPT all ::/0 ::/0 state RELATED,ESTABLISHED
|
||||
2 ACCEPT icmpv6 ::/0 ::/0
|
||||
3 ACCEPT all ::/0 ::/0
|
||||
4 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:80
|
||||
5 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:21
|
||||
6 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:22
|
||||
7 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:25
|
||||
8 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2082
|
||||
9 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2086
|
||||
10 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2083
|
||||
11 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:2087
|
||||
12 ACCEPT tcp ::/0 ::/0 state NEW tcp dpt:10000
|
||||
13 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
1 REJECT all ::/0 ::/0 reject-with icmp6-adm-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
num target prot opt source destination
|
||||
|
||||
iptables: Firewall is not running.
|
||||
irqbalance (pid 1826) is running...
|
||||
Kdump is operational
|
||||
lvmetad is stopped
|
||||
mdmonitor is stopped
|
||||
messagebus (pid 1929) is running...
|
||||
SUCCESS! MySQL running (24376)
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
named is stopped
|
||||
netconsole module not loaded
|
||||
Usage: startup.sh { start | stop }
|
||||
Configured devices:
|
||||
lo eth0 eth1
|
||||
Currently active devices:
|
||||
lo eth0
|
||||
ntpd is stopped
|
||||
portreserve (pid 1749) is running...
|
||||
master (pid 2107) is running...
|
||||
Process accounting is disabled.
|
||||
quota_nld is stopped
|
||||
rdisc is stopped
|
||||
rngd is stopped
|
||||
rpcbind (pid 1840) is running...
|
||||
rsyslogd (pid 1756) is running...
|
||||
sandbox is stopped
|
||||
saslauthd is stopped
|
||||
smartd is stopped
|
||||
openssh-daemon (pid 9859) is running...
|
||||
svnserve is stopped
|
||||
vsftpd (pid 4008) is running...
|
||||
xinetd (pid 2031) is running...
|
||||
zabbix_agentd (pid 2150 2149 2148 2147 2146 2140) is running...
|
||||
|
||||
```
|
||||
|
||||
Run the following command to view only running services in the system.
|
||||
```
|
||||
# service --status-all | grep running
|
||||
|
||||
crond (pid 535) is running...
|
||||
httpd (pid 627) is running...
|
||||
mysqld (pid 911) is running...
|
||||
rndc: neither /etc/rndc.conf nor /etc/rndc.key was found
|
||||
rsyslogd (pid 449) is running...
|
||||
saslauthd (pid 492) is running...
|
||||
sendmail (pid 509) is running...
|
||||
sm-client (pid 519) is running...
|
||||
openssh-daemon (pid 478) is running...
|
||||
xinetd (pid 485) is running...
|
||||
|
||||
```
|
||||
|
||||
Run the following command to view the particular service status.
|
||||
```
|
||||
# service --status-all | grep httpd
|
||||
httpd (pid 627) is running...
|
||||
|
||||
```
|
||||
|
||||
Alternatively use the following command to view the particular service status.
|
||||
```
|
||||
# service httpd status
|
||||
|
||||
httpd (pid 627) is running...
|
||||
|
||||
```
|
||||
|
||||
Use the following command to view the list of running services enabled in boot.
|
||||
```
|
||||
# chkconfig --list
|
||||
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
htcacheclean 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
httpd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
ip6tables 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
modules_dep 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
named 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
netfs 0:off 1:off 2:off 3:off 4:on 5:on 6:off
|
||||
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
nmb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
nscd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
portreserve 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
quota_nld 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rdisc 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
restorecond 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
rpcbind 0:off 1:off 2:on 3:off 4:on 5:on 6:off
|
||||
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
saslauthd 0:off 1:off 2:off 3:on 4:off 5:off 6:off
|
||||
sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
smb 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
snmptrapd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
|
||||
udev-post 0:off 1:on 2:on 3:off 4:on 5:on 6:off
|
||||
winbind 0:off 1:off 2:off 3:off 4:off 5:off 6:off
|
||||
xinetd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
|
||||
|
||||
xinetd based services:
|
||||
chargen-dgram: off
|
||||
chargen-stream: off
|
||||
daytime-dgram: off
|
||||
daytime-stream: off
|
||||
discard-dgram: off
|
||||
discard-stream: off
|
||||
echo-dgram: off
|
||||
echo-stream: off
|
||||
finger: off
|
||||
ntalk: off
|
||||
rsync: off
|
||||
talk: off
|
||||
tcpmux-server: off
|
||||
time-dgram: off
|
||||
time-stream: off
|
||||
|
||||
```
|
||||
|
||||
### Method-2: How To Check Running Services In systemd System
|
||||
|
||||
The below command helps us to check and list all running services in “systemd” system.
|
||||
```
|
||||
# systemctl
|
||||
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
sys-devices-virtual-block-loop0.device loaded active plugged /sys/devices/virtual/block/loop0
|
||||
sys-devices-virtual-block-loop1.device loaded active plugged /sys/devices/virtual/block/loop1
|
||||
sys-devices-virtual-block-loop2.device loaded active plugged /sys/devices/virtual/block/loop2
|
||||
sys-devices-virtual-block-loop3.device loaded active plugged /sys/devices/virtual/block/loop3
|
||||
sys-devices-virtual-block-loop4.device loaded active plugged /sys/devices/virtual/block/loop4
|
||||
sys-devices-virtual-misc-rfkill.device loaded active plugged /sys/devices/virtual/misc/rfkill
|
||||
sys-devices-virtual-tty-ttyprintk.device loaded active plugged /sys/devices/virtual/tty/ttyprintk
|
||||
sys-module-fuse.device loaded active plugged /sys/module/fuse
|
||||
sys-subsystem-net-devices-enp0s3.device loaded active plugged 82540EM Gigabit Ethernet Controller (PRO/1000 MT Desktop Adapter)
|
||||
-.mount loaded active mounted Root Mount
|
||||
dev-hugepages.mount loaded active mounted Huge Pages File System
|
||||
dev-mqueue.mount loaded active mounted POSIX Message Queue File System
|
||||
run-user-1000-gvfs.mount loaded active mounted /run/user/1000/gvfs
|
||||
run-user-1000.mount loaded active mounted /run/user/1000
|
||||
snap-core-3887.mount loaded active mounted Mount unit for core
|
||||
snap-core-4017.mount loaded active mounted Mount unit for core
|
||||
snap-core-4110.mount loaded active mounted Mount unit for core
|
||||
snap-gping-13.mount loaded active mounted Mount unit for gping
|
||||
snap-termius\x2dapp-8.mount loaded active mounted Mount unit for termius-app
|
||||
sys-fs-fuse-connections.mount loaded active mounted FUSE Control File System
|
||||
sys-kernel-debug.mount loaded active mounted Debug File System
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
systemd-ask-password-plymouth.path loaded active waiting Forward Password Requests to Plymouth Directory Watch
|
||||
systemd-ask-password-wall.path loaded active waiting Forward Password Requests to Wall Directory Watch
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
postfix.service loaded active exited Postfix Mail Transport Agent
|
||||
|
||||
```
|
||||
|
||||
* **`UNIT`** Unit describe about the corresponding systemd unit name.
|
||||
* **`LOAD`** This describes whether the corresponding unit currently loaded in memory or not.
|
||||
* **`ACTIVE`** It’s indicate whether the unit is active or not.
|
||||
* **`SUB`** It’s indicate whether the unit is running state or not.
|
||||
* **`DESCRIPTION`** A short description about the unit.
|
||||
|
||||
|
||||
|
||||
The below option help you to list units based on the type.
|
||||
```
|
||||
# systemctl list-units --type service
|
||||
UNIT LOAD ACTIVE SUB DESCRIPTION
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
anacron.service loaded active running Run anacron jobs
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
apparmor.service loaded active exited AppArmor initialization
|
||||
apport.service loaded active exited LSB: automatic crash report generation
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
console-setup.service loaded active exited Set console font and keymap
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
[email protected] loaded active running Getty on tty1
|
||||
grub-common.service loaded active exited LSB: Record successful boot for GRUB
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
keyboard-setup.service loaded active exited Set the console keyboard layout
|
||||
kmod-static-nodes.service loaded active exited Create list of required static device nodes for the current kernel
|
||||
|
||||
```
|
||||
|
||||
The below option help you to list units based on the state. It’s similar to the above output but straight forward.
|
||||
```
|
||||
# systemctl list-unit-files --type service
|
||||
|
||||
UNIT FILE STATE
|
||||
accounts-daemon.service enabled
|
||||
acpid.service disabled
|
||||
alsa-restore.service static
|
||||
alsa-state.service static
|
||||
alsa-utils.service masked
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache-htcacheclean.service disabled
|
||||
[email protected] disabled
|
||||
apache2.service enabled
|
||||
[email protected] disabled
|
||||
apparmor.service enabled
|
||||
[email protected] static
|
||||
apport.service generated
|
||||
apt-daily-upgrade.service static
|
||||
apt-daily.service static
|
||||
aptik-battery-monitor.service generated
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
[email protected] enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
|
||||
```
|
||||
|
||||
Run the following command to view the particular service status.
|
||||
```
|
||||
# systemctl | grep apache2
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
|
||||
```
|
||||
|
||||
Alternatively use the following command to view the particular service status.
|
||||
```
|
||||
# systemctl status apache2
|
||||
● apache2.service - The Apache HTTP Server
|
||||
Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: enabled)
|
||||
Drop-In: /lib/systemd/system/apache2.service.d
|
||||
└─apache2-systemd.conf
|
||||
Active: active (running) since Tue 2018-03-06 12:34:09 IST; 8min ago
|
||||
Process: 2786 ExecReload=/usr/sbin/apachectl graceful (code=exited, status=0/SUCCESS)
|
||||
Main PID: 1171 (apache2)
|
||||
Tasks: 55 (limit: 4915)
|
||||
CGroup: /system.slice/apache2.service
|
||||
├─1171 /usr/sbin/apache2 -k start
|
||||
├─2790 /usr/sbin/apache2 -k start
|
||||
└─2791 /usr/sbin/apache2 -k start
|
||||
|
||||
Mar 06 12:34:08 magi-VirtualBox systemd[1]: Starting The Apache HTTP Server...
|
||||
Mar 06 12:34:09 magi-VirtualBox apachectl[1089]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 10.0.2.15. Set the 'ServerName' directive globally to suppre
|
||||
Mar 06 12:34:09 magi-VirtualBox systemd[1]: Started The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloading The Apache HTTP Server.
|
||||
Mar 06 12:39:10 magi-VirtualBox apachectl[2786]: AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using fe80::7929:4ed1:279f:4d65. Set the 'ServerName' directive gl
|
||||
Mar 06 12:39:10 magi-VirtualBox systemd[1]: Reloaded The Apache HTTP Server.
|
||||
|
||||
```
|
||||
|
||||
Run the following command to view only running services in the system.
|
||||
```
|
||||
# systemctl | grep running
|
||||
acpid.path loaded active running ACPI Events Check
|
||||
cups.path loaded active running CUPS Scheduler
|
||||
init.scope loaded active running System and Service Manager
|
||||
session-c2.scope loaded active running Session c2 of user magi
|
||||
accounts-daemon.service loaded active running Accounts Service
|
||||
acpid.service loaded active running ACPI event daemon
|
||||
apache2.service loaded active running The Apache HTTP Server
|
||||
aptik-battery-monitor.service loaded active running LSB: start/stop the aptik battery monitor daemon
|
||||
atop.service loaded active running Atop advanced performance monitor
|
||||
atopacct.service loaded active running Atop process accounting daemon
|
||||
avahi-daemon.service loaded active running Avahi mDNS/DNS-SD Stack
|
||||
colord.service loaded active running Manage, Install and Generate Color Profiles
|
||||
cron.service loaded active running Regular background program processing daemon
|
||||
cups-browsed.service loaded active running Make remote CUPS printers available locally
|
||||
cups.service loaded active running CUPS Scheduler
|
||||
dbus.service loaded active running D-Bus System Message Bus
|
||||
fwupd.service loaded active running Firmware update daemon
|
||||
[email protected] loaded active running Getty on tty1
|
||||
irqbalance.service loaded active running LSB: daemon to balance interrupts for SMP systems
|
||||
lightdm.service loaded active running Light Display Manager
|
||||
ModemManager.service loaded active running Modem Manager
|
||||
NetworkManager.service loaded active running Network Manager
|
||||
polkit.service loaded active running Authorization Manager
|
||||
|
||||
```
|
||||
|
||||
Use the following command to view the list of running services enabled in boot.
|
||||
```
|
||||
# systemctl list-unit-files | grep enabled
|
||||
acpid.path enabled
|
||||
cups.path enabled
|
||||
accounts-daemon.service enabled
|
||||
anacron-resume.service enabled
|
||||
anacron.service enabled
|
||||
apache2.service enabled
|
||||
apparmor.service enabled
|
||||
atop.service enabled
|
||||
atopacct.service enabled
|
||||
[email protected] enabled
|
||||
avahi-daemon.service enabled
|
||||
bluetooth.service enabled
|
||||
console-setup.service enabled
|
||||
cron.service enabled
|
||||
cups-browsed.service enabled
|
||||
cups.service enabled
|
||||
display-manager.service enabled
|
||||
dns-clean.service enabled
|
||||
friendly-recovery.service enabled
|
||||
[email protected] enabled
|
||||
gpu-manager.service enabled
|
||||
keyboard-setup.service enabled
|
||||
lightdm.service enabled
|
||||
ModemManager.service enabled
|
||||
network-manager.service enabled
|
||||
networking.service enabled
|
||||
NetworkManager-dispatcher.service enabled
|
||||
NetworkManager-wait-online.service enabled
|
||||
NetworkManager.service enabled
|
||||
|
||||
```
|
||||
|
||||
systemd-cgtop show top control groups by their resource usage such as tasks, CPU, Memory, Input, and Output.
|
||||
```
|
||||
# systemd-cgtop
|
||||
|
||||
Control Group Tasks %CPU Memory Input/s Output/s
|
||||
/ - - 1.5G - -
|
||||
/init.scope 1 - - - -
|
||||
/system.slice 153 - - - -
|
||||
/system.slice/ModemManager.service 3 - - - -
|
||||
/system.slice/NetworkManager.service 4 - - - -
|
||||
/system.slice/accounts-daemon.service 3 - - - -
|
||||
/system.slice/acpid.service 1 - - - -
|
||||
/system.slice/apache2.service 55 - - - -
|
||||
/system.slice/aptik-battery-monitor.service 1 - - - -
|
||||
/system.slice/atop.service 1 - - - -
|
||||
/system.slice/atopacct.service 1 - - - -
|
||||
/system.slice/avahi-daemon.service 2 - - - -
|
||||
/system.slice/colord.service 3 - - - -
|
||||
/system.slice/cron.service 1 - - - -
|
||||
/system.slice/cups-browsed.service 3 - - - -
|
||||
/system.slice/cups.service 2 - - - -
|
||||
/system.slice/dbus.service 6 - - - -
|
||||
/system.slice/fwupd.service 5 - - - -
|
||||
/system.slice/irqbalance.service 1 - - - -
|
||||
/system.slice/lightdm.service 7 - - - -
|
||||
/system.slice/polkit.service 3 - - - -
|
||||
/system.slice/repowerd.service 14 - - - -
|
||||
/system.slice/rsyslog.service 4 - - - -
|
||||
/system.slice/rtkit-daemon.service 3 - - - -
|
||||
/system.slice/snapd.service 8 - - - -
|
||||
/system.slice/system-getty.slice 1 - - - -
|
||||
|
||||
```
|
||||
|
||||
Also we can check the running services using pstree command (Output from SysVinit system).
|
||||
```
|
||||
# pstree
|
||||
init-|-crond
|
||||
|-httpd---2*[httpd]
|
||||
|-kthreadd/99149---khelper/99149
|
||||
|-2*[mingetty]
|
||||
|-mysqld_safe---mysqld---9*[{mysqld}]
|
||||
|-rsyslogd---3*[{rsyslogd}]
|
||||
|-saslauthd---saslauthd
|
||||
|-2*[sendmail]
|
||||
|-sshd---sshd---bash---pstree
|
||||
|-udevd
|
||||
`-xinetd
|
||||
|
||||
```
|
||||
|
||||
Also we can check the running services using pstree command (Output from systemd system).
|
||||
```
|
||||
# pstree
|
||||
systemd─┬─ModemManager─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─NetworkManager─┬─dhclient
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─accounts-daemon─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─acpid
|
||||
├─agetty
|
||||
├─anacron
|
||||
├─apache2───2*[apache2───26*[{apache2}]]
|
||||
├─aptd───{gmain}
|
||||
├─aptik-battery-m
|
||||
├─atop
|
||||
├─atopacctd
|
||||
├─avahi-daemon───avahi-daemon
|
||||
├─colord─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cron
|
||||
├─cups-browsed─┬─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─cupsd
|
||||
├─dbus-daemon
|
||||
├─fwupd─┬─{GUsbEventThread}
|
||||
│ ├─{fwupd}
|
||||
│ ├─{gdbus}
|
||||
│ └─{gmain}
|
||||
├─gnome-keyring-d─┬─{gdbus}
|
||||
│ ├─{gmain}
|
||||
│ └─{timer}
|
||||
|
||||
```
|
||||
|
||||
### Method-3: How To Check Running Services In systemd System using chkservice
|
||||
|
||||
chkservice is a new tool for managing systemd units in terminal. It requires super user privileges to manage the units.
|
||||
```
|
||||
# chkservice
|
||||
|
||||
```
|
||||
|
||||
![][1]
|
||||
|
||||
To view help page, hit `?` button. This will shows you available options to manage the systemd services.
|
||||
![][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-check-all-running-services-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
[1]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-1.png
|
||||
[2]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-2.png
|
||||
@ -0,0 +1,78 @@
|
||||
3 open source tools for scientific publishing
|
||||
======
|
||||
|
||||
|
||||
One industry that lags behind others in the adoption of digital or open source tools is the competitive and lucrative world of scientific publishing. Worth over £19B ($26B) annually, according to figures published by Stephen Buranyi in [The Guardian][1] last year, the system for selecting, publishing, and sharing even the most important scientific research today still bears many of the constraints of print media. New digital-era technologies present a huge opportunity to accelerate discovery, make science collaborative instead of competitive, and redirect investments from infrastructure development into research that benefits society.
|
||||
|
||||
The non-profit [eLife initiative][2] was established by the funders of research, in part to encourage the use of these technologies to this end. In addition to publishing an open-access journal for important advances in life science and biomedical research, eLife has made itself into a platform for experimentation and showcasing innovation in research communication—with most of this experimentation based around the open source ethos.
|
||||
|
||||
Working on open publishing infrastructure projects gives us the opportunity to accelerate the reach and adoption of the types of technology and user experience (UX) best practices that we consider important to the advancement of the academic publishing industry. Speaking very generally, the UX of open source products is often left undeveloped, which can in some cases dissuade people from using it. As part of our investment in OSS development, we place a strong emphasis on UX in order to encourage users to adopt these products.
|
||||
|
||||
All of our code is open source, and we actively encourage community involvement in our projects, which to us means faster iteration, more experimentation, greater transparency, and increased reach for our work.
|
||||
|
||||
The projects that we are involved in, such as the development of Libero (formerly known as [eLife Continuum][3]) and the [Reproducible Document Stack][4], along with our recent collaboration with [Hypothesis][5], show how OSS can be used to bring about positive changes in the assessment, publication, and communication of new discoveries.
|
||||
|
||||
### Libero
|
||||
|
||||
Libero is a suite of services and applications available to publishers that includes a post-production publishing system, a full front-end user interface pattern suite, Libero's Lens Reader, an open API, and search and recommendation engines.
|
||||
|
||||
Last year, we took a user-driven approach to redesigning the front end of Libero, resulting in less distracting site “furniture” and a greater focus on research articles. We tested and iterated all the key functional areas of the site with members of the eLife community to ensure the best possible reading experience for everyone. The site’s new API also provides simpler access to content for machine readability, including text mining, machine learning, and online application development.
|
||||
|
||||
The content on our website and the patterns that drive the new design are all open source to encourage future product development for both eLife and other publishers that wish to use it.
|
||||
|
||||
### The Reproducible Document Stack
|
||||
|
||||
In collaboration with [Substance][6] and [Stencila][7], eLife is also engaged in a project to create a Reproducible Document Stack (RDS)—an open stack of tools for authoring, compiling, and publishing computationally reproducible manuscripts online.
|
||||
|
||||
Today, an increasing number of researchers are able to document their computational experiments through languages such as [R Markdown][8] and [Python][9]. These can serve as important parts of the experimental record, and while they can be shared independently from or alongside the resulting research article, traditional publishing workflows tend to relegate these assets as a secondary class of content. To publish papers, researchers using these languages often have little option but to submit their computational results as “flattened” outputs in the form of figures, losing much of the value and reusability of the code and data references used in the computation. And while electronic notebook solutions such as [Jupyter][10] can enable researchers to publish their code in an easily reusable and executable form, that’s still in addition to, rather than as an integral part of, the published manuscript.
|
||||
|
||||
The [Reproducible Document Stack][11] project aims to address these challenges through development and publication of a working prototype of a reproducible manuscript that treats code and data as integral parts of the document, demonstrating a complete end-to-end technology stack from authoring through to publication. It will ultimately allow authors to submit their manuscripts in a format that includes embedded code blocks and computed outputs (statistical results, tables, or graphs), and have those assets remain both visible and executable throughout the publication process. Publishers will then be able to preserve these assets directly as integral parts of the published online article.
|
||||
|
||||
### Open annotation with Hypothesis
|
||||
|
||||
Most recently, we introduced open annotation in collaboration with [Hypothesis][12] to enable users of our website to make comments, highlight important sections of articles, and engage with the reading public online.
|
||||
|
||||
Through this collaboration, the open source Hypothesis software was customized with new moderation features, single sign-on authentication, and user-interface customization options, giving publishers more control over its implementation on their sites. These enhancements are already driving higher-quality discussions around published scholarly content.
|
||||
|
||||
The tool can be integrated seamlessly into publishers’ websites, with the scholarly publishing platform [PubFactory][13] and content solutions provider [Ingenta][14] already taking advantage of its improved feature set. [HighWire][15] and [Silverchair][16] are also offering their publishers the opportunity to implement the service.
|
||||
|
||||
### Other industries and open source
|
||||
|
||||
Over time, we hope to see more publishers adopt Hypothesis, Libero, and other projects to help them foster the discovery and reuse of important scientific research. But the opportunities for innovation eLife has been able to leverage because of these and other OSS technologies are also prevalent in other industries.
|
||||
|
||||
The world of data science would be nowhere without the high-quality, well-supported open source software and the communities built around it; [TensorFlow][17] is a leading example of this. Thanks to OSS and its communities, all areas of AI and machine learning have seen rapid acceleration and advancement compared to other areas of computing. Similar is the explosion in usage of Linux as a cloud web host, followed by containerization with Docker, and now the growth of Kubernetes, one of the most popular open source projects on GitHub.
|
||||
|
||||
All of these technologies enable organizations to do more with less and focus on innovation instead of reinventing the wheel. And in the end, that’s the real benefit of OSS: It lets us all learn from each other’s failures while building on each other's successes.
|
||||
|
||||
We are always on the lookout for opportunities to engage with the best emerging talent and ideas at the interface of research and technology. Find out more about some of these engagements on [eLife Labs][18], or contact [innovation@elifesciences.org][19] for more information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/scientific-publishing-software
|
||||
|
||||
作者:[Paul Shanno][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pshannon
|
||||
[1]:https://www.theguardian.com/science/2017/jun/27/profitable-business-scientific-publishing-bad-for-science
|
||||
[2]:https://elifesciences.org/about
|
||||
[3]:https://elifesciences.org/inside-elife/33e4127f/elife-introduces-continuum-a-new-open-source-tool-for-publishing
|
||||
[4]:https://elifesciences.org/for-the-press/e6038800/elife-supports-development-of-open-technology-stack-for-publishing-reproducible-manuscripts-online
|
||||
[5]:https://elifesciences.org/for-the-press/81d42f7d/elife-enhances-open-annotation-with-hypothesis-to-promote-scientific-discussion-online
|
||||
[6]:https://github.com/substance
|
||||
[7]:https://github.com/stencila/stencila
|
||||
[8]:https://rmarkdown.rstudio.com/
|
||||
[9]:https://www.python.org/
|
||||
[10]:http://jupyter.org/
|
||||
[11]:https://elifesciences.org/labs/7dbeb390/reproducible-document-stack-supporting-the-next-generation-research-article
|
||||
[12]:https://github.com/hypothesis
|
||||
[13]:http://www.pubfactory.com/
|
||||
[14]:http://www.ingenta.com/
|
||||
[15]:https://github.com/highwire
|
||||
[16]:https://www.silverchair.com/community/silverchair-universe/hypothesis/
|
||||
[17]:https://www.tensorflow.org/
|
||||
[18]:https://elifesciences.org/labs
|
||||
[19]:mailto:innovation@elifesciences.org
|
||||
@ -0,0 +1,92 @@
|
||||
translating---geekpi
|
||||
|
||||
An Open Source Desktop YouTube Player For Privacy-minded People
|
||||
======
|
||||
|
||||

|
||||
|
||||
You already know that we need a Google account to subscribe channels and download videos from YouTube. If you don’t want Google track what you’re doing on YouTube, well, there is an open source YouTube player named **“FreeTube”**. It allows you to watch, search and download Youtube videos and subscribe your favorite channels without an account, which prevents Google from having your information. It gives you complete ad-free experience. Another notable advantage is it has a built-in basic HTML5 player to watch videos. Since we’re not using the built-in YouTube player, Google can’t track the “views” and the video analytics either. FreeTube only sends your IP details, but this also can be overcome by using a VPN. It is completely free, open source and available for GNU/Linux, Mac OS X, and Windows.
|
||||
|
||||
### Features
|
||||
|
||||
* Watch videos without ads.
|
||||
* Prevent Google from tracking what you watch using cookies or JavaScript.
|
||||
* Subscribe to channels without an account.
|
||||
* Store subscriptions, history, and saved videos locally.
|
||||
* Import / Backup subscriptions.
|
||||
* Mini Player.
|
||||
* Light / Dark Theme.
|
||||
* Free, Open Source.
|
||||
* Cross-platform.
|
||||
|
||||
|
||||
|
||||
### Installing FreeTube
|
||||
|
||||
Go to the [**releases page**][1] and grab the version depending upon the OS you use. For the purpose of this guide, I will be using **.tar.gz** file.
|
||||
```
|
||||
$ wget https://github.com/FreeTubeApp/FreeTube/releases/download/v0.1.3-beta/FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Extract the downloaded archive:
|
||||
```
|
||||
$ tar xf FreeTube-linux-x64.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Go to the Freetube folder:
|
||||
```
|
||||
$ cd FreeTube-linux-x64/
|
||||
|
||||
```
|
||||
|
||||
Launch Freeube using command:
|
||||
```
|
||||
$ ./FreeTub
|
||||
|
||||
```
|
||||
|
||||
This is how FreeTube default interface looks like.
|
||||
|
||||
![][3]
|
||||
|
||||
### Usage
|
||||
|
||||
FreeTube currently uses **YouTube API** to search for videos. And then, It uses **Youtube-dl HTTP API** to grab the raw video files and play them in a basic HTML5 video player. Since subscriptions, history, and saved videos are stored locally on your system, your details will not be sent to Google or anyone else.
|
||||
|
||||
Enter the video name in the search box and hit ENTER key. FreeTube will list out the results based on your search query.
|
||||
|
||||
![][4]
|
||||
|
||||
You can click on any video to play it.
|
||||
|
||||
![][5]
|
||||
|
||||
If you want to change the theme or default API, import/export subscriptions, go to the **Settings** section.
|
||||
|
||||
![][6]
|
||||
|
||||
Please note that FreeTube is still in **beta** stage, so there will be bugs. If there are any bugs, please report them in the GitHub page given at the end of this guide.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/freetube-an-open-source-desktop-youtube-player-for-privacy-minded-people/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/FreeTubeApp/FreeTube/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-3.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-5-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/FreeTube-2.png
|
||||
@ -0,0 +1,167 @@
|
||||
Protecting Code Integrity with PGP — Part 4: Moving Your Master Key to Offline Storage
|
||||
======
|
||||
|
||||

|
||||
In this tutorial series, we're providing practical guidelines for using PGP. You can catch up on previous articles here:
|
||||
|
||||
[Part 1: Basic Concepts and Tools][1]
|
||||
|
||||
[Part 2: Generating Your Master Key][2]
|
||||
|
||||
[Part 3: Generating PGP Subkeys][3]
|
||||
|
||||
Here in part 4, we continue the series with a look at how and why to move your master key from your home directory to offline storage. Let's get started.
|
||||
|
||||
### Checklist
|
||||
|
||||
* Prepare encrypted detachable storage (ESSENTIAL)
|
||||
|
||||
* Back up your GnuPG directory (ESSENTIAL)
|
||||
|
||||
* Remove the master key from your home directory (NICE)
|
||||
|
||||
* Remove the revocation certificate from your home directory (NICE)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Considerations
|
||||
|
||||
Why would you want to remove your master [C] key from your home directory? This is generally done to prevent your master key from being stolen or accidentally leaked. Private keys are tasty targets for malicious actors -- we know this from several successful malware attacks that scanned users' home directories and uploaded any private key content found there.
|
||||
|
||||
It would be very damaging for any developer to have their PGP keys stolen -- in the Free Software world, this is often tantamount to identity theft. Removing private keys from your home directory helps protect you from such events.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
**!!!Do not skip this step!!!**
|
||||
|
||||
It is important to have a readily available backup of your PGP keys should you need to recover them (this is different from the disaster-level preparedness we did with paperkey).
|
||||
|
||||
##### Prepare detachable encrypted storage
|
||||
|
||||
Start by getting a small USB "thumb" drive (preferably two!) that you will use for backup purposes. You will first need to encrypt them:
|
||||
|
||||
For the encryption passphrase, you can use the same one as on your master key.
|
||||
|
||||
##### Back up your GnuPG directory
|
||||
|
||||
Once the encryption process is over, re-insert the USB drive and make sure it gets properly mounted. Find out the full mount point of the device, for example by running the mount command (under Linux, external media usually gets mounted under /media/disk, under Mac it's /Volumes).
|
||||
|
||||
Once you know the full mount path, copy your entire GnuPG directory there:
|
||||
```
|
||||
$ cp -rp ~/.gnupg [/media/disk/name]/gnupg-backup
|
||||
|
||||
```
|
||||
|
||||
(Note: If you get any Operation not supported on socket errors, those are benign and you can ignore them.)
|
||||
|
||||
You should now test to make sure everything still works:
|
||||
```
|
||||
$ gpg --homedir=[/media/disk/name]/gnupg-backup --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
If you don't get any errors, then you should be good to go. Unmount the USB drive and distinctly label it, so you don't blow it away next time you need to use a random USB drive. Then, put in a safe place -- but not too far away, because you'll need to use it every now and again for things like editing identities, adding or revoking subkeys, or signing other people's keys.
|
||||
|
||||
##### Remove the master key
|
||||
|
||||
The files in our home directory are not as well protected as we like to think. They can be leaked or stolen via many different means:
|
||||
|
||||
* By accident when making quick homedir copies to set up a new workstation
|
||||
|
||||
* By systems administrator negligence or malice
|
||||
|
||||
* Via poorly secured backups
|
||||
|
||||
* Via malware in desktop apps (browsers, pdf viewers, etc)
|
||||
|
||||
* Via coercion when crossing international borders
|
||||
|
||||
|
||||
|
||||
|
||||
Protecting your key with a good passphrase greatly helps reduce the risk of any of the above, but passphrases can be discovered via keyloggers, shoulder-surfing, or any number of other means. For this reason, the recommended setup is to remove your master key from your home directory and store it on offline storage.
|
||||
|
||||
###### Removing your master key
|
||||
|
||||
Please see the previous section and make sure you have backed up your GnuPG directory in its entirety. What we are about to do will render your key useless if you do not have a usable backup!
|
||||
|
||||
First, identify the keygrip of your master key:
|
||||
```
|
||||
$ gpg --with-keygrip --list-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
The output will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
Keygrip = AAAA999988887777666655554444333322221111
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
Keygrip = BBBB999988887777666655554444333322221111
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
Keygrip = CCCC999988887777666655554444333322221111
|
||||
|
||||
```
|
||||
|
||||
Find the keygrip entry that is beneath the pub line (right under the master key fingerprint). This will correspond directly to a file in your home .gnupg directory:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ ls
|
||||
AAAA999988887777666655554444333322221111.key
|
||||
BBBB999988887777666655554444333322221111.key
|
||||
CCCC999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
All you have to do is simply remove the .key file that corresponds to the master keygrip:
|
||||
```
|
||||
$ cd ~/.gnupg/private-keys-v1.d
|
||||
$ rm AAAA999988887777666655554444333322221111.key
|
||||
|
||||
```
|
||||
|
||||
Now, if you issue the --list-secret-keys command, it will show that the master key is missing (the # indicates it is not available):
|
||||
```
|
||||
$ gpg --list-secret-keys
|
||||
sec# rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
ssb rsa2048 2017-12-06 [E]
|
||||
ssb rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### Remove the revocation certificate
|
||||
|
||||
Another file you should remove (but keep in backups) is the revocation certificate that was automatically created with your master key. A revocation certificate allows someone to permanently mark your key as revoked, meaning it can no longer be used or trusted for any purpose. You would normally use it to revoke a key that, for some reason, you can no longer control -- for example, if you had lost the key passphrase.
|
||||
|
||||
Just as with the master key, if a revocation certificate leaks into malicious hands, it can be used to destroy your developer digital identity, so it's better to remove it from your home directory.
|
||||
```
|
||||
cd ~/.gnupg/openpgp-revocs.d
|
||||
rm [fpr].rev
|
||||
|
||||
```
|
||||
|
||||
Next time, you'll learn how to secure your subkeys as well. Stay tuned.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/pgp/2018/3/protecting-code-integrity-pgp-part-4-moving-your-master-key-offline-storage
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[3]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-3-generating-pgp-subkeys
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user