mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
429a99a715
158
sources/talk/20181114 Analyzing the DNA of DevOps.md
Normal file
158
sources/talk/20181114 Analyzing the DNA of DevOps.md
Normal file
@ -0,0 +1,158 @@
|
||||
Analyzing the DNA of DevOps
|
||||
======
|
||||
How have waterfall, agile, and other development frameworks shaped the evolution of DevOps? Here's what we discovered.
|
||||

|
||||
|
||||
If you were to analyze the DNA of DevOps, what would you find in its ancestry report?
|
||||
|
||||
This article is not a methodology bake-off, so if you are looking for advice or a debate on the best approach to software engineering, you can stop reading here. Rather, we are going to explore the genetic sequences that have brought DevOps to the forefront of today's digital transformations.
|
||||
|
||||
Much of DevOps has evolved through trial and error, as companies have struggled to be responsive to customers’ demands while improving quality and standing out in an increasingly competitive marketplace. Adding to the challenge is the transition from a product-driven to a service-driven global economy that connects people in new ways. The software development lifecycle is becoming an increasingly complex system of services and microservices, both interconnected and instrumented. As DevOps is pushed further and faster than ever, the speed of change is wiping out slower traditional methodologies like waterfall.
|
||||
|
||||
We are not slamming the waterfall approach—many organizations have valid reasons to continue using it. However, mature organizations should aim to move away from wasteful processes, and indeed, many startups have a competitive edge over companies that use more traditional approaches in their day-to-day operations.
|
||||
|
||||
Ironically, lean, [Kanban][1], continuous, and agile principles and processes trace back to the early 1940's, so DevOps cannot claim to be a completely new idea.
|
||||
|
||||
Let's start by stepping back a few years and looking at the waterfall, lean, and agile software development approaches. The figure below shows a “haplogroup” of the software development lifecycle. (Remember, we are not looking for the best approach but trying to understand which approach has positively influenced our combined 67 years of software engineering and the evolution to a DevOps mindset.)
|
||||
|
||||

|
||||
|
||||
> “A fool with a tool is still a fool.” -Mathew Mathai
|
||||
|
||||
### The traditional waterfall method
|
||||
|
||||
From our perspective, the oldest genetic material comes from the [waterfall][2] model, first introduced by Dr. Winston W. Royce in a paper published in the 1970's.
|
||||
|
||||

|
||||
|
||||
Like a waterfall, this approach emphasizes a logical and sequential progression through requirements, analysis, coding, testing, and operations in a single pass. You must complete each sequence, meet criteria, and obtain a signoff before you can begin the next one. The waterfall approach benefits projects that need stringent sequences and that have a detailed and predictable scope and milestone-based development. Contrary to popular belief, it also allows teams to experiment and make early design changes during the requirements, analysis, and design stages.
|
||||
|
||||
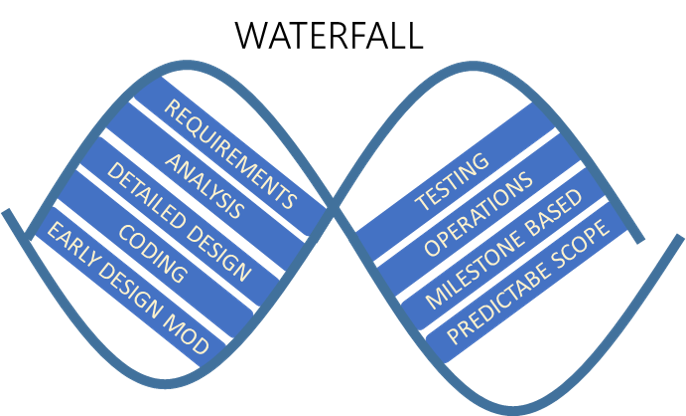
|
||||
|
||||
### Lean thinking
|
||||
|
||||
Although lean thinking dates to the Venetian Arsenal in the 1450s, we start the clock when Toyota created the [Toyota Production System][3], developed by Japanese engineers between 1948 and 1972. Toyota published an official description of the system in 1992.
|
||||
|
||||

|
||||
|
||||
Lean thinking is based on [five principles][4]: value, value stream, flow, pull, and perfection. The core of this approach is to understand and support an effective value stream, eliminate waste, and deliver continuous value to the user. It is about delighting your users without interruption.
|
||||
|
||||

|
||||
|
||||
### Kaizen
|
||||
|
||||
Kaizen is based on incremental improvements; the **Plan- >Do->Check->Act** lifecycle moved companies toward a continuous improvement mindset. Originally developed to improve the flow and processes of the assembly line, the Kaizen concept also adds value across the supply chain. The Toyota Production system was one of the early implementors of Kaizen and continuous improvement. Kaizen and DevOps work well together in environments where workflow goes from design to production. Kaizen focuses on two areas:
|
||||
|
||||
* Flow
|
||||
* Process
|
||||
|
||||
|
||||
|
||||
### Continuous delivery
|
||||
|
||||
Kaizen inspired the development of processes and tools to automate production. Companies were able to speed up production and improve the quality, design, build, test, and delivery phases by removing waste (including culture and mindset) and automating as much as possible using machines, software, and robotics. Much of the Kaizen philosophy also applies to lean business and software practices and continuous delivery deployment for DevOps principles and goals.
|
||||
|
||||
### Agile
|
||||
|
||||
The [Manifesto for Agile Software Development][5] appeared in 2001, authored by Alistair Cockburn, Bob Martin, Jeff Sutherland, Jim Highsmith, Ken Schwaber, Kent Beck, Ward Cunningham, and others.
|
||||
|
||||

|
||||
|
||||
[Agile][6] is not about throwing caution to the wind, ditching design, or building software in the Wild West. It is about being able to create and respond to change. Agile development is [based on twelve principles][7] and a manifesto that values individuals and collaboration, working software, customer collaboration, and responding to change.
|
||||
|
||||

|
||||
|
||||
### Disciplined agile
|
||||
|
||||
Since the Agile Manifesto has remained static for 20 years, many agile practitioners have looked for ways to add choice and subjectivity to the approach. Additionally, the Agile Manifesto focuses heavily on development, so a tweak toward solutions rather than code or software is especially needed in today's fast-paced development environment. Scott Ambler and Mark Lines co-authored [Disciplined Agile Delivery][8] and [The Disciplined Agile Framework][9], based on their experiences at Rational, IBM, and organizations in which teams needed more choice or were not mature enough to implement lean practices, or where context didn't fit the lifecycle.
|
||||
|
||||
The significance of DAD and DA is that it is a [process-decision framework][10] that enables simplified process decisions around incremental and iterative solution delivery. DAD builds on the many practices of agile software development, including scrum, agile modeling, lean software development, and others. The extensive use of agile modeling and refactoring, including encouraging automation through test-driven development (TDD), lean thinking such as Kanban, [XP][11], [scrum][12], and [RUP][13] through a choice of five agile lifecycles, and the introduction of the architect owner, gives agile practitioners added mindsets, processes, and tools to successfully implement DevOps.
|
||||
|
||||
### DevOps
|
||||
|
||||
As far as we can gather, DevOps emerged during a series of DevOpsDays in Belgium in 2009, going on to become the foundation for numerous digital transformations. Microsoft principal DevOps manager [Donovan Brown][14] defines DevOps as “the union of people, process, and products to enable continuous delivery of value to our end users.”
|
||||
|
||||

|
||||
|
||||
Let's go back to our original question: What would you find in the ancestry report of DevOps if you analyzed its DNA?
|
||||
|
||||

|
||||
|
||||
We are looking at history dating back 80, 48, 26, and 17 years—an eternity in today’s fast-paced and often turbulent environment. By nature, we humans continuously experiment, learn, and adapt, inheriting strengths and resolving weaknesses from our genetic strands.
|
||||
|
||||
Under the microscope, we will find traces of waterfall, lean thinking, agile, scrum, Kanban, and other genetic material. For example, there are traces of waterfall for detailed and predictable scope, traces of lean for cutting waste, and traces of agile for promoting increments of shippable code. The genetic strands that define when and how to ship the code are where DevOps lights up in our DNA exploration.
|
||||
|
||||

|
||||
|
||||
You use the telemetry you collect from watching your solution in production to drive experiments, confirm hypotheses, and prioritize your product backlog. In other words, DevOps inherits from a variety of proven and evolving frameworks and enables you to transform your culture, use products as enablers, and most importantly, delight your customers.
|
||||
|
||||
If you are comfortable with lean thinking and agile, you will enjoy the full benefits of DevOps. If you come from a waterfall environment, you will receive help from a DevOps mindset, but your lean and agile counterparts will outperform you.
|
||||
|
||||
### eDevOps
|
||||
|
||||

|
||||
|
||||
In 2016, Brent Reed coined the term eDevOps (no Google or Wikipedia references exist to date), defining it as “a way of working (WoW) that brings continuous improvement across the enterprise seamlessly, through people, processes and tools.”
|
||||
|
||||
Brent found that agile was failing in IT: Businesses that had adopted lean thinking were not achieving the value, focus, and velocity they expected from their trusted IT experts. Frustrated at seeing an "ivory tower" in which siloed IT services were disconnected from architecture, development, operations, and help desk support teams, he applied his practical knowledge of disciplined agile delivery and added some goals and practical applications to the DAD toolset, including:
|
||||
|
||||
* Focus and drive of culture through a continuous improvement (Kaizen) mindset, bringing people together even when they are across the cubicle
|
||||
* Velocity through automation (TDD + refactoring everything possible), removing waste and adopting a [TOGAF][15], JBGE (just barely good enough) approach to documentation
|
||||
* Value through modeling (architecture modeling) and shifting left to enable right through exposing anti-patterns while sharing through collaboration patterns in a more versatile and strategic modern digital repository
|
||||
|
||||
|
||||
|
||||
Using his experience with AI at IBM, Brent designed a maturity model for eDevOps that incrementally automates dashboards for measuring and decision-making purposes so that continuous improvement through a continuous deployment (automating from development to production) is a real possibility for any organization. eDevOps in an effective transformation program based on disciplined DevOps that enables:
|
||||
|
||||
* Business to DevOps (BizDevOps),
|
||||
* Security to DevOps (SecDevOps)
|
||||
* Information to DevOps (DataDevOps)
|
||||
* Loosely coupled technical services while bringing together and delighting all stakeholders
|
||||
* Building potentially consumable solutions every two weeks or faster
|
||||
* Collecting, measuring, analyzing, displaying, and automating actionable insight through the DevOps processes from concept through live production use
|
||||
* Continuous improvement following a Kaizen and disciplined agile approach
|
||||
|
||||
|
||||
|
||||
### The next stage in the development of DevOps
|
||||
|
||||

|
||||
|
||||
Will DevOps ultimately be considered hype—a collection of more tech thrown at corporations and added to the already extensive list of buzzwords? Time, of course, will tell how DevOps will progress. However, DevOps' DNA must continue to mature and be refined, and developers must understand that it is neither a silver bullet nor a remedy to cure all ailments and solve all problems.
|
||||
|
||||
```
|
||||
DevOps != Agile != Lean Thinking != Waterfall
|
||||
|
||||
DevOps != Tools !=Technology
|
||||
|
||||
DevOps Ì Agile Ì Lean Thinking Ì Waterfall
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/analyzing-devops
|
||||
|
||||
作者:[Willy-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/wpschaub
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Kanban
|
||||
[2]: https://airbrake.io/blog/sdlc/waterfall-model
|
||||
[3]: https://en.wikipedia.org/wiki/Toyota_Production_System
|
||||
[4]: https://www.lean.org/WhatsLean/Principles.cfm
|
||||
[5]: http://agilemanifesto.org/
|
||||
[6]: https://www.agilealliance.org/agile101
|
||||
[7]: http://agilemanifesto.org/principles.html
|
||||
[8]: https://books.google.com/books?id=CwvBEKsCY2gC
|
||||
[9]: http://www.disciplinedagiledelivery.com/books/
|
||||
[10]: https://en.wikipedia.org/wiki/Disciplined_agile_delivery
|
||||
[11]: https://en.wikipedia.org/wiki/Extreme_programming
|
||||
[12]: https://www.scrum.org/resources/what-is-scrum
|
||||
[13]: https://en.wikipedia.org/wiki/Rational_Unified_Process
|
||||
[14]: http://donovanbrown.com/
|
||||
[15]: http://www.opengroup.org/togaf
|
||||
@ -0,0 +1,76 @@
|
||||
Is your startup built on open source? 9 tips for getting started
|
||||
======
|
||||
Are open source businesses all that different from normal businesses?
|
||||

|
||||
|
||||
When I started [Gluu][1] in 2009, I had no idea how difficult it would be to start an open source software company. Using the open source development methodology seemed like a good idea, especially for infrastructure software based on protocols defined by open standards. By nature, entrepreneurs are optimistic—we underestimate the difficulty of starting a business. However, Gluu was my fourth business, so I thought I knew what I was in for. But I was in for a surprise!
|
||||
|
||||
Every business is unique. One of the challenges of serial entrepreneurship is that a truth that was core to the success of a previous business may be incorrect in your next business. Building a business around open source forced me to change my plan. How to find the right team members, how to price our offering, how to market our product—all of these aspects of starting a business (and more) were impacted by the open source mission and required an adjustment from my previous experience.
|
||||
|
||||
A few years ago, we started to question whether Gluu was pursuing the right business model. The business was growing, but not as fast as we would have liked.
|
||||
|
||||
One of the things we did at Gluu was to prepare a "business model canvas," an approach detailed in the book [Business Model Generation: A Handbook for Visionaries, Game Changers, and Challengers][2] by Yves Pigneur and Alexander Osterwalder. This is a thought-provoking exercise for any business at any stage. It helped us consider our business more holistically. A business is more than a stream of revenue. You need to think about how you segment the market, how to interact with customers, what are your sales channels, what are your key activities, what is your value proposition, what are your expenses, partnerships, and key resources. We've done this a few times over the years because a business model naturally evolves over time.
|
||||
|
||||
In 2016, I started to wonder how other open source businesses were structuring their business models. Business Model Generation talks about three types of companies: product innovation, customer relationship, and infrastructure.
|
||||
|
||||
* Product innovation companies are first to market with new products and can get a lot of market share because they are first.
|
||||
* Customer relationship companies have a wider offering and need to get "wallet share" not market share.
|
||||
* Infrastructure companies are very scalable but need established operating procedures and lots of capital.
|
||||
|
||||
|
||||
|
||||
![Open Source Underdogs podcast][4]
|
||||
|
||||
Mike Swartz, CC BY
|
||||
|
||||
It's hard to figure out what models and types of business other open source software companies are pursuing by just looking at their website. And most open source companies are private—so there are no SEC filings to examine.
|
||||
|
||||
To find out more, I went to the web. I found a [great talk][5] from Mike Olson, Founder and Chief Strategy Officer at Cloudera, about open source business models. It was recorded as part of a Stanford business lecture series. I wanted more of these kinds of talks! But I couldn't find any. That's when I got the idea to start a podcast where I interview founders of open source companies and ask them to describe what business model they are pursuing.
|
||||
|
||||
In 2018, this idea became a reality when we started a podcast called [Open Source Underdogs][6]. So far, we have recorded nine episodes. There is a lot of great content in all the episodes, but I thought it would be fun to share one piece of advice from each.
|
||||
|
||||
### Advice from 9 open source businesses
|
||||
|
||||
**Peter Wang, CTO of Anaconda: **"Investors coming in to help put more gas in your gas tank want to understand what road you're on and how far you want to go. If you can't communicate to investors on a basis that they understand about your business model and revenue model, then you have no business asking them for their money. Don't get mad at them!"
|
||||
|
||||
**Jim Thompson, Founder of Netgate: **"Businesses survive at the whim of their customers. Solving customer problems and providing value to the business is literally why you have a business!"
|
||||
|
||||
**Michael Howard, CEO of MariaDB: **"My advice to open source software startups? It depends what part of the stack you're in. If you're infrastructure, you have no choice but to be open source."
|
||||
|
||||
**Ian Tien, CEO of** **Mattermost: ** "You want to build something that people love. So start with roles that open source can play in your vision for the product, the distribution model, the community you want to build, and the business you want to build."
|
||||
|
||||
**Mike Olson, Founder and Chief Strategy Officer at Cloudera: **"A business model is a complex construct. Open source is a really important component of strategic thinking. It's a great distributed development model. It's a genius, low-cost distribution model—and those have a bunch of advantages. But you need to think about how you're going to get paid."
|
||||
|
||||
**Elliot Horowitz, Founder of MongoDB: **"The most important thing, whether it's open source or not open source, is to get incredibly close to your users."
|
||||
|
||||
**Tom Hatch, CEO of SaltStack: **"Being able to build an internal culture and a management mindset that deals with open source, and profits from open source, and functions in a stable and responsible way with regard to open source is one of the big challenges you're going to face. It's one thing to make a piece of open source software and get people to use it. It's another to build a company on top of that open source."
|
||||
|
||||
**Matt Mullenweg, CEO of Automattic: **"Open source businesses aren't that different from normal businesses. A mistake that we made, that others can avoid, is not incorporating the best leaders and team members in functions like marketing and sales."
|
||||
|
||||
**Gabriel Engel, CEO of RocketChat: **"Moving from a five-person company, where you are the center of the company, and it's easy to know what everyone is doing, and everyone relies on you for decisions, to a 40-person company—that transition is harder than expected."
|
||||
|
||||
### What we've learned
|
||||
|
||||
After recording these podcasts, we've tweaked Gluu's business model a little. It's become clearer that we need to embrace open core—we've been over-reliant on support revenue. It's a direction we had been going, but listening to our podcast's guests supported our decision.
|
||||
|
||||
We have many new episodes lined up for 2018 and 2019, including conversations with the founders of Liferay, Couchbase, TimescaleDB, Canonical, Redis, and more, who are sure to offer even more great insights about the open source software business. You can find all the podcast episodes by searching for "Open Source Underdogs" on iTunes and Google podcasts or by visiting our [website][6]. We want to hear your opinions and ideas you have to help us improve the podcast, so after you listen, please leave us a review.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/tips-open-source-entrepreneurs
|
||||
|
||||
作者:[Mike Schwartz][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gluufederation
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gluu.org/
|
||||
[2]: https://www.wiley.com/en-us/Business+Model+Generation%3A+A+Handbook+for+Visionaries%2C+Game+Changers%2C+and+Challengers-p-9780470876411
|
||||
[3]: /file/414706
|
||||
[4]: https://opensource.com/sites/default/files/uploads/underdogs_logo.jpg (Open Source Underdogs podcast)
|
||||
[5]: https://youtu.be/T_UM5PYk9NA
|
||||
[6]: https://opensourceunderdogs.com/
|
||||
@ -1,70 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
8 great pytest plugins
|
||||
======
|
||||
|
||||

|
||||
|
||||
We are big fans of [pytest][1] and use it as our default Python testing tool for work and open source projects. For this month's Python column, we're sharing why we love pytest and some of the plugins that make testing with pytest so much fun.
|
||||
|
||||
### What is pytest?
|
||||
|
||||
As the tool's website says, "The pytest framework makes it easy to write small tests, yet scales to support complex functional testing for applications and libraries."
|
||||
|
||||
`test_*.py` and as functions that begin with `test_*`. Pytest will then find all your tests, across your whole project, and run them automatically when you run `pytest` in your console. Pytest accepts `set_trace()` function that can be entered into your test; this will pause your tests and allow you to interact with your variables and otherwise "poke around" in the console to debug your project.
|
||||
|
||||
Pytest allows you to define your tests in any file calledand as functions that begin with. Pytest will then find all your tests, across your whole project, and run them automatically when you runin your console. Pytest accepts [flags and arguments][2] that can change when the testrunner stops, how it outputs results, which tests are run, and what information is included in the output. It also includes afunction that can be entered into your test; this will pause your tests and allow you to interact with your variables and otherwise "poke around" in the console to debug your project.
|
||||
|
||||
One of the best aspects of pytest is its robust plugin ecosystem. Because pytest is such a popular testing library, over the years many plugins have been created to extend, customize, and enhance its capabilities. These eight plugins are among our favorites.
|
||||
|
||||
### Great 8
|
||||
|
||||
**1.[pytest-sugar][3]**
|
||||
`pytest-sugar` changes the default look and feel of pytest, adds a progress bar, and shows failing tests instantly. It requires no configuration; just `pip install pytest-sugar`, run your tests with `pytest`, and enjoy the prettier, more useful output.
|
||||
|
||||
**2.[pytest-cov][4]**
|
||||
`pytest-cov` adds coverage support for pytest to show which lines of code have been tested and which have not. It will also include the percentage of test coverage for your project.
|
||||
|
||||
**3.[pytest-picked][5]**
|
||||
`pytest-picked` runs tests based on code that you have modified but not committed to `git` yet. Install the library and run your tests with `pytest --picked` to test only files that have been changed since your last commit.
|
||||
|
||||
**4.[pytest-instafail][6]**
|
||||
`pytest-instafail` modifies pytest's default behavior to show failures and errors immediately instead of waiting until pytest has finished running every test.
|
||||
|
||||
**5.[pytest-tldr][7]**
|
||||
A brand-new pytest plugin that limits the output to just the things you need. `pytest-tldr` (the `tldr` stands for "too long, didn't read"), like `pytest-sugar`, requires no configuration other than basic installation. Instead of pytest's default output, which is pretty verbose, `pytest-tldr`'s default limits the output to only tracebacks for failing tests and omits the color-coding that some find annoying. Adding a `-v` flag returns the more verbose output for those who prefer it.
|
||||
|
||||
**6.[pytest-xdist][8]**
|
||||
`pytest-xdist` allows you to run multiple tests in parallel via the `-n` flag: `pytest -n 2`, for example, would run your tests on two CPUs. This can significantly speed up your tests. It also includes the `--looponfail` flag, which will automatically re-run your failing tests.
|
||||
|
||||
**7.[pytest-django][9]**
|
||||
`pytest-django` adds pytest support to Django applications and projects. Specifically, `pytest-django` introduces the ability to test Django projects using pytest fixtures, omits the need to import `unittest` and copy/paste other boilerplate testing code, and runs faster than the standard Django test suite.
|
||||
|
||||
**8.[django-test-plus][10]**
|
||||
`django-test-plus` isn't specific to pytest, but it now supports pytest. It includes its own `TestCase` class that your tests can inherit from and enables you to use fewer keystrokes to type out frequent test cases, like checking for specific HTTP error codes.
|
||||
|
||||
The libraries we mentioned above are by no means your only options for extending your pytest usage. The landscape for useful pytest plugins is vast. Check out the [Pytest Plugins Compatibility][11] page to explore on your own. Which ones are your favorites?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/pytest-plugins
|
||||
|
||||
作者:[Jeff Triplett;Lacery Williams Henschel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/sites/default/files/styles/byline_thumbnail/public/pictures/dcus-2017-bw.jpg?itok=s8PhD7Ok
|
||||
[1]:https://docs.pytest.org/en/latest/
|
||||
[2]:https://docs.pytest.org/en/latest/usage.html
|
||||
[3]:https://github.com/Frozenball/pytest-sugar
|
||||
[4]:https://github.com/pytest-dev/pytest-cov
|
||||
[5]:https://github.com/anapaulagomes/pytest-picked
|
||||
[6]:https://github.com/pytest-dev/pytest-instafail
|
||||
[7]:https://github.com/freakboy3742/pytest-tldr
|
||||
[8]:https://github.com/pytest-dev/pytest-xdist
|
||||
[9]:https://pytest-django.readthedocs.io/en/latest/
|
||||
[10]:https://django-test-plus.readthedocs.io/en/latest/
|
||||
[11]:https://plugincompat.herokuapp.com/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Publishing Markdown to HTML with MDwiki
|
||||
======
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
Translating by qhwdw
|
||||
|
||||
|
||||
Greg Kroah-Hartman Explains How the Kernel Community Is Securing Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Kernel maintainer Greg Kroah-Hartman talks about how the kernel community is hardening Linux against vulnerabilities.[Creative Commons Zero][2]
|
||||
|
||||
As Linux adoption expands, it’s increasingly important for the kernel community to improve the security of the world’s most widely used technology. Security is vital not only for enterprise customers, it’s also important for consumers, as 80 percent of mobile devices are powered by Linux. In this article, Linux kernel maintainer Greg Kroah-Hartman provides a glimpse into how the kernel community deals with vulnerabilities.
|
||||
|
||||
### There will be bugs
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman[The Linux Foundation][1]
|
||||
|
||||
As Linus Torvalds once said, most security holes are bugs, and bugs are part of the software development process. As long as the software is being written, there will be bugs.
|
||||
|
||||
“A bug is a bug. We don’t know if a bug is a security bug or not. There is a famous bug that I fixed and then three years later Red Hat realized it was a security hole,” said Kroah-Hartman.
|
||||
|
||||
There is not much the kernel community can do to eliminate bugs, but it can do more testing to find them. The kernel community now has its own security team that’s made up of kernel developers who know the core of the kernel.
|
||||
|
||||
“When we get a report, we involve the domain owner to fix the issue. In some cases it’s the same people, so we made them part of the security team to speed things up,” Kroah Hartman said. But he also stressed that all parts of the kernel have to be aware of these security issues because kernel is a trusted environment and they have to protect it.
|
||||
|
||||
“Once we fix things, we can put them in our stack analysis rules so that they are never reintroduced,” he said.
|
||||
|
||||
Besides fixing bugs, the community also continues to add hardening to the kernel. “We have realized that we need to have mitigations. We need hardening,” said Kroah-Hartman.
|
||||
|
||||
Huge efforts have been made by Kees Cook and others to take the hardening features that have been traditionally outside of the kernel and merge or adapt them for the kernel. With every kernel released, Cook provides a summary of all the new hardening features. But hardening the kernel is not enough, vendors have to enable the new features and take advantage of them. That’s not happening.
|
||||
|
||||
Kroah-Hartman [releases a stable kernel every week][5], and companies pick one to support for a longer period so that device manufacturers can take advantage of it. However, Kroah-Hartman has observed that, aside from the Google Pixel, most Android phones don’t include the additional hardening features, meaning all those phones are vulnerable. “People need to enable this stuff,” he said.
|
||||
|
||||
“I went out and bought all the top of the line phones based on kernel 4.4 to see which one actually updated. I found only one company that updated their kernel,” he said. “I'm working through the whole supply chain trying to solve that problem because it's a tough problem. There are many different groups involved -- the SoC manufacturers, the carriers, and so on. The point is that they have to push the kernel that we create out to people.”
|
||||
|
||||
The good news is that unlike with consumer electronics, the big vendors like Red Hat and SUSE keep the kernel updated even in the enterprise environment. Modern systems with containers, pods, and virtualization make this even easier. It’s effortless to update and reboot with no downtime. It is, in fact, easier to keep things secure than it used to be.
|
||||
|
||||
### Meltdown and Spectre
|
||||
|
||||
No security discussion is complete without the mention of Meltdown and Spectre. The kernel community is still working on fixes as new flaws are discovered. However, Intel has changed its approach in light of these events.
|
||||
|
||||
“They are reworking on how they approach security bugs and how they work with the community because they know they did it wrong,” Kroah-Hartman said. “The kernel has fixes for almost all of the big Spectre issues, but there is going to be a long tail of minor things.”
|
||||
|
||||
The good news is that these Intel vulnerabilities proved that things are getting better for the kernel community. “We are doing more testing. With the latest round of security patches, we worked on our own for four months before releasing them to the world because we were embargoed. But once they hit the real world, it made us realize how much we rely on the infrastructure we have built over the years to do this kind of testing, which ensures that we don’t have bugs before they hit other people,” he said. “So things are certainly getting better.”
|
||||
|
||||
The increasing focus on security is also creating more job opportunities for talented people. Since security is an area that gets eyeballs, those who want to build a career in kernel space, security is a good place to get started with.
|
||||
|
||||
“If there are people who want a job to do this type of work, we have plenty of companies who would love to hire them. I know some people who have started off fixing bugs and then got hired,” Kroah-Hartman said.
|
||||
|
||||
You can hear more in the video below:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
_Check out the schedule of talks for Open Source Summit Europe and sign up to receive updates:_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -1,3 +1,4 @@
|
||||
[translating by ChiZelin]
|
||||
Monitoring database health and behavior: Which metrics matter?
|
||||
======
|
||||
Monitoring your database can be overwhelming or seem not important. Here's how to do it right.
|
||||
|
||||
@ -1,95 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Gitbase: Exploring git repos with SQL
|
||||
======
|
||||
Gitbase is a Go-powered open source project that allows SQL queries to be run on Git repositories.
|
||||

|
||||
|
||||
Git has become the de-facto standard for code versioning, but its popularity didn't remove the complexity of performing deep analyses of the history and contents of source code repositories.
|
||||
|
||||
SQL, on the other hand, is a battle-tested language to query large codebases as its adoption by projects like Spark and BigQuery shows.
|
||||
|
||||
So it is just logical that at source{d} we chose these two technologies to create gitbase: the code-as-data solution for large-scale analysis of git repositories with SQL.
|
||||
|
||||
[Gitbase][1] is a fully open source project that stands on the shoulders of a series of giants which made its development possible, this article aims to point out the main ones.
|
||||
|
||||
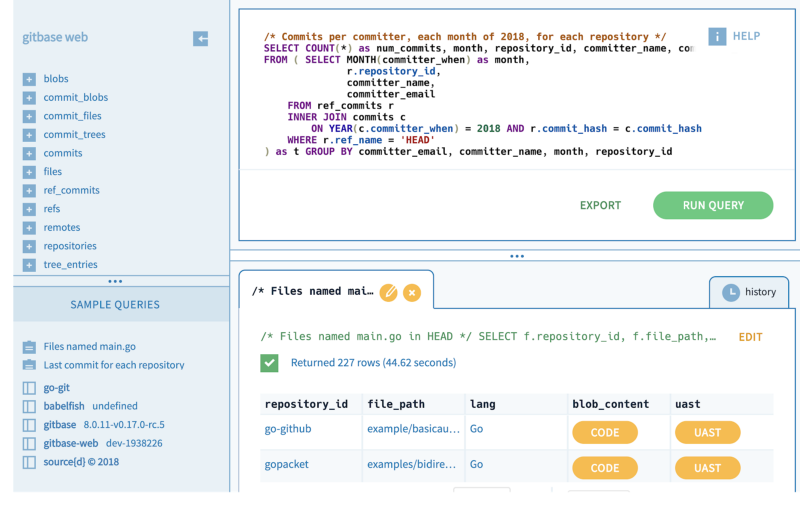
|
||||
|
||||
The [gitbase][2] [playground][2] provides a visual way to use gitbase.
|
||||
|
||||
### Parsing SQL with Vitess
|
||||
|
||||
Gitbase's user interface is SQL. This means we need to be able to parse and understand the SQL requests that arrive through the network following the MySQL protocol. Fortunately for us, this was already implemented by our friends at YouTube and their [Vitess][3] project. Vitess is a database clustering system for horizontal scaling of MySQL.
|
||||
|
||||
We simply grabbed the pieces of code that mattered to us and made it into an [open source project][4] that allows anyone to write a MySQL server in minutes (as I showed in my [justforfunc][5] episode [CSVQL—serving CSV with SQL][6]).
|
||||
|
||||
### Reading git repositories with go-git
|
||||
|
||||
Once we've parsed a request we still need to find how to answer it by reading the git repositories in our dataset. For this, we integrated source{d}'s most successful repository [go-git][7]. Go-git is a* *highly extensible Git implementation in pure Go.
|
||||
|
||||
This allowed us to easily analyze repositories stored on disk as [siva][8] files (again an open source project by source{d}) or simply cloned with git clone.
|
||||
|
||||
### Detecting languages with enry and parsing files with babelfish
|
||||
|
||||
Gitbase does not stop its analytic power at the git history. By integrating language detection with our (obviously) open source project [enry][9] and program parsing with [babelfish][10]. Babelfish is a self-hosted server for universal source code parsing, turning code files into Universal Abstract Syntax Trees (UASTs)
|
||||
|
||||
These two features are exposed in gitbase as the user functions LANGUAGE and UAST. Together they make requests like "find the name of the function that was most often modified during the last month" possible.
|
||||
|
||||
### Making it go fast
|
||||
|
||||
Gitbase analyzes really large datasets—e.g. Public Git Archive, with 3TB of source code from GitHub ([announcement][11]) and in order to do so every CPU cycle counts.
|
||||
|
||||
This is why we integrated two more projects into the mix: Rubex and Pilosa.
|
||||
|
||||
#### Speeding up regular expressions with Rubex and Oniguruma
|
||||
|
||||
[Rubex][12] is a quasi-drop-in replacement for Go's regexp standard library package. I say quasi because they do not implement the LiteralPrefix method on the regexp.Regexp type, but I also had never heard about that method until right now.
|
||||
|
||||
#### Speeding up queries with Pilosa indexes
|
||||
|
||||
Rubex gets its performance from the highly optimized C library [Oniguruma][13] which it calls using [cgo][14]
|
||||
|
||||
Indexes are a well-known feature of basically every relational database, but Vitess does not implement them since it doesn't really need to.
|
||||
|
||||
But again open source came to the rescue with [Pilosa][15], a distributed bitmap index implemented in Go which made gitbase usable on massive datasets. Pilosa is an open source, distributed bitmap index that dramatically accelerates queries across multiple, massive datasets.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I'd like to use this blog post to personally thank the open source community that made it possible for us to create gitbase in such a shorter period that anyone would have expected. At source{d} we are firm believers in open source and every single line of code under github.com/src-d (including our OKRs and investor board) is a testament to that.
|
||||
|
||||
Would you like to give gitbase a try? The fastest and easiest way is with source{d} Engine. Download it from sourced.tech/engine and get gitbase running with a single command!
|
||||
|
||||
Want to know more? Check out the recording of my talk at the [Go SF meetup][16].
|
||||
|
||||
The article was [originally published][17] on Medium and is republished here with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gitbase
|
||||
|
||||
作者:[Francesc Campoy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/francesc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/src-d/gitbase
|
||||
[2]: https://github.com/src-d/gitbase-web
|
||||
[3]: https://github.com/vitessio/vitess
|
||||
[4]: https://github.com/src-d/go-mysql-server
|
||||
[5]: http://justforfunc.com/
|
||||
[6]: https://youtu.be/bcRDXAraprk
|
||||
[7]: https://github.com/src-d/go-git
|
||||
[8]: https://github.com/src-d/siva
|
||||
[9]: https://github.com/src-d/enry
|
||||
[10]: https://github.com/bblfsh/bblfshd
|
||||
[11]: https://blog.sourced.tech/post/announcing-pga/
|
||||
[12]: https://github.com/moovweb/rubex
|
||||
[13]: https://github.com/kkos/oniguruma
|
||||
[14]: https://golang.org/cmd/cgo/
|
||||
[15]: https://github.com/pilosa/pilosa
|
||||
[16]: https://www.meetup.com/golangsf/events/251690574/
|
||||
[17]: https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c
|
||||
@ -1,4 +1,4 @@
|
||||
4 tips for learning Golang
|
||||
translating by dianbanjiu 4 tips for learning Golang
|
||||
======
|
||||
Arriving in Golang land: A senior developer's journey.
|
||||

|
||||
|
||||
@ -0,0 +1,148 @@
|
||||
How to use systemd-nspawn for Linux system recovery
|
||||
======
|
||||
Tap into systemd's ability to launch containers to repair a damaged system's root filesystem.
|
||||

|
||||
|
||||
For as long as GNU/Linux systems have existed, system administrators have needed to recover from root filesystem corruption, accidental configuration changes, or other situations that kept the system from booting into a "normal" state.
|
||||
|
||||
Linux distributions typically offer one or more menu options at boot time (for example, in the GRUB menu) that can be used for rescuing a broken system; typically they boot the system into a single-user mode with most system services disabled. In the worst case, the user could modify the kernel command line in the bootloader to use the standard shell as the init (PID 1) process. This method is the most complex and fraught with complications, which can lead to frustration and lost time when a system needs rescuing.
|
||||
|
||||
Most importantly, these methods all assume that the damaged system has a physical console of some sort, but this is no longer a given in the age of cloud computing. Without a physical console, there are few (if any) options to influence the boot process this way. Even physical machines may be small, embedded devices that don't offer an easy-to-use console, and finding the proper serial port cables and adapters and setting up a serial terminal emulator, all to use a serial console port while dealing with an emergency, is often complicated.
|
||||
|
||||
When another system (of the same architecture and generally similar configuration) is available, a common technique to simplify the repair process is to extract the storage device(s) from the damaged system and connect them to the working system as secondary devices. With physical systems, this is usually straightforward, but most cloud computing platforms can also support this since they allow the root storage volume of the damaged instance to be mounted on another instance.
|
||||
|
||||
Once the root filesystem is attached to another system, addressing filesystem corruption is straightforward using **fsck** and other tools. Addressing configuration mistakes, broken packages, or other issues can be more complex since they require mounting the filesystem and locating and changing the correct configuration files or databases.
|
||||
|
||||
### Using systemd
|
||||
|
||||
Before **[**systemd**][1]** , editing configuration files with a text editor was a practical way to correct a configuration. Locating the necessary files and understanding their contents may be a separate challenge, which is beyond the scope of this article.
|
||||
|
||||
When the GNU/Linux system uses **systemd** though, many configuration changes are best made using the tools it provides—enabling and disabling services, for example, requires the creation or removal of symbolic links in various locations. The **systemctl** tool is used to make these changes, but using it requires a **systemd** instance to be running and listening (on D-Bus) for requests. When the root filesystem is mounted as an additional filesystem on another machine, the running **systemd** instance can't be used to make these changes.
|
||||
|
||||
Manually launching the target system's **systemd** is not practical either, since it is designed to be the PID 1 process on a system and manage all other processes, which would conflict with the already-running instance on the system used for the repairs.
|
||||
|
||||
Thankfully, **systemd** has the ability to launch containers, fully encapsulated GNU/Linux systems with their own PID 1 and environment that utilize various namespace features offered by the Linux kernel. Unlike tools like Docker and Rocket, **systemd** doen't require a container image to launch a container; it can launch one rooted at any point in the existing filesystem. This is done using the **systemd-nspawn** tool, which will create the necessary system namespaces and launch the initial process in the container, then provide a console in the container. In contrast to **chroot** , which only changes the apparent root of the filesystem, this type of container will have a separate filesystem namespace, suitable filesystems mounted on **/dev** , **/run** , and **/proc** , and a separate process namespace and IPC namespaces. Consult the **systemd-nspawn** [man page][2] to learn more about its capabilities.
|
||||
|
||||
### An example to show how it works
|
||||
|
||||
In this example, the storage device containing the damaged system's root filesystem has been attached to a running system, where it appears as **/dev/vdc**. The device name will vary based on the number of existing storage devices, the type of device, and the method used to connect it to the system. The root filesystem could use the entire storage device or be in a partition within the device; since the most common (simple) configuration places the root filesystem in the device's first partition, this example will use **/dev/vdc1.** Make sure to replace the device name in the commands below with your system's correct device name.
|
||||
|
||||
The damaged root filesystem may also be more complex than a single filesystem on a device; it may be a volume in an LVM volume set or on a set of devices combined into a software RAID device. In these cases, the necessary steps to compose and activate the logical device holding the filesystem must be performed before it will be available for mounting. Again, those steps are beyond the scope of this article.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
First, ensure the **systemd-nspawn** tool is installed—most GNU/Linux distributions don't install it by default. It's provided by the **systemd-container** package on most distributions, so use your distribution's package manager to install that package. The instructions in this example were tested using Debian 9 but should work similarly on any modern GNU/Linux distribution.
|
||||
|
||||
Using the commands below will almost certainly require root permissions, so you'll either need to log in as root, use **sudo** to obtain a shell with root permissions, or prefix each of the commands with **sudo**.
|
||||
|
||||
#### Verify and mount the fileystem
|
||||
|
||||
First, use **fsck** to verify the target filesystem's structures and content:
|
||||
|
||||
```
|
||||
$ fsck /dev/vdc1
|
||||
```
|
||||
|
||||
If it finds any problems with the filesystem, answer the questions appropriately to correct them. If the filesystem is sufficiently damaged, it may not be repairable, in which case you'll have to find other ways to extract its contents.
|
||||
|
||||
Now, create a temporary directory and mount the target filesystem onto that directory:
|
||||
|
||||
```
|
||||
$ mkdir /tmp/target-rescue
|
||||
$ mount /dev/vdc1 /tmp/target-rescue
|
||||
```
|
||||
|
||||
With the filesystem mounted, launch a container with that filesystem as its root filesystem:
|
||||
|
||||
```
|
||||
$ systemd-nspawn --directory /tmp/target-rescue --boot -- --unit rescue.target
|
||||
```
|
||||
|
||||
The command-line arguments for launching the container are:
|
||||
|
||||
* **\--directory /tmp/target-rescue** provides the path of the container's root filesystem.
|
||||
* **\--boot** searches for a suitable init program in the container's root filesystem and launches it, passing parameters from the command line to it. In this example, the target system also uses **systemd** as its PID 1 process, so the remaining parameters are intended for it. If the target system you are repairing uses any other tool as its PID 1 process, you'll need to adjust the parameters accordingly.
|
||||
* **\--** separates parameters for **systemd-nspawn** from those intended for the container's PID 1 process.
|
||||
* **\--unit rescue.target** tells **systemd** in the container the name of the target it should try to reach during the boot process. In order to simplify the rescue operations in the target system, boot it into "rescue" mode rather than into its normal multi-user mode.
|
||||
|
||||
|
||||
|
||||
If all goes well, you should see output that looks similar to this:
|
||||
|
||||
```
|
||||
Spawning container target-rescue on /tmp/target-rescue.
|
||||
Press ^] three times within 1s to kill container.
|
||||
systemd 232 running in system mode. (+PAM +AUDIT +SELINUX +IMA +APPARMOR +SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ +LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD +IDN)
|
||||
Detected virtualization systemd-nspawn.
|
||||
Detected architecture arm.
|
||||
|
||||
Welcome to Debian GNU/Linux 9 (Stretch)!
|
||||
|
||||
Set hostname to <test>.
|
||||
Failed to install release agent, ignoring: No such file or directory
|
||||
[ OK ] Reached target Swap.
|
||||
[ OK ] Listening on Journal Socket (/dev/log).
|
||||
[ OK ] Started Dispatch Password Requests to Console Directory Watch.
|
||||
[ OK ] Reached target Encrypted Volumes.
|
||||
[ OK ] Created slice System Slice.
|
||||
Mounting POSIX Message Queue File System...
|
||||
[ OK ] Listening on Journal Socket.
|
||||
Starting Set the console keyboard layout...
|
||||
Starting Restore / save the current clock...
|
||||
Starting Journal Service...
|
||||
Starting Remount Root and Kernel File Systems...
|
||||
[ OK ] Mounted POSIX Message Queue File System.
|
||||
[ OK ] Started Journal Service.
|
||||
[ OK ] Started Remount Root and Kernel File Systems.
|
||||
Starting Flush Journal to Persistent Storage...
|
||||
[ OK ] Started Restore / save the current clock.
|
||||
[ OK ] Started Flush Journal to Persistent Storage.
|
||||
[ OK ] Started Set the console keyboard layout.
|
||||
[ OK ] Reached target Local File Systems (Pre).
|
||||
[ OK ] Reached target Local File Systems.
|
||||
Starting Create Volatile Files and Directories...
|
||||
[ OK ] Started Create Volatile Files and Directories.
|
||||
[ OK ] Reached target System Time Synchronized.
|
||||
Starting Update UTMP about System Boot/Shutdown...
|
||||
[ OK ] Started Update UTMP about System Boot/Shutdown.
|
||||
[ OK ] Reached target System Initialization.
|
||||
[ OK ] Started Rescue Shell.
|
||||
[ OK ] Reached target Rescue Mode.
|
||||
Starting Update UTMP about System Runlevel Changes...
|
||||
[ OK ] Started Update UTMP about System Runlevel Changes.
|
||||
You are in rescue mode. After logging in, type "journalctl -xb" to view
|
||||
system logs, "systemctl reboot" to reboot, "systemctl default" or ^D to
|
||||
boot into default mode.
|
||||
Give root password for maintenance
|
||||
(or press Control-D to continue):
|
||||
```
|
||||
|
||||
In this output, you can see **systemd** launching as the init process in the container and detecting that it is being run inside a container so it can adjust its behavior appropriately. Various unit files are started to bring the container to a usable state, then the target system's root password is requested. You can enter the root password here if you want a shell prompt with root permissions, or you can press **Ctrl+D** to allow the startup process to continue, which will display a normal console login prompt.
|
||||
|
||||
When you have completed the necessary changes to the target system, press **Ctrl+]** three times in rapid succession; this will terminate the container and return you to your original shell. From there, you can clean up by unmounting the target system's filesystem and removing the temporary directory:
|
||||
|
||||
```
|
||||
$ umount /tmp/target-rescue
|
||||
$ rmdir /tmp/target-rescue
|
||||
```
|
||||
|
||||
That's it! You can now remove the target system's storage device(s) and return them to the target system.
|
||||
|
||||
The idea to use **systemd-nspawn** this way, especially the **\--boot parameter** , came from [a question][3] posted on StackExchange. Thanks to Shibumi and kirbyfan64sos for providing useful answers to this question!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/systemd-nspawn-system-recovery
|
||||
|
||||
作者:[Kevin P.Fleming][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kpfleming
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[2]: https://www.freedesktop.org/software/systemd/man/systemd-nspawn.html
|
||||
[3]: https://unix.stackexchange.com/questions/457819/running-systemd-utilities-like-systemctl-under-an-nspawn
|
||||
@ -0,0 +1,260 @@
|
||||
11 Things To Do After Installing elementary OS 5 Juno
|
||||
======
|
||||
I’ve been using [elementary OS 5 Juno][1] for over a month and it has been an amazing experience. It is easily the [best Mac OS inspired Linux distribution][2] and one of the [best Linux distribution for beginners][3].
|
||||
|
||||
However, you will need to take care of a couple of things after installing it.
|
||||
In this article, we will discuss the most important things that you need to do after installing [elementary OS][4] 5 Juno.
|
||||
|
||||
### Things to do after installing elementary OS 5 Juno
|
||||
|
||||
![Things to do after installing elementary OS Juno][5]
|
||||
|
||||
Things I mentioned in this list are from my personal experience and preference. Of course, you are not restricted to these few things. You can explore and tweak the system as much as you like. However, if you follow (some of) these recommendations, things might be smoother for you.
|
||||
|
||||
#### 1.Run a System Update
|
||||
|
||||
![terminal showing system updates in elementary os 5 Juno][6]
|
||||
|
||||
Even when you download the latest version of a distribution – it is always recommended to check for the latest System updates. You might have a quick fix for an annoying bug, or, maybe there’s an important security patch that you shouldn’t ignore. So, no matter what – you should always ensure that you have everything up-to-date.
|
||||
|
||||
To do that, you need to type in the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
```
|
||||
|
||||
#### 2\. Set Window Hotcorner
|
||||
|
||||
![][7]
|
||||
|
||||
You wouldn’t notice the minimize button for a window. So, how do you do it?
|
||||
|
||||
Well, you can just bring up the dock and click the app icon again to minimize it or press **Windows key + H** as a shortcut to minimize the active window.
|
||||
|
||||
But, I’ll recommend something way more easy and intuitive. Maybe you already knew it, but for the users who were unaware of the “ **hotcorners** ” feature, here’s what it does:
|
||||
|
||||
Whenever you hover the cursor to any of the 4 corners of the window, you can set a preset action to happen when you do that. For example, when you move your cursor to the **left corner** of the screen you get the **multi-tasking view** to switch between apps – which acts like a “gesture“.
|
||||
|
||||
In order to utilize the functionality, you can follow the steps below:
|
||||
|
||||
1. Head to the System Settings.
|
||||
2. Click on the “ **Desktop** ” option (as shown in the image above).
|
||||
3. Next, select the “ **Hot Corner** ” section (as shown in the image below).
|
||||
4. Depending on what corner you prefer, choose an appropriate action (refer to the image below – that’s what I personally prefer as my settings)
|
||||
|
||||
|
||||
|
||||
#### 3\. Install Multimedia codecs
|
||||
|
||||
I’ve tried playing MP3/MP4 files – it just works fine. However, there are a lot of file formats when it comes to multimedia.
|
||||
|
||||
So, just to be able to play almost every format of multimedia, you should install the codecs. Here’s what you need to enter in the terminal:
|
||||
|
||||
To get certain proprietary codecs:
|
||||
|
||||
```
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
```
|
||||
|
||||
To specifically install [Libav][8]:
|
||||
|
||||
```
|
||||
sudo apt install libavcodec-extra
|
||||
```
|
||||
|
||||
To install a codec in order to facilitate playing video DVDs:
|
||||
|
||||
```
|
||||
sudo apt install libdvd-pkg
|
||||
```
|
||||
|
||||
#### 4\. Install GDebi
|
||||
|
||||
You don’t get to install .deb files by just double-clicking it on elementary OS 5 Juno. It just does not let you do that.
|
||||
|
||||
So, you need an additional tool to help you install .deb files.
|
||||
|
||||
We’ll recommend you to use **GDebi**. I prefer it because it lets you know about the dependencies even before trying to install it – that way – you can be sure about what you need in order to correctly install an application.
|
||||
|
||||
Simply install GDebi and open any .deb files by performing a right-click on them **open in GDebi Package Installer.**
|
||||
|
||||
To install it, type in the following command:
|
||||
|
||||
```
|
||||
sudo apt install gdebi
|
||||
```
|
||||
|
||||
#### 5\. Add a PPA for your Favorite App
|
||||
|
||||
Yes, elementary OS 5 Juno now supports PPA (unlike its previous version). So, you no longer need to enable the support for PPAs explicitly.
|
||||
|
||||
Just grab a PPA and add it via terminal to install something you like.
|
||||
|
||||
#### 6\. Install Essential Applications
|
||||
|
||||
If you’re a Linux power user, you already know what you want and where to get it, but if you’re new to this Linux distro and looking out for some applications to have installed, I have a few recommendations:
|
||||
|
||||
**Steam app** : If you’re a gamer, this is a must-have app. You just need to type in a single command to install it:
|
||||
|
||||
```
|
||||
sudo apt install steam
|
||||
```
|
||||
|
||||
**GIMP** : It is the best photoshop alternative across every platform. Get it installed for every type of image manipulation:
|
||||
|
||||
```
|
||||
sudo apt install gimp
|
||||
```
|
||||
|
||||
**Wine** : If you want to install an application that only runs on Windows, you can try using Wine to run such Windows apps here on Linux. To install, follow the command:
|
||||
|
||||
```
|
||||
sudo apt install wine-stable
|
||||
```
|
||||
|
||||
**qBittorrent** : If you prefer downloading Torrent files, you should have this installed as your Torrent client. To install it, enter the following command:
|
||||
|
||||
```
|
||||
sudo apt install qbittorrent
|
||||
```
|
||||
|
||||
**Flameshot** : You can obviously utilize the default screenshot tool to take screenshots. But, if you want to instantly share your screenshots and the ability to annotate – install flameshot. Here’s how you can do that:
|
||||
|
||||
```
|
||||
sudo apt install flameshot
|
||||
```
|
||||
|
||||
**Chrome/Firefox: **The default browser isn’t much useful. So, you should install Chrome/Firefox – as per your choice.
|
||||
|
||||
To install chrome, enter the command:
|
||||
|
||||
```
|
||||
sudo apt install chromium-browser
|
||||
```
|
||||
|
||||
To install Firefox, enter:
|
||||
|
||||
```
|
||||
sudo apt install firefox
|
||||
```
|
||||
|
||||
These are some of the most common applications you should definitely have installed. For the rest, you should browse through the App Center or the Flathub to install your favorite applications.
|
||||
|
||||
#### 7\. Install Flatpak (Optional)
|
||||
|
||||
It’s just my personal recommendation – I find flatpak to be the preferred way to install apps on any Linux distro I use.
|
||||
|
||||
You can try it and learn more about it at its [official website][9].
|
||||
|
||||
To install flatpak, type in:
|
||||
|
||||
```
|
||||
sudo apt install flatpak
|
||||
```
|
||||
|
||||
After you are done installing flatpak, you can directly head to [Flathub][10] to install some of your favorite apps and you will also find the command/instruction to install it via the terminal.
|
||||
|
||||
In case you do not want to launch the browser, you can search for your app by typing in (example – finding Discord and installing it):
|
||||
|
||||
```
|
||||
flatpak search discord flathub
|
||||
```
|
||||
|
||||
After gettting the application ID, you can proceed installing it by typing in:
|
||||
|
||||
```
|
||||
flatpak install flathub com.discordapp.Discord
|
||||
```
|
||||
|
||||
#### 8\. Enable the Night Light
|
||||
|
||||
![Night Light in elementary OS Juno][11]
|
||||
|
||||
You might have installed Redshift as per our recommendation for [elemantary OS 0.4 Loki][12] to filter the blue light to avoid straining our eyes- but you do not need any 3rd party tool anymore.
|
||||
|
||||
It comes baked in as the “ **Night Light** ” feature.
|
||||
|
||||
You just head to System Settings and click on “ **Displays** ” (as shown in the image above).
|
||||
|
||||
Select the **Night Light** section and activate it with your preferred settings.
|
||||
|
||||
#### 9\. Install NVIDIA driver metapackage (for NVIDIA GPUs)
|
||||
|
||||
![Nvidia drivers in elementary OS juno][13]
|
||||
|
||||
The NVIDIA driver metapackage should be listed right at the App Center – so you can easily the NVIDIA driver.
|
||||
|
||||
However, it’s not the latest driver version – I have version **390.77** installed and it’s performing just fine.
|
||||
|
||||
If you want the latest version for Linux, you should check out NVIDIA’s [official download page][14].
|
||||
|
||||
Also, if you’re curious about the version installed, just type in the following command:
|
||||
|
||||
```
|
||||
nvidia-smi
|
||||
```
|
||||
|
||||
#### 10\. Install TLP for Advanced Power Management
|
||||
|
||||
We’ve said it before. And, we’ll still recommend it.
|
||||
|
||||
If you want to manage your background tasks/activity and prevent overheating of your system – you should install TLP.
|
||||
|
||||
It does not offer a GUI, but you don’t have to bother. You just install it and let it manage whatever it takes to prevent overheating.
|
||||
|
||||
It’s very helpful for laptop users.
|
||||
|
||||
To install, type in:
|
||||
|
||||
```
|
||||
supo apt install tlp tlp-rdw
|
||||
```
|
||||
|
||||
#### 11\. Perform visual customizations
|
||||
|
||||
![][15]
|
||||
|
||||
If you need to change the look of your Linux distro, you can install GNOME tweaks tool to get the options. In order to install the tweak tool, type in:
|
||||
|
||||
```
|
||||
sudo apt install gnome-tweaks
|
||||
```
|
||||
|
||||
Once you install it, head to the application launcher and search for “Tweaks”, you’ll find something like this:
|
||||
|
||||
Here, you can select the icon, theme, wallpaper, and you’ll also be able to tweak a couple more options that’s not limited to the visual elements.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
It’s the least you should do after installing elementary OS 5 Juno. However, considering that elementary OS 5 Juno comes with numerous new features – you can explore a lot more new things as well.
|
||||
|
||||
Let us know what you did first after installing elementary OS 5 Juno and how’s your experience with it so far?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-elementary-os-5-juno/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/elementary-os-juno-features/
|
||||
[2]: https://itsfoss.com/macos-like-linux-distros/
|
||||
[3]: https://itsfoss.com/best-linux-beginners/
|
||||
[4]: https://elementary.io/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/things-to-do-after-installing-elementary-os-juno.jpeg?ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-system-update.jpg?ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-hotcorners.jpg?ssl=1
|
||||
[8]: https://libav.org/
|
||||
[9]: https://flatpak.org/
|
||||
[10]: https://flathub.org/home
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-night-light.jpg?ssl=1
|
||||
[12]: https://itsfoss.com/things-to-do-after-installing-elementary-os-loki/
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-nvidia-metapackage.jpg?ssl=1
|
||||
[14]: https://www.nvidia.com/Download/index.aspx
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/11/elementary-os-gnome-tweaks.jpg?ssl=1
|
||||
145
sources/tech/20181115 How to install a device driver on Linux.md
Normal file
145
sources/tech/20181115 How to install a device driver on Linux.md
Normal file
@ -0,0 +1,145 @@
|
||||
How to install a device driver on Linux
|
||||
======
|
||||
Learn how Linux drivers work and how to use them.
|
||||

|
||||
|
||||
One of the most daunting challenges for people switching from a familiar Windows or MacOS system to Linux is installing and configuring a driver. This is understandable, as Windows and MacOS have mechanisms that make this process user-friendly. For example, when you plug in a new piece of hardware, Windows automatically detects it and shows a pop-up window asking if you want to continue with the driver's installation. You can also download a driver from the internet, then just double-click it to run a wizard or import the driver through Device Manager.
|
||||
|
||||
This process isn't as easy on a Linux operating system. For one reason, Linux is an open source operating system, so there are [hundreds of Linux distribution variations][1] . This means it's impossible to create one how-to guide that works for all Linux distros. Each Linux operating system handles the driver installation process a different way.
|
||||
|
||||
Second, most default Linux drivers are open source and integrated into the system, which makes installing any drivers that are not included quite complicated, even though most hardware devices can be automatically detected. Third, license policies vary among the different Linux distributions. For example, [Fedora prohibits][2] including drivers that are proprietary, legally encumbered, or that violate US laws. And Ubuntu asks users to [avoid using proprietary or closed hardware][3].
|
||||
|
||||
To learn more about how Linux drivers work, I recommend reading [An Introduction to Device Drivers][4] in the book Linux Device Drivers.
|
||||
|
||||
### Two approaches to finding drivers
|
||||
|
||||
#### 1\. User interfaces
|
||||
|
||||
If you are new to Linux and coming from the Windows or MacOS world, you'll be glad to know that Linux offers ways to see whether a driver is available through wizard-like programs. Ubuntu offers the [Additional Drivers][5] option. Other Linux distributions provide helper programs, like [Package Manager for GNOME][6], that you can check for available drivers.
|
||||
|
||||
#### 2\. Command line
|
||||
|
||||
What if you can't find a driver through your nice user interface application? Or you only have access through the shell with no graphic interface whatsoever? Maybe you've even decided to expand your skills by using a console. You have two options:
|
||||
|
||||
A. **Use a repository**
|
||||
This is similar to the [**homebrew**][7] command in MacOS.** ** By using **yum** , **dnf** , **apt-get** , etc., you're basically adding a repository and updating the package cache.
|
||||
|
||||
|
||||
B. **Download, compile, and build it yourself**
|
||||
This usually involves downloading a package directly from a website or using the **wget** command and running the configuration file and Makefile to install it. This is beyond the scope of this article, but you should be able to find online guides if you choose to go this route.
|
||||
|
||||
|
||||
|
||||
### Check if a driver is already installed
|
||||
|
||||
Before jumping further into installing a driver in Linux, let's look at some commands that will determine whether the driver is already available on your system.
|
||||
|
||||
The [**lspci**][8] command shows detailed information about all PCI buses and devices on the system:
|
||||
|
||||
```
|
||||
$ lscpci
|
||||
```
|
||||
|
||||
Or with **grep** :
|
||||
|
||||
```
|
||||
$ lscpci | grep SOME_DRIVER_KEYWORD
|
||||
```
|
||||
|
||||
For example, you can type **lspci | grep SAMSUNG** if you want to know if a Samsung driver is installed.
|
||||
|
||||
The [**dmesg**][9] command shows all device drivers recognized by the kernel:
|
||||
|
||||
```
|
||||
$ dmesg
|
||||
```
|
||||
|
||||
Or with **grep** :
|
||||
|
||||
```
|
||||
$ dmesg | grep SOME_DRIVER_KEYWORD
|
||||
```
|
||||
|
||||
Any driver that's recognized will show in the results.
|
||||
|
||||
If nothing is recognized by the **dmesg** or **lscpi** commands, try these two commands to see if the driver is at least loaded on the disk:
|
||||
|
||||
```
|
||||
$ /sbin/lsmod
|
||||
```
|
||||
|
||||
and
|
||||
|
||||
```
|
||||
$ find /lib/modules
|
||||
```
|
||||
|
||||
Tip: As with **lspci** or **dmesg** , append **| grep** to either command above to filter the results.
|
||||
|
||||
If a driver is recognized by those commands but not by **lscpi** or **dmesg** , it means the driver is on the disk but not in the kernel. In this case, load the module with the **modprobe** command:
|
||||
|
||||
```
|
||||
$ sudo modprobe MODULE_NAME
|
||||
```
|
||||
|
||||
Run as this command as **sudo** since this module must be installed as a root user.
|
||||
|
||||
### Add the repository and install
|
||||
|
||||
There are different ways to add the repository through **yum** , **dnf** , and **apt-get** ; describing them all is beyond the scope of this article. To make it simple, this example will use **apt-get** , but the idea is similar for the other options.
|
||||
|
||||
**1\. Delete the existing repository, if it exists.**
|
||||
|
||||
```
|
||||
$ sudo apt-get purge NAME_OF_DRIVER*
|
||||
```
|
||||
|
||||
where **NAME_OF_DRIVER** is the probable name of your driver. You can also add pattern match to your regular expression to filter further.
|
||||
|
||||
**2\. Add the repository to the repolist, which should be specified in the driver guide.**
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository REPOLIST_OF_DRIVER
|
||||
```
|
||||
|
||||
where **REPOLIST_OF_DRIVER** should be specified from the driver documentation (e.g., **epel-list** ).
|
||||
|
||||
**3\. Update the repository list.**
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
```
|
||||
|
||||
**4\. Install the package.**
|
||||
|
||||
```
|
||||
$ sudo apt-get install NAME_OF_DRIVER
|
||||
```
|
||||
|
||||
**5\. Check the installation.**
|
||||
|
||||
Run the **lscpi** command (as above) to check that the driver was installed successfully.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/how-install-device-driver-linux
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/List_of_Linux_distributions
|
||||
[2]: https://fedoraproject.org/wiki/Forbidden_items?rd=ForbiddenItems
|
||||
[3]: https://www.ubuntu.com/licensing
|
||||
[4]: https://www.xml.com/ldd/chapter/book/ch01.html
|
||||
[5]: https://askubuntu.com/questions/47506/how-do-i-install-additional-drivers
|
||||
[6]: https://help.gnome.org/users/gnome-packagekit/stable/add-remove.html.en
|
||||
[7]: https://brew.sh/
|
||||
[8]: https://en.wikipedia.org/wiki/Lspci
|
||||
[9]: https://en.wikipedia.org/wiki/Dmesg
|
||||
66
translated/tech/20180626 8 great pytest plugins.md
Normal file
66
translated/tech/20180626 8 great pytest plugins.md
Normal file
@ -0,0 +1,66 @@
|
||||
8 个很好的 pytest 插件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们是 [pytest][1] 的忠实粉丝,并将其作为工作和开源项目的默认 Python 测试工具。在本月的 Python 专栏中,我们分享了为什么我们喜欢 pytest 以及一些让 pytest 测试有趣的插件。
|
||||
|
||||
### 什么是 pytest?
|
||||
|
||||
正如该工具的网站所说,“pytest 框架可以轻松地编写小型测试,也能进行扩展以支持应用和库的复杂功能测试。”
|
||||
|
||||
pytest 允许你在任何名为 test_*.py 的文件中定义测试,并将其定义为以 test_* 开头的函数。然后, pytest 将在整个项目中查找所有测试, 并在控制台中运行 pytest 时自动运行这些测试。pytest 接受[标志和参数][2],它们可以在 testrunner 停止时更改,这些包含如何输出结果,运行哪些测试以及输出中包含哪些信息。它还包括一个 set_trace() 函数, 它可以输入到你的测试中。它会暂停您的测试, 并允许你与变量进行交互, 不然你只能在终端中“四处运行”来调试你的项目。
|
||||
|
||||
pytest 最好的一方面是其强大的插件生态系统。因为 pytest 是一个非常流行的测试库,所以多年来创建了许多插件来扩展、定制和增强其功能。这八个插件是我们的最爱。
|
||||
|
||||
### 8 个很棒的插件
|
||||
|
||||
**1.[pytest-sugar][3]**
|
||||
`pytest-sugar` 改变了 pytest 的默认外观,添加了一个进度条,并立即显示失败的测试。它不需要配置,只需 `pip install pytest-sugar`,用 `pytest` 运行测试,来享受更漂亮,更有用的输出。
|
||||
|
||||
**2.[pytest-cov][4]**
|
||||
`pytest-cov` 在 pytest 中增加了覆盖率支持,来显示哪些代码行已经测试过,哪些还没有。它还将包括项目的测试覆盖率。
|
||||
|
||||
**3.[pytest-picked][5]**
|
||||
`pytest-picked` 对你已经修改但尚未提交 `git` 的代码运行测试。安装库并运行 `pytest --picked` 来仅测试自上次提交后已更改的文件。
|
||||
|
||||
**4.[pytest-instafail][6]**
|
||||
`pytest-instafail` 修改 pytest 的默认行为来立即显示失败和错误,而不是等到 pytest 完成所有测试。
|
||||
|
||||
**5.[pytest-tldr][7]**
|
||||
一个全新的 pytest 插件,可以将输出限制为你需要的东西。`pytest-tldr`(`tldr` 代表 “too long, didn't read”),就像 `pytest-sugar`一样,除基本安装外不需要配置。不像 pytest 的默认输出很详细,`pytest-tldr` 将默认输出限制为失败测试的回溯,并忽略了一些令人讨厌的颜色编码。添加 `-v` 标志会为喜欢它的人返回更详细的输出。
|
||||
|
||||
**6.[pytest-xdist][8]**
|
||||
`pytest-xdist` 允许你通过 `-n` 标志并行运行多个测试:例如,`pytest -n 2` 将在两个 CPU 上运行你的测试。这可以显著加快你的测试速度。它还包括 `--looponfail` 标志,它将自动重新运行你的失败测试。
|
||||
|
||||
**7.[pytest-django][9]**
|
||||
`pytest-django` 为 Django 应用和项目添加了 pytest 支持。具体来说,`pytest-django` 引入了使用 pytest fixture 测试 Django 项目的能力,省略了导入 `unittest` 和复制/粘贴其他样板测试代码的需要,并且比标准的 Django 测试套件运行得更快。
|
||||
|
||||
**8.[django-test-plus][10]**
|
||||
`django-test-plus` 并不是专门为 pytest 开发,但它现在支持 pytest。它包含自己的 `TestCase` 类,你的测试可以继承该类,并使你能够使用较少的按键来输出频繁的测试案例,例如检查特定的 HTTP 错误代码。
|
||||
|
||||
我们上面提到的库绝不是你扩展 pytest 的唯一选择。有用的 pytest 插件的前景是广阔的。查看 [pytest 插件兼容性][11]页面来自行探索。你最喜欢哪些插件?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/pytest-plugins
|
||||
|
||||
作者:[Jeff Triplett;Lacery Williams Henschel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/sites/default/files/styles/byline_thumbnail/public/pictures/dcus-2017-bw.jpg?itok=s8PhD7Ok
|
||||
[1]:https://docs.pytest.org/en/latest/
|
||||
[2]:https://docs.pytest.org/en/latest/usage.html
|
||||
[3]:https://github.com/Frozenball/pytest-sugar
|
||||
[4]:https://github.com/pytest-dev/pytest-cov
|
||||
[5]:https://github.com/anapaulagomes/pytest-picked
|
||||
[6]:https://github.com/pytest-dev/pytest-instafail
|
||||
[7]:https://github.com/freakboy3742/pytest-tldr
|
||||
[8]:https://github.com/pytest-dev/pytest-xdist
|
||||
[9]:https://pytest-django.readthedocs.io/en/latest/
|
||||
[10]:https://django-test-plus.readthedocs.io/en/latest/
|
||||
[11]:https://plugincompat.herokuapp.com/
|
||||
@ -0,0 +1,70 @@
|
||||
|
||||
Greg Kroah-Hartman 解释内核社区如何保护 Linux
|
||||
============================================================
|
||||
|
||||

|
||||
内核维护者 Greg Kroah-Hartman 谈论内核社区如何保护 Linux 不遭受损害。[Creative Commons Zero][2]
|
||||
|
||||
由于 Linux 使用量持续扩大,内核社区去提高全世界最广泛使用的技术 — Linux 内核的安全性的重要程序越来越高。安全不仅对企业客户很重要,它对消费者也很重要,因为 80% 的移动设备都使用了 Linux。在本文中,Linux 内核维护者 Greg Kroah-Hartman 带我们了解内核社区如何应对威胁。
|
||||
|
||||
### bug 不可避免
|
||||
|
||||
|
||||

|
||||
|
||||
Greg Kroah-Hartman [Linux 基金会][1]
|
||||
|
||||
正如 Linus Torvalds 曾经说过,大多数安全问题都是 bug 造成的,而 bug 又是软件开发过程的一部分。是个软件就有 bug。
|
||||
|
||||
Kroah-Hartman 说:“就算是 bug ,我们也不知道它是安全的 bug 还是不安全的 bug。我修复的一个著名 bug,在三年后才被 Red Hat 认定为安全漏洞“。
|
||||
|
||||
在消除 bug 方面,内核社区没有太多的办法,只能做更多的测试来寻找 bug。内核社区现在已经有了自己的安全团队,它们是由熟悉内核核心的内核开发者组成。
|
||||
|
||||
Kroah Hartman 说:”当我们收到一个报告时,我们就让参与这个领域的核心开发者去修复它。在一些情况下,他们可能是同一个人,让他们进入安全团队可以更快地解决问题“。但他也强调,内核所有部分的开发者都必须清楚地了解这些问题,因为内核是一个可信环境,它必须被保护起来。
|
||||
|
||||
Kroah Hartman 说:”一旦我们修复了它,我们就将它放到我们的栈分析规则中,以便于以后不再重新出现这个 bug。“
|
||||
|
||||
除修复 bug 之外,内核社区也不断加固内核。Kroah Hartman 说:“我们意识到,我们需要一些主动的缓减措施。因此我们需要加固内核。”
|
||||
|
||||
Kees Cook 和其他一些人付出了巨大的努力,带来了一直在内核之外的加固特性,并将它们合并或适配到内核中。在每个内核发行后,Cook 都对所有新的加固特性做一个总结。但是只加固内核是不够的,供应商必须要启用这些新特性来让它们充分发挥作用。但他们并没有这么做。
|
||||
|
||||
Kroah-Hartman [每周发布一个稳定版内核][5],而为了长周期的支持,公司只从中挑选一个,以便于设备制造商能够利用它。但是,Kroah-Hartman 注意到,除了 Google Pixel 之外,大多数 Android 手机并不包含这些额外的安全加固特性,这就意味着,所有的这些手机都是有漏洞的。他说:“人们应该去启用这些加固特性”。
|
||||
|
||||
Kroah-Hartman 说:“我购买了基于 Linux 内核 4.4 的所有旗舰级手机,去查看它们中哪些确实升级了新特性。结果我发现只有一家公司升级了它们的内核”。“我在整个供应链中努力去解决这个问题,因为这是一个很棘手的问题。它涉及许多不同的组织 — SoC 制造商、运营商、等等。关键点是,需要他们把我们辛辛苦苦设计的内核去推送给大家。
|
||||
|
||||
好消息是,与消息电子产品不一样,像 Red Hat 和 SUSE 这样的大供应商,在企业环境中持续对内核进行更新。使用容器、pod、和虚拟化的现代系统做到这一点更容易了。无需停机就可以毫不费力地更新和重启。事实上,现在来保证系统安全相比过去容易多了。
|
||||
|
||||
### Meltdown 和 Spectre
|
||||
|
||||
没有任何一个关于安全的讨论能够避免提及 Meltdown 和 Spectre。内核社区一直致力于修改新发现的和已查明的安全漏洞。不管怎样,Intel 已经因为这些事情改变了它们的策略。
|
||||
|
||||
Kroah-Hartman 说:“他们已经重新研究如何处理安全 bug,以及如何与社区合作,因为他们知道他们做错了。内核已经修复了几乎所有大的 Spectre 问题,但是还有一些小问题仍在处理中”。
|
||||
|
||||
好消息是,这些 Intel 漏洞使得内核社区正在变得更好。Kroah-Hartman 说:“我们需要做更多的测试。对于最新一轮的安全补丁,在它们被发布之前,我们自己花了四个月时间来测试它们,因为我们要防止这个安全问题在全世界扩散。而一旦这些漏洞在真实的世界中被利用,将让我们认识到我们所依赖的基础设施是多么的脆弱,我们多年来一直在做这种测试,这确保了其它人不会遭到这些 bug 的伤害。所以说,Intel 的这些漏洞在某种程度上让内核社区变得更好了”。
|
||||
|
||||
对安全的日渐关注也为那些有才华的人创造了更多的工作机会。由于安全是个极具吸引力的领域,那些希望在内核空间中有所建树的人,安全将是他们一个很好的起点。
|
||||
|
||||
Kroah-Hartman 说:“如果有人想从事这方面的工作,我们有大量的公司愿意雇佣他们。我知道一些开始去修复 bug 的人已经被他们雇佣了。”
|
||||
|
||||
你可以在下面链接的视频上查看更多的内容:
|
||||
|
||||
[视频](https://youtu.be/jkGVabyMh1I)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/10/greg-kroah-hartman-explains-how-kernel-community-securing-linux-0
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[2]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[3]:https://www.linux.com/files/images/greg-k-hpng
|
||||
[4]:https://www.linux.com/files/images/kernel-securityjpg-0
|
||||
[5]:https://www.kernel.org/category/releases.html
|
||||
@ -0,0 +1,91 @@
|
||||
使用 gitbase 在 git 仓库进行 SQL 查询
|
||||
======
|
||||
gitbase 是一个使用 go 开发的的开源项目,它实现了在 git 仓库上执行 SQL 查询。
|
||||
|
||||

|
||||
|
||||
git 已经成为了代码版本控制的事实标准,但尽管 git 相当普及,对代码仓库的深入分析的工作难度却没有因此而下降;而 SQL 在大型代码库的查询方面则已经是一种久经考验的语言,因此诸如 Spark 和 BigQuery 这样的项目都采用了它。
|
||||
|
||||
所以,source{d} 很顺理成章地将这两种技术结合起来,就产生了 gitbase。gitbase 是一个<ruby>代码即数据<rt>code-as-data</rt></ruby>的解决方案,可以使用 SQL 对 git 仓库进行大规模分析。
|
||||
|
||||
[gitbase][1] 是一个完全开源的项目。它站在了很多巨人的肩上,因此得到了足够的发展竞争力。下面就来介绍一下其中的一些“巨人”。
|
||||
|
||||

|
||||
|
||||
[gitbase playground][2] 为 gitbase 提供了一个可视化的操作环境。
|
||||
|
||||
### 用 Vitess 解析 SQL
|
||||
|
||||
gitbase 通过 SQL 与用户进行交互,因此需要能够遵循 MySQL 协议来对传入的 SQL 请求作出解析和理解,万幸由 YouTube 建立的 [Vitess][3] 项目已经在这一方面给出了解决方案。Vitess 是一个横向扩展的 MySQL数据库集群系统。
|
||||
|
||||
我们只是使用了这个项目中的部分重要代码,并将其转化为一个可以让任何人在数分钟以内编写出一个 MySQL 服务器的[开源程序][4],就像我在 [justforfunc][5] 视频系列中展示的 [CSVQL][6] 一样,它可以使用 SQL 操作 CSV 文件。
|
||||
|
||||
### 用 go-git 读取 git 仓库
|
||||
|
||||
在成功解析 SQL 请求之后,还需要对数据集中的 git 仓库进行查询才能返回结果。因此,我们还结合使用了 source{d} 最成功的 [go-git][7] 仓库。go-git 是使用纯 go 语言编写的具有高度可扩展性的 git 实现。
|
||||
|
||||
借此我们就可以很方便地将存储在磁盘上的代码仓库保存为 [siva][8] 文件格式(这同样是 source{d} 的一个开源项目),也可以通过 `git clone` 来对代码仓库进行复制。
|
||||
|
||||
### 使用 enry 检测语言、使用 babelfish 解析文件
|
||||
|
||||
gitbase 集成了我们的语言检测开源项目 [enry][9] 以及代码解析项目 [babelfish][10],因此在分析 git 仓库历史代码的能力也相当强大。babelfish 是一个自托管服务,普适于各种源代码解析,并将代码文件转换为<ruby>通用抽象语法树<rt>Universal Abstract Syntax Tree</rt></ruby>(UAST)。
|
||||
|
||||
这两个功能在 gitbase 中可以被用户以函数 LANGUAGE 和 UAST 调用,诸如“查找上个月最常被修改的函数的名称”这样的请求就需要通过这两个功能实现。
|
||||
|
||||
### 提高性能
|
||||
|
||||
gitbase 可以对非常大的数据集进行分析,例如源代码大小达 3 TB 的 Public Git Archive。面临的工作量如此巨大,因此每一点性能都必须运用到极致。于是,我们也使用到了 Rubex 和 Pilosa 这两个项目。
|
||||
|
||||
#### 使用 Rubex 和 Oniguruma 优化正则表达式速度
|
||||
|
||||
[Rubex][12] 是 go 的正则表达式标准库包的一个准替代品。之所以说它是准替代品,是因为它没有在 regexp.Regexp 类中实现 LiteralPrefix 方法,直到现在都还没有。
|
||||
|
||||
Rubex 的高性能是由于使用 [cgo][14] 调用了 [Oniguruma][13],它是一个高度优化的 C 代码库。
|
||||
|
||||
#### 使用 Pilosa 索引优化查询速度
|
||||
|
||||
索引几乎是每个关系型数据库都拥有的特性,但 Vitess 由于不需要用到索引,因此并没有进行实现。
|
||||
|
||||
于是我们引入了 [Pilosa][15] 这个开源项目。Pilosa 是一个使用 go 实现的分布式位图索引,可以显著提升跨多个大型数据集的查询的速度。通过 Pilosa,gitbase 才得以在巨大的数据集中进行查询。
|
||||
|
||||
### 总结
|
||||
|
||||
我想用这一篇文章来对开源社区表达我衷心的感谢,让我们能够不负众望的在短时间内完成 gitbase 的开发。我们 source{d} 的每一位成员都是开源的拥护者,github.com/src-d 下的每一行代码都是见证。
|
||||
|
||||
你想使用 gitbase 吗?最简单快捷的方式是从 sourced.tech/engine 下载 source{d} 引擎,就可以通过单个命令运行 gitbase 了。
|
||||
|
||||
想要了解更多,可以听听我在 [Go SF 大会][16]上的演讲录音。
|
||||
|
||||
本文在 [Medium][17] 首发,并经许可在此发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gitbase
|
||||
|
||||
作者:[Francesc Campoy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/francesc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/src-d/gitbase
|
||||
[2]: https://github.com/src-d/gitbase-web
|
||||
[3]: https://github.com/vitessio/vitess
|
||||
[4]: https://github.com/src-d/go-mysql-server
|
||||
[5]: http://justforfunc.com/
|
||||
[6]: https://youtu.be/bcRDXAraprk
|
||||
[7]: https://github.com/src-d/go-git
|
||||
[8]: https://github.com/src-d/siva
|
||||
[9]: https://github.com/src-d/enry
|
||||
[10]: https://github.com/bblfsh/bblfshd
|
||||
[11]: https://blog.sourced.tech/post/announcing-pga/
|
||||
[12]: https://github.com/moovweb/rubex
|
||||
[13]: https://github.com/kkos/oniguruma
|
||||
[14]: https://golang.org/cmd/cgo/
|
||||
[15]: https://github.com/pilosa/pilosa
|
||||
[16]: https://www.meetup.com/golangsf/events/251690574/
|
||||
[17]: https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c
|
||||
|
||||
Loading…
Reference in New Issue
Block a user