mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
41a575e4d4
220
published/20170918 Fun and Games in Emacs.md
Normal file
220
published/20170918 Fun and Games in Emacs.md
Normal file
@ -0,0 +1,220 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11949-1.html)
|
||||
[#]: subject: (Fun and Games in Emacs)
|
||||
[#]: via: (https://www.masteringemacs.org/article/fun-games-in-emacs)
|
||||
[#]: author: (Mickey Petersen https://www.masteringemacs.org/about)
|
||||
|
||||
“Emacs 游戏机”完全指南
|
||||
======
|
||||
|
||||
又是周一,你正在为你的老板 Lumbergh (LCTT 译注:《上班一条虫》中的副总裁)努力倒腾那些 [无聊之极的文档][1]。为什么不玩玩 Emacs 中类似 zork 的文字冒险游戏来让你的大脑从单调的工作中解脱出来呢?
|
||||
|
||||
但说真的,Emacs 中既有游戏,也有古怪的玩物。有些你可能有所耳闻。这些玩意唯一的共同点就是,它们大多是很久以前就添加到 Emacs 中的:有些东西真的是相当古怪(如你将在下面看到的),而另一些则显然是由无聊的员工或学生们编写的。它们全有一个共同点,都带着一种奇思妙想和随意性,这在今天的 Emacs 中很少见。Emacs 现在变得十分严肃,在某种程度上,它已经与 20 世纪 80 年代那些游戏被编写出来的时候大不一样。
|
||||
|
||||
### 汉诺塔
|
||||
|
||||
[汉诺塔][2] 是一款古老的数学解密游戏,有些人可能对它很熟悉,因为它的递归和迭代解决方案经常被用于计算机科学教学辅助。
|
||||
|
||||
|
||||
|
||||
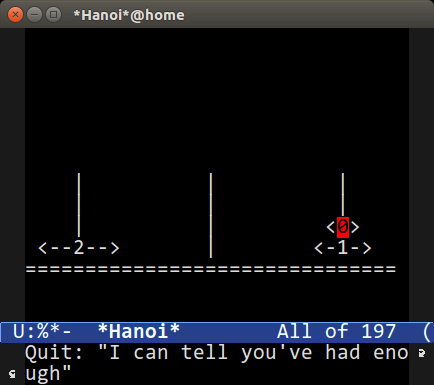
Emacs 中有三个命令可以运行汉诺塔:`M-x hanoi` 默认为 3 个碟子; `M-x hanoi-unix` 和 `M-x hanoi-unix-64` 使用 unix 时间戳的位数(32 位或 64 位)作为默认盘子的个数,并且每秒钟自动移动一次,两者不同之处在于后者假装使用 64 位时钟(因此有 64 个碟子)。
|
||||
|
||||
Emacs 中汉诺塔的实现可以追溯到 20 世纪 80 年代中期——确实是久得可怕。它有一些自定义选项(`M-x customize-group RET hanoi RET`),如启用彩色碟子等。当你离开汉诺塔缓冲区或输入一个字符,你会收到一个讽刺的告别信息(见上图)。
|
||||
|
||||
### 5x5
|
||||
|
||||
|
||||
|
||||
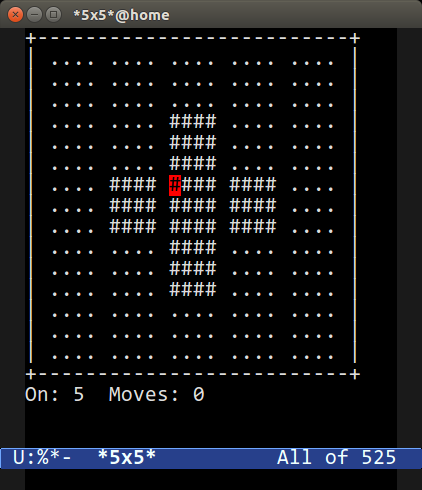
5x5 的游戏是一个逻辑解密游戏:你有一个 5x5 的网格,中间的十字被填满;你的目标是通过按正确的顺序切换它们的空满状态来填充所有的单元格,从而获得胜利。这并不像听起来那么容易!
|
||||
|
||||
输入 `M-x 5x5` 就可以开始玩了,使用可选的数字参数可以改变网格的大小。这款游戏的有趣之处在于它能向你建议下一步行动并尝试找到该游戏网格的解法。它用到了 Emacs 自己的一款非常酷的符号 RPN 计算器 `M-x calc`(在《[Emacs 快乐计算][3]》这篇文章中,我使用它来解决了一个简单的问题)。
|
||||
|
||||
所以我喜欢这个游戏的原因是它提供了一个非常复杂的解题器——真的,你应该通过 `M-x find-library RET 5x5` 来阅读其源代码——这是一个试图通过暴力破解游戏解法的“破解器”。
|
||||
|
||||
创建一个更大的游戏网格,例如输入 `M-10 M-x 5x5`,然后运行下面某个 `crack` 命令。破解器将尝试通过迭代获得最佳解决方案。它会实时运行该游戏,观看起来非常有趣:
|
||||
|
||||
- `M-x 5x5-crack-mutating-best`: 试图通过变异最佳解决方案来破解 5x5。
|
||||
- `M-x 5x5-crack-mutating-current`: 试图通过变异当前解决方案来破解 5x5。
|
||||
- `M-x 5x5-crack-random`: 尝试使用随机方案解破解 5x5。
|
||||
- `M-x 5x5-crack-xor-mutate`: 尝试通过将当前方案和最佳方案进行异或运算来破解 5x5。
|
||||
|
||||
### 文本动画
|
||||
|
||||
你可以通过运行 `M-x animation-birthday-present` 并给出你的名字来显示一个奇特的生日礼物动画。它看起来很酷!
|
||||
|
||||

|
||||
|
||||
这里用的 `animate` 包也用在了 `M-x butterfly` 命令中,这是一个向上面的 [XKCD][4] 漫画致敬而添加到 Emacs 中的命令。当然,漫画中的 Emacs 命令在技术上是无效的,但它的幽默足以弥补这一点。
|
||||
|
||||
### 黑箱
|
||||
|
||||
我将逐字引用这款游戏的目标:
|
||||
|
||||
> 游戏的目标是通过向黑盒子发射光线来找到四个隐藏的球。有四种可能:
|
||||
> 1) 射线将通过盒子不受干扰;
|
||||
> 2) 它将击中一个球并被吸收;
|
||||
> 3) 它将偏转并退出盒子,或
|
||||
> 4) 立即偏转,甚至不能进入盒子。
|
||||
|
||||
所以,这有点像我们小时候玩的[战舰游戏][5],但是……是专为物理专业高学历的人准备的吧?
|
||||
|
||||
这是另一款添加于 20 世纪 80 年代的游戏。我建议你输入 `C-h f blackbox` 来阅读玩法说明(文档巨大)。
|
||||
|
||||
|
||||
### 泡泡
|
||||
|
||||
|
||||
|
||||
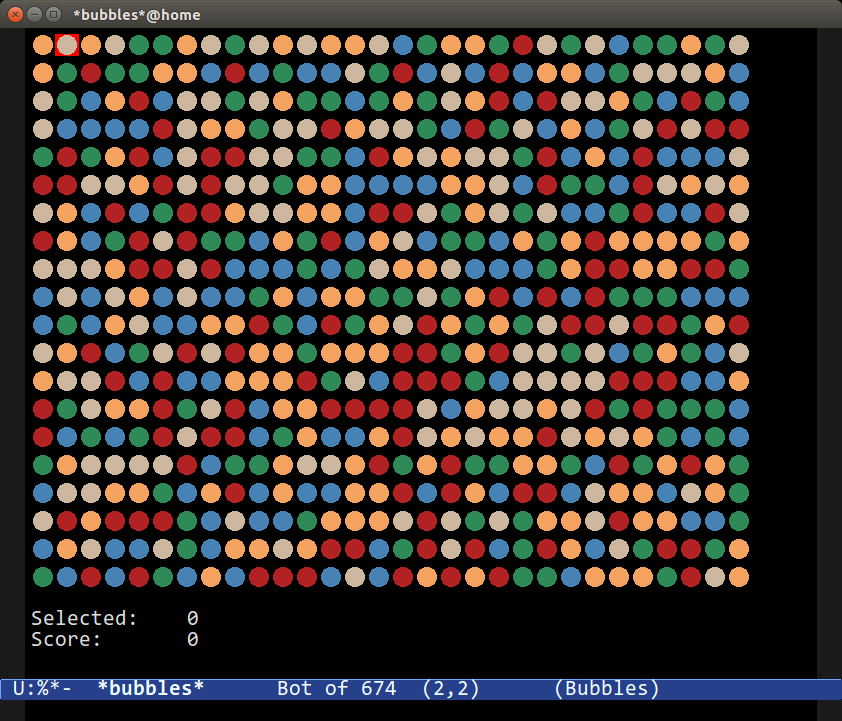
`M-x bubble` 游戏相当简单:你必须用尽可能少移动清除尽可能多的“泡泡”。当你移除气泡时,其他气泡会掉落并粘在一起。这是一款有趣的游戏,此外如果你使用 Emacs 的图形用户界面,它还支持图像显示。而且它还支持鼠标。
|
||||
|
||||
你可以通过调用 `M-x bubbles-set-game-<difficulty>` 来设置难度,其中 `<difficulty>` 可以是这些之一:`easy`、`medium`、`difficult`、`hard` 或 `userdefined`。此外,你可以使用:`M-x custom-group bubbles` 来更改图形、网格大小和颜色。
|
||||
|
||||
由于它即简单又有趣,这是 Emacs 中我最喜欢的游戏之一。
|
||||
|
||||
### 幸运饼干
|
||||
|
||||
我喜欢 `fortune` 命令。每当我启动一个新 shell 时,这些与文学片段、谜语相结合的刻薄、无益、常常带有讽刺意味的“建议”就会点亮我的一天。
|
||||
|
||||
令人困惑的是,Emacs 中有两个包或多或少地做着类似的事情:`fortune` 和 `cookie`。前者主要用于在电子邮件签名中添加幸运饼干消息,而后者只是一个简单的 fortune 格式阅读器。
|
||||
|
||||
不管怎样,使用 Emacs 的 `cookie` 包前,你首先需要通过 `customize-option RET cookie RET` 来自定义变量 `cookie-file` 告诉它从哪找到 fortune 文件。
|
||||
|
||||
如果你的操作系统是 Ubuntu,那么你先安装 `fortune` 软件包,然后就能在 `/usr/share/games/fortune/` 目录中找到这些文件了。
|
||||
|
||||
之后你就可以调用 `M-x cookie` 随机显示 fortune 内容,或者,如果你想的话,也可以调用 `M-x cookie-apropos` 查找所有匹配的饼干。
|
||||
|
||||
### 破译器
|
||||
|
||||
这个包完美地抓住了 Emacs 的功利本质:这个包为你破解简单的替换密码(如“密码谜题”)提供了一个很有用的界面。你知道,二十多年前,有些人确实迫切需要破解很多基本的密码。正是像这个模块这样的小玩意让我非常高兴地用起 Emacs 来:一个只对少数人有用的模块,但是,如果你突然需要它了,那么它就在那里等着你。
|
||||
|
||||
那么如何使用它呢?让我们假设使用 “rot13” 密码:在 26 个字符的字母表中,将字符旋转 13 个位置。
|
||||
通过 `M-x ielm` (Emacs 用于 [运行 Elisp][6] 的 REPL 环境)可以很容易在 Emacs 中进行尝试:
|
||||
|
||||
```
|
||||
*** Welcome to IELM *** Type (describe-mode) for help.
|
||||
ELISP> (rot13 "Hello, World")
|
||||
"Uryyb, Jbeyq"
|
||||
ELISP> (rot13 "Uryyb, Jbeyq")
|
||||
"Hello, World"
|
||||
ELISP>
|
||||
```
|
||||
|
||||
简而言之,你将明文旋转了 13 个位置,就得到了密文。你又旋转了一次 13 个位置,就返回了最初的明文。 这就是这个包可以帮助你解决的问题。
|
||||
|
||||
那么,decipher 模块又是如何帮助我们的呢?让我们创建一个新的缓冲区 `test-cipher` 并输入你的密文(在我的例子中是 `Uryyb,Jbeyq`)。
|
||||
|
||||

|
||||
|
||||
你现在面对的是一个相当复杂的界面。现在把光标放在紫色行的密文的任意字符上,并猜测这个字符可能是什么:Emacs 将根据你的选择更新其他明文的猜测结果,并告诉你目前为止字母表中的字符是如何分配的。
|
||||
|
||||
你现在可以用下面各种助手命令来关闭选项,以帮助推断密码字符可能对应的明文字符:
|
||||
|
||||
- `D`: 列出示意图(该加密算法中双字符对)及其频率
|
||||
- `F`: 表示每个密文字母的频率
|
||||
- `N`: 显示字符的邻近信息。我不确定这是干啥的。
|
||||
- `M` 和 `R`: 保存和恢复一个检查点,允许你对工作进行分支以探索破解密码的不同方法。
|
||||
|
||||
总而言之,对于这样一个深奥的任务,这个包是相当令人印象深刻的!如果你经常破解密码,也许这个程序包能帮上忙?
|
||||
|
||||
### 医生
|
||||
|
||||
|
||||
|
||||
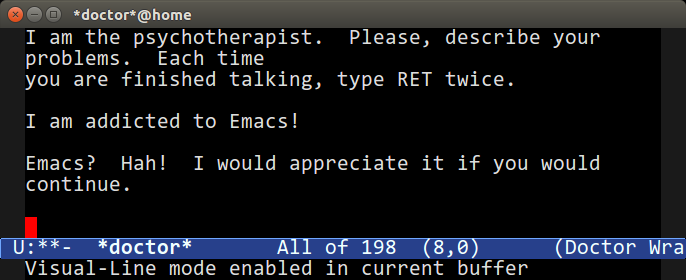
啊,Emacs 医生。其基于最初的 [ELIZA][7],“医生”试图对你说的话进行心理分析,并试图把问题复述给你。体验几分钟,相当有趣,它也是 Emacs 中最著名的古怪玩意之一。你可以使用 `M-x doctor` 来运行它。
|
||||
|
||||
### Dunnet
|
||||
|
||||
Emacs 自己特有的类 Zork 文字冒险游戏。输入 `M-x dunnet` 就能玩了。这是一款相当不错的游戏,简单的说,它是另一款非常著名的 Emacs 游戏,很少有人真正玩到通关。
|
||||
|
||||
如果你发现自己能在无聊的文档工作之间空出时间来,那么这是一个超级棒的游戏,内置“老板屏幕”,因为它是纯文本的。
|
||||
|
||||
哦,还有,不要想着吃掉那块 CPU 卡 :)
|
||||
|
||||
### 五子棋
|
||||
|
||||
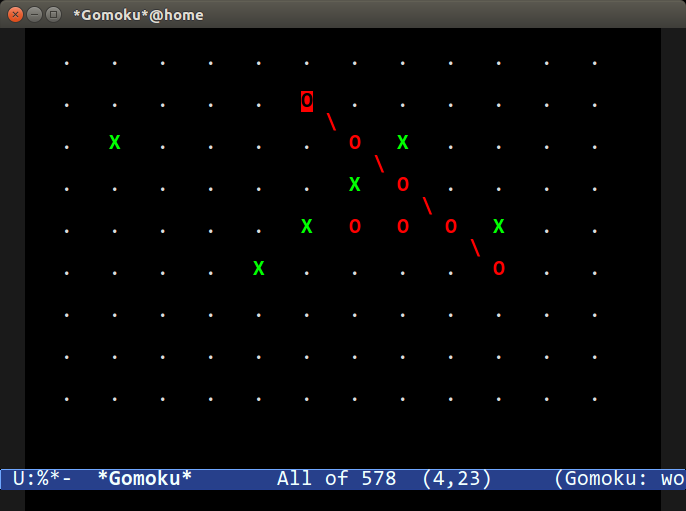
|
||||
|
||||
另一款写于 20 世纪 80 年代的游戏。你必须将 5 个方块连成一条线,井字棋风格。你可以运行 `M-x gomoku` 来与 Emacs 对抗。游戏还支持鼠标,非常方便。你也可以自定义 `gomoku` 组来调整网格的大小。
|
||||
|
||||
### 生命游戏
|
||||
|
||||
[康威的生命游戏][8] 是细胞自动机的一个著名例子。Emacs 版本提供了一些启动模式,你可以(通过 elisp 编程)调整 `life-patterns` 变量来更改这些模式。
|
||||
|
||||
你可以用 `M-x life` 触发生命游戏。事实上,所有的东西,包括显示代码、注释等等一切,总共不到 300 行,这也让人印象深刻。
|
||||
|
||||
### 乒乓,贪吃蛇和俄罗斯方块
|
||||
|
||||
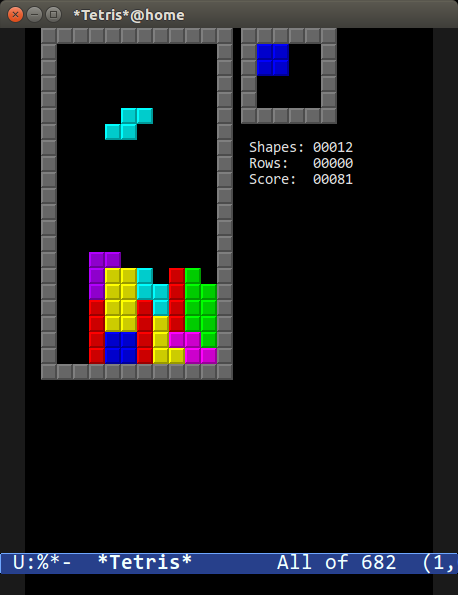
|
||||
|
||||
这些经典游戏都是使用 Emacs 包 `gamegrid` 实现的,这是一个用于构建网格游戏(如俄罗斯方块和贪吃蛇)的通用框架。gamegrid 包的伟大之处在于它同时兼容图形化和终端 Emacs:如果你在 GUI 中运行 Emacs,你会得到精美的图形;如果你没有,你看到简单的 ASCII 艺术。
|
||||
|
||||
你可以通过输入 `M-x pong`、`M-x snake`、`M-x tetris` 来运行这些游戏。
|
||||
|
||||
特别是俄罗斯方块游戏实现的非常到位,会逐渐增加速度并且能够滑块。而且既然你已经有了源代码,你完全可以移除那个讨厌的 Z 形块,没人喜欢它!
|
||||
|
||||
### Solitaire
|
||||
|
||||
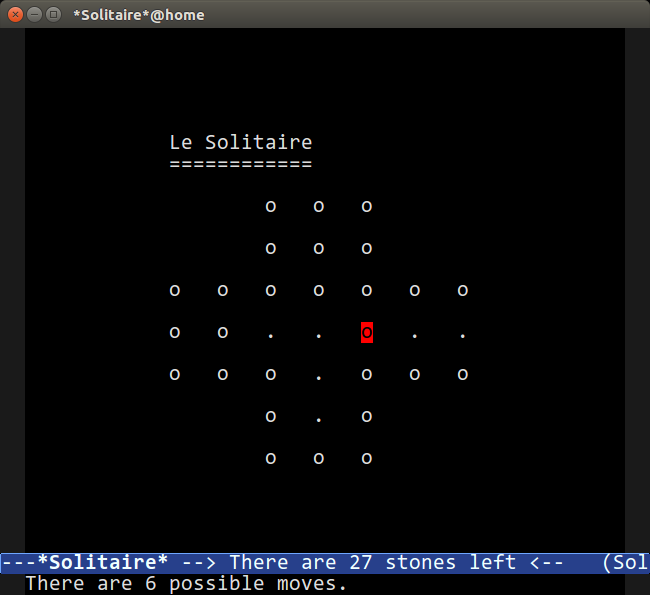
|
||||
|
||||
可惜,这不是纸牌游戏,而是一个基于“钉子”的游戏,你可以选择一块石头(`o`)并“跳过”相邻的石头进入洞中(`.`),并在这个过程中去掉你跳过的石头,最终只能在棋盘上留下一块石头,重复该过程直到棋盘被请空(只保留一个石头)。
|
||||
|
||||
如果你卡住了,有一个内置的解题器名为 `M-x solitire-solve`。
|
||||
|
||||
### Zone
|
||||
|
||||
我的另一个最爱。这是一个屏幕保护程序——或者更确切地说,是一系列的屏幕保护程序。
|
||||
|
||||
输入 `M-x zone`,然后看看屏幕上发生了什么!
|
||||
|
||||
你可以通过运行 `M-x zone-when-idle`(或从 elisp 调用它)来配置屏幕保护程序的空闲时间,时间以秒为单位。你也可以通过 `M-x zone-leave-me-alone` 来关闭它。
|
||||
|
||||
如果在你的同事看着的时候启动它,你的同事肯定会抓狂的。
|
||||
|
||||
### 乘法解谜
|
||||
|
||||
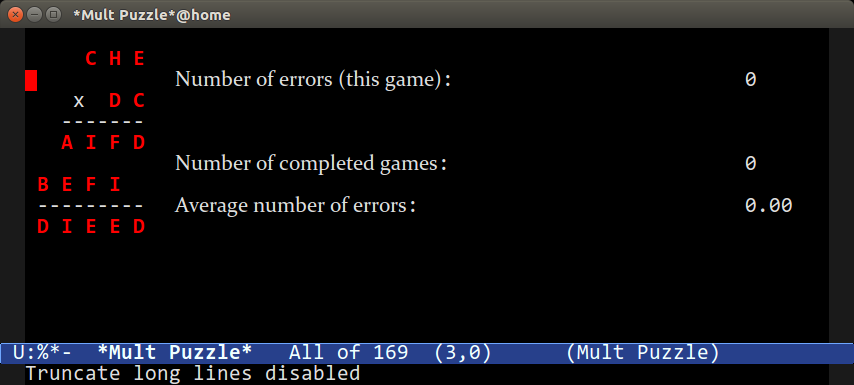
|
||||
|
||||
这是另一个脑筋急转弯的益智游戏。当你运行 `M-x mpuz` 时,将看到一个乘法解谜题,你必须将字母替换为对应的数字,并确保数字相加(相乘?)符合结果。
|
||||
|
||||
如果遇到难题,可以运行 `M-x mpuz-show-solution` 来解决。
|
||||
|
||||
### 杂项
|
||||
|
||||
还有更多好玩的东西,但它们就不如刚才那些那么好玩好用了:
|
||||
|
||||
- 你可以通过 `M-x morse-region` 和 `M-x unmorse-region` 将一个区域翻译成莫尔斯电码。
|
||||
- Dissociated Press 是一个非常简单的命令,它将一个类似随机穿行的马尔可夫链生成器应用到缓冲区中的文本中,并以此生成无意义的文本。试一下 `M-x dissociated-press`。
|
||||
- `gametree` 软件包是一个通过电子邮件记录和跟踪国际象棋游戏的复杂方法。
|
||||
- `M-x spook` 命令插入随机单词(通常是到电子邮件中),目的是混淆/超载 “NSA 拖网渔船” —— 记住,这个模块可以追溯到 20 世纪 80 年代和 90 年代,那时应该有间谍们在监听各种单词。当然,即使是在十年前,这样做也会显得非常偏执和古怪,不过现在看来已经不那么奇怪了……
|
||||
|
||||
### 总结
|
||||
|
||||
我喜欢 Emacs 附带的游戏和玩具。它们大多来自于,嗯,我们姑且称之为一个不同的时代:一个允许或甚至鼓励奇思妙想的时代。有些玩意非常经典(如俄罗斯方块和汉诺塔),有些对经典游戏进行了有趣的变种(如黑盒)——但我很高兴这么多年后它们依然存在于 Emacs 中。我想知道时至今日,类似这些的玩意是否还会再纳入 Emacs 的代码库中;嗯,它们很可能不会——它们将被归入包管理仓库中,而在这个干净而无菌的世界中,它们无疑属于包管理仓库。
|
||||
|
||||
Emacs 要求将对 Emacs 体验不重要的内容转移到包管理仓库 ELPA 中。我的意思是,作为一个开发者,这是有道理的,但是……对于每一个被移出并流放到 ELPA 的包,我们是不是在蚕食 Emacs 的精髓?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.masteringemacs.org/article/fun-games-in-emacs
|
||||
|
||||
作者:[Mickey Petersen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.masteringemacs.org/about
|
||||
[b]:https://github.com/lujun9972
|
||||
[1]:https://en.wikipedia.org/wiki/Office_Space
|
||||
[2]:https://en.wikipedia.org/wiki/Tower_of_Hanoi
|
||||
[3]:https://www.masteringemacs.org/article/fun-emacs-calc
|
||||
[4]:http://www.xkcd.com
|
||||
[5]:https://en.wikipedia.org/wiki/Battleship_(game)
|
||||
[6]:https://www.masteringemacs.org/article/evaluating-elisp-emacs
|
||||
[7]:https://en.wikipedia.org/wiki/ELIZA
|
||||
[8]:https://en.wikipedia.org/wiki/Conway's_Game_of_Life
|
||||
71
published/20180306 Exploring free and open web fonts.md
Normal file
71
published/20180306 Exploring free and open web fonts.md
Normal file
@ -0,0 +1,71 @@
|
||||
探索自由而开放的 Web 字体
|
||||
======
|
||||
|
||||
> 谷歌字体和开放字体库中的免费 Web 字体已经改变了游戏规则,但仅在有限的范围内。
|
||||
|
||||

|
||||
|
||||
毫无疑问,近些年来互联网的面貌已经被开源字体所改变。早在 2010 年之前,你在 Web 浏览器上几乎只能看到微软制作的通常“Web 安全”的[核心字体][1]。但这一年(2010)正好是好几轮技术革新开始的见证之年:<ruby>[Web 开放字体格式][2]<rt>Web Open Font Format</rt></ruby>(WOFF)的引入为通过 HTTP 有效地传输字体文件提供了一个开放的标准,以及像[谷歌字体][3]和<ruby>[开放字体库][4]<rt>Open Font Library</rt></ruby>这样的 Web 字体服务的推出,使得 Web 内容发布者可以在开源许可证之下免费使用海量的字体库。
|
||||
|
||||
这些事件对 Web 排版的积极影响再夸大都不过分。但是要将 Web 开放字体的成功与整个开源排版等同起来,并得到结论——挑战已经远离了我们,困难悉数被解决了——却很容易。然而事实并非如此,如果你很关注字体,那么好消息是你有好多机会参与到对这些字体的改进工作当中去。
|
||||
|
||||
对新手来说,至关重要的是必须要意识到谷歌字体和开放字体库提供了专用的服务(为网页提供字体),而没有为其他使用情况制定字体解决方案。这不是服务方面的缺点,这只是意味着我们必须去开发其它的解决方案。
|
||||
|
||||
需要解决的问题还非常多。可能最明显的例子就是给 Linux 桌面计算机的其他软件安装字体所遇到的尴尬情况。你可以通过任何一种服务下载任何一种 Web 字体,但是你得到的只是一个最普通的压缩包文件,里面有一些 TTF 或 OTF 二进制文件和一个普通文本文件的许可证。接下来会发生什么完完全全需要你去猜。
|
||||
|
||||
大部分用户很快学会了“正确”的步骤就是手动地复制这些字体二进制文件到他们硬盘里几个特殊文件夹里的某一个里。但是这样做只能使这个文件对操作系统可见。它并不能为用户体验带来什么提升。再强调一遍,这不是 Web 字体服务的缺陷,相反它佐证了对于关于服务到哪里停止和需要在其他方面做更多工作的观点。
|
||||
|
||||
在用户视角来说,一个巨大的提升可能就是在“只是下载”这个阶段,操作系统或者桌面环境变得更智能。系统或桌面环境不仅会把字体文件安装到正确的位置上,更重要的是,当用户选择要在一个项目中使用的字体时,它会自己添加用户所需要的重要的元数据。
|
||||
|
||||
这些附加信息包含的内容与它如何呈现给用户与另一个挑战有关:与其它操作系统相比,在 Linux 环境管理一个字体库显然不那么令人满意。字体管理器总是时不时的出现一下(例如 [GTK+ 字体管理器][5],这是最近的一个例子),但是它们很少变得流行起来。我一直在思考一大堆这些软件让人失望的方面。一个核心的原因是它们把自己局限于只展示内嵌在二进制字体文件内的信息:基本字符集的覆盖、粗细/宽度和斜率的设定,内置的许可证和版权说明等等。
|
||||
|
||||
但是除了这些内嵌数据中的内容,在选择字体的过程中还涉及很多决策。严肃的字体用户,像信息设计者、杂志文章作者,或者书籍美工设计者,他们的字体选择是根据每一份文件的要求和需求做出的。这当然包含了许可证信息,但它还包含了更多,像关于设计师和厂商的信息、潮流风格的趋势,或者字体在使用中的细节。
|
||||
|
||||
举个例子,如果你的文档包含了英语和阿拉伯文,你多半想要拉丁文和阿拉伯文的字体由同时熟悉这两种<ruby>字母系统<rt>script</rt></ruby>的设计师所设计。否则,你将浪费一大堆时间来微调字体大小和行间距来使两种字母系统良好地结合在一起。你可能从经验中学到,某些设计师或字体厂商比其他人更善于多种字母系统设计。或许和你职业相关的是今天的时尚杂志几乎无一例外的采用 “[Didone][6]”风格的字体,“[Didone][6]”是指一种两百多年前最先被 [Firmin Didot][7] 和 [Giambattista Bodoni][8] 设计出来的超高反差的字体风格。这种字体恰好就是现在的潮流。
|
||||
|
||||
但是像 Didone、Didot 或 Bodoni 这些术语都不可能会出现在二进制文件的内置数据当中,你也不容易判断拉丁文和阿拉伯文是否相得益彰或其它关于字体的历史背景。这些信息有可能出现在补充的材料中,类似某种字形样本或字体文件中,如果这些东西存在的话。
|
||||
|
||||
<ruby>字形样本<rt>specimen</rt></ruby>是一份设计好的文档(一般是 PDF),它展示了这种字体的使用情况,而且包括了背景信息。字形样本经常在挑选字体时充当市场营销和外观样例的双重角色。一份精心设计的样本展示了字体在实际应用中的情况和在自动生成的字符表中所不能体现的风格。字形样本文件也有可能包含了一些其他重要信息,比如怎样激活字体的 OpenType 特性、提供的数学表达式或古体字,或者它在支持的多种语言上的风格变化。在字体管理应用程序中向用户提供此类材料,对于帮助用户找到适合其项目需求的字体将大有帮助。
|
||||
|
||||
当然,如果我们希望一个字体管理软件能够处理文件和样本问题,我们也必须仔细观察一下各种发行版提供的字体包所随附的内容。Linux 的用户刚开始只有自动安装的那几种字体,并且发行版存储库提供的包是大部分用户除了下载通用的压缩包档案之外的唯一字体来源。这些包往往非常的“简陋”。商业字体总的来说都包含了样本、文档,还有其他的支持项目,然而开源字体往往没有这些配套文件。
|
||||
|
||||
也有一些优秀的开放字体提供了高质量的样本和文档(例如 [SIL Gentium][9] 和 [Bungee][10] 是两种差异明显但是都有效的方案),但是它们几乎不涉足下游的打包工作链。我们显然可以做的更好一些。
|
||||
|
||||
要在系统的字体交互方面提供更丰富的用户体验上面还存在一些技术问题。一方面,[AppStream][11] 的元数据标准定义了一些字体文件特有的参数,但是到现在为止,这些参数没有包含样本、设计师/厂商和其他相关细节的任何信息。另外一个例子,[SPDX][13](<ruby>软件包数据交换<rt>Software Package Data Exchange</rt></ruby>)格式也没有包含太多用于分发字体的软件许可证(及许可证变体)。
|
||||
|
||||
最后,就像任何一个唱片爱好者都会告诉你的,一个不允许你编辑和完善你的 MP3 曲库中的 ID3 信息的音乐播放器很快就会变得令人失望(LCTT 译注:ID3 信息是 MP3 文件头部的元信息,用于存储歌曲信息)。你想要处理标签里的错误、想要添加注释和专辑封面之类的信息,本质上,这就是完善你的音乐库。同样,你可能也想要让你的本地字体库也保持在一个方便使用的状态。
|
||||
|
||||
但是改动字体文件的内置数据一直有所忌讳,因为字体往往是被内置或附加到其他文件里的。如果你随意改变了字体二进制文件中的字段,然后将其与你的演示文稿一起重新分发,那么下载这些演示文稿的任何人最终都会得到错误的元数据,但这个错误不是他们自己造成的。所以任何一个要改善字体管理体验的人都要想明白如何从策略上解决对内置或外置的字体元数据的重复修改。
|
||||
|
||||
除了技术角度之外,丰富的字体管理经验也是一项设计挑战。就像我在前面说的一样,有几种开放字体也带了良好的样本和精心编写的文档。但是更多的字体包这两者都没有,还有大量的更老的字体包已经没有人维护了。这很可能意味着大部分开放字体包想要获得样本和证明文件的唯一办法就是让社区去创建它们。
|
||||
|
||||
也许这是一个很高的要求。但是开源设计社区现在比以往任何时候都要庞大,它是整个自由开源软件运动中的一个高度活跃的组成部分。所以谁知道呢,也许明年这个时候会发现,在 Linux 桌面系统查找、下载和使用字体会变成一种完全不同的体验。
|
||||
|
||||
在这一连串关于现代 Linux 用户的文字设计上的挑战的思考中包含了打包、文档设计,甚至有可能需要在桌面环境加入不少新的软件部分。此外还有其他一系列的东西也需要考虑。其共通性就是在 Web 字体服务不可及的地方,事情就会变得更加困难。
|
||||
|
||||
从我的视角来看,最好的消息是现在比起以前有更多的人对这个话题感兴趣。我认为我们要感谢像谷歌字体和开放字体库这样的 Web 字体服务巨头让开放字体得到了更高的关注。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/webfonts
|
||||
|
||||
作者:[Nathan Willis][a]
|
||||
译者:[Fisherman110](https://github.com/Fisherman110)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/n8willis
|
||||
[1]:https://en.wikipedia.org/wiki/Core_fonts_for_the_Web
|
||||
[2]:https://en.wikipedia.org/wiki/Web_Open_Font_Format
|
||||
[3]:https://fonts.google.com/
|
||||
[4]:https://fontlibrary.org/
|
||||
[5]:https://fontmanager.github.io/
|
||||
[6]:https://en.wikipedia.org/wiki/Didone_(typography)
|
||||
[7]:https://en.wikipedia.org/wiki/Firmin_Didot
|
||||
[8]:https://en.wikipedia.org/wiki/Giambattista_Bodoni
|
||||
[9]:https://software.sil.org/gentium/
|
||||
[10]:https://djr.com/bungee/
|
||||
[11]:https://www.freedesktop.org/wiki/Distributions/AppStream/
|
||||
[12]:https://www.freedesktop.org/software/appstream/docs/sect-Metadata-Fonts.html
|
||||
[13]:https://spdx.org/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11953-1.html)
|
||||
[#]: subject: (Troubleshooting hardware problems in Linux)
|
||||
[#]: via: (https://opensource.com/article/18/12/troubleshooting-hardware-problems-linux)
|
||||
[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
|
||||
@ -12,11 +12,11 @@ Linux 硬件故障排除指南
|
||||
|
||||
> 了解是什么原因导致你的 Linux 硬件发生故障,以便你可以将其恢复并快速运行。
|
||||
|
||||

|
||||

|
||||
|
||||
[Linux 服务器][1]在物理机、虚拟化、私有云、公共云和混合云等许多不同种类的基础设施中运行着关键的业务应用程序。对于 Linux 系统管理员来说,了解如何管理 Linux 硬件基础设施(包括与 [网络][2]、存储、Linux 容器相关的软件定义的功能)和 Linux 服务器上的多种工具非常重要。
|
||||
[Linux 服务器][1]在物理机、虚拟化、私有云、公共云和混合云等许多不同种类的基础设施中运行着关键的业务应用程序。对于 Linux 系统管理员来说,了解如何管理 Linux 硬件基础设施(包括与 [网络][2]、存储、Linux 容器相关的软件定义功能)和 Linux 服务器上的多种工具非常重要。
|
||||
|
||||
在 Linux 上进行故障排除和解决与硬件相关的问题可能需要一些时间。即使是经验丰富的系统管理员,有时也会花费数小时来解决神秘的硬件和软件差异。
|
||||
在 Linux 上进行排除和解决与硬件相关的问题可能需要一些时间。即使是经验丰富的系统管理员,有时也会花费数小时来解决神秘的硬件和软件差异。
|
||||
|
||||
以下提示可以使你更快、更轻松地对 Linux 中的硬件进行故障排除。许多不同的事情都可能导致 Linux 硬件出现问题。在开始诊断它们之前,明智的做法是了解最常见的问题以及最有可能找到问题的地方。
|
||||
|
||||
@ -54,7 +54,7 @@ xvdb 202:16 0 20G 0 disk
|
||||
....
|
||||
```
|
||||
|
||||
### 深入到多个日志当中
|
||||
### 深入到各个日志当中
|
||||
|
||||
使用 `dmesg` 可以找出内核最新消息中的错误和警告。例如,这是 `dmesg | more` 命令的输出:
|
||||
|
||||
@ -93,7 +93,7 @@ Dec 1 13:21:33 bastion dnsmasq[30201]: using nameserver 127.0.0.1#53 for domai
|
||||
|
||||
### 分析网络功能
|
||||
|
||||
你可能有成千上万的云原生应用程序在一个复杂的网络环境中为业务提供服务。其中可能包括虚拟化、多云和混合云。这意味着,作为故障排除的一部分,你应该分析网络连接是否正常工作。弄清 Linux 服务器中网络功能的有用命令包括:`ip addr`、`traceroute`、`nslookup`、`dig` 和 `ping` 等。例如,这是 `ip addr show` 命令的输出:
|
||||
你可能有成千上万的云原生应用程序在一个复杂的网络环境中为业务提供服务,其中可能包括虚拟化、多云和混合云。这意味着,作为故障排除的一部分,你应该分析网络连接是否正常工作。弄清 Linux 服务器中网络功能的有用命令包括:`ip addr`、`traceroute`、`nslookup`、`dig` 和 `ping` 等。例如,这是 `ip addr show` 命令的输出:
|
||||
|
||||
```
|
||||
# ip addr show
|
||||
@ -129,7 +129,7 @@ via: https://opensource.com/article/18/12/troubleshooting-hardware-problems-linu
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
235
published/20190113 Editing Subtitles in Linux.md
Normal file
235
published/20190113 Editing Subtitles in Linux.md
Normal file
@ -0,0 +1,235 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chenmu-kk)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11946-1.html)
|
||||
[#]: subject: (Editing Subtitles in Linux)
|
||||
[#]: via: (https://itsfoss.com/editing-subtitles)
|
||||
[#]: author: (Shirish https://itsfoss.com/author/shirish/)
|
||||
|
||||
如何在 Linux 中编辑字幕
|
||||
======
|
||||
|
||||
我作为一位世界电影和地区电影爱好者已经几十年了。这期间字幕是一个必不可少的工具,它可以使我享受来自不同国家不同语言的优秀电影。
|
||||
|
||||
如果你喜欢观看带有字幕的电影,你可能会注意到有时字幕并不同步或者说并不正确。
|
||||
|
||||
你知道你可以自己编写字幕并使得它们更完美吗?让我们向你展示一些 Linux 中的基本字幕编辑吧。
|
||||
|
||||
![Editing subtitles in Linux][1]
|
||||
|
||||
### 从闭路字幕数据中提取字幕
|
||||
|
||||
大概在 2012、2013 年我开始了解到有一款叫做 [CCEextractor][2] 的工具。随着时间的推移,它已经成为我必不可少的工具之一,尤其是当我偶然发现一份内含有字幕的媒体文件。
|
||||
|
||||
CCExtractor 负责解析视频文件以及从<ruby>闭路字幕<rt>closed captions</rt></ruby>数据中产生独立的字幕文件。
|
||||
|
||||
CCExtractor 是一个跨平台的、自由开源工具。自它形成的那年起该工具已经成熟了不少而如今已成为 [GSOC][3] 和谷歌编码输入的一部分。
|
||||
|
||||
简单来说,这个工具基本上是一系列脚本,这些脚本以一种顺序方式一个接着一个地给你提供提取到的字幕。
|
||||
|
||||
你可以按照[本页][5]的 CCExtractor 安装指南进行操作。
|
||||
|
||||
若安装后你想从媒体文件中提取字幕,请按以下步骤操作:
|
||||
|
||||
```
|
||||
ccextractor <path_to_video_file>
|
||||
```
|
||||
|
||||
该命令将会输出以下内容:
|
||||
|
||||
```
|
||||
$ ccextractor $something.mkv
|
||||
CCExtractor 0.87, Carlos Fernandez Sanz, Volker Quetschke.
|
||||
Teletext portions taken from Petr Kutalek's telxcc
|
||||
--------------------------------------------------------------------------
|
||||
Input: $something.mkv
|
||||
[Extract: 1] [Stream mode: Autodetect]
|
||||
[Program : Auto ] [Hauppage mode: No] [Use MythTV code: Auto]
|
||||
[Timing mode: Auto] [Debug: No] [Buffer input: No]
|
||||
[Use pic_order_cnt_lsb for H.264: No] [Print CC decoder traces: No]
|
||||
[Target format: .srt] [Encoding: UTF-8] [Delay: 0] [Trim lines: No]
|
||||
[Add font color data: Yes] [Add font typesetting: Yes]
|
||||
[Convert case: No] [Video-edit join: No]
|
||||
[Extraction start time: not set (from start)]
|
||||
[Extraction end time: not set (to end)]
|
||||
[Live stream: No] [Clock frequency: 90000]
|
||||
[Teletext page: Autodetect]
|
||||
[Start credits text: None]
|
||||
[Quantisation-mode: CCExtractor's internal function]
|
||||
-----------------------------------------------------------------
|
||||
Opening file: $something.mkv
|
||||
File seems to be a Matroska/WebM container
|
||||
Analyzing data in Matroska mode
|
||||
|
||||
Document type: matroska
|
||||
Timecode scale: 1000000
|
||||
Muxing app: libebml v1.3.1 + libmatroska v1.4.2
|
||||
Writing app: mkvmerge v8.2.0 ('World of Adventure') 64bit
|
||||
Title: $something
|
||||
|
||||
Track entry:
|
||||
Track number: 1
|
||||
UID: 1
|
||||
Type: video
|
||||
Codec ID: V_MPEG4/ISO/AVC
|
||||
Language: mal
|
||||
Name: $something
|
||||
|
||||
Track entry:
|
||||
Track number: 2
|
||||
UID: 2
|
||||
Type: audio
|
||||
Codec ID: A_MPEG/L3
|
||||
Language: mal
|
||||
Name: $something
|
||||
|
||||
Track entry:
|
||||
Track number: 3
|
||||
UID: somenumber
|
||||
Type: subtitle
|
||||
Codec ID: S_TEXT/UTF8
|
||||
Name: $something
|
||||
99% | 144:34
|
||||
100% | 144:34
|
||||
Output file: $something_eng.srt
|
||||
Done, processing time = 6 seconds
|
||||
Issues? Open a ticket here
|
||||
https://github.com/CCExtractor/ccextractor/issues
|
||||
```
|
||||
它会大致浏览媒体文件。在这个例子中,它发现该媒体文件是马拉雅拉姆语言(mal)并且格式是 [.mkv][6]。之后它将字幕文件提取出来,命名为源文件名并添加“_eng”后缀。
|
||||
|
||||
CCExtractor 是一款用来增强字幕功能和字幕编辑的优秀工具,我将在下一部分对它进行介绍。
|
||||
|
||||
> 趣味阅读:在 [vicaps][7] 有一份有趣的字幕提要,它讲解和分享为何字幕对我们如此重要。对于那些对这类话题感兴趣的人来说,这里面也有许多电影制作的细节。
|
||||
|
||||
### 用 SubtitleEditor 工具编辑字幕
|
||||
|
||||
你大概意识到大多数的字幕都是 [.srt 格式][8] 的。这种格式的优点在于你可以将它加载到文本编辑器中并对它进行少量的修改。
|
||||
|
||||
当进入一个简单的文本编辑器时,一个 srt 文件看起来会是这个样子:
|
||||
|
||||
```
|
||||
1
|
||||
00:00:00,959 --> 00:00:13,744
|
||||
"THE CABINET
|
||||
OF DR. CALIGARI"
|
||||
|
||||
2
|
||||
00:00:40,084 --> 00:01:02,088
|
||||
A TALE of the modern re-appearance of an 11th Century Myth
|
||||
involting the strange and mysterious influence
|
||||
of a mountebank monk over a somnambulist.
|
||||
```
|
||||
|
||||
我分享的节选字幕来自于一部非常老的德国电影《[卡里加里博士的小屋][9]》(1920)。
|
||||
|
||||
Subtitleeditor 是一款非常棒的字幕编辑软件。字幕编辑器可以用来设置字幕持续时间、与多媒体文件同步的字幕帧率以及字幕间隔时间等等。接下来我将在这分享一些基本的字幕编辑。
|
||||
|
||||
![][10]
|
||||
|
||||
首先,以安装 ccextractor 工具同样的方式安装 subtitleeditor 工具,使用你自己喜爱的安装方式。在 Debian 中,你可以使用命令:
|
||||
|
||||
```
|
||||
sudo apt install subtitleeditor
|
||||
```
|
||||
|
||||
当你安装完成后,让我们来看一下在你编辑字幕时一些常见的场景。
|
||||
|
||||
#### 调整帧率使其媒体文件同步
|
||||
|
||||
如果你发现字幕与视频不同步,一个原因可能是视频文件的帧率与字幕文件的帧率并不一致。
|
||||
|
||||
你如何得知这些文件的帧率呢,然后呢?为了获取视频文件的帧率,你可以使用 `mediainfo` 工具。首先你可能需要发行版的包管理器来安装它。
|
||||
|
||||
使用 `mediainfo` 非常简单:
|
||||
|
||||
```
|
||||
$ mediainfo somefile.mkv | grep Frame
|
||||
Format settings : CABAC / 4 Ref Frames
|
||||
Format settings, ReFrames : 4 frames
|
||||
Frame rate mode : Constant
|
||||
Frame rate : 25.000 FPS
|
||||
Bits/(Pixel*Frame) : 0.082
|
||||
Frame rate : 46.875 FPS (1024 SPF)
|
||||
```
|
||||
|
||||
现在你可以看到视频文件的帧率是 25.000 FPS 。我们看到的另一个帧率则是音频文件的帧率。虽然我可以分享为何在视频解码和音频解码等地方会使用特定的 fps,但这将会是一个不同的主题,与它相关的历史信息有很多。
|
||||
|
||||
下一个问题是解决字幕文件的帧率,这个稍微有点复杂。
|
||||
|
||||
通常情况下,大多数字幕都是压缩格式的。将.zip 归档文件和字幕文件(以 XXX.srt 结尾)一起解压缩。除此之外,通常还会有一个同名的 .info 文件,该文件可能包含字幕的帧率。
|
||||
|
||||
如果不是,那么通常最好去某个站点并从具有该帧速率信息的站点下载字幕。对于这个特定的德文文件,我使用 [Opensubtitle.org][11] 来找到它。
|
||||
|
||||
正如你在链接中所看到的,字幕的帧率是 23.976 FPS 。很明显,它不能与帧率为 25.000 FPS 的视频文件一起很好地播放。
|
||||
|
||||
在这种情况下,你可以使用字幕编辑工具来改变字幕文件的帧率。
|
||||
|
||||
按下 `CTRL+A` 选择字幕文件中的全部内容。点击 “Timings -> Change Framerate” ,将 23.976 fps 改为 25.000 fps 或者你想要的其他帧率,保存已更改的文件。
|
||||
|
||||
![synchronize frame rates of subtitles in Linux][12]
|
||||
|
||||
#### 改变字幕文件的起点
|
||||
|
||||
有时以上的方法就足够解决问题了,但有时候以上方法并不足够解决问题。
|
||||
|
||||
在帧率相同时,你可能会发现字幕文件的开头与电影或媒体文件中起点并不相同。
|
||||
|
||||
在这种情况下,请按以下步骤进行操作:
|
||||
|
||||
按下 `CTRL+A` 键选中字幕文件的全部内容。点击 “Timings -> Select Move Subtitle” 。
|
||||
|
||||
![Move subtitles using Subtitle Editor on Linux][13]
|
||||
|
||||
设定字幕文件的新起点,保存已更改的文件。
|
||||
|
||||
![Move subtitles using Subtitle Editor in Linux][14]
|
||||
|
||||
如果你想要时间更精确一点,那么可以使用 [mpv][15] 来查看电影或者媒体文件并点击进度条(可以显示电影或者媒体文件的播放进度),它也会显示微秒。
|
||||
|
||||
通常我喜欢精准无误的操作,因此我会试着尽可能地仔细调节。相较于人类的反应时间来说,MPV 中的反应时间很精确。如果我想要极其精确的时间,那么我可以使用像 [Audacity][16] 之类的东西,但是那是另一种工具,你可以在上面做更多的事情。那也将会是我未来博客中将要探讨的东西。
|
||||
|
||||
#### 调整字幕间隔时间
|
||||
|
||||
有时,两种方法都采用了还不够,甚至你可能需要缩短或增加间隔时间以使其与媒体文件同步。这是较为繁琐的工作之一,因为你必须单独确定每个句子的间隔时间。尤其是在媒体文件中帧率可变的情况下(现已很少见,但你仍然会得到此类文件)
|
||||
|
||||
在这种设想下,你可能因为无法实现自动编辑而不得不手动的修改间隔时间。最好的方式是修改视频文件(会降低视频质量)或者换另一个更高质量的片源,用你喜欢的设置对它进行[转码][17] 。这又是一重大任务,以后我会在我的一些博客文章上阐明。
|
||||
|
||||
### 总结
|
||||
|
||||
以上我分享的内容或多或少是对现有字幕文件的改进。如果从头开始,你需要花费大量的时间。我完全没有分享这一点,因为一部电影或一个小时内的任何视频材料都可以轻易地花费 4-6 个小时,甚至更多的时间,这取决于字幕员的技巧、耐心、上下文、行话、口音、是否是以英语为母语的人、翻译等,所有的这些都会对字幕的质量产生影响。
|
||||
|
||||
我希望自此以后你会觉得这件事很有趣,并将你的字幕处理的更好一点。如果你有其他想要补充的问题,请在下方留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/editing-subtitles
|
||||
|
||||
作者:[Shirish][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chenmu-kk](https://github.com/chenmu-kk)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/shirish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?resize=800%2C450&ssl=1
|
||||
[2]: https://www.ccextractor.org/
|
||||
[3]: https://itsfoss.com/best-open-source-internships/
|
||||
[4]: https://www.ccextractor.org/public:codein:google_code-in_2018
|
||||
[5]: https://github.com/CCExtractor/ccextractor/wiki/Installation
|
||||
[6]: https://en.wikipedia.org/wiki/Matroska
|
||||
[7]: https://www.vicaps.com/blog/history-of-silent-movies-and-subtitles/
|
||||
[8]: https://en.wikipedia.org/wiki/SubRip#SubRip_text_file_format
|
||||
[9]: https://www.imdb.com/title/tt0010323/
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/subtitleeditor.jpg?ssl=1
|
||||
[11]: https://www.opensubtitles.org/en/search/sublanguageid-eng/idmovie-4105
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/subtitleeditor-frame-rate-sync.jpg?resize=800%2C450&ssl=1
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Move-subtitles-Caligiri.jpg?resize=800%2C450&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/move-subtitles.jpg?ssl=1
|
||||
[15]: https://itsfoss.com/mpv-video-player/
|
||||
[16]: https://www.audacityteam.org/
|
||||
[17]: https://en.wikipedia.org/wiki/Transcoding
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11960-1.html)
|
||||
[#]: subject: (Syncthing: Open Source P2P File Syncing Tool)
|
||||
[#]: via: (https://itsfoss.com/syncthing/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Syncthing:开源 P2P 文件同步工具
|
||||
======
|
||||
|
||||
> Syncthing 是一个开源的 P2P 文件同步工具,可用于在多个设备(包括 Android 手机)之间同步文件。
|
||||
|
||||

|
||||
|
||||
通常,我们有 [MEGA][1] 或 Dropbox 之类的云同步解决方案,以便在云上备份我们的文件,同时更易于共享。但是,如果要跨多个设备同步文件而不将其存储在云中怎么办?
|
||||
|
||||
这就是 [Syncthing][2] 派上用场的地方了。
|
||||
|
||||
### Syncthing:一个跨设备同步文件的开源工具
|
||||
|
||||
![][3]
|
||||
|
||||
Syncthing 可让你跨多个设备同步文件(包括对 Android 智能手机的支持)。它主要通过 Linux 上的 Web UI 进行工作,但也提供了 GUI(需要单独安装)。
|
||||
|
||||
然而,Syncthing 完全没有利用云,它是 [P2P][4] 文件同步工具。你的数据不会被发送到中央服务器。而是会在所有设备之间同步。因此,它并不能真正取代 [Linux 上的典型云存储服务][5]。
|
||||
|
||||
要添加远程设备,你只需要设备 ID(或直接扫描二维码),而无需 IP 地址。
|
||||
|
||||
如果你想要远程备份文件,那么你可能应该依靠云。
|
||||
|
||||
![Syncthing GUI][6]
|
||||
|
||||
考虑到所有因素,Syncthing 可以在很多方面派上用场。从技术上讲,你可以安全、私密地在多个系统上访问重要文件,而不必担心有人监视你的数据。
|
||||
|
||||
例如,你可能不想在云上存储一些敏感文件,因此你可以添加其他受信任的设备来同步并保留这些文件的副本。
|
||||
|
||||
即使我对它的描述很简单,但它并不像看到的那么简单。如果你感兴趣的话,我建议你阅读[官方 FAQ][7] 来了解它如何工作的。
|
||||
|
||||
### Syncthing 的特性
|
||||
|
||||
你可能不希望同步工具中有很多选项。它要可靠地同步文件,应该非常简单。
|
||||
|
||||
Syncthing 确实非常简单且易于理解。即使这样,如果你想使用它的所有功能,那么也建议你阅读它的[文档][8]。
|
||||
|
||||
在这里,我将重点介绍 Syncthing 的一些有用特性:
|
||||
|
||||
#### 跨平台支持
|
||||
|
||||
![Syncthing on Android][9]
|
||||
|
||||
作为开源解决方案,它支持 Windows、Linux 和 macOS。
|
||||
|
||||
除此之外,它还支持 Android 智能手机。如果你使用的是 iOS 设备,那么你会感到失望。到目前为止,它还没有支持 iOS 的计划。
|
||||
|
||||
#### 文件版本控制
|
||||
|
||||
![Syncthing File Versioning][10]
|
||||
|
||||
如果替换或删除了旧文件,那么 Syncthing 会利用各种[文件版本控制方法][11]来存档旧文件。
|
||||
|
||||
默认情况下,你不会发现它启用。但是,当你创建一个要同步的文件夹时,你将找到将文件版本控制切换为首选方法的选项。
|
||||
|
||||
#### 易于使用
|
||||
|
||||
作为 P2P 文件同步工具,它无需高级调整即可使用。
|
||||
|
||||
但是,它允许你在需要时配置高级设置。
|
||||
|
||||
#### 安全和隐私
|
||||
|
||||
即使你不与任何云服务提供商共享数据,仍会有一些连接可能会引起窃听者的注意。因此,Syncthing 使用 TLS 保护通信。
|
||||
|
||||
此外,它还有可靠的身份验证方法,以确保仅授予只有你允许的设备/连接能够取得同步/读取数据的权限。
|
||||
|
||||
对于 Android 智能手机,如果你使用 [Orbot 应用][12],你还可以强制将流量通过 Tor。在 Android 中你还有几个不同选择。
|
||||
|
||||
#### 其他功能
|
||||
|
||||
![][13]
|
||||
|
||||
当你探索这个工具时,你会注意到可以同步的文件夹数和可同步的设备数没有限制。
|
||||
|
||||
因此,作为一个有着丰富有用特性的自由开源解决方案,对于在寻找 P2P 同步客户端的 Linux 用户而言是一个令人印象深刻的选择。
|
||||
|
||||
### 在 Linux 上安装 Syncthing
|
||||
|
||||
你可能无法在官网上找到 .deb 或者 .AppImage 文件。但是,你可在 [Snap 商店][14]中找到 snap 包。如果你好奇,你可以阅读在 Linux 上[使用 snap 应用][15]的文章来开始使用。
|
||||
|
||||
你可能无法在软件中心找到它(如果你找到了,那它可能不是最新版本)。
|
||||
|
||||
**注意:**如果你需要一个 GUI 应用而不是浏览器来管理它,它还有一个 [Syncthing-GTK][16]。
|
||||
|
||||
- [Syncthing][2]
|
||||
|
||||
如果你有基于 Debian 的发行版,你也可以利用终端来安装它,这些说明位于[官方下载页面][17]上。
|
||||
|
||||
### 我在 Syncthing 方面的体验
|
||||
|
||||
就个人而言,我把它安装在 Pop!_OS 19.10 上,并在写这篇文章之前用了一会儿。
|
||||
|
||||
我尝试同步文件夹、删除它们、添加重复文件以查看文件版本控制是否工作,等等。它工作良好。
|
||||
|
||||
然而,当我尝试同步它到手机(安卓),同步启动有点晚,它不是很快。因此,如果我们可以选择显式强制同步,那会有所帮助。或者,我错过了什么选项吗?如果是的话,请在评论中让我知道。
|
||||
|
||||
从技术上讲,它使用系统资源来工作,因此,如果你连接了多个设备进行同步,这可能会提高同步速度(上传/下载)。
|
||||
|
||||
总体而言,它工作良好,但我必须说,你不应该依赖它作为唯一的数据备份方案。
|
||||
|
||||
### 总结
|
||||
|
||||
你试过 Syncthing 了吗?如果有的话,你的体验如何?欢迎在下面的评论中分享。
|
||||
|
||||
此外,如果你知道一些不错的替代品,也请让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/syncthing/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/install-mega-cloud-storage-linux/
|
||||
[2]: https://syncthing.net/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/syncthing-screenshot.jpg?ssl=1
|
||||
[4]: https://en.wikipedia.org/wiki/Peer-to-peer
|
||||
[5]: https://itsfoss.com/cloud-services-linux/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/01/syncthing-gtk.png?ssl=1
|
||||
[7]: https://docs.syncthing.net/users/faq.html
|
||||
[8]: https://docs.syncthing.net/users/index.html
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/syncthing-android.jpg?ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/syncthing-file-versioning.jpg?ssl=1
|
||||
[11]: https://docs.syncthing.net/users/versioning.html
|
||||
[12]: https://play.google.com/store/apps/details?id=org.torproject.android&hl=en_IN
|
||||
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/syncthing-screenshot1.jpg?ssl=1
|
||||
[14]: https://snapcraft.io/syncthing
|
||||
[15]: https://itsfoss.com/install-snap-linux/
|
||||
[16]: https://github.com/syncthing/syncthing-gtk/releases/latest
|
||||
[17]: https://syncthing.net/downloads/
|
||||
@ -1,63 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11964-1.html)
|
||||
[#]: subject: (Build your own cloud with Fedora 31 and Nextcloud Server)
|
||||
[#]: via: (https://fedoramagazine.org/build-your-own-cloud-with-fedora-31-and-nextcloud-server/)
|
||||
[#]: author: (storyteller https://fedoramagazine.org/author/storyteller/)
|
||||
|
||||
Build your own cloud with Fedora 31 and Nextcloud Server
|
||||
使用 Fedora 31 和 Nextcloud 服务器构建自己的云
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[Nextcloud][2] is a software suite for storing and syncing your data across multiple devices. You can learn more about Nextcloud Server’s features from [https://github.com/nextcloud/server][3].
|
||||
[Nextcloud][2] 是用于跨多个设备存储和同步数据的软件套件。你可以从 [https://github.com/nextcloud/server][3] 了解有关 Nextcloud 服务器的更多特性信息。
|
||||
|
||||
This article demonstrates how to build a personal cloud using Fedora and Nextcloud in a few simple steps. For this tutorial you will need a dedicated computer or a virtual machine running Fedora 31 server edition and an internet connection.
|
||||
本文通过几个简单的步骤演示了如何使用 Fedora 和 Nextcloud 构建个人云。对于本教程,你将需要一台独立计算机或运行 Fedora 31 服务器版的虚拟机,还需要互联网连接。
|
||||
|
||||
### Step 1: Install the prerequisites
|
||||
### 步骤 1:预先安装条件
|
||||
|
||||
Before installing and configuring Nextcloud, a few prerequisites must be satisfied.
|
||||
在安装和配置 Nextcloud 之前,必须满足一些预先条件。
|
||||
|
||||
First, install Apache web server:
|
||||
首先,安装 Apache Web 服务器:
|
||||
|
||||
```
|
||||
# dnf install httpd
|
||||
```
|
||||
|
||||
Next, install PHP and some additional modules. Make sure that the PHP version being installed meets [Nextcloud’s requirements][4]:
|
||||
接下来,安装 PHP 和一些其他模块。确保所安装的 PHP 版本符合 [Nextcloud 的要求][4]:
|
||||
|
||||
```
|
||||
# dnf install php php-gd php-mbstring php-intl php-pecl-apcu php-mysqlnd php-pecl-redis php-opcache php-imagick php-zip php-process
|
||||
```
|
||||
|
||||
After PHP is installed enable and start the Apache web server:
|
||||
安装 PHP 后,启用并启动 Apache Web 服务器:
|
||||
|
||||
```
|
||||
# systemctl enable --now httpd
|
||||
```
|
||||
|
||||
Next, allow _HTTP_ traffic through the firewall:
|
||||
接下来,允许 HTTP 流量穿过防火墙:
|
||||
|
||||
```
|
||||
# firewall-cmd --permanent --add-service=http
|
||||
# firewall-cmd --reload
|
||||
```
|
||||
|
||||
Next, install the MariaDB server and client:
|
||||
接下来,安装 MariaDB 服务器和客户端:
|
||||
|
||||
```
|
||||
# dnf install mariadb mariadb-server
|
||||
```
|
||||
|
||||
Then enable and start the MariaDB server:
|
||||
然后启用并启动 MariaDB 服务器
|
||||
|
||||
```
|
||||
# systemctl enable --now mariadb
|
||||
```
|
||||
|
||||
Now that MariaDB is running on your server, you can run the _mysql_secure_installation_ command to secure it:
|
||||
现在,MariaDB 正在运行,你可以运行 `mysql_secure_installation` 命令来保护它:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
@ -128,7 +128,7 @@ MariaDB installation should now be secure.
|
||||
Thanks for using MariaDB!
|
||||
```
|
||||
|
||||
Next, create a dedicated user and database for your Nextcloud instance:
|
||||
接下来,为你的 Nextcloud 实例创建独立的用户和数据库:
|
||||
|
||||
```
|
||||
# mysql -p
|
||||
@ -139,23 +139,23 @@ Next, create a dedicated user and database for your Nextcloud instance:
|
||||
> exit;
|
||||
```
|
||||
|
||||
### Step 2: Install Nextcloud Server
|
||||
### 步骤 2:安装 Nextcloud 服务器
|
||||
|
||||
Now that the prerequisites for your Nextcloud installation have been satisfied, download and unzip [the Nextcloud archive][5]:
|
||||
现在,你已满足 Nextcloud 安装的预先条件,请下载并解压 [Nextcloud 压缩包][5]:
|
||||
|
||||
```
|
||||
# wget https://download.nextcloud.com/server/releases/nextcloud-17.0.2.zip
|
||||
# unzip nextcloud-17.0.2.zip -d /var/www/html/
|
||||
```
|
||||
|
||||
Next, create a data folder and grant Apache read and write access to the _nextcloud_ directory tree:
|
||||
接下来,创建一个数据文件夹,并授予 Apache 对 `nextcloud` 目录树的读写访问权限:
|
||||
|
||||
```
|
||||
# mkdir /var/www/html/nextcloud/data
|
||||
# chown -R apache:apache /var/www/html/nextcloud
|
||||
```
|
||||
|
||||
SELinux must be configured to work with Nextcloud. The basic commands are those bellow, but a lot more, by features used on nexcloud installation, are posted here: [Nextcloud SELinux configuration][6]
|
||||
SELinux 必须配置为可与 Nextcloud 一起使用。基本命令如下所示,但在 nexcloud 安装中还有很多其他的命令,发布在这里:[Nextcloud SELinux 配置][6]。
|
||||
|
||||
```
|
||||
# semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/nextcloud/config(/.*)?'
|
||||
@ -166,34 +166,32 @@ SELinux must be configured to work with Nextcloud. The basic commands are those
|
||||
# restorecon -Rv '/var/www/html/nextcloud/'
|
||||
```
|
||||
|
||||
### Step 3: Configure N**extclou**d
|
||||
### 步骤 3:配置 Nextcloud
|
||||
|
||||
Nextcloud can be configured using its web interface or from the command line.
|
||||
可以使用它的 Web 界面或在命令行配置 Nextcloud。
|
||||
|
||||
#### Using the web interface
|
||||
#### 使用 Web 界面
|
||||
|
||||
From your favorite browser, access _<http://your\_server\_ip/nextcloud>_ and fill the fields:
|
||||
在你喜欢的浏览器中,访问 <http://your\_server\_ip/nextcloud> 并输入字段:
|
||||
|
||||
![][7]
|
||||
|
||||
#### Using the command line
|
||||
#### 使用命令行
|
||||
|
||||
From the command line, just enter the following, substituting the values you used when you created a dedicated Nextcloud user in MariaDB earlier:
|
||||
在命令行中,只需输入以下内容,使用你之前在 MariaDB 中创建的独立 Nextcloud 用户替换相应的值:
|
||||
|
||||
```
|
||||
# sudo -u apache php occ maintenance:install --data-dir /var/www/html/nextcloud/data/ --database "mysql" --database-name "nextcloud" --database-user "nc_admin" --database-pass "DB_SeCuRe_PaSsWoRd" --admin-user "admin" --admin-pass "Admin_SeCuRe_PaSsWoRd"
|
||||
```
|
||||
|
||||
### Final Notes
|
||||
### 最后几点
|
||||
|
||||
* I used the _http_ protocol, but Nextcloud also works over _https_. I might write a follow-up about securing Nextcloud in a future article.
|
||||
* I disabled SELinux, but your server will be more secure if you configure it.
|
||||
* The recommend PHP memory limit for Nextcloud is 512M. To change it, edit the _memory_limit_ variable in the _/etc/php.ini_ configuration file and restart your _httpd_ service.
|
||||
* By default, the web interface can only be accessed using the _<http://localhost/>_ URL. If you want to allow access using other domain names, [you can do so by editing the _/var/www/html/nextcloud/config/config.php_ file][8]. The * character can be used to bypass the domain name restriction and allow the use of any URL that resolves to one of your server’s IP addresses.
|
||||
* 我使用的是 http 协议,但是 Nextcloud 也可以在 https 上运行。我可能会在以后的文章中写一篇有关保护 Nextcloud 的文章。
|
||||
* 我禁用了 SELinux,但是如果配置它,你的服务器将更加安全。
|
||||
* Nextcloud 的建议 PHP 内存限制为 512M。要更改它,请编辑 `/etc/php.ini` 配置文件中的 `memory_limit` 变量,然后重新启动 httpd 服务。
|
||||
* 默认情况下,只能使用 <http://localhost/> URL 访问 Web 界面。如果要允许使用其他域名访问,[你可编辑 /var/www/html/nextcloud/config/config.php 来进行此操作][8]。`*` 字符可用于绕过域名限制,并允许任何解析为服务器 IP 的 URL 访问。
|
||||
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
'trusted_domains' =>
|
||||
array (
|
||||
0 => 'localhost',
|
||||
@ -201,16 +199,14 @@ From the command line, just enter the following, substituting the values you use
|
||||
),
|
||||
```
|
||||
|
||||
_— Updated on January 28th, 2020 to include SELinux configuration —_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/build-your-own-cloud-with-fedora-31-and-nextcloud-server/
|
||||
|
||||
作者:[storyteller][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,163 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11956-1.html)
|
||||
[#]: subject: (Use Emacs to get social and track your todo list)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-social-track-todo-list)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Emacs 进行社交并跟踪你的待办事项列表
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十九篇文章中,访问 Twitter、Reddit、 交谈、电子邮件 、RSS 和你的待办事项列表。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 使用 Emacs 做(几乎)所有的事情,第 2 部分
|
||||
|
||||
[昨天][2],我谈到了如何在 Emacs 中读取电子邮件、访问电子邮件地址和显示日历。Emacs 功能繁多,你还可以将它用于 Twitter、交谈、待办事项列表等等!
|
||||
|
||||
![在 Emacs 中处理所有事情][3]
|
||||
|
||||
要完成所有这些,你需要安装一些 Emacs 包。和昨天一样,用 `Meta+x package-manager` 打开 Emacs 包管理器(Meta 键在大多数键盘上是 `Alt`,在 MacOS 上是 `Option`)。然后通过 `i` 选择以下带有的软件包,然后输入 `x` 进行安装:
|
||||
|
||||
```
|
||||
nnreddit
|
||||
todotxt
|
||||
twittering-mode
|
||||
```
|
||||
|
||||
安装之后,按下 `Ctrl+x ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(custom-set-variables` 行前加上:
|
||||
|
||||
```
|
||||
;; Todo.txt
|
||||
(require 'todotxt)
|
||||
(setq todotxt-file (expand-file-name "~/.todo/todo.txt"))
|
||||
|
||||
;; Twitter
|
||||
(require 'twittering-mode)
|
||||
(setq twittering-use-master-password t)
|
||||
(setq twittering-icon-mode t)
|
||||
|
||||
;; Python3 for nnreddit
|
||||
(setq elpy-rpc-python-command "python3")
|
||||
```
|
||||
|
||||
按下 `Ctrl+x Ctrl+s` 保存文件,使用 `Ctrl+x Ctrl+c` 退出 Emacs,然后重启 Emacs。
|
||||
|
||||
#### 使用 twittering-mode 在 Emacs 中发推
|
||||
|
||||
![Emacs 中的 Twitter][4]
|
||||
|
||||
[Twittering-mode][5] 是 Twitter 最好的 Emacs 接口之一。它几乎支持 Twitter 的所有功能,并且键盘快捷键也易于使用。
|
||||
|
||||
首先,输入 `Meta+x twit` 来启动 twittering-mode。它会提供一个 URL 并提示你启动浏览器来访问它,你登录该 URL 后就能获得授权令牌。将令牌复制并粘贴到 Emacs 中,你的 Twitter 时间线就会加载了。你可以使用箭头键滚动,使用 `Tab` 从一个项目移动到另一个项目,并按回车访问光标所在的 URL。如果光标在用户名上,按回车将在 web 浏览器中打开时间轴。如果你在一条推文的文本上,按回车将回复该推文。你可以用 `u` 创建一个新的推文,用 `Ctrl+c+Enter` 转发一些内容,然后用 `d` 发送一条即时消息——它打开的对话框中有关于如何发送、取消和缩短 URL 的说明。
|
||||
|
||||
按 `V` 会打开一个提示让你跳转到其他时间线。输入 `:mentions` 打开你的提及。输入 `:home` 打开你的主时间线,输入用户名将进入该用户的时间线。最后,按 `q` 会退出 twittering-mode 并关闭窗口。
|
||||
|
||||
twitter-mode 还有更多功能,我鼓励你阅读它 GitHub 页面上的[完整功能列表][6]。
|
||||
|
||||
#### 在 Emacs 上使用 Todotxt.el 追踪你的待办事项
|
||||
|
||||
![Emacs 中的 todo.txt][7]
|
||||
|
||||
[Todotxt.el][8] 是一个很棒的 [todo.txt][9] 待办列表管理器接口。它的快捷键几乎无所不包。
|
||||
|
||||
输入 `Meta+x todotxt` 启动它将加载 `todotxt-file` 变量中指定的 `todo.txt` 文件(本文的第一部分中设置了该文件)。在 `todo.txt` 的缓冲区(窗口),你可以按 `a` 添加新任务并和按 `c` 标记它已被完成。你还可以使用 `r` 设置优先级,并使用 `t` 添加项目和上下文。完成事项后只需要按下 `A` 即可将任务移如 `done.txt`。你可以使用 `/` 过滤列表,也可以使用 `l` 刷新完整列表。同样,你可以按 `q` 退出。
|
||||
|
||||
#### 在 Emacs 中使用 ERC 进行交谈
|
||||
|
||||
![使用 ERC 与人交谈 ][10]
|
||||
|
||||
Vim 的缺点之一是很难用它与人交谈。另一方面,Emacs 则将 [ERC][11] 客户端内置到默认发行版中。使用 `Meta+x ERC` 启动 ERC,系统将提示你输入服务器、用户名和密码。你可以使用几天前介绍设置 [BitlBee][12] 时使用的相同信息:服务器为 `localhost`,端口为 `6667`,相同用户名,无需密码。
|
||||
|
||||
ERC 使用起来与其他 IRC 客户端一样。每个频道单独一个缓冲区(窗口),你可以使用 `Ctrl+x ctrl+b` 进行频道间切换,这也可以在 Emacs 中的其他缓冲区之间进行切换。`/quit` 命令将退出 ERC。
|
||||
|
||||
#### 使用 Gnus 阅读电子邮件,Reddit 和 RSS
|
||||
|
||||
![Mail,Reddit,and RSS feeds with Gnus][13]
|
||||
|
||||
我相信昨天在我提及在 Emacs 中阅读邮件时,许多 Emacs 的老用户会问,“怎么没有 [Gnus][14] 呢?”
|
||||
|
||||
这个疑问很合理。Gnus 是一个内置在 Emacs 中的邮件和新闻阅读器,尽管它这个邮件阅读器不支持以 [Notmuch][15] 作为搜索引擎。但是,如果你将其配置来阅读 Reddit 和 RSS feed(稍后你将这样做),那么同时使用它来阅读邮件是个聪明的选择。
|
||||
|
||||
Gnus 是为阅读 Usenet 新闻而创建的,并从此发展而来。因此,它的很多外观和感觉(以及术语)看起来很像 Usenet 的新闻阅读器。
|
||||
|
||||
Gnus 以 `~/.gnus` 作为自己的配置文件。(该配置也可以包含在 `~/.emacs.d/init.el` 中)。使用 `Ctrl+x Ctrl+f` 打开 `~/.gnus`,并添加以下内容:
|
||||
|
||||
|
||||
```
|
||||
;; Required packages
|
||||
(require 'nnir)
|
||||
(require 'nnrss)
|
||||
|
||||
;; Primary Mailbox
|
||||
(setq gnus-select-method
|
||||
'(nnmaildir "Local"
|
||||
(directory "~/Maildir")
|
||||
(nnir-search-engine notmuch)
|
||||
))
|
||||
(add-to-list 'gnus-secondary-select-methods
|
||||
'(nnreddit ""))
|
||||
```
|
||||
|
||||
用 `Ctrl+x Ctrl+s` 保存文件。这分配置告诉 Gnus 从 `~/Maildir` 这个本地邮箱中读取邮件作为主源(参见 `gnus-select-method` 变量),并使用 [nnreddit][16] 插件添加辅源(`gnus-secondary-select-methods` 变量)。你还可以定义多个辅助源,包括 Usenet 新闻(nntp)、IMAP (nnimap)、mbox(nnmbox)和虚拟集合(nnvirtual)。你可以在 [Gnus 手册][17] 中了解更多有关所有选项的信息。
|
||||
|
||||
保存文件后,使用 `Meta+x Gnus` 启动 Gnus。第一次运行将在 Python 虚拟环境中安装 [Reddit 终端查看器][18],Gnus 通过它获取 Reddit 上的文章。然后它会启动浏览器来登录 Reddit。之后,它会扫描并加载你订阅的 Reddit 群组。你会看到一个有新邮件的邮件夹列表和一个有新内容的看板列表。在任一列表上按回车将加载该组中的消息列表。你可以使用箭头键导航并按回车加载和读取消息。在查看消息列表时,按 `q` 将返回到前一个视图,从主窗口按 `q` 将退出 Gnus。在阅读 Reddit 群组时,`a` 会创建一条新消息;在邮件组中,`m` 创建一个新的电子邮件;并且在任何一个视图中按 `r` 回复邮件。
|
||||
|
||||
你还可以向 Gnus 接口中添加 RSS 流,并像阅读邮件和新闻组一样阅读它们。要添加 RSS 流,输入 `G+R` 并填写 RSS 流的 URL。会有提示让你输入 RSS 的标题和描述,这些信息可以从流中提取出来并填充进去。现在输入 `g` 来检查新消息(这将检查所有组中的新消息)。阅读 RSS 流 就像阅读 Reddit 群组和邮件一样,它们使用相同的快捷键。
|
||||
|
||||
Gnus 中有*很多*功能,还有大量的键组合。[Gnus 参考卡][19]为每个视图列出了所有这些键组合(以非常小的字体显示在 5 页纸上)。
|
||||
|
||||
#### 使用 nyan-mode 查看位置
|
||||
|
||||
最后,你可能会一些截屏底部注意到 [Nyan cat][20]。这是 [nyan-mode][21],它指示了你在缓冲区中的位置,因此当你接近文档或缓冲区的底部时,它会变长。你可以使用包管理器安装它,并在 `~/.emacs.d/init.el` 中使用以下代码进行设置:
|
||||
|
||||
```
|
||||
;; Nyan Cat
|
||||
(setq nyan-wavy-trail t)
|
||||
(setq nyan-bar-length 20)
|
||||
(nyan-mode)
|
||||
```
|
||||
|
||||
### Emacs 的基本功能
|
||||
|
||||
这只是 Emacs 所有功能的皮毛。Emacs *非常*强大,是我用来提高工作效率的必要工具之一,无论我是在追踪待办事项、阅读和回复邮件、编辑文本,还是与朋友和同事交流我都用它。这需要一点时间来适应,但是一旦你习惯了,它就会成为你桌面上最有用的工具之一。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-social-track-todo-list
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://linux.cn/article-11932-1.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_19-1.png (All the things with Emacs)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/productivity_19-2.png (Twitter in Emacs)
|
||||
[5]: https://github.com/hayamiz/twittering-mode
|
||||
[6]: https://github.com/hayamiz/twittering-mode#features
|
||||
[7]: https://opensource.com/sites/default/files/uploads/productivity_19-3.png (todo.txt in emacs)
|
||||
[8]: https://github.com/rpdillon/todotxt.el
|
||||
[9]: http://todotxt.org/
|
||||
[10]: https://opensource.com/sites/default/files/uploads/productivity_19-4.png (Chatting with erc)
|
||||
[11]: https://www.gnu.org/software/emacs/manual/html_mono/erc.html
|
||||
[12]: https://linux.cn/article-11856-1.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_19-5.png (Mail, Reddit, and RSS feeds with Gnus)
|
||||
[14]: https://www.gnus.org/
|
||||
[15]: https://linux.cn/article-11807-1.html
|
||||
[16]: https://github.com/dickmao/nnreddit
|
||||
[17]: https://www.gnus.org/manual/gnus.html
|
||||
[18]: https://pypi.org/project/rtv/
|
||||
[19]: https://www.gnu.org/software/emacs/refcards/pdf/gnus-refcard.pdf
|
||||
[20]: http://www.nyan.cat/
|
||||
[21]: https://github.com/TeMPOraL/nyan-mode
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11961-1.html)
|
||||
[#]: subject: (4 open source productivity tools on my wishlist)
|
||||
[#]: via: (https://opensource.com/article/20/1/open-source-productivity-tools)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
我的愿望清单上的 4 种开源生产力工具
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的最后一篇文章中,了解开源世界还需要什么。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 然而…
|
||||
|
||||
在搜索生产力应用程序时,我找不到想要的所有应用,而且几乎总是会丢失一些读者与我分享的精彩内容。 因此,当我结束本系列文章时,是时候[再次][2]谈论我在本年度系列文章中未能涵盖的一些主题。
|
||||
|
||||
![Desktop with Joplin, Emacs, and Firefox][3]
|
||||
|
||||
#### 在 Vim 中聊天
|
||||
|
||||
我试过了。我真的非常、非常想能够在 Vim 中聊天,但我做不到。我找到的一个软件包 [VimIRC.vim][4] 一直就工作不起来,我试了几天也没用。我探索的另一个选项是 [Irc it][5],这需要我付出更多的[努力去设置][6],超过了我正常可以付出的耐心或时间。我尝试过了,也确实做到了,但对于同处于相同境地的 Vim 用户,对不起,我无法帮到你。
|
||||
|
||||
#### Org 模式
|
||||
|
||||
![Org Mode in Emacs][7]
|
||||
|
||||
我喜欢 [Org 模式][8],并且每天都使用它。关于 Org 模式我可以滔滔不绝的说上几天。它提供了基本的[任务跟踪][9];谷歌[日历][10]同步和 [CalFW][11] 集成;富文本文档、网站和演示文稿;链接到任何事物;等等、等等……
|
||||
|
||||
我希望你会在 2020 年从我这里收到更多有关 Org 模式的信息,因为它真的很酷。
|
||||
|
||||
#### 图形用户界面程序
|
||||
|
||||
在 2019 年的生产力系列中,我共享了很多图形用户界面程序,而今年几乎都是命令行应用程序。有一些很棒的图形程序可以帮助解决我今年谈论的一些问题,例如可以使用 Maildir 邮箱的[邮件][12]程序、用于读取本地日历文件的日历程序、[天气][13]应用程序等等。我甚至尝试了几项对我而言新奇的事物,看它们是否适合这个主题。除了 [twin][14] 之外,我没有感觉到有什么图形用户界面程序是新颖的(对我而言)或值得注意的(同样对我而言)是今年要写的。至于……
|
||||
|
||||
#### 移动应用程序
|
||||
|
||||
越来越多的人将平板电脑(有时与笔记本电脑结合使用)作为主要设备。我将手机用于大多数社交媒体和即时消息传递,并且经常使用平板电脑(好的,老实说,好几个平板电脑)来阅读或浏览网络。可以肯定的是,并不是没有开源移动应用程序,但是它们与我今年的主题不符。开源和移动应用程序正在发生很多变化,我正在仔细地寻找可以帮助我在手机和平板电脑上提高工作效率的事物。
|
||||
|
||||
### 该你了
|
||||
|
||||
非常感谢你阅读今年的系列文章。请你发表评论,告诉我错过的或需要在 2021 年看到的内容。正如我在 [Productivity Alchemy][15] 播客上所说:“哥们,记着:要保持生产力!”
|
||||
|
||||
### 本系列汇总
|
||||
|
||||
1. [使用 Syncthing 在多个设备间同步文件](https://linux.cn/article-11793-1.html)
|
||||
2. [使用 Stow 管理多台机器配置](https://linux.cn/article-11796-1.html)
|
||||
3. [使用 OfflineIMAP 同步邮件](https://linux.cn/article-11804-1.html)
|
||||
4. [使用 Notmuch 组织你的邮件](https://linux.cn/article-11807-1.html)
|
||||
5. [使用 khal 和 vdirsyncer 组织和同步你的日历](https://linux.cn/article-11812-1.html)
|
||||
6. [用于联系人管理的三个开源工具](https://linux.cn/article-11834-1.html)
|
||||
7. [开始使用开源待办事项清单管理器](https://linux.cn/article-11835-1.html)
|
||||
8. [使用这个 Python 程序记录你的活动](https://linux.cn/article-11846-1.html)
|
||||
9. [一个通过 IRC 管理所有聊天的开源聊天工具](https://linux.cn/article-11856-1.html)
|
||||
10. [使用这个 Twitter 客户端在 Linux 终端中发推特](https://linux.cn/article-11858-1.html)
|
||||
11. [在 Linux 终端中阅读 Reddit](https://linux.cn/article-11869-1.html)
|
||||
12. [使用此开源工具在一起收取你的 RSS 订阅源和播客](https://linux.cn/article-11876-1.html)
|
||||
13. [使用这个开源工具获取本地天气预报](https://linux.cn/article-11879-1.html)
|
||||
14. [使用此开源窗口环境一次运行多个控制台](https://linux.cn/article-11892-1.html)
|
||||
15. [使用 tmux 创建你的梦想主控台](https://linux.cn/article-11900-1.html)
|
||||
16. [使用 Vim 发送邮件和检查日历](https://linux.cn/article-11908-1.html)
|
||||
17. [使用 Vim 管理任务列表和访问 Reddit 和 Twitter](https://linux.cn/article-11912-1.html)
|
||||
18. [使用 Emacs 发送电子邮件和检查日历](https://linux.cn/article-11932-1.html)
|
||||
19. [使用 Emacs 进行社交并跟踪你的待办事项列表](https://linux.cn/article-11956-1.html)
|
||||
20. [我的愿望清单上的 4 种开源生产力工具](https://linux.cn/article-11961-1.html)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/open-source-productivity-tools
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/world_hands_diversity.png?itok=zm4EDxgE (Two diverse hands holding a globe)
|
||||
[2]: https://opensource.com/article/19/1/productivity-tool-wish-list
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_20-1.png (Desktop with Joplin, Emacs, and Firefox)
|
||||
[4]: https://github.com/vim-scripts/VimIRC.vim
|
||||
[5]: https://tools.suckless.org/ii/
|
||||
[6]: https://www.reddit.com/r/vim/comments/48t7ws/vim_ii_irc_client_xpost_runixporn/d0macnl/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/productivity_20-2.png (Org Mode in Emacs)
|
||||
[8]: https://orgmode.org/
|
||||
[9]: https://opensource.com/article/20/1/open-source-to-do-list
|
||||
[10]: https://opensource.com/article/20/1/open-source-calendar
|
||||
[11]: https://github.com/kiwanami/emacs-calfw
|
||||
[12]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[13]: https://opensource.com/article/20/1/open-source-weather-forecast
|
||||
[14]: https://github.com/cosmos72/twin
|
||||
[15]: https://productivityalchemy.com
|
||||
@ -0,0 +1,150 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11938-1.html)
|
||||
[#]: subject: (Some Advice for How to Make Emacs Tetris Harder)
|
||||
[#]: via: (https://nickdrozd.github.io/2019/01/14/tetris.html)
|
||||
[#]: author: (nickdrozd https://nickdrozd.github.io)
|
||||
|
||||
如何让 Emacs 俄罗斯方块变得更难
|
||||
======
|
||||
|
||||
你知道吗,Emacs 捆绑了一个俄罗斯方块的实现?只需要输入 `M-x tetris` 就行了。
|
||||
|
||||
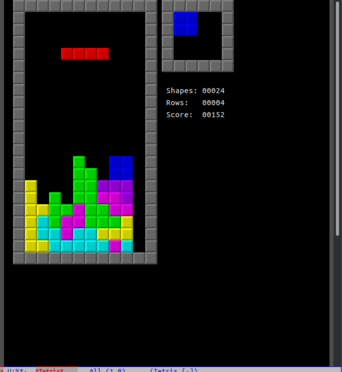
|
||||
|
||||
在对文本编辑器的讨论中,Emacs 鼓吹者经常提到这一点。“没错,但是你那个编辑器能运行俄罗斯方块吗?”我很好奇,这会让大家相信 Emacs 更优秀吗?比如,为什么有人会关心他们是否可以在文本编辑器中玩游戏呢?“没错,但是你那台吸尘器能播放 mp3 吗?”
|
||||
|
||||
有人说,俄罗斯方块总是很有趣的。像 Emacs 中的所有东西一样,它的源代码是开放的,易于检查和修改,因此 **我们可以使它变得更加有趣**。所谓更加有趣,我的意思是更难。
|
||||
|
||||
让游戏变得更难的一个最简单的方法就是“隐藏下一个块预览”。你无法在知道下一个块会填满空间的情况下有意地将 S/Z 块放在一个危险的位置——你必须碰碰运气,希望出现最好的情况。下面是没有预览的情况(如你所见,没有预览,我做出的某些选择带来了“可怕的后果”):
|
||||
|
||||
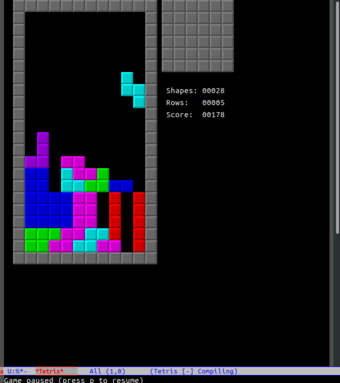
|
||||
|
||||
预览框由一个名为 `tetris-draw-next-shape` [^1] 的函数设置:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(dotimes (x 4)
|
||||
(dotimes (y 4)
|
||||
(gamegrid-set-cell (+ tetris-next-x x)
|
||||
(+ tetris-next-y y)
|
||||
tetris-blank)))
|
||||
(dotimes (i 4)
|
||||
(let ((tetris-shape tetris-next-shape)
|
||||
(tetris-rot 0))
|
||||
(gamegrid-set-cell (+ tetris-next-x
|
||||
(aref (tetris-get-shape-cell i) 0))
|
||||
(+ tetris-next-y
|
||||
(aref (tetris-get-shape-cell i) 1))
|
||||
tetris-shape))))
|
||||
```
|
||||
|
||||
首先,我们引入一个标志,决定是否允许显示下一个预览块 [^2]:
|
||||
|
||||
```
|
||||
(defvar tetris-preview-next-shape nil
|
||||
"When non-nil, show the next block the preview box.")
|
||||
```
|
||||
|
||||
现在的问题是,我们如何才能让 `tetris-draw-next-shape` 遵从这个标志?最明显的方法是重新定义它:
|
||||
|
||||
```
|
||||
(defun tetris-draw-next-shape ()
|
||||
(when tetris-preview-next-shape
|
||||
;; existing tetris-draw-next-shape logic
|
||||
))
|
||||
```
|
||||
|
||||
但这不是理想的解决方案。同一个函数有两个定义,这很容易引起混淆,如果上游版本发生变化,我们必须维护修改后的定义。
|
||||
|
||||
一个更好的方法是使用 **advice**。Emacs 的 advice 类似于 **Python 装饰器**,但是更加灵活,因为 advice 可以从任何地方添加到函数中。这意味着我们可以修改函数而不影响原始的源文件。
|
||||
|
||||
有很多不同的方法使用 Emacs advice([查看手册][4]),但是这里我们只使用 `advice-add` 函数和 `:around` 标志。advice 函数将原始函数作为参数,原始函数可能执行也可能不执行。我们这里,我们让原始函数只有在预览标志是非空的情况下才能执行:
|
||||
|
||||
```
|
||||
(defun tetris-maybe-draw-next-shape (tetris-draw-next-shape)
|
||||
(when tetris-preview-next-shape
|
||||
(funcall tetris-draw-next-shape)))
|
||||
|
||||
(advice-add 'tetris-draw-next-shape :around #'tetris-maybe-draw-next-shape)
|
||||
```
|
||||
|
||||
这段代码将修改 `tetris-draw-next-shape` 的行为,而且它可以存储在配置文件中,与实际的俄罗斯方块代码分离。
|
||||
|
||||
去掉预览框是一个简单的改变。一个更激烈的变化是,**让块随机停止在空中**:
|
||||
|
||||
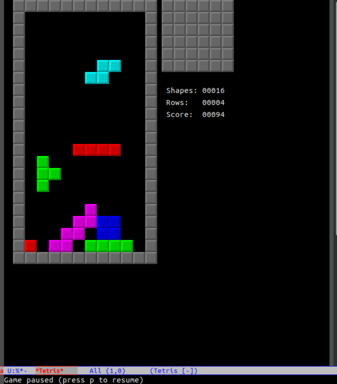
|
||||
|
||||
本图中,红色的 I 和绿色的 T 部分没有掉下来,它们被固定下来了。这会让游戏变得 **极其困难**,但却很容易实现。
|
||||
|
||||
和前面一样,我们首先定义一个标志:
|
||||
|
||||
```
|
||||
(defvar tetris-stop-midair t
|
||||
"If non-nil, pieces will sometimes stop in the air.")
|
||||
```
|
||||
|
||||
目前,**Emacs 俄罗斯方块的工作方式** 类似这样子:活动部件有 x 和 y 坐标。在每个时钟滴答声中,y 坐标递增(块向下移动一行),然后检查是否有与现存的块重叠。如果检测到重叠,则将该块回退(其 y 坐标递减)并设置该活动块到位。为了让一个块在半空中停下来,我们所要做的就是破解检测函数 `tetris-test-shape`。
|
||||
|
||||
**这个函数内部做什么并不重要** —— 重要的是它是一个返回布尔值的无参数函数。我们需要它在正常情况下返回布尔值 true(否则我们将出现奇怪的重叠情况),但在其他时候也需要它返回 true。我相信有很多方法可以做到这一点,以下是我的方法的:
|
||||
|
||||
```
|
||||
(defun tetris-test-shape-random (tetris-test-shape)
|
||||
(or (and
|
||||
tetris-stop-midair
|
||||
;; Don't stop on the first shape.
|
||||
(< 1 tetris-n-shapes )
|
||||
;; Stop every INTERVAL pieces.
|
||||
(let ((interval 7))
|
||||
(zerop (mod tetris-n-shapes interval)))
|
||||
;; Don't stop too early (it makes the game unplayable).
|
||||
(let ((upper-limit 8))
|
||||
(< upper-limit tetris-pos-y))
|
||||
;; Don't stop at the same place every time.
|
||||
(zerop (mod (random 7) 10)))
|
||||
(funcall tetris-test-shape)))
|
||||
|
||||
(advice-add 'tetris-test-shape :around #'tetris-test-shape-random)
|
||||
```
|
||||
|
||||
这里的硬编码参数使游戏变得更困难,但仍然可玩。当时我在飞机上喝醉了,所以它们可能需要进一步调整。
|
||||
|
||||
顺便说一下,根据我的 `tetris-scores` 文件,我的 **最高分** 是:
|
||||
|
||||
```
|
||||
01389 Wed Dec 5 15:32:19 2018
|
||||
```
|
||||
|
||||
该文件中列出的分数默认最多为五位数,因此这个分数看起来不是很好。
|
||||
|
||||
### 给读者的练习
|
||||
|
||||
1. 使用 advice 修改 Emacs 俄罗斯方块,使得每当方块下移动时就闪烁显示讯息 “OH SHIT”。消息的大小与块堆的高度成比例(当没有块时,消息应该很小的或不存在的,当最高块接近天花板时,消息应该很大)。
|
||||
2. 在这里给出的 `tetris-test-shape-random` 版本中,每隔七格就有一个半空中停止。一个玩家有可能能计算出时间间隔,并利用它来获得优势。修改它,使间隔随机在一些合理的范围内(例如,每 5 到 10 格)。
|
||||
3. 另一个对使用 Tetris 使用 advise 的场景,你可以试试 [autotetris-mode][1]。
|
||||
4. 想出一个有趣的方法来打乱块的旋转机制,然后使用 advice 来实现它。
|
||||
|
||||
[^1]: Emacs 只有一个巨大的全局命名空间,因此函数和变量名一般以包名做前缀以避免冲突。
|
||||
[^2]: 很多人会说你不应该使用已有的命名空间前缀而且应该将自己定义的所有东西都放在一个预留的命名空间中,比如像这样 `my/tetris-preview-next-shape`,然而这样很难看而且没什么意义,因此我不会这么干。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nickdrozd.github.io/2019/01/14/tetris.html
|
||||
|
||||
作者:[nickdrozd][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nickdrozd.github.io
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nullprogram.com/blog/2014/10/19/
|
||||
[2]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.1
|
||||
[3]: https://nickdrozd.github.io/2019/01/14/tetris.html#fn.2
|
||||
[4]: https://www.gnu.org/software/emacs/manual/html_node/elisp/Advising-Functions.html
|
||||
[5]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.1
|
||||
[6]: https://nickdrozd.github.io/2019/01/14/tetris.html#fnr.2
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11913-1.html)
|
||||
[#]: subject: (Zipping files on Linux: the many variations and how to use them)
|
||||
[#]: via: (https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
> 除了压缩和解压缩文件外,你还可以使用 zip 命令执行许多有趣的操作。这是一些其他的 zip 选项以及它们如何提供帮助。
|
||||
|
||||

|
||||

|
||||
|
||||
为了节省一些磁盘空间并将文件打包在一起进行归档,我们中的一些人已经在 Unix 和 Linux 系统上压缩文件数十年了。即使这样,并不是所有人都尝试过一些有趣的压缩工具的变体。因此,在本文中,我们将介绍标准的压缩和解压缩以及其他一些有趣的压缩选项。
|
||||
|
||||
### 基本的 zip 命令
|
||||
|
||||
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会留下一个压缩文件,而不是原始文件。 这是工作中的 `gzip` 示例:
|
||||
首先,让我们看一下基本的 `zip` 命令。它使用了与 `gzip` 基本上相同的压缩算法,但是有一些重要的区别。一方面,`gzip` 命令仅用于压缩单个文件,而 `zip` 既可以压缩文件,也可以将多个文件结合在一起成为归档文件。另外,`gzip` 命令是“就地”压缩。换句话说,它会只留下一个压缩文件,而原始文件则没有了。 这是工作中的 `gzip` 示例:
|
||||
|
||||
```
|
||||
$ gzip onefile
|
||||
@ -26,7 +26,7 @@ $ ls -l
|
||||
-rw-rw-r-- 1 shs shs 10514 Jan 15 13:13 onefile.gz
|
||||
```
|
||||
|
||||
而这是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
|
||||
而下面是 `zip`。请注意,此命令要求为压缩存档提供名称,其中 `gzip`(执行压缩操作后)仅使用原始文件名并添加 `.gz` 扩展名。
|
||||
|
||||
```
|
||||
$ zip twofiles.zip file*
|
||||
@ -61,7 +61,7 @@ $ zip mybin.zip ~/bin/*
|
||||
|
||||
### unzip 命令
|
||||
|
||||
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的`gunzip` 命令将仅保留未压缩的文件。
|
||||
`unzip` 命令将从一个 zip 文件中恢复内容,并且,如你所料,原来的 zip 文件还保留在那里,而类似的 `gunzip` 命令将仅保留未压缩的文件。
|
||||
|
||||
```
|
||||
$ unzip twofiles.zip
|
||||
@ -272,13 +272,13 @@ $ zipnote twofiles.zip
|
||||
@ (zip file comment below this line)
|
||||
```
|
||||
|
||||
如果要添加注释,请先将 `zipnote` 命令的输出写入文件:
|
||||
如果要添加注释,请先将 `zipnote` 命令的输出写入到文件:
|
||||
|
||||
```
|
||||
$ zipnote twofiles.zip > comments
|
||||
```
|
||||
|
||||
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的`zipnote` 命令添加注释:
|
||||
接下来,编辑你刚刚创建的文件,将注释插入到 `(comment above this line)` 行上方。然后使用像这样的 `zipnote` 命令添加注释:
|
||||
|
||||
```
|
||||
$ zipnote -w twofiles.zip < comments
|
||||
@ -286,7 +286,7 @@ $ zipnote -w twofiles.zip < comments
|
||||
|
||||
### zipsplit 命令
|
||||
|
||||
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的包含文件。
|
||||
当归档文件太大时,可以使用 `zipsplit` 命令将一个 zip 归档文件分解为多个 zip 归档文件,这样你就可以将其中某一个文件放到小型 U 盘中。最简单的方法似乎是为每个部分的压缩文件指定最大大小,此大小必须足够大以容纳最大的所包含的文件。
|
||||
|
||||
```
|
||||
$ zipsplit -n 12000 twofiles.zip
|
||||
@ -312,7 +312,7 @@ via: https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-t
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhangxiangping)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11927-1.html)
|
||||
[#]: subject: (12 open source tools for natural language processing)
|
||||
[#]: via: (https://opensource.com/article/19/3/natural-language-processing-tools)
|
||||
[#]: author: (Dan Barker https://opensource.com/users/barkerd427)
|
||||
|
||||
12 种自然语言处理的开源工具
|
||||
======
|
||||
|
||||
> 让我们看看可以用在你自己的 NLP 应用中的十几个工具吧。
|
||||
|
||||

|
||||
|
||||
在过去的几年里,自然语言处理(NLP)推动了聊天机器人、语音助手、文本预测等这些渗透到我们的日常生活中的语音或文本应用程技术的发展。目前有着各种各样开源的 NLP 工具,所以我决定调查一下当前开源的 NLP 工具来帮助你制定开发下一个基于语音或文本的应用程序的计划。
|
||||
|
||||
尽管我并不熟悉所有工具,但我将从我所熟悉的编程语言出发来介绍这些工具(对于我不熟悉的语言,我无法找到大量的工具)。也就是说,出于各种原因,我排除了三种我熟悉的语言之外的工具。
|
||||
|
||||
R 语言可能是没有被包含在内的最重要的语言,因为我发现的大多数库都有一年多没有更新了。这并不一定意味着它们没有得到很好的维护,但我认为它们应该得到更多的更新,以便和同一领域的其他工具竞争。我还选择了最有可能用在生产场景中的语言和工具(而不是在学术界和研究中使用),而我主要是使用 R 作为研究和发现工具。
|
||||
|
||||
我也惊讶地发现 Scala 的很多库都没有更新了。我上次使用 Scala 已经过去了两年了,当时它非常流行。但是大多数库从那个时候就再没有更新过,或者只有少数一些有更新。
|
||||
|
||||
最后,我排除了 C++。 这主要是因为我上次使用 C++ 编写程序已经有很多年了,而我所工作的组织还没有将 C++ 用于 NLP 或任何数据科学方面的工作。
|
||||
|
||||
### Python 工具
|
||||
|
||||
#### 自然语言工具包(NLTK)
|
||||
|
||||
毋庸置疑,[自然语言工具包(NLTK)][2]是我调研过的所有工具中功能最完善的一个。它几乎实现了自然语言处理中多数功能组件,比如分类、令牌化、词干化、标注、分词和语义推理。每一个都有多种不同的实现方式,所以你可以选择具体的算法和方式。同时,它也支持不同的语言。然而,它以字符串的形式表示所有的数据,对于一些简单的数据结构来说可能很方便,但是如果要使用一些高级的功能来说就可能有点困难。它的使用文档有点复杂,但也有很多其他人编写的使用文档,比如[这本很棒的书][3]。和其他的工具比起来,这个工具库的运行速度有点慢。但总的来说,这个工具包非常不错,可以用于需要具体算法组合的实验、探索和实际应用当中。
|
||||
|
||||
#### SpaCy
|
||||
|
||||
[SpaCy][4] 可能是 NLTK 的主要竞争者。在大多数情况下都比 NLTK 的速度更快,但是 SpaCy 的每个自然语言处理的功能组件只有一个实现。SpaCy 把所有的东西都表示为一个对象而不是字符串,从而简化了应用构建接口。这也方便它与多种框架和数据科学工具的集成,使得你更容易理解你的文本数据。然而,SpaCy 不像 NLTK 那样支持多种语言。它确实接口简单,具有简化的选项集和完备的文档,以及用于语言处理和分析各种组件的多种神经网络模型。总的来说,对于需要在生产中表现出色且不需要特定算法的新应用程序,这是一个很不错的工具。
|
||||
|
||||
#### TextBlob
|
||||
|
||||
[TextBlob][5] 是 NLTK 的一个扩展库。你可以通过 TextBlob 用一种更简单的方式来使用 NLTK 的功能,TextBlob 也包括了 Pattern 库中的功能。如果你刚刚开始学习,这将会是一个不错的工具,可以用于对性能要求不太高的生产环境的应用。总体来说,TextBlob 适用于任何场景,但是对小型项目尤佳。
|
||||
|
||||
#### Textacy
|
||||
|
||||
这个工具是我用过的名字最好听的。先重读“ex”再带出“cy”,多读“[Textacy][6]”几次试试。它不仅仅是名字读起来好,同时它本身也是一个很不错的工具。它使用 SpaCy 作为它自然语言处理核心功能,但它在处理过程的前后做了很多工作。如果你想要使用 SpaCy,那么最好使用 Textacy,从而不用去编写额外的附加代码就可以处理不同种类的数据。
|
||||
|
||||
#### PyTorch-NLP
|
||||
|
||||
[PyTorch-NLP][7] 才出现短短的一年,但它已经有一个庞大的社区了。它适用于快速原型开发。当出现了最新的研究,或大公司或者研究人员推出了完成新奇的处理任务的其他工具时,比如图像转换,它就会被更新。总体来说,PyTorch 的目标用户是研究人员,但它也能用于原型开发,或使用最先进算法的初始生产载荷中。基于此基础上的创建的库也是值得研究的。
|
||||
|
||||
### Node.js 工具
|
||||
|
||||
#### Retext
|
||||
|
||||
[Retext][8] 是 [Unified 集合][9]的一部分。Unified 是一个接口,能够集成不同的工具和插件以便它们能够高效的工作。Retext 是 Unified 工具中使用的三种语法之一,另外的两个分别是用于 Markdown 的 Remark 和用于 HTML 的 Rehype。这是一个非常有趣的想法,我很高兴看到这个社区的发展。Retext 没有涉及很多的底层技术,更多的是使用插件去完成你在 NLP 任务中想要做的事情。拼写检查、字形修复、情绪检测和增强可读性都可以用简单的插件来完成。总体来说,如果你不想了解底层处理技术又想完成你的任务的话,这个工具和社区是一个不错的选择。
|
||||
|
||||
#### Compromise
|
||||
|
||||
[Compromise][10] 显然不是最复杂的工具,如果你正在找拥有最先进的算法和最完备的系统的话,它可能不适合你。然而,如果你想要一个性能好、功能广泛、还能在客户端运行的工具的话,Compromise 值得一试。总体来说,它的名字(“折中”)是准确的,因为作者更关注更具体功能的小软件包,而在功能性和准确性上有所折中,这些小软件包得益于用户对使用环境的理解。
|
||||
|
||||
#### Natural
|
||||
|
||||
[Natural][11] 包含了常规自然语言处理库所具有的大多数功能。它主要是处理英文文本,但也包括一些其它语言,它的社区也欢迎支持其它的语言。它能够进行令牌化、词干化、分类、语音处理、词频-逆文档频率计算(TF-IDF)、WordNet、字符相似度计算和一些变换。它和 NLTK 有的一比,因为它想要把所有东西都包含在一个包里头,但它更易于使用,而且不一定专注于研究。总的来说,这是一个非常完整的库,目前仍在活跃开发中,但可能需要对底层实现有更多的了解才能完全发挥效力。
|
||||
|
||||
#### Nlp.js
|
||||
|
||||
[Nlp.js][12] 建立在其他几个 NLP 库之上,包括 Franc 和 Brain.js。它为许多 NLP 组件提供了一个很好的接口,比如分类、情感分析、词干化、命名实体识别和自然语言生成。它也支持一些其它语言,在你处理英语之外的语言时能提供一些帮助。总之,它是一个不错的通用工具,并且提供了调用其他工具的简化接口。在你需要更强大或更灵活的工具之前,这个工具可能会在你的应用程序中用上很长一段时间。
|
||||
|
||||
### Java 工具
|
||||
|
||||
#### OpenNLP
|
||||
|
||||
[OpenNLP][13] 是由 Apache 基金会管理的,所以它可以很方便地集成到其他 Apache 项目中,比如 Apache Flink、Apache NiFi 和 Apache Spark。这是一个通用的 NLP 工具,包含了所有 NLP 组件中的通用功能,可以通过命令行或者以包的形式导入到应用中来使用它。它也支持很多种语言。OpenNLP 是一个很高效的工具,包含了很多特性,如果你用 Java 开发生产环境产品的话,它是个很好的选择。
|
||||
|
||||
#### Stanford CoreNLP
|
||||
|
||||
[Stanford CoreNLP][14] 是一个工具集,提供了统计 NLP、深度学习 NLP 和基于规则的 NLP 功能。这个工具也有许多其他编程语言的版本,所以可以脱离 Java 来使用。它是由高水平的研究机构创建的一个高效的工具,但在生产环境中可能不是最好的。此工具采用双许可证,具有可以用于商业目的的特定许可证。总之,在研究和实验中它是一个很棒的工具,但在生产系统中可能会带来一些额外的成本。比起 Java 版本来说,读者可能对它的 Python 版本更感兴趣。同样,在 Coursera 上最好的机器学习课程之一是斯坦福教授提供的,[点此][15]访问其他不错的资源。
|
||||
|
||||
#### CogCompNLP
|
||||
|
||||
[CogCompNLP][16] 由伊利诺斯大学开发的一个工具,它也有一个相似功能的 Python 版本。它可以用于处理文本,包括本地处理和远程处理,能够极大地缓解你本地设备的压力。它提供了很多处理功能,比如令牌化、词性标注、断句、命名实体标注、词型还原、依存分析和语义角色标注。它是一个很好的研究工具,你可以自己探索它的不同功能。我不确定它是否适合生产环境,但如果你使用 Java 的话,它值得一试。
|
||||
|
||||
* * *
|
||||
|
||||
你最喜欢的开源 NLP 工具和库是什么?请在评论区分享文中没有提到的工具。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/3/natural-language-processing-tools
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zxp](https://github.com/zhangxiangping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_communication_team.png?itok=CYfZ_gE7 (Chat bubbles)
|
||||
[2]: http://www.nltk.org/
|
||||
[3]: http://www.nltk.org/book_1ed/
|
||||
[4]: https://spacy.io/
|
||||
[5]: https://textblob.readthedocs.io/en/dev/
|
||||
[6]: https://readthedocs.org/projects/textacy/
|
||||
[7]: https://pytorchnlp.readthedocs.io/en/latest/
|
||||
[8]: https://www.npmjs.com/package/retext
|
||||
[9]: https://unified.js.org/
|
||||
[10]: https://www.npmjs.com/package/compromise
|
||||
[11]: https://www.npmjs.com/package/natural
|
||||
[12]: https://www.npmjs.com/package/node-nlp
|
||||
[13]: https://opennlp.apache.org/
|
||||
[14]: https://stanfordnlp.github.io/CoreNLP/
|
||||
[15]: https://opensource.com/article/19/2/learn-data-science-ai
|
||||
[16]: https://github.com/CogComp/cogcomp-nlp
|
||||
@ -0,0 +1,189 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (mengxinayan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11935-1.html)
|
||||
[#]: subject: (How to structure a multi-file C program: Part 1)
|
||||
[#]: via: (https://opensource.com/article/19/7/structure-multi-file-c-part-1)
|
||||
[#]: author: (Erik O'Shaughnessy https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions)
|
||||
|
||||
如何组织构建多文件 C 语言程序(一)
|
||||
======
|
||||
|
||||
> 准备好你喜欢的饮料、编辑器和编译器,放一些音乐,然后开始构建一个由多个文件组成的 C 语言程序。
|
||||
|
||||

|
||||
|
||||
大家常说计算机编程的艺术部分是处理复杂性,部分是命名某些事物。此外,我认为“有时需要添加绘图”是在很大程度上是正确的。
|
||||
|
||||
在这篇文章里,我会编写一个小型 C 程序,命名一些东西,同时处理一些复杂性。该程序的结构大致基于我在 《[如何写一个好的 C 语言 main 函数][2]》 文中讨论的。但是,这次做一些不同的事。准备好你喜欢的饮料、编辑器和编译器,放一些音乐,让我们一起编写一个有趣的 C 语言程序。
|
||||
|
||||
### 优秀 Unix 程序哲学
|
||||
|
||||
首先,你要知道这个 C 程序是一个 [Unix][3] 命令行工具。这意味着它运行在(或者可被移植到)那些提供 Unix C 运行环境的操作系统中。当贝尔实验室发明 Unix 后,它从一开始便充满了[设计哲学][4]。用我自己的话来说就是:程序只做一件事,并做好它,并且对文件进行一些操作。虽然“只做一件事,并做好它”是有意义的,但是“对文件进行一些操作”的部分似乎有点儿不合适。
|
||||
|
||||
事实证明,Unix 中抽象的 “文件” 非常强大。一个 Unix 文件是以文件结束符(EOF)标志为结尾的字节流。仅此而已。文件中任何其它结构均由应用程序所施加而非操作系统。操作系统提供了系统调用,使得程序能够对文件执行一套标准的操作:打开、读取、写入、寻址和关闭(还有其他,但说起来那就复杂了)。对于文件的标准化访问使得不同的程序共用相同的抽象,而且可以一同工作,即使它们是不同的人用不同语言编写的程序。
|
||||
|
||||
具有共享的文件接口使得构建*可组合的*的程序成为可能。一个程序的输出可以作为另一个程序的输入。Unix 家族的操作系统默认在执行程序时提供了三个文件:标准输入(`stdin`)、标准输出(`stdout`)和标准错误(`stderr`)。其中两个文件是只写的:`stdout` 和 `stderr`。而 `stdin` 是只读的。当我们在常见的 Shell 比如 Bash 中使用文件重定向时,可以看到其效果。
|
||||
|
||||
```
|
||||
$ ls | grep foo | sed -e 's/bar/baz/g' > ack
|
||||
```
|
||||
|
||||
这条指令可以被简要地描述为:`ls` 的结果被写入标准输出,它重定向到 `grep` 的标准输入,`grep` 的标准输出重定向到 `sed` 的标准输入,`sed` 的标准输出重定向到当前目录下文件名为 `ack` 的文件中。
|
||||
|
||||
我们希望我们的程序在这个灵活又出色的生态系统中运作良好,因此让我们编写一个可以读写文件的程序。
|
||||
|
||||
### 喵呜喵呜:流编码器/解码器概念
|
||||
|
||||
当我还是一个露着豁牙的孩子懵懵懂懂地学习计算机科学时,学过很多编码方案。它们中的有些用于压缩文件,有些用于打包文件,另一些毫无用处因此显得十分愚蠢。列举最后这种情况的一个例子:[哞哞编码方案][5]。
|
||||
|
||||
为了让我们的程序有个用途,我为它更新了一个 [21 世纪][6] 的概念,并且实现了一个名为“喵呜喵呜” 的编码方案的概念(毕竟网上大家都喜欢猫)。这里的基本的思路是获取文件并且使用文本 “meow” 对每个半字节(半个字节)进行编码。小写字母代表 0,大写字母代表 1。因为它会将 4 个比特替换为 32 个比特,因此会扩大文件的大小。没错,这毫无意义。但是想象一下人们看到经过这样编码后的惊讶表情。
|
||||
|
||||
```
|
||||
$ cat /home/your_sibling/.super_secret_journal_of_my_innermost_thoughts
|
||||
MeOWmeOWmeowMEoW...
|
||||
```
|
||||
|
||||
这非常棒。
|
||||
|
||||
### 最终的实现
|
||||
|
||||
完整的源代码可以在 [GitHub][7] 上面找到,但是我会写下我在编写程序时的思考。目的是说明如何组织构建多文件 C 语言程序。
|
||||
|
||||
既然已经确定了要编写一个编码和解码“喵呜喵呜”格式的文件的程序时,我在 Shell 中执行了以下的命令 :
|
||||
|
||||
```
|
||||
$ mkdir meowmeow
|
||||
$ cd meowmeow
|
||||
$ git init
|
||||
$ touch Makefile # 编译程序的方法
|
||||
$ touch main.c # 处理命令行选项
|
||||
$ touch main.h # “全局”常量和定义
|
||||
$ touch mmencode.c # 实现对喵呜喵呜文件的编码
|
||||
$ touch mmencode.h # 描述编码 API
|
||||
$ touch mmdecode.c # 实现对喵呜喵呜文件的解码
|
||||
$ touch mmdecode.h # 描述解码 API
|
||||
$ touch table.h # 定义编码查找表
|
||||
$ touch .gitignore # 这个文件中的文件名会被 git 忽略
|
||||
$ git add .
|
||||
$ git commit -m "initial commit of empty files"
|
||||
```
|
||||
|
||||
简单的说,我创建了一个目录,里面全是空文件,并且提交到 git。
|
||||
|
||||
即使这些文件中没有内容,你依旧可以从它的文件名推断每个文件的用途。为了避免万一你无法理解,我在每条 `touch` 命令后面进行了简单描述。
|
||||
|
||||
通常,程序从一个简单 `main.c` 文件开始,只有两三个解决问题的函数。然后程序员轻率地向自己的朋友或者老板展示了该程序,然后为了支持所有新的“功能”和“需求”,文件中的函数数量就迅速爆开了。“程序俱乐部”的第一条规则便是不要谈论“程序俱乐部”,第二条规则是尽量减少单个文件中的函数。
|
||||
|
||||
老实说,C 编译器并不关心程序中的所有函数是否都在一个文件中。但是我们并不是为计算机或编译器写程序,我们是为其他人(有时也包括我们)去写程序的。我知道这可能有些奇怪,但这就是事实。程序体现了计算机解决问题所采用的一组算法,当问题的参数发生了意料之外的变化时,保证人们可以理解它们是非常重要的。当在人们修改程序时,发现一个文件中有 2049 函数时他们会诅咒你的。
|
||||
|
||||
因此,优秀的程序员会将函数分隔开,将相似的函数分组到不同的文件中。这里我用了三个文件 `main.c`、`mmencode.c` 和 `mmdecode.c`。对于这样小的程序,也许看起来有些过头了。但是小的程序很难保证一直小下去,因此哥忒拓展做好计划是一个“好主意”。
|
||||
|
||||
但是那些 `.h` 文件呢?我会在后面解释一般的术语,简单地说,它们被称为头文件,同时它们可以包含 C 语言类型定义和 C 预处理指令。头文件中不应该包含任何函数。你可以认为头文件是提供了应用程序接口(API)的定义的一种 `.c` 文件,可以供其它 `.c` 文件使用。
|
||||
|
||||
### 但是 Makefile 是什么呢?
|
||||
|
||||
我知道下一个轰动一时的应用都是你们这些好孩子们用 “终极代码粉碎者 3000” 集成开发环境来编写的,而构建项目是用 Ctrl-Meta-Shift-Alt-Super-B 等一系列复杂的按键混搭出来的。但是如今(也就是今天),使用 `Makefile` 文件可以在构建 C 程序时帮助做很多有用的工作。`Makefile` 是一个包含如何处理文件的方式的文本文件,程序员可以使用其自动地从源代码构建二进制程序(以及其它东西!)
|
||||
|
||||
以下面这个小东西为例:
|
||||
|
||||
```
|
||||
00 # Makefile
|
||||
01 TARGET= my_sweet_program
|
||||
02 $(TARGET): main.c
|
||||
03 cc -o my_sweet_program main.c
|
||||
```
|
||||
|
||||
`#` 符号后面的文本是注释,例如 00 行。
|
||||
|
||||
01 行是一个变量赋值,将 `TARGET` 变量赋值为字符串 `my_sweet_program`。按照惯例,也是我的习惯,所有 `Makefile` 变量均使用大写字母并用下划线分隔单词。
|
||||
|
||||
02 行包含该<ruby>步骤<rt>recipe</rt></ruby>要创建的文件名和其依赖的文件。在本例中,构建<ruby>目标<rt>target</rt></ruby>是 `my_sweet_program`,其依赖是 `main.c`。
|
||||
|
||||
最后的 03 行使用了一个制表符号(`tab`)而不是四个空格。这是将要执行创建目标的命令。在本例中,我们使用 <ruby>C 编译器<rt>C compiler</rt></ruby>前端 `cc` 以编译链接为 `my_sweet_program`。
|
||||
|
||||
使用 `Makefile` 是非常简单的。
|
||||
|
||||
```
|
||||
$ make
|
||||
cc -o my_sweet_program main.c
|
||||
$ ls
|
||||
Makefile main.c my_sweet_program
|
||||
```
|
||||
|
||||
构建我们喵呜喵呜编码器/解码器的 [Makefile][8] 比上面的例子要复杂,但其基本结构是相同的。我将在另一篇文章中将其分解为 Barney 风格。
|
||||
|
||||
### 形式伴随着功能
|
||||
|
||||
我的想法是程序从一个文件中读取、转换它,并将转换后的结果存储到另一个文件中。以下是我想象使用程序命令行交互时的情况:
|
||||
|
||||
```
|
||||
$ meow < clear.txt > clear.meow
|
||||
$ unmeow < clear.meow > meow.tx
|
||||
$ diff clear.txt meow.tx
|
||||
$
|
||||
```
|
||||
|
||||
我们需要编写代码以进行命令行解析和处理输入/输出流。我们需要一个函数对流进行编码并将结果写到另一个流中。最后,我们需要一个函数对流进行解码并将结果写到另一个流中。等一下,我们在讨论如何写一个程序,但是在上面的例子中,我调用了两个指令:`meow` 和 `unmeow`?我知道你可能会认为这会导致越变越复杂。
|
||||
|
||||
### 次要内容:argv[0] 和 ln 指令
|
||||
|
||||
回想一下,C 语言 main 函数的结构如下:
|
||||
|
||||
```
|
||||
int main(int argc, char *argv[])
|
||||
```
|
||||
|
||||
其中 `argc` 是命令行参数的数量,`argv` 是字符指针(字符串)的列表。`argv[0]` 是包含正在执行的程序的文件路径。在 Unix 系统中许多互补功能的程序(比如:压缩和解压缩)看起来像两个命令,但事实上,它们是在文件系统中拥有两个名称的一个程序。这个技巧是通过使用 `ln` 命令创建文件系统链接来实现两个名称的。
|
||||
|
||||
在我笔记本电脑中 `/usr/bin` 的一个例子如下:
|
||||
|
||||
```
|
||||
$ ls -li /usr/bin/git*
|
||||
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git
|
||||
3376 -rwxr-xr-x. 113 root root 1.5M Aug 30 2018 /usr/bin/git-receive-pack
|
||||
...
|
||||
```
|
||||
|
||||
这里 `git` 和 `git-receive-pack` 是同一个文件但是拥有不同的名字。我们说它们是相同的文件因为它们具有相同的 inode 值(第一列)。inode 是 Unix 文件系统的一个特点,对它的介绍超越了本文的内容范畴。
|
||||
|
||||
优秀或懒惰的程序可以通过 Unix 文件系统的这个特点达到写更少的代码但是交付双倍的程序。首先,我们编写一个基于其 `argv[0]` 的值而作出相应改变的程序,然后我们确保为导致该行为的名称创建链接。
|
||||
|
||||
在我们的 `Makefile` 中,`unmeow` 链接通过以下的方式来创建:
|
||||
|
||||
```
|
||||
# Makefile
|
||||
...
|
||||
$(DECODER): $(ENCODER)
|
||||
$(LN) -f $< $@
|
||||
...
|
||||
```
|
||||
|
||||
我倾向于在 `Makefile` 中将所有内容参数化,很少使用 “裸” 字符串。我将所有的定义都放置在 `Makefile` 文件顶部,以便可以简单地找到并改变它们。当你尝试将程序移植到新的平台上时,需要将 `cc` 改变为某个 `cc` 时,这会很方便。
|
||||
|
||||
除了两个内置变量 `$@` 和 `$<` 之外,该<ruby>步骤<rt>recipe</rt></ruby>看起来相对简单。第一个便是该步骤的目标的快捷方式,在本例中是 `$(DECODER)`(我能记得这个是因为 `@` 符号看起来像是一个目标)。第二个,`$<` 是规则依赖项,在本例中,它解析为 `$(ENCODER)`。
|
||||
|
||||
事情肯定会变得复杂,但它还在管理之中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/structure-multi-file-c-part-1
|
||||
|
||||
作者:[Erik O'Shaughnessy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jnyjnyhttps://opensource.com/users/jnyjnyhttps://opensource.com/users/jim-salterhttps://opensource.com/users/cldxsolutions
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_keyboard_coding.png?itok=E0Vvam7A (Programming keyboard.)
|
||||
[2]: https://linux.cn/article-10949-1.html
|
||||
[3]: https://en.wikipedia.org/wiki/Unix
|
||||
[4]: http://harmful.cat-v.org/cat-v/
|
||||
[5]: http://www.jabberwocky.com/software/moomooencode.html
|
||||
[6]: https://giphy.com/gifs/nyan-cat-sIIhZliB2McAo
|
||||
[7]: https://github.com/JnyJny/meowmeow
|
||||
[8]: https://github.com/JnyJny/meowmeow/blob/master/Makefile
|
||||
@ -1,22 +1,24 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (#:acid 'words: Handle Chromium & Firefox sessions with org-mode)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11926-1.html)
|
||||
[#]: subject: (Handle Chromium & Firefox sessions with org-mode)
|
||||
[#]: via: (https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions-with-org-mode.html)
|
||||
[#]: author: (Sanel Z https://acidwords.com/)
|
||||
|
||||
Handle Chromium & Firefox sessions with org-mode
|
||||
通过 Org 模式管理 Chromium 和 Firefox 会话
|
||||
======
|
||||
|
||||
I was big fan of [Session Manager][1], small addon for Chrome and Chromium that will save all open tabs, assign the name to session and, when is needed, restore it.
|
||||

|
||||
|
||||
Very useful, especially if you are like me, switching between multiple "mind sessions" during the day - research, development or maybe news reading. Or simply, you'd like to remember workflow (and tabs) you had few days ago.
|
||||
我是[会话管理器][1]的铁粉,它是 Chrome 和 Chromium 的小插件,可以保存所有打开的选项卡,为会话命名,并在需要时恢复会话。
|
||||
|
||||
After I decided to ditch all extensions from Chromium except [uBlock Origin][2], it was time to look for alternative. My main goal was it to be browser agnostic and session links had to be stored in text file, so I can enjoy all the goodies of plain text file. What would be better for that than good old [org-mode][3] ;)
|
||||
它非常有用,特别是如果你像我一样,白天的时候需要在多个“思维活动”之间切换——研究、开发或者阅读新闻。或者你只是单纯地希望记住几天前的工作流(和选项卡)。
|
||||
|
||||
Long time ago I found this trick: [Get the currently open tabs in Google Chrome via the command line][4] and with some elisp sugar and coffee, here is the code:
|
||||
在我决定放弃 chromium 上除了 [uBlock Origin][2] 之外的所有扩展后,就必须寻找一些替代品了。我的主要目标是使之与浏览器无关,同时会话链接必须保存在文本文件中,这样我就可以享受所有纯文本的好处了。还有什么比 [org 模式][3]更好呢 ;)
|
||||
|
||||
很久以前我就发现了这个小诀窍:[通过命令行获取当前在谷歌 Chrome 中打开的标签][4] 再加上些 elisp 代码:
|
||||
|
||||
```
|
||||
(require 'cl-lib)
|
||||
@ -57,9 +59,9 @@ Make sure to put cursor on date heading that contains list of urls."
|
||||
(forward-line 1)))))
|
||||
```
|
||||
|
||||
So, how does it work?
|
||||
那么,它的工作原理是什么呢?
|
||||
|
||||
Evaluate above code, open new org-mode file and call `M-x save-chromium-session`. It will create something like this:
|
||||
运行上述代码,打开一个新 org 模式文件并调用 `M-x save-chromium-session`。它会创建类似这样的东西:
|
||||
|
||||
```
|
||||
* [2019-12-04 12:14:02]
|
||||
@ -68,9 +70,9 @@ Evaluate above code, open new org-mode file and call `M-x save-chromium-session`
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
or whatever urls are running in Chromium instance. To restore it back, put cursor on desired date and run `M-x restore-chromium-session`. All tabs should be back.
|
||||
也就是任何在 chromium 实例中运行着的 URL。要还原的话,则将光标置于所需日期上然后运行 `M-x restore-chromium-session`。所有标签都应该恢复了。
|
||||
|
||||
Here is how I use it, with randomly generated data for the purpose of this text:
|
||||
以下是我的使用案例,其中的数据是随机生成的:
|
||||
|
||||
```
|
||||
#+TITLE: Browser sessions
|
||||
@ -88,27 +90,27 @@ Here is how I use it, with randomly generated data for the purpose of this text:
|
||||
- https://news.ycombinator.com
|
||||
```
|
||||
|
||||
Note that hack for reading Chromium session isn't perfect: `strings` will read whatever looks like string and url from binary database and sometimes that will yield small artifacts in urls. But, you can easily edit those and keep session file lean and clean.
|
||||
请注意,用于读取 Chromium 会话的方法并不完美:`strings` 将从二进制数据库中读取任何类似 URL 字符串的内容,有时这将产生不完整的 URL。不过,你可以很方便地地编辑它们,从而保持会话文件简洁。
|
||||
|
||||
To actually open tabs, elisp code will use [browse-url][5] and it can be further customized to run Chromium, Firefox or any other browser with `browse-url-browser-function` variable. Make sure to read documentation for this variable.
|
||||
为了真正打开标签,elisp 代码中使用到了 [browse-url][5],它可以通过 `browse-url-browser-function` 变量进一步定制成运行 Chromium、Firefox 或任何其他浏览器。请务必阅读该变量的相关文档。
|
||||
|
||||
Don't forget to put session file in git, mercurial or svn and enjoy the fact that you will never loose your session history again :)
|
||||
别忘了把会话文件放在 git、mercurial 或 svn 中,这样你就再也不会丢失会话历史记录了 :)
|
||||
|
||||
### What about Firefox?
|
||||
### 那么 Firefox 呢?
|
||||
|
||||
If you are using Firefox (recent versions) and would like to pull session urls, here is how to do it.
|
||||
如果你正在使用 Firefox(最近的版本),并且想要获取会话 URL,下面是操作方法。
|
||||
|
||||
First, download and compile [lz4json][6], small tool that will decompress Mozilla lz4json format, where Firefox stores session data. Session data (at the time of writing this post) is stored in `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backups/recovery.jsonlz4`.
|
||||
首先,下载并编译 [lz4json][6],这是一个可以解压缩 Mozilla lz4json 格式的小工具,Firefox 以这种格式来存储会话数据。会话数据(在撰写本文时)存储在 `$HOME/.mozilla/firefox/<unique-name>/sessionstore-backup /recovery.jsonlz4` 中。
|
||||
|
||||
If Firefox is not running, `recovery.jsonlz4` will not be present, but use `previous.jsonlz4` instead.
|
||||
如果 Firefox 没有运行,则没有 `recovery.jsonlz4`,这种情况下用 `previous.jsonlz4` 代替。
|
||||
|
||||
To extract urls, try this in terminal:
|
||||
要提取网址,尝试在终端运行:
|
||||
|
||||
```
|
||||
$ lz4jsoncat recovery.jsonlz4 | grep -oP '"(http.+?)"' | sed 's/"//g' | sort | uniq
|
||||
```
|
||||
|
||||
and update `save-chromium-session` with:
|
||||
然后更新 `save-chromium-session` 为:
|
||||
|
||||
```
|
||||
(defun save-chromium-session ()
|
||||
@ -122,7 +124,7 @@ and update `save-chromium-session` with:
|
||||
;; rest of the code is unchanged
|
||||
```
|
||||
|
||||
Updating documentation strings, function name and any further refactoring is left for exercise.
|
||||
更新本函数的文档字符串、函数名以及进一步的重构都留作练习。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -131,7 +133,7 @@ via: https://acidwords.com/posts/2019-12-04-handle-chromium-and-firefox-sessions
|
||||
作者:[Sanel Z][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,82 +1,80 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11920-1.html)
|
||||
[#]: subject: (Screenshot your Linux system configuration with Bash tools)
|
||||
[#]: via: (https://opensource.com/article/20/1/screenfetch-neofetch)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
使用 Bash 工具截屏 Linux 系统配置
|
||||
======
|
||||
使用 ScreenFetch 和 Neofetch 与其他人轻松分享 Linux 环境。
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
你可能有很多原因想要与他人分享 Linux 配置。你可能正在寻求帮助来对系统上的问题进行故障排除,或者你对所创建的环境感到非常自豪,因此想向其他开源爱好者展示。
|
||||
> 使用 ScreenFetch 和 Neofetch 与其他人轻松分享你的 Linux 环境。
|
||||
|
||||
你可以在 Bash 提示符下使用 **cat /proc/cpuinfo** 或 **lscpu** 命令获取某些信息。但是,如果你想共享更多详细信息,例如你的操作系统、内核、运行时间、shell 环境,屏幕分辨率等,那么可以选择两个很棒的工具:screenFetch 和 Neofetch。
|
||||
|
||||
|
||||
### ScreenFetch
|
||||
你可能有很多原因想要与他人分享你的 Linux 配置。你可能正在寻求帮助来对系统上的问题进行故障排除,或者你对所创建的环境感到非常自豪,因此想向其他开源爱好者展示。
|
||||
|
||||
[ScreenFetch][2] 是 Bash 命令行程序,它可以产生非常漂亮的系统配置和运行时间的截图。这是方便的与它人共享系统配置的方法。
|
||||
你可以在 Bash 提示符下使用 `cat /proc/cpuinfo` 或 `lscpu` 命令获取某些信息。但是,如果你想共享更多详细信息,例如你的操作系统、内核、运行时间、shell 环境,屏幕分辨率等,那么可以选择两个很棒的工具:screenFetch 和 Neofetch。
|
||||
|
||||
### screenFetch
|
||||
|
||||
[screenFetch][2] 是 Bash 命令行程序,它可以产生非常漂亮的系统配置和运行时间的截图。这是方便的与它人共享系统配置的方法。
|
||||
|
||||
在许多 Linux 发行版上安装 screenFetch 很简单。
|
||||
|
||||
在 Fedora 上,输入:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install screenfetch`
|
||||
$ sudo dnf install screenfetch
|
||||
```
|
||||
|
||||
在 Ubuntu 上,输入:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install screenfetch`
|
||||
$ sudo apt install screenfetch
|
||||
```
|
||||
|
||||
对于其他操作系统,包括 FreeBSD、MacOS 等,请查阅 screenFetch 的 wiki [安装页面][3]。安装 screenFetch 后,它可以生成详细而彩色的截图,如下所示:
|
||||
|
||||
![screenFetch][4]
|
||||
|
||||
ScreenFetch 还提供各种命令行选项来调整你的结果。例如, **screenfetch -v** 返回详细输出,逐行显示每个选项以及上面的显示。
|
||||
ScreenFetch 还提供各种命令行选项来调整你的结果。例如,`screenfetch -v` 返回详细输出,逐行显示每个选项以及上面的显示。
|
||||
|
||||
**screenfetch -n** 在显示系统信息时消除了操作系统图标。
|
||||
`screenfetch -n` 在显示系统信息时消除了操作系统图标。
|
||||
|
||||
![screenfetch -n option][5]
|
||||
|
||||
其他选项包括 **screenfetch -N**,它去除所有输出的颜色。**screenfetch -t**,它根据终端的大小截断输出。**screenFetch -E**,它可抑制错误输出。
|
||||
其他选项包括 `screenfetch -N`,它去除所有输出的颜色。`screenfetch -t`,它根据终端的大小截断输出。`screenFetch -E`,它可抑制错误输出。
|
||||
|
||||
请检查手册页来了解其他选项。ScreenFetch 在 GPLv3 许可证下的开源,你可以在它的 [GitHub 仓库][6]中了解有关该项目的更多信息。
|
||||
请检查手册页来了解其他选项。screenFetch 在 GPLv3 许可证下的开源,你可以在它的 [GitHub 仓库][6]中了解有关该项目的更多信息。
|
||||
|
||||
### Neofetch
|
||||
|
||||
[Neofetch][7] 是创建系统信息截图的另一个工具。它是用 Bash 3.2 编写的,在 [MIT 许可证][8]下开源。
|
||||
|
||||
根据项目网站,“Neofetch 支持近 150 种不同的操作系统。从 Linux 到 Windows,一直到 Minix、AIX 和 Haiku 等更晦涩的操作系统。”
|
||||
根据项目网站所述,“Neofetch 支持近 150 种不同的操作系统。从 Linux 到 Windows,一直到 Minix、AIX 和 Haiku 等更晦涩的操作系统。”
|
||||
|
||||
![Neofetch][9]
|
||||
|
||||
该项目维护了一个 wiki,其中包含用于各种发行版和操作系统的出色的[安装文档] [10]。
|
||||
该项目维护了一个 wiki,其中包含用于各种发行版和操作系统的出色的[安装文档][10]。
|
||||
|
||||
如果你使用的是 Fedora、RHEL 或 CentOS,那么可以在 Bash 提示符下使用以下命令安装 Neofetch:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo dnf install neofetch`
|
||||
$ sudo dnf install neofetch
|
||||
```
|
||||
|
||||
在 Ubuntu 17.10 及更高版本上,你可以使用:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install neofetch`
|
||||
$ sudo apt install neofetch
|
||||
```
|
||||
|
||||
首次运行时,Neofetch 将 **~/.config/neofetch/config.conf** 文件写入主目录(**.config/config.conf**),它让你可以[自定义和控制] [ 11] Neofetch 输出的各个方面。例如,你可以配置 Neofetch 使用图像、ASCII 文件、你选择的壁纸,或者完全不使用。config.conf 文件还让与它人分享配置变得容易。
|
||||
首次运行时,Neofetch 将 `~/.config/neofetch/config.conf` 文件写入主目录(`.config/config.conf`),它让你可以[自定义和控制][11] Neofetch 输出的各个方面。例如,你可以配置 Neofetch 使用图像、ASCII 文件、你选择的壁纸,或者完全不使用。config.conf 文件还让与它人分享配置变得容易。
|
||||
|
||||
如果 Neofetch 不支持你的操作系统或不提供所需选项,请在项目的 [GitHub 仓库] [12]中打开一个问题。
|
||||
如果 Neofetch 不支持你的操作系统或不提供所需选项,请在项目的 [GitHub 仓库][12]中打开一个问题。
|
||||
|
||||
### 总结
|
||||
|
||||
@ -89,7 +87,7 @@ via: https://opensource.com/article/20/1/screenfetch-neofetch
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11908-1.html)
|
||||
[#]: subject: (Use Vim to send email and check your calendar)
|
||||
[#]: via: (https://opensource.com/article/20/1/vim-email-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Vim 发送邮件和检查日历
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十六篇文章中,直接通过文本编辑器管理你的电子邮件和日历。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 用 Vim 做(几乎)所有事情,第一部分
|
||||
|
||||
我经常使用两个文本编辑器 —— [Vim][2] 和 [Emacs][3]。为什么两者都用呢?它们有不同的使用场景,在本系列的后续几篇文章中,我将讨论其中的一些用例。
|
||||
|
||||
![][4]
|
||||
|
||||
好吧,为什么要在 Vim 中执行所有操作?因为如果有一个应用程序是我可以访问的每台计算机上都有的,那就是 Vim。如果你像我一样,可能已经在 Vim 中打发了很多时光。那么,为什么不将其用于**所有事情**呢?
|
||||
|
||||
但是,在此之前,你需要做一些事情。首先是确保你的 Vim 具有 Ruby 支持。你可以使用 `vim --version | grep ruby`。如果结果不是 `+ruby`,则需要解决这个问题。这可能有点麻烦,你应该查看发行版的文档以获取正确的软件包。在 MacOS 上,用的是官方的 MacVim(不是 Brew 发行的),在大多数 Linux 发行版中,用的是 vim-nox 或 vim-gtk,而不是 vim-gtk3。
|
||||
|
||||
我使用 [Pathogen][5] 自动加载插件和捆绑软件。如果你使用 [Vundle][6] 或其他 Vim 软件包管理器,则需要调整以下命令才能使用它。
|
||||
|
||||
#### 在 Vim 中管理你的邮件
|
||||
|
||||
使 Vim 在你的生产力计划中发挥更大作用的一个很好的起点是使用它通过 [Notmuch] [7] 发送和接收电子邮件,和使用 [abook] [8] 访问你的联系人列表。你需要为此安装一些东西。下面的所有示例代码都运行在 Ubuntu 上,因此如果你使用其他发行版,则需要对此进行调整。通过以下步骤进行设置:
|
||||
|
||||
```
|
||||
sudo apt install notmuch-vim ruby-mail
|
||||
curl -o ~/.vim/plugin/abook --create-dirs https://raw.githubusercontent.com/dcbaker/vim-abook/master/plugin/abook.vim
|
||||
```
|
||||
|
||||
到目前为止,一切都很顺利。现在启动 Vim 并执行 `:NotMuch`。由于是用较旧版本的邮件库 `notmuch-vim` 编写的,可能会出现一些警告,但总的来说,Vim 现在将成为功能齐全的 Notmuch 邮件客户端。
|
||||
|
||||
![Reading Mail in Vim][9]
|
||||
|
||||
如果要搜索特定标签,请输入 `\t`,输入标签名称,然后按回车。这将拉出一个带有该标签的所有消息的列表。`\s` 组合键会弹出 `Search:` 提示符,可以对 Notmuch 数据库进行全面搜索。使用箭头键浏览消息列表,按回车键显示所选项目,然后输入 `\q` 退出当前视图。
|
||||
|
||||
要撰写邮件,请使用 `\c` 按键。你将看到一条空白消息。这是 `abook.vim` 插件发挥作用的位置。按下 `Esc` 并输入 `:AbookQuery <SomeName>`,其中 `<SomeName>` 是你要查找的名称或电子邮件地址的一部分。你将在 abook 数据库中找到与你的搜索匹配的条目列表。通过键入你想要的地址的编号,将其添加到电子邮件的地址行中。完成电子邮件的键入和编辑,按 `Esc` 退出编辑模式,然后输入 `,s` 发送。
|
||||
|
||||
如果要在 `:NotMuch` 启动时更改默认文件夹视图,则可以将变量 `g:notmuch_folders` 添加到你的 `.vimrc` 文件中:
|
||||
|
||||
```
|
||||
let g:notmuch_folders = [
|
||||
\ [ 'new', 'tag:inbox and tag:unread' ],
|
||||
\ [ 'inbox', 'tag:inbox' ],
|
||||
\ [ 'unread', 'tag:unread' ],
|
||||
\ [ 'News', 'tag:@sanenews' ],
|
||||
\ [ 'Later', 'tag:@sanelater' ],
|
||||
\ [ 'Patreon', 'tag:@patreon' ],
|
||||
\ [ 'LivestockConservancy', 'tag:livestock-conservancy' ],
|
||||
\ ]
|
||||
```
|
||||
|
||||
Notmuch 插件的文档中涵盖了更多设置,包括设置标签键和使用其它的邮件程序。
|
||||
|
||||
#### 在 Vim 中查询日历
|
||||
|
||||
![][10]
|
||||
|
||||
遗憾的是,似乎没有使用 vCalendar 或 iCalendar 格式的 Vim 日历程序。有个 [Calendar.vim][11],做得很好。设置 Vim 通过以下方式访问你的日历:
|
||||
|
||||
```
|
||||
cd ~/.vim/bundle
|
||||
git clone git@github.com:itchyny/calendar.vim.git
|
||||
```
|
||||
|
||||
现在,你可以通过输入 `:Calendar` 在 Vim 中查看日历。你可以使用 `<` 和 `>` 键在年、月、周、日和时钟视图之间切换。如果要从一个特定的视图开始,请使用 `-view=` 标志告诉它你希望看到哪个视图。你也可以在任何视图中定位日期。例如,如果我想查看 2020 年 7 月 4 日这一周的情况,请输入 `:Calendar -view week 7 4 2020`。它的帮助信息非常好,可以使用 `?` 键参看。
|
||||
|
||||
![][13]
|
||||
|
||||
Calendar.vim 还支持 Google Calendar(我需要),但是在 2019 年 12 月,Google 禁用了它的访问权限。作者已在 [GitHub 上的这个提案][14]中发布了一种变通方法。
|
||||
|
||||
这样你就在 Vim 中有了这些:你的邮件、地址簿和日历。但是这些还没有完成; 下一篇你将在 Vim 上做更多的事情!
|
||||
|
||||
Vim 为作家提供了很多好处,无论他们是否具有技术意识。
|
||||
|
||||
需要保持时间表正确吗?了解如何使用这些免费的开源软件来做到这一点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/vim-email-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/calendar.jpg?itok=jEKbhvDT (Calendar close up snapshot)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/day16-image1.png
|
||||
[5]: https://github.com/tpope/vim-pathogen
|
||||
[6]: https://github.com/VundleVim/Vundle.vim
|
||||
[7]: https://opensource.com/article/20/1/organize-email-notmuch
|
||||
[8]: https://opensource.com/article/20/1/sync-contacts-locally
|
||||
[9]: https://opensource.com/sites/default/files/uploads/productivity_16-2.png (Reading Mail in Vim)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/day16-image3.png
|
||||
[11]: https://github.com/itchyny/calendar.vim
|
||||
[12]: mailto:git@github.com
|
||||
[13]: https://opensource.com/sites/default/files/uploads/day16-image4.png
|
||||
[14]: https://github.com/itchyny/calendar.vim/issues/156
|
||||
@ -1,20 +1,22 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11912-1.html)
|
||||
[#]: subject: (Use Vim to manage your task list and access Reddit and Twitter)
|
||||
[#]: via: (https://opensource.com/article/20/1/vim-task-list-reddit-twitter)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Vim 管理任务列表和访问 Reddit 和 Twitter
|
||||
======
|
||||
在我们的 20 个使用开源提升生产力的系列的第十七篇文章中了解在编辑器中处理待办列表以及获取社交信息。
|
||||
![Chat via email][1]
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十七篇文章中,了解在编辑器中处理待办列表以及获取社交信息。
|
||||
|
||||

|
||||
|
||||
去年,我在 19 天里给你介绍了 19 个新(对你而言)的生产力工具。今年,我换了一种方式:使用你在使用或者还没使用的工具,构建一个使你可以在新一年更加高效的环境。
|
||||
|
||||
### 使用 Vim 执行(几乎)所有操作,第 2 部分
|
||||
### 用 Vim 做(几乎)所有事情,第 2 部分
|
||||
|
||||
在[昨天的文章][2]中,你开始用 Vim 检查邮件和日历。今天,你可以做的更多。首先,你会在 Vim 编辑器中跟踪任务,然后获取社交信息。
|
||||
|
||||
@ -24,13 +26,12 @@
|
||||
|
||||
使用 Vim 编辑一个文本待办事件是一件自然的事,而 [todo.txt-vim][4] 包使其更加简单。首先安装 todo.txt-vim 包:
|
||||
|
||||
|
||||
```
|
||||
git clone <https://github.com/freitass/todo.txt-vim> ~/.vim/bundle/todo.txt-vim
|
||||
git clone https://github.com/freitass/todo.txt-vim ~/.vim/bundle/todo.txt-vim
|
||||
vim ~/path/to/your/todo.txt
|
||||
```
|
||||
|
||||
todo.txt-vim 自动识别以 todo.txt 和 done.txt 结尾的文件作为 [todo.txt][5] 文件。它添加特定于 todo.txt 格式的键绑定。你可以使用 **\x** 标记“已完成”的内容,使用 **\d** 将其设置为当前日期,然后使用 **\a**、**\b** 和 **\c** 更改优先级。你可以提升(**\k**)或降低(**\j**)优先级,并根据项目(**\s+**)、上下文(**\s@**)或日期(**\sd**)排序(**\s**)。完成后,你可以和平常一样关闭和保存文件。
|
||||
todo.txt-vim 自动识别以 `todo.txt` 和 `done.txt` 结尾的文件作为 [todo.txt][5] 文件。它添加特定于 todo.txt 格式的键绑定。你可以使用 `\x` 标记“已完成”的内容,使用 `\d` 将其设置为当前日期,然后使用 `\a`、`\b` 和 `\c` 更改优先级。你可以提升(`\k`)或降低(`\j`)优先级,并根据项目(`\s+`)、上下文(`\s@`)或日期(`\sd`)排序(`\s`)。完成后,你可以和平常一样关闭和保存文件。
|
||||
|
||||
todo.txt-vim 包是我几天前写的 [todo.sh 程序][6]的一个很好的补充,使用 [todo edit][7] 加载项,它可以增强的你待办事项列表跟踪。
|
||||
|
||||
@ -40,13 +41,12 @@ todo.txt-vim 包是我几天前写的 [todo.sh 程序][6]的一个很好的补
|
||||
|
||||
Vim 还有一个不错的用于 [Reddit][9] 的加载项,叫 [vim-reddit][10]。它不如 [Tuir][11] 好,但是用于快速查看最新的文章,它还是不错的。首先安装捆绑包:
|
||||
|
||||
|
||||
```
|
||||
git clone <https://github.com/DougBeney/vim-reddit.git> ~/.vim/bundle/vim-reddit
|
||||
git clone https://github.com/DougBeney/vim-reddit.git ~/.vim/bundle/vim-reddit
|
||||
vim
|
||||
```
|
||||
|
||||
现在输入 **:Reddit** 将加载 Reddit 首页。你可以使用 **:Reddit name** 加载特定子板。打开文章列表后,使用箭头键导航或使用鼠标滚动。按 **o** 将在 Vim 中打开文章(除非它多媒体文章,它会打开浏览器),然后按 **c** 打开评论。如果要直接转到页面,请按 **O** 而不是 **o**。只需按 **u** 就能返回。当你 Reddit 看完后,输入 **:bd** 就行。vim-reddit 唯一的缺点是无法登录或发布新文章和评论。话又说回来,有时这是一件好事。
|
||||
现在输入 `:Reddit` 将加载 Reddit 首页。你可以使用 `:Reddit name` 加载特定子板。打开文章列表后,使用箭头键导航或使用鼠标滚动。按 `o` 将在 Vim 中打开文章(除非它多媒体文章,它会打开浏览器),然后按 `c` 打开评论。如果要直接转到页面,请按 `O` 而不是 `o`。只需按 `u` 就能返回。当你 Reddit 看完后,输入 `:bd` 就行。vim-reddit 唯一的缺点是无法登录或发布新文章和评论。话又说回来,有时这是一件好事。
|
||||
|
||||
#### 使用 twitvim 在 Vim 中发推
|
||||
|
||||
@ -54,17 +54,15 @@ vim
|
||||
|
||||
最后,我们有 [twitvim][13],这是一个于阅读和发布 Twitter 的 Vim 软件包。它需要更多设置。首先从 GitHub 安装 twitvim:
|
||||
|
||||
|
||||
```
|
||||
`git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim`
|
||||
git clone https://github.com/twitvim/twitvim.git ~/.vim/bundle/twitvim
|
||||
```
|
||||
|
||||
现在你需要编辑 **.vimrc** 文件并设置一些选项。它帮助插件知道使用哪些库与 Twitter 交互。运行 **vim --version** 并查看哪些语言的前面有 **+** 就代表你的 Vim 支持它。
|
||||
现在你需要编辑 `.vimrc` 文件并设置一些选项。它帮助插件知道使用哪些库与 Twitter 交互。运行 `vim --version` 并查看哪些语言的前面有 `+` 就代表你的 Vim 支持它。
|
||||
|
||||
![Enabled and Disabled things in vim][14]
|
||||
|
||||
因为我的是 **+perl -python +python3**,所以我知道我可以启用 Perl 和 Python 3 但不是 Python 2 (python)。
|
||||
|
||||
因为我的是 `+perl -python +python3`,所以我知道我可以启用 Perl 和 Python 3 但不是 Python 2 (python)。
|
||||
|
||||
```
|
||||
" TwitVim Settings
|
||||
@ -73,9 +71,9 @@ let twitvim_enable_perl = 1
|
||||
let twitvim_enable_python3 = 1
|
||||
```
|
||||
|
||||
现在,你可以通过运行 **:SetLoginTwitter** 启动浏览器窗口,它会打开一个浏览器窗口要求你授权 VimTwit 访问你的帐户。在 Vim 中输入提供的 PIN 后就可以了。
|
||||
现在,你可以通过运行 `:SetLoginTwitter` 启动浏览器窗口,它会打开一个浏览器窗口要求你授权 VimTwit 访问你的帐户。在 Vim 中输入提供的 PIN 后就可以了。
|
||||
|
||||
Twitvim 的命令不像其他包中一样简单。要加载好友和关注者的时间线,请输入 **:FriendsTwitter**。要列出提及你的和回复,请使用 **:MentionsTwitter**。发布新推文是 **:PosttoTwitter <Your message>**。你可以滚动列表并输入 **\r** 回复特定推文,你可以用 **\d** 直接给某人发消息。
|
||||
Twitvim 的命令不像其他包中一样简单。要加载好友和关注者的时间线,请输入 `:FriendsTwitter`。要列出提及你的和回复,请使用 `:MentionsTwitter`。发布新推文是 `:PosttoTwitter <Your message>`。你可以滚动列表并输入 `\r` 回复特定推文,你可以用 `\d` 直接给某人发消息。
|
||||
|
||||
就是这些了。你现在可以在 Vim 中做(几乎)所有事了!
|
||||
|
||||
@ -86,14 +84,14 @@ via: https://opensource.com/article/20/1/vim-task-list-reddit-twitter
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_chat_communication_message.png?itok=LKjiLnQu (Chat via email)
|
||||
[2]: https://opensource.com/article/20/1/send-email-and-check-your-calendar-vim
|
||||
[2]: https://linux.cn/article-11908-1.html
|
||||
[3]: https://opensource.com/sites/default/files/uploads/productivity_17-1.png (to-dos and Twitter with Vim)
|
||||
[4]: https://github.com/freitass/todo.txt-vim
|
||||
[5]: http://todotxt.org
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11932-1.html)
|
||||
[#]: subject: (Send email and check your calendar with Emacs)
|
||||
[#]: via: (https://opensource.com/article/20/1/emacs-mail-calendar)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
|
||||
|
||||
使用 Emacs 发送电子邮件和检查日历
|
||||
======
|
||||
|
||||
> 在 2020 年用开源实现更高生产力的二十种方式的第十八篇文章中,使用 Emacs 文本编辑器管理电子邮件和查看日程安排。
|
||||
|
||||

|
||||
|
||||
去年,我给你们带来了 2019 年的 19 天新生产力工具系列。今年,我将采取一种不同的方式:建立一个新的环境,让你使用已用或未用的工具来在新的一年里变得更有效率。
|
||||
|
||||
### 使用 Emacs 做(几乎)所有的事情,第 1 部分
|
||||
|
||||
两天前,我曾经说过我经常使用 [Vim][2] 和 [Emacs][3],在本系列的 [16][4] 和 [17][5] 天,我讲解了如何在 Vim 中做几乎所有的事情。现在,Emacs 的时间到了!
|
||||
|
||||
![Emacs 中的邮件和日历][6]
|
||||
|
||||
在深入之前,我需要说明两件事。首先,我这里使用默认的 Emacs 配置,而不是我之前[写过][8]的 [Spacemacs][7]。为什么呢?因为这样一来我使用的就是默认快捷键,从而使你可以参考文档,而不必将“原生的 Emacs” 转换为 Spacemacs。第二,在本系列文章中我没有对 Org 模式进行任何设置。Org 模式本身几乎可以自成一个完整的系列,它非常强大,但是设置可能非常复杂。
|
||||
|
||||
#### 配置 Emacs
|
||||
|
||||
配置 Emacs 比配置 Vim 稍微复杂一些,但以我之见,从长远来看,这样做是值得的。首先我们创建一个配置文件,并在 Emacs 中打开它:
|
||||
|
||||
```
|
||||
mkdir ~/.emacs.d
|
||||
emacs ~/.emacs.d/init.el
|
||||
```
|
||||
|
||||
接下来,向内置的包管理器添加一些额外的包源。在 `init.el` 中添加以下内容:
|
||||
|
||||
```
|
||||
(package-initialize)
|
||||
(add-to-list 'package-archives '("melpa" . "<http://melpa.org/packages/>"))
|
||||
(add-to-list 'package-archives '("org" . "<http://orgmode.org/elpa/>") t)
|
||||
(add-to-list 'package-archives '("gnu" . "<https://elpa.gnu.org/packages/>"))
|
||||
(package-refresh-contents)
|
||||
```
|
||||
|
||||
使用 `Ctrl+x Ctrl+s` 保存文件,然后按下 `Ctrl+x Ctrl+c` 退出,再重启 Emacs。Emacs 会在启动时下载所有的插件包列表,之后你就可以使用内置的包管理器安装插件了。输入 `Meta+x` 会弹出命令提示符(大多数键盘上 `Meta` 键就是的 `Alt` 键,而在 MacOS 上则是 `Option`)。在命令提示符下输入 `package-list-packages` 就会显示可以安装的包列表。遍历该列表并使用 `i` 键选择以下包:
|
||||
|
||||
```
|
||||
bbdb
|
||||
bbdb-vcard
|
||||
calfw
|
||||
calfw-ical
|
||||
notmuch
|
||||
```
|
||||
|
||||
选好软件包后按 `x` 安装它们。根据你的网络连接情况,这可能需要一段时间。你也许会看到一些编译错误,但是可以忽略它们。安装完成后,使用组合键 `Ctrl+x Ctrl+f` 打开 `~/.emacs.d/init.el`,并在 `(package-refresh-packages)` 之后、 `(custom-set-variables` 之前添加以下行到文件中。
|
||||
`(custom-set-variables` 行由 Emacs 内部维护,你永远不应该修改它之后的任何内容。以 `;;` 开头的行则是注释。
|
||||
|
||||
```
|
||||
;; Set up bbdb
|
||||
(require 'bbdb)
|
||||
(bbdb-initialize 'message)
|
||||
(bbdb-insinuate-message)
|
||||
(add-hook 'message-setup-hook 'bbdb-insinuate-mail)
|
||||
;; set up calendar
|
||||
(require 'calfw)
|
||||
(require 'calfw-ical)
|
||||
;; Set this to the URL of your calendar. Google users will use
|
||||
;; the Secret Address in iCalendar Format from the calendar settings
|
||||
(cfw:open-ical-calendar "<https://path/to/my/ics/file.ics>")
|
||||
;; Set up notmuch
|
||||
(require 'notmuch)
|
||||
;; set up mail sending using sendmail
|
||||
(setq send-mail-function (quote sendmail-send-it))
|
||||
(setq user-mail-address "[myemail@mydomain.com][9]"
|
||||
user-full-name "My Name")
|
||||
```
|
||||
|
||||
现在,你已经准备好使用自己的配置启动 Emacs 了!保存 `init.el` 文件(`Ctrl+x Ctrl+s`),退出 Emacs(`Ctrl+x Ctrl+c`),然后重启之。这次重启要多花些时间。
|
||||
|
||||
#### 使用 Notmuch 在 Emacs 中读写电子邮件
|
||||
|
||||
一旦你看到了 Emacs 启动屏幕,你就可以使用 [Notmuch][10] 来阅读电子邮件了。键入 `Meta+x notmuch`,你将看到 notmuch 的 Emacs 界面。
|
||||
|
||||
![使用 notmuch 阅读邮件][11]
|
||||
|
||||
所有加粗的项目都是指向电子邮件视图的链接。你可以通过点击鼠标或者使用 `tab` 键在它们之间跳转并按回车来访问它们。你可以使用搜索栏来搜索 Notmuch 的数据库,语法与 Notmuch 命令行上的[语法][12] 相同。如果你愿意,还可以使用 `[save]` 按钮保存搜索以便未来使用,这些搜索会被添加到屏幕顶部的列表中。如果你进入一个链接就会看到一个相关电子邮件的列表。你可以使用箭头键在列表中导航,并在要读取的消息上按回车。按 `r` 可以回复一条消息,`f` 转发该消息,`q` 退出当前屏幕。
|
||||
|
||||
你可以通过键入 `Meta+x compose-mail` 来编写新消息。撰写、回复和转发都将打开编写邮件的界面。写完邮件后,按 `Ctrl+c Ctrl+c` 发送。如果你决定不发送它,按 `Ctrl+c Ctrl+k` 关闭消息撰写缓冲区(窗口)。
|
||||
|
||||
#### 使用 BBDB 在 Emacs 中自动补完电子邮件地址
|
||||
|
||||
![在消息中使用 BBDB 地址][13]
|
||||
|
||||
那么通讯录怎么办?这就是 [BBDB][14] 发挥作用的地方。但首先我们需要从 [abook][15] 导入所有地址,方法是打开命令行并运行以下导出命令:
|
||||
|
||||
```
|
||||
abook --convert --outformat vcard --outfile ~/all-my-addresses.vcf --infile ~/.abook/addresses
|
||||
```
|
||||
|
||||
Emacs 启动后,运行 `Meta+x bbdb-vcard-import-file`。它将提示你输入要导入的文件名,即 `~/all-my-address.vcf`。导入完成后,在编写消息时,可以开始输入名称并使用 `Tab` 搜索和自动完成 “to” 字段的内容。BBDB 还会打开一个联系人缓冲区,以便你确保它是正确的。
|
||||
|
||||
既然在 [vdirsyncer][16] 中已经为每个地址都生成了对应的 .vcf 文件了,为什么我们还要这样做呢?如果你像我一样,有许多地址,一次处理一个地址是很麻烦的。这样做,你就可以把所有的东西都放在 abook 里,做成一个大文件。
|
||||
|
||||
#### 使用 calfw 在 Emacs 中浏览日历
|
||||
|
||||
![calfw 日历 ][17]
|
||||
|
||||
最后,你可以使用 Emacs 查看日历。在上面的配置中,你安装了 [calfw][18] 包,并添加了一些行来告诉它在哪里可以找到要加载的日历。Calfw 是 “<ruby>Emacs 日历框架<rt>Calendar Framework for Emacs</rt></ruby>”的简称,它支持多种日历格式。我使用的是谷歌日历,这也是我放在配置中的链接。日历将在启动时自动加载,你可以通过 `Ctrl+x+b` 命令切换到 cfw-calendar 缓冲区来查看日历。
|
||||
|
||||
Calfw 提供日、周、双周和月视图。你可以在日历顶部选择视图,并使用箭头键导航日历。不幸的是,calfw 只能查看日历,所以你仍然需要使用 [khal][19] 之类的工具或通过 web 界面来添加、删除和修改事件。
|
||||
|
||||
这就是 Emacs 中的邮件、日历和邮件地址。明天我会展示更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/emacs-mail-calendar
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/email_paper_envelope_document.png?itok=uPj_kouJ (Document sending)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://www.gnu.org/software/emacs/
|
||||
[4]: https://linux.cn/article-11908-1.html
|
||||
[5]: https://linux.cn/article-11912-1.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/productivity_18-1.png (Mail and calendar in Emacs)
|
||||
[7]: https://www.spacemacs.org/
|
||||
[8]: https://opensource.com/article/19/12/spacemacs
|
||||
[9]: mailto:myemail@mydomain.com
|
||||
[10]: https://notmuchmail.org/
|
||||
[11]: https://opensource.com/sites/default/files/uploads/productivity_18-2.png (Reading mail with Notmuch)
|
||||
[12]: https://linux.cn/article-11807-1.html
|
||||
[13]: https://opensource.com/sites/default/files/uploads/productivity_18-3.png (Composing a message with BBDB addressing)
|
||||
[14]: https://www.jwz.org/bbdb/
|
||||
[15]: https://linux.cn/article-11834-1.html
|
||||
[16]: https://linux.cn/article-11812-1.html
|
||||
[17]: https://opensource.com/sites/default/files/uploads/productivity_18-4.png (calfw calendar)
|
||||
[18]: https://github.com/kiwanami/emacs-calfw
|
||||
[19]: https://khal.readthedocs.io/en/v0.9.2/index.html
|
||||
@ -0,0 +1,92 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11915-1.html)
|
||||
[#]: subject: (Meet FuryBSD: A New Desktop BSD Distribution)
|
||||
[#]: via: (https://itsfoss.com/furybsd/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
认识 FuryBSD:一个新的桌面 BSD 发行版
|
||||
======
|
||||
|
||||
在过去的几个月中,出现了一些新的桌面 BSD。之前有 [HyperbolaBSD,它之前是 Hyperbola GNU/Linux][1]。[BSD][2] 世界中的另一个新入者是 [FuryBSD][3]。
|
||||
|
||||
### FuryBSD:一个新的 BSD 发行版
|
||||
|
||||
![][4]
|
||||
|
||||
从本质上讲,FuryBSD 是一个非常简单的小东西。根据[它的网站][5]:“FuryBSD 一个是基于 FreeBSD 的轻量级桌面发行版。” 它基本上是预配置了桌面环境,并预安装了多个应用的 FreeBSD。目地是快速地在你的计算机上运行基于 FreeBSD 的系统。
|
||||
|
||||
你可能会认为这听起来很像其他几个已有的 BSD,例如 [NomadBSD][6] 和 [GhostBSD][7]。这些 BSD 与 FuryBSD 之间的主要区别在于 FuryBSD 与现有的 FreeBSD 更加接近。例如,FuryBSD 使用 FreeBSD 安装程序,而其他发行版则用了自己的安装程序和工具。
|
||||
|
||||
正如[它的网站][8]所说:“尽管 FuryBSD 可能类似于 PC-BSD 和 TrueOS 等图形化 BSD 项目,但 FuryBSD 是由不同的团队创建的,并且采用了不同与 FreeBSD 着重于紧密集成的方法。这样可以降低开销,并保持与上游的兼容性。”开发负责人还告诉我:“FuryBSD 的一个主要重点是使其成为一种小型现场版介质,并带有一些测试硬件驱动程序的辅助工具。”
|
||||
|
||||
当前,你可以进入 [FuryBSD 主页][3]并下载 XFCE 或 KDE 的 LiveCD。GNOME 版本正在开发中。
|
||||
|
||||
### FuryBSD 的背后是谁
|
||||
|
||||
FuryBSD 的主要开发者是 [Joe Maloney][9]。Joe 多年来一直是 FreeBSD 的用户。他为 PC-BSD 等其他 BSD 项目做过贡献。他还与 GhostBSD 的创建者 Eric Turgeon 一起重写了 GhostBSD LiveCD。在此过程中,他对 BSD 有了更好的了解,并开始形成自己如何做一个发行版的想法。
|
||||
|
||||
Joe 与其他参与 BSD 世界多年的开发者一起加入了开发,例如 Jaron Parsons、Josh Smith 和 Damian Szidiropulosz。
|
||||
|
||||
### FuryBSD 的未来
|
||||
|
||||
目前,FuryBSD 仅仅是预配置的 FreeBSD。但是,开发者有一份[要改进的清单][5]。包括:
|
||||
|
||||
* 可靠的加载框架、第三方专有图形驱动、无线网络
|
||||
* 进一步整理 LiveCD 体验,以使其更加友好
|
||||
* 开箱即用的打印支持
|
||||
* 包含更多默认应用,以提供完整的桌面体验
|
||||
* 集成的 [ZFS][10] 复制工具,用于备份和还原
|
||||
* Live 镜像持久化选项
|
||||
* 默认自定义 pkg 仓库
|
||||
* 用于应用更新的持续集成
|
||||
* 桌面 FreeBSD 的质量保证
|
||||
* 自定义、色彩方案和主题
|
||||
* 目录服务集成
|
||||
* 安全加固
|
||||
|
||||
开发者非常清楚地表明,他们所做的任何更改都需要大量的思考和研究。他们不会改进某个功能,只会在它破坏一些东西时删除或者修改它。
|
||||
|
||||
![FuryBSD desktop][11]
|
||||
|
||||
### 你可以如何帮助 FuryBSD?
|
||||
|
||||
目前,该项目还很年轻。由于所有项目都需要帮助才能生存,所以我问 Joe 他们正在寻求什么样的帮助。他说:“我们可以帮助[在论坛上回答问题][12]、回答 [GitHub][13] 上的问题,完善文档。”他还说如果人们想增加对其他桌面环境的支持,欢迎发起拉取请求。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
尽管我还没有尝试过,但是我对 FuryBSD 感觉不错。听起来项目在掌握中。十多年来,Joe Maloney 一直在思考如何达到最佳的 BSD 桌面体验。与大多数 Linux 发行版基本上都是经过重新设计的 Ubuntu 不同,FuryBSD 背后的开发者知道他们在做什么,并且他们在更看重质量而不是花哨的功能。
|
||||
|
||||
你对这个在不断增长的桌面 BSD 市场的新入者怎么看?你尝试过 FuryBSD 或者会尝试一下吗?请在下面的评论中告诉我们。
|
||||
|
||||
如果你觉得这篇文章有趣,请在 Hacker News 或 [Reddit][14] 等社交媒体上分享它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/furybsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/hyperbola-linux-bsd/
|
||||
[2]: https://itsfoss.com/bsd/
|
||||
[3]: https://www.furybsd.org/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/01/fury-bsd.jpg?ssl=1
|
||||
[5]: https://www.furybsd.org/manifesto/
|
||||
[6]: https://itsfoss.com/nomadbsd/
|
||||
[7]: https://ghostbsd.org/
|
||||
[8]: https://www.furybsd.org/furybsd-video-overview-at-knoxbug/
|
||||
[9]: https://github.com/pkgdemon
|
||||
[10]: https://itsfoss.com/what-is-zfs/
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/01/FuryBSDS-desktop.jpg?resize=800%2C450&ssl=1
|
||||
[12]: https://forums.furybsd.org/
|
||||
[13]: https://github.com/furybsd
|
||||
[14]: https://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11930-1.html)
|
||||
[#]: subject: (Troubleshoot Kubernetes with the power of tmux and kubectl)
|
||||
[#]: via: (https://opensource.com/article/20/2/kubernetes-tmux-kubectl)
|
||||
[#]: author: (Abhishek Tamrakar https://opensource.com/users/tamrakar)
|
||||
|
||||
利用 Tmux 和 kubectl 解决 Kubernetes 故障
|
||||
======
|
||||
|
||||
> 一个使用 tmux 的 kubectl 插件可以使 Kubernetes 疑难问题变得更简单。
|
||||
|
||||

|
||||
|
||||
[Kubernetes][2] 是一个活跃的开源容器管理平台,它提供了可扩展性、高可用性、健壮性和富有弹性的应用程序管理。它的众多特性之一是支持通过其主要的二进制客户端 [kubectl][3] 运行定制脚本或可执行程序,kubectl 很强大的,允许用户在 Kubernetes 集群上用它直接做很多事情。
|
||||
|
||||
### 使用别名进行 Kubernetes 的故障排查
|
||||
|
||||
使用 Kubernetes 进行容器编排的人都知道由于设计上原因带来了其功能的复杂性。举例说,迫切需要以更快的速度并且几乎不需要手动干预的方式来简化 Kubernetes 中的故障排除(除过特殊情况)。
|
||||
|
||||
在故障排查功能方面,有很多场景需要考虑。在一种场景下,你知道你需要运行什么,但是这个命令的语法(即使作为一个单独的命令运行)过于复杂,或需要一、两次交互才能起作用。
|
||||
|
||||
例如,如果你需要经常进入一个系统命名空间中运行的容器,你可能发现自己在重复地键入:
|
||||
|
||||
```
|
||||
kubectl --namespace=kube-system exec -i -t <your-pod-name>
|
||||
```
|
||||
|
||||
为了简化故障排查,你可以用这些指令的命令行别名。比如,你可以增加下面命令到你的隐藏配置文件(`.bashrc` 或 `.zshrc`):
|
||||
|
||||
```
|
||||
alias ksysex='kubectl --namespace=kube-system exec -i -t'
|
||||
```
|
||||
|
||||
这是来自于 [Kubernetes 常见别名][4]存储库的一个例子,它展示了一种简化 `kubectl` 中的功能的方法。像这种场景下的简单情形,使用别名很有用。
|
||||
|
||||
### 切换到 kubectl 插件
|
||||
|
||||
更复杂的故障排查场景是需要一个一个的执行很多命令,调查环境,最后得出结论。仅仅用别名方法是不能解决这种情况的;你需要知道你所部署的 Kubernetes 之间逻辑和相关性,你真正需要的是自动化,以在更短的时间内输出你想要的。
|
||||
|
||||
考虑到你的集群有 10 ~ 20 或 50 ~ 100 个命名空间来提供不同的微服务。一般在进行故障排查时,什么对你有帮助?
|
||||
|
||||
* 你需要能够快速分辨出抛出错误的是哪个 命名空间的哪个 Pod 的东西。
|
||||
* 你需要一些可监视一个命名空间的所有 Pod 日志的东西。
|
||||
* 你可能也需要监视特定命名空间的出现错误的某个 Pod 的日志。
|
||||
|
||||
涵盖这些要点的解决方案对于定位生产环境的问题有很大的帮助,以及在开发和测试环节中也很有用。
|
||||
|
||||
你可以用 [kubectl 插件][5]创建比简单的别名更强大的功能。插件类似于其它用任何语言编写的独立脚本,但被设计为可以扩充 Kubernetes 管理员的主要命令。
|
||||
|
||||
创建一个插件,你必须用 `kubectl-<your-plugin-name>` 的正确的语法来拷贝这个脚本到 `$PATH` 中的导出目录之一,并需要为其赋予可执行权限(`chmod +x`)。
|
||||
|
||||
创建插件之后将其移动到路径中,你可以立即运行它。例如,我的路径下有一个 `kubectl-krawl` 和 `kubectl-kmux`:
|
||||
|
||||
```
|
||||
$ kubectl plugin list
|
||||
The following compatible plugins are available:
|
||||
|
||||
/usr/local/bin/kubectl-krawl
|
||||
/usr/local/bin/kubectl-kmux
|
||||
|
||||
$ kubectl kmux
|
||||
```
|
||||
|
||||
现在让我们见识下带有 tmux 的 Kubernetes 的有多强大。
|
||||
|
||||
### 驾驭强大的 tmux
|
||||
|
||||
[Tmux][6] 是一个非常强大的工具,许多管理员和运维团队都依赖它来解决与易操作性相关的问题:通过将窗口分成多个窗格以便在多台计算机上运行并行的调试来监视日志。它的主要的优点是可在命令行或自动化脚本中使用。
|
||||
|
||||
我创建[一个 kubectl 插件][7],使用 tmux 使故障排查更加简单。我将通过注释来解析插件背后的逻辑(插件的完整代码留待给你实现):
|
||||
|
||||
```
|
||||
# NAMESPACE 是要监控的名字空间
|
||||
# POD 是 Pod 名称
|
||||
# Containers 是容器名称
|
||||
|
||||
# 初始化一个计数器 n 以计算循环计数的数量,
|
||||
# 之后 tmux 使用它来拆分窗格。
|
||||
n=0;
|
||||
|
||||
# 在 Pod 和容器列表上开始循环
|
||||
while IFS=' ' read -r POD CONTAINERS
|
||||
do
|
||||
# tmux 为每个 Pod 创建一个新窗口
|
||||
tmux neww $COMMAND -n $POD 2>/dev/null
|
||||
# 对运行中的 Pod 中 的所有容器启动循环
|
||||
for CONTAINER in ${CONTAINERS//,/ }
|
||||
do
|
||||
if [ x$POD = x -o x$CONTAINER = x ]; then
|
||||
# 如果任何值为 null,则退出。
|
||||
warn "Looks like there is a problem getting pods data."
|
||||
break
|
||||
fi
|
||||
|
||||
# 设置要执行的命令
|
||||
COMMAND=”kubectl logs -f $POD -c $CONTAINER -n $NAMESPACE”
|
||||
# 检查 tmux 会话
|
||||
if tmux has-session -t <会话名> 2>/dev/null;
|
||||
then
|
||||
<设置会话退出>
|
||||
else
|
||||
<创建会话>
|
||||
fi
|
||||
# 在当前窗口为每个容器切分窗格
|
||||
tmux selectp -t $n \; \
|
||||
splitw $COMMAND \; \
|
||||
select-layout tiled \;
|
||||
# 终止容器循环
|
||||
done
|
||||
|
||||
# 用 Pod 名称重命名窗口以识别
|
||||
tmux renamew $POD 2>/dev/null
|
||||
|
||||
# 增加计数器
|
||||
((n+=1))
|
||||
|
||||
# 终止 Pod 循环
|
||||
done<<(<从 kubernetes 集群获取 Pod 和容器的列表>)
|
||||
|
||||
# 最后选择窗口并附加会话
|
||||
tmux selectw -t <会话名>:1 \; \
|
||||
attach-session -t <会话名>\;
|
||||
```
|
||||
|
||||
运行插件脚本后,将产生类似于下图的输出。每个 Pod 有一个自己的窗口,每个容器(如果有多个)被分割到其窗口中 Pod 窗格中,并在日志到达时输出。Tmux 之美如下可见;通过正确的配置,你甚至会看到哪个窗口正处于激活运行状态(可看到标签是白色的)。
|
||||
|
||||
![kmux 插件的输出][8]
|
||||
|
||||
### 总结
|
||||
|
||||
别名是在 Kubernetes 环境下常见的也有用的简易故障排查方法。当环境变得复杂,用高级脚本生成的kubectl 插件是一个更强大的方法。至于用哪个编程语言来编写 kubectl 插件是没有限制。唯一的要求是该名字在路径中是可执行的,并且不能与已知的 kubectl 命令重复。
|
||||
|
||||
要阅读完整的插件源码,或试试我创建的插件,请查看我的 [kube-plugins-github][7] 存储库。欢迎提交提案和补丁。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/kubernetes-tmux-kubectl
|
||||
|
||||
作者:[Abhishek Tamrakar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tamrakar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OSDC_women_computing_4.png?itok=VGZO8CxT (一个坐在笔记本面前的妇女)
|
||||
[2]: https://opensource.com/resources/what-is-kubernetes
|
||||
[3]: https://kubernetes.io/docs/reference/kubectl/overview/
|
||||
[4]: https://github.com/ahmetb/kubectl-aliases/blob/master/.kubectl_aliases
|
||||
[5]: https://kubernetes.io/docs/tasks/extend-kubectl/kubectl-plugins/
|
||||
[6]: https://opensource.com/article/19/6/tmux-terminal-joy
|
||||
[7]: https://github.com/abhiTamrakar/kube-plugins
|
||||
[8]: https://raw.githubusercontent.com/abhiTamrakar/kube-plugins/master/kmux/kmux.png
|
||||
@ -1,13 +1,13 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11916-1.html)
|
||||
[#]: subject: (What is WireGuard? Why Linux Users Going Crazy Over it?)
|
||||
[#]: via: (https://itsfoss.com/wireguard/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
什么是 WireGuard?为什么 Linux 用户对它疯狂?
|
||||
什么是 WireGuard?为什么 Linux 用户为它疯狂?
|
||||
======
|
||||
|
||||
从普通的 Linux 用户到 Linux 创建者 [Linus Torvalds][1],每个人都对 WireGuard 很感兴趣。什么是 WireGuard,它为何如此特别?
|
||||
@ -18,7 +18,6 @@
|
||||
|
||||
[WireGuard][3] 是一个易于配置、快速且安全的开源 [VPN][4],它利用了最新的加密技术。目的是提供一种更快、更简单、更精简的通用 VPN,它可以轻松地在树莓派这类低端设备到高端服务器上部署。
|
||||
|
||||
|
||||
[IPsec][5] 和 OpenVPN 等大多数其他解决方案是几十年前开发的。安全研究人员和内核开发人员 Jason Donenfeld 意识到它们速度慢且难以正确配置和管理。
|
||||
|
||||
这让他创建了一个新的开源 VPN 协议和解决方案,它更加快速、安全、易于部署和管理。
|
||||
@ -31,31 +30,31 @@ WireGuard 最初是为 Linux 开发的,但现在可用于 Windows、macOS、BS
|
||||
|
||||
除了可以跨平台之外,WireGuard 的最大优点之一就是易于部署。配置和部署 WireGuard 就像配置和使用 SSH 一样容易。
|
||||
|
||||
看看 [WireGuard 设置指南][7]。安装 WireGuard、生成公钥和私钥(像 SSH 一样),设置防火墙规则并启动服务。现在将它和 [OpenVPN 设置指南][8]进行比较。它有太多要做的了。
|
||||
看看 [WireGuard 设置指南][7]。安装 WireGuard、生成公钥和私钥(像 SSH 一样),设置防火墙规则并启动服务。现在将它和 [OpenVPN 设置指南][8]进行比较——有太多要做的了。
|
||||
|
||||
WireGuard 的另一个好处是它有一个仅 4000 行代码的精简代码库。将它与 [OpenVPN][9](另一个流行的开源 VPN)的 100,000 行代码相比。显然,调试W ireGuard 更加容易。
|
||||
WireGuard 的另一个好处是它有一个仅 4000 行代码的精简代码库。将它与 [OpenVPN][9](另一个流行的开源 VPN)的 100,000 行代码相比。显然,调试 WireGuard 更加容易。
|
||||
|
||||
不要小看它的简单。WireGuard 支持所有最新的加密技术,例如 [Noise协议框架][10]、[Curve25519][11]、[ChaCha20][12]、[Poly1305][13]、[BLAKE2][14]、[SipHash24][15]、[HKDF][16] 和安全受信任结构。
|
||||
不要因其简单而小看它。WireGuard 支持所有最新的加密技术,例如 [Noise 协议框架][10]、[Curve25519][11]、[ChaCha20][12]、[Poly1305][13]、[BLAKE2][14]、[SipHash24][15]、[HKDF][16] 和安全受信任结构。
|
||||
|
||||
由于 WireGuard 运行在[内核空间][17],因此可以高速提供安全的网络。
|
||||
|
||||
这些是 WireGuard 越来越受欢迎的一些原因。Linux 创造者 Linus Torvalds 非常喜欢 WireGuard,以至于将其合并到 [Linux Kernel 5.6][18] 中:
|
||||
|
||||
> 我能否再次声明对它的爱,并希望它能很快合并?也许代码不是完美的,但我已经忽略,与 OpenVPN 和 IPSec 的恐怖相比,这是一件艺术品。
|
||||
> 我能否再次声明对它的爱,并希望它能很快合并?也许代码不是完美的,但我不在乎,与 OpenVPN 和 IPSec 的恐怖相比,这是一件艺术品。
|
||||
>
|
||||
> Linus Torvalds
|
||||
|
||||
### 如果 WireGuard 已经可用,那么将其包含在 Linux 内核中有什么大惊小怪的?
|
||||
|
||||
这可能会让新的 Linux 用户感到困惑。你知道可以在 Linux 上安装和配置 WireGuard VPN 服务器,但同时会看到 Linux Kernel 5.6 将包含 WireGuard 的消息。让我向您解释。
|
||||
这可能会让新的 Linux 用户感到困惑。你知道可以在 Linux 上安装和配置 WireGuard VPN 服务器,但同时也会看到 Linux Kernel 5.6 将包含 WireGuard 的消息。让我向您解释。
|
||||
|
||||
目前,你可以将 WireGuard 作为[内核模块][19]安装在 Linux 中。诸如 VLC、GIMP 等常规应用安装在 Linux 内核之上(在 [用户空间][20]中),而不是内部。
|
||||
目前,你可以将 WireGuard 作为[内核模块][19]安装在 Linux 中。而诸如 VLC、GIMP 等常规应用安装在 Linux 内核之上(在 [用户空间][20]中),而不是内部。
|
||||
|
||||
当将 WireGuard 安装为内核模块时,基本上是自行修改 Linux 内核并向其添加代码。从 5.6 内核开始,你无需手动添加内核模块。默认情况下它将包含在内核中。
|
||||
当将 WireGuard 安装为内核模块时,基本上需要你自行修改 Linux 内核并向其添加代码。从 5.6 内核开始,你无需手动添加内核模块。默认情况下它将包含在内核中。
|
||||
|
||||
在 5.6 内核中包含 WireGuard 很有可能[扩展 WireGuard 的采用,从而改变当前的 VPN 场景][21]。
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
WireGuard 之所以受欢迎是有充分理由的。诸如 [Mullvad VPN][23] 之类的一些流行的[关注隐私的 VPN][22] 已经在使用 WireGuard,并且在不久的将来,采用率可能还会增长。
|
||||
|
||||
@ -68,7 +67,7 @@ via: https://itsfoss.com/wireguard/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -96,4 +95,4 @@ via: https://itsfoss.com/wireguard/
|
||||
[20]: http://www.linfo.org/user_space.html
|
||||
[21]: https://www.zdnet.com/article/vpns-will-change-forever-with-the-arrival-of-wireguard-into-linux/
|
||||
[22]: https://itsfoss.com/best-vpn-linux/
|
||||
[23]: https://mullvad.net/en/
|
||||
[23]: https://mullvad.net/en/
|
||||
@ -0,0 +1,118 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (chai-yuan)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11909-1.html)
|
||||
[#]: subject: (Playing Music on your Fedora Terminal with MPD and ncmpcpp)
|
||||
[#]: via: (https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/)
|
||||
[#]: author: (Carmine Zaccagnino https://fedoramagazine.org/author/carzacc/)
|
||||
|
||||
在你的 Fedora 终端上播放音乐
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
MPD(Music Playing Daemon),顾名思义,是一个音乐(Music)播放(Playing)守护进程(Daemon)。它可以播放音乐,并且作为一个守护进程,任何软件都可以与之交互并播放声音,包括一些 CLI 客户端。
|
||||
|
||||
其中一个被称为 `ncmpcpp`,它是对之前 `ncmpc` 工具的改进。名字的变化与编写它们的语言没有太大关系:都是 C++,而之所以被称为 `ncmpcpp`,因为它是 “NCurses Music Playing Client Plus Plus”。 缘故
|
||||
|
||||
### 安装 MPD 和 ncmpcpp
|
||||
|
||||
`ncmpmpcc` 的客户端可以从官方 Fedora 库中通过 `dnf` 命令直接安装。
|
||||
|
||||
```
|
||||
$ sudo dnf install ncmpcpp
|
||||
```
|
||||
|
||||
另一方面,MPD 必须从 RPMFusion free 库安装,你可以通过运行:
|
||||
|
||||
```
|
||||
$ sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
|
||||
```
|
||||
|
||||
然后你可以运行下面的命令安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install mpd
|
||||
```
|
||||
|
||||
### 配置并启用 MPD
|
||||
|
||||
设置 MPD 最简单的方法是以普通用户的身份运行它。默认情况是以专用 `mpd` 用户的身份运行它,但这会导致各种权限问题。
|
||||
|
||||
在运行它之前,我们需要创建一个本地配置文件,允许我们作为普通用户运行。
|
||||
|
||||
首先在 `~/.config` 里创建一个名叫 `mpd` 的目录:
|
||||
|
||||
```
|
||||
$ mkdir ~/.config/mpd
|
||||
```
|
||||
|
||||
将配置文件拷贝到此目录下:
|
||||
|
||||
```
|
||||
$ cp /etc/mpd.conf ~/.config/mpd
|
||||
```
|
||||
|
||||
然后用 `vim`、`nano` 或 `gedit` 之类的软件编辑它:
|
||||
|
||||
```
|
||||
$ nano ~/.config/mpd/mpd.conf
|
||||
```
|
||||
|
||||
我建议你通读所有内容,检查是否有任何需要做的事情,但对于大多数设置你都可以删除,只需保留以下内容:
|
||||
|
||||
```
|
||||
db_file "~/.config/mpd/mpd.db"
|
||||
log_file "syslog"
|
||||
```
|
||||
|
||||
现在你可以运行它了:
|
||||
|
||||
```
|
||||
$ mpd
|
||||
```
|
||||
|
||||
没有报错,这将在后台启动 MPD 守护进程。
|
||||
|
||||
### 使用 ncmpcpp
|
||||
|
||||
只需运行:
|
||||
|
||||
```
|
||||
$ ncmpcpp
|
||||
```
|
||||
|
||||
你将在终端中看到一个由 ncurses 所支持的图形用户界面。
|
||||
|
||||
按下 `4` 键,然后就可以看到本地的音乐目录,用方向键进行选择并按下回车进行播放。
|
||||
|
||||
多播放几个歌曲就会创建一个*播放列表*,让你可以使用 `>` 键(不是右箭头, 是右尖括号)移动到下一首,并使用 `<` 返回上一首。`+` 和 `–` 键可以调节音量。`Q` 键可以让你退出 `ncmpcpp` 但不停止播放音乐。你可以按下 `P` 来控制暂停和播放。
|
||||
|
||||
你可以按下 `1` 键来查看当前播放列表(这是默认的视图)。从这个视图中,你可以按 `i` 查看有关当前歌曲的信息(标签)。按 `6` 可更改当前歌曲的标签。
|
||||
|
||||
按 `\` 按钮将在视图顶部添加(或删除)信息面板。在左上角,你可以看到如下的内容:
|
||||
|
||||
```
|
||||
[------]
|
||||
```
|
||||
|
||||
按下 `r`、`z`、`y`、`R`、`x` 将会分别切换到 `repeat`、`random`、`single`、`consume` 和 `crossfade` 等播放模式,并将这个小指示器中的 `–` 字符替换为选定模式。
|
||||
|
||||
按下 `F1` 键将会显示一些帮助文档,包含一系列的键绑定列表,因此无需在此处列出完整列表。所以继续吧!做一个极客,在你的终端上播放音乐!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/playing-music-on-your-fedora-terminal-with-mpd-and-ncmpcpp/
|
||||
|
||||
作者:[Carmine Zaccagnino][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[chai-yuan](https://github.com/chai-yuan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/carzacc/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/play_music_mpd-816x346.png
|
||||
[2]: https://rpmfusion.org/Configuration
|
||||
@ -0,0 +1,220 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11936-1.html)
|
||||
[#]: subject: (Scan Kubernetes for errors with KRAWL)
|
||||
[#]: via: (https://opensource.com/article/20/2/kubernetes-scanner)
|
||||
[#]: author: (Abhishek Tamrakar https://opensource.com/users/tamrakar)
|
||||
|
||||
使用 KRAWL 扫描 Kubernetes 错误
|
||||
======
|
||||
|
||||
> 用 KRAWL 脚本来识别 Kubernetes Pod 和容器中的错误。
|
||||
|
||||
![Ship captain sailing the Kubernetes seas][1]
|
||||
|
||||
当你使用 Kubernetes 运行容器时,你通常会发现它们堆积在一起。这是设计使然。它是容器的优点之一:每当需要新的容器时,它们启动成本都很低。你可以使用前端工具(如 OpenShift 或 OKD)来管理 Pod 和容器。这些工具使可视化设置变得容易,并且它具有一组丰富的用于快速交互的命令。
|
||||
|
||||
如果管理容器的平台不符合你的要求,你也可以仅使用 Kubernetes 工具链获取这些信息,但这需要大量命令才能全面了解复杂环境。出于这个原因,我编写了 [KRAWL][2],这是一个简单的脚本,可用于扫描 Kubernetes 集群命名空间下的 Pod 和容器,并在发现任何事件时,显示事件的输出。它也可用作为 Kubernetes 插件使用。这是获取大量有用信息的快速简便方法。
|
||||
|
||||
### 先决条件
|
||||
|
||||
* 必须安装 `kubectl`。
|
||||
* 集群的 kubeconfig 配置必须在它的默认位置(`$HOME/.kube/config`)或已被导出到环境变量(`KUBECONFIG=/path/to/kubeconfig`)。
|
||||
|
||||
### 使用
|
||||
|
||||
|
||||
```
|
||||
$ ./krawl
|
||||
```
|
||||
|
||||
![KRAWL script][3]
|
||||
|
||||
### 脚本
|
||||
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# AUTHOR: Abhishek Tamrakar
|
||||
# EMAIL: abhishek.tamrakar08@gmail.com
|
||||
# LICENSE: Copyright (C) 2018 Abhishek Tamrakar
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
##
|
||||
#define the variables
|
||||
KUBE_LOC=~/.kube/config
|
||||
#define variables
|
||||
KUBECTL=$(which kubectl)
|
||||
GET=$(which egrep)
|
||||
AWK=$(which awk)
|
||||
red=$(tput setaf 1)
|
||||
normal=$(tput sgr0)
|
||||
# define functions
|
||||
|
||||
# wrapper for printing info messages
|
||||
info()
|
||||
{
|
||||
printf '\n\e[34m%s\e[m: %s\n' "INFO" "$@"
|
||||
}
|
||||
|
||||
# cleanup when all done
|
||||
cleanup()
|
||||
{
|
||||
rm -f results.csv
|
||||
}
|
||||
|
||||
# just check if the command we are about to call is available
|
||||
checkcmd()
|
||||
{
|
||||
#check if command exists
|
||||
local cmd=$1
|
||||
if [ -z "${!cmd}" ]
|
||||
then
|
||||
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "check if $1 is installed !!!"
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
get_namespaces()
|
||||
{
|
||||
#get namespaces
|
||||
namespaces=( \
|
||||
$($KUBECTL get namespaces --ignore-not-found=true | \
|
||||
$AWK '/Active/ {print $1}' \
|
||||
ORS=" ") \
|
||||
)
|
||||
#exit if namespaces are not found
|
||||
if [ ${#namespaces[@]} -eq 0 ]
|
||||
then
|
||||
printf '\n\e[31m%s\e[m: %s\n' "ERROR" "No namespaces found!!"
|
||||
exit 1
|
||||
fi
|
||||
}
|
||||
|
||||
#get events for pods in errored state
|
||||
get_pod_events()
|
||||
{
|
||||
printf '\n'
|
||||
if [ ${#ERRORED[@]} -ne 0 ]
|
||||
then
|
||||
info "${#ERRORED[@]} errored pods found."
|
||||
for CULPRIT in ${ERRORED[@]}
|
||||
do
|
||||
info "POD: $CULPRIT"
|
||||
info
|
||||
$KUBECTL get events \
|
||||
--field-selector=involvedObject.name=$CULPRIT \
|
||||
-ocustom-columns=LASTSEEN:.lastTimestamp,REASON:.reason,MESSAGE:.message \
|
||||
--all-namespaces \
|
||||
--ignore-not-found=true
|
||||
done
|
||||
else
|
||||
info "0 pods with errored events found."
|
||||
fi
|
||||
}
|
||||
|
||||
#define the logic
|
||||
get_pod_errors()
|
||||
{
|
||||
printf "%s %s %s\n" "NAMESPACE,POD_NAME,CONTAINER_NAME,ERRORS" > results.csv
|
||||
printf "%s %s %s\n" "---------,--------,--------------,------" >> results.csv
|
||||
for NAMESPACE in ${namespaces[@]}
|
||||
do
|
||||
while IFS=' ' read -r POD CONTAINERS
|
||||
do
|
||||
for CONTAINER in ${CONTAINERS//,/ }
|
||||
do
|
||||
COUNT=$($KUBECTL logs --since=1h --tail=20 $POD -c $CONTAINER -n $NAMESPACE 2>/dev/null| \
|
||||
$GET -c '^error|Error|ERROR|Warn|WARN')
|
||||
if [ $COUNT -gt 0 ]
|
||||
then
|
||||
STATE=("${STATE[@]}" "$NAMESPACE,$POD,$CONTAINER,$COUNT")
|
||||
else
|
||||
#catch pods in errored state
|
||||
ERRORED=($($KUBECTL get pods -n $NAMESPACE --no-headers=true | \
|
||||
awk '!/Running/ {print $1}' ORS=" ") \
|
||||
)
|
||||
fi
|
||||
done
|
||||
done< <($KUBECTL get pods -n $NAMESPACE --ignore-not-found=true -o=custom-columns=NAME:.metadata.name,CONTAINERS:.spec.containers[*].name --no-headers=true)
|
||||
done
|
||||
printf "%s\n" ${STATE[@]:-None} >> results.csv
|
||||
STATE=()
|
||||
}
|
||||
#define usage for seprate run
|
||||
usage()
|
||||
{
|
||||
cat << EOF
|
||||
|
||||
USAGE: "${0##*/} </path/to/kube-config>(optional)"
|
||||
|
||||
This program is a free software under the terms of Apache 2.0 License.
|
||||
COPYRIGHT (C) 2018 Abhishek Tamrakar
|
||||
|
||||
EOF
|
||||
exit 0
|
||||
}
|
||||
|
||||
#check if basic commands are found
|
||||
trap cleanup EXIT
|
||||
checkcmd KUBECTL
|
||||
#
|
||||
#set the ground
|
||||
if [ $# -lt 1 ]; then
|
||||
if [ ! -e ${KUBE_LOC} -a ! -s ${KUBE_LOC} ]
|
||||
then
|
||||
info "A readable kube config location is required!!"
|
||||
usage
|
||||
fi
|
||||
elif [ $# -eq 1 ]
|
||||
then
|
||||
export KUBECONFIG=$1
|
||||
elif [ $# -gt 1 ]
|
||||
then
|
||||
usage
|
||||
fi
|
||||
#play
|
||||
get_namespaces
|
||||
get_pod_errors
|
||||
|
||||
printf '\n%40s\n' 'KRAWL'
|
||||
printf '%s\n' '---------------------------------------------------------------------------------'
|
||||
printf '%s\n' ' Krawl is a command line utility to scan pods and prints name of errored pods '
|
||||
printf '%s\n\n' ' +and containers within. To use it as kubernetes plugin, please check their page '
|
||||
printf '%s\n' '================================================================================='
|
||||
|
||||
cat results.csv | sed 's/,/,|/g'| column -s ',' -t
|
||||
get_pod_events
|
||||
```
|
||||
|
||||
此文最初发布在 [KRAWL 的 GitHub 仓库][2]下的 README 中,并被或许重用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/kubernetes-scanner
|
||||
|
||||
作者:[Abhishek Tamrakar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/tamrakar
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_captain_devops_kubernetes_steer.png?itok=LAHfIpek (Ship captain sailing the Kubernetes seas)
|
||||
[2]: https://github.com/abhiTamrakar/kube-plugins/tree/master/krawl
|
||||
[3]: https://opensource.com/sites/default/files/uploads/krawl_0.png (KRAWL script)
|
||||
[4]: mailto:abhishek.tamrakar08@gmail.com
|
||||
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11919-1.html)
|
||||
[#]: subject: (Top hacks for the YaCy open source search engine)
|
||||
[#]: via: (https://opensource.com/article/20/2/yacy-search-engine-hacks)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用开源搜索引擎 YaCy 的技巧
|
||||
======
|
||||
|
||||
> 无需适应其他人的眼光,而是使用 YaCY 搜索引擎定义你想要的互联网。
|
||||
|
||||

|
||||
|
||||
在我以前介绍 [YaCy 入门][2]的文章中讲述过 [YaCy][3] 这个<ruby>对等<rt>peer-to-peer</rt></ruby>式的搜索引擎是如何安装和使用的。YaCy 最令人兴奋的一点就是它事实上是一个本地客户端,全球范围内的每一个 YaCy 用户都是构成整个这个分布式搜索引擎架构的一个节点,这意味着每个用户都可以掌控自己的互联网搜索体验。
|
||||
|
||||
Google 曾经提供过 google.com/linux 这样的主题简便方式以便快速筛选出和 Linux 相关的搜索内容,这个小功能受到了很多人的青睐,但 Google 最终还是在 2011 年的时候把它[下线][4]了。
|
||||
|
||||
而 YaCy 则让自定义搜索引擎变得可能。
|
||||
|
||||
### 自定义 YaCy
|
||||
|
||||
YaCy 安装好之后,只需要访问 `localhost:8090` 就可以使用了。要自定义搜索引擎,只需要点击右上角的“<ruby>管理<rt>Administration</rt></ruby>”按钮(它可能隐藏在小屏幕的菜单图标中)。
|
||||
|
||||
你可以在管理面板中配置 YaCy 对系统资源的使用策略,以及如何跟其它的 YaCy 客户端进行交互。
|
||||
|
||||
![YaCy profile selector][5]
|
||||
|
||||
例如,点击侧栏中的“<ruby>第一步<rt>First steps</rt></ruby>”按钮可以配置备用端口,以及设置 YaCy 对内存和硬盘的使用量;而“<ruby>监控<rt>Monitoring</rt></ruby>”面板则可以监控 YaCy 的运行状况。大多数功能都只需要在面板上点击几下就可以完成了,例如以下几个常用的功能。
|
||||
|
||||
### 内网搜索应用
|
||||
|
||||
目前市面上也有不少公司推出了[内网搜索应用][6],而 YaCy 可以免费为你提供一个。对于能够通过 HTTP、FTP、Samba 等协议访问的文件,YaCy 都可以进行索引,因此无论是作为私人的文件搜索还是企业内部的本地共享文件搜索,YaCy 都可以实现。它可以让内部网络中的用户使用你个人的 YaCy 实例来查找共享文件,于此同时保持对内部网络以外的用户不可见。
|
||||
|
||||
### 网络配置
|
||||
|
||||
YaCy 在默认情况下就支持隐私和隔离。点击“<ruby>用例与账号<rt>Use Case & Account</rt></ruby>”页面顶部的“<ruby>网络配置<rt>Network Configuration</rt></ruby>”链接,即可进入网络配置面板设置对等网络。
|
||||
|
||||
![YaCy network configuration][7]
|
||||
|
||||
### 爬取站点
|
||||
|
||||
YaCy 的分布式运作方式决定了它对页面的爬取是由用户驱动的。并没有一个大型公司对整个互联网上的所有可访问页面都进行搜索,对于 YaCy 来说也是这样,一个站点只有在被用户指定爬取的前提下,才会被 YaCy 爬取并进入索引。
|
||||
|
||||
YaCy 客户端提供了两种爬取页面的方式:你可以手动爬取,并让 YaCy 根据建议去爬取。
|
||||
|
||||
![YaCy advanced crawler][8]
|
||||
|
||||
#### 手动爬取
|
||||
|
||||
手动爬取是指由用户输入指定的网站 URL 并启动 YaCy 的爬虫任务。只需要点击“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”并输入计划爬取的若干 URL,然后选择页面底部的“<ruby>进行远程索引<rt>Do Remote indexing</rt></ruby>”选项,这个选项会让客户端向互联网广播它要索引的 URL,可选地接受这些请求的客户端可以帮助你爬取这些 URL。
|
||||
|
||||
点击页面底部的“<ruby>开始新爬虫任务<rt>Start New Crawl Job</rt></ruby>”按钮就可以开始进行爬取了,我就是这样对一些常用和有用站点进行爬取和索引的。
|
||||
|
||||
爬虫任务启动之后,YaCy 会将这些 URL 对应的页面在本地生成和存储索引。在高级模式下,也就是本地计算机允许 8090 端口流量进出时,全网的 YaCy 用户都可以使用到这一份索引。
|
||||
|
||||
#### 加入爬虫网络
|
||||
|
||||
尽管一些非常敬业的 YaCy 高级用户已经强迫症般地在互联网上爬取了很多页面,但对于全网浩如烟海的页面而言也只是沧海一粟。单个用户所拥有的资源远不及很多大公司的网络爬虫,但大量 YaCy 用户如果联合起来成为一个社区,能产生的力量就大得多了。只要开启了 YaCy 的爬虫请求广播功能,就可以让其它客户端参与进来爬取更多页面。
|
||||
|
||||
只需要在“<ruby>高级爬虫<rt>Advanced Crawler</rt></ruby>”面板中点击页面顶部的“<ruby>远程爬取<rt>Remote Crawling</rt></ruby>”,勾选“<ruby>加载<rt>Load</rt></ruby>”旁边的复选框,就可以让你的客户端接受其它人发来的爬虫任务请求了。
|
||||
|
||||
![YaCy remote crawling][9]
|
||||
|
||||
### YaCy 监控相关
|
||||
|
||||
YaCy 除了作为一个非常强大的搜索引擎,还提供了很丰富的主题和用户体验。你可以在“<ruby>监控<rt>Monitor</rt></ruby>”面板中监控 YaCy 客户端的网络运行状况,甚至还可以了解到有多少人从 YaCy 社区中获取到了自己所需要的东西。
|
||||
|
||||
![YaCy monitoring screen][10]
|
||||
|
||||
### 搜索引擎发挥了作用
|
||||
|
||||
你使用 YaCy 的时间越长,就越会思考搜索引擎如何改变自己的视野,因为你对互联网的体验很大一部分来自于你在搜索引擎中一次次简单查询的结果。实际上,当你和不同行业的人交流时,可能会注意到每个人对“互联网”的理解都有所不同。有些人会认为,互联网的搜索引擎中充斥着各种广告和推广,同时也仅仅能从搜索结果中获取到有限的信息。例如,假设有人不断搜索关于关键词 X 的内容,那么大部分商业搜索引擎都会在搜索结果中提高关键词 X 的权重,但与此同时,另一个关键词 Y 的权重则会相对降低,从而让关键词 Y 被淹没在搜索结果当中,即使这样对完成特定任务更好。
|
||||
|
||||
就像在现实生活中一样,走出虚拟的世界视野会让你看到一个更广阔的世界。尝试使用 YaCy,看看你发现了什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/yacy-search-engine-hacks
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://linux.cn/article-11905-1.html
|
||||
[3]: https://yacy.net/
|
||||
[4]: https://www.linuxquestions.org/questions/linux-news-59/is-there-no-more-linux-google-884306/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/yacy-profiles.jpg (YaCy profile selector)
|
||||
[6]: https://en.wikipedia.org/wiki/Vivisimo
|
||||
[7]: https://opensource.com/sites/default/files/uploads/yacy-network-config.jpg (YaCy network configuration)
|
||||
[8]: https://opensource.com/sites/default/files/uploads/yacy-advanced-crawler.jpg (YaCy advanced crawler)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/yacy-remote-crawl-accept.jpg (YaCy remote crawling)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/yacy-monitor.jpg (YaCy monitoring screen)
|
||||
@ -1,32 +1,34 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11917-1.html)
|
||||
[#]: subject: (Dino is a Modern Looking Open Source XMPP Client)
|
||||
[#]: via: (https://itsfoss.com/dino-xmpp-client/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Dino 是一个有着现代外观的开源 XMPP 客户端
|
||||
Dino:一个有着现代外观的开源 XMPP 客户端
|
||||
======
|
||||
|
||||
_**简介:Dino 是一个相对较新的开源 XMPP 客户端,它尝试提供良好的用户体验,同时鼓励注重隐私的用户使用 XMPP 发送消息。**_
|
||||
> Dino 是一个相对较新的开源 XMPP 客户端,它试图提供良好的用户体验,鼓励注重隐私的用户使用 XMPP 发送消息。
|
||||
|
||||
|
||||
|
||||
### Dino:一个开源 XMPP 客户端
|
||||
|
||||
![][1]
|
||||
|
||||
[XMPP][2] (可扩展通讯和表示协议) 是一个去中心化的网络模型,可促进即时消息传递和协作。去中心化意味着没有中央服务器可以访问你的数据。通信直接点对点。
|
||||
[XMPP][2](<ruby>可扩展通讯和表示协议<rt>eXtensible Messaging Presence Protocol</rt></ruby>) 是一个去中心化的网络模型,可促进即时消息传递和协作。去中心化意味着没有中央服务器可以访问你的数据。通信直接点对点。
|
||||
|
||||
我们中的一些人可能会称它为"老派"技术,可能是因为 XMPP 客户端通常有着非常糟糕的用户体验,或者仅仅是因为它需要时间来适应(或设置它)。
|
||||
我们中的一些人可能会称它为“老派”技术,可能是因为 XMPP 客户端通常用户体验非常糟糕,或者仅仅是因为它需要时间来适应(或设置它)。
|
||||
|
||||
这时候 [Dino[3] 作为现代 XMPP 客户端出现了,在不损害你的隐私的情况下提供干净清爽的用户体验。
|
||||
这时候 [Dino][3] 作为现代 XMPP 客户端出现了,在不损害你的隐私的情况下提供干净清爽的用户体验。
|
||||
|
||||
### 用户体验
|
||||
|
||||
![][4]
|
||||
|
||||
Dino 有试图改善 XMPP 客户端的用户体验,但值得注意的是,它的外观和感受将在一定程度上取决于你的 Linux 发行版。你的图标主题或 Gnome 主题会让你的个人体验更好或更糟。
|
||||
Dino 试图改善 XMPP 客户端的用户体验,但值得注意的是,它的外观和感受将在一定程度上取决于你的 Linux 发行版。你的图标主题或 Gnome 主题会让你的个人体验更好或更糟。
|
||||
|
||||
从技术上讲,它的用户界面非常简单,易于使用。所以,我建议你看下 Ubuntu 中的[最佳图标主题][5]和 [GNOME 主题][6]来调整 Dino 的外观。
|
||||
|
||||
@ -34,7 +36,7 @@ Dino 有试图改善 XMPP 客户端的用户体验,但值得注意的是,它
|
||||
|
||||
![Dino Screenshot][7]
|
||||
|
||||
你可以期望将 Dino 用作 Slack、[Signal][8] 或 [Wire][9] 的替代产品,来用于你的业务或个人用途。
|
||||
你可以将 Dino 用作 Slack、[Signal][8] 或 [Wire][9] 的替代产品,来用于你的业务或个人用途。
|
||||
|
||||
它提供了消息应用所需的所有基本特性,让我们看下你可以从中得到的:
|
||||
|
||||
@ -47,14 +49,10 @@ Dino 有试图改善 XMPP 客户端的用户体验,但值得注意的是,它
|
||||
* 支持 [OpenPGP][10] 和 [OMEMO][11] 加密
|
||||
* 轻量级原生桌面应用
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上安装 Dino
|
||||
|
||||
你可能会发现它列在你的软件中心中,也可能未找到。Dino 为基于 Debian(deb)和 Fedora(rpm)的发行版提供了可用的二进制文件。
|
||||
|
||||
**对于 Ubuntu:**
|
||||
|
||||
Dino 在 Ubuntu 的 universe 仓库中,你可以使用以下命令安装它:
|
||||
|
||||
```
|
||||
@ -63,15 +61,15 @@ sudo apt install dino-im
|
||||
|
||||
类似地,你可以在 [GitHub 分发包页面][12]上找到其他 Linux 发行版的包。
|
||||
|
||||
如果你想要获取最新的,你可以在 [OpenSUSE 的软件页面][13]找到 Dino 的 **.deb** 和 .**rpm** (每日构建版)安装在 Linux 中。
|
||||
如果你想要获取最新的,你可以在 [OpenSUSE 的软件页面][13]找到 Dino 的 **.deb** 和 .**rpm** (每日构建版)安装在 Linux 中。
|
||||
|
||||
在任何一种情况下,前往它的 [Github 页面][14]或点击下面的链接访问官方网站。
|
||||
|
||||
[下载 Dino][3]
|
||||
- [下载 Dino][3]
|
||||
|
||||
**总结**
|
||||
### 总结
|
||||
|
||||
它工作良好没有出过任何问题(在我编写这篇文章时快速测试过它)。我将尝试探索更多,并希望能涵盖更多有关 XMPP 的文章来鼓励用户使用 XMPP 的客户端和服务器用于通信。
|
||||
在我编写这篇文章时快速测试过它,它工作良好,没有出过问题。我将尝试探索更多,并希望能涵盖更多有关 XMPP 的文章来鼓励用户使用 XMPP 的客户端和服务器用于通信。
|
||||
|
||||
你觉得 Dino 怎么样?你会推荐另一个可能好于 Dino 的开源 XMPP 客户端吗?在下面的评论中让我知道你的想法。
|
||||
|
||||
@ -82,7 +80,7 @@ via: https://itsfoss.com/dino-xmpp-client/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11944-1.html)
|
||||
[#]: subject: (How to use byobu to multiplex SSH sessions)
|
||||
[#]: via: (https://opensource.com/article/20/2/byobu-ssh)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
如何使用 byobu 复用 SSH 会话
|
||||
======
|
||||
|
||||
> Byobu 能让你在保持会话活跃的情况下维护多个终端窗口,通过 SSH 连接、断开、重连以及共享访问。
|
||||
|
||||
![Person drinking a hat drink at the computer][1]
|
||||
|
||||
[Byobu][2] 是基于文本的窗口管理器和终端多路复用器。它类似于 [GNU Screen][3],但更现代、更直观。它还适用于大多数 Linux、BSD 和 Mac 发行版。
|
||||
|
||||
Byobu 能让你在保持会话活跃的情况下维护多个终端窗口、通过 SSH(secure shell)连接、断开、重连,甚至让其他人访问。
|
||||
|
||||
比如,你 SSH 进入树莓派或服务器,并运行(比如) `sudo apt update && sudo apt upgrade`,然后你在它运行的时候失去了互联网连接,你的命令会丢失无效。然而,如果你首先启动 byobu 会话,那么它会继续运行,在你重连后,你会发现它仍在继续运行。
|
||||
|
||||
![The byobu logo is a fun play on screens.][4]
|
||||
|
||||
Byobu 名称来自于日语的装饰性多面板屏风,它可作为折叠式隔断,我认为这很合适。
|
||||
|
||||
要在 Debian/Raspbian/Ubuntu 上安装 byobu:
|
||||
|
||||
```
|
||||
sudo apt install byobu
|
||||
```
|
||||
|
||||
接着启用它:
|
||||
|
||||
```
|
||||
byobu-enable
|
||||
```
|
||||
|
||||
现在,请退出 SSH 会话并重新登录,你将会在 byobu 会话中登录。运行类似 `sudo apt update` 命令并关闭窗口(或输入转义序列([Enter + ~ + .][5])并重新登录。你将看到更新命令在你离开后还在运行。
|
||||
|
||||
有*很多*我不常使用的功能。我通常使用的是:
|
||||
|
||||
* `F2` – 新窗口
|
||||
* `F3/F4` – 在窗口间导航
|
||||
* `Ctrl`+`F2` – 垂直拆分窗格
|
||||
* `Shift`+`F2` – 水平拆分窗格
|
||||
* `Shift`+`左箭头/Shift`+`右箭头` – 在拆分窗格间导航
|
||||
* `Shift`+`F11` – 放大(或缩小)拆分窗格
|
||||
|
||||
### 我们如何使用 byobu
|
||||
|
||||
Byobu 对于维护 [piwheels][6](一个用于树莓派的方便的,预编译 Python 包)很好用。我水平拆分了窗格,在上半部分显示了 piwheels 监视器,在下半部分实时显示了 syslog 条目。接着,如果我们想要做其他事情,我们可以切换到另外一个窗口。当我们进行协作分析时,这特别方便,因为当我在 IRC 中聊天时,我可以看到我的同事 Dave 输入了什么(并纠正他的错字)。
|
||||
|
||||
我在家庭和办公服务器上启用了 byobu,因此,当我登录到任何一台计算机时,一切都与我离开时一样。它正在运行多个作业、在特定目录中保留一个窗口,以另一个用户身份运行进程等。
|
||||
|
||||
![byobu screenshot][7]
|
||||
|
||||
Byobu 对于在树莓派上进行开发也很方便。你可以在桌面上启动它,运行命令,然后 SSH 进入,并连接到该命令运行所在的会话。请注意,启用 byobu 不会更改终端启动器的功能。只需运行 `byobu` 即可启动它。
|
||||
|
||||
本文最初发表在 Ben Nuttall 的 [Tooling blog][8] 中,并获许重用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/byobu-ssh
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/coffee_tea_laptop_computer_work_desk.png?itok=D5yMx_Dr (Person drinking a hat drink at the computer)
|
||||
[2]: https://byobu.org/
|
||||
[3]: http://www.gnu.org/software/screen/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/byobu.png (byobu screen)
|
||||
[5]: https://www.google.com/search?client=ubuntu&channel=fs&q=Enter-tilde-dot&ie=utf-8&oe=utf-8
|
||||
[6]: https://opensource.com/article/20/1/piwheels
|
||||
[7]: https://opensource.com/sites/default/files/uploads/byobu-screenshot.png (byobu screenshot)
|
||||
[8]: https://tooling.bennuttall.com/byobu/
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11939-1.html)
|
||||
[#]: subject: (elementary OS is Building an App Center Where You Can Buy Open Source Apps for Your Linux Distribution)
|
||||
[#]: via: (https://itsfoss.com/appcenter-for-everyone/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
elementary OS 正在构建一个可以买应用的开源应用商店
|
||||
======
|
||||
|
||||
> elementary OS 正在构建一个应用中心生态系统,你可以在其中购买用于 Linux 发行版的开源应用程序。
|
||||
|
||||
### 众筹构建一个开源应用中心
|
||||
|
||||
![][1]
|
||||
|
||||
[elementary OS][2] 最近宣布,它正在[众筹举办一个构建应用中心的活动][3],你可以从这个应用中心购买开源应用程序。应用中心中的应用程序将为 Flatpak 格式。
|
||||
|
||||
尽管这是 elementary OS 发起的活动,但这个新的应用中心也将适用于其他发行版。
|
||||
|
||||
该活动旨在资助在美国科罗拉多州丹佛市进行的一项一周个人开发冲刺活动,其中包括来自 elementary OS、[Endless][4]、[Flathub][5] 和 [GNOME][6] 的开发人员。
|
||||
|
||||
众筹活动已经超过了筹集 1 万美元的目标(LCTT 译注:截止至本译文发布,已近 15000 美金)。但你仍然可以为其提供资金,因为其他资金将用于开发 elementary OS。
|
||||
|
||||
### 这个应用中心将带来什么功能
|
||||
|
||||
其重点是提供“安全”应用程序,因此使用 [Flatpak][7] 应用来提供受限的应用程序。在这种格式下,默认情况下将会限制应用程序访问系统或个人文件,并在技术层面上将它们与其他应用程序隔离。
|
||||
|
||||
仅当你明确表示同意时,应用程序才能访问操作系统和个人文件。
|
||||
|
||||
除了安全性,[Flatpak][8] 还捆绑了所有依赖项。这样,即使当前 Linux 发行版中不提供这些依赖项,应用程序开发人员也可以利用这种最先进的技术使用它。
|
||||
|
||||
AppCenter 还具有钱包功能,可以保存你的信用卡详细信息。这样,你无需每次输入卡的详细信息即可快速为应用付费。
|
||||
|
||||
![][9]
|
||||
|
||||
这个新的开源“应用中心”也将适用于其他 Linux 发行版。
|
||||
|
||||
### 受到了 elementary OS 自己的“按需付费”应用中心模型成功的启发
|
||||
|
||||
几年前,elementary OS 推出了自己的应用中心。应用中心的“按需付费”方法很受欢迎。开发人员可以为其开源应用设置最低金额,而用户可以选择支付等于或高于最低金额的金额。
|
||||
|
||||
![][10]
|
||||
|
||||
这帮助了几位独立开发人员可以对其开源应用程序接受付款。该应用中心现在拥有约 160 个原生应用程序,elementary OS 表示已通过应用中心向开发人员支付了数千美元。
|
||||
|
||||
受到此应用中心实验在 elementary OS 中的成功的启发,他们现在也希望将此应用中心的方法也引入其他发行版。
|
||||
|
||||
### 如果应用程序是开源的,你怎么为此付费?
|
||||
|
||||
某些人仍然对 FOSS(自由而开源)的概念感到困惑。在这里,该软件的“源代码”是“开源的”,任何人都可以“自由”进行修改和重新分发。
|
||||
|
||||
但这并不意味着开源软件必须免费。一些开发者依靠捐赠,而另一些则收取支持费用。
|
||||
|
||||
获得开源应用程序的报酬可能会鼓励开发人员创建 [Linux 应用程序][11]。
|
||||
|
||||
### 让我们拭目以待
|
||||
|
||||
![][12]
|
||||
|
||||
就个人而言,我不是 Flatpak 或 Snap 包格式的忠实拥护者。它们确实有其优点,但是它们花费了相对更多的时间来启动,并且它们的包大小很大。如果安装了多个此类 Snap 或 Flatpak 软件包,磁盘空间就会慢慢耗尽。
|
||||
|
||||
也需要对这个新的应用程序生态系统中的假冒和欺诈开发者保持警惕。想象一下,如果某些骗子开始创建冷门的开源应用程序的 Flatpak 程序包,并将其放在应用中心上?我希望开发人员采用某种机制来淘汰此类应用程序。
|
||||
|
||||
我确实希望这个新的应用中心能够复制在 elementary OS 中已经看到的成功。对于桌面 Linux 的开源应用程序,我们绝对需要更好的生态系统。
|
||||
|
||||
你对此有何看法?这是正确的方法吗?你对改进应用中心有什么建议?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/appcenter-for-everyone/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/appcenter.png?ssl=1
|
||||
[2]: https://elementary.io/
|
||||
[3]: https://www.indiegogo.com/projects/appcenter-for-everyone/
|
||||
[4]: https://itsfoss.com/endless-linux-computers/
|
||||
[5]: https://flathub.org/
|
||||
[6]: https://www.gnome.org/
|
||||
[7]: https://flatpak.org/
|
||||
[8]: https://itsfoss.com/flatpak-guide/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/appcenter-wallet.png?ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/appcenter-payment.png?ssl=1
|
||||
[11]: https://itsfoss.com/essential-linux-applications/
|
||||
[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/open_source_app_center.png?ssl=1
|
||||
@ -0,0 +1,97 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11924-1.html)
|
||||
[#]: subject: (Why developers like to code at night)
|
||||
[#]: via: (https://opensource.com/article/20/2/why-developers-code-night)
|
||||
[#]: author: (Matt Shealy https://opensource.com/users/mshealy)
|
||||
|
||||
程序员为什么喜欢在晚上编码
|
||||
======
|
||||
|
||||
> 对许多开源程序员来说,夜间的工作计划是创造力和生产力来源的关键。
|
||||
|
||||

|
||||
|
||||
如果你问大多数开发人员更喜欢在什么时候工作,大部人会说他们最高效的时间在晚上。这对于那些在工作之余为开源项目做贡献的人来说更是如此(尽管如此,希望在他们的健康范围内[避免透支][2])。
|
||||
|
||||
有些人喜欢从晚上开始,一直工作到凌晨,而另一些人则很早就起床(例如,凌晨 4 点),以便在开始日常工作之前完成大部分编程工作。
|
||||
|
||||
这种工作习惯可能会使许多开发人员看起来像个怪人,不合时宜。但是,为什么有这么多的程序员喜欢在非正常时间工作,原因有很多:
|
||||
|
||||
### 制造者日程
|
||||
|
||||
根据 <ruby>[保罗·格雷厄姆][3]<rt>Paul Graham</rt></ruby> 的观点,“生产东西”的人倾向于遵守 制造者日程 —— 他们更愿意以半天或更长时间为单位使用时间。事实上,大多数[开发人员也有相同的偏好][4]。(LCTT 译注:保罗·格雷厄姆有[一篇文章][8]述及制造者日程和管理者日程。)
|
||||
|
||||
一方面,开发人员从事大型抽象系统工作,需要思维空间来处理整个模型。将他们的日程分割成 15 分钟或 30 分钟的时间段来处理电子邮件、会议、电话以及来自同事的打断,工作效果只会适得其反。
|
||||
|
||||
另一方面,通常不可能以小时为单位进行有效编程。因为这么短的时间几乎不够让你把思绪放在手头的任务上并开始工作。
|
||||
|
||||
上下文切换也会对编程产生不利影响。在晚上工作,开发人员可以避免尽可能多的干扰。在没有不断的干扰的情况下,他们可以花几个小时专注于手头任务,并尽可能提高工作效率。
|
||||
|
||||
### 平和安静的环境
|
||||
|
||||
由于晚上或凌晨不太会有来自各种活动的噪音(例如,办公室闲谈、街道上的交通),这使许多程序员感到放松,促使他们更具创造力和生产力,特别是在处理诸如编码之类的精神刺激任务时。
|
||||
|
||||
独处与平静,加上他们知道自己将有几个小时不被中断的工作时间,通常会使他们摆脱白天工作计划相关的时间压力,从而产出高质量的工作。
|
||||
|
||||
更不用说了,当解决了一个棘手的问题后,没有什么比尽情享受自己最喜欢的午夜小吃更美好的事情了!
|
||||
|
||||
### 沟通
|
||||
|
||||
与在公司内工作的程序员相比,从事开源项目的开发人员可以拥有不同的沟通节奏。大多数开源项目的沟通都是通过邮件或 GitHub 上的评论等渠道异步完成的。很多时候,其他程序员在不同的国家和时区,因此实时交流通常需要开发人员变成一个夜猫子。
|
||||
|
||||
### 昏昏欲睡的大脑
|
||||
|
||||
这听起来可能违反直觉,但是随着时间的推移,大脑会变得非常疲倦,因此只能专注于一项任务。晚上工作从根本上消除了多任务处理,而这是保持专注和高效的主要障碍。当大脑处于昏昏欲睡的状态时,你是无法保持专注的!
|
||||
|
||||
此外,许多开发人员在入睡时思考要解决的问题通常会取得重大进展。潜意识开始工作,答案通常在他们半睡半醒的凌晨时分就出现了。
|
||||
|
||||
这不足为奇,因为[睡眠可增强大脑功能][5],可帮助我们理解新信息并进行更有创造性的思考。当解决方案在凌晨出现时,这些开发人员便会起来开始工作,不错过任何机会。
|
||||
|
||||
### 灵活和创造性思考
|
||||
|
||||
许多程序员体会到晚上创造力会提升。前额叶皮层,即大脑中与集中能力有关的部分,在一天结束时会感到疲倦。这似乎为某些人提供了更灵活和更具创造性的思考。
|
||||
|
||||
匹兹堡大学医学院精神病学助理教授 [Brant Hasler][6] 表示:“由于自上而下的控制和‘认知抑制’的减少,大脑可能会解放出来进行更发散的思考,从而使人们更容易地将不同概念之间的联系建立起来。” 结合轻松环境所带来的积极情绪,开发人员可以更轻松地产生创新想法。
|
||||
|
||||
此外,在没有干扰的情况下集中精力几个小时,“沉浸在你做的事情中”。这可以帮助你更好地专注于项目并参与其中,而不必担心周围发生的事情。
|
||||
|
||||
### 明亮的电脑屏幕
|
||||
|
||||
因为整天看着明亮的屏幕, 许多程序员的睡眠周期被延迟。电脑屏幕发出的蓝光[扰乱我们的昼夜节律][7],延迟了释放诱发睡眠的褪黑激素和提高人的机敏性,并将人体生物钟重置到更晚的时间。从而导致,开发人员往往睡得越来越晚。
|
||||
|
||||
### 来自过去的影响
|
||||
|
||||
过去,大多数开发人员是出于必要在晚上工作,因为在白天当公司其他人都在使用服务器时,共享服务器的计算能力支撑不了编程工作,所以开发人员需要等到深夜才能执行白天无法进行的任务,例如测试项目、运行大量的“编码-编译-运行-调试”周期以及部署新代码。现在尽管服务器功能变强大了,大多数可以满足需求,但夜间工作的趋势仍是这种文化的一部分。
|
||||
|
||||
### 结语
|
||||
|
||||
尽管开发人员喜欢在晚上工作的原因很多,但请记住,做为夜猫子并不意味着你应该克扣睡眠时间。睡眠不足会导致压力和焦虑,并最终导致倦怠。
|
||||
|
||||
获得足够质量的睡眠是维持良好身体健康和大脑功能的关键。例如,它可以帮助你整合新信息、巩固记忆、创造性思考、清除身体积聚的毒素、调节食欲并防止过早衰老。
|
||||
|
||||
无论你是哪种日程,请确保让你的大脑得到充分的休息,这样你就可以在一整天及每天的工作中发挥最大的作用!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/why-developers-code-night
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Morisun029](https://github.com/Morisun029)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/article/19/11/burnout-open-source-communities
|
||||
[3]: http://www.paulgraham.com/makersschedule.html
|
||||
[4]: https://www.chamberofcommerce.com/business-advice/software-development-trends-overtaking-the-market
|
||||
[5]: https://amerisleep.com/blog/sleep-impacts-brain-health/
|
||||
[6]: https://www.vice.com/en_us/article/mb58a8/late-night-creativity-spike
|
||||
[7]: https://www.sleepfoundation.org/articles/how-blue-light-affects-kids-sleep
|
||||
[8]: http://www.paulgraham.com/makersschedule.html
|
||||
@ -1,33 +1,33 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11931-1.html)
|
||||
[#]: subject: (Digging up IP addresses with the Linux dig command)
|
||||
[#]: via: (https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Digging up IP addresses with the Linux dig command
|
||||
使用 dig 命令挖掘域名解析信息
|
||||
======
|
||||
The dig command is extremely versatile both for retrieving information from domain name servers and for troubleshooting.
|
||||
Thinkstock
|
||||
|
||||
Not unlike **nslookup** in function, but with a lot more options, the **dig** command provides information that name servers manage and can be very useful for troubleshooting problems. It’s both simple to use and has lots of useful options.
|
||||
> 命令行工具 `dig` 是用于解析域名和故障排查的一个利器。
|
||||
|
||||
The name “dig” stands for “domain information groper” since domain groping is basically what it does. The amount of information that it provides depends on a series of options that you can use to tailor its output to your needs. Dig can provide a lot of detail or be surprisingly terse.
|
||||

|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
从主要功能上来说,`dig` 和 `nslookup` 之间差异不大,但 `dig` 更像一个加强版的 `nslookup`,可以查询到一些由域名服务器管理的信息,这在排查某些问题的时候非常有用。总的来说,`dig` 是一个既简单易用又功能强大的命令行工具。(LCTT 译注:`dig` 和 `nslookup` 行为的主要区别来自于 `dig` 使用是是操作系统本身的解析库,而 `nslookup` 使用的是该程序自带的解析库,这有时候会带来一些行为差异。此外,从表现形式上看,`dig` 返回是结果是以 BIND 配置信息的格式返回的,也带有更多的技术细节。)
|
||||
|
||||
### Just the IP, please
|
||||
`dig` 最基本的功能就是查询域名信息,因此它的名称实际上是“<ruby>域名信息查询工具<rt>Domain Information Groper</rt></ruby>”的缩写。`dig` 向用户返回的内容可以非常详尽,也可以非常简洁,展现内容的多少完全由用户在查询时使用的选项来决定。
|
||||
|
||||
To get _just_ the IP address for a system, add the **+short** option to your dig command like this:
|
||||
### 我只需要查询 IP 地址
|
||||
|
||||
如果只需要查询某个域名指向的 IP 地址,可以使用 `+short` 选项:
|
||||
|
||||
```
|
||||
$ dig facebook.com +short
|
||||
31.13.66.35
|
||||
```
|
||||
|
||||
Don't be surprised, however, if some domains are tied to multiple IP addresses to make the sites they support more reliable.
|
||||
在查询的时候发现有的域名会指向多个 IP 地址?这其实是网站提高其可用性的一种措施。
|
||||
|
||||
```
|
||||
$ dig networkworld.com +short
|
||||
@ -37,7 +37,7 @@ $ dig networkworld.com +short
|
||||
151.101.194.165
|
||||
```
|
||||
|
||||
Also, don't be surprised if the order of the IP addresses changes from one query to the next. This is a side effect of load balancing.
|
||||
也正是由于这些网站通过负载均衡实现高可用,在下一次查询的时候,或许会发现这几个 IP 地址的排序有所不同。(LCTT 译注:浏览器等应用默认会使用返回的第一个 IP 地址,因此这样实现了一种简单的负载均衡。)
|
||||
|
||||
```
|
||||
$ dig networkworld.com +short
|
||||
@ -47,9 +47,9 @@ $ dig networkworld.com +short
|
||||
151.101.66.165
|
||||
```
|
||||
|
||||
### Standard dig output
|
||||
### 标准返回
|
||||
|
||||
The standard dig display provides details on dig itself along with the response from the name server.
|
||||
`dig` 的标准返回内容则包括这个工具本身的一些信息,以及请求域名服务器时返回的响应内容:
|
||||
|
||||
```
|
||||
$ dig networkworld.com
|
||||
@ -77,9 +77,7 @@ networkworld.com. 300 IN A 151.101.2.165
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
Since name servers generally cache collected data for a while, the query time shown at the bottom of dig output might sometimes might say "0 msec":
|
||||
|
||||
[][2]
|
||||
由于域名服务器有缓存机制,返回的内容可能是之前缓存好的信息。在这种情况下,`dig` 最后显示的<ruby>查询时间<rt>Query time</rt></ruby>会是 0 毫秒(0 msec):
|
||||
|
||||
```
|
||||
;; Query time: 0 msec <==
|
||||
@ -88,11 +86,11 @@ Since name servers generally cache collected data for a while, the query time sh
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
### Who you gonna ask?
|
||||
### 向谁查询?
|
||||
|
||||
By default, dig will refer to your **/etc/resolv.conf** file to determine what name server to query, but you can refer queries to other DNS servers by adding an **@** option.
|
||||
在默认情况下,`dig` 会根据 `/etc/resolv.conf` 这个文件的内容决定向哪个域名服务器获取查询结果。你也可以使用 `@` 来指定 `dig` 请求的域名服务器。
|
||||
|
||||
In the example below, for example, the query is being sent to Google's name server (i.e., 8.8.8.8).
|
||||
在下面的例子中,就指定了 `dig` 向 Google 的域名服务器 8.8.8.8 查询域名信息。
|
||||
|
||||
```
|
||||
$ dig @8.8.8.8 networkworld.com
|
||||
@ -121,21 +119,21 @@ networkworld.com. 299 IN A 151.101.2.165
|
||||
;; MSG SIZE rcvd: 109
|
||||
```
|
||||
|
||||
To determine what version of dig you’re using, use the **-v** option. You should see something like this:
|
||||
想要知道正在使用的 `dig` 工具的版本,可以使用 `-v` 选项。你会看到类似这样:
|
||||
|
||||
```
|
||||
$ dig -v
|
||||
DiG 9.11.5-P4-5.1ubuntu2.1-Ubuntu
|
||||
```
|
||||
|
||||
or this:
|
||||
或者这样的返回信息:
|
||||
|
||||
```
|
||||
$ dig -v
|
||||
DiG 9.11.4-P2-RedHat-9.11.4-22.P2.el8
|
||||
```
|
||||
|
||||
To get just the answer portion of this response, you can omit name server details, but still get the answer you're looking for by using both a **+noall** (don't show everything) and a **+answer** (but show the answer section) like this:
|
||||
如果你觉得 `dig` 返回的内容过于详细,可以使用 `+noall`(不显示所有内容)和 `+answer`(仅显示域名服务器的响应内容)选项,域名服务器的详细信息就会被忽略,只保留域名解析结果。
|
||||
|
||||
```
|
||||
$ dig networkworld.com +noall +answer
|
||||
@ -148,9 +146,9 @@ networkworld.com. 300 IN A 151.101.66.165
|
||||
networkworld.com. 300 IN A 151.101.2.165
|
||||
```
|
||||
|
||||
### Looking up a batch of systems
|
||||
### 批量查询域名
|
||||
|
||||
If you want to dig for a series of domain names, you can list the domain names in a file and then use a command like this one to have dig run through the list and provide the information.
|
||||
如果你要查询多个域名,可以把这些域名写入到一个文件内(`domains`),然后使用下面的 `dig` 命令遍历整个文件并给出所有查询结果。
|
||||
|
||||
```
|
||||
$ dig +noall +answer -f domains
|
||||
@ -165,7 +163,7 @@ amazon.com. 18 IN A 176.32.98.166
|
||||
amazon.com. 18 IN A 205.251.242.103
|
||||
```
|
||||
|
||||
You could add +short to the command above but, with some sites having multiple IP addresses, this might not be very useful. To cut down on the detail but be sure that you can tell which IP belongs to which domain, you could instead pass the output to **awk** to display just the first and last columns of data:
|
||||
你也可以在上面的命令中使用 `+short` 选项,但如果其中有些域名指向多个 IP 地址,就无法看出哪些 IP 地址对应哪个域名了。在这种情况下,更好地做法应该是让 `awk` 对返回内容进行处理,只留下第一列和最后一列:
|
||||
|
||||
```
|
||||
$ dig +noall +answer -f domains | awk '{print $1,$NF}'
|
||||
@ -179,16 +177,14 @@ amazon.com. 205.251.242.103
|
||||
amazon.com. 176.32.103.205
|
||||
```
|
||||
|
||||
Join the Network World communities on [Facebook][3] and [LinkedIn][4] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527430/digging-up-ip-addresses-with-the-dig-command.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
115
published/202002/20200217 How to get MongoDB Server on Fedora.md
Normal file
115
published/202002/20200217 How to get MongoDB Server on Fedora.md
Normal file
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11942-1.html)
|
||||
[#]: subject: (How to get MongoDB Server on Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/)
|
||||
[#]: author: (Honza Horak https://fedoramagazine.org/author/hhorak/)
|
||||
|
||||
如何在 Fedora 上安装 MongoDB 服务器
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Mongo(来自 “humongous” —— 巨大的)是一个高性能、开源、无模式的、面向文档的数据库,它是最受欢迎的 [NoSQL][2] 数据库之一。它使用 JSON 作为文档格式,并且可以在多个服务器节点之间进行扩展和复制。
|
||||
|
||||
### 有关许可证更改的故事
|
||||
|
||||
MongoDB 上游决定更改服务器代码的许可证已经一年多了。先前的许可证是 GNU Affero General Public License v3(AGPLv3)。但是,上游公司写了一个新许可证,旨在使运行 MongoDB 即服务的公司可以回馈社区。新许可证称为 Server Side Public License(SSPLv1),关于这个举措及其解释的更多说明,请参见 [MongoDB SSPL FAQ][3]。
|
||||
|
||||
Fedora 一直只包含自由软件。当 SSPL 发布后,Fedora [确定][4]它并不是自由软件许可证。许可证更改日期(2018 年 10 月)之前发布的所有 MongoDB 版本都可保留在 Fedora 中,但之后再也不更新的软件包会带来安全问题。因此,从 Fedora 30 开始,Fedora 社区决定完全[移除 MongoDB 服务器][5]。
|
||||
|
||||
### 开发人员还有哪些选择?
|
||||
|
||||
是的,还有替代方案,例如 PostgreSQL 在最新版本中也支持 JSON,它可以在无法再使用 MongoDB 的情况下使用它。使用 JSONB 类型,索引在 PostgreSQL 中可以很好地工作,其性能可与 MongoDB 媲美,甚至不会受到 ACID 的影响。
|
||||
|
||||
开发人员可能选择 MongoDB 的技术原因并未随许可证而改变,因此许多人仍想使用它。重要的是要意识到,SSPL 许可证仅更改仅针对 MongoDB 服务器。MongoDB 上游还开发了其他项目,例如 MongoDB 工具、C 和 C++ 客户端库以及用于各种动态语言的连接器,这些项目在客户端使用(通过网络与服务器通信的应用中)。由于这些包的许可证人保持自由(主要是 Apache 许可证),因此它们保留在 Fedora 仓库中,因此用户可以将其用于应用开发。
|
||||
|
||||
唯一的变化实际是服务器软件包本身,它已从 Fedora 仓库中完全删除。让我们看看 Fedora 用户可以如何获取非自由的包。
|
||||
|
||||
### 如何从上游安装 MongoDB 服务器
|
||||
|
||||
当 Fedora 用户想要安装 MongoDB 服务器时,他们需要直接向上游获取 MongoDB。但是,上游不为 Fedora 提供 RPM 包。相反,MongoDB 服务器可以获取源码 tarball,用户需要自己进行编译(这需要一些开发知识),或者 Fedora 用户可以使用一些兼容的包。在兼容的选项中,最好的选择是 RHEL-8 RPM。以下步骤描述了如何安装它们以及如何启动守护进程。
|
||||
|
||||
#### 1、使用上游 RPM 创建仓库(RHEL-8 构建)
|
||||
|
||||
```
|
||||
$ sudo cat > /etc/yum.repos.d/mongodb.repo >>EOF
|
||||
[mongodb-upstream]
|
||||
name=MongoDB Upstream Repository
|
||||
baseurl=https://repo.mongodb.org/yum/redhat/8Server/mongodb-org/4.2/x86_64/
|
||||
gpgcheck=1
|
||||
enabled=1
|
||||
gpgkey=https://www.mongodb.org/static/pgp/server-4.2.asc
|
||||
EOF
|
||||
```
|
||||
|
||||
#### 2、安装元软件包,来拉取服务器和工具包
|
||||
|
||||
```
|
||||
$ sudo dnf install mongodb-org
|
||||
......
|
||||
Installed:
|
||||
mongodb-org-4.2.3-1.el8.x86_64 mongodb-org-mongos-4.2.3-1.el8.x86_64
|
||||
mongodb-org-server-4.2.3-1.el8.x86_64 mongodb-org-shell-4.2.3-1.el8.x86_64
|
||||
mongodb-org-tools-4.2.3-1.el8.x86_64
|
||||
|
||||
Complete!
|
||||
```
|
||||
|
||||
#### 3、启动 MongoDB 守护进程
|
||||
|
||||
```
|
||||
$ sudo systemctl status mongod
|
||||
● mongod.service - MongoDB Database Server
|
||||
Loaded: loaded (/usr/lib/systemd/system/mongod.service; enabled; vendor preset: disabled)
|
||||
Active: active (running) since Sat 2020-02-08 12:33:45 EST; 2s ago
|
||||
Docs: https://docs.mongodb.org/manual
|
||||
Process: 15768 ExecStartPre=/usr/bin/mkdir -p /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15769 ExecStartPre=/usr/bin/chown mongod:mongod /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15770 ExecStartPre=/usr/bin/chmod 0755 /var/run/mongodb (code=exited, status=0/SUCCESS)
|
||||
Process: 15771 ExecStart=/usr/bin/mongod $OPTIONS (code=exited, status=0/SUCCESS)
|
||||
Main PID: 15773 (mongod)
|
||||
Memory: 70.4M
|
||||
CPU: 611ms
|
||||
CGroup: /system.slice/mongod.service
|
||||
|
||||
```
|
||||
|
||||
#### 4、通过 mongo shell 连接服务器来验证是否运行
|
||||
|
||||
```
|
||||
$ mongo
|
||||
MongoDB shell version v4.2.3
|
||||
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
|
||||
Implicit session: session { "id" : UUID("20b6e61f-c7cc-4e9b-a25e-5e306d60482f") }
|
||||
MongoDB server version: 4.2.3
|
||||
Welcome to the MongoDB shell.
|
||||
For interactive help, type "help".
|
||||
For more comprehensive documentation, see
|
||||
http://docs.mongodb.org/
|
||||
---
|
||||
```
|
||||
|
||||
|
||||
就是这样了。如你所见,RHEL-8 包完美兼容,只要 Fedora 包还与 RHEL-8 兼容,它就应该会一直兼容。请注意,在使用时必须遵守 SSPLv1 许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-to-get-mongodb-server-on-fedora/
|
||||
|
||||
作者:[Honza Horak][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/hhorak/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/mongodb-816x348.png
|
||||
[2]: https://en.wikipedia.org/wiki/NoSQL
|
||||
[3]: https://www.mongodb.com/licensing/server-side-public-license/faq
|
||||
[4]: https://lists.fedoraproject.org/archives/list/legal@lists.fedoraproject.org/thread/IQIOBOGWJ247JGKX2WD6N27TZNZZNM6C/
|
||||
[5]: https://fedoraproject.org/wiki/Changes/MongoDB_Removal
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qianmingtian)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11923-1.html)
|
||||
[#]: subject: (How to install Vim plugins)
|
||||
[#]: via: (https://opensource.com/article/20/2/how-install-vim-plugins)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
@ -10,74 +10,73 @@
|
||||
如何安装 Vim 插件
|
||||
======
|
||||
|
||||
无论你是手动安装还是通过包管理器安装,插件都可以帮你为你的工作流中打造一个完美的 Vim 。
|
||||
![Team checklist and to dos][1]
|
||||
> 无论你是手动安装还是通过包管理器安装,插件都可以帮助你在工作流中打造一个完美的 Vim 。
|
||||
|
||||
虽然 [Vim][2] 是快速且高效的,但在默认情况下,它仅仅只是一个文本编辑器。至少,这就是没有插件的情况 Vim 应当具备的样子,插件构建在 Vim 之上,并添加额外的功能,使 Vim 不仅仅是一个输入文本的窗口。有了合适的插件组合,你可以控制你的生活,形成你自己独特的 Vim 体验。你可以[自定义你的主题][3],你可以添加语法高亮,代码 linting ,版本跟踪器等等。
|
||||

|
||||
|
||||
虽然 [Vim][2] 是快速且高效的,但在默认情况下,它仅仅只是一个文本编辑器。至少,这就是没有插件的情况 Vim 应当具备的样子,插件构建在 Vim 之上,并添加额外的功能,使 Vim 不仅仅是一个输入文本的窗口。有了合适的插件组合,你可以控制你的生活,形成你自己独特的 Vim 体验。你可以[自定义你的主题][3],你可以添加语法高亮,代码 linting,版本跟踪器等等。
|
||||
|
||||
### 怎么安装 Vim 插件
|
||||
|
||||
Vim 可以通过插件进行扩展,但很长一段时间以来,并没有官方的安装方式去安装这些插件。从 Vim 8 开始,有一个关于插件如何安装和加载的结构。你可能会在网上或项目自述文件中遇到旧的说明,但只要你运行 Vim 8 或更高版本,你应该根据 Vim 的[官方插件安装方法][4]安装或使用 Vim 包管理器。您可以使用包管理器,无论你运行的是什么版本(包括比 8.x 更老的版本),这使得安装过程比您自己维护更新更容易。
|
||||
Vim 可以通过插件进行扩展,但很长一段时间以来,并没有官方的安装方式去安装这些插件。从 Vim 8 开始,有一个关于插件如何安装和加载的结构。你可能会在网上或项目自述文件中遇到旧的说明,但只要你运行 Vim 8 或更高版本,你应该根据 Vim 的[官方插件安装方法][4]安装或使用 Vim 包管理器。你可以使用包管理器,无论你运行的是什么版本(包括比 8.x 更老的版本),这使得安装过程比你自己维护更新更容易。
|
||||
|
||||
手动和自动安装方法都值得了解,所以请继续阅读以了解这两种方法。
|
||||
|
||||
### 手动安装插件( Vim 8 及以上版本)
|
||||
### 手动安装插件(Vim 8 及以上版本)
|
||||
|
||||
Vim 包是一个包含一个或多个插件的目录。默认情况下,你的 Vim 设置包含在 **~/.vim** 中,这是 vim 在启动时寻找插件的地方。(下面的示例使用了通用名称 **vendor** 来表示插件是从一个不是你的实体获得的。)
|
||||
所谓的 “Vim 包”是一个包含一个或多个插件的目录。默认情况下,你的 Vim 设置包含在 `~/.vim` 中,这是 Vim 在启动时寻找插件的地方。(下面的示例使用了通用名称 `vendor` 来表示插件是从其它地方获得的。)
|
||||
|
||||
当你启动 Vim 时,它首先处理你的 **.vimrc**文件,然后扫描 **~/.vim** 中的所有目录查找包含在 **pack/*/start** 中的插件。
|
||||
当你启动 Vim 时,它首先处理你的 `.vimrc`文件,然后扫描 `~/.vim` 中的所有目录,查找包含在 `pack/*/start` 中的插件。
|
||||
|
||||
默认情况下,你的 **~/.vim** 目录(如果你有一个)没有这样的文件结构,所以设置为:
|
||||
默认情况下,你的 `~/.vim` 目录(如果你有的话)中没有这样的文件结构,所以设置为:
|
||||
|
||||
```
|
||||
`$ mkdir -p ~/.vim/pack/vendor/start`
|
||||
$ mkdir -p ~/.vim/pack/vendor/start
|
||||
```
|
||||
|
||||
现在,你可以将 Vim 插件放在 **~/.vim/pack/vendor/start** 中,它们会在你启动 Vim 时自动加载。
|
||||
|
||||
例如,尝试安装一下 [NERDTree][5] ,一个基于文本的 Vim 文件管理器。首先,使用 Git 克隆 NERDTree 存储库的快照:
|
||||
现在,你可以将 Vim 插件放在 `~/.vim/pack/vendor/start` 中,它们会在你启动 Vim 时自动加载。
|
||||
|
||||
例如,尝试安装一下 [NERDTree][5],这是一个基于文本的 Vim 文件管理器。首先,使用 Git 克隆 NERDTree 存储库的快照:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 \
|
||||
<https://github.com/preservim/nerdtree.git> \
|
||||
https://github.com/preservim/nerdtree.git \
|
||||
~/.vim/pack/vendor/start/nerdtree
|
||||
```
|
||||
|
||||
启动 Vim 或者 gvim ,然后键入如下命令:
|
||||
|
||||
启动 Vim 或者 gvim,然后键入如下命令:
|
||||
|
||||
```
|
||||
`:NERDTree`
|
||||
:NERDTree
|
||||
```
|
||||
|
||||
Vim 窗口左侧将打开一个文件树。
|
||||
|
||||
![NERDTree plugin][6]
|
||||
|
||||
如果你不想每次启动 Vim 时自动加载插件,你可以在 **~/.vim/pack/vendor** 中创建 **opt** 文件夹:
|
||||
如果你不想让一个插件每次启动 Vim 时都自动加载,你可以在 `~/.vim/pack/vendor` 中创建 `opt` 文件夹:
|
||||
|
||||
```
|
||||
`$ mkdir ~/.vim/pack/vendor/opt`
|
||||
$ mkdir ~/.vim/pack/vendor/opt
|
||||
```
|
||||
|
||||
任何安装到 **opt** 的插件都可被 Vim 使用,但是只有当你使用 **packadd** 命令将它们添加到一个会话中时,它们才会被加载到内存中。例如,一个虚构的叫 foo 的插件:
|
||||
任何安装到 `opt` 的插件都可被 Vim 使用,但是只有当你使用 `packadd` 命令将它们添加到一个会话中时,它们才会被加载到内存中。例如,一个虚构的叫 foo 的插件:
|
||||
|
||||
```
|
||||
`:packadd foo`
|
||||
:packadd foo
|
||||
```
|
||||
|
||||
Vim 官方建议每个插件项目在 **~/.Vim /pack** 中有自己的目录。例如,如果你要安装 NERDTree 插件和假想的 foo 插件,你需要创建这样的目录结构:
|
||||
Vim 官方建议每个插件项目在 `~/.Vim/pack` 中创建自己的目录。例如,如果你要安装 NERDTree 插件和假想的 foo 插件,你需要创建这样的目录结构:
|
||||
|
||||
```
|
||||
$ mkdir -p ~/.vim/pack/NERDTree/start/
|
||||
$ git clone --depth 1 \
|
||||
<https://github.com/preservim/nerdtree.git> \
|
||||
~/.vim/pack/NERDTree/start/NERDTree
|
||||
https://github.com/preservim/nerdtree.git \
|
||||
~/.vim/pack/NERDTree/start/NERDTree
|
||||
$ mkdir -p ~/.vim/pack/foo/start/
|
||||
$ git clone --depth 1 \
|
||||
<https://notabug.org/foo/foo.git> \
|
||||
~/.vim/pack/foo/start/foo
|
||||
https://notabug.org/foo/foo.git \
|
||||
~/.vim/pack/foo/start/foo
|
||||
```
|
||||
|
||||
这样做是否方便取决于你。
|
||||
@ -88,14 +87,14 @@ $ git clone --depth 1 \
|
||||
|
||||
#### 使用 vim-plug 安装插件
|
||||
|
||||
安装 vim-plug ,以便它在启动时自动加载:
|
||||
安装 vim-plug,以便它在启动时自动加载:
|
||||
|
||||
```
|
||||
$ curl -fLo ~/.vim/autoload/plug.vim --create-dirs \
|
||||
<https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim>
|
||||
https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vim
|
||||
```
|
||||
|
||||
创建一个 **~/.vimrc** 文件(如果你还没有文件),然后输入以下文本:
|
||||
创建一个 `~/.vimrc` 文件(如果你还没有这个文件),然后输入以下文本:
|
||||
|
||||
```
|
||||
call plug#begin()
|
||||
@ -103,38 +102,38 @@ Plug 'preservim/NERDTree'
|
||||
call plug#end()
|
||||
```
|
||||
|
||||
每次要安装插件时,都必须在 **plug#begin()** 和 **plug#end()** 之间输入插件的名称和位置(上面以 NERDTree 文件管理器为例。)。如果你所需的插件未托管在 GitHub 上,你可以提供完整的 URL ,而不仅仅是 GitHub 用户名和项目 ID 。你甚至可以在 **~/.vim** 目录之外“安装”本地插件。
|
||||
每次要安装插件时,都必须在 `plug#begin()` 和 `plug#end()` 之间输入插件的名称和位置(上面以 NERDTree 文件管理器为例)。如果你所需的插件未托管在 GitHub 上,你可以提供完整的 URL,而不仅仅是 GitHub 的用户名和项目 ID。你甚至可以在 `~/.vim` 目录之外“安装”本地插件。
|
||||
|
||||
最后,启动 Vim 并提示 vim-plug 安装 **~/.vimrc** 中列出的插件:
|
||||
最后,启动 Vim 并提示 vim-plug 安装 `~/.vimrc` 中列出的插件:
|
||||
|
||||
```
|
||||
`:PlugInstall`
|
||||
:PlugInstall
|
||||
```
|
||||
|
||||
等待插件下载。
|
||||
|
||||
#### 通过 vim-plug 更新插件
|
||||
|
||||
与手动安装过程相比,编辑 **~/.vimrc** 并使用命令来进行安装可能看起来并没有多省事,但是 vim-plug 的真正优势在更新。更新所有安装的插件,使用这个 Vim 命令:
|
||||
与手动安装过程相比,编辑 `~/.vimrc` 并使用命令来进行安装可能看起来并没有多省事,但是 vim-plug 的真正优势在更新。更新所有安装的插件,使用这个 Vim 命令:
|
||||
|
||||
```
|
||||
`:PlugUpdate`
|
||||
:PlugUpdate
|
||||
```
|
||||
|
||||
如果你不想更新所有的插件,你可以通过添加插件的名字来更新任何插件:
|
||||
|
||||
```
|
||||
`:PlugUpdate NERDTree`
|
||||
:PlugUpdate NERDTree
|
||||
```
|
||||
|
||||
#### 恢复插件
|
||||
|
||||
vim-plug 的另一个优点是它的导出和恢复功能。 Vim 用户都知道,正是插件的缘故,通常每个用户使用 Vim 的工作方式都是独一无二的。一旦你安装和配置了正确的插件组合,你最不想要的就是再也找不到它们。
|
||||
vim-plug 的另一个优点是它的导出和恢复功能。Vim 用户都知道,正是插件的缘故,通常每个用户使用 Vim 的工作方式都是独一无二的。一旦你安装和配置了正确的插件组合,你最不想要的局面就是再也找不到它们。
|
||||
|
||||
Vim-plug 有这个命令来生成一个脚本来恢复所有当前的插件:
|
||||
|
||||
```
|
||||
`:PlugSnapshot ~/vim-plug.list`
|
||||
:PlugSnapshot ~/vim-plug.list
|
||||
```
|
||||
vim-plug 还有许多其他的功能,所以请参考它的[项目页面][7]以获得完整的文档。
|
||||
|
||||
@ -151,7 +150,7 @@ via: https://opensource.com/article/20/2/how-install-vim-plugins
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qianmingtian][c]
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
104
published/202002/20200219 Don-t like IDEs- Try grepgitvi.md
Normal file
104
published/202002/20200219 Don-t like IDEs- Try grepgitvi.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11934-1.html)
|
||||
[#]: subject: (Don't like IDEs? Try grepgitvi)
|
||||
[#]: via: (https://opensource.com/article/20/2/no-ide-script)
|
||||
[#]: author: (Yedidyah Bar David https://opensource.com/users/didib)
|
||||
|
||||
不喜欢 IDE?试试看 grepgitvi
|
||||
======
|
||||
|
||||
> 一个简单又原始的脚本来用 Vim 打开你选择的文件。
|
||||
|
||||

|
||||
|
||||
像大多数开发者一样,我整天都在搜索和阅读源码。就我个人而言,我从来没有习惯过集成开发环境 (IDE),多年来,我主要使用 `grep` (找到文件),并复制/粘贴文件名来打开 Vi(m)。
|
||||
|
||||
最终,我写了这个脚本,并根据需要缓慢地对其进行了完善。
|
||||
|
||||
它依赖 [Vim][2] 和 [rlwrap][3],并使用 Apache 2.0 许可证开源。要使用该脚本,请[将它放到 PATH 中][4],然后在文本目录下运行:
|
||||
|
||||
```
|
||||
grepgitvi <grep options> <grep/vim search pattern>
|
||||
```
|
||||
|
||||
它将返回搜索结果的编号列表,并提示你输入结果编号并打开 Vim。退出 Vim 后,它将再次显示列表,直到你输入除结果编号以外的任何内容。你也可以使用向上和向下箭头键选择一个文件。(这对我来说)更容易找到我已经看过的结果。
|
||||
|
||||
与现代 IDE 甚至与 Vim 的更复杂的用法相比,它简单而原始,但它对我有用。
|
||||
|
||||
### 脚本
|
||||
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# grepgitvi - grep source files, interactively open vim on results
|
||||
# Doesn't really have to do much with git, other than ignoring .git
|
||||
#
|
||||
# Copyright Yedidyah Bar David 2019
|
||||
#
|
||||
# SPDX-License-Identifier: Apache-2.0
|
||||
#
|
||||
# Requires vim and rlwrap
|
||||
#
|
||||
# Usage: grepgitvi <grep options> <grep/vim pattern>
|
||||
#
|
||||
|
||||
TMPD=$(mktemp -d /tmp/grepgitvi.XXXXXX)
|
||||
UNCOLORED=${TMPD}/uncolored
|
||||
COLORED=${TMPD}/colored
|
||||
|
||||
RLHIST=${TMPD}/readline-history
|
||||
|
||||
[ -z "${DIRS}" ] && DIRS=.
|
||||
|
||||
cleanup() {
|
||||
rm -rf "${TMPD}"
|
||||
}
|
||||
|
||||
trap cleanup 0
|
||||
|
||||
find ${DIRS} -iname .git -prune -o \! -iname "*.min.css*" -type f -print0 > ${TMPD}/allfiles
|
||||
|
||||
cat ${TMPD}/allfiles | xargs -0 grep --color=always -n -H "$@" > $COLORED
|
||||
cat ${TMPD}/allfiles | xargs -0 grep -n -H "$@" > $UNCOLORED
|
||||
|
||||
max=`cat $UNCOLORED | wc -l`
|
||||
pat="${@: -1}"
|
||||
|
||||
inp=''
|
||||
while true; do
|
||||
echo "============================ grep results ==============================="
|
||||
cat $COLORED | nl
|
||||
echo "============================ grep results ==============================="
|
||||
prompt="Enter a number between 1 and $max or anything else to quit: "
|
||||
inp=$(rlwrap -H $RLHIST bash -c "read -p \"$prompt\" inp; echo \$inp")
|
||||
if ! echo "$inp" | grep -q '^[0-9][0-9]*$' || [ "$inp" -gt "$max" ]; then
|
||||
break
|
||||
fi
|
||||
|
||||
filename=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $1}')
|
||||
linenum=$(cat $UNCOLORED | awk -F: "NR==$inp"' {print $2-1}')
|
||||
vim +:"$linenum" +"norm zz" +/"${pat}" "$filename"
|
||||
done
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/no-ide-script
|
||||
|
||||
作者:[Yedidyah Bar David][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/didib
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
|
||||
[2]: https://www.vim.org/
|
||||
[3]: https://linux.die.net/man/1/rlwrap
|
||||
[4]: https://opensource.com/article/17/6/set-path-linux
|
||||
@ -0,0 +1,49 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11940-1.html)
|
||||
[#]: subject: (How Kubernetes Became the Standard for Compute Resources)
|
||||
[#]: via: (https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Kubernetes 如何成为计算资源的标准
|
||||
======
|
||||
|
||||

|
||||
|
||||
对于原生云生态系统来说,2019 年是改变游戏规则的一年。有大的[并购][1],如 Red Hat Docker 和 Pivotal,并出现其他的玩家,如 Rancher Labs 和 Mirantis。
|
||||
|
||||
Rancher Labs (一家为采用容器的团队提供完整软件栈的公司)的联合创始人兼首席执行官盛亮表示:“所有这些整合和并购,都表明这一领域的市场成熟的速度很快。”
|
||||
|
||||
传统上,像 Kubernetes 和 Docker 这样的新兴技术吸引着开发者和像脸书和谷歌这样的超级用户。除了这群人之外则没什么兴趣。然而,这两种技术都在企业层面得到了广泛采用。突然间,出现了一个巨大的市场,有着巨大的机会。几乎每个人都跳了进去。有人带来了创新的解决方案,也有人试图赶上其他人。它很快变得非常拥挤和热闹起来。
|
||||
|
||||
它也改变了创新的方式。[早期采用者通常是精通技术的公司][2]。现在,几乎每个人都在使用它,即使是在不被认为是 Kubernetes 地盘的地方。它改变了市场动态,像 Rancher Labs 这样的公司见证了独特的用例。
|
||||
|
||||
盛亮补充道,“我从来没有经历过像 Kubernete 这样快速、动态的市场或技术演变。当我们五年前开始的时候,这是一个非常拥挤的空间。随着时间的推移,我们大多数的友商因为这样或那样的原因消失了。他们要么无法适应变化,要么选择不适应某些变化。”
|
||||
|
||||
在 Kubernetes 的早期,最明显的机会是建立 Kubernetes 发行版本和 Kubernetes 业务。这是新技术。众所周知,它的安装、升级和操作相当的复杂。
|
||||
|
||||
当谷歌、AWS 和微软进入市场时,一切都变了。当时,一群供应商蜂拥而至,为平台提供解决方案。盛亮表示:“一旦像谷歌这样的云提供商决定将 Kubernetes 作为一项服务,并免费提供亏本出售的商品,以推动基础设施消费;我们就知道,运营和支持 Kubernetes 业务的优势将非常有限了。”
|
||||
|
||||
对谷歌之外的其它玩家来说,并非一切都不好。由于云供应商通过将它作为服务来提供,消除了 Kubernetes 带来的所有复杂性,这意味着更广泛地采用该技术,即使是那些由于运营成本而不愿使用该技术的人也是如此。这意味着 Kubernetes 将变得无处不在,并将成为一个行业标准。
|
||||
|
||||
“Rancher Labs 是极少数将此视为机遇并比其他公司看得更远的公司之一。我们意识到 Kubernetes 将成为新的计算标准,就像 TCP/IP 成为网络标准一样,”盛亮说。
|
||||
|
||||
CNCF 在围绕 Kubernetes 构建一个充满活力的生态系统方面发挥着至关重要的作用,创建了一个庞大的社区来构建、培育和商业化原生云开源技术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/how-kubernetes-became-the-standard-for-compute-resources/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cloudfoundry.org/blog/2019-is-the-year-of-consolidation-why-ibms-deal-with-red-hat-is-a-harbinger-of-things-to-come/
|
||||
[2]: https://www.packet.com/blog/open-source-season-on-the-kubernetes-highway/
|
||||
@ -0,0 +1,128 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11929-1.html)
|
||||
[#]: subject: (How to Install Latest Git Version on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/install-git-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 上安装最新版本的 Git
|
||||
======
|
||||
|
||||
在 Ubuntu 上安装 Git 非常容易。它存在于 [Ubuntu 的主仓库][1]中,你可以像这样[使用 apt 命令][2]安装它:
|
||||
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
很简单?是不是?
|
||||
|
||||
只有一点点小问题(这可能根本不是问题),就是它安装的 [Git][3] 版本。
|
||||
|
||||
在 LTS 系统上,软件稳定性至关重要,这就是为什么 Ubuntu 18.04 和其他发行版经常提供较旧但稳定的软件版本的原因,它们都经过发行版的良好测试。
|
||||
|
||||
这就是为什么当你检查 Git 版本时,会看到安装的版本会比 [Git 网站上当前最新 Git 版本][4]旧:
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.17.1
|
||||
```
|
||||
|
||||
在编写本教程时,网站上提供的版本为 2.25。那么,如何在 Ubuntu 上安装最新的 Git?
|
||||
|
||||
### 在基于 Ubuntu 的 Linux 发行版上安装最新的 Git
|
||||
|
||||
![][5]
|
||||
|
||||
一种方法是[从源代码安装][6]。这种很酷又老派的方法不适合所有人。值得庆幸的是,Ubuntu Git 维护团队提供了 [PPA][7],莫可以使用它轻松地安装最新的稳定 Git 版本。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:git-core/ppa
|
||||
sudo apt update
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
即使你以前使用 `apt` 安装了 Git,它也将更新为最新的稳定版本。
|
||||
|
||||
```
|
||||
$ git --version
|
||||
git version 2.25.0
|
||||
```
|
||||
|
||||
[使用PPA][8] 的好处在于,如果发布了新的 Git 稳定版本,那么就可以通过系统更新获得它。[仅更新 Ubuntu][9] 来获取最新的 Git 稳定版本。
|
||||
|
||||
### 配置 Git (推荐给开发者)
|
||||
|
||||
如果你出于开发目的安装了 Git,你会很快开始克隆仓库,进行更改并提交更改。
|
||||
|
||||
如果你尝试提交代码,那么你可能会看到 “Please tell me who you are” 这样的错误:
|
||||
|
||||
```
|
||||
$ git commit -m "update readme"
|
||||
|
||||
*** Please tell me who you are.
|
||||
|
||||
Run
|
||||
|
||||
git config --global user.email "you@example.com"
|
||||
git config --global user.name "Your Name"
|
||||
|
||||
to set your account's default identity.
|
||||
Omit --global to set the identity only in this repository.
|
||||
|
||||
fatal: unable to auto-detect email address (got 'abhishek@itsfoss.(none)')
|
||||
```
|
||||
|
||||
这是因为你还没配置必要的个人信息。
|
||||
|
||||
正如错误已经暗示的那样,你可以像这样设置全局 Git 配置:
|
||||
|
||||
```
|
||||
git config --global user.name "Your Name"
|
||||
git config --global user.email "you@example.com"
|
||||
```
|
||||
|
||||
你可以使用以下命令检查 Git 配置:
|
||||
|
||||
```
|
||||
git config --list
|
||||
```
|
||||
|
||||
它应该显示如下输出:
|
||||
|
||||
```
|
||||
user.email=you@example.com
|
||||
user.name=Your Name
|
||||
```
|
||||
|
||||
配置保存在 `~/.gitconfig` 中。你可以手动修改配置。
|
||||
|
||||
### 结尾
|
||||
|
||||
我希望这个小教程可以帮助你在 Ubuntu 上安装 Git。使用 PPA,你可以轻松获得最新的 Git 版本。
|
||||
|
||||
如果你有任何疑问或建议,请随时在评论部分提问。也欢迎直接写“谢谢” :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-git-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/ubuntu-repositories/
|
||||
[2]: https://itsfoss.com/apt-command-guide/
|
||||
[3]: https://git-scm.com/
|
||||
[4]: https://git-scm.com/downloads
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/install_git_ubuntu.png?ssl=1
|
||||
[6]: https://itsfoss.com/install-software-from-source-code/
|
||||
[7]: https://launchpad.net/~git-core/+archive/ubuntu/ppa
|
||||
[8]: https://itsfoss.com/ppa-guide/
|
||||
[9]: https://itsfoss.com/update-ubuntu/
|
||||
@ -0,0 +1,483 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11943-1.html)
|
||||
[#]: subject: (Using Python and GNU Octave to plot data)
|
||||
[#]: via: (https://opensource.com/article/20/2/python-gnu-octave-data-science)
|
||||
[#]: author: (Cristiano L. Fontana https://opensource.com/users/cristianofontana)
|
||||
|
||||
使用 Python 和 GNU Octave 绘制数据
|
||||
======
|
||||
|
||||
> 了解如何使用 Python 和 GNU Octave 完成一项常见的数据科学任务。
|
||||
|
||||

|
||||
|
||||
数据科学是跨越编程语言的知识领域。有些语言以解决这一领域的问题而闻名,而另一些则鲜为人知。这篇文章将帮助你熟悉用一些流行的语言完成数据科学的工作。
|
||||
|
||||
### 选择 Python 和 GNU Octave 做数据科学工作
|
||||
|
||||
我经常尝试学习一种新的编程语言。为什么?这既有对旧方式的厌倦,也有对新方式的好奇。当我开始学习编程时,我唯一知道的语言是 C 语言。那些年的编程生涯既艰难又危险,因为我必须手动分配内存、管理指针、并记得释放内存。
|
||||
|
||||
后来一个朋友建议我试试 Python,现在我的编程生活变得轻松多了。虽然程序运行变得慢多了,但我不必通过编写分析软件来受苦了。然而,我很快就意识到每种语言都有比其它语言更适合自己的应用场景。后来我学习了一些其它语言,每种语言都给我带来了一些新的启发。发现新的编程风格让我可以将一些解决方案移植到其他语言中,这样一切都变得有趣多了。
|
||||
|
||||
为了对一种新的编程语言(及其文档)有所了解,我总是从编写一些执行我熟悉的任务的示例程序开始。为此,我将解释如何用 Python 和 GNU Octave 编写一个程序来完成一个你可以归类为数据科学的特殊任务。如果你已经熟悉其中一种语言,从它开始,然后通过其他语言寻找相似之处和不同之处。这篇文章并不是对编程语言的详尽比较,只是一个小小的展示。
|
||||
|
||||
所有的程序都应该在[命令行][2]上运行,而不是用[图形用户界面][3](GUI)。完整的例子可以在 [polyglot_fit 存储库][4]中找到。
|
||||
|
||||
### 编程任务
|
||||
|
||||
你将在本系列中编写的程序:
|
||||
|
||||
* 从 [CSV 文件][5]中读取数据
|
||||
* 用直线插入数据(例如 `f(x)=m ⋅ x + q`)
|
||||
* 将结果生成图像文件
|
||||
|
||||
这是许多数据科学家遇到的常见情况。示例数据是 [Anscombe 的四重奏][6]的第一组,如下表所示。这是一组人工构建的数据,当用直线拟合时会给出相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,以制表符作为列分隔符,开头几行作为标题。此任务将仅使用第一组(即前两列)。
|
||||
|
||||

|
||||
|
||||
### Python 方式
|
||||
|
||||
[Python][7] 是一种通用编程语言,是当今最流行的语言之一(依据 [TIOBE 指数][8]、[RedMonk 编程语言排名][9]、[编程语言流行指数][10]、[GitHub Octoverse 状态][11]和其他来源的调查结果)。它是一种[解释型语言][12];因此,源代码由执行该指令的程序读取和评估。它有一个全面的[标准库][13]并且总体上非常好用(我对这最后一句话没有证据;这只是我的拙见)。
|
||||
|
||||
#### 安装
|
||||
|
||||
要使用 Python 开发,你需要解释器和一些库。最低要求是:
|
||||
|
||||
* [NumPy][14] 用于简化数组和矩阵的操作
|
||||
* [SciPy][15] 用于数据科学
|
||||
* [Matplotlib][16] 用于绘图
|
||||
|
||||
在 [Fedora][17] 安装它们是很容易的:
|
||||
|
||||
```
|
||||
sudo dnf install python3 python3-numpy python3-scipy python3-matplotlib
|
||||
```
|
||||
|
||||
#### 代码注释
|
||||
|
||||
在 Python中,[注释][18]是通过在行首添加一个 `#` 来实现的,该行的其余部分将被解释器丢弃:
|
||||
|
||||
```
|
||||
# 这是被解释器忽略的注释。
|
||||
```
|
||||
|
||||
[fitting_python.py][19] 示例使用注释在源代码中插入许可证信息,第一行是[特殊注释][20],它允许该脚本在命令行上执行:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
```
|
||||
|
||||
这一行通知命令行解释器,该脚本需要由程序 `python3` 执行。
|
||||
|
||||
#### 需要的库
|
||||
|
||||
在 Python 中,库和模块可以作为一个对象导入(如示例中的第一行),其中包含库的所有函数和成员。可以通过使用 `as` 方式用自定义标签重命名它们:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
from scipy import stats
|
||||
import matplotlib.pyplot as plt
|
||||
```
|
||||
|
||||
你也可以决定只导入一个子模块(如第二行和第三行)。语法有两个(基本上)等效的方式:`import module.submodule` 和 `from module import submodule`。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
Python 的变量是在第一次赋值时被声明的:
|
||||
|
||||
```
|
||||
input_file_name = "anscombe.csv"
|
||||
delimiter = "\t"
|
||||
skip_header = 3
|
||||
column_x = 0
|
||||
column_y = 1
|
||||
```
|
||||
|
||||
变量类型由分配给变量的值推断。没有具有常量值的变量,除非它们在模块中声明并且只能被读取。习惯上,不应被修改的变量应该用大写字母命名。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
通过命令行运行程序意味着输出只能打印在终端上。Python 有 [print()][21] 函数,默认情况下,该函数打印其参数,并在输出的末尾添加一个换行符:
|
||||
|
||||
```
|
||||
print("#### Anscombe's first set with Python ####")
|
||||
```
|
||||
|
||||
在 Python 中,可以将 `print()` 函数与[字符串类][23]的[格式化能力][22]相结合。字符串具有`format` 方法,可用于向字符串本身添加一些格式化文本。例如,可以添加格式化的浮点数,例如:
|
||||
|
||||
```
|
||||
print("Slope: {:f}".format(slope))
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
使用 NumPy 和函数 [genfromtxt()][24] 读取 CSV 文件非常容易,该函数生成 [NumPy 数组][25]:
|
||||
|
||||
```
|
||||
data = np.genfromtxt(input_file_name, delimiter = delimiter, skip_header = skip_header)
|
||||
```
|
||||
|
||||
在 Python 中,一个函数可以有数量可变的参数,你可以通过指定所需的参数来传递一个参数的子集。数组是非常强大的矩阵状对象,可以很容易地分割成更小的数组:
|
||||
|
||||
```
|
||||
x = data[:, column_x]
|
||||
y = data[:, column_y]
|
||||
```
|
||||
|
||||
冒号选择整个范围,也可以用来选择子范围。例如,要选择数组的前两行,可以使用:
|
||||
|
||||
```
|
||||
first_two_rows = data[0:1, :]
|
||||
```
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
SciPy 提供了方便的数据拟合功能,例如 [linregress()][26] 功能。该函数提供了一些与拟合相关的重要值,如斜率、截距和两个数据集的相关系数:
|
||||
|
||||
```
|
||||
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
|
||||
|
||||
print("Slope: {:f}".format(slope))
|
||||
print("Intercept: {:f}".format(intercept))
|
||||
print("Correlation coefficient: {:f}".format(r_value))
|
||||
```
|
||||
|
||||
因为 `linregress()` 提供了几条信息,所以结果可以同时保存到几个变量中。
|
||||
|
||||
#### 绘图
|
||||
|
||||
Matplotlib 库仅仅绘制数据点,因此,你应该定义要绘制的点的坐标。已经定义了 `x` 和 `y` 数组,所以你可以直接绘制它们,但是你还需要代表直线的数据点。
|
||||
|
||||
```
|
||||
fit_x = np.linspace(x.min() - 1, x.max() + 1, 100)
|
||||
```
|
||||
|
||||
[linspace()][27] 函数可以方便地在两个值之间生成一组等距值。利用强大的 NumPy 数组可以轻松计算纵坐标,该数组可以像普通数值变量一样在公式中使用:
|
||||
|
||||
```
|
||||
fit_y = slope * fit_x + intercept
|
||||
```
|
||||
|
||||
该公式在数组中逐元素应用;因此,结果在初始数组中具有相同数量的条目。
|
||||
|
||||
要绘图,首先,定义一个包含所有图形的[图形对象][28]:
|
||||
|
||||
```
|
||||
fig_width = 7 #inch
|
||||
fig_height = fig_width / 16 * 9 #inch
|
||||
fig_dpi = 100
|
||||
|
||||
fig = plt.figure(figsize = (fig_width, fig_height), dpi = fig_dpi)
|
||||
```
|
||||
|
||||
一个图形可以画几个图;在 Matplotlib 中,这些图被称为[轴][29]。本示例定义一个单轴对象来绘制数据点:
|
||||
|
||||
```
|
||||
ax = fig.add_subplot(111)
|
||||
|
||||
ax.plot(fit_x, fit_y, label = "Fit", linestyle = '-')
|
||||
ax.plot(x, y, label = "Data", marker = '.', linestyle = '')
|
||||
|
||||
ax.legend()
|
||||
ax.set_xlim(min(x) - 1, max(x) + 1)
|
||||
ax.set_ylim(min(y) - 1, max(y) + 1)
|
||||
ax.set_xlabel('x')
|
||||
ax.set_ylabel('y')
|
||||
```
|
||||
|
||||
将该图保存到 [PNG 图形文件][30]中,有:
|
||||
|
||||
```
|
||||
fig.savefig('fit_python.png')
|
||||
```
|
||||
|
||||
如果要显示(而不是保存)该绘图,请调用:
|
||||
|
||||
```
|
||||
plt.show()
|
||||
```
|
||||
|
||||
此示例引用了绘图部分中使用的所有对象:它定义了对象 `fig` 和对象 `ax`。这在技术上是不必要的,因为 `plt` 对象可以直接用于绘制数据集。《[Matplotlib 教程][31]》展示了这样一个接口:
|
||||
|
||||
```
|
||||
plt.plot(fit_x, fit_y)
|
||||
```
|
||||
|
||||
坦率地说,我不喜欢这种方法,因为它隐藏了各种对象之间发生的重要交互。不幸的是,有时[官方的例子][32]有点令人困惑,因为他们倾向于使用不同的方法。在这个简单的例子中,引用图形对象是不必要的,但是在更复杂的例子中(例如在图形用户界面中嵌入图形时),引用图形对象就变得很重要了。
|
||||
|
||||
#### 结果
|
||||
|
||||
命令行输入:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with Python ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这是 Matplotlib 产生的图像:
|
||||
|
||||
![Plot and fit of the dataset obtained with Python][33]
|
||||
|
||||
### GNU Octave 方式
|
||||
|
||||
[GNU Octave][34] 语言主要用于数值计算。它提供了一个简单的操作向量和矩阵的语法,并且有一些强大的绘图工具。这是一种像 Python 一样的解释语言。由于 Octave 的语法[几乎兼容][35] [MATLAB][36],它经常被描述为一个替代 MATLAB 的免费方案。Octave 没有被列为最流行的编程语言,而 MATLAB 则是,所以 Octave 在某种意义上是相当流行的。MATLAB 早于 NumPy,我觉得它是受到了前者的启发。当你看这个例子时,你会看到相似之处。
|
||||
|
||||
#### 安装
|
||||
|
||||
[fitting_octave.m][37] 的例子只需要基本的 Octave 包,在 Fedora 中安装相当简单:
|
||||
|
||||
```
|
||||
sudo dnf install octave
|
||||
```
|
||||
|
||||
#### 代码注释
|
||||
|
||||
在 Octave 中,你可以用百分比符号(`%`)为代码添加注释,如果不需要与 MATLAB 兼容,你也可以使用 `#`。使用 `#` 的选项允许你编写像 Python 示例一样的特殊注释行,以便直接在命令行上执行脚本。
|
||||
|
||||
#### 必要的库
|
||||
|
||||
本例中使用的所有内容都包含在基本包中,因此你不需要加载任何新的库。如果你需要一个库,[语法][38]是 `pkg load module`。该命令将模块的功能添加到可用功能列表中。在这方面,Python 具有更大的灵活性。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
变量的定义与 Python 的语法基本相同:
|
||||
|
||||
```
|
||||
input_file_name = "anscombe.csv";
|
||||
delimiter = "\t";
|
||||
skip_header = 3;
|
||||
column_x = 1;
|
||||
column_y = 2;
|
||||
```
|
||||
|
||||
请注意,行尾有一个分号;这不是必需的,但是它会抑制该行结果的输出。如果没有分号,解释器将打印表达式的结果:
|
||||
|
||||
```
|
||||
octave:1> input_file_name = "anscombe.csv"
|
||||
input_file_name = anscombe.csv
|
||||
octave:2> sqrt(2)
|
||||
ans = 1.4142
|
||||
```
|
||||
|
||||
#### 打印输出结果
|
||||
|
||||
强大的函数 [printf()][39] 是用来在终端上打印的。与 Python 不同,`printf()` 函数不会自动在打印字符串的末尾添加换行,因此你必须添加它。第一个参数是一个字符串,可以包含要传递给函数的其他参数的格式信息,例如:
|
||||
|
||||
```
|
||||
printf("Slope: %f\n", slope);
|
||||
```
|
||||
|
||||
在 Python 中,格式是内置在字符串本身中的,但是在 Octave 中,它是特定于 `printf()` 函数。
|
||||
|
||||
#### 读取数据
|
||||
|
||||
[dlmread()][40] 函数可以读取类似 CSV 文件的文本内容:
|
||||
|
||||
```
|
||||
data = dlmread(input_file_name, delimiter, skip_header, 0);
|
||||
```
|
||||
|
||||
结果是一个[矩阵][41]对象,这是 Octave 中的基本数据类型之一。矩阵可以用类似于 Python 的语法进行切片:
|
||||
|
||||
```
|
||||
x = data(:, column_x);
|
||||
y = data(:, column_y);
|
||||
```
|
||||
|
||||
根本的区别是索引从 1 开始,而不是从 0 开始。因此,在该示例中,`x` 列是第一列。
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
要用直线拟合数据,可以使用 [polyfit()][42] 函数。它用一个多项式拟合输入数据,所以你只需要使用一阶多项式:
|
||||
|
||||
```
|
||||
p = polyfit(x, y, 1);
|
||||
|
||||
slope = p(1);
|
||||
intercept = p(2);
|
||||
```
|
||||
|
||||
结果是具有多项式系数的矩阵;因此,它选择前两个索引。要确定相关系数,请使用 [corr()][43] 函数:
|
||||
|
||||
```
|
||||
r_value = corr(x, y);
|
||||
```
|
||||
|
||||
最后,使用 `printf()` 函数打印结果:
|
||||
|
||||
```
|
||||
printf("Slope: %f\n", slope);
|
||||
printf("Intercept: %f\n", intercept);
|
||||
printf("Correlation coefficient: %f\n", r_value);
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
与 Matplotlib 示例一样,首先需要创建一个表示拟合直线的数据集:
|
||||
|
||||
```
|
||||
fit_x = linspace(min(x) - 1, max(x) + 1, 100);
|
||||
fit_y = slope * fit_x + intercept;
|
||||
```
|
||||
|
||||
与 NumPy 的相似性也很明显,因为它使用了 [linspace()][44] 函数,其行为就像 Python 的等效版本一样。
|
||||
|
||||
同样,与 Matplotlib 一样,首先创建一个[图][45]对象,然后创建一个[轴][46]对象来保存这些图:
|
||||
|
||||
```
|
||||
fig_width = 7; %inch
|
||||
fig_height = fig_width / 16 * 9; %inch
|
||||
fig_dpi = 100;
|
||||
|
||||
fig = figure("units", "inches",
|
||||
"position", [1, 1, fig_width, fig_height]);
|
||||
|
||||
ax = axes("parent", fig);
|
||||
|
||||
set(ax, "fontsize", 14);
|
||||
set(ax, "linewidth", 2);
|
||||
```
|
||||
|
||||
要设置轴对象的属性,请使用 [set()][47] 函数。然而,该接口相当混乱,因为该函数需要一个逗号分隔的属性和值对列表。这些对只是代表属性名的一个字符串和代表该属性值的第二个对象的连续。还有其他设置各种属性的函数:
|
||||
|
||||
```
|
||||
xlim(ax, [min(x) - 1, max(x) + 1]);
|
||||
ylim(ax, [min(y) - 1, max(y) + 1]);
|
||||
xlabel(ax, 'x');
|
||||
ylabel(ax, 'y');
|
||||
```
|
||||
|
||||
绘图是用 [plot()][48] 功能实现的。默认行为是每次调用都会重置坐标轴,因此需要使用函数 [hold()][49]。
|
||||
|
||||
```
|
||||
hold(ax, "on");
|
||||
|
||||
plot(ax, fit_x, fit_y,
|
||||
"marker", "none",
|
||||
"linestyle", "-",
|
||||
"linewidth", 2);
|
||||
plot(ax, x, y,
|
||||
"marker", ".",
|
||||
"markersize", 20,
|
||||
"linestyle", "none");
|
||||
|
||||
hold(ax, "off");
|
||||
```
|
||||
|
||||
此外,还可以在 `plot()` 函数中添加属性和值对。[legend][50] 必须单独创建,标签应手动声明:
|
||||
|
||||
```
|
||||
lg = legend(ax, "Fit", "Data");
|
||||
set(lg, "location", "northwest");
|
||||
```
|
||||
|
||||
最后,将输出保存到 PNG 图像:
|
||||
|
||||
```
|
||||
image_size = sprintf("-S%f,%f", fig_width * fig_dpi, fig_height * fig_dpi);
|
||||
image_resolution = sprintf("-r%f,%f", fig_dpi);
|
||||
|
||||
print(fig, 'fit_octave.png',
|
||||
'-dpng',
|
||||
image_size,
|
||||
image_resolution);
|
||||
```
|
||||
|
||||
令人困惑的是,在这种情况下,选项被作为一个字符串传递,带有属性名和值。因为在 Octave 字符串中没有 Python 的格式化工具,所以必须使用 [sprintf()][51] 函数。它的行为就像 `printf()` 函数,但是它的结果不是打印出来的,而是作为字符串返回的。
|
||||
|
||||
在这个例子中,就像在 Python 中一样,图形对象很明显被引用以保持它们之间的交互。如果说 Python 在这方面的文档有点混乱,那么 [Octave 的文档][52]就更糟糕了。我发现的大多数例子都不关心引用对象;相反,它们依赖于绘图命令作用于当前活动图形。全局[根图形对象][53]跟踪现有的图形和轴。
|
||||
|
||||
#### 结果
|
||||
|
||||
命令行上的结果输出是:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with Octave ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
它显示了用 Octave 生成的结果图像。
|
||||
|
||||
![Plot and fit of the dataset obtained with Octave][54]
|
||||
|
||||
###接下来
|
||||
|
||||
Python 和 GNU Octave 都可以绘制出相同的信息,尽管它们的实现方式不同。如果你想探索其他语言来完成类似的任务,我强烈建议你看看 [Rosetta Code][55]。这是一个了不起的资源,可以看到如何用多种语言解决同样的问题。
|
||||
|
||||
你喜欢用什么语言绘制数据?在评论中分享你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/python-gnu-octave-data-science
|
||||
|
||||
作者:[Cristiano L. Fontana][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cristianofontana
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/analytics-graphs-charts.png?itok=sersoqbV (Analytics: Charts and Graphs)
|
||||
[2]: https://en.wikipedia.org/wiki/Command-line_interface
|
||||
[3]: https://en.wikipedia.org/wiki/Graphical_user_interface
|
||||
[4]: https://gitlab.com/cristiano.fontana/polyglot_fit
|
||||
[5]: https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[6]: https://en.wikipedia.org/wiki/Anscombe%27s_quartet
|
||||
[7]: https://www.python.org/
|
||||
[8]: https://www.tiobe.com/tiobe-index/
|
||||
[9]: https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/
|
||||
[10]: http://pypl.github.io/PYPL.html
|
||||
[11]: https://octoverse.github.com/
|
||||
[12]: https://en.wikipedia.org/wiki/Interpreted_language
|
||||
[13]: https://docs.python.org/3/library/
|
||||
[14]: https://numpy.org/
|
||||
[15]: https://www.scipy.org/
|
||||
[16]: https://matplotlib.org/
|
||||
[17]: https://getfedora.org/
|
||||
[18]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[19]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_python.py
|
||||
[20]: https://en.wikipedia.org/wiki/Shebang_(Unix)
|
||||
[21]: https://docs.python.org/3/library/functions.html#print
|
||||
[22]: https://docs.python.org/3/library/string.html#string-formatting
|
||||
[23]: https://docs.python.org/3/library/string.html
|
||||
[24]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.genfromtxt.html
|
||||
[25]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.array.html
|
||||
[26]: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.linregress.html
|
||||
[27]: https://docs.scipy.org/doc/numpy/reference/generated/numpy.linspace.html
|
||||
[28]: https://matplotlib.org/api/_as_gen/matplotlib.figure.Figure.html#matplotlib.figure.Figure
|
||||
[29]: https://matplotlib.org/api/axes_api.html#matplotlib.axes.Axes
|
||||
[30]: https://en.wikipedia.org/wiki/Portable_Network_Graphics
|
||||
[31]: https://matplotlib.org/tutorials/introductory/pyplot.html#sphx-glr-tutorials-introductory-pyplot-py
|
||||
[32]: https://matplotlib.org/gallery/index.html
|
||||
[33]: https://opensource.com/sites/default/files/uploads/fit_python.png (Plot and fit of the dataset obtained with Python)
|
||||
[34]: https://www.gnu.org/software/octave/
|
||||
[35]: https://wiki.octave.org/FAQ#Differences_between_Octave_and_Matlab
|
||||
[36]: https://en.wikipedia.org/wiki/MATLAB
|
||||
[37]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_octave.m
|
||||
[38]: https://octave.org/doc/v5.1.0/Using-Packages.html#Using-Packages
|
||||
[39]: https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFprintf
|
||||
[40]: https://octave.org/doc/v5.1.0/Simple-File-I_002fO.html#XREFdlmread
|
||||
[41]: https://octave.org/doc/v5.1.0/Matrices.html
|
||||
[42]: https://octave.org/doc/v5.1.0/Polynomial-Interpolation.html
|
||||
[43]: https://octave.org/doc/v5.1.0/Correlation-and-Regression-Analysis.html#XREFcorr
|
||||
[44]: https://octave.sourceforge.io/octave/function/linspace.html
|
||||
[45]: https://octave.org/doc/v5.1.0/Multiple-Plot-Windows.html
|
||||
[46]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFaxes
|
||||
[47]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFset
|
||||
[48]: https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#XREFplot
|
||||
[49]: https://octave.org/doc/v5.1.0/Manipulation-of-Plot-Windows.html#XREFhold
|
||||
[50]: https://octave.org/doc/v5.1.0/Plot-Annotations.html#XREFlegend
|
||||
[51]: https://octave.org/doc/v5.1.0/Formatted-Output.html#XREFsprintf
|
||||
[52]: https://octave.org/doc/v5.1.0/Two_002dDimensional-Plots.html#Two_002dDimensional-Plots
|
||||
[53]: https://octave.org/doc/v5.1.0/Graphics-Objects.html#XREFgroot
|
||||
[54]: https://opensource.com/sites/default/files/uploads/fit_octave.png (Plot and fit of the dataset obtained with Octave)
|
||||
[55]: http://www.rosettacode.org/
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11959-1.html)
|
||||
[#]: subject: (Extend the life of your SSD drive with fstrim)
|
||||
[#]: via: (https://opensource.com/article/20/2/trim-solid-state-storage-linux)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
在 Linux 下使用 fstrim 延长 SSD 驱动器的寿命
|
||||
======
|
||||
|
||||
> 这个新的系统服务可以使你的生活更轻松。
|
||||
|
||||

|
||||
|
||||
在过去的十年中,固态驱动器(SSD)带来了一种管理存储的新方法。与上一代的转盘产品相比,SSD 具有无声、更冷却的操作和更快的接口规格等优点。当然,新技术带来了新的维护和管理方法。SSD 具有一种称为 TRIM 的功能。从本质上讲,这是一种用于回收设备上未使用的块的方法,该块可能先前已被写入,但不再包含有效数据,因此可以返回到通用存储池以供重用。Opensource.com 的 Don Watkins 首先在其 2017 年的文章《[Linux 固态驱动器:为 SSD 启用 TRIM][2]》中介绍过 TRIM 的内容。
|
||||
|
||||
如果你一直在 Linux 系统上使用此功能,则你可能熟悉下面描述的两种方法。
|
||||
|
||||
### 老的方式
|
||||
|
||||
#### 丢弃选项
|
||||
|
||||
我最初使用 `mount` 命令的 `discard` 选项启用了此功能。每个文件系统的配置都放在 `/etc/fstab` 文件中。
|
||||
|
||||
```
|
||||
# cat /etc/fstab
|
||||
UUID=3453g54-6628-2346-8123435f /home xfs defaults,discard 0 0
|
||||
```
|
||||
|
||||
丢弃选项可启用自动的在线 TRIM。由于可能会对性能造成负面影响,最近关于这是否是最佳方法一直存在争议。使用此选项会在每次将新数据写入驱动器时启动 TRIM。这可能会引入其他磁盘活动,从而影响存储性能。
|
||||
|
||||
#### Cron 作业
|
||||
|
||||
我从 `fstab` 文件中删除了丢弃选项。然后,我创建了一个 cron 作业来按计划调用该命令。
|
||||
|
||||
```
|
||||
# crontab -l
|
||||
@midnight /usr/bin/trim
|
||||
```
|
||||
|
||||
这是我最近在 Ubuntu Linux 系统上使用的方法,直到我了解到另一种方法。
|
||||
|
||||
### 一个新的 TRIM 服务
|
||||
|
||||
我最近发现有一个用于 TRIM 的 systemd 服务。Fedora 在版本 30 中将其[引入][3],尽管默认情况下在版本 30 和 31 中未启用它,但计划在版本 32 中使用它。如果你使用的是 Fedora 工作站 31,并且你想要开始使用此功能,可以非常轻松地启用它。我还将在下面向你展示如何对其进行测试。该服务并非 Fedora 独有的服务。它是否存在及其地位将因发行版而异。
|
||||
|
||||
#### 测试
|
||||
|
||||
我喜欢先进行测试,以更好地了解幕后情况。我通过打开终端并发出配置服务调用的命令来执行此操作。
|
||||
|
||||
```
|
||||
/usr/sbin/fstrim --fstab --verbose --quiet
|
||||
```
|
||||
|
||||
`fstrim` 的 `-help` 参数将描述这些信息和其他参数。
|
||||
|
||||
```
|
||||
$ sudo /usr/sbin/fstrim --help
|
||||
|
||||
Usage:
|
||||
fstrim [options] <mount point>
|
||||
|
||||
Discard unused blocks on a mounted filesystem.
|
||||
|
||||
Options:
|
||||
-a, --all trim all supported mounted filesystems
|
||||
-A, --fstab trim all supported mounted filesystems from /etc/fstab
|
||||
-o, --offset <num> the offset in bytes to start discarding from
|
||||
-l, --length <num> the number of bytes to discard
|
||||
-m, --minimum <num> the minimum extent length to discard
|
||||
-v, --verbose print number of discarded bytes
|
||||
--quiet suppress error messages
|
||||
-n, --dry-run does everything, but trim
|
||||
|
||||
-h, --help display this help
|
||||
-V, --version display version
|
||||
```
|
||||
|
||||
因此,现在我可以看到这个 systemd 服务已配置为在我的 `/etc/fstab` 文件中的所有受支持的挂载文件系统上运行该修剪操作(`-fstab`),并打印出所丢弃的字节数(`-verbose`),但是抑制了任何可能会发生的错误消息(`–quiet`)。了解这些选项对测试很有帮助。例如,我可以从最安全的方法开始,即空运行。我还将去掉 `-quiet` 参数,以便确定驱动器设置是否发生任何错误。
|
||||
|
||||
```
|
||||
$ sudo /usr/sbin/fstrim --fstab --verbose --dry-run
|
||||
```
|
||||
|
||||
这就会显示 `fstrim` 命令根据在 `/etc/fstab` 文件中找到的文件系统要执行的操作。
|
||||
|
||||
```
|
||||
$ sudo /usr/sbin/fstrim --fstab --verbose
|
||||
```
|
||||
|
||||
现在,这会将 TRIM 操作发送到驱动器,并报告每个文件系统中丢弃的字节数。以下是我最近在新的 NVME SSD 上全新安装 Fedora 之后的示例。
|
||||
|
||||
```
|
||||
/home: 291.5 GiB (313011310592 bytes) trimmed on /dev/mapper/wkst-home
|
||||
/boot/efi: 579.2 MiB (607301632 bytes) trimmed on /dev/nvme0n1p1
|
||||
/boot: 787.5 MiB (825778176 bytes) trimmed on /dev/nvme0n1p2
|
||||
/: 60.7 GiB (65154805760 bytes) trimmed on /dev/mapper/wkst-root
|
||||
```
|
||||
|
||||
#### 启用
|
||||
|
||||
Fedora Linux 实现了一个计划每周运行它的 systemd 计时器服务。要检查其是否存在及当前状态,请运行 `systemctl status`。
|
||||
|
||||
```
|
||||
$ sudo systemctl status fstrim.timer
|
||||
```
|
||||
|
||||
现在,启用该服务。
|
||||
|
||||
```
|
||||
$ sudo systemctl enable fstrim.timer
|
||||
```
|
||||
|
||||
#### 验证
|
||||
|
||||
然后,你可以通过列出所有计时器来验证该计时器是否已启用。
|
||||
|
||||
```
|
||||
$ sudo systemctl list-timers --all
|
||||
```
|
||||
|
||||
会显示出下列行,表明 `fstrim.timer` 存在。注意,该计时器实际上激活了 `fstrim.service` 服务。这是实际调用 `fstrim` 的地方。与时间相关的字段显示为 `n/a`,因为该服务已启用且尚未运行。
|
||||
|
||||
```
|
||||
NEXT LEFT LAST PASSED UNIT ACTIVATES
|
||||
n/a n/a n/a n/a fstrim.timer fstrim.service
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
该服务似乎是在驱动器上运行 TRIM 的最佳方法。这比必须创建自己的 crontab 条目来调用 `fstrim` 命令要简单得多。不必编辑 `fstab` 文件也更安全。观察固态存储技术的发展很有趣,并且我很高兴看到 Linux 似乎正在朝着标准且安全的方向实现它。
|
||||
|
||||
在本文中,学习了固态驱动器与传统硬盘驱动器有何不同以及它的含义...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/trim-solid-state-storage-linux
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_keyboard_desktop.png?itok=I2nGw78_ (Linux keys on the keyboard for a desktop computer)
|
||||
[2]: https://linux.cn/article-8177-1.html
|
||||
[3]: https://fedoraproject.org/wiki/Changes/EnableFSTrimTimer (Fedora Project WIKI: Changes/EnableFSTrimTimer)
|
||||
@ -0,0 +1,112 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11968-1.html)
|
||||
[#]: subject: (How to set up your own fast, private open source mesh network)
|
||||
[#]: via: (https://opensource.com/article/20/2/mesh-network-freemesh)
|
||||
[#]: author: (Spencer Thomason https://opensource.com/users/spencerthomason)
|
||||
|
||||
如何建立自己的快速、私有的开源网状网络(mesh)
|
||||
======
|
||||
|
||||
> 只需要不到 10 分钟的安装时间,就可以用 FreeMesh 搭建一个经济实惠、性能卓越、尊重隐私的网格系统。
|
||||
|
||||

|
||||
|
||||
[FreeMesh][2] 系统有望为大众带来完全开源的<ruby>网状网络<rt>mesh network</rt></ruby>(LCTT 译注:也称之为“多跳网络”)。我最近有机会对它进行了测试;它安装迅速,性能非常好 —— 特别是相对它的价格而言。
|
||||
|
||||
### 为什么要网格化和开源?
|
||||
|
||||
使用开源的原因很简单:隐私。有了 FreeMesh,你的数据就是你自己的。它不会跟踪或收集数据。不相信吗?毕竟,你可以轻松检查 —— 它是开源的!而其它大型高科技企业集团提供的一些流行的网状网络解决方案,你是否相信它们会保护你的数据?
|
||||
|
||||
另一个重要因素:更新。FreeMesh 表示,它将致力于定期发布安全性和性能更新。从现在起到 10 年后呢?使用开源解决方案,你可以根据需要自由地更新产品。
|
||||
|
||||
那么为什么要用网状网络呢?在网状网络中,多个无线路由器一起工作以广播单个超大型的无线网络。网状网络中的每个路由器都可与其他路由器智能地通信,以便为你的数据提供最佳的“路径”。FreeMesh 网站上的以下图片突出显示了使用单个无线路由器和网状网络之间的区别。红色网络表示单个无线路由器,绿色网络是网状网络。
|
||||
|
||||
![单路由器网络] [3]
|
||||
|
||||
![网状网络] [4]
|
||||
|
||||
### 采购设备
|
||||
|
||||
要开始使用 FreeMesh,请[订购套件][5]。它提供两种套件:标准套件和 4G LTE。
|
||||
|
||||
顾名思义,4G LTE 套件支持蜂窝数据连接。此功能在消费级网络领域非常罕见,但对某些人来说非常有用。你可以在提供电源和电池的任何地方建立具有完整的快速故障转移功能的便携式网状网络。
|
||||
|
||||
FreeMesh 套件带有一个主路由器和两个节点。路由器和节点使用 802.11ac、802.11r 和 802.11s 标准。随附的固件运行定制版本的 [OpenWrt] [6],这是嵌入式设备的 Linux 发行版。
|
||||
|
||||
FreeMesh 路由器的一些规格非常好:
|
||||
|
||||
* CPU:双核 880MHz MediaTek MT7621AT(双核/四线程!)
|
||||
* 内存:DDR3 512MB
|
||||
* 接口:1 个 GbE WAN、4 个 GbE LAN、1 个 USB 2.0 端口、1 个 microSD 卡插槽、1 个 SIM 插槽
|
||||
* 天线:2 个 5dBi 2.4GHz、2 个 5dBi 5GHz、2 个 3dBi 3G/4G(内置)
|
||||
* 4G LTE 调制解调器:LTE 4 类模块,下行 150Mbps/上行 50Mbps
|
||||
|
||||
### 设置
|
||||
|
||||
设置很容易,FreeMesh 的 [README][7] 提供了简单的说明和图表。首先首先设置主路由器。然后按照以下简单步骤操作:
|
||||
|
||||
1、将第一个节点(蓝色 WAN 端口)连接到主路由器(黄色 LAN 端口)。
|
||||
|
||||
![FreeMesh 设置步骤 1][8]
|
||||
|
||||
2、等待约 30 至 60 秒。设置完成后,节点的 LED 将会闪烁。
|
||||
|
||||
![FreeMesh 设置步骤 2][9]
|
||||
|
||||
3、将节点移到另一个位置。
|
||||
|
||||
仅此而已!节点不需要手动设置。你只需将它们插入主路由器,其余的工作就完成了。你可以以相同的方式添加更多节点;只需重复上述步骤即可。
|
||||
|
||||
### 功能
|
||||
|
||||
FreeMesh 是开箱即用的,它由 OpenWRT 和 LuCI 组合而成。它具有你期望路由器提供的所有功能。是否要安装新功能或软件包?SSH 连入并开始魔改!
|
||||
|
||||
![FreeMesh 网络上的实时负载][10]
|
||||
|
||||
![FreeMesh 网络概览][11]
|
||||
|
||||
![OpenWrt 状态报告][12]
|
||||
|
||||
### 性能如何
|
||||
|
||||
设置完 FreeMesh 系统后,我将节点移动到了房屋周围的各个地方。我使用 [iPerf][13] 测试带宽,它达到了约 150Mbps。WiFi 可能会受到许多环境变量的影响,因此你的结果可能会有所不同。节点与主路由器之间的距离在带宽中也有很大的影响。
|
||||
|
||||
但是,网状网络的真正优势不是高峰速度,而是整个空间的平均速度要好得多。即使在我家很远的地方,我仍然能够用流媒体播放视频并正常工作。我甚至可以在后院工作。在出门之前,我只是将一个节点重新放在窗口前面而已。
|
||||
|
||||
### 结论
|
||||
|
||||
FreeMesh 确实令人信服。它以简单、开源的形式为你提供高性价比和隐私。
|
||||
|
||||
以我的经验,设置非常容易,而且足够快。覆盖范围非常好,远远超过了任何单路由器环境。你可以随意魔改和定制 FreeMesh 设置,但是我觉得没有必要。它提供了我需要的一切。
|
||||
|
||||
如果你正在寻找价格可承受、性能良好且尊重隐私的网格系统,且该系统可以在不到 10 分钟的时间内安装完毕,你可以考虑一下 FreeMesh。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/mesh-network-freemesh
|
||||
|
||||
作者:[Spencer Thomason][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/spencerthomason
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bus-networking.png?itok=fHmulI9p (people on top of a connected globe)
|
||||
[2]: https://freemeshwireless.com/
|
||||
[3]: https://opensource.com/sites/default/files/uploads/singlerouternetwork.png (Single-router network)
|
||||
[4]: https://opensource.com/sites/default/files/uploads/meshnetwork.png (Mesh network)
|
||||
[5]: https://freemeshwireless.com/#pricing
|
||||
[6]: https://openwrt.org/
|
||||
[7]: https://gitlab.com/slthomason/freemesh/-/blob/master/README.md
|
||||
[8]: https://opensource.com/sites/default/files/uploads/connecttorouter.png (FreeMesh setup step 1)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/setupcomplete.png (FreeMesh setup step 2)
|
||||
[10]: https://opensource.com/sites/default/files/uploads/freemeshrealtimeload.png (Real-time load on FreeMesh network)
|
||||
[11]: https://opensource.com/sites/default/files/uploads/freemeshwirelessoverview.png (Overview of FreeMesh network)
|
||||
[12]: https://opensource.com/sites/default/files/uploads/openwrt.png (OpenWrt status report)
|
||||
[13]: https://opensource.com/article/20/1/internet-speed-tests
|
||||
89
published/20200214 PHP Development on Fedora with Eclipse.md
Normal file
89
published/20200214 PHP Development on Fedora with Eclipse.md
Normal file
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11967-1.html)
|
||||
[#]: subject: (PHP Development on Fedora with Eclipse)
|
||||
[#]: via: (https://fedoramagazine.org/php-development-on-fedora-with-eclipse/)
|
||||
[#]: author: (Mehdi Haghgoo https://fedoramagazine.org/author/powergame/)
|
||||
|
||||
使用 Eclipse 在 Fedora 上进行 PHP 开发
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[Eclipse][2] 是由 Eclipse 基金会开发的功能全面的自由开源 IDE。它诞生于 2001 年。你可以在此 IDE 中编写各种程序,从 C/C++ 和 Java 到 PHP,乃至于 Python、HTML、JavaScript、Kotlin 等等。
|
||||
|
||||
### 安装
|
||||
|
||||
该软件可从 Fedora 的官方仓库中获得。要安装它,请用:
|
||||
|
||||
```
|
||||
sudo dnf install eclipse
|
||||
```
|
||||
|
||||
这将安装基本的 IDE 和 Eclipse 平台,能让你开发 Java 应用。为了将 PHP 开发支持添加到 IDE,请运行以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install eclipse-pdt
|
||||
```
|
||||
|
||||
这将安装 PHP 开发工具,如 PHP 项目向导、PHP 服务器配置,composer 支持等。
|
||||
|
||||
### 功能
|
||||
|
||||
该 IDE 有许多使 PHP 开发更加容易的功能。例如,它有全面的项目向导(你可以在其中为新项目配置许多选项)。它还有如 composer 支持、调试支持、浏览器、终端等内置功能。
|
||||
|
||||
### 示例项目
|
||||
|
||||
现在已经安装了 IDE,让我们创建一个简单的 PHP 项目。进入 “File →New → Project”。在出现的对话框中,选择 “PHP project”。输入项目的名称。你可能还需要更改其他一些选项,例如更改项目的默认位置,启用 JavaScript 以及更改 PHP 版本。请看以下截图。
|
||||
|
||||
![Create A New PHP Project in Eclipse][3]
|
||||
|
||||
你可以单击 “Finish” 按钮创建项目,或按 “Next” 配置其他选项,例如添加包含和构建路径。在大多数情况下,你无需更改这些设置。
|
||||
|
||||
创建项目后,右键单击项目文件夹,然后选择 “New→PHP File” 将新的 PHP 文件添加到项目。在本教程中,我将其命名为 `index.php`,这是每个 PHP 项目中公认的默认文件。
|
||||
|
||||
![add a new PHP file][4]
|
||||
|
||||
接着在新文件中添加代码。
|
||||
|
||||
![Demo PHP code][5]
|
||||
|
||||
在上面的例子中,我在同一页面上使用了 CSS、JavaScript 和 PHP 标记,主要是为了展示 IDE 能够支持所有这些标记。
|
||||
|
||||
页面完成后,你可以将文件移至 Web 服务器文档根目录或在项目目录中创建一个 PHP 开发服务器来查看输出。
|
||||
|
||||
借助 Eclipse 中的内置终端,我们可以直接在 IDE 中启动 PHP 开发服务器。只需单击工具栏上的终端图标(![Terminal Icon][6]),然后单击 “OK”。在新终端中,进入项目目录,然后运行以下命令:
|
||||
|
||||
```
|
||||
php -S localhost:8080 -t . index.php
|
||||
```
|
||||
|
||||
![Terminal output][7]
|
||||
|
||||
现在,打开浏览器并进入 <http://localhost:8080>。如果按照说明正确完成了所有操作,并且代码没有错误,那么你将在浏览器中看到 PHP 脚本的输出。
|
||||
|
||||
![PHP output in Fedora][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/php-development-on-fedora-with-eclipse/
|
||||
|
||||
作者:[Mehdi Haghgoo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/powergame/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/php-eclipse-816x346.png
|
||||
[2]: https://projects.eclipse.org/projects/eclipse
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2020/02/Screenshot-from-2020-02-07-01-58-39.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2020/02/Screenshot-from-2020-02-07-02-02-05-1024x576.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/02/code-1024x916.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2020/02/Screenshot-from-2020-02-07-03-50-05.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2020/02/terminal-1024x239.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2020/02/output.png
|
||||
@ -0,0 +1,236 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11966-1.html)
|
||||
[#]: subject: (How to find what you’re looking for on Linux with find)
|
||||
[#]: via: (https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
通过 find 命令找到你要找的东西
|
||||
======
|
||||
|
||||
> find 命令有巨多的选项可以帮助你准确定位你在 Linux 系统上需要寻找的文件。这篇文章讨论了一系列非常有用的选项。
|
||||
|
||||

|
||||
|
||||
在 Linux 系统上有许多用于查找文件的命令,而你在使用它们时也有巨多的选项可以使用。
|
||||
|
||||
例如,你不仅可以通过文件的名称来查找文件,还可以通过文件的所有者或者组、它们的创建时间、大小、分配的权限、最后一次访问它们的时间、关联的信息节点,甚至是文件是否属于系统上不再存在的帐户或组等等来查找文件。
|
||||
|
||||
你还可以指定搜索从哪里开始,搜索应该深入到文件系统的什么位置,以及搜索结果将告诉你它所找到的文件的数量。
|
||||
|
||||
而所有这些要求都可以通过 `find` 命令来处理。
|
||||
|
||||
下面提供了根据这些要求查找文件的示例。在某些命令中,错误(例如试图列出你没有读取权限的文件)输出将被发送到 `/dev/null`,以便我们不必查看它。或者,我们可以简单地以 root 身份运行以避免这个问题。
|
||||
|
||||
请记住,还有更多的其他选项。这篇文章涵盖了很多内容,但并不是 `find` 命令帮助你定位查找文件的所有方式。
|
||||
|
||||
### 选择起点
|
||||
|
||||
使用 `find`,你可以选择一个起点或从你所在的位置开始。要选择的搜索的起点,请在单词 `find` 后输入它。例如,`find /usr` 或 `find ./bin` 将在 `/usr` 目录或当前位置下的 `bin` 目录开始搜索,而 `find ~` 将在你的主目录中开始搜索,即使你当前位于当前文件系统中的其他位置。
|
||||
|
||||
### 选择你要找的
|
||||
|
||||
最常用的搜索策略之一是按名称搜索文件。这需要使用 `-name` 选项。
|
||||
|
||||
默认情况下,`find` 会显示找到的文件的完整路径。如果你在命令中添加 `-print`,你会看到同样的结果。如果你想查看与文件相关的详细信息—-例如:文件的长度、权限等,你需要在你的 `find` 命令的末尾添加 `-ls` 参数。
|
||||
|
||||
```
|
||||
$ find ~/bin -name tryme
|
||||
/home/shs/bin/tryme
|
||||
$ find ~/bin -name tryme -print
|
||||
/home/shs/bin/tryme
|
||||
$ find ~/bin -name tryme -ls
|
||||
917528 4 -rwx------ 1 shs shs 139 Apr 8 2019 /home/shs/bin/tryme
|
||||
```
|
||||
|
||||
你也可以使用子字符串来查找文件。例如,如果你将上面示例中的 `tryme` 替换为 `try*`,你将会找到所有名称以 `try` 开头的文件。(LCTT 译注:如果要使用通配符 `*` ,请将搜索字符串放到单引号或双引号内,以避免通配符被 shell 所解释)
|
||||
|
||||
按名称查找文件可能是 `find` 命令最典型的用法,不过还有很多其他的方式来查找文件,并且有这样做的需要。下面的部分展示了如何使用其他可用的方式。
|
||||
|
||||
此外,当按文件大小、组、索引节点等条件来搜索文件时,你需要确认找到的文件与你要查找的文件是否相匹配。使用 `-ls` 选项来显示细节是非常有用。
|
||||
|
||||
### 通过大小查找文件
|
||||
|
||||
按大小查找文件需要使用 `-size` 选项并且对相应规范使用一点技巧。例如,如果你指定 `-size 189b`,你将找到 189 个块大小的文件,而不是 189 个字节。(LCTT 译注:如果不跟上单位,默认单位是 `b`。一个块是 512 个字节大小,不足或正好 512 个字节将占据一个块。)对于字节,你需要使用 `--size 189c`(字符)。而且,如果你指定 `--size 200w` ,你将会找到 200 个“<ruby>字<rt>word</rt></ruby>”的文件——以“双字节增量”为单位的字,而不是“我们互相谈论的那些事情”中的单词。你还可以通过以千字节(`k`)、兆字节(`M`)和千兆字节(`G`)为单位提供大小来查找文件。(LCTT 译注:乃至还有 `T`、`P`)
|
||||
|
||||
大多数情况下,Linux 用户会搜索比选定大小要大的文件。例如,要查找大于 1 千兆字节的文件,你可以使用这样的命令,其中 `+1G` 表示“大于 1 千兆字节”:
|
||||
|
||||
```
|
||||
$ find -size +1G -ls 2>/dev/null
|
||||
787715 1053976 -rw-rw-r-- 1 shs shs 1079263432 Dec 21 2018 ./backup.zip
|
||||
801834 1052556 -rw-rw-r-- 1 shs shs 1077809525 Dec 21 2018 ./2019/hold.zip
|
||||
```
|
||||
|
||||
### 通过索引节点号查找文件
|
||||
|
||||
你可以通过用于维护文件元数据(即除文件内容和文件名之外的所有内容)的索引节点来查找文件。
|
||||
|
||||
```
|
||||
$ find -inum 919674 -ls 2>/dev/null
|
||||
919674 4 -rw-rw-r-- 1 shs shs 512 Dec 27 15:25 ./bin/my.log
|
||||
```
|
||||
|
||||
### 查找具有特定文件所有者或组的文件
|
||||
|
||||
按所有者或组查找文件也非常简单。这里我们使用 `sudo` 来解决权限问题。
|
||||
|
||||
```
|
||||
$ sudo find /home -user nemo -name "*.png" -ls
|
||||
1705219 4 drwxr-xr-x 2 nemo nemo 4096 Jan 28 08:50 /home/nemo/Pictures/me.png
|
||||
```
|
||||
|
||||
在下面这个命令中,我们寻找一个被称为 `admins` 的多用户组拥有的文件。
|
||||
|
||||
```
|
||||
# find /tmp -group admins -ls
|
||||
262199 4 -rwxr-x--- 1 dory admins 27 Feb 16 18:57 /tmp/testscript
|
||||
```
|
||||
|
||||
### 查找没有所有者或组的文件
|
||||
|
||||
你可以使用如下命令所示的 `-nouser` 选项来查找不属于当前系统上的任何用户的文件。
|
||||
|
||||
```
|
||||
# find /tmp -nouser -ls
|
||||
262204 4 -rwx------ 1 1016 1016 17 Feb 17 16:42 /tmp/hello
|
||||
```
|
||||
|
||||
请注意,该列表显示了旧用户的 UID 和 GID,这清楚地表明该用户未在系统上定义。这种命令将查找帐户已从系统中删除的用户创建在主目录之外的文件,或者在用户帐户被删除后而未被删除的主目录中创建的文件。类似地,`-nogroup` 选项也会找到这样的文件,尤其是当这些用户是相关组的唯一成员时。
|
||||
|
||||
### 按上次更新时间查找文件
|
||||
|
||||
在此命令中,我们在特定用户的主目录中查找过去 24 小时内更新过的文件。`sudo` 用于搜索另一个用户的主目录。
|
||||
|
||||
```
|
||||
$ sudo find /home/nemo -mtime -1
|
||||
/home/nemo
|
||||
/home/nemo/snap/cheat
|
||||
/home/nemo/tryme
|
||||
```
|
||||
|
||||
### 按上次更改权限的时间查找文件
|
||||
|
||||
`-ctime` 选项可以帮助你查找在某个参考时间范围内状态(如权限)发生更改的文件。以下是查找在最后一天内权限发生更改的文件的示例:
|
||||
|
||||
```
|
||||
$ find . -ctime -1 -ls
|
||||
787987 4 -rwxr-xr-x 1 shs shs 189 Feb 11 07:31 ./tryme
|
||||
```
|
||||
|
||||
请记住,显示的日期和时间只反映了对文件内容进行的最后更新。你需要使用像 `stat` 这样的命令来查看与文件相关联的三个状态(文件创建、修改和状态更改)。
|
||||
|
||||
### 按上次访问的时间查找文件
|
||||
|
||||
在这个命令中,我们使用 `-atime` 选项查找在过去两天内访问过的本地 pdf 文件。
|
||||
|
||||
```
|
||||
$ find -name "*.pdf" -atime -2
|
||||
./Wingding_Invites.pdf
|
||||
```
|
||||
|
||||
### 根据文件相对于另一个文件的时间来查找文件
|
||||
|
||||
你可以使用 `-newer` 选项来查找比其他文件更新的文件。
|
||||
|
||||
```
|
||||
$ find . -newer dig1 -ls
|
||||
786434 68 drwxr-xr-x 67 shs shs 69632 Feb 16 19:05 .
|
||||
1064442 4 drwxr-xr-x 5 shs shs 4096 Feb 16 11:06 ./snap/cheat
|
||||
791846 4 -rw-rw-r-- 1 shs shs 649 Feb 13 14:26 ./dig
|
||||
```
|
||||
|
||||
没有相应的 `-older` 选项,但是你可以用 `! -newer` (即更旧)得到类似的结果,它们基本上一样。
|
||||
|
||||
### 按类型查找文件
|
||||
|
||||
通过文件类型找到一个文件,你有很多选项——常规文件、目录、块和字符文件等等。以下是文件类型选项列表:
|
||||
|
||||
```
|
||||
b 块特殊文件(缓冲的)
|
||||
c 字符特殊文件(无缓冲的)
|
||||
d 目录
|
||||
p 命名管道(FIFO)
|
||||
f 常规文件
|
||||
l 符号链接
|
||||
s 套接字
|
||||
```
|
||||
|
||||
这里有一个寻找符号链接的例子:
|
||||
|
||||
```
|
||||
$ find . -type l -ls
|
||||
805717 0 lrwxrwxrwx 1 shs shs 11 Apr 10 2019 ./volcano -> volcano.pdf
|
||||
918552 0 lrwxrwxrwx 1 shs shs 1 Jun 16 2018 ./letter -> pers/letter2mom
|
||||
```
|
||||
|
||||
### 限制查找的深度
|
||||
|
||||
`-mindepth` 和 `-maxdepth` 选项控制在文件系统中搜索的深度(从当前位置或起始点开始)。
|
||||
|
||||
```
|
||||
$ find -maxdepth 3 -name "*loop"
|
||||
./bin/save/oldloop
|
||||
./bin/long-loop
|
||||
./private/loop
|
||||
```
|
||||
|
||||
### 查找空文件
|
||||
|
||||
在这个命令中,我们寻找空文件,但不进入目录及其子目录。
|
||||
|
||||
```
|
||||
$ find . -maxdepth 2 -empty -type f -ls
|
||||
917517 0 -rw-rw-r-- 1 shs shs 0 Sep 23 11:00 ./complaints/newfile
|
||||
792050 0 -rw-rw-r-- 1 shs shs 0 Oct 4 19:02 ./junk
|
||||
```
|
||||
|
||||
### 按权限查找文件
|
||||
|
||||
你可以使用 `-perm` 选项查找具有特定权限集的文件。在下面的示例中,我们只查找常规文件(`-type f`),以避免看到符号链接,默认情况下符号链接被赋予了这种权限,即使它们所引用的文件是受限的。
|
||||
|
||||
```
|
||||
$ find -perm 777 -type f -ls
|
||||
find: ‘./.dbus’: Permission denied
|
||||
798748 4 -rwxrwxrwx 1 shs shs 15 Mar 28 2019 ./runme
|
||||
```
|
||||
|
||||
### 使用查找来帮助你删除文件
|
||||
|
||||
如果使用如下命令,你可以使用 `find` 命令定位并删除文件:
|
||||
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
```
|
||||
|
||||
`{}` 代表根据搜索条件找到的每个文件的名称。
|
||||
|
||||
一个非常有用的选项是将 `-exec` 替换为 `-ok`。当你这样做时,`find` 会在删除任何文件之前要求确认。
|
||||
|
||||
```
|
||||
$ find . -name runme -ok rm -rf {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
```
|
||||
|
||||
删除文件并不是 `-ok` 和 `-exec` 能为你做的唯一事情。例如,你可以复制、重命名或移动文件。
|
||||
|
||||
确实有很多选择可以有效地使用 `find` 命令,毫无疑问还有一些在本文中没有涉及到。我希望你已经找到一些新的,特别有帮助的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527420/how-to-find-what-you-re-looking-for-on-linux-with-find.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[3]: https://www.facebook.com/NetworkWorld/
|
||||
[4]: https://www.linkedin.com/company/network-world
|
||||
104
published/20200220 Tools for SSH key management.md
Normal file
104
published/20200220 Tools for SSH key management.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11947-1.html)
|
||||
[#]: subject: (Tools for SSH key management)
|
||||
[#]: via: (https://opensource.com/article/20/2/ssh-tools)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
SSH 密钥管理工具
|
||||
======
|
||||
|
||||
> 常用开源工具的省时快捷方式。
|
||||
|
||||

|
||||
|
||||
我经常使用 SSH。我发现自己每天都要登录多个服务器和树莓派(与我位于同一房间,并接入互联网)。我有许多设备需要访问,并且获得访问权限的要求也不同,因此,除了使用各种 `ssh` / `scp` 命令选项之外,我还必须维护一个包含所有连接详细信息的配置文件。
|
||||
|
||||
随着时间的推移,我发现了一些省时的技巧和工具,你可能也会发现它们有用。
|
||||
|
||||
### SSH 密钥
|
||||
|
||||
SSH 密钥是一种在不使用密码的情况下认证 SSH 连接的方法,可以用来加快访问速度或作为一种安全措施(如果你关闭了密码访问权限并确保仅允许授权的密钥)。要创建 SSH 密钥,请运行以下命令:
|
||||
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
这将在 `~/.ssh/` 中创建一个密钥对(公钥和私钥)。将私钥(`id_rsa`)保留在 PC 上,切勿共享。你可以与其他人共享公钥(`id_rsa.pub`)或将其放置在其他服务器上。
|
||||
|
||||
### ssh-copy-id
|
||||
|
||||
如果我在家中或公司工作时使用树莓派,则倾向于将 SSH 设置保留为默认设置,因为我不担心内部信任网络上的安全性,并且通常将 SSH 密钥(公钥)复制到树莓派上,以避免每次都使用密码进行身份验证。为此,我使用 `ssh-copy-id` 命令将其复制到树莓派。这会自动将你的密钥(公钥)添加到树莓派:
|
||||
|
||||
```
|
||||
$ ssh-copy-id pi@192.168.1.20
|
||||
```
|
||||
|
||||
在生产服务器上,我倾向于关闭密码身份验证,仅允许授权的 SSH 密钥登录。
|
||||
|
||||
### ssh-import-id
|
||||
|
||||
另一个类似的工具是 `ssh-import-id`。你可以使用此方法通过从 GitHub 导入密钥来授予你自己(或其他人)对计算机或服务器的访问权限。例如,我已经在我的 GitHub 帐户中注册了各个 SSH 密钥,因此无需密码即可推送到 GitHub。这些公钥是有效的,因此 `ssh-import-id` 可以使用它们在我的任何计算机上授权我:
|
||||
|
||||
```
|
||||
$ ssh-import-id gh:bennuttall
|
||||
```
|
||||
|
||||
我还可以使用它来授予其他人访问服务器的权限,而无需询问他们的密钥:
|
||||
|
||||
```
|
||||
$ ssh-import-id gh:waveform80
|
||||
```
|
||||
|
||||
### storm
|
||||
|
||||
我还使用了名为 Storm 的工具,该工具可帮助你将 SSH 连接添加到 SSH 配置中,因此你不必记住这些连接细节信息。你可以使用 `pip` 安装它:
|
||||
|
||||
```
|
||||
$ sudo pip3 install stormssh
|
||||
```
|
||||
|
||||
然后,你可以使用以下命令将 SSH 连接信息添加到配置中:
|
||||
|
||||
```
|
||||
$ storm add pi3 pi@192.168.1.20
|
||||
```
|
||||
|
||||
然后,你可以只使用 `ssh pi3` 来获得访问权限。类似的还有 `scp file.txt pi3:` 或 `sshfs pi pi3:`。
|
||||
|
||||
你还可以使用更多的 SSH 选项,例如端口号:
|
||||
|
||||
```
|
||||
$ storm add pi3 pi@192.168.1.20:2000
|
||||
```
|
||||
|
||||
你可以参考 Storm 的[文档][2]轻松列出、搜索和编辑已保存的连接。Storm 实际所做的只是管理 SSH 配置文件 `~/.ssh/config` 中的项目。一旦了解了它们是如何存储的,你就可以选择手动编辑它们。配置中的示例连接如下所示:
|
||||
|
||||
```
|
||||
Host pi3
|
||||
user pi
|
||||
hostname 192.168.1.20
|
||||
port 22
|
||||
```
|
||||
|
||||
### 结论
|
||||
|
||||
从树莓派到大型的云基础设施,SSH 是系统管理的重要工具。熟悉密钥管理会很方便。你还有其他 SSH 技巧要添加吗?我希望你在评论中分享他们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/ssh-tools
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_BUS_Apple_520.png?itok=ZJu-hBV1 (collection of hardware on blue backround)
|
||||
[2]: https://stormssh.readthedocs.io/en/stable/usage.html
|
||||
514
published/20200224 Using C and C-- for data science.md
Normal file
514
published/20200224 Using C and C-- for data science.md
Normal file
@ -0,0 +1,514 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11950-1.html)
|
||||
[#]: subject: (Using C and C++ for data science)
|
||||
[#]: via: (https://opensource.com/article/20/2/c-data-science)
|
||||
[#]: author: (Cristiano L. Fontana https://opensource.com/users/cristianofontana)
|
||||
|
||||
在数据科学中使用 C 和 C++
|
||||
======
|
||||
|
||||
> 让我们使用 C99 和 C++11 完成常见的数据科学任务。
|
||||
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
虽然 [Python][2] 和 [R][3] 之类的语言在数据科学中越来越受欢迎,但是 C 和 C++ 对于高效的数据科学来说是一个不错的选择。在本文中,我们将使用 [C99][4] 和 [C++11][5] 编写一个程序,该程序使用 [Anscombe 的四重奏][6]数据集,下面将对其进行解释。
|
||||
|
||||
我在一篇涉及 [Python 和 GNU Octave][7] 的文章中写了我不断学习编程语言的动机,值得大家回顾。这里所有的程序都需要在[命令行][8]上运行,而不是在[图形用户界面(GUI)][9]上运行。完整的示例可在 [polyglot_fit 存储库][10]中找到。
|
||||
|
||||
### 编程任务
|
||||
|
||||
你将在本系列中编写的程序:
|
||||
|
||||
* 从 [CSV 文件][11]中读取数据
|
||||
* 用直线插值数据(即 `f(x)=m ⋅ x + q`)
|
||||
* 将结果绘制到图像文件
|
||||
|
||||
这是许多数据科学家遇到的普遍情况。示例数据是 [Anscombe 的四重奏][6]的第一组,如下表所示。这是一组人工构建的数据,当拟合直线时可以提供相同的结果,但是它们的曲线非常不同。数据文件是一个文本文件,其中的制表符用作列分隔符,前几行作为标题。该任务将仅使用第一组(即前两列)。
|
||||
|
||||

|
||||
|
||||
### C 语言的方式
|
||||
|
||||
[C][12] 语言是通用编程语言,是当今使用最广泛的语言之一(依据 [TIOBE 指数][13]、[RedMonk 编程语言排名][14]、[编程语言流行度指数][15]和 [GitHub Octoverse 状态][16] 得来)。这是一种相当古老的语言(大约诞生在 1973 年),并且用它编写了许多成功的程序(例如 Linux 内核和 Git 仅是其中的两个例子)。它也是最接近计算机内部运行机制的语言之一,因为它直接用于操作内存。它是一种[编译语言][17];因此,源代码必须由[编译器][18]转换为[机器代码][19]。它的[标准库][20]很小,功能也不多,因此人们开发了其它库来提供缺少的功能。
|
||||
|
||||
我最常在[数字运算][21]中使用该语言,主要是因为其性能。我觉得使用起来很繁琐,因为它需要很多[样板代码][22],但是它在各种环境中都得到了很好的支持。C99 标准是最新版本,增加了一些漂亮的功能,并且得到了编译器的良好支持。
|
||||
|
||||
我将一路介绍 C 和 C++ 编程的必要背景,以便初学者和高级用户都可以继续学习。
|
||||
|
||||
#### 安装
|
||||
|
||||
要使用 C99 进行开发,你需要一个编译器。我通常使用 [Clang][23],不过 [GCC][24] 是另一个有效的开源编译器。对于线性拟合,我选择使用 [GNU 科学库][25]。对于绘图,我找不到任何明智的库,因此该程序依赖于外部程序:[Gnuplot][26]。该示例还使用动态数据结构来存储数据,该结构在[伯克利软件分发版(BSD)][27]中定义。
|
||||
|
||||
在 [Fedora][28] 中安装很容易:
|
||||
|
||||
```
|
||||
sudo dnf install clang gnuplot gsl gsl-devel
|
||||
```
|
||||
|
||||
#### 代码注释
|
||||
|
||||
在 C99 中,[注释][29]的格式是在行的开头放置 `//`,行的其它部分将被解释器丢弃。另外,`/*` 和 `*/` 之间的任何内容也将被丢弃。
|
||||
|
||||
```
|
||||
// 这是一个注释,会被解释器忽略
|
||||
/* 这也被忽略 */
|
||||
```
|
||||
|
||||
#### 必要的库
|
||||
|
||||
库由两部分组成:
|
||||
|
||||
* [头文件][30],其中包含函数说明
|
||||
* 包含函数定义的源文件
|
||||
|
||||
头文件包含在源文件中,而库文件的源文件则[链接][31]到可执行文件。因此,此示例所需的头文件是:
|
||||
|
||||
```
|
||||
// 输入/输出功能
|
||||
#include <stdio.h>
|
||||
// 标准库
|
||||
#include <stdlib.h>
|
||||
// 字符串操作功能
|
||||
#include <string.h>
|
||||
// BSD 队列
|
||||
#include <sys/queue.h>
|
||||
// GSL 科学功能
|
||||
#include <gsl/gsl_fit.h>
|
||||
#include <gsl/gsl_statistics_double.h>
|
||||
```
|
||||
|
||||
#### 主函数
|
||||
|
||||
在 C 语言中,程序必须位于称为主函数 [main()][32] 的特殊函数内:
|
||||
|
||||
```
|
||||
int main(void) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
这与上一教程中介绍的 Python 不同,后者将运行在源文件中找到的所有代码。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
在 C 语言中,变量必须在使用前声明,并且必须与类型关联。每当你要使用变量时,都必须决定要在其中存储哪种数据。你也可以指定是否打算将变量用作常量值,这不是必需的,但是编译器可以从此信息中受益。 以下来自存储库中的 [fitting_C99.c 程序][33]:
|
||||
|
||||
```
|
||||
const char *input_file_name = "anscombe.csv";
|
||||
const char *delimiter = "\t";
|
||||
const unsigned int skip_header = 3;
|
||||
const unsigned int column_x = 0;
|
||||
const unsigned int column_y = 1;
|
||||
const char *output_file_name = "fit_C99.csv";
|
||||
const unsigned int N = 100;
|
||||
```
|
||||
|
||||
C 语言中的数组不是动态的,从某种意义上说,数组的长度必须事先确定(即,在编译之前):
|
||||
|
||||
```
|
||||
int data_array[1024];
|
||||
```
|
||||
|
||||
由于你通常不知道文件中有多少个数据点,因此请使用[单链列表][34]。这是一个动态数据结构,可以无限增长。幸运的是,BSD [提供了链表][35]。这是一个示例定义:
|
||||
|
||||
```
|
||||
struct data_point {
|
||||
double x;
|
||||
double y;
|
||||
|
||||
SLIST_ENTRY(data_point) entries;
|
||||
};
|
||||
|
||||
SLIST_HEAD(data_list, data_point) head = SLIST_HEAD_INITIALIZER(head);
|
||||
SLIST_INIT(&head);
|
||||
```
|
||||
|
||||
该示例定义了一个由结构化值组成的 `data_point` 列表,该结构化值同时包含 `x` 值和 `y` 值。语法相当复杂,但是很直观,详细描述它就会太冗长了。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
要在终端上打印,可以使用 [printf()][36] 函数,其功能类似于 Octave 的 `printf()` 函数(在第一篇文章中介绍):
|
||||
|
||||
```
|
||||
printf("#### Anscombe's first set with C99 ####\n");
|
||||
```
|
||||
|
||||
`printf()` 函数不会在打印字符串的末尾自动添加换行符,因此你必须添加换行符。第一个参数是一个字符串,可以包含传递给函数的其他参数的格式信息,例如:
|
||||
|
||||
```
|
||||
printf("Slope: %f\n", slope);
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
现在来到了困难的部分……有一些用 C 语言解析 CSV 文件的库,但是似乎没有一个库足够稳定或流行到可以放入到 Fedora 软件包存储库中。我没有为本教程添加依赖项,而是决定自己编写此部分。同样,讨论这些细节太啰嗦了,所以我只会解释大致的思路。为了简洁起见,将忽略源代码中的某些行,但是你可以在存储库中找到完整的示例代码。
|
||||
|
||||
首先,打开输入文件:
|
||||
|
||||
```
|
||||
FILE* input_file = fopen(input_file_name, "r");
|
||||
```
|
||||
|
||||
然后逐行读取文件,直到出现错误或文件结束:
|
||||
|
||||
```
|
||||
while (!ferror(input_file) && !feof(input_file)) {
|
||||
size_t buffer_size = 0;
|
||||
char *buffer = NULL;
|
||||
|
||||
getline(&buffer, &buffer_size, input_file);
|
||||
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
[getline()][39] 函数是 [POSIX.1-2008 标准][40]新增的一个不错的函数。它可以读取文件中的整行,并负责分配必要的内存。然后使用 [strtok()][42] 函数将每一行分成<ruby>[字元][41]<rt>token</rt></ruby>。遍历字元,选择所需的列:
|
||||
|
||||
```
|
||||
char *token = strtok(buffer, delimiter);
|
||||
|
||||
while (token != NULL)
|
||||
{
|
||||
double value;
|
||||
sscanf(token, "%lf", &value);
|
||||
|
||||
if (column == column_x) {
|
||||
x = value;
|
||||
} else if (column == column_y) {
|
||||
y = value;
|
||||
}
|
||||
|
||||
column += 1;
|
||||
token = strtok(NULL, delimiter);
|
||||
}
|
||||
```
|
||||
|
||||
最后,当选择了 `x` 和 `y` 值时,将新数据点插入链表中:
|
||||
|
||||
```
|
||||
struct data_point *datum = malloc(sizeof(struct data_point));
|
||||
datum->x = x;
|
||||
datum->y = y;
|
||||
|
||||
SLIST_INSERT_HEAD(&head, datum, entries);
|
||||
```
|
||||
|
||||
[malloc()][46] 函数为新数据点动态分配(保留)一些持久性内存。
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
GSL 线性拟合函数 [gsl_fit_linear()][47] 期望其输入为简单数组。因此,由于你将不知道要创建的数组的大小,因此必须手动分配它们的内存:
|
||||
|
||||
```
|
||||
const size_t entries_number = row - skip_header - 1;
|
||||
|
||||
double *x = malloc(sizeof(double) * entries_number);
|
||||
double *y = malloc(sizeof(double) * entries_number);
|
||||
```
|
||||
|
||||
然后,遍历链表以将相关数据保存到数组:
|
||||
|
||||
```
|
||||
SLIST_FOREACH(datum, &head, entries) {
|
||||
const double current_x = datum->x;
|
||||
const double current_y = datum->y;
|
||||
|
||||
x[i] = current_x;
|
||||
y[i] = current_y;
|
||||
|
||||
i += 1;
|
||||
}
|
||||
```
|
||||
|
||||
现在你已经处理完了链表,请清理它。要**总是**释放已手动分配的内存,以防止[内存泄漏][48]。内存泄漏是糟糕的、糟糕的、糟糕的(重要的话说三遍)。每次内存没有释放时,花园侏儒都会找不到自己的头:
|
||||
|
||||
```
|
||||
while (!SLIST_EMPTY(&head)) {
|
||||
struct data_point *datum = SLIST_FIRST(&head);
|
||||
|
||||
SLIST_REMOVE_HEAD(&head, entries);
|
||||
|
||||
free(datum);
|
||||
}
|
||||
```
|
||||
|
||||
终于,终于!你可以拟合你的数据了:
|
||||
|
||||
```
|
||||
gsl_fit_linear(x, 1, y, 1, entries_number,
|
||||
&intercept, &slope,
|
||||
&cov00, &cov01, &cov11, &chi_squared);
|
||||
const double r_value = gsl_stats_correlation(x, 1, y, 1, entries_number);
|
||||
|
||||
printf("Slope: %f\n", slope);
|
||||
printf("Intercept: %f\n", intercept);
|
||||
printf("Correlation coefficient: %f\n", r_value);
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
你必须使用外部程序进行绘图。因此,将拟合数据保存到外部文件:
|
||||
|
||||
```
|
||||
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
|
||||
|
||||
for (unsigned int i = 0; i < N; i += 1) {
|
||||
const double current_x = (min_x - 1) + step_x * i;
|
||||
const double current_y = intercept + slope * current_x;
|
||||
|
||||
fprintf(output_file, "%f\t%f\n", current_x, current_y);
|
||||
}
|
||||
```
|
||||
|
||||
用于绘制两个文件的 Gnuplot 命令是:
|
||||
|
||||
```
|
||||
plot 'fit_C99.csv' using 1:2 with lines title 'Fit', 'anscombe.csv' using 1:2 with points pointtype 7 title 'Data'
|
||||
```
|
||||
|
||||
#### 结果
|
||||
|
||||
在运行程序之前,你必须编译它:
|
||||
|
||||
```
|
||||
clang -std=c99 -I/usr/include/ fitting_C99.c -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_C99
|
||||
```
|
||||
|
||||
这个命令告诉编译器使用 C99 标准、读取 `fitting_C99.c` 文件、加载 `gsl` 和 `gslcblas` 库、并将结果保存到 `fitting_C99`。命令行上的结果输出为:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with C99 ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.000091
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这是用 Gnuplot 生成的结果图像:
|
||||
|
||||
![Plot and fit of the dataset obtained with C99][52]
|
||||
|
||||
### C++11 方式
|
||||
|
||||
[C++][53] 语言是一种通用编程语言,也是当今使用的最受欢迎的语言之一。它是作为 [C 的继承人][54]创建的(诞生于 1983 年),重点是[面向对象程序设计(OOP)][55]。C++ 通常被视为 C 的超集,因此 C 程序应该能够使用 C++ 编译器进行编译。这并非完全正确,因为在某些极端情况下它们的行为有所不同。 根据我的经验,C++ 与 C 相比需要更少的样板代码,但是如果要进行面向对象开发,语法会更困难。C++11 标准是最新版本,增加了一些漂亮的功能,并且基本上得到了编译器的支持。
|
||||
|
||||
由于 C++ 在很大程度上与 C 兼容,因此我将仅强调两者之间的区别。我在本部分中没有涵盖的任何部分,则意味着它与 C 中的相同。
|
||||
|
||||
#### 安装
|
||||
|
||||
这个 C++ 示例的依赖项与 C 示例相同。 在 Fedora 上,运行:
|
||||
|
||||
```
|
||||
sudo dnf install clang gnuplot gsl gsl-devel
|
||||
```
|
||||
|
||||
#### 必要的库
|
||||
|
||||
库的工作方式与 C 语言相同,但是 `include` 指令略有不同:
|
||||
|
||||
```
|
||||
#include <cstdlib>
|
||||
#include <cstring>
|
||||
#include <iostream>
|
||||
#include <fstream>
|
||||
#include <string>
|
||||
#include <vector>
|
||||
#include <algorithm>
|
||||
|
||||
extern "C" {
|
||||
#include <gsl/gsl_fit.h>
|
||||
#include <gsl/gsl_statistics_double.h>
|
||||
}
|
||||
```
|
||||
|
||||
由于 GSL 库是用 C 编写的,因此你必须将这个特殊情况告知编译器。
|
||||
|
||||
#### 定义变量
|
||||
|
||||
与 C 语言相比,C++ 支持更多的数据类型(类),例如,与其 C 语言版本相比,`string` 类型具有更多的功能。相应地更新变量的定义:
|
||||
|
||||
```
|
||||
const std::string input_file_name("anscombe.csv");
|
||||
```
|
||||
|
||||
对于字符串之类的结构化对象,你可以定义变量而无需使用 `=` 符号。
|
||||
|
||||
#### 打印输出
|
||||
|
||||
你可以使用 `printf()` 函数,但是 `cout` 对象更惯用。使用运算符 `<<` 来指示要使用 `cout` 打印的字符串(或对象):
|
||||
|
||||
```
|
||||
std::cout << "#### Anscombe's first set with C++11 ####" << std::endl;
|
||||
|
||||
...
|
||||
|
||||
std::cout << "Slope: " << slope << std::endl;
|
||||
std::cout << "Intercept: " << intercept << std::endl;
|
||||
std::cout << "Correlation coefficient: " << r_value << std::endl;
|
||||
```
|
||||
|
||||
#### 读取数据
|
||||
|
||||
该方案与以前相同。将打开文件并逐行读取文件,但语法不同:
|
||||
|
||||
```
|
||||
std::ifstream input_file(input_file_name);
|
||||
|
||||
while (input_file.good()) {
|
||||
std::string line;
|
||||
|
||||
getline(input_file, line);
|
||||
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
使用与 C99 示例相同的功能提取行字元。代替使用标准的 C 数组,而是使用两个[向量][56]。向量是 [C++ 标准库][57]中对 C 数组的扩展,它允许动态管理内存而无需显式调用 `malloc()`:
|
||||
|
||||
```
|
||||
std::vector<double> x;
|
||||
std::vector<double> y;
|
||||
|
||||
// Adding an element to x and y:
|
||||
x.emplace_back(value);
|
||||
y.emplace_back(value);
|
||||
```
|
||||
|
||||
#### 拟合数据
|
||||
|
||||
要在 C++ 中拟合,你不必遍历列表,因为向量可以保证具有连续的内存。你可以将向量缓冲区的指针直接传递给拟合函数:
|
||||
|
||||
```
|
||||
gsl_fit_linear(x.data(), 1, y.data(), 1, entries_number,
|
||||
&intercept, &slope,
|
||||
&cov00, &cov01, &cov11, &chi_squared);
|
||||
const double r_value = gsl_stats_correlation(x.data(), 1, y.data(), 1, entries_number);
|
||||
|
||||
std::cout << "Slope: " << slope << std::endl;
|
||||
std::cout << "Intercept: " << intercept << std::endl;
|
||||
std::cout << "Correlation coefficient: " << r_value << std::endl;
|
||||
```
|
||||
|
||||
#### 绘图
|
||||
|
||||
使用与以前相同的方法进行绘图。 写入文件:
|
||||
|
||||
```
|
||||
const double step_x = ((max_x + 1) - (min_x - 1)) / N;
|
||||
|
||||
for (unsigned int i = 0; i < N; i += 1) {
|
||||
const double current_x = (min_x - 1) + step_x * i;
|
||||
const double current_y = intercept + slope * current_x;
|
||||
|
||||
output_file << current_x << "\t" << current_y << std::endl;
|
||||
}
|
||||
|
||||
output_file.close();
|
||||
```
|
||||
|
||||
然后使用 Gnuplot 进行绘图。
|
||||
|
||||
#### 结果
|
||||
|
||||
在运行程序之前,必须使用类似的命令对其进行编译:
|
||||
|
||||
```
|
||||
clang++ -std=c++11 -I/usr/include/ fitting_Cpp11.cpp -L/usr/lib/ -L/usr/lib64/ -lgsl -lgslcblas -o fitting_Cpp11
|
||||
```
|
||||
|
||||
命令行上的结果输出为:
|
||||
|
||||
```
|
||||
#### Anscombe's first set with C++11 ####
|
||||
Slope: 0.500091
|
||||
Intercept: 3.00009
|
||||
Correlation coefficient: 0.816421
|
||||
```
|
||||
|
||||
这就是用 Gnuplot 生成的结果图像:
|
||||
|
||||
![Plot and fit of the dataset obtained with C++11][58]
|
||||
|
||||
### 结论
|
||||
|
||||
本文提供了用 C99 和 C++11 编写的数据拟合和绘图任务的示例。由于 C++ 在很大程度上与 C 兼容,因此本文利用了它们的相似性来编写了第二个示例。在某些方面,C++ 更易于使用,因为它部分减轻了显式管理内存的负担。但是其语法更加复杂,因为它引入了为 OOP 编写类的可能性。但是,仍然可以用 C 使用 OOP 方法编写软件。由于 OOP 是一种编程风格,因此可以在任何语言中使用。在 C 中有一些很好的 OOP 示例,例如 [GObject][59] 和 [Jansson][60]库。
|
||||
|
||||
对于数字运算,我更喜欢在 C99 中进行,因为它的语法更简单并且得到了广泛的支持。直到最近,C++11 还没有得到广泛的支持,我倾向于避免使用先前版本中的粗糙不足之处。对于更复杂的软件,C++ 可能是一个不错的选择。
|
||||
|
||||
你是否也将 C 或 C++ 用于数据科学?在评论中分享你的经验。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/c-data-science
|
||||
|
||||
作者:[Cristiano L. Fontana][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cristianofontana
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://opensource.com/article/18/9/top-3-python-libraries-data-science
|
||||
[3]: https://opensource.com/article/19/5/learn-python-r-data-science
|
||||
[4]: https://en.wikipedia.org/wiki/C99
|
||||
[5]: https://en.wikipedia.org/wiki/C%2B%2B11
|
||||
[6]: https://en.wikipedia.org/wiki/Anscombe%27s_quartet
|
||||
[7]: https://linux.cn/article-11943-1.html
|
||||
[8]: https://en.wikipedia.org/wiki/Command-line_interface
|
||||
[9]: https://en.wikipedia.org/wiki/Graphical_user_interface
|
||||
[10]: https://gitlab.com/cristiano.fontana/polyglot_fit
|
||||
[11]: https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[12]: https://en.wikipedia.org/wiki/C_%28programming_language%29
|
||||
[13]: https://www.tiobe.com/tiobe-index/
|
||||
[14]: https://redmonk.com/sogrady/2019/07/18/language-rankings-6-19/
|
||||
[15]: http://pypl.github.io/PYPL.html
|
||||
[16]: https://octoverse.github.com/
|
||||
[17]: https://en.wikipedia.org/wiki/Compiled_language
|
||||
[18]: https://en.wikipedia.org/wiki/Compiler
|
||||
[19]: https://en.wikipedia.org/wiki/Machine_code
|
||||
[20]: https://en.wikipedia.org/wiki/C_standard_library
|
||||
[21]: https://en.wiktionary.org/wiki/number-crunching
|
||||
[22]: https://en.wikipedia.org/wiki/Boilerplate_code
|
||||
[23]: https://clang.llvm.org/
|
||||
[24]: https://gcc.gnu.org/
|
||||
[25]: https://www.gnu.org/software/gsl/
|
||||
[26]: http://www.gnuplot.info/
|
||||
[27]: https://en.wikipedia.org/wiki/Berkeley_Software_Distribution
|
||||
[28]: https://getfedora.org/
|
||||
[29]: https://en.wikipedia.org/wiki/Comment_(computer_programming)
|
||||
[30]: https://en.wikipedia.org/wiki/Include_directive
|
||||
[31]: https://en.wikipedia.org/wiki/Linker_%28computing%29
|
||||
[32]: https://en.wikipedia.org/wiki/Entry_point#C_and_C++
|
||||
[33]: https://gitlab.com/cristiano.fontana/polyglot_fit/-/blob/master/fitting_C99.c
|
||||
[34]: https://en.wikipedia.org/wiki/Linked_list#Singly_linked_list
|
||||
[35]: http://man7.org/linux/man-pages/man3/queue.3.html
|
||||
[36]: https://en.wikipedia.org/wiki/Printf_format_string
|
||||
[37]: http://www.opengroup.org/onlinepubs/009695399/functions/ferror.html
|
||||
[38]: http://www.opengroup.org/onlinepubs/009695399/functions/feof.html
|
||||
[39]: http://man7.org/linux/man-pages/man3/getline.3.html
|
||||
[40]: https://en.wikipedia.org/wiki/POSIX
|
||||
[41]: https://en.wikipedia.org/wiki/Lexical_analysis#Token
|
||||
[42]: http://man7.org/linux/man-pages/man3/strtok.3.html
|
||||
[43]: http://www.opengroup.org/onlinepubs/009695399/functions/strtok.html
|
||||
[44]: http://www.opengroup.org/onlinepubs/009695399/functions/sscanf.html
|
||||
[45]: http://www.opengroup.org/onlinepubs/009695399/functions/malloc.html
|
||||
[46]: http://man7.org/linux/man-pages/man3/malloc.3.html
|
||||
[47]: https://www.gnu.org/software/gsl/doc/html/lls.html
|
||||
[48]: https://en.wikipedia.org/wiki/Memory_leak
|
||||
[49]: http://www.opengroup.org/onlinepubs/009695399/functions/free.html
|
||||
[50]: http://www.opengroup.org/onlinepubs/009695399/functions/printf.html
|
||||
[51]: http://www.opengroup.org/onlinepubs/009695399/functions/fprintf.html
|
||||
[52]: https://opensource.com/sites/default/files/uploads/fit_c99.png (Plot and fit of the dataset obtained with C99)
|
||||
[53]: https://en.wikipedia.org/wiki/C%2B%2B
|
||||
[54]: http://www.cplusplus.com/info/history/
|
||||
[55]: https://en.wikipedia.org/wiki/Object-oriented_programming
|
||||
[56]: https://en.wikipedia.org/wiki/Sequence_container_%28C%2B%2B%29#Vector
|
||||
[57]: https://en.wikipedia.org/wiki/C%2B%2B_Standard_Library
|
||||
[58]: https://opensource.com/sites/default/files/uploads/fit_cpp11.png (Plot and fit of the dataset obtained with C++11)
|
||||
[59]: https://en.wikipedia.org/wiki/GObject
|
||||
[60]: http://www.digip.org/jansson/
|
||||
@ -0,0 +1,130 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11957-1.html)
|
||||
[#]: subject: (What developers need to know about domain-specific languages)
|
||||
[#]: via: (https://opensource.com/article/20/2/domain-specific-languages)
|
||||
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||
|
||||
|
||||
开发者需要了解的领域特定语言(DSL)
|
||||
======
|
||||
|
||||
> 领域特定语言是在特定领域下用于特定上下文的语言。作为开发者,很有必要了解领域特定语言的含义,以及为什么要使用特定领域语言。
|
||||
|
||||

|
||||
|
||||
<ruby>领域特定语言<rt>domain-specific language</rt></ruby>(DSL)是一种旨在特定领域下的上下文的语言。这里的领域是指某种商业上的(例如银行业、保险业等)上下文,也可以指某种应用程序的(例如 Web 应用、数据库等)上下文。与之相比的另一个概念是<ruby>通用语言<rt>general-purpose language</rt></ruby>(GPL,LCTT 译注:注意不要和 GPL 许可证混淆),通用语言则可以广泛应用于各种商业或应用问题当中。
|
||||
|
||||
DSL 并不具备很强的普适性,它是仅为某个适用的领域而设计的,但它也足以用于表示这个领域中的问题以及构建对应的解决方案。HTML 是 DSL 的一个典型,它是在 Web 应用上使用的语言,尽管 HTML 无法进行数字运算,但也不影响它在这方面的广泛应用。
|
||||
|
||||
而 GPL 则没有特定针对的领域,这种语言的设计者不可能知道这种语言会在什么领域被使用,更不清楚用户打算解决的问题是什么,因此 GPL 会被设计成可用于解决任何一种问题、适合任何一种业务、满足任何一种需求。例如 Java 就属于 GPL,它可以在 PC 或移动设备上运行,嵌入到银行、金融、保险、制造业等各种行业的应用中去。
|
||||
|
||||
### DSL 的类别
|
||||
|
||||
从使用方式的角度,语言可以划分出以下两类:
|
||||
|
||||
* DSL:使用 DSL 形式编写或表示的语言
|
||||
* <ruby>宿主语言<rt>host language</rt></ruby>:用于执行或处理 DSL 的语言
|
||||
|
||||
由不同的语言编写并由另一种宿主语言处理的 DSL 被称为<ruby>外部<rt>external</rt></ruby> DSL。
|
||||
|
||||
以下就是可以在宿主语言中处理的 SQL 形式的 DSL:
|
||||
|
||||
```
|
||||
SELECT account
|
||||
FROM accounts
|
||||
WHERE account = '123' AND branch = 'abc' AND amount >= 1000
|
||||
```
|
||||
|
||||
因此,只要在规定了词汇和语法的情况下,DSL 也可以直接使用英语来编写,并使用诸如 ANTLR 这样的<ruby>解析器生成器<rt>parser generator</rt></ruby>以另一种宿主语言来处理 DSL:
|
||||
|
||||
```
|
||||
if smokes then increase premium by 10%
|
||||
```
|
||||
|
||||
如果 DSL 和宿主语言是同一种语言,这种 DSL 称为<ruby>内部<rt>internal</rt></ruby>DSL,其中 DSL 由以同一种语义的宿主语言编写和处理,因此又称为<ruby>嵌入式<rt>embedded</rt></ruby> DSL。以下是两个例子:
|
||||
|
||||
* Bash 形式的 DSL 可以由 Bash 解释器执行:
|
||||
|
||||
```
|
||||
if today_is_christmas; then apply_christmas_discount; fi
|
||||
```
|
||||
同时这也是一段看起来符合英语语法的 Bash。
|
||||
* 使用类似 Java 语法编写的 DSL:
|
||||
|
||||
```
|
||||
orderValue = orderValue
|
||||
.applyFestivalDiscount()
|
||||
.applyCustomerLoyalityDiscount()
|
||||
.applyCustomerAgeDiscount();
|
||||
```
|
||||
这一段的可读性也相当强。
|
||||
|
||||
实际上,DSL 和 GPL 之间并没有非常明确的界限。
|
||||
|
||||
### DSL 家族
|
||||
|
||||
以下这些语言都可以作为 DSL 使用:
|
||||
|
||||
* Web 应用:HTML
|
||||
* Shell:用于类 Unix 系统的 sh、Bash、CSH 等;用于 Windows 系统的 MS-DOS、Windows Terminal、PowerShell 等
|
||||
* 标记语言:XML
|
||||
* 建模:UML
|
||||
* 数据处理:SQL 及其变体
|
||||
* 业务规则管理:Drools
|
||||
* 硬件:Verilog、VHD
|
||||
* 构建工具:Maven、Gradle
|
||||
* 数值计算和模拟:MATLAB(商业)、GNU Octave、Scilab
|
||||
* 解析器和生成器:Lex、YACC、GNU Bison、ANTLR
|
||||
|
||||
### 为什么要使用 DSL?
|
||||
|
||||
DSL 的目的是在某个领域中记录一些需求和行为,在某些方面(例如金融商品交易)中,DSL 的适用场景可能更加狭窄。业务团队和技术团队能通过 DSL 有效地协同工作,因此 DSL 除了在业务用途上有所发挥,还可以让设计人员和开发人员用于设计和开发应用程序。
|
||||
|
||||
DSL 还可以用于生成一些用于解决特定问题的代码,但生成代码并不是 DSL 的重点并不在此,而是对专业领域知识的结合。当然,代码生成在领域工程中是一个巨大的优势。
|
||||
|
||||
### DSL 的优点和缺点
|
||||
|
||||
DSL 的优点是,它对于领域的特征捕捉得非常好,同时它不像 GPL 那样包罗万有,学习和使用起来相对比较简单。因此,它在专业人员之间、专业人员和开发人员之间都提供了一个沟通的桥梁。
|
||||
|
||||
而 DSL 最显著的缺点就在于它只能用于一个特定的领域和目标。尽管学习起来不算太难,但学习成本仍然存在。如果使用到 DSL 相关的工具,即使对工作效率有所提升,但开发或配置这些工具也会增加一定的工作负担。另外,如果要设计一款 DSL,设计者必须具备专业领域知识和语言开发知识,而同时具备这两种知识的人却少之又少。
|
||||
|
||||
### DSL 相关软件
|
||||
|
||||
开源的 DSL 软件包括:
|
||||
|
||||
* Xtext:Xtext 可以与 Eclipse 集成,并支持 DSL 开发。它能够实现代码生成,因此一些开源和商业产品都用它来提供特定的功能。用于农业活动建模分析的<ruby>多用途农业数据系统<rt>Multipurpose Agricultural Data System</rt></ruby>(MADS)就是基于 Xtext 实现的一个项目,可惜的是这个项目现在已经不太活跃了。
|
||||
* JetBrains MPS:JetBrains MPS 是一个可供开发 DSL 的<ruby>集成开发环境<rt>Integrated Development Environment</rt></ruby>,它将文档在底层存储为一个抽象树结构(Microsoft Word 也使用了这一概念),因此它也自称为一个<ruby>投影编辑器<rt>projectional editor</rt></ruby>。JetBrains MPS 支持 Java、C、JavaScript 和 XML 的代码生成。
|
||||
|
||||
### DSL 的最佳实践
|
||||
|
||||
如果你想使用 DSL,记住以下几点:
|
||||
|
||||
* DSL 不同于 GPL,DSL 只能用于解决特定领域中有限范围内的问题。
|
||||
* 不必动辄建立自己的 DSL,可以首先尝试寻找已有的 DSL。例如 [DSLFIN][4] 这个网站就提供了很多金融方面的 DSL。在实在找不到合适的 DSL 的情况下,才需要建立自己的 DSL。
|
||||
* DSL 最好像平常的语言一样具有可读性。
|
||||
* 尽管代码生成不是一项必需的工作,但它确实会大大提高工作效率。
|
||||
* 虽然 DSL 被称为语言,但 DSL 不需要像 GPL 一样可以被执行,可执行性并不是 DSL 需要达到的目的。
|
||||
* DSL 可以使用文本编辑器编写,但专门的 DSL 编辑器可以更轻松地完成 DSL 的语法和语义检查。
|
||||
|
||||
如果你正在使用或将要使用 DSL,欢迎在评论区留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/domain-specific-languages
|
||||
|
||||
作者:[Girish Managoli][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gammay
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_language_c.png?itok=mPwqDAD9 (Various programming languages in use)
|
||||
[2]: https://en.wikipedia.org/wiki/Domain-specific_language
|
||||
[3]: http://mads.sourceforge.net/
|
||||
[4]: http://www.dslfin.org/resources.html
|
||||
140
published/20200226 Use logzero for simple logging in Python.md
Normal file
140
published/20200226 Use logzero for simple logging in Python.md
Normal file
@ -0,0 +1,140 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11970-1.html)
|
||||
[#]: subject: (Use logzero for simple logging in Python)
|
||||
[#]: via: (https://opensource.com/article/20/2/logzero-python)
|
||||
[#]: author: (Ben Nuttall https://opensource.com/users/bennuttall)
|
||||
|
||||
使用 logzero 在 Python 中进行简单日志记录
|
||||
======
|
||||
|
||||
> 快速了解一个方便的日志库,来帮助你掌握这个重要的编程概念。
|
||||
|
||||

|
||||
|
||||
logzero 库使日志记录就像打印语句一样容易,是简单性的杰出代表。我不确定 logzero 的名称是否要与 pygame-zero、GPIO Zero 和 guizero 这样的 “zero 样板库”契合,但是肯定属于该类别。它是一个 Python 库,可以使日志记录变得简单明了。
|
||||
|
||||
你可以使用它基本的记录到标准输出的日志记录,就像你可以使用 print 来获得信息和调试一样,学习它的更高级日志记录(例如记录到文件)的学习曲线也很平滑。
|
||||
|
||||
首先,使用 pip 安装 logzero:
|
||||
|
||||
```
|
||||
$ sudo pip3 install logzero
|
||||
```
|
||||
|
||||
在 Python 文件中,导入 logger 并尝试以下一个或所有日志实例:
|
||||
|
||||
```
|
||||
from logzero import logger
|
||||
|
||||
logger.debug("hello")
|
||||
logger.info("info")
|
||||
logger.warning("warning")
|
||||
logger.error("error")
|
||||
```
|
||||
|
||||
输出以易于阅读的方式自动着色:
|
||||
|
||||
![Python, Raspberry Pi: import logger][2]
|
||||
|
||||
因此现在不要再使用 `print` 来了解发生了什么,而应使用有相关日志级别的日志器。
|
||||
|
||||
### 在 Python 中将日志写入文件
|
||||
|
||||
如果你阅读至此,并会在你写代码时做一点改变,这对我就足够了。如果你要了解更多,请继续阅读!
|
||||
|
||||
写到标准输出对于测试新程序不错,但是仅当你登录到运行脚本的计算机时才有用。在很多时候,你需要远程执行代码并在事后查看错误。这种情况下,记录到文件很有帮助。让我们尝试一下:
|
||||
|
||||
```
|
||||
from logzero import logger, logfile
|
||||
|
||||
logfile('/home/pi/test.log')
|
||||
```
|
||||
|
||||
现在,你的日志条目将记录到文件 `test.log` 中。记住确保[脚本有权限][3]写入该文件及其目录结构。
|
||||
|
||||
你也可以指定更多选项:
|
||||
|
||||
```
|
||||
logfile('/home/pi/test.log', maxBytes=1e6, backupCount=3)
|
||||
```
|
||||
|
||||
现在,当提供给 `test.log` 文件的数据达到 1MB(10^6 字节)时,它将通过 `test.log.1`、`test.log.2` 等文件轮替写入。这种行为可以避免系统打开和关闭大量 I/O 密集的日志文件,以至于系统无法打开和关闭。更专业一点,你或许还要记录到 `/var/log`。假设你使用的是 Linux,那么创建一个目录并将用户设为所有者,以便可以写入该目录:
|
||||
|
||||
```
|
||||
$ sudo mkdir /var/log/test
|
||||
$ sudo chown pi /var/log/test
|
||||
```
|
||||
|
||||
然后在你的 Python 代码中,更改 `logfile` 路径:
|
||||
|
||||
```
|
||||
logfile('/var/log/test/test.log', maxBytes=1e6, backupCount=3)
|
||||
```
|
||||
|
||||
当要在 `logfile` 中捕获异常时,可以使用 `logging.exception`:
|
||||
|
||||
```
|
||||
try:
|
||||
c = a / b
|
||||
except Exception as e:
|
||||
logger.exception(e)
|
||||
```
|
||||
|
||||
这将输出(在 `b` 为零的情况下):
|
||||
|
||||
```
|
||||
[E 190422 23:41:59 test:9] division by zero
|
||||
Traceback (most recent call last):
|
||||
File "test.py", line 7, in
|
||||
c = a / b
|
||||
ZeroDivisionError: division by zero
|
||||
```
|
||||
|
||||
你会得到日志,还有完整回溯。另外,你可以使用 `logging.error` 并隐藏回溯:
|
||||
|
||||
```
|
||||
try:
|
||||
c = a / b
|
||||
except Exception as e:
|
||||
logger.error(f"{e.__class__.__name__}: {e}")
|
||||
```
|
||||
|
||||
现在,将产生更简洁的结果:
|
||||
|
||||
```
|
||||
[E 190423 00:04:16 test:9] ZeroDivisionError: division by zero
|
||||
```
|
||||
|
||||
![Logging output][4]
|
||||
|
||||
你可以在 [logzero.readthedocs.io] [5] 中阅读更多选项。
|
||||
|
||||
### logzero 为教育而生
|
||||
|
||||
对于新手程序员来说,日志记录可能是一个具有挑战性的概念。大多数框架依赖于流控制和大量变量操作来生成有意义的日志,但是 logzero 不同。由于它的语法类似于 `print` 语句,因此它在教育上很成功,因为它无需解释其他概念。在你的下个项目中试试它。
|
||||
|
||||
|
||||
此文章最初发布在[我的博客][6]上,经许可重新发布。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/logzero-python
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bennuttall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/getting_started_with_python.png?itok=MFEKm3gl (Snake charmer cartoon with a yellow snake and a blue snake)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/rpi_ben_1.png (Python, Raspberry Pi: import logger)
|
||||
[3]: https://opensource.com/article/19/6/understanding-linux-permissions
|
||||
[4]: https://opensource.com/sites/default/files/uploads/rpi_ben_2.png (Logging output)
|
||||
[5]: https://logzero.readthedocs.io/en/latest/
|
||||
[6]: https://tooling.bennuttall.com/logzero/
|
||||
104
published/20200302 How to Add New Brushes in GIMP -Quick Tip.md
Normal file
104
published/20200302 How to Add New Brushes in GIMP -Quick Tip.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11975-1.html)
|
||||
[#]: subject: (How to Add New Brushes in GIMP [Quick Tip])
|
||||
[#]: via: (https://itsfoss.com/add-brushes-gimp/)
|
||||
[#]: author: (Community https://itsfoss.com/author/itsfoss/)
|
||||
|
||||
快速技巧:如何在 GIMP 中添加新画笔
|
||||
======
|
||||
|
||||
[GIMP][1] 是最流行的自由开源的图像编辑器,它也许是 Linux 上最好的 [Adobe Photoshop 替代品][2]。
|
||||
|
||||
当你[在 Ubuntu 或其他任何操作系统上安装了 GIMP 后][3],你会发现已经安装了一些用于基本图像编辑的画笔。如果你需要更具体的画笔,你可以随时在 GIMP 中添加新画笔。
|
||||
|
||||
怎么样?让我在这个快速教程中向你展示。
|
||||
|
||||
### 如何在 GIMP 中添加画笔
|
||||
|
||||
![][4]
|
||||
|
||||
在 GIMP 中安装新画笔需要三个步骤:
|
||||
|
||||
* 获取新画笔
|
||||
* 将其放入指定的文件夹中
|
||||
* 刷新 GIMP 中的画笔
|
||||
|
||||
#### 步骤 1:下载新的 GIMP 画笔
|
||||
|
||||
第一步是获取新的 GIMP 画笔。你从哪里获取?当然是从互联网上。
|
||||
|
||||
你可以在 Google 或[如 Duck Duck Go 这种隐私搜索引擎][5]来搜索 “GIMP brushes”,并从网站下载一个你喜欢的。
|
||||
|
||||
GIMP 画笔通常以 .gbr 和 .gih 文件格式提供。.gbr 文件用于常规画笔,而 .gih 用于动画画笔。
|
||||
|
||||
> 你知道吗?
|
||||
>
|
||||
> 从 2.4 版本起,GIMP 使安装和使用 Photoshop 画笔(.abr 文件)非常简单。你只需将 Photoshop 画笔文件放在正确的文件夹中。
|
||||
>
|
||||
> 请记住,最新的 Photoshop 画笔可能无法完美地在 GIMP 中使用。
|
||||
|
||||
#### 步骤 2:将新画笔复制到它的位置
|
||||
|
||||
获取画笔文件后,下一步是复制该文件并将其粘贴到 GIMP 配置目录中所在的文件夹。
|
||||
|
||||
> 在微软 Windows 上,你必须进入类似 `C:\Documents and Settings\myusername.gimp-2.10\brushes` 这样的文件夹。
|
||||
|
||||
我将展示 Linux 上的详细步骤,因为我们是一个专注于 Linux 的网站。
|
||||
|
||||
选择画笔文件后,在家目录中按下 `Ctrl+h` [查看 Linux 中的隐藏文件][6]。
|
||||
|
||||
![Press Ctrl+H to see hidden files in the home directory][7]
|
||||
|
||||
你应该进入 `.config/GIMP/2.10/brushes` 文件夹(如果你使用的是 GIMP 2.10)。如果使用其他版本,那么应在 `.config/GIMP` 下看到相应文件夹。
|
||||
|
||||
![Adding New Brushes in GIMP][8]
|
||||
|
||||
将画笔文件粘贴到此文件夹中。可选地,你可以通过再次按 `Ctrl+h` 来隐藏隐藏的文件。
|
||||
|
||||
#### 步骤 3:刷新画笔(避免重启 GIMP)
|
||||
|
||||
GIMP 将在启动时自动加载画笔。如果已在运行,并且不想关闭它,你可以刷新画笔。
|
||||
|
||||
在 GIMP 的主菜单中找到 “Windows->Dockable Dialogues->Brushes”。
|
||||
|
||||
![Refresh GIMP Brushes by going go to Windows->Dockable Dialogues-> Brushes][9]
|
||||
|
||||
在右侧栏的 Brushes 对话框中找到“refresh”图标。
|
||||
|
||||
![Refresh GIMP Brushes][10]
|
||||
|
||||
如果你的画笔没有出现,那么你可以试试重启 GIMP。
|
||||
|
||||
> 额外的技巧!
|
||||
>
|
||||
> 在 [GIMP 中添加新画笔还能让你轻松给图片添加水印][11]。只需将 logo 用作画笔,并点击一下就可添加到图片中。
|
||||
|
||||
我希望你喜欢这个快速 GIMP 技巧。敬请期待更多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/add-brushes-gimp/
|
||||
|
||||
作者:[Community][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/itsfoss/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gimp.org/
|
||||
[2]: https://itsfoss.com/open-source-photoshop-alternatives/
|
||||
[3]: https://itsfoss.com/gimp-2-10-release/
|
||||
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/03/Install-New-Brushes-in-GIMP.jpg?ssl=1
|
||||
[5]: https://itsfoss.com/privacy-search-engines/
|
||||
[6]: https://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/adding-brushes-GIMP-1.jpg?ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/adding-brushes-GIMP.png?ssl=1
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/Refresh-GIMP-Brushes.jpg?ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/03/Refresh-GIMP-Brushes-2.jpg?ssl=1
|
||||
[11]: https://itsfoss.com/add-watermark-gimp-linux/
|
||||
99
published/20200302 Install GNU Emacs on Windows.md
Normal file
99
published/20200302 Install GNU Emacs on Windows.md
Normal file
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11971-1.html)
|
||||
[#]: subject: (Install GNU Emacs on Windows)
|
||||
[#]: via: (https://opensource.com/article/20/3/emacs-windows)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Windows 上安装 GNU Emacs
|
||||
======
|
||||
|
||||
> 即使你的操作系统是闭源的,你仍然可以使用这个流行的开源文本编辑器。
|
||||
|
||||

|
||||
|
||||
GNU Emacs 是一个专为各种程序员设计的流行的文本编辑器。因为它是在 Unix 上开发的,并在 Linux(macOS 中也有)上得到了广泛使用,所以人们有时没有意识到它也可用于微软 Windows 上。你也无需成为有经验的或专职的程序员即可使用 Emacs。只需单击几下就可以下载并安装 Emacs,本文向你展示了如何进行。
|
||||
|
||||
你可以手动安装 Windows,也可以使用包管理器安装,例如 [Chocolatey][2]。
|
||||
|
||||
### 7-zip
|
||||
|
||||
如果还没在 Windows 中安装 7-zip,那么就先安装它。[7-zip][3] 是一个开源的归档程序,能够创建和解压 ZIP、7z、TAR、XZ、BZIP2 和 GZIP(以及更多)文件。对于 Windows 用户来说,这是一个宝贵的工具。
|
||||
|
||||
安装 7-zip 后,在 Windows 资源管理器中浏览文件时,右键单击菜单中就有新的 7-zip 归档选项。
|
||||
|
||||
### Powershell 和 Chocolatey
|
||||
|
||||
要在 Windows 上使用 Chocolatey 安装 GNU Emacs :
|
||||
|
||||
```
|
||||
PS> choco install emacs-full
|
||||
```
|
||||
|
||||
安装后,在 Powershell 中启动 Emacs:
|
||||
|
||||
```
|
||||
PS> emacs
|
||||
```
|
||||
|
||||
![Emacs running on Windows][4]
|
||||
|
||||
### 下载适用于 Windows 的 GNU Emacs
|
||||
|
||||
要在 Windows 上手动安装 GNU Emacs,你必须[下载 Emacs][5]。
|
||||
|
||||
![GNU Windows downloader][6]
|
||||
|
||||
它会打开连接到离你最近的服务器,并展示所有可用的 Emacs 版本。找到发行版本号最高的目录,然后单击进入。Windows 有许多不同的 Emacs 构建,但是最通用的版本只是被命名为 `emacs-VERSION-ARCHITECTURE.zip`。`VERSION` 取决于你要下载的版本,而 `ARCHITECTURE` 取决于你使用的是 32 位还是 64 位计算机。大多数现代计算机都是 64 位的,但是如果你有疑问,可以下载 32 位版本,它可在两者上运行。
|
||||
|
||||
如果要下载 64 位计算机的 Emacs v26,你应该点击 `emacs-26.2-x86_64.zip` 的链接。有较小的下载包(例如 “no-deps” 等),但是你必须熟悉如何从源码构建 Emacs,知道它需要哪些库以及你的计算机上已经拥有哪些库。通常,获取较大版本的 Emacs 最容易,因为它包含了在计算机上运行所需的一切。
|
||||
|
||||
### 解压 Emacs
|
||||
|
||||
接下来,解压下载的 ZIP 文件。要解压缩,请右键单击 Emacs ZIP 文件,然后从 7-zip 子菜单中选择 “Extract to Emacs-VERSION”。这是一个很大的压缩包,因此解压可能需要一段时间,但是完成后,你将拥有一个新目录,其中包含与 Emacs 一起分发的所有文件。例如,在此例中,下载了 `emacs-26.2-x86_64.zip`,因此解压后的目录为 `emacs-26.2-x86_64`。
|
||||
|
||||
### 启动 Emacs
|
||||
|
||||
在 Emacs 目录中,找到 `bin` 目录。此文件夹存储随 Emacs 一起分发的所有二进制可执行文件(EXE 文件)。双击 `emacs.exe` 文件启动应用。
|
||||
|
||||
![Emacs running on Windows][7]
|
||||
|
||||
你可以在桌面上创建 `emacs.exe` 的快捷方式,以便于访问。
|
||||
|
||||
### 学习 Emacs
|
||||
|
||||
Emacs 并不像传闻那样难用。它具有自己的传统和惯例,但是当你其中输入文本时,你可以像在记事本或者网站的文本框中那样使用它。
|
||||
|
||||
重要的区别是在你*编辑*输入的文本时。
|
||||
|
||||
但是,学习的唯一方法是开始使用它,因此,使 Emacs 成为完成简单任务的首选文本编辑器。当你通常打开记事本、Word 或 Evernote 或其他工具来做快速笔记或临时记录时,请启动 Emacs。
|
||||
|
||||
Emacs 以基于终端的应用而闻名,但它显然有 GUI,因此请像使用其他程序一样经常使用它的 GUI。从菜单而不是使用键盘复制、剪切和粘贴(paste)(或用 Emacs 的术语 “yank”),然后从菜单或工具栏打开和保存文件。从头开始,并根据应用本身来学习它,而不是根据你以往对其他编辑器的经验就认为它应该是怎样。
|
||||
|
||||
- 下载[速查表][8]!
|
||||
|
||||
感谢 Matthias Pfuetzner 和 Stephen Smoogen。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/3/emacs-windows
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/windows_building_sky_scale.jpg?itok=mH6CAX29 (Tall building with windows)
|
||||
[2]: https://github.com/chocolatey/choco
|
||||
[3]: https://www.7-zip.org/
|
||||
[4]: https://opensource.com/sites/default/files/uploads/windows-ps-choco-emacs.jpg (Emacs running on Windows)
|
||||
[5]: https://www.gnu.org/software/emacs/download.html
|
||||
[6]: https://opensource.com/sites/default/files/uploads/windows-emacs-download.jpg (GNU Windows downloader)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/windows-emacs.jpg (Emacs running on Windows)
|
||||
[8]: https://opensource.com/downloads/emacs-cheat-sheet
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11972-1.html)
|
||||
[#]: subject: (Drauger OS Linux Aims to Bring Console Gaming Experience on the Desktop)
|
||||
[#]: via: (https://itsfoss.com/drauger-os/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Drauger OS Linux 旨在为台式机带来主机游戏体验
|
||||
======
|
||||
|
||||
多年来(或数十年),人们抱怨不[使用Linux][1] 的原因之一是它缺乏主流游戏。[Linux 上的游戏][2]在最近几年有了显著改进,特别是 [Steam Proton][3] 项目的引入使你可以[在 Linux 上玩很多 Windows 专用的游戏][4]。
|
||||
|
||||
这也鼓励了一些[以游戏为中心的 Linux发行版][5]。以 [Lakka][6] 为例,你可以[借助 Lakka Linux 将旧计算机变成复古的街机游戏机][7]。
|
||||
|
||||
另一个以游戏为中心的 Linux 发行版是 [Draguer OS][8],我们今天将对其进行研究。
|
||||
|
||||
### Drauger OS
|
||||
|
||||
根据[该项目的网站][9],“Drauger OS 是 Linux 桌面游戏操作系统。它旨在为游戏玩家提供一个平台,使他们可以在不牺牲安全性的情况下获得出色的性能。此外,它旨在使任何人都可以轻松玩游戏,无论他们使用键盘和鼠标还是某种控制器。”
|
||||
|
||||
他们强调 Drauger OS 并非供日常使用。因此,大多数其他发行版附带的许多生产力工具都不在 Drauger OS 中。
|
||||
|
||||
![Drauger OS 7.4.1][10]
|
||||
|
||||
Drauger OS [基于][9] Ubuntu 之上。当前版本(7.4.1 Jiangshi)使用 “[Liquorix][11] 低延迟Linux 内核,这是一种预编译的 ZEN 内核,设计时考虑了延迟和吞吐量之间的平衡”。但是,这将在下一版本中更改。他们只有一个桌面环境可供选择,即一个修改版本的 [Xfce][12]。
|
||||
|
||||
Drauger OS 开箱即用地安装了多个应用程序和工具,以改善游戏体验。这些包括:
|
||||
|
||||
* [PlayOnLinux][13]
|
||||
* WINE
|
||||
* [Lutris][14]
|
||||
* Steam
|
||||
* [DXVK][15]
|
||||
|
||||
它还具有一组与游戏无关的有趣工具。[Drauger 安装器][16]是 .deb 安装程序,是 Gdebi 的替代品。[多软件库应用安装器][17](mrai)是“用于基于 Debian 的 Linux 操作系统的类似于 AUR-helper 的脚本”。Mrai 旨在与 apt、snap、flatpaks 配合使用,并且可以从 GitHub 安装应用程序。
|
||||
|
||||
有趣的是,Drauger OS 的名称是一个错误。开发负责人 [Thomas Castleman][18](即 batcastle)曾打算为其发行版命名为 Draugr,但是却打错了名字。在 Drauger OS 播客的[第 23 集][19]中,Castleman 说会保留这个拼写错误的名称,因为要对其进行更正需要大量工作。根据 [Wikipedia][20] 的描述,Draugr 是“来自北欧神话中的不死生物”。
|
||||
|
||||
是的,你没看错。Drauger OS 是仅有的几个具有自己的[播客][21]的发行版之一。当被问到这个问题时,Castleman 告诉我:“无论他们的情况如何,我都希望确保我们的社区拥有最大的透明度。”多数情况下,播客是 Drauger OS 博客的音频版本,但有时他们会在没有时间撰写博客文章时使用它来发布公告。
|
||||
|
||||
### Drauger OS 的未来
|
||||
|
||||
![Drauger OS][22]
|
||||
|
||||
Druager OS 背后的开发人员正在开发其下一个主要版本:7.5.1。此版本将基于 Ubuntu 19.10。将有三个主要变化。首先,将使用“我们内部构建的内核” [替换][23] Liquorix 内核。该内核将基于 Linux 内核 GitHub 存储库,“因此,它会变得越来越原汁原味”。
|
||||
|
||||
新版本的第二个主要变化将是为其桌面提供新布局。根据用户的反馈,他们决定将其更改为看起来更类似于 GNOME 的样子。
|
||||
|
||||
第三,他们放弃了 SystemBack 作为其备份工具和安装程序。相反,他们从头开始编写了新的[安装程序][24]。
|
||||
|
||||
开发团队也正在研究 Drauger OS 的 [ARM 版本][25]。他们希望在 2022 年的某个时候发布它。
|
||||
|
||||
### 系统要求
|
||||
|
||||
Drauger OS [系统要求][25]非常适中。请记住,Drauger OS 仅在 64 位系统上运行。
|
||||
|
||||
#### 最低系统要求
|
||||
|
||||
* CPU:双核、1.8GHz、64 位处理器
|
||||
* RAM:1 GB
|
||||
* 储存空间:16 GB
|
||||
* 图形处理器:集成
|
||||
* 屏幕分辨率:60Hz 时为 1024×768
|
||||
* 外部端口:1 个用于显示的端口(HDMI/DisplayPort/VGA/DVI),2 个用于安装 USB 驱动器和键盘的 USB 端口(鼠标可选,但建议使用)
|
||||
|
||||
#### 推荐系统要求
|
||||
|
||||
* CPU:四核、2.2Ghz、64 位处理器
|
||||
* RAM:4 GB
|
||||
* 储存空间:128 GB
|
||||
* 图形处理器:NVIDIA GTX 1050、AMD RX 460 或同等显卡
|
||||
* 屏幕分辨率:60Hz 时为 1080p
|
||||
* 外部端口:1 个用于显示的端口(HDMI/DisplayPort/VGA/DVI),3 个用于安装 USB 驱动器、键盘和鼠标的 USB 端口,1 个音频输出端口
|
||||
|
||||
### 如何为Drauger OS提供帮助
|
||||
|
||||
如果你有兴趣,可以通过多种方法来帮助 Drauger OS。他们一直在寻找[财政支持][26]以保持发展。
|
||||
|
||||
如果你想贡献代码,他们正在寻找具有 BASH、C++ 和 Python 经验的人员。他们所有的代码都在 [GitHub][27] 上。你也可以在社交媒体上[联系][28]他们。
|
||||
|
||||
### 结语
|
||||
|
||||
Drauger OS 只是这类项目之一。我还见过其他[面向游戏的发行版][29],但 Drauger OS 在专注于游戏方面一心一意。由于我更喜欢休闲游戏,因此该发行版对我个人而言并不具有吸引力。但是,我可以看到它如何吸引游戏爱好者使用 Linux。祝他们在以后的发行中好运。
|
||||
|
||||
你对这个仅限于游戏的发行版有何想法?你最喜欢的 Linux 游戏解决方案是什么?请在下面的评论中告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/drauger-os/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/why-use-linux/
|
||||
[2]: https://linux.cn/article-7316-1.html
|
||||
[3]: https://linux.cn/article-10054-1.html
|
||||
[4]: https://itsfoss.com/steam-play/
|
||||
[5]: https://itsfoss.com/linux-gaming-distributions/
|
||||
[6]: http://www.lakka.tv/
|
||||
[7]: https://itsfoss.com/lakka-retrogaming-linux/
|
||||
[8]: https://draugeros.org/go/
|
||||
[9]: https://www.draugeros.org/go/about/
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/drauger-os-7.4.1.jpg?ssl=1
|
||||
[11]: https://liquorix.net/
|
||||
[12]: https://www.xfce.org/
|
||||
[13]: https://www.playonlinux.com/en/
|
||||
[14]: https://lutris.net/
|
||||
[15]: https://github.com/doitsujin/dxvk
|
||||
[16]: https://github.com/drauger-os-development/drauger-installer
|
||||
[17]: https://github.com/drauger-os-development/mrai
|
||||
[18]: https://github.com/Batcastle
|
||||
[19]: https://anchor.fm/drauger-os/episodes/Episode-23-eapu47
|
||||
[20]: https://en.wikipedia.org/wiki/Draugr
|
||||
[21]: https://anchor.fm/drauger-os
|
||||
[22]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/drauger-os-7.5.1.png?ssl=1
|
||||
[23]: https://www.draugeros.org/go/2020/01/20/major-changes-in-drauger-os-7-5-1/
|
||||
[24]: https://github.com/drauger-os-development/system-installer
|
||||
[25]: https://www.draugeros.org/go/system-requirements/
|
||||
[26]: https://www.draugeros.org/go/contribute/
|
||||
[27]: https://github.com/drauger-os-development
|
||||
[28]: https://www.draugeros.org/go/contact-us/
|
||||
[29]: https://itsfoss.com/manjaro-gaming-linux/
|
||||
[30]: https://reddit.com/r/linuxusersgroup
|
||||
@ -1,71 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (NSA cloud advice, Facebook open source year in review, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/20/1/nsa-facebook-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
NSA cloud advice, Facebook open source year in review, and more industry trends
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Facebook open source year in review][2]
|
||||
|
||||
> Last year was a busy one for our [open source][3] engineers. In 2019 we released 170 new open source projects, bringing our portfolio to a total of 579 [active repositories][3]. While it’s important for our internal engineers to contribute to these projects (and they certainly do — with more than 82,000 commits this year), we are also incredibly grateful for the massive support from external contributors. Approximately 2,500 external contributors committed more than 32,000 changes. In addition to these contributions, nearly 93,000 new people starred our projects this year, growing the most important component of any open source project — the community! Facebook Open Source would not be here without your contributions, so we want to thank you for your participation in 2019.
|
||||
|
||||
**The impact**: Facebook got ~33% more changes than they would have had they decided to develop these as closed projects. Organizations addressing similar challenges got an 82,000-commit boost in exchange. What a clear illustration of the business impact of open source development.
|
||||
|
||||
## [Cloud advice from the NSA][4]
|
||||
|
||||
> This document divides cloud vulnerabilities into four classes (misconfiguration, poor access control, shared tenancy vulnerabilities, and supply chain vulnerabilities) that encompass the vast majority of known vulnerabilities. Cloud customers have a critical role in mitigating misconfiguration and poor access control, but can also take actions to protect cloud resources from the exploitation of shared tenancy and supply chain vulnerabilities. Descriptions of each vulnerability class along with the most effective mitigations are provided to help organizations lock down their cloud resources. By taking a risk-based approach to cloud adoption, organizations can securely benefit from the cloud’s extensive capabilities.
|
||||
|
||||
**The impact**: The Fear, Uncertainty, and Doubt (FUD) that has been associated with cloud adoption is being debunked more all the time. None other then the US Department of Defense has done a lot of the thinking so you don't have to, and there is a good chance that their concerns are at least as dire as yours are.
|
||||
|
||||
## [With Kubernetes, China Minsheng Bank transformed its legacy applications][5]
|
||||
|
||||
> But all of CMBC’s legacy applications—for example, the core banking system, payment systems, and channel systems—were written in C and Java, using traditional architecture. “We wanted to do distributed applications because in the past we used VMs in our own data center, and that was quite expensive and with low resource utilization rate,” says Zhang. “Our biggest challenge is how to make our traditional legacy applications adaptable to the cloud native environment.” So far, around 20 applications are running in production on the Kubernetes platform, and 30 new applications are in active development to adopt the Kubernetes platform.
|
||||
|
||||
**The impact**: This illustrates nicely the challenges and opportunities facing businesses in a competitive environment, and suggests a common adoption pattern. Do new stuff the new way, and move the old stuff as it makes sense.
|
||||
|
||||
## [The '5 Rs' of the move to cloud native: Re-platform, re-host, re-factor, replace, retire][6]
|
||||
|
||||
> The bottom line is that telcos and service providers will go cloud native when it is cheaper for them to migrate to the cloud and pay cloud costs than it is to remain in the data centre. That time is now and by adhering to the "5 Rs" of the move to cloud native, Re-platform, Re-host, Re-factor, Replace and/or Retire, the path is open, clearly marked and the goal eminently achievable.
|
||||
|
||||
**The impact**: Cloud-native is basically used as a synonym for open source in this interview; there is no other type of technology that will deliver the same lift.
|
||||
|
||||
## [Fedora CoreOS out of preview][7]
|
||||
|
||||
> Fedora CoreOS is a new Fedora Edition built specifically for running containerized workloads securely and at scale. It’s the successor to both [Fedora Atomic Host][8] and [CoreOS Container Linux][9] and is part of our effort to explore new ways of assembling and updating an OS. Fedora CoreOS combines the provisioning tools and automatic update model of Container Linux with the packaging technology, OCI support, and SELinux security of Atomic Host. For more on the Fedora CoreOS philosophy, goals, and design, see the [announcement of the preview release][10].
|
||||
|
||||
**The impact**: Collapsing these two branches of the Linux family tree into one another moves the state of the art forward for everyone (once you get through the migration).
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/nsa-facebook-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://opensource.com/article/20/1/hybrid-developer-future-industry-trends
|
||||
[3]: https://opensource.facebook.com/
|
||||
[4]: https://media.defense.gov/2020/Jan/22/2002237484/-1/-1/0/CSI-MITIGATING-CLOUD-VULNERABILITIES_20200121.PDF
|
||||
[5]: https://www.cncf.io/blog/2020/01/23/with-kubernetes-china-minsheng-bank-transformed-its-legacy-applications-and-moved-into-ai-blockchain-and-big-data/
|
||||
[6]: https://www.telecomtv.com/content/cloud-native/the-5-rs-of-the-move-to-cloud-native-re-platform-re-host-re-factor-replace-retire-37473/
|
||||
[7]: https://fedoramagazine.org/fedora-coreos-out-of-preview/
|
||||
[8]: https://www.projectatomic.io/
|
||||
[9]: https://coreos.com/os/docs/latest/
|
||||
[10]: https://fedoramagazine.org/introducing-fedora-coreos/
|
||||
@ -1,71 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Y2038 problem in the Linux kernel, 25 years of Java, and other industry news)
|
||||
[#]: via: (https://opensource.com/article/20/2/linux-java-and-other-industry-news)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
The Y2038 problem in the Linux kernel, 25 years of Java, and other industry news
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Need 32-bit Linux to run past 2038? When version 5.6 of the kernel pops, you're in for a treat][2]
|
||||
|
||||
> Arnd Bergmann, an engineer working on the thorny Y2038 problem in the Linux kernel, posted to the [mailing list][3] that, yup, Linux 5.6 "should be the first release that can serve as a base for a 32-bit system designed to run beyond year 2038."
|
||||
|
||||
**The impact:** Y2K didn't get fixed; it just got bigger and delayed. There is no magic in software or computers; just people trying to solve complicated problems as best they can, and some times introducing more complicated problems for different people to solve at some point in the future.
|
||||
|
||||
## [What the dev? Celebrating Java's 25th anniversary][4]
|
||||
|
||||
> Java is coming up on a big milestone: Its 25th anniversary! To celebrate, we take a look back over the last 25 years to see how Java has evolved over time. In this episode, Social Media and Online Editor Jenna Sargent talks to Rich Sharples, senior director of product management for middleware at Red Hat, to learn more.
|
||||
|
||||
**The impact:** There is something comforting about immersing yourself in a deep well of lived experience. Rich clearly lived through what he is talking about and shares insider knowlege with you (and his dog).
|
||||
|
||||
## [Do I need an API Gateway if I use a service mesh?][5]
|
||||
|
||||
> This post may not be able to break through the noise around API Gateways and Service Mesh. However, it’s 2020 and there is still abundant confusion around these topics. I have chosen to write this to help bring real concrete explanation to help clarify differences, overlap, and when to use which. Feel free to [@ me on twitter (@christianposta)][6] if you feel I’m adding to the confusion, disagree, or wish to buy me a beer (and these are not mutually exclusive reasons).
|
||||
|
||||
**The impact:** Yes, though they use similar terms and concepts they have different concerns and scopes.
|
||||
|
||||
## [What Australia's AGL Energy learned about Cloud Native compliance][7]
|
||||
|
||||
> This is really at the heart of what open source is, enabling everybody to contribute equally. Within large enterprises, there are controls that are needed, but if we can automate the management of the majority of these controls, we can enable an amazing culture and development experience.
|
||||
|
||||
**The impact:** They say "software is eating the world" and "developers are the new kingmakers." The fact that compliance in an energy utility is subject to developer experience improvement basically proves both statements.
|
||||
|
||||
## [Monoliths are the future][8]
|
||||
|
||||
> And then what they end up doing is creating 50 deployables, but it’s really a _distributed_ monolith. So it’s actually the same thing, but instead of function calls and class instantiation, they’re initiating things and throwing it over a network and hoping that it comes back. And since they can’t reliably _make it_ come back, they introduce things like [Prometheus][9], [OpenTracing][10], all of this stuff. I’m like, **“What are you doing?!”**
|
||||
|
||||
**The impact:** Do things for real reasons with a clear-eyed understanding of what those reasons are and how they'll make your business or your organization better.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/linux-java-and-other-industry-news
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.theregister.co.uk/2020/01/30/linux_5_6_2038/
|
||||
[3]: https://lkml.org/lkml/2020/1/29/355
|
||||
[4]: https://whatthedev.buzzsprout.com/673192/2543290-celebrating-java-s-25th-anniversary-episode-16
|
||||
[5]: https://blog.christianposta.com/microservices/do-i-need-an-api-gateway-if-i-have-a-service-mesh/ (Do I Need an API Gateway if I Use a Service Mesh?)
|
||||
[6]: http://twitter.com/christianposta?lang=en
|
||||
[7]: https://thenewstack.io/what-australias-agl-energy-learned-about-cloud-native-compliance/
|
||||
[8]: https://changelog.com/posts/monoliths-are-the-future
|
||||
[9]: https://prometheus.io/
|
||||
[10]: https://opentracing.io
|
||||
@ -1,66 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Building a Linux desktop, CERN powered by Ceph, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/20/2/linux-desktop-cern-more-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
Building a Linux desktop, CERN powered by Ceph, and more industry trends
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Building a Linux desktop for cloud-native development][2]
|
||||
|
||||
> This post covers the building of my Linux Desktop PC for Cloud Native Development. I'll be covering everything from parts, to peripherals, to CLIs, to SaaS software with as many links and snippets as I can manage. I hope that you enjoy reading about my experience, learn something, and possibly go on to build your own Linux Desktop.
|
||||
|
||||
**The impact**: I hope the irony is not lost on anyone that step 1, when doing cloud-native software development, is to install Linux on a physical computer.
|
||||
|
||||
## [Enabling CERN’s particle physics research with open source][3]
|
||||
|
||||
> Ceph is an open-source software-defined storage platform. While it’s not often in the spotlight, it’s working hard behind the scenes, playing a crucial role in enabling ambitious, world-renowned projects such as CERN’s particle physics research, Immunity Bio’s cancer research, The Human Brain Project, MeerKat radio telescope, and more. These ventures are propelling the collective understanding of our planet and the human race beyond imaginable realms, and the outcomes will forever change how we perceive our existence and potential.
|
||||
|
||||
**The impact**: It is not often that you get to see a straight line drawn between storage and the perception of human existence. Thanks for that, CERN!
|
||||
|
||||
## [2020 cloud predictions][4]
|
||||
|
||||
> "Serverless" as a concept provides a simplified developer experience that will become a platform feature. More platform-as-a-service providers will incorporate serverless traits into the daily activities developers perform when building cloud-native applications, becoming the default computing paradigm for the cloud.
|
||||
|
||||
**The impact:** All of the trends in the predictions in this post are basically about maturation as ideas like serverless, edge computing, DevOps, and other cloud-adjacent buzz words move from the early adopters into the early majority phase of the adoption curve.
|
||||
|
||||
## [End-of-life announcement for CoreOS Container Linux][5]
|
||||
|
||||
> As we've [previously announced][6], [Fedora CoreOS][7] is the official successor to CoreOS Container Linux. Fedora CoreOS is a [new Fedora Edition][8] built specifically for running containerized workloads securely and at scale. It combines the provisioning tools and automatic update model of Container Linux with the packaging technology, OCI support, and SELinux security of Atomic Host. For more on the Fedora CoreOS philosophy, goals, and design, see the [announcement of the preview release][9] and the [Fedora CoreOS documentation][10].
|
||||
|
||||
**The impact**: Milestones like this are often bittersweet for both creators and users. The CoreOS team built something that their community loved to use, which is something to be celebrated. Hopefully, that community can find a [new home][11] in the wider [Fedora ecosystem][8].
|
||||
|
||||
_I hope you enjoyed this list and come back next week for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/2/linux-desktop-cern-more-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://blog.alexellis.io/building-a-linux-desktop-for-cloud-native-development/
|
||||
[3]: https://insidehpc.com/2020/02/how-ceph-powers-exciting-research-with-open-source/
|
||||
[4]: https://www.devopsdigest.com/2020-cloud-predictions-2
|
||||
[5]: https://coreos.com/os/eol/
|
||||
[6]: https://groups.google.com/d/msg/coreos-user/zgqkG88DS3U/PFP9yrKbAgAJ
|
||||
[7]: https://getfedora.org/coreos/
|
||||
[8]: https://fedoramagazine.org/fedora-coreos-out-of-preview/
|
||||
[9]: https://fedoramagazine.org/introducing-fedora-coreos/
|
||||
[10]: https://docs.fedoraproject.org/en-US/fedora-coreos/
|
||||
[11]: https://getfedora.org/en/coreos/
|
||||
@ -1,115 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (OpenShot Video Editor Gets a Major Update With Version 2.5 Release)
|
||||
[#]: via: (https://itsfoss.com/openshot-2-5-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
OpenShot Video Editor Gets a Major Update With Version 2.5 Release
|
||||
======
|
||||
|
||||
[OpenShot][1] is one of the [best open-source video editors][2] out there. With all the features that it offered – it was already a good video editor on Linux.
|
||||
|
||||
Now, with a major update to it (**v.2.5.0**), OpenShot has added a lot of new improvements and features. And, trust me, it’s not just any regular release – it is a huge release packed with features that you probably wanted for a very long time.
|
||||
|
||||
In this article, I will briefly mention the key changes involved in the latest release.
|
||||
|
||||
![][3]
|
||||
|
||||
### OpenShot 2.5.0 Key Features
|
||||
|
||||
Here are some of the major new features and improvements in OpenShot 2.5:
|
||||
|
||||
#### Hardware Acceleration Support
|
||||
|
||||
The hardware acceleration support is still an experimental addition – however, it is a useful feature to have.
|
||||
|
||||
Instead of relying on your CPU to do all the hard work, you can utilize your GPU to encode/decode video data when working with MP4/H.264 video files.
|
||||
|
||||
This will affect (or improve) the performance of OpenShot in a meaningful way.
|
||||
|
||||
#### Support Importing/Exporting Files From Final Cut Pro & Premiere
|
||||
|
||||
![][4]
|
||||
|
||||
[Final Cut Pro][5] and [Adobe Premiere][6] are the two popular video editors for professional content creators. OpenShot 2.5 now allows you to work on projects created on these platforms. It can import (or export) the files from Final Cut Pro & Premiere in EDL & XML formats.
|
||||
|
||||
#### Thumbnail Generation Improved
|
||||
|
||||
This isn’t a big feature – but a necessary improvement to most of the video editors. You don’t want broken images in the thumbnails (your timeline/library). So, with this update, OpenShot now generates the thumbnails using a local HTTP server, can check multiple folder locations, and regenerate missing ones.
|
||||
|
||||
#### Blender 2.8+ Support
|
||||
|
||||
The new OpenShot release also supports the latest [Blender][7] (.blend) format – so it should come in handy if you’re using Blender as well.
|
||||
|
||||
#### Easily Recover Previous Saves & Improved Auto-backup
|
||||
|
||||
![][8]
|
||||
|
||||
It was always a horror to lose your timeline work after you accidentally deleted it – which was then auto-saved to overwrite your saved project.
|
||||
|
||||
Now, the auto-backup feature has improved with an added ability to easily recover your previous saved version of the project.
|
||||
|
||||
Even though you can recover your previous saves now – you will find a limited number of the saved versions, so you have to still remain careful.
|
||||
|
||||
#### Other Improvements
|
||||
|
||||
In addition to all the key highlights mentioned above, you will also notice a performance improvement when using the keyframe system.
|
||||
|
||||
Several other issues like SVG compatibility, exporting & modifying keyframe data, and resizable preview window have been fixed in this major update. For privacy-concerned users, OpenShot no longer sends usage data unless you opt-in to share it with them.
|
||||
|
||||
For more information, you can take a look at [OpenShot’s official blog post][9] to get the release notes.
|
||||
|
||||
### Installing OpenShot 2.5 on Linux
|
||||
|
||||
You can simply download the .AppImage file from its [official download page][10] to [install the latest OpenShot version][11]. If you’re new to AppImage, you should also check out [how to use AppImage][12] on Linux to easily launch OpenShot.
|
||||
|
||||
[Download Latest OpenShot Release][10]
|
||||
|
||||
Some distributions like Arch Linux may also provide the latest OpenShot release with regular system updates.
|
||||
|
||||
#### PPA available for Ubuntu-based distributions
|
||||
|
||||
On Ubuntu-based distributions, if you don’t want to use AppImage, you can [use the official PPA][13] from OpenShot:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:openshot.developers/ppa
|
||||
sudo apt update
|
||||
sudo apt install openshot-qt
|
||||
```
|
||||
|
||||
You may want to know how to remove PPA if you want to uninstall it later.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
With all the latest changes/improvements considered, do you see [OpenShot][11] as your primary [video editor on Linux][14]? If not, what more do you expect to see in OpenShot? Feel free to share your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/openshot-2-5-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.openshot.org/
|
||||
[2]: https://itsfoss.com/open-source-video-editors/
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/openshot-2-5-0.png?ssl=1
|
||||
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/openshot-xml-edl.png?ssl=1
|
||||
[5]: https://www.apple.com/in/final-cut-pro/
|
||||
[6]: https://www.adobe.com/in/products/premiere.html
|
||||
[7]: https://www.blender.org/
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/openshot-recovery.jpg?ssl=1
|
||||
[9]: https://www.openshot.org/blog/2020/02/08/openshot-250-released-video-editing-hardware-acceleration/
|
||||
[10]: https://www.openshot.org/download/
|
||||
[11]: https://itsfoss.com/openshot-video-editor-release/
|
||||
[12]: https://itsfoss.com/use-appimage-linux/
|
||||
[13]: https://itsfoss.com/ppa-guide/
|
||||
[14]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
@ -1,121 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (KDE Plasma 5.18 LTS Released With New Features)
|
||||
[#]: via: (https://itsfoss.com/kde-plasma-5-18-release/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
KDE Plasma 5.18 LTS Released With New Features
|
||||
======
|
||||
|
||||
[KDE plasma][1] desktop is undoubtedly one of the most impressive [Linux desktop environments][2] available out there right now.
|
||||
|
||||
Now, with the latest release, the KDE Plasma desktop just got more awesome!
|
||||
|
||||
KDE Plasma 5.18 marks itself as an LTS (Long Term Support) release i.e it will be maintained by the KDE contributors for the next 2 years while the regular versions are maintained for just 4 months.
|
||||
|
||||
![KDE Plasma 5.18 on KDE Neon][3]
|
||||
|
||||
So, if you want more stability on your KDE-powered Linux system, it would be a good idea to upgrade to KDE’s Plasma 5.18 LTS release.
|
||||
|
||||
### KDE Plasma 5.18 LTS Features
|
||||
|
||||
Here are the main new features added in this release:
|
||||
|
||||
#### Emoji Selector
|
||||
|
||||
![Emoji Selector in KDE][4]
|
||||
|
||||
Normally, you would Google an emoji to copy it to your clipboard or simply use the good-old emoticons to express yourself.
|
||||
|
||||
Now, with the latest update, you get an emoji selector in Plasma Desktop. You can simply find it by searching for it in the application launcher or by just pressing (Windows key/Meta/Super Key) + . (**period/dot)**.
|
||||
|
||||
The shortcut should come in handy when you need to use an emoji while sending an email or any other sort of messages.
|
||||
|
||||
#### Global Edit Mode
|
||||
|
||||
![Global Edit Mode][5]
|
||||
|
||||
You probably would have used the old desktop toolbox on the top-right corner of the screen in the Plasma desktop, but the new release gets rid of that and instead – provides you with a global edit mode when you right-click on the desktop and click on “**Customize Layout**“.
|
||||
|
||||
#### Night Color Control
|
||||
|
||||
![Night Color Control][6]
|
||||
|
||||
Now, you can easily toggle the night color mode right from the system tray. In addition to that, you can even choose to set a keyboard shortcut for both night color and the do not disturb mode.
|
||||
|
||||
#### Privacy Improvements For User Feedback
|
||||
|
||||
![Improved Privacy][7]
|
||||
|
||||
It is worth noting that KDE Plasma lets you control the user feedback information that you share with them.
|
||||
|
||||
You can either choose to disable sharing any information at all or control the level of information you share (basic, intermediate, and detailed).
|
||||
|
||||
#### Global Themes
|
||||
|
||||
![Themes][8]
|
||||
|
||||
You can either choose from the default global themes available or download community-crafted themes to set up on your system.
|
||||
|
||||
#### UI Improvements
|
||||
|
||||
There are several subtle improvements and changes. For instance, the look and feel of the notifications have improved.
|
||||
|
||||
You can also notice a couple of differences in the software center (Discover) to help you easily install apps.
|
||||
|
||||
Not just limited to that, but you also get the ability to mute the volume of a window from the taskbar (just like you normally do on your browser’s tab). Similarly, there are a couple of changes here and there to improve the KDE Plasma experience.
|
||||
|
||||
#### Other Changes
|
||||
|
||||
In addition to the visual changes and customization ability, the performance of KDE Plasma has improved when coupled with a graphics hardware.
|
||||
|
||||
To know more about the changes, you can refer the [official announcement post][9] for KDE Plasma 5.18 LTS.
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][10]
|
||||
|
||||
### How To Get KDE Plasma 5.18 LTS?
|
||||
|
||||
If you are using a rolling release distribution like Arch Linux, you might have got it with the system updates. If you haven’t performed an update yet, simply check for updates from the system settings.
|
||||
|
||||
If you are using Kubuntu, you can add the Kubuntu backports PPA to update the Plasma desktop with the following commands:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||
sudo apt update && sudo apt full-upgrade
|
||||
```
|
||||
|
||||
If you do not have KDE as your desktop environment, you can refer our article on [how to install KDE on Ubuntu][11] to get started.
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
KDE Plasma 5.18 may not involve a whole lot of changes – but being an LTS release, the key new features seem helpful and should come in handy to improve the Plasma desktop experience for everyone.
|
||||
|
||||
What do you think about the latest Plasma desktop release? Feel free to let me know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/kde-plasma-5-18-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://kde.org/plasma-desktop/
|
||||
[2]: https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-plasma-5-18-info.jpg?ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-plasma-emoji-pick.jpg?ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-plasma-global-editor.jpg?ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-plasma-night-color.jpg?ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/user-feedback-kde-plasma.png?ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/kde-plasma-global-themes.jpg?ssl=1
|
||||
[9]: https://kde.org/announcements/plasma-5.18.0.php
|
||||
[10]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[11]: https://itsfoss.com/install-kde-on-ubuntu/
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Remember Unity8 from Ubuntu? UBports is Renaming it to Lomiri)
|
||||
[#]: via: (https://itsfoss.com/unity8-lomiri/)
|
||||
[#]: author: (John Paul https://itsfoss.com/author/john/)
|
||||
|
||||
Remember Unity8 from Ubuntu? UBports is Renaming it to Lomiri
|
||||
======
|
||||
|
||||
Ever since Ubuntu abandoned the Unity project, UBports continued the maintenance and development of Unity. On February 27th 2020, [UBports][1] announced that they are giving Unity8 a new branding in the form of Lomiri.
|
||||
|
||||
### Unity8 is now Lomiri
|
||||
|
||||
![Unity8 in action | Image Credit: UBports][2]
|
||||
|
||||
[UBports announced][3] that the Unity8 desktop environment would be renamed as Lomiri. They gave three reasons for this fairly drastic announcement.
|
||||
|
||||
First, they want to avoid confusion with the [Unity game engine][4]. Quite a few people confused the two. UBports noted that they are frequently receiving questions regarding “how to import 3D models and meshes into our shell”. When you search “Unity” in your favorite search engine, most of the top links are for the game engine.
|
||||
|
||||
The second reason for the name change has to do with the new effort to package Unity8 for Debian. Unfortunately, many of the Unity8’s dependencies have Ubuntu in the name, for example, _**ubuntu-ui-toolkit**_. Debian packagers warned that packages that have Ubuntu in the name may not be accepted into [Debian][5].
|
||||
|
||||
Finally, UBports said the name change would improve verbal communications. Saying Unity8 repeatedly can be a mouthful. People would not have to worry about confusing “users of Ubuntu Unity and Unity (the game engine)”.
|
||||
|
||||
UBports went on to stress that the name change was not “triggered by any action from Canonical or the Ubuntu community, legal or otherwise”.
|
||||
|
||||
They noted that this name change was the perfect time for them to switch to [GitHub alternative GitLab][6] for their development.
|
||||
|
||||
Interestingly, the announcement did not explain how they picked Lomiri as the new name. All they said is that “We went through many different names before settling on Lomiri. All of them had problems with pronunciation, availability, or other related issues.”
|
||||
|
||||
UBports noted that most Ubuntu Touch users would be unaffected by the name change. Developers and power users might notice some changes, but UBports “will strive to maintain backwards compatibility within Ubuntu Touch for the foreseeable future”.
|
||||
|
||||
### What Exactly is Being Renamed?
|
||||
|
||||
![][7]
|
||||
|
||||
According to the announcement, packages that have either Ubuntu or Unity in the title will be affected. For example,
|
||||
|
||||
* **unity8**, containing the shell, will become **lomiri**
|
||||
* **ubuntu-ui-toolkit** will become **lomiri-ui-toolkit**
|
||||
* **ubuntu-download-manager** will become **lomiri-download-manager**
|
||||
|
||||
|
||||
|
||||
On top of this, interfaces call will change, as well. “For example, the **Ubuntu.Components** QML import will change to **Lomiri.Components**.” For the sake of backwards compatibility, Ubuntu Touch images will not change too much. “Developers will only need to update to the new API when they’d like to package their apps for other distributions.”
|
||||
|
||||
### What Will Stay the Same?
|
||||
|
||||
Since renaming packages can cause quite a few cascading problems, UBports wants to limit the number of packages they change. They don’t expect the following things to change.
|
||||
|
||||
* Packages that don’t use the “Ubuntu” or “Unity” names
|
||||
* Ubuntu Touch will remain the same
|
||||
* Any components which are already used by other projects and accepted into other distributions
|
||||
|
||||
|
||||
|
||||
### Final Thoughts
|
||||
|
||||
![][8]
|
||||
|
||||
Overall, I think this change will be good for Ubuntu Touch in the long run. I understand why [Canonical][9] picked the Unity name for their convergence desktop, but I think the desktop environment was overshadowed by the game engine from the beginning. This will give them room to breathe and also free up valuable coding time. The less time spent replying to questions about 3D models the more time that can be spent creating a convergent desktop.
|
||||
|
||||
If you have any further questions or concerns about the name change, you visit the [UBports forms][10]. They have set up a thread specifically for this topic.
|
||||
|
||||
Don’t hesitate to share our views on it in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/unity8-lomiri/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://ubports.com/
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/unity8_ubports.png?ssl=1
|
||||
[3]: https://ubports.com/blog/ubports-blog-1/post/lomiri-new-name-same-great-unity8-265
|
||||
[4]: https://en.wikipedia.org/wiki/Unity_(game_engine)
|
||||
[5]: https://www.debian.org/
|
||||
[6]: https://itsfoss.com/github-alternatives/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/Unity8-lomiri.png?ssl=1
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/02/ubports.jpeg?ssl=1
|
||||
[9]: https://canonical.com/
|
||||
[10]: https://forums.ubports.com/topic/3874/unity8-is-now-lomiri
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (Morisun029)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A $399 device that translates brain signals into digital commands)
|
||||
[#]: via: (https://www.networkworld.com/article/3526446/nextmind-wearable-device-translates-brain-signals-into-digital-commands.html)
|
||||
[#]: author: (Patrick Nelson https://www.networkworld.com/author/Patrick-Nelson/)
|
||||
|
||||
A $399 device that translates brain signals into digital commands
|
||||
======
|
||||
Startup NextMind is readying a $399 development kit for its brain-computer interface technology that enables users to interact, hands-free, with computers and VR/AR headsets.
|
||||
MetamorWorks / Getty Images
|
||||
|
||||
Scientists have long envisioned brain-sensing technology that can translate thoughts into digital commands, eliminating the need for computer-input devices like a keyboard and mouse. One company is preparing to ship its latest contribution to the effort: a $399 development package for a noninvasive, AI-based, brain-computer interface.
|
||||
|
||||
The kit will let "users control anything in their digital world by using just their thoughts," [NextMind][1], a commercial spinoff of a cognitive neuroscience lab claims in a [press release][2].
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
The company says that its puck-like device inserts into a cap or headband and rests on the back of the head. The dry electrode-based receiver then grabs data from the electrical signals generated through neuron activity. It uses machine learning algorithms to convert that signal output into computer controls. The interaction could be with a computer, artificial-reality or virtual-reality headset, or [IoT][4] module.
|
||||
|
||||
"Imagine taking your phone to send a text message without ever touching the screen, without using Siri, just by using the speed and power of your thoughts," said NextMind founder Sid Kouider in a [video presentation][5] at Helsinki startup conference Slush in late 2019.
|
||||
|
||||
Advances in neuroscience are enabling real-time consciousness-decoding, without surgery or a doctor visit, according to Kouider.
|
||||
|
||||
One obstacle that has thwarted previous efforts is the human skull, which can act as a barrier to sensors. It’s been difficult for scientists to differentiate indicators from noise, and some past efforts have only been able to discern basic things, such as whether or not a person is in a state of sleep or relaxation. New materials, better sensors, and more sophisticated algorithms and modeling have overcome some of those limitations. NextMind’s noninvasive technology "translates the data in real time," Kouider says.
|
||||
|
||||
Essentially, what happens is that a person’s eyes project an image of what they see onto the visual cortex in the back of the head, a bit like a projector. The NextMind device decodes the neural activity created as the object is viewed and sends that information, via an SDK, back as an input to a computer. So, by fixing one’s gaze on an object, one selects that object. For example, a user could select a screen icon by glancing at it.
|
||||
|
||||
[][6]
|
||||
|
||||
"The demos were by no means perfect, but there was no doubt in my mind that the technology worked," [wrote VentureBeat writer Emil Protalinski][7], who tested a pre-release device in January.
|
||||
|
||||
Kouider has stated it’s the "intent" aspect of the technology that’s most interesting; if a person focuses on one thing more than something else, the technology can decode the neural signals to capture that user’s intent.
|
||||
|
||||
"It really gives you a kind of sixth sense, where you can feel your brain in action, thanks to the feedback loop between your brain and a display," Kouider says in the Slush presentation.
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3526446/nextmind-wearable-device-translates-brain-signals-into-digital-commands.html
|
||||
|
||||
作者:[Patrick Nelson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Patrick-Nelson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.next-mind.com/
|
||||
[2]: https://www.businesswire.com/news/home/20200105005107/en/CES-2020-It%E2%80%99s-Mind-Matter
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: http://www.networkworld.com/cms/article/3207535
|
||||
[5]: https://youtu.be/RHuaNDSxH0o
|
||||
[6]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[7]: https://venturebeat.com/2020/01/05/nextmind-is-building-a-real-time-brain-computer-interface-unveils-dev-kit-for-399/
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fedora at the Czech National Library of Technology)
|
||||
[#]: via: (https://fedoramagazine.org/fedora-at-the-national-library-of-technology/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
Fedora at the Czech National Library of Technology
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Where do you turn when you have a fleet of public workstations to manage? If you’re the Czech [National Library of Technology][2] (NTK), you turn to Fedora. Located in Prague, the NTK is the Czech Republic’s largest science and technology library. As part of its public service mission, the NTK provides 150 workstations for public use.
|
||||
|
||||
In 2018, the NTK moved these workstations from Microsoft Windows to Fedora. In the [press release][3] announcing this change, Director Martin Svoboda said switching to Fedora will “reduce operating system support costs by about two-thirds.” The choice to use Fedora was easy, according to NTK Linux Engineer Miroslav Brabenec. “Our entire Linux infrastructure runs on RHEL or CentOS. So for desktop systems, Fedora was the obvious choice,” he told Fedora Magazine.
|
||||
|
||||
### User reception
|
||||
|
||||
Changing an operating system is always a little bit risky—it requires user training and outreach. Brabenec said that non-IT staff asked for training on the new system. Once they learned that the same (or compatible) software was available, they were fine.
|
||||
|
||||
The Library’s customers were on board right away. The Windows environment was based on thin client terminals, which were slow for intensive tasks like video playback and handling large office suite files. The only end-user education that the NTK needed to create was a [basic usage guide][4] and a desktop wallpaper that pointed to important UI elements.
|
||||
|
||||
![User guidance desktop wallpaper from the National Technology Library.][5]
|
||||
|
||||
Although Fedora provides development tools used by the Faculty of Information Technology at the Czech Technical University—and many of the NTK’s workstation users are CTU students—most of the application usage is what you might expect of a general-purpose workstation. Firefox dominates the application usage, followed by the Evince PDF viewer, and the LibreOffice suite.
|
||||
|
||||
### Updates
|
||||
|
||||
NTK first deployed the workstations with Fedora 28. They decided to skip Fedora 29 and upgraded to Fedora 30 in early June 2019. The process was simple, according to Brabenec. “We prepared configuration, put it into Ansible. Via AWX I restarted all systems to netboot, image with kickstart, after first boot called provisioning callback on AWX, everything automatically set up via Ansible.”
|
||||
|
||||
Initially, they had difficulties applying updates. Now they have a process for installing security updates daily. Each system is rebooted approximately every two weeks to make sure all of the updates get applied.
|
||||
|
||||
Although he isn’t aware of any concrete plans for the future, Brabenec expects the NTK to continue using Fedora for public workstations. “Everyone is happy with it and I think that no one has a good reason to change it.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-at-the-national-library-of-technology/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/czech-techlib-816x345.png
|
||||
[2]: https://www.techlib.cz/en/
|
||||
[3]: https://www.techlib.cz/default/files/download/id/86431/tiskova-zprava-z-31-7-2018.pdf
|
||||
[4]: https://www.techlib.cz/en/82993-public-computers
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2020/02/ntk-wallpaper-1024x576.jpeg
|
||||
@ -0,0 +1,84 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Multicloud, security integration drive massive SD-WAN adoption)
|
||||
[#]: via: (https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Multicloud, security integration drive massive SD-WAN adoption
|
||||
======
|
||||
40% year-over year SD-WAN growth through 2022 is being fueled by relationships built between vendors including Cisco, VMware, Juniper, and Arista and service provders AWS, Microsoft Azure, Google Anthos, and IBM RedHat.
|
||||
[Gratisography][1] [(CC0)][2]
|
||||
|
||||
Increasing cloud adoption as well as improved network security, visibility and manageability are driving enterprise software-defined WAN ([SD-WAN][3]) deployments at a breakneck pace.
|
||||
|
||||
According to research from IDC, software- and infrastructure-as-a-service (SaaS and IaaS) offerings in particular have been driving SD-WAN implementations in the past year, said Rohit Mehra, vice president, network infrastructure at IDC.
|
||||
|
||||
**Read about edge networking**
|
||||
|
||||
* [How edge networking and IoT will reshape data centers][4]
|
||||
* [Edge computing best practices][5]
|
||||
* [How edge computing can help secure the IoT][6]
|
||||
|
||||
|
||||
|
||||
For example, IDC says that its recent surveys of customers show that 95% will be using [SD-WAN][7] technology within two years, and that 42% have already deployed it. IDC also says the SD-WAN infrastructure market will hit $4.5 billion by 2022, growing at a more than 40% yearly clip between now and then.
|
||||
|
||||
“The growth of SD-WAN is a broad-based trend that is driven largely by the enterprise desire to optimize cloud connectivity for remote sites,” Mehra said.
|
||||
|
||||
Indeed the growth of multicloud networking is prompting many businesses to re-tool their networks in favor of SD-WAN technology, Cisco wrote recently. SD-WAN is critical for businesses adopting cloud services, acting as a connective tissue between the campus, branch, [IoT][8], [data center][9] and cloud. The company said surveys show Cisco customers have, on average, 30 paid SaaS applications each. And that they are actually using many more – over 100 in several cases, the company said.
|
||||
|
||||
Part of this trend is driven by the relationships that networking vendors such as Cisco, VMware, Juniper, Arista and others have been building with the likes of Amazon Web Services, Microsoft Azure, Google Anthos and IBM RedHat.
|
||||
|
||||
An indicator of the growing importance of the SD-WAN and multicloud relationship came last December when AWS announced key services for its cloud offering that included new integration technologies such as [AWS Transit Gateway][10], which lets customers connect their Amazon Virtual Private Clouds and their on-premises networks to a single gateway. Aruba, Aviatrix Cisco, Citrix Systems, Silver Peak and Versa already announced support for the technology which promises to simplify and enhance the performance of SD-WAN integration with AWS cloud resources.
|
||||
|
||||
[][11]
|
||||
|
||||
Going forward the addition of features such as cloud-based application insights and performance monitoring will be a key part of SD-WAN rollouts, Mehra said.
|
||||
|
||||
While the SD-WAN and cloud relationship is growing, so, too, is the need for integrated security features.
|
||||
|
||||
“The way SD-WAN offerings integrate security is so much better than traditional ways of securing WAN traffic which usually involved separate packages and services," Mehra said. "SD-WAN is a much more agile security environment.” Security, analytics and WAN optimization are viewed as top SD-WAN component, with integrated security being the top requirement for next-generation SD-WAN solutions, Mehra said.
|
||||
|
||||
Increasingly, enterprises will look less at point SD-WAN solutions and instead will favor platforms that solve a wider range of network management and security needs, Mehra said. They will look for SD-WAN platforms that integrate with other aspects of their IT infrastructure including corporate data-center networks, enterprise campus LANs, or [public-cloud][12] resources, he said. They will look for security services to be baked in, as well as support for a variety of additional functions such as visibility, analytics, and unified communications, he said.
|
||||
|
||||
“As customers continue to integrate their infrastructure components with software they can do things like implement consistent management and security policies based on user, device or application requirements across their LANs and WANs and ultimately achieve a better overall application experience,” Mehra said.
|
||||
|
||||
An emerging trend is the need for SD-WAN packages to support [SD-branch][13] technology. More than 70% of IDC's surveyed customers expect to use SD-Branch within next year, Mehra said. In recent weeks [Juniper][14] and [Aruba][15] have enhanced SD-Branch offerings, a trend that is expected to continue this year.
|
||||
|
||||
SD-Branch builds on the concepts and support of SD-WAN but is more specific to the networking and management needs of LANs in the branch. Going forward, how SD-Branch integrates other technologies such as analytics, voice, unified communications and video will be key drivers of that technology.
|
||||
|
||||
Join the Network World communities on [Facebook][16] and [LinkedIn][17] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3527194/multicloud-security-integration-drive-massive-sd-wan-adoption.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pexels.com/photo/black-and-white-branches-tree-high-279/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[4]: https://www.networkworld.com/article/3291790/data-center/how-edge-networking-and-iot-will-reshape-data-centers.html
|
||||
[5]: https://www.networkworld.com/article/3331978/lan-wan/edge-computing-best-practices.html
|
||||
[6]: https://www.networkworld.com/article/3331905/internet-of-things/how-edge-computing-can-help-secure-the-iot.html
|
||||
[7]: https://www.networkworld.com/article/3489938/what-s-hot-at-the-edge-for-2020-everything.html
|
||||
[8]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[9]: https://www.networkworld.com/article/3223692/what-is-a-data-centerhow-its-changed-and-what-you-need-to-know.html
|
||||
[10]: https://aws.amazon.com/transit-gateway/
|
||||
[11]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[12]: https://www.networkworld.com/article/2159885/cloud-computing-gartner-5-things-a-private-cloud-is-not.html
|
||||
[13]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[14]: https://www.networkworld.com/article/3487801/juniper-broadens-sd-branch-management-switch-options.html
|
||||
[15]: https://www.networkworld.com/article/3513357/aruba-reinforces-sd-branch-with-security-management-upgrades.html
|
||||
[16]: https://www.facebook.com/NetworkWorld/
|
||||
[17]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Google Cloud moves to aid mainframe migration)
|
||||
[#]: via: (https://www.networkworld.com/article/3528451/google-cloud-moves-to-aid-mainframe-migration.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
Google Cloud moves to aid mainframe migration
|
||||
======
|
||||
Google bought Cornerstone Technology, whose technology facilitates moving mainframe applications to the cloud.
|
||||
Thinkstock
|
||||
|
||||
Google Cloud this week bought a mainframe cloud-migration service firm Cornerstone Technology with an eye toward helping Big Iron customers move workloads to the private and public cloud.
|
||||
|
||||
Google said the Cornerstone technology – found in its [G4 platform][1] – will shape the foundation of its future mainframe-to-Google Cloud offerings and help mainframe customers modernize applications and infrastructure.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][2]
|
||||
|
||||
“Through the use of automated processes, Cornerstone’s tools can break down your Cobol, PL/1, or Assembler programs into services and then make them cloud native, such as within a managed, containerized environment” wrote Howard Weale, Google’s director, Transformation Practice, in a [blog][3] about the buy.
|
||||
|
||||
“As the industry increasingly builds applications as a set of services, many customers want to break their mainframe monolith programs into either Java monoliths or Java microservices,” Weale stated.
|
||||
|
||||
Google Cloud’s Cornerstone service will:
|
||||
|
||||
* Develop a migration roadmap where Google will assess a customer’s mainframe environment and create a roadmap to a modern services architecture.
|
||||
* Convert any language to any other language and any database to any other database to prepare applications for modern environments.
|
||||
* Automate the migration of workloads to the Google Cloud.
|
||||
|
||||
|
||||
|
||||
“Easy mainframe migration will go a long way as Google attracts large enterprises to its cloud,” said Matt Eastwood, senior vice president, Enterprise Infrastructure, Cloud, Developers and Alliances, IDC wrote in a statement.
|
||||
|
||||
The Cornerstone move is also part of Google’s effort stay competitive in the face of mainframe-migration offerings from [Amazon Web Services][4], [IBM/RedHat][5] and [Microsoft][6].
|
||||
|
||||
While the idea of moving legacy applications off the mainframe might indeed be beneficial to a business, Gartner last year warned that such decisions should be taken very deliberately.
|
||||
|
||||
“The value gained by moving applications from the traditional enterprise platform onto the next ‘bright, shiny thing’ rarely provides an improvement in the business process or the company’s bottom line. A great deal of analysis must be performed and each cost accounted for,” Gartner stated in a report entitled *[_Considering Leaving Legacy IBM Platforms? Beware, as Cost Savings May Disappoint, While Risking Quality_][7]. * “Legacy platforms may seem old, outdated and due for replacement. Yet IBM and other vendors are continually integrating open-source tools to appeal to more developers while updating the hardware. Application leaders should reassess the capabilities and quality of these platforms before leaving them.”
|
||||
|
||||
Join the Network World communities on [Facebook][8] and [LinkedIn][9] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3528451/google-cloud-moves-to-aid-mainframe-migration.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cornerstone.nl/solutions/modernization
|
||||
[2]: https://www.networkworld.com/newsletters/signup.html
|
||||
[3]: https://cloud.google.com/blog/topics/inside-google-cloud/helping-customers-migrate-their-mainframe-workloads-to-google-cloud
|
||||
[4]: https://aws.amazon.com/blogs/enterprise-strategy/yes-you-should-modernize-your-mainframe-with-the-cloud/
|
||||
[5]: https://www.networkworld.com/article/3438542/ibm-z15-mainframe-amps-up-cloud-security-features.html
|
||||
[6]: https://azure.microsoft.com/en-us/migration/mainframe/
|
||||
[7]: https://www.gartner.com/doc/reprints?id=1-6L80XQJ&ct=190429&st=sb
|
||||
[8]: https://www.facebook.com/NetworkWorld/
|
||||
[9]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,57 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Japanese firm announces potential 80TB hard drives)
|
||||
[#]: via: (https://www.networkworld.com/article/3528211/japanese-firm-announces-potential-80tb-hard-drives.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Japanese firm announces potential 80TB hard drives
|
||||
======
|
||||
Using some very fancy physics for stacking electrons, Showa Denko K.K. plans to quadruple the top end of proposed capacity.
|
||||
[geralt][1] [(CC0)][2]
|
||||
|
||||
Hard drive makers are staving off obsolescence to solid-state drives (SSDs) by offering capacities that are simply not feasible in an SSD. Seagate and Western Digital are both pushing to release 20TB hard disks in the next few years. A 20TB SSD might be doable but also cost more than a new car.
|
||||
|
||||
But Showa Denko K.K. of Japan has gone one further with the announcement of its next-generation of heat-assisted magnetic recording (HAMR) media for hard drives. The platters use all-new magnetic thin films to maximize their data density, with the goal of eventually enabling 70TB to 80TB hard drives in a 3.5-inch form factor.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
Showa Denko is the world’s largest independent maker of platters for hard drives, selling them to basically anyone left making hard drives not named Seagate and Western Digital. Those two make their own platters and are working on their own next-generation drives for release in the coming years.
|
||||
|
||||
While similar in concept, Seagate and Western Digital have chosen different solutions to the same problem. HAMR, championed by Seagate and Showa, works by temporarily heating the disk material during the write process so data can be written to a much smaller space, thus increasing capacity.
|
||||
|
||||
Western Digital supports a different technology called microwave-assisted magnetic recording (MAMR). It operates under a similar concept as HAMR but uses microwaves instead of heat to alter the drive platter. Seagate hopes to get to 48TB by 2023, while Western Digital is planning on releasing 18TB and 20TB drives this year.
|
||||
|
||||
Heat is never good for a piece of electrical equipment, and Showa Denko’s platters for HAMR HDDs are made of a special composite alloy to tolerate temperature and reduce wear, not to mention increase density. A standard hard disk has a density of about 1.1TB per square inch. Showa’s drive platters have a density of 5-6TB per square inch.
|
||||
|
||||
The question is when they will be for sale, and who will use them. Fellow Japanese electronics giant Toshiba is expected to ship drives with Showa platters later this year. Seagate will be the first American company to adopt HAMR, with 20TB drives scheduled to ship in late 2020.
|
||||
|
||||
[][4]
|
||||
|
||||
Know what’s scary? That still may not be enough. IDC predicts that our global datasphere – the total of all of the digital data we create, consume, or capture – will grow from a total of approximately 40 zettabytes of data in 2019 to 175 zettabytes total by 2025.
|
||||
|
||||
So even with the growth in hard-drive density, the growth in the global data pool – everything from Oracle databases to Instagram photos – may still mean deploying thousands upon thousands of hard drives across data centers.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3528211/japanese-firm-announces-potential-80tb-hard-drives.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pixabay.com/en/data-data-loss-missing-data-process-2764823/
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.networkworld.com/article/3440100/take-the-intelligent-route-with-consumption-based-storage.html?utm_source=IDG&utm_medium=promotions&utm_campaign=HPE21620&utm_content=sidebar ( Take the Intelligent Route with Consumption-Based Storage)
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Discussing Past, Present and Future of FreeBSD Project)
|
||||
[#]: via: (https://itsfoss.com/freebsd-interview-deb-goodkin/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Discussing Past, Present and Future of FreeBSD Project
|
||||
======
|
||||
|
||||
[FreeBSD][1] is one of the most popular BSD distributions. It is used on desktop, servers and embedded devices for more than two decades.
|
||||
|
||||
We talked to Deb Goodkin, executive director, [FreeBSD Foundation][2] and discussed the past, present and future of FreeBSD project.
|
||||
|
||||
![][3]
|
||||
|
||||
**It’s FOSS: FreeBSD has been in the scene for more than 25 years. How do you see the journey of FreeBSD? **
|
||||
|
||||
Over the years, we’ve seen a lot of innovation happening on and with FreeBSD. When the Foundation came into play 20 years ago, we were able to step in and help accelerate changes in the operating system. Over the years, we’ve increased our marketing support, to provide more advocacy and educational material, and to increase the awareness and use of FreeBSD.
|
||||
|
||||
In addition, we’ve increased our staff of software developers to allow us to quickly step in to fix bugs, review patches, implement workarounds to hardware issues, and implement new features and functionality. We have also increased the number of development projects we are funding to improve various areas of FreeBSD.
|
||||
|
||||
The history of stability and reliability, along with all the improvements and growth with FreeBSD, is making it a compelling choice for companies, universities, and individuals.
|
||||
|
||||
**It’s FOSS: We know that Netflix uses FreeBSD extensively. What other companies or groups rely on FreeBSD? How do they contribute to BSD/FreeBSD (if they do at all)?**
|
||||
|
||||
Sony’s Playstation 4 uses a modified version of FreeBSD as their operating system, Apple with their MacOS and iOS, NetApp in their ONTAP product, Juniper Networks in [JunOS][4], Trivago in their backend infrastructure, University of Cambridge in security research including the Capability Hardware Enhanced RISC Instruction (CHERI) project, University of Notre Dame in their Engineering Department, Groupon in their datacenter, LA Times in their data center, as well as, other notable companies like Panasonic, and Nintendo.
|
||||
|
||||
I listed a variety of organizations to highlight the different FreeBSD use cases. Companies like [Netflix support FreeBSD][5] by supporting the Project financially, as well as, by upstreaming their code. Some of the companies, like Sony, take advantage of the BSD license and don’t give back at all.
|
||||
|
||||
![Deb Goodkin And Friend Promoting FreeBSD At Oscon][6]
|
||||
|
||||
**It’s FOSS: Linux is ruling the servers and cloud computing. It seems that BSD is lagging in that field?**
|
||||
|
||||
I wouldn’t characterize it as lagging, per se. Linux distributions do have a much higher market share than FreeBSD, but our strength falls in those two markets. FreeBSD does extremely well in these markets, because it provides a consistent and reliable foundation, and tends to just work. Known for having long term API stability, the user will integrate once and upgrade on their terms as both FreeBSD and their product evolves.
|
||||
|
||||
**It’s FOSS: Do you see the emergence of Linux as a threat to BSD? **
|
||||
|
||||
Sure, [there are so many Linux distributions][7] already, and most of them are supported by for profit companies. In fact, companies like Intel have many Linux developers on staff, so Linux is easily supported on their hardware.
|
||||
|
||||
However, thanks to the continuing education efforts and as our market share continues to grow, more developers will be available to support companies’ various FreeBSD use cases.
|
||||
|
||||
**It’s FOSS: Let’s talk about desktop. Recently, the devs of Project Trident announced that they were moving away from FreeBSD as a base. They said that they made this decision because FreeBSD is slow to review updates and support for new hardware. For example, the most recent version of Telegram on FreeBSD is 9 releases behind the version available on Linux. How would you respond to their comments?**
|
||||
|
||||
There are quite a few FreeBSD distros for the desktop, with various focuses. The latest, is [FuryBSD][8], which coincidentally was started by iXsystems employees, but is independent of iXsystems, just like Project Trident is. In addition to FuryBSD, you may want to check out [NomadBSD][9] and [MidnightBSD][10].
|
||||
|
||||
Regarding supporting new hardware, we’ve stepped up our efforts to get FreeBSD working on more popular newer laptops. For example, the Foundation recently purchased a couple of the latest generation Lenovo X1 Carbon laptops and sponsored work to make sure that peripherals are supported out-of-the-box.
|
||||
|
||||
**It’s FOSS: Why should a desktop user consider choosing FreeBSD?**
|
||||
|
||||
There are many reasons people should consider using FreeBSD on their desktop! Just to highlight a few, it has rock solid stability; high performance; supports [ZFS][11] to protect your data; a community that is friendly, helpful, and approachable; excellent documentation to easily find answers; over 30,000 open source software packages that are easy to install, allowing you to easily set up your environment without a lot of extras, and that includes many choices of popular GUIs, and it follows the POLA philosophy ([Principle of Least Astonishment][12]) which means, don’t break things that work and upgrades are generally painless (even across major releases).
|
||||
|
||||
**It’s FOSS: Are there any plans to make it easier to install FreeBSD as a desktop system? The current focus seems to be on servers.**
|
||||
|
||||
The Foundation is supporting efforts to make sure FreeBSD works on the latest hardware and peripherals that appear in desktop systems, and will continue to support making FreeBSD easy to deploy, monitor, and configure to provide a great toolbox for building a desktop on top of it. That allows others to take as much or as little of FreeBSD to build a desktop version to produce a specific user experience they desire.
|
||||
|
||||
Like I mentioned above, there are other FreeBSD distributions that have taken these FreeBSD components and created their own desktop versions.
|
||||
|
||||
**It’s FOSS: What are your plans/roadmap for FreeBSD in the coming years?**
|
||||
|
||||
The FreeBSD Foundation’s purpose is to support the FreeBSD Project. While we’re an entirely separate entity, we work closely with the Core Team and the community to help move the Project forward. The Foundation identifies key areas we should support in the coming years, based on input from users and what we are seeing in the industry.
|
||||
|
||||
In 2019, we embarked on an even broader spectrum advocacy project to recruit new members throughout the world, while raising awareness about the benefits of learning FreeBSD. We are funding development projects including WiFi improvements, supporting OpenJDK, ZFS RAID-Z expansion, security, toolchain, performance improvements, and other features to keep FreeBSD innovative.
|
||||
|
||||
The FreeBSD Foundation will continue to host workshops and expand the amount of training opportunities and materials we provide. Finally, the [BSD Certification program][13] recently launched through Linux Professional Institute with greater availability.
|
||||
|
||||
**It’s FOSS: How can we bring more people to the BSD hold?**
|
||||
|
||||
We need more PR for FreeBSD and get more tech journalists like yourself to write about FreeBSD. We also need more trainings and classes that include FreeBSD in universities, trainings/workshops at technical conferences, more FreeBSD contributors giving talks at those conferences, more technical journalists, as well as, users writing about FreeBSD, and finally we need case studies from companies and organizations successfully using FreeBSD. It all takes having more resources! We’re working on all of the above.
|
||||
|
||||
**It’s FOSS: Any message you would like to convey to our readers?**
|
||||
|
||||
Readers should consider getting involved with the largest and oldest democratically run open source project!
|
||||
|
||||
Whether you want to learn systems programming or how an operating system works, the small size of the operating system makes it a great platform to learn from. The size of the Project makes it easier for anyone to make a notable contribution, and there is a strong mentorship culture to support new contributors.
|
||||
|
||||
Being a democratically run project, allows your voice to be heard and work in the areas you are interested in. I hope your readers will go to [freebsd.org][1] and try it out themselves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/freebsd-interview-deb-goodkin/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.freebsd.org/
|
||||
[2]: https://www.freebsdfoundation.org/
|
||||
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/02/deb-goodkin-interview.png?ssl=1
|
||||
[4]: https://www.juniper.net/us/en/products-services/nos/junos/
|
||||
[5]: https://itsfoss.com/netflix-freebsd-cdn/
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/02/FreeBSDFoundation_Deb_Goodkin_and_friend_promoting_FreeBSD_at_OSCON.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/best-linux-distributions/
|
||||
[8]: https://itsfoss.com/furybsd/
|
||||
[9]: https://itsfoss.com/nomadbsd/
|
||||
[10]: https://itsfoss.com/midnightbsd-1-0-release/
|
||||
[11]: https://itsfoss.com/what-is-zfs/
|
||||
[12]: https://en.wikipedia.org/wiki/Principle_of_least_astonishment
|
||||
[13]: https://www.lpi.org/our-certifications/bsd-overview
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Spilling over: How working openly with anxiety affects my team)
|
||||
[#]: via: (https://opensource.com/open-organization/20/2/working-anxiety-team-performance)
|
||||
[#]: author: (Sam Knuth https://opensource.com/users/samfw)
|
||||
|
||||
Spilling over: How working openly with anxiety affects my team
|
||||
======
|
||||
The team might interpret my behavior as evidence of exacting standards
|
||||
or high expectations. But I know my anxiety does impact their
|
||||
performance.
|
||||
![Spider web on green background][1]
|
||||
|
||||
_Editor's note: This article is part of a series on working with mental health conditions. It details the author's personal experiences and is not meant to convey professional medical advice or guidance._
|
||||
|
||||
I was speaking with one of my direct reports recently about a discussion we'd had with the broader team earlier in the week. In that discussion I had expressed some frustration that we weren't as far along on a particular project as I thought we needed to be.
|
||||
|
||||
"I knew you were disappointed," my staff member said, recalling the meeting, "like you wanted us to be doing something that we weren't doing, or that what we were doing wasn't good enough."
|
||||
|
||||
They paused for a moment and then said, "Sam, I get this feeling from you all the time."
|
||||
|
||||
That comment struck me pretty profoundly. To my team member, perhaps the scenario above is a reflection of my exacting standards, my high expectations, or my desire to see continual improvement with the team. Those are all reasonable explanations for my behavior.
|
||||
|
||||
But there's another ingredient my team may not be aware of: my anxiety.
|
||||
|
||||
### It's not just personal
|
||||
|
||||
[Previously I discussed][2] how my anxiety, beginning with a worry that I'm not "doing enough," can fuel my proactive tendencies, leading to higher performance at work. What I hadn't considered is my team can interpret my _personal_ feeling of not doing enough as an indicator that _they_ are not doing enough.
|
||||
|
||||
Living with anxiety and other mental health conditions feels personal. It's not something I've talked about at work. It's not something I generally discuss, and it's something I've always felt I was coping with as a private part of my life.
|
||||
|
||||
Living with anxiety and other mental health conditions feels personal. It's not something I've talked about at work. It's not something I generally discuss, and it's something I've always felt I was coping with as a private part of my life.
|
||||
|
||||
But that discussion with my staff member made me realize that I can't contain my personality so neatly. In truth, my anxiety spills over to my team in ways I hadn't considered. I don't know if anxiety can "rub off" on someone, but when I try to think about it objectively, I imagine someone with anxiety would feel it heightened if they worked for me (perhaps my anxiety would feed theirs), and one without anxiety might feel I have unreasonable or unmeetable expectations.
|
||||
|
||||
As a leader—even in an open organization, where [hierarchy is not the most important factor][3] in determining influence—I'm aware that I am in a position of a certain amount of power. People observe my behavior more closely than I realize; how I treat people has a big impact on them, the broader organization, and ultimately the success of the team.
|
||||
|
||||
I try hard to treat people with respect, [to assume positive intent][4], to give people the room to do their work in the way they see fit. But, nonetheless, do my team members feel the kind of judgment from me that I continually impose on myself?
|
||||
|
||||
### Counting our achievements
|
||||
|
||||
What feels "good" to me (what calms my anxiety) is to focus _not_ on what we _have achieved_, but on what we _have yet to do_; not to _celebrate success_, but to _find areas for improvement_. So, when we hit a big milestone, my gut reaction is to say, "Great, now that we've come this far, what else can we do to have a bigger impact?" Stopping and celebrating the team's accomplishments before moving on to the next challenge feels foriegn to me. It also makes me anxious that we are pausing in our progress.
|
||||
|
||||
This is [what I've called an anxiety-driven performance loop][2]. The sense of accomplishment (and the external acknowledgement) after an achievement fuels a desire to immediately start looking for the next challenge. To some extent, this performance loop keeps me productive—even though it has other consequences, too.
|
||||
|
||||
What I want to _avoid_ is transferring my anxiety to my team members. I don't want them to feel that I am continually saying, "What have you done for me lately?" even though that is how I feel the world is looking at me. That's an aspect of what I've called [an anxiety inaction loop][5].
|
||||
|
||||
I try hard to treat people with respect, to assume positive intent, to give people the room to do their work in the way they see fit. But, nonetheless, do my team members feel the kind of judgment from me that I continually impose on myself?
|
||||
|
||||
At a fundamental level, I believe work is never done, that there is always another challenge to explore, other ways to have a larger impact. Leaders need to inspire and motivate us to embrace that reality as an exciting opportunity rather than an endless drudge or a source of continual worry.
|
||||
|
||||
As a leader who suffers from anxiety, this is more challenging to do in practice than it is to understand intellectually.
|
||||
|
||||
While this is an area of continual work for me, I've received some good advice on how to shield my colleagues from my own anxiety-driven loops, like:
|
||||
|
||||
* If celebrating success and acknowledging achievement doesn't come naturally for you, build it into the plan from the start. Ensure you have the celebration of accomplishment accounted for from the beginning of a project. This can help reduce the "what have you done for me lately?" impulse that comes from moving quickly to the next challenge without pausing to acknowledge achievements.
|
||||
* Work with another team member on acknowledgment and celebration efforts. Others might have different ideas on how to do this effectively, and may also enjoy the process. Giving this responsibility to someone else can help ensure it isn't lost.
|
||||
* Practice compassion, gratitude, and empathy. This may not come naturally and may take some effort. Putting yourself in someone else's shoes, thinking about their perspective, thanking people for what they have done, and understanding their challenges can go a long way in shifting your own perspective.
|
||||
* If you find yourself judging others, ask yourself, "Is this useful in terms of what I want or need from this situation?" That is, is carrying judgment going to help you accomplish your goal? Most likely, the answer is no. And, in fact, it may have the opposite effect!
|
||||
|
||||
|
||||
|
||||
The above tips have been helpful for me. But the goal of this series hasn't been to provide solutions but rather to share my experiences and to use writing to explore my own tendencies and the impact they have on myself and others. I believe that acknowledging and sharing our personal challenges can reduce the [stigma][6] associated with mental illness, create the space needed to start exploring solutions, and to create environments that are more positive and invigorating to work in.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/20/2/working-anxiety-team-performance
|
||||
|
||||
作者:[Sam Knuth][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/samfw
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc-lead-web-internet.png?itok=UQ0zMNJ3 (Spider web on green background)
|
||||
[2]: https://opensource.com/open-organization/20/1/leading-openly-anxiety
|
||||
[3]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[4]: https://opensource.com/article/17/2/what-happens-when-we-just-assume-positive-intent
|
||||
[5]: https://opensource.com/open-organization/20/2/working-anxiety-inaction-loop
|
||||
[6]: https://www.bloomberg.com/news/articles/2019-11-13/mental-health-is-still-a-don-t-ask-don-t-tell-subject-at-work
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How we decide when to release Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/how-we-decide-when-to-release-fedora/)
|
||||
[#]: author: (Ben Cotton https://fedoramagazine.org/author/bcotton/)
|
||||
|
||||
How we decide when to release Fedora
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
Open source projects can use a variety of different models for deciding when to put out a release. Some projects release on a set schedule. Others decide on what the next release should contain and release whenever that is ready. Some just wake up one day and decide it’s time to release. And other projects go for a rolling release model, avoiding the question entirely.
|
||||
|
||||
For Fedora, we go with a [schedule-based approach][2]. Releasing twice a year means we can give our contributors time to implement large changes while still keeping on the leading edge. Targeting releases for the end of April and the end of October gives everyone predictability: contributors, users, upstreams, and downstreams.
|
||||
|
||||
But it’s not enough to release whatever’s ready on the scheduled date. We want to make sure that we’re releasing _quality_ software. Over the years, the Fedora community has developed a set of processes to help ensure we can meet both our time and and quality targets.
|
||||
|
||||
### Changes process
|
||||
|
||||
Meeting our goals starts months before the release. Contributors propose changes through our [Changes process][3], which ensures that the community has a chance to provide input and be aware of impacts. For changes with a broad impact (called “system-wide changes”), we require a contingency plan that describes how to back out the change if it’s broken or won’t be ready in time. In addition, the change process includes providing steps for testing. This helps make sure we can properly verify the results of a change.
|
||||
|
||||
Change proposals are due 2-3 months before the beta release date. This gives the community time to evaluate the impact of the change and make adjustments necessary. For example, a new compiler release might require other package maintainers to fix bugs exposed by the new compiler or to make changes that take advantage of new capabilities.
|
||||
|
||||
A few weeks before the beta and final releases, we enter a [code freeze][4]. This ensures a stable target for testing. Bugs identified as blockers and non-blocking bugs that are granted a freeze exception are updated in the repo, but everything else must wait. The freeze lasts until the release.
|
||||
|
||||
### Blocker and freeze exception process
|
||||
|
||||
In a project as large as Fedora, it’s impossible to test every possible combination of packages and configurations. So we have a set of test cases that we run to make sure the key features are covered.
|
||||
|
||||
As much as we’d like to ship with zero bugs, if we waited until we reached that state, there’d never be another Fedora release again. Instead, we’ve defined release criteria that define what bugs can [block the release][5]. We have [basic release criteria][6] that apply to all release milestones, and then separate, cumulative criteria for [beta][7] and [final][8] releases. With beta releases, we’re generally a little more forgiving of rough edges. For a final release, it needs to pass all of beta’s criteria, plus some more that help make it a better user experience.
|
||||
|
||||
The week before a scheduled release, we hold a “[go/no go meeting][9]“. During this meeting, the QA team, release engineering team, and the Fedora Engineering Steering Committee (FESCo) decide whether or not we will ship the release. As part of the decision process, we conduct a final review of blocker bugs. If any accepted blockers remain, we push the release back to a later date.
|
||||
|
||||
Some bugs aren’t severe enough to block the release, but we still would like to get them fixed before the release. This is particularly true of bugs that affect the live image experience. In that case, we grant an [exception for updates that fix those bugs][10].
|
||||
|
||||
### How you can help
|
||||
|
||||
In all my years as a Fedora contributor, I’ve never heard the QA team say “we don’t need any more help.” Contributing to the pre-release testing processes can be a great way to make your first Fedora contribution.
|
||||
|
||||
The Blocker Review meetings happen most Mondays in #fedora-blocker-review on IRC. All members of the Fedora community are welcome to participate in the discussion and voting. One particularly useful contribution is to look at the [proposed blockers][11] and see if you can reproduce them. Knowing if a bug is widespread or not is important to the blocker decision.
|
||||
|
||||
In addition, the QA team conducts test days and test weeks focused on various parts of the distribution: the kernel, GNOME, etc. Test days are announced on [Fedora Magazine][12].
|
||||
|
||||
There are plenty of other ways to contribute to the QA process. The Fedora wiki has a [list of tasks and how to contact the QA team][13]. The Fedora 32 Beta release is a few weeks away, so now’s a great time to get started!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/how-we-decide-when-to-release-fedora/
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bcotton/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/02/releasing-fedora-1-816x345.png
|
||||
[2]: https://fedoraproject.org/wiki/Fedora_Release_Life_Cycle#Development_Schedule
|
||||
[3]: https://docs.fedoraproject.org/en-US/program_management/changes_policy/
|
||||
[4]: https://fedoraproject.org/wiki/Milestone_freezes
|
||||
[5]: https://fedoraproject.org/wiki/QA:SOP_blocker_bug_process
|
||||
[6]: https://fedoraproject.org/wiki/Basic_Release_Criteria
|
||||
[7]: https://fedoraproject.org/wiki/Fedora_32_Beta_Release_Criteria
|
||||
[8]: https://fedoraproject.org/wiki/Fedora_32_Final_Release_Criteria
|
||||
[9]: https://fedoraproject.org/wiki/Go_No_Go_Meeting
|
||||
[10]: https://fedoraproject.org/wiki/QA:SOP_freeze_exception_bug_process
|
||||
[11]: https://qa.fedoraproject.org/blockerbugs/
|
||||
[12]: https://fedoramagazine.org/tag/test-day/
|
||||
[13]: https://fedoraproject.org/wiki/QA/Join
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Mirantis: Balancing Open Source with Guardrails)
|
||||
[#]: via: (https://www.linux.com/articles/mirantis-balancing-open-source-with-guardrails/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Mirantis: Balancing Open Source with Guardrails
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
Mirantis, an open infrastructure company that rose to popularity with its OpenStack offering, is now moving into the Kubernetes space very aggressively. [Last year, the company acquired the Docker Enterprise business from Docker.][3] [This week, it announced that they were hiring the Kubernetes experts from the Finnish company Kontena a][4]nd established a Mirantis office in Finland, expanding the company’s footprint in Europe. Mirantis already has a significant presence in Europe due to large customers such as Bosch and [Volkswagen][5].
|
||||
|
||||
The Kontena team primarily focused on two technologies. One was a Kubernetes distro called [Pharos][6], which differentiated itself from other distributions by specializing in addressing life cycle management challenges. They had developed some unique capabilities for deployment and for updating Kubernetes itself.
|
||||
|
||||
The second product by Kontena is [Lens][6]. “It’s like a Kubernetes dashboard on steroids. In addition to offering the standard dashboard functions, it went multiple steps further by providing a terminal for command line interfacing to nodes and containers, and additional real-time insights, role-based access controls and a number of other capabilities that are currently absent from the Kubernetes dashboard,” said [Dave Van Everen][7], SVP of Marketing at Mirantis.
|
||||
|
||||
Everything that Kontena does is open source. These open source projects are already used by hundreds of organizations around the world. “They have a proven track record of contributing valuable technology pieces to the Kubernetes ecosystem, and we saw an opportunity to bring the team on board and capitalized on that opportunity as quickly as we could,” said Van Everen.
|
||||
|
||||
Mirantis will integrate many of the technology concepts and benefits from Pharos into its Docker Enterprise offering. With Kontena engineers on board, Mirantis expects to incorporate the best of what Kontena offered into its commercially supported Docker Enterprise and [Kubernetes][8] technology.
|
||||
|
||||
With this acquisition, Mirantis has hinted at a very aggressive 2020. The company is weeks away from launching the first Docker Enterprise release since the acquisition. The release brings many new capabilities on top of Docker Enterprise 3.0. The company is working on merging the [Mirantis KaaS][9] capabilities with Docker Enterprise. “We will add new capabilities, including multi-cluster management and continuous automated updates to the Kubernetes that’s already within Docker Enterprise,” said Van Everen.
|
||||
|
||||
**What is Mirantis today?**
|
||||
|
||||
Mirantis started out as a pure-play OpenStack company, but as the market dynamics changed, the company adjusted its own positioning and bet on CD platforms like Spinnaker and container orchestration technologies like Kubernetes. So, what are they focusing on today?
|
||||
|
||||
Van Everen said that Mirantis is definitely embracing Kubernetes as the open standard used by enterprises for modern applications. Kubernetes itself has a massive ecosystem of technologies that a customer needs to leverage. “When we speak about Kubernetes, we speak about full-stack Kubernetes, which includes that ecosystem consisting of a couple dozen components in a typical cluster deployment. Our job as a trusted partner in helping our customers accelerate their path to modern applications is to streamline and automate all of the infrastructure and DevOps tooling supporting their app development lifecycle,” san Van Everen.
|
||||
|
||||
In a nutshell, Mirantis is making it easier for customers to use Kubernetes.
|
||||
|
||||
Over the years, [Mirantis][10] has gained expertise in IaaS with the work they did on OpenStack. “All of that plays a role in helping companies move faster and become more agile as they’re modernizing their applications. We apply many of those same strengths to the Kubernetes ecosystem,” he said.
|
||||
|
||||
Mirantis is also building expertise in continuous delivery platforms like [Argo CD][11] and is offering customers a spectrum of professional services around application modernization, from writing code that is based in microservices architecture, to integrating CI/CD pipelines and modernizing the tooling for CI/CD to better support cloud-native patterns. By supporting Kubernetes technology with app modernization services, Mirantis is helping customers wherever they are in their digital transformation and cloud-native journey.
|
||||
|
||||
“All of those things that our services team provides are complementary to the technology. That’s a unique value that only Mirantis can provide to the market, where we can couple open source technologies with strong services to ensure that companies really get the most out of that open source technology and fulfill their ultimate goal, which is to accelerate their pace of innovation,” Van Everen said.
|
||||
|
||||
Container networking is a critical piece of the cloud-native world and Mirantis already has expertise in the area, thanks to their work on OpenStack. The company recently joined the Linux Foundation’s [LF Networking project][12] which is home to [Tungsten Fabric][13] (formerly known as OpenContrail), a technology that Mirantis uses for its [OpenStack][14] offerings.
|
||||
|
||||
He explains, “While we use Calico for the container networking, Tungsten Fabric would be an important part of the underlying networking supporting Kubernetes deployments. Staying true to our heritage, we want to be involved in the open community and have both a voice and a stake in the direction the communities are moving in.”
|
||||
|
||||
[As for the ongoing debate or controversy around two competing service mesh technologies Istio and Linkerd,][15] the company has made its bet on Istio. A few months ago, Mirantis announced a training program for Istio, which was bundled with Mirantis’ KaaS offerings.
|
||||
|
||||
“We include Istio as a service mesh by default in child clusters under Mirantis KaaS management. It’ll be used as an ingress with Docker Enterprise initially. Moving forward, we’re still looking at how to best deploy it in a service mesh configuration by default and provide a configurable but still functional default deployment for Istio as a service mesh,” said Van Everen.
|
||||
|
||||
It might seem like Mirantis is latching on to the latest hot technologies like OpenStack, [Spinnaker][16], Docker Enterprise, Kubernetes, and Istio to see what sticks. In reality, there is a method to it: the company is going where its customers are going, with the technologies that customers are using. It’s a fine balancing act.
|
||||
|
||||
“That’s the type of technology challenge that Mirantis embraces. We are open source experts and continue to provide the greatest flexibility and choice in our industry, but we do it in such a way that there are guardrails in place so that companies don’t end up having something that’s overly complex and unmanageable, or configured incorrectly,” he concluded.
|
||||
|
||||
Note: Cross posted to [TFIR][17]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/articles/mirantis-balancing-open-source-with-guardrails/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.linux.com/wp-content/uploads/2019/09/world-network-1068x713.jpg (world-network)
|
||||
[2]: https://www.linux.com/wp-content/uploads/2019/09/world-network.jpg
|
||||
[3]: https://www.youtube.com/watch?v=cBOrVKuomcU&feature=emb_title
|
||||
[4]: https://containerjournal.com/topics/container-ecosystems/mirantis-acquires-kubernetes-assets-from-kontena/
|
||||
[5]: https://www.mirantis.com/company/press-center/company-news/volkswagen-group-selects-mirantis-openstack-software-next-generation-cloud/
|
||||
[6]: https://github.com/kontena
|
||||
[7]: https://twitter.com/davidvaneveren?lang=en
|
||||
[8]: https://kubernetes.io/
|
||||
[9]: https://www.tfir.io/mirantis-launches-kaas-across-bare-metal-public-and-private-clouds/
|
||||
[10]: https://www.mirantis.com/
|
||||
[11]: https://argoproj.github.io/argo-cd/
|
||||
[12]: https://www.linuxfoundation.org/projects/networking/
|
||||
[13]: https://tungsten.io/
|
||||
[14]: https://www.openstack.org/
|
||||
[15]: https://twitter.com/hashtag/istio?lang=en
|
||||
[16]: https://www.tfir.io/?s=spinnaker
|
||||
[17]: https://www.tfir.io/mirantis-balancing-open-source-with-guardrails/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user