mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
41800ebb36
published
20180228 Why Python devs should use Pipenv.md20180423 An introduction to Python bytecode.md20180425 JavaScript Router.md20180611 Turn Your Raspberry Pi into a Tor Relay Node.md20180615 4 tools for building embedded Linux systems.md20180622 Automatically Change Wallpapers in Linux with Little Simple Wallpaper Changer.md20180626 5 open source puzzle games for Linux.md20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md
sources
talk
20180306 Try, learn, modify- The new IT leader-s code.md20180626 How to build a professional network when you work in a bazaar.md20180627 CIP- Keeping the Lights On with Linux.md20180704 Comparing Twine and Ren-Py for creating interactive fiction.md20180705 New Training Options Address Demand for Blockchain Skills.md
tech
20141127 Keeping (financial) score with Ledger .md20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md20171130 Google launches TensorFlow-based vision recognition kit for RPi Zero W.md20180313 Migrating to Linux- Using Sudo.md20180604 4 cool new projects to try in COPR for June 2018.md20180606 6 Open Source AI Tools to Know.md20180607 Mesos and Kubernetes- It-s Not a Competition.md20180619 Getting started with Open edX to host your course.md20180628 Sosreport - A Tool To Collect System Logs And Diagnostic Information.md20180704 Install an NVIDIA GPU on almost any machine.md20180704 Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS.md20180705 How to use dd in Linux without destroying your disk.md20180706 6 RFCs for understanding how the internet works.md20180706 How to Run Windows Apps on Android with Wine.md20180706 Revisiting wallabag, an open source alternative to Instapaper.md20180706 Robolinux Lets You Easily Run Linux and Windows Without Dual Booting.md20180706 Using Ansible to set up a workstation.md20180708 Getting Started with Debian Packaging.md20180708 simple and elegant free podcast player.md
translated
talk
20180306 Try, learn, modify- The new IT leader-s code.md20180626 How to build a professional network when you work in a bazaar.md
tech
20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md20171130 Google launches TensorFlow-based vision recognition kit for RPi Zero W.md20180103 How To Find The Installed Proprietary Packages In Arch Linux.md20180313 Migrating to Linux- Using Sudo.md20180320 Migrating to Linux- Installing Software.md20180606 6 Open Source AI Tools to Know.md20180607 Mesos and Kubernetes- It-s Not a Competition.md20180615 4 tools for building embedded Linux systems.md20180619 Getting started with Open edX to host your course.md
@ -1,101 +1,101 @@
|
||||
为什么 Python 开发人员应该使用 Pipenv
|
||||
=====
|
||||
|
||||
> 只用了一年, Pipenv 就变成了管理软件包依赖关系的 Python 官方推荐资源。
|
||||
|
||||

|
||||
|
||||
这篇文章是与 [Jeff Triplett][1] 共同撰写的。
|
||||
|
||||
Pipenv 是由 Kenneth Reitz 在一年多前创建的“面向人类(to校正者:这里为人类感觉翻译为为开发者更好一点)而生的 Python 开发工作流”,它已经成为管理软件包依赖关系的[ Python 官方推荐资源][2]。但是对于它解决了什么问题,以及它如何比使用 `pip` 和 `requirements.txt` 文件的标准工作流更有用处,这两点仍然存在困惑。在本月的 Python 专栏中,我们将填补这些空白。
|
||||
Pipenv 是由 Kenneth Reitz 在一年多前创建的“面向开发者而生的 Python 开发工作流”,它已经成为管理软件包依赖关系的[ Python 官方推荐资源][2]。但是对于它解决了什么问题,以及它如何比使用 `pip` 和 `requirements.txt` 文件的标准工作流更有用处,这两点仍然存在困惑。在本月的 Python 专栏中,我们将填补这些空白。
|
||||
|
||||
### Python 包安装简史
|
||||
|
||||
为了理解 Pipenv 所解决的问题,看一看 Python 包管理如何发展十分有用的。
|
||||
|
||||
让我们回到第一个 Python 版本,我们有 Python,但是没有干净的方法来安装软件包。
|
||||
让我们回到第一个 Python 版本,这时我们有了 Python,但是没有干净的方法来安装软件包。
|
||||
|
||||
然后有了 [Easy Install][3],这是一个可以相对容易地安装其他 Python 包的软件包,但它也带来了一个问题:卸载不需要的包并不容易。
|
||||
|
||||
[pip][4] 登场,绝大多数 Python 用户都熟悉它。`pip` 可以让我们安装和卸载包。我们可以指定版本,运行 `pip freeze > requirements.txt` 来输出一个已安装包列表到一个文本文件,还可以用相同的文本文件配合 `pip install -r requirements.txt` 来安装一个应用程序需要的所有包。
|
||||
|
||||
但是 `pip` 并没有包含将包彼此隔离的方法。我们可能会开发使用相同库的不同版本的应用程序,因此我们需要一种方法来实现这一点。随之而来的是[虚拟环境][5],它使我们能够为我们开发的每个应用程序创建一个小型的,隔离的环境。我们已经看到了许多管理虚拟环境的工具:[virtualenv][6], [venv][7], [virtualenvwrapper][8], [pyenv][9], [pyenv-virtualenv][10], [pyenv-virtualenvwrapper][11] 等等。它们都可以很好地使用 `pip` 和 `requirements.txt` 文件。
|
||||
但是 `pip` 并没有包含将软件包彼此隔离的方法。我们可能会开发使用相同库的不同版本的应用程序,因此我们需要一种方法来实现这一点。随之而来的是[虚拟环境][5],它使我们能够为我们开发的每个应用程序创建一个小型的、隔离的环境。我们已经看到了许多管理虚拟环境的工具:[virtualenv][6]、 [venv][7]、 [virtualenvwrapper][8]、 [pyenv][9]、 [pyenv-virtualenv][10]、 [pyenv-virtualenvwrapper][11] 等等。它们都可以很好地使用 `pip` 和 `requirements.txt` 文件。
|
||||
|
||||
### 新方法:Pipenv
|
||||
|
||||
Pipenv 旨在解决几个问题:
|
||||
|
||||
首先,问题是需要 `pip` 库来安装包,外加一个用于创建虚拟环境的库,以及用于管理虚拟环境的库,以及与这些库相关的所有命令。这些都需要管理。Pipenv 附带包管理和虚拟环境支持,因此你可以使用一个工具来安装、卸载、跟踪和记录依赖性,并创建、使用和组织你的虚拟环境。当你使用它启动一个项目时,如果你还没有使用它的话,Pipenv 将自动为该项目创建一个虚拟环境。
|
||||
首先,需要 `pip` 库来安装包,外加一个用于创建虚拟环境的库,以及用于管理虚拟环境的库,再有与这些库相关的所有命令。这些都需要管理。Pipenv 附带包管理和虚拟环境支持,因此你可以使用一个工具来安装、卸载、跟踪和记录依赖性,并创建、使用和组织你的虚拟环境。当你使用它启动一个项目时,如果你还没有使用虚拟环境的话,Pipenv 将自动为该项目创建一个虚拟环境。
|
||||
|
||||
Pipenv 通过放弃 `requirements.txt` 规范转而将其移动到一个名为 [Pipfile][12] 的新文档中来完成这种依赖管理。当你使用 Pipenv 安装一个库时,项目的 `Pipfile` 会自动更新安装细节,包括版本信息,还有可能的 Git 仓库位置,文件路径和其他信息。
|
||||
Pipenv 通过放弃 `requirements.txt` 规范转而将其移动到一个名为 [Pipfile][12] 的新文档中来完成这种依赖管理。当你使用 Pipenv 安装一个库时,项目的 `Pipfile` 会自动更新安装细节,包括版本信息,还有可能的 Git 仓库位置、文件路径和其他信息。
|
||||
|
||||
其次,Pipenv 希望能更容易地管理复杂的相互依赖关系。你的应用程序可能依赖于某个特定版本的库,而那个库可能依赖于另一个特定版本的库,而它只是依赖关系(to 校正者:这句话不太理解)。当你的应用程序使用的两个库有冲突的依赖关系时,你的情况会变得很艰难。Pipenv 希望通过在一个名为 `Pipfile.lock` 的文件中跟踪应用程序相互依赖关系树来减轻这种痛苦。`Pipfile.lock` 还会验证生产中是否使用了正确版本的依赖关系。
|
||||
其次,Pipenv 希望能更容易地管理复杂的相互依赖关系。你的应用程序可能依赖于某个特定版本的库,而那个库可能依赖于另一个特定版本的库,这些依赖关系如海龟般堆叠起来。当你的应用程序使用的两个库有冲突的依赖关系时,你的情况会变得很艰难。Pipenv 希望通过在一个名为 `Pipfile.lock` 的文件中跟踪应用程序相互依赖关系树来减轻这种痛苦。`Pipfile.lock` 还会验证生产中是否使用了正确版本的依赖关系。
|
||||
|
||||
另外,当多个开发人员在开发一个项目时,Pipenv 很方便。通过 `pip` 工作流,Casey 可能会安装一个库,并花两天时间使用该库实现一个新功能。当 Casey 提交更改时,他可能会忘记运行 `pip freeze` 来更新 requirements 文件。第二天,Jamie 拉取 Casey 的变化,突然测试失败。这样会花费好一会儿才能意识到问题是在 requirements 文件中缺少相关库,而 Jamie 尚未在虚拟环境中安装这些文件。
|
||||
另外,当多个开发人员在开发一个项目时,Pipenv 很方便。通过 `pip` 工作流,凯西可能会安装一个库,并花两天时间使用该库实现一个新功能。当凯西提交更改时,他可能会忘记运行 `pip freeze` 来更新 `requirements.txt` 文件。第二天,杰米拉取凯西的改变,测试就突然失败了。这样会花费好一会儿才能意识到问题是在 `requirements.txt` 文件中缺少相关库,而杰米尚未在虚拟环境中安装这些文件。
|
||||
|
||||
因为 Pipenv 会在安装时自动记录依赖性,如果 Jamie 和 Casey 使用了 Pipenv,`Pipfile` 会自动更新并包含在 Casey 的提交中。这样 Jamie 和 Casey 就可以节省时间并更快地运送他们的产品。
|
||||
因为 Pipenv 会在安装时自动记录依赖性,如果杰米和凯西使用了 Pipenv,`Pipfile` 会自动更新并包含在凯西的提交中。这样杰米和凯西就可以节省时间并更快地运送他们的产品。
|
||||
|
||||
最后,将 Pipenv 推荐给在你项目上工作的其他人,因为它使用标准化的方式来安装项目依赖项,开发和测试需求。使用 `pip` 工作流和 requirements 文件意味着你可能只有一个 `requirements.txt` 文件,或针对不同环境的多个 requirements 文件。例如,你的同事可能不清楚他们是否应该在他们的笔记本电脑上运行项目时运行 `dev.txt` 还是 `local.txt`。当两个相似的 requirements 文件彼此不同步时它也会造成混淆:`local.txt` 是否过时了,还是真的应该与 `dev.txt` 不同?多个 requirements 文件需要更多的上下文和文档,以使其他人能够按照预期正确安装依赖关系。这个工作流程有可能会混淆同时并增加你的维护负担。
|
||||
最后,将 Pipenv 推荐给在你项目上工作的其他人,因为它使用标准化的方式来安装项目依赖项和开发和测试的需求。使用 `pip` 工作流和 `requirements.txt` 文件意味着你可能只有一个 `requirements.txt` 文件,或针对不同环境的多个 `requirements.txt` 文件。例如,你的同事可能不清楚他们是否应该在他们的笔记本电脑上运行项目时是运行 `dev.txt` 还是 `local.txt`。当两个相似的 `requirements.txt` 文件彼此不同步时它也会造成混淆:`local.txt` 是否过时了,还是真的应该与 `dev.txt` 不同?多个 `requirements.txt` 文件需要更多的上下文和文档,以使其他人能够按照预期正确安装依赖关系。这个工作流程有可能会混淆同时并增加你的维护负担。
|
||||
|
||||
使用 Pipenv,它会生成 `Pipfile`,通过为你管理对不同环境的依赖关系,可以避免这些问题。该命令将安装主项目依赖项:
|
||||
|
||||
```
|
||||
pipenv install
|
||||
|
||||
```
|
||||
|
||||
添加 `--dev` 标志将安装 dev/testing requirements:
|
||||
添加 `--dev` 标志将安装开发/测试的 `requirements.txt`:
|
||||
|
||||
```
|
||||
pipenv install --dev
|
||||
|
||||
```
|
||||
|
||||
使用 Pipenv 还有其他好处:它具有更好的安全特性,以易于理解的格式绘制你的依赖关系,无缝处理 `.env` 文件,并且可以在一个文件中自动处理开发与生产环境的不同依赖关系。你可以在[文档][13]中阅读更多内容。
|
||||
|
||||
### Pipenv 行动
|
||||
### 使用 Pipenv
|
||||
|
||||
使用 Pipenv 的基础知识在官方 Python 包管理教程[管理应用程序依赖关系][14]部分中详细介绍。要安装 Pipenv,使用 `pip`:
|
||||
|
||||
```
|
||||
pip install pipenv
|
||||
|
||||
```
|
||||
|
||||
要安装在项目中使用的包,请更改为项目的目录。然后安装一个包(我们将使用 Django 作为例子),运行:
|
||||
|
||||
```
|
||||
pipenv install django
|
||||
|
||||
```
|
||||
|
||||
你会看到一些输出,表明 Pipenv 正在为你的项目创建一个 `Pipfile`。
|
||||
|
||||
如果你还没有使用虚拟环境,你还会看到 Pipenv 的一些输出,说明它正在为你创建一个虚拟环境。
|
||||
|
||||
然后,你将看到你在安装包时习惯看到的输出。
|
||||
然后,你将看到你在安装包时常看到的输出。
|
||||
|
||||
为了生成 `Pipfile.lock` 文件,运行:
|
||||
|
||||
```
|
||||
pipenv lock
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 Pipenv 运行 Python 脚本。运行名为 `hello.py` 的(to 校正者:这里 top-level该怎么翻译)Python 脚本:
|
||||
你也可以使用 Pipenv 运行 Python 脚本。运行名为 `hello.py` 的上层 Python 脚本:
|
||||
|
||||
```
|
||||
pipenv run python hello.py
|
||||
|
||||
```
|
||||
|
||||
你将在控制台中看到预期结果。
|
||||
|
||||
启动一个 shell,运行:
|
||||
|
||||
```
|
||||
pipenv shell
|
||||
|
||||
```
|
||||
|
||||
如果你想将当前使用 `requirements.txt` 文件的项目转换为使用 Pipenv,请安装 Pipenv 并运行:
|
||||
|
||||
```
|
||||
pipenv install requirements.txt
|
||||
|
||||
```
|
||||
|
||||
这将创建一个 Pipfile 并安装指定的 requirements。考虑一下升级你的项目!
|
||||
这将创建一个 Pipfile 并安装指定的 `requirements.txt`。考虑一下升级你的项目!
|
||||
|
||||
### 了解更多
|
||||
|
||||
@ -106,9 +106,9 @@ pipenv install requirements.txt
|
||||
|
||||
via: https://opensource.com/article/18/2/why-python-devs-should-use-pipenv
|
||||
|
||||
作者:[Lacey Williams Henschel][a]
|
||||
作者:[Lacey Williams Henschel][a], [Jeff Triplett][1]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,11 @@
|
||||
Python 字节码介绍
|
||||
======
|
||||
|
||||
> 了解 Python 字节码是什么,Python 如何使用它来执行你的代码,以及知道它是如何帮到你的。
|
||||
|
||||

|
||||
如果你从没有写过 Python,或者甚至只是使用过 Python,你或许已经习惯于看 Python 源代码文件;它们的名字以 `.py` 结尾。你可能还看到过其它类型的文件,比如使用 `.pyc` 结尾的文件,或许你可能听说过,它们就是 Python 的 "字节码" 文件。(在 Python 3 上这些可能不容易看到 — 因为它们与你的 `.py` 文件不在同一个目录下,它们在一个叫 `__pycache__` 的子目录中)或者你也听说过,这是节省时间的一种方法,它可以避免每次运行 Python 时去重新解析源代码。
|
||||
|
||||
如果你曾经编写过 Python,或者只是使用过 Python,你或许经常会看到 Python 源代码文件——它们的名字以 `.py` 结尾。你可能还看到过其它类型的文件,比如以 `.pyc` 结尾的文件,或许你可能听说过它们就是 Python 的 “<ruby>字节码<rt>bytecode</rt></ruby>” 文件。(在 Python 3 上这些可能不容易看到 —— 因为它们与你的 `.py` 文件不在同一个目录下,它们在一个叫 `__pycache__` 的子目录中)或者你也听说过,这是节省时间的一种方法,它可以避免每次运行 Python 时去重新解析源代码。
|
||||
|
||||
但是,除了 “噢,原来这就是 Python 字节码” 之外,你还知道这些文件能做什么吗?以及 Python 是如何使用它们的?
|
||||
|
||||
@ -9,29 +13,26 @@ Python 字节码介绍
|
||||
|
||||
### Python 如何工作
|
||||
|
||||
Python 经常被介绍为它是一个解释型语言 — 其中一个原因是程序运行时,你的源代码被转换成 CPU 的原生指令 — 但这样认为只是部分正确。Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
|
||||
Python 经常被介绍为它是一个解释型语言 —— 其中一个原因是在程序运行时,你的源代码被转换成 CPU 的原生指令 —— 但这样的看法只是部分正确。Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
|
||||
|
||||
因此,这些 `.pyc` 文件是 Python 悄悄留下的,是为了让它们运行的 “更快”,或者是针对你的源代码的 “优化” 版本;它们是你的程序在 Python 虚拟机上运行的字节码指令。
|
||||
|
||||
我们来看一个示例。这里是用 Python 写的经典程序 "Hello, World!":
|
||||
我们来看一个示例。这里是用 Python 写的经典程序 “Hello, World!”:
|
||||
|
||||
```
|
||||
def hello()
|
||||
|
||||
print("Hello, World!")
|
||||
|
||||
```
|
||||
|
||||
下面是转换后的字节码(转换为人类可读的格式):
|
||||
```
|
||||
2 0 LOAD_GLOBAL 0 (print)
|
||||
|
||||
2 LOAD_CONST 1 ('Hello, World!')
|
||||
|
||||
4 CALL_FUNCTION 1
|
||||
|
||||
```
|
||||
2 0 LOAD_GLOBAL 0 (print)
|
||||
2 LOAD_CONST 1 ('Hello, World!')
|
||||
4 CALL_FUNCTION 1
|
||||
```
|
||||
|
||||
如果你输入那个 `hello()` 函数,然后使用 [CPython][1] 解释器去运行它,上面的 Python 程序将会运行。它看起来可能有点奇怪,因此,我们来深入了解一下它都做了些什么。
|
||||
如果你输入那个 `hello()` 函数,然后使用 [CPython][1] 解释器去运行它,那么上述列出的内容就是 Python 所运行的。它看起来可能有点奇怪,因此,我们来深入了解一下它都做了些什么。
|
||||
|
||||
### Python 虚拟机内幕
|
||||
|
||||
@ -39,84 +40,68 @@ CPython 使用一个基于栈的虚拟机。也就是说,它完全面向栈数
|
||||
|
||||
CPython 使用三种类型的栈:
|
||||
|
||||
1. **调用栈**。这是运行 Python 程序的主要结构。它为每个当前活动的函数调用使用了一个东西 — "帧“,栈底是程序的入口点。每个函数调用推送一个新帧到调用栈,每当函数调用返回后,这个帧被销毁。
|
||||
2. 在每个帧中,有一个 **计算栈** (也称为 **数据栈**)。这个栈就是 Python 函数运行的地方,运行的 Python 代码大多数是由推入到这个栈中的东西组成的,操作它们,然后在返回后销毁它们。
|
||||
3. 在每个帧中,还有一个 **块栈**。它被 Python 用于去跟踪某些类型的控制结构:loops、`try`/`except` 块、以及 `with` 块,全部推入到块栈中,当你退出这些控制结构时,块栈被销毁。这将帮助 Python 了解任意给定时刻哪个块是活动的,比如,一个 `continue` 或者 `break` 语句可能影响正确的块。
|
||||
|
||||
|
||||
1. <ruby>调用栈<rt>call stack</rt></ruby>。这是运行 Python 程序的主要结构。它为每个当前活动的函数调用使用了一个东西 —— “<ruby>帧<rt>frame</rt></ruby>”,栈底是程序的入口点。每个函数调用推送一个新的帧到调用栈,每当函数调用返回后,这个帧被销毁。
|
||||
2. 在每个帧中,有一个<ruby>计算栈<rt>evaluation stack</rt></ruby> (也称为<ruby>数据栈<rt>data stack</rt></ruby>)。这个栈就是 Python 函数运行的地方,运行的 Python 代码大多数是由推入到这个栈中的东西组成的,操作它们,然后在返回后销毁它们。
|
||||
3. 在每个帧中,还有一个<ruby>块栈<rt>block stack</rt></ruby>。它被 Python 用于去跟踪某些类型的控制结构:循环、`try` / `except` 块、以及 `with` 块,全部推入到块栈中,当你退出这些控制结构时,块栈被销毁。这将帮助 Python 了解任意给定时刻哪个块是活动的,比如,一个 `continue` 或者 `break` 语句可能影响正确的块。
|
||||
|
||||
大多数 Python 字节码指令操作的是当前调用栈帧的计算栈,虽然,还有一些指令可以做其它的事情(比如跳转到指定指令,或者操作块栈)。
|
||||
|
||||
为了更好地理解,假设我们有一些调用函数的代码,比如这个:`my_function(my_variable, 2)`。Python 将转换为一系列字节码指令:
|
||||
|
||||
1. 一个 `LOAD_NAME` 指令去查找函数对象 `my_function`,然后将它推入到计算栈的顶部
|
||||
2. 另一个 `LOAD_NAME` 指令去查找变量 `my_variable`,然后将它推入到计算栈的顶部
|
||||
3. 一个 `LOAD_CONST` 指令去推入一个实整数值 `2` 到计算栈的顶部
|
||||
4. 一个 `CALL_FUNCTION` 指令
|
||||
1. 一个 `LOAD_NAME` 指令去查找函数对象 `my_function`,然后将它推入到计算栈的顶部
|
||||
2. 另一个 `LOAD_NAME` 指令去查找变量 `my_variable`,然后将它推入到计算栈的顶部
|
||||
3. 一个 `LOAD_CONST` 指令去推入一个实整数值 `2` 到计算栈的顶部
|
||||
4. 一个 `CALL_FUNCTION` 指令
|
||||
|
||||
|
||||
|
||||
这个 `CALL_FUNCTION` 指令将有 2 个参数,它表示那个 Python 需要从栈顶弹出两个位置参数;然后函数将在它上面进行调用,并且它也同时被弹出(对于函数涉及的关键字参数,它使用另一个不同的指令 — `CALL_FUNCTION_KW`,但使用的操作原则类似,以及第三个指令 — `CALL_FUNCTION_EX`,它适用于函数调用涉及到使用 `*` 或 `**` 操作符的情况)。一旦 Python 拥有了这些之后,它将在调用栈上分配一个新帧,填充到函数调用的本地变量上,然后,运行那个帧内的 `my_function` 字节码。运行完成后,这个帧将被调用栈销毁,最初的帧内返回的 `my_function` 将被推入到计算栈的顶部。
|
||||
这个 `CALL_FUNCTION` 指令将有 2 个参数,它表示那个 Python 需要从栈顶弹出两个位置参数;然后函数将在它上面进行调用,并且它也同时被弹出(对于函数涉及的关键字参数,它使用另一个不同的指令 —— `CALL_FUNCTION_KW`,但使用的操作原则类似,以及第三个指令 —— `CALL_FUNCTION_EX`,它适用于函数调用涉及到参数使用 `*` 或 `**` 操作符的情况)。一旦 Python 拥有了这些之后,它将在调用栈上分配一个新帧,填充到函数调用的本地变量上,然后,运行那个帧内的 `my_function` 字节码。运行完成后,这个帧将被调用栈销毁,而在最初的帧内,`my_function` 的返回值将被推入到计算栈的顶部。
|
||||
|
||||
### 访问和理解 Python 字节码
|
||||
|
||||
如果你想玩转字节码,那么,Python 标准库中的 `dis` 模块将对你有非常大的帮助;`dis` 模块为 Python 字节码提供了一个 "反汇编",它可以让你更容易地得到一个人类可读的版本,以及查找各种字节码指令。[`dis` 模块的文档][2] 可以让你遍历它的内容,并且提供一个字节码指令能够做什么和有什么样的参数的完整清单。
|
||||
如果你想玩转字节码,那么,Python 标准库中的 `dis` 模块将对你有非常大的帮助;`dis` 模块为 Python 字节码提供了一个 “反汇编”,它可以让你更容易地得到一个人类可读的版本,以及查找各种字节码指令。[`dis` 模块的文档][2] 可以让你遍历它的内容,并且提供一个字节码指令能够做什么和有什么样的参数的完整清单。
|
||||
|
||||
例如,获取上面的 `hello()` 函数的列表,可以在一个 Python 解析器中输入如下内容,然后运行它:
|
||||
|
||||
```
|
||||
import dis
|
||||
|
||||
dis.dis(hello)
|
||||
|
||||
```
|
||||
|
||||
函数 `dis.dis()` 将反汇编一个函数、方法、类、模块、编译过的 Python 代码对象、或者字符串包含的源代码,以及显示出一个人类可读的版本。`dis` 模块中另一个方便的功能是 `distb()`。你可以给它传递一个 Python 追溯对象,或者发生预期外情况时调用它,然后它将反汇编发生预期外情况时在调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
|
||||
函数 `dis.dis()` 将反汇编一个函数、方法、类、模块、编译过的 Python 代码对象、或者字符串包含的源代码,以及显示出一个人类可读的版本。`dis` 模块中另一个方便的功能是 `distb()`。你可以给它传递一个 Python 追溯对象,或者在发生预期外情况时调用它,然后它将在发生预期外情况时反汇编调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
|
||||
|
||||
它也可以用于查看 Python 为每个函数构建的编译后的代码对象,因为运行一个函数将会用到这些代码对象的属性。这里有一个查看 `hello()` 函数的示例:
|
||||
|
||||
```
|
||||
>>> hello.__code__
|
||||
|
||||
<code object hello at 0x104e46930, file "<stdin>", line 1>
|
||||
|
||||
>>> hello.__code__.co_consts
|
||||
|
||||
(None, 'Hello, World!')
|
||||
|
||||
>>> hello.__code__.co_varnames
|
||||
|
||||
()
|
||||
|
||||
>>> hello.__code__.co_names
|
||||
|
||||
('print',)
|
||||
|
||||
```
|
||||
|
||||
代码对象在函数中可以作为属性 `__code__` 来访问,并且携带了一些重要的属性:
|
||||
代码对象在函数中可以以属性 `__code__` 来访问,并且携带了一些重要的属性:
|
||||
|
||||
* `co_consts` 是存在于函数体内的任意实数的元组
|
||||
* `co_varnames` 是函数体内使用的包含任意本地变量名字的元组
|
||||
* `co_names` 是在函数体内引用的任意非本地名字的元组
|
||||
|
||||
|
||||
|
||||
许多字节码指令 — 尤其是那些推入到栈中的加载值,或者在变量和属性中的存储值 — 在这些用作它们参数的元组中使用索引。
|
||||
许多字节码指令 —— 尤其是那些推入到栈中的加载值,或者在变量和属性中的存储值 —— 在这些元组中的索引作为它们参数。
|
||||
|
||||
因此,现在我们能够理解 `hello()` 函数中所列出的字节码:
|
||||
|
||||
1. `LOAD_GLOBAL 0`:告诉 Python 通过 `co_names` (它是 `print` 函数)的索引 0 上的名字去查找它指向的全局对象,然后将它推入到计算栈
|
||||
2. `LOAD_CONST 1`:带入 `co_consts` 在索引 1 上的实数值,并将它推入(索引 0 上的实数值是 `None`,它表示在 `co_consts` 中,因为 Python 函数调用有一个隐式的返回值 `None`,如果没有显式的返回表达式,就返回这个隐式的值 )。
|
||||
3. `CALL_FUNCTION 1`:告诉 Python 去调用一个函数;它需要从栈中弹出一个位置参数,然后,新的栈顶将被函数调用。
|
||||
1. `LOAD_GLOBAL 0`:告诉 Python 通过 `co_names` (它是 `print` 函数)的索引 0 上的名字去查找它指向的全局对象,然后将它推入到计算栈
|
||||
2. `LOAD_CONST 1`:带入 `co_consts` 在索引 1 上的字面值,并将它推入(索引 0 上的字面值是 `None`,它表示在 `co_consts` 中,因为 Python 函数调用有一个隐式的返回值 `None`,如果没有显式的返回表达式,就返回这个隐式的值 )。
|
||||
3. `CALL_FUNCTION 1`:告诉 Python 去调用一个函数;它需要从栈中弹出一个位置参数,然后,新的栈顶将被函数调用。
|
||||
|
||||
|
||||
|
||||
"原始的" 字节码 — 是非人类可读格式的字节 — 也可以在代码对象上作为 `co_code` 属性可用。如果你有兴趣尝试手工反汇编一个函数时,你可以从它们的十进制字节值中,使用列出 `dis.opname` 的方式去查看字节码指令的名字。
|
||||
“原始的” 字节码 —— 是非人类可读格式的字节 —— 也可以在代码对象上作为 `co_code` 属性可用。如果你有兴趣尝试手工反汇编一个函数时,你可以从它们的十进制字节值中,使用列出 `dis.opname` 的方式去查看字节码指令的名字。
|
||||
|
||||
### 字节码的用处
|
||||
|
||||
现在,你已经了解的足够多了,你可能会想 ” OK,我认为它很酷,但是知道这些有什么实际价值呢?“由于对它很好奇,我们去了解它,但是除了好奇之外,Python 字节码在几个方面还是非常有用的。
|
||||
现在,你已经了解的足够多了,你可能会想 “OK,我认为它很酷,但是知道这些有什么实际价值呢?”由于对它很好奇,我们去了解它,但是除了好奇之外,Python 字节码在几个方面还是非常有用的。
|
||||
|
||||
首先,理解 Python 的运行模型可以帮你更好地理解你的代码。人们都开玩笑说,C 将成为一个 ”便携式汇编器“,在那里你可以很好地猜测出一段 C 代码转换成什么样的机器指令。理解 Python 字节码之后,你在使用 Python 时也具备同样的能力 — 如果你能预料到你的 Python 源代码将被转换成什么样的字节码,那么你可以知道如何更好地写和优化 Python 源代码。
|
||||
首先,理解 Python 的运行模型可以帮你更好地理解你的代码。人们都开玩笑说,C 是一种 “可移植汇编器”,你可以很好地猜测出一段 C 代码转换成什么样的机器指令。理解 Python 字节码之后,你在使用 Python 时也具备同样的能力 —— 如果你能预料到你的 Python 源代码将被转换成什么样的字节码,那么你可以知道如何更好地写和优化 Python 源代码。
|
||||
|
||||
第二,理解字节码可以帮你更好地回答有关 Python 的问题。比如,我经常看到一些 Python 新手困惑为什么某些结构比其它结构运行的更快(比如,为什么 `{}` 比 `dict()` 快)。知道如何去访问和阅读 Python 字节码将让你很容易回答这样的问题(尝试对比一下: `dis.dis("{}")` 与 `dis.dis("dict()")` 就会明白)。
|
||||
|
||||
@ -131,7 +116,6 @@ dis.dis(hello)
|
||||
* 最后,CPython 解析器是一个开源软件,你可以在 [GitHub][1] 上阅读它。它在文件 `Python/ceval.c` 中实现了字节码解析器。[这是 Python 3.6.4 发行版中那个文件的链接][5];字节码指令是由第 1266 行开始的 `switch` 语句来处理的。
|
||||
|
||||
|
||||
|
||||
学习更多内容,参与到 James Bennett 的演讲,[有关字节的知识:理解 Python 字节码][6],将在 [PyCon Cleveland 2018][7] 召开。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -141,7 +125,7 @@ via: https://opensource.com/article/18/4/introduction-python-bytecode
|
||||
作者:[James Bennett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,8 @@
|
||||
Translating by qhwdw
|
||||
JavaScript Router
|
||||
JavaScript 路由器
|
||||
======
|
||||
There are a lot of frameworks/libraries to build single page applications, but I wanted something more minimal. I’ve come with a solution and I just wanted to share it 🙂
|
||||
|
||||
构建单页面应用(SPA)有许多的框架/库,但是我希望它们能少一些。我有一个解决方案,我想共享给大家。
|
||||
|
||||
```
|
||||
class Router {
|
||||
constructor() {
|
||||
@ -49,16 +50,16 @@ function notFoundPage() {
|
||||
console.log(router.exec('/')) // home page
|
||||
console.log(router.exec('/users/john')) // john's page
|
||||
console.log(router.exec('/foo')) // not found page
|
||||
|
||||
```
|
||||
|
||||
To use it you add handlers for a URL pattern. This pattern can be a simple string or a regular expression. Using a string will match exactly that, but a regular expression allows you to do fancy things like capture parts from the URL as seen with the user page or match any URL as seen with the not found page.
|
||||
使用它你可以为一个 URL 模式添加处理程序。这个模式可能是一个简单的字符串或一个正则表达式。使用一个字符串将精确匹配它,但是如果使用一个正则表达式将允许你做一些更复杂的事情,比如,从用户页面上看到的 URL 中获取其中的一部分,或者匹配任何没有找到页面的 URL。
|
||||
|
||||
I’ll explain what does that `exec` method… As I said, the URL pattern can be a string or a regular expression, so it first checks for a string. In case the pattern is equal to the given pathname, it returns the execution of the handler. If it is a regular expression, we do a match with the given pathname. In case it matches, it returns the execution of the handler passing to it the captured parameters.
|
||||
我将详细解释这个 `exec` 方法 … 正如我前面说的,URL 模式既有可能是一个字符串,也有可能是一个正则表达式,因此,我首先来检查它是否是一个字符串。如果模式与给定的路径名相同,它返回运行处理程序。如果是一个正则表达式,我们与给定的路径名进行匹配。如果匹配成功,它将获取的参数传递给处理程序,并返回运行这个处理程序。
|
||||
|
||||
### Working Example
|
||||
### 工作示例
|
||||
|
||||
那个例子正好记录到了控制台。我们尝试将它整合到一个页面,看看它是什么样的。
|
||||
|
||||
That example just logs to the console. Let’s try to integrate it to a page and see something.
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
@ -77,40 +78,41 @@ That example just logs to the console. Let’s try to integrate it to a page and
|
||||
<main></main>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
This is the `index.html`. For single page applications, you must do special work on the server side because all unknown paths should return this `index.html`. For development, I’m using an npm tool called [serve][1]. This tool is to serve static content. With the flag `-s`/`--single` you can serve single page applications.
|
||||
这是 `index.html`。对于单页面应用程序来说,你必须在服务器侧做一个特别的工作,因为所有未知的路径都将返回这个 `index.html`。在开发时,我们使用了一个 npm 工具调用了 [serve][1]。这个工具去提供静态内容。使用标志 `-s`/`--single`,你可以提供单页面应用程序。
|
||||
|
||||
使用 [Node.js][2] 和安装的 npm(它与 Node 一起安装),运行:
|
||||
|
||||
With [Node.js][2] and npm (comes with Node) installed, run:
|
||||
```
|
||||
npm i -g serve
|
||||
serve -s
|
||||
|
||||
```
|
||||
|
||||
That HTML file loads the script `main.js` as a module. It has a simple `<header>` and a `<main>` element in which we’ll render the corresponding page.
|
||||
那个 HTML 文件将脚本 `main.js` 加载为一个模块。在我们渲染的相关页面中,它有一个简单的 `<header>` 和一个 `<main>` 元素。
|
||||
|
||||
在 `main.js` 文件中:
|
||||
|
||||
Inside the `main.js` file:
|
||||
```
|
||||
const main = document.querySelector('main')
|
||||
const result = router.exec(location.pathname)
|
||||
main.innerHTML = result
|
||||
|
||||
```
|
||||
|
||||
We call `router.exec()` passing the current pathname and setting the result as HTML in the main element.
|
||||
我们调用传递了当前路径名为参数的 `router.exec()`,然后将 `result` 设置为 `main` 元素的 HTML。
|
||||
|
||||
If you go to localhost and play with it you’ll see that it works, but not as you expect from a SPA. Single page applications shouldn’t refresh when you click on links.
|
||||
如果你访问 `localhost` 并运行它,你将看到它能够正常工作,但不是预期中的来自一个单页面应用程序。当你点击链接时,单页面应用程序将不会被刷新。
|
||||
|
||||
We’ll have to attach event listeners to each anchor link click, prevent the default behavior and do the correct rendering. Because a single page application is something dynamic, you expect creating anchor links on the fly so to add the event listeners I’ll use a technique called [event delegation][3].
|
||||
我们将在每个点击的链接的锚点上附加事件监听器,防止出现缺省行为,并做出正确的渲染。因为一个单页面应用程序是一个动态的东西,你预期要创建的锚点链接是动态的,因此要添加事件监听器,我使用的是一个叫 [事件委托][3] 的方法。
|
||||
|
||||
I’ll attach a click event listener to the whole document and check if that click was on an anchor link (or inside one).
|
||||
我给整个文档附加一个点击事件监听器,然后去检查在锚点上(或内部)是否有点击事件。
|
||||
|
||||
In the `Router` class I’ll have a method that will register a callback that will run for every time we click on a link or a “popstate” event occurs. The popstate event is dispatched every time you use the browser back or forward buttons.
|
||||
在 `Router` 类中,我有一个注册回调的方法,在我们每次点击一个链接或者一个 `popstate` 事件发生时,这个方法将被运行。每次你使用浏览器的返回或者前进按钮时,`popstate` 事件将被发送。
|
||||
|
||||
To the callback we’ll pass that same `router.exec(location.pathname)` for convenience.
|
||||
```class Router {
|
||||
为了方便其见,我们给回调传递与 `router.exec(location.pathname)` 相同的参数。
|
||||
|
||||
```
|
||||
class Router {
|
||||
// ...
|
||||
install(callback) {
|
||||
const execCallback = () => {
|
||||
@ -149,19 +151,20 @@ To the callback we’ll pass that same `router.exec(location.pathname)` for conv
|
||||
}
|
||||
```
|
||||
|
||||
For link clicks, besides calling the callback, we update the URL with `history.pushState()`.
|
||||
对于链接的点击事件,除调用了回调之外,我们还使用 `history.pushState()` 去更新 URL。
|
||||
|
||||
我们将前面的 `main` 元素中的渲染移动到 `install` 回调中。
|
||||
|
||||
We’ll move that previous render we did in the main element into the install callback.
|
||||
```
|
||||
router.install(result => {
|
||||
main.innerHTML = result
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
#### DOM
|
||||
|
||||
Those handlers you pass to the router doesn’t need to return a `string`. If you need more power you can return actual DOM. Ex:
|
||||
你传递给路由器的这些处理程序并不需要返回一个字符串。如果你需要更多的东西,你可以返回实际的 DOM。如:
|
||||
|
||||
```
|
||||
const homeTmpl = document.createElement('template')
|
||||
homeTmpl.innerHTML = `
|
||||
@ -178,7 +181,7 @@ function homePage() {
|
||||
|
||||
```
|
||||
|
||||
And now in the install callback you can check if the result is a `string` or a `Node`.
|
||||
现在,在 `install` 回调中,你可以去检查 `result` 是一个 `string` 还是一个 `Node`。
|
||||
```
|
||||
router.install(result => {
|
||||
if (typeof result === 'string') {
|
||||
@ -190,9 +193,9 @@ router.install(result => {
|
||||
})
|
||||
```
|
||||
|
||||
That will cover the basic features. I wanted to share this because I’ll use this router in next blog posts.
|
||||
这些就是基本的功能。我希望将它共享出来,因为我将在下篇文章中使用到这个路由器。
|
||||
|
||||
I’ve published it as an [npm package][4].
|
||||
我已经以一个 [npm 包][4] 的形式将它发布了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -200,8 +203,8 @@ via: https://nicolasparada.netlify.com/posts/js-router/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
将你的树莓派打造成一个 Tor 中继节点
|
||||
======
|
||||
|
||||
> 在此教程中学习如何将你的旧树莓派打造成一个完美的 Tor 中继节点。
|
||||
|
||||

|
||||
|
||||
你是否和我一样,在第一代或者第二代树莓派发布时买了一个,玩了一段时间就把它搁置“吃灰”了。毕竟,除非你是机器人爱好者,否则一般不太可能去长时间使用一个处理器很慢的并且内存只有 256 MB 的计算机的。这并不是说你不能用它去做一件很酷的东西,但是在工作和其它任务之间,我还没有看到用一些旧的物件发挥新作用的机会。
|
||||
你是否和我一样,在第一代或者第二代树莓派发布时买了一个,玩了一段时间就把它搁置“吃灰”了。毕竟,除非你是机器人爱好者,否则一般不太可能去长时间使用一个处理器很慢的、并且内存只有 256 MB 的计算机。这并不是说你不能用它去做一件很酷的东西,但是在工作和其它任务之间,我还没有看到用一些旧的物件发挥新作用的机会。
|
||||
|
||||
然而,如果你想去好好利用它并且不想花费你太多的时间和资源的话,可以将你的旧树莓派打造成一个完美的 Tor 中继节点。
|
||||
|
||||
@ -11,18 +13,13 @@
|
||||
|
||||
在此之前你或许听说过 [Tor 项目][1],如果恰好你没有听说过,我简单给你介绍一下,“Tor” 是 “The Onion Router(洋葱路由器)” 的缩写,它是用来对付在线追踪和其它违反隐私行为的技术。
|
||||
|
||||
不论你在因特网上做什么事情,都会在你的 IP 包通过的设备上留下一些数字“脚印”:所有的交换机、路由器、负载均衡,以及目标网络记录的来自你的原始会话的 IP 地址,以及你访问的因特网资源(经常是主机名、[甚至是在使用 HTTPS 时][2])的 IP 地址。如何你是在家中上因特网,那么你的 IP 地址可以直接映射到你的家庭所在地。如果你使用了 VPN 服务([你应该使用][3]),那么你的 IP 地址是映射到你的 VPN 提供商那里,而 VPN 提供商是可以映射到你的家庭所在地的。无论如何,有可能在某个地方的某个人正在根据你访问的网络和在网站上呆了多长时间来为你建立一个个人的在线资料。然后将这个资料进行出售,并与从其它服务上收集的资料进行聚合,然后利用广告网络进行赚钱。至少,这是乐观主义者对如何利用这些数据的一些看法 —— 我相信你还可以找到更多的更恶意地使用这些数据的例子。
|
||||
|
||||
Tor 项目尝试去提供一个解决这种问题的方案,使它们不可能(或者至少是更加困难)追踪到你的终端 IP 地址。Tor 是通过让你的连接在一个由匿名的入口节点、中继节点、和出口节点组成的匿名中继链上反复跳转的方式来实现防止追踪的目的:
|
||||
|
||||
1. **入口节点** 只知道你的 IP 地址和中继节点的 IP 地址,但是不知道你最终要访问的目标 IP 地址
|
||||
|
||||
2. **中继节点** 只知道入口节点和出口节点的 IP 地址,以及即不是源也不是最终目标的 IP 地址
|
||||
|
||||
3. **出口节点** 仅知道中继节点和最终目标地址,它是在到达最终目标地址之前解密流量的节点
|
||||
|
||||
不论你在互联网上做什么事情,都会在你的 IP 包通过的设备上留下一些数字“脚印”:所有的交换机、路由器、负载均衡,以及目标网络记录的来自你的原始会话的 IP 地址,以及你访问的互联网资源(通常是它的主机名,[即使是在使用 HTTPS 时][2])的 IP 地址。如过你是在家中上互联网,那么你的 IP 地址可以直接映射到你的家庭所在地。如果你使用了 VPN 服务([你应该使用][3]),那么你的 IP 地址映射到你的 VPN 提供商那里,而 VPN 提供商是可以映射到你的家庭所在地的。无论如何,有可能在某个地方的某个人正在根据你访问的网络和在网站上呆了多长时间来为你建立一个个人的在线资料。然后将这个资料进行出售,并与从其它服务上收集的资料进行聚合,然后利用广告网络进行赚钱。至少,这是乐观主义者对如何利用这些数据的一些看法 —— 我相信你还可以找到更多的更恶意地使用这些数据的例子。
|
||||
|
||||
Tor 项目尝试去提供一个解决这种问题的方案,使它们不可能(或者至少是更加困难)追踪到你的终端 IP 地址。Tor 是通过让你的连接在一个由匿名的入口节点、中继节点和出口节点组成的匿名中继链上反复跳转的方式来实现防止追踪的目的:
|
||||
|
||||
1. **入口节点** 只知道你的 IP 地址和中继节点的 IP 地址,但是不知道你最终要访问的目标 IP 地址
|
||||
2. **中继节点** 只知道入口节点和出口节点的 IP 地址,以及既不是源也不是最终目标的 IP 地址
|
||||
3. **出口节点** 仅知道中继节点和最终目标地址,它是在到达最终目标地址之前解密流量的节点
|
||||
|
||||
中继节点在这个交换过程中扮演一个关键的角色,因为它在源请求和目标地址之间创建了一个加密的障碍。甚至在意图偷窥你数据的对手控制了出口节点的情况下,在他们没有完全控制整个 Tor 中继链的情况下仍然无法知道请求源在哪里。
|
||||
|
||||
@ -30,81 +27,68 @@ Tor 项目尝试去提供一个解决这种问题的方案,使它们不可能
|
||||
|
||||
#### 考虑去做 Tor 中继时要记住的一些事情
|
||||
|
||||
一个 Tor 中继节点仅发送和接收加密流量 —— 它从不访问任何其它站点或者在线资源,因此你不用担心有人会利用你的家庭 IP 地址去直接浏览一些令人担心的站点。话虽如此,但是如果你居住在一个提供匿名增强服务(anonymity-enhancing services)是违法行为的司法管辖区的话,那么你还是不要运营你的 Tor 中继节点了。你还需要去查看你的因特网服务提供商的服务条款是否允许你去运营一个 Tor 中继。
|
||||
一个 Tor 中继节点仅发送和接收加密流量 —— 它从不访问任何其它站点或者在线资源,因此你不用担心有人会利用你的家庭 IP 地址去直接浏览一些令人担心的站点。话虽如此,但是如果你居住在一个提供<ruby>匿名增强服务<rt>anonymity-enhancing services</rt></ruby>是违法行为的司法管辖区的话,那么你还是不要运营你的 Tor 中继节点了。你还需要去查看你的互联网服务提供商的服务条款是否允许你去运营一个 Tor 中继。
|
||||
|
||||
### 需要哪些东西
|
||||
|
||||
* 一个带完整外围附件的树莓派(任何型号/代次都行)
|
||||
|
||||
* 一张有 [Raspbian Stretch Lite][4] 的 SD 卡
|
||||
|
||||
* 一根以太网线缆
|
||||
|
||||
* 一根用于供电的 micro-USB 线缆
|
||||
|
||||
* 一个键盘和带 HDMI 接口的显示器(在配置期间使用)
|
||||
|
||||
|
||||
|
||||
|
||||
本指南假设你已经配置好了你的家庭网络连接的线缆或者 ADSL 路由器,它用于运行 NAT 转换(它几乎是必需的)。大多数型号的树莓派都有一个可用于为树莓派供电的 USB 端口,如果你只是使用路由器的 WiFi 功能,那么路由器应该有空闲的以太网口。但是在我们将树莓派设置为一个“配置完不管”的 Tor 中继之前,我们还需要一个键盘和显示器。
|
||||
|
||||
### 引导脚本
|
||||
|
||||
我改编了一个很流行的 Tor 中继节点引导脚本以适配树莓派上使用 —— 你可以在我的 GitHub 仓库 <https://github.com/mricon/tor-relay-bootstrap-rpi> 上找到它。你用它引导树莓派并使用缺省的用户 “pi” 登入之后,做如下的工作:
|
||||
我改编了一个很流行的 Tor 中继节点引导脚本以适配树莓派上使用 —— 你可以在我的 GitHub 仓库 <https://github.com/mricon/tor-relay-bootstrap-rpi> 上找到它。你用它引导树莓派并使用缺省的用户 `pi` 登入之后,做如下的工作:
|
||||
|
||||
```
|
||||
sudo apt-get install -y git
|
||||
git clone https://github.com/mricon/tor-relay-bootstrap-rpi
|
||||
cd tor-relay-bootstrap-rpi
|
||||
sudo ./bootstrap.sh
|
||||
|
||||
```
|
||||
|
||||
这个脚本将做如下的工作:
|
||||
|
||||
1. 安装最新版本的操作系统更新以确保树莓派打了所有的补丁
|
||||
|
||||
2. 将系统配置为无人值守自动更新,以确保有可用更新时会自动接收并安装
|
||||
|
||||
3. 安装 Tor 软件
|
||||
4. 告诉你的 NAT 路由器去转发所需要的端口(端口一般是 443 和 8080,因为这两个端口最不可能被互联网提供商过滤掉)上的数据包到你的中继节点
|
||||
|
||||
4. 告诉你的 NAT 路由器去转发所需要的端口(端口一般是 443 和 8080,因为这两个端口最不可能被因特网提供商过滤掉)上的数据包到你的中继节点
|
||||
|
||||
|
||||
|
||||
|
||||
脚本运行完成后,你需要去配置 torrc 文件 —— 但是首先,你需要决定打算贡献给 Tor 流量多大带宽。首先,在 Google 中输入 “[Speed Test][5]”,然后点击 “Run Speed Test” 按钮。你可以不用管 “Download speed” 的结果,因为你的 Tor 中继能处理的速度不会超过最大的上行带宽。
|
||||
脚本运行完成后,你需要去配置 `torrc` 文件 —— 但是首先,你需要决定打算贡献给 Tor 流量多大带宽。首先,在 Google 中输入 “[Speed Test][5]”,然后点击 “Run Speed Test” 按钮。你可以不用管 “Download speed” 的结果,因为你的 Tor 中继能处理的速度不会超过最大的上行带宽。
|
||||
|
||||
所以,将 “Mbps upload” 的数字除以 8,然后再乘以 1024,结果就是每秒多少 KB 的宽带速度。比如,如果你得到的上行带宽是 21.5 Mbps,那么这个数字应该是:
|
||||
|
||||
```
|
||||
21.5 Mbps / 8 * 1024 = 2752 KBytes per second
|
||||
|
||||
```
|
||||
|
||||
你可以限制你的中继带宽为那个数字的一半,并允许突发带宽为那个数字的四分之三。确定好之后,使用喜欢的文本编辑器打开 /etc/tor/torrc 文件,调整好带宽设置。
|
||||
你可以限制你的中继带宽为那个数字的一半,并允许突发带宽为那个数字的四分之三。确定好之后,使用喜欢的文本编辑器打开 `/etc/tor/torrc` 文件,调整好带宽设置。
|
||||
|
||||
```
|
||||
RelayBandwidthRate 1300 KBytes
|
||||
RelayBandwidthBurst 2400 KBytes
|
||||
|
||||
```
|
||||
|
||||
当然,如果你想更慷慨,你可以将那几个设置的数字调的更大,但是尽量不要设置为最大的出口带宽 —— 如果设置的太高,它会影响你的日常使用。
|
||||
|
||||
你打开那个文件之后,你应该去设置更多的东西。首先是昵称 —— 只是为了你自己保存记录,第二个是联系信息,只需要一个电子邮件地址。由于你的中继是运行在无人值守模式下的,你应该使用一个定期检查的电子邮件地址 —— 如果你的中继节点离线超过 48 个小时,你将收到 “Tor Weather” 服务的告警信息。
|
||||
|
||||
```
|
||||
Nickname myrpirelay
|
||||
ContactInfo you@example.com
|
||||
|
||||
```
|
||||
|
||||
保存文件并重引导系统去启动 Tor 中继。
|
||||
|
||||
### 测试它确认有 Tor 流量通过
|
||||
|
||||
如果你想去确认中继节点的功能,你可以运行 “arm” 工具:
|
||||
如果你想去确认中继节点的功能,你可以运行 `arm` 工具:
|
||||
|
||||
```
|
||||
sudo -u debian-tor arm
|
||||
|
||||
```
|
||||
|
||||
它需要一点时间才显示,尤其是在老板子上。它通常会给你显示一个表示入站和出站流量(或者是错误信息,它将有助于你去排错)的柱状图。
|
||||
@ -120,7 +104,7 @@ via: https://www.linux.com/blog/intro-to-linux/2018/6/turn-your-raspberry-pi-tor
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,184 @@
|
||||
4 种用于构建嵌入式 Linux 系统的工具
|
||||
======
|
||||
|
||||
> 了解 Yocto、Buildroot、 OpenWRT,和改造过的桌面发行版以确定哪种方式最适合你的项目。
|
||||
|
||||

|
||||
|
||||
|
||||
Linux 被部署到比 Linus Torvalds 在他的宿舍里开发时所预期的更广泛的设备。令人震惊的支持了各种芯片,使得Linux 可以应用于大大小小的设备上:从 [IBM 的巨型机][1]到不如其连接的端口大的[微型设备][2],以及各种大小的设备。它被用于大型企业数据中心、互联网基础设施设备和个人的开发系统。它还为消费类电子产品、移动电话和许多物联网设备提供了动力。
|
||||
|
||||
在为桌面和企业级设备构建 Linux 软件时,开发者通常在他们的构建机器上使用桌面发行版,如 [Ubuntu][3] 以便尽可能与被部署的机器相似。如 [VirtualBox][4] 和 [Docker][5] 这样的工具使得开发、测试和生产环境更好的保持了一致。
|
||||
|
||||
### 什么是嵌入式系统?
|
||||
|
||||
维基百科将[嵌入式系统][6]定义为:“在更大的机械或电气系统中具有专用功能的计算机系统,往往伴随着实时计算限制。”
|
||||
|
||||
我觉得可以很简单地说,嵌入式系统是大多数人不认为是计算机的计算机。它的主要作用是作为某种设备,而不被视为通用计算平台。
|
||||
|
||||
嵌入式系统编程的开发环境通常与测试和生产环境大不相同。它们可能会使用不同的芯片架构、软件堆栈甚至操作系统。开发工作流程对于嵌入式开发人员与桌面和 Web 开发人员来说是非常不同的。通常,其构建后的输出将包含目标设备的整个软件映像,包括内核、设备驱动程序、库和应用程序软件(有时也包括引导加载程序)。
|
||||
|
||||
在本文中,我将对构建嵌入式 Linux 系统的四种常用方式进行纵览。我将介绍一下每种产品的工作原理,并提供足够的信息来帮助读者确定使用哪种工具进行设计。我不会教你如何使用它们中的任何一个;一旦缩小了选择范围,就有大量深入的在线学习资源。没有任何选择适用于所有情况,我希望提供足够的细节来指导您的决定。
|
||||
|
||||
### Yocto
|
||||
|
||||
[Yocto][7] 项目 [定义][8]为“一个开源协作项目,提供模板、工具和方法,帮助您为嵌入式产品创建定制的基于 Linux 的系统,而不管硬件架构如何。”它是用于创建定制的 Linux 运行时映像的配方、配置值和依赖关系的集合,可根据您的特定需求进行定制。
|
||||
|
||||
完全公开:我在嵌入式 Linux 中的大部分工作都集中在 Yocto 项目上,而且我对这个系统的认识和偏见可能很明显。
|
||||
|
||||
Yocto 使用 [Openembedded][9] 作为其构建系统。从技术上讲,这两个是独立的项目;然而,在实践中,用户不需要了解区别,项目名称经常可以互换使用。
|
||||
|
||||
Yocto 项目的输出大致由三部分组成:
|
||||
|
||||
* **目标运行时二进制文件:**这些包括引导加载程序、内核、内核模块、根文件系统映像。以及将 Linux 部署到目标平台所需的任何其他辅助文件。
|
||||
* **包流:**这是可以安装在目标上的软件包集合。您可以根据需要选择软件包格式(例如,deb、rpm、ipk)。其中一些可能预先安装在目标运行时二进制文件中,但可以构建用于安装到已部署系统的软件包。
|
||||
* **目标 SDK:**这些是安装在目标平台上的软件的库和头文件的集合。应用程序开发人员在构建代码时使用它们,以确保它们与适当的库链接
|
||||
|
||||
#### 优点
|
||||
|
||||
Yocto 项目在行业中得到广泛应用,并得到许多有影响力的公司的支持。此外,它还拥有一个庞大且充满活力的开发人员[社区][10]和[生态系统][11]。开源爱好者和企业赞助商的结合的方式有助于推动 Yocto 项目。
|
||||
|
||||
获得 Yocto 的支持有很多选择。如果您想自己动手,有书籍和其他培训材料。如果您想获得专业知识,有许多有 Yocto 经验的工程师。而且许多商业组织可以为您的设计提供基于 Yocto 的 Turnkey 产品或基于服务的实施和定制。
|
||||
|
||||
Yocto 项目很容易通过 [层][12] 进行扩展,层可以独立发布以添加额外的功能,或针对项目发布时尚不可用的平台,或用于保存系统特有定制功能。层可以添加到你的配置中,以添加未特别包含在市面上版本中的独特功能;例如,“[meta-browser] [13]” 层包含 Web 浏览器的清单,可以轻松为您的系统进行构建。因为它们是独立维护的,所以层可以按不同的时间发布(根据层的开发速度),而不是跟着标准的 Yocto 版本发布。
|
||||
|
||||
Yocto 可以说是本文讨论的任何方式中最广泛的设备支持。由于许多半导体和电路板制造商的支持,Yocto 很可能能够支持您选择的任何目标平台。主版本 Yocto [分支][14]仅支持少数几块主板(以便达成合理的测试和发布周期),但是,标准工作模式是使用外部主板支持层。
|
||||
|
||||
最后,Yocto 非常灵活和可定制。您的特定应用程序的自定义可以存储在一个层进行封装和隔离,通常将要素层特有的自定义项存储为层本身的一部分,这可以将相同的设置同时应用于多个系统配置。Yocto 还提供了一个定义良好的层优先和覆盖功能。这使您可以定义层应用和搜索元数据的顺序。它还使您可以覆盖具有更高优先级的层的设置;例如,现有清单的许多自定义功能都将保留。
|
||||
|
||||
#### 缺点
|
||||
|
||||
Yocto 项目最大的缺点是学习曲线陡峭。学习该系统并真正理解系统需要花费大量的时间和精力。 根据您的需求,这可能对您的应用程序不重要的技术和能力投入太大。 在这种情况下,与一家商业供应商合作可能是一个不错的选择。
|
||||
|
||||
Yocto 项目的开发时间和资源相当高。 需要构建的包(包括工具链,内核和所有目标运行时组件)的数量相当不少。 Yocto 开发人员的开发工作站往往是大型系统。 不建议使用小型笔记本电脑。 这可以通过使用许多提供商提供的基于云的构建服务器来缓解。 另外,Yocto 有一个内置的缓存机制,当它确定用于构建特定包的参数没有改变时,它允许它重新使用先前构建的组件。
|
||||
|
||||
#### 建议
|
||||
|
||||
为您的下一个嵌入式 Linux 设计使用 Yocto 项目是一个强有力的选择。 在这里介绍的选项中,无论您的目标用例如何,它都是最广泛适用的。 广泛的行业支持,积极的社区和广泛的平台支持使其成为必须设计师的不错选择。
|
||||
|
||||
### Buildroot
|
||||
|
||||
[Buildroot][15] 项目定义为“通过交叉编译生成嵌入式 Linux 系统的简单、高效且易于使用的工具。”它与 Yocto 项目具有许多相同的目标,但它注重简单性和简约性。一般来说,Buildroot 会禁用所有软件包的所有可选编译时设置(有一些值得注意的例外),从而生成尽可能小的系统。系统设计人员需要启用适用于给定设备的设置。
|
||||
|
||||
Buildroot 从源代码构建所有组件,但不支持按目标包管理。因此,它有时称为固件生成器,因为镜像在构建时大部分是固定的。应用程序可以更新目标文件系统,但是没有机制将新软件包安装到正在运行的系统中。
|
||||
|
||||
Buildroot 输出主要由三部分组成:
|
||||
|
||||
* 将 Linux 部署到目标平台所需的根文件系统映像和任何其他辅助文件
|
||||
* 适用于目标硬件的内核,引导加载程序和内核模块
|
||||
* 用于构建所有目标二进制文件的工具链。
|
||||
|
||||
#### 优点
|
||||
|
||||
Buildroot 对简单性的关注意味着,一般来说,它比 Yocto 更容易学习。核心构建系统用 Make 编写,并且足够短以便开发人员了解整个系统,同时可扩展到足以满足嵌入式 Linux 开发人员的需求。 Buildroot 核心通常只处理常见用例,但它可以通过脚本进行扩展。
|
||||
|
||||
Buildroot 系统使用普通的 Makefile 和 Kconfig 语言来进行配置。 Kconfig 由 Linux 内核社区开发,广泛用于开源项目,使得许多开发人员都熟悉它。
|
||||
|
||||
由于禁用所有可选的构建时设置的设计目标,Buildroot 通常会使用开箱即用的配置生成尽可能最小的镜像。一般来说,构建时间和构建主机资源的规模将比 Yocto 项目的规模更小。
|
||||
|
||||
#### 缺点
|
||||
|
||||
关注简单性和最小化启用的构建方式意味着您可能需要执行大量的自定义来为应用程序配置 Buildroot 构建。此外,所有配置选项都存储在单个文件中,这意味着如果您有多个硬件平台,则需要为每个平台进行每个定制更改。
|
||||
|
||||
对系统配置文件的任何更改都需要全部重新构建所有软件包。与 Yocto 相比,这个问题通过最小的镜像大小和构建时间得到了一定的解决,但在你调整配置时可能会导致构建时间过长。
|
||||
|
||||
中间软件包状态缓存默认情况下未启用,并且不像 Yocto 实施那么彻底。这意味着,虽然第一次构建可能比等效的 Yocto 构建短,但后续构建可能需要重建许多组件。
|
||||
|
||||
#### 建议
|
||||
|
||||
对于大多数应用程序,使用 Buildroot 进行下一个嵌入式 Linux 设计是一个不错的选择。如果您的设计需要多种硬件类型或其他差异,但由于同步多个配置的复杂性,您可能需要重新考虑,但对于由单一设置组成的系统,Buildroot 可能适合您。
|
||||
|
||||
### OpenWRT/LEDE
|
||||
|
||||
[OpenWRT][16] 项目开始为消费类路由器开发定制固件。您当地零售商提供的许多低成本路由器都可以运行 Linux 系统,但可能无法开箱即用。这些路由器的制造商可能无法提供频繁的更新来解决新的威胁,即使他们这样做,安装更新镜像的机制也很困难且容易出错。 OpenWRT 项目为许多已被其制造商放弃的设备生成更新的固件镜像,让这些设备焕发新生。
|
||||
|
||||
OpenWRT 项目的主要交付物是可用于大量商业设备的二进制镜像。它有网络可访问的软件包存储库,允许设备最终用户将新软件添加到他们的系统中。 OpenWRT 构建系统是一个通用构建系统,它允许开发人员创建自定义版本以满足他们自己的需求并添加新软件包,但其主要重点是目标二进制文件。
|
||||
|
||||
#### 优点
|
||||
|
||||
如果您正在为商业设备寻找替代固件,则 OpenWRT 应位于您的选项列表中。它的维护良好,可以保护您免受制造商固件无法解决的问题。您也可以添加额外的功能,使您的设备更有用。
|
||||
|
||||
如果您的嵌入式设计专注于网络,则 OpenWRT 是一个不错的选择。网络应用程序是 OpenWRT 的主要用例,您可能会发现许多可用的软件包。
|
||||
|
||||
#### 缺点
|
||||
|
||||
OpenWRT 对您的设计限制很多(与 Yocto 和 Buildroot 相比)。如果这些决定不符合您的设计目标,则可能需要进行大量的修改。
|
||||
|
||||
在部署的设备中允许基于软件包的更新是很难管理的。按照其定义,这会导致与您的 QA 团队测试的软件负载不同。此外,很难保证大多数软件包管理器的原子安装,以及错误的电源循环可能会使您的设备处于不可预知的状态。
|
||||
|
||||
#### 建议
|
||||
|
||||
OpenWRT 是爱好者项目或商用硬件再利用的不错选择。它也是网络应用程序的不错选择。如果您需要从默认设置进行大量定制,您可能更喜欢 Buildroot 或 Yocto。
|
||||
|
||||
### 桌面发行版
|
||||
|
||||
设计嵌入式 Linux 系统的一种常见方法是从桌面发行版开始,例如 [Debian][17] 或 [Red Hat][18],并删除不需要的组件,直到安装的镜像符合目标设备的占用空间。这是 [Raspberry Pi][20] 平台流行的 [Raspbian][19]发行版的方法。
|
||||
|
||||
#### 优点
|
||||
|
||||
这种方法的主要优点是熟悉。通常,嵌入式 Linux 开发人员也是桌面 Linux 用户,并且精通他们的选择发行版。在目标上使用类似的环境可能会让开发人员更快地入门。根据所选的分布,可以使用 apt 和 yum 等标准封装工具安装许多其他工具。
|
||||
|
||||
可以将显示器和键盘连接到目标设备,并直接在那里进行所有的开发。对于不熟悉嵌入式空间的开发人员来说,这可能是一个更为熟悉的环境,无需配置和使用棘手的跨开发平台设置。
|
||||
|
||||
大多数桌面发行版可用的软件包数量通常大于前面讨论的嵌入式特定的构建器可用软件包数量。由于较大的用户群和更广泛的用例,您可能能够找到您的应用程序所需的所有运行时包,这些包已经构建并可供使用。
|
||||
|
||||
#### 缺点
|
||||
|
||||
将目标平台作为您的主要开发环境可能会很慢。运行编译器工具是一项资源密集型操作,根据您构建的代码的多少,这可能会严重妨碍您的性能。
|
||||
|
||||
除了一些例外情况,桌面发行版的设计并不适合低资源系统,并且可能难以充分裁剪目标映像。同样,桌面环境中的预设工作流程对于大多数嵌入式设计来说都不理想。以这种方式获得可再现的环境很困难。手动添加和删除软件包很容易出错。这可以使用特定于发行版的工具进行脚本化,例如基于 Debian 系统的 [debootstrap][21]。为了进一步提高[可再现性][21],您可以使用配置管理工具,如 [CFEngine][22](我的雇主 [Mender.io][23] 完整披露了
|
||||
这一工具)。但是,您仍然受发行版提供商的支配,他们将更新软件包以满足他们的需求,而不是您的需求。
|
||||
|
||||
#### 建议
|
||||
|
||||
对于您打算推向市场的产品,请谨慎使用此方法。这对于爱好者应用程序来说是一个很好的模型;但是,对于需要支持的产品,这种方法很可能会遇到麻烦。虽然您可能能够获得更快的起步,但从长远来看,您可能会花费您的时间和精力。
|
||||
|
||||
### 其他考虑
|
||||
|
||||
这个讨论集中在构建系统的功能上,但通常有非功能性需求可能会影响您的决定。如果您已经选择了片上系统(SoC)或电路板,则您的选择很可能由供应商决定。如果您的供应商为特定系统提供板级支持包(BSP),使用它通常会节省相当多的时间,但请研究 BSP 的质量以避免在开发周期后期发生问题。
|
||||
|
||||
如果您的预算允许,您可能需要考虑为目标操作系统使用商业供应商。有些公司会为这里讨论的许多选项提供经过验证和支持的配置,除非您拥有嵌入式 Linux 构建系统方面的专业知识,否则这是一个不错的选择,可以让您专注于核心能力。
|
||||
|
||||
作为替代,您可以考虑为您的开发人员进行商业培训。这可能比商业操作系统供应商便宜,并且可以让你更加自给自足。这是快速找到您选择的构建系统基础知识的学习曲线。
|
||||
|
||||
最后,您可能已经有一些开发人员拥有一个或多个系统的经验。如果你的工程师有倾向性,当你做出决定时,肯定值得考虑。
|
||||
|
||||
### 总结
|
||||
|
||||
构建嵌入式 Linux 系统有多种选择,每种都有优点和缺点。将这部分设计放在优先位置至关重要,因为在以后的过程中切换系统的成本非常高。除了这些选择之外,还有新的系统在开发中。希望这次讨论能够为评估新的系统(以及这里提到的系统)提供一些背景,并帮助您为下一个项目做出坚实的决定。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/embedded-linux-build-tools
|
||||
|
||||
作者:[Drew Moseley][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LHRChina](https://github.com/LHRChina)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drewmoseley
|
||||
[1]:https://en.wikipedia.org/wiki/Linux_on_z_Systems
|
||||
[2]:http://www.picotux.com/
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://www.virtualbox.org/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Embedded_system
|
||||
[7]:https://yoctoproject.org/
|
||||
[8]:https://www.yoctoproject.org/about/
|
||||
[9]:https://www.openembedded.org/
|
||||
[10]:https://www.yoctoproject.org/community/
|
||||
[11]:https://www.yoctoproject.org/ecosystem/participants/
|
||||
[12]:https://layers.openembedded.org/layerindex/branch/master/layers/
|
||||
[13]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/
|
||||
[14]:https://yoctoproject.org/downloads
|
||||
[15]:https://buildroot.org/
|
||||
[16]:https://openwrt.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/
|
||||
[19]:https://www.raspbian.org/
|
||||
[20]:https://www.raspberrypi.org/
|
||||
[21]:https://wiki.debian.org/Debootstrap
|
||||
[22]:https://cfengine.com/
|
||||
[23]:http://Mender.io
|
||||
@ -1,17 +1,17 @@
|
||||
使用 LSWC(Little Simple Wallpaper Changer) 在 Linux 中自动更改壁纸
|
||||
使用 LSWC 在 Linux 中自动更改壁纸
|
||||
======
|
||||
|
||||
**简介:这是一个小脚本,可以在 Linux 桌面上定期自动更改壁纸。**
|
||||
> 简介:这是一个小脚本,可以在 Linux 桌面上定期自动更改壁纸。
|
||||
|
||||
顾名思义,LittleSimpleWallpaperChanger 是一个小脚本,可以定期地随机更改壁纸。
|
||||
顾名思义,LittleSimpleWallpaperChanger (LSWC)是一个小脚本,可以定期地随机更改壁纸。
|
||||
|
||||
我知道在“外观”或“更改桌面背景”设置中有一个随机壁纸选项。但那是随机更改预置壁纸而不是你添加的壁纸。
|
||||
我知道在“外观”或“更改桌面背景”设置中有一个随机壁纸选项。但那是随机更改预置的壁纸而不是你添加的壁纸。
|
||||
|
||||
因此,在本文中,我们将看到如何使用 LittleSimpleWallpaperChanger 设置包含照片的随机桌面壁纸。
|
||||
|
||||
### Little Simple Wallpaper Changer (LSWC)
|
||||
|
||||
[LittleSimpleWallpaperChanger][1] 或 LSWC 是一个非常轻量级的脚本,它在后台运行,从用户指定的文件夹中更改壁纸。壁纸以 1 至 5 分钟的随机间隔变化。该软件设置起来相当简单,设置完后,用户就可以忘掉它。
|
||||
[LittleSimpleWallpaperChanger][1] (LSWC) 是一个非常轻量级的脚本,它在后台运行,从用户指定的文件夹中更改壁纸。壁纸以 1 至 5 分钟的随机间隔变化。该软件设置起来相当简单,设置完后,用户就可以不用再操心了。
|
||||
|
||||
![Little Simple Wallpaper Changer to change wallpapers in Linux][2]
|
||||
|
||||
@ -22,13 +22,10 @@
|
||||
* 进入下载位置。
|
||||
* 右键单击下载的 .zip 文件,然后选择“在此处解压”。
|
||||
* 打开解压后的文件夹,右键单击并选择“在终端中打开”。
|
||||
* 在终端中复制粘贴命令并按 Enter 键。
|
||||
`bash ./README_and_install.sh`
|
||||
* 在终端中复制粘贴命令 `bash ./README_and_install.sh` 并按回车键。
|
||||
* 然后会弹出一个对话框,要求你选择包含壁纸的文件夹。单击它,然后选择你存放壁纸的文件夹。
|
||||
* 就是这样。然后重启计算机。
|
||||
|
||||
|
||||
|
||||
![Little Simple Wallpaper Changer for Linux][4]
|
||||
|
||||
#### 使用 LSWC
|
||||
@ -36,26 +33,24 @@
|
||||
安装时,LSWC 会要求你选择包含壁纸的文件夹。因此,我建议你在安装 LSWC 之前创建一个文件夹并将你想要的壁纸全部移动到那。或者你可以使用图片文件夹中的“壁纸”文件夹。**所有壁纸都必须是 .jpg 格式。**
|
||||
|
||||
你可以添加更多壁纸或从所选文件夹中删除当前壁纸。要更改壁纸文件夹位置,你可以从以下文件中编辑壁纸的位置。
|
||||
|
||||
```
|
||||
.config/lswc/homepath.conf
|
||||
|
||||
```
|
||||
|
||||
#### 删除 LSWC
|
||||
|
||||
打开终端并运行以下命令以停止 LSWC
|
||||
打开终端并运行以下命令以停止 LSWC:
|
||||
|
||||
```
|
||||
pkill lswc
|
||||
|
||||
```
|
||||
|
||||
在文件管理器中打开家目录,然后按 ctrl+H 显示隐藏文件,接着删除以下文件:
|
||||
|
||||
* .local 中的 “scripts” 文件夹
|
||||
* .config 中的 “lswc” 文件夹
|
||||
* .config/autostart 中的 “lswc.desktop” 文件
|
||||
|
||||
在文件管理器中打开家目录,然后按 `Ctrl+H` 显示隐藏文件,接着删除以下文件:
|
||||
|
||||
* `.local` 中的 `scripts` 文件夹
|
||||
* `.config` 中的 `lswc` 文件夹
|
||||
* `.config/autostart` 中的 `lswc.desktop` 文件
|
||||
|
||||
这就完成了。创建自己的桌面背景幻灯片。LSWC 非常轻巧,易于使用。安装它然后忘记它。
|
||||
|
||||
@ -70,7 +65,7 @@ via: https://itsfoss.com/little-simple-wallpaper-changer/
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,67 +1,72 @@
|
||||
Linux 上的五个开源益智游戏
|
||||
======
|
||||
|
||||
> 用这些有趣好玩的游戏来测试你的战略能力。
|
||||
|
||||

|
||||
|
||||
游戏一直是 Linux 的弱点之一。由于 Steam、GOG 和其他将商业游戏引入多种操作系统的努力,这种情况近年来有所改变,但这些游戏通常不是开源的。当然,这些游戏可以在开源操作系统上玩,但对于纯粹开源主义者来说还不够好。
|
||||
|
||||
那么,一个只使用开源软件的人,能否找到那些经过足够打磨的游戏,在不损害其开源理念的前提下,提供一种可靠的游戏体验呢?当然可以。虽然开源游戏历来不太可能与一些借由大量预算开发的 AAA 商业游戏相匹敌,但在多种类型的开源游戏中,有很多都很有趣,可以从大多数主要 Linux 发行版的仓库中安装。即使某个特定的游戏没有被打包成特定的发行版本,通常也很容易从项目的网站上下载该游戏以便安装和游戏。
|
||||
那么,一个只使用开源软件的人,能否找到那些经过足够打磨的游戏,在不损害其开源理念的前提下,提供一种可靠的游戏体验呢?当然可以。虽然开源游戏历来不太可能与一些借由大量预算开发的 AAA 商业游戏相匹敌,但在多种类型的开源游戏中,有很多都很有趣,可以从大多数主要 Linux 发行版的仓库中安装。即使某个特定的游戏没有被打包成特定的发行版本,通常也很容易从项目的网站上下载该游戏以便安装和游戏。
|
||||
|
||||
这篇文章着眼于益智游戏。我已经写过[街机风格游戏][1]和[棋牌游戏][2]. 在之后的文章中,我计划涉足赛车,角色扮演,战略和模拟经营游戏。
|
||||
这篇文章着眼于益智游戏。我已经写过[街机风格游戏][1]和[棋牌游戏][2]。 在之后的文章中,我计划涉足赛车,角色扮演、战略和模拟经营游戏。
|
||||
|
||||
### Atomix
|
||||
|
||||
### Atomix
|
||||
|
||||
|
||||
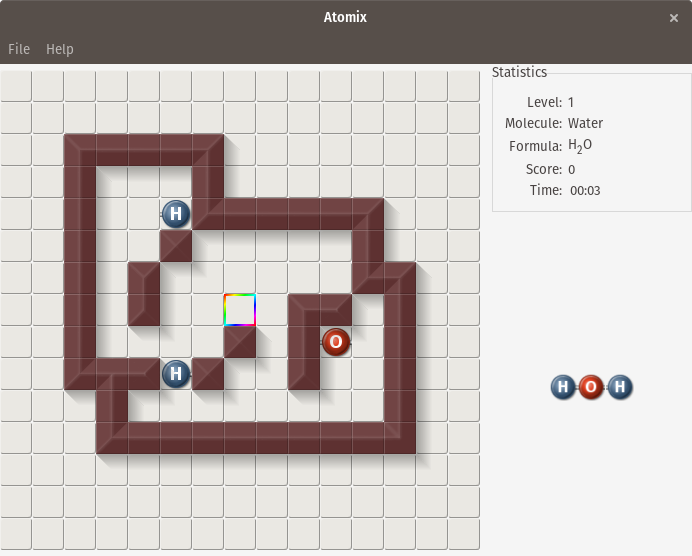
[Atomix][3] 是1990年在 Amiga、Commodore 64、MS-DOS 和其他平台发布的 [Atomix][4] 益智游戏的开源克隆。Atomix 的目标是通过连接原子来构建原子分子。单个原子可以向上、向下、向左或向右移动,并一直朝这个方向移动,直到原子撞上一个障碍物——水平墙或另一个原子。这意味着需要进行规划,以确定在水平上构建分子的位置,以及移动单个部件的顺序。第一关是一个简单的水分子,它由两个氢原子和一个氧原子组成,但后来的关卡是更复杂的分子。
|
||||
[Atomix][3] 是 1990 年在 Amiga、Commodore 64、MS-DOS 和其他平台发布的 [Atomix][4] 益智游戏的开源克隆。Atomix 的目标是通过连接原子来构建原子分子。单个原子可以向上、向下、向左或向右移动,并一直朝这个方向移动,直到原子撞上一个障碍物——水平墙或另一个原子。这意味着需要进行规划,以确定在水平上构建分子的位置,以及移动单个部件的顺序。第一关是一个简单的水分子,它由两个氢原子和一个氧原子组成,但后来的关卡是更复杂的分子。
|
||||
|
||||
要安装 Atomix,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install ``atomix`
|
||||
* 在 Debian/Ubuntu: `apt install`
|
||||
* 在 Fedora: `dnf install atomix`
|
||||
* 在 Debian/Ubuntu: `apt install atomix`
|
||||
|
||||
### Fish Fillets - Next Generation
|
||||
|
||||
### Fish Fillets - Next Generation
|
||||

|
||||
|
||||
[Fish Fillets - Next Generation][5] 是游戏Fish fillet的Linux移植版本,它在1998年在Windows发布,源代码在2004年GPL旗下发布。游戏中,两条鱼试图将物体移出道路来通过不同的关卡。这两条鱼有不同的属性,所以玩家需要为每个任务挑选合适的鱼。较大的鱼可以移动较重的物体,但它更大,这意味着它不适合较小的空隙。较小的鱼可以适应那些较小的间隙,但它不能移动较重的物体。如果一个物体从上面掉下来,两条鱼都会被压死,所以玩家在移动棋子时要小心。
|
||||
[Fish Fillets - Next Generation][5] 是游戏 Fish fillet 的 Linux 移植版本,它于 1998 年在 Windows 发布,源代码在 2004 年以 GPL 许可证发布。游戏中,两条鱼试图将物体移出道路来通过不同的关卡。这两条鱼有不同的属性,所以玩家需要为每个任务挑选合适的鱼。较大的鱼可以移动较重的物体,但它更大,这意味着它不适合较小的空隙。较小的鱼可以适应那些较小的间隙,但它不能移动较重的物体。如果一个物体从上面掉下来,两条鱼都会被压死,所以玩家在移动棋子时要小心。
|
||||
|
||||
要安装 Fish fillet——Next Generation,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install fillets-ng`
|
||||
* 在 Debian/Ubuntu: `apt install fillets-ng`
|
||||
* 在 Fedora:`dnf install fillets-ng`
|
||||
* 在 Debian/Ubuntu: `apt install fillets-ng`
|
||||
|
||||
### Frozen Bubble
|
||||
|
||||
### Frozen Bubble
|
||||
|
||||
|
||||
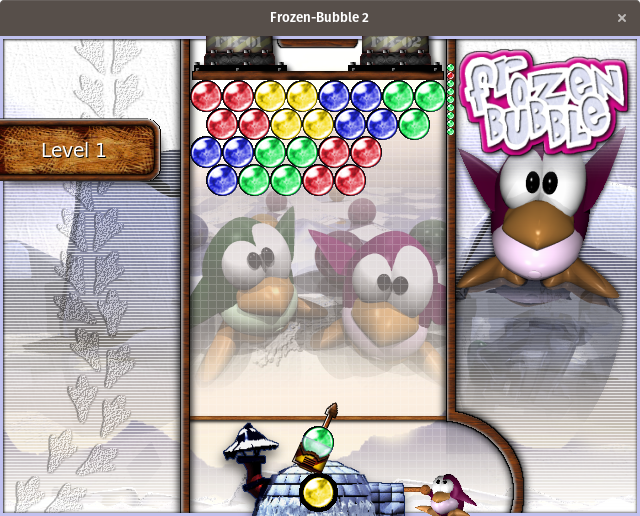
[Frozen Bubble][6] 是一款街机风格的益智游戏,从屏幕底部向屏幕顶部的一堆泡泡射击。如果三个相同颜色的气泡连接在一起,它们就会被从屏幕上移除。任何连接在被移除的气泡下面但没有连接其他任何东西的气泡也会被移除。在拼图模式下,关卡的设计是固定的,玩家只需要在泡泡掉到屏幕底部的线以下前将泡泡从游戏区域中移除。该游戏街机模式和多人模式遵循相同的基本规则,但也有不同,这增加了多样性。Frozen Bubble是一个标志性的开源游戏,所以如果你以前没有玩过它,玩玩看。
|
||||
[Frozen Bubble][6] 是一款街机风格的益智游戏,从屏幕底部向屏幕顶部的一堆泡泡射击。如果三个相同颜色的气泡连接在一起,它们就会被从屏幕上移除。任何连接在被移除的气泡下面但没有连接其他任何东西的气泡也会被移除。在拼图模式下,关卡的设计是固定的,玩家只需要在泡泡掉到屏幕底部的线以下前将泡泡从游戏区域中移除。该游戏街机模式和多人模式遵循相同的基本规则,但也有不同,这增加了多样性。Frozen Bubble 是一个标志性的开源游戏,所以如果你以前没有玩过它,玩玩看。
|
||||
|
||||
要安装 Frozen Bubble,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install frozen-bubble`
|
||||
* 在 Fedora: `dnf install frozen-bubble`
|
||||
* 在 Debian/Ubuntu: `apt install frozen-bubble`
|
||||
|
||||
|
||||
|
||||
### Hex-a-hop
|
||||
|
||||
|
||||
|
||||
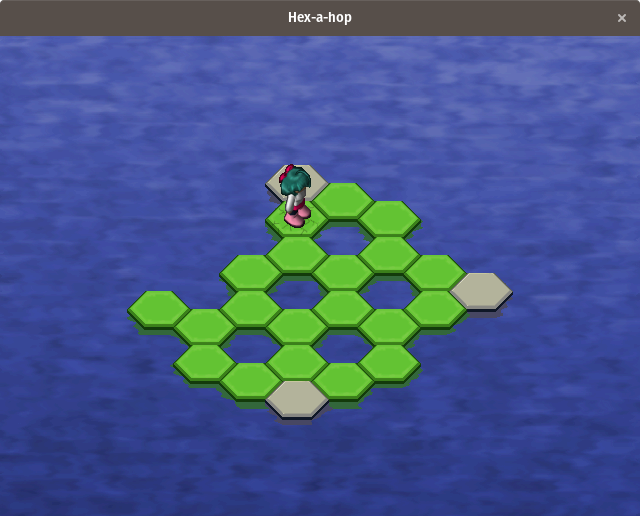
[Hex-a-hop][7] 是一款基于六角形瓦片的益智游戏,玩家需要将所有的绿色瓦片从水平面上移除。瓦片通过移动被移除。由于瓦片在移动后会消失,所以有必要规划出穿过水平面的最佳路径,以便在不被卡住的情况下移除所有的瓦片。但是,如果玩家使用的是次优路径,会有撤销功能。之后的关卡增加了额外的复杂性,包括需要跨越多个时间的瓦片和使玩家跳过一定数量的六角弹跳瓦片。
|
||||
[Hex-a-hop][7] 是一款基于六角形瓦片的益智游戏,玩家需要将所有的绿色瓦片从水平面上移除。瓦片通过移动被移除。由于瓦片在移动后会消失,所以有必要规划出穿过水平面的最佳路径,以便在不被卡住的情况下移除所有的瓦片。但是,如果玩家使用的是次优路径,会有撤销功能。之后的关卡增加了额外的复杂性,包括需要跨越多次的瓦片和使玩家跳过一定数量的六角弹跳瓦片。
|
||||
|
||||
要安装 Hex-a-hop,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install hex-a-hop`
|
||||
* 在 Fedora: `dnf install hex-a-hop`
|
||||
* 在 Debian/Ubuntu: `apt install hex-a-hop`
|
||||
|
||||
|
||||
|
||||
### Pingus
|
||||
|
||||
|
||||
|
||||
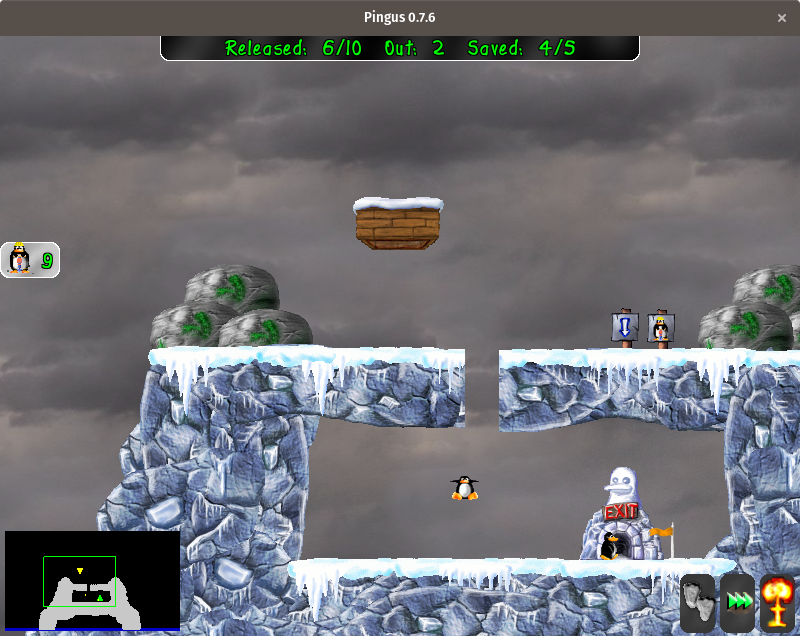
[Pingus][8] 是 [Lemmings][9] 的开源克隆。这不是一个精确的克隆,但游戏非常相似。小动物( Lemmings 里的旅鼠,Pingus 里的企鹅)通过关卡入口进入关卡,开始沿着直线行走。玩家需要使用特殊技能使小动物能够到达关卡的出口而不会被困住或者掉下悬崖。这些技能包括挖掘或建桥。如果有足够数量的小动物进入出口,这个关卡将成功完成,玩家可以进入下一个关卡。Pingus 为标准的 Lemmings 添加了一些额外的特性,包括一个世界地图和一些在原版游戏中没有的技能,但经典 Lemmings 游戏的粉丝们在这个开源版本中仍会感到自在。
|
||||
[Pingus][8] 是 [Lemmings][9] 的开源克隆。这不是一个精确的克隆,但游戏非常相似。小动物(Lemmings 里是旅鼠,Pingus 里是企鹅)通过关卡入口进入关卡,开始沿着直线行走。玩家需要使用特殊技能使小动物能够到达关卡的出口而不会被困住或者掉下悬崖。这些技能包括挖掘或建桥。如果有足够数量的小动物进入出口,这个关卡将成功完成,玩家可以进入下一个关卡。Pingus 为标准的 Lemmings 添加了一些额外的特性,包括一个世界地图和一些在原版游戏中没有的技能,但经典 Lemmings 游戏的粉丝们在这个开源版本中仍会感到自在。
|
||||
|
||||
要安装 Pingus,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install ``pingus`
|
||||
* 在 Debian/Ubuntu: `apt install ``pingus`
|
||||
* 在 Fedora: `dnf install pingus`
|
||||
* 在 Debian/Ubuntu: `apt install pingus`
|
||||
|
||||
|
||||
我漏掉你最喜欢的开源益智游戏了吗? 请在下面的评论中分享。
|
||||
@ -73,7 +78,7 @@ via: https://opensource.com/article/18/6/puzzle-games-linux
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ZenMoore](https://github.com/ZenMoore)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
Sosreport:收集系统日志和诊断信息的工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你是 RHEL 管理员,你可能肯定听说过 **Sosreport** :一个可扩展、可移植的支持数据收集工具。它是一个从类 Unix 操作系统中收集系统配置详细信息和诊断信息的工具。当用户提出支持服务单时,他/她必须运行此工具并将由 Sosreport 工具生成的结果报告发送给 Red Hat 支持人员。然后,执行人员将根据报告进行初步分析,并尝试找出系统中的问题。不仅在 RHEL 系统上,你可以在任何类 Unix 操作系统上使用它来收集系统日志和其他调试信息。
|
||||
|
||||
### 安装 Sosreport
|
||||
|
||||
Sosreport 在 Red Hat 官方系统仓库中,因此你可以使用 Yum 或 DNF 包管理器安装它,如下所示。
|
||||
|
||||
```
|
||||
$ sudo yum install sos
|
||||
```
|
||||
|
||||
要么,
|
||||
|
||||
```
|
||||
$ sudo dnf install sos
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu 和 Linux Mint 上运行:
|
||||
|
||||
```
|
||||
$ sudo apt install sosreport
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
安装后,运行以下命令以收集系统配置详细信息和其他诊断信息。
|
||||
|
||||
```
|
||||
$ sudo sosreport
|
||||
```
|
||||
|
||||
系统将要求你输入系统的一些详细信息,例如系统名称、案例 ID 等。相应地输入详细信息,然后按回车键生成报告。如果你不想更改任何内容并使用默认值,只需按回车键即可。
|
||||
|
||||
我的 CentOS 7 服务器的示例输出:
|
||||
|
||||
```
|
||||
sosreport (version 3.5)
|
||||
|
||||
This command will collect diagnostic and configuration information from
|
||||
this CentOS Linux system and installed applications.
|
||||
|
||||
An archive containing the collected information will be generated in
|
||||
/var/tmp/sos.DiJXi7 and may be provided to a CentOS support
|
||||
representative.
|
||||
|
||||
Any information provided to CentOS will be treated in accordance with
|
||||
the published support policies at:
|
||||
|
||||
https://wiki.centos.org/
|
||||
|
||||
The generated archive may contain data considered sensitive and its
|
||||
content should be reviewed by the originating organization before being
|
||||
passed to any third party.
|
||||
|
||||
No changes will be made to system configuration.
|
||||
|
||||
Press ENTER to continue, or CTRL-C to quit.
|
||||
|
||||
Please enter your first initial and last name [server.ostechnix.local]:
|
||||
Please enter the case id that you are generating this report for []:
|
||||
|
||||
Setting up archive ...
|
||||
Setting up plugins ...
|
||||
Running plugins. Please wait ...
|
||||
|
||||
Running 73/73: yum...
|
||||
Creating compressed archive...
|
||||
|
||||
Your sosreport has been generated and saved in:
|
||||
/var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
|
||||
The checksum is: 8f08f99a1702184ec13a497eff5ce334
|
||||
|
||||
Please send this file to your support representative.
|
||||
|
||||
```
|
||||
|
||||
如果你不希望系统提示你输入此类详细信息,请如下使用批处理模式。
|
||||
|
||||
```
|
||||
$ sudo sosreport --batch
|
||||
```
|
||||
|
||||
正如你在上面的输出中所看到的,生成了一个归档报告并保存在 `/var/tmp/sos.DiJXi7` 中。在 RHEL 6/CentOS 6 中,报告将在 `/tmp` 中生成。你现在可以将此报告发送给你的支持人员,以便他可以进行初步分析并找出问题所在。
|
||||
|
||||
你可能会担心或想知道报告中的内容。如果是这样,你可以通过运行以下命令来查看它:
|
||||
|
||||
```
|
||||
$ sudo tar -tf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
```
|
||||
|
||||
要么,
|
||||
|
||||
```
|
||||
$ sudo vim /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
```
|
||||
|
||||
请注意,上述命令不会解压存档,而只显示存档中的文件和文件夹列表。如果要查看存档中文件的实际内容,请首先使用以下命令解压存档:
|
||||
|
||||
```
|
||||
$ sudo tar -xf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
```
|
||||
|
||||
存档的所有内容都将解压当前工作目录中 `ssosreport-server.ostechnix.local-20180628171844/` 目录中。进入目录并使用 `cat` 命令或任何其他文本浏览器查看文件内容:
|
||||
|
||||
```
|
||||
$ cd sosreport-server.ostechnix.local-20180628171844/
|
||||
|
||||
$ cat uptime
|
||||
17:19:02 up 1:03, 2 users, load average: 0.50, 0.17, 0.10
|
||||
```
|
||||
|
||||
有关 Sosreport 的更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
$ man sosreport
|
||||
```
|
||||
|
||||
就是这些了。希望这些有用。还有更多好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sosreport-a-tool-to-collect-system-logs-and-diagnostic-information/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,59 +0,0 @@
|
||||
Try, learn, modify: The new IT leader's code
|
||||
======
|
||||
|
||||

|
||||
|
||||
Just about every day, new technological developments threaten to destabilize even the most intricate and best-laid business plans. Organizations often find themselves scrambling to adapt to new conditions, and that's created a shift in how they plan for the future.
|
||||
|
||||
According to a 2017 [study][1] by CompTIA, only 34% of companies are currently developing IT architecture plans that extend beyond 12 months. One reason for that shift away from a longer-term plan is that business contexts are changing so quickly that planning any further into the future is nearly impossible. "If your company is trying to set a plan that will last five to 10 years down the road," [CIO.com writes][1], "forget it."
|
||||
|
||||
I've heard similar statements from countless customers and partners around the world. Technological innovations are occurring at an unprecedented pace.
|
||||
|
||||
The result is that long-term planning is dead. We need to be thinking differently about the way we run our organizations if we're going to succeed in this new world.
|
||||
|
||||
### How planning died
|
||||
|
||||
As I wrote in The Open Organization, traditionally-run organizations are optimized for industrial economies. They embrace hierarchical structures and rigidly prescribed processes as they work to achieve positional competitive advantage. To be successful, they have to define the strategic positions they want to achieve. Then they have to formulate and dictate plans for getting there, and execute on those plans in the most efficient ways possible—by coordinating activities and driving compliance.
|
||||
|
||||
Management's role is to optimize this process: plan, prescribe, execute. It consists of saying: Let's think of a competitively advantaged position; let's configure our organization to ultimately get there; and then let's drive execution by making sure all aspects of the organization comply. It's what I'll call "mechanical management," and it's a brilliant solution for a different time.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating. Classic, long-term, strategic planning and execution isn't as effective as it used to be.
|
||||
|
||||
If long-term planning has become so difficult, then prescribing necessary behaviors is even more challenging. And measuring compliance against a plan is next to impossible.
|
||||
|
||||
All this dramatically affects the way people work. Unlike workers in the traditionally-run organizations of the past—who prided themselves on being able to act repetitively, with little variation and comfortable certainty—today's workers operate in contexts of abundant ambiguity. Their work requires greater creativity, intuition, and critical judgment—there is a greater demand to deviate from yesterday's "normal" and adjust to today's new conditions.
|
||||
|
||||
In today's volatile and uncertain world, our ability to predict and define strategic positions is diminishing—because the pace of change, the rate of introduction of new variables, is accelerating.
|
||||
|
||||
Working in this new way has become more critical to value creation. Our management systems must focus on building structures, systems, and processes that help create engaged, motivated workers—people who are enabled to innovate and act with speed and agility.
|
||||
|
||||
We need to come up with a different solution for optimizing organizations for a very different economic era, one that works from the bottom up rather than the top down. We need to replace that old three-step formula for success—plan, prescribe, execute—with one much better suited to today's tumultuous climate: try, learn, modify.
|
||||
|
||||
### Try, learn, modify
|
||||
|
||||
Because conditions can change so rapidly and with so little warning—and because the steps we need to take next are no longer planned in advance—we need to cultivate environments that encourage creative trial and error, not unyielding allegiance to a five-year schedule. Here are just a few implications of beginning to work this way:
|
||||
|
||||
* **Shorter planning cycles (try).** Rather than agonize over long-term strategic directions, managers need to be thinking of short-term experiments they can try quickly. They should be seeking ways to help their teams take calculated risks and leverage the data at their disposal to make best guesses about the most beneficial paths forward. They can do this by lowering overhead and giving teams the freedom to try new approaches quickly.
|
||||
* **Higher tolerance for failure (learn).** Greater frequency of experimentation means greater opportunity for failure. Creative and resilient organizations have a[significantly higher tolerance for failure][2] than traditional organizations do. Managers should treat failures as learning opportunities—moments to gather feedback on the tests their teams are running.
|
||||
* **More adaptable structures (modify).** An ability to easily modify organizational structures and strategic directions—and the willingness to do it when conditions necessitate—is the key to ensuring that organizations can evolve in line with rapidly changing environmental conditions. Managers can't be wedded to any idea any longer than that idea proves itself to be useful for accomplishing a short-term goal.
|
||||
|
||||
|
||||
|
||||
If long-term planning is dead, then long live shorter-term experimentation. Try, learn, and modify—that's the best path forward during uncertain times.
|
||||
|
||||
[Subscribe to our weekly newsletter][3] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/try-learn-modify
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.cio.com/article/3246027/enterprise-architecture/the-death-of-long-term-it-planning.html?upd=1515780110970
|
||||
[2]:https://opensource.com/open-organization/16/12/building-culture-innovation-your-organization
|
||||
[3]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -1,95 +0,0 @@
|
||||
翻译中 by ZenMoore
|
||||
How to build a professional network when you work in a bazaar
|
||||
======
|
||||
|
||||

|
||||
|
||||
Professional social networking—creating interpersonal connections between work colleagues or professionals—can take many forms and span organizations across industries. Establishing professional networks takes time and effort, and when someone either joins or departs an organization, that person's networks often need to be rebuilt in a new work environment.
|
||||
|
||||
Professional social networks perform similar functions in different organizations—information sharing, mentorship, opportunities, work interests, and more—but the methods and reasons for making particular connections in an organization can vary between conventional and open organizations. And these differences make a difference: to the way colleagues relate, to how they build trust, to the amount and kinds of diversity within the organization, and to the forces that create collaboration. All these elements are interrelated, and they contribute to and shape the social networks people form.
|
||||
|
||||
An open organization's emphasis on inclusivity can produce networks more effective at solving business problems than those that emerge in conventional, hierarchical organizations. This notion has a long history in open source thinking. For example, in [The Cathedral and the Bazaar][1], Eric Raymond writes that "Sociologists years ago discovered that the averaged opinion of a mass of equally expert (or equally ignorant) observers is quite a bit more reliable a predictor than the opinion of a single randomly-chosen one of the observers." So let's examine how the structure and purpose of social networks impact what each type of organization values.
|
||||
|
||||
### Social networks in conventional organizations
|
||||
|
||||
When I worked in conventional organizations and would describe what I do for work, the first thing people asked me was how I was related to someone else, usually a director-level leader. "Is that under Hira?" they'd say. "Do you work for Malcolm?" That makes sense considering conventional organizations function in a "top-down" way; when trying to situate work or an employee, people wanted to understand the structure of the network from that top-down perspective.
|
||||
|
||||
In other words, in conventional organizations the social network depends upon the hierarchical structure, so they track one another. In fact, even figuring out where an employee exists within a network is a very "top-down organization" kind of concern.
|
||||
|
||||
But that isn't all that the underlying hierarchy does. It also vets associates. A focus on the top-down network can determine an employee's "value" in the network because the network itself is a system of ongoing power relations that grants people placed in its different locations varying levels of value. It downplays the value of individual talents and skills. Therefore, a person's connections in the conventional organization facilitate that person's ability to be proactive, heard, influential, and supported in their careers.
|
||||
|
||||
An open organization's emphasis on inclusivity can produce networks more effective at solving business problems than those that emerge in conventional, hierarchical organizations.
|
||||
|
||||
The conventional organization's formal structure defines employees' social networks in particular ways—some of which might be benefits, some of which might be disadvantages, depending on one's context—such as:
|
||||
|
||||
* It's easier to know "who's who" and see how people are related more quickly (often this builds trusted networks within the particular hierarchy).
|
||||
* Often, this increased understanding of relationships means there's less redundancy of work (projects have a clear owner embedded in a particular network) and communication (people know who is responsible for communicating what).
|
||||
* Associates can feel "stuck" in a power structure, or like they can't "break into" power structures that sometimes (too often?) don't work, diminishing meritocracy.
|
||||
* Crossing silos of work and effort is difficult and collaboration suffers.
|
||||
* Power transfers slowly; a person's ability to engage is determined more in alignment with network created by the hierarchical structure than by other factors (like individual abilities), reducing what is considered "community" and the benefits of its membership.
|
||||
* Competition seems more clear; understanding "who is vying for what" usually occurs within a recognized and delimited hierarchical structure (and the scarcity of positions in the power network increase competition so competition can be more fierce).
|
||||
* Adaptability can suffer when a more rigid network defines the limits of flexibility; what the network "wants" and the limits of collaboration can be affected this same way.
|
||||
* Execution occurs much more easily in rigid networks, where direction is clear and often leaders manage by overdirecting.
|
||||
* Risk is decreased when the social networks are less flexible; people know what needs to happen, how, and when (but this isn't always "bad" considering the wide range of work in an organization; some job functions require less risk, such as HR, mergers and acquisitions, legal, etc.).
|
||||
* Trust within the network is greater, especially when an employee is part of the formal network (when someone is not part of the network, exclusion can be particularly difficult to manage or to rectify).
|
||||
|
||||
|
||||
|
||||
### Social networks in open organizations
|
||||
|
||||
While open organizations can certainly have hierarchical structures, they don't operate only according to that network. Their professional networking structure is more flexible (or "all over and whenever").
|
||||
|
||||
An open organization is more associate-centric than leader-centric.
|
||||
|
||||
In an open organization, when I've described what I do for work virtually no one asks "for whom?" An open organization is more associate-centric than leader-centric. Open values like inclusivity and specific governance systems like meritocracy contribute to this; it's not who you know but rather it's what you know and how you use it (e.g., "bottom-up"). In an open organization, I don't feel like I'm fighting to show my value; my ideas are inherently valuable. I sometimes have to demonstrate how using my idea is more valuable than using someone else's idea―but that means I'm vetting myself within the community of my associates (including leadership), rather than being vetted solely by top-down leadership.
|
||||
|
||||
In this way, an open organization doesn't assess employees based on the network but rather on what they know of the associate as an individual. Does this person have good ideas? Does she work toward those ideas (lead them) by using the open organization values (that is, share those ideas and work across the organization to include others and work transparently, etc.)?
|
||||
|
||||
Open organizations also structure social networks in particular ways (which, again, could be advantageous or disadvantageous depending on one's goals and desires), including:
|
||||
|
||||
* People are more responsible for their networks, reputations, skills, and careers.
|
||||
* Competition (for resources, power, promotions, etc.) decreases because these organizations are by nature more collaborative (even during a "collision," the best outcome is negotiation, not winning, and competition hones the ideas instead of creating wedges between people).
|
||||
* Power is more fluid and dynamic, flowing from person to person (but this also means there can be a misunderstanding about accountability or responsibility and activities can go undone or unfinished because there is not a clear [sense of ownership][2]).
|
||||
* Trust is created "one associate at a time," rather than through the reputation of the network in which the person is situated.
|
||||
* Networks self-configure around a variety of work and activities, rising reactively around opportunity (this aids innovation but can add to confusion because who makes decisions, and who is in "control" is less clear).
|
||||
* Rate of execution can decrease in confusing contexts because what to do and how and when to do it requires leadership skills in setting direction and creating engaged and skilled associates.
|
||||
* Flexible social networks also increase innovation and risk; ideas circulate faster and are more novel, and execution is less assured.
|
||||
* Trust is based on associate relationships (as it should be!), rather than on sheer deference to structure.
|
||||
|
||||
|
||||
|
||||
### Making it work
|
||||
|
||||
If you're thinking of transitioning from one type of organizational structure to another, consider the following when building and maintaining your professional social networks.
|
||||
|
||||
#### Tips from conventional organizations
|
||||
|
||||
* Structure and control around decision-making isn't a bad thing; operational frameworks need to be clear and transparent, and decision-makers need to account for their decisions.
|
||||
* Excelling at execution requires managers to provide focus and the ability to provide sufficient context while filtering out anything that could distract or confuse.
|
||||
* Established networks help large groups of people work in concert and manage risk.
|
||||
|
||||
|
||||
|
||||
#### Tips from open organizations
|
||||
|
||||
* Strong leaders are those who can provide different levels of clarity and guidance according to the various styles and preferences of associates and teams without creating inflexible networks.
|
||||
* Great ideas win more, not established networks.
|
||||
* People are more responsible for their reputations.
|
||||
* The circulation of ideas and information is key to innovation. Loosening the networks in your organization can help these two elements occur with increased frequency and breadth.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/6/building-professional-social-networks-openly
|
||||
|
||||
作者:[Heidi Hess;von Ludewig][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/ar01s04.html
|
||||
[2]:https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
|
||||
@ -0,0 +1,52 @@
|
||||
CIP: Keeping the Lights On with Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern civil infrastructure is all around us -- in power plants, radar systems, traffic lights, dams, weather systems, and so on. Many of these infrastructure projects exist for decades, if not longer, so security and longevity are paramount.
|
||||
|
||||
And, many of these systems are powered by Linux, which offers technology providers more control over these issues. However, if every provider is building their own solution, this can lead to fragmentation and duplication of effort. Thus, the primary goal of [Civil Infrastructure Platform (CIP)][1] is to create an open source base layer for industrial use-cases in these systems, such as embedded controllers and gateway devices.
|
||||
|
||||
“We have a very conservative culture in this area because once we create a system, it has to be supported for more than ten years; in some cases for over 60 years. That’s why this project was created, because every player in this industry had the same issue of being able to use Linux for a long time,” says Yoshitake Kobayashi is Technical Steering Committee Chair of CIP.
|
||||
|
||||
CIP’s concept is to create a very fundamental system to use open source software on controllers. This base layer comprises the Linux kernel and a small set of common open source software like libc, busybox, and so on. Because longevity of software is a primary concern, CIP chose Linux kernel 4.4, which is the LTS release of the kernel maintained by Greg Kroah-Hartman.
|
||||
|
||||
### Collaboration
|
||||
|
||||
Since CIP has an upstream first policy, the code that they want in the project must be in the upstream kernel. To create a proactive feedback loop with the kernel community, CIP hired Ben Hutchings as the official maintainer of CIP. Hutchings is known for the work he has done on Debian LTS release, which also led to an official collaboration between CIP and the Debian project.
|
||||
|
||||
Under the newly forged collaboration, CIP will use Debian LTS to build the platform. CIP will also help Debian Long Term Support (LTS) to extend the lifetime of all Debian stable releases. CIP will work closely with Freexian, a company that offers commercial services around Debian LTS. The two organizations will focus on interoperability, security, and support for open source software for embedded systems. CIP will also provide funding for some of the Debian LTS activities.
|
||||
|
||||
“We are excited about this collaboration as well as the CIP’s support of the Debian LTS project, which aims to extend the support lifetime to more than five years. Together, we are committed to long-term support for our users and laying the ‘foundation’ for the cities of the future.” said Chris Lamb, Debian Project Leader.
|
||||
|
||||
### Security
|
||||
|
||||
Security is the biggest concern, said Kobayashi. Although most of the civil infrastructure is not connected to the Internet for obvious security reasons (you definitely don’t want a nuclear power plant to be connected to the Internet), there are many other risks.
|
||||
|
||||
Just because the system itself is not connected to the Internet, that doesn’t mean it’s immune to all threats. Other systems -- like user’s laptops -- may connect to the Internet and then be plugged into the local systems. If someone receives a malicious file as an attachment with email, it can “contaminate” the internal infrastructure.
|
||||
|
||||
Thus, it’s critical to keep all software running on such controllers up to date and fully patched. To ensure security, CIP has also backported many components of the Kernel Self Protection project. CIP also follows one of the strictest cybersecurity standards -- IEC 62443 -- which defines processes and tests to ensure the system is more secure.
|
||||
|
||||
### Going forward
|
||||
|
||||
As CIP is maturing, it's extending its collaboration with providers of Linux. In addition to collaboration with Debian and freexian, CIP recently added Cybertrust Japan Co, Ltd., a supplier of enterprise Linux operating system, as a new Silver member.
|
||||
|
||||
Cybertrust joins other industry leaders, such as Siemens, Toshiba, Codethink, Hitachi, Moxa, Plat’Home, and Renesas, in their work to create a reliable and secure Linux-based embedded software platform that is sustainable for decades to come.
|
||||
|
||||
The ongoing work of these companies under the umbrella of CIP will ensure the integrity of the civil infrastructure that runs our modern society.
|
||||
|
||||
Learn more at the [Civil Infrastructure Platform][1] website.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/cip-keeping-lights-linux
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cip-project.org/
|
||||
@ -0,0 +1,70 @@
|
||||
Comparing Twine and Ren'Py for creating interactive fiction
|
||||
======
|
||||
|
||||

|
||||
|
||||
Any experienced technology educator knows engagement and motivation are key to a student's learning. Of the many techniques for stimulating engagement and motivation among learners, storytelling and game creation have good track records of success, and writing interactive fiction is a great way to combine both of those techniques.
|
||||
|
||||
Interactive fiction has a respectable history in computing, stretching back to the text-only adventure games of the early 1980s, and it's enjoyed a new popularity recently. There are many technology tools that can be used for writing interactive fiction, but the two that will be considered here, [Twine][1] and [Ren'Py][2], are ideal for the task. Each has different strengths that make it more attractive for particular types of projects.
|
||||
|
||||
### Twine
|
||||
|
||||
![Twine 2.0][4]
|
||||
|
||||
![][5]
|
||||
|
||||
Twine is a popular cross-platform open source interactive fiction system that developed out of the HTML- and JavaScript-based [TiddlyWiki][6]. If you're not familiar with Twine, multimedia artist and Opensource.com contributor Seth Kenlon's article on how he [uses Twine to create interactive adventure games][7] is a great introduction to the tool.
|
||||
|
||||
One of Twine's advantages is that it produces a single, compiled HTML file, which makes it easy to distribute and play an interactive fiction work on any system with a reasonably modern web browser. But this comes at a cost: While it will support graphics, sound files, and embedded video, Twine is somewhat limited by its roots as a primarily text-based system (even though it has developed a lot over the years).
|
||||
|
||||
This is very appealing to new learners who can rapidly produce something that looks good and is fun to play. However, when they want to add visual effects, graphics, and multimedia, learners can get lost among the different, creative ways to do this and the maze of different Twine program versions and story formats. Even so, there's an impressive amount of resources available on how to use Twine.
|
||||
|
||||
Educators often hope learners will take the skills they have gained using one tool and build on them, but this isn't a strength for Twine. While Twine is great for developing literacy and creative writing skills, the coding and programming side is weaker. The story format scripting language has what you would expect: logic commands, conditional statements, arrays/lists, and loops, but it is not closely related to any popular programming language.
|
||||
|
||||
### Ren'Py
|
||||
|
||||
![Ren'Py 7.0][9]
|
||||
|
||||
![][5]
|
||||
|
||||
Ren'Py approaches interactive fiction from a different angle; [Wikipedia][10] describes it as a "visual novel engine." This means that the integration of graphics and other multimedia elements is a lot smoother and more integrated than in Twine. In addition, as Opensource.com contributor Joshua Allen Holm explained, [you don't need much coding experience][11] to use Ren'Py.
|
||||
|
||||
Ren'Py can export finished work for Android, Linux, Mac, and Windows, which is messier than the "one file for all systems" that comes from Twine, particularly if you get into the complexity of making builds for mobile devices. Bear in mind, too, that finished Ren'Py projects with their multimedia elements are a lot bigger than Twine projects.
|
||||
|
||||
The ease of downloading graphics and multimedia files from the internet for Ren'Py projects also provides a great opportunity to teach learners about the complexities of copyright and advocate (as everyone should!) for [Creative Commons][12] licenses.
|
||||
|
||||
As its name suggests, Ren'Py's scripting languages are a mix of true Python and Python-like additions. This will be very attractive to educators who want learners to progress to Python programming. Python's syntatical rules and strict enforcement of indentation are more intimidating to use than the scripting options in Twine, but the long-term gains are worth it.
|
||||
|
||||
### Comparing Twine and Ren'Py
|
||||
|
||||
There are various reasons why Twine has become so successful, but one that will appeal to open source enthusiasts is that anyone can take a compiled Twine story or game and import it back into Twine. This means if you come across a compiled Twine story or game with a neat feature, you can look at the source code and find out how it was done. Ren'Py allows a level of obfuscation that prevents low-level attempts at hacking.
|
||||
|
||||
When it comes to my work helping people with visual impairments use technology, Ren'Py is superior to Twine. Despite claims to the contrary, Twine's HTML files can be used by screen reader users—but only with difficulty. In contrast, Ren'Py has built-in self-voicing capabilities, something that I am very pleased to see, although Linux users may need to add the [eSpeak package][13] to support it.
|
||||
|
||||
Ren'Py and Twine can be used for similar purposes. Text-based projects tend to be simpler and quicker to create than ones that require creating or sourcing graphics and multimedia elements. If your projects will be more text-based, Twine might be the best choice. And, if your projects make extensive use of graphics and multimedia elements, Ren'Py might suit you better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
|
||||
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/petercheer
|
||||
[1]:http://twinery.org/
|
||||
[2]:https://www.renpy.org/
|
||||
[3]:/file/402696
|
||||
[4]:https://opensource.com/sites/default/files/uploads/twine2.png (Twine 2.0)
|
||||
[5]:data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== (Click and drag to move)
|
||||
[6]:https://tiddlywiki.com/
|
||||
[7]:https://opensource.com/article/18/2/twine-gaming
|
||||
[8]:/file/402701
|
||||
[9]:https://opensource.com/sites/default/files/uploads/renpy.png (Ren'Py 7.0)
|
||||
[10]:https://en.wikipedia.org/wiki/Ren%27Py
|
||||
[11]:https://opensource.com/life/13/8/gaming-renpy
|
||||
[12]:https://creativecommons.org/
|
||||
[13]:http://espeak.sourceforge.net/
|
||||
@ -0,0 +1,45 @@
|
||||
New Training Options Address Demand for Blockchain Skills
|
||||
======
|
||||
|
||||

|
||||
|
||||
Blockchain technology is transforming industries and bringing new levels of trust to contracts, payment processing, asset protection, and supply chain management. Blockchain-related jobs are the second-fastest growing in today’s labor market, [according to TechCrunch][1]. But, as in the rapidly expanding field of artificial intelligence, there is a pronounced blockchain skills gap and a need for expert training resources.
|
||||
|
||||
### Blockchain for Business
|
||||
|
||||
A new training option was recently announced from The Linux Foundation. Enrollment is now open for a free training course called[Blockchain: Understanding Its Uses and Implications][2], as well as a [Blockchain for Business][2] professional certificate program. Delivered through the edX training platform, the new course and program provide a way to learn about the impact of blockchain technologies and a means to demonstrate that knowledge. Certification, in particular, can make a difference for anyone looking to work in the blockchain arena.
|
||||
|
||||
“In the span of only a year or two, blockchain has gone from something seen only as related to cryptocurrencies to a necessity for businesses across a wide variety of industries,” [said][3] Linux Foundation General Manager, Training & Certification Clyde Seepersad. “Providing a free introductory course designed not only for technical staff but business professionals will help improve understanding of this important technology, while offering a certificate program through edX will enable professionals from all over the world to clearly demonstrate their expertise.”
|
||||
|
||||
TechCrunch [also reports][4] that venture capital is rapidly flowing toward blockchain-focused startups. And, this new program is designed for business professionals who need to understand the potential – or threat – of blockchain to their company and industry.
|
||||
|
||||
“Professional Certificate programs on edX deliver career-relevant education in a flexible, affordable way, by focusing on the critical skills industry leaders and successful professionals are seeking today,” said Anant Agarwal, edX CEO and MIT Professor.
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
The Linux Foundation is steward to many valuable blockchain resources and includes some notable community members. In fact, a recent New York Times article — “[The People Leading the Blockchain Revolution][5]” — named Brian Behlendorf, Executive Director of The Linux Foundation’s [Hyperledger Project][6], one of the [top influential voices][7] in the blockchain world.
|
||||
|
||||
Hyperledger offers proven paths for gaining credibility and skills in the blockchain space. For example, the project offers a free course titled Introduction to Hyperledger Fabric for Developers. Fabric has emerged as a key open source toolset in the blockchain world. Through the Hyperledger project, you can also take the B9-lab Certified Hyperledger Fabric Developer course. More information on both courses is available [here][8].
|
||||
|
||||
“As you can imagine, someone needs to do the actual coding when companies move to experiment and replace their legacy systems with blockchain implementations,” states the Hyperledger website. “With training, you could gain serious first-mover advantage.”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/7/new-training-options-address-demand-blockchain-skills
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://techcrunch.com/2018/02/14/blockchain-engineers-are-in-demand/
|
||||
[2]:https://www.edx.org/course/understanding-blockchain-and-its-implications
|
||||
[3]:https://www.linuxfoundation.org/press-release/as-demand-skyrockets-for-blockchain-expertise-the-linux-foundation-and-edx-offer-new-introductory-blockchain-course-and-blockchain-for-business-professional-certificate-program/
|
||||
[4]:https://techcrunch.com/2018/05/20/with-at-least-1-3-billion-invested-globally-in-2018-vc-funding-for-blockchain-blows-past-2017-totals/
|
||||
[5]:https://www.nytimes.com/2018/06/27/business/dealbook/blockchain-stars.html
|
||||
[6]:https://www.hyperledger.org/
|
||||
[7]:https://www.linuxfoundation.org/blog/hyperledgers-brian-behlendorf-named-as-top-blockchain-influencer-by-new-york-times/
|
||||
[8]:https://www.hyperledger.org/resources/training
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Keeping (financial) score with Ledger –
|
||||
======
|
||||
I’ve used [Ledger CLI][1] to keep track of my finances since 2005, when I moved to Canada. I like the plain-text approach, and its support for virtual envelopes means that I can reconcile both my bank account balances and my virtual allocations to different categories. Here’s how we use those virtual envelopes to manage our finances separately.
|
||||
|
||||
@ -1,140 +0,0 @@
|
||||
translating by wenwensnow
|
||||
An Advanced System Configuration Utility For Ubuntu Power Users
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Ubunsys** is a Qt-based advanced system utility for Ubuntu and its derivatives. Most of the configuration can be easily done from the command-line by the advanced users. Just in case, you don’t want to use CLI all the time, you can use Ubunsys utility to configure your Ubuntu desktop system or its derivatives such as Linux Mint, Elementary OS etc. Ubunsys can be used to modify system configuration, install, remove, update packages and old kernels, enable/disable sudo access, install mainline kernel, update software repositories, clean up junk files, upgrade your Ubuntu to latest version, and so on. All of the aforementioned actions can be done with simple mouse clicks. You don’t need to depend on CLI mode anymore. Here is the list of things you can do with Ubunsys:
|
||||
|
||||
* Install, update, and remove packages.
|
||||
* Update and upgrade software repositories.
|
||||
* Install mainline Kernel.
|
||||
* Remove old and unused Kernels.
|
||||
* Full system update.
|
||||
* Complete System upgrade to next available version.
|
||||
* Upgrade to latest development version.
|
||||
* Clean up junk files from your system.
|
||||
* Enable and/or disable sudo access without password.
|
||||
* Make Sudo Passwords visible when you type them in the Terminal.
|
||||
* Enable and/or disable hibernation.
|
||||
* Enable and/or disable firewall.
|
||||
* Open, backup and import sources.list.d and sudoers files.
|
||||
* Show/unshow hidden startup items.
|
||||
* Enable and/or disable Login sounds.
|
||||
* Configure dual boot.
|
||||
* Enable/disable Lock screen.
|
||||
* Smart system update.
|
||||
* Update and/or run all scripts at once using Scripts Manager.
|
||||
* Exec normal user installation script from git.
|
||||
* Check system integrity and missing GPG keys.
|
||||
* Repair network.
|
||||
* Fix broken packages.
|
||||
* And more yet to come.
|
||||
|
||||
|
||||
|
||||
**Important note:** Ubunsys is not for Ubuntu beginners. It is dangerous and not a stable version yet. It might break your system. If you’re a new to Ubuntu, don’t use it. If you are very curious to use this application, go through each option carefully and proceed at your own risk. Do not forget to backup your important data before using this application.
|
||||
|
||||
### Ubunsys – An Advanced System Configuration Utility For Ubuntu Power Users
|
||||
|
||||
#### Install Ubunsys
|
||||
|
||||
Ubunusys developer has made a PPA to make the installation process much easier. Ubunsys will currently work on Ubuntu 16.04 LTS, Ubuntu 17.04 64bit editions.
|
||||
|
||||
Run the following commands one by one to add Ubunsys PPA and install it.
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install ubunsys
|
||||
|
||||
```
|
||||
|
||||
If the PPA doesn’t work, head over to the [**releases page**][1], download and install the Ubunsys package depending upon the architecture you use.
|
||||
|
||||
#### Usage
|
||||
|
||||
Once installed, launch Ubunsys from Menu. This is how Ubunsys main interface looks like.
|
||||
|
||||
![][3]
|
||||
|
||||
As you can see, Ubunusys has four main sections namely **Packages** , **Tweaks** , **System** , and **Repair**. There are one or more sub-sections available for each main tab to do different operations.
|
||||
|
||||
**Packages**
|
||||
|
||||
This section allows you to install, remove, update packages.
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
In this section, we can do various various system tweaks such as,
|
||||
|
||||
* Open, backup, import sources.list and sudoers file;
|
||||
* Configure dual boot;
|
||||
* Enable/disable login sound, firewall, lock screen, hibernation, sudo access without password. You can also enable or disable for sudo access without password to specific users.
|
||||
* Can make the passwords visible while typing them in Terminal (Disable Asterisks).
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
This section further categorized into three sub-categories, each for distinct user type.
|
||||
|
||||
The **Normal user** tab allows us to,
|
||||
|
||||
* Update, upgrade packages and software repos.
|
||||
* Clean system.
|
||||
* Exec normal user installation script.
|
||||
|
||||
|
||||
|
||||
The **Advanced user** section allows us to,
|
||||
|
||||
* Clean Old/Unused Kernels.
|
||||
* Install mainline Kernel.
|
||||
* do smart packages update.
|
||||
* Upgrade system.
|
||||
|
||||
|
||||
|
||||
The **Developer** section allows us to upgrade the Ubuntu system to latest development version.
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
This is the fourth and last section of Ubunsys. As the name says, this section allows us to do repair our system, network, missing GPG keys, and fix broken packages.
|
||||
|
||||
![][7]
|
||||
|
||||
As you can see, Ubunsys helps you to do any system configuration, maintenance and software management tasks with few mouse clicks. You don’t need to depend on Terminal anymore. Ubunsys can help you to accomplish any advanced tasks. Again, I warn you, It’s not for beginners and it is not stable yet. So, you can expect bugs and crashes when using it. Use it with care after studying options and impact.
|
||||
|
||||
Cheers!
|
||||
|
||||
**Resource:**
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
@ -1,86 +0,0 @@
|
||||
Transating by qhwdw
|
||||
# [Google launches TensorFlow-based vision recognition kit for RPi Zero W][26]
|
||||
|
||||
|
||||

|
||||
Google’s $45 “AIY Vision Kit” for the Raspberry Pi Zero W performs TensorFlow-based vision recognition using a “VisionBonnet” board with a Movidius chip.
|
||||
|
||||
Google’s AIY Vision Kit for on-device neural network acceleration follows an earlier [AIY Projects][7] voice/AI kit for the Raspberry Pi that shipped to MagPi subscribers back in May. Like the voice kit and the older Google Cardboard VR viewer, the new AIY Vision Kit has a cardboard enclosure. The kit differs from the [Cloud Vision API][8], which was demo’d in 2015 with a Raspberry Pi based GoPiGo robot, in that it runs entirely on local processing power rather than requiring a cloud connection. The AIY Vision Kit is available now for pre-order at $45, with shipments due in early December.
|
||||
|
||||
|
||||
[][9] [][10]
|
||||
**AIY Vision Kit, fully assembled (left) and Raspberry Pi Zero W**
|
||||
(click images to enlarge)
|
||||
|
||||
|
||||
The kit’s key processing element, aside from the 1GHz ARM11-based Broadcom BCM2836 SoC found on the required [Raspberry Pi Zero W][21] SBC, is Google’s new VisionBonnet RPi accessory board. The VisionBonnet pHAT board uses a Movidius MA2450, a version of the [Movidius Myriad 2 VPU][22] processor. On the VisionBonnet, the processor runs Google’s open source [TensorFlow][23]machine intelligence library for neural networking. The chip enables visual perception processing at up to 30 frames per second.
|
||||
|
||||
The AIY Vision Kit requires a user-supplied RPi Zero W, a [Raspberry Pi Camera v2][11], and a 16GB micro SD card for downloading the Linux-based image. The kit includes the VisionBonnet, an RGB arcade-style button, a piezo speaker, a macro/wide lens kit, and the cardboard enclosure. You also get flex cables, standoffs, a tripod mounting nut, and connecting components.
|
||||
|
||||
|
||||
[][12] [][13]
|
||||
**AIY Vision Kit kit components (left) and VisonBonnet accessory board**
|
||||
(click images to enlarge)
|
||||
|
||||
|
||||
Three neural network models are available. There’s a general-purpose model that can recognize 1,000 common objects, a facial detection model that can also score facial expression on a “joy scale” that ranges from “sad” to “laughing,” and a model that can identify whether the image contains a dog, cat, or human. The 1,000-image model derives from Google’s open source [MobileNets][24], a family of TensorFlow based computer vision models designed for the restricted resources of a mobile or embedded device.
|
||||
|
||||
MobileNet models offer low latency and low power consumption, and are parameterized to meet the resource constraints of different use cases. The models can be built for classification, detection, embeddings, and segmentation, says Google. Earlier this month, Google released a developer preview of a mobile-friendly [TensorFlow Lite][14] library for Android and iOS that is compatible with MobileNets and the Android Neural Networks API.
|
||||
|
||||
|
||||
[][15]
|
||||
**AIY Vision Kit assembly views**
|
||||
(click image to enlarge)
|
||||
|
||||
|
||||
In addition to providing the three models, the AIY Vision Kit provides basic TensorFlow code and a compiler, so users can develop their own models. In addition, Python developers can write new software to customize RGB button colors, piezo element sounds, and 4x GPIO pins on the VisionBonnet that can add additional lights, buttons, or servos. Potential models include recognizing food items, opening a dog door based on visual input, sending a text when your car leaves the driveway, or playing particular music based on facial recognition of a person entering the camera’s viewpoint.
|
||||
|
||||
|
||||
[][16] [][17]
|
||||
**Myriad 2 VPU block diagram (left) and reference board**
|
||||
(click image to enlarge)
|
||||
|
||||
|
||||
The Movidius Myriad 2 processor provides TeraFLOPS of performance within a nominal 1 Watt power envelope. The chip appeared on early Project Tango reference platforms, and is built into the Ubuntu-driven [Fathom][25] neural processing USB stick that Movidius debuted in May 2016, prior to being acquired by Intel. According to Movidius, the Myriad 2 is available “in millions of devices on the market today.”
|
||||
|
||||
**Further information**
|
||||
|
||||
The AIY Vision Kit is available for pre-order from Micro Center at $44.99, with shipments due in early December. More information may be found in the AIY Vision Kit [announcement][18], [Google Blog notice][19], and [Micro Center shopping page][20].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[1]:http://twitter.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&text=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W%20
|
||||
[2]:https://plus.google.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[3]:http://www.facebook.com/sharer.php?u=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[4]:http://www.linkedin.com/shareArticle?mini=true&url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[5]:http://reddit.com/submit?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&title=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W
|
||||
[6]:mailto:?subject=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W&body=%20http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[7]:http://linuxgizmos.com/free-raspberry-pi-voice-kit-taps-google-assistant-sdk/
|
||||
[8]:http://linuxgizmos.com/google-releases-cloud-vision-api-with-demo-for-pi-based-robot/
|
||||
[9]:http://linuxgizmos.com/files/google_aiyvisionkit.jpg
|
||||
[10]:http://linuxgizmos.com/files/rpi_zerow.jpg
|
||||
[11]:http://linuxgizmos.com/raspberry-pi-cameras-jump-to-8mp-keep-25-dollar-price/
|
||||
[12]:http://linuxgizmos.com/files/google_aiyvisionkit_pieces.jpg
|
||||
[13]:http://linuxgizmos.com/files/google_visionbonnet.jpg
|
||||
[14]:https://developers.googleblog.com/2017/11/announcing-tensorflow-lite.html
|
||||
[15]:http://linuxgizmos.com/files/google_aiyvisionkit_assembly.jpg
|
||||
[16]:http://linuxgizmos.com/files/movidius_myriad2vpu_block.jpg
|
||||
[17]:http://linuxgizmos.com/files/movidius_myriad2_reference_board.jpg
|
||||
[18]:https://blog.google/topics/machine-learning/introducing-aiy-vision-kit-make-devices-see/
|
||||
[19]:https://developers.googleblog.com/2017/11/introducing-aiy-vision-kit-add-computer.html
|
||||
[20]:http://www.microcenter.com/site/content/Google_AIY.aspx?ekw=aiy&rd=1
|
||||
[21]:http://linuxgizmos.com/raspberry-pi-zero-w-adds-wifi-and-bluetooth-for-only-5-more/
|
||||
[22]:https://www.movidius.com/solutions/vision-processing-unit
|
||||
[23]:https://www.tensorflow.org/
|
||||
[24]:https://research.googleblog.com/2017/06/mobilenets-open-source-models-for.html
|
||||
[25]:http://linuxgizmos.com/usb-stick-brings-neural-computing-functions-to-devices/
|
||||
[26]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
@ -1,84 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Migrating to Linux: Using Sudo
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article is the fifth in our series about migrating to Linux. If you missed earlier ones, you can catch up here:
|
||||
|
||||
[Part 1 - An Introduction][1]
|
||||
|
||||
[Part 2 - Disks, Files, and Filesystems][2]
|
||||
|
||||
[Part 3 - Graphical Environments][3]
|
||||
|
||||
[Part 4 - The Command Line][4]
|
||||
|
||||
You may have been wondering about Linux for a while. Perhaps it's used in your workplace and you'd be more efficient at your job if you used it on a daily basis. Or, perhaps you'd like to install Linux on some computer equipment you have at home. Whatever the reason, this series of articles is here to make the transition easier.
|
||||
|
||||
Linux, like many other operating systems supports multiple users. It even supports multiple users being logged in simultaneously.
|
||||
|
||||
User accounts are typically assigned a home directory where files can be stored. Usually this home directory is in:
|
||||
```
|
||||
/home/<login name>
|
||||
|
||||
```
|
||||
|
||||
This way, each user has their own separate location for their documents and other files.
|
||||
|
||||
### Admin Tasks
|
||||
|
||||
In a traditional Linux installation, regular user accounts don't have permissions to perform administrative tasks on the system. And instead of assigning rights to each user to perform various tasks, a typical Linux installation will require a user to log in as the admin to do certain tasks.
|
||||
|
||||
The administrator account on Linux is called root.
|
||||
|
||||
### Sudo Explained
|
||||
|
||||
Historically, to perform admin tasks, one would have to login as root, perform the task, and then log back out. This process was a bit tedious, so many folks logged in as root and worked all day long as the admin. This practice could lead to disastrous results, for example, accidentally deleting all the files in the system. The root user, of course, can do anything, so there are no protections to prevent someone from accidentally performing far-reaching actions.
|
||||
|
||||
The sudo facility was created to make it easier to login as your regular user account and occasionally perform admin tasks as root without having to login, do the task, and log back out. Specifically, sudo allows you to run a command as a different user. If you don't specify a specific user, it assumes you mean root.
|
||||
|
||||
Sudo can have complex settings to allow users certain permissions to use sudo for some commands but not for others. Typically, a desktop installation will make it so the first account created has full permissions in sudo, so you as the primary user can fully administer your Linux installation.
|
||||
|
||||
### Using Sudo
|
||||
|
||||
Some Linux installations set up sudo so that you still need to know the password for the root account to perform admin tasks. Others, set up sudo so that you type in your own password. There are different philosophies here.
|
||||
|
||||
When you try to perform an admin task in the graphical environment, it will usually open a dialog box asking for a password. Enter either your own password (e.g., on Ubuntu), or the root account's password (e.g., Red Hat).
|
||||
|
||||
When you try to perform an admin task in the command line, it will usually just give you a "permission denied" error. Then you would re-run the command with sudo in front. For example:
|
||||
```
|
||||
systemctl start vsftpd
|
||||
Failed to start vsftpd.service: Access denied
|
||||
|
||||
sudo systemctl start vsftpd
|
||||
[sudo] password for user1:
|
||||
|
||||
```
|
||||
|
||||
### When to Use Sudo
|
||||
|
||||
Running commands as root (under sudo or otherwise) is not always the best solution to get around permission errors. While will running as root will remove the "permission denied" errors, it's sometimes best to look for the root cause rather than just addressing the symptom. Sometimes files have the wrong owner and permissions.
|
||||
|
||||
Use sudo when you are trying to perform a task or run a program and the program requires root privileges to perform the operation. Don't use sudo if the file just happens to be owned by another user (including root). In this second case, it's better to set the permission on the file correctly.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for June 2018
|
||||
======
|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
Translating by qhwdw
|
||||
6 Open Source AI Tools to Know
|
||||
======
|
||||
|
||||

|
||||
|
||||
In open source, no matter how original your own idea seems, it is always wise to see if someone else has already executed the concept. For organizations and individuals interested in leveraging the growing power of artificial intelligence (AI), many of the best tools are not only free and open source, but, in many cases, have already been hardened and tested.
|
||||
|
||||
At leading companies and non-profit organizations, AI is a huge priority, and many of these companies and organizations are open sourcing valuable tools. Here is a sampling of free, open source AI tools available to anyone.
|
||||
|
||||
**Acumos.** [Acumos AI][1] is a platform and open source framework that makes it easy to build, share, and deploy AI apps. It standardizes the infrastructure stack and components required to run an out-of-the-box general AI environment. This frees data scientists and model trainers to focus on their core competencies rather than endlessly customizing, modeling, and training an AI implementation.
|
||||
|
||||
Acumos is part of the[LF Deep Learning Foundation][2], an organization within The Linux Foundation that supports open source innovation in artificial intelligence, machine learning, and deep learning. The goal is to make these critical new technologies available to developers and data scientists, including those who may have limited experience with deep learning and AI. The LF Deep Learning Foundation just [recently approved a project lifecycle and contribution process][3] and is now accepting proposals for the contribution of projects.
|
||||
|
||||
**Facebook’s Framework.** Facebook[has open sourced][4] its central machine learning system designed for artificial intelligence tasks at large scale, and a series of other AI technologies. The tools are part of a proven platform in use at the company. Facebook has also open sourced a framework for deep learning and AI [called Caffe2][5].
|
||||
|
||||
**Speaking of Caffe.** Yahoo also released its key AI software under an open source license. The[CaffeOnSpark tool][6] is based on deep learning, a branch of artificial intelligence particularly useful in helping machines recognize human speech or the contents of a photo or video. Similarly, IBM’s machine learning program known as [SystemML][7] is freely available to share and modify through the Apache Software Foundation.
|
||||
|
||||
**Google’s Tools.** Google spent years developing its [TensorFlow][8] software framework to support its AI software and other predictive and analytics programs. TensorFlow is the engine behind several Google tools you may already use, including Google Photos and the speech recognition found in the Google app.
|
||||
|
||||
Two [AIY kits][9] open sourced by Google let individuals easily get hands-on with artificial intelligence. Focused on computer vision and voice assistants, the two kits come as small self-assembly cardboard boxes with all the components needed for use. The kits are currently available at Target in the United States, and are based on the open source Raspberry Pi platform — more evidence of how much is happening at the intersection of open source and AI.
|
||||
|
||||
**H2O.ai.** **** I[previously covered][10] H2O.ai, which has carved out a niche in the machine learning and artificial intelligence arena because its primary tools are free and open source. You can get the main H2O platform and Sparkling Water, which works with Apache Spark, simply by[downloading][11] them. These tools operate under the Apache 2.0 license, one of the most flexible open source licenses available, and you can even run them on clusters powered by Amazon Web Services (AWS) and others for just a few hundred dollars.
|
||||
|
||||
**Microsoft Onboard.** “Our goal is to democratize AI to empower every person and every organization to achieve more,” Microsoft CEO Satya Nadella[has said][12]. With that in mind, Microsoft is continuing to iterate its[Microsoft Cognitive Toolkit][13]. It’s an open source software framework that competes with tools such as TensorFlow and Caffe. Cognitive Toolkit works with both Windows and Linux on 64-bit platforms.
|
||||
|
||||
“Cognitive Toolkit enables enterprise-ready, production-grade AI by allowing users to create, train, and evaluate their own neural networks that can then scale efficiently across multiple GPUs and multiple machines on massive data sets,” reports the Cognitive Toolkit Team.
|
||||
|
||||
Learn more about AI in this new ebook from The Linux Foundation. [Open Source AI: Projects, Insights, and Trends by Ibrahim Haddad][14] surveys 16 popular open source AI projects – looking in depth at their histories, codebases, and GitHub contributions. [Download the free ebook now.][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
@ -1,67 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Mesos and Kubernetes: It's Not a Competition
|
||||
======
|
||||
|
||||

|
||||
|
||||
The roots of Mesos can be traced back to 2009 when Ben Hindman was a PhD student at the University of California, Berkeley working on parallel programming. They were doing massive parallel computations on 128-core chips, trying to solve multiple problems such as making software and libraries run more efficiently on those chips. He started talking with fellow students so see if they could borrow ideas from parallel processing and multiple threads and apply them to cluster management.
|
||||
|
||||
“Initially, our focus was on Big Data,” said Hindman. Back then, Big Data was really hot and Hadoop was one of the hottest technologies. “We recognized that the way people were running things like Hadoop on clusters was similar to the way that people were running multiple threaded applications and parallel applications,” said Hindman.
|
||||
|
||||
However, it was not very efficient, so they started thinking how it could be done better through cluster management and resource management. “We looked at many different technologies at that time,” Hindman recalled.
|
||||
|
||||
Hindman and his colleagues, however, decided to adopt a novel approach. “We decided to create a lower level of abstraction for resource management, and run other services on top to that to do scheduling and other things,” said Hindman, “That’s essentially the essence of Mesos -- to separate out the resource management part from the scheduling part.”
|
||||
|
||||
It worked, and Mesos has been going strong ever since.
|
||||
|
||||
### The project goes to Apache
|
||||
|
||||
The project was founded in 2009. In 2010 the team decided to donate the project to the Apache Software Foundation (ASF). It was incubated at Apache and in 2013, it became a Top-Level Project (TLP).
|
||||
|
||||
There were many reasons why the Mesos community chose Apache Software Foundation, such as the permissiveness of Apache licensing, and the fact that they already had a vibrant community of other such projects.
|
||||
|
||||
It was also about influence. A lot of people working on Mesos were also involved with Apache, and many people were working on projects like Hadoop. At the same time, many folks from the Mesos community were working on other Big Data projects like Spark. This cross-pollination led all three projects -- Hadoop, Mesos, and Spark -- to become ASF projects.
|
||||
|
||||
It was also about commerce. Many companies were interested in Mesos, and the developers wanted it to be maintained by a neutral body instead of being a privately owned project.
|
||||
|
||||
### Who is using Mesos?
|
||||
|
||||
A better question would be, who isn’t? Everyone from Apple to Netflix is using Mesos. However, Mesos had its share of challenges that any technology faces in its early days. “Initially, I had to convince people that there was this new technology called ‘containers’ that could be interesting as there is no need to use virtual machines,” said Hindman.
|
||||
|
||||
The industry has changed a great deal since then, and now every conversation around infrastructure starts with ‘containers’ -- thanks to the work done by Docker. Today convincing is not needed, but even in the early days of Mesos, companies like Apple, Netflix, and PayPal saw the potential. They knew they could take advantage of containerization technologies in lieu of virtual machines. “These companies understood the value of containers before it became a phenomenon,” said Hindman.
|
||||
|
||||
These companies saw that they could have a bunch of containers, instead of virtual machines. All they needed was something to manage and run these containers, and they embraced Mesos. Some of the early users of Mesos included Apple, Netflix, PayPal, Yelp, OpenTable, and Groupon.
|
||||
|
||||
“Most of these organizations are using Mesos for just running arbitrary services,” said Hindman, “But there are many that are using it for doing interesting things with data processing, streaming data, analytics workloads and applications.”
|
||||
|
||||
One of the reasons these companies adopted Mesos was the clear separation between the resource management layers. Mesos offers the flexibility that companies need when dealing with containerization.
|
||||
|
||||
“One of the things we tried to do with Mesos was to create a layering so that people could take advantage of our layer, but also build whatever they wanted to on top,” said Hindman. “I think that's worked really well for the big organizations like Netflix and Apple.”
|
||||
|
||||
However, not every company is a tech company; not every company has or should have this expertise. To help those organizations, Hindman co-founded Mesosphere to offer services and solutions around Mesos. “We ultimately decided to build DC/OS for those organizations which didn’t have the technical expertise or didn't want to spend their time building something like that on top.”
|
||||
|
||||
### Mesos vs. Kubernetes?
|
||||
|
||||
People often think in terms of x versus y, but it’s not always a question of one technology versus another. Most technologies overlap in some areas, and they can also be complementary. “I don't tend to see all these things as competition. I think some of them actually can work in complementary ways with one another,” said Hindman.
|
||||
|
||||
“In fact the name Mesos stands for ‘middle’; it’s kind of a middle OS,” said Hindman, “We have the notion of a container scheduler that can be run on top of something like Mesos. When Kubernetes first came out, we actually embraced it in the Mesos ecosystem and saw it as another way of running containers in DC/OS on top of Mesos.”
|
||||
|
||||
Mesos also resurrected a project called [Marathon][1](a container orchestrator for Mesos and DC/OS), which they have made a first-class citizen in the Mesos ecosystem. However, Marathon does not really compare with Kubernetes. “Kubernetes does a lot more than what Marathon does, so you can’t swap them with each other,” said Hindman, “At the same time, we have done many things in Mesos that are not in Kubernetes. So, these technologies are complementary to each other.”
|
||||
|
||||
Instead of viewing such technologies as adversarial, they should be seen as beneficial to the industry. It’s not duplication of technologies; it’s diversity. According to Hindman, “it could be confusing for the end user in the open source space because it's hard to know which technologies are suitable for what kind of workload, but that’s the nature of the beast called Open Source.”
|
||||
|
||||
That just means there are more choices, and everybody wins.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://mesosphere.github.io/marathon/
|
||||
@ -1,90 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Getting started with Open edX to host your course
|
||||
======
|
||||
|
||||

|
||||
|
||||
Now in its [seventh major release][1], the [Open edX platform][2] is a free and open source course management system that is used [all over the world][3] to host Massive Open Online Courses (MOOCs) as well as smaller classes and training modules. To date, Open edX software has powered more than 8,000 original courses and 50 million course enrollments. You can install the platform yourself with on-premise equipment or by leveraging any of the industry-leading cloud infrastructure services providers, but it is also increasingly being made available in a Software-as-a-Service (SaaS) model from several of the project’s growing list of [service providers][4].
|
||||
|
||||
The Open edX platform is used by many of the world’s premier educational institutions as well as private sector companies, public sector institutions, NGOs, non-profits, and educational technology startups, and the project’s global community of service providers continues to make the platform accessible to ever-smaller organizations. If you plan to create and offer educational content to a broad audience, you should consider using the Open edX platform.
|
||||
|
||||
### Installation
|
||||
|
||||
There are multiple ways to install the software, which might be an unwelcome surprise, at least initially. But you get the same application software with the same feature set regardless of how you go about [installing Open edX][5]. The default installation includes a fully functioning learning management system (LMS) for online learners plus a full-featured course management studio (CMS) that your instructor teams can use to author original course content. You can think of the CMS as a “[Wordpress][6]” of course content creation and management, and the LMS as a “[Magento][7]” of course marketing, distribution, and consumption.
|
||||
|
||||
Open edX application software is device-agnostic and fully responsive, and with modest effort, you can also publish native iOS and Android apps that seamlessly integrate to your instance’s backend. The code repositories for the Open edX platform, the native mobile apps, and the installation scripts are all publicly available on [GitHub][8].
|
||||
|
||||
#### What to expect
|
||||
|
||||
The Open edX platform [GitHub repository][9] contains performant, production-ready code that is suitable for organizations of all sizes. Thousands of programmers from hundreds of institutions regularly contribute to the edX repositories, and the platform is a veritable case study on how to build and manage a complex enterprise application the right way. So even though you’re certain to face a multitude of concerns about how to move the platform into production, you should not lose sleep about the general quality and robustness of the Open edX Platform codebase itself.
|
||||
|
||||
With minimal training, your instructors will be able to create good online course content. But bear in mind that Open edX is extensible via its [XBlock][10] component architecture, so your instructors will have the potential to turn good course content into great course content with incremental effort on their parts and yours.
|
||||
|
||||
The platform works well in a single-server environment, and it is highly modular, making it nearly infinitely horizontally scalable. It is theme-able, localizable, and completely open source, providing limitless possibilities to tailor the appearance and functionality of the platform to your needs. The platform runs reliably as an on-premise installation on your own equipment.
|
||||
|
||||
#### Some assembly required
|
||||
|
||||
Bear in mind that a handful of the edX software modules are not included in the default installation and that these modules are often on the requirements lists of organizations. Namely, the Analytics module, the e-commerce module, and the Notes/Annotations course feature are not part of the default platform installation, and each of these individually is a non-trivial installation. Additionally, you’re entirely on your own with regard to data backup-restore and system administration in general. Fortunately, there’s a growing body of community-sourced documentation and how-to articles, all searchable via Google and Bing, to help make your installation production-ready.
|
||||
|
||||
Setting up [oAuth][11] and [SSL/TLS][12] as well as getting the platform’s [REST API][13] up and running can be challenging, depending on your skill level, even though these are all well-documented procedures. Additionally, some organizations require that MySQL and/or MongoDB databases be managed in an existing centralized environment, and if this is your situation, you’ll also need to work through the process of hiving these services out of the default platform installation. The edX design team has done everything possible to simplify this for you, but it’s still a non-trivial change that will likely take some time to implement.
|
||||
|
||||
Not to be discouraged—if you’re facing resource and/or technical headwinds, Open edX community SaaS providers like [appsembler][14] and [eduNEXT][15] offer compelling alternatives to a do-it-yourself installation, particularly if you’re just window shopping.
|
||||
|
||||
### Technology stack
|
||||
|
||||
Poking around in an Open edX platform installation is a real thrill, and architecturally speaking, the project is a masterpiece. The application modules are [Django][16] apps that leverage a plethora of the open source community’s premier projects, including [Ubuntu][17], [MySQL][18], [MongoDB][19], [RabbitMQ][20], [Elasticsearch][21], [Hadoop][22], and others.
|
||||
|
||||
![edx-architecture.png][24]
|
||||
|
||||
The Open edX technology stack (CC BY, by edX)
|
||||
|
||||
Getting all of these components installed and configured is a feat in and of itself, but packaging everything in such a way that organizations of arbitrary size and complexity can tailor installations to their needs without having to perform heart surgery on the codebase would seem impossible—that is, until you see how neatly and intuitively the major platform configuration parameters have been organized and named. Mind you, there’s a learning curve to the platform’s organizational structure, but the upshot is that everything you learn is worth knowing, not just for this project but large IT projects in general.
|
||||
|
||||
One word of caution: The platform's UI is in flux, with the aim of eventually standardizing on [React][25] and [Bootstrap][26]. Meanwhile, you'll find multiple approaches to implementing styling for the base theme, and this can get confusing.
|
||||
|
||||
### Adoption
|
||||
|
||||
The edX project has enjoyed rapid international adoption, due in no small measure to how well the software works. Not surprisingly, the project’s success has attracted a large and growing list of talented participants who contribute to the project as programmers, project consultants, translators, technical writers, and bloggers. The annual [Open edX Conference][27], the [Official edX Google Group][28], and the [Open edX Service Providers List][4] are good starting points for learning more about this diverse and growing ecosystem. As a relative newcomer myself, I’ve found it comparatively easy to engage and to get directly involved with the project in multiple facets.
|
||||
|
||||
Good luck with your journey, and feel free to reach out to me as a sounding board while you’re conceptualizing your project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/getting-started-open-edx
|
||||
|
||||
作者:[Lawrence Mc Daniel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mcdaniel0073
|
||||
[1]:https://openedx.atlassian.net/wiki/spaces/DOC/pages/11108700/Open+edX+Releases
|
||||
[2]:https://open.edx.org/about-open-edx
|
||||
[3]:https://www.edx.org/schools-partners
|
||||
[4]:https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers
|
||||
[5]:https://openedx.atlassian.net/wiki/spaces/OpenOPS/pages/60227779/Open+edX+Installation+Options
|
||||
[6]:https://wordpress.com/
|
||||
[7]:https://magento.com/
|
||||
[8]:https://github.com/edx
|
||||
[9]:https://github.com/edx/edx-platform
|
||||
[10]:https://open.edx.org/xblocks
|
||||
[11]:https://oauth.net/
|
||||
[12]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[13]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[14]:https://www.appsembler.com/
|
||||
[15]:https://www.edunext.co/
|
||||
[16]:https://www.djangoproject.com/
|
||||
[17]:https://www.ubuntu.com/
|
||||
[18]:https://www.mysql.com/
|
||||
[19]:https://www.mongodb.com/
|
||||
[20]:https://www.rabbitmq.com/
|
||||
[21]:https://www.elastic.co/
|
||||
[22]:http://hadoop.apache.org/
|
||||
[23]:/file/400696
|
||||
[24]:https://opensource.com/sites/default/files/uploads/edx-architecture_0.png (edx-architecture.png)
|
||||
[25]:%E2%80%9Chttps://reactjs.org/%E2%80%9C
|
||||
[26]:%E2%80%9Chttps://getbootstrap.com/%E2%80%9C
|
||||
[27]:https://con.openedx.org/
|
||||
[28]:https://groups.google.com/forum/#!forum/openedx-ops
|
||||
@ -1,142 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
|
||||
Sosreport – A Tool To Collect System Logs And Diagnostic Information
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you’re working as RHEL administrator, you might definitely heard about **Sosreport** – an extensible, portable and support data collection tool. It is a tool to collect system configuration details and diagnostic information from a Unix-like operating system. When the user raise a support ticket, he/she has to run this tool and send the resulting report generated by Sosreport tool to the Red Hat support executive. The executive will then perform an initial analysis based on the report and try to find what’s the problem in the system. Not just on RHEL system, you can use it on any Unix-like operating systems for collecting system logs and other debug information.
|
||||
|
||||
### Installing Sosreport
|
||||
|
||||
Sosreport is available on Red Hat official systems, so you can install it using Yum Or DNF package managers as shown below.
|
||||
```
|
||||
$ sudo yum install sos
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ sudo dnf install sos
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu and Linux Mint, run:
|
||||
```
|
||||
$ sudo apt install sosreport
|
||||
|
||||
```
|
||||
|
||||
### Usage
|
||||
|
||||
Once installed, run the following command to collect your system configuration details and other diagnostic information.
|
||||
```
|
||||
$ sudo sosreport
|
||||
|
||||
```
|
||||
|
||||
You will be asked to enter some details of your system, such as system name, case id etc. Type the details accordingly, and press ENTER key to generate the report. If you don’t want to change anything and want to use the default values, simply press ENTER.
|
||||
|
||||
Sample output from my CentOS 7 server:
|
||||
```
|
||||
sosreport (version 3.5)
|
||||
|
||||
This command will collect diagnostic and configuration information from
|
||||
this CentOS Linux system and installed applications.
|
||||
|
||||
An archive containing the collected information will be generated in
|
||||
/var/tmp/sos.DiJXi7 and may be provided to a CentOS support
|
||||
representative.
|
||||
|
||||
Any information provided to CentOS will be treated in accordance with
|
||||
the published support policies at:
|
||||
|
||||
https://wiki.centos.org/
|
||||
|
||||
The generated archive may contain data considered sensitive and its
|
||||
content should be reviewed by the originating organization before being
|
||||
passed to any third party.
|
||||
|
||||
No changes will be made to system configuration.
|
||||
|
||||
Press ENTER to continue, or CTRL-C to quit.
|
||||
|
||||
Please enter your first initial and last name [server.ostechnix.local]:
|
||||
Please enter the case id that you are generating this report for []:
|
||||
|
||||
Setting up archive ...
|
||||
Setting up plugins ...
|
||||
Running plugins. Please wait ...
|
||||
|
||||
Running 73/73: yum...
|
||||
Creating compressed archive...
|
||||
|
||||
Your sosreport has been generated and saved in:
|
||||
/var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
|
||||
The checksum is: 8f08f99a1702184ec13a497eff5ce334
|
||||
|
||||
Please send this file to your support representative.
|
||||
|
||||
```
|
||||
|
||||
If you don’t want to be prompted for entering such details, simply use batch mode like below.
|
||||
```
|
||||
$ sudo sosreport --batch
|
||||
|
||||
```
|
||||
|
||||
As you can see in the above output, an archived report is generated and saved in **/var/tmp/sos.DiJXi7** file. In RHEL 6/CentOS 6, the report will be generated in **/tmp** location. You can now send this report to your support executive, so that he can do initial analysis and find what’s the problem.
|
||||
|
||||
You might be concerned or wanted to know what’s in the report. If so, you can view it by running the following command:
|
||||
```
|
||||
$ sudo tar -tf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ sudo vim /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
|
||||
```
|
||||
|
||||
Please note that above commands will not extract the archive, but only display the list of files and folders in the archive. If you want to view the actual contents of the files in the archive, first extract the archive using command:
|
||||
```
|
||||
$ sudo tar -xf /var/tmp/sosreport-server.ostechnix.local-20180628171844.tar.xz
|
||||
|
||||
```
|
||||
|
||||
All the contents of the archive will be extracted in a directory named “sosreport-server.ostechnix.local-20180628171844/” in the current working directory. Go to the directory and view the contents of any file using cat command or any other text viewer:
|
||||
```
|
||||
$ cd sosreport-server.ostechnix.local-20180628171844/
|
||||
|
||||
$ cat uptime
|
||||
17:19:02 up 1:03, 2 users, load average: 0.50, 0.17, 0.10
|
||||
|
||||
```
|
||||
|
||||
For more details about Sosreport, refer man pages.
|
||||
```
|
||||
$ man sosreport
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/sosreport-a-tool-to-collect-system-logs-and-diagnostic-information/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,3 +1,5 @@
|
||||
translated by hopefully2333
|
||||
|
||||
Install an NVIDIA GPU on almost any machine
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,332 @@
|
||||
Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||

|
||||
|
||||
We already have covered [**setting up Oracle VirtualBox on Ubuntu 18.04**][1] headless server. In this tutorial, we will be discussing how to setup headless virtualization server using **KVM** and how to manage the guest machines from a remote client. As you may know already, KVM ( **K** ernel-based **v** irtual **m** achine) is an open source, full virtualization for Linux. Using KVM, we can easily turn any Linux server in to a complete virtualization environment in minutes and deploy different kind of VMs such as GNU/Linux, *BSD, Windows etc.
|
||||
|
||||
### Setup Headless Virtualization Server Using KVM
|
||||
|
||||
I tested this guide on Ubuntu 18.04 LTS server, however this tutorial will work on other Linux distributions such as Debian, CentOS, RHEL and Scientific Linux. This method will be perfectly suitable for those who wants to setup a simple virtualization environment in a Linux server that doesn’t have any graphical environment.
|
||||
|
||||
For the purpose of this guide, I will be using two systems.
|
||||
|
||||
**KVM virtualization server:**
|
||||
|
||||
* **Host OS** – Ubuntu 18.04 LTS minimal server (No GUI)
|
||||
* **IP Address of Host OS** : 192.168.225.22/24
|
||||
* **Guest OS** (Which we are going to host on Ubuntu 18.04) : Ubuntu 16.04 LTS server
|
||||
|
||||
|
||||
|
||||
**Remote desktop client :**
|
||||
|
||||
* **OS** – Arch Linux
|
||||
|
||||
|
||||
|
||||
### Install KVM
|
||||
|
||||
First, let us check if our system supports hardware virtualization. To do so, run the following command from the Terminal:
|
||||
```
|
||||
$ egrep -c '(vmx|svm)' /proc/cpuinfo
|
||||
|
||||
```
|
||||
|
||||
If the result is **zero (0)** , the system doesn’t support hardware virtualization or the virtualization is disabled in the Bios. Go to your bios and check for the virtualization option and enable it.
|
||||
|
||||
if the result is **1** or **more** , the system will support hardware virtualization. However, you still need to enable the virtualization option in Bios before running the above commands.
|
||||
|
||||
Alternatively, you can use the following command to verify it. You need to install kvm first as described below, in order to use this command.
|
||||
```
|
||||
$ kvm-ok
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
INFO: /dev/kvm exists
|
||||
KVM acceleration can be used
|
||||
|
||||
```
|
||||
|
||||
If you got the following error instead, you still can run guest machines in KVM, but the performance will be very poor.
|
||||
```
|
||||
INFO: Your CPU does not support KVM extensions
|
||||
INFO: For more detailed results, you should run this as root
|
||||
HINT: sudo /usr/sbin/kvm-ok
|
||||
|
||||
```
|
||||
|
||||
Also, there are other ways to find out if your CPU supports Virtualization or not. Refer the following guide for more details.
|
||||
|
||||
Next, Install KVM and other required packages to setup a virtualization environment in Linux.
|
||||
|
||||
On Ubuntu and other DEB based systems, run:
|
||||
```
|
||||
$ sudo apt-get install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
|
||||
|
||||
```
|
||||
|
||||
Once KVM installed, start libvertd service (If it is not started already):
|
||||
```
|
||||
$ sudo systemctl enable libvirtd
|
||||
|
||||
$ sudo systemctl start libvirtd
|
||||
|
||||
```
|
||||
|
||||
### Create Virtual machines
|
||||
|
||||
All virtual machine files and other related files will be stored under **/var/lib/libvirt/**. The default path of ISO images is **/var/lib/libvirt/boot/**.
|
||||
|
||||
First, let us see if there is any virtual machines. To view the list of available virtual machines, run:
|
||||
```
|
||||
$ sudo virsh list --all
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
As you see above, there is no virtual machine available right now.
|
||||
|
||||
Now, let us crate one.
|
||||
|
||||
For example, let us create Ubuntu 16.04 Virtual machine with 512 MB RAM, 1 CPU core, 8 GB Hdd.
|
||||
```
|
||||
$ sudo virt-install --name Ubuntu-16.04 --ram=512 --vcpus=1 --cpu host --hvm --disk path=/var/lib/libvirt/images/ubuntu-16.04-vm1,size=8 --cdrom /var/lib/libvirt/boot/ubuntu-16.04-server-amd64.iso --graphics vnc
|
||||
|
||||
```
|
||||
|
||||
Please make sure you have Ubuntu 16.04 ISO image in path **/var/lib/libvirt/boot/** or any other path you have given in the above command.
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
WARNING Graphics requested but DISPLAY is not set. Not running virt-viewer.
|
||||
WARNING No console to launch for the guest, defaulting to --wait -1
|
||||
|
||||
Starting install...
|
||||
Creating domain... | 0 B 00:00:01
|
||||
Domain installation still in progress. Waiting for installation to complete.
|
||||
Domain has shutdown. Continuing.
|
||||
Domain creation completed.
|
||||
Restarting guest.
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
Let us break down the above command and see what each option do.
|
||||
|
||||
* **–name** : This option defines the name of the virtual name. In our case, the name of VM is **Ubuntu-16.04**.
|
||||
* **–ram=512** : Allocates 512MB RAM to the VM.
|
||||
* **–vcpus=1** : Indicates the number of CPU cores in the VM.
|
||||
* **–cpu host** : Optimizes the CPU properties for the VM by exposing the host’s CPU’s configuration to the guest.
|
||||
* **–hvm** : Request the full hardware virtualization.
|
||||
* **–disk path** : The location to save VM’s hdd and it’s size. In our example, I have allocated 8GB hdd size.
|
||||
* **–cdrom** : The location of installer ISO image. Please note that you must have the actual ISO image in this location.
|
||||
* **–graphics vnc** : Allows VNC access to the VM from a remote client.
|
||||
|
||||
|
||||
|
||||
### Access Virtual machines using VNC client
|
||||
|
||||
Now, go to the remote Desktop system. SSH to the Ubuntu server(Virtualization server) as shown below.
|
||||
|
||||
Here, **sk** is my Ubuntu server’s user name and **192.168.225.22** is its IP address.
|
||||
|
||||
Run the following command to find out the VNC port number. We need this to access the Vm from a remote system.
|
||||
```
|
||||
$ sudo virsh dumpxml Ubuntu-16.04 | grep vnc
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
<graphics type='vnc' port='5900' autoport='yes' listen='127.0.0.1'>
|
||||
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
Note down the port number **5900**. Install any VNC client application. For this guide, I will be using TigerVnc. TigerVNC is available in the Arch Linux default repositories. To install it on Arch based systems, run:
|
||||
```
|
||||
$ sudo pacman -S tigervnc
|
||||
|
||||
```
|
||||
|
||||
Type the following SSH port forwarding command from your remote client system that has VNC client application installed.
|
||||
|
||||
Again, **192.168.225.22** is my Ubuntu server’s (virtualization server) IP address.
|
||||
|
||||
Then, open the VNC client from your Arch Linux (client).
|
||||
|
||||
Type **localhost:5900** in the VNC server field and click **Connect** button.
|
||||
|
||||
![][6]
|
||||
|
||||
Then start installing the Ubuntu VM as the way you do in the physical system.
|
||||
|
||||
![][7]
|
||||
|
||||
![][8]
|
||||
|
||||
Similarly, you can setup as many as virtual machines depending upon server hardware specifications.
|
||||
|
||||
Alternatively, you can use **virt-viewer** utility in order to install operating system in the guest machines. virt-viewer is available in the most Linux distribution’s default repositories. After installing virt-viewer, run the following command to establish VNC access to the VM.
|
||||
```
|
||||
$ sudo virt-viewer --connect=qemu+ssh://192.168.225.22/system --name Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
### Manage virtual machines
|
||||
|
||||
Managing VMs from the command-line using virsh management user interface is very interesting and fun. The commands are very easy to remember. Let us see some examples.
|
||||
|
||||
To view the list of running VMs, run:
|
||||
```
|
||||
$ sudo virsh list
|
||||
|
||||
```
|
||||
|
||||
Or,
|
||||
```
|
||||
$ sudo virsh list --all
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Id Name State
|
||||
----------------------------------------------------
|
||||
2 Ubuntu-16.04 running
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
|
||||
To start a VM, run:
|
||||
```
|
||||
$ sudo virsh start Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can use the VM id to start it.
|
||||
|
||||
![][10]
|
||||
|
||||
As you see in the above output, Ubuntu 16.04 virtual machine’s Id is 2. So, in order to start it, just specify its Id like below.
|
||||
```
|
||||
$ sudo virsh start 2
|
||||
|
||||
```
|
||||
|
||||
To restart a VM, run:
|
||||
```
|
||||
$ sudo virsh reboot Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Domain Ubuntu-16.04 is being rebooted
|
||||
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
To pause a running VM, run:
|
||||
```
|
||||
$ sudo virsh suspend Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Domain Ubuntu-16.04 suspended
|
||||
|
||||
```
|
||||
|
||||
To resume the suspended VM, run:
|
||||
```
|
||||
$ sudo virsh resume Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Domain Ubuntu-16.04 resumed
|
||||
|
||||
```
|
||||
|
||||
To shutdown a VM, run:
|
||||
```
|
||||
$ sudo virsh shutdown Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Domain Ubuntu-16.04 is being shutdown
|
||||
|
||||
```
|
||||
|
||||
To completely remove a VM, run:
|
||||
```
|
||||
$ sudo virsh undefine Ubuntu-16.04
|
||||
|
||||
$ sudo virsh destroy Ubuntu-16.04
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
Domain Ubuntu-16.04 destroyed
|
||||
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
For more options, I recommend you to look into the man pages.
|
||||
```
|
||||
$ man virsh
|
||||
|
||||
```
|
||||
|
||||
That’s all for now folks. Start playing with your new virtualization environment. KVM virtualization will be opt for research & development and testing purposes, but not limited to. If you have sufficient hardware, you can use it for large production environments. Have fun and don’t forget to leave your valuable comments in the comment section below.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/setup-headless-virtualization-server-using-kvm-ubuntu/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/install-oracle-virtualbox-ubuntu-16-04-headless-server/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_001.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_008-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_002.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/11/VNC-Viewer-Connection-Details_005.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/11/QEMU-Ubuntu-16.04-TigerVNC_006.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2016/11/QEMU-Ubuntu-16.04-TigerVNC_007.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_010-1.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_010-2.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_011-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2016/11/sk@ubuntuserver-_012.png
|
||||
@ -0,0 +1,96 @@
|
||||
How to use dd in Linux without destroying your disk
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article is excerpted from chapter 4 of [Linux in Action][1], published by Manning.
|
||||
|
||||
Whether you're trying to rescue data from a dying storage drive, backing up archives to remote storage, or making a perfect copy of an active partition somewhere else, you'll need to know how to safely and reliably copy drives and filesystems. Fortunately, `dd` is a simple and powerful image-copying tool that's been around, well, pretty much forever. And in all that time, nothing's come along that does the job better.
|
||||
|
||||
### Making perfect copies of drives and partitions
|
||||
|
||||
`dd` if you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, use `tar` or even `scp` to replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
|
||||
|
||||
There's all kinds of stuff you can do withif you research hard enough, but where it shines is in the ways it lets you play with partitions. You can, of course, useor evento replicate entire filesystems by copying the files from one computer and then pasting them as-is on top of a fresh Linux install on another computer. But, because those filesystem archives aren't complete images, they'll require a running host OS at both ends to serve as a base.
|
||||
|
||||
Using `dd`, on the other hand, can make perfect byte-for-byte images of, well, just about anything digital. But before you start flinging partitions from one end of the earth to the other, I should mention that there's some truth to that old Unix admin joke: "dd stands for disk destroyer." If you type even one wrong character in a `dd` command, you can instantly and permanently wipe out an entire drive of valuable data. And yes, spelling counts.
|
||||
|
||||
**Remember:** Before pressing that Enter key to invoke `dd`, pause and think very carefully!
|
||||
|
||||
### Basic dd operations
|
||||
|
||||
Now that you've been suitably warned, we'll start with something straightforward. Suppose you want to create an exact image of an entire disk of data that's been designated as `/dev/``sda`. You've plugged in an empty drive (ideally having the same capacity as your `/dev/``sda` system). The syntax is simple: `if=` defines the source drive and `of=` defines the file or location where you want your data saved:
|
||||
```
|
||||
# dd if=/dev/sda of=/dev/sdb
|
||||
|
||||
```
|
||||
|
||||
The next example will create an .img archive of the `/dev/``sda` drive and save it to the home directory of your user account:
|
||||
```
|
||||
# dd if=/dev/sda of=/home/username/sdadisk.img
|
||||
|
||||
```
|
||||
|
||||
Those commands created images of entire drives. You could also focus on a single partition from a drive. The next example does that and also uses `bs` to set the number of bytes to copy at a single time (4,096, in this case). Playing with the `bs` value can have an impact on the overall speed of a `dd` operation, although the ideal setting will depend on your hardware profile and other considerations.
|
||||
```
|
||||
# dd if=/dev/sda2 of=/home/username/partition2.img bs=4096
|
||||
|
||||
```
|
||||
|
||||
Restoring is simple: Effectively, you reverse the values of `if` and `of`. In this case, `if=` takes the image you want to restore, and `of=` takes the target drive to which you want to write the image:
|
||||
```
|
||||
# dd if=sdadisk.img of=/dev/sdb
|
||||
|
||||
```
|
||||
|
||||
You can also perform both the create and copy operations in one command. This example, for instance, will create a compressed image of a remote drive using SSH and save the resulting archive to your local machine:
|
||||
```
|
||||
# ssh username@54.98.132.10 "dd if=/dev/sda | gzip -1 -" | dd of=backup.gz
|
||||
|
||||
```
|
||||
|
||||
You should always test your archives to confirm they're working. If it's a boot drive you've created, stick it into a computer and see if it launches as expected. If it's a normal data partition, mount it to make sure the files both exist and are appropriately accessible.
|
||||
|
||||
### Wiping disks with dd
|
||||
|
||||
Years ago, I had a friend who was responsible for security at his government's overseas embassies. He once told me that each embassy under his watch was provided with an official government-issue hammer. Why? In case the facility was ever at risk of being overrun by unfriendlies, the hammer was to be used to destroy all their hard drives.
|
||||
|
||||
What's that? Why not just delete the data? You're kidding, right? Everyone knows that deleting files containing sensitive data from storage devices doesn't actually remove the data. Given enough time and motivation, nearly anything can be retrieved from virtually any digital media, with the possible exception of the ones that have been well and properly hammered.
|
||||
|
||||
You can, however, use `dd` to make it a whole lot more difficult for the bad guys to get at your old data. This command will spend some time writing millions and millions of zeros over every nook and cranny of the `/dev/sda1` partition:
|
||||
```
|
||||
# dd if=/dev/zero of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
But it gets better. Using `/dev/``urandom` file as your source, you can write over a disk with random characters:
|
||||
```
|
||||
# dd if=/dev/urandom of=/dev/sda1
|
||||
|
||||
```
|
||||
|
||||
### Monitoring dd operations
|
||||
|
||||
Since disk or partition archiving can take a very long time, you might want to add a progress monitor to your command. Install Pipe Viewer (`sudo apt install pv` on Ubuntu) and insert it into `dd`. With `pv`, that last command might look something like this:
|
||||
```
|
||||
# dd if=/dev/urandom | pv | dd of=/dev/sda1
|
||||
|
||||
4,14MB 0:00:05 [ 98kB/s] [ <=> ]
|
||||
|
||||
```
|
||||
|
||||
Putting off backups and disk management? With dd, you aren't left with too many excuses. It's really not difficult, but be careful. Good luck!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/how-use-dd-linux
|
||||
|
||||
作者:[David Clinton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.manning.com/books/linux-in-action?a_aid=bootstrap-it&a_bid=4ca15fc9&chan=opensource
|
||||
@ -0,0 +1,75 @@
|
||||
6 RFCs for understanding how the internet works
|
||||
======
|
||||
|
||||

|
||||
|
||||
Reading the source is an important part of open source software. It means users have the ability to look at the code and see what it does.
|
||||
|
||||
But "read the source" doesn't apply only to code. Understanding the standards the code implements can be just as important. These standards are codified in documents called "Requests for Comments" (RFCs) published by the [Internet Engineering Task Force][1] (IETF). Thousands of RFCs have been published over the years, so we collected a few that our contributors consider must-reads.
|
||||
|
||||
### 6 must-read RFCs
|
||||
|
||||
#### RFC 2119—Key words for use in RFCs to indicate requirement levels
|
||||
|
||||
This is a quick read, but it's important to understanding other RFCs. [RFC 2119][2] defines the requirement levels used in subsequent RFCs. What does "MAY" really mean? If the standard says "SHOULD," do you really have to do it? By giving the requirements a well-defined taxonomy, RFC 2119 helps avoid ambiguity.
|
||||
|
||||
Time is the bane of programmers the world over. [RFC 3339][3] defines how timestamps are to be formatted. Based on the [ISO 8601][4] standard, 3339 gives us a common way to represent time and its relentless march. For example, redundant information like the day of the week should not be included in a stored timestamp since it is easy to compute.
|
||||
|
||||
#### RFC 1918—Address allocation for private internets
|
||||
|
||||
There's the internet that's everyone's and then there's the internet that's just yours. Private networks are used all the time, and [RFC 1918][5] defines those networks. Sure, you could set up your router to route public spaces internally, but that's a bad idea. Alternately, you could take your unused public IP addresses and treat them as an internal network. In either case, you're making it clear you've never read RFC 1918.
|
||||
|
||||
#### RFC 1912—Common DNS operational and configuration errors
|
||||
|
||||
Everything is a #@%@ DNS problem, right? [RFC 1912][6] lays out mistakes that admins make when they're just trying to keep the internet running. Although it was published in 1996, DNS (and the mistakes people make with it) hasn't really changed all that much. To understand why we need DNS in the first place, consider what [RFC 289—What we hope is an official list of host names][7] would look like today.
|
||||
|
||||
#### RFC 2822—Internet message format
|
||||
|
||||
Think you know what a valid email address looks like? If the number of sites that won't accept a "+" in my address is any indication, you don't. [RFC 2822][8] defines what a valid email address looks like. It also goes into detail about the rest of an email message.
|
||||
|
||||
#### RFC 7231—Hypertext Transfer Protocol (HTTP/1.1): Semantics and content
|
||||
|
||||
When you stop to think about it, almost everything we do online relies on HTTP. [RFC 7231][9] is among the most recent updates to that protocol. Weighing in at just over 100 pages, it defines methods, headers, and status codes.
|
||||
|
||||
### 3 should-read RFCs
|
||||
|
||||
Okay, not every RFC is serious business.
|
||||
|
||||
#### RFC 1149—A standard for the transmission of IP datagrams on avian carriers
|
||||
|
||||
Networks pass packets in many different ways. [RFC 1149][10] describes the use of carrier pigeons. They can't be any less reliable than my mobile provider when I'm more than a mile away from an interstate highway.
|
||||
|
||||
#### RFC 2324—Hypertext coffee pot control protocol (HTCPCP/1.0)
|
||||
|
||||
Coffee is very important to getting work done, so of course, we need a programmatic interface for managing our coffee pots. [RFC 2324][11] defines a protocol for interacting with coffee pots and adds HTTP 418 ("I am a teapot").
|
||||
|
||||
#### RFC 69—Distribution list change for M.I.T.
|
||||
|
||||
Is [RFC 69][12] the first published example of a misdirected unsubscribe request?
|
||||
|
||||
What are your must-read RFCs (whether they're serious or not)? Share your list in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/requests-for-comments-to-know
|
||||
|
||||
作者:[Ben Cotton][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://www.ietf.org
|
||||
[2]:https://www.rfc-editor.org/rfc/rfc2119.txt
|
||||
[3]:https://www.rfc-editor.org/rfc/rfc3339.txt
|
||||
[4]:https://www.iso.org/iso-8601-date-and-time-format.html
|
||||
[5]:https://www.rfc-editor.org/rfc/rfc1918.txt
|
||||
[6]:https://www.rfc-editor.org/rfc/rfc1912.txt
|
||||
[7]:https://www.rfc-editor.org/rfc/rfc289.txt
|
||||
[8]:https://www.rfc-editor.org/rfc/rfc2822.txt
|
||||
[9]:https://www.rfc-editor.org/rfc/rfc7231.txt
|
||||
[10]:https://www.rfc-editor.org/rfc/rfc1149.txt
|
||||
[11]:https://www.rfc-editor.org/rfc/rfc2324.txt
|
||||
[12]:https://www.rfc-editor.org/rfc/rfc69.txt
|
||||
@ -0,0 +1,126 @@
|
||||
How to Run Windows Apps on Android with Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
Wine (on Linux, not the one you drink) is a free and open-source compatibility layer for running Windows programs on Unix-like operating systems. Begun in 1993, it could run a wide variety of Windows programs on Linux and macOS, although sometimes with modification. Now the Wine Project has rolled out version 3.0 which is compatible with your Android devices.
|
||||
|
||||
In this article we will show you how you can run Windows apps on your Android device with WINE.
|
||||
|
||||
**Related** : [How to Easily Install Windows Games on Linux with Winepak][1]
|
||||
|
||||
### What can you run on Wine?
|
||||
|
||||
Wine is only a compatibility layer, not a full-blown emulator, so you need an x86 Android device to take full advantage of it. However, most Androids in the hands of consumers are ARM-based.
|
||||
|
||||
Since most of you are using an ARM-based Android device, you will only be able to use Wine to run apps that have been adapted to run on Windows RT. There is a limited, but growing, list of software available for ARM devices. You can find a list of these apps that are compatible in this [thread][2] on XDA Developers Forums.
|
||||
|
||||
Some examples of apps you will be able to run on ARM are:
|
||||
|
||||
* [Keepass Portable][3]: A password storage wallet
|
||||
* [Paint.NET][4]: An image manipulation program
|
||||
* [SumatraPDF][5]: A document reader for PDFs and possibly some other document types
|
||||
* [Audacity][6]: A digital audio recording and editing program
|
||||
|
||||
|
||||
|
||||
There are also some open-source retro games available like [Doom][7] and [Quake 2][8], as well as the open-source clone, [OpenTTD][9], a version of Transport Tycoon.
|
||||
|
||||
The list of programs that Wine can run on Android ARM devices is bound to grow as the popularity of Wine on Android expands. The Wine project is working on using QEMU to emulate x86 CPU instructions on ARM, and when that is complete, the number of apps your Android will be able to run should grow rapidly.
|
||||
|
||||
### Installing Wine
|
||||
|
||||
To install Wine you must first make sure that your device’s settings allow it to download and install APKs from other sources than the Play Store. To do this you’ll need to give your device permission to download apps from unknown sources.
|
||||
|
||||
1\. Open Settings on your phone and select your Security options.
|
||||
|
||||
|
||||
![wine-android-security][10]
|
||||
|
||||
2\. Scroll down and click on the switch next to “Unknown Sources.”
|
||||
|
||||
![wine-android-unknown-sources][11]
|
||||
|
||||
3\. Accept the risks in the warning.
|
||||
|
||||
![wine-android-unknown-sources-warning][12]
|
||||
|
||||
4\. Open the [Wine installation site][13], and tap the first checkbox in the list. The download will automatically begin.
|
||||
|
||||
![wine-android-download-button][14]
|
||||
|
||||
5\. Once the download completes, open it from your Downloads folder, or pull down the notifications menu and click on the completed download there.
|
||||
|
||||
6\. Install the program. It will notify you that it needs access to recording audio and to modify, delete, and read the contents of your SD card. You may also need to give access for audio recording for some apps you will use in the program.
|
||||
|
||||
![wine-android-app-access][15]
|
||||
|
||||
7\. When the installation completes, click on the icon to open the program.
|
||||
|
||||
![wine-android-icon-small][16]
|
||||
|
||||
When you open Wine, the desktop mimics Windows 7.
|
||||
|
||||
![wine-android-desktop][17]
|
||||
|
||||
One drawback of Wine is that you have to have an external keyboard available to type. An external mouse may also be useful if you are running it on a small screen and find it difficult to tap small buttons.
|
||||
|
||||
You can tap the Start button to open two menus – Control Panel and Run.
|
||||
|
||||
![wine-android-start-button][18]
|
||||
|
||||
### Working with Wine
|
||||
|
||||
When you tap “Control panel” you will see three choices – Add/Remove Programs, Game Controllers, and Internet Settings.
|
||||
|
||||
Using “Run,” you can open a dialogue box to issue commands. For instance, launch Internet Explorer by entering `iexplore`.
|
||||
|
||||
![wine-android-run][19]
|
||||
|
||||
### Installing programs on Wine
|
||||
|
||||
1\. Download the application (or sync via the cloud) to your Android device. Take note of where you save it.
|
||||
|
||||
2\. Open the Wine Command Prompt window.
|
||||
|
||||
3\. Type the path to the location of the program. If you have saved it to the Download folder on your SD card, type:
|
||||
|
||||
4\. To run the file in Wine for Android, simply input the name of the EXE file.
|
||||
|
||||
If the ARM-ready file is compatible, it should run. If not, you’ll see a bunch of error messages. At this stage, installing Windows software on Android in Wine can be hit or miss.
|
||||
|
||||
There are still a lot of issues with this new version of Wine for Android. It doesn’t work on all Android devices. It worked on my Galaxy S6 Edge but not on my Galaxy Tab 4. Many games won’t work because the graphics driver doesn’t support Direct3D yet. You need an external keyboard and mouse to be able to easily manipulate the screen because touch-screen is not fully developed yet.
|
||||
|
||||
Even with these issues in the early stages of release, the possibilities for this technology are thought-provoking. It’s certainly likely that it will take some time yet before you can launch Windows programs on your Android smartphone using Wine without a hitch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/run-windows-apps-android-with-wine/
|
||||
|
||||
作者:[Tracey Rosenberger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/traceyrosenberger/
|
||||
[1]:https://www.maketecheasier.com/winepak-install-windows-games-linux/ (How to Easily Install Windows Games on Linux with Winepak)
|
||||
[2]:https://forum.xda-developers.com/showthread.php?t=2092348
|
||||
[3]:http://downloads.sourceforge.net/keepass/KeePass-2.20.1.zip
|
||||
[4]:http://forum.xda-developers.com/showthread.php?t=2411497
|
||||
[5]:http://forum.xda-developers.com/showthread.php?t=2098594
|
||||
[6]:http://forum.xda-developers.com/showthread.php?t=2103779
|
||||
[7]:http://forum.xda-developers.com/showthread.php?t=2175449
|
||||
[8]:http://forum.xda-developers.com/attachment.php?attachmentid=1640830&d=1358070370
|
||||
[9]:http://forum.xda-developers.com/showpost.php?p=36674868&postcount=151
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-security.png (wine-android-security)
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources.jpg (wine-android-unknown-sources)
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-unknown-sources-warning.png (wine-android-unknown-sources-warning)
|
||||
[13]:https://dl.winehq.org/wine-builds/android/
|
||||
[14]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-download-button.png (wine-android-download-button)
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-app-access.jpg (wine-android-app-access)
|
||||
[16]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-icon-small.jpg (wine-android-icon-small)
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-desktop.png (wine-android-desktop)
|
||||
[18]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-start-button.png (wine-android-start-button)
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2018/07/Wine-Android-Run.png (wine-android-run)
|
||||
@ -0,0 +1,70 @@
|
||||
Revisiting wallabag, an open source alternative to Instapaper
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in 2014, I [wrote about wallabag][1], an open source alternative to read-it-later applications like Instapaper and Pocket. Go take a look at that article if you want to. Don't worry, I'll wait for you.
|
||||
|
||||
Done? Great!
|
||||
|
||||
In the four years since I wrote that article, a lot about [wallabag][2] has changed. It's time to take a peek to see how wallabag has matured.
|
||||
|
||||
### What's new
|
||||
|
||||
The biggest change took place behind the scenes. Wallabag's developer Nicolas Lœuillet and the project's contributors did a lot of tinkering with the code, which improved the application. You see and feel the changes wrought by wallabag's newer codebase every time you use it.
|
||||
|
||||
So what are some of those changes? There are [quite a few][3]. Here are the ones I found most interesting and useful.
|
||||
|
||||
Besides making wallabag a bit snappier and more stable, the application's ability to import and export content has improved. You can import articles from Pocket and Instapaper, as well as articles marked as "To read" in bookmarking service [Pinboard][4]. You can also import Firefox and Chrome bookmarks.
|
||||
|
||||
You can also export your articles in several formats including EPUB, MOBI, PDF, and plaintext. You can do that for individual articles, all your unread articles, or every article—read and unread. The version of wallabag that I used four years ago could export to EPUB and PDF, but that export was balky at times. Now, those exports are quick and smooth.
|
||||
|
||||
Annotations and highlighting in the web interface now work much better and more consistently. Admittedly, I don't use them often—but they don't randomly disappear like they sometimes did with version 1 of wallabag.
|
||||
|
||||

|
||||
|
||||
The look and feel of wallabag have improved, too. That's thanks to a new theme inspired by [Material Design][5]. That might not seem like a big deal, but that theme makes wallabag a bit more visually attractive and makes articles easier to scan and read. Yes, kids, good UX can make a difference.
|
||||
|
||||
|
||||
|
||||
One of the biggest changes was the introduction of [a hosted version][6] of wallabag. More than a few people (yours truly included) don't have a server to run web apps and aren't entirely comfortable doing that. When it comes to anything technical, I have 10 thumbs. I don't mind paying € 9 (just over US$ 10 at the time I wrote this) a year to get a fully working version of the application that I don't need to watch over.
|
||||
|
||||
### What hasn't changed
|
||||
|
||||
Overall, wallabag's core functions are the same. The updated codebase, as I mentioned above, makes those functions run quite a bit smoother and quicker.
|
||||
|
||||
Wallabag's [browser extensions][7] do the same job in the same way. I've found that the extensions work a bit better than they did when I first tried them and when the application was at version 1.
|
||||
|
||||
### What's disappointing
|
||||
|
||||
The mobile app is good, but it's not great. It does a good job of rendering articles and has a few configuration options. But you can't highlight or annotate articles. That said, you can use the app to dip into your stock of archived articles.
|
||||
|
||||
|
||||
|
||||
While wallabag does a great job collecting articles, there are sites whose content you can't save to it. I haven't run into many such sites, but there have been enough for the situation to be annoying. I'm not sure how much that has to do with wallabag. Rather, I suspect it has something to do with the way the sites are coded—I ran into the same problem while looking at a couple of proprietary read-it-later tools.
|
||||
|
||||
Wallabag might not be a feature-for-feature replacement for Pocket or Instapaper, but it does a great job. It has improved noticeably in the four years since I first wrote about it. There's still room for improvement, but does what it says on the tin.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Since 2014, wallabag has evolved. It's gotten better, bit by bit and step by step. While it might not be a feature-for-feature replacement for the likes of Instapaper and Pocket, wallabag is a worthy open source alternative to proprietary read-it-later tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/wallabag
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/life/14/4/open-source-read-it-later-app-wallabag
|
||||
[2]:https://wallabag.org/en
|
||||
[3]:https://www.wallabag.org/en/news/wallabag-v2
|
||||
[4]:https://pinboard.in
|
||||
[5]:https://en.wikipedia.org/wiki/Material_Design
|
||||
[6]:https://www.wallabag.it
|
||||
[7]:https://github.com/wallabag/wallabagger
|
||||
@ -0,0 +1,141 @@
|
||||
Robolinux Lets You Easily Run Linux and Windows Without Dual Booting
|
||||
======
|
||||
|
||||

|
||||
|
||||
The number of Linux distributions available just keeps getting bigger. In fact, in the time it took me to write this sentence, another one may have appeared on the market. Many Linux flavors have trouble standing out in this crowd, and some are just a different combination of puzzle pieces joined to form something new: An Ubuntu base with a KDE desktop environment. A Debian base with an Xfce desktop. The combinations go on and on.
|
||||
|
||||
[Robolinux][1], however, does something unique. It’s the only distro, to my knowledge, that makes working with Windows alongside Linux a little easier for the typical user. With just a few clicks, it lets you create a Windows virtual machine (by way of VirtualBox) that can run side by side with Linux. No more dual booting. With this process, you can have Windows XP, Windows 7, or Windows 10 up and running with ease.
|
||||
|
||||
And, you get all this on top of an operating system that’s pretty fantastic on its own. Robolinux not only makes short work of having Windows along for the ride, it simplifies using Linux itself. Installation is easy, and the installed collection of software means anyone can be productive right away.
|
||||
|
||||
Let’s install Robolinux and see what there is to see.
|
||||
|
||||
### Installation
|
||||
|
||||
As I mentioned earlier, installing Robolinux is easy. Obviously, you must first [download an ISO][2] image of the operating system. You have the choice of installing a Cinnamon, Mate, LXDE, or xfce desktop (I opted to go the Mate route). I will warn you, the developers do make a pretty heavy-handed plea for donations. I don’t fault them for this. Developing an operating system takes a great deal of time. So if you have the means, do make a donation.
|
||||
Once you’ve downloaded the file, burn it to a CD/DVD or flash drive. Boot your system with the media and then, once the desktop loads, click the Install icon on the desktop. As soon as the installer opens (Figure 1), you should be immediately familiar with the layout of the tool.
|
||||
|
||||
![Robolinux installer][4]
|
||||
|
||||
Figure 1: The Robolinux installer is quite user-friendly.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Once you’ve walked through the installer, reboot, remove the installation media, and login when prompted. I will say that I installed Robolinux as a VirtualBox VM and it installed to perfection. This however, isn’t a method you should use, if you’re going to take advantage of the Stealth VM option. After logging in, the first thing I did was install the Guest Additions and everything was working smoothly.
|
||||
|
||||
### Default applications
|
||||
|
||||
The collection of default applications is impressive, but not overwhelming. You’ll find all the standard tools to get your work done, including:
|
||||
|
||||
* LibreOffice
|
||||
|
||||
* Atril Document Viewer
|
||||
|
||||
* Backups
|
||||
|
||||
* GNOME Disks
|
||||
|
||||
* Medit text editor
|
||||
|
||||
* Seahorse
|
||||
|
||||
* GIMP
|
||||
|
||||
* Shotwell
|
||||
|
||||
* Simple Scan
|
||||
|
||||
* Firefox
|
||||
|
||||
* Pidgen
|
||||
|
||||
* Thunderbird
|
||||
|
||||
* Transmission
|
||||
|
||||
* Brasero
|
||||
|
||||
* Cheese
|
||||
|
||||
* Kazam
|
||||
|
||||
* Rhythmbox
|
||||
|
||||
* VLC
|
||||
|
||||
* VirtualBox
|
||||
|
||||
* And more
|
||||
|
||||
|
||||
|
||||
|
||||
With that list of software, you shouldn’t want for much. However, should you find a app not installed, click on the desktop menu button and then click Package Manager, which will open Synaptic Package Manager, where you can install any of the Linux software you need.
|
||||
|
||||
If that’s not enough, it’s time to take a look at the Windows side of things.
|
||||
|
||||
### Installing Windows
|
||||
|
||||
This is what sets Robolinux apart from other Linux distributions. If you click on the desktop menu button, you see a Stealth VM entry. Within that sub-menu, a listing of the different Windows VMs that can be installed appears (Figure 2).
|
||||
|
||||
![Windows VMs][7]
|
||||
|
||||
Figure 2: The available Windows VMs that can be installed alongside of Robolinux.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Before you can install one of the VMs, you must first download the Stealth VM file. To do that, double-click on the desktop icon that includes an image of the developer’s face (labeled Robo’s FREE Stealth VM). You must save that file to the ~/Downloads directory. Don’t save it anywhere else, don’t extract it, and don’t rename it. With that file in place, click the start menu and then click Stealth VM. From the listing, click the top entry, Robolinx Stealth VM Installer. When prompted, type your sudo password. You will then be prompted that the Stealth VM is ready to be used. Go back to the start menu and click Stealth VM and select the version of Windows you want to install. A new window will appear (Figure 3). Click Yes and the installation will continue.
|
||||
|
||||
![Installing Windows][9]
|
||||
|
||||
Figure 3: Installing Windows in the Stealth VM.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Next you will be prompted to type your sudo password again (so your user can be added to the vboxusers group). Once you’ve taken care of that, you’ll be prompted to configure the RAM you want to dedicate to the VM. After that, a browser window will appear (once again asking for a donation). At this point everything is (almost) done. Close the browser and the terminal window.
|
||||
|
||||
You’re not finished.
|
||||
|
||||
Next you must insert the Windows installer media that matches the type of Windows VM you installed. You then must start VirtualBox by click start menu > System Tools > Oracle VM VirtualBox. When VirtualBox opens, an entry will already be created for your Windows VM (Figure 4).
|
||||
|
||||
![Windows VM][11]
|
||||
|
||||
Figure 4: Your Windows VM is ready to go.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
You can now click the Start button (in VirtualBox) to finish up the installation. When the Windows installation completes, you’re ready to work with Linux and Windows side-by-side.
|
||||
|
||||
### Making VMs a bit more user-friendly
|
||||
|
||||
You may be thinking to yourself, “Creating a virtual machine for Windows is actually easier than that!”. Although you are correct with that sentiment, not everyone knows how to create a new VM with VirtualBox. In the time it took me to figure out how to work with the Robolinux Stealth VM, I could have had numerous VMs created in VirtualBox. Additionally, this approach doesn’t happen free of charge. You do still have to have a licensed copy of Windows (as well as the installation media). But anything developers can do to make using Linux easier is a plus. That’s how I see this—a Linux distribution doing something just slightly different that could remove a possible barrier to entry for the open source platform. From my perspective, that’s a win-win. And, you’re getting a pretty solid Linux distribution to boot.
|
||||
|
||||
If you already know the ins and outs of VirtualBox, Robolinux might not be your cuppa. But, if you don’t like technology getting in the way of getting your work done and you want to have a Linux distribution that includes all the necessary tools to help make you productive, Robolinux is definitely worth a look.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/robolinux-lets-you-easily-run-linux-and-windows-without-dual-booting
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.robolinux.org
|
||||
[2]:https://www.robolinux.org/downloads/
|
||||
[3]:/files/images/robolinux1jpg
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_1.jpg?itok=MA0MD6KY (Robolinux installer)
|
||||
[5]:/licenses/category/used-permission
|
||||
[6]:/files/images/robolinux2jpg
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_2.jpg?itok=bHktIhhK (Windows VMs)
|
||||
[8]:/files/images/robolinux3jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_3.jpg?itok=B7ar6hZf (Installing Windows)
|
||||
[10]:/files/images/robolinux4jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_4.jpg?itok=nEOt5Vnc (Windows VM)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
168
sources/tech/20180706 Using Ansible to set up a workstation.md
Normal file
168
sources/tech/20180706 Using Ansible to set up a workstation.md
Normal file
@ -0,0 +1,168 @@
|
||||
Using Ansible to set up a workstation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Ansible is an extremely popular [open-source configuration management and software automation project][1]. While IT professionals almost certainly use Ansible on a daily basis, its influence outside the IT industry is not as wide. Ansible is a powerful and flexible tool. It is easily applied to a task common to nearly every desktop computer user: the post-installation “checklist”.
|
||||
|
||||
Most users like to apply one “tweak” after a new installation. Ansible’s idempotent, declarative syntax lends itself perfectly to describing how a system should be configured.
|
||||
|
||||
### Ansible in a nutshell
|
||||
|
||||
The _ansible_ program itself performs a **single task** against a set of hosts. This is roughly conceptualized as:
|
||||
```
|
||||
for HOST in $HOSTS; do
|
||||
ssh $HOST /usr/bin/echo "Hello World"
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
To perform more than one task, Ansible defines the concept of a “playbook”. A playbook is a YAML file describing the _state_ of the targeted machine. When run, Ansible inspects each host and performs only the tasks necessary to enforce the state defined in the playbook.
|
||||
```
|
||||
- hosts: all
|
||||
tasks:
|
||||
- name: Echo "Hello World"
|
||||
command: echo "Hello World"
|
||||
|
||||
```
|
||||
|
||||
Run the playbook using the _ansible-playbook_ command:
|
||||
```
|
||||
$ ansible-playbook ~/playbook.yml
|
||||
|
||||
```
|
||||
|
||||
### Configuring a workstation
|
||||
|
||||
Start by installing ansible:
|
||||
```
|
||||
dnf install ansible
|
||||
|
||||
```
|
||||
|
||||
Next, create a file to store the playbook:
|
||||
```
|
||||
touch ~/post_install.yml
|
||||
|
||||
```
|
||||
|
||||
Start by defining the host on which to run this playbook. In this case, “localhost”:
|
||||
```
|
||||
- hosts: localhost
|
||||
|
||||
```
|
||||
|
||||
Each task consists of a _name_ field and a module field. Ansible has **a lot** of [modules][2]. Be sure to browse the module index to become familiar with all Ansible has to offer.
|
||||
|
||||
#### The package module
|
||||
|
||||
Most users install additional packages after a fresh install, and many like to remove some shipped software they don’t use. The _[package][3]_ module provides a generic wrapper around the system package manager (in Fedora’s case, _dnf_ ).
|
||||
```
|
||||
- hosts: localhost
|
||||
tasks:
|
||||
- name: Install Builder
|
||||
become: yes
|
||||
package:
|
||||
name: gnome-builder
|
||||
state: present
|
||||
- name: Remove Rhythmbox
|
||||
become: yes
|
||||
package:
|
||||
name: rhythmbox
|
||||
state: absent
|
||||
- name: Install GNOME Music
|
||||
become: yes
|
||||
package:
|
||||
name: gnome-music
|
||||
state: present
|
||||
- name: Remove Shotwell
|
||||
become: yes
|
||||
package:
|
||||
name: shotwell
|
||||
state: absent
|
||||
```
|
||||
|
||||
This playbook results in the following outcomes:
|
||||
|
||||
* GNOME Builder and GNOME Music are installed
|
||||
* Rhythmbox is removed
|
||||
* On Fedora 28 or greater, nothing happens with Shotwell (it is not in the default list of packages)
|
||||
* On Fedora 27 or older, Shotwell is removed
|
||||
|
||||
|
||||
|
||||
This playbook also introduces the **become: yes** directive. This specifies the task must be run by a privileged user (in most cases, _root_ ).
|
||||
|
||||
#### The DConf Module
|
||||
|
||||
Ansible can do a lot more than install software. For example, GNOME includes a great color-shifting feature called Night Light. It ships disabled by default, however the Ansible _[dconf][4]_ module can very easily enable it.
|
||||
```
|
||||
- hosts: localhost
|
||||
tasks:
|
||||
- name: Enable Night Light
|
||||
dconf:
|
||||
key: /org/gnome/settings-daemon/plugins/color/night-light-enabled
|
||||
value: true
|
||||
- name: Set Night Light Temperature
|
||||
dconf:
|
||||
key: /org/gnome/settings-daemon/plugins/color/night-light-temperature
|
||||
value: uint32 5500
|
||||
```
|
||||
|
||||
Ansible can also create files at specified locations with the _[copy][5]_ module. In this example, a local file is copied to the destination path.
|
||||
```
|
||||
- hosts: localhost
|
||||
tasks:
|
||||
- name: Enable "AUTH_ADMIN_KEEP" for pkexec
|
||||
become: yes
|
||||
copy:
|
||||
src: files/51-pkexec-auth-admin-keep.rules
|
||||
dest: /etc/polkit-1/rules.d/51-pkexec-auth-admin-keep.rules
|
||||
|
||||
```
|
||||
|
||||
#### The Command Module
|
||||
|
||||
Ansible can still run commands even if no specialized module exists (via the aptly named _[command][6]_ module). This playbook enables the [Flathub][7] repository and installs a few Flatpaks. The commands are crafted in such a way that they are effectively idempotent. This is an important behavior to consider; a playbook should succeed each time it is run on a machine.
|
||||
```
|
||||
- hosts: localhost
|
||||
tasks:
|
||||
- name: Enable Flathub repository
|
||||
become: yes
|
||||
command: flatpak remote-add --if-not-exists flathub https://flathub.org/repo/flathub.flatpakrepo
|
||||
- name: Install Fractal
|
||||
become: yes
|
||||
command: flatpak install --assumeyes flathub org.gnome.Fractal
|
||||
- name: Install Spotify
|
||||
become: yes
|
||||
command: flatpak install --assumeyes flathub com.spotify.Client
|
||||
```
|
||||
|
||||
Combine all these tasks together into a single playbook and, in one command, ** Ansible will customize a freshly installed workstation. Not only that, but 6 months later, after making changes to the playbook, run it again to bring a “seasoned” install back to a known state.
|
||||
```
|
||||
$ ansible-playbook -K ~/post_install.yml
|
||||
|
||||
```
|
||||
|
||||
This article only touched the surface of what’s possible with Ansible. A follow-up article will go into more advanced Ansible concepts such as _roles,_ configuring multiple hosts with a divided set of responsibilities.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/using-ansible-setup-workstation/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/linkdupont/
|
||||
[1]:https://ansible.com
|
||||
[2]:https://docs.ansible.com/ansible/latest/modules/list_of_all_modules.html
|
||||
[3]:https://docs.ansible.com/ansible/latest/modules/package_module.html#package-module
|
||||
[4]:https://docs.ansible.com/ansible/latest/modules/dconf_module.html#dconf-module
|
||||
[5]:https://docs.ansible.com/ansible/latest/modules/copy_module.html#copy-module
|
||||
[6]:https://docs.ansible.com/ansible/latest/modules/command_module.html#command-module
|
||||
[7]:https://flathub.org
|
||||
212
sources/tech/20180708 Getting Started with Debian Packaging.md
Normal file
212
sources/tech/20180708 Getting Started with Debian Packaging.md
Normal file
@ -0,0 +1,212 @@
|
||||
Getting Started with Debian Packaging
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of my tasks in GSoC involved set up of Thunderbird extensions for the user. Some of the more popular add-ons like [‘Lightning’][1] (calendar organiser) already has a Debian package.
|
||||
|
||||
Another important add on is ‘[Cardbook][2]’ which is used to manage contacts for the user based on CardDAV and vCard standards. But it doesn’t have a package yet.
|
||||
|
||||
My mentor, [Daniel][3] motivated me to create a package for it and upload it to [mentors.debian.net][4]. It would ease the installation process as it could get installed through `apt-get`. This blog describes how I learned and created a Debian package for CardBook from scratch.
|
||||
|
||||
Since, I was new to packaging, I did extensive research on basics of building a package from the source code and checked if the license was [DFSG][5] compatible.
|
||||
|
||||
I learned from various Debian wiki guides like ‘[Packaging Intro][6]’, ‘[Building a Package][7]’ and blogs.
|
||||
|
||||
I also studied the amd64 files included in [Lightning extension package][8].
|
||||
|
||||
The package I created could be found [here][9].
|
||||
|
||||
![Debian Package!][10]
|
||||
|
||||
Debian Package
|
||||
|
||||
### Creating an empty package
|
||||
|
||||
I started by creating a `debian` directory by using `dh_make` command
|
||||
```
|
||||
# Empty project folder
|
||||
$ mkdir -p Debian/cardbook
|
||||
|
||||
```
|
||||
```
|
||||
# create files
|
||||
$ dh_make\
|
||||
> --native \
|
||||
> --single \
|
||||
> --packagename cardbook_1.0.0 \
|
||||
> --email minkush@example.com
|
||||
|
||||
```
|
||||
|
||||
Some important files like control, rules, changelog, copyright are initialized with it.
|
||||
|
||||
The list of all the files created:
|
||||
```
|
||||
$ find /debian
|
||||
debian/
|
||||
debian/rules
|
||||
debian/preinst.ex
|
||||
debian/cardbook-docs.docs
|
||||
debian/manpage.1.ex
|
||||
debian/install
|
||||
debian/source
|
||||
debian/source/format
|
||||
debian/cardbook.debhelper.lo
|
||||
debian/manpage.xml.ex
|
||||
debian/README.Debian
|
||||
debian/postrm.ex
|
||||
debian/prerm.ex
|
||||
debian/copyright
|
||||
debian/changelog
|
||||
debian/manpage.sgml.ex
|
||||
debian/cardbook.default.ex
|
||||
debian/README
|
||||
debian/cardbook.doc-base.EX
|
||||
debian/README.source
|
||||
debian/compat
|
||||
debian/control
|
||||
debian/debhelper-build-stamp
|
||||
debian/menu.ex
|
||||
debian/postinst.ex
|
||||
debian/cardbook.substvars
|
||||
debian/files
|
||||
|
||||
```
|
||||
|
||||
I gained an understanding of [Dpkg][11] package management program in Debian and its use to install, remove and manage packages.
|
||||
|
||||
I build an empty package with `dpkg` commands. This created an empty package with four files namely `.changes`, `.deb`, `.dsc`, `.tar.gz`
|
||||
|
||||
`.dsc` file contains the changes made and signature
|
||||
|
||||
`.deb` is the main package file which can be installed
|
||||
|
||||
`.tar.gz` (tarball) contains the source package
|
||||
|
||||
The process also created the README and changelog files in `/usr/share`. They contain the essential notes about the package like description, author and version.
|
||||
|
||||
I installed the package and checked the installed package contents. My new package mentions the version, architecture and description!
|
||||
```
|
||||
$ dpkg -L cardbook
|
||||
/usr
|
||||
/usr/share
|
||||
/usr/share/doc
|
||||
/usr/share/doc/cardbook
|
||||
/usr/share/doc/cardbook/README.Debian
|
||||
/usr/share/doc/cardbook/changelog.gz
|
||||
/usr/share/doc/cardbook/copyright
|
||||
|
||||
```
|
||||
|
||||
### Including CardBook source files
|
||||
|
||||
After successfully creating an empty package, I added the actual CardBook add-on files inside the package. The CardBook’s codebase is hosted [here][12] on Gitlab. I included all the source files inside another directory and told the build package command which files to include in the package.
|
||||
|
||||
I did this by creating a file `debian/install` using vi editor and listed the directories that should be installed. In this process I spent some time learning to use Linux terminal based text editors like vi. It helped me become familiar with editing, creating new files and shortcuts in vi.
|
||||
|
||||
Once, this was done, I updated the package version in the changelog file to document the changes that I have made.
|
||||
```
|
||||
$ dpkg -l | grep cardbook
|
||||
ii cardbook 1.1.0 amd64 Thunderbird add-on for address book
|
||||
|
||||
```
|
||||
|
||||
![Changelog][13]
|
||||
|
||||
Changelog file after updating Package
|
||||
|
||||
After rebuilding it, dependencies and detailed description can be added if necessary. The Debian control file can be edited to add the additional package requirements and dependencies.
|
||||
|
||||
### Local Debian Repository
|
||||
|
||||
Without creating a local repository, CardBook could be installed with:
|
||||
```
|
||||
$ sudo dpkg -i cardbook_1.1.0.deb
|
||||
|
||||
```
|
||||
|
||||
To actually test the installation for the package, I decided to build a local Debian repository. Without it, the `apt-get` command would not locate the package, as it is not in uploaded in Debian packages on net.
|
||||
|
||||
For configuring a local Debian repository, I copied my packages (.deb) to `Packages.gz` file placed in a `/tmp` location.
|
||||
|
||||
![Packages-gz][14]
|
||||
|
||||
Local Debian Repo
|
||||
|
||||
To make it work, I learned about the apt configuration and where it looks for files.
|
||||
|
||||
I researched for a way to add my file location in apt-config. Finally I could accomplish the task by adding `*.list` file with package’s path in APT and updating ‘apt-cache’ afterwards.
|
||||
|
||||
Hence, the latest CardBook version could be successfully installed by `apt-get install cardbook`
|
||||
|
||||
![Package installation!][15]
|
||||
|
||||
CardBook Installation through apt-get
|
||||
|
||||
### Fixing Packaging errors and bugs
|
||||
|
||||
My mentor, Daniel helped me a lot during this process and guided me how to proceed further with the package. He told me to use [Lintian][16] for fixing common packaging error and then using [dput][17] to finally upload the CardBook package.
|
||||
|
||||
> Lintian is a Debian package checker which finds policy violations and bugs. It is one of the most widely used tool by Debian Maintainers to automate checks for Debian policies before uploading the package.
|
||||
|
||||
I have uploaded the second updated version of the package in a separate branch of the repository on Salsa [here][18] inside Debian directory.
|
||||
|
||||
I installed Lintian from backports and learned to use it on a package to fix errors. I researched on the abbreviations used in its errors and how to show detailed response from lintian commands
|
||||
```
|
||||
$ lintian -i -I --show-overrides cardbook_1.2.0.changes
|
||||
|
||||
```
|
||||
|
||||
Initially on running the command on the `.changes` file, I was surprised to see that a large number of errors, warnings and notes were displayed!
|
||||
|
||||
![Package Error Brief!][19]
|
||||
|
||||
Brief errors after running Lintian on Package
|
||||
|
||||
![Lintian error1!][20]
|
||||
|
||||
Detailed Lintian errors
|
||||
|
||||
Detailed Lintian errostyle=”width:200px;”rs
|
||||
|
||||
I spend some days to fix some errors related to Debian package policy violations. I had to dig into every policy and Debian rules carefully to eradicate a simple error. For this I referred various sections on [Debian Policy Manual][21] and [Debian Developer’s Reference][22].
|
||||
|
||||
I am still working on making it flawless and hope to upload it on mentors.debian.net soon!
|
||||
|
||||
It would be grateful if people from the Debian community who use Thunderbird could help fix these errors.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://minkush.me/cardbook-debian-package/
|
||||
|
||||
作者:[Minkush Jain][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://minkush.me/cardbook-debian-package/#
|
||||
[1]:https://addons.mozilla.org/en-US/thunderbird/addon/lightning/
|
||||
[2]:https://addons.mozilla.org/nn-NO/thunderbird/addon/cardbook/?src=hp-dl-featured
|
||||
[3]:https://danielpocock.com/
|
||||
[4]:https://mentors.debian.net/
|
||||
[5]:https://wiki.debian.org/DFSGLicenses
|
||||
[6]:https://wiki.debian.org/Packaging/Intro
|
||||
[7]:https://wiki.debian.org/BuildingAPackage
|
||||
[8]:https://packages.debian.org/stretch/amd64/lightning/filelist
|
||||
[9]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package/Debian
|
||||
[10]:/img/posts/13.png
|
||||
[11]:https://packages.debian.org/stretch/dpkg
|
||||
[12]:https://gitlab.com/CardBook/CardBook
|
||||
[13]:/img/posts/15.png
|
||||
[14]:/img/posts/14.png
|
||||
[15]:/img/posts/11.png
|
||||
[16]:https://packages.debian.org/stretch/lintian
|
||||
[17]:https://packages.debian.org/stretch/dput
|
||||
[18]:https://salsa.debian.org/minkush-guest/CardBook/tree/debian-package
|
||||
[19]:/img/posts/16.png (Running Lintian on package)
|
||||
[20]:/img/posts/10.png
|
||||
[21]:https://www.debian.org/doc/debian-policy/
|
||||
[22]:https://www.debian.org/doc/manuals/developers-reference/
|
||||
119
sources/tech/20180708 simple and elegant free podcast player.md
Normal file
119
sources/tech/20180708 simple and elegant free podcast player.md
Normal file
@ -0,0 +1,119 @@
|
||||
simple and elegant free podcast player
|
||||
======
|
||||
|
||||

|
||||
|
||||
CPod (formerly known as Cumulonimbus) is a cross-platform, open source podcast player for the desktop. The application is built with web technologies – it’s written in the JavaScript programming language and uses the Electron framework. Electron is often (rightly?) criticized for being a memory hog and dog slow. But is that mainly because of poor programming, rather than an inherent flaw in the technology?
|
||||
|
||||
CPod is available for Linux, Mac OS, and Windows. Installation was a breeze on my Ubuntu 18.04 distribution as the author conveniently provides a 64-bit deb package. If you don’t run a Debian/Ubuntu based distro, there’s an AppImage which effortlessly installs the software on all major Linux distributions. There’s also a snap package from the snapcraft website, but bizarrely (and incorrectly) flags the software as proprietary software. As CPod is released under an open source license, there’s the full source code available too.
|
||||
|
||||
The deb package installs the software to /opt/CPod, although the binary is still called cumulonimbus. A bit of tidying up needed there. For Mac OS users, there’s an Apple Disk Image file.
|
||||
|
||||
### Home
|
||||
|
||||
![CPod Playlist][2]
|
||||
First off, you cannot fail to notice the gorgeous attractive interface. Presentation is first class.
|
||||
|
||||
First off, you cannot fail to notice the gorgeous attractive interface. Presentation is first class.
|
||||
|
||||
The home section shows your subscribed podcasts. There are helpful filters at the top. They let you select podcasts of specified duration (handy if time is limited), you can filter by date, filter for podcasts that you’ve downloaded an offline copy, as well as podcasts that have not been listened to, you’ve started listening to, and podcasts you’ve heard to the end.
|
||||
|
||||
Below the filters, there’s the option to select multiple podcasts, download local copies, add podcasts to your queue, as well as actually playing a podcast. The interface is remarkably intuitive.
|
||||
|
||||
One quirk is that offline episodes are downloaded to the directory ~/.config/cumulonimbus/offline_episodes/. The downloaded podcasts are therefore not visible in the Files file manager by default (this is because the standard installation of Files does not display ‘hidden files’). It’s easy to enable hidden files in the file manager. Good news, the developer plans to add a configurable default download directory.
|
||||
|
||||
There’s lots of nice touches which enhance the user experience, such as the progress bars when downloading episodes.
|
||||
|
||||
### Playing a podcast
|
||||
|
||||
![CPod][3]
|
||||
|
||||
Here’s one of my favourite podcasts, Ubuntu Podcast, in playback. There’s visualization effects enabled; they only show when the window has focus. The visualizations don’t always display properly. There’s also the option of changing the playback speed (0.5x – 4x speed). I’m not sure why I’d want to change the playback speed though. Maybe someone could enlighten me?
|
||||
|
||||
More functional is the slider that lets you skip to a specific point of the podcast although this is a tad buggy. The software is in an early stage of development. In any case, I prefer using the keyboard shortcuts to move forwards and backwards, and they work fine. Some podcasts offer links that let you skip to a particular segment; they are displayed in the large pane.
|
||||
|
||||
There’s also the ability to watch video podcasts in both fullscreen and window mode. I spend most of my time listening to audio podcasts, but having full screen video podcasts is a pretty cool feature. Video playback is powered by ffmpeg.
|
||||
|
||||
### Queue
|
||||
|
||||
![CPod Queue][4]
|
||||
There’s not much to say about the queue functionality, but it’s worth noting you can change the order of episodes simply by dragging and dropping them in the interface. It’s well implemented and really simple to use. Another tick for CPod.
|
||||
|
||||
### Subscriptions
|
||||
|
||||
There’s not much to say about the queue functionality, but it’s worth noting you can change the order of episodes simply by dragging and dropping them in the interface. It’s well implemented and really simple to use. Another tick for CPod.
|
||||
|
||||
![CPod Subscriptions][5]
|
||||
|
||||
The interface makes it really easy to subscribe and unsubscribe to podcasts. Clicking the image of a subscribed podcast lets you find an episode, as well as a list of recent episodes, again with the ability to play, queue, and download. It’s all very clean and easy to use.
|
||||
|
||||
### Explore
|
||||
|
||||
In explore you can search for podcasts. Just type some keywords into the Explore dialog box, and you’re presented with a list of podcasts you can listen and subscribe.
|
||||
|
||||
If you’re a fan of YouTube, you’re in luck. There’s the ability to preview and subscribe to YouTube channels by pasting a channel’s URL into the Explore box. That’s great if you have YouTube channel hyperlinks handy, but some sort of YouTube channel finder would be a great addition.
|
||||
|
||||
Here’s a YouTube video in action.
|
||||
|
||||
![CPod YTube][6]
|
||||
|
||||
### Settings
|
||||
|
||||
![CPod Settings][7]
|
||||
|
||||
There’s a lot you can configure in Settings. There’s functionality to:
|
||||
|
||||
* Internationalization support – the ability to select the language displayed. Currently, there’s fairly limited support in this respect. Besides English, there’s Chinese, French, German, Korean, Portuguese, Portuguese (Brazilian), and Spanish available. Contributing translations is probably the easiest way for non-programmers to contribute to an open source project.
|
||||
* Option to group episodes in Home by day or month.
|
||||
* Keyboard shortcuts that let you skip backward, skip forward, and play/pause playback. I love my keyboard shortcuts.
|
||||
* Configure different lengths of forward/backward skip.
|
||||
* Enable waveform visualization – you can see examples of the visualization in our images (Playlist and Subscription sections).
|
||||
* Basic gpodder.net integration (currently only subscriptions and device sync are supported; other functionality such as episodes actions and queue are planned).
|
||||
* Allow pre-releases when auto-updating.
|
||||
* Export subscriptions to OPML – Outline Processor Markup Language is an XML format commonly used to exchange lists of web feeds between web feed aggregators.
|
||||
* Import subscriptions from OPML.
|
||||
* Update podcast cover art.
|
||||
* View offline episodes directory.
|
||||
|
||||
|
||||
|
||||
The software has a bag of neat touches. For example, if I change the language setting, the software presents a pop up saying CPod needs to be restarted for the change to take effect. All very user-friendly.
|
||||
|
||||
The Media Player Remote Interfacing Specification (MPRIS) is a standard D-Bus interface which aims to provide a common programmatic API for controlling media players. CPod offers basic MPRIS integration.
|
||||
|
||||
### Summary
|
||||
|
||||
CPod is another good example of what’s possible with modern web technologies. Sure, it’s got a few quirks, it’s in an early stage of development (read ‘expect to find lots of bugs’), and there’s some useful functionality waiting to be implemented. But I’m using the software on a daily basis, and will definitely keep up-to-date with developments.
|
||||
|
||||
Linux already has some high quality open source podcast players. But CPod is definitely worth a download if you’re passionate about podcasts.
|
||||
|
||||
**Website:** [**github.com/z————-/CPod**][8]
|
||||
**Support:**
|
||||
**Developer:** Zack Guard
|
||||
**License:** Apache License 2.0
|
||||
|
||||
Zack Guard, CPod’s developer, is a student who lives in Hong Kong. You can buy him a coffee at **<https://www.buymeacoffee.com/zackguard>**. Unfortunately, I’m an impoverished student too.
|
||||
|
||||
### Related
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/cpod-simple-elegant-free-podcast-player/
|
||||
|
||||
作者:[Luke Baker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/luke-baker/
|
||||
[1]:https://www.linuxlinks.com/wp-content/plugins/jetpack/modules/lazy-images/images/1x1.trans.gif
|
||||
[2]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Playlist.jpg?resize=750%2C368&ssl=1
|
||||
[3]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Main.jpg?resize=750%2C368&ssl=1
|
||||
[4]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Queue.jpg?resize=750%2C368&ssl=1
|
||||
[5]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Subscriptions.jpg?resize=750%2C368&ssl=1
|
||||
[6]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-YouTube.jpg?resize=750%2C368&ssl=1
|
||||
[7]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/07/CPod-Settings.jpg?resize=750%2C368&ssl=1
|
||||
[8]:https://github.com/z-------------/CPod
|
||||
@ -0,0 +1,56 @@
|
||||
尝试,学习,修改:新 IT 领导者的代码
|
||||
=====
|
||||
|
||||

|
||||
|
||||
几乎每一天,新的技术发展都在威胁破坏,甚至是那些最复杂,最完善的商业计划。组织经常发现自己正在努力适应新的环境,这导致了他们对未来规划的转变。
|
||||
|
||||
根据 CompTIA 2017 年的[研究][1],目前只有 34% 的公司正在制定超过 12 个月的 IT 架构计划。从长期计划转变的一个原因是:商业环境变化如此之快,以至于几乎不可能进一步规划未来。[CIO.com 说道][1]“如果你的公司正视图制定一项将持续五到十年的计划,那就忘了它。”
|
||||
|
||||
我听过来自世界各地无数客户和合作伙伴的类似声明:技术创新正以一种前所未有的速度发生着。
|
||||
|
||||
其结果是长期规划已不复存在。如果我们要在这个新世界取得成功,我们需要以不同的方式思考我们运营组织的方式。
|
||||
|
||||
### 计划是怎么死的
|
||||
|
||||
正如我在 Open Organization(开源组织)中写的那样,传统经营组织针对工业经济进行了优化。他们采用等级结构和严格规定的流程,以实现地位竞争优势。要取得成功,他们必须确定他们想要实现的战略地位。然后,他们必须制定并规划实现目标的计划,并以最有效的方式执行这些计划,通过协调活动和推动合规性。
|
||||
|
||||
管理层的职责是优化这一过程:计划,规定,执行。包括:让我们想象一个有竞争力的优势地位;让我们来配置组织以最终到达那里;然后让我们通过确保组织的所有方面都遵守规定来推动执行。这就是我所说的“机械管理”,对于不同时期来说它都是一个出色的解决方案。
|
||||
|
||||
在当今动荡不定的世界中,我们预测和定义战略位置的能力正在下降,因为变化的速度,新变量的引入速度正在加速。传统的,长期的,战略性规划和执行不像以前那么有效。
|
||||
|
||||
如果长期规划变得如此困难,那么规定必要的行为就更具有挑战性。并且衡量对计划的合规性几乎是不可能的。
|
||||
|
||||
这一切都极大地影响了人们的工作方式。与过去传统经营组织中的工人不同,他们为自己能够重复行动而感到自豪,几乎没有变化和舒适的确定性 -- 今天的工人在充满模糊性的环境中运作。他们的工作需要更大的创造力,直觉和批判性判断 -- 有更大的要求是背离过去的“正常”,适应当今的新情况。
|
||||
|
||||
以这种新方式工作对于价值创造变得更加重要。我们的管理系统必须专注于构建结构,系统和流程,以帮助创建积极主动的工人,他们能够以快速和敏捷的方式进行创新和行动。
|
||||
|
||||
我们需要提出一个不同的解决方案来优化组织,以适应不同的经济时代,从自下而上而不是自上而下开始。我们需要替换过去的三步骤 -- 计划,规定,执行,以一种更适应当今动荡天气的方法来取得成功 -- 尝试,学习,修改。
|
||||
|
||||
### 尝试,学习,修改
|
||||
|
||||
因为环境变化如此之快,而且几乎没有任何预警,并且因为我们需要采取的步骤不再提前计划,我们需要培养鼓励创造性尝试和错误的环境,而不是坚持对五年计划的忠诚。以下是以这种方式开始工作的一些暗示:
|
||||
|
||||
* **更短的计划周期(尝试)。** 管理者需要考虑的是他们可以快速尝试的短期实验,而不是在长期战略方向上苦恼。他们应该寻求方法来帮助他们的团队承担计算风险,并利用他们掌握的数据来对最有利的路径做出最好的猜测。他们可以通过降低开销和让团队自由快速尝试新方法来做到这一点。
|
||||
* **更高的失败容忍度(学习)。** 更多的实验频率意味着更大的失败机会。与传统组织相比,富有创造力和有弹性的组织[对失败的容忍度要高得多][2]。管理者应将失败视为学习的机会,在他们的团队正在运行的测试中收集反馈的时刻。
|
||||
* **更具适应性的结构(修改)。** 能够轻松修改组织结构和战略方向,以及在条件需要时愿意这样做,是确保组织能够根据快速变化的环境条件发展的关键。管理者不能再拘泥于任何想法,因为这个想法证明自己对实现短期目标很有用。
|
||||
|
||||
如果长期计划已经消亡,那么就可以进行长期的短期实验。尝试,学习和修改,这是在不确定时期前进的最佳途径。
|
||||
|
||||
[订阅我们的每周实事通讯][3]以了解有关开源组织的更多信息。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/try-learn-modify
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://www.cio.com/article/3246027/enterprise-architecture/the-death-of-long-term-it-planning.html?upd=1515780110970
|
||||
[2]:https://opensource.com/open-organization/16/12/building-culture-innovation-your-organization
|
||||
[3]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -0,0 +1,88 @@
|
||||
在市场工作时如何建立一个职业网络
|
||||
======
|
||||
|
||||

|
||||
|
||||
职业社交网络——在同事或专业人员之间建立人际联系——可以采用多种形式、在产业内跨组织进行。建立职业网络需要花费时间和精力,并且当某位成员加入或离开一个组织时,此人的网络通常需要被在一个新的工作环境中重建。
|
||||
|
||||
职业社交网络在不同组织中起相似作用——信息共享,导师制,机会,工作利益和其他作用——然而传统组织与开放组织在组织内构建特定联系的方法和原因可能不尽相同。这些差异有其影响:同事联系方式、如何建立信任、组织内多元化的程度和种类以及建立合作的能力,所有这些因素都是相互关联的,而且他们参与并塑造了人们所建立的社交网络。
|
||||
|
||||
一个开放的组织对包容性的强调可以使社交网络在解决商业问题上比传统等级制组织更加高效。这种观念在开源的思考中有很久的历史。例如,在<ruby>[《教堂与市场》][1]<rt>The Cathedral and the Bazaar</rt></ruby>中,埃里克·雷蒙德写道:“许多年前社会学家发现, 相比一个随机选择的观察者的观点,许多同等专业的(或是同等无知的)观察家的普遍观点是可靠得多的预言。”所以让我们了解社交网络的结构和目的如何影响各类组织的价值观。
|
||||
|
||||
### 传统组织中的社交网络
|
||||
|
||||
当我在传统组织工作并要描述我为工作做了什么时,人们问我的第一件事就是我与其他人如何关联,通常是主任级的领导。“你在希拉手下吗?”他们会这么问。“你为马尔科姆工作吗?”这意味着以一种上下级的视角看待传统组织的作用;当试图安排工作或雇员时,人们想要从上下级的角度理解网络结构。
|
||||
|
||||
换言之,在传统组织中社交网络依赖于等级制结构,因此他们彼此追寻。事实上,甚至弄清一个雇员在关系网中处于怎样的位置也算得上是一种“上下级组织”式的担忧。
|
||||
|
||||
然而并非所有潜在等级制都是如此。它还视相关人员而定。对于上下级网络的关注会决定雇员在网络中的“价值”,因为网络本身是一个持续的权力关系的系统,它会根据人不同水平的价值给予他们不同的定位。它淡化了个人的能力和技能的重要性。因此,一个人在传统组织的联系促使其能力具有前瞻性,为人所知,有影响力并在其事业中起到支持作用。
|
||||
|
||||
相比传统等级制组织,一个开放的组织对包容性的强调能使网络解决商业问题更加高效。
|
||||
|
||||
传统组织的正式结构以特定方式决定着雇员的社交网络——有些可能是优点,有些可能是缺点,这取决于具体环境——例如:
|
||||
|
||||
* 要更快速地了解“谁是谁”并看到人们如何关联是较为便捷的(通常这在特定层级内建立信任网络)。
|
||||
* 通常,这种对关系的进一步的理解意味着会有更少的过剩工作(在一个特定网络中项目有清晰的相应的归属者)和过多交流(人们知道谁对交流什么负责)。
|
||||
* 相关人员会感到在一个权力结构中感到束手无策,或好像他们不能“闯入”权力结构中,这些结构有时(或更多时候)因为裁员并不起作用。
|
||||
* 完成大量的工作和努力是困难的,并且合作会很艰难。
|
||||
* 权力转让缓慢;一个人的参与能力更多地决定于等级结构所创造的网络的结盟而非其他因素(比如个人能力),减少了被看做社区和成员利益的东西。
|
||||
* 竞争似乎更加清晰;理解“谁在竞争什么”通常发生在一个公认的、被限定了的等级结构中(权力网络中职位的缺乏增进了竞争因此竞争会更激烈)。
|
||||
* 当更严格的网络决定了灵活性的限度时,适应能力会受损。网络的“夙愿”和合作的限度也会以同样的方式受影响。
|
||||
* 在严格的网络中,方向明确,并且领导人通常靠过度指导经营,在这里,破坏更容易发生。
|
||||
* 当社交网络不那么灵活时,风险下降;人们知道什么需要发生,怎样发生,何时发生(但是考虑到在一个组织中工作的广度,这不见得总是“坏事”;一些工作的职能需要较小的风险,例如:<ruby>人力资源管理<rt>H R</rt></ruby>),企业并购和法律工作等。
|
||||
* 在网络中的信任是更大的,尤其当受雇者是正式网络的一部分的时候(当某人不是网络的一份子时,被排斥的人可能特别难管理或改正)。
|
||||
|
||||
|
||||
|
||||
### 开放组织中的社交网络
|
||||
|
||||
尽管开放组织必定会有等级结构,但他们并不根据那个网络运作。他们的职业网络结构更加灵活(或者说是“随时随地”)。
|
||||
|
||||
在一个开放的组织中,当我描述我做了什么工作时,几乎没人问我“我为谁而干?”一个开放的组织更多的以伙伴为中心,而不是以领导为中心。开放的价值观比如包容和特定的治理系统比如强人治理有助于此;那并不是你了解谁而是你了解什么,你怎样使用(比如:“自底而上的设计”)。在一个开放的组织当中,我并不感觉我在为展示自己的价值而奋斗;我的想法有内在的价值。有时我必须示范说明为何使用我的观点比使用别人的更加有用——但是那意味着我正在同事的社区里面诊疗我自己(包括领导层),而不是单独被自上而下的领导层诊疗。
|
||||
|
||||
如此说来,开放的组织并不基于网络评估员工,而是基于他们对作为个人的同事的了解。这个人有想法吗?她会努力通过利用开放组织的价值实现那些想法吗(领导它们)(也就是说,在开放组织中分享那些观点并且实践以将他人囊括并透明公开的工作等等)?
|
||||
|
||||
开放组织也会以特定的方式构造社交网络(这种方式同样可能会视个人的目的性和渴望程度而很有益或很有害),这包括:
|
||||
|
||||
* 人们会对他们的网络、声望、技能和事业更加负责。
|
||||
* 竞争(为了资源、权力、晋升等)会因这些组织天性更具合作性而变得更少。最好的结果是协商,而不是单赢,并且竞争会磨练创意,而不会在人与人之间筑篱设笆。
|
||||
* 权力是更加流动和有活力的,在人与人之间流动(但这同时也意味着可能有对可说明性或者责任的误解,而且活动可能会因为没有明晰的[主人翁意识][2]而不被完成)。
|
||||
* 信任是“一次一同事”地被建立起来的而不会借助社交网络,在网络中,人是被定位着的。
|
||||
* 网络在多样的运转和事件中会自配置,一有机会便会反应性地自启(这帮助了更新但却会造成混乱,因为谁在决策、谁在“受控”是不那么明确的)。
|
||||
* 执行速度在混乱的环境中会下降,因为所做之事、做事方式和处事时间需要在制定目标和涵养好整以暇的员工方面上的领导力。
|
||||
* 灵活的社交网络同样会增加变革和风险;创意会流通得更快而且更神奇,并且执行会更加自信。
|
||||
* 信任建立在同事合作之上(它本该如此!),而不是在对架构的尊重之上。
|
||||
|
||||
|
||||
|
||||
### 让它有效
|
||||
|
||||
如果你正在考虑从一种组织架构转变为另一种,当你在构建并维持你的职业社交网络时思考一下如下所述内容。
|
||||
|
||||
#### 来自传统组织的小建议
|
||||
|
||||
* 对决策的架构和管控不是坏事; 运作中的框架需要明晰透明,而且决策者需要考虑他们的决定。
|
||||
* 在执行上突出需要经理提供关注,还需要有在滤出任何让人分心或混乱的事务的同时仍能提供足够的来龙去脉的能力。
|
||||
* 已经确立的网络帮助了一大批人同步工作并且能管控风险。
|
||||
|
||||
#### 来自开放组织的小建议
|
||||
* 能力强的领导人是那些可以根据多样的风格和对同事、团队的不同偏好提供不同层次的透明度和指导,同时又不会构建出不灵活的网络的人。。
|
||||
* 伟大的想法比已建立的组织会赢得更多。
|
||||
* 人们对他们得名声会更加负责任。
|
||||
* 创意和信息的流转是变革的关键。松散组织中的关系网络可以使这两种元素生发的频度更高、幅度更广。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/6/building-professional-social-networks-openly
|
||||
|
||||
作者:[Heidi Hess;von Ludewig][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ZenMoore](https://github.com/ZenMoore)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:http://www.catb.org/~esr/writings/cathedral-bazaar/cathedral-bazaar/ar01s04.html
|
||||
[2]:https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
|
||||
@ -0,0 +1,146 @@
|
||||
对Ubuntu标准用户的一个高级系统配置程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
**Ubunsys** 是一个基于Qt 的高级系统程序,可以在Ubuntu和其他Ubuntu系列衍生系统上使用.大多数情况下,高级用户可以使用命令行轻松完成大多数配置.
|
||||
不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如Linux Mint,Elementary OS 等. Ubunsys 可用来修改系统配置,安装,删除,更新包和旧内核,启用或禁用sudo 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的Ubuntu 系统升级到最新版本等等
|
||||
以上提到的所有功能都可以通过鼠标点击完成.你不需要再依赖于命令行模式,下面是你能用Ubunsys 做到的事:
|
||||
|
||||
|
||||
* 安装,删除,更新包
|
||||
* 更新和升级软件源
|
||||
* 安装主线内核
|
||||
* 删除旧的和不再使用的内核
|
||||
* 系统整体更新
|
||||
* 将系统升级到下一个可用的版本
|
||||
* 将系统升级到最新的开发版本
|
||||
* 清理系统垃圾文件
|
||||
* 在不输入密码的情况下启用或者禁用sudo 权限
|
||||
* 当你在terminal输入密码时使Sudo 密码可见
|
||||
* 启用或禁用系统冬眠
|
||||
* 启用或禁用防火墙
|
||||
* 打开,备份和导入 sources.list.d 和sudoers 文件.
|
||||
* 显示或者隐藏启动项
|
||||
* 启用或禁用登录音效
|
||||
* 配置双启动
|
||||
* 启用或禁用锁屏
|
||||
* 智能系统更新
|
||||
* 使用脚本管理器更新/一次性执行脚本
|
||||
* 从git执行常规用户安装脚本
|
||||
* 检查系统完整性和缺失的GPG keys.
|
||||
* 修复网络
|
||||
* 修复已破损的包
|
||||
* 还有更多功能在开发中
|
||||
|
||||
**重要提示:** Ubunsys 不适用于Ubuntu 新手.它很危险并且没有一个稳定的版本.它可能会使你的系统崩溃.如果你刚接触Ubuntu不久,不要使用.但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险.在使用这一应用之前记着备份你自己的重要数据
|
||||
|
||||
### Ubunsys - 对Ubuntu标准用户的一个高级系统配置程序
|
||||
|
||||
#### 安装 Ubunsys
|
||||
|
||||
|
||||
Ubunusys 开发者制作了一个ppa 来简化安装过程,Ubunusys现在可以在Ubuntu 16.04 LTS, Ubuntu 17.04 64 位版本上使用.
|
||||
|
||||
逐条执行下面的命令,将Ubunsys的PPA 添加进去,并安装它
|
||||
```
|
||||
sudo add-apt-repository ppa:adgellida/ubunsys
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install ubunsys
|
||||
|
||||
```
|
||||
|
||||
|
||||
如果ppa 无法使用,你可以在[**发布页面**][1]根据你自己当前系统,选择正确的安装包,直接下载并安装Ubunsys
|
||||
|
||||
#### 用途
|
||||
|
||||
一旦安装完成,从菜单栏启动Ubunsys.下图是Ubunsys 主界面
|
||||
|
||||
![][3]
|
||||
|
||||
你可以看到,Ubunusys 有四个主要部分,分别是 **Packages** , **Tweaks** , **System** ,和**Repair**. 在每一个标签项下面都有一个或多个子标签项以对应不同的操作
|
||||
|
||||
|
||||
**Packages**
|
||||
|
||||
这一部分允许你安装,删除和更新包
|
||||
|
||||
![][4]
|
||||
|
||||
**Tweaks**
|
||||
|
||||
在这一部分,我们可以对系统进行多种调整,例如,
|
||||
|
||||
* 打开,备份和导入 sources.list.d 和sudoers 文件;
|
||||
* 配置双启动;
|
||||
* 启用或禁用登录音效,防火墙,锁屏,系统冬眠,sudo 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用sudo 权限(在不需要密码的情况下)
|
||||
* 在terminal 中输入密码时可见(禁用Asterisk).
|
||||
|
||||
|
||||
|
||||
![][5]
|
||||
|
||||
**System**
|
||||
|
||||
这一部分被进一步分成3个部分,每个都是针对某一特定用户.
|
||||
|
||||
**Normal user** 这一标签下的选项可以,
|
||||
|
||||
* 更新,升级包和软件源
|
||||
* 清理系统
|
||||
* 执行常规用户安装脚本
|
||||
|
||||
|
||||
|
||||
**Advanced user** 这一标签下的选项可以,
|
||||
|
||||
* 清理旧的/无用的内核
|
||||
* 安装主线内核
|
||||
* 智能包更新
|
||||
* 升级系统
|
||||
|
||||
|
||||
|
||||
|
||||
**Developer** 这一部分可以将系统升级到最新的开发版本
|
||||
|
||||
![][6]
|
||||
|
||||
**Repair**
|
||||
|
||||
这是Ubunsys 的第四个也是最后一个部分.正如名字所示,这一部分能让我们修复我们的系统,网络,缺失的GPG keys,和已经缺失的包
|
||||
|
||||
![][7]
|
||||
|
||||
|
||||
正如你所见,Ubunsys可以在几次点击下就能完成诸如系统配置,系统维护和软件维护之类的任务.你不需要一直依赖于Terminal. Ubunsys 能帮你完成任何高级任务.再次声明,我警告你,这个应用不适合新手,而且它并不稳定.所以当你使用的时候,可能会出现bug或者系统崩溃.在仔细研究过每一个选项的影响之后再使用它.
|
||||
|
||||
谢谢阅读!
|
||||
|
||||
**参考资源:**
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/adgellida/ubunsys/releases
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
|
||||
@ -0,0 +1,85 @@
|
||||
# [Google 为树莓派 Zero W 发布了基于TensorFlow 的视觉识别套件][26]
|
||||
|
||||
|
||||

|
||||
Google 发行了一个 45 美元的 “AIY Vision Kit”,它是运行在树莓派 Zero W 上的基于 TensorFlow 的视觉识别开发套件,它使用了一个带 Movidius 芯片的 “VisionBonnet” 板。
|
||||
|
||||
为加速设备上的神经网络,Google 的 AIY 视频套件继承了早期树莓派上运行的 [AIY 项目][7] 的语音/AI 套件,这个型号的树莓派随五月份的 MagPi 杂志一起赠送。与语音套件和老的 Google 硬纸板 VR 查看器一样,这个新的 AIY 视觉套件也使用一个硬纸板包装。这个套件和 [Cloud Vision API][8] 是不一样的,它使用了一个在 2015 年演示过的基于树莓派的 GoPiGo 机器人,它完全在本地的处理能力上运行,而不需要使用一个云端连接。这个 AIY 视觉套件现在可以 45 美元的价格去预订,将在 12 月份发货。
|
||||
|
||||
|
||||
[][9] [][10]
|
||||
**AIY 视觉套件,完整包装(左)和树莓派 Zero W**
|
||||
(点击图片放大)
|
||||
|
||||
|
||||
这个套件的主要处理部分除了所需要的 [树莓派 Zero W][21] 单片机之外 —— 一个基于 ARM11 的 1 GHz 的 Broadcom BCM2836 片上系统,另外的就是 Google 最新的 VisionBonnet RPi 附件板。这个 VisionBonnet pHAT 附件板使用了一个 Movidius MA2450,它是 [Movidius Myriad 2 VPU][22] 版的处理器。在 VisionBonnet 上,处理器为神经网络运行了 Google 的开源机器学习库 [TensorFlow][23]。因为这个芯片,便得视觉处理的速度最高达每秒 30 帧。
|
||||
|
||||
这个 AIY 视觉套件要求用户提供一个树莓派 Zero W、一个 [树莓派摄像机 v2][11]、以及一个 16GB 的 micro SD 卡,它用来下载基于 Linux 的 OS 镜像。这个套件包含了 VisionBonnet、一个 RGB 街机风格的按钮、一个压电扬声器、一个广角镜头套件、以及一个包裹它们的硬纸板。还有一些就是线缆、支架、安装螺母、以及连接部件。
|
||||
|
||||
|
||||
[][12] [][13]
|
||||
**AIY 视觉套件组件(左)和 VisonBonnet 附件板**
|
||||
(点击图片放大)
|
||||
|
||||
|
||||
有三个可用的神经网络模型。一个是通用的模型,它可以识别常见的 1,000 个东西,一个是面部检测模型,它可以对 “快乐程度” 进行评分,从 “悲伤” 到 “大笑”,还有一个模型可以用来辨别图像内容是狗、猫、还是人。这个 1,000-image 模型源自 Google 的开源 [MobileNets][24],它是基于 TensorFlow 家族的计算机视觉模型,它设计用于资源受限的移动或者嵌入式设备。
|
||||
|
||||
MobileNet 模型是低延时、低功耗,和参数化的,以满足资源受限的不同使用案例。Google 说,这个模型可以用于构建分类、检测、嵌入、以及分隔。在本月的早些时候,Google 发布了一个开发者预览版,它是一个对 Android 和 iOS 移动设备友好的 [TensorFlow Lite][14] 库,它与 MobileNets 和 Android 神经网络 API 是兼容的。
|
||||
|
||||
|
||||
[][15]
|
||||
**AIY 视觉套件包装图**
|
||||
(点击图像放大)
|
||||
|
||||
|
||||
除了提供这三个模型之外,AIY 视觉套件还提供了基本的 TensorFlow 代码和一个编译器,因此用户可以去开发自己的模型。另外,Python 开发者可以写一些新软件去定制 RGB 按钮颜色、压电元素声音、以及在 VisionBonnet 上的 4x GPIO 针脚,它可以添加另外的指示灯、按钮、或者伺服机构。Potential 模型包括识别食物、基于可视化输入来打开一个狗门、当你的汽车偏离车道时发出文本信息、或者根据识别到的人的面部表情来播放特定的音乐。
|
||||
|
||||
|
||||
[][16] [][17]
|
||||
**Myriad 2 VPU 结构图(左)和参考板**
|
||||
(点击图像放大)
|
||||
|
||||
|
||||
Movidius Myriad 2 处理器在一个标称 1W 的功耗下提供每秒万亿次浮点运算的性能。在被 Intel 收购之前,这个芯片最早出现在 Tango 项目的参考平台上,并内置在 2016 年 5 月由 Movidius 首次亮相的、Ubuntu 驱动的 USB 的 [Fathom][25] 神经网络处理棒中。根据 Movidius 的说法,Myriad 2 目前已经在 “市场上数百万的设备上使用”。
|
||||
|
||||
**更多信息**
|
||||
|
||||
AIY 视觉套件可以在 Micro Center 上预订,价格为 $44.99,预计在 12 月初发货。更多信息请参考 AIY 视觉套件的 [公告][18]、[Google 博客][19]、以及 [Micro Center 购物页面][20]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
|
||||
作者:[ Eric Brown][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[1]:http://twitter.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&text=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W%20
|
||||
[2]:https://plus.google.com/share?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[3]:http://www.facebook.com/sharer.php?u=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[4]:http://www.linkedin.com/shareArticle?mini=true&url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[5]:http://reddit.com/submit?url=http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/&title=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W
|
||||
[6]:mailto:?subject=Google%20launches%20TensorFlow-based%20vision%20recognition%20kit%20for%20RPi%20Zero%20W&body=%20http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
[7]:http://linuxgizmos.com/free-raspberry-pi-voice-kit-taps-google-assistant-sdk/
|
||||
[8]:http://linuxgizmos.com/google-releases-cloud-vision-api-with-demo-for-pi-based-robot/
|
||||
[9]:http://linuxgizmos.com/files/google_aiyvisionkit.jpg
|
||||
[10]:http://linuxgizmos.com/files/rpi_zerow.jpg
|
||||
[11]:http://linuxgizmos.com/raspberry-pi-cameras-jump-to-8mp-keep-25-dollar-price/
|
||||
[12]:http://linuxgizmos.com/files/google_aiyvisionkit_pieces.jpg
|
||||
[13]:http://linuxgizmos.com/files/google_visionbonnet.jpg
|
||||
[14]:https://developers.googleblog.com/2017/11/announcing-tensorflow-lite.html
|
||||
[15]:http://linuxgizmos.com/files/google_aiyvisionkit_assembly.jpg
|
||||
[16]:http://linuxgizmos.com/files/movidius_myriad2vpu_block.jpg
|
||||
[17]:http://linuxgizmos.com/files/movidius_myriad2_reference_board.jpg
|
||||
[18]:https://blog.google/topics/machine-learning/introducing-aiy-vision-kit-make-devices-see/
|
||||
[19]:https://developers.googleblog.com/2017/11/introducing-aiy-vision-kit-add-computer.html
|
||||
[20]:http://www.microcenter.com/site/content/Google_AIY.aspx?ekw=aiy&rd=1
|
||||
[21]:http://linuxgizmos.com/raspberry-pi-zero-w-adds-wifi-and-bluetooth-for-only-5-more/
|
||||
[22]:https://www.movidius.com/solutions/vision-processing-unit
|
||||
[23]:https://www.tensorflow.org/
|
||||
[24]:https://research.googleblog.com/2017/06/mobilenets-open-source-models-for.html
|
||||
[25]:http://linuxgizmos.com/usb-stick-brings-neural-computing-functions-to-devices/
|
||||
[26]:http://linuxgizmos.com/google-launches-tensorflow-based-vision-recognition-kit-for-rpi-zero-w/
|
||||
@ -1,34 +1,34 @@
|
||||
How To Find The Installed Proprietary Packages In Arch Linux
|
||||
如何在 Arch Linux 中查找已安装的专有软件包?
|
||||
======
|
||||

|
||||
Are you an avid free software supporter and currently using any Arch based distribution? I've got a small tip for you! Now, you can easily find the installed proprietary packages in Arch Linux and its variants such as Antergos, Manjaro Linux etc. You don't need to refer the license details of the installed package in its website or use any external tool to find out whether the package is free or proprietary.
|
||||
你是狂热的自由软件支持者吗?你目前在使用任何基于 Arch 的 Linux 发行版吗?我有一个小小的提示送给你!现在,你可以轻松地在 Arch Linux 及其变体(如 Antergos, Manjaro Linux 等)中找到已安装的专有软件包。你无需在已安装软件包的网站中参考其许可细节,也无需使用任何外部工具来查明软件包是自由的还是专有的。(译注:其实下面还是借助了一个外部程序)
|
||||
|
||||
### Find The Installed Proprietary Packages In Arch Linux
|
||||
### 在 Arch Linux 中查找已安装的专有软件包
|
||||
|
||||
A fellow developer has developed an utility named **" Absolutely Proprietary"**, a proprietary package detector for arch-based distributions. It compares all installed packages in your Arch based system against Parabola's package [blacklist][1] and [aur-blacklist][2] and then prints your **Stallman Freedom Index** (free/total). Additionally, you can save the list to a file and share or compare it with other systems/users.
|
||||
一位开发人员开发了一个名为 **"Absolutely Proprietary"** 的实用程序,它是一种用于基于 Arch 发行版的专有软件包检测器。它将基于 Arch 系统中的所有安装包与 Parabola 的 [blacklist(黑名单)][1]软件包和 [aur-blacklist][2] 进行比较,然后打印你的 **Stallman Freedom Index( Stallman 自由指数)** (free/total(自由/总计))。此外,你可以将列表保存到文件中,并与其他系统/用户共享或比较。
|
||||
|
||||
Before installing it, Make sure you have installed **python** and **git**.
|
||||
在安装之前,确保你安装了 **python** 和 **git**。
|
||||
|
||||
Then, git clone the repository:
|
||||
然后,git clone 仓库:
|
||||
```
|
||||
git clone https://github.com/vmavromatis/absolutely-proprietary.git
|
||||
```
|
||||
|
||||
This command will download all contents in a directory called 'absolutely-proprietary' in your current working directory.
|
||||
这条命令将会下载所有内容到你当前工作目录中的 'absolutely-proprietary' 目录。
|
||||
|
||||
Change to that directory:
|
||||
进入此目录:
|
||||
```
|
||||
cd absolutely-proprietary
|
||||
```
|
||||
|
||||
And, find the installed proprietary packages using command:
|
||||
接着,使用以下命令查找已安装的专有软件:
|
||||
```
|
||||
python main.py
|
||||
```
|
||||
|
||||
This command will download the blacklist.txt, aur-blacklist.txt and compare the locally installed packages with the remote packages and displays the
|
||||
这条命令将会下载 blacklist.txt, aur-blacklist.txt,并将本地已安装的软件包与远程软件包进行比较并显示(to 校正者:原文这里似乎没写完)不同。
|
||||
|
||||
Here is the sample output from my Arch Linux desktop:
|
||||
以下是在我的 Arch Linux 桌面的示例输出:
|
||||
```
|
||||
Retrieving local packages (including AUR)...
|
||||
Downloading https://git.parabola.nu/blacklist.git/plain/blacklist.txt
|
||||
@ -75,7 +75,7 @@ Save list to file? (Y/n)
|
||||
|
||||
[![][3]][4]
|
||||
|
||||
As you can see, I have 47 proprietary packages in my system. Like I said already, we can save it to a file and review them later. To do so, jut press 'y' when you are prompted to save the list in a file. Then press 'y' to accept the defaults or hit 'n' to save it in your preferred format and location.
|
||||
如你所见,我的系统中有 47 个专有软件包。就像我说的那样,我们可以将它保存到文件中稍后查看。为此,当提示你将列表保存在文件时,请按 ‘y’。然后按 ‘y’ 接受默认值或点击 ‘n’,以你喜欢的格式和位置来保存它。
|
||||
```
|
||||
Save list to file? (Y/n) y
|
||||
Save as markdown table? (Y/n) y
|
||||
@ -87,20 +87,17 @@ using the "less -S /home/sk/absolutely-proprietary/y.md"
|
||||
or, if installed, the "most /home/sk/absolutely-proprietary/y.md" commands
|
||||
```
|
||||
|
||||
As you may noticed, I have only the **nonfree** packages. It will display two more type of packages such as semifree, uses-nonfree.
|
||||
你可能已经注意到,我只有 **nonfree** 包。它还会显示另外两种类型的软件包,例如 semifree, uses-nonfree。
|
||||
|
||||
* **nonfree** : This package is blatantly nonfree software.
|
||||
* **semifree** : This package is mostly free, but contains some nonfree software.
|
||||
* **uses-nonfree** : This package depends on, recommends, or otherwise inappropriately integrates with other nonfree software or services.
|
||||
* **nonfree**:这个软件包是公然的非自由软件。
|
||||
* **semifree**:这个软件包大部分是免费的,但包含一些非自由软件。
|
||||
* **uses-nonfree**:这个软件包依赖,推荐或不恰当地与其他自由软件或服务集成。
|
||||
|
||||
该使用程序的另一个显著特点是它不仅显示了专有软件包,而且还显示这些包的替代品。
|
||||
|
||||
希望这有些帮助。我很快就会在这里提供另一份有用的指南。敬请关注!
|
||||
|
||||
Another notable feature of this utility is it's not just displays the propriety packages, but also alternatives to such packages.
|
||||
|
||||
Hope this helps. I will be soon here with another useful guide soon. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -108,7 +105,7 @@ Cheers!
|
||||
via: https://www.ostechnix.com/find-installed-proprietary-packages-arch-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
82
translated/tech/20180313 Migrating to Linux- Using Sudo.md
Normal file
82
translated/tech/20180313 Migrating to Linux- Using Sudo.md
Normal file
@ -0,0 +1,82 @@
|
||||
迁移到 Linux:使用 Sudo
|
||||
======
|
||||
|
||||

|
||||
|
||||
本文是我们关于迁移到 Linux 的系列文章的第五篇。如果你错过了之前的那些,你可以在这里赶上:
|
||||
|
||||
[第1部分 - 介绍][1]
|
||||
|
||||
[第2部分 - 磁盘,文件和文件系统][2]
|
||||
|
||||
[第3部分 - 图形环境][3]
|
||||
|
||||
[第4部分 - 命令行][4]
|
||||
|
||||
你可能一直想了解 Linux。也许它在你的工作场所使用,如果你每天使用它,你的工作效率会更高。或者,也许你想在家里的某些计算机上安装 Linux。无论是什么原因,这一系列文章都是为了让过渡更容易。
|
||||
|
||||
与许多其他操作系统一样,Linux 支持多用户。它甚至支持多个用户同时登录。
|
||||
|
||||
用户帐户通常会被分配一个可以存储文件的家目录。通常这个家目录位于:
|
||||
```
|
||||
/home/<login name>
|
||||
|
||||
```
|
||||
|
||||
这样,每个用户都有存储自己的文档和其他文件的独立位置。
|
||||
|
||||
### 管理任务
|
||||
|
||||
在传统的 Linux 安装中,常规用户帐户无权在系统上执行管理任务。典型的 Linux 安装将要求用户以管理员身份登录以执行某些任务,而不是为每个用户分配权限以执行各种任务。
|
||||
|
||||
Linux 上的管理员帐户称为 root。
|
||||
|
||||
### Sudo 解释
|
||||
|
||||
从历史上看,要执行管理任务,必须以 root 身份登录,执行任务,然后登出。这个过程有点乏味,所以很多人以 root 登录并且整天都以管理员身份工作。这种做法可能会导致灾难性的后果,例如,意外删除系统中的所有文件。当然,root 用户可以做任何事情,因此没有任何保护措施可以防止有人意外地执行影响很大的操作。
|
||||
|
||||
创建 sudo 工具是为了使你更容易以常规用户帐户登录,偶尔以 root 身份执行管理任务,而无需登录、执行任务然后登出。具体来说,sudo 允许你以不同的用户身份运行命令。如果你未指定特定用户,则假定你指的是 root 用户。
|
||||
|
||||
Sudo 可以有复杂的设置,允许用户使用有权限使用 sudo 运行某些命令,而其他的不行。通常,桌面安装会使创建的第一个帐户在 sudo 中有完全的权限,因此你作为主要用户可以完全管理 Linux 安装。
|
||||
|
||||
### 使用 Sudo
|
||||
|
||||
某些 Linux 安装设置了 sudo,因此你仍需要知道 root 帐户的密码才能执行管理任务。其他人,设置 sudo 输入自己的密码。这里有不同的哲学。
|
||||
|
||||
当你尝试在图形环境中执行管理任务时,通常会打开一个要求输入密码的对话框。输入你自己的密码(例如,在 Ubuntu 上)或 root 帐户的密码(例如,Red Hat)。
|
||||
|
||||
当你尝试在命令行中执行管理任务时,它通常只会给你一个 “permission denied” 错误。然后你在前面用 sudo 重新运行命令。例如:
|
||||
```
|
||||
systemctl start vsftpd
|
||||
Failed to start vsftpd.service: Access denied
|
||||
|
||||
sudo systemctl start vsftpd
|
||||
[sudo] password for user1:
|
||||
|
||||
```
|
||||
|
||||
### 何时使用 Sudo
|
||||
|
||||
以 root 身份运行命令(在 sudo 或其他情况下)并不总是解决权限错误的最佳解决方案。虽然将以 root 身份运行将移除 “permission denied” 错误,但有时最好寻找根本原因而不是仅仅解决症状。有时文件拥有错误的所有者和权限。
|
||||
|
||||
当你在尝试一个需要 root 权限来执行操作的任务或者程序时使用 sudo。如果文件恰好由另一个用户(包括 root 用户)拥有,请不要使用 sudo。在第二种情况下,最好正确设置文件的权限。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费[“Linux 介绍”][5]课程了解有关 Linux 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2017/10/migrating-linux-introduction
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/2017/11/migrating-linux-disks-files-and-filesystems
|
||||
[3]:https://www.linux.com/blog/learn/2017/12/migrating-linux-graphical-environments
|
||||
[4]:https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,8 +1,9 @@
|
||||
迁移到 Linux 之安装软件
|
||||
=====
|
||||
======
|
||||
|
||||

|
||||
你看到的所有有关 Linux 的关注,以及它在互联网,以及 Arduino, Beagle 和 Raspberry Pi boards(树莓派板)等设备上的使用,或许你正在考虑是时候尝试一下 Linux 了。本系列将帮助你成功过渡到 Linux。如果你错过了本系列的早期文章,可以在这里找到它们:
|
||||
|
||||
你看到的所有有关 Linux 的关注,以及它在互联网,以及 Arduino,Beagle 和 Raspberry Pi boards(树莓派板)等设备上的使用,或许你正在考虑是时候尝试一下 Linux 了。本系列将帮助你成功过渡到 Linux。如果你错过了本系列的早期文章,可以在这里找到它们:
|
||||
|
||||
[Part 1 - 介绍][1]
|
||||
|
||||
@ -18,36 +19,41 @@
|
||||
|
||||
要在你的计算机上获得新软件,通常的方法是从供应商处获得软件产品,然后运行一个安装程序。过去,软件产品会像 CD-ROM 或 DVD 一样出现在物理媒介上。而现在我们经常从网上下载软件产品。
|
||||
|
||||
使用 Linux,安装软件就像在你的智能手机上安装一样。就像去你的手机应用商店一样,在 Linux 上有个开源软件工具和程序的中央仓库,几乎任何你可能想要的程序都会在你可安装的可用软件包列表中。
|
||||
使用 Linux,安装软件就像在你的智能手机上安装一样。就像去你的手机应用商店一样,在 Linux 上有个开源软件工具和程序的<ruby>中央仓库<rt>central repository</rt></ruby>,几乎任何你可能想要的程序都会在你可安装的可用软件包列表中。
|
||||
|
||||
没有为每个程序运行的单独安装程序。相反,你可以使用 Linux 发行版附带的软件包管理工具。(请记住,Linux 发行版是你安装的 Linux,例如 Ubuntu, Fedora, Debian 等)每个发行版在 Internet 上都有自己的集中位置(称为仓库),用于存储数千个预先安装的应用程序。
|
||||
没有为每个程序运行的单独安装程序。相反,你可以使用 Linux 发行版附带的软件包管理工具。(请记住,Linux 发行版是你安装的 Linux,例如 Ubuntu,Fedora,Debian 等)每个发行版在 Internet 上都有自己的集中位置(称为仓库),用于存储数千个预先安装的应用程序。
|
||||
|
||||
你可能会注意到,在 Linux 上安装软件有几个例外。有时候,你仍然需要去供应商处获取他们的软件,因为该程序不存在于你发行版的中央仓库中。当软件不是开源和/或免费(自由)的时候,通常就是这种情况。
|
||||
|
||||
另外请记住,如果你最终想要安装一个不在发行版仓库中的程序,事情就不是那么简单了,即使你正在安装免费(自由)和开源程序。这篇文章没有涉及到这些更复杂的情况,最好遵循在线引导。
|
||||
另外请记住,如果你最终想要安装一个不在发行版仓库中的程序,事情就不是那么简单了,即使你正在安装免费(自由)和开源程序。这篇文章没有涉及到这些更复杂的情况,最好遵循在线指引。
|
||||
|
||||
有了所有的 Linux 包管理系统和工具,接下来干什么可能仍然令人困惑。本文应该有助于澄清一些事情。
|
||||
|
||||
### 包管理
|
||||
|
||||
一些用于管理、安装和删除软件的包管理系统在 Linux 发行版中竞争。那个发行版背后的人都选择一个包管理系统来使用。Red Hat, Fedora, CentOS, Scientific Linux, SUSE 等使用 Red Hat 包管理(RPM)。Debian, Ubuntu, Linux Mint 等等都使用 Debian 包管理系统,简称 DPKG。其他包管理系统也存在,但 RPM 和 DPKG 是最常见的。
|
||||
一些用于管理、安装和删除软件的包管理系统在 Linux 发行版中竞争。那个发行版背后的人都选择一个<ruby>包管理工具<rt>package management tools<rt></ruby>来使用。Red Hat,Fedora,CentOS,Scientific Linux,SUSE 等使用 Red Hat 包管理(RPM)。Debian,Ubuntu,Linux Mint 等等都使用 Debian 包管理系统,简称 DPKG。其他包管理系统也存在,但 RPM 和 DPKG 是最常见的。
|
||||
|
||||

|
||||
|
||||
图 1: Package installers
|
||||
|
||||
无论你使用的软件包管理是什么,它们通常都附带一组工具,它们是分层的(图 1)。最底层是一个命令行工具,它可以让你做任何事情以及与安装软件相关的一切。你可以列出已安装的程序,删除程序,安装软件包文件等等。
|
||||
无论你使用的软件包管理是什么,它们通常都附带一组工具,它们是分层的(图 1)。最底层是一个命令行工具,它可以让你做任何与安装软件相关的一切。你可以列出已安装的程序,删除程序,安装软件包文件等等。
|
||||
|
||||
这个底层工具并不总是最方便使用的,所以通常会有一个命令行工具,它可以在发行版的中央仓库中找到软件包,并使用单个命令下载和安装它以及任何依赖项。最后,通常会有一个<ruby>图形应用程序<rt>graphical application<rt></ruby>,让你使用鼠标选择任何想要的内容,然后单击 “install” 按钮。
|
||||
|
||||
这个底层工具并不总是最方便使用的,所以通常会有一个命令行工具,它可以在发行版的中央仓库中找到软件包,并使用单个命令下载和安装它以及任何依赖项。最后,通常会有一个图形应用程序,让你使用鼠标选择任何想要的内容,然后单击 “install” 按钮。
|
||||

|
||||
|
||||
图 2: PackageKit
|
||||
|
||||
对于基于 Red Hat 的发行版,包括 Fedora, CentOS, Scientific Linux 等。它们的底层工具是 rpm,高级工具叫做 dnf(在旧系统上是 yum)。图形安装程序称为 PackageKit(图 2),它可能在系统管理下显示为 “Add/Remove Software(添加/删除软件)”。
|
||||
对于基于 Red Hat 的发行版,包括 Fedora,CentOS,Scientific Linux 等。它们的底层工具是 rpm,高级工具叫做 dnf(在旧系统上是 yum)。图形安装程序称为 PackageKit(图 2),它可能在系统管理下显示为 “Add/Remove Software(添加/删除软件)”。
|
||||
|
||||

|
||||
|
||||
图 3: Ubuntu Software
|
||||
|
||||
对于基于 Debian 的发行版,包括 Debian, Ubuntu, Linux Mint, Elementary OS 等。它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为 Synaptic,它也可以安装在 Ubuntu 上。
|
||||
对于基于 Debian 的发行版,包括 Debian,Ubuntu,Linux Mint,Elementary OS 等。它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为<ruby>新立得<rt>Synaptic</rt></ruby>,它也可以安装在 Ubuntu 上。
|
||||
|
||||
你也可以在 Debian 相关发行版上安装基于文本的图形工具 aptitude。它比 Synaptic(新立得)更强大,并且即使你只能访问命令行也能工作。如果你想获得所有花里胡哨的东西,(to 校正者:这句话仔细考虑一下)你可以试试那个,尽管有更多的选择,但使用起来比 Synaptic(新立得)更复杂。其他发行版可能有自己独特的工具。
|
||||
你也可以在 Debian 相关发行版上安装基于文本的图形工具 aptitude。它比 Synaptic(新立得)更强大,并且即使你只能访问命令行也能工作。如果你想获得所有花里胡哨的东西,你可以试试那个,尽管有更多的选择,但使用起来比 Synaptic 更复杂。其他发行版可能有自己独特的工具。
|
||||
|
||||
### 命令行工具
|
||||
|
||||
@ -65,14 +71,13 @@
|
||||
|
||||
通过 Linux 基金会和 edX 的免费 [“Linux 入门”][6]课程了解有关 Linux 的更多信息。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
---
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
|
||||
|
||||
作者:[JOHN BONESIO][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
55
translated/tech/20180606 6 Open Source AI Tools to Know.md
Normal file
55
translated/tech/20180606 6 Open Source AI Tools to Know.md
Normal file
@ -0,0 +1,55 @@
|
||||
应该知道的 6 个开源 AI 工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
在开源领域,不管你的想法是多少的新颖独到,先去看一下别人是否已经做成了这个概念,总是一个很明智的做法。对于有兴趣借助不断成长的人工智能(AI)的力量的组织和个人来说,许多非常好的工具不仅是免费和开源的,而且在很多的情况下,它们都已经过测试和久经考验的。
|
||||
|
||||
在领先的公司和非盈利组织中,AI 的优先级都非常高,并且这些公司和组织都开源了很有价值的工具。下面的样本是任何人都可以使用的免费的、开源的 AI 工具。
|
||||
|
||||
**Acumos.** [Acumos AI][1] 是一个平台和开源框架,使用它可以很容易地去构建、共享和分发 AI 应用。它规范了需要的基础设施栈和组件,使其可以在一个“开箱即用的”通用 AI 环境中运行。这使得数据科学家和模型训练者可以专注于它们的核心竞争力,而不用在无止境的定制、建模、以及训练一个 AI 实现上浪费时间。
|
||||
|
||||
Acumos 是 [LF 深度学习基金会][2] 的一部分,它是 Linux 基金会中的一个组织,它支持在人工智能、机器学习、以及深度学习方面的开源创新。它的目标是让这些重大的新技术可用于开发者和数据科学家,包括那些在深度学习和 AI 上经验有限的人。LF 深度学习基金会 [最近批准了一个项目生命周期和贡献流程][3],并且它现在正接受项目贡献的建议。
|
||||
|
||||
**Facebook 的框架.** Facebook 它自己 [有开源的][4] 中央机器学习系统,它设计用于做一些大规模的人工智能任务,以及一系列其它的 AI 技术。这个工具是经过他们公司验证的平台的一部分。Facebook 也开源了一个叫 [Caffe2][5] 的深度学习和人工智能的框架。
|
||||
|
||||
**说到 Caffe.** Yahoo 也在开源许可证下发布了它自己的关键的 AI 软件。[CaffeOnSpark 工具][6] 是基于深度学习的,它是人工智能的一个分支,在帮助机器识别人类语言、或者照片、视频的内容方面非常有用。同样地,IBM 的机器学习程序 [SystemML][7] 可以通过 Apache 软件基金会免费共享和修改。
|
||||
|
||||
**Google 的工具.** Google 花费了几年的时间开发了它自己的 [TensorFlow][8] 软件框架,用于去支持它的 AI 软件和其它预测和分析程序。TensorFlow 是你可能都已经在使用的一些 Google 工具背后的引擎,包括 Google Photos 和在 Google app 中使用的语言识别。
|
||||
|
||||
Google 开源了两个 [AIY kits][9],它可以让个人很容易地使用人工智能,它们专注于计算机视觉和语音助理。这两个工具包将用到的所有组件封装到一个盒子中。这个工具包目前在美国的 Target 中有售,并且它是基于开源的树莓派平台的 —— 有越来越多的证据表明,在开源和 AI 交集中将发生非常多的事情。
|
||||
|
||||
**H2O.ai.** **** 我 [以前介绍过][10] H2O.ai,它在机器学习和人工智能领域中占有一席之地,因为它的主要工具是免费和开源的。你可以获取主要的 H2O 平台和 Sparkling Water,它与 Apache Spark 一起工作,只需要去 [下载][11] 它们即可。这些工具遵循 Apache 2.0 许可证,它是一个非常灵活的开源许可证,你甚至可以在 Amazon Web 服务(AWS)和其它的集群上运行它们,而这仅需要几百美元而已。
|
||||
|
||||
**Microsoft Onboard.** “我们的目标是让 AI 大众化,让每个人和组织获得更大的成就,“ Microsoft CEO Satya Nadella [说][12]。因此,微软持续迭代它的 [Microsoft Cognitive Toolkit][13]。它是一个能够与 TensorFlow 和 Caffe 去竞争的一个开源软件框架。Cognitive 工具套件可以工作在 64 位的 Windows 和 Linux 平台上。
|
||||
|
||||
Cognitive 工具套件团队的报告称,“Cognitive 工具套件通过允许用户去创建、训练、以及评估他们自己的神经网络,以使企业级的、生产系统级的 AI 成为可能,这些神经网络可能跨多个 GPU 以及多个机器在大量的数据集中高效伸缩。”
|
||||
|
||||
从来自 Linux 基金会的新电子书中学习更多的有关 AI 知识。Ibrahim Haddad 的 [开源 AI:项目、洞察、和趋势][14] 调查了 16 个流行的开源 AI 项目—— 深入研究了他们的历史、代码库、以及 GitHub 的贡献。 [现在可以免费下载这个电子书][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/6-open-source-ai-tools-know
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.acumos.org/
|
||||
[2]:https://www.linuxfoundation.org/projects/deep-learning/
|
||||
[3]:https://www.linuxfoundation.org/blog/lf-deep-learning-foundation-announces-project-contribution-process/
|
||||
[4]:https://code.facebook.com/posts/1687861518126048/facebook-to-open-source-ai-hardware-design/
|
||||
[5]:https://venturebeat.com/2017/04/18/facebook-open-sources-caffe2-a-new-deep-learning-framework/
|
||||
[6]:http://yahoohadoop.tumblr.com/post/139916563586/caffeonspark-open-sourced-for-distributed-deep
|
||||
[7]:https://systemml.apache.org/
|
||||
[8]:https://www.tensorflow.org/
|
||||
[9]:https://www.techradar.com/news/google-assistant-sweetens-raspberry-pi-with-ai-voice-control
|
||||
[10]:https://www.linux.com/news/sparkling-water-bridging-open-source-machine-learning-and-apache-spark
|
||||
[11]:http://www.h2o.ai/download
|
||||
[12]:https://blogs.msdn.microsoft.com/uk_faculty_connection/2017/02/10/microsoft-cognitive-toolkit-cntk/
|
||||
[13]:https://www.microsoft.com/en-us/cognitive-toolkit/
|
||||
[14]:https://www.linuxfoundation.org/publications/open-source-ai-projects-insights-and-trends/
|
||||
@ -0,0 +1,66 @@
|
||||
Mesos 和 Kubernetes:不是竞争者
|
||||
======
|
||||
|
||||

|
||||
|
||||
Mesos 的起源可以追溯到 2009 年,当时,Ben Hindman 还是加州大学伯克利分校研究并行编程的博士生。他们在 128 核的芯片上做大规模的并行计算,并尝试去解决多个问题,比如怎么让软件和库在这些芯片上运行更高效。他与同学们讨论能否借鉴并行处理和多线程的思想,并将它们应用到集群管理上。
|
||||
|
||||
Hindman 说 "最初,我们专注于大数据” 。那时,大数据非常热门,并且 Hadoop 是其中一个热门技术。“我们发现,人们在集群上运行像 Hadoop 这样的程序与运行多线程应用和并行应用很相似。Hindman 说。
|
||||
|
||||
但是,它们的效率并不高,因此,他们开始去思考,如何通过集群管理和资源管理让它们运行的更好。”我们查看了那个时间很多的不同技术“ Hindman 回忆道。
|
||||
|
||||
然而,Hindman 和他的同事们,决定去采用一种全新的方法。”我们决定去对资源管理创建一个低级的抽象,然后在此之上运行调度服务和做其它的事情。“ Hindman 说,“基本上,这就是 Mesos 的本质 —— 将资源管理部分从调度部分中分离出来。”
|
||||
|
||||
他成功了,并且 Mesos 从那时开始强大了起来。
|
||||
|
||||
### 将项目呈献给 Apache
|
||||
|
||||
这个项目发起于 2009 年。在 2010 年时,团队决定将这个项目捐献给 Apache 软件基金会(ASF)。它在 Apache 孵化,并于 2013 年成为顶级项目(TLP)。
|
||||
|
||||
为什么 Mesos 社区选择 Apache 软件基金会有很多的原因,比如,Apache 许可证,以及他们已经拥有了一个充满活力的此类项目的许多其它社区。
|
||||
|
||||
与影响力也有关系。许多在 Mesos 上工作的人,也参与了 Apache,并且许多人也致力于像 Hadoop 这样的项目。同时,来自 Mesos 社区的许多人也致力于其它大数据项目,比如 Spark。这种交叉工作使得这三个项目 —— Hadoop、Mesos、以及 Spark —— 成为 ASF 的项目。
|
||||
|
||||
与商业也有关系。许多公司对 Mesos 很感兴趣,并且开发者希望它能由一个中立的机构来维护它,而不是让它成为一个私有项目。
|
||||
|
||||
### 谁在用 Mesos?
|
||||
|
||||
更好的问题应该是,谁不在用 Mesos?从 Apple 到 Netflix 每个都在用 Mesos。但是,Mesos 也面临任何技术在早期所面对的挑战。”最初,我要说服人们,这是一个很有趣的新技术。它叫做“容器”,因为它不需要使用虚拟机“ Hindman 说。
|
||||
|
||||
从那以后,这个行业发生了许多变化,现在,只要与别人聊到基础设施,必然是从”容器“开始的 —— 感谢 Docker 所做出的工作。今天再也不需要说服工作了,而在 Mesos 出现的早期,前面提到的像 Apple、Netflix、以及 PayPal 这样的公司。他们已经知道了容器化替代虚拟机给他们带来的技术优势。”这些公司在容器化成为一种现象之前,已经明白了容器化的价值所在“, Hindman 说。
|
||||
|
||||
可以在这些公司中看到,他们有大量的容器而不是虚拟机。他们所做的全部工作只是去管理和运行这些容器,并且他们欣然接受了 Mesos。在 Mesos 早期就使用它的公司有 Apple、Netflix、PayPal、Yelp、OpenTable、和 Groupon。
|
||||
|
||||
“大多数组织使用 Mesos 来运行任意需要的服务” Hindman 说,“但也有些公司用它做一些非常有趣的事情,比如,数据处理、数据流、分析负载和应用程序。“
|
||||
|
||||
这些公司采用 Mesos 的其中一个原因是,资源管理层之间有一个明晰的界线。当公司运营容器的时候,Mesos 为他们提供了很好的灵活性。
|
||||
|
||||
“我们尝试使用 Mesos 去做的一件事情是去创建一个层,以让使用者享受到我们的层带来的好处,当然也可以在它之上创建任何他们想要的东西,” Hindman 说。 “我认为这对一些像 Netflix 和 Apple 这样的大公司非常有用。”
|
||||
|
||||
但是,并不是每个公司都是技术型的公司;不是每个公司都有或者应该有这种专长。为帮助这样的组织,Hindman 联合创建了 Mesosphere 去围绕 Mesos 提供服务和解决方案。“我们最终决定,为这样的组织去构建 DC/OS,它不需要技术专长或者不想把时间花费在像构建这样的事情上。”
|
||||
|
||||
### Mesos vs. Kubernetes?
|
||||
|
||||
人们经常用 x 相对于 y 这样的术语来考虑问题,但是它并不是一个技术对另一个技术的问题。大多数的技术在一些领域总是重叠的,并且它们可以是互补的。“我不喜欢将所有的这些东西都看做是竞争者。我认为它们中的一些与另一个在工作中是互补的,” Hindman 说。
|
||||
|
||||
“事实上,名字 Mesos 表示它处于 ‘中间’;它是一种中间的 OS,” Hindman 说,“我们有一个容器调度器的概念,它能够运行在像 Mesos 这样的东西之上。当 Kubernetes 刚出现的时候,我们实际上在 Mesos 的生态系统中接受它的,并将它看做是运行在 Mesos 之上、DC/OS 之中的另一种方式的容器。”
|
||||
|
||||
Mesos 也复活了一个名为 [Marathon][1](一个用于 Mesos 和 DC/OS 的容器编排器)的项目,它在 Mesos 生态系统中是做的最好的容器编排器。但是,Marathon 确实无法与 Kubernetes 相比较。“Kubernetes 比 Marathon 做的更多,因此,你不能将它们简单地相互交换,” Hindman 说,“与此同时,我们在 Mesos 中做了许多 Kubernetes 中没有的东西。因此,这些技术之间是互补的。”
|
||||
|
||||
不要将这些技术视为相互之间是敌对的关系,它们应该被看做是对行业有益的技术。它们不是技术上的重复;它们是多样化的。据 Hindman 说,“对于开源领域的终端用户来说,这可能会让他们很困惑,因为他们很难去知道哪个技术适用于哪种负载,但这是被称为开源的这种东西最令人讨厌的本质所在。“
|
||||
|
||||
这只是意味着有更多的选择,并且每个都是赢家。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/mesos-and-kubernetes-its-not-competition
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://mesosphere.github.io/marathon/
|
||||
@ -1,212 +0,0 @@
|
||||
4种用于构建嵌入式Linux系统的工具
|
||||
======
|
||||

|
||||
|
||||
|
||||
Linux被部署到比Linus Torvalds在他的宿舍里工作时所预期的更广泛的设备。对各种芯片的支持是令人震惊的,使得Linux应用在大大小小的设备上:
|
||||
从[IBM的巨型机][1]到[微型设备][2],没有比他们的连接端口和其间的任何东西都大。它被用于大型企业数据中心,互联网基础设施设备和个人开发系统。
|
||||
它还为消费电子产品、移动电话和许多物联网设备提供动力。
|
||||
|
||||
在为桌面和企业级设备构建Linux软件时,开发者典型的在他们的构建机器上使用桌面发行版,如[Ubuntu][3] 以便尽可能与被部署的机器相似。工具
|
||||
如[VirtualBox][4] and [Docker][5]使得开发测试和生成环境更好的保持一致
|
||||
|
||||
### 什么是嵌入式系统?
|
||||
|
||||
维基百科将[嵌入式系统] [6]定义为:“在更大的机械或电气系统中具有专用功能的计算机系统,往往伴随着实时计算限制。
|
||||
我觉得很简单,可以说嵌入式系统是大多数人不认为是计算机的计算机。它的主要作用是作为某种设备,它不被视为通用计算平台。
|
||||
|
||||
嵌入式系统编程中的开发环境通常与测试和生产环境大不相同。他们可能会使用不同的芯片架构,软件堆栈甚至操作系统。开发工作流程对于嵌入式开发
|
||||
人员与桌面和Web开发人员来说是非常不同通常,构建输出将包含目标设备的整个软件映像,包括内核,设备驱动程序,库和应用程序软件(有时也包括引导
|
||||
加载程序)。
|
||||
|
||||
在本文中,我将对构建嵌入式Linux系统的四种常用选项进行纵览。我将介绍一下每种产品的工作原理,并提供足够的信息来帮助读者确定使用哪种工具
|
||||
进行设计。我不会教你如何使用它们中的任何一个;一旦缩小了选择范围,就有大量深入的在线学习资源。没有任何选择适用于所有用例,我希望提供足够的
|
||||
细节来指导您的决定。
|
||||
### Yocto
|
||||
|
||||
[Yocto] [7]项目[定义] [8]是:一个开源协作项目,提供模板,工具和方法,帮助您为嵌入式产品创建定制的基于Linux的系统,而不管硬件架构如何。
|
||||
它是用于创建定制的Linux运行时映像的配方,配置值和依赖关系的集合,可根据您的特定需求进行定制。
|
||||
完全公开:我在嵌入式Linux中的大部分工作都集中在Yocto项目上,而且我对这个系统的认识和偏见可能很明显。
|
||||
Yocto使用[Openembedded] [9]作为其构建系统。从技术上讲,这两个是独立的项目;然而,在实践中,用户不需要了解区别,项目名称经常可以互换使用。
|
||||
|
||||
Yocto项目的输出大致由三部分组成:
|
||||
|
||||
* **目标运行时二进制文件:**这些包括引导加载程序,内核,内核模块,根文件系统映像。以及将Linux部署到目标平台所需的任何其他辅助文件。
|
||||
* **包流:**这是可以安装在目标上的软件包集合。您可以根据需要选择软件包格式(例如,deb,rpm,ipk)。其中一些可能预先安装在目标运行时
|
||||
二进制文件中,但可以构建用于安装到已部署系统的软件包。
|
||||
* **目标SDK:**这些是表示安装在目标上的软件的库和头文件的集合。应用程序开发人员在构建代码时使用它们,以确保它们与适当的库链接
|
||||
|
||||
#### 优点
|
||||
|
||||
Yocto项目在行业中得到广泛应用,并得到许多有影响力的公司的支持。此外,它还拥有一个庞大且充满活力的开发人员[社区] [10]和[生态系统] [11]。
|
||||
开源爱好者和企业赞助商的结合有助于推动Yocto项目。
|
||||
Yocto获得支持有很多选择。如果您想自己动手,还有书籍和其他培训材料。如果您想获得专业知识,许多有Yocto经验的工程师都可以使用。许多商业组
|
||||
织为您的设计提供基于Yocto的Turnkey产品或基于服务的实施和定制。
|
||||
Yocto项目很容易通过[layer] [12]进行扩展,它可以独立发布以添加额外的功能,将目标平台定位到项目发布中不可用的平台,或存储系统特有的自定义项。
|
||||
layer可以添加到您的配置中,以添加未特别包含在市面上版本中的独特功能;例如,[meta-browser] [13] layer包含Web浏览器的清单,可以轻松为您
|
||||
的系统进行构建。因为它们是独立维护的,所以layer可以在不同的发布时间安排上(根据layer的开发速度)而不是标准的Yocto版本。
|
||||
|
||||
Yocto可以说是本文讨论的任何选项中最广泛的设备支持。由于许多半导体和电路板制造商的支持,Yocto很可能会支持您选择的任何目标平台。
|
||||
主版本Yocto [分支] [14]仅支持少数几块主板(以便进行正确的测试和发布周期),但是,标准工作模式是使用外部主板支持layer。
|
||||
|
||||
最后,Yocto非常灵活和可定制。您的特定应用程序的自定义可以存储在一个layer进行封装和隔离。通常将要素layer特有的自定义项存储为layer本身
|
||||
的一部分,这可以将相同的设置同时应用于多个系统配置。 Yocto还提供了一个定义良好的layer优先和覆盖功能。这使您可以定义layer应用和搜索元数
|
||||
据的顺序。它还使您可以覆盖具有更高优先级的layer的设置;例如,现有清单的许多自定义功能都将保留
|
||||
|
||||
#### 缺点
|
||||
|
||||
Yocto项目最大的缺点是学习曲线。 学习系统并真正理解系统需要花费大量的时间和精力。 根据您的需求,这可能对您的应用程序不重要的技术和能力
|
||||
投入太大。 在这种情况下,与其中一家商业供应商合作可能是一个不错的选择。
|
||||
|
||||
Yocto项目的开发时间和资源相当高。 需要构建的包(包括工具链,内核和所有目标运行时组件)的数量非常重要。 Yocto开发人员的开发工作站往往是
|
||||
大型系统。 不建议使用小型笔记本电脑。 这可以通过使用许多提供商提供的基于云的构建服务器来缓解。 另外,Yocto有一个内置的缓存机制,当它确定
|
||||
用于构建特定包的参数没有改变时,它允许它重新使用先前构建的组件。
|
||||
|
||||
#### 建议
|
||||
|
||||
为您的下一个嵌入式Linux设计使用Yocto项目是一个强有力的选择。 在这里介绍的选项中,无论您的目标用例如何,它都是最广泛适用的。 广泛的行业
|
||||
支持,积极的社区和广泛的平台支持使其成为必须设计师的不错选择。
|
||||
|
||||
### Buildroot
|
||||
|
||||
[Buildroot] [15]项目被定义为:通过交叉编译生成嵌入式Linux系统的简单,高效且易于使用的工具。它与Yocto项目具有许多相同的目标,但它注重
|
||||
简单性和简约性。一般来说,Buildroot会禁用所有软件包的所有可选编译时设置(有一些值得注意的例外),从而导致尽可能小的系统。系统设计人员需要
|
||||
启用适用于给定设备的设置。
|
||||
|
||||
Buildroot从源代码构建所有组件,但不支持按目标包管理。因此,它有时称为固件生成器,因为镜像在构建时大部分是固定的。应用程序可以更新目标
|
||||
文件系统,但是没有机制将新软件包安装到正在运行的系统中。
|
||||
Buildroot输出主要由三部分组成:
|
||||
|
||||
*将Linux部署到目标平台所需的根文件系统映像和任何其他辅助文件
|
||||
*适用于目标硬件的内核,引导加载程序和内核模块
|
||||
*用于构建所有目标二进制文件的工具链。
|
||||
|
||||
### 优点
|
||||
|
||||
Buildroot对简单性的关注意味着,一般来说,它比Yocto更容易学习。核心构建系统用Make编写,并且足够短以允许开发人员了解整个系统,同时可扩展
|
||||
到足以满足嵌入式Linux开发人员的需求。 Buildroot核心通常只处理常见用例,但它可以通过脚本进行扩展。Buildroot系统使用普通的Makefile和Kconfig
|
||||
语言来进行配置。 Kconfig由Linux内核社区开发,广泛用于开源项目,使得许多开发人员都熟悉它。
|
||||
由于禁用所有可选构建时间设置的设计目标,Buildroot通常会使用开箱即用的配置生成尽可能最小的镜像。一般来说,构建时间和构建主机资源的规模
|
||||
将比Yocto项目的规模更小。
|
||||
|
||||
####缺点
|
||||
|
||||
关注简单性和最小化启用的构建选项意味着您可能需要执行重要的自定义来为应用程序配置Buildroot构建。此外,所有配置选项都存储在单个文件中,
|
||||
这意味着如果您有多个硬件平台,则需要为每个平台进行每个定制更改。对系统配置文件的任何更改都需要全部重新构建所有软件包。与Yocto相比,这可以
|
||||
通过最小的镜像大小和构建时间进行缓解,但在您调整配置时可能会导致构建时间过长。
|
||||
|
||||
中间软件包状态缓存默认情况下未启用,并且不像Yocto实施那么彻底。这意味着,虽然第一次构建可能比等效的Yocto构建短,但后续构建可能需要重建
|
||||
许多组件。
|
||||
|
||||
####建议
|
||||
|
||||
对于大多数应用程序,使用Buildroot进行下一个嵌入式Linux设计是一个不错的选择。如果您的设计需要多种硬件类型或其他差异,但由于同步多个配置
|
||||
的复杂性,您可能需要重新考虑,但对于由单一设置组成的系统,Buildroot可能适合您。
|
||||
|
||||
[OpenWRT] [16]项目开始为消费者路由器开发定制固件。您当地零售商提供的许多低成本路由器都可以运行Linux系统,但可能无法使用。这些路由器的
|
||||
制造商可能无法提供频繁的更新来解决新的威胁,即使他们这样做,安装更新镜像的机制也很困难且容易出错。 OpenWRT项目为许多已被其制造商放弃的
|
||||
设备生成更新的固件镜像,并让这些设备更加有效。
|
||||
|
||||
OpenWRT项目的主要交付物是大量商业设备的二进制镜像。有网络可访问的软件包存储库,允许设备最终用户将新软件添加到他们的系统中。 OpenWRT构建
|
||||
系统是一个通用构建系统,它允许开发人员创建自定义版本以满足他们自己的需求并添加新软件包,但其主要重点是目标二进制文件。
|
||||
|
||||
#### 优点
|
||||
|
||||
如果您正在寻找商业设备的替代固件,则OpenWRT应位于您的选项列表中。它的维护良好,可以保护您免受制造商固件无法解决的问题。您也可以添加额外的功能,使您的设备更有用。
|
||||
|
||||
如果您的嵌入式设计专注于网络,则OpenWRT是一个不错的选择。网络应用程序是OpenWRT的主要用例,您可能会发现许多可用的软件包。
|
||||
|
||||
####缺点
|
||||
|
||||
OpenWRT对您的设计施加重大决策(与Yocto和Buildroot相比)。如果这些决定不符合您的设计目标,则可能需要进行非平凡的修改。
|
||||
|
||||
在部署的设备中允许基于软件包的更新很难管理。按照定义,这会导致与您的QA团队测试的软件负载不同。此外,很难保证大多数软件包管理器的原子安装,
|
||||
以及错误的电源循环可能会使您的设备处于不可预知的状态。
|
||||
|
||||
####建议
|
||||
|
||||
OpenWRT是爱好者项目或重复使用商用硬件的不错选择。它也是网络应用程序的不错选择。如果您需要从默认设置进行大量定制,您可能更喜欢Buildroot或Yocto
|
||||
|
||||
### Desktop distros
|
||||
|
||||
设计嵌入式Linux系统的一种常见方法是从桌面发行版开始,例如[Debian] [17]或[Red Hat] [18],并在安装的镜像符合目标设备的占用空间之前删除
|
||||
不需要的组件。这是[Raspberry Pi] [20]平台流行的[Raspbian] [19]分发方法。
|
||||
|
||||
### 优点
|
||||
|
||||
这种方法的主要优点是熟悉。通常,嵌入式Linux开发人员也是桌面Linux用户,并且精通他们的选择发行版。在目标上使用类似的环境可能会让开发人员
|
||||
更快地入门。根据所选的分布,可以使用apt和yum等标准封装工具安装许多其他工具。
|
||||
|
||||
可以将显示器和键盘连接到目标设备,并直接在那里进行所有的开发。对于不熟悉嵌入式空间的开发人员来说,这可能是一个更为熟悉的环境,无需配置和
|
||||
使用棘手的跨开发设置。
|
||||
|
||||
大多数桌面发行版可用的软件包数量通常大于前面讨论的嵌入式特定的构建器可用软件包数量。由于较大的用户群和更广泛的用例,您可能能够找到您的
|
||||
应用程序所需的所有运行时包,这些包已经构建并可供使用。
|
||||
|
||||
####缺点
|
||||
|
||||
将目标作为您的主要开发环境可能会很慢。运行编译器工具是一项资源密集型操作,根据您构建的代码的多少,可能会妨碍您的性能。
|
||||
|
||||
除了一些例外情况,桌面分布的设计并不适合低资源系统,并且可能难以充分修剪目标图像。同样,桌面环境中的预期工作流程对于大多数嵌入式设计来说
|
||||
都不理想。以这种方式获得可重复的环境很困难。手动添加和删除软件包很容易出错。这可以使用特定于发行版的工具进行脚本化,例如基于Debian系统
|
||||
的[debootstrap] [21]。为了进一步提高[可重复性] [21],您可以使用配置管理工具,如[CFEngine] [22](我的雇主[Mender.io] [23]完整披露了
|
||||
这一工具)。但是,您仍然受分发提供商的支配,他们将更新软件包以满足他们的需求,而不是您的需求。
|
||||
|
||||
####建议
|
||||
|
||||
对于您打算推向市场的产品,请谨慎使用此方法。这对于爱好者应用程序来说是一个很好的模型;但是,对于需要支持的产品,这种方法很可能会遇到麻烦。
|
||||
虽然您可能能够获得更快的起步,但从长远来看,您可能会花费您的时间和精力。
|
||||
|
||||
###其他考虑
|
||||
|
||||
这个讨论集中在构建系统的功能上,但通常有非功能性需求可能会影响您的决定。如果您已经选择了片上系统(SoC)或电路板,则您的选择很可能由供应商
|
||||
决定。如果您的供应商为特定系统提供板级支持包(BSP),使用它通常会节省相当多的时间,但请研究BSP的质量以避免在开发周期后期发生问题。
|
||||
|
||||
如果您的预算允许,您可能需要考虑为目标操作系统使用商业供应商。有些公司会为这里讨论的许多选项提供经过验证和支持的配置,除非您拥有嵌入式
|
||||
Linux构建系统方面的专业知识,否则这是一个不错的选择,可以让您专注于核心能力。
|
||||
|
||||
作为替代,您可以考虑为您的开发人员进行商业培训。这可能比商业OS提供商便宜,并且可以让你更加自给自足。这是快速找到您选择的构建系统基础知识
|
||||
的学习曲线。
|
||||
|
||||
最后,您可能已经有一些开发人员拥有一个或多个系统的经验。如果你有工程师有偏好,当你做出决定时,肯定值得考虑。
|
||||
|
||||
###总结
|
||||
|
||||
构建嵌入式Linux系统有多种选择,每种都有优点和缺点。将这部分设计放在优先位置至关重要,因为在以后的过程中切换系统的成本非常高。除了这些
|
||||
选择之外,新系统一直在开发中。希望这次讨论能够为审查新系统(以及这里提到的系统)提供一些背景,并帮助您为下一个项目做出坚实的决定。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/embedded-linux-build-tools
|
||||
|
||||
作者:[Drew Moseley][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LHRChina](https://github.com/LHRChina)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/drewmoseley
|
||||
[1]:https://en.wikipedia.org/wiki/Linux_on_z_Systems
|
||||
[2]:http://www.picotux.com/
|
||||
[3]:https://www.ubuntu.com/
|
||||
[4]:https://www.virtualbox.org/
|
||||
[5]:https://www.docker.com/
|
||||
[6]:https://en.wikipedia.org/wiki/Embedded_system
|
||||
[7]:https://yoctoproject.org/
|
||||
[8]:https://www.yoctoproject.org/about/
|
||||
[9]:https://www.openembedded.org/
|
||||
[10]:https://www.yoctoproject.org/community/
|
||||
[11]:https://www.yoctoproject.org/ecosystem/participants/
|
||||
[12]:https://layers.openembedded.org/layerindex/branch/master/layers/
|
||||
[13]:https://layers.openembedded.org/layerindex/branch/master/layer/meta-browser/
|
||||
[14]:https://yoctoproject.org/downloads
|
||||
[15]:https://buildroot.org/
|
||||
[16]:https://openwrt.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/
|
||||
[19]:https://www.raspbian.org/
|
||||
[20]:https://www.raspberrypi.org/
|
||||
[21]:https://wiki.debian.org/Debootstrap
|
||||
[22]:https://cfengine.com/
|
||||
[23]:http://Mender.io
|
||||
@ -0,0 +1,89 @@
|
||||
使用 Open edX 托管课程入门
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Open edX 平台][2] 是一个免费和开源的课程管理系统,它是 [全世界][3] 都在使用的大规模网络公开课(MOOCs)以及小型课程和培训模块的托管平台。在 Open edX 的 [第七个主要发行版][1] 中,到现在为止,它已经提供了超过 8,000 个原创课程和 5000 万个课程注册数。你可以使用你自己的本地设备或者任何行业领先的云基础设施服务提供商来安装这个平台,但是,随着项目的[服务提供商][4]名单越来越长,来自它们中的软件即服务(SaaS)的可用模型也越来越多了。
|
||||
|
||||
Open edX 平台被来自世界各地的顶尖教育机构、私人公司、公共机构、非政府组织、非营利机构、以及教育技术初创企业广泛地使用,并且项目服务提供商的全球社区持续让越来越小的组织可以访问这个平台。如果你打算向广大的读者设计和提供教育内容,你应该考虑去使用 Open edX 平台。
|
||||
|
||||
### 安装
|
||||
|
||||
安装这个软件有多种方式,这可能是不一个不受欢迎的惊喜,至少刚开始是这样。但是不管你是以何种方式 [安装 Open edX][5],最终你都得到的是有相同功能的应用程序。默认安装包含一个为在线学习者提供的、全功能的学习管理系统(LMS),和一个全功能的课程管理工作室(CMS),CMS 可以让你的讲师团队用它来编写原创课程内容。你可以把 CMS 当做是课程内容设计和管理的 “[Wordpress][6]”,把 LMS 当做是课程销售、分发、和消费的 “[Magento][7]”。
|
||||
|
||||
Open edX 是设备无关的和完全响应式的应用软件,并且不用花费很多的努力就可发布一个原生的 iOS 和 Android apps,它可以无缝地集成到你的实例后端。Open edX 平台的代码库、原生移动应用、以及安装脚本都发布在 [GitHub][8] 上。
|
||||
|
||||
#### 有何期望
|
||||
|
||||
Open edX 平台的 [GitHub 仓库][9] 包含适用于各种类型组织的、性能很好的、产品级的代码。来自数百个机构的数千名程序员定期为 edX 仓库做贡献,并且这个平台是一个名副其实的,研究如何去构建和管理一个复杂的企业级应用的好案例。因此,尽管你可能会遇到大量的类似如何将平台迁移到生产环境中的问题,但是你不应该对 Open edX 平台代码库本身的质量和健状性担忧。
|
||||
|
||||
通过少量的培训,你的讲师就可以去设计很好的在线课程。但是请记住,Open edX 是通过它的 [XBlock][10] 组件架构可扩展的,因此,通过他们和你的努力,你的讲师将有可能将好的课程变成精品课程。
|
||||
|
||||
这个平台在单服务器环境下也运行的很好,并且它是高度模块化的,几乎可以进行无限地水平扩展。它也是主题化的和本地化的,平台的功能和外观可以根据你的需要进行几乎无限制地调整。平台在你的设备上可以按需安装并可靠地运行。
|
||||
|
||||
#### 一些封装要求
|
||||
|
||||
请记住,有大量的 edX 软件模块是不包含在默认安装中的,并且这些模块提供的经常都是组织所需要的功能。比如,分析模块、电商模块、以及课程的通知/公告模块都是不包含在默认安装中的,并且这些单独的模块都是值得安装的。另外,在数据备份/恢复和系统管理方面要完全依赖你自己去处理。幸运的是,有关这方面的内容,社区有越来越多的文档和如何去做的文章。你可以通过 Google 和 Bing 去搜索,以帮助你在生产环境中安装它们。
|
||||
|
||||
虽然有很多文档良好的程序,但是根据你的技能水平,配置 [oAuth][11] 和 [SSL/TLS][12],以及使用平台的 [REST API][13] 可能对你是一个挑战。另外,一些组织要求将 MySQL 和/或 MongoDB 数据库在中心化环境中管理,如果你正好是这种情况,你还需要将这些服务从默认平台安装中分离出来。edX 设计团队已经尽可能地为你做了简化,但是由于它是一个非常重大的更改,因此可能需要一些时间去实现。
|
||||
|
||||
如果你面临资源和/或技术上的困难 —— 不要气馁,Open edX 社区 SaaS 提供商,像 [appsembler][14] 和 [eduNEXT][15],提供了引人入胜的替代方案去进行 DIY 安装,尤其是如果你只适应窗口方式操作。
|
||||
|
||||
### 技术栈
|
||||
|
||||
在 Open edX 平台的安装上探索是件令人兴奋的事情,从架构的角度来说,这个项目是一个典范。应用程序模块是 [Django][16] 应用,它利用了大量的开源社区的顶尖项目,包括 [Ubuntu][17]、[MySQL][18]、[MongoDB][19]、[RabbitMQ][20]、[Elasticsearch][21]、[Hadoop][22]、等等。
|
||||
|
||||
![edx-architecture.png][24]
|
||||
|
||||
Open edX 技术栈(CC BY,来自 edX)
|
||||
|
||||
将这些组件安装并配置好本身就是一件非常不容易的事情,但是以这样的一种方式将所有的组件去打包,并适合于任意规模和复杂性的组织,并且能够按他们的需要进行任意调整搭配而无需在代码上做重大改动,看起来似乎是不可能的事情 —— 它就是这种情况,直到你看到主要的平台配置参数安排和命名是多少的巧妙和直观。请注意,平台的组织结构有一个学习曲线,但是,你所学习的一切都是值的去学习的,不仅是对这个项目,对一般意义上的大型 IT 项目都是如此。
|
||||
|
||||
提醒一点:这个平台的 UI 是在不断变动的,最终的目标是在 [React][25] 和 [Bootstrap][26] 上实现标准化。与此同时,你将会发现基本主题有多个实现的样式,这可能会让你感到困惑。
|
||||
|
||||
### 采用
|
||||
|
||||
edX 项目能够迅速得到世界范围内的采纳,很大程度上取决于软件的运行情况。这一点也不奇怪,这个项目成功地吸引了大量才华卓越的人参与其中,他们作为程序员、项目顾问、翻译者、技术作者、以及博客作者参与了项目的贡献。一年一次的 [Open edX 会议][27]、[官方的 edX Google Group][28]、以及 [Open edX 服务提供商名单][4] 是了解这个多样化的、不断成长的生态系统的非常好的起点。我作为相对而言的新人,我发现参与和直接从事这个项目的各个方面是非常容易的。
|
||||
|
||||
祝你学习之旅一切顺利,并且当你构思你的项目时,你可以随时联系我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/getting-started-open-edx
|
||||
|
||||
作者:[Lawrence Mc Daniel][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mcdaniel0073
|
||||
[1]:https://openedx.atlassian.net/wiki/spaces/DOC/pages/11108700/Open+edX+Releases
|
||||
[2]:https://open.edx.org/about-open-edx
|
||||
[3]:https://www.edx.org/schools-partners
|
||||
[4]:https://openedx.atlassian.net/wiki/spaces/COMM/pages/65667081/Open+edX+Service+Providers
|
||||
[5]:https://openedx.atlassian.net/wiki/spaces/OpenOPS/pages/60227779/Open+edX+Installation+Options
|
||||
[6]:https://wordpress.com/
|
||||
[7]:https://magento.com/
|
||||
[8]:https://github.com/edx
|
||||
[9]:https://github.com/edx/edx-platform
|
||||
[10]:https://open.edx.org/xblocks
|
||||
[11]:https://oauth.net/
|
||||
[12]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[13]:https://en.wikipedia.org/wiki/Representational_state_transfer
|
||||
[14]:https://www.appsembler.com/
|
||||
[15]:https://www.edunext.co/
|
||||
[16]:https://www.djangoproject.com/
|
||||
[17]:https://www.ubuntu.com/
|
||||
[18]:https://www.mysql.com/
|
||||
[19]:https://www.mongodb.com/
|
||||
[20]:https://www.rabbitmq.com/
|
||||
[21]:https://www.elastic.co/
|
||||
[22]:http://hadoop.apache.org/
|
||||
[23]:/file/400696
|
||||
[24]:https://opensource.com/sites/default/files/uploads/edx-architecture_0.png "edx-architecture.png"
|
||||
[25]:%E2%80%9Chttps://reactjs.org/%E2%80%9C
|
||||
[26]:%E2%80%9Chttps://getbootstrap.com/%E2%80%9C
|
||||
[27]:https://con.openedx.org/
|
||||
[28]:https://groups.google.com/forum/#!forum/openedx-ops
|
||||
Loading…
Reference in New Issue
Block a user