mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-01 21:50:13 +08:00
commit
415706104a
@ -0,0 +1,358 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10519-1.html)
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 3 OK03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室之树莓派:课程 3 OK03
|
||||
======
|
||||
|
||||
OK03 课程基于 OK02 课程来构建,它教你在汇编中如何使用函数让代码可复用和可读性更好。假设你已经有了 [课程 2:OK02][1] 的操作系统,我们将以它为基础。
|
||||
|
||||
### 1、可复用的代码
|
||||
|
||||
到目前为止,我们所写的代码都是以我们希望发生的事为顺序来输入的。对于非常小的程序来说,这种做法很好,但是如果我们以这种方式去写一个完整的系统,所写的代码可读性将非常差。我们应该去使用函数。
|
||||
|
||||
> 一个函数是一段可复用的代码片断,可以用于去计算某些答案,或执行某些动作。你也可以称它们为<ruby>过程<rt>procedure</rt></ruby>、<ruby>例程<rt>routine</rt></ruby>或<ruby>子例程<rt>subroutine</rt></ruby>。虽然它们都是不同的,但人们几乎都没有正确地使用这个术语。
|
||||
|
||||
> 你应该在数学上遇到了函数的概念。例如,余弦函数应用于一个给定的数时,会得到介于 -1 到 1 之间的另一个数,这个数就是角的余弦。一般我们写成 `cos(x)` 来表示应用到一个值 `x` 上的余弦函数。
|
||||
|
||||
> 在代码中,函数可以有多个输入(也可以没有输入),然后函数给出多个输出(也可以没有输出),并可能导致副作用。例如一个函数可以在一个文件系统上创建一个文件,第一个输入是它的名字,第二个输入是文件的长度。
|
||||
|
||||
> ![Function as black boxes][2]
|
||||
|
||||
> 函数可以认为是一个“黑匣子”。我们给它输入,然后它给我们输出,而我们不需要知道它是如何工作的。
|
||||
|
||||
在像 C 或 C++ 这样的高级代码中,函数是语言的组成部分。在汇编代码中,函数只是我们的创意。
|
||||
|
||||
理想情况下,我们希望能够在我们的寄存器中设置一些输入值,然后分支切换到某个地址,然后预期在某个时刻分支返回到我们代码,并通过代码来设置输出值到寄存器。这就是我们所设想的汇编代码中的函数。困难之处在于我们用什么样的方式去设置寄存器。如果我们只是使用平时所接触到的某种方法去设置寄存器,每个程序员可能使用不同的方法,这样你将会发现你很难理解其他程序员所写的代码。另外,编译器也不能像使用汇编代码那样轻松地工作,因为它们压根不知道如何去使用函数。为避免这种困惑,为每个汇编语言设计了一个称为<ruby>应用程序二进制接口<rt>Application Binary Interface</rt></ruby>(ABI)的标准,由它来规范函数如何去运行。如果每个人都使用相同的方法去写函数,这样每个人都可以去使用其他人写的函数。在这里,我将教你们这个标准,而从现在开始,我所写的函数将全部遵循这个标准。
|
||||
|
||||
该标准规定,寄存器 `r0`、`r1`、`r2` 和 `r3` 将被依次用于函数的输入。如果函数没有输入,那么它不会在意值是什么。如果只需要一个输入,那么它应该总是在寄存器 `r0` 中,如果它需要两个输入,那么第一个输入在寄存器 `r0` 中,而第二个输入在寄存器 `r1` 中,依此类推。输出值也总是在寄存器 `r0` 中。如果函数没有输出,那么 `r0` 中是什么值就不重要了。
|
||||
|
||||
另外,该标准要求当一个函数运行之后,寄存器 `r4` 到 `r12` 的值必须与函数启动时的值相同。这意味着当你调用一个函数时,你可以确保寄存器 `r4` 到 `r12` 中的值没有发生变化,但是不能确保寄存器 `r0` 到 `r3` 中的值也没有发生变化。
|
||||
|
||||
当一个函数运行完成后,它将返回到启动它的代码分支处。这意味着它必须知道启动它的代码的地址。为此,需要一个称为 `lr`(链接寄存器)的专用寄存器,它总是在保存调用这个函数的指令后面指令的地址。
|
||||
|
||||
表 1.1 ARM ABI 寄存器用法
|
||||
|
||||
| 寄存器 | 简介 | 保留 | 规则 |
|
||||
| ------ | --------- | ---- | ----------------- |
|
||||
| `r0` | 参数和结果 | 否 | `r0` 和 `r1` 用于给函数传递前两个参数,以及函数返回的结果。如果函数返回值不使用它,那么在函数运行之后,它们可以携带任何值。 |
|
||||
| `r1` | 参数和结果 | 否 | |
|
||||
| `r2` | 参数 | 否 | `r2` 和 `r3` 用去给函数传递后两个参数。在函数运行之后,它们可以携带任何值。 |
|
||||
| `r3` | 参数 | 否 | |
|
||||
| `r4` | 通用寄存器 | 是 | `r4` 到 `r12` 用于保存函数运行过程中的值,它们的值在函数调用之后必须与调用之前相同。 |
|
||||
| `r5` | 通用寄存器 | 是 | |
|
||||
| `r6` | 通用寄存器 | 是 | |
|
||||
| `r7` | 通用寄存器 | 是 | |
|
||||
| `r8` | 通用寄存器 | 是 | |
|
||||
| `r9` | 通用寄存器 | 是 | |
|
||||
| `r10` | 通用寄存器 | 是 | |
|
||||
| `r11` | 通用寄存器 | 是 | |
|
||||
| `r12` | 通用寄存器 | 是 | |
|
||||
| `lr` | 返回地址 | 否 | 当函数运行完成后,`lr` 中保存了分支的返回地址,但在函数运行完成之后,它将保存相同的地址。 |
|
||||
| `sp` | 栈指针 | 是 | `sp` 是栈指针,在下面有详细描述。它的值在函数运行完成后,必须是相同的。 |
|
||||
|
||||
通常,函数需要使用很多的寄存器,而不仅是 `r0` 到 `r3`。但是,由于 `r4` 到 `r12` 必须在函数完成之后值必须保持相同,因此它们需要被保存到某个地方。我们将它们保存到称为栈的地方。
|
||||
|
||||
> ![Stack diagram][3]
|
||||
|
||||
> 一个<ruby>栈<rt>stack</rt></ruby>就是我们在计算中用来保存值的一个很形象的方法。就像是摞起来的一堆盘子,你可以从上到下来移除它们,而添加它们时,你只能从下到上来添加。
|
||||
|
||||
> 在函数运行时,使用栈来保存寄存器值是个非常好的创意。例如,如果我有一个函数需要去使用寄存器 `r4` 和 `r5`,它将在一个栈上存放这些寄存器的值。最后用这种方式,它可以再次将它拿回来。更高明的是,如果为了运行完我的函数,需要去运行另一个函数,并且那个函数需要保存一些寄存器,在那个函数运行时,它将把寄存器保存在栈顶上,然后在结束后再将它们拿走。而这并不会影响我保存在寄存器 `r4` 和 `r5` 中的值,因为它们是在栈顶上添加的,拿走时也是从栈顶上取出的。
|
||||
|
||||
> 用来表示使用特定的方法将值放到栈上的专用术语,我们称之为那个方法的“<ruby>栈帧<rt>stack frame</rt></ruby>”。不是每种方法都使用一个栈帧,有些是不需要存储值的。
|
||||
|
||||
因为栈非常有用,它被直接实现在 ARMv6 的指令集中。一个名为 `sp`(栈指针)的专用寄存器用来保存栈的地址。当需要有值添加到栈上时,`sp` 寄存器被更新,这样就总是保证它保存的是栈上第一个值的地址。`push {r4,r5}` 将推送 `r4` 和 `r5` 中的值到栈顶上,而 `pop {r4,r5}` 将(以正确的次序)取回它们。
|
||||
|
||||
### 2、我们的第一个函数
|
||||
|
||||
现在,关于函数的原理我们已经有了一些概念,我们尝试来写一个函数。由于是我们的第一个很基础的例子,我们写一个没有输入的函数,它将输出 GPIO 的地址。在上一节课程中,我们就是写到这个值上,但将它写成函数更好,因为我们在真实的操作系统中经常需要用到它,而我们不可能总是能够记住这个地址。
|
||||
|
||||
复制下列代码到一个名为 `gpio.s` 的新文件中。就像在 `source` 目录中使用的 `main.s` 一样。我们将把与 GPIO 控制器相关的所有函数放到一个文件中,这样更好查找。
|
||||
|
||||
```assembly
|
||||
.globl GetGpioAddress
|
||||
GetGpioAddress:
|
||||
ldr r0,=0x20200000
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
> `.globl lbl` 使标签 `lbl` 从其它文件中可访问。
|
||||
|
||||
> `mov reg1,reg2` 复制 `reg2` 中的值到 `reg1` 中。
|
||||
|
||||
这就是一个很简单的完整的函数。`.globl GetGpioAddress` 命令是通知汇编器,让标签 `GetGpioAddress` 在所有文件中全局可访问。这意味着在我们的 `main.s` 文件中,我们可以使用分支指令到标签 `GetGpioAddress` 上,即便这个标签在那个文件中没有定义也没有问题。
|
||||
|
||||
你应该认得 `ldr r0,=0x20200000` 命令,它将 GPIO 控制器地址保存到 `r0` 中。由于这是一个函数,我们必须要让它输出到寄存器 `r0` 中,我们不能再像以前那样随意使用任意一个寄存器了。
|
||||
|
||||
`mov pc,lr` 将寄存器 `lr` 中的值复制到 `pc` 中。正如前面所提到的,寄存器 `lr` 总是保存着方法完成后我们要返回的代码的地址。`pc` 是一个专用寄存器,它总是包含下一个要运行的指令的地址。一个普通的分支命令只需要改变这个寄存器的值即可。通过将 `lr` 中的值复制到 `pc` 中,我们就可以将要运行的下一行命令改变成我们将要返回的那一行。
|
||||
|
||||
理所当然这里有一个问题,那就是我们如何去运行这个代码?我们将需要一个特殊的分支类型 `bl` 指令。它像一个普通的分支一样切换到一个标签,但它在切换之前先更新 `lr` 的值去包含一个在该分支之后的行的地址。这意味着当函数执行完成后,将返回到 `bl` 指令之后的那一行上。这就确保了函数能够像任何其它命令那样运行,它简单地运行,做任何需要做的事情,然后推进到下一行。这是理解函数最有用的方法。当我们使用它时,就将它们按“黑匣子”处理即可,不需要了解它是如何运行的,我们只了解它需要什么输入,以及它给我们什么输出即可。
|
||||
|
||||
到现在为止,我们已经明白了函数如何使用,下一节我们将使用它。
|
||||
|
||||
### 3、一个大的函数
|
||||
|
||||
现在,我们继续去实现一个更大的函数。我们的第一项任务是启用 GPIO 第 16 号针脚的输出。如果它是一个函数那就太好了。我们能够简单地指定一个针脚号和一个函数作为输入,然后函数将设置那个针脚的值。那样,我们就可以使用这个代码去控制任意的 GPIO 针脚,而不只是 LED 了。
|
||||
|
||||
将下列的命令复制到 `gpio.s` 文件中的 `GetGpioAddress` 函数中。
|
||||
|
||||
```assembly
|
||||
.globl SetGpioFunction
|
||||
SetGpioFunction:
|
||||
cmp r0,#53
|
||||
cmpls r1,#7
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
> 带后缀 `ls` 的命令只有在上一个比较命令的结果是第一个数字小于或与第二个数字相同的情况下才会被运行。它是无符号的。
|
||||
|
||||
> 带后缀 `hi` 的命令只有上一个比较命令的结果是第一个数字大于第二个数字的情况下才会被运行。它是无符号的。
|
||||
|
||||
在写一个函数时,我们首先要考虑的事情就是输入,如果输入错了我们怎么办?在这个函数中,我们有一个输入是 GPIO 针脚号,而它必须是介于 0 到 53 之间的数字,因为只有 54 个针脚。每个针脚有 8 个函数,被编号为 0 到 7,因此函数编号也必须是 0 到 7 之间的数字。我们可以假设输入应该是正确的,但是当在硬件上使用时,这种做法是非常危险的,因为不正确的值将导致非常糟糕的副作用。所以,在这个案例中,我们希望确保输入值在正确的范围。
|
||||
|
||||
为了确保输入值在正确的范围,我们需要做一个检查,即 `r0` <= 53 并且 `r1` <= 7。首先我们使用前面看到的比较命令去将 `r0` 的值与 53 做比较。下一个指令 `cmpls` 仅在前一个比较指令结果是小于或与 53 相同时才会去运行。如果是这种情况,它将寄存器 `r1` 的值与 7 进行比较,其它的部分都和前面的是一样的。如果最后的比较结果是寄存器值大于那个数字,最后我们将返回到运行函数的代码处。
|
||||
|
||||
这正是我们所希望的效果。如果 `r0` 中的值大于 53,那么 `cmpls` 命令将不会去运行,但是 `movhi` 会运行。如果 `r0` 中的值 <= 53,那么 `cmpls` 命令会运行,它会将 `r1` 中的值与 7 进行比较,如果 `r1` > 7,`movhi` 会运行,函数结束,否则 `movhi` 不会运行,这样我们就确定 `r0` <= 53 并且 `r1` <= 7。
|
||||
|
||||
`ls`(低于或相同)与 `le`(小于或等于)有一些细微的差别,以及后缀 `hi`(高于)和 `gt`(大于)也一样有一些细微差别,我们在后面将会讲到。
|
||||
|
||||
将这些命令复制到上面的代码的下面位置。
|
||||
|
||||
```assembly
|
||||
push {lr}
|
||||
mov r2,r0
|
||||
bl GetGpioAddress
|
||||
```
|
||||
|
||||
> `push {reg1,reg2,...}` 复制列出的寄存器 `reg1`、`reg2`、... 到栈顶。该命令仅能用于通用寄存器和 `lr` 寄存器。
|
||||
|
||||
> `bl lbl` 设置 `lr` 为下一个指令的地址并切换到标签 `lbl`。
|
||||
|
||||
这三个命令用于调用我们第一个方法。`push {lr}` 命令复制 `lr` 中的值到栈顶,这样我们在后面可以获取到它。当我们调用 `GetGpioAddress` 时必须要这样做,我们将需要使用 `lr` 去保存我们函数要返回的地址。
|
||||
|
||||
如果我们对 `GetGpioAddress` 函数一无所知,我们必须假设它改变了 `r0`、`r1`、`r2` 和 `r3` 的值 ,并移动我们的值到 `r4` 和 `r5` 中,以在函数完成之后保持它们的值一样。幸运的是,我们知道 `GetGpioAddress` 做了什么,并且我们也知道它仅改变了 `r0` 为 GPIO 地址,它并没有影响 `r1`、`r2` 或 `r3` 的值。因此,我们仅去将 GPIO 针脚号从 `r0` 中移出,这样它就不会被覆盖掉,但我们知道,可以将它安全地移到 `r2` 中,因为 `GetGpioAddress` 并不去改变 `r2`。
|
||||
|
||||
最后我们使用 `bl` 指令去运行 `GetGpioAddress`。通常,运行一个函数,我们使用一个术语叫“调用”,从现在开始我们将一直使用这个术语。正如我们前面讨论过的,`bl` 调用一个函数是通过更新 `lr` 为下一个指令的地址并切换到该函数完成的。
|
||||
|
||||
当一个函数结束时,我们称为“返回”。当一个 `GetGpioAddress` 调用返回时,我们已经知道了 `r0` 中包含了 GPIO 的地址,`r1` 中包含了函数编号,而 `r2` 中包含了 GPIO 针脚号。
|
||||
|
||||
我前面说过,GPIO 函数每 10 个保存在一个块中,因此首先我们需要去判断我们的针脚在哪个块中。这似乎听起来像是要使用一个除法,但是除法做起来非常慢,因此对于这些比较小的数来说,不停地做减法要比除法更好。
|
||||
|
||||
将下面的代码复制到上面的代码中最下面的位置。
|
||||
|
||||
```assembly
|
||||
functionLoop$:
|
||||
|
||||
cmp r2,#9
|
||||
subhi r2,#10
|
||||
addhi r0,#4
|
||||
bhi functionLoop$
|
||||
```
|
||||
|
||||
> `add reg,#val` 将数字 `val` 加到寄存器 `reg` 的内容上。
|
||||
|
||||
这个简单的循环代码将针脚号(`r2`)与 9 进行比较。如果它大于 9,它将从针脚号上减去 10,并且将 GPIO 控制器地址加上 4,然后再次运行检查。
|
||||
|
||||
这样做的效果就是,现在,`r2` 中将包含一个 0 到 9 之间的数字,它是针脚号除以 10 的余数。`r0` 将包含这个针脚的函数所设置的 GPIO 控制器的地址。它就如同是 “GPIO 控制器地址 + 4 × (GPIO 针脚号 ÷ 10)”。
|
||||
|
||||
最后,将下面的代码复制到上面的代码中最下面的位置。
|
||||
|
||||
```assembly
|
||||
add r2, r2,lsl #1
|
||||
lsl r1,r2
|
||||
str r1,[r0]
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
> 移位参数 `reg,lsl #val` 表示将寄存器 `reg` 中二进制表示的数逻辑左移 `val` 位之后的结果作为与前面运算的操作数。
|
||||
|
||||
> `lsl reg,amt` 将寄存器 `reg` 中的二进制数逻辑左移 `amt` 中的位数。
|
||||
|
||||
> `str reg,[dst]` 与 `str reg,[dst,#0]` 相同。
|
||||
|
||||
> `pop {reg1,reg2,...}` 从栈顶复制值到寄存器列表 `reg1`、`reg2`、... 仅有通用寄存器与 `pc` 可以这样弹出值。
|
||||
|
||||
这个代码完成了这个方法。第一行其实是乘以 3 的变体。乘法在汇编中是一个大而慢的指令,因为电路需要很长时间才能给出答案。有时使用一些能够很快给出答案的指令会让它变得更快。在本案例中,我们知道 `r2` × 3 与 `r2` × 2 + `r2` 是相同的。一个寄存器乘以 2 是非常容易的,因为它可以通过将二进制表示的数左移一位来很方便地实现。
|
||||
|
||||
ARMv6 汇编语言其中一个非常有用的特性就是,在使用它之前可以先移动参数所表示的位数。在本案例中,我将 `r2` 加上 `r2` 中二进制表示的数左移一位的结果。在汇编代码中,你可以经常使用这个技巧去更快更容易地计算出答案,但如果你觉得这个技巧使用起来不方便,你也可以写成类似 `mov r3,r2`; `add r2,r3`; `add r2,r3` 这样的代码。
|
||||
|
||||
现在,我们可以将一个函数的值左移 `r2` 中所表示的位数。大多数对数量的指令(比如 `add` 和 `sub`)都有一个可以使用寄存器而不是数字的变体。我们执行这个移位是因为我们想去设置表示针脚号的位,并且每个针脚有三个位。
|
||||
|
||||
然后,我们将函数计算后的值保存到 GPIO 控制器的地址上。我们在循环中已经算出了那个地址,因此我们不需要像 OK01 和 OK02 中那样在一个偏移量上保存它。
|
||||
|
||||
最后,我们从这个方法调用中返回。由于我们将 `lr` 推送到了栈上,因此我们 `pop pc`,它将复制 `lr` 中的值并将它推送到 `pc` 中。这个操作类似于 `mov pc,lr`,因此函数调用将返回到运行它的那一行上。
|
||||
|
||||
敏锐的人可能会注意到,这个函数其实并不能正确工作。虽然它将 GPIO 针脚函数设置为所要求的值,但它会导致在同一个块中的所有的 10 个针脚的函数都归 0!在一个大量使用 GPIO 针脚的系统中,这将是一个很恼人的问题。我将这个问题留给有兴趣去修复这个函数的人,以确保只设置相关的 3 个位而不去覆写其它位,其它的所有位都保持不变。关于这个问题的解决方案可以在本课程的下载页面上找到。你可能会发现非常有用的几个函数是 `and`,它是计算两个寄存器的布尔与函数,`mvns` 是计算布尔非函数,而 `orr` 是计算布尔或函数。
|
||||
|
||||
### 4、另一个函数
|
||||
|
||||
现在,我们已经有了能够管理 GPIO 针脚函数的函数。我们还需要写一个能够打开或关闭 GPIO 针脚的函数。我们不需要写一个打开的函数和一个关闭的函数,只需要一个函数就可以做这两件事情。
|
||||
|
||||
我们将写一个名为 `SetGpio` 的函数,它将 GPIO 针脚号作为第一个输入放入 `r0` 中,而将值作为第二个输入放入 `r1` 中。如果该值为 `0`,我们将关闭针脚,而如果为非零则打开针脚。
|
||||
|
||||
将下列的代码复制粘贴到 `gpio.s` 文件的结尾部分。
|
||||
|
||||
```assembly
|
||||
.globl SetGpio
|
||||
SetGpio:
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
```
|
||||
|
||||
> `alias .req reg` 设置寄存器 `reg` 的别名为 `alias`。
|
||||
|
||||
我们再次需要 `.globl` 命令,标记它为其它文件可访问的全局函数。这次我们将使用寄存器别名。寄存器别名允许我们为寄存器使用名字而不仅是 `r0` 或 `r1`。到目前为止,寄存器别名还不是很重要,但随着我们后面写的方法越来越大,它将被证明非常有用,现在开始我们将尝试使用别名。当在指令中使用到 `pinNum .req r0` 时,它的意思是 `pinNum` 表示 `r0`。
|
||||
|
||||
将下面的代码复制粘贴到上述的代码下面位置。
|
||||
|
||||
```assembly
|
||||
cmp pinNum,#53
|
||||
movhi pc,lr
|
||||
push {lr}
|
||||
mov r2,pinNum
|
||||
.unreq pinNum
|
||||
pinNum .req r2
|
||||
bl GetGpioAddress
|
||||
gpioAddr .req r0
|
||||
```
|
||||
|
||||
> `.unreq alias` 删除别名 `alias`。
|
||||
|
||||
就像在函数 `SetGpio` 中所做的第一件事情是检查给定的针脚号是否有效一样。我们需要同样的方式去将 `pinNum`(`r0`)与 53 进行比较,如果它大于 53 将立即返回。一旦我们想要再次调用 `GetGpioAddress`,我们就需要将 `lr` 推送到栈上来保护它,将 `pinNum` 移动到 `r2` 中。然后我们使用 `.unreq` 语句来删除我们给 `r0` 定义的别名。因为针脚号现在保存在寄存器 `r2` 中,我们希望别名能够反映这个变化,因此我们从 `r0` 移走别名,重新定义到 `r2`。你应该每次在别名使用结束后,立即删除它,这样当它不再存在时,你就不会在后面的代码中因它而产生错误。
|
||||
|
||||
然后,我们调用了 `GetGpioAddress`,并且我们创建了一个指向 `r0`的别名以反映此变化。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的后面位置。
|
||||
|
||||
```assembly
|
||||
pinBank .req r3
|
||||
lsr pinBank,pinNum,#5a
|
||||
lsl pinBank,#2
|
||||
add gpioAddr,pinBank
|
||||
.unreq pinBank
|
||||
```
|
||||
|
||||
> `lsr dst,src,#val` 将 `src` 中二进制表示的数右移 `val` 位,并将结果保存到 `dst`。
|
||||
|
||||
对于打开和关闭 GPIO 针脚,每个针脚在 GPIO 控制器上有两个 4 字节组。第一个 4 字节组每个位控制前 32 个针脚,而第二个 4 字节组控制剩下的 22 个针脚。为了判断我们要设置的针脚在哪个 4 字节组中,我们需要将针脚号除以 32。幸运的是,这很容易,因为它等价于将二进制表示的针脚号右移 5 位。因此,在本案例中,我们将 `r3` 命名为 `pinBank`,然后计算 `pinNum` ÷ 32。因为它是一个 4 字节组,我们需要将它与 4 相乘的结果。它与二进制表示的数左移 2 位相同,这就是下一行的命令。你可能想知道我们能否只将它右移 3 位呢,这样我们就不用先右移再左移。但是这样做是不行的,因为当我们做 ÷ 32 时答案有些位可能被舍弃,而如果我们做 ÷ 8 时却不会这样。
|
||||
|
||||
现在,`gpioAddr` 的结果有可能是 20200000<sub>16</sub>(如果针脚号介于 0 到 31 之间),也有可能是 20200004<sub>16</sub>(如果针脚号介于 32 到 53 之间)。这意味着如果加上 28<sub>10</sub>,我们将得到打开针脚的地址,而如果加上 40<sub>10</sub> ,我们将得到关闭针脚的地址。由于我们用完了 `pinBank` ,所以在它之后立即使用 `.unreq` 去删除它。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的下面位置。
|
||||
|
||||
```assembly
|
||||
and pinNum,#31
|
||||
setBit .req r3
|
||||
mov setBit,#1
|
||||
lsl setBit,pinNum
|
||||
.unreq pinNum
|
||||
```
|
||||
|
||||
> `and reg,#val` 计算寄存器 `reg` 中的数与 `val` 的布尔与。
|
||||
|
||||
该函数的下一个部分是产生一个正确的位集合的数。至于 GPIO 控制器去打开或关闭针脚,我们在针脚号除以 32 的余数里设置了位的数。例如,设置 16 号针脚,我们需要第 16 位设置数字为 1 。设置 45 号针脚,我们需要设置第 13 位数字为 1,因为 45 ÷ 32 = 1 余数 13。
|
||||
|
||||
这个 `and` 命令计算我们需要的余数。它是这样计算的,在两个输入中所有的二进制位都是 1 时,这个 `and` 运算的结果就是 1,否则就是 0。这是一个很基础的二进制操作,`and` 操作非常快。我们给定的输入是 “pinNum and 31<sub>10</sub> = 11111<sub>2</sub>”。这意味着答案的后 5 位中只有 1,因此它肯定是在 0 到 31 之间。尤其是在 `pinNum` 的后 5 位的位置是 1 的地方它只有 1。这就如同被 32 整除的余数部分。就像 31 = 32 - 1 并不是巧合。
|
||||
|
||||
![binary division example][4]
|
||||
|
||||
代码的其余部分使用这个值去左移 1 位。这就有了创建我们所需要的二进制数的效果。
|
||||
|
||||
将下面的代码复制粘贴到上述代码的下面位置。
|
||||
|
||||
```assembly
|
||||
teq pinVal,#0
|
||||
.unreq pinVal
|
||||
streq setBit,[gpioAddr,#40]
|
||||
strne setBit,[gpioAddr,#28]
|
||||
.unreq setBit
|
||||
.unreq gpioAddr
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
> `teq reg,#val` 检查寄存器 `reg` 中的数字与 `val` 是否相等。
|
||||
|
||||
这个代码结束了该方法。如前面所说,当 `pinVal` 为 0 时,我们关闭它,否则就打开它。`teq`(等于测试)是另一个比较操作,它仅能够测试是否相等。它类似于 `cmp` ,但它并不能算出哪个数大。如果你只是希望测试数字是否相同,你可以使用 `teq`。
|
||||
|
||||
如果 `pinVal` 是 0,我们将 `setBit` 保存在 GPIO 地址偏移 40 的位置,我们已经知道,这样会关闭那个针脚。否则将它保存在 GPIO 地址偏移 28 的位置,它将打开那个针脚。最后,我们通过弹出 `pc` 返回,这将设置它为我们推送链接寄存器时保存的值。
|
||||
|
||||
### 5、一个新的开始
|
||||
|
||||
在完成上述工作后,我们终于有了我们的 GPIO 函数。现在,我们需要去修改 `main.s` 去使用它们。因为 `main.s` 现在已经有点大了,也更复杂了。将它分成两节将是一个很好的设计。到目前为止,我们一直使用的 `.init` 应该尽可能的让它保持小。我们可以更改代码来很容易地反映出这一点。
|
||||
|
||||
将下列的代码插入到 `main.s` 文件中 `_start:` 的后面:
|
||||
|
||||
```
|
||||
b main
|
||||
|
||||
.section .text
|
||||
main:
|
||||
mov sp,#0x8000
|
||||
```
|
||||
|
||||
在这里重要的改变是引入了 `.text` 节。我设计了 `makefile` 和链接器脚本,它将 `.text` 节(它是默认节)中的代码放在地址为 8000<sub>16</sub> 的 `.init` 节之后。这是默认加载地址,并且它给我们提供了一些空间去保存栈。由于栈存在于内存中,它也有一个地址。栈向下增长内存,因此每个新值都低于前一个地址,所以,这使得栈顶是最低的一个地址。
|
||||
|
||||
![Layout diagram of operating system][5]
|
||||
|
||||
> 图中的 “ATAGs” 节的位置保存了有关树莓派的信息,比如它有多少内存,默认屏幕分辨率是多少。
|
||||
|
||||
用下面的代码替换掉所有设置 GPIO 函数针脚的代码:
|
||||
|
||||
```assembly
|
||||
pinNum .req r0
|
||||
pinFunc .req r1
|
||||
mov pinNum,#16
|
||||
mov pinFunc,#1
|
||||
bl SetGpioFunction
|
||||
.unreq pinNum
|
||||
.unreq pinFunc
|
||||
```
|
||||
|
||||
这个代码将使用针脚号 16 和函数编号 1 去调用 `SetGpioFunction`。它的效果就是启用了 OK LED 灯的输出。
|
||||
|
||||
用下面的代码去替换打开 OK LED 灯的代码:
|
||||
|
||||
```assembly
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
mov pinNum,#16
|
||||
mov pinVal,#0
|
||||
bl SetGpio
|
||||
.unreq pinNum
|
||||
.unreq pinVal
|
||||
```
|
||||
|
||||
这个代码使用 `SetGpio` 去关闭 GPIO 第 16 号针脚,因此将打开 OK LED。如果我们(将第 4 行)替换成 `mov pinVal,#1` 它将关闭 LED 灯。用以上的代码去替换掉你关闭 LED 灯的旧代码。
|
||||
|
||||
### 6、继续向目标前进
|
||||
|
||||
但愿你能够顺利地在你的树莓派上测试我们所做的这一切。到目前为止,我们已经写了一大段代码,因此不可避免会出现错误。如果有错误,可以去查看我们的排错页面。
|
||||
|
||||
如果你的代码已经正常工作,恭喜你。虽然我们的操作系统除了做 [课程 2:OK02][1] 中的事情,还做不了别的任何事情,但我们已经学会了函数和格式有关的知识,并且我们现在可以更好更快地编写新特性了。现在,我们在操作系统上修改 GPIO 寄存器将变得非常简单,而它就是用于控制硬件的!
|
||||
|
||||
在 [课程 4:OK04][6] 中,我们将处理我们的 `wait` 函数,目前,它的时间控制还不精确,这样我们就可以更好地控制我们的 LED 灯了,进而最终控制所有的 GPIO 针脚。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10478-1.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/functions.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/stack.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/binary3.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/osLayout.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
115
published/20150513 XML vs JSON.md
Normal file
115
published/20150513 XML vs JSON.md
Normal file
@ -0,0 +1,115 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wwhio)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10515-1.html)
|
||||
[#]: subject: (XML vs JSON)
|
||||
[#]: via: (https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html)
|
||||
[#]: author: (TOM STRASSNER tomstrassner@gmail.com)
|
||||
|
||||
XML 与 JSON 优劣对比
|
||||
======
|
||||
|
||||
### 简介
|
||||
|
||||
XML 和 JSON 是现今互联网中最常用的两种数据交换格式。XML 格式由 W3C 于 1996 年提出。JSON 格式由 Douglas Crockford 于 2002 年提出。虽然这两种格式的设计目标并不相同,但它们常常用于同一个任务,也就是数据交换中。XML 和 JSON 的文档都很完善([RFC 7159][1]、[RFC 4825][2]),且都同时具有<ruby>人类可读性<rt>human-readable</rt></ruby>和<ruby>机器可读性<rt>machine-readable</rt></ruby>。这两种格式并没有哪一个比另一个更强,只是各自适用的领域不用。(LCTT 译注:W3C 是[互联网联盟](https://www.w3.org/),制定了各种 Web 相关的标准,如 HTML、CSS 等。Douglas Crockford 除了制定了 JSON 格式,还致力于改进 JavaScript,开发了 JavaScript 相关工具 [JSLint](http://jslint.com/) 和 [JSMin](http://www.crockford.com/javascript/jsmin.html))
|
||||
|
||||
### XML 的优点
|
||||
|
||||
XML 与 JSON 相比有很多优点。二者间最大的不同在于 XML 可以通过在标签中添加属性这一简单的方法来存储<ruby>元数据<rt>metadata</rt></ruby>。而使用 JSON 时需要创建一个对象,把元数据当作对象的成员来存储。虽然二者都能达到存储元数据的目的,但在这一情况下 XML 往往是更好的选择,因为 JSON 的表达形式会让客户端程序开发人员误以为要将数据转换成一个对象。举个例子,如果你的 C++ 程序需要使用 JSON 格式发送一个附带元数据的整型数据,需要创建一个对象,用对象中的一个<ruby>名称/值对<rt>name/value pair</rt></ruby>来记录整型数据的值,再为每一个附带的属性添加一个名称/值对。接收到这个 JSON 的程序在读取后很可能把它当成一个对象,可事实并不是这样。虽然这是使用 JSON 传递元数据的一种变通方法,但他违背了 JSON 的核心理念:“<ruby>JSON 的结构与常规的程序语言中的结构相对应,而无需修改。<rt>JSON's structures look like conventional programming language structures. No restructuring is necessary.</rt></ruby>”[^2]
|
||||
|
||||
虽然稍后我会说这也是 XML 的一个缺点,但 XML 中对命名冲突、<ruby>前缀<rt>prefix</rt></ruby>的处理机制赋予了它 JSON 所不具备的能力。程序员们可以通过前缀来把统一名称给予两个不同的实体。[^1] 当不同的实体在客户端中使用的名称相同时,这一特性会非常有用。
|
||||
|
||||
XML 的另一个优势在于大多数的浏览器可以把它以<ruby>具有高可读性和强组织性的方式<rt>highly readable and organized way</rt></ruby>展现给用户。XML 的树形结构让它易于结构化,浏览器也让用户可以自行展开或折叠树中的元素,这简直就是调试的福音。
|
||||
|
||||
XML 对比 JSON 有一个很重要的优势就是它可以记录<ruby>混合内容<rt>mixed content</rt></ruby>。例如在 XML 中处理包含结构化标记的字符串时,程序员们只要把带有标记的文本放在一个标签内就可以了。可因为 JSON 只包含数据,没有用于指明标签的简单方式,虽然可以使用处理元数据的解决方法,但这总有点滥用之嫌。
|
||||
|
||||
### JSON 的优点
|
||||
|
||||
JSON 自身也有很多优点。其中最显而易见的一点就是 JSON 比 XML 简洁得多。因为 XML 中需要打开和关闭标签,而 JSON 使用名称/值对表示数据,使用简单的 `{` 和 `}` 来标记对象,`[` 和 `]` 来标记数组,`,` 来表示数据的分隔,`:` 表示名称和值的分隔。就算是使用 gzip 压缩,JSON 还是比 XML 要小,而且耗时更少。[^6] 正如 Sumaray 和 Makki 在实验中指出的那样,JSON 在很多方面都比 XML 更具优势,得出同样结果的还有 Nurseitov、Paulson、Reynolds 和 Izurieta。首先,由于 JSON 文件天生的简洁性,与包含相同信息的 XML 相比,JSON 总是更小,这意味着更快的传输和处理速度。第二,在不考虑大小的情况下,两组研究 [^3] [^4] 表明使用 JSON 执行序列化和反序列化的速度显著优于使用 XML。第三,后续的研究指出 JSON 的处理在 CPU 资源的使用上也优于 XML。研究人员发现 JSON 在总体上使用的资源更少,其中更多的 CPU 资源消耗在用户空间,系统空间消耗的 CPU 资源较少。这一实验是在 RedHat 的设备上进行的,RedHat 表示更倾向于在用户空间使用 CPU 资源。[^3a] 不出意外,Sumaray 和 Makki 在研究里还说明了在移动设备上 JSON 的性能也优于 XML。[^4a] 这是有道理的,因为 JSON 消耗的资源更少,而移动设备的性能也更弱。
|
||||
|
||||
JSON 的另一个优点在于其对对象和数组的表述和<ruby>宿主语言<rt>host language</rt></ruby>中的数据结构相对应,例如<ruby>对象<rt>object</rt></ruby>、<ruby>记录<rt>record</rt></ruby>、<ruby>结构体<rt>struct</rt></ruby>、<ruby>字典<rt>dictionary</rt></ruby>、<ruby>哈希表<rt>hash table</rt></ruby>、<ruby>键值列表<rt>keyed list</rt></ruby>还有<ruby>数组<rt>array</rt></ruby>、<ruby>向量<rt>vector</rt></ruby>、<ruby>列表<rt>list</rt></ruby>,以及对象组成的数组等等。[^2a] 虽然 XML 里也能表达这些数据结构,也只需调用一个函数就能完成解析,而往往需要更多的代码才能正确的完成 XML 的序列化和反序列化处理。而且 XML 对于人类来说不如 JSON 那么直观,XML 标准缺乏对象、数组的标签的明确定义。当结构化的标记可以替代嵌套的标签时,JSON 的优势极为突出。JSON 中的花括号和中括号则明确表示了数据的结构,当然这一优势也包含前文中的问题,在表示元数据时 JSON 不如 XML 准确。
|
||||
|
||||
虽然 XML 支持<ruby>命名空间<rt>namespace</rt></ruby>与<ruby>前缀<rt>prefix</rt></ruby>,但这不代表 JSON 没有处理命名冲突的能力。比起 XML 的前缀,它处理命名冲突的方式更简洁,在程序中的处理也更自然。在 JSON 里,每一个对象都在它自己的命名空间中,因此不同对象内的元素名称可以随意重复。在大多数编程语言中,不同的对象中的成员可以包含相同的名字,所以 JSON 根据对象进行名称区分的规则在处理时更加自然。
|
||||
|
||||
也许 JSON 比 XML 更优的部分是因为 JSON 是 JavaScript 的子集,所以在 JavaScript 代码中对它的解析或封装都非常的自然。虽然这看起来对 JavaScript 程序非常有用,而其他程序则不能直接从中获益,可实际上这一问题已经被很好的解决了。现在 JSON 的网站的列表上展示了 64 种不同语言的 175 个工具,它们都实现了处理 JSON 所需的功能。虽然我不能评价大多数工具的质量,但它们的存在明确了开发者社区拥抱 JSON 这一现象,而且它们切实简化了在不同平台使用 JSON 的难度。
|
||||
|
||||
### 二者的动机
|
||||
|
||||
简单地说,XML 的目标是标记文档。这和 JSON 的目标想去甚远,所以只要用得到 XML 的地方就尽管用。它使用树形的结构和包含语义的文本来表达混合内容以实现这一目标。在 XML 中可以表示数据的结构,但这并不是它的长处。
|
||||
|
||||
JSON 的目标是用于数据交换的一种结构化表示。它直接使用对象、数组、数字、字符串、布尔值这些元素来达成这一目标。这完全不同于文档标记语言。正如上面说的那样,JSON 没有原生支持<ruby>混合内容<rt>mixed content</rt></ruby>的记录。
|
||||
|
||||
### 软件
|
||||
|
||||
这些主流的开放 API 仅提供 XML:<ruby>亚马逊产品广告 API<rt>Amazon Product Advertising API</rt></ruby>。
|
||||
|
||||
这些主流 API 仅提供 JSON:<ruby>脸书图 API<rt>Facebook Graph API</rt></ruby>、<ruby>谷歌地图 API<rt>Google Maps API</rt></ruby>、<ruby>推特 API<rt>Twitter API</rt></ruby>、AccuWeather API、Pinterest API、Reddit API、Foursquare API。
|
||||
|
||||
这些主流 API 同时提供 XML 和 JSON:<ruby>谷歌云存储<rt>Google Cloud Storage</rt></ruby>、<ruby>领英 API<rt>Linkedin API</rt></ruby>、Flickr API。
|
||||
|
||||
根据<ruby>可编程网络<rt>Programmable Web</rt></ruby> [^9] 的数据,最流行的 10 个 API 中只有一个是仅提供 XML 且不支持 JSON 的。其他的要么同时支持 XML 和 JSON,要么只支持 JSON。这表明了大多数应用开发者都更倾向于使用支持 JSON 的 API,原因大概是 JSON 更快的处理速度与良好口碑,加之与 XML 相比更加轻量。此外,大多数 API 只是传递数据而非文档,所以 JSON 更加合适。例如 Facebook 的重点在于用户的交流与帖子,谷歌地图则主要处理坐标和地图信息,AccuWeather 就只传递天气数据。总之,虽然不能说天气 API 在使用时究竟是 JSON 用的多还是 XML 用的多,但是趋势明确偏向了 JSON。[^10] [^11]
|
||||
|
||||
这些主流的桌面软件仍然只是用 XML:Microsoft Word、Apache OpenOffice、LibraOffice。
|
||||
|
||||
因为这些软件需要考虑引用、格式、存储等等,所以比起 JSON,XML 优势更大。另外,这三款程序都支持混合内容,而 JSON 在这一点上做得并不如 XML 好。举例说明,当用户使用 Microsoft Word 编辑一篇论文时,用户需要使用不同的文字字形、文字大小、文字颜色、页边距、段落格式等,而 XML 结构化的组织形式与标签属性生来就是为了表达这些信息的。
|
||||
|
||||
这些主流的数据库支持 XML:IBM DB2、Microsoft SQL Server、Oracle Database、PostgresSQL、BaseX、eXistDB、MarkLogic、MySQL。
|
||||
|
||||
这些是支持 JSON 的主流数据库:MongoDB、CouchDB、eXistDB、Elastisearch、BaseX、MarkLogic、OrientDB、Oracle Database、PostgreSQL、Riak。
|
||||
|
||||
在很长一段时间里,SQL 和关系型数据库统治着整个数据库市场。像<ruby>甲骨文<rt>Oracle</rt></ruby>和<ruby>微软<rt>Microsoft</rt></ruby>这样的软件巨头都提供这类数据库,然而近几年 NoSQL 数据库正逐步受到开发者的青睐。也许是正巧碰上了 JSON 的普及,大多数 NoSQL 数据库都支持 JSON,像 MongoDB、CouchDB 和 Riak 这样的数据库甚至使用 JSON 来存储数据。这些数据库有两个重要的特性是它们适用于现代网站:一是它们与关系型数据库相比<ruby>更容易扩展<rt>more scalable</rt></ruby>;二是它们设计的目标就是 web 运行所需的核心组件。[^10a] 由于 JSON 更加轻量,又是 JavaScript 的子集,所以很适合 NoSQL 数据库,并且让这两个品质更容易实现。此外,许多旧的关系型数据库增加了 JSON 支持,例如 Oracle Database 和 PostgreSQL。由于 XML 与 JSON 间的转换比较麻烦,所以大多数开发者会直接在他们的应用里使用 JSON,因此开发数据库的公司才有支持 JSON 的理由。(LCTT 译注:NoSQL 是对不同于传统的关系数据库的数据库管理系统的统称。[参考来源](https://zh.wikipedia.org/wiki/NoSQL)) [^7]
|
||||
|
||||
### 未来
|
||||
|
||||
对互联网的种种变革中,最让人期待的便是<ruby>物联网<rt>Internet of Things</rt></ruby>(IoT)。这会给互联网带来大量计算机之外的设备,例如手表、温度计、电视、冰箱等等。这一势头的发展良好,预期在不久的将来迎来爆发式的增长。据估计,到 2020 年时会有 260 亿 到 2000 亿的物联网设备被接入互联网。[^12] [^13] 几乎所有的物联网设备都是小型设备,因此性能比笔记本或台式电脑要弱很多,而且大多数都是嵌入式系统。因此,当它们需要与互联网上的系统交换数据时,更轻量、更快速的 JSON 自然比 XML 更受青睐。[^10b] 受益于 JSON 在 web 上的快速普及,与 XML 相比,这些新的物联网设备更有可能从使用 JSON 中受益。这是一个典型的梅特卡夫定律的例子,无论是 XML 还是 JSON,抑或是什么其他全新的格式,现存的设备和新的设备都会从支持最广泛使用的格式中受益。
|
||||
|
||||
Node.js 是一款服务器端的 JavaScript 框架,随着她的诞生与快速成长,与 MongoDB 等 NoSQL 数据库一起,让全栈使用 JavaScript 开发成为可能。这些都预示着 JSON 光明的未来,这些软件的出现让 JSON 运用在全栈开发的每一个环节成为可能,这将使应用更加轻量,响应更快。这也是任何应用的追求之一,所以,全栈使用 JavaScript 的趋势在不久的未来都不会消退。[^10c]
|
||||
|
||||
此外,另一个应用开发的趋势是从 SOAP 转向 REST。[^11a] [^15] [^16] XML 和 JSON 都可以用于 REST,可 SOAP 只能使用 XML。
|
||||
|
||||
从这些趋势中可以推断,JSON 的发展将统一 Web 的信息交换格式,XML 的使用率将继续降低。虽然不应该把 JSON 吹过头了,因为 XML 在 Web 中的使用依旧很广,而且它还是 SOAP 的唯一选择,可考虑到 SOAP 到 REST 的迁移,NoSQL 数据库和全栈 JavaScript 的兴起,JSON 卓越的性能,我相信 JSON 很快就会在 Web 开发中超过 XML。至于其他领域,XML 比 JSON 更好的情况并不多。
|
||||
|
||||
|
||||
### 角注
|
||||
|
||||
[^1]: [XML Tutorial](http://www.w3schools.com/xml/default.asp)
|
||||
[^2]: [Introducing JSON](http://www.json.org/)
|
||||
[^2a]: [Introducing JSON](http://www.json.org/)
|
||||
[^3]: [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
[^3a]: [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
[^4]: [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
[^4a]: [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
[^5]: [JSON vs. XML: The Debate](http://ajaxian.com/archives/json-vs-xml-the-debate)
|
||||
[^6]: [JSON vs. XML: Some hard numbers about verbosity](http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity)
|
||||
[^7]: [How JSON sparked NoSQL -- and will return to the RDBMS fold](http://www.infoworld.com/article/2608293/nosql/how-json-sparked-nosql----and-will-return-to-the-rdbms-fold.html)
|
||||
[^8]: [Did You Say "JSON Support" in Oracle 12.1.0.2?](https://blogs.oracle.com/OTN-DBA-DEV-Watercooler/entry/did_you_say_json_support)
|
||||
[^9]: [Most Popular APIs: At Least One Will Surprise You](http://www.programmableweb.com/news/most-popular-apis-least-one-will-surprise-you/2014/01/23)
|
||||
[^10]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10a]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10b]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^10c]: [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
[^11]: [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
[^11a]: [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
[^12]: [A Simple Explanation Of 'The Internet Of Things’](http://www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/)
|
||||
[^13]: [Proofpoint Uncovers Internet of Things (IoT) Cyberattack](http://www.proofpoint.com/about-us/press-releases/01162014.php)
|
||||
[^14]: [The Internet of Things: New Threats Emerge in a Connected World](http://www.symantec.com/connect/blogs/internet-things-new-threats-emerge-connected-world)
|
||||
[^15]: [3,000 Web APIs: Trends From A Quickly Growing Directory](http://www.programmableweb.com/news/3000-web-apis-trends-quickly-growing-directory/2011/03/08)
|
||||
[^16]: [How REST replaced SOAP on the Web: What it means to you](http://www.infoq.com/articles/rest-soap)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html
|
||||
|
||||
作者:[TOM STRASSNER][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wwhio](https://github.com/wwhio)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: tomstrassner@gmail.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tools.ietf.org/html/rfc7159
|
||||
[2]: https://tools.ietf.org/html/rfc4825
|
||||
@ -0,0 +1,76 @@
|
||||
采用 snaps 为 Linux 社区构建 Slack
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
作为一个被数以百万计用户使用的企业级软件平台,[Slack][2] 可以让各种规模的团队和企业有效地沟通。Slack 通过在一个单一集成环境中与其它软件工具无缝衔接,为一个组织内的通讯、信息和项目提供了一个易于接触的档案馆。尽管自从诞生后 Slack 就在过去四年中快速成长,但是他们负责该平台的 Windows、MacOS 和 Linux 桌面的工程师团队仅由四人组成。我们采访了这个团队的主任工程师 Felix Rieseberg(他负责追踪[上月首次发布的 Slack snap][3],LCTT 译注:原文发布于 2018.2),来了解更多有关该公司对于 Linux 社区的态度,以及他们决定构建一个 snap 软件包的原因。
|
||||
|
||||
- [安装 Slack snap][4]
|
||||
|
||||
### 你们能告诉我们更多关于已发布的 Slack snap 的信息吗?
|
||||
|
||||
作为发布给 Linux 社区的一种新形式,我们上月发布了我们的第一个 snap。在企业界,我们发现人们更倾向于以一种相对于个人消费者来说较慢的速度来采用新科技,因此我们将会在未来继续提供 .deb 形式的软件包。
|
||||
|
||||
### 你们觉得 Linux 社区会对 Slack 有多大的兴趣呢?
|
||||
|
||||
我很高兴在所有的平台上人们都对 Slack 的兴趣越来越大。因此,很难说来自 Linux 社区的兴趣和我们大体上所见到的兴趣有什么区别。当然,不管用户们在什么平台上面工作,满足他们对我们都是很重要的。我们有一个专门负责 Linux 的测试工程师,并且我们同时也会尽全力提供最好的用户体验。
|
||||
|
||||
只是我们发现总体相对于 Windows 来说,为 Linux 搭建 snap 略微有点难度,因为我们是在一个较难以预测的平台上工作——而这正是 Linux 社区之光照耀的领域。在汇报程序缺陷以及寻找程序崩溃原因方面,我们有相当多极有帮助的用户。
|
||||
|
||||
### 你们是如何得知 snap 的?
|
||||
|
||||
Canonical 公司的 Martin Wimpress 接触了我,并向我解释了 snap 的概念。说实话尽管我也用 Ubuntu 但最初我还是迟疑的,因为它看起来像需要搭建与维护的另一套标准。然而,一当我了解到其中的好处之后,我确信这是一笔值得的投入。
|
||||
|
||||
### snap 的什么方面吸引了你们并使你们决定投入其中?
|
||||
|
||||
毫无疑问,我们决定搭建 snap 最重要的原因是它的更新特性。在 Slack 上我们大量运用了网页技术,这些技术反过来也使得我们提供大量的特性——比如将 YouTube 视频或者 Spotify 播放列表集成在 Slack 中。与浏览器十分相似,这意味着我们需要频繁更新应用。
|
||||
|
||||
在 MacOS 和 Windows 上,我们已经有了一个专门的自动更新器,甚至无需用户关注更新。任何形式的中断都是一种我们需要避免的烦恼,哪怕是为了更新。因此通过 snap 自动化的更新就显得更加无缝和便捷。
|
||||
|
||||
### 相比于其它形式的打包方式,构建 snap 感觉如何?将它与现有的设施和流程集成在一起有多简便呢?
|
||||
|
||||
就 Linux 而言,我们尚未尝试其它的“新”打包方式,但我们迟早会的。鉴于我们的大多数用户都使用 Ubuntu,snap 是一个自然的选择。同时 snap 在其它发行版上同样也可以使用,这也是一个巨大的加分项。Canonical 正将 snap 做到跨发行版,而不是仅仅集中在 Ubuntu 上,这一点我认为是很好的。
|
||||
|
||||
搭建 snap 极其简单,我们有一个创建安装器和软件包的统一流程,我们的 snap 创建过程就是从一个 .deb 软件包炮制出一个 snap。对于其它技术而言,有时候我们为了支持构建链而先打造一个内部工具。但是 snapcraft 工具正是我们需要的东西。在整个过程中 Canonical 的团队非常有帮助,因为我们一路上确实碰到了一些问题。
|
||||
|
||||
### 你们觉得 snap 商店是如何改变用户们寻找、安装你们软件的方式的呢?
|
||||
|
||||
Slack 真正的独特之处在于人们不仅仅是碰巧发现它,他们从别的地方知道它并积极地试图找到它。因此尽管我们已经有了相当高的觉悟,我希望对于我们的用户来说,在商店中可以获得 snap 能够让安装过程变得简单一点。
|
||||
|
||||
我们总是尽力为用户服务。当我们觉得它比其他安装方式更好,我们就会向用户更多推荐它。
|
||||
|
||||
### 通过使用 snap 而不是为其它发行版打包,你期待或者已经看到的节省是什么?
|
||||
|
||||
我们希望 snap 可以给予我们的用户更多的便利,并确保他们能够更加喜欢使用 Slack。在我们看来,鉴于用户们不必被困在之前的版本,这自然而然地解决了许多问题,因此 snap 可以让我们在客户支持方面节约时间。snap 对我们来说也是一个额外的加分项,因为我们能有一个可供搭建的平台,而不是替换我们现有的东西。
|
||||
|
||||
### 如果存在的话,你们正使用或者准备使用边缘 (edge)、测试 (beta)、候选 (candidate)、稳定 (stable) 中的哪种发行频道?
|
||||
|
||||
我们开发中专门使用边缘 (edge) 频道以与 Canonical 团队合作。为 Linux 打造的 Slack 总体仍处于测试 (beta) 频道中。但是长远来看,拥有不同频道的选择十分有意思,同时能够提早一点为感兴趣的客户发布版本也肯定是有好处的。
|
||||
|
||||
### 你们如何认为将软件打包成一个 snap 能够帮助用户?你们从用户那边得到了什么反馈吗?
|
||||
|
||||
对我们的用户来说一个很大的好处是安装和更新总体来说都会变得简便一点。长远来看,问题是“那些安装 snap 的用户是不是比其它用户少碰到一些困难?”,我十分期望 snap 自带的依赖关系能够使其变成可能。
|
||||
|
||||
### 你们对刚使用 snap 的新用户们有什么建议或知识呢?
|
||||
|
||||
我会推荐从 Debian 软件包来着手搭建你们的 snap ——那出乎意料得简单。这同样也缩小了范围,避免变得不堪重负。这只需要投入相当少的时间,并且很大可能是一笔值得的投入。同样如果你们可以的话,尽量试着找到 Canonical 的人员来协作——他们拥有了不起的工程师。
|
||||
|
||||
### 对于开发来说,你们在什么地方看到了最大的机遇?
|
||||
|
||||
我们现在正一步步来,先是让人们接受 snap,再从那里开始搭建。正在使用 snap 的人们将会感到更加稳健,因为他们将会得益于最新的更新。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/
|
||||
|
||||
作者:[Sarah][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sarahfd/
|
||||
[1]:https://insights.ubuntu.com/wp-content/uploads/a115/Slack_linux_screenshot@2x-2.png
|
||||
[2]:https://slack.com/
|
||||
[3]:https://insights.ubuntu.com/2018/01/18/canonical-brings-slack-to-the-snap-ecosystem/
|
||||
[4]:https://snapcraft.io/slack/
|
||||
@ -1,28 +1,29 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: subject: (An introduction to the Tornado Python web app framework)
|
||||
[#]: via: (https://opensource.com/article/18/6/tornado-framework)
|
||||
[#]: author: (Nicholas Hunt-Walker https://opensource.com/users/nhuntwalker)
|
||||
[#]: url: ( )
|
||||
[#]: url: (https://linux.cn/article-10522-1.html)
|
||||
|
||||
Python Web 框架 Tornado 简介
|
||||
Python Web 应用程序 Tornado 框架简介
|
||||
======
|
||||
|
||||
在比较 Python 框架的系列文章的第三部分中,我们来了解 Tornado,它是为处理异步进程而构建的。
|
||||
> 在比较 Python 框架的系列文章的第三部分中,我们来了解 Tornado,它是为处理异步进程而构建的。
|
||||
|
||||

|
||||
|
||||
在这个由四部分组成的系列文章的前两篇中,我们介绍了 [Pyramid][1] 和 [Flask][2] Web 框架。我们已经构建了两次相同的应用程序,看到了一个完全的 DIY 框架和包含更多电池的框架之间的异同。
|
||||
在这个由四部分组成的系列文章的前两篇中,我们介绍了 [Pyramid][1] 和 [Flask][2] Web 框架。我们已经构建了两次相同的应用程序,看到了一个完整的 DIY 框架和包含了更多功能的框架之间的异同。
|
||||
|
||||
现在让我们来看看另一个稍微不同的选项:[Tornado 框架][3]。Tornado 在很大程度上与 Flask 一样简单,但有一个主要区别:Tornado 是专门为处理异步进程而构建的。在我们本系列所构建的应用程序中,这种特殊的酱料(译者注:这里意思是 Tornado 的异步功能)并不是非常有用,但我们将看到在哪里可以使用它,以及它在更一般的情况下是如何工作的。
|
||||
现在让我们来看看另一个稍微不同的选择:[Tornado 框架][3]。Tornado 在很大程度上与 Flask 一样简单,但有一个主要区别:Tornado 是专门为处理异步进程而构建的。在我们本系列所构建的应用程序中,这种特殊的酱料(LCTT 译注:这里意思是 Tornado 的异步功能)在我们构建的 app 中并不是非常有用,但我们将看到在哪里可以使用它,以及它在更一般的情况下是如何工作的。
|
||||
|
||||
让我们继续前两篇文章中设置的流程,首先从处理设置和配置。
|
||||
让我们继续前两篇文章中模式,首先从处理设置和配置开始。
|
||||
|
||||
### Tornado 启动和配置
|
||||
|
||||
如果你一直关注这个系列,那么第一步应该对你来说习以为常。
|
||||
|
||||
```
|
||||
$ mkdir tornado_todo
|
||||
$ cd tornado_todo
|
||||
@ -32,6 +33,7 @@ $ pipenv shell
|
||||
```
|
||||
|
||||
创建一个 `setup.py` 文件来安装我们的应用程序相关的东西:
|
||||
|
||||
```
|
||||
(tornado-someHash) $ touch setup.py
|
||||
# setup.py
|
||||
@ -61,6 +63,7 @@ setup(
|
||||
```
|
||||
|
||||
因为 Tornado 不需要任何外部配置,所以我们可以直接编写 Python 代码来让程序运行。让我们创建 `todo` 目录,并用需要的前几个文件填充它。
|
||||
|
||||
```
|
||||
todo/
|
||||
__init__.py
|
||||
@ -68,7 +71,18 @@ todo/
|
||||
views.py
|
||||
```
|
||||
|
||||
就像 Flask 和 Pyramid 一样,Tornado 也有一些基本配置,将放在 `__init__.py` 中。从 `tornado.web` 中,我们将导入 `Application` 对象,它将处理路由和视图的连接,包括数据库(当我们谈到那里时再说)以及运行 Tornado 应用程序所需的其它额外设置。
|
||||
就像 Flask 和 Pyramid 一样,Tornado 也有一些基本配置,放在 `__init__.py` 中。从 `tornado.web` 中,我们将导入 `Application` 对象,它将处理路由和视图的连接,包括数据库(当我们谈到那里时再说)以及运行 Tornado 应用程序所需的其它额外设置。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
from tornado.web import Application
|
||||
|
||||
def main():
|
||||
"""Construct and serve the tornado application."""
|
||||
app = Application()
|
||||
```
|
||||
|
||||
像 Flask 一样,Tornado 主要是一个 DIY 框架。当构建我们的 app 时,我们必须设置该应用实例。因为 Tornado 用它自己的 HTTP 服务器来提供该应用,我们必须设置如何提供该应用。首先,在 `tornado.options.define` 中定义要监听的端口。然后我们实例化 Tornado 的 `HTTPServer`,将该 `Application` 对象的实例作为参数传递给它。
|
||||
|
||||
```
|
||||
# __init__.py
|
||||
@ -109,13 +123,13 @@ def main():
|
||||
IOLoop.current().start()
|
||||
```
|
||||
|
||||
我喜欢某种形式的 `print` 声明,告诉我什么时候应用程序正在提供服务,我就是这样子。如果你愿意,可以不使用 `print`。
|
||||
我喜欢某种形式的 `print` 语句,来告诉我什么时候应用程序正在提供服务,这是我的习惯。如果你愿意,可以不使用 `print`。
|
||||
|
||||
我们以 `IOLoop.current().start()` 开始我们的 I/O 循环。让我们进一步讨论输入,输出和异步性。
|
||||
|
||||
### Python 中的异步和 I/O 循环的基础知识
|
||||
|
||||
请允许我提前说明,我绝对,肯定,肯定并且安心地说不是异步编程方面的专家。就像我写的所有内容一样,接下来的内容源于我对这个概念的理解的局限性。因为我是人,可能有很深很深的缺陷。
|
||||
请允许我提前说明,我绝对,肯定,一定并且放心地说不是异步编程方面的专家。就像我写的所有内容一样,接下来的内容源于我对这个概念的理解的局限性。因为我是人,可能有很深很深的缺陷。
|
||||
|
||||
异步程序的主要问题是:
|
||||
|
||||
@ -123,7 +137,7 @@ def main():
|
||||
* 数据如何出去?
|
||||
* 什么时候可以在不占用我全部注意力情况下运行某个过程?
|
||||
|
||||
由于[全局解释器锁][4](GIL),Python 被设计为一种单线程语言。对于 Python 程序必须执行的每个任务,其线程执行的全部注意力都集中在该任务的持续时间内。我们的 HTTP 服务器是用 Python 编写的,因此,当接收到数据(如 HTTP 请求)时,服务器的唯一关心的是传入的数据。这意味着,在大多数情况下,无论是程序需要运行还是处理数据,程序都将完全消耗服务器的执行线程,阻止接收其它可能的数据,直到服务器完成它需要做的事情。
|
||||
由于[全局解释器锁][4](GIL),Python 被设计为一种[单线程][5]语言。对于 Python 程序必须执行的每个任务,其线程执行的全部注意力都集中在该任务的持续时间内。我们的 HTTP 服务器是用 Python 编写的,因此,当接收到数据(如 HTTP 请求)时,服务器的唯一关心的是传入的数据。这意味着,在大多数情况下,无论是程序需要运行还是处理数据,程序都将完全消耗服务器的执行线程,阻止接收其它可能的数据,直到服务器完成它需要做的事情。
|
||||
|
||||
在许多情况下,这不是太成问题。典型的 Web 请求,响应周期只需要几分之一秒。除此之外,构建 HTTP 服务器的套接字可以维护待处理的传入请求的积压。因此,如果请求在该套接字处理其它内容时进入,则它很可能只是在处理之前稍微排队等待一会。对于低到中等流量的站点,几分之一秒的时间并不是什么大问题,你可以使用多个部署的实例以及 [NGINX][6] 等负载均衡器来为更大的请求负载分配流量。
|
||||
|
||||
@ -182,9 +196,9 @@ def main():
|
||||
|
||||
尽管经历了在 Python 中讨论异步的所有麻烦,我们还是决定暂不使用它。先来编写一个基本的 Tornado 视图。
|
||||
|
||||
与我们在 Flask 和 Pyramid 实现中看到的基于函数的视图不同,Tornado 的视图都是基于类的。这意味着我们将不在使用单独的,独立的函数来规定如何处理请求。相反,传入的 HTTP 请求将被捕获并将其分配为我们定义的类的一个属性。然后,它的方法将处理相应的请求类型。
|
||||
与我们在 Flask 和 Pyramid 实现中看到的基于函数的视图不同,Tornado 的视图都是基于类的。这意味着我们将不在使用单独的、独立的函数来规定如何处理请求。相反,传入的 HTTP 请求将被捕获并将其分配为我们定义的类的一个属性。然后,它的方法将处理相应的请求类型。
|
||||
|
||||
让我们从一个基本的视图开始,即在屏幕上打印 "Hello, World"。我们为 Tornado 应用程序构造的每个基于类的视图都必须继承 `tornado.web` 中的 `RequestHandler` 对象。这将设置我们需要(但不想写)的所有底层逻辑来接收请求,同时构造正确格式的 HTTP 响应。
|
||||
让我们从一个基本的视图开始,即在屏幕上打印 “Hello, World”。我们为 Tornado 应用程序构造的每个基于类的视图都必须继承 `tornado.web` 中的 `RequestHandler` 对象。这将设置我们需要(但不想写)的所有底层逻辑来接收请求,同时构造正确格式的 HTTP 响应。
|
||||
|
||||
```
|
||||
from tornado.web import RequestHandler
|
||||
@ -197,7 +211,7 @@ class HelloWorld(RequestHandler):
|
||||
self.write("Hello, world!")
|
||||
```
|
||||
|
||||
因为我们要处理 `GET` 请求,所以我们声明(实际上是重写) `get` 方法。我们提供文本或 JSON 可序列化对象,用 `self.write` 写入响应体。之后,我们让 `RequestHandler` 来做在发送响应之前必须完成的其它工作。
|
||||
因为我们要处理 `GET` 请求,所以我们声明(实际上是重写)了 `get` 方法。我们提供文本或 JSON 可序列化对象,用 `self.write` 写入响应体。之后,我们让 `RequestHandler` 来做在发送响应之前必须完成的其它工作。
|
||||
|
||||
就目前而言,此视图与 Tornado 应用程序本身并没有实际连接。我们必须回到 `__init__.py`,并稍微更新 `main` 函数。以下是新的内容:
|
||||
|
||||
@ -226,15 +240,15 @@ def main():
|
||||
|
||||
我们将 `views.py` 文件中的 `HelloWorld` 视图导入到脚本 `__init__.py` 的顶部。然后我们添加了一个路由-视图对应的列表,作为 `Application` 实例化的第一个参数。每当我们想要在应用程序中声明一个路由时,它必须绑定到一个视图。如果需要,可以对多个路由使用相同的视图,但每个路由必须有一个视图。
|
||||
|
||||
我们可以通过在 `setup.py` 中启用的 `serve_app` 命令来运行应用程序,从而确保这一切都能正常工作。查看 `http://localhost:8888/` 并看到它显示 "Hello, world!"。
|
||||
我们可以通过在 `setup.py` 中启用的 `serve_app` 命令来运行应用程序,从而确保这一切都能正常工作。查看 `http://localhost:8888/` 并看到它显示 “Hello, world!”。
|
||||
|
||||
当然,在这个领域中我们还能做更多,也将做更多,但现在让我们来讨论模型吧。
|
||||
|
||||
### 连接数据库
|
||||
|
||||
如果我们想要保留数据,我们需要连接数据库。与 Flask 一样,我们将使用一个特定于框架的 SQLAchemy 变体,名为 [tornado-sqlalchemy][7]。
|
||||
如果我们想要保留数据,就需要连接数据库。与 Flask 一样,我们将使用一个特定于框架的 SQLAchemy 变体,名为 [tornado-sqlalchemy][7]。
|
||||
|
||||
为什么要使用它而不是 [SQLAlchemy][8] 呢?好吧,其实 `tornado-sqlalchemy` 具有简单 SQLAlchemy 的所有优点,因此我们仍然可以使用通用的 `Base` 声明模型,并使用我们习以为常的所有列数据类型和关系。除了我们已经从习惯中了解到的,`tornado-sqlalchemy` 还为其数据库查询功能提供了一种可访问的异步模式,专门用于与 Tornado 现有的 I/O 循环一起工作。
|
||||
为什么要使用它而不是 [SQLAlchemy][8] 呢?好吧,其实 `tornado-sqlalchemy` 具有简单 SQLAlchemy 的所有优点,因此我们仍然可以使用通用的 `Base` 声明模型,并使用我们习以为常的所有列数据类型和关系。除了我们已经惯常了解到的,`tornado-sqlalchemy` 还为其数据库查询功能提供了一种可访问的异步模式,专门用于与 Tornado 现有的 I/O 循环一起工作。
|
||||
|
||||
我们通过将 `tornado-sqlalchemy` 和 `psycopg2` 添加到 `setup.py` 到所需包的列表并重新安装包来创建环境。在 `models.py` 中,我们声明了模型。这一步看起来与我们在 Flask 和 Pyramid 中已经看到的完全一样,所以我将跳过全部声明,只列出了 `Task` 模型的必要部分。
|
||||
|
||||
@ -463,7 +477,7 @@ class TaskListView(BaseView):
|
||||
})
|
||||
```
|
||||
|
||||
这里的第一个主要部分是 `@coroutine` 装饰器,它从 `tornado.gen` 导入。任何具有与调用堆栈的正常流程不同步的部分的 Python 可调用实际上是“协程”。一个可以与其它协程一起运行的协程。在我的家务劳动的例子中,几乎所有的家务活都是一个共同的例行协程。有些人阻止了例行协程(例如,给地板吸尘),但这种例行协程只会阻碍我开始或关心其它任何事情的能力。它没有阻止已经启动的任何其他协程继续进行。
|
||||
这里的第一个主要部分是 `@coroutine` 装饰器,它从 `tornado.gen` 导入。任何具有与调用堆栈的正常流程不同步的 Python 可调用部分实际上是“协程”,即一个可以与其它协程一起运行的协程。在我的家务劳动的例子中,几乎所有的家务活都是一个共同的例行协程。有些阻止了例行协程(例如,给地板吸尘),但这种例行协程只会阻碍我开始或关心其它任何事情的能力。它没有阻止已经启动的任何其他协程继续进行。
|
||||
|
||||
Tornado 提供了许多方法来构建一个利用协程的应用程序,包括允许我们设置函数调用锁,同步异步协程的条件,以及手动修改控制 I/O 循环的事件系统。
|
||||
|
||||
@ -525,9 +539,9 @@ def post(self, username):
|
||||
|
||||
在我们继续浏览这些 Web 框架时,我们开始看到它们都可以有效地处理相同的问题。对于像这样的待办事项列表,任何框架都可以完成这项任务。但是,有些 Web 框架比其它框架更适合某些工作,这具体取决于对你来说什么“更合适”和你的需求。
|
||||
|
||||
虽然 Tornado 显然能够处理 Pyramid 或 Flask 可以处理的相同工作,但将它用于这样的应用程序实际上是一种浪费,这就像开车从家走一个街区(to 校正:这里意思应该是从家开始走一个街区只需步行即可)。是的,它可以完成“旅行”的工作,但短途旅行不是你选择汽车而不是自行车或者使用双脚的原因。
|
||||
虽然 Tornado 显然和 Pyramid 或 Flask 一样可以处理相同工作,但将它用于这样的应用程序实际上是一种浪费,这就像开车从家走一个街区(LCTT 译注:这里意思应该是从家开始走一个街区只需步行即可)。是的,它可以完成“旅行”的工作,但短途旅行不是你选择汽车而不是自行车或者使用双脚的原因。
|
||||
|
||||
根据文档,Tornado 被称为 “Python Web 框架和异步网络库”。在 Python Web 框架生态系统中很少有人喜欢它。如果你尝试完成的工作需要(或将从中获益)以任何方式,形状或形式的异步性,使用 Tornado。如果你的应用程序需要处理多个长期连接,同时又不想牺牲太多性能,选择 Tornado。如果你的应用程序是多个应用程序,并且需要线程感知以准确处理数据,使用 Tornado。这是它最有效的地方。
|
||||
根据文档,Tornado 被称为 “Python Web 框架和异步网络库”。在 Python Web 框架生态系统中很少有人喜欢它。如果你尝试完成的工作需要(或将从中获益)以任何方式、形状或形式的异步性,使用 Tornado。如果你的应用程序需要处理多个长期连接,同时又不想牺牲太多性能,选择 Tornado。如果你的应用程序是多个应用程序,并且需要线程感知以准确处理数据,使用 Tornado。这是它最有效的地方。
|
||||
|
||||
用你的汽车做“汽车的事情”,使用其他交通工具做其他事情。
|
||||
|
||||
@ -535,13 +549,10 @@ def post(self, username):
|
||||
|
||||
谈到使用合适的工具来完成合适的工作,在选择框架时,请记住应用程序的范围和规模,包括现在和未来。到目前为止,我们只研究了适用于中小型 Web 应用程序的框架。本系列的下一篇也是最后一篇将介绍最受欢迎的 Python 框架之一 Django,它适用于可能会变得更大的大型应用程序。同样,尽管它在技术上能够并且将会处理待办事项列表问题,但请记住,这不是它的真正用途。我们仍然会通过它来展示如何使用它来构建应用程序,但我们必须牢记框架的意图以及它是如何反映在架构中的:
|
||||
|
||||
* **Flask:** 适用于小型,简单的项目。它可以使我们轻松地构建视图并将它们快速连接到路由,它可以简单地封装在一个文件中。
|
||||
|
||||
* **Pyramid:** 适用于可能增长的项目。它包含一些配置来启动和运行。应用程序组件的独立领域可以很容易地划分并构建到任意深度,而不会忽略中央应用程序。
|
||||
|
||||
* **Tornado:** 适用于受益于精确和有意识的 I/O 控制的项目。它允许协程,并轻松公开可以控制如何接收请求或发送响应以及何时发生这些操作的方法。
|
||||
|
||||
* **Django:**(我们将会看到)意味着可能会变得更大的东西。它有着非常庞大的生态系统,包括大量插件和模块。它非常有主见的配置和管理,以保持所有不同部分在同一条线上。
|
||||
* **Flask**: 适用于小型,简单的项目。它可以使我们轻松地构建视图并将它们快速连接到路由,它可以简单地封装在一个文件中。
|
||||
* **Pyramid**: 适用于可能增长的项目。它包含一些配置来启动和运行。应用程序组件的独立领域可以很容易地划分并构建到任意深度,而不会忽略中央应用程序。
|
||||
* **Tornado**: 适用于受益于精确和有意识的 I/O 控制的项目。它允许协程,并轻松公开可以控制如何接收请求或发送响应以及何时发生这些操作的方法。
|
||||
* **Django**:(我们将会看到)意味着可能会变得更大的东西。它有着非常庞大的生态系统,包括大量插件和模块。它非常有主见的配置和管理,以保持所有不同部分在同一条线上。
|
||||
|
||||
无论你是从本系列的第一篇文章开始阅读,还是稍后才加入的,都要感谢阅读!请随意留下问题或意见。下次再见时,我手里会拿着 Django。
|
||||
|
||||
@ -549,7 +560,7 @@ def post(self, username):
|
||||
|
||||
我必须把功劳归于它应得的地方,非常感谢 [Guido van Rossum][12],不仅仅是因为他创造了我最喜欢的编程语言。
|
||||
|
||||
在 [PyCascades 2018][13] 期间,我很幸运的不仅给了基于这个文章系列的演讲,而且还被邀请参加了演讲者的晚宴。整个晚上我都坐在 Guido 旁边,不停地问他问题。其中一个问题是,在 Python 中异步到底是如何工作的,但他没有一点大惊小怪,而是花时间向我解释,让我开始理解这个概念。他后来[推特给我][14]发了一条消息:是用于学习异步 Python 的广阔资源。我随后在三个月内阅读了三次,然后写了这篇文章。你真是一个非常棒的人,Guido!
|
||||
在 [PyCascades 2018][13] 期间,我很幸运的不仅做了基于这个文章系列的演讲,而且还被邀请参加了演讲者的晚宴。整个晚上我都坐在 Guido 旁边,不停地问他问题。其中一个问题是,在 Python 中异步到底是如何工作的,但他没有一点大惊小怪,而是花时间向我解释,让我开始理解这个概念。他后来[推特给我][14]发了一条消息:是用于学习异步 Python 的广阔资源。我随后在三个月内阅读了三次,然后写了这篇文章。你真是一个非常棒的人,Guido!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -558,7 +569,7 @@ via: https://opensource.com/article/18/6/tornado-framework
|
||||
作者:[Nicholas Hunt-Walker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,339 @@
|
||||
如何搜索一个包是否在你的 Linux 发行版中
|
||||
======
|
||||
|
||||
如果你知道包名称,那么你可以直接安装所需的包。
|
||||
|
||||
在某些情况下,如果你不知道确切的包名称或者你想搜索某些包,那么你可以在发行版的包管理器的帮助下轻松搜索该包。搜索会自动包括已安装和可用的包。结果的格式取决于选项。如果你的查询没有输出任何信息,那么意味着没有匹配条件的包。这可以通过发行版的包管理器的各种选项来完成。我已经在本文中添加了所有可能的选项,你可以选择最好的和最合适你的选项。
|
||||
|
||||
或者,我们可以通过 `whohas` 命令实现这一点。它会从所有的主流发行版(例如 Debian、Ubuntu、 Fedora 等)中搜索,而不仅仅是你自己的系统发行版。
|
||||
|
||||
建议阅读:
|
||||
|
||||
- [适用于 Linux 的命令行包管理器列表以及用法][1]
|
||||
- [Linux 包管理器的图形前端工具][2]
|
||||
|
||||
### 如何在 Debian/Ubuntu 中搜索一个包
|
||||
|
||||
我们可以使用 `apt`、`apt-cache` 和 `aptitude` 包管理器在基于 Debian 的发行版上查找给定的包。我为这个包管理器中包括了大量的选项。
|
||||
|
||||
我们可以在基于 Debian 的系统中使用三种方式完成此操作。
|
||||
|
||||
* `apt` 命令
|
||||
* `apt-cache` 命令
|
||||
* `aptitude` 命令
|
||||
|
||||
#### 如何使用 apt 命令搜索一个包
|
||||
|
||||
APT 代表<ruby>高级包管理工具<rt>Advanced Packaging Tool</rt></ruby>(APT),它取代了 `apt-get`。它有功能丰富的命令行工具,包括所有功能包含在一个命令(`apt`)里,包括 `apt-cache`、`apt-search`、`dpkg`、`apt-cdrom`、`apt-config`、`apt-key` 等,还有其他几个独特的功能。
|
||||
|
||||
APT 是一个强大的命令行工具,它可以访问 libapt-pkg 底层库的所有特性,它可以用于安装、下载、删除、搜索和管理以及查询包的信息,另外它还包含一些较少使用的与包管理相关的命令行实用程序。
|
||||
|
||||
```
|
||||
$ apt -q list nano vlc
|
||||
Listing...
|
||||
nano/artful,now 2.8.6-3 amd64 [installed]
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
|
||||
```
|
||||
$ apt search ^vlc
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer
|
||||
|
||||
vlc-bin/artful 2.2.6-6 amd64
|
||||
binaries from VLC
|
||||
|
||||
vlc-data/artful,artful 2.2.6-6 all
|
||||
Common data for VLC
|
||||
|
||||
vlc-l10n/artful,artful 2.2.6-6 all
|
||||
Translations for VLC
|
||||
|
||||
vlc-plugin-access-extra/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (extra access plugins)
|
||||
|
||||
vlc-plugin-base/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (base plugins)
|
||||
```
|
||||
|
||||
#### 如何使用 apt-cache 命令搜索一个包
|
||||
|
||||
`apt-cache` 会在 APT 的包缓存上执行各种操作。它会显示有关指定包的信息。`apt-cache` 不会改变系统的状态,但提供了从包的元数据中搜索和生成有趣输出的操作。
|
||||
|
||||
```
|
||||
$ apt-cache search nano | grep ^nano
|
||||
nano - small, friendly text editor inspired by Pico
|
||||
nano-tiny - small, friendly text editor inspired by Pico - tiny build
|
||||
nanoblogger - Small weblog engine for the command line
|
||||
nanoblogger-extra - Nanoblogger plugins
|
||||
nanoc - static site generator written in Ruby
|
||||
nanoc-doc - static site generator written in Ruby - documentation
|
||||
nanomsg-utils - nanomsg utilities
|
||||
nanopolish - consensus caller for nanopore sequencing data
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
|
||||
```
|
||||
$ apt-cache policy vlc
|
||||
vlc:
|
||||
Installed: (none)
|
||||
Candidate: 2.2.6-6
|
||||
Version table:
|
||||
2.2.6-6 500
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 Packages
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索给定的包。
|
||||
|
||||
```
|
||||
$ apt-cache pkgnames vlc
|
||||
vlc-bin
|
||||
vlc-plugin-video-output
|
||||
vlc-plugin-sdl
|
||||
vlc-plugin-svg
|
||||
vlc-plugin-samba
|
||||
vlc-plugin-fluidsynth
|
||||
vlc-plugin-qt
|
||||
vlc-plugin-skins2
|
||||
vlc-plugin-visualization
|
||||
vlc-l10n
|
||||
vlc-plugin-notify
|
||||
vlc-plugin-zvbi
|
||||
vlc-plugin-vlsub
|
||||
vlc-plugin-jack
|
||||
vlc-plugin-access-extra
|
||||
vlc
|
||||
vlc-data
|
||||
vlc-plugin-video-splitter
|
||||
vlc-plugin-base
|
||||
```
|
||||
|
||||
#### 如何使用 aptitude 命令搜索一个包
|
||||
|
||||
`aptitude` 是一个基于文本的 Debian GNU/Linux 软件包系统的命令行界面。它允许用户查看包列表,并执行包管理任务,例如安装、升级和删除包,它可以从可视化界面或命令行执行操作。
|
||||
|
||||
```
|
||||
$ aptitude search ^vlc
|
||||
p vlc - multimedia player and streamer
|
||||
p vlc:i386 - multimedia player and streamer
|
||||
p vlc-bin - binaries from VLC
|
||||
p vlc-bin:i386 - binaries from VLC
|
||||
p vlc-data - Common data for VLC
|
||||
v vlc-data:i386 -
|
||||
p vlc-l10n - Translations for VLC
|
||||
v vlc-l10n:i386 -
|
||||
p vlc-plugin-access-extra - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-access-extra:i386 - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-base - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-base:i386 - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-fluidsynth - FluidSynth plugin for VLC
|
||||
p vlc-plugin-fluidsynth:i386 - FluidSynth plugin for VLC
|
||||
p vlc-plugin-jack - Jack audio plugins for VLC
|
||||
p vlc-plugin-jack:i386 - Jack audio plugins for VLC
|
||||
p vlc-plugin-notify - LibNotify plugin for VLC
|
||||
p vlc-plugin-notify:i386 - LibNotify plugin for VLC
|
||||
p vlc-plugin-qt - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-qt:i386 - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-samba - Samba plugin for VLC
|
||||
p vlc-plugin-samba:i386 - Samba plugin for VLC
|
||||
p vlc-plugin-sdl - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-sdl:i386 - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-skins2 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-skins2:i386 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-svg - SVG plugin for VLC
|
||||
p vlc-plugin-svg:i386 - SVG plugin for VLC
|
||||
p vlc-plugin-video-output - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-output:i386 - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-splitter - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-video-splitter:i386 - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-visualization - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-visualization:i386 - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-vlsub - VLC extension to download subtitles from opensubtitles.org
|
||||
p vlc-plugin-zvbi - VBI teletext plugin for VLC
|
||||
p vlc-plugin-zvbi:i386
|
||||
```
|
||||
|
||||
### 如何在 RHEL/CentOS 中搜索一个包
|
||||
|
||||
Yum(Yellowdog Updater Modified)是 Linux 操作系统中的包管理器实用程序之一。Yum 命令用于在一些基于 RedHat 的 Linux 发行版上,它用来安装、更新、搜索和删除软件包。
|
||||
|
||||
```
|
||||
# yum search ftpd
|
||||
Loaded plugins: fastestmirror, refresh-packagekit, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.hyve.com
|
||||
* epel: mirrors.coreix.net
|
||||
* extras: centos.hyve.com
|
||||
* rpmforge: www.mirrorservice.org
|
||||
* updates: mirror.sov.uk.goscomb.net
|
||||
============================================================== N/S Matched: ftpd ===============================================================
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
|
||||
Name and summary matches only, use "search all" for everything.
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同内容。
|
||||
|
||||
```
|
||||
# yum list ftpd
|
||||
```
|
||||
|
||||
### 如何在 Fedora 中搜索一个包
|
||||
|
||||
DNF 代表 Dandified yum。我们可以说 DNF 是下一代 yum 包管理器(Yum 的衍生品),它使用 hawkey/libsolv 库作为底层。Aleš Kozumplík 从 Fedora 18 开始开发 DNF,最终在 Fedora 22 中发布。
|
||||
|
||||
```
|
||||
# dnf search ftpd
|
||||
Last metadata expiration check performed 0:42:28 ago on Tue Jun 9 22:52:44 2018.
|
||||
============================== N/S Matched: ftpd ===============================
|
||||
proftpd-utils.x86_64 : ProFTPD - Additional utilities
|
||||
pure-ftpd-selinux.x86_64 : SELinux support for Pure-FTPD
|
||||
proftpd-devel.i686 : ProFTPD - Tools and header files for developers
|
||||
proftpd-devel.x86_64 : ProFTPD - Tools and header files for developers
|
||||
proftpd-ldap.x86_64 : Module to add LDAP support to the ProFTPD FTP server
|
||||
proftpd-mysql.x86_64 : Module to add MySQL support to the ProFTPD FTP server
|
||||
proftpd-postgresql.x86_64 : Module to add PostgreSQL support to the ProFTPD FTP
|
||||
: server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
proftpd.x86_64 : Flexible, stable and highly-configurable FTP server
|
||||
owfs-ftpd.x86_64 : FTP daemon providing access to 1-Wire networks
|
||||
perl-ftpd.noarch : Secure, extensible and configurable Perl FTP server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
pyftpdlib.noarch : Python FTP server library
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同的内容。
|
||||
|
||||
```
|
||||
# dnf list proftpd
|
||||
Failed to synchronize cache for repo 'heikoada-terminix', disabling.
|
||||
Last metadata expiration check: 0:08:02 ago on Tue 26 Jun 2018 04:30:05 PM IST.
|
||||
Available Packages
|
||||
proftpd.x86_64
|
||||
```
|
||||
|
||||
### 如何在 Arch Linux 中搜索一个包
|
||||
|
||||
pacman 代表包管理实用程序(pacman)。它是一个用于安装、构建、删除和管理 Arch Linux 软件包的命令行实用程序。pacman 使用 libalpm(Arch Linux Package Management(ALPM)库)作为底层来执行所有操作。
|
||||
|
||||
在本例中,我将要搜索 chromium 包。
|
||||
|
||||
```
|
||||
# pacman -Ss chromium
|
||||
extra/chromium 48.0.2564.116-1
|
||||
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
|
||||
extra/qt5-webengine 5.5.1-9 (qt qt5)
|
||||
Provides support for web applications using the Chromium browser project
|
||||
community/chromium-bsu 0.9.15.1-2
|
||||
A fast paced top scrolling shooter
|
||||
community/chromium-chromevox latest-1
|
||||
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
|
||||
package does not contain the extension code.
|
||||
community/fcitx-mozc 2.17.2313.102-1
|
||||
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
|
||||
Input)
|
||||
```
|
||||
|
||||
默认情况下,`-s` 选项内置 ERE(扩展正则表达式)会导致很多不需要的结果。使用以下格式会仅匹配包名称。
|
||||
|
||||
```
|
||||
# pacman -Ss '^chromium-'
|
||||
```
|
||||
|
||||
`pkgfile` 是一个用于在 Arch Linux 官方仓库的包中搜索文件的工具。
|
||||
|
||||
```
|
||||
# pkgfile chromium
|
||||
```
|
||||
|
||||
### 如何在 openSUSE 中搜索一个包
|
||||
|
||||
Zypper 是 SUSE 和 openSUSE 发行版的命令行包管理器。它用于安装、更新、搜索和删除包以及管理仓库,执行各种查询等。Zypper 命令行对接到 ZYpp 系统管理库(libzypp)。
|
||||
|
||||
```
|
||||
# zypper search ftp
|
||||
or
|
||||
# zypper se ftp
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Name | Summary | Type
|
||||
--+----------------+-----------------------------------------+--------
|
||||
| proftpd | Highly configurable GPL-licensed FTP -> | package
|
||||
| proftpd-devel | Development files for ProFTPD | package
|
||||
| proftpd-doc | Documentation for ProFTPD | package
|
||||
| proftpd-lang | Languages for package proftpd | package
|
||||
| proftpd-ldap | LDAP Module for ProFTPD | package
|
||||
| proftpd-mysql | MySQL Module for ProFTPD | package
|
||||
| proftpd-pgsql | PostgreSQL Module for ProFTPD | package
|
||||
| proftpd-radius | Radius Module for ProFTPD | package
|
||||
| proftpd-sqlite | SQLite Module for ProFTPD | package
|
||||
| pure-ftpd | A Lightweight, Fast, and Secure FTP S-> | package
|
||||
| vsftpd | Very Secure FTP Daemon - Written from-> | package
|
||||
```
|
||||
|
||||
### 如何使用 whohas 命令搜索一个包
|
||||
|
||||
`whohas` 命令是一个智能工具,从所有主流发行版中搜索指定包,如 Debian、Ubuntu、Gentoo、Arch、AUR、Mandriva、Fedora、Fink、FreeBSD 和 NetBSD。
|
||||
|
||||
```
|
||||
$ whohas nano
|
||||
Mandriva nano-debug 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/0b33dc73bca710749ad14bbc3a67e15a
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.i http://sophie.zarb.org/rpms/d9dfb2567681e09287b27e7ac6cdbc05
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.x http://sophie.zarb.org/rpms/3299516dbc1538cd27a876895f45aee4
|
||||
Mandriva nano 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/98421c894ee30a27d9bd578264625220
|
||||
Mandriva nano 2.3.1-1mdv2010.2.i http://sophie.zarb.org/rpms/cea07b5ef9aa05bac262fc7844dbd223
|
||||
Mandriva nano 2.2.4-1mdv2010.1.s http://sophie.zarb.org/rpms/d61f9341b8981e80424c39c3951067fa
|
||||
Mandriva spring-mod-nanoblobs 0.65-2mdv2010.0.sr http://sophie.zarb.org/rpms/74bb369d4cbb4c8cfe6f6028e8562460
|
||||
Mandriva nanoxml-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/287a4c37bc2a39c0f277b0020df47502
|
||||
Mandriva nanoxml-manual-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/17dc4f638e5e9964038d4d26c53cc9c6
|
||||
Mandriva nanoxml-manual 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/a1b5092cd01fc8bb78a0f3ca9b90370b
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.8 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.7
|
||||
```
|
||||
|
||||
如果你希望只从当前发行版仓库中搜索指定包,使用以下格式:
|
||||
|
||||
```
|
||||
$ whohas -d Ubuntu vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty/vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty-updates/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial-updates/vlc
|
||||
Ubuntu vlc 2.2.6-6 40K all http://packages.ubuntu.com/artful/vlc
|
||||
Ubuntu vlc 3.0.1-3build1 32K all http://packages.ubuntu.com/bionic/vlc
|
||||
Ubuntu vlc 3.0.2-0ubuntu0.1 32K all http://packages.ubuntu.com/bionic-updates/vlc
|
||||
Ubuntu vlc 3.0.3-1 33K all http://packages.ubuntu.com/cosmic/vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-2 55K all http://packages.ubuntu.com/trusty/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/xenial/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/artful/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/bionic/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/cosmic/browser-plugin-vlc
|
||||
Ubuntu libvlc-bin 2.2.6-6 27K all http://packages.ubuntu.com/artful/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.1-3build1 17K all http://packages.ubuntu.com/bionic/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.2-0ubuntu0.1 17K all
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
@ -0,0 +1,267 @@
|
||||
|
||||
如何把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Google 云端硬盘][1] 是全球比较受欢迎的云存储平台. 直到 2017 年, 全球有超过 8 亿的活跃用户在使用它。即使用户数在持续增长,但直到现在 Google 还是没有发布一款可以在 Linux 平台使用的客户端。但这难不倒 Linux 社区。不时就有一些开发者给 Linux 操作系统带来一些客户端。下面我将会介绍三个用于 Linux 系统非官方开发的 Google 云端硬盘客户端。使用这些客户端,你能把 Google 云端硬盘像虚拟磁盘一样挂载到 Linux 系统。请继续阅读。
|
||||
|
||||
### 1、Google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse 把 Google 云端硬盘当做是一个 FUSE 类型的文件系统,它是用 OCam 语言写的。FUSE 意即<ruby>用户态文件系统<rt>Filesystem in Userspace</rt></ruby>,此项目允许非管理员用户在用户空间创建虚拟文件系统。google-drive-ocamlfuse 可以让你把 Google 云端硬盘当做磁盘一样挂载到 Linux 系统。支持对普通文件和目录的读写操作,支持对 Google dock、表单和演示稿的只读操作,支持多个 Googe 云端硬盘用户,重复文件处理,支持访问回收站等等。
|
||||
|
||||
#### 安装 google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse 能在 Arch 系统的 [AUR][2] 上直接找到,所以你可以使用 AUR 助手程序,如 [Yay][3] 来安装。
|
||||
|
||||
```
|
||||
$ yay -S google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
在 Ubuntu 系统:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
安装最新的测试版本:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
#### 使用方法
|
||||
|
||||
安装完成后,直接在终端里面输入如下命令,就可以启动 google-drive-ocamlfuse 程序了:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse
|
||||
```
|
||||
|
||||
当你第一次运行该命令,程序会直接打开你的浏览器并要求你确认是否对 Google 云端硬盘的文件的操作进行授权。当你确认授权后,挂载 Google 云端硬盘所需要的配置文件和目录都会自动进行创建。
|
||||
|
||||
![][5]
|
||||
|
||||
当成功授权后,你会在终端里面看到如下的信息。
|
||||
|
||||
```
|
||||
Access token retrieved correctly.
|
||||
```
|
||||
|
||||
好了,我们可以进行下一步操作了。关闭浏览器并为我们的 Google 云端硬盘创建一个挂载点吧。
|
||||
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
最后操作,使用如下命令挂载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse ~/mygoogledrive
|
||||
```
|
||||
|
||||
恭喜你了!你可以使用终端或文件管理器来访问 Google 云端硬盘里面的文件了。
|
||||
|
||||
使用终端:
|
||||
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
```
|
||||
|
||||
使用文件管理器:
|
||||
|
||||
![][6]
|
||||
|
||||
如何你有不止一个账户,可以使用 `label` 命令对其进行区分不同的账户,就像下面一样:
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse -label label [mountpoint]
|
||||
```
|
||||
|
||||
当操作完成后,你可以使用如下的命令卸载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
```
|
||||
|
||||
获取更多信息,你可以参考 man 手册。
|
||||
|
||||
```
|
||||
$ google-drive-ocamlfuse --help
|
||||
```
|
||||
|
||||
当然你也可以看看[官方文档][7]和该项目的 [GitHub 项目][8]以获取更多内容。
|
||||
|
||||
### 2. GCSF
|
||||
|
||||
GCSF 是基于 Google 云端硬盘的 FUSE 文件系统,使用 Rust 语言编写。GCSF 得名于罗马尼亚语中的“ **G** oogle **C** onduce **S** istem de **F** ișiere”,翻译成英文就是“Google Drive Filesystem”(即 Google 云端硬盘文件系统)。使用 GCSF,你可以把 Google 云端硬盘当做虚拟磁盘一样挂载到 Linux 系统,可以通过终端和文件管理器对其进行操作。你肯定会很好奇,这到底与其它的 Google 云端硬盘 FUSE 项目有什么不同,比如 google-drive-ocamlfuse。GCSF 的开发者回应 [Reddit 上的类似评论][9]:“GCSF 意在某些方面更快(递归列举文件、从 Google 云端硬盘中读取大文件)。当文件被缓存后,在消耗更多的内存后,其缓存策略也能让读取速度更快(相对于 google-drive-ocamlfuse 4-7 倍的提升)”。
|
||||
|
||||
#### 安装 GCSF
|
||||
|
||||
GCSF 能在 [AUR][10] 上面找到,对于 Arch 用户来说直接使用 AUR 助手来安装就行了,例如[Yay][3]。
|
||||
|
||||
```
|
||||
$ yay -S gcsf-git
|
||||
```
|
||||
|
||||
对于其它的发行版,需要进行如下的操作来进行安装。
|
||||
|
||||
首先,你得确认系统中是否安装了Rust语言。
|
||||
|
||||
- [在 Linux 上安装 Rust](https://www.ostechnix.com/install-rust-programming-language-in-linux/)
|
||||
|
||||
确保 `pkg-config` 和 `fuse` 软件包是否安装了。它们在绝大多数的 Linux 发行版的默认仓库中都能找到。例如,在 Ubuntu 及其衍生版本中,你可以使用如下的命令进行安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install -y libfuse-dev pkg-config
|
||||
```
|
||||
|
||||
当所有的依赖软件安装完成后,你可以使用如下的命令来安装 GCSF:
|
||||
|
||||
```
|
||||
$ cargo install gcsf
|
||||
```
|
||||
|
||||
#### 使用方法
|
||||
|
||||
首先,我们需要对 Google 云端硬盘的操作进行授权,简单输入如下命令:
|
||||
|
||||
```
|
||||
$ gcsf login ostechnix
|
||||
```
|
||||
|
||||
你必须指定一个会话名称。请使用自己的会话名称来代 `ostechnix`。你会看到像下图的提示信息和Google 云端硬盘账户的授权验证连接。
|
||||
|
||||
![][11]
|
||||
|
||||
直接复制并用浏览器打开上述 URL,并点击 “allow” 来授权访问你的 Google 云端硬盘账户。当完成授权后,你的终端会显示如下的信息。
|
||||
|
||||
```
|
||||
Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
|
||||
```
|
||||
|
||||
GCSF 会把配置保存文件在 `$XDG_CONFIG_HOME/gcsf/gcsf.toml`,通常位于 `$HOME/.config/gcsf/gcsf.toml`。授权凭证也会保存在此目录当中。
|
||||
|
||||
下一步,创建一个用来挂载 Google 云端硬盘的目录。
|
||||
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
```
|
||||
|
||||
之后,修改 `/etc/fuse.conf` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/fuse.conf
|
||||
```
|
||||
|
||||
注释掉以下的行,以允许非管理员用 `allow_other` 或 `allow_root` 挂载选项来挂载。
|
||||
|
||||
```
|
||||
user_allow_other
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
最后一步,使用如下命令挂载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ gcsf mount ~/mygoogledrive -s ostechnix
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
INFO gcsf > Creating and populating file system...
|
||||
INFO gcsf > File sytem created.
|
||||
INFO gcsf > Mounting to /home/sk/mygoogledrive
|
||||
INFO gcsf > Mounted to /home/sk/mygoogledrive
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
```
|
||||
|
||||
重复一次,使用自己的会话名来更换 `ostechnix`。你可以使用如下的命令来查看已经存在的会话:
|
||||
|
||||
```
|
||||
$ gcsf list
|
||||
Sessions:
|
||||
- ostechnix
|
||||
```
|
||||
|
||||
你现在可以使用终端和文件管理器对 Google 云端硬盘进行操作了。
|
||||
|
||||
使用终端:
|
||||
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
```
|
||||
|
||||
使用文件管理器:
|
||||
|
||||
![][12]
|
||||
|
||||
如果你不知道自己把 Google 云端硬盘挂载到哪个目录了,可以使用 `df` 或者 `mount` 命令,就像下面一样。
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 968M 0 968M 0% /dev
|
||||
tmpfs 200M 1.6M 198M 1% /run
|
||||
/dev/sda1 20G 7.5G 12G 41% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 40K 200M 1% /run/user/1000
|
||||
GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
|
||||
|
||||
$ mount | grep GCSF
|
||||
GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
|
||||
```
|
||||
|
||||
当操作完成后,你可以使用如下命令来卸载 Google 云端硬盘:
|
||||
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
```
|
||||
|
||||
浏览[GCSF GitHub 项目][13]以获取更多内容。
|
||||
|
||||
### 3、Tuxdrive
|
||||
|
||||
Tuxdrive 也是一个非官方 Linux Google 云端硬盘客户端。我们之前有写过一篇关于 Tuxdrive 比较详细的使用方法。可以查看如下链接:
|
||||
|
||||
- [Tuxdrive: 一个 Linux 下的 Google 云端硬盘客户端](https://www.ostechnix.com/tuxdrive-commandline-google-drive-client-linux/)
|
||||
|
||||
当然,之前还有过其它的非官方 Google 云端硬盘客户端,例如 Grive2、Syncdrive。但它们好像都已经停止开发了。当有更受欢迎的 Google 云端硬盘客户端出现,我会对这个列表进行持续的跟进。
|
||||
|
||||
谢谢你的阅读。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[sndnvaps](https://github.com/sndnvaps)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.google.com/drive/
|
||||
[2]:https://aur.archlinux.org/packages/google-drive-ocamlfuse/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-2.png
|
||||
[7]:https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration
|
||||
[8]:https://github.com/astrada/google-drive-ocamlfuse
|
||||
[9]:https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/
|
||||
[10]:https://aur.archlinux.org/packages/gcsf-git/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-4.png
|
||||
[13]:https://github.com/harababurel/gcsf
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: (acyanbird wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10510-1.html)
|
||||
[#]: subject: (Two Years With Emacs as a CEO (and now CTO))
|
||||
[#]: via: (https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html)
|
||||
[#]: author: (Josh Stella https://www.fugue.co/blog/author/josh-stella)
|
||||
|
||||
作为 CEO 使用 Emacs 的两年经验之谈
|
||||
======
|
||||
|
||||
两年前,我写了一篇[博客][1],并取得了一些反响。这让我有点受宠若惊。那篇博客写的是我准备将 Emacs 作为我的主办公软件,当时我还是 CEO,现在已经是 CTO 了。现在回想起来,我发现我之前不是做程序员就是做软件架构师,而且那时我也喜欢用 Emacs 写代码。重新考虑使用 Emacs 是一次令我振奋的尝试,但我不太清楚这次行动会造成什么反响。在网上,那篇博客的评论也是褒贬不一,但是还是有数万的阅读量,所以总的来说,我写的是一个蛮有意思的题材。在 [Reddit][2] 和 [HackerNews][3] 上有些令人哭笑不得的回复,说我的手会变成鸡爪,或者说我会因白色的背景而近视。在这里我可以很高兴地回答,到目前为止并没有出现什么特别糟糕的后果,相反,我的手腕还因此变得更灵活了。还有一些人担心,说使用 Emacs 会耗费一个 CEO 的精力。把 Fugue 从一个在我家后院的灵感变成强大的产品,并有一大批忠实的顾客,我发现在做这种真正复杂之事的时候,Emacs 可以给你带来安慰。还有,我现在仍然在用白色的背景。
|
||||
|
||||
近段时间那篇博客又被翻出来了,并发到了 [HackerNews][4] 上。我收到了大量的跟帖者问我现在使用状况如何,所以我写了这篇博客来回应他们。在本文中,我还将重点讨论为什么 Emacs 和函数式编程有很高的关联性,以及我们是怎样使用 Emacs 来开发我们的产品 —— Fugue,一个使用函数式编程的自动化的云计算平台的。由于我收到了很多反馈,其众多细节和评论很有用,因此这篇博客比较长,而我确实也需要费点精力来解释我如此作为时的想法,但这篇文章的主要内容还是反映了我担任 CEO 时处理的事务。而我想在之后更频繁地用 Emacs 写代码,所以需要提前做一些准备。一如既往,本文因人而异,后果自负。
|
||||
|
||||
### 意外之喜
|
||||
|
||||
我大部分时间都在不断的处理公司内外沟通。交流是解决问题的唯一方法,但也是反思及思考困难或复杂问题的敌人。对我来说,作为创业公司的 CEO,最需要的是能专注工作而不被打扰的时间。一旦你决定投入时间来学习一些有用的命令,Emacs 就能帮助创造这种不被打扰的可贵环境。其他的应用会弹出提示,但是一个配置好了的 Emacs 可以完全不影响你 —— 无论是视觉上还是精神上。除非你想,否则的话它不会改变,况且没有比空白屏幕和漂亮的字体更干净的界面了。不断被打扰是我的日常状况,因此这种简洁让我能够专注于我在想的事情,而不是电脑本身。好的程序能够默默地操纵电脑,并且不会夺取你的注意力。
|
||||
|
||||
一些人指出,我原来的博客有太多对现代图形界面的批判和对 Emacs 的赞许。我既不赞同,也不否认。现代的界面,特别是那些以应用程序为中心的方法(相对于以内容为中心的方法),既不是以用户为中心的,也不是面向任务的。Emacs 避免了这种错误,这也是我如此喜欢它的部分原因,而它也带来了其他优点。Emacs 是带领你体会计算机魅力的传送门,一个值得跳下去的兔子洞(LCTT 译注:爱丽丝梦游仙境里的兔子洞,跳进去会有新世界)。它的核心是发现和创造属于自己的道路,对我来说这本身就是创造了。现代计算的悲哀之处在于,它很大程度上是由带有闪亮界面的黑盒组成的,这些黑盒提供的是瞬间的喜悦,而不是真正的满足感。这让我们变成了消费者,而不是技术的创造者。无论你是谁或者你的背景是什么;你都可以理解你的电脑,你可以用它创造事物。它很有趣,能令人满意,而且不是你想的那么难学!
|
||||
|
||||
我们常常低估了环境对我们心理的影响。Emacs 给人一种平静和自由的感觉,而不是紧迫感、烦恼或兴奋 —— 后者是思考和沉思的敌人。我喜欢那些持久的、不碍事的东西,当我花时间去关注它们的时候,它们会给我带来真知灼见。Emacs 满足我的所有这些标准。我每天都使用 Emacs 来工作,我也很高兴我很少需要注意到它。Emacs 确实有一个学习曲线,但不会比学自行车的学习曲线来的更陡,而且一旦你掌握了它,你会得到相应的回报,而且不必再去想它了。它赋予你一种其他工具所没有的自由感。这是一个优雅的工具,来自一个更加文明的计算时代。我很高兴我们步入了另一个文明的计算时代,我相信 Emacs 也将越来越受欢迎。
|
||||
|
||||
### 弃用 Org 模式处理日程和待办事项
|
||||
|
||||
在原来的文章中,我花了一些时间介绍如何使用 Org 模式来规划日程。不过现在我放弃了使用 Org 模式来处理待办事项一类的事物,因为我每天都有很多会议要开,很多电话要打,我也不能让其他人来适应我选的工具,而且也没有时间将事务转换或是自动移动到 Org 上。我们主要是 Mac 一族,使用谷歌日历等工具,而且原生的 Mac OS/iOS 工具可以很好的进行团队协作。我还有支老钢笔用来在会议中做笔记,因为我发现在会议中使用笔记本电脑或者说键盘记录很不礼貌,而且这也限制了我的聆听和思考。因此,我基本上放弃了用 Org 模式帮我规划日程或安排生活。当然,Org 模式对其他的方面也很有用,它是我编写文档的首选,包括本文。换句话说,我使用它的方式与其作者的想法背道而驰,但它的确做得很好。我也希望有一天也有人如此评价并使用我们的 Fugue。
|
||||
|
||||
### Emacs 已经在 Fugue 公司中扩散
|
||||
|
||||
我在上篇博客就有说,你可能会喜欢 Emacs,也可能不会。因此,当 Fugue 的文档组将 Emacs 作为标准工具时,我是有点担心的,因为我觉得他们可能是受了我的影响才做出这种选择。不过在两年后,我确信他们做出了正确的选择。文档组的组长是一个很聪明的程序员,但是另外两个编写文档的人却没有怎么接触过技术。我想,如果这是一个经理强迫员工使用错误工具的案例,我就会收到投诉要去解决它,因为 Fugue 有反威权文化,大家不怕挑战任何事和任何人。之前的组长在去年辞职了,但[文档组][5]现在有了一个灵活的集成的 CI/CD 工具链,并且文档组的人已经成为了 Emacs 的忠实用户。Emacs 有一条学习曲线,但即使在最陡的时候,也不至于多么困难,并且翻过顶峰后,对生产力和总体幸福感都得到了提升。这也提醒我们,学文科的人在技术方面和程序员一样聪明,一样能干,也许不那么容易受到技术崇拜与习俗产生的影响。
|
||||
|
||||
### 我的手腕感激我的决定
|
||||
|
||||
上世纪 80 年代中期以来,我每天花 12 个小时左右在电脑前工作,这给我的手腕(以及后背)造成了很大的损伤(因此我强烈安利 Tag Capisco 的椅子)。Emacs 和人机工程学键盘的结合让手腕的 [RSI][10](<ruby>重复性压迫损伤<rt>Repetitive Strain Injury</rt></ruby>)问题消失了,我已经一年多没有想过这种问题了。在那之前,我的手腕每天都会疼,尤其是右手。如果你也有这种问题,你就知道这疼痛很让人分心和忧虑。有几个人问过关于选购键盘和鼠标的问题,如果你也对此有兴趣,那么在过去两年里,我主要使用的是 Truly Ergonomic 键盘,不过我现在用的是[这款键盘][6]。我已经换成现在的键盘有几个星期,而且我爱死它了。大写键的形状很神奇,因为你不用看就能知道它在哪里。而人体工学的拇指键也设计的十分合理,尤其是对于 Emacs 用户而言,Control 和 Meta 是你的坚实伴侣,不要再需要用小指做高度重复的任务了!
|
||||
|
||||
我使用鼠标的次数比使用 Office 和 IDE 时要少得多,这对我的工作效率有很大帮助,但我还是需要一个鼠标。我一直在使用外观相当过时,但功能和人体工程学非常优秀的 Clearly Superior 轨迹球,恰如其名。
|
||||
|
||||
撇开具体的工具不谈,事实证明,一个很棒的键盘,再加上避免使用鼠标,在减少身体的磨损方面很有效。Emacs 是达成这方面的核心,因为我不需要在菜单上滑动鼠标来完成任务,而且导航键就在我的手指下面。我现在十分肯定,我的手离开标准打字位置会给我的肌腱造成很大的压力。不过这也因人而异,我不是医生不好下定论。
|
||||
|
||||
### 我并没有做太多配置……
|
||||
|
||||
有人说我会在界面配置上耗费很多的时间。我想验证下他们说的对不对,所以我特别留意了下。我不仅在很多程度上不用配置,关注这个问题还让我意识到,我使用的其他工具是多么的耗费我的精力和时间。Emacs 是我用过的维护成本最低的软件。Mac OS 和 Windows 一直要求我更新它,但在我看来,这远没有 Adobe 套件和 Office 的更新给我带来的困扰那么大。我只是偶尔更新 Emacs,但对我来说它也没什么变化,所以从我的个人观点而言,更新基本上是一个接近于零成本的操作,我高兴什么时候更新就什么时候更新。
|
||||
|
||||
有一点让你们失望了,因为许多人想知道我为跟上重新打造的 Emacs 社区的更新做了些什么,但是在过去的两年中,我只在配置中添加了少部分内容。我认为这也是一种成功,因为 Emacs 只是一个工具,而不是我的爱好。但即便如此,如果你想和我分享关于 Emacs 的新鲜事物,我很乐意聆听。
|
||||
|
||||
### 期望实现云端控制
|
||||
|
||||
在我们 Fugue 公司有很多 Emacs 的粉丝,所以我们有一段时间在用 [Ludwing 模式][7]。Ludwig 模式是我们用于自动化云基础设施和服务的声明式、功能性的 DSL。最近,Alex Schoof 利用在飞机上和晚上的时间来构建 fugue 模式,它在 Fugue CLI 上充当 Emacs 控制台。要是你不熟悉 Fugue,这是我们开发的一个云自动化和治理工具,它利用函数式编程为用户提供与云的 API 交互的良好体验。但它做的不止这些。fugue 模式很酷的原因有很多,它有一个不断报告云基础设施状态的缓冲区,由于我经常修改这些基础设施,这样我就可以快速看到代码的效果。Fugue 将云工作负载当成进程处理,fugue 模式非常类似于为云工作负载设计的 `top` 工具。它还允许我执行一些操作,比如创建新的设备或删除过期的东西,而且也不需要太多输入。Fugue 模式只是个雏形,但它非常方便,而我现在也经常使用它。
|
||||
|
||||
![fugue-mode-edited.gif][8]
|
||||
|
||||
### 模式及监控
|
||||
|
||||
我添加了一些模式和集成插件,但并不是真正用于工作或 CEO 职能。我喜欢在周末时写写 Haskell 和 Scheme 娱乐,所以我添加了 haskell 模式和 geiser。Emacs 很适合拥有 REPL 的语言,因为你可以在不同的窗口中运行不同的模式,包括 REPL 和 shell。geiser 和 Scheme 很配,要是你还没有用过 Scheme,那么阅读《计算机程序的构造和解释》(SICP)也不失为一种乐趣,在这个有很多货物崇拜编程(LCTT 译注:是一种计算机程序设计中的反模式,其特征为不明就里地、仪式性地使用代码或程序架构)例子的时代,阅读此书或许可以启发你。安装 MIT Scheme 和 geiser,你就会感觉有点像 lore 的符号环境。
|
||||
|
||||
这就引出了我在 2015 年的文章中没有提到的另一个话题:屏幕管理。我喜欢使用单独一个纵向模式的显示器来写作,我在家里和我的主要办公室都有这个配置。对于编程或混合使用,我喜欢我们提供给所有 Fugue 人的新型超宽显示器。对于它来说,我更喜欢将屏幕分成三列,中间是主编辑缓冲区,左边是水平分隔的 shell 和 fugue 模式缓冲区,右边是文档缓冲区或另外一、两个编辑缓冲区。这个很简单,首先按 `Ctl-x 3` 两次,然后使用 `Ctl-x =` 使窗口的宽度相等。这将提供三个相等的列,你也可以使用 `Ctl-x 2` 对分割之后的窗口再次进行水平分割。以下是我的截图。
|
||||
|
||||
![Emacs Screen Shot][9]
|
||||
|
||||
### 这将是最后一篇 CEO/Emacs 文章
|
||||
|
||||
首先是因为我现在是 Fugue 的 CTO 而并非 CEO,其次是我有好多要写的博客主题,而我现在刚好有时间。我还打算写些更深入的东西,比如说函数式编程、基础设施即代码的类型安全,以及我们即将推出的一些 Fugue 的新功能、关于 Fugue 在云上可以做什么的博文等等。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html
|
||||
|
||||
作者:[Josh Stella][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[oneforalone](https://github.com/oneforalone)
|
||||
校对:[acyanbird](https://github.com/acyanbird), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.fugue.co/blog/author/josh-stella
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-10401-1.html
|
||||
[2]: https://www.reddit.com/r/emacs/comments/7efpkt/a_ceos_guide_to_emacs/
|
||||
[3]: https://news.ycombinator.com/item?id=10642088
|
||||
[4]: https://news.ycombinator.com/item?id=15753150
|
||||
[5]: https://docs.fugue.co/
|
||||
[6]: https://shop.keyboard.io/
|
||||
[7]: https://github.com/fugue/ludwig-mode
|
||||
[8]: https://www.fugue.co/hubfs/Imported_Blog_Media/fugue-mode-edited-1.gif
|
||||
[9]: https://www.fugue.co/hs-fs/hubfs/Emacs%20Screen%20Shot.png?width=929&name=Emacs%20Screen%20Shot.png
|
||||
[10]: https://baike.baidu.com/item/RSI/21509642
|
||||
@ -1,30 +1,30 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LazyWolfLin)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10521-1.html)
|
||||
[#]: subject: (An Introduction to Go)
|
||||
[#]: via: (https://blog.jak-linux.org/2018/12/24/introduction-to-go/)
|
||||
[#]: author: (Julian Andres Klode https://blog.jak-linux.org/)
|
||||
|
||||
Go 简介
|
||||
Go 编程语言的简单介绍
|
||||
======
|
||||
|
||||
(以下内容是我的硕士论文的摘录,几乎整个 2.1 章节,向具有 CS 背景的人快速介绍 Go)
|
||||
(以下内容是我的硕士论文的摘录,几乎是整个 2.1 章节,向具有 CS 背景的人快速介绍 Go)
|
||||
|
||||
Go 是一门用于并发编程的命令式编程语言,它主要由创造者 Google 进行开发,最初主要由 Robert Griesemer、Rob Pike 和 Ken Thompson开发。这门语言的设计起始于 2017 年,并在 2019 年推出最初版本;而第一个稳定版本是 2012 年发布的 1.0 版本。
|
||||
Go 是一门用于并发编程的命令式编程语言,它主要由创造者 Google 进行开发,最初主要由 Robert Griesemer、Rob Pike 和 Ken Thompson 开发。这门语言的设计起始于 2007 年,并在 2009 年推出最初版本;而第一个稳定版本是 2012 年发布的 1.0 版本。[^1]
|
||||
|
||||
Go 有 C 风格的语法(没有预处理器),垃圾回收机制,而且类似它在贝尔实验室里被开发出来的前辈们:Newsqueak (Rob Pike)、Alef (Phil Winterbottom) 和 Inferno (Pike, Ritchie, et al.),使用所谓的 goroutines 和信道(一种基于 Hoare 的“通信顺序进程”理论的协程)提供内建的并发支持。
|
||||
Go 有 C 风格的语法(没有预处理器)、垃圾回收机制,而且类似它在贝尔实验室里被开发出来的前辈们:Newsqueak(Rob Pike)、Alef(Phil Winterbottom)和 Inferno(Pike、Ritchie 等人),使用所谓的 <ruby>Go 协程<rt>goroutines</rt></ruby>和<ruby>信道<rt>channels</rt></ruby>(一种基于 Hoare 的“通信顺序进程”理论的协程)提供内建的并发支持。[^2]
|
||||
|
||||
Go 程序以包的形式组织。包本质是一个包含 Go 文件的文件夹。包内的所有文件共享相同的命名空间,而包内的符号有两种可见性:以大写字母开头的符号对于其他包是可见,而其他符号则是该包私有的:
|
||||
|
||||
```
|
||||
func PublicFunction() {
|
||||
fmt.Println("Hello world")
|
||||
fmt.Println("Hello world")
|
||||
}
|
||||
|
||||
func privateFunction() {
|
||||
fmt.Println("Hello package")
|
||||
fmt.Println("Hello package")
|
||||
}
|
||||
```
|
||||
|
||||
@ -32,25 +32,16 @@ func privateFunction() {
|
||||
|
||||
Go 有一个相当简单的类型系统:没有子类型(但有类型转换),没有泛型,没有多态函数,只有一些基本的类型:
|
||||
|
||||
1. 基本类型:`int`、`int64`、`int8`、`uint`、`float32`、`float64` 等。
|
||||
|
||||
1. 基本类型:`int`、`int64`、`int8`、`uint`、`float32`、`float64` 等
|
||||
2. `struct`
|
||||
|
||||
3. `interface` \- 一组方法的集合
|
||||
|
||||
4. `map[K, V]` \- 一个从键类型到值类型的映射
|
||||
|
||||
5. `[number]Type` \- 一些 Type 类型的元素组成的数组
|
||||
|
||||
6. `[]Type` \- 某种类型的切片(指向具有长度和功能的数组)
|
||||
|
||||
7. `chan Type` \- 一个线程安全的队列
|
||||
|
||||
3. `interface`:一组方法的集合
|
||||
4. `map[K, V]`:一个从键类型到值类型的映射
|
||||
5. `[number]Type`:一些 Type 类型的元素组成的数组
|
||||
6. `[]Type`:某种类型的切片(具有长度和功能的数组的指针)
|
||||
7. `chan Type`:一个线程安全的队列
|
||||
8. 指针 `*T` 指向其他类型
|
||||
|
||||
9. 函数
|
||||
|
||||
10. 具名类型 - 可能具有关联方法的其他类型的别名(译者注:这里的别名并非指 Go 1.9 中的新特性“类型别名”):
|
||||
10. 具名类型:可能具有关联方法的其他类型的别名(LCTT 译注:这里的别名并非指 Go 1.9 中的新特性“类型别名”):
|
||||
|
||||
```
|
||||
type T struct { foo int }
|
||||
@ -58,9 +49,9 @@ Go 有一个相当简单的类型系统:没有子类型(但有类型转换
|
||||
type T OtherNamedType
|
||||
```
|
||||
|
||||
具名类型完全不同于他们的底层类型,所以你不能让他们互相赋值,但一些运输符,例如 `+`,能够处理同一底层数值类型的具名类型对象们(所以你可以在上面的示例中把两个 `T` 加起来)。
|
||||
具名类型完全不同于它们的底层类型,所以你不能让它们互相赋值,但一些操作符,例如 `+`,能够处理同一底层数值类型的具名类型对象们(所以你可以在上面的示例中把两个 `T` 加起来)。
|
||||
|
||||
Maps、slices 和 channels 是类似于引用的类型——他们实际上是包含指针的结构。包括数组(具有固定长度并可被拷贝)在内的其他类型则是值(拷贝)传递。
|
||||
映射、切片和信道是类似于引用的类型——它们实际上是包含指针的结构。包括数组(具有固定长度并可被拷贝)在内的其他类型则是值传递(拷贝)。
|
||||
|
||||
#### 类型转换
|
||||
|
||||
@ -93,66 +84,60 @@ const bar2 someType = typed // error: int 不能被赋值给 someType
|
||||
|
||||
### 接口和对象
|
||||
|
||||
正如上面所说的,接口是一组方法的集合。Go 本身不是一种面向对象的语言,但它支持将方法关联到命名类型上:当声明一个函数时,可以提供一个接收者。接收者是函数的一个额外参数,可以在函数之前传递并参与函数查找,就像这样:
|
||||
正如上面所说的,接口是一组方法的集合。Go 本身不是一种面向对象的语言,但它支持将方法关联到具名类型上:当声明一个函数时,可以提供一个接收者。接收者是函数的一个额外参数,可以在函数之前传递并参与函数查找,就像这样:
|
||||
|
||||
```
|
||||
type SomeType struct { ... }
|
||||
type SomeType struct { ... }
|
||||
|
||||
func (s *SomeType) MyMethod() {
|
||||
}
|
||||
|
||||
func main() {
|
||||
var s SomeType
|
||||
s.MyMethod()
|
||||
var s SomeType
|
||||
s.MyMethod()
|
||||
}
|
||||
```
|
||||
|
||||
如果对象实现了所有方法,那么它就实现了接口;例如,`*SomeType`(注意指针)实现了下面的接口 `MyMethoder`,因此 `*SomeType` 类型的值就能作为 `MyMethoder` 类型的值使用。最基本的接口类型是 `interface{}`,它是一个带空方法集的接口——任何对象都满足该接口。
|
||||
如果对象实现了所有方法,那么它就实现了接口;例如,`*SomeType`(注意指针)实现了下面的接口 `MyMethoder`,因此 `*SomeType` 类型的值就能作为 `MyMethoder` 类型的值使用。最基本的接口类型是 `interface{}`,它是一个带空方法集的接口 —— 任何对象都满足该接口。
|
||||
|
||||
```
|
||||
type MyMethoder interface {
|
||||
MyMethod()
|
||||
MyMethod()
|
||||
}
|
||||
```
|
||||
|
||||
合法的接收者类型是有些限制的;例如,命名类型可以是指针类型(例如,`type MyIntPointer *int`),但这种类型不是合法的接收者类型。
|
||||
合法的接收者类型是有些限制的;例如,具名类型可以是指针类型(例如,`type MyIntPointer *int`),但这种类型不是合法的接收者类型。
|
||||
|
||||
### 控制流
|
||||
|
||||
Go 提供了三个主要的控制了语句:`if`、`switch` 和 `for`。这些语句同其他 C 风格语言内的语句非常类似,但有一些不同:
|
||||
|
||||
* 条件语句没有括号,所以条件语句是 `if a == b {}` 而不是 `if (a == b) {}`。大括号是必须的。
|
||||
|
||||
* 所有的语句都可以有初始化,比如这个
|
||||
|
||||
`if result, err := someFunction(); err == nil { // use result }`
|
||||
|
||||
* `switch` 语句在 cases 里可以使用任何表达式
|
||||
|
||||
* `switch` 语句可以处理空的表达式(等于 true)
|
||||
|
||||
* 默认情况下,Go 不会从一个 case 进入下一个 case(不需要 `break`语句),在程序块的末尾使用 `fallthrough` 则会进入下一个 case。
|
||||
|
||||
* 所有的语句都可以有初始化,比如这个 `if result, err := someFunction(); err == nil { // use result }`
|
||||
* `switch` 语句在分支里可以使用任何表达式
|
||||
* `switch` 语句可以处理空的表达式(等于 `true`)
|
||||
* 默认情况下,Go 不会从一个分支进入下一个分支(不需要 `break` 语句),在程序块的末尾使用 `fallthrough` 则会进入下一个分支。
|
||||
* 循环语句 `for` 不仅能循环值域:`for key, val := range map { do something }`
|
||||
|
||||
### Goroutines
|
||||
### Go 协程
|
||||
|
||||
关键词 `go` 会产生一个新的 goroutine,一个可以并行执行的函数。它可以用于任何函数调用,甚至一个匿名函数:
|
||||
关键词 `go` 会产生一个新的 <ruby>Go 协程<rt>goroutine</rt></ruby>,这是一个可以并行执行的函数。它可以用于任何函数调用,甚至一个匿名函数:
|
||||
|
||||
```
|
||||
func main() {
|
||||
...
|
||||
go func() {
|
||||
...
|
||||
}()
|
||||
...
|
||||
go func() {
|
||||
...
|
||||
}()
|
||||
|
||||
go some_function(some_argument)
|
||||
go some_function(some_argument)
|
||||
}
|
||||
```
|
||||
|
||||
### 信道
|
||||
|
||||
Goroutines 通常和信道结合,用来提供一种通信顺序进程的扩展。信道是一个并发安全的队列,而且可以选择是否缓冲数据:
|
||||
Go 协程通常和<rub>信道<rt>channels</rt></ruby>结合,用来提供一种通信顺序进程的扩展。信道是一个并发安全的队列,而且可以选择是否缓冲数据:
|
||||
|
||||
```
|
||||
var unbuffered = make(chan int) // 直到数据被读取时完成数据块发送
|
||||
@ -170,21 +155,21 @@ otherChannel <- valueToSend
|
||||
|
||||
```
|
||||
select {
|
||||
case incoming := <- inboundChannel:
|
||||
// 一条新消息
|
||||
case outgoingChannel <- outgoing:
|
||||
// 可以发送消息
|
||||
case incoming := <- inboundChannel:
|
||||
// 一条新消息
|
||||
case outgoingChannel <- outgoing:
|
||||
// 可以发送消息
|
||||
}
|
||||
```
|
||||
|
||||
### `defer` 声明
|
||||
### defer 声明
|
||||
|
||||
Go 提供语句 `defer` 允许函数退出时调用执行预定的函数。它可以用于进行资源释放操作,例如:
|
||||
|
||||
```
|
||||
func myFunc(someFile io.ReadCloser) {
|
||||
defer someFile.close()
|
||||
/* 文件相关操作 */
|
||||
defer someFile.close()
|
||||
/* 文件相关操作 */
|
||||
}
|
||||
```
|
||||
|
||||
@ -199,7 +184,7 @@ func Read(p []byte) (n int, err error)
|
||||
|
||||
// 内建类型:
|
||||
type error interface {
|
||||
Error() string
|
||||
Error() string
|
||||
}
|
||||
```
|
||||
|
||||
@ -209,7 +194,7 @@ type error interface {
|
||||
n0, _ := Read(Buffer) // 忽略错误
|
||||
n, err := Read(buffer)
|
||||
if err != nil {
|
||||
return err
|
||||
return err
|
||||
}
|
||||
```
|
||||
|
||||
@ -217,21 +202,21 @@ if err != nil {
|
||||
|
||||
```
|
||||
func Function() (err error) {
|
||||
defer func() {
|
||||
s := recover()
|
||||
switch s := s.(type) { // type switch
|
||||
case error:
|
||||
err = s // s has type error now
|
||||
default:
|
||||
panic(s)
|
||||
defer func() {
|
||||
s := recover()
|
||||
switch s := s.(type) { // type switch
|
||||
case error:
|
||||
err = s // s has type error now
|
||||
default:
|
||||
panic(s)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 数组和切片
|
||||
|
||||
正如前边说的,数组是值类型而切片是指向数组的指针。切片可以由现有的数组切片产生,也可以使用 `make()` 创建切片,这会创建一个匿名数组以保存元素。
|
||||
正如前边说的,数组是值类型,而切片是指向数组的指针。切片可以由现有的数组切片产生,也可以使用 `make()` 创建切片,这会创建一个匿名数组以保存元素。
|
||||
|
||||
```
|
||||
slice1 := make([]int, 2, 5) // 分配 5 个元素,其中 2 个初始化为0
|
||||
@ -250,15 +235,19 @@ slice = append(slice, arrayOrSlice...)
|
||||
|
||||
切片也可以用于函数的变长参数。
|
||||
|
||||
### Maps
|
||||
### 映射
|
||||
|
||||
Maps 是简单的键值对储存容器并支持索引和分配。但它们不是线程安全的。
|
||||
<ruby>映射<rt>maps<rt></ruby>是简单的键值对储存容器,并支持索引和分配。但它们不是线程安全的。
|
||||
|
||||
```
|
||||
someValue := someMap[someKey]
|
||||
someValue, ok := someMap[someKey] // 如果键值不在 someMap 中,变量 ok 会赋值为 `false`
|
||||
someMap[someKey] = someValue
|
||||
```
|
||||
|
||||
[^1]: Frequently Asked Questions (FAQ) - The Go Programming Language https://golang.org/doc/faq#history [return]
|
||||
[^2]: HOARE, Charles Antony Richard. Communicating sequential processes. Communications of the ACM, 1978, 21. Jg., Nr. 8, S. 666-677. [return]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.jak-linux.org/2018/12/24/introduction-to-go/
|
||||
@ -266,7 +255,7 @@ via: https://blog.jak-linux.org/2018/12/24/introduction-to-go/
|
||||
作者:[Julian Andres Klode][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LazyWolfLin](https://github.com/LazyWolfLin)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,92 +1,84 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10520-1.html)
|
||||
[#]: subject: (Asciinema – Record And Share Your Terminal Sessions On The Fly)
|
||||
[#]: via: (https://www.2daygeek.com/linux-asciinema-record-your-terminal-sessions-share-them-on-web/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Asciinema – Record And Share Your Terminal Sessions On The Fly
|
||||
Asciinema:在云端记录并分享你的终端会话
|
||||
======
|
||||
|
||||
This is known topic and we had already written so many article about this topic.
|
||||
这个众所周知的话题我们早已经写过了足够多的文章。即使这样,我们今天也要去讨论相同的话题。
|
||||
|
||||
Even today also we are going to discuss about the same topic.
|
||||
其他的工具都是在本地运行的,但是 Asciinema 可以以相同的方式在本地和 Web 端运行。我的意思是我们可以在 Web 上分享这个录像。
|
||||
|
||||
Other tools are works locally but Asciinema works in both way like local and web.
|
||||
默认情况下,每个人都更愿意使用 `history` 命令来回看、调用之前在终端内输入的命令。不过,不行的是,这个命令只展示了我们运行的命令却没有展示这些命令上次运行时的输出。
|
||||
|
||||
I mean we can share the recording on the web.
|
||||
在 Linux 下有很多的组件来记录终端会话活动。在过去,我们也写了一些组件,不过今天我们依然要讨论这同一类心的工具。
|
||||
|
||||
By default everyone prefer history command to review/recall the previously entered commands in terminal.
|
||||
如果你想要使用其他工具来记录你的 Linux 终端会话活动,你可以试试 [Script 命令][1]、[Terminalizer 工具][2] 和 [Asciinema 工具][3]。
|
||||
|
||||
But unfortunately, that shows only the commands that we ran and doesn’t shows the commands output which was performed previously.
|
||||
不过如果你想要找一个 [GIF 录制工具][4],可以试试 [Gifine][5]、[Kgif][6] 和 [Peek][7]。
|
||||
|
||||
There are many utilities available in Linux to record the terminal session activity.
|
||||
### 什么是 Asciinema
|
||||
|
||||
Also, we had written about few utilities in the past and today also we are going to discuss about the same kind of topic.
|
||||
`asciinema` 是一个自由开源的用于录制终端会话并将它们分享到网络上的解决方案。
|
||||
|
||||
If you would like to check other utilities to record your Linux terminal session activity then you can give a try to **[Script Command][1]** , **[Terminalizer Tool][2]** and **[Asciinema Tool][3]**.
|
||||
当你在你的终端内运行 `asciinema rec` 来启动录像时,你输入命令的时候,终端内的所有输出都会被抓取。
|
||||
|
||||
But if you are looking for **[GIF Recorder][4]** then try **[Gifine][5]** , **[Kgif][6]** and **[Peek][7]** utilities.
|
||||
当抓取停止时(通过按下 `Ctrl-D` 或输出 `exit`),抓取的输出将会被上传到 asciinema.org 的网站,并为后续的回放做准备。
|
||||
|
||||
### What is Asciinema
|
||||
Asciinema 项目由多个不同的完整的部分组成,比如 `asciinema` 命令行工具、asciinema.org API 和 JavaScript 播放器。
|
||||
|
||||
asciinema is a free and open source solution for recording terminal sessions and sharing them on the web.
|
||||
Asciinema 的灵感来自于 `script` 和 `scriptreplay` 命令。
|
||||
|
||||
When you run asciinema rec in your terminal the recording starts, capturing all output that is being printed to your terminal while you’re issuing the shell commands.
|
||||
### 如何在 Linux 上安装 Asciinema
|
||||
|
||||
When the recording finishes (by hitting `Ctrl-D` or typing `exit`) then the captured output is uploaded to asciinema.org website and prepared for playback on the web.
|
||||
Asciinema 由 Python 写就,在 Linux 上,推荐使用 `pip` 安装的方法来安装。
|
||||
|
||||
Asciinema project is built of several complementary pieces such as asciinema command line tool, API at asciinema.org and javascript player.
|
||||
确保你已经在你的系统里安装了 python-pip 包。如果没有,使用下述命令来安装它。
|
||||
|
||||
Asciinema was inspired by script and scriptreplay commands.
|
||||
|
||||
### How to Install Asciinema In Linux
|
||||
|
||||
It was written in Python and pip installation is a recommended method to install Asciinema on Linux.
|
||||
|
||||
Make sure you should have installed python-pip package on your system. If no, use the following command to install it.
|
||||
|
||||
For Debian/Ubuntu users, use **[Apt Command][8]** or **[Apt-Get Command][9]** to install pip package.
|
||||
对于 Debian/Ubuntu 用户,使用 [Apt 命令][8] 或 [Apt-Get 命令][9] 来安装 pip 包。
|
||||
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
```
|
||||
|
||||
For Archlinux users, use **[Pacman Command][10]** to install pip package.
|
||||
对于 Archlinux 用户,使用 [Pacman 命令][10] 来安装 pip 包。
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
For Fedora users, use **[DNF Command][11]** to install pip package.
|
||||
对于 Fedora 用户,使用 [DNF 命令][11] 来安装 pip 包。
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
```
|
||||
|
||||
For CentOS/RHEL users, use **[YUM Command][12]** to install pip package.
|
||||
对于 CentOS/RHEL 用户,使用 [YUM 命令][12] 来安装 pip 包。
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip
|
||||
```
|
||||
|
||||
For openSUSE users, use **[Zypper Command][13]** to install pip package.
|
||||
对于 openSUSE 用户,使用 [Zypper 命令][13] 来安装 pip 包。
|
||||
|
||||
```
|
||||
$ sudo zypper install python-pip
|
||||
```
|
||||
|
||||
Finally run the following **[pip command][14]** to install Asciinema tool in Linux.
|
||||
最后,运行如下的 [pip 命令][14] 来在 Linux 上安装 Asciinema 工具。
|
||||
|
||||
```
|
||||
$ sudo pip3 install asciinema
|
||||
```
|
||||
|
||||
### How to Record Your Terminal Session Using Asciinema
|
||||
### 如何使用 Asciinema 工具来记录你的终端会话
|
||||
|
||||
Once you successfully installed Asciinema. Just run the following command to start recording.
|
||||
一旦你成功的安装了 Asciinema,只需要运行如下命令来开始录制:
|
||||
|
||||
```
|
||||
$ asciinema rec 2g-test
|
||||
@ -94,7 +86,7 @@ asciinema: recording asciicast to 2g-test
|
||||
asciinema: press "ctrl-d" or type "exit" when you're done
|
||||
```
|
||||
|
||||
For testing purpose run few commands and see whether it’s working fine or not.
|
||||
出于测试的目的,运行一些简单的命令,并看一看它是否运行良好。
|
||||
|
||||
```
|
||||
$ free
|
||||
@ -141,10 +133,10 @@ L1i cache: 32K
|
||||
L2 cache: 256K
|
||||
L3 cache: 6144K
|
||||
NUMA node0 CPU(s): 0-7
|
||||
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp flush_l1d
|
||||
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid ept_add fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp flush_l1d
|
||||
```
|
||||
|
||||
Once you have done, simple press `CTRL+D` or type `exit` to stop the recording. The result will be saved in the same directory.
|
||||
当你完成后,简单的按下 `CTRL+D` 或输入 `exit` 来退出录制。这个结果将会被保存在同一个目录。
|
||||
|
||||
```
|
||||
$ exit
|
||||
@ -153,41 +145,41 @@ asciinema: recording finished
|
||||
asciinema: asciicast saved to 2g-test
|
||||
```
|
||||
|
||||
If you would like to save the output in the different directory then mention the path where you want to save the file.
|
||||
如果你想要保存输出到不同的目录中,就需要提醒 Asciinema 你想要保存文件的目录。
|
||||
|
||||
```
|
||||
$ asciinema rec /opt/session-record/2g-test1
|
||||
```
|
||||
|
||||
We can play the recorded session using the following command.
|
||||
我们可以使用如下命令来回放录制的会话。
|
||||
|
||||
```
|
||||
$ asciinema play 2g-test
|
||||
```
|
||||
|
||||
We can play the recorded session with double speed.
|
||||
我们能够以两倍速来回放录制的会话。
|
||||
|
||||
```
|
||||
$ asciinema play -s 2 2g-test
|
||||
```
|
||||
|
||||
Alternatively we can play the recorded session with normal speed with idle time limited to 2 seconds.
|
||||
或者,我们可以以正常速度播放录制的会话,限制空闲时间为 2 秒。
|
||||
|
||||
```
|
||||
$ asciinema play -i 2 2g-test
|
||||
```
|
||||
|
||||
### How To Share the Recorded Session on The Web
|
||||
### 如何在网络上分享已经录制的会话
|
||||
|
||||
If you would like to share the recorded session with your friends, just run the following command which upload the recording to asciinema.org and provide you the unique link.
|
||||
如果你想要分享录制的会话给你的朋友,只要运行下述命令上传你的会话到 asciinema.org,就可以获得一个唯一链接。
|
||||
|
||||
It will be automatically archived 7 days after upload.
|
||||
它将会在被上传 7 天后被归档。
|
||||
|
||||
```
|
||||
$ asciinema upload 2g-test
|
||||
View the recording at:
|
||||
|
||||
https://asciinema.org/a/jdJrxhDLboeyrhzZRHsve0x8i
|
||||
https://asciinema.org/a/jdJrxhDLboeyrhzZRHsve0x8i
|
||||
|
||||
This installation of asciinema recorder hasn't been linked to any asciinema.org
|
||||
account. All unclaimed recordings (from unknown installations like this one)
|
||||
@ -196,24 +188,24 @@ are automatically archived 7 days after upload.
|
||||
If you want to preserve all recordings made on this machine, connect this
|
||||
installation with asciinema.org account by opening the following link:
|
||||
|
||||
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
|
||||
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
If you would like to share the recorded session on social media, just click the `Share` button in the bottom of the page.
|
||||
如果你想要分享录制的会话在社交媒体上,只需要点击页面底部的 “Share” 按钮。
|
||||
|
||||
If anyone wants to download this recording, just click the `Download` button in the bottom of the page to save on your system.
|
||||
如果任何人想要去下载这个录制,只需要点击页面底部的 “Download” 按钮,就可以将其保存在你系统里。
|
||||
|
||||
### How to Manage Recording on asciinema.org Site
|
||||
### 如何管理 asciinema.org 中的录制片段
|
||||
|
||||
If you want to preserve all recordings made on this machine, connect this installation with asciinema.org account by opening the following link and follow the instructions.
|
||||
如果你想要留存所有在这个机器上录制的片段,点击上述显示的链接并使用你在 asciinema.org 的账户登录,然后跟随这个说明继续操作,来将你的机器和该网站连接起来。
|
||||
|
||||
```
|
||||
https://asciinema.org/connect/10cd4f24-45b6-4f64-b737-ae0e5d12baf8
|
||||
```
|
||||
|
||||
If you have already recorded an asciicast but you don’t see it on your profile on asciinema.org website. Just run the `asciinema auth` command in your terminal to move those.
|
||||
如果你早已录制了一份,但是你没有在你的 asciinema.org 账户界面看到它,只需要运行 `asciinema auth` 命令来移动它们。
|
||||
|
||||
```
|
||||
$ asciinema auth
|
||||
@ -227,7 +219,7 @@ This will associate all recordings uploaded from this machine (past and future o
|
||||
|
||||
![][17]
|
||||
|
||||
Run the following command if you would like to upload the file directly to asciinema.org instead of locally saving.
|
||||
如果你想直接上传文件而不是将其保存在本地,直接运行如下命令:
|
||||
|
||||
```
|
||||
$ asciinema rec
|
||||
@ -235,15 +227,7 @@ asciinema: recording asciicast to /tmp/tmp6kuh4247-ascii.cast
|
||||
asciinema: press "ctrl-d" or type "exit" when you're done
|
||||
```
|
||||
|
||||
Just run the following command to start recording.
|
||||
|
||||
```
|
||||
$ asciinema rec 2g-test
|
||||
asciinema: recording asciicast to 2g-test
|
||||
asciinema: press "ctrl-d" or type "exit" when you're done
|
||||
```
|
||||
|
||||
For testing purpose run few commands and see whether it’s working fine or not.
|
||||
出于测试目的,运行下述命令,并看一看它是否运行的很好。
|
||||
|
||||
```
|
||||
$ free
|
||||
@ -265,9 +249,9 @@ $ uname -a
|
||||
Linux daygeek-Y700 4.19.8-2-MANJARO #1 SMP PREEMPT Sat Dec 8 14:45:36 UTC 2018 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
Once you have done, simple press `CTRL+D` or type `exit` to stop the recording then hit `Enter` button to upload the recording to asciinema.org website.
|
||||
如果你完成了,简单的按下 `CTRL+D` 或输入 `exit` 来停止录制,然后按下回车来上传文件到 asciinema.org 网站。
|
||||
|
||||
It will take few seconds to generate the unique url for your uploaded recording. Once it’s done you will be getting the results same as below.
|
||||
这将会花费一些时间来为你的录制生成唯一链接。一旦它完成,你会看到和下面一样的样式:
|
||||
|
||||
```
|
||||
$ exit
|
||||
@ -286,8 +270,8 @@ via: https://www.2daygeek.com/linux-asciinema-record-your-terminal-sessions-shar
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[Bestony](https://github.com/bestony)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +1,65 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10503-1.html)
|
||||
[#]: subject: (Hegemon – A Modular System And Hardware Monitoring Tool For Linux)
|
||||
[#]: via: (https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-tool-for-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
Hegemon - 一个 Linux 中的模块化系统和硬件监控工具
|
||||
Hegemon:一个 Linux 的模块化系统和硬件监控工具
|
||||
======
|
||||
|
||||
我知道每个人都更喜欢使用 **[top 命令][1]**来监控系统利用率。
|
||||
我知道每个人都更喜欢使用 [top 命令][1]来监控系统利用率。这是被 Linux 系统管理员大量使用的原生命令之一。
|
||||
|
||||
这是被 Linux 系统管理员大量使用的原生命令之一。
|
||||
在 Linux 中,每个包都有一个替代品。Linux 中有许多可用于此的工具,我更喜欢 [htop 命令][2]。
|
||||
|
||||
在 Linux 中,每个包都有一个替代品。
|
||||
如果你想了解其他替代方案,我建议你浏览每个链接了解更多信息。它们有 htop、CorFreq、glances、atop、Dstat、Gtop、Linux Dash、Netdata、Monit 等。
|
||||
|
||||
Linux 中有许多可用于此的工具,我更喜欢 **[htop 命令][2]**。
|
||||
所有这些只允许我们监控系统利用率而不能监控系统硬件。但是 Hegemon 允许我们在单个仪表板中监控两者。
|
||||
|
||||
如果你想了解其他替代方案,我建议你浏览每个链接了解更多信息。
|
||||
|
||||
它们有 htop、CorFreq、glances、atop、Dstat、Gtop、Linux Dash、Netdata、Monit 等。
|
||||
|
||||
所有这些只允许我们监控系统利用率而不能监控系统硬件。
|
||||
|
||||
但是 Hegemon 允许我们在单个仪表板中监控两者。
|
||||
|
||||
如果你正在寻找系统硬件监控软件,那么我建议你看下 **[lm_sensors][3]** 和 **[s-tui 压力终端 UI][4]**。
|
||||
如果你正在寻找系统硬件监控软件,那么我建议你看下 [lm_sensors][3] 和 [s-tui 压力终端 UI][4]。
|
||||
|
||||
### Hegemon 是什么?
|
||||
|
||||
Hegemon 是一个正在开发中的模块化系统监视器, 以安全的 Rust 编写。
|
||||
Hegemon 是一个正在开发中的模块化系统监视器,以安全的 Rust 编写。
|
||||
|
||||
它允许用户在单个仪表板中监控两种使用情况。分别是系统利用率和硬件温度。
|
||||
|
||||
### Hegemon 目前的特性
|
||||
|
||||
* 监控 CPU 和内存使用情况、温度和风扇速度
|
||||
* 展开任何数据流以显示更详细的图表和其他信息
|
||||
* 可调整的更新间隔
|
||||
* 干净的 MVC 架构,具有良好的代码质量
|
||||
* 单元测试
|
||||
|
||||
|
||||
* 展开任何数据流以显示更详细的图表和其他信息
|
||||
* 可调整的更新间隔
|
||||
* 干净的 MVC 架构,具有良好的代码质量
|
||||
* 单元测试
|
||||
|
||||
### 计划的特性包括
|
||||
|
||||
* macOS 和 BSD 支持(目前仅支持 Linux)
|
||||
* 监控磁盘和网络 I/O、GPU使用情况(可能)等
|
||||
* 监控磁盘和网络 I/O、GPU 使用情况(可能)等
|
||||
* 选择并重新排序数据流
|
||||
* 鼠标控制
|
||||
|
||||
|
||||
|
||||
### 如何在 Linux 中安装 Hegemon?
|
||||
|
||||
Hegemon 需要 Rust 1.26 或更高版本以及 libsensors 的开发文件。因此,请确保在安装 Hegemon 之前安装了这些软件包。
|
||||
|
||||
libsensors 库在大多数发行版官方仓库中都有,因此,使用以下命令进行安装。
|
||||
|
||||
对于 **`Debian/Ubuntu`** 系统,使用 **[apt-get 命令][5]** 或 **[apt 命令][6]** 在你的系统上安装 libsensors。
|
||||
对于 Debian/Ubuntu 系统,使用 [apt-get 命令][5] 或 [apt 命令][6] 在你的系统上安装 libsensors。
|
||||
|
||||
```
|
||||
# apt install lm_sensors-devel
|
||||
```
|
||||
|
||||
对于 **`Fedora`** 系统,使用 **[dnf 包管理器][7]**在你的系统上安装 libsensors。
|
||||
对于 Fedora 系统,使用 [dnf 包管理器][7]在你的系统上安装 libsensors。
|
||||
|
||||
```
|
||||
# dnf install libsensors4-dev
|
||||
```
|
||||
|
||||
运行以下命令安装 Rust 语言,并按照指示来做。如果你想要看 **[Rust 安装][8]**的方便教程,请进入这个 URL。
|
||||
运行以下命令安装 Rust 语言,并按照指示来做。如果你想要看 [Rust 安装][8]的方便教程,请进入该 URL。
|
||||
|
||||
```
|
||||
$ curl https://sh.rustup.rs -sSf | sh
|
||||
@ -93,7 +81,7 @@ $ hegemon
|
||||
|
||||
![][10]
|
||||
|
||||
由于 libsensors.so.4 库的问题,我在启动 “Hegemon” 时遇到了一个问题。
|
||||
由于 libsensors.so.4 库的问题,我在启动 Hegemon 时遇到了一个问题。
|
||||
|
||||
```
|
||||
$ hegemon
|
||||
@ -107,9 +95,11 @@ $ sudo ln -s /usr/lib/libsensors.so /usr/lib/libsensors.so.4
|
||||
```
|
||||
|
||||
这是从我的 Lenovo-Y700 笔记本中截取的示例 gif。
|
||||
|
||||
![][11]
|
||||
|
||||
默认它仅显示总体摘要,如果你想查看详细输出,则需要展开每个部分。使用 Hegemon 查看展开内容。
|
||||
默认它仅显示总体摘要,如果你想查看详细输出,则需要展开每个部分。如下是 Hegemon 的展开视图。
|
||||
|
||||
![][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -119,7 +109,7 @@ via: https://www.2daygeek.com/hegemon-a-modular-system-and-hardware-monitoring-t
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
133
published/20190114 Remote Working Survival Guide.md
Normal file
133
published/20190114 Remote Working Survival Guide.md
Normal file
@ -0,0 +1,133 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10518-1.html)
|
||||
[#]: subject: (Remote Working Survival Guide)
|
||||
[#]: via: (https://www.jonobacon.com/2019/01/14/remote-working-survival/)
|
||||
[#]: author: (Jono Bacon https://www.jonobacon.com/author/admin/)
|
||||
|
||||
远程工作生存指南
|
||||
======
|
||||
|
||||

|
||||
|
||||
远程工作似乎是最近的一个热门话题。CNBC 报道称,[70% 的专业人士至少每周在家工作一次][1]。同样地,CoSo Cloud 调查发现, [77% 的人在远程工作时效率更高][2] ,而 aftercollege 的一份调查显示,[8% 的千禧一代会更多地考虑提供远程工作的公司][3]。 这看起来很合理:技术、网络以及文化似乎越来越推动了远程工作的发展。哦,自制咖啡也比以前任何时候更好喝了。
|
||||
|
||||
目前,我准备写另一篇关于公司如何优化远程工作的文章(所以请确保你加入我们的会员以持续关注——这是免费的)。
|
||||
|
||||
但今天,我想 **分享一些个人如何做好远程工作的建议**。不管你是全职远程工作者,或者是可以选择一周某几天在家工作的人,希望这篇文章对你有用。
|
||||
|
||||
眼下,你需要明白,**远程工作不是万能药**。当然,穿着睡衣满屋子乱逛,听听反社会音乐,喝一大杯咖啡看起来似乎挺完美的,但这不适合每个人。
|
||||
|
||||
有的人需要办公室的空间。有的人需要办公室的社会元素。有的人需要从家里走出来。有的人在家里缺乏保持专注的自律。有的人因为好几年未缴退税而怕政府工作人员来住处敲门。
|
||||
|
||||
**远程工作就好像一块肌肉:如果你锻炼并且保持它,那么它能带来极大的力量和能力**。如果不这么做,结果就不一样了。
|
||||
|
||||
在我职业生涯的大多数时间里,我在家工作。我喜欢这么做。当我在家工作的时候,我更有效率,更开心,更有能力。我并非不喜欢在办公室工作,我享受办公室的社会元素,但我更喜欢在家工作时我的“空间”。我喜欢听重金属音乐,但当整个办公室的人不想听到 [After The Burial][5] 的时候,这会引起一些问题。
|
||||
|
||||
![][6]
|
||||
|
||||
*“Squirrel.” [图片来源][7]*
|
||||
|
||||
我已经学会了如何正确平衡工作、旅行以及其他元素来管理我的远程工作,以下是我的一些建议。请务必**在评论中分享一些你的建议**。
|
||||
|
||||
### 1、你需要纪律和习惯(以及了解你的“波动”)
|
||||
|
||||
远程工作确实是需要训练的一块肌肉。就像练出真正的肌肉一样,它需要一个明确的习惯混以健康的纪律。
|
||||
|
||||
永远保持穿戴整齐(不要穿睡衣)。设置你一天工作的开始和结束时间(大多时候我从早上 9 点工作到下午 6 点)。选好你的午餐休息时间(我的是中午 12 点)。选好你的早晨仪式(我的是电子邮件,紧接着是全面审查客户需求)。决定你的主工作场所在哪(我的主工作场所是我家庭办公室)。决定好每天你什么时候运动(大多数时候我在下午 5 点运动)。
|
||||
|
||||
**设计一个实际的习惯并坚持 66 天**。建立一个习惯需要很长时间,尽量不要偏离你的习惯。你越坚持这个习惯,做下去所花费的功夫越少。在这 66 天的末尾,你想都不会想,自然而然地就按习惯去做了。
|
||||
|
||||
话虽这么说,我们又不住在真空里 ([更干净,或者别的什么][8])。我们都有自己的“波动”。
|
||||
|
||||
“波动”是你为了改变做事的方法时,对日常做出的一些改变。举个例子,夏天的时候我通常需要更多的阳光。那时我经常会在室外的花园工作。临近假期的时候我更容易分心,所以我在上班时间会更需要呆在室内。有时候我只想要多点人际接触,因此我会在咖啡馆里工作几周。有时候我就是喜欢在厨房或者长椅上工作。你需要认识你的“波动”并倾听你的身体。 **首先养成习惯,然后在你认识到自己的“波动”的时候再对它进行适当的调整**。
|
||||
|
||||
### 2、与你的上司及同事一起设立预期目标
|
||||
|
||||
不是每个人都知道怎么远程工作,如果你的公司对远程工作没那么熟悉,你尤其需要和同事一起设立预期目标。
|
||||
|
||||
这件事十分简单:**当你要设计自己的日常工作的时候,清楚地跟你的上司和团队进行交流。**让他们知道如何找到你,紧急情况下如何联系你,以及你在家的时候如何保持合作。
|
||||
|
||||
在这里通信方式至关重要。有些远程工作者很怕离开他们的电脑,因为害怕当他们不在的时候有人给他们发消息(他们担心别人会觉得他们在边吃奇多边看 Netflix)。
|
||||
|
||||
你需要离开一会的时间。你需要在吃午餐的时候眼睛不用一直盯着电脑屏幕。你又不是 911 接线员。**设定预期:有时候你可能不能立刻回复,但你会尽快回复**。
|
||||
|
||||
同样地,设定你的通常可响应的时间范围的预期。举个例子,我对客户设立的预期是我一般每天早上 9 点到下午 6 点工作。当然,如果某个客户急需某样东西,我很乐意在这段时间外回应他,但作为一个一般性规则,我通常只在这段时间内工作。这对于生活的平衡是必要的。
|
||||
|
||||
### 3、分心是你的敌人,它们需要管理
|
||||
|
||||
我们都会分心,这是人类的本能。让你分心的事情可能是你的孩子回家了,想玩救援机器人;可能是看看Facebook、Instagram,或者 Twitter 以确保你不会错过任何不受欢迎的政治观点,或者某人的午餐图片;可能是你生活中即将到来的某件事带走了你的注意力(例如,即将举办的婚礼、活动,或者一次大旅行)。
|
||||
|
||||
**你需要明白什么让你分心以及如何管理它**。举个例子,我知道我的电子邮件和 Twitter 会让我分心。我经常查看它们,并且每次查看都会让我脱离我正在工作的空间。拿水或者咖啡的时候我总会分心去吃零食,看 Youtube 的视频。
|
||||
|
||||
![][9]
|
||||
|
||||
*我的分心克星*
|
||||
|
||||
由数字信息造成的分心有一个简单对策:**锁起来**。关闭选项卡,直到你完成了你手头的事情。有一大堆工作的时候我总这么干:我把让我分心的东西锁起来,直到做完手头的工作。这需要控制能力,但所有的一切都需要。
|
||||
|
||||
因为别人影响而分心的元素更难解决。如果你是有家庭的人,你需要明确表示,在你工作的时候常需要独处。这也是为什么家庭办公室这么重要:你需要设一些“爸爸/妈妈正在工作”的界限。如果有急事才能进来,否则让孩子自个儿玩去。
|
||||
|
||||
把让你分心的事锁起来有许多方法:把你的电话静音;把自己的 Facebook 状态设成“离开”;换到一个没有让你分心的事的房间(或建筑物)。再重申一次,了解是什么让你分心并控制好它。如果不这么做,你会永远被分心的事摆布。
|
||||
|
||||
### 4、(良好的)关系需要面对面的关注
|
||||
|
||||
有些角色比其他角色更适合远程工作。例如,我见过工程、质量保证、支持、安全以及其他团队(通常更专注于数字信息协作)的出色工作。其他团队,如设计或营销,往往在远程环境下更难熬(因为它们更注重触觉性)。
|
||||
|
||||
但是,对于任何团队而言,建立牢固的关系至关重要,而现场讨论、协作和社交很有必要。我们的许多感官(例如肢体语言)在数字环境中被剔除,而这些在我们建立信任和关系的方式中发挥着关键作用。
|
||||
|
||||
![][10]
|
||||
|
||||
*火箭也很有帮助*
|
||||
|
||||
这尤为重要,如果(a)你初来这家公司,需要建立关系;(b)对某种角色不熟悉,需要和你的团队建立关系;或者(c)你处于领导地位,构建团队融入和参与是你工作的关键部分。
|
||||
|
||||
**解决方法是?合理搭配远程工作与面对面的时间。** 如果你的公司就在附近,可以用一部分的时间在家工作,一部分时间在公司工作。如果你的公司比较远,安排定期前往办公室(并对你的上司设定你需要这么做的预期)。例如,当我在 XPRIZE 工作的时候,我每几周就会飞往洛杉矶几天。当我在 Canonical 工作时(总部在伦敦),我们每三个月来一次冲刺。
|
||||
|
||||
### 5、保持专注,不要松懈
|
||||
|
||||
本文所有内容的关键在于构建一种(远程工作的)能力,并培养远程工作的肌肉。这就像建立你的日常惯例,坚持它,并认识你的“波动”和让你分心的事情以及如何管理它们一样简单。
|
||||
|
||||
我以一种相当具体的方式来看待这个世界:**我们所做的一切都有机会得到改进和完善**。举个例子,我已经公开演讲超过 15 年,但我总是能发现新的改进方法,以及修复新的错误(说到这些,请参阅我的 [提升你公众演讲的10个方法][11])。
|
||||
|
||||
发现新的改善方法,以及把每个绊脚石和错误视为一个开启新的不同的“啊哈!”时刻让人兴奋。远程工作和这没什么不同:寻找有助于解锁方式的模式,让你的远程工作时间更高效,更舒适,更有趣。
|
||||
|
||||
![][12]
|
||||
|
||||
*看看这些书。它们非常适合个人发展。参阅我的 [150 美元个人发展工具包][13] 文章*
|
||||
|
||||
……但别为此狂热。有的人花尽他们每一分钟来寻求如何变得更好,他们经常以“做得还不够好”、“完成度不够高”等为由打击自己,无法达到他们内心关于完美的不切实际的观点。
|
||||
|
||||
我们都是人,我们是有生命的,不是机器人。始终致力于改进,但要明白不是所有东西都是完美的。你应该有一些休息日或休息周。你也会因为压力和倦怠而挣扎。你也会遇到一些在办公室比远程工作更容易的情况。从这些时刻中学习,但不要沉迷于此。生命太短暂了。
|
||||
|
||||
**你有什么提示,技巧和建议吗?你如何管理远程工作?我的建议中还缺少什么吗?在评论区中与我分享!**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.jonobacon.com/2019/01/14/remote-working-survival/
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.jonobacon.com/author/admin/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html
|
||||
[2]: http://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees
|
||||
[3]: https://www.aftercollege.com/cf/2015-annual-survey
|
||||
[4]: https://www.jonobacon.com/join/
|
||||
[5]: https://www.facebook.com/aftertheburial/
|
||||
[6]: https://www.jonobacon.com/wp-content/uploads/2019/01/aftertheburial2.jpg
|
||||
[7]: https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/
|
||||
[8]: https://www.youtube.com/watch?v=wK1PNNEKZBY
|
||||
[9]: https://www.jonobacon.com/wp-content/uploads/2019/01/IMG_20190114_102429-1024x768.jpg
|
||||
[10]: https://www.jonobacon.com/wp-content/uploads/2019/01/15381733956_3325670fda_k-1024x576.jpg
|
||||
[11]: https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/
|
||||
[12]: https://www.jonobacon.com/wp-content/uploads/2019/01/DwVBxhjX4AgtJgV-1024x532.jpg
|
||||
[13]: https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/
|
||||
@ -0,0 +1,121 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10512-1.html)
|
||||
[#]: subject: (Comparing 3 open source databases: PostgreSQL, MariaDB, and SQLite)
|
||||
[#]: via: (https://opensource.com/article/19/1/open-source-databases)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
开源数据库 PostgreSQL、MariaDB 和 SQLite 的对比
|
||||
======
|
||||
|
||||
> 了解如何选择最适合你的需求的开源数据库。
|
||||
|
||||

|
||||
|
||||
在现代的企业级技术领域中,开源软件已经成为了一股不可忽视的重要力量。借助<ruby>[开源运动][1]<rt>open source movement</rt></ruby>的东风,涌现除了许多重大的技术突破。
|
||||
|
||||
个中原因显而易见,尽管一些基于 Linux 的开源网络标准可能不如专有厂商的那么受欢迎,但是不同制造商的智能设备之间能够互相通信,开源技术功不可没。当然也有不少人认为开源开发出来的应用比厂商提供的产品更加好,所以无论如何,使用开源数据库进行开发确实是相当有利的。
|
||||
|
||||
和其它类型的应用软件一样,不同的开源数据库管理系统之间在功能和特性上可能会存在着比较大的差异。换言之,[不是所有的开源数据库都是平等的][2]。因此,如果要为整个组织选择一个开源数据库,那么应该重点考察数据库是否对用户友好、是否能够持续适应团队需求、是否能够提供足够安全的功能等方面的因素。
|
||||
|
||||
出于这方面考虑,我们在这篇文章中对一些开源数据库进行了概述和优缺点对比。遗憾的是,我们必须忽略一些最常用的数据库。值得注意的是,MongoDB 最近更改了它的许可证,因此它已经不是真正的开源产品了。从商业角度来看,这个决定是很有意义的,因为 MongoDB 已经成为了数据库托管实际上的解决方案,[约 27000 家公司][3]在使用它,但这也意味着 MongoDB 已经不再被视为真正的开源产品。
|
||||
|
||||
另外,自从 MySQL 被 Oracle 收购之后,这个产品就已经不再具有开源性质了,MySQL 可以说是数十年来首选的开源数据库。然而,这为其它真正的开源数据库解决方案提供了挑战它的空间。
|
||||
|
||||
下面是三个值得考虑的开源数据库。
|
||||
|
||||
### PostgreSQL
|
||||
|
||||
没有 [PostgreSQL][4] 的开源数据库清单肯定是不完整的。PostgreSQL 一直都是各种规模企业的首选解决方案。Oracle 对 MySQL 的收购在当时来说可能具有一定的商业意义,但是随着云存储的日益壮大,[开发者对 MySQL 的依赖程度或许并不如以前那么大了][5]。
|
||||
|
||||
尽管 PostgreSQL 不是一个最近几年才面世的新产品,但它却是借助了 [MySQL 相对衰落][6]的机会才逐渐成为最受欢迎的开源数据库之一。由于它和 MySQL 的工作方式非常相似,因此很多热衷于使用开源软件的开发者都纷纷转向 PostgreSQL。
|
||||
|
||||
#### 优势
|
||||
|
||||
* 目前 PostgreSQL 最显著的优点是它的核心算法的效率,这意味着它的性能优于许多宣称更先进数据库。这一点在处理大型数据集的时候就可以很明显地体现出来了,否则 I/O 处理会成为瓶颈。
|
||||
* PostgreSQL 也是最灵活的开源数据库之一,使用 Python、Perl、Java、Ruby、C 或者 R 都能够很方便地调用数据库。
|
||||
* 作为最常用的几个开源数据库之中,PostgreSQL 的社区支持是做得最好的。
|
||||
|
||||
#### 劣势
|
||||
|
||||
* 在数据量比较大的时候,PostgreSQL 的效率毋庸置疑是很高的,但对于数据量较小的情况,使用 PostgreSQL 就显得不如其它的一些工具快了。
|
||||
* 尽管拥有一个很优秀的社区支持,但 PostgreSQL 的核心文档仍然需要作出改进。
|
||||
* 如果你需要使用并行计算或者集群化等高级工具,就需要安装 PostgreSQL 的第三方插件。尽管官方有计划将这些功能逐步添加到主要版本当中,但可能会需要再等待好几年才能出现在标准版本中。
|
||||
|
||||
### MariaDB
|
||||
|
||||
[MariaDB][7] 是 MySQL 的真正开源的发行版本(在 [GNU GPLv2][8] 下发布)。在 Oracle 收购 MySQL 之后,MySQL 的一些核心开发人员认为 Oracle 会破坏 MySQL 的开源理念,因此建立了 MariaDB 这个独立的分支。
|
||||
|
||||
MariaDB 在开发过程中替换了 MySQL 的几个关键组件,但仍然尽可能地保持兼容 MySQL。MariaDB 使用了 Aria 作为存储引擎,这个存储引擎既可以作为事务式引擎,也可以作为非事务式引擎。在 MariaDB 分叉出来之前,就[有一些人推测][10] Aria 会成为 MySQL 未来版本中的标准引擎。
|
||||
|
||||
#### 优势
|
||||
|
||||
* 由于 MariaDB [频繁进行安全发布][11],很多用户选择使用 MariaDB 而不选择 MySQL。尽管这不一定代表 MariaDB 会比 MySQL 更加安全,但确实表明它的开发社区对安全性十分重视。
|
||||
* 有一些人认为,MariaDB 的主要优点就是它在坚持开源的同时会与 MySQL 保持高度兼容,这就意味着从 MySQL 向 MariaDB 的迁移会非常容易。
|
||||
* 也正是由于这种兼容性,MariaDB 也可以和其它常用于 MySQL 的语言配合使用,因此从 MySQL 迁移到 MariaDB 之后,学习和调试代码的时间成本会非常低。
|
||||
* 你可以将 WordPress 和 MariaDB(而不是 MySQL)[配合使用][12]从而获得更好的性能和更丰富的功能。WordPress 是[最受欢迎的][13]<ruby>内容管理系统<rt>Content Management System</rt></ruby>(CMS),占据了一半的互联网份额,并且拥有活跃的开源开发者社区。各种第三方插件在 WordPress 和 MariaDB 配合使用时都能够正常工作。
|
||||
|
||||
#### 劣势
|
||||
|
||||
* MariaDB 有时会变得比较臃肿,尤其是它的 IDX 日志文件在长期使用之后会变得非常大,最终导致性能下降。
|
||||
* 缓存是 MariaDB 的另一个工作领域,并没有期望中那么快,这可能会让人有所失望。
|
||||
* 尽管 MariaDB 最初承诺兼容 MySQL,但目前 MariaDB 已经不是完全兼容 MySQL。如果要从 MySQL 迁移到 MariaDB,就需要额外做一些兼容工作。
|
||||
|
||||
### SQLite
|
||||
|
||||
[SQLite][14] 可以说是世界上实现最多的数据库引擎,因为它被很多流行的 web 浏览器、操作系统和手机所采用。它最初是作为 MySQL 的轻量级分支所开发的。SQLite 和很多其它的数据库不同,它不采用客户端-服务端的引擎架构,而是将整个软件嵌入到每个实现当中。
|
||||
|
||||
这样的架构让 SQLite 拥有一个强大的优势,就是在嵌入式系统或者分布式系统中,每台机器都搭载了数据库的整个实现。这样的做法减少了系统间的调用,从而大大提高了数据库的性能。
|
||||
|
||||
#### 优势
|
||||
|
||||
* 如果你需要构建和实现一个小型数据库,SQLite [可能是最好的选择][15]。它小而灵活,不需要费工夫寻求各种变通方案,就可以在嵌入式系统中实现。
|
||||
* SQLite 体积很小,因此速度极快。其它的一些高级数据库可能会使用复杂的优化方式来提高效率,但SQLite 采用了一种更简单的方法:通过减小数据库及其处理软件的大小,以使处理的数据更少。
|
||||
* SQLite 被广泛采用也导致它可能是兼容性最高的数据库。如果你希望将应用程序集成到智能手机上,这一点尤为重要:只要是可以工作于广泛环境中的第三方应用程序,就可以原生运行于 iOS 上。
|
||||
|
||||
#### 劣势
|
||||
|
||||
* SQLite 的体积小意味着它缺少了很多其它大型数据库的常见功能。例如数据加密就是[抵御黑客攻击][16]的标准功能,而 SQLite 却没有内置这个功能。
|
||||
* SQLite 的广泛流行和源码公开使它易于使用,但是也让它更容易遭受攻击。这是它最大的劣势。SQLite 经常被发现高危的漏洞,例如最近的 [Magellan][17]。
|
||||
* 尽管 SQLite 单文件的方式拥有速度上的优势,但是要使用它实现多用户环境却比较困难。
|
||||
|
||||
### 哪个开源数据库才是最好的?
|
||||
|
||||
当然,对于开源数据库的选择还是取决于业务的需求,尤其是系统的体量。对于小型数据库或者是使用量比较小的数据库,可以使用比较轻量级的解决方案,这样不仅可以加快实现的速度,而且由于系统的复杂程度不算太高,花在调试上的时间成本也不会太高。
|
||||
|
||||
而对于大型的系统,尤其是在成长性企业中,最好还是花时间使用更复杂的数据库(例如 PostgreSQL)。这是一个磨刀不误砍柴工的选择,能够让你不至于在后期再重新选择另一款数据库。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/open-source-databases
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/2/pivotal-moments-history-open-source
|
||||
[2]: https://blog.capterra.com/free-database-software/
|
||||
[3]: https://idatalabs.com/tech/products/mongodb
|
||||
[4]: https://www.postgresql.org/
|
||||
[5]: https://www.theregister.co.uk/2018/05/31/rise_of_the_open_source_data_strategies/
|
||||
[6]: https://www.itworld.com/article/2721995/big-data/signs-of-mysql-decline-on-horizon.html
|
||||
[7]: https://mariadb.org/
|
||||
[8]: https://github.com/MariaDB/server/blob/10.4/COPYING
|
||||
[9]: https://mariadb.com/about-us/
|
||||
[10]: http://kb.askmonty.org/en/aria-faq
|
||||
[11]: https://mariadb.org/tag/security/
|
||||
[12]: https://mariadb.com/resources/blog/how-to-install-and-run-wordpress-with-mariadb/
|
||||
[13]: https://websitesetup.org/popular-cms/
|
||||
[14]: https://www.sqlite.org/index.html
|
||||
[15]: https://www.sqlite.org/aff_short.html
|
||||
[16]: https://hostingcanada.org/most-common-website-vulnerabilities/
|
||||
[17]: https://www.securitynewspaper.com/2018/12/18/critical-vulnerability-in-sqlite-you-should-update-now/
|
||||
|
||||
|
||||
@ -0,0 +1,246 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10514-1.html)
|
||||
[#]: subject: (How to Update/Change Users Password in Linux Using Different Ways)
|
||||
[#]: via: (https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
如何使用不同的方式更改 Linux 用户密码
|
||||
======
|
||||
|
||||
在 Linux 中创建用户账号时,设置用户密码是一件基本的事情。每个人都使用 `passwd` 命令跟上用户名,比如 `passwd USERNAME` 来为用户设置密码。
|
||||
|
||||
确保你一定要设置一个难以猜测的密码,这可以帮助你使系统更安全。我的意思是,密码应该是字母、符号和数字的组合。此外,出于安全原因,我建议你至少每月更改一次密码。
|
||||
|
||||
当你使用 `passwd` 命令时,它会要求你输入两次密码来设置。这是一种设置用户密码的原生方法。
|
||||
|
||||
如果你不想两次更新密码,并希望以不同的方式进行更新,怎么办呢?当然,这可以的,有可能做到。
|
||||
|
||||
如果你是 Linux 管理员,你可能已经多次问过下面的问题。你可能、也可能没有得到这些问题的答案。
|
||||
|
||||
无论如何,不要担心,我们会回答你所有的问题。
|
||||
|
||||
* 如何用一条命令更改用户密码?
|
||||
* 如何在 Linux 中为多个用户更改为相同的密码?
|
||||
* 如何在 Linux 中更改多个用户的密码?
|
||||
* 如何在 Linux 中为多个用户更改为不同的密码?
|
||||
* 如何在多个 Linux 服务器中更改用户的密码?
|
||||
* 如何在多个 Linux 服务器中更改多个用户的密码?
|
||||
|
||||
### 方法-1:使用 passwd 命令
|
||||
|
||||
`passwd` 命令是在 Linux 中为用户设置、更改密码的标准方法。以下是标准方法。
|
||||
|
||||
```
|
||||
# passwd renu
|
||||
Changing password for user renu.
|
||||
New password:
|
||||
BAD PASSWORD: The password contains the user name in some form
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
如果希望在一条命令中设置或更改密码,运行以下命令。它允许用户在一条命令中更新密码。
|
||||
|
||||
```
|
||||
# echo "new_password" | passwd --stdin thanu
|
||||
Changing password for user thanu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### 方法-2:使用 chpasswd 命令
|
||||
|
||||
`chpasswd` 是另一个命令,允许我们为 Linux 中的用户设置、更改密码。如果希望在一条命令中使用 `chpasswd` 命令更改用户密码,用以下格式。
|
||||
|
||||
```
|
||||
# echo "thanu:new_password" | chpasswd
|
||||
```
|
||||
|
||||
### 方法-3:如何为多个用户设置不同的密码
|
||||
|
||||
如果你要为 Linux 中的多个用户设置、更改密码,并且使用不同的密码,使用以下脚本。
|
||||
|
||||
为此,首先我们需要使用以下命令获取用户列表。下面的命令将列出拥有 `/home` 目录的用户,并将输出重定向到 `user-list.txt` 文件。
|
||||
|
||||
```
|
||||
# cat /etc/passwd | grep "/home" | cut -d":" -f1 > user-list.txt
|
||||
```
|
||||
|
||||
使用 `cat` 命令列出用户。如果你不想重置特定用户的密码,那么从列表中移除该用户。
|
||||
|
||||
```
|
||||
# cat user-list.txt
|
||||
centos
|
||||
magi
|
||||
daygeek
|
||||
thanu
|
||||
renu
|
||||
```
|
||||
|
||||
创建以下 shell 小脚本来实现此目的。
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/sh
|
||||
for user in `more user-list.txt`
|
||||
do
|
||||
echo "[email protected]" | passwd --stdin "$user"
|
||||
chage -d 0 $user
|
||||
done
|
||||
```
|
||||
|
||||
给 `password-update.sh` 文件设置可执行权限。
|
||||
|
||||
```
|
||||
# chmod +x password-update.sh
|
||||
```
|
||||
|
||||
最后运行脚本来实现这一目标。
|
||||
|
||||
```
|
||||
# ./password-up.sh
|
||||
|
||||
magi
|
||||
Changing password for user magi.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
daygeek
|
||||
Changing password for user daygeek.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
thanu
|
||||
Changing password for user thanu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
renu
|
||||
Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### 方法-4:如何为多个用户设置相同的密码
|
||||
|
||||
如果要在 Linux 中为多个用户设置、更改相同的密码,使用以下脚本。
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/sh
|
||||
for user in `more user-list.txt`
|
||||
do
|
||||
echo "new_password" | passwd --stdin "$user"
|
||||
chage -d 0 $user
|
||||
done
|
||||
```
|
||||
|
||||
### 方法-5:如何在多个服务器中更改用户密码
|
||||
|
||||
如果希望更改多个服务器中的用户密码,使用以下脚本。在本例中,我们将更改 `renu` 用户的密码,确保你必须提供你希望更新密码的用户名而不是我们的用户名。
|
||||
|
||||
确保你必须将服务器列表保存在 `server-list.txt` 文件中,每个服务器应该在单独一行中。
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for server in `cat server-list.txt`
|
||||
do
|
||||
ssh [email protected]$server 'passwd --stdin renu <<EOF
|
||||
new_passwd
|
||||
new_passwd
|
||||
EOF';
|
||||
done
|
||||
```
|
||||
|
||||
你将得到与我们类似的输出。
|
||||
|
||||
```
|
||||
# ./password-update.sh
|
||||
|
||||
New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password: Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password: Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### 方法-6:如何使用 pssh 命令更改多个服务器中的用户密码
|
||||
|
||||
`pssh` 是一个在多个主机上并行执行 ssh 连接的程序。它提供了一些特性,例如向所有进程发送输入,向 ssh 传递密码,将输出保存到文件以及超时处理。导航到以下链接以了解关于 [PSSH 命令][1]的更多信息。
|
||||
|
||||
```
|
||||
# pssh -i -h /tmp/server-list.txt "printf '%s\n' new_pass new_pass | passwd --stdin root"
|
||||
```
|
||||
|
||||
你将获得与我们类似的输出。
|
||||
|
||||
```
|
||||
[1] 07:58:07 [SUCCESS] CentOS.2daygeek.com
|
||||
Changing password for user root.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password:
|
||||
[2] 07:58:07 [SUCCESS] ArchLinux.2daygeek.com
|
||||
Changing password for user root.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
```
|
||||
|
||||
### 方法-7:如何使用 chpasswd 命令更改多个服务器中的用户密码
|
||||
|
||||
或者,我们可以使用 `chpasswd` 命令更新多个服务器中的用户密码。
|
||||
|
||||
```
|
||||
# ./password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for server in `cat server-list.txt`
|
||||
do
|
||||
ssh [email protected]$server 'echo "magi:new_password" | chpasswd'
|
||||
done
|
||||
```
|
||||
|
||||
### 方法-8:如何使用 chpasswd 命令在 Linux 服务器中更改多个用户的密码
|
||||
|
||||
为此,首先创建一个文件,以下面的格式更新用户名和密码。在本例中,我创建了一个名为 `user-list.txt` 的文件。
|
||||
|
||||
参考下面的详细信息。
|
||||
|
||||
```
|
||||
# cat user-list.txt
|
||||
magi:new@123
|
||||
daygeek:new@123
|
||||
thanu:new@123
|
||||
renu:new@123
|
||||
```
|
||||
|
||||
创建下面的 shell 小脚本来实现这一点。
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for users in `cat user-list.txt`
|
||||
do
|
||||
echo $users | chpasswd
|
||||
done
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
|
||||
@ -0,0 +1,90 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10507-1.html)
|
||||
[#]: subject: (Get started with Roland, a random selection tool for the command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-roland)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Roland 吧,一款命令行随机选择工具
|
||||
======
|
||||
|
||||
> Roland 可以帮你做出艰难的决定,它是我们在开源工具系列中的第七个工具,将帮助你在 2019 年提高工作效率。
|
||||
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
|
||||
|
||||
这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第七个工具来帮助你在 2019 年更有效率。
|
||||
|
||||
### Roland
|
||||
|
||||
当一周的工作结束后,我唯一想做的就是躺到沙发上打一个周末的游戏。但即使我的职业义务在工作日结束后停止了,但我仍然需要管理我的家庭。洗衣、宠物护理、确保我孩子有他所需要的东西,以及最重要的是:决定晚餐吃什么。
|
||||
|
||||
像许多人一样,我经常受到[决策疲劳][1]的困扰,根据速度、准备难易程度以及(坦白地说)任何让我压力最小的方式都会导致不太健康的晚餐选择。
|
||||
|
||||

|
||||
|
||||
[Roland][2] 让我计划饭菜变得容易。Roland 是一款专为桌面角色扮演游戏设计的 Perl 应用。它从怪物和雇佣者等项目列表中随机挑选。从本质上讲,Roland 在命令行做的事情就像游戏管理员在桌子上掷骰子,以便在《要对玩家做的坏事全书》中找个东西一样。
|
||||
|
||||
通过微小的修改,Roland 可以做得更多。例如,只需添加一张表,我就可以让 Roland 帮我选择晚餐。
|
||||
|
||||
第一步是安装 Roland 及其依赖项。
|
||||
|
||||
```
|
||||
git clone git@github.com:rjbs/Roland.git
|
||||
cpan install Getopt::Long::Descriptive Moose \
|
||||
namespace::autoclean List:AllUtils Games::Dice \
|
||||
Sort::ByExample Data::Bucketeer Text::Autoformat \
|
||||
YAML::XS
|
||||
cd oland
|
||||
```
|
||||
|
||||
接下来,创建一个名为 `dinner` 的 YAML 文档,并输入我们所有的用餐选项。
|
||||
|
||||
```
|
||||
type: list
|
||||
pick: 1
|
||||
items:
|
||||
- "frozen pizza"
|
||||
- "chipotle black beans"
|
||||
- "huevos rancheros"
|
||||
- "nachos"
|
||||
- "pork roast"
|
||||
- "15 bean soup"
|
||||
- "roast chicken"
|
||||
- "pot roast"
|
||||
- "grilled cheese sandwiches"
|
||||
```
|
||||
|
||||
运行命令 `bin/roland dinner` 将读取文件并选择其中一项。
|
||||
|
||||
|
||||
|
||||
我想提前计划一周,这样我可以提前购买所有食材。 `pick` 命令确定列表中要选择的物品数量,现在,`pick` 设置为 1。如果我想计划一周的晚餐菜单,我可以将 `pick: 1` 变成 `pick: 7`,它会提供一周的菜单。你还可以使用 `-m` 选项手动输入选择。
|
||||
|
||||
|
||||
|
||||
你也可以用 Roland 做些有趣的事情,比如用经典短语添加一个名为 `8ball` 的文件。
|
||||
|
||||

|
||||
|
||||
你可以创建各种文件来帮助做出长时间工作后看起来非常难做的常见决策。即使你不用来做这个,你仍然可以用它来为今晚的游戏设置哪个狡猾的陷阱做个决定。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tools-roland
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Decision_fatigue
|
||||
[2]: https://github.com/rjbs/Roland
|
||||
@ -1,15 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10500-1.html)
|
||||
[#]: subject: (Get started with HomeBank, an open source personal finance app)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-homebank)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 HomeBank,一个开源个人财务应用
|
||||
开始使用 HomeBank 吧,一款开源个人财务应用
|
||||
======
|
||||
使用 HomeBank 跟踪你的资金流向,这是我们开源工具系列中的第八个工具,它将在 2019 年提高你的工作效率。
|
||||
> 使用 HomeBank 跟踪你的资金流向,这是我们开源工具系列中的第八个工具,它将在 2019 年提高你的工作效率。
|
||||
|
||||

|
||||
|
||||
每年年初似乎都有疯狂的冲动想提高工作效率。新年的决心,渴望开启新的一年,当然,“抛弃旧的,拥抱新的”的态度促成了这一切。通常这时的建议严重偏向闭源和专有软件,但事实上并不用这样。
|
||||
@ -24,7 +25,7 @@
|
||||
|
||||
[HomeBank][1] 是一款个人财务桌面应用,帮助你轻松跟踪你的财务状况,来帮助减少此类压力。它有很好的报告可以帮助你找出你花钱的地方,允许你设置导入交易的规则,并支持大多数现代格式。
|
||||
|
||||
HomeBank 默认可在大多数发行版上可用,因此安装它非常简单。当你第一次启动它时,它将引导你完成设置并让你创建一个帐户。之后,你可以导入任意一种支持的文件格式或开始输入交易。交易簿本身就是一个交易列表。 [与其他一些应用不同][2],你不必学习[复式簿记][3]来使用 HomeBank。
|
||||
HomeBank 默认可在大多数发行版上可用,因此安装它非常简单。当你第一次启动它时,它将引导你完成设置并让你创建一个帐户。之后,你可以导入任意一种支持的文件格式或开始输入交易。交易簿本身就是一个交易列表。[与其他一些应用不同][2],你不必学习[复式记账法][3]来使用 HomeBank。
|
||||
|
||||
|
||||
|
||||
@ -40,7 +41,7 @@ HomeBank 还有预算功能,允许你计划未来几个月的开销。
|
||||
|
||||
对我来说,最棒的功能是 HomeBank 的报告。主页面上不仅有一个图表显示你花钱的地方,而且还有许多其他报告可供你查看。如果你使用预算功能,还会有一份报告会根据预算跟踪你的支出情况。你还可以以饼图和条形图的方式查看报告。它还有趋势报告和余额报告,因此你可以回顾并查看一段时间内的变化或模式。
|
||||
|
||||
总的来说,HomeBank 是一个非常友好,有用的程序,可以帮助你保持良好的财务。如果跟踪你的钱是你生活中的一件麻烦事,它使用起来很简单并且非常有用。
|
||||
总的来说,HomeBank 是一个非常友好,有用的程序,可以帮助你保持良好的财务状况。如果跟踪你的钱是你生活中的一件麻烦事,它使用起来很简单并且非常有用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -50,7 +51,7 @@ via: https://opensource.com/article/19/1/productivity-tools-homebank
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -58,4 +59,4 @@ via: https://opensource.com/article/19/1/productivity-tools-homebank
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://homebank.free.fr/en/index.php
|
||||
[2]: https://www.gnucash.org/
|
||||
[3]: https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system
|
||||
[3]: https://en.wikipedia.org/wiki/Double-entry_bookkeeping_system
|
||||
@ -0,0 +1,180 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (dianbanjiu)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10516-1.html)
|
||||
[#]: subject: (Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems)
|
||||
[#]: via: (https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
dcp:采用对等网络传输文件的方式
|
||||
======
|
||||
|
||||
Linux 本就有 `scp` 和 `rsync` 可以完美地完成这个任务。然而我们今天还是想试点新东西。同时我们也想鼓励那些使用不同的理论和新技术开发新东西的开发者。
|
||||
|
||||
我们也写过其他很多有关这个主题的文章,你可以点击下面的链接访问这些内容。
|
||||
|
||||
它们分别是 [OnionShare][1]、[Magic Wormhole][2]、[Transfer.sh][3] 和 ffsend。
|
||||
|
||||
### 什么是 dcp?
|
||||
|
||||
[dcp][4] 可以在不同主机之间使用 Dat 对等网络复制文件。
|
||||
|
||||
`dcp` 被视作一个像是 `scp` 这样工具的替代品,而无需在主机间进行 SSH 授权。
|
||||
|
||||
这可以让你在两个主机间传输文件时,无需操心所述主机之间互相访问的细节,以及这些主机是否使用了 NAT。
|
||||
|
||||
`dcp` 零配置、安全、快速、且是 P2P 传输。这并不是一个商用软件,使用产生的风险将由使用者自己承担。
|
||||
|
||||
### 什么是 Dat 协议
|
||||
|
||||
Dat 是一个 P2P 协议,是一个致力于下一代 Web 的由社区驱动的项目。
|
||||
|
||||
### dcp 如何工作
|
||||
|
||||
`dcp` 将会为指定的文件或者文件夹创建一个 dat 归档,并生成一个公开密钥,使用这个公开密钥可以让其他人从另外一台主机上下载上面的文件。
|
||||
|
||||
使用网络共享的任何数据都使用该归档的公开密钥加密,也就是说文件的接收权仅限于那些拥有该公开密钥的人。
|
||||
|
||||
### dcp 使用案例
|
||||
|
||||
* 向多个同事发送文件 —— 只需要告诉他们生成的公开密钥,然后他们就可以在他们的机器上收到对应的文件了。
|
||||
* 无需设置 SSH 授权就可以在你本地网络的两个不同物理机上同步文件。
|
||||
* 无需压缩文件并把文件上传到云端就可以轻松地发送文件。
|
||||
* 当你有 shell 授权而没有 SSH 授权时也可以复制文件到远程服务器上。
|
||||
* 在没有很好的 SSH 支持的 Linux/macOS 以及 Windows 系统之间分享文件。
|
||||
|
||||
### 如何在 Linux 上安装 NodeJS & npm?
|
||||
|
||||
`dcp` 是用 JavaScript 写成的,所以在安装 `dcp` 前,需要先安装 NodeJS。在 Linux 上使用下面的命令安装 NodeJS。
|
||||
|
||||
Fedora 系统,使用 [DNF 命令][5] 安装 NodeJS & npm。
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs npm
|
||||
```
|
||||
|
||||
Debian/Ubuntu 系统,使用 [APT-GET 命令][6] 或者 [APT 命令][6] 安装 NodeJS & npm。
|
||||
|
||||
```
|
||||
$ sudo apt install nodejs npm
|
||||
```
|
||||
|
||||
Arch Linux 系统,使用 [Pacman 命令][8] 安装 NodeJS & npm。
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
```
|
||||
|
||||
RHEL/CentOS 系统,使用 [YUM 命令][9] 安装 NodeJS & npm。
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install nodejs npm
|
||||
```
|
||||
|
||||
openSUSE Leap 系统,使用 [Zypper 命令][10] 安装 NodeJS & npm。
|
||||
|
||||
```
|
||||
$ sudo zypper nodejs6
|
||||
```
|
||||
|
||||
### 如何在 Linux 上安装 dcp?
|
||||
|
||||
在安装好 NodeJS 后,使用下面的 `npm` 命令安装 `dcp`。
|
||||
|
||||
`npm` 是一个 JavaScript 的包管理器。它是 JavaScript 的运行环境 Node.js 的默认包管理器。
|
||||
|
||||
```
|
||||
# npm i -g dat-cp
|
||||
```
|
||||
|
||||
### 如何通过 dcp 发送文件?
|
||||
|
||||
在 `dcp` 命令后跟你想要传输的文件或者文件夹。而且无需注明目标机器的名字。
|
||||
|
||||
```
|
||||
# dcp [File Name Which You Want To Transfer]
|
||||
```
|
||||
|
||||
在你运行 `dcp` 命令时将会为传送的文件生成一个 dat 归档。一旦执行完成将会在页面底部生成一个公开密钥。(LCTT 译注:此处并非非对称加密中的公钥/私钥对,而是一种公开的密钥,属于对称加密。)
|
||||
|
||||
### 如何通过 dcp 接收文件
|
||||
|
||||
在远程服务器上输入公开密钥即可接收对应的文件或者文件夹。
|
||||
|
||||
```
|
||||
# dcp [Public Key]
|
||||
```
|
||||
|
||||
以递归形式复制目录。
|
||||
|
||||
```
|
||||
# dcp [Folder Name Which You Want To Transfer] -r
|
||||
```
|
||||
|
||||
下面这个例子我们将会传输单个文件。
|
||||
|
||||
![][12]
|
||||
|
||||
上述文件传输的输出。
|
||||
|
||||
![][13]
|
||||
|
||||
如果你想传输不止一个文件,使用下面的格式。
|
||||
|
||||
![][14]
|
||||
|
||||
上述文件传输的输出。
|
||||
|
||||
![][15]
|
||||
|
||||
递归复制文件夹。
|
||||
|
||||
![][16]
|
||||
|
||||
上述文件夹传输的输出。
|
||||
|
||||
![][17]
|
||||
|
||||
这种方式下你只能够下载一次文件或者文件夹,不可以多次下载。这也就意味着一旦你下载了这些文件或者文件夹,这个链接就会立即失效。
|
||||
|
||||
![][18]
|
||||
|
||||
也可以在手册页查看更多的相关选项。
|
||||
|
||||
```
|
||||
# dcp --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
|
||||
[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
|
||||
[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
|
||||
[4]: https://github.com/tom-james-watson/dat-cp
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-1.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-2.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-3.jpg
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-4.jpg
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-6.jpg
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-7.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-5.jpg
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10502-1.html)
|
||||
[#]: subject: (Understanding Angle Brackets in Bash)
|
||||
[#]: via: (https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash)
|
||||
[#]: author: (Paul Brown https://www.linux.com/users/bro66)
|
||||
@ -10,9 +10,11 @@
|
||||
理解 Bash 中的尖括号
|
||||
======
|
||||
|
||||
> 为初学者介绍尖括号。
|
||||
|
||||

|
||||
|
||||
[Bash][1] 内置了很多诸如 `ls`、`cd`、`mv` 这样的重要的命令,也有很多诸如 `grep`、`awk`、`sed` 这些有用的工具。但除此之外,其实 [Bash][1] 中还有很多可以[起到胶水作用][2]的标点符号,例如点号(`.`)、逗号(`,`)、括号(`<>`)、引号(`"`)之类。下面我们就来看一下可以用来进行数据转换和转移的尖括号()。
|
||||
[Bash][1] 内置了很多诸如 `ls`、`cd`、`mv` 这样的重要的命令,也有很多诸如 `grep`、`awk`、`sed` 这些有用的工具。但除此之外,其实 [Bash][1] 中还有很多可以[起到胶水作用][2]的标点符号,例如点号(`.`)、逗号(`,`)、括号(`<>`)、引号(`"`)之类。下面我们就来看一下可以用来进行数据转换和转移的尖括号(`<>`)。
|
||||
|
||||
### 转移数据
|
||||
|
||||
@ -24,7 +26,7 @@
|
||||
ls > dir_content.txt
|
||||
```
|
||||
|
||||
在上面的例子中,`>` 符号让 shell 将 `ls` 命令的输出结果写入到 `dir_content.txt` 里,而不是直接显示在命令行中。需要注意的是,如果 `dir_content.txt` 这个文件不存在,Bash 会为你创建出来;但是如果 `dir_content.txt` 是一个已有得非空文件,它的内容就会被覆盖掉。所以执行类似的操作之前务必谨慎。
|
||||
在上面的例子中,`>` 符号让 shell 将 `ls` 命令的输出结果写入到 `dir_content.txt` 里,而不是直接显示在命令行中。需要注意的是,如果 `dir_content.txt` 这个文件不存在,Bash 会为你创建;但是如果 `dir_content.txt` 是一个已有的非空文件,它的内容就会被覆盖掉。所以执行类似的操作之前务必谨慎。
|
||||
|
||||
你也可以不使用 `>` 而使用 `>>`,这样就可以把新的数据追加到文件的末端而不会覆盖掉文件中已有的数据了。例如:
|
||||
|
||||
@ -32,7 +34,7 @@ ls > dir_content.txt
|
||||
ls $HOME > dir_content.txt; wc -l dir_content.txt >> dir_content.txt
|
||||
```
|
||||
|
||||
在这串命令里,首先将 home 目录的内容写入到 `dir_content.txt` 文件中,然后使用 `wc -l` 计算出 `dir_content.txt` 文件的行数(也就是 home 目录中的文件数)并追加到 `dir_content.txt` 的末尾。
|
||||
在这串命令里,首先将家目录的内容写入到 `dir_content.txt` 文件中,然后使用 `wc -l` 计算出 `dir_content.txt` 文件的行数(也就是家目录中的文件数)并追加到 `dir_content.txt` 的末尾。
|
||||
|
||||
在我的机器上执行上述命令之后,`dir_content.txt` 的内容会是以下这样:
|
||||
|
||||
@ -57,7 +59,8 @@ Videos
|
||||
17 dir_content.txt
|
||||
```
|
||||
|
||||
你可以将 `>` 和 `>>` 作为箭头来理解。当然,这个箭头的指向也可以反过来。例如,Coen brothers 的一些演员以及他们出演电影的次数保存在 `CBActors` 文件中,就像这样:
|
||||
你可以将 `>` 和 `>>` 作为箭头来理解。当然,这个箭头的指向也可以反过来。例如,Coen brothers
|
||||
(LCTT 译注:科恩兄弟,一个美国电影导演组合)的一些演员以及他们出演电影的次数保存在 `CBActors` 文件中,就像这样:
|
||||
|
||||
```
|
||||
John Goodman 5
|
||||
@ -84,7 +87,7 @@ Steve Buscemi 5
|
||||
Tony Shalhoub 3
|
||||
```
|
||||
|
||||
就可以使用 [`sort`][4] 命令将这个列表按照字母顺序输出。但是,`sort` 命令本来就可以接受传入一个文件,因此在这里使用 `<` 会略显多余,直接执行 `sort CBActors` 就可以得到期望的结果。
|
||||
就可以使用 [sort][4] 命令将这个列表按照字母顺序输出。但是,`sort` 命令本来就可以接受传入一个文件,因此在这里使用 `<` 会略显多余,直接执行 `sort CBActors` 就可以得到期望的结果。
|
||||
|
||||
如果你想知道 Coens 最喜欢的演员是谁,你可以这样操作。首先:
|
||||
|
||||
@ -103,8 +106,8 @@ while read name surname films;\
|
||||
|
||||
下面来分析一下这些命令做了什么:
|
||||
|
||||
* [`while ...; do ... done`][5] 是一个循环结构。当 `while` 后面的条件成立时,`do` 和 `done` 之间的部分会一直重复执行;
|
||||
* [`read`][6] 语句会按行读入内容。`read` 会从标准输入中持续读入,直到没有内容可读入;
|
||||
* [while ...; do ... done][5] 是一个循环结构。当 `while` 后面的条件成立时,`do` 和 `done` 之间的部分会一直重复执行;
|
||||
* [read][6] 语句会按行读入内容。`read` 会从标准输入中持续读入,直到没有内容可读入;
|
||||
* `CBActors` 文件的内容会通过 `<` 从标准输入中读入,因此 `while` 循环会将 `CBActors` 文件逐行完整读入;
|
||||
* `read` 命令可以按照空格将每一行内容划分为三个字段,然后分别将这三个字段赋值给 `name`、`surname` 和 `films` 三个变量,这样就可以很方便地通过 `echo $films $name $surname >> filmsfirst;\` 来重新排列几个字段的放置顺序并存放到 `filmfirst` 文件里面了。
|
||||
|
||||
@ -136,7 +139,7 @@ via: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,16 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10511-1.html)
|
||||
[#]: subject: (Get started with Tint2, an open source taskbar for Linux)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-tint2)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
开始使用 Tint2,一款 Linux 中的开源任务栏
|
||||
开始使用 Tint2 吧,一款 Linux 中的开源任务栏
|
||||
======
|
||||
|
||||
Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年提高你的工作效率,能在任何窗口管理器中提供一致的用户体验。
|
||||
> Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年提高你的工作效率,能在任何窗口管理器中提供一致的用户体验。
|
||||
|
||||

|
||||
|
||||
@ -20,7 +20,7 @@ Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年
|
||||
|
||||
### Tint2
|
||||
|
||||
让我提高工作效率的最佳方法之一是使用尽可能不让我分心的干净界面。作为 Linux 用户,这意味着使用一种最小的窗口管理器,如 [Openbox][1]、[i3][2] 或 [Awesome][3]。它们每种都有让我更有效率的自定义选项。但让我失望的一件事是,它们都没有一致的配置,所以我不得不经常重新调整我的窗口管理器。
|
||||
让我提高工作效率的最佳方法之一是使用尽可能不让我分心的干净界面。作为 Linux 用户,这意味着使用一种极简的窗口管理器,如 [Openbox][1]、[i3][2] 或 [Awesome][3]。它们每种都有让我更有效率的自定义选项。但让我失望的一件事是,它们都没有一致的配置,所以我不得不经常重新调整我的窗口管理器。
|
||||
|
||||

|
||||
|
||||
@ -30,7 +30,7 @@ Tint2 是我们在开源工具系列中的第 14 个工具,它将在 2019 年
|
||||
|
||||
|
||||
|
||||
启动配置工具能让你选择主题并自定义屏幕的顶部、底部和侧边栏。我建议从最接近你想要的主题开始,然后从那里进行自定义。
|
||||
启动该配置工具能让你选择主题并自定义屏幕的顶部、底部和侧边栏。我建议从最接近你想要的主题开始,然后从那里进行自定义。
|
||||
|
||||
|
||||
|
||||
@ -47,7 +47,7 @@ via: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -56,4 +56,4 @@ via: https://opensource.com/article/19/1/productivity-tool-tint2
|
||||
[1]: http://openbox.org/wiki/Main_Page
|
||||
[2]: https://i3wm.org/
|
||||
[3]: https://awesomewm.org/
|
||||
[4]: https://gitlab.com/o9000/tint2
|
||||
[4]: https://gitlab.com/o9000/tint2
|
||||
@ -0,0 +1,495 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zhs852)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-10508-1.html)
|
||||
[#]: subject: (fdisk – Easy Way To Manage Disk Partitions In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
fdisk:Linux 下管理磁盘分区的利器
|
||||
======
|
||||
|
||||
一块硬盘可以被划分成一个或多个逻辑磁盘,我们将其称作分区。我们对硬盘进行的划分信息被储存于建立在扇区 0 的分区表(MBR 或 GPT)中。
|
||||
|
||||
Linux 需要至少一个分区来当作根文件系统,所以我们不能在没有分区的情况下安装 Linux 系统。当我们创建一个分区时,我们必须将它格式化为一个适合的文件系统,否则我们就没办法往里面储存文件了。
|
||||
|
||||
要在 Linux 中完成分区的相关工作,我们需要一些工具。Linux 下有很多可用的相关工具,我们曾介绍过 [Parted 命令][1]。不过,今天我们的主角是 `fdisk`。
|
||||
|
||||
人人都喜欢用 `fdisk`,它是 Linux 下管理磁盘分区的最佳利器之一。它可以操作最大 2TB 的分区。大量 Linux 管理员都喜欢使用这个工具,因为当下 LVM 和 SAN 的原因,并没有多少人会用到 2TB 以上的分区。并且这个工具被世界上许多的基础设施所使用。如果你还是想创建比 2TB 更大的分区,请使用 `parted` 命令 或 `cfdisk` 命令。
|
||||
|
||||
对磁盘进行分区和创建文件系统是 Linux 管理员的日常。如果你在许多不同的环境中工作,你一定每天都会重复几次这项操作。
|
||||
|
||||
### Linux 内核是如何理解硬盘的?
|
||||
|
||||
作为人类,我们可以很轻松地理解一些事情;但是电脑就不是这样了,它们需要合适的命名才能理解这些。
|
||||
|
||||
在 Linux 中,外围设备都位于 `/dev` 挂载点,内核通过以下的方式理解硬盘:
|
||||
|
||||
* `/dev/hdX[a-z]:` IDE 硬盘被命名为 hdX
|
||||
* `/dev/sdX[a-z]:` SCSI 硬盘被命名为 sdX
|
||||
* `/dev/xdX[a-z]:` XT 硬盘被命名为 xdX
|
||||
* `/dev/vdX[a-z]:` 虚拟硬盘被命名为 vdX
|
||||
* `/dev/fdN:` 软盘被命名为 fdN
|
||||
* `/dev/scdN or /dev/srN:` CD-ROM 被命名为 `/dev/scdN` 或 `/dev/srN`
|
||||
|
||||
### 什么是 fdisk 命令?
|
||||
|
||||
`fdisk` 的意思是 <ruby>固定磁盘<rt>Fixed Disk</rt></ruby> 或 <ruby>格式化磁盘<rt>Format Disk</rt></ruby>,它是命令行下允许用户对分区进行查看、创建、调整大小、删除、移动和复制的工具。它支持 MBR、Sun、SGI、BSD 分区表,但是它不支持 GUID 分区表(GPT)。它不是为操作大分区设计的。
|
||||
|
||||
`fdisk` 允许我们在每块硬盘上创建最多四个主分区。它们中的其中一个可以作为扩展分区,并下设多个逻辑分区。1-4 扇区作为主分区被保留,逻辑分区从扇区 5 开始。
|
||||
|
||||
![磁盘分区结构图][3]
|
||||
|
||||
### 如何在 Linux 下安装 fdisk?
|
||||
|
||||
`fdisk` 作为核心组件内置于 Linux 中,所以你不必手动安装它。
|
||||
|
||||
### 如何用 fdisk 列出可用磁盘?
|
||||
|
||||
在执行操作之前,我们必须知道的是哪些磁盘被加入了系统。要想列出所有可用的磁盘,请执行下文的命令。这个命令将会列出磁盘名称、分区数量、分区表类型、磁盘识别代号、分区 ID 和分区类型。
|
||||
|
||||
```shell
|
||||
$ sudo fdisk -l
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
```
|
||||
|
||||
### 如何使用 fdisk 列出特定分区信息?
|
||||
|
||||
如果你希望查看指定分区的信息,请使用以下命令:
|
||||
|
||||
```shell
|
||||
$ sudo fdisk -l /dev/sda
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 * 20973568 62914559 41940992 20G 83 Linux
|
||||
```
|
||||
|
||||
### 如何列出 fdisk 所有的可用操作?
|
||||
|
||||
在 `fdisk` 中敲击 `m`,它便会列出所有可用操作:
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0xe944b373.
|
||||
|
||||
Command (m for help): m
|
||||
|
||||
Help:
|
||||
|
||||
DOS (MBR)
|
||||
a toggle a bootable flag
|
||||
b edit nested BSD disklabel
|
||||
c toggle the dos compatibility flag
|
||||
|
||||
Generic
|
||||
d delete a partition
|
||||
F list free unpartitioned space
|
||||
l list known partition types
|
||||
n add a new partition
|
||||
p print the partition table
|
||||
t change a partition type
|
||||
v verify the partition table
|
||||
i print information about a partition
|
||||
|
||||
Misc
|
||||
m print this menu
|
||||
u change display/entry units
|
||||
x extra functionality (experts only)
|
||||
|
||||
Script
|
||||
I load disk layout from sfdisk script file
|
||||
O dump disk layout to sfdisk script file
|
||||
|
||||
Save & Exit
|
||||
w write table to disk and exit
|
||||
q quit without saving changes
|
||||
|
||||
Create a new label
|
||||
g create a new empty GPT partition table
|
||||
G create a new empty SGI (IRIX) partition table
|
||||
o create a new empty DOS partition table
|
||||
s create a new empty Sun partition table
|
||||
```
|
||||
|
||||
### 如何使用 fdisk 列出分区类型?
|
||||
|
||||
在 `fdisk` 中敲击 `l`,它便会列出所有可用分区的类型:
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0x9ffd00db.
|
||||
|
||||
Command (m for help): l
|
||||
|
||||
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
|
||||
1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT-
|
||||
2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT-
|
||||
3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT-
|
||||
4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx
|
||||
5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data
|
||||
6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / .
|
||||
7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility
|
||||
8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt
|
||||
9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access
|
||||
a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O
|
||||
b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor
|
||||
c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment
|
||||
e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs
|
||||
f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT
|
||||
10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/
|
||||
11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b
|
||||
12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor
|
||||
14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor
|
||||
16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary
|
||||
17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS
|
||||
18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE
|
||||
1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto
|
||||
1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep
|
||||
1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT
|
||||
```
|
||||
### 如何使用 fdisk 创建一个磁盘分区?
|
||||
|
||||
如果你希望新建磁盘分区,请参考下面的步骤。比如我希望在 `/dev/sdc` 中新建四个分区(三个主分区和一个扩展分区),只需要执行下文的命令。
|
||||
|
||||
首先,请在操作 “First sector” 的时候先按下回车,然后在 “Last sector” 中输入你希望创建分区的大小(可以在数字后面加 KB、MB、G 和 TB)。例如,你希望为这个分区扩容 1GB,就应该在 “Last sector” 中输入 `+1G`。当你创建三个分区之后,`fdisk` 默认会将分区类型设为扩展分区,如果你希望创建第四个主分区,请输入 `p` 来替代它的默认值 `e`。
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default p): Enter
|
||||
|
||||
Using default response p.
|
||||
Partition number (1-4, default 1): Enter
|
||||
First sector (2048-20971519, default 2048): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### 如何使用 fdisk 创建扩展分区?
|
||||
|
||||
请注意,创建扩展分区时,你应该使用剩下的所有空间,以便之后在扩展分区下创建逻辑分区。
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (3 primary, 0 extended, 1 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default e): Enter
|
||||
|
||||
Using default response e.
|
||||
Selected partition 4
|
||||
First sector (6293504-20971519, default 6293504): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6293504-20971519, default 20971519): Enter
|
||||
|
||||
Created a new partition 4 of type 'Extended' and of size 7 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### 如何用 fdisk 查看未分配空间?
|
||||
|
||||
上文中,我们总共创建了四个分区(三个主分区和一个扩展分区)。在创建逻辑分区之前,扩展分区的容量将会以未分配空间显示。
|
||||
|
||||
使用以下命令来显示磁盘上的未分配空间,下面的示例中显示的是 7GB:
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): F
|
||||
Unpartitioned space /dev/sdc: 7 GiB, 7515144192 bytes, 14678016 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
Start End Sectors Size
|
||||
6293504 20971519 14678016 7G
|
||||
|
||||
Command (m for help): q
|
||||
```
|
||||
|
||||
### 如何使用 fdisk 创建逻辑分区?
|
||||
|
||||
创建扩展分区后,请按照之前的步骤创建逻辑分区。在这里,我创建了位于 `/dev/sdc5` 的 `1GB` 逻辑分区。你可以查看分区表值来确认这点。
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Command (m for help): n
|
||||
All primary partitions are in use.
|
||||
Adding logical partition 5
|
||||
First sector (6295552-20971519, default 6295552): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6295552-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 5 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### 如何使用 fdisk 命令删除分区?
|
||||
|
||||
如果我们不再使用某个分区,请按照下面的步骤删除它。
|
||||
|
||||
请确保你输入了正确的分区号。在这里,我准备删除 `/dev/sdc2` 分区:
|
||||
|
||||
```shell
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): d
|
||||
Partition number (1-5, default 5): 2
|
||||
|
||||
Partition 2 has been deleted.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### 如何在 Linux 下格式化分区或建立文件系统?
|
||||
|
||||
在计算时,文件系统控制了数据的储存方式,并通过 <ruby>索引节点<rt>Inode Tables</rt></ruby> 来检索数据。如果没有文件系统,操作系统是无法找到信息储存的位置的。
|
||||
|
||||
在此,我准备在 `/dev/sdc1` 上创建分区。有三种方式创建文件系统:
|
||||
|
||||
```shell
|
||||
$ sudo mkfs.ext4 /dev/sdc1
|
||||
或
|
||||
$ sudo mkfs -t ext4 /dev/sdc1
|
||||
或
|
||||
$ sudo mke2fs /dev/sdc1
|
||||
|
||||
mke2fs 1.43.5 (04-Aug-2017)
|
||||
Creating filesystem with 262144 4k blocks and 65536 inodes
|
||||
Filesystem UUID: c0a99b51-2b61-4f6a-b960-eb60915faab0
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (8192 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
当你在分区上建立文件系统时,以下重要信息会同时被创建:
|
||||
|
||||
* `Filesystem UUID:` UUID 代表了通用且独一无二的识别符,UUID 在 Linux 中通常用来识别设备。它 128 位长的数字代表了 32 个十六进制数。
|
||||
* `Superblock:` 超级块储存了文件系统的元数据。如果某个文件系统的超级块被破坏,我们就无法挂载它了(也就是说无法访问其中的文件了)。
|
||||
* `Inode:` Inode 是类 Unix 系统中文件系统的数据结构,它储存了所有除名称以外的文件信息和数据。
|
||||
* `Journal:` 日志式文件系统包含了用来修复电脑意外关机产生下错误信息的日志。
|
||||
|
||||
### 如何在 Linux 中挂载分区?
|
||||
|
||||
在你创建完分区和文件系统之后,我们需要挂载它们以便使用。我们需要创建一个挂载点来挂载分区,使用 `mkdir` 来创建一个挂载点。
|
||||
|
||||
```shell
|
||||
$ sudo mkdir -p /mnt/2g-new
|
||||
```
|
||||
|
||||
如果你希望进行临时挂载,请使用下面的命令。在计算机重启之后,你会丢失这个挂载点。
|
||||
|
||||
```shell
|
||||
$ sudo mount /dev/sdc1 /mnt/2g-new
|
||||
```
|
||||
|
||||
如果你希望永久挂载某个分区,请将分区详情加入 `fstab` 文件。我们既可以输入设备名称,也可以输入 UUID。
|
||||
|
||||
使用设备名称来进行永久挂载:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
|
||||
/dev/sdc1 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
使用 UUID 来进行永久挂载(请使用 `blkid` 来获取 UUID):
|
||||
|
||||
```
|
||||
$ sudo blkid
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
|
||||
# vi /etc/fstab
|
||||
|
||||
UUID=d17e3c31-e2c9-4f11-809c-94a549bc43b7 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
使用 `df` 命令亦可:
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 969M 0 969M 0% /dev
|
||||
tmpfs 200M 7.0M 193M 4% /run
|
||||
/dev/sda1 20G 16G 3.0G 85% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 28K 200M 1% /run/user/121
|
||||
tmpfs 200M 25M 176M 13% /run/user/1000
|
||||
/dev/sdc1 1008M 1.3M 956M 1% /mnt/2g-new
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zhs852](https://github.com/zhs852)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/01/linux-fdisk-command-to-manage-disk-partitions-1a.png
|
||||
@ -1,4 +1,3 @@
|
||||
zgj1024 is translating
|
||||
My Lisp Experiences and the Development of GNU Emacs
|
||||
======
|
||||
|
||||
|
||||
@ -1,107 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wwhio)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (XML vs JSON)
|
||||
[#]: via: (https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#xml-advantages)
|
||||
[#]: author: (TOM STRASSNER tomstrassner@gmail.com)
|
||||
|
||||
XML vs JSON
|
||||
======
|
||||
|
||||
### Introduction
|
||||
|
||||
XML and JSON are the two most common formats for data interchange in the Web today. XML was created by the W3C in 1996, and JSON was publicly specified by Douglas Crockford in 2002. Although their purposes are not identical, they are frequently used to accomplish the same task, which is data interchange. Both have well-documented open standards on the Web ([RFC 7159][1], [RFC 4825][2]), and both are human and machine-readable. Neither one is absolutely superior to the other, as each is better suited for different use cases.
|
||||
|
||||
### XML Advantages
|
||||
|
||||
There are several advantages that XML has over JSON. One of the biggest differences between the two is that in XML you can put metadata into the tags in the form of attributes. With JSON, the programmer could accomplish the same goal that metadata achieves by making the entity an object and adding the attributes as members of the object. However, the way XML does it may often be preferable, given the slightly misleading nature of turning something into an object that is not one in the client program. For example, if your C++ program sends an int via JSON and needs metadata to be sent along with it, you would have to make it an object, with one name/value pair for the actual value of the int, and more name/value pairs for each attribute. The program that receives the JSON would read it as an object, when in fact it is not one. While this is a viable solution, it defies one of JSON’s key advantages: “JSON's structures look like conventional programming language structures. No restructuring is necessary.”[2]
|
||||
|
||||
Although I will argue later that this can also be a drawback of XML, its mechanism to resolve name conflicts, prefixes, gives it power that JSON does not have. With prefixes, the programmer has the ability to name two different kinds of entities the same thing.[1] This would be advantageous in situations where the different entities should have the same name in the client program, perhaps if they are used in entirely different scopes.
|
||||
|
||||
Another advantage of XML is that most browsers render it in a highly readable and organized way. The tree structure of XML lends itself well to this formatting, and allows for browsers to let users to naturally collapse individual tree elements. This feature would be particularly useful in debugging.
|
||||
|
||||
One of the most significant advantages that XML has over JSON is its ability to communicate mixed content, i.e. strings that contain structured markup. In order to handle this with XML, the programmer need only put the marked-up text within a child tag of the parent in which it belongs. Similar to the metadata situation, since JSON only contains data, there is no such simple way to indicate markup. It would again require storing metadata as data, which could be considered an abuse of the format.
|
||||
|
||||
### JSON Advantages
|
||||
|
||||
JSON has several advantages as well. One of the most obvious of these is that JSON is significantly less verbose than XML, because XML necessitates opening and closing tags (or in some cases less verbose self-closing tags), and JSON uses name/value pairs, concisely delineated by “{“ and “}” for objects, “[“ and “]” for arrays, “,” to separate pairs, and “:” to separate name from value. Even when zipped (using gzip), JSON is still smaller and it takes less time to zip it.[6] As determined by Sumaray and Makki as well as Nurseitov, Paulson, Reynolds, and Izurieta in their experimental findings, JSON outperforms XML in a number of ways. First, naturally following from its conciseness, JSON files that contain the same information as their XML counterparts are almost always significantly smaller, which leads to faster transmission and processing. Second, difference in size aside, both groups found that JSON was serialized and deserialized drastically faster than XML.[3][4] Third, the latter study determined that JSON processing outdoes XML in CPU resource utilization. They found that JSON used less total resources, more user CPU, and less system CPU. The experiment used RedHat machines, and RedHat claims that higher user CPU usage is preferable.[3] Unsurprisingly, the Sumaray and Makki study determined that JSON performance is superior to XML on mobile devices too.[4] This makes sense, given that JSON uses less resources, and mobile devices are less powerful than desktop machines.
|
||||
|
||||
Yet another advantage that JSON has over XML is that its representation of objects and arrays allows for direct mapping onto the corresponding data structures in the host language, such as objects, records, structs, dictionaries, hash tables, keyed lists, and associative arrays for objects, and arrays, vectors, lists, and sequences for arrays.[2] Although it is perfectly possible to represent these structures in XML, it is only as a function of the parsing, and it takes more code to serialize and deserialize properly. It also would not always be obvious to the reader of arbitrary XML what tags represent an object and what tags represent an array, especially because nested tags can just as easily be structured markup instead. The curly braces and brackets of JSON definitively show the structure of the data. However, this advantage does come with the caveat explained above, that the JSON can inaccurately represent the data if the need arises to send metadata.
|
||||
|
||||
Although XML supports namespaces and prefixes, JSON’s handling of name collisions is less verbose than prefixes, and arguably feels more natural with the program using it; in JSON, each object is its own namespace, so names may be repeated as long as they are in different scopes. This may be preferable, as in most programming languages members of different objects can have the same name, because they are distinguished by the names of the objects to which they belong.
|
||||
|
||||
Perhaps the most significant advantage that JSON has over XML is that JSON is a subset of JavaScript, so code to parse and package it fits very naturally into JavaScript code. This seems highly beneficial for JavaScript programs, but does not directly benefit any programs that use languages other than JavaScript. However, this drawback has been largely overcome, as currently the JSON website lists over 175 tools for 64 different programming languages that exist to integrate JSON processing. While I cannot speak to the quality of most of these tools, it is clear that the developer community has embraced JSON and has made it simple to use in many different platforms.
|
||||
|
||||
### Purposes
|
||||
|
||||
Simply put, XML’s purpose is document markup. This is decidedly not a purpose of JSON, so XML should be used whenever this is what needs to be done. It accomplishes this purpose by giving semantic meaning to text through its tree-like structure and ability to represent mixed content. Data structures can be represented in XML, but that is not its purpose.
|
||||
|
||||
JSON’s purpose is structured data interchange. It serves this purpose by directly representing objects, arrays, numbers, strings, and booleans. Its purpose is distinctly not document markup. As described above, JSON does not have a natural way to represent mixed content.
|
||||
|
||||
### Software
|
||||
|
||||
The following major public APIs uses XML only: Amazon Product Advertising API.
|
||||
|
||||
The following major APIs use JSON only: Facebook Graph API, Google Maps API, Twitter API, AccuWeather API, Pinterest API, Reddit API, Foursquare API.
|
||||
|
||||
The following major APIs use both XML and JSON: Google Cloud Storage, Linkedin API, Flickr API
|
||||
|
||||
Of the top 10 most popular APIs according to Programmable Web[9], along with a couple more popular ones, only one supports XML and not JSON. Several support both, and several support only JSON. Among developer APIs for modern and popular websites, JSON clearly seems to be preferred. This also indicates that more app developers that use these APIs prefer JSON. This is likely a result of its reputation as the faster and leaner of the two. Furthermore, most of these APIs communicate data rather than documents, so JSON would be more appropriate. For example, Facebook is mainly concerned with communicating data about users and posts, Google Maps deals in coordinates and information about entities on their maps, and AccuWeather just sends weather data. Overall, it is impossible to say whether JSON or XML is currently used more in APIs, but the trend is certainly swinging towards JSON.[10][11]
|
||||
|
||||
The following major desktop software uses XML only: Microsoft Word, Apache OpenOffice, LibreOffice.
|
||||
|
||||
It makes sense for software that is mainly concerned with document creation, manipulation, and storage to use XML rather than JSON. Also, all three of these programs support mixed content, which JSON does not do well. For example, if a user is typing up an essay in Microsoft Word, they may put different font, size, color, positioning, and styling on different blocks of text. XML naturally represents these properties with nested tags and attributes.
|
||||
|
||||
The following major databases support XML: IBM DB2, Microsoft SQL Server, Oracle Database, PostgresSQL, BaseX, eXistDB, MarkLogic, MySQL.
|
||||
|
||||
The following major databases support JSON: MongoDB, CouchDB, eXistDB, Elastisearch, BaseX, MarkLogic, OrientDB, Oracle Database, PostgresSQL, Riak.
|
||||
|
||||
For a long time, SQL and the relational database model dominated the market. Corporate giants like Oracle and Microsoft have always marketed such databases. However, in the last decade, there has been a major rise in popularity of NoSQL databases. As this has coincided with the rise of JSON, most NoSQL databases support JSON, and some, such as MongoDB, CouchDB, and Riak use JSON to store their data. These databases have two important qualities that make them better suited for modern websites: they are generally more scalable than relational SQL databases, and they are designed to the core to run in the Web.[10] Since JSON is more lightweight and a subset of JavaScript, it suits NoSQL databases well, and helps facilitate these two qualities. In addition, many older databases have added support for JSON, such as Oracle Database and PostgresSQL. Conversion between XML and JSON is a hassle, so naturally, as more developers use JSON for their apps, more database companies have incentive to support it.[7]
|
||||
|
||||
### Future
|
||||
|
||||
One of the most heavily anticipated changes in the Internet is the “Internet of Things”, i.e. the addition to the Internet of non-computer devices such as watches, thermostats, televisions, refrigerators, etc. This movement is well underway, and is expected to explode in the near future, as predictions for the number of devices in the Internet of Things in 2020 range from about 26 billion to 200 billion.[12][13][13] Almost all of these devices are smaller and less powerful than laptop and desktop computers. Many of them only run embedded systems. Thus, when they have the need to exchange data with other entities in the Web, the lighter and faster JSON would naturally be preferable to XML.[10] Also, with the recent rapid rise of JSON use in the Web relative to XML, new devices may benefit more from speaking JSON. This highlights an example of Metcalf’s Law; whether XML or JSON or something entirely new becomes the most popular format in the Web, newly added devices and all existing devices will benefit much more if the newly added devices speak the most popular language.
|
||||
|
||||
With the creation and recent rapid increase in popularity of Node.js, a server-side JavaScript framework, along with NoSQL databases like MongoDB, full-stack JavaScript development has become a reality. This bodes well for the future of JSON, as with these new apps, JSON is spoken at every level of the stack, which generally makes the apps very fast and lightweight. This is a desirable trait for any app, so this trend towards full-stack JavaScript is not likely to die out anytime soon.[10]
|
||||
|
||||
Another existing trend in the world of app development is toward REST and away from SOAP.[11][15][16] Both XML and JSON can be used with REST, but SOAP exclusively uses XML.
|
||||
|
||||
The given trends indicate that JSON will continue to dominate the Web, and XML use will continue to decrease. This should not be overblown, however, because XML is still very heavily used in the Web, and it is the only option for apps that use SOAP. Given the widespread migration from SOAP to REST, the rise of NoSQL databases and full-stack JavaScript, and the far superior performance of JSON, I believe that JSON will soon be much more widely used than XML in the Web. There seem to be very few applications where XML is the better choice.
|
||||
|
||||
### References
|
||||
|
||||
1. [XML Tutorial](http://www.w3schools.com/xml/default.asp)
|
||||
2. [Introducing JSON](http://www.json.org/)
|
||||
3. [Comparison of JSON and XML Data Interchange Formats: A Case Study](http://www.cs.montana.edu/izurieta/pubs/caine2009.pdf)
|
||||
4. [A comparison of data serialization formats for optimal efficiency on a mobile platform](http://dl.acm.org/citation.cfm?id=2184810)
|
||||
5. [JSON vs. XML: The Debate](http://ajaxian.com/archives/json-vs-xml-the-debate)
|
||||
6. [JSON vs. XML: Some hard numbers about verbosity](http://www.codeproject.com/Articles/604720/JSON-vs-XML-Some-hard-numbers-about-verbosity)
|
||||
7. [How JSON sparked NoSQL -- and will return to the RDBMS fold](http://www.infoworld.com/article/2608293/nosql/how-json-sparked-nosql----and-will-return-to-the-rdbms-fold.html)
|
||||
8. [Did You Say "JSON Support" in Oracle 12.1.0.2?](https://blogs.oracle.com/OTN-DBA-DEV-Watercooler/entry/did_you_say_json_support)
|
||||
9. [Most Popular APIs: At Least One Will Surprise You](http://www.programmableweb.com/news/most-popular-apis-least-one-will-surprise-you/2014/01/23)
|
||||
10. [Why JSON will continue to push XML out of the picture](https://www.centurylinkcloud.com/blog/post/why-json-will-continue-to-push-xml-out-of-the-picture/)
|
||||
11. [Thousands of APIs Paint a Bright Future for the Web](http://www.webmonkey.com/2011/03/thousand-of-apis-paint-a-bright-future-for-the-web/)
|
||||
12. [A Simple Explanation Of 'The Internet Of Things’](http://www.forbes.com/sites/jacobmorgan/2014/05/13/simple-explanation-internet-things-that-anyone-can-understand/)
|
||||
13. [Proofpoint Uncovers Internet of Things (IoT) Cyberattack](http://www.proofpoint.com/about-us/press-releases/01162014.php)
|
||||
14. [The Internet of Things: New Threats Emerge in a Connected World](http://www.symantec.com/connect/blogs/internet-things-new-threats-emerge-connected-world)
|
||||
15. [3,000 Web APIs: Trends From A Quickly Growing Directory](http://www.programmableweb.com/news/3000-web-apis-trends-quickly-growing-directory/2011/03/08)
|
||||
16. [How REST replaced SOAP on the Web: What it means to you](http://www.infoq.com/articles/rest-soap)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cs.tufts.edu/comp/150IDS/final_papers/tstras01.1/FinalReport/FinalReport.html#xml-advantages
|
||||
|
||||
作者:[TOM STRASSNER][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: tomstrassner@gmail.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tools.ietf.org/html/rfc7159
|
||||
[2]: https://tools.ietf.org/html/rfc4825
|
||||
@ -1,75 +0,0 @@
|
||||
Building Slack for the Linux community and adopting snaps
|
||||
======
|
||||
![][1]
|
||||
|
||||
Used by millions around the world, [Slack][2] is an enterprise software platform that allows teams and businesses of all sizes to communicate effectively. Slack works seamlessly with other software tools within a single integrated environment, providing an accessible archive of an organisation’s communications, information and projects. Although Slack has grown at a rapid rate in the 4 years since their inception, their desktop engineering team who work across Windows, MacOS and Linux consists of just 4 people currently. We spoke to Felix Rieseberg, Staff Software Engineer, who works on this team following the release of Slack’s first [snap last month][3] to discover more about the company’s attitude to the Linux community and why they decided to build a snap.
|
||||
|
||||
[Install Slack snap][4]
|
||||
|
||||
### Can you tell us about the Slack snap which has been published?
|
||||
|
||||
We launched our first snap last month as a new way to distribute to our Linux community. In the enterprise space, we find that people tend to adopt new technology at a slower pace than consumers, so we will continue to offer a .deb package.
|
||||
|
||||
### What level of interest do you see for Slack from the Linux community?
|
||||
|
||||
I’m excited that interest for Slack is growing across all platforms, so it is hard for us to say whether the interest coming out of the Linux community is different from the one we’re generally seeing. However, it is important for us to meet users wherever they do their work. We have a dedicated QA engineer focusing entirely on Linux and we really do try hard to deliver the best possible experience.
|
||||
|
||||
We generally find it is a little harder to build for Linux, than say Windows, as there is a less predictable base to work from – and this is an area where the Linux community truly shines. We have a fairly large number of users that are quite helpful when it comes to reporting bugs and hunting root causes down.
|
||||
|
||||
### How did you find out about snaps?
|
||||
|
||||
Martin Wimpress at Canonical reached out to me and explained the concept of snaps. Honestly, initially I was hesitant – even though I use Ubuntu – because it seemed like another standard to build and maintain. However, once understanding the benefits I was convinced it was a worthwhile investment.
|
||||
|
||||
### What was the appeal of snaps that made you decide to invest in them?
|
||||
|
||||
Without doubt, the biggest reason we decided to build the snap is the updating feature. We at Slack make heavy use of web technologies, which in turn allows us to offer a wide variety of features – like the integration of YouTube videos or Spotify playlists. Much like a browser, that means that we frequently need to update the application.
|
||||
|
||||
On macOS and Windows, we already had a dedicated auto-updater that doesn’t require the user to even think about updates. We have found that any sort of interruption, even for an update, is an annoyance that we’d like to avoid. Therefore, the automatic updates via snaps seemed far more seamless and easy.
|
||||
|
||||
### How does building snaps compare to other forms of packaging you produce? How easy was it to integrate with your existing infrastructure and process?
|
||||
|
||||
As far as Linux is concerned, we have not tried other “new” packaging formats, but we’ll never say never. Snaps were an easy choice given that the majority of our Linux customers do use Ubuntu. The fact that snaps also run on other distributions was a decent bonus. I think it is really neat how Canonical is making snaps cross-distro rather than focusing on just Ubuntu.
|
||||
|
||||
Building it was surprisingly easy: We have one unified build process that creates installers and packages – and our snap creation simply takes the .deb package and churns out a snap. For other technologies, we sometimes had to build in-house tools to support our buildchain, but the `snapcraft` tool turned out to be just the right thing. The team at Canonical were incredibly helpful to push it through as we did experience a few problems along the way.
|
||||
|
||||
### How do you see the store changing the way users find and install your software?
|
||||
|
||||
What is really unique about Slack is that people don’t just stumble upon it – they know about it from elsewhere and actively try to find it. Therefore, our levels of awareness are already high but having the snap available in the store, I hope, will make installation a lot easier for our users.
|
||||
|
||||
We always try to do the best for our users. The more convinced we become that it is better than other installation options, the more we will recommend the snap to our users.
|
||||
|
||||
### What are your expectations or already seen savings by using snaps instead of having to package for other distros?
|
||||
|
||||
We expect the snap to offer more convenience for our users and ensure they enjoy using Slack more. From our side, the snap will save time on customer support as users won’t be stuck on previous versions which will naturally resolve a lot of issues. Having the snap is an additional bonus for us and something to build on, rather than displacing anything we already have.
|
||||
|
||||
### What release channels (edge/beta/candidate/stable) in the store are you using or plan to use, if any?
|
||||
|
||||
We used the edge channel exclusively in the development to share with the team at Canonical. Slack for Linux as a whole is still in beta, but long-term, having the options for channels is interesting and being able to release versions to interested customers a little earlier will certainly be beneficial.
|
||||
|
||||
### How do you think packaging your software as a snap helps your users? Did you get any feedback from them?
|
||||
|
||||
Installation and updating generally being easier will be the big benefit to our users. Long-term, the question is “Will users that installed the snap experience less problems than other customers?” I have a decent amount of hope that the built-in dependencies in snaps make it likely.
|
||||
|
||||
### What advice or knowledge would you share with developers who are new to snaps?
|
||||
|
||||
I would recommend starting with the Debian package to build your snap – that was shockingly easy. It also starts the scope smaller to avoid being overwhelmed. It is a fairly small time investment and probably worth it. Also if you can, try to find someone at Canonical to work with – they have amazing engineers.
|
||||
|
||||
### Where do you see the biggest opportunity for development?
|
||||
|
||||
We are taking it step by step currently – first get people on the snap, and build from there. People using it will already be more secure as they will benefit from the latest updates.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/02/06/building-slack-for-the-linux-community-and-adopting-snaps/
|
||||
|
||||
作者:[Sarah][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/sarahfd/
|
||||
[1]:https://insights.ubuntu.com/wp-content/uploads/a115/Slack_linux_screenshot@2x-2.png
|
||||
[2]:https://slack.com/
|
||||
[3]:https://insights.ubuntu.com/2018/01/18/canonical-brings-slack-to-the-snap-ecosystem/
|
||||
[4]:https://snapcraft.io/slack/
|
||||
@ -1,84 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Hacking math education with Python)
|
||||
[#]: via: (https://opensource.com/article/19/1/hacking-math)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Hacking math education with Python
|
||||
======
|
||||
Teacher, programmer, and author Peter Farrell explains why teaching math with Python works better than the traditional approach.
|
||||

|
||||
|
||||
Mathematics instruction has a bad reputation, especially with people (like me) who've had trouble with the traditional approach, which emphasizes rote memorization and theory that seems far removed from students' real world.
|
||||
|
||||
While teaching a student who was baffled by his math lessons, [Peter Farrell][1], a Python developer and mathematics teacher, decided to try using Python to teach the boy the math concepts he was having trouble learning.
|
||||
|
||||
Peter was inspired by the work of [Seymour Papert][2], the father of the Logo programming language, which lives on in Python's [Turtle module][3]. The Turtle metaphor hooked Peter on Python and using it to teach math, much like [I was drawn to Python][4].
|
||||
|
||||
Peter shares his approach in his new book, [Math Adventures with Python][5]: An Illustrated Guide to Exploring Math with Code. And, I recently interviewed him to learn more about it.
|
||||
|
||||
**Don Watkins:** What is your background?
|
||||
|
||||
**Peter Farrell:** I was a math teacher for eight years, and I tutored math for 10 years after that. When I was a teacher, I read Papert's [Mindstorms][6] and was inspired to introduce all my math classes to Logo and Turtles.
|
||||
|
||||
**DW:** Why did you start using Python?
|
||||
|
||||
**PF:** I was working with a homeschooled boy on a very dry, textbook-driven math curriculum, which at the time seemed like a curse to me. But I found ways to sneak in the Logo Turtles, and he was a programming fan, so he liked that. Once we got into functions and real programming, he asked if we could continue in Python. I didn't know any Python but it didn't seem that different from Logo, so I agreed. And I never looked back!
|
||||
|
||||
I was also looking for a 3D graphics package I could use to model a solar system and lead students through making planets move and get pulled by the force of attraction between the bodies, according to Newton's formula. Many graphics packages required programming in C or something hard, but I found an excellent package called Visual Python that was very easy to use. I used [VPython][7] for years after that.
|
||||
|
||||
So, I was introduced to Python in the context of working with a student on math. For some time after that, he was my programming tutor while I was his math tutor!
|
||||
|
||||
**DW:** What got you interested in math?
|
||||
|
||||
**PF:** I learned it the old-fashioned way: by hand, on paper and blackboards. I was good at manipulating symbols, so algebra was never a problem, and I liked drawing and graphing, so geometry and trig could be fun, too. I did some programming in BASIC and Fortran in college, but it never inspired me. Later on, programming inspired me greatly! I'm still tickled by the way programming makes easy work of the laborious stuff you have to do in math class, freeing you up to do the more fun of exploring, graphing, tweaking, and discovering.
|
||||
|
||||
**DW:** What inspired you to consider your Python approach to math?
|
||||
|
||||
**PF:** When I was teaching the homeschooled student, I was amazed at what we could do by writing a simple function and then calling it a bunch of times with different values using a loop. That would take a half an hour by hand, but the computer spit it out instantly! Then we could look for patterns (which is what a math student should be doing), express the pattern as a function, and extend it further.
|
||||
|
||||
**DW:** How does your approach to teaching help students—especially those who struggle with math? How does it make math more relevant?
|
||||
|
||||
**PF:** Students, especially high-schoolers, question the need to be doing all this calculating, graphing, and solving by hand in the 21st century, and I don't disagree with them. Learning to use Excel, for example, to crunch numbers should be seen as a basic necessity to work in an office. Learning to code, in any language, is becoming a very valuable skill to companies. So, there's a real-world appeal to me.
|
||||
|
||||
But the idea of making art with code can revolutionize math class. Just putting a shape on a screen requires math—the position (x-y coordinates), the dimensions, and even the color are all numbers. If you want something to move or change, you'll need to use variables, and not the "guess what x equals" kind of variable. You'll vary the position using a variable or, more efficiently, using a vector. [This makes] math topics like vectors and matrices seen as helpful tools you can use, rather than required information you'll never use.
|
||||
|
||||
Students who struggle with math might just be turned off to "school math," which is heavy on memorization and following rules and light on creativity and real applications. They might find they're actually good at math, just not the way it was taught in school. I've had parents see the cool graphics their kids have created with code and say, "I never knew that's what sines and cosines were used for!"
|
||||
|
||||
**DW:** How do you see your approach to math and programming encouraging STEM in schools?
|
||||
|
||||
**PF:** I love the idea of combining previously separated topics into an idea like STEM or STEAM! Unfortunately for us math folks, the "M" is very often neglected. I see lots of fun projects being done in STEM labs, even by very young children, and they're obviously getting an education in technology, engineering, and science. But I see precious little math material in the projects. STEM/[mechatronics][8] teacher extraordinaire Ken Hawthorn and I are creating projects to try to remedy that.
|
||||
|
||||
Hopefully, my book helps encourage students, girls and boys, to get creative with technology, real and virtual. There are a lot of beautiful graphics in the book, which I hope will inspire people to go through the coding adventure and make them. All the software I use ([Python Processing][9]) is available for free and can be easily installed, or is already installed, on the Raspberry Pi. Entry into the STEM world should not be cost-prohibitive to schools or individuals.
|
||||
|
||||
**DW:** What would you like to share with other math teachers?
|
||||
|
||||
**PF:** If the math establishment is really serious about teaching students the standards they have agreed upon, like numerical reasoning, logic, analysis, modeling, geometry, interpreting data, and so on, they're going to have to admit that coding can help with every single one of those goals. My approach was born, as I said before, from just trying to enrich a dry, traditional approach, and I think any teacher can do that. They just need somebody who can show them how to do everything they're already doing, just using code to automate the laborious stuff.
|
||||
|
||||
My graphics-heavy approach is made possible by the availability of free graphics software. Folks might need to be shown where to find these packages and how to get started. But a math teacher can soon be leading students through solving problems using 21st-century technology and visualizing progress or results and finding more patterns to pursue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/hacking-math
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/hackingmath
|
||||
[2]: https://en.wikipedia.org/wiki/Seymour_Papert
|
||||
[3]: https://en.wikipedia.org/wiki/Turtle_graphics
|
||||
[4]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[5]: https://nostarch.com/mathadventures
|
||||
[6]: https://en.wikipedia.org/wiki/Mindstorms_(book)
|
||||
[7]: http://vpython.org/
|
||||
[8]: https://en.wikipedia.org/wiki/Mechatronics
|
||||
[9]: https://processing.org/
|
||||
@ -1,130 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Remote Working Survival Guide)
|
||||
[#]: via: (https://www.jonobacon.com/2019/01/14/remote-working-survival/)
|
||||
[#]: author: (Jono Bacon https://www.jonobacon.com/author/admin/)
|
||||
|
||||
Remote Working Survival Guide
|
||||
======
|
||||

|
||||
|
||||
Remote working seems to be all the buzz. Apparently, [70% of professionals work from home at least once a week][1]. Similarly, [77% of people work more productively][2] and [68% of millennials would consider a company more if they offered remote working][3]. It seems to make sense: technology, connectivity, and culture seem to be setting the world up more and more for remote working. Oh, and home-brewed coffee is better than ever too.
|
||||
|
||||
Now, I am going to write another piece for how companies should optimize for remote working (so make sure you [Join As a Member][4] to stay tuned — it is free).
|
||||
|
||||
Today though I want to **share recommendations for how individuals can do remote working well themselves**. Whether you are a full-time remote worker or have the option of working from home a few days a week, this article should hopefully be helpful.
|
||||
|
||||
Now, you need to know that **remote working is not a panacea**. Sure, it seems like hanging around at home in your jimjams, listening to your antisocial music, and sipping on buckets of coffee is perfect, but it isn’t for everyone.
|
||||
|
||||
Some people need the structure of an office. Some people need the social element of an office. Some people need to get out the house. Some people lack the discipline to stay focused at home. Some people are avoiding the government coming and knocking on the door due to years of unpaid back taxes.
|
||||
|
||||
**Remote working is like a muscle: it can bring enormous strength and capabilities IF you train and maintain it**. If you don’t, your results are going to vary.
|
||||
|
||||
I have worked from home for the vast majority of my career. I love it. I am more productive, happier, and empowered when I work from home. I don’t dislike working in an office, and I enjoy the social element, but I am more in my “zone” when I work from home. I also love blisteringly heavy metal, which can pose a problem when the office don’t want to listen to [After The Burial][5].
|
||||
|
||||
![][6]
|
||||
“Squirrel.”
|
||||
[Credit][7]
|
||||
|
||||
I have learned how I need to manage remote work, using the right balance of work routine, travel, and other elements, and here are some of my recommendations. Be sure to **share yours in the comments**.
|
||||
|
||||
### 1\. You need discipline and routine (and to understand your “waves”)
|
||||
|
||||
Remote work really is a muscle that needs to be trained. Just like building actual muscle, there needs to be a clear routine and a healthy dollop of discipline mixed in.
|
||||
|
||||
Always get dressed (no jimjams). Set your start and end time for your day (I work 9am – 6pm most days). Choose your lunch break (mine is 12pm). Choose your morning ritual (mine is email followed by a full review of my client needs). Decide where your main workplace will be (mine is my home office). Decide when you will exercise each day (I do it at 5pm most days).
|
||||
|
||||
**Design a realistic routine and do it for 66 days**. It takes this long to build a habit. Try not to deviate from the routine. The more you stick the routine, the less work it will seem further down the line. By the end of the 66 days it will feel natural and you won’t have to think about it.
|
||||
|
||||
Here’s the deal though, we don’t live in a vacuum ([cleaner, or otherwise][8]). We all have waves.
|
||||
|
||||
A wave is when you need a change of routine to mix things up. For example, in summertime I generally want more sunlight. I will often work outside in the garden. Near the holidays I get more distracted, so I need more structure in my day. Sometimes I just need more human contact, so I will work from coffee shops for a few weeks. Sometimes I just fancy working in the kitchen or on the couch. You need to learn your waves and listen to your body. **Build your habit first, and then modify it as you learn your waves**.
|
||||
|
||||
### 2\. Set expectations with your management and colleagues
|
||||
|
||||
Not everyone knows how to do remote working, and if your company is less familiar with remote working, you especially need to set expectations with colleagues.
|
||||
|
||||
This can be pretty simple: **when you have designed your routine, communicate it clearly to your management and team**. Let them know how they can get hold of you, how to contact you in an emergency, and how you will be collaborating while at home.
|
||||
|
||||
The communication component here is critical. There are some remote workers who are scared to leave their computer for fear that someone will send them a message while they are away (and they are worried people may think they are just eating Cheetos and watching Netflix).
|
||||
|
||||
You need time away. You need to eat lunch without one eye on your computer. You are not a 911 emergency responder. **Set expectations that sometimes you may not be immediately responsive, but you will get back to them as soon as possible**.
|
||||
|
||||
Similarly, set expectations on your general availability. For example, I set expectations with clients that I generally work from 9am – 6pm every day. Sure, if a client needs something urgently, I am more than happy to respond outside of those hours, but as a general rule I am usually working between those hours. This is necessary for a balanced life.
|
||||
|
||||
### 3\. Distractions are your enemy and they need managing
|
||||
|
||||
We all get distracted. It is human nature. It could be your young kid getting home and wanting to play Rescue Bots. It could be checking Facebook, Instagram, or Twitter to ensure you don’t miss any unwanted political opinions or photos of people’s lunches. It could be that there is something else going on your life that is taking your attention (such as an upcoming wedding, event, or big trip.)
|
||||
|
||||
**You need to learn what distracts you and how to manage it**. For example, I know I get distracted by my email and Twitter. I check it religiously and every check gets me out of the zone of what I am working on. I also get distracted by grabbing coffee and water, which then may turn into a snack and a YouTube video.
|
||||
|
||||
![][9]
|
||||
My nemesis for distractions.
|
||||
|
||||
The digital distractions have a simple solution: **lock them out**. Close down the tabs until you complete what you are doing. I do this all the time with big chunks of work: I lock out the distractions until I am done. It requires discipline, but all of this does.
|
||||
|
||||
The human elements are tougher. If you have a family you need to make it clear that when you are work, you need to be generally left alone. This is why a home office is so important: you need to set boundaries that mum or dad is working. Come in if there is emergency, but otherwise they need to be left alone.
|
||||
|
||||
There are all kinds of opportunities for locking these distractions out. Put your phone on silent. Set yourself as away. Move to a different room (or building) where the distraction isn’t there. Again, be honest in what distracts you and manage it. If you don’t, you will always be at their mercy.
|
||||
|
||||
### 4\. Relationships need in-person attention
|
||||
|
||||
Some roles are more attuned to remote working than others. For example, I have seen great work from engineering, quality assurance, support, security, and other teams (typically more focused on digital collaboration). Other teams such as design or marketing often struggle more in remote environments (as they are often more tactile.)
|
||||
|
||||
With any team though, having strong relationship is critical, and in-person discussion, collaboration, and socializing is essential to this. So many of our senses (such as body language) are removed in a digital environment, and these play a key role in how we build trust and relationships.
|
||||
|
||||
![][10]
|
||||
Rockets also help.
|
||||
|
||||
This is especially important if (a) you are new a company and need to build these relationships, (b) are new to a role and need to build relationships with your team, or (c) are in a leadership position where building buy-in and engagement is a key part of your job.
|
||||
|
||||
**The solution? A sensible mix of remote and in-person time.** If your company is nearby, work from home part of the week and at the office part of the week. If your company is further a away, schedule regular trips to the office (and set expectations with your management that you need this). For example, when I worked at XPRIZE I flew to LA every few weeks for a few days. When I worked at Canonical (who were based in London), we had sprints every three months.
|
||||
|
||||
### 5\. Stay focused, but cut yourself some slack
|
||||
|
||||
The crux of everything in this article is about building a capability, and developing a remote working muscle. This is as simple as building a routine, sticking to it, and having an honest view of your “waves” and distractions and how to manage them.
|
||||
|
||||
I see the world in a fairly specific way: **everything we do has the opportunity to be refined and improved**. For example, I have been public speaking now for over 15 years, but I am always discovering new ways to improve, and new mistakes to fix (speaking of which, see my [10 Ways To Up Your Public Speaking Game][11].)
|
||||
|
||||
There is a thrill in the discovery of new ways to get better, and to see every stumbling block and mistake as an “aha!” moment to kick ass in new and different ways. It is no different with remote working: look for patterns that help to unlock ways in which you can make your remote working time more efficient, more comfortable, and more fun.
|
||||
|
||||
![][12]
|
||||
Get these books. They are fantastic for personal development.
|
||||
See my [$150 Personal Development Kit][13] article
|
||||
|
||||
…but don’t go crazy over it. There are some people who obsesses every minute of their day about how to get better. They beat themselves up constantly for “not doing well enough”, “not getting more done”, and not meeting their internal unrealistic view of perfection.
|
||||
|
||||
We are humans. We are animals, and we are not robots. Always strive to improve, but be realistic that not everything will be perfect. You are going to have some off-days or off-weeks. You are going to struggle at times with stress and burnout. You are going to handle a situation poorly remotely that would have been easier in the office. Learn from these moments but don’t obsess over them. Life is too damn short.
|
||||
|
||||
**What are your tips, tricks, and recommendations? How do you manage remote working? What is missing from my recommendations? Share them in the comments box!**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.jonobacon.com/2019/01/14/remote-working-survival/
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.jonobacon.com/author/admin/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cnbc.com/2018/05/30/70-percent-of-people-globally-work-remotely-at-least-once-a-week-iwg-study.html
|
||||
[2]: http://www.cosocloud.com/press-release/connectsolutions-survey-shows-working-remotely-benefits-employers-and-employees
|
||||
[3]: https://www.aftercollege.com/cf/2015-annual-survey
|
||||
[4]: https://www.jonobacon.com/join/
|
||||
[5]: https://www.facebook.com/aftertheburial/
|
||||
[6]: https://www.jonobacon.com/wp-content/uploads/2019/01/aftertheburial2.jpg
|
||||
[7]: https://skullsnbones.com/burial-live-photos-vans-warped-tour-denver-co/
|
||||
[8]: https://www.youtube.com/watch?v=wK1PNNEKZBY
|
||||
[9]: https://www.jonobacon.com/wp-content/uploads/2019/01/IMG_20190114_102429-1024x768.jpg
|
||||
[10]: https://www.jonobacon.com/wp-content/uploads/2019/01/15381733956_3325670fda_k-1024x576.jpg
|
||||
[11]: https://www.jonobacon.com/2018/12/11/10-ways-to-up-your-public-speaking-game/
|
||||
[12]: https://www.jonobacon.com/wp-content/uploads/2019/01/DwVBxhjX4AgtJgV-1024x532.jpg
|
||||
[13]: https://www.jonobacon.com/2017/11/13/150-dollar-personal-development-kit/
|
||||
@ -0,0 +1,68 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What happens when a veteran teacher goes to an open source conference)
|
||||
[#]: via: (https://opensource.com/open-organization/19/1/educator-at-open-source-conference)
|
||||
[#]: author: (Ben Owens https://opensource.com/users/engineerteacher)
|
||||
|
||||
What happens when a veteran teacher goes to an open source conference
|
||||
======
|
||||
Sometimes feeling like a fish out of water is precisely what educators need.
|
||||
|
||||

|
||||
|
||||
"Change is going to be continual, and today is the slowest day society will ever move."—[Tony Fadell][1]
|
||||
|
||||
If ever there was an experience that brought the above quotation home for me, it was my experience at the [All Things Open conference][2] in Raleigh, NC last October. Thousands of people from all over the world attended the conference, and many (if not most), worked as open source coders and developers. As one of the relatively few educators in attendance, I saw and heard things that were completely foreign to me—terms like as Istio, Stack Overflow, Ubuntu, Sidecar, HyperLedger, and Kubernetes tossed around for days.
|
||||
|
||||
I felt like a fish out of water. But in the end, that was the perfect dose of reality I needed to truly understand how open principles can reshape our approach to education.
|
||||
|
||||
### Not-so-strange attractors
|
||||
|
||||
All Things Open attracted me to Raleigh for two reasons, both of which have to do with how our schools must do a better job of creating environments that truly prepare students for a rapidly changing world.
|
||||
|
||||
The first is my belief that schools should embrace the ideals of the [open source way][3]. The second is that educators have to periodically force themselves out of their relatively isolated worlds of "doing school" in order to get a glimpse of what the world is actually doing.
|
||||
|
||||
When I was an engineer for 20 years, I developed a deep sense of the power of an open exchange of ideas, of collaboration, and of the need for rapid prototyping of innovations. Although we didn't call these ideas "open source" at the time, my colleagues and I constantly worked together to identify and solve problems using tools such as [Design Thinking][4] so that our businesses remained competitive and met market demands. When I became a science and math teacher at a small [public school][5] in rural Appalachia, my goal was to adapt these ideas to my classrooms and to the school at large as a way to blur the lines between a traditional school environment and what routinely happens in the "real world."
|
||||
|
||||
Through several years of hard work and many iterations, my fellow teachers and I were eventually able to develop a comprehensive, school-wide project-based learning model, where students worked in collaborative teams on projects that [made real connections][6] between required curriculum and community-based applications. Doing so gave these students the ability to develop skills they can use for a lifetime, rather than just on the next test—skills such as problem solving, critical thinking, oral and written communication, perseverance through setbacks, and adapting to changing conditions, as well as how to have routine conversations with adult mentors form the community. Only after reading [The Open Organization][7] did I realize that what we had been doing essentially embodied what Jim Whitehurst had described. In our case, of course, we applied open principles to an educational context (that model, called Open Way Learning, is the subject of a [book][8] published in December).
|
||||
|
||||
I felt like a fish out of water. But in the end, that was the perfect dose of reality I needed to truly understand how open principles can reshape our approach to education.
|
||||
|
||||
As good as this model is in terms of pushing students into a relevant, engaging, and often unpredictable learning environments, it can only go so far if we, as educators who facilitate this type of project-based learning, do not constantly stay abreast of changing technologies and their respective lexicon. Even this unconventional but proven approach will still leave students ill-prepared for a global, innovation economy if we aren't constantly pushing ourselves into areas outside our own comfort zones. My experience at the All Things Open conference was a perfect example. While humbling, it also forced me to confront what I didn't know so that I can learn from it to help the work I do with other teachers and schools.
|
||||
|
||||
### A critical decision
|
||||
|
||||
I made this point to others when I shared a picture of the All Things Open job board with dozens of colleagues all over the country. I shared it with the caption: "What did you do in your school today to prepare your students for this reality tomorrow?" The honest answer from many was, unfortunately, "not much." That has to change.
|
||||
|
||||

|
||||

|
||||
(Images courtesy of Ben Owens, CC BY-SA)
|
||||
|
||||
People in organizations everywhere have to make a critical decision: either embrace the rapid pace of change that is a fact of life in our world or face the hard reality of irrelevance. Our systems in education are at this same crossroads—even ones who think of themselves as being innovative. It involves admitting to students, "I don't know, but I'm willing to learn." That's the kind of teaching and learning experience our students deserve.
|
||||
|
||||
It can happen, but it will take pioneering educators who are willing to move away from comfortable, back-of-the-book answers to help students as they work on difficult and messy challenges. You may very well be a veritable fish out of water.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/19/1/educator-at-open-source-conference
|
||||
|
||||
作者:[Ben Owens][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/engineerteacher
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Tony_Fadell
|
||||
[2]: https://allthingsopen.org/
|
||||
[3]: https://opensource.com/open-source-way
|
||||
[4]: https://dschool.stanford.edu/resources-collections/a-virtual-crash-course-in-design-thinking
|
||||
[5]: https://www.tricountyearlycollege.org/
|
||||
[6]: https://www.bie.org/about/what_pbl
|
||||
[7]: https://www.redhat.com/en/explore/the-open-organization-book
|
||||
[8]: https://www.amazon.com/Open-Up-Education-Learning-Transform/dp/1475842007/ref=tmm_pap_swatch_0?_encoding=UTF8&qid=&sr=
|
||||
@ -1,383 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 3 OK03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 3 OK03
|
||||
======
|
||||
|
||||
The OK03 lesson builds on OK02 by teaching how to use functions in assembly to make more reusable and rereadable code. It is assumed you have the code for the [Lesson 2: OK02][1] operating system as a basis.
|
||||
|
||||
### 1 Reusable Code
|
||||
|
||||
So far we've made code for our operating system by typing the things we want to happen in order. This is fine for such tiny programs, but if we wrote the whole system like this, the code would be completely unreadable. Instead we use functions.
|
||||
|
||||
```
|
||||
A function is a piece of code that can be reused to compute a certain kind of answer, or perform a certain action. You may also hear them called procedures, routines or subroutines. Although these are all different, people rarely use the correct term.
|
||||
|
||||
You should already be happy with the concept of a function from mathematics. For example the cosine function applied to a number gives another number between -1 and 1 which is the cosine of the angle. Notationally we write cos(x) to be the cosine function applied to the value x.
|
||||
|
||||
In code, functions can take multiple inputs (including none), give multiple outputs (including none), and may cause side effects. For example a function might create a file on the file system, named after the first input, with length based on the second.
|
||||
```
|
||||
|
||||
![Function as black boxes][2]
|
||||
|
||||
```
|
||||
Functions are said to be 'black boxes'. We put inputs in, and outputs come out, but we don't need to know how they work.
|
||||
```
|
||||
|
||||
In higher level code such as C or C++, functions are part of the language itself. In assembly code, functions are just ideas we have.
|
||||
|
||||
Ideally we want to be able to set our registers to some input values, branch to an address, and expect that at some point the code will branch back to our code having set the registers to output values. This is what a function is in assembly code. The difficulty comes in what system we use for setting the registers. If we just used any system we felt like, each programmer may use a different system, and would find other programmers' work hard to understand. Further, compilers would not be able to work with assembly code as easily, as they would not know how to use the functions. To prevent confusion, a standard called the Application Binary Interface (ABI) was devised for each assembly language which is an agreement on how functions should be run. If everyone makes functions in the same way, then everyone will be able to use each others' functions. I will teach that standard here, and from now on I will code all of my functions to meet the standard.
|
||||
|
||||
The standard says that r0,r1,r2 and r3 will be used as inputs to a function in order. If a function needs no inputs, then it doesn't matter what value it takes. If it needs only one it always goes in r0, if it needs two, the first goes in r0, and the second goes on r1, and so on. The output will always be in r0. If a function has no output, it doesn't matter what value r0 takes.
|
||||
|
||||
Further, it also requires that after a function is run, r4 to r12 must have the same values as they had when the function started. This means that when you call a function, you can be sure the r4 to r12 will not change value, but you cannot be so sure about r0 to r3.
|
||||
|
||||
When a function completes it has to branch back to the code that started it. This means it must know the address of the code that started it. To facilitate this, there is a special register called lr (link register) which always holds the address of the instruction after the one that called this function.
|
||||
|
||||
Table 1.1 ARM ABI register usage
|
||||
| Register | Brief | Preserved | Rules |
|
||||
| -------- | ------------------- | --------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| r0 | Argument and result | No | r0 and r1 are used for passing the first two arguments to functions, and returning the results of functions. If a function does not use them for a return value, they can take any value after a function. |
|
||||
| r1 | Argument and result | No | |
|
||||
| r2 | Argument | No | r2 and r3 are used for passing the second two arguments to functions. There values after a function is called can be anything. |
|
||||
| r3 | Argument | No | |
|
||||
| r4 | General purpose | Yes | r4 to r12 are used for working values, and their value after a function is called must be the same as before. |
|
||||
| r5 | General purpose | Yes | |
|
||||
| r6 | General purpose | Yes | |
|
||||
| r7 | General purpose | Yes | |
|
||||
| r8 | General purpose | Yes | |
|
||||
| r9 | General purpose | Yes | |
|
||||
| r10 | General purpose | Yes | |
|
||||
| r11 | General purpose | Yes | |
|
||||
| r12 | General purpose | Yes | |
|
||||
| lr | Return address | No | lr is the address to branch back to when a function is finished, but this does have to contain the same address after the function has finished. |
|
||||
| sp | Stack pointer | Yes | sp is the stack pointer, described below. Its value must be the same after the function has finished. |
|
||||
|
||||
Often functions need to use more registers than just r0 to r3. But, since r4 to r12 must stay the same after the method has run, they must be saved somewhere. We save them on something called the stack.
|
||||
|
||||
|
||||
![Stack diagram][3]
|
||||
```
|
||||
A stack is a metaphor we use in computing for a method of storing values. Just like in a stack of plates, you can only remove items from the top of a stack, and only add items to the top of the stack.
|
||||
|
||||
The stack is a brilliant idea for storing registers on when functions are running. For example if I have a function which needs to use registers r4 and r5, it could place the current values of those registers on a stack. At the end of the method it could take them back off again. What is most clever is that if my function had to run another function in order to complete and that function needed to save some registers, it could put those on the top of the stack while it ran, and then take them off again at the end. That wouldn't affect the values of r4 and r5 that my method had to save, as they would be added to the top of the stack, and then taken off again.
|
||||
|
||||
The terminology we used to refer to the values put on the stack by a particular method is that methods 'stack frame'. Not every method needs a stack frame, some don't need to store values.
|
||||
```
|
||||
|
||||
Because the stack is so useful, it has been implemented in the ARMv6 instruction set directly. A special register called sp (stack pointer) holds the address of the stack. When items are added to the stack, the sp register updates so that it always holds the address of the first item on the stack. push {r4,r5} would put the values in r4 and r5 onto the top of the stack and pop {r4,r5} would take them back off again (in the correct order).
|
||||
|
||||
### 2 Our First Function
|
||||
|
||||
Now that we have some idea about how functions work, let's try to make one. For a basic first example, we are going to make a function that takes no input, and gives an output of the GPIO address. In the last lesson, we just wrote in this value, but it would be better as a function, since it is something we might need to do often in a real operating system, and we might not always remember the address.
|
||||
|
||||
Copy the following code into a new file called 'gpio.s'. Just make the new file in the 'source' directory with 'main.s'. We're going to put all functions related to the GPIO controller in one file to make them easier to find.
|
||||
|
||||
```
|
||||
.globl GetGpioAddress
|
||||
GetGpioAddress:
|
||||
ldr r0,=0x20200000
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
```
|
||||
.globl lbl makes the label lbl accessible from other files.
|
||||
|
||||
mov reg1,reg2 copies the value in reg2 into reg1.
|
||||
```
|
||||
|
||||
This is a very simple complete function. The .globl GetGpioAddress command is a message to the assembler to make the label GetGpioAddress accessible to all files. This means that in our main.s file we can branch to the label GetGpioAddress even though it is not defined in that file.
|
||||
|
||||
You should recognise the ldr r0,=0x20200000 command, which stores the GPIO controller address in r0. Since this is a function, we have to give the output in r0, so we are not as free to use any register as we once were.
|
||||
|
||||
mov pc,lr copies the value in lr to pc. As mentioned earlier lr always contains the address of the code that we have to go back to when a method finishes. pc is a special register which always contains the address of the next instruction to be run. A normal branch command just changes the value of this register. By copying the value in lr to pc we just change the next line to be run to be the one we were told to go back to.
|
||||
|
||||
A reasonable question would now be, how would we actually run this code? A special type of branch bl does what we need. It branches to a label like a normal branch, but before it does it updates lr to contain the address of the line after the branch. That means that when the function finishes, the line it will go back to will be the one after the bl command. This makes a function running just look like any other command, it simply runs, does whatever it needs to do, and then carries on to the next line. This is a really useful way of thinking about functions. We treat them as 'black boxes' in that when we use them, we don't need to think about how they work, we just need to know what inputs they need, and what outputs they give.
|
||||
|
||||
For now, don't worry about using the function, we will use it in the next section.
|
||||
|
||||
### 3 A Big Function
|
||||
|
||||
Now we're going to implement a bigger function. Our first job was to enable output on GPIO pin 16. It would be nice if this was a function. We could simply specify a pin and a function as the input, and the function would set the function of that pin to that value. That way, we could use the code to control any GPIO pin, not just the LED.
|
||||
|
||||
Copy the following commands below the GetGpioAddress function in gpio.s.
|
||||
|
||||
```
|
||||
.globl SetGpioFunction
|
||||
SetGpioFunction:
|
||||
cmp r0,#53
|
||||
cmpls r1,#7
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
```
|
||||
Suffix ls causes the command to be executed only if the last comparison determined that the first number was less than or the same as the second. Unsigned.
|
||||
|
||||
Suffix hi causes the command to be executed only if the last comparison determined that the first number was higher than the second. Unsigned.
|
||||
```
|
||||
|
||||
One of the first things we should always think about when writing functions is our inputs. What do we do if they are wrong? In this function, we have one input which is a GPIO pin number, and so must be a number between 0 and 53, since there are 54 pins. Each pin has 8 functions, numbered 0 to 7 and so the function code must be too. We could just assume that the inputs will be correct, but this is very dangerous when working with hardware, as incorrect values could cause very bad side effects. Therefore, in this case, we wish to make sure the inputs are in the right ranges.
|
||||
|
||||
To do this we need to check that r0 <= 53 and r1 <= 7. First of all, we can use the comparison we've seen before to compare the value of r0 with 53. The next instruction, cmpls is a normal comparison instruction that will only be run if r0 was lower than or the same as 53. If that was the case, it compares r1 with 7, otherwise the result of the comparison is the same as before. Finally we go back to the code that ran the function if the result of the last comparison was that the register was higher than the number.
|
||||
|
||||
The effect of this is exactly what we want. If r0 was bigger than 53, then the cmpls command doesn't run, but the movhi does. If r0 is <= 53, then the cmpls command does run, and so r1 is compared with 7, and then if it is higher than 7, movhi is run, and the function ends, otherwise movhi does not run, and we know for sure that r0 <= 53 and r1 <= 7.
|
||||
|
||||
There is a subtle difference between the ls (lower or same) and le (less or equal) as well as between hi (higher) and gt (greater) suffixes, but I will cover this later.
|
||||
|
||||
Copy these commands below the above.
|
||||
|
||||
```
|
||||
push {lr}
|
||||
mov r2,r0
|
||||
bl GetGpioAddress
|
||||
```
|
||||
|
||||
```
|
||||
push {reg1,reg2,...} copies the registers in the list reg1,reg2,... onto the top of the stack. Only general purpose registers and lr can be pushed.
|
||||
|
||||
bl lbl sets lr to the address of the next instruction and then branches to the label lbl.
|
||||
```
|
||||
|
||||
These next three commands are focused on calling our first method. The push {lr} command copies the value in lr onto the top of the stack, so that we can retrieve it later. We must do this because when we call GetGpioAddress, we will need to use lr to store the address to come back to in our function.
|
||||
|
||||
If we did not know anything about the GetGpioAddress function, we would have to assume it changes r0,r1,r2 and r3, and would have to move our values to r4 and r5 to keep them the same after it finishes. Fortunately, we do know about GetGpioAddress, and we know it only changes r0 to the address, it doesn't affect r1,r2 or r3. Thus, we only have to move the GPIO pin number out of r0 so it doesn't get overwritten, but we know we can safely move it to r2, as GetGpioAddress doesn't change r2.
|
||||
|
||||
Finally we use the bl instruction to run GetGpioAddress. Normally we use the term 'call' for running a function, and I will from now. As discussed earlier bl calls a function by updating the lr to the next instruction's address, and then branching to the function.
|
||||
|
||||
When a function ends we say it has 'returned'. When the call to GetGpioAddress returns, we now know that r0 contains the GPIO address, r1 contains the function code and r2 contains the GPIO pin number. I mentioned earlier that the GPIO functions are stored in blocks of 10, so first we need to determine which block of ten our pin number is in. This sounds like a job we would use a division for, but divisions are very slow indeed, so it is better for such small numbers to do repeated subtraction.
|
||||
|
||||
Copy the following code below the above.
|
||||
|
||||
```
|
||||
functionLoop$:
|
||||
|
||||
cmp r2,#9
|
||||
subhi r2,#10
|
||||
addhi r0,#4
|
||||
bhi functionLoop$
|
||||
```
|
||||
|
||||
```
|
||||
add reg,#val adds the number val to the contents of the register reg.
|
||||
```
|
||||
|
||||
This simple loop code compares the pin number to 9. If it is higher than 9, it subtracts 10 from the pin number, and adds 4 to the GPIO Controller address then runs the check again.
|
||||
|
||||
The effect of this is that r2 will now contain a number from 0 to 9 which represents the remainder of dividing the pin number by 10. r0 will now contain the address in the GPIO controller of this pin's function settings. This would be the same as GPIO Controller Address + 4 × (GPIO Pin Number ÷ 10).
|
||||
|
||||
Finally, copy the following code below the above.
|
||||
|
||||
```
|
||||
add r2, r2,lsl #1
|
||||
lsl r1,r2
|
||||
str r1,[r0]
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
```
|
||||
Argument shift reg,lsl #val shifts the binary representation of the number in reg left by val before using it in the operation before.
|
||||
|
||||
lsl reg,amt shifts the binary representation of the number in reg left by the number in amt.
|
||||
|
||||
str reg,[dst] is the same as str reg,[dst,#0].
|
||||
|
||||
pop {reg1,reg2,...} copies the values from the top of the stack into the register list reg1,reg2,.... Only general purpose registers and pc can be popped.
|
||||
```
|
||||
|
||||
This code finishes off the method. The first line is actually a multiplication by 3 in disguise. Multiplication is a big and slow instruction in assembly code, as the circuit can take a long time to come up with the answer. It is much faster sometimes to use some instructions which can get the answer quicker. In this case, I know that r2 × 3 is the same as r2 × 2 + r2. It is very easy to multiply a register by 2 as this is conveniently the same as shifting the binary representation of the number left by one place.
|
||||
|
||||
One of the very useful features of the ARMv6 assembly code language is the ability to shift an argument before using it. In this case, I add r2 to the result of shifting the binary representation of r2 to the left by one place. In assembly code, you often use tricks such as this to compute answers more easily, but if you're uncomfortable with this, you could also write something like mov r3,r2; add r2,r3; add r2,r3.
|
||||
|
||||
Now we shift the function value left by a number of places equal to r2. Most instructions such as add and sub have a variant which uses a register rather than a number for the amount. We perform this shift because we want to set the bits that correspond to our pin number, and there are three bits per pin.
|
||||
|
||||
We then store the the computed function value at the address in the GPIO controller. We already worked out the address in the loop, so we don't need to store it at an offset like we did in OK01 and OK02.
|
||||
|
||||
Finally, we can return from this method call. Since we pushed lr onto the stack, if we pop pc, it will copy the value that was in lr at the time we pushed it into pc. This would be the same as having used mov pc,lr and so the function call will return when this line is run.
|
||||
|
||||
The very keen may notice that this function doesn't actually work correctly. Although it sets the function of the GPIO pin to the requested value, it causes all the pins in the same block of 10's functions to go back to 0! This would likely be quite annoying in a system which made heavy use of the GPIO pins. I leave it as a challenge to the interested to fix this function so that it does not overwrite other pins values by ensuring that all bits other than the 3 that must be set remain the same. A solution to this can be found on the downloads page for this lesson. Functions that you may find useful are and which computes the Boolean and function of two registers, mvns which computes the Boolean not and orr which computes the Boolean or.
|
||||
|
||||
### 4 Another Function
|
||||
|
||||
So, we now have a function which takes care of the GPIO pin function setting. We now need to make a function to turn a GPIO pin on or off. Rather than having one function for off and one function for on, it would be handy to have a single function which does either.
|
||||
|
||||
We will make a function called SetGpio which takes a GPIO pin number as its first input in r0, and a value as its second in r1. If the value is 0 we will turn the pin off, and if it is not zero we will turn it on.
|
||||
|
||||
Copy and paste the following code at the end of 'gpio.s'.
|
||||
|
||||
```
|
||||
.globl SetGpio
|
||||
SetGpio:
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
```
|
||||
|
||||
```
|
||||
alias .req reg sets alias to mean the register reg.
|
||||
```
|
||||
|
||||
Once again we need the .globl command and the label to make the function accessible from other files. This time we're going to use register aliases. Register aliases allow us to use a name other than just r0 or r1 for registers. This may not be so important now, but it will prove invaluable when writing big methods later, and you should try to use aliases from now on. pinNum .req r0 means that pinNum now means r0 when used in instructions.
|
||||
|
||||
Copy and paste the following code after the above.
|
||||
|
||||
```
|
||||
cmp pinNum,#53
|
||||
movhi pc,lr
|
||||
push {lr}
|
||||
mov r2,pinNum
|
||||
.unreq pinNum
|
||||
pinNum .req r2
|
||||
bl GetGpioAddress
|
||||
gpioAddr .req r0
|
||||
```
|
||||
|
||||
```
|
||||
.unreq alias removes the alias alias.
|
||||
```
|
||||
|
||||
Like in SetGpioFunction the first thing we must do is check that we were actually given a valid pin number. We do this in exactly the same way by comparing pinNum (r0) with 53, and returning immediately if it is higher. Once again we wish to call GetGpioAddress, so we have to preserve lr by pushing it onto the stack, and to move pinNum to r2. We then use the .unreq statement to remove our alias from r0. Since the pin number is now stored in r2 we want our alias to reflect this, so we remove the alias from r0 and remake it on r2. You should always .unreq every alias as soon as it is done with, so that you cannot make the mistake of using it further down the code when it no longer exists.
|
||||
|
||||
We then call GetGpioAddress, and we create an alias for r0 to reflect this.
|
||||
|
||||
Copy and paste the following code after the above.
|
||||
|
||||
```
|
||||
pinBank .req r3
|
||||
lsr pinBank,pinNum,#5
|
||||
lsl pinBank,#2
|
||||
add gpioAddr,pinBank
|
||||
.unreq pinBank
|
||||
```
|
||||
|
||||
```
|
||||
lsr dst,src,#val shifts the binary representation of the number in src right by val, but stores the result in dst.
|
||||
```
|
||||
|
||||
The GPIO controller has two sets of 4 bytes each for turning pins on and off. The first set in each case controls the first 32 pins, and the second set controls the remaining 22. In order to determine which set it is in, we need to divide the pin number by 32. Fortunately this is very easy, at is the same as shifting the binary representation of the pin number right by 5 places. Hence, in this case I've named r3 as pinBank and then computed pinNum ÷ 32. Since it is a set of 4 bytes, we then need to multiply the result of this by 4. This is the same as shifting the binary representation left by 2 places, which is the command that follows. You may wonder if we could just shift it right by 3 places, as we went right then left. This won't work however, as some of the answer may have been rounded away when we did ÷ 32 which may not be if we just ÷ 8.
|
||||
|
||||
The result of this is that gpioAddr now contains either 2020000016 if the pin number is 0-31, and 2020000416 if the pin number is 32-53. This means if we add 2810 we get the address for turning the pin on, and if we add 4010 we get the address for turning the pin off. Since we are done with pinBank, I use .unreq immediately afterwards.
|
||||
|
||||
Copy and paste the following code after the above.
|
||||
|
||||
```
|
||||
and pinNum,#31
|
||||
setBit .req r3
|
||||
mov setBit,#1
|
||||
lsl setBit,pinNum
|
||||
.unreq pinNum
|
||||
```
|
||||
|
||||
```
|
||||
and reg,#val computes the Boolean and function of the number in reg with val.
|
||||
```
|
||||
|
||||
This next part of the function is for generating a number with the correct bit set. For the GPIO controller to turn a pin on or off, we give it a number with a bit set in the place of the remainder of that pin's number divided by 32. For example, to set pin 16, we need a number with the 16th bit a 1. To set pin 45 we would need a number with the 13th bit 1 as 45 ÷ 32 = 1 remainder 13.
|
||||
|
||||
The and command computes the remainder we need. How it does this is that the result of an and operation is a number with 1s in all binary digits which had 1s in both of the inputs, and 0s elsewhere. This is a fundamental binary operation, and is very quick. We have given it inputs of pinNum and 3110 = 111112. This means that the answer can only have 1 bits in the last 5 places, and so is definitely between 0 and 31. Specifically it only has 1s where there were 1s in pinNum's last 5 places. This is the same as the remainder of a division by 32. It is no coincidence that 31 = 32 - 1.
|
||||
|
||||
![binary division example][4]
|
||||
|
||||
The rest of this code simply uses this value to shift the number 1 left. This has the effect of creating the binary number we need.
|
||||
|
||||
Copy and paste the following code after the above.
|
||||
|
||||
```
|
||||
teq pinVal,#0
|
||||
.unreq pinVal
|
||||
streq setBit,[gpioAddr,#40]
|
||||
strne setBit,[gpioAddr,#28]
|
||||
.unreq setBit
|
||||
.unreq gpioAddr
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
```
|
||||
teq reg,#val checks if the number in reg is equal to val.
|
||||
```
|
||||
|
||||
This code ends the method. As stated before, we turn the pin off if pinVal is zero, and on otherwise. teq (test equal) is another comparison operation that can only be used to test for equality. It is similar to cmp but it does not work out which number is bigger. If all you wish to do is test if to numbers are the same, you can use teq.
|
||||
|
||||
If pinVal is zero, we store the setBit at 40 away from the GPIO address, which we already know turns the pin off. Otherwise we store it at 28, which turns the pin on. Finally, we return by popping the pc, which sets it to the value that we stored when we pushed the link register.
|
||||
|
||||
### 5 A New Beginning
|
||||
|
||||
Finally, after all that work we have our GPIO functions. We now need to alter 'main.s' to use them. Since 'main.s' is now getting a lot bigger and more complicated, it is better design to split it into two sections. The '.init' we've been using so far is best kept as small as possible. We can change the code to reflect this easily.
|
||||
|
||||
Insert the following just after _start: in main.s:
|
||||
|
||||
```
|
||||
b main
|
||||
|
||||
.section .text
|
||||
main:
|
||||
mov sp,#0x8000
|
||||
```
|
||||
|
||||
The key change we have made here is to introduce the .text section. I have designed the makefile and linker scripts such that code in the .text section (which is the default section) is placed after the .init section which is placed at address 800016. This is the default load address and gives us some space to store the stack. As the stack exists in memory, it has to have an address. The stack grows down memory, so that each new value is at a lower address, thus making the 'top' of the stack, the lowest address.
|
||||
|
||||
```
|
||||
The 'ATAGs' section in the diagram is a place where information about the Raspberry Pi is stored such as how much memory it has, and what its default screen resolution is.
|
||||
```
|
||||
|
||||
![Layout diagram of operating system][5]
|
||||
|
||||
Replace all the code that set the function of the GPIO pin with the following:
|
||||
|
||||
```
|
||||
pinNum .req r0
|
||||
pinFunc .req r1
|
||||
mov pinNum,#16
|
||||
mov pinFunc,#1
|
||||
bl SetGpioFunction
|
||||
.unreq pinNum
|
||||
.unreq pinFunc
|
||||
```
|
||||
|
||||
This code calls SetGpioFunction with the pin number 16 and the pin function code 1. This has the effect of enabling output to the OK LED.
|
||||
|
||||
Replace any code which turns the OK LED on with the following:
|
||||
|
||||
```
|
||||
pinNum .req r0
|
||||
pinVal .req r1
|
||||
mov pinNum,#16
|
||||
mov pinVal,#0
|
||||
bl SetGpio
|
||||
.unreq pinNum
|
||||
.unreq pinVal
|
||||
```
|
||||
|
||||
This code uses SetGpio to turn off GPIO pin 16, thus turning on the OK LED. If we instead used mov pinVal,#1, it would turn the LED off. Replace your old code to turn the LED off with that.
|
||||
|
||||
### 6 Onwards
|
||||
|
||||
Hopefully now, you should be able to test what you have made on the Raspberry Pi. We've done a large amount of code this time, so there is a lot that can go wrong. If it does, head to the troubleshooting page.
|
||||
|
||||
When you get it working, congratulations. Although our operating system does nothing more than it did in [Lesson 2: OK02][1], we've learned a lot about functions and formatting, and we can now code new features much more quickly. It would be very simple now to make an Operating System that alters any GPIO register, which could be used to control hardware!
|
||||
|
||||
In [Lesson 4: OK04][6], we will address our wait function, which is currently imprecise, so that we can gain better control over our LED, and ultimately over all of the GPIO pins.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok02.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/functions.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/stack.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/binary3.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/osLayout.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
@ -1,161 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 4 OK04)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 4 OK04
|
||||
======
|
||||
|
||||
The OK04 lesson builds on OK03 by teaching how to use the timer to flash the 'OK' or 'ACT' LED at precise intervals. It is assumed you have the code for the [Lesson 3: OK03][1] operating system as a basis.
|
||||
|
||||
### 1 A New Device
|
||||
|
||||
The timer is the only way the Pi can keep time. Most computers have a battery powered clock to keep time when off.
|
||||
|
||||
So far, we've only looked at one piece of hardware on the Raspberry Pi, namely the GPIO Controller. I've simply told you what to do, and it happened. Now we're going to look at the timer, and I'm going to lead you through understanding how it works.
|
||||
|
||||
Just like the GPIO Controller, the timer has an address. In this case, the timer is based at 2000300016. Reading the manual, we find the following table:
|
||||
|
||||
Table 1.1 GPIO Controller Registers
|
||||
| Address | Size / Bytes | Name | Description | Read or Write |
|
||||
| -------- | ------------ | ---------------- | ---------------------------------------------------------- | ---------------- |
|
||||
| 20003000 | 4 | Control / Status | Register used to control and clear timer channel comparator matches. | RW |
|
||||
| 20003004 | 8 | Counter | A counter that increments at 1MHz. | R |
|
||||
| 2000300C | 4 | Compare 0 | 0th Comparison register. | RW |
|
||||
| 20003010 | 4 | Compare 1 | 1st Comparison register. | RW |
|
||||
| 20003014 | 4 | Compare 2 | 2nd Comparison register. | RW |
|
||||
| 20003018 | 4 | Compare 3 | 3rd Comparison register. | RW |
|
||||
|
||||
![Flowchart of the system timer's operation][2]
|
||||
|
||||
This table tells us a lot, but the descriptions in the manual of the various fields tell us the most. The manual explains that the timer fundamentally just increments the value in Counter by 1 every 1 micro second. Each time it does so, it compares the lowest 32 bits (4 bytes) of the counter's value with the 4 comparison registers, and if it matches any of them, it updates Control / Status to reflect which ones matched.
|
||||
|
||||
For more information about bits, bytes, bit fields, and data sizes expand the box below.
|
||||
|
||||
```
|
||||
A bit is a name for a single binary digit. As you may recall, a single binary digit is either a 1 or a 0.
|
||||
|
||||
A byte is the name we give for a collection of 8 bits. Since each bit can be one of two values, there are 28 = 256 different possible values for a byte. We normally interpret a byte as a binary number between 0 and 255 inclusive.
|
||||
|
||||
![Diagram of GPIO function select controller register 0.][3]
|
||||
|
||||
A bit field is another way of interpreting binary. Rather than interpreting it as a number, binary can be interpreted as many different things. A bit field treats binary as a series of switches which are either on (1) or off (0). If we have a meaning for each of these little switches, we can use them to control things. We have actually already met bitfields with the GPIO controller, with the setting a pin on or off. The bit that was a 1 was the GPIO pin to actually turn on or off. Sometimes we need more options than just on or off, so we group several of the switches together, such as with the GPIO controller function settings (pictured), in which every group of 3 bits controls one GPIO pin function.
|
||||
```
|
||||
|
||||
Our goal is to implement a function that we can call with an amount of time as an input that will wait for that amount of time and then return. Think for a moment about how we could do this, given what we have.
|
||||
|
||||
I see there being two options:
|
||||
|
||||
1. Read a value from the counter, and then keep branching back into the same code until the counter is the amount of time to wait more than it was.
|
||||
2. Read a value from the counter, add the amount of time to wait, store this in one of the comparison registers and then keep branching back into the same code until the Control / Status register updates.
|
||||
|
||||
|
||||
```
|
||||
Issues like these are called concurrency problems, and can be almost impossible to fix.
|
||||
```
|
||||
|
||||
Both of these strategies would work fine, but in this tutorial we will only implement the first. The reason is because the comparison registers are more likely to go wrong, as during the time it takes to add the wait time and store it in the comparison register, the counter may have increased, and so it would not match. This could lead to very long unintentional delays if a 1 micro second wait is requested (or worse, a 0 microsecond wait).
|
||||
|
||||
### 2 Implementation
|
||||
|
||||
```
|
||||
Large Operating Systems normally use the Wait function as an opportunity to perform background tasks.
|
||||
```
|
||||
|
||||
I will largely leave the challenge of creating the ideal wait method to you. I suggest you put all code related to the timer in a file called 'systemTimer.s' (for hopefully obvious reasons). The complicated part about this method, is that the counter is an 8 byte value, but each register only holds 4 bytes. Thus, the counter value will span two registers.
|
||||
|
||||
The following code blocks are examples.
|
||||
|
||||
```
|
||||
ldrd r0,r1,[r2,#4]
|
||||
```
|
||||
|
||||
```
|
||||
ldrd regLow,regHigh,[src,#val] loads 8 bytes from the address given by the number in src plus val into regLow and regHigh .
|
||||
```
|
||||
|
||||
An instruction you may find useful is the ldrd instruction above. It loads 8 bytes of memory across 2 registers. In this case, the 8 bytes of memory starting at the address in r2 would be copied into r0 and r1. What is slightly complicated about this arrangement is that r1 actually holds the highest 4 bytes. In other words, if the counter had a value of 999,999,999,99910 = 11101000110101001010010100001111111111112, r1 would contain 111010002 and r0 would contain 110101001010010100001111111111112.
|
||||
|
||||
The most sensible way to implement this would be to compute the difference between the current counter value and the one from when the method started, and then to compare this with the requested amount of time to wait. Conveniently, unless you wish to support wait times that were 8 bytes, the value in r1 in the example above could be discarded, and only the low 4 bytes of the counter need be used.
|
||||
|
||||
When waiting you should always be sure to use higher comparisons not equality comparisons, as if you try to wait for the gap between the time the method started and the time it ends to be exactly the amount requested, you could miss the value, and wait forever.
|
||||
|
||||
If you cannot figure out how to code the wait function, expand the box below for a guide.
|
||||
|
||||
```
|
||||
Borrowing the idea from the GPIO controller, the first function we should write should be to get the address of this system timer. An example of this is shown below:
|
||||
|
||||
.globl GetSystemTimerBase
|
||||
GetSystemTimerBase:
|
||||
ldr r0,=0x20003000
|
||||
mov pc,lr
|
||||
|
||||
Another function that will prove useful would be one that returns the current counter value in registers r0 and r1:
|
||||
|
||||
.globl GetTimeStamp
|
||||
GetTimeStamp:
|
||||
push {lr}
|
||||
bl GetSystemTimerBase
|
||||
ldrd r0,r1,[r0,#4]
|
||||
pop {pc}
|
||||
|
||||
This function simply uses the GetSystemTimerBase function and loads in the counter value using ldrd like we have just learned.
|
||||
|
||||
Now we actually want to code our wait method. First of all, we need to know the counter value when the method started, which we can now get using GetTimeStamp.
|
||||
|
||||
delay .req r2
|
||||
mov delay,r0
|
||||
push {lr}
|
||||
bl GetTimeStamp
|
||||
start .req r3
|
||||
mov start,r0
|
||||
|
||||
This code copies our method's input, the amount of time to delay, into r2, and then calls GetTimeStamp, which we know will return the current counter value in r0 and r1. It then copies the lower 4 bytes of the counter's value to r3.
|
||||
|
||||
Next we need to compute the difference between the current counter value and the reading we just took, and then keep doing so until the gap between them is at least the size of delay.
|
||||
|
||||
loop$:
|
||||
|
||||
bl GetTimeStamp
|
||||
elapsed .req r1
|
||||
sub elapsed,r0,start
|
||||
cmp elapsed,delay
|
||||
.unreq elapsed
|
||||
bls loop$
|
||||
|
||||
This code will wait until the requested amount of time has passed. It takes a reading from the counter, subtracts the initial value from this reading and then compares that to the requested delay. If the amount of time that has elapsed is less than the requested delay, it branches back to loop$.
|
||||
|
||||
.unreq delay
|
||||
.unreq start
|
||||
pop {pc}
|
||||
|
||||
This code finishes off the function by returning.
|
||||
```
|
||||
|
||||
### 3 Another Blinking Light
|
||||
|
||||
Once you have what you believe to be a working wait function, change 'main.s' to use it. Alter everywhere you wait to set the value of r0 to some big number (remember it is in microseconds) and then test it on the Raspberry Pi. If it does not function correctly please see our troubleshooting page.
|
||||
|
||||
Once it is working, congratulations you have now mastered another device, and with it, time itself. In the next and final lesson in the OK series, [Lesson 5: OK05][4] we shall use all we have learned to flash out a pattern on the LED.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/systemTimer.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/gpioControllerFunctionSelect.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
@ -1,108 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 5 OK05
|
||||
======
|
||||
|
||||
The OK05 lesson builds on OK04 using it to flash the SOS Morse Code pattern (...---...). It is assumed you have the code for the [Lesson 4: OK04][1] operating system as a basis.
|
||||
|
||||
### 1 Data
|
||||
|
||||
So far, all we've had to do with our operating system is provide instructions to be followed. Sometimes however, instructions are only half the story. Our operating systems may need data.
|
||||
|
||||
```
|
||||
Some early Operating Systems did only allow certain types of data in certain files, but this was generally found to be too restrictive. The modern way does make programs a lot more complicated however.
|
||||
```
|
||||
|
||||
In general data is just values that are important. You are probably trained to think of data as being of a specific type, e.g. a text file contains text, an image file contains an image, etc. This is, in truth, just an idea. All data on a computer is just binary numbers, how we choose to interpret them is what counts. In this example we're going to store a light flashing sequence as data.
|
||||
|
||||
At the end of 'main.s' copy the following code:
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 2
|
||||
pattern:
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
```
|
||||
.align num ensures the address of the next line is a multiple of 2num .
|
||||
|
||||
.int val outputs the number val .
|
||||
```
|
||||
|
||||
To differentiate between data and code, we put all the data in the .data. I've included this on the operating system memory layout diagram here. I've just chosen to put the data after the end of the code. The reason for keeping our data and instructions separate is so that if we eventually implement some security on our operating system, we need to know what parts of the code can be executed, and what parts can't.
|
||||
|
||||
I've used two new commands here. .align and .int. .align ensures alignment of the following data to a specified power of 2. In this case I've used .align 2 which means that this data will definitely be placed at an address which is a multiple of 22 = 4. It is really important to do this, because the ldr instruction we used to read memory only works at addresses that are multiples of 4.
|
||||
|
||||
The .int command copies the constant after it into the output directly. That means that 111111111010101000100010001010102 will be placed into the output, and so the label pattern actually labels this piece of data as pattern.
|
||||
|
||||
```
|
||||
One challenge with data is finding an efficient and useful representation. This method of storing the sequence as on and off units of time is easy to run, but would be difficult to edit, as the concept of a Morse - or . is lost.
|
||||
```
|
||||
|
||||
As I mentioned, data can mean whatever you want. In this case I've encoded the Morse Code SOS sequence, which is ...---... for those unfamiliar. I've used a 0 to represent a unit of time with the LED off, and a 1 to represent a unit of time with the LED on. That way, we can write some code which just displays a sequence in data like this one, and then all we have to do to make it display a different sequence is change the data. This is a very simple example of what operating systems must do all the time; interpret and display data.
|
||||
|
||||
Copy the following lines before the loop$ label in 'main.s'.
|
||||
|
||||
```
|
||||
ptrn .req r4
|
||||
ldr ptrn,=pattern
|
||||
ldr ptrn,[ptrn]
|
||||
seq .req r5
|
||||
mov seq,#0
|
||||
```
|
||||
|
||||
This code loads the pattern into r4, and loads 0 into r5. r5 will be our sequence position, so we can keep track of how much of the pattern we have displayed.
|
||||
|
||||
The following code puts a non-zero into r1 if and only if there is a 1 in the current part of the pattern.
|
||||
|
||||
```
|
||||
mov r1,#1
|
||||
lsl r1,seq
|
||||
and r1,ptrn
|
||||
```
|
||||
|
||||
This code is useful for your calls to SetGpio, which must have a non-zero value to turn the LED off, and a value of zero to turn the LED on.
|
||||
|
||||
Now modify all of your code in 'main.s' so that each loop the code sets the LED based on the current sequence number, waits for 250000 micro seconds (or any other appropriate delay), and then increments the sequence number. When the sequence number reaches 32, it needs to go back to 0. See if you can implement this, and for an extra challenge, try to do it using only 1 instruction (solution in the download).
|
||||
|
||||
### 2 Time Flies When You're Having Fun...
|
||||
|
||||
You're now ready to test this on the Raspberry Pi. It should flash out a sequence of 3 short pulses, 3 long pulses and then 3 more short pulses. After a delay, the pattern should repeat. If it doesn't work please see our troubleshooting page.
|
||||
|
||||
Once it works, congratulations you have reached the end of the OK series of tutorials.
|
||||
|
||||
In this series we've learnt about assembly code, the GPIO controller and the System Timer. We've learnt about functions and the ABI, as well as several basic Operating System concepts, and also about data.
|
||||
|
||||
You're now ready to move onto one of the more advanced series.
|
||||
|
||||
* The [Screen][2] series is next and teaches you how to use the screen with assembly code.
|
||||
* The [Input][3] series teaches you how to use the keyboard and mouse.
|
||||
|
||||
|
||||
|
||||
By now you already have enough information to make Operating Systems that interact with the GPIO in other ways. If you have any robot kits, you may want to try writing a robot operating system controlled with the GPIO pins!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (ezio )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,6 +7,8 @@
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
ezio is translating
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 10 Input01
|
||||
======
|
||||
|
||||
@ -482,7 +484,7 @@ via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,503 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 6 Screen01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 6 Screen01
|
||||
======
|
||||
|
||||
Welcome to the Screen lesson series. In this series, you will learn how to control the screen using the Raspberry Pi in assembly code, starting at just displaying random data, then moving up to displaying a fixed image, displaying text and then formatting numbers into text. It is assumed that you have already completed the OK series, and so things covered in this series will not be repeated here.
|
||||
|
||||
This first screen lesson teaches some basic theory about graphics, and then applies it to display a gradient pattern to the screen or TV.
|
||||
|
||||
### 1 Getting Started
|
||||
|
||||
It is expected that you have completed the OK series, and so functions in the 'gpio.s' file and 'systemTimer.s' file from that series will be called. If you do not have these files, or prefer to use a correct implementation, download the solution to OK05.s. The 'main.s' file from here will also be useful, up to and including mov sp,#0x8000. Please delete anything after that line.
|
||||
|
||||
### 2 Computer Graphics
|
||||
|
||||
There are a few systems for representing colours as numbers. Here we focus on RGB systems, but HSL is another common system used.
|
||||
|
||||
As you're hopefully beginning to appreciate, at a fundamental level, computers are very stupid. They have a limited number of instructions, almost exclusively to do with maths, and yet somehow they are capable of doing many things. The thing we currently wish to understand is how a computer could possibly put an image on the screen. How would we translate this problem into binary? The answer is relatively straightforward; we devise some system of numbering each colour, and then we store one number for every pixel on the screen. A pixel is a small dot on your screen. If you move very close, you will probably be able to make out individual pixels on your screen, and be able to see that everything image is just made out of these pixels in combination.
|
||||
|
||||
As the computer age advanced, people wanted more and more complicated graphics, and so the concept of a graphics card was invented. The graphics card is a secondary processor on your computer which only exists to draw images to the screen. It has the job of turning the pixel value information into light intensity levels to be transmitted to the screen. On modern computers, graphics cards can also do a lot more than that, such as drawing 3D graphics. In this tutorial however, we will just concentrate on the first use of graphics cards; getting pixel colours from memory out to the screen.
|
||||
|
||||
One issue that is raised immediately by all this is the system we use for numbering colours. There are several choices, each producing outputs of different quality. I will outline a few here for completeness.
|
||||
|
||||
Although some images here have few colours they use a technique called spatial dithering. This allows them to still show a good representation of the image, with very few colours. Many early Operating Systems used this technique.
|
||||
|
||||
| Name | Unique Colours | Description | Examples |
|
||||
| ----------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------- |
|
||||
| Monochrome | 2 | Use 1 bit to store each pixel, with a 1 being white, and a 0 being black. | ![Monochrome image of a bird][1] |
|
||||
| Greyscale | 256 | Use 1 byte to store each pixel, with 255 representing white, 0 representing black, and all values in between representing a linear combination of the two. | ![Geryscale image of a bird][2] |
|
||||
| 8 Colour | 8 | Use 3 bits to store each pixel, the first bit representing the presence of a red channel, the second representing a green channel and the third a blue channel. | ![8 colour image of a bird][3] |
|
||||
| Low Colour | 256 | Use 8 bits to store each pixel, the first 3 bit representing the intensity of the red channel, the next 3 bits representing the intensity of the green channel and the final 2 bits representing the intensity of the blue channel. | ![Low colour image of a bird][4] |
|
||||
| High Colour | 65,536 | Use 16 bits to store each pixel, the first 5 bit representing the intensity of the red channel, the next 6 bits representing the intensity of the green channel and the final 5 bits representing the intensity of the blue channel. | ![High colour image of a bird][5] |
|
||||
| True Colour | 16,777,216 | Use 24 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel and the final 8 bits the blue channel. | ![True colour image of a bird][6] |
|
||||
| RGBA32 | 16,777,216 with 256 transparency levels | Use 32 bits to store each pixel, the first 8 bits representing the intensity of the red channel, the second 8 representing the green channel, the third 8 bits the blue channel, and the final 8 bits a transparency channel. The transparency channel is only considered when drawing one image on top of another and is stored such that a value of 0 indicates the image behind's colour, a value of 255 represents this image's colour, and all values between represent a mix. | |
|
||||
|
||||
|
||||
In this tutorial we shall use High Colour initially. As you can see form the image, it is produces clear, good quality images, but it doesn't take up as much space as True Colour. That said, for quite a small display of 800x600 pixels, it would still take just under 1 megabyte of space. It also has the advantage that the size is a multiple of a power of 2, which greatly reduces the complexity of getting information compared with True Colour.
|
||||
|
||||
```
|
||||
Storing the frame buffer places a heavy memory burden on a computer. For this reason, early computers often cheated, by, for example, storing a screens worth of text, and just drawing each letter to the screen every time it is refreshed separately.
|
||||
```
|
||||
|
||||
The Raspberry Pi has a very special and rather odd relationship with it's graphics processor. On the Raspberry Pi, the graphics processor actually runs first, and is responsible for starting up the main processor. This is very unusual. Ultimately it doesn't make too much difference, but in many interactions, it often feels like the processor is secondary, and the graphics processor is the most important. The two communicate on the Raspberry Pi by what is called the 'mailbox'. Each can deposit mail for the other, which will be collected at some future point and then dealt with. We shall use the mailbox to ask the graphics processor for an address. The address will be a location to which we can write the pixel colour information for the screen, called a frame buffer, and the graphics card will regularly check this location, and update the pixels on the screen appropriately.
|
||||
|
||||
### 3 Programming the Postman
|
||||
|
||||
```
|
||||
Message passing is quite a common way for components to communicate. Some Operating Systems use virtual message passing to allow programs to communicate.
|
||||
```
|
||||
|
||||
The first thing we are going to need to program is a 'postman'. This is just two methods: MailboxRead, reading one message from the mailbox channel in r0. and MailboxWrite, writing the value in the top 28 bits of r0 to the mailbox channel in r1. The Raspberry Pi has 7 mailbox channels for communication with the graphics processor, only the first of which is useful to us, as it is for negotiating the frame buffer.
|
||||
|
||||
The following table and diagrams describe the operation of the mailbox.
|
||||
|
||||
Table 3.1 Mailbox Addresses
|
||||
| Address | Size / Bytes | Name | Description | Read / Write |
|
||||
| 2000B880 | 4 | Read | Receiving mail. | R |
|
||||
| 2000B890 | 4 | Poll | Receive without retrieving. | R |
|
||||
| 2000B894 | 4 | Sender | Sender information. | R |
|
||||
| 2000B898 | 4 | Status | Information. | R |
|
||||
| 2000B89C | 4 | Configuration | Settings. | RW |
|
||||
| 2000B8A0 | 4 | Write | Sending mail. | W |
|
||||
|
||||
In order to send a message to a particular mailbox:
|
||||
|
||||
1. The sender waits until the Status field has a 0 in the top bit.
|
||||
2. The sender writes to Write such that the lowest 4 bits are the mailbox to write to, and the upper 28 bits are the message to write.
|
||||
|
||||
|
||||
|
||||
In order to read a message:
|
||||
|
||||
1. The receiver waits until the Status field has a 0 in the 30th bit.
|
||||
2. The receiver reads from Read.
|
||||
3. The receiver confirms the message is for the correct mailbox, and tries again if not.
|
||||
|
||||
|
||||
|
||||
If you're feeling particularly confident, you now have enough information to write the two methods we need. If not, read on.
|
||||
|
||||
As always the first method I recommend you implement is one to get the address of the mailbox region.
|
||||
|
||||
```
|
||||
.globl GetMailboxBase
|
||||
GetMailboxBase:
|
||||
ldr r0,=0x2000B880
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
The sending procedure is least complicated, so we shall implement this first. As your methods become more and more complicated, you will need to start planning them in advance. A good way to do this might be to write out a simple list of the steps that need to be done, in a fair amount of detail, like below.
|
||||
|
||||
1. Our input will be what to write (r0), and what mailbox to write it to (r1). We must validate this is by checking it is a real mailbox, and that the low 4 bits of the value are 0. Never forget to validate inputs.
|
||||
2. Use GetMailboxBase to retrieve the address.
|
||||
3. Read from the Status field.
|
||||
4. Check the top bit is 0. If not, go back to 3.
|
||||
5. Combine the value to write and the channel.
|
||||
6. Write to the Write.
|
||||
|
||||
|
||||
|
||||
Let's handle each of these in order.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl MailboxWrite
|
||||
MailboxWrite:
|
||||
tst r0,#0b1111
|
||||
movne pc,lr
|
||||
cmp r1,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
```
|
||||
tst reg,#val computes and reg,#val and compares the result with 0.
|
||||
```
|
||||
|
||||
This achieves our validation on r0 and r1. tst is a function that compares two numbers by computing the logical and operation of the numbers, and then comparing the result with 0. In this case it checks that the lowest 4 bits of the input in r0 are all 0.
|
||||
|
||||
2.
|
||||
```
|
||||
channel .req r1
|
||||
value .req r2
|
||||
mov value,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
|
||||
|
||||
3.
|
||||
```
|
||||
wait1$:
|
||||
status .req r3
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
This code loads in the current status.
|
||||
|
||||
4.
|
||||
```
|
||||
tst status,#0x80000000
|
||||
.unreq status
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
This code checks that the top bit of the status field is 0, and loops back to 3. if it is not.
|
||||
|
||||
5.
|
||||
```
|
||||
add value,channel
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
This code combines the channel and value together.
|
||||
|
||||
6.
|
||||
```
|
||||
str value,[mailbox,#0x20]
|
||||
.unreq value
|
||||
.unreq mailbox
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
This code stores the result to the write field.
|
||||
|
||||
|
||||
|
||||
|
||||
The code for MailboxRead is quite similar.
|
||||
|
||||
1. Our input will be what mailbox to read from (r0). We must validate this is by checking it is a real mailbox. Never forget to validate inputs.
|
||||
2. Use GetMailboxBase to retrieve the address.
|
||||
3. Read from the Status field.
|
||||
4. Check the 30th bit is 0. If not, go back to 3.
|
||||
5. Read from the Read field.
|
||||
6. Check the mailbox is the one we want, if not go back to 3.
|
||||
7. Return the result.
|
||||
|
||||
|
||||
|
||||
Let's handle each of these in order.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl MailboxRead
|
||||
MailboxRead:
|
||||
cmp r0,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
This achieves our validation on r0.
|
||||
|
||||
2.
|
||||
```
|
||||
channel .req r1
|
||||
mov channel,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
This code ensures we will not overwrite our value, or link register and calls GetMailboxBase.
|
||||
|
||||
3.
|
||||
```
|
||||
rightmail$:
|
||||
wait2$:
|
||||
status .req r2
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
This code loads in the current status.
|
||||
|
||||
4.
|
||||
```
|
||||
tst status,#0x40000000
|
||||
.unreq status
|
||||
bne wait2$
|
||||
```
|
||||
|
||||
This code checks that the 30th bit of the status field is 0, and loops back to 3. if it is not.
|
||||
|
||||
5.
|
||||
```
|
||||
mail .req r2
|
||||
ldr mail,[mailbox,#0]
|
||||
```
|
||||
|
||||
This code reads the next item from the mailbox.
|
||||
|
||||
6.
|
||||
```
|
||||
inchan .req r3
|
||||
and inchan,mail,#0b1111
|
||||
teq inchan,channel
|
||||
.unreq inchan
|
||||
bne rightmail$
|
||||
.unreq mailbox
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
This code checks that the channel of the mail we just read is the one we were supplied. If not it loops back to 3.
|
||||
|
||||
7.
|
||||
```
|
||||
and r0,mail,#0xfffffff0
|
||||
.unreq mail
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
This code moves the answer (the top 28 bits of mail) to r0.
|
||||
|
||||
|
||||
|
||||
|
||||
### 4 My Dearest Graphics Processor
|
||||
|
||||
Through our new postman, we now have the ability to send a message to the graphics card. What should we send though? This was certainly a difficult question for me to find the answer to, as it isn't in any online manual that I have found. Nevertheless, by looking at the GNU/Linux for the Raspberry Pi, we are able to work out what we needed to send.
|
||||
|
||||
```
|
||||
Since the RAM is shared between the graphics processor and the processor on the Pi, we can just send where to find our message. This is called DMA, many complicated devices use this to speed up access times.
|
||||
```
|
||||
|
||||
The message is very simple. We describe the framebuffer we would like, and the graphics card either agrees to our request, in which case it sends us back a 0, and fills in a small questionnaire we make, or it sends back a non-zero number, in which case we know it is unhappy. Unfortunately, I have no idea what any of the other numbers it can send back are, nor what they mean, but only when it sends a zero it is happy. Fortunately it always seems to send a zero for sensible inputs, so we don't need to worry too much.
|
||||
|
||||
For simplicity we shall design our request in advance, and store it in the .data section. In a file called 'framebuffer.s' place the following code:
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 4
|
||||
.globl FrameBufferInfo
|
||||
FrameBufferInfo:
|
||||
.int 1024 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #0 Physical Width */
|
||||
.int 768 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #4 Physical Height */
|
||||
.int 1024 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #8 Virtual Width */
|
||||
.int 768 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #12 Virtual Height */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #16 GPU - Pitch */
|
||||
.int 16 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #20 Bit Depth */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #24 X */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #28 Y */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #32 GPU - Pointer */
|
||||
.int 0 /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var #36 GPU - Size */
|
||||
```
|
||||
|
||||
This is the format of our messages to the graphics processor. The first two words describe the physical width and height. The second pair is the virtual width and height. The framebuffer's width and height are the virtual width and height, and the GPU scales the framebuffer as need to fit the physical screen. The next word is one of the ones the GPU will fill in if it grants our request. It will be the number of bytes on each row of the frame buffer, in this case 2 × 1024 = 2048. The next word is how many bits to allocate to each pixel. Using a value of 16 means that the graphics processor uses High Colour mode described above. A value of 24 would use True Colour, and 32 would use RGBA32. The next two words are x and y offsets, which mean the number of pixels to skip in the top left corner of the screen when copying the framebuffer to the screen. Finally, the last two words are filled in by the graphics processor, the first of which is the actual pointer to the frame buffer, and the second is the size of the frame buffer in bytes.
|
||||
|
||||
```
|
||||
When working with devices using DMA, alignment constraints become very important. The GPU expects the message to be 16 byte aligned.
|
||||
```
|
||||
|
||||
I was very careful to include a .align 4 here. As discussed before, this ensures the lowest 4 bits of the address of the next line are 0. Thus, we know for sure that FrameBufferInfo will be placed at an address we can send to the graphics processor, as our mailbox only sends values with the low 4 bits all 0.
|
||||
|
||||
So, now that we have our message, we can write code to send it. The communication will go as follows:
|
||||
|
||||
1. Write the address of FrameBufferInfo + 0x40000000 to mailbox 1.
|
||||
2. Read the result from mailbox 1. If it is not zero, we didn't ask for a proper frame buffer.
|
||||
3. Copy our images to the pointer, and they will appear on screen!
|
||||
|
||||
|
||||
|
||||
I've said something that I've not mentioned before in step 1. We have to add 0x40000000 to the address of FrameBufferInfo before sending it. This is actually a special signal to the GPU of how it should write to the structure. If we just send the address, the GPU will write its response, but will not make sure we can see it by flushing its cache. The cache is a piece of memory where a processor stores values its working on before sending them to the RAM. By adding 0x40000000, we tell the GPU not to use its cache for these writes, which ensures we will be able to see the change.
|
||||
|
||||
Since there is quite a lot going on there, it would be best to implement this as a function, rather than just putting the code into main.s. We shall write a function InitialiseFrameBuffer which does all this negotiation and returns the pointer to the frame buffer info data above, once it has a pointer in it. For ease, we should also make it so that the width, height and bit depth of the frame buffer are inputs to this method, so that it is easy to change in main.s without having to get into the details of the negotiation.
|
||||
|
||||
Once again, let's write down in detail the steps we will have to take. If you're feeling confident, try writing the function straight away.
|
||||
|
||||
1. Validate our inputs.
|
||||
2. Write the inputs into the frame buffer.
|
||||
3. Send the address of the frame buffer + 0x40000000 to the mailbox.
|
||||
4. Receive the reply from the mailbox.
|
||||
5. If the reply is not 0, the method has failed. We should return 0 to indicate failure.
|
||||
6. Return a pointer to the frame buffer info.
|
||||
|
||||
|
||||
|
||||
Now we're getting into much bigger methods than before. Below is one implementation of the above.
|
||||
|
||||
1.
|
||||
```
|
||||
.section .text
|
||||
.globl InitialiseFrameBuffer
|
||||
InitialiseFrameBuffer:
|
||||
width .req r0
|
||||
height .req r1
|
||||
bitDepth .req r2
|
||||
cmp width,#4096
|
||||
cmpls height,#4096
|
||||
cmpls bitDepth,#32
|
||||
result .req r0
|
||||
movhi result,#0
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
This code checks that the width and height are less than or equal to 4096, and that the bit depth is less than or equal to 32. This is once again using a trick with conditional execution. Convince yourself that this works.
|
||||
|
||||
2.
|
||||
```
|
||||
fbInfoAddr .req r3
|
||||
push {lr}
|
||||
ldr fbInfoAddr,=FrameBufferInfo
|
||||
str width,[fbInfoAddr,#0]
|
||||
str height,[fbInfoAddr,#4]
|
||||
str width,[fbInfoAddr,#8]
|
||||
str height,[fbInfoAddr,#12]
|
||||
str bitDepth,[fbInfoAddr,#20]
|
||||
.unreq width
|
||||
.unreq height
|
||||
.unreq bitDepth
|
||||
```
|
||||
|
||||
This code simply writes into our frame buffer structure defined above. I also take the opportunity to push the link register onto the stack.
|
||||
|
||||
3.
|
||||
```
|
||||
mov r0,fbInfoAddr
|
||||
add r0,#0x40000000
|
||||
mov r1,#1
|
||||
bl MailboxWrite
|
||||
```
|
||||
|
||||
The inputs to the MailboxWrite method are the value to write in r0, and the channel to write to in r1.
|
||||
|
||||
4.
|
||||
```
|
||||
mov r0,#1
|
||||
bl MailboxRead
|
||||
```
|
||||
|
||||
The inputs to the MailboxRead method is the channel to write to in r0, and the output is the value read.
|
||||
|
||||
5.
|
||||
```
|
||||
teq result,#0
|
||||
movne result,#0
|
||||
popne {pc}
|
||||
```
|
||||
|
||||
This code checks if the result of the MailboxRead method is 0, and returns 0 if not.
|
||||
|
||||
6.
|
||||
```
|
||||
mov result,fbInfoAddr
|
||||
pop {pc}
|
||||
.unreq result
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
This code finishes off and returns the frame buffer info address.
|
||||
|
||||
|
||||
|
||||
|
||||
### 5 A Pixel Within a Row Within a Frame
|
||||
|
||||
So, we've now created our methods to communicate with the graphics processor. It should now be capable of giving us the pointer to a frame buffer we can draw graphics to. Let's draw something now.
|
||||
|
||||
In this first example, we'll just draw consecutive colours to the screen. It won't look pretty, but at least it will be working. How we will do this is by setting each pixel in the framebuffer to a consecutive number, and continually doing so.
|
||||
|
||||
Copy the following code to 'main.s' after mov sp,#0x8000
|
||||
|
||||
```
|
||||
mov r0,#1024
|
||||
mov r1,#768
|
||||
mov r2,#16
|
||||
bl InitialiseFrameBuffer
|
||||
```
|
||||
|
||||
This code simply uses our InitialiseFrameBuffer method to create a frame buffer with width 1024, height 768, and bit depth 16. You can try different values in here if you wish, as long as you are consistent throughout the code. Since it's possible that this method can return 0 if the graphics processor did not give us a frame buffer, we had better check for this, and turn the OK LED on if it happens.
|
||||
|
||||
```
|
||||
teq r0,#0
|
||||
bne noError$
|
||||
|
||||
mov r0,#16
|
||||
mov r1,#1
|
||||
bl SetGpioFunction
|
||||
mov r0,#16
|
||||
mov r1,#0
|
||||
bl SetGpio
|
||||
|
||||
error$:
|
||||
b error$
|
||||
|
||||
noError$:
|
||||
fbInfoAddr .req r4
|
||||
mov fbInfoAddr,r0
|
||||
```
|
||||
|
||||
Now that we have the frame buffer info address, we need to get the frame buffer pointer from it, and start drawing to the screen. We will do this using two loops, one going down the rows, and one going along the columns. On the Raspberry Pi, indeed in most applications, pictures are stored left to right then top to bottom, so we have to do the loops in the order I have said.
|
||||
|
||||
|
||||
```
|
||||
render$:
|
||||
|
||||
fbAddr .req r3
|
||||
ldr fbAddr,[fbInfoAddr,#32]
|
||||
|
||||
colour .req r0
|
||||
y .req r1
|
||||
mov y,#768
|
||||
drawRow$:
|
||||
|
||||
x .req r2
|
||||
mov x,#1024
|
||||
drawPixel$:
|
||||
|
||||
strh colour,[fbAddr]
|
||||
add fbAddr,#2
|
||||
sub x,#1
|
||||
teq x,#0
|
||||
bne drawPixel$
|
||||
|
||||
sub y,#1
|
||||
add colour,#1
|
||||
teq y,#0
|
||||
bne drawRow$
|
||||
|
||||
b render$
|
||||
|
||||
.unreq fbAddr
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
```
|
||||
strh reg,[dest] stores the low half word number in reg at the address given by dest.
|
||||
```
|
||||
|
||||
This is quite a large chunk of code, and has a loop within a loop within a loop. To help get your head around the looping, I've indented the code which is looped, depending on which loop it is in. This is quite common in most high level programming languages, and the assembler simply ignores the tabs. We see here that I load in the frame buffer address from the frame buffer information structure, and then loop over every row, then every pixel on the row. At each pixel, I use an strh (store half word) command to store the current colour, then increment the address we're writing to. After drawing each row, we increment the colour that we are drawing. After drawing the full screen, we branch back to the beginning.
|
||||
|
||||
### 6 Seeing the Light
|
||||
|
||||
Now you're ready to test this code on the Raspberry Pi. You should see a changing gradient pattern. Be careful: until the first message is sent to the mailbox, the Raspberry Pi displays a still gradient pattern between the four corners. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
If it does work, congratulations! You can now control the screen! Feel free to alter this code to draw whatever pattern you like. You can do some very nice gradient patterns, and can compute the value of each pixel directly, since y contains a y-coordinate for the pixel, and x contains an x-coordinate. In the next lesson, [Lesson 7: Screen 02][7], we will look at one of the most common drawing tasks, lines.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour1bImage.png
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8gImage.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour3bImage.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8bImage.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour16bImage.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour24bImage.png
|
||||
[7]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
@ -1,449 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 7 Screen02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 7 Screen02
|
||||
======
|
||||
|
||||
The Screen02 lesson builds on Screen01, by teaching how to draw lines and also a small feature on generating pseudo random numbers. It is assumed you have the code for the [Lesson 6: Screen01][1] operating system as a basis.
|
||||
|
||||
### 1 Dots
|
||||
|
||||
Now that we've got the screen working, it is only natural to start waiting to create sensible images. It would be very nice indeed if we were able to actually draw something. One of the most basic components in all drawings is a line. If we were able to draw a line between any two points on the screen, we could start creating more complicated drawings just using combinations of these lines.
|
||||
|
||||
```
|
||||
To allow complex drawing, some systems use a colouring function rather than just one colour to draw things. Each pixel calls the colouring function to determine what colour to draw there.
|
||||
```
|
||||
|
||||
We will attempt to implement this in assembly code, but first we could really use some other functions to help. We need a function I will call SetPixel that changes the colour of a particular pixel, supplied as inputs in r0 and r1. It will be helpful for future if we write code that could draw to any memory, not just the screen, so first of all, we need some system to control where we are actually going to draw to. I think that the best way to do this would be to have a piece of memory which stores where we are going to draw to. What we should end up with is a stored address which normally points to the frame buffer structure from last time. We will use this at all times in our drawing method. That way, if we want to draw to a different image in another part of our operating system, we could make this value the address of a different structure, and use the exact same code. For simplicity we will use another piece of data to control the colour of our drawings.
|
||||
|
||||
Copy the following code to a new file called 'drawing.s'.
|
||||
|
||||
```
|
||||
.section .data
|
||||
.align 1
|
||||
foreColour:
|
||||
.hword 0xFFFF
|
||||
|
||||
.align 2
|
||||
graphicsAddress:
|
||||
.int 0
|
||||
|
||||
.section .text
|
||||
.globl SetForeColour
|
||||
SetForeColour:
|
||||
cmp r0,#0x10000
|
||||
movhs pc,lr
|
||||
ldr r1,=foreColour
|
||||
strh r0,[r1]
|
||||
mov pc,lr
|
||||
|
||||
.globl SetGraphicsAddress
|
||||
SetGraphicsAddress:
|
||||
ldr r1,=graphicsAddress
|
||||
str r0,[r1]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
This is just the pair of functions that I described above, along with their data. We will use them in 'main.s' before drawing anything to control where and what we are drawing.
|
||||
|
||||
```
|
||||
Building generic methods like SetPixel which we can build other methods on top of is a useful idea. We have to make sure the method is fast though, since we will use it a lot.
|
||||
```
|
||||
|
||||
Our next task is to implement a SetPixel method. This needs to take two parameters, the x and y co-ordinate of a pixel, and it should use the graphicsAddress and foreColour we have just defined to control exactly what and where it is drawing. If you think you can implement this immediately, do, if not I shall outline the steps to be taken, and then give an example implementation.
|
||||
|
||||
1. Load in the graphicsAddress.
|
||||
2. Check that the x and y co-ordinates of the pixel are less than the width and height.
|
||||
3. Compute the address of the pixel to write. (hint: frameBufferAddress + (x + y core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated width) * pixel size)
|
||||
4. Load in the foreColour.
|
||||
5. Store it at the address.
|
||||
|
||||
|
||||
|
||||
An implementation of the above follows.
|
||||
|
||||
1.
|
||||
```
|
||||
.globl DrawPixel
|
||||
DrawPixel:
|
||||
px .req r0
|
||||
py .req r1
|
||||
addr .req r2
|
||||
ldr addr,=graphicsAddress
|
||||
ldr addr,[addr]
|
||||
```
|
||||
|
||||
2.
|
||||
```
|
||||
height .req r3
|
||||
ldr height,[addr,#4]
|
||||
sub height,#1
|
||||
cmp py,height
|
||||
movhi pc,lr
|
||||
.unreq height
|
||||
|
||||
width .req r3
|
||||
ldr width,[addr,#0]
|
||||
sub width,#1
|
||||
cmp px,width
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
Remember that the width and height are stored at offsets of 0 and 4 into the frame buffer description respectively. You can refer back to 'frameBuffer.s' if necessary.
|
||||
|
||||
3.
|
||||
```
|
||||
ldr addr,[addr,#32]
|
||||
add width,#1
|
||||
mla px,py,width,px
|
||||
.unreq width
|
||||
.unreq py
|
||||
add addr, px,lsl #1
|
||||
.unreq px
|
||||
```
|
||||
|
||||
```
|
||||
mla dst,reg1,reg2,reg3 multiplies the values from reg1 and reg2, adds the value from reg3 and places the least significant 32 bits of the result in dst.
|
||||
```
|
||||
|
||||
Admittedly, this code is specific to high colour frame buffers, as I use a bit shift directly to compute this address. You may wish to code a version of this function without the specific requirement to use high colour frame buffers, remembering to update the SetForeColour code. It may be significantly more complicated to implement.
|
||||
|
||||
4.
|
||||
```
|
||||
fore .req r3
|
||||
ldr fore,=foreColour
|
||||
ldrh fore,[fore]
|
||||
```
|
||||
|
||||
As above, this is high colour specific.
|
||||
|
||||
5.
|
||||
```
|
||||
strh fore,[addr]
|
||||
.unreq fore
|
||||
.unreq addr
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
As above, this is high colour specific.
|
||||
|
||||
|
||||
|
||||
|
||||
### 2 Lines
|
||||
|
||||
The trouble is, line drawing isn't quite as simple as you may expect. By now you must realise that when making operating system, we have to do almost everything ourselves, and line drawing is no exception. I suggest for a few minutes you have a think about how you would draw a line between any two points.
|
||||
|
||||
```
|
||||
When programming normally, we tend to be lazy with things like division. Operating Systems must be incredibly efficient, and so we must focus on doing things as best as possible.
|
||||
```
|
||||
|
||||
I expect the central idea of most strategies will involve computing the gradient of the line, and stepping along it. This sounds perfectly reasonable, but is actually a terrible idea. The problem with it is it involves division, which is something that we know can't easily be done in assembly, and also keeping track of decimal numbers, which is again difficult. There is, in fact, an algorithm called Bresenham's Algorithm, which is perfect for assembly code because it only involves addition, subtraction and bit shifts.
|
||||
```
|
||||
Let's start off by defining a reasonably straightforward line drawing algorithm as follows:
|
||||
|
||||
if x1 > x0 then
|
||||
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
|
||||
otherwise
|
||||
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
|
||||
end if
|
||||
|
||||
if y1 > y0 then
|
||||
|
||||
set deltay to y1 - y0
|
||||
set stepy to +1
|
||||
|
||||
otherwise
|
||||
|
||||
set deltay to y0 - y1
|
||||
set stepy to -1
|
||||
|
||||
end if
|
||||
|
||||
if deltax > deltay then
|
||||
|
||||
set error to 0
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax ÷ deltay
|
||||
if error ≥ 0.5 then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - 1
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
otherwise
|
||||
|
||||
end if
|
||||
|
||||
This algorithm is a representation of the sort of thing you may have imagined. The variable error keeps track of how far away from the actual line we are. Every step we take along the x axis increases this error, and every time we move down the y axis, the error decreases by 1 unit again. The error is measured as a distance along the y axis.
|
||||
|
||||
While this algorithm works, it suffers a major problem in that we clearly have to use decimal numbers to store error, and also we have to do a division. An immediate optimisation would therefore be to change the units of error. There is no need to store it in any particular units, as long as we scale every use of it by the same amount. Therefore, we could rewrite the algorithm simply by multiplying all equations involving error by deltay, and simplifying the result. Just showing the main loop:
|
||||
|
||||
set error to 0 × deltay
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax ÷ deltay × deltay
|
||||
if error ≥ 0.5 × deltay then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - 1 × deltay
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
Which simplifies to:
|
||||
|
||||
set error to 0
|
||||
until x0 = x1 + stepx
|
||||
|
||||
setPixel(x0, y0)
|
||||
set error to error + deltax
|
||||
if error × 2 ≥ deltay then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error - deltay
|
||||
|
||||
end if
|
||||
set x0 to x0 + stepx
|
||||
|
||||
repeat
|
||||
|
||||
Suddenly we have a much better algorithm. We see now that we've eliminated the need for division altogether. Better still, the only multiplication is by 2, which we know is just a bit shift left by 1! This is now very close to Bresenham's Algorithm, but one further optimisation can be made. At the moment, we have an if statement which leads to two very similar blocks of code, one for lines with larger x differences, and one for lines with larger y differences. It is worth checking if the code could be converted to a single statement for both types of line.
|
||||
|
||||
The difficulty arises somewhat in that in the first case, error is to do with y, and in the second case error is to do with x. The solution is to track the error in both variables simultaneously, using negative error to represent an error in x, and positive error in y.
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
|
||||
setPixel(x0, y0)
|
||||
if error × 2 > -deltay then
|
||||
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
|
||||
end if
|
||||
if error × 2 < deltax then
|
||||
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
|
||||
end if
|
||||
|
||||
repeat
|
||||
|
||||
It may take some time to convince yourself that this actually works. At each step, we consider if it would be correct to move in x or y. We do this by checking if the magnitude of the error would be lower if we moved in the x or y co-ordinates, and then moving if so.
|
||||
```
|
||||
|
||||
```
|
||||
Bresenham's Line Algorithm was developed in 1962 by Jack Elton Bresenham, 24 at the time, whilst studying for a PhD.
|
||||
```
|
||||
|
||||
Bresenham's Algorithm for drawing a line can be described by the following pseudo code. Pseudo code is just text which looks like computer instructions, but is actually intended for programmers to understand algorithms, rather than being machine readable.
|
||||
|
||||
```
|
||||
/* We wish to draw a line from (x0,y0) to (x1,y1), using only a function setPixel(x,y) which draws a dot in the pixel given by (x,y). */
|
||||
if x1 > x0 then
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
otherwise
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
end if
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
setPixel(x0, y0)
|
||||
if error × 2 ≥ -deltay then
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
end if
|
||||
if error × 2 ≤ deltax then
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
end if
|
||||
repeat
|
||||
```
|
||||
|
||||
Rather than numbered lists as I have used so far, this representation of an algorithm is far more common. See if you can implement this yourself. For reference, I have provided my implementation below.
|
||||
|
||||
```
|
||||
.globl DrawLine
|
||||
DrawLine:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
|
||||
x0 .req r9
|
||||
x1 .req r10
|
||||
y0 .req r11
|
||||
y1 .req r12
|
||||
|
||||
mov x0,r0
|
||||
mov x1,r2
|
||||
mov y0,r1
|
||||
mov y1,r3
|
||||
|
||||
dx .req r4
|
||||
dyn .req r5 /* Note that we only ever use -deltay, so I store its negative for speed. (hence dyn) */
|
||||
sx .req r6
|
||||
sy .req r7
|
||||
err .req r8
|
||||
|
||||
cmp x0,x1
|
||||
subgt dx,x0,x1
|
||||
movgt sx,#-1
|
||||
suble dx,x1,x0
|
||||
movle sx,#1
|
||||
|
||||
cmp y0,y1
|
||||
subgt dyn,y1,y0
|
||||
movgt sy,#-1
|
||||
suble dyn,y0,y1
|
||||
movle sy,#1
|
||||
|
||||
add err,dx,dyn
|
||||
add x1,sx
|
||||
add y1,sy
|
||||
|
||||
pixelLoop$:
|
||||
|
||||
teq x0,x1
|
||||
teqne y0,y1
|
||||
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
|
||||
|
||||
mov r0,x0
|
||||
mov r1,y0
|
||||
bl DrawPixel
|
||||
|
||||
cmp dyn, err,lsl #1
|
||||
addle err,dyn
|
||||
addle x0,sx
|
||||
|
||||
cmp dx, err,lsl #1
|
||||
addge err,dx
|
||||
addge y0,sy
|
||||
|
||||
b pixelLoop$
|
||||
|
||||
.unreq x0
|
||||
.unreq x1
|
||||
.unreq y0
|
||||
.unreq y1
|
||||
.unreq dx
|
||||
.unreq dyn
|
||||
.unreq sx
|
||||
.unreq sy
|
||||
.unreq err
|
||||
```
|
||||
|
||||
### 3 Randomness
|
||||
|
||||
So, now we can draw lines. Although we could use this to draw pictures and whatnot (feel free to do so!), I thought I would take the opportunity to introduce the idea of computer randomness. What we will do is select a pair of random co-ordinates, and then draw a line from the last pair to that point in steadily incrementing colours. I do this purely because it looks quite pretty.
|
||||
|
||||
```
|
||||
Hardware random number generators are occasionally used in security, where the predictability sequence of random numbers may affect the security of some encryption.
|
||||
```
|
||||
|
||||
So, now it comes down to it, how do we be random? Unfortunately for us there isn't some device which generates random numbers (such devices are very rare). So somehow using only the operations we've learned so far we need to invent 'random numbers'. It shouldn't take you long to realise this is impossible. The operations always have well defined results, executing the same sequence of instructions with the same registers yields the same answer. What we instead do is deduce a sequence that is pseudo random. This means numbers that, to the outside observer, look random, but in fact were completely determined. So, we need a formula to generate random numbers. One might be tempted to just spam mathematical operators out for example: 4x2! / 64, but in actuality this generally produces low quality random numbers. In this case for example, if x were 0, the answer would be 0. Stupid though it sounds, we need a very careful choice of equation to produce high quality random numbers.
|
||||
|
||||
```
|
||||
This sort of discussion often begs the question what do we mean by a random number? We generally mean statistical randomness: A sequence of numbers that has no obvious patterns or properties that could be used to generalise it.
|
||||
```
|
||||
|
||||
The method I'm going to teach you is called the quadratic congruence generator. This is a good choice because it can be implemented in 5 instructions, and yet generates a seemingly random order of the numbers from 0 to 232-1.
|
||||
|
||||
The reason why the generator can create such long sequence with so few instructions is unfortunately a little beyond the scope of this course, but I encourage the interested to research it. It all centralises on the following quadratic formula, where xn is the nth random number generated.
|
||||
|
||||
x_(n+1) = ax_(n)^2 + bx_(n) + c mod 2^32
|
||||
|
||||
Subject to the following constraints:
|
||||
|
||||
1. a is even
|
||||
|
||||
2. b = a + 1 mod 4
|
||||
|
||||
3. c is odd
|
||||
|
||||
|
||||
|
||||
|
||||
If you've not seen mod before, it means the remainder of a division by the number after it. For example b = a + 1 mod 4 means that b is the remainder of dividing a + 1 by 4, so if a were 12 say, b would be 1 as a + 1 is 13, and 13 divided by 4 is 3 remainder 1.
|
||||
|
||||
Copy the following code into a file called 'random.s'.
|
||||
|
||||
```
|
||||
.globl Random
|
||||
Random:
|
||||
xnm .req r0
|
||||
a .req r1
|
||||
|
||||
mov a,#0xef00
|
||||
mul a,xnm
|
||||
mul a,xnm
|
||||
add a,xnm
|
||||
.unreq xnm
|
||||
add r0,a,#73
|
||||
|
||||
.unreq a
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
This is an implementation of the random function, with an input of the last value generated in r0, and an output of the next number. In my case, I've used a = EF0016, b = 1, c = 73. This choice was arbitrary but meets the requirements above. Feel free to use any numbers you wish instead, as long as they obey the rules.
|
||||
|
||||
### 4 Pi-casso
|
||||
|
||||
OK, now we have all the functions we're going to need, let's try it out. Alter main to do the following, after getting the frame buffer info address:
|
||||
|
||||
1. Call SetGraphicsAddress with r0 containing the frame buffer info address.
|
||||
2. Set four registers to 0. One will be the last random number, one will be the colour, one will be the last x co-ordinate and one will be the last y co-ordinate.
|
||||
3. Call random to generate the next x-coordinate, using the last random number as the input.
|
||||
4. Call random again to generate the next y-coordinate, using the x-coordinate you generated as an input.
|
||||
5. Update the last random number to contain the y-coordinate.
|
||||
6. Call SetForeColour with the colour, then increment the colour. If it goes above FFFF16, make sure it goes back to 0.
|
||||
7. The x and y coordinates we have generated are between 0 and FFFFFFFF16. Convert them to a number between 0 and 102310 by using a logical shift right of 22.
|
||||
8. Check the y coordinate is on the screen. Valid y coordinates are between 0 and 76710. If not, go back to 3.
|
||||
9. Draw a line from the last x and y coordinates to the current x and y coordinates.
|
||||
10. Update the last x and y coordinates to contain the current ones.
|
||||
11. Go back to 3.
|
||||
|
||||
|
||||
|
||||
As always, a solution for this can be found on the downloads page.
|
||||
|
||||
Once you've finished, test it on the Raspberry Pi. You should see a very fast sequence of random lines being drawn on the screen, in steadily incrementing colours. This should never stop. If it doesn't work, please see our troubleshooting page.
|
||||
|
||||
When you have it working, congratulations! We've now learned about meaningful graphics, and also about random numbers. I encourage you to play with line drawing, as it can be used to render almost anything you want. You may also want to explore more complicated shapes. Most can be made out of lines, but is this necessarily the best strategy? If you like the line program, try experimenting with the SetPixel function. What happens if instead of just setting the value of the pixel, you increase it by a small amount? What other patterns can you make? In the next lesson, [Lesson 8: Screen 03][2], we will look at the invaluable skill of drawing text.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
@ -1,485 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
Computer Laboratory – Raspberry Pi: Lesson 8 Screen03
|
||||
======
|
||||
|
||||
The Screen03 lesson builds on Screen02, by teaching how to draw text, and also a small feature on the command line arguments of the operating system. It is assumed you have the code for the [Lesson 7: Screen02][1] operating system as a basis.
|
||||
|
||||
### 1 String Theory
|
||||
|
||||
So, our task for this operating system is to draw text. We have several problems to address, the most pressing of which is probably about storing text. Unbelievably text has been one of the biggest flaws on computers to date. What should have been a straightforward type of data has brought down operating systems, crippled otherwise wonderful encryption, and caused many problems for users of different alphabets. Nevertheless, it is an incredibly important type of data, as it is an excellent link between the computer and the user. Text can be sufficiently structured that the operating system understands it, as well as sufficiently readable that humans can use it.
|
||||
|
||||
```
|
||||
Variable data types such as text require much more complex handling.
|
||||
```
|
||||
|
||||
So how exactly is text stored? Simply enough, we have some system by which we give each letter a unique number, and then store a sequence of such numbers. Sounds easy. The problem is that the number of numbers is not fixed. Some pieces of text are longer than others. With storing ordinary numbers, we have some fixed limit, e.g. 32 bits, and then we can't go beyond that, we write methods that use numbers of that length, etc. In terms of text, or strings as we often call it, we want to write functions that work on variable length strings, otherwise we would need a lot of functions! This is not a problem for numbers normally, as there are only a few common number formats (byte, word, half, double).
|
||||
|
||||
```
|
||||
Buffer overrun attacks have plagued computers for years. Recently, the Wii, Xbox and Playstation 2 all suffered buffer overrun attacks, as well as large systems like Microsoft's Web and Database servers.
|
||||
```
|
||||
|
||||
So, how do we determine how long the string is? I think the obvious answer is just to store how long the string is, and then to store the characters that make it up. This is called length prefixing, as the length comes before the string. Unfortunately, the pioneers of computer science did not agree. They felt it made more sense to have a special character called the null terminator (denoted \0) which represents when a string ends. This does indeed simplify many string algorithms, as you just keep working until the null terminator. Unfortunately this is the source of many security issues. What if a malicious user gives you a very long string? What if you didn't have enough space to store it. You might run a string copying function that copies until the null terminator, but because the string is so long, it overwrites your program. This may sound far fetched, but nevertheless, such buffer overrun attacks are incredibly common. Length prefixing mitigates this problem as it is easy to deduce the size of the buffer required to store the string. As an operating system developer, I leave it to you to decide how best to store text.
|
||||
|
||||
The next thing we need to establish is how best to map characters to numbers. Fortunately, this is reasonably well standardised, so you have two major choices, Unicode and ASCII. Unicode maps almost every single useful symbol that can be written to a number, in exchange for having a lot more numbers, and a more complicated encoding system. ASCII uses one byte per character, and so only stores the Latin alphabet, numbers, a few symbols and a few special characters. Thus, ASCII is very easy to implement, compared to Unicode, in which not every character takes the same space, making string algorithms tricky. Normally operating systems use ASCII for strings which will not be displayed to end users (but perhaps to developers or experts), and Unicode for displaying messages to users, as Unicode can support things like Japanese characters, and so could be localised.
|
||||
|
||||
Fortunately for us, this decision is irrelevant at the moment, as the first 128 characters of both are exactly the same, and are encoded exactly the same.
|
||||
|
||||
Table 1.1 ASCII/Unicode symbols 0-127
|
||||
|
||||
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|
||||
|----| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ----|
|
||||
| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
|
||||
| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
|
||||
| 20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | | |
|
||||
| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
|
||||
| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
|
||||
| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
|
||||
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
|
||||
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
|
||||
|
||||
The table shows the first 128 symbols. The hexadecimal representation of the number for a symbol is the row value added to the column value, for example A is 4116. What you may find surprising is the first two rows, and the very last value. These 33 special characters are not printed at all. In fact, these days, many are ignored. They exist because ASCII was originally intended as a system for transmitting data over computer networks, and so a lot more information than just the symbols had to be sent. The key special symbols that you should learn are NUL, the null terminator character I mentioned before, HT, horizontal tab is what we normally refer to as a tab and LF, the line feed character is used to make a new line. You may wish to research and use the other characters for special meanings in your operating system.
|
||||
|
||||
### 2 Characters
|
||||
|
||||
So, now that we know a bit about strings, we can start to think about how they're displayed. The fundamental thing we need to do in order to be able to display a string is to be able to display a character. Our first task will be making a DrawCharacter function which takes in a character to draw and a location, and then draws the character.
|
||||
|
||||
```
|
||||
The true type font format used in many Operating Systems is so powerful, it has its own assembly language built in to ensure letters look correct at any resolution.
|
||||
```
|
||||
|
||||
Naturally, this leads to a discussion about fonts. We already know there are many ways to display any given letter in accordance with font choice. So how does a font work? In the very early days of computer science, a font was just a series of little pictures of all the letters, called a bitmap font, and all the draw character method would do is copy one of the pictures to the screen. The trouble with this is when people want to resize the text. Sometimes we need big letters, and sometimes small. Although we could keep drawing new pictures for every font at every size with every character, this would get tedious. Thus, vector fonts were invented. in vector fonts, rather than containing an image of the font, the font file contains a description of how to draw it, e.g. an 'o' could be circle with radius half that of the maximum letter height. Modern operating systems use such fonts almost exclusively, as they are perfect at any resolution.
|
||||
|
||||
Unfortunately, much though I would love to include an implementation of one of the vector font formats, it would take up the remainder of this website. Thus, we will implement a bitmap font, though if you wish to make a decent graphical operating system, a vector font would be useful.
|
||||
```
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
00010000
|
||||
00101000
|
||||
00101000
|
||||
00101000
|
||||
01000100
|
||||
01000100
|
||||
01111100
|
||||
11000110
|
||||
10000010
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
00000000
|
||||
```
|
||||
|
||||
On the downloads page, I have included several '.bin' files in the font section. These are just raw binary data files for a few fonts. For this tutorial, pick your favourite from the monospace, monochrome, 8x16 section. Download it and store it in the 'source' directory as 'font.bin'. These files are just monochrome images of each of the letters in turn, with each letter being exactly 8 by 16 pixels. Thus, each takes 16 bytes, the first byte being the top row, the second the next, etc.
|
||||
|
||||
The diagram shows the 'A' character in the monospace, monochrome, 8x16 font Bitstream Vera Sans Mono. In the file, we would find this starting at the 4116 × 1016 = 41016th byte as the following sequence in hexadecimal:
|
||||
|
||||
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
|
||||
|
||||
We're going to use a monospace font here, because in a monospace font every character is the same size. Unfortunately, yet another complication with most fonts is that the character's widths vary, leading to more complex display code. I've included a few other fonts on the downloads page, as well as an explanation of the format I've stored them all in.
|
||||
|
||||
So let's get down to business. Copy the following to 'drawing.s' after the .int 0 of graphicsAddress.
|
||||
|
||||
```
|
||||
.align 4
|
||||
font:
|
||||
.incbin "font.bin"
|
||||
```
|
||||
|
||||
```
|
||||
.incbin "file" inserts the binary data from the file file.
|
||||
```
|
||||
|
||||
This code copies the font data from the file to the address labelled font. We've used an .align 4 here to ensure each character starts on a multiple of 16 bytes, which can be used for a speed trick later.
|
||||
|
||||
Now we want to write the draw character method. I'll give the pseudo code for this, so you can try to implement it yourself if you want to. Conventionally >> means logical shift right.
|
||||
|
||||
```
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character × 16
|
||||
for row = 0 to 15
|
||||
set bits to readByte(charAddress + row)
|
||||
for bit = 0 to 7
|
||||
if test(bits >> bit, 0x1)
|
||||
then setPixel(x + bit, y + row)
|
||||
next
|
||||
next
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
|
||||
```
|
||||
If implemented directly, this is deliberately not very efficient. With things like drawing characters, efficiency is a top priority, as we will do it a lot. Let's explore some improvements that bring this closer to optimal assembly code. Firstly, we have a × 16, which by now you should spot is the same as a logical shift left by 4 places. Next we have a variable row, which is only ever added to charAddress and to y. Thus, we can eliminate it by increasing these variables instead. The only issue now is how to tell when we've finished. This is where the .align 4 comes in handy. We know that charAddress will start with the low nibble containing 0. This means we can see how far into the character data we are by checking that low nibble.
|
||||
|
||||
Though we can eliminate the need for bits, we must introduce a new variable to do so, so it is best left in. The only other improvement that can be made is to remove the nested bits >> bit.
|
||||
|
||||
```
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character << 4
|
||||
loop
|
||||
set bits to readByte(charAddress)
|
||||
set bit to 8
|
||||
loop
|
||||
set bits to bits << 1
|
||||
set bit to bit - 1
|
||||
if test(bits, 0x100)
|
||||
then setPixel(x + bit, y)
|
||||
until bit = 0
|
||||
set y to y + 1
|
||||
set chadAddress to chadAddress + 1
|
||||
until charAddress AND 0b1111 = 0
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
```
|
||||
|
||||
Now we've got code that is much closer to assembly code, and is near optimal. Below is the assembly code version of the above.
|
||||
|
||||
```
|
||||
.globl DrawCharacter
|
||||
DrawCharacter:
|
||||
cmp r0,#127
|
||||
movhi r0,#0
|
||||
movhi r1,#0
|
||||
movhi pc,lr
|
||||
|
||||
push {r4,r5,r6,r7,r8,lr}
|
||||
x .req r4
|
||||
y .req r5
|
||||
charAddr .req r6
|
||||
mov x,r1
|
||||
mov y,r2
|
||||
ldr charAddr,=font
|
||||
add charAddr, r0,lsl #4
|
||||
|
||||
lineLoop$:
|
||||
|
||||
bits .req r7
|
||||
bit .req r8
|
||||
ldrb bits,[charAddr]
|
||||
mov bit,#8
|
||||
|
||||
charPixelLoop$:
|
||||
|
||||
subs bit,#1
|
||||
blt charPixelLoopEnd$
|
||||
lsl bits,#1
|
||||
tst bits,#0x100
|
||||
beq charPixelLoop$
|
||||
|
||||
add r0,x,bit
|
||||
mov r1,y
|
||||
bl DrawPixel
|
||||
|
||||
teq bit,#0
|
||||
bne charPixelLoop$
|
||||
|
||||
charPixelLoopEnd$:
|
||||
.unreq bit
|
||||
.unreq bits
|
||||
add y,#1
|
||||
add charAddr,#1
|
||||
tst charAddr,#0b1111
|
||||
bne lineLoop$
|
||||
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq charAddr
|
||||
|
||||
width .req r0
|
||||
height .req r1
|
||||
mov width,#8
|
||||
mov height,#16
|
||||
|
||||
pop {r4,r5,r6,r7,r8,pc}
|
||||
.unreq width
|
||||
.unreq height
|
||||
```
|
||||
|
||||
### 3 Strings
|
||||
|
||||
Now that we can draw characters, we can draw text. We need to make a method that, for a given string, draws each character in turn, at incrementing positions. To be nice, we shall also implement new lines and tabs. It's decision time as far as null terminators are concerned, and if you want to make your operating system use them, feel free by changing the code below. To avoid the issue, I will have the length of the string passed as an argument to the DrawString function, along with the address of the string, and the x and y coordinates.
|
||||
|
||||
```
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
for pos = 0 to length - 1
|
||||
set char to loadByte(string + pos)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
until x1 > x0
|
||||
set x1 to x1 + 5 × cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
next
|
||||
end function
|
||||
```
|
||||
|
||||
Once again, this function isn't that close to assembly code. Feel free to try to implement it either directly or by simplifying it. I will give the simplification and then the assembly code below.
|
||||
|
||||
Clearly the person who wrote this function wasn't being very efficient (me in case you were wondering). Once again we have a pos variable that just increments and is added to something else, which is completely unnecessary. We can remove it, and instead simultaneously decrement length until it is 0, saving the need for one register. The rest of the function is probably fine, except for that annoying multiplication by five. A key thing to do here would be to move the multiplication outside the loop; multiplication is slow even with bit shifts, and since we're always adding the same constant multiplied by 5, there is no need to recompute this. It can in fact be implemented in one operation using the argument shifting in assembly code, so I shall rephrase it like that.
|
||||
|
||||
```
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
until length = 0
|
||||
set length to length - 1
|
||||
set char to loadByte(string)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
set cwidth to cwidth + cwidth << 2
|
||||
until x1 > x0
|
||||
set x1 to x1 + cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
set string to string + 1
|
||||
loop
|
||||
end function
|
||||
```
|
||||
|
||||
In assembly code:
|
||||
|
||||
```
|
||||
.globl DrawString
|
||||
DrawString:
|
||||
x .req r4
|
||||
y .req r5
|
||||
x0 .req r6
|
||||
string .req r7
|
||||
length .req r8
|
||||
char .req r9
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
|
||||
mov string,r0
|
||||
mov x,r2
|
||||
mov x0,x
|
||||
mov y,r3
|
||||
mov length,r1
|
||||
|
||||
stringLoop$:
|
||||
subs length,#1
|
||||
blt stringLoopEnd$
|
||||
|
||||
ldrb char,[string]
|
||||
add string,#1
|
||||
|
||||
mov r0,char
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
cwidth .req r0
|
||||
cheight .req r1
|
||||
|
||||
teq char,#'\n'
|
||||
moveq x,x0
|
||||
addeq y,cheight
|
||||
beq stringLoop$
|
||||
|
||||
teq char,#'\t'
|
||||
addne x,cwidth
|
||||
bne stringLoop$
|
||||
|
||||
add cwidth, cwidth,lsl #2
|
||||
x1 .req r1
|
||||
mov x1,x0
|
||||
|
||||
stringLoopTab$:
|
||||
add x1,cwidth
|
||||
cmp x,x1
|
||||
bge stringLoopTab$
|
||||
mov x,x1
|
||||
.unreq x1
|
||||
b stringLoop$
|
||||
stringLoopEnd$:
|
||||
.unreq cwidth
|
||||
.unreq cheight
|
||||
|
||||
pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq x0
|
||||
.unreq string
|
||||
.unreq length
|
||||
```
|
||||
|
||||
```
|
||||
subs reg,#val subtracts val from the register reg and compares the result with 0.
|
||||
```
|
||||
|
||||
This code makes clever use of a new operation, subs which subtracts one number from another, stores the result and then compares it with 0. In truth, all comparisons are implemented as a subtraction and then comparison with 0, but the result is normally discarded. This means that this operation is as fast as cmp.
|
||||
|
||||
### 4 Your Wish is My Command Line
|
||||
|
||||
Now that we can print strings, the challenge is to find an interesting one to draw. Normally in tutorials such as this, people just draw "Hello World!", but after all we've done so far, I feel that is a little patronising (feel free to do so if it helps). Instead we're going to draw our command line.
|
||||
|
||||
A convention has been made for computers running ARM. When they boot, it is important they are given certain information about what they have available to them. Most all processors have some way of ascertaining this information, and on ARM this is by data left at the address 10016. The format of the data is as follows:
|
||||
|
||||
1. The data is broken down into a series of 'tags'.
|
||||
2. There are nine types of tag: 'core', 'mem', 'videotext', 'ramdisk', 'initrd2', 'serial' 'revision', 'videolfb', 'cmdline'.
|
||||
3. Each can only appear once, but all but the 'core' tag don't have to appear.
|
||||
4. The tags are placed from 0x100 in order one after the other.
|
||||
5. The end of the list of tags always contains 2 words which are 0.
|
||||
6. Every tag's size in bytes is a multiple of 4.
|
||||
7. Each tag starts with the size of the tag in words in the tag, including this number.
|
||||
8. This is followed by a half word containing the tag's number. These are numbered from 1 in the order above ('core' is 1, 'cmdline' is 9).
|
||||
9. This is followed by a half word containing 544116.
|
||||
10. After this comes the data of the tag, which varies depending on the tag. The size of the data in words + 2 is always the same as the length mentioned above.
|
||||
11. A 'core' tag is either 2 or 5 words in length. If it is 2, there is no data, if it is 5, it has 3 words.
|
||||
12. A 'mem' tag is always 4 words in length. The data is the first address in a block of memory, and the length of that block.
|
||||
13. A 'cmdline' tag contains a null terminated string which is the parameters of the kernel.
|
||||
|
||||
|
||||
```
|
||||
Almost all Operating Systems support the notion of programs having a 'command line'. The idea is to provide a common mechanism for choosing the desired behaviour of the program.
|
||||
```
|
||||
|
||||
On the current version of the Raspberry Pi, only the 'core', 'mem' and 'cmdline' tags are present. You may find these useful later, and a more complete reference for these is on our Raspberry Pi reference page. The one we're interested in at the moment is the 'cmdline' tag, because it contains a string. We're going to write some code to search for the command line tag, and, if found, to print it out with each item on a new line. The command line is just a list of things that either the graphics processor or the user thought it might be nice for the Operating System to know. On the Raspberry Pi, this includes the MAC Address, serial number and screen resolution. The string itself is just a list of expressions such as 'key.subkey=value' separated by spaces.
|
||||
|
||||
Let's start by finding the 'cmdline' tag. In a new file called 'tags.s' copy the following code.
|
||||
|
||||
```
|
||||
.section .data
|
||||
tag_core: .int 0
|
||||
tag_mem: .int 0
|
||||
tag_videotext: .int 0
|
||||
tag_ramdisk: .int 0
|
||||
tag_initrd2: .int 0
|
||||
tag_serial: .int 0
|
||||
tag_revision: .int 0
|
||||
tag_videolfb: .int 0
|
||||
tag_cmdline: .int 0
|
||||
```
|
||||
|
||||
Looking through the list of tags will be a slow operation, as it involves a lot of memory access. Therefore, we only want to have to do it once. This code creates some data which will store the memory address of the first tag of each of the types. Then, to find a tag the following pseudo code will suffice.
|
||||
|
||||
```
|
||||
function FindTag(r0 is tag)
|
||||
if tag > 9 or tag = 0 then return 0
|
||||
set tagAddr to loadWord(tag_core + (tag - 1) × 4)
|
||||
if not tagAddr = 0 then return tagAddr
|
||||
if readWord(tag_core) = 0 then return 0
|
||||
set tagAddr to 0x100
|
||||
loop forever
|
||||
set tagIndex to readHalfWord(tagAddr + 4)
|
||||
if tagIndex = 0 then return FindTag(tag)
|
||||
if readWord(tag_core+(tagIndex-1)×4) = 0
|
||||
then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
|
||||
set tagAddr to tagAddr + loadWord(tagAddr) × 4
|
||||
end loop
|
||||
end function
|
||||
```
|
||||
This code is already quite well optimised and close to assembly. It is optimistic in that the first thing it tries is loading the tag directly, as all but the first time this should be the case. If that fails, it checks if the core tag has an address. Since there must always be a core tag, the only reason that it would not have an address is if it doesn't exist. If it does have an address, the tag we were looking for didn't. If it doesn't we need to find the addresses of all the tags. It does this by reading the number of the tag. If it is zero, that must mean we are at the end of the list. This means we've now filled in all the tags in our directory. Therefore if we run our function again, it will now be able to produce an answer. If the tag number is not zero, we check to see if this tag type already has an address. If not, we store the address of this tag in our directory. We then add the length of this tag in bytes to the tag address to find the next tag.
|
||||
|
||||
Have a go at implementing this code in assembly. You will need to simplify it. If you get stuck, my answer is below. Don't forget the .section .text!
|
||||
|
||||
```
|
||||
.section .text
|
||||
.globl FindTag
|
||||
FindTag:
|
||||
tag .req r0
|
||||
tagList .req r1
|
||||
tagAddr .req r2
|
||||
|
||||
sub tag,#1
|
||||
cmp tag,#8
|
||||
movhi tag,#0
|
||||
movhi pc,lr
|
||||
|
||||
ldr tagList,=tag_core
|
||||
tagReturn$:
|
||||
add tagAddr,tagList, tag,lsl #2
|
||||
ldr tagAddr,[tagAddr]
|
||||
|
||||
teq tagAddr,#0
|
||||
movne r0,tagAddr
|
||||
movne pc,lr
|
||||
|
||||
ldr tagAddr,[tagList]
|
||||
teq tagAddr,#0
|
||||
movne r0,#0
|
||||
movne pc,lr
|
||||
|
||||
mov tagAddr,#0x100
|
||||
push {r4}
|
||||
tagIndex .req r3
|
||||
oldAddr .req r4
|
||||
tagLoop$:
|
||||
ldrh tagIndex,[tagAddr,#4]
|
||||
subs tagIndex,#1
|
||||
poplt {r4}
|
||||
blt tagReturn$
|
||||
|
||||
add tagIndex,tagList, tagIndex,lsl #2
|
||||
ldr oldAddr,[tagIndex]
|
||||
teq oldAddr,#0
|
||||
.unreq oldAddr
|
||||
streq tagAddr,[tagIndex]
|
||||
|
||||
ldr tagIndex,[tagAddr]
|
||||
add tagAddr, tagIndex,lsl #2
|
||||
b tagLoop$
|
||||
|
||||
.unreq tag
|
||||
.unreq tagList
|
||||
.unreq tagAddr
|
||||
.unreq tagIndex
|
||||
```
|
||||
|
||||
### 5 Hello World
|
||||
|
||||
Now that we have everything we need, we can draw our first string. In 'main.s' delete everything after bl SetGraphicsAddress, and replace it with the following:
|
||||
|
||||
```
|
||||
mov r0,#9
|
||||
bl FindTag
|
||||
ldr r1,[r0]
|
||||
lsl r1,#2
|
||||
sub r1,#8
|
||||
add r0,#8
|
||||
mov r2,#0
|
||||
mov r3,#0
|
||||
bl DrawString
|
||||
loop$:
|
||||
b loop$
|
||||
```
|
||||
|
||||
This code simply uses our FindTag method to find the 9th tag (cmdline) and then calculates its length and passes the command and the length to the DrawString method, and tells it to draw the string at 0,0. Now test this on the Raspberry Pi. You should see a line of text on the screen. If not please see our troubleshooting page.
|
||||
|
||||
Once it works, congratulations you've now got the ability to draw text. But there is still room for improvement. What if we wanted to write out a number, or a section of the memory or manipulate our command line? In [Lesson 9: Screen04][2], we will look at manipulating text and displaying useful numbers and information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -1,144 +0,0 @@
|
||||
Top 5 Linux Music Players
|
||||
======
|
||||
|
||||

|
||||
>Jack Wallen rounds up his five favorite Linux music players. Creative Commons Zero
|
||||
>Pixabay
|
||||
|
||||
No matter what you do, chances are you enjoy a bit of music playing in the background. Whether you're a coder, system administrator, or typical desktop user, enjoying good music might be at the top of your list of things you do on the desktop. And, with the holidays upon us, you might wind up with some gift cards that allow you to purchase some new music. If your music format of choice is of a digital nature (mine happens to be vinyl) and your platform is Linux, you're going to want a good GUI player to enjoy that music.
|
||||
|
||||
Fortunately, Linux has no lack of digital music players. In fact, there are quite a few, most of which are open source and available for free. Let's take a look at a few such players, to see which one might suit your needs.
|
||||
|
||||
### Clementine
|
||||
|
||||
I wanted to start out with the player that has served as my default for years. [Clementine][1] offers probably the single best ratio of ease-of-use to flexibility you'll find in any player. Clementine is a fork of the new defunct [Amarok][2] music player, but isn't limited to Linux-only; Clementine is also available for Mac OS and Windows platforms. The feature set is seriously impressive and includes the likes of:
|
||||
|
||||
* Built-in equalizer
|
||||
|
||||
* Customizable interface (display current album cover as background -- Figure 1)
|
||||
|
||||
* Play local music or from Spotify, Last.fm, and more
|
||||
|
||||
* Sidebar for easy library navigation
|
||||
|
||||
* Built-in audio transcoding (into MP3, OGG, Flac, and more)
|
||||
|
||||
* Remote control using [Android app][3]
|
||||
|
||||
* Handy search function
|
||||
|
||||
* Tabbed playlists
|
||||
|
||||
* Easy creation of regular and smart playlists
|
||||
|
||||
* CUE sheet support
|
||||
|
||||
* Tag support
|
||||
|
||||
|
||||
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
|
||||
Figure 1: The Clementine interface might be a bit old-school, but it's incredibly user-friendly and flexible.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Of all the music players I have used, Clementine is by far the most feature-rich and easy to use. It also includes one of the finest equalizers you'll find on a Linux music player (with 10 bands to adjust). Although it may not enjoy a very modern interface, it is absolutely unmatched for its ability to create and manipulate playlists. If your music collection is large, and you want total control over it, this is the player you want.
|
||||
|
||||
Clementine can be found in the standard repositories and installed from either your distribution's software center or the command line.
|
||||
|
||||
### Rhythmbox
|
||||
|
||||
[Rhythmbox][7] is the default player for the GNOME desktop, but it does function well on other desktops. The Rhythmbox interface is slightly more modern than Clementine and takes a minimal approach to design. That doesn't mean the app is bereft of features. Quite the opposite. Rhythmbox offers gapless playback, Soundcloud support, album cover display, audio scrobbling from Last.fm and Libre.fm, Jamendo support, podcast subscription (from [Apple iTunes][8]), web remote control, and more.
|
||||
|
||||
One very nice feature found in Rhythmbox is plugin support, which allows you to enable features like DAAP Music Sharing, FM Radio, Cover art search, notifications, ReplayGain, Song Lyrics, and more.
|
||||
|
||||
The Rhythmbox playlist feature isn't quite as powerful as that found in Clementine, but it still makes it fairly easy to organize your music into quick playlists for any mood. Although Rhythmbox does offer a slightly more modern interface than Clementine (Figure 2), it's not quite as flexible.
|
||||
|
||||
![Rhythmbox][10]
|
||||
|
||||
|
||||
Figure 2: The Rhythmbox interface is simple and straightforward.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
### VLC Media Player
|
||||
|
||||
For some, [VLC][11] cannot be beat for playing videos. However, VLC isn't limited to the playback of video. In fact, VLC does a great job of playing audio files. For [KDE Neon][12] users, VLC serves as your default for both music and video playback. Although VLC is one of the finest video players on the Linux market (it's my default), it does suffer from some minor limitations with audio--namely the lack of playlists and the inability to connect to remote directories on your network. But if you're looking for an incredibly simple and reliable means to play local files or network mms/rtsp streams VLC is a quality tool.
|
||||
|
||||
VLC does include an equalizer (Figure 3), a compressor, and a spatializer as well as the ability to record from a capture device.
|
||||
|
||||
![VLC][14]
|
||||
|
||||
|
||||
Figure 3: The VLC equalizer in action.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
### Audacious
|
||||
|
||||
If you're looking for a lightweight music player, Audacious perfectly fits that bill. This particular music player is fairly single minded, but it does include an equalizer and a small selection of effects that will please many an audiophile (e.g., Echo, Silence removal, Speed and Pitch, Voice Removal, and more--Figure 4).
|
||||
|
||||
![Audacious ][16]
|
||||
|
||||
|
||||
Figure 4: The Audacious EQ and plugins.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
Audacious also includes a really handy alarm feature, that allows you to set an alarm that will start playing your currently selected track at a user-specified time and duration.
|
||||
|
||||
### Spotify
|
||||
|
||||
I must confess, I use spotify daily. I'm a subscriber and use it to find new music to purchase--which means I am constantly searching and discovering. Fortunately, there is a desktop client for Spotify (Figure 5) that can be easily installed using the [official Spotify Linux installation instructions][17]. Outside of listening to vinyl, I probably make use of Spotify more than any other music player. It also helps that I can seamlessly jump between the desktop client and the [Android app][18], so I never miss out on the music I enjoy.
|
||||
|
||||
![Spotify][20]
|
||||
|
||||
|
||||
Figure 5: The official Spotify client on Linux.
|
||||
|
||||
[Used with permission][6]
|
||||
|
||||
The Spotify interface is very easy to use and, in fact, it beats the web player by leaps and bounds. Do not settle for the [Spotify Web Player][21] on Linux, as the desktop client makes it much easier to create and manage your playlists. If you're a Spotify power user, don't even bother with the built-in support for the streaming client in the other desktop apps--once you've used the Spotify Desktop Client, the other apps pale in comparison.
|
||||
|
||||
### The choice is yours
|
||||
|
||||
Other options are available (check your desktop software center), but these five clients (in my opinion) are the best of the best. For me, the one-two punch of Clementine and Spotify gives me the best of all possible worlds. Try them out and see which one best meets your needs.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][22]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com
|
||||
[1]:https://www.clementine-player.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Amarok_(software)
|
||||
[3]:https://play.google.com/store/apps/details?id=de.qspool.clementineremote
|
||||
[4]:https://www.linux.com/files/images/clementinejpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine.jpg?itok=_k13MtM3 (Clementine)
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:https://www.apple.com/itunes/
|
||||
[9]:https://www.linux.com/files/images/rhythmboxjpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/rhythmbox.jpg?itok=GOjs9vTv (Rhythmbox)
|
||||
[11]:https://www.videolan.org/vlc/index.html
|
||||
[12]:https://neon.kde.org/
|
||||
[13]:https://www.linux.com/files/images/vlcjpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc.jpg?itok=hn7iKkmK (VLC)
|
||||
[15]:https://www.linux.com/files/images/audaciousjpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/audacious.jpg?itok=9YALPzOx (Audacious )
|
||||
[17]:https://www.spotify.com/us/download/linux/
|
||||
[18]:https://play.google.com/store/apps/details?id=com.spotify.music
|
||||
[19]:https://www.linux.com/files/images/spotifyjpg
|
||||
[20]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify.jpg?itok=P3FLfcYt (Spotify)
|
||||
[21]:https://open.spotify.com/browse/featured
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,4 @@
|
||||
beamrolling is translating.
|
||||
Introduction to the Pony programming language
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
tomjlw is translating
|
||||
How to connect to a remote desktop from Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,265 +0,0 @@
|
||||
How To Mount Google Drive Locally As Virtual File System In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
[**Google Drive**][1] is the one of the popular cloud storage provider on the planet. As of 2017, over 800 million users are actively using this service worldwide. Even though the number of users have dramatically increased, Google haven’t released a Google drive client for Linux yet. But it didn’t stop the Linux community. Every now and then, some developers had brought few google drive clients for Linux operating system. In this guide, we will see three unofficial google drive clients for Linux. Using these clients, you can mount Google drive locally as a virtual file system and access your drive files in your Linux box. Read on.
|
||||
|
||||
### 1. Google-drive-ocamlfuse
|
||||
|
||||
The **google-drive-ocamlfuse** is a FUSE filesystem for Google Drive, written in OCaml. For those wondering, FUSE, stands for **F** ilesystem in **Use** rspace, is a project that allows the users to create virtual file systems in user level. **google-drive-ocamlfuse** allows you to mount your Google Drive on Linux system. It features read/write access to ordinary files and folders, read-only access to Google docks, sheets, and slides, support for multiple google drive accounts, duplicate file handling, access to your drive trash directory, and more.
|
||||
|
||||
#### Installing google-drive-ocamlfuse
|
||||
|
||||
google-drive-ocamlfuse is available in the [**AUR**][2], so you can install it using any AUR helper programs, for example [**Yay**][3].
|
||||
```
|
||||
$ yay -S google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
On Ubuntu:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/ppa
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
To install latest beta version, do:
|
||||
```
|
||||
$ sudo add-apt-repository ppa:alessandro-strada/google-drive-ocamlfuse-beta
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
Once installed, run the following command to launch **google-drive-ocamlfuse** utility from your Terminal:
|
||||
```
|
||||
$ google-drive-ocamlfuse
|
||||
|
||||
```
|
||||
|
||||
When you run this first time, the utility will open your web browser and ask your permission to authorize your google drive files. Once you gave authorization, all necessary config files and folders it needs to mount your google drive will be automatically created.
|
||||
|
||||
![][5]
|
||||
|
||||
After successful authentication, you will see the following message in your Terminal.
|
||||
```
|
||||
Access token retrieved correctly.
|
||||
|
||||
```
|
||||
|
||||
You’re good to go now. Close the web browser and then create a mount point to mount your google drive files.
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Finally, mount your google drive using command:
|
||||
```
|
||||
$ google-drive-ocamlfuse ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Congratulations! You can access access your files either from Terminal or file manager.
|
||||
|
||||
From **Terminal** :
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
From **File manager** :
|
||||
|
||||
![][6]
|
||||
|
||||
If you have more than one account, use **label** option to distinguish different accounts like below.
|
||||
```
|
||||
$ google-drive-ocamlfuse -label label [mountpoint]
|
||||
|
||||
```
|
||||
|
||||
Once you’re done, unmount the FUSE flesystem using command:
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
For more details, refer man pages.
|
||||
```
|
||||
$ google-drive-ocamlfuse --help
|
||||
|
||||
```
|
||||
|
||||
Also, do check the [**official wiki**][7] and the [**project GitHub repository**][8] for more details.
|
||||
|
||||
### 2. GCSF
|
||||
|
||||
**GCSF** is a FUSE filesystem based on Google Drive, written using **Rust** programming language. The name GCSF has come from the Romanian word “ **G** oogle **C** onduce **S** istem de **F** ișiere”, which means “Google Drive Filesystem” in English. Using GCSF, you can mount your Google drive as a local virtual file system and access the contents from the Terminal or file manager. You might wonder how it differ from other Google Drive FUSE projects, for example **google-drive-ocamlfuse**. The developer of GCSF replied to a similar [comment on Reddit][9] “GCSF tends to be faster in several cases (listing files recursively, reading large files from Drive). The caching strategy it uses also leads to very fast reads (x4-7 improvement compared to google-drive-ocamlfuse) for files that have been cached, at the cost of using more RAM“.
|
||||
|
||||
#### Installing GCSF
|
||||
|
||||
GCSF is available in the [**AUR**][10], so the Arch Linux users can install it using any AUR helper, for example [**Yay**][3].
|
||||
```
|
||||
$ yay -S gcsf-git
|
||||
|
||||
```
|
||||
|
||||
For other distributions, do the following.
|
||||
|
||||
Make sure you have installed Rust on your system.
|
||||
|
||||
Make sure **pkg-config** and the **fuse** packages are installed. They are available in the default repositories of most Linux distributions. For example, on Ubuntu and derivatives, you can install them using command:
|
||||
```
|
||||
$ sudo apt-get install -y libfuse-dev pkg-config
|
||||
|
||||
```
|
||||
|
||||
Once all dependencies installed, run the following command to install GCSF:
|
||||
```
|
||||
$ cargo install gcsf
|
||||
|
||||
```
|
||||
|
||||
#### Usage
|
||||
|
||||
First, we need to authorize our google drive. To do so, simply run:
|
||||
```
|
||||
$ gcsf login ostechnix
|
||||
|
||||
```
|
||||
|
||||
You must specify a session name. Replace **ostechnix** with your own session name. You will see an output something like below with an URL to authorize your google drive account.
|
||||
|
||||
![][11]
|
||||
|
||||
Just copy and navigate to the above URL from your browser and click **allow** to give permission to access your google drive contents. Once you gave the authentication you will see an output like below.
|
||||
```
|
||||
Successfully logged in. Credentials saved to "/home/sk/.config/gcsf/ostechnix".
|
||||
|
||||
```
|
||||
|
||||
GCSF will create a configuration file in **$XDG_CONFIG_HOME/gcsf/gcsf.toml** , which is usually defined as **$HOME/.config/gcsf/gcsf.toml**. Credentials are stored in the same directory.
|
||||
|
||||
Next, create a directory to mount your google drive contents.
|
||||
```
|
||||
$ mkdir ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Then, edit **/etc/fuse.conf** file:
|
||||
```
|
||||
$ sudo vi /etc/fuse.conf
|
||||
|
||||
```
|
||||
|
||||
Uncomment the following line to allow non-root users to specify the allow_other or allow_root mount options.
|
||||
```
|
||||
user_allow_other
|
||||
|
||||
```
|
||||
|
||||
Save and close the file.
|
||||
|
||||
Finally, mount your google drive using command:
|
||||
```
|
||||
$ gcsf mount ~/mygoogledrive -s ostechnix
|
||||
|
||||
```
|
||||
|
||||
Sample output:
|
||||
```
|
||||
INFO gcsf > Creating and populating file system...
|
||||
INFO gcsf > File sytem created.
|
||||
INFO gcsf > Mounting to /home/sk/mygoogledrive
|
||||
INFO gcsf > Mounted to /home/sk/mygoogledrive
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
INFO gcsf::gcsf::file_manager > Checking for changes and possibly applying them.
|
||||
|
||||
```
|
||||
|
||||
Again, replace **ostechnix** with your session name. You can view the existing sessions using command:
|
||||
```
|
||||
$ gcsf list
|
||||
Sessions:
|
||||
- ostechnix
|
||||
|
||||
```
|
||||
|
||||
You can now access your google drive contents either from the Terminal or from File manager.
|
||||
|
||||
From **Terminal** :
|
||||
```
|
||||
$ ls ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
From **File manager** :
|
||||
|
||||
![][12]
|
||||
|
||||
If you don’t know where your Google drive is mounted, use **df** or **mount** command as shown below.
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 968M 0 968M 0% /dev
|
||||
tmpfs 200M 1.6M 198M 1% /run
|
||||
/dev/sda1 20G 7.5G 12G 41% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 40K 200M 1% /run/user/1000
|
||||
GCSF 15G 857M 15G 6% /home/sk/mygoogledrive
|
||||
|
||||
$ mount | grep GCSF
|
||||
GCSF on /home/sk/mygoogledrive type fuse (rw,nosuid,nodev,relatime,user_id=1000,group_id=1000,allow_other)
|
||||
|
||||
```
|
||||
|
||||
Once done, unmount the google drive using command:
|
||||
```
|
||||
$ fusermount -u ~/mygoogledrive
|
||||
|
||||
```
|
||||
|
||||
Check the [**GCSF GitHub repository**][13] for more details.
|
||||
|
||||
### 3. Tuxdrive
|
||||
|
||||
**Tuxdrive** is yet another unofficial google drive client for Linux. We have written a detailed guide about Tuxdrive a while ago. Please check the following link.
|
||||
|
||||
Of course, there were few other unofficial google drive clients available in the past, such as Grive2, Syncdrive. But it seems that they are discontinued now. I will keep updating this list when I come across any active google drive clients.
|
||||
|
||||
And, that’s all for now, folks. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-mount-google-drive-locally-as-virtual-file-system-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.google.com/drive/
|
||||
[2]:https://aur.archlinux.org/packages/google-drive-ocamlfuse/
|
||||
[3]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[4]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-2.png
|
||||
[7]:https://github.com/astrada/google-drive-ocamlfuse/wiki/Configuration
|
||||
[8]:https://github.com/astrada/google-drive-ocamlfuse
|
||||
[9]:https://www.reddit.com/r/DataHoarder/comments/8vlb2v/google_drive_as_a_file_system/e1oh9q9/
|
||||
[10]:https://aur.archlinux.org/packages/gcsf-git/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-3.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/07/google-drive-4.png
|
||||
[13]:https://github.com/harababurel/gcsf
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (wyxplus)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Go on an adventure in your Linux terminal)
|
||||
[#]: via: (https://opensource.com/article/18/12/linux-toy-adventure)
|
||||
[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
|
||||
|
||||
Go on an adventure in your Linux terminal
|
||||
======
|
||||
|
||||
Our final day of the Linux command-line toys advent calendar ends with the beginning of a grand adventure.
|
||||
|
||||
|
||||
|
||||
Today is the final day of our 24-day-long Linux command-line toys advent calendar. Hopefully, you've been following along, but if not, start back at [the beginning][1] and work your way through. You'll find plenty of games, diversions, and oddities for your Linux terminal.
|
||||
|
||||
And while you may have seen some toys from our calendar before, we hope there’s at least one new thing for everyone.
|
||||
|
||||
Today's toy was suggested by Opensource.com moderator [Joshua Allen Holm][2]:
|
||||
|
||||
"If the last day of your advent calendar is not ESR's [Eric S. Raymond's] [open source release of Adventure][3], which retains use of the classic 'advent' command (Adventure in the BSD Games package uses 'adventure), I will be very, very, very disappointed. ;-)"
|
||||
|
||||
What a perfect way to end our series.
|
||||
|
||||
Colossal Cave Adventure (often just called Adventure), is a text-based game from the 1970s that gave rise to the entire adventure game genre. Despite its age, Adventure is still an easy way to lose hours as you explore a fantasy world, much like a Dungeons and Dragons dungeon master might lead you through an imaginary place.
|
||||
|
||||
Rather than take you through the history of Adventure here, I encourage you to go read Joshua's [history of the game][4] itself and why it was resurrected and re-ported a few years ago. Then, go [clone the source][5] and follow the [installation instructions][6] to launch the game with **advent** **** on your system. Or, as Joshua mentions, another version of the game can be obtained from the **bsd-games** package, which is probably available from your default repositories in your distribution of choice.
|
||||
|
||||
Do you have a favorite command-line toy that you we should have included? Our series concludes today, but we'd still love to feature some cool command-line toys in the new year. Let me know in the comments below, and I'll check it out. And let me know what you thought of today's amusement.
|
||||
|
||||
Be sure to check out yesterday's toy, [The Linux command line can fetch fun from afar][7], and I'll see you next year!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/linux-toy-adventure
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jason-baker
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/12/linux-toy-boxes
|
||||
[2]: https://opensource.com/users/holmja
|
||||
[3]: https://gitlab.com/esr/open-adventure (https://gitlab.com/esr/open-adventure)
|
||||
[4]: https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
|
||||
[5]: https://gitlab.com/esr/open-adventure
|
||||
[6]: https://gitlab.com/esr/open-adventure/blob/master/INSTALL.adoc
|
||||
[7]: https://opensource.com/article/18/12/linux-toy-remote
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to use Magit to manage Git projects)
|
||||
[#]: via: (https://opensource.com/article/19/1/how-use-magit)
|
||||
[#]: author: (Sachin Patil https://opensource.com/users/psachin)
|
||||
|
||||
How to use Magit to manage Git projects
|
||||
======
|
||||
Emacs' Magit extension makes it easy to get started with Git version control.
|
||||

|
||||
|
||||
[Git][1] is an excellent [version control][2] tool for managing projects, but it can be hard for novices to learn. It's difficult to work from the Git command line unless you're familiar with the flags and options and the appropriate situations to use them. This can be discouraging and cause people to be stuck with very limited usage.
|
||||
|
||||
Fortunately, most of today's integrated development environments (IDEs) include Git extensions that make using it a lot easier. One such Git extension available in Emacs is called [Magit][3].
|
||||
|
||||
The Magit project has been around for 10 years and defines itself as "a Git porcelain inside Emacs." In other words, it's an interface where every action can be managed by pressing a key. This article walks you through the Magit interface and explains how to use it to manage a Git project.
|
||||
|
||||
If you haven't already, [install Emacs][4], then [install Magit][5] before you continue with this tutorial.
|
||||
|
||||
### Magit's interface
|
||||
|
||||
Start by visiting a project directory in Emacs' [Dired mode][6]. For example, all my Emacs configurations are stored in the **~/.emacs.d/** directory, which is managed by Git.
|
||||
|
||||
|
||||
|
||||
If you were working from the command line, you would enter **git status** to find a project's current status. Magit has a similar function: **magit-status**. You can call this function using **M-x magit-status** (short for the keystroke **Alt+x magit-status** ). Your result will look something like this:
|
||||
|
||||
|
||||
|
||||
Magit shows much more information than you would get from the **git status** command. It shows a list of untracked files, files that aren't staged, and staged files. It also shows the stash list and the most recent commits—all in a single window.
|
||||
|
||||
If you want to know what has changed, use the Tab key. For example, if I move my cursor over the unstaged file **custom_functions.org** and press the Tab key, Magit will display the changes:
|
||||
|
||||
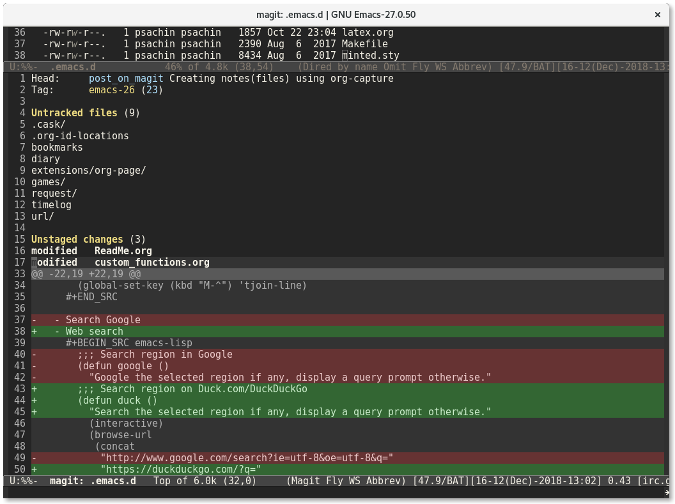
|
||||
|
||||
This is similar to using the command **git diff custom_functions.org**. Staging a file is even easier. Simply move the cursor over a file and press the **s** key. The file will be quickly moved to the staged file list:
|
||||
|
||||
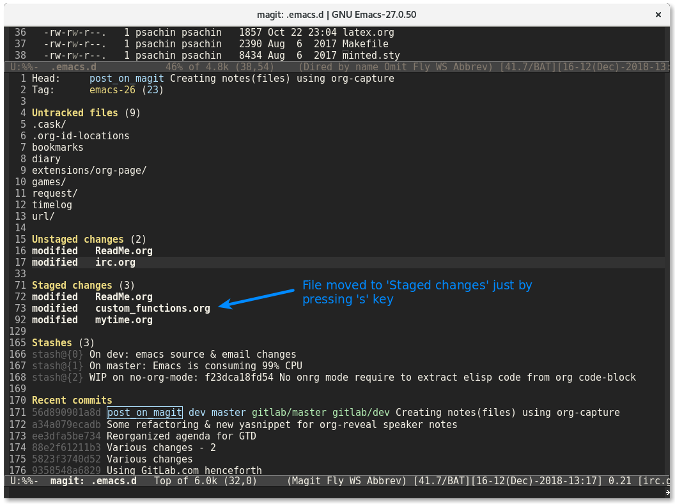
|
||||
|
||||
To unstage a file, use the **u** key. It is quicker and more fun to use **s** and **u** instead of entering **git add -u <file>** and **git reset HEAD <file>** on the command line.
|
||||
|
||||
### Commit changes
|
||||
|
||||
In the same Magit window, pressing the **c** key will display a commit window that provides flags like **\--all** to stage all files or **\--signoff** to add a signoff line to a commit message.
|
||||
|
||||
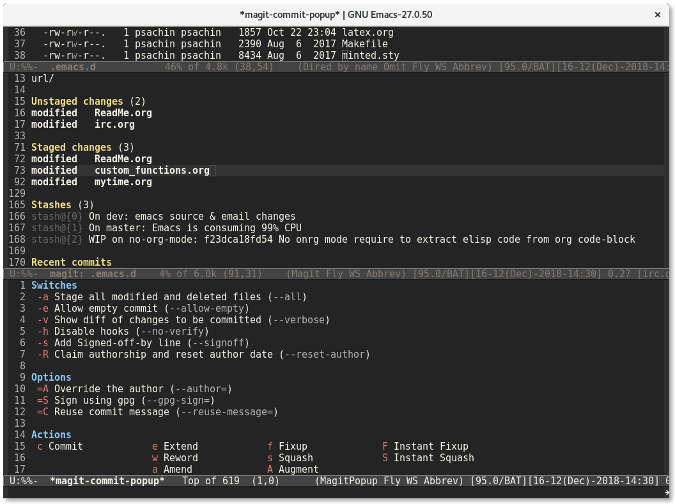
|
||||
|
||||
Move your cursor to the line where you want to enable a signoff flag and press Enter. This will highlight the **\--signoff** text, which indicates that the flag is enabled.
|
||||
|
||||
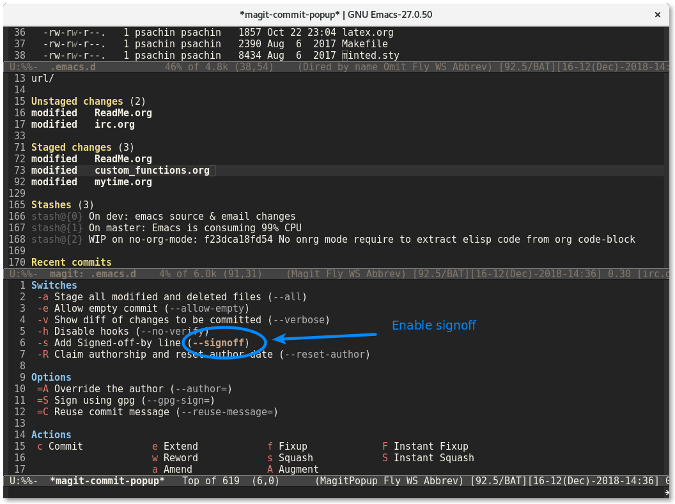
|
||||
|
||||
Pressing **c** again will display the window to write the commit message.
|
||||
|
||||
|
||||
|
||||
Finally, use **C-c C-c **(short form of the keys Ctrl+cc) to commit the changes.
|
||||
|
||||
|
||||
|
||||
### Push changes
|
||||
|
||||
Once the changes are committed, the commit line will appear in the **Recent commits** section.
|
||||
|
||||
|
||||
|
||||
Place the cursor on that commit and press **p** to push the changes.
|
||||
|
||||
I've uploaded a [demonstration][7] on YouTube if you want to get a feel for using Magit. I have just scratched the surface in this article. It has many cool features to help you with Git branches, rebasing, and more. You can find [documentation, support, and more][8] linked from Magit's homepage.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/how-use-magit
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/psachin
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://git-scm.com
|
||||
[2]: https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control
|
||||
[3]: https://magit.vc
|
||||
[4]: https://www.gnu.org/software/emacs/download.html
|
||||
[5]: https://magit.vc/manual/magit/Installing-from-Melpa.html#Installing-from-Melpa
|
||||
[6]: https://www.gnu.org/software/emacs/manual/html_node/emacs/Dired-Enter.html#Dired-Enter
|
||||
[7]: https://youtu.be/Vvw75Pqp7Mc
|
||||
[8]: https://magit.vc/
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Midori: A Lightweight Open Source Web Browser)
|
||||
[#]: via: (https://itsfoss.com/midori-browser)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Midori: A Lightweight Open Source Web Browser
|
||||
======
|
||||
|
||||
**Here’s a quick review of the lightweight, fast, open source web browser Midori, which has returned from the dead.**
|
||||
|
||||
If you are looking for a lightweight [alternative web browser][1], try Midori.
|
||||
|
||||
[Midori][2] is an open source web browser that focuses more on being lightweight than on providing a ton of features.
|
||||
|
||||
If you have never heard of Midori, you might think that it is a new application but Midori was first released in 2007.
|
||||
|
||||
Because it focused on speed, Midori soon gathered a niche following and became the default browser in lightweight Linux distributions like Bodhi Linux, SilTaz etc.
|
||||
|
||||
Other distributions like [elementary OS][3] also used Midori as its default browser. But the development of Midori stalled around 2016 and its fans started wondering if Midori was dead already. elementary OS dropped it from its latest release, I believe, for this reason.
|
||||
|
||||
The good news is that Midori is not dead. After almost two years of inactivity, the development resumed in the last quarter of 2018. A few extensions including an ad-blocker were added in the later releases.
|
||||
|
||||
### Features of Midori web browser
|
||||
|
||||
![Midori web browser][4]
|
||||
|
||||
Here are some of the main features of the Midori browser
|
||||
|
||||
* Written in Vala with GTK+3 and WebKit rendering engine.
|
||||
* Tabs, windows and session management
|
||||
* Speed dial
|
||||
* Saves tab for the next session by default
|
||||
* Uses DuckDuckGo as a default search engine. It can be changed to Google or Yahoo.
|
||||
* Bookmark management
|
||||
* Customizable and extensible interface
|
||||
* Extension modules can be written in C and Vala
|
||||
* Supports HTML5
|
||||
* An extremely limited set of extensions include an ad-blocker, colorful tabs etc. No third-party extensions.
|
||||
* Form history
|
||||
* Private browsing
|
||||
* Available for Linux and Windows
|
||||
|
||||
|
||||
|
||||
Trivia: Midori is a Japanese word that means green. The Midori developer is not Japanese if you were guessing something along that line.
|
||||
|
||||
### Experiencing Midori
|
||||
|
||||
![Midori web browser in Ubuntu 18.04][5]
|
||||
|
||||
I have been using Midori for the past few days. The experience is mostly fine. It supports HTML5 and renders the websites quickly. The ad-blocker is okay. The browsing experience is more or less smooth as you would expect in any standard web browser.
|
||||
|
||||
The lack of extensions has always been a weak point of Midori so I am not going to talk about that.
|
||||
|
||||
What I did notice is that it doesn’t support international languages. I couldn’t find a way to add new language support. It could not render the Hindi fonts at all and I am guessing it’s the same with many other non-[Romance languages][6].
|
||||
|
||||
I also had my fair share of troubles with YouTube videos. Some videos would throw playback error while others would run just fine.
|
||||
|
||||
Midori didn’t eat my RAM like Chrome so that’s a big plus here.
|
||||
|
||||
If you want to try out Midori, let’s see how can you get your hands on it.
|
||||
|
||||
### Install Midori on Linux
|
||||
|
||||
Midori is no longer available in the Ubuntu 18.04 repository. However, the newer versions of Midori can be easily installed using the [Snap packages][7].
|
||||
|
||||
If you are using Ubuntu, you can find Midori (Snap version) in the Software Center and install it from there.
|
||||
|
||||
![Midori browser is available in Ubuntu Software Center][8]Midori browser is available in Ubuntu Software Center
|
||||
|
||||
For other Linux distributions, make sure that you have [Snap support enabled][9] and then you can install Midori using the command below:
|
||||
|
||||
```
|
||||
sudo snap install midori
|
||||
```
|
||||
|
||||
You always have the option to compile from the source code. You can download the source code of Midori from its website.
|
||||
|
||||
If you like Midori and want to help this open source project, please donate to them or [buy Midori merchandise from their shop][10].
|
||||
|
||||
Do you use Midori or have you ever tried it? How’s your experience with it? What other web browser do you prefer to use? Please share your views in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/midori-browser
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/open-source-browsers-linux/
|
||||
[2]: https://www.midori-browser.org/
|
||||
[3]: https://itsfoss.com/elementary-os-juno-features/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?resize=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-browser-linux.jpeg?resize=800%2C491&ssl=1
|
||||
[6]: https://en.wikipedia.org/wiki/Romance_languages
|
||||
[7]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[8]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/midori-ubuntu-software-center.jpeg?ssl=1
|
||||
[9]: https://itsfoss.com/install-snap-linux/
|
||||
[10]: https://www.midori-browser.org/shop
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Midori-web-browser.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,93 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Take to the virtual skies with FlightGear)
|
||||
[#]: via: (https://opensource.com/article/19/1/flightgear)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
Take to the virtual skies with FlightGear
|
||||
======
|
||||
Dreaming of piloting a plane? Try open source flight simulator FlightGear.
|
||||

|
||||
|
||||
If you've ever dreamed of piloting a plane, you'll love [FlightGear][1]. It's a full-featured, [open source][2] flight simulator that runs on Linux, MacOS, and Windows.
|
||||
|
||||
The FlightGear project began in 1996 due to dissatisfaction with commercial flight simulation programs, which were not scalable. Its goal was to create a sophisticated, robust, extensible, and open flight simulator framework for use in academia and pilot training or by anyone who wants to play with a flight simulation scenario.
|
||||
|
||||
### Getting started
|
||||
|
||||
FlightGear's hardware requirements are fairly modest, including an accelerated 3D video card that supports OpenGL for smooth framerates. It runs well on my Linux laptop with an i5 processor and only 4GB of RAM. Its documentation includes an [online manual][3]; a [wiki][4] with portals for [users][5] and [developers][6]; and extensive tutorials (such as one for its default aircraft, the [Cessna 172p][7]) to teach you how to operate it.
|
||||
|
||||
It's easy to install on both [Fedora][8] and [Ubuntu][9] Linux. Fedora users can consult the [Fedora installation page][10] to get FlightGear running.
|
||||
|
||||
On Ubuntu 18.04, I had to install a repository:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:saiarcot895/flightgear
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install flightgear
|
||||
```
|
||||
|
||||
Once the installation finished, I launched it from the GUI, but you can also launch the application from a terminal by entering:
|
||||
|
||||
```
|
||||
$ fgfs
|
||||
```
|
||||
|
||||
### Configuring FlightGear
|
||||
|
||||
The menu on the left side of the application window provides configuration options.
|
||||
|
||||
|
||||
|
||||
**Summary** returns you to the application's home screen.
|
||||
|
||||
**Aircraft** shows the aircraft you have installed and offers the option to install up to 539 other aircraft available in FlightGear's default "hangar." I installed a Cessna 150L, a Piper J-3 Cub, and a Bombardier CRJ-700. Some of the aircraft (including the CRJ-700) have tutorials to teach you how to fly a commercial jet; I found the tutorials informative and accurate.
|
||||
|
||||
|
||||
|
||||
To select an aircraft to pilot, highlight it and click on **Fly!** at the bottom of the menu. I chose the default Cessna 172p and found the cockpit depiction extremely accurate.
|
||||
|
||||
|
||||
|
||||
The default airport is Honolulu, but you can change it in the **Location** menu by providing your favorite airport's [ICAO airport code][11] identifier. I found some small, local, non-towered airports like Olean and Dunkirk, New York, as well as larger airports including Buffalo, O'Hare, and Raleigh—and could even choose a specific runway.
|
||||
|
||||
Under **Environment** , you can adjust the time of day, the season, and the weather. The simulation includes advance weather modeling and the ability to download current weather from [NOAA][12].
|
||||
|
||||
**Settings** provides an option to start the simulation in Paused mode by default. Also in Settings, you can select multi-player mode, which allows you to "fly" with other players on FlightGear supporters' global network of servers that allow for multiple users. You must have a moderately fast internet connection to support this functionality.
|
||||
|
||||
The **Add-ons** menu allows you to download aircraft and additional scenery.
|
||||
|
||||
### Take flight
|
||||
|
||||
To "fly" my Cessna, I used a Logitech joystick that worked well. You can calibrate your joystick using an option in the **File** menu at the top.
|
||||
|
||||
Overall, I found the simulation very accurate and think the graphics are great. Try FlightGear yourself — I think you will find it a very fun and complete simulation package.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/flightgear
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://home.flightgear.org/
|
||||
[2]: http://wiki.flightgear.org/GNU_General_Public_License
|
||||
[3]: http://flightgear.sourceforge.net/getstart-en/getstart-en.html
|
||||
[4]: http://wiki.flightgear.org/FlightGear_Wiki
|
||||
[5]: http://wiki.flightgear.org/Portal:User
|
||||
[6]: http://wiki.flightgear.org/Portal:Developer
|
||||
[7]: http://wiki.flightgear.org/Cessna_172P
|
||||
[8]: http://rpmfind.net/linux/rpm2html/search.php?query=flightgear
|
||||
[9]: https://launchpad.net/~saiarcot895/+archive/ubuntu/flightgear
|
||||
[10]: https://apps.fedoraproject.org/packages/FlightGear/
|
||||
[11]: https://en.wikipedia.org/wiki/ICAO_airport_code
|
||||
[12]: https://www.noaa.gov/
|
||||
@ -1,146 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Comparing 3 open source databases: PostgreSQL, MariaDB, and SQLite)
|
||||
[#]: via: (https://opensource.com/article/19/1/open-source-databases)
|
||||
[#]: author: (Sam Bocetta https://opensource.com/users/sambocetta)
|
||||
|
||||
Comparing 3 open source databases: PostgreSQL, MariaDB, and SQLite
|
||||
======
|
||||
Find out how to choose the best open source database for your needs.
|
||||

|
||||
|
||||
In the world of modern enterprise technologies, open source software has firmly established itself as one of the biggest forces to reckon with. After all, some of the biggest technology developments have emerged because of the [open source movement][1].
|
||||
|
||||
It's not difficult to see why: even though Linux-based open source network standards may not be as popular as proprietary options, they are the reason smart devices from different manufacturers can communicate with each other. In addition, many argue that open source development produces applications that are superior to their proprietary counterparts. This is one reason why the chances are good that your favorite tools (whether open source or proprietary) were developed using open source databases.
|
||||
|
||||
Like any other category of software, the functionality and features of open source database management systems can differ quite significantly. To put that in plainer terms, [not all open source database management systems are equal][2]. If you are choosing an open source database for your organization, it's important to choose one that is user-friendly, can grow with your organization, and offers more-than-adequate security features.
|
||||
|
||||
With that in mind, we've compiled this overview of open source databases and their respective advantages and disadvantages. Sadly, we had to leave out some of the most used databases. Notably, MongoDB has recently changed its licensing model, so it is no longer truly open source. This decision probably made sense from a business perspective, since MongoDB has become the de facto solution for database hosting [with nearly 27,000 companies][3] using it, but it also means MongoDB can no longer be considered a truly open source system.
|
||||
|
||||
In addition, since it acquired MySQL, Oracle has all but killed the open source nature of that project, which was arguably the go-to open source database for decades. However, this has opened space for other truly open source database solutions to challenge it. Here are three of them to consider.
|
||||
|
||||
### PostgreSQL
|
||||
|
||||
No list of open source databases would be complete without [PostgreSQL][4], which has long been the preferred solution for businesses of all sizes. Oracle's acquisition of MySQL might have made good business sense at the time, but the rise of cloud storage has meant that the database [has gradually fallen out of favor with developers][5].
|
||||
|
||||
Although PostgreSQL has been around for a while, the relative [decline of MySQL][6] has made it a serious contender for the title of most used open source database. Since it works very similarly to MySQL, developers who prefer open source software are converting in droves.
|
||||
|
||||
#### Advantages
|
||||
|
||||
* By far, PostgreSQL's most mentioned advantage is the efficiency of its central algorithm, which means it outperforms many databases that are advertised as more advanced. This is especially useful if you are working with large datasets, for which I/O processes can otherwise become a bottleneck.
|
||||
|
||||
* It is also one of the most flexible open source databases around; you can write functions in a wide range of server-side languages: Python, Perl, Java, Ruby, C, and R.
|
||||
|
||||
* As one of the most commonly used open source databases, PostgreSQL's community support is some of the best around.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
* PostgreSQL's efficiency with large datasets is well known, but there are quicker tools available for smaller databases.
|
||||
|
||||
* While its community support is very good, PostgreSQL's core documentation could be improved.
|
||||
|
||||
* If you are used to advanced tools like parallelization and clustering, be aware that these require third-party plugins in PostgreSQL. There are plans to gradually add these features to the main release, but it will likely be a few years before they are offered as standard.
|
||||
|
||||
|
||||
|
||||
|
||||
### MariaDB
|
||||
|
||||
[MariaDB][7] is a truly open source distribution of MySQL (released under the [GNU GPLv2][8]). It was [created after Oracle's acquisition][9] of MySQL, when some of MySQL's core developers were concerned that Oracle would undermine its open source philosophy.
|
||||
|
||||
MariaDB was developed to be as compatible with MySQL as possible while replacing several key components. It uses a storage engine, Aria, that functions as both a transactional and non-transactional engine. [Some even speculated][10] Aria would become the standard engine for MySQL in future releases, before MariaDB diverged.
|
||||
|
||||
#### Advantages
|
||||
|
||||
* Many users choose MariaDB over MySQL due to MariaDB's [frequent security releases][11]. While this does not necessarily mean MariaDB is more secure, it does indicate the development community takes security seriously.
|
||||
|
||||
* Others say MariaDB's major advantages are that it will almost definitely remain open source and highly compatible with MySQL. This means migrating from one system to the other is extremely fast.
|
||||
|
||||
* Because of this compatibility, MariaDB also plays well with many other languages that are commonly used with MySQL. This means less time is spent learning and debugging code.
|
||||
|
||||
* You can [install and run][12] WordPress with MariaDB instead of MySQL for better performance and a richer feature set. WordPress is the [most popular CMS by marketshare][13]—powering nearly half the internet—and has an active open source developer community. Third-party themes and plugins work as intended when WordPress is installed with MariaDB.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
* MariaDB is somewhat liable to bloating. Its central IDX log file, in particular, tends to become very large after protracted use, ultimately slowing performance.
|
||||
|
||||
* Caching is another area where MariaDB could use work—it is not as fast as it could be, which can be frustrating.
|
||||
|
||||
* Despite all the initial promises, MariaDB is no longer completely compatible with MySQL. If you are migrating from MySQL, you will have some re-coding to do.
|
||||
|
||||
|
||||
|
||||
|
||||
### SQLite
|
||||
|
||||
[SQLite][14] is arguably the most implemented database engine in the world, thanks to its adoption by many popular web browsers, operating systems, and mobile phones. Originally developed as a lightweight fork of MySQL, unlike many other databases it is not a client-server engine; rather, the full software is embedded into each implementation.
|
||||
|
||||
This creates SQLite's major advantage: on embedded or distributed systems, each machine carries an entire implementation of the database. This can greatly speed up the performance of databases because it reduces the need for inter-system calls.
|
||||
|
||||
#### Advantages
|
||||
|
||||
* If you are looking to build and implement a small database, SQLite is [arguably the best way to go][15]. It is extremely small, so it can be implemented across a wide range of embedded systems without time-consuming workarounds.
|
||||
|
||||
* Its small size makes the system extremely fast. While some more advanced databases use complex ways of producing efficiency savings, SQLite takes a much simpler approach: By reducing the size of your database and its associated processing software, there is simply less data to work with.
|
||||
|
||||
* Its widespread adoption also means SQLite is probably the most compatible database out there. This is particularly important if you need or plan to integrate your system with smartphones: the system has been native on iOS for as long as there have been third-party apps and works flawlessly in a wide range of environments.
|
||||
|
||||
|
||||
|
||||
|
||||
#### Disadvantages
|
||||
|
||||
* SQLite's tiny size means it lacks some features found in larger databases. It lacks built-in data encryption, for example, something that has become standard to prevent the [most common online hacker attacks][16].
|
||||
|
||||
* While the wide adoption and publicly available code makes SQLite easy to work with, it also increases its attack surface area. This is its most commonly cited disadvantage. New critical vulnerabilities are frequently discovered in SQLite, such as the recent remote attack vector called [Magellan][17].
|
||||
|
||||
* Although SQLite's single-file approach creates speed advantages, there is no easy way to implement a multi-user environment using the system.
|
||||
|
||||
|
||||
|
||||
|
||||
### Which open source database is best?
|
||||
|
||||
Ultimately, your choice of open source database will depend on your business needs and particularly on the size of your system. For small databases or those with limited use, go for a lightweight solution: not only will it speed up implementation but a less-complex system means you will spend less time debugging.
|
||||
|
||||
For larger systems, especially in growing businesses, invest the time to implement a more complex database like PostgreSQL. This will save you time—eventually—by removing the need to re-code your databases as your business grows.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/open-source-databases
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sambocetta
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/2/pivotal-moments-history-open-source
|
||||
[2]: https://blog.capterra.com/free-database-software/
|
||||
[3]: https://idatalabs.com/tech/products/mongodb
|
||||
[4]: https://www.postgresql.org/
|
||||
[5]: https://www.theregister.co.uk/2018/05/31/rise_of_the_open_source_data_strategies/
|
||||
[6]: https://www.itworld.com/article/2721995/big-data/signs-of-mysql-decline-on-horizon.html
|
||||
[7]: https://mariadb.org/
|
||||
[8]: https://github.com/MariaDB/server/blob/10.4/COPYING
|
||||
[9]: https://mariadb.com/about-us/
|
||||
[10]: http://kb.askmonty.org/en/aria-faq
|
||||
[11]: https://mariadb.org/tag/security/
|
||||
[12]: https://mariadb.com/resources/blog/how-to-install-and-run-wordpress-with-mariadb/
|
||||
[13]: https://websitesetup.org/popular-cms/
|
||||
[14]: https://www.sqlite.org/index.html
|
||||
[15]: https://www.sqlite.org/aff_short.html
|
||||
[16]: https://hostingcanada.org/most-common-website-vulnerabilities/
|
||||
[17]: https://www.securitynewspaper.com/2018/12/18/critical-vulnerability-in-sqlite-you-should-update-now/
|
||||
@ -0,0 +1,58 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Getting started with Sandstorm, an open source web app platform)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-sandstorm)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Getting started with Sandstorm, an open source web app platform
|
||||
======
|
||||
Learn about Sandstorm, the third in our series on open source tools that will make you more productive in 2019.
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the third of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Sandstorm
|
||||
|
||||
Being productive isn't just about to-do lists and keeping things organized. Often it requires a suite of tools linked to make a workflow go smoothly.
|
||||
|
||||
|
||||
|
||||
[Sandstorm][1] is an open source collection of packaged apps, all accessible from a single web interface and managed from a central console. You can host it yourself or use the [Sandstorm Oasis][2] service—for a per-user fee.
|
||||
|
||||
|
||||
|
||||
Sandstorm has a marketplace that makes it simple to install the apps that are available. It includes apps for productivity, finance, note taking, task tracking, chat, games, and a whole lot more. You can also package your own apps and upload them by following the application-packaging guidelines in the [developer documentation][3].
|
||||
|
||||
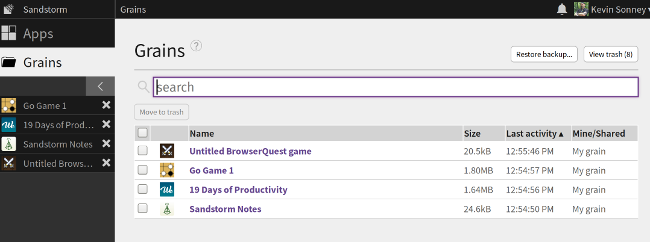
|
||||
|
||||
Once installed, a user can create [grains][4]—basically containerized instances of app data. Grains are private by default and can be shared with other Sandstorm users. This means they are secure by default, and users can chose what to share with others.
|
||||
|
||||
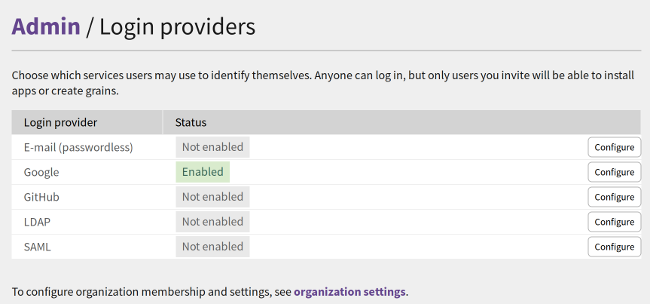
|
||||
|
||||
Sandstorm can authenticate from several different external sources as well as use a "passwordless" email-based authentication. Using an external service means you don't have to manage yet another set of credentials if you already use one of the supported services.
|
||||
|
||||
In the end, Sandstorm makes installing and using supported collaborative apps quick, easy, and secure.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-sandstorm
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://sandstorm.io/
|
||||
[2]: https://oasis.sandstorm.io
|
||||
[3]: https://docs.sandstorm.io/en/latest/developing/
|
||||
[4]: https://sandstorm.io/how-it-works
|
||||
156
sources/tech/20190116 Best Audio Editors For Linux.md
Normal file
156
sources/tech/20190116 Best Audio Editors For Linux.md
Normal file
@ -0,0 +1,156 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Best Audio Editors For Linux)
|
||||
[#]: via: (https://itsfoss.com/best-audio-editors-linux)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
Best Audio Editors For Linux
|
||||
======
|
||||
|
||||
You’ve got a lot of choices when it comes to audio editors for Linux. No matter whether you are a professional music producer or just learning to create awesome music, the audio editors will always come in handy.
|
||||
|
||||
Well, for professional-grade usage, a [DAW][1] (Digital Audio Workstation) is always recommended. However, not everyone needs all the functionalities, so you should know about some of the most simple audio editors as well.
|
||||
|
||||
In this article, we will talk about a couple of DAWs and basic audio editors which are available as **free and open source** solutions for Linux and (probably) for other operating systems.
|
||||
|
||||
### Top Audio Editors for Linux
|
||||
|
||||
![Best audio editors and DAW for Linux][2]
|
||||
|
||||
We will not be focusing on all the functionalities that DAWs offer – but the basic audio editing capabilities. You may still consider this as the list of best DAW for Linux.
|
||||
|
||||
**Installation instruction:** You will find all the mentioned audio editors or DAWs in your AppCenter or Software center. In case, you do not find them listed, please head to their official website for more information.
|
||||
|
||||
#### 1\. Audacity
|
||||
|
||||
![audacity audio editor][3]
|
||||
|
||||
Audacity is one of the most basic yet a capable audio editor available for Linux. It is a free and open-source cross-platform tool. A lot of you must be already knowing about it.
|
||||
|
||||
It has improved a lot when compared to the time when it started trending. I do recall that I utilized it to “try” making karaokes by removing the voice from an audio file. Well, you can still do it – but it depends.
|
||||
|
||||
**Features:**
|
||||
|
||||
It also supports plug-ins that include VST effects. Of course, you should not expect it to support VST Instruments.
|
||||
|
||||
* Live audio recording through a microphone or a mixer
|
||||
* Export/Import capability supporting multiple formats and multiple files at the same time
|
||||
* Plugin support: LADSPA, LV2, Nyquist, VST and Audio Unit effect plug-ins
|
||||
* Easy editing with cut, paste, delete and copy functions.
|
||||
* Spectogram view mode for analyzing frequencies
|
||||
|
||||
|
||||
|
||||
#### 2\. LMMS
|
||||
|
||||
![][4]
|
||||
|
||||
LMMS is a free and open source (cross-platform) digital audio workstation. It includes all the basic audio editing functionalities along with a lot of advanced features.
|
||||
|
||||
You can mix sounds, arrange them, or create them using VST instruments. It does support them. Also, it comes baked in with some samples, presets, VST Instruments, and effects to get started. In addition, you also get a spectrum analyzer for some advanced audio editing.
|
||||
|
||||
**Features:**
|
||||
|
||||
* Note playback via MIDI
|
||||
* VST Instrument support
|
||||
* Native multi-sample support
|
||||
* Built-in compressor, limiter, delay, reverb, distortion and bass enhancer
|
||||
|
||||
|
||||
|
||||
#### 3\. Ardour
|
||||
|
||||
![Ardour audio editor][5]
|
||||
|
||||
Ardour is yet another free and open source digital audio workstation. If you have an audio interface, Ardour will support it. Of course, you can add unlimited multichannel tracks. The multichannel tracks can also be routed to different mixer tapes for the ease of editing and recording.
|
||||
|
||||
You can also import a video to it and edit the audio to export the whole thing. It comes with a lot of built-in plugins and supports VST plugins as well.
|
||||
|
||||
**Features:**
|
||||
|
||||
* Non-linear editing
|
||||
* Vertical window stacking for easy navigation
|
||||
* Strip silence, push-pull trimming, Rhythm Ferret for transient and note onset-based editing
|
||||
|
||||
|
||||
|
||||
#### 4\. Cecilia
|
||||
|
||||
![cecilia audio editor][6]
|
||||
|
||||
Cecilia is not an ordinary audio editor application. It is meant to be used by sound designers or if you are just in the process of becoming one. It is technically an audio signal processing environment. It lets you create ear-bending sound out of them.
|
||||
|
||||
You get in-build modules and plugins for sound effects and synthesis. It is tailored for a specific use – if that is what you were looking for – look no further!
|
||||
|
||||
**Features:**
|
||||
|
||||
* Modules to achieve more (UltimateGrainer – A state-of-the-art granulation processing, RandomAccumulator – Variable speed recording accumulator,
|
||||
UpDistoRes – Distortion with upsampling and resonant lowpass filter)
|
||||
* Automatic Saving of modulations
|
||||
|
||||
|
||||
|
||||
#### 5\. Mixxx
|
||||
|
||||
![Mixxx audio DJ ][7]
|
||||
|
||||
If you want to mix and record something while being able to have a virtual DJ tool, [Mixxx][8] would be a perfect tool. You get to know the BPM, key, and utilize the master sync feature to match the tempo and beats of a song. Also, do not forget that it is yet another free and open source application for Linux!
|
||||
|
||||
It supports custom DJ equipment as well. So, if you have one or a MIDI – you can record your live mixes using this tool.
|
||||
|
||||
**Features**
|
||||
|
||||
* Broadcast and record DJ Mixes of your song
|
||||
* Ability to connect your equipment and perform live
|
||||
* Key detection and BPM detection
|
||||
|
||||
|
||||
|
||||
#### 6\. Rosegarden
|
||||
|
||||
![rosegarden audio editor][9]
|
||||
|
||||
Rosegarden is yet another impressive audio editor for Linux which is free and open source. It is neither a fully featured DAW nor a basic audio editing tool. It is a mixture of both with some scaled down functionalities.
|
||||
|
||||
I wouldn’t recommend this for professionals but if you have a home studio or just want to experiment, this would be one of the best audio editors for Linux to have installed.
|
||||
|
||||
**Features:**
|
||||
|
||||
* Music notation editing
|
||||
* Recording, Mixing, and samples
|
||||
|
||||
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
These are some of the best audio editors you could find out there for Linux. No matter whether you need a DAW, a cut-paste editing tool, or a basic mixing/recording audio editor, the above-mentioned tools should help you out.
|
||||
|
||||
Did we miss any of your favorite? Let us know about it in the comments below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-audio-editors-linux
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Digital_audio_workstation
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/linux-audio-editors-800x450.jpeg?resize=800%2C450&ssl=1
|
||||
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/audacity-audio-editor.jpg?fit=800%2C591&ssl=1
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/lmms-daw.jpg?fit=800%2C472&ssl=1
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/ardour-audio-editor.jpg?fit=800%2C639&ssl=1
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/cecilia.jpg?fit=800%2C510&ssl=1
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/mixxx.jpg?fit=800%2C486&ssl=1
|
||||
[8]: https://itsfoss.com/dj-mixxx-2/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/rosegarden.jpg?fit=800%2C391&ssl=1
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/linux-audio-editors.jpeg?fit=800%2C450&ssl=1
|
||||
@ -0,0 +1,139 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (GameHub – An Unified Library To Put All Games Under One Roof)
|
||||
[#]: via: (https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/)
|
||||
[#]: author: (SK https://www.ostechnix.com/author/sk/)
|
||||
|
||||
GameHub – An Unified Library To Put All Games Under One Roof
|
||||
======
|
||||
|
||||

|
||||
|
||||
**GameHub** is an unified gaming library that allows you to view, install, run and remove games on GNU/Linux operating system. It supports both native and non-native games from various sources including Steam, GOG, Humble Bundle, and Humble Trove etc. The non-native games are supported by [Wine][1], Proton, [DOSBox][2], ScummVM and RetroArch. It also allows you to add custom emulators and download bonus content and DLCs for GOG games. Simply put, Gamehub is a frontend for Steam/GoG/Humblebundle/Retroarch. It can use steam technologies like Proton to run windows gog games. GameHub is free, open source gaming platform written in **Vala** using **GTK+3**. If you’re looking for a way to manage all games under one roof, GameHub might be a good choice.
|
||||
|
||||
### Installing GameHub
|
||||
|
||||
The author of GameHub has designed it specifically for elementary OS. So, you can install it on Debian, Ubuntu, elementary OS and other Ubuntu-derivatives using GameHub PPA.
|
||||
|
||||
```
|
||||
$ sudo apt install --no-install-recommends software-properties-common
|
||||
$ sudo add-apt-repository ppa:tkashkin/gamehub
|
||||
$ sudo apt update
|
||||
$ sudo apt install com.github.tkashkin.gamehub
|
||||
```
|
||||
|
||||
GameHub is available in [**AUR**][3], so just install it on Arch Linux and its variants using any AUR helpers, for example [**YaY**][4].
|
||||
|
||||
```
|
||||
$ yay -S gamehub-git
|
||||
```
|
||||
|
||||
It is also available as **AppImage** and **Flatpak** packages in [**releases page**][5].
|
||||
|
||||
If you prefer AppImage package, do the following:
|
||||
|
||||
```
|
||||
$ wget https://github.com/tkashkin/GameHub/releases/download/0.12.1-91-dev/GameHub-bionic-0.12.1-91-dev-cd55bb5-x86_64.AppImage -O gamehub
|
||||
```
|
||||
|
||||
Make it executable:
|
||||
|
||||
```
|
||||
$ chmod +x gamehub
|
||||
```
|
||||
|
||||
And, run GameHub using command:
|
||||
|
||||
```
|
||||
$ ./gamehub
|
||||
```
|
||||
|
||||
If you want to use Flatpak installer, run the following commands one by one.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/tkashkin/GameHub.git
|
||||
$ cd GameHub
|
||||
$ scripts/build.sh build_flatpak
|
||||
```
|
||||
|
||||
### Put All Games Under One Roof
|
||||
|
||||
Launch GameHub from menu or application launcher. At first launch, you will see the following welcome screen.
|
||||
|
||||
|
||||
|
||||
As you can see in the above screenshot, you need to login to the given sources namely Steam, GoG or Humble Bundle. If you don’t have Steam client on your Linux system, you need to install it first to access your steam account. For GoG and Humble bundle sources, click on the icon to log in to the respective source.
|
||||
|
||||
Once you logged in to your account(s), all games from the all sources can be visible on GameHub dashboard.
|
||||
|
||||

|
||||
|
||||
You will see list of logged-in sources on the top left corner. To view the games from each source, just click on the respective icon.
|
||||
|
||||
You can also switch between list view or grid view, sort the games by applying the filters and search games from the list in GameHub dashboard.
|
||||
|
||||
#### Installing a game
|
||||
|
||||
Click on the game of your choice from the list and click Install button. If the game is non-native, GameHub will automatically choose the compatibility layer (E.g Wine) that suits to run the game and install the selected game. As you see in the below screenshot, Indiana Jones game is not available for Linux platform.
|
||||
|
||||

|
||||
|
||||
If it is a native game (i.e supports Linux), simply press the Install button.
|
||||
|
||||
![][7]
|
||||
|
||||
If you don’t want to install the game, just hit the **Download** button to save it in your games directory. It is also possible to add locally installed games to GameHub using the **Import** option.
|
||||
|
||||
|
||||
|
||||
#### GameHub Settings
|
||||
|
||||
GameHub Settings window can be launched by clicking on the four straight lines on top right corner.
|
||||
|
||||
From Settings section, we can enable, disable and set various settings such as,
|
||||
|
||||
* Switch between light/dark themes.
|
||||
* Use Symbolic icons instead of colored icons for games.
|
||||
* Switch to compact list.
|
||||
* Enable/disable merging games from different sources.
|
||||
* Enable/disable compatibility layers.
|
||||
* Set games collection directory. The default directory for storing the collection is **$HOME/Games/_Collection**.
|
||||
* Set games directories for each source.
|
||||
* Add/remove emulators,
|
||||
* And many.
|
||||
|
||||
|
||||
|
||||
For more details, refer the project links given at the end of this guide.
|
||||
|
||||
**Related read:**
|
||||
|
||||
And, that’s all for now. Hope this helps. I will be soon here with another guide. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/run-windows-games-softwares-ubuntu-16-04/
|
||||
[2]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
|
||||
[3]: https://aur.archlinux.org/packages/gamehub-git/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]: https://github.com/tkashkin/GameHub/releases
|
||||
[6]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[7]: http://www.ostechnix.com/wp-content/uploads/2019/01/gamehub4.png
|
||||
@ -0,0 +1,236 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Evil-Twin Framework: A tool for improving WiFi security)
|
||||
[#]: via: (https://opensource.com/article/19/1/evil-twin-framework)
|
||||
[#]: author: (André Esser https://opensource.com/users/andreesser)
|
||||
|
||||
The Evil-Twin Framework: A tool for improving WiFi security
|
||||
======
|
||||
Learn about a pen-testing tool intended to test the security of WiFi access points for all types of threats.
|
||||

|
||||
|
||||
The increasing number of devices that connect over-the-air to the internet over-the-air and the wide availability of WiFi access points provide many opportunities for attackers to exploit users. By tricking users to connect to [rogue access points][1], hackers gain full control over the users' network connection, which allows them to sniff and alter traffic, redirect users to malicious sites, and launch other attacks over the network..
|
||||
|
||||
To protect users and teach them to avoid risky online behaviors, security auditors and researchers must evaluate users' security practices and understand the reasons they connect to WiFi access points without being confident they are safe. There are a significant number of tools that can conduct WiFi audits, but no single tool can test the many different attack scenarios and none of the tools integrate well with one another.
|
||||
|
||||
The **Evil-Twin Framework** (ETF) aims to fix these problems in the WiFi auditing process by enabling auditors to examine multiple scenarios and integrate multiple tools. This article describes the framework and its functionalities, then provides some examples to show how it can be used.
|
||||
|
||||
### The ETF architecture
|
||||
|
||||
The ETF framework was written in [Python][2] because the development language is very easy to read and make contributions to. In addition, many of the ETF's libraries, such as **[Scapy][3]** , were already developed for Python, making it easy to use them for ETF.
|
||||
|
||||
The ETF architecture (Figure 1) is divided into different modules that interact with each other. The framework's settings are all written in a single configuration file. The user can verify and edit the settings through the user interface via the **ConfigurationManager** class. Other modules can only read these settings and run according to them.
|
||||
|
||||
![Evil-Twin Framework Architecture][5]
|
||||
|
||||
Figure 1: Evil-Twin framework architecture
|
||||
|
||||
The ETF supports multiple user interfaces that interact with the framework. The current default interface is an interactive console, similar to the one on [Metasploit][6]. A graphical user interface (GUI) and a command line interface (CLI) are under development for desktop/browser use, and mobile interfaces may be an option in the future. The user can edit the settings in the configuration file using the interactive console (and eventually with the GUI). The user interface can interact with every other module that exists in the framework.
|
||||
|
||||
The WiFi module ( **AirCommunicator** ) was built to support a wide range of WiFi capabilities and attacks. The framework identifies three basic pillars of Wi-Fi communication: **packet sniffing** , **custom packet injection** , and **access point creation**. The three main WiFi communication modules are **AirScanner** , **AirInjector** , and **AirHost** , which are responsible for packet sniffing, packet injection, and access point creation, respectively. The three classes are wrapped inside the main WiFi module, AirCommunicator, which reads the configuration file before starting the services. Any type of WiFi attack can be built using one or more of these core features.
|
||||
|
||||
To enable man-in-the-middle (MITM) attacks, which are a common way to attack WiFi clients, the framework has an integrated module called ETFITM (Evil-Twin Framework-in-the-Middle). This module is responsible for the creation of a web proxy used to intercept and manipulate HTTP/HTTPS traffic.
|
||||
|
||||
There are many other tools that can leverage the MITM position created by the ETF. Through its extensibility, ETF can support them—and, instead of having to call them separately, you can add the tools to the framework just by extending the Spawner class. This enables a developer or security auditor to call the program with a preconfigured argument string from within the framework.
|
||||
|
||||
The other way to extend the framework is through plugins. There are two categories of plugins: **WiFi plugins** and **MITM plugins**. MITM plugins are scripts that can run while the MITM proxy is active. The proxy passes the HTTP(S) requests and responses through to the plugins where they can be logged or manipulated. WiFi plugins follow a more complex flow of execution but still expose a fairly simple API to contributors who wish to develop and use their own plugins. WiFi plugins can be further divided into three categories, one for each of the core WiFi communication modules.
|
||||
|
||||
Each of the core modules has certain events that trigger the execution of a plugin. For instance, AirScanner has three defined events to which a response can be programmed. The events usually correspond to a setup phase before the service starts running, a mid-execution phase while the service is running, and a teardown or cleanup phase after a service finishes. Since Python allows multiple inheritance, one plugin can subclass more than one plugin class.
|
||||
|
||||
Figure 1 above is a summary of the framework's architecture. Lines pointing away from the ConfigurationManager mean that the module reads information from it and lines pointing towards it mean that the module can write/edit configurations.
|
||||
|
||||
### Examples of using the Evil-Twin Framework
|
||||
|
||||
There are a variety of ways ETF can conduct penetration testing on WiFi network security or work on end users' awareness of WiFi security. The following examples describe some of the framework's pen-testing functionalities, such as access point and client detection, WPA and WEP access point attacks, and evil twin access point creation.
|
||||
|
||||
These examples were devised using ETF with WiFi cards that allow WiFi traffic capture. They also utilize the following abbreviations for ETF setup commands:
|
||||
|
||||
* **APS** access point SSID
|
||||
* **APB** access point BSSID
|
||||
* **APC** access point channel
|
||||
* **CM** client MAC address
|
||||
|
||||
|
||||
|
||||
In a real testing scenario, make sure to replace these abbreviations with the correct information.
|
||||
|
||||
#### Capturing a WPA 4-way handshake after a de-authentication attack
|
||||
|
||||
This scenario (Figure 2) takes two aspects into consideration: the de-authentication attack and the possibility of catching a 4-way WPA handshake. The scenario starts with a running WPA/WPA2-enabled access point with one connected client device (in this case, a smartphone). The goal is to de-authenticate the client with a general de-authentication attack then capture the WPA handshake once it tries to reconnect. The reconnection will be done manually immediately after being de-authenticated.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][8]
|
||||
|
||||
Figure 2: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
The consideration in this example is the ETF's reliability. The goal is to find out if the tools can consistently capture the WPA handshake. The scenario will be performed multiple times with each tool to check its reliability when capturing the WPA handshake.
|
||||
|
||||
There is more than one way to capture a WPA handshake using the ETF. One way is to use a combination of the AirScanner and AirInjector modules; another way is to just use the AirInjector. The following scenario uses a combination of both modules.
|
||||
|
||||
The ETF launches the AirScanner module and analyzes the IEEE 802.11 frames to find a WPA handshake. Then the AirInjector can launch a de-authentication attack to force a reconnection. The following steps must be done to accomplish this on the ETF:
|
||||
|
||||
1. Enter the AirScanner configuration mode: **config airscanner**
|
||||
2. Configure the AirScanner to not hop channels: **config airscanner**
|
||||
3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = <APC>**
|
||||
4. Start the AirScanner module with the CredentialSniffer plugin: **start airscanner with credentialsniffer**
|
||||
5. Add a target access point BSSID (APS) from the sniffed access points list: **add aps where ssid = <APS>**
|
||||
6. Start the AirInjector, which by default lauches the de-authentication attack: **start airinjector**
|
||||
|
||||
|
||||
|
||||
This simple set of commands enables the ETF to perform an efficient and successful de-authentication attack on every test run. The ETF can also capture the WPA handshake on every test run. The following code makes it possible to observe the ETF's successful execution.
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating new temporary session on 02/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config airscanner
|
||||
ETF[etf/aircommunicator/airscanner]::> listargs
|
||||
sniffing_interface = wlan1; (var)
|
||||
probes = True; (var)
|
||||
beacons = True; (var)
|
||||
hop_channels = false; (var)
|
||||
fixed_sniffing_channel = 11; (var)
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with
|
||||
arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
|
||||
ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
|
||||
[+] Successfully added credentialsniffer plugin.
|
||||
[+] Starting packet sniffer on interface 'wlan1'
|
||||
[+] Set fixed channel to 11
|
||||
ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
|
||||
ETF[etf/aircommunicator/airscanner]::> start airinjector
|
||||
ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
|
||||
- 1000 bursts of 1 packets
|
||||
- 1 different packets
|
||||
[+] Injection attacks finished executing.
|
||||
[+] Starting post injection methods
|
||||
[+] Post injection methods finished
|
||||
[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
|
||||
```
|
||||
|
||||
#### Launching an ARP replay attack and cracking a WEP network
|
||||
|
||||
The next scenario (Figure 3) will also focus on the [Address Resolution Protocol][9] (ARP) replay attack's efficiency and the speed of capturing the WEP data packets containing the initialization vectors (IVs). The same network may require a different number of caught IVs to be cracked, so the limit for this scenario is 50,000 IVs. If the network is cracked during the first test with less than 50,000 IVs, that number will be the new limit for the following tests on the network. The cracking tool to be used will be **aircrack-ng**.
|
||||
|
||||
The test scenario starts with an access point using WEP encryption and an offline client that knows the key—the key for testing purposes is 12345, but it can be a larger and more complex key. Once the client connects to the WEP access point, it will send out a gratuitous ARP packet; this is the packet that's meant to be captured and replayed. The test ends once the limit of packets containing IVs is captured.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][11]
|
||||
|
||||
Figure 3: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
ETF uses Python's Scapy library for packet sniffing and injection. To minimize known performance problems in Scapy, ETF tweaks some of its low-level libraries to significantly speed packet injection. For this specific scenario, the ETF uses **tcpdump** as a background process instead of Scapy for more efficient packet sniffing, while Scapy is used to identify the encrypted ARP packet.
|
||||
|
||||
This scenario requires the following commands and operations to be performed on the ETF:
|
||||
|
||||
1. Enter the AirScanner configuration mode: **config airscanner**
|
||||
2. Configure the AirScanner to not hop channels: **set hop_channels = false**
|
||||
3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = <APC>**
|
||||
4. Enter the ARPReplayer plugin configuration mode: **config arpreplayer**
|
||||
5. Set the target access point BSSID (APB) of the WEP network: **set target_ap_bssid <APB>**
|
||||
6. Start the AirScanner module with the ARPReplayer plugin: **start airscanner with arpreplayer**
|
||||
|
||||
|
||||
|
||||
After executing these commands, ETF correctly identifies the encrypted ARP packet, then successfully performs an ARP replay attack, which cracks the network.
|
||||
|
||||
#### Launching a catch-all honeypot
|
||||
|
||||
The scenario in Figure 4 creates multiple access points with the same SSID. This technique discovers the encryption type of a network that was probed for but out of reach. By launching multiple access points with all security settings, the client will automatically connect to the one that matches the security settings of the locally cached access point information.
|
||||
|
||||
![Scenario for capturing a WPA handshake after a de-authentication attack][13]
|
||||
|
||||
Figure 4: Scenario for capturing a WPA handshake after a de-authentication attack
|
||||
|
||||
Using the ETF, it is possible to configure the **hostapd** configuration file then launch the program in the background. Hostapd supports launching multiple access points on the same wireless card by configuring virtual interfaces, and since it supports all types of security configurations, a complete catch-all honeypot can be set up. For the WEP and WPA(2)-PSK networks, a default password is used, and for the WPA(2)-EAP, an "accept all" policy is configured.
|
||||
|
||||
For this scenario, the following commands and operations must be performed on the ETF:
|
||||
|
||||
1. Enter the APLauncher configuration mode: **config aplauncher**
|
||||
2. Set the desired access point SSID (APS): **set ssid = <APS>**
|
||||
3. Configure the APLauncher as a catch-all honeypot: **set catch_all_honeypot = true**
|
||||
4. Start the AirHost module: **start airhost**
|
||||
|
||||
|
||||
|
||||
With these commands, the ETF can launch a complete catch-all honeypot with all types of security configurations. ETF also automatically launches the DHCP and DNS servers that allow clients to stay connected to the internet. ETF offers a better, faster, and more complete solution to create catch-all honeypots. The following code enables the successful execution of the ETF to be observed.
|
||||
|
||||
```
|
||||
███████╗████████╗███████╗
|
||||
██╔════╝╚══██╔══╝██╔════╝
|
||||
█████╗ ██║ █████╗
|
||||
██╔══╝ ██║ ██╔══╝
|
||||
███████╗ ██║ ██║
|
||||
╚══════╝ ╚═╝ ╚═╝
|
||||
|
||||
|
||||
[+] Do you want to load an older session? [Y/n]: n
|
||||
[+] Creating ne´,cxzw temporary session on 03/08/2018
|
||||
[+] Enter the desired session name:
|
||||
ETF[etf/aircommunicator/]::> config aplauncher
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
|
||||
ssid = CatchMe
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
|
||||
catch_all_honeypot = true
|
||||
ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
|
||||
[+] Killing already started processes and restarting network services
|
||||
[+] Stopping dnsmasq and hostapd services
|
||||
[+] Access Point stopped...
|
||||
[+] Running airhost plugins pre_start
|
||||
[+] Starting hostapd background process
|
||||
[+] Starting dnsmasq service
|
||||
[+] Running airhost plugins post_start
|
||||
[+] Access Point launched successfully
|
||||
[+] Starting dnsmasq service
|
||||
```
|
||||
|
||||
### Conclusions and future work
|
||||
|
||||
These scenarios use common and well-known attacks to help validate the ETF's capabilities for testing WiFi networks and clients. The results also validate that the framework's architecture enables new attack vectors and features to be developed on top of it while taking advantage of the platform's existing capabilities. This should accelerate development of new WiFi penetration-testing tools, since a lot of the code is already written. Furthermore, the fact that complementary WiFi technologies are all integrated in a single tool will make WiFi pen-testing simpler and more efficient.
|
||||
|
||||
The ETF's goal is not to replace existing tools but to complement them and offer a broader choice to security auditors when conducting WiFi pen-testing and improving user awareness.
|
||||
|
||||
The ETF is an open source project [available on GitHub][14] and community contributions to its development are welcomed. Following are some of the ways you can help.
|
||||
|
||||
One of the limitations of current WiFi pen-testing is the inability to log important events during tests. This makes reporting identified vulnerabilities both more difficult and less accurate. The framework could implement a logger that can be accessed by every class to create a pen-testing session report.
|
||||
|
||||
The ETF tool's capabilities cover many aspects of WiFi pen-testing. On one hand, it facilitates the phases of WiFi reconnaissance, vulnerability discovery, and attack. On the other hand, it doesn't offer a feature that facilitates the reporting phase. Adding the concept of a session and a session reporting feature, such as the logging of important events during a session, would greatly increase the value of the tool for real pen-testing scenarios.
|
||||
|
||||
Another valuable contribution would be extending the framework to facilitate WiFi fuzzing. The IEEE 802.11 protocol is very complex, and considering there are multiple implementations of it, both on the client and access point side, it's safe to assume these implementations contain bugs and even security flaws. These bugs could be discovered by fuzzing IEEE 802.11 protocol frames. Since Scapy allows custom packet creation and injection, a fuzzer can be implemented through it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/evil-twin-framework
|
||||
|
||||
作者:[André Esser][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/andreesser
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Rogue_access_point
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://scapy.net
|
||||
[4]: /file/417776
|
||||
[5]: https://opensource.com/sites/default/files/uploads/pic1.png (Evil-Twin Framework Architecture)
|
||||
[6]: https://www.metasploit.com
|
||||
[7]: /file/417781
|
||||
[8]: https://opensource.com/sites/default/files/uploads/pic2.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[9]: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
|
||||
[10]: /file/417786
|
||||
[11]: https://opensource.com/sites/default/files/uploads/pic3.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[12]: /file/417791
|
||||
[13]: https://opensource.com/sites/default/files/uploads/pic4.png (Scenario for capturing a WPA handshake after a de-authentication attack)
|
||||
[14]: https://github.com/Esser420/EvilTwinFramework
|
||||
@ -1,251 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Update/Change Users Password in Linux Using Different Ways)
|
||||
[#]: via: (https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
How to Update/Change Users Password in Linux Using Different Ways
|
||||
======
|
||||
|
||||
It’s a basic thing to set a user password whenever you create an user account in Linux.
|
||||
|
||||
Everybody uses passwd command followed by the user name `passwd USERNAME` to set a password for a user.
|
||||
|
||||
Make sure you have to set a hard and guess password that will help you to make the system more secure.
|
||||
|
||||
I mean to say, it should be the combination of Alphabets, Symbols and numbers.
|
||||
|
||||
Also, i advise you to change the password at least once in a month for security reason.
|
||||
|
||||
When you use the passwd command it will ask you to enter the password twice to set it. It’s a native method to set a user password.
|
||||
|
||||
If you don’t want to update the password twice and would like to do this in different way?
|
||||
|
||||
Yes, we can. There will be a possibility to do.
|
||||
|
||||
If you are working as a Linux admin you might have asked the below questions many times.
|
||||
|
||||
Some of you may or may not got answer for these questions.
|
||||
|
||||
Whatever it’s, don’t worry we are here to answer your all questions.
|
||||
|
||||
* How to Update/Change Users Password in Single Command?
|
||||
* How to Update/Change a Same Password for Multiple users in Linux?
|
||||
* How to Update/Change Multiple Users Password in Linux?
|
||||
* How to Update/Change Password for Multiple Users in Linux?
|
||||
* How to Update/Change Different Password for Multiple Users in Linux?
|
||||
* How to Update/Change Users Password in Multiple Linux Servers?
|
||||
* How to Update/Change Multiple Users Password in Multiple Linux Servers?
|
||||
|
||||
|
||||
|
||||
### Method-1: Using passwd Command
|
||||
|
||||
passwd command is a standard method to set or update or change password for users in Linux. The below way is a standard method to do it.
|
||||
|
||||
```
|
||||
# passwd renu
|
||||
Changing password for user renu.
|
||||
New password:
|
||||
BAD PASSWORD: The password contains the user name in some form
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
Run the following command if you would like to set or change password with single command. This allow users to update password in a single command.
|
||||
|
||||
```
|
||||
# echo "new_password" | passwd --stdin thanu
|
||||
Changing password for user thanu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### Method-2: Using chpasswd Command
|
||||
|
||||
chpasswd is an another command will allow us to set or update or change password for users in Linux. Use the following format if you would like to use chpasswd command to change password for user in a single command.
|
||||
|
||||
```
|
||||
# echo "thanu:new_password" | chpasswd
|
||||
```
|
||||
|
||||
### Method-3: How to Set Different Password for Multiple Users
|
||||
|
||||
Use the below script if you would like to set or update or change a password for multiple users in Linux with different password.
|
||||
|
||||
To do so, first we need to get a users list by using the following command. The below command will list the users who’s having `/home` directory and redirect the output to `user-list.txt` file.
|
||||
|
||||
```
|
||||
# cat /etc/passwd | grep "/home" | cut -d":" -f1 > user-list.txt
|
||||
```
|
||||
|
||||
List out the users using cat command. Remove the user from the list if you don’t want to reset the password for the specific user.
|
||||
|
||||
```
|
||||
# cat user-list.txt
|
||||
centos
|
||||
magi
|
||||
daygeek
|
||||
thanu
|
||||
renu
|
||||
```
|
||||
|
||||
Create a following small shell script to achieve this.
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/sh
|
||||
for user in `more user-list.txt`
|
||||
do
|
||||
echo "[email protected]" | passwd --stdin "$user"
|
||||
chage -d 0 $user
|
||||
done
|
||||
```
|
||||
|
||||
Set an executable permission to `password-update.sh` file.
|
||||
|
||||
```
|
||||
# chmod +x password-update.sh
|
||||
```
|
||||
|
||||
Finally run the script to achieve this.
|
||||
|
||||
```
|
||||
# ./password-up.sh
|
||||
|
||||
magi
|
||||
Changing password for user magi.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
daygeek
|
||||
Changing password for user daygeek.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
thanu
|
||||
Changing password for user thanu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
renu
|
||||
Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### Method-4: How to Set a Same Password for Multiple Users
|
||||
|
||||
Use the below script if you would like to set or update or change a same password for multiple users in Linux.
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/sh
|
||||
for user in `more user-list.txt`
|
||||
do
|
||||
echo "new_password" | passwd --stdin "$user"
|
||||
chage -d 0 $user
|
||||
done
|
||||
```
|
||||
|
||||
### Method-5: How to Change User password in Multiple Servers
|
||||
|
||||
Use the following script if you want to change a user password in multiple servers. In my case, we are going to change a password for `renu` user. Make sure you have to give the user name which you want to update the password instead of us.
|
||||
|
||||
Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for server in `cat server-list.txt`
|
||||
do
|
||||
ssh [email protected]$server 'passwd --stdin renu <<EOF
|
||||
new_passwd
|
||||
new_passwd
|
||||
EOF';
|
||||
done
|
||||
```
|
||||
|
||||
You will be getting the output similar to us.
|
||||
|
||||
```
|
||||
# ./password-update.sh
|
||||
|
||||
New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password: Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password: Changing password for user renu.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
```
|
||||
|
||||
### Method-6: How to Change User password in Multiple Servers Using pssh Command
|
||||
|
||||
pssh is a program for executing ssh in parallel on a number of hosts. It provides features such as sending input to all of the processes, passing a password to ssh, saving output to files, and timing out. Navigate to the following link to know more about **[PSSH Command][1]**.
|
||||
|
||||
```
|
||||
# pssh -i -h /tmp/server-list.txt "printf '%s\n' new_pass new_pass | passwd --stdin root"
|
||||
```
|
||||
|
||||
You will be getting the output similar to us.
|
||||
|
||||
```
|
||||
[1] 07:58:07 [SUCCESS] CentOS.2daygeek.com
|
||||
Changing password for user root.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
Retype new password:
|
||||
[2] 07:58:07 [SUCCESS] ArchLinux.2daygeek.com
|
||||
Changing password for user root.
|
||||
passwd: all authentication tokens updated successfully.
|
||||
Stderr: New password: BAD PASSWORD: it is based on a dictionary word
|
||||
BAD PASSWORD: is too simple
|
||||
```
|
||||
|
||||
### Method-7: How to Change User password in Multiple Servers Using chpasswd Command
|
||||
|
||||
Alternatively we can use the chpasswd command to update the password for user in multiple servers.
|
||||
|
||||
```
|
||||
# ./password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for server in `cat server-list.txt`
|
||||
do
|
||||
ssh [email protected]$server 'echo "magi:new_password" | chpasswd'
|
||||
done
|
||||
```
|
||||
|
||||
### Method-8: How to Change Multiple Users password in Linux Servers Using chpasswd Command
|
||||
|
||||
To do so, first create a file and update username and password in the below format. In my case i have created a file called `user-list.txt`.
|
||||
|
||||
See the details below.
|
||||
|
||||
Create a following small shell script to achieve this.
|
||||
|
||||
```
|
||||
# vi password-update.sh
|
||||
|
||||
#!/bin/bash
|
||||
for users in `cat user-list.txt`
|
||||
do
|
||||
echo $users | chpasswd
|
||||
done
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-passwd-chpasswd-command-set-update-change-users-password-in-linux-using-shell-script/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/pssh-parallel-ssh-run-execute-commands-on-multiple-linux-servers/
|
||||
@ -1,90 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Roland, a random selection tool for the command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tools-roland)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Roland, a random selection tool for the command line
|
||||
======
|
||||
|
||||
Get help making hard choices with Roland, the seventh in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the seventh of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Roland
|
||||
|
||||
By the time the workday has ended, often the only thing I want to think about is hitting the couch and playing the video game of the week. But even though my professional obligations stop at the end of the workday, I still have to manage my household. Laundry, pet care, making sure my teenager has what he needs, and most important: deciding what to make for dinner.
|
||||
|
||||
Like many people, I often suffer from [decision fatigue][1], and I make less-than-healthy choices for dinner based on speed, ease of preparation, and (quite frankly) whatever causes me the least stress.
|
||||
|
||||

|
||||
|
||||
[Roland][2] makes planning my meals much easier. Roland is a Perl application designed for tabletop role-playing games. It picks randomly from a list of items, such as monsters and hirelings. In essence, Roland does the same thing at the command line that a game master does when rolling physical dice to look up things in a table from the Game Master's Big Book of Bad Things to Do to Players.
|
||||
|
||||
With minor modifications, Roland can do so much more. For example, just by adding a table, I can enable Roland to help me choose what to cook for dinner.
|
||||
|
||||
The first step is installing Roland and all its dependencies.
|
||||
|
||||
```
|
||||
git clone git@github.com:rjbs/Roland.git
|
||||
cpan install Getopt::Long::Descriptive Moose \
|
||||
namespace::autoclean List:AllUtils Games::Dice \
|
||||
Sort::ByExample Data::Bucketeer Text::Autoformat \
|
||||
YAML::XS
|
||||
cd oland
|
||||
```
|
||||
|
||||
Next, I create a YAML document named **dinner** and enter all our meal options.
|
||||
|
||||
```
|
||||
type: list
|
||||
pick: 1
|
||||
items:
|
||||
- "frozen pizza"
|
||||
- "chipotle black beans"
|
||||
- "huevos rancheros"
|
||||
- "nachos"
|
||||
- "pork roast"
|
||||
- "15 bean soup"
|
||||
- "roast chicken"
|
||||
- "pot roast"
|
||||
- "grilled cheese sandwiches"
|
||||
```
|
||||
|
||||
Running the command **bin/roland dinner** will read the file and pick one of the options.
|
||||
|
||||

|
||||
|
||||
I like to plan for the week ahead so I can shop for all my ingredients in advance. The **pick** command determines how many items from the list to chose, and right now, the **pick** option is set to 1. If I want to plan a full week's dinner menu, I can just change **pick: 1** to **pick: 7** and it will give me a week's worth of dinners. You can also use the **-m** command line option to manually enter the choices.
|
||||
|
||||

|
||||
|
||||
You can also do fun things with Roland, like adding a file named **8ball** with some classic phrases.
|
||||
|
||||

|
||||
|
||||
You can create all kinds of files to help with common decisions that seem so stressful after a long day of work. And even if you don't use it for that, you can still use it to decide which devious trap to set up for tonight's game.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tools-roland
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Decision_fatigue
|
||||
[2]: https://github.com/rjbs/Roland
|
||||
@ -1,177 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems)
|
||||
[#]: via: (https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/)
|
||||
[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
|
||||
|
||||
Dcp (Dat Copy) – Easy And Secure Way To Transfer Files Between Linux Systems
|
||||
======
|
||||
|
||||
Linux has native command to perform this task nicely using scp and rsync. However, we need to try new things.
|
||||
|
||||
Also, we need to encourage the developers who is working new things with different concept and new technology.
|
||||
|
||||
We also written few articles about these kind of topic, you can navigate those by clicking the below appropriate links.
|
||||
|
||||
Those are **[OnionShare][1]** , **[Magic Wormhole][2]** , **[Transfer.sh][3]** and **ffsend**.
|
||||
|
||||
### What’s Dcp?
|
||||
|
||||
[dcp][4] copies files between hosts on a network using the peer-to-peer Dat network.
|
||||
|
||||
dcp can be seen as an alternative to tools like scp, removing the need to configure SSH access between hosts.
|
||||
|
||||
This lets you transfer files between two remote hosts, without you needing to worry about the specifics of how said hosts reach each other and regardless of whether hosts are behind NATs.
|
||||
|
||||
dcp requires zero configuration and is secure, fast, and peer-to-peer. Also, this is not production-ready software. Use at your own risk.
|
||||
|
||||
### What’s Dat Protocol?
|
||||
|
||||
Dat is a peer-to-peer protocol. A community-driven project powering a next-generation Web.
|
||||
|
||||
### How dcp works:
|
||||
|
||||
dcp will create a dat archive for a specified set of files or directories and, using the generated public key, lets you download said archive from a second host.
|
||||
|
||||
Any data shared over the network is encrypted using the public key of the archive, meaning data access is limited to those who have access to said key.
|
||||
|
||||
### dcp Use cases:
|
||||
|
||||
* Send files to multiple colleagues – just send the generated public key via chat and they can receive the files on their machine.
|
||||
* Sync files between two physical computers on your local network, without needing to set up SSH access.
|
||||
* Easily send files to a friend without needing to create a zip and upload it the cloud.
|
||||
* Copy files to a remote server when you have shell access but not SSH, for example on a kubernetes pod.
|
||||
* Share files between Linux/macOS and Windows, which isn’t exactly known for great SSH support.
|
||||
|
||||
|
||||
|
||||
### How To Install NodeJS & npm in Linux?
|
||||
|
||||
dcp package was written in JavaScript programming language so, we need to install NodeJS as a prerequisites to install dcp. Use the following command to install NodeJS in Linux.
|
||||
|
||||
For **`Fedora`** system, use **[DNF Command][5]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs npm
|
||||
```
|
||||
|
||||
For **`Debian/Ubuntu`** systems, use **[APT-GET Command][6]** or **[APT Command][7]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo apt install nodejs npm
|
||||
```
|
||||
|
||||
For **`Arch Linux`** based systems, use **[Pacman Command][8]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** systems, use **[YUM Command][9]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install nodejs npm
|
||||
```
|
||||
|
||||
For **`openSUSE Leap`** system, use **[Zypper Command][10]** to install NodeJS & npm.
|
||||
|
||||
```
|
||||
$ sudo zypper nodejs6
|
||||
```
|
||||
|
||||
### How To Install dcp in Linux?
|
||||
|
||||
Once you have installed the NodeJS, use the following npm command to install dcp.
|
||||
|
||||
npm is a package manager for the JavaScript programming language. It is the default package manager for the JavaScript runtime environment Node.js.
|
||||
|
||||
```
|
||||
# npm i -g dat-cp
|
||||
```
|
||||
|
||||
### How to Send Files Through dcp?
|
||||
|
||||
Enter the files or folders which you want to transfer to remote server followed by the dcp command, And no need to mention the destination machine name.
|
||||
|
||||
```
|
||||
# dcp [File Name Which You Want To Transfer]
|
||||
```
|
||||
|
||||
It will generate a dat archive for the given file when you ran the dcp command. Once it’s done then it will geerate a public key at the bottom of the page.
|
||||
|
||||
### How To Receive Files Through dcp?
|
||||
|
||||
Enter the generated the public key on remote server to receive the files or folders.
|
||||
|
||||
```
|
||||
# dcp [Public Key]
|
||||
```
|
||||
|
||||
To recursively copy directories.
|
||||
|
||||
```
|
||||
# dcp [Folder Name Which You Want To Transfer] -r
|
||||
```
|
||||
|
||||
In the following example, we are going to transfer a single file.
|
||||
![][12]
|
||||
|
||||
Output for the above file transfer.
|
||||
![][13]
|
||||
|
||||
If you want to send more than one file, use the following format.
|
||||
![][14]
|
||||
|
||||
Output for the above file transfer.
|
||||
![][15]
|
||||
|
||||
To recursively copy directories.
|
||||
![][16]
|
||||
|
||||
Output for the above folder transfer.
|
||||
![][17]
|
||||
|
||||
It won’t allow you to download the files or folders in second time. It means once you downloaded the files or folders then immediately the link will be expired.
|
||||
![][18]
|
||||
|
||||
Navigate to man page to know about other options.
|
||||
|
||||
```
|
||||
# dcp --help
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
|
||||
|
||||
作者:[Vinoth Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/vinoth/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
|
||||
[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
|
||||
[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
|
||||
[4]: https://github.com/tom-james-watson/dat-cp
|
||||
[5]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[6]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[7]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[8]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[9]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[10]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[11]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-1.png
|
||||
[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-2.png
|
||||
[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-3.jpg
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-4.jpg
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-6.jpg
|
||||
[17]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-7.jpg
|
||||
[18]: https://www.2daygeek.com/wp-content/uploads/2019/01/Dcp-Dat-Copy-Easy-And-Secure-Way-To-Transfer-Files-Between-Linux-Systems-5.jpg
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (xiqingongzi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (PyGame Zero: Games without boilerplate)
|
||||
[#]: via: (https://opensource.com/article/19/1/pygame-zero)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
PyGame Zero: Games without boilerplate
|
||||
======
|
||||
Say goodbye to boring boilerplate in your game development with PyGame Zero.
|
||||

|
||||
|
||||
Python is a good beginner programming language. And games are a good beginner project: they are visual, self-motivating, and fun to show off to friends and family. However, the most common library to write games in Python, [PyGame][1], can be frustrating for beginners because forgetting seemingly small details can easily lead to nothing rendering.
|
||||
|
||||
Until people understand why all the parts are there, they treat many of them as "mindless boilerplate"—magic paragraphs that need to be copied and pasted into their program to make it work.
|
||||
|
||||
[PyGame Zero][2] is intended to bridge that gap by putting a layer of abstraction over PyGame so it requires literally no boilerplate.
|
||||
|
||||
When we say literally, we mean it.
|
||||
|
||||
This is a valid PyGame Zero file:
|
||||
|
||||
```
|
||||
# This comment is here for clarity reasons
|
||||
```
|
||||
|
||||
We can run put it in a **game.py** file and run:
|
||||
|
||||
```
|
||||
$ pgzrun game.py
|
||||
```
|
||||
|
||||
This will show a window and run a game loop that can be shut down by closing the window or interrupting the program with **CTRL-C**.
|
||||
|
||||
This will, sadly, be a boring game. Nothing happens.
|
||||
|
||||
To make it slightly more interesting, we can draw a different background:
|
||||
|
||||
```
|
||||
def draw():
|
||||
screen.fill((255, 0, 0))
|
||||
```
|
||||
|
||||
This will make the background red instead of black. But it is still a boring game. Nothing is happening. We can make it slightly more interesting:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
```
|
||||
|
||||
This will make a window that starts black, becomes brighter and brighter red, then goes back to black, over and over again.
|
||||
|
||||
The **update** function updates parameters, while the **draw** function renders the game based on these parameters.
|
||||
|
||||
However, there is no way for the player to interact with the game! Let's try something else:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
|
||||
def on_key_down(key, mod, unicode):
|
||||
colors[1] = (colors[1] + 1) % 256
|
||||
```
|
||||
|
||||
Now pressing keys on the keyboard will increase the "greenness."
|
||||
|
||||
These comprise the three important parts of a game loop: respond to user input, update parameters, and re-render the screen.
|
||||
|
||||
PyGame Zero offers much more, including functions for drawing sprites and playing sound clips.
|
||||
|
||||
Try it out and see what type of game you can come up with!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/pygame-zero
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[xiqingongzi](https://github.com/xiqingongzi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pygame.org/news
|
||||
[2]: https://pygame-zero.readthedocs.io/en/stable/
|
||||
@ -1,92 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( dianbanjiu )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using more to view text files at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/more-text-files-linux)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Using more to view text files at the Linux command line
|
||||
======
|
||||
Text files and Linux go hand in hand. Or so it seems. But how you view those text files depends on what tools you're comfortable with.
|
||||
|
||||

|
||||
|
||||
There are a number of utilities that enable you to view text files when you're at the command line. One of them is [**more**][1].
|
||||
|
||||
**more** is similar to another tool I wrote about called **[less][2]**. The main difference is that **more** only allows you to move forward in a file.
|
||||
|
||||
While that may seem limiting, it has some useful features that are good to know about. Let's take a quick look at what **more** can do and how to use it.
|
||||
|
||||
### The basics
|
||||
|
||||
Let's say you have a text file and want to read it at the command line. Just open the terminal, pop into the directory that contains the file, and type this command:
|
||||
|
||||
```
|
||||
more <filename>
|
||||
```
|
||||
|
||||
For example, **more jekyll-article.md**.
|
||||
|
||||
|
||||
|
||||
Press the Spacebar on your keyboard to move through the file or press **q** to quit.
|
||||
|
||||
If you want to search for some text in the file, press the **/** key followed by the word or term you want to find. For example, to find the phrase terminal, type:
|
||||
|
||||
```
|
||||
/terminal
|
||||
```
|
||||
|
||||
|
||||
|
||||
Search is case-sensitive. Typing Terminal isn't the same as typing terminal.
|
||||
|
||||
### Using more with other utilities
|
||||
|
||||
You can pipe text from other command line utilities into **more**. Why do that? Because sometimes the text that those tools spew out spans more than one page.
|
||||
|
||||
To do that, type the command and any options, followed by the pipe symbol ( **|** ), followed by **more**. For example, let's say you have a directory that has a large number of files in it. You can use **more** with the **ls** command to get a full view of the contents of the directory:
|
||||
|
||||
```
|
||||
ls | more
|
||||
```
|
||||
|
||||
|
||||
|
||||
You can also use **more** with the **grep** command to find text in multiple files. In this example, I use **grep** to find the text productivity in multiple source files for my articles:
|
||||
|
||||
```
|
||||
**grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md | more**
|
||||
```
|
||||
|
||||
|
||||
|
||||
Another utility you can combine with **more** is **ps** (which lists processes that are running on your system). Again, this comes in handy when there are a large number of processes running on your system and you need a view of all of them—for example, to find one that you need to kill. To do that, use this command:
|
||||
|
||||
```
|
||||
ps -u scott | more
|
||||
```
|
||||
|
||||
Note that you'd replace scott with your username.
|
||||
|
||||
|
||||
|
||||
As I mentioned at the beginning of this article, **more** is easy to use. It's definitely not as flexible as its cousin **less** , but it can be useful to know.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/more-text-files-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/More_(command)
|
||||
[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
|
||||
@ -1,524 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (fdisk – Easy Way To Manage Disk Partitions In Linux)
|
||||
[#]: via: (https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
fdisk – Easy Way To Manage Disk Partitions In Linux
|
||||
======
|
||||
|
||||
Hard disks can be divided into one or more logical disks called partitions.
|
||||
|
||||
This division is described in the partition table (MBR or GPT) found in sector 0 of the disk.
|
||||
|
||||
Linux needs at least one partition, namely for its root file system and we can’t install Linux OS without partitions.
|
||||
|
||||
Once created, a partition must be formatted with an appropriate file system before files can be written to it.
|
||||
|
||||
To do so, we need some utility to perform this in Linux.
|
||||
|
||||
There are many utilities are available for that in Linux. We had written about **[Parted Command][1]** in the past and today we are going to discuss about fdisk.
|
||||
|
||||
fdisk command is one of the the best tool to manage disk partitions in Linux.
|
||||
|
||||
It supports maximum `2 TB`, and everyone prefer to go with fdisk.
|
||||
|
||||
This tool is used by vast of Linux admin because we don’t use more than 2TB now a days due to LVM and SAN. It’s used in most of the infra structure around the world.
|
||||
|
||||
Still if you want to create a large partitions, like more than 2TB then you have to go either **Parted Command** or **cfdisk Command**.
|
||||
|
||||
Disk partition and file system creations is one of the routine task for Linux admin.
|
||||
|
||||
If you are working on vast environment then you have to perform this task multiple times in a day.
|
||||
|
||||
### How Linux Kernel Understand Hard Disks?
|
||||
|
||||
As a human we can easily understand things but computer needs the proper naming conversion to understand each and everything.
|
||||
|
||||
In Linux, devices are located on `/dev` partition and Kernel understand the hard disk in the following format.
|
||||
|
||||
* **`/dev/hdX[a-z]:`** IDE Disk is named hdX in Linux
|
||||
* **`/dev/sdX[a-z]:`** SCSI Disk is named sdX in Linux
|
||||
* **`/dev/xdX[a-z]:`** XT Disk is named sdX in Linux
|
||||
* **`/dev/vdX[a-z]:`** Virtual Hard Disk is named vdX in Linux
|
||||
* **`/dev/fdN:`** Floppy Drive is named fdN in Linux
|
||||
* **`/dev/scdN or /dev/srN:`** CD-ROM is named /dev/scdN or /dev/srN in Linux
|
||||
|
||||
|
||||
|
||||
### What Is fdisk Command?
|
||||
|
||||
fdisk stands for fixed disk or format disk is a cli utility that allow users to perform following actions on disks. It allows us to view, create, resize, delete, move and copy the partitions.
|
||||
|
||||
It understands MBR, Sun, SGI and BSD partition tables and it doesn’t understand GUID Partition Table (GPT) and it is not designed for large partitions.
|
||||
|
||||
fdisk allows us to create a maximum of four primary partitions per disk. One of these may be an extended partition and it holds multiple logical partitions.
|
||||
|
||||
1-4 is reserved for four primary partitions and Logical partitions start numbering from 5.
|
||||
![][3]
|
||||
|
||||
### How To Install fdisk On Linux
|
||||
|
||||
You don’t need to install fdisk in Linux system because it has installed by default as part of core utility.
|
||||
|
||||
### How To List Available Disks Using fdisk Command
|
||||
|
||||
First we have to know what are the disks were added in the system before performing any action. To list all available disks on your system run the following command.
|
||||
|
||||
It lists possible information about the disks such as disk name, how many partitions are created in it, Disk Size, Disklabel type, Disk Identifier, Partition ID and Partition Type.
|
||||
|
||||
```
|
||||
$ sudo fdisk -l
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
|
||||
|
||||
Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
```
|
||||
|
||||
### How To List A Specific Disk Partitions Using fdisk Command
|
||||
|
||||
If you would like to see a specific disk and it’s partitions, use the following format.
|
||||
|
||||
```
|
||||
$ sudo fdisk -l /dev/sda
|
||||
Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0xeab59449
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
|
||||
```
|
||||
|
||||
### How To List Available Actions For fdisk Command
|
||||
|
||||
When you hit `m` in the fdisk command that will show you available actions for fdisk command.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0xe944b373.
|
||||
|
||||
Command (m for help): m
|
||||
|
||||
Help:
|
||||
|
||||
DOS (MBR)
|
||||
a toggle a bootable flag
|
||||
b edit nested BSD disklabel
|
||||
c toggle the dos compatibility flag
|
||||
|
||||
Generic
|
||||
d delete a partition
|
||||
F list free unpartitioned space
|
||||
l list known partition types
|
||||
n add a new partition
|
||||
p print the partition table
|
||||
t change a partition type
|
||||
v verify the partition table
|
||||
i print information about a partition
|
||||
|
||||
Misc
|
||||
m print this menu
|
||||
u change display/entry units
|
||||
x extra functionality (experts only)
|
||||
|
||||
Script
|
||||
I load disk layout from sfdisk script file
|
||||
O dump disk layout to sfdisk script file
|
||||
|
||||
Save & Exit
|
||||
w write table to disk and exit
|
||||
q quit without saving changes
|
||||
|
||||
Create a new label
|
||||
g create a new empty GPT partition table
|
||||
G create a new empty SGI (IRIX) partition table
|
||||
o create a new empty DOS partition table
|
||||
s create a new empty Sun partition table
|
||||
```
|
||||
|
||||
### How To List Partitions Types Using fdisk Command
|
||||
|
||||
When you hit `l` in the fdisk command that will show you an available partitions type for fdisk command.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Device does not contain a recognized partition table.
|
||||
Created a new DOS disklabel with disk identifier 0x9ffd00db.
|
||||
|
||||
Command (m for help): l
|
||||
|
||||
0 Empty 24 NEC DOS 81 Minix / old Lin bf Solaris
|
||||
1 FAT12 27 Hidden NTFS Win 82 Linux swap / So c1 DRDOS/sec (FAT-
|
||||
2 XENIX root 39 Plan 9 83 Linux c4 DRDOS/sec (FAT-
|
||||
3 XENIX usr 3c PartitionMagic 84 OS/2 hidden or c6 DRDOS/sec (FAT-
|
||||
4 FAT16 <32M 40 Venix 80286 85 Linux extended c7 Syrinx
|
||||
5 Extended 41 PPC PReP Boot 86 NTFS volume set da Non-FS data
|
||||
6 FAT16 42 SFS 87 NTFS volume set db CP/M / CTOS / .
|
||||
7 HPFS/NTFS/exFAT 4d QNX4.x 88 Linux plaintext de Dell Utility
|
||||
8 AIX 4e QNX4.x 2nd part 8e Linux LVM df BootIt
|
||||
9 AIX bootable 4f QNX4.x 3rd part 93 Amoeba e1 DOS access
|
||||
a OS/2 Boot Manag 50 OnTrack DM 94 Amoeba BBT e3 DOS R/O
|
||||
b W95 FAT32 51 OnTrack DM6 Aux 9f BSD/OS e4 SpeedStor
|
||||
c W95 FAT32 (LBA) 52 CP/M a0 IBM Thinkpad hi ea Rufus alignment
|
||||
e W95 FAT16 (LBA) 53 OnTrack DM6 Aux a5 FreeBSD eb BeOS fs
|
||||
f W95 Ext'd (LBA) 54 OnTrackDM6 a6 OpenBSD ee GPT
|
||||
10 OPUS 55 EZ-Drive a7 NeXTSTEP ef EFI (FAT-12/16/
|
||||
11 Hidden FAT12 56 Golden Bow a8 Darwin UFS f0 Linux/PA-RISC b
|
||||
12 Compaq diagnost 5c Priam Edisk a9 NetBSD f1 SpeedStor
|
||||
14 Hidden FAT16 <3 61 SpeedStor ab Darwin boot f4 SpeedStor
|
||||
16 Hidden FAT16 63 GNU HURD or Sys af HFS / HFS+ f2 DOS secondary
|
||||
17 Hidden HPFS/NTF 64 Novell Netware b7 BSDI fs fb VMware VMFS
|
||||
18 AST SmartSleep 65 Novell Netware b8 BSDI swap fc VMware VMKCORE
|
||||
1b Hidden W95 FAT3 70 DiskSecure Mult bb Boot Wizard hid fd Linux raid auto
|
||||
1c Hidden W95 FAT3 75 PC/IX bc Acronis FAT32 L fe LANstep
|
||||
1e Hidden W95 FAT1 80 Old Minix be Solaris boot ff BBT
|
||||
```
|
||||
|
||||
### How To Create A Disk Partition Using fdisk Command
|
||||
|
||||
If you would like to create a new partition use the following steps. In my case, i'm going to create 4 partitions (3 Primary and 1 Extended) on `/dev/sdc` disk. To the same for other partitions too.
|
||||
|
||||
As this takes value from partition table so, hit `Enter` for first sector. Enter the size which you want to set for the partition (We can add a partition size using KB,MB,G and TB) for last sector.
|
||||
|
||||
For example, if you would like to add 1GB partition then the last sector value should be `+1G`. Once you have created 3 partitions, it will automatically change the partition type to extended as a default. If you still want to create a fourth primary partitions then hit `p` instead of default value `e`.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default p): Enter
|
||||
|
||||
Using default response p.
|
||||
Partition number (1-4, default 1): Enter
|
||||
First sector (2048-20971519, default 2048): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Create A Extended Disk Partition Using fdisk Command
|
||||
|
||||
Make a note, you have to use remaining all space when you create a extended partition because again you can able to create multiple logical partition in that.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
Partition type
|
||||
p primary (3 primary, 0 extended, 1 free)
|
||||
e extended (container for logical partitions)
|
||||
Select (default e): Enter
|
||||
|
||||
Using default response e.
|
||||
Selected partition 4
|
||||
First sector (6293504-20971519, default 6293504): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6293504-20971519, default 20971519): Enter
|
||||
|
||||
Created a new partition 4 of type 'Extended' and of size 7 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To View Unpartitioned Disk Space Using fdisk Command
|
||||
|
||||
As described in the above section, we have totally created 4 partitions (3 Primary and 1 Extended). Extended partition disk space will show unpartitioned until you create a logical partitions in that.
|
||||
|
||||
Use the following command to view the unpartitioned space for a disk. As per the below output we have `7GB` unpartitioned disk.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): F
|
||||
Unpartitioned space /dev/sdc: 7 GiB, 7515144192 bytes, 14678016 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
Start End Sectors Size
|
||||
6293504 20971519 14678016 7G
|
||||
|
||||
Command (m for help): q
|
||||
```
|
||||
|
||||
### How To Create A Logical Partition Using fdisk Command
|
||||
|
||||
Follow the same above procedure to create a logical partition once you have created the extended partition.
|
||||
Here, i have created `1GB` of logical partition called `/dev/sdc5`, you can double confirm this by checking the partition table value.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
Command (m for help): n
|
||||
All primary partitions are in use.
|
||||
Adding logical partition 5
|
||||
First sector (6295552-20971519, default 6295552): Enter
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (6295552-20971519, default 20971519): +1G
|
||||
|
||||
Created a new partition 5 of type 'Linux' and of size 1 GiB.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc2 2099200 4196351 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Delete A Partition Using fdisk Command
|
||||
|
||||
If the partition is no more used in the system than we can remove it by using the below steps.
|
||||
|
||||
Make sure you have to enter the correct partition number to delete it. In this case, i'm going to remove `/dev/sdc2` partition.
|
||||
|
||||
```
|
||||
$ sudo fdisk /dev/sdc
|
||||
|
||||
Welcome to fdisk (util-linux 2.30.1).
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
Command (m for help): d
|
||||
Partition number (1-5, default 5): 2
|
||||
|
||||
Partition 2 has been deleted.
|
||||
|
||||
Command (m for help): p
|
||||
Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
|
||||
Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disklabel type: dos
|
||||
Disk identifier: 0x8cc8f9e5
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
/dev/sdc1 2048 2099199 2097152 1G 83 Linux
|
||||
/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
|
||||
/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
|
||||
/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
|
||||
|
||||
Command (m for help): w
|
||||
The partition table has been altered.
|
||||
Calling ioctl() to re-read partition table.
|
||||
Syncing disks.
|
||||
```
|
||||
|
||||
### How To Format A Partition Or Create A FileSystem On The Partition
|
||||
|
||||
In computing, a file system or filesystem controls how data is stored and retrieved through inode tables.
|
||||
|
||||
Without a file system, the system can't find where the information is stored on the partition. Filesystem can be created in three ways. Here, i'm going to create a filesystem on `/dev/sdc1` partition.
|
||||
|
||||
```
|
||||
$ sudo mkfs.ext4 /dev/sdc1
|
||||
or
|
||||
$ sudo mkfs -t ext4 /dev/sdc1
|
||||
or
|
||||
$ sudo mke2fs /dev/sdc1
|
||||
|
||||
mke2fs 1.43.5 (04-Aug-2017)
|
||||
Creating filesystem with 262144 4k blocks and 65536 inodes
|
||||
Filesystem UUID: c0a99b51-2b61-4f6a-b960-eb60915faab0
|
||||
Superblock backups stored on blocks:
|
||||
32768, 98304, 163840, 229376
|
||||
|
||||
Allocating group tables: done
|
||||
Writing inode tables: done
|
||||
Creating journal (8192 blocks): done
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
```
|
||||
|
||||
When you creating a filesystem on tha partition that will create the following important things on it.
|
||||
|
||||
* **`Filesystem UUID:`** UUID stands for Universally Unique Identifier, UUIDs are used to identify block devices in Linux. It's 128 bit long numbers represented by 32 hexadecimal digits.
|
||||
* **`Superblock:`** Superblock stores metadata of the file system. If the superblock of a file system is corrupted, then the filesystem cannot be mounted and thus files cannot be accessed.
|
||||
* **`Inode:`** An inode is a data structure on a filesystem on a Unix-like operating system that stores all the information about a file except its name and its actual data.
|
||||
* **`Journal:`** A journaling filesystem is a filesystem that maintains a special file called a journal that is used to repair any inconsistencies that occur as the result of an improper shutdown of a computer.
|
||||
|
||||
|
||||
|
||||
### How To Mount A Partition In Linux
|
||||
|
||||
Once you have created the partition and filesystem then we need to mount the partition to use.
|
||||
|
||||
To do so, we need to create a mountpoint to mount the partition. Use mkdir command to create a mountpoint.
|
||||
|
||||
```
|
||||
$ sudo mkdir -p /mnt/2g-new
|
||||
```
|
||||
|
||||
For temporary mount, use the following command. You will be lose this mountpoint after rebooting your system.
|
||||
|
||||
```
|
||||
$ sudo mount /dev/sdc1 /mnt/2g-new
|
||||
```
|
||||
|
||||
For permanent mount, add the partition details in the fstab file. It can be done in two ways either adding device name or UUID value.
|
||||
|
||||
Permanent mount using Device Name:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
|
||||
/dev/sdc1 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Permanent mount using UUID Value. To get a UUID of the partition use blkid command.
|
||||
|
||||
```
|
||||
$ sudo blkid
|
||||
/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
|
||||
/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
|
||||
/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
|
||||
/dev/sdc5: PARTUUID="8cc8f9e5-05"
|
||||
|
||||
# vi /etc/fstab
|
||||
|
||||
UUID=d17e3c31-e2c9-4f11-809c-94a549bc43b7 /mnt/2g-new ext4 defaults 0 0
|
||||
```
|
||||
|
||||
The same has been verified using df Command.
|
||||
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
udev 969M 0 969M 0% /dev
|
||||
tmpfs 200M 7.0M 193M 4% /run
|
||||
/dev/sda1 20G 16G 3.0G 85% /
|
||||
tmpfs 997M 0 997M 0% /dev/shm
|
||||
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs 997M 0 997M 0% /sys/fs/cgroup
|
||||
tmpfs 200M 28K 200M 1% /run/user/121
|
||||
tmpfs 200M 25M 176M 13% /run/user/1000
|
||||
/dev/sdc1 1008M 1.3M 956M 1% /mnt/2g-new
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: https://www.2daygeek.com/wp-content/uploads/2019/01/linux-fdisk-command-to-manage-disk-partitions-1a.png
|
||||
@ -0,0 +1,60 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Get started with Budgie Desktop, a Linux environment)
|
||||
[#]: via: (https://opensource.com/article/19/1/productivity-tool-budgie-desktop)
|
||||
[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
|
||||
|
||||
Get started with Budgie Desktop, a Linux environment
|
||||
======
|
||||
Configure your desktop as you want with Budgie, the 18th in our series on open source tools that will make you more productive in 2019.
|
||||
|
||||

|
||||
|
||||
There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
|
||||
|
||||
Here's the 18th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
|
||||
|
||||
### Budgie Desktop
|
||||
|
||||
There are many, many desktop environments for Linux. From the easy to use and graphically stunning [GNOME desktop][1] (default on most major Linux distributions) and [KDE][2], to the minimalist [Openbox][3], to the highly configurable tiling [i3][4], there are a lot of options. What I look for in a good desktop environment is speed, unobtrusiveness, and a clean user experience. It is hard to be productive when a desktop works against you, not with or for you.
|
||||
|
||||
|
||||
|
||||
[Budgie Desktop][5] is the default desktop on the [Solus][6] Linux distribution and is available as an add-on package for most of the major Linux distributions. It is based on GNOME and uses many of the same tools and libraries you likely already have on your computer.
|
||||
|
||||
The default desktop is exceptionally minimalistic, with just the panel and a blank desktop. Budgie includes an integrated sidebar (called Raven) that gives quick access to the calendar, audio controls, and settings menu. Raven also contains an integrated notification area with a unified display of system messages similar to MacOS's.
|
||||
|
||||
|
||||
|
||||
Clicking on the gear icon in Raven brings up Budgie's control panel with its configuration settings. Since Budgie is still in development, it is a little bare-bones compared to GNOME or KDE, and I hope it gets more options over time. The Top Panel option, which allows the user to configure the ordering, positioning, and contents of the top panel, is nice.
|
||||
|
||||
|
||||
|
||||
The Budgie Welcome application (presented at first login) contains options to install additional software, panel applets, snaps, and Flatpack packages. There are applets to handle networking, screenshots, additional clocks and timers, and much, much more.
|
||||
|
||||
|
||||
|
||||
Budgie provides a desktop that is clean and stable. It responds quickly and has many options that allow you to customize it as you see fit.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/productivity-tool-budgie-desktop
|
||||
|
||||
作者:[Kevin Sonney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ksonney (Kevin Sonney)
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.gnome.org/
|
||||
[2]: https://www.kde.org/
|
||||
[3]: http://openbox.org/wiki/Main_Page
|
||||
[4]: https://i3wm.org/
|
||||
[5]: https://getsol.us/solus/experiences/
|
||||
[6]: https://getsol.us/home/
|
||||
@ -1,87 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oneforalone)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Two Years With Emacs as a CEO (and now CTO))
|
||||
[#]: via: (https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html)
|
||||
[#]: author: (Josh Stella https://www.fugue.co/blog/author/josh-stella)
|
||||
|
||||
作为 CEO 使用 Emacs 的两年经验之谈(现任 CTO)
|
||||
======
|
||||
|
||||
两年前,我写了一篇[博客][1],并取得了一些反响。这让我有点受宠若惊。那篇博客写的是我准备将 Emacs 作为我的主办公软件,当时我还是 CEO,现在已经转为 CTO 了。现在回想起来,我发现我之前不是做程序员就是做软件架构师,而且那时我也喜欢用 Emacs 写代码。重新考虑 Emacs 是一次很不错的尝试,但我不太清楚具体该怎么实现。在网上,那篇博客也是褒贬不一,但是还是有数万的阅读量,所以总的来说,我写的还是不错的。在 [Reddit][2] 和 [HackerNews][3] 上有些令人哭笑不得的回复,说我的手会变形,或者说我会因白色的背景而近视。在这里我可以很肯定的回答 —— 完全没有这回事,相反,我的手腕还因此变得更灵活了。还有一些人担心,说使用 Emacs 会耗费一个 CEO 的精力。把 Fugue 从在家得到的想法变成强大的产品,并有一大批忠实的顾客,我觉得 Emacs 可以让你从复杂的事务中解脱出来。我现在还在用白色的背景。
|
||||
|
||||
近段时间那篇博客又被翻出来了,并发到了 [HackerNews][4] 上。我收到了大量的跟帖者问我现在怎么样了,所以我写这篇博客来回应他们。在本文中,我还将重点讨论为什么 Emacs 和函数式编程有很高的相关性,以及我们是怎样使用 Emacs 来开发我们的产品 —— Fugue,一个使用函数式编程的自动化的云计算平台。由于我收到了很多反馈,比较有用的是一些细节的详细程度和有关背景色的注解,因此这篇博客比较长,而我确实也需要费点精力来解释我的想法,但这篇文章的主要内容还是反映了我担任 CEO 时处理的事务。而我想在之后更频繁地用 Emacs 写代码,所以需要提前做一些准备。一如既往,本文因人而异,后果自负。
|
||||
|
||||
### 意外之喜
|
||||
|
||||
我大部分时间都在不断得处理公司内外沟通。交流是解决问题的唯一方法,但也是反思及思考困难或是复杂问题的敌人。对我来说,作为创业公司的 CEO,最需要的是有时间专注工作而不别打扰。一旦开始投入时间来学习一些命令,Emacs 就很适合这种情况。其他的应用弹出提示,但是配置好了的 Emacs 就可以完全的忽略掉,无论是视觉上还是精神上。除非你想修改,否则的话他不会变,而且没有比空白屏幕和漂亮的字体更干净的界面了。在我不断被打扰的情况下,这种简洁让我能够专注于我在想什么,而不是电脑。好的程序能够默默地对电脑的进行访问。
|
||||
|
||||
一些人指出,原来的帖子既是对现代图形界面的批判,也是对 Emacs 的赞许。我既不赞同,也不否认。现代的接口,特别是那些以应用程序为中心的方法(相对于以内容为中心的方法),既不是以用户为中心的,也不是面向进程的。Emacs 避免了这种错误,这也是我如此喜欢它的部分原因,而它也带来了其他优点。Emacs 是进入计算机本身的入口,这打开了一扇新世界的大门。它的核心是发现和创造属于自己的道路,对我来说这就是创造的定义。现代电脑的悲哀之处在于,它很大程度上是由带有闪亮界面的黑盒组成的,这些黑盒提供的是瞬间的满足感,而不是真正的满足感。这让我们变成了消费者,而不是技术的创造者。我不在乎你是谁或者你的背景是什么;你可以理解你的电脑,你可以用它做东西。它很有趣,令人满意,而且不是你想的那么难学!
|
||||
|
||||
我们常常低估了环境对我们心理的影响。Emacs 给人一种平静和自由的感觉,而不是紧迫感、烦恼或兴奋——后者是思想和沉思的敌人。我喜欢那些持久的,不碍事的东西,当我花时间去关注它们的时候,它们会给我带来真知灼见。Emacs 满足我的所有这些标准。我每天都使用 Emacs 来创建内容,我也很高兴我很少考虑它。Emacs 确实有一个学习曲线,但不会比学自行车更陡,而且一旦你完成了它,你会得到相应的回报,你就不必再去想它了,它赋予你一种其他工具所没有的自由感。这是一个优雅的工具,来自一个更加文明的时代。我很高兴我们步入了另一个计算机时代,而 Emacs 也将越来越受欢迎。
|
||||
|
||||
### 放弃用 Emacs 规划日程及处理待办事项
|
||||
|
||||
在原来的文章中,我花了一些时间介绍如何使用 Org 模式来规划日程。我放弃了使用 Org 模式来处理待办事项之类的,因为我每天都有很多会要开,很多电话要打, 而我也不能让其他人来适应我选的工具,我也没有时间将事务转换或是自动移动到 Org 上 。我们主要是用 Mac shop,使用谷歌日历等,原生的 Mac OS/iOS 工具可以很好的进行协作。我还有支比较旧的笔用来在会议中做笔记,因为我发现在会议中使用笔记本电脑或者说键盘很不礼貌,而且这也限制了我的聆听和思考。因此,我基本上放弃了用 Org 帮我规划日程或安排生活的想法。当然,Org 模式对其他的方面也很有用,它是我编写文档的首选,包括本文。换句话说,我与其作者背道而驰,但它在这方面做得很好。我也希望有一天也有人这么说我们在 Fugue 的工作。
|
||||
|
||||
### Emacs 在 Fugue 已经扩散
|
||||
|
||||
我在上篇博客就有说,你可能会喜欢 Emacs,也可能不会。因此,当 Fugue 的文档组将 Emacs 作为标准工具时,我是有点担心的,因为我觉得他们可能是受了我的影响。几年后,我确信他们做出了个正确的选择。那个组长是一个很聪明的程序员,但是那两个编写文档的人却没有怎么接触过技术。我想,如果这是一个经理强加错误工具的案例,我就会得到投诉并去解决,因为 Fugue 有反威权文化,大家不怕惹麻烦,包括我在内。之前的组长去年辞职了,但[文档组][5]现在有了一个灵活的集成的 CI/CD 工具链。并且文档组的人已经成为了 Emacs 的忠实用户。Emacs 有一条学习曲线,但即使很陡,也不会那么陡,翻过后对生产力和总体幸福感都有益。这也提醒我们,学文科的人在技术方面和程序员一样聪明,一样能干,也许不应该那么倾向于技术而产生派别歧视。
|
||||
|
||||
### 我的手腕得益于我的决定
|
||||
|
||||
上世纪80年代中期以来,我每天花12个小时左右在电脑前工作,这给我的手腕(以及后背)造成了很大的损伤,在此我强烈安利 Tag Capisco 的椅子。Emacs 和人机工程学键盘的结合让手腕的 [RSI][10](Repetitive Strain Injury/Repetitive Motion Syndrome) 问题消失了,我已经一年多没有想过这种问题了。在那之前,我的手腕每天都会疼,尤其是右手,如果你也遇到这种问题,你就知道这很让人分心和担心。有几个人问过键盘和鼠标的问题,如果你感兴趣的话,我现在用的是[这款键盘][6]。虽然在过去的几年里我主要使用的是真正符合人体工程学的键盘。我已经换成现在的键盘有几个星期了,而且我爱死它了。键帽的形状很神奇,因为你不用看就能知道自己在哪里,而拇指键设计的很合理,尤其是对于 Emacs, Control和Meta是你的固定伙伴。不要再用小指做高度重复的任务了!
|
||||
|
||||
我使用鼠标的次数比使用 Office 和 IDE 时要少得多,这对我有很大帮助,但我还是会用鼠标。我一直在使用外观相当过时,但功能和人体工程学明显优越的轨迹球,这是名副其实的。
|
||||
|
||||
撇开具体的工具不谈,最重要的一点是,事实证明,一个很棒的键盘,再加上避免使用鼠标,在减少身体的磨损方面很有效。Emacs 是这方面的核心,因为我不需要在菜单上滑动鼠标来完成任务,而且导航键就在我的手指下面。我肯定,手离开标准打字姿势会给我的肌腱造成很大的压力。这因人而异,我也不是医生。
|
||||
|
||||
### 还没完成大部分配置……
|
||||
|
||||
有人说我会在界面配置上花很多的时间。我想验证下他们说的对不对,所以我留意了下。我不仅让配置基本上不受影响,关注这个问题还让我意识到我使用的其他工具是多么的耗费我的精力和时间。Emacs 是我用过的维护成本最低的软件。Mac OS 和 Windows 一直要求我更新它,但在我我看来,这远没有 Adobe 套件和 Office 的更新的困恼那么大。我只是偶尔更新 Emacs,但也没什么变化,所以对我来说,它基本上是一个接近于零成本的操作,我高兴什么时候跟新就什么时候更新。
|
||||
|
||||
有一点然你们失望了,因为许多人想知道我为跟上 Emacs 社区的更新及其输出所做的事情,但是在过去的两年中,我只在配置中添加了一些内容。我认为也是成功的,因为 Emacs 只是一个工具,而不是我的爱好。也就是说,如果你想和我分享,我很乐意听到新的东西。
|
||||
|
||||
### 期望实现控制云端
|
||||
|
||||
我们在 Fugue 有很多 Emacs 的粉丝,所以我们有一段时间在用 [Ludwing 模式][7]。Ludwig 是我们用于自动化云基础设施和服务的声明式、功能性的 DSL。最近,Alex Schoof 利用飞机上和晚上的时间来构建 fugue 模式,它在 Fugue CLI 上充当 Emacs 控制台。要是你不熟悉 Fugue,我们会开发一个云自动化和管理工具,它利用函数式编程为用户提供与云的 api 交互的良好体验。它做的不止这些,但它也做了。fugue 模式很酷的原因有很多。它有一个不断报告云基础设备状态的缓冲区,而由于我经常修改这些设备,所以我可以快速看到编码的效果。Fugue 将云工作负载当成进程处理,fugue 模式非常类似于云工作负载的 top 模式。它还允许我执行一些操作,比如创建新的设备或删除过期的东西,而且也不需要太多输入。Fugue 模式只是个雏形,但它非常方便,而我现在也经常使用它。
|
||||
|
||||
![fugue-mode-edited.gif][8]
|
||||
|
||||
### 模式及监听
|
||||
|
||||
我添加了一些模式和集成插件,但并不是真正用于 CEO 工作。我喜欢在周末时写写 Haskell 和 Scheme,所以我添加了 haskell 模式和 geiser。Emacs 对具有 REPL 的语言很友好,因为你可以在不同的窗口中运行不同的模式,包括 REPL 和 shell。Geiser 和 Scheme 很配,要是你还没有这样做过,那么用 SICP 工作也不失为一种乐趣,在这个有很多土鳖编程的例子的时代,这可能是一种启发。安装 MIT Scheme 和 geiser,你就会感觉有点像 lore 的符号环境。
|
||||
|
||||
这就引出了我在 15 年的文章中没有提到的另一个话题:屏幕管理。我喜欢使用用竖屏来写作,我在家里和我的主要办公室都有这个配置。对于编程或混合使用,我喜欢 fuguer 提供的新的超宽显示器。对于宽屏,我更喜欢将屏幕分成三列,中间是主编辑缓冲区,左边是水平分隔的 shell 和 fugue 模式缓冲区,右边是文档缓冲区或另一个或两个编辑缓冲区。这个很简单,首先按 'Ctl-x 3' 两次,然后使用 'Ctl-x =' 使窗口的宽度相等。这将提供三个相等的列,你也可以使用 'Ctl-x 2' 进行水平分割。以下是我的截图。
|
||||
|
||||
![Emacs Screen Shot][9]
|
||||
|
||||
### 最后一篇 CEO/Emacs 文章……
|
||||
|
||||
首先,我现在是 Fugue 的 CTO,其次我也想要写一些其他方面的博客,而我现在刚好有时间。我还打算写些更深入的东西,比如说函数式编程、基础结构类型安全,以及我们即将推出一些的新功能,还有一些关于 Fugue 在云上可以做什么。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fugue.co/blog/2018-08-09-two-years-with-emacs-as-a-cto.html
|
||||
|
||||
作者:[Josh Stella][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/oneforalone)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.fugue.co/blog/author/josh-stella
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://blog.fugue.co/2015-11-11-guide-to-emacs.html
|
||||
[2]: https://www.reddit.com/r/emacs/comments/7efpkt/a_ceos_guide_to_emacs/
|
||||
[3]: https://news.ycombinator.com/item?id=10642088
|
||||
[4]: https://news.ycombinator.com/item?id=15753150
|
||||
[5]: https://docs.fugue.co/
|
||||
[6]: https://shop.keyboard.io/
|
||||
[7]: https://github.com/fugue/ludwig-mode
|
||||
[8]: https://www.fugue.co/hubfs/Imported_Blog_Media/fugue-mode-edited-1.gif
|
||||
[9]: https://www.fugue.co/hs-fs/hubfs/Emacs%20Screen%20Shot.png?width=929&name=Emacs%20Screen%20Shot.png
|
||||
[10]: https://baike.baidu.com/item/RSI/21509642
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Hacking math education with Python)
|
||||
[#]: via: (https://opensource.com/article/19/1/hacking-math)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
将 Python 结合到数学教育中
|
||||
======
|
||||
> 身兼教师、开发者、作家数职的 Peter Farrell 来讲述为什么使用 Python 来讲数学课会比传统方法更加好。
|
||||
|
||||

|
||||
|
||||
数学课一直都是很讨厌的一件事情,尤其对于在传统教学方法上吃过苦头的人(例如我)来说。传统教学方法强调的是死记硬背和理论知识,这种形式与学生们的现实世界似乎相去甚远。
|
||||
|
||||
[Peter Farrell][1] 作为一位 Python 开发者和数学教师,发现学生在数学课程中遇到了困难,于是决定尝试使用 Python 来帮助介绍数学概念。
|
||||
|
||||
Peter 的灵感来源于 Logo 语言之父 [Seymour Papert][2],他的 Logo 语言现在还存在于 Python 的 [Turtle 模块][3]中。Logo 语言中的海龟形象让 Peter 喜欢上了 Python,并且进一步将 Python 应用到数学教学中。
|
||||
|
||||
Peter 在他的新书《[<ruby>Python 数学奇遇记<rt>Math Adventures with Python</rt></ruby>][5]》中分享了他的方法:“图文并茂地指导如何用代码探索数学”。因此我最近对他进行了一次采访,向他了解更多这方面的情况。
|
||||
|
||||
**Don Watkins(译者注:本文作者):** 你的教学背景是什么?
|
||||
|
||||
**Peter Farrell:** 我曾经当过八年的数学老师,之后又教了十年的数学。我还在当老师的时候,就阅读过 Papert 的 《[<ruby>头脑风暴<rt>Mindstorms</rt></ruby>][6]》并从中受到了启发,将 Logo 语言和海龟引入到了我所有的数学课上。
|
||||
|
||||
**DW:** 你为什么开始使用 Python 呢?
|
||||
|
||||
**PF:** 在我当家教的时候,需要教学一门枯燥刻板的数学课程,这是一个痛苦的过程。后来我引入了 Logo 语言和海龟,我的学生刚好是一个编程爱好者,他非常喜欢这样的方式。在接触到函数和实际的编程之后,他还提议改用 Python。尽管当时我还不了解 Python,但看起来好像和 Logo 语言差别不大,我就同意了。后来我甚至坚持在 Python 上一条道走到黑了!
|
||||
|
||||
我还曾经寻找过 3D 图形方面的软件包,用来模拟太阳系行星的运动轨迹,让学生们理解行星是如何在牛顿的万有引力定律作用下运动的。很多图形软件包都需要用到 C 语言编程或者其它一些很复杂的内容,后来我发现了一个叫做 VisualPython 的软件包,它非常方便使用。于是在那之后的几年里,我就一直在用 [Vpython][7] 这个软件包。
|
||||
|
||||
所以,我是在和学生一起学习数学的时候被介绍使用 Python 的。在那段时间里,他是我的编程老师,而我则是他的数学老师。
|
||||
|
||||
**DW:** 是什么让你对数学感兴趣?
|
||||
|
||||
**PF:** 我是通过传统的方法学习数学的,那时候都是用手写、用纸记、在黑板上计算。我擅长代数和几何,在大学的时候也接触过 Basic 和 Fortran 编程,但那个时候也没有从中获取到灵感。直到后来在从编程中收到了启发,编程可以让你将数学课上一些晦涩难懂的内容变得简单直观,也能让你轻松地绘图、调整、探索,进而发现更多乐趣。
|
||||
|
||||
**DW:** 是什么启发了你使用 Python 教学?
|
||||
|
||||
**PF:** 还是在我当家教的时候,我惊奇地发现可以通过循环来计算对同一个函数输入不同参数的结果。如果用人手计算,可能要花半个小时的时间,但计算机瞬间就完成了。在这样的基础上,我们只要将一些计算的过程抽象成一个函数,再对其进行一些适当的扩展,就可以让计算机来计算了。
|
||||
|
||||
**DW:** 你的教学方法如何帮助学生,特别是在数学上感觉吃力的学生?如何将 Python 编程和数学结合起来
|
||||
|
||||
**PF:** 很多学生,尤其是高中生,都认为通过手工计算和画图来解决问题的方式在当今已经没有必要了,我并不反对这样的观点。例如,使用 Excel 来处理数据确实应该算是办公室工作的基本技能。学习任何一种编程语言,对公司来说都是一项非常有价值的技能。因此,使用计算机计算确实是有实际意义的。
|
||||
|
||||
而使用代码来为数学课创造艺术,则是一项革命性的改变。例如,仅仅是把某个形状显示到屏幕上,就需要使用到数学,因为位置需要用 x-y 坐标去表示,而尺寸、颜色等等都是数字。如果想要移动或者更改某些内容,会需要用到变量。更特殊地,如果需要改变位置,就需要更有效的向量来实现。这样的最终结果是,类似向量、矩阵这些难以捉摸的空洞概念会转变成实打实有意义的数学工具。
|
||||
|
||||
那些看起来在数学上吃力的学生,或许只是不太容易接受“书本上的数学”。因为“书本上的数学”过分强调了死记硬背和循规蹈矩,而有些忽视了创造力和实际应用能力。有些学生其实擅长数学,但并不适应学校的教学方式。我的方法会让父母们看到他们的孩子通过代码画出了很多有趣的图形,然后说:“我从来不知道正弦和余弦还能这样用!”
|
||||
|
||||
**DW:** 你的教学方法是如何在学校里促进 STEM 教育的呢?
|
||||
|
||||
**PF:** 我喜欢将这几个学科统称为 STEM(<ruby>科学、技术、工程、数学<rt>Science, Technology, Engineering and Mathematics</rt></ruby>) 或 STEAM(<ruby>科学、技术、工程、艺术、数学<rt>Science, Technology, Engineering, Art and Mathematics</rt></ruby>)。但作为数学工作者,我很不希望其中的 M 被忽视。我经常看到很多很小的孩子在 STEM 实验室里参与一些有趣的项目,这表明他们已经在接受科学、技术和工程方面的教育。与此同时,我发现数学方面的材料和项目却很少。因此,我和[机电一体化][8]领域的优秀教师 Ken Hawthorn 正在着手解决这个问题。
|
||||
|
||||
希望我的书能够帮助鼓励学生们在技术上有所创新,无论在形式上是切实的还是虚拟的。同时书中还有很多漂亮的图形,希望能够激励大家去体验编程的过程,并且应用到实际中来。我使用的软件([Python Processing][9])是免费的,在树莓派等系统上都可以轻松安装。因为我认为,个人或者学校的成本问题不应该成为学生进入 STEM 世界的门槛。
|
||||
|
||||
**DW:** 你有什么想要跟其他的数学老师分享?
|
||||
|
||||
**PF:** 如果数学教学机构决定要向学生教导数字推理、逻辑、分析、建模、几何、数据解释这些内容,那么它们应该承认,可以通过编程来实现这些目标。正如我上面所说的,我的教学方法是在尝试使传统枯燥的方法变得直观,我认为任何一位老师都可以做到这一点。他们只需要知道其中的本质做法,就可以使用代码来完成大量重复的工作了。
|
||||
|
||||
我的教学方法依赖于一些免费的图形软件,因此只需要知道在哪里找到这些软件包,以及如何使用这些软件包,就可以开始引导学生使用 21 世纪的技术来解决实际问题,将整个过程和结果可视化,并找到更多可以以此实现的模式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/hacking-math
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/hackingmath
|
||||
[2]: https://en.wikipedia.org/wiki/Seymour_Papert
|
||||
[3]: https://en.wikipedia.org/wiki/Turtle_graphics
|
||||
[4]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[5]: https://nostarch.com/mathadventures
|
||||
[6]: https://en.wikipedia.org/wiki/Mindstorms_(book)
|
||||
[7]: http://vpython.org/
|
||||
[8]: https://en.wikipedia.org/wiki/Mechatronics
|
||||
[9]: https://processing.org/
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 4 OK04)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
计算机实验室 – 树莓派:课程 4 OK04
|
||||
======
|
||||
|
||||
OK04 课程在 OK03 的基础上进行构建,它教你如何使用定时器让 `OK` 或 `ACT` LED 灯按精确的时间间隔来闪烁。假设你已经有了 [课程 3:OK03][1] 的操作系统,我们将以它为基础来构建。
|
||||
|
||||
### 1、一个新设备
|
||||
|
||||
定时器是树莓派保持时间的唯一方法。大多数计算机都有一个电池供电的时钟,这样当计算机关机后仍然能保持时间。
|
||||
|
||||
到目前为止,我们仅看了树莓派硬件的一小部分,即 GPIO 控制器。我只是简单地告诉你做什么,然后它会发生什么事情。现在,我们继续看定时器,并继续带你去了解它的工作原理。
|
||||
|
||||
和 GPIO 控制器一样,定时器也有地址。在本案例中,定时器的基地址在 20003000~16~。阅读手册我们可以找到下面的表:
|
||||
|
||||
表 1.1 GPIO 控制器寄存器
|
||||
| 地址 | 大小 / 字节 | 名字 | 描述 | 读或写 |
|
||||
| -------- | ------------ | ---------------- | ---------------------------------------------------------- | ---------------- |
|
||||
| 20003000 | 4 | Control / Status | 用于控制和清除定时器通道比较器匹配的寄存器 | RW |
|
||||
| 20003004 | 8 | Counter | 按 1 MHz 的频率递增的计数器 | R |
|
||||
| 2000300C | 4 | Compare 0 | 0 号比较器寄存器 | RW |
|
||||
| 20003010 | 4 | Compare 1 | 1 号比较器寄存器 | RW |
|
||||
| 20003014 | 4 | Compare 2 | 2 号比较器寄存器 | RW |
|
||||
| 20003018 | 4 | Compare 3 | 3 号比较器寄存器 | RW |
|
||||
|
||||
![Flowchart of the system timer's operation][2]
|
||||
|
||||
这个表只告诉我们一部分内容,在手册中描述了更多的字段。手册上解释说,定时器本质上是按每微秒将计数器递增 1 的方式来运行。每次它是这样做的,它将计数器的低 32 位(4 字节)与 4 个比较器寄存器进行比较,如果匹配它们中的任何一个,它更新 `Control/Status` 以反映出其中有一个是匹配的。
|
||||
|
||||
关于<ruby>位<rt>bit</rt></ruby>、字节、<ruby>位字段<rt>bit field</rt></ruby>、以及数据大小的更多内容如下:
|
||||
|
||||
>
|
||||
> 一个位是一个单个的二进制数的名称。你可能还记得,一个单个的二进制数即可能是一个 1,也可能是一个 0。
|
||||
>
|
||||
> 一个字节是一个 8 位集合的名称。由于每个位可能是 1 或 0 这两个值的其中之一,因此,一个字节有 2^8^ = 256 个不同的可能值。我们一般解释一个字节为一个介于 0 到 255(含)之间的二进制数。
|
||||
>
|
||||
> ![Diagram of GPIO function select controller register 0.][3]
|
||||
>
|
||||
> 一个位字段是解释二进制的另一种方式。二进制可以解释为许多不同的东西,而不仅仅是一个数字。一个位字段可以将二进制看做为一系列的 1(开) 或 0(关)的开关。对于每个小开关,我们都有一个意义,我们可以使用它们去控制一些东西。我们已经遇到了 GPIO 控制器使用的位字段,使用它设置一个针脚的开或关。位为 1 时 GPIO 针脚将准确地打开或关闭。有时我们需要更多的选项,而不仅仅是开或关,因此我们将几个开关组合到一起,比如 GPIO 控制器的函数设置(如上图),每 3 位为一组控制一个 GPIO 针脚的函数。
|
||||
>
|
||||
|
||||
|
||||
我们的目标是实现一个函数,这个函数能够以一个时间数量为输入来调用它,这个输入的时间数量将作为等待的时间,然后返回。想一想如何去做,想想我们都拥有什么。
|
||||
|
||||
我认为这将有两个选择:
|
||||
|
||||
1. 从计数器中读取一个值,然后保持分支返回到相同的代码,直到计数器的等待时间数量大于它。
|
||||
2. 从计数器中读取一个值,加时间数量去等待,保存它到比较器寄存器,然后保持分支返回到相同的代码处,直到 `Control / Status` 寄存器更新。
|
||||
|
||||
|
||||
```
|
||||
像这样存在被称为"并发问题"的问题,并且几乎无法解决。
|
||||
```
|
||||
|
||||
这两种策略都工作的很好,但在本教程中,我们将只实现第一个。原因是比较器寄存器更容易出错,因为在增加等待时间并保存它到比较器的寄存器期间,计数器可能已经增加了,并因此可能会不匹配。如果请求的是 1 微秒(或更糟糕的情况是 0 微秒)的等待,这样可能导致非常长的意外延迟。
|
||||
|
||||
### 2、实现
|
||||
|
||||
```
|
||||
大型的操作系统通常使用等待函数来抓住机会在后台执行任务。
|
||||
```
|
||||
|
||||
我将把这个创建完美的等待方法的挑战留给你。我建议你将所有与定时器相关的代码都放在一个名为 `systemTimer.s` 的文件中(理由很明显)。关于这个方法的复杂部分是,计数器是一个 8 字节值,而每个寄存器仅能保存 4 字节。所以,计数器值将分到 2 个寄存器中。
|
||||
|
||||
下列的代码块是一个示例。
|
||||
|
||||
```assembly
|
||||
ldrd r0,r1,[r2,#4]
|
||||
```
|
||||
|
||||
```assembly
|
||||
ldrd regLow,regHigh,[src,#val] 从 src 加上 val 数的地址上加载 8 字节到寄存器 regLow 和 regHigh 中。
|
||||
```
|
||||
|
||||
上面的代码中你可以发现一个很有用的指令是 `ldrd`。它从两个寄存器中加载 8 字节的内存。在本案例中,这 8 字节内存从寄存器 `r2` 中的地址开始,将被复制进寄存器 `r0` 和 `r1`。这种安排的稍微复杂之处在于 `r1` 实际上只持有了高位 4 字节。换句话说就是,如果如果计数器的值是 999,999,999,999~10~ = 1110100011010100101001010000111111111111~2~ ,那么寄存器 `r1` 中只有 11101000~2~,而寄存器 `r0` 中则是 11010100101001010000111111111111~2~。
|
||||
|
||||
实现它的更明智的方式应该是,去计算当前计数器值与来自方法启动后的那一个值的差,然后将它与要求的等待时间数量进行比较。除非恰好你希望的等待时间是支持 8 字节的,否则上面示例中寄存器 `r1` 中的值将会丢失,而计数器仅需要使用低位 4 字节。
|
||||
|
||||
当等待开始时,你应该总是确保使用大于比较,而不是使用等于比较,因为如果你尝试去等待一个时间,而这个时间正好等于方法开始的时间与结束的时间之差,那么你就错过这个值而永远等待下去。
|
||||
|
||||
如果你不明白如何编写等待函数的代码,可以参考下面的指南。
|
||||
|
||||
>
|
||||
> 借鉴 GPIO 控制器的创意,第一个函数我们应该去写如何取得系统定时器的地址。示例如下:
|
||||
>
|
||||
> ```assembly
|
||||
> .globl GetSystemTimerBase
|
||||
> GetSystemTimerBase:
|
||||
> ldr r0,=0x20003000
|
||||
> mov pc,lr
|
||||
> ```
|
||||
>
|
||||
> 另一个被证明非常有用的函数是在寄存器 `r0` 和 `r1` 中返回当前计数器值:
|
||||
>
|
||||
> ```assembly
|
||||
> .globl GetTimeStamp
|
||||
> GetTimeStamp:
|
||||
> push {lr}
|
||||
> bl GetSystemTimerBase
|
||||
> ldrd r0,r1,[r0,#4]
|
||||
> pop {pc}
|
||||
> ```
|
||||
>
|
||||
> 这个函数简单地使用了 `GetSystemTimerBase` 函数,并像我们前面学过的那样,使用 `ldrd` 去加载当前计数器值。
|
||||
>
|
||||
> 现在,我们可以去写我们的等待方法的代码了。首先,在方法启动后,我们需要知道计数器值,当前计数器值我们现在已经可以使用 `GetTimeStamp` 来取得了。
|
||||
>
|
||||
> ```assembly
|
||||
> delay .req r2
|
||||
> mov delay,r0
|
||||
> push {lr}
|
||||
> bl GetTimeStamp
|
||||
> start .req r3
|
||||
> mov start,r0
|
||||
> ```
|
||||
>
|
||||
> 这个代码复制我们的方法的输入,将延迟时间的数量放到寄存器 `r2` 中,然后调用 `GetTimeStamp`,这个函数将会在寄存器 `r0` 和 `r1` 中返回当前计数器值。接着复制计数器值的低位 4 字节到寄存器 `r3` 中。
|
||||
>
|
||||
> 接下来,我们需要计算当前计数器值与读入的值的差,然后持续这样做,直到它们的差至少是延迟大小为止。
|
||||
>
|
||||
> ```assembly
|
||||
> loop$:
|
||||
>
|
||||
> bl GetTimeStamp
|
||||
> elapsed .req r1
|
||||
> sub elapsed,r0,start
|
||||
> cmp elapsed,delay
|
||||
> .unreq elapsed
|
||||
> bls loop$
|
||||
> ```
|
||||
>
|
||||
> 这个代码将一直等待,一直到等待到传递给它的时间数量为止。它从计数器中读取数值,减去最初从计数器中读取的值,然后与要求的延迟时间进行比较。如果过去的时间数量小于要求的延迟,它切换到 `loop$`。
|
||||
>
|
||||
> ```assembly
|
||||
> .unreq delay
|
||||
> .unreq start
|
||||
> pop {pc}
|
||||
> ```
|
||||
>
|
||||
> 代码完成后,函数返回。
|
||||
>
|
||||
|
||||
|
||||
### 3、另一个闪灯程序
|
||||
|
||||
你一旦明白了等待函数的工作原理,修改 `main.s` 去使用它。修改各处 `r0` 的等待设置值为某个很大的数量(记住它的单位是微秒),然后在树莓派上测试。如果函数不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果正常工作,恭喜你学会控制另一个设备了,会使用它,则时间由你控制。在下一节课程中,我们将完成 OK 系列课程的最后一节 [课程 5:OK05][4],我们将使用我们已经学习过的知识让 LED 按我们的模式进行闪烁。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok03.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/systemTimer.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/gpioControllerFunctionSelect.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (oska874)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 5 OK05)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html)
|
||||
[#]: author: (Robert Mullins http://www.cl.cam.ac.uk/~rdm34)
|
||||
|
||||
translating by ezio
|
||||
|
||||
树莓派计算机实验室 课程 5 OK05
|
||||
======
|
||||
|
||||
OK05 课程构建于课程 OK04 的基础,使用更多代码方式烧、保存写莫尔斯码的 SOS 序列(`...---...`)。这里假设你已经有了 [课程 4: OK04][1] 操作系统的代码基础。
|
||||
|
||||
### 1 数据
|
||||
|
||||
到目前为止,我们与操作系统有关的所有内容都提供了遵循的说明。然而有时候,说明只是一半。我们的操作系统可能需要数据
|
||||
|
||||
> 一些早期的操作系统确实只允许特定文件中的特定类型的数据,但是这通常被认为太严格了。现代方法确实使程序变得复杂的多。
|
||||
|
||||
通常,只是数据的值很重要。你可能经过训练,认为数据是指定类型,比如,一个文本文件包含文章,一个图像文件包含一幅图片,等等。说实话,这只是一个理想罢了。计算机上的全部数据都是二进制数字,重要的是我们选择用什么来解释这些数据。在这个例子中,我们会将一个闪灯序列作为数据保存下来。
|
||||
|
||||
在 `main.s` 结束处复制下面的代码:
|
||||
|
||||
```
|
||||
.section .data %定义 .data 段
|
||||
.align 2 %对齐
|
||||
pattern: %定义整形变量
|
||||
.int 0b11111111101010100010001000101010
|
||||
```
|
||||
|
||||
>`.align num` 保证下一行代码的地址是 `2^num` 的整数倍。
|
||||
|
||||
>`.int val` 输出数值 `val`。
|
||||
|
||||
要区分数据和代码,我们将数据都放在 `.data` 区域。我已经将该区域包含在操作系统的内存布局图。我已经选择将数据放到代码后面。将我们的指令和数据分开保存的原因是,如果最后我们在自己的操作系统上实现一些安全措施,我们就需要知道代码的那些部分是可以执行的,而那些部分是不行的。
|
||||
|
||||
我在这里使用了两个新命令 `.align` 和 `.int`。`.align` 保证下来的数据是按照 2 的乘方对齐的。在这个里,我使用 `.align 2` ,意味着数据最终存放的地址是 `2^2=4` 的整数倍。这个操作是很重要的,因为我们用来读取内寸的指令 `ldr` 要求内存地址是 4 的倍数。
|
||||
|
||||
The .int command copies the constant after it into the output directly. That means that 111111111010101000100010001010102 will be placed into the output, and so the label pattern actually labels this piece of data as pattern.
|
||||
|
||||
命令 `.int` 直接复制它后面的常量到输出。这意味着 `11111111101010100010001000101010`(二进制数) 将会被存放到输出,所以标签模式实际将标记这段数据作为模式。
|
||||
|
||||
> 关于数据的一个挑战是寻找一个高效和有用的展示形式。这种保存一个开、关的时间单元的序列的方式,运行起来很容易,但是将很难编辑,因为摩尔斯的原理 `-` 或 `.` 丢失了。
|
||||
|
||||
如我提到的,数据可以意味这你想要的所有东西。在这里我编码了摩尔斯代码 SOS 序列,对于不熟悉的人,就是 `...---...`。我使用 0 表示一个时间单元的 LED 灭灯,而 1 表示一个时间单元的 LED 亮。这样,我们可以像这样编写一些代码在数据中显示一个序列,然后要显示不同序列,我们所有需要做的就是修改这段数据。下面是一个非常简单的例子,操作系统必须一直执行这段程序,解释和展示数据。
|
||||
|
||||
复制下面几行到 `main.s` 中的标记 `loop$` 之前。
|
||||
|
||||
```
|
||||
ptrn .req r4 %重命名 r4 为 ptrn
|
||||
ldr ptrn,=pattern %加载 pattern 的地址到 ptrn
|
||||
ldr ptrn,[ptrn] %加载地址 ptrn 所在内存的值
|
||||
seq .req r5 %重命名 r5 为 seq
|
||||
mov seq,#0 %seq 赋值为 0
|
||||
```
|
||||
|
||||
这段代码加载 `pattrern` 到寄存器 `r4`,并加载 0 到寄存器 `r5`。`r5` 将是我们的序列位置,所以我们可以追踪有多少 `pattern` 我们已经展示了。
|
||||
|
||||
下面的代码将非零值放入 `r1` ,如果仅仅是如果,这里有个 1 在当前位置的 `pattern`。
|
||||
|
||||
```
|
||||
mov r1,#1 %加载1到 r1
|
||||
lsl r1,seq %对r1 的值逻辑左移 seq 次
|
||||
and r1,ptrn %按位与
|
||||
```
|
||||
|
||||
这段代码对你调用 `SetGpio` 很有用,它必须有一个非零值来关掉 LED,而一个0值会打开 LED。
|
||||
|
||||
现在修改 `main.s` 中全部你的代码,这样代码中每次循环会根据当前的序列数设置 LED,等待 250000 毫秒(或者其他合适的延时),然后增加序列数。当这个序列数到达 32 就需要返回 0.看看你是否能实现这个功能,作为额外的挑战,也可以试着只使用一条指令。
|
||||
|
||||
### 2 Time Flies When You're Having Fun... 当你玩得开心时,过得很快
|
||||
|
||||
你现在准备好在树莓派上实验。应该闪烁一串包含 3 个短脉冲,3 个长脉冲,然后 3 个更短脉冲的序列。在一次延时之后,这种模式应该重复。如果这部工作,请查看我们的问题页。
|
||||
|
||||
一旦它工作,祝贺你已经达到 OK 系列教程的结束。
|
||||
|
||||
在这个谢列我们学习了汇编代码,GPIO 控制器和系统定时器。我们已经学习了函数和 ABI,以及几个基础的操作系统原理,和关于数据的知识。
|
||||
|
||||
你现在已经准备好下面几个更高级的课程的某一个。
|
||||
* [Screen][2] 系列是接下来的,会教你如何通过汇编代码使用屏幕。
|
||||
* [Input][3] 系列教授你如何使用键盘和鼠标。
|
||||
|
||||
到现在,你已经有了足够的信息来制作操作系统,用其它方法和 GPIO 交互。如果你有任何机器人工具,你可能会想尝试编写一个通过 GPIO 管教控制的机器人操作系统。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok05.html
|
||||
|
||||
作者:[Robert Mullins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.cl.cam.ac.uk/~rdm34
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok04.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
|
||||
@ -0,0 +1,504 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 6 Screen01)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室 – 树莓派:课程 6 屏幕01
|
||||
======
|
||||
|
||||
欢迎来到屏幕系列课程。在本系列中,你将学习在树莓派中如何使用汇编代码控制屏幕,从显示随机数据开始,接着学习显示一个固定的图像和显示文本,然后格式化文本中的数字。假设你已经完成了 `OK` 系列课程的学习,所以在本系列中出现的有些知识将不再重复。
|
||||
|
||||
第一节的屏幕课程教你一些关于图形的基础理论,然后用这些理论在屏幕或电视上显示一个图案。
|
||||
|
||||
### 1、入门
|
||||
|
||||
预期你已经完成了 `OK` 系列的课程,以及那个系列课程中在 `gpio.s` 和 `systemTimer.s` 文件中调用的函数。如果你没有完成这些,或你喜欢完美的实现,可以去下载 `OK05.s` 解决方案。在这里也要使用 `main.s` 文件中从开始到包含 `mov sp,#0x8000` 的这一行之前的代码。请删除这一行以后的部分。
|
||||
|
||||
### 2、计算机图形
|
||||
|
||||
将颜色表示为数字有几种方法。在这里我们专注于 RGB 方法,但 HSL 也是很常用的另一种方法。
|
||||
|
||||
正如你所认识到的,从根本上来说,计算机是非常愚蠢的。它们只能执行有限数量的指令,仅仅能做一些数学,但是它们也能以某种方式来做很多很多的事情。而在这些事情中,我们目前想知道的是,计算机是如何将一个图像显示到屏幕上的。我们如何将这个问题转换成二进制?答案相当简单;我们为每个颜色设计一些编码方法,然后我们为生个像素在屏幕上保存一个编码。一个像素在你的屏幕上就是一个非常小的点。如果你离屏幕足够近,你或许能够在你的屏幕上辨别出单个的像素,能够看到每个图像都是由这些像素组成的。
|
||||
|
||||
随着计算机时代的到来,人们希望显示更多更复杂的图形,于是发明了图形卡的概念。图形卡是你的计算机上用来在屏幕上专门绘制图像的第二个处理器。它的任务就是将像素值信息转换成显示在屏幕上的亮度级别。在现代计算机中,图形卡已经能够做更多更复杂的事情了,比如绘制三维图形。但是在本系列教程中,我们只专注于图形卡的基本使用;从内存中取得像素然后把它显示到屏幕上。
|
||||
|
||||
不念经使用哪种方法,现在马上出现的一个问题就是我们使用的颜色编码。这里有几种选择,每个产生不同的输出质量。为了完整起见,我在这里只是简单概述它们。
|
||||
|
||||
不过这里的一些图像几乎没有颜色,因为它们使用了一个叫空间抖动的技术。这允许它们以很少的颜色仍然能表示出非常好的图像。许多早期的操作系统就使用了这种技术。
|
||||
|
||||
| 名字 | 唯一颜色数量 | 描述 | 示例 |
|
||||
| ----------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------- |
|
||||
| 单色 | 2 | 每个像素使用 1 位去保存,其中 1 表示白色,0 表示黑色。 | ![Monochrome image of a bird][1] |
|
||||
| 灰度 | 256 | 每个像素使用 1 个字节去保存,使用 255 表示白色,0 表示黑色,介于这两个值之间的所有值表示这两个颜色的一个线性组合。 | ![Geryscale image of a bird][2] |
|
||||
| 8 色 | 8 | 每个像素使用 3 位去保存,第一位表示红色通道,第二位表示绿色通道,第三位表示蓝色通道。 | ![8 colour image of a bird][3] |
|
||||
| 低色值 | 256 | 每个像素使用 8 位去保存,前三位表示红色通道的强度,接下来的三位表示绿色通道的强度,最后两位表示蓝色通道的强度。 | ![Low colour image of a bird][4] |
|
||||
| 高色值 | 65,536 | 每个像素使用 16 位去保存,前五位表示红色通道的强度,接下来的六位表示绿色通道的强度,最后的五位表示蓝色通道的强度。 | ![High colour image of a bird][5] |
|
||||
| 真彩色 | 16,777,216 | 每个像素使用 24 位去保存,前八位表示红色通道,第二个八位表示绿色通道,最后八位表示蓝色通道。 | ![True colour image of a bird][6] |
|
||||
| RGBA32 | 16,777,216 带 256 级透明度 | 每个像素使用 32 位去保存,前八位表示红色通道,第二个八位表示绿色通道,第三个八位表示蓝色通道。只有一个图像绘制在另一个图像的上方时才考虑使用透明通道,值为 0 时表示下面图像的颜色,值为 255 时表示上面这个图像的颜色,介于这两个值之间的所有值表示这两个图像颜色的混合。 ||
|
||||
|
||||
|
||||
在本教程中,我们将从使用高色值开始。这样你就可以看到图像的构成,它的形成过程清楚,图像质量好,又不像真彩色那样占用太多的空间。也就是说,显示一个比较小的 800x600 像素的图像,它只需要小于 1 MiB 的空间。它另外的好处是它的大小是 2 次幂的倍数,相比真彩色这将极大地降低了获取信息的复杂度。
|
||||
|
||||
```
|
||||
保存帧缓冲给一台计算机带来了很大的内存负担。基于这种原因,早期计算机经常作弊,比如,保存一屏幕文本,在每次单独刷新时,它只绘制刷新了的字母。
|
||||
```
|
||||
|
||||
树莓派和它的图形处理器有一种特殊而奇怪的关系。在树莓派上,首先运行的事实上是图形处理器,它负责启动主处理器。这是很不常见的。最终它不会有太大的差别,但在许多交互中,它经常给人感觉主处理器是次要的,而图形处理器才是主要的。在树莓派上这两者之间依靠一个叫 “邮箱” 的东西来通讯。它们中的每一个都可以为对方投放邮件,这个邮件将在未来的某个时刻被对方收集并处理。我们将使用这个邮箱去向图形处理器请求一个地址。这个地址将是一个我们在屏幕上写入像素颜色信息的位置,我们称为帧缓冲,图形卡将定期检查这个位置,然后更新屏幕上相应的像素。
|
||||
|
||||
### 3、编写邮差程序
|
||||
|
||||
```
|
||||
消息传递是组件间通讯时使用的常见方法。一些操作系统在程序之间使用虚拟消息进行通讯。
|
||||
```
|
||||
|
||||
接下来我们做的第一件事情就是编写一个“邮差”程序。它有两个方法:MailboxRead,从寄存器 `r0` 中的邮箱通道读取一个消息。而 MailboxWrite,将寄存器 `r0` 中的头 28 位的值写到寄存器 `r1` 中的邮箱通道。树莓派有 7 个与图形处理器进行通讯的邮箱通道。但仅第一个对我们有用,因为它用于协调帧缓冲。
|
||||
|
||||
下列的表和示意图描述了邮箱的操作。
|
||||
|
||||
表 3.1 邮箱地址
|
||||
| 地址 | 大小 / 字节 | 名字 | 描述 | 读 / 写 |
|
||||
| 2000B880 | 4 | Read | 接收邮件 | R |
|
||||
| 2000B890 | 4 | Poll | 不检索接收 | R |
|
||||
| 2000B894 | 4 | Sender |发送者信息 | R |
|
||||
| 2000B898 | 4 | Status | 信息 | R |
|
||||
| 2000B89C | 4 | Configuration | 设置 | RW |
|
||||
| 2000B8A0 | 4 | Write | 发送邮件 | W |
|
||||
|
||||
为了给指定的邮箱发送一个消息:
|
||||
|
||||
1. 发送者等待,直到 `Status`字段的头一位为 0。
|
||||
2. 发送者写入到 `Write`,低 4 位是要发送到的邮箱,高 28 位是要写入的消息。
|
||||
|
||||
|
||||
|
||||
为了读取一个消息:
|
||||
|
||||
1. 接收者等待,直到 `Status` 字段的第 30 位为 0。
|
||||
2. 接收者读取消息。
|
||||
3. 接收者确认消息来自正确的邮箱,否则再次重试。
|
||||
|
||||
|
||||
|
||||
如果你觉得有信心,你现在有足够的信息去写出我们所需的两个方法。如果没有信心,请继续往下看。
|
||||
|
||||
与以前一样,我建议你实现的第一个方法是获取邮箱区域的地址。
|
||||
|
||||
```assembly
|
||||
.globl GetMailboxBase
|
||||
GetMailboxBase:
|
||||
ldr r0,=0x2000B880
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
发送程序相对简单一些,因此我们将首先去实现它。随着你的方法越来越复杂,你需要提前去规划它们。规划它们的一个好的方式是写出一个简单步骤列表,详细地列出你需要做的事情,像下面一样。
|
||||
|
||||
1. 我们的输入将要写什么(`r0`),以及写到什么邮箱(`r1`)。我们必须验证邮箱的真实性,以及它的低 4 位的值是否为 0。不要忘了验证输入。
|
||||
2. 使用 `GetMailboxBase` 去检索地址。
|
||||
3. 读取 `Status` 字段。
|
||||
4. 检查头一位是否为 0。如果不是,回到第 3 步。
|
||||
5. 将写入的值和邮箱通道组合到一起。
|
||||
6. 写入到 `Write`。
|
||||
|
||||
|
||||
|
||||
我们来按顺序写出它们中的每一步。
|
||||
|
||||
1.
|
||||
```assembly
|
||||
.globl MailboxWrite
|
||||
MailboxWrite:
|
||||
tst r0,#0b1111
|
||||
movne pc,lr
|
||||
cmp r1,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
```assembly
|
||||
tst reg,#val 计算寄存器 reg 和 #val 的逻辑与,然后将计算结果与 0 进行比较。
|
||||
```
|
||||
|
||||
这将实现我们验证 `r0` 和 `r1` 的目的。`tst` 是通过计算两个操作数的逻辑与来比较两个操作数的函数,然后将结果与 0 进行比较。在本案例中,它将检查在寄存器 `r0` 中的输入的低 4 位是否为全 0。
|
||||
|
||||
2.
|
||||
```assembly
|
||||
channel .req r1
|
||||
value .req r2
|
||||
mov value,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
这段代码确保我们不会覆盖我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
|
||||
|
||||
3.
|
||||
```assembly
|
||||
wait1$:
|
||||
status .req r3
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
这段代码加载当前状态。
|
||||
|
||||
4.
|
||||
```assembly
|
||||
tst status,#0x80000000
|
||||
.unreq status
|
||||
bne wait1$
|
||||
```
|
||||
|
||||
这段代码检查状态字段的头一位是否为 0,如果不为 0,循环回到第 3 步。
|
||||
|
||||
5.
|
||||
```assembly
|
||||
add value,channel
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
这段代码将通道和值组合到一起。
|
||||
|
||||
6.
|
||||
```assembly
|
||||
str value,[mailbox,#0x20]
|
||||
.unreq value
|
||||
.unreq mailbox
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
这段代码保存结果到写入字段。
|
||||
|
||||
|
||||
|
||||
|
||||
MailboxRead 的代码和它非常类似。
|
||||
|
||||
1. 我们的输入将从哪个邮箱读取(`r0`)。我们必须要验证邮箱的真实性。不要忘了验证输入。
|
||||
2. 使用 `GetMailboxBase` 去检索地址。
|
||||
3. 读取 `Status` 字段。
|
||||
4. 检查第 30 位是否为 0。如果不为 0,返回到第 3 步。
|
||||
5. 读取 `Read` 字段。
|
||||
6. 检查邮箱是否是我们所要的,如果不是返回到第 3 步。
|
||||
7. 返回结果。
|
||||
|
||||
|
||||
|
||||
我们来按顺序写出它们中的每一步。
|
||||
|
||||
1.
|
||||
```assembly
|
||||
.globl MailboxRead
|
||||
MailboxRead:
|
||||
cmp r0,#15
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
这一段代码来验证 `r0` 中的值。
|
||||
|
||||
2.
|
||||
```assembly
|
||||
channel .req r1
|
||||
mov channel,r0
|
||||
push {lr}
|
||||
bl GetMailboxBase
|
||||
mailbox .req r0
|
||||
```
|
||||
|
||||
这段代码确保我们不会覆盖掉我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
|
||||
|
||||
3.
|
||||
```assembly
|
||||
rightmail$:
|
||||
wait2$:
|
||||
status .req r2
|
||||
ldr status,[mailbox,#0x18]
|
||||
```
|
||||
|
||||
这段代码加载当前状态。
|
||||
|
||||
4.
|
||||
```assembly
|
||||
tst status,#0x40000000
|
||||
.unreq status
|
||||
bne wait2$
|
||||
```
|
||||
|
||||
这段代码检查状态字段第 30 位是否为 0,如果不为 0,返回到第 3 步。
|
||||
|
||||
5.
|
||||
```assembly
|
||||
mail .req r2
|
||||
ldr mail,[mailbox,#0]
|
||||
```
|
||||
|
||||
这段代码从邮箱中读取下一条消息。
|
||||
|
||||
6.
|
||||
```assembly
|
||||
inchan .req r3
|
||||
and inchan,mail,#0b1111
|
||||
teq inchan,channel
|
||||
.unreq inchan
|
||||
bne rightmail$
|
||||
.unreq mailbox
|
||||
.unreq channel
|
||||
```
|
||||
|
||||
这段代码检查我们正在读取的邮箱通道是否为提供给我们的通道。如果不是,返回到第 3 步。
|
||||
|
||||
7.
|
||||
|
||||
```assembly
|
||||
and r0,mail,#0xfffffff0
|
||||
.unreq mail
|
||||
pop {pc}
|
||||
```
|
||||
|
||||
这段代码将答案(邮件的前 28 位)移动到寄存器 `r0` 中。
|
||||
|
||||
|
||||
|
||||
|
||||
### 4、我心爱的图形处理器
|
||||
|
||||
通过我们新的邮差程序,我们现在已经能够向图形卡上发送消息了。我们应该发送些什么呢?这对我来说可能是个很难找到答案的问题,因为它不是任何线上手册能够找到答案的问题。尽管如此,通过查找有关树莓派的 GNU/Linux,我们能够找出我们需要发送的内容。
|
||||
|
||||
```
|
||||
由于在树莓派的内存是在图形处理器和主处理器之间共享的,我们能够只发送可以找到我们信息的位置即可。这就是 DMA,许多复杂的设备使用这种技术去加速访问时间。
|
||||
```
|
||||
|
||||
消息很简单。我们描述我们想要的帧缓冲区,而图形卡要么接受我们的请求,给我们返回一个 0,然后用我们写的一个小的调查问卷来填充屏幕;要么发送一个非 0 值,我们知道那表示很遗憾(出错了)。不幸的是,我并不知道它返回的其它数字是什么,也不知道它意味着什么,但我们知道仅当它返回一个 0,才表示一切顺利。幸运的是,对于合理的输入,它总是返回一个 0,因此我们不用过于担心。
|
||||
|
||||
为简单起见,我们将提前设计好我们的请求,并将它保存到 `framebuffer.s` 文件的 `.data` 节中,它的代码如下:
|
||||
|
||||
```assembly
|
||||
.section .data
|
||||
.align 4
|
||||
.globl FrameBufferInfo
|
||||
FrameBufferInfo:
|
||||
.int 1024 /* #0 物理宽度 */
|
||||
.int 768 /* #4 物理高度 */
|
||||
.int 1024 /* #8 虚拟宽度 */
|
||||
.int 768 /* #12 虚拟高度 */
|
||||
.int 0 /* #16 GPU - 间距 */
|
||||
.int 16 /* #20 位深 */
|
||||
.int 0 /* #24 X */
|
||||
.int 0 /* #28 Y */
|
||||
.int 0 /* #32 GPU - 指针 */
|
||||
.int 0 /* #36 GPU - 大小 */
|
||||
```
|
||||
|
||||
这就是我们发送到图形处理器的消息格式。第一对两个关键字描述了物理宽度和高度。第二对关键字描述了虚拟宽度和高度。帧缓冲的宽度和高度就是虚拟的宽度和高度,而 GPU 按需要伸缩帧缓冲去填充物理屏幕。如果 GPU 接受我们的请求,接下来的关键字将是 GPU 去填充的参数。它们是帧缓冲每行的字节数,在本案例中它是 `2 × 1024 = 2048`。下一个关键字是每个像素分配的位数。使用了一个 16 作为值意味着图形处理器使用了我们上面所描述的高色值模式。值为 24 是真彩色,而值为 32 则是 RGBA32。接下来的两个关键字是 x 和 y 偏移量,它表示当将帧缓冲复制到屏幕时,从屏幕左上角跳过的像素数目。最后两个关键字是由图形处理器填写的,第一个表示指向帧缓冲的实际指针,第二个是用字节数表示的帧缓冲大小。
|
||||
|
||||
```
|
||||
当设备使用 DMA 时,对齐约束变得非常重要。GPU 预期消息都是 16 字节对齐的。
|
||||
```
|
||||
|
||||
在这里我非常谨慎地使用了一个 `.align 4` 指令。正如前面所讨论的,这样确保了下一行地址的低 4 位是 0。所以,我们可以确保将被放到那个地址上的帧缓冲是可以发送到图形处理器上的,因为我们的邮箱仅发送低 4 位全为 0 的值。
|
||||
|
||||
到目前为止,我们已经有了待发送的消息,我们可以写代码去发送它了。通讯将按如下的步骤进行:
|
||||
|
||||
1. 写入 `FrameBufferInfo + 0x40000000` 的地址到邮箱 1。
|
||||
2. 从邮箱 1 上读取结果。如果它是非 0 值,意味着我们没有请求一个正确的帧缓冲。
|
||||
3. 复制我们的图像到指针,这时图像将出现在屏幕上!
|
||||
|
||||
|
||||
|
||||
我在步骤 1 中说了一些以前没有提到的事情。我们在发送之前,在帧缓冲地址上加了 `0x40000000`。这其实是一个给 GPU 的特殊信号,它告诉 GPU 应该如何写到结构上。如果我们只是发送地址,GPU 将写到它的回复上,这样不能保证我们可以通过刷新缓存看到它。缓存是处理器使用的值在它们被发送到存储之前保存在内存中的片段。通过加上 `0x40000000`,我们告诉 GPU 不要将写入到它的缓存中,这样将确保我们能够看到变化。
|
||||
|
||||
因为在那里发生很多事情,因此最好将它实现为一个函数,而不是将它以代码的方式写入到 `main.s` 中。我们将要写一个函数 `InitialiseFrameBuffer`,由它来完成所有协调和返回指向到上面提到的帧缓冲数据的指针。为方便起见,我们还将帧缓冲的宽度、高度、位深作为这个方法的输入,这样就很容易地修改 `main.s` 而不必知道协调的细节了。
|
||||
|
||||
再一次,来写下我们要做的详细步骤。如果你有信心,可以略过这一步直接尝试去写函数。
|
||||
|
||||
1. 验证我们的输入。
|
||||
2. 写输入到帧缓冲。
|
||||
3. 发送 `frame buffer + 0x40000000` 的地址到邮箱。
|
||||
4. 从邮箱中接收回复。
|
||||
5. 如果回复是非 0 值,方法失败。我们应该返回 0 去表示失败。
|
||||
6. 返回指向帧缓冲信息的指针。
|
||||
|
||||
|
||||
|
||||
现在,我们开始写更多的方法。以下是上面其中一个实现。
|
||||
|
||||
1.
|
||||
```assembly
|
||||
.section .text
|
||||
.globl InitialiseFrameBuffer
|
||||
InitialiseFrameBuffer:
|
||||
width .req r0
|
||||
height .req r1
|
||||
bitDepth .req r2
|
||||
cmp width,#4096
|
||||
cmpls height,#4096
|
||||
cmpls bitDepth,#32
|
||||
result .req r0
|
||||
movhi result,#0
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
这段代码检查宽度和高度是小于或等于 4096,位深小于或等于 32。这里再次使用了条件运行的技巧。相信自己这是可行的。
|
||||
|
||||
2.
|
||||
```assembly
|
||||
fbInfoAddr .req r3
|
||||
push {lr}
|
||||
ldr fbInfoAddr,=FrameBufferInfo
|
||||
str width,[fbInfoAddr,#0]
|
||||
str height,[fbInfoAddr,#4]
|
||||
str width,[fbInfoAddr,#8]
|
||||
str height,[fbInfoAddr,#12]
|
||||
str bitDepth,[fbInfoAddr,#20]
|
||||
.unreq width
|
||||
.unreq height
|
||||
.unreq bitDepth
|
||||
```
|
||||
|
||||
这段代码写入到我们上面定义的帧缓冲结构中。我也趁机将链接寄存器推入到栈上。
|
||||
|
||||
3.
|
||||
```assembly
|
||||
mov r0,fbInfoAddr
|
||||
add r0,#0x40000000
|
||||
mov r1,#1
|
||||
bl MailboxWrite
|
||||
```
|
||||
|
||||
`MailboxWrite` 方法的输入是写入到寄存器 `r0` 中的值,并将通道写入到寄存器 `r1` 中。
|
||||
|
||||
4.
|
||||
```assembly
|
||||
mov r0,#1
|
||||
bl MailboxRead
|
||||
```
|
||||
|
||||
`MailboxRead` 方法的输入是写入到寄存器 `r0` 中的通道,而输出是值读数。
|
||||
|
||||
5.
|
||||
```assembly
|
||||
teq result,#0
|
||||
movne result,#0
|
||||
popne {pc}
|
||||
```
|
||||
|
||||
这段代码检查 `MailboxRead` 方法的结果是否为 0,如果不为 0,则返回 0。
|
||||
|
||||
6.
|
||||
```assembly
|
||||
mov result,fbInfoAddr
|
||||
pop {pc}
|
||||
.unreq result
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
这是代码结束,并返回帧缓冲信息地址。
|
||||
|
||||
|
||||
|
||||
|
||||
### 5、在一帧中一行之内的一个像素
|
||||
|
||||
到目前为止,我们已经创建了与图形处理器通讯的方法。现在它已经能够给我们返回一个指向到帧缓冲的指针去绘制图形了。我们现在来绘制一个图形。
|
||||
|
||||
第一示例,我们将在屏幕上绘制连续的颜色。它看起来并不漂亮,但至少能说明它在工作。我们如何才能在帧缓冲中设置每个像素为一个连续的数字,并且要持续不断地这样做。
|
||||
|
||||
将下列代码复制到 `main.s` 文件中,并放置在 `mov sp,#0x8000` 行之后。
|
||||
|
||||
```assembly
|
||||
mov r0,#1024
|
||||
mov r1,#768
|
||||
mov r2,#16
|
||||
bl InitialiseFrameBuffer
|
||||
```
|
||||
|
||||
这段代码使用了我们的 `InitialiseFrameBuffer` 方法,简单地创建了一个宽 1024、高 768、位深为 16 的帧缓冲区。在这里,如果你愿意可以尝试使用不同的值,只要整个代码中都一样就可以。如果图形处理器没有给我们创建好一个帧缓冲区,这个方法将返回 0,我们最好检查一下返回值,如果出现返回值为 0 的情况,我们打开 `OK` LED 灯。
|
||||
|
||||
```assembly
|
||||
teq r0,#0
|
||||
bne noError$
|
||||
|
||||
mov r0,#16
|
||||
mov r1,#1
|
||||
bl SetGpioFunction
|
||||
mov r0,#16
|
||||
mov r1,#0
|
||||
bl SetGpio
|
||||
|
||||
error$:
|
||||
b error$
|
||||
|
||||
noError$:
|
||||
fbInfoAddr .req r4
|
||||
mov fbInfoAddr,r0
|
||||
```
|
||||
|
||||
现在,我们已经有了帧缓冲信息的地址,我们需要取得帧缓冲信息的指针,并开始绘制屏幕。我们使用两个循环来做实现,一个走行,一个走列。事实上,树莓派中的大多数应用程序中,图片都是以从左右然后从上下到的顺序来保存的,因此我们也按这个顺序来写循环。
|
||||
|
||||
|
||||
```assembly
|
||||
render$:
|
||||
|
||||
fbAddr .req r3
|
||||
ldr fbAddr,[fbInfoAddr,#32]
|
||||
|
||||
colour .req r0
|
||||
y .req r1
|
||||
mov y,#768
|
||||
drawRow$:
|
||||
|
||||
x .req r2
|
||||
mov x,#1024
|
||||
drawPixel$:
|
||||
|
||||
strh colour,[fbAddr]
|
||||
add fbAddr,#2
|
||||
sub x,#1
|
||||
teq x,#0
|
||||
bne drawPixel$
|
||||
|
||||
sub y,#1
|
||||
add colour,#1
|
||||
teq y,#0
|
||||
bne drawRow$
|
||||
|
||||
b render$
|
||||
|
||||
.unreq fbAddr
|
||||
.unreq fbInfoAddr
|
||||
```
|
||||
|
||||
```assembly
|
||||
strh reg,[dest] 将寄存器中的低位半个字保存到给定的 dest 地址上。
|
||||
```
|
||||
|
||||
这是一个很长的代码块,它嵌套了三层循环。为了帮你理清头绪,我们将循环进行缩进处理,这就有点类似于高级编程语言,而汇编器会忽略掉这些用于缩进的 `tab` 字符。我们看到,在这里它从帧缓冲信息结构中加载了帧缓冲的地址,然后基于每行来循环,接着是每行上的每个像素。在每个像素上,我们使用一个 `strh`(保存半个字)命令去保存当前颜色,然后增加地址继续写入。每行绘制完成后,我们增加绘制的颜色号。在整个屏幕绘制完成后,我们跳转到开始位置。
|
||||
|
||||
### 6、看到曙光
|
||||
|
||||
现在,你已经准备好在树莓派上测试这些代码了。你应该会看到一个渐变图案。注意:在第一个消息被发送到邮箱之前,树莓派在它的四个角上一直显示一个渐变图案。如果它不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果一切正常,恭喜你!你现在可以控制屏幕了!你可以随意修改这些代码去绘制你想到的任意图案。你还可以做更精彩的渐变图案,可以直接计算每个像素值,因为每个像素包含了一个 Y 坐标和 X 坐标。在下一个 [课程 7:Screen 02][7] 中,我们将学习一个更常用的绘制任务:行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour1bImage.png
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8gImage.png
|
||||
[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour3bImage.png
|
||||
[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8bImage.png
|
||||
[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour16bImage.png
|
||||
[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour24bImage.png
|
||||
[7]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
@ -0,0 +1,463 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 7 Screen02)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室 – 树莓派:课程 7 屏幕02
|
||||
======
|
||||
|
||||
屏幕02 课程在屏幕01 的基础上构建,它教你如何绘制线和一个生成伪随机数的小特性。假设你已经有了 [课程6:屏幕01][1] 的操作系统代码,我们将以它为基础来构建。
|
||||
|
||||
### 1、点
|
||||
|
||||
现在,我们的屏幕已经正常工作了,现在开始去创建一个更实用的图像,是水到渠成的事。如果我们能够绘制出更实用的图形那就更好了。如果我们能够在屏幕上的两点之间绘制一条线,那我们就能够组合这些线绘制出更复杂的图形了。
|
||||
|
||||
```
|
||||
为了绘制出更复杂的图形,一些方法使用一个着色函数而不是一个颜色去绘制。每个点都能够调用着色函数来确定在那里用什么颜色去绘制。
|
||||
```
|
||||
|
||||
我们将尝试用汇编代码去实现它,但在开始时,我们确实需要使用一些其它的函数去帮助它。我们需要一个函数,我将调用 `SetPixel` 去修改指定像素的颜色,在寄存器 `r0` 和 `r1` 中提供输入。如果我们写出的代码可以在任意内存中而不仅仅是屏幕上绘制图形,这将在以后非常有用,因此,我们首先需要一些控制真实绘制位置的方法。我认为实现上述目标的最好方法是,能够有一个内存片段用于保存将要绘制的图形。我应该最终使用它来保存地址,这个地址就是指向到自上次以来的帧缓存结构上。我们将在后面的代码中使用这个绘制方法。这样,如果我们想在我们的操作系统的另一部分绘制一个不同的图像,我们就可以生成一个不同结构的地址值,而使用的是完全相同的代码。为简单起见,我们将使用另一个数据片段去控制我们绘制的颜色。
|
||||
|
||||
复制下列代码到一个名为 `drawing.s` 的新文件中。
|
||||
|
||||
```assembly
|
||||
.section .data
|
||||
.align 1
|
||||
foreColour:
|
||||
.hword 0xFFFF
|
||||
|
||||
.align 2
|
||||
graphicsAddress:
|
||||
.int 0
|
||||
|
||||
.section .text
|
||||
.globl SetForeColour
|
||||
SetForeColour:
|
||||
cmp r0,#0x10000
|
||||
movhs pc,lr
|
||||
ldr r1,=foreColour
|
||||
strh r0,[r1]
|
||||
mov pc,lr
|
||||
|
||||
.globl SetGraphicsAddress
|
||||
SetGraphicsAddress:
|
||||
ldr r1,=graphicsAddress
|
||||
str r0,[r1]
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
这段代码就是我上面所说的一对函数以及它们的数据。我们将在 `main.s` 中使用它们,在绘制图像之前去控制在何处绘制什么内容。
|
||||
|
||||
```
|
||||
构建一个通用方法,比如 `SetPixel`,我们将在它之上构建另一个方法是一个很好的创意。但我们必须要确保这个方法很快,因为我们要经常使用它。
|
||||
```
|
||||
|
||||
我们的下一个任务是去实现一个 `SetPixel` 方法。它需要带两个参数,像素的 x 和 y 轴,并且它应该会使用 `graphicsAddress` 和 `foreColour`,我们只定义精确控制在哪里绘制什么图像即可。如果你认为你能立即实现这些,那么去动手实现吧,如果不能,按照我们提供的步骤,按示例去实现它。
|
||||
|
||||
1. 加载 `graphicsAddress`。
|
||||
2. 检查像素的 x 和 y 轴是否小于宽度和高度。
|
||||
3. 计算要写入的像素地址(提示:`frameBufferAddress +(x + y * 宽度)* 像素大小`)
|
||||
4. 加载 `foreColour`。
|
||||
5. 保存到地址。
|
||||
|
||||
|
||||
|
||||
上述步骤实现如下:
|
||||
|
||||
1.
|
||||
```assembly
|
||||
.globl DrawPixel
|
||||
DrawPixel:
|
||||
px .req r0
|
||||
py .req r1
|
||||
addr .req r2
|
||||
ldr addr,=graphicsAddress
|
||||
ldr addr,[addr]
|
||||
```
|
||||
|
||||
2.
|
||||
```assembly
|
||||
height .req r3
|
||||
ldr height,[addr,#4]
|
||||
sub height,#1
|
||||
cmp py,height
|
||||
movhi pc,lr
|
||||
.unreq height
|
||||
|
||||
width .req r3
|
||||
ldr width,[addr,#0]
|
||||
sub width,#1
|
||||
cmp px,width
|
||||
movhi pc,lr
|
||||
```
|
||||
|
||||
记住,宽度和高度被各自保存在帧缓冲偏移量的 0 和 4 处。如有必要可以参考 `frameBuffer.s`。
|
||||
|
||||
3.
|
||||
```assembly
|
||||
ldr addr,[addr,#32]
|
||||
add width,#1
|
||||
mla px,py,width,px
|
||||
.unreq width
|
||||
.unreq py
|
||||
add addr, px,lsl #1
|
||||
.unreq px
|
||||
```
|
||||
|
||||
```assembly
|
||||
mla dst,reg1,reg2,reg3 将寄存器 `reg1` 和 `reg2` 中的值相乘,然后将结果与寄存器 `reg3` 中的值相加,并将结果的低 32 位保存到 dst 中。
|
||||
```
|
||||
|
||||
确实,这段代码是专用于高色值帧缓存的,因为我使用一个逻辑左移操作去计算地址。你可能希望去编写一个不需要专用的高色值帧缓冲的函数版本,记得去更新 `SetForeColour` 的代码。它实现起来可能更复杂一些。
|
||||
|
||||
4.
|
||||
```assembly
|
||||
fore .req r3
|
||||
ldr fore,=foreColour
|
||||
ldrh fore,[fore]
|
||||
```
|
||||
|
||||
以上是专用于高色值的。
|
||||
|
||||
5.
|
||||
```assembly
|
||||
strh fore,[addr]
|
||||
.unreq fore
|
||||
.unreq addr
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
以上是专用于高色值的。
|
||||
|
||||
|
||||
|
||||
|
||||
### 2、线
|
||||
|
||||
问题是,线的绘制并不是你所想像的那么简单。到目前为止,你必须认识到,编写一个操作系统时,几乎所有的事情都必须我们自己去做,绘制线条也不例外。我建议你们花点时间想想如何在任意两点之间绘制一条线。
|
||||
|
||||
```
|
||||
在我们日常编程中,我们对像除法这样的运算通常懒得去优化。但是操作系统不同,它必须高效,因此我们要始终专注于如何让事情做的尽可能更好。
|
||||
```
|
||||
|
||||
我估计大多数的策略可能是去计算线的梯度,并沿着它来绘制。这看上去似乎很完美,但它事实上是个很糟糕的主意。主要问题是它涉及到除法,我们知道在汇编中,做除法很不容易,并且还要始终记录小数,这也很困难。事实上,在这里,有一个叫布鲁塞姆的算法,它非常适合汇编代码,因为它只使用加法、减法和位移运算。
|
||||
|
||||
|
||||
|
||||
> 我们从定义一个简单的直线绘制算法开始,代码如下:
|
||||
>
|
||||
> ```matlab
|
||||
> /* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
|
||||
>
|
||||
> if x1 > x0 then
|
||||
>
|
||||
> set deltax to x1 - x0
|
||||
> set stepx to +1
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> set deltax to x0 - x1
|
||||
> set stepx to -1
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> if y1 > y0 then
|
||||
>
|
||||
> set deltay to y1 - y0
|
||||
> set stepy to +1
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> set deltay to y0 - y1
|
||||
> set stepy to -1
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> if deltax > deltay then
|
||||
>
|
||||
> set error to 0
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax ÷ deltay
|
||||
> if error ≥ 0.5 then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - 1
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
>
|
||||
> otherwise
|
||||
>
|
||||
> end if
|
||||
> ```
|
||||
>
|
||||
> 这个算法用来表示你可能想像到的那些东西。变量 `error` 用来记录你离实线的距离。沿着 x 轴每走一步,这个 `error` 的值都会增加,而沿着 y 轴每走一步,这个 `error` 值就会减 1 个单位。`error` 是用于测量距离 y 轴的距离。
|
||||
>
|
||||
> 虽然这个算法是有效的,但它存在一个重要的问题,很明显,我们使用了小数去保存 `error`,并且也使用了除法。所以,一个立即要做的优化将是去改变 `error` 的单位。这里并不需要用特定的单位去保存它,只要我们每次使用它时都按相同数量去伸缩即可。所以,我们可以重写这个算法,通过在所有涉及 `error` 的等式上都简单地乘以 `deltay`,从面让它简化。下面只展示主要的循环:
|
||||
>
|
||||
> ```matlab
|
||||
> set error to 0 × deltay
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax ÷ deltay × deltay
|
||||
> if error ≥ 0.5 × deltay then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - 1 × deltay
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 它将简化为:
|
||||
>
|
||||
> ```matlab
|
||||
> cset error to 0
|
||||
> until x0 = x1 + stepx
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> set error to error + deltax
|
||||
> if error × 2 ≥ deltay then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error - deltay
|
||||
>
|
||||
> end if
|
||||
> set x0 to x0 + stepx
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 突然,我们有了一个更好的算法。现在,我们看一下如何完全去除所需要的除法运算。最好保留唯一的被 2 相乘的乘法运算,我们知道它可以通过左移 1 位来实现!现在,这是非常接近布鲁塞姆算法的,但还可以进一步优化它。现在,我们有一个 `if` 语句,它将导致产生两个代码块,其中一个用于 x 差异较大的线,另一个用于 y 差异较大的线。对于这两种类型的线,如果审查代码能够将它们转换成一个单语句,还是很值得去做的。
|
||||
>
|
||||
> 困难之处在于,在第一种情况下,`error` 是与 y 一起变化,而第二种情况下 `error` 是与 x 一起变化。解决方案是在一个变量中同时记录它们,使用负的 `error` 去表示 x 中的一个 `error`,而用正的 `error` 表示它是 y 中的。
|
||||
>
|
||||
> ```matlab
|
||||
> set error to deltax - deltay
|
||||
> until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
>
|
||||
> setPixel(x0, y0)
|
||||
> if error × 2 > -deltay then
|
||||
>
|
||||
> set x0 to x0 + stepx
|
||||
> set error to error - deltay
|
||||
>
|
||||
> end if
|
||||
> if error × 2 < deltax then
|
||||
>
|
||||
> set y0 to y0 + stepy
|
||||
> set error to error + deltax
|
||||
>
|
||||
> end if
|
||||
>
|
||||
> repeat
|
||||
> ```
|
||||
>
|
||||
> 你可能需要一些时间来搞明白它。在每一步中,我们都认为它正确地在 x 和 y 中移动。我们通过检查来做到这一点,如果我们在 x 或 y 轴上移动,`error` 的数量会变低,那么我们就继续这样移动。
|
||||
>
|
||||
|
||||
|
||||
```
|
||||
布鲁塞姆算法是在 1962 年由 Jack Elton Bresenham 开发,当时他 24 岁,正在攻读博士学位。
|
||||
```
|
||||
|
||||
用于画线的布鲁塞姆算法可以通过以下的伪代码来描述。以下伪代码是文本,它只是看起来有点像是计算机指令而已,但它却能让程序员实实在在地理解算法,而不是为机器可读。
|
||||
|
||||
```matlab
|
||||
/* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
|
||||
|
||||
if x1 > x0 then
|
||||
set deltax to x1 - x0
|
||||
set stepx to +1
|
||||
otherwise
|
||||
set deltax to x0 - x1
|
||||
set stepx to -1
|
||||
end if
|
||||
|
||||
set error to deltax - deltay
|
||||
until x0 = x1 + stepx or y0 = y1 + stepy
|
||||
setPixel(x0, y0)
|
||||
if error × 2 ≥ -deltay then
|
||||
set x0 to x0 + stepx
|
||||
set error to error - deltay
|
||||
end if
|
||||
if error × 2 ≤ deltax then
|
||||
set y0 to y0 + stepy
|
||||
set error to error + deltax
|
||||
end if
|
||||
repeat
|
||||
```
|
||||
|
||||
与我们目前所使用的编号列表不同,这个算法的表示方式更常用。看看你能否自己实现它。我在下面提供了我的实现作为参考。
|
||||
|
||||
```assembly
|
||||
.globl DrawLine
|
||||
DrawLine:
|
||||
push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
|
||||
x0 .req r9
|
||||
x1 .req r10
|
||||
y0 .req r11
|
||||
y1 .req r12
|
||||
|
||||
mov x0,r0
|
||||
mov x1,r2
|
||||
mov y0,r1
|
||||
mov y1,r3
|
||||
|
||||
dx .req r4
|
||||
dyn .req r5 /* 注意,我们只使用 -deltay,因此为了速度,我保存它的负值。(因此命名为 dyn)*/
|
||||
sx .req r6
|
||||
sy .req r7
|
||||
err .req r8
|
||||
|
||||
cmp x0,x1
|
||||
subgt dx,x0,x1
|
||||
movgt sx,#-1
|
||||
suble dx,x1,x0
|
||||
movle sx,#1
|
||||
|
||||
cmp y0,y1
|
||||
subgt dyn,y1,y0
|
||||
movgt sy,#-1
|
||||
suble dyn,y0,y1
|
||||
movle sy,#1
|
||||
|
||||
add err,dx,dyn
|
||||
add x1,sx
|
||||
add y1,sy
|
||||
|
||||
pixelLoop$:
|
||||
|
||||
teq x0,x1
|
||||
teqne y0,y1
|
||||
popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
|
||||
|
||||
mov r0,x0
|
||||
mov r1,y0
|
||||
bl DrawPixel
|
||||
|
||||
cmp dyn, err,lsl #1
|
||||
addle err,dyn
|
||||
addle x0,sx
|
||||
|
||||
cmp dx, err,lsl #1
|
||||
addge err,dx
|
||||
addge y0,sy
|
||||
|
||||
b pixelLoop$
|
||||
|
||||
.unreq x0
|
||||
.unreq x1
|
||||
.unreq y0
|
||||
.unreq y1
|
||||
.unreq dx
|
||||
.unreq dyn
|
||||
.unreq sx
|
||||
.unreq sy
|
||||
.unreq err
|
||||
```
|
||||
|
||||
### 3、随机性
|
||||
|
||||
到目前,我们可以绘制线条了。虽然我们可以使用它来绘制图片及诸如此类的东西(你可以随意去做!),我想应该借此机会引入计算机中随机性的概念。我将这样去做,选择一对随机的坐标,然后从最后一对坐标用渐变色绘制一条线到那个点。我这样做纯粹是认为它看起来很漂亮。
|
||||
|
||||
```
|
||||
硬件随机数生成器是在安全中使用很少,可预测的随机数序列可能影响某些加密的安全。
|
||||
```
|
||||
|
||||
那么,总结一下,我们如何才能产生随机数呢?不幸的是,我们并没有产生随机数的一些设备(这种设备很罕见)。因此只能利用我们目前所学过的操作,需要我们以某种方式来发明`随机数`。你很快就会意识到这是不可能的。操作总是给出定义好的结果,用相同的寄存器运行相同的指令序列总是给出相同的答案。而我们要做的是推导出一个伪随机序列。这意味着数字在外人看来是随机的,但实际上它是完全确定的。因此,我们需要一个生成随机数的公式。其中有人可能会想到很垃圾的数学运算,比如:4x2! / 64,而事实上它产生的是一个低质量的随机数。在这个示例中,如果 x 是 0,那么答案将是 0。看起来很愚蠢,我们需要非常谨慎地选择一个能够产生高质量随机数的方程式。
|
||||
|
||||
```
|
||||
这类讨论经常寻求一个问题,那就是我们所谓的随机数到底是什么?通常从统计学的角度来说的随机性是:一组没有明显模式或属性能够概括它的数的序列。
|
||||
```
|
||||
|
||||
我将要教给你的方法叫“二次同余发生器”。这是一个非常好的选择,因为它能够在 5 个指令中实现,并且能够产生一个从 0 到 232-1 之间的看似很随机的数字序列。
|
||||
|
||||
不幸的是,对为什么使用如此少的指令能够产生如此长的序列的原因的研究,已经远超出了本课程的教学范围。但我还是鼓励有兴趣的人去研究它。它的全部核心所在就是下面的二次方程,其中 `xn` 是产生的第 `n` 个随机数。
|
||||
|
||||
x_(n+1) = ax_(n)^2 + bx_(n) + c mod 2^32
|
||||
|
||||
这个方程受到以下的限制:
|
||||
|
||||
1. a 是偶数
|
||||
|
||||
2. b = a + 1 mod 4
|
||||
|
||||
3. c 是奇数
|
||||
|
||||
|
||||
|
||||
|
||||
如果你之前没有见到过 `mod` 运算,我来解释一下,它的意思是被它后面的数相除之后的余数。比如 `b = a + 1 mod 4` 的意思是 `b` 是 `a + 1` 除以 `4` 的余数,因此,如果 `a` 是 12,那么 `b` 将是 `1`,因为 `a + 1` 是 13,而 `13` 除以 4 的结果是 3 余 1。
|
||||
|
||||
复制下列代码到名为 `random.s` 的文件中。
|
||||
|
||||
```assembly
|
||||
.globl Random
|
||||
Random:
|
||||
xnm .req r0
|
||||
a .req r1
|
||||
|
||||
mov a,#0xef00
|
||||
mul a,xnm
|
||||
mul a,xnm
|
||||
add a,xnm
|
||||
.unreq xnm
|
||||
add r0,a,#73
|
||||
|
||||
.unreq a
|
||||
mov pc,lr
|
||||
```
|
||||
|
||||
这是随机函数的一个实现,使用一个在寄存器 `r0` 中最后生成的值作为输入,而接下来的数字则是输出。在我的案例中,我使用 a = EF00<sub>16</sub>,b = 1, c = 73。这个选择是随意的,但是需要满足上述的限制。你可以使用任何数字代替它们,只要符合上述的规则就行。
|
||||
|
||||
### 4、Pi-casso
|
||||
|
||||
OK,现在我们有了所有我们需要的函数,我们来试用一下它们。获取帧缓冲信息的地址之后,按如下的要求修改 `main`:
|
||||
|
||||
1. 使用包含了帧缓冲信息地址的寄存器 `r0` 调用 `SetGraphicsAddress`。
|
||||
2. 设置四个寄存器为 0。一个将是最后的随机数,一个将是颜色,一个将是最后的 x 坐标,而最后一个将是最后的 y 坐标。
|
||||
3. 调用 `random` 去产生下一个 x 坐标,使用最后一个随机数作为输入。
|
||||
4. 调用 `random` 再次去生成下一个 y 坐标,使用你生成的 x 坐标作为输入。
|
||||
5. 更新最后的随机数为 y 坐标。
|
||||
6. 使用 `colour` 值调用 `SetForeColour`,接着增加 `colour` 值。如果它大于 FFFF~16~,确保它返回为 0。
|
||||
7. 我们生成的 x 和 y 坐标将介于 0 到 FFFFFFFF~16~。通过将它们逻辑右移 22 位,将它们转换为介于 0 到 1023~10~ 之间的数。
|
||||
8. 检查 y 坐标是否在屏幕上。验证 y 坐标是否介于 0 到 767~10~ 之间。如果不在这个区间,返回到第 3 步。
|
||||
9. 从最后的 x 坐标和 y 坐标到当前的 x 坐标和 y 坐标之间绘制一条线。
|
||||
10. 更新最后的 x 和 y 坐标去为当前的坐标。
|
||||
11. 返回到第 3 步。
|
||||
|
||||
|
||||
|
||||
一如既往,你可以在下载页面上找到这个解决方案。
|
||||
|
||||
在你完成之后,在树莓派上做测试。你应该会看到一系列颜色递增的随机线条以非常快的速度出现在屏幕上。它一直持续下去。如果你的代码不能正常工作,请查看我们的排错页面。
|
||||
|
||||
如果一切顺利,恭喜你!我们现在已经学习了有意义的图形和随机数。我鼓励你去使用它绘制线条,因为它能够用于渲染你想要的任何东西,你可以去探索更复杂的图案了。它们中的大多数都可以由线条生成,但这需要更好的策略?如果你愿意写一个画线程序,尝试使用 `SetPixel` 函数。如果不是去设置像素值而是一点点地增加它,会发生什么情况?你可以用它产生什么样的图案?在下一节课 [课程 8:屏幕 03][2] 中,我们将学习绘制文本的宝贵技能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
@ -0,0 +1,469 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qhwdw)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
|
||||
[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
|
||||
[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
|
||||
|
||||
计算机实验室 – 树莓派:课程 8 屏幕03
|
||||
======
|
||||
|
||||
屏幕03 课程基于屏幕02 课程来构建,它教你如何绘制文本,和一个操作系统命令行参数上的一个小特性。假设你已经有了[课程 7:屏幕02][1] 的操作系统代码,我们将以它为基础来构建。
|
||||
|
||||
### 1、字符串的理论知识
|
||||
|
||||
是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,破坏了完美的加密,并给使用不同字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
|
||||
|
||||
```
|
||||
可变数据类型,比如文本要求能够进行很复杂的处理。
|
||||
```
|
||||
|
||||
那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数字是不固定的。一些文本片断可能比其它的长。与保存普通数字一样,我们有一些固有的限制,即:3 位,我们不能超过这个限制,我们添加方法去使用那种长数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于变长字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
|
||||
|
||||
```
|
||||
缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
|
||||
```
|
||||
|
||||
因此,如何判断字符串长度?我想显而易见的答案是存储多长的字符串,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(NULL)的特殊字符(用 \0表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但尽管如此,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
|
||||
|
||||
接下来的事情是,我们需要去维护一个很好的从字符到数字的映射。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个单个的有用的符号都映射为数字,作为交换,我们得到的是很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与 Unicode 相比,它的每个字符占用的空间并不相同,这使得字符串算法更棘手。一般操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
|
||||
|
||||
幸运的是,在这里我们不需要去做选择,因为它们的前 128 个字符是完全相同的,并且编码也是完全一样的。
|
||||
|
||||
表 1.1 ASCII/Unicode 符号 0-127
|
||||
|
||||
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
|
||||
|----| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ----|
|
||||
| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
|
||||
| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
|
||||
| 20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | | |
|
||||
| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
|
||||
| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
|
||||
| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
|
||||
| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
|
||||
| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
|
||||
|
||||
这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 41~16~。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
|
||||
|
||||
### 2、字符
|
||||
|
||||
到目前为止,我们已经知道了一些关于字符串的知识,我们可以开始想想它们是如何显示的。为了显示一个字符串,我们需要做的最基础的事情是能够显示一个字符。我们的第一个任务是编写一个 `DrawCharacter` 函数,给它一个要绘制的字符和一个位置,然后它将这个字符绘制出来。
|
||||
|
||||
```markdown
|
||||
在许多操作系统中使用的 `truetype` 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
|
||||
```
|
||||
|
||||
这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,一种字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
|
||||
|
||||
不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个站点的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个正宗的图形化的操作系统,那么矢量字体将是很有用的。
|
||||
|
||||
在下载页面上的字体节中,我们提供了几个 `.bin` 文件。这些只是字体的原始二进制数据文件。为完成本教程,从等宽、单色、8x16 节中挑选你喜欢的字体。然后下载它并保存到 `source` 目录中并命名为 `font.bin` 文件。这些文件只是每个字母的单色图片,它们每个字母刚好是 8 x 16 个像素。所以,每个字母占用 16 字节,第一个字节是第一行,第二个字节是第二行,依此类推。
|
||||
|
||||

|
||||
|
||||
这个示意图展示了等宽、单色、8x16 的字符 A 的 `Bitstream Vera Sans Mono`。在这个文件中,我们可以找到,它从第 41~16~ × 10~16~ = 410~16~ 字节开始的十六进制序列:
|
||||
|
||||
00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
|
||||
|
||||
在这里我们将使用等宽字体,因为等宽字体的每个字符大小是相同的。不幸的是,大多数字体的复杂之处就是因为它的宽度不同,从而导致它的显示代码更复杂。在下载页面上还包含有几个其它的字体,并包含了这种字体的存储格式介绍。
|
||||
|
||||
我们回到正题。复制下列代码到 `drawing.s` 中的 `graphicsAddress` 的 `.int 0` 之后。
|
||||
|
||||
```assembly
|
||||
.align 4
|
||||
font:
|
||||
.incbin "font.bin"
|
||||
```
|
||||
|
||||
```assembly
|
||||
.incbin "file" 插入来自文件 “file” 中的二进制数据。
|
||||
```
|
||||
|
||||
这段代码复制文件中的字体数据到标签为 `font` 的地址。我们在这里使用了一个 `.align 4` 去确保每个字符都是从 16 字节的倍数开始,这是一个以后经常用到的用于加快访问速度的技巧。
|
||||
|
||||
现在我们去写绘制字符的方法。我在下面给出了伪代码,你可以尝试自己去实现它。按惯例 `>>` 的意思是逻辑右移。
|
||||
|
||||
```c
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character × 16
|
||||
for row = 0 to 15
|
||||
set bits to readByte(charAddress + row)
|
||||
for bit = 0 to 7
|
||||
if test(bits >> bit, 0x1)
|
||||
then setPixel(x + bit, y + row)
|
||||
next
|
||||
next
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
|
||||
```
|
||||
如果直接去实现它,这显然不是个高效率的做法。像绘制字符这样的事情,效率是最重要的。因为我们要频繁使用它。我们来探索一些改善的方法,使其成为最优化的汇编代码。首先,因为我们有一个 `× 16`,你应该会马上想到它等价于逻辑左移 4 位。紧接着我们有一个变量 `row`,它只与 `charAddress` 和 `y` 相加。所以,我们可以通过增加替代变量来消除它。现在唯一的问题是如何判断我们何时完成。这时,一个很好用的 `.align 4` 上场了。我们知道,`charAddress` 将从包含 0 的低位半字节开始。这意味着我们可以通过检查低位半字节来看到进入字符数据的程度。
|
||||
|
||||
虽然我们可以消除对 `bit` 的需求,但我们必须要引入新的变量才能实现,因此最好还是保留它。剩下唯一的改进就是去除嵌套的 `bits >> bit`。
|
||||
|
||||
```c
|
||||
function drawCharacter(r0 is character, r1 is x, r2 is y)
|
||||
if character > 127 then exit
|
||||
set charAddress to font + character << 4
|
||||
loop
|
||||
set bits to readByte(charAddress)
|
||||
set bit to 8
|
||||
loop
|
||||
set bits to bits << 1
|
||||
set bit to bit - 1
|
||||
if test(bits, 0x100)
|
||||
then setPixel(x + bit, y)
|
||||
until bit = 0
|
||||
set y to y + 1
|
||||
set chadAddress to chadAddress + 1
|
||||
until charAddress AND 0b1111 = 0
|
||||
return r0 = 8, r1 = 16
|
||||
end function
|
||||
```
|
||||
|
||||
现在,我们已经得到了非常接近汇编代码的代码了,并且代码也是经过优化的。下面就是上述代码用汇编写出来的代码。
|
||||
|
||||
```assembly
|
||||
.globl DrawCharacter
|
||||
DrawCharacter:
|
||||
cmp r0,#127
|
||||
movhi r0,#0
|
||||
movhi r1,#0
|
||||
movhi pc,lr
|
||||
|
||||
push {r4,r5,r6,r7,r8,lr}
|
||||
x .req r4
|
||||
y .req r5
|
||||
charAddr .req r6
|
||||
mov x,r1
|
||||
mov y,r2
|
||||
ldr charAddr,=font
|
||||
add charAddr, r0,lsl #4
|
||||
|
||||
lineLoop$:
|
||||
|
||||
bits .req r7
|
||||
bit .req r8
|
||||
ldrb bits,[charAddr]
|
||||
mov bit,#8
|
||||
|
||||
charPixelLoop$:
|
||||
|
||||
subs bit,#1
|
||||
blt charPixelLoopEnd$
|
||||
lsl bits,#1
|
||||
tst bits,#0x100
|
||||
beq charPixelLoop$
|
||||
|
||||
add r0,x,bit
|
||||
mov r1,y
|
||||
bl DrawPixel
|
||||
|
||||
teq bit,#0
|
||||
bne charPixelLoop$
|
||||
|
||||
charPixelLoopEnd$:
|
||||
.unreq bit
|
||||
.unreq bits
|
||||
add y,#1
|
||||
add charAddr,#1
|
||||
tst charAddr,#0b1111
|
||||
bne lineLoop$
|
||||
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq charAddr
|
||||
|
||||
width .req r0
|
||||
height .req r1
|
||||
mov width,#8
|
||||
mov height,#16
|
||||
|
||||
pop {r4,r5,r6,r7,r8,pc}
|
||||
.unreq width
|
||||
.unreq height
|
||||
```
|
||||
|
||||
### 3、字符串
|
||||
|
||||
现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 x 和 y 的坐标作为参数。
|
||||
|
||||
```c
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
for pos = 0 to length - 1
|
||||
set char to loadByte(string + pos)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
until x1 > x0
|
||||
set x1 to x1 + 5 × cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
next
|
||||
end function
|
||||
```
|
||||
|
||||
同样,这个函数与汇编代码还有很大的差距。你可以随意去尝试实现它,即可以直接实现它,也可以简化它。我在下面给出了简化后的函数和汇编代码。
|
||||
|
||||
很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增和与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
|
||||
|
||||
```c
|
||||
function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
|
||||
set x0 to x
|
||||
until length = 0
|
||||
set length to length - 1
|
||||
set char to loadByte(string)
|
||||
set (cwidth, cheight) to DrawCharacter(char, x, y)
|
||||
if char = '\n' then
|
||||
set x to x0
|
||||
set y to y + cheight
|
||||
otherwise if char = '\t' then
|
||||
set x1 to x
|
||||
set cwidth to cwidth + cwidth << 2
|
||||
until x1 > x0
|
||||
set x1 to x1 + cwidth
|
||||
loop
|
||||
set x to x1
|
||||
otherwise
|
||||
set x to x + cwidth
|
||||
end if
|
||||
set string to string + 1
|
||||
loop
|
||||
end function
|
||||
```
|
||||
|
||||
以下是它的汇编代码:
|
||||
|
||||
```assembly
|
||||
.globl DrawString
|
||||
DrawString:
|
||||
x .req r4
|
||||
y .req r5
|
||||
x0 .req r6
|
||||
string .req r7
|
||||
length .req r8
|
||||
char .req r9
|
||||
push {r4,r5,r6,r7,r8,r9,lr}
|
||||
|
||||
mov string,r0
|
||||
mov x,r2
|
||||
mov x0,x
|
||||
mov y,r3
|
||||
mov length,r1
|
||||
|
||||
stringLoop$:
|
||||
subs length,#1
|
||||
blt stringLoopEnd$
|
||||
|
||||
ldrb char,[string]
|
||||
add string,#1
|
||||
|
||||
mov r0,char
|
||||
mov r1,x
|
||||
mov r2,y
|
||||
bl DrawCharacter
|
||||
cwidth .req r0
|
||||
cheight .req r1
|
||||
|
||||
teq char,#'\n'
|
||||
moveq x,x0
|
||||
addeq y,cheight
|
||||
beq stringLoop$
|
||||
|
||||
teq char,#'\t'
|
||||
addne x,cwidth
|
||||
bne stringLoop$
|
||||
|
||||
add cwidth, cwidth,lsl #2
|
||||
x1 .req r1
|
||||
mov x1,x0
|
||||
|
||||
stringLoopTab$:
|
||||
add x1,cwidth
|
||||
cmp x,x1
|
||||
bge stringLoopTab$
|
||||
mov x,x1
|
||||
.unreq x1
|
||||
b stringLoop$
|
||||
stringLoopEnd$:
|
||||
.unreq cwidth
|
||||
.unreq cheight
|
||||
|
||||
pop {r4,r5,r6,r7,r8,r9,pc}
|
||||
.unreq x
|
||||
.unreq y
|
||||
.unreq x0
|
||||
.unreq string
|
||||
.unreq length
|
||||
```
|
||||
|
||||
```assembly
|
||||
subs reg,#val 从寄存器 reg 中减去 val,然后将结果与 0 进行比较。
|
||||
```
|
||||
|
||||
这个代码中非常聪明地使用了一个新运算,`subs` 是从一个操作数中减去另一个数,保存结果,然后将结果与 0 进行比较。实现上,所有的比较都可以实现为减法后的结果与 0 进行比较,但是结果通常会丢弃。这意味着这个操作与 `cmp` 一样快。
|
||||
|
||||
### 4、你的愿意是我的命令行
|
||||
|
||||
现在,我们可以输出字符串了,而挑战是找到一个有意思的字符串去绘制。一般在这样的教程中,人们都希望去绘制 “Hello World!”,但是到目前为止,虽然我们已经能做到了,我觉得这有点“君临天下”的感觉(如果喜欢这种感觉,请随意!)。因此,作为替代,我们去继续绘制我们的命令行。
|
||||
|
||||
有一个限制是我们所做的操作系统是用在 ARM 架构的计算机上。最关键的是,在它们引导时,给它一些信息告诉它有哪些可用资源。几乎所有的处理器都有某些方式来确定这些信息,而在 ARM 上,它是通过位于地址 100<sub>16</sub> 处的数据来确定的,这个数据的格式如下:
|
||||
|
||||
1. 数据是可分解的一系列的标签。
|
||||
2. 这里有九种类型的标签:`core`,`mem`,`videotext`,`ramdisk`,`initrd2`,`serial`,`revision`,`videolfb`,`cmdline`。
|
||||
3. 每个标签只能出现一次,除了 'core’ 标签是必不可少的之外,其它的都是可有可无的。
|
||||
4. 所有标签都依次放置在地址 0x100 处。
|
||||
5. 标签列表的结束处总是有两个<ruby>字<rt>word</rt></ruby>,它们全为 0。
|
||||
6. 每个标签的字节数都是 4 的倍数。
|
||||
7. 每个标签都是以标签中(以字为单位)的标签大小开始(标签包含这个数字)。
|
||||
8. 紧接着是包含标签编号的一个半字。编号是按上面列出的顺序,从 1 开始(`core` 是 1,`cmdline` 是 9)。
|
||||
9. 紧接着是一个包含 5441<sub>16</sub> 的半字。
|
||||
10. 之后是标签的数据,它根据标签不同是可变的。数据大小(以字为单位)+ 2 的和总是与前面提到的长度相同。
|
||||
11. 一个 `core` 标签的长度可以是 2 个字也可以是 5 个字。如果是 2 个字,表示没有数据,如果是 5 个字,表示它有 3 个字的数据。
|
||||
12. 一个 `mem` 标签总是 4 个字的长度。数据是内存块的第一个地址,和内存块的长度。
|
||||
13. 一个 `cmdline` 标签包含一个 `null` 终止符字符串,它是个内核参数。
|
||||
|
||||
|
||||
```markdown
|
||||
几乎所有的操作系统都支持一个`命令行`的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
|
||||
```
|
||||
|
||||
在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索命令行标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是为了让操作系统理解图形处理器或用户认为的很好的事情的一个列表。在树莓派上,这包含了 MAC 地址,序列号和屏幕分辨率。字符串本身也是一个像 `key.subkey=value` 这样的由空格隔开的表达式列表。
|
||||
|
||||
我们从查找 `cmdline` 标签开始。将下列的代码复制到一个名为 `tags.s` 的新文件中。
|
||||
|
||||
```assembly
|
||||
.section .data
|
||||
tag_core: .int 0
|
||||
tag_mem: .int 0
|
||||
tag_videotext: .int 0
|
||||
tag_ramdisk: .int 0
|
||||
tag_initrd2: .int 0
|
||||
tag_serial: .int 0
|
||||
tag_revision: .int 0
|
||||
tag_videolfb: .int 0
|
||||
tag_cmdline: .int 0
|
||||
```
|
||||
|
||||
通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只是想实现它一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
|
||||
|
||||
```c
|
||||
function FindTag(r0 is tag)
|
||||
if tag > 9 or tag = 0 then return 0
|
||||
set tagAddr to loadWord(tag_core + (tag - 1) × 4)
|
||||
if not tagAddr = 0 then return tagAddr
|
||||
if readWord(tag_core) = 0 then return 0
|
||||
set tagAddr to 0x100
|
||||
loop forever
|
||||
set tagIndex to readHalfWord(tagAddr + 4)
|
||||
if tagIndex = 0 then return FindTag(tag)
|
||||
if readWord(tag_core+(tagIndex-1)×4) = 0
|
||||
then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
|
||||
set tagAddr to tagAddr + loadWord(tagAddr) × 4
|
||||
end loop
|
||||
end function
|
||||
```
|
||||
这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外 的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
|
||||
|
||||
尝试去用汇编实现这段代码。你将需要简化它。如果被卡住了,下面是我的答案。不要忘了 `.section .text`!
|
||||
|
||||
```assembly
|
||||
.section .text
|
||||
.globl FindTag
|
||||
FindTag:
|
||||
tag .req r0
|
||||
tagList .req r1
|
||||
tagAddr .req r2
|
||||
|
||||
sub tag,#1
|
||||
cmp tag,#8
|
||||
movhi tag,#0
|
||||
movhi pc,lr
|
||||
|
||||
ldr tagList,=tag_core
|
||||
tagReturn$:
|
||||
add tagAddr,tagList, tag,lsl #2
|
||||
ldr tagAddr,[tagAddr]
|
||||
|
||||
teq tagAddr,#0
|
||||
movne r0,tagAddr
|
||||
movne pc,lr
|
||||
|
||||
ldr tagAddr,[tagList]
|
||||
teq tagAddr,#0
|
||||
movne r0,#0
|
||||
movne pc,lr
|
||||
|
||||
mov tagAddr,#0x100
|
||||
push {r4}
|
||||
tagIndex .req r3
|
||||
oldAddr .req r4
|
||||
tagLoop$:
|
||||
ldrh tagIndex,[tagAddr,#4]
|
||||
subs tagIndex,#1
|
||||
poplt {r4}
|
||||
blt tagReturn$
|
||||
|
||||
add tagIndex,tagList, tagIndex,lsl #2
|
||||
ldr oldAddr,[tagIndex]
|
||||
teq oldAddr,#0
|
||||
.unreq oldAddr
|
||||
streq tagAddr,[tagIndex]
|
||||
|
||||
ldr tagIndex,[tagAddr]
|
||||
add tagAddr, tagIndex,lsl #2
|
||||
b tagLoop$
|
||||
|
||||
.unreq tag
|
||||
.unreq tagList
|
||||
.unreq tagAddr
|
||||
.unreq tagIndex
|
||||
```
|
||||
|
||||
### 5、Hello World
|
||||
|
||||
现在,我们已经万事俱备了,我们可以去绘制我们的第一个字符串了。在 `main.s` 文件中删除 `bl SetGraphicsAddress` 之后的所有代码,然后将下面的代码放进去:
|
||||
|
||||
```assembly
|
||||
mov r0,#9
|
||||
bl FindTag
|
||||
ldr r1,[r0]
|
||||
lsl r1,#2
|
||||
sub r1,#8
|
||||
add r0,#8
|
||||
mov r2,#0
|
||||
mov r3,#0
|
||||
bl DrawString
|
||||
loop$:
|
||||
b loop$
|
||||
```
|
||||
|
||||
这段代码简单地使用了我们的 `FindTag` 方法去查找第 9 个标签(`cmdline`),然后计算它的长度,然后传递命令和长度给 `DrawString` 方法,告诉它在 `0,0` 处绘制字符串。现在可以在树莓派上测试它了。你应该会在屏幕上看到一行文本。如果没有,请查看我们的排错页面。
|
||||
|
||||
如果一切正常,恭喜你已经能够绘制文本了。但它还有很大的改进空间。如果想去写了一个数字,或内存的一部分,或操作我们的命令行,该怎么做呢?在 [课程 9:屏幕04][2] 中,我们将学习如何操作文本和显示有用的数字和信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
|
||||
|
||||
作者:[Alex Chadwick][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.cl.cam.ac.uk
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
|
||||
[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
|
||||
131
translated/tech/20171215 Top 5 Linux Music Players.md
Normal file
131
translated/tech/20171215 Top 5 Linux Music Players.md
Normal file
@ -0,0 +1,131 @@
|
||||
Linux 上最好的五款音乐播放器
|
||||
======
|
||||
|
||||

|
||||
>Jack Wallen 盘点他最爱的五款 Linux 音乐播放器。图片来源 Creative Commons Zero
|
||||
>Pixabay
|
||||
|
||||
不管你做什么,你都有时会来一点背景音乐。不管你是码农,运维或是一个典型的电脑用户,享受美妙的音乐都可能是你在电脑上最想做的事情之一。同时随着即将到来的假期,你可能收到一些能让你买几首新歌的礼物卡。如果你所选的音乐是数字形式(我的恰好是唱片形式)而且你的平台是 Linux 的话,你会想要一个好的图形用户界面播放器来享受音乐。
|
||||
|
||||
幸运的是,Linux 不缺好的数字音乐播放器。事实上,Linux 上有不少播放器,大部分是开源并且可以免费获得的。让我们看看其中的几款,看哪个能满足你的需要。
|
||||
|
||||
### Clementine
|
||||
|
||||
我想从当了我许多年默认选项的播放器开始。[Clementine][1] 可能在播放器中提供了最好的易用性与灵活性间的平衡。Clementine是新的停运的 [Amarok][2] 音乐播放器的复刻,但它不仅限于 Linux; Clementine 在 Mac OS 和 Windows 平台上也可以获得。它的一系列特性十分惊艳,包括:
|
||||
|
||||
* 內建的均衡器
|
||||
* 可定制的界面(将现在的专辑封面显示成背景——图一)
|
||||
* 播放本地音乐或者从 Spotify, Last.fm 等播放音乐
|
||||
* 便于库导向的侧边栏
|
||||
* 內建的音频转码(转成 MP3,OGG,Flac等)
|
||||
* 通过 [安卓应用][3] 远程控制
|
||||
* 便利的搜索功能
|
||||
* 分页的播放列表
|
||||
* 简单的规律性和智能化的播放列表创建
|
||||
* 支持音乐追踪表单
|
||||
* 支持标签
|
||||
|
||||
|
||||
|
||||
|
||||
![Clementine][5]
|
||||
|
||||
|
||||
图一:Clementine 界面可能有一点老派,但是它不可思议得灵活好用。
|
||||
|
||||
[受许可使用][6]
|
||||
|
||||
在所有我用过的音乐播放器中,Clementine 是目前为止功能最多也是最容易使用的。它同时也包含了你能在 Linux 音乐播放器中找到的最好的均衡器(有十个频带可以调)。尽管它的界面不够时髦,但它创建、操控播放列表的能力是无与伦比的。如果你的音乐集很大,同时你想完全控制你的音乐集的话,这就是你想要的播放器。
|
||||
|
||||
Clementine 可以在标准仓库中找到。它可以从你的发行版的软件中心或通过命令行来安装。
|
||||
|
||||
### Rhythmbox
|
||||
|
||||
[Rhythmbox][7] 是 GNOME 桌面的默认播放器,但是它在其它桌面工作得也很好。Rhythmbox 的界面比 Clementine 的界面稍微时尚一点,它的设计遵循极简的理念。这并不意味着它缺乏特性,相反 Rhythmbox 提供无间隔回放,Soundcloud 支持,专辑封面显示,从 Last.fm 和 Libre.fm 导入音频,Jamendo 支持,播客订阅 (从 [Apple iTunes][8]),从网页远程控制等特性。
|
||||
|
||||
在 Rhythmbox 中发现的一个很好的特性是插件支持,这使得你可以使用像 DAAP 音乐分享,FM 电台,封面艺术查找,通知,ReplayGain,歌词等特性。
|
||||
|
||||
Rhythmbox 播放列表特性不像 Clementine 上的那么强大,但是将你的音乐整理进任何形式的快速播放列表还是很简单的。尽管 Rhythmbox 的界面(图二)比 Clementine 要时髦一点,但是它不像 Clementine 那样灵活。
|
||||
|
||||
![Rhythmbox][10]
|
||||
|
||||
|
||||
图二: Rhythmbox 界面简单直接。
|
||||
|
||||
[受许可使用][6]
|
||||
|
||||
### VLC Media Player
|
||||
|
||||
对于部分人来说,[VLC][11] 在视频播放方面是无懈可击的。然而 VLC 不仅限于视频播放。事实上,VLC在播放音频文件方面做得也很好。对于 [KDE Neon][12] 用户来说,VLC 既是音乐也是视频的默认播放器。 尽管 VLC 是 Linux 市场最好的视频播放器的之一(它是我的默认播放器),它在音频方面确实略有瑕疵——缺少播放列表以及不能够连接到你网络中的远程仓库。但如果你是在寻找一种播放本地文件或者网络 mms/rtsp 的简单可靠的方式,VLC是上佳之选。VLC 确实包括一个均衡器(图三),一个压缩器以及一个空间音响。它同样也能够从捕捉到的设备录音。
|
||||
|
||||
![VLC][14]
|
||||
|
||||
|
||||
图三: 运转中的 VLC 均衡器。
|
||||
|
||||
[受许可使用][6]
|
||||
|
||||
### Audacious
|
||||
如果你在寻找一个轻量级的音乐播放器,Audacious 完美地满足要求。这个音乐播放器相当的专一,但是它确实包括了一个均衡器和一小部分能够改善许多音频的声效(比如回声,消除默音,调节速度和音调,去除人声等——图四)。
|
||||
|
||||
![Audacious][16]
|
||||
|
||||
|
||||
图四: Audacious 均衡器和插件。
|
||||
|
||||
[受许可使用][6]
|
||||
|
||||
Audacious 也包括了一个十分简便的闹铃功能。它允许你设置一个能在用户选定的时间点和持续的时间段内播放选定乐段的闹铃。
|
||||
|
||||
### Spotify
|
||||
|
||||
我必须承认,我每天都用 Spotify。我是一个 Spotify 的订阅者并用它去发现、购买新的音乐——这意味着我在不停地探索发现。辛运的是,Spotify 有一个我能按照 [Spotify官方 Linux 平台安装指导][17] 轻松安装的桌面客户端。在桌面客户端与 [安卓应用][18] 间无缝转换对我来说也大有帮助,这样我就永远不会错过我喜欢的音乐了。
|
||||
|
||||
![Spotify][16]
|
||||
|
||||
|
||||
图五: Linux 上的 Spotify 官方客户端。
|
||||
|
||||
[受许可使用][6]
|
||||
|
||||
Spotify 界面十分易于使用,事实上它完胜网页端的播放器。不要在 Linux 上装 [Spotify 网页播放器][21] 因为桌面客户端在创建管理你的播放列表方面简便得多。如果你是 Spotify 重度用户,甚至没必要用其他桌面应用的內建流传输客户端支持——一旦你用过 Spotify 桌面客户端,其它应用就根本没可比性。
|
||||
|
||||
### 选择在你
|
||||
|
||||
其它选择也是有的(查看你的桌面软件中心),但这五款客户端(在我看来)是最好的了。对我来说,Clementine 和 Spotify 的组合拳就已经让我美好得唱赞歌了。尝试它们看看哪个能更好地满足你的需要。
|
||||
|
||||
通过 edX 和 Linux Foundation 上免费的 ["Introduction to Linux" ][22] 课程学习更多有关 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/12/top-5-linux-music-players
|
||||
|
||||
作者:[][a]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com
|
||||
[1]:https://www.clementine-player.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Amarok_(software)
|
||||
[3]:https://play.google.com/store/apps/details?id=de.qspool.clementineremote
|
||||
[4]:https://www.linux.com/files/images/clementinejpg
|
||||
[5]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine.jpg?itok=_k13MtM3 (Clementine)
|
||||
[6]:https://www.linux.com/licenses/category/used-permission
|
||||
[7]:https://wiki.gnome.org/Apps/Rhythmbox
|
||||
[8]:https://www.apple.com/itunes/
|
||||
[9]:https://www.linux.com/files/images/rhythmboxjpg
|
||||
[10]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/rhythmbox.jpg?itok=GOjs9vTv (Rhythmbox)
|
||||
[11]:https://www.videolan.org/vlc/index.html
|
||||
[12]:https://neon.kde.org/
|
||||
[13]:https://www.linux.com/files/images/vlcjpg
|
||||
[14]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc.jpg?itok=hn7iKkmK (VLC)
|
||||
[15]:https://www.linux.com/files/images/audaciousjpg
|
||||
[16]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/audacious.jpg?itok=9YALPzOx (Audacious )
|
||||
[17]:https://www.spotify.com/us/download/linux/
|
||||
[18]:https://play.google.com/store/apps/details?id=com.spotify.music
|
||||
[19]:https://www.linux.com/files/images/spotifyjpg
|
||||
[20]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify.jpg?itok=P3FLfcYt (Spotify)
|
||||
[21]:https://open.spotify.com/browse/featured
|
||||
[22]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,336 +0,0 @@
|
||||
如何搜索一个包是否在你的 Linux 发行版中
|
||||
======
|
||||
如果你知道包名称,那么你可以直接安装所需的包。
|
||||
|
||||
在某些情况下,如果你不知道确切的包名称或者你想搜索某些包,那么你可以在分发包管理器的帮助下轻松搜索该包。
|
||||
|
||||
自动搜索包括已安装和可用的包。
|
||||
|
||||
结果的格式取决于选项。如果查询没有生成任何信息,那么意味着没有匹配条件的包。
|
||||
|
||||
这可以通过具有各种选项的分发包管理器来完成。
|
||||
|
||||
我已经在本文中添加了所有可能的选项,你可以选择最好的和最合适你的选项。
|
||||
|
||||
或者,我们可以通过 **whohas** 命令实现这一点。它会从所有的主流发行版(例如 Debian, Ubuntu, Fedora 等)中搜索,而不仅仅是你自己的系统发行版。
|
||||
|
||||
**建议阅读:**
|
||||
**(#)** [适用于 Linux 的命令行包管理器列表以及用法][1]
|
||||
**(#)** [Linux 包管理器的图形前端工具][2]
|
||||
|
||||
### 如何在 Debian/Ubuntu 中搜索一个包
|
||||
|
||||
我们可以使用 apt, apt-cache 和 aptitude 包管理器在基于 Debian 的发行版上查找给定的包。我为这个包管理器中包括了大量的选项。
|
||||
|
||||
我们可以在基于 Debian 的系统中使用三种方式完成此操作。
|
||||
|
||||
* apt 命令
|
||||
* apt-cache 命令
|
||||
* aptitude 命令
|
||||
|
||||
### 如何使用 apt 命令搜索一个包
|
||||
|
||||
APT 代表高级包管理工具 Advanced Packaging Tool(APT),它取代了 apt-get。它有功能丰富的命令行工具,包括所有功能包含在一个命令(APT)里,包括 apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key 等,还有其他几个独特的功能。
|
||||
|
||||
APT 是一个强大的命令行工具,它可以访问 libapt-pkg 底层库的所有特性,它可以用于安装,下载,删除,搜索和管理以及查询关于包的信息,另外它还包含一些较少使用的与包管理相关的命令行实用程序。
|
||||
```
|
||||
$ apt -q list nano vlc
|
||||
Listing...
|
||||
nano/artful,now 2.8.6-3 amd64 [installed]
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
```
|
||||
$ apt search ^vlc
|
||||
Sorting... Done
|
||||
Full Text Search... Done
|
||||
vlc/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer
|
||||
|
||||
vlc-bin/artful 2.2.6-6 amd64
|
||||
binaries from VLC
|
||||
|
||||
vlc-data/artful,artful 2.2.6-6 all
|
||||
Common data for VLC
|
||||
|
||||
vlc-l10n/artful,artful 2.2.6-6 all
|
||||
Translations for VLC
|
||||
|
||||
vlc-plugin-access-extra/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (extra access plugins)
|
||||
|
||||
vlc-plugin-base/artful 2.2.6-6 amd64
|
||||
multimedia player and streamer (base plugins)
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 apt-cache 命令搜索一个包
|
||||
|
||||
apt-cache 会在 APT 的包缓存上执行各种操作。它会显示有关指定包的信息。apt-cache 不会操纵系统的状态,但提供了从包的元数据中搜索和生成有趣输出的操作。
|
||||
```
|
||||
$ apt-cache search nano | grep ^nano
|
||||
nano - small, friendly text editor inspired by Pico
|
||||
nano-tiny - small, friendly text editor inspired by Pico - tiny build
|
||||
nanoblogger - Small weblog engine for the command line
|
||||
nanoblogger-extra - Nanoblogger plugins
|
||||
nanoc - static site generator written in Ruby
|
||||
nanoc-doc - static site generator written in Ruby - documentation
|
||||
nanomsg-utils - nanomsg utilities
|
||||
nanopolish - consensus caller for nanopore sequencing data
|
||||
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索指定的包。
|
||||
```
|
||||
$ apt-cache policy vlc
|
||||
vlc:
|
||||
Installed: (none)
|
||||
Candidate: 2.2.6-6
|
||||
Version table:
|
||||
2.2.6-6 500
|
||||
500 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 Packages
|
||||
|
||||
```
|
||||
|
||||
或者,我们可以使用以下格式搜索给定的包。
|
||||
```
|
||||
$ apt-cache pkgnames vlc
|
||||
vlc-bin
|
||||
vlc-plugin-video-output
|
||||
vlc-plugin-sdl
|
||||
vlc-plugin-svg
|
||||
vlc-plugin-samba
|
||||
vlc-plugin-fluidsynth
|
||||
vlc-plugin-qt
|
||||
vlc-plugin-skins2
|
||||
vlc-plugin-visualization
|
||||
vlc-l10n
|
||||
vlc-plugin-notify
|
||||
vlc-plugin-zvbi
|
||||
vlc-plugin-vlsub
|
||||
vlc-plugin-jack
|
||||
vlc-plugin-access-extra
|
||||
vlc
|
||||
vlc-data
|
||||
vlc-plugin-video-splitter
|
||||
vlc-plugin-base
|
||||
|
||||
```
|
||||
|
||||
### 如何使用 aptitude 命令搜索一个包
|
||||
|
||||
aptitude 一个基于文本的 Debian GNU/Linux 软件包系统的接口。它允许用户查看包列表,并执行包管理任务,例如安装,升级和删除包,它可以从可视化界面或命令行执行操作。
|
||||
```
|
||||
$ aptitude search ^vlc
|
||||
p vlc - multimedia player and streamer
|
||||
p vlc:i386 - multimedia player and streamer
|
||||
p vlc-bin - binaries from VLC
|
||||
p vlc-bin:i386 - binaries from VLC
|
||||
p vlc-data - Common data for VLC
|
||||
v vlc-data:i386 -
|
||||
p vlc-l10n - Translations for VLC
|
||||
v vlc-l10n:i386 -
|
||||
p vlc-plugin-access-extra - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-access-extra:i386 - multimedia player and streamer (extra access plugins)
|
||||
p vlc-plugin-base - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-base:i386 - multimedia player and streamer (base plugins)
|
||||
p vlc-plugin-fluidsynth - FluidSynth plugin for VLC
|
||||
p vlc-plugin-fluidsynth:i386 - FluidSynth plugin for VLC
|
||||
p vlc-plugin-jack - Jack audio plugins for VLC
|
||||
p vlc-plugin-jack:i386 - Jack audio plugins for VLC
|
||||
p vlc-plugin-notify - LibNotify plugin for VLC
|
||||
p vlc-plugin-notify:i386 - LibNotify plugin for VLC
|
||||
p vlc-plugin-qt - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-qt:i386 - multimedia player and streamer (Qt plugin)
|
||||
p vlc-plugin-samba - Samba plugin for VLC
|
||||
p vlc-plugin-samba:i386 - Samba plugin for VLC
|
||||
p vlc-plugin-sdl - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-sdl:i386 - SDL video and audio output plugin for VLC
|
||||
p vlc-plugin-skins2 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-skins2:i386 - multimedia player and streamer (Skins2 plugin)
|
||||
p vlc-plugin-svg - SVG plugin for VLC
|
||||
p vlc-plugin-svg:i386 - SVG plugin for VLC
|
||||
p vlc-plugin-video-output - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-output:i386 - multimedia player and streamer (video output plugins)
|
||||
p vlc-plugin-video-splitter - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-video-splitter:i386 - multimedia player and streamer (video splitter plugins)
|
||||
p vlc-plugin-visualization - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-visualization:i386 - multimedia player and streamer (visualization plugins)
|
||||
p vlc-plugin-vlsub - VLC extension to download subtitles from opensubtitles.org
|
||||
p vlc-plugin-zvbi - VBI teletext plugin for VLC
|
||||
p vlc-plugin-zvbi:i386
|
||||
|
||||
```
|
||||
|
||||
### 如何在 RHEL/CentOS 中搜索一个包
|
||||
|
||||
Yum(Yellowdog Updater Modified)是 Linux 操作系统中的包管理器实用程序之一。Yum 命令用于在一些基于 RedHat 的 Linux 发行版上,它用来安装,更新,搜索和删除软件包。
|
||||
```
|
||||
# yum search ftpd
|
||||
Loaded plugins: fastestmirror, refresh-packagekit, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* base: centos.hyve.com
|
||||
* epel: mirrors.coreix.net
|
||||
* extras: centos.hyve.com
|
||||
* rpmforge: www.mirrorservice.org
|
||||
* updates: mirror.sov.uk.goscomb.net
|
||||
============================================================== N/S Matched: ftpd ===============================================================
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
|
||||
Name and summary matches only, use "search all" for everything.
|
||||
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同内容。
|
||||
```
|
||||
# yum list ftpd
|
||||
```
|
||||
|
||||
### 如何在 Fedora 中搜索一个包
|
||||
|
||||
DNF 代表 Dandified yum。我们可以说 DNF 是下一代 yum 包管理器(Yum 的衍生),它使用 hawkey/libsolv 库作为底层。自从 Fedora 18 开始以及它最终在 Fedora 22 中实施以来,Aleš Kozumplík 就在开始研究 DNF。
|
||||
```
|
||||
# dnf search ftpd
|
||||
Last metadata expiration check performed 0:42:28 ago on Tue Jun 9 22:52:44 2018.
|
||||
============================== N/S Matched: ftpd ===============================
|
||||
proftpd-utils.x86_64 : ProFTPD - Additional utilities
|
||||
pure-ftpd-selinux.x86_64 : SELinux support for Pure-FTPD
|
||||
proftpd-devel.i686 : ProFTPD - Tools and header files for developers
|
||||
proftpd-devel.x86_64 : ProFTPD - Tools and header files for developers
|
||||
proftpd-ldap.x86_64 : Module to add LDAP support to the ProFTPD FTP server
|
||||
proftpd-mysql.x86_64 : Module to add MySQL support to the ProFTPD FTP server
|
||||
proftpd-postgresql.x86_64 : Module to add PostgreSQL support to the ProFTPD FTP
|
||||
: server
|
||||
vsftpd.x86_64 : Very Secure Ftp Daemon
|
||||
proftpd.x86_64 : Flexible, stable and highly-configurable FTP server
|
||||
owfs-ftpd.x86_64 : FTP daemon providing access to 1-Wire networks
|
||||
perl-ftpd.noarch : Secure, extensible and configurable Perl FTP server
|
||||
pure-ftpd.x86_64 : Lightweight, fast and secure FTP server
|
||||
pyftpdlib.noarch : Python FTP server library
|
||||
nordugrid-arc-gridftpd.x86_64 : ARC gridftp server
|
||||
```
|
||||
|
||||
或者,我们可以使用以下命令搜索相同的内容。
|
||||
```
|
||||
# dnf list proftpd
|
||||
Failed to synchronize cache for repo 'heikoada-terminix', disabling.
|
||||
Last metadata expiration check: 0:08:02 ago on Tue 26 Jun 2018 04:30:05 PM IST.
|
||||
Available Packages
|
||||
proftpd.x86_64
|
||||
```
|
||||
|
||||
### 如何在 Arch Linux 中搜索一个包
|
||||
|
||||
pacman 代表包管理实用程序(pacman)。它是一个用于安装,构建,删除和管理 Arch Linux 软件包的命令行实用程序。pacman 使用 libalpm(Arch Linux Package Management(ALPM)库)作为底层来执行所有操作。
|
||||
|
||||
在本例中,我将要搜索 chromium 包。
|
||||
```
|
||||
# pacman -Ss chromium
|
||||
extra/chromium 48.0.2564.116-1
|
||||
The open-source project behind Google Chrome, an attempt at creating a safer, faster, and more stable browser
|
||||
extra/qt5-webengine 5.5.1-9 (qt qt5)
|
||||
Provides support for web applications using the Chromium browser project
|
||||
community/chromium-bsu 0.9.15.1-2
|
||||
A fast paced top scrolling shooter
|
||||
community/chromium-chromevox latest-1
|
||||
Causes the Chromium web browser to automatically install and update the ChromeVox screen reader extention. Note: This
|
||||
package does not contain the extension code.
|
||||
community/fcitx-mozc 2.17.2313.102-1
|
||||
Fcitx Module of A Japanese Input Method for Chromium OS, Windows, Mac and Linux (the Open Source Edition of Google Japanese
|
||||
Input)
|
||||
```
|
||||
|
||||
默认情况下,`-s` 选项内置 ERE(扩展正则表达式)会导致很多不需要的结果。使用以下格式会仅匹配包名称。
|
||||
```
|
||||
# pacman -Ss '^chromium-'
|
||||
|
||||
```
|
||||
|
||||
pkgfile 是一个用于在 Arch Linux 官方仓库的包中搜索文件的工具。
|
||||
```
|
||||
# pkgfile chromium
|
||||
```
|
||||
|
||||
### 如何在 openSUSE 中搜索一个包
|
||||
|
||||
Zypper 是 SUSE 和 openSUSE 发行版的命令行包管理器。它用于安装,更新,搜索和删除包以及管理仓库,执行各种查询等。Zypper 命令行接口到 ZYpp 系统管理库(libzypp)。
|
||||
```
|
||||
# zypper search ftp
|
||||
or
|
||||
# zypper se ftp
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Name | Summary | Type
|
||||
--+----------------+-----------------------------------------+--------
|
||||
| proftpd | Highly configurable GPL-licensed FTP -> | package
|
||||
| proftpd-devel | Development files for ProFTPD | package
|
||||
| proftpd-doc | Documentation for ProFTPD | package
|
||||
| proftpd-lang | Languages for package proftpd | package
|
||||
| proftpd-ldap | LDAP Module for ProFTPD | package
|
||||
| proftpd-mysql | MySQL Module for ProFTPD | package
|
||||
| proftpd-pgsql | PostgreSQL Module for ProFTPD | package
|
||||
| proftpd-radius | Radius Module for ProFTPD | package
|
||||
| proftpd-sqlite | SQLite Module for ProFTPD | package
|
||||
| pure-ftpd | A Lightweight, Fast, and Secure FTP S-> | package
|
||||
| vsftpd | Very Secure FTP Daemon - Written from-> | package
|
||||
```
|
||||
|
||||
### 如何使用 whohas 命令搜索一个包
|
||||
|
||||
whohas 命令是一个智能工具,从所有主流发行版中搜索指定包,如 Debian, Ubuntu, Gentoo, Arch, AUR, Mandriva, Fedora, Fink, FreeBSD 和 NetBSD。
|
||||
```
|
||||
$ whohas nano
|
||||
Mandriva nano-debug 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/0b33dc73bca710749ad14bbc3a67e15a
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.i http://sophie.zarb.org/rpms/d9dfb2567681e09287b27e7ac6cdbc05
|
||||
Mandriva nano-debug 2.2.4-1mdv2010.1.x http://sophie.zarb.org/rpms/3299516dbc1538cd27a876895f45aee4
|
||||
Mandriva nano 2.3.1-1mdv2010.2.x http://sophie.zarb.org/rpms/98421c894ee30a27d9bd578264625220
|
||||
Mandriva nano 2.3.1-1mdv2010.2.i http://sophie.zarb.org/rpms/cea07b5ef9aa05bac262fc7844dbd223
|
||||
Mandriva nano 2.2.4-1mdv2010.1.s http://sophie.zarb.org/rpms/d61f9341b8981e80424c39c3951067fa
|
||||
Mandriva spring-mod-nanoblobs 0.65-2mdv2010.0.sr http://sophie.zarb.org/rpms/74bb369d4cbb4c8cfe6f6028e8562460
|
||||
Mandriva nanoxml-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/287a4c37bc2a39c0f277b0020df47502
|
||||
Mandriva nanoxml-manual-lite 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/17dc4f638e5e9964038d4d26c53cc9c6
|
||||
Mandriva nanoxml-manual 2.2.3-4.1.4mdv2010 http://sophie.zarb.org/rpms/a1b5092cd01fc8bb78a0f3ca9b90370b
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 9999 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.8 http://packages.gentoo.org/package/app-editors/nano
|
||||
Gentoo nano 2.9.7 http://packages.gentoo.org/package/app-editors/nano
|
||||
```
|
||||
|
||||
如果你希望只从当前发行版仓库中搜索指定包,使用以下格式:
|
||||
```
|
||||
$ whohas -d Ubuntu vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty/vlc
|
||||
Ubuntu vlc 2.1.6-0ubuntu14.04 1M all http://packages.ubuntu.com/trusty-updates/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial/vlc
|
||||
Ubuntu vlc 2.2.2-5ubuntu0.16. 1M all http://packages.ubuntu.com/xenial-updates/vlc
|
||||
Ubuntu vlc 2.2.6-6 40K all http://packages.ubuntu.com/artful/vlc
|
||||
Ubuntu vlc 3.0.1-3build1 32K all http://packages.ubuntu.com/bionic/vlc
|
||||
Ubuntu vlc 3.0.2-0ubuntu0.1 32K all http://packages.ubuntu.com/bionic-updates/vlc
|
||||
Ubuntu vlc 3.0.3-1 33K all http://packages.ubuntu.com/cosmic/vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-2 55K all http://packages.ubuntu.com/trusty/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/xenial/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/artful/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/bionic/browser-plugin-vlc
|
||||
Ubuntu browser-plugin-vlc 2.0.6-4 47K all http://packages.ubuntu.com/cosmic/browser-plugin-vlc
|
||||
Ubuntu libvlc-bin 2.2.6-6 27K all http://packages.ubuntu.com/artful/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.1-3build1 17K all http://packages.ubuntu.com/bionic/libvlc-bin
|
||||
Ubuntu libvlc-bin 3.0.2-0ubuntu0.1 17K all http://packages.ubuntu.com/bionic-updates/libvlc-bin
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-search-if-a-package-is-available-on-your-linux-distribution-or-not/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||
[2]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (bestony)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (PyGame Zero: Games without boilerplate)
|
||||
[#]: via: (https://opensource.com/article/19/1/pygame-zero)
|
||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||
|
||||
PyGame Zero: 从 0 开始的游戏
|
||||
======
|
||||
|
||||
在你的游戏开发过程中有了 PyGame Zero,和枯燥的模板说再见吧。
|
||||
|
||||

|
||||
|
||||
Python 说一个很好的入门编程语言。并且,游戏是一个很好的入门项目:它们是可视化的,自驱动的,并且可以很愉快的与朋友和家人分享。虽然,绝大多数的 Python 写就的库,比如 [PyGame][1] ,会让初学者因为忘记微小的细节很容易导致什么都没渲染而感到困扰
|
||||
|
||||
在人们理解所有部分的原因前,他们将其中的许多部分都视为“无意识的样板文件”——需要复制和粘贴到程序中才能使其工作的神奇段落。
|
||||
|
||||
[PyGame Zero][2] 试图通过在 PyGame 上放置一个抽象的层来弥合这一差距,因此它实际上并不需要模板。
|
||||
|
||||
我们在字面上说的,就是我们的意思
|
||||
|
||||
这是一个合格的 PyGame Zero 文件:
|
||||
|
||||
```
|
||||
# This comment is here for clarity reasons
|
||||
```
|
||||
|
||||
我们可以将它放在一个 **game.py** 文件里,并运行:
|
||||
|
||||
```
|
||||
$ pgzrun game.py
|
||||
```
|
||||
|
||||
这将会展示一个可以通过关闭窗口或按下**CTRL-C**中断的窗口,并在后台运行一个游戏循环 ,
|
||||
|
||||
遗憾的是,这将是一场无聊的游戏。什么都没发生。
|
||||
|
||||
为了让他更有趣一点,我们可以画一个不同的背景:
|
||||
|
||||
```
|
||||
def draw():
|
||||
screen.fill((255, 0, 0))
|
||||
```
|
||||
|
||||
这将会把背景色从黑色换为红色。但是这仍是一个很无聊的游戏,什么都没发生。我们可以让它变的更有意思一点:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
```
|
||||
|
||||
这将会让窗口从黑色开始,逐渐变亮,直到变为亮红色,再返回黑色,一遍一遍循环。
|
||||
|
||||
**update** 函数更新了 **draw** 渲染这个游戏所需的这些参数的值。
|
||||
|
||||
即使是这样,这里也没有任何方式给玩家与这个游戏的交互的方式。
|
||||
让我们试试其他一些事情:
|
||||
|
||||
```
|
||||
colors = [0, 0, 0]
|
||||
|
||||
def draw():
|
||||
screen.fill(tuple(colors))
|
||||
|
||||
def update():
|
||||
colors[0] = (colors[0] + 1) % 256
|
||||
|
||||
def on_key_down(key, mod, unicode):
|
||||
colors[1] = (colors[1] + 1) % 256
|
||||
```
|
||||
|
||||
现在,按下按钮来提升亮度。
|
||||
|
||||
这些包括游戏循环的三个重要部分:响应用户输入,更新参数和重新渲染屏幕。
|
||||
|
||||
PyGame Zero 提供了更多功能,包括绘制精灵图和播放声音片段的功能。
|
||||
|
||||
试一试,看看你能想出什么类型的游戏!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/pygame-zero
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[bestony](https://github.com/bestony)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/moshez
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pygame.org/news
|
||||
[2]: https://pygame-zero.readthedocs.io/en/stable/
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( dianbanjiu )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using more to view text files at the Linux command line)
|
||||
[#]: via: (https://opensource.com/article/19/1/more-text-files-linux)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
在 Linux 命令行使用 more 查看文本文件
|
||||
======
|
||||
文本文件和 Linux 一直是携手并进的。或者说看起来如此。那你又是依靠哪些让你使用起来很舒服的工具来查看这些文本文件的呢?
|
||||
|
||||

|
||||
|
||||
Linux 下有很多实用工具可以让你在终端界面查看文本文件。其中一个就是 [**more**][1]。
|
||||
|
||||
**more** 跟我之前另一篇文章里写到的工具 —— **[less][2]** 很相似。它们之间的主要不同点在于 **more** 只允许你向前查看文件。
|
||||
|
||||
尽管它能提供的功能看起来很有限,不过它依旧有很多有用的特性值得你去了解。下面让我们来快速浏览一下 **more** 可以做什么,以及如何使用它吧。
|
||||
|
||||
### 基础使用
|
||||
|
||||
假设你现在想在终端查看一个文本文件。只需打开一个终端,进入对应的目录,然后输入以下命令:
|
||||
|
||||
```shell
|
||||
$ more <filename>
|
||||
```
|
||||
|
||||
例如,
|
||||
|
||||
```shell
|
||||
$ more jekyll-article.md
|
||||
```
|
||||
|
||||

|
||||
|
||||
使用空格键可以向下翻页,输入 **q** 可以退出。
|
||||
|
||||
如果你想在这个文件中搜索一些文本,输入 **/** 字符并在其后加上你想要查找的文字。例如你要查看的字段是 terminal,只需输入:
|
||||
|
||||
```
|
||||
/terminal
|
||||
```
|
||||
|
||||

|
||||
|
||||
搜索的内容是区分大小写的,所以输入 /terminal 跟 /Terminal 会出现不同的结果。
|
||||
|
||||
### 和其他实用工具组合使用
|
||||
你可以通过管道将其他命令行工具得到的文本传输到 **more**。你问为什么这样做?因为有时这些工具获取的文本会超过终端一页可以显示的限度。
|
||||
|
||||
想要做到这个,先输入你想要使用的完整命令,后面跟上管道符(**|**),管道符后跟 **more**。假设现在有一个有很多文件的目录。你就可以组合 **more** 跟 **ls** 命令完整查看这个目录当中的内容。
|
||||
|
||||
```shell
|
||||
$ ls | more
|
||||
```
|
||||
|
||||

|
||||
|
||||
你可以组合 **more** 和 **grep** 命令,从而实现在多个文件中找到指定的文本。下面是我在多篇文章的源文件中查找 productivity 的例子。
|
||||
|
||||
```shell
|
||||
$ grep ‘productivity’ core.md Dict.md lctt2014.md lctt2016.md lctt2018.md README.md | more
|
||||
```
|
||||
|
||||

|
||||
|
||||
另外一个可以和 **more** 组合的实用工具是 **ps**(列出你系统上正在运行的进程)。当你的系统上运行了很多的进程,你现在想要查看他们的时候,这个组合将会派上用场。例如你想找到一个你需要杀死的进程,只需输入下面的命令:
|
||||
|
||||
```shell
|
||||
$ ps -u scott | more
|
||||
```
|
||||
|
||||
注意用你的用户名替换掉 scott。
|
||||
|
||||

|
||||
|
||||
就像我文章开篇提到的, **more** 很容易使用。尽管不如它的双胞胎兄弟 **less** 那般灵活,但是仍然值得了解一下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/1/more-text-files-linux
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/More_(command)
|
||||
[2]: https://opensource.com/article/18/4/using-less-view-text-files-command-line
|
||||
Loading…
Reference in New Issue
Block a user