mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject
This commit is contained in:
commit
410d9c929f
@ -0,0 +1,392 @@
|
|||||||
|
如何用 Python 和 Flask 建立部署一个 Facebook Messenger 机器人
|
||||||
|
==========================================================================
|
||||||
|
|
||||||
|
这是我建立一个简单的 Facebook Messenger 机器人的记录。功能很简单,它是一个回显机器人,只是打印回用户写了什么。
|
||||||
|
|
||||||
|
回显服务器类似于服务器的“Hello World”例子。
|
||||||
|
|
||||||
|
这个项目的目的不是建立最好的 Messenger 机器人,而是让你了解如何建立一个小型机器人和每个事物是如何整合起来的。
|
||||||
|
|
||||||
|
- [技术栈][1]
|
||||||
|
- [机器人架构][2]
|
||||||
|
- [机器人服务器][3]
|
||||||
|
- [部署到 Heroku][4]
|
||||||
|
- [创建 Facebook 应用][5]
|
||||||
|
- [结论][6]
|
||||||
|
|
||||||
|
### 技术栈
|
||||||
|
|
||||||
|
使用到的技术栈:
|
||||||
|
|
||||||
|
- [Heroku][7] 做后端主机。免费级足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
|
||||||
|
- [Python][8] 是我们选择的语言。版本选择 2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
|
||||||
|
- [Flask][9] 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是非常完美的。
|
||||||
|
- 最后 [Git][10] 版本控制系统用来维护代码和部署到 Heroku。
|
||||||
|
- 值得一提:[Virtualenv][11]。这个 python 工具是用来创建清洁的 python 库“环境”的,这样你可以只安装必要的需求和最小化应用的大小。
|
||||||
|
|
||||||
|
### 机器人架构
|
||||||
|
|
||||||
|
Messenger 机器人是由一个响应两种请求的服务器组成的:
|
||||||
|
|
||||||
|
- GET 请求被用来认证。他们与你注册的 FaceBook 认证码一同被 Messenger 发出。
|
||||||
|
- POST 请求被用来实际的通信。典型的工作流是,机器人将通过用户发送带有消息数据的 POST 请求而建立通信,然后我们将处理这些数据,并发回我们的 POST 请求。如果这个请求完全成功(返回一个 200 OK 状态码),我们也将响应一个 200 OK 状态码给初始的 Messenger请求。
|
||||||
|
|
||||||
|
这个教程应用将托管到 Heroku,它提供了一个优雅而简单的部署应用的接口。如前所述,免费级可以满足这个教程。
|
||||||
|
|
||||||
|
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便 Messenger 知道发送请求到哪,这就是我们的机器人。
|
||||||
|
|
||||||
|
### 机器人服务器
|
||||||
|
|
||||||
|
基本的服务器代码可以在 Github 用户 [hult(Magnus Hult)][13] 的 [Chatbot][12] 项目上获取,做了一些只回显消息的代码修改和修正了一些我遇到的错误。最终版本的服务器代码如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
from flask import Flask, request
|
||||||
|
import json
|
||||||
|
import requests
|
||||||
|
|
||||||
|
app = Flask(__name__)
|
||||||
|
|
||||||
|
### 这需要填写被授予的页面通行令牌(PAT)
|
||||||
|
### 它由将要创建的 Facebook 应用提供。
|
||||||
|
PAT = ''
|
||||||
|
|
||||||
|
@app.route('/', methods=['GET'])
|
||||||
|
def handle_verification():
|
||||||
|
print "Handling Verification."
|
||||||
|
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||||
|
print "Verification successful!"
|
||||||
|
return request.args.get('hub.challenge', '')
|
||||||
|
else:
|
||||||
|
print "Verification failed!"
|
||||||
|
return 'Error, wrong validation token'
|
||||||
|
|
||||||
|
@app.route('/', methods=['POST'])
|
||||||
|
def handle_messages():
|
||||||
|
print "Handling Messages"
|
||||||
|
payload = request.get_data()
|
||||||
|
print payload
|
||||||
|
for sender, message in messaging_events(payload):
|
||||||
|
print "Incoming from %s: %s" % (sender, message)
|
||||||
|
send_message(PAT, sender, message)
|
||||||
|
return "ok"
|
||||||
|
|
||||||
|
def messaging_events(payload):
|
||||||
|
"""Generate tuples of (sender_id, message_text) from the
|
||||||
|
provided payload.
|
||||||
|
"""
|
||||||
|
data = json.loads(payload)
|
||||||
|
messaging_events = data["entry"][0]["messaging"]
|
||||||
|
for event in messaging_events:
|
||||||
|
if "message" in event and "text" in event["message"]:
|
||||||
|
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||||
|
else:
|
||||||
|
yield event["sender"]["id"], "I can't echo this"
|
||||||
|
|
||||||
|
|
||||||
|
def send_message(token, recipient, text):
|
||||||
|
"""Send the message text to recipient with id recipient.
|
||||||
|
"""
|
||||||
|
|
||||||
|
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||||
|
params={"access_token": token},
|
||||||
|
data=json.dumps({
|
||||||
|
"recipient": {"id": recipient},
|
||||||
|
"message": {"text": text.decode('unicode_escape')}
|
||||||
|
}),
|
||||||
|
headers={'Content-type': 'application/json'})
|
||||||
|
if r.status_code != requests.codes.ok:
|
||||||
|
print r.text
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
app.run()
|
||||||
|
```
|
||||||
|
|
||||||
|
让我们分解代码。第一部分是引入所需的依赖:
|
||||||
|
|
||||||
|
```
|
||||||
|
from flask import Flask, request
|
||||||
|
import json
|
||||||
|
import requests
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
|
||||||
|
|
||||||
|
```
|
||||||
|
@app.route('/', methods=['GET'])
|
||||||
|
def handle_verification():
|
||||||
|
print "Handling Verification."
|
||||||
|
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
||||||
|
print "Verification successful!"
|
||||||
|
return request.args.get('hub.challenge', '')
|
||||||
|
else:
|
||||||
|
print "Verification failed!"
|
||||||
|
return 'Error, wrong validation token'
|
||||||
|
```
|
||||||
|
|
||||||
|
当我们创建 Facebook 应用时,verify_token 对象将由我们声明的 Messenger 发送。我们必须自己来校验它。最后我们返回“hub.challenge”给 Messenger。
|
||||||
|
|
||||||
|
处理 POST 请求的函数更有意思一些:
|
||||||
|
|
||||||
|
```
|
||||||
|
@app.route('/', methods=['POST'])
|
||||||
|
def handle_messages():
|
||||||
|
print "Handling Messages"
|
||||||
|
payload = request.get_data()
|
||||||
|
print payload
|
||||||
|
for sender, message in messaging_events(payload):
|
||||||
|
print "Incoming from %s: %s" % (sender, message)
|
||||||
|
send_message(PAT, sender, message)
|
||||||
|
return "ok"
|
||||||
|
```
|
||||||
|
|
||||||
|
当被调用时,我们抓取消息载荷,使用函数 messaging_events 来拆解它,并且提取发件人身份和实际发送的消息,生成一个可以循环处理的 python 迭代器。请注意 Messenger 发送的每个请求有可能多于一个消息。
|
||||||
|
|
||||||
|
```
|
||||||
|
def messaging_events(payload):
|
||||||
|
"""Generate tuples of (sender_id, message_text) from the
|
||||||
|
provided payload.
|
||||||
|
"""
|
||||||
|
data = json.loads(payload)
|
||||||
|
messaging_events = data["entry"][0]["messaging"]
|
||||||
|
for event in messaging_events:
|
||||||
|
if "message" in event and "text" in event["message"]:
|
||||||
|
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
||||||
|
else:
|
||||||
|
yield event["sender"]["id"], "I can't echo this"
|
||||||
|
```
|
||||||
|
|
||||||
|
对每个消息迭代时,我们会调用 send_message 函数,然后我们使用 Facebook Graph messages API 对 Messenger 发回 POST 请求。在这期间我们一直没有回应我们阻塞的原始 Messenger请求。这会导致超时和 5XX 错误。
|
||||||
|
|
||||||
|
上述情况是我在解决遇到错误时发现的,当用户发送表情时实际上是发送的 unicode 标识符,但是被 Python 错误的编码了,最终我们发回了一些乱码。
|
||||||
|
|
||||||
|
这个发回 Messenger 的 POST 请求将永远不会完成,这会导致给初始请求返回 5xx 状态码,显示服务不可用。
|
||||||
|
|
||||||
|
通过使用 `encode('unicode_escape')` 封装消息,然后在我们发送回消息前用 `decode('unicode_escape')` 解码消息就可以解决。
|
||||||
|
|
||||||
|
```
|
||||||
|
def send_message(token, recipient, text):
|
||||||
|
"""Send the message text to recipient with id recipient.
|
||||||
|
"""
|
||||||
|
|
||||||
|
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
||||||
|
params={"access_token": token},
|
||||||
|
data=json.dumps({
|
||||||
|
"recipient": {"id": recipient},
|
||||||
|
"message": {"text": text.decode('unicode_escape')}
|
||||||
|
}),
|
||||||
|
headers={'Content-type': 'application/json'})
|
||||||
|
if r.status_code != requests.codes.ok:
|
||||||
|
print r.text
|
||||||
|
```
|
||||||
|
|
||||||
|
### 部署到 Heroku
|
||||||
|
|
||||||
|
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
|
||||||
|
|
||||||
|
那么,该怎么做?
|
||||||
|
|
||||||
|
我之前在 Heroku 上部署过应用(主要是 Rails),然而我总是遵循某种教程做的,所用的配置是创建好了的。而在本文的情况下,我就需要从头开始。
|
||||||
|
|
||||||
|
幸运的是有官方 [Heroku 文档][14]来帮忙。这篇文档很好地说明了运行应用程序所需的最低限度。
|
||||||
|
|
||||||
|
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”,它列出了运行应用所依赖的库。
|
||||||
|
|
||||||
|
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件只需要一点点内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
web: gunicorn echoserver:app
|
||||||
|
```
|
||||||
|
|
||||||
|
Heroku 对它的解读是,我们的应用通过运行 echoserver.py 启动,并且应用将使用 gunicorn 作为 Web 服务器。我们使用一个额外的网站服务器是因为与性能相关,在上面的 Heroku 文档里对此解释了:
|
||||||
|
|
||||||
|
> Web 应用程序并发处理传入的 HTTP 请求比一次只处理一个请求的 Web 应用程序会更有效利地用测试机的资源。由于这个原因,我们建议使用支持并发请求的 Web 服务器来部署和运行产品级服务。
|
||||||
|
|
||||||
|
> Django 和 Flask web 框架提供了一个方便的内建 Web 服务器,但是这些阻塞式服务器一个时刻只能处理一个请求。如果你部署这种服务到 Heroku 上,你的测试机就会资源利用率低下,应用会感觉反应迟钝。
|
||||||
|
|
||||||
|
> Gunicorn 是一个纯 Python 的 HTTP 服务器,用于 WSGI 应用。允许你在单独一个测试机内通过运行多 Python 进程的方式来并发的运行各种 Python 应用。它在性能、灵活性和配置简易性方面取得了完美的平衡。
|
||||||
|
|
||||||
|
回到我们之前提到过的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
|
||||||
|
|
||||||
|
很多情况下,你的开发机器也许已经安装了很多 python 库。当部署应用时你不想全部加载那些库,但是辨认出你实际使用哪些库很困难。
|
||||||
|
|
||||||
|
Virtualenv 可以创建一个新的空白虚拟环境,以便你可以只安装你应用所需要的库。
|
||||||
|
|
||||||
|
你可以运行如下命令来检查当前安装了哪些库:
|
||||||
|
|
||||||
|
```
|
||||||
|
kostis@KostisMBP ~ $ pip freeze
|
||||||
|
cycler==0.10.0
|
||||||
|
Flask==0.10.1
|
||||||
|
gunicorn==19.6.0
|
||||||
|
itsdangerous==0.24
|
||||||
|
Jinja2==2.8
|
||||||
|
MarkupSafe==0.23
|
||||||
|
matplotlib==1.5.1
|
||||||
|
numpy==1.10.4
|
||||||
|
pyparsing==2.1.0
|
||||||
|
python-dateutil==2.5.0
|
||||||
|
pytz==2015.7
|
||||||
|
requests==2.10.0
|
||||||
|
scipy==0.17.0
|
||||||
|
six==1.10.0
|
||||||
|
virtualenv==15.0.1
|
||||||
|
Werkzeug==0.11.10
|
||||||
|
```
|
||||||
|
|
||||||
|
注意:pip 工具应该已经与 Python 一起安装在你的机器上。如果没有,查看[官方网站][15]如何安装它。
|
||||||
|
|
||||||
|
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的项目创建一个新文件夹,然后进到目录下:
|
||||||
|
|
||||||
|
```
|
||||||
|
kostis@KostisMBP projects $ mkdir echoserver
|
||||||
|
kostis@KostisMBP projects $ cd echoserver/
|
||||||
|
kostis@KostisMBP echoserver $
|
||||||
|
```
|
||||||
|
|
||||||
|
现在来创建一个叫做 echobot 的新环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
|
||||||
|
|
||||||
|
```
|
||||||
|
kostis@KostisMBP echoserver $ virtualenv echobot
|
||||||
|
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||||
|
(echobot) kostis@KostisMBP echoserver $
|
||||||
|
```
|
||||||
|
|
||||||
|
我们可以安装需要的库。我们需要是 flask、gunicorn 和 requests,它们被安装后我们就创建 requirements.txt 文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
||||||
|
click==6.6
|
||||||
|
Flask==0.11
|
||||||
|
gunicorn==19.6.0
|
||||||
|
itsdangerous==0.24
|
||||||
|
Jinja2==2.8
|
||||||
|
MarkupSafe==0.23
|
||||||
|
requests==2.10.0
|
||||||
|
Werkzeug==0.11.10
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
上述完成之后,我们用 python 代码创建 echoserver.py 文件,然后用之前提到的命令创建 Procfile,我们最终的文件/文件夹如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ ls
|
||||||
|
Procfile echobot echoserver.py requirements.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
我们现在准备上传到 Heroku。我们需要做两件事。第一是如果还没有安装 Heroku toolbet,就安装它(详见 [Heroku][16])。第二是通过 Heroku [网页界面][17]创建一个新的 Heroku 应用。
|
||||||
|
|
||||||
|
点击右上的大加号然后选择“Create new app”。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
为你的应用选择一个名字,然后点击“Create App”。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你将会重定向到你的应用的控制面板,在那里你可以找到如何部署你的应用到 Heroku 的细节说明。
|
||||||
|
|
||||||
|
```
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ heroku login
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ git init
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ heroku git:remote -a <myappname>
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ git add .
|
||||||
|
(echobot) kostis@KostisMBP echoserver $ git commit -m "Initial commit"
|
||||||
|
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||||
|
...
|
||||||
|
remote: https://<myappname>.herokuapp.com/ deployed to Heroku
|
||||||
|
...
|
||||||
|
(echobot) kostis@KostisMBP echoserver (master) $ heroku config:set WEB_CONCURRENCY=3
|
||||||
|
```
|
||||||
|
|
||||||
|
如上,当你推送你的修改到 Heroku 之后,你会得到一个用于公开访问你新创建的应用的 URL。保存该 URL,下一步需要它。
|
||||||
|
|
||||||
|
### 创建这个 Facebook 应用
|
||||||
|
|
||||||
|
让我们的机器人可以工作的最后一步是创建这个我们将连接到其上的 Facebook 应用。Facebook 通常要求每个应用都有一个相关页面,所以我们来[创建一个][18]。
|
||||||
|
|
||||||
|
接下来我们去 [Facebook 开发者专页][19],点击右上角的“My Apps”按钮并选择“Add a New App”。不要选择建议的那个,而是点击“basic setup”。填入需要的信息并点击“Create App Id”,然后你会重定向到新的应用页面。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
在 “Products” 菜单之下,点击“+ Add Product” ,然后在“Messenger”下点击“Get Started”。跟随这些步骤设置 Messenger,当完成后你就可以设置你的 webhooks 了。Webhooks 简单的来说是你的服务所用的 URL 的名称。点击 “Setup Webhooks” 按钮,并添加该 Heroku 应用的 URL (你之前保存的那个)。在校验元组中写入 ‘my_voice_is_my_password_verify_me’。你可以写入任何你要的内容,但是不管你在这里写入的是什么内容,要确保同时修改代码中 handle_verification 函数。然后勾选 “messages” 选项。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
点击“Verify and Save” 就完成了。Facebook 将访问该 Heroku 应用并校验它。如果不工作,可以试试运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
(echobot) kostis@KostisMBP heroku logs -t
|
||||||
|
```
|
||||||
|
|
||||||
|
然后看看日志中是否有错误。如果发现错误, Google 搜索一下可能是最快的解决方法。
|
||||||
|
|
||||||
|
最后一步是取得页面访问元组(PAT),它可以将该 Facebook 应用于你创建好的页面连接起来。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
从下拉列表中选择你创建好的页面。这会在“Page Access Token”(PAT)下面生成一个字符串。点击复制它,然后编辑 echoserver.py 文件,将其贴入 PAT 变量中。然后在 Git 中添加、提交并推送该修改。
|
||||||
|
|
||||||
|
```
|
||||||
|
(echobot) kostis@KostisMBP echoserver (master) $ git add .
|
||||||
|
(echobot) kostis@KostisMBP echoserver (master) $ git commit -m "Initial commit"
|
||||||
|
(echobot) kostis@KostisMBP echoserver (master) $ git push heroku master
|
||||||
|
```
|
||||||
|
|
||||||
|
最后,在 Webhooks 菜单下再次选择你的页面并点击“Subscribe”。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在去访问你的页面并建立会话:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
成功了,机器人回显了!
|
||||||
|
|
||||||
|
注意:除非你要将这个机器人用在 Messenger 上测试,否则你就是机器人唯一响应的那个人。如果你想让其他人也试试它,到 [Facebook 开发者专页][19]中,选择你的应用、角色,然后添加你要添加的测试者。
|
||||||
|
|
||||||
|
###总结
|
||||||
|
|
||||||
|
这对于我来说是一个非常有用的项目,希望它可以指引你找到开始的正确方向。[官方的 Facebook 指南][20]有更多的资料可以帮你学到更多。
|
||||||
|
|
||||||
|
你可以在 [Github][21] 上找到该项目的代码。
|
||||||
|
|
||||||
|
如果你有任何评论、勘误和建议,请随时联系我。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
||||||
|
|
||||||
|
作者:[Konstantinos Tsaprailis][a]
|
||||||
|
译者:[wyangsun](https://github.com/wyangsun)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://github.com/kostistsaprailis
|
||||||
|
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
||||||
|
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
||||||
|
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
||||||
|
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
||||||
|
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
||||||
|
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
||||||
|
[7]: https://www.heroku.com
|
||||||
|
[8]: https://www.python.org
|
||||||
|
[9]: http://flask.pocoo.org
|
||||||
|
[10]: https://git-scm.com
|
||||||
|
[11]: https://virtualenv.pypa.io/en/stable
|
||||||
|
[12]: https://github.com/hult/facebook-chatbot-python
|
||||||
|
[13]: https://github.com/hult
|
||||||
|
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
||||||
|
[15]: https://pip.pypa.io/en/stable/installing
|
||||||
|
[16]: https://toolbelt.heroku.com
|
||||||
|
[17]: https://dashboard.heroku.com/apps
|
||||||
|
[18]: https://www.facebook.com/pages/create
|
||||||
|
[19]: https://developers.facebook.com/
|
||||||
|
[20]: https://developers.facebook.com/docs/messenger-platform/implementation
|
||||||
|
[21]: https://github.com/kostistsaprailis/messenger-bot-tutorial
|
||||||
176
published/20160718 Creating your first Git repository.md
Normal file
176
published/20160718 Creating your first Git repository.md
Normal file
@ -0,0 +1,176 @@
|
|||||||
|
Git 系列(三):建立你的第一个 Git 仓库
|
||||||
|
======================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现在是时候学习怎样创建你自己的 Git 仓库了,还有怎样增加文件和完成提交。
|
||||||
|
|
||||||
|
在本系列[前面的文章][4]中,你已经学习了怎样作为一个最终用户与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,克隆了仓库,然后你就可以继续钻研它了。你知道了和 Git 进行交互并不像你想的那样困难,或许你只是需要被说服现在去使用 Git 完成你的工作罢了。
|
||||||
|
|
||||||
|
虽然 Git 确实是被许多重要软件选作版本控制工具,但是并不是仅能用于这些重要软件;它也能管理你购物清单(如果它们对你来说很重要的话,当然可以了!)、你的配置文件、周报或日记、项目进展日志、甚至源代码!
|
||||||
|
|
||||||
|
使用 Git 是很有必要的,毕竟,你肯定有过因为一个备份文件不能够辨认出版本信息而抓狂的时候。
|
||||||
|
|
||||||
|
Git 无法帮助你,除非你开始使用它,而现在就是开始学习和使用它的最好时机。或者,用 Git 的话来说,“没有其他的 `push` 能像 `origin HEAD` 一样有帮助了”(千里之行始于足下的意思)。我保证,你很快就会理解这一点的。
|
||||||
|
|
||||||
|
### 类比于录音
|
||||||
|
|
||||||
|
我们经常用名词“快照”来指代计算机上的镜像,因为很多人都能够对插满了不同时光的照片的相册充满了感受。这很有用,不过,我认为 Git 更像是进行一场录音。
|
||||||
|
|
||||||
|
也许你不太熟悉传统的录音棚卡座式录音机,它包括几个部件:一个可以正转或反转的转轴、保存声音波形的磁带,可以通过拾音头在磁带上记录声音波形,或者检测到磁带上的声音波形并播放给听众。
|
||||||
|
|
||||||
|
除了往前播放磁带,你也可以把磁带倒回到之前的部分,或快进跳过后面的部分。
|
||||||
|
|
||||||
|
想象一下上世纪 70 年代乐队录制磁带的情形。你可以想象到他们一遍遍地练习歌曲,直到所有部分都非常完美,然后记录到音轨上。起初,你会录下鼓声,然后是低音,再然后是吉他声,最后是主唱。每次你录音时,录音棚工作人员都会把磁带倒带,然后进入循环模式,这样它就会播放你之前录制的部分。比如说如果你正在录制低音,你就会在背景音乐里听到鼓声,就像你自己在击鼓一样,然后吉他手在录制时会听到鼓声、低音(和牛铃声)等等。在每个循环中,你都会录制一部分,在接下来的循环中,工作人员就会按下录音按钮将其合并记录到磁带中。
|
||||||
|
|
||||||
|
你也可以拷贝或换下整个磁带,如果你要对你的作品重新混音的话。
|
||||||
|
|
||||||
|
现在我希望对于上述的上世纪 70 年代的录音工作的描述足够生动,这样我们就可以把 Git 的工作想象成一个录音工作了。
|
||||||
|
|
||||||
|
### 新建一个 Git 仓库
|
||||||
|
|
||||||
|
首先得为我们的虚拟的录音机买一些磁带。用 Git 的话说,这些磁带就是*仓库*;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
|
||||||
|
|
||||||
|
任何目录都可以成为一个 Git 仓库,但是让我们从一个新目录开始。这需要下面三个命令:
|
||||||
|
|
||||||
|
- 创建目录(如果你喜欢的话,你可以在你的图形化的文件管理器里面完成。)
|
||||||
|
- 在终端里切换到目录。
|
||||||
|
- 将其初始化成一个 Git 管理的目录。
|
||||||
|
|
||||||
|
也就是运行如下代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mkdir ~/jupiter # 创建目录
|
||||||
|
$ cd ~/jupiter # 进入目录
|
||||||
|
$ git init . # 初始化你的新 Git 工作区
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,文件夹 jupiter 是一个空的但是合法的 Git 仓库。
|
||||||
|
|
||||||
|
有了仓库接下来的事情就可以按部就班进行了。你可以克隆该仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建交替的时间线,以及做 Git 能做的其它任何事情。
|
||||||
|
|
||||||
|
在 Git 仓库里面工作和在任何目录里面工作都是一样的,可以在仓库中新建文件、复制文件、保存文件。你可以像平常一样做各种事情;Git 并不复杂,除非你把它想复杂了。
|
||||||
|
|
||||||
|
在本地的 Git 仓库中,一个文件可以有以下这三种状态:
|
||||||
|
|
||||||
|
- 未跟踪文件(Untracked):你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的管理之中。
|
||||||
|
- 已跟踪文件(Tracked):已经加入到 Git 管理的文件。
|
||||||
|
- 暂存区文件(Staged):被修改了的已跟踪文件,并加入到 Git 的提交队列中。
|
||||||
|
|
||||||
|
任何你新加入到 Git 仓库中的文件都是未跟踪文件。这些文件保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要管理的文件,用我们的录音机来类比,就是录音机还没打开;乐队就开始在录音棚里忙碌了,但是录音机并没有准备录音。
|
||||||
|
|
||||||
|
不用担心,Git 会在出现这种情况时告诉你:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo "hello world" > foo
|
||||||
|
$ git status
|
||||||
|
On branch master
|
||||||
|
Untracked files:
|
||||||
|
(use "git add <file>..." to include in what will be committed)
|
||||||
|
foo
|
||||||
|
nothing added but untracked files present (use "git add" to track)
|
||||||
|
```
|
||||||
|
|
||||||
|
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
|
||||||
|
|
||||||
|
### 不使用 Git 命令进行 Git 操作
|
||||||
|
|
||||||
|
在 GitHub 或 GitLab 上创建一个仓库只需要用鼠标点几下即可。这并不难,你单击“New Repository”这个按钮然后跟着提示做就可以了。
|
||||||
|
|
||||||
|
在仓库中包括一个“README”文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库是干什么的,更有用的是可以让你在克隆一个有东西的仓库前知道它有些什么。
|
||||||
|
|
||||||
|
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就稍微复杂一些,为了通过 GitHub 验证你必须有一个 SSH 密钥。如果你使用 Linux 系统,可以通过下面的命令生成:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh-keygen
|
||||||
|
```
|
||||||
|
|
||||||
|
然后复制你的新密钥的内容,它是纯文本文件,你可以使用一个文本编辑器打开它,也可以使用如下 cat 命令查看:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat ~/.ssh/id_rsa.pub
|
||||||
|
```
|
||||||
|
|
||||||
|
现在把你的密钥粘贴到 [GitHub SSH 配置文件][1] 中,或者 [GitLab 配置文件][2]。
|
||||||
|
|
||||||
|
如果你通过使用 SSH 模式克隆了你的项目,你就可以将修改写回到你的仓库了。
|
||||||
|
|
||||||
|
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来添加文件。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 跟踪文件
|
||||||
|
|
||||||
|
正如命令 `git status` 的输出告诉你的那样,如果你想让 git 跟踪一个文件,你必须使用命令 `git add` 把它加入到提交任务中。这个命令把文件存在了暂存区,这里存放的都是等待提交的文件,或者也可以用在快照中。在将文件包括到快照中,和添加要 Git 管理的新的或临时文件时,`git add` 命令的目的是不同的,不过至少现在,你不用为它们之间的不同之处而费神。
|
||||||
|
|
||||||
|
类比录音机,这个动作就像打开录音机开始准备录音一样。你可以想象为对已经在录音的录音机按下暂停按钮,或者倒回开头等着记录下个音轨。
|
||||||
|
|
||||||
|
当你把文件添加到 Git 管理中,它会标识其为已跟踪文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git add foo
|
||||||
|
$ git status
|
||||||
|
On branch master
|
||||||
|
Changes to be committed:
|
||||||
|
(use "git reset HEAD <file>..." to unstage)
|
||||||
|
new file: foo
|
||||||
|
```
|
||||||
|
|
||||||
|
加入文件到提交任务中并不是“准备录音”。这仅仅是将该文件置于准备录音的状态。在你添加文件后,你仍然可以修改该文件;它只是被标记为**已跟踪**和**处于暂存区**,所以在它被写到“磁带”前你可以将它撤出或修改它(当然你也可以再次将它加入来做些修改)。但是请注意:你还没有在磁带中记录该文件,所以如果弄坏了一个之前还是好的文件,你是没有办法恢复的,因为你没有在“磁带”中记下那个文件还是好着的时刻。
|
||||||
|
|
||||||
|
如果你最后决定不把文件记录到 Git 历史列表中,那么你可以撤销提交任务,在 Git 中是这样做的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git reset HEAD foo
|
||||||
|
```
|
||||||
|
|
||||||
|
这实际上就是解除了录音机的准备录音状态,你只是在录音棚中转了一圈而已。
|
||||||
|
|
||||||
|
### 大型提交
|
||||||
|
|
||||||
|
有时候,你想要提交一些内容到仓库;我们以录音机类比,这就好比按下录音键然后记录到磁带中一样。
|
||||||
|
|
||||||
|
在一个项目所经历的不同阶段中,你会按下这个“记录键”无数次。比如,如果你尝试了一个新的 Python 工具包并且最终实现了窗口呈现功能,然后你肯定要进行提交,以便你在实验新的显示选项时搞砸了可以回退到这个阶段。但是如果你在 Inkscape 中画了一些图形草样,在提交前你可能需要等到已经有了一些要开发的内容。尽管你可能提交了很多次,但是 Git 并不会浪费很多,也不会占用太多磁盘空间,所以在我看来,提交的越多越好。
|
||||||
|
|
||||||
|
`commit` 命令会“记录”仓库中所有的暂存区文件。Git 只“记录”已跟踪的文件,即,在过去某个时间点你使用 `git add` 命令加入到暂存区的所有文件,以及从上次提交后被改动的文件。如果之前没有过提交,那么所有跟踪的文件都包含在这次提交中,以 Git 的角度来看,这是一次非常重要的修改,因为它们从没放到仓库中变成了放进去。
|
||||||
|
|
||||||
|
完成一次提交需要运行下面的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git commit -m 'My great project, first commit.'
|
||||||
|
```
|
||||||
|
|
||||||
|
这就保存了所有提交的文件,之后可以用于其它操作(或者,用英国电视剧《神秘博士》中时间领主所讲的 Gallifreyan 语说,它们成为了“固定的时间点” )。这不仅是一个提交事件,也是一个你在 Git 日志中找到该提交的引用指针:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git log --oneline
|
||||||
|
55df4c2 My great project, first commit.
|
||||||
|
```
|
||||||
|
|
||||||
|
如果想浏览更多信息,只需要使用不带 `--oneline` 选项的 `git log` 命令。
|
||||||
|
|
||||||
|
在这个例子中提交时的引用号码是 55df4c2。它被叫做“提交哈希(commit hash)”(LCTT 译注:这是一个 SHA-1 算法生成的哈希码,用于表示一个 git 提交对象),它代表着刚才你的提交所包含的所有新改动,覆盖到了先前的记录上。如果你想要“倒回”到你的提交历史点上,就可以用这个哈希作为依据。
|
||||||
|
|
||||||
|
你可以把这个哈希想象成一个声音磁带上的 [SMPTE 时间码][3],或者再形象一点,这就是好比一个黑胶唱片上两首不同的歌之间的空隙,或是一个 CD 上的音轨编号。
|
||||||
|
|
||||||
|
当你改动了文件之后并且把它们加入到提交任务中,最终完成提交,这就会生成新的提交哈希,它们每一个所标示的历史点都代表着你的产品不同的版本。
|
||||||
|
|
||||||
|
这就是 Charlie Brown 这样的音乐家们为什么用 Git 作为版本控制系统的原因。
|
||||||
|
|
||||||
|
在接下来的文章中,我们将会讨论关于 Git HEAD 的各个方面,我们会真正地向你揭示时间旅行的秘密。不用担心,你只需要继续读下去就行了(或许你已经在读了?)。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[1]: https://github.com/settings/keys
|
||||||
|
[2]: https://gitlab.com/profile/keys
|
||||||
|
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
||||||
|
[4]: https://linux.cn/article-7641-1.html
|
||||||
60
published/20160721 5 tricks for getting started with Vim.md
Normal file
60
published/20160721 5 tricks for getting started with Vim.md
Normal file
@ -0,0 +1,60 @@
|
|||||||
|
Vim 起步的五个技巧
|
||||||
|
=====================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
多年来,我一直想学 Vim。如今 Vim 是我最喜欢的 Linux 文本编辑器,也是开发者和系统管理者最喜爱的开源工具。我说的学习,指的是真正意义上的学习。想要精通确实很难,所以我只想要达到熟练的水平。我使用了这么多年的 Linux ,我会的也仅仅只是打开一个文件,使用上下左右箭头按键来移动光标,切换到插入模式,更改一些文本,保存,然后退出。
|
||||||
|
|
||||||
|
但那只是 Vim 的最最基本的操作。我的技能水平只能让我在终端使用 Vim 修改文本,但是它并没有任何一个我想象中强大的文本处理功能。这样我完全无法用 Vim 发挥出胜出 Pico 和 Nano 的能力。
|
||||||
|
|
||||||
|
所以到底为什么要学习 Vim?因为我花费了相当多的时间用于编辑文本,而且我知道还有很大的效率提升空间。为什么不选择 Emacs,或者是更为现代化的编辑器例如 Atom?因为 Vim 适合我,至少我有一丁点的使用经验。而且,很重要的一点就是,在我需要处理的系统上很少碰见没有装 Vim 或者它的弱化版(Vi)。如果你有强烈的欲望想学习对你来说更给力的 Emacs,我希望这些对于 Emacs 同类编辑器的建议能对你有所帮助。
|
||||||
|
|
||||||
|
花了几周的时间专注提高我的 Vim 使用技巧之后,我想分享的第一个建议就是必须使用它。虽然这看起来就是明知故问的回答,但事实上它比我所预想的计划要困难一些。我的大多数工作是在网页浏览器上进行的,而且每次我需要在浏览器之外打开并编辑一段文本时,就需要避免下意识地打开 Gedit。Gedit 已经放在了我的快速启动栏中,所以第一步就是移除这个快捷方式,然后替换成 Vim 的。
|
||||||
|
|
||||||
|
为了更好的学习 Vim,我尝试了很多。如果你也正想学习,以下列举了一些作为推荐。
|
||||||
|
|
||||||
|
### Vimtutor
|
||||||
|
|
||||||
|
通常如何开始学习最好就是使用应用本身。我找到一个小的应用叫 Vimtutor,当你在学习编辑一个文本时它能辅导你一些基础知识,它向我展示了很多我这些年都忽视的基础命令。Vimtutor 一般在有 Vim 的地方都能找到它,如果你的系统上没有 Vimtutor,Vimtutor 可以很容易从你的包管理器上安装。
|
||||||
|
|
||||||
|
### GVim
|
||||||
|
|
||||||
|
我知道并不是每个人都认同这个,但就是它让我从使用终端中的 Vim 转战到使用 GVim 来满足我基本编辑需求。反对者表示 GVim 鼓励使用鼠标,而 Vim 主要是为键盘党设计的。但是我能通过 GVim 的下拉菜单快速找到想找的指令,并且 GVim 可以提醒我正确的指令然后通过敲键盘执行它。努力学习一个新的编辑器然后陷入无法解决的困境,这种感觉并不好受。每隔几分钟读一下 man 出来的文字或者使用搜索引擎来提醒你该用的按键序列也并不是最好的学习新事物的方法。
|
||||||
|
|
||||||
|
### 键盘表
|
||||||
|
|
||||||
|
当我转战 GVim,我发现有一个键盘的“速查表”来提醒我最基础的按键很是便利。网上有很多这种可用的表,你可以下载、打印,然后贴在你身边的某一处地方。但是为了我的笔记本键盘,我选择买一沓便签纸。这些便签纸在美国不到 10 美元,当我使用键盘编辑文本,尝试新的命令的时候,可以随时提醒我。
|
||||||
|
|
||||||
|
### Vimium
|
||||||
|
|
||||||
|
上文提到,我工作都在浏览器上进行。其中一条我觉得很有帮助的建议就是,使用 [Vimium][1] 来用增强使用 Vim 的体验。Vimium 是 Chrome 浏览器上的一个开源插件,能用 Vim 的指令快捷操作 Chrome。我发现我只用了几次使用快捷键切换上下文,就好像比之前更熟悉这些快捷键了。同样的扩展 Firefox 上也有,例如 [Vimerator][2]。
|
||||||
|
|
||||||
|
### 其它人
|
||||||
|
|
||||||
|
毫无疑问,最好的学习方法就是求助于在你之前探索过的人,让他给你建议、反馈和解决方法。
|
||||||
|
|
||||||
|
如果你住在一个大城市,那么附近可能会有一个 Vim meetup 小组,或者还有 Freenode IRC 上的 #vim 频道。#vim 频道是 Freenode 上最活跃的频道之一,那上面可以针对你个人的问题来提供帮助。听上面的人发发牢骚或者看看别人尝试解决自己没有遇到过的问题,仅仅是这样我都觉得很有趣。
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
那么,现在怎么样了?到现在为止还不错。为它所花的时间是否值得就在于之后它为你节省了多少时间。但是当我发现一个新的按键序列可以来跳过词,或者一些相似的小技巧,我经常会收获意外的惊喜与快乐。每天我至少可以看见,一点点的回报,正在逐渐配得上当初的付出。
|
||||||
|
|
||||||
|
学习 Vim 并不仅仅只有这些建议,还有很多。我很喜欢指引别人去 [Vim Advantures][3],它是一种使用 Vim 按键方式进行移动的在线游戏。而在另外一天我在 [Vimgifts.com][4] 发现了一个非常神奇的虚拟学习工具,那可能就是你真正想要的:用一个小小的 gif 动图来描述 Vim 操作。
|
||||||
|
|
||||||
|
你有花时间学习 Vim 吗?或者是任何需要大量键盘操作的程序?那些经过你努力后掌握的工具,你认为这些努力值得吗?效率的提高有没有达到你的预期?分享你们的故事在下面的评论区吧。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/life/16/7/tips-getting-started-vim
|
||||||
|
|
||||||
|
作者:[Jason Baker][a]
|
||||||
|
译者:[maywanting](https://github.com/maywanting)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jason-baker
|
||||||
|
[1]: https://github.com/philc/vimium
|
||||||
|
[2]: http://www.vimperator.org/
|
||||||
|
[3]: http://vim-adventures.com/
|
||||||
|
[4]: http://vimgifs.com/
|
||||||
@ -1,27 +1,24 @@
|
|||||||
|
awk 系列:怎样使用 awk 变量、数值表达式以及赋值运算符
|
||||||
|
|
||||||
第 8 节--学习怎样使用 Awk 变量,数值表达式以及赋值运算符
|
|
||||||
|
|
||||||
=======================================================================================
|
=======================================================================================
|
||||||
|
|
||||||
|
我觉得 [awk 系列][1] 将会越来越好,在本系列的前七节我们讨论了在 Linux 中处理文件和筛选字符串所需要的一些 awk 命令基础。
|
||||||
|
|
||||||
我相信 [Awk 命令系列][1] 将会令人兴奋不已,在系列的前几节我们讨论了在 Linux 中处理文件和筛选字符串需要的基本 Awk 命令。
|
在这一部分,我们将会进入 awk 更高级的部分,使用 awk 处理更复杂的文本和进行字符串过滤操作。因此,我们将会讲到 Awk 的一些特性,诸如变量、数值表达式和赋值运算符。
|
||||||
|
|
||||||
|
|
||||||
在这一部分,我们会对处理更复杂的文件和筛选字符串操作需要的更高级的命令进行讨论。因此,我们将会看到关于 Awk 的一些特性诸如变量,数值表达式和赋值运算符。
|
|
||||||

|

|
||||||
>学习 Awk 变量,数值表达式和赋值运算符
|
|
||||||
|
|
||||||
你可能已经在很多编程语言中接触过它们,比如 shell,C,Python等;这些概念在理解上和这些语言没有什么不同,所以在这一小节中你不用担心很难理解,我们将会简短的提及常用的一些 Awk 特性。
|
*学习 Awk 变量,数值表达式和赋值运算符*
|
||||||
|
|
||||||
|
你可能已经在很多编程语言中接触过它们,比如 shell,C,Python 等;这些概念在理解上和这些语言没有什么不同,所以在这一小节中你不用担心很难理解,我们将会简短的提及常用的一些 awk 特性。
|
||||||
|
|
||||||
|
这一小节可能是 awk 命令里最容易理解的部分,所以放松点,我们开始吧。
|
||||||
|
|
||||||
这一小节可能是 Awk 命令里最容易理解的部分,所以放松点,我们开始吧。
|
|
||||||
### 1. Awk 变量
|
### 1. Awk 变量
|
||||||
|
|
||||||
|
在很多编程语言中,变量就是一个存储了值的占位符,当你在程序中新建一个变量的时候,程序一运行就会在内存中创建一些空间,你为变量赋的值会存储在这些内存空间上。
|
||||||
在任何编程语言中,当你在程序中新建一个变量的时候这个变量就是一个存储了值的占位符,程序一运行就占用了一些内存空间,你为变量赋的值会存储在这些内存空间上。
|
|
||||||
|
|
||||||
|
|
||||||
你可以像下面这样定义 shell 变量一样定义 Awk 变量:
|
你可以像下面这样定义 shell 变量一样定义 Awk 变量:
|
||||||
|
|
||||||
```
|
```
|
||||||
variable_name=value
|
variable_name=value
|
||||||
```
|
```
|
||||||
@ -32,56 +29,59 @@ variable_name=value
|
|||||||
- `value`: 为变量赋的值
|
- `value`: 为变量赋的值
|
||||||
|
|
||||||
再看下面的一些例子:
|
再看下面的一些例子:
|
||||||
|
|
||||||
```
|
```
|
||||||
computer_name=”tecmint.com”
|
computer_name=”tecmint.com”
|
||||||
port_no=”22”
|
port_no=”22”
|
||||||
email=”admin@tecmint.com”
|
email=”admin@tecmint.com”
|
||||||
server=”computer_name”
|
server=computer_name
|
||||||
```
|
```
|
||||||
|
|
||||||
观察上面的简单的例子,在定义第一个变量的时候,值 'tecmint.com' 被赋给了 'computer_name' 变量。
|
观察上面的简单的例子,在定义第一个变量的时候,值 'tecmint.com' 被赋给了 'computer_name' 变量。
|
||||||
|
|
||||||
|
此外,值 22 也被赋给了 port\_no 变量,把一个变量的值赋给另一个变量也是可以的,在最后的例子中我们把变量 computer\_name 的值赋给了变量 server。
|
||||||
|
|
||||||
此外,值 22 也被赋给了 port_no 变量,把一个变量的值赋给另一个变量也是可以的,在最后的例子中我们把变量 computer_name 的值赋给了变量 server。
|
你可以看看[本系列的第 2 节][2]中提到的字段编辑,我们讨论了 awk 怎样将输入的行分隔为若干字段并且使用标准字段访问操作符 `$` 来访问拆分出来的不同字段。我们也可以像下面这样使用变量为字段赋值。
|
||||||
|
|
||||||
你可以看看 [本系列的第 2 节][2] 中提到的字段编辑,我们讨论了 Awk 怎样将输入的行分隔为若干字段并且使用标准的字段进行输入操作 ,$ 访问不同的被分配的字段。我们也可以像下面这样使用变量为字段赋值。
|
|
||||||
|
|
||||||
```
|
```
|
||||||
first_name=$2
|
first_name=$2
|
||||||
second_name=$3
|
second_name=$3
|
||||||
```
|
```
|
||||||
|
|
||||||
在上面的例子中,变量 first_name 的值设置为第二个字段,second_name 的值设置为第三个字段。
|
在上面的例子中,变量 first\_name 的值设置为第二个字段,second\_name 的值设置为第三个字段。
|
||||||
|
|
||||||
|
再举个例子,有一个名为 names.txt 的文件,这个文件包含了一个应用程序的用户列表,这个用户列表包含了用户的名和姓以及性别。可以使用 [cat 命令][3] 查看文件内容:
|
||||||
|
|
||||||
再举个例子,有一个名为 names.txt 的文件,这个文件包含了一个应用程序的用户列表,这个用户列表显示了用户的名字和曾用名以及性别。可以使用 [cat 命令][3] 查看文件内容:
|
|
||||||
```
|
```
|
||||||
$ cat names.txt
|
$ cat names.txt
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
>使用 cat 命令查看列表文件内容
|
|
||||||
|
|
||||||
|
*使用 cat 命令查看列表文件内容*
|
||||||
|
|
||||||
|
然后,我们也可以使用下面的 awk 命令把列表中第一个用户的第一个和第二个名字分别存储到变量 first\_name 和 second\_name 上:
|
||||||
|
|
||||||
然后,我们也可以使用下面的 Awk 命令把列表中第一个用户的第一个和第二个名字分别存储到变量 first_name 和 second_name 上:
|
|
||||||
```
|
```
|
||||||
$ awk '/Aaron/{ first_name=$2 ; second_name=$3 ; print first_name, second_name ; }' names.txt
|
$ awk '/Aaron/{ first_name=$2 ; second_name=$3 ; print first_name, second_name ; }' names.txt
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
>使用 Awk 命令为变量赋值
|
|
||||||
|
|
||||||
|
*使用 Awk 命令为变量赋值*
|
||||||
|
|
||||||
再看一个例子,当你在终端运行 'uname -a' 时,它可以打印出所有的系统信息。
|
再看一个例子,当你在终端运行 'uname -a' 时,它可以打印出所有的系统信息。
|
||||||
|
|
||||||
第二个字段包含了你的 'hostname',因此,我们可以像下面这样把它赋给一个叫做 hostname 的变量并且用 Awk 打印出来。
|
第二个字段包含了你的主机名,因此,我们可以像下面这样把它赋给一个叫做 hostname 的变量并且用 awk 打印出来。
|
||||||
|
|
||||||
```
|
```
|
||||||
$ uname -a
|
$ uname -a
|
||||||
$ uname -a | awk '{hostname=$2 ; print hostname ; }'
|
$ uname -a | awk '{hostname=$2 ; print hostname ; }'
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
>使用 Awk 把命令的输出赋给变量
|
|
||||||
|
*使用 Awk 把命令的输出赋给变量*
|
||||||
|
|
||||||
### 2. 数值表达式
|
### 2. 数值表达式
|
||||||
|
|
||||||
@ -94,8 +94,8 @@ $ uname -a | awk '{hostname=$2 ; print hostname ; }'
|
|||||||
- `%` : 取模运算符
|
- `%` : 取模运算符
|
||||||
- `^` : 指数运算符
|
- `^` : 指数运算符
|
||||||
|
|
||||||
|
|
||||||
数值表达式的语法是:
|
数值表达式的语法是:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ operand1 operator operand2
|
$ operand1 operator operand2
|
||||||
```
|
```
|
||||||
@ -103,6 +103,7 @@ $ operand1 operator operand2
|
|||||||
上面的 operand1 和 operand2 可以是数值和变量,运算符可以是上面列出的任意一种。
|
上面的 operand1 和 operand2 可以是数值和变量,运算符可以是上面列出的任意一种。
|
||||||
|
|
||||||
下面是一些展示怎样使用数值表达式的例子:
|
下面是一些展示怎样使用数值表达式的例子:
|
||||||
|
|
||||||
```
|
```
|
||||||
counter=0
|
counter=0
|
||||||
num1=5
|
num1=5
|
||||||
@ -112,7 +113,8 @@ counter=counter+1
|
|||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
理解了 Awk 中数值表达式的用法,我们就可以看下面的例子了,文件 domians.txt 里包括了所有属于 Tecmint 的域名。
|
要理解 Awk 中数值表达式的用法,我们可以看看下面的例子,文件 domians.txt 里包括了所有属于 Tecmint 的域名。
|
||||||
|
|
||||||
```
|
```
|
||||||
news.tecmint.com
|
news.tecmint.com
|
||||||
tecmint.com
|
tecmint.com
|
||||||
@ -130,16 +132,19 @@ windows.tecmint.com
|
|||||||
tecmint.com
|
tecmint.com
|
||||||
```
|
```
|
||||||
|
|
||||||
可以使用下面的命令查看文件的内容;
|
可以使用下面的命令查看文件的内容:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ cat domains.txt
|
$ cat domains.txt
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
>查看文件内容
|
|
||||||
|
*查看文件内容*
|
||||||
|
|
||||||
|
|
||||||
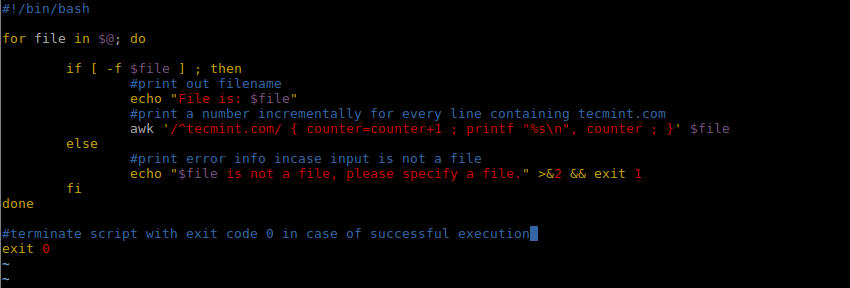
如果想要计算出域名 tecmint.com 在文件中出现的次数,我们就可以通过写一个简单的脚本实现这个功能:
|
如果想要计算出域名 tecmint.com 在文件中出现的次数,我们就可以通过写一个简单的脚本实现这个功能:
|
||||||
|
|
||||||
```
|
```
|
||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
for file in $@; do
|
for file in $@; do
|
||||||
@ -158,7 +163,8 @@ exit 0
|
|||||||
```
|
```
|
||||||
|
|
||||||
|

|
||||||
>计算一个字符串或文本在文件中出现次数的 shell 脚本
|
|
||||||
|
*计算一个字符串或文本在文件中出现次数的 shell 脚本*
|
||||||
|
|
||||||
|
|
||||||
写完脚本后保存并赋予执行权限,当我们使用文件运行脚本的时候,文件 domains.txt 作为脚本的输入,我们会得到下面的输出:
|
写完脚本后保存并赋予执行权限,当我们使用文件运行脚本的时候,文件 domains.txt 作为脚本的输入,我们会得到下面的输出:
|
||||||
@ -168,23 +174,24 @@ $ ./script.sh ~/domains.txt
|
|||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
>计算字符串或文本出现次数的脚本
|
|
||||||
|
|
||||||
|
*计算字符串或文本出现次数的脚本*
|
||||||
|
|
||||||
从脚本执行后的输出中,可以看到在文件 domains.txt 中包含域名 tecmint.com 的地方有 6 行,你可以自己计算进行验证。
|
从脚本执行后的输出中,可以看到在文件 domains.txt 中包含域名 tecmint.com 的地方有 6 行,你可以自己计算进行验证。
|
||||||
|
|
||||||
### 3. 赋值操作符
|
### 3. 赋值操作符
|
||||||
|
|
||||||
我们要说的最后的 Awk 特性是赋值运算符,下面列出的只是 Awk 中的部分赋值运算符:
|
我们要说的最后的 Awk 特性是赋值操作符,下面列出的只是 awk 中的部分赋值运算符:
|
||||||
|
|
||||||
- `*=` : 乘法赋值运算符
|
- `*=` : 乘法赋值操作符
|
||||||
- `+=` : 加法赋值运算符
|
- `+=` : 加法赋值操作符
|
||||||
- `/=` : 除法赋值运算符
|
- `/=` : 除法赋值操作符
|
||||||
- `-=` : 减法赋值运算符
|
- `-=` : 减法赋值操作符
|
||||||
- `%=` : 取模赋值运算符
|
- `%=` : 取模赋值操作符
|
||||||
- `^=` : 指数赋值运算符
|
- `^=` : 指数赋值操作符
|
||||||
|
|
||||||
下面是 Awk 中最简单的一个赋值操作的语法:
|
下面是 Awk 中最简单的一个赋值操作的语法:
|
||||||
|
|
||||||
```
|
```
|
||||||
$ variable_name=variable_name operator operand
|
$ variable_name=variable_name operator operand
|
||||||
```
|
```
|
||||||
@ -199,8 +206,8 @@ num=20
|
|||||||
num=num-1
|
num=num-1
|
||||||
```
|
```
|
||||||
|
|
||||||
|
你可以使用在 awk 中使用上面的赋值操作符使命令更简短,从先前的例子中,我们可以使用下面这种格式进行赋值操作:
|
||||||
|
|
||||||
你可以使用在 Awk 中使用上面的赋值操作符使命令更简短,从先前的例子中,我们可以使用下面这种格式进行赋值操作:
|
|
||||||
```
|
```
|
||||||
variable_name operator=operand
|
variable_name operator=operand
|
||||||
counter=0
|
counter=0
|
||||||
@ -209,8 +216,8 @@ num=20
|
|||||||
num-=1
|
num-=1
|
||||||
```
|
```
|
||||||
|
|
||||||
|
因此,我们可以在 shell 脚本中改变 awk 命令,使用上面提到的 += 操作符:
|
||||||
|
|
||||||
因此,我们可以在 shell 脚本中改变 Awk 命令,使用上面提到的 += 操作符:
|
|
||||||
```
|
```
|
||||||
#!/bin/bash
|
#!/bin/bash
|
||||||
for file in $@; do
|
for file in $@; do
|
||||||
@ -230,14 +237,15 @@ exit 0
|
|||||||
|
|
||||||
|
|
||||||
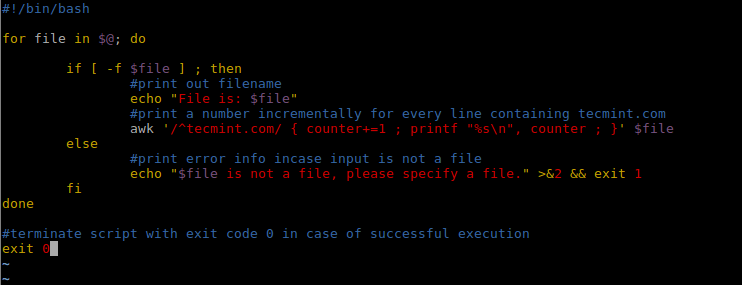
|

|
||||||
>改变了的 shell 脚本
|
|
||||||
|
*修改了的 shell 脚本*
|
||||||
|
|
||||||
|
|
||||||
在 [Awk 系列][4] 的这一部分,我们讨论了一些有用的 Awk 特性,有变量,使用数值表达式和赋值运算符,还有一些使用他们的实例。
|
在 [awk 系列][4] 的这一部分,我们讨论了一些有用的 awk 特性,有变量,使用数值表达式和赋值运算符,还有一些使用它们的实例。
|
||||||
|
|
||||||
这些概念和其他的编程语言没有任何不同,但是可能在 Awk 中有一些意义上的区别。
|
这些概念和其他的编程语言没有任何不同,但是可能在 awk 中有一些意义上的区别。
|
||||||
|
|
||||||
在本系列的第 9 节,我们会学习更多的 Awk 特性,比如特殊格式: BEGIN 和 END。这也会与 Tecmit 有联系。
|
在本系列的第 9 节,我们会学习更多的 awk 特性,比如特殊格式: BEGIN 和 END。请继续关注。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -245,31 +253,12 @@ via: http://www.tecmint.com/learn-awk-variables-numeric-expressions-and-assignme
|
|||||||
|
|
||||||
作者:[Aaron Kili][a]
|
作者:[Aaron Kili][a]
|
||||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||||
校对:[校对ID](https://github.com/校对ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
[a]: http://www.tecmint.com/author/aaronkili/
|
[a]: http://www.tecmint.com/author/aaronkili/
|
||||||
|
[1]: https://linux.cn/article-7586-1.html
|
||||||
|
[2]: https://linux.cn/article-7587-1.html
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
[1]: http://www.tecmint.com/category/awk-command/
|
|
||||||
[2]: http://www.tecmint.com/awk-print-fields-columns-with-space-separator/
|
|
||||||
[3]: http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
[3]: http://www.tecmint.com/13-basic-cat-command-examples-in-linux/
|
||||||
[4]: http://www.tecmint.com/category/awk-command/
|
[4]: https://linux.cn/article-7586-1.html
|
||||||
@ -1,6 +1,7 @@
|
|||||||
Android vs. iPhone: Pros and Cons
|
Android vs. iPhone: Pros and Cons
|
||||||
===================================
|
===================================
|
||||||
|
|
||||||
|
正在翻译 by jovov
|
||||||
>When comparing Android vs. iPhone, clearly Android has certain advantages even as the iPhone is superior in some key ways. But ultimately, which is better?
|
>When comparing Android vs. iPhone, clearly Android has certain advantages even as the iPhone is superior in some key ways. But ultimately, which is better?
|
||||||
|
|
||||||
The question of Android vs. iPhone is a personal one.
|
The question of Android vs. iPhone is a personal one.
|
||||||
|
|||||||
36
sources/talk/20160803 The revenge of Linux.md
Normal file
36
sources/talk/20160803 The revenge of Linux.md
Normal file
@ -0,0 +1,36 @@
|
|||||||
|
The revenge of Linux
|
||||||
|
========================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In the beginning of Linux they laughed at it and didn't think it could do anything. Now Linux is everywhere!
|
||||||
|
|
||||||
|
I was a junior at college studying Computer Engineering in Brazil, and working at the same time in a global auditing and consulting company as a sysadmin. The company decided to implement some enterprise resource planning (ERP) software with an Oracle database. I got training in Digital UNIX OS (DEC Alpha), and it blew my mind.
|
||||||
|
|
||||||
|
The UNIX system was very powerful and gave us absolute control of the machine: storage systems, networking, applications, and everything.
|
||||||
|
|
||||||
|
I started writing lots of scripts in ksh and Bash to automate backup, file transfer, extract, transform, load (ETL) operations, automate DBA routines, and created many other services that came up from different projects. Moreover, doing database and operating system tuning gave me a good understanding of how to get the best from a server. At that time, I used Windows 95 on my PC, and I would have loved to have Digital UNIX in my PC box, or even Solaris or HP-UX, but those UNIX systems were made to run on specific hardware. I read all the documentation that came with the systems, looked for additional books to get more information, and tested crazy ideas in our development environment.
|
||||||
|
|
||||||
|
Later in college, I heard about Linux from my colleagues. I downloaded it back in the time of dialup internet, and I was very excited. The idea of having my standard PC with a UNIX-like system was amazing!
|
||||||
|
|
||||||
|
As Linux is made to run in any general PC hardware, unlike UNIX systems, at the beginning it was really hard to get it working. Linux was just for sysadmins and geeks. I even made adjustments in drivers using C language to get it running. My previous experience with UNIX made me feel at home when I was compiling the Linux kernel, troubleshooting, and so on. It was very challenging for Linux to work with any unexpected hardware setups, as opposed to closed systems that fit just some specific hardware.
|
||||||
|
|
||||||
|
I have been seeing Linux get space in data centers. Some adventurous sysadmins start boxes to help in everyday tasks for monitoring and managing the infrastructure, and then Linux gets more space as DNS and DHCP servers, printer management, and file servers. There used to be lots of FUD (fear, uncertainty and doubt) and criticism about Linux for the enterprise: Who is the owner of it? Who supports it? Are there applications for it?
|
||||||
|
|
||||||
|
But nowadays it seems the revenge of Linux is everywhere! From developer's PCs to huge enterprise servers; we can find it in smart phones, watches, and in the Internet of Things (IoT) devices such as Raspberry Pi. Even Mac OS X has a kind of prompt with commands we are used to. Microsoft is making its own distribution, runs it at Azure, and then... Windows 10 is going to get Bash on it.
|
||||||
|
|
||||||
|
The interesting thing is that the IT market creates and quickly replaces new technologies, but the knowledge we got with old systems such as Digital UNIX, HP-UX, and Solaris is still useful and relevant with Linux, for business and just for fun. Now we can get absolute control of our systems, and use it at its maximum capabilities. Moreover Linux has an enthusiastic community!
|
||||||
|
|
||||||
|
I really recommend that youngsters looking for a career in computing learn Linux. It does not matter what your branch in IT is. If you learn deeply how a standard home PC works, you can get in front of any big box talking basically the same language. With Linux you learn fundamental computing, and build skills that work anywhere in IT.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/life/16/8/revenge-linux
|
||||||
|
|
||||||
|
作者:[Daniel Carvalho][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/danielscarvalho
|
||||||
@ -1,3 +1,8 @@
|
|||||||
|
+@noobfish translating since Aug 2nd,2016.
|
||||||
|
+
|
||||||
|
+
|
||||||
|
|
||||||
|
|
||||||
>This is the third in a series of posts on how to build a Data Science Portfolio. If you like this and want to know when the next post in the series is released, you can [subscribe at the bottom of the page][1].
|
>This is the third in a series of posts on how to build a Data Science Portfolio. If you like this and want to know when the next post in the series is released, you can [subscribe at the bottom of the page][1].
|
||||||
|
|
||||||
Data science companies are increasingly looking at portfolios when making hiring decisions. One of the reasons for this is that a portfolio is the best way to judge someone’s real-world skills. The good news for you is that a portfolio is entirely within your control. If you put some work in, you can make a great portfolio that companies are impressed by.
|
Data science companies are increasingly looking at portfolios when making hiring decisions. One of the reasons for this is that a portfolio is the best way to judge someone’s real-world skills. The good news for you is that a portfolio is entirely within your control. If you put some work in, you can make a great portfolio that companies are impressed by.
|
||||||
|
|||||||
@ -1,65 +1,59 @@
|
|||||||
### Understanding the data
|
|
||||||
|
|
||||||
Let’s take a quick look at the raw data files. Here are the first few rows of the acquisition data from quarter 1 of 2012:
|
|
||||||
|
|
||||||
|
翻译中 by ideas4u
|
||||||
|
### 理解数据
|
||||||
|
我们来简单看一下原始数据文件。下面是2012年1季度前几行的采集数据。
|
||||||
```
|
```
|
||||||
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
100000853384|R|OTHER|4.625|280000|360|02/2012|04/2012|31|31|1|23|801|N|C|SF|1|I|CA|945||FRM|
|
||||||
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
100003735682|R|SUNTRUST MORTGAGE INC.|3.99|466000|360|01/2012|03/2012|80|80|2|30|794|N|P|SF|1|P|MD|208||FRM|788
|
||||||
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
100006367485|C|PHH MORTGAGE CORPORATION|4|229000|360|02/2012|04/2012|67|67|2|36|802|N|R|SF|1|P|CA|959||FRM|794
|
||||||
```
|
```
|
||||||
|
|
||||||
Here are the first few rows of the performance data from quarter 1 of 2012:
|
下面是2012年1季度的前几行执行数据
|
||||||
|
|
||||||
```
|
```
|
||||||
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
100000853384|03/01/2012|OTHER|4.625||0|360|359|03/2042|41860|0|N||||||||||||||||
|
||||||
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
100000853384|04/01/2012||4.625||1|359|358|03/2042|41860|0|N||||||||||||||||
|
||||||
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
100000853384|05/01/2012||4.625||2|358|357|03/2042|41860|0|N||||||||||||||||
|
||||||
```
|
```
|
||||||
|
在开始编码之前,花些时间真正理解数据是值得的。这对于操作项目优为重要,因为我们没有交互式探索数据,将很难察觉到细微的差别除非我们在前期发现他们。在这种情况下,第一个步骤是阅读房利美站点的资料:
|
||||||
|
- [概述][15]
|
||||||
|
- [有用的术语表][16]
|
||||||
|
- [问答][17]
|
||||||
|
- [采集和执行文件中的列][18]
|
||||||
|
- [采集数据文件样本][19]
|
||||||
|
- [执行数据文件样本][20]
|
||||||
|
|
||||||
Before proceeding too far into coding, it’s useful to take some time and really understand the data. This is more critical in operational projects – because we aren’t interactively exploring the data, it can be harder to spot certain nuances unless we find them upfront. In this case, the first step is to read the materials on the Fannie Mae site:
|
在看完这些文件后后,我们了解到一些能帮助我们的关键点:
|
||||||
|
- 从2000年到现在,每季度都有一个采集和执行文件,因数据是滞后一年的,所以到目前为止最新数据是2015年的。
|
||||||
|
- 这些文件是文本格式的,采用管道符号“|”进行分割。
|
||||||
|
- 这些文件是没有表头的,但我们有文件列明各列的名称。
|
||||||
|
- 所有一起,文件包含2200万个贷款的数据。
|
||||||
|
由于执行文件包含过去几年获得的贷款的信息,在早些年获得的贷款将有更多的执行数据(即在2014获得的贷款没有多少历史执行数据)。
|
||||||
|
这些小小的信息将会为我们节省很多时间,因为我们知道如何构造我们的项目和利用这些数据。
|
||||||
|
|
||||||
- [Overview][15]
|
### 构造项目
|
||||||
- [Glossary of useful terms][16]
|
在我们开始下载和探索数据之前,先想一想将如何构造项目是很重要的。当建立端到端项目时,我们的主要目标是:
|
||||||
- [FAQs][17]
|
- 创建一个可行解决方案
|
||||||
- [Columns in the Acquisition and Performance files][18]
|
- 有一个快速运行且占用最小资源的解决方案
|
||||||
- [Sample Acquisition data file][19]
|
- 容易可扩展
|
||||||
- [Sample Performance data file][20]
|
- 写容易理解的代码
|
||||||
|
- 写尽量少的代码
|
||||||
|
|
||||||
After reading through these files, we know some key facts that will help us:
|
为了实现这些目标,需要对我们的项目进行良好的构造。一个结构良好的项目遵循几个原则:
|
||||||
|
- 分离数据文件和代码文件
|
||||||
|
- 从原始数据中分离生成的数据。
|
||||||
|
- 有一个README.md文件帮助人们安装和使用该项目。
|
||||||
|
- 有一个requirements.txt文件列明项目运行所需的所有包。
|
||||||
|
- 有一个单独的settings.py 文件列明其它文件中使用的所有的设置
|
||||||
|
- 例如,如果从多个Python脚本读取相同的文件,把它们全部import设置和从一个集中的地方获得文件名是有用的。
|
||||||
|
- 有一个.gitignore文件,防止大的或秘密文件被提交。
|
||||||
|
- 分解任务中每一步可以单独执行的步骤到单独的文件中。
|
||||||
|
- 例如,我们将有一个文件用于读取数据,一个用于创建特征,一个用于做出预测。
|
||||||
|
- 保存中间结果,例如,一个脚本可输出下一个脚本可读取的文件。
|
||||||
|
|
||||||
- There’s an Acquisition file and a Performance file for each quarter, starting from the year 2000 to present. There’s a 1 year lag in the data, so the most recent data is from 2015 as of this writing.
|
- 这使我们无需重新计算就可以在数据处理流程中进行更改。
|
||||||
- The files are in text format, with a pipe (|) as a delimiter.
|
|
||||||
- The files don’t have headers, but we have a list of what each column is.
|
|
||||||
- All together, the files contain data on 22 million loans.
|
|
||||||
- Because the Performance files contain information on loans acquired in previous years, there will be more performance data for loans acquired in earlier years (ie loans acquired in 2014 won’t have much performance history).
|
|
||||||
|
|
||||||
These small bits of information will save us a ton of time as we figure out how to structure our project and work with the data.
|
|
||||||
|
|
||||||
### Structuring the project
|
我们的文件结构大体如下:
|
||||||
|
|
||||||
Before we start downloading and exploring the data, it’s important to think about how we’ll structure the project. When building an end-to-end project, our primary goals are:
|
|
||||||
|
|
||||||
- Creating a solution that works
|
|
||||||
- Having a solution that runs quickly and uses minimal resources
|
|
||||||
- Enabling others to easily extend our work
|
|
||||||
- Making it easy for others to understand our code
|
|
||||||
- Writing as little code as possible
|
|
||||||
|
|
||||||
In order to achieve these goals, we’ll need to structure our project well. A well structured project follows a few principles:
|
|
||||||
|
|
||||||
- Separates data files and code files.
|
|
||||||
- Separates raw data from generated data.
|
|
||||||
- Has a README.md file that walks people through installing and using the project.
|
|
||||||
- Has a requirements.txt file that contains all the packages needed to run the project.
|
|
||||||
- Has a single settings.py file that contains any settings that are used in other files.
|
|
||||||
- For example, if you are reading the same file from multiple Python scripts, it’s useful to have them all import settings and get the file name from a centralized place.
|
|
||||||
- Has a .gitignore file that prevents large or secret files from being committed.
|
|
||||||
- Breaks each step in our task into a separate file that can be executed separately.
|
|
||||||
- For example, we may have one file for reading in the data, one for creating features, and one for making predictions.
|
|
||||||
- Stores intermediate values. For example, one script may output a file that the next script can read.
|
|
||||||
- This enables us to make changes in our data processing flow without recalculating everything.
|
|
||||||
|
|
||||||
Our file structure will look something like this shortly:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
loan-prediction
|
loan-prediction
|
||||||
@ -71,23 +65,17 @@ loan-prediction
|
|||||||
├── settings.py
|
├── settings.py
|
||||||
```
|
```
|
||||||
|
|
||||||
### Creating the initial files
|
### 创建初始文件
|
||||||
|
首先,我们需要创建一个loan-prediction文件夹,在此文件夹下面,再创建一个data文件夹和一个processed文件夹。data文件夹存放原始数据,processed文件夹存放所有的中间计算结果。
|
||||||
To start with, we’ll need to create a loan-prediction folder. Inside that folder, we’ll need to make a data folder and a processed folder. The first will store our raw data, and the second will store any intermediate calculated values.
|
其次,创建.gitignore文件,.gitignore文件将保证某些文件被git忽略而不会被推送至github。关于这个文件的一个好的例子是由OSX在每一个文件夹都会创建的.DS_Store文件,.gitignore文件一个很好的起点就是在这了。我们还想忽略数据文件因为他们实在是太大了,同时房利美的条文禁止我们重新分发该数据文件,所以我们应该在我们的文件后面添加以下2行:
|
||||||
|
|
||||||
Next, we’ll make a .gitignore file. A .gitignore file will make sure certain files are ignored by git and not pushed to Github. One good example of such a file is the .DS_Store file created by OSX in every folder. A good starting point for a .gitignore file is here. We’ll also want to ignore the data files because they are very large, and the Fannie Mae terms prevent us from redistributing them, so we should add two lines to the end of our file:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
data
|
data
|
||||||
processed
|
processed
|
||||||
```
|
```
|
||||||
|
|
||||||
[Here’s][21] an example .gitignore file for this project.
|
这是该项目的一个关于.gitignore文件的例子。
|
||||||
|
再次,我们需要创建README.md文件,它将帮助人们理解该项目。后缀.md表示这个文件采用markdown格式。Markdown使你能够写纯文本文件,同时还可以添加你想要的梦幻格式。这是关于markdown的导引。如果你上传一个叫README.md的文件至Github,Github会自动处理该markdown,同时展示给浏览该项目的人。
|
||||||
Next, we’ll need to create README.md, which will help people understand the project. .md indicates that the file is in markdown format. Markdown enables you write plain text, but also add some fancy formatting if you want. [Here’s][22] a guide on markdown. If you upload a file called README.md to Github, Github will automatically process the markdown, and show it to anyone who views the project. [Here’s][23] an example.
|
至此,我们仅需在README.md文件中添加简单的描述:
|
||||||
|
|
||||||
For now, we just need to put a simple description in README.md:
|
|
||||||
|
|
||||||
```
|
```
|
||||||
Loan Prediction
|
Loan Prediction
|
||||||
-----------------------
|
-----------------------
|
||||||
@ -95,8 +83,7 @@ Loan Prediction
|
|||||||
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
Predict whether or not loans acquired by Fannie Mae will go into foreclosure. Fannie Mae acquires loans from other lenders as a way of inducing them to lend more. Fannie Mae releases data on the loans it has acquired and their performance afterwards [here](http://www.fanniemae.com/portal/funding-the-market/data/loan-performance-data.html).
|
||||||
```
|
```
|
||||||
|
|
||||||
Now, we can create a requirements.txt file. This will make it easy for other people to install our project. We don’t know exactly what libraries we’ll be using yet, but here’s a good starting point:
|
现在,我们可以创建requirements.txt文件了。这会唯其它人可以很方便地安装我们的项目。我们还不知道我们将会具体用到哪些库,但是以下几个库是一个很好的开始:
|
||||||
|
|
||||||
```
|
```
|
||||||
pandas
|
pandas
|
||||||
matplotlib
|
matplotlib
|
||||||
@ -106,9 +93,6 @@ ipython
|
|||||||
scipy
|
scipy
|
||||||
```
|
```
|
||||||
|
|
||||||
The above libraries are the most commonly used for data analysis tasks in Python, and its fair to assume that we’ll be using most of them. [Here’s][24] an example requirements file for this project.
|
以上几个是在python数据分析任务中最常用到的库。可以认为我们将会用到大部分这些库。这里是【24】该项目requirements文件的一个例子。
|
||||||
|
创建requirements.txt文件之后,你应该安装包了。我们将会使用python3.如果你没有安装python,你应该考虑使用 [Anaconda][25],一个python安装程序,同时安装了上面列出的所有包。
|
||||||
After creating requirements.txt, you should install the packages. For this post, we’ll be using Python 3. If you don’t have Python installed, you should look into using [Anaconda][25], a Python installer that also installs all the packages listed above.
|
最后,我们可以建立一个空白的settings.py文件,因为我们的项目还没有任何设置。
|
||||||
|
|
||||||
Finally, we can just make a blank settings.py file, since we don’t have any settings for our project yet.
|
|
||||||
|
|
||||||
|
|||||||
@ -1,38 +1,44 @@
|
|||||||
注解数据
|
|
||||||
我们已经在annotate.py中添加了一些功能, 现在我们来看一看数据文件. 我们需要将采集到的数据转换到training dataset来进行机器学习的训练. 这涉及到以下几件事情:
|
|
||||||
|
|
||||||
转换所以列数字.
|
### 注解数据
|
||||||
填充缺失值.
|
|
||||||
分配 performance_count 和 foreclosure_status.
|
|
||||||
移除出现次数很少的行(performance_count 计数低).
|
|
||||||
我们有几个列是strings类型的, 看起来对于机器学习算法来说并不是很有用. 然而, 他们实际上是分类变量, 其中有很多不同的类别代码, 例如R,S等等. 我们可以把这些类别标签转换为数值:
|
|
||||||
|
|
||||||
|
我们已经在annotate.py中添加了一些功能, 现在我们来看一看数据文件. 我们需要将采集到的数据转换到训练数据表来进行机器学习的训练. 这涉及到以下几件事情:
|
||||||
|
|
||||||
|
- 转换所以列数字.
|
||||||
|
- 填充缺失值.
|
||||||
|
- 分配 performance_count 和 foreclosure_status.
|
||||||
|
- 移除出现次数很少的行(performance_count 计数低).
|
||||||
|
|
||||||
|
我们有几个列是文本类型的, 看起来对于机器学习算法来说并不是很有用. 然而, 他们实际上是分类变量, 其中有很多不同的类别代码, 例如R,S等等. 我们可以把这些类别标签转换为数值:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
通过这种方法转换的列我们可以应用到机器学习算法中.
|
通过这种方法转换的列我们可以应用到机器学习算法中.
|
||||||
|
|
||||||
还有一些包含日期的列 (first_payment_date 和 origination_date). 我们可以将这些日期放到两个列中:
|
还有一些包含日期的列 (first_payment_date 和 origination_date). 我们可以将这些日期放到两个列中:
|
||||||
|
|
||||||
在下面的代码中, 我们将转换采集到的数据. 我们将定义一个函数如下:
|

|
||||||
|
在下面的代码中, 我们将转换采集到的数据. 我们将定义一个函数如下:
|
||||||
|
|
||||||
在采集到的数据中创建foreclosure_status列 .
|
- 在采集到的数据中创建foreclosure_status列 .
|
||||||
在采集到的数据中创建performance_count列.
|
- 在采集到的数据中创建performance_count列.
|
||||||
将下面的string列转换为integer列:
|
- 将下面的string列转换为integer列:
|
||||||
channel
|
- channel
|
||||||
seller
|
- seller
|
||||||
first_time_homebuyer
|
- first_time_homebuyer
|
||||||
loan_purpose
|
- loan_purpose
|
||||||
property_type
|
- property_type
|
||||||
occupancy_status
|
- occupancy_status
|
||||||
property_state
|
- property_state
|
||||||
product_type
|
- product_type
|
||||||
转换first_payment_date 和 origination_date 为两列:
|
- 转换first_payment_date 和 origination_date 为两列:
|
||||||
通过斜杠分离列.
|
- 通过斜杠分离列.
|
||||||
将第一部分分离成月清单.
|
- 将第一部分分离成月清单.
|
||||||
将第二部分分离成年清单.
|
- 将第二部分分离成年清单.
|
||||||
删除这一列.
|
- 删除这一列.
|
||||||
最后, 我们得到 first_payment_month, first_payment_year, origination_month, and origination_year.
|
- 最后, 我们得到 first_payment_month, first_payment_year, origination_month, and origination_year.
|
||||||
所有缺失值填充为-1.
|
- 所有缺失值填充为-1.
|
||||||
|
|
||||||
|
```
|
||||||
def annotate(acquisition, counts):
|
def annotate(acquisition, counts):
|
||||||
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
acquisition["foreclosure_status"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "foreclosure_status", counts))
|
||||||
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
acquisition["performance_count"] = acquisition["id"].apply(lambda x: get_performance_summary_value(x, "performance_count", counts))
|
||||||
@ -57,17 +63,21 @@ def annotate(acquisition, counts):
|
|||||||
acquisition = acquisition.fillna(-1)
|
acquisition = acquisition.fillna(-1)
|
||||||
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
acquisition = acquisition[acquisition["performance_count"] > settings.MINIMUM_TRACKING_QUARTERS]
|
||||||
return acquisition
|
return acquisition
|
||||||
|
```
|
||||||
|
|
||||||
|
### 聚合到一起
|
||||||
|
|
||||||
聚合到一起
|
|
||||||
我们差不多准备就绪了, 我们只需要再在annotate.py添加一点点代码. 在下面代码中, 我们将:
|
我们差不多准备就绪了, 我们只需要再在annotate.py添加一点点代码. 在下面代码中, 我们将:
|
||||||
|
|
||||||
定义一个函数来读取采集的数据.
|
- 定义一个函数来读取采集的数据.
|
||||||
定义一个函数来写入数据到/train.csv
|
- 定义一个函数来写入数据到/train.csv
|
||||||
如果我们在命令行运行annotate.py来读取更新过的数据文件,它将做如下事情:
|
- 如果我们在命令行运行annotate.py来读取更新过的数据文件,它将做如下事情:
|
||||||
读取采集到的数据.
|
- 读取采集到的数据.
|
||||||
计算数据性能.
|
- 计算数据性能.
|
||||||
注解数据.
|
- 注解数据.
|
||||||
将注解数据写入到train.csv.
|
- 将注解数据写入到train.csv.
|
||||||
|
|
||||||
|
```
|
||||||
def read():
|
def read():
|
||||||
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
acquisition = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "Acquisition.txt"), sep="|")
|
||||||
return acquisition
|
return acquisition
|
||||||
@ -80,11 +90,13 @@ if __name__ == "__main__":
|
|||||||
counts = count_performance_rows()
|
counts = count_performance_rows()
|
||||||
acquisition = annotate(acquisition, counts)
|
acquisition = annotate(acquisition, counts)
|
||||||
write(acquisition)
|
write(acquisition)
|
||||||
|
```
|
||||||
|
|
||||||
修改完成以后为了确保annotate.py能够生成train.csv文件. 你可以在这里找到完整的 annotate.py file [here][34].
|
修改完成以后为了确保annotate.py能够生成train.csv文件. 你可以在这里找到完整的 annotate.py file [here][34].
|
||||||
|
|
||||||
文件夹结果应该像这样:
|
文件夹结果应该像这样:
|
||||||
|
|
||||||
|
```
|
||||||
loan-prediction
|
loan-prediction
|
||||||
├── data
|
├── data
|
||||||
│ ├── Acquisition_2012Q1.txt
|
│ ├── Acquisition_2012Q1.txt
|
||||||
@ -102,37 +114,45 @@ loan-prediction
|
|||||||
├── README.md
|
├── README.md
|
||||||
├── requirements.txt
|
├── requirements.txt
|
||||||
├── settings.py
|
├── settings.py
|
||||||
|
```
|
||||||
|
|
||||||
找到标准
|
### 找到标准
|
||||||
我们已经完成了training dataset的生成, 现在我们需要最后一步, 生成预测. 我们需要找到错误的标准, 以及该如何评估我们的数据. 在这种情况下, 因为有很多的贷款没有收回, 所以根本不可能做到精确的计算.
|
|
||||||
|
我们已经完成了训练数据表的生成, 现在我们需要最后一步, 生成预测. 我们需要找到错误的标准, 以及该如何评估我们的数据. 在这种情况下, 因为有很多的贷款没有收回, 所以根本不可能做到精确的计算.
|
||||||
|
|
||||||
我们需要读取数据, 并且计算foreclosure_status列, 我们将得到如下信息:
|
我们需要读取数据, 并且计算foreclosure_status列, 我们将得到如下信息:
|
||||||
|
|
||||||
|
```
|
||||||
import pandas as pd
|
import pandas as pd
|
||||||
import settings
|
import settings
|
||||||
|
|
||||||
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
train = pd.read_csv(os.path.join(settings.PROCESSED_DIR, "train.csv"))
|
||||||
train["foreclosure_status"].value_counts()
|
train["foreclosure_status"].value_counts()
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
False 4635982
|
False 4635982
|
||||||
True 1585
|
True 1585
|
||||||
Name: foreclosure_status, dtype: int64
|
Name: foreclosure_status, dtype: int64
|
||||||
|
```
|
||||||
|
|
||||||
因为只有一点点贷款收回, 通过百分比标签来建立的机器学习模型会把每行都设置为Fasle, 所以我们在这里要考虑每个样本的不平衡性,确保我们做出的预测是准确的. 我们不想要这么多假的false, 我们将预计贷款收回但是它并没有收回, 我们预计贷款不会回收但是却回收了. 通过以上两点, Fannie Mae的false太多了, 因此显示他们可能无法收回投资.
|
因为只有一点点贷款收回, 通过百分比标签来建立的机器学习模型会把每行都设置为Fasle, 所以我们在这里要考虑每个样本的不平衡性,确保我们做出的预测是准确的. 我们不想要这么多假的false, 我们将预计贷款收回但是它并没有收回, 我们预计贷款不会回收但是却回收了. 通过以上两点, Fannie Mae的false太多了, 因此显示他们可能无法收回投资.
|
||||||
|
|
||||||
所以我们将定义一个百分比,就是模型预测没有收回但是实际上收回了, 这个数除以总的负债回收总数. 这个负债回收百分比模型实际上是“没有的”. 下面看这个图表:
|
所以我们将定义一个百分比,就是模型预测没有收回但是实际上收回了, 这个数除以总的负债回收总数. 这个负债回收百分比模型实际上是“没有的”. 下面看这个图表:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
通过上面的图表, 1个负债预计不会回收, 也确实没有回收. 如果我们将这个数除以总数, 2, 我们将得到false的概率为50%. 我们将使用这个标准, 因此我们可以评估一下模型的性能.
|
通过上面的图表, 1个负债预计不会回收, 也确实没有回收. 如果我们将这个数除以总数, 2, 我们将得到false的概率为50%. 我们将使用这个标准, 因此我们可以评估一下模型的性能.
|
||||||
|
|
||||||
设置机器学习分类器
|
### 设置机器学习分类器
|
||||||
|
|
||||||
我们使用交叉验证预测. 通过交叉验证法, 我们将数据分为3组. 按照下面的方法来做:
|
我们使用交叉验证预测. 通过交叉验证法, 我们将数据分为3组. 按照下面的方法来做:
|
||||||
|
|
||||||
Train a model on groups 1 and 2, and use the model to make predictions for group 3.
|
- Train a model on groups 1 and 2, and use the model to make predictions for group 3.
|
||||||
Train a model on groups 1 and 3, and use the model to make predictions for group 2.
|
- Train a model on groups 1 and 3, and use the model to make predictions for group 2.
|
||||||
Train a model on groups 2 and 3, and use the model to make predictions for group 1.
|
- Train a model on groups 2 and 3, and use the model to make predictions for group 1.
|
||||||
将它们分割到不同的组 ,这意味着我们永远不会用相同的数据来为预测训练模型. 这样就避免了 overfitting. 如果我们overfit, 我们将得到很低的false概率, 这使得我们难以改进算法或者应用到现实生活中.
|
|
||||||
|
将它们分割到不同的组 ,这意味着我们永远不会用相同的数据来为预测训练模型. 这样就避免了overfitting(过拟合). 如果我们overfit(过拟合), 我们将得到很低的false概率, 这使得我们难以改进算法或者应用到现实生活中.
|
||||||
|
|
||||||
[Scikit-learn][35] 有一个叫做 [cross_val_predict][36] 他可以帮助我们理解交叉算法.
|
[Scikit-learn][35] 有一个叫做 [cross_val_predict][36] 他可以帮助我们理解交叉算法.
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by StdioA
|
||||||
Let’s Build A Web Server. Part 1.
|
Let’s Build A Web Server. Part 1.
|
||||||
=====================================
|
=====================================
|
||||||
|
|
||||||
|
|||||||
@ -1,133 +0,0 @@
|
|||||||
FSSlc translating
|
|
||||||
|
|
||||||
bc: Command line calculator
|
|
||||||
============================
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
If you run a graphical desktop environment, you probably point and click your way to a calculator when you need one. The Fedora Workstation, for example, includes the Calculator tool. It features several different operating modes that allow you to do, for example, complex math or financial calculations. But did you know the command line also offers a similar calculator called bc?
|
|
||||||
|
|
||||||
The bc utility gives you everything you expect from a scientific, financial, or even simple calculator. What’s more, it can be scripted from the command line if needed. This allows you to use it in shell scripts, in case you need to do more complex math.
|
|
||||||
|
|
||||||
Because bc is used by some other system software, like CUPS printing services, it’s probably installed on your Fedora system already. You can check with this command:
|
|
||||||
|
|
||||||
```
|
|
||||||
dnf list installed bc
|
|
||||||
```
|
|
||||||
|
|
||||||
If you don’t see it for some reason, you can install the package with this command:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo dnf install bc
|
|
||||||
```
|
|
||||||
|
|
||||||
### Doing simple math with bc
|
|
||||||
|
|
||||||
One way to use bc is to enter the calculator’s own shell. There you can run many calculations in a row. When you enter, the first thing that appears is a notice about the program:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ bc
|
|
||||||
bc 1.06.95
|
|
||||||
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
|
||||||
This is free software with ABSOLUTELY NO WARRANTY.
|
|
||||||
For details type `warranty'.
|
|
||||||
```
|
|
||||||
|
|
||||||
Now you can type in calculations or commands, one per line:
|
|
||||||
|
|
||||||
```
|
|
||||||
1+1
|
|
||||||
```
|
|
||||||
|
|
||||||
The calculator helpfully answers:
|
|
||||||
|
|
||||||
```
|
|
||||||
2
|
|
||||||
```
|
|
||||||
|
|
||||||
You can perform other commands here. You can use addition (+), subtraction (-), multiplication (*), division (/), parentheses, exponents (^), and so forth. Note that the calculator respects all expected conventions such as order of operations. Try these examples:
|
|
||||||
|
|
||||||
```
|
|
||||||
(4+7)*2
|
|
||||||
4+7*2
|
|
||||||
```
|
|
||||||
|
|
||||||
To exit, send the “end of input” signal with the key combination Ctrl+D.
|
|
||||||
|
|
||||||
Another way is to use the echo command to send calculations or commands. Here’s the calculator equivalent of “Hello, world,” using the shell’s pipe function (|) to send output from echo into bc:
|
|
||||||
|
|
||||||
```
|
|
||||||
echo '1+1' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
You can send more than one calculation using the shell pipe, with a semicolon to separate entries. The results are returned on separate lines.
|
|
||||||
|
|
||||||
```
|
|
||||||
echo '1+1; 2+2' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
### Scale
|
|
||||||
|
|
||||||
The bc calculator uses the concept of scale, or the number of digits after a decimal point, in some calculations. The default scale is 0. Division operations always use the scale setting. So if you don’t set scale, you may get unexpected answers:
|
|
||||||
|
|
||||||
```
|
|
||||||
echo '3/2' | bc
|
|
||||||
echo 'scale=3; 3/2' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
Multiplication uses a more complex decision for scale:
|
|
||||||
|
|
||||||
```
|
|
||||||
echo '3*2' | bc
|
|
||||||
echo '3*2.0' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
Meanwhile, addition and subtraction are more as expected:
|
|
||||||
|
|
||||||
```
|
|
||||||
echo '7-4.15' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
### Other base number systems
|
|
||||||
|
|
||||||
Another useful function is the ability to use number systems other than base-10 (decimal). For instance, you can easily do hexadecimal or binary math. Use the ibase and obase commands to set input and output base systems between base-2 and base-16. Remember that once you use ibase, any number you enter is expected to be in the new declared base.
|
|
||||||
|
|
||||||
To do hexadecimal to decimal conversions or math, you can use a command like this. Note the hexadecimal digits above 9 must be in uppercase (A-F):
|
|
||||||
|
|
||||||
```
|
|
||||||
echo 'ibase=16; A42F' | bc
|
|
||||||
echo 'ibase=16; 5F72+C39B' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
To get results in hexadecimal, set the obase as well:
|
|
||||||
|
|
||||||
```
|
|
||||||
echo 'obase=16; ibase=16; 5F72+C39B' | bc
|
|
||||||
```
|
|
||||||
|
|
||||||
Here’s a trick, though. If you’re doing these calculations in the shell, how do you switch back to input in base-10? The answer is to use ibase, but you must set it to the equivalent of decimal number 10 in the current input base. For instance, if ibase was set to hexadecimal, enter:
|
|
||||||
|
|
||||||
```
|
|
||||||
ibase=A
|
|
||||||
```
|
|
||||||
|
|
||||||
Once you do this, all input numbers are now decimal again, so you can enter obase=10 to reset the output base system.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
This is only the beginning of what bc can do. It also allows you to define functions, variables, and loops for complex calculations and programs. You can save these programs as text files on your system to run whenever you need. You can find numerous resources on the web that offer examples and additional function libraries. Happy calculating!
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
|
||||||
|
|
||||||
作者:[Paul W. Frields][a]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://fedoramagazine.org/author/pfrields/
|
|
||||||
[1]: http://phodd.net/gnu-bc/
|
|
||||||
@ -0,0 +1,182 @@
|
|||||||
|
translated by strugglingyouth
|
||||||
|
How to restore older file versions in Git
|
||||||
|
=============================================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In today's article you will learn how to find out where you are in the history of your project, how to restore older file versions, and how to make Git branches so you can safely conduct wild experiments.
|
||||||
|
|
||||||
|
Where you are in the history of your Git project, much like your location in the span of a rock album, is determined by a marker called HEAD (like the playhead of a tape recorder or record player). To move HEAD around in your own Git timeline, use the git checkout command.
|
||||||
|
|
||||||
|
There are two ways to use the git checkout command. A common use is to restore a file from a previous commit, and you can also rewind your entire tape reel and go in an entirely different direction.
|
||||||
|
|
||||||
|
### Restore a file
|
||||||
|
|
||||||
|
This happens when you realize you've utterly destroyed an otherwise good file. We all do it; we get a file to a great place, we add and commit it, and then we decide that what it really needs is one last adjustment, and the file ends up completely unrecognizable.
|
||||||
|
|
||||||
|
To restore it to its former glory, use git checkout from the last known commit, which is HEAD:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout HEAD filename
|
||||||
|
```
|
||||||
|
|
||||||
|
If you accidentally committed a bad version of a file and need to yank a version from even further back in time, look in your Git log to see your previous commits, and then check it out from the appropriate commit:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git log --oneline
|
||||||
|
79a4e5f bad take
|
||||||
|
f449007 The second commit
|
||||||
|
55df4c2 My great project, first commit.
|
||||||
|
|
||||||
|
$ git checkout 55df4c2 filename
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
Now the older version of the file is restored into your current position. (You can see your current status at any time with the git status command.) You need to add the file because it has changed, and then commit it:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git add filename
|
||||||
|
$ git commit -m 'restoring filename from first commit.'
|
||||||
|
```
|
||||||
|
|
||||||
|
Look in your Git log to verify what you did:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git log --oneline
|
||||||
|
d512580 restoring filename from first commit
|
||||||
|
79a4e5f bad take
|
||||||
|
f449007 The second commit
|
||||||
|
55df4c2 My great project, first commit.
|
||||||
|
```
|
||||||
|
|
||||||
|
Essentially, you have rewound the tape and are taping over a bad take. So you need to re-record the good take.
|
||||||
|
|
||||||
|
### Rewind the timeline
|
||||||
|
|
||||||
|
The other way to check out a file is to rewind the entire Git project. This introduces the idea of branches, which are, in a way, alternate takes of the same song.
|
||||||
|
|
||||||
|
When you go back in history, you rewind your Git HEAD to a previous version of your project. This example rewinds all the way back to your original commit:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git log --oneline
|
||||||
|
d512580 restoring filename from first commit
|
||||||
|
79a4e5f bad take
|
||||||
|
f449007 The second commit
|
||||||
|
55df4c2 My great project, first commit.
|
||||||
|
|
||||||
|
$ git checkout 55df4c2
|
||||||
|
```
|
||||||
|
|
||||||
|
When you rewind the tape in this way, if you hit the record button and go forward, you are destroying your future work. By default, Git assumes you do not want to do this, so it detaches HEAD from the project and lets you work as needed without accidentally recording over something you have recorded later.
|
||||||
|
|
||||||
|
If you look at your previous version and realise suddenly that you want to re-do everything, or at least try a different approach, then the safe way to do that is to create a new branch. You can think of this process as trying out a different version of the same song, or creating a remix. The original material exists, but you're branching off and doing your own version for fun.
|
||||||
|
|
||||||
|
To get your Git HEAD back down on blank tape, make a new branch:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout -b remix
|
||||||
|
Switched to a new branch 'remix'
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you've moved back in time, with an alternate and clean workspace in front of you, ready for whatever changes you want to make.
|
||||||
|
|
||||||
|
You can do the same thing without moving in time. Maybe you're perfectly happy with how your progress is going, but would like to switch to a temporary workspace just to try some crazy ideas out. That's a perfectly acceptable workflow, as well:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git status
|
||||||
|
On branch master
|
||||||
|
nothing to commit, working directory clean
|
||||||
|
|
||||||
|
$ git checkout -b crazy_idea
|
||||||
|
Switched to a new branch 'crazy_idea'
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you have a clean workspace where you can sandbox some crazy new ideas. Once you're done, you can either keep your changes, or you can forget they ever existed and switch back to your master branch.
|
||||||
|
|
||||||
|
To forget your ideas in shame, change back to your master branch and pretend your new branch doesn't exist:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout master
|
||||||
|
```
|
||||||
|
|
||||||
|
To keep your crazy ideas and pull them back into your master branch, change back to your master branch and merge your new branch:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout master
|
||||||
|
$ git merge crazy_idea
|
||||||
|
```
|
||||||
|
|
||||||
|
Branches are powerful aspects of git, and it's common for developers to create a new branch immediately after cloning a repository; that way, all of their work is contained on their own branch, which they can submit for merging to the master branch. Git is pretty flexible, so there's no "right" or "wrong" way (even a master branch can be distinguished from what remote it belongs to), but branching makes it easy to separate tasks and contributions. Don't get too carried away, but between you and me, you can have as many Git branches as you please. They're free!
|
||||||
|
|
||||||
|
### Working with remotes
|
||||||
|
|
||||||
|
So far you've maintained a Git repository in the comfort and privacy of your own home, but what about when you're working with other people?
|
||||||
|
|
||||||
|
There are several different ways to set Git up so that many people can work on a project at once, so for now we'll focus on working on a clone, whether you got that clone from someone's personal Git server or their GitHub page, or from a shared drive on the same network.
|
||||||
|
|
||||||
|
The only difference between working on your own private Git repository and working on something you want to share with others is that at some point, you need to push your changes to someone else's repository. We call the repository you are working in a local repository, and any other repository a remote.
|
||||||
|
|
||||||
|
When you clone a repository with read and write permissions from another source, your clone inherits the remote from whence it came as its origin. You can see a clone's remote:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git remote --verbose
|
||||||
|
origin seth@example.com:~/myproject.Git (fetch)
|
||||||
|
origin seth@example.com:~/myproject.Git (push)
|
||||||
|
```
|
||||||
|
|
||||||
|
Having a remote origin is handy because it is functionally an offsite backup, and it also allows someone else to be working on the project.
|
||||||
|
|
||||||
|
If your clone didn't inherit a remote origin, or if you choose to add one later, use the git remote command:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git remote add seth@example.com:~/myproject.Git
|
||||||
|
```
|
||||||
|
|
||||||
|
If you have changed files and want to send them to your remote origin, and have read and write permissions to the repository, use git push. The first time you push changes, you must also send your branch information. It is a good practice to not work on master, unless you've been told to do so:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout -b seth-dev
|
||||||
|
$ git add exciting-new-file.txt
|
||||||
|
$ git commit -m 'first push to remote'
|
||||||
|
$ git push -u origin HEAD
|
||||||
|
```
|
||||||
|
|
||||||
|
This pushes your current location (HEAD, naturally) and the branch it exists on to the remote. After you've pushed your branch once, you can drop the -u option:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git add another-file.txt
|
||||||
|
$ git commit -m 'another push to remote'
|
||||||
|
$ git push origin HEAD
|
||||||
|
```
|
||||||
|
|
||||||
|
### Merging branches
|
||||||
|
|
||||||
|
When you're working alone in a Git repository you can merge test branches into your master branch whenever you want. When working in tandem with a contributor, you'll probably want to review their changes before merging them into your master branch:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git checkout contributor
|
||||||
|
$ git pull
|
||||||
|
$ less blah.txt # review the changed files
|
||||||
|
$ git checkout master
|
||||||
|
$ git merge contributor
|
||||||
|
```
|
||||||
|
|
||||||
|
If you are using GitHub or GitLab or something similar, the process is different. There, it is traditional to fork the project and treat it as though it is your own repository. You can work in the repository and send changes to your GitHub or GitLab account without getting permission from anyone, because it's your repository.
|
||||||
|
|
||||||
|
If you want the person you forked it from to receive your changes, you create a pull request, which uses the web service's backend to send patches to the real owner, and allows them to review and pull in your changes.
|
||||||
|
|
||||||
|
Forking a project is usually done on the web service, but the Git commands to manage your copy of the project are the same, even the push process. Then it's back to the web service to open a pull request, and the job is done.
|
||||||
|
|
||||||
|
In our next installment we'll look at some convenience add-ons to help you integrate Git comfortably into your everyday workflow.
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/life/16/7/how-restore-older-file-versions-git
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
117
sources/tech/20160802 3 graphical tools for Git.md
Normal file
117
sources/tech/20160802 3 graphical tools for Git.md
Normal file
@ -0,0 +1,117 @@
|
|||||||
|
3 graphical tools for Git
|
||||||
|
=============================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
In this article, we'll take a look at some convenience add-ons to help you integrate Git comfortably into your everyday workflow.
|
||||||
|
|
||||||
|
I learned Git before many of these fancy interfaces existed, and my workflow is frequently text-based anyway, so most of the inbuilt conveniences of Git suit me pretty well. It is always best, in my opinion, to understand how Git works natively. However, it is always nice to have options, so these are some of the ways you can start using Git outside of the terminal.
|
||||||
|
|
||||||
|
### Git in KDE Dolphin
|
||||||
|
|
||||||
|
I am a KDE user, if not always within the Plasma desktop, then as my application layer in Fluxbox. Dolphin is an excellent file manager with lots of options and plenty of secret little features. Particularly useful are all the plugins people develop for it, one of which is a nearly-complete Git interface. Yes, you can manage your Git repositories natively from the comfort of your own desktop.
|
||||||
|
|
||||||
|
But first, you'll need to make sure the add-ons are installed. Some distros come with a filled-to-the-brim KDE, while others give you just the basics, so if you don't see the Git options in the next few steps, search your repository for something like dolphin-extras or dolphin-plugins.
|
||||||
|
|
||||||
|
To activate Git integration, go to the Settings menu in any Dolphin window and select Configure Dolphin.
|
||||||
|
|
||||||
|
In the Configure Dolphin window, click on the Services icon in the left column.
|
||||||
|
|
||||||
|
In the Services panel, scroll through the list of available plugins until you find Git.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Save your changes and close your Dolphin window. When you re-launch Dolphin, navigate to a Git repository and have a look around. Notice that all icons now have emblems: green boxes for committed files, solid green boxes for modified files, no icon for untracked files, and so on.
|
||||||
|
|
||||||
|
Your right-click menu now has contextual Git options when invoked inside a Git repository. You can initiate a checkout, push or pull when clicking inside a Dolphin window, and you can even do a git add or git remove on your files.
|
||||||
|
|
||||||
|
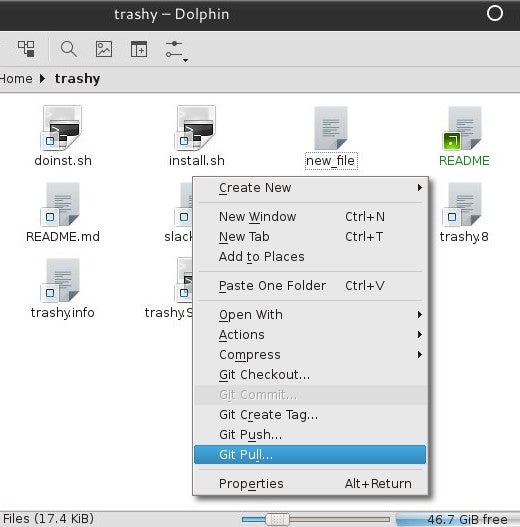
|
||||||
|
|
||||||
|
You can't clone a repository or change remote paths in Dolphin, but will have to drop to a terminal, which is just an F4 away.
|
||||||
|
|
||||||
|
Frankly, this feature of KDE is so kool [sic] that this article could just end here. The integration of Git in your native file manager makes working with Git almost transparent; everything you need to do just happens no matter what stage of the process you are in. Git in the terminal, and Git waiting for you when you switch to the GUI. It is perfection.
|
||||||
|
|
||||||
|
But wait, there's more!
|
||||||
|
|
||||||
|
### Sparkleshare
|
||||||
|
|
||||||
|
From the other side of the desktop pond comes SparkleShare, a project that uses a file synchronization model ("like Dropbox!") that got started by some GNOME developers. It is not integrated into any specific part of GNOME, so you can use it on all platforms.
|
||||||
|
|
||||||
|
If you run Linux, install SparkleShare from your software repository. Other operating systems should download from the SparkleShare website. You can safely ignore the instructions on the SparkleShare website, which are for setting up a SparkleShare server, which is not what we will do here. You certainly can set up a SparkleShare server if you want, but SparkleShare is compatible with any Git repository, so you don't need to create your own server.
|
||||||
|
|
||||||
|
After it is installed, launch SparkleShare from your applications menu. Step through the setup wizard, which is two steps plus a brief tutorial, and optionally set SparkleShare as a startup item for your desktop.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
An orange SparkleShare directory is now in your system tray. Currently, SparkleShare is oblivious to anything on your computer, so you need to add a hosted project.
|
||||||
|
|
||||||
|
To add a directory for SparkleShare to track, click the SparkleShare icon in your system tray and select Add Hosted Project.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
SparkleShare can work with self-hosted Git projects, or projects hosted on public Git services like GitHub and Bitbucket. For full access, you'll probably need to use the Client ID that SparkleShare provides to you. This is an SSH key acting as the authentication token for the service you use for hosting, including your own Git server, which should also use SSH public key authentication rather than password login. Copy the Client ID into the authorized_hosts file of your Git user on your server, or into the SSH key panel of your Git host.
|
||||||
|
|
||||||
|
After configuring the host you want to use, SparkleShare downloads the Git project, including, at your option, the commit history. Find the files in ~/SparkleShare.
|
||||||
|
|
||||||
|
Unlike Dolphin's Git integration, SparkleShare is unnervingly invisible. When you make a change, it quietly syncs the change to your remote project. For many people, that is a huge benefit: all the power of Git with none of the maintenance. To me, it is unsettling, because I like to govern what I commit and which branch I use.
|
||||||
|
|
||||||
|
SparkleShare may not be for everyone, but it is a powerful and simple Git solution that shows how different open source projects fit together in perfect harmony to create something unique.
|
||||||
|
|
||||||
|
### Git-cola
|
||||||
|
|
||||||
|
Yet another model of working with Git repositories is less native and more of a monitoring approach; rather than using an integrated application to interact directly with your Git project, you can use a desktop client to monitor changes in your project and deal with each change in whatever way you choose. An advantage to this approach is focus. You might not care about all 125 files in your project when only three of them are actively being worked on, so it is helpful to bring them to the forefront.
|
||||||
|
|
||||||
|
If you thought there were a lot of Git web hosts out there, you haven't seen anything yet. [Git clients for your desktop][1] are a dime-a-dozen. In fact, Git actually ships with an inbuilt graphical Git client. The most cross-platform and most configurable of them all is the open source Git-cola client, written in Python and Qt.
|
||||||
|
|
||||||
|
If you're on Linux, Git-cola may be in your software repository. Otherwise, just download it from the site and install it:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python setup.py install
|
||||||
|
```
|
||||||
|
|
||||||
|
When Git-cola launches, you're given three buttons to open an existing repository, create a new repo, or clone an existing repository.
|
||||||
|
|
||||||
|
Whichever you choose, at some point you end up with a Git repository. Git-cola, and indeed most desktop clients that I've used, don't try to be your interface into your repository; they leave that up to your normal operating system tools. In other words, I might start a repository with Git-cola, but then I would open that repository in Thunar or Emacs to start my work. Leaving Git-cola open as a monitor works quite well, because as you create new files, or change existing ones, they appear in Git-cola's Status panel.
|
||||||
|
|
||||||
|
The default layout of Git-cola is a little non-linear. I prefer to move from left-to-right, and because Git-cola happens to be very configurable, you're welcome to change your layout. I set mine up so that the left-most panel is Status, showing any changes made to my current branch, then to the right, a Diff panel in case I want to review a change, and the Actions panel for quick-access buttons to common tasks, and finally the right-most panel is a Commit panel where I can write commit messages.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
Even if you use a different layout, this is the general flow of Git-cola:
|
||||||
|
|
||||||
|
Changes appear in the Status panel. Right-click a change entry, or select a file and click the Stage button in the Action panel, to stage a file.
|
||||||
|
|
||||||
|
A staged file's icon changes to a green triangle to indicate that it has been both modified and staged. You can unstage a file by right-clicking and selecting Unstage Selected, or by clicking the Unstage button in the Actions panel.
|
||||||
|
|
||||||
|
Review your changes in the Diff panel.
|
||||||
|
|
||||||
|
When you are ready to commit, enter a commit message and click the Commit button.
|
||||||
|
|
||||||
|
There are other buttons in the Actions panel for other common tasks like a git pull or git push. The menus round out the task list, with dedicated actions for branching, reviewing diffs, rebasing, and a lot more.
|
||||||
|
|
||||||
|
I tend to think of Git-cola as a kind of floating panel for my file manager (and I only use Git-cola when Dolphin is not available). On one hand, it's less interactive than a fully integrated and Git-aware file manager, but on the other, it offers practically everything that raw Git does, so it's actually more powerful.
|
||||||
|
|
||||||
|
There are plenty of graphical Git clients. Some are paid software with no source code available, others are viewers only, others attempt to reinvent Git with special terms that are specific to the client ("sync" instead of "push"..?), and still others are platform-specific. Git-Cola has consistently been the easiest to use on any platform, and the one that stays closest to pure Git so that users learn Git whilst using it, and experts feel comfortable with the interface and terminology.
|
||||||
|
|
||||||
|
### Git or graphical?
|
||||||
|
|
||||||
|
I don't generally use graphical tools to access Git; mostly I use the ones I've discussed when helping other people find a comfortable interface for themselves. At the end of the day, though, it comes down to what fits with how you work. I like terminal-based Git because it integrates well with Emacs, but on a day where I'm working mostly in Inkscape, I might naturally fall back to using Git in Dolphin because I'm in Dolphin anyway.
|
||||||
|
|
||||||
|
It's up to you how you use Git; the most important thing to remember is that Git is meant to make your life easier and those crazy ideas you have for your work safer to try out. Get familiar with the way Git works, and then use Git from whatever angle you find works best for you.
|
||||||
|
|
||||||
|
In our next installment, we will learn how to set up and manage a Git server, including user access and management, and running custom scripts.
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/life/16/8/graphical-tools-git
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[1]: https://git-scm.com/downloads/guis
|
||||||
@ -0,0 +1,95 @@
|
|||||||
|
How to Allow Awk to Use Shell Variables – Part 11
|
||||||
|
==================================================
|
||||||
|
|
||||||
|
When we write shell scripts, we normally include other smaller programs or commands such as Awk operations in our scripts. In the case of Awk, we have to find ways of passing some values from the shell to Awk operations.
|
||||||
|
|
||||||
|
This can be done by using shell variables within Awk commands, and in this part of the series, we shall learn how to allow Awk to use shell variables that may contain values we want to pass to Awk commands.
|
||||||
|
|
||||||
|
There possibly two ways you can enable Awk to use shell variables:
|
||||||
|
|
||||||
|
### 1. Using Shell Quoting
|
||||||
|
|
||||||
|
Let us take a look at an example to illustrate how you can actually use shell quoting to substitute the value of a shell variable in an Awk command. In this example, we want to search for a username in the file /etc/passwd, filter and print the user’s account information.
|
||||||
|
|
||||||
|
Therefore, we can write a `test.sh` script with the following content:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
#read user input
|
||||||
|
read -p "Please enter username:" username
|
||||||
|
|
||||||
|
#search for username in /etc/passwd file and print details on the screen
|
||||||
|
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||||
|
```
|
||||||
|
|
||||||
|
Thereafter, save the file and exit.
|
||||||
|
|
||||||
|
Interpretation of the Awk command in the test.sh script above:
|
||||||
|
|
||||||
|
```
|
||||||
|
cat /etc/passwd | awk "/$username/ "' { print $0 }'
|
||||||
|
```
|
||||||
|
|
||||||
|
`"/$username/ "` – shell quoting used to substitute value of shell variable username in Awk command. The value of username is the pattern to be searched in the file /etc/passwd.
|
||||||
|
|
||||||
|
Note that the double quote is outside the Awk script, `‘{ print $0 }’`.
|
||||||
|
|
||||||
|
Then make the script executable and run it as follows:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ chmod +x test.sh
|
||||||
|
$ ./text.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
After running the script, you will be prompted to enter a username, type a valid username and hit Enter. You will view the user’s account details from the /etc/passwd file as below:
|
||||||
|
|
||||||
|
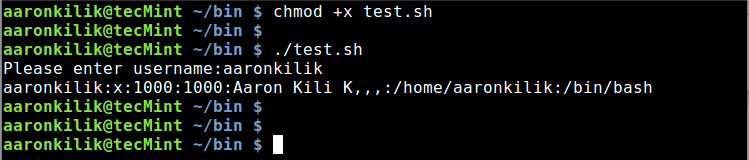
|
||||||
|
>Shell Script to Find Username in Password File
|
||||||
|
|
||||||
|
### 2. Using Awk’s Variable Assignment
|
||||||
|
|
||||||
|
This method is much simpler and better in comparison to method one above. Considering the example above, we can run a simple command to accomplish the job. Under this method, we use the -v option to assign a shell variable to a Awk variable.
|
||||||
|
|
||||||
|
Firstly, create a shell variable, username and assign it the name that we want to search in the /etc/passswd file:
|
||||||
|
|
||||||
|
```
|
||||||
|
username="aaronkilik"
|
||||||
|
```
|
||||||
|
|
||||||
|
Then type the command below and hit Enter:
|
||||||
|
|
||||||
|
```
|
||||||
|
# cat /etc/passwd | awk -v name="$username" ' $0 ~ name {print $0}'
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
>Find Username in Password File Using Awk
|
||||||
|
|
||||||
|
Explanation of the above command:
|
||||||
|
|
||||||
|
- `-v` – Awk option to declare a variable
|
||||||
|
- `username` – is the shell variable
|
||||||
|
- `name` – is the Awk variable
|
||||||
|
Let us take a careful look at `$0 ~ name` inside the Awk script, `' $0 ~ name {print $0}'`. Remember, when we covered Awk comparison operators in Part 4 of this series, one of the comparison operators was value ~ pattern, which means: true if value matches the pattern.
|
||||||
|
|
||||||
|
The `output($0)` of cat command piped to Awk matches the pattern `(aaronkilik)` which is the name we are searching for in /etc/passwd, as a result, the comparison operation is true. The line containing the user’s account information is then printed on the screen.
|
||||||
|
|
||||||
|
### Conclusion
|
||||||
|
|
||||||
|
We have covered an important section of Awk features, that can help us use shell variables within Awk commands. Many times, you will write small Awk programs or commands within shell scripts and therefore, you need to have a clear understanding of how to use shell variables within Awk commands.
|
||||||
|
|
||||||
|
In the next part of the Awk series, we shall dive into yet another critical section of Awk features, that is flow control statements. So stay tunned and let’s keep learning and sharing.
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/use-shell-script-variable-in-awk/?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+tecmint+%28Tecmint%3A+Linux+Howto%27s+Guide%29
|
||||||
|
|
||||||
|
作者:[Aaron Kili][a]
|
||||||
|
译者:[译者ID](https://github.com/译者ID)
|
||||||
|
校对:[校对ID](https://github.com/校对ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: http://www.tecmint.com/author/aaronkili/
|
||||||
@ -1,319 +0,0 @@
|
|||||||
如何用Python和Flask建立部署一个Facebook信使机器人教程
|
|
||||||
==========================================================================
|
|
||||||
|
|
||||||
这是我建立一个简单的Facebook信使机器人的记录。功能很简单,他是一个回显机器人,只是打印回用户写了什么。
|
|
||||||
|
|
||||||
回显服务器类似于服务器的“Hello World”例子。
|
|
||||||
|
|
||||||
这个项目的目的不是建立最好的信使机器人,而是获得建立一个小型机器人和每个事物是如何整合起来的感觉。
|
|
||||||
|
|
||||||
- [技术栈][1]
|
|
||||||
- [机器人架构][2]
|
|
||||||
- [机器人服务器][3]
|
|
||||||
- [部署到 Heroku][4]
|
|
||||||
- [创建 Facebook 应用][5]
|
|
||||||
- [结论][6]
|
|
||||||
|
|
||||||
### 技术栈
|
|
||||||
|
|
||||||
使用到的技术栈:
|
|
||||||
|
|
||||||
- [Heroku][7] 做后端主机。免费层足够这个等级的教程。回显机器人不需要任何种类的数据持久,所以不需要数据库。
|
|
||||||
- [Python][8] 是选择的一个语言。版本选择2.7,虽然它移植到 Pyhton 3 很容易,只需要很少的改动。
|
|
||||||
- [Flask][9] 作为网站开发框架。它是非常轻量的框架,用在小型工程或微服务是完美的。
|
|
||||||
- 最后 [Git][10] 版本控制系统用来维护代码和部署到 Heroku。
|
|
||||||
- 值得一提:[Virtualenv][11]。这个 python 工具是用来创建清洁的 python 库“环境”的,你只用安装必要的需求和最小化的应用封装。
|
|
||||||
|
|
||||||
### 机器人架构
|
|
||||||
|
|
||||||
信使机器人是由一个服务器组成,响应两种请求:
|
|
||||||
|
|
||||||
- GET 请求被用来认证。他们与你注册的 FB 认证码一同被信使发出。
|
|
||||||
- POST 请求被用来真实的通信。传统的工作流是,机器人将通过发送 POST 请求与用户发送的消息数据建立通信,我们将处理它,发送一个我们自己的 POST 请求回去。如果这一个完全成功(返回一个200 OK 状态)我们也响应一个200 OK 码给初始信使请求。
|
|
||||||
这个教程应用将托管到Heroku,他提供了一个很好并且简单的接口来部署应用。如前所述,免费层可以满足这个教程。
|
|
||||||
|
|
||||||
在应用已经部署并且运行后,我们将创建一个 Facebook 应用然后连接它到我们的应用,以便信使知道发送请求到哪,这就是我们的机器人。
|
|
||||||
|
|
||||||
### 机器人服务器
|
|
||||||
|
|
||||||
基本的服务器代码可以在Github用户 [hult(Magnus Hult)][13] 的 [Chatbot][12] 工程上获取,经过一些代码修改只回显消息和一些我遇到的错误更正。最终版本的服务器代码:
|
|
||||||
|
|
||||||
```
|
|
||||||
from flask import Flask, request
|
|
||||||
import json
|
|
||||||
import requests
|
|
||||||
|
|
||||||
app = Flask(__name__)
|
|
||||||
|
|
||||||
# 这需要填写被授予的页面通行令牌
|
|
||||||
# 通过 Facebook 应用创建令牌。
|
|
||||||
PAT = ''
|
|
||||||
|
|
||||||
@app.route('/', methods=['GET'])
|
|
||||||
def handle_verification():
|
|
||||||
print "Handling Verification."
|
|
||||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
|
||||||
print "Verification successful!"
|
|
||||||
return request.args.get('hub.challenge', '')
|
|
||||||
else:
|
|
||||||
print "Verification failed!"
|
|
||||||
return 'Error, wrong validation token'
|
|
||||||
|
|
||||||
@app.route('/', methods=['POST'])
|
|
||||||
def handle_messages():
|
|
||||||
print "Handling Messages"
|
|
||||||
payload = request.get_data()
|
|
||||||
print payload
|
|
||||||
for sender, message in messaging_events(payload):
|
|
||||||
print "Incoming from %s: %s" % (sender, message)
|
|
||||||
send_message(PAT, sender, message)
|
|
||||||
return "ok"
|
|
||||||
|
|
||||||
def messaging_events(payload):
|
|
||||||
"""Generate tuples of (sender_id, message_text) from the
|
|
||||||
provided payload.
|
|
||||||
"""
|
|
||||||
data = json.loads(payload)
|
|
||||||
messaging_events = data["entry"][0]["messaging"]
|
|
||||||
for event in messaging_events:
|
|
||||||
if "message" in event and "text" in event["message"]:
|
|
||||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
|
||||||
else:
|
|
||||||
yield event["sender"]["id"], "I can't echo this"
|
|
||||||
|
|
||||||
|
|
||||||
def send_message(token, recipient, text):
|
|
||||||
"""Send the message text to recipient with id recipient.
|
|
||||||
"""
|
|
||||||
|
|
||||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
|
||||||
params={"access_token": token},
|
|
||||||
data=json.dumps({
|
|
||||||
"recipient": {"id": recipient},
|
|
||||||
"message": {"text": text.decode('unicode_escape')}
|
|
||||||
}),
|
|
||||||
headers={'Content-type': 'application/json'})
|
|
||||||
if r.status_code != requests.codes.ok:
|
|
||||||
print r.text
|
|
||||||
|
|
||||||
if __name__ == '__main__':
|
|
||||||
app.run()
|
|
||||||
```
|
|
||||||
|
|
||||||
让我们分解代码。第一部分是引入所需:
|
|
||||||
|
|
||||||
```
|
|
||||||
from flask import Flask, request
|
|
||||||
import json
|
|
||||||
import requests
|
|
||||||
```
|
|
||||||
|
|
||||||
接下来我们定义两个函数(使用 Flask 特定的 app.route 装饰器),用来处理到我们的机器人的 GET 和 POST 请求。
|
|
||||||
|
|
||||||
```
|
|
||||||
@app.route('/', methods=['GET'])
|
|
||||||
def handle_verification():
|
|
||||||
print "Handling Verification."
|
|
||||||
if request.args.get('hub.verify_token', '') == 'my_voice_is_my_password_verify_me':
|
|
||||||
print "Verification successful!"
|
|
||||||
return request.args.get('hub.challenge', '')
|
|
||||||
else:
|
|
||||||
print "Verification failed!"
|
|
||||||
return 'Error, wrong validation token'
|
|
||||||
```
|
|
||||||
|
|
||||||
当我们创建 Facebook 应用时声明由信使发送的 verify_token 对象。我们必须对自己进行认证。最后我们返回“hub.challenge”给信使。
|
|
||||||
|
|
||||||
处理 POST 请求的函数更有趣
|
|
||||||
|
|
||||||
```
|
|
||||||
@app.route('/', methods=['POST'])
|
|
||||||
def handle_messages():
|
|
||||||
print "Handling Messages"
|
|
||||||
payload = request.get_data()
|
|
||||||
print payload
|
|
||||||
for sender, message in messaging_events(payload):
|
|
||||||
print "Incoming from %s: %s" % (sender, message)
|
|
||||||
send_message(PAT, sender, message)
|
|
||||||
return "ok"
|
|
||||||
```
|
|
||||||
|
|
||||||
当调用我们抓取的消息负载时,使用函数 messaging_events 来中断它并且提取发件人身份和真实发送消息,生成一个 python 迭代器循环遍历。请注意信使发送的每个请求有可能多于一个消息。
|
|
||||||
|
|
||||||
```
|
|
||||||
def messaging_events(payload):
|
|
||||||
"""Generate tuples of (sender_id, message_text) from the
|
|
||||||
provided payload.
|
|
||||||
"""
|
|
||||||
data = json.loads(payload)
|
|
||||||
messaging_events = data["entry"][0]["messaging"]
|
|
||||||
for event in messaging_events:
|
|
||||||
if "message" in event and "text" in event["message"]:
|
|
||||||
yield event["sender"]["id"], event["message"]["text"].encode('unicode_escape')
|
|
||||||
else:
|
|
||||||
yield event["sender"]["id"], "I can't echo this"
|
|
||||||
```
|
|
||||||
|
|
||||||
迭代完每个消息时我们调用send_message函数然后我们执行POST请求回给使用Facebook图形消息接口信使。在这期间我们一直没有回应我们阻塞的原始信使请求。这会导致超时和5XX错误。
|
|
||||||
|
|
||||||
上述的发现错误是中断期间我偶然发现的,当用户发送表情时其实的是当成了 unicode 标识,无论如何 Python 发生了误编码。我们以发送回垃圾结束。
|
|
||||||
|
|
||||||
这个 POST 请求回到信使将不会结束,这会导致发生5xx状态返回给原始的请求,显示服务不可用。
|
|
||||||
|
|
||||||
通过使用`encode('unicode_escape')`转义消息然后在我们发送回消息前用`decode('unicode_escape')`解码消息就可以解决。
|
|
||||||
|
|
||||||
```
|
|
||||||
def send_message(token, recipient, text):
|
|
||||||
"""Send the message text to recipient with id recipient.
|
|
||||||
"""
|
|
||||||
|
|
||||||
r = requests.post("https://graph.facebook.com/v2.6/me/messages",
|
|
||||||
params={"access_token": token},
|
|
||||||
data=json.dumps({
|
|
||||||
"recipient": {"id": recipient},
|
|
||||||
"message": {"text": text.decode('unicode_escape')}
|
|
||||||
}),
|
|
||||||
headers={'Content-type': 'application/json'})
|
|
||||||
if r.status_code != requests.codes.ok:
|
|
||||||
print r.text
|
|
||||||
```
|
|
||||||
|
|
||||||
### 部署到 Heroku
|
|
||||||
|
|
||||||
一旦代码已经建立成我想要的样子时就可以进行下一步。部署应用。
|
|
||||||
|
|
||||||
当然,但是怎么做?
|
|
||||||
|
|
||||||
我之前已经部署了应用到 Heroku (主要是 Rails)然而我总是遵循某种教程,所以配置已经创建。在这种情况下,尽管我必须从头开始。
|
|
||||||
|
|
||||||
幸运的是有官方[Heroku文档][14]来帮忙。这篇文章很好地说明了运行应用程序所需的最低限度。
|
|
||||||
|
|
||||||
长话短说,我们需要的除了我们的代码还有两个文件。第一个文件是“requirements.txt”他列出了运行应用所依赖的库。
|
|
||||||
|
|
||||||
需要的第二个文件是“Procfile”。这个文件通知 Heroku 如何运行我们的服务。此外这个文件最低限度如下:
|
|
||||||
|
|
||||||
>web: gunicorn echoserver:app
|
|
||||||
|
|
||||||
heroku解读他的方式是我们的应用通过运行 echoserver.py 开始并且应用将使用 gunicorn 作为网站服务器。我们使用一个额外的网站服务器是因为与性能相关并在上面的Heroku文档里解释了:
|
|
||||||
|
|
||||||
>Web 应用程序并发处理传入的HTTP请求比一次只处理一个请求的Web应用程序,更有效利地用动态资源。由于这个原因,我们建议使用支持并发请求的 web 服务器处理开发和生产运行的服务。
|
|
||||||
|
|
||||||
>Django 和 Flask web 框架特性方便内建 web 服务器,但是这些阻塞式服务器一个时刻只处理一个请求。如果你部署这种服务到 Heroku上,你的动态资源不会充分使用并且你的应用会感觉迟钝。
|
|
||||||
|
|
||||||
>Gunicorn 是一个纯 Python HTTP 的 WSGI 引用服务器。允许你在单独一个动态资源内通过并发运行多 Python 进程的方式运行任一 Python 应用。它提供了一个完美性能,弹性,简单配置的平衡。
|
|
||||||
|
|
||||||
回到我们提到的“requirements.txt”文件,让我们看看它如何结合 Virtualenv 工具。
|
|
||||||
|
|
||||||
在任何时候,你的开发机器也许有若干已安装的 python 库。当部署应用时你不想这些库被加载因为很难辨认出你实际使用哪些库。
|
|
||||||
|
|
||||||
Virtualenv 创建一个新的空白虚拟环境,因此你可以只安装你应用需要的库。
|
|
||||||
|
|
||||||
你可以检查当前安装使用哪些库的命令如下:
|
|
||||||
|
|
||||||
```
|
|
||||||
kostis@KostisMBP ~ $ pip freeze
|
|
||||||
cycler==0.10.0
|
|
||||||
Flask==0.10.1
|
|
||||||
gunicorn==19.6.0
|
|
||||||
itsdangerous==0.24
|
|
||||||
Jinja2==2.8
|
|
||||||
MarkupSafe==0.23
|
|
||||||
matplotlib==1.5.1
|
|
||||||
numpy==1.10.4
|
|
||||||
pyparsing==2.1.0
|
|
||||||
python-dateutil==2.5.0
|
|
||||||
pytz==2015.7
|
|
||||||
requests==2.10.0
|
|
||||||
scipy==0.17.0
|
|
||||||
six==1.10.0
|
|
||||||
virtualenv==15.0.1
|
|
||||||
Werkzeug==0.11.10
|
|
||||||
```
|
|
||||||
|
|
||||||
注意:pip 工具应该已经与 Python 一起安装在你的机器上。
|
|
||||||
|
|
||||||
如果没有,查看[官方网站][15]如何安装他。
|
|
||||||
|
|
||||||
现在让我们使用 Virtualenv 来创建一个新的空白环境。首先我们给我们的工程创建一个新文件夹,然后进到目录下:
|
|
||||||
|
|
||||||
```
|
|
||||||
kostis@KostisMBP projects $ mkdir echoserver
|
|
||||||
kostis@KostisMBP projects $ cd echoserver/
|
|
||||||
kostis@KostisMBP echoserver $
|
|
||||||
```
|
|
||||||
|
|
||||||
现在来创建一个叫做 echobot 新的环境。运行下面的 source 命令激活它,然后使用 pip freeze 检查,我们能看到现在是空的。
|
|
||||||
|
|
||||||
```
|
|
||||||
kostis@KostisMBP echoserver $ virtualenv echobot
|
|
||||||
kostis@KostisMBP echoserver $ source echobot/bin/activate
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
|
||||||
(echobot) kostis@KostisMBP echoserver $
|
|
||||||
```
|
|
||||||
|
|
||||||
我们可以安装需要的库。我们需要是 flask,gunicorn,和 requests,他们被安装完我们就创建 requirements.txt 文件:
|
|
||||||
|
|
||||||
```
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip install flask
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip install gunicorn
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip install requests
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip freeze
|
|
||||||
click==6.6
|
|
||||||
Flask==0.11
|
|
||||||
gunicorn==19.6.0
|
|
||||||
itsdangerous==0.24
|
|
||||||
Jinja2==2.8
|
|
||||||
MarkupSafe==0.23
|
|
||||||
requests==2.10.0
|
|
||||||
Werkzeug==0.11.10
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ pip freeze > requirements.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
毕竟上文已经被运行,我们用 python 代码创建 echoserver.py 文件然后用之前提到的命令创建 Procfile,我们应该以下面的文件/文件夹结束:
|
|
||||||
|
|
||||||
```
|
|
||||||
(echobot) kostis@KostisMBP echoserver $ ls
|
|
||||||
Procfile echobot echoserver.py requirements.txt
|
|
||||||
```
|
|
||||||
|
|
||||||
我们现在准备上传到 Heroku。我们需要做两件事。第一是安装 Heroku toolbet 如果你还没安装到你的系统中(详细看[Heroku][16])。第二通过[网页接口][17]创建一个新的 Heroku 应用。
|
|
||||||
|
|
||||||
点击右上的大加号然后选择“Create new app”。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/
|
|
||||||
|
|
||||||
作者:[Konstantinos Tsaprailis][a]
|
|
||||||
译者:[wyangsun](https://github.com/wyangsun)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://github.com/kostistsaprailis
|
|
||||||
[1]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#tech-stack
|
|
||||||
[2]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#bot-architecture
|
|
||||||
[3]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#the-bot-server
|
|
||||||
[4]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#deploying-to-heroku
|
|
||||||
[5]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#creating-the-facebook-app
|
|
||||||
[6]: http://tsaprailis.com/2016/06/02/How-to-build-and-deploy-a-Facebook-Messenger-bot-with-Python-and-Flask-a-tutorial/#conclusion
|
|
||||||
[7]: https://www.heroku.com
|
|
||||||
[8]: https://www.python.org
|
|
||||||
[9]: http://flask.pocoo.org
|
|
||||||
[10]: https://git-scm.com
|
|
||||||
[11]: https://virtualenv.pypa.io/en/stable
|
|
||||||
[12]: https://github.com/hult/facebook-chatbot-python
|
|
||||||
[13]: https://github.com/hult
|
|
||||||
[14]: https://devcenter.heroku.com/articles/python-gunicorn
|
|
||||||
[15]: https://pip.pypa.io/en/stable/installing
|
|
||||||
[16]: https://toolbelt.heroku.com
|
|
||||||
[17]: https://dashboard.heroku.com/apps
|
|
||||||
|
|
||||||
|
|
||||||
@ -3,51 +3,51 @@
|
|||||||
|
|
||||||
我相信,Linux 最好也是最坏的事情,就是内核空间和用户空间之间的巨大差别。
|
我相信,Linux 最好也是最坏的事情,就是内核空间和用户空间之间的巨大差别。
|
||||||
|
|
||||||
但是如果抛开这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 已经拥有世界上最大数量的用户,和最大范围的应用。尽管大多数用户并不知道,当他们进行谷歌搜索,或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(苹果在他们的电脑产品中使用 BSD 发行版)。
|
但是如果没有这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 的使用范围在世界上是最大的,而这些应用又有着世界上最大的用户群——尽管大多数用户并不知道,当他们进行谷歌搜索或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(即在他们的电脑产品中使用 BSD 的技术)(注:Linux 获得成功后,Apple 曾与 Linus 协商使用 Linux 核心作为 Apple 电脑的操作系统并帮助开发的事宜,但遭到拒绝。因此,Apple 转向使用许可证更为宽松的 BSD 。)。
|
||||||
|
|
||||||
不用担心,用户空间是 Linux 内核开发中的一个特性,并不是一个缺陷。正如 Linus 在 2003 的极客巡航中提到的那样,“”我只做内核相关技术……我并不知道内核之外发生的事情,而且我并不关心。我只关注内核部分发生的事情。” 在 Andrew Morton 在多年之后的另一个极客巡航上给我上了另外的一课,我写到:
|
不(需要)关注用户空间是 Linux 内核开发中的一个特点而非缺陷。正如 Linus 在 2003 的极客巡航中提到的那样,“我只做内核相关技术……我并不知道内核之外发生的事情,而且我并不关心。我只关注内核部分发生的事情。” 多年之后的另一个极客巡航上, Andrew Morton 给我上了另外的一课,这之后我写道:
|
||||||
|
|
||||||
> 内核空间是 Linux 核心存在的地方。用户空间是使用 Linux 时使用的空间,和其他的自然的建筑材料一样。内核空间和用户空间的区别,和自然材料和人类从中生产的人造材料的区别很类似。
|
> Linux 存在于内核空间,而在用户空间中被使用,和其他的自然的建筑材料一样。内核空间和用户空间的区别,和自然材料与人类从中生产的人造材料的区别很类似。
|
||||||
|
|
||||||
这个区别的自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加我们社区团体的数量,我希望指出两件事情。第一件已经非常火热,另外一件可能热门。
|
这个区别的自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加哪怕一点我们社区团体的规模,我希望指出两件事情。第一件已经非常火了,另外一件可能会火起来。
|
||||||
|
|
||||||
第一件事情就是 [blockchain][1],出自著名的分布式货币,比特币之手。当你正在阅读这篇文章的同时,对 blockchain 的[兴趣已经直线上升][2]。
|
第一件事情就是 [blockchain][1],出自著名的分布式货币——比特币之手。当你正在阅读这篇文章的同时,人们对 blockchain 的[关注度正在直线上升][2]。
|
||||||
|
|
||||||

|

|
||||||
> 图1. 谷歌 Blockchain 的趋势
|
> 图1. Blockchain 的谷歌搜索趋势
|
||||||
|
|
||||||
第二件事就是自主身份。为了解释这个,让我先来问你,你是谁或者你是什么。
|
第二件事就是自主身份。为了解释这个概念,让我先来问你:你是谁,你来自哪里?
|
||||||
|
|
||||||
如果你从你的雇员,你的医生,或者车管所,Facebook,Twitter 或者谷歌上得到答案,你就会发现他们每一个都有明显的社会性: 为了他们自己的便利,在进入这些机构的控制前,他们都会添加自己的命名空间。正如 Timothy Ruff 在 [Evernym][3] 中解释的,”你并不为了他们而存在,你只为了自己的身份而活。“。你的身份可能会变化,但是唯一不变的就是控制着身份的人,也就是这个组织。
|
如果你从你的雇员、你的医生或者车管所,Facebook、Twitter 或者谷歌上得到答案,你就会发现它们都是行政身份——机构完全以自己的便利为原因设置这些身份和职位。正如 [Evernym][3] 的 Timothy Ruff 所说,“你并不因组织而存在,但你的身份却因此存在。”身份是个因变量。自变量——即控制着身份的变量——是(你所在的)组织。
|
||||||
|
|
||||||
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
|
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
|
||||||
|
|
||||||
第一个解释这个的人,据我所知,是 [Devon Loffreto][4]。在 2012 年 2 月,在的他的博客中,他写道 ”什么是' Sovereign Source Authority'?“,[Moxy Tongue][5]。在他发表在 2016 年 2 月的 "[Self-Sovereign Identity][6]" 中,他写道:
|
据我所知,第一个解释这个的人是 [Devon Loffreto][4]。在 2012 年 2 月,他在博客[Moxy Tongue][5] 中写道:“什么是'Sovereign Source Authority'?”。在发表于 2016 年 2 月的 "[Self-Sovereign Identity][6]" 中,他写道:
|
||||||
|
|
||||||
> 自主身份必须是独立个人提出的,并且不包含社会因素。。。自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且 依旧可以同各种形式的人类社会保持联系。
|
> 自主身份必须是独立个人提出的,并且不包含社会因素……自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且依旧可以同各种形式的人类社会保持联系。
|
||||||
|
|
||||||
为了将这个发布在 Linux 条款中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常偶然的事件。举个例子,我自己的身份包括:
|
将这个概念放在 Linux 领域中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常正从的事件。举个例子,我自己的身份包括:
|
||||||
|
|
||||||
- David Allen Searls,我父母会这样叫我。
|
- David Allen Searls,我父母会这样叫我。
|
||||||
- David Searls,正式场合下我会这么称呼自己。
|
- David Searls,正式场合下我会这么称呼自己。
|
||||||
- Dave,我的亲戚和好朋友会这么叫我。
|
- Dave,我的亲戚和好朋友会这么叫我。
|
||||||
- Doc,大多数人会这么叫我。
|
- Doc,大多数人会这么叫我。
|
||||||
|
|
||||||
在上述提到的身份认证中,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls(我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
作为承认以上称呼的自主身份来源,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls(我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
|
||||||
|
|
||||||
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我依旧假设我有时会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
|
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我想会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
|
||||||
|
|
||||||
现在,最简单的方式来联系账号,就是通过 "Log in with Facebook" 或者 "Login in with Twitter" 来进行身份认证。在这些例子中,我们中的每一个甚至并不是真正意义上的自己,或者某种程度上是我们希望被大家认识的自己(如果我们希望被其他人认识的话)。
|
现在,最简单的方式来联系账号,就是通过 "Log in with Facebook" 或者 "Login in with Twitter" 来进行身份认证。在这种情况下,我们中的每一个甚至并不是真正意义上的自己,甚至(如果我们希望被其他人认识的话)缺乏对其他实体如何认识我们的控制。
|
||||||
|
|
||||||
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 "监视资本主义",她如此说道:
|
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 "监视资本主义",她如此说道:
|
||||||
|
|
||||||
>...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。真相就是,被热衷于监视的资本家开发监视系统,是每一个国家安全机构真正的恶。
|
>...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。讲道理,热衷于监视的资本家开发的监视系统是每一个国家安全机构都渴望的。
|
||||||
|
|
||||||
然后,她问道,”我们怎样才能保护自己远离他人的影响?“
|
然后,她问道,”我们怎样才能保护自己远离他人的影响?“
|
||||||
|
|
||||||
我建议使用自主身份。我相信这是我们唯一的方式,来保证我们从一个被监视的世界中脱离出来。以此为基础,我们才可以完全无顾忌的和社会,政治,商业上的人交流。
|
我建议使用自主身份。我相信这是我们唯一的既可以保证我们从监视中逃脱、又可以使我们有一个有序的世界的办法。以此为基础,我们才可以完全无顾忌地和社会,政治,商业上的人交流。
|
||||||
|
|
||||||
我在五月联合国举行的 [ID2020][7] 会议中总结了这个临时的结论。很高兴,Devon Loffreto 也在那,自从他在2013年被选为作为轮值主席之后。这就是[我曾经写的一些文章][8],引用了 Devon 的早期博客(比如上面的原文)。
|
我在五月联合国举行的 [ID2020][7] 会议中总结了这个临时的结论。很高兴,Devon Loffreto 也在那,他于 2013 年推动了自主身份的创立。这是[我那时写的一些文章][8],引用了 Devon 的早期博客(比如上面的原文)。
|
||||||
|
|
||||||
这有三篇这个领域的准则:
|
这有三篇这个领域的准则:
|
||||||
|
|
||||||
@ -55,14 +55,14 @@
|
|||||||
- "[System or Human First][10]" - Devon Loffreto.
|
- "[System or Human First][10]" - Devon Loffreto.
|
||||||
- "[The Path to Self-Sovereign Identity][11]" - Christopher Allen.
|
- "[The Path to Self-Sovereign Identity][11]" - Christopher Allen.
|
||||||
|
|
||||||
从Evernym 的简要说明中,[digi.me][12], [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为”current model“) 的对比结果,显示在图二中。
|
从Evernym 的简要说明中,[digi.me][12], [iRespond][13] 和 [Respect Network][14] 也被包括在内。自主身份和社会身份 (也被称为“current model”) 的对比结果,显示在图二中。
|
||||||
|
|
||||||

|

|
||||||
> 图 2. Current Model 身份 vs. 自主身份
|
> 图 2. Current Model 身份 vs. 自主身份
|
||||||
|
|
||||||
为此而生的[平台][15]就是 Sovrin,也被解释为“”依托于先进技术的,授权机制的,分布式货币上的一个完全开源,基于标识,声明身份的图平台“ 同时,这也有一本[白皮书][16]。代号为 [plenum][17],而且它在 Github 上。
|
Sovrin 就是为此而生的[平台][15],它阐述自己为一个“依托于先进、专用、经授权、分布式平台的,完全开源、基于标识的身份声明图平台”。同时,这也有一本[白皮书][16]。它的代码名为 [plenum][17],并且公开在 Github 上。
|
||||||
|
|
||||||
在这-或者其他类似的地方-我们就可以在用户空间中重现我们在上一个的四分之一世纪中已经做过的事情。
|
在这里——或者其他类似的地方——我们就可以在用户空间中重现我们在过去 25 年中在内核空间做过的事情。
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -70,8 +70,8 @@
|
|||||||
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
via: https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space
|
||||||
|
|
||||||
作者:[Doc Searls][a]
|
作者:[Doc Searls][a]
|
||||||
译者:[译者ID](https://github.com/MikeCoder)
|
译者:[MikeCoder](https://github.com/MikeCoder)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[PurlingNayuki](https://github.com/PurlingNayuki)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
129
translated/tech/20160715 bc - Command line calculator.md
Normal file
129
translated/tech/20160715 bc - Command line calculator.md
Normal file
@ -0,0 +1,129 @@
|
|||||||
|
bc : 一个命令行计算器
|
||||||
|
============================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
假如你运行在一个图形桌面环境中,当你需要一个计算器时,你可能只需要一路进行点击便可以找到一个计算器。例如,Fedora 工作站中就已经包含了一个名为 `Calculator` 的工具。它有着几种不同的操作模式,例如,你可以进行复杂的数学运算或者金融运算。但是,你知道吗,命令行也提供了一个与之相似的名为 `bc` 的工具?
|
||||||
|
|
||||||
|
`bc` 工具可以为你提供你期望一个科学计算器、金融计算器或者是简单的计算器所能提供的所有功能。另外,假如需要的话,它还可以从命令行中被脚本化。这使得当你需要做复杂的数学运算时,你可以在 shell 脚本中使用它。
|
||||||
|
|
||||||
|
因为 bc 被其他的系统软件所使用,例如 CUPS 打印服务,它可能已经在你的 Fedora 系统中被安装了。你可以使用下面这个命令来进行检查:
|
||||||
|
|
||||||
|
```
|
||||||
|
dnf list installed bc
|
||||||
|
```
|
||||||
|
|
||||||
|
假如因为某些原因你没有在上面命令的输出中看到它,你可以使用下面的这个命令来安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo dnf install bc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 用 bc 做一些简单的数学运算
|
||||||
|
|
||||||
|
使用 bc 的一种方式是进入它自己的 shell。在那里你可以在一行中做许多次计算。但在你键入 bc 后,首先出现的是有关这个程序的警告:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ bc
|
||||||
|
bc 1.06.95
|
||||||
|
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
|
||||||
|
This is free software with ABSOLUTELY NO WARRANTY.
|
||||||
|
For details type `warranty'.
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你可以按照每行一个输入运算式或者命令了:
|
||||||
|
|
||||||
|
```
|
||||||
|
1+1
|
||||||
|
```
|
||||||
|
|
||||||
|
bc 会回答上面计算式的答案是:
|
||||||
|
|
||||||
|
```
|
||||||
|
2
|
||||||
|
```
|
||||||
|
|
||||||
|
在这里你还可以执行其他的命令。你可以使用 加(+)、减(-)、乘(*)、除(/)、圆括号、指数符号(^) 等等。请注意 bc 同样也遵循所有约定俗成的运算规定,例如运算的先后顺序。你可以试试下面的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
(4+7)*2
|
||||||
|
4+7*2
|
||||||
|
```
|
||||||
|
|
||||||
|
若要离开 bc 可以通过按键组合 `Ctrl+D` 来发送 “输入结束”信号给 bc 。
|
||||||
|
|
||||||
|
使用 bc 的另一种方式是使用 `echo` 命令来传递运算式或命令。下面这个示例类似于计算器中的 "Hello, world" 例子,使用 shell 的管道函数(|) 来将 `echo` 的输出传入 `bc` 中:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo '1+1' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 shell 的管道,你可以发送不止一个运算操作,你需要使用分号来分隔不同的运算。结果将在不同的行中返回。
|
||||||
|
|
||||||
|
```
|
||||||
|
echo '1+1; 2+2' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 精度
|
||||||
|
|
||||||
|
在某些计算中,bc 会使用精度的概念,即小数点后面的数字位数。默认的精度是 0。除法操作总是使用精度的设定。所以,如果你没有设置精度,有可能会带来意想不到的答案:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo '3/2' | bc
|
||||||
|
echo 'scale=3; 3/2' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
乘法使用一个更复杂的精度选择机制:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo '3*2' | bc
|
||||||
|
echo '3*2.0' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
同时,加法和减法的相关运算则与之相似:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo '7-4.15' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
### 其他进制系统
|
||||||
|
|
||||||
|
bc 的另一个有用的功能是可以使用除 十进制以外的其他计数系统。例如,你可以轻松地做十六进制或二进制的数学运算。可以使用 `ibase` 和 `obase` 命令来分别设定输入和输出的进制系统。需要记住的是一旦你使用了 `ibase`,之后你输入的任何数字都将被认为是在新定义的进制系统中。
|
||||||
|
|
||||||
|
要做十六进制数到十进制数的转换或运算,你可以使用类似下面的命令。请注意大于 9 的十六进制数必须是大写的(A-F):
|
||||||
|
|
||||||
|
```
|
||||||
|
echo 'ibase=16; A42F' | bc
|
||||||
|
echo 'ibase=16; 5F72+C39B' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
若要使得结果是十六进制数,则需要设定 `obase` :
|
||||||
|
|
||||||
|
```
|
||||||
|
echo 'obase=16; ibase=16; 5F72+C39B' | bc
|
||||||
|
```
|
||||||
|
|
||||||
|
下面是一个小技巧。假如你在 shell 中做这些运算,怎样才能使得输入重新为十进制数呢?答案是使用 `ibase` 命令,但你必须设定它为在当前进制中与十进制中的 10 等价的值。例如,假如 `ibase` 被设定为十六进制,你需要输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
ibase=A
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦你执行了上面的命令,所有输入的数字都将是十进制的了,接着你便可以输入 `obase=10` 来重置输出的进制系统。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
上面所提到的只是 bc 所能做到的基础。它还允许你为某些复杂的运算和程序定义函数、变量和循环结构。你可以在你的系统中将这些程序保存为文本文件以便你在需要的时候使用。你还可以在网上找到更多的资源,它们提供了更多的例子以及额外的函数库。快乐地计算吧!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/
|
||||||
|
|
||||||
|
作者:[Paul W. Frields][a]
|
||||||
|
译者:[FSSlc](https://github.com/FSSlc)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/pfrields/
|
||||||
|
[1]: http://phodd.net/gnu-bc/
|
||||||
@ -1,199 +0,0 @@
|
|||||||
|
|
||||||
|
|
||||||
建立你的第一个仓库
|
|
||||||
======================================
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
现在是时候学习怎样创建你自己的仓库了,还有怎样增加文件和完成提交。
|
|
||||||
|
|
||||||
在本系列前面文章的安装过程中,你已经学习了作为一个目标用户怎样与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,然后克隆了仓库,Git 走进了你的生活。学习怎样和 Git 进行交互并不像你想的那样困难,或许你并不确信现在是否应该使用 Git 完成你的工作。
|
|
||||||
|
|
||||||
|
|
||||||
Git 被认为是选择大多软件项目的工具,它不仅能够完成大多软件项目的工作;它也能管理你杂乱项目的列表(如果他们不重要,也可以这样说!),你的配置文件,一个日记,项目进展日志,甚至源代码!
|
|
||||||
|
|
||||||
使用 Git 是很有必要的,毕竟,你肯定有因为一个备份文件不能够辨认出版本信息而烦恼的时候。
|
|
||||||
|
|
||||||
你不使用 Git,它也就不会为你工作,或者也可以把 Git 理解为“没有任何推送就像源头指针一样”【译注: HEAD 可以理解为“头指针”,是当前工作区的“基础版本”,当执行提交时, HEAD 指向的提交将作为新提交的父提交。】。我保证,你很快就会对 Git 有所了解 。
|
|
||||||
|
|
||||||
|
|
||||||
### 类比于录音
|
|
||||||
|
|
||||||
|
|
||||||
我们更喜欢谈论快照上的图像,因为很多人都可以通过一个相册很快辨认出每个照片上特有的信息。这可能很有用,然而,我认为 Git 更像是在进行声音的记录。
|
|
||||||
|
|
||||||
传统的录音机,可能你对于它的部件不是很清楚:它包含转轴并且正转或反转,使用磁带保存声音波形,通过放音头记录声音并保存到磁带上然后播放给收听者。
|
|
||||||
|
|
||||||
|
|
||||||
除了往前退磁带,你也可以把磁带多绕几圈到磁带前面的部分,或快进跳过前面的部分到最后。
|
|
||||||
|
|
||||||
想象一下 70 年代的磁带录制的声音。你可能想到那会正在反复练习一首歌直到非常完美,它们最终被记录下来了。起初,你记录了鼓声,低音,然后是吉他声,还有其他的声音。每次你录音,工作人员都会把磁带重绕并设置为环绕模式,这样在你演唱的时候录音磁带就会播放之前录制的声音。如果你是低音歌唱,你唱歌的时候就需要把有鼓声的部分作为背景音乐,然后就是吉他声、鼓声、低音(和牛铃声【译注:一种打击乐器,状如四棱锥。】)等等。在每一环,你完成了整个部分,到了下一环,工作人员就开始在磁带上制作你的演唱作品。
|
|
||||||
|
|
||||||
|
|
||||||
你也可以拷贝或换出整个磁带,这是你需要继续录音并且进行多次混合的时候需要做的。
|
|
||||||
|
|
||||||
|
|
||||||
现在我希望对于上述 70 年代的录音工作的描述足够生动,我们就可以把 Git 的工作想象成一个录音磁带了。
|
|
||||||
|
|
||||||
|
|
||||||
### 新建一个 Git 仓库
|
|
||||||
|
|
||||||
|
|
||||||
首先得为我们的虚拟的录音机买一些磁带。在 Git 术语中,这就是仓库;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
|
|
||||||
|
|
||||||
任何目录都可以是一个 Git 仓库,但是在开始的时候需要进行一次更新。需要下面三个命令:
|
|
||||||
|
|
||||||
|
|
||||||
- 创建目录(如果你喜欢的话,你可以在你的 GUI 文件管理器里面完成。)
|
|
||||||
- 在终端里查看目录。
|
|
||||||
- 初始化这个目录使它可以被 Git管理。
|
|
||||||
|
|
||||||
|
|
||||||
特别是运行如下代码:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ mkdir ~/jupiter # 创建目录
|
|
||||||
$ cd ~/jupiter # 进入目录
|
|
||||||
$ git init . # 初始化你的新 Git 工作区
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
在这个例子中,文件夹 jupiter 是空的但却成为了你的 Git 仓库。
|
|
||||||
|
|
||||||
有了仓库接下来的事件就按部就班了。你可以克隆项目仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建可交替时间线,然后剩下的工作 Git 就都能正常完成了。
|
|
||||||
|
|
||||||
|
|
||||||
在 Git 仓库里面工作和在任何目录里面工作都是一样的;在仓库中新建文件,复制文件,保存文件。你可以像平常一样完成工作;Git 并不复杂,除非你把它想复杂了。
|
|
||||||
|
|
||||||
在本地的 Git 仓库中,一个文件可以有下面这三种状态:
|
|
||||||
- 未跟踪文件:你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的提交任务(提交暂存区,stage)中。
|
|
||||||
- 已跟踪文件:已经加入到 Git 暂存区的文件。
|
|
||||||
- 暂存区文件:存在于暂存区的文件已经加入到 Git 的提交队列中。
|
|
||||||
|
|
||||||
|
|
||||||
任何你新加入到 Git 仓库中的文件都是未跟踪文件。文件还保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要提交的文件,就像我们的录音机,如果你没有打开录音机;乐队开始演唱了,但是录音机并没有准备录音。
|
|
||||||
|
|
||||||
不用担心,Git 会告诉你存在的问题并提示你怎么解决:
|
|
||||||
```
|
|
||||||
$ echo "hello world" > foo
|
|
||||||
$ git status
|
|
||||||
位于您当前工作的分支 master 上
|
|
||||||
未跟踪文件:
|
|
||||||
(使用 "git add <file>" 更新要提交的内容)
|
|
||||||
foo
|
|
||||||
没有任何提交任务,但是存在未跟踪文件(用 "git add" 命令加入到提交任务)
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
|
|
||||||
|
|
||||||
### 不使用 Git 命令进行 Git 操作
|
|
||||||
|
|
||||||
|
|
||||||
在 GitHub 或 GitLab(译注:GitLab 是一个用于仓库管理系统的开源项目。使用Git作为代码管理工具,并在此基础上搭建起来的web服务。)上创建一个仓库大多是使用鼠标点击完成的。这不会很难,你单击 New Repository 这个按钮就会很快创建一个仓库。
|
|
||||||
|
|
||||||
在仓库中新建一个 README 文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库基于什么项目,更有用的是通过 README 文件可以确定克隆的是否为一个非空仓库。
|
|
||||||
|
|
||||||
|
|
||||||
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就不简单了,为了进行用户验证你必须有一个 SSH 秘钥。如果你使用 Linux 系统,通过下面的命令可以生成一个秘钥:
|
|
||||||
```
|
|
||||||
$ ssh-keygen
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
复制纯文本文件里的秘钥。你可以使用一个文本编辑器打开它,也可以使用 cat 命令:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ cat ~/.ssh/id_rsa.pub
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
现在把你的秘钥拷贝到 [GitHub SSH 配置文件][1] 中,或者 [GitLab 配置文件[2]。
|
|
||||||
|
|
||||||
如果你通过使用 SSH 模式克隆了你的项目,就可以在你的仓库开始工作了。
|
|
||||||
|
|
||||||
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来克隆仓库。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
### 跟踪文件
|
|
||||||
|
|
||||||
命令 git status 的输出会告诉你如果你想让 git 跟踪一个文件,你必须使用命令 git add 把它加入到提交任务中。这个命令把文件存在了暂存区,暂存区存放的都是等待提交的文件,或者把仓库保存为一个快照。git add 命令的最主要目的是为了区分你已经保存在仓库快照里的文件,还有新建的或你想提交的临时文件,至少现在,你都不用为它们之间的不同之处而费神了。
|
|
||||||
|
|
||||||
类比大型录音机,这个动作就像打开录音机开始准备录音一样。你可以按已经录音的录音机上的 pause 按钮来完成推送,或者按下重置按钮等待开始跟踪下一个文件。
|
|
||||||
|
|
||||||
如果你把文件加入到提交任务中,Git 会自动标识为跟踪文件:
|
|
||||||
|
|
||||||
```
|
|
||||||
$ git add foo
|
|
||||||
$ git status
|
|
||||||
位于您当前工作的分支 master 上
|
|
||||||
下列修改将被提交:
|
|
||||||
(使用 "git reset HEAD <file>..." 将下列改动撤出提交任务)
|
|
||||||
新增文件:foo
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
加入文件到提交任务中并不会生成一个记录。这仅仅是为了之后方便记录而把文件存放到暂存区。在你把文件加入到提交任务后仍然可以修改文件;文件会被标记为跟踪文件并且存放到暂存区,所以你在最终提交之前都可以改动文件或撤出提交任务(但是请注意:你并没有记录文件,所以如果你完全改变了文件就没有办法撤销了,因为你没有记住最终修改的准确时间。)。
|
|
||||||
|
|
||||||
如果你决定不把文件记录到 Git 历史列表中,那么你可以撤出提交任务,在 Git 中是这样做的:
|
|
||||||
```
|
|
||||||
$ git reset HEAD foo
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
这实际上就是删除了录音机里面的录音,你只是在工作区转了一圈而已而已。
|
|
||||||
|
|
||||||
### 大型提交
|
|
||||||
|
|
||||||
有时候,你会需要完成很多提交;我们以录音机类比,这就好比按下录音键并最终按下保存键一样。
|
|
||||||
|
|
||||||
在一个项目从建立到完成,你会按记录键无数次。比如,如果你通过你的方式使用一个新的 Python 工具包并且最终实现了窗口展示,然后你就很肯定的提交了文件,但是不可避免的会发生一些错误,现在你却不能撤销你的提交操作了。
|
|
||||||
|
|
||||||
一次提交会记录仓库中所有的暂存区文件。Git 只记录加入到提交任务中的文件,也就是说在过去某个时刻你使用 git add 命令加入到暂存区的所有文件。还有从先前的提交开始被改动的文件。如果没有其他的提交,所有的跟踪文件都包含在这次提交中,因为在浏览 Git 历史点的时候,它们没有存在于仓库中。
|
|
||||||
|
|
||||||
完成一次提交需要运行下面的命令:
|
|
||||||
```
|
|
||||||
$ git commit -m 'My great project, first commit.'
|
|
||||||
```
|
|
||||||
|
|
||||||
这就保存了所有需要在仓库中提交的文件(或者,如果你说到 Gallifreyan【译注:英国电视剧《神秘博士》里的时间领主使用的一种优雅的语言,】,它们可能就是“固定的时间点” )。你不仅能看到整个提交记录,还能通过 git log 命令查看修改日志找到提交时的版本号:
|
|
||||||
```
|
|
||||||
$ git log --oneline
|
|
||||||
55df4c2 My great project, first commit.
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
如果想浏览更多信息,只需要使用不带 --oneline 选项的 git log 命令。
|
|
||||||
|
|
||||||
|
|
||||||
在这个例子中提交时的版本号是 55df4c2。它被叫做 commit hash(译注:一个SHA-1生成的哈希码,用于表示一个git commit对象。),它表示着刚才你的提交包含的所有改动,覆盖了先前的记录。如果你想要“倒回”到你的提交历史点上就可以用这个 commit hash 作为依据。
|
|
||||||
|
|
||||||
你可以把 commit hash 想象成一个声音磁带上的 [SMPTE timecode][3],或者再夸张一点,这就是好比一个黑胶唱片上两首不同的歌之间的不同点,或是一个 CD 上的轨段编号。
|
|
||||||
|
|
||||||
|
|
||||||
你在很久前改动了文件并且把它们加入到提交任务中,最终完成提交,这就会生成新的 commit hashes,每个 commit hashes 标示的历史点都代表着你的产品不同的版本。
|
|
||||||
|
|
||||||
|
|
||||||
这就是 Charlie Brown 把 Git 称为版本控制系统的原因。
|
|
||||||
|
|
||||||
在接下来的文章中,我们将会讨论你需要知道的关于 Git HEAD 的一切,我们不准备讨论关于 Git 的提交历史问题。基本不会提及,但是你可能会需要了解它(或许你已经有所了解?)。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/life/16/7/creating-your-first-git-repository
|
|
||||||
|
|
||||||
作者:[Seth Kenlon][a]
|
|
||||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/seth
|
|
||||||
[1]: https://github.com/settings/keys
|
|
||||||
[2]: https://gitlab.com/profile/keys
|
|
||||||
[3]: http://slackermedia.ml/handbook/doku.php?id=timecode
|
|
||||||
@ -1,60 +0,0 @@
|
|||||||
Vim 学习的 5 个技巧
|
|
||||||
=====================================
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
多年来,我一直想学 Vim。如今 Vim 是我最喜欢的 Linux 文本编辑器,也是开发者和系统管理者最喜爱的开源工具。我说的学习,指的是真正意义上的学习。想要精通确实很难,所以我只想要达到熟练的水平。根据我多年使用 Linux 的经验,我会的也仅仅只是打开一个文件,使用上下左右箭头按键来移动光标,切换到 insert 模式,更改一些文本,保存,然后退出。
|
|
||||||
|
|
||||||
但那只是 Vim 的最基本操作。Vim 可以让我在终端修改文本,但是它并没有任何一个我想象中强大的文本处理功能。这样我无法说明 Vim 完全优于 Pico 和 Nano。
|
|
||||||
|
|
||||||
所以到底为什么要学习 Vim?因为我需要花费相当多的时间用于编辑文本,而且有很大的效率提升空间。为什么不选择 Emacs,或者是更为现代化的编辑器例如 Atom?因为 Vim 适合我,至少我有一丁点的使用经验。而且,很重要的一点就是,在我需要处理的系统上很少碰见没有装 Vim 或者它的简化版(Vi)。如果你有强烈的欲望想学习 Emacs,我希望这些对于 Emacs 同类编辑器的建议能对你有所帮助。
|
|
||||||
|
|
||||||
花了几周的时间专注提高我的 Vim 使用技巧之后,我想分享的第一个建议就是必须使用工具。虽然这看起来就是明知故问的回答,但事实上比我所想的在代码层面上还要困难。我的大多数工作是在网页浏览器上进行的,而且我每次都得有针对性的用 Gedit 打开并修改一段浏览器之外的文本。Gedit 需要快捷键来启动,所以第一步就是移出快捷键然后替换成 Vim 的快捷键。
|
|
||||||
|
|
||||||
为了跟更好的学习 Vim,我尝试了很多。如果你也正想学习,以下列举了一些作为推荐。
|
|
||||||
|
|
||||||
### Vimtutor
|
|
||||||
|
|
||||||
通常如何开始学习最好就是使用应用本身。我找到一个小的应用叫 Vimtutor,当你在学习编辑一个文本时它能辅导你一些基础知识,它向我展示了很多我这些年都忽视的基础命令。Vimtutor 上到处都是 Vim 影子,如果你的系统上没有 Vimtutor,Vimtutor可以很容易从你的包管理器上下载。
|
|
||||||
|
|
||||||
### GVim
|
|
||||||
|
|
||||||
我知道并不是每个人都认同这个,但就是它让我从使用在终端的 Vim 转战到使用 GVim 来满足我基本编辑需求。反对者表示 GVim 鼓励使用鼠标,而 Vim 主要是为键盘党设计的。但是我能通过 GVim 的下拉菜单快速找到想找的指令,并且 GVim 可以提醒我正确的指令然后通过敲键盘执行它。努力学习一个新的编辑器然后陷入无法解决的困境,这种感觉并不好受。每隔几分钟读一下 man 出来的文字或者使用搜索引擎来提醒你指令也并不是最好的学习新事务的方法。
|
|
||||||
|
|
||||||
### Keyboard maps
|
|
||||||
|
|
||||||
当我转战 GVim,我发现有一个键盘的“作弊表”来提醒我最基础的按键很是便利。网上有很多这种可用的表,你可以下载,打印,然后贴在你身边的某一处地方。但是为了我的笔记本键盘,我选择买一沓便签纸。这些便签纸在美国不到10美元,而且当我使用键盘编辑文本尝试新的命令的时候,可以随时提醒我。
|
|
||||||
|
|
||||||
### Vimium
|
|
||||||
|
|
||||||
上文提到,我工作都在浏览器上进行。其中一条我觉得很有帮助的建议就是,使用 [Vimium][1] 来用增强使用 Vim 的体验。Vimium 是 Chrome 浏览器上的一个开源插件,能用 Vim 的指令快捷操作 Chrome。当我有意识的使用快捷键切换文本的次数越少时,这说明我越来越多的使用这些快捷键。同样的扩展 Firefox 上也有,例如 [Vimerator][2]。
|
|
||||||
|
|
||||||
### 人
|
|
||||||
|
|
||||||
毫无疑问,最好的学习方法就是求助于在你之前探索过的人,让他给你建议、反馈和解决方法。
|
|
||||||
|
|
||||||
如果你住在一个大城市,那么附近可能会有一个 Vim meetup 组,不然就是在 Freenode IRC 上的 #vim 频道。#vim 频道是 Freenode 上最活跃的频道之一,那上面可以针对你个人的问题来提供帮助。听上面的人发发牢骚或者看看别人尝试解决自己没有遇到过的问题,仅仅是这样我都觉得很有趣。
|
|
||||||
|
|
||||||
------
|
|
||||||
|
|
||||||
所以是什么成就了现在?如今便是极好。为它所花的时间是否值得就在于之后它为你节省了多少时间。但是我经常收到意外的惊喜与快乐,当我发现一个新的按键指令来复制、跳过词,或者一些相似的小技巧。每天我至少可以看见,一点点回报,正在逐渐配得上当初的付出。
|
|
||||||
|
|
||||||
学习 Vim 并不仅仅只有这些建议,还有很多。我很喜欢指引别人去 [Vim Advantures][3],它是一种只能使用 Vim 的快捷键的在线游戏。而且某天我发现了一个非常神奇的虚拟学习工具,在 [Vimgifts.com][4],那上面有明确的你想要的:用一个 gif 动图来描述,使用一点点 Vim 操作来达到他们想要的。
|
|
||||||
|
|
||||||
你有花时间学习 Vim 吗?或者有大量键盘操作交互体验的程序上投资时间吗?那些经过你努力后掌握的工具,你认为这些努力值得吗?效率的提高有达到你的预期?分享你们的故事在下面的评论区吧。
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/life/16/7/tips-getting-started-vim
|
|
||||||
|
|
||||||
作者:[Jason Baker ][a]
|
|
||||||
译者:[maywanting](https://github.com/maywanting)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/jason-baker
|
|
||||||
[1]: https://github.com/philc/vimium
|
|
||||||
[2]: http://www.vimperator.org/
|
|
||||||
[3]: http://vim-adventures.com/
|
|
||||||
[4]: http://vimgifs.com/
|
|
||||||
Loading…
Reference in New Issue
Block a user