mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
commit
40650460af
@ -0,0 +1,99 @@
|
||||
如何记录你在终端中执行的所有操作
|
||||
======
|
||||
|
||||

|
||||
|
||||
几天前,我们发布了一个解释如何[保存终端中的命令并按需使用][1]的指南。对于那些不想记忆冗长的 Linux 命令的人来说,这非常有用。今天,在本指南中,我们将看到如何使用 `script` 命令记录你在终端中执行的所有操作。你可能已经在终端中运行了一个命令,或创建了一个目录,或者安装了一个程序。`script` 命令会保存你在终端中执行的任何操作。如果你想知道你几小时或几天前做了什么,那么你可以查看它们。我知道我知道,我们可以使用上/下箭头或 `history` 命令查看以前运行的命令。但是,你无法查看这些命令的输出。而 `script` 命令记录并显示完整的终端会话活动。
|
||||
|
||||
`script` 命令会在终端中创建你所做的所有事件的记录。无论你是安装程序,创建目录/文件还是删除文件夹,一切都会被记录下来,包括命令和相应的输出。这个命令对那些想要一份交互式会话拷贝作为作业证明的人有用。无论是学生还是导师,你都可以将所有在终端中执行的操作和所有输出复制一份。
|
||||
|
||||
### 在 Linux 中使用 script 命令记录终端中的所有内容
|
||||
|
||||
`script` 命令预先安装在大多数现代 Linux 操作系统上。所以,我们不用担心安装。
|
||||
|
||||
让我们继续看看如何实时使用它。
|
||||
|
||||
运行以下命令启动终端会话记录。
|
||||
|
||||
```
|
||||
$ script -a my_terminal_activities
|
||||
```
|
||||
|
||||
其中,`-a` 标志用于将输出追加到文件(记录)中,并保留以前的内容。上述命令会记录你在终端中执行的所有操作,并将输出追加到名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Script started, file is my_terminal_activities
|
||||
```
|
||||
|
||||
现在,在终端中运行一些随机的 Linux 命令。
|
||||
|
||||
```
|
||||
$ mkdir ostechnix
|
||||
$ cd ostechnix/
|
||||
$ touch hello_world.txt
|
||||
$ cd ..
|
||||
$ uname -r
|
||||
```
|
||||
|
||||
运行所有命令后,使用以下命令结束 `script` 命令的会话:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
exit
|
||||
Script done, file is my_terminal_activities
|
||||
```
|
||||
|
||||
如你所见,终端活动已存储在名为 `my_terminal_activities` 的文件中,并将其保存在当前工作目录中。
|
||||
|
||||
要查看你的终端活动,只需在任何编辑器中打开此文件,或者使用 `cat` 命令直接显示它。
|
||||
|
||||
```
|
||||
$ cat my_terminal_activities
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Script started on Thu 09 Mar 2017 03:33:44 PM IST
|
||||
[sk@sk]: ~>$ mkdir ostechnix
|
||||
[sk@sk]: ~>$ cd ostechnix/
|
||||
[sk@sk]: ~/ostechnix>$ touch hello_world.txt
|
||||
[sk@sk]: ~/ostechnix>$ cd ..
|
||||
[sk@sk]: ~>$ uname -r
|
||||
4.9.11-1-ARCH
|
||||
[sk@sk]: ~>$ exit
|
||||
exit
|
||||
|
||||
Script done on Thu 09 Mar 2017 03:37:49 PM IST
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的,`script` 命令记录了我所有的终端活动,包括 `script` 命令的开始和结束时间。真棒,不是吗?使用 `script` 命令的原因不仅仅是记录命令,还有命令的输出。简单地说,脚本命令将记录你在终端上执行的所有操作。
|
||||
|
||||
### 结论
|
||||
|
||||
就像我说的那样,脚本命令对于想要保留其终端活动记录的学生,教师和 Linux 用户非常有用。尽管有很多 CLI 和 GUI 可用来执行此操作,但 `script` 命令是记录终端会话活动的最简单快捷的方式。
|
||||
|
||||
就是这些。希望这有帮助。如果你发现本指南有用,请在你的社交,专业网络上分享,并支持我们。
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/record-everything-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
@ -0,0 +1,48 @@
|
||||
容器基础知识:你需要知道的术语
|
||||
======
|
||||
|
||||

|
||||
|
||||
[在前一篇文章中][1],我们谈到了<ruby>容器<rt>container</rt></ruby>是什么以及它是如何培育创新并助力企业快速发展的。在以后的文章中,我们将讨论如何使用容器。然而,在深入探讨这个话题之前,我们需要了解关于容器的一些术语和命令。掌握了这些术语,才不至于产生混淆。
|
||||
|
||||
让我们来探讨 [Docker][2] 容器世界中使用的一些基本术语吧。
|
||||
|
||||
<ruby>容器<rt>Container</rt></ruby>:到底什么是容器呢?它是一个 Docker <ruby>镜像<rt>image</rt></ruby>的运行实例。它包含一个 Docker 镜像、执行环境和说明。它与系统完全隔离,所以可以在系统上运行多个容器,并且完全无视对方的存在。你可以从同一镜像中复制出多个容器,并在需求较高时扩展服务,在需求低时对这些容器进行缩减。
|
||||
|
||||
Docker <ruby>镜像<rt>Image</rt></ruby>:这与你下载的 Linux 发行版的镜像别无二致。它是一个安装包,包含了用于创建、部署和执行容器的一系列依赖关系和信息。你可以在几秒钟内创建任意数量的完全相同的容器。镜像是分层叠加的。一旦镜像被创建出来,是不能更改的。如果你想对容器进行更改,则只需创建一个新的镜像并从该镜像部署新的容器即可。
|
||||
|
||||
<ruby>仓库<rt>Repository</rt></ruby>(repo):Linux 的用户对于仓库这个术语一定不陌生吧。它是一个软件库,存储了可下载并安装在系统中的软件包。在 Docker 容器中,唯一的区别是它管理的是通过标签分类的 Docker 镜像。你可以找到同一个应用程序的不同版本或不同变体,他们都有适当的标记。
|
||||
|
||||
<ruby>镜像管理服务<rt>Registry</rt></ruby>:可以将其想象成 GitHub。这是一个在线服务,管理并提供了对 Docker 镜像仓库的访问,例如默认的公共镜像仓库——DockerHub。供应商可以将他们的镜像库上传到 DockerHub 上,以便他们的客户下载和使用官方镜像。一些公司为他们的镜像提供自己的服务。镜像管理服务不必由第三方机构来运行和管理。组织机构可以使用预置的服务来管理内部范围的镜像库访问。
|
||||
|
||||
<ruby>标签<rt>Tag</rt></ruby>:当你创建 Docker 镜像时,可以给它添加一个合适的标签,以便轻松识别不同的变体或版本。这与你在任何软件包中看到的并无区别。Docker 镜像在添加到镜像仓库时被标记。
|
||||
|
||||
现在你已经掌握了基本知识,下一个阶段是理解实际使用 Docker 容器时用到的术语。
|
||||
|
||||
**Dockerfile** :这是一个文本文件,包含为了为构建 Docker 镜像需手动执行的命令。Docker 使用这些指令自动构建镜像。
|
||||
|
||||
<ruby>构建<rt>Build</rt></ruby>:这是从 Dockerfile 创建成镜像的过程。
|
||||
|
||||
<ruby>推送<rt>Push</rt></ruby>:一旦镜像创建完成,“push” 是将镜像发布到仓库的过程。该术语也是我们下一篇文章要学习的命令之一。
|
||||
|
||||
<ruby>拉取<rt>Pull</rt></ruby>:用户可以通过 “pull” 过程从仓库检索该镜像。
|
||||
|
||||
<ruby>编组<rt>Compose</rt></ruby>:复杂的应用程序会包含多个容器。docker-compose 是一个用于运行多容器应用程序的命令行工具。它允许你用单条命令运行一个多容器的应用程序,简化了多容器带来的问题。
|
||||
|
||||
### 总结
|
||||
|
||||
容器术语的范围很广泛,这里是经常遇到的一些基本术语。下一次当你看到这些术语时,你会确切地知道它们的含义。在下一篇文章中,我们将开始使用 Docker 容器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://linux.cn/article-9468-1.html
|
||||
[2]:https://www.docker.com/
|
||||
@ -4,11 +4,12 @@
|
||||
> 这是许多事情的第一步
|
||||
|
||||

|
||||
|
||||
图片提供 : [WOCinTech Chat][16]. 图片修改 : Opensource.com. [CC BY-SA 4.0][17]
|
||||
|
||||
有一个普遍的误解,那就是对开源做出贡献是一件很难的事。你可能会想,“有时我甚至不能理解我自己的代码;那我怎么可能理解别人的?”
|
||||
|
||||
放轻松。直到去年,我都以为是这样。阅读和理解他人的代码,然后把你自己的写在顶上,这是一件令人气馁的任务;但如果有合适的资源,这不像你想象的那么糟。
|
||||
放轻松。直到去年,我都以为是这样。阅读和理解他人的代码,然后在他们的基础上写上你自己的代码,这是一件令人气馁的任务;但如果有合适的资源,这不像你想象的那么糟。
|
||||
|
||||
第一步要做的是选择一个项目。这个决定是可能是一个菜鸟转变成一个老练的开源贡献者的关键一步。
|
||||
|
||||
@ -16,7 +17,7 @@
|
||||
|
||||
### 理解产品
|
||||
|
||||
在开始贡献之前,你需要理解项目是怎么工作的。为了理解这一点,你需要自己来尝试。如果你发现这个产品很有趣并且游泳,它就值得你来做贡献。
|
||||
在开始贡献之前,你需要理解项目是怎么工作的。为了理解这一点,你需要自己来尝试。如果你发现这个产品很有趣并且有用,它就值得你来做贡献。
|
||||
|
||||
初学者常常选择参与贡献那些他们没有使用过的软件。他们会失望,并且最终放弃贡献。如果你没有用过这个软件,你不会理解它是怎么工作的。如果你不理解它是怎么工作的,你怎么能解决 bug 或添加新特性呢?
|
||||
|
||||
@ -31,77 +32,59 @@
|
||||
这里介绍了怎么确认一个项目是否还是活跃的:
|
||||
|
||||
* **贡献者数量:** 一个增加的贡献者数量表明开发者社区乐于接受新的贡献者。
|
||||
|
||||
* **<ruby>提交<rt>commit</rt></ruby>频率:** 查看最近的提交时间。如果是一周之内,甚至是一两个月内,这个项目应该是定期维护的。
|
||||
|
||||
* **维护者数量:** 维护者的数量越多,你越可能得到指导。
|
||||
|
||||
* **聊天室活动等级:** 一个繁忙的聊天室意味着你的问题可以更快得到回复。
|
||||
* **<ruby>提交<rt>commit</rt></ruby>频率:** 查看最近的提交时间。如果是一周之内,甚至是一两个月内,这个项目应该是定期维护的。
|
||||
* **维护者数量:** 维护者的数量越多,你越可能得到指导。
|
||||
* **聊天室或 IRC 活跃度:** 一个繁忙的聊天室意味着你的问题可以更快得到回复。
|
||||
|
||||
### 新手资源
|
||||
|
||||
Coala 是一个开源项目的例子。它有自己的教程和文档,让你可以使用它(每一个类和方法)的 API。这个网站还设计了一个有吸引力的界面,让你有阅读的兴趣。
|
||||
|
||||
**文档:** 所有水平的开发者都需要可靠的,被很好地维护的文档,来理解项目的细节。找找在 [GitHub][19](或者承载的任何位置)上,或者在单独的类似于 [阅读文档][20] 的页面上提供完善文档的项目,这样可以帮助你深入了解代码。
|
||||
|
||||
### [Coala 新手指南.png][2]
|
||||
**文档:** 不管哪种水平的开发者都需要可靠的、被很好地维护的文档,来理解项目的细节。找找在 [GitHub][19](或者放在其它位置)或者类似于 [Read the Docs][20] 之类的独立站点上提供了完善文档的项目,这样可以帮助你深入了解代码。
|
||||
|
||||

|
||||
|
||||
**教程:** 教程会给新手解释如何在项目里添加特性 (然而,你可以在任何项目里找到它)。例如,Coala 提供了 [tutorials for writing _bears_][21] (执行代码分析的<ruby>格式化代码<rt>linting</rt></ruby>工具的Python 包装器).
|
||||
|
||||
### [Coala 界面.png][3]
|
||||
**教程:** 教程会给新手解释如何在项目里添加特性 (然而,你不是在每个项目中都能找到它)。例如,Coala 提供了 [小熊编写指南][21] (进行代码分析的<ruby>代码格式化<rt>linting</rt></ruby>工具的 Python 包装器)。
|
||||
|
||||

|
||||
|
||||
**添加标签的<ruby>讨论点<rt>issue</rt></ruby>:** 对刚刚想明白如何选择第一个项目的初学者来说,选择一个讨论点是一个更加困难的任务。标签被设为“难度/低”,“难度/新手”,“利于初学者”,以及“low-hanging fruit”都表明是对新手友好的。F
|
||||
|
||||
### [Coala 讨论点标签.png][4]
|
||||
**分类的<ruby>讨论点<rt>issue</rt></ruby>:** 对刚刚想明白如何选择第一个项目的初学者来说,选择一个讨论点是一个更加困难的任务。标签被设为“难度/低”、“难度/新手”、“利于初学者”,以及“<ruby>触手可及<rt>low-hanging fruit</rt></ruby>”都表明是对新手友好的。
|
||||
|
||||

|
||||
|
||||
### 其他因素
|
||||
|
||||
### [ci_历史纪录.png][5]
|
||||
|
||||

|
||||
|
||||
* **维护者对新的贡献者的态度:** 从我的经验来看,大部分开源贡献者都很乐于帮助他们项目里的新手。然而,当你问问题时,你也有可能遇到一些不太友好的人(甚至可能有点粗鲁)。不要因为这些人失去信心。他们只是因为在比他们经验更丰富的人那儿得不到发泄的机会。还有很多其他人愿意提供帮助。
|
||||
|
||||
* **审阅过程/结构:** 你的拉取请求将被你的同事和有经验的开发者查看和更改很多次——这就是你学习软件开发最主要的方式。一个具有严格审阅过程的项目使您能够通过编写生产级代码来作为开发人员成长。
|
||||
|
||||
* **一个稳健的<ruby>持续整合<rt>continuous integration</rt></ruby>管道:** 开源项目会向新手们介绍持续整合和部署服务。一个稳健的 CI 管道将帮助你学习阅读和理解 CI 日志。它也将带给你处理失败的测试案例和代码覆盖率问题的经验。
|
||||
|
||||
* **参加编程项目 (例如 [Google Summer Of Code][1]):** 参加组织证明了你乐于对一个项目的长期发展做贡献。他们也会给新手提供一个机会来获得现实世界中的开发经验,从而获得报酬。大多数参加这些项目的组织都欢迎新人加入。
|
||||
* **维护者对新的贡献者的态度:** 从我的经验来看,大部分开源贡献者都很乐于帮助他们项目里的新手。然而,当你问问题时,你也有可能遇到一些不太友好的人(甚至可能有点粗鲁)。不要因为这些人失去信心。他们只是因为在比他们经验更丰富的人那儿得不到发泄的机会而已。还有很多其他人愿意提供帮助。
|
||||
* **审阅过程/机制:** 你的拉取请求将经历几遍你的同伴和有经验的开发者的查看和更改——这就是你学习软件开发最主要的方式。一个具有严格审阅过程的项目使您在编写生产级代码的过程中成长。
|
||||
* **一个稳健的<ruby>持续集成<rt>continuous integration</rt></ruby>管道:** 开源项目会向新手们介绍持续集成和部署服务。一个稳健的 CI 管道将帮助你学习阅读和理解 CI 日志。它也将带给你处理失败的测试用例和代码覆盖率问题的经验。
|
||||
* **参加编程项目(例如 [Google Summer Of Code][1]):** 参加组织证明了你乐于对一个项目的长期发展做贡献。他们也会给新手提供一个机会来获得现实世界中的开发经验,从而获得报酬。大多数参加这些项目的组织都欢迎新人加入。
|
||||
|
||||
### 7 对新手友好的组织
|
||||
|
||||
* [coala (Python)][7]
|
||||
|
||||
* [oppia (Python, Django)][8]
|
||||
|
||||
* [DuckDuckGo (Perl, JavaScript)][9]
|
||||
|
||||
* [OpenGenus (JavaScript)][10]
|
||||
|
||||
* [Kinto (Python, JavaScript)][11]
|
||||
|
||||
* [FOSSASIA (Python, JavaScript)][12]
|
||||
|
||||
* [Kubernetes (Go)][13]
|
||||
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][22] Palash Nigam - 我是一个印度计算机科学专业本科生,十分乐于参与开源软件的开发,我在 GitHub 上花费了大部分的时间。我现在的兴趣包括 web 后端开发,区块链,和 All things python.[更多关于我][14]
|
||||
[][22]
|
||||
|
||||
Palash Nigam - 我是一个印度计算机科学专业本科生,十分乐于参与开源软件的开发,我在 GitHub 上花费了大部分的时间。我现在的兴趣包括 web 后端开发,区块链,和 All things python。[更多关于我][14]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/get-started-open-source-project
|
||||
|
||||
作者:[ Palash Nigam ][a]
|
||||
作者:[Palash Nigam][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
208
published/20180418 The Linux Filesystem Explained.md
Normal file
208
published/20180418 The Linux Filesystem Explained.md
Normal file
@ -0,0 +1,208 @@
|
||||
Linux 文件系统详解
|
||||
=====================
|
||||
|
||||
> 这篇教程将帮你快速了解 Linux 文件系统。
|
||||
|
||||

|
||||
|
||||
早在 1996 年,在真正理解文件系统的结构之前,我就学会了如何在我崭新的 Linux 上安装软件。这是一个问题,但对程序来说不是大问题,因为即使我不知道实际的可执行文件在哪里,它们也会神奇地工作。问题在于文档。
|
||||
|
||||
你知道,那时候,Linux 不是像今天这样直观、用户友好的系统。你必须读很多东西。你必须知道你的 CRT 显示器的扫描频率以及拨号调制解调器的噪音来龙去脉,以及其他数以百计的事情。 我很快就意识到我需要花一些时间来掌握目录的组织方式以及 `/etc`(不是用于“其它”文件),`/usr`(不是用于“用户”文件)和 `/bin` (不是“垃圾桶”)的意思。
|
||||
|
||||
本教程将帮助你比我当时更快地了解这些。
|
||||
|
||||
### 结构
|
||||
|
||||
从终端窗口探索 Linux 文件系统是有道理的,这并不是因为作者是一个脾气暴躁的老人,并且对新孩子和他们漂亮的图形工具不以为然(尽管某些事实如此),而是因为终端,尽管只是文本界面,才是更好地显示 Linux 目录树结构的工具。
|
||||
|
||||
事实上,帮助你了解这一切的、应该首先安装的第一个工具的名为:`tree`。如果你正在使用 Ubuntu 或 Debian ,你可以:
|
||||
|
||||
```
|
||||
sudo apt install tree
|
||||
```
|
||||
|
||||
在 Red Hat 或 Fedora :
|
||||
|
||||
```
|
||||
sudo dnf install tree
|
||||
```
|
||||
|
||||
对于 SUSE/openSUSE 可以使用 `zypper`:
|
||||
|
||||
```
|
||||
sudo zypper install tree
|
||||
```
|
||||
|
||||
对于使用 Arch (Manjaro,Antergos,等等)使用:
|
||||
|
||||
```
|
||||
sudo pacman -S tree
|
||||
```
|
||||
|
||||
……等等。
|
||||
|
||||
一旦安装好,在终端窗口运行 `tree` 命令:
|
||||
|
||||
```
|
||||
tree /
|
||||
```
|
||||
|
||||
上述指令中的 `/` 指的是根目录。系统中的其他目录都是从根目录分支而出,当你运行 `tree` 命令,并且告诉它从根目录开始,那么你就可以看到整个目录树,系统中的所有目录及其子目录,还有它们的文件。
|
||||
|
||||
如果你已经使用你的系统有一段时间了,这可能需要一段时间,因为即使你自己还没有生成很多文件,Linux 系统及其应用程序总是在记录、缓存和存储各种临时文件。文件系统中的条目数量会快速增长。
|
||||
|
||||
不过,不要感到不知所措。 相反,试试这个:
|
||||
|
||||
```
|
||||
tree -L 1 /
|
||||
```
|
||||
|
||||
你应该看到如图 1 所示。
|
||||
|
||||

|
||||
|
||||
上面的指令可以翻译为“只显示以 `/`(根目录) 开头的目录树的第一级”。 `-L` 选项告诉树你想看到多少层目录。
|
||||
|
||||
大多数 Linux 发行版都会向你显示与你在上图中看到的相同或非常类似的结构。 这意味着,即使你现在感到困惑,掌握这一点,你将掌握大部分(如果不是全部的话)全世界的 Linux 文件系统。
|
||||
|
||||
为了让你开始走上掌控之路,让我们看看每个目录的用途。 当我们查看每一个目录的时候,你可以使用 `ls` 来查看他们的内容。
|
||||
|
||||
### 目录
|
||||
|
||||
从上到下,你所看到的目录如下
|
||||
|
||||
#### /bin
|
||||
|
||||
`/bin` 目录是包含一些二进制文件的目录,即可以运行的一些应用程序。 你会在这个目录中找到上面提到的 `ls` 程序,以及用于新建和删除文件和目录、移动它们基本工具。还有其它一些程序,等等。文件系统树的其他部分有更多的 *bin* 目录,但我们将在一会儿讨论这些目录。
|
||||
|
||||
#### /boot
|
||||
|
||||
`/boot` 目录包含启动系统所需的文件。我必须要说吗? 好吧,我会说:**不要动它**! 如果你在这里弄乱了其中一个文件,你可能无法运行你的 Linux,修复被破坏的系统是非常痛苦的一件事。 另一方面,不要太担心无意中破坏系统:你必须拥有超级用户权限才能执行此操作。
|
||||
|
||||
#### /dev
|
||||
|
||||
`/dev 目录包含设备文件。 其中许多是在启动时或甚至在运行时生成的。 例如,如果你将新的网络摄像头或 USB 随身碟连接到你的机器中,则会自动弹出一个新的设备条目。
|
||||
|
||||
#### /etc
|
||||
|
||||
`/etc` 的目录名称会让人变得非常的困惑。`/etc` 得名于最早的 Unix 系统们,它的字面意思是 “etcetera”(诸如此类) ,因为它是系统文件管理员不确定在哪里放置的文件的垃圾场。
|
||||
|
||||
现在,说 `/etc` 是“<ruby>要配置的所有内容<rt>Everything To Configure</rt></ruby>”更为恰当,因为它包含大部分(如果不是全部的话)的系统配置文件。 例如,包含系统名称、用户及其密码、网络上计算机名称以及硬盘上分区的安装位置和时间的文件都在这里。 再说一遍,如果你是 Linux 的新手,最好是不要在这里接触太多,直到你对系统的工作有更好的理解。
|
||||
|
||||
#### /home
|
||||
|
||||
`/home` 是你可以找到用户个人目录的地方。在我的情况下,`/home` 下有两个目录:`/home/paul`,其中包含我所有的东西;另外一个目录是 `/home/guest` 目录,以防有客人需要使用我的电脑。
|
||||
|
||||
#### /lib
|
||||
|
||||
`/lib` 是库文件所在的地方。库是包含应用程序可以使用的代码文件。它们包含应用程序用于在桌面上绘制窗口、控制外围设备或将文件发送到硬盘的代码片段。
|
||||
|
||||
在文件系统周围散布着更多的 `lib` 目录,但是这个直接挂载在 `/` 的 `/lib` 目录是特殊的,除此之外,它包含了所有重要的内核模块。 内核模块是使你的显卡、声卡、WiFi、打印机等工作的驱动程序。
|
||||
|
||||
#### /media
|
||||
|
||||
在 `/media` 目录中,当你插入外部存储器试图访问它时,将自动挂载它。与此列表中的大多数其他项目不同,`/media` 并不追溯到 1970 年代,主要是因为当计算机正在运行而动态地插入和检测存储(U 盘、USB 硬盘、SD 卡、外部 SSD 等),这是近些年才发生的事。
|
||||
|
||||
#### /mnt
|
||||
|
||||
然而,`/mnt` 目录是一些过去的残余。这是你手动挂载存储设备或分区的地方。现在不常用了。
|
||||
|
||||
#### /opt
|
||||
|
||||
`/opt` 目录通常是你编译软件(即,你从源代码构建,并不是从你的系统的软件库中安装软件)的地方。应用程序最终会出现在 `/opt/bin` 目录,库会在 `/opt/lib` 目录中出现。
|
||||
|
||||
稍微的题外话:应用程序和库的另一个地方是 `/usr/local`,在这里安装软件时,也会有 `/usr/local/bin` 和 `/usr/local/lib` 目录。开发人员如何配置文件来控制编译和安装过程,这就决定了软件安装到哪个地方。
|
||||
|
||||
#### /proc
|
||||
|
||||
`/proc`,就像 `/dev` 是一个虚拟目录。它包含有关你的计算机的信息,例如关于你的 CPU 和你的 Linux 系统正在运行的内核的信息。与 `/dev` 一样,文件和目录是在计算机启动或运行时生成的,因为你的系统正在运行且会发生变化。
|
||||
|
||||
#### /root
|
||||
|
||||
`/root` 是系统的超级用户(也称为“管理员”)的主目录。 它与其他用户的主目录是分开的,**因为你不应该动它**。 所以把自己的东西放在你自己的目录中,伙计们。
|
||||
|
||||
#### /run
|
||||
|
||||
`/run` 是另一个新出现的目录。系统进程出于自己不可告人的原因使用它来存储临时数据。这是另一个**不要动它**的文件夹。
|
||||
|
||||
#### /sbin
|
||||
|
||||
`/sbin` 与 `/bin` 类似,但它包含的应用程序只有超级用户(即首字母的 `s` )才需要。你可以使用 `sudo` 命令使用这些应用程序,该命令暂时允许你在许多 Linux 发行版上拥有超级用户权限。`/sbin` 目录通常包含可以安装、删除和格式化各种东西的工具。你可以想象,如果你使用不当,这些指令中有一些是致命的,所以要小心处理。
|
||||
|
||||
#### /usr
|
||||
|
||||
`/usr` 目录是在 UNIX 早期用户的主目录所处的地方。然而,正如我们上面看到的,现在 `/home` 是用户保存他们的东西的地方。如今,`/usr` 包含了大量目录,而这些目录又包含了应用程序、库、文档、壁纸、图标和许多其他需要应用程序和服务共享的内容。
|
||||
|
||||
你还可以在 `/usr` 目录下找到 `bin`,`sbin`,`lib` 目录,它们与挂载到根目录下的那些有什么区别呢?现在的区别不是很大。在早期,`/bin` 目录(挂载在根目录下的)只会包含一些基本的命令,例如 `ls`、`mv` 和 `rm` ;这是一些在安装系统的时候就会预装的一些命令,用于维护系统的一个基本的命令。 而 `/usr/bin` 目录则包含了用户自己安装和用于工作的软件,例如文字处理器,浏览器和一些其他的软件。
|
||||
|
||||
但是许多现代的 Linux 发行版只是把所有的东西都放到 `/usr/bin` 中,并让 `/bin` 指向 `/usr/bin`,以防彻底删除它会破坏某些东西。因此,Debian、Ubuntu 和 Mint 仍然保持 `/bin` 和 `/usr/bin` (和 `/sbin` 和 `/usr/sbin` )分离;其他的,比如 Arch 和它衍生版,只是有一个“真实”存储二进制程序的目录,`/usr/bin`,其余的任何 `bin` 目录是指向 `/usr/`bin` 的“假”目录。
|
||||
|
||||
#### /srv
|
||||
|
||||
`/srv` 目录包含服务器的数据。如果你正在 Linux 机器上运行 Web 服务器,你网站的 HTML文件将放到 `/srv/http`(或 `/srv/www`)。 如果你正在运行 FTP 服务器,则你的文件将放到 `/srv/ftp`。
|
||||
|
||||
#### /sys
|
||||
|
||||
`/sys` 是另一个类似 `/proc` 和 `/dev` 的虚拟目录,它还包含连接到计算机的设备的信息。
|
||||
|
||||
在某些情况下,你还可以操纵这些设备。 例如,我可以通过修改存储在 `/sys/devices/pci0000:00/0000:00:02.0/drm/card1/card1-eDP-1/intel_backlight/brightness` 中的值来更改笔记本电脑屏幕的亮度(在你的机器上你可能会有不同的文件)。但要做到这一点,你必须成为超级用户。原因是,与许多其它虚拟目录一样,在 `/sys` 中打乱内容和文件可能是危险的,你可能会破坏系统。直到你确信你知道你在做什么。否则不要动它。
|
||||
|
||||
#### /tmp
|
||||
|
||||
`/tmp` 包含临时文件,通常由正在运行的应用程序放置。文件和目录通常(并非总是)包含应用程序现在不需要但以后可能需要的数据。
|
||||
|
||||
你还可以使用 `/tmp` 来存储你自己的临时文件 —— `/tmp` 是少数挂载到根目录下而你可以在不成为超级用户的情况下与它进行实际交互的目录之一。
|
||||
|
||||
#### /var
|
||||
|
||||
`/var` 最初被如此命名是因为它的内容被认为是<ruby>可变的<rt>variable</rt></ruby>,因为它经常变化。今天,它有点用词不当,因为还有许多其他目录也包含频繁更改的数据,特别是我们上面看到的虚拟目录。
|
||||
|
||||
不管怎样,`/var` 目录包含了放在 `/var/log` 子目录的日志文件之类。日志是记录系统中发生的事件的文件。如果内核中出现了什么问题,它将被记录到 `/var/log` 下的文件中;如果有人试图从外部侵入你的计算机,你的防火墙也将记录尝试。它还包含用于任务的假脱机程序。这些“任务”可以是你发送给共享打印机必须等待执行的任务,因为另一个用户正在打印一个长文档,或者是等待递交给系统上的用户的邮件。
|
||||
|
||||
你的系统可能还有一些我们上面没有提到的目录。例如,在屏幕截图中,有一个 `/snap` 目录。这是因为这张截图是在 Ubuntu 系统上截取的。Ubuntu 最近将 [snap][1] 包作为一种分发软件的方式。`/snap` 目录包含所有文件和从 snaps 安装的软件。
|
||||
|
||||
### 更深入的研究
|
||||
|
||||
这里仅仅谈了根目录,但是许多子目录都指向它们自己的一组文件和子目录。图 2 给出了基本文件系统的总体概念(图片是在 Paul Gardner 的 CC BY-SA 许可下提供的),[Wikipedia 对每个目录的用途进行了总结][2]。
|
||||
|
||||
|
||||
![filesystem][4]
|
||||
|
||||
*图 2:标准 Unix 文件系统 [许可][5] Paul Gardner*
|
||||
|
||||
要自行探索文件系统,请使用 `cd` 命令:`cd`将带你到你所选择的目录( `cd` 代表更改目录)。
|
||||
|
||||
如果你不知道你在哪儿,`pwd`会告诉你,你到底在哪里,( `pwd` 代表打印工作目录 ),同时 `cd`命令在没有任何选项或者参数的时候,将会直接带你到你自己的主目录,这是一个安全舒适的地方。
|
||||
|
||||
最后,`cd ..`将会带你到上一层目录,会使你更加接近根目录,如果你在 `/usr/share/wallpapers` 目录,然后你执行 `cd ..` 命令,你将会跳转到 `/usr/share` 目录
|
||||
|
||||
要查看目录里有什么内容,使用 `ls` 或这简单的使用 `l` 列出你所在目录的内容。
|
||||
|
||||
当然,你总是可以使用 `tree` 来获得目录中内容的概述。在 `/usr/share` 上试试——里面有很多有趣的东西。
|
||||
|
||||
### 总结
|
||||
|
||||
尽管 Linux 发行版之间存在细微差别,但它们的文件系统的布局非常相似。 你可以这么说:一旦你了解一个,你就会都了解了。 了解文件系统的最好方法就是探索它。 因此,伴随 `tree` ,`ls` 和 `cd` 进入未知的领域吧。
|
||||
|
||||
你不会只是因为查看文件系统就破坏了文件系统,因此请从一个目录移动到另一个目录并进行浏览。 很快你就会发现 Linux 文件系统及其布局的确很有意义,并且你会直观地知道在哪里可以找到应用程序,文档和其他资源。
|
||||
|
||||
通过 Linux 基金会和 edX 免费的 “[Linux入门][6]” 课程了解更多有关 Linux 的信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/4/linux-filesystem-explained
|
||||
|
||||
作者:[PAUL BROWN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.ubuntu.com/desktop/snappy
|
||||
[2]:https://en.wikipedia.org/wiki/Unix_filesystem#Conventional_directory_layout
|
||||
[3]:https://www.linux.com/files/images/standard-unix-filesystem-hierarchypng
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/standard-unix-filesystem-hierarchy.png?itok=CVqmyk6P "filesystem"
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
69
published/20180519 Python Debugging Tips.md
Normal file
69
published/20180519 Python Debugging Tips.md
Normal file
@ -0,0 +1,69 @@
|
||||
Python 调试技巧
|
||||
======
|
||||
|
||||
当进行调试时,你有很多选择,但是很难给出一直有效的通用建议(除了“你试过关闭再打开么?”以外)。
|
||||
|
||||
这里有一些我最喜欢的 Python 调试技巧。
|
||||
|
||||
### 建立一个分支
|
||||
|
||||
请相信我。即使你从来没有打算将修改提交回上游,你也会很乐意将你的实验被包含在它们自己的分支中。
|
||||
|
||||
不说别的,它会使清理更容易!
|
||||
|
||||
### 安装 pdb++
|
||||
|
||||
认真地说,如果你使用命令行,它会让你的生活更轻松。
|
||||
|
||||
pdb++ 所做的一切就是用更好的模块替换标准的 pdb 模块。以下是你在 `pip install pdbpp` 会看到的:
|
||||
|
||||
* 彩色提示!
|
||||
* 制表符补全!(非常适合探索!)
|
||||
* 支持切分!
|
||||
|
||||
好的,也许最后一个是有点多余……但是非常认真地说,安装 pdb++ 非常值得。
|
||||
|
||||
### 探索
|
||||
|
||||
有时候最好的办法就是胡乱试试,然后看看会发生什么。在“明显”的位置放置一个断点并确保它被命中。在代码中加入 `print()` 和/或 `logging.debug()` 语句,并查看代码执行的位置。
|
||||
|
||||
检查传递给你的函数的参数,检查库的版本(如果你已经非常绝望了)。
|
||||
|
||||
### 一次只能改变一件事
|
||||
|
||||
在你在探索了一下后,你将会对你可以做的事情有所了解。但在你开始摆弄代码之前,先退一步,考虑一下你可以改变什么,然后只改变一件事。
|
||||
|
||||
做出改变后,然后测试一下,看看你是否接近解决问题。如果没有,请将它改回来,然后尝试其他方法。
|
||||
|
||||
只更改一件事就可以让你知道什可以工作,哪些不工作。另外,一旦可以工作后,你的新提交将会小得多(因为将有更少的变化)。
|
||||
|
||||
这几乎是<ruby>科学过程<rt>Scientific Process</rt></ruby>中所做的事情:一次只更改一个变量。通过让自己看到并衡量一次更改的结果,你可以节省你的理智,并更快地找到解决方案。
|
||||
|
||||
### 不要假设,提出问题
|
||||
|
||||
偶尔一个开发人员(当然不是你咯!)会匆忙提交一些有问题的代码。当你去调试这段代码时,你需要停下来,并确保你明白它想要完成什么。
|
||||
|
||||
不要做任何假设。仅仅因为代码在 `model.py` 文件中并不意味着它不会尝试渲染一些 HTML。
|
||||
|
||||
同样,在做任何破坏性的事情之前,仔细检查你的所有外部关联。要删除一些配置数据?**请确保你没有连接到你的生产系统。**
|
||||
|
||||
### 聪明,但不要聪明过头
|
||||
|
||||
有时候我们编写的代码神奇般地奏效,不知道它是如何做的。
|
||||
|
||||
当我们发布代码时,我们可能会觉得自己很聪明,但当代码崩溃时,我们往往会感到愚蠢,我们必须记住它是如何工作的,以便弄清楚它为什么不起作用。
|
||||
|
||||
留意任何看起来过于复杂、冗长或极短的代码段。这些可能是隐藏复杂并导致错误的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pythondebugging.com/articles/python-debugging-tips
|
||||
|
||||
作者:[PythonDebugging.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://pythondebugging.com
|
||||
@ -0,0 +1,184 @@
|
||||
10 条加速 Ubuntu Linux 的杀手级技巧
|
||||
======
|
||||
|
||||
> 一些实用的**加速 Ubuntu Linux 的技巧**。 这里的技巧对于大多数版本的 Ubuntu 是有效的,也可以应用于 Linux Mint 以及其他的基于 Ubuntu 的发行版。
|
||||
|
||||
也许你经历过使用 Ubuntu 一段时间后系统开始运行缓慢的情况。 在这篇文章里,我们将看到几项调整以及使 Ubuntu 运行更快的窍门。
|
||||
|
||||
在我们了解如何提升 Ubuntu 的总体系统表现之前,首先让我们思考为什么系统逐渐变慢。这个问题可能有很多原因。也许你有一台只有基础配置的简陋的电脑;也许你安装了一些在启动时即耗尽资源的应用。事实上原因无穷无尽。
|
||||
|
||||
这里我列出一些能够帮助你稍微加速 Ubuntu 的小调整。也有一些你能够采用以获取一个更流畅、有所提升的系统表现的经验。你可以选择遵循全部或部分的建议。将各项调整一点一点的结合就能给你一个更流畅、更迅捷快速的 Ubuntu。
|
||||
|
||||
### 使 Ubuntu 更快的技巧
|
||||
|
||||
![Tips to speed up Ubuntu][1]
|
||||
|
||||
我在一个较老版本的 Ubuntu 上使用了这些调整,但是我相信其他的 Ubuntu 版本以及其他的例如 Linux Mint、 Elementary OS Luna 等基 Ubuntu 的 Linux 版本也是同样适用的。
|
||||
|
||||
#### 1、 减少默认的 grub 载入时间
|
||||
|
||||
Grub 给你 10 秒的时间以让你在多系统启动项或恢复模式之间改变。对我而言,它是多余的。它也意味着你将不得不坐在电脑旁,敲下回车键以尽可能快的启动进入 Ubuntu。这花了一点时间,不是吗? 第一个技巧便是改变这个启动时间。如果你使用图形工具更舒适,阅读这篇文章来[使用 Grub 定制器改变 grub 时间以及启动顺序][2]。
|
||||
|
||||
如果更倾向于命令行,你可以简单地使用以下的命令来打开 grub 配置:
|
||||
|
||||
```
|
||||
sudo gedit /etc/default/grub &
|
||||
```
|
||||
|
||||
并且将 `GRUB_TIMEOUT=10` 改为 `GRUB_TIMEOUT=2`。这将改变启动时间为 2 秒。最好不要将这里改为 0,因为这样你将会失去在操作系统及恢复选项之间切换的机会。一旦你更改了 grub 配置,使用以下命令来使更改生效:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
#### 2、 管理开机启动的应用
|
||||
|
||||
渐渐地你开始安装各种应用。 如果你是我们的老读者, 你也许从 [App of the week][3] 系列安装了许多应用。
|
||||
|
||||
这些应用中的一些在每次开机时都会启动,当然资源运行这些应用也会陷入繁忙。结果:一台电脑因为每次启动时的持续时间而变得缓慢。进入 Unity Dash 寻找 “Startup Applications”:
|
||||
|
||||

|
||||
|
||||
在这里,看看哪些应用在开机时被载入。现在考虑在你每次启动 Ubuntu 时是否有不需要启动的应用。尽管移除它们:
|
||||
|
||||

|
||||
|
||||
但是要是你不想从启动里移除它们怎么办?举个例子,如果你安装了 [Ubuntu 最好的指示器程序][4]之一, 你将想要它们在每次开机时自动地启动。
|
||||
|
||||
这里你所能做的就是延迟一些程序的启动时间。这样你将能够释放开机启动时的资源,并且一段时间后你的应用将被自动启动。在上一张图片里点击 Edit 并使用 sleep 选项来更改运行命令。
|
||||
|
||||
例如,如果你想要延迟 Dropbox 指示器的运行,我们指定时间 20 秒,你只需要在已有的命令里像这样**加入一个命令**:
|
||||
|
||||
```
|
||||
sleep 20;
|
||||
```
|
||||
|
||||
所以,命令 `dropbox start -i` 变为 `sleep 20; drobox start -i` 。这意味着现在 Dropbox 将延迟 20 秒启动。你可以通过相似的方法来改变另一个开机启动应用的启动时间。
|
||||
|
||||

|
||||
|
||||
#### 3、 安装 preload 来加速应用载入时间:
|
||||
|
||||
Preload 是一个后台运行的守护进程,它分析用户行为和频繁运行的应用。打开终端,使用如下的命令来安装 preload:
|
||||
|
||||
```
|
||||
sudo apt-get install preload
|
||||
```
|
||||
|
||||
安装后,重启你的电脑就不用管它了。它将在后台工作。[阅读更多关于preload][5]
|
||||
|
||||
#### 4、 选择最好的软件更新镜像
|
||||
|
||||
验证你更新软件是否正在使用最好的镜像是很好的做法。Ubuntu 的软件仓库镜像跨过全球,使用离你最近的一个是相当明智的。随着从服务器获取包的时间减少,这将形成更快的系统更新。
|
||||
|
||||
在 “Software & Updates->Ubuntu Software tab->Download From” 里选择 “Other” 紧接着点击 “Select Best Server”:
|
||||
|
||||

|
||||
|
||||
它将运行测试来告知你那个是最好的镜像。正常地,最好的镜像已经被设置,但是我说过,验证它没什么坏处。并且,如果仓库缓存的最近的镜像没有频繁更新的话,这将引起获取更新时的一些延迟。这对于网速相对慢的人们是有用的。你可以使用这些技巧来[加速 Ubuntu 的 wifi][6]。
|
||||
|
||||
#### 5、 为了更快的更新,使用 apt-fast 而不是 apt-get
|
||||
|
||||
`apt-fast` 是 `apt-get` 的一个 shell 脚本包装器,通过从多连接同时下载包来提升更新及包下载速度。 如果你经常使用终端以及 `apt-get` 来安装和更新包,你也许会想要试一试 `apt-fast`。使用下面的命令来通过官方 PPA 安装 `apt-fast`:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:apt-fast/stable
|
||||
sudo apt-get update
|
||||
sudo apt-get install apt-fast
|
||||
```
|
||||
|
||||
#### 6、 从 apt-get 更新移除语言相关的 ign
|
||||
|
||||
你曾经注意过 `sudo apt-get` 更新的输出吗?其中有三种行,`hit`、`ign` 和 `get`。 你可以在[这里][7]阅读它们的意义。如果你看到 IGN 行,你会发现它们中的大多数都与语言翻译有关。如果你使用所有的英文应用及包,你将完全不需要英文向英文的包数据库的翻译。
|
||||
|
||||
如果你从 `apt-get` 制止语言相关的更新,它将略微地增加 `apt-get` 的更新速度。为了那样,打开如下的文件:
|
||||
|
||||
```
|
||||
sudo gedit /etc/apt/apt.conf.d/00aptitude
|
||||
```
|
||||
|
||||
然后在文件末尾添加如下行:
|
||||
|
||||
```
|
||||
Acquire::Languages "none";
|
||||
```
|
||||
|
||||
[![speed up apt get update in Ubuntu][8]][9]
|
||||
|
||||
#### 7、 减少过热
|
||||
|
||||
现在过热是电脑普遍的问题。一台过热的电脑运行相当缓慢。当你的 CPU 风扇转得像 [尤塞恩·博尔特][10] 一样快,打开一个程序将花费很长的时间。有两个工具你可以用来减少过热,使 Ubuntu 获得更好的系统表现,即 TLP 和 CPUFREQ。
|
||||
|
||||
在终端里使用以下命令来安装 TLP:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:linrunner/tlp
|
||||
sudo apt-get update
|
||||
sudo apt-get install tlp tlp-rdw
|
||||
sudo tlp start
|
||||
```
|
||||
|
||||
安装完 TLP 后你不需要做任何事。它在后台工作。
|
||||
|
||||
使用如下命令来安装 CPUFREQ 指示器:
|
||||
|
||||
```
|
||||
sudo apt-get install indicator-cpufreq
|
||||
```
|
||||
|
||||
重启你的电脑并使用 Powersave 模式:
|
||||
|
||||

|
||||
|
||||
#### 8、 调整 LibreOffice 来使它更快
|
||||
|
||||
如果你是频繁使用 office 产品的用户,那么你会想要稍微调整默认的 LibreOffice 使它更快。这里你将调整内存选项。打开 Open LibreOffice,进入 “Tools->Options”。在那里,从左边的侧栏选择“Memory”并启用 “Systray Quickstarter” 以及增加内存分配。
|
||||
|
||||

|
||||
|
||||
你可以阅读更多关于[如何提速 LibreOffice][11] 的细节。
|
||||
|
||||
#### 9、 使用轻量级的桌面环境 (如果你可以)
|
||||
|
||||
如果你选择安装默认的 Unity of GNOME 桌面环境, 你也许会选择一个轻量级的桌面环境像 [Xfce][12] 或 [LXDE][13]。
|
||||
|
||||
这些桌面环境使用更少的内存,消耗更少的 CPU。它们也自带轻量应用集来更深入地帮助更快地使用 Ubuntu。你可以参考这篇详细指南来学习[如何在 Ubuntu 上安装 Xfce][14]。
|
||||
|
||||
当然,桌面也许没有 Unity 或 GNOME 看起来现代化。那是你必须做出的妥协。
|
||||
|
||||
#### 10、 使用不同应用的更轻量可选
|
||||
|
||||
这不仅仅是建议和喜好。一些默认的或者流行的应用是耗资源的且可能不适合低端的电脑。你能做的就是使用这些应用的一些替代品。例如,使用 [AppGrid][15] 而不是 Ubuntu 软件中心。使用 [Gdebi][16] 来安装包。使用 AbiWord 而不是 LibreOffice Writer 等。
|
||||
|
||||
可以断定这些技巧的汇总使 Ubuntu 14.04,16.04 以及其他版本更快。我确定这些技巧会提供一个总体上更好的系统表现。
|
||||
|
||||
对于加速 Ubuntu 你也有妙计吗?这些技巧也帮到你了吗?分享你的观点。 问题,建议总是受欢迎的。请在评论区里提出来。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/speed-up-ubuntu-1310/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[darsh8](https://github.com/darsh8)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2017/07/speed-up-ubuntu-featured-800x450.jpeg
|
||||
[2]:https://itsfoss.com/windows-default-os-dual-boot-ubuntu-1304-easy/ (Make Windows Default OS In Dual Boot With Ubuntu 13.04: The Easy Way)
|
||||
[3]:https://itsfoss.com/tag/app-of-the-week/
|
||||
[4]:https://itsfoss.com/best-indicator-applets-ubuntu/ (7 Best Indicator Applets For Ubuntu 13.10)
|
||||
[5]:https://itsfoss.com/improve-application-startup-speed-with-preload-in-ubuntu/ (Improve Application Startup Speed With Preload in Ubuntu)
|
||||
[6]:https://itsfoss.com/speed-up-slow-wifi-connection-ubuntu/ (Speed Up Slow WiFi Connection In Ubuntu 13.04)
|
||||
[7]:http://ubuntuforums.org/showthread.php?t=231300
|
||||
[8]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update-e1510129903529.jpeg
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2014/01/ign_language-apt_get_update.jpeg
|
||||
[10]:http://en.wikipedia.org/wiki/Usain_Bolt
|
||||
[11]:https://itsfoss.com/speed-libre-office-simple-trick/ (Speed Up LibreOffice With This Simple Trick)
|
||||
[12]:https://xfce.org/
|
||||
[13]:https://lxde.org/
|
||||
[14]:https://itsfoss.com/install-xfce-desktop-xubuntu/
|
||||
[15]:https://itsfoss.com/app-grid-lighter-alternative-ubuntu-software-center/ (App Grid: Lighter Alternative Of Ubuntu Software Center)
|
||||
[16]:https://itsfoss.com/install-deb-files-easily-and-quickly-in-ubuntu-12-10-quick-tip/ (Install .deb Files Easily And Quickly In Ubuntu 12.10 [Quick Tip])
|
||||
@ -0,0 +1,113 @@
|
||||
如何在 Linux 中的特定时间运行命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
有一天,我使用 `rsync` 将大文件传输到局域网上的另一个系统。由于它是非常大的文件,大约需要 20 分钟才能完成。我不想再等了,我也不想按 `CTRL+C` 来终止这个过程。我只是想知道在类 Unix 操作系统中是否有简单的方法可以在特定的时间运行一个命令,并且一旦超时就自动杀死它 —— 因此有了这篇文章。请继续阅读。
|
||||
|
||||
### 在 Linux 中在特定时间运行命令
|
||||
|
||||
我们可以用两种方法做到这一点。
|
||||
|
||||
#### 方法 1 - 使用 timeout 命令
|
||||
|
||||
最常用的方法是使用 `timeout` 命令。对于那些不知道的人来说,`timeout` 命令会有效地限制一个进程的绝对执行时间。`timeout` 命令是 GNU coreutils 包的一部分,因此它预装在所有 GNU/Linux 系统中。
|
||||
|
||||
假设你只想运行一个命令 5 秒钟,然后杀死它。为此,我们使用:
|
||||
|
||||
```
|
||||
$ timeout <time-limit-interval> <command>
|
||||
```
|
||||
|
||||
例如,以下命令将在 10 秒后终止。
|
||||
|
||||
```
|
||||
$ timeout 10s tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
你也可以不用在秒数后加后缀 `s`。以下命令与上面的相同。
|
||||
|
||||
```
|
||||
$ timeout 10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
其他可用的后缀有:
|
||||
|
||||
* `m` 代表分钟。
|
||||
* `h` 代表小时。
|
||||
* `d` 代表天。
|
||||
|
||||
|
||||
如果你运行这个 `tail -f /var/log/pacman.log` 命令,它将继续运行,直到你按 `CTRL+C` 手动结束它。但是,如果你使用 `timeout` 命令运行它,它将在给定的时间间隔后自动终止。如果该命令在超时后仍在运行,则可以发送 `kill` 信号,如下所示。
|
||||
|
||||
```
|
||||
$ timeout -k 20 10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
在这种情况下,如果 `tail` 命令在 10 秒后仍然运行,`timeout` 命令将在 20 秒后发送一个 kill 信号并结束。
|
||||
|
||||
有关更多详细信息,请查看手册页。
|
||||
|
||||
```
|
||||
$ man timeout
|
||||
```
|
||||
|
||||
有时,某个特定程序可能需要很长时间才能完成并最终冻结你的系统。在这种情况下,你可以使用此技巧在特定时间后自动结束该进程。
|
||||
|
||||
另外,可以考虑使用 `cpulimit`,一个简单的限制进程的 CPU 使用率的程序。有关更多详细信息,请查看下面的链接。
|
||||
|
||||
- [如何在 Linux 中限制一个进程的使用的 CPU][8]
|
||||
|
||||
#### 方法 2 - 使用 timelimit 程序
|
||||
|
||||
`timelimit` 使用提供的参数执行给定的命令,并在给定的时间后使用给定的信号终止进程。首先,它会发送警告信号,然后在超时后发送 kill 信号。
|
||||
|
||||
与 `timeout` 不同,`timelimit` 有更多选项。你可以传递参数数量,如 `killsig`、`warnsig`、`killtime`、`warntime` 等。它存在于基于 Debian 的系统的默认仓库中。所以,你可以使用命令来安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install timelimit
|
||||
```
|
||||
|
||||
对于基于 Arch 的系统,它在 AUR 中存在。因此,你可以使用任何 AUR 助手进行安装,例如 [Pacaur][3]、[Packer][4]、[Yay][5]、[Yaourt][6] 等。
|
||||
|
||||
对于其他发行版,请[在这里][7]下载源码并手动安装。安装 `timelimit` 后,运行下面的命令执行一段特定的时间,例如 10 秒钟:
|
||||
|
||||
```
|
||||
$ timelimit -t10 tail -f /var/log/pacman.log
|
||||
```
|
||||
|
||||
如果不带任何参数运行 `timelimit`,它将使用默认值:`warntime=3600` 秒、`warnsig=15` 秒、`killtime=120` 秒、`killsig=9`。有关更多详细信息,请参阅本指南最后给出的手册页和项目网站。
|
||||
|
||||
```
|
||||
$ man timelimit
|
||||
```
|
||||
|
||||
今天就是这些。我希望对你有用。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
### 资源
|
||||
|
||||
- [timelimit 网站][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/run-command-specific-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/Timeout.gif
|
||||
[3]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[4]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[5]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:http://devel.ringlet.net/sysutils/timelimit/#download
|
||||
[8]:https://www.ostechnix.com/how-to-limit-cpu-usage-of-a-process-in-linux/
|
||||
[9]:http://devel.ringlet.net/sysutils/timelimit/
|
||||
@ -1,16 +1,19 @@
|
||||
密码学及公钥基础设施入门
|
||||
======
|
||||
|
||||
> 学习密码学背后的基本概念,主要是保密性、完整性和身份认证。
|
||||
|
||||

|
||||
|
||||
安全通信正快速成为当今互联网的规范。从 2018 年 7 月起,Google Chrome 将对**全部**使用 HTTP 传输(而不是 HTTPS 传输)的站点[开始显示“不安全”警告][1]。虽然密码学已经逐渐变广为人知,但其本身并没有变得更容易理解。[Let's Encrypt][3] 设计并实现了一套令人惊叹的解决方案,可以提供免费安全证书和周期性续签;但如果不了解底层概念和缺陷,你也不过是加入了类似”[<ruby>船货崇拜<rt>cargo cult</rt></ruby>][4]“的技术崇拜的程序员大军。
|
||||
安全通信正快速成为当今互联网的规范。从 2018 年 7 月起,Google Chrome 将对**全部**使用 HTTP 传输(而不是 HTTPS 传输)的站点[开始显示“不安全”警告][1]。虽然密码学已经逐渐变广为人知,但其本身并没有变得更容易理解。[Let's Encrypt][3] 设计并实现了一套令人惊叹的解决方案,可以提供免费安全证书和周期性续签;但如果不了解底层概念和缺陷,你也不过是加入了类似“[<ruby>货物崇拜<rt>cargo cult</rt></ruby>][4]”的技术崇拜的程序员大军。
|
||||
|
||||
### 安全通信的特性
|
||||
|
||||
密码学最直观明显的目标是<ruby>保密性<rt>confidentiality</rt></ruby>:<ruby>消息<rt>message</rt></ruby>传输过程中不会被窥探内容。为了保密性,我们对消息进行加密:对于给定消息,我们结合一个<ruby>密钥<rt>key</rt></ruby>生成一个无意义的乱码,只有通过相同的密钥逆转加密过程(即解密过程)才能将其转换为可读的消息。假设我们有两个朋友 [Alice 和 Bob][5],以及他们的<ruby>八卦<rt>nosy</rt></ruby>邻居 Eve。Alice 加密类似 "Eve 很讨厌" 的消息,将其发送给 Bob,期间不用担心 Eve 会窥探到这条消息的内容。
|
||||
|
||||
对于真正的安全通信,保密性是不够的。假如 Eve 收集了足够多 Alice 和 Bob 之间的消息,发现单词 "Eve" 被加密为 "Xyzzy"。除此之外,Eve 还知道 Alice 和 Bob 正在准备一个派对,Alice 会将访客名单发送给 Bob。如果 Eve 拦截了消息并将 "Xyzzy" 加到访客列表的末尾,那么她已经成功的破坏了这个派对。因此,Alice 和 Bob 需要他们之间的通信可以提供<ruby>完整性<rt>integrity</rt></ruby>:消息应该不会被篡改。
|
||||
对于真正的安全通信,保密性是不够的。假如 Eve 收集了足够多 Alice 和 Bob 之间的消息,发现单词 “Eve” 被加密为 "Xyzzy"。除此之外,Eve 还知道 Alice 和 Bob 正在准备一个派对,Alice 会将访客名单发送给 Bob。如果 Eve 拦截了消息并将 “Xyzzy” 加到访客列表的末尾,那么她已经成功的破坏了这个派对。因此,Alice 和 Bob 需要他们之间的通信可以提供<ruby>完整性<rt>integrity</rt></ruby>:消息应该不会被篡改。
|
||||
|
||||
而且我们还有一个问题有待解决。假如 Eve 观察到 Bob 打开了标记为”来自 Alice“的信封,信封中包含一条来自 Alice 的消息”再买一加仑冰淇淋“。Eve 看到 Bob 外出,回家时带着冰淇淋,这样虽然 Eve 并不知道消息的完整内容,但她对消息有了大致的了解。Bob 将上述消息丢弃,但 Eve 找出了它并在下一周中的每一天都向 Bob 的邮箱中投递一封标记为”来自 Alice“的信封,内容拷贝自之前 Bob 丢弃的那封信。这样到了派对的时候,冰淇淋严重超量;派对当晚结束后,Bob 分发剩余的冰淇淋,Eve 带着免费的冰淇淋回到家。消息是加密的,完整性也没问题,但 Bob 被误导了,没有认出发信人的真实身份。<ruby>身份认证<rt>Authentication</rt></ruby>这个特性用于保证你正在通信的人的确是其声称的那样。
|
||||
而且我们还有一个问题有待解决。假如 Eve 观察到 Bob 打开了标记为“来自 Alice”的信封,信封中包含一条来自 Alice 的消息“再买一加仑冰淇淋”。Eve 看到 Bob 外出,回家时带着冰淇淋,这样虽然 Eve 并不知道消息的完整内容,但她对消息有了大致的了解。Bob 将上述消息丢弃,但 Eve 找出了它并在下一周中的每一天都向 Bob 的邮箱中投递一封标记为“来自 Alice”的信封,内容拷贝自之前 Bob 丢弃的那封信。这样到了派对的时候,冰淇淋严重超量;派对当晚结束后,Bob 分发剩余的冰淇淋,Eve 带着免费的冰淇淋回到家。消息是加密的,完整性也没问题,但 Bob 被误导了,没有认出发信人的真实身份。<ruby>身份认证<rt>Authentication</rt></ruby>这个特性用于保证你正在通信的人的确是其声称的那样。
|
||||
|
||||
信息安全还有[其它特性][6],但保密性、完整性和身份验证是你必须了解的三大特性。
|
||||
|
||||
@ -20,17 +23,17 @@
|
||||
|
||||
(LCTT 译注:cipher 一般被翻译为密码,但其具体表达的意思是加密算法,这里采用加密算法的翻译)
|
||||
|
||||
加密算法使用密钥加密明文。考虑到希望能够解密密文,我们用到的加密算法也必须是<ruby>可逆的<rt>reversible</rt></ruby>。作为简单示例,我们可以使用 [XOR][7]。该算子可逆,而且逆算子就是本身(P ^ K = C; C ^ K = P),故可同时用于加密和解密。该算子的平凡应用可以是<ruby>一次性密码本<rt>one-time pad</rt></ruby>,但一般而言并不[可行][9]。但可以将 XOR 与一个基于单个密钥生成<ruby>任意随机数据流<rt>arbitrary stream of random data</rt></ruby>的函数结合起来。现代加密算法 AES 和 Chacha20 就是这么设计的。
|
||||
加密算法使用密钥加密明文。考虑到希望能够解密密文,我们用到的加密算法也必须是<ruby>可逆的<rt>reversible</rt></ruby>。作为简单示例,我们可以使用 [XOR][7]。该算子可逆,而且逆算子就是本身(`P ^ K = C; C ^ K = P`),故可同时用于加密和解密。该算子的平凡应用可以是<ruby>一次性密码本<rt>one-time pad</rt></ruby>,不过一般而言并不[可行][9]。但可以将 XOR 与一个基于单个密钥生成<ruby>任意随机数据流<rt>arbitrary stream of random data</rt></ruby>的函数结合起来。现代加密算法 AES 和 Chacha20 就是这么设计的。
|
||||
|
||||
我们把加密和解密使用同一个密钥的加密算法称为<ruby>对称加密算法<rt>symmetric cipher</rt></ruby>。对称加密算法分为<ruby>流加密算法<rt>stream ciphers</rt></ruby>和分组加密算法两类。流加密算法依次对明文中的每个比特或字节进行加密。例如,我们上面提到的 XOR 加密算法就是一个流加密算法。流加密算法适用于明文长度未知的情形,例如数据从管道或 socket 传入。[RC4][10] 是最为人知的流加密算法,但在多种不同的攻击面前比较脆弱,以至于最新版本 (1.3)的 TLS ("HTTPS" 中的 "S")已经不再支持该加密算法。[Efforts][11] 正着手创建新的加密算法,候选算法 [ChaCha20][12] 已经被 TLS 支持。
|
||||
我们把加密和解密使用同一个密钥的加密算法称为<ruby>对称加密算法<rt>symmetric cipher</rt></ruby>。对称加密算法分为<ruby>流加密算法<rt>stream ciphers</rt></ruby>和分组加密算法两类。流加密算法依次对明文中的每个比特或字节进行加密。例如,我们上面提到的 XOR 加密算法就是一个流加密算法。流加密算法适用于明文长度未知的情形,例如数据从管道或 socket 传入。[RC4][10] 是最为人知的流加密算法,但在多种不同的攻击面前比较脆弱,以至于最新版本 (1.3)的 TLS (“HTTPS” 中的 “S”)已经不再支持该加密算法。[Efforts][11] 正着手创建新的加密算法,候选算法 [ChaCha20][12] 已经被 TLS 支持。
|
||||
|
||||
分组加密算法对固定长度的分组,使用固定长度的密钥加密。在分组加密算法领域,排行第一的是 [<ruby>先进加密标准<rt>Advanced Encryption Standard, AES</rt></ruby>][13],使用的分组长度为 128 比特。分组包含的数据并不多,因而分组加密算法包含一个[工作模式][14],用于描述如何对任意长度的明文执行分组加密。最简单的工作模式是 [<ruby>电子密码本<rt>Electronic Code Book, ECB</rt></ruby>][15],将明文按分组大小划分成多个分组(在必要情况下,填充最后一个分组),使用密钥独立的加密各个分组。
|
||||
分组加密算法对固定长度的分组,使用固定长度的密钥加密。在分组加密算法领域,排行第一的是 [<ruby>先进加密标准<rt>Advanced Encryption Standard</rt></ruby>][13](AES),使用的分组长度为 128 比特。分组包含的数据并不多,因而分组加密算法包含一个[工作模式][14],用于描述如何对任意长度的明文执行分组加密。最简单的工作模式是 [<ruby>电子密码本<rt>Electronic Code Book</rt></ruby>][15](ECB),将明文按分组大小划分成多个分组(在必要情况下,填充最后一个分组),使用密钥独立的加密各个分组。
|
||||
|
||||

|
||||
|
||||
这里我们留意到一个问题:如果相同的分组在明文中出现多次(例如互联网流量中的 "GET / HTTP/1.1" 词组),由于我们使用相同的密钥加密分组,我们会得到相同的加密结果。我们的安全通信中会出现一种<ruby>模式规律<rt>pattern</rt></ruby>,容易受到攻击。
|
||||
这里我们留意到一个问题:如果相同的分组在明文中出现多次(例如互联网流量中的 `GET / HTTP/1.1` 词组),由于我们使用相同的密钥加密分组,我们会得到相同的加密结果。我们的安全通信中会出现一种<ruby>模式规律<rt>pattern</rt></ruby>,容易受到攻击。
|
||||
|
||||
因此还有很多高级的工作模式,例如 [<ruby>密码分组链接<rt>Cipher Block Chaining, CBC</rt></ruby>][16],其中每个分组的明文在加密前会与前一个分组的密文进行 XOR 操作,而第一个分组的明文与一个随机数构成的初始化向量进行 XOR 操作。还有其它一些工作模式,在安全性和执行速度方面各有优缺点。甚至还有 Counter (CTR) 这种工作模式,可以将分组加密算法转换为流加密算法。
|
||||
因此还有很多高级的工作模式,例如 [<ruby>密码分组链接<rt>Cipher Block Chaining</rt></ruby>][16](CBC),其中每个分组的明文在加密前会与前一个分组的密文进行 XOR 操作,而第一个分组的明文与一个随机数构成的初始化向量进行 XOR 操作。还有其它一些工作模式,在安全性和执行速度方面各有优缺点。甚至还有 Counter (CTR) 这种工作模式,可以将分组加密算法转换为流加密算法。
|
||||
|
||||
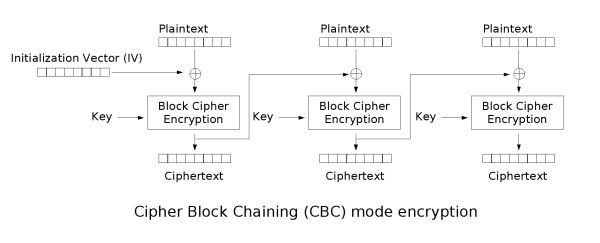
|
||||
|
||||
@ -54,7 +57,7 @@
|
||||
|
||||
如果我们同时发送消息及其摘要,接收者可以使用相同的哈希函数独立计算摘要。如果两个摘要相同,可以认为消息没有被篡改。考虑到 [SHA-1][25] 已经变得[有些过时][26],目前最流行的密码散列函数是 [SHA-256][24]。
|
||||
|
||||
散列函数看起来不错,但如果有人可以同时篡改消息及其摘要,那么消息发送仍然是不安全的。我们需要将哈希与加密算法结合起来。在对称加密算法领域,我们有<ruby>消息认证码<rt>message authentication codes, MACs</rt></ruby>技术。MACs 有多种形式,但<ruby>哈希消息认证码<rt>hash message authentication codes, HMAC</rt></ruby> 这类是基于哈希的。[HMAC][27] 使用哈希函数 H 处理密钥 K、消息 M,公式为 H(K + H(K + M)),其中 "+" 代表<ruby>连接<rt>concatenation</rt></ruby>。公式的独特之处并不在本文讨论范围内,大致来说与保护 HMAC 自身的完整性有关。发送加密消息的同时也发送 MAC。Eve 可以任意篡改消息,但一旦 Bob 独立计算 MAC 并与接收到的 MAC 做比较,就会发现消息已经被篡改。
|
||||
散列函数看起来不错,但如果有人可以同时篡改消息及其摘要,那么消息发送仍然是不安全的。我们需要将哈希与加密算法结合起来。在对称加密算法领域,我们有<ruby>消息认证码<rt>message authentication codes</rt></ruby>(MAC)技术。MAC 有多种形式,但<ruby>哈希消息认证码<rt>hash message authentication codes</rt></ruby>(HMAC) 这类是基于哈希的。[HMAC][27] 使用哈希函数 H 处理密钥 K、消息 M,公式为 `H(K + H(K + M))`,其中 `+` 代表<ruby>连接<rt>concatenation</rt></ruby>。公式的独特之处并不在本文讨论范围内,大致来说与保护 HMAC 自身的完整性有关。发送加密消息的同时也发送 MAC。Eve 可以任意篡改消息,但一旦 Bob 独立计算 MAC 并与接收到的 MAC 做比较,就会发现消息已经被篡改。
|
||||
|
||||
在非对称加密算法领域,我们有<ruby>数字签名<rt>digital signatures</rt></ruby>技术。如果使用 RSA,使用公钥加密的内容只能通过私钥解密,反过来也是如此;这种机制可用于创建一种签名。如果只有我持有私钥并用其加密文档,那么只有我的公钥可以用于解密,那么大家潜在的承认文档是我写的:这是一种身份验证。事实上,我们无需加密整个文档。如果生成文档的摘要,只要对这个指纹加密即可。对摘要签名比对整个文档签名要快得多,而且可以解决非对称加密存在的消息长度限制问题。接收者解密出摘要信息,独立计算消息的摘要并进行比对,可以确保消息的完整性。对于不同的非对称加密算法,数字签名的方法也各不相同;但核心都是使用公钥来检验已有签名。
|
||||
|
||||
@ -64,7 +67,7 @@
|
||||
|
||||
密码学的世界博大精深,我希望这篇文章能让你对密码学的核心目标及其组件有一个大致的了解。这些概念为你打下坚实的基础,让你可以继续深入学习。
|
||||
|
||||
感谢 Hubert Kario,Florian Weimer 和 Mike Bursell 在本文写作过程中提供的帮助。
|
||||
感谢 Hubert Kario、Florian Weimer 和 Mike Bursell 在本文写作过程中提供的帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +76,7 @@ via: https://opensource.com/article/18/5/cryptography-pki
|
||||
作者:[Alex Wood][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,64 +1,63 @@
|
||||
你的路由器有多不安全?
|
||||
======
|
||||
|
||||
> 你的路由器是你与互联网之间的第一个联系点。它给你带来了多少风险?
|
||||
|
||||

|
||||
|
||||
我一直对写在 T 恤上的“127.0.0.1 这个地方是独一无二的” 这句话持有异议。我知道你可能会认为应该将它读作是“家”,但是对于我来说,我认为应该是“本地主机是独一无二的地方”,就像世界上没有完全相同的二个戒指一样。在本文中,我想去讨论一些宽泛的问题:家庭网络的入口,对大多数人来说它是线缆或宽带路由器。英国和美国政府刚公布了“俄罗斯”攻击路由器的通告。我估计这次的攻击主要针对的是机构,而不是家庭,(看我以前的文章 "[国家行为者是什么,我们应该注意些什么?][1]"),但这对我们所有人都是一个警示。
|
||||
我一直对写在 T 恤上的“127.0.0.1 是独一无二的地方” 这句话持有异议。我知道你可能会认为应该将它看作是“家”,但是对于我来说,我认为应该是“本地主机是独一无二的地方”,就像世界上没有完全相同的二个戒指一样。在本文中,我想去讨论一些宽泛的问题:家庭网络的入口,对大多数人来说它是线缆或宽带路由器。^1 英国和美国政府刚公布了“俄罗斯” ^2 攻击路由器的通告。我估计这次的攻击主要针对的是机构,而不是家庭,(看我以前的文章 “[国家行为者是什么,我们应该注意些什么?][1]”),但这对我们所有人都是一个警示。
|
||||
|
||||
### 路由器有什么用?
|
||||
|
||||
路由器很重要。它用于将一个网络(在本文中,是我们的家庭网络)与另外一个网络(在本文中,是指因特网,通过我们的因特网服务提供商的网络)连接。事实上,对于大多数人来说,我们所谓的”路由器“这个小盒子能够做的事情远比我们想到的要多。"routing" 比特就像它的发音一样;它让网络中的计算机能够找到一条向外部网络中计算机发送数据的路径 —— 当你接收数据时,正好是相反的方式。
|
||||
路由器很重要。它用于将一个网络(在本文中,是我们的家庭网络)与另外一个网络(在本文中,是指互联网,通过我们的互联网服务提供商的网络)连接。事实上,对于大多数人来说,我们所谓的“路由器” ^3 这个小盒子能够做的事情远比我们想到的要多。“路由” 一个比特就就如其听起来的意思一样:它让网络中的计算机能够找到一条向外部网络中计算机发送数据的路径 —— 当你接收数据时,反之。
|
||||
|
||||
在路由器的其它功能中,大多数时候也作为一台调制解调器来使用。在英国大部分到因特网的连接是通过电话线来实现的 —— 无论是电缆还是标准电话线 —— 尽管现在的最新趋势是通过移动互联网连接到家庭中。当你通过电话线连接时,我们所使用的因特网信号必须转换成其它的一些东西,(从另一端来的)返回信号也是如此。对于那些还记得过去的”拨号上网“时代的人来说,它就是你的电脑边上那个用于上网的发出刺耳声音的小盒子。
|
||||
在路由器的其它功能中,大多数时候也作为一台调制解调器来使用。我们中的大部分人 ^4 到互联网的连接是通过电话线来实现的 —— 无论是电缆还是标准电话线 —— 尽管现在的最新趋势是通过移动互联网连接到家庭中。当你通过电话线连接时,我们所使用的互联网信号必须转换成其它的一些东西,(从另一端来的)返回信号也是如此。对于那些还记得过去的“拨号上网”时代的人来说,它就是你的电脑边上那个用于上网的发出刺耳声音的小盒子。
|
||||
|
||||
但是路由器能做的事情很多,有时候很多的事情,包括流量记录、作为一个无线接入点、提供 VPN 功能以便于从外部访问你的内网、儿童上网控制、防火墙等等。
|
||||
|
||||
现在的家用路由器越来越复杂;虽然国家行为者并不想参与其中,但是其它人可以。
|
||||
现在的家用路由器越来越复杂;虽然国家行为者也行不会想着攻破它,但是其它人也许会。
|
||||
|
||||
你会问,这很重要吗?如果其它人可以进入你的系统,他们可以很容易地攻击你的笔记本电脑、电话、网络设备等等。他们可以访问和删除未被保护的个人数据。他们可以假装是你。他们使用你的网络去寄存非法数据或者用于攻击其它人。基本上所有的坏事都可以做。
|
||||
|
||||
幸运的是,现在的路由器趋向于因特网提供商来做设置,言外之意是你可以忘了它的存在,他们将保证它是运行良好和安全的。
|
||||
幸运的是,现在的路由器趋向于由互联网提供商来做设置,言外之意是你可以忘了它的存在,他们将保证它是运行良好和安全的。
|
||||
|
||||
### 因此,我们是安全的吗?
|
||||
|
||||
不幸的是,事实并非如此。
|
||||
|
||||
第一个问题是,因特网提供商是在有限的预算范围内做这些事情,而使用便宜的设备来做这些事可以让他们的利益最大化。因特网提供商的路由器质量越来越差。它是恶意攻击者的首选目标:如果他们知道特定型号的路由器被安装在几百万个家庭使用,那么很容易找到攻击的动机,因为攻击那个型号的路由器对他们来说是非常有价值的。
|
||||
第一个问题是,互联网提供商是在有限的预算范围内做这些事情,而使用便宜的设备来做这些事可以让他们的利益最大化。互联网提供商的路由器质量越来越差。它是恶意攻击者的首选目标:如果他们知道特定型号的路由器被安装在几百万个家庭使用,那么很容易找到攻击的动机,因为攻击那个型号的路由器对他们来说是非常有价值的。
|
||||
|
||||
产生的其它问题还包括:
|
||||
|
||||
* 修复 bug 或者漏洞的过程很缓慢。升级固件可能会让因特网提供商产生较高的成本,因此,修复过程可能非常缓慢(如果他们打算修复的话)。
|
||||
* 修复 bug 或者漏洞的过程很缓慢。升级固件可能会让互联网提供商产生较高的成本,因此,修复过程可能非常缓慢(如果他们打算修复的话)。
|
||||
* 非常容易获得或者默认的管理员密码,这意味着攻击者甚至都不需要去找到真实的漏洞 —— 他们就可以登入到路由器中。
|
||||
|
||||
|
||||
|
||||
### 对策
|
||||
|
||||
对于进入因特网第一跳的路由器,如何才能提升它的安全性,这里给你提供一个快速应对的清单。我是按从简单到复杂的顺序来列出它们的。在你对路由器做任何改变之前,需要先保存配置数据,以便于你需要的时候回滚它们。
|
||||
|
||||
1. **密码:** 一定,一定,一定要改变你的路由器的管理员密码。你可能很少会用到它,所以你一定要把密码记录在某个地方。它用的次数很少,你可以考虑将密码粘贴到路由器上,因为路由器一般都放置在仅授权的人(你和你的家人)才可以接触到的地方。
|
||||
2. **仅允许管理员从内部进行访问:** 除非你有足够好的理由和你知道如何去做,否则不要允许任何机器从外部的因特网上管理你的路由器。在你的路由器上有一个这样的设置。
|
||||
3. **WiFi 密码:** 一旦你做到了第 2 点,也要确保在你的网络上的那个 WiFi 密码 —— 无论是设置为你的路由器管理密码还是别的 —— 一定要是强密码。为了简单,为连接你的网络的访客设置一个”友好的“简单密码,但是,如果附近一个恶意的人猜到了密码,他做的第一件事情就是查找网络中的路由器。由于他在内部网络,他是可以访问路由器的(因此,第 1 点很重要)。
|
||||
4. **仅打开你知道的并且是你需要的功能:** 正如我在上面所提到的,现代的路由器有各种很酷的选项。不要使用它们。除非你真的需要它们,并且你真正理解了它们是做什么的,并且打开它们后有什么危险。否则,将增加你的路由器被攻击的风险。
|
||||
5. **购买你自己的路由器:** 用一个更好的路由器替换掉因特网提供商给你的路由器。去到你本地的电脑商店,让他们给你一些建议。你可能会花很多钱,但是也可能会遇到一些非常便宜的设备,而且比你现在拥有的更好、性能更强、更安全。你也可以只买一个调制解调器。一般设置调制解调器和路由器都很简单,并且,你可以从你的因特网提供商给你的设备中复制配置,它一般就能”正常工作“。
|
||||
6. **更新固件:** 我喜欢使用最新的功能,但是通常这并不容易。有时,你的路由器上会出现固件更新的提示。大多数的路由器会自动检查并且提示你在下次登入的时候去更新它。问题是如果更新失败则会产生灾难性后果或者丢失配置数据,那就需要你重新输入。但是你真的需要考虑去持续关注修复安全问题的固件更新,并更新它们。
|
||||
7. **转向开源:** 有一些非常好的开源路由器项目,可以让你用在现有的路由器上,用开源的软件去替换它的固件/软件。你可以在 [Wikipedia][2] 上找到许多这样的项目,以及在 [Opensource.com 上搜索 "router"][3],你将看到很多非常好的东西。对于谨慎的人来说要小心,这将会让你的路由器失去保修,但是如果你想真正控制你的路由器,开源永远是最好的选择。
|
||||
|
||||
对于进入互联网第一跳的路由器,如何才能提升它的安全性,这里给你提供一个快速应对的清单。我是按从简单到复杂的顺序来列出它们的。在你对路由器做任何改变之前,需要先保存配置数据,以便于你需要的时候回滚它们。
|
||||
|
||||
1. **密码:** 一定,一定,一定要改变你的路由器的管理员密码。你可能很少会用到它,所以你一定要把密码记录在某个地方。它用的次数很少,你可以考虑将密码粘贴到路由器上,因为路由器一般都放置在仅供授权的人(你和你的家人 ^5 )才可以接触到的地方。
|
||||
2. **仅允许管理员从内部进行访问:** 除非你有足够好的理由和你知道如何去做,否则不要允许任何机器从外部的互联网上管理你的路由器。在你的路由器上有一个这样的设置。
|
||||
3. **WiFi 密码:** 一旦你做到了第 2 点,也要确保在你的网络上的那个 WiFi 密码 —— 无论是设置为你的路由器管理密码还是别的 —— 一定要是强密码。为了简单,为连接你的网络的访客设置一个“友好的”简单密码,但是,如果附近一个恶意的人猜到了密码,他做的第一件事情就是查找网络中的路由器。由于他在内部网络,他是可以访问路由器的(因此,第 1 点很重要)。
|
||||
4. **仅打开你知道的并且是你需要的功能:** 正如我在上面所提到的,现代的路由器有各种很酷的选项。不要使用它们。除非你真的需要它们,并且你真正理解了它们是做什么的,以及打开它们后有什么危险。否则,将增加你的路由器被攻击的风险。
|
||||
5. **购买你自己的路由器:** 用一个更好的路由器替换掉互联网提供商给你的路由器。去到你本地的电脑商店,让他们给你一些建议。你可能会花很多钱,但是也可能会遇到一些非常便宜的设备,而且比你现在拥有的更好、性能更强、更安全。你也可以只买一个调制解调器。一般设置调制解调器和路由器都很简单,并且,你可以从你的互联网提供商给你的设备中复制配置,它一般就能“正常工作”。
|
||||
6. **更新固件:** 我喜欢使用最新的功能,但是通常这并不容易。有时,你的路由器上会出现固件更新的提示。大多数的路由器会自动检查并且提示你在下次登入的时候去更新它。问题是如果更新失败则会产生灾难性后果 ^6 或者丢失配置数据,那就需要你重新输入。但是你真的需要考虑去持续关注修复安全问题的固件更新,并更新它们。
|
||||
7. **转向开源:** 有一些非常好的开源路由器项目,可以让你用在现有的路由器上,用开源的软件去替换它的固件/软件。你可以在 [Wikipedia][2] 上找到许多这样的项目,以及在 [Opensource.com 上搜索 “router”][3],你将看到很多非常好的东西。对于谨慎的人来说要小心,这将会让你的路由器失去保修,但是如果你想真正控制你的路由器,开源永远是最好的选择。
|
||||
|
||||
### 其它问题
|
||||
|
||||
一旦你提升了你的路由器的安全性,你的家庭网络将变的很好,这是假像,事实并不是如此。你家里的物联网设备(Alexa、Nest、门铃、智能灯泡、等等)安全性如何?连接到其它网络的 VPN 安全性如何?通过 WiFi 的恶意主机、你的孩子手机上的恶意应用程序 …?
|
||||
一旦你提升了你的路由器的安全性,你的家庭网络将变的很好——这是假像,事实并不是如此。你家里的物联网设备(Alexa、Nest、门铃、智能灯泡、等等)安全性如何?连接到其它网络的 VPN 安全性如何?通过 WiFi 的恶意主机、你的孩子手机上的恶意应用程序 …?
|
||||
|
||||
不,你永远不会有绝对的安全。但是正如我们前面讨论的,虽然没有绝对的”安全“这种事情,但是并不意味着我们不需要去提升安全标准,以让坏人干坏事更困难。
|
||||
不,你永远不会有绝对的安全。但是正如我们前面讨论的,虽然没有绝对的“安全”这种事情,但是并不意味着我们不需要去提升安全标准,以让坏人干坏事更困难。
|
||||
|
||||
### 脚注
|
||||
|
||||
1. 我写的很简单 — 但请继续读下去,我们将达到目的。
|
||||
2. "俄罗斯政府赞助的信息技术国家行为者"
|
||||
3. 或者,以我父母的例子来说,我不相信 ”这个路由器“。
|
||||
2. “俄罗斯政府赞助的信息技术国家行为者”
|
||||
3. 或者,以我父母的例子来说,我猜叫做 “互联网盒子”。
|
||||
4. 这里还有一种这样的情况,我不希望在评论区告诉我,你是直接以 1TB/s 的带宽连接到本地骨干网络的。非常感谢!
|
||||
5. 或许并没有包含全部的家庭。
|
||||
6. 你的路由器现在是一块”砖“,并且你不想访问因特网。
|
||||
|
||||
|
||||
5. 或许并没有包含整个家庭。
|
||||
6. 你的路由器现在是一块“砖”,并且你不能访问互联网了。
|
||||
|
||||
这篇文章最初发表在 [Alice, Eve, 和 Bob – 安全博客][4] 并授权重发布。
|
||||
|
||||
@ -69,7 +68,7 @@ via: https://opensource.com/article/18/5/how-insecure-your-router
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
48
published/201806/20180603 Let-s migrate away from GitHub.md
Normal file
48
published/201806/20180603 Let-s migrate away from GitHub.md
Normal file
@ -0,0 +1,48 @@
|
||||
让我们从 GitHub 中迁移出来
|
||||
======
|
||||
|
||||
正如你们之前听到的那样,[微软收购了 GitHub][1]。这对 GitHub 的未来意味着什么尚不清楚,但 [Gitlab 的人][2]认为微软的最终目标是将 GitHub 整合到他们的 Azure 帝国。对我来说,这很有道理。
|
||||
|
||||
尽管我仍然不情愿地将 GitHub 用于某些项目,但我前一段时间将所有个人仓库迁移到了 Gitlab 中。现在是时候让你做同样的事情,并抛弃 GitHub。
|
||||
|
||||
![Microsft loven't Linux][3]
|
||||
|
||||
有些人可能认为微软的收购没有问题,但对我来说,这是压垮骆驼的最后一根稻草。几年来,微软一直在开展一场关于他们如何热爱 Linux 的大型营销活动,并突然决定用所有它的形式拥抱自由软件。更像 MS BS 给我的。
|
||||
|
||||
让我们花点时间提醒自己:
|
||||
|
||||
* Windows 仍然是一个巨大的专有怪物,数十亿人每天都丧失了他们的隐私和权利中。
|
||||
* 微软公司(曾经)以传播自由软件的“危害”闻名,以防止政府和学校放弃 Windows,转而支持 FOSS。
|
||||
* 为了确保他们的垄断地位,微软通过向全世界的小学颁发“免费”许可证来吸引孩子使用 Windows。毒品经销商使用相同的策略并提供免费样品来获取新客户。
|
||||
* 微软的 Azure 平台 - 即使它可以运行 Linux 虚拟机 - 它仍然是一个巨大的专有管理程序。
|
||||
|
||||
我知道移动 git 仓库看起来像是一件痛苦的事情,但是 Gitlab 的员工正在乘着人们离开 GitHub 的浪潮,并通过[提供 GitHub 导入器][4]使迁移变得容易。
|
||||
|
||||
如果你不想使用 Gitlab 的主实例([gitlab.org][5]),下面是另外两个你可以用于自由软件项目的备选实例:
|
||||
|
||||
* [Debian Gitlab 实例][6]适用于每个 FOSS 项目,它不仅适用于与 Debian 相关的项目。只要项目符合 [Debian 自由软件指南][7],你就可以使用该实例及其 CI。
|
||||
* Riseup 为名为 [0xacab][8] 的激进项目维护了一个 Gitlab 实例。如果你的[理念与 Riseup 的一致][9],他们很乐意在那里托管你的项目。
|
||||
|
||||
朋友不要再让人使用 Github 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/lets-migrate-away-from-github.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://www.bloomberg.com/news/articles/2018-06-03/microsoft-is-said-to-have-agreed-to-acquire-coding-site-github
|
||||
[2]:https://about.gitlab.com/2018/06/03/microsoft-acquires-github/
|
||||
[3]:https://veronneau.org/media/blog/2018-06-03/ms-lovent-linux.png (Microsoft loven't Linux)
|
||||
[4]:https://docs.gitlab.com/ee/user/project/import/github.html
|
||||
[5]:https://gitlab.org
|
||||
[6]:https://salsa.debian.org
|
||||
[7]:https://en.wikipedia.org/wiki/Debian_Free_Software_Guidelines
|
||||
[8]:https://0xacab.org
|
||||
[9]:https://riseup.net/en/about-us/politics
|
||||
@ -1,7 +1,7 @@
|
||||
如何暂时禁用 iptables 防火墙
|
||||
======
|
||||
|
||||
了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
|
||||
> 了解如何在 Linux 中暂时禁用 iptables 防火墙来进行故障排除。还要学习如何保存策略以及如何在启用防火墙时恢复它们。
|
||||
|
||||
![How to disable iptables firewall temporarily][1]
|
||||
|
||||
@ -32,6 +32,7 @@ root@kerneltalks # iptables-save > /root/firewall_rules.backup
|
||||
对于较老的 Linux 内核,你可以选择使用 `service iptables stop` 停止 iptables 服务,但是如果你在用新内核,则只需清除所有策略并允许所有流量通过防火墙。这和你停止防火墙效果一样。
|
||||
|
||||
使用下面的命令列表来做到这一点。
|
||||
|
||||
```
|
||||
root@kerneltalks # iptables -F
|
||||
root@kerneltalks # iptables -X
|
||||
@ -42,11 +43,9 @@ root@kerneltalks # iptables -P FORWARD ACCEPT
|
||||
|
||||
这里 –
|
||||
|
||||
* -F:删除所有策略链
|
||||
* -X:删除用户定义的链
|
||||
* -P INPUT/OUTPUT/FORWARD :接受指定的流量
|
||||
|
||||
|
||||
* `-F`:删除所有策略链
|
||||
* `-X`:删除用户定义的链
|
||||
* `-P INPUT/OUTPUT/FORWARD` :接受指定的流量
|
||||
|
||||
完成后,检查当前的防火墙策略。它应该看起来像下面这样接受所有流量(和禁用/停止防火墙一样)
|
||||
|
||||
@ -69,6 +68,7 @@ target prot opt source destination
|
||||
```
|
||||
root@kerneltalks # iptables-restore </root/firewall_rules.backup
|
||||
```
|
||||
|
||||
### 启动 iptables 防火墙
|
||||
|
||||
然后启动 iptables 服务,以防止你在上一步中使用 `service iptables start` 停止了它。如果你已经停止服务,那么只有恢复策略才能有用。检查所有策略是否恢复到 iptables 配置中:
|
||||
@ -94,7 +94,7 @@ via: https://kerneltalks.com/howto/how-to-disable-iptables-firewall-temporarily/
|
||||
作者:[kerneltalks][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
用这样的 Vi 配置来保存和组织你的笔记
|
||||
===============
|
||||
|
||||
> Vimwiki 和 GitLab 是记录笔记的强大组合。
|
||||
|
||||
![1][]
|
||||
|
||||
用 vi 来管理 wiki 来记录你的笔记,这听起来不像是一个符合常规的主意,但当你的日常工作都会用到 vi , 那它是有意义的。
|
||||
|
||||
作为一个软件开发人员,使用同编码一样的工具来写笔记会更加简单。我想将我的笔记变成一种编辑器命令,无论我在哪里,都能够用管理我代码的方法来管理我的笔记。这便是我创建一个基于 vi 的环境来搭建我自己的知识库的原因。简单概括起来,我在笔记本电脑上用 vi 插件 [Viwiki][2] 来本地管理我的 wiki。用 Git 来进行版本控制(以保留一个中心化的更新版本),并用 GitLab 来进行在线修改(例如在我的手机上)。
|
||||
|
||||
### 为什么用 wiki 来进行笔记保存是有意义
|
||||
|
||||
我尝试过许多不同的工具来持续的记录我的笔记,笔记里保存着我的灵感以及需要记住的任务安排。这包括线下的笔记本 (没错,纸质的)、特殊的记录笔记的软件,以及思维导图软件。
|
||||
|
||||
但每种方案都有不好一面,没有一个能够满足我所有的需求。例如[思维导图][6],能够很好的形象化你的想法(因而得名),但是这种工具的搜索功能很差(和纸质笔记本一样)。此外,当一段时间过去,思维导图会变得很难阅读,所以思维导图不适合长时间保存的笔记。
|
||||
|
||||
我为一个合作项目配置了 [DokuWiki][2],我发现这个 wiki 模型符合了我大多数的需求。在 wiki 上,你能够创建一个笔记(和你在文本编辑器中所作的一样),并在笔记间创建链接。如果一个链接指向一个不存在的页面(你想让本页面添加一条还没有创建的信息), wiki 会为你建立这个页面。这个特性使得 wiki 很好的适应了那些需要快速写下心中所想的人的需求,而仍将你的笔记保持在能够容易浏览和搜索关键字的页面结构中。
|
||||
|
||||
这看起来很有希望,并且配置 DokuWiki 也很容易,但我发现只是为了记个笔记而配置整个 wiki 需要花费太多工作。在一番搜索后,我发现了 Vimwiki,这是一个我想要的 vi 插件。因为我每天使用 vi,记录笔记就行编辑代码一样。甚至在 vimwiki 创建一个页面比 Dokuwiki 更简单。你只需要对光标下的单词按下回车键就行。如果没有文件是这个名字,vimwiki 会为你创建一个。
|
||||
|
||||
为了更一步的实现用每天都会使用的工具来做笔记的计划,我不仅用这个我最爱的 IDE 来写笔记,而且用 Git 和 GitLab —— 我最爱的代码管理工具 —— 在我的各个机器间分发我的笔记,以便我可以在线访问它们。我也是在 Gitlab 的在线 markdown 工具上用 markdown 语法来写的这篇文章。
|
||||
|
||||
### 配置 vimwiki
|
||||
|
||||
用你已有的插件管理工具来安装 vimwiki 很简单,只需要添加 vimwiki/vimwiki 到你的插件。对于我的喜爱的插件管理器 Vundle 来说,你只需要在 `/.vimrc` 中添加 `plugin vimwiki/vimwiki` 这一行,然后执行 `:source ~/.vimrc | PluginInstall` 就行。
|
||||
|
||||
下面是我的文件 `.vimrc` 的一部分,展示了一些 vimwiki 配置。你能在 [vimwiki][2] 页面学到更多的配置和使用的的信息。
|
||||
|
||||
```
|
||||
let wiki_1 = {}
|
||||
let wiki_1.path = '~/vimwiki_work_md/'
|
||||
let wiki_1.syntax = 'markdown'
|
||||
let wiki_1.ext = '.md'
|
||||
|
||||
let wiki_2 = {}
|
||||
let wiki_2.path = '~/vimwiki_personal_md/'
|
||||
let wiki_2.syntax = 'markdown'
|
||||
let wiki_2.ext = '.md'
|
||||
|
||||
let g:vimwiki_list = [wiki_1, wiki_2]
|
||||
let g:vimwiki_ext2syntax = {'.md': 'markdown', '.markdown': 'markdown', '.mdown': 'markdown'}
|
||||
```
|
||||
|
||||
如你在上述配置中所见,我的配置还有一个优点。你能简单的区分个人和工作相关的笔记,而不用切换笔记软件。我想让我的个人笔记可以随时随地访问,而不想我的工作笔记同步到我私人的 GitLab 和计算机中。在 vimwiki 这样配置要比我试过的其他软件都要简单。
|
||||
|
||||
这个配置告诉 vimwiki 有两个不同 Wiki,都使用 markdown 语法(再一次,因为我的日常工作中天天都在用 markdown 语法)。我也告诉 Vimwiki 在哪个文件夹存储 wiki 页面。
|
||||
|
||||
如果你进入存储 wiki 页面的文件夹,你会找到你的 wiki 的普通的 markdown 页面文件,而没有其他特殊的 Vimwiki 相关内容,这使得很容易的初始化 Git 仓库和同步你的 wiki 到中心仓库。
|
||||
|
||||
### 同步你的 wiki 到 GitLab
|
||||
|
||||
这一步检出一个 GitLab 项目到本地的 VimWiki 文件夹,这步操作和你操作任何 GitHub 的仓库相同,只不过因为我更喜欢保存我的笔记到我的私人 GitLab 仓库,所以我运行了一个 GitLab 实例用于我个人的项目。
|
||||
|
||||
GitLab 的 wiki 功能可以用来为你的项目创建 wiki 页面。这些 wiki 就是 Git 仓库本身。它们使用 markdown 语法,你懂得。
|
||||
|
||||
只需要初始化你需要的 wiki ,让它与你为笔记而创建的项目的 wiki 同步即可。
|
||||
|
||||
```
|
||||
cd ~/vimwiki_personal_md/
|
||||
git init
|
||||
git remote add origin git@your.gitlab.com:your_user/vimwiki_personal_md.wiki
|
||||
git add .
|
||||
git commit -m "Initial commit"
|
||||
git push -u origin master
|
||||
```
|
||||
|
||||
在 GitLab 创建一个新的项目后,你就可以从页面上复制这些步骤的代码。唯一的改变是仓库地址结尾是 .wiki(而不是 .git)。 这会告诉 Git 克隆 wiki 仓库而不是项目本身。
|
||||
|
||||
就是这样!现在你能够通过 Git 来管理你的笔记,通过 GitLab wiki 用户界面来修改笔记。
|
||||
|
||||
你可能(像我一样)不想手动的为每个添加到笔记本的笔记创建一个提交。为了解决这个问题,我使用了 Vim 插件 [chazy/dirsetting][4]。我添加一个 `.vimaddr` 文件,已经下面的内容:
|
||||
|
||||
```
|
||||
:cd %:p:h
|
||||
silent! !git pull > /dev/null
|
||||
:e!
|
||||
autocmd! BufWritePost * silent! !git add .;git commit -m "vim autocommit" > /dev/null; git push > /dev/null&
|
||||
```
|
||||
|
||||
每当我打开 Wiki 文件按下 `:w` 发布我的修改时,它就会更新到最新的版本。这样做会使你的本地文件与中心仓库保持同步。如果你有合并冲突,通常你需要解决它们。
|
||||
|
||||
目前,这就是以我的知识来互动的方法,我很喜欢这方法;请告诉我你对于这个方法的想法,可以在评论区分享你如何追踪笔记的方法。
|
||||
|
||||
-----------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/vimwiki-gitlab-notes
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[octopus](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://camo.githubusercontent.com/9901c750dce2008ea7a459201121077c355fc257/68747470733a2f2f6f70656e736f757263652e636f6d2f73697465732f64656661756c742f66696c65732f7374796c65732f696d6167652d66756c6c2d73697a652f7075626c69632f6c6561642d696d616765732f636865636b6c6973745f68616e64735f7465616d5f636f6c6c61626f726174696f6e2e706e673f69746f6b3d753832516570506b
|
||||
[2]:https://vimwiki.github.io/
|
||||
[3]:https://www.dokuwiki.org/dokuwiki
|
||||
[4]:https://github.com/chazy/dirsettings
|
||||
[6]:https://opensource.com/article/17/8/mind-maps-creative-dashboard
|
||||
@ -0,0 +1,86 @@
|
||||
协同编辑器的历史性清单
|
||||
======
|
||||
|
||||
按时间顺序快速列出主要协同编辑器的演变。
|
||||
|
||||
正如任何这样的清单一样,它必定会在一开始便提到被誉为“<ruby>[所有演示之母][25]<rt>the mother of all demos</rt></ruby>”,在这个演示里<ruby>[道格·恩格尔巴特][26]<rt>Doug Engelbart</rt></ruby>早在 1968 年就描述了几乎所有软件的详尽清单。这不仅包括协同编辑器,还包括图形、编程和数学编辑器。
|
||||
|
||||
一切都始于那个演示,只不过软件的实现跟不上硬件的发展罢了。
|
||||
|
||||
> 软件发展的速度比硬件提升的速度慢。——沃斯定律
|
||||
|
||||
闲话少说,这里是我找到的可圈可点的协同编辑器的清单。我说“可圈可点”的意思是它们具有可圈可点的特征或实现细节。
|
||||
|
||||
| 项目 | 日期 | 平台 | 说明 |
|
||||
| --- | --- | --- | --- |
|
||||
| [SubEthaEdit][1] | 2003-2015? | 仅 Mac|我能找到的首个协同的、实时的、多光标的编辑器, [有个在 Emacs 上的逆向工程的尝试][2]却没有什么结果。 |
|
||||
| [DocSynch][3] | 2004-2007 | ? | 建立于 IRC 之上! |
|
||||
| [Gobby][4] | 2005 至今 | C,多平台 | 首个开源、稳固可靠的实现。 仍然存在!众所周知 [libinfinoted][5] 协议很难移植到其他编辑器中(例如: [Rudel][6] 不能在 Emacs 上实现此协议)。 2017 年 1 月发行的 0.7 版本添加了也许可以改善这种状况的 Python 绑定。 值得注意的插件: 自动保存到磁盘。|
|
||||
| [Ethercalc][27] | 2005 至今 | Web,JavaScript | 首个电子表格,随同 [Google Docs][28]。 |
|
||||
| [moonedit][7] | 2005-2008? | ? | 原网站已关闭。其他用户的光标可见并且会模仿击键的声音。 包括一个计算器和音乐定序器。 |
|
||||
| [synchroedit][8] | 2006-2007 | ? | 首个 Web 应用。|
|
||||
| [Inkscape][29] | 2007-2011 | C++ | 首个具备协同功能的图形编辑器,其背后的“whiteboard” 插件构建于 Jabber 之上,现已停摆。|
|
||||
| [Abiword][30] | 2008 至今|C++| 首个文字处理器。|
|
||||
| [Etherpad][9] | 2008 至今 | Web |首款稳定的 Web 应用。 最初在 2008 年被开发时是一款大型 Java 应用,在 2009 年被谷歌收购并开源,然后在 2011 年被用 Node.JS 重写。使用广泛。|
|
||||
| [Wave][31]|2009-2010|Web, Java| 在大一统协议的尝试上失败。|
|
||||
| [CRDT][10] | 2011 | 特定平台| 在不同电脑间可靠地复制一个文件的数据结构的标准。 |
|
||||
| [Operational transform][11] | 2013 | 特定平台| 与 CRDT 类似,然而确切地说,两者是不同的。 |
|
||||
| [Floobits][12] | 2013 至今 | ? | 商业软件,但有对各种编辑器的开源插件。 |
|
||||
| [LibreOffice Online][32]| 2015至今| Web| 免费的 Google docs 替代品,现已集成到 [Nextcloud][33] |
|
||||
| [HackMD][13] | 2015 至今| ? | 商业软件,[开源][14]。灵感来自于(已被 Dropbox 收购的) hackpad。 |
|
||||
| [Cryptpad][15] | 2016 至今 | Web ? | Xwiki 的副产品。服务器端的加密的、“零知识” 产品。|
|
||||
| [Prosemirror][16] | 2016 至今 | Web, Node.JS | “试图架起消除 Markdown 文本编辑和传统的所见即所得编辑器之间隔阂的桥梁。”不是完全意义上的编辑器,而是一种可以用来构建编辑器的工具。 |
|
||||
| [Qill][17] | 2013 至今 | Web, Node.JS | 富文本编辑器,同时也是 JavaScript 编辑器。不确定是否是协同式的。 |
|
||||
| [Teletype][19] | 2017 至今 | WebRTC, Node.JS | 为 GitHub 的 [Atom 编辑器][20] 引入了“门户”的思路 ,使得访客可以夸多个文档跟踪主人的操作。访问介绍服务器后使用实时通讯的点对点技术(P2P),基于 CRDT。 |
|
||||
| [Tandem][21] | 2018 至今 | Node.JS? | Atom、 Vim、Neovim、 Sublime 等的插件。 使用中继来设置基于 CRDT 的 P2P 连接。多亏 Debian 开发者的参与,[可疑证书问题][22]已被解决,这使它成为很有希望在未来被遵循的标准。 |
|
||||
|
||||
### 其他清单
|
||||
|
||||
* [Emacs 维基][23]
|
||||
* [维基百科][24]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-06-26-collaborative-editors-history/
|
||||
|
||||
作者:[Anacr][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ZenMoore](https://github.com/ZenMoore)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://anarc.at
|
||||
[1]:https://www.codingmonkeys.de/subethaedit/
|
||||
[2]:https://www.emacswiki.org/emacs/SubEthaEmacs
|
||||
[3]:http://docsynch.sourceforge.net/
|
||||
[4]:https://gobby.github.io/
|
||||
[5]:http://infinote.0x539.de/libinfinity/API/libinfinity/
|
||||
[6]:https://www.emacswiki.org/emacs/Rudel
|
||||
[7]:https://web.archive.org/web/20060423192346/http://www.moonedit.com:80/
|
||||
[8]:http://www.synchroedit.com/
|
||||
[9]:http://etherpad.org/
|
||||
[10]:https://en.wikipedia.org/wiki/Conflict-free_replicated_data_type
|
||||
[11]:http://operational-transformation.github.io/
|
||||
[12]:https://floobits.com/
|
||||
[13]:https://hackmd.io/
|
||||
[14]:https://github.com/hackmdio/hackmd
|
||||
[15]:https://cryptpad.fr/
|
||||
[16]:https://prosemirror.net/
|
||||
[17]:https://quilljs.com/
|
||||
[18]:https://nextcloud.com/collaboraonline/
|
||||
[19]:https://teletype.atom.io/
|
||||
[20]:https://atom.io
|
||||
[21]:http://typeintandem.com/
|
||||
[22]:https://github.com/typeintandem/tandem/issues/131
|
||||
[23]:https://www.emacswiki.org/emacs/CollaborativeEditing
|
||||
[24]:https://en.wikipedia.org/wiki/Collaborative_real-time_editor
|
||||
[25]:https://en.wikipedia.org/wiki/The_Mother_of_All_Demos
|
||||
[26]:https://en.wikipedia.org/wiki/Douglas_Engelbart
|
||||
[27]:https://ethercalc.net/
|
||||
[28]:https://en.wikipedia.org/wiki/Google_docs
|
||||
[29]:http://wiki.inkscape.org/wiki/index.php/WhiteBoard
|
||||
[30]:https://en.wikipedia.org/wiki/AbiWord
|
||||
[31]:https://en.wikipedia.org/wiki/Apache_Wave
|
||||
[32]:https://wiki.documentfoundation.org/Development/LibreOffice_Online
|
||||
[33]:https://nextcloud.com/collaboraonline/
|
||||
@ -1,70 +0,0 @@
|
||||
Can we build a social network that serves users rather than advertisers?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, open source software is far-reaching and has played a key role driving innovation in our digital economy. The world is undergoing radical change at a rapid pace. People in all parts of the world need a purpose-built, neutral, and transparent online platform to meet the challenges of our time.
|
||||
|
||||
And open principles might just be the way to get us there. What would happen if we married digital innovation with social innovation using open-focused thinking?
|
||||
|
||||
This question is at the heart of our work at [Human Connection][1], a forward-thinking, Germany-based knowledge and action network with a mission to create a truly social network that serves the world. We're guided by the notion that human beings are inherently generous and sympathetic, and that they thrive on benevolent actions. But we haven't seen a social network that has fully supported our natural tendency towards helpfulness and cooperation to promote the common good. Human Connection aspires to be the platform that allows everyone to become an active changemaker.
|
||||
|
||||
In order to achieve the dream of a solution-oriented platform that enables people to take action around social causes by engaging with charities, community groups, and social change activists, Human Connection embraces open values as a vehicle for social innovation.
|
||||
|
||||
Here's how.
|
||||
|
||||
### Transparency first
|
||||
|
||||
Transparency is one of Human Connection's guiding principles. Human Connection invites programmers around the world to jointly work on the platform's source code (JavaScript, Vue, nuxt) by [making their source code available on Github][2] and support the idea of a truly social network by contributing to the code or programming additional functions.
|
||||
|
||||
But our commitment to transparency extends beyond our development practices. In fact—when it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better—making the source code available is just one step towards being transparent.
|
||||
|
||||
To facilitate open dialogue, the Human Connection team holds [regular public meetings online][3]. Here we answer questions, encourage suggestions, and respond to potential concerns. Our Meet The Team events are also recorded and made available to the public afterwards. By being fully transparent with our process, our source code, and our finances, we can protect ourselves against critics or other potential backlashes.
|
||||
|
||||
The commitment to transparency also means that all user contributions that shared publicly on Human Connection will be released under a Creative Commons license and can eventually be downloaded as a data pack. By making crowd knowledge available, especially in a decentralized way, we create the opportunity for social pluralism.
|
||||
|
||||
Guiding all of our organizational decisions is one question: "Does it serve the people and the greater good?" And we use the [UN Charter][4] and the Universal Declaration of Human Rights as a foundation for our value system. As we'll grow bigger, especially with our upcoming open beta launch, it's important for us to stay accountable to that mission. I'm even open to the idea of inviting the Chaos Computer Club or other hacker clubs to verify the integrity of our code and our actions by randomly checking into our platform.
|
||||
|
||||
When it comes to building a new kind of social network that promotes true connection and interaction between people who are passionate about changing the world for the better, making the source code available is just one step towards being transparent.
|
||||
|
||||
### A collaborative community
|
||||
|
||||
A [collaborative, community-centered approach][5] to programming the Human Connection platform is the foundation for an idea that extends beyond the practical applications of a social network. Our team is driven by finding an answer to the question: "What makes a social network truly social?"
|
||||
|
||||
A network that abandons the idea of a profit-driven algorithm serving advertisers instead of end-users can only thrive by turning to the process of peer production and collaboration. Organizations like [Code Alliance][6] and [Code for America][7], for example, have demonstrated how technology can be created in an open source environment to benefit humanity and disrupt the status quo. Community-driven projects like the map-based reporting platform [FixMyStreet][8] or the [Tasking Manager][9] built for the Humanitarian OpenStreetMap initiative have embraced crowdsourcing as a way to move their mission forward.
|
||||
|
||||
Our approach to building Human Connection has been collaborative from the start. To gather initial data on the necessary functions and the purpose of a truly social network, we collaborated with the National Institute for Oriental Languages and Civilizations (INALCO) at the University Sorbonne in Paris and the Stuttgart Media University in Germany. Research findings from both projects were incorporated into the early development of Human Connection. Thanks to that research, [users will have a whole new set of functions available][10] that put them in control of what content they see and how they engage with others. As early supporters are [invited to the network's alpha version][10], they can experience the first available noteworthy functions. Here are just a few:
|
||||
|
||||
* Linking information to action was one key theme emerging from our research sessions. Current social networks leave users in the information stage. Student groups at both universities saw a need for an action-oriented component that serves our human instinct of working together to solve problems. So we built a ["Can Do" function][11] into our platform. It's one of the ways individuals can take action after reading about a certain topic. "Can Do's" are user-suggested activities in the "Take Action" area that everyone can implement.
|
||||
* The "Versus" function is another defining result. Where traditional social networks are limited to a comment function, our student groups saw the need for a more structured and useful way to engage in discussions and arguments. A "Versus" is a counter-argument to a public post that is displayed separately and provides an opportunity to highlight different opinions around an issue.
|
||||
* Today's social networks don't provide a lot of options to filter content. Research has shown that a filtering option by emotions can help us navigate the social space in accordance with our daily mood and potentially protect our emotional wellbeing by not displaying sad or upsetting posts on a day where we want to see uplifting content only.
|
||||
|
||||
|
||||
|
||||
Human Connection invites changemakers to collaborate on the development of a network with the potential to mobilize individuals and groups around the world to turn negative news into "Can Do's"—and participate in social innovation projects in conjunction with charities and non-profit organizations.
|
||||
|
||||
[Subscribe to our weekly newsletter][12] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/open-social-human-connection
|
||||
|
||||
作者:[Dennis Hack][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dhack
|
||||
[1]:https://human-connection.org/en/
|
||||
[2]:https://github.com/human-connection/
|
||||
[3]:https://youtu.be/tPcYRQcepYE
|
||||
[4]:http://www.un.org/en/charter-united-nations/index.html
|
||||
[5]:https://youtu.be/BQHBno-efRI
|
||||
[6]:http://codealliance.org/
|
||||
[7]:https://www.codeforamerica.org/
|
||||
[8]:http://fixmystreet.org/
|
||||
[9]:https://tasks.hotosm.org/
|
||||
[10]:https://youtu.be/AwSx06DK2oU
|
||||
[11]:https://youtu.be/g2gYLNx686I
|
||||
[12]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -1,53 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Let's migrate away from GitHub
|
||||
======
|
||||
As many of you heard today, [Microsoft is acquiring GitHub][1]. What this means for the future of GitHub is not yet clear, but [the folks at Gitlab][2] think Microsoft's end goal is to integrate GitHub in their Azure empire. To me, this makes a lot of sense.
|
||||
|
||||
Even though I still reluctantly use GitHub for some projects, I migrated all my personal repositories to Gitlab instances a while ago. Now is time for you to do the same and ditch GitHub.
|
||||
|
||||
![Microsft loven't Linux][3]
|
||||
|
||||
Some people might be fine with Microsoft's takeover, but to me it's the straw that breaks the camel's back. For a few years now, MS has been running a large marketing campaign on how they love Linux and suddenly decided to embrace Free Software in all of its forms. More like MS BS to me.
|
||||
|
||||
Let us take a moment to remind ourselves that:
|
||||
|
||||
* Windows is still a huge proprietary monster that rips billions of people from their privacy and rights every day.
|
||||
* Microsoft is known for spreading FUD about "the dangers" of Free Software in order to keep governments and schools from dropping Windows in favor of FOSS.
|
||||
* To secure their monopoly, Microsoft hooks up kids on Windows by giving out "free" licences to primary schools around the world. Drug dealers use the same tactics and give out free samples to secure new clients.
|
||||
* Microsoft's Azure platform - even though it can run Linux VMs - is still a giant proprietary hypervisor.
|
||||
|
||||
|
||||
|
||||
I know moving git repositories around can seem like a pain in the ass, but the folks at Gitlab are riding the wave of people leaving GitHub and made the the migration easy [by providing a GitHub importer][4].
|
||||
|
||||
If you don't want to use Gitlab's main instance ([gitlab.org][5]), here are two other alternative instances you can use for Free Software projects:
|
||||
|
||||
* The [Debian Gitlab instance][6] is available for every FOSS project and not only for Debian-related ones. As long as the project respects the [Debian Free Software Guidelines][7], you can use the instance and its CI runners.
|
||||
* Riseup maintains a Gitlab instance for radical projects named [0xacab][8]. If your [ethos aligns with Riseup's][9], chances are they'll be happy to host your projects there.
|
||||
|
||||
|
||||
|
||||
Friends don't let friends use GitHub anymore.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/lets-migrate-away-from-github.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://www.bloomberg.com/news/articles/2018-06-03/microsoft-is-said-to-have-agreed-to-acquire-coding-site-github
|
||||
[2]:https://about.gitlab.com/2018/06/03/microsoft-acquires-github/
|
||||
[3]:https://veronneau.org/media/blog/2018-06-03/ms-lovent-linux.png (Microsoft loven't Linux)
|
||||
[4]:https://docs.gitlab.com/ee/user/project/import/github.html
|
||||
[5]:https://gitlab.org
|
||||
[6]:https://salsa.debian.org
|
||||
[7]:https://en.wikipedia.org/wiki/Debian_Free_Software_Guidelines
|
||||
[8]:https://0xacab.org
|
||||
[9]:https://riseup.net/en/about-us/politics
|
||||
@ -1,92 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Record Everything You Do In Terminal
|
||||
======
|
||||

|
||||
|
||||
A few days ago, we published a guide that explained how to [**save commands in terminal itself and use them on demand**][1]. It is very useful for those who don’t want to memorize a lengthy Linux command. Today, in this guide, we are going to see how to record everything you do in Terminal using **‘script’** command. You might have run a command, or created a directory, or installed an application in Terminal. Script command simply saves whatever you do in the Terminal. You can then view them if you want to know what you did few hours or few days ago. I know I know, we can use UP/DOWN arrow keys or history command to view previously running commands. However, you can’t view the output of those commands. But, Script command records and displays complete terminal session activities.
|
||||
|
||||
The script command creates a typescript of everything you do in the Terminal. It doesn’t matter whether you install an application, create a directory/file, remove a folder. Everything will be recorded, including the commands and the respective outputs. This command will be helpful who wants a hard-copy record of an interactive session as proof of an assignment. Whether you’re a student or a tutor, you can make a copy of everything you do in the Terminal along with all outputs.
|
||||
|
||||
### Record Everything You Do In Terminal using script command in Linux
|
||||
|
||||
The script command comes pre-installed on most modern Linux operating systems. So, let us not bother about the installation.
|
||||
|
||||
Let us go ahead and see how to use it in real time.
|
||||
|
||||
Run the following command to start the Terminal session recording.
|
||||
```
|
||||
$ script -a my_terminal_activities
|
||||
|
||||
```
|
||||
|
||||
Where, **-a** flag is used to append the output to file or to typescript, retaining the prior contents. The above command records everything you do in the Terminal and append the output to a file called **‘my_terminal_activities’** and save it in your current working directory.
|
||||
|
||||
Sample output would be:
|
||||
```
|
||||
Script started, file is my_terminal_activities
|
||||
|
||||
```
|
||||
|
||||
Now, run some random Linux commands in your Terminal.
|
||||
```
|
||||
$ mkdir ostechnix
|
||||
|
||||
$ cd ostechnix/
|
||||
|
||||
$ touch hello_world.txt
|
||||
|
||||
$ cd ..
|
||||
|
||||
$ uname -r
|
||||
|
||||
```
|
||||
|
||||
After running all commands, end the ‘script’ command’s session using command:
|
||||
```
|
||||
$ exit
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
exit
|
||||
Script done, file is my_terminal_activities
|
||||
|
||||
```
|
||||
|
||||
As you see, the Terminal activities have been stored in a file called **‘my_terminal_activities’** and saves it in the current working directory.
|
||||
|
||||
To view your Terminal activities, just open this file in any editor or simply display it using the ‘cat’ command.
|
||||
```
|
||||
$ cat my_terminal_activities
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||
As you see in the above output, script command has recorded all my Terminal activities, including the start and end time of the script command. Awesome, isn’t it? The reason to use script command is it’s not just records the commands, but also the commands’ output as well. To put this simply, Script command will record everything you do on the Terminal.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Like I said, script command would be useful for students, teachers and any Linux users who wants to keep the record of their Terminal activities. Even though there are many CLI and GUI to do this, script command is an easiest and quickest way to record the Terminal session activities.
|
||||
|
||||
And, that’s all. Hope this helps. If you find this guide useful, please share it on your social, professional networks and **support OSTechNix**.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/record-everything-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
@ -1,217 +0,0 @@
|
||||
Translating by qhwdw
|
||||
Operating a Kubernetes network
|
||||
============================================================
|
||||
|
||||
I’ve been working on Kubernetes networking a lot recently. One thing I’ve noticed is, while there’s a reasonable amount written about how to **set up** your Kubernetes network, I haven’t seen much about how to **operate** your network and be confident that it won’t create a lot of production incidents for you down the line.
|
||||
|
||||
In this post I’m going to try to convince you of three things: (all I think pretty reasonable :))
|
||||
|
||||
* Avoiding networking outages in production is important
|
||||
|
||||
* Operating networking software is hard
|
||||
|
||||
* It’s worth thinking critically about major changes to your networking infrastructure and the impact that will have on your reliability, even if very fancy Googlers say “this is what we do at Google”. (google engineers are doing great work on Kubernetes!! But I think it’s important to still look at the architecture and make sure it makes sense for your organization.)
|
||||
|
||||
I’m definitely not a Kubernetes networking expert by any means, but I have run into a few issues while setting things up and definitely know a LOT more about Kubernetes networking than I used to.
|
||||
|
||||
### Operating networking software is hard
|
||||
|
||||
Here I’m not talking about operating physical networks (I don’t know anything about that), but instead about keeping software like DNS servers & load balancers & proxies working correctly.
|
||||
|
||||
I have been working on a team that’s responsible for a lot of networking infrastructure for a year, and I have learned a few things about operating networking infrastructure! (though I still have a lot to learn obviously). 3 overall thoughts before we start:
|
||||
|
||||
* Networking software often relies very heavily on the Linux kernel. So in addition to configuring the software correctly you also need to make sure that a bunch of different sysctls are set correctly, and a misconfigured sysctl can easily be the difference between “everything is 100% fine” and “everything is on fire”.
|
||||
|
||||
* Networking requirements change over time (for example maybe you’re doing 5x more DNS lookups than you were last year! Maybe your DNS server suddenly started returning TCP DNS responses instead of UDP which is a totally different kernel workload!). This means software that was working fine before can suddenly start having issues.
|
||||
|
||||
* To fix a production networking issues you often need a lot of expertise. (for example see this [great post by Sophie Haskins on debugging a kube-dns issue][1]) I’m a lot better at debugging networking issues than I was, but that’s only after spending a huge amount of time investing in my knowledge of Linux networking.
|
||||
|
||||
I am still far from an expert at networking operations but I think it seems important to:
|
||||
|
||||
1. Very rarely make major changes to the production networking infrastructure (because it’s super disruptive)
|
||||
|
||||
2. When you _are_ making major changes, think really carefully about what the failure modes are for the new network architecture are
|
||||
|
||||
3. Have multiple people who are able to understand your networking setup
|
||||
|
||||
Switching to Kubernetes is obviously a pretty major networking change! So let’s talk about what some of the things that can go wrong are!
|
||||
|
||||
### Kubernetes networking components
|
||||
|
||||
The Kubernetes networking components we’re going to talk about in this post are:
|
||||
|
||||
* Your overlay network backend (like flannel/calico/weave net/romana)
|
||||
|
||||
* `kube-dns`
|
||||
|
||||
* `kube-proxy`
|
||||
|
||||
* Ingress controllers / load balancers
|
||||
|
||||
* The `kubelet`
|
||||
|
||||
If you’re going to set up HTTP services you probably need all of these. I’m not using most of these components yet but I’m trying to understand them, so that’s what this post is about.
|
||||
|
||||
### The simplest way: Use host networking for all your containers
|
||||
|
||||
Let’s start with the simplest possible thing you can do. This won’t let you run HTTP services in Kubernetes. I think it’s pretty safe because there are less moving parts.
|
||||
|
||||
If you use host networking for all your containers I think all you need to do is:
|
||||
|
||||
1. Configure the kubelet to configure DNS correctly inside your containers
|
||||
|
||||
2. That’s it
|
||||
|
||||
If you use host networking for literally every pod you don’t need kube-dns or kube-proxy. You don’t even need a working overlay network.
|
||||
|
||||
In this setup your pods can connect to the outside world (the same way any process on your hosts would talk to the outside world) but the outside world can’t connect to your pods.
|
||||
|
||||
This isn’t super important (I think most people want to run HTTP services inside Kubernetes and actually communicate with those services) but I do think it’s interesting to realize that at some level all of this networking complexity isn’t strictly required and sometimes you can get away without using it. Avoiding networking complexity seems like a good idea to me if you can.
|
||||
|
||||
### Operating an overlay network
|
||||
|
||||
The first networking component we’re going to talk about is your overlay network. Kubernetes assumes that every pod has an IP address and that you can communicate with services inside that pod by using that IP address. When I say “overlay network” this is what I mean (“the system that lets you refer to a pod by its IP address”).
|
||||
|
||||
All other Kubernetes networking stuff relies on the overlay networking working correctly. You can read more about the [kubernetes networking model here][10].
|
||||
|
||||
The way Kelsey Hightower describes in [kubernetes the hard way][11] seems pretty good but it’s not really viable on AWS for clusters more than 50 nodes or so, so I’m not going to talk about that.
|
||||
|
||||
There are a lot of overlay network backends (calico, flannel, weaveworks, romana) and the landscape is pretty confusing. But as far as I’m concerned an overlay network has 2 responsibilities:
|
||||
|
||||
1. Make sure your pods can send network requests outside your cluster
|
||||
|
||||
2. Keep a stable mapping of nodes to subnets and keep every node in your cluster updated with that mapping. Do the right thing when nodes are added & removed.
|
||||
|
||||
Okay! So! What can go wrong with your overlay network?
|
||||
|
||||
* The overlay network is responsible for setting up iptables rules (basically `iptables -A -t nat POSTROUTING -s $SUBNET -j MASQUERADE`) to ensure that containers can make network requests outside Kubernetes. If something goes wrong with this rule then your containers can’t connect to the external network. This isn’t that hard (it’s just a few iptables rules) but it is important. I made a [pull request][2] because I wanted to make sure this was resilient
|
||||
|
||||
* Something can go wrong with adding or deleting nodes. We’re using the flannel hostgw backend and at the time we started using it, node deletion [did not work][3].
|
||||
|
||||
* Your overlay network is probably dependent on a distributed database (etcd). If that database has an incident, this can cause issues. For example [https://github.com/coreos/flannel/issues/610][4] says that if you have data loss in your flannel etcd cluster it can result in containers losing network connectivity. (this has now been fixed)
|
||||
|
||||
* You upgrade Docker and everything breaks
|
||||
|
||||
* Probably more things!
|
||||
|
||||
I’m mostly talking about past issues in Flannel here but I promise I’m not picking on Flannel – I actually really **like** Flannel because I feel like it’s relatively simple (for instance the [vxlan backend part of it][12] is like 500 lines of code) and I feel like it’s possible for me to reason through any issues with it. And it’s obviously continuously improving. They’ve been great about reviewing pull requests.
|
||||
|
||||
My approach to operating an overlay network so far has been:
|
||||
|
||||
* Learn how it works in detail and how to debug it (for example the hostgw network backend for Flannel works by creating routes, so you mostly just need to do `sudo ip route list` to see whether it’s doing the correct thing)
|
||||
|
||||
* Maintain an internal build so it’s easy to patch it if needed
|
||||
|
||||
* When there are issues, contribute patches upstream
|
||||
|
||||
I think it’s actually really useful to go through the list of merged PRs and see bugs that have been fixed in the past – it’s a bit time consuming but is a great way to get a concrete list of kinds of issues other people have run into.
|
||||
|
||||
It’s possible that for other people their overlay networks just work but that hasn’t been my experience and I’ve heard other folks report similar issues. If you have an overlay network setup that is a) on AWS and b) works on a cluster more than 50-100 nodes where you feel more confident about operating it I would like to know.
|
||||
|
||||
### Operating kube-proxy and kube-dns?
|
||||
|
||||
Now that we have some thoughts about operating overlay networks, let’s talk about
|
||||
|
||||
There’s a question mark next to this one because I haven’t done this. Here I have more questions than answers.
|
||||
|
||||
Here’s how Kubernetes services work! A service is a collection of pods, which each have their own IP address (like 10.1.0.3, 10.2.3.5, 10.3.5.6)
|
||||
|
||||
1. Every Kubernetes service gets an IP address (like 10.23.1.2)
|
||||
|
||||
2. `kube-dns` resolves Kubernetes service DNS names to IP addresses (so my-svc.my-namespace.svc.cluster.local might map to 10.23.1.2)
|
||||
|
||||
3. `kube-proxy` sets up iptables rules in order to do random load balancing between them. Kube-proxy also has a userspace round-robin load balancer but my impression is that they don’t recommend using it.
|
||||
|
||||
So when you make a request to `my-svc.my-namespace.svc.cluster.local`, it resolves to 10.23.1.2, and then iptables rules on your local host (generated by kube-proxy) redirect it to one of 10.1.0.3 or 10.2.3.5 or 10.3.5.6 at random.
|
||||
|
||||
Some things that I can imagine going wrong with this:
|
||||
|
||||
* `kube-dns` is misconfigured
|
||||
|
||||
* `kube-proxy` dies and your iptables rules don’t get updated
|
||||
|
||||
* Some issue related to maintaining a large number of iptables rules
|
||||
|
||||
Let’s talk about the iptables rules a bit, since doing load balancing by creating a bajillion iptables rules is something I had never heard of before!
|
||||
|
||||
kube-proxy creates one iptables rule per target host like this: (these rules are from [this github issue][13])
|
||||
|
||||
```
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.20000000019 -j KUBE-SEP-E4QKA7SLJRFZZ2DD[b][c]
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.25000000000 -j KUBE-SEP-LZ7EGMG4DRXMY26H
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-RKIFTWKKG3OHTTMI
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-CGDKBCNM24SZWCMS
|
||||
-A KUBE-SVC-LI77LBOOMGYET5US -m comment --comment "default/showreadiness:showreadiness" -j KUBE-SEP-RI4SRNQQXWSTGE2Y
|
||||
|
||||
```
|
||||
|
||||
So kube-proxy creates a **lot** of iptables rules. What does that mean? What are the implications of that in for my network? There’s a great talk from Huawei called [Scale Kubernetes to Support 50,000 services][14] that says if you have 5,000 services in your kubernetes cluster, it takes **11 minutes** to add a new rule. If that happened to your real cluster I think it would be very bad.
|
||||
|
||||
I definitely don’t have 5,000 services in my cluster, but 5,000 isn’t SUCH a bit number. The proposal they give to solve this problem is to replace this iptables backend for kube-proxy with IPVS which is a load balancer that lives in the Linux kernel.
|
||||
|
||||
It seems like kube-proxy is going in the direction of various Linux kernel based load balancers. I think this is partly because they support UDP load balancing, and other load balancers (like HAProxy) don’t support UDP load balancing.
|
||||
|
||||
But I feel comfortable with HAProxy! Is it possible to replace kube-proxy with HAProxy! I googled this and I found this [thread on kubernetes-sig-network][15] saying:
|
||||
|
||||
> kube-proxy is so awesome, we have used in production for almost a year, it works well most of time, but as we have more and more services in our cluster, we found it was getting hard to debug and maintain. There is no iptables expert in our team, we do have HAProxy&LVS experts, as we have used these for several years, so we decided to replace this distributed proxy with a centralized HAProxy. I think this maybe useful for some other people who are considering using HAProxy with kubernetes, so we just update this project and make it open source: [https://github.com/AdoHe/kube2haproxy][5]. If you found it’s useful , please take a look and give a try.
|
||||
|
||||
So that’s an interesting option! I definitely don’t have answers here, but, some thoughts:
|
||||
|
||||
* Load balancers are complicated
|
||||
|
||||
* DNS is also complicated
|
||||
|
||||
* If you already have a lot of experience operating one kind of load balancer (like HAProxy), it might make sense to do some extra work to use that instead of starting to use an entirely new kind of load balancer (like kube-proxy)
|
||||
|
||||
* I’ve been thinking about where we want to be using kube-proxy or kube-dns at all – I think instead it might be better to just invest in Envoy and rely entirely on Envoy for all load balancing & service discovery. So then you just need to be good at operating Envoy.
|
||||
|
||||
As you can see my thoughts on how to operate your Kubernetes internal proxies are still pretty confused and I’m still not super experienced with them. It’s totally possible that kube-proxy and kube-dns are fine and that they will just work fine but I still find it helpful to think through what some of the implications of using them are (for example “you can’t have 5,000 Kubernetes services”).
|
||||
|
||||
### Ingress
|
||||
|
||||
If you’re running a Kubernetes cluster, it’s pretty likely that you actually need HTTP requests to get into your cluster so far. This blog post is already too long and I don’t know much about ingress yet so we’re not going to talk about that.
|
||||
|
||||
### Useful links
|
||||
|
||||
A couple of useful links, to summarize:
|
||||
|
||||
* [The Kubernetes networking model][6]
|
||||
|
||||
* How GKE networking works: [https://www.youtube.com/watch?v=y2bhV81MfKQ][7]
|
||||
|
||||
* The aforementioned talk on `kube-proxy` performance: [https://www.youtube.com/watch?v=4-pawkiazEg][8]
|
||||
|
||||
### I think networking operations is important
|
||||
|
||||
My sense of all this Kubernetes networking software is that it’s all still quite new and I’m not sure we (as a community) really know how to operate all of it well. This makes me worried as an operator because I really want my network to keep working! :) Also I feel like as an organization running your own Kubernetes cluster you need to make a pretty large investment into making sure you understand all the pieces so that you can fix things when they break. Which isn’t a bad thing, it’s just a thing.
|
||||
|
||||
My plan right now is just to keep learning about how things work and reduce the number of moving parts I need to worry about as much as possible.
|
||||
|
||||
As usual I hope this was helpful and I would very much like to know what I got wrong in this post!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/10/10/operating-a-kubernetes-network/
|
||||
|
||||
作者:[Julia Evans ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/about
|
||||
[1]:http://blog.sophaskins.net/blog/misadventures-with-kube-dns/
|
||||
[2]:https://github.com/coreos/flannel/pull/808
|
||||
[3]:https://github.com/coreos/flannel/pull/803
|
||||
[4]:https://github.com/coreos/flannel/issues/610
|
||||
[5]:https://github.com/AdoHe/kube2haproxy
|
||||
[6]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[7]:https://www.youtube.com/watch?v=y2bhV81MfKQ
|
||||
[8]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[9]:https://jvns.ca/categories/kubernetes
|
||||
[10]:https://kubernetes.io/docs/concepts/cluster-administration/networking/#kubernetes-model
|
||||
[11]:https://github.com/kelseyhightower/kubernetes-the-hard-way/blob/master/docs/11-pod-network-routes.md
|
||||
[12]:https://github.com/coreos/flannel/tree/master/backend/vxlan
|
||||
[13]:https://github.com/kubernetes/kubernetes/issues/37932
|
||||
[14]:https://www.youtube.com/watch?v=4-pawkiazEg
|
||||
[15]:https://groups.google.com/forum/#!topic/kubernetes-sig-network/3NlBVbTUUU0
|
||||
@ -1,48 +0,0 @@
|
||||
Container Basics: Terms You Need to Know
|
||||
======
|
||||
|
||||

|
||||
|
||||
[In the previous article][1], we talked about what containers are and how they breed innovation and help companies move faster. And, in the following articles in this series, we will discuss how to use them. Before we dive more deeply into the topic, however, we need to understand some of the terms and commands used in the container world. Without a confident grasp of this terminology, things could get confusing.
|
||||
|
||||
Let's explore some of the basic terms used in the [Docker][2] container world.
|
||||
|
||||
**Container** **:** What exactly is container? It 's a runtime instance of a Docker image. It contains a Docker image, an execution environment, and instructions. It's totally isolated from the system so multiple containers can run on the system, completely oblivious of each other. You can replicate multiple containers from the same image and scale the service when the demand is high and nuke those containers when demand is low.
|
||||
|
||||
**Docker Image** **:** This is no different from the image of a Linux distribution that you download. It's a package of dependencies and information for creating, deploying, and executing a container. You can spin up as many containers as you want in a matter of seconds. Each behaves exactly the same. Images are built on top of one another in layers. Once an image is created, it doesn't change. If you want to make changes to your container, you simply create a new image and deploy new containers from that image.
|
||||
|
||||
**Repository (repo)** **:** Linux users will already be familiar with the term repository; it's a reservoir where packages are stored that can be downloaded and installed on a system. In the context of Docker containers, the only difference is that it hosts Docker images which are categorized via labels. You can have different variants of the same applications or different versions, all tagged appropriately.
|
||||
|
||||
**Registry** **:** Think of this as like GitHub. It 's an online service that hosts and provides access to repositories of docker images. DockerHub, for example is the default registry for public images. Vendors can upload their repositories on DockerHub so that their customers can download and use official images. Some companies offer their own registries for their images. Registries don't have to be run and managed by third party vendors. Organizations can have on-prem registries to manage organization-wide access to repositories.
|
||||
|
||||
**Tag** **:** When you create a Docker image, you can tag it appropriately so that different variants or versions can be easily identified. It's no different from what you see in any software package. Docker images are tagged when you add them to the repository.
|
||||
|
||||
Now that you have an understanding of the basics, the next phase is understanding the terminology used when working with actual Docker containers.
|
||||
|
||||
**Dockerfile** **:** This is a text file that comprises the commands that are executed manually in order to build a Docker image. These instructions are used by Docker to automatically build images.
|
||||
|
||||
**Build** **:** This is the process that creates an image from Dockerfile.
|
||||
|
||||
**Push** **:** Once the image is created, "push" is the process to publish that image to the repository. The term is also used as part of a command that we will learn in the next articles.
|
||||
|
||||
**Pull** **:** A user can retrieve that image from repository through the "pull" process.
|
||||
|
||||
**Compose** **:** Most complex applications comprise more than one container. Compose is a command-line tool that 's used to run a multi-container application. It allows you to run a multi-container application with one command. It eases the headache of running multiple containers needed for that application.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The scope of container terminology is massive, but these are some basic terms that you will frequently encounter. The next time you see these terms, you will know exactly what they mean. In the next article, we will get started working with Docker containers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/intro-to-linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
[2]:https://www.docker.com/
|
||||
@ -1,136 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
Why Python devs should use Pipenv
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was co-written with [Jeff Triplett][1].
|
||||
|
||||
Pipenv, the "Python Development Workflow for Humans" created by Kenneth Reitz a little more than a year ago, has become the [official Python-recommended resource][2] for managing package dependencies. But there is still confusion about what problems it solves and how it's more useful than the standard workflow using `pip` and a `requirements.txt` file. In this month's Python column, we'll fill in the gaps.
|
||||
|
||||
### A brief history of Python package installation
|
||||
|
||||
To understand the problems that Pipenv solves, it's useful to show how Python package management has evolved.
|
||||
|
||||
Take yourself back to the first Python iteration. We had Python, but there was no clean way to install packages.
|
||||
|
||||
Then came [Easy Install][3], a package that installs other Python packages with relative ease. But it came with a catch: it wasn't easy to uninstall packages that were no longer needed.
|
||||
|
||||
Enter [pip][4], which most Python users are familiar with. `pip` lets us install and uninstall packages. We could specify versions, run `pip freeze > requirements.txt` to output a list of installed packages to a text file, and use that same text file to install everything an app needed with `pip install -r requirements.txt`.
|
||||
|
||||
But `pip` didn't include a way to isolate packages from each other. We might work on apps that use different versions of the same libraries, so we needed a way to enable that. Along came [virtual environments][5], which enabled us to create small, isolated environments for each app we worked on. We've seen many tools for managing virtual environments: [virtualenv][6], [venv][7], [virtualenvwrapper][8], [pyenv][9], [pyenv-virtualenv][10], [pyenv-virtualenvwrapper][11], and even more. They all play well with `pip` and `requirements.txt` files.
|
||||
|
||||
### The new kid: Pipenv
|
||||
|
||||
Pipenv aims to solve several problems.
|
||||
|
||||
`pip` library for package installation, plus a library for creating a virtual environment, plus a library for managing virtual environments, plus all the commands associated with those libraries. That's a lot to manage. Pipenv ships with package management and virtual environment support, so you can use one tool to install, uninstall, track, and document your dependencies and to create, use, and organize your virtual environments. When you start a project with it, Pipenv will automatically create a virtual environment for that project if you aren't already using one.
|
||||
|
||||
First, the problem of needing thelibrary for package installation, plus a library for creating a virtual environment, plus a library for managing virtual environments, plus all the commands associated with those libraries. That's a lot to manage. Pipenv ships with package management and virtual environment support, so you can use one tool to install, uninstall, track, and document your dependencies and to create, use, and organize your virtual environments. When you start a project with it, Pipenv will automatically create a virtual environment for that project if you aren't already using one.
|
||||
|
||||
Pipenv accomplishes this dependency management by abandoning the `requirements.txt` norm and trading it for a new document called a [Pipfile][12]. When you install a library with Pipenv, a `Pipfile` for your project is automatically updated with the details of that installation, including version information and possibly the Git repository location, file path, and other information.
|
||||
|
||||
Second, Pipenv wants to make it easier to manage complex interdependencies. Your app might depend on a specific version of a library, and that library might depend on a specific version of another library, and it's just dependencies and turtles all the way down. When two libraries your app uses have conflicting dependencies, your life can become hard. Pipenv wants to ease that pain by keeping track of a tree of your app's interdependencies in a file called `Pipfile.lock`. `Pipfile.lock` also verifies that the right versions of dependencies are used in production.
|
||||
|
||||
Also, Pipenv is handy when multiple developers are working on a project. With a `pip` workflow, Casey might install a library and spend two days implementing a new feature using that library. When Casey commits the changes, they might forget to run `pip freeze` to update the requirements file. The next day, Jamie pulls down Casey's changes, and suddenly tests are failing. It takes time to realize that the problem is libraries missing from the requirements file that Jamie doesn't have installed in the virtual environment.
|
||||
|
||||
Because Pipenv auto-documents dependencies as you install them, if Jamie and Casey had been using Pipenv, the `Pipfile` would have been automatically updated and included in Casey's commit. Jamie and Casey would have saved time and shipped their product faster.
|
||||
|
||||
Finally, using Pipenv signals to other people who work on your project that it ships with a standardized way to install project dependencies and development and testing requirements. Using a workflow with `pip` and requirements files means that you may have one single `requirements.txt` file, or several requirements files for different environments. It might not be clear to your colleagues whether they should run `dev.txt` or `local.txt` when they're running the project on their laptops, for example. It can also create confusion when two similar requirements files get wildly out of sync with each other: Is `local.txt` out of date, or is it really supposed to be that different from `dev.txt`? Multiple requirements files require more context and documentation to enable others to install the dependencies properly and as expected. This workflow has the potential to confuse colleagues and increase your maintenance burden.
|
||||
|
||||
Using Pipenv, which gives you `Pipfile`, lets you avoid these problems by managing dependencies for different environments for you. This command will install the main project dependencies:
|
||||
```
|
||||
pipenv install
|
||||
|
||||
```
|
||||
|
||||
Adding the `--dev` tag will install the dev/testing requirements:
|
||||
```
|
||||
pipenv install --dev
|
||||
|
||||
```
|
||||
|
||||
There are other benefits to using Pipenv: It has better security features, graphs your dependencies in an easier-to-understand format, seamlessly handles `.env` files, and can automatically handle differing dependencies for development versus production environments in one file. You can read more in the [documentation][13].
|
||||
|
||||
### Pipenv in action
|
||||
|
||||
The basics of using Pipenv are detailed in the [Managing Application Dependencies][14] section of the official Python packaging tutorial. To install Pipenv, use `pip`:
|
||||
```
|
||||
pip install pipenv
|
||||
|
||||
```
|
||||
|
||||
To install packages to use in your project, change into the directory for your project. Then to install a package (we'll use Django as an example), run:
|
||||
```
|
||||
pipenv install django
|
||||
|
||||
```
|
||||
|
||||
You will see some output that indicates that Pipenv is creating a `Pipfile` for your project.
|
||||
|
||||
If you aren't already using a virtual environment, you will also see some output from Pipenv saying it is creating a virtual environment for you.
|
||||
|
||||
Then, you will see the output you are used to seeing when you install packages.
|
||||
|
||||
To generate a `Pipfile.lock` file, run:
|
||||
```
|
||||
pipenv lock
|
||||
|
||||
```
|
||||
|
||||
You can also run Python scripts with Pipenv. To run a top-level Python script called `hello.py`, run:
|
||||
```
|
||||
pipenv run python hello.py
|
||||
|
||||
```
|
||||
|
||||
And you will see your expected result in the console.
|
||||
|
||||
To start a shell, run:
|
||||
```
|
||||
pipenv shell
|
||||
|
||||
```
|
||||
|
||||
If you would like to convert a project that currently uses a `requirements.txt` file to use Pipenv, install Pipenv and run:
|
||||
```
|
||||
pipenv install requirements.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a Pipfile and install the specified requirements. Consider your project upgraded!
|
||||
|
||||
### Learn more
|
||||
|
||||
Check out the Pipenv documentation, particularly [Basic Usage of Pipenv][15], to take you further. Pipenv creator Kenneth Reitz gave a talk on Pipenv, "[The Future of Python Dependency Management][16]," at a recent PyTennessee event. The talk wasn't recorded, but his [slides][17] are helpful in understanding what Pipenv does and the problems it solves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/why-python-devs-should-use-pipenv
|
||||
|
||||
作者:[Lacey Williams Henschel][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laceynwilliams
|
||||
[1]:https://opensource.com/users/jefftriplett
|
||||
[2]:https://packaging.python.org/tutorials/managing-dependencies/#managing-dependencies
|
||||
[3]:http://peak.telecommunity.com/DevCenter/EasyInstall
|
||||
[4]:https://packaging.python.org/tutorials/installing-packages/#use-pip-for-installing
|
||||
[5]:https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments
|
||||
[6]:https://virtualenv.pypa.io/en/stable/
|
||||
[7]:https://docs.python.org/3/library/venv.html
|
||||
[8]:https://virtualenvwrapper.readthedocs.io/en/latest/
|
||||
[9]:https://github.com/pyenv/pyenv
|
||||
[10]:https://github.com/pyenv/pyenv-virtualenv
|
||||
[11]:https://github.com/pyenv/pyenv-virtualenvwrapper
|
||||
[12]:https://github.com/pypa/pipfile
|
||||
[13]:https://docs.pipenv.org/
|
||||
[14]:https://packaging.python.org/tutorials/managing-dependencies/
|
||||
[15]:https://docs.pipenv.org/basics/
|
||||
[16]:https://www.pytennessee.org/schedule/presentation/158/
|
||||
[17]:https://speakerdeck.com/kennethreitz/the-future-of-python-dependency-management
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user