diff --git a/.gitignore b/.gitignore
index 7b56441580..b5bb51a97a 100644
--- a/.gitignore
+++ b/.gitignore
@@ -3,3 +3,5 @@ members.md
*.html
*.bak
.DS_Store
+sources/*/.*
+translated/*/.*
\ No newline at end of file
diff --git a/published/20141127 Keeping (financial) score with Ledger .md b/published/20141127 Keeping (financial) score with Ledger .md
new file mode 100644
index 0000000000..2bcecd2174
--- /dev/null
+++ b/published/20141127 Keeping (financial) score with Ledger .md
@@ -0,0 +1,75 @@
+使用 Ledger 记录(财务)情况
+======
+
+自 2005 年搬到加拿大以来,我使用 [Ledger CLI][1] 来跟踪我的财务状况。我喜欢纯文本的方式,它支持虚拟信封意味着我可以同时将我的银行帐户余额和我的虚拟分配到不同的目录下。以下是我们如何使用这些虚拟信封分别管理我们的财务状况。
+
+每个月,我都有一个条目将我生活开支分配到不同的目录中,包括家庭开支的分配。W- 不要求太多, 所以我要谨慎地处理这两者之间的差别和我自己的生活费用。我们处理它的方式是我支付固定金额,这是贷记我支付的杂货。由于我们的杂货总额通常低于我预算的家庭开支,因此任何差异都会留在标签上。我过去常常给他写支票,但最近我只是支付偶尔额外的大笔费用。
+
+这是个示例信封分配:
+
+```
+2014.10.01 * Budget
+ [Envelopes:Living]
+ [Envelopes:Household] $500
+ ;; More lines go here
+```
+
+这是设置的信封规则之一。它鼓励我正确地分类支出。所有支出都从我的 “Play” 信封中取出。
+
+```
+= /^Expenses/
+ (Envelopes:Play) -1.0
+```
+
+这个为家庭支出报销 “Play” 信封,将金额从 “Household” 信封转移到 “Play” 信封。
+
+```
+= /^Expenses:House$/
+ (Envelopes:Play) 1.0
+ (Envelopes:Household) -1.0
+```
+
+我有一套定期的支出来模拟我的预算中的家庭开支。例如,这是 10 月份的。
+
+```
+2014.10.1 * House
+ Expenses:House
+ Assets:Household $-500
+```
+
+这是杂货交易的形式:
+
+```
+2014.09.28 * No Frills
+ Assets:Household:Groceries $70.45
+ Liabilities:MBNA:September $-70.45
+
+```
+
+接着 `ledger bal Assets:Household` 就会告诉我是否欠他钱(负余额)。如果我支付大笔费用(例如:机票、通管道),那么正常家庭开支预算会逐渐减少余额。
+
+我从 W- 那找到了一个为我的信用卡交易添加一个月标签的技巧,他还使用 Ledger 跟踪他的交易。它允许我再次检查条目的余额,看看前一个条目是否已被正确清除。
+
+这个资产分类使用有点奇怪,但它在精神上对我有用。
+
+使用 Ledger 以这种方式跟踪它可以让我跟踪我们的杂货费用以及我实际支付费用和我预算费用之间的差额。如果我最终支出超出预期,我可以从更多可自由支配的信封中移动虚拟货币,因此我的预算始终保持平衡。
+
+Ledger 是一个强大的工具。相当极客,但也许更多的工作流描述可能会帮助那些正在搞清楚它的人!
+
+--------------------------------------------------------------------------------
+
+via: http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
+
+作者:[Sacha Chua][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://sachachua.com
+[1]:http://www.ledger-cli.org/
+[2]:http://sachachua.com/blog/category/finance/
+[3]:http://sachachua.com/blog/tag/ledger/
+[4]:http://pages.sachachua.com/sharing/blog.html?url=http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/
+[5]:http://sachachua.com/blog/2014/11/keeping-financial-score-ledger/#comments
diff --git a/published/201703/20170223 How to install Arch Linux on VirtualBox.md b/published/201703/20170223 How to install Arch Linux on VirtualBox.md
index 58a094b048..cdd68a0642 100644
--- a/published/201703/20170223 How to install Arch Linux on VirtualBox.md
+++ b/published/201703/20170223 How to install Arch Linux on VirtualBox.md
@@ -104,10 +104,10 @@ Arch Linux 也因其丰富的 Wiki 帮助文档而大受推崇。该系统基于
][23]
输入下面的命令来检查网络连接。
-
+
```
ping google.com
-```
+```
这个单词 ping 表示网路封包搜寻。你将会看到下面的返回信息,表明 Arch Linux 已经连接到外网了。这是执行安装过程中的很关键的一点。(LCTT 译注:或许你 ping 不到那个不存在的网站,你选个存在的吧。)
@@ -117,8 +117,8 @@ ping google.com
输入如下命令清屏:
-```
-clear
+```
+clear
```
在开始安装之前,你得先为硬盘分区。输入 `fdisk -l` ,你将会看到当前系统的磁盘分区情况。注意一开始你给 Arch Linux 系统分配的 20 GB 存储空间。
@@ -137,8 +137,8 @@ clear
输入下面的命令:
-```
-cfdisk
+```
+cfdisk
```
你将看到 `gpt`、`dos`、`sgi` 和 `sun` 类型,选择 `dos` 选项,然后按回车。
@@ -185,8 +185,8 @@ cfdisk
以同样的方式创建逻辑分区。在“退出(quit)”选项按回车键,然后输入下面的命令来清屏:
-```
-clear
+```
+clear
```
[
@@ -195,21 +195,21 @@ clear
输入下面的命令来格式化新建的分区:
-```
+```
mkfs.ext4 /dev/sda1
-```
+```
这里的 `sda1` 是分区名。使用同样的命令来格式化第二个分区 `sda3` :
-```
+```
mkfs.ext4 /dev/sda3
-```
+```
格式化 swap 分区:
-```
+```
mkswap /dev/sda2
-```
+```
[
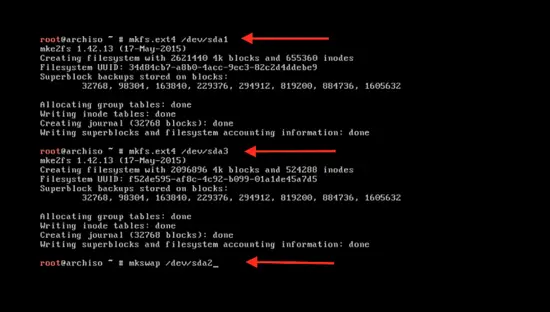
@@ -217,14 +217,14 @@ mkswap /dev/sda2
使用下面的命令来激活 swap 分区:
-```
-swapon /dev/sda2
+```
+swapon /dev/sda2
```
输入 clear 命令清屏:
-```
-clear
+```
+clear
```
[
@@ -233,9 +233,9 @@ clear
输入下面的命令来挂载主分区以开始系统安装:
-```
-mount /dev/sda1 / mnt
-```
+```
+mount /dev/sda1 /mnt
+```
[
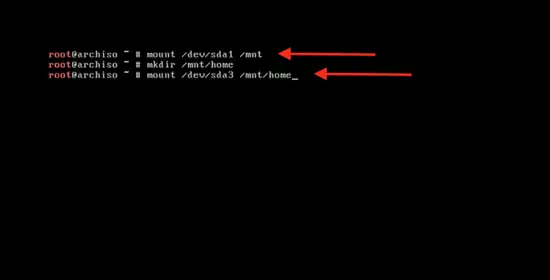
@@ -245,9 +245,9 @@ mount /dev/sda1 / mnt
输入下面的命令来引导系统启动:
-```
+```
pacstrap /mnt base base-devel
-```
+```
可以看到系统正在同步数据包。
@@ -263,9 +263,9 @@ pacstrap /mnt base base-devel
系统基本软件安装完成后,输入下面的命令来创建 fstab 文件:
-```
+```
genfstab /mnt>> /mnt/etc/fstab
-```
+```
[
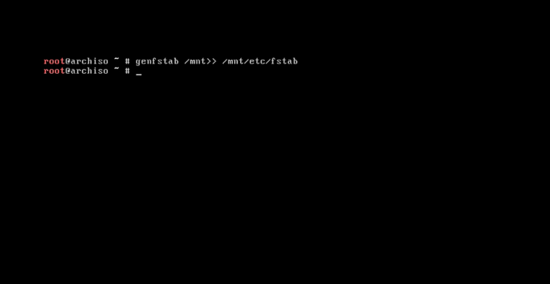
@@ -275,14 +275,14 @@ genfstab /mnt>> /mnt/etc/fstab
输入下面的命令来更改系统的根目录为 Arch Linux 的安装目录:
-```
+```
arch-chroot /mnt /bin/bash
-```
+```
现在来更改语言配置:
-```
-nano /etc/local.gen
+```
+nano /etc/locale.gen
```
[
@@ -297,9 +297,9 @@ nano /etc/local.gen
输入下面的命令来激活它:
-```
+```
locale-gen
-```
+```
按回车。
@@ -309,8 +309,8 @@ locale-gen
使用下面的命令来创建 `/etc/locale.conf` 配置文件:
-```
-nano /etc/locale.conf
+```
+nano /etc/locale.conf
```
然后按回车。现在你就可以在配置文件中输入下面一行内容来为系统添加语言:
@@ -326,9 +326,9 @@ LANG=en_US.UTF-8
][44]
输入下面的命令来同步时区:
-
+
```
-ls user/share/zoneinfo
+ls /usr/share/zoneinfo
```
下面你将看到整个世界的时区列表。
@@ -339,9 +339,9 @@ ls user/share/zoneinfo
输入下面的命令来选择你所在的时区:
-```
+```
ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
-```
+```
或者你可以从下面的列表中选择其它名称。
@@ -351,8 +351,8 @@ ln –s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
使用下面的命令来设置标准时间:
-```
-hwclock --systohc –utc
+```
+hwclock --systohc --utc
```
硬件时钟已同步。
@@ -363,8 +363,8 @@ hwclock --systohc –utc
设置 root 帐号密码:
-```
-passwd
+```
+passwd
```
按回车。 然而输入你想设置的密码,按回车确认。
@@ -377,9 +377,9 @@ passwd
使用下面的命令来设置主机名:
-```
+```
nano /etc/hostname
-```
+```
然后按回车。输入你想设置的主机名称,按 `control + x` ,按 `y` ,再按回车 。
@@ -389,9 +389,9 @@ nano /etc/hostname
启用 dhcpcd :
-```
+```
systemctl enable dhcpcd
-```
+```
这样在下一次系统启动时, dhcpcd 将会自动启动,并自动获取一个 IP 地址:
@@ -403,9 +403,9 @@ systemctl enable dhcpcd
最后一步,输入以下命令来初始化 grub 安装。输入以下命令:
-```
+```
pacman –S grub os-rober
-```
+```
然后按 `y` ,将会下载相关程序。
@@ -415,14 +415,14 @@ pacman –S grub os-rober
使用下面的命令来将启动加载程序安装到硬盘上:
-```
+```
grub-install /dev/sda
-```
+```
然后进行配置:
-```
-grub-mkconfig -o /boot/grub/grub.cfg
+```
+grub-mkconfig -o /boot/grub/grub.cfg
```
[
@@ -431,9 +431,9 @@ grub-mkconfig -o /boot/grub/grub.cfg
最后重启系统:
-```
+```
reboot
-```
+```
然后按回车 。
@@ -459,7 +459,7 @@ reboot
via: https://www.howtoforge.com/tutorial/install-arch-linux-on-virtualbox/
-译者简介:
+译者简介:
rusking:春城初春/春水初生/春林初盛/春風十裏不如妳
diff --git a/translated/tech/20170404 Kernel Tracing with Ftrace.md b/published/20170404 Kernel Tracing with Ftrace.md
similarity index 75%
rename from translated/tech/20170404 Kernel Tracing with Ftrace.md
rename to published/20170404 Kernel Tracing with Ftrace.md
index 6ed3a87bf9..6c209d4e0d 100644
--- a/translated/tech/20170404 Kernel Tracing with Ftrace.md
+++ b/published/20170404 Kernel Tracing with Ftrace.md
@@ -1,49 +1,45 @@
-使用 Ftrace 跟踪内核
+使用 ftrace 跟踪内核
============================================================
-标签: [ftrace][8],[kernel][9],[kernel profiling][10],[kernel tracing][11],[linux][12],[tracepoints][13]
-

-在内核级别上分析事件有很多的工具:[SystemTap][14],[ktap][15],[Sysdig][16],[LTTNG][17]等等,并且你也可以在网络上找到关于这些工具的大量介绍文章和资料。
+在内核层面上分析事件有很多的工具:[SystemTap][14]、[ktap][15]、[Sysdig][16]、[LTTNG][17] 等等,你也可以在网络上找到关于这些工具的大量介绍文章和资料。
而对于使用 Linux 原生机制去跟踪系统事件以及检索/分析故障信息的方面的资料却很少找的到。这就是 [ftrace][18],它是添加到内核中的第一款跟踪工具,今天我们来看一下它都能做什么,让我们从它的一些重要术语开始吧。
### 内核跟踪和分析
-内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 一个事件的总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
+内核分析可以发现性能“瓶颈”。分析能够帮我们发现在一个程序中性能损失的准确位置。特定的程序生成一个概述 — 这是一个事件总结 — 它能够用于帮我们找出哪个函数占用了大量的运行时间。尽管这些程序并不能识别出为什么会损失性能。
-瓶颈经常发生在无法通过分析来识别的情况下。去推断出为什么会发生事件,去保存发生事件时的相关上下文,这就需要去跟踪。
+瓶颈经常发生在无法通过分析来识别的情况下。要推断出为什么会发生事件,就必须保存发生事件时的相关上下文,这就需要去跟踪。
-跟踪可以理解为在一个正常工作的系统上活动的信息收集进程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种注册的系统事件。
+跟踪可以理解为在一个正常工作的系统上活动的信息收集过程。它使用特定的工具来完成这项工作,就像录音机来记录声音一样,用它来记录各种系统事件。
跟踪程序能够同时跟踪应用级和操作系统级的事件。它们收集的信息能够用于诊断多种系统问题。
有时候会将跟踪与日志比较。它们两者确时很相似,但是也有不同的地方。
-对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登陆系统、应用程序错误、数据库事务等等。
+对于跟踪,记录的信息都是些低级别事件。它们的数量是成百上千的,甚至是成千上万的。对于日志,记录的信息都是些高级别事件,数量上通常少多了。这些包含用户登录系统、应用程序错误、数据库事务等等。
就像日志一样,跟踪数据可以被原样读取,但是用特定的应用程序提取的信息更有用。所有的跟踪程序都能这样做。
在内核跟踪和分析方面,Linux 内核有三个主要的机制:
-* 跟踪点 —— 一种基于静态测试代码的工作机制
-
-* 探针 —— 一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回。
-
-* perf_events —— 一个访问 PMU(性能监视单元)的接口
+* 跟踪点:一种基于静态测试代码的工作机制
+* 探针:一种动态跟踪机制,用于在任意时刻中断内核代码的运行,调用它自己的处理程序,在完成需要的操作之后再返回
+* perf_events —— 一个访问 PMU(性能监视单元)的接口
我并不想在这里写关于这些机制方面的内容,任何对它们感兴趣的人可以去访问 [Brendan Gregg 的博客][19]。
使用 ftrace,我们可以与这些机制进行交互,并可以从用户空间直接得到调试信息。下面我们将讨论这方面的详细内容。示例中的所有命令行都是在内核版本为 3.13.0-24 的 Ubuntu 14.04 中运行的。
-### Ftrace:常用信息
+### ftrace:常用信息
-Ftrace 是函数 Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
+ftrace 是 Function Trace 的简写,但它能做的远不止这些:它可以跟踪上下文切换、测量进程阻塞时间、计算高优先级任务的活动时间等等。
-Ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 `Ring` 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
+ftrace 是由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。这是为记录数据提供的一个调试 Ring 缓冲区的框架。这些数据由集成到内核中的跟踪程序来采集。
-Ftrace 工作在 debugfs 文件系统上,这是在大多数现代 Linux 分发版中默认挂载的文件系统。为开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
+ftrace 工作在 debugfs 文件系统上,在大多数现代 Linux 发行版中都默认挂载了。要开始使用 ftrace,你将进入到 `sys/kernel/debug/tracing` 目录(仅对 root 用户可用):
```
# cd /sys/kernel/debug/tracing
@@ -70,16 +66,13 @@ kprobe_profile stack_max_size uprobe_profile
我不想去描述这些文件和子目录;它们的描述在 [官方文档][20] 中已经写的很详细了。我只想去详细介绍与我们这篇文章相关的这几个文件:
* available_tracers —— 可用的跟踪程序
-
* current_tracer —— 正在运行的跟踪程序
-
-* tracing_on —— 负责启用或禁用数据写入到 `Ring` 缓冲区的系统文件(如果启用它,在文件中添加数字 1,禁用它,添加数字 0)
-
+* tracing_on —— 负责启用或禁用数据写入到 Ring 缓冲区的系统文件(如果启用它,数字 1 被添加到文件中,禁用它,数字 0 被添加)
* trace —— 以人类友好格式保存跟踪数据的文件
### 可用的跟踪程序
-我们可以使用如下的命令去查看可用的跟踪程序的一个列表
+我们可以使用如下的命令去查看可用的跟踪程序的一个列表:
```
root@andrei:/sys/kernel/debug/tracing#: cat available_tracers
@@ -89,18 +82,14 @@ blk mmiotrace function_graph wakeup_rt wakeup function nop
我们来快速浏览一下每个跟踪程序的特性:
* function —— 一个无需参数的函数调用跟踪程序
-
* function_graph —— 一个使用子调用的函数调用跟踪程序
-
-* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 的用途)
-
+* blk —— 一个与块 I/O 跟踪相关的调用和事件跟踪程序(它是 blktrace 使用的)
* mmiotrace —— 一个内存映射 I/O 操作跟踪程序
-
-* nop —— 简化的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
+* nop —— 最简单的跟踪程序,就像它的名字所暗示的那样,它不做任何事情(尽管在某些情况下可能会派上用场,我们将在后文中详细解释)
### 函数跟踪程序
-在开始介绍函数跟踪程序 ftrace 之前,我们先看一下测试脚本:
+在开始介绍函数跟踪程序 ftrace 之前,我们先看一个测试脚本:
```
#!/bin/sh
@@ -117,7 +106,7 @@ less ${dir}/trace
这个脚本是非常简单的,但是还有几个需要注意的地方。命令 `sysctl ftrace.enabled=1` 启用了函数跟踪程序。然后我们通过写它的名字到 `current_tracer` 文件来启用 `current tracer`。
-接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 `Ring` 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
+接下来,我们写入一个 `1` 到 `tracing_on`,它启用了 Ring 缓冲区。这些语法都要求在 `1` 和 `>` 符号前后有一个空格;写成像 `echo 1> tracing_on` 这样将不能工作。一行之后我们禁用它(如果 `0` 写入到 `tracing_on`, 缓冲区不会被清除并且 ftrace 并不会被禁用)。
我们为什么这样做呢?在两个 `echo` 命令之间,我们看到了命令 `sleep 1`。我们启用了缓冲区,运行了这个命令,然后禁用它。这将使跟踪程序采集了这个命令运行期间发生的所有系统调用的信息。
@@ -156,21 +145,18 @@ less ${dir}/trace
trace.sh-1295 [000] d... 90.502879: __acct_update_integrals <-acct_account_cputime
```
-这个输出以缓冲区中的信息条目数量和写入的条目数量开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
+这个输出以“缓冲区中的信息条目数量”和“写入的全部条目数量”开始。这两者的数据差异是缓冲区中事件的丢失数量(在我们的示例中没有发生丢失)。
在这里有一个包含下列信息的函数列表:
* 进程标识符(PID)
-
* 运行这个进程的 CPU(CPU#)
-
* 进程开始时间(TIMESTAMP)
-
* 被跟踪函数的名字以及调用它的父级函数;例如,在我们输出的第一行,`rb_simple_write` 调用了 `mutex-unlock` 函数。
-### Function_graph 跟踪程序
+### function_graph 跟踪程序
-`function_graph` 跟踪程序的工作和函数一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
+function_graph 跟踪程序的工作和函数跟踪程序一样,但是它更详细:它显示了每个函数的进入和退出点。使用这个跟踪程序,我们可以跟踪函数的子调用并且测量每个函数的运行时间。
我们来编辑一下最后一个示例的脚本:
@@ -215,11 +201,11 @@ less ${dir}/trace
0) ! 208.154 us | } /* ip_local_deliver_finish */
```
-在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(+)意思是这个函数花费的时间超过 10 毫秒;而感叹号(!)意思是这个函数花费的时间超过了 100 毫秒。
+在这个图中,`DURATION` 展示了花费在每个运行的函数上的时间。注意使用 `+` 和 `!` 符号标记的地方。加号(`+`)意思是这个函数花费的时间超过 10 毫秒;而感叹号(`!`)意思是这个函数花费的时间超过了 100 毫秒。
在 `FUNCTION_CALLS` 下面,我们可以看到每个函数调用的信息。
-和 C 语言一样使用了花括号({)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(;)标记。
+和 C 语言一样使用了花括号(`{`)标记每个函数的边界,它展示了每个函数的开始和结束,一个用于开始,一个用于结束;不能调用其它任何函数的叶子函数用一个分号(`;`)标记。
### 函数过滤器
@@ -249,13 +235,13 @@ ftrace 还有很多过滤选项。对于它们更详细的介绍,你可以去
### 跟踪事件
-我们在上面提到到跟踪点机制。跟踪点是插入的由系统事件触发的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
+我们在上面提到到跟踪点机制。跟踪点是插入的触发系统事件的特定代码。跟踪点可以是动态的(意味着可能会在它们上面附加几个检查),也可以是静态的(意味着不会附加任何检查)。
-静态跟踪点不会对系统有任何影响;它们只是增加几个字节用于调用测试函数以及在一个独立的节上增加一个数据结构。
+静态跟踪点不会对系统有任何影响;它们只是在测试的函数末尾增加几个字节的函数调用以及在一个独立的节上增加一个数据结构。
-当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 `Ring` 缓冲区。
+当相关代码片断运行时,动态跟踪点调用一个跟踪函数。跟踪数据是写入到 Ring 缓冲区。
-跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(它在 [这里][22]):
+跟踪点可以设置在代码的任何位置;事实上,它们确实可以在许多的内核函数中找到。我们来看一下 `kmem_cache_alloc` 函数(取自 [这里][22]):
```
{
@@ -294,7 +280,7 @@ fs kvm power scsi vfs
ftrace kvmmmu printk signal vmscan
```
-所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 `Ring` 缓冲区写入:
+所有可能的事件都按子系统分组到子目录中。在我们开始跟踪事件之前,我们要先确保启用了 Ring 缓冲区写入:
```
root@andrei:/sys/kernel/debug/tracing# cat tracing_on
@@ -306,25 +292,25 @@ root@andrei:/sys/kernel/debug/tracing# cat tracing_on
root@andrei:/sys/kernel/debug/tracing# echo 1 > tracing_on
```
-在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。为了跟踪,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
+在我们上一篇的文章中,我们写了关于 `chroot()` 系统调用的内容;我们来跟踪访问一下这个系统调用。对于我们的跟踪程序,我们使用 `nop` 因为函数跟踪程序和 `function_graph` 跟踪程序记录的信息太多,它包含了我们不感兴趣的事件信息。
```
root@andrei:/sys/kernel/debug/tracing# echo nop > current_tracer
```
-所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出多个系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
+所有事件相关的系统调用都保存在系统调用目录下。在这里我们将找到一个进入和退出各种系统调用的目录。我们需要在相关的文件中通过写入数字 `1` 来激活跟踪点:
```
root@andrei:/sys/kernel/debug/tracing# echo 1 > events/syscalls/sys_enter_chroot/enable
```
-然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息出现在输出中:
+然后我们使用 `chroot` 来创建一个独立的文件系统(更多内容,请查看 [之前这篇文章][23])。在我们执行完我们需要的命令之后,我们将禁用跟踪程序,以便于不需要的信息或者过量信息不会出现在输出中:
```
root@andrei:/sys/kernel/debug/tracing# echo 0 > tracing_on
```
-然后,我们去查看 `Ring` 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
+然后,我们去查看 Ring 缓冲区的内容。在输出的结束部分,我们找到了有关的系统调用信息(这里只是一个节选)。
```
root@andrei:/sys/kernel/debug/tracing# сat trace
@@ -343,15 +329,10 @@ root@andrei:/sys/kernel/debug/tracing# сat trace
在这篇文篇中,我们做了一个 ftrace 的功能概述。我们非常感谢你的任何意见或者补充。如果你想深入研究这个主题,我们为你推荐下列的资源:
* [https://www.kernel.org/doc/Documentation/trace/tracepoints.txt][1] — 一个跟踪点机制的详细描述
-
* [https://www.kernel.org/doc/Documentation/trace/events.txt][2] — 在 Linux 中跟踪系统事件的指南
-
* [https://www.kernel.org/doc/Documentation/trace/ftrace.txt][3] — ftrace 的官方文档
-
* [https://lttng.org/files/thesis/desnoyers-dissertation-2009-12-v27.pdf][4] — Mathieu Desnoyers(作者是跟踪点和 LTTNG 的创建者)的关于内核跟踪和分析的学术论文。
-
* [https://lwn.net/Articles/370423/][5] — Steven Rostedt 的关于 ftrace 功能的文章
-
* [http://alex.dzyoba.com/linux/profiling-ftrace.html][6] — 用 ftrace 分析实际案例的一个概述
--------------------------------------------------------------------------------
@@ -360,7 +341,7 @@ via:https://blog.selectel.com/kernel-tracing-ftrace/
作者:[Andrej Yemelianov][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md b/published/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
new file mode 100644
index 0000000000..07b851caf2
--- /dev/null
+++ b/published/20170829 An Advanced System Configuration Utility For Ubuntu Power Users.md
@@ -0,0 +1,129 @@
+Ubunsys:面向 Ubuntu 资深用户的一个高级系统配置工具
+======
+
+
+
+
+**Ubunsys** 是一个面向 Ubuntu 及其衍生版的基于 Qt 的高级系统工具。高级用户可以使用命令行轻松完成大多数配置。不过为了以防万一某天,你突然不想用命令行了,就可以用 Ubnusys 这个程序来配置你的系统或其衍生系统,如 Linux Mint、Elementary OS 等。Ubunsys 可用来修改系统配置,安装、删除、更新包和旧内核,启用或禁用 `sudo` 权限,安装主线内核,更新软件安装源,清理垃圾文件,将你的 Ubuntu 系统升级到最新版本等等。以上提到的所有功能都可以通过鼠标点击完成。你不需要再依赖于命令行模式,下面是你能用 Ubunsys 做到的事:
+
+ * 安装、删除、更新包
+ * 更新和升级软件源
+ * 安装主线内核
+ * 删除旧的和不再使用的内核
+ * 系统整体更新
+ * 将系统升级到下一个可用的版本
+ * 将系统升级到最新的开发版本
+ * 清理系统垃圾文件
+ * 在不输入密码的情况下启用或者禁用 `sudo` 权限
+ * 当你在终端输入密码时使 `sudo` 密码可见
+ * 启用或禁用系统休眠
+ * 启用或禁用防火墙
+ * 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件
+ * 显示或者隐藏启动项
+ * 启用或禁用登录音效
+ * 配置双启动
+ * 启用或禁用锁屏
+ * 智能系统更新
+ * 使用脚本管理器更新/一次性执行脚本
+ * 从 `git` 执行常规用户安装脚本
+ * 检查系统完整性和缺失的 GPG 密钥
+ * 修复网络
+ * 修复已破损的包
+ * 还有更多功能在开发中
+
+**重要提示:** Ubunsys 不适用于 Ubuntu 新手。它很危险并且仍然不是稳定版。它可能会使你的系统崩溃。如果你刚接触 Ubuntu 不久,不要使用。但如果你真的很好奇这个应用能做什么,仔细浏览每一个选项,并确定自己能承担风险。在使用这一应用之前记着备份你自己的重要数据。
+
+### 安装 Ubunsys
+
+Ubunsys 开发者制作了一个 PPA 来简化安装过程,Ubunsys 现在可以在 Ubuntu 16.04 LTS、 Ubuntu 17.04 64 位版本上使用。
+
+逐条执行下面的命令,将 Ubunsys 的 PPA 添加进去,并安装它。
+
+```
+sudo add-apt-repository ppa:adgellida/ubunsys
+sudo apt-get update
+sudo apt-get install ubunsys
+```
+
+如果 PPA 无法使用,你可以在[发布页面][1]根据你自己当前系统,选择正确的安装包,直接下载并安装 Ubunsys。
+
+### 用途
+
+一旦安装完成,从菜单栏启动 Ubunsys。下图是 Ubunsys 主界面。
+
+![][3]
+
+你可以看到,Ubunsys 有四个主要部分,分别是 Packages、Tweaks、System 和 Repair。在每一个标签项下面都有一个或多个子标签项以对应不同的操作。
+
+**Packages**
+
+这一部分允许你安装、删除和更新包。
+
+![][4]
+
+**Tweaks**
+
+在这一部分,我们可以对系统进行多种调整,例如:
+
+ * 打开、备份和导入 `sources.list.d` 和 `sudoers` 文件;
+ * 配置双启动;
+ * 启用或禁用登录音效、防火墙、锁屏、系统休眠、`sudo` 权限(在不需要密码的情况下)同时你还可以针对某一用户启用或禁用 `sudo` 权限(在不需要密码的情况下);
+ * 在终端中输入密码时可见(禁用星号)。
+
+![][5]
+
+**System**
+
+这一部分被进一步分成 3 个部分,每个都是针对某一特定用户类型。
+
+**Normal user** 这一标签下的选项可以:
+
+ * 更新、升级包和软件源
+ * 清理系统
+ * 执行常规用户安装脚本
+
+**Advanced user** 这一标签下的选项可以:
+
+* 清理旧的/无用的内核
+* 安装主线内核
+* 智能包更新
+* 升级系统
+
+**Developer** 这一部分可以将系统升级到最新的开发版本。
+
+![][6]
+
+**Repair**
+
+这是 Ubunsys 的第四个也是最后一个部分。正如名字所示,这一部分能让我们修复我们的系统、网络、缺失的 GPG 密钥,和已经缺失的包。
+
+![][7]
+
+正如你所见,Ubunsys 可以在几次点击下就能完成诸如系统配置、系统维护和软件维护之类的任务。你不需要一直依赖于终端。Ubunsys 能帮你完成任何高级任务。再次声明,我警告你,这个应用不适合新手,而且它并不稳定。所以当你使用的时候,能会出现 bug 或者系统崩溃。在仔细研究过每一个选项的影响之后再使用它。
+
+谢谢阅读!
+
+### 参考资源
+
+- [Ubunsys GitHub Repository][8]
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/ubunsys-advanced-system-configuration-utility-ubuntu-power-users/
+
+作者:[SK][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[wenwensnow](https://github.com/wenwensnow)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://github.com/adgellida/ubunsys/releases
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-1.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-2.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-5.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-9.png
+[7]:http://www.ostechnix.com/wp-content/uploads/2017/08/Ubunsys-11.png
+[8]:https://github.com/adgellida/ubunsys
\ No newline at end of file
diff --git a/published/20171003 Streams a new general purpose data structure in Redis.md b/published/20171003 Streams a new general purpose data structure in Redis.md
new file mode 100644
index 0000000000..92933058bb
--- /dev/null
+++ b/published/20171003 Streams a new general purpose data structure in Redis.md
@@ -0,0 +1,183 @@
+Streams:一个新的 Redis 通用数据结构
+======
+
+直到几个月以前,对于我来说,在消息传递的环境中,流只是一个有趣且相对简单的概念。这个概念在 Kafka 流行之后,我主要研究它们在 Disque 案例中的应用,Disque 是一个消息队列,它将在 Redis 4.2 中被转换为 Redis 的一个模块。后来我决定让 Disque 都用 AP 消息(LCTT 译注:参见 [CAP 定理][1]) ,也就是说,它将在不需要客户端过多参与的情况下实现容错和可用性,这样一来,我更加确定地认为流的概念在那种情况下并不适用。
+
+然而在那时 Redis 有个问题,那就是缺省情况下导出数据结构并不轻松。它在 Redis 列表、有序集、发布/订阅功能之间有某些缺陷。你可以权衡使用这些工具对一系列消息或事件建模。
+
+有序集是内存消耗大户,那自然就不能对投递的相同消息进行一次又一次的建模,客户端不能阻塞新消息。因为有序集并不是一个序列化的数据结构,它是一个元素可以根据它们量的变化而移动的集合:所以它不像时序性的数据那样。
+
+列表有另外的问题,它在某些特定的用例中会产生类似的适用性问题:你无法浏览列表中间的内容,因为在那种情况下,访问时间是线性的。此外,没有任何指定输出的功能,列表上的阻塞操作仅为单个客户端提供单个元素。列表中没有固定的元素标识,也就是说,不能指定从哪个元素开始给我提供内容。
+
+对于一对多的工作任务,有发布/订阅机制,它在大多数情况下是非常好的,但是,对于某些不想“即发即弃”的东西:保留一个历史是很重要的,不只是因为是断开之后会重新获得消息,也因为某些如时序性的消息列表,用范围查询浏览是非常重要的:比如在这 10 秒范围内温度读数是多少?
+
+我试图解决上述问题,我想规划一个通用的有序集合,并列入一个独特的、更灵活的数据结构,然而,我的设计尝试最终以生成一个比当前的数据结构更加矫揉造作的结果而告终。Redis 有个好处,它的数据结构导出更像自然的计算机科学的数据结构,而不是 “Salvatore 发明的 API”。因此,我最终停止了我的尝试,并且说,“ok,这是我们目前能提供的”,或许我会为发布/订阅增加一些历史信息,或者为列表访问增加一些更灵活的方式。然而,每次在会议上有用户对我说 “你如何在 Redis 中模拟时间系列” 或者类似的问题时,我的脸就绿了。
+
+### 起源
+
+在 Redis 4.0 中引入模块之后,用户开始考虑他们自己怎么去修复这些问题。其中一个用户 Timothy Downs 通过 IRC 和我说道:
+
+ \ 我计划给这个模块增加一个事务日志式的数据类型 —— 这意味着大量的订阅者可以在不导致 redis 内存激增的情况下做一些像发布/订阅那样的事情
+ \ 订阅者持有他们在消息队列中的位置,而不是让 Redis 必须维护每个消费者的位置和为每个订阅者复制消息
+
+他的思路启发了我。我想了几天,并且意识到这可能是我们马上同时解决上面所有问题的契机。我需要去重新构思 “日志” 的概念是什么。日志是个基本的编程元素,每个人都使用过它,因为它只是简单地以追加模式打开一个文件,并以一定的格式写入数据。然而 Redis 数据结构必须是抽象的。它们在内存中,并且我们使用内存并不是因为我们懒,而是因为使用一些指针,我们可以概念化数据结构并把它们抽象,以使它们摆脱明确的限制。例如,一般来说日志有几个问题:偏移不是逻辑化的,而是真实的字节偏移,如果你想要与条目插入的时间相关的逻辑偏移应该怎么办?我们有范围查询可用。同样,日志通常很难进行垃圾回收:在一个只能进行追加操作的数据结构中怎么去删除旧的元素?好吧,在我们理想的日志中,我们只需要说,我想要数字最大的那个条目,而旧的元素一个也不要,等等。
+
+当我从 Timothy 的想法中受到启发,去尝试着写一个规范的时候,我使用了 Redis 集群中的 radix 树去实现,优化了它内部的某些部分。这为实现一个有效利用空间的日志提供了基础,而且仍然有可能在对数时间内访问范围。同时,我开始去读关于 Kafka 的流相关的内容以获得另外的灵感,它也非常适合我的设计,最后借鉴了 Kafka 消费组的概念,并且再次针对 Redis 进行优化,以适用于 Redis 在内存中使用的情况。然而,该规范仅停留在纸面上,在一段时间后我几乎把它从头到尾重写了一遍,以便将我与别人讨论的所得到的许多建议一起增加到 Redis 升级中。我希望 Redis 流能成为对于时间序列有用的特性,而不仅是一个常见的事件和消息类的应用程序。
+
+### 让我们写一些代码吧
+
+从 Redis 大会回来后,整个夏天我都在实现一个叫 listpack 的库。这个库是 `ziplist.c` 的继任者,那是一个表示在单个分配中的字符串元素列表的数据结构。它是一个非常特殊的序列化格式,其特点在于也能够以逆序(从右到左)解析:以便在各种用例中替代 ziplists。
+
+结合 radix 树和 listpacks 的特性,它可以很容易地去构建一个空间高效的日志,并且还是可索引的,这意味着允许通过 ID 和时间进行随机访问。自从这些就绪后,我开始去写一些代码以实现流数据结构。我还在完成这个实现,不管怎样,现在在 Github 上的 Redis 的 streams 分支里它已经可以跑起来了。我并没有声称那个 API 是 100% 的最终版本,但是,这有两个有意思的事实:一,在那时只有消费群组是缺失的,加上一些不太重要的操作流的命令,但是,所有的大的方面都已经实现了。二,一旦各个方面比较稳定了之后,我决定大概用两个月的时间将所有的流的特性向后移植到 4.0 分支。这意味着 Redis 用户想要使用流,不用等待 Redis 4.2 发布,它们在生产环境马上就可用了。这是可能的,因为作为一个新的数据结构,几乎所有的代码改变都出现在新的代码里面。除了阻塞列表操作之外:该代码被重构了,我们对于流和列表阻塞操作共享了相同的代码,而极大地简化了 Redis 内部实现。
+
+### 教程:欢迎使用 Redis 的 streams
+
+在某些方面,你可以认为流是 Redis 列表的一个增强版本。流元素不再是一个单一的字符串,而是一个字段和值组成的对象。范围查询更适用而且更快。在流中,每个条目都有一个 ID,它是一个逻辑偏移量。不同的客户端可以阻塞等待比指定的 ID 更大的元素。Redis 流的一个基本的命令是 `XADD`。是的,所有的 Redis 流命令都是以一个 `X` 为前缀的。
+
+```
+> XADD mystream * sensor-id 1234 temperature 10.5
+1506871964177.0
+```
+
+这个 `XADD` 命令将追加指定的条目作为一个指定的流 —— “mystream” 的新元素。上面示例中的这个条目有两个字段:`sensor-id` 和 `temperature`,每个条目在同一个流中可以有不同的字段。使用相同的字段名可以更好地利用内存。有意思的是,字段的排序是可以保证顺序的。`XADD` 仅返回插入的条目的 ID,因为在第三个参数中是星号(`*`),表示由命令自动生成 ID。通常这样做就够了,但是也可以去强制指定一个 ID,这种情况用于复制这个命令到从服务器和 AOF 文件。
+
+这个 ID 是由两部分组成的:一个毫秒时间和一个序列号。`1506871964177` 是毫秒时间,它只是一个毫秒级的 UNIX 时间戳。圆点(`.`)后面的数字 `0` 是一个序号,它是为了区分相同毫秒数的条目增加上去的。这两个数字都是 64 位的无符号整数。这意味着,我们可以在流中增加所有想要的条目,即使是在同一毫秒中。ID 的毫秒部分使用 Redis 服务器的当前本地时间生成的 ID 和流中的最后一个条目 ID 两者间的最大的一个。因此,举例来说,即使是计算机时间回跳,这个 ID 仍然是增加的。在某些情况下,你可以认为流条目的 ID 是完整的 128 位数字。然而,事实上它们与被添加到的实例的本地时间有关,这意味着我们可以在毫秒级的精度的范围随意查询。
+
+正如你想的那样,快速添加两个条目后,结果是仅一个序号递增了。我们可以用一个 `MULTI`/`EXEC` 块来简单模拟“快速插入”:
+
+```
+> MULTI
+OK
+> XADD mystream * foo 10
+QUEUED
+> XADD mystream * bar 20
+QUEUED
+> EXEC
+1) 1506872463535.0
+2) 1506872463535.1
+```
+
+在上面的示例中,也展示了无需指定任何初始模式的情况下,对不同的条目使用不同的字段。会发生什么呢?就像前面提到的一样,只有每个块(它通常包含 50-150 个消息内容)的第一个消息被使用。并且,相同字段的连续条目都使用了一个标志进行了压缩,这个标志表示与“它们与这个块中的第一个条目的字段相同”。因此,使用相同字段的连续消息可以节省许多内存,即使是字段集随着时间发生缓慢变化的情况下也很节省内存。
+
+为了从流中检索数据,这里有两种方法:范围查询,它是通过 `XRANGE` 命令实现的;流播,它是通过 `XREAD` 命令实现的。`XRANGE` 命令仅取得包括从开始到停止范围内的全部条目。因此,举例来说,如果我知道它的 ID,我可以使用如下的命名取得单个条目:
+
+```
+> XRANGE mystream 1506871964177.0 1506871964177.0
+1) 1) 1506871964177.0
+ 2) 1) "sensor-id"
+ 2) "1234"
+ 3) "temperature"
+ 4) "10.5"
+```
+
+不管怎样,你都可以使用指定的开始符号 `-` 和停止符号 `+` 表示最小和最大的 ID。为了限制返回条目的数量,也可以使用 `COUNT` 选项。下面是一个更复杂的 `XRANGE` 示例:
+
+```
+> XRANGE mystream - + COUNT 2
+1) 1) 1506871964177.0
+ 2) 1) "sensor-id"
+ 2) "1234"
+ 3) "temperature"
+ 4) "10.5"
+2) 1) 1506872463535.0
+ 2) 1) "foo"
+ 2) "10"
+```
+
+这里我们讲的是 ID 的范围,然后,为了取得在一个给定时间范围内的特定范围的元素,你可以使用 `XRANGE`,因为 ID 的“序号” 部分可以省略。因此,你可以只指定“毫秒”时间即可,下面的命令的意思是:“从 UNIX 时间 1506872463 开始给我 10 个条目”:
+
+```
+127.0.0.1:6379> XRANGE mystream 1506872463000 + COUNT 10
+1) 1) 1506872463535.0
+ 2) 1) "foo"
+ 2) "10"
+2) 1) 1506872463535.1
+ 2) 1) "bar"
+ 2) "20"
+```
+
+关于 `XRANGE` 需要注意的最重要的事情是,假设我们在回复中收到 ID,随后连续的 ID 只是增加了序号部分,所以可以使用 `XRANGE` 遍历整个流,接收每个调用的指定个数的元素。Redis 中的`*SCAN` 系列命令允许迭代 Redis 数据结构,尽管事实上它们不是为迭代设计的,但这样可以避免再犯相同的错误。
+
+### 使用 XREAD 处理流播:阻塞新的数据
+
+当我们想通过 ID 或时间去访问流中的一个范围或者是通过 ID 去获取单个元素时,使用 `XRANGE` 是非常完美的。然而,在使用流的案例中,当数据到达时,它必须由不同的客户端来消费时,这就不是一个很好的解决方案,这需要某种形式的汇聚池。(对于 *某些* 应用程序来说,这可能是个好主意,因为它们仅是偶尔连接查询的)
+
+`XREAD` 命令是为读取设计的,在同一个时间,从多个流中仅指定我们从该流中得到的最后条目的 ID。此外,如果没有数据可用,我们可以要求阻塞,当数据到达时,就解除阻塞。类似于阻塞列表操作产生的效果,但是这里并没有消费从流中得到的数据,并且多个客户端可以同时访问同一份数据。
+
+这里有一个典型的 `XREAD` 调用示例:
+
+```
+> XREAD BLOCK 5000 STREAMS mystream otherstream $ $
+```
+
+它的意思是:从 `mystream` 和 `otherstream` 取得数据。如果没有数据可用,阻塞客户端 5000 毫秒。在 `STREAMS` 选项之后指定我们想要监听的关键字,最后的是指定想要监听的 ID,指定的 ID 为 `$` 的意思是:假设我现在需要流中的所有元素,因此,只需要从下一个到达的元素开始给我。
+
+如果我从另一个客户端发送这样的命令:
+
+```
+> XADD otherstream * message “Hi There”
+```
+
+在 `XREAD` 侧会出现什么情况呢?
+
+```
+1) 1) "otherstream"
+ 2) 1) 1) 1506935385635.0
+ 2) 1) "message"
+ 2) "Hi There"
+```
+
+与收到的数据一起,我们也得到了数据的关键字。在下次调用中,我们将使用接收到的最新消息的 ID:
+
+```
+> XREAD BLOCK 5000 STREAMS mystream otherstream $ 1506935385635.0
+```
+
+依次类推。然而需要注意的是使用方式,客户端有可能在一个非常大的延迟之后再次连接(因为它处理消息需要时间,或者其它什么原因)。在这种情况下,期间会有很多消息堆积,为了确保客户端不被消息淹没,以及服务器不会因为给单个客户端提供大量消息而浪费太多的时间,使用 `XREAD` 的 `COUNT` 选项是非常明智的。
+
+### 流封顶
+
+目前看起来还不错……然而,有些时候,流需要删除一些旧的消息。幸运的是,这可以使用 `XADD` 命令的 `MAXLEN` 选项去做:
+
+```
+> XADD mystream MAXLEN 1000000 * field1 value1 field2 value2
+```
+
+它是基本意思是,如果在流中添加新元素后发现消息数量超过了 `1000000` 个,那么就删除旧的消息,以便于元素总量重新回到 `1000000` 以内。它很像是在列表中使用的 `RPUSH` + `LTRIM`,但是,这次我们是使用了一个内置机制去完成的。然而,需要注意的是,上面的意思是每次我们增加一个新的消息时,我们还需要另外的工作去从流中删除旧的消息。这将消耗一些 CPU 资源,所以在计算 `MAXLEN` 之前,尽可能使用 `~` 符号,以表明我们不要求非常 *精确* 的 1000000 个消息,就是稍微多一些也不是大问题:
+
+```
+> XADD mystream MAXLEN ~ 1000000 * foo bar
+```
+
+这种方式的 XADD 仅当它可以删除整个节点的时候才会删除消息。相比普通的 `XADD`,这种方式几乎可以自由地对流进行封顶。
+
+### 消费组(开发中)
+
+这是第一个 Redis 中尚未实现而在开发中的特性。灵感也是来自 Kafka,尽管在这里是以不同的方式实现的。重点是使用了 `XREAD`,客户端也可以增加一个 `GROUP ` 选项。相同组的所有客户端将自动得到 *不同的* 消息。当然,同一个流可以被多个组读取。在这种情况下,所有的组将收到流中到达的消息的相同副本。但是,在每个组内,消息是不会重复的。
+
+当指定组时,能够指定一个 `RETRY ` 选项去扩展组:在这种情况下,如果消息没有通过 `XACK` 进行确认,它将在指定的毫秒数后进行再次投递。这将为消息投递提供更佳的可靠性,这种情况下,客户端没有私有的方法将消息标记为已处理。这一部分也正在开发中。
+
+### 内存使用和节省加载时间
+
+因为用来建模 Redis 流的设计,内存使用率是非常低的。这取决于它们的字段、值的数量和长度,对于简单的消息,每使用 100MB 内存可以有几百万条消息。此外,该格式设想为需要极少的序列化:listpack 块以 radix 树节点方式存储,在磁盘上和内存中都以相同方式表示的,因此它们可以很轻松地存储和读取。例如,Redis 可以在 0.3 秒内从 RDB 文件中读取 500 万个条目。这使流的复制和持久存储非常高效。
+
+我还计划允许从条目中间进行部分删除。现在仅实现了一部分,策略是在条目在标记中标识条目为已删除,并且,当已删除条目占全部条目的比例达到指定值时,这个块将被回收重写,如果需要,它将被连到相邻的另一个块上,以避免碎片化。
+
+### 关于最终发布时间的结论
+
+Redis 的流特性将包含在年底前(LCTT 译注:本文原文发布于 2017 年 10 月)推出的 Redis 4.0 系列的稳定版中。我认为这个通用的数据结构将为 Redis 提供一个巨大的补丁,以用于解决很多现在很难以解决的情况:那意味着你(之前)需要创造性地“滥用”当前提供的数据结构去解决那些问题。一个非常重要的使用场景是时间序列,但是,我觉得对于其它场景来说,通过 `TREAD` 来流播消息将是非常有趣的,因为对于那些需要更高可靠性的应用程序,可以使用发布/订阅模式来替换“即用即弃”,还有其它全新的使用场景。现在,如果你想在有问题环境中评估这个新数据结构,可以更新 GitHub 上的 streams 分支开始试用。欢迎向我们报告所有的 bug。:-)
+
+如果你喜欢观看视频的方式,这里有一个现场演示:https://www.youtube.com/watch?v=ELDzy9lCFHQ
+
+---
+
+via: http://antirez.com/news/114
+
+作者:[antirez][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://antirez.com/
+[1]: https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86
diff --git a/translated/tech/20171024 Learn Blockchains by Building One.md b/published/20171024 Learn Blockchains by Building One.md
similarity index 70%
rename from translated/tech/20171024 Learn Blockchains by Building One.md
rename to published/20171024 Learn Blockchains by Building One.md
index 23135eeec9..acbcaed1de 100644
--- a/translated/tech/20171024 Learn Blockchains by Building One.md
+++ b/published/20171024 Learn Blockchains by Building One.md
@@ -1,40 +1,41 @@
-通过构建一个区块链来学习区块链技术
+想学习区块链?那就用 Python 构建一个
======
+> 了解区块链是如何工作的最快的方法是构建一个。
+

-你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术是什么。
+
+你看到这篇文章是因为和我一样,对加密货币的大热而感到兴奋。并且想知道区块链是如何工作的 —— 它们背后的技术基础是什么。
但是理解区块链并不容易 —— 至少对我来说是这样。我徜徉在各种难懂的视频中,并且因为示例太少而陷入深深的挫败感中。
-我喜欢在实践中学习。这迫使我去处理被卡在代码级别上的难题。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
+我喜欢在实践中学习。这会使得我在代码层面上处理主要问题,从而可以让我坚持到底。如果你也是这么做的,在本指南结束的时候,你将拥有一个功能正常的区块链,并且实实在在地理解了它的工作原理。
### 开始之前 …
-记住,区块链是一个 _不可更改的、有序的_ 被称为区块的记录链。它们可以包括事务~~(交易???校对确认一下,下同)~~、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
+记住,区块链是一个 _不可更改的、有序的_ 记录(被称为区块)的链。它们可以包括交易、文件或者任何你希望的真实数据。最重要的是它们是通过使用_哈希_链接到一起的。
如果你不知道哈希是什么,[这里有解释][1]。
- **_本指南的目标读者是谁?_** 你应该能很容易地读和写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
+ **_本指南的目标读者是谁?_** 你应该能轻松地读、写一些基本的 Python 代码,并能够理解 HTTP 请求是如何工作的,因为我们讨论的区块链将基于 HTTP。
**_我需要做什么?_** 确保安装了 [Python 3.6][2]+(以及 `pip`),还需要去安装 Flask 和非常好用的 Requests 库:
```
- pip install Flask==0.12.2 requests==2.18.4
+pip install Flask==0.12.2 requests==2.18.4
```
当然,你也需要一个 HTTP 客户端,像 [Postman][3] 或者 cURL。哪个都行。
**_最终的代码在哪里可以找到?_** 源代码在 [这里][4]。
-* * *
-
### 第 1 步:构建一个区块链
-打开你喜欢的文本编辑器或者 IDE,我个人 ❤️ [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将使用一个单个的文件,如果你看晕了,可以去参考 [源代码][6]。
+打开你喜欢的文本编辑器或者 IDE,我个人喜欢 [PyCharm][5]。创建一个名为 `blockchain.py` 的新文件。我将仅使用一个文件,如果你看晕了,可以去参考 [源代码][6]。
#### 描述一个区块链
-我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存事务。下面是我们的类规划:
+我们将创建一个 `Blockchain` 类,它的构造函数将去初始化一个空列表(去存储我们的区块链),以及另一个列表去保存交易。下面是我们的类规划:
```
class Blockchain(object):
@@ -58,15 +59,16 @@ class Blockchain(object):
@property
def last_block(self):
# Returns the last Block in the chain
-pass
+ pass
```
+*我们的 Blockchain 类的原型*
-我们的区块链类负责管理链。它将存储事务并且有一些为链中增加新区块的助理性质的方法。现在我们开始去充实一些类的方法。
+我们的 `Blockchain` 类负责管理链。它将存储交易并且有一些为链中增加新区块的辅助性质的方法。现在我们开始去充实一些类的方法。
-#### 一个区块是什么样子的?
+#### 区块是什么样子的?
-每个区块有一个索引、一个时间戳(Unix 时间)、一个事务的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
+每个区块有一个索引、一个时间戳(Unix 时间)、一个交易的列表、一个证明(后面会详细解释)、以及前一个区块的哈希。
单个区块的示例应该是下面的样子:
@@ -86,13 +88,15 @@ block = {
}
```
-此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。这一点非常重要,因为这就是区块链不可更改的原因:如果攻击者修改了一个早期的区块,那么所有的后续区块将包含错误的哈希。
+*我们的区块链中的块示例*
-这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。
+此刻,链的概念应该非常明显 —— 每个新区块包含它自身的信息和前一个区域的哈希。**这一点非常重要,因为这就是区块链不可更改的原因**:如果攻击者修改了一个早期的区块,那么**所有**的后续区块将包含错误的哈希。
-#### 添加事务到一个区块
+*这样做有意义吗?如果没有,就让时间来埋葬它吧 —— 这就是区块链背后的核心思想。*
-我们将需要一种区块中添加事务的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
+#### 添加交易到一个区块
+
+我们将需要一种区块中添加交易的方式。我们的 `new_transaction()` 就是做这个的,它非常简单明了:
```
class Blockchain(object):
@@ -113,14 +117,14 @@ class Blockchain(object):
'amount': amount,
})
-return self.last_block['index'] + 1
+ return self.last_block['index'] + 1
```
-在 `new_transaction()` 运行后将在列表中添加一个事务,它返回添加事务后的那个区块的索引 —— 那个区块接下来将被挖矿。提交事务的用户后面会用到这些。
+在 `new_transaction()` 运行后将在列表中添加一个交易,它返回添加交易后的那个区块的索引 —— 那个区块接下来将被挖矿。提交交易的用户后面会用到这些。
#### 创建新区块
-当我们的区块链被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
+当我们的 `Blockchain` 被实例化后,我们需要一个创世区块(一个没有祖先的区块)来播种它。我们也需要去添加一些 “证明” 到创世区块,它是挖矿(工作量证明 PoW)的成果。我们在后面将讨论更多挖矿的内容。
除了在我们的构造函数中创建创世区块之外,我们还需要写一些方法,如 `new_block()`、`new_transaction()` 以及 `hash()`:
@@ -190,18 +194,18 @@ class Blockchain(object):
# We must make sure that the Dictionary is Ordered, or we'll have inconsistent hashes
block_string = json.dumps(block, sort_keys=True).encode()
-return hashlib.sha256(block_string).hexdigest()
+ return hashlib.sha256(block_string).hexdigest()
```
上面的内容简单明了 —— 我添加了一些注释和文档字符串,以使代码清晰可读。到此为止,表示我们的区块链基本上要完成了。但是,你肯定想知道新区块是如何被创建、打造或者挖矿的。
#### 理解工作量证明
-一个工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
+工作量证明(PoW)算法是在区块链上创建或者挖出新区块的方法。PoW 的目标是去撞出一个能够解决问题的数字。这个数字必须满足“找到它很困难但是验证它很容易”的条件 —— 网络上的任何人都可以计算它。这就是 PoW 背后的核心思想。
我们来看一个非常简单的示例来帮助你了解它。
-我们来解决一个问题,一些整数 x 乘以另外一个整数 y 的结果的哈希值必须以 0 结束。因此,hash(x * y) = ac23dc…0。为简单起见,我们先把 x = 5 固定下来。在 Python 中的实现如下:
+我们来解决一个问题,一些整数 `x` 乘以另外一个整数 `y` 的结果的哈希值必须以 `0` 结束。因此,`hash(x * y) = ac23dc…0`。为简单起见,我们先把 `x = 5` 固定下来。在 Python 中的实现如下:
```
from hashlib import sha256
@@ -215,19 +219,21 @@ while sha256(f'{x*y}'.encode()).hexdigest()[-1] != "0":
print(f'The solution is y = {y}')
```
-在这里的答案是 y = 21。因为它产生的哈希值是以 0 结尾的:
+在这里的答案是 `y = 21`。因为它产生的哈希值是以 0 结尾的:
```
hash(5 * 21) = 1253e9373e...5e3600155e860
```
+在比特币中,工作量证明算法被称之为 [Hashcash][10]。与我们上面的例子没有太大的差别。这就是矿工们进行竞赛以决定谁来创建新块的算法。一般来说,其难度取决于在一个字符串中所查找的字符数量。然后矿工会因其做出的求解而得到奖励的币——在一个交易当中。
+
网络上的任何人都可以很容易地去核验它的答案。
#### 实现基本的 PoW
为我们的区块链来实现一个简单的算法。我们的规则与上面的示例类似:
-> 找出一个数字 p,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 0 组成。
+> 找出一个数字 `p`,它与前一个区块的答案进行哈希运算得到一个哈希值,这个哈希值的前四位必须是由 `0` 组成。
```
import hashlib
@@ -266,25 +272,21 @@ class Blockchain(object):
guess = f'{last_proof}{proof}'.encode()
guess_hash = hashlib.sha256(guess).hexdigest()
-return guess_hash[:4] == "0000"
+ return guess_hash[:4] == "0000"
```
为了调整算法的难度,我们可以修改前导 0 的数量。但是 4 个零已经足够难了。你会发现,将前导 0 的数量每增加一,那么找到正确答案所需要的时间难度将大幅增加。
我们的类基本完成了,现在我们开始去使用 HTTP 请求与它交互。
-* * *
-
### 第 2 步:以 API 方式去访问我们的区块链
-我们将去使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
+我们将使用 Python Flask 框架。它是个微框架,使用它去做端点到 Python 函数的映射很容易。这样我们可以使用 HTTP 请求基于 web 来与我们的区块链对话。
我们将创建三个方法:
-* `/transactions/new` 在一个区块上创建一个新事务
-
+* `/transactions/new` 在一个区块上创建一个新交易
* `/mine` 告诉我们的服务器去挖矿一个新区块
-
* `/chain` 返回完整的区块链
#### 配置 Flask
@@ -332,33 +334,33 @@ def full_chain():
return jsonify(response), 200
if __name__ == '__main__':
-app.run(host='0.0.0.0', port=5000)
+ app.run(host='0.0.0.0', port=5000)
```
对上面的代码,我们做添加一些详细的解释:
* Line 15:实例化我们的节点。更多关于 Flask 的知识读 [这里][7]。
-
* Line 18:为我们的节点创建一个随机的名字。
-
* Line 21:实例化我们的区块链类。
-
-* Line 24–26:创建 /mine 端点,这是一个 GET 请求。
-
-* Line 28–30:创建 /transactions/new 端点,这是一个 POST 请求,因为我们要发送数据给它。
-
-* Line 32–38:创建 /chain 端点,它返回全部区块链。
-
+* Line 24–26:创建 `/mine` 端点,这是一个 GET 请求。
+* Line 28–30:创建 `/transactions/new` 端点,这是一个 POST 请求,因为我们要发送数据给它。
+* Line 32–38:创建 `/chain` 端点,它返回全部区块链。
* Line 40–41:在 5000 端口上运行服务器。
-#### 事务端点
+#### 交易端点
-这就是对一个事务的请求,它是用户发送给服务器的:
+这就是对一个交易的请求,它是用户发送给服务器的:
```
-{ "sender": "my address", "recipient": "someone else's address", "amount": 5}
+{
+ "sender": "my address",
+ "recipient": "someone else's address",
+ "amount": 5
+}
```
+因为我们已经有了添加交易到块中的类方法,剩下的就很容易了。让我们写个函数来添加交易:
+
```
import hashlib
import json
@@ -383,18 +385,17 @@ def new_transaction():
index = blockchain.new_transaction(values['sender'], values['recipient'], values['amount'])
response = {'message': f'Transaction will be added to Block {index}'}
-return jsonify(response), 201
+ return jsonify(response), 201
```
-创建事务的方法
+
+*创建交易的方法*
#### 挖矿端点
我们的挖矿端点是见证奇迹的地方,它实现起来很容易。它要做三件事情:
1. 计算工作量证明
-
-2. 因为矿工(我们)添加一个事务而获得报酬,奖励矿工(我们) 1 个硬币
-
+2. 因为矿工(我们)添加一个交易而获得报酬,奖励矿工(我们) 1 个币
3. 通过将它添加到链上而打造一个新区块
```
@@ -434,10 +435,10 @@ def mine():
'proof': block['proof'],
'previous_hash': block['previous_hash'],
}
-return jsonify(response), 200
+ return jsonify(response), 200
```
-注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的区块链类的方法进行交互的。到目前为止,我们已经做到了,现在开始与我们的区块链去交互。
+注意,挖掘出的区块的接收方是我们的节点地址。现在,我们所做的大部分工作都只是与我们的 `Blockchain` 类的方法进行交互的。到目前为止,我们已经做完了,现在开始与我们的区块链去交互。
### 第 3 步:与我们的区块链去交互
@@ -447,24 +448,33 @@ return jsonify(response), 200
```
$ python blockchain.py
+* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
```
-我们通过生成一个 GET 请求到 http://localhost:5000/mine 去尝试挖一个区块:
+我们通过生成一个 `GET` 请求到 `http://localhost:5000/mine` 去尝试挖一个区块:
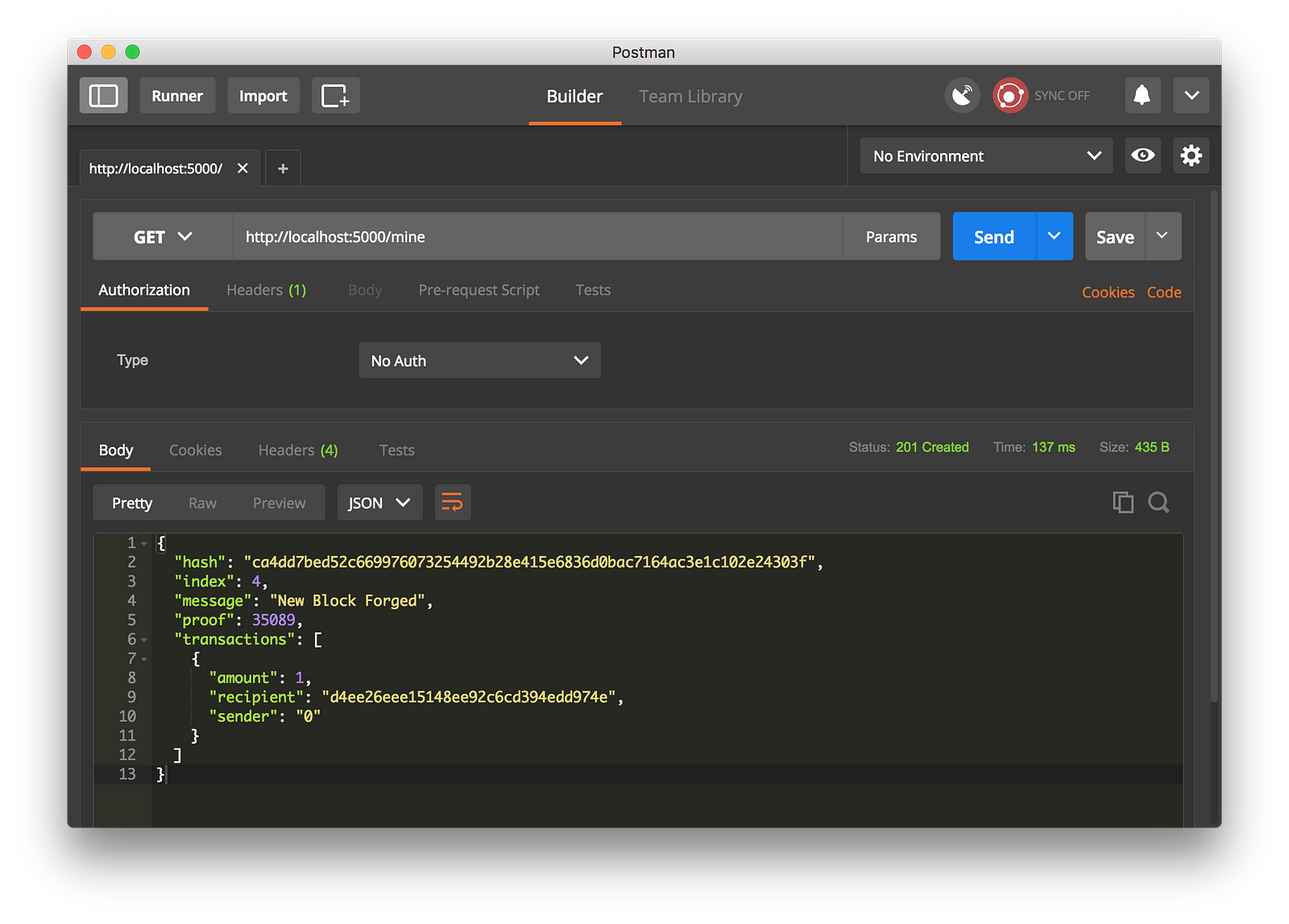
-使用 Postman 去生成一个 GET 请求
-我们通过生成一个 POST 请求到 http://localhost:5000/transactions/new 去创建一个区块,它带有一个包含我们的事务结构的 `Body`:
+*使用 Postman 去生成一个 GET 请求*
+
+我们通过生成一个 `POST` 请求到 `http://localhost:5000/transactions/new` 去创建一个区块,请求数据包含我们的交易结构:
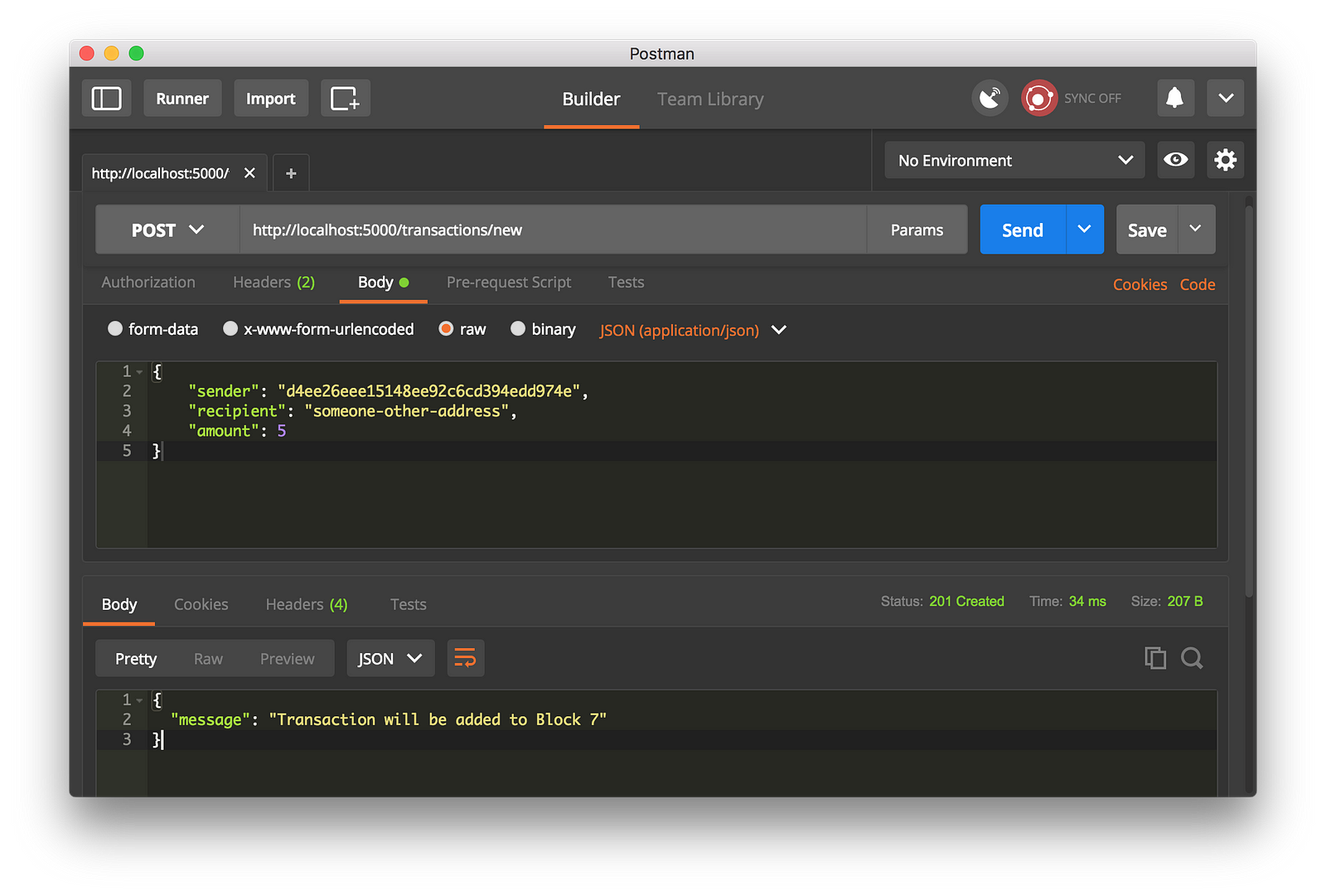
-使用 Postman 去生成一个 POST 请求
+
+*使用 Postman 去生成一个 POST 请求*
如果你不使用 Postman,也可以使用 cURL 去生成一个等价的请求:
```
-$ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee15148ee92c6cd394edd974e", "recipient": "someone-other-address", "amount": 5}' "http://localhost:5000/transactions/new"
+$ curl -X POST -H "Content-Type: application/json" -d '{
+ "sender": "d4ee26eee15148ee92c6cd394edd974e",
+ "recipient": "someone-other-address",
+ "amount": 5
+}' "http://localhost:5000/transactions/new"
```
-我重启动我的服务器,然后我挖到了两个区块,这样总共有了3 个区块。我们通过请求 http://localhost:5000/chain 来检查整个区块链:
+
+我重启动我的服务器,然后我挖到了两个区块,这样总共有了 3 个区块。我们通过请求 `http://localhost:5000/chain` 来检查整个区块链:
+
```
{
"chain": [
@@ -503,18 +513,18 @@ $ curl -X POST -H "Content-Type: application/json" -d '{ "sender": "d4ee26eee151
}
],
"length": 3
+}
```
### 第 4 步:共识
-这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收事务并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
+这是很酷的一个地方。我们已经有了一个基本的区块链,它可以接收交易并允许我们去挖掘出新区块。但是区块链的整个重点在于它是去中心化的。而如果它们是去中心化的,那我们如何才能确保它们表示在同一个区块链上?这就是共识问题,如果我们希望在我们的网络上有多于一个的节点运行,那么我们将必须去实现一个共识算法。
#### 注册新节点
在我们能实现一个共识算法之前,我们需要一个办法去让一个节点知道网络上的邻居节点。我们网络上的每个节点都保留有一个该网络上其它节点的注册信息。因此,我们需要更多的端点:
-1. /nodes/register 以 URLs 的形式去接受一个新节点列表
-
-2. /nodes/resolve 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
+1. `/nodes/register` 以 URL 的形式去接受一个新节点列表
+2. `/nodes/resolve` 去实现我们的共识算法,由它来解决任何的冲突 —— 确保节点有一个正确的链。
我们需要去修改我们的区块链的构造函数,来提供一个注册节点的方法:
@@ -538,11 +548,12 @@ class Blockchain(object):
"""
parsed_url = urlparse(address)
-self.nodes.add(parsed_url.netloc)
+ self.nodes.add(parsed_url.netloc)
```
-一个添加邻居节点到我们的网络的方法
-注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的内容是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
+*一个添加邻居节点到我们的网络的方法*
+
+注意,我们将使用一个 `set()` 去保存节点列表。这是一个非常合算的方式,它将确保添加的节点是幂等的 —— 这意味着不论你将特定的节点添加多少次,它都是精确地只出现一次。
#### 实现共识算法
@@ -615,12 +626,12 @@ class Blockchain(object)
self.chain = new_chain
return True
-return False
+ return False
```
第一个方法 `valid_chain()` 是负责来检查链是否有效,它通过遍历区块链上的每个区块并验证它们的哈希和工作量证明来检查这个区块链是否有效。
-`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。
+`resolve_conflicts()` 方法用于遍历所有的邻居节点,下载它们的链并使用上面的方法去验证它们是否有效。**如果找到有效的链,确定谁是最长的链,然后我们就用最长的链来替换我们的当前的链。**
在我们的 API 上来注册两个端点,一个用于添加邻居节点,另一个用于解决冲突:
@@ -658,18 +669,20 @@ def consensus():
'chain': blockchain.chain
}
-return jsonify(response), 200
+ return jsonify(response), 200
```
-这种情况下,如果你愿意可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:[http://localhost:5000][9] 和 http://localhost:5001。
+这种情况下,如果你愿意,可以使用不同的机器来做,然后在你的网络上启动不同的节点。或者是在同一台机器上使用不同的端口启动另一个进程。我是在我的机器上使用了不同的端口启动了另一个节点,并将它注册到了当前的节点上。因此,我现在有了两个节点:`http://localhost:5000` 和 `http://localhost:5001`。
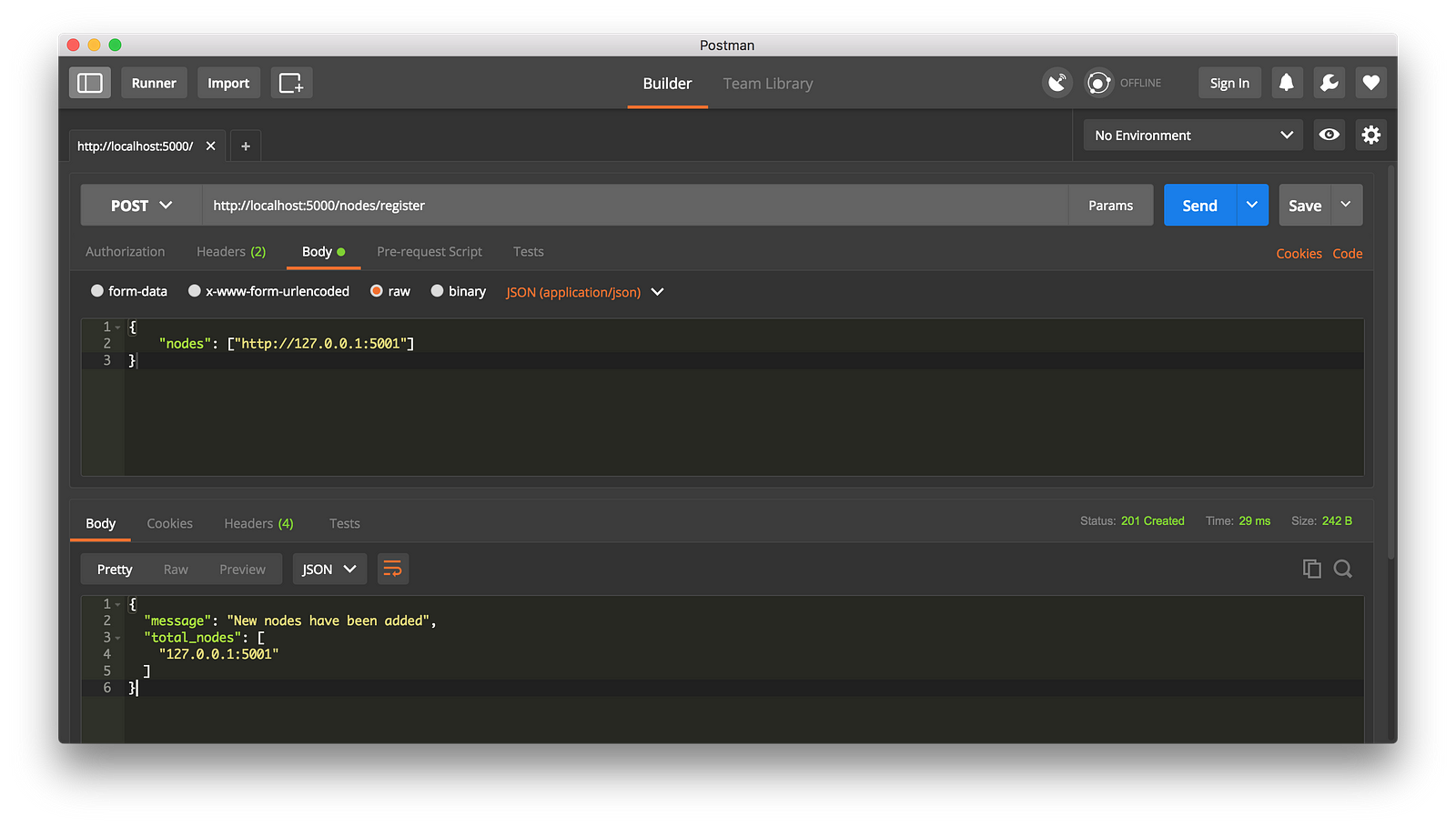
-注册一个新节点
+
+*注册一个新节点*
我接着在节点 2 上挖出一些新区块,以确保这个链是最长的。之后我在节点 1 上以 `GET` 方式调用了 `/nodes/resolve`,这时,节点 1 上的链被共识算法替换成节点 2 上的链了:
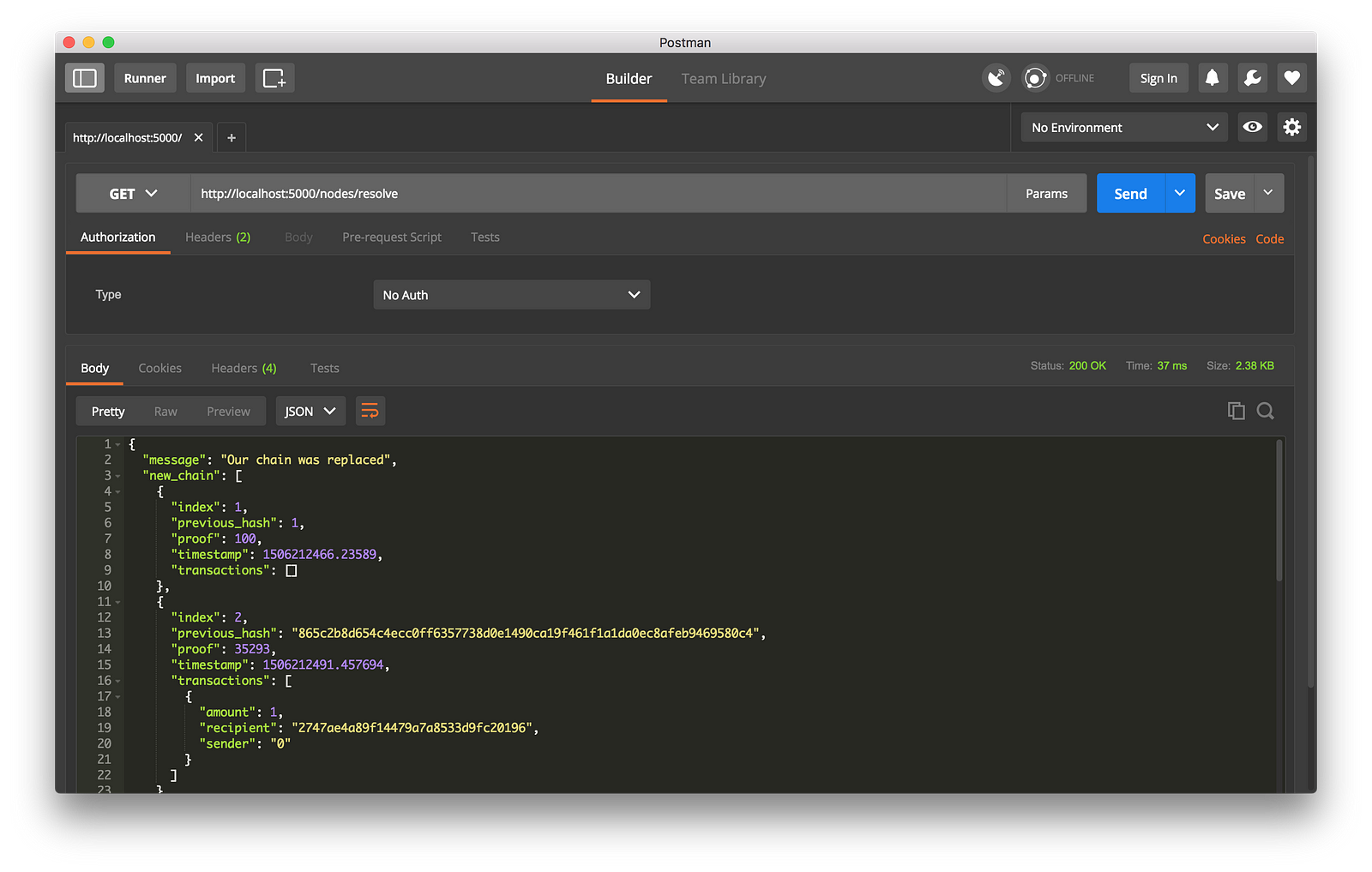
-工作中的共识算法
+
+*工作中的共识算法*
然后将它们封装起来 … 找一些朋友来帮你一起测试你的区块链。
@@ -677,7 +690,7 @@ return jsonify(response), 200
我希望以上内容能够鼓舞你去创建一些新的东西。我是加密货币的狂热拥护者,因此我相信区块链将迅速改变我们对经济、政府和记录保存的看法。
-**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备事务验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。
+**更新:** 我正计划继续它的第二部分,其中我将扩展我们的区块链,使它具备交易验证机制,同时讨论一些你可以在其上产生你自己的区块链的方式。(LCTT 译注:第二篇并没有~!)
--------------------------------------------------------------------------------
@@ -685,7 +698,7 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
作者:[Daniel van Flymen][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -699,3 +712,4 @@ via: https://hackernoon.com/learn-blockchains-by-building-one-117428612f46
[7]:http://flask.pocoo.org/docs/0.12/quickstart/#a-minimal-application
[8]:http://localhost:5000/transactions/new
[9]:http://localhost:5000
+[10]:https://en.wikipedia.org/wiki/Hashcash
\ No newline at end of file
diff --git a/translated/tech/20171116 How to improve ROI on automation- 4 tips.md b/published/20171116 How to improve ROI on automation- 4 tips.md
similarity index 87%
rename from translated/tech/20171116 How to improve ROI on automation- 4 tips.md
rename to published/20171116 How to improve ROI on automation- 4 tips.md
index edce4dcdb2..2139c43c64 100644
--- a/translated/tech/20171116 How to improve ROI on automation- 4 tips.md
+++ b/published/20171116 How to improve ROI on automation- 4 tips.md
@@ -1,12 +1,15 @@
如何提升自动化的 ROI:4 个小提示
======
+> 想要在你的自动化项目上达成强 RIO?采取如下步骤来规避失败。
+

-在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对成本随着工作量的增加而增加的这一事实可以重新定义而感到震惊。
-机器人流程自动化(RPA)似乎预示着运营的圣杯(Holy Grail):“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
+在过去的几年间,有关自动化技术的讨论已经很多了。COO 们和运营团队(事实上还有其它的业务部门)对于可以重新定义成本随着工作量的增加而增加的这一事实而感到震惊。
-低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处即实用可行度又高。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
+机器人流程自动化(RPA)似乎预示着运营的圣杯:“我们提供了开箱即用的功能来满足你的日常操作所需 —— 检查电子邮件、保存附件、取数据、更新表格、生成报告、文件以及目录操作。构建一个机器人就像配置这些功能一样简单,然后用机器人将这些操作链接到一起,而不用去请求 IT 部门来构建它们。”这是一个多么诱人的话题。
+
+低成本、几乎不出错、非常遵守流程 —— 对 COO 们和运营领导来说,这些好处真实可及。RPA 工具承诺,它从运营中节省下来的费用就足够支付它的成本(有一个短的回报期),这一事实使得业务的观点更具有吸引力。
自动化的谈论都趋向于类似的话题:COO 们和他们的团队想知道,自动化操作能够给他们带来什么好处。他们想知道 RPA 平台特性和功能,以及自动化在现实中的真实案例。从这一点到概念验证的实现过程通常很短暂。
@@ -14,7 +17,7 @@
但是自动化带来的现实好处有时候可能比你所预期的时间要晚。采用 RPA 的公司在其实施后可能会对它们自身的 ROI 提出一些质疑。一些人没有看到预期之中的成本节省,并对其中的原因感到疑惑。
-## 你是不是自动化了错误的东西?
+### 你是不是自动化了错误的东西?
在这些情况下,自动化的愿景和现实之间的差距是什么呢?我们来分析一下它,在决定去继续进行一个自动化验证项目(甚至是一个成熟的实践)之后,我们来看一下通常会发生什么。
@@ -26,7 +29,7 @@
那么,对于领导们来说,怎么才能确保实施自动化能够带来他们想要的 ROI 呢?实现这个目标有四步:
-## 1. 教育团队
+### 1. 教育团队
在你的团队中,从 COO 职位以下的人中,很有可能都听说过 RPA 和运营自动化。同样很有可能他们都有许多的问题和担心。在你开始启动实施之前解决这些问题和担心是非常重要的。
@@ -36,23 +39,23 @@
“实施自动化的第一步是更好地理解你的流程。”
-## 2. 审查内部流程
+### 2. 审查内部流程
实施自动化的第一步是更好地理解你的流程。每个 RPA 实施之前都应该进行流程清单、动作分析、以及成本/价值的绘制练习。
-这些练习对于理解流程中何处价值产生(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
+这些练习对于理解流程中何处产生价值(或成本,如果没有价值的情况下)是至关重要的。并且这些练习需要在每个流程或者每个任务这样的粒度级别上来做。
这将有助你去识别和优先考虑最合适的自动化候选者。由于能够或者可能需要自动化的任务数量较多,流程一般需要分段实施自动化,因此优先级很重要。
**建议**:设置一个小的工作团队,每个运营团队都参与其中。从每个运营团队中提名一个协调人 —— 一般是运营团队的领导或者团队管理者。在团队级别上组织一次研讨会,去构建流程清单、识别候选流程、以及推动购买。你的自动化合作伙伴很可能有“加速器” —— 调查问卷、计分卡等等 —— 这些将帮助你加速完成这项活动。
-## 3. 为优先业务提供强有力的指导
+### 3. 为优先业务提供强有力的指导
实施自动化经常会涉及到在运营团队之间,基于业务价值对流程选择和自动化优先级上要达成共识(有时候是打破平衡)虽然团队的参与仍然是分析和实施的关键部分,但是领导仍然应该是最终的决策者。
**建议**:安排定期会议从工作团队中获取最新信息。除了像推动达成共识和购买之外,工作团队还应该在团队层面上去查看领导们关于 ROI、平台选择、以及自动化优先级上的指导性决定。
-## 4. 应该推动 CIO 和 COO 的紧密合作
+### 4. 应该推动 CIO 和 COO 的紧密合作
当运营团队和技术团队紧密合作时,自动化的实施将异常顺利。COO 需要去帮助推动与 CIO 团队的合作。
@@ -68,7 +71,7 @@ via: https://enterprisersproject.com/article/2017/11/how-improve-roi-automation-
作者:[Rajesh Kamath][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md b/published/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
similarity index 63%
rename from sources/tech/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
rename to published/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
index 69b523426c..29c05462ac 100644
--- a/sources/tech/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
+++ b/published/20180103 How To Find The Installed Proprietary Packages In Arch Linux.md
@@ -1,34 +1,40 @@
-How To Find The Installed Proprietary Packages In Arch Linux
+如何在 Arch Linux 中查找已安装的专有软件包?
======
+

-Are you an avid free software supporter and currently using any Arch based distribution? I've got a small tip for you! Now, you can easily find the installed proprietary packages in Arch Linux and its variants such as Antergos, Manjaro Linux etc. You don't need to refer the license details of the installed package in its website or use any external tool to find out whether the package is free or proprietary.
-### Find The Installed Proprietary Packages In Arch Linux
+你是狂热的自由软件支持者吗?你目前在使用任何基于 Arch 的 Linux 发行版吗?我有一个小小的提示送给你!现在,你可以轻松地在 Arch Linux 及其变体(如 Antergos、Manjaro Linux 等)中找到已安装的专有软件包。你无需在已安装软件包的网站中参考其许可细节,也无需使用任何其它外部工具来查明软件包是自由的还是专有的。(LCTT 译注:其实下面还是借助了一个外部程序)
-A fellow developer has developed an utility named **" Absolutely Proprietary"**, a proprietary package detector for arch-based distributions. It compares all installed packages in your Arch based system against Parabola's package [blacklist][1] and [aur-blacklist][2] and then prints your **Stallman Freedom Index** (free/total). Additionally, you can save the list to a file and share or compare it with other systems/users.
+### 在 Arch Linux 中查找已安装的专有软件包
-Before installing it, Make sure you have installed **python** and **git**.
+一位开发人员开发了一个名为 “[Absolutely Proprietary][5]” 的实用程序,它是一种用于基于 Arch 发行版的专有软件包检测器。它将基于 Arch 系统中的所有安装包与 Parabola 的软件包 [blacklist][1]和 [aur-blacklist][2] 进行比较,然后显示出你的斯托曼自由指数(“自由/总计”比分)。此外,你可以将该列表保存到文件中,并与其他系统/用户共享或比较。
+
+在安装之前,确保你安装了 Python 和 Git。
+
+然后,`git clone` 仓库:
-Then, git clone the repository:
```
git clone https://github.com/vmavromatis/absolutely-proprietary.git
```
-This command will download all contents in a directory called 'absolutely-proprietary' in your current working directory.
+这条命令将会下载所有内容到你当前工作目录中的 `absolutely-proprietary` 目录。
+
+进入此目录:
-Change to that directory:
```
cd absolutely-proprietary
```
-And, find the installed proprietary packages using command:
+接着,使用以下命令查找已安装的专有软件:
+
```
python main.py
```
-This command will download the blacklist.txt, aur-blacklist.txt and compare the locally installed packages with the remote packages and displays the
+这条命令将会下载 `blacklist.txt`、`aur-blacklist.txt`,并将本地已安装的软件包与远程软件包进行比较并显示其指数。
+
+以下是在我的 Arch Linux 桌面的示例输出:
-Here is the sample output from my Arch Linux desktop:
```
Retrieving local packages (including AUR)...
Downloading https://git.parabola.nu/blacklist.git/plain/blacklist.txt
@@ -73,9 +79,10 @@ Your Stallman Freedom Index is 96.57
Save list to file? (Y/n)
```
-[![][3]][4]
+![][4]
+
+如你所见,我的系统中有 47 个专有软件包。就像我说的那样,我们可以将它保存到文件中稍后查看。为此,当提示你将列表保存在文件时,请按 `y`。然后按 `y` 接受默认值,或按 `n` 以你喜欢的格式和位置来保存它。
-As you can see, I have 47 proprietary packages in my system. Like I said already, we can save it to a file and review them later. To do so, jut press 'y' when you are prompted to save the list in a file. Then press 'y' to accept the defaults or hit 'n' to save it in your preferred format and location.
```
Save list to file? (Y/n) y
Save as markdown table? (Y/n) y
@@ -87,29 +94,29 @@ using the "less -S /home/sk/absolutely-proprietary/y.md"
or, if installed, the "most /home/sk/absolutely-proprietary/y.md" commands
```
-As you may noticed, I have only the **nonfree** packages. It will display two more type of packages such as semifree, uses-nonfree.
+你可能已经注意到,我只有 **nonfree** 包。它还会显示另外两种类型的软件包,例如 semifree、 uses-nonfree。
- * **nonfree** : This package is blatantly nonfree software.
- * **semifree** : This package is mostly free, but contains some nonfree software.
- * **uses-nonfree** : This package depends on, recommends, or otherwise inappropriately integrates with other nonfree software or services.
+ * **nonfree**:这个软件包是公然的非自由软件。
+ * **semifree**:这个软件包大部分是自由的,但包含一些非自由软件。
+ * **uses-nonfree**:这个软件包依赖、推荐或不恰当地与其他自由软件或服务集成。
+该使用程序的另一个显著特点是它不仅显示了专有软件包,而且还显示这些包的替代品。
+希望这有些帮助。我很快就会在这里提供另一份有用的指南。敬请关注!
-Another notable feature of this utility is it's not just displays the propriety packages, but also alternatives to such packages.
-
-Hope this helps. I will be soon here with another useful guide soon. Stay tuned!
-
-Cheers!
+干杯!
+资源:
+- [Absolutely Proprietary][5]
--------------------------------------------------------------------------------
via: https://www.ostechnix.com/find-installed-proprietary-packages-arch-linux/
作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -117,4 +124,5 @@ via: https://www.ostechnix.com/find-installed-proprietary-packages-arch-linux/
[1]:https://git.parabola.nu/blacklist.git/plain/blacklist.txt
[2]:https://git.parabola.nu/blacklist.git/plain/aur-blacklist.txt
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/Proprietary-Packages-1-1.png ()
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/Proprietary-Packages-1-1.png
+[5]:https://github.com/vmavromatis/absolutely-proprietary
\ No newline at end of file
diff --git a/translated/tech/20180115 How debuggers really work.md b/published/20180115 How debuggers really work.md
similarity index 85%
rename from translated/tech/20180115 How debuggers really work.md
rename to published/20180115 How debuggers really work.md
index b4b5740fe1..e7f2772948 100644
--- a/translated/tech/20180115 How debuggers really work.md
+++ b/published/20180115 How debuggers really work.md
@@ -1,13 +1,15 @@
调试器到底怎样工作
======
+> 你也许用过调速器检查过你的代码,但你知道它们是如何做到的吗?
+

供图:opensource.com
-调试器是那些大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器...使用 [Rust][2]!
+调试器是大多数(即使不是每个)开发人员在软件工程职业生涯中至少使用过一次的那些软件之一,但是你们中有多少人知道它们到底是如何工作的?我在悉尼 [linux.conf.au 2018][1] 的演讲中,将讨论从头开始编写调试器……使用 [Rust][2]!
-在本文中,术语调试器/跟踪器可以互换。 “被跟踪者”是指正在被跟踪者跟踪的进程。
+在本文中,术语调试器和跟踪器可以互换。 “被跟踪者”是指正在被跟踪器跟踪的进程。
### ptrace 系统调用
@@ -17,59 +19,46 @@
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
```
-这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是......我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
+这是一个可以操纵进程几乎所有方面的系统调用;但是,在调试器可以连接到一个进程之前,“被跟踪者”必须以请求 `PTRACE_TRACEME` 调用 `ptrace`。这告诉 Linux,父进程通过 `ptrace` 连接到这个进程是合法的。但是……我们如何强制一个进程调用 `ptrace`?很简单!`fork/execve` 提供了在 `fork` 之后但在被跟踪者真正开始使用 `execve` 之前调用 `ptrace` 的简单方法。很方便地,`fork` 还会返回被跟踪者的 `pid`,这是后面使用 `ptrace` 所必需的。
现在被跟踪者可以被调试器追踪,重要的变化发生了:
- * 每当一个信号被传送到被调试者时,它就会停止,并且一个可以被 `wait` 系列系统调用捕获的等待事件被传送给跟踪器。
+ * 每当一个信号被传送到被跟踪者时,它就会停止,并且一个可以被 `wait` 系列的系统调用捕获的等待事件被传送给跟踪器。
* 每个 `execve` 系统调用都会导致 `SIGTRAP` 被传递给被跟踪者。(与之前的项目相结合,这意味着被跟踪者在一个 `execve` 完全发生之前停止。)
这意味着,一旦我们发出 `PTRACE_TRACEME` 请求并调用 `execve` 系统调用来实际在被跟踪者(进程上下文)中启动程序时,被跟踪者将立即停止,因为 `execve` 会传递一个 `SIGTRAP`,并且会被跟踪器中的等待事件捕获。我们如何继续?正如人们所期望的那样,`ptrace` 有大量的请求可以用来告诉被跟踪者可以继续:
-
* `PTRACE_CONT`:这是最简单的。 被跟踪者运行,直到它接收到一个信号,此时等待事件被传递给跟踪器。这是最常见的实现真实世界调试器的“继续直至断点”和“永远继续”选项的方式。断点将在下面介绍。
* `PTRACE_SYSCALL`:与 `PTRACE_CONT` 非常相似,但在进入系统调用之前以及在系统调用返回到用户空间之前停止。它可以与其他请求(我们将在本文后面介绍)结合使用来监视和修改系统调用的参数或返回值。系统调用追踪程序 `strace` 很大程度上使用这个请求来获知进程发起了哪些系统调用。
* `PTRACE_SINGLESTEP`:这个很好理解。如果您之前使用过调试器(你会知道),此请求会执行下一条指令,然后立即停止。
-
-
我们可以通过各种各样的请求停止进程,但我们如何获得被调试者的状态?进程的状态大多是通过其寄存器捕获的,所以当然 `ptrace` 有一个请求来获得(或修改)寄存器:
* `PTRACE_GETREGS`:这个请求将给出被跟踪者刚刚被停止时的寄存器的状态。
- * `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值并使用 `PTRACE_SETREGS` 将寄存器设为新值。
+ * `PTRACE_SETREGS`:如果跟踪器之前通过调用 `PTRACE_GETREGS` 得到了寄存器的值,它可以在参数结构中修改相应寄存器的值,并使用 `PTRACE_SETREGS` 将寄存器设为新值。
* `PTRACE_PEEKUSER` 和 `PTRACE_POKEUSER`:这些允许从被跟踪者的 `USER` 区读取信息,这里保存了寄存器和其他有用的信息。 这可以用来修改单一寄存器,而避免使用更重的 `PTRACE_{GET,SET}REGS` 请求。
-
-
在调试器仅仅修改寄存器是不够的。调试器有时需要读取一部分内存,甚至对其进行修改。GDB 可以使用 `print` 得到一个内存位置或变量的值。`ptrace` 通过下面的方法实现这个功能:
* `PTRACE_PEEKTEXT` 和 `PTRACE_POKETEXT`:这些允许读取和写入被跟踪者地址空间中的一个字。当然,使用这个功能时被跟踪者要被暂停。
-
-
-真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑x86。
+真实世界的调试器也有类似断点和观察点的功能。 在接下来的部分中,我将深入体系结构对调试器支持的细节。为了清晰和简洁,本文将只考虑 x86。
### 体系结构的支持
`ptrace` 很酷,但它是如何工作? 在前面的部分中,我们已经看到 `ptrace` 跟信号有很大关系:`SIGTRAP` 可以在单步跟踪、`execve` 之前以及系统调用前后被传送。信号可以通过一些方式产生,但我们将研究两个具体的例子,以展示信号可以被调试器用来在给定的位置停止程序(有效地创建一个断点!):
-
* **未定义的指令**:当一个进程尝试执行一个未定义的指令,CPU 将产生一个异常。此异常通过 CPU 中断处理,内核中相应的中断处理程序被调用。这将导致一个 `SIGILL` 信号被发送给进程。 这依次导致进程被停止,跟踪器通过一个等待事件被通知,然后它可以决定后面做什么。在 x86 上,指令 `ud2` 被确保始终是未定义的。
-
* **调试中断**:前面的方法的问题是,`ud2` 指令需要占用两个字节的机器码。存在一条特殊的单字节指令能够触发一个中断,它是 `int $3`,机器码是 `0xCC`。 当该中断发出时,内核向进程发送一个 `SIGTRAP`,如前所述,跟踪器被通知。
-
-
-这很好,但如何做我们胁迫的被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
+这很好,但如何我们才能胁迫被跟踪者执行这些指令? 这很简单:利用 `ptrace` 的 `PTRACE_POKETEXT` 请求,它可以覆盖内存中的一个字。 调试器将使用 `PTRACE_PEEKTEXT` 读取该位置原来的值并替换为 `0xCC` ,然后在其内部状态中记录该处原来的值,以及它是一个断点的事实。 下次被跟踪者执行到该位置时,它将被通过 `SIGTRAP` 信号自动停止。 然后调试器的最终用户可以决定如何继续(例如,检查寄存器)。
好吧,我们已经讲过了断点,那观察点呢? 当一个特定的内存位置被读或写,调试器如何停止程序? 当然你不可能为了能够读或写内存而去把每一个指令都覆盖为 `int $3`。有一组调试寄存器为了更有效的满足这个目的而被设计出来:
-
* `DR0` 到 `DR3`:这些寄存器中的每个都包含一个地址(内存位置),调试器因为某种原因希望被跟踪者在那些地址那里停止。 其原因以掩码方式被设定在 `DR7` 寄存器中。
- * `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7`过时的别名。
+ * `DR4` 和 `DR5`:这些分别是 `DR6` 和 `DR7` 过时的别名。
* `DR6`:调试状态。包含有关 `DR0` 到 `DR3` 中的哪个寄存器导致调试异常被引发的信息。这被 Linux 用来计算与 `SIGTRAP` 信号一起传递给被跟踪者的信息。
- * `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释DR0至DR3中指定的地址。位掩码控制监视点的尺寸(监视1,2,4或8个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
-
+ * `DR7`:调试控制。通过使用这些寄存器中的位,调试器可以控制如何解释 `DR0` 至 `DR3` 中指定的地址。位掩码控制监视点的尺寸(监视1、2、4 或 8 个字节)以及是否在执行、读取、写入时引发异常,或在读取或写入时引发异常。
由于调试寄存器是进程的 `USER` 区域的一部分,调试器可以使用 `PTRACE_POKEUSER` 将值写入调试寄存器。调试寄存器只与特定进程相关,因此在进程抢占并重新获得 CPU 控制权之前,调试寄存器会被恢复。
@@ -88,7 +77,7 @@ via: https://opensource.com/article/18/1/how-debuggers-really-work
作者:[Levente Kurusa][a]
译者:[stephenxs](https://github.com/stephenxs)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180115 Why DevSecOps matters to IT leaders.md b/published/20180115 Why DevSecOps matters to IT leaders.md
new file mode 100644
index 0000000000..3ca2d5d3ea
--- /dev/null
+++ b/published/20180115 Why DevSecOps matters to IT leaders.md
@@ -0,0 +1,87 @@
+为什么 DevSecOps 对 IT 领导来说如此重要
+======
+
+> DevSecOps 也许不是一个优雅的词汇,但是其结果很吸引人:更强的安全、提前出现在开发周期中。来看看一个 IT 领导与 Meltdown 的拼搏。
+
+
+
+如果 [DevOps][1] 最终是关于创造更好的软件,那也就意味着是更安全的软件。
+
+而到了术语 “DevSecOps”,就像任何其他 IT 术语一样,DevSecOps —— 一个更成熟的 DevOps 的后代 ——可能容易受到炒作和盗用。但这个术语对那些拥抱了 DevOps 文化的领导者们来说具有重要的意义,并且其实践和工具可以帮助他们实现其承诺。
+
+说道这里:“DevSecOps”是什么意思?
+
+“DevSecOps 是开发、安全、运营的混合,”来自 [Datical][2] 的首席技术官和联合创始人 Robert 说。“这提醒我们,对我们的应用程序来说安全和创建并部署应用到生产中一样重要。”
+
+**[想阅读其他首席技术官的 DevOps 文章吗?查阅我们丰富的资源,[DevOps:IT 领导者指南][3]]**
+
+向非技术人员解释 DevSecOps 的一个简单的方法是:它是指将安全有意并提前加入到开发过程中。
+
+“安全团队从历史上一直都被孤立于开发团队——每个团队在 IT 的不同领域都发展了很强的专业能力”,来自红帽安全策的专家 Kirsten 最近告诉我们。“不需要这样,非常关注安全也关注他们通过软件来兑现商业价值的能力的企业正在寻找能够在应用开发生命周期中加入安全的方法。他们通过在整个 CI/CD 管道中集成安全实践、工具和自动化来采用 DevSecOps。”
+
+“为了能够做的更好,他们正在整合他们的团队——专业的安全人员从开始设计到部署到生产中都融入到了开发团队中了,”她说,“双方都收获了价值——每个团队都拓展了他们的技能和基础知识,使他们自己都成更有价值的技术人员。 DevOps 做的很正确——或者说 DevSecOps——提高了 IT 的安全性。”
+
+IT 团队比任何以往都要求要快速频繁的交付服务。DevOps 在某种程度上可以成为一个很棒的推动者,因为它能够消除开发和运营之间通常遇到的一些摩擦,运营一直被排挤在整个过程之外直到要部署的时候,开发者把代码随便一放之后就不再去管理,他们承担更少的基础架构的责任。那种孤立的方法引起了很多问题,委婉的说,在数字时代,如果将安全孤立起来同样的情况也会发生。
+
+“我们已经采用了 DevOps,因为它已经被证明通过移除开发和运营之间的阻碍来提高 IT 的绩效,”Reevess 说,“就像我们不应该在开发周期要结束时才加入运营,我们不应该在快要结束时才加入安全。”
+
+### 为什么 DevSecOps 必然出现
+
+或许会把 DevSecOps 看作是另一个时髦词,但对于安全意识很强的IT领导者来说,它是一个实质性的术语:在软件开发管道中安全必须是第一层面的要素,而不是部署前的最后一步的螺栓,或者更糟的是,作为一个团队只有当一个实际的事故发生的时候安全人员才会被重用争抢。
+
+“DevSecOps 不只是一个时髦的术语——因为多种原因它是现在和未来 IT 将呈现的状态”,来自 [Sumo Logic] 的安全和合规副总裁 George 说道,“最重要的好处是将安全融入到开发和运营当中开提供保护的能力”
+
+此外,DevSecOps 的出现可能是 DevOps 自身逐渐成熟并扎根于 IT 之中的一个征兆。
+
+“企业中的 DevOps 文化已成定局,而且那意味着开发者们正以不断增长的速度交付功能和更新,特别是自我管理的组织会对合作和衡量的结果更加满意”,来自 [CYBRIC] 的首席技术官和联合创始人 Mike 说道。
+
+在实施 DevOps 的同时继续保留原有安全措施的团队和公司,随着他们继续部署的更快更频繁可能正在经历越来越多的安全管理风险上的痛苦。
+
+“现在的手工的安全测试方法会继续远远被甩在后面。”
+
+“如今,手动的安全测试方法正被甩得越来越远,利用自动化和协作将安全测试转移到软件开发生命周期中,因此推动 DevSecOps 的文化是 IT 领导者们为增加整体的灵活性提供安全保证的唯一途径”,Kail 说。
+
+转移安全测试也使开发者受益:他们能够在开放的较早的阶段验证并解决潜在的问题——这样很少需要或者甚至不需要安全人员的介入,而不是在一个新的服务或者更新部署之前在他们的代码中发现一个明显的漏洞。
+
+“做的正确,DevSecOps 能够将安全融入到开发生命周期中,允许开发者们在没有安全中断的情况下更加快速容易的保证他们应用的安全”,来自 [SAS][8] 的首席信息安全员 Wilson 说道。
+
+Wilson 指出静态(SAST)和源组合分析(SCA)工具,集成到团队的持续交付管道中,作为有用的技术通过给予开发者关于他们的代码中的潜在问题和第三方依赖中的漏洞的反馈来使之逐渐成为可能。
+
+“因此,开发者们能够主动和迭代的缓解应用安全的问题,然后在不需要安全人员介入的情况下重新进行安全扫描。” Wilson 说。他同时指出 DevSecOps 能够帮助开发者简化更新和打补丁。
+
+DevSecOps 并不意味着你不再需要安全组的意见了,就如同 DevOps 并不意味着你不再需要基础架构专家;它只是帮助你减少在生产中发现缺陷的可能性,或者减少导致降低部署速度的阻碍,因为缺陷已经在开发周期中被发现解决了。
+
+“如果他们有问题或者需要帮助,我们就在这儿,但是因为已经给了开发者他们需要的保护他们应用安全的工具,我们很少在一个深入的测试中发现一个导致中断的问题,”Wilson 说道。
+
+### DevSecOps 遇到 Meltdown
+
+Sumo Locic 的 Gerchow 向我们分享了一个在运转中的 DevSecOps 文化的一个及时案例:当最近 [Meltdown 和 Spectre] 的消息传来的时候,团队的 DevSecOps 方法使得有了一个快速的响应来减轻风险,没有任何的通知去打扰内部或者外部的顾客,Gerchow 所说的这点对原生云、高监管的公司来说特别的重要。
+
+第一步:Gerchow 的小型安全团队都具有一定的开发能力,能够通过 Slack 和它的主要云供应商协同工作来确保它的基础架构能够在 24 小时之内完成修复。
+
+“接着我的团队立即开始进行系统级的修复,实现终端客户的零停机时间,不需要去开工单给工程师,如果那样那意味着你需要等待很长的变更过程。所有的变更都是通过 Slack 的自动 jira 票据进行,通过我们的日志监控和分析解决方案”,Gerchow 解释道。
+
+在本质上,它听起来非常像 DevOps 文化,匹配正确的人员、过程和工具,但它明确的将安全作为文化中的一部分进行了混合。
+
+“在传统的环境中,这将花费数周或数月的停机时间来处理,因为开发、运维和安全三者是相互独立的”,Gerchow 说道,“通过一个 DevSecOps 的过程和习惯,终端用户可以通过简单的沟通和当日修复获得无缝的体验。”
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
+
+作者:[Kevin Casey][a]
+译者:[FelixYFZ](https://github.com/FelixYFZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/kevin-casey
+[1]:https://enterprisersproject.com/tags/devops
+[2]:https://www.datical.com/
+[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
+[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
+[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
+[6]:https://www.sumologic.com/
+[7]:https://www.cybric.io/
+[8]:https://www.sas.com/en_us/home.html
+[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
diff --git a/published/20180126 Running a Python application on Kubernetes.md b/published/20180126 Running a Python application on Kubernetes.md
new file mode 100644
index 0000000000..a6b709a22c
--- /dev/null
+++ b/published/20180126 Running a Python application on Kubernetes.md
@@ -0,0 +1,276 @@
+在 Kubernetes 上运行一个 Python 应用程序
+============================================================
+
+> 这个分步指导教程教你通过在 Kubernetes 上部署一个简单的 Python 应用程序来学习部署的流程。
+
+
+
+Kubernetes 是一个具备部署、维护和可伸缩特性的开源平台。它在提供可移植性、可扩展性以及自我修复能力的同时,简化了容器化 Python 应用程序的管理。
+
+不论你的 Python 应用程序是简单还是复杂,Kubernetes 都可以帮你高效地部署和伸缩它们,在有限的资源范围内滚动升级新特性。
+
+在本文中,我将描述在 Kubernetes 上部署一个简单的 Python 应用程序的过程,它包括:
+
+* 创建 Python 容器镜像
+* 发布容器镜像到镜像注册中心
+* 使用持久卷
+* 在 Kubernetes 上部署 Python 应用程序
+
+### 必需条件
+
+你需要 Docker、`kubectl` 以及这个 [源代码][10]。
+
+Docker 是一个构建和承载已发布的应用程序的开源平台。可以参照 [官方文档][11] 去安装 Docker。运行如下的命令去验证你的系统上运行的 Docker:
+
+```
+$ docker info
+Containers: 0
+Images: 289
+Storage Driver: aufs
+ Root Dir: /var/lib/docker/aufs
+ Dirs: 289
+Execution Driver: native-0.2
+Kernel Version: 3.16.0-4-amd64
+Operating System: Debian GNU/Linux 8 (jessie)
+WARNING: No memory limit support
+WARNING: No swap limit support
+```
+
+`kubectl` 是在 Kubernetes 集群上运行命令的一个命令行界面。运行下面的 shell 脚本去安装 `kubectl`:
+
+```
+curl -LO https://storage.googleapis.com/kubernetes-release/release/$(curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt)/bin/linux/amd64/kubectl
+```
+
+部署到 Kubernetes 的应用要求必须是一个容器化的应用程序。我们来回顾一下 Python 应用程序的容器化过程。
+
+### 一句话了解容器化
+
+容器化是指将一个应用程序所需要的东西打包进一个自带操作系统的容器中。这种完整机器虚拟化的好处是,一个应用程序能够在任何机器上运行而无需考虑它的依赖项。
+
+我们以 Roman Gaponov 的 [文章][12] 为参考,来为我们的 Python 代码创建一个容器。
+
+### 创建一个 Python 容器镜像
+
+为创建这些镜像,我们将使用 Docker,它可以让我们在一个隔离的 Linux 软件容器中部署应用程序。Docker 可以使用来自一个 Dockerfile 中的指令来自动化构建镜像。
+
+这是我们的 Python 应用程序的 Dockerfile:
+
+```
+FROM python:3.6
+MAINTAINER XenonStack
+
+# Creating Application Source Code Directory
+RUN mkdir -p /k8s_python_sample_code/src
+
+# Setting Home Directory for containers
+WORKDIR /k8s_python_sample_code/src
+
+# Installing python dependencies
+COPY requirements.txt /k8s_python_sample_code/src
+RUN pip install --no-cache-dir -r requirements.txt
+
+# Copying src code to Container
+COPY . /k8s_python_sample_code/src/app
+
+# Application Environment variables
+ENV APP_ENV development
+
+# Exposing Ports
+EXPOSE 5035
+
+# Setting Persistent data
+VOLUME ["/app-data"]
+
+# Running Python Application
+CMD ["python", "app.py"]
+```
+
+这个 Dockerfile 包含运行我们的示例 Python 代码的指令。它使用的开发环境是 Python 3.5。
+
+### 构建一个 Python Docker 镜像
+
+现在,我们可以使用下面的这个命令按照那些指令来构建 Docker 镜像:
+
+```
+docker build -t k8s_python_sample_code .
+```
+
+这个命令为我们的 Python 应用程序创建了一个 Docker 镜像。
+
+### 发布容器镜像
+
+我们可以将我们的 Python 容器镜像发布到不同的私有/公共云仓库中,像 Docker Hub、AWS ECR、Google Container Registry 等等。本教程中我们将发布到 Docker Hub。
+
+在发布镜像之前,我们需要给它标记一个版本号:
+
+```
+docker tag k8s_python_sample_code:latest k8s_python_sample_code:0.1
+```
+
+### 推送镜像到一个云仓库
+
+如果使用一个 Docker 注册中心而不是 Docker Hub 去保存镜像,那么你需要在你本地的 Docker 守护程序和 Kubernetes Docker 守护程序上添加一个容器注册中心。对于不同的云注册中心,你可以在它上面找到相关信息。我们在示例中使用的是 Docker Hub。
+
+运行下面的 Docker 命令去推送镜像:
+
+```
+docker push k8s_python_sample_code
+```
+
+### 使用 CephFS 持久卷
+
+Kubernetes 支持许多的持久存储提供商,包括 AWS EBS、CephFS、GlusterFS、Azure Disk、NFS 等等。我在示例中使用 CephFS 做为 Kubernetes 的持久卷。
+
+为使用 CephFS 存储 Kubernetes 的容器数据,我们将创建两个文件:
+
+`persistent-volume.yml` :
+
+```
+apiVersion: v1
+kind: PersistentVolume
+metadata:
+ name: app-disk1
+ namespace: k8s_python_sample_code
+spec:
+ capacity:
+ storage: 50Gi
+ accessModes:
+ - ReadWriteMany
+ cephfs:
+ monitors:
+ - "172.17.0.1:6789"
+ user: admin
+ secretRef:
+ name: ceph-secret
+ readOnly: false
+```
+
+`persistent_volume_claim.yaml`:
+
+```
+apiVersion: v1
+kind: PersistentVolumeClaim
+metadata:
+ name: appclaim1
+ namespace: k8s_python_sample_code
+spec:
+ accessModes:
+ - ReadWriteMany
+ resources:
+ requests:
+ storage: 10Gi
+```
+
+现在,我们将使用 `kubectl` 去添加持久卷并声明到 Kubernetes 集群中:
+
+```
+$ kubectl create -f persistent-volume.yml
+$ kubectl create -f persistent-volume-claim.yml
+```
+
+现在,我们准备去部署 Kubernetes。
+
+### 在 Kubernetes 上部署应用程序
+
+为管理部署应用程序到 Kubernetes 上的最后一步,我们将创建两个重要文件:一个服务文件和一个部署文件。
+
+使用下列的内容创建服务文件,并将它命名为 `k8s_python_sample_code.service.yml`:
+
+```
+apiVersion: v1
+kind: Service
+metadata:
+ labels:
+ k8s-app: k8s_python_sample_code
+ name: k8s_python_sample_code
+ namespace: k8s_python_sample_code
+spec:
+ type: NodePort
+ ports:
+ - port: 5035
+ selector:
+ k8s-app: k8s_python_sample_code
+```
+
+使用下列的内容创建部署文件并将它命名为 `k8s_python_sample_code.deployment.yml`:
+
+```
+apiVersion: extensions/v1beta1
+kind: Deployment
+metadata:
+ name: k8s_python_sample_code
+ namespace: k8s_python_sample_code
+spec:
+ replicas: 1
+ template:
+ metadata:
+ labels:
+ k8s-app: k8s_python_sample_code
+ spec:
+ containers:
+ - name: k8s_python_sample_code
+ image: k8s_python_sample_code:0.1
+ imagePullPolicy: "IfNotPresent"
+ ports:
+ - containerPort: 5035
+ volumeMounts:
+ - mountPath: /app-data
+ name: k8s_python_sample_code
+ volumes:
+ - name:
+ persistentVolumeClaim:
+ claimName: appclaim1
+```
+
+最后,我们使用 `kubectl` 将应用程序部署到 Kubernetes:
+
+```
+$ kubectl create -f k8s_python_sample_code.deployment.yml $ kubectl create -f k8s_python_sample_code.service.yml
+```
+
+现在,你的应用程序已经成功部署到 Kubernetes。
+
+你可以通过检查运行的服务来验证你的应用程序是否在运行:
+
+```
+kubectl get services
+```
+
+或许 Kubernetes 可以解决未来你部署应用程序的各种麻烦!
+
+ _想学习更多关于 Python 的知识?Nanjekye 的书,[和平共处的 Python 2 和 3][7] 提供了完整的方法,让你写的代码在 Python 2 和 3 上完美运行,包括如何转换已有的 Python 2 代码为能够可靠运行在 Python 2 和 3 上的代码的详细示例。_
+
+
+### 关于作者
+
+ [][13] Joannah Nanjekye - Straight Outta 256,只要结果不问原因,充满激情的飞行员,喜欢用代码说话。[关于我的更多信息][8]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/running-python-application-kubernetes
+
+作者:[Joannah Nanjekye][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/nanjekyejoannah
+[1]:https://opensource.com/resources/python?intcmp=7016000000127cYAAQ
+[2]:https://opensource.com/resources/python/ides?intcmp=7016000000127cYAAQ
+[3]:https://opensource.com/resources/python/gui-frameworks?intcmp=7016000000127cYAAQ
+[4]:https://opensource.com/tags/python?intcmp=7016000000127cYAAQ
+[5]:https://developers.redhat.com/?intcmp=7016000000127cYAAQ
+[6]:https://opensource.com/article/18/1/running-python-application-kubernetes?rate=D9iKksKbd9q9vOVb92Mg-v0Iyqn0QVO5fbIERTbSHz4
+[7]:https://www.apress.com/gp/book/9781484229545
+[8]:https://opensource.com/users/nanjekyejoannah
+[9]:https://opensource.com/user/196386/feed
+[10]:https://github.com/jnanjekye/k8s_python_sample_code/tree/master
+[11]:https://docs.docker.com/engine/installation/
+[12]:https://hackernoon.com/docker-tutorial-getting-started-with-python-redis-and-nginx-81a9d740d091
+[13]:https://opensource.com/users/nanjekyejoannah
+[14]:https://opensource.com/users/nanjekyejoannah
+[15]:https://opensource.com/users/nanjekyejoannah
+[16]:https://opensource.com/tags/python
+[17]:https://opensource.com/tags/kubernetes
diff --git a/published/20180128 Being open about data privacy.md b/published/20180128 Being open about data privacy.md
new file mode 100644
index 0000000000..d927af148d
--- /dev/null
+++ b/published/20180128 Being open about data privacy.md
@@ -0,0 +1,95 @@
+对数据隐私持开放的态度
+======
+
+> 尽管有包括 GDPR 在内的法规,数据隐私对于几乎所有的人来说都是很重要的事情。
+
+
+
+今天(LCTT 译注:本文发表于 2018/1/28)是[数据隐私日][1],(在欧洲叫“数据保护日”),你可能会认为现在我们处于一个开源的世界中,所有的数据都应该是自由的,[就像人们想的那样][2],但是现实并没那么简单。主要有两个原因:
+
+1. 我们中的大多数(不仅仅是在开源中)认为至少有些关于我们自己的数据是不愿意分享出去的(我在之前发表的一篇文章中列举了一些例子[3])
+2. 我们很多人虽然在开源中工作,但事实上是为了一些商业公司或者其他一些组织工作,也是在合法的要求范围内分享数据。
+
+所以实际上,数据隐私对于每个人来说是很重要的。
+
+事实证明,在美国和欧洲之间,人们和政府认为让组织使用哪些数据的出发点是有些不同的。前者通常为商业实体(特别是愤世嫉俗的人们会指出是大型的商业实体)利用他们所收集到的关于我们的数据提供了更多的自由度。在欧洲,完全是另一观念,一直以来持有的多是有更多约束限制的观念,而且在 5 月 25 日,欧洲的观点可以说取得了胜利。
+
+### 通用数据保护条例(GDPR)的影响
+
+那是一个相当全面的声明,其实事实上这是 2016 年欧盟通过的一项称之为通用数据保护条例(GDPR)的立法的日期。数据通用保护条例在私人数据怎样才能被保存,如何才能被使用,谁能使用,能被持有多长时间这些方面设置了严格的规则。它描述了什么数据属于私人数据——而且涉及的条目范围非常广泛,从你的姓名、家庭住址到你的医疗记录以及接通你电脑的 IP 地址。
+
+通用数据保护条例的重要之处是它并不仅仅适用于欧洲的公司,如果你是阿根廷人、日本人、美国人或者是俄罗斯的公司而且你正在收集涉及到欧盟居民的数据,你就要受到这个条例的约束管辖。
+
+“哼!” 你可能会这样说^注1 ,“我的业务不在欧洲:他们能对我有啥约束?” 答案很简单:如果你想继续在欧盟做任何生意,你最好遵守,因为一旦你违反了通用数据保护条例的规则,你将会受到你的全球总收入百分之四的惩罚。是的,你没听错,是全球总收入,而不是仅仅在欧盟某一国家的的收入,也不只是净利润,而是全球总收入。这将会让你去叮嘱告知你的法律团队,他们就会知会你的整个团队,同时也会立即去指引你的 IT 团队,确保你的行为在相当短的时间内合规。
+
+看上去这和非欧盟公民没有什么相关性,但其实不然,对大多数公司来说,对所有的他们的顾客、合作伙伴以及员工实行同样的数据保护措施是件既简单又有效的事情,而不是仅针对欧盟公民实施,这将会是一件很有利的事情。^注2
+
+然而,数据通用保护条例不久将在全球实施并不意味着一切都会变的很美好^注3 :事实并非如此,我们一直在丢弃关于我们自己的信息——而且允许公司去使用它。
+
+有一句话是这么说的(尽管很争议):“如果你没有在付费,那么你就是产品。”这句话的意思就是如果你没有为某一项服务付费,那么其他的人就在付费使用你的数据。你有付费使用 Facebook、推特、谷歌邮箱?你觉得他们是如何赚钱的?大部分是通过广告,一些人会争论那是他们向你提供的一项服务而已,但事实上是他们在利用你的数据从广告商里获取收益。你不是一个真正的广告的顾客——只有当你从看了广告后买了他们的商品之后你才变成了他们的顾客,但直到这个发生之前,都是广告平台和广告商的关系。
+
+有些服务是允许你通过付费来消除广告的(流媒体音乐平台声破天就是这样的),但从另一方面来讲,即使你认为付费的服务也可以启用广告(例如,亚马逊正在努力让 Alexa 发广告),除非我们想要开始为这些所有的免费服务付费,我们需要清楚我们所放弃的,而且在我们暴露的和不想暴露的之间做一些选择。
+
+### 谁是顾客?
+
+关于数据的另一个问题一直在困扰着我们,它是产生的数据量的直接结果。有许多组织一直在产生巨量的数据,包括公共的组织比如大学、医院或者是政府部门^注4 ——而且他们没有能力去储存这些数据。如果这些数据没有长久的价值也就没什么要紧的,但事实正好相反,随着处理大数据的工具正在开发中,而且这些组织也认识到他们现在以及在不久的将来将能够去挖掘这些数据。
+
+然而他们面临的是,随着数据的增长和存储量无法跟上该怎么办。幸运的是——而且我是带有讽刺意味的使用了这个词^注5 ,大公司正在介入去帮助他们。“把你们的数据给我们,”他们说,“我们将免费保存。我们甚至让你随时能够使用你所收集到的数据!”这听起来很棒,是吗?这是大公司^注6 的一个极具代表性的例子,站在慈善的立场上帮助公共组织管理他们收集到的关于我们的数据。
+
+不幸的是,慈善不是唯一的理由。他们是附有条件的:作为同意保存数据的交换条件,这些公司得到了将数据访问权限出售给第三方的权利。你认为公共组织,或者是被收集数据的人在数据被出售使用权使给第三方,以及在他们如何使用上能有发言权吗?我将把这个问题当做一个练习留给读者去思考。^注7
+
+### 开放和积极
+
+然而并不只有坏消息。政府中有一项在逐渐发展起来的“开放数据”运动鼓励各个部门免费开放大量他们的数据给公众或者其他组织。在某些情况下,这是专门立法的。许多志愿组织——尤其是那些接受公共资金的——正在开始这样做。甚至商业组织也有感兴趣的苗头。而且,有一些技术已经可行了,例如围绕不同的隐私和多方计算上,正在允许跨越多个数据集挖掘数据,而不用太多披露个人的信息——这个计算问题从未如现在比你想象的更容易。
+
+这些对我们来说意味着什么呢?我之前在网站 Opensource.com 上写过关于[开源的共享福利][4],而且我越来越相信我们需要把我们的视野从软件拓展到其他区域:硬件、组织,和这次讨论有关的,数据。让我们假设一下你是 A 公司要提向另一家公司客户 B^注8 提供一项服务 。在此有四种不同类型的数据:
+
+ 1. 数据完全开放:对 A 和 B 都是可得到的,世界上任何人都可以得到
+ 2. 数据是已知的、共享的,和机密的:A 和 B 可得到,但其他人不能得到
+ 3. 数据是公司级别上保密的:A 公司可以得到,但 B 顾客不能
+ 4. 数据是顾客级别保密的:B 顾客可以得到,但 A 公司不能
+
+首先,也许我们对数据应该更开放些,将数据默认放到选项 1 中。如果那些数据对所有人开放——在无人驾驶、语音识别,矿藏以及人口数据统计会有相当大的作用的。^注9 如果我们能够找到方法将数据放到选项 2、3 和 4 中,不是很好吗?——或者至少它们中的一些——在选项 1 中是可以实现的,同时仍将细节保密?这就是研究这些新技术的希望。
+然而有很长的路要走,所以不要太兴奋,同时,开始考虑将你的的一些数据默认开放。
+
+### 一些具体的措施
+
+我们如何处理数据的隐私和开放?下面是我想到的一些具体的措施:欢迎大家评论做出更多的贡献。
+
+ * 检查你的组织是否正在认真严格的执行通用数据保护条例。如果没有,去推动实施它。
+ * 要默认加密敏感数据(或者适当的时候用散列算法),当不再需要的时候及时删掉——除非数据正在被处理使用,否则没有任何借口让数据清晰可见。
+ * 当你注册了一个服务的时候考虑一下你公开了什么信息,特别是社交媒体类的。
+ * 和你的非技术朋友讨论这个话题。
+ * 教育你的孩子、你朋友的孩子以及他们的朋友。然而最好是去他们的学校和他们的老师谈谈在他们的学校中展示。
+ * 鼓励你所服务和志愿贡献的组织,或者和他们沟通一些推动数据的默认开放。不是去思考为什么我要使数据开放,而是从我为什么不让数据开放开始。
+ * 尝试去访问一些开源数据。挖掘使用它、开发应用来使用它,进行数据分析,画漂亮的图,^注10 制作有趣的音乐,考虑使用它来做些事。告诉组织去使用它们,感谢它们,而且鼓励他们去做更多。
+
+**注:**
+
+1. 我承认你可能尽管不会。
+2. 假设你坚信你的个人数据应该被保护。
+3. 如果你在思考“极好的”的寓意,在这点上你并不孤独。
+4. 事实上这些机构能够有多开放取决于你所居住的地方。
+5. 假设我是英国人,那是非常非常大的剂量。
+6. 他们可能是巨大的公司:没有其他人能够负担得起这么大的存储和基础架构来使数据保持可用。
+7. 不,答案是“不”。
+8. 尽管这个例子也同样适用于个人。看看:A 可能是 Alice,B 可能是 BOb……
+9. 并不是说我们应该暴露个人的数据或者是这样的数据应该被保密,当然——不是那类的数据。
+10. 我的一个朋友当她接孩子放学的时候总是下雨,所以为了避免确认失误,她在整个学年都访问天气信息并制作了图表分享到社交媒体上。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/being-open-about-data-privacy
+
+作者:[Mike Bursell][a]
+译者:[FelixYFZ](https://github.com/FelixYFZ)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/mikecamel
+[1]:https://en.wikipedia.org/wiki/Data_Privacy_Day
+[2]:https://en.wikipedia.org/wiki/Information_wants_to_be_free
+[3]:https://aliceevebob.wordpress.com/2017/06/06/helping-our-governments-differently/
+[4]:https://opensource.com/article/17/11/commonwealth-open-source
+[5]:http://www.outpost9.com/reference/jargon/jargon_40.html#TAG2036
diff --git a/translated/tech/20180228 Why Python devs should use Pipenv.md b/published/20180228 Why Python devs should use Pipenv.md
similarity index 54%
rename from translated/tech/20180228 Why Python devs should use Pipenv.md
rename to published/20180228 Why Python devs should use Pipenv.md
index 1e5d3dcd79..57a305f4b4 100644
--- a/translated/tech/20180228 Why Python devs should use Pipenv.md
+++ b/published/20180228 Why Python devs should use Pipenv.md
@@ -1,101 +1,101 @@
为什么 Python 开发人员应该使用 Pipenv
=====
+> 只用了一年, Pipenv 就变成了管理软件包依赖关系的 Python 官方推荐资源。
+

-这篇文章是与 [Jeff Triplett][1] 共同撰写的。
-
-Pipenv 是由 Kenneth Reitz 在一年多前创建的“面向人类(to校正者:这里为人类感觉翻译为为开发者更好一点)而生的 Python 开发工作流”,它已经成为管理软件包依赖关系的[ Python 官方推荐资源][2]。但是对于它解决了什么问题,以及它如何比使用 `pip` 和 `requirements.txt` 文件的标准工作流更有用处,这两点仍然存在困惑。在本月的 Python 专栏中,我们将填补这些空白。
+Pipenv 是由 Kenneth Reitz 在一年多前创建的“面向开发者而生的 Python 开发工作流”,它已经成为管理软件包依赖关系的[ Python 官方推荐资源][2]。但是对于它解决了什么问题,以及它如何比使用 `pip` 和 `requirements.txt` 文件的标准工作流更有用处,这两点仍然存在困惑。在本月的 Python 专栏中,我们将填补这些空白。
### Python 包安装简史
为了理解 Pipenv 所解决的问题,看一看 Python 包管理如何发展十分有用的。
-让我们回到第一个 Python 版本,我们有 Python,但是没有干净的方法来安装软件包。
+让我们回到第一个 Python 版本,这时我们有了 Python,但是没有干净的方法来安装软件包。
然后有了 [Easy Install][3],这是一个可以相对容易地安装其他 Python 包的软件包,但它也带来了一个问题:卸载不需要的包并不容易。
[pip][4] 登场,绝大多数 Python 用户都熟悉它。`pip` 可以让我们安装和卸载包。我们可以指定版本,运行 `pip freeze > requirements.txt` 来输出一个已安装包列表到一个文本文件,还可以用相同的文本文件配合 `pip install -r requirements.txt` 来安装一个应用程序需要的所有包。
-但是 `pip` 并没有包含将包彼此隔离的方法。我们可能会开发使用相同库的不同版本的应用程序,因此我们需要一种方法来实现这一点。随之而来的是[虚拟环境][5],它使我们能够为我们开发的每个应用程序创建一个小型的,隔离的环境。我们已经看到了许多管理虚拟环境的工具:[virtualenv][6], [venv][7], [virtualenvwrapper][8], [pyenv][9], [pyenv-virtualenv][10], [pyenv-virtualenvwrapper][11] 等等。它们都可以很好地使用 `pip` 和 `requirements.txt` 文件。
+但是 `pip` 并没有包含将软件包彼此隔离的方法。我们可能会开发使用相同库的不同版本的应用程序,因此我们需要一种方法来实现这一点。随之而来的是[虚拟环境][5],它使我们能够为我们开发的每个应用程序创建一个小型的、隔离的环境。我们已经看到了许多管理虚拟环境的工具:[virtualenv][6]、 [venv][7]、 [virtualenvwrapper][8]、 [pyenv][9]、 [pyenv-virtualenv][10]、 [pyenv-virtualenvwrapper][11] 等等。它们都可以很好地使用 `pip` 和 `requirements.txt` 文件。
### 新方法:Pipenv
Pipenv 旨在解决几个问题:
-首先,问题是需要 `pip` 库来安装包,外加一个用于创建虚拟环境的库,以及用于管理虚拟环境的库,以及与这些库相关的所有命令。这些都需要管理。Pipenv 附带包管理和虚拟环境支持,因此你可以使用一个工具来安装、卸载、跟踪和记录依赖性,并创建、使用和组织你的虚拟环境。当你使用它启动一个项目时,如果你还没有使用它的话,Pipenv 将自动为该项目创建一个虚拟环境。
+首先,需要 `pip` 库来安装包,外加一个用于创建虚拟环境的库,以及用于管理虚拟环境的库,再有与这些库相关的所有命令。这些都需要管理。Pipenv 附带包管理和虚拟环境支持,因此你可以使用一个工具来安装、卸载、跟踪和记录依赖性,并创建、使用和组织你的虚拟环境。当你使用它启动一个项目时,如果你还没有使用虚拟环境的话,Pipenv 将自动为该项目创建一个虚拟环境。
-Pipenv 通过放弃 `requirements.txt` 规范转而将其移动到一个名为 [Pipfile][12] 的新文档中来完成这种依赖管理。当你使用 Pipenv 安装一个库时,项目的 `Pipfile` 会自动更新安装细节,包括版本信息,还有可能的 Git 仓库位置,文件路径和其他信息。
+Pipenv 通过放弃 `requirements.txt` 规范转而将其移动到一个名为 [Pipfile][12] 的新文档中来完成这种依赖管理。当你使用 Pipenv 安装一个库时,项目的 `Pipfile` 会自动更新安装细节,包括版本信息,还有可能的 Git 仓库位置、文件路径和其他信息。
-其次,Pipenv 希望能更容易地管理复杂的相互依赖关系。你的应用程序可能依赖于某个特定版本的库,而那个库可能依赖于另一个特定版本的库,而它只是依赖关系(to 校正者:这句话不太理解)。当你的应用程序使用的两个库有冲突的依赖关系时,你的情况会变得很艰难。Pipenv 希望通过在一个名为 `Pipfile.lock` 的文件中跟踪应用程序相互依赖关系树来减轻这种痛苦。`Pipfile.lock` 还会验证生产中是否使用了正确版本的依赖关系。
+其次,Pipenv 希望能更容易地管理复杂的相互依赖关系。你的应用程序可能依赖于某个特定版本的库,而那个库可能依赖于另一个特定版本的库,这些依赖关系如海龟般堆叠起来。当你的应用程序使用的两个库有冲突的依赖关系时,你的情况会变得很艰难。Pipenv 希望通过在一个名为 `Pipfile.lock` 的文件中跟踪应用程序相互依赖关系树来减轻这种痛苦。`Pipfile.lock` 还会验证生产中是否使用了正确版本的依赖关系。
-另外,当多个开发人员在开发一个项目时,Pipenv 很方便。通过 `pip` 工作流,Casey 可能会安装一个库,并花两天时间使用该库实现一个新功能。当 Casey 提交更改时,他可能会忘记运行 `pip freeze` 来更新 requirements 文件。第二天,Jamie 拉取 Casey 的变化,突然测试失败。这样会花费好一会儿才能意识到问题是在 requirements 文件中缺少相关库,而 Jamie 尚未在虚拟环境中安装这些文件。
+另外,当多个开发人员在开发一个项目时,Pipenv 很方便。通过 `pip` 工作流,凯西可能会安装一个库,并花两天时间使用该库实现一个新功能。当凯西提交更改时,他可能会忘记运行 `pip freeze` 来更新 `requirements.txt` 文件。第二天,杰米拉取凯西的改变,测试就突然失败了。这样会花费好一会儿才能意识到问题是在 `requirements.txt` 文件中缺少相关库,而杰米尚未在虚拟环境中安装这些文件。
-因为 Pipenv 会在安装时自动记录依赖性,如果 Jamie 和 Casey 使用了 Pipenv,`Pipfile` 会自动更新并包含在 Casey 的提交中。这样 Jamie 和 Casey 就可以节省时间并更快地运送他们的产品。
+因为 Pipenv 会在安装时自动记录依赖性,如果杰米和凯西使用了 Pipenv,`Pipfile` 会自动更新并包含在凯西的提交中。这样杰米和凯西就可以节省时间并更快地运送他们的产品。
-最后,将 Pipenv 推荐给在你项目上工作的其他人,因为它使用标准化的方式来安装项目依赖项,开发和测试需求。使用 `pip` 工作流和 requirements 文件意味着你可能只有一个 `requirements.txt` 文件,或针对不同环境的多个 requirements 文件。例如,你的同事可能不清楚他们是否应该在他们的笔记本电脑上运行项目时运行 `dev.txt` 还是 `local.txt`。当两个相似的 requirements 文件彼此不同步时它也会造成混淆:`local.txt` 是否过时了,还是真的应该与 `dev.txt` 不同?多个 requirements 文件需要更多的上下文和文档,以使其他人能够按照预期正确安装依赖关系。这个工作流程有可能会混淆同时并增加你的维护负担。
+最后,将 Pipenv 推荐给在你项目上工作的其他人,因为它使用标准化的方式来安装项目依赖项和开发和测试的需求。使用 `pip` 工作流和 `requirements.txt` 文件意味着你可能只有一个 `requirements.txt` 文件,或针对不同环境的多个 `requirements.txt` 文件。例如,你的同事可能不清楚他们是否应该在他们的笔记本电脑上运行项目时是运行 `dev.txt` 还是 `local.txt`。当两个相似的 `requirements.txt` 文件彼此不同步时它也会造成混淆:`local.txt` 是否过时了,还是真的应该与 `dev.txt` 不同?多个 `requirements.txt` 文件需要更多的上下文和文档,以使其他人能够按照预期正确安装依赖关系。这个工作流程有可能会混淆同时并增加你的维护负担。
使用 Pipenv,它会生成 `Pipfile`,通过为你管理对不同环境的依赖关系,可以避免这些问题。该命令将安装主项目依赖项:
+
```
pipenv install
-
```
-添加 `--dev` 标志将安装 dev/testing requirements:
+添加 `--dev` 标志将安装开发/测试的 `requirements.txt`:
+
```
pipenv install --dev
-
```
使用 Pipenv 还有其他好处:它具有更好的安全特性,以易于理解的格式绘制你的依赖关系,无缝处理 `.env` 文件,并且可以在一个文件中自动处理开发与生产环境的不同依赖关系。你可以在[文档][13]中阅读更多内容。
-### Pipenv 行动
+### 使用 Pipenv
使用 Pipenv 的基础知识在官方 Python 包管理教程[管理应用程序依赖关系][14]部分中详细介绍。要安装 Pipenv,使用 `pip`:
+
```
pip install pipenv
-
```
要安装在项目中使用的包,请更改为项目的目录。然后安装一个包(我们将使用 Django 作为例子),运行:
+
```
pipenv install django
-
```
你会看到一些输出,表明 Pipenv 正在为你的项目创建一个 `Pipfile`。
如果你还没有使用虚拟环境,你还会看到 Pipenv 的一些输出,说明它正在为你创建一个虚拟环境。
-然后,你将看到你在安装包时习惯看到的输出。
+然后,你将看到你在安装包时常看到的输出。
为了生成 `Pipfile.lock` 文件,运行:
+
```
pipenv lock
-
```
-你也可以使用 Pipenv 运行 Python 脚本。运行名为 `hello.py` 的(to 校正者:这里 top-level该怎么翻译)Python 脚本:
+你也可以使用 Pipenv 运行 Python 脚本。运行名为 `hello.py` 的上层 Python 脚本:
+
```
pipenv run python hello.py
-
```
你将在控制台中看到预期结果。
启动一个 shell,运行:
+
```
pipenv shell
-
```
如果你想将当前使用 `requirements.txt` 文件的项目转换为使用 Pipenv,请安装 Pipenv 并运行:
+
```
pipenv install requirements.txt
-
```
-这将创建一个 Pipfile 并安装指定的 requirements。考虑一下升级你的项目!
+这将创建一个 Pipfile 并安装指定的 `requirements.txt`。考虑一下升级你的项目!
### 了解更多
@@ -106,9 +106,9 @@ pipenv install requirements.txt
via: https://opensource.com/article/18/2/why-python-devs-should-use-pipenv
-作者:[Lacey Williams Henschel][a]
+作者:[Lacey Williams Henschel][a], [Jeff Triplett][1]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180302 5 open source software tools for supply chain management.md b/published/20180302 5 open source software tools for supply chain management.md
similarity index 56%
rename from translated/tech/20180302 5 open source software tools for supply chain management.md
rename to published/20180302 5 open source software tools for supply chain management.md
index 8ead3394de..3c000a2717 100644
--- a/translated/tech/20180302 5 open source software tools for supply chain management.md
+++ b/published/20180302 5 open source software tools for supply chain management.md
@@ -1,23 +1,25 @@
供应链管理方面的 5 个开源软件工具
======
+> 跟踪您的库存和您需要的材料,用这些供应链管理工具制造产品。
+

本文最初发表于 2016 年 1 月 14 日,最后的更新日期为 2018 年 3 月 2 日。
-如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
+如果你正在管理着处理实体货物的业务,[供应链管理][1] 是你的业务流程中非常重要的一部分。不论你是经营着一个只有几个客户的小商店,还是在世界各地拥有数以百万计客户和成千上万产品的世界财富 500 强的制造商或零售商,很清楚地知道你的库存和制造产品所需要的零部件,对你来说都是非常重要的事情。
-保持对货品、供应商、客户的持续跟踪,并且所有与它们相关的变动部分都会从中受益,并且,在某些情况下完全依赖专门的软件来帮助管理这些工作流。在本文中,我们将去了解一些免费的和开源的供应链管理方面的软件,以及它们的其中一些功能。
+保持对货品、供应商、客户的持续跟踪,而且所有与它们相关的变动部分都会受益于这些用来帮助管理工作流的专门软件,而在某些情况下需要完全依赖这些软件。在本文中,我们将去了解一些自由及开源的供应链管理方面的软件,以及它们的其中一些功能。
-供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是合法性、最低品质要求、还是社会和环境的合规性。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
+供应链管理比单纯的库存管理更为强大。它能帮你去跟踪货物流以降低成本,以及为可能发生的各种糟糕的变化来制定应对计划。它能够帮你对出口合规性进行跟踪,不论是否是出于法律要求、最低品质要求、还是社会和环境责任。它能够帮你计划最低供应量,让你能够在订单数量和交付时间之间做出明智的决策。
-由于它的本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
+由于其本质决定了许多供应链管理软件是与类似的软件捆绑在一起的,比如,[客户关系管理][2](CRM)和 [企业资源计划管理][3] (ERP)。因此,当你选择哪个工具更适合你的组织时,你可能会考虑与其它工具集成作为你的决策依据之一。
### Apache OFBiz
-[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,目录、电子商务网站、帐户、和销售点,它在供应链管理方面的主要功能关注于仓库管理、履行、订单、和生产管理。它的可定制性很强,但是,它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层、和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
+[Apache OFBiz][4] 是一套帮你管理多种业务流程的相关工具。虽然它能管理多种相关问题,比如,分类、电子商务网站、会计和 POS,它在供应链管理方面的主要功能关注于仓库管理、履行、订单和生产管理。它的可定制性很强,但是,对应的它需要大量的规划去设置和集成到你现有的流程中。这就是它适用于中大型业务的原因之一。项目的功能构建于三个层面:展示层、业务层和数据层,它是一个弹性很好的解决方案,但是,再强调一遍,它也很复杂。
-Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 license][6] 授权的。
+Apache OFBiz 的源代码在其 [项目仓库][5] 中可以找到。Apache OFBiz 是用 Java 写的,并且它是按 [Apache 2.0 许可证][6] 授权的。
如果你对它感兴趣,你也可以去查看 [opentaps][7],它是在 OFBiz 之上构建的。Opentaps 强化了 OFBiz 的用户界面,并且添加了 ERP 和 CRM 的核心功能,包括仓库管理、采购和计划。它是按 [AGPL 3.0][8] 授权使用的,对于不接受开源授权的组织,它也提供了商业授权。
@@ -25,25 +27,25 @@ Apache OFBiz 的源代码在 [项目仓库][5] 中可以找到。Apache OFBiz
[OpenBoxes][9] 是一个供应链管理和存货管理项目,最初的主要设计目标是为了医疗行业中的药品跟踪管理,但是,它可以通过修改去跟踪任何类型的货品和相关的业务流。它有一个需求预测工具,可以基于历史订单数量、存储跟踪、支持多种场所、过期日期跟踪、销售点支持等进行预测,并且它还有许多其它功能,这使它成为医疗行业的理想选择,但是,它也可以用于其它行业。
-它在 [Eclipse Public License][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
+它在 [Eclipse 公开许可证][10] 下可用,OpenBoxes 主要是由 Groovy 写的,它的源代码可以在 [GitHub][11] 上看到。
### OpenLMIS
-与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由络克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达 盖茨基金会。
+与 OpenBoxes 类似,[OpenLMIS][12] 也是一个医疗行业的供应链管理工具,但是,它专用设计用于在非洲的资源缺乏地区使用,以确保有限的药物和医疗用品能够用到需要的病人上。它是 API 驱动的,这样用户可以去定制和扩展 OpenLMIS,同时还能维护一个与通用基准代码的连接。它是由洛克菲勒基金会开发的,其它的贡献者包括联合国、美国国际开发署、和比尔 & 梅林达·盖茨基金会。
-OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 license][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
+OpenLMIS 是用 Java 和 JavaScript 的 AngularJS 写的。它在 [AGPL 3.0 许可证][13] 下使用,它的源代码在 [GitHub][13] 上可以找到。
### Odoo
-你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和销售点连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
+你可能在我们以前的 [ERP 项目][3] 榜的文章上见到过 [Odoo][14]。事实上,根据你的需要,一个全功能的 ERP 对你来说是最适合的。Odoo 的供应链管理工具主要围绕存货和采购管理,同时还与电子商务网站和 POS 连接,但是,它也可以与其它的工具连接,比如,与 [frePPLe][15] 连接,它是一个开源的生产计划工具。
-Odoo 既有软件即服务的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
+Odoo 既有软件即服务(SaaS)的解决方案,也有开源的社区版本。开源的版本是以 [LGPL][16] 版本 3 下发行的,源代码在 [GitHub][17] 上可以找到。Odoo 主要是用 Python 来写的。
### xTuple
-[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是帐务、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
+[xTuple][18] 标称自己是“为成长中的企业提供供应链管理软件”,它专注于已经超越了其传统的小型企业 ERP 和 CRM 解决方案的企业。它的开源版本称为 Postbooks,添加了一些存货、分销、采购、以及供应商报告的功能,它提供的核心功能是会计、CRM、以及 ERP 功能,而它的商业版本扩展了制造和分销的 [功能][19]。
-xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去 fork 它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
+xTuple 在 [CPAL][20] 下使用,这个项目欢迎开发者去复刻它,为基于存货的制造商去创建其它的业务软件。它的 Web 应用核心是用 JavaScript 写的,它的源代码在 [GitHub][21] 上可以找到。
就这些,当然了,还有其它的可以帮你处理供应链管理的开源软件。如果你知道还有更好的软件,请在下面的评论区告诉我们。
@@ -53,14 +55,14 @@ via: https://opensource.com/tools/supply-chain-management
作者:[Jason Baker][a]
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
[a]:https://opensource.com/users/jason-baker
[1]:https://en.wikipedia.org/wiki/Supply_chain_management
[2]:https://opensource.com/business/14/7/top-5-open-source-crm-tools
-[3]:https://opensource.com/resources/top-4-open-source-erp-systems
+[3]:https://linux.cn/article-9785-1.html
[4]:http://ofbiz.apache.org/
[5]:http://ofbiz.apache.org/source-repositories.html
[6]:http://www.apache.org/licenses/LICENSE-2.0
diff --git a/published/20180305 What-s next in IT automation- 6 trends to watch.md b/published/20180305 What-s next in IT automation- 6 trends to watch.md
new file mode 100644
index 0000000000..d907efbf41
--- /dev/null
+++ b/published/20180305 What-s next in IT automation- 6 trends to watch.md
@@ -0,0 +1,132 @@
+IT 自动化的下一步是什么: 6 大趋势
+======
+
+> 自动化专家分享了一点对 [自动化][6]不远的将来的看法。请将这些保留在你的视线之内。
+
+
+
+我们最近讨论了 [推动 IT 自动化的因素][1],可以看到[当前趋势][2]正在增长,以及那些给刚开始使用自动化部分流程的组织的 [有用的技巧][3] 。
+
+噢,我们也分享了如何在贵公司[进行自动化的案例][4]及 [长期成功的关键][5]的专家建议。
+
+现在,只有一个问题:自动化的下一步是什么? 我们邀请一系列专家分享一下 [自动化][6]不远的将来的看法。 以下是他们建议 IT 领域领导需密切关注的六大趋势。
+
+### 1、 机器学习的成熟
+
+对于关于 [机器学习][7](与“自我学习系统”相似的定义)的讨论,对于绝大多数组织的项目来说,实际执行起来它仍然为时过早。但预计这将发生变化,机器学习将在下一次 IT 自动化浪潮中将扮演着至关重要的角色。
+
+[Advanced Systems Concepts, Inc.][8] 公司的工程总监 Mehul Amin 指出机器学习是 IT 自动化下一个关键增长领域之一。
+
+“随着数据化的发展,自动化软件理应可以自我决策,否则这就是开发人员的责任了”,Amin 说。 “例如,开发者构建了需要执行的内容,但通过使用来自系统内部分析的软件,可以确定执行该流程的最佳系统。”
+
+假设将这个系统延伸到其他地方中。Amin 指出,机器学习可以使自动化系统在必要的时候提供额外的资源,以需要满足时间线或 SLA,同样在不需要资源以及其他的可能性的时候退出。
+
+显然不只有 Amin 一个人这样认为。
+
+“IT 自动化正在走向自我学习的方向” ,[Sungard Availability Services][9] 公司首席架构师 Kiran Chitturi 表示,“系统将会能测试和监控自己,加强业务流程和软件交付能力。”
+
+Chitturi 指出自动化测试就是个例子。脚本测试已经被广泛采用,但很快这些自动化测试流程将会更容易学习,更快发展,例如开发出新的代码或将更为广泛地影响生产环境。
+
+### 2、 人工智能催生的自动化
+
+上述原则同样适合与相关的(但是独立的) [人工智能][10]的领域。根据对人工智能的定义,机器学习在短时间内可能会对 IT 领域产生巨大的影响(并且我们可能会看到这两个领域的许多重叠的定义和理解)。假定新兴的人工智能技术将也会产生新的自动化机会。
+
+[SolarWinds][11] 公司技术负责人 Patrick Hubbard 说,“人工智能和机器学习的整合普遍被认为对未来几年的商业成功起至关重要的作用。”
+
+### 3、 这并不意味着不再需要人力
+
+让我们试着安慰一下那些不知所措的人:前两种趋势并不一定意味着我们将失去工作。
+
+这很可能意味着各种角色的改变,以及[全新角色][12]的创造。
+
+但是在可预见的将来,至少,你不必需要对机器人鞠躬。
+
+“一台机器只能运行在给定的环境变量中——它不能选择包含新的变量,在今天只有人类可以这样做,” Hubbard 解释说。“但是,对于 IT 专业人员来说,这将需要培养 AI 和自动化技能,如对程序设计、编程、管理人工智能和机器学习功能算法的基本理解,以及用强大的安全状态面对更复杂的网络攻击。”
+
+Hubbard 分享一些新的工具或功能例子,例如支持人工智能的安全软件或机器学习的应用程序,这些应用程序可以远程发现石油管道中的维护需求。两者都可以提高效益和效果,自然不会代替需要信息安全或管道维护的人员。
+
+“许多新功能仍需要人工监控,”Hubbard 说。“例如,为了让机器确定一些‘预测’是否可能成为‘规律’,人为的管理是必要的。”
+
+即使你把机器学习和 AI 先放在一边,看待一般的 IT 自动化,同样原理也是成立的,尤其是在软件开发生命周期中。
+
+[Juniper Networks][13] 公司自动化首席架构师 Matthew Oswalt ,指出 IT 自动化增长的根本原因是它通过减少操作基础设施所需的人工工作量来创造直接价值。
+
+> 在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。
+
+“它也将操作工作流程作为代码而不再是容易过时的文档或系统知识阶段,”Oswalt 解释说。“操作人员仍然需要在[自动化]工具响应事件方面后发挥积极作用。采用自动化的下一个阶段是建立一个能够跨 IT 频谱识别发生的有趣事件的系统,并以自主方式进行响应。在代码上,操作工程师可以使用事件驱动的自动化提前定义他们的工作流程,而不是在凌晨 3 点来应对基础设施的问题。他们可以依靠这个系统在任何时候以同样的方式作出回应。”
+
+### 4、 对自动化的焦虑将会减少
+
+SolarWinds 公司的 Hubbard 指出,“自动化”一词本身就产生大量的不确定性和担忧,不仅仅是在 IT 领域,而且是跨专业领域,他说这种担忧是合理的。但一些随之而来的担忧可能被夸大了,甚至与科技产业本身共存。现实可能实际上是这方面的镇静力:当自动化的实际实施和实践帮助人们认识到这个列表中的第 3 项时,我们将看到第 4 项的出现。
+
+“今年我们可能会看到对自动化焦虑的减少,更多的组织开始接受人工智能和机器学习作为增加现有人力资源的一种方式,”Hubbard 说。“自动化历史上为更多的工作创造了空间,通过降低成本和时间来完成较小任务,并将劳动力重新集中到无法自动化并需要人力的事情上。人工智能和机器学习也是如此。”
+
+自动化还将减少令 IT 领导者神经紧张的一些焦虑:安全。正如[红帽][14]公司首席架构师 Matt Smith 最近[指出][15]的那样,自动化将越来越多地帮助 IT 部门降低与维护任务相关的安全风险。
+
+他的建议是:“首先在维护活动期间记录和自动化 IT 资产之间的交互。通过依靠自动化,您不仅可以消除之前需要大量手动操作和手术技巧的任务,还可以降低人为错误的风险,并展示当您的 IT 组织采纳变更和新工作方法时可能发生的情况。最终,这将迅速减少对应用安全补丁的抵制。而且它还可以帮助您的企业在下一次重大安全事件中摆脱头条新闻。”
+
+**[ 阅读全文: [12个企业安全坏习惯要打破。][16] ] **
+
+### 5、 脚本和自动化工具将持续发展
+
+许多组织看到了增加自动化的第一步,通常以脚本或自动化工具(有时称为配置管理工具)的形式作为“早期”工作。
+
+但是随着各种自动化技术的使用,对这些工具的观点也在不断发展。
+
+[DataVision][18] 首席运营官 Mark Abolafia 表示:“数据中心环境中存在很多重复性过程,容易出现人为错误,[Ansible][17] 等技术有助于缓解这些问题。“通过 Ansible ,人们可以为一组操作编写特定的步骤,并输入不同的变量,例如地址等,使过去长时间的过程链实现自动化,而这些过程以前都需要人为触摸和更长的交付时间。”
+
+**[想了解更多关于 Ansible 这个方面的知识吗?阅读相关文章:[使用 Ansible 时的成功秘诀][19]。 ]**
+
+另一个因素是:工具本身将继续变得更先进。
+
+“使用先进的 IT 自动化工具,开发人员将能够在更短的时间内构建和自动化工作流程,减少易出错的编码,” ASCI 公司的 Amin 说。“这些工具包括预先构建的、预先测试过的拖放式集成,API 作业,丰富的变量使用,参考功能和对象修订历史记录。”
+
+### 6、 自动化开创了新的指标机会
+
+正如我们在此前所说的那样,IT 自动化不是万能的。它不会修复被破坏的流程,或者以其他方式为您的组织提供全面的灵丹妙药。这也是持续不断的:自动化并不排除衡量性能的必要性。
+
+**[ 参见我们的相关文章 [DevOps 指标:你在衡量什么重要吗?][20] ]**
+
+实际上,自动化应该打开了新的机会。
+
+[Janeiro Digital][21] 公司架构师总裁 Josh Collins 说,“随着越来越多的开发活动 —— 源代码管理、DevOps 管道、工作项目跟踪等转向 API 驱动的平台,将这些原始数据拼接在一起以描绘组织效率提升的机会和图景”。
+
+Collins 认为这是一种可能的新型“开发组织度量指标”。但不要误认为这意味着机器和算法可以突然预测 IT 所做的一切。
+
+“无论是衡量个人资源还是整体团队,这些指标都可以很强大 —— 但应该用大量的背景来衡量。”Collins 说,“将这些数据用于高层次趋势并确认定性观察 —— 而不是临床评级你的团队。”
+
+**想要更多这样知识, IT 领导者?[注册我们的每周电子邮件通讯][22]。**
+
+--------------------------------------------------------------------------------
+
+via: https://enterprisersproject.com/article/2018/3/what-s-next-it-automation-6-trends-watch
+
+作者:[Kevin Casey][a]
+译者:[MZqk](https://github.com/MZqk)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://enterprisersproject.com/user/kevin-casey
+[1]:https://enterprisersproject.com/article/2017/12/5-factors-fueling-automation-it-now
+[2]:https://enterprisersproject.com/article/2017/12/4-trends-watch-it-automation-expands
+[3]:https://enterprisersproject.com/article/2018/1/getting-started-automation-6-tips
+[4]:https://enterprisersproject.com/article/2018/1/how-make-case-it-automation
+[5]:https://enterprisersproject.com/article/2018/1/it-automation-best-practices-7-keys-long-term-success
+[6]:https://enterprisersproject.com/tags/automation
+[7]:https://enterprisersproject.com/article/2018/2/how-spot-machine-learning-opportunity
+[8]:https://www.advsyscon.com/en-us/
+[9]:https://www.sungardas.com/en/
+[10]:https://enterprisersproject.com/tags/artificial-intelligence
+[11]:https://www.solarwinds.com/
+[12]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros
+[13]:https://www.juniper.net/
+[14]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
+[15]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break
+[16]:https://enterprisersproject.com/article/2018/2/12-bad-enterprise-security-habits-break?sc_cid=70160000000h0aXAAQ
+[17]:https://opensource.com/tags/ansible
+[18]:https://datavision.com/
+[19]:https://opensource.com/article/18/2/tips-success-when-getting-started-ansible?intcmp=701f2000000tjyaAAA
+[20]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters?sc_cid=70160000000h0aXAAQ
+[21]:https://www.janeirodigital.com/
+[22]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
diff --git a/published/20180313 Migrating to Linux- Using Sudo.md b/published/20180313 Migrating to Linux- Using Sudo.md
new file mode 100644
index 0000000000..2eb4b7d47e
--- /dev/null
+++ b/published/20180313 Migrating to Linux- Using Sudo.md
@@ -0,0 +1,81 @@
+迁移到 Linux:使用 sudo
+======
+
+> sudo 机制可以让你轻松以普通用户偶尔执行管理任务。让我们来学习一下。
+
+
+
+本文是我们关于迁移到 Linux 的系列文章的第五篇。如果你错过了之前的那些,你可以在这里赶上:
+
+[第1部分 - 入门介绍][1]
+[第2部分 - 磁盘、文件和文件系统][2]
+[第3部分 - 图形操作环境][3]
+[第4部分 - 命令行][4]
+
+你可能一直想了解 Linux。也许它在你的工作场所使用,如果你每天使用它,你的工作效率会更高。或者,也许你想在家里的某些计算机上安装 Linux。无论是什么原因,这一系列文章都是为了让过渡更容易。
+
+与许多其他操作系统一样,Linux 支持多用户。它甚至支持多个用户同时登录。
+
+用户帐户通常会被分配一个可以存储文件的家目录。通常这个家目录位于:
+
+```
+/home/
+```
+
+这样,每个用户都有存储自己的文档和其他文件的独立位置。
+
+### 管理任务
+
+在传统的 Linux 安装中,常规用户帐户无权在系统上执行管理任务。典型的安装 Linux 的系统会要求用户以管理员身份登录以执行某些任务,而不是为每个用户分配权限以执行各种任务。
+
+Linux 上的管理员帐户称为 root。
+
+### Sudo 解释
+
+从历史上看,要执行管理任务,必须以 root 身份登录,执行任务,然后登出。这个过程有点乏味,所以很多人以 root 登录并且整天都以管理员身份工作。这种做法可能会导致灾难性的后果,例如,意外删除系统中的所有文件。当然,root 用户可以做任何事情,因此没有任何保护措施可以防止有人意外地执行影响很大的操作。
+
+创建 `sudo` 工具是为了使你更容易以常规用户帐户登录,偶尔以 root 身份执行管理任务,而无需登录、执行任务然后登出。具体来说,`sudo` 允许你以不同的用户身份运行命令。如果你未指定特定用户,则假定你指的是 root 用户。
+
+`sudo` 可以有复杂的设置,允许用户有权限使用 `sudo` 运行某些命令,而其他的不行。通常,安装的桌面系统会使创建的第一个帐户在 `sudo` 中有完全的权限,因此你作为主要用户可以完全管理 Linux 安装。
+
+### 使用 Sudo
+
+某些安装 Linux 的系统设置了 `sudo`,因此你仍需要知道 root 帐户的密码才能执行管理任务。其他人,设置 `sudo` 输入自己的密码。这里有不同的哲学。
+
+当你尝试在图形环境中执行管理任务时,通常会打开一个要求输入密码的对话框。输入你自己的密码(例如,在 Ubuntu 上)或 root 帐户的密码(例如,Red Hat)。
+
+当你尝试在命令行中执行管理任务时,它通常只会给你一个 “permission denied” 错误。然后你在前面用 `sudo` 重新运行命令。例如:
+
+```
+systemctl start vsftpd
+Failed to start vsftpd.service: Access denied
+
+sudo systemctl start vsftpd
+[sudo] password for user1:
+```
+
+### 何时使用 Sudo
+
+以 root 身份运行命令(在 `sudo` 或其他情况下)并不总是解决权限错误的最佳解决方案。虽然将以 root 身份运行会消除 “permission denied” 错误,但有时最好寻找根本原因而不是仅仅解决症状。有时文件拥有错误的所有者和权限。
+
+当你在尝试一个需要 root 权限来执行操作的任务或者程序时使用 `sudo`。如果文件恰好由另一个用户(包括 root 用户)拥有,请不要使用 `sudo`。在第二种情况下,最好正确设置文件的权限。
+
+通过 Linux 基金会和 edX 的免费[“Linux 介绍”][5]课程了解有关 Linux 的更多信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2018/3/migrating-linux-using-sudo
+
+作者:[John Bonesio][a]
+选题:[lujun9972](https://github.com/lujun9972)
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/johnbonesio
+[1]:https://linux.cn/article-9212-1.html
+[2]:https://linux.cn/article-9213-1.html
+[3]:https://linux.cn/article-9293-1.html
+[4]:https://linux.cn/article-9565-1.html
+[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md b/published/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
similarity index 81%
rename from translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
rename to published/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
index a05307301a..612b84c53d 100644
--- a/translated/tech/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
+++ b/published/20180315 Kubernetes distributed application deployment with sample Face Recognition App.md
@@ -1,9 +1,11 @@
-Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
+Kubernetes 分布式应用部署实战:以人脸识别应用为例
============================================================
-# 简介
+
-伙计们,请做好准备,下面将是一段漫长的旅程,期望你能够乐在其中。
+## 简介
+
+伙计们,请搬好小板凳坐好,下面将是一段漫长的旅程,期望你能够乐在其中。
我将基于 [Kubernetes][5] 部署一个分布式应用。我曾试图编写一个尽可能真实的应用,但由于时间和精力有限,最终砍掉了很多细节。
@@ -11,17 +13,17 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
让我们开始吧。
-# 应用
+## 应用
### TL;DR
-应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
+该应用本身由 6 个组件构成。代码可以从如下链接中找到:[Kubenetes 集群示例][6]。
这是一个人脸识别服务,通过比较已知个人的图片,识别给定图片对应的个人。前端页面用表格形式简要的展示图片及对应的个人。具体而言,向 [接收器][6] 发送请求,请求包含指向一个图片的链接。图片可以位于任何位置。接受器将图片地址存储到数据库 (MySQL) 中,然后向队列发送处理请求,请求中包含已保存图片的 ID。这里我们使用 [NSQ][8] 建立队列。
-[图片处理][9]服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的[人脸识别][10]后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
+[图片处理][9] 服务一直监听处理请求队列,从中获取任务。处理过程包括如下几步:获取图片 ID,读取图片,通过 [gRPC][11] 将图片路径发送至 Python 编写的 [人脸识别][10] 后端。如果识别成功,后端给出图片对应个人的名字。图片处理器进而根据个人 ID 更新图片记录,将其标记为处理成功。如果识别不成功,图片被标记为待解决。如果图片识别过程中出现错误,图片被标记为失败。
标记为失败的图片可以通过计划任务等方式进行重试。
@@ -33,39 +35,31 @@ Kubernetes 分布式应用部署实战 -- 以人脸识别应用为例
```
curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image/post
-
```
-此时,接收器将路径存储到共享数据库集群中,对应的条目包括数据库服务提供的 ID。本应用采用”持久层提供条目对象唯一标识“的模型。获得条目 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
+此时,接收器将路径存储到共享数据库集群中,该实体存储后将从数据库服务收到对应的 ID。本应用采用“实体对象的唯一标识由持久层提供”的模型。获得实体 ID 后,接收器向 NSQ 发送消息,至此接收器的工作完成。
### 图片处理器
-从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go routines,具体为:
+从这里开始变得有趣起来。图片处理器首次运行时会创建两个 Go 协程,具体为:
### Consume
-这是一个 NSQ 消费者,需要完成三项任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个 routine 处理。最后,告知第二个 routine 处理新任务,方法为 [sync.Condition][12]。
+这是一个 NSQ 消费者,需要完成三项必需的任务。首先,监听队列中的消息。其次,当有新消息到达时,将对应的 ID 追加到一个线程安全的 ID 片段中,以供第二个协程处理。最后,告知第二个协程处理新任务,方法为 [sync.Condition][12]。
### ProcessImages
-该 routine 会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该 routine 并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
+该协程会处理指定 ID 片段,直到对应片段全部处理完成。当处理完一个片段后,该协程并不是在一个通道上睡眠等待,而是进入悬挂状态。对每个 ID,按如下步骤顺序处理:
* 与人脸识别服务建立 gRPC 连接,其中人脸识别服务会在人脸识别部分进行介绍
-
-* 从数据库获取图片对应的条目
-
+* 从数据库获取图片对应的实体
* 为 [断路器][1] 准备两个函数
* 函数 1: 用于 RPC 方法调用的主函数
-
* 函数 2: 基于 ping 的断路器健康检查
-
* 调用函数 1 将图片路径发送至人脸识别服务,其中路径应该是人脸识别服务可以访问的,最好是共享的,例如 NFS
-
-* 如果调用失败,将图片条目状态更新为 FAILEDPROCESSING
-
+* 如果调用失败,将图片实体状态更新为 FAILEDPROCESSING
* 如果调用成功,返回值是一个图片的名字,对应数据库中的一个个人。通过联合 SQL 查询,获取对应个人的 ID
-
-* 将数据库中的图片条目状态更新为 PROCESSED,更新图片被识别成的个人的 ID
+* 将数据库中的图片实体状态更新为 PROCESSED,更新图片被识别成的个人的 ID
这个服务可以复制多份同时运行。
@@ -89,7 +83,7 @@ curl -d '{"path":"/unknown_images/unknown0001.jpg"}' http://127.0.0.1:8000/image
注意:我曾经试图使用 [GoCV][14],这是一个极好的 Go 库,但欠缺所需的 C 绑定。推荐马上了解一下这个库,它会让你大吃一惊,例如编写若干行代码即可实现实时摄像处理。
-这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg, hannibal_2.jpg, gergely_1.jpg, john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person, person_images`,具体如下:
+这个 Python 库的工作方式本质上很简单。准备一些你认识的人的图片,把信息记录下来。对于我而言,我有一个图片文件夹,包含若干图片,名称分别为 `hannibal_1.jpg`、 `hannibal_2.jpg`、 `gergely_1.jpg`、 `john_doe.jpg`。在数据库中,我使用两个表记录信息,分别为 `person`、 `person_images`,具体如下:
```
+----+----------+
@@ -126,13 +120,13 @@ NSQ 是 Go 编写的小规模队列,可扩展且占用系统内存较少。NSQ
### 配置
-为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 .env 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
+为了尽可能增加灵活性以及使用 Kubernetes 的 ConfigSet 特性,我在开发过程中使用 `.env` 文件记录配置信息,例如数据库服务的地址以及 NSQ 的查询地址。在生产环境或 Kubernetes 环境中,我将使用环境变量属性配置。
### 应用小结
这就是待部署应用的全部架构信息。应用的各个组件都是可变更的,他们之间仅通过数据库、消息队列和 gRPC 进行耦合。考虑到更新机制的原理,这是部署分布式应用所必须的;在部署部分我会继续分析。
-# 使用 Kubernetes 部署应用
+## 使用 Kubernetes 部署应用
### 基础知识
@@ -144,55 +138,51 @@ Kubernetes 是容器化服务及应用的管理器。它易于扩展,可以管
在 Kubernetes 中,你给出期望的应用状态,Kubernetes 会尽其所能达到对应的状态。状态可以是已部署、已暂停,有 2 个副本等,以此类推。
-Kubernetes 使用标签和注释标记组件,包括服务,部署,副本组,守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与 应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
+Kubernetes 使用标签和注释标记组件,包括服务、部署、副本组、守护进程组等在内的全部组件都被标记。考虑如下场景,为了识别 pod 与应用的对应关系,使用 `app: myapp` 标签。假设应用已部署 2 个容器,如果你移除其中一个容器的 `app` 标签,Kubernetes 只能识别到一个容器(隶属于应用),进而启动一个新的具有 `myapp` 标签的实例。
### Kubernetes 集群
-要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求 Nodes 并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
+要使用 Kubernetes,需要先搭建一个 Kubernetes 集群。搭建 Kubernetes 集群可能是一个痛苦的经历,但所幸有工具可以帮助我们。Minikube 为我们在本地搭建一个单节点集群。AWS 的一个 beta 服务工作方式类似于 Kubernetes 集群,你只需请求节点并定义你的部署即可。Kubernetes 集群组件的文档如下:[Kubernetes 集群组件][17]。
-### 节点 (Nodes)
+### 节点
-节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
+节点是工作单位,形式可以是虚拟机、物理机,也可以是各种类型的云主机。
-### Pods
+### Pod
-Pods 是本地容器组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和 虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
+Pod 是本地容器逻辑上组成的集合,即一个 Pod 中可能包含若干个容器。Pod 创建后具有自己的 DNS 和虚拟 IP,这样 Kubernetes 可以对到达流量进行负载均衡。你几乎不需要直接和容器打交道;即使是调试的时候,例如查看日志,你通常调用 `kubectl logs deployment/your-app -f` 查看部署日志,而不是使用 `-c container_name` 查看具体某个容器的日志。`-f` 参数表示从日志尾部进行流式输出。
-### 部署 (Deployments)
+### 部署
-在 Kubernetes 中创建任何类型的资源时,后台使用一个部署,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
+在 Kubernetes 中创建任何类型的资源时,后台使用一个部署组件,它指定了资源的期望状态。使用部署对象,你可以将 Pod 或服务变更为另外的状态,也可以更新应用或上线新版本应用。你一般不会直接操作副本组 (后续会描述),而是通过部署对象创建并管理。
-### 服务 (Services)
+### 服务
-默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,mysql,内部 API 或前端,都需要长期运行并使用保持不变的 IP 或 更佳的 DNS 记录。
+默认情况下,Pod 会获取一个 IP 地址。但考虑到 Pod 是 Kubernetes 中的易失性组件,我们需要更加持久的组件。不论是队列,MySQL、内部 API 或前端,都需要长期运行并使用保持不变的 IP 或更好的 DNS 记录。
-为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡,简单 IP 或 内部 DNS。
+为解决这个问题,Kubernetes 提供了服务组件,可以定义访问模式,支持的模式包括负载均衡、简单 IP 或内部 DNS。
Kubernetes 如何获知服务运行正常呢?你可以配置健康性检查和可用性检查。健康性检查是指检查容器是否处于运行状态,但容器处于运行状态并不意味着服务运行正常。对此,你应该使用可用性检查,即请求应用的一个特别接口。
-由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络,服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
+由于服务非常重要,推荐你找时间阅读以下文档:[服务][18]。严肃的说,需要阅读的东西很多,有 24 页 A4 纸的篇幅,涉及网络、服务及自动发现。这也有助于你决定是否真的打算在生产环境中使用 Kubernetes。
### DNS / 服务发现
-在 Kubernetes 集群中创建服务后,该服务会从名为 kube-proxy 和 kube-dns 的特殊 Kubernetes 部署中获取一个 DNS 记录。他们两个用于提供集群内的服务发现。如果你有一个正在运行的 mysql 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
+在 Kubernetes 集群中创建服务后,该服务会从名为 `kube-proxy` 和 `kube-dns` 的特殊 Kubernetes 部署中获取一个 DNS 记录。它们两个用于提供集群内的服务发现。如果你有一个正在运行的 MySQL 服务并配置 `clusterIP: no`,那么集群内部任何人都可以通过 `mysql.default.svc.cluster.local` 访问该服务,其中:
* `mysql` – 服务的名称
-
* `default` – 命名空间的名称
-
* `svc` – 对应服务分类
-
* `cluster.local` – 本地集群的域名
-可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 提供程序并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
+可以使用自定义设置更改本地集群的域名。如果想让服务可以从集群外访问,需要使用 DNS 服务,并使用例如 Nginx 将 IP 地址绑定至记录。服务对应的对外 IP 地址可以使用如下命令查询:
* 节点端口方式 – `kubectl get -o jsonpath="{.spec.ports[0].nodePort}" services mysql`
-
* 负载均衡方式 – `kubectl get -o jsonpath="{.spec.ports[0].LoadBalancer}" services mysql`
### 模板文件
-类似 Docker Compose, TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
+类似 Docker Compose、TerraForm 或其它的服务管理工具,Kubernetes 也提供了基础设施描述模板。这意味着,你几乎不用手动操作。
以 Nginx 部署为例,查看下面的 yaml 模板:
@@ -218,26 +208,26 @@ spec: #(4)
image: nginx:1.7.9
ports:
- containerPort: 80
-
```
在这个示例部署中,我们做了如下操作:
-* (1) 使用 kind 关键字定义模板类型
-* (2) 使用 metadata 关键字,增加该部署的识别信息,使用 labels 标记每个需要创建的资源 (3)
-* (4) 然后使用 spec 关键字描述所需的状态
- * (5) nginx 应用需要 3 个副本
- * (6) Pod 中容器的模板定义部分
- * 容器名称为 nginx
- * 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
+* (1) 使用 `kind` 关键字定义模板类型
+* (2) 使用 `metadata` 关键字,增加该部署的识别信息
+* (3) 使用 `labels` 标记每个需要创建的资源
+* (4) 然后使用 `spec` 关键字描述所需的状态
+* (5) nginx 应用需要 3 个副本
+* (6) Pod 中容器的模板定义部分
+* 容器名称为 nginx
+* 容器模板为 nginx:1.7.9 (本例使用 Docker 镜像)
-### 副本组 (ReplicaSet)
+### 副本组
-副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
+副本组是一个底层的副本管理器,用于保证运行正确数目的应用副本。相比而言,部署是更高层级的操作,应该用于管理副本组。除非你遇到特殊的情况,需要控制副本的特性,否则你几乎不需要直接操作副本组。
-### 守护进程组 (DaemonSet)
+### 守护进程组
-上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
+上面提到 Kubernetes 始终使用标签,还有印象吗?守护进程组是一个控制器,用于确保守护进程化的应用一直运行在具有特定标签的节点中。
例如,你将所有节点增加 `logger` 或 `mission_critical` 的标签,以便运行日志 / 审计服务的守护进程。接着,你创建一个守护进程组并使用 `logger` 或 `mission_critical` 节点选择器。Kubernetes 会查找具有该标签的节点,确保守护进程的实例一直运行在这些节点中。因而,节点中运行的所有进程都可以在节点内访问对应的守护进程。
@@ -253,7 +243,7 @@ spec: #(4)
### Kubernetes 部分小结
-Kubernetes 是容器编排的便捷工具,工作单元为 Pods,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
+Kubernetes 是容器编排的便捷工具,工作单元为 Pod,具有分层架构。最顶层是部署,用于操作其它资源,具有高度可配置性。对于你的每个命令调用,Kubernetes 提供了对应的 API,故理论上你可以编写自己的代码,向 Kubernetes API 发送数据,得到与 `kubectl` 命令同样的效果。
截至目前,Kubernetes 原生支持所有主流云服务供应商,而且完全开源。如果你愿意,可以贡献代码;如果你希望对工作原理有深入了解,可以查阅代码:[GitHub 上的 Kubernetes 项目][22]。
@@ -272,7 +262,7 @@ kubectl get nodes -o yaml
### 构建容器
-Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python,NSQ 和 MySQL 使用对应的容器。
+Kubernetes 支持大多数现有的容器技术。我这里使用 Docker。每一个构建的服务容器,对应代码库中的一个 Dockerfile 文件。我推荐你仔细阅读它们,其中大多数都比较简单。对于 Go 服务,我采用了最近引入的多步构建的方式。Go 服务基于 Alpine Linux 镜像创建。人脸识别程序使用 Python、NSQ 和 MySQL 使用对应的容器。
### 上下文
@@ -293,9 +283,9 @@ Switched to context "kube-face-cluster".
```
此后,所有 `kubectl` 命令都会使用 `face` 命名空间。
-(译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
+(LCTT 译注:作者后续并没有使用 face 命名空间,模板文件中的命名空间仍为 default,可能 face 命名空间用于开发环境。如果希望使用 face 命令空间,需要将内部 DNS 地址中的 default 改成 face;如果只是测试,可以不执行这两条命令。)
-### 应用部署
+## 应用部署
Pods 和 服务概览:
@@ -318,7 +308,6 @@ type: Opaque
data:
mysql_password: base64codehere
mysql_userpassword: base64codehere
-
```
其中 base64 编码通过如下命令生成:
@@ -326,10 +315,9 @@ data:
```
echo -n "ubersecurepassword" | base64
echo -n "root:ubersecurepassword" | base64
-
```
-(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 mysql_password, 仅包含密码;另一条对应 mysql_userpassword,包含用户和密码。后文会用到 mysql_userpassword,但没有提及相应的生成)
+(LCTT 译注:secret yaml 文件中的 data 应该有两条,一条对应 `mysql_password`,仅包含密码;另一条对应 `mysql_userpassword`,包含用户和密码。后文会用到 `mysql_userpassword`,但没有提及相应的生成)
我的部署 yaml 对应部分如下:
@@ -362,13 +350,12 @@ echo -n "root:ubersecurepassword" | base64
其中 `presistentVolumeClain` 是关键,告知 Kubernetes 当前资源需要持久化存储。持久化存储的提供方式对用户透明。类似 Pods,如果想了解更多细节,参考文档:[Kubernetes 持久化存储][27]。
-(LCTT 译注:使用 presistentVolumeClain 之前需要创建 presistentVolume,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
+(LCTT 译注:使用 `presistentVolumeClain` 之前需要创建 `presistentVolume`,对于单节点可以使用本地存储,对于多节点需要使用共享存储,因为 Pod 可以能调度到任何一个节点)
使用如下命令部署 MySQL 服务:
```
kubectl apply -f mysql.yaml
-
```
这里比较一下 `create` 和 `apply`。`apply` 是一种宣告式的对象配置命令,而 `create` 是命令式的命令。当下我们需要知道的是,`create` 通常对应一项任务,例如运行某个组件或创建一个部署;相比而言,当我们使用 `apply` 的时候,用户并没有指定具体操作,Kubernetes 会根据集群目前的状态定义需要执行的操作。故如果不存在名为 `mysql` 的服务,当我执行 `apply -f mysql.yaml` 时,Kubernetes 会创建该服务。如果再次执行这个命令,Kubernetes 会忽略该命令。但如果我再次运行 `create`,Kubernetes 会报错,告知服务已经创建。
@@ -460,7 +447,7 @@ volumes:
```
-(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,person_images 表中的 person_id 列数字都小 1,作者默认 id 从 0 开始,但应该是从 1 开始)
+(LCTT 译注:数据库初始化脚本需要改成对应的路径,如果是多节点,需要是共享存储中的路径。另外,作者给的 sql 文件似乎有误,`person_images` 表中的 `person_id` 列数字都小 1,作者默认 `id` 从 0 开始,但应该是从 1 开始)
运行如下命令查看引导脚本是否正确执行:
@@ -489,7 +476,6 @@ mysql>
```
kubectl logs deployment/mysql -f
-
```
### NSQ 查询
@@ -505,7 +491,7 @@ NSQ 查询将以内部服务的形式运行。由于不需要外部访问,这
```
-那么,内部 DNS 对应的条目类似于:`nsqlookup.default.svc.cluster.local`。
+那么,内部 DNS 对应的实体类似于:`nsqlookup.default.svc.cluster.local`。
无头服务的更多细节,可以参考:[无头服务][32]。
@@ -517,7 +503,7 @@ args: ["--broadcast-address=nsqlookup.default.svc.cluster.local"]
```
-你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,nsqlookup 使用 `hostname` (LCTT 译注:这里是指容器的主机名,而不是 hostname 字符串本身)作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
+你可能会疑惑,`--broadcast-address` 参数是做什么用的?默认情况下,`nsqlookup` 使用容器的主机名作为广播地址;这意味着,当用户运行回调时,回调试图访问的地址类似于 `http://nsqlookup-234kf-asdf:4161/lookup?topics=image`,但这显然不是我们期望的。将广播地址设置为内部 DNS 后,回调地址将是 `http://nsqlookup.default.svc.cluster.local:4161/lookup?topic=images`,这正是我们期望的。
NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsqd 守护进程的回调。在 Dockerfile 中暴露相应端口,在 Kubernetes 模板中使用它们,类似如下:
@@ -533,6 +519,7 @@ NSQ 查询还需要转发两个端口,一个用于广播,另一个用于 nsq
```
服务模板:
+
```
spec:
ports:
@@ -592,13 +579,13 @@ NSQ 守护进程也需要一些调整的参数配置:
```
-其中我们配置了 lookup-tcp-address 和 broadcast-address 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
+其中我们配置了 `lookup-tcp-address` 和 `broadcast-address` 参数。前者是 nslookup 服务的 DNS 地址,后者用于回调,就像 nsqlookupd 配置中那样。
#### 对外公开
下面即将创建第一个对外公开的服务。有两种方式可供选择。考虑到该 API 负载较高,可以使用负载均衡的方式。另外,如果希望将其部署到生产环境中的任选节点,也应该使用负载均衡方式。
-但由于我使用的本地集群只有一个节点,那么使用 `节点端口` 的方式就足够了。`节点端口` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `:` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
+但由于我使用的本地集群只有一个节点,那么使用 `NodePort` 的方式就足够了。`NodePort` 方式将服务暴露在对应节点的固定端口上。如果未指定端口,将从 30000-32767 数字范围内随机选其一个。也可以指定端口,可以在模板文件中使用 `nodePort` 设置即可。可以通过 `:` 访问该服务。如果使用多个节点,负载均衡可以将多个 IP 合并为一个 IP。
更多信息,请参考文档:[服务发布][33]。
@@ -643,7 +630,7 @@ spec:
### 图片处理器
-图片处理器用于将图片传送至识别组件。它需要访问 nslookupd, mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
+图片处理器用于将图片传送至识别组件。它需要访问 nslookupd、 mysql 以及后续部署的人脸识别服务的 gRPC 接口。事实上,这是一个无聊的服务,甚至其实并不是服务(LCTT 译注:第一个服务是指在整个架构中,图片处理器作为一个服务;第二个服务是指 Kubernetes 服务)。它并需要对外暴露端口,这是第一个只包含部署的组件。长话短说,下面是完整的模板:
```
---
@@ -781,7 +768,7 @@ curl -d '{"path":"/unknown_people/unknown220.jpg"}' http://192.168.99.100:30251/
```
-图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 known_foler 文件中找到 unknown220.jpg 对应个人的图片,最后返回匹配图片的名称。
+图像处理器会在 `/unknown_people` 目录搜索名为 unknown220.jpg 的图片,接着在 `known_folder` 文件中找到 `unknown220.jpg` 对应个人的图片,最后返回匹配图片的名称。
查看日志,大致信息如下:
@@ -861,9 +848,9 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
```
-### 滚动更新 (Rolling Update)
+## 滚动更新
-滚动更新过程中会发生什么呢?
+滚动更新过程中会发生什么呢?
@@ -871,7 +858,7 @@ receiver-deployment-5cb4797598-sf5ds 1/1 Running 0 26s
目前的 API 一次只能处理一个图片,不能批量处理,对此我并不满意。
-#### 代码
+### 代码
目前,我们使用下面的代码段处理单个图片的情形:
@@ -900,7 +887,7 @@ func main() {
这里,你可能会说你并不需要保留旧代码;某些情况下,确实如此。因此,我们打算直接修改旧代码,让其通过少量参数调用新代码。这样操作操作相当于移除了旧代码。当所有客户端迁移完毕后,这部分代码也可以安全地删除。
-#### 新的 Endpoint
+### 新的接口
让我们添加新的路由方法:
@@ -941,7 +928,7 @@ func PostImage(w http.ResponseWriter, r *http.Request) {
```
-当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片 PR][34] 中可以找到更多的修改方式。
+当然,方法名可能容易混淆,但你应该能够理解我想表达的意思。我将请求中的单个路径封装成新方法所需格式,然后将其作为请求发送给新接口处理。仅此而已。在 [滚动更新批量图片的 PR][34] 中可以找到更多的修改方式。
至此,我们使用两种方法调用接收器:
@@ -958,7 +945,7 @@ curl -d '{"paths":[{"path":"unknown4456.jpg"}]}' http://127.0.0.1:8000/images/po
为了简洁,我不打算为 NSQ 和其它组件增加批量图片处理的能力。这些组件仍然是一次处理一个图片。这部分修改将留给你作为扩展内容。 :)
-#### 新镜像
+### 新镜像
为实现滚动更新,我首先需要为接收器服务创建一个新的镜像。新镜像使用新标签,告诉大家版本号为 v1.1。
@@ -969,11 +956,11 @@ docker build -t skarlso/kube-receiver-alpine:v1.1 .
新镜像创建后,我们可以开始滚动更新了。
-#### 滚动更新
+### 滚动更新
在 Kubernetes 中,可以使用多种方式完成滚动更新。
-##### 手动更新
+#### 手动更新
不妨假设在我配置文件中使用的容器版本为 `v1.0`,那么实现滚动更新只需运行如下命令:
@@ -991,7 +978,7 @@ kubectl rolling-update receiver --rollback
容器将回滚到使用上一个版本镜像,操作简捷无烦恼。
-##### 应用新的配置文件
+#### 应用新的配置文件
手动更新的不足在于无法版本管理。
@@ -1051,7 +1038,7 @@ kubectl delete services -all
```
-# 写在最后的话
+## 写在最后的话
各位看官,本文就写到这里了。我们在 Kubernetes 上编写、部署、更新和扩展(老实说,并没有实现)了一个分布式应用。
@@ -1065,9 +1052,9 @@ Gergely 感谢你阅读本文。
via: https://skarlso.github.io/2018/03/15/kubernetes-distributed-application/
-作者:[hannibal ][a]
+作者:[hannibal][a]
译者:[pinewall](https://github.com/pinewall)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md b/published/20180320 Can we build a social network that serves users rather than advertisers.md
similarity index 56%
rename from translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md
rename to published/20180320 Can we build a social network that serves users rather than advertisers.md
index bd279216ca..f7d378580b 100644
--- a/translated/talk/20180320 Can we build a social network that serves users rather than advertisers.md
+++ b/published/20180320 Can we build a social network that serves users rather than advertisers.md
@@ -1,13 +1,15 @@
我们能否建立一个服务于用户而非广告商的社交网络?
=====
+> 找出 Human Connection 是如何将透明度和社区放在首位的。
+

-如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的,中立的,透明的在线平台来迎接我们这个时代的挑战。
+如今,开源软件具有深远的意义,在推动数字经济创新方面发挥着关键作用。世界正在快速彻底地改变。世界各地的人们需要一个专门的、中立的、透明的在线平台来迎接我们这个时代的挑战。
-开放的原则可能会成为让我们到达那里的方法(to 校正者:这句上下文没有理解)。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
+开放的原则也许是让我们达成这一目标的方法。如果我们用开放的思维方式将数字创新与社会创新结合在一起,会发生什么?
-这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们自然倾向,于乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
+这个问题是我们在 [Human Connection][1] 工作的核心,这是一个具有前瞻性的,以德国为基础的知识和行动网络,其使命是创建一个服务于全球的真正的社交网络。我们受到这样一种观念为指引,即人类天生慷慨而富有同情心,并且他们在慈善行为上茁壮成长。但我们还没有看到一个完全支持我们的自然趋势,与乐于助人和合作以促进共同利益的社交网络。Human Connection 渴望成为让每个人都成为积极变革者的平台。
为了实现一个以解决方案为导向的平台的梦想,让人们通过与慈善机构、社区团体和社会变革活动人士的接触,围绕社会公益事业采取行动,Human Connection 将开放的价值观作为社会创新的载体。
@@ -15,31 +17,28 @@
### 首先是透明
-透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript, Vue, nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
+透明是 Human Connection 的指导原则之一。Human Connection 邀请世界各地的程序员通过[在 Github 上提交他们的源代码][2]共同开发平台的源代码(JavaScript、Vue、nuxt),并通过贡献代码或编程附加功能来支持真正的社交网络。
-但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些对让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
+但我们对透明的承诺超出了我们的发展实践。事实上,当涉及到建立一种新的社交网络,促进那些让世界变得更好的人之间的真正联系和互动,分享源代码只是迈向透明的一步。
-为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team (to 校正者:这里如果可以,请翻译得稍微优雅,我想不出来一个词)活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
+为促进公开对话,Human Connection 团队举行[定期在线公开会议][3]。我们在这里回答问题,鼓励建议并对潜在的问题作出回应。我们的 Meet The Team 活动也会记录下来,并在事后向公众开放。通过对我们的流程,源代码和财务状况完全透明,我们可以保护自己免受批评或其他潜在的不利影响。
对透明的承诺意味着,所有在 Human Connection 上公开分享的用户贡献者将在 Creative Commons 许可下发布,最终作为数据包下载。通过让大众知识变得可用,特别是以一种分散的方式,我们创造了一个多元化社会的机会。
-一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章(UN Charter)][4]和“世界人权宣言(Universal Declaration of Human Rights)”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (译者注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
+有一个问题指导我们所有的组织决策:“它是否服务于人民和更大的利益?”我们用[联合国宪章][4]和“世界人权宣言”作为我们价值体系的基础。随着我们的规模越来越大,尤其是即将推出的公测版,我们必须对此任务负责。我甚至愿意邀请 Chaos Computer Club (LCTT 译注:这是欧洲最大的黑客联盟)或其他黑客俱乐部通过随机检查我们的平台来验证我们的代码和行为的完整性。
### 一个合作的社会
以一种[以社区为中心的协作方法][5]来编写 Human Connection 平台是超越社交网络实际应用理念的基础。我们的团队是通过找到问题的答案来驱动:“是什么让一个社交网络真正地社会化?”
-一个抛弃了以利润为导向的算法,为广告商而不是最终用户服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并破坏(to 校正:这里译为改变较好)现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
+一个抛弃了以利润为导向的算法、为最终用户而不是广告商服务的网络,只能通过转向对等生产和协作的过程而繁荣起来。例如,像 [Code Alliance][6] 和 [Code for America][7] 这样的组织已经证明了如何在一个开源环境中创造技术,造福人类并变革现状。社区驱动的项目,如基于地图的报告平台 [FixMyStreet][8],或者为 Humanitarian OpenStreetMap 而建立的 [Tasking Manager][9],已经将众包作为推动其使用的一种方式。
-我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学(University Sorbonne)的国家东方语言与文明研究所(National Institute for Oriental Languages and Civilizations (INALCO) )和德国斯图加特媒体大学(Stuttgart Media University )合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
-
- * 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动(Take Action)”领域,每个人都可以实现。
-
- * “Versus” 功能是另一个定义结果的方式(to 校正者:这句话稍微注意一下)。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
+我们建立 Human Connection 的方法从一开始就是合作。为了收集关于必要功能和真正社交网络的目的的初步数据,我们与巴黎索邦大学的国家东方语言与文明研究所(INALCO)和德国斯图加特媒体大学合作。这两个项目的研究结果都被纳入了 Human Connection 的早期开发。多亏了这项研究,[用户将拥有一套全新的功能][10],让他们可以控制自己看到的内容以及他们如何与他人的互动。由于早期的支持者[被邀请到网络的 alpha 版本][10],他们可以体验到第一个可用的值得注意的功能。这里有一些:
+ * 将信息与行动联系起来是我们研究会议的一个重要主题。当前的社交网络让用户处于信息阶段。这两所大学的学生团体都认为,需要一个以行动为导向的组件,以满足人类共同解决问题的本能。所以我们在平台上构建了一个[“Can Do”功能][11]。这是一个人在阅读了某个话题后可以采取行动的一种方式。“Can Do” 是用户建议的活动,在“采取行动”领域,每个人都可以实现。
+ * “Versus” 功能是另一个成果。在传统社交网络仅限于评论功能的地方,我们的学生团体认为需要采用更加结构化且有用的方式进行讨论和争论。“Versus” 是对公共帖子的反驳,它是单独显示的,并提供了一个机会来突出围绕某个问题的不同意见。
* 今天的社交网络并没有提供很多过滤内容的选项。研究表明,情绪过滤选项可以帮助我们根据日常情绪驾驭社交空间,并可能通过在我们希望仅看到令人振奋的内容的那一天时,不显示悲伤或难过的帖子来潜在地保护我们的情绪健康。
-
Human Connection 邀请改革者合作开发一个网络,有可能动员世界各地的个人和团体将负面新闻变成 “Can Do”,并与慈善机构和非营利组织一起参与社会创新项目。
[订阅我们的每周时事通讯][12]以了解有关开放组织的更多信息。
@@ -51,7 +50,7 @@ via: https://opensource.com/open-organization/18/3/open-social-human-connection
作者:[Dennis Hack][a]
译者:[MjSeven](https://github.com/MjSeven)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20180320 Migrating to Linux- Installing Software.md b/published/20180320 Migrating to Linux- Installing Software.md
new file mode 100644
index 0000000000..5975f7edfc
--- /dev/null
+++ b/published/20180320 Migrating to Linux- Installing Software.md
@@ -0,0 +1,88 @@
+迁移到 Linux:安装软件
+======
+
+> 所有的 Linux 打包系统和工具都会让人迷惑,但是这篇面向初学者的教程可以帮助你搞明白。
+
+
+
+如你所见,众所瞩目的 Linux 已经用在互联网,以及 Arduino、Beagle 和树莓派主板等设备上,或许你正在考虑是时候尝试一下 Linux 了。本系列将帮助你成功过渡到 Linux。如果你错过了本系列的早期文章,可以在这里找到它们:
+
+- [第1部分 - 入门介绍][1]
+- [第2部分 - 磁盘、文件和文件系统][2]
+- [第3部分 - 图形操作环境][3]
+- [第4部分 - 命令行][4]
+- [第5部分 - 使用 sudo][5]
+
+### 安装软件
+
+要在你的计算机上获得新软件,通常的方法是从供应商处获得软件产品,然后运行一个安装程序。过去,软件产品会出现在像 CD-ROM 或 DVD 一样的物理媒介上,而现在我们经常从互联网上下载软件产品。
+
+使用 Linux,安装软件就像在你的智能手机上安装一样。如同你的手机应用商店一样,在 Linux 上有个提供开源软件工具和程序的中央仓库,几乎任何你想要的程序都会出现在可用软件包列表中以供你安装。
+
+每个程序并不需要运行单独的安装程序,而是你可以使用 Linux 发行版附带的软件包管理工具。(这里说的 Linux 发行版就是你安装的 Linux,例如 Ubuntu、Fedora、Debian 等)每个发行版在互联网上都有它自己的集中存储库(称为仓库),它们存储了数千个预先构建好的应用程序。
+
+你可能会注意到,在 Linux 上安装软件有几种例外情况。有时候,你仍然需要去供应商那里获取他们的软件,因为该程序不存在于你的发行版的中央仓库中。当软件不是开源和/或自由软件的时候,通常就是这种情况。
+
+另外请记住,如果你想要安装一个不在发行版仓库中的程序时,事情就不是那么简单了,即使你正在安装自由及开源程序。这篇文章没有涉及到这些更复杂的情况,请遵循在线的指引。
+
+有了所有的 Linux 包管理系统和工具,接下来干什么可能仍然令人困惑。本文应该有助于澄清一些事情。
+
+### 包管理
+
+目前在 Linux 发行版中有几个相互竞争的用于管理、安装和删除软件的包管理系统。每个发行版都选择使用了一个包管理工具。Red Hat、Fedora、CentOS、Scientific Linux、SUSE 等使用 Red Hat 包管理(RPM)。Debian、Ubuntu、Linux Mint 等等都使用 Debian 包管理系统,简称 DPKG。还有一些其它包管理系统,但 RPM 和 DPKG 是最常见的。
+
+
+
+*图 1: Package installers*
+
+无论你使用的软件包管理是什么,它们通常都是一组构建于另外一种工具之上的工具(图 1)。最底层是一个命令行工具,它可以让你做任何与安装软件相关的一切工作。你可以列出已安装的程序、删除程序、安装软件包文件等等。
+
+这个底层工具并不总是最方便使用的,所以通常会有一个命令行工具,它可以使用单个命令在发行版的中央仓库中找到软件包,并下载和安装它以及任何依赖项。最后,通常会有一个图形应用程序,可以让你使用鼠标选择任何想要的内容,然后单击 “install” 按钮即可。
+
+
+
+*图 2: PackageKit*
+
+对于基于 Red Hat 的发行版,包括 Fedora、CentOS、Scientific Linux 等,它们的底层工具是 rpm,高级工具叫做 dnf(在旧系统上是 yum)。图形安装程序称为 PackageKit(图 2),它可能在系统管理菜单下显示名字为 “Add/Remove Software(添加/删除软件)”。
+
+
+
+*图 3: Ubuntu Software*
+
+对于基于 Debian 的发行版,包括 Debian、Ubuntu、Linux Mint、Elementary OS 等,它们的底层命令行工具是 dpkg,高级工具称为 apt。在 Ubuntu 上管理已安装软件的图形工具是 Ubuntu Software(图 3)。对于 Debian 和 Linux Mint,图形工具称为新立得,它也可以安装在 Ubuntu 上。
+
+你也可以在 Debian 相关发行版上安装一个基于文本的图形化工具 aptitude。它比新立得更强大,并且即使你只能访问命令行也能工作。如果你想通过各种选项进行各种操作,你可以试试这个,但它使用起来比新立得更复杂。其它发行版也可能有自己独特的工具。
+
+### 命令行工具
+
+在 Linux 上安装软件的在线说明通常描述了在命令行中键入的命令。这些说明通常更容易理解,并且将命令复制粘贴到命令行窗口中,可以在不出错的情况下一步步进行。这与下面的说明相反:“打开这个菜单,选择这个程序,输入这个搜索模式,点击这个标签,选择这个程序,然后点击这个按钮”,这经常让你在各种操作中迷失。
+
+有时你正在使用的 Linux 没有图形环境,因此熟悉从命令行安装软件包是件好事。表 1 和表 2 列出了基于 RPM 和 DPKG 系统的一下常见操作及其相关命令。
+
+
+
+
+
+请注意 SUSE,它像 RedHat 和 Fedora 一样使用 RPM,却没有 dnf 或 yum。相反,它使用一个名为 zypper 的程序作为高级命令行工具。其他发行版也可能有不同的工具,例如 Arch Linux 上的 pacman 或 Gentoo 上的 emerge。有很多包管理工具,所以你可能需要查找哪个适用于你的发行版。
+
+这些技巧应该能让你更好地了解如何在新的 Linux 中安装程序,以及更好地了解 Linux 中各种软件包管理方式如何相互关联。
+
+通过 Linux 基金会和 edX 的免费 [“Linux 入门”][6]课程了解有关 Linux 的更多信息。
+
+---
+
+via: https://www.linux.com/blog/learn/2018/3/migrating-linux-installing-software
+
+作者:[JOHN BONESIO][a]
+译者:[MjSeven](https://github.com/MjSeven)
+校对:[pityonline](https://github.com/pityonline), [wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/johnbonesio
+[1]:https://linux.cn/article-9212-1.html
+[2]:https://linux.cn/article-9213-1.html
+[3]:https://linux.cn/article-9293-1.html
+[4]:https://linux.cn/article-9565-1.html
+[5]:https://linux.cn/article-9819-1.html
+[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/translated/tech/20180423 An introduction to Python bytecode.md b/published/20180423 An introduction to Python bytecode.md
similarity index 50%
rename from translated/tech/20180423 An introduction to Python bytecode.md
rename to published/20180423 An introduction to Python bytecode.md
index c27346bc91..832f6a4c1c 100644
--- a/translated/tech/20180423 An introduction to Python bytecode.md
+++ b/published/20180423 An introduction to Python bytecode.md
@@ -1,7 +1,11 @@
Python 字节码介绍
======
+
+> 了解 Python 字节码是什么,Python 如何使用它来执行你的代码,以及知道它是如何帮到你的。
+

-如果你从没有写过 Python,或者甚至只是使用过 Python,你或许已经习惯于看 Python 源代码文件;它们的名字以 `.py` 结尾。你可能还看到过其它类型的文件,比如使用 `.pyc` 结尾的文件,或许你可能听说过,它们就是 Python 的 "字节码" 文件。(在 Python 3 上这些可能不容易看到 — 因为它们与你的 `.py` 文件不在同一个目录下,它们在一个叫 `__pycache__` 的子目录中)或者你也听说过,这是节省时间的一种方法,它可以避免每次运行 Python 时去重新解析源代码。
+
+如果你曾经编写过 Python,或者只是使用过 Python,你或许经常会看到 Python 源代码文件——它们的名字以 `.py` 结尾。你可能还看到过其它类型的文件,比如以 `.pyc` 结尾的文件,或许你可能听说过它们就是 Python 的 “字节码” 文件。(在 Python 3 上这些可能不容易看到 —— 因为它们与你的 `.py` 文件不在同一个目录下,它们在一个叫 `__pycache__` 的子目录中)或者你也听说过,这是节省时间的一种方法,它可以避免每次运行 Python 时去重新解析源代码。
但是,除了 “噢,原来这就是 Python 字节码” 之外,你还知道这些文件能做什么吗?以及 Python 是如何使用它们的?
@@ -9,29 +13,26 @@ Python 字节码介绍
### Python 如何工作
-Python 经常被介绍为它是一个解释型语言 — 其中一个原因是程序运行时,你的源代码被转换成 CPU 的原生指令 — 但这样认为只是部分正确。Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
+Python 经常被介绍为它是一个解释型语言 —— 其中一个原因是在程序运行时,你的源代码被转换成 CPU 的原生指令 —— 但这样的看法只是部分正确。Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
因此,这些 `.pyc` 文件是 Python 悄悄留下的,是为了让它们运行的 “更快”,或者是针对你的源代码的 “优化” 版本;它们是你的程序在 Python 虚拟机上运行的字节码指令。
-我们来看一个示例。这里是用 Python 写的经典程序 "Hello, World!":
+我们来看一个示例。这里是用 Python 写的经典程序 “Hello, World!”:
+
```
def hello()
-
print("Hello, World!")
-
```
下面是转换后的字节码(转换为人类可读的格式):
-```
-2 0 LOAD_GLOBAL 0 (print)
-
- 2 LOAD_CONST 1 ('Hello, World!')
-
- 4 CALL_FUNCTION 1
```
+2 0 LOAD_GLOBAL 0 (print)
+ 2 LOAD_CONST 1 ('Hello, World!')
+ 4 CALL_FUNCTION 1
+```
-如果你输入那个 `hello()` 函数,然后使用 [CPython][1] 解释器去运行它,上面的 Python 程序将会运行。它看起来可能有点奇怪,因此,我们来深入了解一下它都做了些什么。
+如果你输入那个 `hello()` 函数,然后使用 [CPython][1] 解释器去运行它,那么上述列出的内容就是 Python 所运行的。它看起来可能有点奇怪,因此,我们来深入了解一下它都做了些什么。
### Python 虚拟机内幕
@@ -39,84 +40,68 @@ CPython 使用一个基于栈的虚拟机。也就是说,它完全面向栈数
CPython 使用三种类型的栈:
- 1. **调用栈**。这是运行 Python 程序的主要结构。它为每个当前活动的函数调用使用了一个东西 — "帧“,栈底是程序的入口点。每个函数调用推送一个新帧到调用栈,每当函数调用返回后,这个帧被销毁。
- 2. 在每个帧中,有一个 **计算栈** (也称为 **数据栈**)。这个栈就是 Python 函数运行的地方,运行的 Python 代码大多数是由推入到这个栈中的东西组成的,操作它们,然后在返回后销毁它们。
- 3. 在每个帧中,还有一个 **块栈**。它被 Python 用于去跟踪某些类型的控制结构:loops、`try`/`except` 块、以及 `with` 块,全部推入到块栈中,当你退出这些控制结构时,块栈被销毁。这将帮助 Python 了解任意给定时刻哪个块是活动的,比如,一个 `continue` 或者 `break` 语句可能影响正确的块。
-
-
+1. 调用栈。这是运行 Python 程序的主要结构。它为每个当前活动的函数调用使用了一个东西 —— “帧”,栈底是程序的入口点。每个函数调用推送一个新的帧到调用栈,每当函数调用返回后,这个帧被销毁。
+2. 在每个帧中,有一个计算栈 (也称为数据栈)。这个栈就是 Python 函数运行的地方,运行的 Python 代码大多数是由推入到这个栈中的东西组成的,操作它们,然后在返回后销毁它们。
+3. 在每个帧中,还有一个块栈。它被 Python 用于去跟踪某些类型的控制结构:循环、`try` / `except` 块、以及 `with` 块,全部推入到块栈中,当你退出这些控制结构时,块栈被销毁。这将帮助 Python 了解任意给定时刻哪个块是活动的,比如,一个 `continue` 或者 `break` 语句可能影响正确的块。
大多数 Python 字节码指令操作的是当前调用栈帧的计算栈,虽然,还有一些指令可以做其它的事情(比如跳转到指定指令,或者操作块栈)。
为了更好地理解,假设我们有一些调用函数的代码,比如这个:`my_function(my_variable, 2)`。Python 将转换为一系列字节码指令:
- 1. 一个 `LOAD_NAME` 指令去查找函数对象 `my_function`,然后将它推入到计算栈的顶部
- 2. 另一个 `LOAD_NAME` 指令去查找变量 `my_variable`,然后将它推入到计算栈的顶部
- 3. 一个 `LOAD_CONST` 指令去推入一个实整数值 `2` 到计算栈的顶部
- 4. 一个 `CALL_FUNCTION` 指令
+1. 一个 `LOAD_NAME` 指令去查找函数对象 `my_function`,然后将它推入到计算栈的顶部
+2. 另一个 `LOAD_NAME` 指令去查找变量 `my_variable`,然后将它推入到计算栈的顶部
+3. 一个 `LOAD_CONST` 指令去推入一个实整数值 `2` 到计算栈的顶部
+4. 一个 `CALL_FUNCTION` 指令
-
-
-这个 `CALL_FUNCTION` 指令将有 2 个参数,它表示那个 Python 需要从栈顶弹出两个位置参数;然后函数将在它上面进行调用,并且它也同时被弹出(对于函数涉及的关键字参数,它使用另一个不同的指令 — `CALL_FUNCTION_KW`,但使用的操作原则类似,以及第三个指令 — `CALL_FUNCTION_EX`,它适用于函数调用涉及到使用 `*` 或 `**` 操作符的情况)。一旦 Python 拥有了这些之后,它将在调用栈上分配一个新帧,填充到函数调用的本地变量上,然后,运行那个帧内的 `my_function` 字节码。运行完成后,这个帧将被调用栈销毁,最初的帧内返回的 `my_function` 将被推入到计算栈的顶部。
+这个 `CALL_FUNCTION` 指令将有 2 个参数,它表示那个 Python 需要从栈顶弹出两个位置参数;然后函数将在它上面进行调用,并且它也同时被弹出(对于函数涉及的关键字参数,它使用另一个不同的指令 —— `CALL_FUNCTION_KW`,但使用的操作原则类似,以及第三个指令 —— `CALL_FUNCTION_EX`,它适用于函数调用涉及到参数使用 `*` 或 `**` 操作符的情况)。一旦 Python 拥有了这些之后,它将在调用栈上分配一个新帧,填充到函数调用的本地变量上,然后,运行那个帧内的 `my_function` 字节码。运行完成后,这个帧将被调用栈销毁,而在最初的帧内,`my_function` 的返回值将被推入到计算栈的顶部。
### 访问和理解 Python 字节码
-如果你想玩转字节码,那么,Python 标准库中的 `dis` 模块将对你有非常大的帮助;`dis` 模块为 Python 字节码提供了一个 "反汇编",它可以让你更容易地得到一个人类可读的版本,以及查找各种字节码指令。[`dis` 模块的文档][2] 可以让你遍历它的内容,并且提供一个字节码指令能够做什么和有什么样的参数的完整清单。
+如果你想玩转字节码,那么,Python 标准库中的 `dis` 模块将对你有非常大的帮助;`dis` 模块为 Python 字节码提供了一个 “反汇编”,它可以让你更容易地得到一个人类可读的版本,以及查找各种字节码指令。[`dis` 模块的文档][2] 可以让你遍历它的内容,并且提供一个字节码指令能够做什么和有什么样的参数的完整清单。
例如,获取上面的 `hello()` 函数的列表,可以在一个 Python 解析器中输入如下内容,然后运行它:
+
```
import dis
-
dis.dis(hello)
-
```
-函数 `dis.dis()` 将反汇编一个函数、方法、类、模块、编译过的 Python 代码对象、或者字符串包含的源代码,以及显示出一个人类可读的版本。`dis` 模块中另一个方便的功能是 `distb()`。你可以给它传递一个 Python 追溯对象,或者发生预期外情况时调用它,然后它将反汇编发生预期外情况时在调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
+函数 `dis.dis()` 将反汇编一个函数、方法、类、模块、编译过的 Python 代码对象、或者字符串包含的源代码,以及显示出一个人类可读的版本。`dis` 模块中另一个方便的功能是 `distb()`。你可以给它传递一个 Python 追溯对象,或者在发生预期外情况时调用它,然后它将在发生预期外情况时反汇编调用栈上最顶端的函数,并显示它的字节码,以及插入一个指向到引发意外情况的指令的指针。
它也可以用于查看 Python 为每个函数构建的编译后的代码对象,因为运行一个函数将会用到这些代码对象的属性。这里有一个查看 `hello()` 函数的示例:
+
```
>>> hello.__code__
-
", line 1>
-
>>> hello.__code__.co_consts
-
(None, 'Hello, World!')
-
>>> hello.__code__.co_varnames
-
()
-
>>> hello.__code__.co_names
-
('print',)
-
```
-代码对象在函数中可以作为属性 `__code__` 来访问,并且携带了一些重要的属性:
+代码对象在函数中可以以属性 `__code__` 来访问,并且携带了一些重要的属性:
* `co_consts` 是存在于函数体内的任意实数的元组
* `co_varnames` 是函数体内使用的包含任意本地变量名字的元组
* `co_names` 是在函数体内引用的任意非本地名字的元组
-
-
-许多字节码指令 — 尤其是那些推入到栈中的加载值,或者在变量和属性中的存储值 — 在这些用作它们参数的元组中使用索引。
+许多字节码指令 —— 尤其是那些推入到栈中的加载值,或者在变量和属性中的存储值 —— 在这些元组中的索引作为它们参数。
因此,现在我们能够理解 `hello()` 函数中所列出的字节码:
- 1. `LOAD_GLOBAL 0`:告诉 Python 通过 `co_names` (它是 `print` 函数)的索引 0 上的名字去查找它指向的全局对象,然后将它推入到计算栈
- 2. `LOAD_CONST 1`:带入 `co_consts` 在索引 1 上的实数值,并将它推入(索引 0 上的实数值是 `None`,它表示在 `co_consts` 中,因为 Python 函数调用有一个隐式的返回值 `None`,如果没有显式的返回表达式,就返回这个隐式的值 )。
- 3. `CALL_FUNCTION 1`:告诉 Python 去调用一个函数;它需要从栈中弹出一个位置参数,然后,新的栈顶将被函数调用。
+1. `LOAD_GLOBAL 0`:告诉 Python 通过 `co_names` (它是 `print` 函数)的索引 0 上的名字去查找它指向的全局对象,然后将它推入到计算栈
+2. `LOAD_CONST 1`:带入 `co_consts` 在索引 1 上的字面值,并将它推入(索引 0 上的字面值是 `None`,它表示在 `co_consts` 中,因为 Python 函数调用有一个隐式的返回值 `None`,如果没有显式的返回表达式,就返回这个隐式的值 )。
+3. `CALL_FUNCTION 1`:告诉 Python 去调用一个函数;它需要从栈中弹出一个位置参数,然后,新的栈顶将被函数调用。
-
-
-"原始的" 字节码 — 是非人类可读格式的字节 — 也可以在代码对象上作为 `co_code` 属性可用。如果你有兴趣尝试手工反汇编一个函数时,你可以从它们的十进制字节值中,使用列出 `dis.opname` 的方式去查看字节码指令的名字。
+“原始的” 字节码 —— 是非人类可读格式的字节 —— 也可以在代码对象上作为 `co_code` 属性可用。如果你有兴趣尝试手工反汇编一个函数时,你可以从它们的十进制字节值中,使用列出 `dis.opname` 的方式去查看字节码指令的名字。
### 字节码的用处
-现在,你已经了解的足够多了,你可能会想 ” OK,我认为它很酷,但是知道这些有什么实际价值呢?“由于对它很好奇,我们去了解它,但是除了好奇之外,Python 字节码在几个方面还是非常有用的。
+现在,你已经了解的足够多了,你可能会想 “OK,我认为它很酷,但是知道这些有什么实际价值呢?”由于对它很好奇,我们去了解它,但是除了好奇之外,Python 字节码在几个方面还是非常有用的。
-首先,理解 Python 的运行模型可以帮你更好地理解你的代码。人们都开玩笑说,C 将成为一个 ”便携式汇编器“,在那里你可以很好地猜测出一段 C 代码转换成什么样的机器指令。理解 Python 字节码之后,你在使用 Python 时也具备同样的能力 — 如果你能预料到你的 Python 源代码将被转换成什么样的字节码,那么你可以知道如何更好地写和优化 Python 源代码。
+首先,理解 Python 的运行模型可以帮你更好地理解你的代码。人们都开玩笑说,C 是一种 “可移植汇编器”,你可以很好地猜测出一段 C 代码转换成什么样的机器指令。理解 Python 字节码之后,你在使用 Python 时也具备同样的能力 —— 如果你能预料到你的 Python 源代码将被转换成什么样的字节码,那么你可以知道如何更好地写和优化 Python 源代码。
第二,理解字节码可以帮你更好地回答有关 Python 的问题。比如,我经常看到一些 Python 新手困惑为什么某些结构比其它结构运行的更快(比如,为什么 `{}` 比 `dict()` 快)。知道如何去访问和阅读 Python 字节码将让你很容易回答这样的问题(尝试对比一下: `dis.dis("{}")` 与 `dis.dis("dict()")` 就会明白)。
@@ -131,7 +116,6 @@ dis.dis(hello)
* 最后,CPython 解析器是一个开源软件,你可以在 [GitHub][1] 上阅读它。它在文件 `Python/ceval.c` 中实现了字节码解析器。[这是 Python 3.6.4 发行版中那个文件的链接][5];字节码指令是由第 1266 行开始的 `switch` 语句来处理的。
-
学习更多内容,参与到 James Bennett 的演讲,[有关字节的知识:理解 Python 字节码][6],将在 [PyCon Cleveland 2018][7] 召开。
--------------------------------------------------------------------------------
@@ -141,7 +125,7 @@ via: https://opensource.com/article/18/4/introduction-python-bytecode
作者:[James Bennett][a]
选题:[lujun9972](https://github.com/lujun9972)
译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/sources/tech/20180425 JavaScript Router.md b/published/20180425 JavaScript Router.md
similarity index 51%
rename from sources/tech/20180425 JavaScript Router.md
rename to published/20180425 JavaScript Router.md
index feb543fba8..34bf9cff3d 100644
--- a/sources/tech/20180425 JavaScript Router.md
+++ b/published/20180425 JavaScript Router.md
@@ -1,7 +1,8 @@
-Translating by qhwdw
-JavaScript Router
+JavaScript 路由器
======
-There are a lot of frameworks/libraries to build single page applications, but I wanted something more minimal. I’ve come with a solution and I just wanted to share it 🙂
+
+构建单页面应用(SPA)有许多的框架/库,但是我希望它们能少一些。我有一个解决方案,我想共享给大家。
+
```
class Router {
constructor() {
@@ -49,16 +50,16 @@ function notFoundPage() {
console.log(router.exec('/')) // home page
console.log(router.exec('/users/john')) // john's page
console.log(router.exec('/foo')) // not found page
-
```
-To use it you add handlers for a URL pattern. This pattern can be a simple string or a regular expression. Using a string will match exactly that, but a regular expression allows you to do fancy things like capture parts from the URL as seen with the user page or match any URL as seen with the not found page.
+使用它你可以为一个 URL 模式添加处理程序。这个模式可能是一个简单的字符串或一个正则表达式。使用一个字符串将精确匹配它,但是如果使用一个正则表达式将允许你做一些更复杂的事情,比如,从用户页面上看到的 URL 中获取其中的一部分,或者匹配任何没有找到页面的 URL。
-I’ll explain what does that `exec` method… As I said, the URL pattern can be a string or a regular expression, so it first checks for a string. In case the pattern is equal to the given pathname, it returns the execution of the handler. If it is a regular expression, we do a match with the given pathname. In case it matches, it returns the execution of the handler passing to it the captured parameters.
+我将详细解释这个 `exec` 方法 … 正如我前面说的,URL 模式既有可能是一个字符串,也有可能是一个正则表达式,因此,我首先来检查它是否是一个字符串。如果模式与给定的路径名相同,它返回运行处理程序。如果是一个正则表达式,我们与给定的路径名进行匹配。如果匹配成功,它将获取的参数传递给处理程序,并返回运行这个处理程序。
-### Working Example
+### 工作示例
+
+那个例子正好记录到了控制台。我们尝试将它整合到一个页面,看看它是什么样的。
-That example just logs to the console. Let’s try to integrate it to a page and see something.
```
@@ -77,40 +78,41 @@ That example just logs to the console. Let’s try to integrate it to a page and