mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
3ee0f5f750
@ -1,21 +1,17 @@
|
||||
如何在 Linux 上使用网络配置工具 Netplan
|
||||
======
|
||||
> netplan 是一个命令行工具,用于在某些 Linux 发行版上配置网络。
|
||||
|
||||

|
||||
|
||||
多年以来 Linux 管理员和用户们使用相同的方式配置他们的网络接口。例如,如果你是 Ubuntu 用户,你能够用桌面 GUI 配置网络连接,也可以在 /etc/network/interfaces 文件里配置。配置相当简单且从未失败。在文件中配置看起来就像这样:
|
||||
多年以来 Linux 管理员和用户们以相同的方式配置他们的网络接口。例如,如果你是 Ubuntu 用户,你能够用桌面 GUI 配置网络连接,也可以在 `/etc/network/interfaces` 文件里配置。配置相当简单且可以奏效。在文件中配置看起来就像这样:
|
||||
|
||||
```
|
||||
auto enp10s0
|
||||
|
||||
iface enp10s0 inet static
|
||||
|
||||
address 192.168.1.162
|
||||
|
||||
netmask 255.255.255.0
|
||||
|
||||
gateway 192.168.1.100
|
||||
|
||||
dns-nameservers 1.0.0.1,1.1.1.1
|
||||
```
|
||||
|
||||
@ -25,7 +21,7 @@ dns-nameservers 1.0.0.1,1.1.1.1
|
||||
sudo systemctl restart networking
|
||||
```
|
||||
|
||||
或者,如果你使用不带systemd 的发行版,你可以通过老办法来重启网络:
|
||||
或者,如果你使用不带 systemd 的发行版,你可以通过老办法来重启网络:
|
||||
|
||||
```
|
||||
sudo /etc/init.d/networking restart
|
||||
@ -33,13 +29,13 @@ sudo /etc/init.d/networking restart
|
||||
|
||||
你的网络将会重新启动,新的配置将会生效。
|
||||
|
||||
这就是多年以来的做法。但是现在,在某些发行版上(例如 Ubuntu Linux 18.04),网络的配置与控制发生了很大的变化。不需要那个 interfaces 文件和 /etc/init.d/networking 脚本,我们现在转向使用 [Netplan][1]。Netplan 是一个在某些 Linux 发行版上配置网络连接的命令行工具。Netplan 使用 YAML 描述文件来配置网络接口,然后,通过这些描述为任何给定的呈现工具生成必要的配置选项。
|
||||
这就是多年以来的做法。但是现在,在某些发行版上(例如 Ubuntu Linux 18.04),网络的配置与控制发生了很大的变化。不需要那个 `interfaces` 文件和 `/etc/init.d/networking` 脚本,我们现在转向使用 [Netplan][1]。Netplan 是一个在某些 Linux 发行版上配置网络连接的命令行工具。Netplan 使用 YAML 描述文件来配置网络接口,然后,通过这些描述为任何给定的呈现工具生成必要的配置选项。
|
||||
|
||||
我将向你展示如何在 Linux 上使用 Netplan 配置静态 IP 地址和 DHCP 地址。我会在 Ubuntu Server 18.04 上演示。有句忠告,你创建的 .yaml 文件中的间距必须保持一致,否则将会失败。你不用为每行使用特定的间距,只需保持一致就行了。
|
||||
我将向你展示如何在 Linux 上使用 Netplan 配置静态 IP 地址和 DHCP 地址。我会在 Ubuntu Server 18.04 上演示。有句忠告,你创建的 .yaml 文件中的缩进必须保持一致,否则将会失败。你不用为每行使用特定的缩进间距,只需保持一致就行了。
|
||||
|
||||
### 新的配置文件
|
||||
|
||||
打开终端窗口(或者通过 SSH 登录进 Ubuntu 服务器)。你会在 /etc/netplan 文件夹下发现 Netplan 的新配置文件。使用 cd/etc/netplan 命令进入到那个文件夹下。一旦进到了那个文件夹,也许你就能够看到一个文件:
|
||||
打开终端窗口(或者通过 SSH 登录进 Ubuntu 服务器)。你会在 `/etc/netplan` 文件夹下发现 Netplan 的新配置文件。使用 `cd /etc/netplan` 命令进入到那个文件夹下。一旦进到了那个文件夹,也许你就能够看到一个文件:
|
||||
|
||||
```
|
||||
01-netcfg.yaml
|
||||
@ -55,13 +51,11 @@ sudo cp /etc/netplan/01-netcfg.yaml /etc/netplan/01-netcfg.yaml.bak
|
||||
|
||||
### 网络设备名称
|
||||
|
||||
在你开始配置静态 IP 之前,你需要知道设备名称。要做到这一点,你可以使用命令 ip a,然后找出哪一个设备将会被用到(图 1)。
|
||||
在你开始配置静态 IP 之前,你需要知道设备名称。要做到这一点,你可以使用命令 `ip a`,然后找出哪一个设备将会被用到(图 1)。
|
||||
|
||||
![netplan][3]
|
||||
|
||||
图 1:使用 ip a 命令找出设备名称
|
||||
|
||||
[Used with permission][4] (译注:这是什么鬼?)
|
||||
*图 1:使用 ip a 命令找出设备名称*
|
||||
|
||||
我将为 ens5 配置一个静态的 IP。
|
||||
|
||||
@ -75,67 +69,46 @@ sudo nano /etc/netplan/01-netcfg.yaml
|
||||
|
||||
文件的布局看起来就像这样:
|
||||
|
||||
```
|
||||
network:
|
||||
|
||||
Version: 2
|
||||
|
||||
Renderer: networkd
|
||||
|
||||
ethernets:
|
||||
|
||||
DEVICE_NAME:
|
||||
|
||||
Dhcp4: yes/no
|
||||
|
||||
Addresses: [IP/NETMASK]
|
||||
|
||||
Gateway: GATEWAY
|
||||
|
||||
Nameservers:
|
||||
|
||||
Addresses: [NAMESERVER, NAMESERVER]
|
||||
Version: 2
|
||||
Renderer: networkd
|
||||
ethernets:
|
||||
DEVICE_NAME:
|
||||
Dhcp4: yes/no
|
||||
Addresses: [IP/NETMASK]
|
||||
Gateway: GATEWAY
|
||||
Nameservers:
|
||||
Addresses: [NAMESERVER, NAMESERVER]
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* DEVICE_NAME 是需要配置设备的实际名称。
|
||||
|
||||
* yes/no 代表是否启用 dhcp4。
|
||||
|
||||
* IP 是设备的 IP 地址。
|
||||
|
||||
* NETMASK 是 IP 地址的掩码。
|
||||
|
||||
* GATEWAY 是网关的地址。
|
||||
|
||||
* NAMESERVER 是由逗号分开的 DNS 服务器列表。
|
||||
* `DEVICE_NAME` 是需要配置设备的实际名称。
|
||||
* `yes`/`no` 代表是否启用 dhcp4。
|
||||
* `IP` 是设备的 IP 地址。
|
||||
* `NETMASK` 是 IP 地址的掩码。
|
||||
* `GATEWAY` 是网关的地址。
|
||||
* `NAMESERVER` 是由逗号分开的 DNS 服务器列表。
|
||||
|
||||
这是一份 .yaml 文件的样例:
|
||||
|
||||
```
|
||||
network:
|
||||
|
||||
version: 2
|
||||
|
||||
renderer: networkd
|
||||
|
||||
ethernets:
|
||||
|
||||
ens5:
|
||||
|
||||
dhcp4: no
|
||||
|
||||
addresses: [192.168.1.230/24]
|
||||
|
||||
gateway4: 192.168.1.254
|
||||
|
||||
nameservers:
|
||||
|
||||
addresses: [8.8.4.4,8.8.8.8]
|
||||
version: 2
|
||||
renderer: networkd
|
||||
ethernets:
|
||||
ens5:
|
||||
dhcp4: no
|
||||
addresses: [192.168.1.230/24]
|
||||
gateway4: 192.168.1.254
|
||||
nameservers:
|
||||
addresses: [8.8.4.4,8.8.8.8]
|
||||
```
|
||||
|
||||
编辑上面的文件以达到你想要的效果。保存并关闭文件。
|
||||
|
||||
注意,掩码已经不用再配置为 255.255.255.0 这种形式。取而代之的是,掩码已被添加进了 IP 地址中。
|
||||
注意,掩码已经不用再配置为 `255.255.255.0` 这种形式。取而代之的是,掩码已被添加进了 IP 地址中。
|
||||
|
||||
### 测试配置
|
||||
|
||||
@ -165,20 +138,13 @@ sudo netplan apply
|
||||
|
||||
```
|
||||
network:
|
||||
|
||||
version: 2
|
||||
|
||||
renderer: networkd
|
||||
|
||||
ethernets:
|
||||
|
||||
ens5:
|
||||
|
||||
Addresses: []
|
||||
|
||||
dhcp4: true
|
||||
|
||||
optional: true
|
||||
version: 2
|
||||
renderer: networkd
|
||||
ethernets:
|
||||
ens5:
|
||||
Addresses: []
|
||||
dhcp4: true
|
||||
optional: true
|
||||
```
|
||||
|
||||
保存并退出。用下面命令来测试文件:
|
||||
@ -187,15 +153,15 @@ network:
|
||||
sudo netplan try
|
||||
```
|
||||
|
||||
Netplan 应该会成功配置 DHCP 服务。这时你可以使用 ip a 命令得到动态分配的地址,然后重新配置静态地址。或者,你可以直接使用 DHCP 分配的地址(但看看这是一个服务器,你可能不想这样做)。
|
||||
Netplan 应该会成功配置 DHCP 服务。这时你可以使用 `ip a` 命令得到动态分配的地址,然后重新配置静态地址。或者,你可以直接使用 DHCP 分配的地址(但看看这是一个服务器,你可能不想这样做)。
|
||||
|
||||
也许你有不只一个的网络接口,你可以命名第二个 .yaml 文件为 02-netcfg.yaml 。Netplan 会按照数字顺序应用配置文件,因此 01 会在 02 之前使用。根据你的需要创建多个配置文件。
|
||||
也许你有不只一个的网络接口,你可以命名第二个 .yaml 文件为 `02-netcfg.yaml` 。Netplan 会按照数字顺序应用配置文件,因此 01 会在 02 之前使用。根据你的需要创建多个配置文件。
|
||||
|
||||
### 就是这些了
|
||||
|
||||
不管你信不信,那些就是所有关于使用 Netplan 的东西了。虽然它对于我们习惯性的配置网络地址来说是一个相当大的改变,但并不是所有人都用的惯。但这种配置方式值得一提...因此你会适应的。
|
||||
不管怎样,那些就是所有关于使用 Netplan 的东西了。虽然它对于我们习惯性的配置网络地址来说是一个相当大的改变,但并不是所有人都用的惯。但这种配置方式值得一提……因此你会适应的。
|
||||
|
||||
在 Linux Foundation 和 edX 上通过 ["Introduction to Linux"] 课程学习更多关于 Linux 的内容。
|
||||
在 Linux Foundation 和 edX 上通过 [“Introduction to Linux”][5] 课程学习更多关于 Linux 的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -204,7 +170,7 @@ via: https://www.linux.com/learn/intro-to-linux/2018/9/how-use-netplan-network-c
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,75 @@
|
||||
Troubleshooting Node.js Issues with llnode
|
||||
======
|
||||
|
||||

|
||||
|
||||
The llnode plugin lets you inspect Node.js processes and core dumps; it adds the ability to inspect JavaScript stack frames, objects, source code and more. At [Node+JS Interactive][1], Matheus Marchini, Node.js Collaborator and Lead Software Engineer at Sthima, will host a [workshop][2] on how to use llnode to find and fix issues quickly and reliably, without bloating your application with logs or compromising performance. He explains more in this interview.
|
||||
|
||||
**Linux.com: What are some common issues that happen with a Node.js application in production?**
|
||||
|
||||
**Matheus Marchini:** One of the most common issues Node.js developers might experience -- either in production or during development -- are unhandled exceptions. They happen when your code throws an error, and this error is not properly handled. There's a variation of this issue with Promises, although in this case, the problem is worse: if a Promise is rejected but there's no handler for that rejection, the application might enter into an undefined state and it can start to misbehave.
|
||||
|
||||
The application might also crash when it's using too much memory. This usually happens when there's a memory leak in the application, although we usually don't have classic memory leaks in Node.js. Instead of unreferenced objects, we might have objects that are not used anymore but are still retained by another object, leading the Garbage Collector to ignore them. If this happens with several objects, we can quickly exhaust our available memory.
|
||||
|
||||
Memory is not the only resource that might get exhausted. Given the asynchronous nature of Node.js and how it scales for a large number of requests, the application might start to run out on other resources such as opened file descriptions and a number of concurrent connections to a database.
|
||||
|
||||
Infinite loops are not that common because we usually catch those during development, but every once in a while one manages to slip through our tests and get into our production servers. These are pretty catastrophic because they will block the main thread, rendering the entire application unresponsive.
|
||||
|
||||
The last issues I'd like to point out are performance issues. Those can happen for a variety of reasons, ranging from unoptimized function to I/O latency.
|
||||
|
||||
**Linux.com: Are there any quick tests you can do to determine what might be happening with your Node.js application?**
|
||||
|
||||
**Marchini:** Node.js and V8 have several tools and features built-in which developers can use to find issues faster. For example, if you're facing performance issues, you might want to use the built-in [V8 CpuProfiler][3]. Memory issues can be tracked down with [V8 Sampling Heap Profiler][4]. All of these options are interesting because you can open their results in Chrome DevTools and get some nice graphical visualizations by default.
|
||||
|
||||
If you are using native modules on your project, V8 built-in tools might not give you enough insights, since they focus only on JavaScript metrics. As an alternative to V8 CpuProfiler, you can use system profiler tools, such as [perf for Linux][5] and Dtrace for FreeBSD / OS X. You can grab the result from these tools and turn them into flamegraphs, making it easier to find which functions are taking more time to process.
|
||||
|
||||
You can use third-party tools as well: [node-report][6] is an amazing first failure data capture which doesn't introduce a significant overhead. When your application crashes, it will generate a report with detailed information about the state of the system, including environment variables, flags used, operating system details, etc. You can also generate this report on demand, and it is extremely useful when asking for help in forums, for example. The best part is that, after installing it through npm, you can enable it with a flag -- no need to make changes in your code!
|
||||
|
||||
But one of the tools I'm most amazed by is [llnode][7].
|
||||
|
||||
**Linux.com: When would you want to use something like llnode; and what exactly is it?**
|
||||
|
||||
**Marchini:** **** llnode is useful when debugging infinite loops, uncaught exceptions or out of memory issues since it allows you to inspect the state of your application when it crashed. How does llnode do this? You can tell Node.js and your operating system to take a core dump of your application when it crashes and load it into llnode. llnode will analyze this core dump and give you useful information such as how many objects were allocated in the heap, the complete stack trace for the process (including native calls and V8 internals), pending requests and handlers in the event loop queue, etc.
|
||||
|
||||
The most impressive feature llnode has is its ability to inspect objects and functions: you can see which variables are available for a given function, look at the function's code and inspect which properties your objects have with their respective values. For example, you can look up which variables are available for your HTTP handler function and which parameters it received. You can also look at headers and the payload of a given request.
|
||||
|
||||
llnode is a plugin for [lldb][8], and it uses lldb features alongside hints provided by V8 and Node.js to recreate the process heap. It uses a few heuristics, too, so results might not be entirely correct sometimes. But most of the times the results are good enough -- and way better than not using any tool.
|
||||
|
||||
This technique -- which is called post-mortem debugging -- is not something new, though, and it has been part of the Node.js project since 2012. This is a common technique used by C and C++ developers, but not many dynamic runtimes support it. I'm happy we can say Node.js is one of those runtimes.
|
||||
|
||||
**Linux.com: What are some key items folks should know before adding llnode to their environment?**
|
||||
|
||||
**Marchini:** To install and use llnode you'll need to have lldb installed on your system. If you're on OS X, lldb is installed as part of Xcode. On Linux, you can install it from your distribution's repository. We recommend using LLDB 3.9 or later.
|
||||
|
||||
You'll also have to set up your environment to generate core dumps. First, remember to set the flag --abort-on-uncaught-exception when running a Node.js application, otherwise, Node.js won't generate a core dump when an uncaught exception happens. You'll also need to tell your operating system to generate core dumps when an application crashes. The most common way to do that is by running `ulimit -c unlimited`, but this will only apply to your current shell session. If you're using a process manager such as systemd I suggest looking at the process manager docs. You can also generate on-demand core dumps of a running process with tools such as gcore.
|
||||
|
||||
**Linux.com: What can we expect from llnode in the future?**
|
||||
|
||||
**Marchini:** llnode collaborators are working on several features and improvements to make the project more accessible for developers less familiar with native debugging tools. To accomplish that, we're improving the overall user experience as well as the project's documentation and installation process. Future versions will include colorized output, more reliable output for some commands and a simplified mode focused on JavaScript information. We are also working on a JavaScript API which can be used to automate some analysis, create graphical user interfaces, etc.
|
||||
|
||||
If this project sounds interesting to you, and you would like to get involved, feel free join the conversation in [our issues tracker][9] or contact me on social [@mmarkini][10]. I would love to help you get started!
|
||||
|
||||
Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/9/troubleshooting-nodejs-issues-llnode
|
||||
|
||||
作者:[The Linux Foundation][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
|
||||
[2]: http://sched.co/G285
|
||||
[3]: https://nodejs.org/api/inspector.html#inspector_cpu_profiler
|
||||
[4]: https://github.com/v8/sampling-heap-profiler
|
||||
[5]: http://www.brendangregg.com/blog/2014-09-17/node-flame-graphs-on-linux.html
|
||||
[6]: https://github.com/nodejs/node-report
|
||||
[7]: https://github.com/nodejs/llnode
|
||||
[8]: https://lldb.llvm.org/
|
||||
[9]: https://github.com/nodejs/llnode/issues
|
||||
[10]: https://twitter.com/mmarkini
|
||||
@ -0,0 +1,44 @@
|
||||
Creator of the World Wide Web is Creating a New Decentralized Web
|
||||
======
|
||||
**Creator of the world wide web, Tim Berners-Lee has unveiled his plans to create a new decentralized web where the data will be controlled by the users.**
|
||||
|
||||
[Tim Berners-Lee][1] is known for creating the world wide web, i.e., the internet you know today. More than two decades later, Tim is working to free the internet from the clutches of corporate giants and give the power back to the people via a decentralized web.
|
||||
|
||||
Berners-Lee was unhappy with the way ‘powerful forces’ of the internet handle data of the users for their own agenda. So he [started working on his own open source project][2] Solid “to restore the power and agency of individuals on the web.”
|
||||
|
||||
> Solid changes the current model where users have to hand over personal data to digital giants in exchange for perceived value. As we’ve all discovered, this hasn’t been in our best interests. Solid is how we evolve the web in order to restore balance — by giving every one of us complete control over data, personal or not, in a revolutionary way.
|
||||
|
||||
![Tim Berners-Lee is creating a decentralized web with open source project Solid][3]
|
||||
|
||||
Basically, [Solid][4] is a platform built using the existing web where you create own ‘pods’ (personal data store). You decide where this pod will be hosted, who will access which data element and how the data will be shared through this pod.
|
||||
|
||||
Berners-Lee believes that Solid “will empower individuals, developers and businesses with entirely new ways to conceive, build and find innovative, trusted and beneficial applications and services.”
|
||||
|
||||
Developers need to integrate Solid into their apps and sites. Solid is still in the early stages so there are no apps for now but the project website claims that “the first wave of Solid apps are being created now.”
|
||||
|
||||
Berners-Lee has created a startup called [Inrupt][5] and has taken a sabbatical from MIT to work full-time on Solid and to take it “from the vision of a few to the reality of many.”
|
||||
|
||||
If you are interested in Solid, [learn how to create apps][6] or [contribute to the project][7] in your own way. Of course, it will take a lot of effort to build and drive the broad adoption of Solid so every bit of contribution will count to the success of a decentralized web.
|
||||
|
||||
Do you think a [decentralized web][8] will be a reality? What do you think of decentralized web in general and project Solid in particular?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/solid-decentralized-web/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://en.wikipedia.org/wiki/Tim_Berners-Lee
|
||||
[2]: https://medium.com/@timberners_lee/one-small-step-for-the-web-87f92217d085
|
||||
[3]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/09/tim-berners-lee-solid-project.jpeg
|
||||
[4]: https://solid.inrupt.com/
|
||||
[5]: https://www.inrupt.com/
|
||||
[6]: https://solid.inrupt.com/docs/getting-started
|
||||
[7]: https://solid.inrupt.com/community
|
||||
[8]: https://tech.co/decentralized-internet-guide-2018-02
|
||||
@ -0,0 +1,97 @@
|
||||
Interview With Peter Ganten, CEO of Univention GmbH
|
||||
======
|
||||
I have been asking the Univention team to share the behind-the-scenes story of [**Univention**][1] for a couple of months. Finally, today we got the interview of **Mr. Peter H. Ganten** , CEO of Univention GmbH. Despite his busy schedule, in this interview, he shares what he thinks of the Univention project and its impact on open source ecosystem, what open source developers and companies will need to do to keep thriving and what are the biggest challenges for open source projects.
|
||||
|
||||
**OSTechNix: What’s your background and why have you founded Univention?**
|
||||
|
||||
**Peter Ganten:** I studied physics and psychology. In psychology I was a research assistant and coded evaluation software. I realized how important it is that results have to be disclosed in order to verify or falsify them. The same goes for the code that leads to the results. This brought me into contact with Open Source Software (OSS) and Linux.
|
||||
|
||||

|
||||
|
||||
I was a kind of technical lab manager and I had the opportunity to try out a lot, which led to my book about Debian. That was still in the New Economy era where the first business models emerged on how to make money with Open Source. When the bubble burst, I had the plan to make OSS a solid business model without venture capital but with Hanseatic business style – seriously, steadily, no bling bling.
|
||||
|
||||
**What were the biggest challenges at the beginning?**
|
||||
|
||||
When I came from the university, the biggest challenge clearly was to gain entrepreneurial and business management knowledge. I quickly learned that it’s not about Open Source software as an end to itself but always about customer value, and the benefits OSS offers its customers. We all had to learn a lot.
|
||||
|
||||
In the beginning, we expected that Linux on the desktop would become established in a similar way as Linux on the server. However, this has not yet been proven true. The replacement has happened with Android and the iPhone. Our conclusion then was to change our offerings towards ID management and enterprise servers.
|
||||
|
||||
**Why does UCS matter? And for whom makes it sense to use it?**
|
||||
|
||||
There is cool OSS in all areas, but many organizations are not capable to combine it all together and make it manageable. For the basic infrastructure (Windows desktops, users, user rights, roles, ID management, apps) we need a central instance to which groupware, CRM etc. is connected. Without Univention this would have to be laboriously assembled and maintained manually. This is possible for very large companies, but far too complex for many other organizations.
|
||||
|
||||
[**UCS**][2] can be used out of the box and is scalable. That’s why it’s becoming more and more popular – more than 10,000 organizations are using UCS already today.
|
||||
|
||||
**Who are your users and most important clients? What do they love most about UCS?**
|
||||
|
||||
The Core Edition is free of charge and used by organizations from all sectors and industries such as associations, micro-enterprises, universities or large organizations with thousands of users. In the enterprise environment, where Long Term Servicing (LTS) and professional support are particularly important, we have organizations ranging in size from 30-50 users to several thousand users. One of the target groups is the education system in Germany. In many large cities and within their school administrations UCS is used, for example, in Cologne, Hannover, Bremen, Kassel and in several federal states. They are looking for manageable IT and apps for schools. That’s what we offer, because we can guarantee these authorities full control over their users’ identities.
|
||||
|
||||
Also, more and more cloud service providers and MSPs want to take UCS to deliver a selection of cloud-based app solutions.
|
||||
|
||||
**Is UCS 100% Open Source? If so, how can you run a profitable business selling it?**
|
||||
|
||||
Yes, UCS is 100% Open Source, every line, the whole code is OSS. You can download and use UCS Core Edition for **FREE!**
|
||||
|
||||
We know that in large, complex organizations, vendor support and liability is needed for LTS, SLAs, and we offer that with our Enterprise subscriptions and consulting services. We don’t offer these in the Core Edition.
|
||||
|
||||
**And what are you giving back to the OS community?**
|
||||
|
||||
A lot. We are involved in the Debian team and co-finance the LTS maintenance for Debian. For important OS components in UCS like [**OpenLDAP**][3], Samba or KVM we co-finance the development or have co-developed them ourselves. We make it all freely available.
|
||||
|
||||
We are also involved on the political level in ensuring that OSS is used. We are engaged, for example, in the [**Free Software Foundation Europe (FSFE)**][4] and the [**German Open Source Business Alliance**][5], of which I am the chairman. We are working hard to make OSS more successful.
|
||||
|
||||
**How can I get started with UCS?**
|
||||
|
||||
It’s easy to get started with the Core Edition, which, like the Enterprise Edition, has an App Center and can be easily installed on your own hardware or as an appliance in a virtual machine. Just [**download Univention ISO**][6] and install it as described in the below link.
|
||||
|
||||
Alternatively, you can try the [**UCS Online Demo**][7] to get a first impression of Univention Corporate Server without actually installing it on your system.
|
||||
|
||||
**What do you think are the biggest challenges for Open Source?**
|
||||
|
||||
There is a certain attitude you can see over and over again even in bigger projects: OSS alone is viewed as an almost mandatory prerequisite for a good, sustainable, secure and trustworthy IT solution – but just having decided to use OSS is no guarantee for success. You have to carry out projects professionally and cooperate with the manufacturers. A danger is that in complex projects people think: “Oh, OSS is free, I just put it all together by myself”. But normally you do not have the know-how to successfully implement complex software solutions. You would never proceed like this with Closed Source. There people think: “Oh, the software costs 3 $ millions, so it’s okay if I have to spend another 300,000 Dollars on consultants.”
|
||||
|
||||
At OSS this is different. If such projects fail and leave burnt ground behind, we have to explain again and again that the failure of such projects is not due to the nature of OSS but to its poor implementation and organization in a specific project: You have to conclude reasonable contracts and involve partners as in the proprietary world, but you’ll gain a better solution.
|
||||
|
||||
Another challenge: We must stay innovative, move forward, attract new people who are enthusiastic about working on projects. That’s sometimes a challenge. For example, there are a number of proprietary cloud services that are good but lead to extremely high dependency. There are approaches to alternatives in OSS, but no suitable business models yet. So it’s hard to find and fund developers. For example, I can think of Evernote and OneNote for which there is no reasonable OSS alternative.
|
||||
|
||||
**And what will the future bring for Univention?**
|
||||
|
||||
I don’t have a crystal ball, but we are extremely optimistic. We see a very high growth potential in the education market. More OSS is being made in the public sector, because we have repeatedly experienced the dead ends that can be reached if we solely rely on Closed Source.
|
||||
|
||||
Overall, we will continue our organic growth at double-digit rates year after year.
|
||||
|
||||
UCS and its core functionalities of identity management, infrastructure management and app center will increasingly be offered and used from the cloud as a managed service. We will support our technology in this direction, e.g., through containers, so that a hypervisor or bare metal is not always necessary for operation.
|
||||
|
||||
**You have been the CEO of Univention for a long time. What keeps you motivated?**
|
||||
|
||||
I have been the CEO of Univention for more than 16 years now. My biggest motivation is to realize that something is moving. That we offer the better way for IT. That the people who go this way with us are excited to work with us. I go home satisfied in the evening (of course not every evening). It’s totally cool to work with the team I have. It motivates and pushes you every time I need it myself.
|
||||
|
||||
I’m a techie and nerd at heart, I enjoy dealing with technology. So I’m totally happy at this place and I’m grateful to the world that I can do whatever I want every day. Not everyone can say that.
|
||||
|
||||
**Who gives you inspiration?**
|
||||
|
||||
My employees, the customers and the Open Source projects. The exchange with other people.
|
||||
|
||||
The motivation behind everything is that we want to make sure that mankind will be able to influence and change the IT that surrounds us today and in the future just the way we want it and we thinks it’s good. We want to make a contribution to this. That is why Univention is there. That is important to us every day.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/interview-with-peter-ganten-ceo-of-univention-gmbh/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/introduction-univention-corporate-server/
|
||||
[2]: https://www.univention.com/products/ucs/
|
||||
[3]: https://www.ostechnix.com/redhat-and-suse-announced-to-withdraw-support-for-openldap/
|
||||
[4]: https://fsfe.org/
|
||||
[5]: https://osb-alliance.de/
|
||||
[6]: https://www.univention.com/downloads/download-ucs/
|
||||
[7]: https://www.univention.com/downloads/ucs-online-demo/
|
||||
@ -0,0 +1,637 @@
|
||||
# Compiling Lisp to JavaScript From Scratch in 350
|
||||
|
||||
In this article we will look at a from-scratch implementation of a compiler from a simple LISP-like calculator language to JavaScript. The complete source code can be found [here][7].
|
||||
|
||||
We will:
|
||||
|
||||
1. Define our language and write a simple program in it
|
||||
|
||||
2. Implement a simple parser combinator library
|
||||
|
||||
3. Implement a parser for our language
|
||||
|
||||
4. Implement a pretty printer for our language
|
||||
|
||||
5. Define a subset of JavaScript for our usage
|
||||
|
||||
6. Implement a code translator to the JavaScript subset we defined
|
||||
|
||||
7. Glue it all together
|
||||
|
||||
Let's start!
|
||||
|
||||
### 1\. Defining the language
|
||||
|
||||
The main attraction of lisps is that their syntax already represent a tree, this is why they are so easy to parse. We'll see that soon. But first let's define our language. Here's a BNF description of our language's syntax:
|
||||
|
||||
```
|
||||
program ::= expr
|
||||
expr ::= <integer> | <name> | ([<expr>])
|
||||
```
|
||||
|
||||
Basically, our language let's us define one expression at the top level which it will evaluate. An expression is composed of either an integer, for example `5`, a variable, for example `x`, or a list of expressions, for example `(add x 1)`.
|
||||
|
||||
An integer evaluate to itself, a variable evaluates to what it's bound in the current environment, and a list evaluates to a function call where the first argument is the function and the rest are the arguments to the function.
|
||||
|
||||
We have some built-in special forms in our language so we can do more interesting stuff:
|
||||
|
||||
* let expression let's us introduce new variables in the environment of the body of the let. The syntax is:
|
||||
|
||||
```
|
||||
let ::= (let ([<letarg>]) <body>)
|
||||
letargs ::= (<name> <expr>)
|
||||
body ::= <expr>
|
||||
```
|
||||
|
||||
* lambda expression: evaluates to an anonymous function definition. The syntax is:
|
||||
|
||||
```
|
||||
lambda ::= (lambda ([<name>]) <body>)
|
||||
```
|
||||
|
||||
We also have a few built in functions: `add`, `mul`, `sub`, `div` and `print`.
|
||||
|
||||
Let's see a quick example of a program written in our language:
|
||||
|
||||
```
|
||||
(let
|
||||
((compose
|
||||
(lambda (f g)
|
||||
(lambda (x) (f (g x)))))
|
||||
(square
|
||||
(lambda (x) (mul x x)))
|
||||
(add1
|
||||
(lambda (x) (add x 1))))
|
||||
(print ((compose square add1) 5)))
|
||||
```
|
||||
|
||||
This program defines 3 functions: `compose`, `square` and `add1`. And then prints the result of the computation:`((compose square add1) 5)`
|
||||
|
||||
I hope this is enough information about the language. Let's start implementing it!
|
||||
|
||||
We can define the language in Haskell like this:
|
||||
|
||||
```
|
||||
type Name = String
|
||||
|
||||
data Expr
|
||||
= ATOM Atom
|
||||
| LIST [Expr]
|
||||
deriving (Eq, Read, Show)
|
||||
|
||||
data Atom
|
||||
= Int Int
|
||||
| Symbol Name
|
||||
deriving (Eq, Read, Show)
|
||||
```
|
||||
|
||||
We can parse programs in the language we defined to an `Expr`. Also, we are giving the new data types `Eq`, `Read`and `Show` instances to aid in testing and debugging. You'll be able to use those in the REPL for example to verify all this actually works.
|
||||
|
||||
The reason we did not define `lambda`, `let` and the other built-in functions as part of the syntax is because we can get away with it in this case. These functions are just a more specific case of a `LIST`. So I decided to leave this to a later phase.
|
||||
|
||||
Usually, you would like to define these special cases in the abstract syntax - to improve error messages, to unable static analysis and optimizations and such, but we won't do that here so this is enough for us.
|
||||
|
||||
Another thing you would like to do usually is add some annotation to the syntax. For example the location: Which file did this `Expr` come from and which row and col in the file. You can use this in later stages to print the location of errors, even if they are not in the parser stage.
|
||||
|
||||
* _Exercise 1_ : Add a `Program` data type to include multiple `Expr` sequentially
|
||||
|
||||
* _Exercise 2_ : Add location annotation to the syntax tree.
|
||||
|
||||
### 2\. Implement a simple parser combinator library
|
||||
|
||||
First thing we are going to do is define an Embedded Domain Specific Language (or EDSL) which we will use to define our languages' parser. This is often referred to as parser combinator library. The reason we are doing it is strictly for learning purposes, Haskell has great parsing libraries and you should definitely use them when building real software, or even when just experimenting. One such library is [megaparsec][8].
|
||||
|
||||
First let's talk about the idea behind our parser library implementation. In it's essence, our parser is a function that takes some input, might consume some or all of the input, and returns the value it managed to parse and the rest of the input it didn't parse yet, or throws an error if it failed. Let's write that down.
|
||||
|
||||
```
|
||||
newtype Parser a
|
||||
= Parser (ParseString -> Either ParseError (a, ParseString))
|
||||
|
||||
data ParseString
|
||||
= ParseString Name (Int, Int) String
|
||||
|
||||
data ParseError
|
||||
= ParseError ParseString Error
|
||||
|
||||
type Error = String
|
||||
|
||||
```
|
||||
|
||||
Here we defined three main new types.
|
||||
|
||||
First, `Parser a`, is the parsing function we described before.
|
||||
|
||||
Second, `ParseString` is our input or state we carry along. It has three significant parts:
|
||||
|
||||
* `Name`: This is the name of the source
|
||||
|
||||
* `(Int, Int)`: This is the current location in the source
|
||||
|
||||
* `String`: This is the remaining string left to parse
|
||||
|
||||
Third, `ParseError` contains the current state of the parser and an error message.
|
||||
|
||||
Now we want our parser to be flexible, so we will define a few instances for common type classes for it. These instances will allow us to combine small parsers to make bigger parsers (hence the name 'parser combinators').
|
||||
|
||||
The first one is a `Functor` instance. We want a `Functor` instance because we want to be able to define a parser using another parser simply by applying a function on the parsed value. We will see an example of this when we define the parser for our language.
|
||||
|
||||
```
|
||||
instance Functor Parser where
|
||||
fmap f (Parser parser) =
|
||||
Parser (\str -> first f <$> parser str)
|
||||
```
|
||||
|
||||
The second instance is an `Applicative` instance. One common use case for this instance instance is to lift a pure function on multiple parsers.
|
||||
|
||||
```
|
||||
instance Applicative Parser where
|
||||
pure x = Parser (\str -> Right (x, str))
|
||||
(Parser p1) <*> (Parser p2) =
|
||||
Parser $
|
||||
\str -> do
|
||||
(f, rest) <- p1 str
|
||||
(x, rest') <- p2 rest
|
||||
pure (f x, rest')
|
||||
|
||||
```
|
||||
|
||||
(Note: _We will also implement a Monad instance so we can use do notation here._ )
|
||||
|
||||
The third instance is an `Alternative` instance. We want to be able to supply an alternative parser in case one fails.
|
||||
|
||||
```
|
||||
instance Alternative Parser where
|
||||
empty = Parser (`throwErr` "Failed consuming input")
|
||||
(Parser p1) <|> (Parser p2) =
|
||||
Parser $
|
||||
\pstr -> case p1 pstr of
|
||||
Right result -> Right result
|
||||
Left _ -> p2 pstr
|
||||
```
|
||||
|
||||
The forth instance is a `Monad` instance. So we'll be able to chain parsers.
|
||||
|
||||
```
|
||||
instance Monad Parser where
|
||||
(Parser p1) >>= f =
|
||||
Parser $
|
||||
\str -> case p1 str of
|
||||
Left err -> Left err
|
||||
Right (rs, rest) ->
|
||||
case f rs of
|
||||
Parser parser -> parser rest
|
||||
|
||||
```
|
||||
|
||||
Next, let's define a way to run a parser and a utility function for failure:
|
||||
|
||||
```
|
||||
|
||||
runParser :: String -> String -> Parser a -> Either ParseError (a, ParseString)
|
||||
runParser name str (Parser parser) = parser $ ParseString name (0,0) str
|
||||
|
||||
throwErr :: ParseString -> String -> Either ParseError a
|
||||
throwErr ps@(ParseString name (row,col) _) errMsg =
|
||||
Left $ ParseError ps $ unlines
|
||||
[ "*** " ++ name ++ ": " ++ errMsg
|
||||
, "* On row " ++ show row ++ ", column " ++ show col ++ "."
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
Now we'll start implementing the combinators which are the API and heart of the EDSL.
|
||||
|
||||
First, we'll define `oneOf`. `oneOf` will succeed if one of the characters in the list supplied to it is the next character of the input and will fail otherwise.
|
||||
|
||||
```
|
||||
oneOf :: [Char] -> Parser Char
|
||||
oneOf chars =
|
||||
Parser $ \case
|
||||
ps@(ParseString name (row, col) str) ->
|
||||
case str of
|
||||
[] -> throwErr ps "Cannot read character of empty string"
|
||||
(c:cs) ->
|
||||
if c `elem` chars
|
||||
then Right (c, ParseString name (row, col+1) cs)
|
||||
else throwErr ps $ unlines ["Unexpected character " ++ [c], "Expecting one of: " ++ show chars]
|
||||
```
|
||||
|
||||
`optional` will stop a parser from throwing an error. It will just return `Nothing` on failure.
|
||||
|
||||
```
|
||||
optional :: Parser a -> Parser (Maybe a)
|
||||
optional (Parser parser) =
|
||||
Parser $
|
||||
\pstr -> case parser pstr of
|
||||
Left _ -> Right (Nothing, pstr)
|
||||
Right (x, rest) -> Right (Just x, rest)
|
||||
```
|
||||
|
||||
`many` will try to run a parser repeatedly until it fails. When it does, it'll return a list of successful parses. `many1`will do the same, but will throw an error if it fails to parse at least once.
|
||||
|
||||
```
|
||||
many :: Parser a -> Parser [a]
|
||||
many parser = go []
|
||||
where go cs = (parser >>= \c -> go (c:cs)) <|> pure (reverse cs)
|
||||
|
||||
many1 :: Parser a -> Parser [a]
|
||||
many1 parser =
|
||||
(:) <$> parser <*> many parser
|
||||
|
||||
```
|
||||
|
||||
These next few parsers use the combinators we defined to make more specific parsers:
|
||||
|
||||
```
|
||||
char :: Char -> Parser Char
|
||||
char c = oneOf [c]
|
||||
|
||||
string :: String -> Parser String
|
||||
string = traverse char
|
||||
|
||||
space :: Parser Char
|
||||
space = oneOf " \n"
|
||||
|
||||
spaces :: Parser String
|
||||
spaces = many space
|
||||
|
||||
spaces1 :: Parser String
|
||||
spaces1 = many1 space
|
||||
|
||||
withSpaces :: Parser a -> Parser a
|
||||
withSpaces parser =
|
||||
spaces *> parser <* spaces
|
||||
|
||||
parens :: Parser a -> Parser a
|
||||
parens parser =
|
||||
(withSpaces $ char '(')
|
||||
*> withSpaces parser
|
||||
<* (spaces *> char ')')
|
||||
|
||||
sepBy :: Parser a -> Parser b -> Parser [b]
|
||||
sepBy sep parser = do
|
||||
frst <- optional parser
|
||||
rest <- many (sep *> parser)
|
||||
pure $ maybe rest (:rest) frst
|
||||
|
||||
```
|
||||
|
||||
Now we have everything we need to start defining a parser for our language.
|
||||
|
||||
* _Exercise_ : implement an EOF (end of file/input) parser combinator.
|
||||
|
||||
### 3\. Implementing a parser for our language
|
||||
|
||||
To define our parser, we'll use the top-bottom method.
|
||||
|
||||
```
|
||||
parseExpr :: Parser Expr
|
||||
parseExpr = fmap ATOM parseAtom <|> fmap LIST parseList
|
||||
|
||||
parseList :: Parser [Expr]
|
||||
parseList = parens $ sepBy spaces1 parseExpr
|
||||
|
||||
parseAtom :: Parser Atom
|
||||
parseAtom = parseSymbol <|> parseInt
|
||||
|
||||
parseSymbol :: Parser Atom
|
||||
parseSymbol = fmap Symbol parseName
|
||||
|
||||
```
|
||||
|
||||
Notice that these four function are a very high-level description of our language. This demonstrate why Haskell is so nice for parsing. Still, after defining the high-level parts, we still need to define the lower-level `parseName` and `parseInt`.
|
||||
|
||||
What characters can we use as names in our language? Let's decide to use lowercase letters, digits and underscores, where the first character must be a letter.
|
||||
|
||||
```
|
||||
parseName :: Parser Name
|
||||
parseName = do
|
||||
c <- oneOf ['a'..'z']
|
||||
cs <- many $ oneOf $ ['a'..'z'] ++ "0123456789" ++ "_"
|
||||
pure (c:cs)
|
||||
```
|
||||
|
||||
For integers, we want a sequence of digits optionally preceding by '-':
|
||||
|
||||
```
|
||||
parseInt :: Parser Atom
|
||||
parseInt = do
|
||||
sign <- optional $ char '-'
|
||||
num <- many1 $ oneOf "0123456789"
|
||||
let result = read $ maybe num (:num) sign of
|
||||
pure $ Int result
|
||||
```
|
||||
|
||||
Lastly, we'll define a function to run a parser and get back an `Expr` or an error message.
|
||||
|
||||
```
|
||||
runExprParser :: Name -> String -> Either String Expr
|
||||
runExprParser name str =
|
||||
case runParser name str (withSpaces parseExpr) of
|
||||
Left (ParseError _ errMsg) -> Left errMsg
|
||||
Right (result, _) -> Right result
|
||||
```
|
||||
|
||||
* _Exercise 1_ : Write a parser for the `Program` type you defined in the first section
|
||||
|
||||
* _Exercise 2_ : Rewrite `parseName` in Applicative style
|
||||
|
||||
* _Exercise 3_ : Find a way to handle the overflow case in `parseInt` instead of using `read`.
|
||||
|
||||
### 4\. Implement a pretty printer for our language
|
||||
|
||||
One more thing we'd like to do is be able to print our programs as source code. This is useful for better error messages.
|
||||
|
||||
```
|
||||
printExpr :: Expr -> String
|
||||
printExpr = printExpr' False 0
|
||||
|
||||
printAtom :: Atom -> String
|
||||
printAtom = \case
|
||||
Symbol s -> s
|
||||
Int i -> show i
|
||||
|
||||
printExpr' :: Bool -> Int -> Expr -> String
|
||||
printExpr' doindent level = \case
|
||||
ATOM a -> indent (bool 0 level doindent) (printAtom a)
|
||||
LIST (e:es) ->
|
||||
indent (bool 0 level doindent) $
|
||||
concat
|
||||
[ "("
|
||||
, printExpr' False (level + 1) e
|
||||
, bool "\n" "" (null es)
|
||||
, intercalate "\n" $ map (printExpr' True (level + 1)) es
|
||||
, ")"
|
||||
]
|
||||
|
||||
indent :: Int -> String -> String
|
||||
indent tabs e = concat (replicate tabs " ") ++ e
|
||||
```
|
||||
|
||||
* _Exercise_ : Write a pretty printer for the `Program` type you defined in the first section
|
||||
|
||||
Okay, we wrote around 200 lines so far of what's typically called the front-end of the compiler. We have around 150 more lines to go and three more tasks: We need to define a subset of JS for our usage, define the translator from our language to that subset, and glue the whole thing together. Let's go!
|
||||
|
||||
### 5\. Define a subset of JavaScript for our usage
|
||||
|
||||
First, we'll define the subset of JavaScript we are going to use:
|
||||
|
||||
```
|
||||
data JSExpr
|
||||
= JSInt Int
|
||||
| JSSymbol Name
|
||||
| JSBinOp JSBinOp JSExpr JSExpr
|
||||
| JSLambda [Name] JSExpr
|
||||
| JSFunCall JSExpr [JSExpr]
|
||||
| JSReturn JSExpr
|
||||
deriving (Eq, Show, Read)
|
||||
|
||||
type JSBinOp = String
|
||||
```
|
||||
|
||||
This data type represent a JavaScript expression. We have two atoms - `JSInt` and `JSSymbol` to which we'll translate our languages' `Atom`, We have `JSBinOp` to represent a binary operation such as `+` or `*`, we have `JSLambda`for anonymous functions same as our `lambda expression`, We have `JSFunCall` which we'll use both for calling functions and introducing new names as in `let`, and we have `JSReturn` to return values from functions as that's required in JavaScript.
|
||||
|
||||
This `JSExpr` type is an **abstract representation** of a JavaScript expression. We will translate our own `Expr`which is an abstract representation of our languages' expression to `JSExpr` and from there to JavaScript. But in order to do that we need to take this `JSExpr` and produce JavaScript code from it. We'll do that by pattern matching on `JSExpr` recursively and emit JS code as a `String`. This is basically the same thing we did in `printExpr`. We'll also track the scoping of elements so we can indent the generated code in a nice way.
|
||||
|
||||
```
|
||||
printJSOp :: JSBinOp -> String
|
||||
printJSOp op = op
|
||||
|
||||
printJSExpr :: Bool -> Int -> JSExpr -> String
|
||||
printJSExpr doindent tabs = \case
|
||||
JSInt i -> show i
|
||||
JSSymbol name -> name
|
||||
JSLambda vars expr -> (if doindent then indent tabs else id) $ unlines
|
||||
["function(" ++ intercalate ", " vars ++ ") {"
|
||||
,indent (tabs+1) $ printJSExpr False (tabs+1) expr
|
||||
] ++ indent tabs "}"
|
||||
JSBinOp op e1 e2 -> "(" ++ printJSExpr False tabs e1 ++ " " ++ printJSOp op ++ " " ++ printJSExpr False tabs e2 ++ ")"
|
||||
JSFunCall f exprs -> "(" ++ printJSExpr False tabs f ++ ")(" ++ intercalate ", " (fmap (printJSExpr False tabs) exprs) ++ ")"
|
||||
JSReturn expr -> (if doindent then indent tabs else id) $ "return " ++ printJSExpr False tabs expr ++ ";"
|
||||
```
|
||||
|
||||
* _Exercise 1_ : Add a `JSProgram` type that will hold multiple `JSExpr` and create a function `printJSExprProgram` to generate code for it.
|
||||
|
||||
* _Exercise 2_ : Add a new type of `JSExpr` - `JSIf`, and generate code for it.
|
||||
|
||||
### 6\. Implement a code translator to the JavaScript subset we defined
|
||||
|
||||
We are almost there. In this section we'll create a function to translate `Expr` to `JSExpr`.
|
||||
|
||||
The basic idea is simple, we'll translate `ATOM` to `JSSymbol` or `JSInt` and `LIST` to either a function call or a special case we'll translate later.
|
||||
|
||||
```
|
||||
type TransError = String
|
||||
|
||||
translateToJS :: Expr -> Either TransError JSExpr
|
||||
translateToJS = \case
|
||||
ATOM (Symbol s) -> pure $ JSSymbol s
|
||||
ATOM (Int i) -> pure $ JSInt i
|
||||
LIST xs -> translateList xs
|
||||
|
||||
translateList :: [Expr] -> Either TransError JSExpr
|
||||
translateList = \case
|
||||
[] -> Left "translating empty list"
|
||||
ATOM (Symbol s):xs
|
||||
| Just f <- lookup s builtins ->
|
||||
f xs
|
||||
f:xs ->
|
||||
JSFunCall <$> translateToJS f <*> traverse translateToJS xs
|
||||
|
||||
```
|
||||
|
||||
`builtins` is a list of special cases to translate, like `lambda` and `let`. Every case gets the list of arguments for it, verify that its syntactically valid and translates it to the equivalent `JSExpr`.
|
||||
|
||||
```
|
||||
type Builtin = [Expr] -> Either TransError JSExpr
|
||||
type Builtins = [(Name, Builtin)]
|
||||
|
||||
builtins :: Builtins
|
||||
builtins =
|
||||
[("lambda", transLambda)
|
||||
,("let", transLet)
|
||||
,("add", transBinOp "add" "+")
|
||||
,("mul", transBinOp "mul" "*")
|
||||
,("sub", transBinOp "sub" "-")
|
||||
,("div", transBinOp "div" "/")
|
||||
,("print", transPrint)
|
||||
]
|
||||
|
||||
```
|
||||
|
||||
In our case, we treat built-in special forms as special and not first class, so will not be able to use them as first class functions and such.
|
||||
|
||||
We'll translate a Lambda to an anonymous function:
|
||||
|
||||
```
|
||||
transLambda :: [Expr] -> Either TransError JSExpr
|
||||
transLambda = \case
|
||||
[LIST vars, body] -> do
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSLambda vars' <$> (JSReturn <$> translateToJS body)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for lambda."
|
||||
,"expecting 2 arguments, the first is the list of vars and the second is the body of the lambda."
|
||||
,"In expression: " ++ show (LIST $ ATOM (Symbol "lambda") : vars)
|
||||
]
|
||||
|
||||
fromSymbol :: Expr -> Either String Name
|
||||
fromSymbol (ATOM (Symbol s)) = Right s
|
||||
fromSymbol e = Left $ "cannot bind value to non symbol type: " ++ show e
|
||||
|
||||
```
|
||||
|
||||
We'll translate let to a definition of a function with the relevant named arguments and call it with the values, Thus introducing the variables in that scope:
|
||||
|
||||
```
|
||||
transLet :: [Expr] -> Either TransError JSExpr
|
||||
transLet = \case
|
||||
[LIST binds, body] -> do
|
||||
(vars, vals) <- letParams binds
|
||||
vars' <- traverse fromSymbol vars
|
||||
JSFunCall . JSLambda vars' <$> (JSReturn <$> translateToJS body) <*> traverse translateToJS vals
|
||||
where
|
||||
letParams :: [Expr] -> Either Error ([Expr],[Expr])
|
||||
letParams = \case
|
||||
[] -> pure ([],[])
|
||||
LIST [x,y] : rest -> ((x:) *** (y:)) <$> letParams rest
|
||||
x : _ -> Left ("Unexpected argument in let list in expression:\n" ++ printExpr x)
|
||||
|
||||
vars ->
|
||||
Left $ unlines
|
||||
["Syntax error: unexpected arguments for let."
|
||||
,"expecting 2 arguments, the first is the list of var/val pairs and the second is the let body."
|
||||
,"In expression:\n" ++ printExpr (LIST $ ATOM (Symbol "let") : vars)
|
||||
]
|
||||
```
|
||||
|
||||
We'll translate an operation that can work on multiple arguments to a chain of binary operations. For example: `(add 1 2 3)` will become `1 + (2 + 3)`
|
||||
|
||||
```
|
||||
transBinOp :: Name -> Name -> [Expr] -> Either TransError JSExpr
|
||||
transBinOp f _ [] = Left $ "Syntax error: '" ++ f ++ "' expected at least 1 argument, got: 0"
|
||||
transBinOp _ _ [x] = translateToJS x
|
||||
transBinOp _ f list = foldl1 (JSBinOp f) <$> traverse translateToJS list
|
||||
```
|
||||
|
||||
And we'll translate a `print` as a call to `console.log`
|
||||
|
||||
```
|
||||
transPrint :: [Expr] -> Either TransError JSExpr
|
||||
transPrint [expr] = JSFunCall (JSSymbol "console.log") . (:[]) <$> translateToJS expr
|
||||
transPrint xs = Left $ "Syntax error. print expected 1 arguments, got: " ++ show (length xs)
|
||||
|
||||
```
|
||||
|
||||
Notice that we could have skipped verifying the syntax if we'd parse those as special cases of `Expr`.
|
||||
|
||||
* _Exercise 1_ : Translate `Program` to `JSProgram`
|
||||
|
||||
* _Exercise 2_ : add a special case for `if Expr Expr Expr` and translate it to the `JSIf` case you implemented in the last exercise
|
||||
|
||||
### 7\. Glue it all together
|
||||
|
||||
Finally, we are going to glue this all together. We'll:
|
||||
|
||||
1. Read a file
|
||||
|
||||
2. Parse it to `Expr`
|
||||
|
||||
3. Translate it to `JSExpr`
|
||||
|
||||
4. Emit JavaScript code to the standard output
|
||||
|
||||
We'll also enable a few flags for testing:
|
||||
|
||||
* `--e` will parse and print the abstract representation of the expression (`Expr`)
|
||||
|
||||
* `--pp` will parse and pretty print
|
||||
|
||||
* `--jse` will parse, translate and print the abstract representation of the resulting JS (`JSExpr`)
|
||||
|
||||
* `--ppc` will parse, pretty print and compile
|
||||
|
||||
```
|
||||
main :: IO ()
|
||||
main = getArgs >>= \case
|
||||
[file] ->
|
||||
printCompile =<< readFile file
|
||||
["--e",file] ->
|
||||
either putStrLn print . runExprParser "--e" =<< readFile file
|
||||
["--pp",file] ->
|
||||
either putStrLn (putStrLn . printExpr) . runExprParser "--pp" =<< readFile file
|
||||
["--jse",file] ->
|
||||
either print (either putStrLn print . translateToJS) . runExprParser "--jse" =<< readFile file
|
||||
["--ppc",file] ->
|
||||
either putStrLn (either putStrLn putStrLn) . fmap (compile . printExpr) . runExprParser "--ppc" =<< readFile file
|
||||
_ ->
|
||||
putStrLn $ unlines
|
||||
["Usage: runghc Main.hs [ --e, --pp, --jse, --ppc ] <filename>"
|
||||
,"--e print the Expr"
|
||||
,"--pp pretty print Expr"
|
||||
,"--jse print the JSExpr"
|
||||
,"--ppc pretty print Expr and then compile"
|
||||
]
|
||||
|
||||
printCompile :: String -> IO ()
|
||||
printCompile = either putStrLn putStrLn . compile
|
||||
|
||||
compile :: String -> Either Error String
|
||||
compile str = printJSExpr False 0 <$> (translateToJS =<< runExprParser "compile" str)
|
||||
|
||||
```
|
||||
|
||||
That's it. We have a compiler from our language to JS. Again, you can view the full source file [here][9].
|
||||
|
||||
Running our compiler with the example from the first section yields this JavaScript code:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp
|
||||
(function(compose, square, add1) {
|
||||
return (console.log)(((compose)(square, add1))(5));
|
||||
})(function(f, g) {
|
||||
return function(x) {
|
||||
return (f)((g)(x));
|
||||
};
|
||||
}, function(x) {
|
||||
return (x * x);
|
||||
}, function(x) {
|
||||
return (x + 1);
|
||||
})
|
||||
```
|
||||
|
||||
If you have node.js installed on your computer, you can run this code by running:
|
||||
|
||||
```
|
||||
$ runhaskell Lisp.hs example.lsp | node -p
|
||||
36
|
||||
undefined
|
||||
```
|
||||
|
||||
* _Final exercise_ : instead of compiling an expression, compile a program of multiple expressions.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
|
||||
作者:[ Gil Mizrahi ][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://gilmi.me/home
|
||||
[b]:https://github.com/oska874
|
||||
[1]:https://gilmi.me/blog/authors/Gil
|
||||
[2]:https://gilmi.me/blog/tags/compilers
|
||||
[3]:https://gilmi.me/blog/tags/fp
|
||||
[4]:https://gilmi.me/blog/tags/haskell
|
||||
[5]:https://gilmi.me/blog/tags/lisp
|
||||
[6]:https://gilmi.me/blog/tags/parsing
|
||||
[7]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[8]:https://mrkkrp.github.io/megaparsec/
|
||||
[9]:https://gist.github.com/soupi/d4ff0727ccb739045fad6cdf533ca7dd
|
||||
[10]:https://gilmi.me/blog/post/2016/10/14/lisp-to-js
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
A Desktop GUI Application For NPM
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Complete Sed Command Guide [Explained with Practical Examples]
|
||||
======
|
||||
In a previous article, I showed the [basic usage of Sed][1], the stream editor, on a practical use case. Today, be prepared to gain more insight about Sed as we will take an in-depth tour of the sed execution model. This will be also an opportunity to make an exhaustive review of all Sed commands and to dive into their details and subtleties. So, if you are ready, launch a terminal, [download the test files][2] and sit comfortably before your keyboard: we will start our exploration right now!
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Install Oracle VirtualBox On Ubuntu 18.04 LTS Headless Server
|
||||
======
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
Setup Headless Virtualization Server Using KVM In Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||
|
||||
205
sources/tech/20180715 Why is Python so slow.md
Normal file
205
sources/tech/20180715 Why is Python so slow.md
Normal file
@ -0,0 +1,205 @@
|
||||
Why is Python so slow?
|
||||
============================================================
|
||||
|
||||
Python is booming in popularity. It is used in DevOps, Data Science, Web Development and Security.
|
||||
|
||||
It does not, however, win any medals for speed.
|
||||
|
||||
|
||||

|
||||
|
||||
> How does Java compare in terms of speed to C or C++ or C# or Python? The answer depends greatly on the type of application you’re running. No benchmark is perfect, but The Computer Language Benchmarks Game is [a good starting point][5].
|
||||
|
||||
I’ve been referring to the Computer Language Benchmarks Game for over a decade; compared with other languages like Java, C#, Go, JavaScript, C++, Python is [one of the slowest][6]. This includes [JIT][7] (C#, Java) and [AOT][8] (C, C++) compilers, as well as interpreted languages like JavaScript.
|
||||
|
||||
_NB: When I say “Python”, I’m talking about the reference implementation of the language, CPython. I will refer to other runtimes in this article._
|
||||
|
||||
> I want to answer this question: When Python completes a comparable application 2–10x slower than another language, _why is it slow_ and can’t we _make it faster_ ?
|
||||
|
||||
Here are the top theories:
|
||||
|
||||
* “ _It’s the GIL (Global Interpreter Lock)_ ”
|
||||
|
||||
* “ _It’s because its interpreted and not compiled_ ”
|
||||
|
||||
* “ _It’s because its a dynamically typed language_ ”
|
||||
|
||||
Which one of these reasons has the biggest impact on performance?
|
||||
|
||||
### “It’s the GIL”
|
||||
|
||||
Modern computers come with CPU’s that have multiple cores, and sometimes multiple processors. In order to utilise all this extra processing power, the Operating System defines a low-level structure called a thread, where a process (e.g. Chrome Browser) can spawn multiple threads and have instructions for the system inside. That way if one process is particularly CPU-intensive, that load can be shared across the cores and this effectively makes most applications complete tasks faster.
|
||||
|
||||
My Chrome Browser, as I’m writing this article, has 44 threads open. Keep in mind that the structure and API of threading are different between POSIX-based (e.g. Mac OS and Linux) and Windows OS. The operating system also handles the scheduling of threads.
|
||||
|
||||
IF you haven’t done multi-threaded programming before, a concept you’ll need to quickly become familiar with locks. Unlike a single-threaded process, you need to ensure that when changing variables in memory, multiple threads don’t try and access/change the same memory address at the same time.
|
||||
|
||||
When CPython creates variables, it allocates the memory and then counts how many references to that variable exist, this is a concept known as reference counting. If the number of references is 0, then it frees that piece of memory from the system. This is why creating a “temporary” variable within say, the scope of a for loop, doesn’t blow up the memory consumption of your application.
|
||||
|
||||
The challenge then becomes when variables are shared within multiple threads, how CPython locks the reference count. There is a “global interpreter lock” that carefully controls thread execution. The interpreter can only execute one operation at a time, regardless of how many threads it has.
|
||||
|
||||
#### What does this mean to the performance of Python application?
|
||||
|
||||
If you have a single-threaded, single interpreter application. It will make no difference to the speed. Removing the GIL would have no impact on the performance of your code.
|
||||
|
||||
If you wanted to implement concurrency within a single interpreter (Python process) by using threading, and your threads were IO intensive (e.g. Network IO or Disk IO), you would see the consequences of GIL-contention.
|
||||
|
||||

|
||||
From David Beazley’s GIL visualised post [http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html][1]
|
||||
|
||||
If you have a web-application (e.g. Django) and you’re using WSGI, then each request to your web-app is a separate Python interpreter, so there is only 1 lock _per_ request. Because the Python interpreter is slow to start, some WSGI implementations have a “Daemon Mode” [which keep Python process(es) on the go for you.][9]
|
||||
|
||||
#### What about other Python runtimes?
|
||||
|
||||
[PyPy has a GIL][10] and it is typically >3x faster than CPython.
|
||||
|
||||
[Jython does not have a GIL][11] because a Python thread in Jython is represented by a Java thread and benefits from the JVM memory-management system.
|
||||
|
||||
#### How does JavaScript do this?
|
||||
|
||||
Well, firstly all Javascript engines [use mark-and-sweep Garbage Collection][12]. As stated, the primary need for the GIL is CPython’s memory-management algorithm.
|
||||
|
||||
JavaScript does not have a GIL, but it’s also single-threaded so it doesn’t require one. JavaScript’s event-loop and Promise/Callback pattern are how asynchronous-programming is achieved in place of concurrency. Python has a similar thing with the asyncio event-loop.
|
||||
|
||||
### “It’s because its an interpreted language”
|
||||
|
||||
I hear this a lot and I find it a gross-simplification of the way CPython actually works. If at a terminal you wrote `python myscript.py` then CPython would start a long sequence of reading, lexing, parsing, compiling, interpreting and executing that code.
|
||||
|
||||
If you’re interested in how that process works, I’ve written about it before:
|
||||
|
||||
[Modifying the Python language in 6 minutes
|
||||
This week I raised my first pull-request to the CPython core project, which was declined :-( but as to not completely…hackernoon.com][13][][14]
|
||||
|
||||
An important point in that process is the creation of a `.pyc` file, at the compiler stage, the bytecode sequence is written to a file inside `__pycache__/`on Python 3 or in the same directory in Python 2\. This doesn’t just apply to your script, but all of the code you imported, including 3rd party modules.
|
||||
|
||||
So most of the time (unless you write code which you only ever run once?), Python is interpreting bytecode and executing it locally. Compare that with Java and C#.NET:
|
||||
|
||||
> Java compiles to an “Intermediate Language” and the Java Virtual Machine reads the bytecode and just-in-time compiles it to machine code. The .NET CIL is the same, the .NET Common-Language-Runtime, CLR, uses just-in-time compilation to machine code.
|
||||
|
||||
So, why is Python so much slower than both Java and C# in the benchmarks if they all use a virtual machine and some sort of Bytecode? Firstly, .NET and Java are JIT-Compiled.
|
||||
|
||||
JIT or Just-in-time compilation requires an intermediate language to allow the code to be split into chunks (or frames). Ahead of time (AOT) compilers are designed to ensure that the CPU can understand every line in the code before any interaction takes place.
|
||||
|
||||
The JIT itself does not make the execution any faster, because it is still executing the same bytecode sequences. However, JIT enables optimizations to be made at runtime. A good JIT optimizer will see which parts of the application are being executed a lot, call these “hot spots”. It will then make optimizations to those bits of code, by replacing them with more efficient versions.
|
||||
|
||||
This means that when your application does the same thing again and again, it can be significantly faster. Also, keep in mind that Java and C# are strongly-typed languages so the optimiser can make many more assumptions about the code.
|
||||
|
||||
PyPy has a JIT and as mentioned in the previous section, is significantly faster than CPython. This performance benchmark article goes into more detail —
|
||||
|
||||
[Which is the fastest version of Python?
|
||||
Of course, “it depends”, but what does it depend on and how can you assess which is the fastest version of Python for…hackernoon.com][15][][16]
|
||||
|
||||
#### So why doesn’t CPython use a JIT?
|
||||
|
||||
There are downsides to JITs: one of those is startup time. CPython startup time is already comparatively slow, PyPy is 2–3x slower to start than CPython. The Java Virtual Machine is notoriously slow to boot. The .NET CLR gets around this by starting at system-startup, but the developers of the CLR also develop the Operating System on which the CLR runs.
|
||||
|
||||
If you have a single Python process running for a long time, with code that can be optimized because it contains “hot spots”, then a JIT makes a lot of sense.
|
||||
|
||||
However, CPython is a general-purpose implementation. So if you were developing command-line applications using Python, having to wait for a JIT to start every time the CLI was called would be horribly slow.
|
||||
|
||||
CPython has to try and serve as many use cases as possible. There was the possibility of [plugging a JIT into CPython][17] but this project has largely stalled.
|
||||
|
||||
> If you want the benefits of a JIT and you have a workload that suits it, use PyPy.
|
||||
|
||||
### “It’s because its a dynamically typed language”
|
||||
|
||||
In a “Statically-Typed” language, you have to specify the type of a variable when it is declared. Those would include C, C++, Java, C#, Go.
|
||||
|
||||
In a dynamically-typed language, there are still the concept of types, but the type of a variable is dynamic.
|
||||
|
||||
```
|
||||
a = 1
|
||||
a = "foo"
|
||||
```
|
||||
|
||||
In this toy-example, Python creates a second variable with the same name and a type of `str` and deallocates the memory created for the first instance of `a`
|
||||
|
||||
Statically-typed languages aren’t designed as such to make your life hard, they are designed that way because of the way the CPU operates. If everything eventually needs to equate to a simple binary operation, you have to convert objects and types down to a low-level data structure.
|
||||
|
||||
Python does this for you, you just never see it, nor do you need to care.
|
||||
|
||||
Not having to declare the type isn’t what makes Python slow, the design of the Python language enables you to make almost anything dynamic. You can replace the methods on objects at runtime, you can monkey-patch low-level system calls to a value declared at runtime. Almost anything is possible.
|
||||
|
||||
It’s this design that makes it incredibly hard to optimise Python.
|
||||
|
||||
To illustrate my point, I’m going to use a syscall tracing tool that works in Mac OS called Dtrace. CPython distributions do not come with DTrace builtin, so you have to recompile CPython. I’m using 3.6.6 for my demo
|
||||
|
||||
```
|
||||
wget https://github.com/python/cpython/archive/v3.6.6.zip
|
||||
unzip v3.6.6.zip
|
||||
cd v3.6.6
|
||||
./configure --with-dtrace
|
||||
make
|
||||
```
|
||||
|
||||
Now `python.exe` will have Dtrace tracers throughout the code. [Paul Ross wrote an awesome Lightning Talk on Dtrace][19]. You can [download DTrace starter files][20] for Python to measure function calls, execution time, CPU time, syscalls, all sorts of fun. e.g.
|
||||
|
||||
`sudo dtrace -s toolkit/<tracer>.d -c ‘../cpython/python.exe script.py’`
|
||||
|
||||
The `py_callflow` tracer shows all the function calls in your application
|
||||
|
||||
|
||||

|
||||
|
||||
So, does Python’s dynamic typing make it slow?
|
||||
|
||||
* Comparing and converting types is costly, every time a variable is read, written to or referenced the type is checked
|
||||
|
||||
* It is hard to optimise a language that is so dynamic. The reason many alternatives to Python are so much faster is that they make compromises to flexibility in the name of performance
|
||||
|
||||
* Looking at [Cython][2], which combines C-Static Types and Python to optimise code where the types are known[ can provide ][3]an 84x performanceimprovement.
|
||||
|
||||
### Conclusion
|
||||
|
||||
> Python is primarily slow because of its dynamic nature and versatility. It can be used as a tool for all sorts of problems, where more optimised and faster alternatives are probably available.
|
||||
|
||||
There are, however, ways of optimising your Python applications by leveraging async, understanding the profiling tools, and consider using multiple-interpreters.
|
||||
|
||||
For applications where startup time is unimportant and the code would benefit a JIT, consider PyPy.
|
||||
|
||||
For parts of your code where performance is critical and you have more statically-typed variables, consider using [Cython][4].
|
||||
|
||||
#### Further reading
|
||||
|
||||
Jake VDP’s excellent article (although slightly dated) [https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/][21]
|
||||
|
||||
Dave Beazley’s talk on the GIL [http://www.dabeaz.com/python/GIL.pdf][22]
|
||||
|
||||
All about JIT compilers [https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b
|
||||
|
||||
作者:[Anthony Shaw][a]
|
||||
选题:[oska874][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@anthonypjshaw?source=post_header_lockup
|
||||
[b]:https://github.com/oska874
|
||||
[1]:http://dabeaz.blogspot.com/2010/01/python-gil-visualized.html
|
||||
[2]:http://cython.org/
|
||||
[3]:http://notes-on-cython.readthedocs.io/en/latest/std_dev.html
|
||||
[4]:http://cython.org/
|
||||
[5]:http://algs4.cs.princeton.edu/faq/
|
||||
[6]:https://benchmarksgame-team.pages.debian.net/benchmarksgame/faster/python.html
|
||||
[7]:https://en.wikipedia.org/wiki/Just-in-time_compilation
|
||||
[8]:https://en.wikipedia.org/wiki/Ahead-of-time_compilation
|
||||
[9]:https://www.slideshare.net/GrahamDumpleton/secrets-of-a-wsgi-master
|
||||
[10]:http://doc.pypy.org/en/latest/faq.html#does-pypy-have-a-gil-why
|
||||
[11]:http://www.jython.org/jythonbook/en/1.0/Concurrency.html#no-global-interpreter-lock
|
||||
[12]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Memory_Management
|
||||
[13]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
|
||||
[14]:https://hackernoon.com/modifying-the-python-language-in-7-minutes-b94b0a99ce14
|
||||
[15]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
|
||||
[16]:https://hackernoon.com/which-is-the-fastest-version-of-python-2ae7c61a6b2b
|
||||
[17]:https://www.slideshare.net/AnthonyShaw5/pyjion-a-jit-extension-system-for-cpython
|
||||
[18]:https://github.com/python/cpython/archive/v3.6.6.zip
|
||||
[19]:https://github.com/paulross/dtrace-py#the-lightning-talk
|
||||
[20]:https://github.com/paulross/dtrace-py/tree/master/toolkit
|
||||
[21]:https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
|
||||
[22]:http://www.dabeaz.com/python/GIL.pdf
|
||||
[23]:https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/
|
||||
@ -1,284 +0,0 @@
|
||||
Building a network attached storage device with a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this three-part series, I'll explain how to set up a simple, useful NAS (network attached storage) system. I use this kind of setup to store my files on a central system, creating incremental backups automatically every night. To mount the disk on devices that are located in the same network, NFS is installed. To access files offline and share them with friends, I use [Nextcloud][1].
|
||||
|
||||
This article will cover the basic setup of software and hardware to mount the data disk on a remote device. In the second article, I will discuss a backup strategy and set up a cron job to create daily backups. In the third and last article, we will install Nextcloud, a tool for easy file access to devices synced offline as well as online using a web interface. It supports multiple users and public file-sharing so you can share pictures with friends, for example, by sending a password-protected link.
|
||||
|
||||
The target architecture of our system looks like this:
|
||||
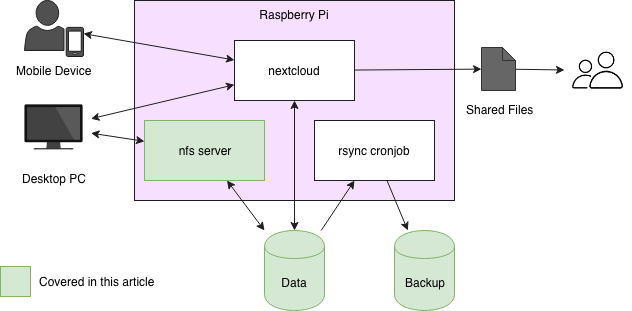
|
||||
|
||||
### Hardware
|
||||
|
||||
Let's get started with the hardware you need. You might come up with a different shopping list, so consider this one an example.
|
||||
|
||||
The computing power is delivered by a [Raspberry Pi 3][2], which comes with a quad-core CPU, a gigabyte of RAM, and (somewhat) fast ethernet. Data will be stored on two USB hard drives (I use 1-TB disks); one is used for the everyday traffic, the other is used to store backups. Be sure to use either active USB hard drives or a USB hub with an additional power supply, as the Raspberry Pi will not be able to power two USB drives.
|
||||
|
||||
### Software
|
||||
|
||||
The operating system with the highest visibility in the community is [Raspbian][3] , which is excellent for custom projects. There are plenty of [guides][4] that explain how to install Raspbian on a Raspberry Pi, so I won't go into details here. The latest official supported version at the time of this writing is [Raspbian Stretch][5] , which worked fine for me.
|
||||
|
||||
At this point, I will assume you have configured your basic Raspbian and are able to connect to the Raspberry Pi by `ssh`.
|
||||
|
||||
### Prepare the USB drives
|
||||
|
||||
To achieve good performance reading from and writing to the USB hard drives, I recommend formatting them with ext4. To do so, you must first find out which disks are attached to the Raspberry Pi. You can find the disk devices in `/dev/sd/<x>`. Using the command `fdisk -l`, you can find out which two USB drives you just attached. Please note that all data on the USB drives will be lost as soon as you follow these steps.
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk -l
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0xe8900690
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x6aa4f598
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
|
||||
|
||||
```
|
||||
|
||||
As those devices are the only 1TB disks attached to the Raspberry Pi, we can easily see that `/dev/sda` and `/dev/sdb` are the two USB drives. The partition table at the end of each disk shows how it should look after the following steps, which create the partition table and format the disks. To do this, repeat the following steps for each of the two devices by replacing `sda` with `sdb` the second time (assuming your devices are also listed as `/dev/sda` and `/dev/sdb` in `fdisk`).
|
||||
|
||||
First, delete the partition table of the disk and create a new one containing only one partition. In `fdisk`, you can use interactive one-letter commands to tell the program what to do. Simply insert them after the prompt `Command (m for help):` as follows (you can also use the `m` command anytime to get more information):
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk /dev/sda
|
||||
|
||||
|
||||
|
||||
Welcome to fdisk (util-linux 2.29.2).
|
||||
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Command (m for help): o
|
||||
|
||||
Created a new DOS disklabel with disk identifier 0x9c310964.
|
||||
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
|
||||
Partition type
|
||||
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
|
||||
e extended (container for logical partitions)
|
||||
|
||||
Select (default p): p
|
||||
|
||||
Partition number (1-4, default 1):
|
||||
|
||||
First sector (2048-1953525167, default 2048):
|
||||
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
|
||||
|
||||
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
|
||||
|
||||
|
||||
|
||||
Command (m for help): p
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x9c310964
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
Command (m for help): w
|
||||
|
||||
The partition table has been altered.
|
||||
|
||||
Syncing disks.
|
||||
|
||||
```
|
||||
|
||||
Now we will format the newly created partition `/dev/sda1` using the ext4 filesystem:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
|
||||
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
|
||||
Discarding device blocks: done
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Allocating group tables: done
|
||||
|
||||
Writing inode tables: done
|
||||
|
||||
Creating journal (1024 blocks): done
|
||||
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
After repeating the above steps, let's label the new partitions according to their usage in your system:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
|
||||
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
|
||||
|
||||
```
|
||||
|
||||
Now let's get those disks mounted to store some data. My experience, based on running this setup for over a year now, is that USB drives are not always available to get mounted when the Raspberry Pi boots up (for example, after a power outage), so I recommend using autofs to mount them when needed.
|
||||
|
||||
First install autofs and create the mount point for the storage:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install autofs
|
||||
|
||||
pi@raspberrypi:~ $ sudo mkdir /nas
|
||||
|
||||
```
|
||||
|
||||
Then mount the devices by adding the following line to `/etc/auto.master`:
|
||||
```
|
||||
/nas /etc/auto.usb
|
||||
|
||||
```
|
||||
|
||||
Create the file `/etc/auto.usb` if not existing with the following content, and restart the autofs service:
|
||||
```
|
||||
data -fstype=ext4,rw :/dev/disk/by-label/data
|
||||
|
||||
backup -fstype=ext4,rw :/dev/disk/by-label/backup
|
||||
|
||||
pi@raspberrypi3:~ $ sudo service autofs restart
|
||||
|
||||
```
|
||||
|
||||
Now you should be able to access the disks at `/nas/data` and `/nas/backup`, respectively. Clearly, the content will not be too thrilling, as you just erased all the data from the disks. Nevertheless, you should be able to verify the devices are mounted by executing the following commands:
|
||||
```
|
||||
pi@raspberrypi3:~ $ cd /nas/data
|
||||
|
||||
pi@raspberrypi3:/nas/data $ cd /nas/backup
|
||||
|
||||
pi@raspberrypi3:/nas/backup $ mount
|
||||
|
||||
<...>
|
||||
|
||||
/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
|
||||
|
||||
<...>
|
||||
|
||||
/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
```
|
||||
|
||||
First move into the directories to make sure autofs mounts the devices. Autofs tracks access to the filesystems and mounts the needed devices on the go. Then the `mount` command shows that the two devices are actually mounted where we wanted them.
|
||||
|
||||
Setting up autofs is a bit fault-prone, so do not get frustrated if mounting doesn't work on the first try. Give it another chance, search for more detailed resources (there is plenty of documentation online), or leave a comment.
|
||||
|
||||
### Mount network storage
|
||||
|
||||
Now that you have set up the basic network storage, we want it to be mounted on a remote Linux machine. We will use the network file system (NFS) for this. First, install the NFS server on the Raspberry Pi:
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
|
||||
|
||||
```
|
||||
|
||||
Next we need to tell the NFS server to expose the `/nas/data` directory, which will be the only device accessible from outside the Raspberry Pi (the other one will be used for backups only). To export the directory, edit the file `/etc/exports` and add the following line to allow all devices with access to the NAS to mount your storage:
|
||||
```
|
||||
/nas/data *(rw,sync,no_subtree_check)
|
||||
|
||||
```
|
||||
|
||||
For more information about restricting the mount to single devices and so on, refer to `man exports`. In the configuration above, anyone will be able to mount your data as long as they have access to the ports needed by NFS: `111` and `2049`. I use the configuration above and allow access to my home network only for ports 22 and 443 using the routers firewall. That way, only devices in the home network can reach the NFS server.
|
||||
|
||||
To mount the storage on a Linux computer, run the commands:
|
||||
```
|
||||
you@desktop:~ $ sudo mkdir /nas/data
|
||||
|
||||
you@desktop:~ $ sudo mount -t nfs <raspberry-pi-hostname-or-ip>:/nas/data /nas/data
|
||||
|
||||
```
|
||||
|
||||
Again, I recommend using autofs to mount this network device. For extra help, check out [How to use autofs to mount NFS shares][6].
|
||||
|
||||
Now you are able to access files stored on your own RaspberryPi-powered NAS from remote devices using the NFS mount. In the next part of this series, I will cover how to automatically back up your data to the second hard drive using `rsync`. To save space on the device while still doing daily backups, you will learn how to create incremental backups with `rsync`.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ntlx
|
||||
[1]:https://nextcloud.com/
|
||||
[2]:https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[3]:https://www.raspbian.org/
|
||||
[4]:https://www.raspberrypi.org/documentation/installation/installing-images/
|
||||
[5]:https://www.raspberrypi.org/blog/raspbian-stretch/
|
||||
[6]:https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
@ -1,170 +0,0 @@
|
||||
A checklist for submitting your first Linux kernel patch
|
||||
======
|
||||
|
||||

|
||||
|
||||
One of the biggest—and the fastest moving—open source projects, the Linux kernel, is composed of about 53,600 files and nearly 20-million lines of code. With more than 15,600 programmers contributing to the project worldwide, the Linux kernel follows a maintainer model for collaboration.
|
||||
|
||||

|
||||
|
||||
In this article, I'll provide a quick checklist of steps involved with making your first kernel contribution, and look at what you should know before submitting a patch. For a more in-depth look at the submission process for contributing your first patch, read the [KernelNewbies First Kernel Patch tutorial][1].
|
||||
|
||||
### Contributing to the kernel
|
||||
|
||||
#### Step 1: Prepare your system.
|
||||
|
||||
Steps in this article assume you have the following tools on your system:
|
||||
|
||||
+ Text editor
|
||||
+ Email client
|
||||
+ Version control system (e.g., git)
|
||||
|
||||
#### Step 2: Download the Linux kernel code repository`:`
|
||||
```
|
||||
git clone -b staging-testing
|
||||
|
||||
git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
|
||||
|
||||
```
|
||||
|
||||
### Copy your current config: ````
|
||||
```
|
||||
cp /boot/config-`uname -r`* .config
|
||||
|
||||
```
|
||||
|
||||
### Step 3: Build/install your kernel.
|
||||
```
|
||||
make -jX
|
||||
|
||||
sudo make modules_install install
|
||||
|
||||
```
|
||||
|
||||
### Step 4: Make a branch and switch to it.
|
||||
```
|
||||
git checkout -b first-patch
|
||||
|
||||
```
|
||||
|
||||
### Step 5: Update your kernel to point to the latest code base.
|
||||
```
|
||||
git fetch origin
|
||||
|
||||
git rebase origin/staging-testing
|
||||
|
||||
```
|
||||
|
||||
### Step 6: Make a change to the code base.
|
||||
|
||||
Recompile using `make` command to ensure that your change does not produce errors.
|
||||
|
||||
### Step 7: Commit your changes and create a patch.
|
||||
```
|
||||
git add <file>
|
||||
|
||||
git commit -s -v
|
||||
|
||||
git format-patch -o /tmp/ HEAD^
|
||||
|
||||
```
|
||||
|
||||
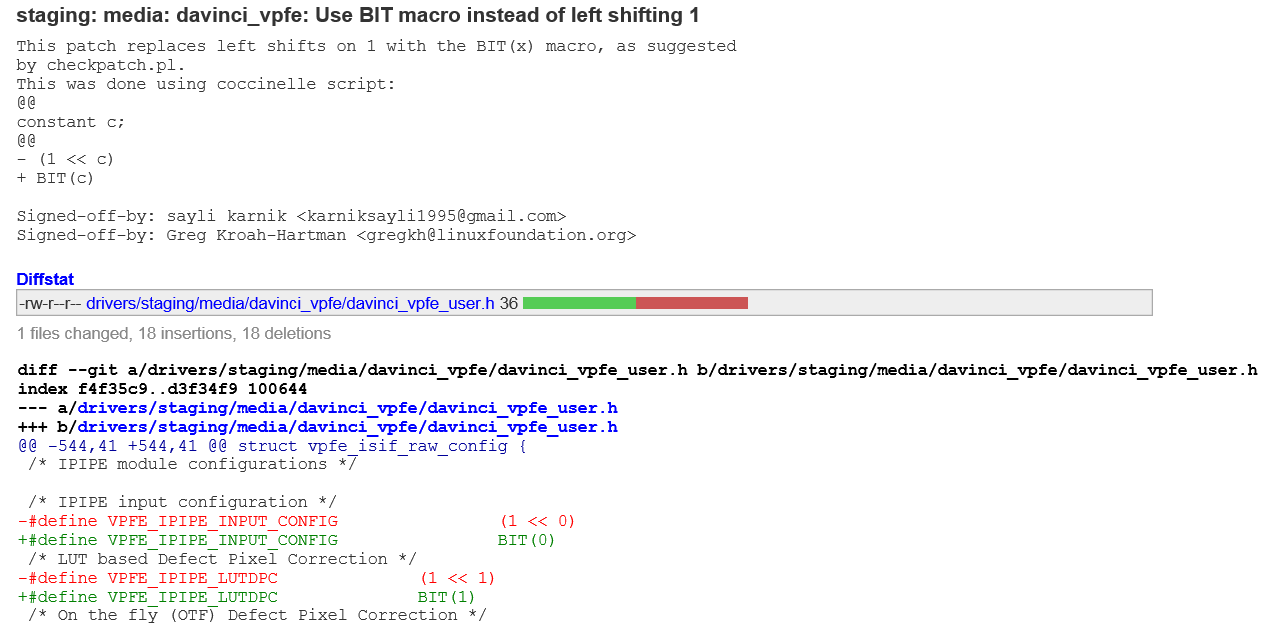
|
||||
|
||||
The subject consists of the path to the file name separated by colons, followed by what the patch does in the imperative tense. After a blank line comes the description of the patch and the mandatory signed off tag and, lastly, a diff of your patch.
|
||||
|
||||
Here is another example of a simple patch:
|
||||
|
||||
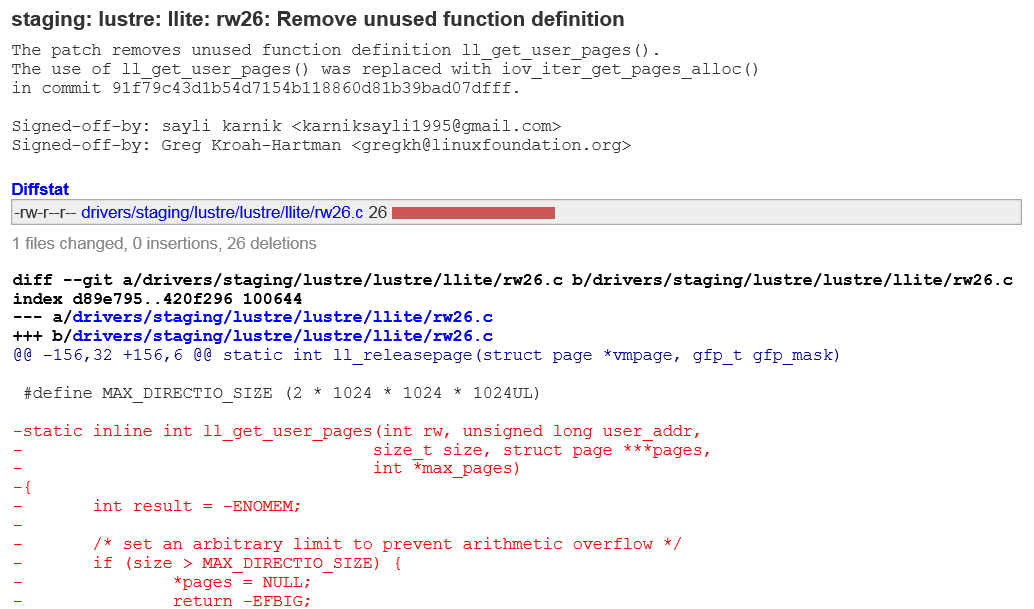
|
||||
|
||||
Next, send the patch [using email from the command line][2] (in this case, Mutt): ``
|
||||
```
|
||||
mutt -H /tmp/0001-<whatever your filename is>
|
||||
|
||||
```
|
||||
|
||||
To know the list of maintainers to whom to send the patch, use the [get_maintainer.pl script][11].
|
||||
|
||||
|
||||
### What to know before submitting your first patch
|
||||
|
||||
* [Greg Kroah-Hartman][3]'s [staging tree][4] is a good place to submit your [first patch][1] as he accepts easy patches from new contributors. When you get familiar with the patch-sending process, you could send subsystem-specific patches with increased complexity.
|
||||
|
||||
* You also could start with correcting coding style issues in the code. To learn more, read the [Linux kernel coding style documentation][5].
|
||||
|
||||
* The script [checkpatch.pl][6] detects coding style errors for you. For example, run:
|
||||
```
|
||||
perl scripts/checkpatch.pl -f drivers/staging/android/* | less
|
||||
|
||||
```
|
||||
|
||||
* You could complete TODOs left incomplete by developers:
|
||||
```
|
||||
find drivers/staging -name TODO
|
||||
```
|
||||
|
||||
* [Coccinelle][7] is a helpful tool for pattern matching.
|
||||
|
||||
* Read the [kernel mailing archives][8].
|
||||
|
||||
* Go through the [linux.git log][9] to see commits by previous authors for inspiration.
|
||||
|
||||
* Note: Do not top-post to communicate with the reviewer of your patch! Here's an example:
|
||||
|
||||
**Wrong way:**
|
||||
|
||||
Chris,
|
||||
_Yes let’s schedule the meeting tomorrow, on the second floor._
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
> 2\. On which floor in the office?
|
||||
> 3\. What time is suitable to you?
|
||||
|
||||
(Notice that the last question was unintentionally left unanswered in the reply.)
|
||||
|
||||
**Correct way:**
|
||||
|
||||
Chris,
|
||||
See my answers below...
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
_Yes tomorrow is fine._
|
||||
> 2\. On which floor in the office?
|
||||
_Let's keep it on the second floor._
|
||||
> 3\. What time is suitable to you?
|
||||
_09:00 am would be alright._
|
||||
|
||||
(All questions were answered, and this way saves reading time.)
|
||||
|
||||
* The [Eudyptula challenge][10] is a great way to learn kernel basics.
|
||||
|
||||
|
||||
To learn more, read the [KernelNewbies First Kernel Patch tutorial][1]. After that, if you still have any questions, ask on the [kernelnewbies mailing list][12] or in the [#kernelnewbies IRC channel][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/first-linux-kernel-patch
|
||||
|
||||
作者:[Sayli Karnik][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sayli
|
||||
[1]:https://kernelnewbies.org/FirstKernelPatch
|
||||
[2]:https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
[3]:https://twitter.com/gregkh
|
||||
[4]:https://www.kernel.org/doc/html/v4.15/process/2.Process.html
|
||||
[5]:https://www.kernel.org/doc/html/v4.10/process/coding-style.html
|
||||
[6]:https://github.com/torvalds/linux/blob/master/scripts/checkpatch.pl
|
||||
[7]:http://coccinelle.lip6.fr/
|
||||
[8]:linux-kernel@vger.kernel.org
|
||||
[9]:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/log/
|
||||
[10]:http://eudyptula-challenge.org/
|
||||
[11]:https://github.com/torvalds/linux/blob/master/scripts/get_maintainer.pl
|
||||
[12]:https://kernelnewbies.org/MailingList
|
||||
[13]:https://kernelnewbies.org/IRC
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
What Stable Kernel Should I Use?
|
||||
======
|
||||
I get a lot of questions about people asking me about what stable kernel should they be using for their product/device/laptop/server/etc. all the time. Especially given the now-extended length of time that some kernels are being supported by me and others, this isn’t always a very obvious thing to determine. So this post is an attempt to write down my opinions on the matter. Of course, you are free to use what ever kernel version you want, but here’s what I recommend.
|
||||
|
||||
@ -1,260 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
How to use the Scikit-learn Python library for data science projects
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Scikit-learn Python library, initially released in 2007, is commonly used in solving machine learning and data science problems—from the beginning to the end. The versatile library offers an uncluttered, consistent, and efficient API and thorough online documentation.
|
||||
|
||||
### What is Scikit-learn?
|
||||
|
||||
[Scikit-learn][1] is an open source Python library that has powerful tools for data analysis and data mining. It's available under the BSD license and is built on the following machine learning libraries:
|
||||
|
||||
* **NumPy** , a library for manipulating multi-dimensional arrays and matrices. It also has an extensive compilation of mathematical functions for performing various calculations.
|
||||
* **SciPy** , an ecosystem consisting of various libraries for completing technical computing tasks.
|
||||
* **Matplotlib** , a library for plotting various charts and graphs.
|
||||
|
||||
|
||||
|
||||
Scikit-learn offers an extensive range of built-in algorithms that make the most of data science projects.
|
||||
|
||||
Here are the main ways the Scikit-learn library is used.
|
||||
|
||||
#### 1. Classification
|
||||
|
||||
The [classification][2] tools identify the category associated with provided data. For example, they can be used to categorize email messages as either spam or not.
|
||||
|
||||
* Support vector machines (SVMs)
|
||||
* Nearest neighbors
|
||||
* Random forest
|
||||
|
||||
|
||||
|
||||
#### 2. Regression
|
||||
|
||||
Classification algorithms in Scikit-learn include:
|
||||
|
||||
Regression involves creating a model that tries to comprehend the relationship between input and output data. For example, regression tools can be used to understand the behavior of stock prices.
|
||||
|
||||
Regression algorithms include:
|
||||
|
||||
* SVMs
|
||||
* Ridge regression
|
||||
* Lasso
|
||||
|
||||
|
||||
|
||||
#### 3. Clustering
|
||||
|
||||
The Scikit-learn clustering tools are used to automatically group data with the same characteristics into sets. For example, customer data can be segmented based on their localities.
|
||||
|
||||
Clustering algorithms include:
|
||||
|
||||
* K-means
|
||||
* Spectral clustering
|
||||
* Mean-shift
|
||||
|
||||
|
||||
|
||||
#### 4. Dimensionality reduction
|
||||
|
||||
Dimensionality reduction lowers the number of random variables for analysis. For example, to increase the efficiency of visualizations, outlying data may not be considered.
|
||||
|
||||
Dimensionality reduction algorithms include:
|
||||
|
||||
* Principal component analysis (PCA)
|
||||
* Feature selection
|
||||
* Non-negative matrix factorization
|
||||
|
||||
|
||||
|
||||
#### 5. Model selection
|
||||
|
||||
Model selection algorithms offer tools to compare, validate, and select the best parameters and models to use in your data science projects.
|
||||
|
||||
Model selection modules that can deliver enhanced accuracy through parameter tuning include:
|
||||
|
||||
* Grid search
|
||||
* Cross-validation
|
||||
* Metrics
|
||||
|
||||
|
||||
|
||||
#### 6. Preprocessing
|
||||
|
||||
The Scikit-learn preprocessing tools are important in feature extraction and normalization during data analysis. For example, you can use these tools to transform input data—such as text—and apply their features in your analysis.
|
||||
|
||||
Preprocessing modules include:
|
||||
|
||||
* Preprocessing
|
||||
* Feature extraction
|
||||
|
||||
|
||||
|
||||
### A Scikit-learn library example
|
||||
|
||||
Let's use a simple example to illustrate how you can use the Scikit-learn library in your data science projects.
|
||||
|
||||
We'll use the [Iris flower dataset][3], which is incorporated in the Scikit-learn library. The Iris flower dataset contains 150 details about three flower species:
|
||||
|
||||
* Setosa—labeled 0
|
||||
* Versicolor—labeled 1
|
||||
* Virginica—labeled 2
|
||||
|
||||
|
||||
|
||||
The dataset includes the following characteristics of each flower species (in centimeters):
|
||||
|
||||
* Sepal length
|
||||
* Sepal width
|
||||
* Petal length
|
||||
* Petal width
|
||||
|
||||
|
||||
|
||||
#### Step 1: Importing the library
|
||||
|
||||
Since the Iris dataset is included in the Scikit-learn data science library, we can load it into our workspace as follows:
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
```
|
||||
|
||||
These commands import the **datasets** module from **sklearn** , then use the **load_digits()** method from **datasets** to include the data in the workspace.
|
||||
|
||||
#### Step 2: Getting dataset characteristics
|
||||
|
||||
The **datasets** module contains several methods that make it easier to get acquainted with handling data.
|
||||
|
||||
In Scikit-learn, a dataset refers to a dictionary-like object that has all the details about the data. The data is stored using the **.data** key, which is an array list.
|
||||
|
||||
For instance, we can utilize **iris.data** to output information about the Iris flower dataset.
|
||||
|
||||
```
|
||||
print(iris.data)
|
||||
```
|
||||
|
||||
Here is the output (the results have been truncated):
|
||||
|
||||
```
|
||||
[[5.1 3.5 1.4 0.2]
|
||||
[4.9 3. 1.4 0.2]
|
||||
[4.7 3.2 1.3 0.2]
|
||||
[4.6 3.1 1.5 0.2]
|
||||
[5. 3.6 1.4 0.2]
|
||||
[5.4 3.9 1.7 0.4]
|
||||
[4.6 3.4 1.4 0.3]
|
||||
[5. 3.4 1.5 0.2]
|
||||
[4.4 2.9 1.4 0.2]
|
||||
[4.9 3.1 1.5 0.1]
|
||||
[5.4 3.7 1.5 0.2]
|
||||
[4.8 3.4 1.6 0.2]
|
||||
[4.8 3. 1.4 0.1]
|
||||
[4.3 3. 1.1 0.1]
|
||||
[5.8 4. 1.2 0.2]
|
||||
[5.7 4.4 1.5 0.4]
|
||||
[5.4 3.9 1.3 0.4]
|
||||
[5.1 3.5 1.4 0.3]
|
||||
```
|
||||
|
||||
Let's also use **iris.target** to give us information about the different labels of the flowers.
|
||||
|
||||
```
|
||||
print(iris.target)
|
||||
```
|
||||
|
||||
Here is the output:
|
||||
|
||||
```
|
||||
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
|
||||
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2]
|
||||
|
||||
```
|
||||
|
||||
If we use **iris.target_names** , we'll output an array of the names of the labels found in the dataset.
|
||||
|
||||
```
|
||||
print(iris.target_names)
|
||||
```
|
||||
|
||||
Here is the result after running the Python code:
|
||||
|
||||
```
|
||||
['setosa' 'versicolor' 'virginica']
|
||||
```
|
||||
|
||||
#### Step 3: Visualizing the dataset
|
||||
|
||||
We can use the [box plot][4] to produce a visual depiction of the Iris flower dataset. The box plot illustrates how the data is distributed over the plane through their quartiles.
|
||||
|
||||
Here's how to achieve this:
|
||||
|
||||
```
|
||||
import seaborn as sns
|
||||
box_data = iris.data #variable representing the data array
|
||||
box_target = iris.target #variable representing the labels array
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
Let's see the result:
|
||||
|
||||
|
||||
|
||||
On the horizontal axis:
|
||||
|
||||
* 0 is sepal length
|
||||
* 1 is sepal width
|
||||
* 2 is petal length
|
||||
* 3 is petal width
|
||||
|
||||
|
||||
|
||||
The vertical axis is dimensions in centimeters.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
Here is the entire code for this simple Scikit-learn data science tutorial.
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
print(iris.data)
|
||||
print(iris.target)
|
||||
print(iris.target_names)
|
||||
import seaborn as sns
|
||||
box_data = iris.data #variable representing the data array
|
||||
box_target = iris.target #variable representing the labels array
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
Scikit-learn is a versatile Python library you can use to efficiently complete data science projects.
|
||||
|
||||
If you want to learn more, check out the tutorials on [LiveEdu][5], such as Andrey Bulezyuk's video on using the Scikit-learn library to create a [machine learning application][6].
|
||||
|
||||
Do you have any questions or comments? Feel free to share them below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: http://scikit-learn.org/stable/index.html
|
||||
[2]: https://blog.liveedu.tv/regression-versus-classification-machine-learning-whats-the-difference/
|
||||
[3]: https://en.wikipedia.org/wiki/Iris_flower_data_set
|
||||
[4]: https://en.wikipedia.org/wiki/Box_plot
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
[6]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
@ -0,0 +1,261 @@
|
||||
16 iptables tips and tricks for sysadmins
|
||||
======
|
||||
Iptables provides powerful capabilities to control traffic coming in and out of your system.
|
||||
|
||||

|
||||
|
||||
Modern Linux kernels come with a packet-filtering framework named [Netfilter][1]. Netfilter enables you to allow, drop, and modify traffic coming in and going out of a system. The **iptables** userspace command-line tool builds upon this functionality to provide a powerful firewall, which you can configure by adding rules to form a firewall policy. [iptables][2] can be very daunting with its rich set of capabilities and baroque command syntax. Let's explore some of them and develop a set of iptables tips and tricks for many situations a system administrator might encounter.
|
||||
|
||||
### Avoid locking yourself out
|
||||
|
||||
Scenario: You are going to make changes to the iptables policy rules on your company's primary server. You want to avoid locking yourself—and potentially everybody else—out. (This costs time and money and causes your phone to ring off the wall.)
|
||||
|
||||
#### Tip #1: Take a backup of your iptables configuration before you start working on it.
|
||||
|
||||
Back up your configuration with the command:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works
|
||||
|
||||
```
|
||||
#### Tip #2: Even better, include a timestamp in the filename.
|
||||
|
||||
Add the timestamp with the command:
|
||||
|
||||
```
|
||||
/sbin/iptables-save > /root/iptables-works-`date +%F`
|
||||
|
||||
```
|
||||
|
||||
You get a file with a name like:
|
||||
|
||||
```
|
||||
/root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
If you do something that prevents your system from working, you can quickly restore it:
|
||||
|
||||
```
|
||||
/sbin/iptables-restore < /root/iptables-works-2018-09-11
|
||||
|
||||
```
|
||||
|
||||
#### Tip #3: Every time you create a backup copy of the iptables policy, create a link to the file with 'latest' in the name.
|
||||
|
||||
```
|
||||
ln –s /root/iptables-works-`date +%F` /root/iptables-works-latest
|
||||
|
||||
```
|
||||
|
||||
#### Tip #4: Put specific rules at the top of the policy and generic rules at the bottom.
|
||||
|
||||
Avoid generic rules like this at the top of the policy rules:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 -j DROP
|
||||
|
||||
```
|
||||
|
||||
The more criteria you specify in the rule, the less chance you will have of locking yourself out. Instead of the very generic rule above, use something like this:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp --dport 22 –s 10.0.0.0/8 –d 192.168.100.101 -j DROP
|
||||
|
||||
```
|
||||
|
||||
This rule appends ( **-A** ) to the **INPUT** chain a rule that will **DROP** any packets originating from the CIDR block **10.0.0.0/8** on TCP ( **-p tcp** ) port 22 ( **\--dport 22** ) destined for IP address 192.168.100.101 ( **-d 192.168.100.101** ).
|
||||
|
||||
There are plenty of ways you can be more specific. For example, using **-i eth0** will limit the processing to a single NIC in your server. This way, the filtering actions will not apply the rule to **eth1**.
|
||||
|
||||
#### Tip #5: Whitelist your IP address at the top of your policy rules.
|
||||
|
||||
This is a very effective method of not locking yourself out. Everybody else, not so much.
|
||||
|
||||
```
|
||||
iptables -I INPUT -s <your IP> -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
You need to put this as the first rule for it to work properly. Remember, **-I** inserts it as the first rule; **-A** appends it to the end of the list.
|
||||
|
||||
#### Tip #6: Know and understand all the rules in your current policy.
|
||||
|
||||
Not making a mistake in the first place is half the battle. If you understand the inner workings behind your iptables policy, it will make your life easier. Draw a flowchart if you must. Also remember: What the policy does and what it is supposed to do can be two different things.
|
||||
|
||||
### Set up a workstation firewall policy
|
||||
|
||||
Scenario: You want to set up a workstation with a restrictive firewall policy.
|
||||
|
||||
#### Tip #1: Set the default policy as DROP.
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
```
|
||||
|
||||
#### Tip #2: Allow users the minimum amount of services needed to get their work done.
|
||||
|
||||
The iptables rules need to allow the workstation to get an IP address, netmask, and other important information via DHCP ( **-p udp --dport 67:68 --sport 67:68** ). For remote management, the rules need to allow inbound SSH ( **\--dport 22** ), outbound mail ( **\--dport 25** ), DNS ( **\--dport 53** ), outbound ping ( **-p icmp** ), Network Time Protocol ( **\--dport 123 --sport 123** ), and outbound HTTP ( **\--dport 80** ) and HTTPS ( **\--dport 443** ).
|
||||
|
||||
```
|
||||
# Set a default policy of DROP
|
||||
*filter
|
||||
:INPUT DROP [0:0]
|
||||
:FORWARD DROP [0:0]
|
||||
:OUTPUT DROP [0:0]
|
||||
|
||||
# Accept any related or established connections
|
||||
-I INPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
-I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
# Allow all traffic on the loopback interface
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
-A OUTPUT -o lo -j ACCEPT
|
||||
|
||||
# Allow outbound DHCP request
|
||||
-A OUTPUT –o eth0 -p udp --dport 67:68 --sport 67:68 -j ACCEPT
|
||||
|
||||
# Allow inbound SSH
|
||||
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Allow outbound email
|
||||
-A OUTPUT -i eth0 -p tcp -m tcp --dport 25 -m state --state NEW -j ACCEPT
|
||||
|
||||
# Outbound DNS lookups
|
||||
-A OUTPUT -o eth0 -p udp -m udp --dport 53 -j ACCEPT
|
||||
|
||||
# Outbound PING requests
|
||||
-A OUTPUT –o eth0 -p icmp -j ACCEPT
|
||||
|
||||
# Outbound Network Time Protocol (NTP) requests
|
||||
-A OUTPUT –o eth0 -p udp --dport 123 --sport 123 -j ACCEPT
|
||||
|
||||
# Outbound HTTP
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 80 -m state --state NEW -j ACCEPT
|
||||
-A OUTPUT -o eth0 -p tcp -m tcp --dport 443 -m state --state NEW -j ACCEPT
|
||||
|
||||
COMMIT
|
||||
```
|
||||
|
||||
### Restrict an IP address range
|
||||
|
||||
Scenario: The CEO of your company thinks the employees are spending too much time on Facebook and not getting any work done. The CEO tells the CIO to do something about the employees wasting time on Facebook. The CIO tells the CISO to do something about employees wasting time on Facebook. Eventually, you are told the employees are wasting too much time on Facebook, and you have to do something about it. You decide to block all access to Facebook. First, find out Facebook's IP address by using the **host** and **whois** commands.
|
||||
|
||||
```
|
||||
host -t a www.facebook.com
|
||||
www.facebook.com is an alias for star.c10r.facebook.com.
|
||||
star.c10r.facebook.com has address 31.13.65.17
|
||||
whois 31.13.65.17 | grep inetnum
|
||||
inetnum: 31.13.64.0 - 31.13.127.255
|
||||
```
|
||||
|
||||
Then convert that range to CIDR notation by using the [CIDR to IPv4 Conversion][3] page. You get **31.13.64.0/18**. To prevent outgoing access to [www.facebook.com][4], enter:
|
||||
|
||||
```
|
||||
iptables -A OUTPUT -p tcp -i eth0 –o eth1 –d 31.13.64.0/18 -j DROP
|
||||
```
|
||||
|
||||
### Regulate by time
|
||||
|
||||
Scenario: The backlash from the company's employees over denying access to Facebook access causes the CEO to relent a little (that and his administrative assistant's reminding him that she keeps HIS Facebook page up-to-date). The CEO decides to allow access to Facebook.com only at lunchtime (12PM to 1PM). Assuming the default policy is DROP, use iptables' time features to open up access.
|
||||
|
||||
```
|
||||
iptables –A OUTPUT -p tcp -m multiport --dport http,https -i eth0 -o eth1 -m time --timestart 12:00 --timestart 12:00 –timestop 13:00 –d
|
||||
31.13.64.0/18 -j ACCEPT
|
||||
```
|
||||
|
||||
This command sets the policy to allow ( **-j ACCEPT** ) http and https ( **-m multiport --dport http,https** ) between noon ( **\--timestart 12:00** ) and 13PM ( **\--timestop 13:00** ) to Facebook.com ( **–d[31.13.64.0/18][5]** ).
|
||||
|
||||
### Regulate by time—Take 2
|
||||
|
||||
Scenario: During planned downtime for system maintenance, you need to deny all TCP and UDP traffic between the hours of 2AM and 3AM so maintenance tasks won't be disrupted by incoming traffic. This will take two iptables rules:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
iptables -A INPUT -p udp -m time --timestart 02:00 --timestop 03:00 -j DROP
|
||||
```
|
||||
|
||||
With these rules, TCP and UDP traffic ( **-p tcp and -p udp** ) are denied ( **-j DROP** ) between the hours of 2AM ( **\--timestart 02:00** ) and 3AM ( **\--timestop 03:00** ) on input ( **-A INPUT** ).
|
||||
|
||||
### Limit connections with iptables
|
||||
|
||||
Scenario: Your internet-connected web servers are under attack by bad actors from around the world attempting to DoS (Denial of Service) them. To mitigate these attacks, you restrict the number of connections a single IP address can have to your web server:
|
||||
|
||||
```
|
||||
iptables –A INPUT –p tcp –syn -m multiport -–dport http,https –m connlimit -–connlimit-above 20 –j REJECT -–reject-with-tcp-reset
|
||||
```
|
||||
|
||||
Let's look at what this rule does. If a host makes more than 20 ( **-–connlimit-above 20** ) new connections ( **–p tcp –syn** ) in a minute to the web servers ( **-–dport http,https** ), reject the new connection ( **–j REJECT** ) and tell the connecting host you are rejecting the connection ( **-–reject-with-tcp-reset** ).
|
||||
|
||||
### Monitor iptables rules
|
||||
|
||||
Scenario: Since iptables operates on a "first match wins" basis as packets traverse the rules in a chain, frequently matched rules should be near the top of the policy and less frequently matched rules should be near the bottom. How do you know which rules are traversed the most or the least so they can be ordered nearer the top or the bottom?
|
||||
|
||||
#### Tip #1: See how many times each rule has been hit.
|
||||
|
||||
Use this command:
|
||||
|
||||
```
|
||||
iptables -L -v -n –line-numbers
|
||||
```
|
||||
|
||||
The command will list all the rules in the chain ( **-L** ). Since no chain was specified, all the chains will be listed with verbose output ( **-v** ) showing packet and byte counters in numeric format ( **-n** ) with line numbers at the beginning of each rule corresponding to that rule's position in the chain.
|
||||
|
||||
Using the packet and bytes counts, you can order the most frequently traversed rules to the top and the least frequently traversed rules towards the bottom.
|
||||
|
||||
#### Tip #2: Remove unnecessary rules.
|
||||
|
||||
Which rules aren't getting any matches at all? These would be good candidates for removal from the policy. You can find that out with this command:
|
||||
|
||||
```
|
||||
iptables -nvL | grep -v "0 0"
|
||||
```
|
||||
|
||||
Note: that's not a tab between the zeros; there are five spaces between the zeros.
|
||||
|
||||
#### Tip #3: Monitor what's going on.
|
||||
|
||||
You would like to monitor what's going on with iptables in real time, like with **top**. Use this command to monitor the activity of iptables activity dynamically and show only the rules that are actively being traversed:
|
||||
|
||||
```
|
||||
watch --interval=5 'iptables -nvL | grep -v "0 0"'
|
||||
```
|
||||
|
||||
**watch** runs **'iptables -nvL | grep -v "0 0"'** every five seconds and displays the first screen of its output. This allows you to watch the packet and byte counts change over time.
|
||||
|
||||
### Report on iptables
|
||||
|
||||
Scenario: Your manager thinks this iptables firewall stuff is just great, but a daily activity report would be even better. Sometimes it's more important to write a report than to do the work.
|
||||
|
||||
Use the packet filter/firewall/IDS log analyzer [FWLogwatch][6] to create reports based on the iptables firewall logs. FWLogwatch supports many log formats and offers many analysis options. It generates daily and monthly summaries of the log files, allowing the security administrator to free up substantial time, maintain better control over network security, and reduce unnoticed attacks.
|
||||
|
||||
Here is sample output from FWLogwatch:
|
||||
|
||||
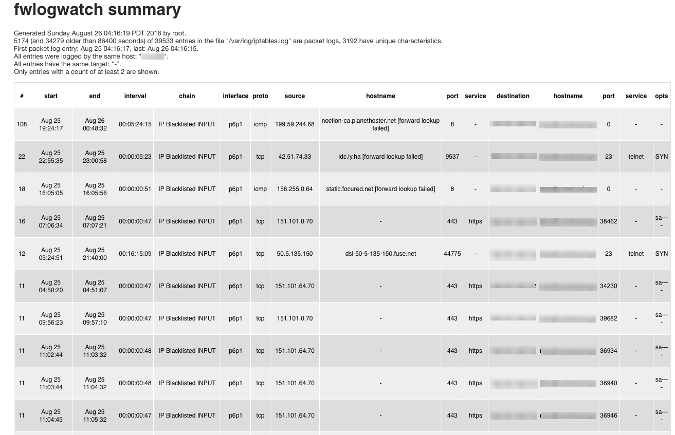
|
||||
|
||||
### More than just ACCEPT and DROP
|
||||
|
||||
We've covered many facets of iptables, all the way from making sure you don't lock yourself out when working with iptables to monitoring iptables to visualizing the activity of an iptables firewall. These will get you started down the path to realizing even more iptables tips and tricks.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/iptables-tips-and-tricks
|
||||
|
||||
作者:[Gary Smith][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greptile
|
||||
[1]: https://en.wikipedia.org/wiki/Netfilter
|
||||
[2]: https://en.wikipedia.org/wiki/Iptables
|
||||
[3]: http://www.ipaddressguide.com/cidr
|
||||
[4]: http://www.facebook.com
|
||||
[5]: http://31.13.64.0/18
|
||||
[6]: http://fwlogwatch.inside-security.de/
|
||||
179
sources/tech/20181001 How to Install Pip on Ubuntu.md
Normal file
179
sources/tech/20181001 How to Install Pip on Ubuntu.md
Normal file
@ -0,0 +1,179 @@
|
||||
How to Install Pip on Ubuntu
|
||||
======
|
||||
**Pip is a command line tool that allows you to install software packages written in Python. Learn how to install Pip on Ubuntu and how to use it for installing Python applications.**
|
||||
|
||||
There are numerous ways to [install software on Ubuntu][1]. You can install applications from the software center, from downloaded DEB files, from PPA, from [Snap packages][2], [using Flatpak][3], using [AppImage][4] and even from the good old source code.
|
||||
|
||||
There is one more way to install packages in [Ubuntu][5]. It’s called Pip and you can use it to install Python-based applications.
|
||||
|
||||
### What is Pip
|
||||
|
||||
[Pip][6] stands for “Pip Installs Packages”. [Pip][7] is a command line based package management system. It is used to install and manage software written in [Python language][8].
|
||||
|
||||
You can use Pip to install packages listed in the Python Package Index ([PyPI][9]).
|
||||
|
||||
As a software developer, you can use pip to install various Python module and packages for your own Python projects.
|
||||
|
||||
As an end user, you may need pip in order to install some applications that are developed using Python and can be installed easily using pip. One such example is [Stress Terminal][10] application that you can easily install with pip.
|
||||
|
||||
Let’s see how you can install pip on Ubuntu and other Ubuntu-based distributions.
|
||||
|
||||
### How to install Pip on Ubuntu
|
||||
|
||||
![Install pip on Ubuntu Linux][11]
|
||||
|
||||
Pip is not installed on Ubuntu by default. You’ll have to install it. Installing pip on Ubuntu is really easy. I’ll show it to you in a moment.
|
||||
|
||||
Ubuntu 18.04 has both Python 2 and Python 3 installed by default. And hence, you should install pip for both Python versions.
|
||||
|
||||
Pip, by default, refers to the Python 2. Pip in Python 3 is referred by pip3.
|
||||
|
||||
Note: I am using Ubuntu 18.04 in this tutorial. But the instructions here should be valid for other versions like Ubuntu 16.04, 18.10 etc. You may also use the same commands on other Linux distributions based on Ubuntu such as Linux Mint, Linux Lite, Xubuntu, Kubuntu etc.
|
||||
|
||||
#### Install pip for Python 2
|
||||
|
||||
First, make sure that you have Python 2 installed. On Ubuntu, use the command below to verify.
|
||||
|
||||
```
|
||||
python2 --version
|
||||
|
||||
```
|
||||
|
||||
If there is no error and a valid output that shows the Python version, you have Python 2 installed. So now you can install pip for Python 2 using this command:
|
||||
|
||||
```
|
||||
sudo apt install python-pip
|
||||
|
||||
```
|
||||
|
||||
It will install pip and a number of other dependencies with it. Once installed, verify that you have pip installed correctly.
|
||||
|
||||
```
|
||||
pip --version
|
||||
|
||||
```
|
||||
|
||||
It should show you a version number, something like this:
|
||||
|
||||
```
|
||||
pip 9.0.1 from /usr/lib/python2.7/dist-packages (python 2.7)
|
||||
|
||||
```
|
||||
|
||||
This mans that you have successfully installed pip on Ubuntu.
|
||||
|
||||
#### Install pip for Python 3
|
||||
|
||||
You have to make sure that Python 3 is installed on Ubuntu. To check that, use this command:
|
||||
|
||||
```
|
||||
python3 --version
|
||||
|
||||
```
|
||||
|
||||
If it shows you a number like Python 3.6.6, Python 3 is installed on your Linux system.
|
||||
|
||||
Now, you can install pip3 using the command below:
|
||||
|
||||
```
|
||||
sudo apt install python3-pip
|
||||
|
||||
```
|
||||
|
||||
You should verify that pip3 has been installed correctly using this command:
|
||||
|
||||
```
|
||||
pip3 --version
|
||||
|
||||
```
|
||||
|
||||
It should show you a number like this:
|
||||
|
||||
```
|
||||
pip 9.0.1 from /usr/lib/python3/dist-packages (python 3.6)
|
||||
|
||||
```
|
||||
|
||||
It means that pip3 is successfully installed on your system.
|
||||
|
||||
### How to use Pip command
|
||||
|
||||
Now that you have installed pip, let’s quickly see some of the basic pip commands. These commands will help you use pip commands for searching, installing and removing Python packages.
|
||||
|
||||
To search packages from the Python Package Index, you can use the following pip command:
|
||||
|
||||
```
|
||||
pip search <search_string>
|
||||
|
||||
```
|
||||
|
||||
For example, if you search or stress, it will show all the packages that have the string ‘stress’ in its name or description.
|
||||
|
||||
```
|
||||
pip search stress
|
||||
stress (1.0.0) - A trivial utility for consuming system resources.
|
||||
s-tui (0.8.2) - Stress Terminal UI stress test and monitoring tool
|
||||
stressypy (0.0.12) - A simple program for calling stress and/or stress-ng from python
|
||||
fuzzing (0.3.2) - Tools for stress testing applications.
|
||||
stressant (0.4.1) - Simple stress-test tool
|
||||
stressberry (0.1.7) - Stress tests for the Raspberry Pi
|
||||
mobbage (0.2) - A HTTP stress test and benchmark tool
|
||||
stresser (0.2.1) - A large-scale stress testing framework.
|
||||
cyanide (1.3.0) - Celery stress testing and integration test support.
|
||||
pysle (1.5.7) - An interface to ISLEX, a pronunciation dictionary with stress markings.
|
||||
ggf (0.3.2) - global geometric factors and corresponding stresses of the optical stretcher
|
||||
pathod (0.17) - A pathological HTTP/S daemon for testing and stressing clients.
|
||||
MatPy (1.0) - A toolbox for intelligent material design, and automatic yield stress determination
|
||||
netblow (0.1.2) - Vendor agnostic network testing framework to stress network failures
|
||||
russtress (0.1.3) - Package that helps you to put lexical stress in russian text
|
||||
switchy (0.1.0a1) - A fast FreeSWITCH control library purpose-built on traffic theory and stress testing.
|
||||
nx4_selenium_test (0.1) - Provides a Python class and apps which monitor and/or stress-test the NoMachine NX4 web interface
|
||||
physical_dualism (1.0.0) - Python library that approximates the natural frequency from stress via physical dualism, and vice versa.
|
||||
fsm_effective_stress (1.0.0) - Python library that uses the rheological-dynamical analogy (RDA) to compute damage and effective buckling stress in prismatic shell structures.
|
||||
processpathway (0.3.11) - A nifty little toolkit to create stress-free, frustrationless image processing pathways from your webcam for computer vision experiments. Or observing your cat.
|
||||
|
||||
```
|
||||
|
||||
If you want to install an application using pip, you can use it in the following manner:
|
||||
|
||||
```
|
||||
pip install <package_name>
|
||||
|
||||
```
|
||||
|
||||
Pip doesn’t support tab completion so the package name should be exact. It will download all the necessary files and installed that package.
|
||||
|
||||
If you want to remove a Python package installed via pip, you can use the remove option in pip.
|
||||
|
||||
```
|
||||
pip uninstall <installed_package_name>
|
||||
|
||||
```
|
||||
|
||||
You can use pip3 instead of pip in the above commands.
|
||||
|
||||
I hope this quick tip helped you to install pip on Ubuntu. If you have any questions or suggestions, please let me know in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-pip-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]: https://itsfoss.com/how-to-add-remove-programs-in-ubuntu/
|
||||
[2]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[3]: https://itsfoss.com/flatpak-guide/
|
||||
[4]: https://itsfoss.com/use-appimage-linux/
|
||||
[5]: https://www.ubuntu.com/
|
||||
[6]: https://en.wikipedia.org/wiki/Pip_(package_manager)
|
||||
[7]: https://pypi.org/project/pip/
|
||||
[8]: https://www.python.org/
|
||||
[9]: https://pypi.org/
|
||||
[10]: https://itsfoss.com/stress-terminal-ui/
|
||||
[11]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/10/install-pip-ubuntu.png
|
||||
@ -0,0 +1,263 @@
|
||||
Turn your book into a website and an ePub using Pandoc
|
||||
======
|
||||
Write once, publish twice using Markdown and Pandoc.
|
||||
|
||||

|
||||
|
||||
Pandoc is a command-line tool for converting files from one markup language to another. In my [introduction to Pandoc][1], I explained how to convert text written in Markdown into a website, a slideshow, and a PDF.
|
||||
|
||||
In this follow-up article, I'll dive deeper into [Pandoc][2], showing how to produce a website and an ePub book from the same Markdown source file. I'll use my upcoming e-book, [GRASP Principles for the Object-Oriented Mind][3], which I created using this process, as an example.
|
||||
|
||||
First I will explain the file structure used for the book, then how to use Pandoc to generate a website and deploy it in GitHub. Finally, I demonstrate how to generate its companion ePub book.
|
||||
|
||||
You can find the code in my [Programming Fight Club][4] GitHub repository.
|
||||
|
||||
### Setting up the writing structure
|
||||
|
||||
I do all of my writing in Markdown syntax. You can also use HTML, but the more HTML you introduce the highest risk that problems arise when Pandoc converts Markdown to an ePub document. My books follow the one-chapter-per-file pattern. Declare chapters using the Markdown heading H1 ( **#** ). You can put more than one chapter in each file, but putting them in separate files makes it easier to find content and do updates later.
|
||||
|
||||
The meta-information follows a similar pattern: each output format has its own meta-information file. Meta-information files define information about your documents, such as text to add to your HTML or the license of your ePub. I store all of my Markdown documents in a folder named parts (this is important for the Makefile that generates the website and ePub). As an example, let's take the table of contents, the preface, and the about chapters (divided into the files toc.md, preface.md, and about.md) and, for clarity, we will leave out the remaining chapters.
|
||||
|
||||
My about file might begin like:
|
||||
|
||||
```
|
||||
# About this book {-}
|
||||
|
||||
## Who should read this book {-}
|
||||
|
||||
Before creating a complex software system one needs to create a solid foundation.
|
||||
General Responsibility Assignment Software Principles (GRASP) are guidelines to assign
|
||||
responsibilities to software classes in object-oriented programming.
|
||||
```
|
||||
|
||||
Once the chapters are finished, the next step is to add meta-information to setup the format for the website and the ePub.
|
||||
|
||||
### Generating the website
|
||||
|
||||
#### Create the HTML meta-information file
|
||||
|
||||
The meta-information file (web-metadata.yaml) for my website is a simple YAML file that contains information about the author, title, rights, content for the **< head>** tag, and content for the beginning and end of the HTML file.
|
||||
|
||||
I recommend (at minimum) including the following fields in the web-metadata.yaml file:
|
||||
|
||||
```
|
||||
---
|
||||
title: <a href="/grasp-principles/toc/">GRASP principles for the Object-oriented mind</a>
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
header-includes:
|
||||
- |
|
||||
\```{=html}
|
||||
<link href="https://fonts.googleapis.com/css?family=Inconsolata" rel="stylesheet">
|
||||
<link href="https://fonts.googleapis.com/css?family=Gentium+Basic|Inconsolata" rel="stylesheet">
|
||||
\```
|
||||
include-before:
|
||||
- |
|
||||
\```{=html}
|
||||
<p>If you like this book, please consider
|
||||
spreading the word or
|
||||
<a href="https://www.buymeacoffee.com/programming">
|
||||
buying me a coffee
|
||||
</a>
|
||||
</p>
|
||||
\```
|
||||
include-after:
|
||||
- |
|
||||
```{=html}
|
||||
<div class="footnotes">
|
||||
<hr>
|
||||
<div class="container">
|
||||
<nav class="pagination" role="pagination">
|
||||
<ul>
|
||||
<p>
|
||||
<span class="page-number">Designed with</span> ❤️ <span class="page-number"> from Uppsala, Sweden</span>
|
||||
</p>
|
||||
<p>
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
</p>
|
||||
</ul>
|
||||
</nav>
|
||||
</div>
|
||||
</div>
|
||||
\```
|
||||
---
|
||||
```
|
||||
|
||||
Some variables to note:
|
||||
|
||||
* The **header-includes** variable contains HTML that will be embedded inside the **< head>** tag.
|
||||
* The line after calling a variable must be **\- |**. The next line must begin with triple backquotes that are aligned with the **|** or Pandoc will reject it. **{=html}** tells Pandoc that this is raw text and should not be processed as Markdown. (For this to work, you need to check that the **raw_attribute** extension in Pandoc is enabled. To check, type **pandoc --list-extensions | grep raw** and make sure the returned list contains an item named **+raw_html** ; the plus sign indicates it is enabled.)
|
||||
* The variable **include-before** adds some HTML at the beginning of your website, and I ask readers to consider spreading the word or buying me a coffee.
|
||||
* The **include-after** variable appends raw HTML at the end of the website and shows my book's license.
|
||||
|
||||
|
||||
|
||||
These are only some of the fields available; take a look at the template variables in HTML (my article [introduction to Pandoc][1] covered this for LaTeX but the process is the same for HTML) to learn about others.
|
||||
|
||||
#### Split the website into chapters
|
||||
|
||||
The website can be generated as a whole, resulting in a long page with all the content, or split into chapters, which I think is easier to read. I'll explain how to divide the website into chapters so the reader doesn't get intimidated by a long website.
|
||||
|
||||
To make the website easy to deploy on GitHub Pages, we need to create a root folder called docs (which is the root folder that GitHub Pages uses by default to render a website). Then we need to create folders for each chapter under docs, place the HTML chapters in their own folders, and the file content in a file named index.html.
|
||||
|
||||
For example, the about.md file is converted to a file named index.html that is placed in a folder named about (about/index.html). This way, when users type **http:// <your-website.com>/about/**, the index.html file from the folder about will be displayed in their browser.
|
||||
|
||||
The following Makefile does all of this:
|
||||
|
||||
```
|
||||
# Your book files
|
||||
DEPENDENCIES= toc preface about
|
||||
|
||||
# Placement of your HTML files
|
||||
DOCS=docs
|
||||
|
||||
all: web
|
||||
|
||||
web: setup $(DEPENDENCIES)
|
||||
@cp $(DOCS)/toc/index.html $(DOCS)
|
||||
|
||||
|
||||
# Creation and copy of stylesheet and images into
|
||||
# the assets folder. This is important to deploy the
|
||||
# website to Github Pages.
|
||||
setup:
|
||||
@mkdir -p $(DOCS)
|
||||
@cp -r assets $(DOCS)
|
||||
|
||||
|
||||
# Creation of folder and index.html file on a
|
||||
# per-chapter basis
|
||||
|
||||
$(DEPENDENCIES):
|
||||
@mkdir -p $(DOCS)/$@
|
||||
@pandoc -s --toc web-metadata.yaml parts/$@.md \
|
||||
-c /assets/pandoc.css -o $(DOCS)/$@/index.html
|
||||
|
||||
clean:
|
||||
@rm -rf $(DOCS)
|
||||
|
||||
.PHONY: all clean web setup
|
||||
```
|
||||
|
||||
The option **-c /assets/pandoc.css** declares which CSS stylesheet to use; it will be fetched from **/assets/pandoc.css**. In other words, inside the **< head>** HTML tag, Pandoc adds the following line:
|
||||
|
||||
```
|
||||
<link rel="stylesheet" href="/assets/pandoc.css">
|
||||
```
|
||||
|
||||
To generate the website, type:
|
||||
|
||||
```
|
||||
make
|
||||
```
|
||||
|
||||
The root folder should contain now the following structure and files:
|
||||
|
||||
```
|
||||
.---parts
|
||||
| |--- toc.md
|
||||
| |--- preface.md
|
||||
| |--- about.md
|
||||
|
|
||||
|---docs
|
||||
|--- assets/
|
||||
|--- index.html
|
||||
|--- toc
|
||||
| |--- index.html
|
||||
|
|
||||
|--- preface
|
||||
| |--- index.html
|
||||
|
|
||||
|--- about
|
||||
|--- index.html
|
||||
|
||||
```
|
||||
|
||||
#### Deploy the website
|
||||
|
||||
To deploy the website on GitHub, follow these steps:
|
||||
|
||||
1. Create a new repository
|
||||
2. Push your content to the repository
|
||||
3. Go to the GitHub Pages section in the repository's Settings and select the option for GitHub to use the content from the Master branch
|
||||
|
||||
|
||||
|
||||
You can get more details on the [GitHub Pages][5] site.
|
||||
|
||||
Check out [my book's website][6], generated using this process, to see the result.
|
||||
|
||||
### Generating the ePub book
|
||||
|
||||
#### Create the ePub meta-information file
|
||||
|
||||
The ePub meta-information file, epub-meta.yaml, is similar to the HTML meta-information file. The main difference is that ePub offers other template variables, such as **publisher** and **cover-image**. Your ePub book's stylesheet will probably differ from your website's; mine uses one named epub.css.
|
||||
|
||||
```
|
||||
---
|
||||
title: 'GRASP principles for the Object-oriented Mind'
|
||||
publisher: 'Programming Language Fight Club'
|
||||
author: Kiko Fernandez-Reyes
|
||||
rights: 2017 Kiko Fernandez-Reyes, CC-BY-NC-SA 4.0 International
|
||||
cover-image: assets/cover.png
|
||||
stylesheet: assets/epub.css
|
||||
...
|
||||
```
|
||||
|
||||
Add the following content to the previous Makefile:
|
||||
|
||||
```
|
||||
epub:
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
$(addprefix parts/, $(DEPENDENCIES:=.md)) -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
The command for the ePub target takes all the dependencies from the HTML version (your chapter names), appends to them the Markdown extension, and prepends them with the path to the folder chapters' so Pandoc knows how to process them. For example, if **$(DEPENDENCIES)** was only **preface about** , then the Makefile would call:
|
||||
|
||||
```
|
||||
@pandoc -s --toc epub-meta.yaml \
|
||||
parts/preface.md parts/about.md -o $(DOCS)/assets/book.epub
|
||||
```
|
||||
|
||||
Pandoc would take these two chapters, combine them, generate an ePub, and place the book under the Assets folder.
|
||||
|
||||
Here's an [example][7] of an ePub created using this process.
|
||||
|
||||
### Summarizing the process
|
||||
|
||||
The process to create a website and an ePub from a Markdown file isn't difficult, but there are a lot of details. The following outline may make it easier for you to follow.
|
||||
|
||||
* HTML book:
|
||||
* Write chapters in Markdown
|
||||
* Add metadata
|
||||
* Create a Makefile to glue pieces together
|
||||
* Set up GitHub Pages
|
||||
* Deploy
|
||||
* ePub book:
|
||||
* Reuse chapters from previous work
|
||||
* Add new metadata file
|
||||
* Create a Makefile to glue pieces together
|
||||
* Set up GitHub Pages
|
||||
* Deploy
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/book-to-website-epub-using-pandoc
|
||||
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kikofernandez
|
||||
[1]: https://opensource.com/article/18/9/intro-pandoc
|
||||
[2]: https://pandoc.org/
|
||||
[3]: https://www.programmingfightclub.com/
|
||||
[4]: https://github.com/kikofernandez/programmingfightclub
|
||||
[5]: https://pages.github.com/
|
||||
[6]: https://www.programmingfightclub.com/grasp-principles/
|
||||
[7]: https://github.com/kikofernandez/programmingfightclub/raw/master/docs/web_assets/demo.epub
|
||||
@ -0,0 +1,76 @@
|
||||
4 open source invoicing tools for small businesses
|
||||
======
|
||||
Manage your billing and get paid with easy-to-use, web-based invoicing software.
|
||||
|
||||

|
||||
|
||||
No matter what your reasons for starting a small business, the key to keeping that business going is getting paid. Getting paid usually means sending a client an invoice.
|
||||
|
||||
It's easy enough to whip up an invoice using LibreOffice Writer or LibreOffice Calc, but sometimes you need a bit more. A more professional look. A way of keeping track of your invoices. Reminders about when to follow up on the invoices you've sent.
|
||||
|
||||
There's a wide range of commercial and closed-source invoicing tools out there. But the offerings on the open source side of the fence are just as good, and maybe even more flexible, than their closed source counterparts.
|
||||
|
||||
Let's take a look at four web-based open source invoicing tools that are great choices for freelancers and small businesses on a tight budget. I reviewed two of them in 2014, in an [earlier version][1] of this article. These four picks are easy to use and you can use them on just about any device.
|
||||
|
||||
### Invoice Ninja
|
||||
|
||||
I've never been a fan of the term ninja. Despite that, I like [Invoice Ninja][2]. A lot. It melds a simple interface with a set of features that let you create, manage, and send invoices to clients and customers.
|
||||
|
||||
You can easily configure multiple clients, track payments and outstanding invoices, generate quotes, and email invoices. What sets Invoice Ninja apart from its competitors is its [integration with][3] over 40 online popular payment gateways, including PayPal, Stripe, WePay, and Apple Pay.
|
||||
|
||||
[Download][4] a version that you can install on your own server or get an account with the [hosted version][5] of Invoice Ninja. There's a free version and a paid tier that will set you back US$ 8 a month.
|
||||
|
||||
### InvoicePlane
|
||||
|
||||
Once upon a time, there was a nifty open source invoicing tool called FusionInvoice. One day, its creators took the latest version of the code proprietary. That didn't end happily, as FusionInvoice's doors were shut for good in 2018. But that wasn't the end of the application. An old version of the code stayed open source and morphed into [InvoicePlane][6], which packs all of FusionInvoice's goodness.
|
||||
|
||||
Creating an invoice takes just a couple of clicks. You can make them as minimal or detailed as you need. When you're ready, you can email your invoices or output them as PDFs. You can also create recurring invoices for clients or customers you regularly bill.
|
||||
|
||||
InvoicePlane does more than generate and track invoices. You can also create quotes for jobs or goods, track products you sell, view and enter payments, and run reports on your invoices.
|
||||
|
||||
[Grab the code][7] and install it on your web server. Or, if you're not quite ready to do that, [take the demo][8] for a spin.
|
||||
|
||||
### OpenSourceBilling
|
||||
|
||||
Described by its developer as "beautifully simple billing software," [OpenSourceBilling][9] lives up to the description. It has one of the cleanest interfaces I've seen, which makes configuring and using the tool a breeze.
|
||||
|
||||
OpenSourceBilling stands out because of its dashboard, which tracks your current and past invoices, as well as any outstanding amounts. Your information is broken up into graphs and tables, which makes it easy to follow.
|
||||
|
||||
You do much of the configuration on the invoice itself. You can add items, tax rates, clients, and even payment terms with a click and a few keystrokes. OpenSourceBilling saves that information across all of your invoices, both new and old.
|
||||
|
||||
As with some of the other tools we've looked at, OpenSourceBilling has a [demo][10] you can try.
|
||||
|
||||
### BambooInvoice
|
||||
|
||||
When I was a full-time freelance writer and consultant, I used [BambooInvoice][11] to bill my clients. When its original developer stopped working on the software, I was a bit disappointed. But BambooInvoice is back, and it's as good as ever.
|
||||
|
||||
What attracted me to BambooInvoice is its simplicity. It does one thing and does it well. You can create and edit invoices, and BambooInvoice keeps track of them by client and by the invoice numbers you assign to them. It also lets you know which invoices are open or overdue. You can email the invoices from within the application or generate PDFs. You can also run reports to keep tabs on your income.
|
||||
|
||||
To [install][12] and use BambooInvoice, you'll need a web server running PHP 5 or newer as well as a MySQL database. Chances are you already have access to one, so you're good to go.
|
||||
|
||||
Do you have a favorite open source invoicing tool? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/open-source-invoicing-tools
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://opensource.com/business/14/9/4-open-source-invoice-tools
|
||||
[2]: https://www.invoiceninja.org/
|
||||
[3]: https://www.invoiceninja.com/integrations/
|
||||
[4]: https://github.com/invoiceninja/invoiceninja
|
||||
[5]: https://www.invoiceninja.com/invoicing-pricing-plans/
|
||||
[6]: https://invoiceplane.com/
|
||||
[7]: https://wiki.invoiceplane.com/en/1.5/getting-started/installation
|
||||
[8]: https://demo.invoiceplane.com/
|
||||
[9]: http://www.opensourcebilling.org/
|
||||
[10]: http://demo.opensourcebilling.org/
|
||||
[11]: https://www.bambooinvoice.net/
|
||||
[12]: https://sourceforge.net/projects/bambooinvoice/
|
||||
@ -0,0 +1,76 @@
|
||||
How to use the SSH and SFTP protocols on your home network
|
||||
======
|
||||
|
||||
Use the SSH and SFTP protocols to access other devices, efficiently and securely transfer files, and more.
|
||||
|
||||

|
||||
|
||||
Years ago, I decided to set up an extra computer (I always have extra computers) so that I could access it from work to transfer files I might need. To do this, the basic first step is to have your ISP assign a fixed IP address.
|
||||
|
||||
The not-so-basic but much more important next step is to set up your accessible system safely. In this particular case, I was planning to access it only from work, so I could restrict access to that IP address. Even so, you want to use all possible security features. What is amazing—and scary—is that as soon as you set this up, people from all over the world will immediately attempt to access your system. You can discover this by checking the logs. I presume there are bots constantly searching for open doors wherever they can find them.
|
||||
|
||||
Not long after I set up my computer, I decided my access was more a toy than a need, so I turned it off and gave myself one less thing to worry about. Nonetheless, there is another use for SSH and SFTP inside your home network, and it is more or less already set up for you.
|
||||
|
||||
One requirement, of course, is that the other computer in your home must be turned on, although it doesn’t matter whether someone is logged on or not. You also need to know its IP address. There are two ways to find this out. One is to get access to the router, which you can do through a browser. Typically, its address is something like **192.168.1.254**. With some searching, it should be easy enough to find out what is currently on and hooked up to the system by eth0 or WiFi. What can be challenging is recognizing the computer you’re interested in.
|
||||
|
||||
I find it easier to go to the computer in question, bring up a shell, and type:
|
||||
|
||||
```
|
||||
ifconfig
|
||||
|
||||
```
|
||||
|
||||
This spits out a lot of information, but the bit you want is right after `inet` and might look something like **192.168.1.234**. After you find that, go back to the client computer you want to access this host, and on the command line, type:
|
||||
|
||||
```
|
||||
ssh gregp@192.168.1.234
|
||||
|
||||
```
|
||||
|
||||
For this to work, **gregp** must be a valid user on that system. You will then be asked for his password, and if you enter it correctly, you will be connected to that other computer in a shell environment. I confess that I don’t use SSH in this way very often. I have used it at times so I can run `dnf` to upgrade some other computer than the one I’m sitting at. Usually, I use SFTP:
|
||||
|
||||
```
|
||||
sftp gregp@192.168.1.234
|
||||
|
||||
```
|
||||
|
||||
because I have a greater need for an easy method of transferring files from one computer to another. It’s certainly more convenient and less time-consuming than using a USB stick or an external drive.
|
||||
|
||||
`get`, to receive files from the host; and `put`, to send files to the host. I usually migrate to the directory on my client where I either want to save files I will get from the host or send to the host before I connect. When you connect, you will be in the top-level directory—in this example, **home/gregp**. Once connected, you can then use `cd` just as you would in your client, except now you’re changing your working directory on the host. You may need to use `ls` to make sure you know where you are.
|
||||
|
||||
Once you’re connected, the two basic commands for SFTP are, to receive files from the host; and, to send files to the host. I usually migrate to the directory on my client where I either want to save files I will get from the host or send to the host before I connect. When you connect, you will be in the top-level directory—in this example,. Once connected, you can then usejust as you would in your client, except now you’re changing your working directory on the host. You may need to useto make sure you know where you are.
|
||||
|
||||
If you need to change the working directory on your client, use the command `lcd` (as in **local change directory** ). Similarly, use `lls` to show the working directory contents on your client system.
|
||||
|
||||
What if the host doesn’t have a directory with the name you would like? Use `mkdir` to make a new directory on it. Or you might copy a whole directory of files to the host with this:
|
||||
|
||||
```
|
||||
put -r ThisDir/
|
||||
|
||||
```
|
||||
|
||||
which creates the directory and then copies all of its files and subdirectories to the host. These transfers are extremely fast, as fast as your hardware allows, and have none of the bottlenecks you might encounter on the internet. To see a list of commands you can use in an SFTP session, check:
|
||||
|
||||
```
|
||||
man sftp
|
||||
|
||||
```
|
||||
|
||||
I have also been able to put SFTP to use on a Windows VM on my computer, yet another advantage of setting up a VM rather than a dual-boot system. This lets me move files to or from the Linux part of the system. So far I have only done this using a client in Windows.
|
||||
|
||||
You can also use SSH and SFTP to access any devices connected to your router by wire or WiFi. For a while, I used an app called [SSHDroid][1], which runs SSH in a passive mode. In other words, you use your computer to access the Android device that is the host. Recently I found another app, [Admin Hands][2], where the tablet or phone is the client and can be used for either SSH or SFTP operations. This app is great for backing up or sharing photos from your phone.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/ssh-sftp-home-network
|
||||
|
||||
作者:[Geg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[1]: https://play.google.com/store/apps/details?id=berserker.android.apps.sshdroid
|
||||
[2]: https://play.google.com/store/apps/details?id=com.arpaplus.adminhands&hl=en_US
|
||||
70
sources/tech/20181003 Introducing Swift on Fedora.md
Normal file
70
sources/tech/20181003 Introducing Swift on Fedora.md
Normal file
@ -0,0 +1,70 @@
|
||||
Introducing Swift on Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Swift is a general-purpose programming language built using a modern approach to safety, performance, and software design patterns. It aims to be the best language for a variety of programming projects, ranging from systems programming to desktop applications and scaling up to cloud services. Read more about it and how to try it out in Fedora.
|
||||
|
||||
### Safe, Fast, Expressive
|
||||
|
||||
Like many modern programming languages, Swift was designed to be safer than C-based languages. For example, variables are always initialized before they can be used. Arrays and integers are checked for overflow. Memory is automatically managed.
|
||||
|
||||
Swift puts intent right in the syntax. To declare a variable, use the var keyword. To declare a constant, use let.
|
||||
|
||||
Swift also guarantees that objects can never be nil; in fact, trying to use an object known to be nil will cause a compile-time error. When using a nil value is appropriate, it supports a mechanism called **optionals**. An optional may contain nil, but is safely unwrapped using the **?** operator.
|
||||
|
||||
Some additional features include:
|
||||
|
||||
* Closures unified with function pointers
|
||||
* Tuples and multiple return values
|
||||
* Generics
|
||||
* Fast and concise iteration over a range or collection
|
||||
* Structs that support methods, extensions, and protocols
|
||||
* Functional programming patterns, e.g., map and filter
|
||||
* Powerful error handling built-in
|
||||
* Advanced control flow with do, guard, defer, and repeat keywords
|
||||
|
||||
|
||||
|
||||
### Try Swift out
|
||||
|
||||
Swift is available in Fedora 28 under then package name **swift-lang**. Once installed, run swift and the REPL console starts up.
|
||||
|
||||
```
|
||||
$ swift
|
||||
Welcome to Swift version 4.2 (swift-4.2-RELEASE). Type :help for assistance.
|
||||
1> let greeting="Hello world!"
|
||||
greeting: String = "Hello world!"
|
||||
2> print(greeting)
|
||||
Hello world!
|
||||
3> greeting = "Hello universe!"
|
||||
error: repl.swift:3:10: error: cannot assign to value: 'greeting' is a 'let' constant
|
||||
greeting = "Hello universe!"
|
||||
~~~~~~~~ ^
|
||||
|
||||
|
||||
3>
|
||||
|
||||
```
|
||||
|
||||
Swift has a growing community, and in particular, a [work group][1] dedicated to making it an efficient and effective server-side programming language. Be sure to visit [its home page][2] for more ways to get involved.
|
||||
|
||||
Photo by [Uillian Vargas][3] on [Unsplash][4].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/introducing-swift-fedora/
|
||||
|
||||
作者:[Link Dupont][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/linkdupont/
|
||||
[1]: https://swift.org/server/
|
||||
[2]: http://swift.org
|
||||
[3]: https://unsplash.com/photos/7oJpVR1inGk?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[4]: https://unsplash.com/search/photos/fast?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,128 @@
|
||||
Oomox – Customize And Create Your Own GTK2, GTK3 Themes
|
||||
======
|
||||
|
||||

|
||||
|
||||
Theming and Visual customization is one of the main advantages of Linux. Since all the code is open, you can change how your Linux system looks and behaves to a greater degree than you ever could with Windows/Mac OS. GTK theming is perhaps the most popular way in which people customize their Linux desktops. The GTK toolkit is used by a wide variety of desktop environments like Gnome, Cinnamon, Unity, XFCE, and budgie. This means that a single theme made for GTK can be applied to any of these Desktop Environments with little changes.
|
||||
|
||||
There are a lot of very high quality popular GTK themes out there, such as **Arc** , **Numix** , and **Adapta**. But if you want to customize these themes and create your own visual design, you can use **Oomox**.
|
||||
|
||||
The Oomox is a graphical app for customizing and creating your own GTK theme complete with your own color, icon and terminal style. It comes with several presets, which you can apply on a Numix, Arc, or Materia style theme to create your own GTK theme.
|
||||
|
||||
### Installing Oomox
|
||||
|
||||
On Arch Linux and its variants:
|
||||
|
||||
Oomox is available on [**AUR**][1], so you can install it using any AUR helper programs like [**Yay**][2].
|
||||
|
||||
```
|
||||
$ yay -S oomox
|
||||
|
||||
```
|
||||
|
||||
On Debian/Ubuntu/Linux Mint, download `oomox.deb`package from [**here**][3] and install it as shown below. As of writing this guide, the latest version was **oomox_1.7.0.5.deb**.
|
||||
|
||||
```
|
||||
$ sudo dpkg -i oomox_1.7.0.5.deb
|
||||
$ sudo apt install -f
|
||||
|
||||
```
|
||||
|
||||
On Fedora, Oomox is available in third-party **COPR** repository.
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable tcg/themes
|
||||
$ sudo dnf install oomox
|
||||
|
||||
```
|
||||
|
||||
Oomox is also available as a [**Flatpak app**][4]. Make sure you have installed Flatpak as described in [**this guide**][5]. And then, install and run Oomox using the following commands:
|
||||
|
||||
```
|
||||
$ flatpak install flathub com.github.themix_project.Oomox
|
||||
|
||||
$ flatpak run com.github.themix_project.Oomox
|
||||
|
||||
```
|
||||
|
||||
For other Linux distributions, go to the Oomox project page (Link is given at the end of this guide) on Github and compile and install it manually from source.
|
||||
|
||||
### Customize And Create Your Own GTK2, GTK3 Themes
|
||||
|
||||
**Theme Customization**
|
||||
|
||||
|
||||
|
||||
You can change the colour of practically every UI element, like:
|
||||
|
||||
1. Headers
|
||||
2. Buttons
|
||||
3. Buttons inside Headers
|
||||
4. Menus
|
||||
5. Selected Text
|
||||
|
||||
|
||||
|
||||
To the left, there are a number of presets, like the Cars theme, modern themes like Materia, and Numix, and retro themes. Then, at the top of the main window, there’s an option called **Theme Style** , that lets you set the overall visual style of the theme. You can choose from between Numix, Arc, and Materia.
|
||||
|
||||
With certain styles like Numix, you can even change things like the Header Gradient, Outline Width and Panel Opacity. You can also add a Dark Mode for your theme that will be automatically created from the default theme.
|
||||
|
||||
|
||||
|
||||
**Iconset Customization**
|
||||
|
||||
You can customize the iconset that will be used for the theme icons. There are 2 options – Gnome Colors and Archdroid. You an change the base, and stroke colours of the iconset.
|
||||
|
||||
**Terminal Customization**
|
||||
|
||||
You can also customize the terminal colours. The app has several presets for this, but you can customize the exact colour code for each colour value like red, green,black, and so on. You can also auto swap the foreground and background colours.
|
||||
|
||||
**Spotify Theme**
|
||||
|
||||
A unique feature this app has is that you can theme the spotify app to your liking. You can change the foreground, background, and accent color of the spotify app to match the overall GTK theme.
|
||||
|
||||
Then, just press the **Apply Spotify Theme** button, and you’ll get this window:
|
||||
|
||||
|
||||
|
||||
Just hit apply, and you’re done.
|
||||
|
||||
**Exporting your Theme**
|
||||
|
||||
Once you’re done customizing the theme to your liking, you can rename it by clicking the rename button at the top left:
|
||||
|
||||

|
||||
|
||||
And then, just hit **Export Theme** to export the theme to your system.
|
||||
|
||||
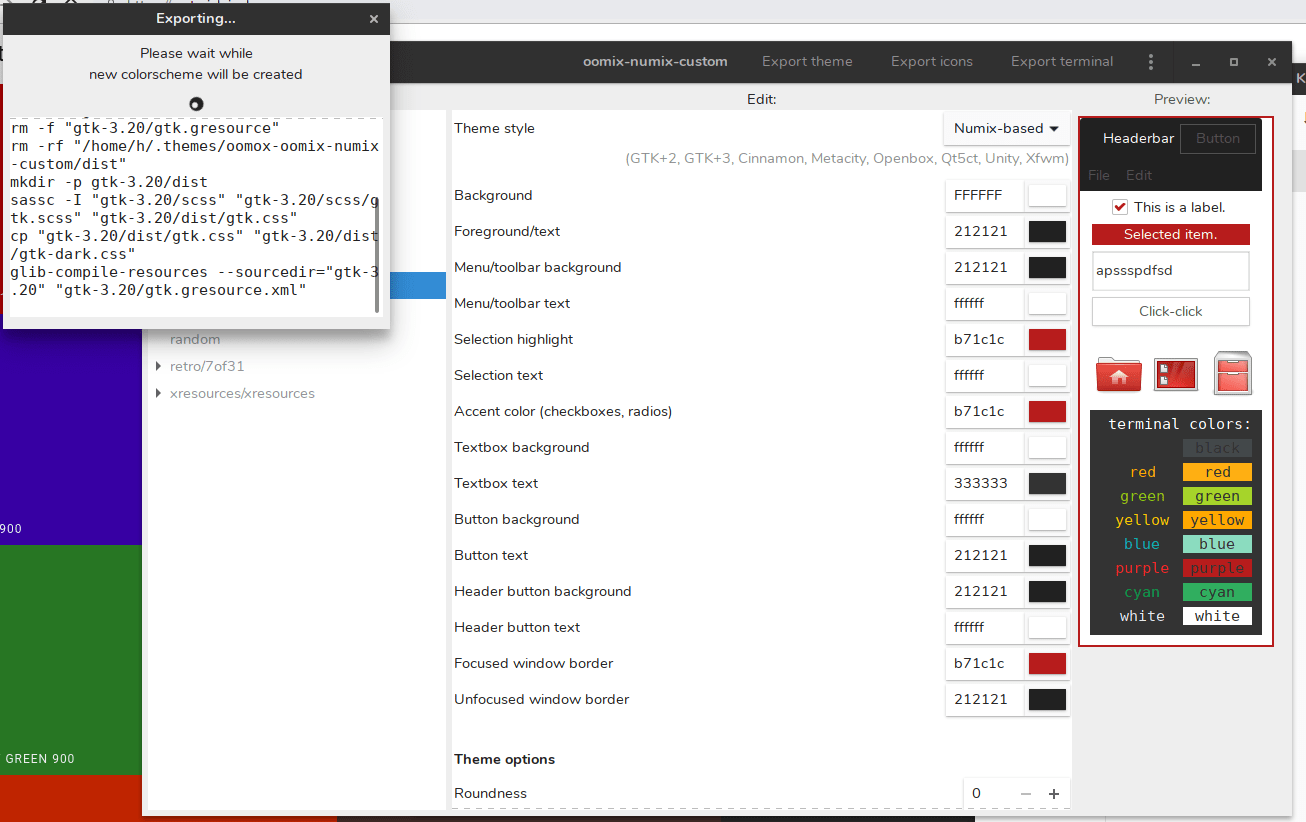
|
||||
|
||||
You can also just export just the Iconset or the terminal theme.
|
||||
|
||||
After this, you can open any Visual Customization app for your Desktop Environment, like Tweaks for Gnome based DEs, or the **XFCE Appearance Settings** , and select your exported GTK and Shell theme.
|
||||
|
||||
### Verdict
|
||||
|
||||
If you are a Linux theme junkie, and you know exactly how each button, how each header in your system should look like, Oomox is worth a look. For extreme customizers, it lets you change virtually everything about how your system looks. For people who just want to tweak an existing theme a little bit, it has many, many presets so you can get what you want without a lot of effort.
|
||||
|
||||
Have you tried it? What are your thoughts on Oomox? Put them in the comments below!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/oomox-customize-and-create-your-own-gtk2-gtk3-themes/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://aur.archlinux.org/packages/oomox/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[3]: https://github.com/themix-project/oomox/releases
|
||||
[4]: https://flathub.org/apps/details/com.github.themix_project.Oomox
|
||||
[5]: https://www.ostechnix.com/flatpak-new-framework-desktop-applications-linux/
|
||||
@ -0,0 +1,171 @@
|
||||
Terminalizer – A Tool To Record Your Terminal And Generate Animated Gif Images
|
||||
======
|
||||
This is know topic for most of us and i don’t want to give you the detailed information about this flow. Also, we had written many article under this topics.
|
||||
|
||||
Script command is the one of the standard command to record Linux terminal sessions. Today we are going to discuss about same kind of tool called Terminalizer.
|
||||
|
||||
This tool will help us to record the users terminal activity, also will help us to identify other useful information from the output.
|
||||
|
||||
### What Is Terminalizer
|
||||
|
||||
Terminalizer allow users to record their terminal activity and allow them to generate animated gif images. It’s highly customizable CLI tool that user can share a link for an online player, web player for a recording file.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Script – A Simple Command To Record Your Terminal Session Activity][1]
|
||||
**(#)** [Automatically Record/Capture All Users Terminal Sessions Activity In Linux][2]
|
||||
**(#)** [Teleconsole – A Tool To Share Your Terminal Session Instantly To Anyone In Seconds][3]
|
||||
**(#)** [tmate – Instantly Share Your Terminal Session To Anyone In Seconds][4]
|
||||
**(#)** [Peek – Create a Animated GIF Recorder in Linux][5]
|
||||
**(#)** [Kgif – A Simple Shell Script to Create a Gif File from Active Window][6]
|
||||
**(#)** [Gifine – Quickly Create An Animated GIF Video In Ubuntu/Debian][7]
|
||||
|
||||
There is no distribution official package to install this utility and we can easily install it by using Node.js.
|
||||
|
||||
### How To Install Noje.js in Linux
|
||||
|
||||
Node.js can be installed in multiple ways. Here, we are going to teach you the standard method.
|
||||
|
||||
For Ubuntu/LinuxMint use [APT-GET Command][8] or [APT Command][9] to install Node.js
|
||||
|
||||
```
|
||||
$ curl -sL https://deb.nodesource.com/setup_8.x | sudo -E bash -
|
||||
$ sudo apt-get install -y nodejs
|
||||
|
||||
```
|
||||
|
||||
For Debian use [APT-GET Command][8] or [APT Command][9] to install Node.js
|
||||
|
||||
```
|
||||
# curl -sL https://deb.nodesource.com/setup_8.x | bash -
|
||||
# apt-get install -y nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`RHEL/CentOS`** , use [YUM Command][10] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo curl --silent --location https://rpm.nodesource.com/setup_8.x | sudo bash -
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum -y install nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`Fedora`** , use [DNF Command][11] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo dnf install nodejs
|
||||
|
||||
```
|
||||
|
||||
For **`Arch Linux`** , use [Pacman Command][12] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo pacman -S nodejs npm
|
||||
|
||||
```
|
||||
|
||||
For **`openSUSE`** , use [Zypper Command][13] to install tmux.
|
||||
|
||||
```
|
||||
$ sudo zypper in nodejs6
|
||||
|
||||
```
|
||||
|
||||
### How to Install Terminalizer
|
||||
|
||||
As you have already installed prerequisite package called Node.js, now it’s time to install Terminalizer on your system. Simple run the below npm command to install Terminalizer.
|
||||
|
||||
```
|
||||
$ sudo npm install -g terminalizer
|
||||
|
||||
```
|
||||
|
||||
### How to Use Terminalizer
|
||||
|
||||
To record your session activity using Terminalizer, just run the following Terminalizer command. Once you started the recording then play around it and finally hit `CTRL+D` to exit and save the recording.
|
||||
|
||||
```
|
||||
# terminalizer record 2g-session
|
||||
|
||||
defaultConfigPath
|
||||
The recording session is started
|
||||
Press CTRL+D to exit and save the recording
|
||||
|
||||
```
|
||||
|
||||
This will save your recording session as a YAML file, in this case my filename would be 2g-session-activity.yml.
|
||||
![][15]
|
||||
|
||||
Just type few commands to verify this and finally hit `CTRL+D` to exit the current capture. When you hit `CTRL+D` on the terminal and you will be getting the below output.
|
||||
|
||||
```
|
||||
# logout
|
||||
Successfully Recorded
|
||||
The recording data is saved into the file:
|
||||
/home/daygeek/2g-session.yml
|
||||
You can edit the file and even change the configurations.
|
||||
|
||||
```
|
||||
|
||||
![][16]
|
||||
|
||||
### How to Play the Recorded File
|
||||
|
||||
Use the below command format to paly your recorded YAML file. Make sure, you have to input your recorded file instead of us.
|
||||
|
||||
```
|
||||
# terminalizer play 2g-session
|
||||
|
||||
```
|
||||
|
||||
Render a recording file as an animated gif image.
|
||||
|
||||
```
|
||||
# terminalizer render 2g-session
|
||||
|
||||
```
|
||||
|
||||
`Note:` Below two commands are not implemented yet in the current version and will be available in the next version.
|
||||
|
||||
If you would like to share your recording to others then upload a recording file and get a link for an online player and share it.
|
||||
|
||||
```
|
||||
terminalizer share 2g-session
|
||||
|
||||
```
|
||||
|
||||
Generate a web player for a recording file
|
||||
|
||||
```
|
||||
# terminalizer generate 2g-session
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/terminalizer-a-tool-to-record-your-terminal-and-generate-animated-gif-images/
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/prakash/
|
||||
[1]: https://www.2daygeek.com/script-command-record-save-your-terminal-session-activity-linux/
|
||||
[2]: https://www.2daygeek.com/automatically-record-all-users-terminal-sessions-activity-linux-script-command/
|
||||
[3]: https://www.2daygeek.com/teleconsole-share-terminal-session-instantly-to-anyone-in-seconds/
|
||||
[4]: https://www.2daygeek.com/tmate-instantly-share-your-terminal-session-to-anyone-in-seconds/
|
||||
[5]: https://www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[6]: https://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
[7]: https://www.2daygeek.com/gifine-create-animated-gif-vedio-recorder-linux-mint-debian-ubuntu/
|
||||
[8]: https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[9]: https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[10]: https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||
[11]: https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[12]: https://www.2daygeek.com/pacman-command-examples-manage-packages-arch-linux-system/
|
||||
[13]: https://www.2daygeek.com/zypper-command-examples-manage-packages-opensuse-system/
|
||||
[14]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[15]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-record-2g-session-1.gif
|
||||
[16]: https://www.2daygeek.com/wp-content/uploads/2018/10/terminalizer-play-2g-session.gif
|
||||
@ -0,0 +1,110 @@
|
||||
KeeWeb – An Open Source, Cross Platform Password Manager
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you’ve been using the internet for any amount of time, chances are, you have a lot of accounts on a lot of websites. All of those accounts must have passwords, and you have to remember all those passwords. Either that, or write them down somewhere. Writing down passwords on paper may not be secure, and remembering them won’t be practically possible if you have more than a few passwords. This is why Password Managers have exploded in popularity in the last few years. A password Manager is like a central repository where you store all your passwords for all your accounts, and you lock it with a master password. With this approach, the only thing you need to remember is the Master password.
|
||||
|
||||
**KeePass** is one such open source password manager. KeePass has an official client, but it’s pretty barebones. But there are a lot of other apps, both for your computer and for your phone, that are compatible with the KeePass file format for storing encrypted passwords. One such app is **KeeWeb**.
|
||||
|
||||
KeeWeb is an open source, cross platform password manager with features like cloud sync, keyboard shortcuts and plugin support. KeeWeb uses Electron, which means it runs on Windows, Linux, and Mac OS.
|
||||
|
||||
### Using KeeWeb Password Manager
|
||||
|
||||
When it comes to using KeeWeb, you actually have 2 options. You can either use KeeWeb webapp without having to install it on your system and use it on the fly or simply install KeeWeb client in your local system.
|
||||
|
||||
**Using the KeeWeb webapp**
|
||||
|
||||
If you don’t want to bother installing a desktop app, you can just go to [**https://app.keeweb.info/**][1] and use it as a password manager.
|
||||
|
||||
|
||||
|
||||
It has all the features of the desktop app. Obviously, this requires you to be online when using the app.
|
||||
|
||||
**Installing KeeWeb on your Desktop**
|
||||
|
||||
If you like the comfort and offline availability of using a desktop app, you can also install it on your desktop.
|
||||
|
||||
If you use Ubuntu/Debian, you can just go to [**releases pages**][2] and download KeeWeb latest **.deb** file, which you can install via this command:
|
||||
|
||||
```
|
||||
$ sudo dpkg -i KeeWeb-1.6.3.linux.x64.deb
|
||||
|
||||
```
|
||||
|
||||
If you’re on Arch, it is available in the [**AUR**][3], so you can install using any helper programs like [**Yay**][4]:
|
||||
|
||||
```
|
||||
$ yay -S keeweb
|
||||
|
||||
```
|
||||
|
||||
Once installed, launch it from Menu or application launcher. This is how KeeWeb default interface looks like:
|
||||
|
||||
|
||||
|
||||
### General Layout
|
||||
|
||||
KeeWeb basically shows a list of all your passwords, along with all your tags to the left. Clicking on a tag will filter the list to only passwords of that tag. To the right, all the fields for the selected account are shown. You can set username, password, website, or just add a custom note. You can even create your own fields and mark them as secure fields, which is great when storing things like credit card information. You can copy passwords by just clicking on them. KeeWeb also shows the date when an account was created and modified. Deleted passwords are kept in the trash, where they can be restored or permanently deleted.
|
||||
|
||||

|
||||
|
||||
### KeeWeb Features
|
||||
|
||||
**Cloud Sync**
|
||||
|
||||
One of the main features of KeeWeb is the support for a wide variety of remote locations and cloud services.
|
||||
Other than loading local files, you can open files from:
|
||||
|
||||
1. WebDAV Servers
|
||||
2. Google Drive
|
||||
3. Dropbox
|
||||
4. OneDrive
|
||||
|
||||
|
||||
|
||||
This means that if you use multiple computers, you can synchronize the password files between them, so you don’t have to worry about not having all the passwords available on all devices.
|
||||
|
||||
**Password Generator**
|
||||
|
||||
|
||||
|
||||
Along with encrypting your passwords, it’s also important to create new, strong passwords for every single account. This means that if one of your account gets hacked, the attacker won’t be able to get in to your other accounts using the same password.
|
||||
|
||||
To achieve this, KeeWeb has a built-in password generator, that lets you generate a custom password of a specific length, including specific type of characters.
|
||||
|
||||
**Plugins**
|
||||
|
||||
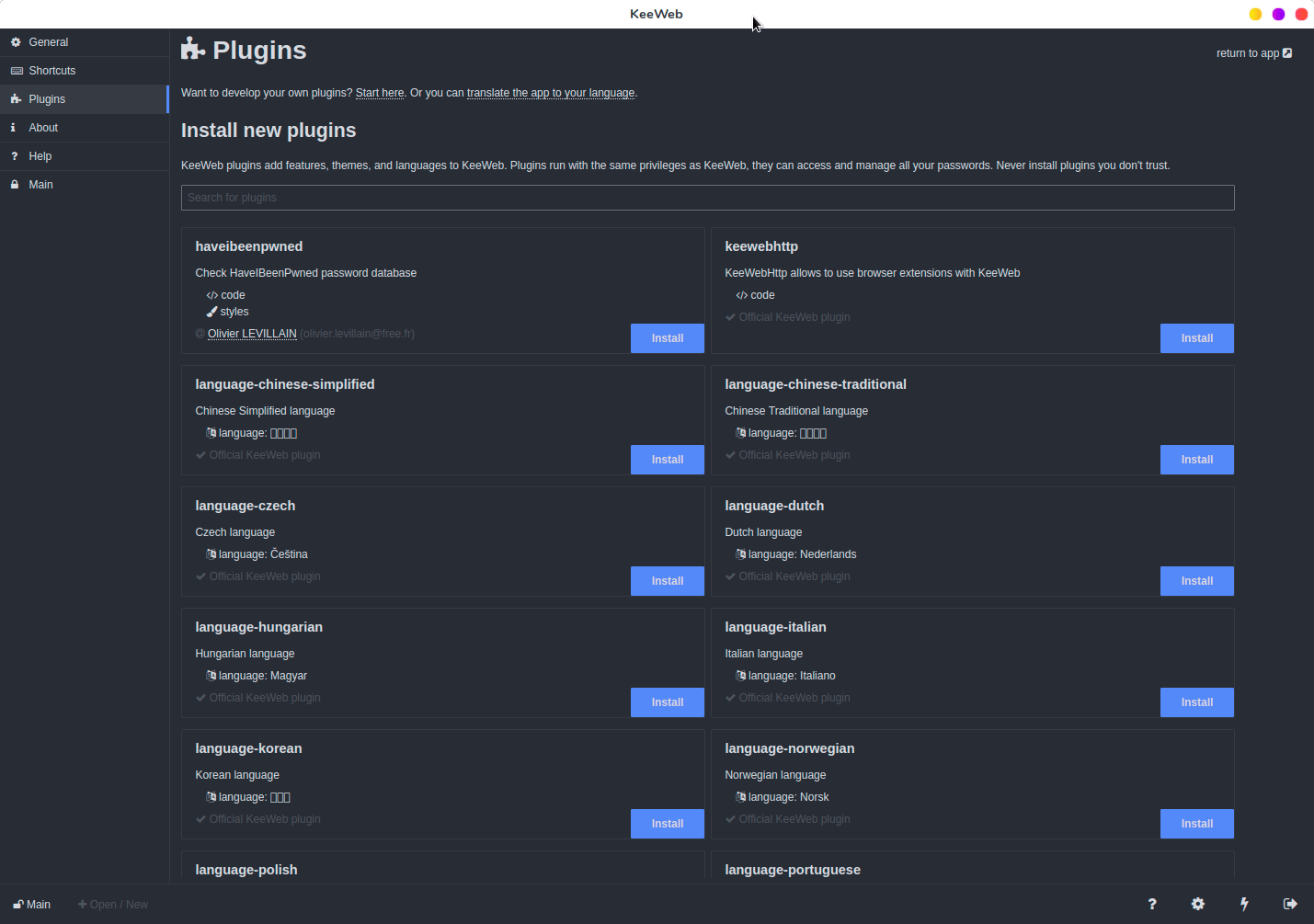
|
||||
|
||||
You can extend KeeWeb functionality with plugins. Some of these plugins are translations for other languages, while others add new functionality, like checking **<https://haveibeenpwned.com>** for exposed passwords.
|
||||
|
||||
**Local Backups**
|
||||
|
||||
|
||||
|
||||
Regardless of where your password file is stored, you should probably keep local backups of the file on your computer. Luckily, KeeWeb has this feature built-in. You can backup to a specific path, and set it to backup periodically, or just whenever the file is changed.
|
||||
|
||||
|
||||
### Verdict
|
||||
|
||||
I have actually been using KeeWeb for several years now. It completely changed the way I store my passwords. The cloud sync is basically the feature that makes it a done deal for me. I don’t have to worry about keeping multiple unsynchronized files on multiple devices. If you want a great looking password manager that has cloud sync, KeeWeb is something you should look at.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/keeweb-an-open-source-cross-platform-password-manager/
|
||||
|
||||
作者:[EDITOR][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[1]: https://app.keeweb.info/
|
||||
[2]: https://github.com/keeweb/keeweb/releases/latest
|
||||
[3]: https://aur.archlinux.org/packages/keeweb/
|
||||
[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
@ -0,0 +1,103 @@
|
||||
Play Windows games on Fedora with Steam Play and Proton
|
||||
======
|
||||
|
||||

|
||||
|
||||
Some weeks ago, Steam [announced][1] a new addition to Steam Play with Linux support for Windows games using Proton, a fork from WINE. This capability is still in beta, and not all games work. Here are some more details about Steam and Proton.
|
||||
|
||||
According to the Steam website, there are new features in the beta release:
|
||||
|
||||
* Windows games with no Linux version currently available can now be installed and run directly from the Linux Steam client, complete with native Steamworks and OpenVR support.
|
||||
* DirectX 11 and 12 implementations are now based on Vulkan, which improves game compatibility and reduces performance impact.
|
||||
* Fullscreen support has been improved. Fullscreen games seamlessly stretch to the desired display without interfering with the native monitor resolution or requiring the use of a virtual desktop.
|
||||
* Improved game controller support. Games automatically recognize all controllers supported by Steam. Expect more out-of-the-box controller compatibility than even the original version of the game.
|
||||
* Performance for multi-threaded games has been greatly improved compared to vanilla WINE.
|
||||
|
||||
|
||||
|
||||
### Installation
|
||||
|
||||
If you’re interested in trying Steam with Proton out, just follow these easy steps. (Note that you can ignore the first steps to enable the Steam Beta if you have the [latest updated version of Steam installed][2]. In that case you no longer need Steam Beta to use Proton.)
|
||||
|
||||
Open up Steam and log in to your account. This example screenshot shows support for only 22 games before enabling Proton.
|
||||
|
||||
![][3]
|
||||
|
||||
Now click on Steam option on top of the client. This displays a drop down menu. Then select Settings.
|
||||
|
||||
![][4]
|
||||
|
||||
Now the settings window pops up. Select the Account option and next to Beta participation, click on change.
|
||||
|
||||
![][5]
|
||||
|
||||
Now change None to Steam Beta Update.
|
||||
|
||||
![][6]
|
||||
|
||||
Click on OK and a prompt asks you to restart.
|
||||
|
||||
![][7]
|
||||
|
||||
Let Steam download the update. This can take a while depending on your internet speed and computer resources.
|
||||
|
||||
![][8]
|
||||
|
||||
After restarting, go back to the Settings window. This time you’ll see a new option. Make sure the check boxes for Enable Steam Play for supported titles, Enable Steam Play for all titles and Use this tool instead of game-specific selections from Steam are enabled. The compatibility tool should be Proton.
|
||||
|
||||
![][9]
|
||||
|
||||
The Steam client asks you to restart. Do so, and once you log back into your Steam account, your game library for Linux should be extended.
|
||||
|
||||
![][10]
|
||||
|
||||
### Installing a Windows game using Steam Play
|
||||
|
||||
Now that you have Proton enabled, install a game. Select the title you want and you’ll find the process is similar to installing a normal game on Steam, as shown in these screenshots.
|
||||
|
||||
![][11]
|
||||
|
||||
![][12]
|
||||
|
||||
![][13]
|
||||
|
||||
![][14]
|
||||
|
||||
After the game is done downloading and installing, you can play it.
|
||||
|
||||
![][15]
|
||||
|
||||
![][16]
|
||||
|
||||
Some games may be affected by the beta nature of Proton. The game in this example, Chantelise, had no audio and a low frame rate. Keep in mind this capability is still in beta and Fedora is not responsible for results. If you’d like to read further, the community has created a [Google doc][17] with a list of games that have been tested.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/play-windows-games-steam-play-proton/
|
||||
|
||||
作者:[Francisco J. Vergara Torres][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/patxi/
|
||||
[1]: https://steamcommunity.com/games/221410/announcements/detail/1696055855739350561
|
||||
[2]: https://fedoramagazine.org/third-party-repositories-fedora/
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2018/09/listOfGamesLinux-300x197.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2018/09/1-300x169.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2018/09/2-300x196.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2018/09/4-300x272.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2018/09/6-300x237.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2018/09/7-300x126.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2018/09/10-300x237.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2018/09/12-300x196.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2018/09/13-300x196.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2018/09/14-300x195.png
|
||||
[13]: https://fedoramagazine.org/wp-content/uploads/2018/09/15-300x196.png
|
||||
[14]: https://fedoramagazine.org/wp-content/uploads/2018/09/16-300x195.png
|
||||
[15]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-14-59-300x169.png
|
||||
[16]: https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-08-30-15-19-34-300x169.png
|
||||
[17]: https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/edit#gid=1003113831
|
||||
@ -0,0 +1,101 @@
|
||||
Python at the pump: A script for filling your gas tank
|
||||
======
|
||||
Here's how I used Python to discover a strategy for cost-effective fill-ups.
|
||||
|
||||

|
||||
|
||||
I recently began driving a car that had traditionally used premium gas (93 octane). According to the maker, though, it requires only 91 octane. The thing is, in the US, you can buy only 87, 89, or 93 octane. Where I live, gas prices jump 30 cents per gallon jump from one grade to the next, so premium costs 60 cents more than regular. So why not try to save some money?
|
||||
|
||||
It’s easy enough to wait until the gas gauge shows that the tank is half full and then fill it with 89 octane, and there you have 91 octane. But it gets tricky to know what to do next—half a tank of 91 octane plus half a tank of 93 ends up being 92, and where do you go from there? You can make continuing calculations, but they get increasingly messy. This is where Python came into the picture.
|
||||
|
||||
I wanted to come up with a simple scheme in which I could fill the tank at some level with 93 octane, then at the same or some other level with 89 octane, with the primary goal to never get below 91 octane with the final mixture. What I needed to do was create some recurring calculation that uses the previous octane value for the preceding fill-up. I suppose there would be some polynomial equation that would solve this, but in Python, this sounds like a loop.
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# octane.py
|
||||
|
||||
o = 93.0
|
||||
newgas = 93.0 # this represents the octane of the last fillup
|
||||
i = 1
|
||||
while i < 21: # 20 iterations (trips to the pump)
|
||||
if newgas == 89.0: # if the last fillup was with 89 octane
|
||||
# switch to 93
|
||||
newgas = 93.0
|
||||
o = newgas/2 + o/2 # fill when gauge is 1/2 full
|
||||
else: # if it wasn't 89 octane, switch to that
|
||||
newgas = 89.0
|
||||
o = newgas/2 + o/2 # fill when gauge says 1/2 full
|
||||
print str(i) + ': '+ str(o)
|
||||
i += 1
|
||||
```
|
||||
|
||||
As you can see, I am initializing the variable o (the current octane mixture in the tank) and the variable newgas (what I last filled the tank with) at the same value of 93. The loop then will repeat 20 times, for 20 fill-ups, switching from 89 octane and 93 octane for every other trip to the station.
|
||||
|
||||
```
|
||||
1: 91.0
|
||||
2: 92.0
|
||||
3: 90.5
|
||||
4: 91.75
|
||||
5: 90.375
|
||||
6: 91.6875
|
||||
7: 90.34375
|
||||
8: 91.671875
|
||||
9: 90.3359375
|
||||
10: 91.66796875
|
||||
11: 90.333984375
|
||||
12: 91.6669921875
|
||||
13: 90.3334960938
|
||||
14: 91.6667480469
|
||||
15: 90.3333740234
|
||||
16: 91.6666870117
|
||||
17: 90.3333435059
|
||||
18: 91.6666717529
|
||||
19: 90.3333358765
|
||||
20: 91.6666679382
|
||||
```
|
||||
|
||||
This shows is that I probably need only 10 or 15 loops to see stabilization. It also shows that soon enough, I undershoot my 91 octane target. It’s also interesting to see this stabilization of the alternating mixture values, and it turns out this happens with any scheme where you choose the same amounts each time. In fact, it is true even if the amount of the fill-up is different for 89 and 93 octane.
|
||||
|
||||
So at this point, I began playing with fractions, reasoning that I would probably need a bigger 93 octane fill-up than the 89 fill-up. I also didn’t want to make frequent trips to the gas station. What I ended up with (which seemed pretty good to me) was to wait until the tank was about 7⁄12 full and fill it with 89 octane, then wait until it was ¼ full and fill it with 93 octane.
|
||||
|
||||
Here is what the changes in the loop look like:
|
||||
|
||||
```
|
||||
if newgas == 89.0:
|
||||
|
||||
newgas = 93.0
|
||||
o = 3*newgas/4 + o/4
|
||||
else:
|
||||
newgas = 89.0
|
||||
o = 5*newgas/12 + 7*o/12
|
||||
```
|
||||
|
||||
Here are the numbers, starting with the tenth fill-up:
|
||||
|
||||
```
|
||||
10: 92.5122272978
|
||||
11: 91.0487992571
|
||||
12: 92.5121998143
|
||||
13: 91.048783225
|
||||
14: 92.5121958062
|
||||
15: 91.048780887
|
||||
```
|
||||
|
||||
As you can see, this keeps the final octane very slightly above 91 all the time. Of course, my gas gauge isn’t marked in twelfths, but 7⁄12 is slightly less than 5⁄8, and I can handle that.
|
||||
|
||||
An alternative simple solution might have been run the tank to empty and fill with 93 octane, then next time only half-fill it for 89—and perhaps this will be my default plan. Personally, I’m not a fan of running the tank all the way down since this isn’t always convenient. On the other hand, it could easily work on a long trip. And sometimes I buy gas because of a sudden drop in prices. So in the end, this scheme is one of a series of options that I can consider.
|
||||
|
||||
The most important thing for Python users: Don’t code while driving!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/python-gas-pump
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
@ -0,0 +1,128 @@
|
||||
Taking notes with Laverna, a web-based information organizer
|
||||
======
|
||||
|
||||

|
||||
|
||||
I don’t know anyone who doesn’t take notes. Most of the people I know use an online note-taking application like Evernote, Simplenote, or Google Keep.
|
||||
|
||||
All of those are good tools, but they’re proprietary. And you have to wonder about the privacy of your information—especially in light of [Evernote’s great privacy flip-flop of 2016][1]. If you want more control over your notes and your data, you need to turn to an open source tool—preferably one that you can host yourself.
|
||||
|
||||
And there are a number of good [open source alternatives to Evernote][2]. One of these is Laverna. Let’s take a look at it.
|
||||
|
||||
### Getting Laverna
|
||||
|
||||
You can [host Laverna yourself][3] or use the [web version][4]
|
||||
|
||||
Since I have nowhere to host the application, I’ll focus here on using the web version of Laverna. Aside from the installation and setting up storage (more on that below), I’m told that the experience with a self-hosted version of Laverna is the same.
|
||||
|
||||
### Setting up Laverna
|
||||
|
||||
To start using Laverna right away, click the **Start using now** button on the front page of [Laverna.cc][5].
|
||||
|
||||
On the welcome screen, click **Next**. You’ll be asked to enter an encryption password to secure your notes and get to them when you need to. You’ll also be asked to choose a way to synchronize your notes. I’ll discuss synchronization in a moment, so just enter a password and click **Next**.
|
||||
|
||||
|
||||
|
||||
When you log in, you'll see a blank canvas:
|
||||
|
||||
|
||||
|
||||
### Storing your notes
|
||||
|
||||
Before diving into how to use Laverna, let’s walk through how to store your notes.
|
||||
|
||||
Out of the box, Laverna stores your notes in your browser’s cache. The problem with that is when you clear the cache, you lose your notes. You can also store your notes using:
|
||||
|
||||
* Dropbox, a popular and proprietary web-based file syncing and storing service
|
||||
* [remoteStorage][6], which offers a way for web applications to store information in the cloud.
|
||||
|
||||
|
||||
|
||||
Using Dropbox is convenient, but it’s proprietary. There are also concerns about [privacy and surveillance][7]. Laverna encrypts your notes before saving them, but not all encryption is foolproof. Even if you don’t have anything illegal or sensitive in your notes, they’re no one’s business but your own.
|
||||
|
||||
remoteStorage, on the other hand, is kind of techie to set up. There are few hosted storage services out there. I use [5apps][8].
|
||||
|
||||
To change how Laverna stores your notes, click the hamburger menu in the top-left corner. Click **Settings** and then **Sync**.
|
||||
|
||||

|
||||
|
||||
Select the service you want to use, then click **Save**. After that, click the left arrow in the top-left corner. You’ll be asked to authorize Laverna with the service you chose.
|
||||
|
||||
### Using Laverna
|
||||
|
||||
With that out of the way, let’s get down to using Laverna. Create a new note by clicking the **New Note** icon, which opens the note editor:
|
||||
|
||||
|
||||
|
||||
Type a title for your note, then start typing the note in the left pane of the editor. The right pane displays a preview of your note:
|
||||
|
||||
|
||||
|
||||
You can format your notes using Markdown; add formatting using your keyboard or the toolbar at the top of the window.
|
||||
|
||||
You can also embed an image or file from your computer into a note, or link to one on the web. When you embed an image, it’s stored with your note.
|
||||
|
||||
When you’re done, click **Save**.
|
||||
|
||||
### Organizing your notes
|
||||
|
||||
Like some other note-taking tools, Laverna lists the last note that you created or edited at the top. If you have a lot of notes, it can take a bit of work to find the one you're looking for.
|
||||
|
||||
To better organize your notes, you can group them into notebooks, where you can quickly filter them based on a topic or a grouping.
|
||||
|
||||
When you’re creating or editing a note, you can select a notebook from the **Select notebook** list in the top-left corner of the window. If you don’t have any notebooks, select **Add a new notebook** from the list and type the notebook’s name.
|
||||
|
||||
You can also make that notebook a child of another notebook. Let’s say, for example, you maintain three blogs. You can create a notebook called **Blog Post Notes** and name children for each blog.
|
||||
|
||||
To filter your notes by notebook, click the hamburger menu, followed by the name of a notebook. Only the notes in the notebook you choose will appear in the list.
|
||||
|
||||
|
||||
|
||||
### Using Laverna across devices
|
||||
|
||||
I use Laverna on my laptop and on an eight-inch tablet running [LineageOS][9]. Getting the two devices to use the same storage and display the same notes takes a little work.
|
||||
|
||||
First, you’ll need to export your settings. Log into wherever you’re using Laverna and click the hamburger menu. Click **Settings** , then **Import & Export**. Under **Settings** , click **Export settings**. Laverna saves a file named laverna-settings.json to your device.
|
||||
|
||||
Copy that file to the other device or devices on which you want to use Laverna. You can do that by emailing it to yourself or by syncing the file across devices using an application like [ownCloud][10] or [Nextcloud][11].
|
||||
|
||||
On the other device, click **Import** on the splash screen. Otherwise, click the hamburger menu and then **Settings > Import & Export**. Click **Import settings**. Find the JSON file with your settings, click **Open** and then **Save**.
|
||||
|
||||
Laverna will ask you to:
|
||||
|
||||
* Log back in using your password.
|
||||
* Register with the storage service you’re using.
|
||||
|
||||
|
||||
|
||||
Repeat this process for each device that you want to use. It’s cumbersome, I know. I’ve done it. You should need to do it only once per device, though.
|
||||
|
||||
### Final thoughts
|
||||
|
||||
Once you set up Laverna, it’s easy to use and has just the right features for what I need to do. I’m hoping that the developers can expand the storage and syncing options to include open source applications like Nextcloud and ownCloud.
|
||||
|
||||
While Laverna doesn’t have all the bells and whistles of a note-taking application like Evernote, it does a great job of letting you take and organize your notes. The fact that Laverna is open source and supports Markdown are two additional great reasons to use it.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/taking-notes-laverna
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[1]: https://blog.evernote.com/blog/2016/12/15/evernote-revisits-privacy-policy/
|
||||
[2]: https://opensource.com/life/16/8/open-source-alternatives-evernote
|
||||
[3]: https://github.com/Laverna/laverna
|
||||
[4]: https://laverna.cc/
|
||||
[5]: http://laverna.cc/
|
||||
[6]: https://remotestorage.io/
|
||||
[7]: https://www.zdnet.com/article/dropbox-faces-questions-over-claims-of-improper-data-sharing/
|
||||
[8]: https://5apps.com/storage/beta
|
||||
[9]: https://lineageos.org/
|
||||
[10]: https://owncloud.com/
|
||||
[11]: https://nextcloud.com/
|
||||
@ -1,21 +1,22 @@
|
||||
The df Command Tutorial With Examples For Beginners
|
||||
df 命令的新手教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this guide, we are going to learn to use **df** command. The df command, stands for **D** isk **F** ree, reports file system disk space usage. It displays the amount of disk space available on the file system in a Linux system. The df command is not to be confused with **du** command. Both serves different purposes. The df command reports **how much disk space we have** (i.e free space) whereas the du command reports **how much disk space is being consumed** by the files and folders. Hope I made myself clear. Let us go ahead and see some practical examples of df command, so you can understand it better.
|
||||
在本指南中,我们将学习如何使用 **df** 命令。df 命令是 `Disk Free` 的首字母组合,它报告文件系统磁盘空间的使用情况。它显示一个 Linux 系统中文件系统上可用磁盘空间的数量。df 命令很容易与 **du** 命令混淆。它们的用途不同。df 命令报告 **我们拥有多少磁盘空间**(空闲磁盘空间),而 du 命令报告 **被文件和目录占用了多少磁盘空间**。希望我这样的解释你能更清楚。在继续之前,我们来看一些 df 命令的实例,以便于你更好地理解它。
|
||||
|
||||
### The df Command Tutorial With Examples
|
||||
### df 命令使用举例
|
||||
|
||||
**1\. View entire file system disk space usage**
|
||||
**1、查看整个文件系统磁盘空间使用情况**
|
||||
|
||||
Run df command without any arguments to display the entire file system disk space.
|
||||
无需任何参数来运行 df 命令,以显示整个文件系统磁盘空间使用情况。
|
||||
```
|
||||
$ df
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
**示例输出:**
|
||||
|
||||
```
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
dev 4033216 0 4033216 0% /dev
|
||||
@ -32,20 +33,20 @@ tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see, the result is divided into six columns. Let us see what each column means.
|
||||
正如你所见,输出结果分为六列。我们来看一下每一列的含义。
|
||||
|
||||
* **Filesystem** – the filesystem on the system.
|
||||
* **1K-blocks** – the size of the filesystem, measured in 1K blocks.
|
||||
* **Used** – the amount of space used in 1K blocks.
|
||||
* **Available** – the amount of available space in 1K blocks.
|
||||
* **Use%** – the percentage that the filesystem is in use.
|
||||
* **Mounted on** – the mount point where the filesystem is mounted.
|
||||
* **Filesystem** – Linux 系统中的文件系统
|
||||
* **1K-blocks** – 文件系统的大小,用 1K 大小的块来表示。
|
||||
* **Used** – 以 1K 大小的块所表示的已使用数量。
|
||||
* **Available** – 以 1K 大小的块所表示的可用空间的数量。
|
||||
* **Use%** – 文件系统中已使用的百分比。
|
||||
* **Mounted on** – 已挂载的文件系统的挂载点。
|
||||
|
||||
|
||||
|
||||
**2\. Display file system disk usage in human readable format**
|
||||
**2、以人类友好格式显示文件系统硬盘空间使用情况**
|
||||
|
||||
As you may noticed in the above examples, the usage is showed in 1k blocks. If you want to display them in human readable format, use **-h** flag.
|
||||
在上面的示例中你可能已经注意到了,它使用 1K 大小的块为单位来表示使用情况,如果你以人类友好格式来显示它们,可以使用 **-h** 标志。
|
||||
```
|
||||
$ df -h
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
@ -61,11 +62,11 @@ tmpfs 789M 28K 789M 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
Now look at the **Size** and **Avail** columns, the usage is shown in GB and MB.
|
||||
现在,在 **Size** 列和 **Avail** 列,使用情况是以 GB 和 MB 为单位来显示的。
|
||||
|
||||
**3\. Display disk space usage only in MB**
|
||||
|
||||
To view file system disk space usage only in Megabytes, use **-m** flag.
|
||||
如果仅以 MB 为单位来显示文件系统磁盘空间使用情况,使用 **-m** 标志。
|
||||
```
|
||||
$ df -m
|
||||
Filesystem 1M-blocks Used Available Use% Mounted on
|
||||
@ -81,9 +82,9 @@ tmpfs 789 1 789 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**4\. List inode information instead of block usage**
|
||||
**4、列出节点而不是块的使用情况**
|
||||
|
||||
We can list inode information instead of block usage by using **-i** flag as shown below.
|
||||
如下所示,我们可以通过使用 **-i** 标记来列出节点而不是块的使用情况。
|
||||
```
|
||||
$ df -i
|
||||
Filesystem Inodes IUsed IFree IUse% Mounted on
|
||||
@ -99,9 +100,9 @@ tmpfs 1009720 29 1009691 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
**5\. Display the file system type**
|
||||
**5、显示文件系统类型**
|
||||
|
||||
To display the file system type, use **-T** flag.
|
||||
使用 **-T** 标志显示文件系统类型。
|
||||
```
|
||||
$ df -T
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
@ -117,11 +118,11 @@ tmpfs tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
As you see, there is an extra column (second from left) that shows the file system type.
|
||||
正如你所见,现在出现了显示文件系统类型的额外的列(从左数的第二列)。
|
||||
|
||||
**6\. Display only the specific file system type**
|
||||
**6、仅显示指定类型的文件系统**
|
||||
|
||||
We can limit the listing to a certain file systems. for example **ext4**. To do so, we use **-t** flag.
|
||||
我们可以限制仅列出某些文件系统。比如,只列出 **ext4** 文件系统。我们使用 **-t** 标志。
|
||||
```
|
||||
$ df -t ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
@ -130,11 +131,11 @@ Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
|
||||
```
|
||||
|
||||
See? This command shows only the ext4 file system disk space usage.
|
||||
看到了吗?这个命令仅显示了 ext4 文件系统的磁盘空间使用情况。
|
||||
|
||||
**7\. Exclude specific file system type**
|
||||
**7、不列出指定类型的文件系统**
|
||||
|
||||
Some times, you may want to exclude a specific file system from the result. This can be achieved by using **-x** flag.
|
||||
有时,我们可能需要从结果中去排除指定类型的文件系统。我们可以使用 **-x** 标记达到我们的目的。
|
||||
```
|
||||
$ df -x ext4
|
||||
Filesystem 1K-blocks Used Available Use% Mounted on
|
||||
@ -148,11 +149,11 @@ tmpfs 807776 28 807748 1% /run/user/1000
|
||||
|
||||
```
|
||||
|
||||
The above command will display all file systems usage, except **ext4**.
|
||||
上面的命令列出了除 **ext4** 类型以外的全部文件系统。
|
||||
|
||||
**8\. Display usage for a folder**
|
||||
**8、显示一个目录的磁盘使用情况**
|
||||
|
||||
To display the disk space available and where it is mounted for a folder, for example **/home/sk/** , use this command:
|
||||
去显示某个目录的硬盘空间使用情况以及它的挂载点,例如 **/home/sk/** 目录,可以使用如下的命令:
|
||||
```
|
||||
$ df -hT /home/sk/
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
@ -160,19 +161,19 @@ Filesystem Type Size Used Avail Use% Mounted on
|
||||
|
||||
```
|
||||
|
||||
This command shows the file system type, used and available space in human readable form and where it is mounted. If you don’t to display the file system type, just ignore the **-t** flag.
|
||||
这个命令显示文件系统类型、以人类友好格式显示已使用和可用磁盘空间、以及它的挂载点。如果你不想去显示文件系统类型,只需要忽略 **-t** 标志即可。
|
||||
|
||||
For more details, refer the man pages.
|
||||
更详细的使用情况,请参阅 man 手册页。
|
||||
```
|
||||
$ man df
|
||||
|
||||
```
|
||||
|
||||
**Recommended read:**
|
||||
**建议阅读:**
|
||||
|
||||
And, that’s all for today! I hope this was useful. More good stuffs to come. Stay tuned!
|
||||
今天就到此这止!我希望对你有用。还有更多更好玩的东西即将奉上。请继续关注!
|
||||
|
||||
Cheers!
|
||||
再见!
|
||||
|
||||
|
||||
|
||||
@ -181,7 +182,7 @@ Cheers!
|
||||
via: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
@ -190,3 +191,4 @@ via: https://www.ostechnix.com/the-df-command-tutorial-with-examples-for-beginne
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/04/df-command.png
|
||||
|
||||
@ -0,0 +1,298 @@
|
||||
树莓派自建 NAS 云盘之-树莓派搭建网络存储盘
|
||||
======
|
||||
|
||||

|
||||
|
||||
我将在接下来的三篇文章中讲述如何搭建一个简便、实用的 NAS 云盘系统。我在这个中心化的存储系统中存储数据,并且让它每晚都会自动的备份增量数据。本系列文章将利用 NFS 文件系统将磁盘挂载到同一网络下的不同设备上,使用 [Nextcloud][1] 来离线访问数据、分享数据。
|
||||
|
||||
本文主要讲述将数据盘挂载到远程设备上的软硬件步骤。本系列第二篇文章将讨论数据备份策略、如何添加定时备份数据任务。最后一篇文章中我们将会安装 Nextcloud 软件,用户通过Nextcloud 提供的 web 接口可以方便的离线或在线访问数据。本系列教程最终搭建的 NAS 云盘支持多用户操作、文件共享等功能,所以你可以通过它方便的分享数据,比如说你可以发送一个加密链接,跟朋友分享你的照片等等。
|
||||
|
||||
最终的系统架构如下图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
### 硬件
|
||||
|
||||
首先需要准备硬件。本文所列方案只是其中一种示例,你也可以按不同的硬件方案进行采购。
|
||||
|
||||
最主要的就是[树莓派3][2],它带有四核 CPU,1G RAM,以及(有些)快速的网络接口。数据将存储在两个 USB 磁盘驱动器上(这里使用 1TB 磁盘);其中一个磁盘用于每天数据存储,另一个用于数据备份。请务必使用有源 USB 磁盘驱动器或者带附加电源的 USB 集线器,因为树莓派无法为两个 USB 磁盘驱动器供电。
|
||||
|
||||
### 软件
|
||||
|
||||
社区中最活跃的操作系统当属 [Raspbian][3],便于定制个性化项目。已经有很多 [操作指南][4] 讲述如何在树莓派中安装 Raspbian 系统,所以这里不再赘述。在撰写本文时,最新的官方支持版本是 [Raspbian Stretch][5],它对我来说很好使用。
|
||||
|
||||
到此,我将假设你已经配置好了基本的 Raspbian 系统并且可以通过 `ssh` 访问到你的树莓派。
|
||||
|
||||
### 准备 USB 磁盘驱动器
|
||||
|
||||
为了更好地读写数据,我建议使用 ext4 文件系统去格式化磁盘。首先,你必须先找到连接到树莓派的磁盘。你可以在 `/dev/sd/<x>` 中找到磁盘设备。使用命令 `fdisk -l`,你可以找到刚刚连接的两块 USB 磁盘驱动器。请注意,操作下面的步骤将会清除 USB 磁盘驱动器上的所有数据,请做好备份。
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk -l
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0xe8900690
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Disk /dev/sdb: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x6aa4f598
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sdb1 * 2048 1953521663 1953519616 931.5G 83 Linux
|
||||
|
||||
```
|
||||
|
||||
由于这些设备是连接到树莓派的唯一的 1TB 的磁盘,所以我们可以很容易的辨别出 `/dev/sda` 和 `/dev/sdb` 就是那两个 USB 磁盘驱动器。每个磁盘末尾的分区表提示了在执行以下的步骤后如何查看,这些步骤将会格式化磁盘并创建分区表。为每个 USB 磁盘驱动器按以下步骤进行操作(假设你的磁盘也是 `/dev/sda` 和 `/dev/sdb`,第二次操作你只要替换命令中的 `sda` 为 `sdb` 即可)。
|
||||
|
||||
首先,删除磁盘分区表,创建一个新的并且只包含一个分区的新分区表。在 `fdisk` 中,你可以使用交互单字母命令来告诉程序你想要执行的操作。只需要在提示符 `Command(m for help):` 后输入相应的字母即可(可以使用 `m` 命令获得更多详细信息):
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo fdisk /dev/sda
|
||||
|
||||
|
||||
|
||||
Welcome to fdisk (util-linux 2.29.2).
|
||||
|
||||
Changes will remain in memory only, until you decide to write them.
|
||||
|
||||
Be careful before using the write command.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Command (m for help): o
|
||||
|
||||
Created a new DOS disklabel with disk identifier 0x9c310964.
|
||||
|
||||
|
||||
|
||||
Command (m for help): n
|
||||
|
||||
Partition type
|
||||
|
||||
p primary (0 primary, 0 extended, 4 free)
|
||||
|
||||
e extended (container for logical partitions)
|
||||
|
||||
Select (default p): p
|
||||
|
||||
Partition number (1-4, default 1):
|
||||
|
||||
First sector (2048-1953525167, default 2048):
|
||||
|
||||
Last sector, +sectors or +size{K,M,G,T,P} (2048-1953525167, default 1953525167):
|
||||
|
||||
|
||||
|
||||
Created a new partition 1 of type 'Linux' and of size 931.5 GiB.
|
||||
|
||||
|
||||
|
||||
Command (m for help): p
|
||||
|
||||
|
||||
|
||||
Disk /dev/sda: 931.5 GiB, 1000204886016 bytes, 1953525168 sectors
|
||||
|
||||
Units: sectors of 1 * 512 = 512 bytes
|
||||
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
Disklabel type: dos
|
||||
|
||||
Disk identifier: 0x9c310964
|
||||
|
||||
|
||||
|
||||
Device Boot Start End Sectors Size Id Type
|
||||
|
||||
/dev/sda1 2048 1953525167 1953523120 931.5G 83 Linux
|
||||
|
||||
|
||||
|
||||
Command (m for help): w
|
||||
|
||||
The partition table has been altered.
|
||||
|
||||
Syncing disks.
|
||||
|
||||
```
|
||||
|
||||
现在,我们将用 ext4 文件系统格式化新创建的分区 `/dev/sda1`:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo mkfs.ext4 /dev/sda1
|
||||
|
||||
mke2fs 1.43.4 (31-Jan-2017)
|
||||
|
||||
Discarding device blocks: done
|
||||
|
||||
|
||||
|
||||
<...>
|
||||
|
||||
|
||||
|
||||
Allocating group tables: done
|
||||
|
||||
Writing inode tables: done
|
||||
|
||||
Creating journal (1024 blocks): done
|
||||
|
||||
Writing superblocks and filesystem accounting information: done
|
||||
|
||||
```
|
||||
|
||||
重复以上步骤后,让我们根据用途来对它们建立标签:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sda1 data
|
||||
|
||||
pi@raspberrypi:~ $ sudo e2label /dev/sdb1 backup
|
||||
|
||||
```
|
||||
|
||||
现在,让我们安装这些磁盘并存储一些数据。以我运营该系统超过一年的经验来看,当树莓派启动时(例如在断电后),USB 磁盘驱动器并不是总被安装,因此我建议使用 autofs 在需要的时候进行安装。
|
||||
|
||||
首先,安装 autofs 并创建挂载点:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install autofs
|
||||
|
||||
pi@raspberrypi:~ $ sudo mkdir /nas
|
||||
|
||||
```
|
||||
|
||||
然后添加下面这行来挂载设备
|
||||
`/etc/auto.master`:
|
||||
```
|
||||
/nas /etc/auto.usb
|
||||
|
||||
```
|
||||
|
||||
如果不存在以下内容,则创建 `/etc/auto.usb`,然后重新启动 autofs 服务:
|
||||
|
||||
```
|
||||
data -fstype=ext4,rw :/dev/disk/by-label/data
|
||||
|
||||
backup -fstype=ext4,rw :/dev/disk/by-label/backup
|
||||
|
||||
pi@raspberrypi3:~ $ sudo service autofs restart
|
||||
|
||||
```
|
||||
|
||||
现在你应该可以分别访问 `/nas/data` 以及 `/nas/backup` 磁盘了。显然,到此还不会令人太兴奋,因为你只是擦除了磁盘中的数据。不过,你可以执行以下命令来确认设备是否已经挂载成功:
|
||||
|
||||
```
|
||||
pi@raspberrypi3:~ $ cd /nas/data
|
||||
|
||||
pi@raspberrypi3:/nas/data $ cd /nas/backup
|
||||
|
||||
pi@raspberrypi3:/nas/backup $ mount
|
||||
|
||||
<...>
|
||||
|
||||
/etc/auto.usb on /nas type autofs (rw,relatime,fd=6,pgrp=463,timeout=300,minproto=5,maxproto=5,indirect)
|
||||
|
||||
<...>
|
||||
|
||||
/dev/sda1 on /nas/data type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
/dev/sdb1 on /nas/backup type ext4 (rw,relatime,data=ordered)
|
||||
|
||||
```
|
||||
|
||||
首先进入对应目录以确保 autofs 能够挂载设备。Autofs 会跟踪文件系统的访问记录,并随时挂载所需要的设备。然后 `mount` 命令会显示这两个 USB 磁盘驱动器已经挂载到我们想要的位置了。
|
||||
|
||||
设置 autofs 的过程容易出错,如果第一次尝试失败,请不要沮丧。你可以上网搜索有关教程。
|
||||
|
||||
### 挂载网络存储
|
||||
|
||||
现在你已经设置了基本的网络存储,我们希望将它安装到远程 Linux 机器上。这里使用 NFS 文件系统,首先在树莓派上安装 NFS 服务器:
|
||||
|
||||
```
|
||||
pi@raspberrypi:~ $ sudo apt install nfs-kernel-server
|
||||
|
||||
```
|
||||
|
||||
然后,需要告诉 NFS 服务器公开 `/nas/data` 目录,这是从树莓派外部可以访问的唯一设备(另一个用于备份)。编辑 `/etc/exports` 添加如下内容以允许所有可以访问 NAS 云盘的设备挂载存储:
|
||||
|
||||
```
|
||||
/nas/data *(rw,sync,no_subtree_check)
|
||||
|
||||
```
|
||||
|
||||
更多有关限制挂载到单个设备的详细信息,请参阅 `man exports`。经过上面的配置,任何人都可以访问数据,只要他们可以访问 NFS 所需的端口:`111`和`2049`。我通过上面的配置,只允许通过路由器防火墙访问到我的家庭网络的 22 和 443 端口。这样,只有在家庭网络中的设备才能访问 NFS 服务器。
|
||||
|
||||
如果要在 Linux 计算机挂载存储,运行以下命令:
|
||||
|
||||
```
|
||||
you@desktop:~ $ sudo mkdir /nas/data
|
||||
|
||||
you@desktop:~ $ sudo mount -t nfs <raspberry-pi-hostname-or-ip>:/nas/data /nas/data
|
||||
|
||||
```
|
||||
|
||||
同样,我建议使用 autofs 来挂载该网络设备。如果需要其他帮助,请参看 [如何使用 Autofs 来挂载 NFS 共享][6]。
|
||||
|
||||
现在你可以在远程设备上通过 NFS 系统访问位于你树莓派 NAS 云盘上的数据了。在后面一篇文章中,我将介绍如何使用 `rsync` 自动将数据备份到第二个 USB 磁盘驱动器。你将会学到如何使用 `rsync` 创建增量备份,在进行日常备份的同时还能节省设备空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/network-attached-storage-Raspberry-Pi
|
||||
|
||||
作者:[Manuel Dewald][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jrg](https://github.com/jrglinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ntlx
|
||||
[1]: https://nextcloud.com/
|
||||
[2]: https://www.raspberrypi.org/products/raspberry-pi-3-model-b/
|
||||
[3]: https://www.raspbian.org/
|
||||
[4]: https://www.raspberrypi.org/documentation/installation/installing-images/
|
||||
[5]: https://www.raspberrypi.org/blog/raspbian-stretch/
|
||||
[6]: https://opensource.com/article/18/6/using-autofs-mount-nfs-shares
|
||||
|
||||
@ -0,0 +1,173 @@
|
||||
提交你的第一个 Linux 内核补丁时的一个检查列表
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux 内核是最大的且变动最快的开源项目之一,它由大约 53,600 个文件和近 2,000 万行代码组成。在全世界范围内超过 15,600 位程序员为它贡献代码,Linux 内核项目的维护者使用了如下的协作模型。
|
||||
|
||||

|
||||
|
||||
本文中,为了便于在 Linux 内核中提交你的第一个贡献,我将为你提供一个必需的快速检查列表,以告诉你在提交补丁时,应该去查看和了解的内容。对于你贡献的第一个补丁的提交流程方面的更多内容,请阅读 [KernelNewbies 第一个内核补丁教程][1]。
|
||||
|
||||
### 为内核作贡献
|
||||
|
||||
#### 第 1 步:准备你的系统
|
||||
|
||||
本文开始之前,假设你的系统已经具备了如下的工具:
|
||||
|
||||
+ 文本编辑器
|
||||
+ Email 客户端
|
||||
+ 版本控制系统(即:git)
|
||||
|
||||
#### 第 2 步:下载 Linux 内核代码仓库:
|
||||
```
|
||||
git clone -b staging-testing
|
||||
|
||||
git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/staging.git
|
||||
|
||||
```
|
||||
|
||||
### 复制你的当前配置:
|
||||
```
|
||||
cp /boot/config-`uname -r`* .config
|
||||
|
||||
```
|
||||
|
||||
### 第 3 步:构建/安装你的内核
|
||||
```
|
||||
make -jX
|
||||
|
||||
sudo make modules_install install
|
||||
|
||||
```
|
||||
|
||||
### 第 4 步:创建一个分支并切换到它
|
||||
```
|
||||
git checkout -b first-patch
|
||||
|
||||
```
|
||||
|
||||
### 第 5 步:更新你的内核并指向到最新的代码
|
||||
```
|
||||
git fetch origin
|
||||
|
||||
git rebase origin/staging-testing
|
||||
|
||||
```
|
||||
|
||||
### 第 6 步:在最新的代码基础上产生一个变更
|
||||
|
||||
使用 `make` 命令重新编译,确保你的变更没有错误。
|
||||
|
||||
### 第 7 步:提交你的变更并创建一个补丁
|
||||
```
|
||||
git add <file>
|
||||
|
||||
git commit -s -v
|
||||
|
||||
git format-patch -o /tmp/ HEAD^
|
||||
|
||||
```
|
||||
|
||||

|
||||
|
||||
主题是由冒号分隔的文件名组成,接下来是使用祈使语态来描述补丁做了什么。空行之后是强制规定的 `off` 标记,最后是你的补丁的 `diff` 信息。
|
||||
|
||||
下面是另外一个简单补丁的示例:
|
||||
|
||||

|
||||
|
||||
接下来,[使用 email 从命令行][2](在本例子中使用的是 Mutt)发送这个补丁:
|
||||
```
|
||||
mutt -H /tmp/0001-<whatever your filename is>
|
||||
|
||||
```
|
||||
|
||||
使用 [get_maintainer.pl 脚本][11],去了解你的补丁应该发送给哪位维护者的列表。
|
||||
|
||||
|
||||
### 提交你的第一个补丁之前,你应该知道的事情
|
||||
|
||||
* [Greg Kroah-Hartman](3) 的 [staging tree][4] 是提交你的 [第一个补丁][1] 的最好的地方,因为他更容易接受新贡献者的补丁。在你熟悉了补丁发送流程以后,你就可以去发送复杂度更高的子系统专用的补丁。
|
||||
|
||||
* 你也可以从纠正代码中的编码风格开始。想学习更多关于这方面的内容,请阅读 [Linux 内核编码风格文档][5]。
|
||||
|
||||
* [checkpatch.pl][6] 脚本可以检测你的编码风格方面的错误。例如,运行如下的命令:
|
||||
|
||||
```
|
||||
perl scripts/checkpatch.pl -f drivers/staging/android/* | less
|
||||
|
||||
```
|
||||
|
||||
* 你可以去补全开发者留下的 TODO 注释中未完成的内容:
|
||||
```
|
||||
find drivers/staging -name TODO
|
||||
```
|
||||
|
||||
* [Coccinelle][7] 是一个模式匹配的有用工具。
|
||||
|
||||
* 阅读 [归档的内核邮件][8]。
|
||||
|
||||
* 为找到灵感,你可以去遍历 [linux.git log][9] 查看以前的作者的提交内容。
|
||||
|
||||
* 注意:不要为了评估你的补丁而在社区置顶帖子!下面就是一个这样的例子:
|
||||
|
||||
**错误的方式:**
|
||||
|
||||
Chris,
|
||||
_Yes let’s schedule the meeting tomorrow, on the second floor._
|
||||
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
> 2\. On which floor in the office?
|
||||
> 3\. What time is suitable to you?
|
||||
|
||||
(注意那最后一个问题,在回复中无意中落下了。)
|
||||
|
||||
**正确的方式:**
|
||||
|
||||
Chris,
|
||||
See my answers below...
|
||||
|
||||
> On Fri, Apr 26, 2013 at 9:25 AM, Chris wrote:
|
||||
> Hey John, I had some questions:
|
||||
> 1\. Do you want to schedule the meeting tomorrow?
|
||||
_Yes tomorrow is fine._
|
||||
> 2\. On which floor in the office?
|
||||
_Let's keep it on the second floor._
|
||||
> 3\. What time is suitable to you?
|
||||
_09:00 am would be alright._
|
||||
|
||||
(所有问题全部回复,并且这种方式还保存了阅读的时间。)
|
||||
|
||||
* [Eudyptula challenge][10] 是学习内核基础知识的非常好的方式。
|
||||
|
||||
|
||||
想学习更多内容,阅读 [KernelNewbies 第一个内核补丁教程][1]。之后如果你还有任何问题,可以在 [kernelnewbies 邮件列表][12] 或者 [#kernelnewbies IRC channel][13] 中提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/first-linux-kernel-patch
|
||||
|
||||
作者:[Sayli Karnik][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sayli
|
||||
[1]:https://kernelnewbies.org/FirstKernelPatch
|
||||
[2]:https://opensource.com/life/15/8/top-4-open-source-command-line-email-clients
|
||||
[3]:https://twitter.com/gregkh
|
||||
[4]:https://www.kernel.org/doc/html/v4.15/process/2.Process.html
|
||||
[5]:https://www.kernel.org/doc/html/v4.10/process/coding-style.html
|
||||
[6]:https://github.com/torvalds/linux/blob/master/scripts/checkpatch.pl
|
||||
[7]:http://coccinelle.lip6.fr/
|
||||
[8]:linux-kernel@vger.kernel.org
|
||||
[9]:https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/log/
|
||||
[10]:http://eudyptula-challenge.org/
|
||||
[11]:https://github.com/torvalds/linux/blob/master/scripts/get_maintainer.pl
|
||||
[12]:https://kernelnewbies.org/MailingList
|
||||
[13]:https://kernelnewbies.org/IRC
|
||||
@ -0,0 +1,238 @@
|
||||
如何将Scikit-learn Python库用于数据科学项目
|
||||
======
|
||||
|
||||

|
||||
|
||||
Scikit-learn Python库最初于2007年发布,从头到尾都通常用于解决机器学习和数据科学问题。 多功能库提供整洁,一致,高效的API和全面的在线文档。
|
||||
|
||||
### 什么是Scikit-learn?
|
||||
|
||||
[Scikit-learn][1]是一个开源Python库,拥有强大的数据分析和数据挖掘工具。 在BSD许可下可用,并建立在以下机器学习库上:
|
||||
|
||||
- **NumPy**,一个用于操作多维数组和矩阵的库。 它还具有广泛的数学函数汇集,可用于执行各种计算。
|
||||
- **SciPy**,一个由各种库组成的生态系统,用于完成技术计算任务。
|
||||
- **Matplotlib**,一个用于绘制各种图表和图形的库。
|
||||
|
||||
Scikit-learn提供了广泛的内置算法,可以充分用于数据科学项目。
|
||||
|
||||
以下是使用Scikit-learn库的主要方法。
|
||||
|
||||
#### 1. 分类
|
||||
|
||||
[分类][2]工具识别与提供的数据相关联的类别。 例如,它们可用于将电子邮件分类为垃圾邮件或非垃圾邮件。
|
||||
|
||||
Scikit-learn中的分类算法包括:
|
||||
|
||||
- 支持向量机(SVM)
|
||||
- 最邻近
|
||||
- 随机森林
|
||||
|
||||
#### 2. 回归
|
||||
|
||||
回归涉及到创建一个模型去试图理解输入和输出数据之间的关系。 例如,回归工具可用于了解股票价格的行为。
|
||||
|
||||
回归算法包括:
|
||||
|
||||
- SVM
|
||||
- 岭回归Ridge regression
|
||||
- Lasso(LCTT译者注:Lasso 即 least absolute shrinkage and selection operator,又译最小绝对值收敛和选择算子、套索算法)
|
||||
|
||||
#### 3. 聚类
|
||||
|
||||
Scikit-learn聚类工具用于自动将具有相同特征的数据分组。 例如,可以根据客户数据的地点对客户数据进行细分。
|
||||
|
||||
聚类算法包括:
|
||||
|
||||
- K-means
|
||||
- 谱聚类Spectral clustering
|
||||
- Mean-shift
|
||||
|
||||
#### 4. 降维
|
||||
|
||||
降维降低了用于分析的随机变量的数量。 例如,为了提高可视化效率,可能不会考虑外围数据。
|
||||
|
||||
降维算法包括:
|
||||
|
||||
- 主成分分析Principal component analysis(PCA)
|
||||
- 功能选择Feature selection
|
||||
- 非负矩阵分解Non-negative matrix factorization
|
||||
|
||||
#### 5. 模型选择
|
||||
|
||||
模型选择算法提供了用于比较,验证和选择要在数据科学项目中使用的最佳参数和模型的工具。
|
||||
|
||||
通过参数调整能够增强精度的模型选择模块包括:
|
||||
|
||||
- 网格搜索Grid search
|
||||
- 交叉验证Cross-validation
|
||||
- 指标Metrics
|
||||
|
||||
#### 6. 预处理
|
||||
|
||||
Scikit-learn预处理工具在数据分析期间的特征提取和规范化中非常重要。 例如,您可以使用这些工具转换输入数据(如文本)并在分析中应用其特征。
|
||||
|
||||
预处理模块包括:
|
||||
|
||||
- 预处理
|
||||
- 特征提取
|
||||
|
||||
### Scikit-learn库示例
|
||||
|
||||
让我们用一个简单的例子来说明如何在数据科学项目中使用Scikit-learn库。
|
||||
|
||||
我们将使用[鸢尾花花卉数据集][3],该数据集包含在Scikit-learn库中。 鸢尾花数据集包含有关三种花种的150个细节,三种花种分别为:
|
||||
|
||||
- Setosa-标记为0
|
||||
- Versicolor-标记为1
|
||||
- Virginica-标记为2
|
||||
|
||||
数据集包括每种花种的以下特征(以厘米为单位):
|
||||
|
||||
- 萼片长度
|
||||
- 萼片宽度
|
||||
- 花瓣长度
|
||||
- 花瓣宽度
|
||||
|
||||
#### 第1步:导入库
|
||||
|
||||
由于Iris数据集包含在Scikit-learn数据科学库中,我们可以将其加载到我们的工作区中,如下所示:
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
```
|
||||
|
||||
这些命令从**sklearn**导入数据集**datasets**模块,然后使用**datasets**中的**load_iris()**方法将数据包含在工作空间中。
|
||||
|
||||
#### 第2步:获取数据集特征
|
||||
|
||||
数据集**datasets**模块包含几种方法,使您更容易熟悉处理数据。
|
||||
|
||||
在Scikit-learn中,数据集指的是类似字典的对象,其中包含有关数据的所有详细信息。 使用**.data**键存储数据,该数据列是一个数组列表。
|
||||
|
||||
例如,我们可以利用**iris.data**输出有关Iris花卉数据集的信息。
|
||||
|
||||
```
|
||||
print(iris.data)
|
||||
```
|
||||
|
||||
这是输出(结果已被截断):
|
||||
|
||||
```
|
||||
[[5.1 3.5 1.4 0.2]
|
||||
[4.9 3. 1.4 0.2]
|
||||
[4.7 3.2 1.3 0.2]
|
||||
[4.6 3.1 1.5 0.2]
|
||||
[5. 3.6 1.4 0.2]
|
||||
[5.4 3.9 1.7 0.4]
|
||||
[4.6 3.4 1.4 0.3]
|
||||
[5. 3.4 1.5 0.2]
|
||||
[4.4 2.9 1.4 0.2]
|
||||
[4.9 3.1 1.5 0.1]
|
||||
[5.4 3.7 1.5 0.2]
|
||||
[4.8 3.4 1.6 0.2]
|
||||
[4.8 3. 1.4 0.1]
|
||||
[4.3 3. 1.1 0.1]
|
||||
[5.8 4. 1.2 0.2]
|
||||
[5.7 4.4 1.5 0.4]
|
||||
[5.4 3.9 1.3 0.4]
|
||||
[5.1 3.5 1.4 0.3]
|
||||
```
|
||||
|
||||
我们还使用**iris.target**向我们提供有关花朵不同标签的信息。
|
||||
|
||||
```
|
||||
print(iris.target)
|
||||
```
|
||||
|
||||
这是输出:
|
||||
|
||||
```
|
||||
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
|
||||
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
|
||||
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
|
||||
2 2]
|
||||
|
||||
```
|
||||
|
||||
如果我们使用**iris.target_names**,我们将输出数据集中找到的标签名称的数组。
|
||||
|
||||
```
|
||||
print(iris.target_names)
|
||||
```
|
||||
|
||||
以下是运行Python代码后的结果:
|
||||
|
||||
```
|
||||
['setosa' 'versicolor' 'virginica']
|
||||
```
|
||||
|
||||
#### 第3步:可视化数据集
|
||||
|
||||
我们可以使用[箱形图][4]来生成鸢尾花数据集的视觉描绘。 箱形图说明了数据如何通过四分位数在平面上分布的。
|
||||
|
||||
以下是如何实现这一目标:
|
||||
|
||||
```
|
||||
import seaborn as sns
|
||||
box_data = iris.data # 表示数据数组的变量
|
||||
box_target = iris.target # 表示标签数组的变量
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
让我们看看结果:
|
||||
|
||||

|
||||
|
||||
在横轴上:
|
||||
|
||||
* 0是萼片长度
|
||||
* 1是萼片宽度
|
||||
* 2是花瓣长度
|
||||
* 3是花瓣宽度
|
||||
|
||||
垂直轴的尺寸以厘米为单位。
|
||||
|
||||
### 总结
|
||||
|
||||
以下是这个简单的Scikit-learn数据科学教程的完整代码。
|
||||
|
||||
```
|
||||
from sklearn import datasets
|
||||
iris = datasets.load_iris()
|
||||
print(iris.data)
|
||||
print(iris.target)
|
||||
print(iris.target_names)
|
||||
import seaborn as sns
|
||||
box_data = iris.data # 表示数据数组的变量
|
||||
box_target = iris.target # 表示标签数组的变量
|
||||
sns.boxplot(data = box_data,width=0.5,fliersize=5)
|
||||
sns.set(rc={'figure.figsize':(2,15)})
|
||||
```
|
||||
|
||||
Scikit-learn是一个多功能的Python库,可用于高效完成数据科学项目。
|
||||
|
||||
如果您想了解更多信息,请查看[LiveEdu][5]上的教程,例如Andrey Bulezyuk关于使用Scikit-learn库创建[机器学习应用程序][6]的视频。
|
||||
|
||||
有什么评价或者疑问吗? 欢迎在下面分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/how-use-scikit-learn-data-science-projects
|
||||
|
||||
作者:[Dr.Michael J.Garbade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/drmjg
|
||||
[1]: http://scikit-learn.org/stable/index.html
|
||||
[2]: https://blog.liveedu.tv/regression-versus-classification-machine-learning-whats-the-difference/
|
||||
[3]: https://en.wikipedia.org/wiki/Iris_flower_data_set
|
||||
[4]: https://en.wikipedia.org/wiki/Box_plot
|
||||
[5]: https://www.liveedu.tv/guides/data-science/
|
||||
[6]: https://www.liveedu.tv/andreybu/REaxr-machine-learning-model-python-sklearn-kera/oPGdP-machine-learning-model-python-sklearn-kera/
|
||||
Loading…
Reference in New Issue
Block a user