diff --git a/published/20140702 How to install Raspberry Pi camera board.md b/published/20140702 How to install Raspberry Pi camera board.md
new file mode 100644
index 0000000000..381ad861ce
--- /dev/null
+++ b/published/20140702 How to install Raspberry Pi camera board.md
@@ -0,0 +1,109 @@
+如何安装树莓派摄像头模块
+==============================================================================
+[树莓派摄像头模块(Pi Cam)][1]发售于2013年5月。其第一个发布版本配备了500万像素的传感器,通过排线链接树莓派上的CSI接口。而Pi Cam的第二个发布版本——也被叫做[Pi NoIR][2]中,配备了相同的传感器,但没有红外线过滤装置。因此第二版的摄像头模块就像安全监控摄像机一样,可以观测到近红外线的波长(700 - 1000 nm),不过当然同时也就牺牲了一定的显色性。
+
+本文将会展示**如何在[树莓派][3]上安装摄像头模块**。我们将使用第一版摄像头模块来演示。在安装完摄像头模块之后,你将会使用三个应用程序来访问这个模块:raspistill, raspiyuv 和raspivid。其中前两个应用用来捕捉图像,第三个应用来捕捉视频。raspistill 工具生成标准的图片文件,例如 .jpg 图像,而 raspiyuv 可以通过摄像头生成未处理的 raw 图像文件。
+
+### 安装树莓派摄像头模块 ###
+
+按照以下步骤来将树莓派摄像头模块连接搭配树莓派:
+
+1. 找到 CSI 接口(CSI接口在以太网接口旁边),掀起深色胶带。
+
+2. 拉起 CSI 接口挡板。
+
+3. 拿起你的摄像头模块,将贴在镜头上的塑料保护膜撕掉。确保黄色部分的PCB(有字的一面)是安装完美的(可以轻轻按一下黄色的部分来保证安装完美)。
+
+4. 将排线插入CSI接口。记住,有蓝色胶带的一面应该面向以太网接口方向。同样,这时也确认一下排线安装好了之后,将挡板拉下。
+
+
+
+好了,现在你的 Pi Cam 已经准备就绪,可以拍摄照片或视频了。
+
+### 在树莓派上启用摄像头模块 ###
+
+在安装完摄像头模块之后,首先要确认你已经升级了树莓派系统并应用了最新的固件。可以输入以下命令来操作:
+
+ $ sudo apt-get update
+ $ sudo apt-get upgrade
+
+运行树莓派配置工具来激活摄像头模块:
+
+ $ sudo raspi-config
+
+移动光标至菜单中的 "Enable Camera(启用摄像头)",将其设为Enable(启用状态)。完成之后重启树莓派。
+
+
+
+
+
+
+
+安装完摄像头模块后的完成照:
+
+
+
+### 通过摄像头模块拍照 ###
+
+在重启完树莓派后,我们就可以使用Pi Cam了。要用它来拍摄照片的话,可以从命令行运行raspistill:
+
+ $ raspistill -o keychain.jpg -t 2000
+
+这句命令将在 2000ms 后拍摄一张照片,然后保存为 keychain.jpg。下面就是一张由 Pi Cam 拍摄的我的小熊公仔钥匙链。
+
+
+
+raspiyuv 工具用法差不多,只不过拍摄得到的是一张未处理过的raw图像。
+
+### 通过摄像头模块拍视频 ###
+
+想要用摄像头模块拍一段视频的话,可以从命令行运行 raspivid 工具。下面这句命令会按照默认配置(长度5秒,分辨率1920x1080,比特率 17Mbps)拍摄一段视频。
+
+ $ raspivid -o mykeychain.h264
+
+如果你想改变拍摄时长,只要通过 "-t" 选项来设置你想要的长度就行了(单位是毫秒)。
+
+ $ raspivid -o mykeychain.h264 -t 10000
+
+使用 "-w" 和 "-h" 选项将分辨率降为 1280x720...
+
+ $ raspivid -o mykeychain.h264 -t 10000 -w 1280 -h 720
+
+raspivid 的输出是一段未压缩的 H.264 视频流,而且这段视频不含声音。为了能被通常的视频播放器所播放,这个 raw 的 H.264 视频还需要转换。可以使用 gpac 包中所带有的 MP4Box 应用。
+
+在 Raspbian 上安装 gpac,输入命令:
+
+ $ sudo apt-get install -y gpac
+
+然后将这段 raw 的 H.264 格式的视频流转换为每秒30帧的 .mp4 格式视频:
+
+ $ MP4Box -fps 30 -add keychain.h264 keychain.mp4
+
+视频长度为10秒,使用默认分辨率以及比特率。下面是一段通过 Pi Camera 拍摄的一段实例视频。
+
+注:youtube视频地址
+
+
+
+如果想要获取 raspistill, raspiyuv 和 raspivid 的完整命令行选项,不加任何选项直接运行以上命令即可。
+
+
+----------------
+
+### [Kristophorus Hadiono][a] ###
+
+Kristophorus Hadiono是一名 Linux 爱好者,并且是印度尼西亚一所民办高等学府的教师。他在日常生活中使用 Linux,也在给学生们教学的时候使用。他现在仍靠着政府的奖学金,在泰国曼谷的一所民办大学继续着学业。
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/07/install-raspberry-pi-camera-board.html
+
+译者:[ThomazL](https://github.com/ThomazL) 校对:[reinoir](https://github.com/reinoir)
+
+本文由 [lctt](https://github.com/lctt/translateproject) 原创翻译,[linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://xmodulo.com/go/picam
+[2]:http://xmodulo.com/go/pinoir
+[3]:http://xmodulo.com/go/raspberrypi
+[a]:http://hadiono.org/blog
+
diff --git a/translated/tech/20140718 Linux Kernel Testing and Debugging 2.md b/published/20140718 Linux Kernel Testing and Debugging 2.md
similarity index 95%
rename from translated/tech/20140718 Linux Kernel Testing and Debugging 2.md
rename to published/20140718 Linux Kernel Testing and Debugging 2.md
index c21125a984..a7682d0a8c 100644
--- a/translated/tech/20140718 Linux Kernel Testing and Debugging 2.md
+++ b/published/20140718 Linux Kernel Testing and Debugging 2.md
@@ -1,4 +1,4 @@
-Linux 内核测试与调试 - 2
+Linux 内核测试与调试(2)
================================================================================
### 编译安装稳定版内核 ###
@@ -79,7 +79,7 @@ linux-next 状态的内核源码:
### 打补丁 ###
-Linux 内核的补丁是一个文本文件,包含新源码与老源码之间的改变量。每个补丁只包含自己依赖的源码的增量,除非它被特意包含进一系列补丁之中。打补丁方法如下:
+Linux 内核的补丁是一个文本文件,包含新源码与老源码之间的差异。每个补丁只包含自己所依赖的源码的改动,除非它被特意包含进一系列补丁之中。打补丁方法如下:
patch -p1 < file.patch
@@ -101,6 +101,6 @@ Linux 内核的补丁是一个文本文件,包含新源码与老源码之间
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,1
-译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
+译者:[bazz2](https://github.com/bazz2) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20140718 Linux Kernel Testing and Debugging 3.md b/published/20140718 Linux Kernel Testing and Debugging 3.md
similarity index 72%
rename from translated/tech/20140718 Linux Kernel Testing and Debugging 3.md
rename to published/20140718 Linux Kernel Testing and Debugging 3.md
index 0ba9c4a18c..ed93f5485e 100644
--- a/translated/tech/20140718 Linux Kernel Testing and Debugging 3.md
+++ b/published/20140718 Linux Kernel Testing and Debugging 3.md
@@ -1,4 +1,4 @@
-Linux 内核测试与调试 - 3
+Linux 内核测试与调试(3)
================================================================================
### 基本测试 ###
@@ -27,7 +27,7 @@ Linux 内核测试与调试 - 3
- dmesg -t -k
- dmesg -t
-下面的脚本运行了上面的命令,并且将输出保存起来,以便与老的内核的 dmesg 输出作比较(LCTT:老内核的 dmesg 输出在本系列的第一篇文章中有介绍)。然后运行 diff 命令,查看新老内核 dmesg 日志之间的不同。脚本需要输入老内核版本号,如果不输入参数,它只会生成新内核的 dmesg 日志文件后直接退出,不再作比较(LCTT:话是这么说没错,但点开脚本一看,没输参数的话,这货会直接退出,连新内核的 dmesg 日志也不会保存的)。如果 dmesg 日志有新的警告信息,表示新发布的内核有漏网之鱼(LCTT:嗯,漏网之 bug 会更好理解些么?),这些 bug 逃过了自测和系统测试。你要看看,那些警告信息后面有没有栈跟踪信息?也许这里有很多问题需要你进一步调查分析。
+下面的脚本运行了上面的命令,并且将输出保存起来,以便与老的内核的 dmesg 输出作比较(LCTT:老内核的 dmesg 输出在本系列的[第二篇文章][3]中有介绍)。然后运行 diff 命令,查看新老内核 dmesg 日志之间的不同。这个脚本需要输入老内核版本号,如果不输入参数,它只会生成新内核的 dmesg 日志文件后直接退出,不再作比较(LCTT:话是这么说没错,但点开脚本一看,没输参数的话,这货会直接退出,连新内核的 dmesg 日志也不会保存的)。如果 dmesg 日志有新的警告信息,表示新发布的内核有漏网之“虫”,这些 bug 逃过了自测和系统测试。你要看看,那些警告信息后面有没有栈跟踪信息?也许这里有很多问题需要你进一步调查分析。
- [**dmesg 测试脚本**][1]
@@ -67,40 +67,40 @@ ktest 是一个自动测试套件,它可以提供编译安装启动内核一
failslab (默认选项)
- 产生 slab 分配错误。作用于 kmalloc(), kmem_cache_alloc() 等函数(LCTT:产生的结果是调用这些函数就会返回失败,可以模拟程序分不到内存时是否还能稳定运行下去)。
+> 产生 slab 分配错误。作用于 kmalloc(), kmem_cache_alloc() 等函数(LCTT:产生的结果是调用这些函数就会返回失败,可以模拟程序分不到内存时是否还能稳定运行下去)。
-fail_page_alloc
+fail\_page\_alloc
- 产生内存页分配的错误。作用于 alloc_pages(), get_free_pages() 等函数(LCTT:同上,调用这些函数,返回错误)。
+> 产生内存页分配的错误。作用于 alloc_pages(), get_free_pages() 等函数(LCTT:同上,调用这些函数,返回错误)。
-fail_make_request
+fail\_make\_request
- 对满足条件(可以设置 /sys/block//make-it-fail 或 /sys/block///make-it-fail 文件)的磁盘产生 IO 错误,作用于 generic_make_request() 函数(LCTT:所有针对这块磁盘的读或写请求都会出错)。
+> 对满足条件(可以设置 /sys/block//make-it-fail 或 /sys/block///make-it-fail 文件)的磁盘产生 IO 错误,作用于 generic_make_request() 函数(LCTT:所有针对这块磁盘的读或写请求都会出错)。
-fail_mmc_request
+fail\_mmc\_request
- 对满足条件(可以设置 /sys/kernel/debug/mmc0/fail_mmc_request 这个 debugfs 属性)的磁盘产生 MMC 数据错误。
+> 对满足条件(可以设置 /sys/kernel/debug/mmc0/fail\_mmc\_request 这个 debugfs 属性)的磁盘产生 MMC 数据错误。
你可以自己配置 fault-injection 套件的功能。fault-inject-debugfs 内核模块在系统运行时会在 debugfs 文件系统下面提供一些属性文件。你可以指定出错的概率,指定两个错误之间的时间间隔,当然本套件还能提供更多其他功能,具体请查看 Documentation/fault-injection/fault-injection.txt。 Boot 选项可以让你的系统在 debugfs 文件系统起来之前就可以产生错误,下面列出几个 boot 选项:
- failslab=
-- fail_page_alloc=
-- fail_make_request=
-- mmc_core.fail_request=[interval],[probability],[space],[times]
+- fail\_page_alloc=
+- fail\_make\_request=
+- mmc\_core.fail\_request=[interval],[probability],[space],[times]
fault-injection 套件提供接口,以便增加新的功能。下面简单介绍下增加新功能的步骤,详细信息请参考上面提到过的文档:
-使用 DECLARE_FAULT_INJECTION(name) 定义默认属性;
+使用 DECLARE\_FAULT\_INJECTION(name) 定义默认属性;
-> 详细信息可查看 fault-inject.h 中定义的 struct fault_attr 结构体。
+> 详细信息可查看 fault-inject.h 中定义的 struct fault\_attr 结构体。
配置 fault 属性,新建一个 boot 选项;
-> 这步可以使用 setup_fault_attr(attr, str) 函数完成,为了能在系统启动的早期产生错误,添加一个 boot 选项这一步是必须要有的。
+> 这步可以使用 setup\_fault\_attr(attr, str) 函数完成,为了能在系统启动的早期产生错误,添加一个 boot 选项这一步是必须要有的。
添加 debugfs 属性;
-> 使用 fault_create_debugfs_attr(name, parent, attr) 函数,为新功能添加新的 debugfs 属性。
+> 使用 fault\_create\_debugfs\_attr(name, parent, attr) 函数,为新功能添加新的 debugfs 属性。
为模块设置参数;
@@ -108,7 +108,7 @@ fault-injection 套件提供接口,以便增加新的功能。下面简单介
添加一个钩子函数到错误测试的代码中。
-> should_fail(attr, size) —— 当这个钩子函数返回 true 时,用户的代码就应该产生一个错误。
+> should\_fail(attr, size) —— 当这个钩子函数返回 true 时,用户的代码就应该产生一个错误。
应用程序使用这个 fault-injection 套件可以指定某个具体的内核模块产生 slab 和内存页分配的错误,这样就可以缩小性能测试的范围。
@@ -116,9 +116,10 @@ fault-injection 套件提供接口,以便增加新的功能。下面简单介
via: http://www.linuxjournal.com/content/linux-kernel-testing-and-debugging?page=0,2
-译者:[bazz2](https://github.com/bazz2) 校对:[校对者ID](https://github.com/校对者ID)
+译者:[bazz2](https://github.com/bazz2) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
[1]:http://linuxdriverproject.org/mediawiki/index.php/Dmesg_regression_check_script
[2]:http://elinux.org/Ktest#Git_Bisect_type
+[3]:http://linux.cn/article-3629-1.html
\ No newline at end of file
diff --git a/translated/tech/20140808 How to set up a Samba file server to use with Windows clients.md b/published/20140808 How to set up a Samba file server to use with Windows clients.md
similarity index 82%
rename from translated/tech/20140808 How to set up a Samba file server to use with Windows clients.md
rename to published/20140808 How to set up a Samba file server to use with Windows clients.md
index 3896d75feb..1c05808bb6 100644
--- a/translated/tech/20140808 How to set up a Samba file server to use with Windows clients.md
+++ b/published/20140808 How to set up a Samba file server to use with Windows clients.md
@@ -1,10 +1,10 @@
-设置Samba文件服务器以使用Windows客户端
+怎样设置Samba文件服务器以使用Windows客户端
================================================================================
-根据[Samba][1]项目网站所述,Samba是一个开源/自由软件套件,提供了到SMB/CIFS客户端的无缝文件和打印服务。不同于其它SMB/CIFS网络协议部署(如HP-UX的LM服务器,OS/2的LAN服务器,或者VisionFS),Samba(及其源代码)是可以自由获取的(终端用户无需付费),允许在Linux/Unixt服务器和Windows/Unix/Linux客户端之间的互操作。
+根据[Samba][1]项目网站所述,Samba是一个开源/自由软件套件,提供了到SMB/CIFS客户端的无缝文件和打印服务。不同于其它SMB/CIFS网络协议部署(如HP-UX的LM服务器,OS/2的LAN服务器,或者VisionFS),Samba(及其源代码)是可以自由获取的(终端用户无需付费),允许在Linux/Unixt服务器和Windows/Unix/Linux客户端之间互操作。
出于这些理由,Samba在不同操作系统(除了Linux)共存的网络中首选的文件服务器解决方案——最常见的结构是多个微软Windows客户端访问安装有Samba的Linux服务器,该情形也是本文将要解决的问题。
-请注意,另外一方面,如果我们的网络仅仅是由基于Unix的客户端(如Linux,AIX,或者Solaris,还可以举更多的例子)组成,我们可以考虑使用NFS(尽管在此种情况下Samba仍然是可选方案),它可以提供更快的速度。
+请注意,另外一方面,如果我们的网络仅仅是由基于Unix的客户端(如Linux,AIX,或者Solaris,等等)组成,我们可以考虑使用NFS(尽管在此种情况下Samba仍然是可选方案),它可以提供更快的速度。
### 在Debian和CentOS中安装Samba ###
@@ -22,7 +22,7 @@
-现在让我们来安装Samba吧(下面的截图来自Debian 7[Wheezy]服务器上的安装):
+现在让我们来安装Samba吧(下面的截图来自Debian 7[Wheezy]服务器上的安装):
在Debian上:
@@ -58,7 +58,7 @@
public = yes
writeable = yes
-我们现在必须重启Samba——以防万一——使用testparm命令来检查smb.conf文件的语法错误:
+我们现在必须重启Samba—以防万一—使用testparm命令来检查smb.conf文件的语法错误:
# service samba restart
# testparm
@@ -113,25 +113,27 @@
-每个文件系统具有最多5种类型,能够强制使用的配额限制:用户软限制,用户硬限制,组软限制,组硬限制,以及宽限期限。
+每个文件系统最多有5种类型,能够强制使用的配额限制:用户软限制,用户硬限制,组软限制,组硬限制,以及宽限期限。
我们现在将为/home文件系统启用磁盘配额,在/etc/fstab文件对应的/home文件系统行现存的默认选项后添加usrquota和grpquto挂载选项,然后重新挂载文件系统以令修改生效:

-接下来,我们需要在**/home**目录各自创建两个文件以用于作为用户和组配额的数据库文件:**aquota.user**和**aquota.group**。然后,我们将生成启用配合后每个文件系统的当前磁盘使用表:
+接下来,我们需要在**/home**目录创建两个文件以用于作为用户和组配额的数据库文件:**aquota.user**和**aquota.group**。然后,我们将生成启用配额后每个文件系统的当前磁盘使用表:
# quotacheck -cug /home
# quotacheck -avugm

+尽管已经为/home文件系统启用磁盘配额,我们还没有给任何用户或组设置权限。检查现有用户/组的配额信息:
+
# quota -u
# quota -g
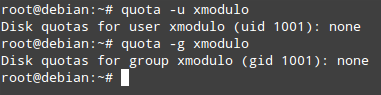
-最后,在这最后两步中,使用quotatool命令来为每个用户和/或组来分配磁盘配额(注意,该任务也可以使用edquota来完成,但是quotatool更为直接,更不易犯错)。
+在这最后几步中,使用quotatool命令来为每个用户和/或组来分配磁盘配额(注意,该任务也可以使用edquota来完成,但是quotatool更为直接,更不易犯错)。
要为用户xmodulo设置软限制为4MB,硬限制为5MB,xmodulo组为10MB/15MB:
@@ -150,7 +152,7 @@ via: http://xmodulo.com/2014/08/samba-file-server-windows-clients.html
作者:[Gabriel Cánepa][a]
译者:[GOLinux](https://github.com/GOLinux)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/talk/20140808 Lime Text--An Open Source Alternative Of Sublime Text.md b/published/20140808 Lime Text--An Open Source Alternative Of Sublime Text.md
similarity index 100%
rename from translated/talk/20140808 Lime Text--An Open Source Alternative Of Sublime Text.md
rename to published/20140808 Lime Text--An Open Source Alternative Of Sublime Text.md
diff --git a/translated/talk/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md b/published/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md
similarity index 64%
rename from translated/talk/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md
rename to published/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md
index f1cd698ba2..f4bc6dc12d 100644
--- a/translated/talk/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md
+++ b/published/20140811 10 More Tweaks To Make Ubuntu Feel Like Home.md
@@ -1,53 +1,54 @@
-10个调整让Ubuntu找到家的感觉
+10个调整让Ubuntu宾至如归
================================================================================

-不久以前我提供给大家[12个调整Ubuntu的小建议][1]。 然而,从那以后多了一段时间了, 我们又提出了另外10个建议,能够使你的Ubuntu找到家的感觉。
+不久前我提供给大家[12个调整Ubuntu的小建议][1]。 然而,已经是一段时间以前的事情了,现在我们又提出了另外10个建议,能够使你的Ubuntu宾至如归。
这10个建议执行起来十分简单方便,那就让我们开始吧!
-### 安装 TLP ###
+### 1. 安装 TLP ###

-[We covered TLP a while back][2], 这是一款优化电源设置的软件,为了让你能享受到一个更长的电池寿命。之前我们深入的探讨过TLP, 并且我们也在列表中提到这真是一个好东西。要安装它,在终端运行以下命令:
+[我们不久前涉及到了TLP][2], 这是一款优化电源设置的软件,可以让你享受更长的电池寿命。之前我们深入的探讨过TLP, 并且我们也在列表中提到这软件真不错。要安装它,在终端运行以下命令:
sudo add-apt-repository -y ppa:linrunner/tlp && sudo apt-get update && sudo apt-get install -y tlp tlp-rdw tp-smapi-dkms acpi-call-tools && sudo tlp start
上面的命令将添加必要的仓库,更新包的列表以便它能包含被新仓库提供的包,安装TLP并且开启这个服务。
-### 系统负载指示器 ###
+### 2. 系统负载指示器 ###

-给你的Ubuntu桌面添加一个系统负载指示器能让你了解到你的系统资源被占用了多少。 如果你宁愿不在桌面上添加这个技术图表,那么可以不要添加它, 但是对于那些对这个感兴趣的人来说,这真是一个好的扩展。 你可以运行这个命令去安装它:
+给你的Ubuntu桌面添加一个系统负载指示器能让你快速了解到你的系统资源占用率。 如果你不想在桌面上添加这个技术图表,那么可以不要添加, 但是对于那些对它感兴趣的人来说,这个扩展真是很好。 你可以运行这个命令去安装它:
sudo apt-get install indicator-multiload
-然后在Dash里面找到它并且打开。
+然后在Dash里面找到它并且打开。
-### 天气指示器 ###
+### 3. 天气指示器 ###

-Ubuntu过去提供内置的天气指示器, 但是自从它切换到Gnome 3以后,就不在默认提供了。代替地,你需要安装一个独立的指示器。 你可以通过以下命令安装它:
+Ubuntu过去提供内置的天气指示器,但是自从它切换到Gnome 3以后,就不再默认提供了。你需要安装一个独立的指示器来代替。 你可以通过以下命令安装它:
+
sudo add-apt-repository -y ppa:atareao/atareao && sudo apt-get update && sudo apt-get install -y my-weather-indicator
这将添加另外一个仓库,更新包的列表,并且安装这个指示器。然后在Dash里面找到并开启它。
-### 安装 Dropbox 或其他云存储解决方案 ###
+### 4. 安装 Dropbox 或其他云存储解决方案 ###

-我在我所有的Linux系统里面都安装过的一个东西就是Dropbox。没有它,真的就找不到一个家的感觉,主要是因为我所有经常使用的文件都储存在Dropbox中。安装Dropbox非常直截了当,但是要花点时间执行一个简单的命令。 在开始之前,你需要运行这个命令为了你能在系统托盘里看到Dropbox的图标:
+我在我所有的Linux系统里面都安装过的一个软件,那就是Dropbox。没有它,真的就找不到家的感觉,主要是因为我所有经常使用的文件都储存在Dropbox中。安装Dropbox非常直截了当,但是要花点时间执行一个简单的命令。 在开始之前,为了你能在系统托盘里看到Dropbox的图标,你需要运行这个命令:
sudo apt-get install libappindicator1
然后你需要去Dropbox的下载页面,接着安装你已下载的.deb文件。现在你的Dropbox应该已经运行了。
-如果你有点讨厌Dropbox, 你也可以尝试使用Copy [或者OneDrive][3]。两者提供更多免费存储空间,这是考虑使用他们的很大一个原因。比起OneDrive我更推荐使用Copy因为Copy能工作在所有的Linux发行版上。
+如果你有点讨厌Dropbox, 你也可以尝试使用Copy [或者OneDrive][3]。两者提供更多免费存储空间,这是考虑使用它们的很大一个原因。比起OneDrive我更推荐使用Copy,因为Copy能工作在所有的Linux发行版上。
-### 安装Pidgin和Skype ###
+### 5. 安装Pidgin和Skype ###

@@ -57,14 +58,14 @@ Ubuntu过去提供内置的天气指示器, 但是自从它切换到Gnome 3以
安装Skype也很简单 — 你仅仅需要去Skype的下载页面并且下载你Ubuntu12.04对应架构的.deb文件就可以了。
-###移除键盘指示器 ###
+### 6. 移除键盘指示器 ###

-在桌面上显示键盘指示器可能让一些人很苦恼。对于讲英语的人来说,它仅仅显示一个“EN”,这可能是恼人的,因为很多人不需要改变键盘布局或者被提醒他们正则使用英语。要移除这个指示器,选择系统设置,然后文本输入,接着去掉“在菜单栏显示当前输入源”的勾。
->[译注]:国人可能并不适合这个建议。
+在桌面上显示键盘指示器可能让一些人很苦恼。对于讲英语的人来说,它仅仅显示一个“EN”,这可能是恼人的,因为很多人不需要改变键盘布局或者被提醒他们正在使用英语。要移除这个指示器,选择系统设置,然后文本输入,接着去掉“在菜单栏显示当前输入源”的勾。
+(译注:国人可能并不适合这个建议。)
-### 回归传统菜单###
+### 7. 回归传统菜单###

@@ -72,23 +73,23 @@ Ubuntu过去提供内置的天气指示器, 但是自从它切换到Gnome 3以
sudo add-apt-repository -y ppa:diesch/testing && sudo apt-get update && sudo apt-get install -y classicmenu-indicator
-### 安装Flash和Java ###
+### 8. 安装Flash和Java ###
-在之前的文章中我提到了安装解码器和Silverlight,我应该也提到了Flash和Java是他们所需要的主要插件,虽然他们有时可能忘了它们。要安装它们只需运行这个命令:
+在之前的文章中我提到了安装解码器和Silverlight,我应该也提到了Flash和Java是它们所需要的主要插件,虽然有时可能它们可能被遗忘。要安装它们只需运行这个命令:
sudo add-apt-repository -y ppa:webupd8team/java && sudo apt-get update && sudo apt-get install oracle-java7-installer flashplugin-installer
安装Java需要新增仓库,因为Ubuntu不再包含它的专利版本(大多数人为了最好的性能推荐使用这个版本),而是使用开源的OpenJDK。
-### 安装VLC ###
+### 9. 安装VLC ###

-默认的媒体播放器, Totem,十分优秀但是它依赖很多独立安装的解码器才能很好的工作。我个人推荐你安装VLC媒体播放器, 因为它包含所有解码器并且实际上它支持世界上每一种媒体格式。要安装它,仅仅需要运行如下命令:
+默认的媒体播放器Totem十分优秀但是它依赖很多独立安装的解码器才能很好的工作。我个人推荐你安装VLC媒体播放器, 因为它包含所有解码器并且实际上它支持世界上每一种媒体格式。要安装它,仅仅需要运行如下命令:
sudo apt-get install vlc
-### 安装PuTTY (或者不) ###
+### 10. 安装PuTTY (或者不) ###

@@ -104,9 +105,9 @@ Ubuntu过去提供内置的天气指示器, 但是自从它切换到Gnome 3以
### 你推荐如何调整? ###
-补充了这10个调整,你应该感觉你的Ubuntu真的找到了家的感觉,这很容易重建或击溃你的Linux体验。有许多不同的方式去定制你自己的体验去让它更适合你的需要;你只需要环顾自己并且找到你想要的东西
+补充了这10个调整,你应该感觉你的Ubuntu真的有家的感觉,这很容易建立起或击溃你的Linux体验。有许多不同的方式去定制你自己的体验去让它更适合你的需要;你只需自己寻找来发现你想要的东西。
-**你有什么调整和建议想和读者分享?**在评论中让我们知道吧!
+**您有什么其它的调整和建议想和读者分享?**在评论中告诉我们吧!
*图片致谢: Home doormat Via Shutterstock*
@@ -116,7 +117,7 @@ via: http://www.makeuseof.com/tag/10-tweaks-make-ubuntu-feel-like-home/
作者:[Danny Stieben][a]
译者:[guodongxiaren](https://github.com/guodongxiaren)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md b/published/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md
similarity index 95%
rename from translated/tech/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md
rename to published/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md
index 9865b7f70f..2ccfd07356 100644
--- a/translated/tech/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md
+++ b/published/20140812 'Ifconfig' Command Not Found In CentOS 7 Minimal Installation--A Quick Tip To Fix It.md
@@ -2,7 +2,7 @@ CentOS 7最小化安装后找不到‘ifconfig’命令——修复小提示
================================================================================

-就像我们所知道的,“**ifconfig**”命令用于配置GNU/Linux系统的网络接口。它显示网络接口卡的详细信息,包括IP地址,MAC地址,以及网络接口卡状态之类。但是,该命令已经过时了,而且在最小化版本的RHEL 7以及它的克隆版本CentOS 7,Oracle Linux 7以和Scientific Linux 7中也找不到该命令。
+就像我们所知道的,“**ifconfig**”命令用于配置GNU/Linux系统的网络接口。它显示网络接口卡的详细信息,包括IP地址,MAC地址,以及网络接口卡状态之类。但是,该命令已经过时了,而且在最小化版本的RHEL 7以及它的克隆版本CentOS 7,Oracle Linux 7和Scientific Linux 7中也找不到该命令。
### 在CentOS最小化服务器版本中如何查找网卡IP和其它详细信息? ###
@@ -24,7 +24,7 @@ CentOS 7最小化系统,使用“**ip addr**”和“**ip link**”命令来
inet 127.0.0.1/32 scope host venet0
inet 192.168.1.101/32 brd 192.168.1.101 scope global venet0:0
-要查看网络接口统计数据,输入命令:
+要查看网络接口统计数据,输入命令:
ip link
@@ -56,7 +56,7 @@ CentOS 7最小化系统,使用“**ip addr**”和“**ip link**”命令来
### 在CentOS 7最小化服务器版本中如何启用并使用“ifconfig”命令? ###
-如果你不知道在哪里可以找到ifconfig命令,请按照以下简单的步骤来找到它。首先,让我们找出哪个包提供了ifconfig命令。要完成这事,输入以下命令:
+如果你不知道在哪里可以找到ifconfig命令,请按照以下简单的步骤来找到它。首先,让我们找出哪个包提供了ifconfig命令。要完成这项任务,输入以下命令:
yum provides ifconfig
@@ -117,7 +117,7 @@ via: http://www.unixmen.com/ifconfig-command-found-centos-7-minimal-installation
作者:[Senthilkumar][a]
译者:[GOLinux](https://github.com/GOLinux)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md b/published/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md
similarity index 81%
rename from translated/tech/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md
rename to published/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md
index bfd280a2b7..a4feb3c2d7 100644
--- a/translated/tech/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md
+++ b/published/20140813 Linux FAQs with Answers--How to turn off server signature on Apache web server.md
@@ -1,6 +1,6 @@
-Linux常见问题与答案——如何在Apache网站服务器上关闭服务器签名
+Linux常见问题与答案—如何在Apache网站服务器上关闭服务器签名
================================================================================
->**问题**:每当Apache2网站服务器返回错误页时(如,404 页面无法找到,403 禁止访问页面),它会在页面底部显示网站服务器签名(如,Apache版本号和操作系统信息)。同时,当Apache2网站服务器为PHP页面服务时,它也会显示PHP的版本信息。我如何在Apache2网站服务器上关闭这些网站服务器签名?
+>**问题**:每当Apache2网站服务器返回错误页时(如,404 页面无法找到,403 禁止访问页面),它会在页面底部显示网站服务器签名(如,Apache版本号和操作系统信息)。同时,当Apache2网站服务器为PHP页面服务时,它也会显示PHP的版本信息。我如何在Apache2网站服务器上关闭这些网站服务器签名呢?
透露网站服务器带有服务器/PHP版本信息的签名会带来安全隐患,因为你基本上将你系统上的已知漏洞告诉给了攻击者。因此,作为服务器加固的一个部分,强烈推荐你禁用所有网站服务器签名。
@@ -34,19 +34,19 @@ Linux常见问题与答案——如何在Apache网站服务器上关闭服务器

-然而,没有第二行的‘ServerTokens Prod’,Apache服务器将仍然在HTTP回应头部包含详细的服务器标记,这会泄漏Apache的版本号。
+然而,若没有第二行的‘ServerTokens Prod’,Apache服务器将仍然在HTTP回应头部包含详细的服务器标记,这会泄漏Apache的版本号。

-第二行‘**ServerTokens Prod**’所要做的是在HTTP回应头中将服务器标记压缩到最小。
+第二行‘**ServerTokens Prod**’所要做的是在HTTP响应头中将服务器标记压缩到最小。
-因此,同时放置两行时,Apache将不会在页面中或者HTTP回应头中泄漏版本信息。
+因此,同时放置两行时,Apache将不会在页面中或者HTTP响应头中泄漏版本信息。

### 隐藏PHP版本 ###
-另外一个潜在的安全威胁是HTTP回应头中的PHP版本信息泄漏。默认情况下,Apache网站服务器通过HTTP回应头中的“X-Powered-By”字段包含有PHP版本信息。如果你想要在HTTP头部中隐藏PHP版本,请使用文本编辑器打开php.ini文件,找到“expose_php = On”这一行,将它改为“expose_php = Off”即可。
+另外一个潜在的安全威胁是HTTP响应头中的PHP版本信息泄漏。默认情况下,Apache网站服务器通过HTTP响应头中的“X-Powered-By”字段包含有PHP版本信息。如果你想要在HTTP头部中隐藏PHP版本,请使用文本编辑器打开php.ini文件,找到“expose_php = On”这一行,将它改为“expose_php = Off”即可。

@@ -60,15 +60,15 @@ Linux常见问题与答案——如何在Apache网站服务器上关闭服务器
> expose_php = Off
-最后,重启Apache2网站服务器以重新加载更新的PHP配置文件。
+最后,重启Apache2网站服务器来重新加载已更新的PHP配置文件。
-现在,你不会再看到带有“X-Powered-By”字段的HTTP回应头部了。
+现在,你不会再看到带有“X-Powered-By”字段的HTTP响应头了。
--------------------------------------------------------------------------------
via: http://ask.xmodulo.com/turn-off-server-signature-apache-web-server.html
译者:[GOLinux](https://github.com/GOLinux)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20180813 Command Line Tuesdays--Part Eight.md b/published/20180813 Command Line Tuesdays--Part Eight.md
similarity index 75%
rename from translated/tech/20180813 Command Line Tuesdays--Part Eight.md
rename to published/20180813 Command Line Tuesdays--Part Eight.md
index 5f868ba869..21fa109e65 100644
--- a/translated/tech/20180813 Command Line Tuesdays--Part Eight.md
+++ b/published/20180813 Command Line Tuesdays--Part Eight.md
@@ -8,7 +8,7 @@
dolphin
-……dolphin,这个文件管理器,就打开了。如果在进程打开时你查看终端,你就不能访问命令提示符了,而且你也不能在同一个窗口中写一个新命令进去了。如果你终止dolphin,提示符又会出现了,而你又能输入一个新命令到shell中去了。那么,我们怎么能在CLI运行一个程序时,同时又能获得提示符以便进一步发命令。
+……dolphin,这个文件管理器,就打开了。如果在这个进程打开时你查看终端,你会发现不能访问命令提示符了,而且你也不能在同一个窗口中写一个新命令进去了。如果你终止dolphin,提示符又会出现了,而你又能输入一个新命令到shell中去了。那么,我们怎么能在CLI运行一个程序时,同时又能获得提示符以便进一步发命令。
dolphin &
@@ -22,7 +22,7 @@
### jobs, ps ###
-由于我们在后台运行着进程,你可以使用jobs或者使用ps来来列出它们。试试吧,只要输入jobs或者输入ps就行了。下面是我得到的结果:
+由于我们在后台运行着进程,你可以使用jobs或者使用ps来列出它们。试试吧,只要输入jobs或者输入ps就行了。下面是我得到的结果:
nenad@linux-zr04:~> ps
PID TTY TIME CMD
@@ -39,9 +39,9 @@
……那么,它就把dolphin给杀死了。
-### Kill更多细节 ###
+### kill的更多细节 ###
-Kill的存在,不仅仅是为了终止进程,它最初是设计用来发送信号给进程。当然,有许多kill信号可以使用,根据你使用的应用程序不同而不同。请看下面的表:
+kill的存在,不仅仅是为了终止进程,它最初是设计用来发送信号给进程。当然,有许多kill信号可以使用,根据你使用的应用程序不同而不同。请看下面的表:

@@ -49,9 +49,10 @@ Kill的存在,不仅仅是为了终止进程,它最初是设计用来发送
### 结尾 ###
-我们以本节课来结束我们的CLT系列和周二必达,我希望其他像我这样的新手们能设法在他们的思想中摆脱控制台的神秘而学习掌握一些基本技能。现在对你们而言,所有剩下来要做的事,就是尽情摆弄它吧(只是别把/目录搞得太乱七八糟,因而你也不会诋毁什么东西了 :D)。
-We’ll be seeing a lot more of each other soon, as there’s more series of articles from where these came from. Stay tuned, and meanwhile…
+我们以本节课来结束我们的CLT系列和周二必达,我希望其他像我这样的新手们能设法在他们的思想中摆脱控制台的神秘而学习掌握一些基本技能。现在对你们而言,所有剩下来要做的事,就是尽情摆弄它吧(只是别把“/”目录搞得太乱七八糟,因而你也不会诋毁什么东西了 :D)。
+
我们将在不久的将来看到其它更多的东西,因为有更多的系列文章来自这些文章的出处。别走开,同时……
+
### ……尽情享受! ###
--------------------------------------------------------------------------------
@@ -60,7 +61,7 @@ via: https://news.opensuse.org/2014/08/12/command-line-tuesdays-part-eight/
作者:[Nenad Latinović][a]
译者:[GOLinux](https://github.com/GOLinux)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/sources/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md b/sources/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md
deleted file mode 100644
index 6e582f341c..0000000000
--- a/sources/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md
+++ /dev/null
@@ -1,43 +0,0 @@
-linuhap翻译中
-Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users
-================================================================================
-
-
-**The developer of Evolve OS, Ikey Doherty, has made a new desktop environment called Budgie Desktop and released a new version of it.**
-
-Evolve OS hasn't been launched yet, but the developer is actively working on it. Instead of adopting an existing desktop environment, he decided that it would be better to make his own. It's based on GNOME and uses quite a few GNOME packages, but it looks very different. In fact, it follows the same paradigm as MATE and Cinnamon, although Budgie seems to be a little more modern and polished.
-
-It's quite interesting to see that a critical piece of technology is released before the operating system that it's going to serve, but potential users don't have to be completely taken by surprise. To that effect, a [PPA][1] has been put in place for Ubuntu 14.04 LTS and Ubuntu 14.10, although it's not official. Also, the Arch Linux users will find the new desktop environment in the AUR repository.
-
-“Almost all of the changes since v4 have been related to the panel. It’s been completely rewritten in Vala, lowering the maintenance overhead and significantly reducing the barrier of entry for new contributors. So, when your update comes through later on (hopefully) today through OBS if you use it, or for Evolve OS users you already have the update, you should only see minor visual differences. The idea was not to change the look, but to rewrite what was there and make it moar better.”
-
-“The rewrite into Vala took quite some effort, but has immediately paid off. In the future all of the desktop will be rewritten to use Vala, and being the ‘second write’ – we do things better the second time around,” says Ikey Doherty in the release [announcement][2].
-
-Even if the desktop environment looks pretty advanced, judging by the version number, there is still room for improvements. The developer has promised that the next release in the series, 6.x, will allow users to write plugins in any language supported by libpeas, and that includes C, Vala, JavaScript, and Python.
-
-Users will also notice that some of the main elements from Budgie Desktop have remained in place, like the position of the menu and the size of the icons. In the future, it will be possible to change them, but for now, users need to contend with what's available.
-
-Even in this incipient phase, Budgie Desktop 5.1 looks better than many of the alternatives that can be found right now on other OSes.
-
-Download the source package right now for Ubuntu and Arch Linux:
-
-- [GIT sources][3][sources] [0 KB]
-- [Ubuntu 14.04 PPA Repository][4][ubuntu_deb] [0 KB]
-- [Arch Linux binary][5][binary] [0 KB]
-
---------------------------------------------------------------------------------
-
-via: http://news.softpedia.com/news/Budgie-Desktop-5-1-Is-a-Superb-New-Desktop-Environment-For-Conservative-Users-451477.shtml
-
-原文作者:[Silviu Stahie][a]
-
-译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://news.softpedia.com/editors/browse/silviu-stahie
-[1]:https://launchpad.net/~sukso96100/+archive/ubuntu/budgie-desktop
-[2]:https://evolve-os.com/2014/07/20/budgie-desktop-v5-1-released/
-[3]:https://github.com/evolve-os/budgie-desktop/
-[4]:https://launchpad.net/~sukso96100/+archive/ubuntu/budgie-desktop?field.series_filter=trusty
-[5]:https://aur.archlinux.org/packages/budgie-desktop-git
diff --git a/sources/news/20140821 Microsoft Lobby Denies the State of Chile Access to Free Software.md b/sources/news/20140821 Microsoft Lobby Denies the State of Chile Access to Free Software.md
new file mode 100644
index 0000000000..d321e0b961
--- /dev/null
+++ b/sources/news/20140821 Microsoft Lobby Denies the State of Chile Access to Free Software.md
@@ -0,0 +1,37 @@
+Microsoft Lobby Denies the State of Chile Access to Free Software
+================================================================================
+
+Fuerza Chile
+
+Fresh on the heels of the entire Munich and Linux debacle, another story involving Microsoft and free software has popped up across the world, in Chile. A prolific magazine from the South American country says that the powerful Microsoft lobby managed to turn around a law that would allow the authorities to use free software.
+
+The story broke out from a magazine called El Sábado de El Mercurio, which explains in great detail how the Microsoft lobby works and how it can overturn a law that may harm its financial interests.
+
+An independent member of the Chilean Parliament, Vlado Mirosevic, pushed a bill that would allow the state to consider free software when the authorities needed to purchase or renew licenses. The state of Chile pays $2.7 billion (€2 billion) on licenses from various companies, including Microsoft.
+
+According to [ubuntizando.com][1], Microsoft representatives met with Vlado Mirosevic shortly after he announced his intentions, but the bill passed the vote, with 64 votes in favor, 12 abstentions, and one vote against it. That one vote was cast by Daniel Farcas, a member of a Chilean party.
+
+A while later, the same member of the Parliament, Daniel Farcas, proposed another bill that actually nullified the effects of the previous one that had just been adopted. To make things even more interesting, some of the people who voted in favor of the first law also voted in favor of the second one.
+
+The new bill is even more egregious, because it aggressively pushes for the adoption of proprietary software. Companies that choose to use proprietary software will receive certain tax breaks, which makes it very hard for free software to get adopted.
+
+Microsoft has been in the news in the last few days because the [German city of Munich that adopted Linux][2] and dropped Windows system from its administration was considering, supposedly, returning to proprietary software.
+
+This new situation in Chile give us a sample of the kind of pull a company like Microsoft has and it shows us just how fragile laws really are. This is not the first time a company tries to bend the laws in a country to maximize the profits, but the advent of free software and the clear financial advantages that it offers are really making a dent.
+
+Five years ago, few people or governments would have considered adopting free software, but the quality of that software has risen dramatically and it has become a real competition [for the likes of Microsoft][3].
+
+--------------------------------------------------------------------------------
+
+via: http://news.softpedia.com/news/Microsoft-Lobby-Denies-the-State-of-Chile-Access-to-Free-Software-455598.shtml
+
+作者:[Silviu Stahie][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/silviu-stahie
+[1]:http://www.ubuntizando.com/2014/08/20/microsoft-chile-y-el-poder-del-lobby/
+[2]:http://news.softpedia.com/news/Munich-Disappointed-with-Linux-Plans-to-Switch-Back-to-Windows-455405.shtml
+[3]:http://news.softpedia.com/news/Munich-Switching-to-Windows-from-Linux-Is-Proof-that-Microsoft-Is-Still-an-Evil-Company-455510.shtml
\ No newline at end of file
diff --git a/sources/news/20140821 Transport Tycoon Deluxe Remake OpenTTD 1.4.2 Is an Almost Perfect Sim.md b/sources/news/20140821 Transport Tycoon Deluxe Remake OpenTTD 1.4.2 Is an Almost Perfect Sim.md
new file mode 100644
index 0000000000..7ef1024938
--- /dev/null
+++ b/sources/news/20140821 Transport Tycoon Deluxe Remake OpenTTD 1.4.2 Is an Almost Perfect Sim.md
@@ -0,0 +1,40 @@
+Transport Tycoon Deluxe Remake OpenTTD 1.4.2 Is an Almost Perfect Sim
+================================================================================
+
+Transport Tycoon
+
+**OpenTTD 1.4.2, an open source simulation game based on the popular Microprose title Transport Tycoon written by Chris Sawyer, has been officially released.**
+
+Transport Tycoon is a very old game that was originally launched back in 1995, but it made such a huge impact on the gaming community that, even almost 20 years later, it still has a powerful fan base.
+
+In fact, Transport Tycoon Deluxe had such an impact on the gaming industry that it managed to spawn an entire generation of similar games and it has yet to be surpassed by any new title, even though many have tried.
+
+Despite the aging graphics, the developers of OpenTTD have tried to provide new challenges for the fans of the original games. To put things into perspective, the original game is already two decades old. That means that someone who was 20 years old back then is now in his forties and he is the main audience for OpenTTD.
+
+"OpenTTD is modelled after the original Transport Tycoon game by Chris Sawyer and enhances the game experience dramatically. Many features were inspired by TTDPatch while others are original," reads the official announcement.
+
+OpenTTD features bigger maps (up to 64 times in size), stable multiplayer mode for up to 255 players in 15 companies, a dedicated server mode and an in-game console for administration, IPv6 and IPv4 support for all communication of the client and server, new pathfinding algorithms that makes vehicles go where you want them to, different configurable models for acceleration of vehicles, and much more.
+
+According to the changelog, awk is now used instead of trying to convince cpp to preprocess nfo files, CMD_CLEAR_ORDER_BACKUP is no longer suppressed by pause modes, the Wrong breakdown sound is no longer played for ships, integer overflow in the acceleration code is no longer causing either too low acceleration or too high acceleration, incorrectly saved order backups are now discarded when clients join, and the game no longer crashes when trying to show an error about vehicle in a NewGRF and the NewGRF was not loaded at all.
+
+Also, the Slovak language no longer uses space as group separator in numbers, the parameter bound checks are now tighter on GSCargoMonitor functions, the days in dates are not represented by ordinal numbers in all languages, and the incorrect usage of string commands in the base language has been fixed.
+
+Check out the [changelog][1] for a complete list of updates and fixes.
+
+Download OpenTTD 1.4.2:
+
+- [http://www.openttd.org/en/download-stable][2]
+
+--------------------------------------------------------------------------------
+
+via: http://news.softpedia.com/news/Transport-Tycoon-Deluxe-Remake-OpenTTD-1-4-2-Is-an-Almost-Perfect-Sim-455715.shtml
+
+作者:[Silviu Stahie][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/silviu-stahie
+[1]:http://ftp.snt.utwente.nl/pub/games/openttd/binaries/releases/1.4.2/changelog.txt
+[2]:http://www.openttd.org/en/download-stable
\ No newline at end of file
diff --git a/sources/talk/20140731 Top 10 Free Linux Games.md b/sources/talk/20140731 Top 10 Free Linux Games.md
index 4112cf895e..714bb8db54 100644
--- a/sources/talk/20140731 Top 10 Free Linux Games.md
+++ b/sources/talk/20140731 Top 10 Free Linux Games.md
@@ -1,3 +1,4 @@
+[Translating by SteveArcher]
Top 10 Free Linux Games
================================================================================
If the term “Can I game on it?” has been bothering you while thinking to switch on Linux from Windows platform, then here is an answer for that – “Go for it!”. Thanks to the Open source community who has been consistently developing different genre games for Linux OS and the online content distribution platform – Steam, there is no dearth of good commercial games which are as fun to play on Linux as on its other counterparts (like Windows).
diff --git a/sources/talk/20140818 Can Ubuntu Do This--Answers to The 4 Questions New Users Ask Most.md b/sources/talk/20140818 Can Ubuntu Do This--Answers to The 4 Questions New Users Ask Most.md
new file mode 100644
index 0000000000..69831d7704
--- /dev/null
+++ b/sources/talk/20140818 Can Ubuntu Do This--Answers to The 4 Questions New Users Ask Most.md
@@ -0,0 +1,78 @@
+Can Ubuntu Do This? — Answers to The 4 Questions New Users Ask Most
+================================================================================
+
+
+**Type ‘Can Ubuntu’ into Google and you’ll see a stream of auto suggested terms put before you, all based on the queries asked most often by curious searchers. **
+
+For long-time Linux users these queries all have rather obvious answers. But for new users or those feeling out whether a distribution like Ubuntu is for them the answers are not quite so obvious; they’re pertinent, real and essential asks.
+
+So, in this article, I’m going to answer the top four most searched for questions asking “*Can Ubuntu…?*”
+
+### Can Ubuntu Replace Windows? ###
+
+
+Windows isn’t to everyones tastes — or needs
+
+Yes. Ubuntu (and most other Linux distributions) can be installed on just about any computer capable of running Microsoft Windows.
+
+Whether you **should** replace it will, invariably, depend on your own needs.
+
+For example, if you’re attending a school or college that requires access to Windows-only software, you may want to hold off replacing it entirely. Same goes for businesses; if your work depends on Microsoft Office, Adobe Creative Suite or a specific AutoCAD application you may find it easier to stick with what you have.
+
+But for most of us Ubuntu can replace Windows full-time. It offers a safe, dependable desktop experience that can run on and support a wide range of hardware. Software available covers everything from office suites to web browsers, video and music apps to games.
+
+### Can Ubuntu Run .exe Files? ###
+
+
+You can run some Windows apps in Ubuntu
+
+Yes, though not out of the box, and not with guaranteed success. This is because software distributed in .exe are meant to run on Windows. These are not natively compatible with any other desktop operating system, including Mac OS X or Android.
+
+Software installers made for Ubuntu (and other Linux distributions) tend to come as ‘.deb’ files. These can be installed similarly to .exe — you just double-click and follow any on-screen prompts.
+
+But Linux is versatile. Using a compatibility layer called ‘Wine’ (which technically is not an emulator, but for simplicity’s sake can be referred to as one for shorthand) that can run many popular apps. They won’t work quite as well as they do on Windows, nor look as pretty. But, for many, it works well enough to use on a daily basis.
+
+Notable Windows software that can run on Ubuntu through Wine includes older versions of Photoshop and early versions of Microsoft Office . For a list of compatible software [refer to the Wine App Database][1].
+
+### Can Ubuntu Get Viruses? ###
+
+
+It may have errors, but it doesn’t have viruses
+
+Theoretically, yes. But in reality, no.
+
+Linux distributions are built in a way that makes it incredibly hard for viruses, malware and root kits to be installed, much less run and do any significant damage.
+
+For example, most applications run as a ‘regular user’ with no special administrative privileges, required for a virus to access critical parts of the operating system. Most software is also installed from well maintained and centralised sources, like the Ubuntu Software Center, and not random websites. This makes the risk of installing something that is infected negligible.
+
+Should you use anti-virus on Ubuntu? That’s up to you. For peace of mind, or if you’re regularly using Windows software through Wine or dual-booting, you can install a free and open-source virus scanner app like ClamAV, available from the Software Center.
+
+You can learn more about the potential for viruses on Linux/Ubuntu [on the Ubuntu Wiki][2].
+
+### Can Ubuntu Play Games? ###
+
+
+Steam has hundreds of high-quality games for Linux
+
+Oh yes it can. From the traditionally simple distractions of 2D chess, word games and minesweeper to modern AAA titles requiring powerful graphics cards, Ubuntu has a diverse range of games available for it.
+
+Your first port of call will be the **Ubuntu Software Center**. Here you’ll find a sizeable number of free, open-source and paid-for games, including acclaimed indie titles like World of Goo and Braid, as well as several sections filled with more traditional offerings, like PyChess, four-in-a-row and Scrabble clones.
+
+For serious gaming you’ll want to grab **Steam for Linux**. This is where you’ll find some of the latest and greatest games available, spanning the full gamut of genres.
+
+Also keep an eye on the [Humble Bundle][3]. These ‘pay what you want’ packages are held for two weeks every month or so. The folks at Humble have been fantastic supporters of Linux as a gaming platform, single-handily ensuring the Linux debut of many touted titles.
+
+--------------------------------------------------------------------------------
+
+via: http://www.omgubuntu.co.uk/2014/08/ubuntu-can-play-games-replace-windows-questions
+
+作者:[Joey-Elijah Sneddon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://plus.google.com/117485690627814051450/?rel=author
+[1]:https://appdb.winehq.org/
+[2]:https://help.ubuntu.com/community/Antivirus
+[3]:https://www.humblebundle.com/
\ No newline at end of file
diff --git a/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md b/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md
new file mode 100644
index 0000000000..fc1c708b14
--- /dev/null
+++ b/sources/talk/20140818 Upstream and Downstream--why packaging takes time.md
@@ -0,0 +1,97 @@
+Upstream and Downstream: why packaging takes time
+================================================================================
+Here in the KDE office in Barcelona some people spend their time on purely upstream KDE projects and some of us are primarily interested in making distros work which mean our users can get all the stuff we make. I've been asked why we don't just automate the packaging and go and do more productive things. One view of making on a distro like Kubuntu is that its just a way to package up the hard work done by others to take all the credit. I don't deny that, but there's quite a lot to the packaging of all that hard work, for a start there's a lot of it these days.
+
+"KDE" used to be released once every nine months or less frequently. But yesterday I released the [first bugfix update to Plasma][1], to make that happen I spent some time on Thursday with David making the [first update to Frameworks 5][2]. But Plasma 5 is still a work in progress for us distros, let's not forget about [KDE SC 4.13.3][3] which Philip has done his usual spectacular job of updating in the 14.04 LTS archive or [KDE SC 4.14 betas][4] which Scarlett has been packaging for utopic and backporting to 14.04 LTS. KDE SC used to be 20 tars, now it's 169 and over 50 langauge packs.
+
+### Patches ###
+
+If we were packaging it without any automation as used to be done it would take an age but of course we do automate the repetative tasks, the [KDE SC 4.13.97 status][5] page shows all the packages and highlights obvious problems. But with 169 tars even running the automated script takes a while, then you have to fix any patches that no longer apply. We have [policies][6] to disuade having patches, any patches should be upstream in KDE or on their way upstream, but sometimes it's unavoidable that we have some to maintain which often need small changes for each upstream release.
+
+### Symbols ###
+
+Much of what we package are libraries and if one small bit changes in the library, any applications which use that library will crash. This is ABI and the rules for [binary compatibility][7] in C++ are nuts. Not infrequently someone in KDE will alter a library ABI without realising. So we maintain symbol files to list all the symbols, these can often feel like more trouble than they're worth because they need updated when a new version of GCC produces different symbols or when symbols disappear and on investigation they turn out to be marked private and nobody will be using them anyway, but if you miss a change and apps start crashing as nearly happened in KDE PIM last week then people get grumpy.
+
+### Copyright ###
+
+Debian, and so Ubuntu, documents the copyright licence of every files in every package. This is a very slow and tedious job but it's important that it's done both upstream and downstream because it you don't people won't want to use your software in a commercial setting and at worst you could end up in court. So I maintain the [licensing policy][8] and not infrequently have to fix bits which are incorrectly or unclearly licenced and answer questions such as today I was reviewing whether a kcm in frameworks had to be LGPL licenced for Eike. We write a copyright file for every package and again this can feel like more trouble than its worth, there's no easy way to automate it but by some readings of the licence texts it's necessary to comply with them and it's just good practice. It also means that if someone starts making claims like requiring licencing for already distributed binary packages I'm in an informed position to correct such nonsense.
+
+### Descriptions ###
+
+When we were packaging KDE Frameworks from scratch we had to find a descirption of each Framework. Despite policies for metadata some were quite underdescribed so we had to go and search for a sensible descirption for them. Infact not infrequently we'll need to use a new library which doesn't even have a sensible paragraph describing what it does. We need to be able to make a package show something of a human face.
+
+### Multiarch ###
+
+A recent addition to the world of .deb packaging is [MultiArch][9] which allows i386 packages to be installed on amd64 computers as well as some even more obscure combinations (powerpc on ppcel64 anyone?). This lets you run Skype on your amd64 computer without messy cludges like the ia32-libs package. However it needs quite a lot of attention from packagers of libraries marking which packages are multiarch, which depend on other multiarch or arch independent packages and even after packaging KDE Frameworks I'm not entirely comfortable with doing it.
+
+### Splitting up Packages ###
+
+We spend lots of time splitting up packages. When say Calligra gets released it's all in one big tar but you don't want all of it on your system because you just want to write a letter in Calligra Words and Krita has lots of image and other data files which take up lots of space you don't care for. So for each new release we have to work out which of the installed files go into which .deb package. It takes time and even worse occationally we can get it wrong but if you don't want heaps of stuff on your computer you don't need then it needs to be done. It's also needed for library upgrades, if there's a new version of libfoo and not all the programs have been ported to it then you can install libfoo1 and libfoo2 on the same system without problems. That's not possible with distros which don't split up packages.
+
+One messy side effect of this is that when a file moves from one .deb to another .deb made by the same sources, maybe Debian chose to split it another way and we want to follow them, then it needs a Breaks/Replaces/Conflicts added. This is a pretty messy part of .deb packaging, you need to specify which version it Breaks/Replaces/Conflicts and depending on the type of move you need to specify some combination of these three fields but even experienced packages seem to be unclear on which. And then if a backport (with files in original places) is released which has a newer version than the version you specify in the Breaks/Replaces/Conflicts it just refuses to install and stops half way through installing until a new upload is made which updates the Breaks/Replaces/Conflicts version in the packaging. I'd be interested in how this is solved in the RPM world.
+
+### Debian Merges ###
+
+Ubuntu is forked from Debian and to piggy back on their work (and add our own bugs while taking the credit) we merge in Debian's packaging at the start of each cycle. This is fiddly work involving going through the diff (and for patches that's often a diff of a diff) and changelog to work out why each alternation was made. Then we merge them together, it takes time and it's error prone but it's what allows Ubuntu to be one of the most up to date distros around even while much of the work gone into maintaining universe packages not part of some flavour has slowed down.
+
+### Stable Release Updates ###
+
+You have Kubuntu 14.04 LTS but you want more? You want bugfixes too? Oh but you want them without the possibility of regressions? Ubuntu has quite strict definition of what's allowed in after an Ubuntu release is made, this is because once upon a time someone uploaded a fix for X which had the side effect of breaking X on half the installs out there. So for any updates to get into the archive they can only be for certain packages with a track record of making bug fix releases without sneaking in new features or breaking bits. They need to be tested, have some time passed to allow for wider testing, be tested again using the versions compiled in Launchpad and then released. KDE makes bugfix releases of KDE SC every month and we update them in the latest stable and LTS releases as [4.13.3 was this week][10]. But it's not a process you can rush and will take a couple of weeks usually. That 4.13.3 update was even later then usual because we were busy with Plasma 5 and whatnot. And it's not perfect, a bug in Baloo did get through with 4.13.2. But it would be even worse if we did rush it.
+
+### Backports ###
+
+Ah but you want new features too? We don't allow in new features into the normal updates because they will have more chance of having regressions. That's why we make backports, either in the kubuntu-ppa/backports archive or in the ubuntu backports archive. This involves running the package through another automation script to change whever needs changed for the backport then compiling it all, testing it and releasing it. Maintaining and running that backport script is quite faffy so sending your thanks is always appreciated.
+
+We have an allowance to upload new bugfix (micro releases) of KDE SC to the ubuntu archive because KDE SC has a good track record of fixing things and not breaking them. When we come to wanting to update Plasma we'll need to argue for another allowance. One controvertial issue in KDE Frameworks is that there's no bugfix releases, only monthly releases with new features. These are unlikely to get into the Ubuntu archive, we can try to argue the case that with automated tests and other processes the quality is high enough, but it'll be a hard sell.
+
+### Crack of the Day ###
+
+Project Neon provides packages of daily builds of parts of KDE from Git. And there's weekly ISOs that are made from this too. These guys rock. The packages are monolithic and install in /opt to be able to live alongside your normal KDE software.
+
+### Co-installability ###
+
+You should be able to run KDELibs 4 software on a Plasma 5 desktop. I spent quite a bit of time ensuring this is possible by having no overlapping files in kdelibs/kde-runtime and kde frameworks and some parts of Plasma. This wasn't done primarily for Kubuntu, many of the files could have been split out into .deb packages that could be shared between KDELibs 4 and Plasma 5, but other disros which just installs packages in a monolithic style benefitted. Some projects like Baloo didn't ensure they were co-installable, fine for Kubuntu as we can separate the libraries that need to be coinstalled from the binaries, but other distros won't be so happy.
+
+### Automated Testing ###
+
+Increasingly KDE software comes with its own test suite. Test suites are something that has been late coming to free software (and maybe software in general) but now it's here we can have higher confidence that the software is bug free. We run these test suites as part of the package compilation process and not infrequently find that the test suite doesn't run, I've been told that it's not expected for packagers to use it in the past. And of course tests fail.
+
+### Obscure Architectures ###
+
+In Ubuntu we have some obscure architectures. 64-bit Arm is likely to be a useful platform in the years to come. I'm not sure why we care about 64-bit powerpc, I can only assume someone has paid Canonical to care about it. Not infrequently we find software compiles fine on normal PCs but breaks on these obscure platforms and we need to debug why they is. This can be a slow process on ARM which takes an age to do anything, or very slow where I don't even have access to a machine to test on, but it's all part of being part of a distro with many use-cases.
+
+### Future Changes ###
+
+At Kubuntu we've never shared infrstructure with Debian despite having 99% the same packaging. This is because Ubuntu to an extent defines itself as being the technical awesomeness of Debian with smoother processes. But for some time Debian has used git while we've used the slower bzr (it was an early plan to make Ubuntu take over the world of distributed revision control with Bzr but then Git came along and turned out to be much faster even if harder to get your head around) and they've also moved to team maintainership so at last we're planning [shared repositories][11]. That'll mean many changes in our scripts but should remove much of the headache of merges each cycle.
+
+There's also a proposal to [move our packaging to daily builds][12] so we won't have to spend a lot of time updating packaging at every release. I'm skeptical if the hassle of the infrastructure for this plus fixing packaging problems as they occur each day will be less work than doing it for each release but it's worth a try.
+
+### ISO Testing ###
+
+Every 6 months we make an Ubuntu release (which includes all the flavours of which Ubuntu [Unity] is the flagship and Kubuntu is the most handsome) and there's alphas and betas before that which all need to be tested to ensure they actually install and run. Some of the pain of this has reduced since we've done away with the alternative (text debian-installer) images but we're nowhere near where Ubuntu [Unity] or OpenSUSE is with OpenQA where there are automated installs running all the time in various setups and some magic detects problems. I'd love to have this set up.
+
+I'd welcome comments on how any workflow here can be improved or how it compares to other distributions. It takes time but in Kubuntu we have a good track record of contributing fixes upstream and we all are part of KDE as well as Kubuntu. As well as the tasks I list above about checking copyright or co-installability I do Plasma releases currently, I just saw Harald do a Phonon release and Scott's just applied for a KDE account for fixes to PyKDE. And as ever we welcome more people to join us, we're in #kubuntu-devel where free hugs can be found, and we're having a whole day of Kubuntu love at Akademy.
+
+--------------------------------------------------------------------------------
+
+via: https://blogs.kde.org/2014/08/13/upstream-and-downstream-why-packaging-takes-time
+
+作者:[Jonathan Riddell][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:https://blogs.kde.org/users/jriddell
+[1]:https://dot.kde.org/2014/08/12/first-bugfix-update-plasma-5
+[2]:https://dot.kde.org/2014/08/07/kde-frameworks-5.1
+[3]:http://www.kubuntu.org/news/kde-sc-4.13.3
+[4]:https://dot.kde.org/2014/07/18/kde-ships-july-updates-and-second-beta-applications-and-platform-414
+[5]:http://qa.kubuntu.co.uk/ninjas-status/build_status_4.13.97_utopic.html
+[6]:https://community.kde.org/Kubuntu/Policies
+[7]:https://techbase.kde.org/Policies/Binary_Compatibility_Issues_With_C++
+[8]:https://techbase.kde.org/Policies/Licensing_Policy
+[9]:https://help.ubuntu.com/community/MultiArch
+[10]:http://www.kubuntu.org/news/kde-sc-4.13.3
+[11]:http://lists.alioth.debian.org/pipermail/pkg-kde-talk/2014-August/001934.html
+[12]:https://lists.ubuntu.com/archives/kubuntu-devel/2014-August/008651.html
\ No newline at end of file
diff --git a/sources/talk/20140818 Where And How To Code--Choosing The Best Free Code Editor.md b/sources/talk/20140818 Where And How To Code--Choosing The Best Free Code Editor.md
new file mode 100644
index 0000000000..76f0e50e96
--- /dev/null
+++ b/sources/talk/20140818 Where And How To Code--Choosing The Best Free Code Editor.md
@@ -0,0 +1,104 @@
+Where And How To Code: Choosing The Best Free Code Editor
+================================================================================
+A close look at Cloud9, Koding and Nitrous.IO.
+
+
+
+**Ready to start your first coding project? Great! Just configure** Terminal or Command Prompt, learn to use it and then install all the languages, add-on libraries and APIs you’ll need. When you're finally through with all that, you can get started with installing [Visual Studio][1] so you can preview your work.
+
+At least that's how you used to have to do it.
+
+No wonder beginning coders are increasingly turning to online integrated development environments (IDEs). An IDE is a code editor that comes ready to work with languages and all their dependencies, saving you the hassle of installing them on your computer.
+
+I wanted to learn more about what constitutes the typical IDE, so I took a look at the free tier for three of the most popular integrated development environments out there: [Cloud9][2], [Koding][3], and [Nitrous.IO][4]. In the process, I learned a lot about the cases in which programmers would and would not want to use IDEs.
+
+### Why Use An IDE? ###
+
+If a text editor is like Microsoft Word, think of an IDE as Google Drive. You get similar functionality, but it's accessible from any computer and ready to share. As the Internet becomes an increasingly influential part of project workflow, IDEs make life easier.
+
+I used Nitrous.IO for my last ReadWrite tutorial, the Python app in [Create Your Own Obnoxiously Simple Messaging App Just Like Yo][5]. When you use an IDE, you select the language you want to work in so you can test and preview how it looks on the IDE’s Virtual Machine (VM) designed to run programs written specifically in that language.
+
+If you read the tutorial, you'll see there are only two API libraries that my app depended on—messaging service Twilio and Python microframework Flask. That would have been easy to build using a text editor and Terminal on my computer, but I chose an IDE for yet another convenience: when everyone is using the same developer environment, it’s easier to follow along with a tutorial.
+
+### What An IDE Is Not ###
+
+Still, an IDE is not a long term hosting solution.
+
+When you’re working on an IDE, you’re able to build, test and preview your app in the cloud. You’re even able to share the final draft via link.
+
+But you can’t use an IDE to store your project permanently. You wouldn't ditch your blog in favor of hosting your posts as Google Drive documents. Like Google Drive, IDEs allow you to link and share content, but neither are equipped to replace real hosting.
+
+What's more, IDEs aren't designed for wide-spread sharing. Despite the increased functionality IDEs add to the preview capability of most text editors, stick with showing off your app preview to friends and coworkers, not with, say, the front page of Hacker News. In that case, your IDE would probably shut you down for excessive traffic.
+
+Think of it this way: an IDE is a place to build and test your app; a host is a place for it to live. So once you’ve finalized your app, you’ll want to deploy it on a cloud-based service that lets you host apps long term, preferably one with a free hosting option like [Heroku][6].
+
+### Choosing An IDE ###
+
+
+
+As IDEs become more popular, more are popping up all the time. In my opinion, there’s no perfect IDE. However, some IDEs are better for certain work process priorities than others.
+
+I took a look at the free tier for three of the most popular integrated development environments out there: Cloud9, Koding, and Nitrous.IO. Each has its benefits, depending on what you're working on. Here's what I found.
+
+### Cloud9: Ready To Collaborate ###
+
+When I signed up for Cloud9, one of the first things it prompted me to do was integrate my GitHub and BitBucket accounts. Instantly, all my GitHub projects, solo and collaborative, were ready to clone and work on in Cloud9’s development tool. Other IDEs have nowhere near this level of GitHub integration.
+
+Out of the three IDEs I looked at, Cloud9 seemed most intent on ensuring an environment where I could work seamlessly with co-coders. Here, it’s not just a chat function in the corner. In fact, said CEO Ruben Daniels, Cloud9 collaborators can see each others coding in real time, just like co-authors are able to on Google Drive.
+
+“Most services’ collaborative features only work on a single file,” said Daniels. “Ours work on multiples throughout the project. Collaboration is fully integrated within the IDE.”
+
+### Koding: Help When You Need It ###
+
+IDEs give you the tools you need to build and test applications in the gamut of open source languages. For a beginner, that can be a little bit intimidating. For example, if I’m working on a project with both Python and Ruby components, which VM do I use for testing?
+
+The answer is both, though on a free account, you can only turn on one VM for testing at a time. I was able to find that out right on my Koding dashboard, which doubles as a place for users to give and get advice on their Koding projects. Of the three, it’s the most transparent when it comes to where you can ask for assistance and hear back in minutes.
+
+“We have an active community built into the application,” said Nitin Gupta, Chief Business Officer at Koding. “We wanted to create an environment that is extremely attractive to people who need help and who want to help.”
+
+### Nitrous.IO: An IDE Wherever You Want ###
+
+The ultimate advantage of using an IDE over your own desktop environment is that it’s self-contained. You don’t have to install anything to use it. On the other hand, the ultimate advantage of using your own desktop environment is that you can work locally, even without Internet.
+
+Nitrous.IO gives you the best of both worlds. You can use the IDE on the Web, or you can download it to your own computer, said cofounder AJ Solimine. The advantage is that you can merge the integrations of Nitrous with the familiarity of your preferred text editor.
+
+“You can access Nitrous.IO from any modern web browser via our online Web IDE, but we also have handy desktop applications for Windows and Mac that let you edit with your favorite editor,” he said.
+
+### The Bottom Line ###
+
+The most surprising thing I learned from a week of [using][7] three different IDEs? How similar they are. [When it comes to the basics of coding][8], they’re all equally helpful.
+
+Cloud9, Koding, [and Nitrous.IO all support][9] every major open source language, from Ruby to Python to PHP to HTML5. You can choose from any of those VMs.
+
+Both Cloud9 and Nitrous.IO have built-in one-click GitHub integration. For Koding there are a [couple more steps][10], but it can be done.
+
+Each integrated easily with the APIs I needed. Each let me install my preferred package installers, too (and Koding made me do it as a superuser). They all have a built in Terminal for easily testing and deploying projects. All three allow you to easily preview your project. And of course, they all hosted my project in the cloud so I could work on it anywhere.
+
+On the downside, they all had the same negatives, which is reasonable when you consider they're free. You can only run one VM at a time to test a program written in a particular language. When you’re not using your VM for a while, the IDE preserves bandwidth by putting it into hibernation and you have to wait for it to reload next time you use it (and Cloud9 was especially laborious). None of them make a good permanent host for your finished projects.
+
+So to answer those who ask me if there’s a perfect free IDE out there, probably not. But depending on your priorities, there might be one that’s perfect for your project.
+
+Lead image courtesy of [Shutterstock][11]
+
+--------------------------------------------------------------------------------
+
+via: http://readwrite.com/2014/08/14/cloud9-koding-nitrousio-integrated-development-environment-ide-coding
+
+作者:[Lauren Orsini][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://readwrite.com/author/lauren-orsini
+[1]:http://www.visualstudio.com/
+[2]:http://c9.io/
+[3]:https://koding.com/
+[4]:http://nitrous.io/
+[5]:http://readwrite.com/2014/07/11/one-click-messaging-app
+[6]:http://heroku.com/
+[7]:http://help.nitrous.io/ide-general/
+[8]:https://www.nitrous.io/desktop
+[9]:https://www.nitrous.io/desktop
+[10]:https://koding.com/Activity/steps-clone-projects-github-koding-1-create-account-github-2-open-your-terminal-3
+[11]:http://www.shutterstock.com/
\ No newline at end of file
diff --git a/sources/talk/20140818 Why Your Company Needs To Write More Open Source Software.md b/sources/talk/20140818 Why Your Company Needs To Write More Open Source Software.md
new file mode 100644
index 0000000000..04aa33c138
--- /dev/null
+++ b/sources/talk/20140818 Why Your Company Needs To Write More Open Source Software.md
@@ -0,0 +1,68 @@
+Why Your Company Needs To Write More Open Source Software - ReadWrite
+================================================================================
+> Real innovation doesn't happen behind closed doors.
+
+
+
+**The Wall Street Journal [thinks][1] it's news that Zulily is developing** "more software in-house." It's not. At all. As [Eric Raymond wrote][2] years ago, 95% of the world's software is written for use, not for sale. The reasons are many, but one stands out: as Zulily CIO Luke Friang declares, it's "nearly impossible for a [off the shelf] solution to keep up with our pace."
+
+True now, just as it was true 20 years ago.
+
+But one thing is different, and it's something the WSJ completely missed. Historically software developed in-house was zealously kept proprietary because, the reasoning went, it was the source of a firm's competitive advantage. Today, however, companies increasingly realize the opposite: there is far more to be gained by open sourcing in-house software than keeping it closed.
+
+Which is why your company needs to contribute more open-source code. Much more.
+
+We've gone through an anomalous time these past 20 years. While most software continued to be written for internal use, most of the attention has been focused on vendors like SAP and Microsoft that build solutions that apply to a wide range of companies.
+
+That's the theory, anyway.
+
+In practice, buyers spent a small fortune on license fees, then a 5X multiple on top of that to make the software fit their requirements. For example, a company may spend $100,000 on an ERP system, but they're going to spend another $500,000 making it work.
+
+One of the reasons open source took off, even in applications, was that companies could get a less functional product for free (or a relatively inexpensive fee) and then spend their implementation dollars tuning it to their needs. Either way, customization was necessary, but the open source approach was less costly and arguably more likely to result in a more tailored result.
+
+Meanwhile, technology vendors doubled-down on "sameness," as Redmonk analyst [Stephen O'Grady describes][3]:
+
+> The mainstream technology industry has, in recent years, eschewed specialization. Virtual appliances, each running a version of the operating system customized for an application or purpose, have entirely failed to dent the sales of general purpose alternatives such as RHEL or Windows. For better than twenty years, the answer to any application data persistence requirement has meant one thing: a relational database. If you were talking about enterprise application development, you were talking about Java. And so on.
+
+Along the way, however, companies discovered that vendors weren't really meeting their needs, even for well-understood product categories like Content Management Systems. They needed different, not same.
+
+So the customers went rogue. They became vendors. Sort of.
+
+As is often the case, [O'Grady nails][4] this point. Writing in 2010, O'Grady uncovers an interesting trend: "Software vendors are facing a powerful new market competitor: their customers."
+
+Think about the most visible technologies today. Most are open source, and nearly all of them were originally written for some company's internal use, or some developer's hobby. Linux, Git, Hadoop, Cassandra, MongoDB, Android, etc. None of these technologies were originally written to be sold as products.
+
+Instead, they were developed by companies—usually Web companies—building software to "[scratch their own itches][5]," to use the open source phrase. And unlike previous generations of in-house software developed at banks, hospitals and other organizations, they open sourced the code.
+
+While [some companies eschew developing custom software][6] because they don't want to maintain it, open source (somewhat) mitigates this by letting a community grow up to extend and maintain a project, thereby amortizing the costs of development for the code originators. Yahoo! started Hadoop, but its biggest contributors today are Cloudera and Hortonworks. Facebook kickstarted Cassandra, but DataStax primarily maintains it today. And so on.
+
+Today real software innovation doesn't happen behind closed doors. Or, if it does, it doesn't stay there. It's open source, and it's upending decades of established software orthodoxy.
+
+Not that it's for the faint of heart.
+
+The best open-source projects [innovate very fast][7]. Which is not the same as saying anyone will care about your open-source code. There are [significant pros and cons to open sourcing your code][8]. But one massive "pro" is that the best developers want to work on open code: if you need to hire quality developers, you need to give them an open source outlet for their work. (Just [ask Netflix][9].)
+
+But that's no excuse to sit on the sidelines. It's time to get involved, and not for the good of some ill-defined "community." No, the primary beneficiary of open-source software development is you and your company. Better get started.
+
+Lead image courtesy of Shutterstock.
+
+--------------------------------------------------------------------------------
+
+via: http://readwrite.com/2014/08/16/open-source-software-business-zulily-erp-wall-street-journal
+
+作者:[Matt Asay][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://readwrite.com/author/matt-asay
+[1]:http://blogs.wsj.com/cio/2014/08/08/zulily-calls-in-house-software-a-differentiator-for-competitive-advantage/
+[2]:http://oreilly.com/catalog/cathbazpaper/chapter/ch05.html
+[3]:http://redmonk.com/sogrady/2010/01/12/roll-your-own/#ixzz3ATBuZsef
+[4]:http://redmonk.com/sogrady/2010/01/12/roll-your-own/
+[5]:http://en.wikipedia.org/wiki/The_Cathedral_and_the_Bazaar
+[6]:http://www.abajournal.com/magazine/article/roll_your_own_software_hidden_dangers_on_the_road_less_traveled/
+[7]:http://readwrite.com/2013/12/12/open-source-innovation
+[8]:http://readwrite.com/2014/07/07/open-source-software-pros-cons
+[9]:http://techblog.netflix.com/2012/07/open-source-at-netflix-by-ruslan.html
\ No newline at end of file
diff --git a/sources/talk/20140818 Will Linux ever be able to give consumers what they want.md b/sources/talk/20140818 Will Linux ever be able to give consumers what they want.md
new file mode 100644
index 0000000000..9dd2021f43
--- /dev/null
+++ b/sources/talk/20140818 Will Linux ever be able to give consumers what they want.md
@@ -0,0 +1,51 @@
+Will Linux ever be able to give consumers what they want?
+================================================================================
+> Jack Wallen offers up the novel idea that giving the consumers what they want might well be the key to boundless success.
+
+
+
+In the world of consumer electronics, if you don't give the buyer what they want, they'll go elsewhere. We've recently witnessed this with the Firefox browser. The consumer wanted a faster, less-bloated piece of software, and the developers went in the other direction. In the end, the users migrated to Chrome or Chromium.
+
+Linux needs to gaze deep into their crystal ball, watch carefully the final fallout of that browser war, and heed this bit of advice:
+
+If you don't give them what they want, they'll leave.
+
+Another great illustration of this backfiring is Windows 8. The consumer didn't want that interface. Microsoft, however, wanted it because it was necessary to begin the drive to all things Surface. This same scenario could have been applied to Canonical and Ubuntu Unity -- however, their goal wasn't geared singularly and specifically towards tablets (so, the interface was still highly functional and intuitive on the desktop).
+
+For the longest time, it seemed like Linux developers and designers were gearing everything they did toward themselves. They took the "eat your own dog food" too far. In that, they forgot one very important thing:
+
+Without new users, their "base" would only ever belong to them.
+
+In other words, the choir had not only been preached to, it was the one doing the preaching. Let me give you three examples to hit this point home.
+
+- For years, Linux has needed an equivalent of Active Directory. I would love to hand that title over to LDAP, but have you honestly tried to work with LDAP? It's a nightmare. Developers have tried to make LDAP easy, but none have succeeded. It amazes me that a platform that has thrived in multi-user situations still has nothing that can go toe-to-toe with AD. A team of developers needs to step up, start from scratch, and create the open-source equivalent to AD. This would be such a boon to mid-size companies looking to migrate away from Microsoft products. But until this product is created, the migration won't happen.
+- Another Microsoft-driven need -Exchange/Outlook. Yes, I realize that many are going to the cloud. But the truth is that mediumto large-scale businesses will continue relying on the Exchange/Outlook combo until something better comes along. This could very well happen within the open-source community. One piece of this puzzle is already there (though it needs some work) -the groupware client, Evolution. If someone could take, say, a fork of Zimbra and re-tool it such a way that it would work with Evolution (and even Thunderbird) to serve as a drop-in replacement for Exchange, the game would change, and the trickle-down to consumers would be massive.
+- Cheap, cheap, cheap. This one is a hard pill for most to swallow -but consumers (and businesses) want cheap. Look at the Chromebook sales over the last year. Now, do a search for a Linux laptop and see if you can find one for under $700.00 (USD). For a third of that cost, you can get a Chromebook (a platform running the Linux kernel) that will serve you well. But because Linux is still such a niche market, it's hard to get the cost down. A company like Red Hat Linux could change that. They already have the server hardware in place. Why not crank out a bunch of low-cost, mid-range laptops that work in similar fashion to the Chromebook but only run a full-blown Linux environment? (see "[Is the Cloudbook the future of Linux?][1]") The key is that these devices must be low-cost and meet the needs of the average consumer. Stop thinking with your gamer/developer hat on and remember what the average user really needs -a web browser and not much more. That's why the Chromebook is succeeding so handily. Google knew exactly what the consumer wanted, and they delivered. On the Linux front, companies still think the only way to attract buyers is to crank out high-end, expensive Linux hardware. There's a touch of irony there, considering one of the most-often shouted battle cries is that Linux runs on slower, older hardware.
+
+Finally, Linux needs to take a page from the good ol' Book Of Jobs and figure out how to convince the consumer that what they truly need is Linux. In their businesses and in their homes -- everyone can benefit from using Linux. Honestly, how can the open-source community not pull that off? Linux already has the perfect built-in buzzwords: Stability, reliability, security, cloud, free -- plus Linux is already in the hands of an overwhelming amount of users (they just don't know it). It's now time to let them know. If you use Android or Chromebooks, you use (in one form or another) Linux.
+
+Knowing just what the consumer wants has always been a bit of a stumbling block for the Linux community. And I get that -- so much of the development of Linux happens because a developer has a particular need. This means development is targeted to a "micro-niche." It's time, however, for the Linux development community to think globally. "What does the average user need, and how do we give it to them?" Let me offer up the most basic of primers.
+
+The average user needs:
+
+- Low cost
+- Seamless integration with devices and services
+- Intuitive and modern designs
+- A 100% solid browser experience
+
+That's pretty much it. With those four points in mind, it should be easy to take a foundation of Linux and create exactly what the user wants. Google did it... certainly the Linux community can build on what Google has done and create something even better. Mix that in with AD integration, give it an Exchange/Outlook or cloud-based groupware set of tools, and something very special will happen -- people will buy it.
+
+Do you think the Linux community will ever be able to give the consumer what they want? Share your opinion in the discussion thread below.
+
+--------------------------------------------------------------------------------
+
+via: http://www.techrepublic.com/article/will-linux-ever-be-able-to-give-consumers-what-they-want/
+
+作者:[Jack Wallen][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.techrepublic.com/search/?a=jack+wallen
+[1]:http://www.techrepublic.com/article/is-the-cloudbook-the-future-of-linux/
\ No newline at end of file
diff --git a/sources/talk/20140819 KDE Plasma 5--For those Linux users undecided on the kernel' s future.md b/sources/talk/20140819 KDE Plasma 5--For those Linux users undecided on the kernel' s future.md
new file mode 100644
index 0000000000..dd6bd15534
--- /dev/null
+++ b/sources/talk/20140819 KDE Plasma 5--For those Linux users undecided on the kernel' s future.md
@@ -0,0 +1,199 @@
+KDE Plasma 5—For those Linux users undecided on the kernel’s future
+================================================================================
+> Review—new release straddles traditional desktop needs, long term multi-device plans.
+
+Finally, the KDE project has released KDE Plasma 5, a major new version of the venerable K Desktop Environment.
+
+Plasma 5 arrives in the middle of an ongoing debate about the future of the Linux desktop. On one hand there are the brand new desktop paradigms represented by GNOME and Unity. Both break from the traditional desktop model in significant ways, and both attempt to create interfaces that will work on the desktop and the much-anticipated, tablet-based future (which [may or may not ever arrive][1]).
+
+Linux desktops like KDE, XFCE, LXDE, Mate, and even Cinnamon are the other side of the fence. None has re-invented itself too much. They continue to offer users a traditional desktop experience, which is not to say these projects aren't growing and refining. All of them continue to turn out incremental releases that fine tune what is a well-proven desktop model.
+
+
+Ubuntu's Unity desktop
+
+
+GNOME 3 desktop
+
+GNOME and Unity end up getting the lion's share of attention in this ongoing debate. They're both new and different. They're both opinionated and polarizing. For every Linux user that loves them, there's another that loves to hate them. It makes for, if nothing else, lively comments and forum posts in the Linux world. But the difference between these two Linux camps is about more than just how your desktop looks and behaves. It's about what the future of computing looks like.
+
+GNOME and Unity believe that the future of computing consists of multiple devices all running the same software—the new desktop these two create only makes sense within this vision. These new versions aren't really built as desktops for the future, but they include a hybrid desktop fallback mode for now and appear to believe in devices going forward. The other side of the Linux schism largely seems to ignore those.
+
+And unlike the world of closed source OSes—where changes are handed down, like them or leave them—the Linux world is in the middle of a conversation about these two opposite ideas.
+
+For users, it can be frustrating. The last thing you need when you're trying to get work done is an update that completely changes your desktop, forcing you to learn new ways of working. Even the best case scenario, moving to another desktop when your old favorite suddenly veers off in a new direction, usually means jettisoning years of muscle memory and familiarity.
+
+Luckily, there's a simple way to navigate this mess and find the right desktop for you. Here it is in a nutshell: do you want to bend your will to your desktop or do you want to bend your desktop to your will?
+
+If you fall in the first camp and don't mind learning new ways of working, Unity and GNOME 3 will be your best bets. If you fall in the latter camp, XFCE, Cinnamon, Mate, and a host of others will all likely prove a good fit. And even if you want to go non-traditional in a different direction from GNOME 3 and Unity, there's always Xmonad, Ratpoison, and others that very few Linux users will ever try. (This is a small shame, as Xmonad may be the best thing in Linux since Linus said, uh, hey, here's a kernel for your GNU system.)
+
+
+KDE Plasma 5's new boot screen.
+
+So what about the undecided Linux users, all those people in the middle? You like the traditional desktop experience, and you're not ready to give up your menu and shortcuts for HUDs and other new tools. But at the same time, you're curious about tablets and other form factors, and you want something that will work across them all. You, my hypothetical friend, are an excellent candidate for the brand new KDE Plasma 5.
+
+KDE is attempting to do something no other desktop in Linux has tried to date—move toward the tablet and mobile device future while still producing a desktop experience that's familiar, functional, and infinitely customizable.
+
+### KDE Plasma 5 and the world of "convergence" ###
+
+KDE users who made it through the transition from KDE 3.5 to 4 likely still flinch at the mention of a major upgrade to any part of KDE, but there's good news for KDE fans in Plasma 5. This is a major update, yes, but it comes with a handful of exceptions (which I'll get into in a minute because you'd never know it).
+
+It turns out that the incredibly bumpy move to KDE 4 really did lay the groundwork for a better future—we are now in that future.
+
+With this update, KDE is laying future groundwork in a less disruptive way. We're referring to an inevitable move to tablets and other form factors, but fear not. KDE seems poised to do what GNOME and Unity could not—branch out to other form factors without abandoning the traditional desktop. In other words, this release resisted the urge to mess with the tried and true just because something new is on the horizon.
+
+(As a quick aside: You'd be forgiven for not remembering this, but the whole convergence thing that Canonical goes on about with each new Unity update? KDE started using the word "convergence" way back when Canonical was still running user tests to determine the optimal shade of brown for GNOME 2 menus.)
+
+With KDE Frameworks 5, Qt5, and some other updates to the plumbing that come along with Plasma 5, KDE's version of convergence is here. It's simply under the hood where it belongs.
+
+So while the components are there to allow the KDE project and its developers to build different interfaces—KDE calls these new frameworks the "converged Plasma shell," which is what loads up the desktop in Plasma 5—the Plasma 5 desktop is, thus far, the only interface. KDE plans to build out others, but the [official release announcement][2] for Plasma 5 says that "a tablet-centric and media center user experience are under development."
+
+In this sense, KDE's vision of convergence is not unlike what Ubuntu envisions; the user interface will change based on the device and hardware. For example, you might have the "tablet-centric" interface that's in the works running while you're reading the Web on the couch. But get up, walk back to your office, connect to your wireless keyboard, and the interface shifts to something more keyboard-friendly.
+
+This scenario has some potential problems, some of which Windows 8 users are likely already familiar with. For example, what will happen when a keyboard is plugged in, but you still want to interact with the screen via touch? What happens if you plug in a mouse, but you still want to scroll with your fingers?
+
+We mention these small points not to say that KDE hasn't thought them through (here's hoping they have), but because this idea of "convergence" of adaptive user interfaces will be very difficult to get right. And one thing KDE has long had that gives users hope for the project's success is limitless configurability.
+
+The hope for KDE on a tablet is that any user would be able to configure every last detail of the experience. Simply put, there would be a way for you to determine what you want to happen when a keyboard is detected rather than letting the OS determine it.
+
+### The Plasma 5 desktop ###
+
+KDE Plasma 5 is KDE 4 evolved rather than any kind of revolutionary new interface.
+
+
+The KDE Plasma 5 desktop.
+
+We've been using this release—still not completely stable during testing, though most of the glitches have been graphical, not data threatening—for over a month now in virtual machines. We've been dual booting on a Retina MacBook Pro and, to see how well it holds up on older hardware, an aging, underpowered Toshiba laptop. KDE Plasma 5 was tested using Kubuntu (virtual machine and the Toshiba) and atop a fresh install of Arch Linux (dual boot MacBook).
+
+If you'd like to try out Plasma 5, the simplest way is to grab the [Neon live CD available from KDE][3]. That will get you Plasma with Ubuntu under the hood. If you want to commit and test it on an existing Kubuntu install, here are the commands for that:
+
+ sudo add-apt-repository ppa:neon/kf5
+ sudo apt-get update
+ sudo apt-get install project-neon5-session project-neon5-utils project-neon5-konsole project-neon5-breeze project-neon5-plasma-workspace-wallpapers
+
+Restart your machine and you should see a new option at the login screen offering to start up a Neon session.
+
+Once you have Plasma 5 up and running, the first thing you'll notice is the new default KDE theme, known as Breeze.
+
+### Plasma 5's Breezy new look ###
+
+Breeze is what KDE refers to as a modernized interface, with "reduced visual clutter throughout the workspace." Sure enough, the busy, somewhat cluttered feel that has long been a part of the default KDE look is gone.
+
+
+The KDE Plasma 5 desktop's Breeze theme is most complete in the Kickoff menu. Note the type to search message.
+
+The entire interface has been flattened out, with bigger fonts, better contrast, and a sort of flat, "frosted" look that's somewhere between OS X Yosemite, Android L, and KDE 4.x. That's not to say KDE ripped off Apple or Google. They couldn't have, since Plasma 5 and the Breeze theme were well on their way before Apple revealed Yosemite or Google announced Android L.
+
+Still, while it would be incorrect to say KDE has ripped anyone off, Breeze's visual design and overall aesthetic are very much a product of its time. In that sense it looks "modern," so long as you define modern to mean lots of strong type, few textures or outlines, lots of translucency, and monochrome iconography.
+
+KDE's designers have put a lot of work into Breeze and it shows. This isn't just a new coat of paint. Breeze makes KDE more approachable out of the box with cleaned up menus, a less cluttered notification center, and a revamped Kickoff start menu.
+
+
+A cleaner, less nagging notification center.
+
+How much Breeze matters depends on whether or not you'll ever even use it. KDE tends to attract users that like customizing their systems, which, presumably, includes customizing the theme. One thing to look forward to is what distros that heavily customize the default KDE theme—notably OpenSUSE—will do now that Breeze provides a somewhat higher starting bar.
+
+Currently, most distros will likely not jump on Breeze, since it is very much a work in progress. And coincidently, Breeze is where you'll notice some of the first signs of incompleteness in Plasma 5. While the Kickoff menu has some nice new icons, much of the rest of the interface does not. And as of the latest updates available in the Kubuntu ppa, Breeze does not use its new Window Decorations. The Window Decorations are installed, but they aren't turned on by default. You can head to the System Settings app and turn them on for a more complete, though possibly buggier, Breeze experience.
+
+
+Top is the default Oxygen Window Decorations, bottom the new Breeze theme.
+
+Not everything is ideal, and sometimes it's hard to tell what's a bug or incomplete feature and what is just poorly designed. For example, there's quite a bit of window and overlay translucency in Breeze, some of which looks nice. At other times, this gets in the way. Stacked windows and preview overlays bleed into what's behind them and become hard to read in the background. Pulling them to the foreground solves the problem, but it's hard to say what the value of the transparency is in this case.
+
+
+Transparency... why?
+
+So yes, Breeze is still a work in progress, and not just in terms of features and design; things are still being worked out in terms of genuine bugs and glitches. We have encountered some unexpected behavior accordingly, particularly with regard to screen redraws. Those happen frequently and slow enough to notice. Windows disappear at times, and the menu bar occasionally only draws half of itself.
+
+Plasma 5 has never crashed during our testing, nor has it lost any data. But be warned—little visual glitches abound. We would suggest waiting for things to stabilize and for the distro of your choice to integrate it before jumping in with both feet.
+
+### Plasma menus go vertical ###
+
+Breeze gives Plasma 5 a new look, but there are also a number of changes in behavior. For example, both the widget explorer and the alt-tab window switcher are now vertically oriented and located in the same place by default—the far left side of the screen.
+
+
+The default look for the alt-tab switcher menu.
+
+While that consistency is probably good for KDE newcomers, who need to learn to expect that various stuff will appear to the left of the screen, it can be a little frustrating for long-time users anticipating something else. Some of these changes seem somewhat arbitrary.
+
+
+The widget explorer menu.
+
+The KDE project claims the shift to vertical instead of horizontal lists, in things like the widget explorer and window switcher, "provide better usability." It stops short of saying how exactly. The release docs claim that moving the window switcher to the side of the screen "shifts the user's focus towards the applications and documents, clearing the stage for the task at hand." But if you only call up the window switcher when you're, ahem, switching windows, then it seems more likely that the user is between tasks rather than involved in one.
+
+
+KDE still loves offering options. Notice the dark gray bar to the right that's an artifact (glitch) from dragging the window.
+
+This is KDE, though, not Unity; infinite customization is a feature, not a bug. A trip to the System Settings will get your old style window switcher back, and there are some 10 different visual possibilities for the window switcher in Plasma 5. If the default is not to your liking, customize away.
+
+### So long Nepomuk, thanks for all the spinning fans ###
+
+If you're a heavy user of KDE's sometimes awesome, sometimes not, search features, this may be the biggest news in Plasma 5. It's true, KDE has ditched Nepomuk in favor of a new search engine known as Baloo.
+
+Nepomuk started life as an EU-funded metadata search project, with the lofty-sounding goal of creating a "Networked Environment for Personalized, Ontology-based Management of Unified Knowledge." By the time it trickled down to the KDE project, Nepomuk became a somewhat more mundane desktop search tool that alternated between brilliant and maddening.
+
+
+Searching for files in Plasma 5.
+
+Baloo takes much of what made Nepomuk great—namely, full text file search and an uncanny ability to pick up on relationships between files, for example, knowing that particular document is related to a contact—and [improves it][4]. Actually use the search features in Plasma 5 and you'll notice two things right off the bat: it's faster and your fan doesn't go haywire every time something new is indexed.
+
+Baloo significantly reduces the resource footprint of searching and, according to KDE, is more accurate. We can't vouch for the latter, since we never used search much in older versions of KDE (see fan spinning comments), but in terms of accuracy, simple file searches in Plasma 5 are on par with what you'll find in Ubuntu, OS X, and elsewhere. The success of more complex searches involving relationships or complex metadata will vary depending on how much you use the default KDE apps. For example, you need to use the Kontact Suite if you want to take advantage of Baloo-based searches involving relationships between contacts and files.
+
+That will likely change as time goes on, though, because another big change from Nepomuk is the new, improved developer API. The API for searching means third-party apps can tie in Plasma 5's Semantic Search infrastructure and take advantage of the same tools the default apps use.
+
+Curiously, for something that has seen as much work as Baloo has, the visibility and discoverability of the search feature has taken a step backward. Fire up Plasma 5's Kickoff menu—KDE's answer to the Windows Start menu—and search is nowhere to be found. If you look closely, you'll see a tiny little reminder to "type to search," which is a step up from the first release (which had no indication that you could search). Still, this isn't as discoverable as a dedicated search box.
+
+### Kickoff and its new cousin, Kicker ###
+
+KDE's answer to the Windows Start button has always been overkill in these eyes, packing too much in too little space, but with Breeze the menu has been cleaned up a bit and feels less visually overwhelming.
+
+
+The Kickoff menu in the default theme.
+
+If it's still a bit too much for your needs, Plasma 5 offers a new, more traditional menu-based launcher called Kicker. Kicker does less—it's much closer to the Start menu in XP, a single, narrower pane that offers expanding menus where needed—and makes a lightweight alternative if all you want to do is launch applications and files. It also has a very obvious search box.
+
+
+The new Kicker menu option.
+
+The other side of the menu bar has been revamped and cleaned up a bit as well. The most notable change is the notification app, which seems to kick up fewer notifications and does a better job of displaying them and quickly getting them out of the way.
+
+### OpenGL, QtQuick, and HiDPI Screens ###
+
+Plasma 5 finishes up KDE's migration to Qt 5 and QtQuick, the latter of which uses a hardware-accelerated OpenGL scenegraph to render graphics. Most of what's new with OpenGL pertains to offloading graphics to any available GPU. That means, provided you've got the hardware for it, Plasma 5 can take full advantage of today's powerful GPUs.
+
+Indeed, on newish hardware (our test MacBook's NVIDIA GeForce GT graphics card, for example) Plasma 5 is snappy, considerably snappier than its predecessor. Perhaps even more impressive, take away whatever GPU advantage Plasma 5 might gain over KDE 4.x systems, and it still feels faster. That is, running on older hardware still isn't KDE's strong point, but the story is better than it used to be. Still, if you're looking to get some extra mileage out of older hardware, stick with Xfce, LXDE or something even simpler like Openbox.
+
+Interestingly, the revamped Frameworks that make up Plasma 5's graphics stack also pave the way for KDE to switch to the Wayland display server protocol. KDE doesn't seem to be in a hurry to make the switch to Wayland though, noting only that full support will be available in "a future release."
+
+This release also claims improved support for HDPI displays. But, as with the HDPI support in GNOME and Unity, the actual experience is a very mixed bag. Font rendering in particular is nowhere near as smooth as what OS X offers. Even installing and fiddling with Infinality has never produced satisfactory results for me. We're still not sure if the problem is in setup, and we're not in fact seeing the new HDPI features. Or, possibly the KDE project just has a very different definition of what constitutes HDPI support. Hopefully it's the former.
+
+### What's missing ###
+
+Earlier in this review, we said that the transition from KDE 4 to the Plasma 5 desktop would not be as bumpy as the move from KDE 3.x to 4.x. For the most part, that's true, but, for some people, there may be exceptions.
+
+The KDE project says the focus for this release has been "concentrated on tools that make up the central workflows" and notes that "not all features from the Plasma 4.x series are available yet." That might ring a bell for those who made it through the KDE 3 to 4 transition.
+
+In testing, we didn't run across any noticeable gaps in functionality or obvious missing features, save what was mentioned: the incomplete Breeze theme, some graphical glitches, and some questionable design choices. That said, have a look at the [list of known issues][5], in particular the note about performance.
+
+And we suggest trying Plasma 5 first to make sure all your must-haves are there before you jump in with both feet.
+
+### Conclusion ###
+
+KDE's Plasma 5 release lacks the attention-grabbing, paradigm-shifting changes that keep Unity and GNOME in the spotlight. Instead, the KDE project has been focused on improving its core desktop experience. Plasma 5 is not perfect by any means, but, unlike Unity and GNOME, it's easy to change the things you don't like.
+
+What's perhaps most heartening about this release is that KDE has managed to get a lot of the groundwork done for alternate interfaces without messing with their desktop interface much at all. The speed improvements are also good news. If you've tried KDE in the past and found it too "heavy," you might want to give Plasma 5 a fresh look.
+
+--------------------------------------------------------------------------------
+
+via: http://arstechnica.com/information-technology/2014/08/kde-plasma-5-for-those-linux-users-undecided-on-the-kernels-future/
+
+作者:Scott Gilbertson
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://arstechnica.com/gadgets/2014/08/op-ed-tables-really-are-pcsbecause-theres-no-point-in-buying-new-ones/
+[2]:http://www.kde.org/announcements/plasma5.0/
+[3]:http://files.kde.org/snapshots/neon5-latest.iso.mirrorlist
+[4]:https://dot.kde.org/2014/02/24/kdes-next-generation-semantic-search
+[5]:https://community.kde.org/Plasma/5.0_Errata
\ No newline at end of file
diff --git a/sources/talk/20140819 Top 4 Linux download managers.md b/sources/talk/20140819 Top 4 Linux download managers.md
new file mode 100644
index 0000000000..1d3e1d27a6
--- /dev/null
+++ b/sources/talk/20140819 Top 4 Linux download managers.md
@@ -0,0 +1,148 @@
+Top 4 Linux download managers
+================================================================================
+**Improve and better manage your web downloads for mirroring, mass grabs or just better control over your files**
+
+Download managers seem to be old news these days, but there are still some excellent uses for them. We compare the top four of them on Linux.
+
+### [uGet][1] ###
+
+Advertised as lightweight and full- featured like a majority of other Linux apps, uGet can handle multi- threaded streams, includes filters and can integrate with an undefined selection of web browsers. It’s been around for over ten years now, starting out as UrlGet, and can also run on Windows.
+
+
+uGet is actually very full-featured, with a lot of the kind of functions that advanced torrent clients use
+
+#### Interface ####
+
+uGet reminds us of any number of torrent client interfaces, with categories for Active, Finished, Paused and so on for the different downloads. Although there is a lot of information to take in, it’s all presented very cleanly and clearly. The main downloading controls are easy to access, with more advanced ones alongside them.
+
+#### Integration ####
+
+While it can see into the clipboard for URLs, uGet doesn’t natively integrate into browsers like Chromium and Firefox. Still, there are add-ons for both these browsers that allow them to connect to uGet: Firefox via FlashGot and Chromium with a dedicated plug-in. Not ideal, but good enough.
+
+#### Features ####
+
+uGet’s maturity affords it a range of features, including advanced scheduling to switch downloading on and off, batch download via the clipboard and the ability to change which file types it looks for in the clipboard. There are plug-in options, but not a huge amount.
+
+#### Availability ####
+
+While it’s also available in most major distro repos, the uGet website includes regularly updated binaries for a variety of popular distributions as well as easily accessible source code. It runs on GTK 3+ so it has a smaller footprint in some desktop environments than others, although we’d say it’s worth the extra dependancies in KDE or other Qt desktops.
+
+#### Overall ####
+
+8/10
+
+We very much like uGet – its wide variety of features and popularity have allowed it to develop quite a lot to be an all-encompassing solution to download management, with some decent integration with Linux browsers.
+
+### [KGet][2] ###
+
+KDE’s own download manager seems to have been originally designed to work with Konqueror, the KDE web browser. It comes with the kind of features we’re looking for in this test: control of multiple downloads and the ability to run a checksum alongside the downloaded product.
+
+
+You need to manually activate the ability to keep an eye on the clipboard for links
+
+#### Interface ####
+
+As expected of a KDE app, KGet fits the aesthetic style of the desktop environment with similar icons and curves throughout. It’s quite a simple design as well, with only the most necessary functions available on the main toolbars and a minimal view of the current downloads.
+
+#### Integration ####
+
+KGet natively integrates with KDE’s Konqueror browser, although it’s not the most popular. Support for it in Firefox is done via FlashGot as usual, but there’s no real way to do it in Chromium. You can turn on a feature that asks if you want to download copied URLs, however it doesn’t parse the clipboard very well and sometimes wants to download text.
+
+#### Features ####
+
+The selection of features available are not that high. No scheduling, no batch operations and generally an almost bare-minimum amount of downloading features. The clipboard-scanning feature is a nice idea but it’s a bit buggy. It’s a little weird as the Settings menu looks like it’s designed to have more settings and options.
+
+#### Availability ####
+
+While it doesn’t come by default with a KDE install, it is available for any distro that supports KDE. It does need a few KDE libraries to run though, and it’s a bit tricky to find the source code. There isn’t a selection of binaries that you can use with a few distros either.
+
+#### Overall ####
+
+6/10
+
+KGet doesnt really offer users a huge amount more than the download manager in the majority of popular browsers, although at least you can use it while the browsers are otherwise turned off.
+
+### [DownThemAll!][3] ###
+
+DownThemAll, being somewhat platform-independent, comes to Linux by way of Firefox as an add- on. This limits it somewhat to use with only Firefox, however as one of the most popular browsers in the world its tighter integration may be just what some are looking for in a download manager.
+
+
+There are actually a whole lot of options available for DownThemAll! that make it very flexible
+
+#### Interface ####
+
+Part of the integration in Firefox allows DownThemAll! to slot into the standard aesthetic of the browser, with right-clicking bringing up options alongside the normal downloading ones. The extra dialog menus are generally themed after Firefox as well, while the main download window is clean and based on its own design
+
+#### Integration ####
+
+It doesn’t integrate system-wide but its ability to camouflage itself with Firefox makes it seem like an extra part of the original browser. It can also run alongside the normal downloader if you want, and can find specific link types on a webpage with little manual filtering, and no need for copy and pasting.
+
+#### Features ####
+
+With the ability to control how many downloads can happen at once, limit bandwidth when not idle and advanced auto or manual filtering, DownThemAll! is full of excellent features that aid mass downloading. The One Click function also allows it to very quickly start downloads to a pre- determined folder faster than normal download functions.
+
+#### Availability ####
+
+Firefox is available on just about every distro and other operating system around, which makes DownThemAll! just as prolific. Unfortunately this is a double-edged sword, as Firefox may not be your browser of choice. It also adds a little weight to the browser, which isn’t the lightest to begin with.
+
+#### Overall ####
+
+7/10
+
+DownThemAll! is excellent and if you use Firefox you may not need to use anything else. Not everyone uses Firefox as their preferred browser though, and it needs to be left on for the manager to start running.
+
+### [Steadyflow][4] ###
+
+Easily available in Ubuntu and some Debian-based distros, Steadyflow may be limited in terms of where you can get it but it’s got a reputation in some circles as one of the better managers available for any distro. It can read the clipboard for URLs, use GNOME’s preset proxies and has many other features.
+
+
+The settings in Steady flow are extremely limiting and somewhat difficult to access
+
+#### Interface ####
+
+Steadyflow is quite simple in appearance with a pleasant, clean interface that doesn’t clutter the download window. The dialog for adding downloads is simple enough, with basic options for how to treat it and where the file should live. It’s nothing we can really complain about, although it does remind us of the lack of features in the app.
+
+#### Integration ####
+
+Reading copied URLs is as standard and there’s a plug-in for Chromium to integrate with that. Again, you can use FlashGot to link it up to Firefox if that’s your preferred browser. You can’t really edit what it parses from the clipboard though and there’s no batch ability like in uGet and DownThemAll!
+
+#### Features ####
+
+Extremely lacking in features and the Options menu is very limited as well. The Pause and Resume function also doesn’t seem to work – a basic part of any browser’s file download features. Still, notifications and default action on finished files can be edited, along with an option to run a script once downloads are finished.
+
+#### Availability ####
+
+Only available on Ubuntu and there’s no easy way to get the source code for the app either. This means while it’s easily obtainable on all Ubuntu- based distros, it’s limited to these types of distros. As it’s not even the best download manager available on Linux, that shouldn’t be too big of a concern.
+
+#### Overall ####
+
+5/10
+
+Frankly, not that good. With very basic options and limited to only working on Ubuntu, Steadyflow doesn’t do enough to differentiate itself from the standard downloading options you’ll get on your web browser.
+
+### And the winner is… ###
+
+#### uGet ####
+
+In this test we’ve proven that there is a place for download managers on modern computers, even if the better ones have cribbed from the torrent clients that seem to have usurped them. While torrenting may be a more effective way for some, with ISPs getting wiser to torrent traffic some people may get better results with a good download manager. Not only are transfer caps imposed by most major ISPs, some are even beginning to slow- down or even block torrent traffic in peak hours – even legal traffic such as distro ISOs and other free software are throttled.
+
+Steadyflow seems to be a very popular solution for this, but our usage and tests showed an underdeveloped and weak product. The much older uGet was the star of the show, with an amazing selection of features that can aid in downloading single items or filtering through an entire webpage for relevant items to grab. The same goes for DownThemAll!, the excellent Firefox add-on that, while stuck with Firefox, has just about the same level of features, albeit with better integration.
+
+If you’re choosing between the two it really comes down to what your preferred browser is and whether you need to have downloads and uploads going around the clock. DownThemAll! requires Firefox running, whereas uGet runs on its own, saving a lot of resources and electricity in the process – obviously this makes uGet a much better prospect for 24-hour data transferring and it really isn’t a major hassle to set up big batch downloads, or even just get the download information from your browser.
+
+Give download managers another chance. You will not be disappointed with the results.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxuser.co.uk/reviews/top-4-linux-download-managers
+
+作者:Rob Zwetsloot
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://bit.ly/1mx4Uwz
+[2]:http://bit.ly/1lilqU9
+[3]:http://bit.ly/1lilqU9
+[4]:http://bit.ly/1lilymS
\ No newline at end of file
diff --git a/sources/talk/20140821 What is a good EPUB reader on Linux.md b/sources/talk/20140821 What is a good EPUB reader on Linux.md
new file mode 100644
index 0000000000..7e1958256b
--- /dev/null
+++ b/sources/talk/20140821 What is a good EPUB reader on Linux.md
@@ -0,0 +1,66 @@
+What is a good EPUB reader on Linux
+================================================================================
+If the habit on reading books on electronic tablets is still on its way, reading books on a computer is even rarer. It is hard enough to focus on the classics of the 16th century literature, so who needs the Facebook chat pop up sound in the background in addition? But if for some reasons you wish to open an electronic book in your computer, chances are that you will need specific software. Indeed, most editors agreed with using the EPUB format for electronic books (for "Electronic PUBlication"). Hopefully, Linux is not deprived of good programs capable of dealing with such format. In short, here is a non-exhaustive list of good EPUB readers on Linux.
+
+### 1. Calibre ###
+
+
+
+Let's dive in with maybe the biggest name of that list: [Calibre][1]. More than just an ebook reader, Calibre is a fully packaged e-library. It supports a plethora of formats (almost every I can think of), integrates a reader, a manager, a meta-data editor which can download covers from the Internet, an EPUB editor, a news reader, and a search engine to download additional books. To top it all, the interface is slick and has nothing to envy to other professional software. The only potential downside is that if you are looking for an EPUB reader, and are not interested in the whole library manager aspect, the program is too heavy for your needs.
+
+### 2. FBReader ###
+
+
+
+[FBReader][2] is also a library manager, but in a lighter way than Calibre. The interface is more sober, and is clearly cut in two: (1) the library aspect where you can add files, edit the meta-data, or download new books, and (2) the reader aspect. If you like simplicity, you might enjoy this program. I personally appreciate its straightforward tag and series system for classifying books.
+
+### 3. Cool Reader ###
+
+
+
+For all of you who are just looking for a way to visualize the content of an EPUB file, I recommend [Cool Reader][5]. In the spirit of Linux applications which do only one thing and do it well, Cool Reader is optimized to just open an EPUB file, and navigate through it via handy shortcuts. And since it is based on Qt, it also follows Qt's mentality by giving a ton of settings to mess around with.
+
+### 4. Okular ###
+
+
+
+Since we were talking about Qt applications, one of KDE's main document viewer, [Okular][3], also has the capacity to view EPUB files, once an EPUB library has been installed on the system. However, this is probably not a very good option if you are not a KDE user.
+
+### 5. pPub ###
+
+
+
+[pPub][4] is an old project that you can still find on Github. Its latest change seems to have been made two years ago. However, pPub is one of those programs that really deserve a second life. Written in Python and based on GTK3 and WebKit, pPub is lightweight and intuitive. The interface probably needs a little updating and is beyond sober, but the core is very good. It even supports JavaScript. So please, someone kick that up again.
+
+### 6. epub ###
+
+
+
+If all you need is a quick and easy way to check the content of an EPUB file, without caring about any fancy GUI, maybe an EPUB reader with command line interface might just do. [epub][6] is a minimalistic EPUB reader written in Python, which allows you to read an EPUB file in a terminal environment. You can switch between chapter/TOC views, up/down a page, and nothing more. This is as simple as any EPUB reader can possibly get.
+
+### 7. Sigil ###
+
+
+
+Finally, last of the list is not actually an EPUB reader, but more of a standalone editor. [Sigil][7] is able to extract the content of an EPUB file, and break it down for what it really is: xhtml text, images, styles, and sometimes audio. The interface is a lot more complex than the one for a basic reader, but remains clear and well thought, on par with the features it provides. I particularly appreciate the tab system. If you are familiar with editing web pages, you will be in know territory here.
+
+To conclude, there are a lot of open source EPUB readers out there. Some do nothing more, while others go way beyond that. As usual, I recommend using the one that makes the most sense for you to use. If you know more good EPUB readers on Linux that you like, please let us know in the comments.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/08/good-epub-reader-linux.html
+
+作者:[Adrien Brochard][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/adrien
+[1]:http://calibre-ebook.com/
+[2]:http://fbreader.org/
+[3]:http://okular.kde.org/
+[4]:https://github.com/sakisds/pPub
+[5]:http://crengine.sourceforge.net/
+[6]:https://github.com/rupa/epub
+[7]:https://github.com/user-none/Sigil
\ No newline at end of file
diff --git a/sources/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md b/sources/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md
deleted file mode 100644
index 6eb0617afa..0000000000
--- a/sources/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md
+++ /dev/null
@@ -1,140 +0,0 @@
-(translated by runningwater)
-Test read/write speed of usb and ssd drives with dd command on Linux
-================================================================================
-### Drive speed ###
-
-The speed of a drive is measured in terms of how much data it can read or write in unit time. The dd command is a simple command line tool that can be used to read and write arbitrary blocks of data to a drive and measure the speed at which the data transfer took place.
-
-In this post we shall use the dd command to test and read and write speed of usb and ssd drives using the dd command.
-
-The data transfer speed does not depend solely on the drive, but also on the interface it is connected to. For example a usb 2.0 port has a maximum operational speed limit of 35 Mbytes/s, so even if you were to plug a high speed usb 3 pen drive into a usb 2 port, the speed would be capped to the lower limit.
-
-The same applies to SSD. SSD connect via SATA ports which have different versions. Sata 2.0 has a maximum theoretical speed limit of 3Gbits/s which is roughly 375 Mbytes/s. Whereas Sata 3.0 supports twice that speed.
-
-### Test Method ###
-
-Mount the drive and navigate into it from the terminal. Then use the dd command to first write a file using fixed sized blocks. Then read the same file out using the same block site.
-
-The general syntax of the dd command looks like this
-
- dd if=path/to/input_file of=/path/to/output_file bs=block_size count=number_of_blocks
-
-When writing to the drive, we simply read from /dev/zero which is a source of infinite useless bytes. And when read from the drive, we read the file written earlier and send it to /dev/null which is nowhere. In the whole process, dd keeps track of the speed with which the transfer takes place and reports it.
-
-### SSD ###
-
-The SSD that we are using is a "Samsung Evo 120GB" ssd. It is a beginner level ssd that comes within a decent budget and is also my first SSD. It is also one of the best performing ssds, in the market.
-
-In this test the ssd is connected to a sata 2.0 port.
-
-#### Write speed ####
-
-Lets first write to the ssd
-
- $ dd if=/dev/zero of=./largefile bs=1M count=1024
- 1024+0 records in
- 1024+0 records out
- 1073741824 bytes (1.1 GB) copied, 4.82364 s, 223 MB/s
-
-Block size is actually quite large. You can try with smaller sizes like 64k or even 4k.
-
-#### Read speed ####
-
-Now read back the same file. However, first clear the memory cache to ensure that the file is actually read from drive.
-
-Run the following command to clear the memory cache
-
- $ sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
-
-Now read the file
-
- $ dd if=./largefile of=/dev/null bs=4k
- 165118+0 records in
- 165118+0 records out
- 676323328 bytes (676 MB) copied, 3.0114 s, 225 MB/s
-
-The Arch Linux wiki has a page full of information about the read/write speed of various SSDs from different vendors like Intel, Samsung, Sandisk etc. Check it out at the following url.
-
-[https://wiki.archlinux.org/index.php/SSD_Benchmarking][1]
-
-### USB ###
-
-In this test we shall measure the read and write speed of ordinary usb/pen drives. The drives are plugged to standard usb 2 ports. The first one is a sony 4gb usb drive and the second is a strontium 16gb drive.
-
-First plug the drive into the port and mount it, so that it is readable. Then navigate into the mount directory from the command line.
-
-#### Sony 4GB - Write ####
-
-In this test, the dd command is used to write 10,000 chunks of 8 Kbyte each to a single file on the drive.
-
- # dd if=/dev/zero of=./largefile bs=8k count=10000
- 10000+0 records in
- 10000+0 records out
- 81920000 bytes (82 MB) copied, 11.0626 s, 7.4 MB/s
-
-So the write speed is around 7.5 MBytes/s. This is a low figure.
-
-#### Sony 4GB - Read ####
-
-The same file is read back to test the read speed. Run the following command to clear the memory cache
-
- $ sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
-
-Now read the file using the dd command
-
- # dd if=./largefile of=/dev/null bs=8k
- 8000+0 records in
- 8000+0 records out
- 65536000 bytes (66 MB) copied, 2.65218 s, 24.7 MB/s
-
-The read speed comes out around 25 Mbytes/s which is a more or less the standard for cheap usb drives.
-
-> USB 2.0 has a theoretical maximum signaling rate of 480 Mbits/s or 60 Mbytes/s. However due to various constraints the maximum throughput is restricted to around 280 Mbit/s or 35 Mbytes/s. Beyond this the actual speed achieved depends on the quality of the pen drives and other factors too.
-
-And the above usb drive was plugged inside a USB 2.0 port and it achieved a read speed of 24.7 Mbytes/s which is not very bad. But the write speed lags much behind
-
-Now lets do the same test with a Strontium 16gb drive. Strontium is another very cheapy brand, although usb drives are reliable.
-
-#### Strontium 16gb write speed ####
-
- # dd if=/dev/zero of=./largefile bs=64k count=1000
- 1000+0 records in
- 1000+0 records out
- 65536000 bytes (66 MB) copied, 8.3834 s, 7.8 MB/s
-
-Strontium 16gb read speed
-
- # sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
-
- # dd if=./largefile of=/dev/null bs=8k
- 8000+0 records in
- 8000+0 records out
- 65536000 bytes (66 MB) copied, 2.90366 s, 22.6 MB/s
-
-The read speed is lower than the Sony drive.
-
-### Resources ###
-
-- [http://en.wikipedia.org/wiki/USB][2]
-- [https://wiki.archlinux.org/index.php/SSD_Benchmarking][1]
-
-----------
-
-
-
-About Silver Moon
-
-Php developer, blogger and Linux enthusiast. He can be reached at [m00n.silv3r@gmail.com][e]. Or find him on [Google+][g]
-
---------------------------------------------------------------------------------
-
-via: http://www.binarytides.com/linux-test-drive-speed/
-
-译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://wiki.archlinux.org/index.php/SSD_Benchmarking
-[2]:http://en.wikipedia.org/wiki/USB
-[e]:m00n.silv3r@gmail.com
-[g]:http://plus.google.com/117145272367995638274/posts
\ No newline at end of file
diff --git a/sources/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md b/sources/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md
deleted file mode 100644
index 19ebcc0986..0000000000
--- a/sources/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md
+++ /dev/null
@@ -1,283 +0,0 @@
-Translating by GOLinux ...
-How to Extend/Reduce LVM’s (Logical Volume Management) in Linux – Part II
-================================================================================
-Previously we have seen how to create a flexible disk storage using LVM. Here, we are going to see how to extend volume group, extend and reduce a logical volume. Here we can reduce or extend the partitions in Logical volume management (LVM) also called as flexible volume file-system.
-
-
-
-### Requirements ###
-
-- [Create Flexible Disk Storage with LVM – Part I][1]
-注:两篇都翻译完了的话,发布的时候将这个链接做成发布的中文的文章地址
-
-#### When do we need to reduce volume? ####
-
-May be we need to create a separate partition for any other use or we need to expand the size of any low space partition, if so we can reduce the large size partition and we can expand the low space partition very easily by the following simple easy steps.
-
-#### My Server Setup – Requirements ####
-
-- Operating System – CentOS 6.5 with LVM Installation
-- Server IP – 192.168.0.200
-
-### How to Extend Volume Group and Reduce Logical Volume ###
-
-#### Logical Volume Extending ####
-
-Currently, we have One PV, VG and 2 LV. Let’s list them one by one using following commands.
-
- # pvs
- # vgs
- # lvs
-
-
-Logical Volume Extending
-
-There are no free space available in Physical Volume and Volume group. So, now we can’t extend the lvm size, for extending we need to add one physical volume (**PV**), and then we have to extend the volume group by extending the **vg**. We will get enough space to extend the Logical volume size. So first we are going to add one physical volume.
-
-For adding a new **PV** we have to use fdisk to create the LVM partition.
-
- # fdisk -cu /dev/sda
-
-- To Create new partition Press **n**.
-- Choose primary partition use **p**.
-- Choose which number of partition to be selected to create the primary partition.
-- Press **1** if any other disk available.
-- Change the type using **t**.
-- Type **8e** to change the partition type to Linux LVM.
-- Use **p** to print the create partition ( here we have not used the option).
-- Press **w** to write the changes.
-
-Restart the system once completed.
-
-
-Create LVM Partition
-
-List and check the partition we have created using fdisk.
-
- # fdisk -l /dev/sda
-
-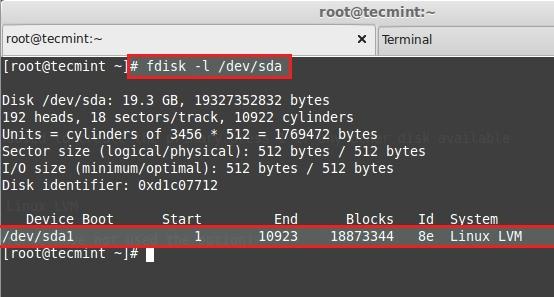
-Verify LVM Partition
-
-Next, create new **PV** (Physical Volume) using following command.
-
- # pvcreate /dev/sda1
-
-Verify the pv using below command.
-
- # pvs
-
-
-Create Physical Volume
-
-#### Extending Volume Group ####
-
-Add this pv to **vg_tecmint** vg to extend the size of a volume group to get more space for expanding **lv**.
-
- # vgextend vg_tecmint /dev/sda1
-
-Let us check the size of a Volume Group now using.
-
- # vgs
-
-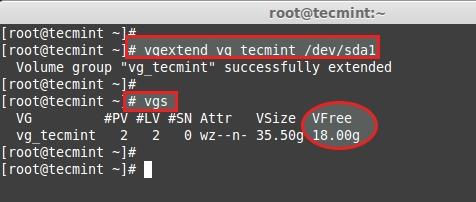
-Extend Volume Group
-
-We can even see which **PV** are used to create particular Volume group using.
-
- # pvscan
-
-
-Check Volume Group
-
-Here, we can see which Volume groups are under Which Physical Volumes. We have just added one pv and its totally free. Let us see the size of each logical volume we have currently before expanding it.
-
-
-Check All Logical Volume
-
-- LogVol00 defined for Swap.
-- LogVol01 defined for /.
-- Now we have 16.50 GB size for / (root).
-- Currently there are 4226 Physical Extend (PE) available.
-
-Now we are going to expand the / partition **LogVol01**. After expanding we can list out the size as above for confirmation. We can extend using GB or PE as I have explained it in LVM PART-I, here I’m using PE to extend.
-
-For getting the available Physical Extend size run.
-
- # vgdisplay
-
-
-Check Available Physical Size
-
-There are **4607** free PE available = **18GB** Free space available. So we can expand our logical volume up-to **18GB** more. Let us use the PE size to extend.
-
- # lvextend -l +4607 /dev/vg_tecmint/LogVol01
-
-Use **+** to add the more space. After Extending, we need to re-size the file-system using.
-
- # resize2fs /dev/vg_tecmint/LogVol01
-
-
-Expand Logical Volume
-
-- Command used to extend the logical volume using Physical extends.
-- Here we can see it is extended to 34GB from 16.51GB.
-- Re-size the file system, If the file-system is mounted and currently under use.
-- For extending Logical volumes we don’t need to unmount the file-system.
-
-Now let’s see the size of re-sized logical volume using.
-
- # lvdisplay
-
-
-Resize Logical Volume
-
-- LogVol01 defined for / extended volume.
-- After extending there is 34.50GB from 16.50GB.
-- Current extends, Before extending there was 4226, we have added 4607 extends to expand so totally there are 8833.
-
-Now if we check the vg available Free PE it will be 0.
-
- # vgdisplay
-
-See the result of extending.
-
- # pvs
- # vgs
- # lvs
-
-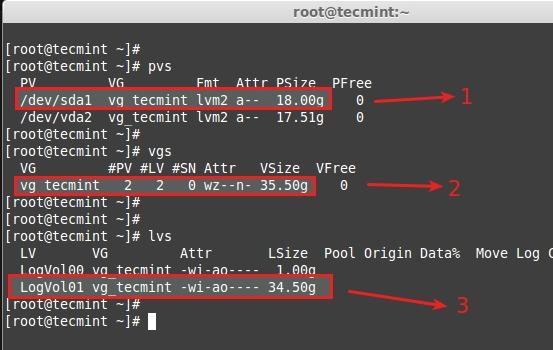
-Verify Resize Partition
-
-- New Physical Volume added.
-- Volume group vg_tecmint extended from 17.51GB to 35.50GB.
-- Logical volume LogVol01 extended from 16.51GB to 34.50GB.
-
-Here we have completed the process of extending volume group and logical volumes. Let us move towards some interesting part in Logical volume management.
-
-#### Reducing Logical Volume (LVM) ####
-
-Here we are going to see how to reduce the Logical Volumes. Everyone say its critical and may end up with disaster while we reduce the lvm. Reducing lvm is really interesting than any other part in Logical volume management.
-
-- Before starting, it is always good to backup the data, so that it will not be a headache if something goes wrong.
-- To Reduce a logical volume there are 5 steps needed to be done very carefully.
-- While extending a volume we can extend it while the volume under mount status (online), but for reduce we must need to unmount the file system before reducing.
-
-Let’s wee what are the 5 steps below.
-
-- unmount the file system for reducing.
-- Check the file system after unmount.
-- Reduce the file system.
-- Reduce the Logical Volume size than Current size.
-- Recheck the file system for error.
-- Remount the file-system back to stage.
-
-For demonstration, I have created separate volume group and logical volume. Here, I’m going to reduce the logical volume **tecmint_reduce_test**. Now its 18GB in size. We need to reduce it to **10GB** without data-loss. That means we need to reduce **8GB** out of **18GB**. Already there is **4GB** data in the volume.
-
- 18GB ---> 10GB
-
-While reducing size, we need to reduce only 8GB so it will roundup to 10GB after the reduce.
-
- # lvs
-
-
-Reduce Logical Volume
-
-Here we can see the file-system information.
-
- # df -h
-
-
-Check File System Size
-
-- The size of the Volume is 18GB.
-- Already it used upto 3.9GB.
-- Available Space is 13GB.
-
-First unmount the mount point.
-
- # umount -v /mnt/tecmint_reduce_test/
-
-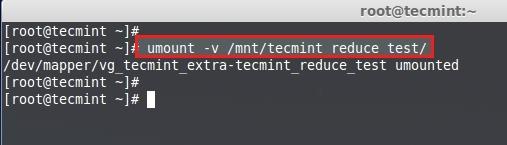
-Unmount Parition
-
-Then check for the file-system error using following command.
-
- # e2fsck -ff /dev/vg_tecmint_extra/tecmint_reduce_test
-
-
-Scan Parition for Errors
-
-**Note**: Must pass in every 5 steps of file-system check if not there might be some issue with your file-system.
-
-Next, reduce the file-system.
-
- # resize2fs /dev/vg_tecmint_extra/tecmint_reduce_test 8GB
-
-
-Reduce File System
-
-Reduce the Logical volume using GB size.
-
- # lvreduce -L -8G /dev/vg_tecmint_extra/tecmint_reduce_test
-
-
-Reduce Logical Partition
-
-To Reduce Logical volume using PE Size we need to Know the size of default PE size and total PE size of a Volume Group to put a small calculation for accurate Reduce size.
-
- # lvdisplay vg_tecmint_extra
-
-Here we need to do a little calculation to get the PE size of 10GB using bc command.
-
- 1024MB x 10GB = 10240MB or 10GB
-
- 10240MB / 4PE = 2048PE
-
-Press **CRTL+D** to exit from BC.
-
-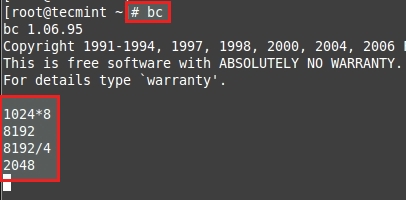
-Calculate PE Size
-
-Reduce the size using PE.
-
- # lvreduce -l -2048 /dev/vg_tecmint_extra/tecmint_reduce_test
-
-
-Reduce Size Using PE
-
-Re-size the file-system back, In this step if there is any error that means we have messed-up our file-system.
-
- # resize2fs /dev/vg_tecmint_extra/tecmint_reduce_test
-
-
-
-Mount the file-system back to same point.
-
- # mount /dev/vg_tecmint_extra/tecmint_reduce_test /mnt/tecmint_reduce_test/
-
-
-Mount File System
-
-Check the size of partition and files.
-
- # lvdisplay vg_tecmint_extra
-
-Here we can see the final result as the logical volume was reduced to 10GB size.
-
-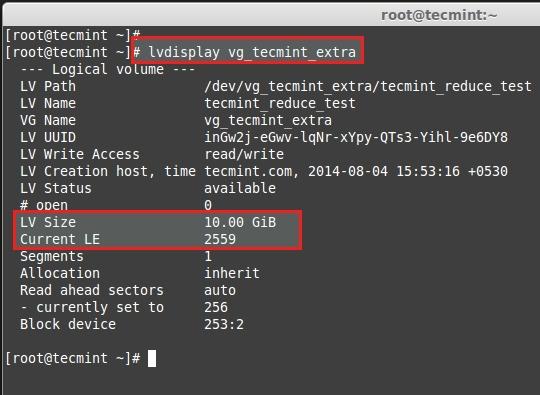
-
-In this article, we have seen how to extend the volume group, logical volume and reduce the logical volume. In the next part (Part III), we will see how to take a Snapshot of logical volume and restore it to earlier stage.
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/extend-and-reduce-lvms-in-linux/
-
-作者:[Babin Lonston][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
-
-[a]:http://www.tecmint.com/author/babinlonston/
-[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
diff --git a/sources/tech/20140818 Disable reboot using Ctrl-Alt-Del Keys in RHEL or CentOS.md b/sources/tech/20140818 Disable reboot using Ctrl-Alt-Del Keys in RHEL or CentOS.md
new file mode 100644
index 0000000000..2162c8fbb4
--- /dev/null
+++ b/sources/tech/20140818 Disable reboot using Ctrl-Alt-Del Keys in RHEL or CentOS.md
@@ -0,0 +1,44 @@
+Disable reboot using Ctrl-Alt-Del Keys in RHEL / CentOS
+================================================================================
+In Linux , It's a security concern for us to allow anyone to **reboot** the server using **Ctrl-Alt-Del keys**. It is always recommended in production boxes that one should disable reboot uisng Ctrl-Alt-Del keys.
+
+In this article we will discuss how can we disable reboot via above keys in RHEL & CentOS
+
+### For RHEL 5.X & CentOS 5.X ###
+
+To prevent the **init** process from handling **Ctrl-Alt-Del**, edit the file '**/etc/inittab**' comment the line which begins with '**ca::ctrlaltdel**:' as shown below :
+
+ [root@localhost ~]# cat /etc/inittab
+ # Trap CTRL-ALT-DELETE
+ #ca::ctrlaltdel:/sbin/shutdown -t3 -r now
+
+We can also modify the line 'ca::ctrlaltdel:' to generate logs , if anybody try to reboot the server using the keys ,
+
+ [root@localhost ~]# cat /etc/inittab
+ # Trap CTRL-ALT-DELETE
+ ca::ctrlaltdel:/bin/logger -p authpriv.warning -t init "Console-invoked Ctrl-Alt-Del was ignored"
+
+### For RHEL6.X & CentOS 6.X ###
+
+In RHEL 6.X / CentOS 6.X , reboot using the keys are handled by the file '**/etc/init/control-alt-delete.conf**'.
+
+**Step:1** Before making the changes , first take the backup using below command
+
+ [root@localhost ~]# cp -v /etc/init/control-alt-delete.conf /etc/init/control-alt-delete.override
+
+**Step:2** Edit the file , replacing the 'exec /sbin/shutdown' line with the following, which will simply generate a log entry each time Ctrl-Alt-Del is pressed:
+
+ [root@localhost ~]# cat /etc/init/control-alt-delete.conf
+ exec /usr/bin/logger -p authpriv.notice -t init "Ctrl-Alt-Del was pressed and ignored"
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxtechi.com/disable-reboot-using-ctrl-alt-del-keys/
+
+作者:[Pradeep Kumar][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxtechi.com/author/pradeep/
\ No newline at end of file
diff --git a/sources/tech/20140818 How to Take 'Snapshot of Logical Volume and Restore' in LVM--Part III.md b/sources/tech/20140818 How to Take 'Snapshot of Logical Volume and Restore' in LVM--Part III.md
new file mode 100644
index 0000000000..fa5024fe1c
--- /dev/null
+++ b/sources/tech/20140818 How to Take 'Snapshot of Logical Volume and Restore' in LVM--Part III.md
@@ -0,0 +1,200 @@
+How to Take ‘Snapshot of Logical Volume and Restore’ in LVM – Part III
+================================================================================
+**LVM Snapshots** are space efficient pointing time copies of lvm volumes. It works only with lvm and consume the space only when changes are made to the source logical volume to snapshot volume. If source volume has a huge changes made to sum of 1GB the same changes will be made to the snapshot volume. Its best to always have a small size of changes for space efficient. Incase the snapshot runs out of storage, we can use lvextend to grow. And if we need to shrink the snapshot we can use lvreduce.
+
+
+Take Snapshot in LVM
+
+If we have accidentally deleted any file after creating a Snapshot we don’t have to worry because the snapshot have the original file which we have deleted. It is possible if the file was there when the snapshot was created. Don’t alter the snapshot volume, keep as it while snapshot used to do a fast recovery.
+
+Snapshots can’t be use for backup option. Backups are Primary Copy of some data’s, so we cant use snapshot as a backup option.
+
+#### Requirements ####
+
+注:此两篇文章如果发布后可换成发布后链接,原文在前几天更新中
+
+- [Create Disk Storage with LVM in Linux – PART 1][1]
+- [How to Extend/Reduce LVM’s in Linux – Part II][2]
+
+### My Server Setup ###
+
+- Operating System – CentOS 6.5 with LVM Installation
+- Server IP – 192.168.0.200
+
+#### Step 1: Creating LVM Snapshot ####
+
+First, check for free space in volume group to create a new snapshot using following ‘**vgs**‘ command.
+
+ # vgs
+ # lvs
+
+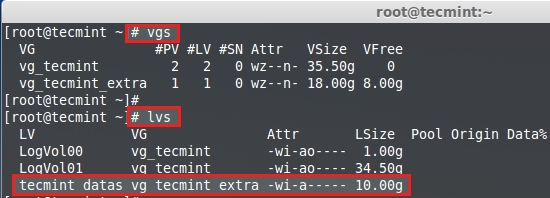
+Check LVM Disk Space
+
+You see, there is 8GB of free space left in above **vgs** output. So, let’s create a snapshot for one of my volume named **tecmint_datas**. For demonstration purpose, I am going to create only 1GB snapshot volume using following commands.
+
+ # lvcreate -L 1GB -s -n tecmint_datas_snap /dev/vg_tecmint_extra/tecmint_datas
+
+OR
+
+ # lvcreate --size 1G --snapshot --name tecmint_datas_snap /dev/vg_tecmint_extra/tecmint_datas
+
+Both the above commands does the same thing:
+
+- **-s** – Creates Snapshot
+- **-n** – Name for snapshot
+
+
+Create LVM Snapshot
+
+Here, is the explanation of each point highlighted above.
+
+- Size of snapshot Iam creating here.
+- Creates snapshot.
+- Creates name for the snapshot.
+- New snapshots name.
+- Volume which we are going to create a snapshot.
+
+If you want to remove a snapshot, you can use ‘**lvremove**‘ command.
+
+# lvremove /dev/vg_tecmint_extra/tecmint_datas_snap
+
+
+Remove LVM Snapshot
+
+Now, list the newly created snapshot using following command.
+
+ # lvs
+
+
+Verify LVM Snapshot
+
+You see above, a snapshot was created successfully. I have marked with an arrow where snapshots origin from where its created, Its **tecmint_datas**. Yes, because we have created a snapshot for **tecmint_datas l-volume**.
+
+
+Check LVM Snapshot Space
+
+Let’s add some new files into **tecmint_datas**. Now volume has some data’s around 650MB and our snapshot size is 1GB. So there is enough space to backup our changes in snap volume. Here we can see, what is the status of our snapshot using below command.
+
+ # lvs
+
+
+Check Snapshot Status
+
+You see, **51%** of snapshot volume was used now, no issue for more modification in your files. For more detailed information use command.
+
+ # lvdisplay vg_tecmint_extra/tecmint_data_snap
+
+
+View Snapshot Information
+
+Again, here is the clear explanation of each point highlighted in the above picture.
+
+- Name of Snapshot Logical Volume.
+- Volume group name currently under use.
+- Snapshot volume in read and write mode, we can even mount the volume and use it.
+- Time when the snapshot was created. This is very important because snapshot will look for every changes after this time.
+- This snapshot belongs to tecmint_datas logical volume.
+- Logical volume is online and available to use.
+- Size of Source volume which we took snapshot.
+- Cow-table size = copy on Write, that means whatever changes was made to the tecmint_data volume will be written to this snapshot.
+- Currently snapshot size used, our tecmint_datas was 10G but our snapshot size was 1GB that means our file is around 650 MB. So what its now in 51% if the file grow to 2GB size in tecmint_datas size will increase more than snapshot allocated size, sure we will be in trouble with snapshot. That means we need to extend the size of logical volume (snapshot volume).
+- Gives the size of chunk for snapshot.
+
+Now, let’s copy more than 1GB of files in **tecmint_datas**, let’s see what will happen. If you do, you will get error message saying ‘**Input/output error**‘, it means out of space in snapshot.
+
+
+Add Files to Snapshot
+
+If the logical volume become full it will get dropped automatically and we can’t use it any more, even if we extend the size of snapshot volume. It is the best idea to have the same size of Source while creating a snapshot, **tecmint_datas** size was 10G, if I create a snapshot size of 10GB it will never over flow like above because it has enough space to take snap of your volume.
+
+#### Step 2: Extend Snapshot in LVM ####
+
+If we need to extend the snapshot size before overflow we can do it using.
+
+ # lvextend -L +1G /dev/vg_tecmint_extra/tecmint_data_snap
+
+Now there was totally 2GB size for snapshot.
+
+
+Extend LVM Snapshot
+
+Next, verify the new size and COW table using following command.
+
+ # lvdisplay /dev/vg_tecmint_extra/tecmint_data_snap
+
+To know the size of snap volume and usage **%**.
+
+ # lvs
+
+
+Check Size of Snapshot
+
+But if, you have snapshot volume with the same size of Source volume we don’t need to worry about these issues.
+
+#### Step 3: Restoring Snapshot or Merging ####
+
+To restore the snapshot, we need to un-mount the file system first.
+
+ # unmount /mnt/tecmint_datas/
+
+
+Un-mount File System
+
+Just check for the mount point whether its unmounted or not.
+
+ # df -h
+
+
+Check File System Mount Points
+
+Here our mount has been unmounted, so we can continue to restore the snapshot. To restore the snap using command **lvconvert**.
+
+ # lvconvert --merge /dev/vg_tecmint_extra/tecmint_data_snap
+
+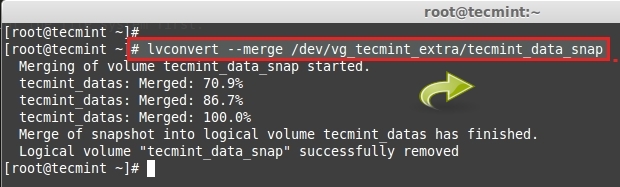
+Restore LVM Snapshot
+
+After the merge is completed, snapshot volume will be removed automatically. Now we can see the space of our partition using **df** command.
+
+ # df -Th
+
+
+
+After the snapshot volume removed automatically. You can see the size of logical volume.
+
+ # lvs
+
+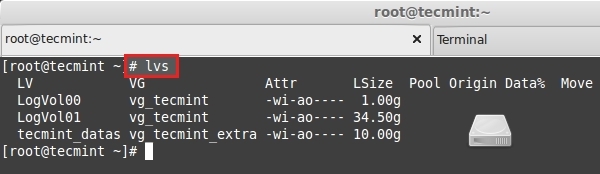
+Check Size of Logical Volume
+
+**Important**: To Extend the Snapshots automatically, we can do it using some modification in conf file. For manual we can extend using lvextend.
+
+Open the lvm configuration file using your choice of editor.
+
+ # vim /etc/lvm/lvm.conf
+
+Search for word autoextend. By Default the value will be similar to below.
+
+
+LVM Configuration
+
+Change the **100** to **75** here, if so auto extend threshold is **75** and auto extend percent is 20, it will expand the size more by **20 Percent**
+
+If the snapshot volume reach **75%** it will automatically expand the size of snap volume by **20%** more. Thus,we can expand automatically. Save and exit the file using **wq!**.
+
+This will save snapshot from overflow drop. This will also help you to save more time. LVM is the only Partition method in which we can expand more and have many features as thin Provisioning, Striping, Virtual volume and more Using thin-pool, let us see them in the next topic.
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/take-snapshot-of-logical-volume-and-restore-in-lvm/
+
+作者:[Babin Lonston][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/babinlonston/
+[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
+[2]:http://www.tecmint.com/extend-and-reduce-lvms-in-linux/
\ No newline at end of file
diff --git a/sources/tech/20140818 How to configure Access Control Lists (ACLs) on Linux.md b/sources/tech/20140818 How to configure Access Control Lists (ACLs) on Linux.md
new file mode 100644
index 0000000000..5b8146276f
--- /dev/null
+++ b/sources/tech/20140818 How to configure Access Control Lists (ACLs) on Linux.md
@@ -0,0 +1,120 @@
+How to configure Access Control Lists (ACLs) on Linux
+================================================================================
+Working with permissions on Linux is rather a simple task. You can define permissions for users, groups or others. This works really well when you work on a desktop PC or a virtual Linux instance which typically doesn't have a lot of users, or when users don't share files among themselves. However, what if you are a big organization where you operate NFS or Samba servers for diverse users. Then you will need to be neat picky and set up more complex configurations and permissions to meet the requirements of your organization.
+
+Linux (and other Unixes, that are POSIX compliant) has so-called Access Control Lists (ACLs), which are a way to assign permissions beyond the common paradigm. For example, by default you apply three permission groups: owner, group, and others. With ACLs, you can add permissions for other users or groups that are not simple "others" or any other group that the owner is not part of it. You can allow particular users A, B and C to have write permissions without letting their whole group to have writing permission.
+
+ACLs are available for a variety of Linux filesystems including ext2, ext3, ext4, XFS, Btfrs, etc. If you are not sure if the filesystem you are using supports ACLs, just read the documentation.
+
+### Enable ACLs on your Filesystem ###
+
+First of all, we need to install the tools to manage ACLs.
+
+On Ubuntu/Debian:
+
+ $ sudo apt-get install acl
+
+On CentOS/Fedora/RHEL:
+
+ # yum -y install acl
+
+On Archlinux:
+
+ # pacman -S acl
+
+For demonstration purpose, I will use Ubuntu server, but other distributions should work the same.
+
+After installing ACL tools, it is necessary to enable ACL feature on our disk partitions so that we can start using it.
+
+First, we can check if ACL feature is already enabled:
+
+ $ mount
+
+
+
+As you noticed, my root partition has the ACL attribute enabled. In case yours doesn't, you need to edit your /etc/fstab file. Add acl flag in front of your options for the partition you want to enable ACL.
+
+
+
+Now we need to re-mount the partition (I prefer to reboot completely, because I don't like losing data). If you enabled ACL for any other partitions, you have to remount them as well.
+
+ $ sudo mount / -o remount
+
+Awesome! Now that we have enable ACL in our system, let's start to work with it.
+
+### ACL Examples ###
+
+Basically ACLs are managed by two commands: **setfacl** which is used to add or modify ACLs, and getfacl which shows assigned ACLs. Let's do some testing.
+
+I created a directory /shared owned by a hypothetical user named freeuser.
+
+ $ ls -lh /
+
+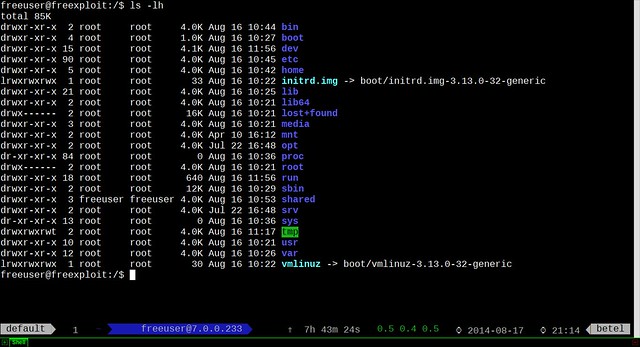
+
+I want to share this directory with two other users test and test2, one with full permissions and the other with just read permission.
+
+First, to set ACLs for user test:
+
+ $ sudo setfacl -m u:test:rwx /shared
+
+Now user test can create directories, files, and access anything under /shared directory.
+
+
+
+Now we will add read-only permission for user test2:
+
+ $ sudo setfacl -m u:test2:rx /shared
+
+Note that execution permission is necessary so test2 can read directories.
+
+
+
+Let me explain the syntax of setfacl command:
+
+- **-m** means modify ACL. You can add new, or modify existing ACLs.
+- **u:** means user. You can use **g** to set group permissions.
+- **test** is the name of the user.
+- **:rwx** represents permissions you want to set.
+
+Now let me show you how to read ACLs.
+
+ $ ls -lh /shared
+
+
+
+As you noticed, there is a + (plus) sign after normal permissions. It means that there are ACLs set up. To actually read ACLs, we need to run:
+
+ $ sudo getfacl /shared
+
+
+
+Finally if you want to remove ACL:
+
+ $ sudo setfacl -x u:test /shared
+
+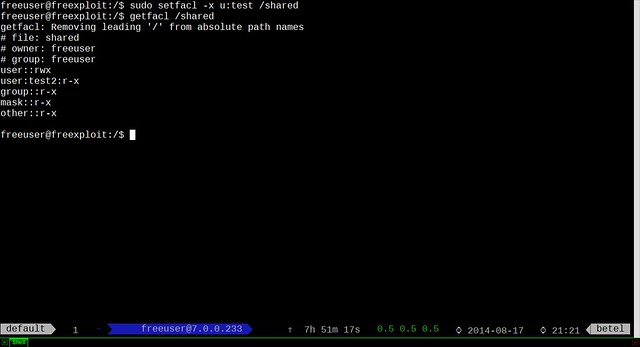
+
+If you want to wipe out all ACL entries at once:
+
+ $ sudo setfacl -b /shared
+
+
+
+One last thing. The commands cp and mv can change their behavior when they work over files or directories with ACLs. In the case of cp, you need to add the '-p' parameter to copy ACLs. If this is not posible, it will show you a warning. mv will always move the ACLs, and also if it is not posible, it will show you a warning.
+
+### Conclusion ###
+
+Using ACLs gives you a tremendous power and control over files you want to share, especially on NFS/Samba servers. Moreover, if you administer shared hosting, this tool is a must have.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/08/configure-access-control-lists-acls-linux.html
+
+作者:[Christopher Valerio][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/valerio
\ No newline at end of file
diff --git a/sources/tech/20140818 Linux FAQs with Answers--How to fix 'X11 forwarding request failed on channel 0'.md b/sources/tech/20140818 Linux FAQs with Answers--How to fix 'X11 forwarding request failed on channel 0'.md
new file mode 100644
index 0000000000..554cbe0c74
--- /dev/null
+++ b/sources/tech/20140818 Linux FAQs with Answers--How to fix 'X11 forwarding request failed on channel 0'.md
@@ -0,0 +1,49 @@
+Linux FAQs with Answers--How to fix “X11 forwarding request failed on channel 0″
+================================================================================
+> **Question**: When I tried to SSH to a remote host with X11 forwarding option, I got "X11 forwarding request failed on channel 0" error after logging in. Why am I getting this error, and how can I fix this problem?
+
+
+
+First of all, we assume that you already enabled [X11 forwarding over SSH][1] properly.
+
+If you are getting "X11 forwarding request failed on channel 0" message upon SSH login, there could be several reasons. Solutions vary as well.
+
+### Solution One ###
+
+For security reason, OpenSSH server, by default, binds X11 forwarding server to the local loopback address, and sets the hostname in DISPLAY environment variable to "localhost". Under this setup, some X11 clients cannot handle X11 forwarding properly, which causes the reported error. To fix this problem, add the following line in /etc/ssh/sshd_config file, which will let X11 forwarding server bind on the wild card address.
+
+ $ sudo vi /etc/ssh/sshd_config
+
+----------
+
+ X11Forwarding yes
+ X11UseLocalhost no
+
+Restart SSH server to activate the change:
+
+ $ sudo /etc/init.d/ssh restart (Debian 6, Ubuntu or Linux Mint)
+ $ sudo systemctl restart ssh.service (Debian 7, CentOS/RHEL 7, Fedora)
+ $ sudo service sshd restart (CentOS/RHEL 6)
+
+### Solution Two ###
+
+The broken X11 forwarding error may also happen if the remote host where SSH server is running has IPv6 disabled. To fix the error in this case, open /etc/ssh/sshd_config file, and uncomment "AddressFamily all" (if any). Then add the following line. This will force SSH server to use IPv4 only, but not IPv6.
+
+ $ sudo vi /etc/ssh/sshd_config
+
+----------
+
+ AddressFamily inet
+
+Again, restart SSH server to finalize the change.
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/fix-broken-x11-forwarding-ssh.html
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://xmodulo.com/2012/11/how-to-enable-x11-forwarding-using-ssh.html
\ No newline at end of file
diff --git a/sources/tech/20140818 Linux FAQs with Answers--How to set a static MAC address on VMware ESXi virtual machine.md b/sources/tech/20140818 Linux FAQs with Answers--How to set a static MAC address on VMware ESXi virtual machine.md
new file mode 100644
index 0000000000..a19df648f1
--- /dev/null
+++ b/sources/tech/20140818 Linux FAQs with Answers--How to set a static MAC address on VMware ESXi virtual machine.md
@@ -0,0 +1,42 @@
+Linux FAQs with Answers--How to set a static MAC address on VMware ESXi virtual machine
+================================================================================
+> **Question**: I want to assign a static MAC address to a virtual machine (VM) on VMware ESXi. However, when I attempt to start a VM with a static MAC address, the VM fails to start and throws an error "00:0c:29:1f:4a:ab is not an allowed static Ethernet address. It conflicts with VMware reserved MACs". How can I set a static MAC address on VMware ESXi VMs?
+
+When you create a VM on VMware ESXi, each network interface of the VM is assigned a dynamically generated MAC address. If you want to change this default behavior and assign a static MAC address to your VM, here is how to do it.
+
+
+
+As you can see above, VMware's vSphere GUI client already has a menu for setting a static MAC address for a VM. However, this GUI-based method only allows you to choose a static MAC address from **00:50:56:xx:xx:xx**, which is VMware-reserved MAC address range. If you attempt to set any arbitrary MAC address outside this MAC range, you will fail to launch the VM, and get the following error.
+
+
+
+Then what if I want to assign any arbitrary MAC address to a VM?
+
+Fortunately, there is a workaround to this limitation. The solution is, instead of using vSphere GUI client, editing .vmx file of your VM directly, after logging in to the ESXi host.
+
+First, turn off the VM to which you want to assign a static MAC address.
+
+[Enable SSH access to your ESXi host][1] if you haven't done it already. Then log in to the ESXi host via SSH.
+
+Move to the directory where your VM's .vmx file is located:
+
+ # cd vmfs/volumes/datastore1/[name-of-vm]
+
+Open .vmx file with a text editor, and add the following fields. Replace the MAC address field with your own.
+
+ ethernet0.addressType = "static"
+ ethernet0.checkMACAddress = "false"
+ ethernet0.address = "00:0c:29:1f:4b:ac"
+
+Now you should be able to launch a VM with the static MAC address you defined in .vmx file.
+
+--------------------------------------------------------------------------------
+
+via: http://ask.xmodulo.com/static-mac-address-vmware-esxi-virtual-machine.html
+
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://ask.xmodulo.com/enable-ssh-remote-access-vmware-esxi5.html
\ No newline at end of file
diff --git a/sources/tech/20140818 What are useful CLI tools for Linux system admins.md b/sources/tech/20140818 What are useful CLI tools for Linux system admins.md
new file mode 100644
index 0000000000..261af07857
--- /dev/null
+++ b/sources/tech/20140818 What are useful CLI tools for Linux system admins.md
@@ -0,0 +1,187 @@
+What are useful CLI tools for Linux system admins
+================================================================================
+System administrators (sysadmins) are responsible for day-to-day operations of production systems and services. One of the critical roles of sysadmins is to ensure that operational services are available round the clock. For that, they have to carefully plan backup policies, disaster management strategies, scheduled maintenance, security audits, etc. Like every other discipline, sysadmins have their tools of trade. Utilizing proper tools in the right case at the right time can help maintain the health of operating systems with minimal service interruptions and maximum uptime.
+
+This article will present some of the most popular and useful CLI tools recommended for sysadmins in their day to day activities. If you would like to recommend any useful tool which is not listed here, don't forget to share it in the comment section.
+
+### Network Tools ###
+
+1. **ping**: Check end-to-end connectivity (RTT delay, jitter, packet loss) of a remote host with ICMP echo/reply. Useful to check system status and reachability.
+
+2. **[phping][1]**: Network scanning and testing tool that can generate ICMP/TCP/UDP ping packets. Often used for advanced port scanning, firewall testing, manual path MTU discovery and fragmentation testing.
+
+3. **traceroute**: Discover a layer-3 forwarding path from a local host to a remote destination host with TTL-limited ICMP/UDP/TCP probe packets. Useful to troubleshoot network reachability and routing problems.
+
+4. **mtr**: A variation of traceroute which characterizes per-hop packet loss/jitter with running statistics. Useful to characterize routing path delays.
+
+5. **[netcat][2]/[socat][3]**: A swiss army knife of TCP/IP networking, allowing to read/write byte streams over TCP/UDP. Useful to troubleshoot firewall policies and service availability.
+
+6. **dig**: DNS troubleshooting tool that can generate forward queries, reverse queries, find authoritative name servers, check CNAME, MX and other DNS records. Can be instructed to query a specific DNS server of your choosing.
+
+7. **nslookup**: Another DNS checking/troubleshooting tool. Works with all DNS queries and records. Can query a particular DNS server.
+
+8. **dnsyo**: A DNS testing tool which checks DNS propagation by performing DNS lookup from over a number of open resolvers located across 1,500 different networks around the world.
+
+9. **lsof**: Show information about files (e.g., regular files, pipes or sockets) which are opened by processes. Useful to monitor open network connections.
+
+10. **iftop**: A ncurses-based TUI utility that can be used to monitor in real time bandwidth utilization and network connections for each network interfaces. Useful to keep track of bandwidth hogging applications, users, destinations and ports.
+
+11. **netstat**: A network statistics utility that can show status information and statistics about open network connections (TCP/UDP ports, IP addresses), routing tables, TX/RX traffic and protocols. Useful for network related diagnosis and performance tuning.
+
+12. **[tcpdump][4]**: A popular packet sniffer tool based on libpcap packet capture library. Can define packet capturing filters in Berkeley Packet Filters format.
+
+13. **[tshark][5]**: Another CLI packet sniffer software with full compatibility with its GUI counterpart, Wireshark. Supports [1,000 protocols][6] and the list is growing. Useful to troubleshoot, analyze and store information on live packets.
+
+14. **ip**: A versatile CLI networking tool which is part of iproute2 package. Used to check and modifying routing tables, network device state, and IP tunneling settings. Useful to view routing tables, add/remove static routes, configure network interfaces, and otherwise troubleshoot routing issues.
+
+15. **ifup/ifdown**: Used to bring up or shut down a particular network interface. Often a preferred alternative to restarting the entire network service.
+
+16. **[autossh][7]**: A program which create an SSH session and automatically restarts the session should it disconnect. Often useful to create a persistent reverse SSH tunnel across restrictive corporate networks.
+
+17. **iperf**: A network testing tool which measures maximum bi-directional throughput between a pair of hosts by injecting customizable TCP/UDP data streams in between.
+
+18. **[elinks][8]/[lynx][9]**: text-based web browsers for CLI-based server environment.
+
+### Security Tools ###
+
+19. **[iptables][10]**: A user-space CLI tool for configuring Linux kernel firewall. Provides means to create and modify rules for incoming, transit and outgoing packets within Linux kernel space.
+
+20. **[nmap][11]**: A popular port scanning and network discovery tool used for security auditing purposes. Useful to find out which hosts are up and running on the local network, and what ports are open on a particular host.
+
+21. **[TCP Wrappers][12]**: A host-based network ACL tool that can be used to filter incoming/outgoing reqeuests/replies. Often used alongside iptables as an additional layer of security.
+
+22. **getfacl/setfacl**: View and customize access control lists of files and directories, as extensions to traditional file permissions.
+
+23. **cryptsetup**: Used to create and manage LUKS-encrypted disk partitions.
+
+24. **lynis**: A CLI-based vulnerability scanner tool. Can scan the entire Linux system, and report potential vulnerabilities along with possible solutions.
+
+25. **maldet**: A malware scanner CLI tool which can detect and quarantine potentially malware-infected files. Can run as a background daemon for continuous monitoring.
+
+26. **[rkhunter][13]/[chkrootkit][14]**: CLI tools which scan for potential rootkits, hidden backdoors and suspected exploits on a local system, and disable them.
+
+### Storage Tools ###
+
+27. **fdisk**: A disk partition editor tool. Used to view, create and modify disk partitions on hard drives and removable media.
+
+28. **sfdisk**: A variant of fdisk which accesses or updates a partition table in a non-interactive fashion. Useful to automate disk partitioning as part of backup and recovery procedure.
+
+29. **[parted][15]**: Another disk partition editor which can support disk larger than 2TB with GPT (GUID Partitioning Table). Gparted is a GTK+ GUI front-end of parted.
+
+30. **df**: Used to check used/available storage and mount point of different partitions or file directories. A user-friendly variant dfc exists.
+
+31. **du**: Used to view current disk usage associated with different files and directories (e.g., du -sh *).
+
+32. **mkfs**: A disk formatting command used to build a filesystem on individual disk partitions. Filesystem-specific versions of mkfs exist for a number of filesystems including ext2, ext3, ext4, bfs, ntfs, vfat/fat.
+
+33. **fsck**: A CLI tool used to check a filesystem for errors and repair where possible. Typically run automatically upon boot when necessary, but also invoked manually on demand once unmounting a partition.
+
+34. **mount**: Used to map a physical disk partition, network share or remote storage to a local mount point. Any read/write in the mount point makes actual data being read/written in the correspoinding actual storage.
+
+35. **mdadm**: A CLI tool for managing software RAID devices on top of physical block devices. Can create, build, grow or monitor RAID array.
+
+36. **lvm**: A suite of CLI tools for managing volume groups and physical/logical volumes, which allows one to create, resize, split and merge volumes on top of multiple physical disks with minimum downtime.
+
+### Log Processing Tools ###
+
+37. **tail**: Used to monitor trailing part of a (growing) log file. Other variants include multitail (multi-window monitoring) and [ztail][16] (inotify support and regex filtering and coloring).
+
+38. **logrotate**: A CLI tool that can split, compresse and mail old/large log files in a pre-defined interval. Useful for administration of busy servers which may produce a large amount of log files.
+
+39. **grep/egrep**: Can be used to filter log content for a particular pattern or a regular expression. Variants include user-friendly ack and faster ag.
+
+40. **awk**: A versatile text scanning and processing tool. Often used to extract certain columns or fields from text/log files, and feed the result to other tools.
+
+41. **sed**: A text stream editor tool which can filter and transform (e.g., remove line/whitespace, substitute/convert a word, add numbering) text streams and pipeline the result to stdout/stderr or another tool.
+
+### Backup Tools ###
+
+42. **[rsync][17]**: A fast one-way incremental backup and mirroring tool. Often used to replicate a data repository to an offsite storage, optionally over a secure connection such as SSH or stunnel.
+
+43. **[rdiff-backup][18]**: Another bandwidth-efficient, incremental backup tool. Maintains differential of two consecutive snapshots.
+
+44. **duplicity**: An encrypted incremental backup utility. Uses GnuPG to encrypt a backup, and transfers to a remote server over SSH.
+
+### Performance Monitoring Tools ###
+
+45. **top**: A CLI-based process viewer program. Can monitor system load, process states, CPU and memory utilization. Variants include more user-friendly htop.
+
+46. **ps**: Shows a snapshot of all running processes in the system. The output can be customized to show PID, PPID, user, load, memory, cummulative user/system time, start time, and more. Variants include pstree which shows
+
+### processes in a tree hierarchy. ###
+
+47. **[nethogs][19]**: A bandwidth monitoring tool which groups active network connections by processes, and reports per-process (upload/download) bandwidth consumption in real-time.
+
+48. **ngxtop**: A web-server access log parser and monitoring tool whose interface is inspired by top command. It can report, in real time, a sorted list of web requests along with frequency, size, HTTP return code, IP address, etc.
+
+49. **vmstat**: A simple CLI tool which shows various run-time system properties such as process count, free memory, paging status, CPU utilization, block I/O activities, interrupt/context switch statistics, and more.
+
+50. **iotop**: An ncurses-based I/O monitoring tool which shows in real time disk I/O activities of all running processes in sorted order.
+
+51. **iostat**: A CLI tool which reports current CPU utilization, as well as device I/O utilization, where I/O utilization (e.g., block transfer rate, byte read/write rate) is reported on a per-device or per-partition basis.
+
+### Productivity Tools ###
+
+52. **screen**: Used to split a single terminal into multiple persistent virtual terminals, which can also be made accessible to remote users, like teamviewer-like screen sharing.
+
+53. **tmux**: Another terminal multiplexer tool which enables multiple persistent sessions, as well as horizontal/vertial splits of a terminal.
+
+54. **cheat**: A simple CLI tool which allows you to read cheat sheets of many common Linux commands, conveniently right at your fingertips. Pre-built cheat sheets are fully customizable.
+
+55. **apropos**: Useful when you are searching man pages for descriptions or keywords.
+
+### Package Management Tools ###
+
+56. **apt**: The de facto package manager for Debian based systems like Debain, Ubuntu or Backtrack. A life saver.
+
+57. **apt-fast**: A supporting utility for apt-get, which can significantly improve apt-get's download speed by using multiple concurrent connections.
+
+58. **apt-file**: Used to find out which .deb package a specific file belongs to, or to show all files in a particular .deb package. Works on both installed and non-installed packages.
+
+59. **dpkg**: A CLI utility to install a .deb package manually. Highly advised to use apt whenever possible.
+
+60. **yum**: The de facto automatic package manager for Red Hat based systems like RHEL, CentOS or Fedora. Yet another life saver.
+
+61. **rpm**: Typically I use rpmyum something. Has some useful parameters like -q, -f, -l for querying, files and locations, respectively.
+
+### Hardware Tools ###
+
+62. **lspci**: A command line tool which shows various information about installed PCI devices, such as model names, device drivers, capabilities, memory address, PCI bus address.
+
+63. **lshw**: A command line tool which queries and displays detailed information of hardware configuration in various categories (e.g., processor, memory, motherboard, network, storage). Supports multiple output formats: html, xml, json, text.
+
+64. **[inxi][20]**: A comprehensive hardware reporting tool which gives an overview of various hardware components such as CPU, graphics card, sound card, network card, temperature/fan sensors, etc.
+
+If you would like to recommend any useful tool which is not listed here, feel free to share it in the comment section.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/08/useful-cli-tools-linux-system-admins.html
+
+作者:[Sarmed Rahman][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/sarmed
+[1]:http://www.hping.org/
+[2]:http://netcat.sourceforge.net/
+[3]:http://www.dest-unreach.org/socat/
+[4]:http://www.tcpdump.org/
+[5]:https://www.wireshark.org/docs/man-pages/tshark.html
+[6]:https://www.wireshark.org/docs/dfref/
+[7]:http://www.harding.motd.ca/autossh/
+[8]:http://elinks.or.cz/
+[9]:http://lynx.isc.org/
+[10]:http://www.netfilter.org/projects/iptables/
+[11]:http://nmap.org/
+[12]:http://en.wikipedia.org/wiki/TCP_Wrapper
+[13]:http://rkhunter.sourceforge.net/
+[14]:http://www.chkrootkit.org/
+[15]:http://www.gnu.org/software/parted/
+[16]:https://hackage.haskell.org/package/ztail
+[17]:http://rsync.samba.org/
+[18]:http://www.nongnu.org/rdiff-backup/
+[19]:http://nethogs.sourceforge.net/
+[20]:http://code.google.com/p/inxi/
\ No newline at end of file
diff --git a/sources/tech/20140819 8 Options to Trace or Debug Programs using Linux strace Command.md b/sources/tech/20140819 8 Options to Trace or Debug Programs using Linux strace Command.md
new file mode 100644
index 0000000000..3cbf25c52b
--- /dev/null
+++ b/sources/tech/20140819 8 Options to Trace or Debug Programs using Linux strace Command.md
@@ -0,0 +1,112 @@
+8 Options to Trace/Debug Programs using Linux strace Command
+================================================================================
+The strace is the tool that helps in debugging issues by tracing system calls executed by a program. It is handy when you want to see how the program interacts with the operating system, like what system calls are executed in what order.
+
+This simple yet very powerful tool is available for almost all the Linux based operating systems and can be used to debug a large number of programs.
+
+### 1. Command Usage ###
+
+Let’s see how we can use strace command to trace the execution of a program.
+
+In the simplest form, any command can follow strace. It will list a whole lot of system calls. Not all of it would make sence at first, but if you’re really looking for something particular, then you should be able to figure something out of this output.
+Lets see the system calls trace for simple ls command.
+
+ raghu@raghu-Linoxide ~ $ strace ls
+
+
+
+This output shows the first few lines for strace command. The rest of the output is truncated.
+
+
+
+The above part of the output shows the write system call where it outputs to STDOUT the current directory’s listing. Following image shows the listing of the directoy by ls command (without strace).
+
+ raghu@raghu-Linoxide ~ $ ls
+
+
+
+#### 1.1 Find configuration file read by program ####
+
+One use of strace (Except debugging some problem) is that you can find out which configuration files are read by a program. For example,
+
+ raghu@raghu-Linoxide ~ $ strace php 2>&1 | grep php.ini
+
+
+
+#### 1.2 Trace specific system call ####
+
+The -e option to strace command can be used to display certain system calls only (for example, open, write etc.)
+
+Lets trace only ‘open’ system call for cat command.
+
+ raghu@raghu-Linoxide ~ $ strace -e open cat dead.letter
+
+
+
+#### 1.3 Stracing a process ####
+
+The strace command can not only be used on the commands, but also on the running processes with -p option.
+
+ raghu@raghu-Linoxide ~ $ sudo strace -p 1846
+
+
+
+#### 1.4 Statistical summary of strace ####
+
+The summary of the system calls, time of execution, errors etc. can be displayed in a neat manner with -c option:
+
+ raghu@raghu-Linoxide ~ $ strace -c ls
+
+
+
+#### 1.5 Saving output ####
+
+The output of strace command can be saved into a file with -o option.
+
+ raghu@raghu-Linoxide ~ $ sudo strace -o process_strace -p 3229
+
+
+
+The above command is run with sudo as it will display error in case the user ID does not match with the process owner.
+
+### 1.6 Displaying timestamp ###
+
+The timestamp can be displayed before each output line with -t option.
+
+ raghu@raghu-Linoxide ~ $ strace -t ls
+
+
+
+#### 1.7 The Finer timestamp ####
+
+The -tt option displays timestamp followed by microsecond.
+
+ raghu@raghu-Linoxide ~ $ strace -tt ls
+
+
+
+The -ttt displays microseconds like above, but instead of printing surrent time, it displays the number of seconds since the epoch.
+
+ raghu@raghu-Linoxide ~ $ strace -ttt ls
+
+
+
+#### 1.8 Relative Time ####
+
+The -r option displays the relative timestamp between the system calls.
+
+ raghu@raghu-Linoxide ~ $ strace -r ls
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-command/linux-strace-command-examples/
+
+作者:[Raghu][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/raghu/
\ No newline at end of file
diff --git a/sources/tech/20140819 A Pocket Guide for Linux ssh Command with Examples.md b/sources/tech/20140819 A Pocket Guide for Linux ssh Command with Examples.md
new file mode 100644
index 0000000000..ff2a301066
--- /dev/null
+++ b/sources/tech/20140819 A Pocket Guide for Linux ssh Command with Examples.md
@@ -0,0 +1,133 @@
+A Pocket Guide for Linux ssh Command with Examples
+================================================================================
+If you have been in the IT world for quite some time you probably have heard about SSH, how great a tool it is and all its cool security features. In this tutorial you will learn how to use SSH in a few minutes and login to your remote computers seamlessly and securely.
+
+If you have no clue what SSH is you can visit [Wikipedia][1] before proceeding.
+
+### Basic Usage ###
+
+The simplest usage of SSH is where you specify a user and the hostname. The hostname could be an IP address or a domain name an in the following format.
+
+ $ ssh user@hostname
+
+For example to login to a Raspberry Pi on my LAN, I would simply type the command in the terminal as follows:
+
+ $ ssh pi@10.42.0.47
+
+Where pi is the user and 10.42.0.47 is the IP of the Raspberry Pi on my LAN. Change this accordingly to reflect your LAN configuration or your remote computer’s IP address.
+
+
+
+If you have logged in successfully then the rest of the guide shall be a breeze for you.
+
+### Using A Different Port ###
+
+By default ssh uses port 22, but for various reasons you may want to connect to another port.
+
+ $ ssh -p 10022 user@hostname
+
+This will connect to ssh via port 10022 instead of port 22.
+
+### Execute Commands Remotely ###
+
+At times its convenient to execute a command on the remote host and get the output and continue working on the local machine. Well SSH has catered for this need,
+
+ $ ssh pi@10.42.0.47 ls -l
+
+This command for example will list the contents of the home directory and return the prompt to you. Cool? Try it out with other commands as well.
+
+
+
+### Mounting remote filesystems ###
+
+Another great tool based on ssh is sshfs. With sshfs you can mount remote filesystems and have the remote files on the local machine.
+
+ $ sshfs -o idmap=user user@hostname:/home/user ~/Remote
+
+For example this command can be used as:
+
+ $ sshfs -o idmap=user pi@10.42.0.47:/home/pi ~/Pi
+
+This will mount pi’s home directory to a folder on the local machine called Pi.
+
+For more details on sshfs [look at our sshfs tutorial][2].
+
+### X11 Forwarding ###
+
+Suppose now you want to run a GUI program on your remote computer? SSH had you in mind! Login to the remote machine with the basic SSH command but -X option. This will allow X11 forwarding. After you login you might not see any difference, but once you invoke a GUI based program you notice the difference.
+
+ $ ssh -X pi@10.42.0.47
+
+ $ pistore
+
+Now you may want to do other stuff on the command line while running the GUI program. Simply suffix the command with &.
+
+ $ pistore&
+
+
+
+### Escape Sequences ###
+
+There are various escape sequences provided by SSH. To view them, SSH to any remote machine then type tilde(~) followed by a question mark. You will see a couple of other supported escape sequences. In this example you can the output of **~#** and **~C**.
+
+
+
+### Edit SSH Configuration ###
+
+If you need to change SSH configuration, open the file **/etc/ssh/sshd_config** with your favourite text editor and edit whatever you need to. For example we might need to change the banner. In your text editor find the following line:
+
+ #Banner none
+
+Uncomment the line by deleting the # then add a path to the file with the message you want displayed. The line should now read as:
+
+ Banner /etc/issue
+
+In this /etc/ssh/sshd_config file you will also find the options of changing the port number, idle logout timeout e.t.c . These are fairly straight forward, but refer to the ssh manual for anything that might not be familiar before attempting to make changes.
+
+### Generate SSH Key Pair ###
+
+To generate a new key pair run the command as follows:
+
+ $ ssh-keygen -t dsa
+
+You will be asked for a passphrase then the key pair will be generated. This command will also give you the key’s randomart image.
+
+
+
+### Finding A Hostkey ###
+
+Now before you add that key pair it does no harm to see if it exists already.
+
+ $ ssh-keygen -F 10.42.0.47
+
+
+
+### Removing A Hostkey ###
+
+Sometimes its necessary to remove a key pair you had generated, for example when the host has changed or perhaps when you need to remove keys that are no longer used.
+
+ $ ssh-keygen -R 10.42.0.47
+
+This is much more convenient than opening **~/.ssh/known_hosts**
+and removing the keys manually.
+
+
+
+### Conclusion ###
+
+With the above commands you will be able to use SSH with ease. There is more to explore and your imagination is your limitation.
+
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-command/pocket-guide-linux-ssh-command/
+
+作者:[Bobbin Zachariah][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/bobbin/
+[1]:http://en.wikipedia.org/wiki/Secure_Shell
+[2]:http://linoxide.com/how-tos/sshfs-mount-remote-directories/
\ No newline at end of file
diff --git a/sources/tech/20140819 Build a Raspberry Pi Arcade Machine.md b/sources/tech/20140819 Build a Raspberry Pi Arcade Machine.md
new file mode 100644
index 0000000000..6c0663723e
--- /dev/null
+++ b/sources/tech/20140819 Build a Raspberry Pi Arcade Machine.md
@@ -0,0 +1,135 @@
+Build a Raspberry Pi Arcade Machine
+================================================================================
+**Relive the golden majesty of the 80s with a little help from a marvel of the current decade.**
+
+### WHAT YOU’LL NEED ###
+
+- Raspberry Pi w/4GB SD-CARD.
+- HDMI LCD monitor.
+- Games controller or…
+- A JAMMA arcade cabinet.
+- J-Pac or I-Pac.
+
+The 1980s were memorable for many things; the end of the cold war, a carbonated drink called Quatro, the Korg Polysix synthesiser and the Commodore 64. But to a certain teenager, none of these were as potent, or as perhaps familiarly illicit, as the games arcade. Enveloped by cigarette smoke and a barrage of 8-bit sound effects, they were caverns you visited only on borrowed time: 50 pence and a portion of chips to see you through lunchtime while you honed your skills at Galaga, Rampage, Centipede, Asteroids, Ms Pacman, Phoenix, R-Rype, Donkey Kong, Rolling Thunder, Gauntlet, Street Fighter, Outrun, Defender… The list is endless.
+
+These games, and the arcade machine form factor that held them, are just as compelling today as they were 30 years ago. And unlike the teenage version of yourself, you can now play many of them without needing a pocket full of change, finally giving you an edge over the rich kids and their endless ‘Continues’. It’s time to build your own Linux-based arcade machine and beat that old high score.
+
+We’re going to cover all the steps required to turn a cheap shell of an arcade machine into a Linux-powered multi-platform retro games system. But that doesn’t mean you’ve got to build the whole system at the same scale. You could, for example, forgo the large, heavy and potentially carcinogenic hulk of the cabinet itself and stuff the controlling innards into an old games console or an even smaller case. Or you could just as easily forgo the diminutive Raspberry Pi and replace the brains of your system with a much more capable Linux machine. This might make an ideal platform for SteamOS, for example, and for playing some of its excellent modern arcade games.
+
+Over the next few pages we’ll construct a Raspberry Pi-based arcade machine, but you should be able to see plenty of ideas for your own projects, even if they don’t look just like ours. And because we’re building it on the staggeringly powerful MAME, you’ll be able to get it running on almost anything.
+
+
+
+We did this project before the model B+ came out. It should all work exactly the same on the newer board, and you should be able to get by without a powered USB Hub (click for larger).
+
+### Disclaimer ###
+
+One again we’re messing with electrical components that could cause you a shock. Make sure you get any modifications you make checked by a qualified electrician. We don’t go into any details on how to obtain games, but there are legal sources such as old games releases and newer commercial titles based on the MAME emulator.
+
+#### Step1: The Cabinet ####
+
+The cabinet itself is the biggest challenge. We bought an old two-player Bubble Bobble machine from the early 90s from eBay. It cost £220 delivered in the back of an old estate car. The prices for cabinets like these can vary. We’ve seen many for less than £100. At the other end of the scale, people pay thousands for machines with original decals on the side.
+
+There are two major considerations when it comes to buying a cabinet. The first is the size: These things are big and heavy. They take up a lot of space and it takes at least two people to move them around. If you’ve got the money, you can buy DIY cabinets or new smaller form-factors, such as cabinets that fit on tables. And cocktail cabinets can be easier to fit, too.
+
+
+
+Cabinets can be cheap, but they’re heavy. Don’t lift them on your own. Older ones may need some TLC, such as are-spray and some repair work(click for larger).
+
+One of the best reasons for buying an original cabinet, apart from getting a much more authentic gaming experience, is being able to use the original controls. Many machines you can buy on eBay will be for two concurrent players, with two joysticks and a variety of buttons for each player, plus the player one and player two controls. For compatibility with the widest number of games, we’d recommend finding a machine with six buttons for each player, which is a common configuration. You might also want to look into a panel with more than two players, or one with space for other input controllers, such as an arcade trackball (for games like Marble Madness), or a spinner (Arkanoid). These can be added without too much difficulty later, as modern USB devices exist.
+
+Controls are the second, and we’d say most important consideration, because it’s these that transfer your twitches and tweaks into game movement. What you need to consider for when buying a cabinet is something called JAMMA, an acronym for Japan Amusement Machinery Manufacturers. JAMMA is a standard in arcade machines that defines how the circuit board containing the game chips connects to the game controllers and the coin mechanism. It’s an interface conduit for all the cables coming from the buttons and the joysticks, for two players, bringing them into a standard edge connector. The JAMMA part is the size and layout of this connector, as it means the buttons and controls will be connected to the same functions on whichever board you install so that the arcade owner would only have to change the cabinet artwork to bring in new players.
+
+But first, a word of warning: the JAMMA connector also carries the 12V power supply, usually from a power unit installed in most arcade machines. We disconnecting the power supply completely to avoid damaging anything with a wayward short-circuit or dropped screwdriver. We don’t use any of the power connectors in any further stage of the tutorial.
+
+
+
+#### Step 2: J-PAC ####
+
+What’s brilliant is that you can buy a device that connects to the JAMMA connector inside your cabinet and a USB port on your computer, transforming all the buttons presses and keyboard movements into (configurable) keyboard commands that you can use from Linux to control any game you wish. This device is called the J-Pac ([www.ultimarc.com/jpac.html][1] – approximately £54).
+
+Its best feature isn’t the connectivity; it’s the way it handles and converts the input signals, because it’s vastly superior to a standard USB joystick. Every input generates its own interrupt, and there’s no limit to the number of simultaneous buttons and directions you can press or hold down. This is vital for games like Street Fighter, because they rely on chords of buttons being pressed simultaneously and quickly, but it’s also essential when delivering the killing blow to cheating players who sulk and hold down all their own buttons. Many other controllers, especially those that create keyboard inputs, are restricted by their USB keyboard controllers to six inputs and a variety of Alt, Shift and Ctrl hacks. The J-Pac can also be connected to a tilt sensor and even some coin mechanisms, and it works in Linux without any pre-configuration.
+
+Another option is a similar device called an I-Pac. It does the same thing as the J-Pac, only without the JAMMA connector. That means you can’t connect your JAMMA controls, but it does mean you can design your own controller layout and wire each control to the I-Pac yourself. This might be a little ambitious for a first project, but it’s a route that many arcade aficionados take, especially when they want to design a panel for four players, or one that incorporates many different kinds of controls. Our approach isn’t necessarily one we’d recommend, but we re-wired an old X-Arcade Tankstick control panel that suffered from input contention, replaced the joysticks and buttons with new units and connected it to a new JAMMA harness, which is an excellent way of buying all the cables you need plus the edge connector for a low price (£8).
+
+
+
+Our J-Pac in situ. The blue and red wires on the right connect to the extra 1- and 2-player buttons on our cabinet (click for larger).
+
+Whether you choose an I-Pac or a J-Pac, all the keys generated by both devices are the default values for MAME. That means you won’t have to make any manual input changes when you start to run the emulator. Player 1, for example, creates cursor up, down, left and right as well as left Ctrl, left ALT, Space and left Shift for fire buttons 1–4. But the really useful feature, for us, is the two-button shortcuts. While holding down the player 1 button, you can generate the P key to pause the game by pulling down on the player 1 joystick, adjust the volume by pressing up and enter MAME’s own configuration menu by pushing right. These escape codes are cleverly engineered to not get in the way of playing games, as they’re only activated when holding down the Player 1 button, and they enable you to do almost anything you need to from within a running game. You can completely reconfigure MAME, for example, using its own menus, and change input assignments and sensitivity while playing the game itself.
+
+Finally, holding down Player 1 and then pressing Player 2 will quit MAME, which is useful if you’re using a launch menu or MAME manager, as these manage launching games automatically, and let you get on with playing another game as quickly as possible.
+
+We took a rather cowardly route with the screen, removing the original, bulky and broken CRT that came with the cabinet and replacing it with a low-cost LCD monitor. This approach has many advantages. First, the screen has HDMI, so it will interface with a Raspberry Pi or a modern graphics card without any difficulty. Second, you don’t have to configure the low-frequency update modes required to drive an arcade machine’s screen, nor do you need the specific graphics hardware that drives it. And third, this is the safest option because an arcade machine’s screen is often unprotected from the rear of a case, leaving very high voltages inches away from your hands. That’s not to say you shouldn’t use a CRT if that’s the experience you’re after – it’s the most authentic way to get the gaming experience you’re after, but we’ve fined-tuned the CRT emulation enough in software that we’re happy with the output, and we’re definitely happier not to be using an ageing CRT.
+
+You might also want to look into using an older LCD with a 4:3 aspect ratio, rather than the widescreen modern options, because 4:3 is more practical for playing both vertical and horizontal games. A vertical shooter such as Raiden, for example, will have black bars on either side of the gaming area if you use a widescreen monitor. Those black bars can be used to display the game instructions, or you could rotate the screen 90 degrees so that every pixel is used, but this is impractical unless you’re only going to play vertical games or have easy access to a rotating mount.
+
+Mounting a screen is also important. If you’ve removed a CRT, there’s nowhere for an LCD to go. Our solution was to buy some MDF cut to fit the space where the CRT was. This was then screwed into position and we fitted a cheap VESA mounting plate into the centre of the new MDF. VESA mounts can be used by the vast majority of screens, big and small. Finally, because our cabinet was fronted with smoked glass, we had to be sure both the brightness and contrast were set high enough.
+
+### Step 3: Installation ###
+
+With the large hardware choices now made, and presumably the cabinet close to where you finally want to install it, putting the physical pieces together isn’t that difficult. We safely split the power input from the rear of the cabinet and wired a multiple socket into the space at the back. We did this to the cable after it connects to the power switch.
+
+Nearly all arcade cabinets have a power switch on the top-right surface, but there’s usually plenty of cable to splice into this at a lower point in the cabinet, and it meant we could use normal power connectors for our equipment. Our cabinet has a fluorescent tube, used to backlight the top marquee on the machine, connected directly to the power, and we were able to keep this connected by attaching a regular plug. When you turn the power on from the cabinet switch, power flows to the components inside the case – your Raspberry Pi and screen will come on, and all will be well with the world.
+
+The J-Pac slides straight into the JAMMA interface, but you may also have to do a little manual wiring. The JAMMA standard only supports up to three buttons for each player (although many unofficially support four), while the J-Pac can handle up to six buttons. To get those extra buttons connected, you need to connect one side of the button’s switch to GND fed from the J-Pac with the other side of the switch going into one of the screw-mounted inputs in the side of the J-Pac. These are labelled 1SW4, 1SW5, 1SW6, 2SW4, 2SW5 and 2SW6. The J-Pac also includes passthrough connections for audio, but we’ve found this to be incredibly noisy. Instead, we wired the speaker in our cabinet to an old SoundBlaster amplifier and connected this to the audio outputs on the Raspberry Pi. You don’t want audio to be pristine, but you do want it to be loud enough.
+
+
+
+Our Raspberry Pi is now connected to the J-Pac on the left and both the screen and the USB hub (click for larger).
+
+The J-Pac or I-Pac then connects to your PC or Raspberry Pi using a PS2-to-USB cable, which should also be used to connect to a PS2 port on your PC directly. There is an additional option to use an old PS2 connector, if your PC is old enough to have one, but we found in testing that the USB performance is identical. This won’t apply to the PS2-less Raspberry Pi, of course, and don’t forget that the Pi will also need powering. We always recommend doing so from a compatible powered hub, as a lack of power is the most common source of Raspberry Pi errors. You’ll also need to get networking to your Raspberry Pi, either through the Ethernet port (perhaps using a powerline adaptor hidden in the cabinet), or by using a wireless USB device. Networking is essential because it enables you to reconfigure your PI while it’s tucked away within the cabinet, and it also enables you to change settings and perform administration tasks without having to connect a keyboard or mouse.
+
+> ### Coin Mechanism ###
+
+> In the emulation community, getting your coin mechanism to work with your emulator was often considered a step too close to commercial production. It meant you could potential charge people to use your machine. Not only would this be wrong, but considering the provenance of many of the games you run on your own arcade machine, it could also be illegal. And it’s definitely against the spirit of emulation. However, we and many other devotees thinking that a working coin mechanism is another step closer to the realism of an arcade machine, and is worth the effort in recreating the nostalgia of an old arcade. There’s nothing like dropping a 10p piece into the coin tray and to hear the sound of the credits being added to the machine.
+
+> It’s not actually that difficult. It depends on the coin mechanism in your arcade machine and how it sends a signal to say how many credits had been inserted. Most coin mechanisms come in two parts. The large part is the coin acceptor/validator. This is the physical side of the process that detects whether a coin is authentic, and determines its value. It does this with the help of a credit/logic board, usually attached via a ribbon cable and featuring lots of DIP switches. These switches are used to change which coins are accepted and how many credits they generate. It’s then usually as simple as finding the output switch, which is triggered with a credit, and connecting this to the coin input on your JAMMA connector, or directly onto the J-Pac. Our coin mechanism is a Mars MS111, common in the UK in the early 90s, and there’s plenty of information online about what each of the DIP switches do, as well as how to programme the controller for newer coins. We were also able to wire the 12V connector from the mechanism to a small light for behind the coin entry slot.
+
+#### Step 4: Software ####
+
+MAME is the only viable emulator for a project of this scale, and it now supports many thousands of different games running on countless different platforms, from the first arcade machines through to some more recent ones. It’s a project that has also spawned MESS, the multi-emulator super system, which targets platforms such as home computers and consoles from the 80s and 90s.
+
+Configuring MAME could take a six-page article in itself. It’s a complex, sprawling, magnificent piece of software that emulates so many CPUs, so many sound devices, chips, controllers with so many options, that like MythTV, you never really stop configuring it.
+
+But there’s an easier option, and one that’s purpose-built for the Raspberry Pi. It’s called PiMAME. This is both a distribution download and a script you can run on top of Raspbian, the Pi’s default distribution. Not only does it install MAME on your Raspberry Pi (which is useful because it’s not part of any of the default repositories), it also installs a selection of other emulators along with front-ends to manage them. MAME, for example, is a command-line utility with dozens of options. But PiMAME has another clever trick up its sleeve – it installs a simple web server that enables you to install new games through a browser connected to your network. This is a great advantage, because getting games into the correct folders is one of the trials of dealing with MAME, and it also enables you to make best use of whatever storage you’ve got connected to your Pi. Plus, PiMAME will update itself from the same script you use to install it, so keeping on top of updates couldn’t be easier. This could be especially useful at the moment, as at the time of writing the project was on the cusp of a major upgrade in the form of the 0.8 release. We found it slightly unstable in early March, but we’re sure everything will be sorted by the time you read this.
+
+The best way to install PiMAME is to install Raspbian first. You can do this either through NOOBS, using a graphical tool from your desktop, or by using the dd command to copy the contents of the Raspbian image directly onto your SD card. As we mentioned in last month’s BrewPi tutorial, this process has been documented many times before, so we won’t waste the space here. Just install NOOBS if you want the easy option, following the instructions on the Raspberry Pi site. With Raspbian installed and running, make sure you use the configuration tool to free the space on your SD card, and that the system is up to date (sudo apt-get update; sudo apt-get upgrade). You then need to make sure you’ve got the git package already installed. Any recent version of Raspbian will have installed git already, but you can check by typing sudo apt-get install git just to check.
+
+You then have to type the following command to clone the PiMAME installer from the project’s GitHub repository:
+
+ git clone https://github.com/ssilverm/pimame_installer
+
+After that, you should get the following feedback if the command works:
+
+ Cloning into ‘pimame_installer’...
+ remote: Reusing existing pack: 2306, done.
+ remote: Total 2306 (delta 0), reused 0 (delta 0)
+ Receiving objects: 100% (2306/2306), 4.61 MiB | 11 KiB/s, done.
+ Resolving deltas: 100% (823/823), done.
+
+This command will create a new folder called ‘pimame_installer’, and the next step is to switch into this and run the script it contains:
+
+ cd pimame_installer/
+ sudo ./install.sh
+
+This command installs and configures a lot of software. The length of time it takes will depend on your internet connection, as a lot of extra packages are downloaded. Our humble Pi with a 15Mb internet connection took around 45 minutes to complete the script, after which you’re invited to restart the machine. You can do this safely by typing sudo shutdown -r now, as this command will automatically handle any remaining write operations to the SD card.
+
+And that’s all there is to the installation. After rebooting your Pi, you will be automatically logged in and the PiMAME launch menu will appear. It’s a great-looking interface in version 0.8, with photos of each of the platforms supported, plus small red icons to indicate how many games you’ve got installed.This should now be navigable through your controller. If you want to make sure the controller is correctly detected, use SSH to connect to your Pi and check for the existence of **/dev/input/by-id/usb-Ultimarc_I-PAC_Ultimarc_I-PAC-event-kbd**.
+
+The default keyboard controls will enable you to select what kind of emulator you want to run on your arcade machine. The option we’re most interested in is the first, labelled ‘AdvMAME’, but you might also be surprised to see another MAME on offer, MAME4ALL. MAME4ALL is built specifically for the Raspberry Pi, and takes an old version of the MAME source code so that the performance of the ROMS that it does support is optimal. This makes a lot of sense, because there’s no way your Pi is going to be able to play anything too demanding, so there’s no reason to belabour the emulator with unneeded compatibility. All that’s left to do now is get some games onto your system (see the boxout below), and have fun!
+
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxvoice.com/arcade-machine/
+
+作者:[Ben Everard][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxvoice.com/author/ben_everard/
+[1]:http://www.ultimarc.com/jpac.html
\ No newline at end of file
diff --git a/sources/tech/20140819 How to Encrypt Email in Linux.md b/sources/tech/20140819 How to Encrypt Email in Linux.md
new file mode 100644
index 0000000000..cfa3e429e4
--- /dev/null
+++ b/sources/tech/20140819 How to Encrypt Email in Linux.md
@@ -0,0 +1,105 @@
+How to Encrypt Email in Linux
+================================================================================
+
+Kgpg provides a nice GUI for creating and managing your encryption keys.
+
+If you've been thinking of encrypting your email, it is a rather bewildering maze to sort through thanks to the multitude of email services and mail clients. There are two levels of encryption to consider: SSL/TLS encryption protects your login and password to your mailserver. [GnuPG][1] is the standard strong Linux encryption tool, and it encrypts and authenticates your messages. It is best if you manage your own GPG encryption and not leave it up to third parties, which we will discuss in a moment.
+
+Encrypting messages still leaves you vulnerable to traffic analysis, as message headers must be in the clear. So that necessitates yet another tool such as the [Tor network][2] for hiding your Internet footprints. Let's look at various mail services and clients, and the pitfalls and benefits therein.
+
+### Forget Webmail ###
+
+If you use GMail, Yahoo, Hotmail, or another Web mail provider, forget about it. Anything you type in a Web browser is vulnerable to JavaScript attacks, and whatever mischiefs the service provider engages in. GMail, Yahoo, and Hotmail all offer SSL/TLS encryption to protect your messages from wiretapping. But they offer no protections from their own data-mining habits, so they don't offer end-to-end encryption. Yahoo and Google both claim they're going to roll out end-to-end encryption next year. Color me skeptical, because they will wither and die if anything interferes with the data-mining that is their core business.
+
+There are various third-party email security services such as [Virtru][3] and [SafeMess][4] that claim to offer secure encryption for all types of email. Again I am skeptical, because whoever holds your encryption keys has access to your messages, so you're still depending on trust rather than technology.
+
+Peer messaging avoids many of the pitfalls of using centralized services. [RetroShare][5] and [Bitmessage][6] are two popular examples of this. I don't know if they live up to their claims, but the concept certainly has merit.
+
+What about Android and iOS? It's safest to assume that the majority of Android and iOS apps are out to get you. Don't take my word for it-- read their terms of service and examine the permissions they require to install on your devices. And even if their terms are acceptable when you first install them, unilateral TOS changes are industry standard, so it is safest to assume the worst.
+
+### Zero Knowledge ###
+
+[Proton Mail][7] is a new email service that claims zero-knowledge message encryption. Authentication and message encryption are two separate steps, Proton is under Swiss privacy laws, and they do not log user activity. Zero knowledge encryption offers real security. This means that only you possess your encryption keys, and if you lose them your messages are not recoverable.
+
+There are many encrypted email services that claim to protect your privacy. Read the fine print carefully and look for red flags such as limited user data collection, sharing with partners, and cooperation with law enforcement. These indicate that they collect and share user data, and have access to your encryption keys and can read your messages.
+
+### Linux Mail Clients ###
+
+A standalone open source mail client such as KMail, Thunderbird, Mutt, Claws, Evolution, Sylpheed, or Alpine, set up with your own GnuPG keys that you control gives you the most protection. (The easiest way to set up more secure email and Web surfing is to run the TAILS live Linux distribution. See [Protect Yourself Online With Tor, TAILS, and Debian][8].)
+
+Whether you use TAILS or a standard Linux distro, managing GnuPG is the same, so let's learn how to encrypt messages with GnuPG.
+
+### How to Use GnuPG ###
+
+First, a quick bit of terminology. OpenPGP is an open email encryption and authentication protocol, based on Phil Zimmerman's Pretty Good Privacy (PGP). GNU Privacy Guard (GnuPG or GPG) is the GPL implementation of OpenPGP. GnuPG uses symmetric public key cryptography. This means that you create pairs of keys: a public key that anyone can use to encrypt messages to send to you, and a private key that only you possess to decrypt them. GnuPG performs two separate functions: digitally-signing messages to prove they came from you, and encrypting messages. Anyone can read your digitally-signed messages, but only people you have exchanged keys with can read your encrypted messages. Remember, never share your private keys! Only public keys.
+
+Seahorse is GNOME's graphical front-end to GnuPG, and KGpg is KDE's graphical GnuPG tool.
+
+Now let's run through the basic steps of creating and managing GnuPG keys. This command creates a new key:
+
+ $ gpg --gen-key
+
+This is a multi-step process; just answer all the questions, and the defaults are fine for most people. When you create your passphrase, write it down and keep it in a secure place because if you lose it you cannot decrypt anything. All that advice about never writing down your passwords is wrong. Most of us have dozens of logins and passwords to track, including some that we rarely use, so it's not realistic to remember all of them. You know what happens when people don't write down their passwords? They create simple passwords and re-use them. Anything you store on your computer is potentially vulnerable; a nice little notebook kept in a locked drawer is impervious to everything but a physical intrusion, if an intruder even knew to look for it.
+
+I must leave it as your homework to figure out how to configure your mail client to use your new key, as every one is different. You can list your key or keys:
+
+ $ gpg --list-keys
+ /home/carla/.gnupg/pubring.gpg
+ ------------------------------
+ pub 2048R/587DD0F5 2014-08-13
+ uid Carla Schroder (my gpg key)
+ sub 2048R/AE05E1E4 2014-08-13
+
+This is a fast way to grab necessary information like the location of your keys, and your key name, which is the UID. Suppose you want to upload your public key to a keyserver; this is how it looks using my example key:
+
+ $ gpg --send-keys 'Carla Schroder' --keyserver http://example.com
+
+When you create a new key for upload to public key servers, you should also create a revocation certificate. Don't do it later-- create it when you create your new key. You can give it any arbitrary name, so instead of revoke.asc you could give it a descriptive name like mycodeproject.asc:
+
+ $ gpg --output revoke.asc --gen-revoke 'Carla Schroder'
+
+Now if your key ever becomes compromised you can revoke it by first importing the revocation certificate into your keyring:
+
+ $ gpg --import ~/.gnupg/revoke.asc
+
+Then create and upload a new key to replace it. Any users of your old key will be notified as they refresh their key databases.
+
+You must guard your revocation certificate just as zealously as your private key. Copy it to a CD or USB stick and lock it up, and delete it from your computer. It is a plain-text key, so you could even print it on paper.
+
+If you ever need a copy-and-paste key, for example on public keyrings that allow pasting your key into a web form, or if you want to post your public key on your Web site, then you must create an ASCII-armored version of your public key:
+
+ $ gpg --output carla-pubkey.asc --export -a 'Carla Schroder'
+
+This creates the familiar plain-text public key you've probably seen, like this shortened example:
+
+ -----BEGIN PGP PUBLIC KEY BLOCK-----
+ Version: GnuPG v1
+ mQENBFPrn4gBCADeEXKdrDOV3AFXL7QQQ+i61rMOZKwFTxlJlNbAVczpawkWRC3l
+ IrWeeJiy2VyoMQ2ZXpBLDwGEjVQ5H7/UyjUsP8h2ufIJt01NO1pQJMwaOMcS5yTS
+ [...]
+ I+LNrbP23HEvgAdNSBWqa8MaZGUWBietQP7JsKjmE+ukalm8jY8mdWDyS4nMhZY=
+ =QL65
+ -----END PGP PUBLIC KEY BLOCK-----
+
+That should get you started learning your way around GnuPG. [The GnuPG manuals][9] have complete details on using GnuPG and all of its options.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linux.com/learn/tutorials/784165-how-to-encrypt-email-in-linux
+
+作者:[Carla Schroder][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.linux.com/component/ninjaboard/person/3734
+[1]:http://www.openpgp.org/members/gnupg.shtml
+[2]:https://www.torproject.org/
+[3]:https://www.virtru.com/
+[4]:https://www.safemess.com/
+[5]:http://retroshare.sourceforge.net/
+[6]:http://retroshare.sourceforge.net/
+[7]:https://protonmail.ch/
+[8]:http://www.linux.com/learn/docs/718398-protect-yourself-online-with-tor-+tails-and-debian
+[9]:https://www.gnupg.org/documentation/manuals.html
\ No newline at end of file
diff --git a/sources/tech/20140819 Linux Systemd--Start or Stop or Restart Services in RHEL or CentOS 7.md b/sources/tech/20140819 Linux Systemd--Start or Stop or Restart Services in RHEL or CentOS 7.md
new file mode 100644
index 0000000000..51f1d8a1ce
--- /dev/null
+++ b/sources/tech/20140819 Linux Systemd--Start or Stop or Restart Services in RHEL or CentOS 7.md
@@ -0,0 +1,68 @@
+Linux Systemd - Start/Stop/Restart Services in RHEL / CentOS 7
+================================================================================
+One of the major changes in RHEL / CentOS 7.0 is the swtich to **systemd**, a system and service manager, that replaces SysV and Upstart used in previous releases of Red Hat Enterprise Linux. systemd is compatible with SysV and Linux Standard Base init scripts.
+
+**Systemd** is a system and service manager for Linux operating systems. It is designed to be backwards compatible with SysV init scripts, and provides a number of features such as parallel startup of system services at boot time, on-demand activation of daemons, support for system state snapshots, or dependency-based service control logic.
+
+Previous versions of Red Hat Enterprise Linux, which were distributed with SysV init or Upstart, used init scripts written in bash located in the /etc/rc.d/init.d/ directory. In RHEL 7 / CentOS 7, these init scripts have been replaced with service units. Service units end with the .service file extension and serve a similar purpose as init scripts. To view, start, stop, restart, enable, or disable system services you will use the systemctl instead of the old service command.
+
+> Note: for backwards compatibility the old service command is still available in CentOS 7 and it will redirect any command to the new systemctl utility.
+
+### Start/Stop/Restart Services with systemctl ###
+
+To start a service with systemctl you will need to use the command like this:
+
+ # systemctl start httpd.service
+
+This will start the httpd service, in our case Apache HTTP Server.
+
+To stop it use this command as root:
+
+ # systemctl stop httpd.service
+
+To restart you can use either the restart options, it will restart the service if it’s running or start it if it’s not running. You can also use the try-restart option that will restart the service only if it’s already running. Also you have the reload option that will reload the configuration files.
+
+ # systemctl restart httpd.service
+ # systemctl try-restart httpd.service
+ # systemctl reload httpd.service
+
+The commands in our example look like this:
+
+
+
+### Checking the status of a service ###
+
+To check the status of a service you can use the status option like this:
+
+ # systemctl status httpd.service
+
+And the output should look like this:
+
+
+
+Informing you of various aspects of the running service.
+
+### Enable / Disable services to run at boot time ###
+
+You can also use the enable / disable options to make a service run at boot time, using the command like this:
+
+ # systemctl enable httpd.service
+ # systemctl disable httpd.service
+
+The output looks like this:
+
+
+
+Although the adoption of systemd has been very controversial in the last few years, slowly most of the major Linux distributions have either adopted or are planning to have it in the next point release, so it’s a useful tool to get used to.
+
+--------------------------------------------------------------------------------
+
+via: http://linoxide.com/linux-command/start-stop-services-systemd/
+
+作者:[Adrian Dinu][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://linoxide.com/author/adriand/
\ No newline at end of file
diff --git a/sources/tech/20140821 How to configure a network printer and scanner on Ubuntu desktop.md b/sources/tech/20140821 How to configure a network printer and scanner on Ubuntu desktop.md
new file mode 100644
index 0000000000..0703a11d9a
--- /dev/null
+++ b/sources/tech/20140821 How to configure a network printer and scanner on Ubuntu desktop.md
@@ -0,0 +1,200 @@
+How to configure a network printer and scanner on Ubuntu desktop
+================================================================================
+In a [previous article][1](注:这篇文章在2014年8月12号的原文里做过,不知道翻译了没有,如果翻译发布了,发布此文章的时候可改成翻译后的链接), we discussed how to install several kinds of printers (and also a network scanner) in a Linux server. Today we will deal with the other end of the line: how to access the network printer/scanner devices from a desktop client.
+
+### Network Environment ###
+
+For this setup, our server's (Debian Wheezy 7.2) IP address is 192.168.0.10, and our client's (Ubuntu 12.04) IP address is 192.168.0.105. Note that both boxes are on the same network (192.168.0.0/24). If we want to allow printing from other networks, we need to modify the following section in the cupsd.conf file on the sever:
+
+
+ Order allow,deny
+ Allow localhost
+ Allow from XXX.YYY.ZZZ.*
+
+
+(in the above example, we grant access to the printer from localhost and from any system whose IPv4 address starts with XXX.YYY.ZZZ)
+
+To verify which printers are available on our server, we can either use lpstat command on the server, or browse to the https://192.168.0.10:631/printers page.
+
+ root@debian:~# lpstat -a
+
+----------
+
+ EPSON_Stylus_CX3900 accepting requests since Mon 18 Aug 2014 10:49:33 AM WARST
+ PDF accepting requests since Mon 06 May 2013 04:46:11 PM WARST
+ SamsungML1640Series accepting requests since Wed 13 Aug 2014 10:13:47 PM WARST
+
+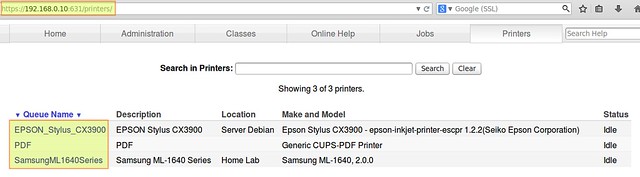
+
+### Installing Network Printers in Ubuntu Desktop ###
+
+In our Ubuntu 12.04 client, we will open the "Printing" menu (Dash -> Printing). Note that in other distributions the name may differ a little (such as "Printers" or "Print & Fax", for example):
+
+
+
+No printers have been added to our Ubuntu client yet:
+
+
+
+Here are the steps to install a network printer on Ubuntu desktop client.
+
+**1)** The "Add" button will fire up the "New Printer" menu. We will choose "Network printer" -> "Find Network Printer" and enter the IP address of our server, then click "Find":
+
+
+
+**2)** At the bottom we will see the names of the available printers. Let's choose the Samsung printer and press "Forward":
+
+
+
+**3)** We will be asked to fill in some information about our printer. When we're done, we'll click on "Apply":
+
+
+
+**4)** We will then be asked whether we want to print a test page. Let’s click on "Print test page":
+
+
+
+The print job was created with local id 2:
+
+
+
+5) Using our server's CUPS web interface, we can observe that the print job has been submitted successfully (Printers -> SamsungML1640Series -> Show completed jobs):
+
+
+
+We can also display this same information by running the following command on the printer server:
+
+ root@debian:~# cat /var/log/cups/page_log | grep -i samsung
+
+----------
+
+ SamsungML1640Series root 27 [13/Aug/2014:22:15:34 -0300] 1 1 - localhost Test Page - -
+ SamsungML1640Series gacanepa 28 [18/Aug/2014:11:28:50 -0300] 1 1 - 192.168.0.105 Test Page - -
+ SamsungML1640Series gacanepa 29 [18/Aug/2014:11:45:57 -0300] 1 1 - 192.168.0.105 Test Page - -
+
+The page_log log file shows every page that has been printed, along with the user who sent the print job, the date & time, and the client's IPv4 address.
+
+To install the Epson inkjet and PDF printers, we need to repeat steps 1 through 5, and choose the right print queue each time. For example, in the image below we are selecting the PDF printer:
+
+
+
+However, please note that according to the [CUPS-PDF documentation][2], by default:
+
+> PDF files will be placed in subdirectories named after the owner of the print job. In case the owner cannot be identified (i.e. does not exist on the server) the output is placed in the directory for anonymous operation (if not disabled in cups-pdf.conf - defaults to /var/spool/cups-pdf/ANONYMOUS/).
+
+These default directories can be modified by changing the value of the **Out** and **AnonDirName** variables in the /etc/cups/cups-pdf.conf file. Here, ${HOME} is expanded to the user's home directory:
+
+ Out ${HOME}/PDF
+ AnonDirName /var/spool/cups-pdf/ANONYMOUS
+
+### Network Printing Examples ###
+
+#### Example #1 ####
+
+Printing from Ubuntu 12.04, logged on locally as gacanepa (an account with the same name exists on the printer server).
+
+
+
+After printing to the PDF printer, let's check the contents of the /home/gacanepa/PDF directory on the printer server:
+
+ root@debian:~# ls -l /home/gacanepa/PDF
+
+----------
+
+ total 368
+ -rw------- 1 gacanepa gacanepa 279176 Aug 18 13:49 Test_Page.pdf
+ -rw------- 1 gacanepa gacanepa 7994 Aug 18 13:50 Untitled1.pdf
+ -rw------- 1 gacanepa gacanepa 74911 Aug 18 14:36 Welcome_to_Conference_-_Thomas_S__Monson.pdf
+
+The PDF files are created with permissions set to 600 (-rw-------), which means that only the owner (gacanepa in this case) can have access to them. We can change this behavior by editing the value of the **UserUMask** variable in the /etc/cups/cups-pdf.conf file. For example, a umask of 0033 will cause the PDF printer to create files with all permissions for the owner, but read-only privileges to all others.
+
+ root@debian:~# grep -i UserUMask /etc/cups/cups-pdf.conf
+
+----------
+
+ ### Key: UserUMask
+ UserUMask 0033
+
+For those unfamiliar with umask (aka user file-creation mode mask), it acts as a set of permissions that can be used to control the default file permissions that are set for new files when they are created. Given a certain umask, the final file permissions are calculated by performing a bitwise boolean AND operation between the file base permissions (0666) and the unary bitwise complement of the umask. Thus, for a umask set to 0033, the default permissions for new files will be NOT (0033) AND 0666 = 644 (read / write / execute privileges for the owner, read-only for all others.
+
+### Example #2 ###
+
+Printing from Ubuntu 12.04, logged on locally as jdoe (an account with the same name doesn't exist on the server).
+
+
+
+ root@debian:~# ls -l /var/spool/cups-pdf/ANONYMOUS
+
+----------
+
+ total 5428
+ -rw-rw-rw- 1 nobody nogroup 5543070 Aug 18 15:57 Linux_-_Wikipedia__the_free_encyclopedia.pdf
+
+The PDF files are created with permissions set to 666 (-rw-rw-rw-), which means that everyone has access to them. We can change this behavior by editing the value of the **AnonUMask** variable in the /etc/cups/cups-pdf.conf file.
+
+At this point, you may be wondering about this: Why bother to install a network PDF printer when most (if not all) current Linux desktop distributions come with a built-in "Print to file" utility that allows users to create PDF files on-the-fly?
+
+There are a couple of benefits of using a network PDF printer:
+
+- A network printer (of whatever kind) lets you print directly from the command line without having to open the file first.
+- In a network with other operating system installed on the clients, a PDF network printer spares the system administrator from having to install a PDF creator utility on each individual machine (and also the danger of allowing end-users to install such tools).
+- The network PDF printer allows to print directly to a network share with configurable permissions, as we have seen.
+
+### Installing a Network Scanner in Ubuntu Desktop ###
+
+Here are the steps to installing and accessing a network scanner from Ubuntu desktop client. It is assumed that the network scanner server is already up and running as described [here][3].
+
+**1)** Let us first check whether there is a scanner available on our Ubuntu client host. Without any prior setup, you will see the message saying that "No scanners were identified."
+
+ $ scanimage -L
+
+
+
+**2)** Now we need to enable saned daemon which comes pre-installed on Ubuntu desktop. To enable it, we need to edit the /etc/default/saned file, and set the RUN variable to yes:
+
+ $ sudo vim /etc/default/saned
+
+----------
+
+ # Set to yes to start saned
+ RUN=yes
+
+**3)** Let's edit the /etc/sane.d/net.conf file, and add the IP address of the server where the scanner is installed:
+
+
+
+**4)** Restart saned:
+
+ $ sudo service saned restart
+
+**5)** Let's see if the scanner is available now:
+
+
+
+Now we can open "Simple Scan" (or other scanning utility) and start scanning documents. We can rotate, crop, and save the resulting image:
+
+
+
+### Summary ###
+
+Having one or more network printers and scanner is a nice convenience in any office or home network, and offers several advantages at the same time. To name a few:
+
+- Multiple users (connecting from different platforms / places) are able to send print jobs to the printer's queue.
+- Cost and maintenance savings can be achieved due to hardware sharing.
+
+I hope this article helps you make use of those advantages.
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/08/configure-network-printer-scanner-ubuntu-desktop.html
+
+作者:[Gabriel Cánepa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/gabriel
+[1]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html
+[2]:http://www.cups-pdf.de/documentation.shtml
+[3]:http://xmodulo.com/2014/08/usb-network-printer-and-scanner-server-debian.html#scanner
\ No newline at end of file
diff --git a/sources/tech/20140821 How to sniff HTTP traffic from the command line on Linux.md b/sources/tech/20140821 How to sniff HTTP traffic from the command line on Linux.md
new file mode 100644
index 0000000000..69d3402043
--- /dev/null
+++ b/sources/tech/20140821 How to sniff HTTP traffic from the command line on Linux.md
@@ -0,0 +1,103 @@
+How to sniff HTTP traffic from the command line on Linux
+================================================================================
+Suppose you want to sniff live HTTP web traffic (i.e., HTTP requests and responses) on the wire for some reason. For example, you may be testing experimental features of a web server. Or you may be debugging a web application or a RESTful service. Or you may be trying to troubleshoot [PAC (proxy auto config)][1] or check for any malware files surreptitiously downloaded from a website. Whatever the reason is, there are cases where HTTP traffic sniffing is helpful, for system admins, developers, or even end users.
+
+While [packet sniffing tools][2] such as tcpdump are popularly used for live packet dump, you need to set up proper filtering to capture HTTP traffic, and even then, their raw output typically cannot be interpreted on the HTTP protocol level so easily. Real-time web server log parsers such as [ngxtop][3] provide human-readable real-time web traffic traces, but only applicable with a full access to live web server logs.
+
+What will be nice is to have tcpdump-like traffic sniffing tool, but targeting HTTP traffic only. In fact, [httpry][4] is extactly that: **HTTP packet sniffing tool**. httpry captures live HTTP packets on the wire, and displays their content at the HTTP protocol level in a human-readable format. In this tutorial, let's see how we can sniff HTTP traffic with httpry.
+
+### Install httpry on Linux ###
+
+On Debian-based systems (Ubuntu or Linux Mint), httpry is not available in base repositories. So build it from the source:
+
+ $ sudo apt-get install gcc make git libpcap0.8-dev
+ $ git clone https://github.com/jbittel/httpry.git
+ $ cd httpry
+ $ make
+ $ sudo make install
+
+On Fedora, CentOS or RHEL, you can install httpry with yum as follows. On CentOS/RHEL, enable [EPEL repo][5] before running yum.
+
+ $ sudo yum install httpry
+
+If you still want to build httpry from the source, you can easily do that by:
+
+ $ sudo yum install gcc make git libpcap-devel
+ $ git clone https://github.com/jbittel/httpry.git
+ $ cd httpry
+ $ make
+ $ sudo make install
+
+### Basic Usage of httpry ###
+
+The basic use case of httpry is as follows.
+
+ $ sudo httpry -i
+
+httpry then listens on a specified network interface, and displays captured HTTP requests/responses in real time.
+
+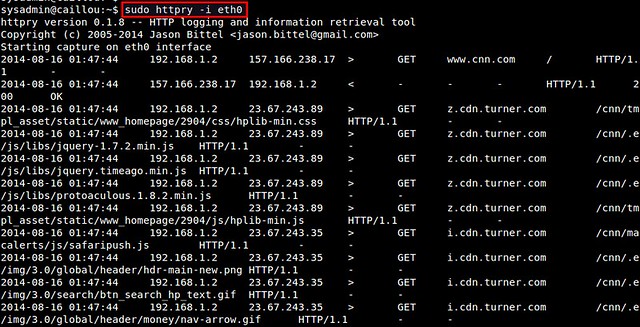
+
+In most cases, however, you will be swamped with the fast scrolling output as packets are coming in and out. So you want to save captured HTTP packets for offline analysis. For that, use either '-b' or '-o' options. The '-b' option allows you to save raw HTTP packets into a binary file as is, which then can be replayed with httpry later. On the other hand, '-o' option saves human-readable output of httpry into a text file.
+
+To save raw HTTP packets into a binary file:
+
+ $ sudo httpry -i eth0 -b output.dump
+
+To replay saved HTTP packets:
+
+ $ httpry -r output.dump
+
+Note that when you read a dump file with '-r' option, you don't need root privilege.
+
+To save httpr's output to a text file:
+
+ $ sudo httpry -i eth0 -o output.txt
+
+### Advanced Usage of httpry ###
+
+If you want to monitor only specific HTTP methods (e.g., GET, POST, PUT, HEAD, CONNECT, etc), use '-m' option:
+
+ $ sudo httpry -i eth0 -m get,head
+
+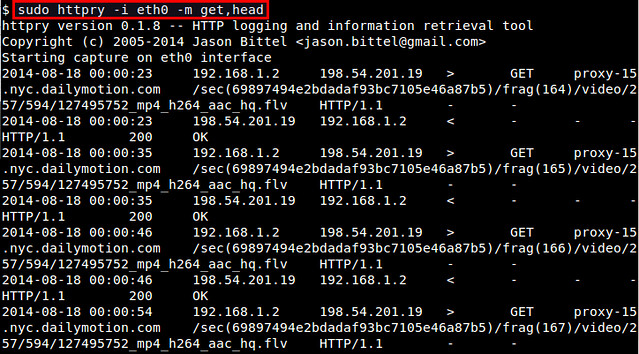
+
+If you downloaded httpry's source code, you will notice that the source code comes with a collection of Perl scripts which aid in analyzing httpry's output. These scripts are found in httpry/scripts/plugins directory. If you want to write a custom parser for httpry's output, these scripts can be good examples to start from. Some of their capabilities are:
+
+- **hostnames**: Displays a list of unique host names with counts.
+- **find_proxies**: Detect web proxies.
+- **search_terms**: Find and count search terms entered in search services.
+- **content_analysis**: Find URIs which contain specific keywords.
+- **xml_output**: Convert output into XML format.
+- **log_summary**: Generate a summary of log.
+- **db_dump**: Dump log file data into a database.
+
+Before using these scripts, first run httpry with '-o' option for some time. Once you obtained the output file, run the scripts on it at once by using this command:
+
+ $ cd httpry/scripts
+ $ perl parse_log.pl -d ./plugins
+
+You may encounter warnings with several plugins. For example, db_dump plugin may fail if you haven't set up a MySQL database with DBI interface. If a plugin fails to initialize, it will automatically be disabled. So you can ignore those warnings.
+
+After parse_log.pl is completed, you will see a number of analysis results (*.txt/xml) in httpry/scripts directory. For example, log_summary.txt looks like the following.
+
+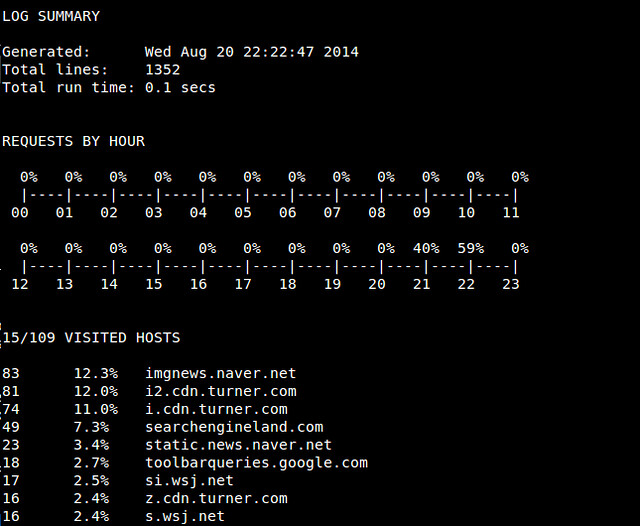
+
+To conclude, httpry can be a life saver if you are in a situation where you need to interpret live HTTP packets. That might not be so common for average Linux users, but it never hurts to be prepared. What do you think of this tool?
+
+--------------------------------------------------------------------------------
+
+via: http://xmodulo.com/2014/08/sniff-http-traffic-command-line-linux.html
+
+作者:[Dan Nanni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://xmodulo.com/author/nanni
+[1]:http://xmodulo.com/2012/12/how-to-set-up-proxy-auto-config-on-ubuntu-desktop.html
+[2]:http://xmodulo.com/2012/11/what-are-popular-packet-sniffers-on-linux.html
+[3]:http://xmodulo.com/2014/06/monitor-nginx-web-server-command-line-real-time.html
+[4]:http://dumpsterventures.com/jason/httpry/
+[5]:http://xmodulo.com/2013/03/how-to-set-up-epel-repository-on-centos.html
\ No newline at end of file
diff --git a/translated/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md b/translated/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md
new file mode 100644
index 0000000000..1010004f2d
--- /dev/null
+++ b/translated/news/20140722 Budgie Desktop 5.1 Is a Superb New Desktop Environment for Conservative Users.md
@@ -0,0 +1,42 @@
+Budgie桌面5.1 对保守的用户来说是一个极好的新桌面环境
+================================================================================
+
+
+**Evolve OS的开发者Ikey Doherty,制作了这款叫做Budgie Desktop的新桌面环境并且发布了它的新版本。**
+
+Evolve OS还没有发布,但开发者正积极地进行关于它的工作。系统中并没有采用一个现有的桌面环境,他决定最好还是制作一个自己的。这个桌面基于GNOME并用了不少GNOME的包,但它看起来却截然不同。事实上,它使用了与MATE和Cinnamon桌面相同的模式,尽管Budgie似乎更有现代感更优美一些。
+
+有趣的是,桌面这个关键的技术部分却先于其将要服务的操作系统发布了,但是潜在的用户完全不必惊讶。由此也出现了可用于Ubuntu 14.04 LTS 和Ubuntu 14.10的[PPA][1],但这不是官方的。Arch Linux用户也将还会在AUR库中发现新的桌面环境。
+
+“从V4版本以来,几乎所有的改变都与面板有关。它已被使用Vala语言重写,这降低了维护开销也大大降低了新贡献者进入的门槛。所以,如果你使用OBS的话,当你于(希望是)今天在OBS上获取到更新,或者对Evolve OS用户,你已经安装了更新,你将只能感觉到很小的视觉差异。我的想法是不去改变外观,而是重写代码来使它更好些。”
+
+“将它重写成Vala语言的程序付出了很多努力,但马上就会见到成效。将来桌面整个都将会用Vala重写,成为‘第二次写’——第二次我们会做的更好”Ikey Doherty在发布[公告][2]中这样说。
+
+虽然这个桌面环境看起来已经很好了,但从版本号码可以看出,还是有很多的提升空间。开发者承诺,下一个版本6.x系列,将允许用户使用任何libpeas支持的语言编写插件,其中语言包括C,Vala,JavaScript和Python。
+
+用户还会注意到,Budgie桌面的一些主要元素仍然保持原样,像菜单的位置以及图标的大小。将来,有可能可以去改变它们,但现在,用户需要关心的是哪些是可用的。
+
+即使在这个初期阶段,Budgie桌面5.1看起来也要比那些可以在其他操作系统上找到的很多可选的桌面要好。
+
+立即下载支持Ubuntu和Arch Linux的源代码包
+
+- [GIT 源代码][3][sources] [0 KB]
+- [Ubuntu 14.04 PPA 库][4][ubuntu_deb] [0 KB]
+- [Arch Linux 二进制包][5][binary] [0 KB]
+
+--------------------------------------------------------------------------------
+
+via: http://news.softpedia.com/news/Budgie-Desktop-5-1-Is-a-Superb-New-Desktop-Environment-For-Conservative-Users-451477.shtml
+
+原文作者:[Silviu Stahie][a]
+
+译者:[linuhap](https://github.com/linuhap) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://news.softpedia.com/editors/browse/silviu-stahie
+[1]:https://launchpad.net/~sukso96100/+archive/ubuntu/budgie-desktop
+[2]:https://evolve-os.com/2014/07/20/budgie-desktop-v5-1-released/
+[3]:https://github.com/evolve-os/budgie-desktop/
+[4]:https://launchpad.net/~sukso96100/+archive/ubuntu/budgie-desktop?field.series_filter=trusty
+[5]:https://aur.archlinux.org/packages/budgie-desktop-git
\ No newline at end of file
diff --git a/translated/tech/20140702 How to install Raspberry Pi camera board.md b/translated/tech/20140702 How to install Raspberry Pi camera board.md
deleted file mode 100644
index 3ce4315ad5..0000000000
--- a/translated/tech/20140702 How to install Raspberry Pi camera board.md
+++ /dev/null
@@ -1,105 +0,0 @@
-如何安装树莓派摄像头模块
-==============================================================================
-[树莓派摄像头模块(Pi Cam)][1]发售于2013年5月。在首发时,Pi Cam配备了500万像素的传感器,通过排线链接树莓派上的CSI接口。第二次发布时,Pi Cam改名为[Pi NoIR][2]并配备了相同的传感器,不同之处在于第二版摄像头模块没有红外线过滤装置。因此使用第二版的摄像头模块可以观测到近红外线的波长(700 - 1000 nm),如同一个安全监控摄像机一样,当然实现红外线的感应牺牲了传感器的显色性。
-
-本文将会展示**如何在[树莓派][3]上安装摄像头模块**。我们会使用第一版摄像头模块来演示。在安装完摄像头模块之后,你将会使用三个应用来访问这个模块:raspistill, raspiyuv 和raspivid。其中前两个应用用来捕捉图像,第三个应用来捕捉视频。raspistill 工具会生成标准的图片文件例如 .jpg 图像,但是 raspiyuv 可以通过摄像头生成未处理的 raw 图像文件。
-
-### 安装树莓派摄像头模块 ###
-
-按照以下指示来安装树莓派摄像头模块:
-
-1. 找到 CSI 接口(CSI接口在以太网接口旁边),掀起深色胶带。
-
-2. 拉起 CSI 接口挡板。
-
-3. 将摄像头模块贴在透镜上的塑料保护膜撕掉。确保黄色部分的PCB(有字的一面)是安装完美的。
-
-4. 将排线插入CSI接口。记住,有蓝色胶带的一面应该面向以太网接口方向。在检查排线安装好了之后,将挡板拉下。
-
-
-
-好了,现在你的 Pi Cam 已经准备就绪来拍摄相片以及视频了。
-
-### 在树莓派上启用摄像头模块 ###
-
-在安装完摄像头模块之后,确认你已经升级了树莓派系统并应用了最新的固件。输入以下命令来更新:
-
- $ sudo apt-get update
- $ sudo apt-get upgrade
-
-运行树莓派配置工具来激活摄像头模块:
-
- $ sudo raspi-config
-
-移动光标至菜单中的 "Enable Camera",确认启用。完成之后重启树莓派。
-
-
-
-
-
-
-
-安装完摄像头模块后的完成照:
-
-
-
-### 通过摄像头模块拍照 ###
-
-在重启完树莓派后,我们就可以使用它了。输入以下命令通过摄像头模块拍摄照片:
-
- $ raspistill -o keychain.jpg -t 2000
-
-这句命令会在执行 2000ms 之后捕捉图像。然后保存为 keychain.jpg。下面是一张由 下面是一张由 Pi Cam 拍摄的钥匙链。
-
-
-
-raspivid 工具用法差不多,从命令行运行 raspivid 工具。下面这句命令会按照默认配置(5秒,分辨率1920x1080,比特率 17Mbps)拍摄一段视频。
-
- $ raspivid -o mykeychain.h264
-
-如果你想改变拍摄时长,只要通过 "-t" 选项来设置长度就行了。
-
- $ raspivid -o mykeychain.h264 -t 10000
-
-使用 "-w" 和 "-h" 选项将分辨率降为 1280x720...
-
- $ raspivid -o mykeychain.h264 -t 10000 -w 1280 -h 720
-
-raspivid 的输出是一段未压缩的 H.264 视频流,而且这段视频没有声音。因此这段视频需要转换在能被通常的视频播放器所播放。使用 gpac 包中所带有的 MP4Box 应用。
-
-在 Raspbian 上安装 gpac,输入命令:
-
- $ sudo apt-get install -y gpac
-
-然后将这段 raw 的 H.264 格式的视频流转换为30帧每秒的 .mp4 格式视频:
-
- $ MP4Box -fps 30 -add keychain.h264 keychain.mp4
-
-视频长度为10秒,默认分辨率以及比特率。下面是一段通过 Pi Camera 拍摄的一段实例视频。
-
-注:youtube视频地址
-
-
-
-如果想要看到 raspistill, raspiyuv 和 raspivid 的完整命令行选项,直接运行以上命令(不加选项)就行了。
-
-
-----------------
-
-### [Kristophorus Hadiono][a] ###
-
-我是一个 Linux 爱好者。我在日常生活中使用 Linux,甚至在我给学生们教学的时候。我的梦想是成为一名优秀的作家。
-
---------------------------------------------------------------------------------
-
-via: http://xmodulo.com/2014/07/install-raspberry-pi-camera-board.html
-
-译者:[ThomazL](https://github.com/ThomazL) 校对:[校对者id](https://github.com/校对者id)
-
-本文由 [lctt](https://github.com/lctt/translateproject) 原创翻译,[linux中国](http://linux.cn/) 荣誉推出
-
-[1]:http://xmodulo.com/go/picam
-[2]:http://xmodulo.com/go/pinoir
-[3]:http://xmodulo.com/go/raspberrypi
-[a]:http://hadiono.org/blog
-
diff --git a/translated/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md b/translated/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md
new file mode 100644
index 0000000000..dc1b7c3101
--- /dev/null
+++ b/translated/tech/20140714 Test read or write speed of usb and ssd drives with dd command on Linux.md
@@ -0,0 +1,139 @@
+Linux系统中使用 DD 命令测试 USB 和 SSD 硬盘的读写速度
+================================================================================
+### 磁盘驱动器速度 ###
+
+磁盘驱动器的速度是以在一个单位时间内能读写数据量的多少来衡量的。DD 命令是一个简单的命令行工具,它可用对磁盘进行任意数据块的读取和写入,同时可以度量读取写入的速度。
+
+在这篇文章中,我们将会使用 DD 命令来测试 USB 和 SSD 磁盘的读取和写入速度。
+
+数据传输速度不但取决于驱动盘本身,而且还与连接的接口有关。比如, USB 2.0 端口的最大传输速度是 35 兆字节/秒,所以如果您把一个支持高速传输的 USB 3.0 驱动盘插入 USB 2.0 端口的话,它实际的传输速度将是 2.0 端口的上下限。
+
+这对于 SSD 也是一样的。 SSD 连接的 SATA 端口有不同的类型。平均是 375 兆字节/秒的 SATA 2.0 端口理论上最大传输速度是 3 Gbit/秒,而 SATA 3.0 是这个速度的两倍。
+
+### 测试方法 ###
+
+挂载上驱动盘,终端上进入此盘目录下。然后使用 DD 命令,首先写入固定大小块的一个文件,接着读取这个文件。
+
+DD 命令通用语法格式如下:
+
+ dd if=path/to/input_file of=/path/to/output_file bs=block_size count=number_of_blocks
+
+当写入到驱动盘的时候,我们简单的从无穷无用字节的源 /dev/zero 读取,当从驱动盘读取的时候,我们读取的是刚才的文件,并把输出结果发送到无用的 /dev/null。在整个操作过程中, DD 命令会跟踪数据传输的速度并且报告出结果。
+
+### 固态硬盘 ###
+
+我们使用的是一块“三星 Evo 120G” 的固态硬盘。它性价比很高,很适合刚开始用固态硬盘的用户,也是我的第一块固态硬盘,并且在市场上表现的也非常不错。
+
+这次实验中,我们把硬盘接在 SATA 2.0 端口上。
+
+#### 写入速度 ####
+
+首先让我们写入固态硬盘
+
+ $ dd if=/dev/zero of=./largefile bs=1M count=1024
+ 1024+0 records in
+ 1024+0 records out
+ 1073741824 bytes (1.1 GB) copied, 4.82364 s, 223 MB/s
+
+的大小实际上是相当大的。你可以尝试用更小的尺寸如 64 K甚至是 4K 的。
+
+#### 读取速度 ####
+
+现在读回这个文件。但是,得首先清除内存的缓存,以确保这个文件确实是从驱动盘读取的。
+
+运行下面的命令来清除内存缓存
+
+ $ sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
+
+现在读取此文件
+
+ $ dd if=./largefile of=/dev/null bs=4k
+ 165118+0 records in
+ 165118+0 records out
+ 676323328 bytes (676 MB) copied, 3.0114 s, 225 MB/s
+
+在 Arch Linux 的维基页上有一整页的关于从同的厂商,如英特尔、三星、Sandisk 等提供的各类固态硬盘的读/写速度的信息。点击如下的 url 可得到得到想着信息。
+
+[https://wiki.archlinux.org/index.php/SSD_Benchmarking][1]
+
+### USB ###
+
+此次实验我们会测量普通的 USB/随身笔的读写速度。驱动盘都是接入标准的 USB 2.0 端口的。首先用的是一个 4GB 大小的 sony USB 驱动盘,随后用的是一个 16GB 大小的 strontium 驱动盘。
+
+首先把驱动盘插入端口,并挂载上,使其可读的。然后从命令行下面进入挂载的文件目录下。
+
+#### Sony 4GB - 写入 ####
+
+这个实验中,用 DD 命令向驱动盘写入一个有 10000 块,每块 8K 字节的文件。
+
+ # dd if=/dev/zero of=./largefile bs=8k count=10000
+ 10000+0 records in
+ 10000+0 records out
+ 81920000 bytes (82 MB) copied, 11.0626 s, 7.4 MB/s
+
+因此,写入速度约为7.5兆字节/秒。这是一个很低的数字。
+
+#### Sony 4GB - 读取 ####
+
+把相同的文件读取回来,测试速度。首先运行如下命令清除内存缓存
+
+ $ sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
+
+现在就可以使用 DD 命令来读取文件了
+
+ # dd if=./largefile of=/dev/null bs=8k
+ 8000+0 records in
+ 8000+0 records out
+ 65536000 bytes (66 MB) copied, 2.65218 s, 24.7 MB/s
+
+读取速度出来大约是25兆字节/秒,这大致跟廉价 USB 驱动盘的标准相匹配吧。
+
+> USB2.0 理论上最大信号传输速率为480兆比特/秒,最小为60兆字节/秒。然而,由于各种限制实际传输速率大约280兆比特/秒和35兆字节/秒之间。除了这个,实际的速度还取决于驱动盘本身的质量好坏以及其他的因素。
+
+上面实验中, USB 驱动盘插入USB 2.0 端口,读取的速度达到了 24.7兆字节/秒,这是很不错的读速度。但写入速度就不敢恭维了。
+
+下面让我们用 Strontium 的 16GB 的驱动盘来做相同的实验。虽然 Strontium 的 USB 驱动盘很稳定,但它也是一款很便宜的品牌。
+
+#### Strontium 16gb 盘写入速度 ####
+
+ # dd if=/dev/zero of=./largefile bs=64k count=1000
+ 1000+0 records in
+ 1000+0 records out
+ 65536000 bytes (66 MB) copied, 8.3834 s, 7.8 MB/s
+
+#### Strontium 16gb 盘读取速度 ####
+
+ # sudo sh -c "sync && echo 3 > /proc/sys/vm/drop_caches"
+
+ # dd if=./largefile of=/dev/null bs=8k
+ 8000+0 records in
+ 8000+0 records out
+ 65536000 bytes (66 MB) copied, 2.90366 s, 22.6 MB/s
+
+它的读取速度就要比 Sony 的低了。
+
+### 参考资料 ###
+
+- [http://en.wikipedia.org/wiki/USB][2]
+- [https://wiki.archlinux.org/index.php/SSD_Benchmarking][1]
+
+----------
+
+
+
+关于 Silver Moon
+
+Php 开发者, 博主 和 Linux 爱好者. 通过 [m00n.silv3r@gmail.com][e] 或者 [Google+][g] 可联系到他。
+
+--------------------------------------------------------------------------------
+
+via: http://www.binarytides.com/linux-test-drive-speed/
+
+译者:[runningwater](https://github.com/runningwater) 校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[1]:http://wiki.archlinux.org/index.php/SSD_Benchmarking
+[2]:http://en.wikipedia.org/wiki/USB
+[e]:m00n.silv3r@gmail.com
+[g]:http://plus.google.com/117145272367995638274/posts
\ No newline at end of file
diff --git a/translated/tech/20140807 Linux FAQs with Answers--How to fix 'fatal error--jsoncpp or json or json.h--No such file or directory'.md b/translated/tech/20140807 Linux FAQs with Answers--How to fix 'fatal error--jsoncpp or json or json.h--No such file or directory'.md
index b68e101c09..888927b7cb 100644
--- a/translated/tech/20140807 Linux FAQs with Answers--How to fix 'fatal error--jsoncpp or json or json.h--No such file or directory'.md
+++ b/translated/tech/20140807 Linux FAQs with Answers--How to fix 'fatal error--jsoncpp or json or json.h--No such file or directory'.md
@@ -16,7 +16,7 @@ Linux常见问题与答案——如何修复“fatal error: jsoncpp/json/json.h:
$ sudo yum install jsoncpp-devel
-在CentOS上,没有JsonCpp的预编译包。因此你可以通过以下方法从源码构建一个JsonCpp包并安装。
+在CentOS上,没有JsonCpp的预编译包。因此你可以通过以下源码构建一个JsonCpp包并安装。
$ sudo yum install cmake
$ git clone https://github.com/open-source-parsers/jsoncpp.git
@@ -32,7 +32,7 @@ Linux常见问题与答案——如何修复“fatal error: jsoncpp/json/json.h:
via: http://ask.xmodulo.com/fix-fatal-error-jsoncpp.html
译者:[GOLinux](https://github.com/GOLinux)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20140808 Check Hard drive for bad sectors or bad blocks in linux.md b/translated/tech/20140808 Check Hard drive for bad sectors or bad blocks in linux.md
index d4dcbb7d5a..31c51c2938 100644
--- a/translated/tech/20140808 Check Hard drive for bad sectors or bad blocks in linux.md
+++ b/translated/tech/20140808 Check Hard drive for bad sectors or bad blocks in linux.md
@@ -1,10 +1,10 @@
-检查linux中的损坏的扇区和区块
+检查linux中硬盘损坏的扇区和区块
================================================================================
**badblocks**是linux及其类似的操作系统中,扫描检查硬盘和外部设备损坏扇区的命令工具。损坏的扇区或者损坏的区块是硬盘中因为永久损坏或者是操作系统不能读取的空间。
-Badblocks命令可以探测硬盘中所有损坏的扇区或者区块并将结果保存在一个文本文档中,这样,我们就可以使用**e2fsck**命令来配置操作系统不在这些损坏的扇区中存储。
+Badblocks命令可以探测硬盘中所有损坏的扇区或者区块并将结果保存在一个文本文档中,这样,我们就可以使用**e2fsck**命令来配置操作系统不在这些损坏的扇区中存储数据。
-### 步骤:1 使用fdisk识别硬盘信息 ###
+### 步骤:1 使用fdisk命令识别硬盘信息 ###
# sudo fdisk -l
@@ -12,13 +12,13 @@ Badblocks命令可以探测硬盘中所有损坏的扇区或者区块并将结
# sudo badblocks -v /dev/sdb > /tmp/bad-blocks.txt
-只需将“/dev/sdb”替换为自己机器的/分区。执行完成上述命令后,一个名为“bad-blocks”文本文档将会在/tmp下创建,它将包含所有的损坏区块。
+只需将“/dev/sdb”替换为自己机器的硬盘/分区。执行完成上述命令后,一个名为“bad-blocks”文本文档将会在/tmp下创建,它将包含所有的损坏区块。
例如:

-### 步骤:3 告诉操作系统不要使用损坏区块存储 ###
+### 步骤:3 提示 操作系统不要使用损坏区块存储 ###
扫描完成后,如果损坏区块被发现了,然后通过e2fsck命令使用“bad-blocks.txt”,强迫操作系统不使用这些损坏的区块存储数据。
@@ -37,7 +37,7 @@ via: http://www.linuxtechi.com/check-hard-drive-for-bad-sector-linux/
作者:[Pradeep Kumar][a]
译者:[Vic___](http://www.vicyu.net)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Caroline](https://github.com/carolinewuyan)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
diff --git a/translated/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md b/translated/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md
new file mode 100644
index 0000000000..4013367d2f
--- /dev/null
+++ b/translated/tech/20140813 How to Extend or Reduce LVM' s (Logical Volume Management) in Linux--Part II.md
@@ -0,0 +1,292 @@
+在Linux中扩展/缩减LVM(逻辑卷管理)—— 第二部分
+================================================================================
+
+前面我们已经了解了怎样使用LVM创建弹性的磁盘存储。这里,我们将了解怎样来扩展卷组,扩展和缩减逻辑卷。在这里,我们可以缩减或者扩展逻辑卷管理(LVM)中的分区,LVM也可称之为弹性卷文件系统。
+
+
+
+### 需求 ###
+
+- [使用LVM创建弹性磁盘存储——第一部分][1]
+注:两篇都翻译完了的话,发布的时候将这个链接做成发布的中文的文章地址
+
+#### 什么时候我们需要缩减卷? ####
+
+或许我们需要创建一个独立的分区用于其它用途,或者我们需要扩展任何空间低的分区。真是这样的话,我们可以很容易地缩减大尺寸的分区,并且扩展空间低的分区,只要按下面几个简易的步骤来即可。
+
+#### 我的服务器设置 —— 需求 ####
+
+- 操作系统 – 安装有LVM的CentOS 6.5
+- 服务器IP – 192.168.0.200
+
+### 如何扩展卷组以及缩减逻辑卷 ###
+
+#### 逻辑卷扩展 ####
+
+目前,我们已经有一个PV,VG和2个LV。让我们用下面的命令来列出它们。
+
+ # pvs
+ # vgs
+ # lvs
+
+
+
+逻辑卷扩展
+
+在物理卷和卷组中没有空闲空间可用了,所以,现在我们不能扩展逻辑卷的大小。要扩展,我们需要添加一个物理卷(**PV**),然后通过扩展**vg**来扩展卷组,这样我们就会得到足够大的空间来扩展逻辑卷大小了。所以,首先我们应该去添加一个物理卷。
+
+要添加一个新**PV**,我们必须使用fdisk来创建一个LVM分区。
+
+ # fdisk -cu /dev/sda
+
+- 选择**n**来创建新分区。
+- 选择**p**来创建主分区。
+- 选择我们需要创建的分区号。
+- 如果有其它可用磁盘,请按**1**。
+- 使用**t**来修改分区类型。
+- 输入**8e**来将分区类型修改为Linux LVM。
+- 使用**p**来打印创建的分区(这里我们没有使用该选项)。
+- 按**w**写入修改。
+
+完成后重启系统。
+
+
+创建LVM分区
+
+使用fdisk列出并检查我们创建的分区。
+
+ # fdisk -l /dev/sda
+
+
+验证LVM分区
+
+接下来,使用下列命令来创建新**PV**(物理卷)。
+
+ # pvcreate /dev/sda1
+
+使用下面的命令来验证pv。
+
+ # pvs
+
+
+
+创建物理卷
+
+#### 扩展卷组 ####
+
+添加该pv到**vg_tecmint**卷组来扩展卷组的大小,以获取更多空间来扩展**lv**。
+
+ # vgextend vg_tecmint /dev/sda1
+
+让我们检查现在正在使用的卷组的大小。
+
+ # vgs
+
+
+
+扩展卷组
+
+我们甚至可以看到哪个**PV**用于创建使用中的特定卷组。
+
+ # pvscan
+
+
+检查卷组
+
+这里,我们可以看到卷组所处的物理卷。我们已经添加了一个pv,而且它完全空着。在扩展逻辑卷之前,让我们先看看我们所拥有的各个卷组的大小。
+
+
+
+检查所有逻辑卷
+
+- LogVol00用于Swap。
+- LogVol01用于/。
+- 现在我们有16.50GB大小的空间用于/(root)。
+- 当前有4226物理扩展(PE)可用。
+
+现在,我们打算去扩展/分区**LogVol01**。在扩展后,我们可以像上面那样列出它的大小以确认。我们能可以使用GB或PE来扩展,这一点我已经在LVM第一部分解释过了,这里我使用PE来扩展。
+
+要获取可用的物理扩展大小,运行以下命令。
+
+ # vgdisplay
+
+
+
+检查可用的物理扩展
+
+总共有**4607**空闲PE可用,亦即有**18GB**空间空间可用。因此,我们可以将我们的逻辑卷扩展到**18GB**这么大。让我们使用PE大小来扩展。
+
+ # lvextend -l +4607 /dev/vg_tecmint/LogVol01
+
+使用**+**来添加更多空间。在扩展后,我们需要改变文件系统大小,使用以下命令。
+
+ # resize2fs /dev/vg_tecmint/LogVol01
+
+
+扩展逻辑卷
+
+- 用来使用物理扩展扩展逻辑卷的命令。
+- 这里我们可以看到它从16.51GB扩展到了34GB。
+- 如果文件系统已被挂载并处于使用中,改变文件系统大小。
+- 要扩展逻辑卷,我们不需要卸载文件系统
+
+现在,让我们看看当前使用的改变大小后的逻辑卷。
+
+ # lvdisplay
+
+
+
+改变逻辑卷大小
+
+- LogVol01用于扩展的卷 /。
+- 扩展后,从16.50GB上升到了34.50GB。
+- C当前扩展,在扩展前有4226,我们已经添加了4607个扩展,因此现在有8833。
+
+现在,如果我们检查可用的vg的话,空闲PE将会是0。
+
+ # vgdisplay
+
+查看扩展的结果。
+
+ # pvs
+ # vgs
+ # lvs
+
+
+
+验证分区大小改变
+
+- 添加的新物理卷。
+- 卷组vg_tecmint从17.51GB扩展到了35.50GB。
+- 逻辑卷LogVol01从16.51GB扩展到了34.50GB。
+
+这里,我们已经完成扩展卷组和逻辑卷的过程。让我们一起迈向逻辑卷管理中一些有趣的部分。
+
+#### 缩减逻辑卷(LVM) ####
+
+这里,我们将了解如何缩减逻辑卷。人人都说它很危险,在缩减lvm的时候可能会导致灾难。缩减lvm在逻辑卷管理中比其它部分要来得确实有趣得多。
+
+- 在开始之前,备份好数据总是对的,这样如果出错,就不会头痛了。
+- 要缩减逻辑卷,需要小心翼翼地完成5个步骤。
+- 在扩展一个卷的时候,我们可以在该卷挂载时扩展它(在线),但对于缩减,我们必须在缩减前卸载文件系统。
+
+让我们来了解一下下面这5个步骤。
+
+- 卸载文件系统以便缩减。
+- 在卸载后检查文件系统。
+- 缩减文件系统。
+- 5减少当前逻辑卷大小。
+- 再检查文件系统以防出错。
+- 将文件系统再次挂载回去。
+
+为了演示,我已经创建了独立的卷组和逻辑卷。这里,我将缩减逻辑卷**tecmint_reduce_test**。现在它有18GB大小,我们需要将它缩减到**10GB**而不丢失数据。也就是说,我们需要从**18GB**中减少**8GB**。卷中已经有**4GB**被使用。
+
+ 18GB ---> 10GB
+
+在缩减大小的时候,我们只需要缩减8GB,所以在缩减后它总计会有10GB。
+
+ # lvs
+
+
+缩减逻辑卷
+
+这里,我们可以看到文件系统信息。
+
+ # df -h
+
+
+检查文件系统大小
+
+- 卷大小是18GB。
+- 它已经使用了3.9GB。
+- 可用空间是13GB。
+
+首先,卸载挂载点。
+
+ # umount -v /mnt/tecmint_reduce_test/
+
+
+
+卸载分区
+
+然后,使用以下命令来检查文件系统错误。
+
+ # e2fsck -ff /dev/vg_tecmint_extra/tecmint_reduce_test
+
+
+扫描分区错误
+
+**注意**:必须通过所有文件系统检查的5个步骤,若未完全通过,则你的文件系统可能存在问题。
+
+接下来,缩减文件系统。
+
+ # resize2fs /dev/vg_tecmint_extra/tecmint_reduce_test 8GB
+
+
+缩减文件系统
+
+使用GB来缩减逻辑卷。
+
+ # lvreduce -L -8G /dev/vg_tecmint_extra/tecmint_reduce_test
+
+
+缩减逻辑分区
+
+要使用PE来缩减逻辑卷,我们需要知道默认PE大小和卷组的总PE大小,以进行一次小小的计算来得出准确的缩减大小。
+
+ # lvdisplay vg_tecmint_extra
+
+这里,我们需要使用bc命令来做一些小计算来获得10GB的PE大小。
+
+ 1024MB x 10GB = 10240MB or 10GB
+
+ 10240MB / 4PE = 2048PE
+
+按**CTRL+D**来退出BC。
+
+
+
+计算PE大小
+
+使用PE来缩减大小。
+
+ # lvreduce -l -2048 /dev/vg_tecmint_extra/tecmint_reduce_test
+
+
+使用PE来缩减大小
+
+将文件系统大小调整回去。在这一步中,如果发生任何错误,这就意味着我们已经将文件系统搞乱了。
+
+ # resize2fs /dev/vg_tecmint_extra/tecmint_reduce_test
+
+
+
+将文件系统挂载回同样的挂载点。
+
+ # mount /dev/vg_tecmint_extra/tecmint_reduce_test /mnt/tecmint_reduce_test/
+
+
+挂载文件系统
+
+检查分区和文件的大小。
+
+ # lvdisplay vg_tecmint_extra
+
+这里,我们可以看到最后的结果,逻辑已经被缩减到10GB。
+
+
+
+在本文中,我们已经了解了如何来扩增卷组、逻辑卷以及缩减逻辑卷。在下一部分(第三部分)中,我们将了解如何为逻辑卷做快照并将它恢复到更早的状态。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/extend-and-reduce-lvms-in-linux/
+
+作者:[Babin Lonston][a]
+译者:[GOLinux](https://github.com/GOLinux)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/babinlonston/
+[1]:http://www.tecmint.com/create-lvm-storage-in-linux/
diff --git a/translated/tech/20140818 How To Schedule A Shutdown In Ubuntu 14.04 [Quick Tip].md b/translated/tech/20140818 How To Schedule A Shutdown In Ubuntu 14.04 [Quick Tip].md
new file mode 100644
index 0000000000..7ea6e88bc0
--- /dev/null
+++ b/translated/tech/20140818 How To Schedule A Shutdown In Ubuntu 14.04 [Quick Tip].md
@@ -0,0 +1,42 @@
+如何安排你的Ubuntu 14.04自动关机[快速技巧]
+===
+
+
+
+当你系统还在运行某些程序的时候,无法关闭计算机?但是你又不能让计算机跑个一整夜!可能你会发现你曾面临相似的处境:因为刚刚提到的问题,你需要在Ubuntu或者其余Linux系统下安排计算机关机
+
+在这篇文章中,我们就来看看如何使用GUI或者在CLI下安排你的Ubuntu关机
+
+### 使用EasyShutdown安排你的Ubuntu关机 ###
+
+EasyShutdown是一个轻量级的应用程序,它提供给你简洁的GUI,你可以很容易就能安排你的Ubuntu关机。你可以在[EasyShutdown的launchpad页面下载.deb文件][1]。只要双击它,就可以安装了。默认情况下,它会打开Ubuntu Software Center
+
+安装完成,从Unity Dash启动它。界面非常简单,你只需要提供你想关机的时间就可以了。举个例子:如果你想在03:30 AM关机,像下面那样操作:
+
+
+
+请注意:EasyShutdown并没有后台程序或者系统托盘,所以,你必须让它一直运行,否则将不能正常工作。但EasyShutdown的优点是:它会在你安排关机时间的前一分钟通知你,那样你就可以选择停止它
+
+### 使用命令行安排Ubuntu关机 ###
+
+使用命令行选项来**安排Ubuntu关机**同样很简单。你要做的就是使用“shutdown”命令。举个例子:想在03:30 AM关机,你可以使用下面的命令:
+
+ sudo shutdown -h 03:30
+
+注意,你必须一直运行这个命令。所以要么保持这个终端,要么在后台运行
+
+我希望这些快速技巧可以帮助你们,学会如何安排Ubuntu或者其余Linux系统比如Linux Mint自动关机。欢迎你们提出问题或者建议
+
+---
+
+via: http://itsfoss.com/schedule-shutdown-ubuntu/
+
+作者:[Abhishek][a]
+译者:[su-kaiyao](https://github.com/su-kaiyao)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/Abhishek/
+[1]:https://launchpad.net/easyshutdown
+
diff --git a/translated/tech/20140818 Install Atom Text Editor In Ubuntu 14.04 & Linux Mint 17.md b/translated/tech/20140818 Install Atom Text Editor In Ubuntu 14.04 & Linux Mint 17.md
new file mode 100644
index 0000000000..17cff6a4af
--- /dev/null
+++ b/translated/tech/20140818 Install Atom Text Editor In Ubuntu 14.04 & Linux Mint 17.md
@@ -0,0 +1,56 @@
+在 Ubuntu 14.04 和 Linux Mint 17 上安装 Atom 文本编辑器
+===
+
+
+
+[Atom][1]是[Github][2]上时髦的,功能丰富的开源文本编辑器。目前,它正处于测试阶段,但如果你对它很好奇,那我们就来看看**如何在 Ubuntu 14.04 和 Linux Mint 17 上安装 Atom**
+
+
+
+无论是在外观,还是在功能上,Atom 都有很多与[Sublime Text editor][3]相似之处。Sublime Text editor是一个功能强大,并深受程序员喜爱的跨平台文本编辑器,可惜它是闭源的。事实上,在Sublime Text的灵感下,Atom 并不是唯一即将到来的文本编辑器。[Lime Text][4]是 Sublime Text 的开源克隆,目前正处于开发中。
+
+废话不多说,让我们来看看如何在 Ubuntu 14.04 和 Linux Mint 17 下安装 Atom 编辑器。
+
+### 通过PPA源,在Ubuntu和Linux Mint下安装Atom ###
+
+因为 Atom 正处于测试阶段,截止到我写这篇文章前,还没有 Linux 下的二进制文件。但是不用担心,你不需要亲自去编译这些代码(当然如果你乐意的话,你也可以这么做)。感谢[Webupd8 team’s][5]的努力,我们拥有了一个可以很容易将 Atom 安装在32位和64位系统上的PPA。
+
+打开终端,然后使用下面的命令行:
+
+ sudo add-apt-repository ppa:webupd8team/atom
+ sudo apt-get update
+ sudo apt-get install atom
+
+就这么简单,你可以通过 Ubuntu 下的 Unity Dash 和 Linux Mint 里的应用程序菜单启动 Atom 编辑器。
+
+### 从Ubuntu和Linux Mint卸载Atom ###
+
+可能,你想要从系统中卸载 Atom 的原因有很多种。不稳定可能是主要原因之一。好吧,不管什么原因,我来说下怎么卸载Atom:
+
+ sudo apt-get remove atom
+ sudo add-apt-repository --remove ppa:webupd8team/atom
+
+这些命令会移除 Atom 和 PPA 仓库,运行 auto remove 也是个好方法:
+
+ sudo apt-get autoremove
+
+### 你有哪些使用 Atom 的体验? ###
+
+如果你尝试了Atom,请和我们分享你的体验。你觉的它会成为你最喜欢的文本编辑器吗?
+
+---
+
+via: http://itsfoss.com/install-atom-text-editor-ubuntu-1404-linux-mint-17/
+
+作者:[Abhishek][a]
+译者:[su-kaiyao](https://github.com/su-kaiyao)
+校对:[Caroline](https://github.com/carolinewuyan)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
+
+[a]:http://itsfoss.com/author/Abhishek/
+[1]:https://atom.io/
+[2]:https://github.com/
+[3]:http://www.sublimetext.com/
+[4]:http://itsfoss.com/lime-text-open-source-alternative/
+[5]:https://launchpad.net/~nilarimogard/+archive/ubuntu/webupd8