mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
3dd4e0d28e
@ -2,8 +2,6 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源 : opensource.com
|
||||
|
||||
经过了一整天的Opensource.com[社区版主][1]年会,最后一项日程提了上来,内容只有“特邀嘉宾:待定”几个字。作为[Opensource.com][3]的项目负责人和社区管理员,[Jason Hibbets][2]起身解释道,“因为这个嘉宾有可能无法到场,因此我不想提前说是谁。在几个月前我问他何时有空过来,他给了我两个时间点,我选了其中一个。今天是这三周中Jim唯一能来的一天”。(译者注:Jim是指下文中提到的Jim Whitehurst,即红帽公司总裁兼首席执行官)
|
||||
|
||||
这句话在版主们(Moderators)中引起一阵轰动,他们从世界各地赶来参加此次的[拥抱开源大会(All Things Open Conference)][4]。版主们纷纷往前挪动椅子,仔细聆听。
|
||||
@ -14,7 +12,7 @@
|
||||
|
||||
“大家好!”,这个家伙开口了。他没穿正装,只是衬衫和休闲裤。
|
||||
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版本今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
这时会场中第二高个子的人,红帽全球意识部门(Global Awareness)的高级主管[Jeff Mackanic][5],告诉他大部分社区版主今天都在场,然后让每个人开始作简单的自我介绍。
|
||||
|
||||
“我叫[Jen Wike Huger][6],负责Opensource.com的内容管理,很高兴见到大家。”
|
||||
|
||||
@ -22,13 +20,13 @@
|
||||
|
||||
“我叫[Robin][9],从2013年开始参与版主项目。我在OSDC做了一些事情,工作是在[City of the Hague][10]维护[网站][11]。”
|
||||
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS科学软件的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能加入FOSS和开源科学。”
|
||||
“我叫[Marcus Hanwell][12],来自英格兰,在[Kitware][13]工作。同时,我是FOSS science software的技术总监,和国家实验室在[Titan][14] Z和[Gpu programming][15]方面合作。我主要使用[Gentoo][16]和[KDE][17]。最后,我很激动能参与到FOSS和开源科学。”
|
||||
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
“我叫[Phil Shapiro][18],是华盛顿的一个小图书馆的28个Linux工作站的管理员。我视各位为我的同事。非常高兴能一起交流分享,贡献力量。我主要关注FOSS和自豪感的关系,以及FOSS如何提升自豪感。”
|
||||
|
||||
“我叫[Joshua Holm][19]。我大多数时间都在关注系统更新,以及帮助人们在网上找工作。”
|
||||
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets]和[Mark Bohannon]一起主要关注政府渠道方面。”
|
||||
“我叫[Mel Chernoff][20],在红帽工作,和[Jason Hibbets][22]和[Mark Bohannon][23]一起主要关注[政府][21]渠道方面。”
|
||||
|
||||
“我叫[Scott Nesbitt][24],写过很多东西,使用FOSS很久了。我是个普通人,不是系统管理员,也不是程序员,只希望能更加高效工作。我帮助人们在商业和生活中使用FOSS。”
|
||||
|
||||
@ -38,41 +36,41 @@
|
||||
|
||||
“你在[新FOSS Minor][30]教书?!”,Jim说道,“很酷!”
|
||||
|
||||
“我叫[Jason Baker][31]。我是红慢的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
“我叫[Jason Baker][31]。我是红帽的一个云专家,主要做[OpenStack][32]方面的工作。”
|
||||
|
||||
“我叫[Mark Bohannan][33],是红帽全球开放协议的一员,在华盛顿外工作。和Mel一样,我花了相当多时间写作,也从法律和政府部门中找合作者。我做了一个很好的小册子来讨论正在发生在政府中的积极变化。”
|
||||
|
||||
“我叫[Jason Hibbets][34],我组织了这次会议。”
|
||||
“我叫[Jason Hibbets][34],我组织了这次讨论。”
|
||||
|
||||
会场中一片笑声。
|
||||
|
||||
“我也组织了这片讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
“我也组织了这个讨论,可以这么说,”这个棕红色头发笑容灿烂的家伙说道。笑声持续一会逐渐平息。
|
||||
|
||||
我当时在他左边,时不时从转录空隙中抬头看一眼,然后从眼神中注意到微笑背后暗示的那个自2008年1月起开始领导公司的人,红帽的CEO[Jim Whitehurst][35]。
|
||||
我当时在他左边,时不时从记录的间隙中抬头看一眼,我注意到淡淡微笑背后的那个令人瞩目的人,是自2008年1月起开始领导红帽公司的CEO [Jim Whitehurst][35]。
|
||||
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的美好的事情是开源已经脱离了条条框框。我现在认为,IT正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代走向创新驱动力。”用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能提供和创新的解决方案。这也十一个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的控制。
|
||||
“我有世界上最好的工作,”稍稍向后靠、叉腿抱头,Whitehurst开始了演讲。“我开始领导红帽,在世界各地旅行到处看看情况。在这里的七年中,FOSS和广泛的开源创新所发生的最美好的事情是开源已经脱离了条条框框。我现在认为,信息技术正处在FOSS之前所在的位置。我们可以预见FOSS从一个替代品走向创新驱动力。我们的用户也看到了这一点。他们用FOSS并不是因为它便宜,而是因为它能带来可控和创新的解决方案。这也是个全球现象。比如,我刚才还在印度,然后发现那里的用户拥抱开源的两个理由:一个是创新,另一个是那里的市场有些特殊,需要完全的可控。”
|
||||
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这在证券交易领域闻所未闻。那时FOSS正在重复发明轮子。今天看来,FOSS正在做几乎所有的结合了大数据的事物。几乎所有的新框架,语言和方法论,包括流动(尽管不包括设备),都首先发生在开源世界。”
|
||||
“[孟买证券交易所][36]想得到源代码并加以控制,五年前这种事情在证券交易领域就没有听说过。那时FOSS正在重复发明轮子。今天看来,实际上大数据的每件事情都出现在FOSS领域。几乎所有的新框架,语言和方法论,包括移动通讯(尽管不包括设备),都首先发生在开源世界。”
|
||||
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop在厂商们意识的规模带来的问题。他们实际上有足够的资和资源金来解决自己的问题。”开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的物理产品。”
|
||||
“这是因为用户数量已经达到了相当的规模。这不只是红帽遇到的情况,[Google][37],[Amazon][38],[Facebook][39]等也出现这样的情况。他们想解决自己的问题,用开源的方式。忘掉许可协议吧,开源绝不仅如此。我们建立了一个交通工具,一套规则,例如[Hadoop][40],[Cassandra][41]和其他工具。事实上,开源驱动创新。例如,Hadoop是在厂商们意识到规模带来的问题时的一个解决方案。他们实际上有足够的资金和资源来解决自己的问题。开源是许多领域的默认技术方案。这在一个更加注重内容的世界中更是如此,例如[3D打印][42]和其他使用信息内容的实体产品。”
|
||||
|
||||
“源代码的开源确实很酷,但开源不应当仅限于此。在各行各业不同领域开源仍有可以用武之地。我们要问下自己:‘开源能够为教育,政府,法律带来什么?其它的呢?其它的领域如何能学习我们?’”
|
||||
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新能带来更好,那么我们需要更多的商业模式。”
|
||||
“还有内容的问题。内容在现在是免费的,当然我们可以投资更多的免费内容,不过我们也需要商业模式围绕的内容。这是我们更应该关注的。如果你相信开放的创新更好,那么我们需要更多的商业模式。”
|
||||
|
||||
“教育让我担心其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
“教育让我担心,其相比与‘社区’它更关注‘内容’。例如,无论我走到哪里,大学的校长们都会说,‘等等,难道教育将会免费?!’对于下游来说FOSS免费很棒,但别忘了上游很强大。免费课程很棒,但我们同样需要社区来不断迭代和完善。这是很多人都在做的事情,Opensource.com是一个提供交流的社区。问题不是‘我们如何控制内容’,也不是‘如何建立和分发内容’,而是要确保它处在不断的完善当中,而且能给其他领域提供有价值的参考。”
|
||||
|
||||
“改变世界的潜力是无穷无尽的,我们已经取得了很棒的进步。”六年前我们痴迷于制定宣言,我们说‘我们是领导者’。我们用错词了,因为那潜在意味着控制。积极的参与者们同样也不能很好理解……[Máirín Duffy][43]提出了[催化剂][44]这个词。然后我们组成了红帽,不断地促进行动,指引方向。”
|
||||
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
“Opensource.com也是其他领域的催化剂,而这正是它的本义所在,我希望你们也这样认为。当时的内容质量和现在比起来都令人难以置信。你可以看到每季度它都在进步。谢谢你们付出的时间!谢谢成为了催化剂!这是一个让世界变得更好的机会。我想听听你们的看法。”
|
||||
|
||||
我瞥了一下桌子,发现几个人眼中带泪。
|
||||
|
||||
然后Whitehurst又回顾了大会的开放教育议题。“极端一点看,如果你有一门[Ulysses][45]的公开课。在这里你能和一群人一起合作体验课堂。这样就和代码块一样的:大家一起努力,代码随着时间不断改进。”
|
||||
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,向基础和可能的不调和这些词语都跳了出来。
|
||||
在这一点上,我有发言权。当谈论其FOSS和学术团体之间的差异,像“基础”和“可能不调和”这些词语都跳了出来。
|
||||
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中烦了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
**Remy**: “倒退带来死亡。如果你在论文或者发布的代码中犯了一个错误,有可能带来十分严重的后果。学校一直都是避免失败寻求正确答案的地方。复制意味着抄袭。轮子在一遍遍地教条地被发明。FOSS让你能快速失败,但在学术界,你只能带来无效的结果。”
|
||||
|
||||
**Nicole**: “学术界有太多自我的家伙,你们需要一个发布经理。”
|
||||
|
||||
@ -80,20 +78,21 @@
|
||||
|
||||
**Luis**: “团队和分享应该优先考虑,红帽可以多向它们强调这一点。”
|
||||
|
||||
**Jim**: “还有公司在其中扮演积极角色吗?”
|
||||
**Jim**: “还有公司在其中扮演积极角色了吗?”
|
||||
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。联邦没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
[Phil Shapiro][46]: “我对FOSS的临界点感兴趣。Fed没有改用[LibreOffice][47]把我逼疯了。我们没有在软件上花税款,也不应当在字处理软件或者微软的Office上浪费税钱。”
|
||||
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均话费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作又更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
**Jim**: “我们经常提倡这一点。我们能做更多吗?这是个问题。首先,我们在我们的产品涉足的地方取得了进步。我们在政府中有坚实的专营权。我们比私有公司平均花费更多。银行和电信业都和政府挨着。我们在欧洲做的更好,我认为在那工作有更低的税。下一代计算就像‘终结者’,我们到处取得了进步,但仍然需要忧患意识。”
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着出了门……留给我们更多的激励。
|
||||
|
||||
突然,门开了。Jim转身向门口站着的执行助理点头。他要去参加下一场会了。他并拢双腿,站着向前微倾。然后,他再次向每个人的工作和奉献表示感谢,微笑着除了门……留给我们更多的激励。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/business/14/12/jim-whitehurst-inspiration-open-source
|
||||
|
||||
作者:[Remy][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[fyh](https://github.com/fyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
7 个驱动开源发展的社区
|
||||
================================================================================
|
||||
不久前,开源模式还被成熟的工业级厂商以怀疑的态度认作是叛逆小孩的玩物。如今,开源的促进会和基金会在一长列的供应商提供者的支持下正蓬勃发展,而他们将开源模式视作创新的关键。
|
||||
|
||||

|
||||
|
||||
### 技术的开放发展驱动着创新 ###
|
||||
|
||||
在过去的 20 几年间,技术的开源推进已被视作驱动创新的关键因素。即使那些以前将开源视作威胁的公司也开始接受这个观点 — 例如微软,如今它在一系列的开源的促进会中表现活跃。到目前为止,大多数的开源推进都集中在软件方面,但甚至这个也正在改变,因为社区已经开始向开源硬件倡议方面聚拢。这里介绍 7 个成功地在硬件和软件方面同时促进和发展开源技术的组织。
|
||||
|
||||
### OpenPOWER 基金会 ###
|
||||
|
||||

|
||||
|
||||
[OpenPOWER 基金会][2] 由 IBM, Google, Mellanox, Tyan 和 NVIDIA 于 2013 年共同创建,在与开源软件发展相同的精神下,旨在驱动开放协作硬件的发展,在过去的 20 几年间,开源软件发展已经找到了肥沃的土壤。
|
||||
|
||||
IBM 通过开放其基于 Power 架构的硬件和软件技术,向使用 Power IP 的独立硬件产品提供许可证等方式为基金会的建立播下种子。如今超过 70 个成员共同协作来为基于 Linux 的数据中心提供自定义的开放服务器,组件和硬件。
|
||||
|
||||
去年四月,在比最新基于 x86 系统快 50 倍的数据分析能力的新的 POWER8 处理器的服务器的基础上, OpenPOWER 推出了一个技术路线图。七月, IBM 和 Google 发布了一个固件堆栈。去年十月见证了 NVIDIA GPU 带来加速 POWER8 系统的能力和来自 Tyan 的第一个 OpenPOWER 参考服务器。
|
||||
|
||||
### Linux 基金会 ###
|
||||
|
||||

|
||||
|
||||
于 2000 年建立的 [Linux 基金会][2] 如今成为掌控着历史上最大的开源协同开发成果,它有着超过 180 个合作成员和许多独立成员及学生成员。它赞助 Linux 核心开发者的工作并促进、保护和推进 Linux 操作系统,并协调软件的协作开发。
|
||||
|
||||
它最为成功的协作项目包括 Code Aurora Forum (一个拥有为移动无线产业服务的企业财团),MeeGo (一个为移动设备和 IVI [注:指的是车载消息娱乐设备,为 In-Vehicle Infotainment 的简称] 构建一个基于 Linux 内核的操作系统的项目) 和 Open Virtualization Alliance (开放虚拟化联盟,它促进自由和开源软件虚拟化解决方案的采用)。
|
||||
|
||||
### 开放虚拟化联盟 ###
|
||||
|
||||

|
||||
|
||||
[开放虚拟化联盟(OVA)][3] 的存在目的为:通过提供使用案例和对具有互操作性的通用接口和 API 的发展提供支持,来促进自由、开源软件的虚拟化解决方案,例如 KVM 的采用。KVM 将 Linux 内核转变为一个虚拟机管理程序。
|
||||
|
||||
如今, KVM 已成为和 OpenStack 共同使用的最为常见的虚拟机管理程序。
|
||||
|
||||
### OpenStack 基金会 ###
|
||||
|
||||

|
||||
|
||||
原本作为一个 IaaS(基础设施即服务) 产品由 NASA 和 Rackspace 于 2010 年启动,[OpenStack 基金会][4] 已成为最大的开源项目聚居地之一。它拥有超过 200 家公司成员,其中包括 AT&T, AMD, Avaya, Canonical, Cisco, Dell 和 HP。
|
||||
|
||||
大约以 6 个月为一个发行周期,基金会的 OpenStack 项目开发用于通过一个基于 Web 的仪表盘,命令行工具或一个 RESTful 风格的 API 来控制或调配流经一个数据中心的处理存储池和网络资源。至今为止,基金会支持的协同开发已经孕育出了一系列 OpenStack 组件,其中包括 OpenStack Compute(一个云计算网络控制器,它是一个 IaaS 系统的主要部分),OpenStack Networking(一个用以管理网络和 IP 地址的系统) 和 OpenStack Object Storage(一个可扩展的冗余存储系统)。
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
作为来自 Linux 基金会的另一个协作项目, [OpenDaylight][5] 是一个由诸如 Dell, HP, Oracle 和 Avaya 等行业厂商于 2013 年 4 月建立的联合倡议。它的任务是建立一个由社区主导、开源、有工业支持的针对软件定义网络( SDN: Software-Defined Networking)的包含代码和蓝图的框架。其思路是提供一个可直接部署的全功能 SDN 平台,而不需要其他组件,供应商可提供附件组件和增强组件。
|
||||
|
||||
### Apache 软件基金会 ###
|
||||
|
||||

|
||||
|
||||
[Apache 软件基金会 (ASF)][7] 是将近 150 个顶级项目的聚居地,这些项目涵盖从开源的企业级自动化软件到与 Apache Hadoop 相关的分布式计算的整个生态系统。这些项目分发企业级、可免费获取的软件产品,而 Apache 协议则是为了让无论是商业用户还是个人用户更方便地部署 Apache 的产品。
|
||||
|
||||
ASF 是 1999 年成立的一个会员制,非盈利公司,以精英为其核心 — 要成为它的成员,你必须首先在基金会的一个或多个协作项目中做出积极贡献。
|
||||
|
||||
### 开放计算项目 ###
|
||||
|
||||

|
||||
|
||||
作为 Facebook 重新设计其 Oregon 数据中心的副产物, [开放计算项目][7] 旨在发展针对数据中心的开源硬件解决方案。 OCP 是一个由廉价无浪费的服务器、针对 Open Rack(为数据中心设计的机架标准,来让机架集成到数据中心的基础设施中) 的模块化 I/O 存储和一个相对 "绿色" 的数据中心设计方案等构成。
|
||||
|
||||
OCP 董事会成员包括来自 Facebook,Intel,Goldman Sachs,Rackspace 和 Microsoft 的代表。
|
||||
|
||||
OCP 最近宣布了有两种可选的许可证: 一个类似 Apache 2.0 的允许衍生工作的许可证,和一个更规范的鼓励将更改回馈到原有软件的许可证。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
@ -1,20 +1,20 @@
|
||||
如何在 Ubuntu 中管理和使用 LVM(Logical Volume Management,逻辑卷管理)
|
||||
如何在 Ubuntu 中管理和使用 逻辑卷管理 LVM
|
||||
================================================================================
|
||||

|
||||
|
||||
在我们之前的文章中,我们介绍了[什么是 LVM 以及能用 LVM 做什么][1],今天我们会给你介绍一些 LVM 的主要管理工具,使得你在设置和扩展安装时更游刃有余。
|
||||
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是,你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘驱动汇集而成或是一个软件磁盘阵列。
|
||||
正如之前所述,LVM 是介于你的操作系统和物理硬盘驱动器之间的抽象层。这意味着你的物理硬盘驱动器和分区不再依赖于他们所在的硬盘驱动和分区。而是你的操作系统所见的硬盘驱动和分区可以是由任意数目的独立硬盘汇集而成的或是一个软件磁盘阵列。
|
||||
|
||||
要管理 LVM,这里有很多可用的 GUI 工具,但要真正理解 LVM 配置发生的事情,最好要知道一些命令行工具。这当你在一个服务器或不提供 GUI 工具的发行版上管理 LVM 时尤为有用。
|
||||
|
||||
LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以下其中之一开头:
|
||||
|
||||
- Physical Volume = pv
|
||||
- Volume Group = vg
|
||||
- Logical Volume = lv
|
||||
- Physical Volume (物理卷) = pv
|
||||
- Volume Group (卷组)= vg
|
||||
- Logical Volume (逻辑卷)= lv
|
||||
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组使得你的操作系统能使用指定的空间。
|
||||
物理卷命令用于在卷组中添加或删除硬盘驱动。卷组命令用于为你的逻辑卷操作更改显示的物理分区抽象集。逻辑卷命令会以分区形式显示卷组,使得你的操作系统能使用指定的空间。
|
||||
|
||||
### 可下载的 LVM 备忘单 ###
|
||||
|
||||
@ -26,7 +26,7 @@ LVM 的大部分命令和彼此都非常相似。每个可用的命令都由以
|
||||
|
||||
### 如何查看当前 LVM 信息 ###
|
||||
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置好的开始点。
|
||||
你首先需要做的事情是检查你的 LVM 设置。s 和 display 命令可以和物理卷(pv)、卷组(vg)以及逻辑卷(lv)一起使用,是一个找出当前设置的好起点。
|
||||
|
||||
display 命令会格式化输出信息,因此比 s 命令更易于理解。对每个命令你会看到名称和 pv/vg 的路径,它还会给出空闲和已使用空间的信息。
|
||||
|
||||
@ -40,17 +40,17 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||
#### 创建物理卷 ####
|
||||
|
||||
我们会从一个完全新的没有任何分区和信息的硬盘驱动开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
我们会从一个全新的没有任何分区和信息的硬盘开始。首先找出你将要使用的磁盘。(/dev/sda, sdb, 等)
|
||||
|
||||
> 注意:记住所有的命令都要以 root 身份运行或者在命令前面添加 'sudo' 。
|
||||
|
||||
fdisk -l
|
||||
|
||||
如果之前你的硬盘驱动从没有格式化或分区,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
如果之前你的硬盘从未格式化或分区过,在 fdisk 的输出中你很可能看到类似下面的信息。这完全正常,因为我们会在下面的步骤中创建需要的分区。
|
||||
|
||||

|
||||
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在驱动上创建一个新的分区。
|
||||
我们的新磁盘位置是 /dev/sdb,让我们用 fdisk 命令在磁盘上创建一个新的分区。
|
||||
|
||||
这里有大量能创建新分区的 GUI 工具,包括 [Gparted][2],但由于我们已经打开了终端,我们将使用 fdisk 命令创建需要的分区。
|
||||
|
||||
@ -62,9 +62,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
以指定的顺序输入命令创建一个使用新硬盘驱动 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或相应多个分区,我建议使用 GParted 或自己了解关于 fdisk 命令的使用。
|
||||
以指定的顺序输入命令创建一个使用新硬盘 100% 空间的主分区并为 LVM 做好了准备。如果你需要更改分区的大小或想要多个分区,我建议使用 GParted 或自己了解一下关于 fdisk 命令的使用。
|
||||
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何信息。**
|
||||
**警告:下面的步骤会格式化你的硬盘驱动。确保在进行下面步骤之前你的硬盘驱动中没有任何有用的信息。**
|
||||
|
||||
- n = 创建新分区
|
||||
- p = 创建主分区
|
||||
@ -79,9 +79,9 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
- t = 更改分区类型
|
||||
- 8e = 更改为 LVM 分区类型
|
||||
|
||||
核实并将信息写入硬盘驱动器。
|
||||
核实并将信息写入硬盘。
|
||||
|
||||
- p = 查看分区设置使得写入更改到磁盘之前可以回看
|
||||
- p = 查看分区设置使得在写入更改到磁盘之前可以回看
|
||||
- w = 写入更改到磁盘
|
||||
|
||||

|
||||
@ -102,7 +102,7 @@ display 命令会格式化输出信息,因此比 s 命令更易于理解。对
|
||||
|
||||

|
||||
|
||||
Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称,但建议标签以 vg 开头,以便后面你使用它时能意识到这是一个卷组。
|
||||
|
||||
#### 创建逻辑卷 ####
|
||||
|
||||
@ -112,7 +112,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 所以 lvcreate 命令知道从什么卷获取空间。
|
||||
-L 命令指定逻辑卷的大小,在该情况中是 3 GB,-n 命令指定卷的名称。 指定 vgpool 以便 lvcreate 命令知道从什么卷获取空间。
|
||||
|
||||
#### 格式化并挂载逻辑卷 ####
|
||||
|
||||
@ -131,7 +131,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
#### 重新设置逻辑卷大小 ####
|
||||
|
||||
逻辑卷的一个好处是你能使你的共享物理变大或变小而不需要移动所有东西到一个更大的硬盘驱动。另外,你可以添加新的硬盘驱动并同时扩展你的卷组。或者如果你有一个不使用的硬盘驱动,你可以从卷组中移除它使得逻辑卷变小。
|
||||
逻辑卷的一个好处是你能使你的存储物理地变大或变小,而不需要移动所有东西到一个更大的硬盘。另外,你可以添加新的硬盘并同时扩展你的卷组。或者如果你有一个不使用的硬盘,你可以从卷组中移除它使得逻辑卷变小。
|
||||
|
||||
这里有三个用于使物理卷、卷组和逻辑卷变大或变小的基础工具。
|
||||
|
||||
@ -147,9 +147,9 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
按照上面创建新分区并更改分区类型为 LVM(8e) 的步骤安装一个新硬盘驱动。然后用 pvcreate 命令创建一个 LVM 能识别的物理卷。
|
||||
|
||||
#### 添加新硬盘驱动到卷组 ####
|
||||
#### 添加新硬盘到卷组 ####
|
||||
|
||||
要添加新的硬盘驱动到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
要添加新的硬盘到一个卷组,你只需要知道你的新分区,在我们的例子中是 /dev/sdc1,以及想要添加到的卷组的名称。
|
||||
|
||||
这会添加新物理卷到已存在的卷组中。
|
||||
|
||||
@ -189,7 +189,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||
1. 调整文件系统大小 (调整之前确保已经移动文件到硬盘驱动安全的地方)
|
||||
1. 减小逻辑卷 (除了 + 可以扩展大小,你也可以用 - 压缩大小)
|
||||
1. 用 vgreduce 从卷组中移除硬盘驱动
|
||||
1. 用 vgreduce 从卷组中移除硬盘
|
||||
|
||||
#### 备份逻辑卷 ####
|
||||
|
||||
@ -197,7 +197,7 @@ Vgpool 是新创建的卷组的名称。你可以使用任何你喜欢的名称
|
||||
|
||||

|
||||
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该照片可以用于在不同的硬盘驱动上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
LVM 获取快照的时候,会有一张和逻辑卷完全相同的“照片”,该“照片”可以用于在不同的硬盘上进行备份。生成一个备份的时候,任何需要添加到逻辑卷的新信息会如往常一样写入磁盘,但会跟踪更改使得原始快照永远不会损毁。
|
||||
|
||||
要创建一个快照,我们需要创建拥有足够空闲空间的逻辑卷,用于保存我们备份的时候会写入该逻辑卷的任何新信息。如果驱动并不是经常写入,你可以使用很小的一个存储空间。备份完成的时候我们只需要移除临时逻辑卷,原始逻辑卷会和往常一样。
|
||||
|
||||
@ -209,7 +209,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为驱动实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
这里我们创建了一个只有 512MB 的逻辑卷,因为该硬盘实际上并不会使用。512MB 的空间会保存备份时产生的任何新数据。
|
||||
|
||||
#### 挂载新快照 ####
|
||||
|
||||
@ -222,7 +222,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||
#### 复制快照和删除逻辑卷 ####
|
||||
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘驱动或者打包所有文件到一个文件。
|
||||
你剩下需要做的是从 /mnt/lvstuffbackup/ 中复制所有文件到一个外部的硬盘或者打包所有文件到一个文件。
|
||||
|
||||
**注意:tar -c 会创建一个归档文件,-f 要指出归档文件的名称和路径。要获取 tar 命令的帮助信息,可以在终端中输入 man tar。**
|
||||
|
||||
@ -230,7 +230,7 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
|
||||

|
||||
|
||||
记住备份发生的时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
记住备份时候写到 lvstuff 的所有文件都会在我们之前创建的临时逻辑卷中被跟踪。确保备份的时候你有足够的空闲空间。
|
||||
|
||||
备份完成后,卸载卷并移除临时快照。
|
||||
|
||||
@ -259,10 +259,10 @@ LVM 获取快照的时候,会有一张和逻辑卷完全相同的照片,该
|
||||
via: http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
[1]:https://linux.cn/article-5953-1.html
|
||||
[2]:http://www.howtogeek.com/howto/17001/how-to-format-a-usb-drive-in-ubuntu-using-gparted/
|
||||
[3]:http://www.howtogeek.com/howto/33552/htg-explains-which-linux-file-system-should-you-choose/
|
||||
@ -0,0 +1,131 @@
|
||||
如何通过反向 SSH 隧道访问 NAT 后面的 Linux 服务器
|
||||
================================================================================
|
||||
你在家里运行着一台 Linux 服务器,它放在一个 NAT 路由器或者限制性防火墙后面。现在你想在外出时用 SSH 登录到这台服务器。你如何才能做到呢?SSH 端口转发当然是一种选择。但是,如果你需要处理多级嵌套的 NAT 环境,端口转发可能会变得非常棘手。另外,在多种 ISP 特定条件下可能会受到干扰,例如阻塞转发端口的限制性 ISP 防火墙、或者在用户间共享 IPv4 地址的运营商级 NAT。
|
||||
|
||||
### 什么是反向 SSH 隧道? ###
|
||||
|
||||
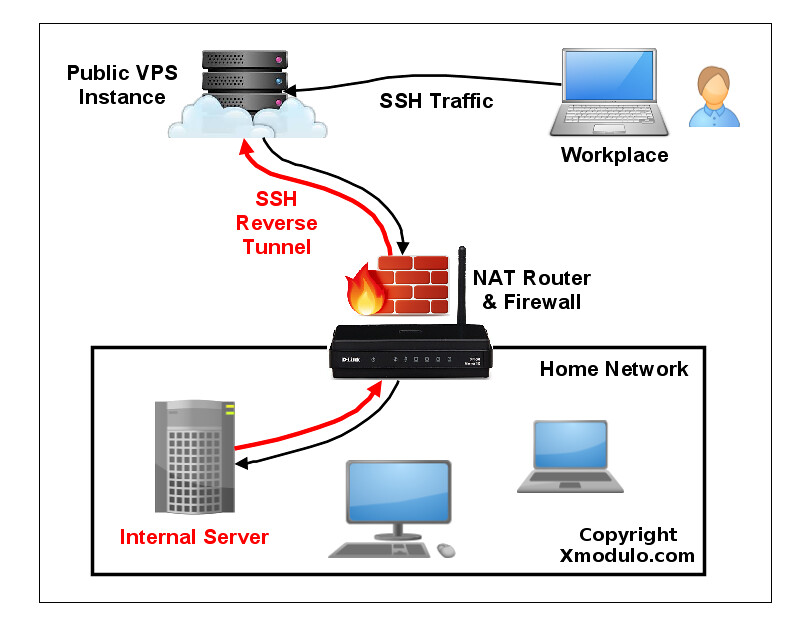
SSH 端口转发的一种替代方案是 **反向 SSH 隧道**。反向 SSH 隧道的概念非常简单。使用这种方案,在你的受限的家庭网络之外你需要另一台主机(所谓的“中继主机”),你能从当前所在地通过 SSH 登录到它。你可以用有公网 IP 地址的 [VPS 实例][1] 配置一个中继主机。然后要做的就是从你的家庭网络服务器中建立一个到公网中继主机的永久 SSH 隧道。有了这个隧道,你就可以从中继主机中连接“回”家庭服务器(这就是为什么称之为 “反向” 隧道)。不管你在哪里、你的家庭网络中的 NAT 或 防火墙限制多么严格,只要你可以访问中继主机,你就可以连接到家庭服务器。
|
||||
|
||||
|
||||
|
||||
### 在 Linux 上设置反向 SSH 隧道 ###
|
||||
|
||||
让我们来看看怎样创建和使用反向 SSH 隧道。我们做如下假设:我们会设置一个从家庭服务器(homeserver)到中继服务器(relayserver)的反向 SSH 隧道,然后我们可以通过中继服务器从客户端计算机(clientcomputer) SSH 登录到家庭服务器。本例中的**中继服务器** 的公网 IP 地址是 1.1.1.1。
|
||||
|
||||
在家庭服务器上,按照以下方式打开一个到中继服务器的 SSH 连接。
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
这里端口 10022 是任何你可以使用的端口数字。只需要确保中继服务器上不会有其它程序使用这个端口。
|
||||
|
||||
“-R 10022:localhost:22” 选项定义了一个反向隧道。它转发中继服务器 10022 端口的流量到家庭服务器的 22 号端口。
|
||||
|
||||
用 “-fN” 选项,当你成功通过 SSH 服务器验证时 SSH 会进入后台运行。当你不想在远程 SSH 服务器执行任何命令,就像我们的例子中只想转发端口的时候非常有用。
|
||||
|
||||
运行上面的命令之后,你就会回到家庭主机的命令行提示框中。
|
||||
|
||||
登录到中继服务器,确认其 127.0.0.1:10022 绑定到了 sshd。如果是的话就表示已经正确设置了反向隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
|
||||
|
||||
现在就可以从任何其它计算机(客户端计算机)登录到中继服务器,然后按照下面的方法访问家庭服务器。
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
需要注意的一点是你在上面为localhost输入的 SSH 登录/密码应该是家庭服务器的,而不是中继服务器的,因为你是通过隧道的本地端点登录到家庭服务器,因此不要错误输入中继服务器的登录/密码。成功登录后,你就在家庭服务器上了。
|
||||
|
||||
### 通过反向 SSH 隧道直接连接到网络地址变换后的服务器 ###
|
||||
|
||||
上面的方法允许你访问 NAT 后面的 **家庭服务器**,但你需要登录两次:首先登录到 **中继服务器**,然后再登录到**家庭服务器**。这是因为中继服务器上 SSH 隧道的端点绑定到了回环地址(127.0.0.1)。
|
||||
|
||||
事实上,有一种方法可以只需要登录到中继服务器就能直接访问NAT之后的家庭服务器。要做到这点,你需要让中继服务器上的 sshd 不仅转发回环地址上的端口,还要转发外部主机的端口。这通过指定中继服务器上运行的 sshd 的 **GatewayPorts** 实现。
|
||||
|
||||
打开**中继服务器**的 /etc/ssh/sshd_conf 并添加下面的行。
|
||||
|
||||
relayserver~$ vi /etc/ssh/sshd_conf
|
||||
|
||||
----------
|
||||
|
||||
GatewayPorts clientspecified
|
||||
|
||||
重启 sshd。
|
||||
|
||||
基于 Debian 的系统:
|
||||
|
||||
relayserver~$ sudo /etc/init.d/ssh restart
|
||||
|
||||
基于红帽的系统:
|
||||
|
||||
relayserver~$ sudo systemctl restart sshd
|
||||
|
||||
现在在家庭服务器中按照下面方式初始化一个反向 SSH 隧道。
|
||||
|
||||
homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
登录到中继服务器然后用 netstat 命令确认成功建立的一个反向 SSH 隧道。
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
不像之前的情况,现在隧道的端点是 1.1.1.1:10022(中继服务器的公网 IP 地址),而不是 127.0.0.1:10022。这就意味着从外部主机可以访问隧道的另一端。
|
||||
|
||||
现在在任何其它计算机(客户端计算机),输入以下命令访问网络地址变换之后的家庭服务器。
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
在上面的命令中,1.1.1.1 是中继服务器的公共 IP 地址,homeserver_user必须是家庭服务器上的用户账户。这是因为你真正登录到的主机是家庭服务器,而不是中继服务器。后者只是中继你的 SSH 流量到家庭服务器。
|
||||
|
||||
### 在 Linux 上设置一个永久反向 SSH 隧道 ###
|
||||
|
||||
现在你已经明白了怎样创建一个反向 SSH 隧道,然后把隧道设置为 “永久”,这样隧道启动后就会一直运行(不管临时的网络拥塞、SSH 超时、中继主机重启,等等)。毕竟,如果隧道不是一直有效,你就不能可靠的登录到你的家庭服务器。
|
||||
|
||||
对于永久隧道,我打算使用一个叫 autossh 的工具。正如名字暗示的,这个程序可以让你的 SSH 会话无论因为什么原因中断都会自动重连。因此对于保持一个反向 SSH 隧道非常有用。
|
||||
|
||||
第一步,我们要设置从家庭服务器到中继服务器的[无密码 SSH 登录][2]。这样的话,autossh 可以不需要用户干预就能重启一个损坏的反向 SSH 隧道。
|
||||
|
||||
下一步,在建立隧道的家庭服务器上[安装 autossh][3]。
|
||||
|
||||
在家庭服务器上,用下面的参数运行 autossh 来创建一个连接到中继服务器的永久 SSH 隧道。
|
||||
|
||||
homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
“-M 10900” 选项指定中继服务器上的监视端口,用于交换监视 SSH 会话的测试数据。中继服务器上的其它程序不能使用这个端口。
|
||||
|
||||
“-fN” 选项传递给 ssh 命令,让 SSH 隧道在后台运行。
|
||||
|
||||
“-o XXXX” 选项让 ssh:
|
||||
|
||||
- 使用密钥验证,而不是密码验证。
|
||||
- 自动接受(未知)SSH 主机密钥。
|
||||
- 每 60 秒交换 keep-alive 消息。
|
||||
- 没有收到任何响应时最多发送 3 条 keep-alive 消息。
|
||||
|
||||
其余 SSH 隧道相关的选项和之前介绍的一样。
|
||||
|
||||
如果你想系统启动时自动运行 SSH 隧道,你可以将上面的 autossh 命令添加到 /etc/rc.local。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在这篇博文中,我介绍了你如何能从外部通过反向 SSH 隧道访问限制性防火墙或 NAT 网关之后的 Linux 服务器。这里我介绍了家庭网络中的一个使用事例,但在企业网络中使用时你尤其要小心。这样的一个隧道可能被视为违反公司政策,因为它绕过了企业的防火墙并把企业网络暴露给外部攻击。这很可能被误用或者滥用。因此在使用之前一定要记住它的作用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:https://linux.cn/article-5444-1.html
|
||||
[3]:https://linux.cn/article-5459-1.html
|
||||
183
published/20150522 Analyzing Linux Logs.md
Normal file
183
published/20150522 Analyzing Linux Logs.md
Normal file
@ -0,0 +1,183 @@
|
||||
如何分析 Linux 日志
|
||||
==============================================================================
|
||||

|
||||
|
||||
日志中有大量的信息需要你处理,尽管有时候想要提取并非想象中的容易。在这篇文章中我们会介绍一些你现在就能做的基本日志分析例子(只需要搜索即可)。我们还将涉及一些更高级的分析,但这些需要你前期努力做出适当的设置,后期就能节省很多时间。对数据进行高级分析的例子包括生成汇总计数、对有效值进行过滤,等等。
|
||||
|
||||
我们首先会向你展示如何在命令行中使用多个不同的工具,然后展示了一个日志管理工具如何能自动完成大部分繁重工作从而使得日志分析变得简单。
|
||||
|
||||
### 用 Grep 搜索 ###
|
||||
|
||||
搜索文本是查找信息最基本的方式。搜索文本最常用的工具是 [grep][1]。这个命令行工具在大部分 Linux 发行版中都有,它允许你用正则表达式搜索日志。正则表达式是一种用特殊的语言写的、能识别匹配文本的模式。最简单的模式就是用引号把你想要查找的字符串括起来。
|
||||
|
||||
#### 正则表达式 ####
|
||||
|
||||
这是一个在 Ubuntu 系统的认证日志中查找 “user hoover” 的例子:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
构建精确的正则表达式可能很难。例如,如果我们想要搜索一个类似端口 “4792” 的数字,它可能也会匹配时间戳、URL 以及其它不需要的数据。Ubuntu 中下面的例子,它匹配了一个我们不想要的 Apache 日志。
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972 HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### 环绕搜索 ####
|
||||
|
||||
另一个有用的小技巧是你可以用 grep 做环绕搜索。这会向你展示一个匹配前面或后面几行是什么。它能帮助你调试导致错误或问题的东西。`B` 选项展示前面几行,`A` 选项展示后面几行。举个例子,我们知道当一个人以管理员员身份登录失败时,同时他们的 IP 也没有反向解析,也就意味着他们可能没有有效的域名。这非常可疑!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
你也可以把 grep 和 [tail][2] 结合使用来获取一个文件的最后几行,或者跟踪日志并实时打印。这在你做交互式更改的时候非常有用,例如启动服务器或者测试代码更改。
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
关于 grep 和正则表达式的详细介绍并不在本指南的范围,但 [Ryan’s Tutorials][3] 有更深入的介绍。
|
||||
|
||||
日志管理系统有更高的性能和更强大的搜索能力。它们通常会索引数据并进行并行查询,因此你可以很快的在几秒内就能搜索 GB 或 TB 的日志。相比之下,grep 就需要几分钟,在极端情况下可能甚至几小时。日志管理系统也使用类似 [Lucene][4] 的查询语言,它提供更简单的语法来检索数字、域以及其它。
|
||||
|
||||
### 用 Cut、 AWK、 和 Grok 解析 ###
|
||||
|
||||
#### 命令行工具 ####
|
||||
|
||||
Linux 提供了多个命令行工具用于文本解析和分析。当你想要快速解析少量数据时非常有用,但处理大量数据时可能需要很长时间。
|
||||
|
||||
#### Cut ####
|
||||
|
||||
[cut][5] 命令允许你从有分隔符的日志解析字段。分隔符是指能分开字段或键值对的等号或逗号等。
|
||||
|
||||
假设我们想从下面的日志中解析出用户:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
我们可以像下面这样用 cut 命令获取用等号分割后的第八个字段的文本。这是一个 Ubuntu 系统上的例子:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
另外,你也可以使用 [awk][6],它能提供更强大的解析字段功能。它提供了一个脚本语言,你可以过滤出几乎任何不相干的东西。
|
||||
|
||||
例如,假设在 Ubuntu 系统中我们有下面的一行日志,我们想要提取登录失败的用户名称:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
你可以像下面这样使用 awk 命令。首先,用一个正则表达式 /sshd.*invalid user/ 来匹配 sshd invalid user 行。然后用 { print $9 } 根据默认的分隔符空格打印第九个字段。这样就输出了用户名。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
你可以在 [Awk 用户指南][7] 中阅读更多关于如何使用正则表达式和输出字段的信息。
|
||||
|
||||
#### 日志管理系统 ####
|
||||
|
||||
日志管理系统使得解析变得更加简单,使用户能快速的分析很多的日志文件。他们能自动解析标准的日志格式,比如常见的 Linux 日志和 Web 服务器日志。这能节省很多时间,因为当处理系统问题的时候你不需要考虑自己写解析逻辑。
|
||||
|
||||
下面是一个 sshd 日志消息的例子,解析出了每个 remoteHost 和 user。这是 Loggly 中的一张截图,它是一个基于云的日志管理服务。
|
||||
|
||||

|
||||
|
||||
你也可以对非标准格式自定义解析。一个常用的工具是 [Grok][8],它用一个常见正则表达式库,可以解析原始文本为结构化 JSON。下面是一个 Grok 在 Logstash 中解析内核日志文件的事例配置:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
下图是 Grok 解析后输出的结果:
|
||||
|
||||

|
||||
|
||||
### 用 Rsyslog 和 AWK 过滤 ###
|
||||
|
||||
过滤使得你能检索一个特定的字段值而不是进行全文检索。这使你的日志分析更加准确,因为它会忽略来自其它部分日志信息不需要的匹配。为了对一个字段值进行搜索,你首先需要解析日志或者至少有对事件结构进行检索的方式。
|
||||
|
||||
#### 如何对应用进行过滤 ####
|
||||
|
||||
通常,你可能只想看一个应用的日志。如果你的应用把记录都保存到一个文件中就会很容易。如果你需要在一个聚集或集中式日志中过滤一个应用就会比较复杂。下面有几种方法来实现:
|
||||
|
||||
1. 用 rsyslog 守护进程解析和过滤日志。下面的例子将 sshd 应用的日志写入一个名为 sshd-message 的文件,然后丢弃事件以便它不会在其它地方重复出现。你可以将它添加到你的 rsyslog.conf 文件中测试这个例子。
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. 用类似 awk 的命令行工具提取特定字段的值,例如 sshd 用户名。下面是 Ubuntu 系统中的一个例子。
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. 用日志管理系统自动解析日志,然后在需要的应用名称上点击过滤。下面是在 Loggly 日志管理服务中提取 syslog 域的截图。我们对应用名称 “sshd” 进行过滤,如维恩图图标所示。
|
||||
|
||||

|
||||
|
||||
#### 如何过滤错误 ####
|
||||
|
||||
一个人最希望看到日志中的错误。不幸的是,默认的 syslog 配置不直接输出错误的严重性,也就使得难以过滤它们。
|
||||
|
||||
这里有两个解决该问题的方法。首先,你可以修改你的 rsyslog 配置,在日志文件中输出错误的严重性,使得便于查看和检索。在你的 rsyslog 配置中你可以用 pri-text 添加一个 [模板][9],像下面这样:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
这个例子会按照下面的格式输出。你可以看到该信息中指示错误的 err。
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你可以用 awk 或者 grep 检索错误信息。在 Ubuntu 中,对这个例子,我们可以用一些语法特征,例如 . 和 >,它们只会匹配这个域。
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
你的第二个选择是使用日志管理系统。好的日志管理系统能自动解析 syslog 消息并抽取错误域。它们也允许你用简单的点击过滤日志消息中的特定错误。
|
||||
|
||||
下面是 Loggly 中一个截图,显示了高亮错误严重性的 syslog 域,表示我们正在过滤错误:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a],[Amy Echeverri][b],[ Sadequl Hussain][c]
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -1,18 +1,18 @@
|
||||
Ubuntu 15.04上配置OpenVPN服务器-客户端
|
||||
在 Ubuntu 15.04 上配置 OpenVPN 服务器和客户端
|
||||
================================================================================
|
||||
虚拟专用网(VPN)是几种用于建立与其它网络连接的网络技术中常见的一个名称。它被称为虚拟网,因为各个节点的连接不是通过物理线路实现的。而由于没有网络所有者的正确授权是不能通过公共线路访问到网络,所以它是专用的。
|
||||
虚拟专用网(VPN)常指几种通过其它网络建立连接技术。它之所以被称为“虚拟”,是因为各个节点间的连接不是通过物理线路实现的,而“专用”是指如果没有网络所有者的正确授权是不能被公开访问到。
|
||||
|
||||

|
||||
|
||||
[OpenVPN][1]软件通过TUN/TAP驱动的帮助,使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提额外提供了灵活的配置,可以帮助你避免防火墙限制。
|
||||
[OpenVPN][1]软件借助TUN/TAP驱动使用TCP和UDP协议来传输数据。UDP协议和TUN驱动允许NAT后的用户建立到OpenVPN服务器的连接。此外,OpenVPN允许指定自定义端口。它提供了更多的灵活配置,可以帮助你避免防火墙限制。
|
||||
|
||||
OpenVPN中,由OpenSSL库和传输层安全协议(TLS)提供了安全和加密。TLS是SSL协议的一个改进版本。
|
||||
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何预备使用带有公共密钥非对称加密和TLS协议基础结构(PKI)。
|
||||
OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示了如何配置OpenVPN的服务器端,以及如何配置使用带有公共密钥基础结构(PKI)的非对称加密和TLS协议。
|
||||
|
||||
### 服务器端配置 ###
|
||||
|
||||
首先,我们必须安装OpenVPN。在Ubuntu 15.04和其它带有‘apt’报管理器的Unix系统中,可以通过如下命令安装:
|
||||
首先,我们必须安装OpenVPN软件。在Ubuntu 15.04和其它带有‘apt’包管理器的Unix系统中,可以通过如下命令安装:
|
||||
|
||||
sudo apt-get install openvpn
|
||||
|
||||
@ -20,7 +20,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
sudo apt-get unstall easy-rsa
|
||||
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在“sudo -i”命令后;此外,你可以使用“sudo -E”作为接下来所有命令的前缀。
|
||||
**注意**: 所有接下来的命令要以超级用户权限执行,如在使用`sudo -i`命令后执行,或者你可以使用`sudo -E`作为接下来所有命令的前缀。
|
||||
|
||||
开始之前,我们需要拷贝“easy-rsa”到openvpn文件夹。
|
||||
|
||||
@ -32,15 +32,15 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
这里,我们开启了一个密钥生成进程。
|
||||
这里,我们开始密钥生成进程。
|
||||
|
||||
首先,我们编辑一个“var”文件。为了简化生成过程,我们需要在里面指定数据。这里是“var”文件的一个样例:
|
||||
首先,我们编辑一个“vars”文件。为了简化生成过程,我们需要在里面指定数据。这里是“vars”文件的一个样例:
|
||||
|
||||
export KEY_COUNTRY="US"
|
||||
export KEY_PROVINCE="CA"
|
||||
export KEY_CITY="SanFrancisco"
|
||||
export KEY_ORG="Fort-Funston"
|
||||
export KEY_EMAIL="my@myhost.mydomain"
|
||||
export KEY_COUNTRY="CN"
|
||||
export KEY_PROVINCE="BJ"
|
||||
export KEY_CITY="Beijing"
|
||||
export KEY_ORG="Linux.CN"
|
||||
export KEY_EMAIL="open@vpn.linux.cn"
|
||||
export KEY_OU=server
|
||||
|
||||
希望这些字段名称对你而言已经很清楚,不需要进一步说明了。
|
||||
@ -61,7 +61,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
./build-ca
|
||||
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查以下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
在对话中,我们可以看到默认的变量,这些变量是我们先前在“vars”中指定的。我们可以检查一下,如有必要进行编辑,然后按回车几次。对话如下
|
||||
|
||||
Generating a 2048 bit RSA private key
|
||||
.............................................+++
|
||||
@ -75,14 +75,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [Fort-Funston CA]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN CA]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
接下来,我们需要生成一个服务器密钥
|
||||
|
||||
@ -102,14 +102,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
For some fields there will be a default value,
|
||||
If you enter '.', the field will be left blank.
|
||||
-----
|
||||
Country Name (2 letter code) [US]:
|
||||
State or Province Name (full name) [CA]:
|
||||
Locality Name (eg, city) [SanFrancisco]:
|
||||
Organization Name (eg, company) [Fort-Funston]:
|
||||
Organizational Unit Name (eg, section) [MyOrganizationalUnit]:
|
||||
Common Name (eg, your name or your server's hostname) [server]:
|
||||
Country Name (2 letter code) [CN]:
|
||||
State or Province Name (full name) [BJ]:
|
||||
Locality Name (eg, city) [Beijing]:
|
||||
Organization Name (eg, company) [Linux.CN]:
|
||||
Organizational Unit Name (eg, section) [Tech]:
|
||||
Common Name (eg, your name or your server's hostname) [Linux.CN server]:
|
||||
Name [EasyRSA]:
|
||||
Email Address [me@myhost.mydomain]:
|
||||
Email Address [open@vpn.linux.cn]:
|
||||
|
||||
Please enter the following 'extra' attributes
|
||||
to be sent with your certificate request
|
||||
@ -119,14 +119,14 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
Check that the request matches the signature
|
||||
Signature ok
|
||||
The Subject's Distinguished Name is as follows
|
||||
countryName :PRINTABLE:'US'
|
||||
stateOrProvinceName :PRINTABLE:'CA'
|
||||
localityName :PRINTABLE:'SanFrancisco'
|
||||
organizationName :PRINTABLE:'Fort-Funston'
|
||||
organizationalUnitName:PRINTABLE:'MyOrganizationalUnit'
|
||||
commonName :PRINTABLE:'server'
|
||||
countryName :PRINTABLE:'CN'
|
||||
stateOrProvinceName :PRINTABLE:'BJ'
|
||||
localityName :PRINTABLE:'Beijing'
|
||||
organizationName :PRINTABLE:'Linux.CN'
|
||||
organizationalUnitName:PRINTABLE:'Tech'
|
||||
commonName :PRINTABLE:'Linux.CN server'
|
||||
name :PRINTABLE:'EasyRSA'
|
||||
emailAddress :IA5STRING:'me@myhost.mydomain'
|
||||
emailAddress :IA5STRING:'open@vpn.linux.cn'
|
||||
Certificate is to be certified until May 22 19:00:25 2025 GMT (3650 days)
|
||||
Sign the certificate? [y/n]:y
|
||||
1 out of 1 certificate requests certified, commit? [y/n]y
|
||||
@ -143,7 +143,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
Generating DH parameters, 2048 bit long safe prime, generator 2
|
||||
This is going to take a long time
|
||||
................................+................<and many many dots>
|
||||
................................+................<许多的点>
|
||||
|
||||
在漫长的等待之后,我们可以继续生成最后的密钥了,该密钥用于TLS验证。命令如下:
|
||||
|
||||
@ -176,7 +176,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
### Unix的客户端配置 ###
|
||||
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要从先前的部分连接到OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的目录中:
|
||||
假定我们有一台装有类Unix操作系统的设备,比如Ubuntu 15.04,并安装有OpenVPN。我们想要连接到前面建立的OpenVPN服务器。首先,我们需要为客户端生成密钥。为了生成该密钥,请转到服务器上的对应目录中:
|
||||
|
||||
cd /etc/openvpn/easy-rsa/2.0
|
||||
|
||||
@ -211,7 +211,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -243,7 +243,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
安卓设备上的OpenVPN配置和Unix系统上的十分类似,我们需要一个含有配置文件、密钥和证书的包。文件列表如下:
|
||||
|
||||
- configuration file (.ovpn),
|
||||
- 配置文件 (扩展名 .ovpn),
|
||||
- ca.crt,
|
||||
- dh2048.pem,
|
||||
- client.crt,
|
||||
@ -257,7 +257,7 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
dev tun
|
||||
proto udp
|
||||
|
||||
# IP and Port of remote host with OpenVPN server
|
||||
# 远程 OpenVPN 服务器的 IP 和 端口号
|
||||
remote 111.222.333.444 1194
|
||||
|
||||
resolv-retry infinite
|
||||
@ -274,21 +274,21 @@ OpenSSL提供了两种加密方法:对称和非对称。下面,我们展示
|
||||
|
||||
所有这些文件我们必须移动我们设备的SD卡上。
|
||||
|
||||
然后,我们需要安装[OpenVPN连接][2]。
|
||||
然后,我们需要安装一个[OpenVPN Connect][2] 应用。
|
||||
|
||||
接下来,配置过程很是简单:
|
||||
|
||||
open setting of OpenVPN and select Import options
|
||||
select Import Profile from SD card option
|
||||
in opened window go to folder with prepared files and select .ovpn file
|
||||
application offered us to create a new profile
|
||||
tap on the Connect button and wait a second
|
||||
- 打开 OpenVPN 并选择“Import”选项
|
||||
- 选择“Import Profile from SD card”
|
||||
- 在打开的窗口中导航到我们放置好文件的目录,并选择那个 .ovpn 文件
|
||||
- 应用会要求我们创建一个新的配置文件
|
||||
- 点击“Connect”按钮并稍等一下
|
||||
|
||||
搞定。现在,我们的安卓设备已经通过安全的VPN连接连接到我们的专用网。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和在企业中使用。
|
||||
虽然OpenVPN初始配置花费不少时间,但是简易的客户端配置为我们弥补了时间上的损失,也提供了从任何设备连接的能力。此外,OpenVPN提供了一个很高的安全等级,以及从不同地方连接的能力,包括位于NAT后面的客户端。因此,OpenVPN可以同时在家和企业中使用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -296,7 +296,7 @@ via: http://linoxide.com/ubuntu-how-to/configure-openvpn-server-client-ubuntu-15
|
||||
|
||||
作者:[Ivan Zabrovskiy][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,205 @@
|
||||
关于Linux防火墙'iptables'的面试问答
|
||||
================================================================================
|
||||
Nishita Agarwal是Tecmint的用户,她将分享关于她刚刚经历的一家公司(印度的一家私人公司Pune)的面试经验。在面试中她被问及许多不同的问题,但她是iptables方面的专家,因此她想分享这些关于iptables的问题和相应的答案给那些以后可能会进行相关面试的人。
|
||||
|
||||

|
||||
|
||||
所有的问题和相应的答案都基于Nishita Agarwal的记忆并经过了重写。
|
||||
|
||||
> “嗨,朋友!我叫**Nishita Agarwal**。我已经取得了理学学士学位,我的专业集中在UNIX和它的变种(BSD,Linux)。它们一直深深的吸引着我。我在存储方面有1年多的经验。我正在寻求职业上的变化,并将供职于印度的Pune公司。”
|
||||
|
||||
下面是我在面试中被问到的问题的集合。我已经把我记忆中有关iptables的问题和它们的答案记录了下来。希望这会对您未来的面试有所帮助。
|
||||
|
||||
### 1. 你听说过Linux下面的iptables和Firewalld么?知不知道它们是什么,是用来干什么的? ###
|
||||
|
||||
**答案** : iptables和Firewalld我都知道,并且我已经使用iptables好一段时间了。iptables主要由C语言写成,并且以GNU GPL许可证发布。它是从系统管理员的角度写的,最新的稳定版是iptables 1.4.21。iptables通常被用作类UNIX系统中的防火墙,更准确的说,可以称为iptables/netfilter。管理员通过终端/GUI工具与iptables打交道,来添加和定义防火墙规则到预定义的表中。Netfilter是内核中的一个模块,它执行包过滤的任务。
|
||||
|
||||
Firewalld是RHEL/CentOS 7(也许还有其他发行版,但我不太清楚)中最新的过滤规则的实现。它已经取代了iptables接口,并与netfilter相连接。
|
||||
|
||||
### 2. 你用过一些iptables的GUI或命令行工具么? ###
|
||||
|
||||
**答案** : 虽然我既用过GUI工具,比如与[Webmin][1]结合的Shorewall;以及直接通过终端访问iptables,但我必须承认通过Linux终端直接访问iptables能给予用户更高级的灵活性、以及对其背后工作更好的理解的能力。GUI适合初级管理员,而终端适合有经验的管理员。
|
||||
|
||||
### 3. 那么iptables和firewalld的基本区别是什么呢? ###
|
||||
|
||||
**答案** : iptables和firewalld都有着同样的目的(包过滤),但它们使用不同的方式。iptables与firewalld不同,在每次发生更改时都刷新整个规则集。通常iptables配置文件位于‘/etc/sysconfig/iptables‘,而firewalld的配置文件位于‘/etc/firewalld/‘。firewalld的配置文件是一组XML文件。以XML为基础进行配置的firewalld比iptables的配置更加容易,但是两者都可以完成同样的任务。例如,firewalld可以在自己的命令行界面以及基于XML的配置文件下使用iptables。
|
||||
|
||||
### 4. 如果有机会的话,你会在你所有的服务器上用firewalld替换iptables么? ###
|
||||
|
||||
**答案** : 我对iptables很熟悉,它也工作的很好。如果没有任何需求需要firewalld的动态特性,那么没有理由把所有的配置都从iptables移动到firewalld。通常情况下,目前为止,我还没有看到iptables造成什么麻烦。IT技术的通用准则也说道“为什么要修一件没有坏的东西呢?”。上面是我自己的想法,但如果组织愿意用firewalld替换iptables的话,我不介意。
|
||||
|
||||
### 5. 你看上去对iptables很有信心,巧的是,我们的服务器也在使用iptables。 ###
|
||||
|
||||
iptables使用的表有哪些?请简要的描述iptables使用的表以及它们所支持的链。
|
||||
|
||||
**答案** : 谢谢您的赞赏。至于您问的问题,iptables使用的表有四个,它们是:
|
||||
|
||||
- Nat 表
|
||||
- Mangle 表
|
||||
- Filter 表
|
||||
- Raw 表
|
||||
|
||||
Nat表 : Nat表主要用于网络地址转换。根据表中的每一条规则修改网络包的IP地址。流中的包仅遍历一遍Nat表。例如,如果一个通过某个接口的包被修饰(修改了IP地址),该流中其余的包将不再遍历这个表。通常不建议在这个表中进行过滤,由NAT表支持的链称为PREROUTING 链,POSTROUTING 链和OUTPUT 链。
|
||||
|
||||
Mangle表 : 正如它的名字一样,这个表用于校正网络包。它用来对特殊的包进行修改。它能够修改不同包的头部和内容。Mangle表不能用于地址伪装。支持的链包括PREROUTING 链,OUTPUT 链,Forward 链,Input 链和POSTROUTING 链。
|
||||
|
||||
Filter表 : Filter表是iptables中使用的默认表,它用来过滤网络包。如果没有定义任何规则,Filter表则被当作默认的表,并且基于它来过滤。支持的链有INPUT 链,OUTPUT 链,FORWARD 链。
|
||||
|
||||
Raw表 : Raw表在我们想要配置之前被豁免的包时被使用。它支持PREROUTING 链和OUTPUT 链。
|
||||
|
||||
### 6. 简要谈谈什么是iptables中的目标值(能被指定为目标),他们有什么用 ###
|
||||
|
||||
**答案** : 下面是在iptables中可以指定为目标的值:
|
||||
|
||||
- ACCEPT : 接受包
|
||||
- QUEUE : 将包传递到用户空间 (应用程序和驱动所在的地方)
|
||||
- DROP : 丢弃包
|
||||
- RETURN : 将控制权交回调用的链并且为当前链中的包停止执行下一调用规则
|
||||
|
||||
### 7. 让我们来谈谈iptables技术方面的东西,我的意思是说实际使用方面 ###
|
||||
|
||||
你怎么检测在CentOS中安装iptables时需要的iptables的rpm?
|
||||
|
||||
**答案** : iptables已经被默认安装在CentOS中,我们不需要单独安装它。但可以这样检测rpm:
|
||||
|
||||
# rpm -qa iptables
|
||||
|
||||
iptables-1.4.21-13.el7.x86_64
|
||||
|
||||
如果您需要安装它,您可以用yum来安装。
|
||||
|
||||
# yum install iptables-services
|
||||
|
||||
### 8. 怎样检测并且确保iptables服务正在运行? ###
|
||||
|
||||
**答案** : 您可以在终端中运行下面的命令来检测iptables的状态。
|
||||
|
||||
# service status iptables [On CentOS 6/5]
|
||||
# systemctl status iptables [On CentOS 7]
|
||||
|
||||
如果iptables没有在运行,可以使用下面的语句
|
||||
|
||||
---------------- 在CentOS 6/5下 ----------------
|
||||
# chkconfig --level 35 iptables on
|
||||
# service iptables start
|
||||
|
||||
---------------- 在CentOS 7下 ----------------
|
||||
# systemctl enable iptables
|
||||
# systemctl start iptables
|
||||
|
||||
我们还可以检测iptables的模块是否被加载:
|
||||
|
||||
# lsmod | grep ip_tables
|
||||
|
||||
### 9. 你怎么检查iptables中当前定义的规则呢? ###
|
||||
|
||||
**答案** : 当前的规则可以简单的用下面的命令查看:
|
||||
|
||||
# iptables -L
|
||||
|
||||
示例输出
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
### 10. 你怎样刷新所有的iptables规则或者特定的链呢? ###
|
||||
|
||||
**答案** : 您可以使用下面的命令来刷新一个特定的链。
|
||||
|
||||
# iptables --flush OUTPUT
|
||||
|
||||
要刷新所有的规则,可以用:
|
||||
|
||||
# iptables --flush
|
||||
|
||||
### 11. 请在iptables中添加一条规则,接受所有从一个信任的IP地址(例如,192.168.0.7)过来的包。 ###
|
||||
|
||||
**答案** : 上面的场景可以通过运行下面的命令来完成。
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
|
||||
我们还可以在源IP中使用标准的斜线和子网掩码:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
# iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. 怎样在iptables中添加规则以ACCEPT,REJECT,DENY和DROP ssh的服务? ###
|
||||
|
||||
**答案** : 但愿ssh运行在22端口,那也是ssh的默认端口,我们可以在iptables中添加规则来ACCEPT ssh的tcp包(在22号端口上)。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
REJECT ssh服务(22号端口)的tcp包。
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j REJECT
|
||||
|
||||
DENY ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DENY
|
||||
|
||||
DROP ssh服务(22号端口)的tcp包。
|
||||
|
||||
|
||||
# iptables -A INPUT -s -p tcp --dport 22 -j DROP
|
||||
|
||||
### 13. 让我给你另一个场景,假如有一台电脑的本地IP地址是192.168.0.6。你需要封锁在21、22、23和80号端口上的连接,你会怎么做? ###
|
||||
|
||||
**答案** : 这时,我所需要的就是在iptables中使用‘multiport‘选项,并将要封锁的端口号跟在它后面。上面的场景可以用下面的一条语句搞定:
|
||||
|
||||
# iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
|
||||
可以用下面的语句查看写入的规则。
|
||||
|
||||
# iptables -L
|
||||
|
||||
Chain INPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
ACCEPT icmp -- anywhere anywhere
|
||||
ACCEPT all -- anywhere anywhere
|
||||
ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
|
||||
Chain FORWARD (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
|
||||
Chain OUTPUT (policy ACCEPT)
|
||||
target prot opt source destination
|
||||
|
||||
**面试官** : 好了,我问的就是这些。你是一个很有价值的雇员,我们不会错过你的。我将会向HR推荐你的名字。如果你有什么问题,请问我。
|
||||
|
||||
作为一个候选人我不愿不断的问将来要做的项目的事以及公司里其他的事,这样会打断愉快的对话。更不用说HR轮会不会比较难,总之,我获得了机会。
|
||||
|
||||
同时我要感谢Avishek和Ravi(我的朋友)花时间帮我整理我的面试。
|
||||
|
||||
朋友!如果您有过类似的面试,并且愿意与数百万Tecmint读者一起分享您的面试经历,请将您的问题和答案发送到admin@tecmint.com。
|
||||
|
||||
谢谢!保持联系。如果我能更好的回答我上面的问题的话,请记得告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -0,0 +1,126 @@
|
||||
如何使用Docker Machine部署Swarm集群
|
||||
================================================================================
|
||||
|
||||
大家好,今天我们来研究一下如何使用Docker Machine部署Swarm集群。Docker Machine提供了标准的Docker API 支持,所以任何可以与Docker守护进程进行交互的工具都可以使用Swarm来(透明地)扩增到多台主机上。Docker Machine可以用来在个人电脑、云端以及的数据中心里创建Docker主机。它为创建服务器,安装Docker以及根据用户设定来配置Docker客户端提供了便捷化的解决方案。我们可以使用任何驱动来部署swarm集群,并且swarm集群将由于使用了TLS加密具有极好的安全性。
|
||||
|
||||
下面是我提供的简便方法。
|
||||
|
||||
### 1. 安装Docker Machine ###
|
||||
|
||||
Docker Machine 在各种Linux系统上都支持的很好。首先,我们需要从Github上下载最新版本的Docker Machine。我们使用curl命令来下载最先版本Docker Machine ie 0.2.0。
|
||||
|
||||
64位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
32位操作系统:
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
下载了最先版本的Docker Machine之后,我们需要对 /usr/local/bin/ 目录下的docker-machine文件的权限进行修改。命令如下:
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
在做完上面的事情以后,我们要确保docker-machine已经安装正确。怎么检查呢?运行`docker-machine -v`指令,该指令将会给出我们系统上所安装的docker-machine版本。
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
为了让Docker命令能够在我们的机器上运行,必须还要在机器上安装Docker客户端。命令如下。
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. 创建Machine ###
|
||||
|
||||
在将Docker Machine安装到我们的设备上之后,我们需要使用Docker Machine创建一个machine。在这篇文章中,我们会将其部署在Digital Ocean Platform上。所以我们将使用“digitalocean”作为它的Driver API,然后将docker swarm运行在其中。这个Droplet会被设置为Swarm主控节点,我们还要创建另外一个Droplet,并将其设定为Swarm节点代理。
|
||||
|
||||
创建machine的命令如下:
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**备注**: 假设我们要创建一个名为“linux-dev”的machine。<API-Token>是用户在Digital Ocean Cloud Platform的Digital Ocean控制面板中生成的密钥。为了获取这个密钥,我们需要登录我们的Digital Ocean控制面板,然后点击API选项,之后点击Generate New Token,起个名字,然后在Read和Write两个选项上打钩。之后我们将得到一个很长的十六进制密钥,这个就是<API-Token>了。用其替换上面那条命令中的API-Token字段。
|
||||
|
||||
现在,运行下面的指令,将Machine 的配置变量加载进shell里。
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
然后,我们使用如下命令将我们的machine标记为ACTIVE状态。
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
现在,我们检查它(指machine)是否被标记为了 ACTIVE "*"。
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. 运行Swarm Docker镜像 ###
|
||||
|
||||
现在,在我们创建完成了machine之后。我们需要将swarm docker镜像部署上去。这个machine将会运行这个docker镜像,并且控制Swarm主控节点和从节点。使用下面的指令运行镜像:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
如果你想要在**32位操作系统**上运行swarm docker镜像。你需要SSH登录到Droplet当中。
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. 创建Swarm主控节点 ###
|
||||
|
||||
在我们的swarm image已经运行在machine当中之后,我们将要创建一个Swarm主控节点。使用下面的语句,添加一个主控节点。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. 创建Swarm从节点 ###
|
||||
|
||||
现在,我们将要创建一个swarm从节点,此节点将与Swarm主控节点相连接。下面的指令将创建一个新的名为swarm-node的droplet,其与Swarm主控节点相连。到此,我们就拥有了一个两节点的swarm集群了。
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. 与Swarm主控节点连接 ###
|
||||
|
||||
现在,我们连接Swarm主控节点以便我们可以依照需求和配置文件在节点间部署Docker容器。运行下列命令将Swarm主控节点的Machine配置文件加载到环境当中。
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
然后,我们就可以跨节点地运行我们所需的容器了。在这里,我们还要检查一下是否一切正常。所以,运行**docker info**命令来检查Swarm集群的信息。
|
||||
|
||||
# docker info
|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们可以用Docker Machine轻而易举地创建Swarm集群。这种方法有非常高的效率,因为它极大地减少了系统管理员和用户的时间消耗。在这篇文章中,我们以Digital Ocean作为驱动,通过创建一个主控节点和一个从节点成功地部署了集群。其他类似的驱动还有VirtualBox,Google Cloud Computing,Amazon Web Service,Microsoft Azure等等。这些连接都是通过TLS进行加密的,具有很高的安全性。如果你有任何的疑问,建议,反馈,欢迎在下面的评论框中注明以便我们可以更好地提高文章的质量!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[DongShuaike](https://github.com/DongShuaike)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
@ -1,53 +1,54 @@
|
||||
Autojump – 一个高级的‘cd’命令用以快速浏览 Linux 文件系统
|
||||
Autojump:一个可以在 Linux 文件系统快速导航的高级 cd 命令
|
||||
================================================================================
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行浏览有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
对于那些主要通过控制台或终端使用 Linux 命令行来工作的 Linux 用户来说,他们真切地感受到了 Linux 的强大。 然而在 Linux 的分层文件系统中进行导航有时或许是一件头疼的事,尤其是对于那些新手来说。
|
||||
|
||||
现在,有一个用 Python 写的名为 `autojump` 的 Linux 命令行实用程序,它是 Linux ‘[cd][1]’命令的高级版本。
|
||||
|
||||

|
||||
|
||||
Autojump – 浏览 Linux 文件系统的最快方式
|
||||
*Autojump – Linux 文件系统导航的最快方式*
|
||||
|
||||
这个应用原本由 Joël Schaerer 编写,现在由 +William Ting 维护。
|
||||
|
||||
Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录浏览。与传统的 `cd` 命令相比,autojump 能够更加快速地浏览至目的目录。
|
||||
Autojump 应用可以从用户那里学习并帮助用户在 Linux 命令行中进行更轻松的目录导航。与传统的 `cd` 命令相比,autojump 能够更加快速地导航至目的目录。
|
||||
|
||||
#### autojump 的特色 ####
|
||||
|
||||
- 免费且开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的浏览习惯中学习。
|
||||
- 更快速地浏览。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat and Fedora。
|
||||
- 自由开源的应用,在 GPL V3 协议下发布。
|
||||
- 自主学习的应用,从用户的导航习惯中学习。
|
||||
- 更快速地导航。不必包含子目录的名称。
|
||||
- 对于大多数的标准 Linux 发行版本,能够在软件仓库中下载得到,它们包括 Debian (testing/unstable), Ubuntu, Mint, Arch, Gentoo, Slackware, CentOS, RedHat 和 Fedora。
|
||||
- 也能在其他平台中使用,例如 OS X(使用 Homebrew) 和 Windows (通过 Clink 来实现)
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以打开文件管理器来到达某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
- 使用 autojump 你可以跳至任何特定的目录或一个子目录。你还可以用文件管理器打开某个目录,并查看你在某个目录中所待时间的统计数据。
|
||||
|
||||
#### 前提 ####
|
||||
|
||||
- 版本号不低于 2.6 的 Python
|
||||
|
||||
### 第 1 步: 做一次全局系统升级 ###
|
||||
### 第 1 步: 做一次完整的系统升级 ###
|
||||
|
||||
1. 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
1、 以 **root** 用户的身份,做一次系统更新或升级,以此保证你安装有最新版本的 Python。
|
||||
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [APT based systems]
|
||||
# yum update && yum upgrade [YUM based systems]
|
||||
# dnf update && dnf upgrade [DNF based systems]
|
||||
# apt-get update && apt-get upgrade && apt-get dist-upgrade [基于 APT 的系统]
|
||||
# yum update && yum upgrade [基于 YUM 的系统]
|
||||
# dnf update && dnf upgrade [基于 DNF 的系统]
|
||||
|
||||
**注** : 这里特别提醒,在基于 YUM 或 DNF 的系统中,更新和升级执行相同的行动,大多数时间里它们是通用的,这点与基于 APT 的系统不同。
|
||||
|
||||
### 第 2 步: 下载和安装 Autojump ###
|
||||
|
||||
2. 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
2、 正如前面所言,在大多数的 Linux 发行版本的软件仓库中, autojump 都可获取到。通过包管理器你就可以安装它。但若你想从源代码开始来安装它,你需要克隆源代码并执行 python 脚本,如下面所示:
|
||||
|
||||
#### 从源代码安装 ####
|
||||
|
||||
若没有安装 git,请安装它。我们需要使用它来克隆 git 仓库。
|
||||
|
||||
# apt-get install git [APT based systems]
|
||||
# yum install git [YUM based systems]
|
||||
# dnf install git [DNF based systems]
|
||||
# apt-get install git [基于 APT 的系统]
|
||||
# yum install git [基于 YUM 的系统]
|
||||
# dnf install git [基于 DNF 的系统]
|
||||
|
||||
一旦安装完 git,以常规用户身份登录,然后像下面那样来克隆 autojump:
|
||||
一旦安装完 git,以普通用户身份登录,然后像下面那样来克隆 autojump:
|
||||
|
||||
$ git clone git://github.com/joelthelion/autojump.git
|
||||
|
||||
@ -55,29 +56,29 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
$ cd autojump
|
||||
|
||||
下载,赋予脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
下载,赋予安装脚本文件可执行权限,并以 root 用户身份来运行安装脚本。
|
||||
|
||||
# chmod 755 install.py
|
||||
# ./install.py
|
||||
|
||||
#### 从软件仓库中安装 ####
|
||||
|
||||
3. 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
3、 假如你不想麻烦,你可以以 **root** 用户身份从软件仓库中直接安装它:
|
||||
|
||||
在 Debian, Ubuntu, Mint 及类似系统中安装 autojump :
|
||||
|
||||
# apt-get install autojump (注: 这里原文为 autojumo, 应该为 autojump)
|
||||
# apt-get install autojump
|
||||
|
||||
为了在 Fedora, CentOS, RedHat 及类似系统中安装 autojump, 你需要启用 [EPEL 软件仓库][2]。
|
||||
|
||||
# yum install epel-release
|
||||
# yum install autojump
|
||||
OR
|
||||
或
|
||||
# dnf install autojump
|
||||
|
||||
### 第 3 步: 安装后的配置 ###
|
||||
|
||||
4. 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
4、 在 Debian 及其衍生系统 (Ubuntu, Mint,…) 中, 激活 autojump 应用是非常重要的。
|
||||
|
||||
为了暂时激活 autojump 应用,即直到你关闭当前会话或打开一个新的会话之前让 autojump 均有效,你需要以常规用户身份运行下面的命令:
|
||||
|
||||
@ -89,7 +90,7 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
### 第 4 步: Autojump 的预测试和使用 ###
|
||||
|
||||
5. 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
5、 如先前所言, autojump 将只跳到先前 `cd` 命令到过的目录。所以在我们开始测试之前,我们要使用 `cd` 切换到一些目录中去,并创建一些目录。下面是我所执行的命令。
|
||||
|
||||
$ cd
|
||||
$ cd
|
||||
@ -120,45 +121,45 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
现在,我们已经切换到过上面所列的目录,并为了测试创建了一些目录,一切准备就绪,让我们开始吧。
|
||||
|
||||
**需要记住的一点** : `j` 是 autojump 的一个包装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
**需要记住的一点** : `j` 是 autojump 的一个封装,你可以使用 j 来代替 autojump, 相反亦可。
|
||||
|
||||
6. 使用 -v 选项查看安装的 autojump 的版本。
|
||||
6、 使用 -v 选项查看安装的 autojump 的版本。
|
||||
|
||||
$ j -v
|
||||
or
|
||||
或
|
||||
$ autojump -v
|
||||
|
||||

|
||||
|
||||
查看 Autojump 的版本
|
||||
*查看 Autojump 的版本*
|
||||
|
||||
7. 跳到先前到过的目录 ‘/var/www‘。
|
||||
7、 跳到先前到过的目录 ‘/var/www‘。
|
||||
|
||||
$ j www
|
||||
|
||||
|
||||
|
||||
跳到目录
|
||||
*跳到目录*
|
||||
|
||||
8. 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
8、 跳到先前到过的子目录‘/home/avi/autojump-test/b‘ 而不键入子目录的全名。
|
||||
|
||||
$ jc b
|
||||
|
||||

|
||||
|
||||
跳到子目录
|
||||
*跳到子目录*
|
||||
|
||||
9. 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
9、 使用下面的命令,你就可以从命令行打开一个文件管理器,例如 GNOME Nautilus ,而不是跳到一个目录。
|
||||
|
||||
$ jo www
|
||||
|
||||
|
||||

|
||||
|
||||
跳到目录
|
||||
*打开目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开目录
|
||||
*在文件管理器中打开目录*
|
||||
|
||||
你也可以在一个文件管理器中打开一个子目录。
|
||||
|
||||
@ -166,19 +167,19 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||

|
||||
|
||||
打开子目录
|
||||
*打开子目录*
|
||||
|
||||

|
||||
|
||||
在文件管理器中打开子目录
|
||||
*在文件管理器中打开子目录*
|
||||
|
||||
10. 查看每个文件夹的关键权重和在所有目录权重中的总关键权重的相关统计数据。文件夹的关键权重代表在这个文件夹中所花的总时间。 目录权重是列表中目录的数目。(注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
10、 查看每个文件夹的权重和全部文件夹计算得出的总权重的统计数据。文件夹的权重代表在这个文件夹中所花的总时间。 文件夹权重是该列表中目录的数字。(LCTT 译注: 在这一句中,我觉得原文中的 if 应该为 is)
|
||||
|
||||
$ j --stat
|
||||
|
||||

|
||||

|
||||
|
||||
查看目录统计数据
|
||||
*查看文件夹统计数据*
|
||||
|
||||
**提醒** : autojump 存储其运行日志和错误日志的地方是文件夹 `~/.local/share/autojump/`。千万不要重写这些文件,否则你将失去你所有的统计状态结果。
|
||||
|
||||
@ -186,15 +187,15 @@ Autojump 应用从用户那里学习并帮助用户在 Linux 命令行中进行
|
||||
|
||||
|
||||
|
||||
Autojump 的日志
|
||||
*Autojump 的日志*
|
||||
|
||||
11. 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
11、 假如需要,你只需运行下面的命令就可以查看帮助 :
|
||||
|
||||
$ j --help
|
||||
|
||||

|
||||
|
||||
Autojump 的帮助和选项
|
||||
*Autojump 的帮助和选项*
|
||||
|
||||
### 功能需求和已知的冲突 ###
|
||||
|
||||
@ -204,18 +205,19 @@ Autojump 的帮助和选项
|
||||
|
||||
### 结论: ###
|
||||
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中浏览 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
假如你是一个命令行用户, autojump 是你必备的实用程序。它可以简化许多事情。它是一个在命令行中导航 Linux 目录的绝佳的程序。请自行尝试它,并在下面的评论框中让我知晓你宝贵的反馈。保持联系,保持分享。喜爱并分享,帮助我们更好地传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/autojump-a-quickest-way-to-navigate-linux-filesystem/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cd-command-in-linux/
|
||||
[2]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
|
||||
[2]:https://linux.cn/article-2324-1.html
|
||||
[3]:http://www.tecmint.com/manage-linux-filenames-with-special-characters/
|
||||
@ -1,8 +1,11 @@
|
||||
修复Linux中的提供最小化类BASH命令行编辑GRUB错误
|
||||
修复Linux中的“提供类似行编辑的袖珍BASH...”的GRUB错误
|
||||
================================================================================
|
||||
|
||||
这两天我[安装了Elementary OS和Windows双系统][1],在启动的时候遇到了一个Grub错误。命令行中呈现如下信息:
|
||||
|
||||
**提供最小化类BASH命令行编辑。对于第一个词,TAB键补全可以使用的命令。除此之外,TAB键补全可用的设备或文件。**
|
||||
**Minimal BASH like line editing is supported. For the first word, TAB lists possible command completions. anywhere else TAB lists possible device or file completions.**
|
||||
|
||||
**提供类似行编辑的袖珍 BASH。TAB键补全第一个词,列出可以使用的命令。除此之外,TAB键补全可以列出可用的设备或文件。**
|
||||
|
||||

|
||||
|
||||
@ -10,7 +13,7 @@
|
||||
|
||||
通过这篇文章里我们可以学到基于Linux系统**如何修复Ubuntu中出现的“minimal BASH like line editing is supported” Grub错误**。
|
||||
|
||||
> 你可以参阅这篇教程来修复类似的高频问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
> 你可以参阅这篇教程来修复类似的常见问题,[错误:分区未找到Linux grub救援模式][3]。
|
||||
|
||||
### 先决条件 ###
|
||||
|
||||
@ -19,11 +22,11 @@
|
||||
- 一个包含相同版本、相同OS的LiveUSB或磁盘
|
||||
- 当前会话的Internet连接正常工作
|
||||
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话;))。
|
||||
在确认了你拥有先决条件了之后,让我们看看如何修复Linux的死亡黑屏(如果我可以这样的称呼它的话 ;) )。
|
||||
|
||||
### 如何在基于Ubuntu的Linux中修复“minimal BASH like line editing is supported” Grub错误 ###
|
||||
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法并叫作**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复minimal BASH like line editing is supported Grub错误。
|
||||
我知道你一定疑问这种Grub错误并不局限于在基于Ubuntu的Linux发行版上发生,那为什么我要强调在基于Ubuntu的发行版上呢?原因是,在这里我们将采用一个简单的方法,用个叫做**Boot Repair**的工具来修复我们的问题。我并不确定在其他的诸如Fedora的发行版中是否有这个工具可用。不再浪费时间,我们来看如何修复“minimal BASH like line editing is supported” Grub错误。
|
||||
|
||||
### 步骤 1: 引导进入lives会话 ###
|
||||
|
||||
@ -75,7 +78,7 @@ via: http://itsfoss.com/fix-minimal-bash-line-editing-supported-grub-error-linux
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
FreeBSD 和 Linux 有什么不同?
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
### 简介 ###
|
||||
|
||||
BSD最初从UNIX继承而来,目前,有许多的类Unix操作系统是基于BSD的。FreeBSD是使用最广泛的开源的伯克利软件发行版(即 BSD 发行版)。就像它隐含的意思一样,它是一个自由开源的类Unix操作系统,并且是公共服务器平台。FreeBSD源代码通常以宽松的BSD许可证发布。它与Linux有很多相似的地方,但我们得承认它们在很多方面仍有不同。
|
||||
|
||||
本文的其余部分组织如下:FreeBSD的描述在第一部分,FreeBSD和Linux的相似点在第二部分,它们的区别将在第三部分讨论,对他们功能的讨论和总结在最后一节。
|
||||
|
||||
### FreeBSD描述 ###
|
||||
|
||||
#### 历史 ####
|
||||
|
||||
- FreeBSD的第一个版本发布于1993年,它的第一张CD-ROM是FreeBSD1.0,发行于1993年12月。接下来,FreeBSD 2.1.0在1995年发布,并且获得了所有用户的青睐。实际上许多IT公司都使用FreeBSD并且很满意,我们可以列出其中的一些:IBM、Nokia、NetApp和Juniper Network。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 关于它的许可证,FreeBSD以多种开源许可证进行发布,它的名为Kernel的最新代码以两句版BSD许可证进行了发布,给予使用和重新发布FreeBSD的绝对自由。其它的代码则以三句版或四句版BSD许可证进行发布,有些是以GPL和CDDL的许可证发布的。
|
||||
|
||||
(LCTT 译注:BSD 许可证与 GPL 许可证相比,相当简短,最初只有四句规则;1999年应 RMS 请求,删除了第三句,新的许可证称作“新 BSD”或三句版BSD;原来的 BSD 许可证称作“旧 BSD”、“修订的 BSD”或四句版BSD;也有一种删除了第三、第四两句的版本,称之为两句版 BSD,等价于 MIT 许可证。)
|
||||
|
||||
#### 用户 ####
|
||||
|
||||
- FreeBSD的重要特点之一就是它的用户多样性。实际上,FreeBSD可以作为邮件服务器、Web 服务器、FTP 服务器以及路由器等,您只需要在它上运行服务相关的软件即可。而且FreeBSD还支持ARM、PowerPC、MIPS、x86、x86-64架构。
|
||||
|
||||
### FreeBSD和Linux的相似处 ###
|
||||
|
||||
FreeBSD和Linux是两个自由开源的软件。实际上,它们的用户可以很容易的检查并修改源代码,用户拥有绝对的自由。而且,FreeBSD和Linux都是类Unix系统,它们的内核、内部组件、库程序都使用从历史上的AT&T Unix继承来的算法。FreeBSD从根基上更像Unix系统,而Linux是作为自由的类Unix系统发布的。许多工具应用都可以在FreeBSD和Linux中找到,实际上,他们几乎有同样的功能。
|
||||
|
||||
此外,FreeBSD能够运行大量的Linux应用。它可以安装一个Linux的兼容层,这个兼容层可以在编译FreeBSD时加入AAC Compact Linux得到,或通过下载已编译了Linux兼容层的FreeBSD系统,其中会包括兼容程序:aac_linux.ko。不同于FreeBSD的是,Linux无法运行FreeBSD的软件。
|
||||
|
||||
最后,我们注意到虽然二者有同样的目标,但二者还是有一些不同之处,我们在下一节中列出。
|
||||
|
||||
### FreeBSD和Linux的区别 ###
|
||||
|
||||
目前对于大多数用户来说并没有一个选择FreeBSD还是Linux的明确的准则。因为他们有着很多同样的应用程序,因为他们都被称作类Unix系统。
|
||||
|
||||
在这一章,我们将列出这两种系统的一些重要的不同之处。
|
||||
|
||||
#### 许可证 ####
|
||||
|
||||
- 两个系统的区别首先在于它们的许可证。Linux以GPL许可证发行,它为用户提供阅读、发行和修改源代码的自由,GPL许可证帮助用户避免仅仅发行二进制。而FreeBSD以BSD许可证发布,BSD许可证比GPL更宽容,因为其衍生著作不需要仍以该许可证发布。这意味着任何用户能够使用、发布、修改代码,并且不需要维持之前的许可证。
|
||||
- 您可以依据您的需求,在两种许可证中选择一种。首先是BSD许可证,由于其特殊的条款,它更受用户青睐。实际上,这个许可证使用户在保证源代码的封闭性的同时,可以售卖以该许可证发布的软件。再说说GPL,它需要每个使用以该许可证发布的软件的用户多加注意。
|
||||
- 如果想在以不同许可证发布的两种软件中做出选择,您需要了解他们各自的许可证,以及他们开发中的方法论,从而能了解他们特性的区别,来选择更适合自己需求的。
|
||||
|
||||
#### 控制 ####
|
||||
|
||||
- 由于FreeBSD和Linux是以不同的许可证发布的,Linus Torvalds控制着Linux的内核,而FreeBSD却与Linux不同,它并未被控制。我个人更倾向于使用FreeBSD而不是Linux,这是因为FreeBSD才是绝对自由的软件,没有任何控制许可证的存在。Linux和FreeBSD还有其他的不同之处,我建议您先不急着做出选择,等读完本文后再做出您的选择。
|
||||
|
||||
#### 操作系统 ####
|
||||
|
||||
- Linux主要指内核系统,这与FreeBSD不同,FreeBSD的整个系统都被维护着。FreeBSD的内核和一组由FreeBSD团队开发的软件被作为一个整体进行维护。实际上,FreeBSD开发人员能够远程且高效的管理核心操作系统。
|
||||
- 而Linux方面,在管理系统方面有一些困难。由于不同的组件由不同的源维护,Linux开发者需要将它们汇集起来,才能达到同样的功能。
|
||||
- FreeBSD和Linux都给了用户大量的可选软件和发行版,但他们管理的方式不同。FreeBSD是统一的管理方式,而Linux需要被分别维护。
|
||||
|
||||
#### 硬件支持 ####
|
||||
|
||||
- 说到硬件支持,Linux比FreeBSD做的更好。但这不意味着FreeBSD没有像Linux那样支持硬件的能力。他们只是在管理的方式不同,这通常还依赖于您的需求。因此,如果您在寻找最新的解决方案,FreeBSD更适应您;但如果您在寻找更多的普适性,那最好使用Linux。
|
||||
|
||||
#### 原生FreeBSD Vs 原生Linux ####
|
||||
|
||||
- 两者的原生系统的区别又有不同。就像我之前说的,Linux是一个Unix的替代系统,由Linux Torvalds编写,并由网络上的许多极客一起协助实现的。Linux有一个现代系统所需要的全部功能,诸如虚拟内存、共享库、动态加载、优秀的内存管理等。它以GPL许可证发布。
|
||||
- FreeBSD也继承了Unix的许多重要的特性。FreeBSD作为在加州大学开发的BSD的一种发行版。开发BSD的最重要的原因是用一个开源的系统来替代AT&T操作系统,从而给用户无需AT&T许可证便可使用的能力。
|
||||
- 许可证的问题是开发者们最关心的问题。他们试图提供一个最大化克隆Unix的开源系统。这影响了用户的选择,由于FreeBSD使用BSD许可证进行发布,因而相比Linux更加自由。
|
||||
|
||||
#### 支持的软件包 ####
|
||||
|
||||
- 从用户的角度来看,另一个二者不同的地方便是软件包以及从源码安装的软件的可用性和支持。Linux只提供了预编译的二进制包,这与FreeBSD不同,它不但提供预编译的包,而且还提供从源码编译和安装的构建系统。使用它的 ports 工具,FreeBSD给了您选择使用预编译的软件包(默认)和在编译时定制您软件的能力。(LCTT 译注:此处说明有误。Linux 也提供了源代码方式的包,并支持自己构建。)
|
||||
- 这些 ports 允许您构建所有支持FreeBSD的软件。而且,它们的管理还是层次化的,您可以在/usr/ports下找到源文件的地址以及一些正确使用FreeBSD的文档。
|
||||
- 这些提到的 ports给予你产生不同软件包版本的可能性。FreeBSD给了您通过源代码构建以及预编译的两种软件,而不是像Linux一样只有预编译的软件包。您可以使用两种安装方式管理您的系统。
|
||||
|
||||
#### FreeBSD 和 Linux 常用工具比较 ####
|
||||
|
||||
- 有大量的常用工具在FreeBSD上可用,并且有趣的是他们由FreeBSD的团队所拥有。相反的,Linux工具来自GNU,这就是为什么在使用中有一些限制。(LCTT 译注:这也是 Linux 正式的名称被称作“GNU/Linux”的原因,因为本质上 Linux 其实只是指内核。)
|
||||
- 实际上FreeBSD采用的BSD许可证非常有益且有用。因此,您有能力维护核心操作系统,控制这些应用程序的开发。有一些工具类似于它们的祖先 - BSD和Unix的工具,但不同于GNU的套件,GNU套件只想做到最小的向后兼容。
|
||||
|
||||
#### 标准 Shell ####
|
||||
|
||||
- FreeBSD默认使用tcsh。它是csh的评估版,由于FreeBSD以BSD许可证发行,因此不建议您在其中使用GNU的组件 bash shell。bash和tcsh的区别仅仅在于tcsh的脚本功能。实际上,我们更推荐在FreeBSD中使用sh shell,因为它更加可靠,可以避免一些使用tcsh和csh时出现的脚本问题。
|
||||
|
||||
#### 一个更加层次化的文件系统 ####
|
||||
|
||||
- 像之前提到的一样,使用FreeBSD时,基础操作系统以及可选组件可以被很容易的区别开来。这导致了一些管理它们的标准。在Linux下,/bin,/sbin,/usr/bin或者/usr/sbin都是存放可执行文件的目录。FreeBSD不同,它有一些附加的对其进行组织的规范。基础操作系统被放在/usr/local/bin或者/usr/local/sbin目录下。这种方法可以帮助管理和区分基础操作系统和可选组件。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
FreeBSD和Linux都是自由且开源的系统,他们有相似点也有不同点。上面列出的内容并不能说哪个系统比另一个更好。实际上,FreeBSD和Linux都有自己的特点和技术规格,这使它们与别的系统区别开来。那么,您有什么看法呢?您已经有在使用它们中的某个系统了么?如果答案为是的话,请给我们您的反馈;如果答案是否的话,在读完我们的描述后,您怎么看?请在留言处发表您的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/comparative-introduction-freebsd-linux-users/
|
||||
|
||||
作者:[anismaj][a]
|
||||
译者:[wwy-hust](https://github.com/wwy-hust)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.unixmen.com/author/anis/
|
||||
@ -1,13 +1,14 @@
|
||||
在Linux中使用‘Systemctl’管理‘Systemd’服务和单元
|
||||
systemctl 完全指南
|
||||
================================================================================
|
||||
Systemctl是一个systemd工具,主要负责控制systemd系统和服务管理器。
|
||||
|
||||
Systemd是一个系统管理守护进程、工具和库的集合,用于取代System V初始进程。Systemd的功能是用于集中管理和配置类UNIX系统。
|
||||
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有位数不多的几个尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
在Linux生态系统中,Systemd被部署到了大多数的标准Linux发行版中,只有为数不多的几个发行版尚未部署。Systemd通常是所有其它守护进程的父进程,但并非总是如此。
|
||||
|
||||

|
||||
使用Systemctl管理Linux服务
|
||||
|
||||
*使用Systemctl管理Linux服务*
|
||||
|
||||
本文旨在阐明在运行systemd的系统上“如何控制系统和服务”。
|
||||
|
||||
@ -41,11 +42,9 @@ Systemd是一个系统管理守护进程、工具和库的集合,用于取代S
|
||||
root 555 1 0 16:27 ? 00:00:00 /usr/lib/systemd/systemd-logind
|
||||
dbus 556 1 0 16:27 ? 00:00:00 /bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
|
||||
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-
|
||||
**注意**:systemd是作为父进程(PID=1)运行的。在上面带(-e)参数的ps命令输出中,选择所有进程,(-a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(即 -eaf)。
|
||||
|
||||
a)选择除会话前导外的所有进程,并使用(-f)参数输出完整格式列表(如 -eaf)。
|
||||
|
||||
也请注意上例中后随的方括号和样例剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
也请注意上例中后随的方括号和例子中剩余部分。方括号表达式是grep的字符类表达式的一部分。
|
||||
|
||||
#### 4. 分析systemd启动进程 ####
|
||||
|
||||
@ -147,7 +146,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
1 loaded units listed. Pass --all to see loaded but inactive units, too.
|
||||
To show all installed unit files use 'systemctl list-unit-files'.
|
||||
|
||||
#### 10. 检查某个单元(cron.service)是否启用 ####
|
||||
#### 10. 检查某个单元(如 cron.service)是否启用 ####
|
||||
|
||||
# systemctl is-enabled crond.service
|
||||
|
||||
@ -187,7 +186,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
dbus-org.fedoraproject.FirewallD1.service enabled
|
||||
....
|
||||
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(httpd.service)状态 ####
|
||||
#### 13. Linux中如何启动、重启、停止、重载服务以及检查服务(如 httpd.service)状态 ####
|
||||
|
||||
# systemctl start httpd.service
|
||||
# systemctl restart httpd.service
|
||||
@ -214,15 +213,15 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
Apr 28 17:21:30 tecmint systemd[1]: Started The Apache HTTP Server.
|
||||
Hint: Some lines were ellipsized, use -l to show in full.
|
||||
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
**注意**:当我们使用systemctl的start,restart,stop和reload命令时,我们不会从终端获取到任何输出内容,只有status命令可以打印输出。
|
||||
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(系统启动时自动启动服务) ####
|
||||
#### 14. 如何激活服务并在启动时启用或禁用服务(即系统启动时自动启动服务) ####
|
||||
|
||||
# systemctl is-active httpd.service
|
||||
# systemctl enable httpd.service
|
||||
# systemctl disable httpd.service
|
||||
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(httpd.service) ####
|
||||
#### 15. 如何屏蔽(让它不能启动)或显示服务(如 httpd.service) ####
|
||||
|
||||
# systemctl mask httpd.service
|
||||
ln -s '/dev/null' '/etc/systemd/system/httpd.service'
|
||||
@ -297,7 +296,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
# systemctl enable tmp.mount
|
||||
# systemctl disable tmp.mount
|
||||
|
||||
#### 20. 在Linux中屏蔽(让它不能启动)或显示挂载点 ####
|
||||
#### 20. 在Linux中屏蔽(让它不能启用)或可见挂载点 ####
|
||||
|
||||
# systemctl mask tmp.mount
|
||||
|
||||
@ -375,7 +374,7 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
|
||||
CPUShares=2000
|
||||
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
**注意**:当你为某个服务设置CPUShares,会自动创建一个以服务名命名的目录(如 httpd.service),里面包含了一个名为90-CPUShares.conf的文件,该文件含有CPUShare限制信息,你可以通过以下方式查看该文件:
|
||||
|
||||
# vi /etc/systemd/system/httpd.service.d/90-CPUShares.conf
|
||||
|
||||
@ -528,13 +527,13 @@ a)选择除会话前导外的所有进程,并使用(-f)参数输出完
|
||||
#### 35. 启动运行等级5,即图形模式 ####
|
||||
|
||||
# systemctl isolate runlevel5.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate graphical.target
|
||||
|
||||
#### 36. 启动运行等级3,即多用户模式(命令行) ####
|
||||
|
||||
# systemctl isolate runlevel3.target
|
||||
OR
|
||||
或
|
||||
# systemctl isolate multiuser.target
|
||||
|
||||
#### 36. 设置多用户模式或图形模式为默认运行等级 ####
|
||||
@ -572,7 +571,7 @@ via: http://www.tecmint.com/manage-services-using-systemd-and-systemctl-in-linux
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,98 @@
|
||||
如何配置一个 Docker Swarm 原生集群
|
||||
================================================================================
|
||||
|
||||
嗨,大家好。今天我们来学一学Swarm相关的内容吧,我们将学习通过Swarm来创建Docker原生集群。[Docker Swarm][1]是用于Docker的原生集群项目,它可以将一个Docker主机池转换成单个的虚拟主机。Swarm工作于标准的Docker API,所以任何可以和Docker守护进程通信的工具都可以使用Swarm来透明地伸缩到多个主机上。就像其它Docker项目一样,Swarm遵循“内置电池,并可拆卸”的原则(LCTT 译注:batteries included,内置电池原来是 Python 圈里面对 Python 的一种赞誉,指自给自足,无需外求的丰富环境;but removable,并可拆卸应该指的是非强制耦合)。它附带有一个开箱即用的简单的后端调度程序,而且作为初始开发套件,也为其开发了一个可插拔不同后端的API。其目标在于为一些简单的使用情况提供一个平滑的、开箱即用的体验,并且它允许切换为更强大的后端,如Mesos,以用于大规模生产环境部署。Swarm配置和使用极其简单。
|
||||
|
||||
这里给大家提供Swarm 0.2开箱的即用一些特性。
|
||||
|
||||
1. Swarm 0.2.0大约85%与Docker引擎兼容。
|
||||
2. 它支持资源管理。
|
||||
3. 它具有一些带有限制和类同功能的高级调度特性。
|
||||
4. 它支持多个发现后端(hubs,consul,etcd,zookeeper)
|
||||
5. 它使用TLS加密方法进行安全通信和验证。
|
||||
|
||||
那么,我们来看一看Swarm的一些相当简单而简用的使用步骤吧。
|
||||
|
||||
### 1. 运行Swarm的先决条件 ###
|
||||
|
||||
我们必须在所有节点安装Docker 1.4.0或更高版本。虽然各个节点的IP地址不需要要公共地址,但是Swarm管理器必须可以通过网络访问各个节点。
|
||||
|
||||
**注意**:Swarm当前还处于beta版本,因此功能特性等还有可能发生改变,我们不推荐你在生产环境中使用。
|
||||
|
||||
### 2. 创建Swarm集群 ###
|
||||
|
||||
现在,我们将通过运行下面的命令来创建Swarm集群。各个节点都将运行一个swarm节点代理,该代理会注册、监控相关的Docker守护进程,并更新发现后端获取的节点状态。下面的命令会返回一个唯一的集群ID标记,在启动节点上的Swarm代理时会用到它。
|
||||
|
||||
在集群管理器中:
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. 启动各个节点上的Docker守护进程 ###
|
||||
|
||||
我们需要登录进我们将用来创建集群的每个节点,并在其上使用-H标记启动Docker守护进程。它会保证Swarm管理器能够通过TCP访问到各个节点上的Docker远程API。要启动Docker守护进程,我们需要在各个节点内部运行以下命令。
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. 添加节点 ###
|
||||
|
||||
在启用Docker守护进程后,我们需要添加Swarm节点到发现服务,我们必须确保节点IP可从Swarm管理器访问到。要完成该操作,我们需要运行以下命令。
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要用步骤2中获取到的节点IP地址和集群ID替换这里的<node_ip>和<cluster_id>。
|
||||
|
||||
### 5. 开启Swarm管理器 ###
|
||||
|
||||
现在,由于我们已经获得了连接到集群的节点,我们将启动swarm管理器。我们需要在节点中运行以下命令。
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. 检查配置 ###
|
||||
|
||||
一旦管理运行起来后,我们可以通过运行以下命令来检查配置。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**注意**:我们需要替换<manager_ip:manager_port>为运行swarm管理器的主机的IP地址和端口。
|
||||
|
||||
### 7. 使用docker CLI来访问节点 ###
|
||||
|
||||
在一切都像上面说得那样完美地完成后,这一部分是Docker Swarm最为重要的部分。我们可以使用Docker CLI来访问节点,并在节点上运行容器。
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. 监听集群中的节点 ###
|
||||
|
||||
我们可以使用swarm list命令来获取所有运行中节点的列表。
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 尾声 ###
|
||||
|
||||
Swarm真的是一个有着相当不错的功能的docker,它可以用于创建和管理集群。它相当易于配置和使用,当我们在它上面使用限制器和类同器时它更为出色。高级调度程序是一个相当不错的特性,它可以应用过滤器来通过端口、标签、健康状况来排除节点,并且它使用策略来挑选最佳节点。那么,如果你有任何问题、评论、反馈,请在下面的评论框中写出来吧,好让我们知道哪些材料需要补充或改进。谢谢大家了!尽情享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
177
published/201507/20150616 LINUX 101--POWER UP YOUR SHELL.md
Normal file
@ -0,0 +1,177 @@
|
||||
LINUX 101: 让你的 SHELL 更强大
|
||||
================================================================================
|
||||
> 在我们的关于 shell 基础的指导下, 得到一个更灵活,功能更强大且多彩的命令行界面
|
||||
|
||||
**为何要这样做?**
|
||||
|
||||
- 使得在 shell 提示符下过得更轻松,高效
|
||||
- 在失去连接后恢复先前的会话
|
||||
- Stop pushing around that fiddly rodent!
|
||||
|
||||
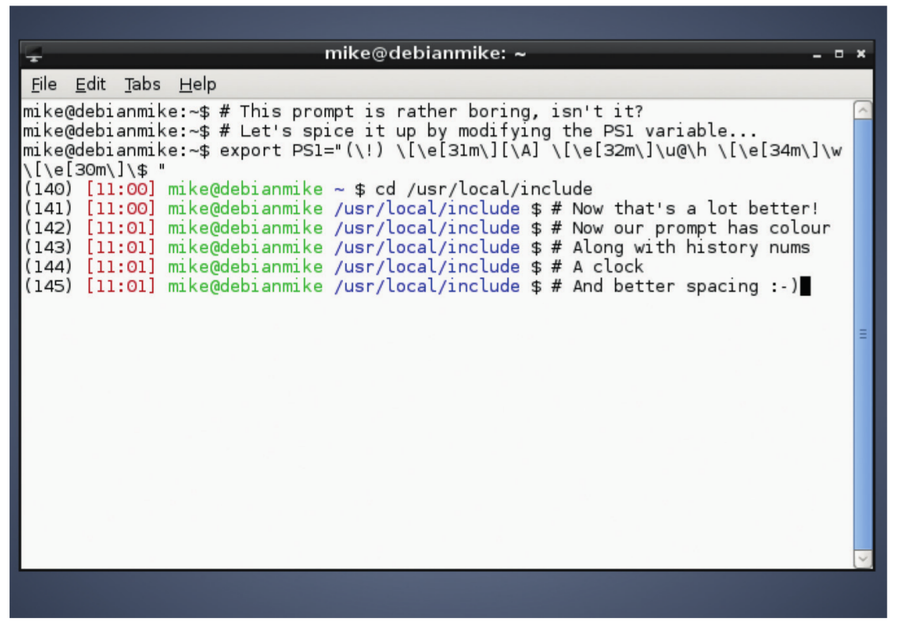
|
||||
|
||||
这是我的命令行提示符的设置。对于这个小的终端窗口来说,这或许有些长。但你可以根据你的喜好来调整它。
|
||||
|
||||
作为一个 Linux 用户, 你可能熟悉 shell (又名为命令行)。 或许你需要时不时的打开终端来完成那些不能在 GUI 下处理的必要任务,抑或是因为你处在一个将窗口铺满桌面的环境中,而 shell 是你与你的 linux 机器交互的主要方式。
|
||||
|
||||
在上面那些情况下,你可能正在使用你所使用的发行版本自带的 Bash 配置。 尽管对于大多数的任务而言,它足够好了,但它可以更加强大。 在本教程中,我们将向你展示如何使得你的 shell 提供更多有用信息、更加实用且更适合工作。 我们将对提示符进行自定义,让它比默认情况下提供更好的反馈,并向你展示如何使用炫酷的 `tmux` 工具来管理会话并同时运行多个程序。 并且,为了让眼睛舒服一点,我们还将关注配色方案。那么,进击吧,少女!
|
||||
|
||||
### 让提示符更美妙 ###
|
||||
|
||||
大多数的发行版本配置有一个非常简单的提示符,它们大多向你展示了一些基本信息, 但提示符可以为你提供更多的内容。例如,在 Debian 7 下,默认的提示符是这样的:
|
||||
|
||||
mike@somebox:~$
|
||||
|
||||
上面的提示符展示出了用户、主机名、当前目录和账户类型符号(假如你切换到 root 账户, **$** 会变为 **#**)。 那这些信息是在哪里存储的呢? 答案是:在 **PS1** 环境变量中。 假如你键入 `echo $PS1`, 你将会在这个命令的输出字符串的最后有如下的字符:
|
||||
|
||||
\u@\h:\w$
|
||||
|
||||
这看起来有一些丑陋,并在瞥见它的第一眼时,你可能会开始尖叫,认为它是令人恐惧的正则表达式,但我们不打算用这些复杂的字符来煎熬我们的大脑。这不是正则表达式,这里的斜杠是转义序列,它告诉提示符进行一些特别的处理。 例如,上面的 **u** 部分,告诉提示符展示用户名, 而 w 则展示工作路径.
|
||||
|
||||
下面是一些你可以在提示符中用到的字符的列表:
|
||||
|
||||
- d 当前的日期
|
||||
- h 主机名
|
||||
- n 代表换行的字符
|
||||
- A 当前的时间 (HH:MM)
|
||||
- u 当前的用户
|
||||
- w (小写) 整个工作路径的全称
|
||||
- W (大写) 工作路径的简短名称
|
||||
- $ 一个提示符号,对于 root 用户为 # 号
|
||||
- ! 当前命令在 shell 历史记录中的序号
|
||||
|
||||
下面解释 **w** 和 **W** 选项的区别: 对于前者,你将看到你所在的工作路径的完整地址,(例如 **/usr/local/bin**),而对于后者, 它则只显示 **bin** 这一部分。
|
||||
|
||||
现在,我们该怎样改变提示符呢? 你需要更改 **PS1** 环境变量的内容,试试下面这个:
|
||||
|
||||
export PS1="I am \u and it is \A $"
|
||||
|
||||
现在,你的提示符将会像下面这样:
|
||||
|
||||
I am mike and it is 11:26 $
|
||||
|
||||
从这个例子出发,你就可以按照你的想法来试验一下上面列出的其他转义序列。 但等等 – 当你登出后,你的这些努力都将消失,因为在你每次打开终端时,**PS1** 环境变量的值都会被重置。解决这个问题的最简单方式是打开 **.bashrc** 配置文件(在你的家目录下) 并在这个文件的最下方添加上完整的 `export` 命令。在每次你启动一个新的 shell 会话时,这个 **.bashrc** 会被 `Bash` 读取, 所以你的加强的提示符就可以一直出现。你还可以使用额外的颜色来装扮提示符。刚开始,这将有点棘手,因为你必须使用一些相当奇怪的转义序列,但结果是非常漂亮的。 将下面的字符添加到你的 **PS1**字符串中的某个位置,最终这将把文本变为红色:
|
||||
|
||||
\[\e[31m\]
|
||||
|
||||
你可以将这里的 31 更改为其他的数字来获得不同的颜色:
|
||||
|
||||
- 30 黑色
|
||||
- 32 绿色
|
||||
- 33 黄色
|
||||
- 34 蓝色
|
||||
- 35 洋红色
|
||||
- 36 青色
|
||||
- 37 白色
|
||||
|
||||
所以,让我们使用先前看到的转义序列和颜色来创造一个提示符,以此来结束这一小节的内容。深吸一口气,弯曲你的手指,然后键入下面这只“野兽”:
|
||||
|
||||
export PS1="(\!) \[\e[31m\] \[\A\] \[\e[32m\]\u@\h \[\e[34m\]\w \[\e[30m\]$"
|
||||
|
||||
上面的命令提供了一个 Bash 命令历史序号、当前的时间、彩色的用户或主机名组合、以及工作路径。假如你“野心勃勃”,利用一些惊人的组合,你还可以更改提示符的背景色和前景色。非常有用的 Arch wiki 有一个关于颜色代码的完整列表:[http://tinyurl.com/3gvz4ec][1]。
|
||||
|
||||
> **Shell 精要**
|
||||
>
|
||||
> 假如你是一个彻底的 Linux 新手并第一次阅读这份杂志,或许你会发觉阅读这些教程有些吃力。 所以这里有一些基础知识来让你熟悉一些 shell。 通常在你的菜单中, shell 指的是 Terminal、 XTerm 或 Konsole, 当你启动它后, 最为实用的命令有这些:
|
||||
>
|
||||
> **ls** (列出文件名); **cp one.txt two.txt** (复制文件); **rm file.txt** (移除文件); **mv old.txt new.txt** (移动或重命名文件);
|
||||
>
|
||||
> **cd /some/directory** (改变目录); **cd ..** (回到上级目录); **./program** (在当前目录下运行一个程序); **ls > list.txt** (重定向输出到一个文件)。
|
||||
>
|
||||
> 几乎每个命令都有一个手册页用来解释其选项(例如 **man ls** – 按 Q 来退出)。在那里,你可以知晓命令的选项,这样你就知道 **ls -la** 展示一个详细的列表,其中也列出了隐藏文件, 并且在键入一个文件或目录的名字的一部分后, 可以使用 Tab 键来自动补全。
|
||||
|
||||
### Tmux: 针对 shell 的窗口管理器 ###
|
||||
|
||||
在文本模式的环境中使用一个窗口管理器 – 这听起来有点不可思议, 是吧? 然而,你应该记得当 Web 浏览器第一次实现分页浏览的时候吧? 在当时, 这是在可用性上的一个重大进步,它减少了桌面任务栏的杂乱无章和繁多的窗口列表。 对于你的浏览器来说,你只需要一个按钮便可以在浏览器中切换到你打开的每个单独网站, 而不是针对每个网站都有一个任务栏或导航图标。 这个功能非常有意义。
|
||||
|
||||
若有时你同时运行着几个虚拟终端,你便会遇到相似的情况; 在这些终端之间跳转,或每次在任务栏或窗口列表中找到你所需要的那一个终端,都可能会让你觉得麻烦。 拥有一个文本模式的窗口管理器不仅可以让你像在同一个终端窗口中运行多个 shell 会话,而且你甚至还可以将这些窗口排列在一起。
|
||||
|
||||
另外,这样还有另一个好处:可以将这些窗口进行分离和重新连接。想要看看这是如何运行的最好方式是自己尝试一下。在一个终端窗口中,输入 `screen` (在大多数发行版本中,它已经默认安装了或者可以在软件包仓库中找到)。 某些欢迎的文字将会出现 – 只需敲击 Enter 键这些文字就会消失。 现在运行一个交互式的文本模式的程序,例如 `nano`, 并关闭这个终端窗口。
|
||||
|
||||
在一个正常的 shell 对话中, 关闭窗口将会终止所有在该终端中运行的进程 – 所以刚才的 Nano 编辑对话也就被终止了, 但对于 screen 来说,并不是这样的。打开一个新的终端并输入如下命令:
|
||||
|
||||
screen -r
|
||||
|
||||
瞧,你刚开打开的 Nano 会话又回来了!
|
||||
|
||||
当刚才你运行 **screen** 时, 它会创建了一个新的独立的 shell 会话, 它不与某个特定的终端窗口绑定在一起,所以可以在后面被分离并重新连接(即 **-r** 选项)。
|
||||
|
||||
当你正使用 SSH 去连接另一台机器并做着某些工作时, 但并不想因为一个脆弱的连接而影响你的进度,这个方法尤其有用。假如你在一个 **screen** 会话中做着某些工作,并且你的连接突然中断了(或者你的笔记本没电了,又或者你的电脑报废了——不是这么悲催吧),你只需重新连接或给电脑充电或重新买一台电脑,接着运行 **screen -r** 来重新连接到远程的电脑,并在刚才掉线的地方接着开始。
|
||||
|
||||
现在,我们都一直在讨论 GNU 的 **screen**,但这个小节的标题提到的是 tmux。 实质上, **tmux** (terminal multiplexer) 就像是 **screen** 的一个进阶版本,带有许多有用的额外功能,所以现在我们开始关注 tmux。 某些发行版本默认包含了 **tmux**; 在其他的发行版本上,通常只需要一个 **apt-get、 yum install** 或 **pacman -S** 命令便可以安装它。
|
||||
|
||||
一旦你安装了它过后,键入 **tmux** 来启动它。接着你将注意到,在终端窗口的底部有一条绿色的信息栏,它非常像传统的窗口管理器中的任务栏: 上面显示着一个运行着的程序的列表、机器的主机名、当前时间和日期。 现在运行一个程序,同样以 Nano 为例, 敲击 Ctrl+B 后接着按 C 键, 这将在 tmux 会话中创建一个新的窗口,你便可以在终端的底部的任务栏中看到如下的信息:
|
||||
|
||||
0:nano- 1:bash*
|
||||
|
||||
每一个窗口都有一个数字,当前呈现的程序被一个星号所标记。 Ctrl+B 是与 tmux 交互的标准方式, 所以若你敲击这个按键组合并带上一个窗口序号, 那么就会切换到对应的那个窗口。你也可以使用 Ctrl+B 再加上 N 或 P 来分别切换到下一个或上一个窗口 – 或者使用 Ctrl+B 加上 L 来在最近使用的两个窗口之间来进行切换(有点类似于桌面中的经典的 Alt+Tab 组合键的效果)。 若需要知道窗口列表,使用 Ctrl+B 再加上 W。
|
||||
|
||||
目前为止,一切都还好:现在你可以在一个单独的终端窗口中运行多个程序,避免混乱(尤其是当你经常与同一个远程主机保持多个 SSH 连接时)。 当想同时看两个程序又该怎么办呢?
|
||||
|
||||
针对这种情况, 可以使用 tmux 中的窗格。 敲击 Ctrl+B 再加上 % , 则当前窗口将分为两个部分:一个在左一个在右。你可以使用 Ctrl+B 再加上 O 来在这两个部分之间切换。 这尤其在你想同时看两个东西时非常实用, – 例如一个窗格看指导手册,另一个窗格里用编辑器看一个配置文件。
|
||||
|
||||
有时,你想对一个单独的窗格进行缩放,而这需要一定的技巧。 首先你需要敲击 Ctrl+B 再加上一个 :(冒号),这将使得位于底部的 tmux 栏变为深橙色。 现在,你进入了命令模式,在这里你可以输入命令来操作 tmux。 输入 **resize-pane -R** 来使当前窗格向右移动一个字符的间距, 或使用 **-L** 来向左移动。 对于一个简单的操作,这些命令似乎有些长,但请注意,在 tmux 的命令模式(前面提到的一个分号开始的模式)下,可以使用 Tab 键来补全命令。 另外需要提及的是, **tmux** 同样也有一个命令历史记录,所以若你想重复刚才的缩放操作,可以先敲击 Ctrl+B 再跟上一个分号,并使用向上的箭头来取回刚才输入的命令。
|
||||
|
||||
最后,让我们看一下分离和重新连接 - 即我们刚才介绍的 screen 的特色功能。 在 tmux 中,敲击 Ctrl+B 再加上 D 来从当前的终端窗口中分离当前的 tmux 会话。这使得这个会话的一切工作都在后台中运行、使用 `tmux a` 可以再重新连接到刚才的会话。但若你同时有多个 tmux 会话在运行时,又该怎么办呢? 我们可以使用下面的命令来列出它们:
|
||||
|
||||
tmux ls
|
||||
|
||||
这个命令将为每个会话分配一个序号; 假如你想重新连接到会话 1, 可以使用 `tmux a -t 1`. tmux 是可以高度定制的,你可以自定义按键绑定并更改配色方案, 所以一旦你适应了它的主要功能,请钻研指导手册以了解更多的内容。
|
||||
|
||||
|
||||
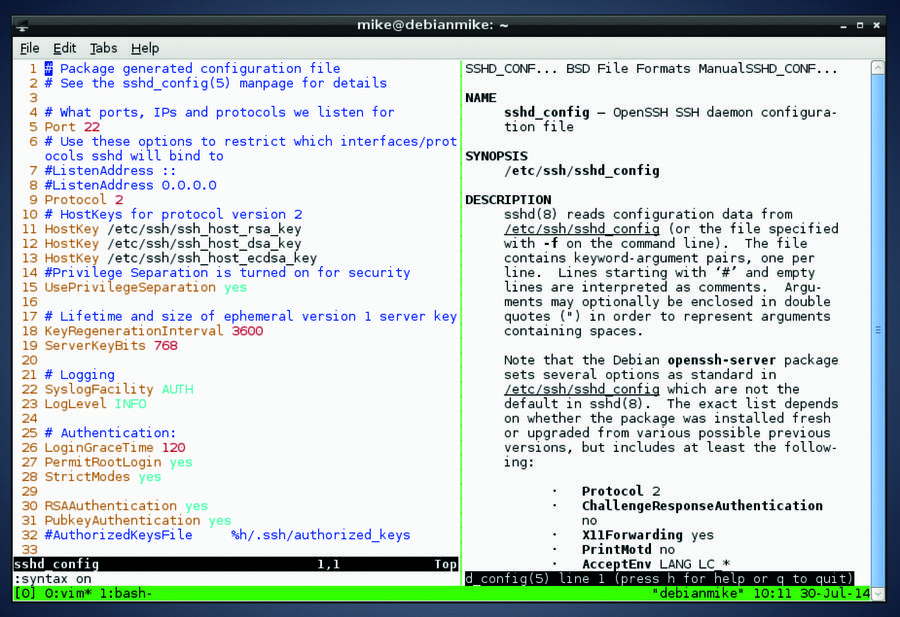
|
||||
|
||||
上图中, tmux 开启了两个窗格: 左边是 Vim 正在编辑一个配置文件,而右边则展示着指导手册页。
|
||||
|
||||
> **Zsh: 另一个 shell**
|
||||
>
|
||||
> 选择是好的,但标准同样重要。 你要知道几乎每个主流的 Linux 发行版本都默认使用 Bash shell – 尽管还存在其他的 shell。 Bash 为你提供了一个 shell 能够给你提供的几乎任何功能,包括命令历史记录,文件名补全和许多脚本编程的能力。它成熟、可靠并文档丰富 – 但它不是你唯一的选择。
|
||||
>
|
||||
> 许多高级用户热衷于 Zsh, 即 Z shell。 这是 Bash 的一个替代品并提供了 Bash 的几乎所有功能,另外还提供了一些额外的功能。 例如, 在 Zsh 中,你输入 **ls** ,并敲击 Tab 键可以得到 **ls** 可用的各种不同选项的一个大致描述。 而不需要再打开 man page 了!
|
||||
>
|
||||
> Zsh 还支持其他强大的自动补全功能: 例如,输入 **cd /u/lo/bi** 再敲击 Tab 键, 则完整的路径名 **/usr/local/bin** 就会出现(这里假设没有其他的路径包含 **u**, **lo** 和 **bi** 等字符)。 或者只输入 **cd** 再跟上 Tab 键,则你将看到着色后的路径名的列表 – 这比 Bash 给出的简单的结果好看得多。
|
||||
>
|
||||
> Zsh 在大多数的主要发行版本上都可以得到了; 安装它后并输入 **zsh** 便可启动它。 要将你的默认 shell 从 Bash 改为 Zsh, 可以使用 **chsh** 命令。 若需了解更多的信息,请访问 [www.zsh.org][2]。
|
||||
|
||||
### “未来”的终端 ###
|
||||
|
||||
你或许会好奇为什么包含你的命令行提示符的应用被叫做终端。 这需要追溯到 Unix 的早期, 那时人们一般工作在一个多用户的机器上,这个巨大的电脑主机将占据一座建筑中的一个房间, 人们通过某些线路,使用屏幕和键盘来连接到这个主机, 这些终端机通常被称为“哑终端”, 因为它们不能靠自己做任何重要的执行任务 – 它们只展示通过线路从主机传来的信息,并输送回从键盘的敲击中得到的输入信息。
|
||||
|
||||
今天,我们在自己的机器上执行几乎所有的实际操作,所以我们的电脑不是传统意义下的终端,这就是为什么诸如 **XTerm**、 Gnome Terminal、 Konsole 等程序被称为“终端模拟器” 的原因 – 他们提供了同昔日的物理终端一样的功能。事实上,在许多方面它们并没有改变多少。诚然,现在我们有了反锯齿字体,更好的颜色和点击网址的能力,但总的来说,几十年来我们一直以同样的方式在工作。
|
||||
|
||||
所以某些程序员正尝试改变这个状况。 **Terminology** ([http://tinyurl.com/osopjv9][3]), 它来自于超级时髦的 Enlightenment 窗口管理器背后的团队,旨在让终端步入到 21 世纪,例如带有在线媒体显示功能。你可以在一个充满图片的目录里输入 **ls** 命令,便可以看到它们的缩略图,或甚至可以直接在你的终端里播放视频。 这使得一个终端有点类似于一个文件管理器,意味着你可以快速地检查媒体文件的内容而不必用另一个应用来打开它们。
|
||||
|
||||
接着还有 Xiki ([www.xiki.org][4]),它自身的描述为“命令的革新”。它就像是一个传统的 shell、一个 GUI 和一个 wiki 之间的过渡;你可以在任何地方输入命令,并在后面将它们的输出存储为笔记以作为参考,并可以创建非常强大的自定义命令。用几句话是很能描述它的,所以作者们已经创作了一个视频来展示它的潜力是多么的巨大(请看 **Xiki** 网站的截屏视频部分)。
|
||||
|
||||
并且 Xiki 绝不是那种在几个月之内就消亡的昙花一现的项目,作者们成功地进行了一次 Kickstarter 众筹,在七月底已募集到超过 $84,000。 是的,你没有看错 – $84K 来支持一个终端模拟器。这可能是最不寻常的集资活动了,因为某些疯狂的家伙已经决定开始创办它们自己的 Linux 杂志 ......
|
||||
|
||||
### 下一代终端 ###
|
||||
|
||||
许多命令行和基于文本的程序在功能上与它们的 GUI 程序是相同的,并且常常更加快速和高效。我们的推荐有:
|
||||
**Irssi** (IRC 客户端); **Mutt** (mail 客户端); **rTorrent** (BitTorrent); **Ranger** (文件管理器); **htop** (进程监视器)。 若给定在终端的限制下来进行 Web 浏览, Elinks 确实做的很好,并且对于阅读那些以文字为主的网站例如 Wikipedia 来说。它非常实用。
|
||||
|
||||
> **微调配色方案**
|
||||
>
|
||||
> 在《Linux Voice》杂志社中,我们并不迷恋那些养眼的东西,但当你每天花费几个小时盯着屏幕看东西时,我们确实认识到美学的重要性。我们中的许多人都喜欢调整我们的桌面和窗口管理器来达到完美的效果,调整阴影效果、摆弄不同的配色方案,直到我们 100% 的满意(然后出于习惯,摆弄更多的东西)。
|
||||
>
|
||||
> 但我们倾向于忽视终端窗口,它理应也获得我们的喜爱,并且在 [http://ciembor.github.io/4bit][5] 你将看到一个极其棒的配色方案设计器,对于所有受欢迎的终端模拟器(**XTerm, Gnome Terminal, Konsole 和 Xfce4 Terminal 等都是支持的应用。**),它可以输出其设定。移动滑块直到你看到配色方案最佳, 然后点击位于该页面右上角的 `得到方案` 按钮。
|
||||
>
|
||||
> 相似的,假如你在一个文本编辑器,如 Vim 或 Emacs 上花费了很多的时间,使用一个精心设计的调色板也是非常值得的。 **Solarized** [http://ethanschoonover.com/solarized][6] 是一个卓越的方案,它不仅漂亮,而且因追求最大的可用性而设计,在其背后有着大量的研究和测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxvoice.com/linux-101-power-up-your-shell-8/
|
||||
|
||||
作者:[Ben Everard][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/ben_everard/
|
||||
[1]:http://tinyurl.com/3gvz4ec
|
||||
[2]:http://www.zsh.org/
|
||||
[3]:http://tinyurl.com/osopjv9
|
||||
[4]:http://www.xiki.org/
|
||||
[5]:http://ciembor.github.io/4bit
|
||||
[6]:http://ethanschoonover.com/solarized
|
||||
@ -0,0 +1,83 @@
|
||||
监控 Linux 系统的 7 个命令行工具
|
||||
================================================================================
|
||||
**这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。**
|
||||
|
||||

|
||||
|
||||
### 深入 ###
|
||||
|
||||
关于Linux最棒的一件事之一是你能深入操作系统,来探索它是如何工作的,并寻找机会来微调性能或诊断问题。这里有一些基本的命令行工具,让你能更简单地探索和操作Linux。大多数的这些命令是在你的Linux系统中已经内建的,但假如它们没有的话,就用谷歌搜索命令名和你的发行版名吧,你会找到哪些包需要安装(注意,一些命令是和其它命令捆绑起来打成一个包的,你所找的包可能写的是其它的名字)。如果你知道一些你所使用的其它工具,欢迎评论。
|
||||
|
||||
|
||||
### 我们怎么开始 ###
|
||||
|
||||
|
||||
|
||||
须知: 本文中的截图取自一台[Debian Linux 8.1][1] (“Jessie”),其运行在[OS X 10.10.3][3] (“Yosemite”)操作系统下的[Oracle VirtualBox 4.3.28][2]中的一台虚拟机里。想要建立你的Debian虚拟机,可以看看我的这篇教程——“[如何在 VirtualBox VM 下安装 Debian][4]”。
|
||||
|
||||
|
||||
### Top ###
|
||||
|
||||
|
||||
|
||||
作为Linux系统监控工具中比较易用的一个,**top命令**能带我们一览Linux中的几乎每一处。以下这张图是它的默认界面,但是按“z”键可以切换不同的显示颜色。其它热键和命令则有其它的功能,例如显示概要信息和内存信息(第四行第二个),根据各种不一样的条件排序、终止进程任务等等(你可以在[这里][5]找到完整的列表)。
|
||||
|
||||
|
||||
### htop ###
|
||||
|
||||
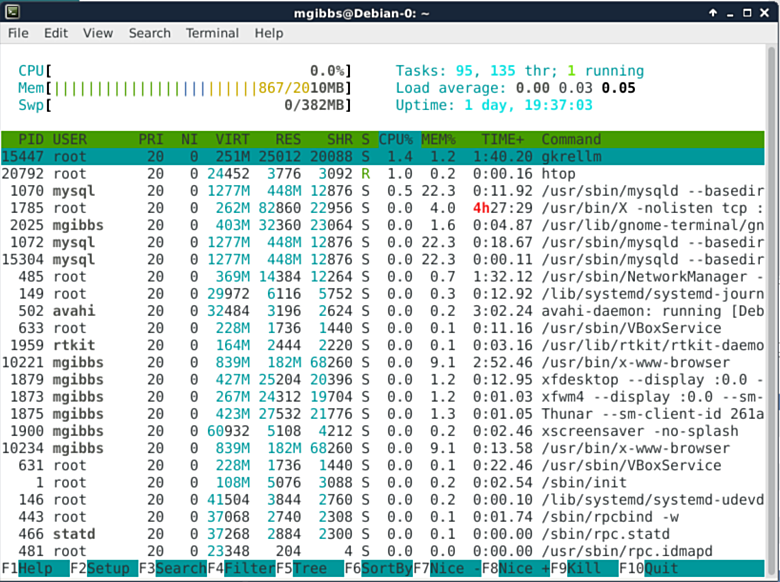
|
||||
|
||||
相比top,它的替代品Htop则更为精致。维基百科是这样描述的:“用户经常会部署htop以免Unix top不能提供关于系统进程的足够信息,比如说当你在尝试发现应用程序里的一个小的内存泄露问题,Htop一般也能作为一个系统监听器来使用。相比top,它提供了一个更方便的光标控制界面来向进程发送信号。” (想了解更多细节猛戳[这里][6])
|
||||
|
||||
|
||||
### Vmstat ###
|
||||
|
||||
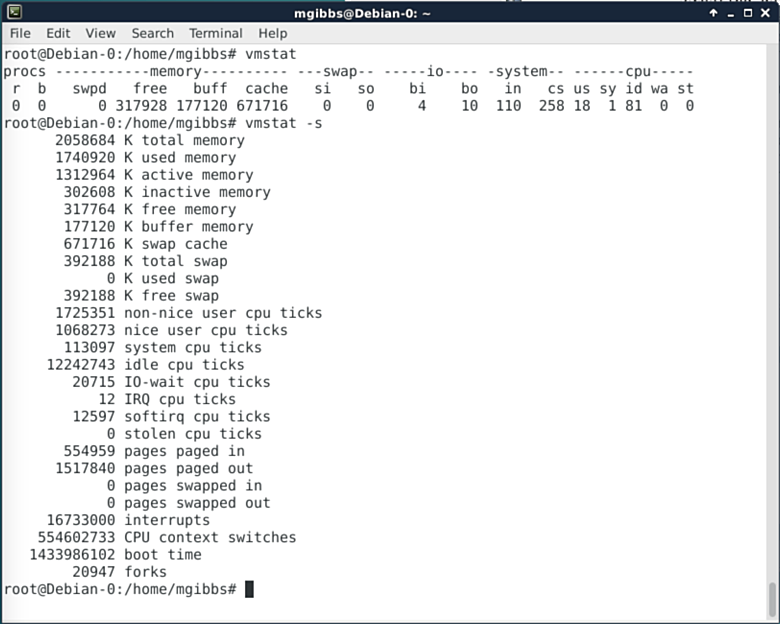
|
||||
|
||||
Vmstat是一款监控Linux系统性能数据的简易工具,这让它更合适使用在shell脚本中。使出你的正则表达式绝招,用vmstat和cron作业来做一些激动人心的事情吧。“后面的报告给出的是上一次系统重启之后的均值,另外一份报告给出的则是从前一个报告起间隔周期中的信息。其它的进程和内存报告是那个瞬态的情况”(猛戳[这里][7]获取更多信息)。
|
||||
|
||||
### ps ###
|
||||
|
||||
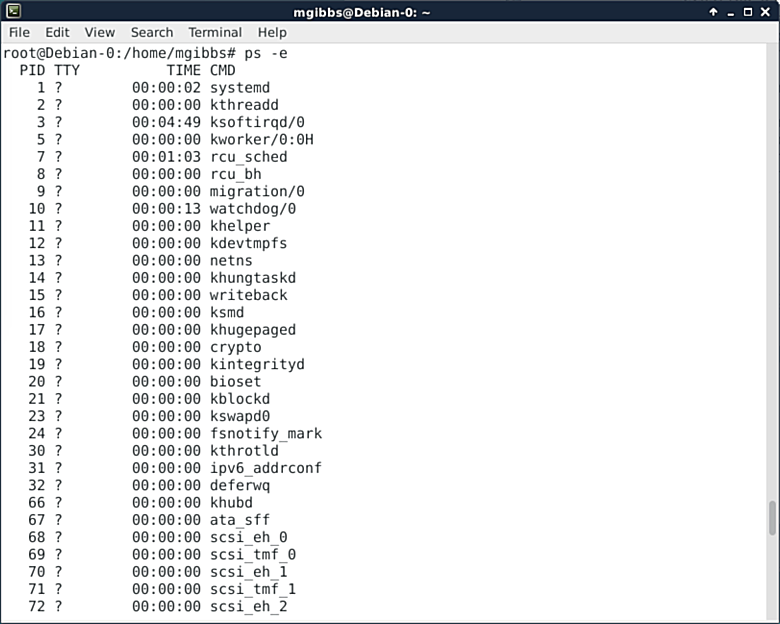
|
||||
|
||||
ps命令展现的是正在运行中的进程列表。在这种情况下,我们用“-e”选项来显示每个进程,也就是所有正在运行的进程了(我把列表滚动到了前面,否则列名就看不到了)。这个命令有很多选项允许你去按需格式化输出。只要使用上述一点点的正则表达式技巧,你就能得到一个强大的工具了。猛戳[这里][8]获取更多信息。
|
||||
|
||||
### Pstree ###
|
||||
|
||||
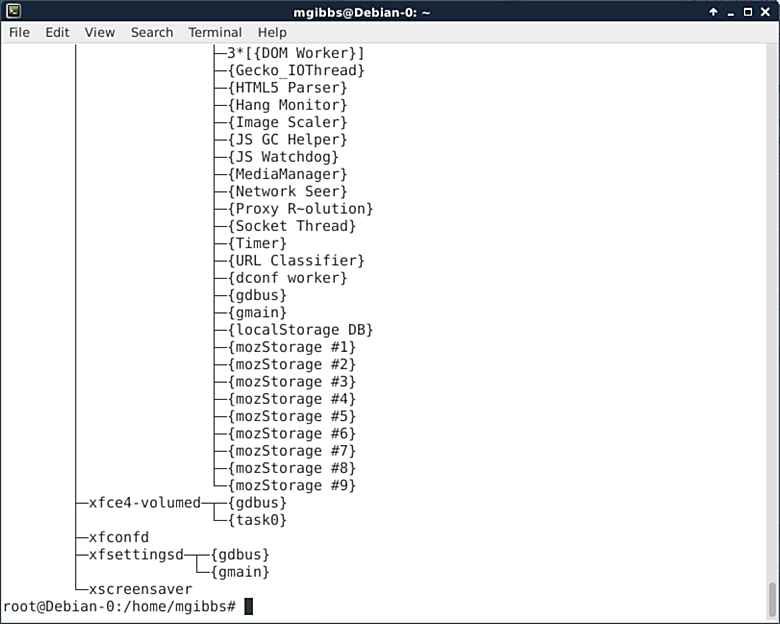
|
||||
|
||||
Pstree“以树状图显示正在运行中的进程。这个进程树是以某个 pid 为根节点的,如果pid被省略的话那树是以init为根节点的。如果指定用户名,那所有进程树都会以该用户所属的进程为父进程进行显示。”以树状图来帮你将进程之间的所属关系进行分类,这的确是个很有效的工具(戳[这里][9])。
|
||||
|
||||
### pmap ###
|
||||
|
||||
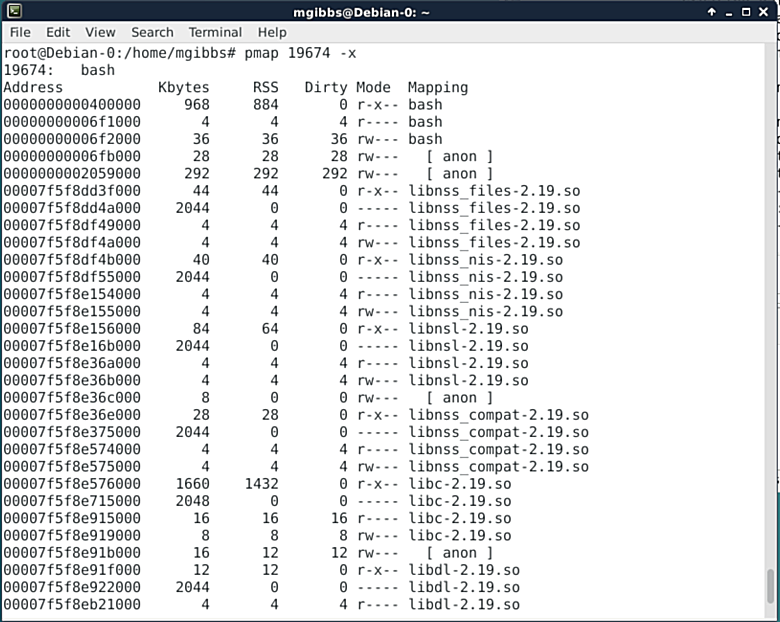
|
||||
|
||||
在调试过程中,理解一个应用程序如何使用内存是至关重要的,而pmap的作用就是当给出一个进程ID时显示出相关信息。上面的截图展示的是使用“-x”选项所产生的部分输出,你也可以用pmap的“-X”选项来获取更多的细节信息,但是前提是你要有个更宽的终端窗口。
|
||||
|
||||
### iostat ###
|
||||
|
||||
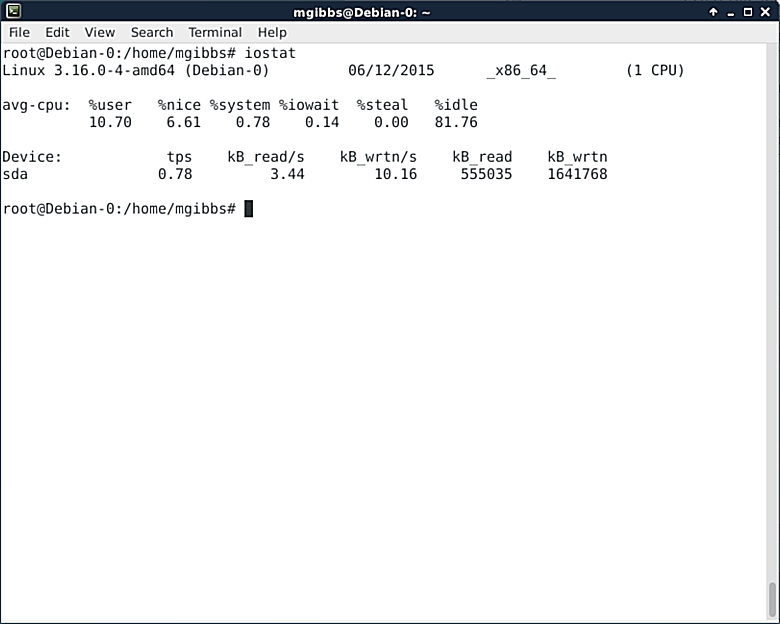
|
||||
|
||||
Linux系统的一个至关重要的性能指标是处理器和存储的使用率,它也是iostat命令所报告的内容。如同ps命令一样,iostat有很多选项允许你选择你需要的输出格式,除此之外还可以在某一段时间范围内的重复采样几次。详情请戳[这里][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2937219/linux/7-command-line-tools-for-monitoring-your-linux-system.html
|
||||
|
||||
作者:[Mark Gibbs][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Mark-Gibbs/
|
||||
[1]:https://www.debian.org/releases/stable/
|
||||
[2]:https://www.virtualbox.org/
|
||||
[3]:http://www.apple.com/osx/
|
||||
[4]:http://www.networkworld.com/article/2937148/how-to-install-debian-linux-8-1-in-a-virtualbox-vm
|
||||
[5]:http://linux.die.net/man/1/top
|
||||
[6]:http://linux.die.net/man/1/htop
|
||||
[7]:http://linuxcommand.org/man_pages/vmstat8.html
|
||||
[8]:http://linux.die.net/man/1/ps
|
||||
[9]:http://linux.die.net/man/1/pstree
|
||||
[10]:http://linux.die.net/man/1/iostat
|
||||
@ -1,24 +1,25 @@
|
||||
在 Linux 中安装 Google 环聊桌面客户端
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
先前,我们已经介绍了如何[在 Linux 中安装 Facebook Messenger][1] 和[WhatsApp 桌面客户端][2]。这些应用都是非官方的应用。今天,我将为你推荐另一款非官方的应用,它就是 [Google 环聊][3]
|
||||
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它把。
|
||||
当然,你可以在 Web 浏览器中使用 Google 环聊,但相比于此,使用桌面客户端会更加有趣。好奇吗?那就跟着我看看如何 **在 Linux 中安装 Google 环聊** 以及如何使用它吧。
|
||||
|
||||
### 在 Linux 中安装 Google 环聊 ###
|
||||
|
||||
我们将使用一个名为 [yakyak][4] 的开源项目,它是一个针对 Linux,Windows 和 OS X 平台的非官方 Google 环聊客户端。我将向你展示如何在 Ubuntu 中使用 yakyak,但我相信在其他的 Linux 发行版本中,你可以使用同样的方法来使用它。在了解如何使用它之前,让我们先看看 yakyak 的主要特点:
|
||||
|
||||
- 发送和接受聊天信息
|
||||
- 创建和更改对话 (重命名, 添加人物)
|
||||
- 创建和更改对话 (重命名, 添加参与者)
|
||||
- 离开或删除对话
|
||||
- 桌面提醒通知
|
||||
- 打开或关闭通知
|
||||
- 针对图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(实际的用户图片) (注: 这里翻译不到位,希望改善一下)
|
||||
- 对于图片上传,支持拖放,复制粘贴或使用上传按钮
|
||||
- Hangupsbot 房间同步(使用用户实际的图片)
|
||||
- 展示行内图片
|
||||
- 历史回放
|
||||
- 翻阅历史
|
||||
|
||||
听起来不错吧,你可以从下面的链接下载到该软件的安装文件:
|
||||
|
||||
@ -36,7 +37,7 @@
|
||||
|
||||

|
||||
|
||||
假如你想看看对话的配置图,你可以选择 `查看-> 展示对话缩略图`
|
||||
假如你想在联系人里面显示用户头像,你可以选择 `查看-> 展示对话缩略图`
|
||||
|
||||

|
||||
|
||||
@ -54,7 +55,7 @@ via: http://itsfoss.com/install-google-hangouts-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,9 @@
|
||||
|
||||
如何修复ubuntu 14.04中检测到系统程序错误的问题
|
||||
如何修复 ubuntu 中检测到系统程序错误的问题
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误(system program problem detected on startup in Ubuntu 15.04)** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
在过去的几个星期,(几乎)每次都有消息 **Ubuntu 15.04在启动时检测到系统程序错误** 跑出来“欢迎”我。那时我是直接忽略掉它的,但是这种情况到了某个时刻,它就让人觉得非常烦人了!
|
||||
|
||||
> 检测到系统程序错误(System program problem detected)
|
||||
>
|
||||
@ -18,15 +17,16 @@
|
||||
|
||||
#### 那么这个通知到底是关于什么的? ####
|
||||
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在以前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
大体上讲,它是在告知你,你的系统的一部分崩溃了。可别因为“崩溃”这个词而恐慌。这不是一个严重的问题,你的系统还是完完全全可用的。只是在之前的某个时刻某个程序崩溃了,而Ubuntu想让你决定要不要把这个问题报告给开发者,这样他们就能够修复这个问题。
|
||||
|
||||
#### 那么,我们点了“报告错误”的按钮后,它以后就不再显示了?####
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”一下:
|
||||
|
||||
不,不是的!即使你点了“报告错误”按钮,最后你还是会被一个如下的弹窗再次“欢迎”:
|
||||

|
||||
|
||||
[对不起,Ubuntu发生了一个内部错误(Sorry, Ubuntu has experienced an internal error)][1]是一个Apport(Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇,译者注),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成.
|
||||
[对不起,Ubuntu发生了一个内部错误][1]是个Apport(LCTT 译注:Apport是Ubuntu中错误信息的收集报告系统,详见Ubuntu Wiki中的Apport篇),它将会进一步的打开网页浏览器,然后你可以通过登录或创建[Launchpad][2]帐户来填写一份漏洞(Bug)报告文件。你看,这是一个复杂的过程,它要花整整四步来完成。
|
||||
|
||||
#### 但是我想帮助开发者,让他们知道这个漏洞啊 !####
|
||||
|
||||
你这样想的确非常地周到体贴,而且这样做也是正确的。但是这样做的话,存在两个问题。第一,存在非常高的概率,这个漏洞已经被报告过了;第二,即使你报告了个这次崩溃,也无法保证你不会再看到它。
|
||||
@ -34,35 +34,38 @@
|
||||
#### 那么,你的意思就是说别报告这次崩溃了?####
|
||||
|
||||
对,也不对。如果你想的话,在你第一次看到它的时候报告它。你可以在上面图片显示的“显示细节(Show Details)”中,查看崩溃的程序。但是如果你总是看到它,或者你不想报告漏洞(Bug),那么我建议你还是一次性摆脱这个问题吧。
|
||||
|
||||
### 修复Ubuntu中“检测到系统程序错误”的错误 ###
|
||||
|
||||
这些错误报告被存放在Ubuntu中目录/var/crash中。如果你翻看这个目录的话,应该可以看到有一些以crash结尾的文件。
|
||||
|
||||

|
||||
|
||||
我的建议是删除这些错误报告。打开一个终端,执行下面的命令:
|
||||
|
||||
sudo rm /var/crash/*
|
||||
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果有一个程序又崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
这个操作会删除所有在/var/crash目录下的所有内容。这样你就不会再被这些报告以前程序错误的弹窗所扰。但是如果又有一个程序崩溃了,你就会再次看到“检测到系统程序错误”的错误。你可以再次删除这些报告文件,或者你可以禁用Apport来彻底地摆脱这个错误弹窗。
|
||||
|
||||
#### 彻底地摆脱Ubuntu中的系统错误弹窗 ####
|
||||
|
||||
如果你这样做,系统中任何程序崩溃时,系统都不会再通知你。如果你想问问我的看法的话,我会说,这不是一件坏事,除非你愿意填写错误报告。如果你不想填写错误报告,那么这些错误通知存不存在都不会有什么区别。
|
||||
|
||||
要禁止Apport,并且彻底地摆脱Ubuntu系统中的程序崩溃报告,打开一个终端,输入以下命令:
|
||||
|
||||
gksu gedit /etc/default/apport
|
||||
|
||||
这个文件的内容是:
|
||||
|
||||
# set this to 0 to disable apport, or to 1 to enable it
|
||||
# 设置0表示禁用Apportw,或者1开启它。译者注,下同。
|
||||
# you can temporarily override this with
|
||||
# 设置0表示禁用Apportw,或者1开启它。
|
||||
# 你可以用下面的命令暂时关闭它:
|
||||
# sudo service apport start force_start=1
|
||||
enabled=1
|
||||
|
||||
把**enabled=1**改为**enabled=0**.保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
把**enabled=1**改为**enabled=0**。保存并关闭文件。完成之后你就再也不会看到弹窗报告错误了。很显然,如果我们想重新开启错误报告功能,只要再打开这个文件,把enabled设置为1就可以了。
|
||||
|
||||
#### 你的有效吗? ####
|
||||
|
||||
我希望这篇教程能够帮助你修复Ubuntu 14.04和Ubuntu 15.04中检测到系统程序错误的问题。如果这个小窍门帮你摆脱了这个烦人的问题,请让我知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -71,7 +74,7 @@ via: http://itsfoss.com/how-to-fix-system-program-problem-detected-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[XLCYun](https://github.com/XLCYun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
每个Linux人应知应会的12个有用的PHP命令行用法
|
||||
在 Linux 命令行中使用和执行 PHP 代码(二):12 个 PHP 交互性 shell 的用法
|
||||
================================================================================
|
||||
在我上一篇文章“[在Linux命令行中使用并执行PHP代码][1]”中,我同时着重讨论了直接在Linux命令行中运行PHP代码以及在Linux终端中执行PHP脚本文件。
|
||||
在上一篇文章“[在 Linux 命令行中使用和执行 PHP 代码(一)][1]”中,我同时着重讨论了直接在Linux命令行中运行PHP代码以及在Linux终端中执行PHP脚本文件。
|
||||
|
||||

|
||||
|
||||
在Linux命令行运行PHP代码——第二部分
|
||||
本文旨在让你了解一些相当不错的Linux终端中的PHP交互性 shell 的用法特性。
|
||||
|
||||
本文旨在让你了解一些相当不错的Linux终端中的PHP用法特性。
|
||||
|
||||
让我们先在PHP交互shell中来对`php.ini`设置进行一些配置吧。
|
||||
让我们先在PHP 的交互shell中来对`php.ini`设置进行一些配置吧。
|
||||
|
||||
**6. 设置PHP命令行提示符**
|
||||
|
||||
@ -21,7 +19,8 @@
|
||||
php > #cli.prompt=Hi Tecmint ::
|
||||
|
||||

|
||||
启用PHP交互Shell
|
||||
|
||||
*启用PHP交互Shell*
|
||||
|
||||
同时,你也可以设置当前时间作为你的命令行提示符,操作如下:
|
||||
|
||||
@ -31,20 +30,22 @@
|
||||
|
||||
**7. 每次输出一屏**
|
||||
|
||||
在我们上一篇文章中,我们已经在原始命令中通过管道在很多地方使用了‘less‘命令。通过该操作,我们可以在那些不能一次满屏输出的地方获得每次一屏的输出。但是,我们可以通过配置php.ini文件,设置pager的值为less以每次输出一屏,操作如下:
|
||||
在我们上一篇文章中,我们已经在原始命令中通过管道在很多地方使用了`less`命令。通过该操作,我们可以在那些不能一屏全部输出的地方获得分屏显示。但是,我们可以通过配置php.ini文件,设置pager的值为less以每次输出一屏,操作如下:
|
||||
|
||||
$ php -a
|
||||
php > #cli.pager=less
|
||||
|
||||

|
||||
固定PHP屏幕输出
|
||||
|
||||
*限制PHP屏幕输出*
|
||||
|
||||
这样,下次当你运行一个命令(比如说条调试器`phpinfo();`)的时候,而该命令的输出内容又太过庞大而不能固定在一屏,它就会自动产生适合你当前屏幕的输出结果。
|
||||
|
||||
php > phpinfo();
|
||||
|
||||

|
||||
PHP信息输出
|
||||
|
||||
*PHP信息输出*
|
||||
|
||||
**8. 建议和TAB补全**
|
||||
|
||||
@ -58,50 +59,53 @@ PHP shell足够智能,它可以显示给你建议和进行TAB补全,你可
|
||||
|
||||
php > #cli.pager [TAB]
|
||||
|
||||
你可以一直按TAB键来获得选项,直到选项值满足要求。所有的行为都将记录到`~/.php-history`文件。
|
||||
你可以一直按TAB键来获得建议的补全,直到该值满足要求。所有的行为都将记录到`~/.php-history`文件。
|
||||
|
||||
要检查你的PHP交互shell活动日志,你可以执行:
|
||||
|
||||
$ nano ~/.php_history | less
|
||||
|
||||

|
||||
检查PHP交互Shell日志
|
||||
|
||||
*检查PHP交互Shell日志*
|
||||
|
||||
**9. 你可以在PHP交互shell中使用颜色,你所需要知道的仅仅是颜色代码。**
|
||||
|
||||
使用echo来打印各种颜色的输出结果,看我信手拈来:
|
||||
使用echo来打印各种颜色的输出结果,类似这样:
|
||||
|
||||
php > echo “color_code1 TEXT second_color_code”;
|
||||
php > echo "color_code1 TEXT second_color_code";
|
||||
|
||||
一个更能说明问题的例子是:
|
||||
具体来说是:
|
||||
|
||||
php > echo "\033[0;31m Hi Tecmint \x1B[0m";
|
||||
|
||||

|
||||
在PHP Shell中启用彩色
|
||||
|
||||
*在PHP Shell中启用彩色*
|
||||
|
||||
到目前为止,我们已经看到,按回车键意味着执行命令,然而PHP Shell中各个命令结尾的分号是必须的。
|
||||
|
||||
**10. PHP shell中的用以打印后续组件的路径名称**
|
||||
**10. 在PHP shell中用basename()输出路径中最后一部分**
|
||||
|
||||
PHP shell中的basename函数从给出的包含有到文件或目录路径的后续组件的路径名称。
|
||||
PHP shell中的basename函数可以从给出的包含有到文件或目录路径的最后部分。
|
||||
|
||||
basename()样例#1和#2。
|
||||
|
||||
php > echo basename("/var/www/html/wp/wp-content/plugins");
|
||||
php > echo basename("www.tecmint.com/contact-us.html");
|
||||
|
||||
上述两个样例都将输出:
|
||||
上述两个样例将输出:
|
||||
|
||||
plugins
|
||||
contact-us.html
|
||||
|
||||

|
||||
在PHP中打印基本名称
|
||||
|
||||
*在PHP中打印基本名称*
|
||||
|
||||
**11. 你可以使用PHP交互shell在你的桌面创建文件(比如说test1.txt),就像下面这么简单**
|
||||
|
||||
$ touch("/home/avi/Desktop/test1.txt");
|
||||
php> touch("/home/avi/Desktop/test1.txt");
|
||||
|
||||
我们已经见识了PHP交互shell在数学运算中有多优秀,这里还有更多一些例子会令你吃惊。
|
||||
|
||||
@ -112,7 +116,8 @@ strlen函数用于获取指定字符串的长度。
|
||||
php > echo strlen("tecmint.com");
|
||||
|
||||

|
||||
在PHP中打印字符串长度
|
||||
|
||||
*在PHP中打印字符串长度*
|
||||
|
||||
**13. PHP交互shell可以对数组排序,是的,你没听错**
|
||||
|
||||
@ -137,9 +142,10 @@ strlen函数用于获取指定字符串的长度。
|
||||
)
|
||||
|
||||

|
||||
在PHP中对数组排序
|
||||
|
||||
**14. 在PHP交互Shell中获取Pi的值**
|
||||
*在PHP中对数组排序*
|
||||
|
||||
**14. 在PHP交互Shell中获取π的值**
|
||||
|
||||
php > echo pi();
|
||||
|
||||
@ -151,14 +157,15 @@ strlen函数用于获取指定字符串的长度。
|
||||
|
||||
12.247448713916
|
||||
|
||||
**16. 从0-10的范围内回显一个随机数**
|
||||
**16. 从0-10的范围内挑选一个随机数**
|
||||
|
||||
php > echo rand(0, 10);
|
||||
|
||||

|
||||
在PHP中获取随机数
|
||||
|
||||
**17. 获取某个指定字符串的md5sum和sha1sum,例如,让我们在PHP Shell中检查某个字符串(比如说avi)的md5sum和sha1sum,并交叉检查这些带有bash shell生成的md5sum和sha1sum的结果。**
|
||||
*在PHP中获取随机数*
|
||||
|
||||
**17. 获取某个指定字符串的md5校验和sha1校验,例如,让我们在PHP Shell中检查某个字符串(比如说avi)的md5校验和sha1校验,并交叉校验bash shell生成的md5校验和sha1校验的结果。**
|
||||
|
||||
php > echo md5(avi);
|
||||
3fca379b3f0e322b7b7967bfcfb948ad
|
||||
@ -175,9 +182,10 @@ strlen函数用于获取指定字符串的长度。
|
||||
8f920f22884d6fea9df883843c4a8095a2e5ac6f -
|
||||
|
||||

|
||||
在PHP中检查md5sum和sha1sum
|
||||
|
||||
这里只是PHP Shell中所能获取的功能和PHP Shell的交互特性的惊鸿一瞥,这些就是到现在为止我所讨论的一切。保持和tecmint的连线,在评论中为我们提供你有价值的反馈吧。为我们点赞并分享,帮助我们扩散哦。
|
||||
*在PHP中检查md5校验和sha1校验*
|
||||
|
||||
这里只是PHP Shell中所能获取的功能和PHP Shell的交互特性的惊鸿一瞥,这些就是到现在为止我所讨论的一切。保持连线,在评论中为我们提供你有价值的反馈吧。为我们点赞并分享,帮助我们扩散哦。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -185,9 +193,9 @@ via: http://www.tecmint.com/execute-php-codes-functions-in-linux-commandline/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||
[1]:https://linux.cn/article-5906-1.html
|
||||
@ -1,10 +1,12 @@
|
||||
Linux命令行中使用和执行PHP代码——第一部分
|
||||
在 Linux 命令行中使用和执行 PHP 代码(一)
|
||||
================================================================================
|
||||
PHP是一个开元服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||

|
||||
Linux命令行中运行PHP代码——第一部分
|
||||
PHP是一个开源服务器端脚本语言,最初这三个字母代表的是“Personal Home Page”,而现在则代表的是“PHP:Hypertext Preprocessor”,它是个递归首字母缩写。它是一个跨平台脚本语言,深受C、C++和Java的影响。
|
||||
|
||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它眼下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||

|
||||
|
||||
*在 Linux 命令行中运行 PHP 代码*
|
||||
|
||||
PHP的语法和C、Java以及带有一些PHP特性的Perl变成语言中的语法十分相似,它当下大约正被2.6亿个网站所使用,当前最新的稳定版本是PHP版本5.6.10。
|
||||
|
||||
PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页面。PHP主要用于服务器端(而Javascript则用于客户端)以通过HTTP生成动态网页,然而,当你知道可以在Linux终端中不需要网页浏览器来执行PHP时,你或许会大为惊讶。
|
||||
|
||||
@ -12,40 +14,44 @@ PHP是HTML的嵌入脚本,它便于开发人员快速写出动态生成的页
|
||||
|
||||
**1. 在安装完PHP和Apache2后,我们需要安装PHP命令行解释器。**
|
||||
|
||||
# apt-get install php5-cli [Debian and alike System)
|
||||
# yum install php-cli [CentOS and alike System)
|
||||
# apt-get install php5-cli [Debian 及类似系统]
|
||||
# yum install php-cli [CentOS 及类似系统]
|
||||
|
||||
接下来我们通常要做的是,在‘/var/www/html‘(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 ‘<?php phpinfo(); ?>‘,名为 ‘infophp.php‘ 的文件来测试(是否安装正确),执行以下命令即可。
|
||||
接下来我们通常要做的是,在`/var/www/html`(这是 Apache2 在大多数发行版中的工作目录)这个位置创建一个内容为 `<?php phpinfo(); ?>`,名为 `infophp.php` 的文件来测试(PHP是否安装正确),执行以下命令即可。
|
||||
|
||||
# echo '<?php phpinfo(); ?>' > /var/www/html/infophp.php
|
||||
|
||||
然后,将浏览器指向http://127.0.0.1/infophp.php, 这将会在网络浏览器中打开该文件。
|
||||
然后,将浏览器访问 http://127.0.0.1/infophp.php ,这将会在网络浏览器中打开该文件。
|
||||
|
||||

|
||||
检查PHP信息
|
||||
|
||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行‘/var/www/html/infophp.php‘,如:
|
||||
*检查PHP信息*
|
||||
|
||||
不需要任何浏览器,在Linux终端中也可以获得相同的结果。在Linux命令行中执行`/var/www/html/infophp.php`,如:
|
||||
|
||||
# php -f /var/www/html/infophp.php
|
||||
|
||||

|
||||
从命令行检查PHP信息
|
||||
|
||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 ‘less‘ 命令,这样就可以一次输出一屏了,命令如下:
|
||||
*从命令行检查PHP信息*
|
||||
|
||||
由于输出结果太大,我们可以通过管道将上述输出结果输送给 `less` 命令,这样就可以一次输出一屏了,命令如下:
|
||||
|
||||
# php -f /var/www/html/infophp.php | less
|
||||
|
||||

|
||||
检查所有PHP信息
|
||||
|
||||
这里,‘-f‘选项解析病执行命令后跟随的文件。
|
||||
*检查所有PHP信息*
|
||||
|
||||
这里,‘-f‘选项解析并执行命令后跟随的文件。
|
||||
|
||||
**2. 我们可以直接在Linux命令行使用`phpinfo()`这个十分有价值的调试工具而不需要从文件来调用,只需执行以下命令:**
|
||||
|
||||
# php -r 'phpinfo();'
|
||||
|
||||

|
||||
PHP调试工具
|
||||
|
||||
*PHP调试工具*
|
||||
|
||||
这里,‘-r‘ 选项会让PHP代码在Linux终端中不带`<`和`>`标记直接执行。
|
||||
|
||||
@ -74,13 +80,14 @@ PHP调试工具
|
||||
输入 ‘exit‘ 或者按下 ‘ctrl+c‘ 来关闭PHP交互模式。
|
||||
|
||||

|
||||
启用PHP交互模式
|
||||
|
||||
*启用PHP交互模式*
|
||||
|
||||
**4. 你可以仅仅将PHP脚本作为shell脚本来运行。首先,创建在你当前工作目录中创建一个PHP样例脚本。**
|
||||
|
||||
# echo -e '#!/usr/bin/php\n<?php phpinfo(); ?>' > phpscript.php
|
||||
|
||||
注意,我们在该PHP脚本的第一行使用#!/usr/bin/php,就像在shell脚本中那样(/bin/bash)。第一行的#!/usr/bin/php告诉Linux命令行将该脚本文件解析到PHP解释器中。
|
||||
注意,我们在该PHP脚本的第一行使用`#!/usr/bin/php`,就像在shell脚本中那样(`/bin/bash`)。第一行的`#!/usr/bin/php`告诉Linux命令行用 PHP 解释器来解析该脚本文件。
|
||||
|
||||
其次,让该脚本可执行:
|
||||
|
||||
@ -96,7 +103,7 @@ PHP调试工具
|
||||
|
||||
# php -a
|
||||
|
||||
创建一个函授,将它命名为 addition。同时,声明两个变量 $a 和 $b。
|
||||
创建一个函数,将它命名为 `addition`。同时,声明两个变量 `$a` 和 `$b`。
|
||||
|
||||
php > function addition ($a, $b)
|
||||
|
||||
@ -133,7 +140,8 @@ PHP调试工具
|
||||
12.3NULL
|
||||
|
||||

|
||||
创建PHP函数
|
||||
|
||||
*创建PHP函数*
|
||||
|
||||
你可以一直运行该函数,直至退出交互模式(ctrl+z)。同时,你也应该注意到了,上面输出结果中返回的数据类型为 NULL。这个问题可以通过要求 php 交互 shell用 return 代替 echo 返回结果来修复。
|
||||
|
||||
@ -152,11 +160,12 @@ PHP调试工具
|
||||
这里是一个样例,在该样例的输出结果中返回了正确的数据类型。
|
||||
|
||||

|
||||
PHP函数
|
||||
|
||||
*PHP函数*
|
||||
|
||||
永远都记住,用户定义的函数不会从一个shell会话保留到下一个shell会话,因此,一旦你退出交互shell,它就会丢失了。
|
||||
|
||||
希望你喜欢此次会话。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||
希望你喜欢此次教程。保持连线,你会获得更多此类文章。保持关注,保持健康。请在下面的评论中为我们提供有价值的反馈。点赞并分享,帮助我们扩散。
|
||||
|
||||
还请阅读: [12个Linux终端中有用的的PHP命令行用法——第二部分][1]
|
||||
|
||||
@ -164,9 +173,9 @@ PHP函数
|
||||
|
||||
via: http://www.tecmint.com/run-php-codes-from-linux-commandline/
|
||||
|
||||
作者:[vishek Kumar][a]
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,188 @@
|
||||
如何在 Ubuntu/CentOS7.1/Fedora22 上安装 Plex Media Server
|
||||
================================================================================
|
||||
在本文中我们将会向你展示如何容易地在主流的最新Linux发行版上安装Plex Media Server。在Plex安装成功后你将可以使用你的中央式家庭媒体播放系统,该系统能让多个Plex播放器App共享它的媒体资源,并且该系统允许你设置你的环境,增加你的设备以及设置一个可以一起使用Plex的用户组。让我们首先在Ubuntu15.04上开始Plex的安装。
|
||||
|
||||
### 基本的系统资源 ###
|
||||
|
||||
系统资源主要取决于你打算用来连接服务的设备类型和数量, 所以根据我们的需求我们将会在一个单独的服务器上使用以下系统资源。
|
||||
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>基础操作系统</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM 和 CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>硬盘</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### 在Ubuntu 15.04上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们现在准备开始在Ubuntu上安装Plex Media Server,让我们从下面的步骤开始来让Plex做好准备。
|
||||
|
||||
#### 步骤 1: 系统更新 ####
|
||||
|
||||
用root权限登录你的服务器。确保你的系统是最新的,如果不是就使用下面的命令。
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### 步骤 2: 下载最新的Plex Media Server包 ####
|
||||
|
||||
创建一个新目录,用wget命令从[Plex官网](https://plex.tv/)下载为Ubuntu提供的.deb包并放入该目录中。
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### 步骤 3: 安装Plex Media Server的Debian包 ####
|
||||
|
||||
现在在相同的目录下执行下面的命令来开始debian包的安装, 然后检查plexmediaserver服务的状态。
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### 在Ubuntu 15.04上设置Plex Media Web应用 ###
|
||||
|
||||
让我们在你的本地网络主机中打开web浏览器, 并用你的本地主机IP以及端口32400来打开Web界面,并完成以下步骤来配置Plex。
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### 步骤 1: 登录前先注册 ####
|
||||
|
||||
在你访问到Plex Media Server的Web界面之后, 确保注册并填上你的用户名和密码来登录。
|
||||
|
||||

|
||||
|
||||
#### 输入你的PIN码来保护你的Plex Media用户####
|
||||
|
||||

|
||||
|
||||
现在你已经成功的在Plex Media下配置你的用户。
|
||||
|
||||

|
||||
|
||||
### 在设备上而不是本地服务器上打开Plex Web应用 ###
|
||||
|
||||
如我们在Plex Media主页看到的提示“你没有权限访问这个服务”。 这说明我们跟服务器计算机不在同个网络。
|
||||
|
||||

|
||||
|
||||
现在我们需要解决这个权限问题,以便我们通过设备访问服务器而不是只能在服务器上访问。通过完成下面的步骤完成。
|
||||
|
||||
### 设置SSH隧道使Windows系统可以访问到Linux服务器 ###
|
||||
|
||||
首先我们需要建立一条SSH隧道以便我们访问远程服务器资源,就好像资源在本地一样。 这仅仅是必要的初始设置。
|
||||
|
||||
如果你正在使用Windows作为你的本地系统,Linux作为服务器,那么我们可以参照下图通过Putty来设置SSH隧道。
|
||||
(LCTT译注: 首先要在Putty的Session中用Plex服务器IP配置一个SSH的会话,才能进行下面的隧道转发规则配置。
|
||||
然后点击“Open”,输入远端服务器用户名密码, 来保持SSH会话连接。)
|
||||
|
||||

|
||||
|
||||
**一旦你完成SSH隧道设置:**
|
||||
|
||||
打开你的Web浏览器窗口并在地址栏输入下面的URL。
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
浏览器将会连接到Plex服务器并且加载与服务器本地功能一致的Plex Web应用。 同意服务条款并开始。
|
||||
|
||||

|
||||
|
||||
现在一个功能齐全的Plex Media Server已经准备好添加新的媒体库、频道、播放列表等资源。
|
||||
|
||||

|
||||
|
||||
### 在CentOS 7.1上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
我们将会按照上述在Ubuntu15.04上安装Plex Media Server的步骤来将Plex安装到CentOS 7.1上。
|
||||
|
||||
让我们从安装Plex Media Server开始。
|
||||
|
||||
#### 步骤1: 安装Plex Media Server ####
|
||||
|
||||
为了在CentOS7.1上安装Plex Media Server,我们需要从Plex官网下载rpm安装包。 因此我们使用wget命令来将rpm包下载到一个新的目录下。
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤2: 安装RPM包 ####
|
||||
|
||||
在完成安装包完整的下载之后, 我们将会使用rpm命令在相同的目录下安装这个rpm包。
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### 步骤3: 启动Plexmediaservice ####
|
||||
|
||||
我们已经成功地安装Plex Media Server, 现在我们只需要重启它的服务然后让它永久地启用。
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### 在CentOS-7.1上设置Plex Media Web应用 ###
|
||||
|
||||
现在我们只需要重复在Ubuntu上设置Plex Web应用的所有步骤就可以了。 让我们在Web浏览器上打开一个新窗口并用localhost或者Plex服务器的IP来访问Plex Media Web应用。
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
为了获取服务的完整权限你需要重复创建SSH隧道的步骤。 在你用新账户注册后我们将可以访问到服务的所有特性,并且可以添加新用户、添加新的媒体库以及根据我们的需求来设置它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上安装Plex Media Server 0.9.12.3 ###
|
||||
|
||||
下载和安装Plex Media Server步骤基本跟在CentOS 7.1上安装的步骤一致。我们只需要下载对应的rpm包然后用rpm命令来安装它。
|
||||
|
||||

|
||||
|
||||
### 在Fedora 22工作站上配置Plex Media Web应用 ###
|
||||
|
||||
我们在(与Plex服务器)相同的主机上配置Plex Media Server,因此不需要设置SSH隧道。只要在你的Fedora 22工作站上用Plex Media Server的默认端口号32400打开Web浏览器并同意Plex的服务条款即可。
|
||||
|
||||

|
||||
|
||||
*欢迎来到Fedora 22工作站上的Plex Media Server*
|
||||
|
||||
让我们用你的Plex账户登录,并且开始将你喜欢的电影频道添加到媒体库、创建你的播放列表、添加你的图片以及享用更多其他的特性。
|
||||
|
||||

|
||||
|
||||
### 总结 ###
|
||||
|
||||
我们已经成功完成Plex Media Server在主流Linux发行版上安装和配置。Plex Media Server永远都是媒体管理的最佳选择。 它在跨平台上的设置是如此的简单,就像我们在Ubuntu,CentOS以及Fedora上的设置一样。它简化了你组织媒体内容的工作,并将媒体内容“流”向其他计算机以及设备以便你跟你的朋友分享媒体内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,6 +1,6 @@
|
||||
如何在Ubuntu 14.04/15.04上配置Chef(服务端/客户端)
|
||||
如何在 Ubuntu 上安装配置管理系统 Chef (大厨)
|
||||
================================================================================
|
||||
Chef是对于信息技术专业人员的一款配置管理和自动化工具,它可以配置和管理你的设备无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,涉及到成百甚至上千的服务器和程序来支持大量的客户群。chef最有用的是让设备变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端设备或者终端用户。
|
||||
Chef是面对IT专业人员的一款配置管理和自动化工具,它可以配置和管理你的基础设施,无论它在本地还是在云上。它可以用于加速应用部署并协调多个系统管理员和开发人员的工作,这涉及到可支持大量的客户群的成百上千的服务器和程序。chef最有用的是让基础设施变成代码。一旦你掌握了Chef,你可以获得一流的网络IT支持来自动化管理你的云端基础设施或者终端用户。
|
||||
|
||||
下面是我们将要在本篇中要设置和配置Chef的主要组件。
|
||||
|
||||
@ -10,34 +10,13 @@ Chef是对于信息技术专业人员的一款配置管理和自动化工具,
|
||||
|
||||
我们将在下面的基础环境下设置Chef配置管理系统。
|
||||
|
||||
注:表格
|
||||
<table width="701" style="height: 284px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="660" colspan="2"><strong>管理和配置工具:Chef</strong></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>基础操作系统</strong></td>
|
||||
<td width="492">Ubuntu 14.04.1 LTS (x86_64)</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Server</strong></td>
|
||||
<td width="492">Version 12.1.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Manage</strong></td>
|
||||
<td width="492">Version 1.17.0</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>Chef Development Kit</strong></td>
|
||||
<td width="492">Version 0.6.2</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="220"><strong>内存和CPU</strong></td>
|
||||
<td width="492">4 GB , 2.0+2.0 GHZ</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|管理和配置工具:Chef||
|
||||
|-------------------------------|---|
|
||||
|基础操作系统|Ubuntu 14.04.1 LTS (x86_64)|
|
||||
|Chef Server|Version 12.1.0|
|
||||
|Chef Manage|Version 1.17.0|
|
||||
|Chef Development Kit|Version 0.6.2|
|
||||
|内存和CPU|4 GB , 2.0+2.0 GHz|
|
||||
|
||||
### Chef服务端的安装和配置 ###
|
||||
|
||||
@ -45,15 +24,15 @@ Chef服务端是核心组件,它存储配置以及其他和工作站交互的
|
||||
|
||||
我使用下面的命令来下载和安装它。
|
||||
|
||||
**1) 下载Chef服务端**
|
||||
####1) 下载Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef服务端**
|
||||
####2) 安装Chef服务端
|
||||
|
||||
root@ubuntu-14-chef:/tmp# dpkg -i chef-server-core_12.1.0-1_amd64.deb
|
||||
|
||||
**3) 重新配置Chef服务端**
|
||||
####3) 重新配置Chef服务端
|
||||
|
||||
现在运行下面的命令来启动所有的chef服务端服务,这步也许会花费一些时间,因为它有许多不同一起工作的服务组成来创建一个正常运作的系统。
|
||||
|
||||
@ -64,35 +43,35 @@ chef服务端启动命令'chef-server-ctl reconfigure'需要运行两次,这
|
||||
Chef Client finished, 342/350 resources updated in 113.71139964 seconds
|
||||
opscode Reconfigured!
|
||||
|
||||
**4) 重启系统 **
|
||||
####4) 重启系统
|
||||
|
||||
安装完成后重启系统使系统能最好的工作,不然我们或许会在创建用户的时候看到下面的SSL连接错误。
|
||||
|
||||
ERROR: Errno::ECONNRESET: Connection reset by peer - SSL_connect
|
||||
|
||||
**5) 创建心的管理员**
|
||||
####5) 创建新的管理员
|
||||
|
||||
运行下面的命令来创建一个新的用它自己的配置的管理员账户。创建过程中,用户的RSA私钥会自动生成并需要被保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
运行下面的命令来创建一个新的管理员账户及其配置。创建过程中,用户的RSA私钥会自动生成,它需要保存到一个安全的地方。--file选项会保存RSA私钥到指定的路径下。
|
||||
|
||||
root@ubuntu-14-chef:/tmp# chef-server-ctl user-create kashi kashi kashi kashif.fareedi@gmail.com kashi123 --filename /root/kashi.pem
|
||||
|
||||
### Chef服务端的管理设置 ###
|
||||
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可视化的web用户界面并可以管理节点、数据包、规则、环境、配置和基于角色的访问控制(RBAC)
|
||||
Chef Manage是一个针对企业Chef用户的管理控制台,它提供了可视化的web用户界面,可以管理节点、数据包、规则、环境、Cookbook 和基于角色的访问控制(RBAC)
|
||||
|
||||
**1) 下载Chef Manage**
|
||||
####1) 下载Chef Manage
|
||||
|
||||
从官网复制链接病下载chef manage的安装包。
|
||||
从官网复制链接并下载chef manage的安装包。
|
||||
|
||||
root@ubuntu-14-chef:~# wget https://web-dl.packagecloud.io/chef/stable/packages/ubuntu/trusty/opscode-manage_1.17.0-1_amd64.deb
|
||||
|
||||
**2) 安装Chef Manage**
|
||||
####2) 安装Chef Manage
|
||||
|
||||
使用下面的命令在root的家目录下安装它。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl install opscode-manage --path /root
|
||||
|
||||
**3) 重启Chef Manage和服务端**
|
||||
####3) 重启Chef Manage和服务端
|
||||
|
||||
安装完成后我们需要运行下面的命令来重启chef manage和服务端。
|
||||
|
||||
@ -101,28 +80,27 @@ Chef Manage是一个针对企业Chef用户的管理控制台,它启用了可
|
||||
|
||||
### Chef Manage网页控制台 ###
|
||||
|
||||
我们可以使用localhost访问网页控制台以及fqdn,并用已经创建的管理员登录
|
||||
我们可以使用localhost或它的全称域名来访问网页控制台,并用已经创建的管理员登录
|
||||
|
||||

|
||||
|
||||
**1) Chef Manage创建新的组织 **
|
||||
####1) Chef Manage创建新的组织
|
||||
|
||||
你或许被要求创建新的组织或者接受其他阻止的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
你或许被要求创建新的组织,或者也可以接受其他组织的邀请。如下所示,使用缩写和全名来创建一个新的组织。
|
||||
|
||||

|
||||
|
||||
**2) 用命令行创建心的组织 **
|
||||
####2) 用命令行创建新的组织
|
||||
|
||||
We can also create new Organization from the command line by executing the following command.
|
||||
我们同样也可以运行下面的命令来创建新的组织。
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create linux Linoxide Linux Org. --association_user kashi --filename linux.pem
|
||||
|
||||
### 设置工作站 ###
|
||||
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes、cookbooks、属性和其他任何的我们想要对Chef的修改。
|
||||
我们已经完成安装chef服务端,现在我们可以开始创建任何recipes([基础配置元素](https://docs.chef.io/recipes.html))、cookbooks([基础配置集](https://docs.chef.io/cookbooks.html))、attributes([节点属性](https://docs.chef.io/attributes.html))和其他任何的我们想要对Chef做的修改。
|
||||
|
||||
**1) 在Chef服务端上创建新的用户和组织 **
|
||||
####1) 在Chef服务端上创建新的用户和组织
|
||||
|
||||
为了设置工作站,我们用命令行创建一个新的用户和组织。
|
||||
|
||||
@ -130,25 +108,23 @@ We can also create new Organization from the command line by executing the follo
|
||||
|
||||
root@ubuntu-14-chef:~# chef-server-ctl org-create blogs Linoxide Blogs Inc. --association_user bloger --filename blogs.pem
|
||||
|
||||
**2) 下载工作站入门套件 **
|
||||
####2) 下载工作站入门套件
|
||||
|
||||
Now Download and Save starter-kit from the chef manage web console on a workstation and use it to work with Chef server.
|
||||
在工作站的网页控制台中下面并保存入门套件用于与服务端协同工作
|
||||
在工作站的网页控制台中下载保存入门套件,它用于与服务端协同工作
|
||||
|
||||

|
||||
|
||||
**3) 点击"Proceed"下载套件 **
|
||||
####3) 下载套件后,点击"Proceed"
|
||||
|
||||

|
||||
|
||||
### 对于工作站的Chef开发套件设置 ###
|
||||
### 用于工作站的Chef开发套件设置 ###
|
||||
|
||||
Chef开发套件是一款包含所有开发chef所需工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
Chef开发套件是一款包含开发chef所需的所有工具的软件包。它捆绑了由Chef开发的带Chef客户端的工具。
|
||||
|
||||
**1) 下载 Chef DK**
|
||||
####1) 下载 Chef DK
|
||||
|
||||
We can Download chef development kit from its official web link and choose the required operating system to get its chef development tool kit.
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来得到chef开发包。
|
||||
我们可以从它的官网链接中下载开发包,并选择操作系统来下载chef开发包。
|
||||
|
||||

|
||||
|
||||
@ -156,13 +132,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:~# wget https://opscode-omnibus-packages.s3.amazonaws.com/ubuntu/12.04/x86_64/chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**1) Chef开发套件安装**
|
||||
####2) Chef开发套件安装
|
||||
|
||||
使用dpkg命令安装开发套件
|
||||
|
||||
root@ubuntu-15-WKS:~# dpkg -i chefdk_0.6.2-1_amd64.deb
|
||||
|
||||
**3) Chef DK 验证**
|
||||
####3) Chef DK 验证
|
||||
|
||||
使用下面的命令验证客户端是否已经正确安装。
|
||||
|
||||
@ -195,7 +171,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
Verification of component 'chefspec' succeeded.
|
||||
Verification of component 'package installation' succeeded.
|
||||
|
||||
**连接Chef服务端**
|
||||
####4) 连接Chef服务端
|
||||
|
||||
我们将创建 ~/.chef并从chef服务端复制两个用户和组织的pem文件到chef的文件到这个目录下。
|
||||
|
||||
@ -209,7 +185,7 @@ We can Download chef development kit from its official web link and choose the r
|
||||
kashi.pem 100% 1678 1.6KB/s 00:00
|
||||
linux.pem 100% 1678 1.6KB/s 00:00
|
||||
|
||||
** 编辑配置来管理chef环境 **
|
||||
####5) 编辑配置来管理chef环境
|
||||
|
||||
现在使用下面的内容创建"~/.chef/knife.rb"。
|
||||
|
||||
@ -231,13 +207,13 @@ We can Download chef development kit from its official web link and choose the r
|
||||
|
||||
root@ubuntu-15-WKS:/# mkdir cookbooks
|
||||
|
||||
**测试Knife配置**
|
||||
####6) 测试Knife配置
|
||||
|
||||
运行“knife user list”和“knife client list”来验证knife是否在工作。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife user list
|
||||
|
||||
第一次运行的时候可能会得到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
第一次运行的时候可能会看到下面的错误,这是因为工作站上还没有chef服务端的SSL证书。
|
||||
|
||||
ERROR: SSL Validation failure connecting to host: 172.25.10.173 - SSL_connect returned=1 errno=0 state=SSLv3 read server certificate B: certificate verify failed
|
||||
ERROR: Could not establish a secure connection to the server.
|
||||
@ -245,24 +221,24 @@ We can Download chef development kit from its official web link and choose the r
|
||||
If your Chef Server uses a self-signed certificate, you can use
|
||||
`knife ssl fetch` to make knife trust the server's certificates.
|
||||
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl整数并重新运行knife user和client list,这时候应该就可以了。
|
||||
要从上面的命令中恢复,运行下面的命令来获取ssl证书,并重新运行knife user和client list,这时候应该就可以了。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef# knife ssl fetch
|
||||
WARNING: Certificates from 172.25.10.173 will be fetched and placed in your trusted_cert
|
||||
directory (/.chef/trusted_certs).
|
||||
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
knife没有办法验证这些是有效的证书。你应该在下载时候验证这些证书的真实性。
|
||||
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
在/.chef/trusted_certs/ubuntu-14-chef_test_com.crt下面添加ubuntu-14-chef.test.com的证书。
|
||||
|
||||
在上面的命令取得ssl证书后,接着运行下面的命令。
|
||||
|
||||
root@ubuntu-15-WKS:/.chef#knife client list
|
||||
kashi-linux
|
||||
|
||||
### 与chef服务端交互的新的节点 ###
|
||||
### 配置与chef服务端交互的新节点 ###
|
||||
|
||||
节点是执行所有设备自动化的chef客户端。因此是时侯添加新的服务端到我们的chef环境下,在配置完chef-server和knife工作站后配置新的节点与chef-server交互。
|
||||
节点是执行所有基础设施自动化的chef客户端。因此,在配置完chef-server和knife工作站后,通过配置新的与chef-server交互的节点,来添加新的服务端到我们的chef环境下。
|
||||
|
||||
我们使用下面的命令来添加新的节点与chef服务端工作。
|
||||
|
||||
@ -291,16 +267,16 @@ We can Download chef development kit from its official web link and choose the r
|
||||
172.25.10.170 to file /tmp/install.sh.26024/metadata.txt
|
||||
172.25.10.170 trying wget...
|
||||
|
||||
之后我们可以在knife节点列表下看到新创建的节点,也会新节点列表下创建新的客户端。
|
||||
之后我们可以在knife节点列表下看到新创建的节点,它也会在新节点创建新的客户端。
|
||||
|
||||
root@ubuntu-15-WKS:~# knife node list
|
||||
mydns
|
||||
|
||||
相似地我们只要提供ssh证书通过上面的knife命令来创建多个节点到chef设备上。
|
||||
相似地我们只要提供ssh证书通过上面的knife命令,就可以在chef设施上创建多个节点。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置浏览了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
本篇我们学习了chef管理工具并通过安装和配置设置基本了解了它的组件。我希望你在学习安装和配置Chef服务端以及它的工作站和客户端节点中获得乐趣。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -308,7 +284,7 @@ via: http://linoxide.com/ubuntu-how-to/install-configure-chef-ubuntu-14-04-15-04
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
178
published/20150717 How to collect NGINX metrics - Part 2.md
Normal file
@ -0,0 +1,178 @@
|
||||
|
||||
如何收集 NGINX 指标(第二篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### 如何获取你所需要的 NGINX 指标 ###
|
||||
|
||||
如何获取需要的指标取决于你正在使用的 NGINX 版本以及你希望看到哪些指标。(参见 [如何监控 NGINX(第一篇)][1] 来深入了解NGINX指标。)自由开源的 NGINX 和商业版的 NGINX Plus 都有可以报告指标度量的状态模块,NGINX 也可以在其日志中配置输出特定指标:
|
||||
|
||||
**指标可用性**
|
||||
|
||||
| 指标 | [NGINX (开源)](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source) | [NGINX Plus](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#plus) | [NGINX 日志](https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#logs)|
|
||||
|-----|------|-------|-----|
|
||||
|accepts(接受) / accepted(已接受)|x|x| |
|
||||
|handled(已处理)|x|x| |
|
||||
|dropped(已丢弃)|x|x| |
|
||||
|active(活跃)|x|x| |
|
||||
|requests (请求数)/ total(全部请求数)|x|x| |
|
||||
|4xx 代码||x|x|
|
||||
|5xx 代码||x|x|
|
||||
|request time(请求处理时间)|||x|
|
||||
|
||||
#### 指标收集:NGINX(开源版) ####
|
||||
|
||||
开源版的 NGINX 会在一个简单的状态页面上显示几个与服务器状态有关的基本指标,它们由你启用的 HTTP [stub status module][2] 所提供。要检查该模块是否已启用,运行以下命令:
|
||||
|
||||
nginx -V 2>&1 | grep -o with-http_stub_status_module
|
||||
|
||||
如果你看到终端输出了 **http_stub_status_module**,说明该状态模块已启用。
|
||||
|
||||
如果该命令没有输出,你需要启用该状态模块。你可以在[从源代码构建 NGINX ][3]时使用 `--with-http_stub_status_module` 配置参数:
|
||||
|
||||
./configure \
|
||||
… \
|
||||
--with-http_stub_status_module
|
||||
make
|
||||
sudo make install
|
||||
|
||||
在验证该模块已经启用或你自己启用它后,你还需要修改 NGINX 配置文件,来给状态页面设置一个本地可访问的 URL(例如: /nginx_status):
|
||||
|
||||
server {
|
||||
location /nginx_status {
|
||||
stub_status on;
|
||||
|
||||
access_log off;
|
||||
allow 127.0.0.1;
|
||||
deny all;
|
||||
}
|
||||
}
|
||||
|
||||
注:nginx 配置中的 server 块通常并不放在主配置文件中(例如:/etc/nginx/nginx.conf),而是放在主配置会加载的辅助配置文件中。要找到主配置文件,首先运行以下命令:
|
||||
|
||||
nginx -t
|
||||
|
||||
打开列出的主配置文件,在以 http 块结尾的附近查找以 include 开头的行,如:
|
||||
|
||||
include /etc/nginx/conf.d/*.conf;
|
||||
|
||||
在其中一个包含的配置文件中,你应该会找到主 **server** 块,你可以如上所示配置 NGINX 的指标输出。更改任何配置后,通过执行以下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
现在,你可以浏览状态页看到你的指标:
|
||||
|
||||
Active connections: 24
|
||||
server accepts handled requests
|
||||
1156958 1156958 4491319
|
||||
Reading: 0 Writing: 18 Waiting : 6
|
||||
|
||||
请注意,如果你希望从远程计算机访问该状态页面,则需要将远程计算机的 IP 地址添加到你的状态配置文件的白名单中,在上面的配置文件中的白名单仅有 127.0.0.1。
|
||||
|
||||
NGINX 的状态页面是一种快速查看指标状况的简单方法,但当连续监测时,你需要按照标准间隔自动记录该数据。监控工具箱 [Nagios][4] 或者 [Datadog][5],以及收集统计信息的服务 [collectD][6] 已经可以解析 NGINX 的状态信息了。
|
||||
|
||||
#### 指标收集: NGINX Plus ####
|
||||
|
||||
商业版的 NGINX Plus 通过它的 ngx_http_status_module 提供了比开源版 NGINX [更多的指标][7]。NGINX Plus 以字节流的方式提供这些额外的指标,提供了关于上游系统和高速缓存的信息。NGINX Plus 也会报告所有的 HTTP 状态码类型(1XX,2XX,3XX,4XX,5XX)的计数。一个 NGINX Plus 状态报告例子[可在此查看][8]:
|
||||
|
||||

|
||||
|
||||
注:NGINX Plus 在状态仪表盘中的“Active”连接的定义和开源 NGINX 通过 stub_status_module 收集的“Active”连接指标略有不同。在 NGINX Plus 指标中,“Active”连接不包括Waiting状态的连接(即“Idle”连接)。
|
||||
|
||||
NGINX Plus 也可以输出 [JSON 格式的指标][9],可以用于集成到其他监控系统。在 NGINX Plus 中,你可以看到 [给定的上游服务器组][10]的指标和健康状况,或者简单地从上游服务器的[单个服务器][11]得到响应代码的计数:
|
||||
|
||||
{"1xx":0,"2xx":3483032,"3xx":0,"4xx":23,"5xx":0,"total":3483055}
|
||||
|
||||
要启动 NGINX Plus 指标仪表盘,你可以在 NGINX 配置文件的 http 块内添加状态 server 块。 (参见上一节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。)例如,要设置一个状态仪表盘 (http://your.ip.address:8080/status.html)和一个 JSON 接口(http://your.ip.address:8080/status),可以添加以下 server 块来设定:
|
||||
|
||||
server {
|
||||
listen 8080;
|
||||
root /usr/share/nginx/html;
|
||||
|
||||
location /status {
|
||||
status;
|
||||
}
|
||||
|
||||
location = /status.html {
|
||||
}
|
||||
}
|
||||
|
||||
当你重新加载 NGINX 配置后,状态页就可以用了:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
关于如何配置扩展状态模块,官方 NGINX Plus 文档有 [详细介绍][13] 。
|
||||
|
||||
#### 指标收集:NGINX 日志 ####
|
||||
|
||||
NGINX 的 [日志模块][14] 会把可自定义的访问日志写到你配置的指定位置。你可以通过[添加或移除变量][15]来自定义日志的格式和包含的数据。要存储详细的日志,最简单的方法是添加下面一行在你配置文件的 server 块中(参见上上节,为收集开源版 NGINX 指标而如何查找相关的配置文件的说明。):
|
||||
|
||||
access_log logs/host.access.log combined;
|
||||
|
||||
更改 NGINX 配置文件后,执行如下命令重新加载配置文件:
|
||||
|
||||
nginx -s reload
|
||||
|
||||
默认包含的 “combined” 的日志格式,会包括[一系列关键的数据][17],如实际的 HTTP 请求和相应的响应代码。在下面的示例日志中,NGINX 记录了请求 /index.html 时的 200(成功)状态码和访问不存在的请求文件 /fail 的 404(未找到)错误。
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:10:46 -0500] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari 537.36"
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:12:11:05 -0500] "GET /fail HTTP/1.1" 404 570 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以通过在 NGINX 配置文件中的 http 块添加一个新的日志格式来记录请求处理时间:
|
||||
|
||||
log_format nginx '$remote_addr - $remote_user [$time_local] '
|
||||
'"$request" $status $body_bytes_sent $request_time '
|
||||
'"$http_referer" "$http_user_agent"';
|
||||
|
||||
并修改配置文件中 **server** 块的 access_log 行:
|
||||
|
||||
access_log logs/host.access.log nginx;
|
||||
|
||||
重新加载配置文件后(运行 `nginx -s reload`),你的访问日志将包括响应时间,如下所示。单位为秒,精度到毫秒。在这个例子中,服务器接收到一个对 /big.pdf 的请求时,发送 33973115 字节后返回 206(成功)状态码。处理请求用时 0.202 秒(202毫秒):
|
||||
|
||||
127.0.0.1 - - [19/Feb/2015:15:50:36 -0500] "GET /big.pdf HTTP/1.1" 206 33973115 0.202 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.111 Safari/537.36"
|
||||
|
||||
你可以使用各种工具和服务来解析和分析 NGINX 日志。例如,[rsyslog][18] 可以监视你的日志,并将其传递给多个日志分析服务;你也可以使用自由开源工具,比如 [logstash][19] 来收集和分析日志;或者你可以使用一个统一日志记录层,如 [Fluentd][20] 来收集和解析你的 NGINX 日志。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
监视 NGINX 的哪一项指标将取决于你可用的工具,以及监控指标所提供的信息是否满足你们的需要。举例来说,错误率的收集是否足够重要到需要你们购买 NGINX Plus ,还是架设一个可以捕获和分析日志的系统就够了?
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最小的设置来收集和监控所有 Web 服务器的指标。[在本文中][21]了解如何用 NGINX Datadog 来监控 ,并开始 [Datadog 的免费试用][22]吧。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
[2]:http://nginx.org/en/docs/http/ngx_http_stub_status_module.html
|
||||
[3]:http://wiki.nginx.org/InstallOptions
|
||||
[4]:https://exchange.nagios.org/directory/Plugins/Web-Servers/nginx
|
||||
[5]:http://docs.datadoghq.com/integrations/nginx/
|
||||
[6]:https://collectd.org/wiki/index.php/Plugin:nginx
|
||||
[7]:http://nginx.org/en/docs/http/ngx_http_status_module.html#data
|
||||
[8]:http://demo.nginx.com/status.html
|
||||
[9]:http://demo.nginx.com/status
|
||||
[10]:http://demo.nginx.com/status/upstreams/demoupstreams
|
||||
[11]:http://demo.nginx.com/status/upstreams/demoupstreams/0/responses
|
||||
[12]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[13]:http://nginx.org/en/docs/http/ngx_http_status_module.html#example
|
||||
[14]:http://nginx.org/en/docs/http/ngx_http_log_module.html
|
||||
[15]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#open-source
|
||||
[17]:http://nginx.org/en/docs/http/ngx_http_log_module.html#log_format
|
||||
[18]:http://www.rsyslog.com/
|
||||
[19]:https://www.elastic.co/products/logstash
|
||||
[20]:http://www.fluentd.org/
|
||||
[21]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[22]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/#sign-up
|
||||
[23]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_collect_nginx_metrics.md
|
||||
[24]:https://github.com/DataDog/the-monitor/issues
|
||||
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
231
published/20150717 How to monitor NGINX- Part 1.md
Normal file
@ -0,0 +1,231 @@
|
||||
如何监控 NGINX(第一篇)
|
||||
================================================================================
|
||||

|
||||
|
||||
### NGINX 是什么? ###
|
||||
|
||||
[NGINX][1] (发音为 “engine X”) 是一种流行的 HTTP 和反向代理服务器。作为一个 HTTP 服务器,NGINX 可以使用较少的内存非常高效可靠地提供静态内容。作为[反向代理][2],它可以用作多个后端服务器或类似缓存和负载平衡这样的其它应用的单一访问控制点。NGINX 是一个自由开源的产品,并有一个具备更全的功能的叫做 NGINX Plus 的商业版。
|
||||
|
||||
NGINX 也可以用作邮件代理和通用的 TCP 代理,但本文并不直接讨论 NGINX 的那些用例的监控。
|
||||
|
||||
### NGINX 主要指标 ###
|
||||
|
||||
通过监控 NGINX 可以 捕获到两类问题:NGINX 本身的资源问题,和出现在你的基础网络设施的其它问题。大多数 NGINX 用户会用到以下指标的监控,包括**每秒请求数**,它提供了一个由所有最终用户活动组成的上层视图;**服务器错误率** ,这表明你的服务器已经多长没有处理看似有效的请求;还有**请求处理时间**,这说明你的服务器处理客户端请求的总共时长(并且可以看出性能降低或当前环境的其他问题)。
|
||||
|
||||
更一般地,至少有三个主要的指标类别来监视:
|
||||
|
||||
- 基本活动指标
|
||||
- 错误指标
|
||||
- 性能指标
|
||||
|
||||
下面我们将分析在每个类别中最重要的 NGINX 指标,以及用一个相当普遍但是值得特别提到的案例来说明:使用 NGINX Plus 作反向代理。我们还将介绍如何使用图形工具或可选择的监控工具来监控所有的指标。
|
||||
|
||||
本文引用指标术语[来自我们的“监控 101 系列”][3],,它提供了一个指标收集和警告框架。
|
||||
|
||||
#### 基本活跃指标 ####
|
||||
|
||||
无论你在怎样的情况下使用 NGINX,毫无疑问你要监视服务器接收多少客户端请求和如何处理这些请求。
|
||||
|
||||
NGINX Plus 上像开源 NGINX 一样可以报告基本活跃指标,但它也提供了略有不同的辅助模块。我们首先讨论开源的 NGINX,再来说明 NGINX Plus 提供的其他指标的功能。
|
||||
|
||||
**NGINX**
|
||||
|
||||
下图显示了一个客户端连接的过程,以及开源版本的 NGINX 如何在连接过程中收集指标。
|
||||
|
||||

|
||||
|
||||
Accepts(接受)、Handled(已处理)、Requests(请求)是一直在增加的计数器。Active(活跃)、Waiting(等待)、Reading(读)、Writing(写)随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepts | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Handled | 成功的客户端连接数 | 资源: 功能 |
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Dropped(已丢弃,计算得出)| 丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Requests | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
NGINX worker 进程接受 OS 的连接请求时 **Accepts** 计数器增加,而**Handled** 是当实际的请求得到连接时(通过建立一个新的连接或重新使用一个空闲的)。这两个计数器的值通常都是相同的,如果它们有差别则表明连接被**Dropped**,往往这是由于资源限制,比如已经达到 NGINX 的[worker_connections][4]的限制。
|
||||
|
||||
一旦 NGINX 成功处理一个连接时,连接会移动到**Active**状态,在这里对客户端请求进行处理:
|
||||
|
||||
Active状态
|
||||
|
||||
- **Waiting**: 活跃的连接也可以处于 Waiting 子状态,如果有在此刻没有活跃请求的话。新连接可以绕过这个状态并直接变为到 Reading 状态,最常见的是在使用“accept filter(接受过滤器)” 和 “deferred accept(延迟接受)”时,在这种情况下,NGINX 不会接收 worker 进程的通知,直到它具有足够的数据才开始响应。如果连接设置为 keep-alive ,那么它在发送响应后将处于等待状态。
|
||||
|
||||
- **Reading**: 当接收到请求时,连接离开 Waiting 状态,并且该请求本身使 Reading 状态计数增加。在这种状态下 NGINX 会读取客户端请求首部。请求首部是比较小的,因此这通常是一个快速的操作。
|
||||
|
||||
- **Writing**: 请求被读取之后,其使 Writing 状态计数增加,并保持在该状态,直到响应返回给客户端。这意味着,该请求在 Writing 状态时, 一方面 NGINX 等待来自上游系统的结果(系统放在 NGINX “后面”),另外一方面,NGINX 也在同时响应。请求往往会在 Writing 状态花费大量的时间。
|
||||
|
||||
通常,一个连接在同一时间只接受一个请求。在这种情况下,Active 连接的数目 == Waiting 的连接 + Reading 请求 + Writing 。然而,较新的 SPDY 和 HTTP/2 协议允许多个并发请求/响应复用一个连接,所以 Active 可小于 Waiting 的连接、 Reading 请求、Writing 请求的总和。 (在撰写本文时,NGINX 不支持 HTTP/2,但预计到2015年期间将会支持。)
|
||||
|
||||
**NGINX Plus**
|
||||
|
||||
正如上面提到的,所有开源 NGINX 的指标在 NGINX Plus 中是可用的,但另外也提供其他的指标。本节仅说明了 NGINX Plus 可用的指标。
|
||||
|
||||
|
||||

|
||||
|
||||
Accepted (已接受)、Dropped,总数是不断增加的计数器。Active、 Idle(空闲)和处于 Current(当前)处理阶段的各种状态下的连接或请求的当前数量随着请求量而增减。
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)|
|
||||
|-----------|-----------------|-------------------------------------------------------------------------------------------------------------------------|
|
||||
| Accepted | NGINX 所接受的客户端连接数 | 资源: 功能 |
|
||||
| Dropped |丢弃的连接数(接受 - 已处理)| 工作:错误*|
|
||||
| Active | 当前活跃的客户端连接数| 资源: 功能 |
|
||||
| Idle | 没有当前请求的客户端连接| 资源: 功能 |
|
||||
| Total(全部) | 客户端请求数 | 工作:吞吐量 |
|
||||
|
||||
_*严格的来说,丢弃的连接是 [一个资源饱和指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#resource-metrics),但是因为饱和会导致 NGINX 停止服务(而不是延后该请求),所以,“已丢弃”视作 [一个工作指标](https://www.datadoghq.com/blog/monitoring-101-collecting-data/#work-metrics) 比较合适。_
|
||||
|
||||
当 NGINX Plus worker 进程接受 OS 的连接请求时 **Accepted** 计数器递增。如果 worker 进程为请求建立连接失败(通过建立一个新的连接或重新使用一个空闲),则该连接被丢弃, **Dropped** 计数增加。通常连接被丢弃是因为资源限制,如 NGINX Plus 的[worker_connections][4]的限制已经达到。
|
||||
|
||||
**Active** 和 **Idle** 和[如上所述][5]的开源 NGINX 的“active” 和 “waiting”状态是相同的,但是有一点关键的不同:在开源 NGINX 上,“waiting”状态包括在“active”中,而在 NGINX Plus 上“idle”的连接被排除在“active” 计数外。**Current** 和开源 NGINX 是一样的也是由“reading + writing” 状态组成。
|
||||
|
||||
**Total** 为客户端请求的累积计数。请注意,单个客户端连接可涉及多个请求,所以这个数字可能会比连接的累计次数明显大。事实上,(total / accepted)是每个连接的平均请求数量。
|
||||
|
||||
**开源 和 Plus 之间指标的不同**
|
||||
|
||||
|NGINX (开源) |NGINX Plus|
|
||||
|-----------------------|----------------|
|
||||
| accepts | accepted |
|
||||
| dropped 通过计算得来| dropped 直接得到 |
|
||||
| reading + writing| current|
|
||||
| waiting| idle|
|
||||
| active (包括 “waiting”状态) | active (排除 “idle” 状态)|
|
||||
| requests| total|
|
||||
|
||||
**提醒指标: 丢弃连接**
|
||||
|
||||
被丢弃的连接数目等于 Accepts 和 Handled 之差(NGINX 中),或是可直接得到标准指标(NGINX Plus 中)。在正常情况下,丢弃连接数应该是零。如果在每个单位时间内丢弃连接的速度开始上升,那么应该看看是否资源饱和了。
|
||||
|
||||

|
||||
|
||||
**提醒指标: 每秒请求数**
|
||||
|
||||
按固定时间间隔采样你的请求数据(开源 NGINX 的**requests**或者 NGINX Plus 中**total**) 会提供给你单位时间内(通常是分钟或秒)所接受的请求数量。监测这个指标可以查看进入的 Web 流量尖峰,无论是合法的还是恶意的,或者突然的下降,这通常都代表着出现了问题。每秒请求数若发生急剧变化可以提醒你的环境出现问题了,即使它不能告诉你确切问题的位置所在。请注意,所有的请求都同样计数,无论 URL 是什么。
|
||||
|
||||

|
||||
|
||||
**收集活跃指标**
|
||||
|
||||
开源的 NGINX 提供了一个简单状态页面来显示基本的服务器指标。该状态信息以标准格式显示,实际上任何图形或监控工具可以被配置去解析这些相关数据,以用于分析、可视化、或提醒。NGINX Plus 提供一个 JSON 接口来供给更多的数据。阅读相关文章“[NGINX 指标收集][6]”来启用指标收集的功能。
|
||||
|
||||
#### 错误指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 4xx 代码 | 客户端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
| 5xx 代码| 服务器端错误计数 | 工作:错误 | NGINX 日志, NGINX Plus|
|
||||
|
||||
NGINX 错误指标告诉你服务器是否经常返回错误而不是正常工作。客户端错误返回4XX状态码,服务器端错误返回5XX状态码。
|
||||
|
||||
**提醒指标: 服务器错误率**
|
||||
|
||||
服务器错误率等于在单位时间(通常为一到五分钟)内5xx错误状态代码的总数除以[状态码][7](1XX,2XX,3XX,4XX,5XX)的总数。如果你的错误率随着时间的推移开始攀升,调查可能的原因。如果突然增加,可能需要采取紧急行动,因为客户端可能收到错误信息。
|
||||
|
||||

|
||||
|
||||
关于客户端错误的注意事项:虽然监控4XX是很有用的,但从该指标中你仅可以捕捉有限的信息,因为它只是衡量客户的行为而不捕捉任何特殊的 URL。换句话说,4xx出现的变化可能是一个信号,例如网络扫描器正在寻找你的网站漏洞时。
|
||||
|
||||
**收集错误度量**
|
||||
|
||||
虽然开源 NGINX 不能马上得到用于监测的错误率,但至少有两种方法可以得到:
|
||||
|
||||
- 使用商业支持的 NGINX Plus 提供的扩展状态模块
|
||||
- 配置 NGINX 的日志模块将响应码写入访问日志
|
||||
|
||||
关于这两种方法,请阅读相关文章“[NGINX 指标收集][6]”。
|
||||
|
||||
#### 性能指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| request time (请求处理时间)| 处理每个请求的时间,单位为秒 | 工作:性能 | NGINX 日志|
|
||||
|
||||
**提醒指标: 请求处理时间**
|
||||
|
||||
请求处理时间指标记录了 NGINX 处理每个请求的时间,从读到客户端的第一个请求字节到完成请求。较长的响应时间说明问题在上游。
|
||||
|
||||
**收集处理时间指标**
|
||||
|
||||
NGINX 和 NGINX Plus 用户可以通过添加 $request_time 变量到访问日志格式中来捕捉处理时间数据。关于配置日志监控的更多细节在[NGINX指标收集][6]。
|
||||
|
||||
#### 反向代理指标 ####
|
||||
|
||||
| 名称 | 描述| [指标类型](https://www.datadoghq.com/blog/monitoring-101-collecting-data/)| 可用于 |
|
||||
|-----------|-----------------|--------------------------------------------------------------------------------------------------------|----------------|
|
||||
| 上游服务器的活跃链接 | 当前活跃的客户端连接 | 资源:功能 | NGINX Plus |
|
||||
| 上游服务器的 5xx 错误代码| 服务器错误 | 工作:错误 | NGINX Plus |
|
||||
| 每个上游组的可用服务器 | 服务器传递健康检查 | 资源:可用性| NGINX Plus
|
||||
|
||||
[反向代理][9]是 NGINX 最常见的使用方法之一。商业支持的 NGINX Plus 显示了大量有关后端(或“上游 upstream”)的服务器指标,这些与反向代理设置相关的。本节重点介绍了几个 NGINX Plus 用户可用的关键上游指标。
|
||||
|
||||
NGINX Plus 首先将它的上游指标按组分开,然后是针对单个服务器的。因此,例如,你的反向代理将请求分配到五个上游的 Web 服务器上,你可以一眼看出是否有单个服务器压力过大,也可以看出上游组中服务器的健康状况,以确保良好的响应时间。
|
||||
|
||||
**活跃指标**
|
||||
|
||||
**每上游服务器的活跃连接**的数量可以帮助你确认反向代理是否正确的分配工作到你的整个服务器组上。如果你正在使用 NGINX 作为负载均衡器,任何一台服务器处理的连接数的明显偏差都可能表明服务器正在努力消化请求,或者是你配置使用的负载均衡的方法(例如[round-robin 或 IP hashing][10])不是最适合你流量模式的。
|
||||
|
||||
**错误指标**
|
||||
|
||||
错误指标,上面所说的高于5XX(服务器错误)状态码,是监控指标中有价值的一个,尤其是响应码部分。 NGINX Plus 允许你轻松地提取**每个上游服务器的 5xx 错误代码**的数量,以及响应的总数量,以此来确定某个特定服务器的错误率。
|
||||
|
||||
**可用性指标**
|
||||
|
||||
对于 web 服务器的运行状况,还有另一种角度,NGINX 可以通过**每个组中当前可用服务器的总量**很方便监控你的上游组的健康。在一个大的反向代理上,你可能不会非常关心其中一个服务器的当前状态,就像你只要有可用的服务器组能够处理当前的负载就行了。但监视上游组内的所有工作的服务器总量可为判断 Web 服务器的健康状况提供一个更高层面的视角。
|
||||
|
||||
**收集上游指标**
|
||||
|
||||
NGINX Plus 上游指标显示在内部 NGINX Plus 的监控仪表盘上,并且也可通过一个JSON 接口来服务于各种外部监控平台。在我们的相关文章“[NGINX指标收集][6]”中有个例子。
|
||||
|
||||
### 结论 ###
|
||||
|
||||
在这篇文章中,我们已经谈到了一些有用的指标,你可以使用表格来监控 NGINX 服务器。如果你是刚开始使用 NGINX,监控下面提供的大部分或全部指标,可以让你很好的了解你的网络基础设施的健康和活跃程度:
|
||||
|
||||
- [已丢弃的连接][12]
|
||||
- [每秒请求数][13]
|
||||
- [服务器错误率][14]
|
||||
- [请求处理数据][15]
|
||||
|
||||
最终,你会学到更多,更专业的衡量指标,尤其是关于你自己基础设施和使用情况的。当然,监控哪一项指标将取决于你可用的工具。参见相关的文章来[逐步指导你的指标收集][6],不管你使用 NGINX 还是 NGINX Plus。
|
||||
|
||||
在 Datadog 中,我们已经集成了 NGINX 和 NGINX Plus,这样你就可以以最少的设置来收集和监控所有 Web 服务器的指标。 [在本文中][17]了解如何用 NGINX Datadog来监控,并开始[免费试用 Datadog][18]吧。
|
||||
|
||||
### 诚谢 ###
|
||||
|
||||
在文章发表之前非常感谢 NGINX 团队审阅这篇,并提供重要的反馈和说明。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datadoghq.com/blog/how-to-monitor-nginx/
|
||||
|
||||
作者:K Young
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://nginx.org/en/
|
||||
[2]:http://nginx.com/resources/glossary/reverse-proxy-server/
|
||||
[3]:https://www.datadoghq.com/blog/monitoring-101-collecting-data/
|
||||
[4]:http://nginx.org/en/docs/ngx_core_module.html#worker_connections
|
||||
[5]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#active-state
|
||||
[6]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[7]:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
|
||||
[8]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[9]:https://en.wikipedia.org/wiki/Reverse_proxy
|
||||
[10]:http://nginx.com/blog/load-balancing-with-nginx-plus/
|
||||
[11]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[12]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#dropped-connections
|
||||
[13]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#requests-per-second
|
||||
[14]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#server-error-rate
|
||||
[15]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#request-processing-time
|
||||
[16]:https://www.datadoghq.com/blog/how-to-collect-nginx-metrics/
|
||||
[17]:https://www.datadoghq.com/blog/how-to-monitor-nginx-with-datadog/
|
||||
[18]:https://www.datadoghq.com/blog/how-to-monitor-nginx/#sign-up
|
||||
[19]:https://github.com/DataDog/the-monitor/blob/master/nginx/how_to_monitor_nginx.md
|
||||
[20]:https://github.com/DataDog/the-monitor/issues
|
||||
@ -1,11 +1,13 @@
|
||||
如何在 Fedora 22 上配置 Proftpd 服务器
|
||||
================================================================================
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款免费的基于 GPL 授权开源的 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是具备许多高级功能以及能为用户提供丰富的配置选项可以轻松实现定制。它的许多配置选项在其他一些 FTP 服务器软件里仍然没有集成。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
在本文中,我们将了解如何在运行 Fedora 22 的电脑或服务器上使用 Proftpd 架设 FTP 服务器。[ProFTPD][1] 是一款基于 GPL 授权的自由开源 FTP 服务器软件,是 Linux 上的主流 FTP 服务器。它的主要设计目标是提供许多高级功能以及给用户提供丰富的配置选项以轻松实现定制。它具备许多在其他一些 FTP 服务器软件里仍然没有的配置选项。最初它是被开发作为 wu-ftpd 服务器的一个更安全更容易配置的替代。
|
||||
|
||||
- 每个目录都包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
FTP 服务器是这样一个软件,用户可以通过 FTP 客户端从安装了它的远端服务器上传或下载文件和目录。下面是一些 ProFTPD 服务器的主要功能,更详细的资料可以访问 [http://www.proftpd.org/features.html][2]。
|
||||
|
||||
- 每个目录都可以包含 ".ftpaccess" 文件用于访问控制,类似 Apache 的 ".htaccess"
|
||||
- 支持多个虚拟 FTP 服务器以及多用户登录和匿名 FTP 服务。
|
||||
- 可以作为独立进程启动服务或者通过 inetd/xinetd 启动
|
||||
- 它的文件/目录属性、属主和权限采用类 UNIX 方式。
|
||||
- 它的文件/目录属性、属主和权限是基于 UNIX 方式的。
|
||||
- 它可以独立运行,保护系统避免 root 访问可能带来的损坏。
|
||||
- 模块化的设计让它可以轻松扩展其他模块,比如 LDAP 服务器,SSL/TLS 加密,RADIUS 支持,等等。
|
||||
- ProFTPD 服务器还支持 IPv6.
|
||||
@ -38,7 +40,7 @@
|
||||
|
||||
### 3. 添加 FTP 用户 ###
|
||||
|
||||
在设定好了基本的配置文件后,我们很自然地希望为指定目录添加 FTP 用户。目前用来登录的用户是 FTP 服务自动生成的,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
在设定好了基本的配置文件后,我们很自然地希望添加一个以特定目录为根目录的 FTP 用户。目前登录的用户自动就可以使用 FTP 服务,可以用来登录到 FTP 服务器。但是,在这篇教程里,我们将创建一个以 ftp 服务器上指定目录为主目录的新用户。
|
||||
|
||||
下面,我们将建立一个名字是 ftpgroup 的新用户组。
|
||||
|
||||
@ -57,7 +59,7 @@
|
||||
Retype new password:
|
||||
passwd: all authentication tokens updated successfully.
|
||||
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限。
|
||||
现在,我们将通过下面命令为这个 ftp 用户设定主目录的读写权限(LCTT 译注:这是SELinux 相关设置,如果未启用 SELinux,可以不用)。
|
||||
|
||||
$ sudo setsebool -P allow_ftpd_full_access=1
|
||||
$ sudo setsebool -P ftp_home_dir=1
|
||||
@ -129,7 +131,7 @@
|
||||
|
||||
如果 **打开了 TLS/SSL 加密**,执行下面的命令。
|
||||
|
||||
$sudo firewall-cmd --add-port=1024-65534/tcp
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp
|
||||
$ sudo firewall-cmd --add-port=1024-65534/tcp --permanent
|
||||
|
||||
如果 **没有打开 TLS/SSL 加密**,执行下面的命令。
|
||||
@ -158,7 +160,7 @@
|
||||
|
||||
### 7. 登录到 FTP 服务器 ###
|
||||
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或 URL **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **显式要求基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
现在,如果都是按照本教程设置好的,我们一定可以连接到 ftp 服务器并使用以上设置的信息登录上去。在这里,我们将配置一下 FTP 客户端 filezilla,使用 **服务器的 IP 或名称 **作为主机名,协议选择 **FTP**,用户名填入 **arunftp**,密码是在上面第 3 步中设定的密码。如果你按照第 4 步中的方式打开了 TLS 支持,还需要在加密类型中选择 **要求显式的基于 TLS 的 FTP**,如果没有打开,也不想使用 TLS 加密,那么加密类型选择 **简单 FTP**。
|
||||
|
||||

|
||||
|
||||
@ -170,7 +172,7 @@
|
||||
|
||||
### 总结 ###
|
||||
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度配置和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
最后,我们成功地在 Fedora 22 机器上安装并配置好了 Proftpd FTP 服务器。Proftpd 是一个超级强大,能高度定制和扩展的 FTP 守护软件。上面的教程展示了如何配置一个采用 TLS 加密的安全 FTP 服务器。强烈建议设置 FTP 服务器支持 TLS 加密,因为它允许使用 SSL 凭证加密数据传输和登录。本文中,我们也没有配置 FTP 的匿名访问,因为一般受保护的 FTP 系统不建议这样做。 FTP 访问让人们的上传和下载变得非常简单也更高效。我们还可以改变用户端口增加安全性。好吧,如果你有任何疑问,建议,反馈,请在下面评论区留言,这样我们就能够改善并更新文章内容。谢谢!玩的开心 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -178,7 +180,7 @@ via: http://linoxide.com/linux-how-to/configure-ftp-proftpd-fedora-22/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -6,17 +6,17 @@
|
||||
|
||||
每当你开机进入一个操作系统,一系列的应用将会自动启动。这些应用被称为‘开机启动应用’ 或‘开机启动程序’。随着时间的推移,当你在系统中安装了足够多的应用时,你将发现有太多的‘开机启动应用’在开机时自动地启动了,它们吃掉了很多的系统资源,并将你的系统拖慢。这可能会让你感觉卡顿,我想这种情况并不是你想要的。
|
||||
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你发现这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
让 Ubuntu 变得更快的方法之一是对这些开机启动应用进行控制。 Ubuntu 为你提供了一个 GUI 工具来让你找到这些开机启动应用,然后完全禁止或延迟它们的启动,这样就可以不让每个应用在开机时同时运行。
|
||||
|
||||
在这篇文章中,我们将看到 **在 Ubuntu 中,如何控制开机启动应用,如何让一个应用在开机时启动以及如何发现隐藏的开机启动应用。**这里提供的指导对所有的 Ubuntu 版本均适用,例如 Ubuntu 12.04, Ubuntu 14.04 和 Ubuntu 15.04。
|
||||
|
||||
### 在 Ubuntu 中管理开机启动应用 ###
|
||||
|
||||
默认情况下, Ubuntu 提供了一个`开机启动应用工具`来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
默认情况下, Ubuntu 提供了一个`Startup Applications`工具来供你使用,你不必再进行安装。只需到 Unity 面板中就可以查找到该工具。
|
||||
|
||||

|
||||
|
||||
点击它来启动。下面是我的`开机启动应用`的样子:
|
||||
点击它来启动。下面是我的`Startup Applications`的样子:
|
||||
|
||||

|
||||
|
||||
@ -84,7 +84,7 @@
|
||||
|
||||
就这样,你将在下一次开机时看到这个程序会自动运行。这就是在 Ubuntu 中你能做的关于开机启动应用的所有事情。
|
||||
|
||||
到现在为止,我们已经讨论在开机时可见的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
到现在为止,我们已经讨论在开机时可见到的应用,但仍有更多的服务,守护进程和程序并不在`开机启动应用工具`中可见。下一节中,我们将看到如何在 Ubuntu 中查看这些隐藏的开机启动程序。
|
||||
|
||||
### 在 Ubuntu 中查看隐藏的开机启动程序 ###
|
||||
|
||||
@ -97,13 +97,14 @@
|
||||

|
||||
|
||||
你可以像先前我们讨论的那样管理这些开机启动应用。我希望这篇教程可以帮助你在 Ubuntu 中控制开机启动程序。任何的问题或建议总是欢迎的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/manage-startup-applications-ubuntu/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,92 @@
|
||||
无忧之道:Docker中容器的备份、恢复和迁移
|
||||
================================================================================
|
||||
今天,我们将学习如何快速地对docker容器进行快捷备份、恢复和迁移。[Docker][1]是一个开源平台,用于自动化部署应用,以通过快捷的途径在称之为容器的轻量级软件层下打包、发布和运行这些应用。它使得应用平台独立,因为它扮演了Linux上一个额外的操作系统级虚拟化的自动化抽象层。它通过其组件cgroups和命名空间利用Linux内核的资源分离特性,达到避免虚拟机开销的目的。它使得用于部署和扩展web应用、数据库和后端服务的大规模构建组件无需依赖于特定的堆栈或供应者。
|
||||
|
||||
所谓的容器,就是那些创建自Docker镜像的软件层,它包含了独立的Linux文件系统和开箱即用的应用程序。如果我们有一个在机器中运行着的Docker容器,并且想要备份这些容器以便今后使用,或者想要迁移这些容器,那么,本教程将帮助你掌握在Linux操作系统中备份、恢复和迁移Docker容器的方法。
|
||||
|
||||
我们怎样才能在Linux中备份、恢复和迁移Docker容器呢?这里为您提供了一些便捷的步骤。
|
||||
|
||||
### 1. 备份容器 ###
|
||||
|
||||
首先,为了备份Docker中的容器,我们会想看看我们想要备份的容器列表。要达成该目的,我们需要在我们运行着Docker引擎,并已创建了容器的Linux机器中运行 docker ps 命令。
|
||||
|
||||
# docker ps
|
||||
|
||||

|
||||
|
||||
在此之后,我们要选择我们想要备份的容器,然后去创建该容器的快照。我们可以使用 docker commit 命令来创建快照。
|
||||
|
||||
# docker commit -p 30b8f18f20b4 container-backup
|
||||
|
||||

|
||||
|
||||
该命令会生成一个作为Docker镜像的容器快照,我们可以通过运行 `docker images` 命令来查看Docker镜像,如下。
|
||||
|
||||
# docker images
|
||||
|
||||

|
||||
|
||||
正如我们所看见的,上面做的快照已经作为Docker镜像保存了。现在,为了备份该快照,我们有两个选择,一个是我们可以登录进Docker注册中心,并推送该镜像;另一个是我们可以将Docker镜像打包成tar包备份,以供今后使用。
|
||||
|
||||
如果我们想要在[Docker注册中心][2]上传或备份镜像,我们只需要运行 docker login 命令来登录进Docker注册中心,然后推送所需的镜像即可。
|
||||
|
||||
# docker login
|
||||
|
||||

|
||||
|
||||
# docker tag a25ddfec4d2a arunpyasi/container-backup:test
|
||||
# docker push arunpyasi/container-backup
|
||||
|
||||

|
||||
|
||||
如果我们不想备份到docker注册中心,而是想要将此镜像保存在本地机器中,以供日后使用,那么我们可以将其作为tar包备份。要完成该操作,我们需要运行以下 `docker save` 命令。
|
||||
|
||||
# docker save -o ~/container-backup.tar container-backup
|
||||
|
||||

|
||||
|
||||
要验证tar包是否已经生成,我们只需要在保存tar包的目录中运行 ls 命令即可。
|
||||
|
||||
### 2. 恢复容器 ###
|
||||
|
||||
接下来,在我们成功备份了我们的Docker容器后,我们现在来恢复这些制作了Docker镜像快照的容器。如果我们已经在注册中心推送了这些Docker镜像,那么我们仅仅需要把那个Docker镜像拖回并直接运行即可。
|
||||
|
||||
# docker pull arunpyasi/container-backup:test
|
||||
|
||||

|
||||
|
||||
但是,如果我们将这些Docker镜像作为tar包文件备份到了本地,那么我们只要使用 docker load 命令,后面加上tar包的备份路径,就可以加载该Docker镜像了。
|
||||
|
||||
# docker load -i ~/container-backup.tar
|
||||
|
||||
现在,为了确保这些Docker镜像已经加载成功,我们来运行 docker images 命令。
|
||||
|
||||
# docker images
|
||||
|
||||
在镜像被加载后,我们将用加载的镜像去运行Docker容器。
|
||||
|
||||
# docker run -d -p 80:80 container-backup
|
||||
|
||||

|
||||
|
||||
### 3. 迁移Docker容器 ###
|
||||
|
||||
迁移容器同时涉及到了上面两个操作,备份和恢复。我们可以将任何一个Docker容器从一台机器迁移到另一台机器。在迁移过程中,首先我们将把容器备份为Docker镜像快照。然后,该Docker镜像或者是被推送到了Docker注册中心,或者被作为tar包文件保存到了本地。如果我们将镜像推送到了Docker注册中心,我们简单地从任何我们想要的机器上使用 docker run 命令来恢复并运行该容器。但是,如果我们将镜像打包成tar包备份到了本地,我们只需要拷贝或移动该镜像到我们想要的机器上,加载该镜像并运行需要的容器即可。
|
||||
|
||||
### 尾声 ###
|
||||
|
||||
最后,我们已经学习了如何快速地备份、恢复和迁移Docker容器,本教程适用于各个可以成功运行Docker的操作系统平台。真的,Docker是一个相当简单易用,然而功能却十分强大的工具。它的命令相当易记,这些命令都非常短,带有许多简单而强大的标记和参数。上面的方法让我们备份容器时很是安逸,使得我们可以在日后很轻松地恢复它们。这会帮助我们恢复我们的容器和镜像,即便主机系统崩溃,甚至意外地被清除。如果你还有很多问题、建议、反馈,请在下面的评论框中写出来吧,可以帮助我们改进或更新我们的内容。谢谢大家!享受吧 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/backup-restore-migrate-containers-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://docker.com/
|
||||
[2]:https://registry.hub.docker.com/
|
||||
@ -0,0 +1,53 @@
|
||||
如何修复:There is no command installed for 7-zip archive files
|
||||
================================================================================
|
||||
### 问题 ###
|
||||
|
||||
我试着在Ubuntu中安装Emerald图标主题,而这个主题被打包成了.7z归档包。和以往一样,我试着通过在GUI中右击并选择“提取到这里”来将它解压缩。但是Ubuntu 15.04却并没有解压文件,取而代之的,却是丢给了我一个下面这样的错误信息:
|
||||
|
||||
> Could not open this file
|
||||
>
|
||||
> 无法打开该文件
|
||||
>
|
||||
> There is no command installed for 7-zip archive files. Do you want to search for a command to open this file?
|
||||
>
|
||||
> 没有安装用于7-zip归档文件的命令。你是否想要搜索用于来打开该文件的命令?
|
||||
|
||||
错误信息看上去是这样的:
|
||||
|
||||

|
||||
|
||||
### 原因 ###
|
||||
|
||||
发生该错误的原因从错误信息本身来看就十分明了。7Z,称之为[7-zip][1]更好,该程序没有安装,因此7Z压缩文件就无法解压缩。这也暗示着Ubuntu默认不支持7-zip文件。
|
||||
|
||||
### 解决方案:在Ubuntu中安装 7zip ###
|
||||
|
||||
要解决该问题也十分简单,在Ubuntu中安装7-Zip包即可。现在,你也许想知道如何在Ubuntu中安装 7Zip吧?好吧,在前面的错误对话框中,如果你右击“Search Command”搜索命令,它会查找可用的 p7zip 包。只要点击“Install”安装,如下图:
|
||||
|
||||

|
||||
|
||||
### 可选方案:在终端中安装 7Zip ###
|
||||
|
||||
如果偏好使用终端,你可以使用以下命令在终端中安装 7zip:
|
||||
|
||||
sudo apt-get install p7zip-full
|
||||
|
||||
注意:在Ubuntu中,你会发现有3个7zip包:p7zip,p7zip-full 和 p7zip-rar。p7zip和p7zip-full的区别在于,p7zip是一个更轻量化的版本,仅仅提供了对 .7z 和 .7za 文件的支持,而完整版则提供了对更多(用于音频文件等的) 7z 压缩算法的支持。对于 p7zip-rar,它除了对 7z 文件的支持外,也提供了对 .rar 文件的支持。
|
||||
|
||||
事实上,相同的错误也会发生在[Ubuntu中的RAR文件][2]身上。解决方案也一样,安装正确的程序即可。
|
||||
|
||||
希望这篇快文帮助你解决了**Ubuntu 14.04中如何打开 7zip**的谜团。如有任何问题或建议,我们将无任欢迎。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/fix-there-is-no-command-installed-for-7-zip-archive-files/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:http://www.7-zip.org/
|
||||
[2]:http://itsfoss.com/fix-there-is-no-command-installed-for-rar-archive-files/
|
||||
@ -0,0 +1,118 @@
|
||||
轻松使用“Explain Shell”脚本来理解 Shell 命令
|
||||
================================================================================
|
||||
我们在Linux上工作时,每个人都会遇到需要查找shell命令的帮助信息的时候。 尽管内置的帮助像man pages、whatis命令有所助益, 但man pages的输出非常冗长, 除非是个有linux经验的人,不然从大量的man pages中获取帮助信息是非常困难的,而whatis命令的输出很少超过一行, 这对初学者来说是不够的。
|
||||
|
||||

|
||||
|
||||
*在Linux Shell中解释Shell命令*
|
||||
|
||||
有一些第三方应用程序, 像我们在[Linux 用户的命令行速查表][1]提及过的'cheat'命令。cheat是个优秀的应用程序,即使计算机没有联网也能提供shell命令的帮助, 但是它仅限于预先定义好的命令。
|
||||
|
||||
Jackson写了一小段代码,它能非常有效地在bash shell里面解释shell命令,可能最美之处就是你不需要安装第三方包了。他把包含这段代码的的文件命名为“explain.sh”。
|
||||
|
||||
#### explain.sh工具的特性 ####
|
||||
|
||||
- 易嵌入代码。
|
||||
- 不需要安装第三方工具。
|
||||
- 在解释过程中输出恰到好处的信息。
|
||||
- 需要网络连接才能工作。
|
||||
- 纯命令行工具。
|
||||
- 可以解释bash shell里面的大部分shell命令。
|
||||
- 无需使用root账户。
|
||||
|
||||
**先决条件**
|
||||
|
||||
唯一的条件就是'curl'包了。 在如今大多数Linux发行版里面已经预安装了curl包, 如果没有你可以按照下面的命令来安装。
|
||||
|
||||
# apt-get install curl [On Debian systems]
|
||||
# yum install curl [On CentOS systems]
|
||||
|
||||
### 在Linux上安装explain.sh工具 ###
|
||||
|
||||
我们要将下面这段代码插入'~/.bashrc'文件(LCTT译注: 若没有该文件可以自己新建一个)中。我们要为每个用户以及对应的'.bashrc'文件插入这段代码,但是建议你不要加在root用户下。
|
||||
|
||||
我们注意到.bashrc文件的第一行代码以(#)开始, 这个是可选的并且只是为了区分余下的代码。
|
||||
|
||||
\# explain.sh 标记代码的开始, 我们将代码插入.bashrc文件的底部。
|
||||
|
||||
# explain.sh begins
|
||||
explain () {
|
||||
if [ "$#" -eq 0 ]; then
|
||||
while read -p "Command: " cmd; do
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$cmd"
|
||||
done
|
||||
echo "Bye!"
|
||||
elif [ "$#" -eq 1 ]; then
|
||||
curl -Gs "https://www.mankier.com/api/explain/?cols="$(tput cols) --data-urlencode "q=$1"
|
||||
else
|
||||
echo "Usage"
|
||||
echo "explain interactive mode."
|
||||
echo "explain 'cmd -o | ...' one quoted command to explain it."
|
||||
fi
|
||||
}
|
||||
|
||||
### explain.sh工具的使用 ###
|
||||
|
||||
在插入代码并保存之后,你必须退出当前的会话然后重新登录来使改变生效(LCTT译注:你也可以直接使用命令`source~/.bashrc` 来让改变生效)。每件事情都是交由‘curl’命令处理, 它负责将需要解释的命令以及命令选项传送给mankier服务,然后将必要的信息打印到Linux命令行。不必说的就是使用这个工具你总是需要连接网络。
|
||||
|
||||
让我们用explain.sh脚本测试几个笔者不懂的命令例子。
|
||||
|
||||
**1.我忘了‘du -h’是干嘛用的, 我只需要这样做:**
|
||||
|
||||
$ explain 'du -h'
|
||||
|
||||

|
||||
|
||||
*获得du命令的帮助*
|
||||
|
||||
**2.如果你忘了'tar -zxvf'的作用,你可以简单地如此做:**
|
||||
|
||||
$ explain 'tar -zxvf'
|
||||
|
||||

|
||||
|
||||
*Tar命令帮助*
|
||||
|
||||
**3.我的一个朋友经常对'whatis'以及'whereis'命令的使用感到困惑,所以我建议他:**
|
||||
|
||||
在终端简单的地敲下explain命令进入交互模式。
|
||||
|
||||
$ explain
|
||||
|
||||
然后一个接着一个地输入命令,就能在一个窗口看到他们各自的作用:
|
||||
|
||||
Command: whatis
|
||||
Command: whereis
|
||||
|
||||

|
||||
|
||||
*Whatis/Whereis命令的帮助*
|
||||
|
||||
你只需要使用“Ctrl+c”就能退出交互模式。
|
||||
|
||||
**4. 你可以通过管道来请求解释更多的命令。**
|
||||
|
||||
$ explain 'ls -l | grep -i Desktop'
|
||||
|
||||

|
||||
|
||||
*获取多条命令的帮助*
|
||||
|
||||
同样地,你可以请求你的shell来解释任何shell命令。 前提是你需要一个可用的网络。输出的信息是基于需要解释的命令,从服务器中生成的,因此输出的结果是不可定制的。
|
||||
|
||||
对于我来说这个工具真的很有用,并且它已经荣幸地添加在我的.bashrc文件中。你对这个项目有什么想法?它对你有用么?它的解释令你满意吗?请让我知道吧!
|
||||
|
||||
请在下面评论为我们提供宝贵意见,喜欢并分享我们以及帮助我们得到传播。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/explain-shell-commands-in-the-linux-shell/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[dingdongnigetou](https://github.com/dingdongnigetou)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/cheat-command-line-cheat-sheet-for-linux-users/
|
||||
@ -0,0 +1,71 @@
|
||||
什么是逻辑分区管理 LVM ,如何在Ubuntu中使用?
|
||||
================================================================================
|
||||
|
||||
> 逻辑分区管理(LVM)是每一个主流Linux发行版都含有的磁盘管理选项。无论是你需要设置存储池,还是只想动态创建分区,那么LVM就是你正在寻找的。
|
||||
|
||||
### 什么是 LVM? ###
|
||||
|
||||
逻辑分区管理是一个存在于磁盘/分区和操作系统之间的一个抽象层。在传统的磁盘管理中,你的操作系统寻找有哪些磁盘可用(/dev/sda、/dev/sdb等等),并且这些磁盘有哪些可用的分区(如/dev/sda1、/dev/sda2等等)。
|
||||
|
||||
在LVM下,磁盘和分区可以抽象成一个含有多个磁盘和分区的设备。你的操作系统将不会知道这些区别,因为LVM只会给操作系统展示你设置的卷组(磁盘)和逻辑卷(分区)
|
||||
|
||||
因为卷组和逻辑卷并不物理地对应到影片,因此可以很容易地动态调整和创建新的磁盘和分区。除此之外,LVM带来了你的文件系统所不具备的功能。比如,ext3不支持实时快照,但是如果你正在使用LVM你可以不卸载磁盘的情况下做一个逻辑卷的快照。
|
||||
|
||||
### 你什么时候该使用LVM? ###
|
||||
|
||||
在使用LVM之前首先得考虑的一件事是你要用你的磁盘和分区来做什么。注意,一些发行版如Fedora已经默认安装了LVM。
|
||||
|
||||
如果你使用的是一台只有一块磁盘的Ubuntu笔记本电脑,并且你不需要像实时快照这样的扩展功能,那么你或许不需要LVM。如果你想要轻松地扩展或者想要将多块磁盘组成一个存储池,那么LVM或许正是你所寻找的。
|
||||
|
||||
### 在Ubuntu中设置LVM ###
|
||||
|
||||
使用LVM首先要了解的一件事是,没有一个简单的方法可以将已有的传统分区转换成逻辑卷。可以将数据移到一个使用LVM的新分区下,但是这并不会在本篇中提到;在这里,我们将全新安装一台Ubuntu 10.10来设置LVM。(LCTT 译注:本文针对的是较老的版本,新的版本已经不需如此麻烦了)
|
||||
|
||||
要使用LVM安装Ubuntu你需要使用另外的安装CD。从下面的链接中下载并烧录到CD中或者[使用unetbootin创建一个USB盘][1]。
|
||||
|
||||

|
||||
|
||||
从安装盘启动你的电脑,并在磁盘选择界面选择整个磁盘并设置LVM。
|
||||
|
||||
*注意:这会格式化你的整个磁盘,因此如果正在尝试双启动或者其他的安装选择,选择手动。*
|
||||
|
||||

|
||||
|
||||
选择你想用的主磁盘,最典型的是使用你最大的磁盘,接着进入下一步。
|
||||
|
||||

|
||||
|
||||
你马上会将改变写入磁盘所以确保此时你选择的是正确的磁盘接着才写入设置。
|
||||
|
||||

|
||||
|
||||
选择第一个逻辑卷的大小并继续。
|
||||
|
||||

|
||||
|
||||
确认你的磁盘分区并继续安装。
|
||||
|
||||

|
||||
|
||||
最后一步将GRUB的bootloader写到磁盘中。重点注意的是GRUB不能作为一个LVM分区因为计算机BIOS不能直接从逻辑卷中读取数据。Ubuntu将自动创建一个255MB的ext2分区用于bootloder。
|
||||
|
||||

|
||||
|
||||
安装完成之后。重启电脑并如往常一样进入Ubuntu。使用这种方式安装之后应该就感受不到LVM和传统磁盘管理之间的区别了。
|
||||
|
||||

|
||||
|
||||
要使用LVM的全部功能,静待我们的下篇关于管理LVM的文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/howto/36568/what-is-logical-volume-management-and-how-do-you-enable-it-in-ubuntu/
|
||||
|
||||
作者:[How-To Geek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/+howtogeek?prsrc=5
|
||||
[1]:http://www.howtogeek.com/howto/13379/create-a-bootable-ubuntu-9.10-usb-flash-drive/
|
||||
48
published/20150730 Compare PDF Files on Ubuntu.md
Normal file
48
published/20150730 Compare PDF Files on Ubuntu.md
Normal file
@ -0,0 +1,48 @@
|
||||
如何在 Ubuntu 上比较 PDF 文件
|
||||
================================================================================
|
||||
|
||||
如果你想要对PDF文件进行比较,你可以使用下面工具之一。
|
||||
|
||||
### Comparepdf ###
|
||||
|
||||
comparepdf是一个命令行应用,用于将两个PDF文件进行对比。默认对比模式是文本模式,该模式会对各对相关页面进行文字对比。只要一检测到差异,该程序就会终止,并显示一条信息(除非设置了-v0)和一个指示性的返回码。
|
||||
|
||||
用于文本模式对比的选项有 -ct 或 --compare=text(默认),用于视觉对比(这对图标或其它图像发生改变时很有用)的选项有 -ca 或 --compare=appearance。而 -v=1 或 --verbose=1 选项则用于报告差异(或者对匹配文件不作任何回应);使用 -v=0 选项取消报告,或者 -v=2 来同时报告不同的和匹配的文件。
|
||||
|
||||
#### 安装comparepdf到Ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install comparepdf
|
||||
|
||||
**Comparepdf 语法**
|
||||
|
||||
comparepdf [OPTIONS] file1.pdf file2.pdf
|
||||
|
||||
###Diffpdf###
|
||||
|
||||
DiffPDF是一个图形化应用程序,用于对两个PDF文件进行对比。默认情况下,它只会对比两个相关页面的文字,但是也支持对图形化页面进行对比(例如,如果图表被修改过,或者段落被重新格式化过)。它也可以对特定的页面或者页面范围进行对比。例如,如果同一个PDF文件有两个版本,其中一个有页面1-12,而另一个则有页面1-13,因为这里添加了一个额外的页面4,它们可以通过指定两个页面范围来进行对比,第一个是1-12,而1-3,5-13则可以作为第二个页面范围。这将使得DiffPDF成对地对比这些页面(1,1),(2,2),(3,3),(4,5),(5,6),以此类推,直到(12,13)。
|
||||
|
||||
#### 安装 diffpdf 到 ubuntu ####
|
||||
|
||||
打开终端,然后运行以下命令
|
||||
|
||||
sudo apt-get install diffpdf
|
||||
|
||||
#### 截图 ####
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/compare-pdf-files-on-ubuntu.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
186
published/20150730 Must-Know Linux Commands For New Users.md
Normal file
186
published/20150730 Must-Know Linux Commands For New Users.md
Normal file
@ -0,0 +1,186 @@
|
||||
新手应知应会的Linux命令
|
||||
================================================================================
|
||||
|
||||
|
||||
*在Fedora上通过命令行使用dnf来管理系统更新*
|
||||
|
||||
基于Linux的系统最美妙的一点,就是你可以在终端中使用命令行来管理整个系统。使用命令行的优势在于,你可以使用相同的知识和技能来管理随便哪个Linux发行版。
|
||||
|
||||
对于各个发行版以及桌面环境(DE)而言,要一致地使用图形化用户界面(GUI)却几乎是不可能的,因为它们都提供了各自的用户界面。要明确的是,有些情况下在不同的发行版上需要使用不同的命令来执行某些特定的任务,但是,基本来说它们的思路和目的是一致的。
|
||||
|
||||
在本文中,我们打算讨论Linux用户应当掌握的一些基本命令。我将给大家演示怎样使用命令行来更新系统、管理软件、操作文件以及切换到root,这些操作将在三个主要发行版上进行:Ubuntu(也包括其定制版和衍生版,还有Debian),openSUSE,以及Fedora。
|
||||
|
||||
*让我们开始吧!*
|
||||
|
||||
### 保持系统安全和最新 ###
|
||||
|
||||
Linux是基于安全设计的,但事实上是,任何软件都有缺陷,会导致安全漏洞。所以,保持你的系统更新到最新是十分重要的。这么想吧:运行过时的操作系统,就像是你坐在全副武装的坦克里头,而门却没有锁。武器会保护你吗?任何人都可以进入开放的大门,对你造成伤害。同样,在你的系统中也有没有打补丁的漏洞,这些漏洞会危害到你的系统。开源社区,不像专利世界,在漏洞补丁方面反应是相当快的,所以,如果你保持系统最新,你也获得了安全保证。
|
||||
|
||||
留意新闻站点,了解安全漏洞。如果发现了一个漏洞,了解它,然后在补丁出来的第一时间更新。不管怎样,在生产环境上,你每星期必须至少运行一次更新命令。如果你运行着一台复杂的服务器,那么就要额外当心了。仔细阅读变更日志,以确保更新不会搞坏你的自定义服务。
|
||||
|
||||
**Ubuntu**:牢记一点:你在升级系统或安装不管什么软件之前,都必须要刷新仓库(也就是repos)。在Ubuntu上,你可以使用下面的命令来更新系统,第一个命令用于刷新仓库:
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
仓库更新后,现在你可以运行系统更新命令了:
|
||||
|
||||
sudo apt-get upgrade
|
||||
|
||||
然而,这个命令不会更新内核和其它一些包,所以你也必须要运行下面这个命令:
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
**openSUSE**:如果你是在openSUSE上,你可以使用以下命令来更新系统(照例,第一个命令的意思是更新仓库):
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper up
|
||||
|
||||
**Fedora**:如果你是在Fedora上,你可以使用'dnf'命令,它是zypper和apt-get的'同类':
|
||||
|
||||
sudo dnf update
|
||||
sudo dnf upgrade
|
||||
|
||||
### 软件安装与移除 ###
|
||||
|
||||
你只可以安装那些你系统上启用的仓库中可用的包,各个发行版默认都附带有并启用了一些官方或者第三方仓库。
|
||||
|
||||
**Ubuntu**:要在Ubuntu上安装包,首先更新仓库,然后使用下面的语句:
|
||||
|
||||
sudo apt-get install [package_name]
|
||||
|
||||
样例:
|
||||
|
||||
sudo apt-get install gimp
|
||||
|
||||
**openSUSE**:命令是这样的:
|
||||
|
||||
sudo zypper install [package_name]
|
||||
|
||||
**Fedora**:Fedora已经丢弃了'yum',现在换成了'dnf',所以命令是这样的:
|
||||
|
||||
sudo dnf install [package_name]
|
||||
|
||||
移除软件的过程也一样,只要把'install'改成'remove'。
|
||||
|
||||
**Ubuntu**:
|
||||
|
||||
sudo apt-get remove [package_name]
|
||||
|
||||
**openSUSE**:
|
||||
|
||||
sudo zypper remove [package_name]
|
||||
|
||||
**Fedora**:
|
||||
|
||||
sudo dnf remove [package_name]
|
||||
|
||||
### 如何管理第三方软件? ###
|
||||
|
||||
在一个庞大的开发者社区中,这些开发者们为用户提供了许多的软件。不同的发行版有不同的机制来将这些第三方软件提供给用户。当然,同时也取决于开发者怎样将这些软件提供给用户,有些开发者会提供二进制包,而另外一些开发者则将软件发布到仓库中。
|
||||
|
||||
Ubuntu很多地方都用到PPA(个人包归档),但是,不幸的是,它却没有提供一个内建工具来帮助用于搜索这些PPA仓库。在安装软件前,你将需要通过Google搜索PPA,然后手工添加该仓库。下面就是添加PPA到系统的方法:
|
||||
|
||||
sudo add-apt-repository ppa:<repository-name>
|
||||
|
||||
样例:比如说,我想要添加LibreOffice PPA到我的系统中。我应该Google该PPA,然后从Launchpad获得该仓库的名称,在本例中它是"libreoffice/ppa"。然后,使用下面的命令来添加该PPA:
|
||||
|
||||
sudo add-apt-repository ppa:libreoffice/ppa
|
||||
|
||||
它会要你按下回车键来导入密钥。完成后,使用'update'命令来刷新仓库,然后安装该包。
|
||||
|
||||
openSUSE拥有一个针对第三方应用的优雅的解决方案。你可以访问software.opensuse.org,一键点击搜索并安装相应包,它会自动将对应的仓库添加到你的系统中。如果你想要手工添加仓库,可以使用该命令:
|
||||
|
||||
sudo zypper ar -f url_of_the_repo name_of_repo
|
||||
sudo zypper ar -f http://download.opensuse.org/repositories/LibreOffice:Factory/openSUSE_13.2/LibreOffice:Factory.repo LOF
|
||||
|
||||
然后,刷新仓库并安装软件:
|
||||
|
||||
sudo zypper refresh
|
||||
sudo zypper install libreoffice
|
||||
|
||||
Fedora用户只需要添加RPMFusion(包括自由软件和非自由软件仓库),该仓库包含了大量的应用。如果你需要添加该仓库,命令如下:
|
||||
|
||||
dnf config-manager --add-repo http://www.example.com/example.repo
|
||||
|
||||
### 一些基本命令 ###
|
||||
|
||||
我已经写了一些关于使用CLI来管理你系统上的文件的[文章][1],下面介绍一些基本命令,这些命令在所有发行版上都经常会用到。
|
||||
|
||||
拷贝文件或目录到一个新的位置:
|
||||
|
||||
cp path_of_file_1 path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将某个目录中的所有文件拷贝到一个新的位置(注意斜线和星号,它指的是该目录下的所有文件):
|
||||
|
||||
cp path_of_files/* path_of_the_directory_where_you_want_to_copy/
|
||||
|
||||
将一个文件从某个位置移动到另一个位置(尾斜杠是说放在该目录中):
|
||||
|
||||
mv path_of_file_1 path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
将所有文件从一个位置移动到另一个位置:
|
||||
|
||||
mv path_of_directory_where_files_are/* path_of_the_directory_where_you_want_to_move/
|
||||
|
||||
删除一个文件:
|
||||
|
||||
rm path_of_file
|
||||
|
||||
删除一个目录:
|
||||
|
||||
rm -r path_of_directory
|
||||
|
||||
移除目录中所有内容,完整保留目录文件夹:
|
||||
|
||||
rm -r path_of_directory/*
|
||||
|
||||
### 创建新目录 ###
|
||||
|
||||
要创建一个新目录,首先进入到你要创建该目录的位置。比如说,你想要在你的Documents目录中创建一个名为'foundation'的文件夹。让我们使用 cd (即change directory,改变目录)命令来改变目录:
|
||||
|
||||
cd /home/swapnil/Documents
|
||||
|
||||
(替换'swapnil'为你系统中的用户名)
|
||||
|
||||
然后,使用 mkdir 命令来创建该目录:
|
||||
|
||||
mkdir foundation
|
||||
|
||||
你也可以从任何地方创建一个目录,通过指定该目录的路径即可。例如:
|
||||
|
||||
mdkir /home/swapnil/Documents/foundation
|
||||
|
||||
如果你想要连父目录一起创建,那么可以使用 -p 选项。它会在指定路径中创建所有目录:
|
||||
|
||||
mdkir -p /home/swapnil/Documents/linux/foundation
|
||||
|
||||
### 成为root ###
|
||||
|
||||
你或许需要成为root,或者具有sudo权力的用户,来实施一些管理任务,如管理软件包或者对根目录或其下的文件进行一些修改。其中一个例子就是编辑'fstab'文件,该文件记录了挂载的硬盘驱动器。它在'etc'目录中,而该目录又在根目录中,你只能作为超级用户来修改该文件。在大多数的发行版中,你可以通过'su'来成为root。比如说,在openSUSE上,我想要成为root,因为我要在根目录中工作,你可以使用下面的命令之一:
|
||||
|
||||
sudo su -
|
||||
|
||||
或
|
||||
|
||||
su -
|
||||
|
||||
该命令会要求输入密码,然后你就具有root特权了。记住一点:千万不要以root用户来运行系统,除非你知道你正在做什么。另外重要的一点需要注意的是,你以root什么对目录或文件进行修改后,会将它们的拥有关系从该用户或特定的服务改变为root。你必须恢复这些文件的拥有关系,否则该服务或用户就不能访问或写入到那些文件。要改变用户,命令如下:
|
||||
|
||||
sudo chown -R 用户:组 文件或目录名
|
||||
|
||||
当你将其它发行版上的分区挂载到系统中时,你可能经常需要该操作。当你试着访问这些分区上的文件时,你可能会碰到权限拒绝错误,你只需要改变这些分区的拥有关系就可以访问它们了。需要额外当心的是,不要改变根目录的权限或者拥有关系。
|
||||
|
||||
这些就是Linux新手们需要的基本命令。如果你有任何问题,或者如果你想要我们涵盖一个特定的话题,请在下面的评论中告诉我们吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/842251-must-know-linux-commands-for-new-users
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/61003
|
||||
[1]:http://www.linux.com/learn/tutorials/828027-how-to-manage-your-files-from-the-command-line
|
||||
@ -0,0 +1,65 @@
|
||||
使用 Find 命令来帮你找到那些需要清理的文件
|
||||
================================================================================
|
||||

|
||||
|
||||
*Credit: Sandra H-S*
|
||||
|
||||
有一个问题几乎困扰着所有的文件系统 -- 包括 Unix 和其他的 -- 那就是文件的不断积累。几乎没有人愿意花时间清理掉他们不再使用的文件和整理文件系统,结果,文件变得很混乱,很难找到有用的东西,要使它们运行良好、维护备份、易于管理,这将是一种持久的挑战。
|
||||
|
||||
我见过的一种解决问题的方法是建议使用者将所有的数据碎屑创建一个文件集合的总结报告或"概况",来报告诸如所有的文件数量;最老的,最新的,最大的文件;并统计谁拥有这些文件等数据。如果有人看到五年前的一个包含五十万个文件的文件夹,他们可能会去删除哪些文件 -- 或者,至少会归档和压缩。主要问题是太大的文件夹会使人担心误删一些重要的东西。如果有一个描述文件夹的方法能帮助显示文件的性质,那么你就可以去清理它了。
|
||||
|
||||
当我准备做 Unix 文件系统的总结报告时,几个有用的 Unix 命令能提供一些非常有用的统计信息。要计算目录中的文件数,你可以使用这样一个 find 命令。
|
||||
|
||||
$ find . -type f | wc -l
|
||||
187534
|
||||
|
||||
虽然查找最老的和最新的文件是比较复杂,但还是相当方便的。在下面的命令,我们使用 find 命令再次查找文件,以文件时间排序并按年-月-日的格式显示,在列表顶部的显然是最老的。
|
||||
|
||||
在第二个命令,我们做同样的,但打印的是最后一行,这是最新的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | sort | head -n 1
|
||||
2006-02-03+02:40:33 ./skel/.xemacs/init.el
|
||||
$ find -type f -printf '%T+ %p\n' | sort | tail -n 1
|
||||
2015-07-19+14:20:16 ./.bash_history
|
||||
|
||||
printf 命令输出 %T(文件日期和时间)和 %P(带路径的文件名)参数。
|
||||
|
||||
如果我们在查找家目录时,无疑会发现,history 文件(如 .bash_history)是最新的,这并没有什么用。你可以通过 "un-grepping" 来忽略这些文件,也可以忽略以.开头的文件,如下图所示的。
|
||||
|
||||
$ find -type f -printf '%T+ %p\n' | grep -v "\./\." | sort | tail -n 1
|
||||
2015-07-19+13:02:12 ./isPrime
|
||||
|
||||
寻找最大的文件使用 %s(大小)参数,包括文件名(%f),因为这就是我们想要在报告中显示的。
|
||||
|
||||
$ find -type f -printf '%s %f \n' | sort -n | uniq | tail -1
|
||||
20183040 project.org.tar
|
||||
|
||||
统计文件的所有者,使用%u(所有者)
|
||||
|
||||
$ find -type f -printf '%u \n' | grep -v "\./\." | sort | uniq -c
|
||||
180034 shs
|
||||
7500 jdoe
|
||||
|
||||
如果文件系统能记录上次的访问日期,也将是非常有用的,可以用来看该文件有没有被访问过,比方说,两年之内没访问过。这将使你能明确分辨这些文件的价值。这个最后访问(%a)参数这样使用:
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | head -n 1
|
||||
Fri Dec 15 03:00:30 2006+ ./statreport
|
||||
|
||||
当然,如果大多数最近访问的文件也是在很久之前的,这看起来你需要处理更多文件了。
|
||||
|
||||
$ find -type f -printf '%a+ %p\n' | sort | tail -n 1
|
||||
Wed Nov 26 03:00:27 2007+ ./my-notes
|
||||
|
||||
要想层次分明,可以为一个文件系统或大目录创建一个总结报告,显示这些文件的日期范围、最大的文件、文件所有者们、最老的文件和最新访问时间,可以帮助文件拥有者判断当前有哪些文件夹是重要的哪些该清理了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itworld.com/article/2949898/linux/profiling-your-file-systems.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[strugglingyouth](https://github.com/strugglingyouth)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itworld.com/author/Sandra-Henry_Stocker/
|
||||
88
published/20150803 Linux Logging Basics.md
Normal file
88
published/20150803 Linux Logging Basics.md
Normal file
@ -0,0 +1,88 @@
|
||||
Linux 日志基础
|
||||
================================================================================
|
||||
首先,我们将描述有关 Linux 日志是什么,到哪儿去找它们,以及它们是如何创建的基础知识。如果你已经知道这些,请随意跳至下一节。
|
||||
|
||||
### Linux 系统日志 ###
|
||||
|
||||
许多有价值的日志文件都是由 Linux 自动地为你创建的。你可以在 `/var/log` 目录中找到它们。下面是在一个典型的 Ubuntu 系统中这个目录的样子:
|
||||
|
||||

|
||||
|
||||
一些最为重要的 Linux 系统日志包括:
|
||||
|
||||
- `/var/log/syslog` 或 `/var/log/messages` 存储所有的全局系统活动数据,包括开机信息。基于 Debian 的系统如 Ubuntu 在 `/var/log/syslog` 中存储它们,而基于 RedHat 的系统如 RHEL 或 CentOS 则在 `/var/log/messages` 中存储它们。
|
||||
- `/var/log/auth.log` 或 `/var/log/secure` 存储来自可插拔认证模块(PAM)的日志,包括成功的登录,失败的登录尝试和认证方式。Ubuntu 和 Debian 在 `/var/log/auth.log` 中存储认证信息,而 RedHat 和 CentOS 则在 `/var/log/secure` 中存储该信息。
|
||||
- `/var/log/kern` 存储内核的错误和警告数据,这对于排除与定制内核相关的故障尤为实用。
|
||||
- `/var/log/cron` 存储有关 cron 作业的信息。使用这个数据来确保你的 cron 作业正成功地运行着。
|
||||
|
||||
Digital Ocean 有一个关于这些文件的完整[教程][1],介绍了 rsyslog 如何在常见的发行版本如 RedHat 和 CentOS 中创建它们。
|
||||
|
||||
应用程序也会在这个目录中写入日志文件。例如像 Apache,Nginx,MySQL 等常见的服务器程序可以在这个目录中写入日志文件。其中一些日志文件由应用程序自己创建,其他的则通过 syslog (具体见下文)来创建。
|
||||
|
||||
### 什么是 Syslog? ###
|
||||
|
||||
Linux 系统日志文件是如何创建的呢?答案是通过 syslog 守护程序,它在 syslog 套接字 `/dev/log` 上监听日志信息,然后将它们写入适当的日志文件中。
|
||||
|
||||
单词“syslog” 代表几个意思,并经常被用来简称如下的几个名称之一:
|
||||
|
||||
1. **Syslog 守护进程** — 一个用来接收、处理和发送 syslog 信息的程序。它可以[远程发送 syslog][2] 到一个集中式的服务器或写入到一个本地文件。常见的例子包括 rsyslogd 和 syslog-ng。在这种使用方式中,人们常说“发送到 syslog”。
|
||||
1. **Syslog 协议** — 一个指定日志如何通过网络来传送的传输协议和一个针对 syslog 信息(具体见下文) 的数据格式的定义。它在 [RFC-5424][3] 中被正式定义。对于文本日志,标准的端口是 514,对于加密日志,端口是 6514。在这种使用方式中,人们常说“通过 syslog 传送”。
|
||||
1. **Syslog 信息** — syslog 格式的日志信息或事件,它包括一个带有几个标准字段的消息头。在这种使用方式中,人们常说“发送 syslog”。
|
||||
|
||||
Syslog 信息或事件包括一个带有几个标准字段的消息头,可以使分析和路由更方便。它们包括时间戳、应用程序的名称、在系统中信息来源的分类或位置、以及事件的优先级。
|
||||
|
||||
下面展示的是一个包含 syslog 消息头的日志信息,它来自于控制着到该系统的远程登录的 sshd 守护进程,这个信息描述的是一次失败的登录尝试:
|
||||
|
||||
<34>1 2003-10-11T22:14:15.003Z server1.com sshd - - pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=10.0.2.2
|
||||
|
||||
### Syslog 格式和字段 ###
|
||||
|
||||
每条 syslog 信息包含一个带有字段的信息头,这些字段是结构化的数据,使得分析和路由事件更加容易。下面是我们使用的用来产生上面的 syslog 例子的格式,你可以将每个值匹配到一个特定的字段的名称上。
|
||||
|
||||
<%pri%>%protocol-version% %timestamp:::date-rfc3339% %HOSTNAME% %app-name% %procid% %msgid% %msg%n
|
||||
|
||||
下面,你将看到一些在查找或排错时最常使用的 syslog 字段:
|
||||
|
||||
#### 时间戳 ####
|
||||
|
||||
[时间戳][4] (上面的例子为 2003-10-11T22:14:15.003Z) 暗示了在系统中发送该信息的时间和日期。这个时间在另一系统上接收该信息时可能会有所不同。上面例子中的时间戳可以分解为:
|
||||
|
||||
- **2003-10-11** 年,月,日。
|
||||
- **T** 为时间戳的必需元素,它将日期和时间分隔开。
|
||||
- **22:14:15.003** 是 24 小时制的时间,包括进入下一秒的毫秒数(**003**)。
|
||||
- **Z** 是一个可选元素,指的是 UTC 时间,除了 Z,这个例子还可以包括一个偏移量,例如 -08:00,这意味着时间从 UTC 偏移 8 小时,即 PST 时间。
|
||||
|
||||
#### 主机名 ####
|
||||
|
||||
[主机名][5] 字段(在上面的例子中对应 server1.com) 指的是主机的名称或发送信息的系统.
|
||||
|
||||
#### 应用名 ####
|
||||
|
||||
[应用名][6] 字段(在上面的例子中对应 sshd:auth) 指的是发送信息的程序的名称.
|
||||
|
||||
#### 优先级 ####
|
||||
|
||||
优先级字段或缩写为 [pri][7] (在上面的例子中对应 <34>) 告诉我们这个事件有多紧急或多严峻。它由两个数字字段组成:设备字段和紧急性字段。紧急性字段从代表 debug 类事件的数字 7 一直到代表紧急事件的数字 0 。设备字段描述了哪个进程创建了该事件。它从代表内核信息的数字 0 到代表本地应用使用的 23 。
|
||||
|
||||
Pri 有两种输出方式。第一种是以一个单独的数字表示,可以这样计算:先用设备字段的值乘以 8,再加上紧急性字段的值:(设备字段)(8) + (紧急性字段)。第二种是 pri 文本,将以“设备字段.紧急性字段” 的字符串格式输出。后一种格式更方便阅读和搜索,但占据更多的存储空间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/linux-logging-basics/
|
||||
|
||||
作者:[Jason Skowronski][a1],[Amy Echeverri][a2],[Sadequl Hussain][a3]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a1]:https://www.linkedin.com/in/jasonskowronski
|
||||
[a2]:https://www.linkedin.com/in/amyecheverri
|
||||
[a3]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:https://www.digitalocean.com/community/tutorials/how-to-view-and-configure-linux-logs-on-ubuntu-and-centos
|
||||
[2]:https://docs.google.com/document/d/11LXZxWlkNSHkcrCWTUdnLRf_CiZz9kK0cr3yGM_BU_0/edit#heading=h.y2e9tdfk1cdb
|
||||
[3]:https://tools.ietf.org/html/rfc5424
|
||||
[4]:https://tools.ietf.org/html/rfc5424#section-6.2.3
|
||||
[5]:https://tools.ietf.org/html/rfc5424#section-6.2.4
|
||||
[6]:https://tools.ietf.org/html/rfc5424#section-6.2.5
|
||||
[7]:https://tools.ietf.org/html/rfc5424#section-6.2.1
|
||||
@ -0,0 +1,75 @@
|
||||
选择成为软件开发工程师的5个原因
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
这个星期我将给本地一所高中做一次有关于程序猿是怎样工作的演讲。我是志愿(由 [Transfer][1] 组织的)来到这所学校谈论我的工作的。这个学校本周将有一个技术主题日,并且他们很想听听科技行业是怎样工作的。因为我是从事软件开发的,这也是我将和学生们讲的内容。演讲的其中一部分是我为什么觉得软件开发是一个很酷的职业。主要原因如下:
|
||||
|
||||
### 5个原因 ###
|
||||
|
||||
**1、创造性**
|
||||
|
||||
如果你问别人创造性的工作有哪些,别人通常会说像作家,音乐家或者画家那样的(工作)。但是极少有人知道软件开发也是一项非常具有创造性的工作。它是最符合创造性定义的了,因为你创造了一个以前没有的新功能。这种解决方案可以在整体和细节上以很多形式来展现。我们经常会遇到一些需要做权衡的场景(比如说运行速度与内存消耗的权衡)。当然前提是这种解决方案必须是正确的。这些所有的行为都是需要强大的创造性的。
|
||||
|
||||
**2、协作性**
|
||||
|
||||
另外一个表象是程序猿们独自坐在他们的电脑前,然后撸一天的代码。但是软件开发事实上通常总是一个团队努力的结果。你会经常和你的同事讨论编程问题以及解决方案,并且和产品经理、测试人员、客户讨论需求以及其他问题。
|
||||
经常有人说,结对编程(2个开发人员一起在一个电脑上编程)是一种流行的最佳实践。
|
||||
|
||||
**3、高需性**
|
||||
|
||||
世界上越来越多的人在用软件,正如 [Marc Andreessen](https://en.wikipedia.org/wiki/Marc_Andreessen) 所说 " [软件正在吞噬世界][2] "。虽然程序猿现在的数量非常巨大(在斯德哥尔摩,程序猿现在是 [最普遍的职业][3] ),但是,需求量一直处于供不应求的局面。据软件公司说,他们最大的挑战之一就是 [找到优秀的程序猿][4] 。我也经常接到那些想让我跳槽的招聘人员打来的电话。我知道至少除软件行业之外的其他行业的雇主不会那么拼(的去招聘)。
|
||||
|
||||
**4、高酬性**
|
||||
|
||||
软件开发可以带来不菲的收入。卖一份你已经开发好的软件的额外副本是没有 [边际成本][5] 的。这个事实与对程序猿的高需求意味着收入相当可观。当然还有许多更捞金的职业,但是相比一般人群,我认为软件开发者确实“日进斗金”(知足吧!骚年~~)。
|
||||
|
||||
**5、前瞻性**
|
||||
|
||||
有许多工作岗位消失,往往是由于它们可以被计算机和软件代替。但是所有这些新的程序依然需要开发和维护,因此,程序猿的前景还是相当好的。
|
||||
|
||||
### 但是...###
|
||||
|
||||
**外包又是怎么一回事呢?**
|
||||
|
||||
难道所有外包到其他国家的软件开发的薪水都很低吗?这是一个理想丰满,现实骨感的例子(有点像 [瀑布开发模型][6] )。软件开发基本上跟设计的工作一样,是一个探索发现的工作。它受益于强有力的合作。更进一步说,特别当你的主打产品是软件的时候,你所掌握的开发知识是绝对的优势。知识在整个公司中分享的越容易,那么公司的发展也将越来越好。
|
||||
|
||||
换一种方式去看待这个问题。软件外包已经存在了相当一段时间了。但是对本土程序猿的需求量依旧非常高。因为许多软件公司看到了雇佣本土程序猿的带来的收益要远远超过了相对较高的成本(其实还是赚了)。
|
||||
|
||||
### 如何成为人生大赢家 ###
|
||||
|
||||
虽然我有许多我认为软件开发是一件非常有趣的事情的理由 (详情见: [为什么我热爱编程][7] )。但是这些理由,并不适用于所有人。幸运的是,尝试编程是一件非常容易的事情。在互联网上有数不尽的学习编程的资源。例如,[Coursera][8] 和 [Udacity][9] 都拥有很好的入门课程。如果你从来没有撸过码,可以尝试其中一个免费的课程,找找感觉。
|
||||
|
||||
寻找一个既热爱又能谋生的事情至少有2个好处。首先,由于你天天去做,工作将比你简单的只为谋生要有趣的多。其次,如果你真的非常喜欢,你将更好的擅长它。我非常喜欢下面一副关于伟大工作组成的韦恩图(作者 [@eskimon)][10]) 。因为编码的薪水确实相当不错,我认为如果你真的喜欢它,你将有一个很好的机会,成为人生的大赢家!
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://henrikwarne.com/2014/12/08/5-reasons-why-software-developer-is-a-great-career-choice/
|
||||
|
||||
作者:[Henrik Warne][a]
|
||||
译者:[mousycoder](https://github.com/mousycoder)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:http://henrikwarne.com/
|
||||
[1]:http://www.transfer.nu/omoss/transferinenglish.jspx?pageId=23
|
||||
[2]:http://www.wsj.com/articles/SB10001424053111903480904576512250915629460
|
||||
[3]:http://www.di.se/artiklar/2014/6/12/jobbet-som-tar-over-landet/
|
||||
[4]:http://computersweden.idg.se/2.2683/1.600324/examinationstakten-racker-inte-for-branschens-behov
|
||||
[5]:https://en.wikipedia.org/wiki/Marginal_cost
|
||||
[6]:https://en.wikipedia.org/wiki/Waterfall_model
|
||||
[7]:http://henrikwarne.com/2012/06/02/why-i-love-coding/
|
||||
[8]:https://www.coursera.org/
|
||||
[9]:https://www.udacity.com/
|
||||
[10]:https://eskimon.wordpress.com/about/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,75 @@
|
||||
Linux有问必答:如何在Linux上安装Git
|
||||
================================================================================
|
||||
|
||||
> **问题:** 我尝试从一个Git公共仓库克隆项目,但出现了这样的错误提示:“git: command not found”。 请问我该如何在某某发行版上安装Git?
|
||||
|
||||
Git是一个流行的开源版本控制系统(VCS),最初是为Linux环境开发的。跟CVS或者SVN这些版本控制系统不同的是,Git的版本控制被认为是“分布式的”,某种意义上,git的本地工作目录可以作为一个功能完善的仓库来使用,它具备完整的历史记录和版本追踪能力。在这种工作模型之下,各个协作者将内容提交到他们的本地仓库中(与之相对的会总是提交到核心仓库),如果有必要,再有选择性地推送到核心仓库。这就为Git这个版本管理系统带来了大型协作系统所必须的可扩展能力和冗余能力。
|
||||
|
||||
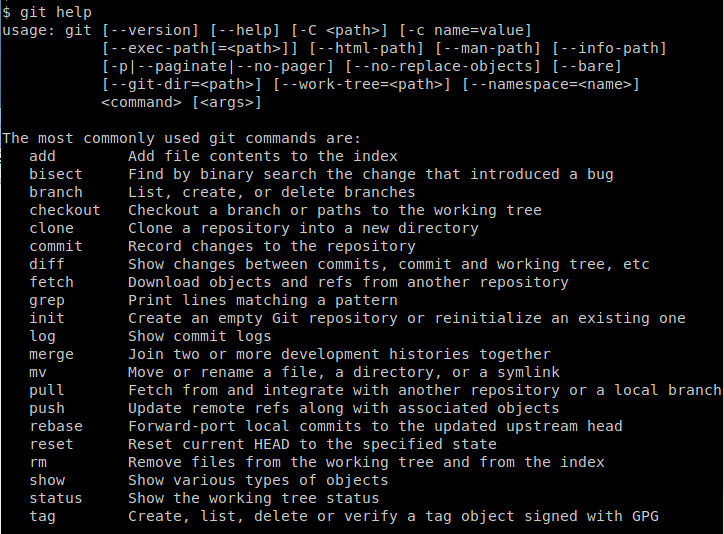
|
||||
|
||||
### 使用包管理器安装Git ###
|
||||
|
||||
Git已经被所有的主流Linux发行版所支持。所以安装它最简单的方法就是使用各个Linux发行版的包管理器。
|
||||
|
||||
**Debian, Ubuntu, 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install git
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install git
|
||||
或
|
||||
$ sudo dnf install git
|
||||
|
||||
**Arch Linux**
|
||||
|
||||
$ sudo pacman -S git
|
||||
|
||||
**OpenSUSE**
|
||||
|
||||
$ sudo zypper install git
|
||||
|
||||
**Gentoo**
|
||||
|
||||
$ emerge --ask --verbose dev-vcs/git
|
||||
|
||||
### 从源码安装Git ###
|
||||
|
||||
如果由于某些原因,你希望从源码安装Git,按照如下介绍操作。
|
||||
|
||||
**安装依赖包**
|
||||
|
||||
在构建Git之前,先安装它的依赖包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
$ sudo apt-get install libcurl4-gnutls-dev libexpat1-dev gettext libz-dev libssl-dev asciidoc xmlto docbook2x
|
||||
|
||||
**Fedora, CentOS 或 RHEL**
|
||||
|
||||
$ sudo yum install curl-devel expat-devel gettext-devel openssl-devel zlib-devel asciidoc xmlto docbook2x
|
||||
|
||||
#### 从源码编译Git ####
|
||||
|
||||
从 [https://github.com/git/git/releases][1] 下载最新版本的Git。然后在/usr下构建和安装。
|
||||
|
||||
注意,如果你打算安装到其他目录下(例如:/opt),那就把"--prefix=/usr"这个配置命令使用其他路径替换掉。
|
||||
|
||||
$ cd git-x.x.x
|
||||
$ make configure
|
||||
$ ./configure --prefix=/usr
|
||||
$ make all doc info
|
||||
$ sudo make install install-doc install-html install-info
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-git-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[mr-ping](https://github.com/mr-ping)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ask.xmodulo.com/author/nanni
|
||||
[1]:https://github.com/git/git/releases
|
||||
@ -0,0 +1,98 @@
|
||||
如何在 Linux 上运行命令前临时清空 Bash 环境变量
|
||||
================================================================================
|
||||
我是个 bash shell 用户。我想临时清空 bash shell 环境变量。但我不想删除或者 unset 一个输出的环境变量。我怎样才能在 bash 或 ksh shell 的临时环境中运行程序呢?
|
||||
|
||||
你可以在 Linux 或类 Unix 系统中使用 env 命令设置并打印环境。env 命令可以按命令行指定的变量来修改环境,之后再执行程序。
|
||||
|
||||
### 如何显示当前环境? ###
|
||||
|
||||
打开终端应用程序并输入下面的其中一个命令:
|
||||
|
||||
printenv
|
||||
|
||||
或
|
||||
|
||||
env
|
||||
|
||||
输出样例:
|
||||
|
||||
|
||||
|
||||
*Fig.01: Unix/Linux: 列出所有环境变量*
|
||||
|
||||
### 统计环境变量数目 ###
|
||||
|
||||
输入下面的命令:
|
||||
|
||||
env | wc -l
|
||||
printenv | wc -l # 或者
|
||||
|
||||
输出样例:
|
||||
|
||||
20
|
||||
|
||||
### 在干净的 bash/ksh/zsh 环境中运行程序 ###
|
||||
|
||||
语法如下所示:
|
||||
|
||||
env -i your-program-name-here arg1 arg2 ...
|
||||
|
||||
例如,要在不使用 http_proxy 和/或任何其它环境变量的情况下运行 wget 程序。临时清除所有 bash/ksh/zsh 环境变量并运行 wget 程序:
|
||||
|
||||
env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
env -i wget www.cyberciti.biz # 或者
|
||||
|
||||
这当你想忽视任何已经设置的环境变量来运行命令时非常有用。我每天都会多次使用这个命令,以便忽视 http_proxy 和其它我设置的环境变量。
|
||||
|
||||
#### 例子:使用 http_proxy ####
|
||||
|
||||
$ wget www.cyberciti.biz
|
||||
--2015-08-03 23:20:23-- http://www.cyberciti.biz/
|
||||
Connecting to 10.12.249.194:3128... connected.
|
||||
Proxy request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html'
|
||||
index.html [ <=> ] 36.17K 87.0KB/s in 0.4s
|
||||
2015-08-03 23:20:24 (87.0 KB/s) - 'index.html' saved [37041]
|
||||
|
||||
#### 例子:忽视 http_proxy ####
|
||||
|
||||
$ env -i /usr/local/bin/wget www.cyberciti.biz
|
||||
--2015-08-03 23:25:17-- http://www.cyberciti.biz/
|
||||
Resolving www.cyberciti.biz... 74.86.144.194
|
||||
Connecting to www.cyberciti.biz|74.86.144.194|:80... connected.
|
||||
HTTP request sent, awaiting response... 200 OK
|
||||
Length: unspecified [text/html]
|
||||
Saving to: 'index.html.1'
|
||||
index.html.1 [ <=> ] 36.17K 115KB/s in 0.3s
|
||||
2015-08-03 23:25:18 (115 KB/s) - 'index.html.1' saved [37041]
|
||||
|
||||
-i 选项使 env 命令完全忽视它继承的环境。但是,它并不会阻止你的命令(例如 wget 或 curl)设置新的变量。同时,也要注意运行 bash/ksh shell 的副作用:
|
||||
|
||||
env -i env | wc -l ## 空的 ##
|
||||
# 现在运行 bash ##
|
||||
env -i bash
|
||||
## bash 设置了新的环境变量 ##
|
||||
env | wc -l
|
||||
|
||||
#### 例子:设置一个环境变量 ####
|
||||
|
||||
语法如下:
|
||||
|
||||
env var=value /path/to/command arg1 arg2 ...
|
||||
## 或 ##
|
||||
var=value /path/to/command arg1 arg2 ...
|
||||
|
||||
例如设置 http_proxy:
|
||||
|
||||
env http_proxy="http://USER:PASSWORD@server1.cyberciti.biz:3128/" /usr/local/bin/wget www.cyberciti.biz
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/linux-unix-temporarily-clearing-environment-variables-command/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[ictlyh](https://github.com/ictlyh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
61
published/20150810 For Linux, Supercomputers R Us.md
Normal file
@ -0,0 +1,61 @@
|
||||
有了 Linux,你就可以搭建自己的超级计算机
|
||||
================================================================================
|
||||
|
||||
> 几乎所有超级计算机上运行的系统都是 Linux,其中包括那些由树莓派(Raspberry Pi)板卡和 PlayStation 3游戏机组成的计算机。
|
||||
|
||||

|
||||
|
||||
*题图来源:By Michel Ngilen,[ CC BY 2.0 ], via Wikimedia Commons*
|
||||
|
||||
超级计算机是一种严肃的工具,做的都是高大上的计算。它们往往从事于严肃的用途,比如原子弹模拟、气候模拟和高等物理学。当然,它们的花费也很高大上。在最新的超级计算机 [Top500][1] 排名中,中国国防科技大学研制的天河 2 号位居第一,而天河 2 号的建造耗资约 3.9 亿美元!
|
||||
|
||||
但是,也有一个超级计算机,是由博伊西州立大学电气和计算机工程系的一名在读博士 Joshua Kiepert [用树莓派构建完成][2]的,其建造成本低于2000美元。
|
||||
|
||||
不,这不是我编造的。它一个真实的超级计算机,由超频到 1GHz 的 [B 型树莓派][3]的 ARM11 处理器与 VideoCore IV GPU 组成。每个都配备了 512MB 的内存、一对 USB 端口和 1 个 10/100 BaseT 以太网端口。
|
||||
|
||||
那么天河 2 号和博伊西州立大学的超级计算机有什么共同点吗?它们都运行 Linux 系统。世界最快的超级计算机[前 500 强中有 486][4] 个也同样运行的是 Linux 系统。这是从 20 多年前就开始的格局。而现在的趋势是超级计算机开始由廉价单元组成,因为 Kiepert 的机器并不是唯一一个无所谓预算的超级计算机。
|
||||
|
||||
麻省大学达特茅斯分校的物理学副教授 Gaurav Khanna 创建了一台超级计算机仅用了[不足 200 台的 PlayStation3 视频游戏机][5]。
|
||||
|
||||
PlayStation 游戏机由一个 3.2 GHz 的基于 PowerPC 的 Power 处理器所驱动。每个都配有 512M 的内存。你现在仍然可以花 200 美元买到一个,尽管索尼将在年底逐步淘汰它们。Khanna 仅用了 16 个 PlayStation 3 构建了他第一台超级计算机,所以你也可以花费不到 4000 美元就拥有你自己的超级计算机。
|
||||
|
||||
这些机器可能是用玩具建成的,但他们不是玩具。Khanna 已经用它做了严肃的天体物理学研究。一个白帽子黑客组织使用了类似的 [PlayStation 3 超级计算机在 2008 年破解了 SSL 的 MD5 哈希算法][6]。
|
||||
|
||||
两年后,美国空军研究实验室研制的 [Condor Cluster,使用了 1760 个索尼的 PlayStation 3 的处理器][7]和168 个通用的图形处理单元。这个低廉的超级计算机,每秒运行约 500 TFLOP ,即每秒可进行 500 万亿次浮点运算。
|
||||
|
||||
其他的一些便宜且适用于构建家庭超级计算机的构件包括,专业并行处理板卡,比如信用卡大小的 [99 美元的 Parallella 板卡][8],以及高端显卡,比如 [Nvidia 的 Titan Z][9] 和 [ AMD 的 FirePro W9100][10]。这些高端板卡的市场零售价约 3000 美元,一些想要一台梦幻般的机器的玩家为此参加了[英特尔极限大师赛:英雄联盟世界锦标赛][11],要是甚至有机会得到了第一名的话,能获得超过 10 万美元奖金。另一方面,一个能够自己提供超过 2.5TFLOPS 计算能力的计算机,对于科学家和研究人员来说,这为他们提供了一个可以拥有自己专属的超级计算机的经济的方法。
|
||||
|
||||
而超级计算机与 Linux 的连接,这一切都始于 1994 年戈达德航天中心的第一个名为 [Beowulf 超级计算机][13]。
|
||||
|
||||
按照我们的标准,Beowulf 不能算是最优越的。但在那个时期,作为第一台自制的超级计算机,它的 16 个英特尔486DX 处理器和 10Mbps 的以太网总线,是个伟大的创举。[Beowulf 是由美国航空航天局的承建商 Don Becker 和 Thomas Sterling 所设计的][14],是第一台“创客”超级计算机。它的“计算部件” 486DX PC,成本仅有几千美元。尽管它的速度只有个位数的 GFLOPS (吉拍,每秒10亿次)浮点运算,[Beowulf][15] 表明了你可以用商用现货(COTS)硬件和 Linux 创建超级计算机。
|
||||
|
||||
我真希望我参与创建了一部分,但是我 1994 年就离开了戈达德,开始了作为一名全职的科技记者的职业生涯。该死。
|
||||
|
||||
但是尽管我只是使用笔记本的记者,我依然能够体会到 COTS 和开源软件是如何永远的改变了超级计算机。我希望现在读这篇文章的你也能。因为,无论是 Raspberry Pi 集群,还是超过 300 万个英特尔的 Ivy Bridge 和 Xeon Phi 芯片的庞然大物,几乎所有当代的超级计算机都可以追溯到 Beowulf。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworld.com/article/2960701/linux/for-linux-supercomputers-r-us.html
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[xiaoyu33](https://github.com/xiaoyu33)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[1]:http://www.top500.org/
|
||||
[2]:http://www.zdnet.com/article/build-your-own-supercomputer-out-of-raspberry-pi-boards/
|
||||
[3]:https://www.raspberrypi.org/products/model-b/
|
||||
[4]:http://www.zdnet.com/article/linux-still-rules-supercomputing/
|
||||
[5]:http://www.nytimes.com/2014/12/23/science/an-economical-way-to-save-progress.html?smid=fb-nytimes&smtyp=cur&bicmp=AD&bicmlukp=WT.mc_id&bicmst=1409232722000&bicmet=1419773522000&_r=4
|
||||
[6]:http://www.computerworld.com/article/2529932/cybercrime-hacking/researchers-hack-verisign-s-ssl-scheme-for-securing-web-sites.html
|
||||
[7]:http://phys.org/news/2010-12-air-playstation-3s-supercomputer.html
|
||||
[8]:http://www.zdnet.com/article/parallella-the-99-linux-supercomputer/
|
||||
[9]:http://blogs.nvidia.com/blog/2014/03/25/titan-z/
|
||||
[10]:http://www.amd.com/en-us/press-releases/Pages/amd-flagship-professional-2014apr7.aspx
|
||||
[11]:http://en.intelextrememasters.com/news/check-out-the-intel-extreme-masters-katowice-prize-money-distribution/
|
||||
|
||||
[13]:http://www.beowulf.org/overview/history.html
|
||||
[14]:http://yclept.ucdavis.edu/Beowulf/aboutbeowulf.html
|
||||
[15]:http://www.beowulf.org/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by xiaoyu33
|
||||
|
||||
Tickr Is An Open-Source RSS News Ticker for Linux Desktops
|
||||
================================================================================
|
||||

|
||||
@ -92,4 +94,4 @@ via: http://www.omgubuntu.co.uk/2015/06/tickr-open-source-desktop-rss-news-ticke
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:apt://tickr
|
||||
[1]:apt://tickr
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
2015 will be the year Linux takes over the enterprise (and other predictions)
|
||||
================================================================================
|
||||
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
|
||||
|
||||

|
||||
|
||||
The crystal ball has been vague and fuzzy for quite some time. Every pundit and voice has opined on what the upcoming year will mean to whatever topic it is they hold dear to their heart. In my case, we're talking Linux and open source.
|
||||
|
||||
In previous years, I'd don the rose-colored glasses and make predictions that would shine a fantastic light over the Linux landscape and proclaim 20** will be the year of Linux on the _____ (name your platform). Many times, those predictions were wrong, and Linux would wind up grinding on in the background.
|
||||
|
||||
This coming year, however, there are some fairly bold predictions to be made, some of which are sure things. Read on and see if you agree.
|
||||
|
||||
### Linux takes over big data ###
|
||||
|
||||
This should come as no surprise, considering the advancements Linux and open source has made over the previous few years. With the help of SuSE, Red Hat, and SAP Hana, Linux will hold powerful sway over big data in 2015. In-memory computing and live kernel patching will be the thing that catapults big data into realms of uptime and reliability never before known. SuSE will lead this charge like a warrior rushing into a battle it cannot possibly lose.
|
||||
|
||||
This rise of Linux in the world of big data will have serious trickle down over the rest of the business world. We already know how fond enterprise businesses are of Linux and big data. What we don't know is how this relationship will alter the course of Linux with regards to the rest of the business world.
|
||||
|
||||
My prediction is that the success of Linux with big data will skyrocket the popularity of Linux throughout the business landscape. More contracts for SuSE and Red Hat will equate to more deployments of Linux servers that handle more tasks within the business world. This will especially apply to the cloud, where OpenStack should easily become an overwhelming leader.
|
||||
|
||||
As the end of 2015 draws to a close, Linux will continue its take over of more backend services, which may include the likes of collaboration servers, security, and much more.
|
||||
|
||||
### Smart machines ###
|
||||
|
||||
Linux is already leading the trend for making homes and autos more intelligent. With improvements in the likes of Nest (which currently uses an embedded Linux), the open source platform is poised to take over your machines. Because 2015 should see a massive rise in smart machines, it goes without saying that Linux will be a huge part of that growth. I firmly believe more homes and businesses will take advantage of such smart controls, and that will lead to more innovations (all of which will be built on Linux).
|
||||
|
||||
One of the issues facing Nest, however, is that it was purchased by Google. What does this mean for the thermostat controller? Will Google continue using the Linux platform -- or will it opt to scrap that in favor of Android? Of course, a switch would set the Nest platform back a bit.
|
||||
|
||||
The upcoming year will see Linux lead the rise in popularity of home automation. Wink, Iris, Q Station, Staples Connect, and more (similar) systems will help to bridge Linux and home users together.
|
||||
|
||||
### The desktop ###
|
||||
|
||||
The big question, as always, is one that tends to hang over the heads of the Linux community like a dark cloud. That question is in relation to the desktop. Unfortunately, my predictions here aren't nearly as positive. I believe that the year 2015 will remain quite stagnant for Linux on the desktop. That complacency will center around Ubuntu.
|
||||
|
||||
As much as I love Ubuntu (and the Unity desktop), this particular distribution will continue to drag the Linux desktop down. Why?
|
||||
|
||||
Convergence... or the lack thereof.
|
||||
|
||||
Canonical has been so headstrong about converging the desktop and mobile experience that they are neglecting the current state of the desktop. The last two releases of Ubuntu (one being an LTS release) have been stagnant (at best). The past year saw two of the most unexciting releases of Ubuntu that I can recall. The reason? Because the developers of Ubuntu are desperately trying to make Unity 8/Mir and the ubiquitous Ubuntu Phone a reality. The vaporware that is the Ubuntu Phone will continue on through 2015, and Unity 8/Mir may or may not be released.
|
||||
|
||||
When the new iteration of the Ubuntu Unity desktop is finally released, it will suffer a serious setback, because there will be so little hardware available to truly show it off. [System76][1] will sell their outstanding [Sable Touch][2], which will probably become the flagship system for Unity 8/Mir. As for the Ubuntu Phone? How many reports have you read that proclaimed "Ubuntu Phone will ship this year"?
|
||||
|
||||
I'm now going on the record to predict that the Ubuntu Phone will not ship in 2015. Why? Canonical created partnerships with two OEMs over a year ago. Those partnerships have yet to produce a single shippable product. The closest thing to a shippable product is the Meizu MX4 phone. The "Pro" version of that phone was supposed to have a formal launch of Sept 25. Like everything associated with the Ubuntu Phone, it didn't happen.
|
||||
|
||||
Unless Canonical stops putting all of its eggs in one vaporware basket, desktop Linux will take a major hit in 2015. Ubuntu needs to release something major -- something to make heads turn -- otherwise, 2015 will be just another year where we all look back and think "we could have done something special."
|
||||
|
||||
Outside of Ubuntu, I do believe there are some outside chances that Linux could still make some noise on the desktop. I think two distributions, in particular, will bring something rather special to the table:
|
||||
|
||||
- [Evolve OS][3] -- a ChromeOS-like Linux distribution
|
||||
- [Quantum OS][4] -- a Linux distribution that uses Android's Material Design specs
|
||||
|
||||
Both of these projects are quite exciting and offer unique, user-friendly takes on the Linux desktop. This is quickly become a necessity in a landscape being dragged down by out-of-date design standards (think the likes of Cinnamon, Mate, XFCE, LXCE -- all desperately clinging to the past).
|
||||
|
||||
This is not to say that Linux on the desktop doesn't have a chance in 2015. It does. In order to grasp the reins of that chance, it will have to move beyond the past and drop the anchors that prevent it from moving out to deeper, more viable waters.
|
||||
|
||||
Linux stands to make more waves in 2015 than it has in a very long time. From enterprise to home automation -- the world could be the oyster that Linux uses as a springboard to the desktop and beyond.
|
||||
|
||||
What are your predictions for Linux and open source in 2015? Share your thoughts in the discussion thread below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techrepublic.com/article/2015-will-be-the-year-linux-takes-over-the-enterprise-and-other-predictions/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techrepublic.com/search/?a=jack+wallen
|
||||
[1]:https://system76.com/
|
||||
[2]:https://system76.com/desktops/sable
|
||||
[3]:https://evolve-os.com/
|
||||
[4]:http://quantum-os.github.io/
|
||||
@ -1,120 +0,0 @@
|
||||
The Curious Case of the Disappearing Distros
|
||||
================================================================================
|
||||

|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread, but corporations are taking control, and slowly but systematically, community distros are being killed," said Google+ blogger Alessandro Ebersol. "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return."
|
||||
|
||||
Well the holidays are pretty much upon us at last here in the Linux blogosphere, and there's nowhere left to hide. The next two weeks or so promise little more than a blur of forced social occasions and too-large meals, punctuated only -- for the luckier ones among us -- by occasional respite down at the Broken Windows Lounge.
|
||||
|
||||
Perhaps that's why Linux bloggers seized with such glee upon the good old-fashioned mystery that came up recently -- delivered in the nick of time, as if on cue.
|
||||
|
||||
"Why is the Number of Linux Distros Declining?" is the [question][1] posed over at Datamation, and it's just the distraction so many FOSS fans have been needing.
|
||||
|
||||
"Until about 2011, the number of active distributions slowly increased by a few each year," wrote author Bruce Byfield. "By contrast, the last three years have seen a 12 percent decline -- a decrease too high to be likely to be coincidence.
|
||||
|
||||
"So what's happening?" Byfield wondered.
|
||||
|
||||
It would be difficult to imagine a more thought-provoking question with which to spend the Northern hemisphere's shortest days.
|
||||
|
||||
### 'There Are Too Many Distros' ###
|
||||
|
||||

|
||||
|
||||
"That's an easy question," began blogger [Robert Pogson][2]. "There are too many distros."
|
||||
|
||||
After all, "if a fanatic like me can enjoy life having sampled only a dozen distros, why have any more?" Pogson explained. "If someone has a concept different from the dozen or so most common distros, that concept can likely be demonstrated by documenting the tweaks and package-lists and, perhaps, some code."
|
||||
|
||||
Trying to compete with some 40,000 package repositories like Debian's, however, is "just silly," he said.
|
||||
|
||||
"No startup can compete with such a distro," Pogson asserted. "Why try? Just use it to do what you want and tell the world about it."
|
||||
|
||||
### 'I Don't Distro-Hop Anymore' ###
|
||||
|
||||
The major existing distros are doing a good job, so "we don't need so many derivative works," Google+ blogger Kevin O'Brien agreed.
|
||||
|
||||
"I know I don't 'distro-hop' anymore, and my focus is on using my computer to get work done," O'Brien added.
|
||||
|
||||
"If my apps run fine every day, that is all that I need," he said. "Right now I am sticking with Ubuntu LTS 14.04, and probably will until 2016."
|
||||
|
||||
### 'The More Distros, the Better' ###
|
||||
|
||||
It stands to reason that "as distros get better, there will be less reasons to roll your own," concurred [Linux Rants][3] blogger Mike Stone.
|
||||
|
||||
"I think the modern Linux distros cover the bases of a larger portion of the Linux-using crowd, so fewer and fewer people are starting their own distribution to compensate for something that the others aren't satisfying," he explained. "Add to that the fact that corporations are more heavily involved in the development of Linux now than they ever have been, and they're going to focus their resources."
|
||||
|
||||
So, the decline isn't necessarily a bad thing, as it only points to the strength of the current offerings, he asserted.
|
||||
|
||||
At the same time, "I do think there are some negative consequences as well," Stone added. "Variation in the distros is a way that Linux grows and evolves, and with a narrower field, we're seeing less opportunity to put new ideas out there. In my mind, the more distros, the better -- hopefully the trend reverses soon."
|
||||
|
||||
### 'I Hope Some Diversity Survives' ###
|
||||
|
||||
Indeed, "the era of novelty and experimentation is over," Google+ blogger Gonzalo Velasco C. told Linux Girl.
|
||||
|
||||
"Linux is 20+ years old and got professional," he noted. "There is always room for experimentation, but the top 20 are here since more than a decade ago.
|
||||
|
||||
"Godspeed GNU/Linux," he added. "I hope some diversity survives -- especially distros without Systemd; on the other hand, some standards are reached through consensus."
|
||||
|
||||
### A Question of Package Managers ###
|
||||
|
||||
There are two trends at work here, suggested consultant and [Slashdot][4] blogger Gerhard Mack.
|
||||
|
||||
First, "there are fewer reasons to start a new distro," he said. "The basic nuts and bolts are mostly done, installation is pretty easy across most distros, and it's not difficult on most hardware to get a working system without having to resort to using the command line."
|
||||
|
||||
The second thing is that "we are seeing a reduction of distros with inferior package managers," Mack suggested. "It is clear that .deb-based distros had fewer losses and ended up with a larger overall share."
|
||||
|
||||
### Survival of the Fittest ###
|
||||
|
||||
It's like survival of the fittest, suggested consultant Rodolfo Saenz, who is certified in Linux, IBM Tivoli Storage Manager and Microsoft Active Directory.
|
||||
|
||||
"I prefer to see a strong Linux with less distros," Saenz added. "Too many distros dilutes development efforts and can confuse potential future users."
|
||||
|
||||
Fewer distros, on the other hand, "focuses development efforts into the stronger distros and also attracts new potential users with clear choices for their needs," he said.
|
||||
|
||||
### All About the Money ###
|
||||
|
||||
Google+ blogger Alessandro Ebersol also saw survival of the fittest at play, but he took a darker view.
|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread," Ebersol began. "But corporations are taking control, and slowly but systematically, community distros are being killed."
|
||||
|
||||
It's difficult for community distros to keep pace with the ever-changing field, and cash is a necessity, he conceded.
|
||||
|
||||
Still, "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return," Ebersol said. "It saddens me, but GNU/Linux's best days were 10 years ago, circa 2002 to 2004. Now, it's the survival of the fittest -- and of course, the ones with more money will prevail."
|
||||
|
||||
### 'Fewer Devs Care' ###
|
||||
|
||||
SoylentNews blogger hairyfeet focused on today's altered computing landscape.
|
||||
|
||||
"The reason there are fewer distros is simple: With everybody moving to the Google Playwall of Android, and Windows 10 looking to be the next XP, fewer devs care," hairyfeet said.
|
||||
|
||||
"Why should they?" he went on. "The desktop wars are over, MSFT won, and the mobile wars are gonna be proprietary Google, proprietary Apple and proprietary MSFT. The money is in apps and services, and with a slow economy, there just isn't time for pulling a Taco Bell and rerolling yet another distro.
|
||||
|
||||
"For the few that care about Linux desktops you have Ubuntu, Mint and Cent, and that is plenty," hairyfeet said.
|
||||
|
||||
### 'No Less Diversity' ###
|
||||
|
||||
Last but not least, Chris Travers, a [blogger][5] who works on the [LedgerSMB][6] project, took an optimistic view.
|
||||
|
||||
"Ever since I have been around Linux, there have been a few main families -- [SuSE][7], [Red Hat][8], Debian, Gentoo, Slackware -- and a number of forks of these," Travers said. "The number of major families of distros has been declining for some time -- Mandrake and Connectiva merging, for example, Caldera disappearing -- but each of these families is ending up with fewer members as well.
|
||||
|
||||
"I think this is a good thing," he concluded.
|
||||
|
||||
"The big community distros -- Debian, Slackware, Gentoo, Fedora -- are going strong and picking up a lot of the niche users that other distros catered to," he pointed out. "Many of these distros are making it easier to come up with customized variants for niche markets. So what you have is a greater connectedness within the big distros, and no less diversity."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/The-Curious-Case-of-the-Disappearing-Distros-81518.html
|
||||
|
||||
作者:Katherine Noyes
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.datamation.com/open-source/why-is-the-number-of-linux-distros-declining.html
|
||||
[2]:http://mrpogson.com/
|
||||
[3]:http://linuxrants.com/
|
||||
[4]:http://slashdot.org/
|
||||
[5]:http://ledgersmbdev.blogspot.com/
|
||||
[6]:http://www.ledgersmb.org/
|
||||
[7]:http://www.novell.com/linux
|
||||
[8]:http://www.redhat.com/
|
||||
@ -1,36 +0,0 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
**David Drysdale** wanted to add Capsicum security features to Linux after he noticed that FreeBSD already had Capsicum support. Capsicum defines fine-grained security privileges, not unlike filesystem capabilities. But as David discovered, Capsicum also has some controversy surrounding it.
|
||||
|
||||
Capsicum has been around for a while and was described in a USENIX paper in 2010: [http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf][1].
|
||||
|
||||
Part of the controversy is just because of the similarity with capabilities. As Eric Biderman pointed out during the discussion, it would be possible to implement features approaching Capsicum's as an extension of capabilities, but implementing Capsicum directly would involve creating a whole new (and extensive) abstraction layer in the kernel. Although David argued that capabilities couldn't actually be extended far enough to match Capsicum's fine-grained security controls.
|
||||
|
||||
Capsicum also was controversial within its own developer community. For example, as Eric described, it lacked a specification for how to revoke privileges. And, David pointed out that this was because the community couldn't agree on how that could best be done. David quoted an e-mail sent by Ben Laurie to the cl-capsicum-discuss mailing list in 2011, where Ben said, "It would require additional book-keeping to find and revoke outstanding capabilities, which requires knowing how to reach capabilities, and then whether they are derived from the capability being revoked. It also requires an authorization model for revocation. The former two points mean additional overhead in terms of data structure operations and synchronisation."
|
||||
|
||||
Given the ongoing controversy within the Capsicum developer community and the corresponding lack of specification of key features, and given the existence of capabilities that already perform a similar function in the kernel and the invasiveness of Capsicum patches, Eric was opposed to David implementing Capsicum in Linux.
|
||||
|
||||
But, given the fact that capabilities are much coarser-grained than Capsicum's security features, to the point that capabilities can't really be extended far enough to mimic Capsicum's features, and given that FreeBSD already has Capsicum implemented in its kernel, showing that it can be done and that people might want it, it seems there will remain a lot of folks interested in getting Capsicum into the Linux kernel.
|
||||
|
||||
Sometimes it's unclear whether there's a bug in the code or just a bug in the written specification. Henrique de Moraes Holschuh noticed that the Intel Software Developer Manual (vol. 3A, section 9.11.6) said quite clearly that microcode updates required 16-byte alignment for the P6 family of CPUs, the Pentium 4 and the Xeon. But, the code in the kernel's microcode driver didn't enforce that alignment.
|
||||
|
||||
In fact, Henrique's investigation uncovered the fact that some Intel chips, like the Xeon X5550 and the second-generation i5 chips, needed only 4-byte alignment in practice, and not 16. However, to conform to the documented specification, he suggested fixing the kernel code to match the spec.
|
||||
|
||||
Borislav Petkov objected to this. He said Henrique was looking for problems where there weren't any. He said that Henrique simply had discovered a bug in Intel's documentation, because the alignment issue clearly wasn't a problem in the real world. He suggested alerting the Intel folks to the documentation problem and moving on. As he put it, "If the processor accepts the non-16-byte-aligned update, why do you care?"
|
||||
|
||||
But, as H. Peter Anvin remarked, the written spec was Intel's guarantee that certain behaviors would work. If the kernel ignored the spec, it could lead to subtle bugs later on. And, Bill Davidsen said that if the kernel ignored the alignment requirement, and "if the requirement is enforced in some future revision, and updates then fail in some insane way, the vendor is justified in claiming 'I told you so'."
|
||||
|
||||
The end result was that Henrique sent in some patches to make the microcode driver enforce the 16-byte alignment requirement.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-6
|
||||
|
||||
作者:[Zack Brown][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
[1]:http://www.cl.cam.ac.uk/research/security/capsicum/papers/2010usenix-security-capsicum-website.pdf
|
||||
@ -1,91 +0,0 @@
|
||||
Did this JavaScript break the console?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Just doing some JavaScript stuff in google chrome (don't want to try in other browsers for now, in case this is really doing real damage) and I'm not sure why this seemed to break my console.
|
||||
|
||||
```javascript
|
||||
>var x = "http://www.foo.bar/q?name=%%this%%";
|
||||
<undefined
|
||||
>x
|
||||
```
|
||||
|
||||
After x (and enter) the console stops working... I restarted chrome and now when I do a simple
|
||||
|
||||
```javascript
|
||||
console.clear();
|
||||
```
|
||||
|
||||
It's giving me
|
||||
|
||||
```javascript
|
||||
Console was cleared
|
||||
```
|
||||
|
||||
And not clearing the console. Now in my scripts console.log's do not register and I'm wondering what is going on. 99% sure it has to do with the double percent signs (%%).
|
||||
|
||||
Anyone know what I did wrong or better yet, how to fix the console?
|
||||
|
||||
[A bug report for this issue has been filed here.][1]
|
||||
Edit: Feeling pretty dumb, but I had Preserve log checked... That's why the console wasn't clearing.
|
||||
|
||||
#A:
|
||||
|
||||
As discussed in the comments, there are actually many different ways of constructing a string that causes this issue, and it is not necessary for there to be two percent signs in most cases.
|
||||
|
||||
```TXT
|
||||
http://example.com/%
|
||||
http://%%%
|
||||
http://ab%
|
||||
http://%ab
|
||||
http://%zz
|
||||
```
|
||||
|
||||
However, it's not just the presence of a percent sign that breaks the Chrome console, as when we enter the following well-formed URL, the console continues to work properly and produces a clickable link.
|
||||
|
||||
```TXT
|
||||
http://ab%20cd
|
||||
```
|
||||
|
||||
Additionally, the strings `http://%`, and `http://%%` will also print properly, since Chrome will not auto-link a URL-link string unless the [`http://`][2] is followed by at least 3 characters.
|
||||
|
||||
From here I hypothesized that the issue must be in the process of linking a URL string in the console, likely in the process of decoding a malformed URL. I remembered that the JavaScript function `decodeURI` will throw an exception if given a malformed URL, and since Chrome's developer tools are largely written in JavaScript, could this be the issue that is evidently crashing the developer console?
|
||||
|
||||
To test this theory, I ran Chrome by the command link, to see if any errors were being logged.
|
||||
|
||||
Indeed, the same error you would see if you ran decodeURI on a malformed URL (i.e. decodeURI('http://example.com/%')) was being printed to the console:
|
||||
|
||||
>[4810:1287:0107/164725:ERROR:CONSOLE(683)] "Uncaught URIError: URI malformed", source: chrome-devtools://devtools/bundled/devtools.js (683)
|
||||
>So, I opened the URL 'chrome-devtools://devtools/bundled/devtools.js' in Chrome, and on line 683, I found the following.
|
||||
|
||||
```javascript
|
||||
{var parsedURL=new WebInspector.ParsedURL(decodeURI(url));var origin;var folderPath;var name;if(parsedURL.isValid){origin=parsedURL.scheme+"://"+parsedURL.host;if(parsedURL.port)
|
||||
```
|
||||
|
||||
As we can see, `decodeURI(url)` is being called on the URL without any error checking, thus throwing the exception and crashing the developer console.
|
||||
|
||||
A real fix for this issue will come from adding error handling to the Chrome console code, but in the meantime, one way to avoid the issue would be to wrap the string in a complex data type like an array to prevent parsing when logging.
|
||||
|
||||
```javascript
|
||||
var x = "http://example.com/%";
|
||||
console.log([x]);
|
||||
```
|
||||
|
||||
Thankfully, the broken console issue does not persist once the tab is closed, and will not affect other tabs.
|
||||
|
||||
###Update:
|
||||
|
||||
Apparently, the issue can persist across tabs and restarts if Preserve Log is checked. Uncheck this if you are having this issue.
|
||||
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27828804/did-this-javascript-break-the-console/27830948#27830948)
|
||||
|
||||
作者:[Alexander O'Mara][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/3155639/alexander-omara
|
||||
[1]:https://code.google.com/p/chromium/issues/detail?id=446975
|
||||
[2]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/decodeURI
|
||||
@ -1,88 +0,0 @@
|
||||
FSSlc Translating
|
||||
|
||||
7 communities driving open source development
|
||||
================================================================================
|
||||
Not so long ago, the open source model was the rebellious kid on the block, viewed with suspicion by established industry players. Today, open initiatives and foundations are flourishing with long lists of vendor committers who see the model as a key to innovation.
|
||||
|
||||

|
||||
|
||||
### Open Development of Tech Drives Innovation ###
|
||||
|
||||
Over the past two decades, open development of technology has come to be seen as a key to driving innovation. Even companies that once saw open source as a threat have come around — Microsoft, for example, is now active in a number of open source initiatives. To date, most open development has focused on software. But even that is changing as communities have begun to coalesce around open hardware initiatives. Here are seven organizations that are successfully promoting and developing open technologies, both hardware and software.
|
||||
|
||||
### OpenPOWER Foundation ###
|
||||
|
||||

|
||||
|
||||
The [OpenPOWER Foundation][2] was founded by IBM, Google, Mellanox, Tyan and NVIDIA in 2013 to drive open collaboration hardware development in the same spirit as the open source software development which has found fertile ground in the past two decades.
|
||||
|
||||
IBM seeded the foundation by opening up its Power-based hardware and software technologies, offering licenses to use Power IP in independent hardware products. More than 70 members now work together to create custom open servers, components and software for Linux-based data centers.
|
||||
|
||||
In April, OpenPOWER unveiled a technology roadmap based on new POWER8 process-based servers capable of analyzing data 50 times faster than the latest x86-based systems. In July, IBM and Google released a firmware stack. October saw the availability of NVIDIA GPU accelerated POWER8 systems and the first OpenPOWER reference server from Tyan.
|
||||
|
||||
### The Linux Foundation ###
|
||||
|
||||

|
||||
|
||||
Founded in 2000, [The Linux Foundation][2] is now the host for the largest open source, collaborative development effort in history, with more than 180 corporate members and many individual and student members. It sponsors the work of key Linux developers and promotes, protects and advances the Linux operating system and collaborative software development.
|
||||
|
||||
Some of its most successful collaborative projects include Code Aurora Forum (a consortium of companies with projects serving the mobile wireless industry), MeeGo (a project to build a Linux kernel-based operating system for mobile devices and IVI) and the Open Virtualization Alliance (which fosters the adoption of free and open source software virtualization solutions).
|
||||
|
||||
### Open Virtualization Alliance ###
|
||||
|
||||

|
||||
|
||||
The [Open Virtualization Alliance (OVA)][3] exists to foster the adoption of free and open source software virtualization solutions like Kernel-based Virtual Machine (KVM) through use cases and support for the development of interoperable common interfaces and APIs. KVM turns the Linux kernel into a hypervisor.
|
||||
|
||||
Today, KVM is the most commonly used hypervisor with OpenStack.
|
||||
|
||||
### The OpenStack Foundation ###
|
||||
|
||||

|
||||
|
||||
Originally launched as an Infrastructure-as-a-Service (IaaS) product by NASA and Rackspace hosting in 2010, the [OpenStack Foundation][4] has become the home for one of the biggest open source projects around. It boasts more than 200 member companies, including AT&T, AMD, Avaya, Canonical, Cisco, Dell and HP.
|
||||
|
||||
Organized around a six-month release cycle, the foundation's OpenStack projects are developed to control pools of processing, storage and networking resources through a data center — all managed or provisioned through a Web-based dashboard, command-line tools or a RESTful API. So far, the collaborative development supported by the foundation has resulted in the creation of OpenStack components including OpenStack Compute (a cloud computing fabric controller that is the main part of an IaaS system), OpenStack Networking (a system for managing networks and IP addresses) and OpenStack Object Storage (a scalable redundant storage system).
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||

|
||||
|
||||
Another collaborative project to come out of the Linux Foundation, [OpenDaylight][5] is a joint initiative of industry vendors, like Dell, HP, Oracle and Avaya founded in April 2013. Its mandate is the creation of a community-led, open, industry-supported framework consisting of code and blueprints for Software-Defined Networking (SDN). The idea is to provide a fully functional SDN platform that can be deployed directly, without requiring other components, though vendors can offer add-ons and enhancements.
|
||||
|
||||
### Apache Software Foundation ###
|
||||
|
||||

|
||||
|
||||
The [Apache Software Foundation (ASF)][7] is home to nearly 150 top level projects ranging from open source enterprise automation software to a whole ecosystem of distributed computing projects related to Apache Hadoop. These projects deliver enterprise-grade, freely available software products, while the Apache License is intended to make it easy for users, whether commercial or individual, to deploy Apache products.
|
||||
|
||||
ASF was incorporated in 1999 as a membership-based, not-for-profit corporation with meritocracy at its heart — to become a member you must first be actively contributing to one or more of the foundation's collaborative projects.
|
||||
|
||||
### Open Compute Project ###
|
||||
|
||||

|
||||
|
||||
An outgrowth of Facebook's redesign of its Oregon data center, the [Open Compute Project (OCP)][7] aims to develop open hardware solutions for data centers. The OCP is an initiative made up of cheap, vanity-free servers, modular I/O storage for Open Rack (a rack standard designed for data centers to integrate the rack into the data center infrastructure) and a relatively "green" data center design.
|
||||
|
||||
OCP board members include representatives from Facebook, Intel, Goldman Sachs, Rackspace and Microsoft.
|
||||
|
||||
OCP recently announced two options for licensing: an Apache 2.0-like license that allows for derivative works and a more prescriptive license that encourages changes to be rolled back into the original software.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2866074/opensource-subnet/7-communities-driving-open-source-development.html
|
||||
|
||||
作者:[Thor Olavsrud][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Thor-Olavsrud/
|
||||
[1]:http://openpowerfoundation.org/
|
||||
[2]:http://www.linuxfoundation.org/
|
||||
[3]:https://openvirtualizationalliance.org/
|
||||
[4]:http://www.openstack.org/foundation/
|
||||
[5]:http://www.opendaylight.org/
|
||||
[6]:http://www.apache.org/
|
||||
[7]:http://www.opencompute.org/
|
||||
@ -1,66 +0,0 @@
|
||||
Revealed: The best and worst of Docker
|
||||
================================================================================
|
||||

|
||||
Credit: [Shutterstock][1]
|
||||
|
||||
> Docker experts talk about the good, the bad, and the ugly of the ubiquitous application container system
|
||||
|
||||
No question about it: Docker's app container system has made its mark and become a staple in many IT environments. With its accelerating adoption, it's bound to stick around for a good long time.
|
||||
|
||||
But there's no end to the debate about what Docker's best for, where it falls short, or how to most sensibly move it forward without alienating its existing users or damaging its utility. Here, we've turned to a few of the folks who have made Docker their business to get their takes on Docker's good, bad, and ugly sides.
|
||||
|
||||
### The good ###
|
||||
|
||||
One hardly expects Steve Francia, chief of operations of the Docker open source project, to speak of Docker in anything less than glowing terms. When asked by email about Docker's best attributes, he didn't disappoint: "I think the best thing about Docker is that it enables people, enables developers, enables users to very easily run an application anywhere," he said. "It's almost like the Holy Grail of development in that you can run an application on your desktop, and the exact same application without any changes can run on the server. That's never been done before."
|
||||
|
||||
Alexis Richardson of [Weaveworks][2], a virtual networking product, praised Docker for enabling simplicity. "Docker offers immense potential to radically simplify and speed up how software gets built," he replied in an email. "This is why it has delivered record-breaking initial mind share and traction."
|
||||
|
||||
Bob Quillin, CEO of [StackEngine][3], which makes Docker management and automation solutions, noted in an email that Docker (the company) has done a fine job of maintaining Docker's (the product) appeal to its audience. "Docker has been best at delivering strong developer support and focused investment in its product," he wrote. "Clearly, they know they have to keep the momentum, and they are doing that by putting intense effort into product functionality." He also mentioned that Docker's commitment to open source has accelerated adoption by "[allowing] people to build around their features as they are being built."
|
||||
|
||||
Though containerization itself isn't new, as Rob Markovich of IT monitoring-service makers [Moogsoft][4] pointed out, Docker's implementation makes it new. "Docker is considered a next-generation virtualization technology given its more modern, lightweight form [of containerization]," he wrote in an email. "[It] brings an opportunity for an order-of-magnitude leap forward for software development teams seeking to deploy code faster."
|
||||
|
||||
### The bad ###
|
||||
|
||||
What's less appealing about Docker boils down to two issues: the complexity of using the product, and the direction of the company behind it.
|
||||
|
||||
Samir Ghosh, CEO of enterprise PaaS outfit [WaveMaker][5], gave Docker a thumbs-up for simplifying the complex scripting typically needed for continuous delivery. That said, he added, "That doesn't mean Docker is simple. Implementing Docker is complicated. There are a lot of supporting technologies needed for things like container management, orchestration, app stack packaging, intercontainer networking, data snapshots, and so on."
|
||||
|
||||
Ghosh noted the ones who feel the most of that pain are enterprises that want to leverage Docker for continuous delivery, but "it's even more complicated for enterprises that have diverse workloads, various app stacks, heterogenous infrastructures, and limited resources, not to mention unique IT needs for visibility, control and security."
|
||||
|
||||
Complexity also becomes an issue in troubleshooting and analysis, and Markovich cited the fact that Docker provides application abstraction as the reason why. "It is nearly impossible to relate problems with application performance running on Docker to the performance of the underlying infrastructure domains," he said in an email. "IT teams are going to need visibility -- a new class of monitoring and analysis tools that can correlate across and relate how everything is working up and down the Docker stack, from the applications down to the private or public infrastructure."
|
||||
|
||||
Quillin is most concerned about Docker's direction vis-à-vis its partner community: "Where will Docker make money, and where will their partners? If [Docker] wants to be the next VMware, it will need to take a page out of VMware's playbook in how to build and support a thriving partner ecosystem.
|
||||
|
||||
"Additionally, to drive broader adoption, especially in the enterprise, Docker needs to start acting like a market leader by releasing more fully formed capabilities that organizations can count on, versus announcements of features with 'some assembly required,' that don't exist yet, or that require you to 'submit a pull request' to fix it yourself."
|
||||
|
||||
Francia pointed to Docker's rapid ascent for creating its own difficulties. "[Docker] caught on so quickly that there's definitely places that we're focused on to add some features that a lot of users are looking forward to."
|
||||
|
||||
One such feature, he noted, was having a GUI. "Right now to use Docker," he said, "you have to be comfortable with the command line. There's no visual interface to using Docker. Right now it's all command line-based. And we know if we want to really be as successful as we think we can be, we need to be more approachable and a lot of people when they see a command line, it's a bit intimidating for a lot of users."
|
||||
|
||||
### The future ###
|
||||
|
||||
In that last respect, Docker recently started to make advances. Last week it [bought the startup Kitematic][6], whose product gave Docker a convenient GUI on Mac OS X (and will eventually do the same for Windows). Another acqui-hire, [SocketPlane][7], is being spun in to work on Docker's networking.
|
||||
|
||||
What remains to be seen is whether Docker's proposed solutions to its problems will be adopted, or whether another party -- say, [Red Hat][8] -- will provide a more immediately useful solution for enterprise customers who can't wait around for the chips to stop falling.
|
||||
|
||||
"Good technology is hard and takes time to build," said Richardson. "The big risk is that expectations spin wildly out of control and customers are disappointed."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/2896895/application-virtualization/best-and-worst-about-docker.html
|
||||
|
||||
作者:[Serdar Yegulalp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/author/Serdar-Yegulalp/
|
||||
[1]:http://shutterstock.com/
|
||||
[2]:http://weave.works/
|
||||
[3]:http://stackengine.com/
|
||||
[4]:http://www.moogsoft.com/
|
||||
[5]:http://www.wavemaker.com/
|
||||
[6]:http://www.infoworld.com/article/2896099/application-virtualization/dockers-new-acquisition-does-containers-on-the-desktop.html
|
||||
[7]:http://www.infoworld.com/article/2892916/application-virtualization/docker-snaps-up-socketplane-to-fix-networking-flaws.html
|
||||
[8]:http://www.infoworld.com/article/2895804/application-virtualization/red-hat-wants-to-do-for-containers-what-its-done-for-linux.html
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
Interviews: Linus Torvalds Answers Your Question
|
||||
================================================================================
|
||||
Last Thursday you had a chance to [ask Linus Torvalds][1] about programming, hardware, and all things Linux. You can read his answers to those questions below. If you'd like to see what he had to say the last time we sat down with him, [you can do so here][2].
|
||||
@ -181,4 +182,4 @@ via: http://linux.slashdot.org/story/15/06/30/0058243/interviews-linus-torvalds-
|
||||
[a]:samzenpus@slashdot.org
|
||||
[1]:http://interviews.slashdot.org/story/15/06/24/1718247/interview-ask-linus-torvalds-a-question
|
||||
[2]:http://meta.slashdot.org/story/12/10/11/0030249/linus-torvalds-answers-your-questions
|
||||
[3]:https://lwn.net/Articles/604695/
|
||||
[3]:https://lwn.net/Articles/604695/
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
martin
|
||||
|
||||
Interview: Larry Wall
|
||||
================================================================================
|
||||
> Perl 6 has been 15 years in the making, and is now due to be released at the end of this year. We speak to its creator to find out what’s going on.
|
||||
@ -122,4 +124,4 @@ via: http://www.linuxvoice.com/interview-larry-wall/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
[a]:http://www.linuxvoice.com/author/mike/
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
Torvalds 2.0: Patricia Torvalds on computing, college, feminism, and increasing diversity in tech
|
||||
================================================================================
|
||||

|
||||
Image by : Photo by Becky Svartström. Modified by Opensource.com. [CC BY-SA 4.0][1]
|
||||
|
||||
Patricia Torvalds isn't the Torvalds name that pops up in Linux and open source circles. Yet.
|
||||
|
||||

|
||||
|
||||
At 18, Patricia is a feminist with a growing list of tech achievements, open source industry experience, and her sights set on diving into her freshman year of college at Duke University's Pratt School of Engineering. She works for [Puppet Labs][2] in Portland, Oregon, as an intern, but soon she'll head to Durham, North Carolina, to start the fall semester of college.
|
||||
|
||||
In this exclusive interview, Patricia explains what got her interested in computer science and engineering (spoiler alert: it wasn't her father), what her high school did "right" with teaching tech, the important role feminism plays in her life, and her thoughts on the lack of diversity in technology.
|
||||
|
||||

|
||||
|
||||
### What made you interested in studying computer science and engineering? ###
|
||||
|
||||
My interest in tech really grew throughout high school. I wanted to go into biology for a while, until around my sophomore year. I had a web design internship at the Portland VA after my sophomore year. And I took an engineering class called Exploratory Ventures, which sent an ROV into the Pacific ocean late in my sophomore year, but the turning point was probably when I was named a regional winner and national runner up for the [NCWIT Aspirations in Computing][3] award halfway through my junior year.
|
||||
|
||||
The award made me feel validated in my interest, of course, but I think the most important part of it was getting to join a Facebook group for all the award winners. The girls who have won the award are absolutely incredible and so supportive of each other. I was definitely interested in computer science before I won the award, because of my work in XV and at the VA, but having these girls to talk to solidified my interest and has kept it really strong. Teaching XV—more on that later—my junior and senior year, also, made engineering and computer science really fun for me.
|
||||
|
||||
### What do you plan to study? And do you already know what you want to do after college? ###
|
||||
|
||||
I hope to major in either Mechanical or Electrical and Computer Engineering as well as Computer Science, and minor in Women's Studies. After college, I hope to work for a company that supports or creates technology for social good, or start my own company.
|
||||
|
||||
### My daughter had one high school programming class—Visual Basic. She was the only girl in her class, and she ended up getting harassed and having a miserable experience. What was your experience like? ###
|
||||
|
||||
My high school began offering computer science classes my senior year, and I took Visual Basic as well! The class wasn't bad, but I was definitely one of three or four girls in the class of 20 or so students. Other computing classes seemed to have similar gender breakdowns. However, my high school was extremely small and the teacher was supportive of inclusivity in tech, so there was no harassment that I noticed. Hopefully the classes become more diverse in future years.
|
||||
|
||||
### What did your schools do right technology-wise? And how could they have been better? ###
|
||||
|
||||
My high school gave us consistent access to computers, and teachers occasionally assigned technology-based assignments in unrelated classes—we had to create a website for a social studies class a few times—which I think is great because it exposes everyone to tech. The robotics club was also pretty active and well-funded, but fairly small; I was not a member. One very strong component of the school's technology/engineering program is actually a student-taught engineering class called Exploratory Ventures, which is a hands-on class that tackles a new engineering or computer science problem every year. I taught it for two years with a classmate of mine, and have had students come up to me and tell me they're interested in pursuing engineering or computer science as a result of the class.
|
||||
|
||||
However, my high school was not particularly focused on deliberately including young women in these programs, and it isn't very racially diverse. The computing-based classes and clubs were, by a vast majority, filled with white male students. This could definitely be improved on.
|
||||
|
||||
### Growing up, how did you use technology at home? ###
|
||||
|
||||
Honestly, when I was younger I used my computer time (my dad created a tracker, which logged us off after an hour of Internet use) to play Neopets or similar games. I guess I could have tried to mess with the tracker or played on the computer without Internet use, but I just didn't. I sometimes did little science projects with my dad, and I remember once printing "Hello world" in the terminal with him a thousand times, but mostly I just played online games with my sisters and didn't get my start in computing until high school.
|
||||
|
||||
### You were active in the Feminism Club at your high school. What did you learn from that experience? What feminist issues are most important to you now? ###
|
||||
|
||||
My friend and I co-founded Feminism Club at our high school late in our sophomore year. We did receive lots of resistance to the club at first, and while that never entirely went away, by the time we graduated feminist ideals were absolutely a part of the school's culture. The feminist work we did at my high school was generally on a more immediate scale and focused on issues like the dress code.
|
||||
|
||||
Personally, I'm very focused on intersectional feminism, which is feminism as it applies to other aspects of oppression like racism and classism. The Facebook page [Guerrilla Feminism][4] is a great example of an intersectional feminism and has done so much to educate me. I currently run the Portland branch.
|
||||
|
||||
Feminism is also important to me in terms of diversity in tech, although as an upper-class white woman with strong connections in the tech world, the problems here affect me much less than they do other people. The same goes for my involvement in intersectional feminism. Publications like [Model View Culture][5] are very inspiring to me, and I admire Shanley Kane so much for what she does.
|
||||
|
||||
### What advice would you give parents who want to teach their children how to program? ###
|
||||
|
||||
Honestly, nobody ever pushed me into computer science or engineering. Like I said, for a long time I wanted to be a geneticist. I got a summer internship doing web design for the VA the summer after my sophomore year and totally changed my mind. So I don't know if I can fully answer that question.
|
||||
|
||||
I do think genuine interest is important, though. If my dad had sat me down in front of the computer and told me to configure a webserver when I was 12, I don't think I'd be interested in computer science. Instead, my parents gave me a lot of free reign to do what I wanted, which was mostly coding terrible little HTML sites for my Neopets. Neither of my younger sisters are interested in engineering or computer science, and my parents don't care. I'm really lucky my parents have given me and my sisters the encouragement and resources to explore our interests.
|
||||
|
||||
Still, I grew up saying my future career would be "like my dad's"—even when I didn't know what he did. He has a pretty cool job. Also, one time when I was in middle school, I told him that and he got a little choked up and said I wouldn't think that in high school. So I guess that motivated me a bit.
|
||||
|
||||
### What suggestions do you have for leaders in open source communities to help them attract and maintain a more diverse mix of contributors? ###
|
||||
|
||||
I'm actually not active in particular open source communities. I feel much more comfortable discussing computing with other women; I'm a member of the [NCWIT Aspirations in Computing][6] network and it's been one of the most important aspects of my continued interest in technology, as well as the Facebook group [Ladies Storm Hackathons][7].
|
||||
|
||||
I think this applies well to attracting and maintaining a talented and diverse mix of contributors: Safe spaces are important. I have seen the misogynistic and racist comments made in some open source communities, and subsequent dismissals when people point out the issues. I think that in maintaining a professional community there have to be strong standards on what constitutes harassment or inappropriate conduct. Of course, people can—and will—have a variety of opinions on what they should be able to express in open source communities, or any community. However, if community leaders actually want to attract and maintain diverse talent, they need to create a safe space and hold community members to high standards.
|
||||
|
||||
I also think that some community leaders just don't value diversity. It's really easy to argue that tech is a meritocracy, and the reason there are so few marginalized people in tech is just that they aren't interested, and that the problem comes from earlier on in the pipeline. They argue that if someone is good enough at their job, their gender or race or sexual orientation doesn't matter. That's the easy argument. But I was raised not to make excuses for mistakes. And I think the lack of diversity is a mistake, and that we should be taking responsibility for it and actively trying to make it better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/life/15/8/patricia-torvalds-interview
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/rikki-endsley
|
||||
[1]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[2]:https://puppetlabs.com/
|
||||
[3]:https://www.aspirations.org/
|
||||
[4]:https://www.facebook.com/guerrillafeminism
|
||||
[5]:https://modelviewculture.com/
|
||||
[6]:https://www.aspirations.org/
|
||||
[7]:https://www.facebook.com/groups/LadiesStormHackathons/
|
||||
@ -1,149 +0,0 @@
|
||||
Install OpenQRM Cloud Computing Platform In Debian
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
**openQRM** is a web-based open source Cloud computing and datacenter management platform that integrates flexibly with existing components in enterprise data centers.
|
||||
|
||||
It supports the following virtualization technologies:
|
||||
|
||||
- KVM,
|
||||
- XEN,
|
||||
- Citrix XenServer,
|
||||
- VMWare ESX,
|
||||
- LXC,
|
||||
- OpenVZ.
|
||||
|
||||
The Hybrid Cloud Connector in openQRM supports a range of private or public cloud providers to extend your infrastructure on demand via **Amazon AWS**, **Eucalyptus** or **OpenStack**. It, also, automates provisioning, virtualization, storage and configuration management, and it takes care of high-availability. A self-service cloud portal with integrated billing system enables end-users to request new servers and application stacks on-demand.
|
||||
|
||||
openQRM is available in two different flavours such as:
|
||||
|
||||
- Enterprise Edition
|
||||
- Community Edition
|
||||
|
||||
You can view the difference between both editions [here][1].
|
||||
|
||||
### Features ###
|
||||
|
||||
- Private/Hybrid Cloud Computing Platform;
|
||||
- Manages physical and virtualized server systems;
|
||||
- Integrates with all major open and commercial storage technologies;
|
||||
- Cross-platform: Linux, Windows, OpenSolaris, and *BSD;
|
||||
- Supports KVM, XEN, Citrix XenServer, VMWare ESX(i), lxc, OpenVZ and VirtualBox;
|
||||
- Support for Hybrid Cloud setups using additional Amazon AWS, Eucalyptus, Ubuntu UEC cloud resources;
|
||||
- Supports P2V, P2P, V2P, V2V Migrations and High-Availability;
|
||||
- Integrates with the best Open Source management tools – like puppet, nagios/Icinga or collectd;
|
||||
- Over 50 plugins for extended features and integration with your infrastructure;
|
||||
- Self-Service Portal for end-users;
|
||||
- Integrated billing system.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Here, we will install openQRM in Ubuntu 14.04 LTS. Your server must atleast meet the following requirements.
|
||||
|
||||
- 1 GB RAM;
|
||||
- 100 GB Hdd;
|
||||
- Optional: Virtualization enabled (VT for Intel CPUs or AMD-V for AMD CPUs) in Bios.
|
||||
|
||||
First, install make package to compile openQRM source package.
|
||||
|
||||
sudo apt-get update
|
||||
sudo apt-get upgrade
|
||||
sudo apt-get install make
|
||||
|
||||
Then, run the following commands one by one to install openQRM.
|
||||
|
||||
Download the latest available version [from here][2].
|
||||
|
||||
wget http://sourceforge.net/projects/openqrm/files/openQRM-Community-5.1/openqrm-community-5.1.tgz
|
||||
|
||||
tar -xvzf openqrm-community-5.1.tgz
|
||||
|
||||
cd openqrm-community-5.1/src/
|
||||
|
||||
sudo make
|
||||
|
||||
sudo make install
|
||||
|
||||
sudo make start
|
||||
|
||||
During installation, you’ll be asked to update the php.ini file.
|
||||
|
||||

|
||||
|
||||
Enter mysql root user password.
|
||||
|
||||

|
||||
|
||||
Re-enter password:
|
||||
|
||||

|
||||
|
||||
Select the mail server configuration type.
|
||||
|
||||

|
||||
|
||||
If you’re not sure, select Local only. In our case, I go with **Local only** option.
|
||||
|
||||

|
||||
|
||||
Enter your system mail name, and finally enter the Nagios administration password.
|
||||
|
||||

|
||||
|
||||
The above commands will take long time depending upon your Internet connection to download all packages required to run openQRM. Be patient.
|
||||
|
||||
Finally, you’ll get the openQRM configuration URL along with username and password.
|
||||
|
||||

|
||||
|
||||
### Configuration ###
|
||||
|
||||
After installing openQRM, open up your web browser and navigate to the URL: **http://ip-address/openqrm**.
|
||||
|
||||
For example, in my case http://192.168.1.100/openqrm.
|
||||
|
||||
The default username and password is: **openqrm/openqrm**.
|
||||
|
||||

|
||||
|
||||
Select a network card to use for the openQRM management network.
|
||||
|
||||

|
||||
|
||||
Select a database type. In our case, I selected mysql.
|
||||
|
||||

|
||||
|
||||
Now, configure the database connection and initialize openQRM. Here, I use **openQRM** as database name, and user as **root** and debian as password for the database. Be mindful that you should enter the mysql root user password that you have created while installing openQRM.
|
||||
|
||||

|
||||
|
||||
Congratulations!! openQRM has been installed and configured.
|
||||
|
||||

|
||||
|
||||
### Update openQRM ###
|
||||
|
||||
To update openQRM at any time run the following command:
|
||||
|
||||
cd openqrm/src/
|
||||
make update
|
||||
|
||||
What we have done so far is just installed and configured openQRM in our Ubuntu server. For creating, running Virtual Machines, managing Storage, integrating additional systems and running your own private Cloud, I suggest you to read the [openQRM Administrator Guide][3].
|
||||
|
||||
That’s all now. Cheers! Happy weekend!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-openqrm-cloud-computing-platform-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://www.openqrm-enterprise.com/products/edition-comparison.html
|
||||
[2]:http://sourceforge.net/projects/openqrm/files/?source=navbar
|
||||
[3]:http://www.openqrm-enterprise.com/fileadmin/Documents/Whitepaper/openQRM-Enterprise-Administrator-Guide-5.2.pdf
|
||||
@ -1,260 +0,0 @@
|
||||
translating...
|
||||
|
||||
How to set up IPv6 BGP peering and filtering in Quagga BGP router
|
||||
================================================================================
|
||||
In the previous tutorials, we demonstrated how we can set up a [full-fledged BGP router][1] and configure [prefix filtering][2] with Quagga. In this tutorial, we are going to show you how we can set up IPv6 BGP peering and advertise IPv6 prefixes through BGP. We will also demonstrate how we can filter IPv6 prefixes advertised or received by using prefix-list and route-map features.
|
||||
|
||||
### Topology ###
|
||||
|
||||
For this tutorial, we will be considering the following topology.
|
||||
|
||||

|
||||
|
||||
Service providers A and B want to establish an IPv6 BGP peering between them. Their IPv6 and AS information is as follows.
|
||||
|
||||
- Peering IP block: 2001:DB8:3::/64
|
||||
- Service provider A: AS 100, 2001:DB8:1::/48
|
||||
- Service provider B: AS 200, 2001:DB8:2::/48
|
||||
|
||||
### Installing Quagga on CentOS/RHEL ###
|
||||
|
||||
If Quagga has not already been installed, we can install it using yum.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
On CentOS/RHEL 7, the default SELinux policy, which prevents /usr/sbin/zebra from writing to its configuration directory, can interfere with the setup procedure we are going to describe. Thus we want to disable this policy as follows. Skip this step if you are using CentOS/RHEL 6.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
### Creating Configuration Files ###
|
||||
|
||||
After installation, we start the configuration process by creating the zebra/bgpd configuration files.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
# cp /usr/share/doc/quagga-XXXXX/bgpd.conf.sample /etc/quagga/bgpd.conf
|
||||
|
||||
Next, enable auto-start of these services.
|
||||
|
||||
**On CentOS/RHEL 6:**
|
||||
|
||||
# service zebra start; service bgpd start
|
||||
# chkconfig zebra on; chkconfig bgpd on
|
||||
|
||||
**On CentOS/RHEL 7:**
|
||||
|
||||
# systemctl start zebra; systemctl start bgpd
|
||||
# systemctl enable zebra; systmectl enable bgpd
|
||||
|
||||
Quagga provides a built-in shell called vtysh, whose interface is similar to those of major router vendors such as Cisco or Juniper. Launch vtysh command shell:
|
||||
|
||||
# vtysh
|
||||
|
||||
The prompt will be changed to:
|
||||
|
||||
router-a#
|
||||
|
||||
or
|
||||
|
||||
router-b#
|
||||
|
||||
In the rest of the tutorials, these prompts indicate that you are inside vtysh shell of either router.
|
||||
|
||||
### Specifying Log File for Zebra ###
|
||||
|
||||
Let's configure the log file for Zebra, which will be helpful for debugging.
|
||||
|
||||
First, enter the global configuration mode by typing:
|
||||
|
||||
router-a# configure terminal
|
||||
|
||||
The prompt will be changed to:
|
||||
|
||||
router-a(config)#
|
||||
|
||||
Now specify log file location. Then exit the configuration mode:
|
||||
|
||||
router-a(config)# log file /var/log/quagga/quagga.log
|
||||
router-a(config)# exit
|
||||
|
||||
Save configuration permanently by:
|
||||
|
||||
router-a# write
|
||||
|
||||
### Configuring Interface IP Addresses ###
|
||||
|
||||
Let's now configure the IP addresses for Quagga's physical interfaces.
|
||||
|
||||
First, we check the available interfaces from inside vtysh.
|
||||
|
||||
router-a# show interfaces
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
## OUTPUT TRUNCATED ###
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
## OUTPUT TRUNCATED ##
|
||||
|
||||
Now we assign necessary IPv6 addresses.
|
||||
|
||||
router-a# conf terminal
|
||||
router-a(config)# interface eth0
|
||||
router-a(config-if)# ipv6 address 2001:db8:3::1/64
|
||||
router-a(config-if)# interface eth1
|
||||
router-a(config-if)# ipv6 address 2001:db8:1::1/64
|
||||
|
||||
We use the same method to assign IPv6 addresses to router-B. I am summarizing the configuration below.
|
||||
|
||||
router-b# show running-config
|
||||
|
||||
----------
|
||||
|
||||
interface eth0
|
||||
ipv6 address 2001:db8:3::2/64
|
||||
|
||||
interface eth1
|
||||
ipv6 address 2001:db8:2::1/64
|
||||
|
||||
Since the eth0 interface of both routers are in the same subnet, i.e., 2001:DB8:3::/64, you should be able to ping from one router to another. Make sure that you can ping successfully before moving on to the next step.
|
||||
|
||||
router-a# ping ipv6 2001:db8:3::2
|
||||
|
||||
----------
|
||||
|
||||
PING 2001:db8:3::2(2001:db8:3::2) 56 data bytes
|
||||
64 bytes from 2001:db8:3::2: icmp_seq=1 ttl=64 time=3.20 ms
|
||||
64 bytes from 2001:db8:3::2: icmp_seq=2 ttl=64 time=1.05 ms
|
||||
|
||||
### Phase 1: IPv6 BGP Peering ###
|
||||
|
||||
In this section, we will configure IPv6 BGP between the two routers. We start by specifying BGP neighbors in router-A.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# router bgp 100
|
||||
router-a(config-router)# no auto-summary
|
||||
router-a(config-router)# no synchronization
|
||||
router-a(config-router)# neighbor 2001:DB8:3::2 remote-as 200
|
||||
|
||||
Next, we define the address family for IPv6. Within the address family section, we will define the network to be advertised, and activate the neighbors as well.
|
||||
|
||||
router-a(config-router)# address-family ipv6
|
||||
router-a(config-router-af)# network 2001:DB8:1::/48
|
||||
router-a(config-router-af)# neighbor 2001:DB8:3::2 activate
|
||||
|
||||
We will go through the same configuration for router-B. I'm providing the summary of the configuration.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# no auto-summary
|
||||
router-b(config-router)# no synchronization
|
||||
router-b(config-router)# neighbor 2001:DB8:3::1 remote-as 100
|
||||
router-b(config-router)# address-family ipv6
|
||||
router-b(config-router-af)# network 2001:DB8:2::/48
|
||||
router-b(config-router-af)# neighbor 2001:DB8:3::1 activate
|
||||
|
||||
If all goes well, an IPv6 BGP session should be up between the two routers. If not already done, please make sure that necessary ports (TCP 179) are [open in your firewall][3].
|
||||
|
||||
We can check IPv6 BGP session information using the following commands.
|
||||
|
||||
**For BGP summary:**
|
||||
|
||||
router-a# show bgp ipv6 unicast summary
|
||||
|
||||
**For BGP advertised routes:**
|
||||
|
||||
router-a# show bgp ipv6 neighbors <neighbor-IPv6-address> advertised-routes
|
||||
|
||||
**For BGP received routes:**
|
||||
|
||||
router-a# show bgp ipv6 neighbors <neighbor-IPv6-address> routes
|
||||
|
||||

|
||||
|
||||
### Phase 2: Filtering IPv6 Prefixes ###
|
||||
|
||||
As we can see from the above output, the routers are advertising their full /48 IPv6 prefix. For demonstration purposes, we will consider the following requirements.
|
||||
|
||||
- Router-B will advertise one /64 prefix, one /56 prefix, as well as one full /48 prefix.
|
||||
- Router-A will accept any IPv6 prefix owned by service provider B, which has a netmask length between /56 and /64.
|
||||
|
||||
We are going to filter the prefix as required, using prefix-list and route-map in router-A.
|
||||
|
||||

|
||||
|
||||
#### Modifying prefix advertisement for Router-B ####
|
||||
|
||||
Currently, router-B is advertising only one /48 prefix. We will modify router-B's BGP configuration so that it advertises additional /56 and /64 prefixes as well.
|
||||
|
||||
router-b# conf t
|
||||
router-b(config)# router bgp 200
|
||||
router-b(config-router)# address-family ipv6
|
||||
router-b(config-router-af)# network 2001:DB8:2::/56
|
||||
router-b(config-router-af)# network 2001:DB8:2::/64
|
||||
|
||||
We will verify that all prefixes are received at router-A.
|
||||
|
||||
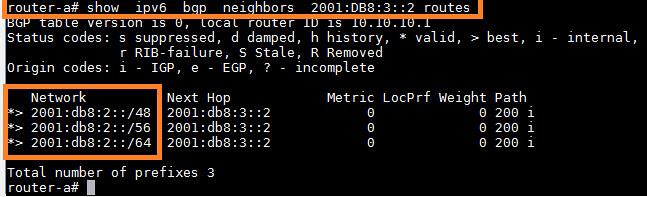
|
||||
|
||||
Great! As we are receiving all prefixes in router-A, we will move forward and create prefix-list and route-map entries to filter these prefixes.
|
||||
|
||||
#### Creating Prefix-List ####
|
||||
|
||||
As described in the [previous tutorial][4], prefix-list is a mechanism that is used to match an IP address prefix with a subnet length. Once a matched prefix is found, we can apply filtering or other actions to the matched prefix. To meet our requirements, we will go ahead and create a necessary prefix-list entry in router-A.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# ipv6 prefix-list FILTER-IPV6-PRFX permit 2001:DB8:2::/56 le 64
|
||||
|
||||
The above commands will create a prefix-list entry named 'FILTER-IPV6-PRFX' which will match any prefix in the 2001:DB8:2:: pool with a netmask between 56 and 64.
|
||||
|
||||
#### Creating and Applying Route-Map ####
|
||||
|
||||
Now that the prefix-list entry is created, we will create a corresponding route-map rule which uses the prefix-list entry.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# route-map FILTER-IPV6-RMAP permit 10
|
||||
router-a(config-route-map)# match ipv6 address prefix-list FILTER-IPV6-PRFX
|
||||
|
||||
The above commands will create a route-map rule named 'FILTER-IPV6-RMAP'. This rule will permit IPv6 addresses matched by the prefix-list 'FILTER-IPV6-PRFX' that we have created earlier.
|
||||
|
||||
Remember that a route-map rule is only effective when it is applied to a neighbor or an interface in a certain direction. We will apply the route-map in the BGP neighbor configuration. As the filter is meant for inbound prefixes, we apply the route-map in the inbound direction.
|
||||
|
||||
router-a# conf t
|
||||
router-a(config)# router bgp 100
|
||||
router-a(config-router)# address-family ipv6
|
||||
router-a(config-router-af)# neighbor 2001:DB8:3::2 route-map FILTER-IPV6-RMAP in
|
||||
|
||||
Now when we check the routes received at router-A, we should see only two prefixes that are allowed.
|
||||
|
||||

|
||||
|
||||
**Note**: You may need to reset the BGP session for the route-map to take effect.
|
||||
|
||||
All IPv6 BGP sessions can be restarted using the following command:
|
||||
|
||||
router-a# clear bgp ipv6 *
|
||||
|
||||
I am summarizing the configuration of both routers so you get a clear picture at a glance.
|
||||
|
||||
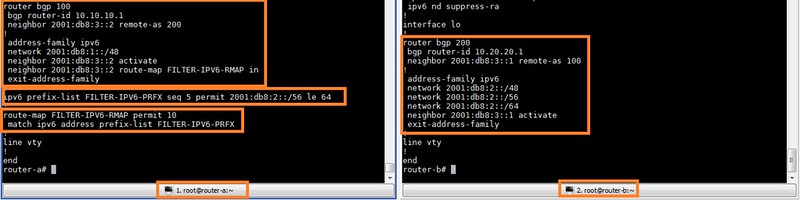
|
||||
|
||||
### Summary ###
|
||||
|
||||
To sum up, this tutorial focused on how to set up BGP peering and filtering using IPv6. We showed how to advertise IPv6 prefixes to a neighboring BGP router, and how to filter the prefixes advertised or received are advertised. Note that the process described in this tutorial may affect production networks of a service provider, so please use caution.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ipv6-bgp-peering-filtering-quagga-bgp-router.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://xmodulo.com/centos-bgp-router-quagga.html
|
||||
[2]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
[3]:http://ask.xmodulo.com/open-port-firewall-centos-rhel.html
|
||||
[4]:http://xmodulo.com/filter-bgp-routes-quagga-bgp-router.html
|
||||
@ -1,68 +0,0 @@
|
||||
|
||||
How to Use LVM on Ubuntu for Easy Partition Resizing and Snapshots
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu’s installer offers an easy “Use LVM” checkbox. The description says it enables Logical Volume Management so you can take snapshots and more easily resize your hard disk partitions — here’s how to do that.
|
||||
|
||||
LVM is a technology that’s similar to [RAID arrays][1] or [Storage Spaces on Windows][2] in some ways. While this technology is particularly useful on servers, it can be used on desktop PCs, too.
|
||||
|
||||
### Should You Use LVM With Your New Ubuntu Installation? ###
|
||||
|
||||
The first question is whether you even want to use LVM with your Ubuntu installation. Ubuntu makes this easy to enable with a quick click, but this option isn’t enabled by default. As the installer says, this allows you to resize partitions, create snapshots, merge multiple disks into a single logical volume, and so on — all while the system is running. Unlike with typical partitions, you don’t have to shut down your system, boot from a live CD or USB drive, and [resize your partitions while they aren’t in use][3].
|
||||
|
||||
To be perfectly honest, the average Ubuntu desktop user probably won’t realize whether they’re using LVM or not. But, if you want to do more advanced things later, LVM can help. LVM is potentially more complex, which could cause problems if you need to recover your data later — especially if you’re not that experienced with it. There shouldn’t be a noticeable performance penalty here — LVM is implemented right down in the Linux kernel.
|
||||
|
||||

|
||||
|
||||
### Logical Volume Management Explained ###
|
||||
|
||||
We’re previously [explained what LVM is][4]. In a nutshell, it provides a layer of abstraction between your physical disks and the partitions presented to your operating system. For example, your computer might have two hard drives inside it, each 1 TB in size. You’d have to have at least two partitions on these disks, and each of these partitions would be 1 TB in size.
|
||||
|
||||
LVM provides a layer of abstraction over this. Instead of the traditional partition on a disk, LVM would treat the disks as two separate “physical volumes” after you initialize them. You could then create “logical volumes” based on these physical volumes. For example, you could combine those two 1 TB disks into a single 2 TB partition. Your operating system would just see a 2 TB volume, and LVM would deal with everything in the background. A group of physical volumes and logical volumes is known as a “volume group.” A typical system will just have a single volume group.
|
||||
|
||||
This layer of abstraction makes it possibly to easily resize partitions, combine multiple disks into a single volume, and even take “snapshots” of a partition’s file system while it’s running, all without unmounting it.
|
||||
|
||||
Note that merging multiple disks into a single volume can be a bad idea if you’re not creating backups. It’s like with RAID 0 — if you combine two 1 TB volumes into a single 2 TB volume, you could lose important data on the volume if just one of your hard disks fails. Backups are crucial if you go this route.
|
||||
|
||||
### Graphical Utilities for Managing Your LVM Volumes ###
|
||||
|
||||
Traditionally, [LVM volumes are managed with Linux terminal commands][5].These will work for you on Ubuntu, but there’s an easier, graphical method anyone can take advantage of. If you’re a Linux user used to using GParted or a similar partition manager, don’t bother — GParted doesn’t have support for LVM disks.
|
||||
|
||||
Instead, you can use the Disks utility included along with Ubuntu for this. This utility is also known as GNOME Disk Utility, or Palimpsest. Launch it by clicking the icon on the dash, searching for Disks, and pressing Enter. Unlike GParted, the Disks utility will display your LVM partitions under “Other Devices,” so you can format them and adjust other options if you need to. This utility will also work from a live CD or USB drive, too.
|
||||
|
||||

|
||||
|
||||
Unfortunately, the Disks utility doesn’t include support for taking advantage of LVM’s most powerful features. There’s no options for managing your volume groups, extending partitions, or taking snapshots. You could do that from the terminal, but you don’t have to. Instead, you can open the Ubuntu Software Center, search for LVM, and install the Logical Volume Management tool. You could also just run the **sudo apt-get install system-config-lvm** command in a terminal window. After it’s installed, you can open the Logical Volume Management utility from the dash.
|
||||
|
||||
This graphical configuration tool was made by Red Hat. It’s a bit dated, but it’s the only graphical way to do this stuff without resorting to terminal commands.
|
||||
|
||||
Let’s say you wanted to add a new physical volume to your volume group. You’d open the tool, select the new disk under Uninitialized Entries, and click the “Initialize Entry” button. You’d then find the new physical volume under Unallocated Volumes, and you could use the “Add to existing Volume Group” button to add it to the “ubuntu-vg” volume group Ubuntu created during the installation process.
|
||||
|
||||

|
||||
|
||||
The volume group view shows you a visual overview of your physical volumes and logical volumes. Here, we have two physical partitions across two separate hard drives. We have a swap partition and a root partition, just as Ubuntu sets up its partitioning scheme by default. Because we’ve added a second physical partition from another drive, there’s now a good chunk of unused space.
|
||||
|
||||

|
||||
|
||||
To expand a logical partition into the physical space, you could select it under Logical View, click Edit Properties, and modify the size to grow the partition. You could also shrink it from here.
|
||||
|
||||

|
||||
|
||||
The other options in system-config-lvm allow you to set up snapshots and mirroring. You probably won’t need these features on a typical desktop, but they’re available graphically here. Remember, you can also [do all of this with terminal commands][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/211937/how-to-use-lvm-on-ubuntu-for-easy-partition-resizing-and-snapshots/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/162676/how-to-use-multiple-disks-intelligently-an-introduction-to-raid/
|
||||
[2]:http://www.howtogeek.com/109380/how-to-use-windows-8s-storage-spaces-to-mirror-combine-drives/
|
||||
[3]:http://www.howtogeek.com/114503/how-to-resize-your-ubuntu-partitions/
|
||||
[4]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
[5]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
[6]:http://www.howtogeek.com/howto/40702/how-to-manage-and-use-lvm-logical-volume-management-in-ubuntu/
|
||||
@ -1,89 +0,0 @@
|
||||
How to run Ubuntu Snappy Core on Raspberry Pi 2
|
||||
================================================================================
|
||||
The Internet of Things (IoT) is upon us. In a couple of years some of us might ask ourselves how we ever survived without it, just like we question our past without cellphones today. Canonical is a contender in this fast growing, but still wide open market. The company wants to claim their stakes in IoT just as they already did for the cloud. At the end of January, the company launched a small operating system that goes by the name of [Ubuntu Snappy Core][1] which is based on Ubuntu Core.
|
||||
|
||||
Snappy, the new component in the mix, represents a package format that is derived from DEB, is a frontend to update the system that lends its idea from atomic upgrades used in CoreOS, Red Hat's Atomic and elsewhere. As soon as the Raspberry Pi 2 was marketed, Canonical released Snappy Core for that plattform. The first edition of the Raspberry Pi was not able to run Ubuntu because Ubuntu's ARM images use the ARMv7 architecture, while the first Raspberry Pis were based on ARMv6. That has changed now, and Canonical, by releasing a RPI2-Image of Snappy Core, took the opportunity to make clear that Snappy was meant for the cloud and especially for IoT.
|
||||
|
||||
Snappy also runs on other platforms like Amazon EC2, Microsofts Azure, and Google's Compute Engine, and can also be virtualized with KVM, Virtualbox, or Vagrant. Canonical has embraced big players like Microsoft, Google, Docker or OpenStack and, at the same time, also included small projects from the maker scene as partners. Besides startups like Ninja Sphere and Erle Robotics, there are board manufacturers like Odroid, Banana Pro, Udoo, PCDuino and Parallella as well as Allwinner. Snappy Core will also run in routers soon to help with the poor upgrade policy that vendors perform.
|
||||
|
||||
In this post, let's see how we can test Ubuntu Snappy Core on Raspberry Pi 2.
|
||||
|
||||
The image for Snappy Core for the RPI2 can be downloaded from the [Raspberry Pi website][2]. Unpacked from the archive, the resulting image should be [written to an SD card][3] of at least 8 GB. Even though the OS is small, atomic upgrades and the rollback function eat up quite a bit of space. After booting up your Raspberry Pi 2 with Snappy Core, you can log into the system with the default username and password being 'ubuntu'.
|
||||
|
||||
|
||||
|
||||
sudo is already configured and ready for use. For security reasons you should change the username with:
|
||||
|
||||
$ sudo usermod -l <new name> <old name>
|
||||
|
||||
Alternatively, you can add a new user with the command `adduser`.
|
||||
|
||||
Due to the lack of a hardware clock on the RPI, that the Snappy Core image does not take account of, the image has a small bug that will throw a lot of errors when processing commands. It is easy to fix.
|
||||
|
||||
To find out if the bug affects you, use the command:
|
||||
|
||||
$ date
|
||||
|
||||
If the output is "Thu Jan 1 01:56:44 UTC 1970", you can fix it with:
|
||||
|
||||
$ sudo date --set="Sun Apr 04 17:43:26 UTC 2015"
|
||||
|
||||
adapted to your actual time.
|
||||
|
||||

|
||||
|
||||
Now you might want to check if there are any updates available. Note that the usual commands:
|
||||
|
||||
$ sudo apt-get update && sudo apt-get distupgrade
|
||||
|
||||
will not get you very far though, as Snappy uses its own simplified package management system which is based on dpkg. This makes sense, as Snappy will run on a lot of embedded appliances, and you want things to be as simple as possible.
|
||||
|
||||
Let's dive into the engine room for a minute to understand how things work with Snappy. The SD card you run Snappy on has three partitions besides the boot partition. Two of those house a duplicated file system. Both of those parallel file systems are permanently mounted as "read only", and only one is active at any given time. The third partition holds a partial writable file system and the users persistent data. With a fresh system, the partition labeled 'system-a' holds one complete file system, called a core, leaving the parallel partition still empty.
|
||||
|
||||

|
||||
|
||||
If we run the following command now:
|
||||
|
||||
$ sudo snappy update
|
||||
|
||||
the system will install the update as a complete core, similar to an image, on 'system-b'. You will be asked to reboot your device afterwards to activate the new core.
|
||||
|
||||
After the reboot, run the following command to check if your system is up to date and which core is active.
|
||||
|
||||
$ sudo snappy versions -a
|
||||
|
||||
After rolling out the update and rebooting, you should see that the core that is now active has changed.
|
||||
|
||||
As we have not installed any apps yet, the following command:
|
||||
|
||||
$ sudo snappy update ubuntu-core
|
||||
|
||||
would have been sufficient, and is the way if you want to upgrade just the underlying OS. Should something go wrong, you can rollback by:
|
||||
|
||||
$ sudo snappy rollback ubuntu-core
|
||||
|
||||
which will take you back to the system's state before the update.
|
||||
|
||||
|
||||
|
||||
Speaking of apps, they are what makes Snappy useful. There are not that many at this point, but the IRC channel #snappy on Freenode is humming along nicely and with a lot of people involved, the Snappy App Store gets new apps added on a regular basis. You can visit the shop by pointing your browser to http://<ip-address>:4200, and you can install apps right from the shop and then launch them with http://webdm.local in your browser. Building apps yourself for Snappy is not all that hard, and [well documented][4]. You can also port DEB packages into the snappy format quite easily.
|
||||
|
||||
|
||||
|
||||
Ubuntu Snappy Core, due to the limited number of available apps, is not overly useful in a productive way at this point in time, although it invites us to dive into the new Snappy package format and play with atomic upgrades the Canonical way. Since it is easy to set up, this seems like a good opportunity to learn something new.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/ubuntu-snappy-core-raspberry-pi-2.html
|
||||
|
||||
作者:[Ferdinand Thommes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/ferdinand
|
||||
[1]:http://www.ubuntu.com/things
|
||||
[2]:http://www.raspberrypi.org/downloads/
|
||||
[3]:http://xmodulo.com/write-raspberry-pi-image-sd-card.html
|
||||
[4]:https://developer.ubuntu.com/en/snappy/
|
||||
@ -1,131 +0,0 @@
|
||||
2q1w2007申领
|
||||
How to access a Linux server behind NAT via reverse SSH tunnel
|
||||
================================================================================
|
||||
You are running a Linux server at home, which is behind a NAT router or restrictive firewall. Now you want to SSH to the home server while you are away from home. How would you set that up? SSH port forwarding will certainly be an option. However, port forwarding can become tricky if you are dealing with multiple nested NAT environment. Besides, it can be interfered with under various ISP-specific conditions, such as restrictive ISP firewalls which block forwarded ports, or carrier-grade NAT which shares IPv4 addresses among users.
|
||||
|
||||
### What is Reverse SSH Tunneling? ###
|
||||
|
||||
One alternative to SSH port forwarding is **reverse SSH tunneling**. The concept of reverse SSH tunneling is simple. For this, you will need another host (so-called "relay host") outside your restrictive home network, which you can connect to via SSH from where you are. You could set up a relay host using a [VPS instance][1] with a public IP address. What you do then is to set up a persistent SSH tunnel from the server in your home network to the public relay host. With that, you can connect "back" to the home server from the relay host (which is why it's called a "reverse" tunnel). As long as the relay host is reachable to you, you can connect to your home server wherever you are, or however restrictive your NAT or firewall is in your home network.
|
||||
|
||||

|
||||
|
||||
### Set up a Reverse SSH Tunnel on Linux ###
|
||||
|
||||
Let's see how we can create and use a reverse SSH tunnel. We assume the following. We will be setting up a reverse SSH tunnel from homeserver to relayserver, so that we can SSH to homeserver via relayserver from another computer called clientcomputer. The public IP address of **relayserver** is 1.1.1.1.
|
||||
|
||||
On homeserver, open an SSH connection to relayserver as follows.
|
||||
|
||||
homeserver~$ ssh -fN -R 10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
Here the port 10022 is any arbitrary port number you can choose. Just make sure that this port is not used by other programs on relayserver.
|
||||
|
||||
The "-R 10022:localhost:22" option defines a reverse tunnel. It forwards traffic on port 10022 of relayserver to port 22 of homeserver.
|
||||
|
||||
With "-fN" option, SSH will go right into the background once you successfully authenticate with an SSH server. This option is useful when you do not want to execute any command on a remote SSH server, and just want to forward ports, like in our case.
|
||||
|
||||
After running the above command, you will be right back to the command prompt of homeserver.
|
||||
|
||||
Log in to relayserver, and verify that 127.0.0.1:10022 is bound to sshd. If so, that means a reverse tunnel is set up correctly.
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 127.0.0.1:10022 0.0.0.0:* LISTEN 8493/sshd
|
||||
|
||||
Now from any other computer (e.g., clientcomputer), log in to relayserver. Then access homeserver as follows.
|
||||
|
||||
relayserver~$ ssh -p 10022 homeserver_user@localhost
|
||||
|
||||
One thing to take note is that the SSH login/password you type for localhost should be for homeserver, not for relayserver, since you are logging in to homeserver via the tunnel's local endpoint. So do not type login/password for relayserver. After successful login, you will be on homeserver.
|
||||
|
||||
### Connect Directly to a NATed Server via a Reverse SSH Tunnel ###
|
||||
|
||||
While the above method allows you to reach **homeserver** behind NAT, you need to log in twice: first to **relayserver**, and then to **homeserver**. This is because the end point of an SSH tunnel on relayserver is binding to loopback address (127.0.0.1).
|
||||
|
||||
But in fact, there is a way to reach NATed homeserver directly with a single login to relayserver. For this, you will need to let sshd on relayserver forward a port not only from loopback address, but also from an external host. This is achieved by specifying **GatewayPorts** option in sshd running on relayserver.
|
||||
|
||||
Open /etc/ssh/sshd_conf of **relayserver** and add the following line.
|
||||
|
||||
relayserver~$ vi /etc/ssh/sshd_conf
|
||||
|
||||
----------
|
||||
|
||||
GatewayPorts clientspecified
|
||||
|
||||
Restart sshd.
|
||||
|
||||
Debian-based system:
|
||||
|
||||
relayserver~$ sudo /etc/init.d/ssh restart
|
||||
|
||||
Red Hat-based system:
|
||||
|
||||
relayserver~$ sudo systemctl restart sshd
|
||||
|
||||
Now let's initiate a reverse SSH tunnel from homeserver as follows.
|
||||
homeserver~$ ssh -fN -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
Log in to relayserver and confirm with netstat command that a reverse SSH tunnel is established successfully.
|
||||
|
||||
relayserver~$ sudo netstat -nap | grep 10022
|
||||
|
||||
----------
|
||||
|
||||
tcp 0 0 1.1.1.1:10022 0.0.0.0:* LISTEN 1538/sshd: dev
|
||||
|
||||
Unlike a previous case, the end point of a tunnel is now at 1.1.1.1:10022 (relayserver's public IP address), not 127.0.0.1:10022. This means that the end point of the tunnel is reachable from an external host.
|
||||
|
||||
Now from any other computer (e.g., clientcomputer), type the following command to gain access to NATed homeserver.
|
||||
|
||||
clientcomputer~$ ssh -p 10022 homeserver_user@1.1.1.1
|
||||
|
||||
In the above command, while 1.1.1.1 is the public IP address of relayserver, homeserver_user must be the user account associated with homeserver. This is because the real host you are logging in to is homeserver, not relayserver. The latter simply relays your SSH traffic to homeserver.
|
||||
|
||||
### Set up a Persistent Reverse SSH Tunnel on Linux ###
|
||||
|
||||
Now that you understand how to create a reverse SSH tunnel, let's make the tunnel "persistent", so that the tunnel is up and running all the time (regardless of temporary network congestion, SSH timeout, relay host rebooting, etc.). After all, if the tunnel is not always up, you won't be able to connect to your home server reliably.
|
||||
|
||||
For a persistent tunnel, I am going to use a tool called autossh. As the name implies, this program allows you to automatically restart an SSH session should it breaks for any reason. So it is useful to keep a reverse SSH tunnel active.
|
||||
|
||||
As the first step, let's set up [passwordless SSH login][2] from homeserver to relayserver. That way, autossh can restart a broken reverse SSH tunnel without user's involvement.
|
||||
|
||||
Next, [install autossh][3] on homeserver where a tunnel is initiated.
|
||||
|
||||
From homeserver, run autossh with the following arguments to create a persistent SSH tunnel destined to relayserver.
|
||||
|
||||
homeserver~$ autossh -M 10900 -fN -o "PubkeyAuthentication=yes" -o "StrictHostKeyChecking=false" -o "PasswordAuthentication=no" -o "ServerAliveInterval 60" -o "ServerAliveCountMax 3" -R 1.1.1.1:10022:localhost:22 relayserver_user@1.1.1.1
|
||||
|
||||
The "-M 10900" option specifies a monitoring port on relayserver which will be used to exchange test data to monitor an SSH session. This port should not be used by any program on relayserver.
|
||||
|
||||
The "-fN" option is passed to ssh command, which will let the SSH tunnel run in the background.
|
||||
|
||||
The "-o XXXX" options tell ssh to:
|
||||
|
||||
- Use key authentication, not password authentication.
|
||||
- Automatically accept (unknown) SSH host keys.
|
||||
- Exchange keep-alive messages every 60 seconds.
|
||||
- Send up to 3 keep-alive messages without receiving any response back.
|
||||
|
||||
The rest of reverse SSH tunneling related options remain the same as before.
|
||||
|
||||
If you want an SSH tunnel to be automatically up upon boot, you can add the above autossh command in /etc/rc.local.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this post, I talked about how you can use a reverse SSH tunnel to access a Linux server behind a restrictive firewall or NAT gateway from outside world. While I demonstrated its use case for a home network, you must be careful when applying it for corporate networks. Such a tunnel can be considered as a breach of a corporate policy, as it circumvents corporate firewalls and can expose corporate networks to outside attacks. There is a great chance it can be misused or abused. So always remember its implication before setting it up.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/access-linux-server-behind-nat-reverse-ssh-tunnel.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/go/digitalocean
|
||||
[2]:http://xmodulo.com/how-to-enable-ssh-login-without.html
|
||||
[3]:http://ask.xmodulo.com/install-autossh-linux.html
|
||||
@ -1,193 +0,0 @@
|
||||
Translating by dingdongnigetou
|
||||
|
||||
Install Plex Media Server On Ubuntu / CentOS 7.1 / Fedora 22
|
||||
================================================================================
|
||||
In this article we will show you how easily you can setup Plex Home Media Server on major Linux distributions with their latest releases. After its successful installation of Plex you will be able to use your centralized home media playback system that streams its media to many Plex player Apps and the Plex Home will allows you to setup your environment by adding your devices and to setup a group of users that all can use Plex Together. So let’s start its installation first on Ubuntu 15.04.
|
||||
|
||||
### Basic System Resources ###
|
||||
|
||||
System resources mainly depend on the type and number of devices that you are planning to connect with the server. So according to our requirements we will be using as following system resources and software for a standalone server.
|
||||
|
||||
注:表格
|
||||
<table width="666" style="height: 181px;">
|
||||
<tbody>
|
||||
<tr>
|
||||
<td width="670" colspan="2"><b>Plex Home Media Server</b></td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Base Operating System</b></td>
|
||||
<td width="425">Ubuntu 15.04 / CentOS 7.1 / Fedora 22 Work Station</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Plex Media Server</b></td>
|
||||
<td width="425">Version 0.9.12.3.1173-937aac3</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>RAM and CPU</b></td>
|
||||
<td width="425">1 GB , 2.0 GHZ</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td width="236"><b>Hard Disk</b></td>
|
||||
<td width="425">30 GB</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
### Plex Media Server 0.9.12.3 on Ubuntu 15.04 ###
|
||||
|
||||
We are now ready to start the installations process of Plex Media Server on Ubuntu so let’s start with the following steps to get it ready.
|
||||
|
||||
#### Step 1: System Update ####
|
||||
|
||||
Login to your server with root privileges Make your that your system is upto date if not then do by using below command.
|
||||
|
||||
root@ubuntu-15:~#apt-get update
|
||||
|
||||
#### Step 2: Download the Latest Plex Media Server Package ####
|
||||
|
||||
Create a new directory and download .deb plex Media Package in it from the official website of Plex for Ubuntu using wget command.
|
||||
|
||||
root@ubuntu-15:~# cd /plex/
|
||||
root@ubuntu-15:/plex#
|
||||
root@ubuntu-15:/plex# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
#### Step 3: Install the Debian Package of Plex Media Server ####
|
||||
|
||||
Now within the same directory run following command to start installation of debian package and then check the status of plekmediaserver.
|
||||
|
||||
root@ubuntu-15:/plex# dpkg -i plexmediaserver_0.9.12.3.1173-937aac3_amd64.deb
|
||||
|
||||
----------
|
||||
|
||||
root@ubuntu-15:~# service plexmediaserver status
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Ubuntu 15.04 ###
|
||||
|
||||
Let's open your web browser within your localhost network and open the Web Interface with your localhost IP and port 32400 and do following steps to configure it:
|
||||
|
||||
http://172.25.10.179:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
#### Step 1:Sign UP before Login ####
|
||||
|
||||
After you have access to the web interface of Plesk Media Server make sure to Sign Up and set your username email ID and Password to login as.
|
||||
|
||||

|
||||
|
||||
#### Step 2: Enter Your Pin to Secure Your Plex Media Home User ####
|
||||
|
||||

|
||||
|
||||
Now you have successfully configured your user under Plex Home Media.
|
||||
|
||||

|
||||
|
||||
### Opening Plex Web App on Devices Other than Localhost Server ###
|
||||
|
||||
As we have seen in our Plex media home page that it indicates that "You do not have permissions to access this server". Its because of we are on a different network than the Server computer.
|
||||
|
||||

|
||||
|
||||
Now we need to resolve this permissions issue so that we can have access to server on the devices other than the hosted server by doing following setup.
|
||||
|
||||
### Setup SSH Tunnel for Windows System to access Linux Server ###
|
||||
|
||||
First we need to set up a SSH tunnel so that we can access things as if they were local. This is only necessary for the initial setup.
|
||||
|
||||
If you are using Windows as your local system and server on Linux then we can setup SSH-Tunneling using Putty as shown.
|
||||
|
||||

|
||||
|
||||
**Once you have the SSH tunnel set up:**
|
||||
|
||||
Open your Web browser window and type following URL in the address bar.
|
||||
|
||||
http://localhost:8888/web
|
||||
|
||||
The browser will connect to the server and load the Plex Web App with same functionality as on local.
|
||||
Agree to the terms of Services and start
|
||||
|
||||

|
||||
|
||||
Now a fully functional Plex Home Media Server is ready to add new media libraries, channels, playlists etc.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on CentOS 7.1 ###
|
||||
|
||||
We will follow the same steps on CentOS-7.1 that we did for the installation of Plex Home Media Server on Ubuntu 15.04.
|
||||
|
||||
So lets start with Plex Media Servers Package Installation.
|
||||
|
||||
#### Step 1: Plex Media Server Installation ####
|
||||
|
||||
To install Plex Media Server on centOS 7.1 we need to download the .rpm package from the official website of Plex. So we will use wget command to download .rpm package for this purpose in a new directory.
|
||||
|
||||
[root@linux-tutorials ~]# cd /plex
|
||||
[root@linux-tutorials plex]# wget https://downloads.plex.tv/plex-media-server/0.9.12.3.1173-937aac3/plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 2: Install .RPM Package ####
|
||||
|
||||
After completion of complete download package we will install this package using rpm command within the same direcory where we installed the .rpm package.
|
||||
|
||||
[root@linux-tutorials plex]# ls
|
||||
plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
[root@linux-tutorials plex]# rpm -i plexmediaserver-0.9.12.3.1173-937aac3.x86_64.rpm
|
||||
|
||||
#### Step 3: Start Plexmediaservice ####
|
||||
|
||||
We have successfully installed Plex Media Server Now we just need to restart its service and then enable it permanently.
|
||||
|
||||
[root@linux-tutorials plex]# systemctl start plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl enable plexmediaserver.service
|
||||
[root@linux-tutorials plex]# systemctl status plexmediaserver.service
|
||||
|
||||
### Plex Home Media Web App Setup on CentOS-7.1 ###
|
||||
|
||||
Now we just need to repeat all steps that we performed during the Web app setup of Ubuntu.
|
||||
So let's Open a new window in your web browser and access the Plex Media Server Web app using localhost or IP or your Plex server.
|
||||
|
||||
http://172.20.3.174:32400/web
|
||||
http://localhost:32400/web
|
||||
|
||||
Then to get full permissions on the server you need to repeat the steps to create the SSH-Tunnel.
|
||||
After signing up with new user account we will be able to access its all features and can add new users, add new libraries and setup it per our needs.
|
||||
|
||||

|
||||
|
||||
### Plex Media Server 0.9.12.3 on Fedora 22 Work Station ###
|
||||
|
||||
The Basic steps to download and install Plex Media Server are the same as its we did for in CentOS 7.1.
|
||||
We just need to download its .rpm package and then install it with rpm command.
|
||||
|
||||

|
||||
|
||||
### Plex Home Media Web App Setup on Fedora 22 Work Station ###
|
||||
|
||||
We had setup Plex Media Server on the same host so we don't need to setup SSH-Tunnel in this time scenario. Just open the web browser in your Fedora 22 Workstation with default port 32400 of Plex Home Media Server and accept the Plex Terms of Services Agreement.
|
||||
|
||||

|
||||
|
||||
**Welcome to Plex Home Media Server on Fedora 22 Workstation**
|
||||
|
||||
Lets login with your plex account and start with adding your libraries for your favorite movie channels , create your playlists, add your photos and enjoy with many other features of Plex Home Media Server.
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We had successfully installed and configured Plex Media Server on Major Linux Distributions. So, Plex Home Media Server has always been a best choice for media management. Its so simple to setup on cross platform as we did for Ubuntu, CentOS and Fedora. It has simplifies the tasks of organizing your media content and streaming to other computers and devices then to share it with your friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-plex-media-server-ubuntu-centos-7-1-fedora-22/
|
||||
|
||||
作者:[Kashif Siddique][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/kashifs/
|
||||
@ -1,182 +0,0 @@
|
||||
How to set up a Replica Set on MongoDB
|
||||
================================================================================
|
||||
MongoDB has become the most famous NoSQL database on the market. MongoDB is document-oriented, and its scheme-free design makes it a really attractive solution for all kinds of web applications. One of the features that I like the most is Replica Set, where multiple copies of the same data set are maintained by a group of mongod nodes for redundancy and high availability.
|
||||
|
||||
This tutorial describes how to configure a Replica Set on MonoDB.
|
||||
|
||||
The most common configuration for a Replica Set involves one primary and multiple secondary nodes. The replication will then be initiated from the primary toward the secondaries. Replica Sets can not only provide database protection against unexpected hardware failure and service downtime, but also improve read throughput of database clients as they can be configured to read from different nodes.
|
||||
|
||||
### Set up the Environment ###
|
||||
|
||||
In this tutorial, we are going to set up a Replica Set with one primary and two secondary nodes.
|
||||
|
||||

|
||||
|
||||
In order to implement this lab, we will use three virtual machines (VMs) running on VirtualBox. I am going to install Ubuntu 14.04 on the VMs, and install official packages for Mongodb.
|
||||
|
||||
I am going to set up a necessary environment on one VM instance, and then clone it to the other two VM instances. Thus pick one VM named master, and perform the following installations.
|
||||
|
||||
First, we need to add the MongoDB key for apt:
|
||||
|
||||
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 7F0CEB10
|
||||
|
||||
Then we need to add the official MongoDB repository to our source.list:
|
||||
|
||||
$ sudo su
|
||||
# echo "deb http://repo.mongodb.org/apt/ubuntu "$(lsb_release -sc)"/mongodb-org/3.0 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-3.0.list
|
||||
|
||||
Let's update repositories and install MongoDB.
|
||||
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install -y mongodb-org
|
||||
|
||||
Now let's make some changes in /etc/mongodb.conf.
|
||||
|
||||
auth = true
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
replSet=myReplica
|
||||
|
||||
The first line is to make sure that we are going to have authentication on our database. keyFile is to set up a keyfile that is going to be used by MongoDB to replicate between nodes. replSet sets up the name of our replica set.
|
||||
|
||||
Now we are going to create our keyfile, so that it can be in all our instances.
|
||||
|
||||
$ echo -n "MyRandomStringForReplicaSet" | md5sum > keyFile
|
||||
|
||||
This will create keyfile that contains a MD5 string, but it has some noise that we need to clean up before using it in MongoDB. Use the following command to clean it up:
|
||||
|
||||
$ echo -n "MyReplicaSetKey" | md5sum|grep -o "[0-9a-z]\+" > keyFile
|
||||
|
||||
What grep command does is to print MD5 string with no spaces or other characters that we don't want.
|
||||
|
||||
Now we are going to make the keyfile ready for use:
|
||||
|
||||
$ sudo cp keyFile /var/lib/mongodb
|
||||
$ sudo chown mongodb:nogroup keyFile
|
||||
$ sudo chmod 400 keyFile
|
||||
|
||||
Now we have our Ubuntu VM ready to be cloned. Power it off, and clone it to the other VMs.
|
||||
|
||||

|
||||
|
||||
I name the cloned VMs secondary1 and secondary2. Make sure to reinitialize the MAC address of cloned VMs and clone full disks.
|
||||
|
||||

|
||||
|
||||
All three VM instances should be on the same network to communicate with each other. For this, we are going to attach all three VMs to "Internet Network".
|
||||
|
||||
It is recommended that each VM instances be assigned a static IP address, as opposed to DHCP IP address, so that the VMs will not lose connectivity among themselves when a DHCP server assigns different IP addresses to them.
|
||||
|
||||
Let's edit /etc/networks/interfaces of each VM as follows.
|
||||
|
||||
On primary:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.2
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary1:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.3
|
||||
netmask 255.255.255.0
|
||||
|
||||
On secondary2:
|
||||
|
||||
auto eth1
|
||||
iface eth1 inet static
|
||||
address 192.168.50.4
|
||||
netmask 255.255.255.0
|
||||
|
||||
Another file that needs to be set up is /etc/hosts, because we don't have DNS. We need to set the hostnames in /etc/hosts.
|
||||
|
||||
On primary:
|
||||
|
||||
127.0.0.1 localhost primary
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary1:
|
||||
|
||||
127.0.0.1 localhost secondary1
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
On secondary2:
|
||||
|
||||
127.0.0.1 localhost secondary2
|
||||
192.168.50.2 primary
|
||||
192.168.50.3 secondary1
|
||||
192.168.50.4 secondary2
|
||||
|
||||
Check connectivity among themselves by using ping command:
|
||||
|
||||
$ ping primary
|
||||
$ ping secondary1
|
||||
$ ping secondary2
|
||||
|
||||
### Set up a Replica Set ###
|
||||
|
||||
After verifying connectivity among VMs, we can go ahead and create the admin user so that we can start working on the Replica Set.
|
||||
|
||||
On primary node, open /etc/mongodb.conf, and comment out two lines that start with auth and replSet:
|
||||
|
||||
dbpath=/var/lib/mongodb
|
||||
logpath=/var/log/mongodb/mongod.log
|
||||
logappend=true
|
||||
#auth = true
|
||||
keyFile=/var/lib/mongodb/keyFile
|
||||
#replSet=myReplica
|
||||
|
||||
Restart mongod daemon.
|
||||
|
||||
$ sudo service mongod restart
|
||||
|
||||
Create an admin user after conencting to MongoDB:
|
||||
|
||||
> use admin
|
||||
> db.createUser({
|
||||
user:"admin",
|
||||
pwd:"
|
||||
})
|
||||
$ sudo service mongod restart
|
||||
|
||||
Connect to MongoDB and use these commands to add secondary1 and secondary2 to our Replicat Set.
|
||||
|
||||
> use admin
|
||||
> db.auth("admin","myreallyhardpassword")
|
||||
> rs.initiate()
|
||||
> rs.add ("secondary1:27017")
|
||||
> rs.add("secondary2:27017")
|
||||
|
||||
Now that we have our Replica Set, we can start working on our project. Consult the [official driver documentation][1] to see how to connect to a Replica Set. In case you want to query from shell, you have to connect to primary instance to insert or query the database. Secondary nodes will not let you do that. If you attempt to access the database on a secondary node, you will get this error message:
|
||||
|
||||
myReplica:SECONDARY>
|
||||
myReplica:SECONDARY> show databases
|
||||
2015-05-10T03:09:24.131+0000 E QUERY Error: listDatabases failed:{ "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
|
||||
at Error ()
|
||||
at Mongo.getDBs (src/mongo/shell/mongo.js:47:15)
|
||||
at shellHelper.show (src/mongo/shell/utils.js:630:33)
|
||||
at shellHelper (src/mongo/shell/utils.js:524:36)
|
||||
at (shellhelp2):1:1 at src/mongo/shell/mongo.js:47
|
||||
|
||||
I hope you find this tutorial useful. You can use Vagrant to automate your local environments and help you code faster.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/setup-replica-set-mongodb.html
|
||||
|
||||
作者:[Christopher Valerio][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/valerio
|
||||
[1]:http://docs.mongodb.org/ecosystem/drivers/
|
||||
@ -1,182 +0,0 @@
|
||||
translating by zhangboyue
|
||||
Analyzing Linux Logs
|
||||
================================================================================
|
||||
There’s a great deal of information waiting for you within your logs, although it’s not always as easy as you’d like to extract it. In this section we will cover some examples of basic analysis you can do with your logs right away (just search what’s there). We’ll also cover more advanced analysis that may take some upfront effort to set up properly, but will save you time on the back end. Examples of advanced analysis you can do on parsed data include generating summary counts, filtering on field values, and more.
|
||||
|
||||
We’ll show you first how to do this yourself on the command line using several different tools and then show you how a log management tool can automate much of the grunt work and make this so much more streamlined.
|
||||
|
||||
### Searching with Grep ###
|
||||
|
||||
Searching for text is the most basic way to find what you’re looking for. The most common tool for searching text is [grep][1]. This command line tool, available on most Linux distributions, allows you to search your logs using regular expressions. A regular expression is a pattern written in a special language that can identify matching text. The simplest pattern is to put the string you’re searching for surrounded by quotes
|
||||
|
||||
#### Regular Expressions ####
|
||||
|
||||
Here’s an example to find authentication logs for “user hoover” on an Ubuntu system:
|
||||
|
||||
$ grep "user hoover" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
pam_unix(sshd:session): session opened for user hoover by (uid=0)
|
||||
pam_unix(sshd:session): session closed for user hoover
|
||||
|
||||
It can be hard to construct regular expressions that are accurate. For example, if we searched for a number like the port “4792” it could also match timestamps, URLs, and other undesired data. In the below example for Ubuntu, it matched an Apache log that we didn’t want.
|
||||
|
||||
$ grep "4792" /var/log/auth.log
|
||||
Accepted password for hoover from 10.0.2.2 port 4792 ssh2
|
||||
74.91.21.46 - - [31/Mar/2015:19:44:32 +0000] "GET /scripts/samples/search?q=4972HTTP/1.0" 404 545 "-" "-”
|
||||
|
||||
#### Surround Search ####
|
||||
|
||||
Another useful tip is that you can do surround search with grep. This will show you what happened a few lines before or after a match. It can help you debug what lead up to a particular error or problem. The B flag gives you lines before, and A gives you lines after. For example, we can see that when someone failed to login as an admin, they also failed the reverse mapping which means they might not have a valid domain name. This is very suspicious!
|
||||
|
||||
$ grep -B 3 -A 2 'Invalid user' /var/log/auth.log
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: reverse mapping checking getaddrinfo for 216-19-2-8.commspeed.net [216.19.2.8] failed - POSSIBLE BREAK-IN ATTEMPT!
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12545]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Invalid user admin from 216.19.2.8
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: input_userauth_request: invalid user admin [preauth]
|
||||
Apr 28 17:06:20 ip-172-31-11-241 sshd[12547]: Received disconnect from 216.19.2.8: 11: Bye Bye [preauth]
|
||||
|
||||
#### Tail ####
|
||||
|
||||
You can also pair grep with [tail][2] to get the last few lines of a file, or to follow the logs and print them in real time. This is useful if you are making interactive changes like starting a server or testing a code change.
|
||||
|
||||
$ tail -f /var/log/auth.log | grep 'Invalid user'
|
||||
Apr 30 19:49:48 ip-172-31-11-241 sshd[6512]: Invalid user ubnt from 219.140.64.136
|
||||
Apr 30 19:49:49 ip-172-31-11-241 sshd[6514]: Invalid user admin from 219.140.64.136
|
||||
|
||||
A full introduction on grep and regular expressions is outside the scope of this guide, but [Ryan’s Tutorials][3] include more in-depth information.
|
||||
|
||||
Log management systems have higher performance and more powerful searching abilities. They often index their data and parallelize queries so you can quickly search gigabytes or terabytes of logs in seconds. In contrast, this would take minutes or in extreme cases hours with grep. Log management systems also use query languages like [Lucene][4] which offer an easier syntax for searching on numbers, fields, and more.
|
||||
|
||||
### Parsing with Cut, AWK, and Grok ###
|
||||
|
||||
#### Command Line Tools ####
|
||||
|
||||
Linux offers several command line tools for text parsing and analysis. They are great if you want to quickly parse a small amount of data but can take a long time to process large volumes of data
|
||||
|
||||
#### Cut ####
|
||||
|
||||
The [cut][5] command allows you to parse fields from delimited logs. Delimiters are characters like equal signs or commas that break up fields or key value pairs.
|
||||
|
||||
Let’s say we want to parse the user from this log:
|
||||
|
||||
pam_unix(su:auth): authentication failure; logname=hoover uid=1000 euid=0 tty=/dev/pts/0 ruser=hoover rhost= user=root
|
||||
|
||||
We can use the cut command like this to get the text after the eighth equal sign. This example is on an Ubuntu system:
|
||||
|
||||
$ grep "authentication failure" /var/log/auth.log | cut -d '=' -f 8
|
||||
root
|
||||
hoover
|
||||
root
|
||||
nagios
|
||||
nagios
|
||||
|
||||
#### AWK ####
|
||||
|
||||
Alternately, you can use [awk][6], which offers more powerful features to parse out fields. It offers a scripting language so you can filter out nearly everything that’s not relevant.
|
||||
|
||||
For example, let’s say we have the following log line on an Ubuntu system and we want to extract the username that failed to login:
|
||||
|
||||
Mar 24 08:28:18 ip-172-31-11-241 sshd[32701]: input_userauth_request: invalid user guest [preauth]
|
||||
|
||||
Here’s how you can use the awk command. First, put a regular expression /sshd.*invalid user/ to match the sshd invalid user lines. Then print the ninth field using the default delimiter of space using { print $9 }. This outputs the usernames.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
You can read more about how to use regular expressions and print fields in the [Awk User’s Guide][7].
|
||||
|
||||
#### Log Management Systems ####
|
||||
|
||||
Log management systems make parsing easier and enable users to quickly analyze large collections of log files. They can automatically parse standard log formats like common Linux logs or web server logs. This saves a lot of time because you don’t have to think about writing your own parsing logic when troubleshooting a system problem.
|
||||
|
||||
Here you can see an example log message from sshd which has each of the fields remoteHost and user parsed out. This is a screenshot from Loggly, a cloud-based log management service.
|
||||
|
||||

|
||||
|
||||
You can also do custom parsing for non-standard formats. A common tool to use is [Grok][8] which uses a library of common regular expressions to parse raw text into structured JSON. Here is an example configuration for Grok to parse kernel log files inside Logstash:
|
||||
|
||||
filter{
|
||||
grok {
|
||||
match => {"message" => "%{CISCOTIMESTAMP:timestamp} %{HOST:host} %{WORD:program}%{NOTSPACE} %{NOTSPACE}%{NUMBER:duration}%{NOTSPACE} %{GREEDYDATA:kernel_logs}"
|
||||
}
|
||||
}
|
||||
|
||||
And here is what the parsed output looks like from Grok:
|
||||
|
||||

|
||||
|
||||
### Filtering with Rsyslog and AWK ###
|
||||
|
||||
Filtering allows you to search on a specific field value instead of doing a full text search. This makes your log analysis more accurate because it will ignore undesired matches from other parts of the log message. In order to search on a field value, you need to parse your logs first or at least have a way of searching based on the event structure.
|
||||
|
||||
#### How to Filter on One App ####
|
||||
|
||||
Often, you just want to see the logs from just one application. This is easy if your application always logs to a single file. It’s more complicated if you need to filter one application among many in an aggregated or centralized log. Here are several ways to do this:
|
||||
|
||||
1. Use the rsyslog daemon to parse and filter logs. This example writes logs from the sshd application to a file named sshd-messages, then discards the event so it’s not repeated elsewhere. You can try this example by adding it to your rsyslog.conf file.
|
||||
|
||||
:programname, isequal, “sshd” /var/log/sshd-messages
|
||||
&~
|
||||
|
||||
2. Use command line tools like awk to extract the values of a particular field like the sshd username. This example is from an Ubuntu system.
|
||||
|
||||
$ awk '/sshd.*invalid user/ { print $9 }' /var/log/auth.log
|
||||
guest
|
||||
admin
|
||||
info
|
||||
test
|
||||
ubnt
|
||||
|
||||
3. Use a log management system that automatically parses your logs, then click to filter on the desired application name. Here is a screenshot showing the syslog fields in a log management service called Loggly. We are filtering on the appName “sshd” as indicated by the Venn diagram icon.
|
||||
|
||||

|
||||
|
||||
#### How to Filter on Errors ####
|
||||
|
||||
One of the most common thing people want to see in their logs is errors. Unfortunately, the default syslog configuration doesn’t output the severity of errors directly, making it difficult to filter on them.
|
||||
|
||||
There are two ways you can solve this problem. First, you can modify your rsyslog configuration to output the severity in the log file to make it easier to read and search. In your rsyslog configuration you can add a [template][9] with pri-text such as the following:
|
||||
|
||||
"<%pri-text%> : %timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
|
||||
|
||||
This example gives you output in the following format. You can see that the severity in this message is err.
|
||||
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
You can use awk or grep to search for just the error messages. In this example for Ubuntu, we’re including some surrounding syntax like the . and the > which match only this field.
|
||||
|
||||
$ grep '.err>' /var/log/auth.log
|
||||
<authpriv.err> : Mar 11 18:18:00,hoover-VirtualBox,su[5026]:, pam_authenticate: Authentication failure
|
||||
|
||||
Your second option is to use a log management system. Good log management systems automatically parse syslog messages and extract the severity field. They also allow you to filter on log messages of a certain severity with a single click.
|
||||
|
||||
Here is a screenshot from Loggly showing the syslog fields with the error severity highlighted to show we are filtering for errors:
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.loggly.com/ultimate-guide/logging/analyzing-linux-logs/
|
||||
|
||||
作者:[Jason Skowronski][a] [Amy Echeverri][b] [ Sadequl Hussain][c]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jasonskowronski
|
||||
[b]:https://www.linkedin.com/in/amyecheverri
|
||||
[c]:https://www.linkedin.com/pub/sadequl-hussain/14/711/1a7
|
||||
[1]:http://linux.die.net/man/1/grep
|
||||
[2]:http://linux.die.net/man/1/tail
|
||||
[3]:http://ryanstutorials.net/linuxtutorial/grep.php
|
||||
[4]:https://lucene.apache.org/core/2_9_4/queryparsersyntax.html
|
||||
[5]:http://linux.die.net/man/1/cut
|
||||
[6]:http://linux.die.net/man/1/awk
|
||||
[7]:http://www.delorie.com/gnu/docs/gawk/gawk_26.html#IDX155
|
||||
[8]:http://logstash.net/docs/1.4.2/filters/grok
|
||||
[9]:http://www.rsyslog.com/doc/v8-stable/configuration/templates.html
|
||||
@ -1,209 +0,0 @@
|
||||
translating by wwy-hust
|
||||
|
||||
Nishita Agarwal Shares Her Interview Experience on Linux ‘iptables’ Firewall
|
||||
================================================================================
|
||||
Nishita Agarwal, a frequent Tecmint Visitor shared her experience (Question and Answer) with us regarding the job interview she had just given in a privately owned hosting company in Pune, India. She was asked a lot of questions on a variety of topics however she is an expert in iptables and she wanted to share those questions and their answer (she gave) related to iptables to others who may be going to give interview in near future.
|
||||
|
||||

|
||||
|
||||
All the questions and their Answer are rewritten based upon the memory of Nishita Agarwal.
|
||||
|
||||
> “Hello Friends! My name is **Nishita Agarwal**. I have Pursued Bachelor Degree in Technology. My area of Specialization is UNIX and Variants of UNIX (BSD, Linux) fascinates me since the time I heard it. I have 1+ years of experience in storage. I was looking for a job change which ended with a hosting company in Pune, India.”
|
||||
|
||||
Here is the collection of what I was asked during the Interview. I’ve documented only those questions and their answer that were related to iptables based upon my memory. Hope this will help you in cracking your Interview.
|
||||
|
||||
### 1. Have you heard of iptables and firewall in Linux? Any idea of what they are and for what it is used? ###
|
||||
|
||||
> **Answer** : I’ve been using iptables for quite long time and I am aware of both iptables and firewall. Iptables is an application program mostly written in C Programming Language and is released under GNU General Public License. Written for System administration point of view, the latest stable release if iptables 1.4.21.iptables may be considered as firewall for UNIX like operating system which can be called as iptables/netfilter, more accurately. The Administrator interact with iptables via console/GUI front end tools to add and define firewall rules into predefined tables. Netfilter is a module built inside of kernel that do the job of filtering.
|
||||
>
|
||||
> Firewalld is the latest implementation of filtering rules in RHEL/CentOS 7 (may be implemented in other distributions which I may not be aware of). It has replaced iptables interface and connects to netfilter.
|
||||
|
||||
### 2. Have you used some kind of GUI based front end tool for iptables or the Linux Command Line? ###
|
||||
|
||||
> **Answer** : Though I have used both the GUI based front end tools for iptables like Shorewall in conjugation of [Webmin][1] in GUI and Direct access to iptables via console.And I must admit that direct access to iptables via Linux console gives a user immense power in the form of higher degree of flexibility and better understanding of what is going on in the background, if not anything other. GUI is for novice administrator while console is for experienced.
|
||||
|
||||
### 3. What are the basic differences between between iptables and firewalld? ###
|
||||
|
||||
> **Answer** : iptables and firewalld serves the same purpose (Packet Filtering) but with different approach. iptables flush the entire rules set each time a change is made unlike firewalld. Typically the location of iptables configuration lies at ‘/etc/sysconfig/iptables‘ whereas firewalld configuration lies at ‘/etc/firewalld/‘, which is a set of XML files.Configuring a XML based firewalld is easier as compared to configuration of iptables, however same task can be achieved using both the packet filtering application ie., iptables and firewalld. Firewalld runs iptables under its hood along with it’s own command line interface and configuration file that is XML based and said above.
|
||||
|
||||
### 4. Would you replace iptables with firewalld on all your servers, if given a chance? ###
|
||||
|
||||
> **Answer** : I am familiar with iptables and it’s working and if there is nothing that requires dynamic aspect of firewalld, there seems no reason to migrate all my configuration from iptables to firewalld.In most of the cases, so far I have never seen iptables creating an issue. Also the general rule of Information technology says “why fix if it is not broken”. However this is my personal thought and I would never mind implementing firewalld if the Organization is going to replace iptables with firewalld.
|
||||
|
||||
### 5. You seems confident with iptables and the plus point is even we are using iptables on our server. ###
|
||||
|
||||
What are the tables used in iptables? Give a brief description of the tables used in iptables and the chains they support.
|
||||
|
||||
> **Answer** : Thanks for the recognition. Moving to question part, There are four tables used in iptables, namely they are:
|
||||
>
|
||||
> Nat Table
|
||||
> Mangle Table
|
||||
> Filter Table
|
||||
> Raw Table
|
||||
>
|
||||
> Nat Table : Nat table is primarily used for Network Address Translation. Masqueraded packets get their IP address altered as per the rules in the table. Packets in the stream traverse Nat Table only once. ie., If a packet from a jet of Packets is masqueraded they rest of the packages in the stream will not traverse through this table again. It is recommended not to filter in this table. Chains Supported by NAT Table are PREROUTING Chain, POSTROUTING Chain and OUTPUT Chain.
|
||||
>
|
||||
> Mangle Table : As the name suggests, this table serves for mangling the packets. It is used for Special package alteration. It can be used to alter the content of different packets and their headers. Mangle table can’t be used for Masquerading. Supported chains are PREROUTING Chain, OUTPUT Chain, Forward Chain, INPUT Chain, POSTROUTING Chain.
|
||||
>
|
||||
> Filter Table : Filter Table is the default table used in iptables. It is used for filtering Packets. If no rules are defined, Filter Table is taken as default table and filtering is done on the basis of this table. Supported Chains are INPUT Chain, OUTPUT Chain, FORWARD Chain.
|
||||
>
|
||||
> Raw Table : Raw table comes into action when we want to configure packages that were exempted earlier. It supports PREROUTING Chain and OUTPUT Chain.
|
||||
|
||||
### 6. What are the target values (that can be specified in target) in iptables and what they do, be brief! ###
|
||||
|
||||
> **Answer** : Following are the target values that we can specify in target in iptables:
|
||||
>
|
||||
> ACCEPT : Accept Packets
|
||||
> QUEUE : Paas Package to user space (place where application and drivers reside)
|
||||
> DROP : Drop Packets
|
||||
> RETURN : Return Control to calling chain and stop executing next set of rules for the current Packets in the chain.
|
||||
|
||||
|
||||
### 7. Lets move to the technical aspects of iptables, by technical I means practical. ###
|
||||
|
||||
How will you Check iptables rpm that is required to install iptables in CentOS?.
|
||||
|
||||
> **Answer** : iptables rpm are included in standard CentOS installation and we do not need to install it separately. We can check the rpm as:
|
||||
>
|
||||
> # rpm -qa iptables
|
||||
>
|
||||
> iptables-1.4.21-13.el7.x86_64
|
||||
>
|
||||
> If you need to install it, you may do yum to get it.
|
||||
>
|
||||
> # yum install iptables-services
|
||||
|
||||
### 8. How to Check and ensure if iptables service is running? ###
|
||||
|
||||
> **Answer** : To check the status of iptables, you may run the following command on the terminal.
|
||||
>
|
||||
> # service status iptables [On CentOS 6/5]
|
||||
> # systemctl status iptables [On CentOS 7]
|
||||
>
|
||||
> If it is not running, the below command may be executed.
|
||||
>
|
||||
> ---------------- On CentOS 6/5 ----------------
|
||||
> # chkconfig --level 35 iptables on
|
||||
> # service iptables start
|
||||
>
|
||||
> ---------------- On CentOS 7 ----------------
|
||||
> # systemctl enable iptables
|
||||
> # systemctl start iptables
|
||||
>
|
||||
> We may also check if the iptables module is loaded or not, as:
|
||||
>
|
||||
> # lsmod | grep ip_tables
|
||||
|
||||
### 9. How will you review the current Rules defined in iptables? ###
|
||||
|
||||
> **Answer** : The current rules in iptables can be review as simple as:
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Sample Output
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
### 10. How will you flush all iptables rules or a particular chain? ###
|
||||
|
||||
> **Answer** : To flush a particular iptables chain, you may use following commands.
|
||||
>
|
||||
>
|
||||
> # iptables --flush OUTPUT
|
||||
>
|
||||
> To Flush all the iptables rules.
|
||||
>
|
||||
> # iptables --flush
|
||||
|
||||
### 11. Add a rule in iptables to accept packets from a trusted IP Address (say 192.168.0.7) ###
|
||||
|
||||
> **Answer** : The above scenario can be achieved simply by running the below command.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7 -j ACCEPT
|
||||
>
|
||||
> We may include standard slash or subnet mask in the source as:
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.7/24 -j ACCEPT
|
||||
> # iptables -A INPUT -s 192.168.0.7/255.255.255.0 -j ACCEPT
|
||||
|
||||
### 12. How to add rules to ACCEPT, REJECT, DENY and DROP ssh service in iptables. ###
|
||||
|
||||
> **Answer** : Hoping ssh is running on port 22, which is also the default port for ssh, we can add rule to iptables as:To ACCEPT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j ACCEPT
|
||||
>
|
||||
> To REJECT tcp packets for ssh service (port 22).
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j REJECT
|
||||
>
|
||||
> To DENY tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DENY
|
||||
>
|
||||
> To DROP tcp packets for ssh service (port 22).
|
||||
>
|
||||
>
|
||||
> # iptables -A INPUT -s -p tcp - -dport -j DROP
|
||||
|
||||
### 13. Let me give you a scenario. Say there is a machine the local ip address of which is 192.168.0.6. You need to block connections on port 21, 22, 23, and 80 to your machine. What will you do? ###
|
||||
|
||||
> **Answer** : Well all I need to use is the ‘multiport‘ option with iptables followed by port numbers to be blocked and the above scenario can be achieved in a single go as.
|
||||
>
|
||||
> # iptables -A INPUT -s 192.168.0.6 -p tcp -m multiport --dport 22,23,80,8080 -j DROP
|
||||
>
|
||||
> The written rules can be checked using the below command.
|
||||
>
|
||||
> # iptables -L
|
||||
>
|
||||
> Chain INPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> ACCEPT all -- anywhere anywhere state RELATED,ESTABLISHED
|
||||
> ACCEPT icmp -- anywhere anywhere
|
||||
> ACCEPT all -- anywhere anywhere
|
||||
> ACCEPT tcp -- anywhere anywhere state NEW tcp dpt:ssh
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
> DROP tcp -- 192.168.0.6 anywhere multiport dports ssh,telnet,http,webcache
|
||||
>
|
||||
> Chain FORWARD (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
> REJECT all -- anywhere anywhere reject-with icmp-host-prohibited
|
||||
>
|
||||
> Chain OUTPUT (policy ACCEPT)
|
||||
> target prot opt source destination
|
||||
|
||||
**Interviewer** : That’s all I wanted to ask. You are a valuable employee we won’t like to miss. I will recommend your name to the HR. If you have any question you may ask me.
|
||||
|
||||
As a candidate I don’t wanted to kill the conversation hence keep asking about the projects I would be handling if selected and what are the other openings in the company. Not to mention HR round was not difficult to crack and I got the opportunity.
|
||||
|
||||
Also I would like to thank Avishek and Ravi (whom I am a friend since long) for taking the time to document my interview.
|
||||
|
||||
Friends! If you had given any such interview and you would like to share your interview experience to millions of Tecmint readers around the globe? then send your questions and answers to admin@tecmint.com.
|
||||
|
||||
Thank you! Keep Connected. Also let me know if I could have answered a question more correctly than what I did.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-firewall-iptables-interview-questions-and-answers/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/install-webmin-web-based-system-administration-tool-for-rhel-centos-fedora/
|
||||
@ -1,95 +0,0 @@
|
||||
How to Configure Swarm Native Clustering for Docker
|
||||
================================================================================
|
||||
Hi everyone, today we'll learn about Swarm and how we can create native clusters using Docker with Swarm. [Docker Swarm][1] is a native clustering program for Docker which turns a pool of Docker hosts into a single virtual host. Swarm serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Swarm follows the "batteries included but removable" principle as other Docker Projects. It ships with a simple scheduling backend out of the box, and as initial development settles, an API will develop to enable pluggable backends. The goal is to provide a smooth out-of-box experience for simple use cases, and allow swapping in more powerful backends, like Mesos, for large scale production deployments. Swarm is extremely easy to setup and get started.
|
||||
|
||||
So, here are some features of Swarm 0.2 out of the box.
|
||||
|
||||
1. Swarm 0.2.0 is about 85% compatible with the Docker Engine.
|
||||
2. It supports Resource Management.
|
||||
3. It has Advanced Scheduling feature with constraints and affinities.
|
||||
4. It supports multiple Discovery Backends (hubs, consul, etcd, zookeeper)
|
||||
5. It uses TLS encryption method for security and authentication.
|
||||
|
||||
So, here are some very simple and easy steps on how we can use Swarm.
|
||||
|
||||
### 1. Pre-requisites to run Swarm ###
|
||||
|
||||
We must install Docker 1.4.0 or later on all nodes. While each node's IP need not be public, the Swarm manager must be able to access each node across the network.
|
||||
|
||||
Note: Swarm is currently in beta, so things are likely to change. We don't recommend you use it in production yet.
|
||||
|
||||
### 2. Creating Swarm Cluster ###
|
||||
|
||||
Now, we'll create swarm cluster by running the below command. Each node will run a swarm node agent. The agent registers the referenced Docker daemon, monitors it, and updates the discovery backend with the node's status. The below command returns a token which is a unique cluster id, it will be used when starting the Swarm Agent on nodes.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
### 3. Starting the Docker Daemon in each nodes ###
|
||||
|
||||
We'll need to login into each node that we'll use to create clusters and start the Docker Daemon into it using flag -H . It ensures that the docker remote API on the node is available over TCP for the Swarm Manager. To do start the docker daemon, we'll need to run the following command inside the nodes.
|
||||
|
||||
# docker -H tcp://0.0.0.0:2375 -d
|
||||
|
||||

|
||||
|
||||
### 4. Adding the Nodes ###
|
||||
|
||||
After enabling Docker Daemon, we'll need to add the Swarm Nodes to the discovery service. We must ensure that node's IP must be accessible from the Swarm Manager. To do so, we'll need to run the following command.
|
||||
|
||||
# docker run -d swarm join --addr=<node_ip>:2375 token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
**Note**: Here, we'll need to replace <node_ip> and <cluster_id> with the IP address of the Node and the cluster ID we got from step 2.
|
||||
|
||||
### 5. Starting the Swarm Manager ###
|
||||
|
||||
Now, as we have got the nodes connected to the cluster. Now, we'll start the swarm manager, we'll need to run the following command in the node.
|
||||
|
||||
# docker run -d -p <swarm_port>:2375 swarm manage token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### 6. Checking the Configuration ###
|
||||
|
||||
Once the manager is running, we can check the configuration by running the following command.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
|
||||

|
||||
|
||||
**Note**: We'll need to replace <manager_ip:manager_port> with the ip address and port of the host running the swarm manager.
|
||||
|
||||
### 7. Using the docker CLI to access nodes ###
|
||||
|
||||
After everything is done perfectly as explained above, this part is the most important part of the Docker Swarm. We can use Docker CLI to access the nodes and run containers on them.
|
||||
|
||||
# docker -H tcp://<manager_ip:manager_port> info
|
||||
# docker -H tcp://<manager_ip:manager_port> run ...
|
||||
|
||||
### 8. Listing nodes in the cluster ###
|
||||
|
||||
We can get a list of all of the running nodes using the swarm list command.
|
||||
|
||||
# docker run --rm swarm list token://<cluster_id>
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Swarm is really an awesome feature of docker that can be used for creating and managing clusters. It is pretty easy to setup and use. It is more beautiful when we use constraints and affinities on top of it. Advanced Scheduling is an awesome feature of it which applies filters to exclude nodes with ports, labels, health and it uses strategies to pick the best node. So, if you have any questions, comments, feedback please do write on the comment box below and let us know what stuffs needs to be added or improved. Thank You! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/configure-swarm-clustering-docker/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://docs.docker.com/swarm/
|
||||
@ -1,348 +0,0 @@
|
||||
Shilpa Nair Shares Her Interview Experience on RedHat Linux Package Management
|
||||
================================================================================
|
||||
**Shilpa Nair has just graduated in the year 2015. She went to apply for Trainee position in a National News Television located in Noida, Delhi. When she was in the last year of graduation and searching for help on her assignments she came across Tecmint. Since then she has been visiting Tecmint regularly.**
|
||||
|
||||

|
||||
|
||||
Linux Interview Questions on RPM
|
||||
|
||||
All the questions and answers are rewritten based upon the memory of Shilpa Nair.
|
||||
|
||||
> “Hi friends! I am Shilpa Nair from Delhi. I have completed my graduation very recently and was hunting for a Trainee role soon after my degree. I have developed a passion for UNIX since my early days in the collage and I was looking for a role that suits me and satisfies my soul. I was asked a lots of questions and most of them were basic questions related to RedHat Package Management.”
|
||||
|
||||
Here are the questions, that I was asked and their corresponding answers. I am posting only those questions that are related to RedHat GNU/Linux Package Management, as they were mainly asked.
|
||||
|
||||
### 1. How will you find if a package is installed or not? Say you have to find if ‘nano’ is installed or not, what will you do? ###
|
||||
|
||||
> **Answer** : To find the package nano, weather installed or not, we can use rpm command with the option -q is for query and -a stands for all the installed packages.
|
||||
>
|
||||
> # rpm -qa nano
|
||||
> OR
|
||||
> # rpm -qa | grep -i nano
|
||||
>
|
||||
> nano-2.3.1-10.el7.x86_64
|
||||
>
|
||||
> Also the package name must be complete, an incomplete package name will return the prompt without printing anything which means that package (incomplete package name) is not installed. It can be understood easily by the example below:
|
||||
>
|
||||
> We generally substitute vim command with vi. But if we find package vi/vim we will get no result on the standard output.
|
||||
>
|
||||
> # vi
|
||||
> # vim
|
||||
>
|
||||
> However we can clearly see that the package is installed by firing vi/vim command. Here is culprit is incomplete file name. If we are not sure of the exact file-name we can use wildcard as:
|
||||
>
|
||||
> # rpm -qa vim*
|
||||
>
|
||||
> vim-minimal-7.4.160-1.el7.x86_64
|
||||
>
|
||||
> This way we can find information about any package, if installed or not.
|
||||
|
||||
### 2. How will you install a package XYZ using rpm? ###
|
||||
|
||||
> **Answer** : We can install any package (*.rpm) using rpm command a shown below, here options -i (install), -v (verbose or display additional information) and -h (print hash mark during package installation).
|
||||
>
|
||||
> # rpm -ivh peazip-1.11-1.el6.rf.x86_64.rpm
|
||||
>
|
||||
> Preparing... ################################# [100%]
|
||||
> Updating / installing...
|
||||
> 1:peazip-1.11-1.el6.rf ################################# [100%]
|
||||
>
|
||||
> If upgrading a package from earlier version -U switch should be used, option -v and -h follows to make sure we get a verbose output along with hash Mark, that makes it readable.
|
||||
|
||||
### 3. You have installed a package (say httpd) and now you want to see all the files and directories installed and created by the above package. What will you do? ###
|
||||
|
||||
> **Answer** : We can list all the files (Linux treat everything as file including directories) installed by the package httpd using options -l (List all the files) and -q (is for query).
|
||||
>
|
||||
> # rpm -ql httpd
|
||||
>
|
||||
> /etc/httpd
|
||||
> /etc/httpd/conf
|
||||
> /etc/httpd/conf.d
|
||||
> ...
|
||||
|
||||
### 4. You are supposed to remove a package say postfix. What will you do? ###
|
||||
|
||||
> **Answer** : First we need to know postfix was installed by what package. Find the package name that installed postfix using options -e erase/uninstall a package) and –v (verbose output).
|
||||
>
|
||||
> # rpm -qa postfix*
|
||||
>
|
||||
> postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> and then remove postfix as:
|
||||
>
|
||||
> # rpm -ev postfix-2.10.1-6.el7.x86_64
|
||||
>
|
||||
> Preparing packages...
|
||||
> postfix-2:3.0.1-2.fc22.x86_64
|
||||
|
||||
### 5. Get detailed information about an installed package, means information like Version, Release, Install Date, Size, Summary and a brief description. ###
|
||||
|
||||
> **Answer** : We can get detailed information about an installed package by using option -qa with rpm followed by package name.
|
||||
>
|
||||
> For example to find details of package openssh, all I need to do is:
|
||||
>
|
||||
> # rpm -qi openssh
|
||||
>
|
||||
> [root@tecmint tecmint]# rpm -qi openssh
|
||||
> Name : openssh
|
||||
> Version : 6.8p1
|
||||
> Release : 5.fc22
|
||||
> Architecture: x86_64
|
||||
> Install Date: Thursday 28 May 2015 12:34:50 PM IST
|
||||
> Group : Applications/Internet
|
||||
> Size : 1542057
|
||||
> License : BSD
|
||||
> ....
|
||||
|
||||
### 6. You are not sure about what are the configuration files provided by a specific package say httpd. How will you find list of all the configuration files provided by httpd and their location. ###
|
||||
|
||||
> **Answer** : We need to run option -c followed by package name with rpm command and it will list the name of all the configuration file and their location.
|
||||
>
|
||||
> # rpm -qc httpd
|
||||
>
|
||||
> /etc/httpd/conf.d/autoindex.conf
|
||||
> /etc/httpd/conf.d/userdir.conf
|
||||
> /etc/httpd/conf.d/welcome.conf
|
||||
> /etc/httpd/conf.modules.d/00-base.conf
|
||||
> /etc/httpd/conf/httpd.conf
|
||||
> /etc/sysconfig/httpd
|
||||
>
|
||||
> Similarly we can list all the associated document files as:
|
||||
>
|
||||
> # rpm -qd httpd
|
||||
>
|
||||
> /usr/share/doc/httpd/ABOUT_APACHE
|
||||
> /usr/share/doc/httpd/CHANGES
|
||||
> /usr/share/doc/httpd/LICENSE
|
||||
> ...
|
||||
>
|
||||
> also, we can list the associated License file as:
|
||||
>
|
||||
> # rpm -qL openssh
|
||||
>
|
||||
> /usr/share/licenses/openssh/LICENCE
|
||||
>
|
||||
> Not to mention that the option -d and option -L in the above command stands for ‘documents‘ and ‘License‘, respectively.
|
||||
|
||||
### 7. You came across a configuration file located at ‘/usr/share/alsa/cards/AACI.conf’ and you are not sure this configuration file is associated with what package. How will you find out the parent package name? ###
|
||||
|
||||
> **Answer** : When a package is installed, the relevant information gets stored in the database. So it is easy to trace what provides the above package using option -qf (-f query packages owning files).
|
||||
>
|
||||
> # rpm -qf /usr/share/alsa/cards/AACI.conf
|
||||
> alsa-lib-1.0.28-2.el7.x86_64
|
||||
>
|
||||
> Similarly we can find (what provides) information about any sub-packge, document files and License files.
|
||||
|
||||
### 8. How will you find list of recently installed software’s using rpm? ###
|
||||
|
||||
> **Answer** : As said earlier, everything being installed is logged in database. So it is not difficult to query the rpm database and find the list of recently installed software’s.
|
||||
>
|
||||
> We can do this by running the below commands using option –last (prints the most recent installed software’s).
|
||||
>
|
||||
> # rpm -qa --last
|
||||
>
|
||||
> The above command will print all the packages installed in a order such that, the last installed software appears at the top.
|
||||
>
|
||||
> If our concern is to find out specific package, we can grep that package (say sqlite) from the list, simply as:
|
||||
>
|
||||
> # rpm -qa --last | grep -i sqlite
|
||||
>
|
||||
> sqlite-3.8.10.2-1.fc22.x86_64 Thursday 18 June 2015 05:05:43 PM IST
|
||||
>
|
||||
> We can also get a list of 10 most recently installed software simply as:
|
||||
>
|
||||
> # rpm -qa --last | head
|
||||
>
|
||||
> We can refine the result to output a more custom result simply as:
|
||||
>
|
||||
> # rpm -qa --last | head -n 2
|
||||
>
|
||||
> In the above command -n represents number followed by a numeric value. The above command prints a list of 2 most recent installed software.
|
||||
|
||||
### 9. Before installing a package, you are supposed to check its dependencies. What will you do? ###
|
||||
|
||||
> **Answer** : To check the dependencies of a rpm package (XYZ.rpm), we can use switches -q (query package), -p (query a package file) and -R (Requires / List packages on which this package depends i.e., dependencies).
|
||||
>
|
||||
> # rpm -qpR gedit-3.16.1-1.fc22.i686.rpm
|
||||
>
|
||||
> /bin/sh
|
||||
> /usr/bin/env
|
||||
> glib2(x86-32) >= 2.40.0
|
||||
> gsettings-desktop-schemas
|
||||
> gtk3(x86-32) >= 3.16
|
||||
> gtksourceview3(x86-32) >= 3.16
|
||||
> gvfs
|
||||
> libX11.so.6
|
||||
> ...
|
||||
|
||||
### 10. Is rpm a front-end Package Management Tool? ###
|
||||
|
||||
> **Answer** : No! rpm is a back-end package management for RPM based Linux Distribution.
|
||||
>
|
||||
> [YUM][1] which stands for Yellowdog Updater Modified is the front-end for rpm. YUM automates the overall process of resolving dependencies and everything else.
|
||||
>
|
||||
> Very recently [DNF][2] (Dandified YUM) replaced YUM in Fedora 22. Though YUM is still available to be used in RHEL and CentOS, we can install dnf and use it alongside of YUM. DNF is said to have a lots of improvement over YUM.
|
||||
>
|
||||
> Good to know, you keep yourself updated. Lets move to the front-end part.
|
||||
|
||||
### 11. How will you list all the enabled repolist on a system. ###
|
||||
|
||||
> **Answer** : We can list all the enabled repos on a system simply using following commands.
|
||||
>
|
||||
> # yum repolist
|
||||
> or
|
||||
> # dnf repolist
|
||||
>
|
||||
> Last metadata expiration check performed 0:30:03 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 44,762
|
||||
> ozonos Repository for Ozon OS 61
|
||||
> *updates Fedora 22 - x86_64 - Updates
|
||||
>
|
||||
> The above command will only list those repos that are enabled. If we need to list all the repos, enabled or not, we can do.
|
||||
>
|
||||
> # yum repolist all
|
||||
> or
|
||||
> # dnf repolist all
|
||||
>
|
||||
> Last metadata expiration check performed 0:29:45 ago on Mon Jun 22 16:50:00 2015.
|
||||
> repo id repo name status
|
||||
> *fedora Fedora 22 - x86_64 enabled: 44,762
|
||||
> fedora-debuginfo Fedora 22 - x86_64 - Debug disabled
|
||||
> fedora-source Fedora 22 - Source disabled
|
||||
> ozonos Repository for Ozon OS enabled: 61
|
||||
> *updates Fedora 22 - x86_64 - Updates enabled: 5,018
|
||||
> updates-debuginfo Fedora 22 - x86_64 - Updates - Debug
|
||||
|
||||
### 12. How will you list all the available and installed packages on a system? ###
|
||||
|
||||
> **Answer** : To list all the available packages on a system, we can do:
|
||||
>
|
||||
> # yum list available
|
||||
> or
|
||||
> # dnf list available
|
||||
>
|
||||
> ast metadata expiration check performed 0:34:09 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Available Packages
|
||||
> 0ad.x86_64 0.0.18-1.fc22 fedora
|
||||
> 0ad-data.noarch 0.0.18-1.fc22 fedora
|
||||
> 0install.x86_64 2.6.1-2.fc21 fedora
|
||||
> 0xFFFF.x86_64 0.3.9-11.fc22 fedora
|
||||
> 2048-cli.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> 2048-cli-nocurses.x86_64 0.9-4.git20141214.723738c.fc22 fedora
|
||||
> ....
|
||||
>
|
||||
> To list all the installed Packages on a system, we can do.
|
||||
>
|
||||
> # yum list installed
|
||||
> or
|
||||
> # dnf list installed
|
||||
>
|
||||
> Last metadata expiration check performed 0:34:30 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> ....
|
||||
>
|
||||
> To list all the available and installed packages on a system, we can do.
|
||||
>
|
||||
> # yum list
|
||||
> or
|
||||
> # dnf list
|
||||
>
|
||||
> Last metadata expiration check performed 0:32:56 ago on Mon Jun 22 16:50:00 2015.
|
||||
> Installed Packages
|
||||
> GeoIP.x86_64 1.6.5-1.fc22 @System
|
||||
> GeoIP-GeoLite-data.noarch 2015.05-1.fc22 @System
|
||||
> NetworkManager.x86_64 1:1.0.2-1.fc22 @System
|
||||
> NetworkManager-libnm.x86_64 1:1.0.2-1.fc22 @System
|
||||
> aajohan-comfortaa-fonts.noarch 2.004-4.fc22 @System
|
||||
> acl.x86_64 2.2.52-7.fc22 @System
|
||||
> ....
|
||||
|
||||
### 13. How will you install and update a package and a group of packages separately on a system using YUM/DNF? ###
|
||||
|
||||
> Answer : To Install a package (say nano), we can do,
|
||||
>
|
||||
> # yum install nano
|
||||
>
|
||||
> To Install a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupinstall 'haskell'
|
||||
>
|
||||
> To update a package (say nano), we can do.
|
||||
>
|
||||
> # yum update nano
|
||||
>
|
||||
> To update a Group of Package (say Haskell), we can do.
|
||||
>
|
||||
> # yum groupupdate 'haskell'
|
||||
|
||||
### 14. How will you SYNC all the installed packages on a system to stable release? ###
|
||||
|
||||
> **Answer** : We can sync all the packages on a system (say CentOS or Fedora) to stable release as,
|
||||
>
|
||||
> # yum distro-sync [On CentOS/RHEL]
|
||||
> or
|
||||
> # dnf distro-sync [On Fedora 20 Onwards]
|
||||
|
||||
Seems you have done a good homework before coming for the interview,Good!. Before proceeding further I just want to ask one more question.
|
||||
|
||||
### 15. Are you familiar with YUM local repository? Have you tried making a Local YUM repository? Let me know in brief what you will do to create a local YUM repo. ###
|
||||
|
||||
> **Answer** : First I would like to Thank you Sir for appreciation. Coming to question, I must admit that I am quiet familiar with Local YUM repositories and I have already implemented it for testing purpose in my local machine.
|
||||
>
|
||||
> 1. To set up Local YUM repository, we need to install the below three packages as:
|
||||
>
|
||||
> # yum install deltarpm python-deltarpm createrepo
|
||||
>
|
||||
> 2. Create a directory (say /home/$USER/rpm) and copy all the RPMs from RedHat/CentOS DVD to that folder.
|
||||
>
|
||||
> # mkdir /home/$USER/rpm
|
||||
> # cp /path/to/rpm/on/DVD/*.rpm /home/$USER/rpm
|
||||
>
|
||||
> 3. Create base repository headers as.
|
||||
>
|
||||
> # createrepo -v /home/$USER/rpm
|
||||
>
|
||||
> 4. Create the .repo file (say abc.repo) at the location /etc/yum.repos.d simply as:
|
||||
>
|
||||
> cd /etc/yum.repos.d && cat << EOF > abc.repo
|
||||
> [local-installation]name=yum-local
|
||||
> baseurl=file:///home/$USER/rpm
|
||||
> enabled=1
|
||||
> gpgcheck=0
|
||||
> EOF
|
||||
|
||||
**Important**: Make sure to remove $USER with user_name.
|
||||
|
||||
That’s all we need to do to create a Local YUM repository. We can now install applications from here, that is relatively fast, secure and most important don’t need an Internet connection.
|
||||
|
||||
Okay! It was nice interviewing you. I am done. I am going to suggest your name to HR. You are a young and brilliant candidate we would like to have in our organization. If you have any question you may ask me.
|
||||
|
||||
**Me**: Sir, it was really a very nice interview and I feel very lucky today, to have cracked the interview..
|
||||
|
||||
Obviously it didn’t end here. I asked a lots of questions like the project they are handling. What would be my role and responsibility and blah..blah..blah
|
||||
|
||||
Friends, by the time all these were documented I have been called for HR round which is 3 days from now. Hope I do my best there as well. All your blessings will count.
|
||||
|
||||
Thankyou friends and Tecmint for taking time and documenting my experience. Mates I believe Tecmint is doing some really extra-ordinary which must be praised. When we share ours experience with other, other get to know many things from us and we get to know our mistakes.
|
||||
|
||||
It enhances our confidence level. If you have given any such interview recently, don’t keep it to yourself. Spread it! Let all of us know that. You may use the below form to share your experience with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-rpm-package-management-interview-questions/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/avishek/
|
||||
[1]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
|
||||
[2]:http://www.tecmint.com/dnf-commands-for-fedora-rpm-package-management/
|
||||
@ -1,127 +0,0 @@
|
||||
Translating by DongShuaike
|
||||
|
||||
How to Provision Swarm Clusters using Docker Machine
|
||||
================================================================================
|
||||
Hi all, today we'll learn how we can deploy Swarm Clusters using Docker Machine. It serves the standard Docker API, so any tool which can communicate with a Docker daemon can use Swarm to transparently scale to multiple hosts. Docker Machine is an application that helps to create Docker hosts on our computer, on cloud providers and inside our own data center. It provides easy solution for creating servers, installing Docker on them and then configuring the Docker client according the users configuration and requirements. We can provision swarm clusters with any driver we need and is highly secured with TLS Encryption.
|
||||
|
||||
Here are some quick and easy steps on how to provision swarm clusters with Docker Machine.
|
||||
|
||||
### 1. Installing Docker Machine ###
|
||||
|
||||
Docker Machine supports awesome on every Linux Operating System. First of all, we'll need to download the latest version of Docker Machine from the Github site . Here, we'll use curl to download the latest version of Docker Machine ie 0.2.0 .
|
||||
|
||||
For 64 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-amd64 > /usr/local/bin/docker-machine
|
||||
|
||||
For 32 Bit Operating System
|
||||
|
||||
# curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_linux-i386 > /usr/local/bin/docker-machine
|
||||
|
||||
After downloading the latest release of Docker Machine, we'll make the file named docker-machine under /usr/local/bin/ executable using the command below.
|
||||
|
||||
# chmod +x /usr/local/bin/docker-machine
|
||||
|
||||
After doing the above, we'll wanna ensure that we have successfully installed docker-machine. To check it, we can run the docker-machine -v which will give output of the version of docker-machine installed in our system.
|
||||
|
||||
# docker-machine -v
|
||||
|
||||

|
||||
|
||||
To enable Docker commands on our machines, make sure to install the Docker client as well by running the command below.
|
||||
|
||||
# curl -L https://get.docker.com/builds/linux/x86_64/docker-latest > /usr/local/bin/docker
|
||||
# chmod +x /usr/local/bin/docker
|
||||
|
||||
### 2. Creating Machine ###
|
||||
|
||||
After installing Machine into our working PC or device, we'll wanna go forward to create a machine using Docker Machine. Here, in this tutorial we'll gonna deploy a machine in the Digital Ocean Platform so we'll gonna use "digitalocean" as its Driver API then, docker swarm will be running into that Droplet which will be further configured as Swarm Master and another droplet will be created which will be configured as Swarm Node Agent.
|
||||
|
||||
So, to create the machine, we'll need to run the following command.
|
||||
|
||||
# docker-machine create --driver digitalocean --digitalocean-access-token <API-Token> linux-dev
|
||||
|
||||
**Note**: Here, linux-dev is the name of the machine we are wanting to create. <API-Token> is a security key which can be generated from the Digital Ocean Control Panel of the account holder of Digital Ocean Cloud Platform. To retrieve that key, we simply need to login to our Digital Ocean Control Panel then click on API, then click on Generate New Token and give it a name tick on both Read and Write. Then we'll get a long hex key, thats the <API-Token> now, simply replace it into the command above.
|
||||
|
||||
Now, to load the Machine configuration into the shell we are running the comamands, run the following command.
|
||||
|
||||
# eval "$(docker-machine env linux-dev)"
|
||||
|
||||

|
||||
|
||||
Then, we'll mark our machine as ACTIVE by running the below command.
|
||||
|
||||
# docker-machine active linux-dev
|
||||
|
||||
Now, we'll check whether its been marked as ACTIVE "*" or not.
|
||||
|
||||
# docker-machine ls
|
||||
|
||||

|
||||
|
||||
### 3. Running Swarm Docker Image ###
|
||||
|
||||
Now, after we finish creating the required machine. We'll gonna deploy swarm docker image in our active machine. This machine will run the docker image and will control over the Swarm master and node. To run the image, we can simply run the below command.
|
||||
|
||||
# docker run swarm create
|
||||
|
||||

|
||||
|
||||
If you are trying to run swarm docker image using **32 bit Operating System** in the computer where Docker Machine is running, we'll need to SSH into the Droplet.
|
||||
|
||||
# docker-machine ssh
|
||||
#docker run swarm create
|
||||
#exit
|
||||
|
||||
### 4. Creating Swarm Master ###
|
||||
|
||||
Now, after our machine and swarm image is running into the machine, we'll now create a Swarm Master. This will also add the master as a node. To do so, here's the command below.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-master \
|
||||
--swarm-discovery token://<CLUSTER-ID> \
|
||||
swarm-master
|
||||
|
||||

|
||||
|
||||
### 5. Creating Swarm Nodes ###
|
||||
|
||||
Now, we'll create a swarm node which will get connected with the Swarm Master. The command below will create a new droplet which will be named as swarm-node and will get connected with the Swarm Master as node. This will create a Swarm cluster across the two nodes.
|
||||
|
||||
# docker-machine create \
|
||||
-d digitalocean \
|
||||
--digitalocean-access-token <DIGITALOCEAN-TOKEN>
|
||||
--swarm \
|
||||
--swarm-discovery token://<TOKEN-FROM-ABOVE> \
|
||||
swarm-node
|
||||
|
||||

|
||||
|
||||
### 6. Connecting to the Swarm Master ###
|
||||
|
||||
We, now connect to the Swarm Master so that we can deploy Docker containers across the nodes as per the requirement and configuration. To load the Swarm Master's Machine configuration into our environment, we can run the below command.
|
||||
|
||||
# eval "$(docker-machine env --swarm swarm-master)"
|
||||
|
||||
After that, we can run the required containers of our choice across the nodes. Here, we'll check if everything went fine or not. So, we'll run **docker info** to check the information about the Swarm Clusters.
|
||||
|
||||
# docker info
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
We can pretty easily create Swarm Cluster with Docker Machine. This method is a lot productive because it reduces a lot of time of a system admin or users. In this article, we successfully provisioned clusters by creating a master and a node using a machine with Digital Ocean as driver. It can be created using any driver like VirtualBox, Google Cloud Computing, Amazon Web Service, Microsoft Azure and more according to the need and requirement of the user and the connection is highly secured with TLS Encryption. If you have any questions, suggestions, feedback please write them in the comment box below so that we can improve or update our contents. Thank you ! Enjoy :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/provision-swarm-clusters-using-docker-machine/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user